
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
horovod/horovod | machine-learning | 2,961 | PyTorch sparse allreduce fails with torch nightly | Repro:
```
pip install --no-cache-dir --pre torch torchvision -f https://download.pytorch.org/whl/nightly/cpu/torch_nightly.html
# install horovod
horovodrun -np 2 pytest -vs "test/parallel/test_torch.py::TorchTests::test_async_sparse_allreduce"
```
The test hangs, which has been causing test failures.
cc ... | closed | 2021-06-08T19:31:19Z | 2021-06-10T03:11:05Z | https://github.com/horovod/horovod/issues/2961 | [
"bug"
] | tgaddair | 2 |
huggingface/datasets | numpy | 6,819 | Give more details in `DataFilesNotFoundError` when getting the config names | ### Feature request
After https://huggingface.co/datasets/cis-lmu/Glot500/commit/39060e01272ff228cc0ce1d31ae53789cacae8c3, the dataset viewer gives the following error:
```
{
"error": "Cannot get the config names for the dataset.",
"cause_exception": "DataFilesNotFoundError",
"cause_message": "No (support... | open | 2024-04-17T11:19:47Z | 2024-04-17T11:19:47Z | https://github.com/huggingface/datasets/issues/6819 | [
"enhancement"
] | severo | 0 |
CorentinJ/Real-Time-Voice-Cloning | python | 706 | Can't start demo_cli or demo_toolbox.py | C:\Users\n-har\Desktop\deepaudio>python demo_cli.py
> Traceback (most recent call last):
File "demo_cli.py", line 4, in <module>
from synthesizer.inference import Synthesizer
File "C:\Users\n-har\Desktop\deepaudio\synthesizer\inference.py", line 1, in <module>
import torch
File "C:\Users\n-har\AppDa... | closed | 2021-03-16T19:17:31Z | 2021-03-16T20:55:35Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/706 | [] | t0g3pii | 1 |
fastapi/fastapi | fastapi | 12,402 | [BUG] In version 0.115.0 of FastAPI, the pydantic model that has declared an alias cannot correctly receive query parameters | Thank you for all the work you have done. I have initiated the [discussion ](https://github.com/fastapi/fastapi/discussions/12401)as requested, but I think this issue is quite important. Initiating this issue is just to prevent the discussion from being drowned out, and I apologize for any offense.
### Example Code
... | open | 2024-10-08T06:42:41Z | 2025-01-21T06:56:01Z | https://github.com/fastapi/fastapi/issues/12402 | [] | insistence | 10 |
miguelgrinberg/Flask-SocketIO | flask | 754 | Buffer/Queue fills up when client is not consuming socketio emit | I have a flask-socketio server which when the client is connected emits log messages. The intention is for real time log viewing. I noticed the application was leaking memory (occasionally) so after some investigation I found that on occasion the disconnect message from the client was getting lost and therefore the ser... | closed | 2018-08-01T19:58:49Z | 2019-06-08T23:16:06Z | https://github.com/miguelgrinberg/Flask-SocketIO/issues/754 | [
"investigate"
] | maximillion90 | 3 |
JaidedAI/EasyOCR | deep-learning | 492 | When do you plan to release v1.4 to pypi | Hi! You have added dict output at v1.4. I look forward to trying this opportunity, but latest version at pypi is still 1.3.2. When do you plan to update it? | closed | 2021-07-19T15:16:32Z | 2021-07-20T08:57:28Z | https://github.com/JaidedAI/EasyOCR/issues/492 | [] | AndreyGurevich | 1 |
python-restx/flask-restx | flask | 420 | flask restx user case to adopt flask-oidc authentication | Hello Team,
Recently I am working on oidc auth for my flask restx app.
The most examples I see online about flask-oidc is just based on a barebone flask app.
That usually works.
But through googling, I do not see any user case where flask restx can adopt flask-oidc for authentication so we can enjoy the benefit o... | open | 2022-03-17T19:13:57Z | 2022-03-17T19:13:57Z | https://github.com/python-restx/flask-restx/issues/420 | [
"question"
] | zhoupoko2000 | 0 |
SYSTRAN/faster-whisper | deep-learning | 618 | faster_whisper batch encode time-consume issue | I have made a test, for batching in faster-whisper.
But faster_whisper batch encode consume multiple time as sample's amount, it seems encode in batch not work as expected by CTranslate?
By the way, the decode/generate have the same issue when in-Batch ops.
 package to run tests for that code. | open | 2021-08-07T15:16:47Z | 2021-08-07T15:16:47Z | https://github.com/ContextLab/hypertools/issues/251 | [
"enhancement",
"help wanted"
] | jeremymanning | 0 |
mljar/mercury | jupyter | 474 | Notebook hangs in "WorkerState.Busy" indefinitely | Hi, I haven't been able to deploy any notebooks in Mercury (unable than the demo). I've followed the documentation and set up the requirements.txt file, but the Worker never finishes. I've waited up to an hour. Any suggestions? | open | 2024-12-04T19:10:26Z | 2024-12-05T21:50:02Z | https://github.com/mljar/mercury/issues/474 | [] | Pancake205 | 3 |
iperov/DeepFaceLab | machine-learning | 5,576 | Merge error | after learning through Quick96, I put on the merge. As a result, it writes "no faces found for 00001.png, copying without faces" and a window with hot keys appears. Inside the data_dst folder, a merged folder appeared, containing one frame that really does not contain the desired face, as well as a merged_masked folder... | open | 2022-10-30T16:54:12Z | 2023-09-21T04:21:43Z | https://github.com/iperov/DeepFaceLab/issues/5576 | [] | Margaret93 | 2 |
tfranzel/drf-spectacular | rest-api | 1,094 | How to only include `ApiKeyAuth` authentication/authorization strategy? | ### Describe the bug
We are only exposing endpoints that use `djangorestframework-api-key` in our generated schemas. We're following the blueprint instructions [here](https://github.com/tfranzel/drf-spectacular/blob/0.25.1/docs/blueprints.rst#djangorestframework-api-key) to include `ApiKeyAuth`.
However, we're al... | closed | 2023-10-31T15:58:33Z | 2023-11-02T17:57:37Z | https://github.com/tfranzel/drf-spectacular/issues/1094 | [] | alexburner | 6 |
dynaconf/dynaconf | fastapi | 449 | [bug] LazyFormatted TypeError exception in Django TEMPLATES DIRS | **Describe the bug**
TypeError exception (expected str, bytes or os.PathLike object, not Lazy) if add templates dir path with `@format` or `@jinja` tokens.
