
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
miguelgrinberg/Flask-SocketIO | flask | 916 | Socketio doesn't work properly when Flask is streaming video | I am trying to build a RPi zero controlled toy car with camera and stream video to web page.
I found your project [flask-video-streaming](https://github.com/miguelgrinberg/flask-video-streaming/blob/master/base_camera.py) which works great, and I try to combine it with the [ZeroBot project](https://github.com/Corete... | closed | 2019-03-06T19:58:57Z | 2019-06-08T08:00:21Z | https://github.com/miguelgrinberg/Flask-SocketIO/issues/916 | [
"question"
] | hyansuper | 5 |
benbusby/whoogle-search | flask | 255 | Does pre-config apply to heroku deployment as that? | hi, i have a question about heroku deployment.
https://github.com/IniUe/whoogle-search#environment-variables
`# You can set Whoogle environment variables here, but must set`
`# WHOOGLE_DOTENV=1 in your deployment to enable these values`
https://github.com/benbusby/whoogle-search/blob/develop/whoogle.env
Is i... | closed | 2021-04-02T07:35:38Z | 2021-04-02T12:55:58Z | https://github.com/benbusby/whoogle-search/issues/255 | [
"question"
] | ghost | 4 |
tensorflow/tensor2tensor | deep-learning | 1,659 | Getting to work with MultiProblem | #### Please refer to https://github.com/tensorflow/tensor2tensor/issues/1687
----
For training models, I have separated the data generation pipeline from t2t. For that I have implemented my own problem which, in essence, already expects a created dataset.
```python
@registry.register_problem
class ConfigBase... | closed | 2019-08-13T13:30:34Z | 2019-09-05T10:00:01Z | https://github.com/tensorflow/tensor2tensor/issues/1659 | [] | stefan-falk | 0 |
scikit-learn/scikit-learn | python | 30,056 | LinearSVC does not correctly handle sample_weight under class_weight strategy 'balanced' | ### Describe the bug
LinearSVC does not pass sample weights through when computing class weights under the "balanced" strategy leading to sample weight invariance issues cross-linked to meta-issue #16298
### Steps/Code to Reproduce
```python
from sklearn.svm import LinearSVC
from sklearn.base import clone
from ... | closed | 2024-10-13T15:09:29Z | 2025-02-11T18:20:03Z | https://github.com/scikit-learn/scikit-learn/issues/30056 | [
"Bug"
] | snath-xoc | 1 |
globaleaks/globaleaks-whistleblowing-software | sqlalchemy | 3,193 | Fields of old default whistleblower_identity and new default are shown together after version upgrade | **Describe the bug**
After upgradin GL from 4.0.54 to 4.7.17 Fields of old default whistleblower_identity and new default are shown together in identity section of a previously installaed tenant.
Steps to reproduce the behavior:
1. upgrading GL from 4.0.54 to 4.7.17
2. going to step identity -> whistleblowi... | closed | 2022-03-10T16:50:06Z | 2022-03-12T22:08:41Z | https://github.com/globaleaks/globaleaks-whistleblowing-software/issues/3193 | [
"T: Bug",
"C: Backend"
] | larrykind | 1 |
bmoscon/cryptofeed | asyncio | 341 | Example for OHLC information does not work | The example code here
https://github.com/bmoscon/cryptofeed/blob/master/examples/demo_ohlcv.py
fails with this error
TypeError: __call__() got an unexpected keyword argument 'order_type' | closed | 2020-11-30T01:02:18Z | 2020-11-30T04:27:06Z | https://github.com/bmoscon/cryptofeed/issues/341 | [
"bug"
] | mccoydj1 | 3 |
ymcui/Chinese-BERT-wwm | tensorflow | 92 | 想请问怎么把这个模型放到TFBertModel中,可否提供模型的h5文件? | closed | 2020-03-16T08:44:17Z | 2020-03-25T10:02:18Z | https://github.com/ymcui/Chinese-BERT-wwm/issues/92 | [] | JOHNYXUU | 3 | |
plotly/dash-bio | dash | 106 | invalid plotly syntax in component factory manhattan component | The syntax in https://github.com/plotly/dash-bio/blob/master/dash_bio/component_factory/_manhattan.py#L440 and https://github.com/plotly/dash-bio/blob/master/dash_bio/component_factory/_manhattan.py#L453 may need to be updated.
when running locally (after `pip install -r requirements.txt`) I'm getting:
```
(venv3... | closed | 2019-01-17T00:16:51Z | 2019-01-21T18:01:40Z | https://github.com/plotly/dash-bio/issues/106 | [] | cldougl | 5 |
huggingface/datasets | nlp | 7,249 | How to debugging | ### Describe the bug
I wanted to use my own script to handle the processing, and followed the tutorial documentation by rewriting the MyDatasetConfig and MyDatasetBuilder (which contains the _info,_split_generators and _generate_examples methods) classes. Testing with simple data was able to output the results of the ... | open | 2024-10-24T01:03:51Z | 2024-10-24T01:03:51Z | https://github.com/huggingface/datasets/issues/7249 | [] | ShDdu | 0 |
qwj/python-proxy | asyncio | 141 | Custom filter functions? | Hello, is it possible to add custom filtering functions based on the content?
Basically I want to filter YouTube videos based on their metadata, something I can do by leveraging the YouTube Data API. It is ok if the request takes several seconds.
I took a quick look of the code and I think I could add this in the co... | closed | 2021-12-05T03:51:36Z | 2022-07-05T07:35:41Z | https://github.com/qwj/python-proxy/issues/141 | [] | crorella | 0 |
jina-ai/serve | deep-learning | 5,585 | Change documentation for `CONTEXT` environment variables | **Describe your proposal/problem**
<!-- A clear and concise description of what the proposal is. -->
The [docs](https://docs.jina.ai/concepts/flow/yaml-spec/#context-variables) don't specify how to use context variables in a flow yaml.
It should be made clear that when defining a flow using the YAML specificatio... | closed | 2023-01-09T16:05:59Z | 2023-04-24T00:18:00Z | https://github.com/jina-ai/serve/issues/5585 | [
"Stale",
"area/docs"
] | npitsillos | 2 |
nalepae/pandarallel | pandas | 112 | Weird return from parallel_apply() | (duplicated) #111 | closed | 2020-10-06T03:54:32Z | 2020-10-06T03:55:15Z | https://github.com/nalepae/pandarallel/issues/112 | [] | conraddd | 0 |
HIT-SCIR/ltp | nlp | 380 | 您好,咨询3.3.2版本otcws训练分词模型cws.model的问题 | 您好,用otcws训练人民日报1998六个月的分词模型总是失败,build-featurespace: 30% instances is extracted.提取到30%的时候就退出了,训练5万行以下的文本可以,训练5万行以上的文本就总是失败,我想问一下用otcws训练模型的时候有什么限制吗,比如不能存在特殊字符,单行文本字符限制,整个训练样本不能过长等,期待收到您的回复!
