
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
koxudaxi/datamodel-code-generator | fastapi | 1,496 | Optional not generated for nullable array items defined according to OpenAPI 3.0 spec, despite using --strict-nullable | Items in an array are not generated as `Optional`, despite adding the `nullable: true` property.
**To Reproduce**
Example schema:
```yaml
# test.yml
properties:
list1:
type: array
items:
type: string
nullable: true
required:
- list1
```
Used commandline:
```
datamodel-codeg... | closed | 2023-08-18T05:50:09Z | 2023-12-04T15:11:57Z | https://github.com/koxudaxi/datamodel-code-generator/issues/1496 | [
"bug"
] | tfausten | 1 |
huggingface/transformers | pytorch | 36,109 | Wrong corners format of bboxes in function center_to_corners_format (image_transforms.py) | In [image_transforms.py](https://github.com/huggingface/transformers/blob/main/src/transformers/image_transforms.py), function `center_to_corners_format` describes the corners format as "_corners format: contains the coordinates for the top-left and bottom-right corners of the box (top_left_x, top_left_y, bottom_right_... | closed | 2025-02-10T09:30:54Z | 2025-02-12T14:31:14Z | https://github.com/huggingface/transformers/issues/36109 | [] | majakolar | 3 |
davidteather/TikTok-Api | api | 479 | How to run the API in FastAPI / in a testing environment | Hi there.
We are trying to add some testing around the API interactions. Namely `getUser`.
We are doing something like this within a FastAPI endpoint.
```python
tik_tok_api = TikTokApi.get_instance()
return tik_tok_api.getUser(handle)
```
This is fine when making this call from the `requests` library. Howeve... | closed | 2021-01-26T13:28:29Z | 2022-02-14T03:08:27Z | https://github.com/davidteather/TikTok-Api/issues/479 | [
"bug"
] | jaoxford | 4 |
FactoryBoy/factory_boy | sqlalchemy | 635 | Mutually dependent django model fields, with defaults | #### The problem
Suppose I have a model with two fields, which need to be set according to some relationship between them. Eg (contrived example) I have a product_type field and a size field. I'd like to be able to provide either, neither or both fields. If I provide eg. product_type, I'd like to be able to set the si... | closed | 2019-08-15T13:09:19Z | 2019-08-22T16:28:43Z | https://github.com/FactoryBoy/factory_boy/issues/635 | [] | Joeboy | 2 |
laughingman7743/PyAthena | sqlalchemy | 13 | jpype._jexception.OutOfMemoryErrorPyRaisable: java.lang.OutOfMemoryError: GC overhead limit exceeded | Hi,
I am running into this error after running several big queries and reusing the connection:
```
jpype._jexception.OutOfMemoryErrorPyRaisable: java.lang.OutOfMemoryError: GC overhead limit exceeded
```
Any ideas? Any way to pass the JVM args to JPype to increase the mem given to the JVM on start?
Thanks!
... | closed | 2017-06-19T19:12:23Z | 2017-06-22T12:51:19Z | https://github.com/laughingman7743/PyAthena/issues/13 | [] | arnaudsj | 2 |
psf/requests | python | 6,223 | requests.package.chardet* references not assigned correctly? | I found that packages.py is assigning sys.modules['requests.package.chardet'] over and over with different modules, is this intentional or a bug?
I looked at the code and this `target` variable confuses me, it is assigned again in loop and placed with itself(so completely?), looks like a name confliction to me. Code... | closed | 2022-08-31T10:56:22Z | 2024-05-14T22:53:44Z | https://github.com/psf/requests/issues/6223 | [] | babyhoo976 | 2 |
HIT-SCIR/ltp | nlp | 506 | ltp.seg: illegal instruction(core dumped) when using machine with ubuntu 14 | 机器: Ubuntu 14
初始化: ltp = LTP(path=model_path) model_path对应small模型的本地路径
调用: seg, hidden = ltp.seg([text]) => 出现 illegal instruction(core dumped) 错误 .
部署: 使用docker 部署
之前Ubuntu 16.04是没有遇到这个问题的, 我是使用docke部署的 理论上应该不会和系统有耦合. 不知道ltp分词是否会依赖机器操作系统的相关版本或者底层库 | closed | 2021-04-22T06:13:20Z | 2021-04-22T08:04:31Z | https://github.com/HIT-SCIR/ltp/issues/506 | [] | cl011 | 1 |
prisma-labs/python-graphql-client | graphql | 3 | Is there any way to specify an authorization path, a token for example? | closed | 2017-10-09T21:33:01Z | 2017-12-08T21:32:58Z | https://github.com/prisma-labs/python-graphql-client/issues/3 | [] | eamigo86 | 3 | |
521xueweihan/HelloGitHub | python | 2,514 | 【开源自荐】为数据科学家和算法工程师打造的AI IDE | ## 推荐项目
<!-- 这里是 HelloGitHub 月刊推荐项目的入口,欢迎自荐和推荐开源项目,唯一要求:请按照下面的提示介绍项目。-->
<!-- 点击上方 “Preview” 立刻查看提交的内容 -->
<!--仅收录 GitHub 上的开源项目,请填写 GitHub 的项目地址-->
- 项目地址:https://github.com/BaihaiAI/IDP
<!--请从中选择(C、C#、C++、CSS、Go、Java、JS、Kotlin、Objective-C、PHP、Python、Ruby、Rust、Swift、其它、书籍、机器学习)-->
- 类别:TypeScript, Ja... | open | 2023-03-04T02:53:54Z | 2023-03-04T02:58:35Z | https://github.com/521xueweihan/HelloGitHub/issues/2514 | [] | liminniu | 0 |
Evil0ctal/Douyin_TikTok_Download_API | web-scraping | 540 | [BUG] 抖音-获取指定视频的评论回复数据 返回400 | 大佬你好, 拉去项目后,测试 抖音-获取指定视频的评论回复数据 返回400
之后仔细查看文档,并在你的在线接口测试同样也返回400
https://douyin.wtf/docs#/Douyin-Web-API/fetch_video_comments_reply_api_douyin_web_fetch_video_comment_replies_get

| closed | 2025-01-17T09:47:12Z | 2025-02-14T09:04:35Z | https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues/540 | [
"BUG"
] | yumingzhu | 4 |
ray-project/ray | pytorch | 50,917 | [Data] Timestamptz type loses its time zone after map transforming. | ### What happened + What you expected to happen
Timestamptz type loses its time zone after map transforming.
