
PulseCheck457: A Diagnostic Benchmark for 6D Spatial Reasoning of Large Multimodal Models
Paper • 2502.08636 • Published
Error code: ConfigNamesError
Exception: RuntimeError
Message: Dataset scripts are no longer supported, but found Spatial457.py
Traceback: Traceback (most recent call last):
File "/src/services/worker/src/worker/job_runners/dataset/config_names.py", line 66, in compute_config_names_response
config_names = get_dataset_config_names(
^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/site-packages/datasets/inspect.py", line 161, in get_dataset_config_names
dataset_module = dataset_module_factory(
^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/site-packages/datasets/load.py", line 1029, in dataset_module_factory
raise e1 from None
File "/usr/local/lib/python3.12/site-packages/datasets/load.py", line 989, in dataset_module_factory
raise RuntimeError(f"Dataset scripts are no longer supported, but found {filename}")
RuntimeError: Dataset scripts are no longer supported, but found Spatial457.pyNeed help to make the dataset viewer work? Make sure to review how to configure the dataset viewer, and open a discussion for direct support.
Xingrui Wang1, Wufei Ma1, Tiezheng Zhang1, Celso M. de Melo2, Jieneng Chen1, Alan Yuille1
1 Johns Hopkins University 2 DEVCOM Army Research Laboratory
🌐 Project Page • 📄 Paper • 🤗 Dataset • 💻 Code
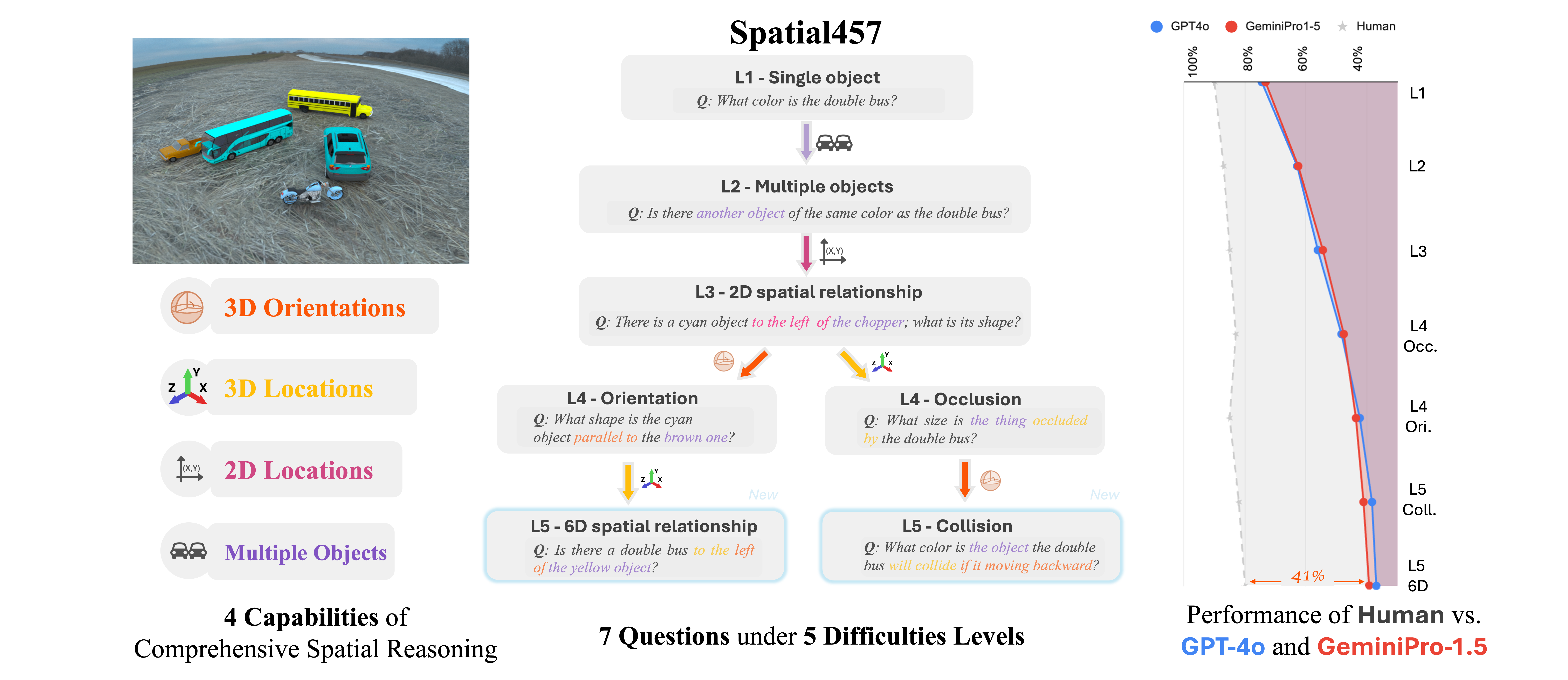
Spatial457 is a diagnostic benchmark designed to evaluate 6D spatial reasoning in large multimodal models (LMMs). It systematically introduces four core spatial capabilities:
These are assessed across five difficulty levels and seven diverse question types, ranging from simple object queries to complex reasoning about physical interactions.