ps:硬件环境为16核 128GB,window下命令otcws.exe learn --reference people1998.seg --development people1998.seg --algorithm pa --model cws.mo... | closed | 2020-07-09T08:45:27Z | 2020-07-10T07:43:48Z | https://github.com/HIT-SCIR/ltp/issues/380 | [] | GuohyCoding | 1 |
nalepae/pandarallel | pandas | 7 | Implement GroupBy.parallel_apply | open | 2019-03-16T13:28:36Z | 2019-03-16T13:31:14Z | https://github.com/nalepae/pandarallel/issues/7 | [
"enhancement"
] | nalepae | 0 | |
microsoft/nni | tensorflow | 4,817 | Why does SlimPruner utilize the WeightTrainerBasedDataCollector instead of the WeightDataCollector before model compressing? | open | 2022-04-27T11:43:29Z | 2022-04-29T01:50:48Z | https://github.com/microsoft/nni/issues/4817 | [] | songkq | 1 | |
TencentARC/GFPGAN | pytorch | 176 | Some colors in black and white photo | A minor detail, in some black and white photos, colors appear that are not in the photo, but it seems that the model "suggests" what colors it should have. It is also remarkable the improvement of the V1.3 model. Although the 1.1 model has behaved very generous with this image. I must also add that some faces have been... | open | 2022-03-13T08:45:33Z | 2022-03-14T23:23:38Z | https://github.com/TencentARC/GFPGAN/issues/176 | [] | GOZARCK | 2 |
nltk/nltk | nlp | 3,149 | TclError resizing download dialog table column | When attempting to resize a column in the downloader dialog, and error is raised and the column does not resize.
Steps to reproduce:
- Run `nltk.download()` to open downloading interface
- Try resizing any of the table columns (e.g. "Identifier" in the first tab)
An example full traceback is as follows:
```
E... | closed | 2023-05-04T10:38:45Z | 2023-05-08T08:23:10Z | https://github.com/nltk/nltk/issues/3149 | [] | E-Paine | 0 |
huggingface/datasets | deep-learning | 7,215 | Iterable dataset map with explicit features causes slowdown for Sequence features | ### Describe the bug
When performing map, it's nice to be able to pass the new feature type, and indeed required by interleave and concatenate datasets.
However, this can cause a major slowdown for certain types of array features due to the features being re-encoded.
This is separate to the slowdown reported i... | open | 2024-10-10T22:08:20Z | 2024-10-10T22:10:32Z | https://github.com/huggingface/datasets/issues/7215 | [] | alex-hh | 0 |
viewflow/viewflow | django | 449 | CreateViewMixin doesn't check permissions before adding "Add new" page action | `class CreateViewMixin(metaclass=ViewsetMeta):
create_view_class = CreateModelView
create_form_layout = DEFAULT
create_form_class = DEFAULT
create_form_widgets = DEFAULT
def has_add_permission(self, user):
return has_object_perm(user, "add", self.model)
def get_create_view_kwa... | closed | 2024-06-19T22:41:26Z | 2024-06-24T10:26:05Z | https://github.com/viewflow/viewflow/issues/449 | [] | SamuelLayNZ | 1 |
cs230-stanford/cs230-code-examples | computer-vision | 17 | Error when run build_dataset.py on windows | In Windows OS, folder names in a path join together with back slash [ \ ] instead of slash [ / ] like this:
> C:\Program Files\NVIDIA GPU Computing Toolkit
so build_dataset.py throw an error. because it can't split filename from directory.
I solve it by replace the slash with double back slash '\\'
`image.s... | open | 2019-04-05T11:21:30Z | 2024-01-23T11:41:54Z | https://github.com/cs230-stanford/cs230-code-examples/issues/17 | [] | Amin-Tgz | 1 |
zhiyiYo/Fluent-M3U8 | dash | 5 | 是不是下载完没有文件列表完整性校验?网络波动一下就下载不全,然后合成失败 | 特别是下载外网视频时,一旦梯子不稳断线重连一下,断线时正在下载的ts文件就一直是temp后缀,下完合成失败,打开下载文件夹一看还有temp后缀的ts文件在。能不能合成之前先进行已下载文件列表完整性校验,把下载失败的文件单独再下载? | closed | 2025-02-16T14:24:25Z | 2025-02-17T16:21:46Z | https://github.com/zhiyiYo/Fluent-M3U8/issues/5 | [
"enhancement"
] | cai1niao1 | 2 |
miguelgrinberg/microblog | flask | 62 | Problem with sending email | I have searched, compared line by line and can't for the life of me figure out what I have done wrong.
Seems the error originates in the email.py file.
```
powershell
127.0.0.1 - - [03/Jan/2018 18:57:27] "GET /reset_password_request HTTP/1.1" 200 -
[2018-01-03 18:57:32,933] ERROR in app: Exception on /reset_pass... | closed | 2018-01-03T18:16:55Z | 2018-01-04T18:44:44Z | https://github.com/miguelgrinberg/microblog/issues/62 | [
"bug"
] | Callero | 2 |
flairNLP/flair | nlp | 3,428 | [Bug]: Error message: "learning rate too small - quitting training!" | ### Describe the bug
Model training quits after epoch 1 with a "learning rate too small - quitting training!" error message even though the "patience" parameter is set to 10.
### To Reproduce
```python
In Google Colab:
!pip install flair -qq
import os
from os import mkdir, listdir
from os.path import join, ... | closed | 2024-03-18T14:58:03Z | 2024-03-18T16:14:55Z | https://github.com/flairNLP/flair/issues/3428 | [
"bug"
] | azkgit | 1 |
lukas-blecher/LaTeX-OCR | pytorch | 319 | Training isn't working properly | I tried to train a custom model. This model's intention was to detect matrices, so I created a dataset, tokenizer, and config.yaml file.
However, I am here for a reason. For some reason it doesn't appear to actually be training. This is the output from the following command:
```
!python -m pix2tex.train --config col... | open | 2023-09-21T16:36:56Z | 2023-09-21T16:37:19Z | https://github.com/lukas-blecher/LaTeX-OCR/issues/319 | [] | frankvp11 | 0 |
Ehco1996/django-sspanel | django | 649 | 节点名称中文乱码 | **问题的描述**
使用potatso lite添加ss订阅,中文乱码
**相关截图/log**

| closed | 2022-03-15T08:20:21Z | 2022-03-19T09:24:13Z | https://github.com/Ehco1996/django-sspanel/issues/649 | [
"bug"
] | dymasch | 2 |
tensorflow/tensor2tensor | machine-learning | 1,631 | Most straight forward way to train summarization on new data with simpler format than CNN/DM datasets? Make a new data_generator ? | ### Description
I would like to train a summarizer on my own data, and I am wondering what's the most straightforward way to do this. The CNN/DailyMail datasets have a bit of an odd format which seems tricky to convert regular summarization datasets (CSVs with 1 column for source, 1 column for summary) into.
So ... | closed | 2019-07-12T22:51:02Z | 2021-03-03T13:07:17Z | https://github.com/tensorflow/tensor2tensor/issues/1631 | [] | Santosh-Gupta | 2 |
LibreTranslate/LibreTranslate | api | 679 | Basque translation project needs update in Weblate | Comparing with English string quantity [161](https://hosted.weblate.org/projects/libretranslate/app/en/), there are less available in the Basque project: [143](https://hosted.weblate.org/projects/libretranslate/app/eu/)
For example "Albanian", "Chinese (traditional)", "Kabyle" and some other are missing.