### Versions / Dependencies
```
In [45]: ray.__version__
Out[45]: '2.42.1'
```
### Reproduction script
```
import ray
import pyarrow as pa
ray.init()
table = pa.table({
"ts": pa.array([1735689600, 1... | closed | 2025-02-26T11:37:27Z | 2025-03-03T11:28:21Z | https://github.com/ray-project/ray/issues/50917 | [
"bug",
"triage",
"data"
] | sharkdtu | 1 |
plotly/dash-table | plotly | 591 | row/column selectable single applies to all tables on the page | Make 2 tables with row or column selectable=single - you can only select one row and one column on the page, should be one per table.
reported in https://community.plot.ly/t/multiple-dash-tables-selection-error/28802
```
import dash
import dash_html_components as html
import dash_table
keys = ['a', 'b', 'c'... | closed | 2019-09-19T05:03:09Z | 2019-09-19T20:41:36Z | https://github.com/plotly/dash-table/issues/591 | [
"dash-type-bug",
"size: 0.5"
] | alexcjohnson | 3 |
gradio-app/gradio | python | 10,864 | Cannot Upgrade Gradio - rvc_pipe Is Missing, Cannot Be Installed | ### Describe the bug
When attempting to upgrade Gradio, it requires music_tag, after that is installed, rvc_pipe is required.
C:\Users\Mehdi\Downloads\ai-voice-cloning-3.0\src>pip install rvc_pipe
Defaulting to user installation because normal site-packages is not writeable
ERROR: Could not find a version that satisf... | closed | 2025-03-22T17:06:19Z | 2025-03-23T21:31:56Z | https://github.com/gradio-app/gradio/issues/10864 | [
"bug"
] | gyprosetti | 1 |
wkentaro/labelme | computer-vision | 976 | [Feature] Create specific-sized box | I want to create a box with (256x256).
How can I do with labelme?
| closed | 2022-01-14T03:54:12Z | 2022-06-25T04:30:44Z | https://github.com/wkentaro/labelme/issues/976 | [] | alicera | 6 |
tableau/server-client-python | rest-api | 973 | Create/Update site missing support for newer settings | The server side API does not appear to support interacting with the following settings:
- Schedule linked tasks
- Mobile offline favorites
- Flow web authoring enable/disable
- Mobile app lock
- Tag limit
- Cross database join toggle
- Toggle personal space
- Personal space storage limits | open | 2022-01-13T14:51:43Z | 2022-01-25T22:08:21Z | https://github.com/tableau/server-client-python/issues/973 | [
"gap"
] | jorwoods | 0 |
ydataai/ydata-profiling | jupyter | 1,129 | Feature Request: support for Polars | ### Missing functionality
Polars integration ? https://www.pola.rs/
### Proposed feature
Use polars dataframe as a compute backend.
Or let the user give a polars dataframe to the ProfileReport.
### Alternatives considered
Spark integration.
### Additional context
Polars help to optimize queries and reduce mem... | open | 2022-10-25T20:11:49Z | 2025-03-24T01:52:27Z | https://github.com/ydataai/ydata-profiling/issues/1129 | [
"needs-triage"
] | PierreSnell | 11 |
TheKevJames/coveralls-python | pytest | 1 | Remove 3d-party modules from coverage report | I'm added HTTPretty to my module, and coveralls-python [added HTTPretty to coverage report](https://coveralls.io/builds/5097)
It will be good, if python-coverage don't include 3d-party modules in coverage report.
| closed | 2013-02-26T17:16:10Z | 2013-02-26T18:43:34Z | https://github.com/TheKevJames/coveralls-python/issues/1 | [] | tyrannosaurus | 2 |
matterport/Mask_RCNN | tensorflow | 2,339 | Training doesn't go beyond 1 epoch and no masks, rois produced | Hello guys,
I have been training on the custom dataset.
I have changed a few parameters such as:
```
STEPS_PER_EPOCH = 10
epochs = 5
```
The training starts well but it is stuck after almost completing the first epoch. You can see below in the image

memberList = itchat.get_friends()[1:5]
# 创建群聊,... | closed | 2018-09-10T12:34:59Z | 2018-10-15T02:00:01Z | https://github.com/littlecodersh/ItChat/issues/727 | [
"duplicate"
] | nenuwangd | 1 |
OpenInterpreter/open-interpreter | python | 912 | OpenAI API key required? | ### Describe the bug
Project Readme states that you are not affiliated with OpenAI, nor server their product but once launched it requires you to insert an OpenAI API key...
`OpenAI API key not found ... | closed | 2024-01-13T09:10:55Z | 2024-03-19T21:03:52Z | https://github.com/OpenInterpreter/open-interpreter/issues/912 | [
"Documentation"
] | andreylisovskiy | 9 |
keras-team/keras | deep-learning | 20,627 | GlobalAveragePooling1D data_format Question | My rig
- Ubuntu 24.04 VM , RTX3060Ti with driver nvidia 535
- tensorflow-2.14-gpu/tensorflow-2.18 , both pull from docker
- Nvidia Container Toolkit if running in gpu version
About[ this example](https://keras.io/examples/timeseries/timeseries_classification_transformer/)
The transformer blocks of this example... | open | 2024-12-11T05:51:31Z | 2024-12-13T06:28:57Z | https://github.com/keras-team/keras/issues/20627 | [
"type:Bug"
] | cptang2007 | 0 |
huggingface/transformers | tensorflow | 36,848 | GPT2 repetition of words in output | ### System Info
- `transformers` version: 4.45.2
- Platform: Linux-5.15.0-122-generic-x86_64-with-glibc2.35
- Python version: 3.10.12
- Huggingface_hub version: 0.28.1
- Safetensors version: 0.5.2
- Accelerate version: 1.2.1
- Accelerate config: not found
- PyTorch version (GPU?): 2.4.1+cpu (False)
- Tensorflow ver... | closed | 2025-03-20T10:55:28Z | 2025-03-20T13:05:33Z | https://github.com/huggingface/transformers/issues/36848 | [
"bug"
] | vpandya-quic | 1 |
keras-rl/keras-rl | tensorflow | 192 | Continue training using saved weights | My question basically is:
Is there a way to save the weights/memory and use them after for more training? In my environment I want to train some model and afterwards continue this training changing some features, in order to adapt it to each situation. I think it will be accomplished maybe by saving the memory (e.g.... | closed | 2018-04-05T11:15:58Z | 2019-01-12T16:20:27Z | https://github.com/keras-rl/keras-rl/issues/192 | [
"wontfix"
] | ghub-c | 4 |
aleju/imgaug | machine-learning | 706 | how to know which augmenters are used? | hi~,
i want to know when i use (Someof), how to know which augmenters are used?
thank you very much!