**To Reproduce**
Steps to reproduce the behavior:
1. Having the following config files:
<!-- Please adjust if you are using different files and formats! ... | closed | 2020-10-14T16:46:43Z | 2021-03-01T17:50:04Z | https://github.com/dynaconf/dynaconf/issues/449 | [
"bug"
] | dgavrilov | 0 |
NVlabs/neuralangelo | computer-vision | 214 | Error during "requirements.txt" installation | Hello,
I did everything like in this tutorial video "https://www.youtube.com/watch?v=NEF5bGyTqmk" but when I run
`pip install -r requirements.txt`
I got this error:
`Collecting git+https://github.com/NVlabs/tiny-cuda-nn/#subdirectory=bindings/torch (from -r requirements.txt (line 3))
... | open | 2024-10-25T21:20:28Z | 2024-10-25T21:36:59Z | https://github.com/NVlabs/neuralangelo/issues/214 | [] | canonar | 1 |
microsoft/nni | data-science | 5,110 | Using 2 GPUs training to train DARTS in parallel, but get 2 different search architecture? | **Describe the issue**:
I used 2 GPUs to train DARTS, but from the output, I find that I get 2 different results.
And I used 'export_onnx', but I didn't get the output model under the specified directory.
```python
if __name__ == "__main__":
parser = ArgumentParser("darts")
parser.add_argument("--l... | open | 2022-09-05T06:59:23Z | 2023-10-12T02:12:07Z | https://github.com/microsoft/nni/issues/5110 | [
"NAS 2.0"
] | toufunao | 2 |
huggingface/peft | pytorch | 1,363 | Error while fetching adapter layer from huggingface library | ### System Info
```
pa_extractor = LlamaForCausalLM.from_pretrained(LLAMA_MODEL_NAME,
token=HF_ACCESS_TOKEN,
max_length=LLAMA2_MAX_LENGTH,
... | closed | 2024-01-16T11:39:08Z | 2024-03-10T15:03:37Z | https://github.com/huggingface/peft/issues/1363 | [] | Muskanb | 2 |
comfyanonymous/ComfyUI | pytorch | 7,000 | Pinning | ### Feature Idea
To pin means to fix something in place.

If I move a group with pinned nodes, I expect, that the nodes are pinned to the group, but it isn't. The nodes are teared off the group instead. Looks strange.
. When that argument is not an integer, the XREAD will hang.
Example:
`await r.xread(["system_event_stream"], timeout=0.1, latest_ids=[0])` shows up in `redis monitor` as `15541913... | closed | 2019-04-02T07:55:47Z | 2019-07-09T14:17:28Z | https://github.com/aio-libs-abandoned/aioredis-py/issues/567 | [] | tino | 1 |
holoviz/panel | matplotlib | 7,190 | test | Thanks for contacting us! Please read and follow these instructions carefully, then delete this introductory text to keep your issue easy to read. Note that the issue tracker is NOT the place for usage questions and technical assistance; post those at [Discourse](https://discourse.holoviz.org) instead. Issues without t... | closed | 2024-08-27T08:48:25Z | 2024-08-27T08:49:23Z | https://github.com/holoviz/panel/issues/7190 | [
"TRIAGE"
] | hoxbro | 0 |
microsoft/unilm | nlp | 1,583 | Kosmo2.5 Chinese performance very bad | Why not consider add Chinese support? | open | 2024-06-23T03:30:22Z | 2024-07-14T14:56:19Z | https://github.com/microsoft/unilm/issues/1583 | [] | luohao123 | 2 |
Miserlou/Zappa | django | 1,509 | Can't parse ".serverless/requirements/xlrd/biffh.py" unless encoding is latin | <!--- Provide a general summary of the issue in the Title above -->
## Context
when detect_flask is called during zappa init, it fails on an encoding issue because of the commented out block at the head of xlrd/biffh.py
<!--- Provide a more detailed introduction to the issue itself, and why you consider it to be a b... | open | 2018-05-14T18:00:14Z | 2018-05-14T18:00:14Z | https://github.com/Miserlou/Zappa/issues/1509 | [] | joshmalina | 0 |
httpie/http-prompt | api | 193 | Preview request? | While the `env` command is somewhat useful it would be nice to preview a request before sending it… perhaps a `show` or `dump` or `req` command would be helpful? | open | 2021-04-24T02:03:26Z | 2021-05-07T06:40:29Z | https://github.com/httpie/http-prompt/issues/193 | [] | jenstroeger | 2 |
newpanjing/simpleui | django | 401 | simpleui 的 layer对话框 失效。 | **bug描述**
* *Bug description * *
layer对话框,点击确定按钮,ajax 请求地址错误。导致失效,代码相关问题如下。
simpletags.py 文件 get_model_ajax_url 方法。
key 值编写错误,应将: {}:{}_{}_changelist 改为 {}:{}_{}_ajax | closed | 2021-10-15T02:12:01Z | 2021-10-15T06:27:45Z | https://github.com/newpanjing/simpleui/issues/401 | [
"bug"
] | cqjinxiaotao | 0 |
JohnSnowLabs/nlu | streamlit | 246 | Model Loading | I am loading model like this
```
import sparknlp
import nlu
spark = sparknlp.start()
df = spark.read.csv("nlp_data.csv")
res = nlu.load("pos").predict(df[["text"]].rdd.flatMap(lambda x: x).collect())
print(res)
spark.stop()
```
Each time I get the following messages in my console:
```
com.johnsnowlabs... | open | 2024-02-06T09:22:44Z | 2024-02-06T09:22:44Z | https://github.com/JohnSnowLabs/nlu/issues/246 | [] | ArijitSinghEDA | 0 |
python-visualization/folium | data-visualization | 1,596 | Formatted popups or tooltips with variable strings? | I'm using Python 3.10.4 and the most recent version of folium. My needs are simple: to create popups or tooltips on a map showing the name of the location and some information. I am fetching the results from a pandas dataframe, over which I'm iterating with iterrows. The salient code currently is this:
toolti... | closed | 2022-05-23T05:29:25Z | 2022-11-17T15:29:11Z | https://github.com/python-visualization/folium/issues/1596 | [] | amca01 | 1 |
microsoft/unilm | nlp | 1,275 | [BEIT3] How to apply GradCam on the beit3 models? | Hi. I want to see the gradcam image of the beit3 model. I used the grad-cam library [https://github.com/jacobgil/pytorch-grad-cam], but I got this error. 'RuntimeError: element 0 of tensors does not require grad and does not have a grad_fn'.
Please help..