I guess ... | closed | 2024-09-20T23:31:15Z | 2024-09-21T16:41:37Z | https://github.com/LibreTranslate/LibreTranslate/issues/679 | [
"enhancement"
] | urtzai | 1 |
xlwings/xlwings | automation | 1,724 | while accessing worksheet.range com_error: (-2147352573, 'Member not found.', None, None) | #### OS Windows 7 professional
#### Versions of xlwings 0.24.9, Excel 2010 and Python 3.8.10
#### Describe your issue (incl. Traceback!)
The code worked fine the yesterday, but today it is not working.
```python
# Your traceback here
Traceback (most recent call last):
File "C:\Users\ssp\SpyderPythonPro... | closed | 2021-10-01T00:58:54Z | 2022-02-05T20:09:49Z | https://github.com/xlwings/xlwings/issues/1724 | [] | ssprakash-seeni | 5 |
polakowo/vectorbt | data-visualization | 493 | Pulling fundamental data | Thank you to the vectorbt team for all their hard work with this great library!
I was wondering if it were possible to pull more fundamental-style data into vectorbt? I'm interested in things like total current assets, long term investments, total current liabilities, etc.? I'm not sure if there is a particular data... | closed | 2022-09-06T15:44:44Z | 2022-09-20T01:14:25Z | https://github.com/polakowo/vectorbt/issues/493 | [] | aclifton314 | 1 |
drivendataorg/cookiecutter-data-science | data-science | 8 | Add option to choose different data storage back ends | - S3 (get AWS settings)
- Git Large File Storage
- Git Annex
- dat
| closed | 2016-04-23T17:56:20Z | 2023-08-30T21:26:21Z | https://github.com/drivendataorg/cookiecutter-data-science/issues/8 | [] | pjbull | 2 |
huggingface/transformers | pytorch | 36,571 | In the latest version of transformers (4.49.0) matrix transformation error is encountered | ### System Info
transformer Version : 4.49.0
python version: python3.10
env : HuggingFace spaces
Looks to be working in : 4.48.3
Please find the following HuggingFace Space code which works in (4.48.3) but fails in (4.49.0)
Code :
`
import os
--
| import random
| import uuid
| import gradio as gr
| import ... | open | 2025-03-06T05:33:31Z | 2025-03-07T05:39:13Z | https://github.com/huggingface/transformers/issues/36571 | [
"bug"
] | idebroy | 3 |
ymcui/Chinese-LLaMA-Alpaca | nlp | 558 | 合并Lora时报错NotImplementedError | chinese-alpaca-plus-lora-13b
chinese-llama-plus-lora-13b
chinese-llama-plus-lora-7b
执行单LoRA权重合并时候,报错NotImplementedError
(fastchat) root@estar-ESC8000-G4:~# pip list \| grep*
Package Version
------------------- ------------
accelerate 0.19.0
aiofiles 23.1.0
aiohttp ... | closed | 2023-06-10T12:29:52Z | 2023-06-12T00:16:39Z | https://github.com/ymcui/Chinese-LLaMA-Alpaca/issues/558 | [] | wuxiulike | 5 |
PrefectHQ/prefect | automation | 17,017 | Validation error when using anonymous volumes | ### Bug summary
It looks like Prefect's validation doesn't allow anonymous volumes. This is my volume configuration:
<img width="548" alt="Image" src="https://github.com/user-attachments/assets/8f91b48e-a923-4745-8a32-be386c68368f" />
That throws the following Validation error:
```
19:30:34.753 | ERROR | prefect.... | closed | 2025-02-06T19:46:55Z | 2025-02-07T01:07:56Z | https://github.com/PrefectHQ/prefect/issues/17017 | [
"bug"
] | anze3db | 2 |
Lightning-AI/pytorch-lightning | pytorch | 20,249 | Shuffle order is the same across runs when using strategy='ddp' | ### Bug description
The batches and their order are the same across different executions of the script when using strategy='ddp' and dataloader with shuffle=True
### What version are you seeing the problem on?
v2.2
### How to reproduce the bug
Say you have train.py that prints the current input on each ... | open | 2024-09-05T17:40:58Z | 2024-10-25T08:54:44Z | https://github.com/Lightning-AI/pytorch-lightning/issues/20249 | [
"bug",
"needs triage",
"ver: 2.2.x"
] | bogdanmagometa | 2 |
rthalley/dnspython | asyncio | 670 | Support DoH over HTTP/2 | `dns.query.https` currently queries DoH endpoints with HTTP/1.1 requests with no way to switch to HTTP/2. This is a problem for querying endpoints supporting only HTTP/2 (such as `odvr.nic.cz/dns-query`).
I realize that `requests` are [unlikely](https://github.com/psf/requests/issues/5757) to add HTTP/2 support and ... | closed | 2021-06-17T11:44:19Z | 2021-11-20T14:38:12Z | https://github.com/rthalley/dnspython/issues/670 | [
"Enhancement Request"
] | balaziks | 6 |
ccxt/ccxt | api | 24,928 | Greetings, similar question | > @sc0Vu Thank you, I thought that it called same everywhere. Found what I was looking for everywhere except the exchange Gate, there are such a method, it called - GET /wallet/currency_chains. But I can t find function that use it in ccxt. Maybe you would be so kind as to tell me.
_Originally posted by @AlwxDavydov... | closed | 2025-01-17T17:22:33Z | 2025-01-17T17:33:08Z | https://github.com/ccxt/ccxt/issues/24928 | [] | X1r0s | 0 |
huggingface/transformers | tensorflow | 36,321 | Config' object has no attribute 'get_text_config on 4.49.0 VS 4.46.0 all OK | Hello, was using ComfyUI node for BiRefNet models (https://github.com/MoonHugo/ComfyUI-BiRefNet-Hugo) with Transformers 4.46.0 and it was running all perfect. Now, when I upgrade to transformers 4.49.0 it stops with the error "Config' object has no attribute 'get_text_config". If I downgrade back to 4.46.0 version the ... | closed | 2025-02-21T07:31:47Z | 2025-02-24T10:23:59Z | https://github.com/huggingface/transformers/issues/36321 | [] | MegaCocos | 12 |
man-group/arctic | pandas | 789 | Accessing keep_mins kwarg in _prune_previous_versions | Hello,
I was wondering how the user can set the keep_mins kwarg when removing older versions. Thank you.
https://github.com/manahl/arctic/blob/722316c0f9fa7d1d7b757483b8573b57169d97ca/arctic/store/version_store.py#L858 | closed | 2019-06-25T20:58:33Z | 2019-07-05T17:41:22Z | https://github.com/man-group/arctic/issues/789 | [] | mschrem | 6 |
Farama-Foundation/Gymnasium | api | 871 | [Bug Report] max_episode_steps is not passed to the env's spec attribute anymore | ### Describe the bug
In [previous versions of gym](https://github.com/openai/gym/blob/dcd185843a62953e27c2d54dc8c2d647d604b635/gym/envs/registration.py#L502C1-L503C1), an env registered with `max_episode_steps=N` could see its `env.spec.max_episode_steps` refelect this value.
