
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
AirtestProject/Airtest | automation | 690 | name 'args' is not defined | 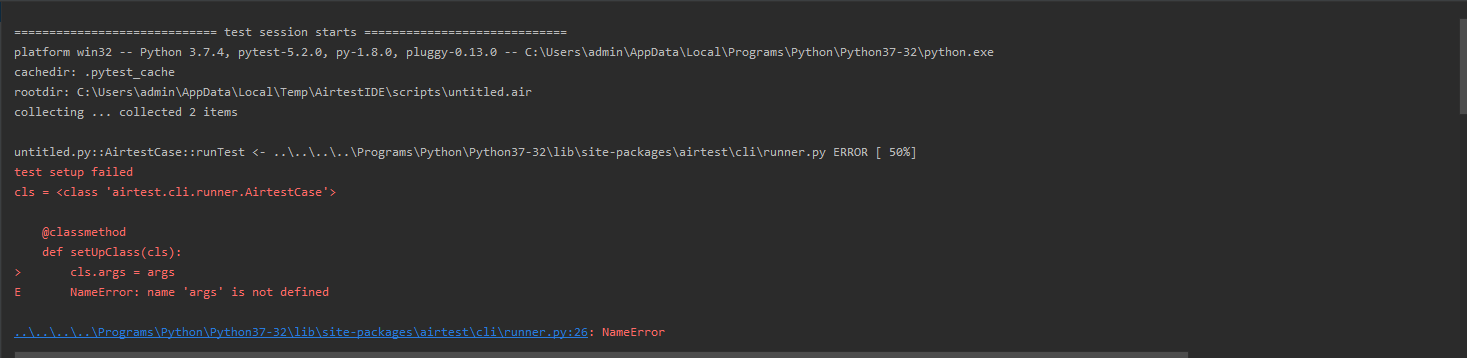
i follow http://airtest.netease.com/docs/en/1_online_help/advanced_features.html?highlight=setup and give error. Am I wrong setup? | closed | 2020-02-10T01:29:52Z | 2020-02-13T08:48:04Z | https://github.com/AirtestProject/Airtest/issues/690 | [] | giangnb-dev | 3 |
MilesCranmer/PySR | scikit-learn | 566 | Windows Julia Install - could not load library "libpcre2-8" The specified module could not be found. | ### What happened?
After installing PySR on windows, on the first import of the module, the Julia install starts, but fails with this error message:
> ...
> fatal: error thrown and no exception handler available.
> InitError(mod=:Sys, error=ErrorException("could not load library "libpcre2-8"
> The specified modu... | closed | 2024-03-13T12:06:21Z | 2024-06-17T18:09:56Z | https://github.com/MilesCranmer/PySR/issues/566 | [
"bug"
] | tbuckworth | 21 |
vimalloc/flask-jwt-extended | flask | 287 | Incomplete docs | Hey guys :),
I love the work you have done with this package. Thank You!
Unfortunately the doc-page https://flask-jwt-extended.readthedocs.io/en/stable/blacklist_and_token_revoking.html is not available.
Could you have a look into this issue?
Best regards from Berlin,
Luca | closed | 2019-11-01T09:20:44Z | 2019-11-01T13:42:55Z | https://github.com/vimalloc/flask-jwt-extended/issues/287 | [] | LucaTabone | 3 |
pytorch/pytorch | deep-learning | 148,891 | Upgrading FlashAttention to V3 | # Summary
We are currently building and utilizing FlashAttention2 for torch.nn.functional.scaled_dot_product_attention
Up until recently the files we build and our integration was very manual. We recently changed this and made FA a third_party/submodule: https://github.com/pytorch/pytorch/pull/146372
This makes it ... | open | 2025-03-10T16:54:15Z | 2025-03-14T19:43:47Z | https://github.com/pytorch/pytorch/issues/148891 | [
"triaged",
"module: sdpa"
] | drisspg | 2 |
graphql-python/graphene | graphql | 1,468 | Is there any way to transform variables before resolving fields? | **Is your feature request related to a problem? Please describe.**
We got queries with variables. One variable is popular and it's need to be transformed every time when query calling.
**Describe the solution you'd like**
Need something function like `transform_before_xvariablenamex()` or another variant to transf... | closed | 2022-10-19T16:11:15Z | 2022-12-10T11:35:40Z | https://github.com/graphql-python/graphene/issues/1468 | [
"question"
] | SomeAkk | 3 |
mitmproxy/mitmproxy | python | 6,590 | Binary doesn't run on Mac M1 (silicon) | #### Problem Description
I apologize if this is somehow an expected outcome as I can see that there's only `x86_64` dmg file provided for macOS. I'm using macOS 14.2.1 on a M1 Max machine, and I cannot get mitmproxy to work. It's complaining about the CPU type.
I do not have Rosetta installed on my system.
#### ... | closed | 2024-01-08T21:45:24Z | 2024-09-30T12:00:25Z | https://github.com/mitmproxy/mitmproxy/issues/6590 | [
"kind/triage"
] | ngocphamm | 4 |
matterport/Mask_RCNN | tensorflow | 2,625 | WARNING:root:You are using the default load_mask(), maybe you need to define your own one. | WARNING:root:You are using the default load_mask(), maybe you need to define your own one.
Epoch 1/10
WARNING:root:You are using the default load_mask(), maybe you need to define your own one.
WARNING:root:You are using the default load_mask(), maybe you need to define your own one.
WARNING:root:You are using the d... | open | 2021-07-06T21:32:55Z | 2024-03-31T20:49:39Z | https://github.com/matterport/Mask_RCNN/issues/2625 | [] | AidaSilva | 12 |
ARM-DOE/pyart | data-visualization | 1,720 | LIDAR ppi converation in gridded format. | I have LiDAR data that I'd like to convert to radar format (because I want to use pyart package) and then grid it. However, after gridding, I noticed that the ds.rsw values are NaN. Could you please advise on how to retrieve valid values for ds.rsw?
import pyart
import numpy as np
from datetime import datetime
from ne... | open | 2025-01-18T18:09:02Z | 2025-01-22T16:59:16Z | https://github.com/ARM-DOE/pyart/issues/1720 | [] | priya1809 | 13 |
gradio-app/gradio | data-science | 9,967 | MultimodalTextbox interactive=False doesn't work with the submit button | ### Describe the bug
When setting interactive=False with MultimodalTextbox, it doesn't disable the submit button.
The text entry and image upload button are disabled so the content cannot be changed, but the submission can still take place.
### Have you searched existing issues? 🔎
- [X] I have searched and... | open | 2024-11-16T03:21:18Z | 2024-11-16T03:29:07Z | https://github.com/gradio-app/gradio/issues/9967 | [
"bug"
] | sthemeow | 0 |
skforecast/skforecast | scikit-learn | 427 | MLPRegressor Bayesian search | Hi, can I search hidden_layer_sizes for MLPRegressor using Bayesian search?
If yes, how can I write search_space code for it?
E.g, I use for grid search param_grid = {'hidden_layer_sizes':[[50,50], [70,50], [100,50], [100,100],[100],[100,50,30],[256,256],[256,256,128]].
I would like to write something like this fo... | closed | 2023-05-11T11:13:24Z | 2023-05-17T06:34:02Z | https://github.com/skforecast/skforecast/issues/427 | [
"question"
] | AVPokrovsky | 3 |
ivy-llc/ivy | numpy | 28,847 | Add Numpy Frontend Support to Ivy Transpiler | **Description**:
The current implementation of `ivy.transpile` supports `"torch"` as the sole `source` argument. This allows transpiling PyTorch functions or classes to target frameworks like TensorFlow, JAX, or NumPy. This task aims to extend the functionality by adding Numpy as a valid `source`, enabling transpila... | open | 2024-12-17T09:59:44Z | 2025-03-18T14:48:26Z | https://github.com/ivy-llc/ivy/issues/28847 | [
"NumPy Frontend",
"ToDo",
"Transpiler"
] | YushaArif99 | 1 |
aleju/imgaug | machine-learning | 617 | Augment bounding boxes is broken when only _augment_keypoints is defined | I have an augmenter that implements `_augment_keypoints` and `_augment_images`, which should be sufficient for augmenting both vector and raster representations of data. However, I noticed when I updated imgaug, my boxes were no longer being augmented.