Thank you! | closed | 2023-08-30T08:29:48Z | 2023-08-30T10:12:15Z | https://github.com/microsoft/unilm/issues/1275 | [] | TheNha | 6 |
scrapy/scrapy | web-scraping | 5,850 | Invalid Copyright Notice | I am not a lawyer but I believe your copyright notice at https://github.com/scrapy/scrapy/blob/master/LICENSE
is invalid in the USA (and probably elsewhere) because it lacks a date.
Copyright (c) Scrapy developers.
Should be:
Copyright (c) 2011 Scrapy developers.
Or
Copyright (c) 2011-2023 Scrapy dev... | closed | 2023-03-15T16:38:43Z | 2024-01-03T18:17:56Z | https://github.com/scrapy/scrapy/issues/5850 | [] | RogerHaase | 1 |
QuivrHQ/quivr | api | 2,960 | TOtot | closed | 2024-08-07T10:59:51Z | 2024-08-07T11:00:57Z | https://github.com/QuivrHQ/quivr/issues/2960 | [] | StanGirard | 1 | |
python-gitlab/python-gitlab | api | 2,575 | How to use python-gitlab library to search a string in every commits? | I noticed `commits = project.commits.list(all=True)` can list every commits, but I don't know how to perform a search against each commits, can it be done? :) | closed | 2023-05-25T02:39:41Z | 2024-05-27T01:20:03Z | https://github.com/python-gitlab/python-gitlab/issues/2575 | [] | umeharasang | 1 |
modelscope/data-juicer | data-visualization | 98 | [Bug]: alphanumeric_filter, char.isalnum() | ### Before Reporting 报告之前
- [X] I have pulled the latest code of main branch to run again and the bug still existed. 我已经拉取了主分支上最新的代码,重新运行之后,问题仍不能解决。
- [X] I have read the [README](https://github.com/alibaba/data-juicer/blob/main/README.md) carefully and no error occurred during the installation process. (Otherwise, w... | closed | 2023-11-24T01:52:00Z | 2023-12-22T09:32:20Z | https://github.com/modelscope/data-juicer/issues/98 | [
"bug",
"stale-issue"
] | simplew2011 | 3 |
ageitgey/face_recognition | python | 1,355 | [Question] : Is any way to recognise masked face img | Hello guys ,
Face_recognition is failing while detecting faces with mask and person name.
How we can tackle this issue ?
Any suggestions
Thanks | open | 2021-08-11T11:34:08Z | 2021-08-24T00:39:04Z | https://github.com/ageitgey/face_recognition/issues/1355 | [] | VinayChaudhari1996 | 1 |
StructuredLabs/preswald | data-visualization | 231 | [FEATURE] Use API endpoints as a source | **Is your feature request related to a problem? Please describe.**
Today, users can add in CSV, Postgres, and Clickhouse as sources. S3 is coming soon too. We want to support APIs as sources.
**Describe the solution you'd like**
An API source type which pulls from the API (w/ necessary keys/auth) upon running a query.... | open | 2025-03-13T00:27:50Z | 2025-03-15T14:46:04Z | https://github.com/StructuredLabs/preswald/issues/231 | [
"enhancement"
] | shivam-singhal | 1 |
ultralytics/yolov5 | deep-learning | 13,216 | gpu memory usage is low but out of memory | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) and found no similar questions.
### Question
When training yolov5, I found that the GPU memory was not used, GPU memory usage is versy... | open | 2024-07-24T15:52:07Z | 2024-10-27T13:30:50Z | https://github.com/ultralytics/yolov5/issues/13216 | [
"question"
] | leooobreak | 2 |
AutoGPTQ/AutoGPTQ | nlp | 611 | [QUESTION] How to unload AutoGPTQForCausalLM.from_quantized model from GPU to CPU in order to free up GPU memory | Hi
I have loaded a model with the follow code:
```
DEVICE = "cuda:0" if torch.cuda.is_available() else "cpu"
print(DEVICE)
embeddings = HuggingFaceInstructEmbeddings(
model_name="hkunlp/instructor-xl",model_kwargs={"device":DEVICE}
)
model_name_or_path = "./models/Llama-... | open | 2024-03-26T10:58:28Z | 2024-03-26T10:58:28Z | https://github.com/AutoGPTQ/AutoGPTQ/issues/611 | [] | tommycmy | 0 |
CorentinJ/Real-Time-Voice-Cloning | tensorflow | 787 | LibriTTS & older models | Hey - I've been playing with the Tensorflow version of this repo with a LibriTTS model for some time now & have had some good results from it. The model i've been using was from here & had a partial train of a LibriTTS dataset which was really good for punctuation etc.
Just upgraded my GPU to a 3080ti (rare I know!... | closed | 2021-07-02T20:46:51Z | 2021-09-14T17:35:29Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/787 | [] | ThePowerOfMonkeys | 1 |
inducer/pudb | pytest | 375 | source not displayed (linecache filename mismatch) | I'm debugging a Python 3 script, which I typically invoke from the directory it lives in, as:
> ./fooBar.py parm1
If I instrument my script with a `set_trace()` call and start the script as above, it hits the breakpoint and stops. However, no source code is displayed. If, on the other hand, I enter the debugger ... | open | 2020-01-23T16:00:46Z | 2020-01-27T22:40:09Z | https://github.com/inducer/pudb/issues/375 | [] | dccarson | 1 |
whitphx/streamlit-webrtc | streamlit | 1,119 | Camera doesn't start when offline state | I'm creating a camera app that runs locally.
Also, I want to run it even when the PC is not connected to network, but if I press the start button when the PC is not connected to network, the camera does not start and nothing is output to the log.
<img width="617" alt="camera_image" src="https://user-images.githubuse... | closed | 2022-11-01T07:47:25Z | 2022-12-06T04:26:35Z | https://github.com/whitphx/streamlit-webrtc/issues/1119 | [] | RoloAfrole | 2 |
ultralytics/ultralytics | deep-learning | 19,320 | About YOLOv12 support | ### Search before asking
- [x] I have searched the Ultralytics [issues](https://github.com/ultralytics/ultralytics/issues) and found no similar feature requests.
### Description
Since YOLOv12 is released at https://github.com/sunsmarterjie/yolov12, will the models of YOLOv12 be supported? Thank you.