and i got a problem it seem like that
error: OpenCV(4.1.1) C:\projects\opencv-python\opencv\modules\core\src\alloc.app:72:error(-4:Insufficient memory) Failed to allocate ***** bytes in function 'cv:... | closed | 2020-07-30T08:33:55Z | 2020-08-03T04:16:53Z | https://github.com/aleju/imgaug/issues/706 | [] | TyrionChou | 2 |
aiogram/aiogram | asyncio | 1,457 | Invalid webhook response given with handle_in_background=False | ### Checklist
- [X] I am sure the error is coming from aiogram code
- [X] I have searched in the issue tracker for similar bug reports, including closed ones
### Operating system
mac os x
### Python version
3.12.2
### aiogram version
3.4.1
### Expected behavior
Bot handles incoming requests and replies with a ... | open | 2024-04-11T06:28:58Z | 2024-04-11T06:28:58Z | https://github.com/aiogram/aiogram/issues/1457 | [
"bug"
] | unintended | 0 |
hankcs/HanLP | nlp | 1,356 | CoreStopWordDictionary.add() 如何持久化 | <!--
注意事项和版本号必填,否则不回复。若希望尽快得到回复,请按模板认真填写,谢谢合作。
-->
## 注意事项
请确认下列注意事项:
* 我已仔细阅读下列文档,都没有找到答案:
- [首页文档](https://github.com/hankcs/HanLP)
- [wiki](https://github.com/hankcs/HanLP/wiki)
- [常见问题](https://github.com/hankcs/HanLP/wiki/FAQ)
* 我已经通过[Google](https://www.google.com/#newwindow=1&q=HanLP)和[issue区检... | closed | 2019-12-17T06:54:56Z | 2019-12-20T02:06:11Z | https://github.com/hankcs/HanLP/issues/1356 | [
"question"
] | xiuqiang1995 | 2 |
OFA-Sys/Chinese-CLIP | computer-vision | 358 | 保存微调后模型,效果没有微调过程中好 | 我微调过程中文本到图片以及图片到文本都到达了90%以上的情况下,我保存了过程中的pt文件,并基于extracts feature中的代码构建了基于图片匹配描述的demo,但是匹配表达答案时计算的概率只有百分之四五十。


| open | 2024-09-12T07:14:45Z | 2024-09-12T07:14:45Z | https://github.com/OFA-Sys/Chinese-CLIP/issues/358 | [] | wangly1998 | 0 |
vaexio/vaex | data-science | 1,836 | [FEATURE-REQUEST]: Remove the df.*func* when using a function after "register_function" + "auto add". | **Description**
When registering a new function `foo()` with `@vaex.register_function()`, there is a need to
also apply it to the dataframe with `df.add_function("foo", foo)` or the state won't save it.
Later you can use it with `df.func.foo()`.
1. It will be very cool to have it without the `df.*func*.foo()` → ... | open | 2022-01-17T15:11:41Z | 2022-01-17T15:12:40Z | https://github.com/vaexio/vaex/issues/1836 | [] | xdssio | 0 |
ets-labs/python-dependency-injector | asyncio | 393 | A service becomes a _asyncio.Future if it has an asynchronous dependency | di version: 4.20.2
python: 3.9.1
os: linux
```python
from dependency_injector import containers, providers
async def init_resource():
yield ...
class Service:
def __init__(self, res):
...
class AppContainer(containers.DeclarativeContainer):
res = providers.Resource(init_resource)
... | closed | 2021-02-09T18:23:13Z | 2021-02-09T19:27:17Z | https://github.com/ets-labs/python-dependency-injector/issues/393 | [
"question"
] | gtors | 3 |
fastapi-admin/fastapi-admin | fastapi | 61 | NoSQL db support | Hello, I am using both PostgreSQL and MongoDB on my fastapi project.
Is there any possibility to add Mongodb collections to admin dashboard and enable CRUD operations for them as well? | closed | 2021-07-29T21:31:27Z | 2021-07-30T01:44:18Z | https://github.com/fastapi-admin/fastapi-admin/issues/61 | [] | royalwood | 1 |
hindupuravinash/the-gan-zoo | machine-learning | 54 | AttGAN code | AttGAN code has been released recently. https://github.com/LynnHo/AttGAN-Tensorflow | closed | 2018-05-08T02:00:22Z | 2018-05-10T16:31:33Z | https://github.com/hindupuravinash/the-gan-zoo/issues/54 | [] | LynnHo | 1 |
pydata/xarray | pandas | 9,129 | scatter plot is slow | ### What happened?
scatter plot is slow when the dataset has large (length) coordinates even though those coordinates are not involved in the scatter plot.
### What did you expect to happen?
scatter plot speed does not depend on coordinates that are not involved in the scatter plot, which was the case at some ... | closed | 2024-06-16T21:11:31Z | 2024-07-09T07:09:19Z | https://github.com/pydata/xarray/issues/9129 | [
"bug",
"topic-plotting",
"topic-performance"
] | mktippett | 1 |
flasgger/flasgger | flask | 611 | flask-marshmallow - generating Marshmallow schemas from SQLAlchemy models seemingly breaks flasgger | I have a SQLAlchemy model from which I derive a flask-marshmallow schema:
```python
class Customer(db.Model):
__tablename__ = 'customer'
customer_id: Mapped[int] = mapped_column('pk_customer_id', primary_key=True)
first_name: Mapped[str] = mapped_column(String(100))
last_name: Mapped[str] = ma... | open | 2024-02-29T11:37:39Z | 2024-03-07T20:49:01Z | https://github.com/flasgger/flasgger/issues/611 | [] | snctfd | 1 |
jmcnamara/XlsxWriter | pandas | 254 | Unable to set x axis intervals to floating point number | Hi,
My requirement is to set the x axis between 1.045 and 1.21 with intervals of 0.055. Thus, the four points for x-axis are: 1.045, 1.1, 1.155, 1.21. I am unable to achieve this in xlsxwriter. I have tried the below code which failed:
``` python
chart.set_x_axis({'min': 1.045, 'max': 1.21})
chart.set_x_axis({'interv... | closed | 2015-05-14T07:01:58Z | 2015-05-14T07:45:01Z | https://github.com/jmcnamara/XlsxWriter/issues/254 | [
"question"
] | amitrasudan | 1 |
seleniumbase/SeleniumBase | web-scraping | 2,879 | Add support for `uc_gui_handle_cf()` with `Driver()` and `DriverContext()` formats | ### Add support for `uc_gui_handle_cf()` with `Driver()` and `DriverContext()` formats
Currently, if running this code:
```python
from seleniumbase import DriverContext
with DriverContext(uc=True) as driver:
url = "https://www.virtualmanager.com/en/login"
driver.uc_open_with_reconnect(url, 4)
d... | closed | 2024-06-27T15:20:13Z | 2024-07-02T14:29:16Z | https://github.com/seleniumbase/SeleniumBase/issues/2879 | [
"enhancement",
"UC Mode / CDP Mode"
] | mdmintz | 7 |
Sanster/IOPaint | pytorch | 50 | how can we use our own trained model checkpoints and model config to test. | like we have trained Lama Inpaining model with our own datasets and now i want to inference using our trained model config and checkpoints .
or simply provide the code to produce mask image using cursor for some selected area in any given images.
Thank you in advance , | closed | 2022-05-24T07:50:25Z | 2022-05-24T08:38:20Z | https://github.com/Sanster/IOPaint/issues/50 | [] | ram-parvesh | 0 |
graphql-python/graphene | graphql | 1,452 | Confusing/incorrect DataLoader example in docs | Hi all,
I'm very much new to Graphene, so please excuse me if this is incorrect, but it seems to me the code in the docs (screenshot below) will in fact make 4 round trips to the backend?