It looks like 0.4.0 broke the behavior where `augment_bounding_... | closed | 2020-02-16T23:40:51Z | 2020-02-17T20:08:51Z | https://github.com/aleju/imgaug/issues/617 | [] | Erotemic | 1 |
miguelgrinberg/python-socketio | asyncio | 923 | client doesn't receives if *args is in the event function parameters | Hello Miguel, first of all , a ton of thanks to you for creating such amazing product and making it awailable for the community, I really appreciate your efforts. I'm a newbie in python world so please bear with me. I'm trying to provide as much info as I can, to help you to help me solve this issue.
I'm getting live... | closed | 2022-05-11T09:51:11Z | 2022-05-11T10:11:24Z | https://github.com/miguelgrinberg/python-socketio/issues/923 | [] | akshay7892 | 1 |
amidaware/tacticalrmm | django | 1,847 | allow variables to be used in alert templates recipient | **Is your feature request related to a problem? Please describe.**
Currently only manual work is possible when sending email alerts to different recipients and when recipients can be as many a 1 per devices/site the number of alert template can quickly get out of control
**Describe the solution you'd like**
allow... | open | 2024-04-17T09:19:32Z | 2024-04-17T09:19:32Z | https://github.com/amidaware/tacticalrmm/issues/1847 | [] | P6g9YHK6 | 0 |
datadvance/DjangoChannelsGraphqlWs | graphql | 95 | how to fix it | WebSocket client does not request for the subprotocol graphql-ws! | closed | 2022-09-30T06:55:12Z | 2022-10-14T07:29:31Z | https://github.com/datadvance/DjangoChannelsGraphqlWs/issues/95 | [] | George191 | 0 |
HIT-SCIR/ltp | nlp | 541 | pyltp和新版ltp之间的差别在哪里呢 | 最近在做事件抽取的任务,发现很多项目都是用pyltp写的,用ltp4重写方法的时候找不到pyltp输出结果,可以出一个教程么 | closed | 2021-10-29T03:09:20Z | 2022-09-12T06:49:20Z | https://github.com/HIT-SCIR/ltp/issues/541 | [] | jwc19890114 | 1 |
bloomberg/pytest-memray | pytest | 10 | Ability to persist the binary dump post test run | ## Feature Request
I'd like to allow the user to explicitly request persisting the binary files via a `--memray-persist-bin` flag that can take a folder as an argument. This would change the folder where the temporary files are stored from temporary to the passed in argument. To help identify which binary belongs to... | closed | 2022-05-10T20:51:13Z | 2022-05-17T16:36:50Z | https://github.com/bloomberg/pytest-memray/issues/10 | [] | gaborbernat | 0 |
matplotlib/matplotlib | data-science | 29,204 | [Bug]: twiny in log scale can't set `tick_params(top=False)` | ### Bug summary
If `ax2=ax.twiny()` in linear scale, `ax2.tick_params(top=False)` works fine, but failed when set `ax2.set_xscale('log')` .
### Code for reproduction
```Python
import numpy as np
import matplotlib.pyplot as plt
fig, ax = plt.subplots(1, 1)
x = np.arange(0.1, 100, 0.1)
y = np.sin(x)
xlim = ... | closed | 2024-11-29T02:54:11Z | 2024-11-29T16:27:08Z | https://github.com/matplotlib/matplotlib/issues/29204 | [
"Community support"
] | Dengda98 | 1 |
davidsandberg/facenet | computer-vision | 756 | ImportError: No module named src.generative.models.dfc_vae | when i have execute this command on Ubuntu ..
python src/generative/train_vae.py src.generative.models.dfc_vae ~/datasets/clf_mtcnnpy_128 src/models/inception_resnet_v1 ~/models/export/20170512-110547/model-20170512-110547.ckpt-250000 --models_base_dir ~/vae/ --reconstruction_loss_type PERCEPTUAL --loss_features '... | open | 2018-05-23T08:27:37Z | 2018-05-24T16:26:33Z | https://github.com/davidsandberg/facenet/issues/756 | [] | praveenkumarchandaliya | 1 |
horovod/horovod | machine-learning | 3,170 | Stall ranks with tf.keras.callbacks.TensorBoard | **Environment:**
1. Framework: TensorFlow
2. Framework version: 2.5.0
3. Horovod version: 0.22.1
4. MPI version: 3.0.0
5. CUDA version: 11.2
6. NCCL version: 2.8.4-1+cuda10.2
7. Python version: 3.6.9
8. Spark / PySpark version:
9. Ray version:
10. OS and version: 18.04
11. GCC version: 7.5.0
12. CMake versi... | open | 2021-09-17T12:33:32Z | 2022-07-01T02:52:25Z | https://github.com/horovod/horovod/issues/3170 | [
"bug"
] | acmore | 10 |
kizniche/Mycodo | automation | 644 | Backup transfer to another SD Card | How it is possible to transfer an backup from Card A to another SD Card B and restore it there?
I tried to copy the Backup but 1 file cant be copied.
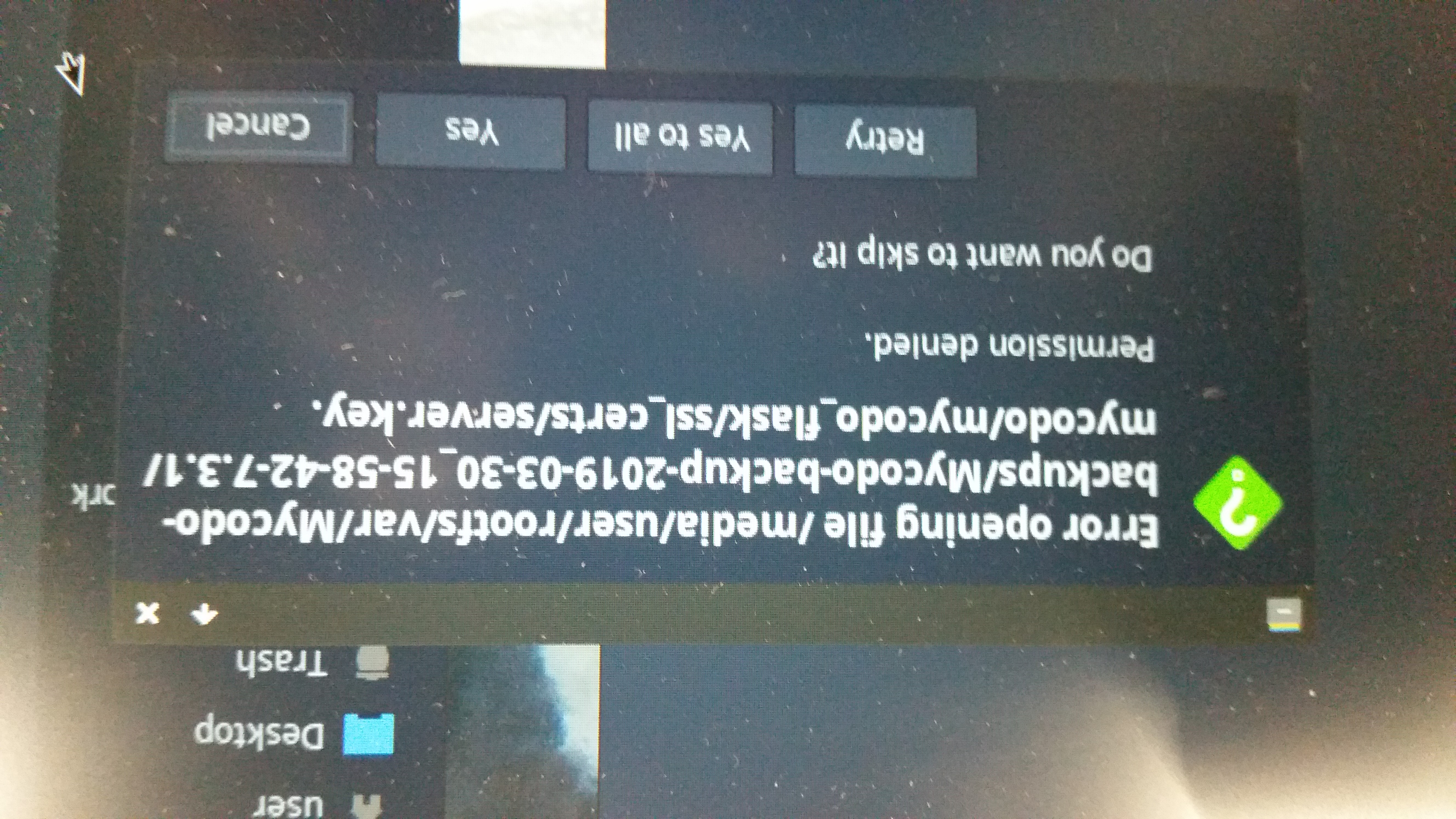
| closed | 2019-03-31T00:11:01Z | 2019-04-02T21:18:01Z | https://github.com/kizniche/Mycodo/issues/644 | [] | RynFlutsch | 5 |
ymcui/Chinese-LLaMA-Alpaca-2 | nlp | 442 | Forgetting English During Chinese LLM Training | ### Check before submitting issues
- [X] Make sure to pull the latest code, as some issues and bugs have been fixed.