### Use case
... | closed | 2025-02-20T01:09:22Z | 2025-02-21T08:41:36Z | https://github.com/ultralytics/ultralytics/issues/19320 | [
"enhancement",
"question",
"fixed"
] | curtis18 | 5 |
HIT-SCIR/ltp | nlp | 268 | srl_srl_train项目编译错误 |
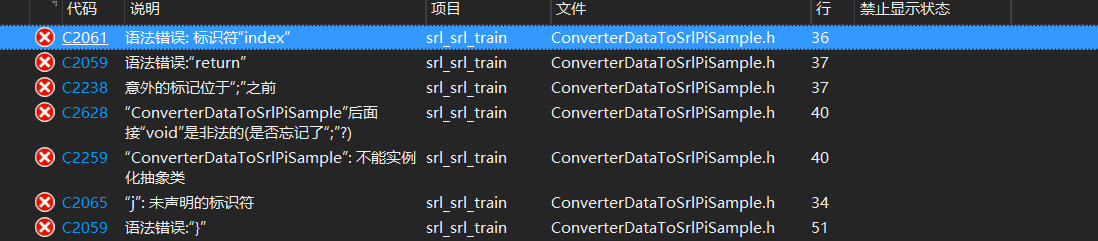
| closed | 2017-12-09T06:51:22Z | 2017-12-10T03:54:40Z | https://github.com/HIT-SCIR/ltp/issues/268 | [] | JaneWangle | 1 |
SciTools/cartopy | matplotlib | 2,228 | Source code no longer included on PyPI | On conda-forge, we're trying to build 0.22.0:
https://github.com/conda-forge/cartopy-feedstock/pull/156
However, we're running into issues because a `.tar.gz` file wasn't included in the PyPI release. First, our bot was not able to create a PR for the release (see https://github.com/conda-forge/cartopy-feedstock/i... | closed | 2023-08-05T09:04:07Z | 2023-08-07T22:04:16Z | https://github.com/SciTools/cartopy/issues/2228 | [] | xylar | 4 |
modin-project/modin | pandas | 7,043 | `BaseQueryCompiler.repartition()` works slow | [`BaseQueryCompiler.repartition()`](https://github.com/modin-project/modin/blob/14452a8414bdec10e3b5cfa05e98bd26c6e1bafc/modin/core/storage_formats/base/query_compiler.py#L6711) works slower than the same logic implemented on partition's level (see perf measurements in [this PR](https://github.com/modin-project/modin/p... | open | 2024-03-08T13:16:37Z | 2024-03-08T13:16:38Z | https://github.com/modin-project/modin/issues/7043 | [
"Performance 🚀",
"P2"
] | dchigarev | 0 |
ultralytics/yolov5 | machine-learning | 12,730 | export int8 tflite with customdataset | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) and found no similar questions.
### Question
Hi, there
I trained custom dataset and got a .pt file and I tried to convert .pt to .t... | closed | 2024-02-13T05:34:06Z | 2024-02-13T11:45:58Z | https://github.com/ultralytics/yolov5/issues/12730 | [
"question"
] | timingisnow | 2 |
2noise/ChatTTS | python | 744 | decoder error on all_codes.masked_fill & what's the correct vesion of vector_quantize_pytorch | An error occurred as follows during the process of changing the default decoder to DVAE (inferring with `use_decoder=False`). Could it be attributed to an incompatible version of `vector_quantize_pytorch==1.17.3`? However, I have attempted `vector-quantize-pytorch==1.16.1`, `vector-quantize-pytorch==1.15.5`, and `vecto... | closed | 2024-09-05T08:09:57Z | 2024-10-23T04:01:31Z | https://github.com/2noise/ChatTTS/issues/744 | [
"question",
"stale"
] | unbelievable3513 | 2 |
netbox-community/netbox | django | 17,688 | GraphQL filters (AND, OR and NOT) don't work for custom filterset fields | ### Deployment Type
Self-hosted
### NetBox Version
v4.1.3
### Python Version
3.10
### Steps to Reproduce
Using a GraphQL filter with AND, OR, NOT for a field that has custom implementation in the filterset (or only appears in the filterset) for example asn_id on Site. Doesn't work
1. Create 4 sites with ID's ... | closed | 2024-10-07T17:00:19Z | 2025-03-10T19:19:02Z | https://github.com/netbox-community/netbox/issues/17688 | [
"type: bug",
"status: accepted",
"topic: GraphQL",
"severity: medium",
"netbox"
] | arthanson | 6 |
sgl-project/sglang | pytorch | 3,880 | [Feature] Run DeepSeek V3 W4-only | ### Checklist
- [x] 1. If the issue you raised is not a feature but a question, please raise a discussion at https://github.com/sgl-project/sglang/discussions/new/choose Otherwise, it will be closed.
- [x] 2. Please use English, otherwise it will be closed.
### Motivation
I don't have a hopper GPU, I only have the A... | open | 2025-02-26T08:04:05Z | 2025-03-09T12:25:05Z | https://github.com/sgl-project/sglang/issues/3880 | [] | QingshuiL | 3 |
deepspeedai/DeepSpeed | machine-learning | 6,501 | [BUG] Config mesh_device None | I am using ds 0.15.1 on two A6000 GPUs, following the [huggingface Non-Trainer DeepSpeed integration](https://huggingface.co/docs/transformers/main/en/deepspeed?models=pretrained+model#non-trainer-deepspeed-integration),
got assertion error:
```
guanhua@guanhua-Lambda:~/DiscQuant$ deepspeed test_hf_ds.py
[2024-09... | open | 2024-09-06T22:56:15Z | 2024-11-18T02:10:44Z | https://github.com/deepspeedai/DeepSpeed/issues/6501 | [
"bug",
"training"
] | GuanhuaWang | 2 |
axnsan12/drf-yasg | rest-api | 720 | api/swagger/?format=openapi response 500 |

| open | 2021-06-04T09:25:46Z | 2025-03-07T12:13:02Z | https://github.com/axnsan12/drf-yasg/issues/720 | [
"triage"
] | dpreal | 2 |
ludwig-ai/ludwig | data-science | 3,760 | Jupyter/Colab notebooks that utilize Ludwig should require only standard "pip install ludwig" (i.e., without latest development branch) | **Describe the bug**
Today, in order to use Ludwig in a Jupyter/Colab notebook, one needs to install the latest Ludwig from the development tree:
```
pip install -U git+https://github.com/ludwig-ai/ludwig.git@master
pip install -U git+https://github.com/huggingface/transformers
pip install -U git+https://github.co... | closed | 2023-11-01T22:03:14Z | 2023-11-11T16:07:42Z | https://github.com/ludwig-ai/ludwig/issues/3760 | [] | alexsherstinsky | 3 |
LibreTranslate/LibreTranslate | api | 141 | English -> Turkish translation results in inappropriate websites ? | Hi, I am really confused right now. If you enter meaningless words like random characters, English to Turkish translation has some really weirds results.