<img width="901" alt="image" src="https://user-images.githubusercontent.com/1187758/186154207-041da5ed-9341-4c75-bc10-73d3e950... | closed | 2022-08-23T12:13:54Z | 2022-08-25T03:22:23Z | https://github.com/graphql-python/graphene/issues/1452 | [
"🐛 bug"
] | lopatin | 0 |
keras-team/keras | deep-learning | 20,278 | Incompatibility of compute_dtype with complex-valued inputs | Hi,
In #19872, you introduced the possibility for layers with complex-valued inputs.
It then seems that this statement of the API Documentation is now wrong:

When I feed a complex-valued input tensor into a layer (as in ... | open | 2024-09-23T11:48:24Z | 2024-09-25T19:31:05Z | https://github.com/keras-team/keras/issues/20278 | [
"type:feature"
] | jhoydis | 1 |
deepspeedai/DeepSpeed | deep-learning | 6,906 | [BUG] RuntimeError: Unable to JIT load the fp_quantizer op due to it not being compatible due to hardware/software issue. FP Quantizer is using an untested triton version (3.1.0), only 2.3.(0, 1) and 3.0.0 are known to be compatible with these kernels | **Describe the bug**
I am out of my depth here but I'll try.
Installed deepspeed on vllm/vllm-openai docker via pip install deepspeed. Install went fine but when I tried to do an FP6 quant inflight on a model I got the error in the subject line. Noodling around, I see op_builder/fp_quantizer.py is checking the Triton v... | closed | 2024-12-23T22:27:19Z | 2025-01-13T17:26:35Z | https://github.com/deepspeedai/DeepSpeed/issues/6906 | [
"bug",
"compression"
] | GHBigD | 3 |
babysor/MockingBird | pytorch | 511 | 请教作者及各位大佬,模型声音机械怎么办 | 纯小白,请教
1继续作者75K训练到200K,loss02左右,声音有点奇怪,最主要是效果机械,这是什么情况。要怎么办
2是训练还不到位吗?要继续训练还是咋办
3软件顶端的区域,怎么加载。就是下图这个,灰色
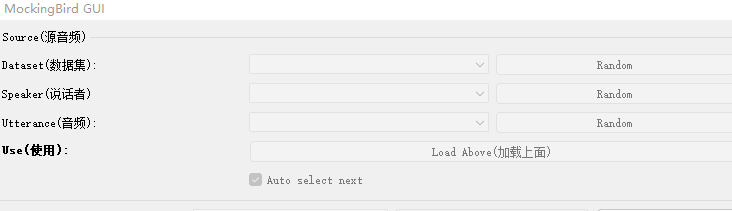
| open | 2022-04-20T14:24:24Z | 2022-04-22T14:04:29Z | https://github.com/babysor/MockingBird/issues/511 | [] | 1239hy | 2 |
Aeternalis-Ingenium/FastAPI-Backend-Template | sqlalchemy | 33 | Running pytests | Hi.
In root dir README it says:
Make sure that you are in the backend/ directory
In backend/README.md:
INFO: For running the test, make sure you are in the root directory and NOT in the backend/ directory!
Try both ways i am not able to run tests,
```
from src.main import backend_app
E ModuleNotFou... | closed | 2023-12-19T07:41:34Z | 2023-12-19T08:10:03Z | https://github.com/Aeternalis-Ingenium/FastAPI-Backend-Template/issues/33 | [] | djo10 | 0 |
tensorflow/datasets | numpy | 5,263 | [data request] <dataset name> | * Name of dataset: NYU Depth Dataset V2
* URL of dataset: http://horatio.cs.nyu.edu/mit/silberman/nyu_depth_v2/bathrooms_part1.zip
I am not able to download this dataset now (which I could years ago). It says the site can't be reached. Any help would be appreciated. Thanks. | closed | 2024-01-29T15:37:50Z | 2024-02-14T11:47:34Z | https://github.com/tensorflow/datasets/issues/5263 | [
"dataset request"
] | Moushumi9medhi | 2 |
strawberry-graphql/strawberry | graphql | 3,631 | strawberry.ext.mypy_plugin Pydantic 2.9.0 PydanticModelField.to_argument error missing 'model_strict' and 'is_root_model_root' | Hello!
It seems the Pydantic 2.9.0 version introduced a breaking change on PydanticModelField.to_argument adding two new arguments:
https://github.com/pydantic/pydantic/commit/d6df62aaa34c21272cb5fcbcbe3a8b88474732f8
and
https://github.com/pydantic/pydantic/commit/93ced97b00491da4778e0608f2a3be62e64437a8
##... | open | 2024-09-13T12:02:43Z | 2025-03-20T15:56:52Z | https://github.com/strawberry-graphql/strawberry/issues/3631 | [
"bug"
] | victor-nb | 0 |
Lightning-AI/pytorch-lightning | data-science | 19,768 | Script freezes when Trainer is instantiated | ### Bug description
I can run once a training script with pytorch-lightning. However, after the training finishes, if train to run it again, the code freezes when the `L.Trainer` is instantiated. There are no error messages.
Only if I shutdown and restart, I can run it once again, but then the problem persist for t... | closed | 2024-04-12T14:11:34Z | 2024-06-22T22:46:07Z | https://github.com/Lightning-AI/pytorch-lightning/issues/19768 | [
"question"
] | PabloVD | 5 |
cvat-ai/cvat | tensorflow | 8,764 | Can access CVAT over LAN but not Internet | Hi, i did all in https://github.com/cvat-ai/cvat/issues/1095 but http://localhost:7070/auth/login don't login and show message "Could not check authentication on the server Open the Browser Console to get details" but on http://localhost:8080/auth/login no problem.it on WAN also http://myip:7060/, i have same state. ca... | closed | 2024-12-02T12:04:18Z | 2024-12-10T17:54:18Z | https://github.com/cvat-ai/cvat/issues/8764 | [
"need info"
] | alirezajafarishahedan | 1 |
microsoft/MMdnn | tensorflow | 378 | load pytorch vgg16 converted from tensorflow : ImportError: No module named 'MainModel' | Platform (like ubuntu 16.04/win10): ubuntu16
Python version: 3.6
Source framework with version (like Tensorflow 1.4.1 with GPU): 1.3
Destination framework with version (like CNTK 2.3 with GPU):
Pre-trained model path (webpath or webdisk path):
Running scripts:
when torch.load have converted pretrain m... | closed | 2018-08-27T04:56:18Z | 2019-03-21T01:26:58Z | https://github.com/microsoft/MMdnn/issues/378 | [] | Proxiaowen | 8 |
healthchecks/healthchecks | django | 549 | log entries: keep last n failure entries | Hello,
when the log entries hit the maximum, old messages are removed.