- [X] I have read the [Wiki](https://github.com/ymcui/Chinese-LLaMA-Alpaca-2/wiki) and [FAQ section](https://github.com/ymcui/Chinese-LLaMA-Alpaca-2/wiki/FAQ) AND searched for similar issues and did ... | closed | 2023-12-05T13:01:06Z | 2024-01-14T06:47:58Z | https://github.com/ymcui/Chinese-LLaMA-Alpaca-2/issues/442 | [
"stale"
] | Abolfazl-kr | 11 |
sqlalchemy/alembic | sqlalchemy | 868 | ENUM with metadata is not translated to sql CREATE TYPE in autogenerate | Hi,
I know that ENUM autogeneration is not entirely complete and polished, but I think I might have encountered not something not working, but working incorrectly :)
**Describe the bug**
1. Autogenerate for postgres ENUM with `metadata=...` generates a migration with `Metadata(bind=None)` without importing `Meta... | open | 2021-06-24T19:33:12Z | 2021-06-25T08:44:41Z | https://github.com/sqlalchemy/alembic/issues/868 | [
"duplicate",
"question",
"autogenerate for enums"
] | bluefish6 | 1 |
smiley/steamapi | rest-api | 43 | Adding pleyerstats attribute to a game entity. | Currently, a lot of information dropped out of GetUserStatsForGame response. Only achievements are used.
But there is more useful information for some games in 'playerstats'.
Was trying to create a pull request with that tweak :) | closed | 2017-02-19T03:16:31Z | 2019-04-11T02:05:03Z | https://github.com/smiley/steamapi/issues/43 | [
"question",
"steamworks"
] | theSimplex | 4 |
deepspeedai/DeepSpeed | machine-learning | 5,776 | [BUG] Universal checkpoint conversion - "Cannot find layer_01* files in there" | I am tryin to use the universal checkpoint conversion code, `python ds_to_universal.py `, but I get this error that can't find a layer number. I'm not sure why, but I am missing layer 01 and 16, my code just skips creating them when saving the checkpoint. Deepspeed ckpt conversion is expecting them, and therefore bre... | open | 2024-07-17T07:06:08Z | 2024-09-09T12:09:31Z | https://github.com/deepspeedai/DeepSpeed/issues/5776 | [
"bug",
"training"
] | exnx | 3 |
dask/dask | scikit-learn | 11,343 | Bug: Can't perform a (meaningful) "outer" concatenation with dask-expr on `axis=1` | <!-- Please include a self-contained copy-pastable example that generates the issue if possible.
Please be concise with code posted. See guidelines below on how to provide a good bug report:
- Craft Minimal Bug Reports http://matthewrocklin.com/blog/work/2018/02/28/minimal-bug-reports
- Minimal Complete Verifiab... | closed | 2024-08-23T13:33:03Z | 2024-08-26T15:36:10Z | https://github.com/dask/dask/issues/11343 | [
"dask-expr"
] | benrutter | 1 |
huggingface/text-generation-inference | nlp | 2,853 | Entire system crashes when get to warm up model | ### System Info
```
model=meta-llama/Llama-3.3-70B-Instruct
# share a volume with the Docker container to avoid downloading weights every run
volume=/srv/ai/data/tgi
docker run --gpus "1,2,3,4" --shm-size 1g -e HF_TOKEN=[TOKEN] -p 8080:80 -v $volume:/data \
ghcr.io/huggingface/text-generation-inference:3.0.0 ... | open | 2024-12-17T18:02:57Z | 2024-12-18T04:46:58Z | https://github.com/huggingface/text-generation-inference/issues/2853 | [] | ad-astra-video | 1 |
jumpserver/jumpserver | django | 14,951 | [Bug] jms_core sleep 365 days | ### Product Version
v4.7.0-ce
### Product Edition
- [x] Community Edition
- [ ] Enterprise Edition
- [ ] Enterprise Trial Edition
### Installation Method
- [ ] Online Installation (One-click command installation)
- [x] Offline Package Installation
- [ ] All-in-One
- [ ] 1Panel
- [ ] Kubernetes
- [ ] Source Code
#... | closed | 2025-02-28T06:57:11Z | 2025-03-04T06:27:12Z | https://github.com/jumpserver/jumpserver/issues/14951 | [
"🐛 Bug"
] | spiritman1990 | 8 |
horovod/horovod | tensorflow | 2,976 | The speed of multi-node is slower than single-node | I used pytorch and Horovod with two 1080ti GPU on one machine.
When I use single-node, each epoch step will take 3s, but it will take 7s when I use two-node.
Is it normal for the data exchange between nodes to take so long? | closed | 2021-06-11T09:42:32Z | 2024-01-31T03:54:50Z | https://github.com/horovod/horovod/issues/2976 | [] | walt676 | 1 |
ludwig-ai/ludwig | data-science | 3,430 | Throws 'IndexError: Dimension specified as 0 but tensor has no dimensions' during training. | **Describe the bug**
I am trying to run the LLM_few-shot example (https://github.com/ludwig-ai/ludwig/blob/master/examples/llm_few_shot_learning/simple_model_training.py) on google colab and getting the following error in the training stage.
==== Log ====
```
INFO:ludwig.models.llm:Done.