Here they are :

![2021-09... | closed | 2021-09-22T22:42:13Z | 2022-05-19T08:31:16Z | https://github.com/LibreTranslate/LibreTranslate/issues/141 | [
"bug"
] | CaptainCaptcha | 6 |
httpie/cli | rest-api | 1,270 | [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:997) | ## Checklist
- [*] I've searched for similar issues.
- [*] I'm using the latest version of HTTPie.
---
## Minimal reproduction code and steps
Call https drwg.ru
## Current result

## Expect... | closed | 2022-01-20T14:59:42Z | 2022-01-20T16:18:10Z | https://github.com/httpie/cli/issues/1270 | [
"bug",
"new"
] | Kirill | 3 |
pallets/quart | asyncio | 411 | Application configuration and context to run pytest? | <!--
This issue tracker is a tool to address bugs in Quart itself. Please use
GitHub Discussions or the Pallets Discord for questions about your own code.
Replace this comment with a clear outline of what the bug is.
-->
```
import pytest, sys, asyncio
from hypercorn.config import Config
from hypercorn.asyncio import ... | closed | 2025-02-22T07:12:34Z | 2025-02-22T07:17:55Z | https://github.com/pallets/quart/issues/411 | [] | khteh | 0 |
recommenders-team/recommenders | data-science | 1,197 | [ASK] Running RBM_movielens.ipynb | ### Description
Hi, in general just trying to learn more about different algorithms and new to all this. When I try to run the RBM notebook using TensorFlow 1.12, I’m told other functions are not available in this version of TensorFlow but when I use a newer version, it says different functions have been deprecated wi... | closed | 2020-09-01T04:49:30Z | 2020-09-02T02:35:27Z | https://github.com/recommenders-team/recommenders/issues/1197 | [
"help wanted"
] | festusojo123 | 0 |
flasgger/flasgger | api | 601 | How can I protect the swagger endpoints, by making it a child of another existing endpoint? | I have an application, flask, that contains all the api endpoints below /api/. as a before_request on the api blueprint I am making the validation of credentials, tokens, etc. I would like to set swagger to be a child of that /api/, so that whenever a request comes for it the credentials are also checked.
I have bee... | closed | 2023-11-10T17:24:34Z | 2023-12-17T12:49:25Z | https://github.com/flasgger/flasgger/issues/601 | [] | flixman | 1 |
keras-team/keras | data-science | 20,058 | "No gradients provided for any variable." when variable uses an integer data type | When using an integer data type for a trainable variable, training will always throw a "No gradients provided for any variable." `ValueError`. Here is a very simple example to reproduce the issue:
```python
import keras
import tensorflow as tf
import numpy as np
variable_dtype = tf.int32
# variable_dtype = tf... | closed | 2024-07-29T05:39:48Z | 2024-08-28T04:48:49Z | https://github.com/keras-team/keras/issues/20058 | [
"type:support"
] | solidDoWant | 9 |
OFA-Sys/Chinese-CLIP | computer-vision | 282 | 在GPU 推理报错 Segmentation fault | 在GPU 推理报错 Segmentation fault,CPU上是没有问题的 | open | 2024-04-06T03:26:38Z | 2024-04-28T16:10:25Z | https://github.com/OFA-Sys/Chinese-CLIP/issues/282 | [] | shiqwang | 1 |
gradio-app/gradio | data-science | 9,983 | Multi-user session state conflict using gr.State (and gr.BrowserState) | ### Describe the bug
I have a Gradio app with a complex Blocks UI, which has a set of variables (including dictionaries, lists, and even other class instances) that I encapsulate in a `deepcopy`-able class and maintain an instance of that class as a `gr.State` object. I need to support simultaneous multi-user access t... | closed | 2024-11-18T09:28:09Z | 2024-11-21T14:20:06Z | https://github.com/gradio-app/gradio/issues/9983 | [
"bug",
"pending clarification"
] | anirbanbasu | 14 |
tensorflow/tensor2tensor | machine-learning | 1,582 | 2 foundational questions about self-attention/multihead | Hello everyone,
I have 2 questions.
1. We know multi-head. So among each head, why we use different matrix Wiq, Wik, Wiv to multiply the output of last layer, instead of using a same matrix Wi
I mean, like 8 heads, we have the output of last layer T = 512dim. first get K = 64dim, V=64dim, Q=64dim. K≠... | open | 2019-05-23T17:32:02Z | 2019-05-23T18:34:56Z | https://github.com/tensorflow/tensor2tensor/issues/1582 | [] | Mingyu-academic | 1 |
ultralytics/ultralytics | deep-learning | 19,661 | yolov11 how to improve large object performace? | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
<img width="466" alt="Image" src="https://github.com/user-attachments/assets... | open | 2025-03-12T08:40:05Z | 2025-03-12T08:45:12Z | https://github.com/ultralytics/ultralytics/issues/19661 | [
"question",
"OBB"
] | sjtu-cz | 2 |
onnx/onnx | deep-learning | 6,215 | reporting a vulnerability of download_model function | A vulnerability in the `download_model` function of the onnx/onnx framework, version 1.16.1, allows for arbitrary file overwrite due to inadequate prevention of path traversal attacks in malicious tar files.
I found the same vulnerability as CVE-2024-5187 in the download_model function that has not been fixed as... | closed | 2024-07-06T14:52:30Z | 2024-08-07T10:30:18Z | https://github.com/onnx/onnx/issues/6215 | [
"bug"
] | Arashimu | 12 |
ultrafunkamsterdam/undetected-chromedriver | automation | 1,906 | Exsist Java Version? | open | 2024-06-02T15:24:03Z | 2024-06-02T15:24:03Z | https://github.com/ultrafunkamsterdam/undetected-chromedriver/issues/1906 | [] | 488442 | 0 | |
pytest-dev/pytest-mock | pytest | 282 | Unclear Docs - mocker.patch - no attribute assert_called_once_with | I can't seem to find in the documentation anywhere how to assert mock function created with mocker.patch is called
Example:
```
def test(self, x):
return True
mock_a = mocker.patch('SomeClass.test', test)
SomeClass.some_test_method_that_calls_mocked_method()
mock_a.assert_called_once_with("a")
```
... | closed | 2022-02-26T20:34:10Z | 2022-06-10T00:54:51Z | https://github.com/pytest-dev/pytest-mock/issues/282 | [
"question"
] | ahurlburt | 3 |
python-gitlab/python-gitlab | api | 2,200 | RFE: Support Personal Access Token deletion using value | In GitLab 15.0 they added the ability to delete a Personal Access Token (PAT) by value. Previously could only delete a PAT by the ID. But if you have a lot of PATs and want to delete one with a specific value it was difficult, unless you had maintained a document mapping PAT values to IDs.