Now this attribute is automatically [set... | closed | 2024-01-11T08:05:18Z | 2024-01-21T19:31:18Z | https://github.com/Farama-Foundation/Gymnasium/issues/871 | [
"bug"
] | vmoens | 17 |
cvat-ai/cvat | computer-vision | 8,450 | Didn't receive all labels for images when downloading dataset in YOLOv8 detection format | ### Actions before raising this issue
- [X] I searched the existing issues and did not find anything similar.
- [X] I read/searched [the docs](https://docs.cvat.ai/docs/)
### Steps to Reproduce
1. Right click on project
2. Click export dataset
3. Export in YOLOv8 detection format
### Expected Behavior
... | closed | 2024-09-17T13:48:11Z | 2024-10-08T16:20:05Z | https://github.com/cvat-ai/cvat/issues/8450 | [
"bug",
"need info"
] | benjiroooo | 1 |
InstaPy/InstaPy | automation | 5,941 | dont get this bot | this bot is a cheat it follows the same people over and over and likes and comments them ...i tried multiple accounts..chanegd ip...blocked those people it give me an eror....i didnt even give a follow command but its following them...and its the same people always nice cheat..ofc free bot cuz u are making profit with... | closed | 2020-12-07T17:09:42Z | 2021-01-19T01:02:34Z | https://github.com/InstaPy/InstaPy/issues/5941 | [
"wontfix"
] | dphenom21 | 2 |
autokey/autokey | automation | 713 | updated libnotify 0.8.0-1 breaks autokey-gtk on arch linux | ### Has this issue already been reported?
- [X] I have searched through the existing issues.
### Is this a question rather than an issue?
- [X] This is not a question.
### What type of issue is this?
Crash/Hang/Data loss
### Which Linux distribution did you use?
OS: EndeavourOS Linux x86_64
Kernel: 5.15.54-1-lt... | closed | 2022-07-16T06:27:38Z | 2022-07-20T19:42:24Z | https://github.com/autokey/autokey/issues/713 | [
"upstream bug"
] | pierostrada | 12 |
RobertCraigie/prisma-client-py | pydantic | 252 | Prompt the user to specify recursive type depth if they haven't already | ## Problem
<!-- A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] -->
Currently, I imagine that most people will just use pseudo-recursive types as that is default and they don't know that there is a better option. We should try and make this option more present.
## S... | closed | 2022-01-28T14:55:41Z | 2022-05-22T12:49:51Z | https://github.com/RobertCraigie/prisma-client-py/issues/252 | [
"kind/improvement",
"good first issue",
"level/beginner",
"priority/medium"
] | RobertCraigie | 0 |
explosion/spaCy | nlp | 13,190 | Spacy high memory consumption issue | Hello,
I am running spacy model with english medium weights inside kubernetes pod.
As I am observing after loading spacy model, it's taking around 500mb space and while after every prediction it keeps increasing.
I am wondering even after deleting spacy object then also it's not releasing memory.
I have allot... | closed | 2023-12-08T19:00:46Z | 2023-12-11T07:45:34Z | https://github.com/explosion/spaCy/issues/13190 | [
"perf / memory"
] | nikhilcms | 1 |
Nemo2011/bilibili-api | api | 670 | [提问] 如何搜索超过1000条结果? | **Python 版本:** 3.10
**模块版本:** 16.1.1
**运行环境:** Windows
<!-- 务必提供模块版本并确保为最新版 -->
---
请问目前的search.search_by_type()每次仅能返回50页,每页20项,一共1000项,如果想获得更多数据怎么做?
| closed | 2024-02-04T14:13:06Z | 2024-03-15T14:19:10Z | https://github.com/Nemo2011/bilibili-api/issues/670 | [
"question"
] | tomriddle1234 | 3 |
deepspeedai/DeepSpeed | machine-learning | 6,007 | [BUG] Trainer saves global_steps300 in LoRA training with deepspeed | **Describe the bug**
I trained LLama 2 with deepspeed/
Trainer with 2 GPU but on saving the checkpoint with the following configuration deepspeed saves a large folder global_step50, which is 44GB. How I can automatically **not** save this folder? I just need adapter checkpoints.
![Screenshot from 2024-08-16 02-44-... | open | 2024-08-16T07:49:01Z | 2024-08-16T07:50:03Z | https://github.com/deepspeedai/DeepSpeed/issues/6007 | [
"bug",
"training"
] | YerongLi | 0 |
fastapi/sqlmodel | pydantic | 336 | How to reuse SelectOfScalar[Sequence] | ### First Check
- [X] I added a very descriptive title to this issue.
- [X] I used the GitHub search to find a similar issue and didn't find it.
- [X] I searched the SQLModel documentation, with the integrated search.
- [X] I already searched in Google "How to X in SQLModel" and didn't find any information.
- [X] I al... | closed | 2022-05-10T13:56:12Z | 2022-06-10T06:02:59Z | https://github.com/fastapi/sqlmodel/issues/336 | [
"question"
] | northtree | 1 |
PrefectHQ/prefect | automation | 17,513 | Add PREFECT_API_URL config setup step before the work pool creation for self hosted | ### Describe the current behavior
Current behavior is when a new user jumps on `self-hosted` [documentation](https://docs.prefect.io/v3/tutorials/schedule) if the user run ` prefect worker start --pool my-work-pool` they will get the error of:
```
:~/prefect/prefect$ prefect worker start --pool my-work-pool
Traceback... | open | 2025-03-17T18:01:52Z | 2025-03-17T18:01:52Z | https://github.com/PrefectHQ/prefect/issues/17513 | [
"enhancement"
] | octonawish-akcodes | 0 |
Anjok07/ultimatevocalremovergui | pytorch | 1,170 | Failed to execute script 'UVR' due to unhandled exception | After updating to the newest version I'm getting the following error when trying to run the program:
`Failed to execute script 'UVR' due to unhandled exception: cannot import name '_get_cpp_backtrace' from 'torch._C' (D:\Ultilate Vocal Remover\Ultilate Vocal Remover\torch\_C.cp39-win_amd64.pyd)`
```
Traceback (mos... | open | 2024-02-16T12:04:10Z | 2024-05-21T04:48:52Z | https://github.com/Anjok07/ultimatevocalremovergui/issues/1170 | [] | SCSR-is-too-short-username | 1 |
BayesWitnesses/m2cgen | scikit-learn | 350 | Add support for Naive Bayes | Hi folks, should be possible support sklearn stacking and naives bayes? | closed | 2021-02-09T22:37:00Z | 2022-01-26T17:27:03Z | https://github.com/BayesWitnesses/m2cgen/issues/350 | [
"enhancement"
] | rspadim | 4 |
dask/dask | scikit-learn | 11,018 | `vindex` as outer indexer: memory and time performance | <!-- Please include a self-contained copy-pastable example that generates the issue if possible.