INFO:ludwig.utils.tokeni... | closed | 2023-06-05T09:51:38Z | 2024-10-18T13:36:14Z | https://github.com/ludwig-ai/ludwig/issues/3430 | [] | chayanray | 6 |
Miksus/rocketry | automation | 227 | Conditions: cron "0/20 * * * *" is not same as "*/20 * * * *" | **Describe the bug**
"0/20 * * * *" cron pattern launches my tasks hourly while "*/20 * * * *" launches tasks every 20 minutes
There is a screenshot of my log stats from heroku for 0/20 * * * * pattern

there is o... | closed | 2023-11-15T13:57:31Z | 2023-12-14T09:32:03Z | https://github.com/Miksus/rocketry/issues/227 | [
"bug"
] | nikitazavadsky | 2 |
yezz123/authx | pydantic | 560 | ♻️ refactor error handling | closed | 2024-03-30T23:49:05Z | 2024-04-04T02:17:15Z | https://github.com/yezz123/authx/issues/560 | [
"enhancement",
"v1"
] | yezz123 | 0 | |
gradio-app/gradio | deep-learning | 10,665 | Gradio Microphone recording not working | ### Describe the bug
1. Go to https://www.gradio.app/guides/real-time-speech-recognition
2. Record yourself under https://www.gradio.app/guides/real-time-speech-recognition#2-create-a-full-context-asr-demo-with-transformers
3. Hit submit after website hangs on you
4. The waveform is not as recorded and the output text... | closed | 2025-02-24T09:41:52Z | 2025-02-26T01:26:57Z | https://github.com/gradio-app/gradio/issues/10665 | [
"bug"
] | meng-hui | 2 |
marshmallow-code/flask-marshmallow | rest-api | 34 | Schema.loads().data return dictionary instead of SQLAlchemy Object | I'm trying to deserialize a json object in a `POST` request into an `SQLAlchemy Model` object.
```
class UserSchema(ma.Schema):
class Meta:
model = User
UserSerializer = UserSchema()
(inside my Flask-Restful Post method)
json = request.get_json()
user = UserSerializer.load(json).data
```
After the deserializat... | closed | 2016-01-14T21:22:23Z | 2020-08-20T02:39:56Z | https://github.com/marshmallow-code/flask-marshmallow/issues/34 | [] | ffleandro | 4 |
LibreTranslate/LibreTranslate | api | 521 | UX Web interface - Difficult to use on a smartphone | 
It would be more accessible to read if the translation appears below but not on the side from a smartphone.
It's a no for me to use in this state. | closed | 2023-10-23T21:09:16Z | 2023-10-27T14:04:59Z | https://github.com/LibreTranslate/LibreTranslate/issues/521 | [
"enhancement"
] | skytux | 1 |
pallets/quart | asyncio | 109 | Can not refer to blueprint's static folder | Hi, So you can find code [here](https://repl.it/@gptsahaj28/quartTodoApp#main.py)
here you will see that `main` is a blueprint with sub directory `static` and `templates`
now `line 4` of `app/main/templates/index.html` looks like
```HTML
<link href="{{ url_for('main.static', filename = 'css/model.css') }}" rel="sty... | closed | 2020-08-16T20:26:34Z | 2022-07-05T01:59:01Z | https://github.com/pallets/quart/issues/109 | [] | itsDrac | 1 |
horovod/horovod | deep-learning | 3,751 | error: missing ranks | **Environment:**
1. Docker version: 20.10.18, build b40c2f6
2. Host driver version: 515.43.04
3. image: horovod version 0.25.0
4. cuda-toolkit version: 11.2
**Checklist:**
1. Did you search issues to find if somebody asked this question before? Yes
2. If your question is about hang, did you read [this doc](htt... | closed | 2022-10-18T10:03:28Z | 2022-12-28T04:17:21Z | https://github.com/horovod/horovod/issues/3751 | [
"question",
"wontfix"
] | zero-piB | 2 |
microsoft/JARVIS | pytorch | 180 | Support for ChatGPT | I noticed that currently Jarvis only support text-DaVinci and gpt-4. Do you have any plan to support gpt-3.5-turbo in the near future? Cause it's more cheaper compared with current LLMs.
Thanks for your wonderful work. | open | 2023-04-21T07:03:47Z | 2023-04-23T08:26:49Z | https://github.com/microsoft/JARVIS/issues/180 | [] | ustcwhy | 1 |
donnemartin/data-science-ipython-notebooks | machine-learning | 16 | Add SAWS: A Supercharged AWS Command Line Interface (CLI) to AWS Section. | closed | 2015-10-04T10:40:50Z | 2016-05-18T02:09:55Z | https://github.com/donnemartin/data-science-ipython-notebooks/issues/16 | [
"feature-request"
] | donnemartin | 1 | |
psf/black | python | 4,513 | `# fmt: skip` doesn't work with multiline strings | I found this while messing around with #4511
[playground link](https://black.vercel.app/?version=stable&state=_Td6WFoAAATm1rRGAgAhARYAAAB0L-Wj4AC2AF1dAD2IimZxl1N_WhQxS683Co8P8Minjqpb4QfnoC1BJcmjUY2YuL-n7hzVFArdqsZ6zAZpQS4lesRd3PXpISXEGuFOqt4C4cGfy1KruABcKF9lrI40h6GcoFdNTaEKAAAAAAByImBZgAFMjgABebcBAAAAtTsj9bHEZ_sCAAA... | open | 2024-11-15T01:35:38Z | 2025-02-26T13:44:04Z | https://github.com/psf/black/issues/4513 | [
"T: bug",
"F: strings"
] | MeGaGiGaGon | 5 |
ShishirPatil/gorilla | api | 83 | deploying to replicate | **Describe the solution you'd like**
I would love to see a model of Gorilla hosted to Replicate, it would be nice to be able to utilize their API and hosting.
**Additional context**
Had a blast playing with the colab
| closed | 2023-08-04T16:18:57Z | 2024-02-04T08:58:21Z | https://github.com/ShishirPatil/gorilla/issues/83 | [
"enhancement"
] | walter-grace | 1 |
harry0703/MoneyPrinterTurbo | automation | 92 | ImageMagick的安全策略阻止了与临时文件@/tmp/tmpur5hyyto.txt相关的操作。 | 记录一个已解决的问题。
报错:
OSError: MoviePy Error: creation of None failed because of the following error: convert-im6.q16: attempt to perform an operation not allowed by the security policy `@/tmp/tmpur5hyyto.txt' @ error/property.c/InterpretImageProperties/3668. convert-im6.q16: no images defined `PNG32:/tmp/tmpkq291k_5.png... | closed | 2024-03-28T07:59:09Z | 2024-10-08T10:41:21Z | https://github.com/harry0703/MoneyPrinterTurbo/issues/92 | [] | chenhengzh | 3 |
mkhorasani/Streamlit-Authenticator | streamlit | 138 | When I click lagout to log out, and log-in again, My interface cannot load, help me, please |


| closed | 2024-02-26T09:08:50Z | 2024-03-28T11:05:20Z | https://github.com/mkhorasani/Streamlit-Authenticator/issues/138 | [
"help wanted"
] | likescentific | 2 |
ijl/orjson | numpy | 358 | Out of Memory error when building orjson wheel for armv7 Docker on Ubuntu64 | I'm trying to compile Docker image on Ubuntu64 for [Home Assistant](https://github.com/home-assistant/core/), but it always fails with an Out of Memory error when it tries to build the armv7 version.
```
#0 24.80 Downloading orjson-3.8.6.tar.gz (655 kB) ... | closed | 2023-02-25T17:09:46Z | 2023-02-28T13:34:18Z | https://github.com/ijl/orjson/issues/358 | [] | magicse | 1 |
Asabeneh/30-Days-Of-Python | flask | 422 | Needed support | Hi, Asabeneh
For some exercises there are some links that looks like they're not available any more in Day 20 PIP.