The dataset is organized as follows:
Spatial457/
├── images/ # RGB images used in VQA tasks
├── questions/ # JSONs for each subtask
│ ├── L1_single.json
│ ├── L2_objects.json
│ ├── L3_2d_spatial.json
│ ├── L4_occ.json
│ └── ...
├── Spatial457.py # Hugging Face dataset loader script
├── README.md # Documentation
Each JSON file contains a list of VQA examples, where each item includes:
This modular structure supports scalable multi-task evaluation across levels and reasoning types.
You can load the dataset directly using the Hugging Face 🤗 datasets library:
from datasets import load_dataset
# Load dataset from Hugging Face Hub
dataset = load_dataset(
"RyanWW/Spatial457",
name="L5_6d_spatial",
split="validation",
trust_remote_code=True # Required for custom loading script
)
Important Notes:
trust_remote_code=True to enable the custom dataset loading scriptdata_dir parameter when loading from Hugging Face HubEach example is a dictionary like:
{
'image': <PIL.Image.Image>,
'image_filename': 'superCLEVR_new_000001.png',
'question': 'Is the large red object in front of the yellow car?',
'answer': 'True',
'program': [...],
'question_index': 100001
}
configs = [
"L1_single", # Single object identification
"L2_objects", # Multi-object understanding
"L3_2d_spatial", # 2D spatial reasoning
"L4_occ", # Object occlusion
"L4_pose", # 3D pose estimation
"L5_6d_spatial", # 6D spatial reasoning
"L5_collision" # Collision detection
]
You can swap name="..." in load_dataset(...) to evaluate different spatial reasoning capabilities.
from datasets import load_dataset
# Load dataset
dataset = load_dataset(
"RyanWW/Spatial457",
name="L5_6d_spatial",
split="validation",
trust_remote_code=True
)
print(f"Number of examples: {len(dataset)}")
# Access first example
example = dataset[0]
print(f"Question: {example['question']}")
print(f"Answer: {example['answer']}")
print(f"Image size: {example['image'].size}")
We benchmarked a wide range of state-of-the-art models—including GPT-4o, Gemini, Claude, and several open-source LMMs—across all subsets. The results below have been updated after rerunning the evaluation. While they show minor variance compared to the results in the published paper, the conclusions remain unchanged.
The inference script supports VLMEvalKit and is run by setting the dataset to Spatial457. You can find the detailed inference scripts here.
| Model | L1_single | L2_objects | L3_2d_spatial | L4_occ | L4_pose | L5_6d_spatial | L5_collision |
|---|---|---|---|---|---|---|---|
| GPT-4o | 72.39 | 64.54 | 58.04 | 48.87 | 43.62 | 43.06 | 44.54 |
| GeminiPro-1.5 | 69.40 | 66.73 | 55.12 | 51.41 | 44.50 | 43.11 | 44.73 |
| Claude 3.5 Sonnet | 61.04 | 59.20 | 55.20 | 40.49 | 41.38 | 38.81 | 46.27 |
| Qwen2-VL-7B-Instruct | 62.84 | 58.90 | 53.73 | 26.85 | 26.83 | 36.20 | 34.84 |
@inproceedings{wang2025spatial457,
title = {Spatial457: A Diagnostic Benchmark for 6D Spatial Reasoning of Large Multimodal Models},
author = {Wang, Xingrui and Ma, Wufei and Zhang, Tiezheng and de Melo, Celso M and Chen, Jieneng and Yuille, Alan},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2025},
url = {https://arxiv.org/abs/2502.08636}
}