New API:
https://docs.git... | closed | 2022-07-29T04:15:43Z | 2023-07-31T01:24:28Z | https://github.com/python-gitlab/python-gitlab/issues/2200 | [] | JohnVillalovos | 1 |
PokemonGoF/PokemonGo-Bot | automation | 6,131 | Smart pinap function | ### Short Description
<!-- Tell us a short description of your request -->
I made a "smart pinap" function to maximize the use of pinap berries.
Ex1) If catch rate is over 85% for a normal mon use a pinap, but spare 3 for VIPs
Ex2) If catch rate is over a threshold (90%) for a VIP use a pinap, if under that thresho... | closed | 2017-07-25T12:17:00Z | 2017-07-25T14:57:27Z | https://github.com/PokemonGoF/PokemonGo-Bot/issues/6131 | [] | ChiefM3 | 1 |
mars-project/mars | scikit-learn | 2,560 | Reduction over different columns of a single DataFrame can be merged | When calculating series aggregations like `execute(df.a.sum(),df.b.mean())`, aggregations over different columns can be merged as `df.agg({'a': 'sum', 'b': 'mean'})`. An optimizer can be added to reduce num of subtasks. | open | 2021-10-28T08:55:47Z | 2021-10-28T08:56:50Z | https://github.com/mars-project/mars/issues/2560 | [
"type: enhancement",
"mod: dataframe"
] | wjsi | 0 |
ExpDev07/coronavirus-tracker-api | rest-api | 49 | I'm using your API | Thanks for implementing this Web API!
[CoronavirusDashboard](https://github.com/kw0006667/CoronavirusDashboardDemo) | closed | 2020-03-15T23:19:15Z | 2020-04-19T17:53:16Z | https://github.com/ExpDev07/coronavirus-tracker-api/issues/49 | [
"user-created"
] | kw0006667 | 0 |
dfki-ric/pytransform3d | matplotlib | 45 | Quaternion SLERP fails for identical Quaternions | def _slerp_weights(angle, t):
return (np.sin((1.0 - t) * angle) / np.sin(angle),
np.sin(t * angle) / np.sin(angle))
_slerp_weights divides by 0 when the angle between the rotations to interpolate between is zero, this leads to a nan Quaternion in SLERP. It would be preferable if a SLERP between two... | closed | 2020-05-06T15:48:01Z | 2020-05-07T12:07:22Z | https://github.com/dfki-ric/pytransform3d/issues/45 | [
"bug"
] | ruehr | 4 |
roboflow/supervision | computer-vision | 1,143 | I want to filter detections so that only the classes "No Helmet", "Person", "Rider" are detected. | ### Search before asking
- [X] I have searched the Supervision [issues](https://github.com/roboflow/supervision/issues) and found no similar feature requests.
### Question
My model has 4 classes: `"No Helmet", "Person", "Rider", "Wear a helmet"`
**I want to filter detections so that only the classes "No Hel... | closed | 2024-04-26T11:21:30Z | 2024-04-26T12:03:17Z | https://github.com/roboflow/supervision/issues/1143 | [
"question"
] | REZIZ-TER | 1 |
man-group/arctic | pandas | 81 | Need to check that metadata exists before enumerating | https://github.com/manahl/arctic/commit/702ac62789642b159f03382a4a7246be0c1cd039
(see _pandas_ndarray_store.py, line 75)
Should check that recarr.dtype.metadata.get('index_tz') is not None before enumerating to avoid the error "TypeError: 'NoneType' object is not iterable"
| closed | 2016-01-04T15:19:50Z | 2016-01-04T17:28:34Z | https://github.com/man-group/arctic/issues/81 | [
"bug"
] | bmoscon | 0 |
jacobgil/pytorch-grad-cam | computer-vision | 154 | how can i visual a model which not is a Classifier model? | closed | 2021-10-22T11:52:51Z | 2021-11-05T18:43:21Z | https://github.com/jacobgil/pytorch-grad-cam/issues/154 | [] | GuangtaoLyu | 1 | |
sinaptik-ai/pandas-ai | data-science | 988 | Trailing space in Column Header of CSV file causes incorrect response | ### System Info
OS Version: Ubuntu Ubuntu 22.04.4 LTS
Python Version: 3.9
pandasai Version: 2.0.2
### 🐛 Describe the bug
pandasai shows wrong results if column name has trailing space in it.
The following code works well on a CSV file with two columns 'Description' & 'Amount'.
The same code will just s... | closed | 2024-03-03T18:42:37Z | 2024-06-13T16:03:37Z | https://github.com/sinaptik-ai/pandas-ai/issues/988 | [
"bug"
] | ulloogeo | 1 |
dpgaspar/Flask-AppBuilder | flask | 1,370 | Potential dependency conflicts between flask-appbuilder and marshmallow | Hi, as shown in the following full dependency graph of **_flask-appbuilder_**, **_flask-appbuilder_** requires **_marshmallow <3.0.0,>=2.18.0_**, **_flask-appbuilder_** requires **_marshmallow-sqlalchemy >=0.16.1,<1_** (**_marshmallow-sqlalchemy 0.23.0_** will be installed, i.e., the newest version satisfying the versi... | closed | 2020-05-13T08:16:01Z | 2020-08-22T19:01:48Z | https://github.com/dpgaspar/Flask-AppBuilder/issues/1370 | [
"urgent",
"stale",
"dependency-bump"
] | NeolithEra | 3 |
D4Vinci/Scrapling | web-scraping | 42 | stealth=True parameter fails with sandbox error when running as root | ### Have you searched if there an existing issue for this?
- [x] I have searched the existing issues
### Python version (python --version)
3.10.12
### Scrapling version (scrapling.__version__)
0.2.95
### Dependencies version (pip3 freeze)
root@Ubuntu-2204-jammy-amd64-base ~ # pip3 freeze --all
aiofiles==24.1.0
... | closed | 2025-03-02T10:19:16Z | 2025-03-02T19:29:50Z | https://github.com/D4Vinci/Scrapling/issues/42 | [
"bug"
] | antonyderoshan | 3 |
chaos-genius/chaos_genius | data-visualization | 405 | [BUG] KPI validation for datetime column does not work | ## Describe the bug
The validation that checks the datetime column datatype does not work properly, as it does add valid datetime columns as well
## Current behavior
Valid datetime columns can not be added
## Expected behavior
Datetime columns should pass through the validation checks
## Screenshots
![im... | closed | 2021-11-15T10:34:35Z | 2021-11-15T13:07:48Z | https://github.com/chaos-genius/chaos_genius/issues/405 | [] | Fletchersan | 1 |
arnaudmiribel/streamlit-extras | streamlit | 162 | 🐛 [BUG] - dataframe sort by date column seems broken | ### Description
Hi, I passed a dataframe into dataframe_explorer, in the UI when I try to sort by date columns it raise a warning which indicates a problem in the source code, and in the UI the table is not sorted correctly for the date columns.