Please be concise with code posted. See guidelines below on how to provide a good bug report:
- Craft Minimal Bug Reports http://matthewrocklin.com/blog/work/2018/02/28/minimal-bug-reports
- Minimal Complete Verifiab... | closed | 2024-03-23T20:41:48Z | 2025-01-02T17:00:05Z | https://github.com/dask/dask/issues/11018 | [
"array",
"needs triage"
] | ilan-gold | 1 |
sktime/sktime | scikit-learn | 7,855 | [DOC] Add Documentation for `_safe_import()` utility | #7702 adds a `_safe_import()` utility for isolation of soft dependencies. Earlier vendoring a new library in `sktime` or interfacing one required `_check_soft_dependencies()` to check if any soft dependency like `torch` or `transformers` is present in the environment, if it is present then it would import them or else ... | open | 2025-02-17T19:37:58Z | 2025-02-17T19:46:56Z | https://github.com/sktime/sktime/issues/7855 | [
"documentation"
] | jgyasu | 1 |
noirbizarre/flask-restplus | flask | 591 | Marshall fields from a session.query | I work a lot with geo-stuff, and often data is stored as binary geometry, but converted to a JSON representation for the browser. This poses a problem for flask-restplus - I can't really declare my model as one of the fields is based on a function, but if I write the model as a session.query object, I don't get an obje... | open | 2019-02-11T16:04:57Z | 2019-03-27T09:44:11Z | https://github.com/noirbizarre/flask-restplus/issues/591 | [
"Needed: Feedback"
] | stev-0 | 1 |
pydantic/pydantic-ai | pydantic | 857 | 'OpenAIModel' object has no attribute 'client' | I am running a local instance of my ollama and I want to try the ollama model, but when I try to run it. It returns me an 'OpenAIModel' object has no attribute 'client' error.
```
from pydantic import BaseModel
from pydantic_ai import Agent
from pydantic_ai.models.openai import OpenAIModel
class CityLocation(BaseMo... | closed | 2025-02-06T09:22:37Z | 2025-02-07T03:29:09Z | https://github.com/pydantic/pydantic-ai/issues/857 | [] | edilberto-pajunar | 2 |
davidsandberg/facenet | tensorflow | 370 | cluster random images into folders | Hi
I have set of random images in a folder. how can i cluster similar images into specific folder. I tried using LBP approach but it was not solving the problem. Using facenet pls suggest how can i achieve the same.
Thanks
vij | closed | 2017-07-12T10:12:56Z | 2017-12-04T07:25:21Z | https://github.com/davidsandberg/facenet/issues/370 | [] | myinzack | 7 |
pydata/bottleneck | numpy | 88 | Porting bottleneck to numpy 1.9 | Just a heads up that nansum now returns 0 for empty slices.
```
======================================================================
FAIL: Test nansum.
----------------------------------------------------------------------
Traceback (most recent call last):
File "X:\Python27-x64\lib\site-packages\nose\case.py", li... | closed | 2014-07-04T22:04:40Z | 2015-02-04T16:47:29Z | https://github.com/pydata/bottleneck/issues/88 | [] | charris | 7 |
chaoss/augur | data-visualization | 2,630 | Change Request Acceptance Ratio metric API | The canonical definition is here: https://chaoss.community/?p=3598 | open | 2023-11-30T18:05:34Z | 2023-11-30T18:20:26Z | https://github.com/chaoss/augur/issues/2630 | [
"API",
"first-timers-only"
] | sgoggins | 0 |
litestar-org/litestar | asyncio | 3,054 | Bug: Pydantic's `json_schema_extra` is not passed to the generated OpenAPI spec | ### Description
The generated OpenAPI schema is missing `model_config = ConfigDict(json_schema_extra=...)` and `Field(json_schema_extra=...)` in Pydantic models.
The `json_schema_extra` (and other fields?) should be copied over to the schema.
### MCVE
```python
import uvicorn
from litestar import Litestar... | closed | 2024-01-31T20:43:46Z | 2025-03-20T15:54:23Z | https://github.com/litestar-org/litestar/issues/3054 | [
"Bug :bug:"
] | tuukkamustonen | 4 |
LAION-AI/Open-Assistant | machine-learning | 3,144 | Curate SFT-9 dataset mixes | Iterate on the SFT-8 dataset mixes to create pretraining and final SFT mixes for SFT-9. This requires investigating the quality and usefulness of the datasets. Community input welcome below. See the `sft8_training` [branch](https://github.com/LAION-AI/Open-Assistant/tree/sft8_training) for the code state corresponding ... | open | 2023-05-13T09:57:48Z | 2023-05-25T15:13:33Z | https://github.com/LAION-AI/Open-Assistant/issues/3144 | [
"research",
"ml",
"data"
] | olliestanley | 10 |
pyppeteer/pyppeteer | automation | 105 | SSL error while downloading chromium for the first time | While downloading chromium for the first time, i got the following error:
`OpenSSL.SSL.Error: [('SSL routines', 'tls_process_server_certificate', 'certificate verify failed')]`
I had to use [https://github.com/kiwi0fruit/pyppdf/blob/11d082f7a35cdac2ae3e7ffa7022c1d1e9747cd2/pyppdf/patch_pyppeteer/patch_pyppeteer.p... | open | 2020-05-12T09:59:37Z | 2020-08-07T10:27:24Z | https://github.com/pyppeteer/pyppeteer/issues/105 | [
"bug",
"fixed-in-2.1.1"
] | ravisumit33 | 5 |
keras-team/keras | deep-learning | 20,726 | keras.mixed_precision not working with TorchModuleWrapper | When using a torch model with TorchModuleWrapper, the mixed_precision doesnt work.
I guess somehow in the call of TorchModuleWrapper we are supposed to wrap the call to the torch model with
`with torch.cuda.amp.autocast():`
Here is some code that doesnt work:
```
import os
os.environ["KERAS_BACKEND"] = "torch"
... | closed | 2025-01-05T14:43:35Z | 2025-02-06T02:01:25Z | https://github.com/keras-team/keras/issues/20726 | [
"stat:awaiting response from contributor",
"stale",
"type:Bug"
] | yonigottesman | 4 |
babysor/MockingBird | pytorch | 757 | gpu换大的后碰到这个问题,是什么原因呢? | <string>:6: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray.