Especially with higher frequency intervals, keeping a few of those "failure" events (which may contain important debug information's in the body) would be useful, as opposed to remove log entries solely based on the timestamp. Positive log e... | closed | 2021-08-06T12:07:32Z | 2022-06-19T13:57:26Z | https://github.com/healthchecks/healthchecks/issues/549 | [
"feature"
] | lukastribus | 6 |
dpgaspar/Flask-AppBuilder | flask | 1,516 | How to use OR operation in Rison | In the docunment, I found we can use `AND` operations like this `(filters:!((col:name,opr:sw,value:a),(col:name,opr:ew,value:z)))`, but how to use `OR` operation? | closed | 2020-11-11T00:18:15Z | 2021-06-29T00:56:11Z | https://github.com/dpgaspar/Flask-AppBuilder/issues/1516 | [
"question",
"stale"
] | HugoPu | 2 |
biolab/orange3 | data-visualization | 6,892 | Problem with SVM widget (degree must be int but only allows float) | <!--
Thanks for taking the time to report a bug!
If you're raising an issue about an add-on (i.e., installed via Options > Add-ons), raise an issue in the relevant add-on's issue tracker instead. See: https://github.com/biolab?q=orange3
To fix the bug, we need to be able to reproduce it. Please answer the following... | closed | 2024-09-17T11:34:04Z | 2024-11-21T10:19:00Z | https://github.com/biolab/orange3/issues/6892 | [
"bug report"
] | TonciG | 5 |
RobertCraigie/prisma-client-py | pydantic | 28 | Add group_by action method | [https://www.prisma.io/docs/reference/api-reference/prisma-client-reference#groupby](https://www.prisma.io/docs/reference/api-reference/prisma-client-reference#groupby)
The design decision we need to make here is how to represent the data that prisms returns. | closed | 2021-06-21T17:34:52Z | 2022-01-23T01:32:48Z | https://github.com/RobertCraigie/prisma-client-py/issues/28 | [
"kind/feature"
] | RobertCraigie | 6 |
tflearn/tflearn | tensorflow | 983 | What's the reason for removing the second parameter for to_categorical | Old version of to_categorical took 2 parameters, the second one is nb_classes, why should it be removed from new version? What are the benefits of doing this? In my opinion, sometimes we must list all the labels in a list_file, but that do not mean we have all labels in each dataset, e.g. we may not see any sample in t... | open | 2017-12-22T11:58:26Z | 2017-12-22T11:58:26Z | https://github.com/tflearn/tflearn/issues/983 | [] | wronsky317 | 0 |
KevinMusgrave/pytorch-metric-learning | computer-vision | 87 | Add trainer for MoCo | It would be nice to have a trainer for [MoCo](https://arxiv.org/abs/1911.05722). It would be similar to [UnsupervisedEmbeddingsUsingAugmentations](https://github.com/KevinMusgrave/pytorch-metric-learning/blob/master/src/pytorch_metric_learning/trainers/unsupervised_embeddings_using_augmentations.py) but would need to u... | closed | 2020-05-03T18:51:45Z | 2023-01-21T05:14:46Z | https://github.com/KevinMusgrave/pytorch-metric-learning/issues/87 | [
"help wanted",
"new algorithm request"
] | KevinMusgrave | 0 |
Anjok07/ultimatevocalremovergui | pytorch | 1,019 | Unable to open on Mac, OS Big Sur | Program cannot open, running into this issue as seen on the command line:
\# /Applications/Ultimate\ Vocal\ Remover.app/Contents/MacOS/UVR
Traceback (most recent call last):
File "UVR.py", line 8, in <module>
File "PyInstaller/loader/pyimod02_importers.py", line 391, in exec_module
File "librosa/__init__.... | open | 2023-12-10T08:11:00Z | 2023-12-13T14:10:05Z | https://github.com/Anjok07/ultimatevocalremovergui/issues/1019 | [] | Syntoca | 1 |
DistrictDataLabs/yellowbrick | matplotlib | 1,248 | Create test for utilizing Sklearn pipelines with Visualizers | **Describe the issue**
ModelVisualizers should be tested to see if they would work within pipelines. This addresses issue #498 and PR #1245
This is being addressed in PR #1249
The test should cover these visualizers
- [x] - ClassPredictionError
- [x] - ClassificationReport
- [x] - ConfusionMatrix
- [ ] ... | closed | 2022-05-15T00:00:27Z | 2022-05-28T19:17:41Z | https://github.com/DistrictDataLabs/yellowbrick/issues/1248 | [] | lwgray | 0 |
CorentinJ/Real-Time-Voice-Cloning | python | 861 | There is no speaker id in my dataset, what should I do? | closed | 2021-10-05T17:03:40Z | 2021-10-06T19:35:21Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/861 | [] | fancat-programer | 6 | |
huggingface/diffusers | deep-learning | 10,223 | Where should I obtain the lora-sdxl-dreambooth-id in Inference | ### Describe the bug
I tried to upload the download link from the README file generated during training, but an error indicated it was incorrect. Where should I obtain the lora-id for Inference?
### Reproduction
README.md:
---
base_model: /data/ziqiang/czc/diffusers/examples/dreambooth/model
library_name: diffuse... | open | 2024-12-14T06:34:56Z | 2025-02-07T15:03:24Z | https://github.com/huggingface/diffusers/issues/10223 | [
"bug",
"stale"
] | Zarato2122 | 5 |
ultralytics/ultralytics | python | 19,277 | about post model labels | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
What does the labeling of the model do
### Additional
What is the relation... | open | 2025-02-17T08:56:32Z | 2025-02-17T09:27:51Z | https://github.com/ultralytics/ultralytics/issues/19277 | [
"question",
"pose"
] | liwenewil | 5 |
dnouri/nolearn | scikit-learn | 8 | ValueError: 'total size of new array must be unchanged' | Am I doing something wrong here:
``` python
net1 = NeuralNet(
layers=[ # three layers: one hidden layer
('input', layers.InputLayer),
('conv1', layers.Conv2DLayer),
('pool1', layers.MaxPool2DLayer),
('dropout1', layers.DropoutLayer),
('hidden', layers.DenseLayer),
(... | closed | 2014-12-27T17:39:49Z | 2015-01-02T01:42:50Z | https://github.com/dnouri/nolearn/issues/8 | [] | cancan101 | 7 |
cvat-ai/cvat | tensorflow | 8,353 | Exporting review comments with annotations | Hello,
I want to save not only annotations but also their issues (comments that are made during review by clicking right mouse button and choosing "Open Issue") however I cannot find any export format that would do that.
Am I missing something, or it isn't implemented? If not, there are any possibilities to get such ... | closed | 2024-08-27T10:29:16Z | 2024-08-27T11:14:45Z | https://github.com/cvat-ai/cvat/issues/8353 | [] | DainiusGaidamaviciuss | 5 |
sqlalchemy/alembic | sqlalchemy | 335 | autogen primary key renderer uses `column.key` instead of `column.name` when assembling list of columns | **Migrated issue, originally created by Jesse Dhillon ([@jessedhillon](https://github.com/jessedhillon))**
Possibly related to #259
When rendering `PrimaryKeyConstraint`, I've noticed that I have to manually fix the output because the list of columns references each column's `key` property instead of `name`. Reading ... | closed | 2015-10-25T21:47:29Z | 2016-01-29T15:53:24Z | https://github.com/sqlalchemy/alembic/issues/335 | [
"bug",
"autogenerate - rendering"
] | sqlalchemy-bot | 6 |
miguelgrinberg/Flask-SocketIO | flask | 1,260 | Access Azure API in Python | My boss sent me an url which has the following format:
`https://{appname}.azurewebsites.net/api/Authentication/Token?username=XXXX&password=YYYY
`
I would like to access the api and fetch the data from a python script.