Some of them are:
countries API
https://archive.ics.uci.edu/datasets.php
Thanks for your help. | open | 2023-07-25T00:10:15Z | 2023-08-25T17:51:33Z | https://github.com/Asabeneh/30-Days-Of-Python/issues/422 | [] | Isaias-program | 0 |
matterport/Mask_RCNN | tensorflow | 2,784 | How to train using dataset which is in segmented masks in png format ? | The dataset is in segmented masks in png format as shown below structure, any suggestion on how to train it. The dataset structure is :
Object_Images
-> img1.png
-> img2.png
. . .
Object_Segmented_Masks
->img1_seg_mask.png
->img2_seg_mask.png
. . .
The... | closed | 2022-03-02T05:50:09Z | 2022-03-30T14:24:19Z | https://github.com/matterport/Mask_RCNN/issues/2784 | [] | dd2-42 | 7 |
kizniche/Mycodo | automation | 1,143 | How to configure the reverse proxy to use other services on the same system along with mycodo? | Hi,
I have mycodo working on a Raspberry Pi. **I would like to add another service on the same system**. I know nginx is deployed along with mycodo in the standard installation, and that **nginx can be used as a reverse proxy**. Then I should be able to deploy other services easily.
I figure out this is certainly... | closed | 2022-01-22T14:58:36Z | 2022-01-28T21:24:05Z | https://github.com/kizniche/Mycodo/issues/1143 | [] | lalebarde | 1 |
CorentinJ/Real-Time-Voice-Cloning | python | 790 | Difference about speaker_embedding part in Synthesizer? | Hi, firstly thanks for your work!
I find that in model.py of Synthesizer, it use Tacotron but, in forward part of that , the "speaker_embedding default ==None", so it don't use speaker_embedding when train synthesizer?
I remember that in older version, the speaker_embedding is used in model Tacotron2. Could you ple... | closed | 2021-07-07T07:47:54Z | 2021-08-25T09:58:11Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/790 | [] | ymzlygw | 1 |
plotly/dash | data-visualization | 2,360 | Variable Path not accounting for HTML encoding | **Describe your context**
```
async-dash 0.1.0a1
dash 2.7.0
dash-bootstrap-components 1.2.1
dash-core-components 2.0.0
dash-daq 0.5.0
dash-extensions 0.1.5
dash-html-components 2.0.0
dash-iconify 0.1.2
dash-loading-spinners ... | open | 2022-12-08T16:16:08Z | 2024-08-13T19:24:23Z | https://github.com/plotly/dash/issues/2360 | [
"bug",
"P3"
] | BSd3v | 4 |
jowilf/starlette-admin | sqlalchemy | 444 | Question: How to validate a @row_action or @action with `form` attribute? | As I said in #440, I'm using `row_actions` to create child-models. I have constructed the `@row_action` with the `form` parameter and some of the inputs are required and some of them have attributes like `min=2023`. When I click the `Yes, Proceed` button, the form is submitted without satisfying the form requirements, ... | open | 2023-12-27T15:54:18Z | 2023-12-29T00:15:27Z | https://github.com/jowilf/starlette-admin/issues/444 | [
"bug"
] | hasansezertasan | 3 |
psf/black | python | 4,188 | SyntaxWarning on regexp on first run of black | When running `black` on the following code:
```
text = re.sub(
"([_a-zA-Z0-9-+]+)(\.[_a-zA-Z0-9-+]+)*"
"@([a-zA-Z0-9-]+)(\.[a-zA-Z0-9-]+)*(\.[a-zA-Z]{2,4})",
'<a href="mailto:\g<0>">\g<0></a>',
text,
)
text = re.sub(
"(ftp|http|https):\/\/(\w+:{0,1}\w*@)?"
"(\S+)(:[0-9]+)?(\/|\/([\w#... | closed | 2024-01-28T08:13:57Z | 2024-01-28T15:05:58Z | https://github.com/psf/black/issues/4188 | [
"T: bug"
] | Julien-Elie | 2 |
Lightning-AI/pytorch-lightning | machine-learning | 19,880 | can't fit with ddp_notebook on a Vertex AI Workbench instance (CUDA initialized) | ### Bug description
Using this minimal code example:
```
import torch
import lightning as L
print(torch.cuda.is_initialized())
trainer = L.Trainer(
accelerator="auto",
strategy="ddp_notebook",
devices="auto",
max_epochs=1,
# callbacks=callbacks,
log_every_n_steps=1
)
print(tor... | open | 2024-05-16T21:32:16Z | 2024-05-16T21:32:16Z | https://github.com/Lightning-AI/pytorch-lightning/issues/19880 | [
"bug",
"needs triage"
] | jasonbrancazio | 0 |
ageitgey/face_recognition | python | 861 | face_recognition fails to detect some obvious faces. | * face_recognition version:1.2.3
* Python version: Python 3.5.6 :: Anaconda, Inc.
* Operating System: Ubuntu 16.04
### Description
Thank you for a great tool! I am trying to detect faces for COCO dataset(Images which have faces). For 50% of times, it is able to detect the faces correctly, but other 50% of images ... | closed | 2019-06-21T20:15:59Z | 2021-08-18T20:21:57Z | https://github.com/ageitgey/face_recognition/issues/861 | [] | nbansal90 | 2 |
ultralytics/ultralytics | deep-learning | 19,454 | Triton inference bug for latest version | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and found no similar bug report.
### Ultralytics YOLO Component
Predict
### Bug
## Bug Report: Negative Dimension Error When Deploying official YOLOv11 (or other YOLO version as yolov8) ... | closed | 2025-02-27T07:22:59Z | 2025-02-27T12:38:32Z | https://github.com/ultralytics/ultralytics/issues/19454 | [
"bug",
"fixed",
"detect",
"exports"
] | hoangl-hle | 6 |
streamlit/streamlit | deep-learning | 10,000 | st.dialog The pop-up window: Click to click the second time and it will not pop up | ### Checklist
- [X] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar issues.
- [X] I added a very descriptive title to this issue.
- [X] I have provided sufficient information below to help reproduce this issue.
### Summary
hi, I have a problem, when I click th... | closed | 2024-12-11T10:36:09Z | 2024-12-13T10:06:28Z | https://github.com/streamlit/streamlit/issues/10000 | [
"type:bug",
"status:awaiting-user-response",
"feature:st.dialog"
] | dtiosd | 5 |
JoeanAmier/XHS-Downloader | api | 185 | 你的项目很棒,但是希望能够对个别下载笔记/视频提示网络异常做出修复 | 我发现很多人都遇到网络异常了并且包括我,User-Agent更新后还是有网络异常,请问下作者能够对这个做出修复吗 | closed | 2024-10-20T12:27:31Z | 2024-10-20T13:43:54Z | https://github.com/JoeanAmier/XHS-Downloader/issues/185 | [] | lixida123 | 0 |
huggingface/datasets | pandas | 7,369 | Importing dataset gives unhelpful error message when filenames in metadata.csv are not found in the directory | ### Describe the bug
While importing an audiofolder dataset, where the names of the audiofiles don't correspond to the filenames in the metadata.csv, we get an unclear error message that is not helpful for the debugging, i.e.
```
ValueError: Instruction "train" corresponds to no data!
```
### Steps to reproduce the ... | open | 2025-01-14T13:53:21Z | 2025-01-14T15:05:51Z | https://github.com/huggingface/datasets/issues/7369 | [] | svencornetsdegroot | 1 |
onnx/onnx | machine-learning | 6,787 | .github/workflows/sdist_test.yml is failing | # Bug Report
https://github.com/onnx/onnx/blob/main/.github/workflows/sdist_test.yml is failing. The original idea was to extract "pip install -e ." from auto update doc to a separate pr which test installing onnx from source. | closed | 2025-03-10T05:55:22Z | 2025-03-23T19:44:55Z | https://github.com/onnx/onnx/issues/6787 | [
"bug",
"module: CI pipelines"
] | andife | 0 |
mars-project/mars | pandas | 2,691 | Use direct async call for in-process rpc | <!--
Thank you for your contribution!