Traceback (most recent call last):
Fil... | open | 2022-10-01T15:43:40Z | 2022-10-01T15:43:40Z | https://github.com/babysor/MockingBird/issues/757 | [] | everschen | 0 |
onnx/onnx | machine-learning | 6,149 | [Question] Where is `onnx-operators-ml.pb.h` | https://github.com/onnx/onnx/blob/b86cc54efce19530fb953e4b21f57e6b3888534c/onnx/onnx-operators_pb.h#L9 | closed | 2024-05-28T08:28:32Z | 2024-05-31T00:32:07Z | https://github.com/onnx/onnx/issues/6149 | [
"question"
] | AIYoungcino | 1 |
holoviz/panel | plotly | 7,119 | pixi run docs-build missing Webdriver | I followed https://holoviz-dev.github.io/panel/developer_guide/index.html#documentation to run
```
panel $ pixi run docs-build
```
which ran
```
✨ Pixi task (_docs-generate in docs): nbsite build --what=html --output=builtdocs --org holoviz --project-name panel
```
which gave this RuntimeError:
```
getting t... | open | 2024-08-10T18:22:27Z | 2024-08-24T12:03:53Z | https://github.com/holoviz/panel/issues/7119 | [] | cdeil | 6 |
postmanlabs/httpbin | api | 511 | arraybuffer inconsistencies | Here's my pseudo code request:
```
url: 'https://httpbin.org/anything',
responseType: 'arraybuffer',
body: new Uint8Array(10000),
method: 'POST',
mode: 'cors'
```
The bug: I am receiving a 60715 bytes (1/6 average ratio) ArrayBuffer. | closed | 2018-09-17T13:50:52Z | 2018-09-19T14:24:27Z | https://github.com/postmanlabs/httpbin/issues/511 | [] | Mouvedia | 3 |
noirbizarre/flask-restplus | api | 188 | Serve Swagger UI as HTML, keeping JSON for everything else | I have a REST API where I set the response class' type to `application/json`. Unfortunately this sets the `Content-Type` for the Swagger UI, so the page doesn't render in browsers.
Is there a way to change the Swagger UI Content type to html, while keeping JSON for the rest of the app? What am I missing here?
``` py
... | closed | 2016-08-02T16:09:52Z | 2016-08-04T09:09:10Z | https://github.com/noirbizarre/flask-restplus/issues/188 | [] | vincevargadev | 5 |
zihangdai/xlnet | nlp | 100 | What should i do to display the F1 score for my own dataset? | closed | 2019-07-02T10:39:02Z | 2019-07-02T14:43:00Z | https://github.com/zihangdai/xlnet/issues/100 | [] | bishalgaire | 0 | |
scrapy/scrapy | python | 6,717 | Scrapy Issues Warning for 'parse' Method in ActressListSpider: Generator Detection Problem |
### Description:
```
I am encountering a warning in Scrapy, where it is unable to determine if the parse method of my spider is a generator. The warning does not prevent the spider from functioning, but it does prevent Scrapy from properly identifying potential issues with my implementation.
```
### Steps to Re... | open | 2025-03-10T09:58:01Z | 2025-03-11T03:56:53Z | https://github.com/scrapy/scrapy/issues/6717 | [] | MajorTomMan | 5 |
junyanz/pytorch-CycleGAN-and-pix2pix | pytorch | 1,309 | inference about cycleGAN | thanks for your contribution, I have trained my own cycleGAN model according to the instructions. My question is, when I plan to inference the data which include 1000 data set (testA), do I have to have 1000 testB corresponding to testA? | closed | 2021-08-25T02:54:44Z | 2023-11-10T21:34:13Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/1309 | [] | cena001plus | 2 |
tqdm/tqdm | jupyter | 764 | color printing not possible in jupyter notebook after importing tqdm? | Printing colored text in jupyter notebook doesn't seem to work after importing tqdm
Example:

tqdm 4.23.4
python 3.6.8
ipython 7.5.0
windows server 2012R2
Any suggestions? | closed | 2019-06-26T09:05:41Z | 2022-11-07T12:45:48Z | https://github.com/tqdm/tqdm/issues/764 | [
"need-feedback 📢",
"p2-bug-warning ⚠",
"submodule-notebook 📓"
] | Ruler26 | 3 |
widgetti/solara | flask | 144 | [Enhancement] Select widget missing keyword disabled | Select and SelectMultiple widgets seem missing keyword disabled.
Is it by design or still under implementation?
Is there any work around instead of using ipyvuetify directly.
thanks! | closed | 2023-06-05T19:30:32Z | 2023-06-30T02:47:18Z | https://github.com/widgetti/solara/issues/144 | [] | lp9052 | 1 |
pytest-dev/pytest-django | pytest | 873 | Pytest scope='module' fixture not delete model instance after testing module | I create the message instance in a fixture with scope='module', right in the test file. But when the test reaches another module, this message instance still exists in the database.
**in .../apps/dialogs/test/api/test_message.py**
```py
@pytest.fixture(scope='module')
def message_by_auth_user(django_db_setup, d... | closed | 2020-10-05T04:31:05Z | 2020-10-16T18:50:46Z | https://github.com/pytest-dev/pytest-django/issues/873 | [] | MaximMukhametov | 1 |
SALib/SALib | numpy | 550 | Expand documentation for Sobol' analysis | Documentation with regard to usage and interpretation of Sobol' analysis should be expanded.
See issue raised in #549 as an example of what users may face.
Although this is a general issue across the SALib package, lets start with Sobol'. | open | 2022-12-16T07:19:48Z | 2023-04-10T04:29:58Z | https://github.com/SALib/SALib/issues/550 | [] | ConnectedSystems | 1 |
pandas-dev/pandas | pandas | 60,564 | BUG: The isna function returns False for NaN values in a column of type 'double [pyarrow]'. | ### Pandas version checks
- [X] I have checked that this issue has not already been reported.
- [X] I have confirmed this bug exists on the [latest version](https://pandas.pydata.org/docs/whatsnew/index.html) of pandas.
- [X] I have confirmed this bug exists on the [main branch](https://pandas.pydata.org/docs/... | closed | 2024-12-14T10:44:50Z | 2024-12-14T12:49:15Z | https://github.com/pandas-dev/pandas/issues/60564 | [
"Bug",
"Duplicate Report",
"Arrow",
"PDEP missing values"
] | zhengchl | 1 |
comfyanonymous/ComfyUI | pytorch | 6,907 | mat1 and mat2 must have the same dtype, but got Float and Half | ### Expected Behavior
The issue happens after the auto update of the ComfyUI Desktop app on my M4 Mac Mini (16 GB)
### Actual Behavior
I include an attachment with my workflow, the error got triggered on the KSampler module
### Steps to Reproduce
Press Queue to the attached Workflow
### Debug Logs
```powershell
... | open | 2025-02-21T06:37:42Z | 2025-02-27T19:59:50Z | https://github.com/comfyanonymous/ComfyUI/issues/6907 | [
"Potential Bug"
] | ozonostudio | 1 |
onnx/onnx | tensorflow | 6,101 | output different between onnx and pytorch | # Ask a Question
### Question
when i try to convert layernorm to onnx, I found that the precision between onnx and pytorch model is different, here my easy python test code:
```python
import torch
import torch.nn as nn
import torch.onnx
import onnxruntime
import torch
import onnx
class SimpleModel(nn.... | closed | 2024-04-25T10:36:40Z | 2024-04-26T18:53:14Z | https://github.com/onnx/onnx/issues/6101 | [
"question"
] | MichaelH717 | 7 |
idealo/imagededup | computer-vision | 91 | ValueError: Error when checking input: expected input_1 to have 4 dimensions, but got array with shape (1, 224, 224) | phasher.encode_image(image_array=th2)
th2 is an image with shape (610, 1280) and while encoding it gives the above error | closed | 2020-02-06T14:46:16Z | 2020-10-19T15:57:35Z | https://github.com/idealo/imagededup/issues/91 | [
"bug",
"next release"
] | vyaslkv | 3 |
huggingface/text-generation-inference | nlp | 2,737 | Local installation: weight backbone.embeddings.weight does not exist (Mamba) | ### System Info
## System Specifications
2024-11-10T21:20:44.880890Z INFO text_generation_launcher: Runtime environment:
Target: x86_64-unknown-linux-gnu
Cargo version: 1.80.1
Commit sha: 97f7a22f0b0f57edc840beaf152e7fd102ed8311
Docker label: N/A
nvidia-smi:
Sun Nov 10 21:20:43 2024
+-------------... | closed | 2024-11-10T21:26:22Z | 2024-11-15T12:16:16Z | https://github.com/huggingface/text-generation-inference/issues/2737 | [] | mokeddembillel | 1 |
mars-project/mars | scikit-learn | 3,042 | [BUG] test_ownership_when_scale_in hang | <!--
Thank you for your contribution!