I tried the following in script :
```
import requests
response= requests... | closed | 2020-04-20T17:20:27Z | 2020-04-20T17:45:06Z | https://github.com/miguelgrinberg/Flask-SocketIO/issues/1260 | [] | chloe-v | 1 |
wger-project/wger | django | 1,679 | Trailing zero in weight chart | 
| open | 2024-05-25T13:22:31Z | 2024-06-23T16:52:46Z | https://github.com/wger-project/wger/issues/1679 | [] | tomyan112 | 2 |
QingdaoU/OnlineJudge | django | 219 | 并发可能导致同一个用户的同一个考试产生多条ACMContestRank | https://github.com/QingdaoU/OnlineJudge/blob/f7bd9f16b44f944e0bb370dcc7e0e82a1f2b5eb4/judge/dispatcher.py#L327
ACMContestRank没有设置唯一索引,同一个用户有可能创建出多条数据。之后get就会一直抛出异常 | closed | 2019-01-22T11:37:10Z | 2019-03-28T03:15:47Z | https://github.com/QingdaoU/OnlineJudge/issues/219 | [] | michaelzf | 1 |
yzhao062/pyod | data-science | 545 | TypeError: SUOD.__init__() got an unexpected keyword argument 'cost_forecast_loc_fit' | I was trying to use SUOD model from pyod model list. Initially when importing SUOD ; throwing error of module not found. So I have installed SUOD with command `! pip install --pre suod `. Then I was getting error of `SUOD.__init__() got an unexpected keyword argument 'cost_forecast_loc_fit'`.
` is called the `warm_up()` for every component is run. We want to avoid that an expensive operation is executed multiple times, we cannot to this from the pipeline side. We should review that every component which has a `warm_up()` makes this check.
For instance, `... | closed | 2025-02-06T11:37:13Z | 2025-02-06T11:41:31Z | https://github.com/deepset-ai/haystack/issues/8824 | [] | davidsbatista | 1 |
encode/httpx | asyncio | 3,223 | http2协议发送请求会发送两次,第一次数据,第二次空包End Stream,如何将第二次空包的End Stream放到第一次包中 | The starting point for issues should usually be a discussion...
https://github.com/encode/httpx/discussions
Possible bugs may be raised as a "Potential Issue" discussion, feature requests may be raised as an "Ideas" discussion. We can then determine if the discussion needs to be escalated into an "Issue" or not.
... | closed | 2024-06-14T10:14:33Z | 2024-06-14T10:15:28Z | https://github.com/encode/httpx/issues/3223 | [] | mayanan-py-go | 0 |
yezz123/authx | pydantic | 611 | 📝 Fix All typing Problems in codebase | Fix All this related issues for typing:
- [x] #610
- [x] #609
- [x] #608
- [x] #607
- [x] #606
- [x] #605
- [x] #604 | closed | 2024-06-13T15:29:18Z | 2024-06-17T16:48:06Z | https://github.com/yezz123/authx/issues/611 | [
"enhancement",
"Extra Large",
"python",
"investigate",
"Typing"
] | yezz123 | 0 |
aiortc/aiortc | asyncio | 249 | server example not working in new Chrome / Chromium | I just tried the server example on ubuntu 18.04. It works well in Firefox but doesn't establish a data channel in Chromium 79.
Since the offer sdp differ I suppose there is the error. Especially since Chromium just uses mDNS candidates.
Chromium:
```
v=0
o=- 3306756189431829391 2 IN IP4 127.0.0.1
s=-
t=0 0
... | closed | 2020-01-07T18:20:11Z | 2021-01-29T08:50:00Z | https://github.com/aiortc/aiortc/issues/249 | [
"bug"
] | hobbeshunter | 4 |
feder-cr/Jobs_Applier_AI_Agent_AIHawk | automation | 123 | Getting selector errors | Traceback (most recent call last):
File "d:\LinkedIn_AIHawk_automatic_job_application\src\linkedIn_easy_applier.py", line 63, in job_apply
self._fill_application_form(job)
File "d:\LinkedIn_AIHawk_automatic_job_application\src\linkedIn_easy_applier.py", line 129, in _fill_application_form
self.fill_up(j... | closed | 2024-08-29T01:36:01Z | 2024-08-29T17:23:31Z | https://github.com/feder-cr/Jobs_Applier_AI_Agent_AIHawk/issues/123 | [] | safakhan413 | 1 |
deezer/spleeter | tensorflow | 488 | [Discussion] Standalone Mac app | Hi folks,
I've succeeded to build standalone Mac Application for separation(5stems).
No needs to interact with Terminal(command line). Only you have to is to download my "MySpleeter" app from below
because this app includes python, spleeter, ffmpeg, tensowflow and dependencies.
(changed at 2020/09/04)
https:/... | open | 2020-09-02T12:58:32Z | 2022-03-13T08:40:18Z | https://github.com/deezer/spleeter/issues/488 | [
"question"
] | kyab | 22 |
pytorch/pytorch | deep-learning | 149,119 | The device_id parameter of distributed.init_process_group will cause each process to occupy video memory on the first accessible GPU | ### 🐛 Describe the bug
The device_id parameter of distributed.init_process_group will cause each process to occupy video memory on the first accessible GPU.
For example, I set the environment variable to "CUDA_VISIBLE_DEVICES": "0,1" . After init_process_group is executed, rank 1 will also occupy some video memory o... | open | 2025-03-13T11:29:00Z | 2025-03-13T18:51:35Z | https://github.com/pytorch/pytorch/issues/149119 | [
"oncall: distributed",
"triaged",
"bug"
] | Staten-Wang | 1 |
yezyilomo/django-restql | graphql | 254 | Problem when creating/updating ManyToOne nested field if a serializer is using fields = '__all__' | when try to create nested record; show this error `Field name `_` is not valid for model `ModelName`.`
| closed | 2021-08-03T19:18:53Z | 2021-08-05T20:42:48Z | https://github.com/yezyilomo/django-restql/issues/254 | [
"bug"
] | farasu | 12 |
sqlalchemy/sqlalchemy | sqlalchemy | 10,355 | Insert performance regression of ORM models with multiple Enums and async engine | ### Describe the bug
Adding a second Enum column to an ORM model leads to unpredictable performance regression during the insert commit when running with an async engine and null pool size. This issue is not reproduced with a synchronous engine.