```
filtered_df = dataframe_explorer(df, case=False)
col_c... | open | 2023-08-07T09:43:52Z | 2024-07-31T12:30:32Z | https://github.com/arnaudmiribel/streamlit-extras/issues/162 | [
"bug"
] | yulevern | 1 |
Kanaries/pygwalker | matplotlib | 564 | [BUG] pygwalker bug report: retrieving specs when app URL has path | **Describe the bug**
It looks like Pygwalker cannot **read** specs when the app's url is composed of a host + path. **Writting** seems fine though.
For example, I have an app deployed with the following URL structure:
ORIGIN/PATHNAME
This URL structure comes from corporate constraints within the company I work fo... | closed | 2024-05-31T09:47:37Z | 2024-05-31T23:53:56Z | https://github.com/Kanaries/pygwalker/issues/564 | [
"bug"
] | thomasbs17 | 2 |
exaloop/codon | numpy | 122 | why linux install conda module not found? | closed | 2022-12-19T05:55:07Z | 2022-12-19T07:34:30Z | https://github.com/exaloop/codon/issues/122 | [] | DongYangYang621 | 0 | |
comfyanonymous/ComfyUI | pytorch | 6,623 | CFG++ implementation for gradient_estimation sampler | ### Feature Idea
I would love to see a CFG++ implementation for the gradient_estimation sampler (https://github.com/comfyanonymous/ComfyUI/pull/6554)!
### Existing Solutions
See: `res_multistep_cfg_pp` sampler: https://github.com/comfyanonymous/ComfyUI/blob/255edf22463f597a1e136091e0f5cbbbe5f400a4/comfy/k_diffusion/... | open | 2025-01-27T22:22:06Z | 2025-01-28T02:45:10Z | https://github.com/comfyanonymous/ComfyUI/issues/6623 | [
"Feature"
] | not-ski | 2 |
AntonOsika/gpt-engineer | python | 688 | Sweep: Add a continuous mode | This new mode and capability will allow for autonomous and continuous code generation, debugging, and code running/testing by engineer. When this mode is enabled, only the user/operator can manually stop it by exiting the terminal window by hand. Otherwise, gpt-engineer should especially remember to keep running, even ... | closed | 2023-09-11T19:49:40Z | 2023-09-12T09:29:36Z | https://github.com/AntonOsika/gpt-engineer/issues/688 | [
"sweep"
] | meyerjohn1 | 2 |
twelvedata/twelvedata-python | matplotlib | 47 | [Bug] Weekend data (inconsistently) appearing in time_series data. | **Describe the bug**
When requesting time_series data, saturday/sunday candles randomly appear. (I'm assuming this is a bug server side and not python side. But not sure how to raise that).
`1day`: saturday candle (2022-03-05)
```
{'datetime': '2022-03-07', 'open': '1.32290', 'high': '1.32410', 'low': '1.31025', ... | closed | 2022-03-09T12:03:55Z | 2022-03-10T09:48:18Z | https://github.com/twelvedata/twelvedata-python/issues/47 | [] | EdgyEdgemond | 1 |
napari/napari | numpy | 7,074 | Shape gets highlighted if hovered on loosing focus | ### 🐛 Bug Report
When a Shape is hovered with the mouse, and the napari application looses focus, the Shape will be highlighted. This also emits a highlight event.
### 💡 Steps to Reproduce
Add a `Shapes` layer and hover over a shape.
Then loose the focus from the napari application with for example tabbin... | closed | 2024-07-05T22:10:12Z | 2024-11-21T05:50:51Z | https://github.com/napari/napari/issues/7074 | [
"bug",
"UI/UX"
] | OnionKiller | 3 |
graphdeco-inria/gaussian-splatting | computer-vision | 1,139 | pruning questions | When I use the point cloud generated by open3d as input, the number of Gauss rises briefly, and then filters out some of the non-eligible Gauss at the 3000th iteration, but why filter out more than half of the original Gauss I input | open | 2025-01-09T07:05:52Z | 2025-01-10T23:29:37Z | https://github.com/graphdeco-inria/gaussian-splatting/issues/1139 | [] | thespecialyan | 1 |
unytics/bigfunctions | data-visualization | 19 | [new] `json_items(json_string)` | Takes a json_string as input which has flat (no nested) key values and returns an `array<struct<key string, value string>>` | closed | 2022-12-06T23:28:17Z | 2022-12-09T09:58:49Z | https://github.com/unytics/bigfunctions/issues/19 | [
"good first issue",
"new-bigfunction"
] | unytics | 1 |
tensorly/tensorly | numpy | 113 | Error: Too many values to unpack (expected 2) | Hi, @JeanKossaifi
When I was using your latest version (0.4.4) installed from the github website, an error occurs which provides the following error messages:
`
13 sparse_factors = sparse_parafac(tensor=dataset['source_tensor'], rank=5, init='random', random_state=123456, return_errors=True, mask=dataset['mask_t... | closed | 2019-05-29T07:33:52Z | 2019-06-16T05:54:41Z | https://github.com/tensorly/tensorly/issues/113 | [] | zhuyf8899 | 4 |
miguelgrinberg/Flask-Migrate | flask | 375 | sqlalchemy.exc.OperationalError: (sqlite3.OperationalError) table sqlite_sequence may not be dropped | when i run 'db migrate' , show

Then i run 'db upgrade' ,i get expection:

how can i ... | closed | 2020-11-29T18:02:06Z | 2022-07-09T18:50:28Z | https://github.com/miguelgrinberg/Flask-Migrate/issues/375 | [
"question"
] | Mr-NB | 3 |
huggingface/datasets | tensorflow | 6,891 | Unable to load JSON saved using `to_json` | ### Describe the bug
Datasets stored in the JSON format cannot be loaded using `json.load()`
### Steps to reproduce the bug
```
import json
from datasets import load_dataset
dataset = load_dataset("squad")
train_dataset, test_dataset = dataset["train"], dataset["validation"]
test_dataset.to_json("full_dataset... | closed | 2024-05-12T01:02:51Z | 2024-05-16T14:32:55Z | https://github.com/huggingface/datasets/issues/6891 | [] | DarshanDeshpande | 2 |
microsoft/qlib | deep-learning | 1,317 | on qrun:"mlflow.exceptions.MlflowException: Param value .... had length 780, which exceeded length limit of 500 " | ## 🐛 Bug Description
<!-- A clear and concise description of what the bug is. -->
when I do the example:
qrun qrun benchmarks\GATs\workflow_config_gats_Alpha158.yaml
I got the error info:
(py38) D:\worksPool\works2021\adair2021\S92\P4\qlib-main\examples>qrun benchmarks\GATs\workflow_config_gats_Alpha1... | closed | 2022-10-14T00:51:57Z | 2022-11-06T07:00:01Z | https://github.com/microsoft/qlib/issues/1317 | [
"bug"
] | nkchem09 | 4 |
ShishirPatil/gorilla | api | 92 | retrain results are poor | Great work thanks for sharing!!!