Please review https://github.com/mars-project/mars/blob/master/CONTRIBUTING.rst before opening an issue.
-->
**Describe the bug**
When running test case `DEBUG_OSCAR=1 pytest -v -s mars/deploy/oscar/tests/test_ray.py::test_ownership_when_scale_in`, it hangs occasionally.
... | open | 2022-05-17T12:34:04Z | 2022-05-17T14:05:02Z | https://github.com/mars-project/mars/issues/3042 | [] | chaokunyang | 3 |
MilesCranmer/PySR | scikit-learn | 682 | [BUG]: Hard crash on import from MacOS System Integrity Protection (SIP) | ### What happened?
upon pip installing pysr into a virtual environment, making sure my PATH variable has the bin, exporting LD_LIBRARY_PATH as specified in github readme, and even removing quarantine status for the environment, importing pysr still results in python quitting
julia version supports arch64 (silicon)
... | closed | 2024-07-28T04:48:53Z | 2024-07-29T07:29:35Z | https://github.com/MilesCranmer/PySR/issues/682 | [
"bug"
] | ev-watson | 10 |
d2l-ai/d2l-en | pytorch | 2,134 | A mistake in seq2seq prediction implementation? | https://github.com/d2l-ai/d2l-en/blob/9e4fbb1e97f4e0b3919563073344368755fe205b/d2l/torch.py#L2996-L3030
**Bugs here:**
``` Python
for _ in range(num_steps):
Y, dec_state = net.decoder(dec_X, dec_state)
```
As you can see here, dec_state will update in every loop. But it not only affects the hidden sta... | closed | 2022-05-16T09:12:58Z | 2022-12-14T04:24:45Z | https://github.com/d2l-ai/d2l-en/issues/2134 | [] | zhmou | 2 |
pydata/bottleneck | numpy | 162 | warning: self-comparison always evaluates to true | The build logs on Debian report the following warnings:
```
bottleneck/src/move.c: In function ‘move_rank_int64’:
bottleneck/src/move.c:2009:24: warning: self-comparison always evaluates to true [-Wtautological-compare]
if (aj == aj) {
^~
bottleneck/src/move.c: In function... | closed | 2017-02-08T08:44:52Z | 2017-02-09T20:45:49Z | https://github.com/pydata/bottleneck/issues/162 | [] | ghisvail | 1 |
mwaskom/seaborn | matplotlib | 3,077 | Plan to reintroduce fitted models on plots (apart from `PolyFit`) | The functional API (`regplot`) had the option to draw logistic, robust or lowess regressions via statsmodels but the new object API only offers polynomial fit with `PolyFit`.
Is this an intentional choice or will these be added as extensions?
This gap feels odd since the related `Agg` and `Est` stats have been i... | closed | 2022-10-12T09:40:17Z | 2022-10-13T10:44:20Z | https://github.com/mwaskom/seaborn/issues/3077 | [] | Rabeez | 0 |
axnsan12/drf-yasg | rest-api | 699 | swagger_serializer_method doesn't support swagger_schema_fields | I've tried setting the `serializer_or_field` to a field type that defines `swagger_schema_fields` on the Meta object, but it seems to be ignored entirely.
Notably, I think if this was supported it would provide a way to workaround things like #684 and #685 by providing the new schema directly. | open | 2021-02-04T10:41:22Z | 2025-03-07T12:13:28Z | https://github.com/axnsan12/drf-yasg/issues/699 | [
"triage"
] | palfrey | 0 |
jina-ai/clip-as-service | pytorch | 43 | Dependency between sentences embeddings within request | I run this code :
```
bc = BertClient()
a = bc.encode['hey you', 'hey you']
b = bc.encode['hey you']
c = bc.encode['hey you']
```
---
If I compare `b` and `c`, these are the same :
`print((b == c).all())`
> True
This is expected behavior
---
**But why `a[0]` and `a[1]` are not the same ?**
... | closed | 2018-11-23T01:33:53Z | 2018-11-23T10:48:52Z | https://github.com/jina-ai/clip-as-service/issues/43 | [] | astariul | 1 |
iperov/DeepFaceLab | machine-learning | 5,491 | Is there a way to give setting by redirecting input? | I have been trying to automate merging process by redirecting input for settings. But i have encountered loss of setting in the stage of interactive y/n.
I get EOFError: EOF when reading a line. before interactive option input_bool
My question is "is there a way to do these jobs in other way? or am i missing som... | closed | 2022-03-08T02:27:34Z | 2022-03-17T01:50:23Z | https://github.com/iperov/DeepFaceLab/issues/5491 | [] | jinwonkim93 | 0 |
tox-dev/tox | automation | 2,535 | specifying processor architecture does not work reliable | When a specific processor architecture is requested which is not installed tox implicitly falls back to another installed interpreter of the same version. I.e. if `envlist=py39-x86` is specified and only `python3.9-64` is installed on the system instead of printing an error (or skipping the environment if `skip_missing... | open | 2022-11-12T22:32:03Z | 2023-06-16T17:11:32Z | https://github.com/tox-dev/tox/issues/2535 | [
"bug:normal",
"help:wanted"
] | mrh1997 | 2 |
pallets-eco/flask-sqlalchemy | sqlalchemy | 947 | `NoneType` object has no attribute `setdefault` | I'm aware a previous ticket has been closed about this (#928), but it seems that the issue is still present with the latest versions of SQLAlchemy + Flask-SQLAlchemy
In order to make it work, I had to revert both libs to the following version:
```
SQLAlchemy==1.3.24
Flask-SQLAlchemy==2.4.4
```
The issue for... | closed | 2021-03-31T21:58:20Z | 2021-04-16T00:12:37Z | https://github.com/pallets-eco/flask-sqlalchemy/issues/947 | [] | cnicodeme | 3 |
allenai/allennlp | nlp | 5,017 | A guide with the updated API | **Is your feature request related to a problem? Please describe.**
<!--- A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] -->
- As someone who is trying to get to know the library, I was looking at the documentation, which links to the guide [guide.allennlp.org](https://gui... | closed | 2021-02-24T04:31:17Z | 2021-02-26T16:42:24Z | https://github.com/allenai/allennlp/issues/5017 | [
"Feature request"
] | ekdnam | 7 |
ansible/ansible | python | 84,850 | Ansible silently handles any exceptions raised in inventory plugin | ### Summary
We have custom inventory plugin (that fetches list of hosts & their data via external service API). One would expect when AnsibleParserError is raised inside parse() method, this will be shown in stderr.