### SQLAlchemy Version in Use
2.0.20
### DBAPI (i.e. the datab... | closed | 2023-09-17T01:29:30Z | 2023-09-17T01:58:50Z | https://github.com/sqlalchemy/sqlalchemy/issues/10355 | [
"performance",
"external driver issues"
] | cepbuch | 1 |
graphql-python/graphene-sqlalchemy | graphql | 242 | Many to Many relationships! How to Mutation? | i have models
```python
user_role = db.Table(
"user_role",
db.metadata,
db.Column("user_id", db.Integer, db.ForeignKey("user.id")),
db.Column("role_id", db.Integer, db.ForeignKey("role.id")),
db.UniqueConstraint("user_id", "role_id"),
)
class User(db.Model):
__tablename__ = "user"... | closed | 2019-08-06T07:13:37Z | 2023-02-25T00:48:27Z | https://github.com/graphql-python/graphene-sqlalchemy/issues/242 | [] | goodking-bq | 4 |
aeon-toolkit/aeon | scikit-learn | 2,650 | [ENH] Improve `create_multi_comparison_matrix` parameters and saving | ### Describe the feature or idea you want to propose
The MCM figure creator has a lot of parameters, some of which could be a lot tidier IMO. i.e. we probably dont need 5 (or more) parameters for output.
```
output_dir="./",
pdf_savename=None,
png_savename=None,
csv_savename=None,
tex_savename=No... | open | 2025-03-18T19:33:37Z | 2025-03-20T10:32:55Z | https://github.com/aeon-toolkit/aeon/issues/2650 | [
"enhancement",
"visualisation"
] | MatthewMiddlehurst | 2 |
huggingface/datasets | numpy | 7,018 | `load_dataset` fails to load dataset saved by `save_to_disk` | ### Describe the bug
This code fails to load the dataset it just saved:
```python
from datasets import load_dataset
from transformers import AutoTokenizer
MODEL = "google-bert/bert-base-cased"
tokenizer = AutoTokenizer.from_pretrained(MODEL)
dataset = load_dataset("yelp_review_full")
def tokenize_functi... | open | 2024-07-01T12:19:19Z | 2024-12-03T11:26:17Z | https://github.com/huggingface/datasets/issues/7018 | [] | sliedes | 4 |
cvat-ai/cvat | computer-vision | 9,125 | Images are not uploaded when trying to create a new task | I am using CVAT version 2.5.0 locally installed on an ubuntu 22.04 operating system. Everything was working fine until we needed to install the server operating system again. I backed up CVAT data by following the [backup guide](https://docs.cvat.ai/docs/administration/advanced/backup_guide/).
After installing CVAT aga... | open | 2025-02-20T00:21:38Z | 2025-02-21T13:10:01Z | https://github.com/cvat-ai/cvat/issues/9125 | [
"need info"
] | fshaker | 1 |
blacklanternsecurity/bbot | automation | 1,594 | Bug with RAW_DNS_RECORD discovery_path | ```
{"type": "RAW_DNS_RECORD", "id": "RAW_DNS_RECORD:78f971682ee9ef651f9740456466e53ed8da3ba1", "data": {"host": "ind.dell.com", "type": "MX", "answer": "10 dmx1.bfi0.com."}, "host": "ind.dell.com", "resolved_hosts": ["208.70.143.18"], "dns_children": {"A": ["208.70.143.18"], "MX": ["dmx1.bfi0.com"], "TXT": ["dmx1.bfi... | closed | 2024-07-28T16:37:52Z | 2024-08-02T14:47:26Z | https://github.com/blacklanternsecurity/bbot/issues/1594 | [
"bug"
] | TheTechromancer | 3 |
ray-project/ray | pytorch | 51,018 | [core] Performance evaluation on GCS key-value storage | ### Description
For the current GCS key-value storage implementation, we're storing value (protobuf message) as a serialized string.
Eg:
protobuf message serialization
https://github.com/ray-project/ray/blob/a04cb06bb1a2c09e93b882b611492d62b8d1837a/src/ray/gcs/gcs_server/gcs_table_storage.cc#L40
flat hash map
http... | open | 2025-03-02T02:12:32Z | 2025-03-03T19:23:36Z | https://github.com/ray-project/ray/issues/51018 | [
"enhancement",
"P2",
"core"
] | dentiny | 1 |
pydantic/pydantic-ai | pydantic | 1,070 | Documentation on Instrumentation? | ### Description
I see InstrumentedModel in the codebase, but no documentation of it.
Is the feature not yet prepared, and/or can we expect documentation?
### References
_No response_ | closed | 2025-03-06T11:01:31Z | 2025-03-20T11:40:14Z | https://github.com/pydantic/pydantic-ai/issues/1070 | [
"documentation"
] | pedroallenrevez | 6 |
oegedijk/explainerdashboard | plotly | 152 | Encountering an AttributeError: 'NoneType' object has no attribute 'dim' | Hi all,
trying to implement the dashboard on a PyTorch NN classification model. I am using a similar function that was on In GitHub for this case:
`def get_skorch_classifier():
X_train_m = X_train.astype(np.float32)
y_train_m = y_train.astype(np.int64)
X_train_df = pd.DataFrame(X_train_m, columns=X.... | closed | 2021-10-28T07:54:16Z | 2021-10-30T06:42:52Z | https://github.com/oegedijk/explainerdashboard/issues/152 | [] | Waeara | 0 |
gradio-app/gradio | machine-learning | 10,223 | Request for Adding error handling for gradio_client's TypeError: can only concatenate str (not "bool") to str | gradio_client/client.py has an issue at the line 1181. The issue seem to be same as described in [#4884](https://github.com/gradio-app/gradio/issues/4884) which has been fixed in [PR #4886](https://github.com/gradio-app/gradio/pull/4886).
https://github.com/gradio-app/gradio/blob/501adefd0c3d5769055ef2156c85e586eb60... | closed | 2024-12-18T02:28:42Z | 2024-12-18T17:20:33Z | https://github.com/gradio-app/gradio/issues/10223 | [
"needs repro"
] | yokomizo-tech | 3 |
rougier/numpy-100 | numpy | 197 | Alternative solution to q4 | Use `Z.nbytes` to find the memory size directly.
```python
print("%d bytes" % (Z.nbytes))
``` | closed | 2023-03-02T06:45:11Z | 2023-10-11T04:12:40Z | https://github.com/rougier/numpy-100/issues/197 | [] | jeremy-feng | 2 |
dpgaspar/Flask-AppBuilder | rest-api | 1,717 | Can I modify add form field to have select list from data got by external API? | I want to extend one field from add form, to be able to choose option from select list got by external API. Let me explain the question.
I've got model like:
```
class ContactGroup(Model):
id = Column(Integer, primary_key=True)
name = Column(String(50), unique=True, nullable=False)
my_field_id = Colum... | closed | 2021-10-15T10:00:57Z | 2022-02-07T11:56:58Z | https://github.com/dpgaspar/Flask-AppBuilder/issues/1717 | [] | Shhad | 4 |
JaidedAI/EasyOCR | pytorch | 776 | Is there any onnx model deploy example? | closed | 2022-07-05T16:07:03Z | 2022-07-11T02:22:24Z | https://github.com/JaidedAI/EasyOCR/issues/776 | [] | yuanyan3060 | 1 | |
ray-project/ray | python | 51,518 | [Autoscaler] Issue when using ray start --head with --autoscaling-config | ### What happened + What you expected to happen
## Describe
When running ray start --head with --autoscaling-config, the head node is deployed, but the head node creation request defined in head_node_type(autoscaling-config) remains in a pending state in the autoscaler, even though the head node is already running.