Please review https://github.com/mars-project/mars/blob/master/CONTRIBUTING.rst before opening an issue.
-->
**Is your feature request related to a problem? Please describe.**
Mars oscar actor uses at least one `asyncio.Task` for every actor call, which is expensive when t... | open | 2022-02-09T07:20:21Z | 2022-02-09T07:20:21Z | https://github.com/mars-project/mars/issues/2691 | [] | chaokunyang | 0 |
mwouts/itables | jupyter | 227 | How to copy a table column name? | How to copy a table column name?
The current behavior when **click** on the `table column name` triggers a **sort**.
Is it possible to allow something like `alt+mouse drag`,, to **select** & copy the name,, instead of triggering sort? | open | 2024-02-06T23:16:26Z | 2024-06-17T08:30:19Z | https://github.com/mwouts/itables/issues/227 | [] | Norlandz | 11 |
wandb/wandb | data-science | 8,717 | [Q]: Is there more detailed introduction or example of Query panels combined plot? | ### Ask your question
Hi, this issue comes from https://github.com/wandb/examples/issues/577, maybe you only need to answer once.
I combine my two tables together through a key with inner or outer join. The new table is like this, joined on the first column, and other columns have two values (from the original two ta... | open | 2024-10-26T14:43:38Z | 2024-11-11T10:40:58Z | https://github.com/wandb/wandb/issues/8717 | [
"ty:question",
"c:docs",
"a:app"
] | Neronjust2017 | 4 |
Farama-Foundation/PettingZoo | api | 498 | Warnings in CI tests to resolve | Looking at CI, there are several warnings in pettingzoo that likely should be addressed:
There's this:
test/pytest_runner.py::test_module[classic/texas_holdem_no_limit_v5-pettingzoo.classic.texas_holdem_no_limit_v5]
/opt/hostedtoolcache/Python/3.6.15/x64/lib/python3.6/site-packages/gym/logger.py:34: UserWarnin... | closed | 2021-10-05T19:16:38Z | 2021-12-12T19:29:57Z | https://github.com/Farama-Foundation/PettingZoo/issues/498 | [] | jkterry1 | 3 |
frol/flask-restplus-server-example | rest-api | 105 | How do I marshal pagination data ? | Hello, thank you for this great project !
I have a problem with marshmallow, which the example doesn't cover.
-------
My schema :
```
from flask_restplus_patched import ModelSchema
from src.extensions import ma
# # ma init at app startup
# from flask_marshmallow import Marshmallow
# ma = Marshmallow... | closed | 2018-04-26T02:57:32Z | 2018-04-27T02:09:03Z | https://github.com/frol/flask-restplus-server-example/issues/105 | [
"question"
] | eromoe | 8 |
ivy-llc/ivy | pytorch | 28,256 | Fix Ivy Failing Test: torch - shape.shape__radd__ | closed | 2024-02-12T15:49:49Z | 2024-02-13T09:32:14Z | https://github.com/ivy-llc/ivy/issues/28256 | [
"Sub Task"
] | fnhirwa | 0 | |
Lightning-AI/pytorch-lightning | pytorch | 20,536 | lightning.Fabric meets deadlock when loading nn.Module | ### Bug description
When I try to use `lightning.Fabric.setup()` to load `torch.nn.Module` under multi-process, the program will meet deadlock and stuck in `lightning/fabric/strategies/launchers/subprocess_script.py`.
I doubt this problem comes from `popen` start method of process, but I have not more evidence.
... | closed | 2025-01-07T16:36:03Z | 2025-01-20T13:08:03Z | https://github.com/Lightning-AI/pytorch-lightning/issues/20536 | [
"repro needed",
"ver: 2.4.x",
"ver: 2.5.x"
] | forestbat | 8 |
noirbizarre/flask-restplus | flask | 389 | Flask restplus fails on a certain GET call on Chrome - but not elsewhere. | We're faced with a very weird issue, reproducible with our code - https://github.com/vedavaapi/vedavaapi_py_api/issues/3 (README and setup script in the same repo).
Observations:
- https://api.vedavaapi.org/py/ullekhanam/v1/schemas fails on chrome, but succeeds on swagger UI, firefox and with curl. So do other rout... | open | 2018-02-05T22:11:17Z | 2018-05-16T14:26:27Z | https://github.com/noirbizarre/flask-restplus/issues/389 | [] | vvasuki | 5 |
jonaswinkler/paperless-ng | django | 1,394 | [BUG] Mail rule filter attachment filename is case sensitive | The "Mail rules" interface says the Filter attachment filename should be case insensitive:
> Only consume documents which entirely match this filename if specified. Wildcards such as *.pdf or \*invoice\* are allowed. Case insensitive.
The latest revision of mail.py uses fnmatch, which follows the operating system... | open | 2021-10-17T03:42:01Z | 2021-10-31T11:05:58Z | https://github.com/jonaswinkler/paperless-ng/issues/1394 | [] | dpaulat | 1 |
joke2k/django-environ | django | 507 | db_url() fail with oracle dsn | `db_url` fail with `oracle` url without path, for example:
```python
import environ
env = environ.Env()
DB_URL = 'oracle://super_user:super_pass@(DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=oracle_dev)(PORT=1521))(CONNECT_DATA=(SERVICE_NAME=XEPDB1)))'
DB = env.db('', default=DB_URL)
print("NAME:", DB['NAME'])
`... | open | 2023-10-25T13:54:11Z | 2023-10-25T13:54:11Z | https://github.com/joke2k/django-environ/issues/507 | [] | lsaavedr | 0 |
marcomusy/vedo | numpy | 792 | Having issues rendering anything with vedo | I had to do a clean install of my Ubuntu with WSL2 and Windows 11 and I have had issues in rendering things with vedo. It has worked fine in the past on the same computer. My new install didn't have libGL.so.1 installed so I did `apt-get install libgl1-mesa-glx libgl1-mesa-dri`. I have the same issue with PyVista rende... | closed | 2023-01-19T04:48:13Z | 2023-02-23T01:11:39Z | https://github.com/marcomusy/vedo/issues/792 | [] | daniel-a-diaz | 6 |
graphistry/pygraphistry | pandas | 504 | Fwiw, do we need to update to track latest dirty car, as it has been awhile? | Fwiw, do we need to update to track latest dirty car, as it has been awhile?
(Maybe do as a follow-on PR after this lands?)