But looking at ansible-core it is silently handles (ANY!) exception and execution continues. I stumbl... | open | 2025-03-18T11:20:18Z | 2025-03-18T18:45:49Z | https://github.com/ansible/ansible/issues/84850 | [
"bug",
"data_tagging"
] | eleksis | 7 |
geex-arts/django-jet | django | 97 | Change login.html name 'ADMIN SITE' | <body class=" login">
```
<div class="login-title">
<span class="bright">Admin</span> Site
</div>
<div class="login-container" id="content-main">
<div class="login-container-header">
Iniciar sesión
</div>
<div class="login-container-content">
<form action="/admin/login/?next=/admin/" m... | closed | 2016-08-09T23:39:58Z | 2016-08-19T09:00:37Z | https://github.com/geex-arts/django-jet/issues/97 | [] | sagoyanfisic | 5 |
minimaxir/textgenrnn | tensorflow | 157 | Migrate to TF 2.0/tf.keras | I had made textgenrnn with external Keras since native TF was missing features. Now that there is parity, I am OK with merging it back into native TF with TF 2.0 support. textgenrnn does not use much custom Keras code so it should be a relatively simply change; the concern is not breaking old models, which may be possi... | closed | 2019-12-01T18:52:33Z | 2020-02-03T03:32:47Z | https://github.com/minimaxir/textgenrnn/issues/157 | [
"enhancement"
] | minimaxir | 5 |
InstaPy/InstaPy | automation | 5,797 | TypeError: document.getElementsByClassName(...)[0] is undefined | Hello everyone,
I have a problem started today, yesterday i was using instapy with no mistake and today when i started instapy after some likings it gives me following message "TypeError: document.getElementsByClassName(...)[0] is undefined" what should i do? please i am waiting for your support.
| closed | 2020-09-23T07:59:37Z | 2020-11-10T12:40:41Z | https://github.com/InstaPy/InstaPy/issues/5797 | [
"wontfix"
] | blackchayenne | 3 |
plotly/dash-core-components | dash | 273 | Nested Tabs | I have come across a behavior of the tabs component I can’t quite make sense of. A minimal example code is provided below.
```
import dash
import dash_core_components as dcc
import dash_html_components as html
app = dash.Dash()
app.layout = html.Div([
dcc.Tabs(
id='tabs-1',
value='tab-... | closed | 2018-08-22T13:16:04Z | 2021-11-14T12:40:10Z | https://github.com/plotly/dash-core-components/issues/273 | [] | roeap | 6 |
polakowo/vectorbt | data-visualization | 401 | How to change column name generated by indicator.run()? | 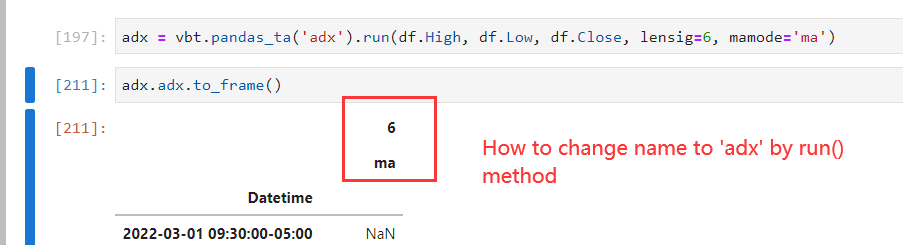
| closed | 2022-03-02T02:35:30Z | 2022-03-11T08:20:56Z | https://github.com/polakowo/vectorbt/issues/401 | [] | GF-Huang | 2 |
aiortc/aiortc | asyncio | 129 | RTX packet with empty payload causes DTLS to shutdown | Hi jlaine:
I opened a new issue for the dtls close issue in 2 minutes.
I never find this issue on 0.9.13 and it happened on 0.9.18.
I add the debug info in dtlstransport.py in line 480.
The error info is "FAILED unpack requires a buffer of 2 bytes"
Can you give some comments?
I pasted the log here.
"DEBUG:rtp:re... | closed | 2019-01-22T00:57:29Z | 2019-01-23T09:36:37Z | https://github.com/aiortc/aiortc/issues/129 | [] | zhiweny1122 | 7 |
pytest-dev/pytest-django | pytest | 581 | Add pytest to requirements.txt... | It would be a kindness to projects using pyteste-django if pytest (which is a direct dependency for pytest-django) could be added to requirements.txt. Otherwise, pip / pipenv can't infer the dependency graph, and projects using pytest-django must themselves add pytest *before* pytest-django in their own dependencies. ... | closed | 2018-02-11T02:38:55Z | 2018-04-14T13:45:25Z | https://github.com/pytest-dev/pytest-django/issues/581 | [] | ptressel | 2 |
jupyterlab/jupyter-ai | jupyter | 521 | Allow additional properties in AgentChatMessage | ### Problem
`AgentChatMessage` represents replies of LLM agents to users. Currently model is limited in its ability to handle diverse types of responses beyond plain text, for example error messages (see https://github.com/jupyterlab/jupyter-ai/pull/513/commits/b7ef4e32bf30932129444770b5872e36a8c19b35 in #513) or mu... | open | 2023-12-18T18:32:32Z | 2023-12-18T22:51:14Z | https://github.com/jupyterlab/jupyter-ai/issues/521 | [
"enhancement"
] | andrii-i | 0 |
mwaskom/seaborn | matplotlib | 3,794 | Question about abstraction | https://github.com/mwaskom/seaborn/blob/b4e5f8d261d6d5524a00b7dd35e00a40e4855872/seaborn/distributions.py#L1449
Is there an architectural reason you don't expose the stats data? (i.e. something like `ax.p = p`)
Most academic publications want to see the number behind the plots. | closed | 2024-11-30T23:48:10Z | 2024-12-01T19:42:42Z | https://github.com/mwaskom/seaborn/issues/3794 | [] | refack | 1 |
OFA-Sys/Chinese-CLIP | nlp | 301 | finetune时报错,且Traceback疑似被截断,无法定位出错线程 | (torch) ppop@DESKTOP-NMJBJQC:~/Chinese-CLIP$ sudo bash run_scripts/muge_finetune_vit-b-16_rbt-base.sh ~/Chinese-CLIP/datapath
Loading vision model config from cn_clip/clip/model_configs/ViT-L-14.json
Loading text model config from cn_clip/clip/model_configs/RoBERTa-wwm-ext-base-chinese.json
2024-04-18,22:23:46 | INF... | open | 2024-04-18T14:26:33Z | 2024-05-14T06:05:03Z | https://github.com/OFA-Sys/Chinese-CLIP/issues/301 | [] | wrtppp | 3 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.