I used the fastchat code combined with the apibench/huggingface_train.json data and the llamav2-7b model to retrain to get a new model, but the inference result of the model is very poor. The data uses the fastchat conversation format and the vicuna template, and the data content valu... | open | 2023-08-10T08:31:22Z | 2023-08-10T08:31:22Z | https://github.com/ShishirPatil/gorilla/issues/92 | [] | fan-niu | 0 |
keras-team/keras | pytorch | 20,487 | Add parameter axis to tversky loss | Add parameter axis to tversky loss similar to dice loss.
I can implement that if someone give me green light :) | closed | 2024-11-12T20:37:45Z | 2024-12-01T08:43:06Z | https://github.com/keras-team/keras/issues/20487 | [
"type:feature"
] | jakubxy08 | 4 |
statsmodels/statsmodels | data-science | 8,630 | Autocorrelation function of AR(p) returns nan when coefficient are high (but still < 1)of $X_{t-1}$ or too many time points | #### Describe the bug
I am not sure if this is a bug, I created some time series and I want to play around with it.
When I set the first coefficient above 0.8, 0.9 (depending on how many time points) I get nan values from tsa.stattools.acf or pacf.
The more timepoints there are the lower the the threshold.
I woul... | closed | 2023-01-22T11:41:45Z | 2023-04-14T15:04:27Z | https://github.com/statsmodels/statsmodels/issues/8630 | [] | aegonwolf | 1 |
sktime/pytorch-forecasting | pandas | 1,138 | index out of range in self when training a trained model on additional data | - PyTorch-Forecasting version: 0.10.3
- PyTorch version: 1.12.1
- Python version: 3.9.12
- Operating System: amazon linux 2
### Expected behavior
I executed the code in the Demand forecasting with the Temporal Fusion Transformer tutorial on similar dataset of my own.
I save the trained model to file. Next, I ... | open | 2022-09-21T14:03:21Z | 2023-02-16T20:19:08Z | https://github.com/sktime/pytorch-forecasting/issues/1138 | [] | id5h | 1 |
litestar-org/litestar | api | 3,722 | Bug: Pydantic `json_schema_extra` fields aren't all merged | ### Description
When defining schema overrides on a Pydantic model via `json_schema_extra`, not all of them are applied to the generated schema
### MCVE
```python
import pydantic
from litestar import Litestar, get
class Model(pydantic.BaseModel):
with_title: str = pydantic.Field(title="WITH_title... | closed | 2024-09-08T08:26:43Z | 2025-03-20T15:54:54Z | https://github.com/litestar-org/litestar/issues/3722 | [
"Bug :bug:"
] | provinzkraut | 0 |
neuml/txtai | nlp | 108 | Add notebook for ONNX pipeline | Add notebook that shows how to export to ONNX and shows how an ONNX model can be run in other programming languages. | closed | 2021-08-27T22:36:51Z | 2021-08-27T22:41:31Z | https://github.com/neuml/txtai/issues/108 | [] | davidmezzetti | 0 |
CorentinJ/Real-Time-Voice-Cloning | deep-learning | 1,200 | webrtcvad wont install | When I try to install webrtcvad with pip install webrtcvad it throws out
Collecting webrtcvad
Using cached webrtcvad-2.0.10.tar.gz (66 kB)
Preparing metadata (setup.py) ... done
Building wheels for collected packages: webrtcvad
Building wheel for webrtcvad (setup.py) ... error
error: subprocess-exited... | open | 2023-04-21T22:17:25Z | 2024-08-06T16:59:22Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/1200 | [] | zamonster | 6 |
Lightning-AI/pytorch-lightning | pytorch | 20,046 | ModelCheckpoint could not find key in returned metrics | ### Bug description
I have a model with several `ModelCheckpoint` callbacks. When loading it from a checkpoint using `trainer.fit(model, datamodule=dm, ckpt_path=training_ckpt_path)`, I get the following error:
```
lightning_fabric.utilities.exceptions.MisconfigurationException: `ModelCheckpoint(monitor='v_nll_uns... | open | 2024-07-04T14:19:45Z | 2024-07-25T14:06:42Z | https://github.com/Lightning-AI/pytorch-lightning/issues/20046 | [
"bug",
"help wanted",
"callback: model checkpoint",
"ver: 2.1.x"
] | TheAeryan | 1 |
SYSTRAN/faster-whisper | deep-learning | 159 | Can faster-whisper return the left/right mono channel? | Since faster-whisper seems always separate segments if not same channel, also can decode stereo to mono channels, I'm wondering if it's easy for faster-whisper to return which channel is for the segment? | closed | 2023-04-16T21:16:08Z | 2023-05-09T00:50:32Z | https://github.com/SYSTRAN/faster-whisper/issues/159 | [] | junchen6072 | 2 |
napari/napari | numpy | 6,990 | Add tests for scalebar visibility | ## 🧰 Task
I tracked the bugs in #6959 and #6961 to #5432. It seems this part of the code is untested even though it was covered. So it would be good to add tests for it so our scale bars don't disappear again. 😅 | closed | 2024-06-15T07:13:20Z | 2024-06-23T13:40:43Z | https://github.com/napari/napari/issues/6990 | [
"task"
] | jni | 6 |
pyppeteer/pyppeteer | automation | 238 | Browser.pages() being inconsistent when new pages created | When a new tab is created; and if within a very less time gap, browser.pages is called; then the page object return from Browser.newPage() is not present in the list of pages. The newPage function returns a different Page object than the one in the Browser.pages() but there does exit a different Page object in the list... | open | 2021-03-17T16:10:07Z | 2023-04-09T11:23:02Z | https://github.com/pyppeteer/pyppeteer/issues/238 | [] | bytefoot | 1 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.