_Originally posted by @lmeyerov in https://github.com/graphistry/pygraphistry/pull/486#discussion_r1300244745_
https://github.com/graphistry/cu-cat/pull/4 | open | 2023-09-06T08:25:12Z | 2023-09-28T07:04:41Z | https://github.com/graphistry/pygraphistry/issues/504 | [] | dcolinmorgan | 1 |
marcomusy/vedo | numpy | 321 | Tube Shape Circle Orientation | While I'm sure building up my own mesh from equations will work, it would be nice if the input to the Tube function could be vectors that defined each circle's orientation rather than just points. While this isn't very useful for the body of the tube, orienting the end circles is necessary for creating an accurate grap... | closed | 2021-02-23T19:07:58Z | 2021-02-23T20:49:49Z | https://github.com/marcomusy/vedo/issues/321 | [] | JGarrett7 | 3 |
statsmodels/statsmodels | data-science | 9,056 | How to use X-13ARIMA-SEATS in Ubuntu? | Hi,
I would like to use X-13ARIMA-SEATS with Ubuntu. Do I understand correctly that in:
`statsmodels.tsa.x13.x13_arima_select_order(endog,
maxorder=(2, 1),
maxdiff=(2, 1),
diff=None,
exog=None,
log=None,
outlier=True,
trading=False,
forecast_periods=None,
start=None, freq=None,
print_stdout=Fal... | open | 2023-11-04T17:14:41Z | 2023-11-04T22:04:20Z | https://github.com/statsmodels/statsmodels/issues/9056 | [] | PeterPirog | 2 |
tensorpack/tensorpack | tensorflow | 1,460 | Base64 as input | Here is my code to make an inference:
```
def send_request(im_path):
img = np.array(Image.open(im_path))
data = json.dumps({"signature_name": "serving_default", "instances": img.tolist()})
headers = {"content-type": "application/json"}
json_response = requests.post('http://' + SERVER_ADDRESS + '... | closed | 2020-06-27T08:11:52Z | 2020-06-27T18:12:31Z | https://github.com/tensorpack/tensorpack/issues/1460 | [
"unrelated"
] | Adblu | 3 |
stanfordnlp/stanza | nlp | 1,380 | [QUESTION] Spanish Constituency to English Constituency Translation Dictionary? | Hello,
We have a program that relies heavily on the constituency parse for its English usage, and we're looking to expand our program to also handle Spanish text. We noticed that Spanish does have constituency information available, but the labels are all different (they're in Spanish). Is there any information you ... | closed | 2024-04-09T18:17:23Z | 2025-01-22T00:53:08Z | https://github.com/stanfordnlp/stanza/issues/1380 | [
"question",
"stale"
] | jack-dempsey-cascade | 3 |
cvat-ai/cvat | pytorch | 8,630 | @lakshmikantdeshpande , it should be possible. We are going to use KeyCloak for auth purpose in the nearest future. | @lakshmikantdeshpande , it should be possible. We are going to use KeyCloak for auth purpose in the nearest future.
_Originally posted by @nmanovic in https://github.com/cvat-ai/cvat/issues/1217#issuecomment-607787437_
| closed | 2024-11-01T08:14:10Z | 2024-11-15T03:25:38Z | https://github.com/cvat-ai/cvat/issues/8630 | [] | Brokendisme | 2 |
nonebot/nonebot2 | fastapi | 3,237 | Plugin: nonebot_plugin_dingzhen | ### PyPI 项目名
nonebot_plugin_dingzhen
### 插件 import 包名
nonebot_plugin_dingzhen
### 标签
[{"label":"丁真","color":"#ff337b"},{"label":"语音合成","color":"#1942ff"},{"label":"QQ","color":"#b6f111"}]
### 插件配置项
```dotenv
```
```httpx
```
### 插件测试
- [ ] 如需重新运行插件测试,请勾选左侧勾选框 | closed | 2025-01-05T05:30:55Z | 2025-01-05T06:05:30Z | https://github.com/nonebot/nonebot2/issues/3237 | [
"Plugin",
"Publish"
] | Pochinki98 | 2 |
JaidedAI/EasyOCR | deep-learning | 914 | Greek Language | First of all thank you soo much for this wonderful work. What about the Greek language isn't it developed yet?
Or plz tell me how I can trained easy-OCR model with Greek language | open | 2022-12-23T10:09:31Z | 2023-01-14T04:57:15Z | https://github.com/JaidedAI/EasyOCR/issues/914 | [] | Ham714 | 1 |
CorentinJ/Real-Time-Voice-Cloning | deep-learning | 488 | preprocessing VoxCele2 is not working | While running encoder_preprocess on voxceleb2 dataset, I'm getting the following warning and nothing else happens. Not sure why?
```
raw: Preprocessing data for 5994 speakers.
raw: 0%| | 0/5994 [00:00<?, ?speakers/s]
/ho... | closed | 2020-08-12T21:31:06Z | 2020-08-19T08:31:25Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/488 | [] | amintavakol | 5 |
raphaelvallat/pingouin | pandas | 151 | Sorting data farme is changing the results of pairwise_ttests despite same values | Hi, thanks for the great package.
I think I ran into a potentially worrisome issue. After sorting a data frame, the pairwise_ttests gives the wrong result after sorting despite the same values. The mixed_anova is not affected.
I encountered it with my own data but reproduced it using the example dataset:
Bef... | closed | 2021-01-15T17:09:28Z | 2021-01-20T01:24:47Z | https://github.com/raphaelvallat/pingouin/issues/151 | [
"bug :boom:",
"invalid :triangular_flag_on_post:"
] | mpcoll | 5 |
donnemartin/data-science-ipython-notebooks | machine-learning | 92 | . | closed | 2022-12-20T10:56:58Z | 2022-12-21T14:53:19Z | https://github.com/donnemartin/data-science-ipython-notebooks/issues/92 | [] | Alihadi919 | 1 | |
aiortc/aiortc | asyncio | 437 | Low fps of output rtmp stream. | Hello. I am trying to use this solution to relay webrtc-> rtmp. Faced a problem with low fps of the output video, while the processor load on the server does not exceed 10-15%. What can be done to ensure that the solution consumes all available resources? | closed | 2020-11-26T06:14:00Z | 2021-03-07T14:51:17Z | https://github.com/aiortc/aiortc/issues/437 | [
"invalid"
] | MsWik | 1 |
coqui-ai/TTS | deep-learning | 3,758 | [Bug] ValueError: Can't infer missing attention mask on `mps` device. Please provide an `attention_mask` or use a different device. | ### Describe the bug
```
(ai) (base) yuki@yuki pho % python tts.py
OMP: Info #276: omp_set_nested routine deprecated, please use omp_set_max_active_levels instead.
> Downloading model to /Users/yuki/Library/Application Support/tts/tts_models--multilingual--multi-dataset--xtts_v2
100%|███████████████████████████... | closed | 2024-05-26T08:26:24Z | 2024-11-11T08:36:26Z | https://github.com/coqui-ai/TTS/issues/3758 | [
"bug",
"wontfix"
] | yukiarimo | 22 |
encode/apistar | api | 395 | View anotated type not used in schema generation | The generated schemas does not have response type, even when I am anoting it.
| closed | 2018-02-11T22:50:07Z | 2018-03-19T21:59:19Z | https://github.com/encode/apistar/issues/395 | [] | leiserfg | 3 |
Lightning-AI/pytorch-lightning | deep-learning | 20,466 | Allowing setting timeout in DeepSpeedStrategy | ### Outline & Motivation
In DDPStrategy / FSDPStrategy, the `timeout=datetime.timedelta(seconds=1800)` flag is exposed and thus allowing user to tune. However, in DeepSpeedStrategy, which is a subclass of DDPStrategy, this flag is not exposed, which makes it hard to change the timeout behavior.
Is there any workaro... | closed | 2024-12-04T14:24:22Z | 2024-12-10T10:15:22Z | https://github.com/Lightning-AI/pytorch-lightning/issues/20466 | [
"feature",
"strategy: deepspeed"
] | jedyang97 | 1 |
RomelTorres/alpha_vantage | pandas | 332 | TimeSeries.get_daily() possibly retrieving incorrect stock data? | Hello, sorry if this doesn't classify as an API issue, but upon retrieving data for NVDA, some of the numbers seem a bit off? I can't find evidence that this stock was over $500, but this is what returns from throughout early last year.
Code snippet:
`import alpha_vantage`
`from alpha_vantage.timeseries import Ti... | closed | 2022-01-14T18:57:51Z | 2022-01-18T17:36:26Z | https://github.com/RomelTorres/alpha_vantage/issues/332 | [] | ChristopheBrown | 5 |
nok/sklearn-porter | scikit-learn | 59 | Invalid java generated for random forrest | There are several compile errors when transpiling random forrests to java:
* At the start of each predict_x method:
`int[] classes = new int[[2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2]];`should be
`int[] classes = new int[] { 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2 };`.