I... | open | 2025-03-19T09:29:43Z | 2025-03-20T00:33:48Z | https://github.com/ray-project/ray/issues/51518 | [
"bug",
"P2",
"core"
] | nadongjun | 2 |
sqlalchemy/sqlalchemy | sqlalchemy | 9,828 | add reflect kw for DeferredReflection.prepare | the API here seems dated as it accepts only an Engine, but we can at least add reflection kw, see https://github.com/sqlalchemy/sqlalchemy/issues/5499#issuecomment-1560262233 | closed | 2023-05-24T02:01:03Z | 2023-05-24T13:17:43Z | https://github.com/sqlalchemy/sqlalchemy/issues/9828 | [
"orm",
"sqlalchemy.ext",
"declarative",
"reflection",
"use case"
] | zzzeek | 1 |
PokeAPI/pokeapi | api | 492 | Missing moveset information | The database doesn't provide information about Pokemon's egg and event moves such as island scan or global distributions. | closed | 2020-05-12T17:30:37Z | 2020-08-19T10:53:35Z | https://github.com/PokeAPI/pokeapi/issues/492 | [] | ghost | 3 |
seleniumbase/SeleniumBase | web-scraping | 3,343 | why when i press enter it make for me a new line | for i in "seleniumbase2025\n": sb.sleep(0.5) ,sb.cdp.press_keys('[name="q"]', i)
i use this line to press Enter after write the keyword but it make a new line can i know how to press Enter ? | closed | 2024-12-15T23:00:52Z | 2024-12-16T02:19:44Z | https://github.com/seleniumbase/SeleniumBase/issues/3343 | [
"can't reproduce",
"UC Mode / CDP Mode"
] | pythondeveloperz | 1 |
sanic-org/sanic | asyncio | 2,649 | There is a problem with the Extend.register method | ### Is there an existing issue for this?
- [X] I have searched the existing issues
### Describe the bug
I have asked for help on forums before, and I feel that there is a bug in the `Extend.register` method https://community.sanicframework.org/t/use-dependency-method-in-custom-extensions-not-work/1107/7
### Code sn... | open | 2023-01-05T09:26:20Z | 2023-01-05T09:26:20Z | https://github.com/sanic-org/sanic/issues/2649 | [
"bug"
] | tqq1994516 | 0 |
keras-team/autokeras | tensorflow | 1,856 | Bug: | ### On binary classifier, AutoKeras returns only one class's probability on `predict` call.
```
# model: is trained autokeras model
prob = model.predict(vector)
print(prob)
```
Data used by the code: Any binary classifier data
### Expected Behavior.
It should return probabilities... | open | 2023-02-24T09:15:06Z | 2023-02-24T09:29:46Z | https://github.com/keras-team/autokeras/issues/1856 | [
"bug report"
] | shabir1 | 0 |
tensorflow/tensor2tensor | machine-learning | 1,605 | [bug] img2img generation: likelihood error for hparams_set advised in ReadMe | ### Description
I am not able to run a training job for the img2img transformer example.
I have tested it with hparams_set =
* img2img_transformer2d_base
* img2img_transformer2d_tiny
* img2img_transformer_b1
* img2img_transformer_base
* img2img_transformer_tiny
### Environment ... | closed | 2019-06-18T13:54:38Z | 2019-06-20T16:48:02Z | https://github.com/tensorflow/tensor2tensor/issues/1605 | [] | Vargeel | 4 |
huggingface/datasets | deep-learning | 7,059 | None values are skipped when reading jsonl in subobjects | ### Describe the bug
I have been fighting against my machine since this morning only to find out this is some kind of a bug.
When loading a dataset composed of `metadata.jsonl`, if you have nullable values (Optional[str]), they can be ignored by the parser, shifting things around.
E.g., let's take this example
... | open | 2024-07-22T13:02:42Z | 2024-07-22T13:02:53Z | https://github.com/huggingface/datasets/issues/7059 | [] | PonteIneptique | 0 |
MaartenGr/BERTopic | nlp | 1,722 | Output the distance/correlation matrix of topics | In the visualisation heatmap, the calculation of the correlation matrix of topics is actually very useful, e.g. for debugging purpose and as a guide to do topic reduction. Any chance it can become part of the class attribute of the bertopic or an output from calling visualize_heatmap ? | open | 2024-01-04T16:47:45Z | 2024-01-09T08:13:29Z | https://github.com/MaartenGr/BERTopic/issues/1722 | [] | swl-dm | 3 |
encode/apistar | api | 76 | Websockets support | Requires either of #29, #9 first.
Client side support for live endpoints with content-diffs.
Support for notifications of updating live endpoints. | closed | 2017-04-20T14:23:00Z | 2018-09-25T14:46:05Z | https://github.com/encode/apistar/issues/76 | [
"Headline feature"
] | tomchristie | 6 |
onnx/onnx | scikit-learn | 6,006 | how onnx models stores weights and layer parameters | I am working on generating an ONNX translator for a machine learning framework, and for that, I need to have a clear understanding of how weights and layer parameters are stored in an ONNX model. After exploring several ONNX models, I realized that some of the ONNX models store their weights and layer parameters in sep... | open | 2024-03-09T08:00:08Z | 2024-03-09T08:00:08Z | https://github.com/onnx/onnx/issues/6006 | [
"question"
] | kumar-utkarsh0317 | 0 |
BeastByteAI/scikit-llm | scikit-learn | 76 | Azure OpenAI Embeddings | You have added support for Azure OpenAI GPT models. Please add support for Azure OpenAI embedding models too. Due to this problem, I can't use the GPTVectorizer as well as Dynamic Few Shot Classification. | closed | 2023-10-31T15:44:46Z | 2024-05-24T14:39:43Z | https://github.com/BeastByteAI/scikit-llm/issues/76 | [] | Ioannis-Pikoulis | 2 |
sanic-org/sanic | asyncio | 3,004 | Named middleware doesn't work | ### Is there an existing issue for this?
- [X] I have searched the existing issues
### Describe the bug
Middlewares registered with app.register_named_middleware don't seem to work.
### Code snippet
```python
# playground.py
from sanic import Sanic, text
app = Sanic("my-app")
@app.get("/test", name="test")... | closed | 2024-10-23T08:56:30Z | 2024-12-12T16:31:08Z | https://github.com/sanic-org/sanic/issues/3004 | [
"bug"
] | atticusfyj | 2 |
grillazz/fastapi-sqlalchemy-asyncpg | sqlalchemy | 150 | postgres vector poc | open | 2024-05-08T10:46:53Z | 2024-05-08T10:46:53Z | https://github.com/grillazz/fastapi-sqlalchemy-asyncpg/issues/150 | [] | grillazz | 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.