* At the end of each predict_x method:
`for (int i = 1... | closed | 2019-09-10T12:51:00Z | 2022-05-16T21:56:05Z | https://github.com/nok/sklearn-porter/issues/59 | [] | markusheiden | 1 |
KevinMusgrave/pytorch-metric-learning | computer-vision | 231 | Multi-Label Datasets | Hi There,
Firstly, great package! I have a question regarding multi-label datasets. I have a set of images that could belong to multiple classes and I cannot find in the documentation a way of training a model in a multi-label scenario? or a way of generating custom triplets which can then be passed to the loss func... | closed | 2020-11-12T20:34:14Z | 2023-10-14T05:21:08Z | https://github.com/KevinMusgrave/pytorch-metric-learning/issues/231 | [
"question"
] | harpalsahota | 6 |
skforecast/skforecast | scikit-learn | 283 | About multiseries: level and level weights setting in grid_search_forecaster_multiseries | Hi developers,
For better utilizing the multi-series function, I am trying to learn the multi-series deeper by understanding the mechanism based on the [case study](https://www.cienciadedatos.net/documentos/py44-multi-series-forecasting-skforecast.html). However, I still have some confusions about it.
1. Mechan... | closed | 2022-11-10T16:15:27Z | 2022-12-06T08:50:25Z | https://github.com/skforecast/skforecast/issues/283 | [] | kennis222 | 1 |
desec-io/desec-stack | rest-api | 670 | GUI Setup Instructions for dedyn.io Domains Misleading | When creating a new dedyn domain, the GUI shows this:

This is misleading because the user **does not** need to setup any DS records for the case for dedyn domains.
Proposed fix: the GUI should check i... | open | 2023-01-31T10:24:25Z | 2024-10-07T16:59:10Z | https://github.com/desec-io/desec-stack/issues/670 | [
"bug",
"help wanted",
"easy",
"gui"
] | nils-wisiol | 1 |
tflearn/tflearn | tensorflow | 775 | Googlenet | I have the following issue just running the code in
https://github.com/tflearn/tflearn/blob/master/examples/images/googlenet.py
Run id: googlenet_oxflowers17
Log directory: /tmp/tflearn_logs/
INFO:tensorflow:Summary name Accuracy/ (raw) is illegal; using Accuracy/__raw_ instead.
-----------------------------... | open | 2017-05-28T06:28:40Z | 2017-05-28T06:28:40Z | https://github.com/tflearn/tflearn/issues/775 | [] | agulli | 0 |
allure-framework/allure-python | pytest | 369 | allure-pytest 2.6.2,execute test only generates json and TXT files | allure-pytest 2.6.2,Execute test only generates json and TXT files, execute “allure generate reports/ -o reports/html“:
Exception in thread "main" ru.yandex.qatools.allure.data.ReportGenerationExcepti
on: Could not find any allure results
at ru.yandex.qatools.allure.data.AllureReportGenerator.generate(Allure... | closed | 2019-04-16T01:49:59Z | 2019-07-12T04:33:22Z | https://github.com/allure-framework/allure-python/issues/369 | [] | lc308903655 | 4 |
ultralytics/ultralytics | machine-learning | 19,188 | Selecting a better metric for the "best" model | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
Hi!
I am using YOLO11 segmentation with the large model. For my use case, I... | open | 2025-02-11T17:09:35Z | 2025-02-14T19:42:37Z | https://github.com/ultralytics/ultralytics/issues/19188 | [
"question",
"segment"
] | Tom-Forsyth | 6 |
pallets-eco/flask-wtf | flask | 355 | Pinning down wtfforms | Can you consider pinning down versions of your dependencies? | closed | 2019-01-17T22:12:22Z | 2021-05-26T00:55:04Z | https://github.com/pallets-eco/flask-wtf/issues/355 | [] | szb0 | 1 |
saulpw/visidata | pandas | 1,860 | BigQuery TypeError: connect() got an unexpected keyword argument 'database' | I installed using `pip install ibis-framework[bigquery] vdsql` on python 3.8 on WSL.
Connecting with `vdsql bigquery:///my-project-name` resulted in a listing of all the datasets within the project. So far so good.
Upon highlighting a dataset, I got the error: `TypeError: connect() got an unexpected keyword argu... | closed | 2022-11-15T13:52:31Z | 2023-11-01T18:10:03Z | https://github.com/saulpw/visidata/issues/1860 | [
"vdsql"
] | ghost | 8 |
airtai/faststream | asyncio | 1,856 | Bug: Duplicate logs when using application factory | **Describe the bug**
When running the code using an application factory, logs are duplicated. If you uncomment the block of code that does not use the factory, logs are written three times. It appears that multiple instances of CriticalLogMiddleware are being created, even though only one middleware is listed in broke... | closed | 2024-10-18T17:32:20Z | 2024-11-07T16:37:58Z | https://github.com/airtai/faststream/issues/1856 | [
"bug"
] | ulbwa | 0 |
tqdm/tqdm | jupyter | 624 | tqdm.__repr__() crashes when disable=True | - [x] I have visited the [source website], and in particular
read the [known issues]
- [x] I have searched through the [issue tracker] for duplicates
- [x] I have mentioned version numbers, operating system and
environment, where applicable:
```python
>>> import tqdm, sys
>>> print(tqdm.__version__, sys.ve... | closed | 2018-10-04T23:33:02Z | 2021-02-09T18:07:17Z | https://github.com/tqdm/tqdm/issues/624 | [
"p0-bug-critical ☢",
"to-fix ⌛",
"c1-quick 🕐"
] | kratsg | 3 |
STVIR/pysot | computer-vision | 539 | performance drops when fine-tuning resnet50 in siamrpn++ | Has anyone encountered this problem when training siamrpn++? Before fine-tuning the backbone network, the success rate of OTB2015 is 0.6. Once the backbone network is fine-tuned, it drops straight to 0.4. The training loss drops normally. | closed | 2021-07-08T08:50:01Z | 2021-07-12T10:57:45Z | https://github.com/STVIR/pysot/issues/539 | [] | WuFengGit | 0 |
Lightning-AI/pytorch-lightning | pytorch | 19,563 | EarlyStopping in the middle of an epoch | ### Description & Motivation
I'm fitting a normalizing flow to learn the mapping between two embedding spaces. The first embedding space is sampled using the mapper of a pretrained stylegan and the second embedding space is derived by a pretrained covnet. I want to learn a mapper from the second embedding space back t... | open | 2024-03-03T06:43:20Z | 2024-03-03T18:12:25Z | https://github.com/Lightning-AI/pytorch-lightning/issues/19563 | [
"feature",
"callback: early stopping"
] | Richienb | 0 |
autokey/autokey | automation | 283 | Support unicode | Currently both trigger and replacement parts of hotstrings/abbreviations seem to ignore non-ASCII chars.
#114 covers the trigger part, but the same is absolutely valid for replacement part.
Try to make a hotstring/abbreviation that would send `θ` or any other non-ASCII char - those chars will simply get filtered ou... | open | 2019-05-14T16:24:58Z | 2024-03-30T11:53:50Z | https://github.com/autokey/autokey/issues/283 | [
"duplicate",
"enhancement",
"phrase expansion",
"scripting",
"autokey triggers"
] | Drugoy | 5 |
ultralytics/ultralytics | deep-learning | 19,082 | nms=true for exporting to onnx | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and found no similar bug report.
### Ultralytics YOLO Component
_No response_
### Bug
i get this error
```
(yolo) root@workstation-016:/mnt/4T/Tohidi/object_detector_service# yolo ex... | closed | 2025-02-05T12:00:05Z | 2025-02-06T02:43:54Z | https://github.com/ultralytics/ultralytics/issues/19082 | [
"bug",
"fixed",
"exports"
] | mohamad-tohidi | 2 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.